













































































































































































































































Автор: Брокмайер Дж. Лебланк Д.Э. Маккарти Р. Мл.
Теги: компьютерные технологии программирование операционные системы компьютерные науки издательство санкт-петербург операционная система linux
ISBN: 5-8459-0271-1
Год: 2022




Маршрутизация
в Linux®
ВИЛЬЯМС
Джо Брокмайер
Ди-Энн Лебланк
Рональд Маккарти, мл.
Маршрутизация
в Linux®
Linux® Routing
Joe "Zonker" Brockmeier
Dee-Ann LeBlank
Ronald W. McCarty, Jr.
201 West 103rd St.,
Indianapolis, Indiana, 46290
An Imprint of Pearson Education
Boston • Indianapolis • London • Munich • New York • San Francisco
Джо Брокмайер
Ди-Энн Лебланк
Рональд Маккарти, мл.
ВИЛЬЯМС т.
Москва • Санкт-Петербург • Киев
IffiM 2002
ББК 32.973.26-018.2.75
Б88
УДК 681.3.07
Издательский дом “Вильямс”
Зав. редакцией С.Н. Тригуб
Перевод с английского и редакция В.Р. Гинзбурга
По общим вопросам обращайтесь в Издательский дом “Вильямс”
по адресу: info@williamspublishing.com, http://www.williamspublishing.com
Брокмайер, Джо, Лебланк, Ди-Энн, Маккарти, Рональд, У.
Б88 Маршрутизация в Linux. : Пер. с англ. — М. : Издательский дом
“Вильямс”, 2002. — 240 с.: ил. — Парал. тит. англ.
ISBN 5-8459-0271-1 (рус.)
Данная книга является учебным пособием, написанным профессионалами с целью
научить читателей настраивать подсистему маршрутизации в Linux. В книге излагает-
ся теория маршрутизации, рассказывается об основных протоколах и утилитах,
имеющихся в распоряжении пользователей Linux, описывается, в каких ситуациях
лучше всего применять те или иные средства.
Книга предназначена опытным пользователям и администраторам Linux, кото-
рых интересует не только создание простейших сетей и подсетей, но и реализация
более сложных решений, связанных с различными протоколами маршрутизации.
ББК 32.973.26-018.2.75
Все названия программных продуктов являются зарегистрированными торговыми марками со-
ответствующих фирм.
Никакая часть настоящего издания ни в каких целях не может быть воспроизведена в какой бы
то ни было форме и какими бы то ни было средствами, будь то электронные или механические,
включая фотокопирование и запись на магнитный носитель, если на это нет письменного разреше-
ния издательства New Riders Publishing.
Authorized translation from the English language edition published by New Riders Publishing,
Copyright © 2002.
All rights reserved. No part of this book may be reproduced or transmitted in any form or by any
means, electronic or mechanical, including photocopying, recording or by any information storage
retrieval system, without permission from the Publisher.
Russian language edition published by Williams Publishing House according to the Agreement with
R&I Enterprises International, Copyright © 2002.
ISBN 5-8459-0271-1 (pyc.)
ISBN 1-57870-267-4 (англ.)
© Издательский дом “Вильямс”, 2002
© New Riders Publishing, 2002
Оглавление
Часть I. Основы маршрутизации 15
Глава 1. Протоколы одноадресной маршрутизации 16
Глава 2. Протоколы многоадресной маршрутизации 44
Глава 3. Введение в протоколы пограничной маршрутизации 59
Глава 4. Адресация в стандартах IPv4 и IPv6 67
Часть II. Средства и технологии маршрутизации в Linux 83
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 84
Глава 6. Демоны многоадресной маршрутизации в ядре 2.2.x 117
Глава 7. Вспомогательные демоны 123
Глава 8. Средства маршрутизации в ядре версии 2.4.x 134
Глава 9. Сетевые команды 138
Глава 10. Планирование системы маршрутизации 159
Глава 11. Основы маршрутизации в Linux 169
Глава 12. Сетевые аппаратные компоненты 174
Глава 13. Включение в ядро функций маршрутизации 188
Глава 14. Безопасность и система NAT 198
Глава 15. Мониторинг, анализ и управление сетевым трафиком 207
Часть III. Приложения 227
Приложение А. Ресурсы, посвященные маршрутизации в Linux 228
Приложение Б. Аппаратные решения 231
Содержание
Введение 11
Часть I. Основы маршрутизации 15
Глава 1. Протоколы одноадресной маршрутизации 16
Демонстрационная сеть 17
Статическая маршрутизация 20
Протокол RIP-1 21
Протокол RIP-2 29
Протокол OSPF 31
Резюме 43
Глава 2. Протоколы многоадресной маршрутизации 44
Протокол RIP-2 44
Протокол MOSPF 45
Протокол DVMRP 45
Протокольно-независимая многоадресная маршрутизация 53
Резюме 57
Глава 3. Введение в протоколы пограничной маршрутизации 59
ПротоколIGP 59
Протокол EGP 60
Протокол BGP 62
Протокол BGMP 64
Протокол MSDP 65
Резюме 66
Глава 4. Адресация в стандартах IPv4 и IPv6 67
Адресация в стандарте IPv4 67
Бесклассовая адресация в стандарте IPv4 73
Адресация в стандарте IPv6 78
Резюме 82
Часть II. Средства и технологии маршрутизации в Linux 83
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 84
Демон routed 84
Демон gated 87
Резюме 116
Глава 6. Демоны многоадресной маршрутизации в ядре 2.2.x 117
Демон протокола PIM-SM: pimd 117
Демон протокола DVMRP: mrouted 120
Резюме 122
Глава 7. Вспомогательные демоны 123
Обзор протокола РРР 123
Протокол РРР в Linux: демон pppd 128
Программа rip2ad 131
Резюме 133
6
Содержание
Глава 8. Средства маршрутизации в ядре версии 2.4.x 134
Различия между ядрами версий 2.2.x и 2.4.x 134
Новые сетевые возможности ядра версии 2.4.x 135
Виртуальные закрытые (частные) сети 136
Резюме 137
Глава 9. Сетевые команды 138
Команда ifconfig 138
Команда route 143
Команда ping 145
Команда агр 146
Команда traceroute 148
Команда netstat 150
Команда tcpdump 152
Резюме 158
Глава 10. Планирование системы маршрутизации 159
Введение в сетевое планирование 159
Концепции эффективного управления маршрутизаторами 162
Специальные функции маршрутизатора 166
Резюме 168
Глава 11. Основы маршрутизации в Linux 169
Маршрутизация в локальных сетях 169
Маршрутизация в глобальных сетях 171
Маршрутизация в виртуальной закрытой (частной) сети 172
Резюме 173
Глава 12. Сетевые аппаратные компоненты 174
Аналоговые коммуникации и модемы 174
Кабельные модемы . 180
Технология DSL 181
Передача данных с участием маршрутизаторов 182
Резюме 187
Глава 13. Включение в ядро функций маршрутизации 188
Зачем создавать новое ядро 188
Создание ядра Linux 190
Специальные дистрибутивы 194
Резюме 197
Глава 14. Безопасность и система NAT 198
Фильтрация и обработка пакетов маршрутизатором 199
1Р-маскирование 204
Система NAT 205
Резюме 206
Глава 15. Мониторинг, анализ и управление сетевым трафиком 207
Средства мониторинга и анализа 207
Качество обслуживания 224
Резюме 226
Содержание
7
Часть Ш. Приложения 227
Приложение А. Ресурсы, посвященные маршрутизации в Linux 228
Демоны маршрутизации 228
Программы маршрутизации и,управления трафиком 229
Дополнительные ресурсы 230
Официальные справочные документы 230
Приложение Б. Аппаратные решения 231
Выделенные маршрутизаторы 231
Linux-совместимые платы маршрутизации 231
8
Содержание
От Джо:
Эту книгу я посвящаю всем разработчикам и пользователям, которые работают с GNU/Linux
и свободно распространяемым программным обеспечением, поскольку они способствуют про-
цветанию всего компьютерного сообщества, а не только своих банковских счетов.
От Ди-Энн:
Моей маме, которая сказала, что никогда не будет лишним посвятить своей, маме еще одну книгу.
От Рона:
Я бы хотел посвятить эту книгу своей жене Клаудии.
Об авторах
Джо Брокмайер (Joe Brockmeier) работает в Linux
с 1996 г. и примерно с этого же времени занимается жур-
налистикой. Он регулярно пишет статьи для Linux
Magazine и UnixReview.com и имеет ряд других интерактив-
ных и печатных публикаций.
Ди-Энн Лебланк (Dee-Ann LeBlanc) является автором
и соавтором десяти книг по компьютерной тематике, еще
целый ряд готовится к выпуску. Она специализируется на
Linux и написала такие книги: Linux Install, Configuration
Little Black Book, General Linux I Exam Prep, Linux System
Administration Black Book издательства Coriolis Group, а так-
же Linux for Dummies Third Edition издательства IDG/Hungry
Minds. Она была в числе первых, кто получили сертифи-
каты RedHat Certified Engineer.
Ди-Энн преподает компьютерные курсы по Linux, UNIX
и другим темам. Она также разрабатывает интерактивные
обучающие материалы для различных организаций. Все это
помогает ей быть в курсе того, что люди хотят знать, когда
изучают Linux и сопутствующие утилиты. С Ди-Энн можно
связаться по адресу dee@renaissof t. com, естьу нее и свой
Web-узел: www. Dee-AnnLeBlanc. com.
Рональд Маккарти, мл. (Ronald W. McCarty, Jr.) являет-
ся старшим системным инженером компании
Sonus Networks, одного из лидеров сетей следующего поко-
ления. Рональд публиковал статьи, посвященные протоколу
RADIUS, IP-безопасности и другим сетевым темам. В на-
стоящее время он ведет ежемесячную колонку “Net Admin” в
журнале SysAdmin.
О научных консультантах
Эти люди внесли значительный вклад в написание книги. Они просмотрели материал
книги на предмет технической грамотности и организации. Их советы и рецензии позво-
лили авторам убедиться в том, что они не обманут ожидания читателей.
Брэд Харрис (Brad Harris) работает в сфере информа-
ционных технологий шесть лет, начав свою деятельность
с проектирования биометрических моделей для Мини-
стерства обороны США. Он получил фундаментальную
подготовку в области сетевых протоколов, операционных
систем и различных языков программирования. В настоя-
щее время он работает старшим инженером-программис-
том в компании ACS, Inc., где специализируется на про-
блемах проникновения в сети и системы.
Джозеф Хамм (Joseph Hamm) — свободный консуль-
тант, имеет опыт проектирования и внедрения коммуни-
кационных IP-систем. В настоящее время он занимается
написанием статей об эволюции компьютерных платформ
и операционных систем.
Благодарности
От Джо:
Быть автором приятно, по крайней мере можно открыто выразить признательность
тем людям, которые повлияли на мою жизнь.
Я хочу поблагодарить мою семью за то, что она... моя семья! Большое спасибо также
Дениз Бей и ее близким за то, что стали моей “второй семьей”.
Спасибо всем моим друзьям, которые слушали мои рассказы о Linux и компьютерах, не
выдавая свою скуку. Я вам очень признателен! Бонни, Сьюзан, Джейсон, Пит, Бевин,
Барб — вы замечательны.
Большое спасибо друзьям из Linux Magazine, Адаму, Ларе и Бобу (вы думали, я о вас за-
был?). Было приятно работать с вами. Выражаю также благодарность ребятам из
UnixReview. сот.
За последние три года я встретил много людей из сообщества GNU/Linux, которые
оказали на меня большое влияние. И хоть я не могу видеться и общаться с вами регулярно,
мне приятно, что все это время вы работаете в GNU/Linux.
От Ди-Энн:
В первую очередь я бы хотела поблагодарить участников списка рассылки IP Multicast
(www. stardust. com) за то, что они помогли мне разобраться с технологией многоадрес-
ной маршрутизации. Я признательна также тем людям, которые дали свою оценку того,
что я собиралась написать. Во многом благодаря их комментариям была сформирована
структура книги.
Дополнительно выражаю благодарность научным консультантам, которые поддержи-
вали наш проект. Их задача заключалась не только в поиске моих глупых ошибок, но и в
том, чтобы читатели почерпнули из книги максимум полезной информации.
Наконец, я благодарна моим соавторам Джо и Рону. В процессе работы над книгой я за-
болела, и после долгих поисков мы нашли этих двух джентльменов, которые помогли нам не
только закончить книгу в срок, но и сделать ее качественной и полезной для читателей.
От Рона:
Я выражаю особую благодарность научным консультантам Брэду Харрису и Джозефу
Хамму.
От Ди-Энн, Рона и Джо:
Мы хотим поблагодарить Криса Зана (Chris Zahn) и Энн Куинн (Ann Quinn), наших ре-
дакторов, за их профессионализм и старательность, которые они проявили в процессе
работы над книгой. Благодарим также остальных сотрудников издательства New Riders,
трудившихся вместе с нами над этой книгой: Стефани Уолл (Stephanie Wall), Кристи Кноп
(Kristy Knoop), Крисси Андри (Chrissy Andry), Джой Дин Ли (Joy Dean Lee) и Рона Уайза
(Ron Wise).
Введение
Когда в среде Linux говорится о маршрутизации, то обычно подразумевается исполь-
зование команды route для задания простейших маршрутов доставки информации.
Но ОС Linux способна на гораздо большее. Правильно сконфигурировав и настроив сис-
тему, можно получить стабильный и эффективный маршрутизатор. В данной книге изла-
гаются теоретически сведения и методики, знакомство с которыми позволит читателям
научиться правильно выбирать протоколы маршрутизации, конфигурировать демоны
маршрутизации, защищать сети и компьютеры, настраивать системное ядро и даже кон-
тролировать сетевой трафик.
Структура книги
Книга разбита на три части.
Часть I, “Основы маршрутизации”, содержит главы 1-4.
Часть II, “Средства и технологии маршрутизации в Linux”, содержит главы 5-15.
Часть III, “Приложения”, содержит приложения А и Б.
Глава 1, “Протоколы одноадресной маршрутизации”
Как говорится у классика, лучше начать с начала. Протоколы одноадресной маршрути-
зации являются одними из самых старых в семействе Internet-протоколов, но они по-
прежнему используются. В этой главе описывается демонстрационная сеть, вокруг кото-
рой строится изложение всех глав части I. На примере этой сети сравниваются протоко-
лы RIP-1, RIP-2 и OSPF.
Глава 2, “Протоколы многоадресной маршрутизации”
В этой главе рассматриваются популярные протоколы многоадресной маршрутизации:
DVMRP, MOSPF, PIM-DM и PIM-SM. Работа протоколов описывается на примере демонст-
рационной сети.
Глава 3, “Введение в протоколы пограничной маршрутизации”
В предыдущих главах шла речь о том, что происходит внутри автономных систем. Но
сами автономные системы тоже должны иметь средства общения друг с другом, иначе не
было бы сети Internet. В этой главе описываются протоколы одно- и многоадресной по-
граничной маршрутизации: EGP, BGP, BGMP и MSDP.
Глава 4, “Адресация в стандартах IPv4 и IPv6”
Многие из тех, кто работают в Linux, знают детали адресации в стандарте IPv4. Эта
глава начинается со знакомства с подсетями IPv4, после чего описывается протокол CIDR,
позволяющий отказаться от строгого разделения сетей на классы А, В и С. В конце описы-
вается система адресации стандарта IPv6.
Глава 5, “Демоны одноадресной маршрутизации в ядре 2.2.x”
В Linux есть целый ряд демонов маршрутизации. Их подробное описание заняло бы
целую книгу, поэтому в данной главе рассматриваются лишь присутствующий в большин-
стве систем демон routed и открытая версия демона gated.
12 Введение
Глава 6, “Демоны многоадресной маршрутизации в ядре 2.2.x”
В этой главе описываются два демона многоадресной маршрутизации, имеющиеся в
Linux. Один из них, mrouted, обычно применяется для подключения к многоадресной
магистрали MBONE, так как он реализует протокол DVMRP. В остальных случаях исполь-
зуется демон pimd, реализующий протокол PIM-SM.
Глава 7, “Вспомогательные демоны”
Компьютеры и сети не всегда соединяются между собой посредством кабелей Ethernet.
Зачастую между ними существуют коммутируемые соединения, что требует применения
протокола РРР. В этой главе рассматриваются особенности данного протокола и его воз-
можности. Описывается также применение демона pppd для установления РРР-соедине-
ний в Linux. В конце главы рассказывается о демоне rip2ad, позволяющем выполнять ба-
зовые функции протокола RIP-2 при наличии только РРР-соединения.
Глава 8, “Средства маршрутизации в ядре версии 2.4.x”
В этой главе речь идет об изменениях подсистемы маршрутизации, произошедших при
переходе от ядер серии 2.2.x к ядрам серии 2.4.x, а также о средствах создания виртуаль-
ных закрытых (частных) сетей.
Глава 9, “Сетевые команды”
В Linux есть набор стандартных утилит, предназначенных для работы в сети. Боль-
шинство этих программ намного сложнее, чем обычно представляют себе пользователи.
В данной главе описываются утилиты arp, ifconfig, netstat, ping, route, tcpdump и
traceroute.
Глава 10, “Планирование системы маршрутизации”
В этой главе речь идет о принципах и методиках, лежащих в основе сетевого планиро-
вания. Здесь рассказывается о том, как правильно управлять таблицами маршрутизации.
Глава 11, “Основы маршрутизации в Linux”
В этой главе излагаются базовые принципы маршрутизации в сетях основных типов:
локальных, глобальных и виртуальных.
Глава 12, “Сетевые аппаратные компоненты”
Сети — особенно те, что подключены к Internet, — не могут существовать без телеком-
муникационного оборудования. В этой главе рассказывается о различных аппаратных уст-
ройствах и технологиях (как аналоговых, так и цифровых), используемых для подключе-
ния к сетям.
Глава 13, “Включение в ядро функций маршрутизации”
Когда компьютер планируется использовать для какой-то конкретной цели, важно от-
менить все лишние функции. Это касается не только программ, но и ядра. Затем нужно
включить специальные функции, которые в обычных системах отключены. В данной гла-
ве описываются процессы компиляции и настройки ядра Linux.
Глава 14, “Безопасность и система NAT”
В этой главе описываются средства, позволяющие превратить маршрутизатор в пере-
довую линию обороны сети: фильтрация пакетов, IP-маскирование и система NAT.
Введение 13
Глава 15, “Мониторинг, анализ и управление сетевым трафиком”
Эта глава стоит немного в стороне от темы маршрутизации, так как в ней рассказыва-
ется о средствах сетевого анализа и мониторинга. С помощью таких программ, как NET-
SNMP, MRTG и IPTraf, можно собрать информацию о том, как работает сеть и какие в ней
есть проблемы.
Приложение А, “Ресурсы, посвященные маршрутизации в Linux”
Это приложение предназначено для того, чтобы читатели могли быстро найти ресур-
сы, посвященные рассматриваемым в книге программам и протоколам. Здесь же приво-
дятся ссылки на стандарты и дополнительные материалы, посвященные сетям.
Приложение Б, “Аппаратные решения”
В этом приложении приводятся адреса Web-узлов компаний, выпускающих маршрути-
заторы и специальные сетевые платы для Linux.
Для кого предназначена книга
Эта книга предназначена опытным пользователям и администраторам Linux, которых
интересует не только создание простейших сетей и подсетей, но и реализация более
сложных решений, связанных с различными протоколами маршрутизации.
Для кого не предназначена книга
Эта книга не предназначена новичкам Linux и тем читателям, которые только начи-
нают свое знакомство с миром компьютерных сетей. Зачастую инструкции, связанные с
инсталляцией и компиляцией пакетов, минимальны, так как подразумевается, что читате-
ли сами умеют это делать.
Соглашения, принятые в книге
В книге используются следующие типографские соглашения.
Тексты программ и результаты их работы, имена файлов, команд и опций, а также
адреса Web-узлов выделены моноширинным шрифтом.
Курсивом выделяются аргументы команд, значения которых должны подставляться
пользователем.
Если строка программы не помещается в рамках книжного листа, на месте вынуж-
денного разрыва ставится символ
14 Введение
Основы маршрутизации
В этой части...
Глава 1. Протоколы одноадресной маршрутизации
Глава 2. Протоколы многоадресной маршрутизации
Глава 3. Введение в протоколы пограничной маршрутизации
Глава 4. Адресация в стандартах IPv4 и IPv6
Протоколы одноадресной
маршрутизации
В этой главе...
Демонстрационная сеть 17
Статическая маршрутизация 20
Протокол RIP-1 21
Протокол RIP-2 29
Протокол OSPF 31
Резюме 43
Большинство людей лишь в самых общих чертах представляют себе, что такое мар-
шрутизация и как она осуществляется. Для пользователей Linux и администраторов-
новичков маршрутизатор выглядит “черным ящиком”, который принимает пакеты с дан-
ными, определяет, куда они должны быть адресованы, и посылает пакеты в нужном на-
правлении. В общем-то, это не так уж далеко от истины.
Маршрутизатор — это устройство, управляющее трафиком. Данные, передаваемые по
IP-сетям, да и по любым другим сетям, могут распространяться самыми разными путями.
Все данные формируются в пакеты — отдельные блоки, посылаемые в сеть. В общем случае
задача маршрутизатора состоит в выборе наилучшего из текущих маршрутов, следуя кото-
рому заданный пакет попадет в пункт своего назначения.
Способ принятия такого решения зависит от используемого протокола маршрутиза-
ции. У каждого протокола свой алгоритм слежения за тем, какие маршруты доступны и ка-
кие из них наиболее эффективны. В частности, демон, работающий по протоколу одноад-
ресной маршрутизации, посылает информацию непосредственно тем маршрутизаторам,
на общение с которыми он сконфигурирован. Протоколы этого класса эксплуатируются в
тех сетях, где оч'ень важна пропускная способность. Не меньшее значение здесь имеет на-
стройка всех используемых протоколов, чтобы соответствующие демоны знали, с какими
маршрутизаторами предстоит взаимодействовать.
Те, кого интересуют вопросы настройки, могут сразу переходить к главе 10, “Планиро-
вание системы маршрутизации”. Но важно понимать особенности функционирования
протоколов, чтобы суметь выбрать нужный протокол для конкретной сети.
Демонстрационная сеть
Проще всего излагать теорию маршрутизации на реальном примере смешанной сети.
С этой целью ниже будет описана демонстрационная сеть, на которую мы будем постоян-
но ссылаться.
Internet — это одна огромная IP-сеть, где каждый компьютер имеет свой IP-адрес вида
ххх. ххх. ххх. ххх. В случае использования частных схем адресации адреса несколько упроща-
ются, к примеру 192.168.xxx.xxx или 10.ххх.ххх.ххх. Естественно, демонстрировать работу
протоколов маршрутизации на примере глобальной сети неразумно. Мы определим не-
большую локальную сеть, рабочим узлом которой будет Linux-компьютер Red с IP-адресом
из частного диапазона: 192.168.15.10.
Схема сети приведена на рис. 1.1. В этой сети используется диапазон частных адресов
192.168.15.x (192.168.15.0) класса С, и в нее входят компьютеры с самыми разными опера-
ционными системами. Выбор операционных систем на данный момент не суть важен.
Многие просто не знают, что любая операционная система, в основе которой лежит стек
TCP/IP (а это большинство современных операционных систем), способна без проблем
устанавливать Ethernet-соединение с любой другой подобной ОС. Трудности возникают
при совместном использовании данных и файлов.
Orange
(Red Hat
192.168.15.8
192.168.15.9 192.168.15.10 192.168.15.11 192.168.15.12 192.168.15.13
Рис. 1.1. Linux-компьютер Red в сети 192.168.15.0
Глава 1. Протоколы одноадресной маршрутизации 17
Когда приложение пытается отправить или принять данные по сети, например по-
слать файл от компьютера Red компьютеру Teal (оба работают под управлением Linux),
протокол маршрутизации не нужен. Компьютеры, находящиеся в одной подсети или сети,
где нет подсетей, используют другие методики поиска друг друга. Только при выходе за
пределы подсети или сети появляется потребность в маршрутизации.
Чтобы соединить демонстрационную сеть с другими сетями, необходимо установить
на центральном компьютере Orange новую сетевую плату (рис. 1.2). При переходе из од-
ной подсети или сети в другую обязательно нужны два сетевых интерфейса, независимо от
того, являются ли они физическими или виртуальными. В данном случае один интерфейс
(192.168.15.1) подключен к Internet, а другой (192.168.15.2) — к внутренней сети.
Теперь предположим, что наша демонстрационная сеть соединена с компьютером Em-
erald, расположенным в другой части здания (рис. 1.3).
Сеть, в которую входит компьютер Emerald, имеет адрес 192.168.90.x. Именно здесь, на
пересечении границ сетей, требуется маршрутизация. Необходим способ определения то-
го, как данные из одной сети смогут попасть в другую сеть.
Если из сети есть выход в Internet, как у большинства современных сетей, то она имеет
соединение с провайдером Internet. К провайдеру могут быть напрямую подключены де-
сятки, сотни и даже тысячи сетей и отдельных компьютеров. Многие из этих сетей делят-
ся на подсети, часть из которых имеет выход к другому провайдеру с его собственным на-
бором подключений.
(Windows 98)
(Caldera Linux)
(Windows NT
4 Workstation)
(Mandrake
Linux)
(Red Hat
Linux)
(Windows
2000
Professional)
192.168.15.9
192.168.15.8
192.168.15.10
192.168.15.11
192.168.15.12
192.168.15.13
Рис. 1.2. Сеть 192.168.15.0 соединяется с другими сетями
18 Часть I. Основы маршрутизации
Другие сети
(Windows 98)
(Caldera Linux)
(Mandrake
Linux)
(Red Hat
Linux)
(Windows
NT 4
Workstation)
(Windows
2000
Professional)
192.168.15.8 192.168.15.9
192.168.15.10 192.168.15.11 192.168.15.12 192.168.15.13
Рис. 1.3. Демонстрационная сеть
соединена
расположенным в другой сети
с компьютером Emerald,
Представьте, что пакет передается из одного Internet-узла в другой. Скорость передачи
данных не имеет значения. Географическое местоположение узлов также неважно. В рас-
чет берутся только границы сетей. В момент перехода пакета через границу подсети или
сети ему нужна помощь в выборе дальнейшего направления.
Давайте посмотрим, как это реализуется. Требуется переслать данные с компьютера
Red на некую машину Abacus. В результате поиска имени в DNS выясняется, что пакет
должен быть направлен по адресу 192.169.13.9. Но пакет достигает только узла
192.169.90.26 (Emerald), где известно лишь, что пакет адресован узлу 192.169.13.9. Сам па-
кет не несет информации о том, в какой точке земного шара находится сеть 192.169.13 и к
какому провайдеру она подключена. Поиск сети вообще не является задачей пакета. Для
этого задействуются другие компьютеры, протоколы и инструментальные средства.
К счастью, машина Emerald является одним из таких специальных средств: это мар-
шрутизатор. В данный момент не имеет значения, какой протокол (или протоколы) мар-
шрутизации здесь используются. Задачей любого протокола является определение схемы
перемещения пакета. На рис. 1.4 представлены маршрутизаторы, которые могут встре-
титься на пути пакета. Здесь подразумевается некий университетский городок, в котором
машины Emerald и Abacus являются кафедральными маршрутизаторами, а за остальными
маршрутизаторами скрываются факультетские сети.
Глава 1. Протоколы одноадресной маршрутизации 19
Emerald
i-——।
Hum
Phys
Eng
192.168.90.26
Ag
Arts
Chem
Math
Abacus
192.168.13.9
Рис. 1.4. Путь от машины Emerald к машине Abacus должен быть
проложен через ряд маршрутизаторов
Для анализа того, как работают протоколы маршрутизации, нам потребуется знать ха-
рактеристики физических соединений между маршрутизаторами (табл. 1.1).
Таблица 1.1. Характеристики соединений между конечными точками
демонстрационной сети
Начало Конец Тип соединения Скорость
Emerald Hum ISDN, двойной канал 128 Кбит/с
Hum Phys T1/DS1.24 канала 1,54 Мбит/с
Hum Chem T1/DS1, 24 канала 1,54 Мбит/с
Hum Ails DSL 3 Мбит/с
Chem Math ISDN, одиночный канал 64 Кбит/с
Phys Arts T3/DS3 44,736 Мбит/с
Ails Math T3/DS3 44,736 Мбит/с
Ails Eng T3/DS3 44,736 Мбит/с
Eng Ag T1/DS1, 24 канала 1,54 Мбит/с
Math Ag T1/DS1,24 канала 1,54 Мбит/с
Ag Abacus ISDN, двойной канал 128Кбит/с
Math Abacus модем 56 Кбит/с
Статическая маршрутизация
Простейшей формой маршрутизации является статическая маршрутизация. В этом слу-
чае создается обычная маршрутная таблица, которая остается неизменной до тех пор, по-
ка не будет выдана соответствующая команда. Программы не пытаются проверять истин-
ность маршрутов, приведенных в таблице, и не пытаются отслеживать изменения в топо-
логии сети. Все это нужно делать вручную.
Статическая маршрутизация оказывается полезной лишь в некоторых случаях. На каж-
дом сетевом компьютере приходится самостоятельно вести отдельную статическую таб-
лицу, поэтому несложно представить, сколько труда занимает внесение любых изменений
в крупную сеть. Ситуация ухудшается, когда есть ограничения по срокам, например при
устранении неисправных маршрутов.
20 Часть I. Основы маршрутизации
В Linux под статической маршрутизацией понимается назначение маршрутной ин-
формации с помощью команды route (описана в главе 9, “Сетевые команды”). О конфи-
гурировании подсистемы статической маршрутизации речь пойдет в главе 5, “Демоны од-
ноадресной маршрутизации в ядре 2.2.x”.
Протокол RIP-1
RIP (Routing Information Protocol — протокол маршрутной информации) был первым
маршрутным протоколом семейства TCP/IP, который начал использоваться в сети, сей-
час называемой Internet. В настоящее время есть две версии этого протокола: RIP-1 и
RIP-2. Обе они по-прежнему занимают важное место в системах маршрутизации: первая
используется для обратной совместимости, а вторая обладает широкими возможностями.
Алгоритм
Давайте сначала поговорим не о самом протоколе RIP-1, а о лежащем в его основе ал-
горитме дистанционно-векторной маршрутизации. Если быть более точным, то для вычисле-
ния маршрутов применяется алгоритм Беллмана-Форда. Алгоритм начинает работу в точ-
ке, к которой следует проложить маршрут (называется исходной точкой). Расстояние от
этой точки до самой себя задается равным нулю, а расстояние до всех остальных точек
считается равным бесконечности.
Основное предположение, выдвигаемое в данном алгоритме, заключается в том, что от
любой точки системы существует как минимум один маршрут к исходной точке. Ни одна
точка не является полностью изолированной. Кроме того, по достижении исходной точки
маршрут заканчивается. Он не может пройти через исходную точку, а затем вернуться назад,
образовав петлю. Таким образом, нельзя пройти по одному и тому же пути дважды.
Цель алгоритма Беллмана-Форда заключается в нахождении кратчайшего пути от лю-
бой заданной точки к исходной точке. Сам алгоритм является итерационным. Начальная
топология изображена на рис. 1.5.
На каждой итерации на схему наносится путь от каждой удаленной точки к' исходной
точке, причем количество переходов на этом пути соответствует номеру итерации. Рядом
с каждым переходом записывается его физическая длина. На рис. 1.6 изображен результат
первой итерации.
Hum Ад
Arts
Math
Рис. 1.5. Узлы графа для демонстрации алгоритма Беллмана-Форда
Глава 1. Протоколы одноадресной маршрутизации 21
Наличие прямого пути от удаленной точки к исходной еще не означает, что этот путь
является оптимальным. Более того, даже когда найден кратчайший путь, алгоритм не уз-
нает об этом, пока не пройдет все итерации: вторую (рис. 1.7), третью (рис. 1.8) и т.д.
Phys
Рис. 1.6. Первая итерация алгоритма Беллмана-Форда
22 Часть' I. Основы маршрутизации
Phys
Рис. 1.8. Третья итерация алгоритма Беллмана-Форда
Оценим пока что только первые три итерации. В табл. 1.2 показана общая длина пути
от каждой точки к исходной точке на трех итерациях.
Таблица 1.2. Анализ маршрутных расстояний для трех итераций алгоритма Беллмана-Форда
Точка Итерация 1 (м) Итерация 2 (м) Итерация 3 (м)
Ag 21,5 95 151
Eng 60 56,5 147,5
Phys 108 106,5 106,5
Hum 134 133,5 137,5
Arts 72,5 87 97,5
Chem 112 106 146
Math 51 108,5 121,5
Обратите внимание на существенный разброс результатов. Иногда кратчайший мар-
шрут занимает один-единственный переход, иногда — два. Три перехода ни одной из точек
не выгодны, как видно из таблицы. Конечно же, не всегда бывает так. На практике это за-
висит от реальной топологии сети. В нашем случае потребуются четыре дополнительные
итерации, всего семь — столько же, сколько узлов в графе, не считая исходной точки.
Естественно, в протоколе RIP-1 данный алгоритм применяется с учетом особенностей
сетей TCP/IP. С точки зрения протокола маршрутизации расстояние — это не единствен-
ный фактор, который следует учитывать. Не менее важным аспектом является время пе-
редачи данных через соединение. Иногда учитывается и стоимость эксплуатации соеди-
нения. Таким образом, кратчайшее физическое расстояние не всегда означает самый бы-
стрый маршрут.
В протоколе RIP-1 под расстоянием между' точками А и Б понимается не чисто физиче-
ское расстояние, а весовой коэффициент, называемый метрикой стоимости. Изначально
Глава 1. Протоколы одноадресной маршрутизации 23
стоимость перехода между любыми двумя маршрутизаторами считалась равной единице, а
расстояние от заданной точки к исходной точке определялось по числу переходов. В со-
временных системах часто учитывают скорость соединения и другие критерии, поэтому
расстояние между соседними маршрутизаторами может быть больше единицы.
Давайте вернемся к табл. 1.1 и определим стоимость перехода между любыми двумя
точками. Пример того, как это можно сделать, представлен на рис. 1.9. i
Рис. 1.9. Фактор скорости соединений в применении к демонстраци-
онной сети
Обратите внимание на два момента. Во-первых, в отличие от базового алгоритма
Беллмана-Форда, не все точки соединены между собой. Действительными считаются
только те маршруты, где между точками есть физическое соединение. Во-вторых, разница
в скорости соединения не обязательно означает разницу в стоимости перехода. Всем со-
единениям, скорость работы которых соответствует как минимум скорости линии Т1, на-
значена стоимость 1. Если скорость соединения ниже, стоимость возрастает. Это лишь
один из возможных вариантов назначения метрик стоимости.
Наша таблица маршрутизации будет создаваться на компьютере Emerald. В нее нужно
занести информацию о кратчайших путях ко всем узлам сети (в данном случае это машина
Abacus и факультетские маршрутизаторы). Давайте определим кратчайший путь от ком-
пьютера Emerald к машине Abacus. С помощью алгоритма Беллмана-Форда построим
маршруты в соответствии с числом переходов и номером итерации. Маршрутов длиной
один переход нет, как нет и маршрутов длиной два и три перехода. Зато есть более длин-
ные маршруты, например четыре перехода:
A) Emerald —> Hum —> Chem —> Math —> Abacus
В) Emerald —> Hum —> Arts —» Math —> Abacus
Пять переходов:
C) Emerald —> Hum —> Phys —> Arts —> Math —» Abacus
D) Emerald —> Hum —> Chem —> Math —> Ag —> Abacus
Шесть переходов:
E) Emerald —> Hum —> Phys —> Arts —> Eng —> Ag —> Abacus
F) Emerald —> Hum —> Phys —> Arts —> Math —> Ag —> Abacus
G) Emerald —» Hum —> Arts —> Eng —» Ag —> Math —» Abacus
24 Часть I. Основы маршрутизации
Семь переходов:
Н) Emerald —> Hum —> Chem —» Math —> Arts —> Eng —> Ag —» Abacus
I) Emerald —> Hum —» Phys —» Arts —> Eng —» Ag —> Math —» Abacus
И, наконец, восемь переходов:
J) Emerald —> Hum —> Chem —> Math —> Arts —» Eng —> Ag —> Math —» Abacus
В табл. 1.3 показана стоимость каждого из этих маршрутов. Как видите, наилучший мар-
шрут— В. Если бы учитывалось только число переходов, а не скорость соединений, крат-
чайшими стали бы маршруты А и В, хотя в таблице маршрут А занимает только третье место.
Таблица 1.3. Стоимости маршрутов в демонстрационной сети по алгоритму Беллмана-Форда
Маршрут Стоимости Итог
А 2+1+3+3 9
В 2+1+1+3 7
С 2+1+1+1+3 8
D 2+1+3+1+2 9
Е 2+1+1+1+1+2 8
F 2+1+1+1+1+2 8
G 2+1+1+1+1+3 9
Н 2+1+3+1+1+1+2 . 11
I 2+1+1+1+1+1+3 10
J 2+1+3+1+1+1+1+3 13
Следует помнить о том, что в протоколе RIP-1 точки, находящиеся на расстоянии бо-
лее 15 переходов, считаются недоступными. Это историческое ограничение протокола,
так как он разрабатывался в те времена, когда серверы были очень дорогими, а сети — от-
носительно маленькими. Из этого следует, что в крупных сетях с более чем пятнадцатью
маршрутизаторами (точнее, переходами) на одном пути протокол RIP-1 использовать
нельзя. Он применяется в пределах сетевых групп, например в офисных или университет-
ских зданиях с разветвленной сетевой структурой.
Зачастую протокол RIP-1 считается “наименьшим общим знаменателем”, так как он
поддерживается в большинстве систем. Когда неизвестно, с какими протоколами работа-
ют удаленные маршрутизаторы, используйте для надежности протокол RIP-1.
Маршрутизатор, работающий по протоколу RIP-1, хранит свои данные в таблице мар-
шрутизации. В ней находится информация о следующих компонентах.
Сетевые шлюзы. Это компьютеры, имеющие более одного сетевого интерфейса
(например, несколько Ethernet-плат или IP-псевдонимов, если это Linux-шлюз), ка-
ждый из которых ведет в другую подсеть или сеть.
Маршрутизаторы. Это координаторы трафика в информационной магистрали.
Узлы. Это отдельные компьютеры, заслуживающие особого внимания, например
компьютеры, находящиеся в виртуальных частных сетях.
Маршрутизатор время от времени посылает копии таблицы своим прямым соседям и
получает от них маршрутные обновления. Получив обновленную таблицу от одного из
своих соседей, маршрутизатор проверяет, не изменились ли в том направлении метрики
стоимости. Предположим, к примеру, что маршрутизатор Emerald получил обновление от
маршрутизатора Hum. Emerald знает о том, что стоимость маршрута до Hum равна двум,
поэтому он прибавляет значение 2 ко всем метрикам стоимости, указанным в полученной
Глава 1. Протоколы одноадресной маршрутизации 25
таблице, и сравнивает новые маршруты с имеющимися. В таблице маршрутизации прото-
кола RIP-1 содержатся следующие данные:
IP-адрес сети или узла, куда ведет маршрут;
первый шлюз, через который следует пройти, чтобы попасть по заданному адресу;
аппаратный интерфейс, через который можно попасть на шлюз;
метрика стоимости маршрута;
время последнего обновления маршрута.
Если значения метрик стоимости в двух аналогичных строках не совпадают, маршрут
из таблицы Hum копируется в таблицу Emerald (как уже было сказано, к значению метри-
ки добавляется 2).
Побеждает лучший
Каждому маршруту в таблице протокола RIP-1 соответствует одна запись. Сохраняется только
информация о наилучшем из текущих маршрутов, все остальные результаты вычислений по
алгоритму Беллмана-Форда отбрасываются.
В алгоритме Беллмана-Форда не учитывается тот факт, что какие-то из узлов могут
быть временно недоступны. Но маршрутизатор должен избегать риска посылать данные
машине, которая не функционирует или соединение с которой было разорвано.
В протоколе RIP-1 маршрутные обновления рассылаются каждые 30 секунд. Когда от
какой-то машины поступает обновление, в таблице маршрутизации меняется дата послед-
него изменения. Если маршрутизатор не подавал никаких сигналов в течение 180 секунд,
он помечается в таблице как недоступный. Для этого расстояние до него задается равным:
16 — на единицу больше предельно допустимого расстояния.
Принцип работы
Вернемся к нашей демонстрационной сети. Как уже упоминалось выше, компьютеру
Emerald требуется послать данные на машину Abacus. Компьютеру Emerald известно лишь
то, что для доставки данных в сеть 192.168.13.x нужно направить их через интерфейс, ве-
дущий к маршрутизатору Hum. Тот, в свою очередь, знает, что кратчайший путь в сеть
192-168.13.хлежит через маршрутизатор Arts. Последний посылает данные через маршру-
тизатор Math, который напрямую соединен с машиной Abacus.
Описанная схема работает до тех пор, пока в один прекрасный момент не обнаружива-
ется, что маршрутизатор Arts не подавал “признаков жизни” в течение 180 секунд (шесть
проверок подряд). Маршрутизатор Hum помечает узел Arts как недоступный и сообщает
об этом компьютеру Emerald. В результате путь от Emerald к Abacus исчезает, ведь в таб-
лице маршрутизации протокола RIP-1 ему соответствует одна-единственная строка.
Причина возникшей проблемы может быть разной.
Маршрутизатор Arts был намеренно удален. На нем произошел аппаратный сбой, и
замена ему будет найдена только через неделю.
Не дожидаясь, пока маршрутизаторы сами обнаружат источник проблемы, админи-
стратор явно сообщает маршрутизатору Phys о том, что новая стоимость перехода к
узлу Ai ts равна 16, т.е. этот узел недоступен. Выждав привычные 30 секунд, маршру-
тизатор Phys рассылает своим соседям обновления. В рассылке указываются все
маршруты, известные на узле Phys.
Единственным соседом маршрутизатора Phys теперь является узел Hum. Phys сооб-
щает ему список сетей, маршрут к которым ему известен, а также стоимость перехо-
26 Часть I. Основы маршрутизации
да к каждой из сетей. В этом списке указано, что стоимость перехода от Phys к Arts
равна 16. Маршрутизатор Hum знает о том, что стоимость перехода от него к Phys
равна единице, поэтому он складывает обе стоимости и записывает для себя, что
общая стоимость маршрута к Arts через Phys равна 17. Проблемы пока что не возни-
кает, так как узел Phys не является частью маршрута к сети 192.168.13.x.
Но через 180 секунд, не получив сведений от узла Arts, маршрутизатор Hum осозна-
ет, что узел Arts недоступен, и устанавливает стоимость перехода к нему равной 16.
Проблема заключается в том, что маршрутизатор Hum не знает другого способа по-
падания в сеть 192.168.13.x, кроме как через узел Arts. Теперь любые данные, посту-
пающие от компьютера Emerald и адресованные в сеть 192.168.13.x, будут возвра-
щаться обратно или просто исчезать. То же самое со временем произойдет и на всех
других маршрутизаторах, которым требуется пересылать данные через узел Arts.
Маршрутизатор Arts был намеренно удален, и замены ему не предвидится. Админи-
стратор обращается к маршрутизатору Chem и обновляет его таблицы, заменяя
маршруты через узел Arts маршрутами через узел Math.
Администратор маршрутизатора Chem удаляет из таблицы узел Arts и пересчитыва-
ет массив расстояний. Через 30 секунд после изменения таблицы маршрутизатор
Chem сообщает своим соседям Math и Hum о том, что они могут обращаться к не-
доступным сетям через него. Стоимость маршрута от Chem к Abacus через Math
равна шести (3+3). Это значение записывается в таблицу маршрутизации узла Chem
как стоимость доступа к сети 192.168.13.x. Маршрутизатор Hum знает о том, что
стоимость перехода от него к Chem равна единице, поэтому он сообщает узлам Em-
erald и Phys о появлении нового маршрута к сети 192.168.13.x со стоимостью 7
(3+3+1). Эта информация распространяется по сети до тех пор, пока работа сети не
стабилизируется.
Соединение маршрутизатора Arts с сетью временно вышло из строя, что привело к
изоляции маршрутизатора, компьютеров подключенной к нему сети, а также всех
остальных сетей, данные к которым передаются через этот маршрутизатор. Соеди-
нение остается неактивным в течение трех часов.
К тому времени, когда соединение восстановится, все соседние маршрутизаторы
давно уже пометят узел Arts как недоступный и сообщат об этом всем остальным
маршрутизаторам демонстрационной сети. Начав снова функционировать, маршру-
тизатор Arts также обнаружит, что соседние маршрутизаторы недоступны. Сцена-
рий решения этой проблемы описан в конце данного раздела.
Во всех описанных случаях возникает одна общая проблема. Маршрутизаторы посы-
лают обновления всем своим соседям, даже тем, от которых они сами только что получи-
ли обновление. Если маршрутизатор будет слепо доверять своим соседям, возникнет хаос.
Маршрутизатор мог пометить соседний узел как недоступный, а другой маршрутизатор
продолжает сообщать ему, что все в порядке, хотя это не так. Пока маршрутизаторы спо-
рят друг с другом, пакеты данных теряются.
Разрубить гордиев узел помогает метод, называемый простым сужением обзора (simple
split horizon). В нем используется правило здравого смысла: не нужно посылать обновле-
ния маршрутизатору, от которого они только что были получены. Рассмотрим еще раз си-
туацию, когда маршрутизатор Arts выходит из строя. В сценарии 1 администратор сооб-
щает маршрутизатору Phys о том, что узел Arts недоступен. Тридцать секунд спустя мар-
шрутизатор Phys включает эти данные в свою таблицу, помечает некоторые сети как
недоступные и делится информацией со своими соседями, т.е. с маршрутизатором Hum.
Глава 1. Протоколы одноадресной маршрутизации 27
Через 30 секунд то же самое делает маршрутизатор Hum. Его соседями будут узлы Phys,
Emerald и Chem, но благодаря сужению обзора информацию о маршрутах через Phys по-
лучат только узлы Emerald и Chem. Правда, маршрутизатор Hum располагает также ин-
формацией о маршрутах, не проходящих через узел Phys, и ею он поделится с ним.
Далее маршрутизатор Chem сообщает об обновлениях маршрутизатору Math, но не посы-
лает узлу Hum его же данные. Маршрутизатор Math делится информацией с узлами Ag и Abacus.
Узел Abacus передает данные маршрутизатору Ag, а тот — узлам Eng и Abacus (здесь нет проти-
воречия, так как обмен обновлениями между узлами Ag и Abacus происходит одновременно, а
не последовательно). Схема распространения информации изображена на рис. 1.10.
Рис. 1.10. Распространение маршрутных обновлений по методу простого сужения обзора
Метод простого сужения обзора позволяет избежать образования петли между двумя
маршрутизаторами, обменивающимися устаревшей информацией. Суть в том, что мар-
шрут, не включаемый в сообщения об обновлении (ложная ветвь петли), через опреде-
ленное время, т.е. несколько циклов, устареет и будет удален из таблицы. Это не идеаль-
ный подход, но применять его эффективнее, чем позволить противоречивой информа-
ции многократно передаваться между компьютерами.
В протоколе RIP-1 в действительности применяется метод сужения обзора с обратным ис-
правлением (split horizon with poisoned reverse). По сути, он означает возврат к тому, что
было раньше. Маршрутизаторы рассылают обновления всем своим соседям, даже тем, от
которых была получена эта информация. Разница вот в чем. Обратимся к сценарию 3.
Маршрутизатор Phys сообщает маршрутизатору Hum о том, что узел Arts вновь заработал
и стоимость перехода до него равна единице. Маршрутизатор Hum оповещает об этом уз-
лы Emerald и Chem, одновременно информируя узел Phys о том, что стоимость перехода
от Hum до Arts через Phys равна 16, т.е. бесконечность. Непонятно? Давайте проанализи-
руем эту ситуацию пошагово.
1. Соединение маршрутизатора Arts с сетью восстанавливается.
2. К этому времени все машины перестали работать с маршрутизатором Arts, а тот
пометил как недоступные всех своих соседей.
3. Администратор маршрутизатора Phys узнает о том, что узел Arts заработал, и вручную
восстанавливает в таблице маршрутизации прежнюю стоимость перехода к узлу Arts (1).
4. Тридцать секунд спустя маршрутизатор Phys посылает обновления узлам Hum и
Arts, сообщая первому о том, что узел Arts заработал, а второму — что у него появи-
лись соседи.
28 Часть I. Основы маршрутизации
5. Чтобы не усложнять пример, мы оставим в покое маршрутизатор Arts и посмотрим,
что происходит на узле Hum. Используя метод сужения обзора с обратным исправ-
лением, маршрутизатор Hum посылает следующее обновление узлам Emerald, Phys,
Arts и Chem, но данные для узла Phys отличаются от остальных. Маршрутизатор
Hum сообщает узлу Phys о всех своих маршрутах, но тем из них, которые проходят
через узел Phys, назначается стоимость 16.
6. Обновления распространяются до тех пор, пока все маршрутизаторы не узнают о
появлении узла Arts.
Данный вариант метода позволяет немедленно разорвать петлю между двумя маршру-
тизаторами, если она существует.
Как видите, протокол RIP-1 относительно прост. В нем есть базовые средства опреде-
ления того, какие машины доступны, но он оказывается слишком ненадежным в сетях с
часто изменяемой топологией. В Linux этот протокол реализован в демоне routed. Мож-
но также применять мультипротокольные демоны gated и zebra. Обо всех них рассказы-
вается в главе 5, “Демоны одноадресной маршрутизации в ядре 2.2.x”.
Протокол RIP-2
Протокол RIP версии 2 (RIP-2) является обновленной версией исходной специфика-
ции RIP. В нем есть ряд дополнительных особенностей, которые делают данный протокол
гораздо привлекательнее для сетевых администраторов, чем RIP-1, особенно в свете не-
хватки адресного пространства. Первое из нововведений — это возможность добавления
информации, собранной по протоколу EGP, о котором пойдет речь в главе 3, “Введение в
протоколы пограничной маршрутизации”.
В пакетах RIP-2 зарезервировано место, в которое помещаются данные EGP, перено-
симые от маршрутизатора к маршрутизатору. Вернемся к демонстрационной сети, изо-
браженной на рис. 1.9. Там она показана как бы изолированной, но на самом деле в одной
из точек она имеет выход в Internet.
Предположим, через маршрутизатор Phys вся кампусная сеть подключается к провай-
деру Internet (рис. 1.11). В самой сети теперь используется протокол RIP-2, а не RIP-1.
Маршрутизатор Campus работает с другим протоколом: EGP (рис. 1.12).
Рис. 1.11. Соединение демонстрационной сети с
внешним миром
Глава 1. Протоколы одноадресной маршрутизации 29
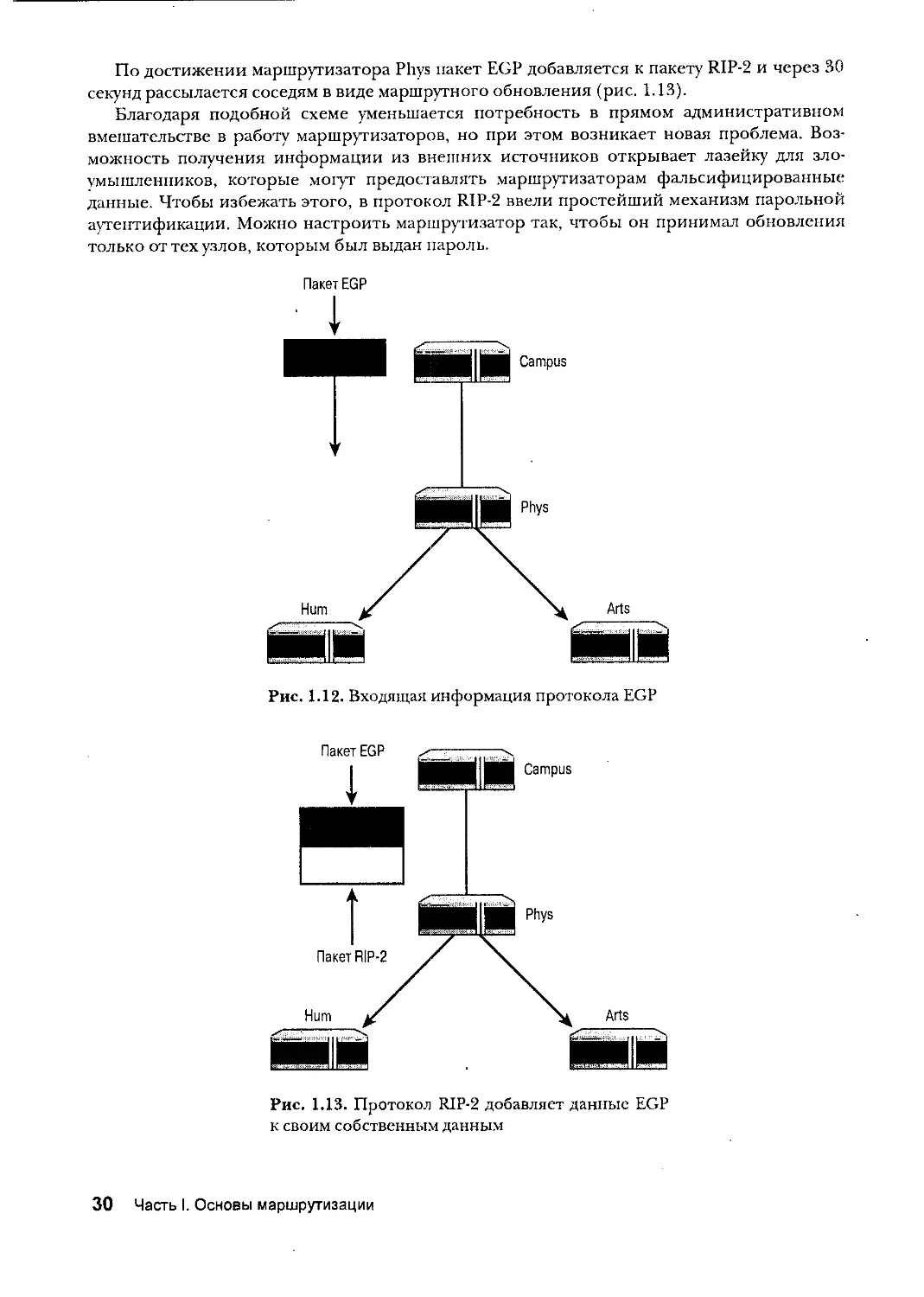
По достижении маршрутизатора Phys пакет EGP добавляется к пакету RIP-2 и через 30
секунд рассылается соседям в виде маршрутного обновления (рис. 1.13).
Благодаря подобной схеме уменьшается потребность в прямом административном
вмешательстве в работу маршрутизаторов, но при этом возникает новая проблема. Воз-
можность получения информации из внешних источников открывает лазейку для зло-
умышленников, которые могут предоставлять маршрутизаторам фальсифицированные
данные. Чтобы избежать этого, в протокол RIP-2 ввели простейший механизм парольной
аутентификации. Можно настроить маршрутизатор так, чтобы он принимал обновления
только от тех узлов, которым был выдан пароль.
Пакет EGP
Рис. 1.12. Входящая информация протокола EGP
Рис. 1.13. Протокол RIP-2 добавляет данные EGP
к своим собственным данным
30 Часть I. Основы маршрутизации
Администраторы в нашей демонстрационной сети доверяют друг другу. Но чтобы не
использовать один пароль на всех маршрутизаторах, каждый из администраторов выби-
рает свой пароль и посылает его соседям. Понятно, что передача пароля по электронной
почте — не самый безопасный вариант, но можно воспользоваться системой шифрования,
например PGP. Далее администраторы вносят полученные пароли в текстовом виде в
конфигурационные файлы для каждого из соседей. Например, маршрутизатор Phys полу-
чит пароли доступа к маршрутизаторам Campus, Hum и Arts. Если есть соседи, от которых
не нужно принимать обновления, администратор просто не высылает им пароль. При от-
сутствии пароля данные по-прежнему будут передаваться между маршрутизаторами, про-
сто соседи не смогут менять содержимое недоступных им таблиц маршрутизации.
Еще одной интересной особенностью протокола RIP-2 является возможность сообщать
другим маршрутизаторам RIP-2 об альтернативных маршрутах, где используются иные про-
токолы. Для этого на одном маршрутизаторе должны функционировать оба протокола: RIP-2
и второй, альтернативный. Рассмотрим еще раз демонстрационную сеть. Предположим, се-
ти, которые подключены к маршрутизаторам Chem и Math, имеют сложную структуру с
большим количеством кафедральных подсетей и отдельных рабочих групп в пределах ка-
федр. Поэтому было принято решение, что для обслуживания таких сетей вместо протокола
RIP-2 должен использоваться другой протокол. Какой — не имеет значения.
В случае протокола RIP-1 маршрутизаторы Chem и Math потеряли бы возможность пе-
редавать своим соседям маршрутные обновления. Если же в дополнение к альтернативно-
му протоколу установить на этих маршрутизаторах протокол RIP-2, то обновления будут
продолжать рассылаться, так как протокол RIP-2 выступит в роли транслятора.
Наконец, еще одна важная особенность протокола RIP-2, делающая его столь полез-
ным в современном мире Internet, заключается в том, что вместе с информацией о мар-
шруте передается маска подсети. По сути, отсутствие этой возможности в RIP-1 и послу-
жило причиной появления новой версии протокола. Одно из решений проблемы сокра-
щения адресного пространства как раз и состоит в том, что вместо единой сетевой маски
применяются маски подсетей переменной длины.
Как видите, протокол RIP-2 гораздо сложнее, чем RIP-1. Он лучше справляется с об-
новлением информации о маршрутах и более адаптирован к современным Internet-
технологиям. Тем не менее он тоже неприменим в глобальных сетях. В Linux этот прото-
кол реализован в демонах gated и zebra. Оба демона способны одновременно работать с
несколькими протоколами.
Протокол OSPF
OSPF (Open Shortest Path First — открытый протокол первоочередного обнаружения
кратчайших маршрутов) относится к семейству топологических протоколов, или протоко-
лов состояния канала. Это означает, что в нем отслеживается гораздо меньше информации,
чем, скажем, в RIP-2. В топологических протоколах используется совершенно иной метод
выбора маршрутов, чем в дистанционно-векторных протоколах.
Алгоритм
Топологические протоколы основаны на алгоритмах первоочередного обнаружения
кратчайших маршрутов. Изначально эти алгоритмы применялись в теории графов и лишь
затем были перенесены в сетевые протоколы. В случае OSPF используется алгоритм Дейк-
стры. Мы будем анализировать ту же сеть, которая была изображена на рис. 1.4.
В данном случае нужно заранее определить, какие точки сети соединены друг с другом.
Здесь нет необходимости строить граф, где каждый узел связан с каждым. Кроме того,
граф теперь является направленным. Иногда один узел может обращаться к соседу, а об-
Глава 1. Протоколы одноадресной маршрутизации 31
ратное соединение невозможно. Иногда стоимость соединения в противоположных на-
правлениях разная. Мы возьмем за основу структуру сети, представленную на рис. 1.9, но
применим к ней иную схему вычисления стоимости, учитывающую оба направления тра-
фика (рис. 1.14).
Рис. 1.14. Демонстрационная сеть с двунаправленными путями пере-
дачи данных
Вернемся к табл. 1.1. Маршруты, где данные передаются по технологии Tl, ТЗ или
ISDN, будут иметь одинаковую полосу пропускания в обоих направлениях. Там же, где ис-
пользуется технология DSL или модем на 56 Кбит/с, ситуация иная. В трех наиболее по-
пулярных вариантах DSL линия передачи разделяется на два канала (рис. 1.15), а в четвер-
том варианте каналов вообще четыре.
передача )
. прием
Рис. 1.15. Передача данных в двух типах DSL-соединений
В технологии ADSL (Asymmetric Digital Subscriber Line — асимметричная цифровая
абонентская линия) данные передаются по двум разнонаправленным каналам с неодина-
ковой пропускной способностью. Даже когда один канал переполняется, данные не начи-
нают “перетекать” во второй канал. В технологии HDSL (High-speed DSL) каналов четыре,
и пропускная способность у них одинаковая. Технология IDSL (ISDN DSL) является гиб-
ридом технологий ISDN и DSL. В ней соединение является постоянно открытым, тогда
как в других вариантах соединение устанавливается по запросу. В технологии SDSL
(Symmetric DSL) используются два разнонаправленных канала с одинаковой пропускной
способностью. Для наглядности предположим, что указанное в табл. 1.1 DSL-соединение
относится к типу ADSL.
32 Часть I. Основы маршрутизации
Интересна также ситуация с модемом. Это устройство имеет разные скорости приема
и передачи данных. Скорость 56 Кбит/с возможна только при загрузке данных, если во-
обще достижима. Скорость передачи во многих моделях ограничена величиной
33,6 Кбит/с, но даже если этот показатель выше, он все равно оказывается меньшим ско-
рости приема. С учетом всего вышесказанного построим новую схему стоимостей перехо-
дов в демонстрационной сети (рис. 1.16).
Рис. 1.16. Стоимости переходов в демонстрационной сети при исполь-
зовании протокола OSPF
Теперь, когда маршруты и стоимости переходов выяснены, настало время искать
кратчайшие пути. Как всегда, мы начнем с компьютера Emerald. Единственный узел, на
который можно попасть с узла Emerald, — это Hum (рис. 1.17).
Emerald
Рис. 1.17. Первая итерация алгоритма Дейкстры
От узла Hum можно пойти в трех разных направлениях, не считая компьютер Emerald
(нельзя пройти одну и ту же точку дважды): Phys, Arts и Chem. Расстояния по каждому на-
правлению равны 2, 1 и 2 соответственно. Второе является наименьшим, поэтому крат-
чайший маршрут пока что выглядит так: Emerald —> Hum —> Arts (рис. 1.18).
Phys
Рис. 1.18. Вторая итерация алгоритма Дейкстры; выделенные линии
обозначают кратчайший маршрут
Глава 1. Протоколы одноадресной маршрутизации 33
Следующая итерация начинается сразу в трех точках: Arts, Phys и Chem. Поскольку че-
рез одну и ту же точку нельзя пройти дважды, узел Phys выбывает из игры и перестает уча-
ствовать в дальнейших итерациях. Но суть алгоритма в том, что ищется не один конкрет-
ный маршрут, а кратчайшие маршруты от узла Emerald к любому другому узлу сети. Так что
маршруты, изображенные на рис. 1.18 более тонкими линиями, тоже запоминаются.
В игре остались узлы Arts и Chem. Маршрутизатор Arts имеет доступ к неиспользовав-
шимся ранее узлам Eng и Math. Для маршрутизатора Chem свободных узлов не остается,
поэтому он тоже становится тупиковым (рис. 1.19).
Phys Eng
Emerald
Chem
Arts
Math
Рис. 1.19. Частичная третья итерация алгоритма Дейкстры
Обратите внимание на одинаковую стоимость перехода от узла Arts на узлы Eng и Math.
Это не имеет значения с точки зрения выбора того, куда должны быть направлены дан-
ные, но важно для определения центрального кратчайшего пути. Маршрутизаторы, нахо-
дящиеся на кратчайшем пути, будут первыми обслуживаться на каждой итерации.
В протоколе OSPF проблема выбора решается за счет метода распределения нагрузки, т.е.
протокол выбирает оба маршрута, с тем чтобы поток данных передавался максимально
быстро. Но это не помогает нам в самом алгоритме. В данном случае выбирается узел, по-
сле которого нужно сделать меньшее число переходов (рис. 1.20).
Phys Eng
Hum
Chem
Рис. 1.20. Завершение третьей итерации алгоритма Дейкстры
34 Часть I. Основы маршрутизации
На четвертой итерации проверяются маршрутизаторы Eng и Math. Первый имеет дос-
туп к узлу Ag, а второй — к узлам Ag и Abacus. Но маршрутизатор Math имеет приоритет,
так как он стоит на центральном кратчайшем пути, поэтому узел Eng оказывается тупико-
вым. Конечный результат работы алгоритма представлен на рис. 1.21.
Phys Eng
Ao
Chem
Рис. 1.21. Завершение последней итерации алгоритма Дейкстры; выделенные
линии обозначают кратчайший маршрут, а тонкие линии ведут к тупиковым
узлам
Принцип работы
Разобравшись с работой алгоритма Дейкстры, рассмотрим применение протокола
OSPF в нашей демонстрационной сети. Этот протокол намного сложнее, чем RIP-2, так
что объяснение будет непростым. Как всегда, требуется передать данные от машины Em-
erald к машине Abacus. Компьютеру Emerald известно следующее.
Какие сетевые интерфейсы ведут к каким маршрутизаторам в пределах текущей об-
ласти.
Область в OSPF — это обособленная совокупность сетей, в рамках которой распро-
страняется информация о состоянии канала. В рассматриваемом случае демонстра-
ционная сеть представляет собой отдельную область, а маршрутизатор Phys являет-
ся назначенным.
Назначенный маршрутизатор собирает данные о состоянии канала от остальных
маршрутизаторов области и рассылает итоговый отчет. Он также отвечает за связь с
соседними областями, посылая им маршрутные резюме. Маршрутизаторы, находя-
щиеся за пределами данной области, видят только ее назначенный маршрутизатор.
Они направляют весь трафик ему, а он на основании своих маршрутных таблиц оп-
ределяет реального получателя пакетов.
Область никогда не существует сама по себе, иначе в ней нет никакого смысла. Груп-
пы областей формируют автономную систему (АС), находящуюся под единым адми-
нистративным контролем. Концептуальная связь компонентов изображена на
рис. 1.22. Маршрутизатор Phys имеет сетевые интерфейсы в обеих областях. В авто-
номной системе есть также пограничный маршрутизатор, осуществляющий ее связь
с внешним миром, т.е. с другими автономными системами.
Глава 1. Протоколы одноадресной маршрутизации 35
Рис. 1.22. Демонстрационная сеть находится в своей собственной об-
ласти, входящей в состав автономной системы
Размер таблицы маршрутизации
Размер маршрутных таблиц очень важен независимо от используемого протокола. Первоначаль-
но никто не задумывался над данной проблемой, поскольку в конце 60-х— начале 70-х гг. (когда
еще существовала сеть ARPANET) подключенных к сети компьютеров было очень мало. Сего-
дня, конечно же, ситуация совсем другая.
Причина, по которой старые протоколы маршрутизации, такие как RIP-1 и RIP-2, неэффективны в
крупных сетях, заключается в том, что все маршрутизаторы вынуждены хранить информацию о
каждой существующей сети или подсети. Чем больше становится таблица маршрутов, тем
дольше занимает поиск данных в ней.
Появление новых протоколов и внедрение средств сегментации сетей, в частности областей,
автономных систем и др., позволили администраторам существенно уменьшить размеры
маршрутных таблиц. Зато сильно усложнилась программная логика маршрутизаторов.
Стоимость передачи данных через каждый из интерфейсов.
В OSPF метрика стоимости не рассматривается как показатель расстояния. На осно-
вании метрик определяется лишь, какие интерфейсы способны пропускать больший
объем трафика, а какие — меньший.
Дерево кратчайших путей.
Компьютер Emerald будет располагать информацией, вычисленной нами выше и
схематически представленной на рис. 1.21. Помните о том, что в OSPF каждый ком-
пьютер имеет свое собственное дерево кратчайших путей.
36 Часть I. Основы маршрутизации
Маршрут отправки данных в опорную магистраль и стоимость этого маршрута.
Компьютер Emerald с помощью алгоритма Дейкстры уже определил кратчайшие пути
ко всем остальным маршрутизаторам. Ему теперь известен не только следующий переход,
но и каждый шаг на пути доставки данных в нужную точку. Остается просто отправить
данные маршрутизатору Hum, который осуществит их дальнейшую пересылку.
Маршрутизатор Hum тоже хранит всю карту сети с указанием метрик стоимости в
обоих направлениях, но центральный кратчайший маршрут он вычисляет самостоятель-
но. Результат этих вычислений изображен на рис. 1.23.
Рис. 1.23. Результаты алгоритма Дейкстры с точки зрения маршрутизатора Hum
Маршрутизатор Hum определил, что кратчайший путь к узлу Abacus пролегает через
узел Arts, поэтому он посылает данные туда. У маршрутизатора Arts своя собственная схема
центрального кратчайшего пути (рис. 1.24).
Chem
Рис. 1.24. Результаты алгоритма Дейкстры с точки зрения маршрутизатора Arts
После маршрутизатора Arts данные попадают на узел Math и, наконец, на узел Abacus.
Итак, основной алгоритм нам понятен. Рассмотрим более сложный случай. Что если
пресловутый маршрутизатор Arts выйдет из строя, как это было в случае протокола RIP-1?
Глава 1. Протоколы одноадресной маршрутизации 37
Проанализируем аналогичные три сценария, чтобы подчеркнуть различия между прото-
колами RIP-1 и OSPF.
Сценарий 1: маршрутизатор Arts был намеренно удален. На нем произошел аппа-
ратный сбой, и замена ему будет найдена только через неделю.
Все маршрутизаторы, работающие по протоколу OSPF, регулярно (в соответствии
со значением переменной Hellolnterval) проверяют состояние канала с помо-
щью протокола HELLO. Это отдельный коммуникационный протокол, применяе-
мый исключительно для связи с соседними маршрутизаторами в OSPF (теми, к кото-
рым данный маршрутизатор подключен напрямую) и для поддержания соединения
открытым в обоих направлениях. В протоколе HELLO используются специальные
пакеты HELLO. В таком пакете описывается пославший его маршрутизатор: его ад-
рес, стоимость перехода через его сетевые интерфейсы и адреса соседей.
Соседи маршрутизатора Arts (Hum, Eng и Math) благополучно рассылают пакеты
HELLO и получают на них ответы. Но по прошествии времени, указанного в пере-
менной Hellolnterval, соседи замечают, что от маршрутизатора Arts ничего не
слышно. С этого момента начинается отсчет времени, заданного в переменной
RouterDeadlnterval. Если по его истечении маршрутизатор не даст о себе знать,
соседи пометят его как недоступный.
Отказавшись работать с узлом Arts, каждый из маршрутизаторов Hum, Phys и Math
самостоятельно строит новое дерево кратчайших путей. Например, на рис. 1.25
изображены новые результаты алгоритма Дейкстры, полученные на узле Hum.
Hum
Emerald
Phys
Eng
Ag
Abacus
Math
2
2
Chem
Рис. 1.25. Новое дерево кратчайших путей, построенное на узле Hum
после выхода из строя маршрутизатора Arts
Когда маршрутизаторы Hum, Phys и Math начнут посылать обновленные пакеты
HELLO своим соседям, те заметят отсутствие упоминания о маршрутизаторе Arts и
тоже выполнят перерасчеты кратчайших путей.
Сценарий 2: маршрутизатор Arts был намеренно удален, и замены ему не предвидится.
В случае протокола RIP-1 здесь требовалось административное вмешательство. Од-
нако в протоколе OSPF маршрутизаторы быстро все узнают сами и строят новые
маршрутные таблицы, как описано в сценарии 1.
38 Часть I. Основы маршрутизации
Сценарий 3: соединение маршрутизатора Arts с сетью временно вышло из строя, что
привело к изоляции маршрутизатора, компьютеров подключенной к нему сети, а
также всех остальных сетей, данные к которым передаются через этот маршрутиза-
тор. Соединение остается неактивным в течение трех часов.
Сначала все развивается так, как в сценарии 1. Информация об отсутствии маршру-
тизатора Arts мигом разносится по сети. А вот когда маршрутизатор снова появляет-
ся в сети, все происходит совершенно по-другому, чем в протоколе RIP-1.
В момент своего появления маршрутизатор Arts осуществляет широковещательную
рассылку пакетов HELLO. Все соседи (Phys, Hum, Eng и Math) получат эти пакеты и
ответят на них маршрутизатору Arts. Впоследствии, когда соседи будут рассылать
свои собственные пакеты HELLO, они включат в них информацию о маршрутиза-
торе Arts, благодаря чему о нем узнает вся сеть. Административное вмешательство
здесь также не требуется.
Протокол OSPF и аутентификация
! Следует помнить о том, что все маршрутизаторы области применяют одинаковую схему аутенти-
фикации, а в разных областях одной автономной системы могут использоваться разные схемы.
Это удобный способ разделения сети на зоны, защищенные сильнее или слабее, что особенно
эффективно в сочетании с другими мерами защиты.
OSPF-пакеты проходят также проверку контрольных сумм. Получив пакет, маршрутизатор прове-
ряет, содержится ли в нем столько битов, сколько было на момент отправки. Если пакет
поврежден или изменен, он не будет принят.
Проблема заключается в том, что, если кто-то подключится к линии, соединяющей два мар-
шрутизатора, он сможет установить анализатор пакетов — программу, которая перехватывает
все пакеты, идущие по заданному адресу. С ее помощью можно узнать пароль, записанный в
пакете. Средства защиты, имеющиеся в протоколе OSPF, не помогают избежать подобной
ситуации.
Теперь рассмотрим функционирование автономной системы в целом. Как было изо-
бражено на рис. 1.22, система состоит из двух областей. Маршрутизатор Phys является на-
значенным. Это означает, что он считается соседом каждого маршрутизатора в своей об-
ласти. Все маршрутизаторы посылают ему пакеты HELLO, а он отвечает на них. Таким
образом, он постоянно отслеживает топологию области. Кроме того, маршрутизатор Phys
является пограничным, поскольку имеет сетевые интерфейсы в нескольких областях.
На рис. 1.26 представлена структура второй области (это сети университетских обще-
житий, подключенные к общей кампусной сети). Назначенным в ней является маршрути-
затор East, дерево кратчайших путей которого изображено на рис. 1.27. Теперь следует
сделать важное замечание. Раньше под маршрутизатором Phys понималась машина нашей
демонстрационной сети, так как ничего не было известно о дополнительных областях.
В действительности имя Phys соответствует Ethernet-плате, напрямую подключенной к
кампусной сети. А имя East закреплено за Ethernet-платой, которая напрямую подключена
к сети общежитий.
Дерево кратчайших путей каждой области хранится отдельно, а на самом маршрутиза-
торе Phys/East работают два OSPF-демона — по одному для каждой области. Все OSPF па-
кеты помечаются идентификатором области, из которой они поступили, поэтому “утечки”
пакетов в соседнюю область не происходит.
Взглянем на ситуацию еще шире. У каждой автономной системы должна быть точка
приема и передачи данных, связанных с внешним миром. Это требует наличия как мини-
мум одного (лучше двух) пограничных маршрутизаторов АС. Предположим, у нашей авто-
номной системы один такой маршрутизатор (рис. 1.28).
Глава 1. Протоколы одноадресной маршрутизации 39
Рис. 1.26. Вторая область автономной системы, где маршрутизатор East
является другим интерфейсом маршрутизатора Phys
Рис. 1.27. Дерево кратчайших путей маршрутизатора East
40 Часть I. Основы маршрутизации
Пограничный маршрутизатор АС будет принимать маршрутные уведомления из внеш-
него мира, а также посылать свои уведомления во внешний мир. Такие сообщения назы-
ваются внешними канальными анонсами. Эта информация передается Всем маршрутизато-
рам автономной системы, но стоимость маршрутов может быть разной.
Тип 1. Алгоритм вычисления кратчайшего пути расширяется за пределы АС. В дан-
ном случае учитывается стоимость каждого дополнительного перехода.
Тип 2. То же, что и в предыдущем случае, но внешним переходам назначается до-
бавленная стоимость, чтобы они всегда стоили больше, чем любой внутренний
маршрут.
Нужно понимать, что маршрутизаторы Phys и East не становятся назначенными мар-
шрутизаторами своих областей просто так. Выбор назначенного и резервного назначен-
ного маршрутизаторов осуществляется в ходе общения по протоколу HELLO на основа-
нии приоритетов маршрутизаторов. Чем выше приоритет маршрутизатора, тем больше у
него шансов быть выбранным.
Любая область автономной системы должна быть внутренне согласованной. В табл. 1.4
перечислены параметры, которые должны быть одинаковыми у всех маршрутизаторов
области (в случае пограничного маршрутизатора — у всех его интерфейсов).
Глава 1. Протоколы одноадресной маршрутизации 41
Таблица 1.4. Параметры маршрутизаторов OSPF, которые должны быть идентичными в
пределах области
Установка Назначение
Идентификатор области Резервный назначенный маршрутизатор Назначенный маршрути- затор Тип Позволяет различать пакеты данной области IP-адрес интерфейса, ведущего к резервному назначенному маршру- тизатору IP-адрес интерфейса, ведущего к назначенному маршрутизатору Тип сети, в которую ведет данный интерфейс: широковещательная, нешироковещательная, двухточечная или виртуальный канал
Необходимо также добиться внутреннего согласования сетей. Если к одной сети под- ключено несколько маршрутизаторов (например, для достижения избыточности), то у каждого из них должен быть ряд одинаковых установок (табл. 1.5). Таблица 1.5. Параметры маршрутизаторов OSPF, которые должны быть идентичными в пределах сети
Установка Назначение
Hellolnterval Сетевая маска RouteгDeadinterval Число секунд, в течение которых маршрутизатор OSPF ждет, прежде чем послать следующий пакет HELLO Маска данной сети или 0, если это двухточечная сеть или виртуаль- ный канал Число секунд с момента получения последнего пакета HELLO, в тече- ние которых маршрутизатор OSPF ждет, прежде чем пометить мар- шрутизатор как недоступный
Пакеты HELLO и тип сети
Работа с OSPF-пакетом HELLO ведется по-разному в зависимости от типа сети, в которую он
помещается. Если это нешироковещательная сеть, то все маршрутизаторы OSPF данной сети
должны вести список соседей и их приоритетов, чтобы иметь возможность выбрать назначенный
маршрутизатор. В сетях других типов этого не требуется.
Перечислим, что хранится в таблице маршрутизатора OSPF.
IP-адреса сетей, подсетей и узлов, к которым данный маршрутизатор может направ-
лять информацию.
Сетевая маска, если маршрут ведет к сети или подсети, либо Oxffffffff, если маршрут
ведет к отдельному узлу.
Значение поля TOS (Type Of Service — тип обслуживания), которое будут иметь все
пакеты, направляемые по данному маршруту. Протокол OSPF способен по-разному
обрабатывать пакеты в зависимости от типа обслуживания.
Тип маршрута: внутри области, между соседними областями, тип 1 внешний, тип 2
внешний.
Полная стоимость маршрута.
Если маршрут относится ко второму внешнему типу, указывается стоимость отправ-
ки данных за пределы автономной системы.
Если есть два маршрута к одному и тому же адресу с одинаковой стоимостью', в од-
ной записи хранится информация об обоих маршрутах. Помимо стандартной ин-
формации указывается интерфейс, через который данные будут пересланы следую-
42 Часть I. Основы маршрутизации
щему маршрутизатору, и адрес этого маршрутизатора. Если адресат находится в дру-
гой области или автономной системе, указывается идентификатор маршрутизатора,
через который должны пройти данные.
Наконец, возникает вопрос: каким образом данные передаются между областями,
формируя собственно автономную систему? Подобно сети Internet, у которой есть опор-
ная магистраль, автономная система имеет свою магистраль. Она состоит из пограничных
маршрутизаторов областей, пограничных маршрутизаторов самой АС, а также сетей и
маршрутизаторов, которые не входят ни в какую область.
Если два опорных маршрутизатора не соединены друг с другом напрямую, между ними
нужно образовать виртуальный канал. Этот канал должен быть создан на обоих маршрути-
заторах, которые сделают вид, будто между ними имеется двухточечное соединение.
Стоимость прохода по такому соединению равна стоимости реального пути, который
проделывают данные.
Как видите, протокол OSPF гораздо сложнее протоколов семейства RIP. Он быстро и
эффективно реагирует на изменения структуры сети и повышает ее устойчивость. В Linux
этот протокол реализован в демонах gated и zebra.
Резюме
Протоколы одноадресной маршрутизации, чаще всего применяемые в Linux-сетях, —
это RIP-1, RIP-2 и OSPF. Протокол RIP-1 является одним из самых старых протоколов
маршрутизации в семействе TCP/IP. Он наименее гибок и подходит лишь для небольших
сетей. RIP-2 — более новый и безопасный протокол, хотя он также не подходит для круп-
ных сетей. Наконец, протокол OSPF является самым надежным. Это наилучший выбор,
если сеть должна быстро реагировать на возникающие аппаратные проблемы.
В табл. 1.6 указано, где описан и реализован каждый из рассмотренных протоколов.
Таблица 1.6. Информация о протоколах одноадресной маршрутизации
Протокол Где реализован RFC
RIP-1 routed, gated, zebra 1058
RIP-2 gated, zebra 1721
OSPF gated, zebra 2328
Получить доступ к документам RFC можно на Web-узле www.faqs.org. Программи-
стам будет полезно изучить код проекта libnet на Web-узле www.packetfactory.net,
где показано, как работать с протоколами RIP-1 и OSPF.
Глава 1. Протоколы одноадресной маршрутизации 43
Протоколы многоадресной
маршрутизации
В этой главе...
Протокол RIP-2 44
Протокол MOSPF 45
Протокол DVMRP 45
Протокольно-независимая многоадресная маршрутизация 53
Резюме 57
Протоколы многоадресной маршрутизации осуществляют доставку информации по
IP-адресу (называемому каналом или группой), к которому может подключиться лю-
бой компьютер, поддерживающий режим группового вещания. Маршрутизатор, реали-
зующий такой протокол, не обязан проверять, кто установил связь с группой в данный
момент времени. В общем случае это зависит от используемого протокола.
В этой главе описываются наиболее распространенные протоколы многоадресной
маршрутизации.
Протокол RIP-2
Да, дорогие читатели, ваши глаза вас не обманывают! Протокол RIP-2 поддерживает и
одноадресный, и многоадресный режимы маршрутизации. Маршрутизатор, где использу-
ется этот протокол, можно сконфигурировать на периодическую рассылку обновлений по
групповому адресу (по умолчанию — 224.0.0.9). В протоколе RIP-2 есть четыре установки,
определяющие поведение маршрутизатора.
None. Отмена всех сообщений RIP-1.
RIP-1. Маршрутизатор будет вести себя так, как если бы на нем был реализован
только протокол RIP-1.
RIP-1 Compatibility. Маршрутизатор будет осуществлять широковещательную
рассылку обновлений всем остальным маршрутизаторам, принимая во внимание то,
что некоторым из них информация должна быть предоставлена в формате RIP-1.
RIP-2. Маршрутизатор будет осуществлять многоадресную доставку обновлений.
Все эти параметры влияют лишь на рассылку маршрутных обновлений, но не самих
данных.
Протокол MOSPF
MOSPF (Multicast OSPF) — это версия протокола OSPF, где в пределах автономной сис-
темы разрешена маршрутизация многоадресных пакетов наряду с одноадресными. Здесь
применяется также протокол IGMP (Internet Group Management Protocol — межсетевой
протокол управления группами), определяющий порядок членства в группах многоадрес-
ной рассылки. Поддерживаются и механизмы аутентификации OSPF.
В протоколе MOSPF отслеживается, кто в настоящий момент является членом группы.
Для этого используются знакомые нам запросы протокола HELLO. Каждый маршрутиза-
тор вычисляет свои собственные деревья. Обратите внимание на множественное число.
Для каждой пары отправитель/получатель строится свое дерево. Оно простирается от
источника через маршрутизатор вплоть до сети, где находятся члены группы.
Задумайтесь на секунду о смысле сказанного. Если бы маршрутизатору пришлось стро-
ить деревья для всех возможных отправителей многоадресных сообщений и всех возмож-
ных групп в автономной системе, объем вычислений оказался бы столь огромным, что у
маршрутизатора просто не было бы времени на обработку собственно информационного
трафика. Вместо этого построение дерева откладывается до момента непосредственной
передачи данных.
В механизме группового вещания данные передаются всем членам группы. Это означа-
ет, что по мере прохождения пакета (дейтаграммы) по кратчайшему пути его копия остав-
ляется каждому члену группы. Но дерево кратчайших путей не уникально на каждом мар-
шрутизаторе, как это было в случае протокола OSPF. “Стволом” дерева является маршру-
тизатор, от которого поступают данные. Таким образом, все принимающие маршрути-
заторы строят свои деревья от одной начальной точки. Дерево кратчайших путей в любом
случае окажется одинаковым, просто каждый раз оно строится заново.
Обработка равнозначностей при построении деревьев
Если есть маршруты с одинаковой стоимостью, принцип распределения нагрузки не применяет-
ся. Выбор маршрута зависит от конкретной реализации протокола OSPF.
Интересен тот факт, что протоколы OSPF и MOSPF могут совместно применяться в
рамках области и даже целой автономной системы. Необходимо лишь, чтобы существова-
ла непрерывная цепочка маршрутизаторов, поддерживающих многоадресную доставку
пакетов во все нужные точки автономной системы.
Демон, в котором реализован протокол MOSPF, называется mrouted. О нем рассказы-
вается в главе 6, “Демоны многоадресной маршрутизации в ядре 2.2.x”.
Протокол DVMRP
DVMRP (Distance Vector Multicast Routing Protocol — дистанционно-векторный прото-
кол многоадресной маршрутизации) является потомком протокола RIP-1 и используется
только в пределах одной автономной системы. Он не обрабатывает одноадресные дан-
Глава 2. Протоколы многоадресной маршрутизации 45
ные — для этого нужен дополнительный протокол (подойдет любой из описанных в пре-
дыдущей главе).
Протокол DVMRP все еще считается экспериментальным, поэтому существует вероят-
ность его изменений в будущем. Чтобы проверить наличие более новой версии, выполни-
те следующие действия.
1. Обратитесь на Web-узел www. ietf . org.
2. Перейдите по ссылке “Internet-Drafts”.
3. Щелкните на ссылке “I-D Keyword Search”. Это позволит осуществить поиск требуе-
мого документа, а не просматривать весь иерархический список существующих
стандартов.
4. Введите в текстовое поле слово dvmrp и нажмите кнопку “Search”. Среди выданных
результатов будет название “Distance Vector Multicast Routing Protocol”. Имя доку-
мента должно быть таким: draft-ietf-idmr-dvmrp-v3-10.txt. Если указана более новая
версия, потратьте немного времени на изучение изменений.
Алгоритмы: введение
Раньше протокол DVMRP целиком основывался на алгоритме TRPB (Truncated Reverse
Path Broadcasting — широковещательная рассылка с учетом усеченного обратного маршру-
та), являющемся улучшенной версией алгоритма RPB (Reverse Path Broadcasting — широ-
ковещательная рассылка с учетом обратного маршрута). Сегодня алгоритм TRPB приме-
няется только для первого пакета в последовательности многоадресных данных. Даль-
нейшие пакеты обрабатываются при помощи алгоритма RPM (Reverse Path Multicasting —
многоадресная рассылка с учетом обратного маршрута), в котором используется улучшен-
ная методика построения дерева, основанная на алгоритмах TRPB и RPB. Эта методика
напоминает алгоритм Беллмана-Форда, применяющийся в протоколе RIP-1.
Алгоритмы: широковещательная рассылка с учетом
усеченного обратного маршрута (TRPB)
В протоколе DVMRP алгоритмы построения дерева не задействуются до тех пор, пока не
начнется передача данных. Если же оказывается, что информация уже записывалась в дан-
ный многоадресный канал, процесс построения дерева вообще опускается. В разделе
“Принцип работы” описан порядок обновления дерева после того, как оно было построено.
Когда узел-отправитель начинает посылать пакеты, в действие вступает алгоритм
TRPB. Предположим, в сети нашего университетского городка (рис. 2.1) через маршрути-
затор Emerald транслируется радиопередача в режиме группового вещания. Прежде всего
следует узнать, какие маршрутизаторы в нашей автономной системе поддерживают мно-
гоадресный режим. Пусть это будр- маршрутизаторы Prime, Emerald, Hum, Chem, Math,
Arts, Phys/East, Runk, Trud и Poin.
В тот момент, когда компьютер Radio Show посылает в канал многоадресной рассылки
первый пакет, активизируется упоминавшийся выше протокол IGMP. Пакет доставляется на
машину Emerald, затем — на узлы East и Chem и далее на все маршрутизаторы, поддержи-
вающие групповой режим (подробнее о том, как осуществить доставку данных па маршрути-
заторы, с которыми нет прямого соединения, рассказывается в разделе “Принцип работы”).
Когда на маршрутизатор приходит такой пакет, IGMP-подсистеме передается адрес
канала групповой рассылки. Протокол IGMP должен определить, какие сети и подсети со-
держат членов группы. Только в эти сети будет доставлен пакет. Рассмотрим поведение
маршрутизатора Math (рис. 2.2).
46 Часть I. Основы маршрутизации
Рис. 2.1. Автономная система, в которой некоторые маршру-
тизаторы поддерживают многоадресную рассылку
Math
Рис. 2.2. Сети, обслуживаемые маршрутизатором Math (члены
многоадресной группы помечены кружком)
Глава 2. Протоколы многоадресной маршрутизации 47
В данном случае в сетях I и III имеется по крайней мере один член группы. Сеть II раз-
бита на подсети, из которых только подсеть 1 содержит члена группы.
В процессе анализа сетевой топологии строится дерево TRPB. Вид дерева изображен
на рис. 2.3. Помните, что это дистанционно-векторный алгоритм, поэтому каждому пере-
ходу будет также соответствовать весовой коэффициент.
Poin Wash
Рис. 2.3. Дерево доставки пакетов, транслируемых машиной Radio
Show в канал группового вещания
Алгоритмы: многоадресная рассылка с учетом
обратного маршрута (RPM)
После доставки первого пакета начинает выполняться алгоритм RPM. В его основе ле-
жит идея отсечения ветвей (pruning): первоначальное дерево TRPB “очищается” от не-
функциональных ветвей для уменьшения трафика многоадресных пакетов, занимающих
полосу пропускания всей автономной системы.
В отличие от маршрутизатора Math, некоторые маршрутизаторы обнаружат, что в их
сетях и подсетях нет членов группы. Допустим, это маршрутизаторы Arts, Trud, Poin и
East. Каждый из них пошлет вышестоящему маршрутизатору сообщение об отсечении.
1. Маршрутизатор Arts пошлет сообщение узлу Hum.
2. Маршрутизатор Trud пошлет сообщение узлу Runk.
3. Маршрутизатор Poin пошлет сообщение узлу Trud.
4. Маршрутизатор Phys/East пошлет сообщение узлу Hum.
48 Часть I. Основы маршрутизации
Протокол DVMRP постоянно проверяет эти сообщения, так как у них есть определен-
ное время жизни. Обнаружив маршрутизатор, удовлетворяющий перечисленным ниже
двум критериям, протокол перестает посылать ему пакеты через данный канал групповой
рассылки.
1. Получены сообщения об отсечении от всех нижестоящих маршрутизаторов. При-
мер: маршрутизаторы Trud и Runk.
2. Он послал вышестоящему маршрутизатору сообщение об отсечении самого себя.
Пример: маршрутизатор Trud.
Таким образом, маршрутизаторы Trud и Poin не будут получать пакеты, направляемые
в данный канал, пока не истечет срок действия сообщений об отсечении. Следующий па-
кет, поступивший в тот же канал от того же источника, будет подвергнут широковеща-
тельной рассылке с помощью алгоритма TRPB, и снова начнет действовать процесс отсе-
чения ветвей.
Принцип работы
Давайте подробнее рассмотрим, как работает протокол DVMRP. Предположим, все
DVMRP-маршрутизаторы в нашей демонстрационной сети были только что сконфигури-
рованы. Возможно, на них уже функционирует протокол OSPF или RIP-2, а теперь настало
время предоставить пользователям услуги многоадресной рассылки.
Все маршрутизаторы начинают привычный процесс поиска соседей. Каждый из них
посылает пробные сообщения через все свои интерфейсы, поддерживающие многоадрес-
ный режим. Получив пробное сообщение от соседа, маршрутизатор включает его адрес в
свои пробные сообщения, посылаемые через соответствующий интерфейс. Возьмем, к
примеру, машину Emerald. Она отправляет в сеть пробные сообщения, а машина Hum
принимает одно из них через конкретный интерфейс. Маршрутизатор Hum осуществляет
собственную рассылку пробных сообщений. Узнав о появлении узла Emerald, маршрутиза-
тор Hum включает его адрес во все пробные сообщения, посылаемые через интерфейс, из
которого пришло сообщение от данного узла. На самом деле, когда маршрутизатор, рабо-
тающий по протоколу DVMRP, впервые получает сообщение от неизвестного маршрути-
затора, он отправляет ему всю свою таблицу маршрутизации.
Увидев свое имя в списке узла Hum, маршрутизатор Emerald узнает о существовании
двустороннего функционирующего соединения с маршрутизатором Hum. Теперь каждые
60 секунд маршрутизаторы будут посылать друг другу копии своих таблиц и проверять их
согласованность. Маршрутизатор Emerald, кроме того, добавит узел Hum в собственный
список обнаруженных соседей, поэтому когда узел Hum получит следующее пробное со-
общение от узла Emerald, он тоже сделает вывод о существовании двустороннего соедине-
ния. Аналогичные процессы происходят по всей сети до тех пор, пока все маршрутизато-
ры, поддерживающие многоадресный режим, не обнаружат друг друга.
Результатом проделанной работы будет коллективная таблица маршрутизации для
многоадресного трафика. Каждые 10 секунд все маршрутизаторы, работающие по прото-
колу DVMRP, будут посылать пробное сообщение в каждый сетевой интерфейс, поддер-
живающий многоадресный режим. Коллективная таблица пересылается и меняется по
мере появления и исчезновения соседей (узел считается исчезнувшим, если от него ниче-
го не поступало в течение 35 секунд).
Необходимо также постоянно проверять, не предоставляют ли маршрутизаторы, под-
ключенные к одной и той же сети, дублирующиеся услуги. Дублирование приводит к на-
прасному расходу вычислительных ресурсов маршрутизаторов, не говоря уже о полосе
пропускания. Здесь уместно вспомнить о том, что протокол DVMRP является дистанцион-
Глава 2. Протоколы многоадресной маршрутизации 49
но-векторным. Если есть несколько маршрутизаторов, способных передавать данные от
источника в заданную сеть, тогда тот из них, у которого обратный путь к источнику ока-
жется короче, станет назначенным ретранслятором (designated forwarder). Именно через
него будет проходить трафик в сеть и из нее.
Назначенный ретранслятор должен знать, какие нижестоящие маршрутизаторы буду!'
использовать его в процессе обмена данными с соответствующим источником. Для этого
применяется уже знакомый нам метод обратного исправления (poison reverse). Если ниже-
стоящий маршрутизатор определяет, что следующий переход кратчайшего обратного пу-
ти к данному источнику ведет к назначенному ретранслятору, он посылает ему копию
маршрутной таблицы, в которой стоимость всех маршрутов через этот ретранслятор рав-
на исходной стоимости плюс бесконечность (в протоколе DVMRP бесконечности соот-
ветствует метрика 32). Появление маршруга со стоимостью, большей чем 32, сигнализи-
рует назначенному ретранслятору о том, что соответствующий нижестоящий маршрути-
затор является зависимым. Список зависимых маршрутизаторов применяется в процессе
отсечения ветвей дерева многоадресной рассылки.
Для каждого источника, посылающего данные в конкретный канал многоадресной
рассылки, в таблице маршрутизации содержатся следующие сведения.
IP-адрес источника и интерфейс, через который он посылает данные. В одной
строке маршрутной таблицы протокола DVMRP содержатся данные об одном ис-
точнике.
IP-адрес канала групповой рассылки, в который направляются данные. В одной
строке маршрутной таблицы протокола DVMRP содержатся данные об одном ис-
точнике, посылающем данные в один конкретный канал.
Интерфейс, через который поступают пакеты для заданной пары источ-
ник/получатель. Это будет IP-адрес соответствующего интерфейса.
Общая стоимость передачи данных от источника к данному интерфейсу. Метри-
ки отдельных переходов не хранятся в маршрутной таблице.
Старший и младший номера версий протокола DVMRP, функционирующего на
удаленном интерфейсе. Наличие данной информации гарантирует, что маршрути-
заторы, работающие со старыми версиями протокола, не получат бесполезные для
них данные.
Флаги возможностей протокола DVMRP на удаленном интерфейсе. Большая
часть флагов присутствует из соображений обратной совместимости.
Номер поколения, который был записан в последнем пробном сообщении, полу-
ченном от удаленного интерфейса. Этот идентификатор меняется, только когда
маршрутизатор Перезапускается или его интерфейс временно не функционировал, а
потом вновь заработал. Номер поколения включается в каждое пробное сообщение.
Его изменение служит сигналом соседним маршрутизаторам послать копию всей
маршрутной таблицы удаленному интерфейсу. Это позволяет согласовать работу
маршрутизаторов во всей сети.
По мере передачи таблицы от узла к узлу стоимость записанных в ней маршрутов уве-
личивается минимум на единицу при прохождении каждого интерфейса. Компонуя таб-
лицы, полученные от своих соседей, маршрутизатор самостоятельно определяет крат-
чайшие маршруты ко всем известным источникам.
Давайте снова обратимся ко все тому же маршрутизатору Arts и посмотрим, как в про-
токоле DVMRP обрабатываются уже знакомые нам ситуации.
50 Часть I. Основы маршрутизации
Сценарий 1: маршрутизатор Arts был намеренно удален. На нем произошел аппа-
ратный сбой, и замена ему будет найдена только через неделю.
Не получив пробные сообщения в течение 35 секунд, единственный сосед узла Arts,
поддерживающий многоадресный режим, — маршрутизатор Hum — начинает устра-
нять возникшую проблему, чтобы не посылать данные в пустоту. Последователь-
ность действий такова.
Узел Hum проверяет свои маршрутные таблицы. Любой маршрут, полученный
от узла Arts, дезактивируется — не удаляется, а именно дезактивируется.
В данном примере у маршрутизатора Arts нет нижестоящих маршрутизато-
ров. Но если бы они были, маршрутизатор Hum удалил бы все записи зависимых
маршрутизаторов.
Все маршруты, для которых узел Arts являлся назначенным ретранслятором
по отношению к маршрутизатору Hum, должны быть рассчитаны повторно.
Если есть несколько путей доступа в сети, подключенные к маршрутизатору Arts,
должен быть выбран новый назначенный ретранслятор.
Все члены группы, которые находятся в сетях, обслуживаемых маршрутизатором
Arts, попадают в затруднительное положение. Они теперь не могут получать много-
адресные пакеты, поскольку не имеют резервный ретранслятор. Но из этой ситуа-
ции есть выход, требующий, правда, ручного вмешательства, зато позволяющий
создать постоянный резервный канал.
В первую очередь необходимо запустить протокол DVMRP на другом маршрутиза-
торе, подключенном к тем же сетям, что и Arts. В нашей сети это маршрутизатор
Eng, но проблема в том, что он изолирован от других маршрутизаторов, работаю-
щих в многоадресном режиме. К счастью, в протоколе DVMRP поддерживаются два
вида туннелей (виртуальных соединений между машинами), создаваемых на основе
либо протокола IP-IP, либо протокола GRE (Generic Routing Encapsulation — общая
инкапсуляция маршрутной информации). После образования туннеля маршрутиза-
тор Eng начнет считать, что у него есть соседи, поэтому все алгоритмы будут функ-
ционировать правильно.
Подробнее о средствах создания туннелей рассказывается в главе 6, “Демоны мно-
гоадресной маршрутизации в ядре 2.2.x”. На рис. 2.4 изображена схема требуемого
туннеля. Данные не смогут быть переданы членам группы, которых обслуживал
маршрутизатор Arts, пока администратор не обнаружит сбой этого маршрутизатора
и не создаст туннель в обход него.
Сценарий 2: маршрутизатор Arts был намеренно удален, и замены ему не предвидится.
Этот сценарий практически не отличается от предыдущего случая. Разница только в
том, что, прежде чем удалять маршрутизатор Arts, можно создать туннель к маршру-
тизатору Eng.
Сценарий 3: соединение маршрутизатора Arts с сетью временно вышло из строя, что
привело к изоляции маршрутизатора, компьютеров подключенной к нему сети, а
также всех остальных сетей, данные к которым передаются через этот маршрутиза-
тор. Соединение остается неактивным в течение трех часов.
Глава 2. Протоколы многоадресной маршрутизации 51
Рис. 2.4. Новое дерево маршрутов; пунктирные линии обозначают
1Р-туннель
Когда узел Arts исчезает, все происходит по сценарию 1. А вот когда он снова появля-
ется, начинается самое интересное. Находясь во временной изоляции, маршрутизатор
Arts дезактивировал все маршруты к соседям, ведь он считал себя единственным суще-
ствующим DVMRP-маршрутизатором. Но в протоколе DVMRP маршрутизаторы нико-
гда не сдаются! Настойчивый узел Arts продолжает непрерывно посылать пробные со-
общения через все свои интерфейсы в канал All-DVMRP-Routers (224.0.0.4). Когда со-
единение с сетью восстановится, маршрутизатор Hum внезапно получит от узла Arts
пробное сообщение.
Если информация, которую маршрутизатор Arts сообщает узлу Hum, совпадает с
той, что была раньше, узел Hum повторно активизирует маршруты, проходящие
через узел Arts. В противном случае происходит обмен маршрутными таблицами и
их редактирование.
Осталось рассмотреть еще один вопрос. Раньше говорилось лишь о том, что в протоколе
DVMRP применяется алгоритм RPM для отсечения ветвей дерева многоадресной рассылки.
Но протокол IGMP обрабатывает запросы не только на выход из группы, но и на подключе-
ние к группе. Как вернуть адресата в групп}' после того, как он был из нее удален?
Соответствующий метод называется прививанием ветвей (grafting). Любой отсеченный
элемент можно в любое время “привить” обратно к заданному дереву “источник/прием-
ник”. Маршрутизатор, работающий по протоколу DVMRP, отслеживает запросы на член-
ство в группах. Чтобы исключить себя из группы, компьютер должен послать сообщение
52 Часть I. Основы маршрутизации
Prune. Маршрутизатор хранит это сообщение определенное время. Если в течение данно-
го времени от того же компьютера придет сообщение Graft, маршрутизатор отменит со-
общение Prune, вернет компьютеру подтверждающее сообщение Graft Ack и присоединит
соответствующую ветвь обратно к дереву. Может случиться так, что сам маршрутизатор,
обрабатывающий подобные запросы, уже отсоединился от дерева. В таком случае он по-
сылает вышестоящему маршрутизатору запрос Graft на присоединение к конкретной паре
источник/приемник и т.д.
В Linux протокол DVMRP, как и MOSPF, реализован в демоне mrouted (описан в гла-
ве 6, “Демоны многоадресной маршрутизации в ядре 2.2.x”).
Протокольно-независимая многоадресная
маршрутизация
PIM (Protocol Independent Multicast — протокольно-независимая многоадресная мар-
шрутизация) является протоколом маршрутизации, не похожим ни на один из сущест-
вующих протоколов. Он способен работать поверх произвольного протокола одноадрес-
ной маршрутизации и не обрабатывает никаких одноадресных пакетов, что отличает его
от протокола DVMRP, которому иногда приходится иметь дело с одноадресной передачей
данных, например в случае туннелирования и отправки пробных сообщений.
Существуют две разновидности протокола. Выбор нужного варианта зависит от того,
как расположены члены групп: разреженно {разреженныйрежим — Sparse Mode) или плотно
(насыщенный режим — Dense Mode).
Разреженный режим (PIM-SM)
В разреженной сети гораздо больше компьютеров и подсетей, не являющихся членами
групп многоадресной рассылки. Сами члены групп распределены в широком географиче-
ском или адресном ареале. Идея заключается в том, чтобы не перегружать сеть ненужным
многоадресным трафиком.
Дерево точки встречи
В протоколе PIM-SM используются два разных набора деревьев. Дерево первого типа
называется деревом точки встречи (rendezvous point tree, RPT), или коллективным деревом.
Оно является центральной магистралью протокола PIM-SM.
У каждой группы многоадресной рассылки, существующей в пределах домена, имеется
точка встречи, под которой понимается маршрутизатор, управляющий трафиком данной
группы. Один маршрутизатор может быть закреплен за несколькими группами. На прак-
тике ему назначается диапазон групповых адресов. Для каждой группы строится дерево,
корнем которого является точка встречи, а ветвями — все остальные маршрутизаторы, об-
служивающие членов группы, включая те устройства, которые просто передают инфор-
мацию от точки встречи нижестоящим маршрутизаторам и наоборот.
Какой алгоритм применяется для построения такого дерева? В том-то и весь смысл,
что никакого. В протоколе PIM-SM используется маршрутная таблица протокола одноад-
ресной маршрутизации, используемого в сети. Просто каждый маршрутизатор добавляет
в эту таблицу запись, идентифицирующую источник сообщений, группу, точку встречи и
нижестоящие маршрутизаторы.
Дерево кратчайших путей
Дерево второго типа называется деревом кратчайших путей (shortest path tree, SPT). Оно
простирается от источника к каждому члену группы. Дерево строится и задействуется
только в том случае, когда от данного конкретного источника поступает большой объем
Глава 2. Протоколы многоадресной маршрутизации 53
данных (правило определения того, насколько интенсивным является трафик, зависит от
реализации). Каждый маршрутизатор самостоятельно решает, присоединиться ли ему к
дереву кратчайших путей или продолжать работать с деревом точки встречи.
Если маршрутизатор выбирает первый вариант, он посылает сообщение Join непо-
средственно источнику. Это сообщение должно пройти через другие маршрутизаторы,
каждый из которых посылает свое сообщение Join, если еще не является частью дерева
кратчайших путей к данному источнику.
Став частью дерева SPT, маршрутизатор посылает сообщение Prune в точку встречи.
По мере прохождения этого сообщения через промежуточные маршрутизаторы все они
проверяют, не является ли нижестоящий маршрутизатор, от которого получено сообще-
ние Prune, единственным обслуживаемым устройством. Если это так, они посылают соб-
ственные сообщения Prune, вследствие чего с маршрутизатора точки встречи снимается
часть нагрузки по управлению данной группой.
В конце концов всплеск трафика прекратится, и интенсивность потока данных может
стать ниже пороговой величины. Тогда начнется обратный процесс. Маршрутизатор по-
шлет сообщение Join в точку встречи, чтобы присоединиться к дереву RPT; то же самое
сделают и промежуточные маршрутизаторы. Когда вся цепочка закрепится, маршрутиза-
тор пошлет источнику сообщение Prune, чтобы отсоединиться от дерева SPT.
Принцип работы
Предположим, маршрутизаторы Phys и Arts являются самыми мощными в домене. Они
также имеют наиболее скоростные соединения со своими соседями, поэтому являются
наилучшими кандидатами на роль маршрутизаторов точки встречи. Поскольку в демонст-
рационной сети обслуживается много групп, обязанности точки встречи распределятся
между обоими маршрутизаторами.
После того как протокол одноадресной маршрутизации и протокол PIM-SM сконфигу-
рированы, от одного из компьютеров сети может поступить запрос на вхождение в группу
многоадресной рассылки. Вот что при этом произойдет.
1. Протокол IGMP уведомит ближайший назначенный маршрутизатор (НМ) о том, что
в данной конкретной группе появился новый член. Выбор маршрутизатора зависит
от ситуации.
Если данную часть сети обслуживает один маршрутизатор, он автоматически
становится назначенным.
а Если данную часть сети обслуживает несколько маршрутизаторов, проводятся
выборы с целью определения того, кто из них станет назначенным. Это позволя-
ет избежать дублирования пакетов. На выборах побеждает маршрутизатор, чей
МАС-адрес оказывается наибольшим.
2. НМ ищет в своих таблицах адрес точки встречи для данной группы.
3. Если в таблице маршрутизации еще нет записи для данной группы, такая запись
создается.
4. НМ добавляет в соответствующую запись таблицы адрес члена группы. Если это не
первый член группы, остальные этапы не выполняются.-
5. Если НМ еще не начал обрабатывать трафик этой группы (например, из-за того, что
это первый член, добавляемый в группу), он создает пакет Join.
6. НМ добавляет к пакету Join адрес интерфейса, ведущего по направлению к точке
встречи.
7. НМ посылает naKeTjoin через интерфейс, заданный в п. 6.
54 Часть I. Основы маршрутизации
8. Вероятнее всего, этот пакет получит промежуточный маршрутизатор. Если данный
маршрутизатор еще не является частью дерева RPT, он добавит в пакет Join адрес
интерфейса, по которому поступил пакет.
9. Промежуточный маршрутизатор посылает пакет через интерфейс, ведущий по на-
правлению к точке встречи.
10. Если пакет снова приходит на промежуточный маршрутизатор, повторяются пп. 8, 9.
11. Весь трафик группы, к которой только что присоединился компьютер, теперь по-
сылается в точку встречи, проходит по дереву RPT и, в конечном счете, попадает на
данный компьютер.
Еще один важный момент, который следует запомнить: конечный пользователь не вы-
бирает, к какому дереву присоединиться, — это делают маршрутизаторы. Данный процесс
совершенно незаметен для членов группы.
Вы, очевидно, догадываетесь, что произойдет дальше. Маршрутизатор Arts, как всегда,
выходит из строя.
Сценарий 1: маршрутизатор Arts был намеренно удален. На нем произошел аппа-
ратный сбой, и замена ему будет найдена только через неделю.
Внезапно обнаруживается, что у половины групп исчезла точка встречи. Здесь не-
обходимо уточнить, что назначение маршрутизаторов на роль точек встречи про-
изводится не вручную. Процесс выглядит следующим образом. Первоначально в до-
мене выбирается конфигурирующий маршрутизатор (bootstrap router). Все маршрути-
заторы, являющиеся кандидатами на роль точек встречи, начинают периодически
посылать ему анонсирующие сообщения. Конфигурирующий маршрутизатор на ос-
новании заданных приоритетов формирует из кандидатов набор точек встречи и
рассылает его по сети в виде конфигурирующих сообщений.
Когда маршрутизатор Arts отключается от сети, конфигурирующий маршрутизатор
перестает получать от него анонсы. В результате формируется и рассылается новый
набор точек встречи. Получив конфигурирующее сообщение, в котором отсутствует
информация об узле Arts, все маршрутизаторы удалят этот узел из своих таблиц мно-
гоадресной рассылки.
Теперь становится ясно, зачем нужно несколько точек встречи. Маршрутизатору точки
встречи назначается не только диапазон групповых адресов, но и приоритет. Маршрути-
затор Aits обрабатывает трафик половины групп с высоким приоритетом, а половины —
с низким. У маршрутизатора Phys распределение приоритетов противоположное.
При выборе точки встречи для заданной группы назначенный маршрутизатор от-
бирает из конфигурирующего набора те маршрутизаторы, в диапазон которых вхо-
дит адрес группы. К полученному списку применяется специальная хеш-функция,
которая закрепляет за группой одну из точек встречи. Если маршрутизатор Arts вы-
ходит из строя, в списке остается маршрутизатор Phys, хоть и с низким приорите-
том. Таким образом, выбор будет сделан, таблицы — перестроены, и сеть продолжит
нормальное функционирование.
Сценарий 2: маршрутизатор Aits был намеренно удален, и замены ему не предвидится.
Несложно заметить, что в современных протоколах маршрутизации сценарий 2 ни-
чем не отличается от сценария 1. Протокол PIM-SM — не исключение.
Сценарий 3: соединение маршрутизатора Arts с сетью временно вышло из строя, что
привело к изоляции маршрутизатора, компьютеров подключенной к нему сети, а
также всех остальных сетей, данные к которым передаются через этот маршрутиза-
тор. Соединение остается неактивным в течение трех часов.
Глава 2. Протоколы многоадресной маршрутизации 55
Первая часть сценария обрабатывается идентично сценарию 1. Конфигурирующий
маршрутизатор перестает получать анонсы от точки встречи Arts и уведомляет об
этом все остальные маршрутизаторы PIM-SM. Они удаляют узел Arts из своих таб-
лиц, а затем, благодаря хеш-функции, выбирают новую точку встречи — узел Phys.
Гибкость протокола PIM-SM проявляется, когда маршрутизатор Arts вновь начинает
функционировать. В первую очередь узел Arts посылает анонс конфигурирующему
маршрутизатору, который включает этот узел в конфигурирующее сообщение. По-
лучив новый список точек встречи, остальные маршрутизаторы применяют к нему
хеш-функцию, которая определяет, что часть групп должна присоединиться к точке
встречи с более высоким приоритетом. Один за другим маршрутизаторы посылают
сообщения Join узлу Arts и сообщения Prune узлу Phys. Вмешательство администра-
тора здесь не требуется.
В Linux протокол PIM-SM реализован в демоне gated. В сети должен также функциони-
ровать какой-нибудь протокол одноадресной маршрутизации, например OSPF или RIP-2.
Насыщенный режим (PIM-DM)
В насыщенной сети, где в одном географическом или адресном ареале присутствует
множество членов групп многоадресной рассылки, лучше применять протокол PIM-DM. В
некотором смысле он является расширением протокола PIM-SM.
Протокол PIM-DM также функционирует поверх произвольного протокола одноадрес-
ной маршрутизации. Деревья строятся от источника через маршрутизаторы к членам групп
с использованием алгоритма, применяемого в нижележащем протоколе. Вопрос заключает-
ся в том, что происходит, когда член группы начинает посылать многоадресные пакеты.
Предположим, компьютер Radio Show не функционировал несколько месяцев, а теперь
вновь заработал. Тем временем в сети стал применяться протокол PIM-DM. Когда компь-
ютер посылает групповой пакет, каждый маршрутизатор автоматически передает этот па-
кет другим маршрутизаторам, а также направляет его во все непосредственно подключен-
ные сети. В этом суть насыщенного режима. Предполагается, что в нижестоящих сетях
присутствует много членов групп и они готовы принимать данные.
Для каждой пары источник/канал создается отдельная таблица. В ней описано, должен
ли задействоваться тот или иной интерфейс. Дело в том, что в протоколе PIM-DM также ис-
пользуются принципы отсечения и прививания ветвей. Маршрутизаторы, у которых нет
нижестоящих членов групп, могут отсоединить себя от дерева, а если впоследствии кто-
нибудь захочет стать членом группы, маршрутизатор опять присоединится к дереву.
Интересно то, что сообщения Prune посылаются не отдельным маршрутизаторам, а по
конкретному групповому адресу. Узел, генерирующий запрос, идентифицирует себя и
маршрутизатор, от которого он хочет отсоединиться. После этого выдерживается при-
мерно трехсекупдная пауза, чтобы нижестоящие маршрутизаторы имели возможность по-
слать сообщение Prune-Override (если у них есть активные члены группы).
Протокол PIM-DM и специальные маршрутизаторы
В протоколе PIM-DM обычно не используются точки встречи и назначенные маршрутизаторы. Но
протокол IGMP версии 1 требует наличия назначенного маршрутизатора, если к одной сети или
сетевой группе подключено несколько маршрутизаторов. В этих случаях назначенным
становится маршрутизатор с наибольшим IP-адресом.
Сказанное не означает, что протокол PIM-DM позволяет пакетам попадать в сеть двумя разными
путями. Если такая возможность обнаруживается, выбирается маршрутизатор с наилучшей
стоимостью передачи данных от источника (стоимость определяется в нижележащем протоколе
одноадресной маршрутизации).
56 Часть I. Основы маршрутизации
Давайте опять проверим работу протокола в уже привычных ситуациях.
Сценарий 1: маршрутизатор Arts был намеренно удален. На нем произошел аппа-
ратный сбой, и замена ему будет найдена только через неделю.
Все маршрутизаторы, работающие по протоколу PIM-DM, периодически рассылают
сообщения “Hello” через все свои интерфейсы. Соседи узла Arts заметят, что через
определенное число секунд (задается в поле Holdtime пакета Hello) он не отозвал-
ся, поэтому они дезактивируют все ссылки на него в своих таблицах. В результате на
какое-то время данные, которые должны проходить через этот маршрутизатор, не
смогут быть никуда отправлены.
Маршрутизатор Arts исчезает не только в протоколе PIM-DM, но и в нижележащем про-
токоле. В результате будут перестроены таблицы одноадресной маршрутизации, и на ос-
новании этой информации протокол PIM-DM разрешит проблему своего трафика.
Сценарий 2: маршрутизатор Aits был намеренно удален, и замены ему не предвидится.
Опять-таки, этот сценарий обрабатывается точно так же, как и сценарий 1.
Сценарий 3: соединение маршрутизатора Ai ts с сетью временно вышло из строя, что
привело к изоляции маршрутизатора, компьютеров подключенной к нему сети, а
также всех остальных сетей, данные к которым передаются через этот маршрутиза-
тор. Соединение остается неактивным в течение трех часов.
Сначала все происходит так же, как и в сценарии 1. Затем, когда маршрутизатор Ai ts
вновь появляется в сети, его соседи неожиданно получают сообщение Hello. Оно
всегда посылается через все интерфейсы, хоть узел Arts и пометил своих соседей как
недоступных.
После того как соседние маршрутизаторы восстановили маршруты через узел Arts,
могут последовать выборы назначенного маршрутизатора, если вдруг окажется, что
узел Arts дублирует чей-то чужой трафик. Вскоре функционирование сети восстано-
вится в прежнем виде.
В Linux протокол PIM-SM реализован в демоне gated. Еще раз напомним, что в сети
должен также функционировать какой-нибудь протокол одноадресной маршрутизации,
например OSPF или RIP-2.
Резюме
Протоколы многоадресной маршрутизации, чаще всего применяемые в Linux-сетях, —
это MOSPF, DVMRP и либо PIM-SM, либо PIM-DM. Протокол MOSPF наиболее эффекти-
вен в небольших группах, где необходимо, чтобы один протокол обрабатывал как одноад-
ресные, так и многоадресные пакеты. Остальные протоколы не могут работать без ниже-
лежащего протокола одноадресной маршрутизации. Протокол PIM-SM используется то-
гда, когда члены групп распределены очень широко. А протоколы PIM-DM и DVMRP,
наоборот, предполагают плотное распределение членов групп.
Глава 2. Протоколы многоадресной маршрутизации 57
В табл. 2.1 указано, где описан и реализован каждый из рассмотренных протоколов.
Таблица 2.1. Информация о протоколах многоадресной маршрутизации
Протокол Где реализован RFC или проект стандарта
MOSPF mrouted 1585
DVMRP mrouted draft-ietf-idmr-dvmrp-v3-10.txt
PIM-SM gated 2362
PIM-DM gated draft-ietf-pim-v2-dm-03.txt
Чтобы получить ответы на вопросы о многоадресной маршрутизации в целом, обрати-
тесь к ресурсу http: //www.multicasttech. com/inulticast_faq. html.
58 Часть I. Основы маршрутизации
jSS*Sr* Q
- Л
HHREZXidriifli
Введение в протоколы
пограничной маршрутизации
В этой главе...
Протокол IGP
Протокол EGP
Протокол BGP
Протокол BGMP
Протокол MSDP
Резюме
59
60
62
64
65
66
I I о сих пор в книге рассматривались протоколы маршрутизации, применяемые внутри
Павтономной системы (АС). Их оказывается недостаточно, когда АС соединяется с In-
ternet или с другой АС. В этом случае в дополнение к протоколам внутренней маршрутиза-
ции необходимо задействовать протоколы пограничной маршрутизации. Они отслеживают
информацию, распространяемую в пределах АС, и определяют, какими частями этой ин-
формации можно поделиться с внешним миром. Кроме того, они принимают данные из
внешнего мира.
Для начала мы узнаем, чем отличаются друг от друга протоколы внешних и внутренних
шлюзов, а затем перейдем к сравнению протоколов одноадресной и многоадресной по-
граничной маршрутизации.
Протокол IGP
В первую очередь необходимо выяснить, что происходит внутри самой АС, и ввести
ряд терминов. Как уже было сказано, автономная система делится на области. В них при-
меняется как минимум один протокол одноадресной маршрутизации и, возможно, один
или несколько многоадресных протоколов. Все они относятся к семейству протоколов
внутреннего шлюза (Interior Gateway Protocol — IGP).
Под шлюзом понимается устройство, соединяющее две сети. Это может быть либо специ-
альное аппаратное устройство, либо программный компонент. Шлюзами считаются компью-
теры, предоставляющие услуги маршрутизации, компьютеры, соединяющие разные физиче-
ские сети (например, Token Ring и Ethernet), а также компьютеры, позволяющие нескольким
семействам сетевых протоколов (скажем, TCP/IP и IPX) взаимодействовать друг с другом.
Теперь познакомимся с наиболее популярными протоколами пограничной маршрути-
зации.
Протокол EGP
EGP (Exterior Gateway Protocol — протокол внешнего шлюза) был первым протоколом
семейства TCP/IP, применяемым для организации взаимодействия автономных систем.
Он до сих пор иногда используется. В EGP пограничный маршрутизатор АС не ищет сосе-
дей самостоятельно. Ему нужно заранее сообщить IP-адреса или полные доменные имена
других пограничных маршрутизаторов, с которыми он будет обмениваться информацией.
Когда пограничный EGP-маршрутизатор начинает работать, он находится в состоянии
разведки (acquisition state). В протоколе EGP под состоянием понимается статус погранич-
ного маршрутизатора. Ниже перечислены возможные состояния.
Разведка (Acquisition). Маршрутизатор периодически пытается обнаружить своих
EGP-соседей.
Отключение (Cease). Маршрутизатор периодически уведомляет соседей о прекра-
щении работы и, получив все необходимые подтверждения, переходит в состояние
простоя.
Останов (Down). Маршрутизатор реагирует лишь на небольшое число команд.
Простой (Idle). Маршрутизатор не хранит никакой маршрутной информации и реагиру-
ет лишь на команды, запрашивающие переход в одно из более активных состояний.
Функционирование (Up). Маршрутизатор поддерживает активные связи со своими
соседями.
Состояние маршрутизатора определяет, на какие команды он будет реагировать. Об-
наружив нового соседа, маршрутизатор начинает периодически посылать ему сообщение
Request. В это сообщение включается следующая информация.
Порядковый номер, назначенный данному сообщению. Все пакеты Request име-
ют порядковый номер, который отслеживается двумя маршрутизаторами, устанавли-
вающими связь друг с другом.
Периодичность поступления сообщений Hello. К этому вопросу мы вскоре вер-
немся, а пока отметим, что данные сообщения отличаются от тех, что используются
в протоколе OSPF. Установка по умолчанию — 30 секунд.
Периодичность поступления сообщений Poll. Этот вопрос также рассматривается
ниже. Стандартная установка — 60 секунд.
Допустимое время ожидания. Если пограничный маршрутизатор не получает све-
дений от соседа в пределах заданного интервала, он считает его недоступным. По
умолчанию интервал ожидания — 120 секунд.
В ответ соседний маршрутизатор возвращает сообщение Confirm, подтверждая факт
своего функционирования, и пополняет список своих соседей. Тогда пограничный мар-
шрутизатор посылает соседу блок данных, включающий перечисленные выше значения, а
также дополнительную информацию.
60 Часть I. Основы маршрутизации
Порядковый номер сообщения Confirm. Как и пакеты Request, все пакеты Confirm
имеют порядковый номер.
Режим, в котором данный пограничный маршрутизатор находится по отноше-
нию к соседу. Маршрутизатор может находиться в активном или пассивном режиме.
От этого зависит реакция на сообщения Hello и Poll. Будучи в активном режиме,
маршрутизатор отвечает на эти запросы одним из следующих сообщений: Confirm,
IHU (I Heard You, т.е. “я тебя услышал”) или Update. В пассивном режиме маршру-
тизатор переходит в состояние функционирования (Up).
Время поступления сообщения Confirm. Это приводит к сбросу в нуль трех пере-
менных. Первая отсчитывает, сколько времени осталось до момента отправки по-
граничному маршрутизатору следующего сообщения Request. Вторая определяет,
сколько нужно ждать до отправки сообщения Poll. В третьей подсчитывается,
сколько времени прошло с момента получения последнего сообщения от погранич-
ного маршрутизатора.
Далее маршрутизатор переходит в состояние останова (Down). В этом состоянии могут
обрабатываться сообщения Cease, Hello и Request. EGP-маршрутизатор переходит в со-
стояние отключения (Cease) от данного соседа, если администратор ввел команду Stop. В
ответ на эту команду маршрутизатор сначала переходит в состояние отключения, а затем
посылает сообщение Cease конкретному соседу, связь с которым временно прекращается.
Далее могут быть следующие варианты.
Сосед получает сообщение Cease. Если сосед находится в состоянии функциони-
рования, он возвращает сообщение Cease-ack и переходит в состояние простоя
(Idle). В этом состоянии воспринимается только сообщение Request, поступающее
от соответствующего соседа.
Сообщение Cease не доходит до соседа. Если ответ на сообщение не был получен
из-за проблем в сети или выхода соседнего маршрутизатора из строя, пограничный
маршрутизатор остается в состоянии отключения, продолжая периодически посы-
лать сообщения Cease. В этом случае администратор может ввести еще одну команду
Stop, чтобы немедленно прервать цикл ожидания сообщения Cease-ack и перевести
маршрутизатор в состояние простоя по отношению к данному соседу.
Теперь познакомимся с сообщениями Hello и Poll. Периодичность их отправки задава-
лась в команде Request. Получив сообщение Hello, пограничный маршрутизатор возвра-
щает уже упоминавшееся сообщение IHU, подтверждая факт своего функционирования.
Реакция на команду' Poll зависит от того, в каком состоянии и режиме находится маршру-
тизатор. В состоянии останова и в пассивном режиме эта команда игнорируется. В про-
тивном случае возвращается сообщение Update. Именно в нем передается информация о
сетях, доступных в каждой автономной системе. Эта информация включает следующее.
Шлюзы, существующие в пределах АС. Помните, что шлюзами считаются устрой-
ства, соединяющие две и больше сетей.
Известные маршрутизатору шлюзы, существующие за пределами данной АС.
Это позволяет создавать более полные маршрутные таблицы при меньшем количе-
стве запросов.
Сети, доступные через каждый из шлюзов. Соседи пограничного маршрутизатора
должны знать, куда можно посылать данные.
Число маршрутизаторов и шлюзов, через которые должны пройти данные, что-
бы попасть в каждую из сетей. На основании этой информации можно вычислять
кратчайшие пути в пределах автономной системы.
Глава 3. Введение в протоколы пограничной маршрутизации 61
Текущее состояние каждого Соседа. С помощью этой информации каждый мар-
шрутизатор определяет, какие данные ожидают от него соседи.
В Linux этот протокол реализован в демоне gated.
Протокол BGP
Потомком протокола EGP является BGP (Border Gateway Protocol — протокол погра-
ничного шлюза). С момента своего появления он подвергался целому ряду обновлений, а
самая последняя версия называется BGP-4. Основное преимущество данного протокола в
сравнении с EGP заключается в улучшенной поддержке стандарта IPv6.
В протоколе BGP администратор сообщает пограничному маршрутизатору о том, кто
его соседи, а дальнейшая информация собирается в автоматическом режиме. Находясь в
активном состоянии, пограничный маршрутизатор устанавливает TCP-соединение с но-
вым соседом. После того как соединение установлено, маршрутизатор выполняет следую-
щие действия.
Устанавливает счетчик таймера ConnectRetry равным нулю. Обычно этот тай-
мер осуществляет подсчет от нуля до 120 секунд. По достижении предельного зна-
чения пограничный маршрутизатор считает TCP-соединение разорванным и пыта-
ется установить его заново.
Формирует среду для хранения информации о новом соседе. При этом создаются
все необходимые переменные.
Устанавливает таймер удержания на четыре минуты. Таймер удержания (hold
timer) определяет максимальный промежуток времени между двумя сообщениями,
после которого связь с соседом будет разорвана.
Далее между двумя устройствами начинают передаваться сообщения. В первую очередь
маршрутизатор посылает соседу сообщение OPEN. В нем содержится следующее.
Номер версии BGP. Здесь указывается версия 4.
Номер автономной системы отправителя. У каждой автономной системы есть
уникальный идентификатор, назначаемый главным администратором.
Значение таймера удержания. Если у двух пограничных маршрутизаторов разные
установки, выбирается наименьшая из них.
IP-адрес отправителя. Он называется идентификатором BGP.
Приняв сообщение OPEN, сосед сохраняет полученную информацию и возвращает со-
общение KEEPALIVE, в ответ на которое значение таймера удержания сбрасывается в
нуль. С этого момента начинается последовательный обмен сообщениями KEEPALIVE,
периодичность которых равна примерно одной трети от принятого интервала удержа-
ния. Если на протяжении времени удержания ни одно такое сообщение не поступило, со-
сед считается недоступным.
Наконец, пограничный маршрутизатор переходит по отношению к своему соседу в со-
стояние OpenSent и начинает ожидать сообщение OPEN. Несмотря на то что соединение
уже установлено, это сообщение должно быть получено, так как только с его помощьвэ
можно узнать информацию о соседе. После прихода сообщения пограничный маршрути-
затор сравнивает содержащиеся в нем данные с уже имеющимися и, если есть необходи-
мость, обновляет их.
После завершения этого процесса маршрутизатор переходит в состояние ОрепСоп-
firm и остается в нем до момента получения от соседа сообщения KEEPALIVE. Далее осу-
62 Часть I. Основы маршрутизации
ществляется переход в состояние Established. Находясь в этом состоянии, пограничные
маршрутизаторы регулярно обмениваются сообщениями UPDATE. В зависимости от на-
значения этого сообщения в нем может содержаться разная информация. Например, со-
общение UPDATE, анонсирующее новый маршрут, содержит такие данные.
Тип маршрута (атрибут ORIGIN). Это значение говорит о том, находится ли мар-
шрут в той же автономной системе, из которой получено сообщение UPDATE, или
нет. Пограничные маршрутизаторы могут анонсировать внешние маршруты.
Тип сегмента (атрибут AS_PATH). Это значение определяет, является ли список авто-
номных систем, через которые прошла маршрутная информация, упорядоченным.
Автономные системы, через которые прошла маршрутная информация. Это
упорядоченный или неупорядоченный список номеров автономных систем.
IP-адрес пограничного маршрутизатора, к которому данный маршрутизатор
должен отсылать пакеты, идущие по текущему маршруту. Это называется атрибу-
том следующего перехода (NEXT_HOP).
Количество битов в следующем ниже IP-адресе. Поскольку маршрутизация осуще-
ствляется между сетями и подсетями, а не между' отдельными IP-адресами, маршру-
тизаторы передают друг другу IP-префиксы. Префикс — это часть IP-адреса, опреде-
ляющая сеть или подсеть.
IP-префикс, определяющий сеть или подсеть, на которую указывает этот мар-
шрут. Префикс должен заканчиваться на границе байта. Например, если маршрут
ведет к адресу 192.14.14.51 в сети класса С, префикс будет таким: 192.14.14.
В сообщении UPDATE разрешается указывать только один новый маршрут. В то же
время можно удалять сколько угодно существующих маршрутов. В каждый блок удаления
включается вся нижеперечисленная информация или ее часть.
Общий размер секции удаляемых маршрутов. Это значение позволяет корректно
обрабатывать разные секции. Значение 0 говорит о том, что удаляемые маршруты
отсутствуют.
Количество битов в следующем ниже IP-адресе. Еще раз повторим, что между по-
граничными маршрутизаторами пересылаются IP-префиксы.
IP-префикс, определяющий сеть или подсеть, на которую указывает этот мар-
шрут. Префикс должен заканчиваться на границе байта.
Общий размер секции атрибутов маршрута. Это значение позволяет избежать не-
правильного чтения данных.
Каким образом пограничный маршрутизатор решает, о каких маршрутах следует со-
общать соседям? Дело в том, что на каждом маршрутизаторе ведется база информационной
политики (Policy Information Base — PIB), в которой содержатся правила, задаваемые ад-
министратором вручную. Есть также ряд баз специального назначения. Все известные
данному устройству маршруты перечислены в базе Adj-RIB-In. За аббревиатурой RIB
(Routing Information Base — база маршрутной информации) скрывается маршрутная таб-
лица. Пограничный маршрутизатор применяет правила, содержащиеся в базе PIB, к каж-
дому маршруту в базе Adj-RIB-In. Из тех маршрутов, которые соответствуют правилам,
создается база Adj-RIB-Out.
На основании правил PIB определяется предпочтительность каждого маршрута. Собрав
всю нужную информацию, пограничный маршрутизатор проверяет все адреса, к которым
у него есть маршруты, и находит наилучший маршрут к каждому адресу. Лучшие маршруты
сохраняются в базе Loc-RIB.
Глава 3. Введение в протоколы пограничной маршрутизации 63
Осталось выполнить еще одну задачу. Не забывайте, что все базы данных периодиче-
ски обновляются. Каждый раз, когда в базу Adj-RIB-In или Loc-RIB заносится новая ин-
формация, обновляется зависящая от них база Adj-RIB-Out. В некоторых реализациях
протокола BGP эта база подвергается дополнительной обработке: из нее удаляются все
дублирующиеся маршруты, чтобы она не становилась слишком большой. В случае измене-
ния базы Adj-RIB-Out маршрутизатор посылает сообщение UPDATE своим соседям.
Как видите, протокол BGP сложнее, чем EGP: в нем выполняется больше внутренних
проверок и осуществляется более тонкая настройка маршрутов. В Linux протокол BGP
реализован в демонах zebra и gated.
Протокол BGMP
В протоколах многоадресной рассылки также может потребоваться участие погранич-
ного маршрутизатора автономной системы. С этой целью был разработан протокол BGMP
(Border Gateway Multicast Protocol— многоадресный протокол пограничного шлюза).
В нем строятся такие же деревья, как и в протоколе PIM-SM (в любой момент времени де-
реву принадлежат только члены группы). Но в дерево включаются не маршрутизаторы от-
дельных сетей, а лишь пограничные маршрутизаторы. После того как дерево построено, в
некоторых доменах к нему могут “прививаться” внутренние деревья, формат которых за-
висит от используемого протокола.
Домен, анонсирующий доступность определенного диапазона групповых адресов, счи-
тается корневым доменом этого диапазона. Напомним, что каждый канал многоадресной
рассылки идентифицируется адресом класса D из диапазона 224.0.0.0-239.255.255.255. По-
этому автономная система может, к примеру, быть корневым доменом в диапазоне
231.15.19.120-231.15.19.140.
Когда пользователь пытается присоединиться к группе за пределами своего домена
или автономной системы, соответствующий запрос пересылается маршрутизатору BGMP.
Тот, в свою очередь, ищет адрес маршрутизатора, управляющего корневым доменом дан-
ного многоадресного канала. По завершении поиска маршрутизатор BGMP генерирует
сообщение UPDATE, содержащее следующую информацию.
Префикс адреса. Этот префикс сообщает маршрутизатору BGMP длину приложен-
ной ниже сетевой маски.
Семейство адресов или семейство протоколов (что, в данном случае, одно и то
же). Здесь указан тип сети, по которой предполагалось переслать пакет. Чаще всего
указывается семейство TCP/IP.
Адрес. Групповой адрес, которому предназначено данное сообщение UPDATE.
Сетевая маска. Это маска группового адреса, указанного в сообщении.
Объявление сообщения JOIN. Этот параметр говорит о том, что данное сообще-
ние UPDATE в действительности является сообщением JOIN.
Дополнительные объявления. В протоколе BGMP сообщение UPDATE может нести
в себе сообщения различных типов. В рассматриваемом случае это тип JOIN, который
может иметь модификации GROUP, SOURCE и POISON_REVERSE. Внутри дополни-
тельных объявлений могут содержаться другие сообщения: JOIN, PRUNE и т.д.
Это сообщение посылается маршрутизатору, который находится на один шаг ближе к
корневому домену. Данный маршрутизатор проверяет, есть ли в его таблице запись, по-
зволяющая выполнять обратную передачу данных от группы пользователю. Если такой за-
писи нет, она создается, после чего пакет посылается следующему ближайшему маршрути-
затору BGMP. На нем описанный процесс повторяется. Так происходит до тех пор, пока
сообщение UPDATE не достигнет корневого домена.
64 Часть I. Основы маршрутизации
Рано или поздно пользователь покинет группу. Когда пользователь отключается от ка-
нала многоадресной рассылки, находящегося за пределами текущего домена, маршрутиза-
тор BGMP получает уведомление. В первую очередь маршрутизатор проверяет, есть ли в
его домене другие члены группы. Если таковых нет, маршрутизатор генерирует несколько
иное сообщение UPDATE: в него вложено сообщение PRUNE, a HeJOIN.
Это сообщение передается по дереву так, как было описано выше: шаг за шагом оно
идет по кратчайшему пути в направлении корневого домена. Каждый получивший его
маршрутизатор проверяет, обслуживает ли он других членов группы. Если это так, нет не-
обходимости передавать сообщение дальше. В противном случае сообщение отправляется
на следующий маршрутизатор.
Маршрутизаторы BGMP должны не только управлять членством пользователей в груп-
пах, но также контролировать изменения, происходящие в таблицах многоадресной мар-
шрутизации. Ведь помимо пользователей появляться и исчезать могут целые каналы.
Протокол BGMP все еще считается экспериментальным. В Linux он реализован в мно-
гоадресной версии демона gated.
Протокол MSDP
Другим пограничным протоколом многоадресной маршрутизации является MSDP
(Multicast Source Discovery Protocol — протокол обнаружения источников многоадресных
сообщений). Он позволяет соединять только домены, внутри которых применяется про-
токол PIM-SM (см. главу 2, “Протоколы многоадресной маршрутизации”). Другой его осо-
бенностью является использование маршрутных таблиц BGP вместо того, чтобы создавать
собственные таблицы одноадресной рассылки.
Маршрутизаторы MSDP постоянно держат открытыми TCP-соединения со своими со-
седями. Имеется специальный таймер, задающий интервал, в пределах которого от соседа
должно поступить сообщение KeepAlive или SourceActive (SA). Если сообщение не было
получено вовремя, TCP-соединение устанавливается заново.
Разработчики протокола MSDP решили не изобретать колесо, применив для общения
маршрутизаторов MSDP и PIM-SM существующие деревья точки встречи (rendezvous point).
Когда новый источник начинает вещание и поток данных достигает точки встречи, ее
маршрутизатор создает сообщение SA, содержащее следующую информацию:
IP-адрес источника;
адрес канала групповой рассылки, в который направляются данные;
IP-адрес маршрутизатора точки встречи, управляющего этим каналом.
Данное сообщение посылается пограничному маршрутизатору MSDP, который рассы-
лает его всем соседям кроме собственно отправителя сообщения. Это называется лавинной
маршрутизацией. Получив сообщение SA, каждый сосед проверяет, кто из его соседей яв-
ляется ближайшим ретранслятором (reverse path forwarding peer) для данного канала. Бли-
жайший ретранслятор — это тот маршрутизатор MSDP, который расположен ближе всех к
исходному отправителю сообщения SA.
Подобная проверка необходима во избежание образования петель. Если сообщение SA
поступает от машины, которая расположена ближе к исходному отправителю, чем данный
маршрутизатор, но дальше, чем ближайший ретранслятор, такое сообщение игнорирует-
ся. В противном случае маршрутизатор пересылает сообщение тем соседям, которые от-
стоят от отправителя не ближе, чем он сам. Эти процессы происходят по всей сети Inter-
net, пока не будут пройдены все маршрутизаторы MSDP.
Кроме того, каждый маршрутизатор MSDP проверяет, не является ли он точкой встречи
PIM-SM для своего домена. Если машина играет двойную роль, она смотрит, есть ли в ее до-
Глава 3. Введение в протоколы пограничной маршрутизации 65
мене компьютеры, запросившие доступ к данному каналу. При наличии хотя бы одного за-
проса маршрутизатор точки встречи PIM-SM посылает запрос Join в точку встречи канала.
Как видите, протокол MSDP относительно прост, поскольку он опирается на таблицы
маршрутизации протокола BGP и на протокол PIM-SM, отслеживающий членство в груп-
пах. В Linux протокол MSDP реализован в многоадресной версии демона gated.
Резюме
Наряду с протоколами семейства IGP, применяемыми внутри автономных систем, ад-
министраторы глобальных сетей сталкиваются также с протоколами пограничной мар-
шрутизации. В этой главе были рассмотрены как одноадресные разновидности этих про-
токолов (EGP и BGP), так и многоадресные (BGMP и MSDP). В первом случае протокол
BGP считается более предпочтительным, так как он надежнее и современнее. Что касает-
ся второго случая, то выбор между протоколами BGMP и MSDP зависит от того, использу-
ется ли в автономных системах протокол PIM-SM.
В табл. 3.1 указано, где описан и реализован каждый из рассмотренных протоколов.
Таблица 3.1. Информация о протоколах пограничной маршрутизации
Протокол Где реализован RFC или проект стандарта
EGP gated 904
BGP gated, zebra 1771
BGMP gated draft-ietf-bgmp-spec-01 .txt
MSDP gated draft-ietf-msdp-spec-06.txt
66 Часть I. Основы маршрутизации
Адресация в стандартах
IPv4 и IPv6
В этой главе...
Адресация в стандарте IPv4 67
Бесклассовая адресация в стандарте IPv4 73
Адресация в стандарте IPv6 78
Резюме 82
В Linux используется семейство сетевых протоколов TCP/IP. Особенностью данного
семейства является то, что каждая машина в сети должна иметь уникальный адрес,
назначенный ей в соответствии с принципами IP-адресации. Большинство из нас уже
имеют опыт работы с этими адресами в Internet и в локальных сетях. Те, кто свободно
чувствуют себя в данном вопросе, могут сразу переходить к разделам “Бесклассовая адре-
сация в стандарте IPv4” и “Адресация в стандарте IPv6”. Для всех остальных ниже излага-
ются основы IP-адресации.
Адресация в стандарте IPv4
За многие годы сетевое сообщество привыкло к протоколу IP версии 4. Этот протокол
основан на применении сетевых адресов длиной 32 бита. Адресное пространство разделя-
ется на три основных класса: А, В и С. Класс D выделен для каналов групповой рассылки.
Класс адреса определяет, сколько битов IP-адреса относится к номеру сети, а сколько — к
номеру узла.
Адресная арифметика IPv4
IP-адрес можно записать двумя способами.
В компьютерном (двоичном) формате:
где каждый бит (х) может иметь значение либо 0, либо 1. Адрес состоит из четырех
октетов, или четырех 8-битовых двоичных чисел.
В читаемом (десятичном) формате:
где значение ххх находится в диапазоне от ООО до 255. Это десятичный эквивалент 8-би-
тового двоичного числа.
Рядовому пользователю, конфигурирующему свой домашний компьютер, достаточно
знать лишь десятичные IP-адреса. Но при планировании сложных сетей полезно, а иногда
даже необходимо уметь переходить от десятичного к двоичному представлению. Давайте
для начала научимся читать один 8-битовый октет (байт) двоичного IP-адреса. Каждому бит/
соответствует определенное десятичное число в зависимости от значения бита (0 или 1) и
его расположения в октете. Нулевой бит, в отличие от единичного, всегда “равен” нулю.
Все биты байта нумеруются от 0 до 7. Самый младший бит имеет номер 0. Десятичный
эквивалент бита составляет 2 в степени, равной номеру бита.
2Л0= 1
2Л1 = 2
2Л2 = 4
2Л3 = 8
2Л4 = 16
2Л5 = 32
2Л6 = 64
2Л7= 128
На рис. 4.1 эти значения расставлены в соответствии с расположением битов в байте.
”428 64 32 1б 8 4 2 i
Рис. 4.1. Каждому биту в байте IP-адреса соответст-
вует определенная степень числа 2; отсчет ведется
справа налево, начиная с нуля
Рассмотрим пример. Допустим, имеется двоичный IP-адрес
01001101.00011101.10111001.10110110. Как записать его в десятичном виде? Каждый байт
вычисляется отдельно, независимо от расположения. Начнем слева. Первый байт,
01001101, раскладывается следующим образом:
0х2Л7+1х2л6 + 0х2л5 + 0х2л4 + 1х2л3 + 1х2л2 + 0х2л1 + 1х2л0 = 77
или
0x128 + 1x64 + 0x32 + 0x16 + 1x8 + 1x4 + 0x2 + 1x1 = 77
Второй байт, 00011101, раскладывается так:
0x128 + 0x64 + 0x32 + 1x16 + 1x8 + 1x4 + 0x2 + 1x1 = 29
Третий байт, 10111001:
1x128 + 0x64 + 1x32 + 1x16 + 1x8 + 0x4 + 0x2 + 1x1 = 185
Четвертый байт, 10110110:
1x128 + 0x64 + 1x32 + 1x16 + 0x8 + 1x4 + 1x2 + 0x1 = 182
68 Часть I. Основы маршрутизации
Таким образом, в десятичном виде IP-адрес записывается как 77.29.185.182. Теперь
нужно узнать, как определить, где номер сети, а где — номер узла. Для этого взглянем на
табл. 4.1, в которой приведено сравнение классов IP-адресов.
Таблица 4.1. Классы IP-адресов (специальные адреса не показаны, сетевая часть адреса
выделена)
Класс Начало Конец
Двоичный Десятичный Двоичный Десятичный
А 00000001.00000000.00000000.00000000 1.0.0.0 01111111.00000000.00000000.00000000 127.0.0.0
В lOOOOOOODOOOOOOO.OOOOOOOO.OOOOOOOO 128.0.0.0 10111111.11111111.00000000.00000000 191.255.0.0
С НОООООО.ОООООООО.ООООООООШПЮОО 192.0.0.0 110111111111111111111111.00000000 223.255.255.0
D ШОООООЛООООООО.ООООООООЛООООООО 224.0.0.0 11101111111111111111111111111111 239255255255
На самом деле не все из показанных адресов доступны. Например, вся сеть 127.0.0.0 за-
резервирована для интерфейса обратной связи с компьютером, за которым ведется рабо-
та. Адреса этой сети не назначаются компьютерам. В таблице не показана еще сеть 0.0.0.0,
которая используется для указания на стандартный маршрут.
Нельзя также использовать первый и последний адреса каждого класса. Все адреса, в ко-
торых переменная часть (номер узла) состоит из одних нулей или одних единиц, зарезерви-
рованы для специального применения. Это означает, что следующие адреса недоступны.
Класс А. Они уже упоминались, но повторим еще раз: 0.0.0.0 и 127.0.0.0.
Класс В. 128.0.0.0 и 191.255.0.0.
Класс С. 192.0.0.0 и 223.255.255.0.
Класс D. 224.0.0.0 и 239.255.255.255. Как видно из таблицы, в этом классе нет номе-
ров узлов. Они просто не нужны. Многоадресные группы — это каналы, к которым
подключаются отдельные компьютеры со своими собственными адресами.
Еще один набор недоступных адресов зарезервирован для частных сетей. Эти адреса
специально выделены для внутреннего использования и никогда не указывают на компью-
тер, расположенный в глобальной сети. Диапазоны этих адресов перечислены в табл. 4.2
(показаны адреса целых сетей).
Таблица 4.2. Адреса, зарезервированные для частных сетей
Класс Начало Конец
А 10.0.0.0 10.0.0.0
В 172.16.0.0 172.31.0.0 .
С 192.168.0.0 192.168.255.0
D 239.0.0.0 239.255.255.255
Из адресного пространства удаляются не только адреса сетей, но и отдельные адреса узлов.
Адрес х.х.х.0 зарезервирован для ссылки на саму сеть.
Адрес хх.х.255 является широковещательным. Именно этому “узлу” протоколы TCP/IP
посылают широковещательные сообщения, предназначенные всем членам сети.
При создании подсетей “исчезает” еще часть адресов, но об этом пойдет речь ниже.
У всех адресов имеется сетевая маска, которая неизменна в пределах класса, если речь
идет о сетях, не разделенных на подсети (табл. 4.3).
Глава 4. Адресация в стандартах IPv4 и IPv6 69
Таблица 4.3. Стандартные сетевые маски для классов IP-адресов
Класс Сетевая маска
"А.........255.0.0.0...........................................
В 255.255.0.0
С 255.255.255.0
D 255.255.255.255
Как видите, в каждом байте номера сети все биты сетевой маски равны единице. Нуле-
вая часть маски соответствует номеру узла или подсети.
Адресация подсетей
Иногда одной сети оказывается недостаточно. Существуют административные, гео-
графические и другие причины, заставляющие делить сеть на группу подсетей. Это требу-
ет определенного труда. Во-первых, нужно правильно настроить подсистему маршрутиза-
ции, чтобы компьютеры каждой подсети знали, как посылать данные в другие подсети и
во внешний мир. Во-вторых, нужно пересчитать сетевые маски, сетевые адреса, широко-
вещательные адреса и т.д.
IP-сеть превращается в группу подсетей путем переноса нескольких битов из машин-
ной части адреса в сетевую. Это не какой-то волшебный трюк. Достаточно соответствую-
щим образом поменять маску. Нестандартная маска говорит о том, что в рамках данного
класса существуют подсети. Рассмотрим, как это реализуется на практике.
В классах А и В создавать подсети проще всего. Берем, к примеру, сеть 120.0.0.0 класса
А с сетевой маской 255.0.0.0 и выделяем в ней диапазон 120.1.0.0-120.254.0.0 с маской
255.255.0.0. Получилось 254 подсети класса В. То же самое применимо в отношении сети
класса В. Берем сеть 142.182.0.0 с маской 255.255.0.0, выделяем в ней диапазон 142.186.1.0-
142.185.254.0 с маской 255.255.255.0 и получаем 254 подсети класса С. Однако все это не
слишком актуально в наши дни, так как классы А и В давно уже заняты и с адресами этих
классов редко кто сталкивается.
Ситуация усложняется при выделении подсетей в сети класса С. Описанный выше
прием здесь не подходит, так как он приведет к созданию отдельного адреса класса I). Вы-
ход заключается в том, чтобы создать маску нестандартной длины, в которой часть битов
номера узла отнесена к сетевой части адреса.
Поскольку в классе С первые три байта маски жестко зафиксированы (255.255.255),
рассмотрим только последний байт. Чтобы разделить сеть на две подсети, нужно отнести
старший бит к сетевой части. Тогда адрес будет выглядеть так: сссссссс.сссссссс.сссссссс.сууууууу,
где с— биты номера сети, а у — биты номера узла.
Для разделения сети на четыре подсети нужно отнять от номера узла два бита (00, 01,
10, 11). Все это контролируется посредством сетевой маски. Ее наименьший значащий бит
определяет конец сетевой части адреса и начало подсети. Таким образом, если в сети две
подсети, маска будет равна 255.255.255.128, а если четыре подсети — 255.255.255.192. В
табл. 4.4 описаны возможные варианты разделения сети класса С на подсети.
Таблица 4.4. Выделение подсетей в сети класса С
Число подсетей Структура последнего байта адреса Двоичная маска Десятичная маска
2 сууууууу .10000000 255.255.255.128
4 ссуууууу .11000000 255.255.255.192
8 сссууууу .11100000 255.255.255.224
16 ссссуууу .11110000 255.255.255.240
70 Часть I. Основы маршрутизации
Окончание табл. 4.4
Число подсетей Структура последнего байта адреса Двоичная маска Десятичная маска
32 сссссууу .11111000 255.255.255.248
64 ссссссуу .11111100 255.255.255.252
128 сссссссу .11111110 255.255.255.254
Теперь перейдем к вопросу о размерах подсетей. Возьмем для начала пример с двумя
подсетями. Поскольку количество битов в номере узла равно 7, общее число узлов подсети
должно составлять 2Л7, т.е. 128. Это означает, что подсеть 1 будет иметь диапазон х.х.х.О-
х.х.х.127, а подсеть 2 — диапазон х.х.х.128-х.х.х.255.
Но не все так просто. Первый и последний адреса в диапазоне всегда зарезервирова-
ны, даже если сеть разделена на подсети. В первую очередь отнимается адрес самой сети
(х.х.х.0) и ее широковещательный адрес (х.х.х.255). Остаются диапазоны х.х.х.1-х.х.х.127 и
х.х.х.128-х.х.х.254. Идем дальше. В подсети 1 сетевой адрес (идентифицирует саму подсеть)
равен х.х.х.1, в подсети 2— х.х.х.128. Их тоже нужно отнять. Остаются диапазоны х.х.х.2-
х.х.х.127 и х.х.х.129-х.х.х.254. Но и это еще не все! У каждой подсети есть свой широкове-
щательный адрес, который используется для широковещательной рассылки пакетов в
пределах подсети, но не всей сети; В случае подсети 1 это адрес х.х.х.127, а в случае подсе-
ти 2 — х.х.х254. Таким образом, итоговые диапазоны адресов будут следующими: х.х.х.2-
х.х.х.126 и х.х.х.129-х.х.х.253. Как видите, разделение сети на две подсети потребовало
принести в жертву четыре адреса (по два для каждой подсети), не считая два адреса, заре-
зервированные в самой сети.
Еще сложнее обстоит дело с разделением сети класса С на четыре подсети. Теоретиче-
ски размер подсети должен составлять 64, поэтому получится четыре адресных диапазона:
х.х.х.0-х.х.х.63, х.х.х.64-х.х.х.127, х.х.х.128-х.х.х.191 и х.х.х.192-х.х.х.255. Но снова теряются
адреса х.х.х.0 и х.х.х.255 (идентификатор сети и ее широковещательный адрес). Далее
нужно отнять идентификаторы подсетей (х.х.х.1, х.х.х.64, х.х.х.128 и х.х.х.192) и соответст-
вующие широковещательные адреса (х.х.х.63, х.х.х.127, х.х.х.191 и х.х.х.254). Результат по-
казан в табл. 4.5. Там же приведены адресные диапазоны для других вариантов разделения
сети класса С на подсети.
Таблица 4.5. Адреса узлов и специальные адреса при разделении сети класса С на подсети
(предполагается, что адреса х.х.х.0 и х.х.х.255 всегда зарезервированы)
Число подсетей Идентифи- каторы подсетей Широкове- щательные адреса Адреса узлов
2 х.х.х.1, х.х.х.127, х.х.х.2”Х.х.х.126,
х.х. х.128 х.х. х.254 х. х.х. 129-х. х.х.253
4 х.х. х.1, х.х. х.63, х.х.х.2-х.х.х.62,
х.х.х.64, х. х.х. 127, х. х. х. 6 5- х. х. х. 12 6,
х.х.х.128, х.х. х.191, х.х.х. 129-х. х.х. 190,
х.х.х.192 х.х. х.254 х. х.х. 193-х.х. х.253
8 Х.Х.Х.1, х.х.х.31, х.х.х.2- х.х.х.30,
х.х. х.32, х.х. х.63, х.х. х.ЗЗ-х.х.х.62,
х.х.х.64, х. х. х.95, х.х.х.65-х.х.х.94,
х.х. х.96, х.х.х.127, х. х.х. 97-х. х. х.126,
х.х.х.128, х. х.х. 159, х.х.х.129-х. х.х. 158,
х.х.х.160, х. х. х. 191, х.х.х.161-х. х.х. 190,
х. х.х. 192, х.х.х.223. х.х.х.19Я-х.х.х.222,
х.х.х.224 х.х.х.254 х. х. х. 225- х. х. х. 2 5 3
Глава 4. Адресация в стандартах IPv4 и IPv6 71
Окончание табл. 4.5
Число подсетей Идентифи- каторы подсетей Широкове- щательные адреса Адреса узлов
16 X. X. X. 1, х.х.х.15, х.х.х.2-х. х.х.14,
X. Х.Х.16, х.х.х.31, х.х. х.17-х. х. х.ЗО,
х. х.х. 32, х.х.х.47, х.х. х.ЗЗ-х.х.х.46,
х.х.хА8, х.х. х.63, х.х. х.49-х.х. х.63,
х.х.х.64, х.х.х.79, х. х.х.65-х. х. х. 78,
х. х.х.80, х.х.х.95, х. х. х. 81-х. х. х. 94,
х.х.х.96, Х.Х.Х.111, х. х.х.97-х. х.х.110,
х.х.х.112, XXX. 127, х.х.х.113-х.х.х.126,
х.х. х.128, х. х.х. 143, х.х. х. 129-х. х.х. 142,
х.х. х.144, х.х.х.159, х.х.х. 145-х.х. х.158,
х.х. х.160, х. х.х.175, х.х.х. 161-х. х.х.174,
х.х.х.176, х.х.х.191, х. х. х. 17 7- х. х. х. 19 0,
х.х.х.192, х.х. х.207, х. х. х. 19 3- х. х. х.206,
х. х.х.208, х.х.х.223, Х.Х.Х.209-Х.Х.Х.222,
х.х.х.224, х.х.х.239, х. х.х. 225-х. х.х.238,
х.х.х.240 ххх. 2 54 х.х.х.241-х.х.х.253
32 X. X. х. 1, х.х.х.7, х. х. х.2-х. х. х.6,
х.х. х.8, х.х. х.15, х. х.х. 9-х.х.х. 14,
х.х.х.16, х.х. х.23, х.х.х.17-х.х.х.22,
х. х. х.24, х.х.х.31, х.х.х.25-х.х.х.ЗО,
х.х.х.32, х. х.х.39. х.х.х.33~х.х.х.38,
х. х.х.40, х.х. х.47, х.х.х.41-х. х. х.46,
х.х.х.48, х. х. х.55, х.х.х.49-х.х.х.54,
х.х. х.56, х.х. х.63, х.х.х.57-х. х. х.62,
х.х. х.64, х. х. х.71, х.х.х.65-х. х.х.70,
х.х.х.72, х.х. х.79, х.х. х.73-х. х. х.78,
х. х.х. 80, х.х.х.87. х.х. х.81-х.х.х.88,
х. х.х. 88, х.х.х.95, х. х.х.89-х.х.х.94.
х.х. х.96, х. х.х. 103, х.х.х.97-х.х. х.102,
х. х.х. 104, X. х.х.111, х. х.х. 105-х. х.х. 110,
х. х.х.112, х.х.х. 119, х.х.х.113-х.х.х.118,
х. х.х. 120, х.х. х.127, х.х. х. 121-х. х. х.126,
х.х. х.128, х. х. х.135, х. х. х. 129-х. х. х. 134,
х. х.х. 136, х.х.х. 143, х. х.х. 137-х. х.х. 142,
х.х. х.144, х. х. х. 151, х. х. х. 145-х. х. х. 150,
х. х.х. 152, х. х.х.159, х.х.х. 153-х. х.х. 158,
х.х. х.160, х.х.х.167, х.х.х.161-х. X. х.166,
х. х.х. 168, х. х.х.175, х.х.х. 169-х. х.х. 174,
х.х. х.176, х.х.х.183, х. х. х. 17 7- х. х. х. 18 2,
х. х.х.184, х.х.х.191, х.х.х. 185-х. х.х. 190,
х. х.х. 192, х.х.х.199, х. х.х. 193-х. х. х.198,
хх.х200, х.х. х.207, х. х. х.201-х. х.х. 206,
х. х.х.208, х.х. х.215, х.х,х.209-х.х.х.214,
х. х.х.216, х.х. х.223, х.х.х.217х.х.х.222,
ххх224, х.х.х.231, х. х.х. 22 5- х. х. х. 230,
х.х.х.232, х.х. х.239, Х.Х.Х.233-Х. х.х.238,
х.х.х.240, х.х.х.47, х.х. х.241-х. х.х. 246,
х.х. х.248 х.х.х.254 Х.Х.Х.249-Х.Х.Х.253
72 Часть I. Основы маршрутизации
Беглого взгляда на таблицу достаточно, чтобы понять, почему мы остановились в ле-
вом столбце на числе 32. Уже на этом уровне число узлов в подсети равно 6 (в первой и по-
следней подсетях — 5). Дальнейшее дробление сети приведет к тому, что подсети станут
слишком маленькими и потеряют всякий практический смысл.
Маршрутизация по стандарту IPv4
Как известно, в крупной сети адресное пространство — это важнейший ресурс. К сожа-
лению, как было показано выше, с введением подсетей адресное пространство начинает
стремительно сокращаться, теряя сетевые и широковещательные адреса. Хуже того, ис-
ходная спецификация IP-подсетей (RFC950) запрещала использовать первую и последнюю
подсети в каждом варианте разбивки (их сетевая часть последнего байта состоит из одних
нулей и одних единиц соответственно). Таким образом, показанный в табл. 4.5 вариант
разбивки на две подсети оказывается бессмысленным. Из четырех подсетей можно будет
задействовать только две, из восьми — шесть и т.д. Правда, требования спецификации иг-
норируются многими маршрутизаторами, но не всеми.
Внешним маршрутизаторам известен лишь адрес сети и ее маска. Когда данные дости-
гают внутреннего маршрутизатора, он выбирает нужную подсеть.
Бесклассовая адресация в стандарте IPv4
При бесклассовой адресации сохраняются основные положения стандарта IPv4, но за-
действуется новый протокол: CIDR (Classless Interdomain Protocol — бесклассовая междо-
менная маршрутизация). Вместе с ним появляются и новые понятия, например формирова-
ние. суперсетей и маски подсетей переменной длины..
Различия между классовой и бесклассовой адресацией
В протоколе CIDR адреса не делятся на классы А, В и т.д., что, впрочем, не вызывает
хаоса. Вместо этого все десятичные адреса формата xxx.xxx.xxx.xxx сопровождаются бито-
вой маской (задает длину префикса). По сути, это просто сокращение, позволяющее не запи-
сывать полную маску. Тем не менее в следующем разделе мы опишем арифметику, стоя-
щую за битовыми масками.
В исходной (классовой) спецификации IPv4 структура подсетей примерно такая, как та,
что изображена на рис. 4.2. Все подсети имеют одинаковый-размер и входят в состав более
крупной сети. Иногда эта структура оказывается довольно удобной, но она ведет к значи-
тельным потерям адресов и не позволяет осуществлять дальнейшее деление подсетей.
х.х.х.О
х.х.х.1 х.х.х.64
х.х.х.128 х.х.х.192
Рис. 4.2. Формирование подсетей с точки
зрения “классовой” версии стандарта IPv4
Глава 4. Адресация в стандартах IPv4 и IPv6 73
Арифметика бесклассовых адресов
Как было сказано, в протоколе CIDR длина адресного префикса задается битовой мас-
кой. Она записывается так: /хх, где х— это цифра. В стандарте IPv4 существуют лишь мас-
ки /8, /16 и /24. Они задают количество битов в сетевой части IP-адреса. Например, ад-
рес класса А имеет структуру сссссссс.уууууууу.уууууууу.уууууууу, поэтому ему соответствует маска
/8. Адресу класса В соответствует маска /16, адресу класса С — маска /24.
В бесклассовой адресации маска задается из расчета того, сколько узлов должно быть в
подсети: 4, 8, 16, 32, 64, 128, 256, 512 и т.д. Предположим, для нашей кампусной сети тре-
буется адресный блок размером 4096, т.е. 2Л12. Таким образом, длина машинной части ад-
реса будет составлять 12 битов, а сетевой части — 20, что соответствует маске /20. Не име-
ет значения, чему равны биты в сетевой части. В протоколе CIDR компьютеры не прове-
ряют их содержимое.
Как на основании длины префикса получить привычную сетевую маску? Это легко. Ес-
ли длина префикса равна 20, значит, первые два байта маски заполнены и равны 255. В
третьем байте установлены лишь четыре старших бита, которым соответствуют значения
128, 64, 32 и 16, что в сумме дает 240. Последний байт равен нулю. Итого, получаем сете-
вую маску 255.255.240.0. В табл. 4.6 перечислены битовые и сетевые маски, используемые в
протоколе CIDR.
Таблица 4.6. Маски и соответствующие им размеры подсетей в протоколе CIDR
Битовая маска Сетевая маска Число узлов
/17 255.255.128.0 32766
/18 255.255.192.0 16382
/19 255.255.224.0 8190
/20 255.255.240.0 4094
/21 255.255.248.0 2046
/22 255.255.252.0 1022
/23 255.255.254.0 510
/24 255.255.255.0 254
/25 255.255.255.128 126
/26 255.255.255.192 62
/27 255.255.255.224 30
/28 255.255.255.240 14
/29 255.255.255.248 6
Обратите внимание: количество доступных адресов — это степень двойки минус 2.
От адресного диапазона по-прежнему отнимаются сетевой и широковещательный адреса.
Бесклассовая адресация подсетей
Концепция подсетей также актуальна при бесклассовой адресации. Что если нужно
взять выделенный блок адресов и разбить его на несколько блоков меньшего размера? К
тому же необязательно, чтобы все подсети были в точности одного размера. Здесь-то и
появляются маски подсетей переменного размера.
Согласно протоколу CIDR в общей сети могут применяться различные маски, позво-
ляющие формировать подсети разного размера. Это делается иерархически. Сначала соз-
дается группа более крупных подсетей одного размера, затем в них выделяются меньшие
подсети и т.д. Теперь становится ясным назначение расширенного префикса. Возьмем за
основу упоминавшуюся выше сеть с битовой маской /20. Это достаточно крупная сеть: в
74 Часть I. Основы маршрутизации
ней может существовать 4096 узлов. Нам нужно разбить ее на подсети. Вспомним, что рас-
сматривавшаяся в предыдущих главах автономная система представляет собой универси-
тетскую сеть, в которой есть две достаточно крупные области маршрутизации: одна — для
факультетов, другая — для общежитий.
Итак, первый этап очевиден: делим сеть 192.168.240.0/20 на две крупные подсети. Для
этого понадобится добавить к префиксу один-единственный бит. Биты, расширяющие се-
тевую часть адреса, будем обозначать как р. Тогда структура адреса первых двух подсетей
будет выглядеть так: сссссссс.сссссссс.ссссрууу.уууууууу.
Назначить подсетям адреса проще, чем кажется. У первой подсети будет адрес
192.168.240.0/21, у второй -192.168.248.0/21 (рис. 4.3).
управляющий сетью здания. Следовательно,
Рис. 4.3. Начальный этап формирования ие-
рархической структуры бесклассовой сети
каждом здании есть свой маршрутизатор,
необходимо выделить дополнительные под-
сети. Начнем с факультетов. В нашей демонстрационной сети семь факультетских зданий.
Подсети выделяются группами, причем размер каждой группы равен степени числа 2. По-
этому мы создадим 8 подсетей (одна на будущее). Можно, конечно, создать сразу 16 подсе-
тей с учетом будущего разрастания университета, но тогда в каждой сети было бы 126 уз-
лов (/25), а не 254 (/24). Как мы определили размер подсети? Группа из восьми подсетей
описывается тремя битами адреса. Обозначим эти биты как ф. Тогда структура адреса бу-
дет такой: сссссссс.сссссссс.ссссрффф.уууууууу, или /24. В машинной части адреса 8 битов, что
дает 254 (2Л8 - 2) узла.
Все восемь подсетей перечислены в табл. 4.7.
Таблица 4.7. Восемь факультетских подсетей в сети 194.168.240.0/21 (показаны только
изменяющиеся биты)
Подсеть Битовая структура адреса Сетевая маска
Ag . ccccpQ 0 0 .уууууууу 192.168.240.0/24
Eng . ccccjfi 01 .уууууууу 192.168.241.0/24
Phys . ccccfft 10 .уууууууу 192.168.242.0/24
Hum . ccccjfi 11 .уууууууу 192.168.243.0/24
Arts . сссср 100 .уууууууу 192.168.244.0/24
Chem . ccccpl 01 .уууууууу 192.168.245.0/24
Math . ccccpl 10 .уууууууу 192.168.246.0/24
резерв . ccccpl 11 .уууууууу 192.168.247.0/24
По сути, мы получили те же сети класса С, так как длина маски — 24 бита. Далее эти се-
ти можно делить по кафедрам и рабочим группам.
Глава 4. Адресация в стандартах IPv4 и IPv6 75
В университетском городке шесть общежитий. Для каждого из них нужно создать свою
подсеть. Как и в предыдущем случае, всего будет выделено восемь подсетей (две в запасе).
Все они перечислены в табл. 4.8.
Таблица 4.8. Восемь подсетей общежитий в сети 194.168.248.0/21 (показаны только
изменяющиеся биты)
Подсеть Битовая структура адреса Сетевая маска
Runk .ссссрООО.уууууууу 192.168.248.0/24
East .ссссрОО 1 уууууууу 192.168.249.0/24
Trud .ссссрО 10.уууууууу 192.168.250.0/24
Wash .ссссрО 11 УУУУУУУУ 192.168.251.0/24
Wall .сссср ЮО.уууууууу 192.168.252.0/24
Poin .сссср 101 уууууууу 192.168.253.0/24
резерв .ccccpl Ю.уууууууу 192.168.254.0/24
резерв .ccccplll УУУУУУУУ 192.168.255.0/24
На рис. 4.4 изображена схема адресации всей сети.
Рис. 4.4. Текущая иерархическая структура демонстрационной сети
76 Часть I. Основы маршрутизации
Бесклассовая маршрутизация по стандарту IPv4
Кому-то может показаться, что бесклассовая адресация ложится тяжелым бременем на
маршрутизаторы или приводит к такому разрастанию маршрутных таблиц, что замедляет-
ся весь трафик в сети Internet. К счастью, это не так. При правильном планировании мож-
но скрывать внутреннюю структуру сетей от внешнего мира (подробнее об этом говорится
в главе 10, “Планирование системы маршрутизации”).
Принцип сокрытия внутренних адресов называется агрегированием маршрутов. Давайте
проанализируем описанную в предыдущем разделе сеть с масками переменной длины. Все
подсети входят в главную сеть с адресом 192.168.240.0/20. Двадцатиразрядная маска зада-
ет следующую структуру адресов: сссссссс.сссссссс.ссссуууу.уууууууу, где с— бит номера сети, а у—
бит номера узла. Это означает, что диапазон адресов, используемых в сети, таков:
192.168.240.0-192.168.255.255.
В главной сети есть две подсети первого уровня с адресами 192.168.240.0/21 и
192.168.248.0/21. Оба адреса находятся в родительском диапазоне. Следовательно, неза-
висимо от того, в какую подсеть направляется трафик, он сначала должен попасть в сеть
192.168.240.0/20. Маршрутизаторы, находящиеся за пределами автономной системы, не
обязаны знать о том, что в ней есть какие-то подсети.
Подсети первого уровня имеют собственные адресные диапазоны. Для факультетской
подсети (192.168.240.0/21) это 192.168.240.0-192.168.247.255, для сети общежитий
(192.168.248.0/21)— 192.168.248.0-192.168.255.255. А теперь посмотрите еще раз на
табл. 4.7, 4.8. Все приведенные в них адреса попадают в один из этих диапазонов. Это оз-
начает, что пакет, адресованный какому-то компьютеру, сначала должен пройти универ-
ситетский маршрутизатор, после него — маршрутизатор области факультетов или обще-
житий, затем — маршрутизатор соответствующего здания. В каждом случае только выше-
стоящий маршрутизатор знает о существовании подсетей на следующем уровне. Это
хороший пример агрегирования маршрутов, которое является ключом к успеху протокола
CIDR. Чем больше маршрутной информации можно скрыть на локальном уровне, тем
меньше становится общий размер маршрутных таблиц.
Маршрутизаторы, работающие с бесклассовыми адресами, распространяют информа-
цию, которую обычные маршрутизаторы не понимают. Если обычно передается сетевая
маска, то в бесклассовом режиме — битовая маска. Выбор маршрута осуществляется по
принципу самого длинного префикса. Это означает, что среди всех маршрутов, ведущих к за-
данной сети, выбирается тот, у которого более длинная маска.
Предположим, внешнему маршрутизатору требуется доставить информацию по адресу
192.168.250.52. В таблице маршрутизации ищется запись, конечный пункт которой распо-
ложен ближе всего к данному адресу. Дальнейшее развитие событий зависит от того, на-
сколько далеко расположен сам маршрутизатор. В его таблице может присутствовать ад-
рес сети 192.168.240.0/20, который и будет выбран по правилу самого длинного префикса.
Но вполне вероятно, что вся сеть 192.168.0.0 принадлежит некоему провайдеру, осуществ-
ляющему дальнейшее распределение фрагментов сети, а маршрутизатор не является ча-
стью этой сети. В таком случае пакет, адресованный компьютеру 192.168.250.52, сначала
попадет в сеть провайдера.
Возьмем за основу второй вариант. Попав в сеть 192.168.0.0, пакет окажется на мар-
шрутизаторе провайдера. В его маршрутных таблицах будет найдена запись о сети
192.168.240.0/20. Ее префикс самый длинный, поэтому пакет уйдет на пограничный мар-
шрутизатор Prime. В его таблице обнаружится сеть 192.168.248.0/21, вследствие чего па-
кет переместится на маршрутизатор East. Далее окажется, что следующее звено цепи—
маршрутизатор Trud (192.168.250.x). Он уже знает непосредственного получателя пакета:
компьютер 192.168.250.52.
Глава 4. Адресация в стандартах IPv4 и IPv6 77
Данный пример не только иллюстрирует принцип самого длинного префикса, но и по-
казывает, как много информации не нужно знать внешним маршрутизаторам. Все, что им
нужно, — доставить пакет маршрутизатору Prime, который возьмет на себя все остальное.
Компьютеры, не поддерживающие протокол CIDR
Не все системы по умолчанию поддерживают протокол CIDR. В их число входит и Linux. Тот,
кому доводилось работать с командой route (описана в главе 9, “Сетевые команды”), знает, что
ей нужно задавать IP-адрес, адрес шлюза и маску сети. О битовой маске нигде не говорится.
Следовательно, подразумевается, что у каждого IP-адреса есть класс. То же самое касается
других команд и самого ядра.
Первые версии ядра Linux, в которых появилась поддержка бесклассовой адресации, имели
номер 2.2.x. Но даже в них модуль бесклассовой адресации помечен как экспериментальный.
Чтобы компьютер мог работать по протоколу CIDR, необходимо перекомпилировать ядро,
подключив к нему соответствующие модули, а затем обратиться по адресу http://www.
tazenda.demon.co.uk/phil/net-tools/ и загрузить последнюю версию пакета сетевых
утилит. В нем есть все необходимое для работы в сетях Linux, в том числе средства поддержки
бесклассовой адресации.
Адресация в стандарте IPv6
Все мы являемся свидетелями широкомасштабных изменений сети Internet. Многие
годы мы осваивали тонкости IP-адресации, подсетей и т.п., а тем временем пространство
IP-адресов исчерпалось быстрее, чем кто-либо мог предположить. Что мы делаем, когда
программы или операционные системы устаревают? Правильно: меняем их. То же самое
касается и протоколов, которые начинают проявлять признаки старения и перестают
справляться с возложенными на них задачами. Одно из решений проблемы сокращения
адресного пространства — это бесклассовая адресация, но со временем ее тоже может ока-
заться недостаточно. Другим решением стал стандарт IPv6.
Основы адресации IPv6
Шестая версия протокола IP не основана на четвертой. Это совершенно новый меха-
низм сетевой адресации, в котором адреса стали 128-разрядными, а не 32-разрядными, что
позволяет на сотни лет вперед удовлетворить потребность в новых адресах. В IPv6 больше
нет широковещательных адресов. Вместо них используются однонаправленные (unicast),
групповые (multicast) и совмещенные (anycast) адреса. Под совмещением понимается закре-
пление нескольких аппаратных интерфейсов за одним IP-адресом. Данные, направляемые
по этому адресу, попадут на ближайший из интерфейсов (выбор производится маршрути-
затором). Можно также назначать одному интерфейсу несколько адресов.
Адреса IPv6 отображаются иначе, чем в IPv4. Они разбиваются на восемь частей, раз-
деленных двоеточиями. Каждая часть состоит из двух байтов: бб.бб.бб.бб.бб.бб.бб.бб, где б—
отдельный байт. Но адреса обычно записываются в шестнадцатеричном виде, поэтому
каждый бат разбивается на две шестнадцатеричные цифры:
где ш— шестнадцатеричная цифра.
В IPv6, как и в IPv4, есть специальные адреса. Один из них — это адрес обратной связи
(loopback address), 0:0:0:0:0:0:0:1, эквивалентный адресу 127.0.0.1. Его еще можно записать
так: ::1. Есть также неуточненный адрес (unspecified address), 0:0:0:0:0:0:0:0, используемый,
когда реальный адрес еще не был задан.
Группы адресов специального назначения определяются префиксами формата. Многие
группы зарезервированы, но еще не нашли конкретного применения. В табл. 4.9 перечис-
лены префиксы, назначение которых уже определено (полный вариант таблицы приведен
в документе RFC2373).
78 Часть I. Основы маршрутизации
Таблица 4.9. Зарезервированные префиксы IPv6, имеющие конкретное назначение
Двоичный префикс Шестнадцатери- чный префикс Назначение
00000000 00 Зарезервирован
0000001 02+ Зарезервирован для NSAP (Network Service Access Point — точка доступа к сетевому сервису)
0000010 04+ Зарезервирован для протокола IPX
001 2+ Определяет агрегированный глобальный однона- правленный адрес
1111111010 FE8+ Определяет локальный канальный адрес
1111111011 FEC+ Определяет локальный адрес в пределах организации
11111111 FF Определяет групповой адрес
Введение в шестнадцатеричную арифметику
Возможно, кому-то из читателей требуется вспомнить основы шестнадцатеричной
арифметики. Что ж, давайте вспоминать вместе.
Шестнадцатеричные операции выполняются по основанию 16, а не 2 или 10.
Шестнадцатеричные цифры обозначаются от 0 до 9, а затем от Адо F.
Шестнадцатеричная цифра описывается четырьмя битами.
Байт состоит из двух шестнадцатеричных цифр.
Вернемся к табл. 4.9. Первый префикс преобразовать в шестнадцатеричный вид легко.
Двоичное 00000000 —это десятичное 0 и шестнадцатеричное 00. Второй префикс, 0000001,
соответствует неполному байту. Воспользовавшись формулой, приведенной в разделе
“Адресная арифметика IPv4”, найдем его десятичный эквивалент:
0x128 + 0x64 + 0x32 + 0x16 + 0x8 + 0x4 + 1x2 + ?х1 = 2+
Знак + в полученном результате говорит о том, что итоговое значение определяется на
основании недостающих битов.
Но нам нужно преобразовать двоичное значение в шестнадцатеричное. Поскольку
байт состоит из двух шестнадцатеричных цифр, разобьем двоичное число на два квартета
битов: 0000 и 001 ?. Первый квартет преобразуется в шестнадцатеричный нуль. Для второ-
го квартета применим ту же формулу:
0x8 + 0x4 + 1x2 + ?х1 = 2+
Аналогичным образом находим шестнадцатеричные эквиваленты остальных префиксов:
0000010? =0000 010?
= 0 | 0x8 + 1x4 + 0x2 + ?Х1
= 04+
001?????
= 001?????
= 0x8+ 0x4+ 1х2 + ?х1 | ?
= 2+
11111110 10 = 1111 1110 10
= 1x8 + 1x4 + 1x2 + 1x1 I 1x8 + 1x4 + 1x2 + 0x1 | 1x8 + 0x4 + ?х2 + ?х1
= (15 десятичное)(14 десятичное)8?
= FE8+
Глава 4. Адресация в стандартах IPv4 и IPv6 79
11111110 11 = 1111 1110 11
= 1x8 + 1x4 + 1x2 + 1x1 I 1x8 + 1x4 + 1x2 + 0x1 | 1x8 + 1x4 + ?x2 + ?xl
= (15 десятичное)(14 десятичное)(12 десятичное)?
= FEC+
11111111 = 1111 1111
= 1x8 + 1x4 + 1x2 + 1x1 | 1x8 + 1x4 + 1x2 + 1x1
= (15 десятичное)(15 десятичное)
= FF
Чтение адресов IPv6
Большинство из нас умеют читать адреса IPv4, что называется, с закрытыми глазами
Переход на бесклассовую адресацию тоже не составил особого труда, так как многие были
знакомы с механизмом применения масок. Что касается адресов IPv6, то тут требуются
иные навыки. Прежде всего подчеркнем имеющиеся сходства.
Адрес IPv6 читается слева направо.
По-прежнему может задаваться битовая маска.
В стандарте IPv6 интерпретация адреса зависит от префикса, т.е. начальных битов. Са-
мое приятное то, что отличать групповые адреса стало намного проще. Любой адрес, начи-
нающийся с префикса FF, является групповым. Все остальные адреса —либо однонаправлен-
ные, либо совмещенные (синтаксической разницы между этими двумя типами нет).
Далее мы сосредоточимся на анализе однонаправленных адресов, поскольку именно
они встречаются чаще всего. К однонаправленным относятся следующие виды адресов:
агрегированный, IPX, NSAP, локальный канальный (link-local), локальный в пределах ор-
ганизации (site-local), а также производный (построенный на основе старого адреса IPv4).
В принципе, для компьютеров такое разделение не имеет никакого значения. Оно важно
для маршрутизаторов.
В документе RFC2874 описаны следующие правила создания агрегируемых глобальных
однонаправленных адресов, являющихся потомками адресов IPv4 в традиционном пони-
мании.
Первые 3 бита адреса задают префикс. Как видно из табл. 4.9, для агрегируемых
адресов префикс равен 001.
Следующие 13 битов задают идентификатор агрегата верхнего уровня (Top-
Level Aggregator, TLA). Это первый пункт, куда маршрутизаторы должны достав-
лять данные. Идентификаторы TLA назначаются организацией IANA (Internet As-
signed Numbers Authority — агентство по выделению имен и уникальных параметров
протоколов Internet) магистральным провайдерам, а также национальным адрес-
ным канцеляриям.
Следующие 8 битов пока не используются. В настоящее время они равны нулю и
зарезервированы на будущее, если вдруг идентификаторов TLA или NLA станет не-
достаточно.
Следующие 24 бита задают идентификатор агрегата второго уровня (Next-Level
Aggregator, NLA). Эти биты находятся в полном распоряжении соответствующего
агрегата верхнего уровня. Он может выдавать идентификаторы региональным про-
вайдерам, а те — провайдерам нижнего уровня или конкретным организациям. При
этом формируется иерархия сетей провайдеров.
80 Часть I. Основы маршрутизации
Следующие 16 битов задают идентификатор агрегата уровня организации (Site-
Level Aggregator). Организация может создавать иерархию собственных подсетей,
назначая им идентификаторы из своего адресного пространства.
Последние 64 бита задают собственно идентификатор интерфейса. Этот иден-
тификатор представляется в формате IEEE EUI-64.
Каким образом можно создать идентификатор интерфейса в соответствии с форматом
EUI-64? В первую очередь нужно учитывать, что идентификаторы бывают как универсаль-
ными, так и локальными. Универсальные идентификаторы являются глобально уникаль-
ными, а локальные — нет.
Идентификатор интерфейса обычно является универсальным и создается на основании
МАС-адреса сетевой платы. В случае технологии Ethernet МАС-адрес имеет 48 разрядов. Где
взять еще 16 битов? Нужно просто вставить между третьим и четвертым байтами МАС-адреса
цепочку байтов FFFE. Специальный бит МАС-адреса (седьмой слева в старшем байте), называе-
мый битом и (universal/local bit), определяет, является ли этот адрес универсальным или ло-
кальным. В универсальном идентификаторе IPv6 этот бит должен быть равен единице.
Теперь познакомимся с локальными адресами. Они бывают двух видов: локальными ка-
нальными (link-local) и локальными в пределах организации (site-local). Оба используются только в
подсетях и позволяют маршрутизаторам осуществлять фильтрацию локальных пакетов.
Каждый сетевой интерфейс компьютера, поддерживающего протокол IPv6, должен
иметь локальный канальный адрес. Он применяется при обмене информацией с соседни-
ми компьютерами, а также для автоматического получения от маршрутизатора конфигу-
рирующей информации. Подобные адреса можно узнать по 10-битовому префиксу:
11111110 10. Эти адреса не должны быть известны за пределами локальной сети.
Адрес, локальный в пределах организации, известен чуть более широкому кругу узлов.
Он также назначается каждому сетевому интерфейсу компьютера и может использоваться
при обмене данными между двумя компьютерами, находящимися в разных подсетях.
Маршрутизаторы фильтруют пакеты с такими адресами, если они пытаются уйти во
внешний мир. Префикс адреса таков: 11111110 11.
Следует также сказать, что в IPv6 предусмотрен механизм передачи старых адресов
IPv4. Достаточно просто добавить к ним нулевой префикс длиной 96 битов. На начальном
этапе это упрощает переход от IPv4 к IPv6.
Маршрутизация по стандарту IPv6
В стандарте IPv6 удобно то, что новая схема адресации может использоваться с теми
же протоколами маршрутизации, что и раньше: RIP-2, OSPF и т.д. Но ряд новых особен-
ностей, несомненно, усложнит жизнь администраторам.
В отличие от пакета IPv4, у которого только один заголовок, пакет IPv6 может иметь
произвольное число добавочных заголовков. Среди них есть маршрутный заголовок.
В нем содержится список промежуточных адресов, через которые должен пройти пакет.
Наличие такой информации позволяет направлять ответные данные по тому же пути, а
также отслеживать местоположение мобильных пользователей.
Другой удобной особенностью является то, что маршрутизатор IPv6 способен автома-
тически конфигурировать адреса сетевых интерфейсов в своей сети. Определив локаль-
ный канальный адрес интерфейса, компьютер посылает маршрутизатору запрос по про-
токолу ICMPv6 с указанием этого адреса. В ответ маршрутизатор сообщает компьютеру
глобальный префикс сети. Далее компьютер самостоятельно создает глобальный адрес
IPv6, записывая в конец префикса идентификатор интерфейса. Если какой-нибудь другой
компьютер заявит о том, что такой идентификатор уже используется, придется конфигу-
рировать интерфейс вручную.
Глава 4. Адресация в стандартах IPv4 и IPv6 81
Резюме
В этой главе были описаны три схемы адресации, применяемые в настоящее время в
сети Internet. Приведенная информация поможет читателям подготовиться к переходу на
протокол CIDR или стандарт IPv6.
82 Часть I. Основы маршрутизации
II
Средства и технологии
маршрутизации в Linux
В этой части...
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x
Глава 6. Демоны многоадресной маршрутизации в ядре 2.2.x
Глава 7. Вспомогательные демоны
Глава 8. Средства маршрутизации в ядре версии 2.4.x
Глава 9. Сетевые команды
Глава 10. Планирование системы маршрутизации
Глава 11. Основы маршрутизации в Linux
Глава 12. Сетевые аппаратные компоненты
Глава 13. Включение в ядро функций маршрутизации
Глава 14. Безопасность и система NAT
Глава 15. Мониторинг, анализ и управление сетевым трафиком
Демоны одноадресной
маршрутизации в ядре 2.2.x
В этой главе...
Демон routed
Демон gated
Резюме
84
87
116
В Linux есть целая группа демонов маршрутизации, у каждого из которых множество
функциональных возможностей. Все их описать в данной книге не получится, по-
этому мы рассмотрим лишь несколько наиболее распространенных демонов. Начнем с
демонов, управляющих одноадресной маршрутизацией в ядре версии 2.2.x.
Демон routed
Демон routed, поставляемый вместе с ядром Linux версии 2.2.x, по умолчанию обра-
батывает только одноадресные пакеты IPv4. Если предполагается использовать лишь про-
токол RIP в контексте IPv4, то кроме этого демона ничего больше не понадобится. Правда,
даже в документации к самому демону, в разделе “BUGS”, сказано буквально следующее:
“Польза демона routed сомнительна. Лучше использовать gated(8) или zebra(8)”. Тем
не менее в некоторых ситуациях демон routed действительно позволяет решать все не-
обходимые задачи.
Принцип работы
Демон routed обычно запускается на этапе начальной загрузки. Проверив, какие из се-
тевых интерфейсов активны, демон выясняет, со сколькими из них ему придется работать.
Если интерфейсов больше одного, потребуется обслуживать несколько внутренних сетей.
Далее демон определяет типы пакетов, поддерживаемые каждым из интерфейсов. Ес-
ли интерфейс способен обрабатывать только одноадресные данные, демон посылает че-
рез него пакет Request (запрос) всем узлам, перечисленным в файле /etc/hosts. Если же
интерфейс поддерживает широковещание, пакет Request рассылается в широковещатель-
ном режиме, т.е. в нем указывается широковещательный адрес. Такой пакет получат все
узлы, способные принимать широковещательный трафик.
Разослав запросы, демон routed переходит в цикл ожидания. С этого момента он при-
нимает пакеты лишь двух видов: Request и Response (ответ). Пакет Request говорит демону
о необходимости сформировать на основании маршрутной таблицы список со следующей
информацией по каждому маршруту:
IP-адрес узла или сети, куда ведет данный маршрут;
сетевая маска;
RIP-стоимость данного маршрута (см. главу 1, “Протоколы одноадресной маршрути-
зации”).
Полученный список высылается запрашивающему компьютеру в виде пакета Response.
В ответ на этот пакет демону придется немного подумать. Процесс принятия решения
схематически представлен на рис. 5.1.
Тем временем демон routed продолжает каждые 30 секунд рассылать копии своей
маршрутной таблицы в обычном или широковещательном режиме. Все остальные мар-
шрутизаторы, присутствующие в сети, делают то же самое. Когда приходит следующий
пакет Response, его содержимое затирает соответствующие записи маршрутной таблицы,
т.е. любые отличия в таблице будут разрешены в пользу нового пакета. При этом поле
времени последнего изменения сбрасывается в нуль. Если какого-то маршрута еще нет в
таблице, он добавляется в нее.
Когда время последнего изменения какой-либо записи становится равным 180 секунд,
стоимость маршрута задается равной 16 (бесконечность в протоколе RIP), а сам маршрут
помечается как кандидат на удаление. Реальное удаление маршрута произойдет еще через
60 секунд, т.е. через два цикла рассылки. После этого демону придется выбрать новый
маршрут к соответствующему адресату.
Конфигурирование
Список узлов, с которыми демон routed будет общаться в одноадресном режиме, зада-
ется в файле /etc/hosts. В широковещательном режиме сообщения рассылаются всем
узлам сети. Можно также задать список активных и пассивных шлюзов. Для этого предна-
значен файл /etc/gateways. Активный шлюз способен отвечать на маршрутные запро-
сы, пассивный — нет. Поскольку пассивный шлюз не будет отвечать на запросы, демон
routed не сможет обнаружить его самостоятельно.
Файл /etc/gateways должен быть создан пользователем root. Каждому пассивному
шлюзу в нем соответствует запись следующего вида:
адрес имя шлюз стоимость passive *
Перечислим назначение полей записи.
Адрес. IP-адрес узла или сети, куда указывает данная запись.
Имя. Имя узла, заданное в файле /etc/hosts, имя сети, заданное в файле
/etc/networ ks, или полное имя компьютера в формате узел.домен.расширение.
Шлюз. Имя или IP-адрес шлюза, через который должен проходить трафик, идущий
по указанному адресу.
Стоимость. RIP-стоимость прохода через шлюз.
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 85
Рис. 5.1. Схема анализа пакета Responce
Информация о пассивных шлюзах запрашивается на этапе начальной загрузки, когда за-
пускается демон routed. Она не будет обновляться, если только не перезапустить демон.
Запуск
Как уже было сказано, демон gated запускается на этапе начальной загрузки. Для этого
нужно добавить строку вызова демона в соответствующий стартовый сценарий, например
rc . local. При вызове демону могут передаваться различные опции (табл. 5.1).
Таблица 5.1. Опции демона routed
Опция Назначение
Сохранение расширенной отладочной информации
Задание стандартного маршрута, к примеру 192.168.52.1. Обычно указываются
внешние маршруты, которые демон routed не может обнаружить самостоятельно
“S Перевод демона в режим сервера. В этом режиме маршрутная информация рассы-
лается даже в том случае, когда имеется всего один сетевой интерфейс
_Ч Перевод демона в “бесшумный” режим. В этом, режиме маршрутная информация не
рассылается даже в том случае, когда имеется несколько сетевых интерфейсов
_t Привязка демона к терминалу, благодаря чему информация о пакетах будет запи-
сываться в поток stdout, а сам демон можно будет уничтожить, нажав <Ctrl+C>
имя_файла Если командная строка оканчивается именем файла, в этот файл будут записывать-
ся журнальные сообщения, выдаваемые демоном
Демон gated
Демон gated уже неоднократно упоминался в нашей книге. Существует несколько его
версий, выбор которых зависит от того, в каком режиме — одноадресном или многоадрес-
ном — должен использоваться демон и с каким стандартом предполагается работать: IPv4 или
IPv6 (табл. 5.2). Этот демон входит во многие дистрибутивы Linux, хотя может располагаться
среди вспомогательных материалов. Сам демон доступен на Web-узле www.gated.org или
www.gated.merit.edu.
Таблица 5.2. Версии демона gated и их возможности
Версия Поддерживаемые протоколы
GateD IPv6 Статическая маршрутизация IPv6, RIPng
GateD Multicast IGMP, MP-BGP, MSDP, DVMRP, PIM-SM и PIM-DM
GateD Unicast EGP, BGP, RIP-1, RIP-2, OSPF и IS IS
GateD Public EGP, BGP, RIP-1, RIP-2 и OSPF
Открытая версия демона является несколько устаревшей, зато очень стабильной.
Ее исходные тексты общедоступны, тогда как для получения исходных текстов новых вер-
сий необходимо приобрести лицензию. В этой главе рассматривается открытая версия.
Принцип работы открытой версии gated
Подобно большинству демонов маршрутизации, демон gated запускается на этапе на-
чальной загрузки. Лучше делать это не вручную, а с помощью программы gdc, описанной в
разделе “Запуск открытой версии gated”.
При запуске демон определяет, сколько памяти ему нужно для размещения массивов и
других структур данных. После этого ему назначается виртуальная машина с 32-разрядным
адресным пространством, расположенным либо в ОЗУ, либо на жестком диске (именно
так Linux управляет всеми процессами). Демон резервирует фрагмент адресного про-
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 87
странства, в котором будет храниться информация, и очищает его — это называется ини-
циализацией памяти. Затем резервируется еще по одному фрагменту для каждого из созда-
ваемых потоков и создается среда для структур данных, например маршрутных таблиц, к
которым необходим быстрый доступ.
Далее демон загружает в память свои маршрутные таблицы. Эта операция делается од-
нократно, и чтобы ее повторить, нужно послать демону специальную команду или переза-
грузить его. Следующим шагом является поиск сетевых интерфейсов компьютера и запись
их адресов и состояния.
Теперь настал черед инициализации отдельных потоков. Сначала демон устанавливает
глобальные переменные, а затем читает файл /etc/gated. conf. Демон работает по мо-
дульному принципу, поэтому ему не нужно загружать средства поддержки всех возможных
протоколов. Загружаются модули только тех протоколов, которые обозначены в файле
/etc/gated. conf как функционирующие.
Далее из файла конфигурации загружаются правила импорта маршрутов, информация
о которых была получена из внешних источников, а также правила экспорта маршрутов
другим маршрутизаторам и в другие протоколы. Это завершающая стадия инициализации.
После этого демон входит в бесконечный цикл, в котором остается до тех пор, пока не бу-
дет получена соответствующая команда.
В цикле демон устанавливает таймеры, используемые в различных протоколах, создает
сокеты, через которые будет происходить обмен данными с другими программами, и за-
гружает данные для этих сокетов. Если необходимо запустить какие-то задания, они ста-
вятся в очередь. Задания могут работать в интерактивном или фоновом режиме. Интерак-
тивные задания выполняются однократно. Чаще всего это запросы со стороны прото-
кольных модулей. Фоновые задания скрыты от посторонних глаз и могут выполняться
либо непрерывно, либо через заданные промежутки времени.
Конфигурирование открытой версии gated
Конфигурационный файл демона gated называется gated, conf. Инструкции в этом
файле могут занимать несколько строк, поэтому они оканчиваются точкой с запятой. Под-
держиваются комментарии двух видов. Символ # превращает в комментарий оставшуюся
часть строки. Многострочные комментарии начинаются символами /* и заканчиваются
символами */.
Важно понимать порядок следования инструкций. Имеется несколько типов инструк-
ций (табл. 5.3). Инструкции каждого типа должны размещаться рядом в конфигурацион-
ном файле, а секции необходимо располагать в определенном порядке. Опции трассиров-
ки и директивы могут находиться где угодно.
Таблица 5.3. Типы инструкций в файле gated, conf
Тип Порядок Инструкции
Опции Первый options
Интерфейсы Второй interfaces
Определения Третий autonomoussystem, martians,routerid
Протоколы Четвертый bgp, egp, icmp, isis, kernel, ospf,
redirect, rip, snmp
Статические маршруты Пятый static
Управление маршрутами Шестой aggregate, export,generate,import
Директивы Произвольный %directory,%include
Трассировка Произвольный traceoptions
88 Часть II. Средства и технологии маршрутизации в Linux
Инструкция options
Как правило, файл gated, conf начинается с инструкции options, в которой задают-
ся глобальные параметры всех нижеследующих инструкций. Если глобальные параметры
отсутствуют, то и в инструкции options нет необходимости. Перечисленные в табл. 5.4
параметры инструкции могут стоять в произвольном порядке.
Таблица 5.4. Параметры инструкции options
Параметр Назначение Формат Значение
mark Запись метки времени в жур- нальный файл через указан- ный интервал mark время Период ожидания до момен- та записи метки времени
noresolv Запрет попыток преобразова- ния IP-адресов в доменный формат noresolv —
nosend Запрет рассылки пакетов, пе- ревод демона в режим про- слушивания трафика nosend —
syslog Задание степени детальности информации, регистрируемой в системе Syslog. Поддержи- ваются два варианта синтакси- са. В первом случае регистри- руются сообщения только ука- занного уровня, а во втором случае — всех уровней от само- го нижнего до указанного syslog уровень syslog upto уровень Уровень регистрации сооб- щений (от наиболее к наиме- нее детальным): debug, info, notice, warning, err, crit, alert и emerg. Уро- вень debug считается самым нижним. Чем ниже уровень, тем больше объем регистри- руемой информации
Формат инструкции options таков:
options
параметр_1
параметр_Я
Инструкция interfaces
После глобальных опций нужно сообщить демону gated о сетевых интерфейсах,
имеющихся на данном компьютере. Для этого предназначена инструкция interfaces,
внутри которой могут находиться вложенные инструкции:
interfaces {
икс трукция_ 1
параметры
ин с трукция_ N
параметры
}
Вложенными могут быть следующие инструкции: options, interface и define. Же-
лательно придерживаться указанного порядка, хотя это не является строгим требованием.
Инструкция options отличается от той, что была описана в предыдущем разделе, так
как задает параметры, касающиеся только перечисленных интерфейсов (табл. 5.5).
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 89
Таблица 5.5. Параметры инструкции options в инструкции interfaces
Параметр Назначение Формат Значение
scaninterval strictinterfaces Задает частоту, с которой демон gated проверяет файлы ядра на предмет появления или исчез- новения интерфейсов. Стан- дартная установка — 15 минут Задает поведение демона при обнаружении интерфейса, поя- вившегося после начальной за- грузки, но не указанного явно в файле конфигурации. По умол- чанию демон выдает ошибку, но продолжает работать. Если установлена эта опция, демон аварийно завершит работу scaninterval время strictinterfaces Интервал ожида- ния между про- верками
После инструкции options следует одна или несколько инструкций interface. В од-
ной инструкции можно задать целый список интерфейсов, если у них одинаковые пара-
метры (табл. 5.6).
Таблица 5.6. Параметры инструкции interface в инструкции interfaces
Параметр Назначение Формат Значение
down Задает приоритет интер- down preference Чем выше приоритет, тем
preference фейса на случай, если де- мон пометил его как по- тенциально ненадежный интерфейс приоритет меньше вероятность, что демон выберет этот интер- фейс. Стандартный приори- тет — 120
passive Запрещает демону менять приоритет интерфейса, даже когда тот не функ- ционирует passive
preference Задает приоритет интер- фейса на случай, если де- мон пометил его как пра- вильно функционирующий интерфейс preference приоритет Чем ниже приоритет, тем выше вероятность, что де- мон выберет этот интер- фейс. Стандартный приори- тет — 0
simplex Запрещает интерфейсу получать свои собствен- ные широковещательные пакеты. На основании этих пакетов не будет де- латься вывод о том, пра- вильно ли функционирует интерфейс simplex
Инструкция define должна присутствовать, если установлена опция strictinter-
faces. В ней объявляются интерфейсы, которые могут не функционировать в момент запус-
ка демона gated. Параметры инструкции перечислены в табл. 5.7.
90 Часть II. Средства и технологии маршрутизации в Linux
Таблица 5.7. Параметры инструкции define в инструкции interfaces
Параметр Назначение Формат Значение
broadcast Сообщает демону о том, что интерфейс способен обра- батывать широковещатель- ные сообщения (это могут делать платы Ethernet и To- ken Ring), и задает широко- вещательный адрес broadcast адрес Широковещательный IP-адрес, к которому данный интерфейс имеет доступ
multicast Сообщает демону о том, что интерфейс способен обра- батывать многоадресный трафик multicast —
netmask Задает сетевую маску (игнорируется РРР- интерфейсами) netmask адрес Сетевая маска интер- фейса
pointtopoint Сообщает демону о том, что данный интерфейс являет- ся модемом или другим уст- ройством, работающим по протоколу SLIP либо РРР pointtopoint адрес Локальный адрес ин- терфейса. В этом случае адрес, заданный в инст- рукции define, указыва- ет на удаленную часть соединения
Приведем пример инструкции interfaces:
interfaces {
options
strictinterfaces
interface 192.168.232.*
simplex
interface 192.168.251.*
simplex
passive
define 192.168.232.*
broadcast 192.168.232.255
netmask 255.255.255.0
define 192.168.251.*
broadcast 192.168.251.255
netmask 255.255.255.127
}
Обратите внимание на IP-адреса с метасимволами (*). Есть разные форматы задания
интерфейсов.
all. Ключевое слово all обозначает все интерфейсы
ххх. ххх. ххх. ххх. Полный 1Р-адрес.
ххх. ххх. ххх. *, ххх. ххх. *, ххх. *. Частичный IP-адрес с метасимволом на конце.
eth*. Семейство интерфейсов (в данном случае — все сетевые платы Ethernet).
е t h 0. Конкретное устройство.
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 91
Допускается также указывать доменные имена интерфейсов. Однако это сопряжено с
определенными проблемами, так как служба DNS может оказаться недоступной на этапе
конфигурирования демона, что приведет к зависанию. В связи с этим рекомендуется избе-
гать доменных имен в конфигурационном файле.
Инструкции autonomoussystem, martians и routerid
Перечисленные ниже инструкции, если они присутствуют в конфигурационном файле,
должны предшествовать инструкциям, описанным далее в этой главе. Назначение и фор-
мат инструкций приведены в табл. 5.8.
Таблица 5.8. Специальные определения в файле gated, conf
Параметр Назначение Формат Значение
autonomoussystem Задает номер автоном- ной системы, которую обслуживает данный по- граничный маршрути- затор. Необходим для протоколов BGP и EGP autonomoussystem номер Номер автономной системы, назначенный ей организацией NIC (Network Information Center — сетевой ин- формационный центр)
martians Применяется для фильт- рации известных непра- вильных маршрутов martians { ма ршрут_ 1 маршрут N } Список фильтруемых маршрутов
routerid Задает IP-адрес данного маршрутизатора routerid адрес По умолчанию это IP-адрес первого фи- зического интерфейса, обнаруживаемого де- моном gated
Инструкция martians чаще всего имеет следующий вид:
martians {
сеть правила;
}
В качестве аргумента сеть задается IP-адрес сети. Под правилами понимается либо клю-
чевое слово exact, либо refines. Эти ключевые слова определяют два способа сопостав-
ления указанного адреса с проверяемым. Ключевое слово exact говорит демону о том,
что проверяемый адрес должен в точности соответствовать указанному. Точное совпаде-
ние определяет выбор самой сети, но не ее подсетей или отдельных узлов. Если задано
ключевое слово refines, проверяемый адрес должен иметь более длинный префикс. Это
эквивалентно выбору подсети, но не самой сети.
Более сложный формат инструкции таков:
martians {
сеть mask маска правила;
}
Под аргументом маска понимается маска сети. Существует еще один вариант инструкции:
martians {
сеть masklen длина_маски правила;
I
Вспомните из главы 4, “Адресация в стандартах IPv4 и IPv6”, что у адресов класса А
длина маски равна 8, у адресов класса В — 16, у адресов класса С — 24.
92 Часть II. Средства и технологии маршрутизации в Linux
В инструкции martians допускается указывать несколько адресов, каждый из которых
может иметь свой формат. Ключевое слово allow позволяет разрешить адрес, запрещен-
ный ранее более общей спецификацией. Например, следующая инструкция задает игно-
рирование маршрутной информации для всей сети 192.168.0.0 класса В, за исключением
подсети 192.168.10.0 класса С:
martians {
192.168.0.0 exact;
192.168.10.0 mask 255.255.255.0 refines allow
1
Настройка протокола RIP
Каждый поддерживаемый протокол маршрутизации должен конфигурироваться от-
дельно. Начнем с самого старого и простого: RIP. Обе версии протокола конфигурируют-
ся с помощью инструкции rip, начинающейся следующим образом:
rip статус
Аргумент статус может быть следующим:
по — RIP-трафик не обрабатывается;
off — RIP-трафик не обрабатывается;
on — RIP-трафик обрабатывается;
yes — RIP-трафик обрабатывается.
В принципе, достаточно указать
rip on;
ИЛИ
rip yes;
чтобы были приняты установки по умолчанию. Но можно в фигурных скобках задать
собственные установки (табл. 5.9).
Таблица 5.9. Параметры инструкции rip
Параметр Назначение Формат Значение
broadcast Переводит демон в режим широковещательной рас- сылки RIP-пакетов, даже если имеется только один активный интерфейс broadcast;
defaultmetric Задает стандартную defaultmetric Принимаемая стой-
RIP-стоимость маршрутов, полученных из другого протокола стоимость; мость маршрута. Значе- ние по умолчанию — 16, т.е. маршрут недоступен
interface Задает поведение кон- кретного интерфейса в отношении протокола RIP interface список параметр_1 параметр_К; Список интерфейсов и их параметров (перечислены отдельно в табл. 5.10)
nobroadcast Запрещает демону осущест- влять широковещательную рассылку RIP-пакетов, даже если имеется несколько ак- тивных интерфейсов nobroadcast;
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 93
Окончание табл. 5.9
Параметр Назначение Формат Значение
nocheckzero Заставляет демон не от- вергать пакеты RIP-1, у ко- торых зарезервированные поля не являются пустыми nocheckzero;
preference Задает приоритет маршру- тов, полученных по про- токолу RIP (в сравнении с другими протоколами) preference приоритет; Уровень приоритета. Если маршрут был по- лучен от нескольких протоколов, выбирает- ся протокол с наимень- шим приоритетом. Стандартная установка для протокола RIP — 100
query Определяет, должен ли query Атрибут может быть еле-
authentication демон принимать запросы RIP-2, поступающие не от маршрутизаторов authentication атрибут; дующим: попе (по умолча- нию), simple илитйб. В последних двух сл\чаях нужно также указывать пароль
sourcegateways Определяет узлы, RIP- обновления к которым должны посылаться на- прямую, а не широковеща- тельно sourcegateways список_шлюзов; Список шлюзов состоит из одного или несколь- ких IP-адресов, разде- ленных пробелами
traceoptions Задает параметры жур- нальной регистрации (трассировки) traceoptions параметры; Здесь могут присутство- вать как общие пара- метры трассировки де- мона gated (табл. 5.11), так и параметры, спе- цифичные для протоко- ла RIP (табл. 5.12)
trustedgateways Определяет, от каких уз- лов разрешается прини- мать обновления trustedgateways спи с о к_шлюз о в; Список шлюзов состоит из одного или несколь- ких IP-адресов, разде- ленных пробелами
Среди перечисленных параметров два заслуживают отдельного пояснения. В инструк-
ции rip интерфейсы задаются следующим образом:
rip on {
ОПЦИИ
interface список
параметры
опции
};
Адреса в списке задаются по тем же правилам, что и в инструкции interfaces. Воз-
можные параметры перечислены в табл. 5.10. Помните, что все указанные в списке ин-
терфейсы будут иметь одинаковые установки. Если у каких-то интерфейсов иные установ-
ки, создайте для них другую инструкцию interface.
94 Часть II. Средства и технологии маршрутизации в Linux
Таблица 5.10. Параметры инструкции interface в инструкции rip
Параметр Назначение Формат Значение
authentication Задает способ аутенти- фикации соединений между маршрутизатора- ми. Применяется только в протоколе RIP-2 метод authentication правило Атрибут метод не задан, если это первый из двух возможных методов аутентификации, или равен secondary, если это второй метод (для каждого интерфейса можно задать два метода). Атрибут правило мо- жет быть равен none, md5 или simple. В последних двух слу- чаях нужно указать пароль
broadcast Сообщает демону о не- обходимости осущест- влять широковеща- тельную, а не группо- вую рассылку пакетов RIP-2, совместимых с протоколом RIP-1, чтобы маршрутизато- ры RIP-1 могли их по- лучать broadcast
metricin Задает RIP-стоимость, добавляемую к посту- пающим маршрутам перед их занесением в таблицу. Это заставля- ет демон отдавать предпочтение маршру- там, полученным от других интерфейсов metricin стоимость Целое число от 1 до 15, если маршрут должен оставаться в таблицах, или 16, если нужно отменить любые маршруты, поступающие через этот ин- терфейс. Значение по умолча- нию — 1 плюс метрика интер- фейса, полученная от ядра
metricout Задает RIP-стоимость, которая добавляется к маршрутам, посылае- мым через указанный интерфейс (интерфейсы). Это за- ставляет другие мар- шрутизаторы отдавать предпочтение иным источникам маршрут- ной информации metricout стоимость Целое число от 1 до 15, если маршрут должен оставаться в таблицах, или 16, если нужно отменить любые маршруты, поступающие через этот ин- терфейс. Значение по умолча- нию — 0
multicast Заставляет демон gated общаться с дру- гими маршрутизатора- ми RIP-2 посредством многоадресных пакетов multicast
noripin Заставляет демон gated игнорировать RIP-пакеты, поступаю- щие на указанный ин- терфейс (интерфейсы) noripin
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 95
Окончание табл. 5.10
Параметр Назначение Формат Значение
noripout Запрещает демону по- сылать RIP-пакеты че- рез указанный интер- фейс (интерфейсы) noripout
ripin Заставляет демон gated принимать RIP- пакеты, поступающие на указанный интер- фейс (интерфейсы). Это установка по умол- чанию ripin
ripout Заставляет демон gated посылать RIP- пакеты через указан- ный интерфейс (интерфейсы). Это ус- тановка по умолчанию ripout
version 1 Заставляет демон gated посылать через указанный интерфейс (интерфейсы) пакеты RIP-1 version 1
version 2 Заставляет демон gated посылать через указанный интерфейс (интерфейсы) пакеты RIP-2 version 2
Другая инструкция, которой следует уделить особое внимание, — это traceoptions.
Дело в том, что есть два набора параметров трассировки: один применим ко всем прото-
колам (табл. 5.11), а другой— к каждому конкретному протоколу, в частности к RIP
(табл. 5.12). Правда, есть еще глобальные опции, но они не имеют смысла в протокольных
инструкциях, как rip, например.
Таблица 5.11. Параметры трассировки, доступные для всех протоколов
Параметр Назначение
all Активизирует все перечисленные в таблице опции. Если опция не имеет смысла для конкретного протокола, она игнорируется
general normal Активизирует опции normal и route Включает регистрацию обычных протокольных операций, а также ненормальных ситуаций
policy route state Включает регистрацию сведений об импортируемых и экспортируемых маршрутах Включает регистрацию изменений в маршрутной таблице Для протоколов, в которых маршрутизатор имеет несколько состояний (RIP в их число не входит), включает регистрацию изменений состояния
task timer Включает регистрацию сведений об использовании интерфейса и процессора Включает регистрацию сведений об использовании таймера
96 Часть II. Средства и технологии маршрутизации в Linux
Таблица 5.12. Параметры трассировки для протокола RIP
Параметр Назначение
other Включает регистрацию пакетов, не попавших в область действия других опций
packets Включает регистрацию всех RIP-пакетов
г eque s t Включает регистрацию пакетов, содержащих запросы на получение RIP-информации
response Включает регистрацию пакетов, содержащих RIP-информацию
Настройка протокола OSPF
Одним из наиболее популярных внутренних протоколов одноадресной маршрутиза-
ции является OSPF. Этот протокол сложнее, чем RIP, поэтому и параметров у него гораздо
больше. Ниже будут описаны лишь самые основные из них.
Протокол OSPF конфигурируется с помощью инструкции ospf, начинающейся сле-
дующим образом:
ospf статус
Аргумент статус может быть следующим:
по — OSPF-трафик не обрабатывается;
off — OSPF-трафик не обрабатывается;
on — OSPF-трафик обрабатывается;
yes — OSPF-трафик обрабатывается.
Обычно первой инструкцией внутри ospf является defaults. Ее параметры перечис-
лены в табл. 5.13.
Таблица 5.13. Параметры инструкции defaults в инструкции ospf
Параметр Назначение Формат Значение
cost Задает стоимость экспортируемого маршрута, который был получен не по протоколу OSPF cost стоимость; Целое число, задающее добавоч- ную стоимость. Значение по умол- чанию — 1
ospfarea Сообщает демону о том, что все интер- фейсы находятся в пределах одной и той же области ospfarea местоположение; Аргумент местоположение может быть равен либо backbone, либо идентификатору области. Опорная область имеет идентификатор 0. Идентификаторы остальных об- ластей должны быть 32- разрядными числами. Разрешается указывать IP-адрес в формате ххх. ххх. ххх. ххх
preference Задает приоритет маршрутов, получен- ных по протоколу’ OSPF, в сравнении с другими протоколами preference приоритет; Приоритет задается числом от 0 до 255. Чем меньше значение, тем выше приоритет. Стандартный приоритет OSPF-маршрутов — 10
router-prio Позволяет данному’ маршрутизатору участвовать в выбо- ре назначенного маршрутизатора router-prio;
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 97
Окончание табл. 5.1.3
Параметр Назначение Формат Значение
tag Позволяет снабжать экспортируемые маршруты меткой tag длинная^метка; ИЛИ tag короткая_метка; Метка может иметь длину 32 бита или 16 бит
type Задает тип экспор- тируемых маршрутов type число; 1 или 2
После задания стандартных установок можно переходить к главной части инструкции
ospf. Некоторые ее параметры и инструкции перечислены в табл. 5.14.
Таблица 5.14. Некоторые параметры инструкции ospf
Параметр Назначение Формат Значение
backbone Задает атрибуты опор- ной области OSPF backbone { параметр_1; параметр N; ); Параметры этой инструк- ции перечислены в табл. 5.15
exportinterval Задает величину ин- тервала между рассыл- ками OSPF-обновлений внешним системам exportinterval время; Число секунд между широ- ковещательными рассыл- ками (по умолчанию — 1)
exportlimit Задает количество маршрутов, включае- мых в одно OSPF- обновление exportlimit число; Число маршрутов (по умолчанию — 100)
monitorauthkey Задает пароль, исполь- зуемый программой ospf_monitor для проверки работы про- токола monitorauthkey пароль; Используемый пароль (по умолчанию отсутствует)
traceoptions Задает параметры журнальной регистра- ции (трассировки) traceoptions параметры; Параметры, доступные для всех протоколов, были пе- речислены в табл. 5.11. Па- раметры, специфичные для инструкции ospf, приве- дены в табл. 5.16
Об инструкции backbone следует сказать отдельно. На любом маршрутизаторе OSPF
должна быть сконфигурирована как минимум одна опорная область. Ее номер всегда равен
нулю. Внутри инструкции backbone задаются сети, формирующие опорную область. Па-
раметры инструкции перечислены в табл. 5.15.
98 Часть II. Средства и технологии маршрутизации в Linux
Таблица 5.15. Параметры инструкции backbone в инструкции ospf
Параметр Назначение Формат Значение
networks Задает границы опорной области networks { правило_1; правило N; }; Есть несколько способов описания се- тей. Можно задать просто IP-адрес сети, например 192.168.15.0;. Можно за- дать IP-адрес и маску, например 192.168.15.0 mask 255.255.255.0;. Можно задать IP-адрес и длину маски, например 192.168.15.0 masklen 24;. Можно даже задать IP-адрес отдель- ного узла: host 192.168.15.5;. В кон- це каждого правила допускается наличие ключевого слова restrict, запрещаю- щего анонсировать данный адрес за пре- делы области
stub Указывает на то, что в данной об- ласти нет экспор- тируемых мар- шрутов stub; или stub cost стоимость; Стоимость передачи данных в эту об- ласть от текущего маршрутизатора
stubhosts Задает непосред- ственно подклю- ченные узлы, ко- торые анонсиру- ются за пределы области stubhosts { адрес cost стоимость; адрес cost стоимость; }; В каждой записи указывается IP-адрес уз- ла и OSPF-стоимость пересылки данных через него
Таблица 5.16. Параметры трассировки для протокола OSPF
Параметр Назначение
ack Включает регистрацию пакетов ack, используемых для синхронизации баз данных
OSPF
dd Включает регистрацию пакетов, несущих описание баз данных
hello Включает регистрацию пакетов HELLO
lsabuild Включает регистрацию действий, связанных с созданием канальных анонсов
1SU Включает регистрацию пакетов, несущих канальные обновления
request Включает регистрацию пакетов, несущих запросы канальной информации
spf Включает регистрацию действий, связанных с вычислением кратчайших путей
Настройка протокола EGP
Если нужно обмениваться маршрутной информацией с сетями, расположенными за пре-
делами данной автономной системы, необходим протокол пограничной маршрутизации.
Один из них — EGP (см. главу 3, “Введение в протоколы пограничной маршрутизации”). На-
стройку данного протокола нужно выполнять только на пограничных маршрутизаторах.
Протокол EGP конфигурируется с помощью инструкции egp, начинающейся следую-
щим образом:
egp on {
Вложенные инструкции перечислены в табл. 5.17.
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 99
Таблица 5.17. Параметры инструкции едр
Параметр Назначенце Формат Значение
defaultmetric Задает EGP-стоимость маршрутов, анонси- руемых данным погра- ничным маршрутиза- тором своим соседям defaultmetric стоимость; Целое число от 1 до 255. Если указана стоимость 255, некото- рые маршрутизаторы могут счи- тать такую сеть недоступной
group Сообщает демону о том, кто его EGP-сосе- ди и как взаимодейст- вовать с ними group опции { neighbor параметры; }; Формат данной инструкции опи- сан ниже
packetsize Задает ожидаемый максимальный размер пакетов, получаемых от EGP-соседей packetsize размер; Размер указан в байтах. Если приходит пакет большего раз- мера, он усекается и посему от- брасывается. Однако при этом значение данного параметра ав- томатически увеличивается. Значение по умолчанию — 8192
preference Задает приоритет маршрутов, получен- ных по протоколу EGP, в сравнении с другими протоколами preference приоритет; Чем ниже указанное значение, тем выше приоритет (установка по умолчанию — 200)
traceoptions Задает параметры журнальной регистра- ции (трассировки) traceoptions параметры; Параметры, доступные для всех протоколов, были перечислены в табл. 5.11. Параметры, специ-
фичные для инструкции едр,
приведены в табл. 5.18
Таблица 5.18. Параметры трассировки для протокола EGP
Параметр Назначение
acquire Включает регистрацию пакетов ACQUIRE и CEASE, начинающих и завер-
шающих EGP-сеанс
hello Включает регистрацию пакетов HELLO и IHU, предназначенных для слеже-
ния за соседями
packets Включает регистрацию всех EGP-пакетов
update Включает регистрацию пакетов POLL и UPDATE, используемых для запроса и
рассылки маршрутных обновлений
С помощью инструкции group обычно задаются все соседи, расположенные в одной
автономной системе. Можно вводить несколько таких инструкций, если маршрутизатор
контактирует с несколькими автономными системами. В начале инструкции group указы-
ваются следующие опции.
maxup число. Задает максимальное число членов группы, с которыми должен об-
щаться демон gated. По умолчанию он контактирует со всеми членами.
peeras число. Сообщает демону номер автономной системы, в которой находятся
члены группы.
100 Часть II. Средства и технологии маршрутизации в Linux
В круглых скобках перечисляются инструкции neighbor, каждая из которых опреде-
ляет один из EGP-маршрутизаторов в автономной системе. В целом инструкция group вы-
глядит так:
group опции {
neighbor сосед_1
параметр_1
параметр_М
neighbor сосед_Ы
параметр_1
параметрам
);
Аргумент сосед— это просто IP-адрес EGP-маршрутизатора. Все остальные параметры
являются необязательными и позволяют осуществлять более тонкую настройку маршрути-
заторов (табл. 5.19).
Таблица 5.19. Параметры инструкции neighbor в инструкции group
Параметр Назначение Формат Значение
exportdefault Заставляет демон gated вклю- чать в EGP-обновления, посы- лаемые данному соседу, стан- дартный маршрут (по умолча- нию — 0.0.0.0) exportdefault;
importdefault Заставляет демон gated при- нимать от соседа стандартный маршрут, если он включен в рассылку importdefault; —
Icladdr Задает локальный интерфейс, через который будет осуществ- ляться взаимодействие с соседом Icladdr адрес; IP-адрес локального интерфейса
metricout Задает EGP-стоимость маршру- тов, анонсируемых данному соседу metricout стоимость; Целое число
minhello Задает минимальный интервал между отправками пакета HELLO minhello время; Аргумент время — это число секунд, которое должно пройти после отправки пакета HELLO, прежде чем демон gated пошлет новый пакет. Если со- сед не отвечает на три таких пакета, он поме- чается как недоступ- ный. Стандартный ин- тервал — 30 секунд
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 101
Окончание табл. 5.19
Параметр Назначение Формат Значение
minpoll Задает интервал между опроса- ми соседа minpoll время; Аргумент время — это число секунд, которое должно пройти после отправки пакета POLL, прежде чем демон gated пошлет новый пакет. Если сосед не отвечает на три таких пакета, он помечается как недос- тупный, а его маршру- ты удаляются из табли- цы. Стандартный ин- тервал — 120 секунд
nogendefault Запрещает демону генериро- вать стандартный маршрут nogende fault; —
preference Задает приоритет маршрутов, полученных от данного соседа, в сравнении с другими соседями preference приоритет; Чем ниже указанное значение, тем выше приоритет
preference2 Задает дополнительный при- оритет на случай равенства ос- новных приоритетов preference2 приоритет; Чем ниже указанное значение, тем выше приоритет (установка по умолчанию — 0)
traceoptions Задает параметры журнальной регистрации (трассировки) для данного соседа traceoptions параметры; Параметры, доступ- ные для всех протоко- лов, были перечисле- ны в табл. 5.11. Пара- метры, специфичные для инструкции е др, приведены в табл. 5.18
ttl Переопределяет стандартный параметр TTL (время жизни пакета) протокола IP ttl значение; Время жизни пакетов, посылаемых соседям (по умолчанию — 1)
Настройка протокола BGP
Другой возможный протокол пограничной маршрутизации — BGP. Он конфигурирует-
ся с помощью инструкции bgp, параметры которой перечислены в табл. 5.20.
Таблица 5.20. Параметры инструкции bgp
Параметр Назначение Формат Значение
defaultmetric Задает BGP-стоимость маршру- тов, анонсируемых данным по- граничным маршрутизатором своим соседям defaultmetric стоимость; Стандартная метрика, присваиваемая всем BGP-маршрутам
group type Позволяет формировать груп- пы BGP-соседей group type спе- цифика ция_ типа { allow { параметры }; peer пара- метры; }; Формат данной инст- рукции описан ниже
102 Часть II. Средства и технологии маршрутизации в Linux
Окончание табл. 5.20
Параметр Назначение Формат Значение
preference Задает приоритет маршрутов, полученных по протоколу BGP, в сравнении с другими прото- колами preference приоритет; Чем ниже указанное значение, тем выше приоритет (установка по умолчанию — 170)
traceoptions Задает параметры журнальной регистрации (трассировки) traceoptions параметры; Параметры, доступ- ные для всех протоко- лов, были перечисле- ны в табл. 5.11. Пара- метры, специфичные для инструкции bgp,
приведены в табл. 5.21
Таблица 5.21. Параметры трассировки для протокола BGP
Параметр Назначение
keepalive Включает регистрацию всех BGP-пакетов KEEPALIVE
open packets update Включает регистрацию всех BGP-пакетов OPEN Включает регистрацию веек BGP-пакетов Включает регистрацию всех BGP-пакетов UPDATE
Все остальные параметры сконцентрированы в самой сложной инструкции — group
type. Указываемый в ней тип группы может быть следующим.
external peeras. Определяет группу BGP-маршрутизаторов, находящихся за пре-
делами данной автономной системы.
igp peeras. Определяет группу маршрутизаторов, находящихся внутри данной ав-
тономной системы и не являющихся пограничными, но с которыми нужно обмени-
ваться информацией по протоколу BGP.
internal peeras. Определяет группу маршрутизаторов, находящихся внутри дан-
ной автономной системы и не использующих протокол маршрутизации семейства
TCP/IP.
routing peeras. Определяет группу BGP-маршрутизаторов, находящихся внутри
данной автономной системы и используемых совместно с внутренними маршрути-
заторами для преобразования адресов.
test peeras. Определяет тестовую группу BGP-маршрутизаторов, с помощью ко-
торых можно убедиться в правильном распространении информации.
Далее указывается номер автономной системы, которой принадлежит группа. Таким
образом, начало группы выглядит так:
group type тип peeras номер_АС
В случае групп типа external, internal и test — это все, что необходимо указать.
Для групп типа igp и routing требуется задать также имя внутреннего протокола:
group type тип peeras номер_АС proto протокол
Возможные значения аргумента протокол — rip, ospf и isi (протокол IS-IS). Наконец,
для групп типа routing можно указать список внутренних интерфейсов, к которым могут
существовать внешние маршруты:
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 103
group type тип peeras номер_АС proto протокол
interface список_интерфейсов
Внутри инструкции group type должна присутствовать одна из двух подчиненных
инструкций: allow или peer. Первая определяет диапазон адресов, вторая — параметры
отдельного узла. Мы уже говорили о том, какие существуют способы задания адресов, по-
этому просто приведем инструкцию allow с адресами всех возможных форматов:
group type спецификация_типа
{
allow
{
192.168.15.0
192.168.15.0 mask 255.255.255.0
192.168.15.0 masklen 24
all
host 192.168.15.5
};
}
Инструкция peer имеет следующий формат:
peer IP-адрес
параметр_1
параметр_М;
Возможные параметры перечислены в табл. 5.22.
Таблица 5.22. Параметры BGP-узлов в инструкции Ьдр
Параметр Назначение Формат Значение
analretentive Заставляет демон gated вы- давать предупреждения о со- бытиях, которые обычно иг- норируются, например о дуб- лировании обновлений analretentive
gateway Сообщает демону о том, что BGP-сосед не является непо- средственно подключенным и для общения с ним нужно по- сылать данные через другой маршрутизатор gateway IP-адрес IP-адрес промежуточ- ного интерфейса
holdtime Задает интервал ожидания, по истечении которого про- изойдет отключение от BGP- соседа holdtime время Число секунд от 0 до 3
indelay Задает время, в течение ко- торого BGP-маршрут должен существовать, чтобы быть за- несенным в таблицу маршру- тизации демона gated indelay время Число секунд (по умолчанию — 0)
keep all Сообщает демону о необхо- димости заносить в BGP- таблицу все маршруты, даже те, у которых номер автоном- ной системы совпадает с те- кущим keep all
104 Часть II. Средства и технологии маршрутизации в Linux
Продолжение табл. 5.22
Параметр Назначение Формат Значение
keepalivesal- ways Заставляет демон gated по- сылать сообщения KEEPALIVE даже тогда, когда соседу достаточно сообщений UPDATE keepalivesalways
Icladdr Задает интерфейс для под- ключения к соседу Icladdr IP-адрес Правила задания IP-адреса будут раз- ными в зависимости от типа группы. Для типа external тре- буется, чтобы адрес находился в той же сети, что и сосед или его шлюз. Для осталь- ных типов информа- ция о сети не. важна
localas Задает номер автономной сис- темы, которую демон пред- ставляет для данного узла localas номер Номер АС (по умол- чанию берется из ин- струкции autonomous system)
logupdown Указывает на необходимость добавления записи в жур- нальный файл всякий раз, ко- гда BGP-модуль демона пере- . ходит в состояние ESTABLISHED или из него logupdown
metricout Задает BGP-стоимость мар- шрутов, посылаемых данному соседу metricout СТОИМОСТЬ BGP-стоимость пере- сылки данных через соседа
noaggregatorid Запрещает демону включать идентификатор маршрутиза- тора в пакеты, посылаемые соседу noaggregatorid
noauthcheck Заставляет демон gated иг- норировать аутентификаци- онную часть входящих BGP- пакетов noauthcheck
outdelay Задает время, в течение ко- торого BGP-маршрут должен находиться в таблице, чтобы демон начал анонсировать его соседям outdelay время Число секунд (по умолчанию — 0)
passive Запрещает демону посылать пакеты OPEN данному соседу, который сам должен иниции- ровать соединение passive
preference Задает приоритет маршрутов, полученных от данного сосе- да, в сравнении с другими со- седями preference приоритет Чем ниже указанное значение, тем выше приоритет
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 105
Окончание табл. 5.22
Параметр Назначение Формат Значение
preference2 Задает дополнительный при- оритет на случай равенства основных приоритетов preference2 приоритет Чем нижеуказанное значение, тем выше приоритет (установка по умолчанию — 0)
ttl Переопределяет стандартный параметр TTL (время жизни пакета) протокола IP ttl число_переходов Время жизни пакетов, посылаемых соседу (по умолчанию — 1)
traceoptions Задает параметры журнальной регистрации (трассировки) для данного соседа traceoptions параметры Параметры, доступ- ные для всех прото- колов, были перечис- лены в табл. 5.11. Па- раметры, специфич- ные для инструкции bgp, приведены в табл. 5.21
version Сообщает демону версию протокола BGP, используе- мую для общения с данным соседом version версия Поддерживаются три версии: 2, 3 и 4. Уста- новка по умолчанию — 4
Протокол IS-IS
Не рассматривавшийся ранее протокол IS-IS (Intermediate System to Intermediate System —
протокол связи между промежуточными системами) используется в том случае, когда в сети есть
множество подсетей с самыми разными сетевыми аппаратными и программными средствами.
В этом протоколе соединения не устанавливаются, т.е. обмен данными осуществляется с
помощью дейтаграмм. Подробнее протокол описан в документе RFC1142.
Настройка SNMP-запросов
Протокол SNMP (Simple Network Management Protocol) применяется администратора-
ми для управления крупными сетями. Сам демон gated не реализует данный протокол, но
позволяет маршрутизаторам Linux взаимодействовать с серверами SNMP. Спецификация
протокола SNMP дана в документе RFC1157.
Конфигурация SNMP-сеансов осуществляется посредством инструкции snmp, начи-
нающейся следующим образом:
snmp on {
В фигурных скобках задается всего несколько параметров.
debug. Эта опция включает отладку SNMP-сеанса (по умолчанию отладка отключена).
port номер. Эта опция задает порт, через который передаются SNMP-пакеты
(по умолчанию —167).
traceoptions параметры. Как обычно, эта инструкция задает параметры жур-
нальной регистрации (трассировки). Общепротокольные установки были перечис-
лены в табл. 5.11. Параметры, специфичные для протокола SNMP, приведены в
табл. 5.23.
106 Часть II. Средства и технологии маршрутизации в Linux -
Таблица 5.23. Параметры трассировки для протокола SNMP
Параметр Назначение
receive Включает регистрацию SNMP-запросов, поступающих от демона SNMP, а также ответов на них
register Включает регистрацию SNMP-запросов на создание Новых переменных
resolve Включает регистрацию SNMP-запросов на получение значений переменных
trap Включает регистрацию сообщений об SNMP-прерываниях
Статические маршруты
Демону gated можно сообщить об узлах, маршруты к которым существуют всегда и их не
нужно искать. Такие маршруты называются статическими и конфигурируются посредством
инструкции static (в файле gated. conf может быть несколько таких инструкций):
static {
спецификация_маршрута
параметры;
};
Параметров не так много, зато спецификации маршрутов могут быть самыми разными.
Перечислим основные из них.
default gateway список_шлюзов. Сообщает демону о том, что через указанный
шлюз (шлюзы) данные должны посылаться по умолчанию.
host IP-адрес gateway список_шлюзов. Сообщает демону о том, что трафик к
заданному узлу должен проходить через указанный шлюз.
сеть mask маска gateway список_шлюзов. Сообщает демону о том, что трафик к
заданной сети (маска приведена в явном виде) должен проходить через указанный шлюз.
сеть masklen длина gateway список_шлюзов. Сообщает демону о том, что
трафик к заданной сети (приведена только длина маски) должен проходить через
указанный шлюз.
сеть mask маска interface интерфейс. Сообщает демону о том, что трафик к
заданной сети (маска приведена в явном виде) должен проходить через указанный
интерфейс.
сеть masklen длина interface интерфейс. Сообщает демону о том, что тра-
фик к заданной сети (приведена только длина маски) должен проходить через ука-
занный интерфейс.
сеть interface интерфейс. Сообщает демону о том, что трафик к заданной сети
должен проходить через указанный интерфейс.
interface интерфейс. Задает стандартный интерфейс, через который демон
должен пропускать маршрутный трафик.
Варианты с ключевым словом interface полезны, когда одному сетевому интерфейсу
соответствует несколько адресов. В основном используются варианты с ключевым словом
gateway. Поддерживаемые в этом случае параметры перечислены в табл. 5.24.
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 107
Таблица 5.24. Параметры инструкции static
Параметр Назначение Формат Значение
blackhole Запрещает демону перена- правлять пакеты, идущие по данному маршруту. Пакеты просто удаляются -blackhole
interface Если обозначенный шлюз не находится в непосредствен- но подключенной сети (спи- сок интерфейсов прилагает- ся), маршрут игнорируется interface список_интерфейсов Список адресов, имен устройств или ключевое слово all
noinstall Если статический маршрут к данному адресату имеет са- мый низкий приоритет, ин- формация о нем не сохраня- ется в таблице маршрутиза- ции ядра noinstall
preference Задает приоритет статиче- ских маршрутов в сравнении с маршрутами, полученными посредством других прото- колов preference приоритет Чем ниже указанное значение, тем выше приоритет (установка по умол- чанию — 160)
reject Запрещает демону осущест- влять перенаправление па- кетов, идущих по данному маршруту. В ответ на полу- чение пакета отправителю возвращается ICMP-сообще- ние о недоступности адресата reject .
retain Запрещает удалять этот маршрут из таблиц ядра, ко- гда демон gated не работает retain —
Импортируемые маршруты
Маршрутизаторы не только занимаются анонсированием маршрутной информации в
другие сети. Они также принимают из внешнего мира аналогичные анонсы, содержащие
сведения о перенаправлении пакетов. Эти данные нельзя просто “сбрасывать” в маршрут-
ные таблицы демона gated. Нужно задать правила, по которым будет происходить им-
порт маршрутов.
В файле gated, conf можно задавать различные правила для каждого протокола.
Давайте последовательно рассмотрим известные нам протоколы, начав, естественно, с
RIP. Инструкция импорта RIP-маршрутов начинается следующим образом:
import proto rip
Далее можно ввести одну из спецификаций, запрещающих импорт.
restrict. Запрещает помещать RIP-маршруты в таблицу маршрутизации.
interface список_интерфейсов restrict. Запрещает помещать в таблицу
RIP-маршруты, полученные через заданные интерфейсы.
gateway список_шлюзов restrict. Запрещает помещать в таблицу
RIP-маршруты, поступившие от указанных шлюзов.
108 Часть II. Средства и технологии маршрутизации в Linux
Следующие спецификации, наоборот, разрешают импорт.
interface список_интерфейсов. Разрешает помещать в таблицу RIP-маршруты,
полученные через заданные интерфейсы.
gateway список__шлюзов. Разрешает помещать в таблицу RIP-маршруты, поступив-
шие от указанных шлюзов.
С помощью предложения preference приоритет задается приоритет RIP-маршру-
тов, подчиняющихся заданным правилам, в сравнении с маршрутами других протоколов.
По умолчанию приоритет равен 100. Таким образом, инструкция импорта может выгля-
деть так:
import proto rip interface список_интерфейсов preference приоритет
import proto rip gateway список_шлюзов preference приоритет
Далее в фигурных скобках традиционным способом задается перечень узлов или сетей,
на которые распространяются описанные правила.
192.168.15.0
192.168.15.0 mask 255.255.255.0
192.168.15.0 masklen 24
all
host 192.168.15.5
В конце строки со спецификацией адреса можно указывать следующие предложения.
restrict. Запрещает импорт маршрутов, подчиняющихся заданному правилу.
preference приоритет. Разрешает импорт маршрутов, подчиняющихся заданно-
му правилу, и назначает им указанный приоритет.
В файле gated, conf может присутствовать сколько угодно правил импорта RIP-марш-
рутов. Каждое правило описывает определенный набор интерфейсов или шлюзов. Для
других интерфейсов или шлюзов нужно задавать отдельные правила.
Обработка директив переадресации
ICMP (Internet Control Message Protocol — протокол управляющих сообщений в сети Internet)
является одним из наиболее простых протоколов. В его пакете передается одна-единственная
команда. Если, например, это команда echo, то принимающая машина должна вернуть ответный
пакет с указанием метрики перехода от отправителя к получателю и обратно. Другая возможная
ICMP-команда— redirect (переадресация).
Бывают случаи, когда наилучший путь к заданному компьютеру пролегает не через стандартный
маршрутизатор. В этом случае стандартному маршрутизатору возвращается переадресующая
ICMP-директива, говорящая о том, что трафик должен проходить через другой узел. Директивы
переадресации обычно имеют короткое время жизни. Соответствующая запись удаляется из
маршрутной таблицы демона gated в течение трех минут.
Теперь перейдем к протоколу OSPF. В первую очередь необходимо отметить, что де-
мон gated не контролирует импорт маршрутов внутри областей автономной системы и
между областями. Такие маршруты всегда импортируются с приоритетом 10. Правила
можно задавать только для маршрутов, получаемых из других автономных систем.
Инструкция импорта OSPF-маршрутов начинается следующим образом:
import proto ospfase
Далее можно добавить предложение tag метка. OSPF-метка состоит из идентифика-
тора исходного маршрутизатора, а также контрольной суммы, позволяющей убедиться в
том, что содержимое пакета не было повреждено в процессе передачи. Таким образом,
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 109
путем задания метки можно ограничивать импорт только пакетами, поступающими от
конкретного маршрутизатора.
Если необходимо запретить импорт внешних OSPF-маршрутов, добавьте ключевое
слово restrict:
import proto ospfase restrict
По умолчанию приоритет внешних OSPF-маршрутов равен 150. Эту установку можно
изменить, добавив в конец строки импорта предложение preference приоритет.
В фигурных скобках задается перечень узлов или сетей, на которые распространяются
описанные правила, например:
import proto ospfase
параметры {
192.168.15.*
};
В конце строки со спецификацией адреса можно указать ключевое слово restrict,
чтобы запретить импорт данных конкретных маршрутов, или предложение preference
приоритет, чтобы изменить стандартный приоритет (150). Полученная инструкция мо-
жет выглядеть так:
import proto ospfase
параметры- {
192.168.15.* preference 200;
};
На очереди — протокол EGP. Инструкция импорта EGP-маршрутов начинается сле-
дующим образом:
import proto egp autonomoussystem номер
Аргумент номер соответствует номеру автономной системы, к которой применяется
данное правило. Если маршруты, полученные от этой автономной системы по протоколу
EGP, не нужно сохранять в маршрутной таблице, добавьте ключевое слово restrict:
import proto egp autonomoussystem номер restrict
С помощью предложения preference приоритет можно изменить приоритет EGP-
маршрутов (значение по умолчанию — 200):
import proto egp autonomoussystem номер preference приоритет
Выражение в фигурных скобках будет таким же, как и в случае протоколов RIP и OSPF,
например:
import proto egp autonomoussystem номер preference приоритет
{
all;
}
В случае протокола BGP инструкция импорта имеет следующий формат:
import proto bgp aspath регулярное_выражение origin тип
В регулярном выражении задается фильтр списка номеров автономных систем. Здесь
имеется в виду не та автономная система, из которой непосредственно поступил пакет,
хотя ее номер тоже есть в списке, а все автономные системы, через которые прошли дан-
ные на пути от отправителя к получателю.
В поле тип указывается тип полученной маршрутной информации. Возможны следую-
щие варианты.
110 Часть II. Средства и технологии маршрутизации в Linux
igp. Маршрут получен по протоколу внутридоменной маршрутизации и, скорее все-
го, является полным.
egp. Маршрут получен по протоколу междоменной маршрутизации, не поддержи-
вающему понятие списка исходных автономных систем (например, EGP), и, скорее
всего, является неполным.
incomplete. Маршрут является неполным.
any. Маршрут получен из произвольного источника.
Если маршруты, полученные по протоколу BGP, не нужно сохранять в маршрутной таб-
лице, добавьте ключевое слово restrict. С помощью предложения preference приори-
тет можно изменить приоритет BGP-маршрутов (значение по умолчанию — 170). В фигур-
ных скобках, как всегда, задается перечень узлов или сетей, на которые распространяются
описанные правила. Формат списка будет таким же, как и в описанных выше протоколах.
Экспортируемые маршруты
Во многих случаях демон gated выступает в роли транслятора, принимая информа-
цию от одного протокола и направляя ее в другой протокол. Это осуществляется с помо-
щью инструкции export proto, которая, как и инструкция import proto, имеет не-
сколько иной формат в зависимости от конкретных протоколов.
Начнем с протокола RIP. Инструкция экспорта маршрутов в протокол RIP начинается так:
export proto rip
Далее указывается список интерфейсов или шлюзов, куда экспортируется информация:
interface список_интерфейсов
gateway список_шлюзов
Чтобы запретить экспорт маршрутов, достаточно добавить в конец строки ключевое
слово restrict. В противном случае можно указать метрику, назначаемую экспортируе-
мым маршрутам:
metric стоимость
После метрики в фигурных скобках перечисляются экспортируемые наборы данных.
Каждому из них соответствует инструкция следующего вида:
proto протокол {
список_маршрутов;
};
ИЛИ
proto протокол restrict;
Ниже мы подробнее опишем формат задания экспортируемых маршрутов, а пока рас-
смотрим правила экспорта маршрутов в протокол OSPF. Соответствующая инструкция
начинается так:
export proto ospfase
Далее может быть указано правило экспорта.
type 1. Это правило применяется к сетям, чьи метрики стоимости совместимы с
метриками OSPF.
type 2. Это правило применяется к сетям, чьи метрики стоимости несовместимы с
метриками OSPF.
tag метка. Это правило применяется к OSPF-маршрутизаторам той автономной
системы, номер которой указан в метке.
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 111
Чтобы запретить экспорт маршрутов, нужно добавить в конец строки ключевое слово
restrict. В противном случае можно указать метрику, назначаемую экспортируемым
маршрутам:
metric стоимость
После метрики в фигурных скобках перечисляются экспортируемые наборы данных.
Рассмотрим ситуацию, когда экспортируемый набор был получен по протоколу OSPF. В
этом случае соответствующая инструкция примет одну из двух форм:
proto ospf
или
proto ospfase
Если инструкция оканчивается ключевым словом restrict, экспорт соответствующей
группы OSPF-маршрутов будет запрещен. Если экспорт разрешен, группе можно назначить
метрику (metric стоимость), а в фигурных скобках нужно указать перечень адресных
спецификаций. Ниже показан пример инструкции.
proto ospfase {
192.168.15.*;
host 192.168.15.2 metric 300;
host 192.168.15.9 restrict;
};
Как видите, ключевые слова restrict и metric могут встречаться в инструкции
export proto неоднократно. Сначала они применяются ко всем маршрутам, экспорти-
руемым в заданный протокол, затем — к группе экспортируемых маршрутов, полученных
по одному протоколу, и, наконец, к отдельному маршруту. Приоритет имеет самая кон-
кретная спецификация.
Перейдем к правилам экспорта маршрутов в протоколы EGP и BGP. В обоих случаях
формат инструкций будет одинаковым, отличается лишь обозначение протокола: egp и
Ьдр соответственно. Поэтому мы будем применять обобщенное обозначение _др. Чтобы
запретить экспорт данных во внешние маршрутизаторы EGP или BGP, воспользуйтесь та-
кой инструкцией:
export proto _gp as номер restrict;
Если экспорт разрешен, можно уточнить его правила:
export proto _gp as номер
metric метрика {
экспортируемый_список_1 ;
экспортируемый_список_Н;
);
Предложение metric необязательно. Если оно отсутствует, будет использована стан-
дартная метрика.
Если в экспортируемом списке присутствуют маршруты, полученные по протоколу
EGP или BGP, формат инструкции proto будет таким:
proto _gp as номер
metric метрика {
маршрут_ 1;
маршрут_М;
};
112 Часть II. Средства и технологии маршрутизации в Linux
Опять-таки, предложение metric является необязательным. В конце каждой строки с
описанием маршрута также можно указывать ключевое слово restrict или предложение
metric.
Не все сетевые маршруты поступают от какого-то протокола. Ниже перечислены до-
полнительные значения аргумента протокол инструкции proto:
direct. Указывает на сетевые интерфейсы самого маршрутизатора.
kernel. Указывает на маршруты, добавленные в таблицы ядра с помощью команды
route.
static. Указывает на статические маршруты, перечисленные в инструкции static.
Далее может быть приведен список конкретных интерфейсов, из которых были полу-
чены маршруты. В конце строки разрешается указывать ключевое слово restrict, за-
прещающее экспорт таких маршрутов, или предложение metric, назначающее всем мар-
шрутам стоимость. Во втором случае в фигурных скобках должны быть перечислены кон-
кретные маршруты. Каждый из них тоже можно пометить ключевым словом restrict,
чтобы исключить маршрут из более общей спецификации, или предложением metric,
чтобы присвоить маршруту другую стоимость. По умолчанию стоимость маршрутов типа
direct равна 0, маршрутов типа kernel —40, маршрутов типа static — 60.
Агрегированные маршруты
Как говорилось в главе 4, “Адресация в стандартах IPv4 и IPv6”, маршрутизатор может
анонсировать сетевой адрес внешнему миру так, как если бы это была цельная сеть, даже
если она в действительности разделена на подсети. Агрегированные маршруты задаются
одним из следующих способов:
aggregate
aggregate
aggregate
aggregate
Далее может быть указано предложение preference, если требуется поменять стан-
дартный приоритет агрегированных маршрутов (130). Затем приводится список маршру-
тов, которые можно или нельзя анонсировать таким способом. Каждая группа маршрутов
начинается с ключевого слова proto. Вслед за ним может быть указан тип протокола.
aggregate. Это правило применимо ко всем маршрутам, которые демон gated
сделал агрегированными.
all. Это правило применимо ко всем типам маршрутов.
direct. Это правило применимо к сетевым интерфейсам маршрутизатора.
kernel. Это правило применимо к маршрутам, добавленным в таблицу маршрути-
зации ядра с помощью команды route.
static. Это правило применимо к статическим маршрутам, заданным в инструкции
static.
имя. Это правило применимо к маршрутам одного из тех протоколов, который под-
держивается демоном gated.
Кроме типа протокола может быть задана спецификация автономной системы.
as номер. Это правило применимо к конкретной автономной системе.
аз регулярное_выражение. Это правило применимо к конкретной автономной
системе, номер которой соответствует регулярному выражению.
tag метка. Это правило применимо к маршрутам, имеющим указанную метку.
default
сеть
сеть mask маска
сеть masklen длина
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 113
Любую группу маршрутов и любой маршрут в группе можно пометить ключевым сло-
вом restrict, чтобы запретить агрегирование. Любому агрегированному маршрут}' мож-
но также явно назначить приоритет с помощью предложения preference (стандартный
приоритет —130).
Запуск открытой версии gated
Конфигурирование — это самая сложная часть работы с демоном gated. По заверше-
нии данного этапа нужно проверить правильность работы маршрутизатора. Желательно
ввести тестовые команды вручную и непосредственно пронаблюдать результат. Только
после этого можно добавить команду запуска демона gated в файл /etc/rc. local или в
сценарий начальной загрузки демона init.
Как правило, с демоном gated не работают напрямую. Вместе с демоном распростра-
няется служебная программа gdc, являющаяся его управляющим модулем.
Запуск программы gdc
Программа gdc не работает в непрерывном режиме. Всякий раз ее нужно запускать за-
ново с требуемыми флагами и командами. Возможные флаги перечислены в табл. 5.25.
Таблица 5.25. Флаги программы gdc
Флаг Назначение Формат Значение
-с Задает максимальный размер дампа памяти, создаваемого демоном. Эта установка при- нимается лишь в том случае, если демон был запущен с помощью программы gdc -с размер Размер в байтах
-f Задает максимальный размер дампа со- стояния демона. Эта установка принима- ется лишь в том случае, если демон был запущен с помощью программы gdc -f размер ' Размер в байтах
-m Задает максимальный размер сегмента данных демона. Эта установка принима- ется лишь в том случае, если демон был запущен с помощью программы gdc -m pa змер Размер в байтах
-n Запрещает демону модифицировать таб- лицу маршрутизации ядра -n —
-q Переводит демон в “бесшумный” режим, в котором ничего не записывается в поток stdout. Сообщения об ошибках регист- рируются в соответствии с установками файла syslog.conf -q
-s Задает максимальный размер стека демо- на. Эта установка принимается лишь в том случае, если демон был запущен с по- мощью программы gdc -s размер Размер в байтах
-t Задает продолжительность времени, в течение которого программа gdc ожида- ет завершения определенных операций "t время Число секунд, в течение которых демон должен завершить запрашивае- мую операцию (по умол- чанию — 10)
Опции -с, -f, -m и —s используются для устранения проблем, связанных с нехваткой
памяти при запуске демона.
114 Часть II. Средства и технологии маршрутизации в Linux
Проверка файла gated.conf
Первое, что нужно сделать по завершении конфигурирования демона, — запустить
программу gdc для проверки файла /etc/gated. conf на предмет наличия синтаксиче-
ских ошибок и для поиска прочих ошибок. Для этого предназначены команды, перечис-
ленные в табл. 5.26. Необходимо помнить, что демон gated ведет несколько версий дан-
ного файла, благодаря чему изменения могут быть корректно загружены. Подробнее об
этом речь пойдет в следующем разделе.
Таблица 5.26. Команды тестирования демона gated в программе gdc
Команда Назначение
checkconf Заставляет программу проверить файл /etc/gated. conf на предмет наличия синтаксических ошибок
checknew Заставляет программу проверить файл /etc/gated. conf + на предмет наличия синтаксических ошибок
COREDUMP Заставляет программу скопировать все содержимое своей памяти в файл и за- вершить работу
dump Заставляет программу послать демону запрос на сохранение своих текущих уста- новок в файле/tmp/gated.dump
interface Заставляет программу послать демону запрос на немедленную проверку состоя- ния всех непосредственно подключенных сетевых интерфейсов
rmcore Заставляет программу удалить последнюю версию файла дампа памяти
rmdump Заставляет программу удалить последнюю версию файла дампа состояния
rmparse Заставляет программу удалить последнюю версию файла, содержащего список синтаксических ошибок файла gated.conf
running Заставляет программу определить, запущен ли демон
toggletrace Заставляет программу включить или отключить режим журнальной регистрации событий
Управление демоном gated
У программы gdc есть множество других команд, позволяющих запускать и останавли-
вать демон gated, а также модифицировать его поведение и даже обновлять его текущие
данные (табл. 5.27). Здесь самое время рассказать о том, с какими версиями конфигураци-
онного файла работает демон. После того как содержимое файла было хотя бы один раз
изменено, создаются три копии файла.
/etc/gated. conf+. Новый конфигурационный файл, который должен быть за-
гружен демоном.
/etc/gated. conf. Текущий конфигурационный файл.
/etc/gated. conf-. Предыдущий конфигурационный файл.
Таблица 5.27. Команды манипулирования демоном gated в программе gdc
Команда Назначение
backout Если файл /etc/gated. conf- пуст или не существует либо если файл
/etc/gated. conf + уже есть, эта команда ничего не делает. В противном случае
программа осуществляет “откат” изменений, перемещая файл /etc/gated. conf
в /etc/gated. conf+, файл /etc/gated. conf-------в /etc/gated. conf, а затем
загружая старый конфигурационный файл
BACKOUT Если файл /etc/gated. conf - пуст или не существует, эта команда ничего не де-
лает. В противном случае программа осуществляет “откат” изменений, перемещая
файл /etc/gated.conf в /etc/gated. conf+, файл /etc/gated. conf— в
/etc/gated. conf, а затем загружая старый конфигурационный файл
Глава 5. Демоны одноадресной маршрутизации в ядре 2.2.x 115
Окончание табл. 5.27
Команда createconf Назначение Если файл /etc/gated. conf + существует, эта команда ничего не делает. В про- тивном случае программа создает пустой файл /etc/gated. conf+ , назначает его владельцами пользователя root и группу gdmaint и устанавливает код режима доступа равным 664
KILL modeconf Заставляет программу послать демону команду kill -9 Заставляет программу сделать владельцами всех конфигурационных файлов поль- зователя root и группу gdmaint и установить код режима доступа равным 664
newconf Если файл /etc/gated. conf + не существует, эта команда ничего не делает. В противном случае программа перезаписывает существующий файл /etc/gated. conf - содержимым файла /etc/gated. conf, после чего переме- щает файл /etc/gated.conf+в файл /etc/gated.conf
reconfig Заставляет программу послать демону сигнал о необходимости загрузки файла /etc/gated. conf и соответствующей модификации установок
restart Заставляет программу остановить процесс демона gated и запустить новый про- цесс. Если демон еще не запущен, выполняется команда start
start Если демон уже запущен, команда завершается выдачей сообщения об ошибке. В противном случае она заставляет программу запустить демон. Если это не уда- лось сделать сразу, программа ждет определенное время (по умолчанию — 10 секунд; см. табл. 5.25), после чего выдает сообщение об ошибке
stop Если демон не запущен, команда завершается выдачей сообщения об ошибке. В противном случае она заставляет программу послать демону команду заверше- ния работы (shutoff) и перейти в режим ожидания (по умолчанию — 10 секунд; см. табл. 5.25). Если по истечении этого времени демон не смог завершиться, ко- манда посылается повторно. Если и на этот раз демон не завершился, ему посыла- ется команда kill -9
term Заставляет программу послать демону сигнал на выгрузку всех протокольных мо- дулей и последующее завершение. Если демон не завершил работу и команда term посылается повторно, вместо нее выдается команда kill -9
version Если демон запущен, эта команда завершается ошибкой. В противном случае она заставляет программу выдать информацию о версии демона
Демоны bird И zebra
Среди прочих демонов маршрутизации упомянем два: bird и zebra. Демон bird (http://bird.
network.cz) поддерживает статическую маршрутизацию в стандартах IPv4 и IPv6, а также
протоколы RIP, OSPF и BGP. Располагает он и средствами фильтрации маршрутов. Демон zebra
(www.zebra.org) обладает теми же функциональными возможностями. Преимуществами обоих
является то, что они являются свободно распространяемыми и работают в Linux.
Резюме
В этой главе приведена основная информация о работе с демоном routed, а также с
открытой версией демона gated, который позволяет выполнять все необходимые опера-
ции по настройке подсистемы маршрутизации в Linux. В следующей главе мы познако-
мимся с демонами многоадресной маршрутизации, поддерживаемыми в ядре 2.2.x.
116 Часть II. Средства и технологии маршрутизации в Linux
Демоны многоадресной
маршрутизации в ядре 2.2.x
В этой главе...
Демон протокола PIM-SM: pimd
Демон протокола DVMRP: mrouted
Резюме
117
120
122
Для работы в режиме группового вещания требуется маршрутизирующая подсистема,
осуществляющая перенаправление многоадресных пакетов. Есть целый ряд демонов,
служащих этой цели в Linux. Среди них мы выбрали два: демон pimd для протокола
PIM-SM и демон mrouted для протокола DVMRP.
Демон протокола PIM-SM: pimd
Среди протоколов многоадресной маршрутизации протокол PIM-SM является одним
из наиболее популярных. Он прост в реализации и эффективно обрабатывает трафик,
особенно в разреженном режиме (sparse mode, SM), когда компьютеры подписчиков ка-
нала групповой рассылки распределены по всей сети.
Демон pimd (http://catarina.usc.edu/pim/pimd), в котором реализован данный
протокол, является узкоспециализированным, поэтому его несложно конфигурировать. Это
особенно приятно, если вспомнить, насколько сложно конфигурировать демон gated.
Многоадресная версия демона gated
В многоадресной версии демона gated (www.gated.org) реализованы протоколы PIM-SM,
PIM-DM, DVMRP и MSDP. Мы не описываем здесь возможности этой версии, поскольку она не
является свободно распространяемой. Тем не менее она заслуживает внимания, так как иногда
требуется на одном компьютере обрабатывать трафик сразу нескольких протоколов многоад-
ресной маршрутизации.
Конфигурирование
Поскольку демон pimd является однопротокольным, его конфигурация относительно
проста, по крайней мере в сравнении с таким “монстром”, как gated. Конфигурационные
данные хранятся в файле /etc/pimd. conf. Описанный ниже порядок инструкций не явля-
ется обязательным. Мы просто расскажем о том, что чаще всего добавляется в этот файл.
Конфигурационный файл начинается со следующей инструкции:
default_source_prefегепсе приоритет
Все маршрутизаторы участвуют в выборах главного маршрутизатора организации. Де-
мон pimd решает свою узкую задачу, поэтому, как правило, ему не нужно давать шанса на
таких выборах. Приоритет 101 — это тот минимум, который позволит гарантировать по-
беду демона gated или какого-нибудь другого демона маршрутизации, оставив демону
pimd право обслуживать лишь трафик протокола PIM-SM.
Следующая инструкция такова:
default_source_metric метрика
Она задает стоимость пересылки данных через этот маршрутизатор. Опять-таки, нас
интересует лишь трафик протокола PIM-SM, поэтому желательно задать высокую стои-
мость, чтобы предотвратить непреднамеренное использование демона не по прямому на-
значению. Рекомендуемая установка по умолчанию — 1024.
Первые две инструкции можно менять местами, но далее обязательно должен идти
блок инструкций phyint:
phyint интерфейс (
Эти инструкции задают правила использования сетевых интерфейсов. Интерфейс
можно указывать по имени (например, ethO) или IP-адресу. Если нужно просто активизи-
ровать интерфейс со стандартными установками, то идентификатора интерфейса вполне
достаточно. Вообще же у инструкции phyint есть следующие параметры.
disable. Запрещает посылать трафик протокола PIM-SM через этот интерфейс и
принимать от него аналогичный трафик.
preference приоритет. Задает приоритет интерфейса на выборах. По умолчанию
приоритет берется из инструкции default_source_preference.
metric стоимость. Задает стоимость передачи данных через этот интерфейс. По
умолчанию стоимость берется из инструкции default_source_metric.
Каждому сетевому интерфейсу маршрутизатора должна соответствовать отдельная ин-
струкция phyint. Если для какого-то интерфейса такая инструкция отсутствует, демон
pimd активизирует его со стандартными установками.
Следующая инструкция будет такой:
cand_rp
Она задает интерфейс, который будет участвовать в выборах точки встречи (rendezvous
point, RP). Ниже перечислены параметры инструкции.
IP-адрес. По умолчанию выбирается старший из активизируемых IP-адресов. Если
это нежелательно, укажите адрес нужного интерфейса.
time время. Задает интервал между анонсами кандидата на роль точки встречи.
Стандартный интервал — 60 секунд.
priority приоритет. Задает приоритет данного интерфейса в сравнении с дру-
гими кандидатами. Чем ниже указанное значение, тем выше приоритет.
118 Часть II. Средства и технологии маршрутизации в Linux
Далее идет инструкция
cand_bootstrap_router
Она позволяет определенному интерфейсу компьютера участвовать в выборах конфигу-
рирующего маршрутизатора (bootstrap router). У этой инструкции такие же параметры, как и
у инструкции cand_rp.
Затем задается группа инструкций
grpup_prefix
В каждой такой инструкции определяется диапазон групповых адресов, которые мар-
шрутизатор точки встречи, если он победит на выборах, будет анонсировать другим мар-
шрутизаторам. У этой инструкции два параметра.
Адрес_группы. Задает конкретный IP-адрес или диапазон адресов, обслуживаемых
данным маршрутизатором. Если помните, групповой IP-адрес обозначает не кон-
кретный компьютер, а канал групповой рассылки.
masklen длина. Задает число сегментов IP-адреса, занимаемых маской. Напомним,
что групповые адреса принадлежат классу D и имеют маску 255.255.255.255, т.е. ее
реальная длина составляет 4 байта.
В конце файла могут стоять такие инструкции:
switch_data_threshold rate порог interval интервал
switch_register_threshold rate порог interval интервал
Первая инструкция определяет пороговую интенсивность трафика, при которой проис-
ходит переход от дерева точки встречи к дереву кратчайших путей. Вторая инструкция зада-
ет правило обратного перехода. Аргумент порог обозначает скорость передачи в битах в се-
кунду, а аргумент интервал— периодичность замера в секундах (рекомендуемый минимум — 5
секунд). Рекомендуется, чтобы в обеих инструкциях интервал замера был одинаковым.
Приведем пример файла конфигурации (замените указанные адреса реальными).
default_source_preference 105
phyint 199.60.103.90 disable
phyint 199.60.103.91 preference 1029
phyint 199.60.103.92 preference 1024
cand_rp 199.60.103.91
cand_bootstrap_router 199.60.103.92
group_prefix 199.60.103.0 masklen 4
switch_data_threshold rate 60000 interval 10
switch_register_threshold rate 60000 interval 10
Запуск
После создания конфигурационного файла необходимо проверить работу демона
pimd. Мы рекомендуем сначала запустить демон вручную, а затем, убедившись, что все
правильно, добавить строку запуска демона со всеми необходимыми флагами в системные
стартовые сценарии.
Формат запуска демона таков:
pimd -с файл -d уровенъ_1, . . ., уровенъ_М
Оба флага с соответствующими аргументами являются необязательными.
-с файл. Задает иной конфигурационный файл, чем тот, что принят по умолчанию
(/etc/pimd. conf).
-d уровень_1, . . . , уровень_М. Задает уровень (уровни) отладки демона. Чтобы
получить список всех уровней, введите pimd -h.
Глава 6. Демоны многоадресной маршрутизации в ядре 2.2.x 119
Демон протокола DVMRP: mrouted
Считается, что протокол DVMRP не очень хорошо подходит для использования во
внутренних сетях. Он плохо работает в условиях высокой нагрузки, в отличие от протоко-
ла PIM-SM. В настоящее время протокол DVMRP применяется в основном при подключе-
нии сети к магистрали MBONE (http: //www. live . com/mbone/).
Среди демонов, реализующих протокол DVMRP, мы выбрали mrouted (ftp: //parcftp.
xerox.com/pub/net-research/ipmulti/), поскольку он является узкоспециализирован-
ным и свободно распространяемым, как и pimd.
Конфигурир ов ание
Процесс конфигурирования демона mrouted также достаточно прост. Файл конфигу-
рации называется /etc/mrouted. conf. Некоторые его инструкции должны идти в опре-
деленном порядке, но в основном приведенные ниже инструкции даны в том порядке, в
каком они чаще всего встречаются.
Обычно конфигурационный файл начинается с инструкции name:
name имя_диапазона диапазон/длина_маски
Назначение ее аргументов таково.
имя_диапазона. Имя, закрепляемое за конкретной группой адресов.
диапазон. Адресный диапазон, которому присваивается имя.
длина_маски. Число значащих битов маски.
Далее обычно стоит инструкция cache_lifetime:
cache_lifetime секунды
Аргумент секунды задает время, в течение которого информация, полученная по прото-
колу DVMRP, остается в ядре. Стандартная установка — 300 секунд.
Следом идет одна из двух инструкций:
prune on
или
prune off
Они определяют, поддерживает ли маршрутизатор DVMRP операцию отсечения ветвей.
На этом конфигурационный файл можно закончить. Демон mrouted по умолчанию ак-
тивизирует все интерфейсы, способные передавать многоадресные данные, и присваива-
ет им стандартные параметры. Если же интерфейсы нужно сконфигурировать как-то по-
другому, задайте для каждого из них инструкцию phyint, общий формат которой таков:
phyint интерфейс
Аргумент интерфейс определяет IP-адрес физического интерфейса или его имя
(например, ethO). Остальные параметры инструкции перечислены ниже.
disable. Запрещает передавать трафик протокола DVMRP через этот интерфейс.
metric стоимость. Назначает стоимость передачи данных через этот интерфейс.
Она должна быть меньше, чем 31. Чаще всего рекомендуют значение 1.
threshold порог. Задает минимальное значение поля TTL, которое должен иметь
IP-пакет, чтобы демон mrouted пропустил его через данный интерфейс. Это значе-
ние задается в секундах.
120 Часть II. Средства и технологии маршрутизации в Linux
rate_limit предельная_скорость. Задает предельную скорость многоадресного
трафика (в килобитах в секунду), принимаемого этим интерфейсом.
boundary имя_диапазона. Применяет данный набор правил к блоку сетей, опре-
деленному ранее в инструкции name. Таких параметров может быть несколько.
boundary диапазон/длина_маски. Задает блок сетей, к которому применяются
данные правила (способ задания такой же, как и в инструкции name). Таких пара-
метров может быть несколько.
altnet подсеть/длина_маски. Если интерфейс ведет к нескольким подсетям, то
с помощью данного параметра можно уточнить, к какой из них применяются прави-
ла. Аргумент подсеть задает адрес подсети, а аргумент длина_маски интерпретируется
так же, как и в инструкции name. Параметров altnet может быть несколько.
altnet подсеть. Если интерфейс ведет к нескольким подсетям, то с помощью
данного параметра можно уточнить, к какой из них применяются правила. Аргумент
подсеть задает адрес подсети (предполагается, что маски не требуется). Таких пара-
метров может быть несколько.
Последней может стоять инструкция tunnel. С ее помощью формируется туннель-
канал передачи многоадресных данных от одного демона mrouted к другому через одно-
адресное сетевое пространство. Общий формат инструкции таков:
tunnel локальный_интерфейс удаленный_интерфейс
Первый аргумент задает IP-адрес или имя локального интерфейса, служащего началом
туннеля. Второй аргумент задает IP-адрес удаленного интерфейса, который будет принимать
данные. Остальные параметры этой инструкции такие же, как и у инструкции phyint.
Приведем пример конфигурационного файла.
name multi 199.60.103.0/32
cache_lifetime 21600
pruning on
phyint 199.60.103.90 disable
phyint 199.60.103.91 rate_limit 60 threshold 10 \
preference 1029 boundary multi
phyint 199.60.103.92 rate_limit 60 threshold 10 \
preference 1024 boundary multi
tunnel 199.60.103.92 210.17.105.9 rate_limit 60 \
threshold 10 preference 1024 boundary multi
Запуск
После создания конфигурационного файла необходимо проверить работу демона
mrouted. Как всегда, прежде чем организовывать автоматический запуск и останов демо-
на, желательно запустить демон вручную и определить требуемую комбинацию парамет-
ров и флагов. Формат запуска демона таков:
mrouted флаги
Возможны следующие флаги.
-р. Запрещает операции отсечения ветвей.
-с файл. Задает иной конфигурационный файл, чем тот, что принят по умолчанию
(/etc/mrouted. conf). Не забудьте указать полное путевое имя файла.
-d. Переводит демон на уровень отладки 2.
-d уровень. Задает уровень отладки демона (табл. 6.1).
Глава 6. Демоны многоадресной маршрутизации в ядре 2.2.x 121
Таблица 6.1. Уровни отладки демона mrouted
Уровень 1 2 Описание Направление всех журнальных сообщений в поток stderr Направление в поток stderr всех сообщений уровня 1, а также сообщений, поме- ченных словом "significant1' (важное)
3 Направление в поток stderr всех сообщений уровня 2, а также сообщений, фикси- рующих прибытие и отправку каждого пакета
Резюме
В этой главе были рассмотрены демоны многоадресной маршрутизации. Простой уз-
коспециализированный демон pimd предназначен для работы по протоколу PIM-SM. Этот
протокол чаще всего применяется для организации группового вещания. Если же возни-
кает необходимость подключиться к магистрали MBONE, нужно воспользоваться прото-
колом DVMRP и демоном mrouted. Существует также многоадресная версия демона
gated, в которой реализованы одновременно оба протокола.
122 Часть II. Средства и технологии маршрутизации в Linux
Вспомогательные демоны
В этой главе...
Обзор протокола РРР 123
Протокол РРР в Linux: демон pppd 128
Программа rip2ad 131
Резюме 133
В этой главе будут рассмотрены две вспомогательные Linux-утилиты: pppd и rip2ad.
Первая из них предоставляет ядру и сетевым процессам функции РРР (Point-to-Point
Protocol — протокол двухточечного соединения). Этот демон работает незаметно для
пользователя, которому не нужно знать о том, что протокол РРР используется. Прежде
чем знакомиться с демоном, полезно будет узнать, что представляет собой протокол РРР и
где он применяется.
Программа rip2ad позволяет рассылать RIP-анонсы в отсутствие полнофункциональ-
ного демона маршрутизации. Это идеальное средство для Linux-маршрутизаторов, кото-
рые являются шлюзами к RIP-системам, но при этом не требуют использовать протокол
RIP в своих локальных системах.
Обзор протокола РРР
Протокол РРР предназначен для передачи пакетов по последовательным каналам и стал
Internet-стандартом для коммутируемых и выделенных линий. Открытость этого стандарта
обеспечила поддержку протокола со стороны поставщиков операционных систем, а исполь-
зование последовательных соединений для подключения к сети Internet привело к широко-
му распространению протокола. Сам протокол описан в документе RFC1661.
Протокол РРР основан на другом протоколе: HDLC (High-level Data Link Control — вы-
сокоуровневый протокол управления каналом). К кадру HDLC добавляется заголовок РРР,
состоящий из двух полей: в одном содержится размер пакета, а в другом — код протокола
более высокого уровня, пакет которого передается. В РРР поддерживаются сотни прото-
колов. Самые распространенные из них перечислены в табл. 7.1.
Таблица 7.1. Распространенные протоколы, поддерживаемые в РРР
Код Протокол
' 0x0021..ip......................................................................
0x002D TCP со сжатием заголовков
Ox002F TCP без сжатия заголовков
OxOO3D MP (Multilink Protocol — протокол многоканальной передачи)
0x8021 IPCP (Internet Protocol Control Protocol — протокол управления протоколом IP)
0хС021 LCP (Link Control Protocol — протокол управления каналом)
0хС023 PAP (Password Authentication Protocol — протокол парольной аутентификации)
0хС223 CHAP (Challenge Handshake Authentication Protocol — протокол аутентификации с
предварительным согласованием вызова)
Схема работы
Протокол РРР не просто инкапсулирует пакеты для передачи их по каналу. На протя-
жении всего PPP-сеанса должна выполняться определенная последовательность функций.
В документе RFC1661 эти функции названы фазами (рис. 7.1).
Рис. 7.1. Фазы протокола РРР
Фаза отсутствия канала
Фаза отсутствия канала (link dead phase) существует перед началом PPP-сеанса и по его
окончании. Выход из этой фазы инициируется протоколом LCP.
Фаза организации канала
Протокол LCP управляет фазой организации канала (link established phase). Соединение
устанавливается с минимумом необходимых опций, после чего канал начинает функцио-
нировать. Ни одна из сторон не знает о возможностях противоположной стороны — ис-
ключение составляет лишь выбор протокола аутентификации. Если аутентификация не-
обходима, ее тип определяется на данной фазе.
Протокол LCP описан в документах RFC1570 и RFC1661. LCP-пакет состоит из LCP-
заголовка и блока данных (рис. 7.2) и инкапсулируется в РРР-пакет.
124 Часть II. Средства и технологии маршрутизации в Linux
Код Идентификатор Длина
Данные
Рис. 7.2. LCP-пакет
В LCP-заголовке содержится код, определяющий тип сообщения (табл. 7.2). Содержи-
мое блока данных зависит от кода сообщения.
Таблица 7.2. Коды протокола LCP
Код Сообщение
1 Configure-Request
2 Configure-Ack
3 Configure-Nak
4 Configure-Reject
5 Terminate-Request
6 Terminate-Ack
7 Code-Reject
8 Protocol-Reject
9 Echo-Request
10 Echo-Reply
11 Discard-Request
Фаза аутентификации
После того как обе стороны установили соединение, они могут аутентифицировать
друг друга, прежде чем переходить к определению возможностей сетевого протокола. Фа-
за аутентификации не является обязательной, но обычно нет причин ее избегать. В боль-
шинстве организаций есть центральный сервер удаленного доступа, и только он занима-
ется аутентификацией удаленных узлов. Но аутентификация поддерживается в обоих на-
правлениях независимо от того, какой узел инициировал РРР-сеанс.
В РРР поддерживаются два метода аутентификации: PAP (Password Authentication
Protocol — протокол парольной аутентификации) и CHAP (Challenge Handshake Authenti-
cation Protocolпротокол аутентификации с предварительным согласованием вызова).
В протоколе РАР узел посылает имя пользователя и пароль в незашифрованном виде, а
удаленный узел либо принимает их, либо отвергает.
В протоколе CHAP применяется более сложная процедура трехфазового квитирования,
при которой вместо имени пользователя и пароля передаются три сообщения: оклик
(Challenge), ответ (Response) и подтверждение (Success или Failure). Компьютер, который
хочет аутентифицировать удаленный узел, посылает ему сообщение Challenge, в котором со-
держится код оклика, сгенерированный на основании секретного кода. Секретный код из-
вестен обеим сторонам и, как видите, не передается по сети в чистом виде. Удаленный узел
объединяет код оклика с секретным кодом и применяет к ним специальную одностороннюю
хеш-функцию для получения кода ответа, возвращаемого отправителю. Узнав ответ, отпра-
витель сравнивает его с результатом работы собственной хеш-функции. Если результаты
совпадают, возвращается сообщение Success, в противном случае — сообщение Failure.
Сообщения Challenge продолжают периодически посылаться и во время следующей фа-
зы. Это делается для предотвращения внезапного несанкционированного захвата канала.
Глава 7. Вспомогательные демоны 125
Фаза протокола сетевого уровня
Семейство NCP (Network Control Protocol — протокол управления сетью) предназначе-
но для определения параметров протоколов сетевого уровня. Каждому из поддерживае-
мых сетевых протоколов соответствует свой протокол NCP. Несколько таких протоколов
может работать параллельно. Например, трафик протоколов IP и IPX можно передавать
одновременно. Для IP-сетей стандартом является протокол IPCP (Internet Protocol Control
Protocol — протокол управления протоколом IP), определенный в документе RFC1332.
В IPCP используются пакеты формата LCP, но поддерживаются только первые семь
кодов сообщений (табл. 7.3).
Таблица 7.3. Коды протокола IPCP
Код Сообщение
1 Configure-Request
2 Configure-Ack
3 Configure-Nak
4 Conflgure-Reject
5 Terminate-Request
6 Terminate-Ack
7 Code-Reject
Чтобы пакеты IPCP отличались от пакетов LCP, в поле протокола PPP-заголовка нужно
поместить код 0x8021.
Во время фазы протокола сетевого уровня определяется не только то, поддерживается
в канале протокол IP или нет, но также IP-адрес локального конца канала и необходимость
сжатия IP-заголовков. В большинстве реализаций РРР администратору разрешается пре-
доставлять требуемый IP-адрес. Во многих организациях IP-адреса назначаются централь-
ным сервером удаленного доступа.
Фаза разрыва канала
В идеальном случае сигнал о переходе в фазу разрыва канала (link termination phase) посы-
лается из одного конца канала в другой в виде сообщения Terminate-Request. Однако эта фаза
может наступить и в результате потери несущей или вследствие команды администратора.
Применение протокола РРР
Пользователи склонны считать РРР клиент-серверным протоколом, так как он часто
применяется для подключения удаленных ресурсов (например, персональных компьюте-
ров) к центральному офису (серверу доступа к сети). На самом же деле — это протокол со-
единения одноранговых компьютеров, обладающих равными правами (по крайней мере,
так сказано в стандарте). Тем не менее в типичном случае протокол служит для реализа-
ции архитектуры клиент-сервер. Например, персональный компьютер, работающий под
управлением Windows, будет аутентифицировать себя на удаленном узле, но не наоборот.
Помимо простого коммутируемого доступа протокол РРР находит целый ряд других
применений. С точки зрения стандарта протокол не ориентирован именно на эти приме-
нения, но зачастую других вариантов, кроме РРР, просто не существует.
Выделенные линии
Протокол РРР хорошо функционирует в выделенных линиях, так как обеспечивает со-
гласование разнородных протоколов. Это то, чего не делает протокол HDLC.
126 Часть II. Средства и технологии маршрутизации в Linux
РРР поверх ISDN
Стандарт ISDN (Integrated Digital Services Network — цифровая сеть с комплексным об-
служиванием) очень популярен в Европе. Для передачи PPP-пакетов через ISDN-линии раз-
работана технология ISDN4Linux (www.isdn41inux.de). В ISDN появляются дополнитель-
ные особенности, например идентификация звонящего, обратный вызов и ряд других.
Коммутация по запросу
Если коммутируемое соединение, будь то асинхронное (модем) или ISDN, является
шлюзом в другую сеть или в Internet, маршрутизатор должен инициировать соединение.
Обычно сигналом к установлению соединения является появление трафика, адресованно-
го PPP-интерфейсу. Принцип коммутации по запросу часто применяется для реализации
специальных возможностей, например резервного коммутируемого соединения и расши-
рения полосы по запросу.
Резервное коммутируемое соединение
Резервный коммутируемый канал служит альтернативным маршрутом в заданную сеть,
активизируемым в случае сбоя основного канала. Факт сбоя можно определить на основа-
нии статуса интерфейса или по сигналу от протокола. Рассмотрим рис. 7.3. Linux-
маршрутизатор Sleepy подключен к маршрутизатору Tired через усеченную выделенную
линию Т1 с полосой пропускания 256 Кбит/с (без сжатия).
Рис. 7.3. Основной канал
Предположим, в выделенной линии произошел сбой. Тогда активизируется резервное
соединение, чтобы связь между узлами не прерывалась.
Sleepy
Рис. 7.4. Резервный коммутируемый канал
Расширение полосы по запросу
В технологии расширения полосы пропускания по запросу используется дополнитель-
ный коммутируемый канал, который усиливает возможности существующего соединения
по алгоритму распределения нагрузки. Дополнительная часть полосы задействуется по
достижении порогового уровня трафика в основном канале.
Глава 7. Вспомогательные демоны 127
В PPP применяется протокол MP (Multilink Protocol — протокол многоканальной пере-
дачи), позволяющий объединять несколько PPP-каналов. Этот протокол определен в до-
кументе RFC 1990.
Протокол РРР в Linux: демон pppd
Демон pppd для Linux доступен по адресу f tp: //cs . anu.edu.au/pub/software/ррр.
В ядре Linux (версий 2.2 и 2.4) имеются необходимые драйверы, обеспечивающие поддерж-
ку протокола РРР со стороны ядра, а PPP-пакет содержит пользовательский демон, вспомо-
гательные программы, документацию и примеры конфигурационных файдов. Поддержка
протокола МР имеется только в ядре версии 2.4.
В большинстве дистрибутивов Linux протокол РРР поддерживается по умолчанию. Если
же это не так, то соответствующий пакет легко добавляется с помощью менеджера пакетов.
Компиляция
Скомпилировать демон pppd несложно. Загрузите пакет ррр по адресу ftp: / /cs ,anu.
edu.au/pub/software/ppp и поместите его в исходный каталог, например /usr/src/.
Раскройте архив и распакуйте его:
[rootSlefty src]# gunzip ppp-2.4.1.tar.gz
[root@lefty src]# tar xvf ppp-2.4.1.tar
В результате будет создан подкаталог ррр-2.4.1. Перейдите в него и запустите кон-
фигурационный сценарий:
[rootSlefty src]# cd /usr/src/ppp-2.4.1
[root@lefty ppp-2.4.1]# ./configure
Затем выполните команду make и инсталлируйте дистрибутив с помощью команды
make install:
[root@lefty ppp-2.4.1]# make
[root@lefty ppp-2.4.1]# make install
Конфигурирование
В результате инсталляции файлы пакета помещаются в два каталога: /usr/sbin/ и
/etc/ррр/. В первом из них находятся следующие файлы: pppd — PPP-демон, pppdump —
утилита создания дампов и pppstats — утилита вывода отчета по статистике работы ука-
занного PPP-интерфейса. В каталоге /etc/ррр/ содержатся такие файлы: chap-secrets
и pap-secrets — хранят аутентификационную информацию, ip-up и ip-down — сцена-
рии управления интерфейсами, options — определяет поведение демона pppd.
Демон pppd поддерживает более ста опций, которые гарантируют его взаимодействие
практически со всеми реализациями протокола РРР. К счастью, большинство современ-
ных реализаций соответствует стандартным требованиям, поэтому многие опции не нуж-
ны. Наиболее часто используемые опции перечислены в табл. 7.4.
Таблица 7.4. Распространенные опции демона pppd
Опция Описание
auth Требует аутентифицировать противоположную сторону соединения. Если
локальный узел не имеет стандартного маршрута и ни опция auth, ни оп-
ция noauth не указана, демон не будет требовать аутентификации. Тем не
менее удаленный узел должен иметь IP-адрес, для которого на локальном
узле еще нет записи в маршрутной таблице
128 Часть II. Средства и технологии маршрутизации в Linux
Окончание табл. 7.4
Опция Описание
call имя Сообщает демону о необходимости прочитать опции настройки из файла /etc/ppp/peers/имя. Это очень удобно, если поддерживаются соедине- ния с несколькими узлами
connect сценарий Заставляет демон использовать указанный сценарий (или исполняемый файл) для взаимодействия с последовательным портом и модемом
crtscts | Соответственно включает и отключает аппаратный контроль передачи
nocrtscts данных
defaultroute Заставляет демон pppd создать стандартную маршрутную запись к удален- ному узлу. Обычно это необходимо при подключении к сети Internet
file файл Заставляет демон прочитать параметры конфигурации из указанного фай- ла. Это должен быть текстовый файл, в каждой строке которого задается один параметр
lock Заставляет демон захватить последовательный порт для монопольного ис- пользования
локальный_ адрес: удаленный_адрес Таким способом задаются адреса локального и удаленного РРР-интерфейсов
debug Включает регистрацию отладочной информации через систему Syslog
demand Заставляет демон функционировать в режиме коммутации по запросу. По- сле отправки данных на удаленный узел демон автоматически разорвет со- единение без вмешательства пользователя. Такое поведение требуется на сетевых шлюзах
require-chap | Задание протокола аутентификации
'require-pap
Запуск
Демон pppd может сам устанавливать соединение с удаленным узлом или ждать запро-
са на установление связи. В первом случае демон называется клиентом, а во втором — сер-
вером. Напомним, что в модели клиент/сервер клиентом считается инициатор соедине-
ния. С точки же зрения протокола РРР оба узла абсолютно равноправны и не делятся на
клиент или сервер.
Чтобы демон pppd мог установить соединение, ему должны быть известны параметры
конфигурации сервера (их необходимо поместить в конфигурационные файлы). Показан-
ный ниже пример типичен для подключения к серверу провайдера Internet.
Демону нужна следующая конфигурационная информация: имя пользователя и пароль
РАР либо имя узла и пароль CHAP, номер телефона, способ назначения IP-адреса
(статически или динамически) и последовательный порт, к которому подключен модем.
Предположим, нам известно следующее.
Имя пользователя PAP: customerl
Пароль PAP: customerpassword
Номер телефона для подключения: 800-555-5555
IP-адрес: назначается динамически
Последовательный порт: /dev/ttySO
Эту информацию нужно включить в соответствующие файлы. Поскольку в данном
примере применяется протокол аутентификации РАР, в файл /etc/ppp/pap-secrets
должна быть добавлена такая запись:
Глава 7. Вспомогательные демоны 129
# Секретные данные для аутентификации по протоколу РАР
# клиент сервер секретный пароль IP-адреса
customerl isp customerpassword
Демон pppci не осуществляет собственно дозвон, следовательно, нужна дополнитель-
ная программа. Обычно это утилита chat. Она использует сценарий диалогового взаимо-
действия, который когда-то играл очень важную роль для серверов удаленного доступа,
требовавших, чтобы сеанс регистрации начался раньше, чем PPP-сеанс. Сегодня большин-
ство серверов способно начинать PPP-сеанс сразу после того, как модем снял трубку. Про-
грамме chat достаточно послать модему строки инициализации и команду dial. Установ-
ки программы задаются в конфигурационном параметре connect, который вместе с не-
сколькими другими важными параметрами включается в файл /etc/ppp/options:
lock
debug
/dev/ttySO
crtscts
defaultroute
connect '/usr/sbin/chat -v " " ATZ OK ATDT 8005555555'
Все эти опции были перечислены в табл. 7.4, но вкратце напомним их назначение.
Итак, в данном файле говорится о том, что демон pppd должен захватить (lock) последо-
вательный порт /dev/ttySO, включить регистрацию отладочной информации (debug) и
аппаратный контроль передачи данных (crtscts), создать стандартный маршрут к уда-
ленному узлу (defaultroute), а затем подключиться к нему с помощью указанной коман-
ды chat.
Теперь, чтобы подключиться к провайдеру, достаточно ввести следующее:
[root@lefty /root]# pppd
Если возникают какие-то проблемы, то они обычно связаны либо с модемом, либо с ау-
тентификацией. Узнать о проблемах можно, просмотрев файл /var/log/messages. На-
пример, следующие записи говорят о том, что диалоговый сценарий окончился неудачей,
так как модем не ответил:
Jun 3 09:08:45 lefty pppd[11857]: pppd 2.4.1 started by root, uid 0
Jun 3 09:08:45 lefty pppd[11857J: Removed stale lock on ttySO
(pid 11850)
Jun 3 09:08:46 lefty chat[11858]: expect ( )
Jun 3 09:09:31 lefty chat£11858]: alarm
Jun 3 09:09:31 lefty chat[11858]: Failed
Jun 3 09:09:31 lefty pppd[11857J: Connect script failed
Jun 3 09:09:32 lefty pppd[11857]: Exit.
Самый простой способ проверить работу модема — это запустить программу chat са-
мому, предварительно включив динамик модема:
/usr/sbin/chat -v " " ATZ OK ATL2M2 ATDT 8005555555
Если маршрутизатор Linux не смог аутентифицировать себя на удаленном узле, будет
выдано сообщение “Failed to authenticate ourselves to peer”. Если же удаленный узел не ау-
тентифицировал себя, сообщение будет таким: “Authentication failed”.
Дополнительные сетевые сервисы
Если маршрутизатор Linux выступает в качестве шлюза, сетевой администратор дол-
жен определить, какие дополнительные сервисы следует запустить на нем.
130 Часть II. Средства и технологии маршрутизации в Linux
Электронная почта
Почтовые сервисы обеспечивают доставку электронной почты, в основном глобаль-
ной, т.е. связанной с сетью Internet. В Linux имеются очень мощные почтовые сервисы,
позволяющие создавать корпоративные почтовые системы. Но если эти сервисы будут ра-
ботать на том же сервере, что и демон pppd, это создаст потенциальную угрозу безопасно-
сти электронной почты.
Служба доменных имен (DNS)
Служба DNS часто работает на том же шлюзе, что и демон pppd. Как и почтовые сер-
веры, серверы DNS (как правило, BIND) тоже открыты для атак, но считаются более
безопасными по ряду причин: они менее интересны хакерам, традиционно в них меньше
“дыр” (ситуация постепенно выравнивается по мере совершенствования почтовых серве-
ров) и обычно они подвержены лишь атакам типа “отказ от обслуживания”.
На корпоративных и Internet-шлюзах имеет смысл устанавливать DNS-сервер, рабо-
тающий в кэширующем режиме. Такой сервер сохраняет в кэше результаты всех запросов,
чтобы при повторном обращении их не нужно было выполнять заново. Это сокращает
время, затрачиваемое на поиск имен узлов, и уменьшает глобальный трафик.
Что касается корпоративных шлюзов, то и для них полезно переместить информацию
о внутренних доменах на сервер имен. Это позволит осуществлять преобразование имен
локально, вместо того чтобы посылать запросы в глобальную сеть. Определенный внеш-
ний трафик все же существует, так как сервер имен периодически запрашивает зонные
данные, но этот трафик невелик.
Программа rip2ad
Программа rip2ad, написанная Андреа Бек (Andrea Beck), осуществляет рассылку
маршрутов RIP-2 по указанному адресу, не будучи при этом полнофункциональным демо-
ном маршрутизации и не требуя использования протокола RIP в локальной сети. Эта про-
грамма доступна по адресу http: //www. ibh. de/~beck/stuff/ripper. Раньше похожие
функции предоставлял демон bcastd, но он больше не поддерживается.
Пример
Рассмотрим сеть, изображенную на рис. 7.5. Узел Ritz должен сообщить корпоратив-
ному маршрутизатору Gate о локальных сетях 192.168.0.0/24, 192.168.1.0/24, 192.168.2.0/
24 и 192.168.3.0/24, обобщенно - 192.168.0.0/22.
Решить задачу можно, запустив в сети протокол RIP, запустив на узле Ritz протокол RIP
со статическими маршрутами, ведущими в локальную сеть, или добавив статический мар-
шрут на узле Gate. Но создание статических маршрутов может быть запрещено админист-
ративными правилами, ведь узел Gate будет анонсировать маршрут даже в том случае, ко-
гда канал отключен.
Запуск демона маршрутизации на узле Ritz явно ни к чему. Зато можно воспользоваться
программой rip2ad, которая сообщит маршрутизатору Gate о требуемых сетях, не требуя
запуска протокола RIP как на узле Ritz, так и на узлах Jos и Hild.
Компиляция и инсталляция
Компиляция программы rip2ad осуществляется одной командой:
[root@lefty ripper] # gcc rip2ad.c -о rip2ad
Исполняемый файл нужно поместить в требуемый каталог, например /usr/local/sbin:
[root@lefty ripper]# ср rip2ad /usr/local/sbin
Глава?. Вспомогательные демоны 131
192.168.1.0/24
Рис. 7.5. Пример сети, в которой применяется программа rip2ad
Программа имеет несколько опций командной строки.
-f файл. Задает файл, из которого берутся анонсируемые маршруты. Предельное
их число — 25 (один RIP-пакет).
-с секунды. Задает периодичность, с которой будут анонсироваться маршруты.
Если период равен нулю или не указан, команда выполняется ровно один раз.
-d IP-адрес. Задает адрес, по которому посылаются пакеты. По умолчанию это
групповой адрес rip2-routers.mcast.net.
Формат анонсируемых маршрутов таков:
IP-адрес маска шлюз метрика
В случае сети, изображенной на рис. 7.5, содержимое файла / etc/riptable будет таким:
192.168.0.0 255.255.255.0 0 1
192.168.1.0 255.255.255.0 0 1
192.168.2.0 255.255.255.0 0 1
192.168.3.0 255.255.255.0 0 1
Адрес шлюза 0 (0.0.0.0) свидетельствует о том, что отправитель таблицы как раз и яв-
ляется шлюзом.
Чтобы заставить программу анонсировать маршруты каждые 30 секунд, введите сле-
дующую команду:
[rootOlefty ripper]# rip2ad -f /etc/riptable -c 30 &
Если теперь проверить с помощью утилиты tcpdump работу сетевых интерфейсов,
можно будет обнаружить пакеты RIP-2, направляемые по групповому адресу:
[root@lefty ripper]# tcpdump
Kernel filter, protocol ALL, datagram packet socket
tcpdump: listening on all devices
09:33:38.311593 ethO > 192.168.1.254.route > 224.0.0.9.route:
132 Часть II. Средства и технологии маршрутизации в Linux
'brip-resp 4:
{192.168.0.0/255.255.255.0}(1) {192.168.1.0/255.255.255.0} (1)
{192.168.2.0/255.255.255.0}(1) {192.168.3.0/255.255.255.0}(1)
Mttl 1]
1 packets received by filter
Но соединение между узлами Gate и Ritz является двухточечным, поэтому групповая
рассылка в нем не действует. Нужно задать обычный адрес узла Gate:
[rootSlefty ripper]# rip2ad -f /etc/riptable -c 30 -d 10.1.1.1 &
Посмотрим, что сообщает утилита tcpdump:
[rootSlefty ripper]# tcpdump
Kernel filter, protocol ALL, datagram packet socket
tcpdump: listening on all devices
09:41:35.679407 ethO > 192.168.1.254.route > 10.1.1.1.route:
4>rip-resp 4 :
{192.168.0.0/255.255.255.0}(1) {192.168.1.0/255.255.255.0}(1)
{192.16 8.2.0/255.255.255.0}(1) {192.168.3.0/255.255.255.0} (1)
1 packets received by filter
Как уже говорилось, анонсируемые сети можно объединить в один маршрут:
192.168.0.0 (маска 255.255.252.0). Тогда файл /etc/riptable будет выглядеть так:
192.168.0.0 255.255.252.0 0 1
Запустив снова программу rip2ad, получим следующий отчет утилиты tcpdump:
[rootSlefty ripper]# tcpdump -n host 192.168.1.1
09:49:32.124445 ethO > 192.168.1.254.route > 10.1.1.1.route:
'brip-resp 1:
{192.168.0.0/255.255.252.0}(1)
Резюме
В этой главе был описан протокол РРР, предназначенный для организации двухточеч-
ных соединений. Мы также познакомились с PPP-демоном pppd и рассмотрели процедуру
его конфигурирования. Кроме того, описывалась программа rip2ad, которая играет роль
RIP-шлюза, не являясь полнофункциональным демоном маршрутизации.
Глава 7. Вспомогательные демоны 133
Средства маршрутизации
в ядре версии 2.4.x
В этой главе...
Различия между ядрами версий 2.2.x и 2.4.x 134
Новые сетевые возможности ядра версии 2.4.x 135
Виртуальные закрытые (частные) сети 136
Резюме 137
В этой главе мы узнаем о некоторых изменениях, произошедших в ядре Linux версии
2.4.x, и о том, как они связаны с маршрутизацией. Будет также рассмотрен ряд вспо-
могательных утилит.
Различия между ядрами версий 2.2.x и 2.4.x
Самое важное отличие ядер серии 2.2.x от ядер серии 2.4.x, по крайней мере с точки
зрения работы в сети, заключается в переходе от программы ipchains к системе Netfil-
ter. Последняя предоставляет новый уровень сетевых услуг, включая фильтрацию пакетов
с учетом состояния сеанса и улучшенную систему NAT.
Появление системы Netfilter позволило Linux-компьютерам осуществлять более слож-
ную маршрутизацию. В ядрах версий 2.2.хне были предусмотрены такие возможности, как
SNAT (Source Network Address Translation— трансляция исходных сетевых адресов),
DNAT (Destination Network Address Translation — трансляция целевых сетевых адресов) и
перенаправление пакетов, тогда как система Netfilter делает конфигурирование этих ва-
риантов NAT относительно несложным.
Фильтрация пакетов, основанная на анализе их содержимого, повышает безопасность
системы и эффективность маршрутизации. В некоторой степени она повышает также
сложность конфигурирования системы, но это разумная плата за те возможности, кото-
рые появляются в результате.
Подробнее о фильтрации пакетов и системе NAT рассказывается в главе 14, “Безопасность
и система NAT”.
Включение поддержки программ ipfwadm и ipchains
В принципе, вопросы конфигурирования ядра рассматриваются в главе 13, “Включение в
ядро функций маршрутизации”, однако изменения, касающиеся программ ipfwadm и
ipchains, мы решили описать здесь. Мы считаем, что программа iptables гораздо лучше
подходит для настройки брандмауэров и системы NAT, но чтобы переход на нее не был
столь болезненным, в ядрах версии 2.4.x имеются модули совместимости с программами
ipfwadmи ipchains.
На этапе компиляции нового ядра нужно включить поддержку драйверов и кода, нахо-
дящихся в стадии разработки. Если используется сценарий компиляции'menuconf ig или
xconfig, то соответствующая опция находится в меню Code Maturity Level Options и на-
зывается Prompt For Development and/or Incomplete Code/Drivers. Далее нужно в меню
Networking Options включить пункт IP: Netfilter Configuration. В ядрах версий 2.4.x про-
граммы ipfwadm и ipchains работают поверх механизма Netfilter.
Программы iptables, ipfwadm и ipchains нельзя использовать одновременно.
Можно скомпилировать модули для всех трех программ, но в ядре нужно включить под-
держку только какого-то одного модуля. В случае необходимости ядро можно будет пере-
компилировать.
Драйверы, находящиеся в стадии разработки
Не пугайтесь! Включение данной опции не сделает ядро нестабильным. Так называемые
"нестабильные” компоненты в действительности достаточно надежны, зачастую гораздо более
надежны, чем некоторые коммерческие программы. Просто планка уровня стабильности для
продуктов, выпускаемых в рамках проектов Free Software и Open Source, находится существенно
выше, чем для многих коммерческих программ. “Нестабильные” версии обычно не обладают
всеми анонсированными функциональными возможностями.
Новые сетевые возможности ядра версии 2.4.x
Те, кому доводилось компилировать ядра версий 2.2.x, заметят, что изменений в новой
версии ядра не так много. Некоторые опции были перемещены или удалены, но в основ-
ном ничего радикального в сетевой части не произошло.
Поддержка технологии ATM
Важным новшеством является появление поддержки технологии ATM (Asynchronous
Transfer Mode — режим асинхронной передачи). Правда, средства поддержки пока что
считаются экспериментальными. Для использования технологии ATM в Linux понадобит-
ся несколько программ пользовательского уровня. Их можно найти по адресу http://
linux-atm.sourceforge.net.
Поддержка явных уведомлений о загруженности сети
Включение опции TCP Explicit Congestion Notification Support позволяет маршрутиза-
торам уведомлять клиентов о перегрузке сети. К сожалению, не все маршрутизаторы рас-
полагают соответствующими средствами. На данный момент лучше всего оставить эту оп-
цию отключенной, так как некоторые узлы отказываются устанавливать соединения с
клиентами, требующими подобных уведомлений.
Можно также скомпилировать ядро с поддержкой рассматриваемой опции, но при
этом отключить саму опцию такой командой:
echo 0 > /proc/sys/net/ipv4/tcp_ecn
Глава 8. Средства маршрутизации в ядре версии 2.4.x 135
Это проще всего, так как впоследствии можно будет включить опцию без перекомпи-
ляции ядра.
Интерфейсы глобальных сетей
В ядрах версии 2.4.x поддерживается много интерфейсов глобальных сетей. Эта под-
держка включается с помощью опции WAN Interface Support.
Беспроводные локальные сети
Беспроводные сетевые устройства пока еще относительно дороги, но поддержка их
имеется в ядрах версии 2.4.x. Это может оказаться полезным при работе с устройствами
PCMCIA.
Поддержка интерфейса USB
В ядрах версии 2.4.x поддерживается множество USB-устройств: модемов, плат Ether-
net и др. Со временем они могут вытеснить “традиционные” устройства, а пока же многие
из них находятся на начальных этапах своего жизненного цикла и их драйверы могут не-
достаточно хорошо работать в Linux.
Виртуальные закрытые (частные) сети
Еще одной полезной новой особенностью стала возможность реализации виртуальной
частной сети (Virtual Private Network, VPN). Это становится все более популярным реше-
нием для защиты корпоративных глобальных сетей.
Пакет РоРТоР
Лучшим средством для создания виртуальной частной сети в Linux является пакет
РоРТоР. Он реализует протокол РРТР (Point-to-Point Tunneling Protocol — протокол двух-
точечного туннельного соединения) и перенесен также в операционные системы Solaris,
OpenBSD и FreeBSD. Пакет поддерживает работу не только с клиентами UNIX, но и с кли-
ентами Windows (95, 98, NT и 2000), ведь зачастую корпоративные сети являются смешан-
ными. Самое приятное то, что пакет распространяется на условиях открытой лицензии
GNU, т.е. бесплатно.
Получение исходных кодов
На момент написания книги последняя стабильная версия пакета имела номер 1.0.1. Ее код
для операционных систем Linux, Solaris и др. можно получить на Web-узле poptop. lineo. com.
Там же имеются модули RPM, скомпилированные для платформы i386, и файлы “заплат” для
клиентов Windows.
Инсталляция
Загрузив исходные коды пакета, поместите их в начальный каталог, например /tmp
или /usr/local/src. Распакуйте tar-архив, перейдите в созданный каталог и выполни-
те приведенную ниже последовательность команд:
. / configure
make
make install
Если все прошло без ошибок, двоичные файлы пакета будут помещены в каталог
/us г/local/bin. Запуск демона pptpd разрешен только пользователю root.
136 Часть II. Средства и технологии маршрутизации в Linux
Конфигурирование и отладка
Чтобы правильно настроить работу пакета, нужно отредактировать три файла:
/etc/pptpd.conf,/etc/ppp/chap-secrets и/etc/ppp/options.
Текстовый файл /etc/ppp/chap-secrets содержит имя пользователя, пароль, имя
сервера и список разрешенных IP-адресов, от которых могут поступать запросы. В этот
файл можно добавить записи дополнительных пользователей.
Файл /etc/pptpd. conf содержит настройки демона pptpd. Здесь можно указывать
локальные и удаленные IP-адреса, скорости, на которых клиенты могут подключаться,
порты, прослушиваемые демоном, и уровень отладки. Если демон pptpd запускается в ре-
жиме регистрации событий, нужно перезапустить демон syslogd.
Наконец, файл /etc/ppp/options содержит настройки протокола РРТР.
На Web-узле poptop.lineo.com содержатся рекомендации по поводу конфигуриро-
вания пакета РоРТоР и настройки конкретных клиентов.
Коммерческие решения
Есть несколько коммерческих систем, позволяющих организовывать виртуальные ча-
стные сети. От открытых программ они отличаются в основном расширенными средст-
вами конфигурирования. Мы особо хотим отметить продукт NetMAX VPN Server. Это спе-
циализированный Linux-пакет, позволяющий быстро создать виртуальную частную сеть
на базе протокола IPSec. К нему прилагается клиентская Windows-программа. Недостаток
пакета заключается в том, что плата взимается за каждую инсталлированную копию кли-
ента и сервера. Нельзя купить одну копию сервера и установить ее на нескольких маши-
нах. Кроме того, отсутствует клиент для Linux, поэтому клиентские системы придется
конфигурировать вручную. С другой стороны, с этим пакетом удобно работать, а его цена
относительно невысока в сравнении с другими коммерческими решениями.
Резюме
В этой главе были вкратце рассмотрены изменения в ядре Linux версий 2.4.x, связан-
ные с маршрутизацией и работой в сети. Были также в общих чертах описаны средства,
позволяющие создавать виртуальные частные сети в Linux.
Глава 8. Средства маршрутизации в ядре версии 2.4.x 137
Сетевые команды
В этой главе...
Команда ifconfig 138
Команда route 143
Команда ping 145
Командаагр 146
Команда traceroute 148
Команда netstat 150
Команда tcpdump 152
Резюме 158
В Linux есть целый ряд команд, позволяющих осуществлять поиск неисправностей в
сети, конфигурировать сетевые интерфейсы и выполнять задачи, связанные с мар-
шрутизацией. Наиболее важные из них рассматриваются в данной главе: ifconfig,
route, ping, traceroute, arp, netstat и tcpdump. Все они, за исключением tcpdump,
входят в большинство дистрибутивов Linux.
Команда ifconfig
Команда ifconfig обслуживает сетевые интерфейсы на нижних уровнях модели OSI,
позволяя задавать тип передающей среды, скорость работы интерфейса и сетевые адреса.
Обычно команда находится в каталоге /sbin, и запускать ее могут непривилегированные
пользователи. Но менять конфигурацию интерфейсов разрешено только суперпользова-
телю. В большинстве версий Linux команда ifconfig входит в пакет net-tools, кото-
рый можно получить по адресу http: //www. tazenda. demon. co. uk/phil/net-tools.
Функции, выполняемые командой ifconfig, можно разделить на две группы: выдача
статистики работы интерфейсов и конфигурирование интерфейсов.
Отчет о состоянии интерфейсов
Команда if conf ig часто используется при поиске неисправностей в сети, так как по-
зволяет получить отчет о состоянии сетевых интерфейсов. Даже будучи вызванной без ар-
гументов, она выдает очень полезную информацию:
[root@lefty /sbin]# /sbin/ifconfig
ethO Link encap:Ethernet HWaddr 00:E0:29:4B:AC:0C
inet addr:192.168.1.254 Beast: 192.168.1.255
'ЪMask: 255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:9833 errors:0 dropped:0 overruns:0 frame:0
TX packets:10195 errors:0 dropped:0 overruns:0 carrier:0
collisions:306 txqueuelen:100
Interrupt:10 Base address:0xb800
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:3924 Metric:1
RX packets:18 errors:0 dropped:0 overruns:0 frame :0
TX packets:18 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
Команда сообщила обо всех интерфейсах, известных ядру. Взглянув на описание ин-
терфейса ethO, легко определить, что это — Ethernet-плата. В первой строке показан ее
МАС-адрес (48 битов), во второй — IP-адрес, широковещательный адрес и сетевая маска.
В третьей строке говорится о том, что интерфейс запущен (UP), т.е. может посылать и
принимать трафик, работает в широковещательном режиме (стандарт для сетей Ethernet)
и может принимать многоадресный трафик. Максимальный размер передаваемого блока
(maximum transmission unit — MTU) равен 1500 байтам, что составляет стандартный Eth-
ernet-кадр. Это предельный размер пакетов, передаваемых через данный интерфейс. Если
администратор вручную задаст меньшее значение, то это повлияет только на исходящие
пакеты, т.е. при получении пакетов система по-прежнему будет ориентироваться на зна-
чение параметра MTU, принятое для сети данного типа. Предельные размеры пакетов в
различных сетях перечислены в табл. 9.1.
Таблица 9.1. Максимальные размеры пакетов в сетях различных типов
Тип сети MTU
Ethernet 1500
FDDI 4352
РРР 1500
SLIP 1006
Token Ring 4464
В строках 4-6 отображается статистика работы интерфейса. Отношение числа колли-
зий к числу отправленных пакетов достаточно велико. Возможно, это говорит о несогла-
сованности работы полудуплексного порта Linux-маршрутизатора и полнодуплексного
порта Ethernet-платы. В последней строке сообщается о ресурсах, используемых драйве-
ром сетевой платы. В данном случае это прерывание 10 и сегмент памяти, начинающийся
с адреса 0хЬ800.
Приведенное описание сетевой платы весьма типично, так как технология Ethernet
очень популярна. Но в Linux поддерживаются и другие сетевые технологии.
Глава 9. Сетевые команды 139
Типы сетевых интерфейсов
В табл. 9.2 перечислены типы сетевых интерфейсов, поддерживаемых в операционной
системе Linux.
Таблица 9.2. Типы сетевых интерфейсов, поддерживаемых в Linux, и их обозначения в команде ifconfig
Тип Обозначение
Adaptive Serial Line IP adaptive
Amateur NET /ROM netrom
Amateur ROSE rose '
Amateur X.25 ax25
ARCnet arcnet
Ash ash
Cisco HDLC hdlc
Compressed Serial Line IP cslip
Compressed Serial Line IP 6 bit cslip6
Econet ec
Ethernet ether
Fiber Distributed Data Interface fddi
Frame Relay Access Device f rad
Frame Relay DLCI dlci
High-Performance Parallel Interface hippi
IP in IP Tunneling tunnel
IPv6 in IPv4 Tunneling sit
IrLAP irda
LAPB lapb
Локальная сеть обратной связи loop
Point-to-Point Protocol PPP
Serial Line IP slip
Serial Line IP 6 bit slip6
Token Ring tr
Остановимся чуть подробнее на некоторых типах.
Тип slip
SLIP (Serial Line Internet Protocol — межсетевой протокол для последовательного кана-
ла) используется при соединении двух систем последовательными линиями, но в настоя-
щее время в основном вытеснен протоколом РРР. В Linux поддерживается и другая разно-
видность этого протокола — CSLIP, в которой используется сжатие по методу Ван Джей-
кобсона (Van Jacobson), описанное в документе RFC1144. Следует также упомянуть вариан-
ты SLIP6 и CSLIP6.
Тип ррр
Протокол РРР — это стандарт де-факто для соединений, устанавливаемых через после-
довательные линии связи. Однако он находит применение и в других типах сетей. Напри-
мер, с его помощью реализуется передача IP-пакетов по сетям SONET. О протоколе РРР
см. в главе 7, “Вспомогательные демоны”.
140 Часть II. Средства и технологии маршрутизации в Linux
Тип tunnel
Протокол IPIP (IP over IP) часто применяется для соединения автономных сетей тран-
зитной сетью-туннелем. С его помощью можно также создавать виртуальные частные сети.
Тип loop
Логические интерфейсы обратной связи существуют для того, чтобы приложения
могли получать доступ к сервисам, расположенным на локальном узле, не обращаясь к фи-
зическим интерфейсам.
Типы адресов
Если снова обратиться к отчету, выданному командой ifconfig, то можно заметить,
что все приведенные в нем IP-адреса записаны в стандарте IPv4. В Linux поддерживаются
и другие типы адресов. Некоторые из них перечислены в табл. 9.3.
Таблица 9.3. Типы адресов, поддерживаемых в Linux, и их обозначения в команде
ifconfig
Протокол Обозначение
IPv6 inet6
Amateur Radio Х.25 ax25
Internetwork Packet Exchange ipx
AppleTalk Datagram Delivery Protocol ddp
Конфигурирование интерфейсов
Команда ifconfig позволяет менять параметры сетевых интерфейсов. Она обычно
выполняется во время начальной загрузки системы, но может применяться и для динами-
ческого изменения конфигурации сети. Такие изменения будут иметь силу до того момен-
та, пока не произойдет перезагрузка системы. Чтобы установки сохранялись постоянно,
соответствующие команды нужно поместить в сценарии начальной загрузки (этот процесс
здесь не показан). Будьте осторожны: в случае ошибки компьютер может оказаться отклю-
ченным от сети.
Подключение и отключение интерфейсов
Чаще всего команда ifconfig применяется для активизации и отключения интерфей-
сов. Например, следующая команда отключает интерфейс ethO:
[root@lefty /root]# ifconfig ethO down
А эта команда снова включает его:
[root@lefty /root]# ifconfig ethO down
Изменение IP-адресов
С помощью команды ifconfig можно назначить интерфейсу новый IP-адрес, например:
[root@lefty /root]# ifconfig ethO 192.168.1.253
Разрешается также менять сетевую маску:
[rootOlefty /root]# ifconfig ethO 192.168.1.253 mask 255.255.255.248
Глава 9. Сетевые команды 141
Назначение интерфейсу нескольких IP-адресов
Одному физическому интерфейсу может соответствовать несколько IP-адресов. Для
этого вводится понятие виртуального, или логического, интерфейса. Правило именования
виртуальных интерфейсов таково: берется имя физического интерфейса и через двоето-
чие к нему добавляется логический номер, например ethO: 1.
Следующая команда создает новый виртуальный интерфейс:
[root@lefty /root]# ifconfig ethO:1 192.168.1.250 mask
^255.255.255.240
В результате за интерфейсом ethO:1 будет закреплен адрес 192.168.1.250, а сам ин-
терфейс будет активизирован. Давайте посмотрим, что получилось в результате:
[root@lefty /root]# ifconfig
ethO Link encap:Ethernet HWaddr 00:E0:29:4B:AC:0C
inet addr:192.168.1.254 Beast:192.168.1.255
^Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:!
RX packets:169 errors:0 dropped:0 overruns:0 frame:0
TX packets:125 errors:0 dropped-.O overruns:0 carrier:0
collisions:0 txqueuelen:100
Interrupt:10 Base address:0xb800
ethO:1 Link encap:Ethernet HWaddr 00:E0:29:4B:AC:0C
inet addr:192.168.1.250 Beast:192.168.1.255
^Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:!
Interrupt:10 Base address:0xb800
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:3924 Metric:!
RX packets:18 errors:0 dropped:0 overruns:0 frame:0
TX packets:18 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
Необходимо помнить об ограничениях виртуальных интерфейсов. Во-первых, как
видно из результатов работы команды ifconfig, статистика выдается только по физиче-
скому интерфейсу, в данном случае ethO. Во-вторых, при отключении физического ин-
терфейса отключаются и все его виртуальные интерфейсы, т.е. команда
ifconfig ethO down
эквивалентна команде
ifconfig eth0:l down
Когда виртуальный интерфейс неактивен, он не отображается в результатах работы
команды ifconfig.
Задание типа передающей среды
Сети Ethernet могут создаваться на основе различных кабельных систем, требующих
разных сетевых плат. Например, в стандарте 10Base2 (10 Мбит/с) используется коакси-
альный кабель и BNC-коннекторы. В стандарте lOBaseT (10 Мбит/с) используется витая
пара и разъем RJ-45. Различные варианты технологии Ethernet, поддерживаемые в Linux,
описаны в табл. 9.4.
142 Часть II. Средства и технологии маршрутизации в Linux
Таблица 9.4. Поддерживаемые варианты Ethernet
Стандарт Скорость Среда Разъем
10Base2 10 Мбит/с Тонкий коаксиальный кабель BNC
10Base5 10 Мбит/с Толстый коаксиальный кабель AUI, подключаемый к MAU
lOBaseT 10 Мбит/с Витая пара RJ-45
lOOBaseT 100 Мбит/с Витая пара RJ-45
Обычно не возникает необходимости задавать тип среды, поскольку современные се-
тевые платы и драйверы определяют его автоматически на этапе начальной загрузки. Но
бывают и исключения.
Предположим, плата поддерживает соединения RJ-45 и AUI, и есть подозрение, что
соединение RJ-45 не функционирует. Исправить ситуацию позволяет следующая команда:
(rootSlefty /root]# ifconfig ethO medi lObaseT
Прочие параметры
Мы описали далеко не все параметры команды ifconfig, так как многие из них ис-
пользуются крайне редко. Тем не менее о некоторых параметрах нужно упомянуть хотя бы
вкратце.
Режим группового вещания можно отключить с помощью опции -allmulti. Опция
promise переводит интерфейс в “беспорядочный” режим, а опция -promise отключает
этот режим. Данный режим представляет интерес для разработчиков сетевых приложе-
ний. В этом режиме работают многие анализаторы пакетов, например команда tcpdump,
рассматриваемая ниже. “Беспорядочный” режим рекомендуется включать лишь на корот-
кие промежутки времени, так как производительность работы интерфейса снижается.
Параметр metric позволяет назначать приоритеты интерфейсам, находящимся в одной
сети. Эта возможность требует поддержки со стороны драйверов и демонов маршрутизации.
Опция mtu позволяет администраторам менять значение параметра MTU (максималь-
ный размер передаваемого блока). Время от времени публикуются разные методики по-
вышения производительности путем регулирования данного параметра, но их практиче-
ская польза сомнительна. Обычно менять параметр MTU нужно лишь в том случае, когда в
сети возникают проблемы с предварительным определением максимального размера бло-
ка (из-за наличия разных типов сред).
Опция broadcast позволяет указывать другой широковещательный адрес, чем тот,
что определяется на основании IP-адреса и маски интерфейса.
Команда route
Команда route предназначена для доступа к маршрутным таблицам ядра. Она может
работать в трех режимах: отображение, добавление и удаление.
Отображение информации о маршрутах
Будучи вызванной без параметров, команда route отображает содержимое таблицы
маршрутизации:
[root@lefty /root]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
lefty * 255.255.255.255 UH 0 00 ethO
192.168.1.0 * 255.255.255.0 U 0 00 ethO
127.0.0.0 * 255.0.0.0 U 0 0 0 lo
default 192.168.1.1 0.0.0.0 UG 0 0 0 ethO
Глава 9. Сетевые команды 143
Собственно маршрут определяется значениями в столбце Destination (IP-адрес) и
Genmask (маска сети). В столбце Gateway указан шлюз для доступа в данную сеть. Флаги,
приведенные в поле Flags, задают способ интерпретации маршрутной записи. Возмож-
ные флаги перечислены в табл. 9.5.
Таблица 9.5. Флаги команды route
Флаг Описание
1 Маршруты, полученные из данной сети, отвергаются
А Маршрут, добавленный протоколом конфигурирования адресов IPv6
(http://www.ietf.cnri.reston.va.us/proceedings/95apr/charters/addrconf
-charter.html)
С Кэшированная запись
D Маршрут, созданный демоном или в результате переадресующего ICMP-запроса
G Трафик, идущий по данному маршруту, проходит через шлюз, указанный в столбце Gateway
м Маршрут, модифицированный демоном или в результате переадресующего ICMP-запроса
U Маршрут, созданный и используемый ядром
Команда route без аргументов эквивалентна команде netstat -г, которая рассмат-
ривается далее в главе.
Опция -С
При наличии опции -С отображается информация о кэшированных маршрутных за-
писях и непосредственно подключенных узлах. Это позволяет узнать, какие маршруты ак-
тивны и используются в настоящее время. Приведем пример:
[root@lefty /root]# route -С
Kernel IP routing cache
Source Destination Gateway Flags Metric Ref Use If ace
lefty host4.some.com 192.168.1.1 0 0 10 ethO
lefty 192.168.1.102 192.168.1.102 0 2 4 ethO
lefty host4.some.com 192.168.1.1 0 0 10 ethO
В каждой строке показан исходный адрес, адрес получателя и шлюз, через который
должен проходить трафик. Обратите внимание на вторую строку, в которой адреса полу-
чателя и шлюза одинаковы. Это указывает на непосредственно подключенный узел.
В столбце Use показано количество пакетов, отправленных по данному маршруту, а в
столбце If асе указан физический интерфейс локального узла, через который проходит
соответствующий трафик.
Опция -п
Опция —п запрещает команде route осуществлять поиск доменных имен.
Опция -V
Первоначально эта опция заставляла команду route выдавать расширенную информа-
цию, например сообщать о сетевой маске. Но современные версии команды по умолча-
нию работают в таком режиме.
Опция -V
При наличии опции -V команда route сообщает свою версию и версию пакета net-
tools, а также выдает перечень поддерживаемых протоколов.
[root@lefty /root] route -v
net-tools 1.54
route 1.96 (1999-01-01)
144 Часть II. Средства и технологии маршрутизации в Linux
+NEW_ADDRT +RTF_IRTT +RTF_REJECT + I18N
AF: (inet) +UNIX +INET +INET6 + IPX +AX25 +NETROM +ATALK +ECONET +ROSE
HW: +ETHER +ARC +SLIP +PPP +TUNNEL +TR +AX25 +NETROM +FR +ROSE +ASH
+SIT +FDDI +HIPPI +HDLS/LAPB
Добавление маршрутов
Основное достоинство команды route заключается в возможности добавления стати-
ческих маршрутов в таблицу ядра. Команда, добавляющая маршрут, имеет такой формат:
route add -net адрес_получателя netmask маска gw шлюз
Вот как, к примеру, можно перенаправить весь трафик, адресованный сети
10.1.1.0/24, на шлюз 192.168.1.253:
[root@lefty /root]# route add -net 10.1.1.0 netmask 255.255.255.0
4>gw 192.168.1.253
Если требуется добавить маршрут к конкретному узлу, нужно воспользоваться опцией
-host, а не -net, и опустить опцию netmask:
[rootOlefty /root]# route add -host 192.168.1.200 gw 192.168.1.1
Этот маршрут будет отображаться в таблице следующим образом:
[rootOlefty /root]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use I face
192.168.1.200 192.168.1.1 255.255.255.255 UGH 000 ethO
В PPP-сетях иногда требуется создать маршрут, проходящий не через шлюз, а через се-
тевой интерфейс:
[rootOlefty /root]# route add -net 10.10.10.0 netmask 255.255.255.0 pppO
Команда ping
Команда ping сообщает о том, доступен ли заданный узел. Она посылает эхо-запрос
ICMP удаленному узлу, который должен вернуть эхо-ответ ICMP. Поскольку с помощью
данной команды можно легко выяснить структуру сети, многие сетевые фильтры и бранд-
мауэры удаляют ICMP-пакеты в целях безопасности.
Команда ping входит в пакет iputils, который можно получить по адресу
ftp: //ftp.sunet.se/pub/Linux/ip-routing. Этот пакет поставляется с большинст-
вом дистрибутивов Linux.
Опция -d
С помощью опции -d можно получить дополнительную отладочную информацию, вы-
даваемую командой ping. Будут, например, показываться ICMP-сообщения о недоступно-
сти сети.
Опция -f
Опцию -f нужно использовать осторожно, так как она заставляет команду ping посы-
лать столько эхо-запросов, сколько позволяет пропускная способность сети. С помощью
этой опции можно имитировать состояние перегруженности сети.
Глава 9. Сетевые команды 145
Опция -i
Обычно команда ping ждет одну секунду, прежде чем посылать следующий эхо-запрос.
Опция -i интервал позволяет задать больший интервал ожидания (в секундах).
Опция -S
Посредством опции -з размер задается размер ICMP-пакетов, который по умолча-
нию составляет 64 байта. В сочетании с командой tcpdump (она рассматривается ниже)
это позволяет проверить, осуществляется ли фрагментация 1Р-дейтаграмм.
Опция -I
Опция -I интерфейс заставляет команду ping посылать эхо-запросы через указанный
интерфейс. Это полезно, если в системе имеется несколько интерфейсов и, таким обра-
зом, существует несколько маршрутов к получателю.
Команда агр
ARP (Address Resolution Protocol — протокол преобразования адресов) транслирует
IP-адреса в аппаратные МАС-адреса. Знать особенности этого протокола важно, чтобы
понимать, как работает команда агр. Когда компьютер хочет послать трафик по конкрет-
ному IP-адресу, он сверяет этот адрес со своим собственным адресом и маской, чтобы оп-
ределить, находится ли получатель в непосредственно подключенной сети. Если это не
так, компьютер обращается к маршрутной таблице и находит шлюз, ведущий к получате-
лю. Далее формируется широковещательный ARP-запрос who-has, в который включают-
ся исходные IP-адрес и маска, а также IP-адрес шлюза. Этот запрос рассылается через со-
ответствующий сетевой интерфейс и принимается всеми компьютерами данного широко-
вещательного домена. Тот компьютер, который узнает свой IP-адрес, возвращает
отправителю свой аппаратный МАС-адрес. Это позволяет компьютерам устанавливать со-
единения на канальном уровне.
В протоколе ARP формируется специальная кэш-таблица с результатами последних за-
просов. Доступ к этой таблице осуществляется посредством команды агр. Как и команда
ifconfig, она является частью пакета net-tools (http://www.tazenda.demon.co.
uk/phil/net-tools).
Будучи вызванной без параметров, команда отображает текущее содержимое таблицы:
[root@lefty /root]# агр
Address HWtype HWaddress Flags Mask Iface
192.168.1.1 ether 00:20:78:CF:3D:66 C ethO
speedy ether 00:40:DO:08:6A:72 C ethO
Показывается IP-адрес, тип сетевого интерфейса, МАС-адрес и интерфейс, из которого
была получена эта информация. Раньше сообщалась также маска, но теперь она не использу-
ется. Флаг С говорит о том, что запись является полной, т.е. аппаратный адрес определен.
Так бывает не всегда. Иногда в таблице присутствуют неполные записи, например:
[root@lefty /root]# агр
Address HWtype HWaddress Flags Mask Iface
192.168.1.5 (incomplete) ethO
192.168.1.1 ether 00:20:78:CF:3D:66 C ethO
speedy ether 00:40:DO:08:6A:72 C ethO
146 Часть II. Средства и технологии маршрутизации в Linux
Опция -а
При наличии опции -а узел команда агр выдаст информацию только о заданном уз-
ле. Можно указать либо имя узла, либо его IP-адрес. Следующая команда сообщает о том,
какой МАС-адрес соответствует IP-адресу 192.168.1.100:
[root@lefty /root]# агр -а 192.168.1.100
Address HWtype HWaddress Flags Mask Iface
192.168.1.100 ether 00:20:58:CC:66:3D C ethO
С помощью этой команды можно легко узнать, какие компьютеры в сети сконфигури-
рованы неправильно, т.е. имеют одинаковый IP-адрес, но разные МАС-адреса.
Опция -Н
Параметр -Н тип заставляет команду агр выдавать записи, относящиеся только к се-
тевым интерфейсам определенного типа. Например, приведенная ниже команда сообща-
ет обо всех Ethernet-записях:
[root@lefty /root]# агр -Н ether
Address 192.168.1.1 speedy HWtype HWaddress Flags Mask Iface ether 00:20:78:CF:3D:66 C ethO ether 00:40:DO:08:6A:72 C ethO
Вот что будет выдано при попытке узнать о записях Token Ring:
[root@lefty net]# агр -H tr
агр: in 2 entries no match found
Команда агр поддерживает те же типы сетевых интерфейсов, что и команда
ifconfig (см. табл. 9.2).
Опция -i
Команда агр может сообщить обо всех записях, полученных через заданный интер-
фейс. Для этого предназначена опция -i интерфейс.
[root@righty /root]# агр -i ethl
Address HWtype HWaddress Flags Mask Iface
10.1.1.4 ether 00:40:68:CF:33:22 C ethl
blue ether 00:40:D7:08:6A:52 C ethl
Опция -n
Опция -n отключает преобразование IP-адресов в доменные имена. Рассмотрим вы-
полнение команды без этой опции:
[root@lefty /root]# агр
Address HWtype HWaddress Flags Mask Iface
192.168.1.1 ether 00:20:78:CF:3D:66 C ethO
speedy ether 00:40:DO:08:6A:72 C ethO
Как видите, во второй строке отображается имя speedy, а не IP-адрес. Теперь зададим
опцию -п:
[root@lefty /root]# агр -п
Address HWtype HWaddress Flags Mask Iface
192.168.1.1 ether 00:20:78:CF:3D:66 C ethO
192.168.1.101 ether 00:40:DO:08:6A:72 C ethO
Глава 9. Сетевые команды 147
Опция -d
Иногда вследствие возникших проблем требуется удалить запись из ARP-таблицы. На-
пример, может оказаться, что два компьютера используют один и тот же IP-адрес или ка-
кая-то сетевая плата работает неправильно. Для удаления записей предназначена опция
-d узел. Следующая команда удаляет запись узла speedy:
[root@lefty /root]# arp -d speedy
Посмотрим на полученную таблицу:
[root@lefty /root]# arp
Address HWtype HWaddress Flags Mask Iface
192.168.1.1 ether 00:20:18:CF:3D:66 C ethO
Бывают ситуации, когда необходимо очистить всю таблицу. Приведенный ниже сце-
нарий darpcache решает поставленную задачу.
# !/bin/bash
# darpcache
# Этот сценарий удаляет все записи из ARP-кэша
for host in 'arp -n | awk ’{print $1}’ | grep -v Address'
do
echo "Deleted entry for host: $host"
arp -d $host+
done
Результаты работы сценария будут примерно такими:
[root@lefty /root]# ./darpcache
Deleted entry for host: 192.168.1.1
Deleted entry for host: 192.168.1.101
Протокол RARP
Назначение RARP (Reverse ARP — обратный протокол ARP) заключается том, чтобы
позволить компьютеру осуществить поиск своего IP-адреса путем широковещательной
рассылки МАС-адреса. Ответ на этот запрос будет получен от центрального сервера В на-
стоящее время RARP практически вытеснен более новым протоколом DHCP (Dynamic
Host Configuration Protocol — протокол динамического конфигурирования узлов), кото-
рый позволяет сообщать компьютеру не только его IP-адреса, но и другую конфигураци-
онную информацию, например адрес сервера имен. Протокол DHCP широко поддержи-
вается во многих системах.
Таблицей протокола RARP управляет команда гагр.
Команда traceroute
Команда traceroute чрезвычайно широко применяется при поиске неисправностей
в сетях. Она показывает путь от исходного узла (Linux-машины, на которой была введена
команда) к адресату.
Алгоритм работы команды таков. Она посылает по указанному адресу UDP-пакет, вре-
мя жизни которого (поле TTL) равно 1. Первый же маршрутизатор, получивший такой
пакет, уменьшит значение TTL на 1 и обнаружит, что пакет устарел. Тогда он вернет от-
правителю ICMP-сообщение time exceeded и удалит пакет. Суть в том, что в ICMP-
сообщении приводится адрес маршрутизатора. Команда traceroute отображает этот ад-
рес и формирует следующий пакет, в котором поле TTL равно уже 2.
148 Часть II. Средства и технологии маршрутизации в Linux
Первый маршрутизатор уменьшает значение TTL на единицу и пересылает пакет
дальше. Второй маршрутизатор удаляет пакет и генерирует описанное выше ICMP-сооб-
щение. Так продолжается до тех пор, пока не будет достигнут заданный адресат. При этом
поле TTL будет равно числу переходов.
Опция -d
Опция -d включает отображение дополнительной отладочной информации. Иногда
это помогает обнаруживать проблемы в сети. Например, следующая команда сообщает о
том, что либо возникли проблемы с маршрутизацией (сеть недоступна), либо интерфейс,
через который осуществляется доступ в заданную сеть, перестал работать.
[root@lefty /root]# traceroute -d host.anydomain.com
traceroute to host.anydomain.com (192.168.100.100), 30 hops max,
4>38 byte packets
traceroute: sendto: Network is unreachable
1 traceroute: wrote host.anydomain.com 38 chars, ret=-l
Опция -f
Опция -f ttl заставляет команду traceroute начать отсчет поля TTL с указанного
значения, а не с единицы. Это может понадобиться, если брандмауэр не отвечает на паке-
ты команды traceroute, но пропускает их во внешний мир.
Опция -F.
Опция -F запрещает осуществлять фрагментацию дейтаграмм (пакеты отправляются с
установленным флагом DF). Маршрутизатор, получивший такой пакет, удалит его, если
размер пакета окажется больше, чем параметр MTU сетевого интерфейса, через который
он должен быть переслан.
Опция -i
Иногда требуется указать, через какой локальный интерфейс команда trace route
должна посылать свои пакеты. Для этого предназначена опция -i интерфейс.
Опция -I
Как уже говорилось выше, команда traceroute посылает UDP-пакеты. Но если задать
опцию -I, вместо UDP-пакетов будут использоваться эхо-запросы ICMP. Это может ока-
заться полезным, если брандмауэр не пропускает UDP-трафик, но разрешает ICMP-
запросы. В результате команда trace route начнет функционировать подобно команде
tracert, применяющейся для аналогичных целей в Windows. В остальном алгоритм ра-
боты остается прежним.
Опция -п
Опция -п отключает преобразование IP-адресов в доменные имена. Обычно это уско-
ряет работу команды traceroute, особенно в случае, когда сервер имен недоступен. В
противном случае на каждом переходе команда будет пытаться определить имя соответст-
вующего узла.
Опция -ш
Опция -т число_переходов задает предельное число переходов, по достижении ко-
торого команда traceroute прекратит свою работу.
Глава 9. Сетевые команды 149
[root@lefty /root]# traceroute -m 3 host.somedomain.com
traceroute to host.somedomain.com (192.168.50.50), 3 hops max, 38
4>byte packets
1 gw4.ispl.net (192.168.14.2) 39.331 ms 33.990 ms 51.079 ms
2 router3.isp2.net (10.1.1.254) 25.888 ms 31.675 ms 25.988 ms
3 router5.isp2.net (10.5.5.254) 25.296 ms 26.012 ms 26.335 ms
Опция -t
Опция -t тип_обслуживания задает требуемый тип обслуживания IP-пакетов. В на-
стоящее время эта технология применяется в основном только при передаче по сети го-
лосовых данных.
Известные недостатки
Команда traceroute — это очень полезное средство поиска неисправностей в сети.
Но ей не всегда можно доверять, так как на ее работу могут влиять различные факторы.
В сложных сетях к адресату может вести несколько маршрутов. Как следствие, возни-
кают ситуации, когда ICMP-ответ возвращается не тем путем, по которому прошел исход-
ный UDP-пакет.
Кроме того, команда tracerout£ может применяться в защищенных сетях, где
брандмауэр не пропускает UDP-трафик из соображений безопасности. Но даже если UDP-
трафик разрешен, конкретный пакет может быть удален, если он не прошел все правила
проверки.
Команда netstat
Команда netstat отображает информацию о состоянии сетевого программного обес-
печения на локальном узле. Чаще всего она используется с аргументом - г, задающим ото-
бражение таблицы маршрутов:
[root@lefty /root]# netstat -r
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
lefty ★ 255.255.255.255 UH 0 0 0 ethO
192.168.1.0 * 255.255.255.0 U 0 0 0 ethO
127.0.0.0 255.0.0.0 U 0 0 0 lo
default 192.168.1.1 0.0.0.0 UG 0 0 0 ethO
Опция -а
Опция -а заставляет команду netstat отобразить информацию обо всех сокетах, от-
крытых на локальном узле. Учитываются также все демоны, прослушивающие сетевые
порты.
[root@lefty /root]# netstat -а
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 138 lefty:telnet 192.168 1.102:1062 ESTABLISHED
tcp 0 0 * : WWW LISTEN
tcp 0 0 * : snmp * • * LISTEN
tcp 0 0 *:printer LISTEN
tcp 0 0 *: linuxconf * . * LISTEN
tcp 0 0 *:finger * . * LISTEN
tcp 0 0 *:login ★ • it LISTEN
tcp 0 0 *:shell it . It LISTEN
tcp 0 0 *:telnet * . * LISTEN
tcp 0 0 *: f tp ★ • h LISTEN
tcp 0 0 *:auth * . * LISTEN
150 Часть II. Средства и технологии маршрутизации в Linux
tcp 0 0 *:980 * * LISTEN
tcp 0 0 *:1024 * * LISTEN
tcp 0 0 *:sunrpc * * LISTEN
udp 0 0 *:ntalk * *
udp 0 0 *:talk * *
udp 0 0 *:978 * ★
udp 0 0 *:1024 *
udp 0 0 *:sunrpc * *
raw 0 0 *:icmp * * 7
raw 0 0 * : tcp * * 7
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-node Path
unix 0 [ ACC ] STREAM LISTENING 474 /dev/printer
unix 0 [ ACC ] STREAM LISTENING 573 /trap/.font-unix/fs-1
unix 7 [ ] DGRAM 380 /dev/log
unix 0 [ ACC ] STREAM LISTENING 531 /dev/gpmctl
unix 0 [ ] DGRAM 13679
unix 0 [ ] DGRAM 843
unix 0 [ ] DGRAM 576
unix 0 [ ] DGRAM 518
unix 0 [ ] DGRAM 468
unix 0 [ ] DGRAM 402
unix 0 [ ] DGRAM 390
В столбце Proto указан протокол, по которому ведется работа с портом. Возможные
значения таковы: top (TCP-сокеты), udp (UDP-сокеты) и raw (неструктурированные соке-
ты). В столбце Recv-Q приведено число пакетов, принятых ядром, но еще не прочитан-
ных демоном, прослушивающим данный порт. В столбце Send-Q отображается число па-
кетов, для которых ожидается подтверждение от удаленного узла.
В столбце Local Address показаны IP-адрес локального узла и логическое имя порта.
В рассмотренном выше примере первая запись соответствует сеансу telnet. Если вместо IP-
адреса стоит звездочка, то это означает, что демон прослушивает все сетевые интерфейсы.
В поле Foreign Address отображаются IP-адрес удаленного узла и порт, с которым
установлено соединение. В случае сеанса telnet удаленный клиент работает с портом
1062 (локальному клиенту соответствует стандартный порт 23).
Столбец State применим только к TCP-соединениям и сообщает о состоянии соедине-
ния: CLOSING, CLOSED, CLOSE_WAIT, ESTABLISHED, FIN_WAIT1, FIN_WAIT2, LAST_ACK,
LISTEN, SYN_SENT, SYN_RECV, TIME_WAIT.
Во второй части списка приводится таблица локальных сокетов, доступ к которым
осуществляется через драйверы устройств, а не через демоны.
Опция -1
С помощью опции -1 можно определить, какие порты прослушиваются на локальном
узле. Результат будет эквивалентен команде netstat -а, за исключением того, что исхо-
дящие соединения, устанавливаемые пользователями, не отображаются.
Опция -р
Опция -р позволяет узнать, какой процесс работает с тем или иным портом.
[root@lefty /root]# netstat -а
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
4>PID/Program name
tcp 0 0 *:www *:* LISTEN
4>602/httpd
tcp 0 0 *: snmp *:* LISTEN
4>571/sendmail: accep
Глава 9. Сетевые команды 151
tcp 0 0 *:printer *:* LISTEN
4>527/lpd
tcp 0 4>513/inetd 0 *:linuxconf *:* LISTEN
tcp 0 4>513 /inetd 0 *:finger *:* LISTEN
tcp 0 4>513/inetd 0 *:login *:* LISTEN
tcp 0 4>513/inetd 0 *:shell *:* LISTEN
tcp 0 4>513/inetd 0 *:telnet *:* LISTEN
tcp 0 ^513/inetd 0. * : f tp * : * LISTEN
tcp 0 4>463 /identd 0 *:auth *:* LISTEN
tcp 0 ^375/rpc.statd 0 *:980 *:* LISTEN
tcp 0 V 0 *:1024 *:* LISTEN
tcp 0 ^350/portmap 0 *:sunrpc *:* LISTEN
udp 0 4>513 /inetd 0 *:ntalk *:*
udp 0 4>513/inetd 0 *:talk * : *
udp 0 4>375/rpc. statd 0 *:978 *:*
udp 0 V 0 *:1024 *:*
udp 0 ^350/portmap 0 * : sunrpc * : *
raw 0 V 0 *:icmp *:* 7
raw 0 V 0 *:tcp * : * 7
Active UNIX domain sockets (only servers)
Proto RefCnt Flags Type State I-node PID/Program name
4>Path Unix 0 [ ACC ] STREAM LISTENING 474 527/lpd
'b/dev/printer Unix 0 [ ACC ] STREAM LISTENING 573 645/xfs
^/tmp/ . f ont-unix/f s- Unix 0 [ ACC ] -1 STREAM LISTENING 531 586/gpm
'b/dev/gpmctl
Команда tcpdump
Описанные выше команды входят практически во все дистрибутивы Linux. А вот ко-
манда tcpdump, несмотря на свою популярность, существует отдельно. Ее исходные коды
можно найти на Web-узле www. tcpdump . org. Для работы команды требуется библиотека
libpcap, которая доступна там же.
Команда tcpdump относится к классу утилит, называемых анализаторами пакетов. Она
инсталлируется на Linux-узлах, выполняющих функции маршрутизации, и является вели-
колепным средством слежения за трафиком.
152 Часть II. Средства и технологии маршрутизации в Linux
Анализаторы пакетов и безопасность
Некоторые специалисты в области компьютерной безопасности осуждают практику размещения
анализаторов пакетов на маршрутизаторах, полагая, что это открывает дополнительные возмож-
ности хакеру, взломавшему маршрутизатор. Однако хакеру, взломавшему маршрутизатор, ничего
не мешает поместить на него собственный анализатор пакетов! В любом случае, работая с
анализаторами, никогда не следует забывать о безопасности.
Если команда tcpdump запускается без аргументов, она переводит все локальные ин-
терфейсы в “беспорядочный” режим и записывают информацию обо всех входящих и ис-
ходящих пакетах в поток stdout, т.е. чаще всего на терминал. Обычно в столь детальной
информации нет никакой необходимости. С помощью опций командной строки нужно
ограничить поток анализируемых пакетов, оставив только полезные сведения.
Опция -i
С помощью опции -1 интерфейс можно заставить команду tcpdump перехватывать
пакеты только указанного интерфейса, например ethl:
[root@lefty /root]# tcpdump -i ethl
Kernel filter, protocol ALL, datagram packet socket
tcpdump: listening on ethl
Прежде чем знакомиться с остальными опциями, давайте проанализируем отдельную
строку, выдаваемую командой:
11:22:53.138977 < 192.168.1.101.1041 > 192.168.1.254.telnet: .
Ъ0:0(0) ack 288 win 7479 (DF)
В первом поле указана метка времени, к которой добавлен порядковый номер. Далее
стоит символ, обозначающий направление пакета: < — входящий, > — исходящий. В дан-
ном случае пакет является входящим. Затем указаны IP-адрес и номер порта (1041) отпра-
вителя пакета, а после символа > — IP-адрес и порт (telnet) получателя. Обозначение DF
говорит о том, что для пакета установлен флаг запрета фрагментации.
Опция -п
Опция -п запрещает осуществлять преобразование IP-адресов в доменные имена.
Обычно эта опция необходима, так как в ее отсутствие создается повышенная нагрузка на
компьютер и сеть, ведь команда tcpdump будет пытаться проанализировать адрес каждого
пакета. Приведем пример совместного использования опций -п и -1:
[root@lefty /root]# tcpdump -i ethO -n
Kernel filter, protocol ALL, datagram packet socket
tcpdump: listening on ethO
11:22:52.739123 < 192.168.1.101.1041 > 192.168.1.254.telnet: .
«537 68 648:37 68 648(0) ack 2572562729 win 7766 (DF)
11:22:52.739231 < 192.168.1.254.telnet > 192.168.1.101.1041: P
«51:82(81) ack 0 win 32120 (DF)
11:22:52.939102 < 192.168.1.101.1041 > 192.168.1.254.telnet: .
«50:0(0) ack 82 win 7685 (DF)
11:22:52.939142 < 192.168.1.254.telnet > 192.168.1.101.1041: P
«582:288 (206) ack 0 win 32120 (DF)
11:22:53.138977 < 192.168.1.101.1041 > 192.168.1.254.telnet: .
«50:0(0) ack 288 win 7479 (DF)
11:22:53.139013 < 192.168.1.245.telnet > 192.168.1.101.1041: P
«5288:477(189) ack 0 win 32120 (DF)
6 packets received by filter
Глава 9. Сетевые команды 153
Опция -q
Опция -q переводит команду tcpdump в “бесшумный” режим, в котором пакет анали-
зируется на транспортном уровне (протоколы TCP, UDP и ICMP), а не на сетевом
(протокол IP). Для каждого пакета будет сообщаться только основная протокольная ин-
формация. Рассмотрим пример трафика утилиты telnet (протокол TCP):
[root@lefty /root]# tcpdump -i ethO -nq
Kernel filter, protocol ALL, datagram packet socket
tcpdump: listening on ethO
11:26:39.114679 < 192.168.1.101.1041 > 192.168.1.254.telnet: tcp
«>0 (DF)
11:26:39.114788 < 192.168.1.254.telnet > 192.168.1.101.1041: tcp
«>81 (DF)
11:26:39.314634 < 192.168.1.101.1041 > 192.168.1.254.telnet: tcp
«>0 (DF)
11:26:39.314674 < 192.168.1.245.telnet > 192.168.1.101.1041: tcp
«>147 (DF)
4 packets received by filter
Следующие результаты получены при использовании команды ping (протокол ICMP):
[root@lefty /root]# tcpdump -i ethO -nq
Kernel filter, protocol ALL, datagram packet socket
tcpdump: listening on ethO
11:27:59.459644 < 192.168.1.101 > 192.168.1.254: icmp: echo request
11:27:59.459708 < 192.168.1.254 > 192.168.1.101: icmp: echo reply
2 packets received by filter
Опция -t
Опция -t заставляет команду tcpdump не включать в отчет метку времени.
Опция -W
Если нужно сохранить результаты выполнения команды tcpdump, то это позволяет
сделать опция -w имя_файла. Файл сохраняется в формате библиотеки libpcap, что, во-
первых, приводит к сокращению его объема, а во-вторых, делает содержимое файла по-
нятным для других сетевых анализаторов.
Опция -г
Файл, сохраненный командой tcpdump -w, можно повторно проанализировать, задав
файл в командной строке с помощью опции - г:
[root@lefty /root]# tcpdump -г savedfile -n host 192.168.1.101
11:39:52.498409 < 192.168.1.101.1041 > 192.168.1.254.telnet: .
«>37 68 803:37 68803(0) ack 2572567146 win 7781 (DF)
11:39:52.498518 < 192.168.1.254.telnet > 192.168.1.101.1041: P
- «>1:89 (88) ack 0 win 32120 (DF)
11:39:52.698395 < 192.168.1.101.1041 > 192.168.1.254.telnet: .
«>0:0 (0) ack 89 win 7693 (DF)
Опция -V
При наличии опции -v команда tcpdump выдает более детальное описание каждого
пакета. В частности, отображается значение поля TTL:
154 Часть II. Средства и технологии маршрутизации в Linux
[rootglefty /root]# tcpdump -r savedfile -n -v host 192.168.1.101
11:39:52.498409 < 192.168.1.101.1041 > 192.168.1.254.telnet: .
4>3768803:3768803 (0) ack 2572567146 win 7781 (DF) (ttl 128, id 37383)
11:39:52.498518 < 192.168.1.254.telnet > 192.168.1.101.1041: P
M:89(88) ack 0 win 32120 (DF) (ttl 64, id 21483)
11:39:52.698395 < 192.168.1.101.1041 > 192.168.1.254.telnet: .
4>0:0(0) ack 89 win 7693 (DF) (ttl 128, id 37639)
Выражения
В команде tcpdump можно задать выражение, определяющее правило фильтрации па-
кетов. Выражение ставится после опций командной строки и состоит из квалификатора,
за которым следует идентификатор. Квалификатор определяет либо тип идентификатора
(узел, сеть, порт), либо направление пакета (исходящий, входящий), либо протокол. Что-
бы было понятно, взгляните еще раз на последний пример. В нем уже используется выра-
жение host 192.168.1.101, заставляющее команду tcpdump отображать все пакеты, у
которых в поле отправителя или в поле получателя стоит адрес 192.168.1.101.
Вот как можно отобразить только пакеты, поступающие от адреса 192.168.1.254:
tcpdump -n -v src 192.168.1.254
Следующая команда отображает пакеты, направляемые по адресу 192.168.1.254:
tcpdump -n -v dst 192.168.1.254
Можно задать еще более жесткое правило, ограничив исходящий трафик только паке-
тами службы DNS (порт 53):
tcpdump -n -v src 192.168.1.254 and port 53
Не обязательно указывать номер порта. Команда tcpdump понимает логические имена
сервисов (протоколов), назначенные организацией IANA (http://www.iana.org/
assignments/port-numbers). В табл. 9.6 перечислены некоторые распространенные
сервисы. Номера портов и соответствующие им логические имена хранятся в файле
/etc/services.
Таблица 9.6. Порты распространенных протоколов и их логические имена
Приложение Протокол прикладного уровня Протокол транспортного уровня Номер порта Логическое имя порта
Электронная почта SMTP TCP 25 smtp
Электронная почта POP3 TCP по рор-3
Загрузка файлов FTP UDP 20 (данные) ftp
UDP 21 (команды) ftp-data
Преобразование DNS TCP/UDP 53 domain
имен
Преобразование NetBIOS UDP 137 netbios-ns
имен (Microsoft) TCP 137
Управление сетью SNMP UDP 161 snmp
UDP 162 snmp-trap
(прерывания)
Сетевое время NTP UDP 123 ntp
TCP (редко реализуется)
Удаленный доступ Telnet TCP 23 telnet
Глава 9. Сетевые команды 155
Окончание табл. 9.6
Приложение Протокол прикладного уровня Протокол транспортного уровня Номер порта Логическое имя порта
Протокол маршру- BGP UDP 179 bgp
тизации TCP 179
Регистрация сис- темных событий Syslog UDP 514 syslog
WWW HTTP TCP 80 WWW
UDP (редко реализуется) 80
Таким образом, команду
tcpdump -n -V dst 192.168.1.254 and port 53
можно записать так:
tcpdump -n -v dst 192.168.1.254 and port domain
Если во время работы этой команды кто-то попытается обратиться по адресу
http: //www. newriders . com, будет обнаружена попытка выполнить преобразование имен:
[root@lefty /root]# tcpdump -n -v dst 192.168.1.254 and port domain
Kernel filter, protocol ALL, datagram packet socket
tcpdump: listening on all devices
10:36:31.504218 < 10.1.1.1.domain > 192.168.1.254.1026: 1552
2/12/12 www.newriders.com. CNAME newriders.com., newriders.com.
A 63.69.110.220 (465) (DF) (ttl 250, id 31400)
Помимо оператора and поддерживаются также операторы not и or. Следующая ко-
манда отображает все пакеты, связанные с узлом 192.168.1.254, кроме пакетов программы
telnet:
tcpdump host 192.168.1.254 and not port telnet
Наиболее распространенные варианты выражений просуммированы в табл. 9.7.
Таблица 9.7. Выражения команды tcpdump
Выражение Аргумент Действие Значение аргумента
dst Узел Проверяется, совпадает ли адрес получателя IP-пакета с указанным аргументом IP-адрес или имя контро- лируемого узла. Если за- данному имени соответст- вует несколько IP-адресов, все они будут проверяться
dst host Узел То же То же
src Узел Проверяется, совпадает ли адрес отправителя IP- пакета с указанным аргу- ментом То же
src host Узел То же То же
host Узел Проверяется, совпадает ли адрес отправителя или по- лучателя IP-пакета с указан- ным аргументом То же
156 Часть II. Средства и технологии маршрутизации в Linux
Окончание табл. 9.7
Выр: ажение Аргумент Действие Значение аргумента
ip | arp | rarp host gateway dst I src net [tcp I udp] dst port [tcp | udp] src port [tcp | udp] port ip broadcast Узел Узел Сеть Сеть Порт Порт Порт Проверяется, принадлежит ли пакет протоколу IP, ARP или RARP и совпадает ли адрес его отправителя или получателя с указанным ар- гументом Проверяется, был ли ука- занный узел шлюзом паке- та. Это значит, что данному узлу должен соответство- вать МАС-адрес отправите- ля или получателя пакета, но не их IP-адреса Проверяется, находится ли адрес отправителя (или по- лучателя) IP-пакета в ука- занной сети Проверяется, находится ли адрес отправителя или по- лучателя IP-пакета в ука- занной сети Проверяется, принадлежит ли пакет протоколу TCP или UDP и равен ли порт получа- теля указанному значению Проверяется, принадлежит ли пакет протоколу7 TCP или UDP и равен ли порт отправителя указанному значению Проверяется, принадлежит ли пакет протоколу TCP или UDP и равен ли порт отправителя или получате- ля указанному7 значению Проверяется, является ли IP-пакет широковещательным То же Имя узла Доменное имя сети, за- данное в файле /etc/networks, сетевой адрес, например 192.168.1.0, или CIDR- адрес, например 192.168.1.0/24 То же Номер или логическое имя порта (см. табл. 9.6) То же То же
Пример
С помощью команды tcpdump удобно анализировать работу других сетевых команд,
например traceroute. Предположим, проверяется путь от исходного узла (192.168.1.254)
к адресату (10.2.2.254), между которыми расположен промежуточный маршрутизатор
(10.1.1.254). Для наглядности переключим команду traceroute в режим отправки ICMP-
запросов, а не UDP-пакетов.
[rootSlefty /root]# traceroute -In 10.2.2.254
Глава 9. Сетевые команды 157
В команде tcpdump отключим трансляцию адресов в доменные имена (-п) и включим
вывод поля TTL (-v). Ниже показаны перехваченные ею результаты работы команды
traceroute (все строки пронумерованы для удобства):
[root@lefty /root]# tcpdump -nv
1 11:56:57.885796 ethO > 192.168.1.254 > 10.2.2.254: icmp: echo
4>request (ttl 1, id 34072)
2 11:56:57.949353 ethO < 10.1.1.254 > 192.168.1.254: icmp: time
^exceeded in-transit (ttl 64, id 11798)
3 11:56:57.949738 ethO > 192.168.1.254 > 10.2.2.254: icmp: echo
4>request (ttl 1, id 34073)
4 11:56:57.984039 ethO < 10.1.1.254 > 192.168.1.254: icmp: time
^exceeded in-transit (ttl 64, id 11804)
5 11:56:57.984272 ethO > 192.168.1.254 > 10.2.2.254: icmp: echo
4>request (ttl 1, id 34074)
6 11:56:58.017169 ethO < 10.1.1.254 > 192.168.1.254: icmp: time
^exceeded in-transit (ttl 64, id 11810)
7 11:56:58.017459 ethO > 192.168.1.254 > 10.2.2.254: icmp: echo
4>request (ttl 2, id 34075)
8 11:56:58.043489 ethO < 10.2.2.254 > 192.168.1.254: icmp: echo
4>reply (ttl 254, id 34075)
9 11:56:58.043740 ethO > 192.168.1.254 > 10.2.2.254: icmp: echo
^request (ttl 2, id 34076)
10 11:56:58.068649 ethO < 10.2.2.254.> 192.168.1.254: icmp: echo
4>reply (ttl 254, id 34076)
11 11:56:58.068873 ethO > 192.168.1.254 > 10.2.2.254: icmp: echo
^request (ttl 2, id 34077)
12 11:56:58.0694390 ethO < 10.2.2.254 > 192.168.1.254: icmp: echo
'breply (ttl 254, id 34077)
34 packets received by filter
В строках 1, 3 и 5 показаны три эхо-запроса, посланных узлом 192.168.1.254 по адресу
10.2.2.254 с параметром TTL, равным 1. Эти запросы попадают на маршрутизатор
10.1.1.254, который определяет, что пакет устарел, и возвращает ICMP-сообщение time
exceeded (строки 2, 4 и 6). Затем команда traceroute делает значение TTL равным 2 и
посылает новую порцию запросов (строки 7, 9 и 11), которые на этот раз доходят до адре-
сата (узел 10.2.2.254), возвращающего эхо-ответ (строки 8, 10 и 12).
Резюме
В этой главе были рассмотрены Linux-команды if conf ig, route, ping, traceroute,
arp, netstat и tcpdump, широко используемые при работе в сети. Команда ifconfig
служит для конфигурирования сетевых интерфейсов. Команда route предназначена для
удаления и добавления маршрутов, а также для просмотра маршрутных таблиц. То же са-
мое делает и команда агр, но она работает с кэш-таблицами протокола ARP. Команда
netstat позволяет просматривать не только маршрутные таблицы, но и список сетевых
соединений, установленных на локальном компьютере.
Команды ping и traceroute применяются для выявления проблем со связью и обна-
ружения нефункционирующих узлов. Наконец, команда tcpdump является анализатором
пакетов, позволяющим перехватывать сетевой трафик.
158 Часть II. Средства и технологии маршрутизации в Linux
Планирование системы
маршрутизации
В этой главе...
Введение в сетевое планирование 159
Концепции эффективного управления маршрутизаторами 162
Специальные функции маршрутизатора 166
Резюме 168
После рассмотрения основ маршрутизации и средств ее реализации в Linux пора пе-
реходить к планированию. В частности, нужно определить место, занимаемое мар-
шрутизатором в общей структуре сети. Если же развертывание сети осуществляется “с ну-
ля”, тогда необходимо спроектировать схему самой сети.
Введение в сетевое планирование
Сетевое планирование — это не строгая научная дисциплина. Теорий создания сетей
существует, наверное, столько же, сколько и сетевых администраторов. Мы приведем ряд
советов относительно внедрения маршрутизатора в структуру сети. Это действительно не
более чем советы. Ведь каждый конкретный случай по-своему уникален, и двух одинако-
вых сетей не бывает.
Вопросы, требующие рассмотрения
В этом разделе будут описаны наиболее важные аспекты сетевого планирования.
Цели
Первое, что нужно учесть, планируя структуру сети, — это общее назначение сети. Яв-
ляется ли она небольшой домашней сетью, в которой два или три компьютера делят об-
щее коммутируемое соединение, канал DSL или кабельный модем? Или это глобальная
сеть, объединяющая различные офисы компании и ее мобильных сотрудников, подклю-
чающихся к сети где-то в дороге? Ответы на эти вопросы помогут осуществить выбор про-
токолов и соответствующего аппаратного обеспечения.
Ресурсы
Следующий вопрос таков: какие ресурсы имеются в распоряжении? Знание ответа на него
поможет понять, насколько свободно можно себя чувствовать при выборе компонентов сети.
Например, можно ли себе позволить установить резервные системы? Это очень важно в кор-
поративных сетях, где каждое критическое звено должно быть продублировано. Введение та-
кого дублирования в небольших удаленных офисах позволит обойтись без специального об-
служивающего персонала. Если в какой-то системе произойдет аппаратный сбой, достаточно
будет осуществить замену вышедшего из строя компонента дубликатом, сократив тем самым
время простоя с нескольких часов или дней до нескольких минут. Практически любого сотруд-
ника можно обучить тому, как заменять стандартные компоненты.
Несколько слов по поводу надежности
Мы не имеем в виду, что Linux— ненадежная система. Все как раз наоборот. Многие Linux-
системы непрерывно работают годами. Именно так: годами! Но если система создается на базе
персональных компьютеров стандартной комплектации, то ее механические компоненты со
временем выйдут из строя. К сожалению, это неизбежно. Вопрос лишь в том, насколько
подготовленными вы будете, когда это случится.
Другой важный вопрос: планируется ли покупка нового оборудования или компания
попытается найти новое применение имеющимся устройствам? Если запросы компании
невелики, то определенно имеет смысл вдохнуть новую жизнь в старые компьютеры, пе-
реоснастив их операционной системой Linux. Нас радует тот факт, что Linux спасает от
уничтожения многие компьютеры, которые в противном случае давным-давно оказались
бы на свалке. Если же компания может себе позволить приобрести новую систему, то из
старых компонентов можно собрать резервную систему, которая будет введена в строй в
случае сбоя основного звена.
Бюджет
В идеальных условиях, обладая бюджетом, равным годовому доходу Билла Гейтса,
можно позволить себе не экономить на оборудовании. В реальной жизни на проект по
развертыванию сети выделяют конкретные деньги и ставят конкретный срок исполнения.
И все же лучше не экономить на оборудовании и сроках, чтобы потом не пришлось тра-
тить еще больше денег и времени на исправление ошибок и недочетов, которые можно
было предусмотреть заранее.
Масштабируемость
Будет ли сеть расти (или уменьшаться!) в обозримом будущем? Если есть все основания
полагать, что сеть подвергнется существенному разрастанию в ближайшие полгода-год, ее
структуру необходимо планировать так, как будто этот рост уже наступил. Например, если
известно, что компания собирается через несколько месяцев открыть новый офис, нужно
заранее позаботиться об организации глобальной сети и закупке соответствующего обо-
рудования, его наладке и тестировании. Когда придет день открытия офиса, останется
лишь все подключить.
Безопасность
Безопасность имеет первостепенное значение при планировании сети и конфигури-
ровании маршрутизатора. Спросите себя, насколько подозрительным нужно быть и какие
шаги следует предпринять, чтобы гарантировать максимальную защищенность сети. Оп-
160 Часть II. Средства и технологии маршрутизации в Linux
ределенная степень паранойи абсолютно необходима, когда речь идет о защите информа-
ции. Даже если создается домашняя сеть, не исключено, что на компьютере хранятся дан-
ные, которые нежелательно выставлять на всеобщее обозрение. А в корпоративной сети
безопасность данных обязательна, ведь хакеры могут попытаться, к примеру, украсть ин-
формацию о кредитных карточках или же конкуренты попробуют похитить коммерче-
ские секреты. Особенно бдительными следует быть администраторам школьных и уни-
верситетских сетей, так как нет ничего опаснее талантливых компьютерных хулиганов,
которые все свое свободное время тратят на то, что им кажется невинными шалостями.
Помните, что проблема безопасности не всегда формулируется как “мы против них”.
Бывает и “мы против самих себя”. Конечно, не хочется верить, что кто-то из сослуживцев
замышляет что-то нехорошее, но никогда нельзя напрочь отвергать это предположение.
Просто существуют разные уровни атак. Возможно, ни у кого из сотрудников и в мыслях
нет уничтожать файлы или красть пароль суперпользователя. Но они могут попытаться
получить доступ к ведомостям по зарплате, чтобы узнать, сколько зарабатывают их колле-
ги из соседних отделов. Не исключено, что их также заинтересует электронная почта на-
чальника (“Не упоминает ли он меня в своих письмах?”).
При необходимости можно разбить офисную сеть на подсети отделов, чтобы разде-
лить проходящий в них трафик. Если бюджет позволяет, воспользуйтесь услугами специа-
листа по вопросам безопасности, который оценит предпринятые меры защиты и поможет
найти слабые места в системе. Даже самые опытные системные администраторы не всегда
обладают подобными знаниями. Как говорится, лучше предвидеть, чем карать.
Зоны безопасности
Зачастую необходимость в защите информации влечет за собой повышение сложности
сети. Это особенно справедливо, когда внутренняя сеть должна быть открыта для доступа
извне. Предположим, компания предоставляет дилерам доступ к базе данных с информа-
цией о товарах, чтобы они могли составлять динамические каталоги предлагаемых това-
ров. Или же разработчики двух компаний совместно работают над проектом, вследствие
чего им требуется получать доступ в сети друг друга. Подобная открытость создает новые
возможности в плане ведения бизнеса, но она же становится причиной головной боли
системных администраторов и профессионалов в области безопасности.
Что такое ДМ3?
ДМ3 означает “демилитаризованная зона” — термин, впервые вошедший в обиход во время войны в
Корее. На сетевом жаргоне ДМ3 — это компьютер, играющий роль буфера между маршрутизатором и
внутренней сетью. Он представляет собой дополнительный барьер на пути любого, кто пытается
незаконно проникнуть в сеть. Даже если попытка взлома маршрутизатора/брандмауэра окажется
) успешной, понадобится пройти через еще один узел, прежде чем попасть в саму сеть.
Особо осторожные администраторы создают не только ДМ3, но и приманку. Под при-
манкой понимается компьютер, который умышленно делается доступным для взломщи-
ков. У него есть ряд брешей в системе защиты, намеренно оставленных в расчете на то,
что хакеры соблазнятся легкой добычей и не заметят более важные машины. Компьюте-
ры-приманки обычно оснащены системами обнаружения взлома, благодаря которым ад-
министраторы узнают, что их сеть привлекла нежелательное внимание. При благоприят-
ном раскладе опытный администратор сможет выследить нарушителя, с тем чтобы тот
был опознан и, возможно, наказан.
Глава 10. Планирование системы маршрутизации 161
Простота администрирования
Еще один аспект планирования — это простота администрирования сети. Что можно
сделать, чтобы облегчить жизнь себе и всему персоналу, обслуживающему сеть? Крупную
сеть следует проектировать так, чтобы передавать полномочия по управлению подсетями
другим администраторам, равномерно распределяя между ними нагрузку. Необходимо ав-
томатизировать как можно большую часть административных задач и создать систему
оповещения, которая будет сигнализировать о сбоях в сети. Здесь опять же стоит вспом-
нить об избыточности. Наличие резервных звеньев позволит избежать ситуации “все рух-
нуло” и чинить неисправности по мере появления свободного времени.
Выбор роли маршрутизатора
Прежде чем приступить к настройке маршрутизатора Linux, нужно понять, какие
функции от него требуются. Решает ли он лишь самые распространенные задачи или же
он сконфигурирован на работу в виртуальной частной сети? Должны ли эти функции быть
сосредоточены в одном месте или нужно выделить для них разные машины?
Одноцелевые и многоцелевые маршрутизаторы
Одноцелевые маршрутизаторы занимаются лишь тем, чем и должны заниматься.
Раньше использовать маршрутизатор в каких-то других целях было нельзя, ведь он пред-
ставлял собой аппаратное устройство'с ограниченной областью применения. С появлени-
ем Linux стало возможным выполнять на одном компьютере не только маршрутизацию,
но и фильтрацию пакетов, а также организовывать файловый сервер, сервер печати и да-
же Web-сервер. В то же время мы считаем, что в производственной среде желательно раз-
делять все эти функции. Не стоит пытаться делать все сразу, причем на одной машине.
Например, было бы заманчиво возложить на маршрутизатор еще и роль брандмауэра.
Во многих сетях именно так и делают. Но если бюджет позволяет, то лучше купить спе-
циализированный брандмауэр. Аппаратные средства сейчас относительно недороги, опе-
рационная система Linux вообще бесплатна, а восстановление системы после взлома под-
час стоит немалых денег. Так что считайте сами.
Концепции эффективного управления
маршрутизаторами
Одной из задач администраторов является эффективное управление маршрутизатора-
ми, особенно размером маршрутных таблиц. Это не так-то просто в корпоративных сетях,
где изменения в таблицы зачастую должны вноситься безотлагательно, из-за чего конфи-
гурация сети становится неоптимальной. О последствиях задумываются уже тогда, когда
возникают сложности администрирования.
Есть несколько стратегий, как функциональных, так и чисто технических, позволяю-
щих добиться того, чтобы конфигурация маршрутизатора оставалась согласованной, а
размеры маршрутных таблиц не становились больше, чем нужно.
Функциональные аспекты
В какой бы платформе ни эксплуатировался маршрутизатор, всегда появляются усо-
вершенствованные версии его программного обеспечения, и ОС Linux — не исключение.
В новых версиях исправляются обнаруженные ошибки и вводятся дополнительные функ-
циональные возможности, но также добавляются новые ошибки и возникают проблемы
совместимости. Важно не дать возобладать принципу “я заменяю старую версию, потому
что появилась новая”.
162 Часть II. Средства и технологии маршрутизации в Linux
Нужно следить за выпуском свежих версий программ и всегда читать комментарии к
ним, обращая внимание на следующие моменты.
Решена ли в этой версии какая-то из проблем, с которой организация уже сталкива-
лась раньше?
Выявлена ли какая-нибудь новая проблема, которая важна, но прежде оставалась не-
замеченной?
Добавлены ли новые функциональные возможности, которые необходимы прямо
сейчас или понадобятся в ближайшем будущем?
Устранены ли какие-то бреши в защите?
Существенно ли повысилась производительность?
Если на один из этих вопросов дан утвердительный ответ, следует обновить программ-
ное обеспечение маршрутизатора. Но предварительно нужно выяснить, не возникает ли
проблем совместимости с существующим оборудованием или другими программами. Бы-
вает, что обновления носят лавинный характер.
Технические аспекты
Основным критерием эффективности настройки маршрутизатора является его табли-
ца, точнее, ее размер. Чем он меньше, тем быстрее маршрутизатор будет принимать ре-
шения. Это также упрощает задачу администрирования, поскольку таблицы меньшего
размера легче просматривать и исправлять.
Маршрутные таблицы в сетях со статической маршрутизацией
Сети, в которых существуют статические маршруты, обычно изначально организованы
очень эффективно, но затем утрачивают это свойство по мере того, как в них вносятся ло-
кальные изменения, ориентированные на решение конкретной задачи и не учитывающие
структуру всей сети. Приведенные ниже советы позволят поддержать размер маршрутной
таблицы на минимально необходимом уровне.
Эффективное использование стандартного маршрута
Очень часто администраторы недооценивают важность стандартного маршрута. Мно-
гие администраторы имеют привычку создавать маршрут к новой сети на всех маршрути-
заторах. В большинстве статических сетей в этом нет никакой необходимости, потому что
такие сети очень просты и имеют тенденцию направлять трафик к центральному маршру-
тизатору, граничащему в том числе и с новой сетью.
Рассмотрим сеть, изображенную на рис. 10.1. При подключении сети Д (10.1.40.0/24)
не нужно создавать маршрутную запись к ней на узлах Б, В и Г. Все они общаются с сетью Д
через узел А, на который указывает их стандартный маршрут. Таким образом, новый мар-
шрут необходимо задать только на узле А.
Эффективное управление суперсетями и масками переменной длины
В сети, изображенной на рис. 10.2, где удаленные узлы имеют собственный выход в In-
ternet, стандартный маршрут нельзя применять при добавлении новой сети 10.128.1.0/24.
Но в соответствии с документом RFC1918 все частное адресное пространство сети отно-
сится к диапазону 10.0.0.0/8, поэтому маршрутная запись суперсети 10.0.0.0/8 на .узлах Б и
В будет включать новую сеть 10.128.1.0/24.
На узле А маршрут к сети 10.128.0.0/24 нужно заменить так, чтобы охватывалась и но-
вая сеть 10.128.1.0/24. Для этого должна быть создана суперсеть 10.128.0.0/23, которая
позволит не добавлять маршрут к узлу Б.
Глава 10. Планирование системы маршрутизации 163
10.1.40.0/24
Рис. 10.1. Эффективное использование стандартного маршрута
Удалить маршрут 10.128.0.0/24, добавить Трафик сети 10.128.1.0/24 маршрутизируется
новую суперсеть: 10.128.0.0/23 через суперсеть 10.0.0.0/8
Рис. 10.2. Эффективное использование суперсетей
164 Часть II. Средства и технологии маршрутизации в Linux
В этом примере демонстрируется эффективное применение сетевых масок перемен-
ной длины, которые позволяют создавать маршруты, “суммирующие” остальную часть се-
ти. При этом маршрутная запись может не указывать на конкретную сеть, как маршрут
10.0.0.0/8 в данном случае.
Как избежать неэффективного использования масок переменной длины
Сетевые маски переменной сети позволяют минимизировать число IP-адресов, ис-
пользуемых в каждой сети. Но когда имеется множество масок, возникает ненужная слож-
ность. В статической сети, как правило, нужно не более одной-двух масок: одна (чаще все-
го 255.255.255.0)— для локальных сетей, а вторая (255.255.255.255) — для транзитных се-
тей, к которым обычно относятся PPP-каналы. Но даже для транзитных сетей отдельная
маска зачастую не нужна, поскольку в диапазоне 10.0.0.0/8 более чем достаточно адресов,
особенно если речь идет о сети со статической маршрутизацией.
Маршрутные таблицы в сетях с динамической маршрутизацией
В сетях с динамической маршрутизацией тоже следует избегать неэффективного исполь-
зования масок переменной длины. В динамических сетях наличие множества масок создает
еще большую сложность, так как эти сети обычно крупнее, чем их статические аналоги.
Суммирование маршрутов
Суммирующие маршруты играют примерно ту же роль, что и суперсети: несколько
маршрутов к подсетям объединяются в одну запись. Поскольку это выполняется динами-
чески, а не статически, демоны маршрутизации по-прежнему имеют возможность узнавать
об изменениях топологии сети посредством маршрутных анонсов.
На рис. 10.3 изображен маршрутизатор А, который посылает суммирующую запись
10.0.0.0/8 через интерфейс А1. Если стоимость перехода к маршрутизаторам Б и В одинако-
ва, суммирующая запись будет также посылаться через интерфейс А2, но маршрутизатор В
воспользуется ею только при потере связи с маршрутизатором А, так как путь через интер-
фейс А1 короче. Маршрутизатор Б может рассылать собственную суммирующую запись.
Маршрутизатор Б
Рис. 10.3. Сеть с суммированием маршрутов
Глава 10. Планирование системы маршрутизации 165
Мультипротокольная поддержка
Следует избегать использования в одной сети нескольких протоколов динамической
маршрутизации. Мультипротокольная поддержка обычно является следствием приобре-
тения другой компании или неудачных попыток перехода от старого дистанционно-
векторного протокола к топологическому (например, OSPF).
Прг»использовании нескольких протоколов нужно понимать не только принципы их
функционирования, но и особенности их взаимодействия на маршрутизаторе. Следует
выяснить, пакеты какого протокола имеют больший приоритет, какие маршруты распро-
страняются посредством “чужого” протокола и как устранять проблемы, вызванные не-
правильным взаимодействием.
Специальные функции маршрутизатора
В процессе планирования и развертывания сети может оказаться, что некоторые зве-
нья сети должны функционировать особым образом. Об этих специальных случаях пойдет
речь ниже.
Поддержка стандарта IPv6
В главе 4, “Адресация в стандартах IPv4 и IPv6”, рассказывалось о том, что в сети Inter-
net существуют два стандарта адресации: IPv4 и IPv6. Организации, в которых требуется
поддержка стандарта IPv6, вынуждены использовать обе версии протокола IP.
В документе RFC1933 определены два способа перехода на IPv6: путем использования
двойного стека IP и путем туннельной передачи пакетов IPv6 через сети IPv4. Первый спо-
соб напоминает применение двухпротокольных стеков. К примеру, многие рабочие стан-
ции и персональные компьютеры поддерживали стеки IP и IPX в эпоху популярности се-
тей Novell в 90-х годах. Этот подход применяется централизованно, т.е. один компьютер
делается посредником между станциями IPv6 и станциями IPv4.
Многие организации предпочитают развертывать целые сети IPv6. Если на пути между
такими сетями стоит сеть IPv4, требуется организовать туннель. Пример подобного тун-
неля приведен на рис. 10.4.
Узлы А и Б имеют сетевые интерфейсы, рассчитанные как на стандарт IPv6, так и на
стандарт IPv4. Передавая трафик на узел Б, узел А инкапсулирует пакет IPv6, полученный
через интерфейс А1, в пакет IPv4 и посылает его через интерфейс А2. Узел Б принимает
этот пакет через интерфейс Б1, удаляет заголовок IPv4 и передает оставшуюся часть даль-
ше уже как пакет IPv6.
166 Часть II. Средства и технологии маршрутизации в Linux
Многоканальный доступ
В общем случае под многоканальным доступом (multihoming) понимается подключение
компьютера сразу к нескольким сетям. Маршрутизатор, по определению, является много-
канальным. В этом разделе мы рассмотрим частный случай: подключение узла как мини-
мум к двум провайдерам Internet.
Простой многоканальный доступ
Простейшая схема многоканального доступа изображена на рис. 10.5.
В данном случае корпоративная сеть соединена с провайдерами А и Б линиями Т1.
На корпоративном шлюзе существуют два стандартных маршрута с одинаковой стоимо-
стью, указывающих на каждого из провайдеров. Это Позволяет распределять трафик меж-
ду провайдерами.
Основным преимуществом данного решения является его простота и возможность по-
лучения канала доступа в Internet с общей пропускной способностью 3 Мбит/с. Недостат-
ком следует считать то, что половина трафика к внешним сервисам провайдера А, таким
как WWW, DNS и даже электронная почта, должна будет проходить через провайдера Б и
наоборот. Можно создать статические маршруты к сетям провайдера, но у провайдеров
есть множество клиентов, трафик к которым также должен идти по определенному кана-
лу, поэтому следует поискать более эффективное решение.
Многоканальный доступ и протокол BGP
Когда оба провайдера используют протокол BGP, пограничный маршрутизатор спосо-
бен находить наилучшие маршруты к клиентам провайдеров. Это можно реализовать не-
сколькими способами. Если провайдер анонсирует только сети своих клиентов, то соот-
ветствующие маршруты можно напрямую занести в таблицы BGP. Если же провайдер
анонсирует все маршруты, то необходимо ввести механизм фильтрации либо на маршру-
тизаторе провайдера, либо на стороне клиентов.
Фильтрация предпочтительнее, чем простое добавление маршрутов к сетям провайде-
ра, так как во втором случае не учитывается вероятность сбоя. Рассмотрим сеть, изобра-
женную на рис. 10.6. При наличии статического маршрута соединение корпоративной се-
ти с клиентом окажется разорванным в случае сбоя, так как весь трафик направляется в
канал А1. Если же маршрутизатор А узнает о сбое сети посредством маршрутного обнов-
ления, он воспользуется каналом А2, и весь трафик пойдет через провайдера Б.
Глава 10. Планирование системы маршрутизации 167
Сбой
Рис. 10.6. Обход вышедшего из строя канала
Сложности многоканального доступа
Провайдеры часто отказываются анонсировать сети, не входящие в их домен CIDR.
А многоканальный доступ по своей природе создает ситуацию, когда провайдер вынужден
анонсировать часть CIDR-диапазона другого провайдера в своей сети. Но даже в этом слу-
чае маршрутизаторы, находящиеся за пределами домена, не знают о том, что оба провай-
дера имеют маршрут в заданную сеть.
В связи с участившимся числом атак на Internet-узлы с использованием поддельных адре-
сов провайдеры фильтруют пакеты, исходные адреса которых не принадлежат их доменам.
Многие применяют систему NAT, обеспечивающую трансляцию исходных адресов. Это так-
же нужно учитывать при проектировании сетевого доступа в многоканальной среде.
Резюме
В этой главе рассматривались базовые вопросы подготовки к внедрению в сеть мар-
шрутизатора. Мы не привели конкретный план, а дали лишь обзор того, что нужно учиты-
вать при планировании системы маршрутизации. В главе также шла речь о концепциях
эффективного управлении маршрутными таблицами и специальных функциях, выполняе-
мых маршрутизаторами, в частности о поддержке стандарта IPv6 и подключении к двум и
более провайдерам.
168 Часть II. Средства и технологии маршрутизации в Linux
Основы маршрутизации в Linux
В этой главе...
Маршрутизация в локальных сетях 169
Маршрутизация в глобальных сетях 171
Маршрутизация в виртуальной закрытой (частной) сети 172
Резюме 173
В этой главе мы познакомимся с ключевыми принципами маршрутизации в операци-
онной системе Linux. Будет также рассмотрен ряд общих вопросов сетевого конфи-
гурирования.
Маршрутизация в локальных сетях
В наши дни конфигурировать локальную сеть (ЛВС) в Linux довольно легко. Конечно,
можно вспомнить те времена, когда сетевые утилиты еще не были столь совершенными,
как сегодня, но за последние три-четыре года ОС Linux сделала большой шаг вперед.
В Linux всегда имелись мощные сетевые средства, и со временем они только улучшились.
Что касается средств маршрутизации, то они выдвинулись на передний план в ядре
версии 2.4.x. В простых локальных сетях многие из расширенных средств не нужны, хотя
система Netfilter может упрощать работу в сети.
Создание цельной ЛВС
Создать обычную ЛВС несложно. Не имеет значения, сколько компьютеров в ней нахо-
дится: один или сто. Если деления на подсети не происходит, то конфигурация сети будет
одинаковой независимо от того, какое число компьютеров скрыто за маршрутизатором.
В подобных простейших сетях достаточно запустить на одном из компьютеров систему
IP-маскирования или систему NAT (описаны в главе 14, “Безопасность и система NAT”).
Как-то по-особому настраивать маршрутизацию обычно не требуется, поскольку большин-
ство необходимых функций ядро выполняет автоматически.
Статические и динамические IP-адреса
Первое, с чем приходится сталкиваться, — это проблема выбора между статическими и
динамическими адресами. Если ЛВС невелика и насчитывает не более двадцати компью-
теров, то управлять статическими адресами будет несложно. Задать их вручную проще,
чем организовывать сервер DHCP. Сетевому администратору не составит труда запомнить
IP-адреса всех компьютеров.
.С другой стороны, если в сеть непрерывно добавляются новые компьютеры или число
узлов в сети более 20-30, то DHCP-сервер избавит администратора от головной боли.
В качестве DHCP-сервера можно использовать старый компьютер i486 или Pentium либо
сконфигурировать соответствующим образом маршрутизатор.
Некоторые приложения осуществляют аутентификацию на основании IP-адресов. Это
справедливо для систем печати и передачи электронной почты, а также NFS и NAT. Если
DHCP-сервер будет неправильно сконфигурирован, это может привести к проблемам пе-
чати, совместного доступа к файлам и т.д.
Допускается создавать и смешанные среды. Если в компании есть надомные работни-
ки, которые лишь изредка посещают офис, то для “нерегулярных” компьютеров можно
настроить DHCP-сервер, а всем остальным компьютерам в сети назначить статические
IP-адреса. По сути, в любом офисе желательно предусмотреть появление “случайного” по-
сетителя, который придет со своим ноутбуком и захочет проверить почту.
Создать DHCP-сервер одинаково несложно в любой клиентской системе, будь то Linux,
Windows, MacOS или одна из разновидностей BSD. Мы не будем здесь рассказывать о том,
как это делается, поскольку в большинстве систем имеются свои собственные средства на-
стройки сервиса DHCP.
Еще одним преимуществом протокола DHCP является возможность повторного ис-
пользования IP-адресов. Компьютеры “берут в аренду” IP-адреса и через некоторое время
возвращают их обратно в общий пул адресов. Таким образом, когда менеджер включает
свой ноутбук, ему динамически выделяется IP-адрес, который будет затребован назад по-
сле отключения компьютера от сети. При повторном подключении компьютера ему, ско-
рее всего, будет назначен другой адрес.
Разделение ЛВС на подсети
Если в сети имеются подсети, ситуация немного усложняется с появлением масок под-
сетей (о них рассказывалось в главе 4, “Адресация в стандартах IPv4 и IPv6”).
IPv6
Поскольку протокол IPv6 реализуется крайне редко, мы не будем рассказывать о создании
подсетей IPv6. Стандарт IPv6 предусматривает наличие такого количества адресов, что создавать
подсети, очевидно, никогда не понадобится.
Зачем нужны подсети
Подсети создаются по ряду причин. Обычно они разделяют физические или геогра-
фические сегменты сети и задают внутренние административные границы. Изоляция
внутренних сетей друг от друга по причинам безопасности нами еще не рассматривалась.
Разве вы оставите папку с ведомостями по зарплате лежать в раскрытом виде в приемной,
где ее может увидеть каждый? Конечно, нет. По той же причине имеет смысл разбить
офисную ЛВС на подсети отделов, сделав маршрутизатор/брандмауэр барьером на пути
того, кто захочет получить доступ к чужим данным. С помощью программы ipchains или
iptables можно задать правила фильтрации определенных видов трафика между подсе-
тями и правила регистрации попыток несанкционированного доступа.
170 Часть II. Средства и технологии маршрутизации в Linux
Ничто не мешает в разных подсетях работать с общими ресурсами, например с сете-
вым лазерным принтером. Программы ipchains и iptables позволяют разграничивать
доступ по исходным и конечным IP-адресам, портам и даже протоколам. Эти программы
обладают огромным числом конфигурационных опций, поэтому являются чрезвычайно
гибкими и удобными в использовании. Подробнее речь о них пойдет в главе 14,
“Безопасность и система NAT”.
Подсети одинакового размера
Подсети одинакового размера существуют при разделении диапазона имеющихся IP-
адресов на равные части. Например, если взять сеть класса С и разбить ее на четыре оди-
наковые подсети, в каждой из них будет насчитываться 62 узла. Допускаются также вари-
анты разбивки на 2, 8, 16, 32 и 64 сети. Правда, в последнем случае в подсеть будут входить
всего два компьютера, так что этот вариант следует рассматривать лишь как теоретиче-
скую возможность.
В сети класса В число подсетей одинакового размера может быть гораздо большим,
вплоть до 16384 подсетей по два компьютера в каждой. На практике для большинства ор-
ганизаций вполне подходит схема адресации класса С. ,
Подсети разного размера
Подсети неодинакового размера создаются путем указания масок разной длины. Что
если для отдела информационных технологий требуется гораздо больше адресов, чем для
финансового отдела? В первом отделе масса серверов, рабочих станций и прочей техни-
ки, а во втором работают всего три человека. В этом случае за каждой подсетью нужно за-
крепить свою маску, длина которой будет зависеть от требуемого количества узлов.
Маршрутизация в глобальных сетях
Как нетрудно догадаться, организовать глобальную сеть гораздо сложнее, чем локаль-
ную. В частности, в локальной сети все вопросы в той или иной степени находятся под
четким административным контролем. При создании глобальной сети неизбежно появ-
ляются факторы, которые администратор не может контролировать.
Выбор типа внешнего соединения
В первую очередь нужно выбрать тип соединения, который обеспечит оптимальную
пропускную способность канала и при этом не выйдет за рамки предусмотренного бюдже-
та. В ряде случаев выбор может быть достаточно широким: коммутируемое соединение,
DSL, ISDN, кабельный модем, канал Т1, высокоскоростная спутниковая тарелка. В других
случаях выбор ограничен всего одним или двумя типами.
Реже всего глобальные каналы организуются посредством коммутируемого соедине-
ния. Прошли те времена, когда скорость 56 Кбит/с казалась фантастической. Сегодня это
решение для тех, кто подключается к сети нерегулярно. Если есть возможность выбора,
лучше предпочесть любой другой вариант.
Технология ISDN распространена достаточно широко. Если других вариантов нет, то
ISDN-соединение вполне подойдет для небольших офисов. Однако соотношение це-
на/производительность в ISDN гораздо выше, чем у соединений, основанных на техноло-
гии DSL, или кабельных модемов. Соединения последних двух типов доступны как для до-
машнего, так и для корпоративного применения. Подробнее об этом речь пойдет в гла-
ве 12, “Сетевые аппаратные компоненты”.
Глава 11. Основы маршрутизации в Linux 171
Пакет WANPIPE
В распоряжении пользователей Linux есть пакет WANPIPE, предназначенный для ор-
ганизации глобальных сетей. Чтобы работать с ним, необходимо иметь в наличии специ-
альную сетевую плату, а также скомпилировать ядро с поддержкой маршрутизации и ин-
терфейсов глобальных сетей (об этом рассказывается в главе 13, “Включение в ядро функ-
ций маршрутизации”).
Исходные коды пакета можно загрузить с FTP-узла Sangoma по адресу ftp://ftp.
sangoma.com/linux/current_wanpipe/. Чтобы инсталлировать пакет, следуйте инст-
рукциям, приведенным в файле README . install. Пользователям Debian GNU/Linux еще
проще. Выполните команды
apt-get update
apt-get install wanpipe
от имени суперпользователя, и программа apt-get автоматически загрузит и инстал-
лирует пакет при условии, что нужный адрес указан в файле /etc/apt/sources . list.
Учтите, что в выпуске Debian GNU/Linux, который помечен как стабильный (“stable”);
далеко не всегда используются самые последние версии пакетов.
Программа wanpipe вызывает программу wanconf ig, которая загружает конфигурационный
файл с опциями, соответствующими имеющейся сетевой плате. Файл /etc/wanpipe/wanpipel.
conf является символической ссылкой на файл /etc/wanpipe/router. conf, в котором содер-
жатся все сведения о глобальном сетевом устройстве (или устройствах), определения интерфей-
сов глобальных сетей, а также секция физических интерфейсов.
Работать с программой wanpipe очень просто. Единственная сложность состоит в пра-
вильной настройке конфигурационного файла. Поскольку в нем очень много всевозможных
опций, мы не будем углубляться в эту тему. На узле Sangoma ведется список рассылки, посвя-
щенный пакету WANPIPE. Если у вас есть вопросы, касающиеся конкретной конфигурации,
направьте их в список рассылки. Скорее всего, кто-нибудь из подписчиков вам ответит.
После настройки конфигурационного файла нужно активизировать глобальные сете-
вые устройства. Это делает следующая команда:
wanpipe start
Она подключает все интерфейсы, перечисленные в конфигурационном файле. Чтобы
отключить интерфейсы, введите такую команду:
wanpipe stop
Можно также подключать и отключать отдельные интерфейсы. Соответствующая ко-
манда выглядит так:
wanpipe {start | stop} wanpipe#
где # — это номер интерфейса. Нумерация устройств начинается с единицы, а всего
разрешено иметь 16 устройств, что более чем достаточно.
Маршрутизация в виртуальной закрытой
(частной) сети
Обычно виртуальные частные сети подключаются к внешнему миру через брандмауэр,
а не маршрутизатор. Но в Linux оба устройства могут объединяться в единое целое. С дру-
гой стороны, из соображений безопасности маршрутизатор и брандмауэр часто реализу-
ются в разных Linux-системах.
172 Часть II. Средства и технологии маршрутизации в Linux
Виртуальная частная сеть — это альтернатива дорогостоящим выделенным каналам,
которые недоступны для стороннего трафика. Используя среду Internet в качестве “моста”
между сетями, компании могут экономить существенные денежные средства, не жертвуя
при этом безопасностью.
Естественно, о какой-либо безопасности самой сети Internet говорить не приходится,
поэтому все важные данные должны передаваться в зашифрованном виде. В распоряже-
нии тех, кто занимаются электронной коммерцией, есть протокол HTTPS. Те, кому про-
сто нужно запустить удаленный сеанс интерпретатора команд или X Window, могут вос-
пользоваться пакетом SSH. Но что делать, когда нужно безопасно соединить две удален-
ные сети, которые должны совместно использовать через Internet все общие ресурсы?
В этом случае на помощь приходят виртуальные частные сети.
Метафора, которую чаще всего применяют для описания безопасного способа соеди-
нения между собой двух сетей, — это туннель. Взаимодействие, имеющее место между дву-
мя сетями, скрыто под несколькими “оболочками”. Данные по-прежнему передаются по
протоколам TCP/IP, но при этом шифруются, т.е. даже если злоумышленник начнет пе-
рехватывать пакеты — а подобную возможность нельзя предотвратить в незащищенной
сети общего доступа, — он не сможет понять смысл этих пакетов. Теоретически данные
защищены от посторонних глаз, а сеть — от незаконного проникновения.
Таким образом, сеть считается закрытой даже несмотря на то, что передача данных
происходит по открытым каналам. Виртуальные частные сети не всегда удобны для орга-
низации глобальных сетей, но они являются выгодной альтернативой, когда бюджет и ре-
сурсы ограничены.
Чаще всего в виртуальных частных сетях используется протокол РРТР (Point-to-Point
Tunneling Protocol — протокол двухточечного туннельного соединения), основанный на
протоколе РРР. В Linux есть ряд реализаций протокола РРТР, которые способны взаимо-
действовать и с другими операционными системами, в частности с Windows. Об этом рас-
сказывалось в главе 8, “Средства маршрутизации в ядре версии 2.4.x”.
Резюме
В этой главе были рассмотрены основы использования ОС Linux в качестве маршрути-
затора в сетях основных типов. В большинстве случаев настройка системы маршрутиза-
ции не представляет особых сложностей, поскольку большинство операций выполняется
ядром и специализированными программными пакетами автоматически. ОС Linux сильна
как раз своим сетевым инструментарием, поэтому данную систему можно использовать в
качестве связующего звена даже в тех локальных и глобальных сетях, основную часть ко-
торых составляют компьютеры, работающие под управлением Windows, MacOS и др.
Глава 11. Основы маршрутизации в Linux 173
Сетевые аппаратные
компоненты
В этой главе...
Аналоговые коммуникации и модемы 174
Кабельные модемы 180
Технология DSL 181
Передача данных с участием маршрутизаторов 182
Резюме 187
Локальные и глобальные сети состоят из компьютеров, серверов, маршрутизаторов и
телекоммуникационного оборудования. В этой главе будут описаны технологии пере-
дачи данных, лежащие в основе большинства сетей. Термин “оператор” употребляется в
этой главе для обозначения любой организации, предоставляющей описанные ниже услуги.
Аналоговые коммуникации и модемы
Модем — это устройство, посредством которого удаленные пользователи подключаются к
корпоративным сетям и сети Internet. Модем преобразует цифровой сигнал, поступающий
от персонального компьютера, в аналоговый сигнал, который посылается по телефонной
линии. Модем выполняет также обратное преобразование: аналоговый сигнал, принимае-
мый из телефонной сети, превращается в цифровой сигнал, понятный компьютеру.
В идеале модемы обеспечивают скорость соединения до 56 Кбит/с, на практике же
скорость колеблется от 33,6 до 44 Кбит/с. Стандарт 56 Кбит/с требует, чтобы соединение
было очень “чистым” (интерференция сигналов была минимальной) и выполнялось толь-
ко преобразование аналогового сигнала в цифровой. В США, в связи с регуляцией мощно-
сти электропитания, максимальная скорость загрузки (приема) данных составляет
53 Кбит/с, а выгрузки (передачи) — 33 Кбит/с.
Из-за того что модемы преобразуют компьютерный цифровой сигнал в аналоговый,
возникло неправильное представление о том, будто бы телефонная сеть является аналого-
вой. Это не так. Аналоговый сигнал, передаваемый по медному проводу от абонента к те-
лефонной компании, преобразуется в цифровой сигнал с полосой 64 Кбит/с. Сигнал дан-
ного типа называют DS0. Он объединяется (мультиплексируется) с 23-мя другими такими
же сигналами, формируя сигнал DS1 с полосой 1,54 Мбит/с. Канал, в котором распро-
страняется такой сигнал, называется Т1, или транк. Канал Т1 обычно мультиплексируется
с другим трафиком, вследствие чего образуется канал DS3/T3 (672 сигнала DS0).
На рис. 12.1 изображена схема соединения между двумя модемами. Подобного рода со-,
единения существовали в 80-х годах в системах электронных досок объявлений и состав-
ляли основу сетей с промежуточным хранением данных, в частности FidoNet. В настоящее
время межмодемные соединения почти не применяются, разве что их используют сетевые
администраторы для связи с удаленными системами. Но даже для этих целей все чаще за-
действуют терминальные серверы, о которых пойдет речь ниже.
Рис. 12.1. Телекоммуникационная схема межмодемного соединения
Схема модуляции, применяемая модемами на обоих концах соединения, должна совпа-
дать. Именно она определяет скорость обмена данными, обычно выражаемую в битах в се-
кунду. В табл. 12.1 указаны наиболее распространенные скорости передачи данных, соответ-
ствующие им стандарты модуляции и сферы действия этих стандартов. Раньше протоколы
модуляции определяли, могут ли модемы взаимодействовать друг с другом. В наши дни мик-
ропрограммное обеспечение модемов существенно улучшилось, что позволяет большинству
модемов работать по единому протоколу. Серверы удаленного доступа, описанные ниже,
также поддерживают большое число протоколов модуляции и коррекции ошибок.
Таблица 12.1. Скорости и стандарты работы модемов
Скорость (бит/с) Стандарт Область действия
300 Bell 103 США
CCITTV.21 За пределами США
1200 Ве11212А США
CCITTV.22 За пределами США
CCITTV.23 Европа
2400 CCITTV.22bis Международный
9600 CCITTV.32 Международный
14400 CCITTV.32bis Международный
28800 CCITTV.34 Международный
33600 CCITTV.34 Международный
56000' ITU V.90 Международный
Это максимальная скорость приема данных (реальный предел - 53 Кбит/с). Скорость передачи данных со-
ставляет 33 Кбит/с.
Глава 12. Сетевые аппаратные компоненты 175
Внутренние и внешние модемы
Внутренние модемы очень популярны у изготовителей персональных компьютеров.
Как правило, они стоят на 50% меньше своих внешних аналогов, поскольку им не нужен
экранирующий корпус и блок питания (они есть у самого компьютера). Основным недос-
татком внутренних модемов является отсутствие индикаторных лампочек, по которым
проверяется работа устройства. Кроме того, внешний модем, в отличие от внутреннего,
можно легко подключить к другому ПК.
Сравнительно недавно на рынке внутренних модемов появились так называемые устрой-
ства WinModem. Они перекладывают на центральный процессор ПК большинство функций,
обычно выполняемых аппаратурой модема, включая коррекцию ошибок и контроль переда-
чи. Это означает, что данные устройства оказывают более сильное влияние на производи-
тельность системы, чем обычные внутренние модемы. К тому же область их применения ог-
раничена ОС Windows, поэтому мы не рекомендуем пользоваться ими. Правда, в настоящее
время предпринимаются попытки заставить устройства WinModem работать в Linux. Теку-
щую информацию об этом можно получить на Web-узле www. 1 inmodems. org.
Внутренние модемы могут подключаться к 16-разрядной шине ISA или 32-разрядной
шине PCI. В Linux поддерживаются модемы первого типа, тогда как поддержка PCI-
модема зависит от имеющегося драйвера. В ядре версии 2.4 поддержка шины PCI сущест-
венно расширена, но все же перед покупкой модема желательно узнать, есть ли для него
драйверы.
Внешние модемы подключаются к последовательному порту ПК с помощью разъемно-
го соединения DB-25 или DB-9 (рис. 12.2). Назначение контактов модемного порта описа-
но в табл. 12.2 и 12.3. На самом модеме установлено разъемное гнездо (розетка). Вилка
расположена на соединительном кабеле.
Розетка DB-9
Вилка DB-9
Рис. 12.2. Разъемные соединения DB-25 и DB-9
Таблица 12.2. Контакты разъема DB-25
Контакт Функция
1 2 3 4 5 6 7 8 20 22 Защитное заземление (PG) Передаваемые данные (TD) Принимаемые данные (RD) Сигнал готовности к передаче (RTS) Сигнал готовности к приему (CTS) Сигнал готовности данных (DSR) Сигнальная земля (SG) Сигнал обнаружения несущей (CD) Сигнал готовности терминала (DTR) Индикатор вызова (RI)
176 Часть II. Средства и технологии маршрутизации в Linux
Таблица 12.3. Контакты разъема DB-9
Контакт Функция
1 Сигнал обнаружения несущей (CD)
2 Принимаемые данные (RD)
3 Передаваемые данные (TD)
4 Сигнал готовности терминала (DTR)
5 Сигнальная земля (SG)
6 Сигнал готовности данных (DSR)
7 Сигнал готовности к передаче (RTS)
8 Сигнал готовности к приему (CTS)
Все модемы — как внешние, так и внутренние — используют микросхему UART (Universal
Asynchronous Receiver/Transmitter— универсальный асинхронный приемопередатчик).
Раньше было важно убедиться в том, что на плате последовательного порта или внутреннего
модема установлена микросхема UART 16550, которая является улучшенной версией микро-
схемы UART 8250. В UART 16550 есть 16-байтовый буфер, позволяющий более плавно осу-
ществлять операции обмена данными. В настоящее время это не имеет особого значения,
так как все производители используют эту микросхему или, по крайней мере, обеспечивают
режим совместимости с ней.
Стандартные команды модема
Чтобы модем мог общаться с другими системами, ему необходимо коммуникационное ПО.
Поставщики первых модемов прилагали к ним терминальные программы, которые посредст-
вом патентованных протоколов взаимодействовали с микропрограммным обеспечением кон-
кретного поставщика. Компания Hayes Microcomputer создала набор команд, в котором назва-
ния всех команд начинались с префикса АТ. Этот набор стал известен как АТ-команды. Многие
поставщики начали эмулировать в своих модемах данные команды, что привело к появлению
стандарта де-факто. АТ-команды еще называют стандартными командами модема. Практически
все современные модемы совместимы со стандартом компании Hayes.
Стандартные команды реализуют все процессы взаимодействия, происходящие в мо-
деме, и выполняют такие функции, как дозвон, аппаратный контроль передачи, ожидание
гудка в линии перед набором номера и т.д. Специальные функции модема можно реализо-
вать, не модифицируя стандартный набор команд. Для этого предназначены регистры,
которые напоминают переменные в языках программирования, но сохраняются в энерго-
независимой памяти и не сбрасывают свои значения при отключении питания.
В большинстве микропрограмм АТ-команды заранее сконфигурированы на оптималь-
ное использование. Тем не менее не помешает ознакомиться с их назначением, так как по-
добная информация может оказаться полезной в случае поиска неисправностей. Наиболее
важные команды перечислены в табл. 12.4. Префикс АТ не показан.
Таблица 12.4. Несколько стандартных команд модема
Команда Назначение
А Ответ на входящий звонок
D ппп-ппп-ппп Набор телефонного номера ппп-ппп-ппп. Команда D принимает ряд дополни-
тельных аргументов, из которых наиболее распространены Р (импульсный
набор), Т (тоновый набор) и DL (повторный набор номера)
Еп Вывод данных на терминал в режиме эха. Если параметр п равен нулю, режим
эхо отключен, если равен единице — включен
Глава 12. Сетевые аппаратные компоненты 177
Окончание табл. 12.4
Команда Назначение
Н Разрыв текущего соединения
Хп Расширенная обработка ошибок. Часто используется команда ХЗ, которая за- дает игнорирование режима тонового набора, что полезно в случае, когда мо- дем подключен к офисной АТС
Z Сброс состояния модема
Терминальные программы
Появление класса современных сетевых приложений сделало ненужным большинство
прежних коммуникационных программ. В то же время системным администраторам часто
нужны терминальные программы, с помощью которых они получают консольный доступ к
персональным компьютерам, модемам, маршрутизаторам и другим сетевым устройствам.
В большинстве дистрибутивов Linux есть соответствующая программа под названием
minicomm, напоминающая старое DOS-приложение Telix. Список коммуникационных
Linux-программ можно получить по адресу http://www.ibiblio.org/pub/Linux/
apps/serialcomm/.
Другие применения аналоговых коммуникаций
Оставшаяся часть главы будет посвящена цифровым коммуникациям, но мы не можем
не упомянуть о нескольких важных функциях, которые по-прежнему выполняют аналого-
вые коммуникации.
Терминальные серверы
Межмодемные соединения в настоящее время используются лишь сетевыми админи-
страторами для подключения к удаленным системам, в которых для удаленного управле-
ния специально выделены модемы. Но даже для этих целей все чаще применяют терми-
нальные серверы.
Терминальный сервер — это специализированное устройство удаленного доступа, имеющее
несколько последовательных портов. К каждому порту могут непосредственно подключаться
системы, предназначенные для удаленного управления, и модемы — для коммутации соеди-
нений. Например, терминальный сервер, изображенный на рис. 12.3, можно использовать
для доступа к Linux-системе righty. Это наилучшее решение для ситуаций, когда непонятно,
чем вызвано отсутствие связи: проблемой с системой или с сетью. В данном конкретном слу-
чае администратор имеет в своем распоряжении “экстренный” метод доступа к компьютеру
righty: он может с помощью программы telnet зайти на терминальный сервер, а затем
обратиться к Linux-системе через последовательное соединение. Если же доступ посредст-
вом программы telnet невозможен из-за проблем с сетью, администратор может подклю-
читься к Linux-системе по модему через терминальный сервер.
Терминальный сервер
Рис. 12.3. Терминальный сервер
178 Часть II. Средства и технологии маршрутизации в Linux
Основное преимущество терминальных серверов по сравнению с выделенными моде-
мами заключается в консолидации ресурсов и средств защиты в одном месте. Тем самым
перекрываются “черные ходы”, появляющиеся, когда служащие “забывают” выключать
модемы. Упрощается также администрирование, потому что с терминального сервера
можно обратиться к большинству маршрутизаторов (через консоль) и UNIX-станций
(через последовательное соединение). Это означает, что не потребуется специальная
конфигурация модема.
Linux-компьютер может служить в качестве терминального сервера, но в большинстве
ПК установлены всего два последовательных порта, что явно недостаточно. Придется по-
купать многопортовую плату.
Серверы удаленного доступа
Сервер удаленного доступа, как предполагает сам термин, позволяет удаленным пользо-
вателям подключаться к сети. Такой доступ осуществляется посредством коммутируемых ка-
налов, аналоговых (асинхронные модемные соединения) или цифровых (сервис ISDN PRI,
рассматриваемый ниже). На рис. 12.4 изображен типичный корпоративный сервер удален-
ного доступа, к которому подключен канал Т1 с 24-мя коммутируемыми линиями.
Серверы удаленного доступа поддерживают множество протоколов, основной из ко-
торых — IP, хотя в старом оборудовании Novell встречаются протоколы семейства IPX.
Обычно эти серверы не хранят информацию о пользователях (параметры аутентифика-
ции и фильтрации пакетов, доступные протоколы) локально, а получают ее по специаль-
ному протоколу, например RADIUS (Remote Authentication Dial In User Services — сервисы
аутентификации удаленных абонентов; определен в документе RFC2058). Linux является
идеальной платформой для организации сервера RADIUS. В табл. 12.5 перечислено не-
сколько серверов RADIUS, работающих в Linux.
Глава 12. Сетевые аппаратные компоненты 179
Таблица 12.5. Серверы RADIUS для Linux
Сервер Организация Исходные коды
Ascend RADIUS версии 970224 Lucent ftp://ftp.ascend.сот/pub/Softwa- re -Re leases /Radius
Cistron Radius Seiver версии 1.6.4 Cistron Telecom http://www.radius.cistron.nl/
AAA Radius Server Interlink Networks http://www.interlinknetworks.com/ downloads/freeware_download_license. html
Кабельные модемы
Сети кабельного телевидения, если не считать коммутируемые телефонные сети обще-
го пользования, наиболее распространены среди домашних пользователей. Это позволяет
задействовать инфраструктуру кабельных сетей для организации широкополосных сетей
передачи данных.
Кабельный модем представляет собой устройство, подключаемое к Internet через ка-
бельную сеть. Традиционные кабельные сети по своей природе были однонаправленны-
ми, в то время как сети передачи данных — двунаправленными. Но операторы кабельных
сетей уже давно искали способы передачи данных от клиентов, что позволило бы им пре-
доставлять дополнительные услуги, например “плату за просмотр”. С появлением новых
технологий и расширением полосы пропускания кабельных сетей это стало возможным.
На рис. 12.5 изображена структура сети с кабельным модемом.
На кабельном модеме есть разъем ЛВС
(обычно RJ-45 для витой пары) и разъем ГВС, ко-
торый подключается к локальному делителю сиг-
налов, распределяющему сигнал между кабельным
модемом и телевизором (либо компьютерной
приставкой к нему). Делитель отвечает за переда-
чу входного (downstream) сигнала частотой 6 МГц
и выходного (upstream) сигнала частотой 2 МГц
между модемом и терминальной системой.
Входной канал частотой 6 МГц обеспечивает
полосу пропускания вплоть до 56 Мбит/с, а вы-
ходной канал частотой 2 МГц— вплоть до
3 Мбит/с. Следует отметить: несмотря на то что к
терминальной системе ведет канал совместного
пользования, кабельные модемы не могут непо-
средственно общаться друг с другом — трафик
должен сначала пройти через терминальную сис-
тему. Важно также знать, что терминальная сис-
тема не имеет средств 1Р-маршрутизации.
Рис. 12.5. Сеть с кабельным модемом
Терминальная система
Оптоволоконный мультиплексор
ПК
180 Часть II. Средства и технологии маршрутизации в Linux
Технология DSL
В технологии DSL (Digital Subscriber Line — цифровая абонентская линия) не выполня-
ется преобразование цифрового сигнала в аналоговый. Она реализует интерфейс переда-
чи цифрового сигнала по той же абонентской линии, по которой распространяется ана-
логовый телефонный сигнал. Нет ничего необычного в том, что на стороне бизнес-
клиентов устанавливается цифровое оборудование, но аппаратура подключения частных
клиентов традиционно была аналоговой. С появлением технологии DSL ситуация стала
меняться. Наиболее распространенным вариантом реализации DSL является ADSL
(асимметричная DSL), но используются и другие варианты.
HDSL
Технология HDSL (High-speed DSL — высокоскоростная DSL) предназначена для заме-
ны каналов Т1 (в Европе — Е1). В HDSL используются две пары медных проводов, а данные
передаются на расстояние до 3,7 километра (в Т1 повторители нужно устанавливать через
каждые 1,8 километра).
HDSL-2
Технология HDSL-2 позиционируется как следующее поколение технологии HDSL. Она
обеспечивает ту же скорость передачи данных, что и HDSL, но используется всего одна пара
проводов, что соответствует возможностям большинства современных устройств.
SDSL
Технология SDSL (Symmetric DSL — симметричная DSL) изначально позиционирова-
лась как более дешевая альтернатива каналам Т1/Е1. В ней используется одна пара прово-
дов, а скорость передачи данных уменьшается с увеличением расстояния до оператора,
которое может составлять до 6,7 километра.
ADSL
В технологии ADSL (Asymmetric DSL — асимметричная DSL), как следует из названия,
скорость передачи в обоих направлениях разная, причем скорость получения данных вы-
ше, чем скорость их отправки. Такая схема идеально подходит для работы в Internet, где
объем загружаемой информации на порядок выше, чем объем отправляемых данных. По-
следние — это, как правило, всего лишь подтверждения о том, что данные были получены.
ADSL— это наиболее популярный вариант DSL, обычно применяемый домашними
пользователями и в небольших офисах. Предлагаемая полоса пропускания — 8,44 Мбит/с,
а расстояние — до 5,5 километра. Правда, реальная скорость передачи данных неодинако-
ва и зависит от оператора.
На рис. 12.6 изображена схема реализации технологии ADSL, которой придерживают-
ся большинство операторов.
DSL-модем
DSL-модем располагается у клиента. Он имеет интерфейс ЛВС, предназначенный для под-
ключения 10-мегабитовой сети Ethernet, и интерфейс ГВС, подключаемый к делителю сигна-
лов. Нижние 4 КГц полосы пропускания отводятся делителем для телефонных сигналов.
Глава 12. Сетевые аппаратные компоненты 181
Internet
Коммутатор ATM
и маршрутизатор Internet
|g о g ag)
лйс
ПК
Рис. 12.6. Типичная схема ADSL
DSLAM
Устройство DSLAM (DSL Access Multiplexer — мультиплексор доступа к DSL) объединя-
ет сигналы, поступающие от абонентов DSL, направляя их в сеть оператора. Текущее по-
коление устройств DSLAM соединяется с сетью оператора посредством интерфейсов
ATM, хотя раньше чаще применялись интерфейсы, работающие по технологии ретранс-
ляции кадров (рассматривается ниже). Сторонники DSL ожидают, что мультиплексоры
следующего поколения будут работать по протоколу IP, однако существующие реалии та-
ковы, что поставщики устройств, скорее всего, будут предлагать несколько интерфейсов,
оставляя выбор за операторами.
Передача данных с участием маршрутизаторов
До появления широкополосных технологий маршрутизаторы были наиболее распро-
страненными устройствами, применявшимися для соединения узлов многопользователь-
ского доступа. Маршрутизаторы работают на сетевом уровне и имеют несколько физиче-
ских интерфейсов.
В настоящее время в роли маршрутизатора может выступать Linux-система. Одно из
основных преимуществ аппаратных маршрутизаторов над программными заключается в
простоте эксплуатации и наличии специализированной ОС. В операционной системе об-
щего назначения какой-нибудь вспомогательный сервис способен серьезно повлиять на
182 Часть II. Средства и технологии маршрутизации в Linux
функции маршрутизации. Например, в ядре может быть скомпилирован совершенно не-
нужный, да к тому же содержащий ошибки стек протокола IPX. Кроме того, пользователи
имеют склонность активизировать дополнительные сервисы просто потому, что “система
способна это делать”.
Многие аппаратные маршрутизаторы, как и их Linux-аналоги, имеют встроенные
функции защиты, например средства фильтрации пакетов, трансляции сетевых адресов.
Помимо этого, они могут обладать дополнительными сетевыми возможностями, напри-
мер выступать в качестве устройства доступа к сети с ретрансляцией кадров. Маршрутиза-
торы высшего класса способны обрабатывать гораздо большее число пакетов, чем мате-
ринская плата персонального компьютера. По этой причине маршрутизаторы встречают-
ся в большинстве сетевых сред. По крайней мере, маршрутизаторы провайдеров Internet
являются аппаратными.
Ниже мы рассмотрим применение маршрутизаторов в корпоративных сетях.
Каналы Т1 и Е1
Т1 — это цифровой канал с полосой пропускания 1,544 Мбит/с. Он широко применяется
в сетях передачи голосовых данных. Это проверенная технология, доказавшая свою эффек-
тивность и ставшая стандартом узкополосных цифровых коммуникаций. Конкуренцию ей
начинают составлять лишь современные широкополосные технологии, в частности HDSL.
Канал Т1 делится на 24 линии с полосой 64 Кбит/с, называемые каналами DS0. В связи
с высокой стоимостью эксплуатации каналов Т1 американские телефонные компании
предоставляют частичный сервис Т1, выделяя клиентам не все 24 канала, а лишь часть из
них, в зависимости от уровня сервиса. Такая схема завоевала популярность у клиентов,
подключающихся к сети Internet или покупающих соединения типа “точка-точка”. Канал
Т1, полный или частичный, называют выделенной линией, поскольку в нем не происхо-
дит коммутации сигналов — соединение присутствует всегда.
Е1 — это цифровой канал с полосой пропускания 2,048 Мбит/с, популярный в Европе
(и других частях света). Он делится на 32 канала DS0.
Два маршрутизатора, взаимодействующих по каналу Т1, должны использовать одина-
ковый коммуникационный протокол. Фаворитом является протокол РРР (см. главу 7,
“Вспомогательные демоны”), позволяющий соединять разнородные системы. Если же
маршрутизаторы относятся к одному типу, то можно воспользоваться протоколом HDLC.
Если пропускной способности канала Т1 или Е1 оказывается недостаточно, в распоря-
жении имеется канал DS3 с полосой 44,736 Мбит/с. Канал ЕЗ с пропускной способностью
34,368 Мбит/с обычно недоступен для частных клиентов. Естественно, стоимость экс-
плуатации таких каналов возрастает экспоненциально, поэтому выбор обычно делают в
пользу покупки дополнительных линий Т1.
Если к одному узлу подведено несколько линий коммуникации, необходим протокол,
позволяющий интерпретировать два соединения как одно. Существуют маршрутизаторы,
выполняющие распределение нагрузки. Это означает, что очередной прибывший кадр
данных посылается не через то соединение, в которое был направлен предыдущий кадр.
Протокол РРР MP (Multilink Protocol), определенный в документе RFC1717, позволяет
объединять два физических соединения в одно логическое и совместим со многими сете-
выми протоколами.
Технология ISDN
Технология ISDN (Integrated Services Digital Network — цифровая сеть с комплексным об-
служиванием) была первой попыткой предоставления клиентам услуг цифровой связи и ста-
ла предшественницей ADSL. ISDN реализуется в двух вариантах: BRI (Basic Rate Interface —
интерфейс базового уровня) и PRI (Primary Rate Interface — интерфейс основного уровня).
Глава 12. Сетевые аппаратные компоненты 183
Рис. 12.7. Схема распределения нагрузки
Сервис BRI представляет собой два канала передачи данных со скоростью 64 Кбит/с и
один конфигурационный канал со скоростью передачи 16 Кбит/с. Первые называются
B-каналами, а второй — D-каналом.
Сервис PRI реализует 24 канала для линии Т1 (32 для Е1). Чаще всего он применяется в
офисных АТС, где необходимы такие функции, как голосовая почта и скоростная комму-
тация. Он также популярен в системах удаленного доступа. Сервис BRI широко распро-
странен в Европе, но он не получил аналогичного распространения в США, особенно в
системах передачи голосовых данных.
Применение ISDN
У сервиса BRI есть ряд интересных сетевых применений, например коммутация по за-
просу, расширение полосы пропускания по запросу и резервирование канала. Поскольку
технология ISDN является цифровой, обмен сигналами при подключении происходит
очень быстро, в отличие от модема. Этот факт в сочетании с общей скоростью передачи
данных, равной 128 Кбит/с, позволяет разработчикам создавать более эффективные се-
тевые решения.
Сети с коммутацией по запросу являются альтернативой выделенным линиям и рабо-
тают прозрачно для пользователей и приложений. Если два узла соединены линией ISDN,
один или оба В-канала можно активизировать тогда, когда появляется трафик, связанный
с удаленным узлом. После определенного периода неактивности каналы снова отключа-
ются. Подобное применение технологии ISDN распространено там, где частичные серви-
сы Т1 недоступны (в основном в Европе) или же стоимость каналов ISDN ниже, чем у Т1.
С помощью дополнительных ISDN-каналов можно расширять полосу пропускания в ча-
сы пиковой нагрузки. Например, маршрутизатор можно сконфигурировать так, что он бу-
дет активизировать второй канал, когда загруженность первого достигнет отметки 98%, и
отключать его, когда показатель загруженности вернется к отметке 95%. “Главный” канал
может быть выделенной линией или же ISDN-соединением.
В Северной Америке наиболее популярным применением технологии ISDN является ре-
зервирование каналов, когда в случае потери связи с удаленным узлом маршрутизатор пере-
ключается на резервное ISDN-соединение. Потеря связи выявляется по факту пропадания
сигнала на выделенной линии или при наступлении определенного сетевого события, на-
пример получения маршрутного анонса, в котором сообщается о недоступности маршрута.
Ретрансляция кадров
Основным недостатком выделенных линий является то, что для каждой такой линии
требуется отдельное интерфейсное устройство. Рассмотрим сеть, изображенную на
рис. 12.8. Здесь есть центральный узел, к которому подключены четыре удаленных узла.
Если используются выделенные линии, центральному маршрутизатору потребуются че-
тыре физических интерфейса для каждого из удаленных узлов. Кроме того, при общении
184 Часть II. Средства и технологии маршрутизации в Linux
друг с другом все узлы вынуждены направлять данные на центральный узел, иначе им при-
дется прокладывать дополнительные выделенные линии к каждому соседу. В случае с че-
тырьмя удаленными сетями это означает наличие десяти выделенных линий.
Даллас
Центральный
маршрутизатор
с одним
интерфейсом Т1
Рис. 12.8. Удаленные сети с соединениями “точка-точка”
В связи с тем что выделенные линии очень дороги, причем стоимость их эксплуатации
тем выше, чем больше дальность связи, возникла потребность в более масштабируемой
архитектуре глобальных сетей. Это привело к появлению технологии ретрансляции кадров
(frame relay).
Сети ретрансляции кадров реализуются на канальном уровне телефонными компания-
ми. С их помощью крупные компании могут создавать масштабируемые глобальные сети, в
которых нет необходимости за каждым соединением закреплять физический интерфейс
или прокладывать выделенные линии к отдельным узлам.
На рис. 12.9 изображена типичная сеть ретрансляции кадров с точки зрения корпора-
тивного клиента. Следует отметить, что в подобного рода сетях не обязательно присутст-
вуют попарные соединения между всеми узлами. Чтобы иметь доступ ко всем узлам, кли-
ент должен платить отдельно. Если прямой связи с удаленным узлом нет, трафик будет на-
правляться центральному узлу, в котором выполняется маршрутизация пакетов.
Центральному маршрутизатору требуется лишь один интерфейс Т1.
На рис. 12.10 представлена та же самая сеть, но уже с точки зрения оператора. Реаль-
ный интерфейс доступа к сети предоставляется коммутатором. Несмотря на то что для
клиента сеть ретрансляции кадров кажется частной, коммутатор является ресурсом со-
вместного пользования, обеспечивающим доступ в сеть множеству клиентов в каждом из
городов, где поставщик имеет так называемую “точку присутствия”.
Глава 12. Сетевые аппаратные компоненты 185
Рис. 12.9. Типичная сеть ретрансляции кадров
Даллас
Коммутатор
Центральный
маршрутизатор
с четырьмя
интерфейсами Т1
Рис. 12.10. Сеть ретрансляции кадров с точки зрения оператора
186 Часть II. Средства и технологии маршрутизации в Linux
Важно помнить о том, что технология ретрансляции кадров существует и играет важ-
ную роль в глобальных сетях. Она может применяться там, где требуется соединить между
собой группу узлов.
Резюме
В этой главе описывались принципы создания телекоммуникаций, лежащие в основе
сетей передачи данных. Были рассмотрены различные технологии, как аналоговые, так и
цифровые, в том числе DSL, ISDN, Т1 и ретрансляция кадров.
Глава 12. Сетевые аппаратные компоненты 187
1".
Включение в ядро функций
маршрутизации
В этой главе...
Зачем создавать новое ядро
Создание ядра Linux
Специальные дистрибутивы
Резюме
188
190
194
197
Одно из главных достоинств системы GNU/Linux заключается в возможности пере-
компиляции ядра системы по запросу. Способность динамически добавлять нужные
функции и удалять ненужные сделала ОС Linux столь популярной. Системные администра-
торы, разработчики ПО и опытные пользователи получили в свое распоряжение средства,
отсутствующие в коммерческих операционных системах и аппаратных маршрутизаторах.
Зачем создавать новое ядро
В типичном дистрибутиве Linux часть функций маршрутизации можно включить, не
перекомпилируя ядро. Если маршрутизация — это лишь одна из задач, решаемых данной
системой, то заранее скомпилированное ядро вполне подойдет. Если же система должна
служить исключительно целям маршрутизации, то лишние функции будут только увеличи-
вать размер ядра. Например, в большинство предварительно скомпилированных ядер
встроена поддержка звуковых драйверов, протоколов CSLIP и РРР, контроллеров RAID и
прочих всевозможных протоколов и устройств, совершенно ненужных с точки зрения
маршрутизации (вряд ли какому-нибудь маршрутизатору нужна звуковая плата).
В этой главе мы рассмотрим, как настраивать ядро Linux-системы, выступающей в ка-
честве выделенного маршрутизатора. Будут также описаны специализированные дистри-
бутивы, созданные специально для целей маршрутизации.
Читатели могут поинтересоваться: так ли уж необходимо перекомпилировать ядро, если
в нем уже есть требуемые функции? Ответ почти всегда будет положительным. Ядра практи-
чески всех коммерческих дистрибутивов Linux “набиты” всем, чем только можно. Просто
это наилучший способ гарантировать, что большинство пользователей смогут инсталлиро-
вать систему и немедленно начать с ней работать. Такой подход обеспечивает высокую ско-
рость инсталляции, но сомнителен с точки зрения оптимизации и безопасности.
Даже в специализированных дистрибутивах, рассматриваемых в конце главы, время от
времени приходится обновлять ядра или устанавливать “заплаты”, устраняющие бреши в
системе защиты. Преимущество Linux по сравнению с патентованными операционными
системами, используемыми в маршрутизаторах Cisco и прочем сетевом оборудовании, за-
ключается в простоте модификации.
Гибкость обновлений
По правде говоря, маршрутизаторы Cisco и другие устройства маршрутизации тоже можно
обновлять, если найдена брешь в системе защиты или обнаружена какая-то иная ошибка. Но они
не обеспечивают тот уровень гибкости и настраиваемости, который присущ Linux.
Меньше и быстрее
Очевидное преимущество настройки ядра заключается в том, что ядро можно сделать
меньшим по объему и более производительным. Конечно, сегодня это уже не так актуаль-
но, как несколько лет назад, ведь быстродействие современных процессоров Intel дости-
гает 1,5 ГГц, а стоимость мегабайта оперативной памяти меньше одного доллара. Во мно-
гих случаях администраторы покупают новую систему, не заботясь о ее стоимости. Но в то
же время ОС Linux часто устанавливают на старые компьютеры, извлекаемые со складов
списанного оборудования. Они далеко не так мощны, как их современные аналоги, зато
позволяют компаниям экономить средства на покупке новых компьютеров. Старый
“классический” Pentium, пылившийся в шкафу, оказывается, вполне может прослужить
еще несколько лет.
Специализированные функции
Готовые ядра, входящие в состав системных дистрибутивов, не располагают такими
функциями, как, например, поддержка протокола RARP, хотя она нужна Linux-маршрути-
затору. Единственный способ добиться включения нужных функций — перекомпилировать
ядро (заодно можно будет отключить все лишнее). Это основная причина наряду с обновле-
ниями и мерами защиты, по которой пользователи создают собственные ядра.
Те, кто захотят включить поддержку стека протоколов IPv6 (и многих других редко ис-
пользуемых протоколов), наверняка столкнутся с необходимостью перекомпилировать
ядро. Но сам факт, что в Linux поддерживаются данные протоколы, подчеркивает силу
этой открытой операционной системы. Разработчики коммерческих ОС, например ком-
пании Microsoft, Sun и Novell, решают за пользователей, какие протоколы должны под-
держиваться, а какие — нет. Поддерживаются наиболее распространенные варианты, а
пользователи “экзотических” или старых систем остаются ни с чем. Конечно, разработчи-
ки ядра Linux тоже могут решить, что реализовывать такой-то протокол нет необходимо-
сти, но ничто не мешает стороннему разработчику создать собственный модуль для под-
держки этого протокола и передать его в распоряжение группы лиц, занимающихся со-
провождением ядра.
Глава 13. Включение в ядро функций маршрутизации 189
Специализированное оборудование
В общем случае ядро скомпилировано таким образом, что поддерживаются лишь са-
мые распространенные аппаратные устройства. Если есть какие-то специальные платы
или устройства, функции работы с которыми не включены в стандартное ядро, то его
придется перекомпилировать.
Распространенный случай — добавление к ядру “экспериментального” кода для под-
держки относительно нового устройства или такого, которое еще не считается стабильно
работающим. Например, в ядре 2.4.3 некоторые модули системы Netfilter все еще счита-
ются экспериментальными, хотя многие пользователи успешно с ними работают, не до-
жидаясь, пока модули будут объявлены стабильными.
Платы маршрутизаторов ГВС — это хороший пример специализированного оборудо-
вания. Рядовому пользователю такие платы не нужны, но в Linux они поддерживаются и
есть возможность выполнять маршрутизацию по протоколу Х.25 или в сетях с ретрансля-
цией кадров.
Планируя работу маршрутизатора, нужно убедиться в том, что имеющееся оборудова-
ние поддерживается в Linux. Если твердой уверенности в этом нет, попробуйте выпол-
нить поиск в Internet, введя в поисковом сервере имя устройства и слово “Linux”. В 98-ми
случаях из ста будут выданы действительные ссылки на статьи в списках рассылки, посвя-
щенных Linux.
Устранение брешей в системе защиты и исправление
ошибок
Иногда ядра приходится перекомпилировать, чтобы повысить безопасность системы
или исправить выявленные в ней ошибки. Для любого дистрибутива со временем появля-
ются исправления и “заплаты”. Группа разработчиков ядра может не спешить с выпуском
новых версий ядра, но незначительные изменения вносятся регулярно. Обычно это свя-
зано как раз с исправлением ошибок и устранением брешей защиты. Даже если на момент
конфигурирования системы использовалось ядро самой последней модификации, почти
наверняка в ближайшие шесть месяцев появится новая модификация.
Те, кого особенно волнуют вопросы безопасности, могут запретить использование за-
гружаемых модулей ядра. Это не позволит злоумышленнику, проникшему в систему,
“замести следы” или выполнить какие-то нежелательные действия путем загрузки нужных
модулей ядра. Конечно, если хакер взломал учетную запись суперпользователя, последст-
вия в любом случае будут разрушительными, но ограничение потенциального ущерба яв-
ляется основой систем защиты. Кроме того, хакер не сможет выгрузить модули ядра, со-
держащие функции защиты, поскольку эти функции будут скомпилированы как часть ядра.
Дополнительная защита
Если ядро компилируется в статическом режиме, не забудьте удалить исходные коды ядра и
конфигурационные файлы, чтобы хакер не смог узнать, какие средства встроены в ядро.
Создание ядра Linux
Разобравшись с тем, зачем нужно создавать новое ядро, давайте узнаем, как оно собст-
венно компилируется. Тому, кто раньше этого никогда не делал, посоветуем попробовать
свои силы на тестовой машине или создать резервную копию старого ядра. Если на ком-
пьютере работает загрузчик LILO, перед началом компиляции нужно создать копию ядра
и добавить в файл /etc/lilo. conf запись о старом ядре. Этот файл будет выглядеть
примерно так:
190 Часть II. Средства и технологии маршрутизации в Linux
root=/dev/hda2
boot=/dev/hda
install=/boot/boot.b
map=/boot/map
vga=normal
timeout=300
prompt
default=Linux
lba32
image=/vmlinuz
label=Linux.
read-only
initrd=/boot/root.bin
root=/dev/hda2
image=/vmlinuz.old
label=01d_Kernel
read-only
optional
root=/dev/hda2
Далее остается запустить программу lilo, которая автоматически загрузит старое ра-
бочее ядро, если при компиляции нового произойдет ошибка.
Выбор ядра
На момент написания книги текущая версия ядра Linux имела номер 2.4.3, но боль-
шинство коммерческих пользователей работали с ядрами серии 2.2.x. Конечно, в серии
2.4.x есть целый ряд новых функциональных возможностей и улучшений, но должно
пройти время, прежде чем ядра этой серии получат массовое распространение. Среди
коммерческих дистрибутивов только в SuSE, Red Hat и Linux-Mandrake включены ядра
версии 2.4, при этом ядра версии 2.2 тоже можно загрузить по выбору.
Очевидно, что ядра серии 2.2.хтщательнее протестированы и более стабильны. С дру-
гой стороны, в ядрах 2.4.x существенно повышена производительность и появилось много
новых привлекательных возможностей. Если нет никаких дополнительных ограничений,
то, наверное, все же имеет смысл остановиться на самой последней версии ядра. Ядра
версии 2.4, возможно, не такие стабильные, но именно на них сосредоточены усилия раз-
работчиков, поэтому уже сейчас они работают быстрее и обладают более современными
сетевыми средствами.
Ниже будет описан процесс получения и компиляции ядра серии 2.4.x. В случае ядра
серии 2.2.x ряд опций будет отличаться, но в целом все выполняется точно так же. Ничего
страшного в этом процессе нет, он на самом деле достаточно прост.
В конце концов, ничто не мешает вам испытать оба ядра. Это же все-таки открытая
система. Если есть такая возможность, потратьте несколько дней на эксперименты по на-
стройке маршрутизатора и тестированию его в разных конфигурациях.
Переход от версии 2.2.x к версии 2.4.x
Перейти от ядра версии 2.2.x к ядру версии 2.4.x не сложно, но нужно выполнить не-
сколько предварительных действий, прежде чем компилировать ядро. В частности, необ-
ходимо обновить целый ряд вспомогательных программ и библиотек. Соответствующие
данные приведены в файле /usr/src/linux/Documentation/Changes. Как минимум,
обновлению подвергнутся программы GNU С, GNU Make, binutils, modutils и
e2f sprogs, если они еще не были модернизированы.
Глава 13. Включение в ядро функций маршрутизации 191
Получение исходных кодов
Первое, что предстоит сделать, — это получить исходные коды ядра Linux. В имею-
щийся дистрибутив входят исходные коды самой последней версии ядра на момент выпус-
ка дистрибутива, хотя эта версия, скорее всего, устарела еще до того, как дистрибутив по-
пал на ваш компьютер. За получением исходных кодов ядер всех серий следует обращать-
ся на Web-узел www.kernel.org. У этого узла есть множество “зеркал”, поэтому можно
будет выбрать самый быстрый вариант загрузки.
Исходные коды доступны в форматах gzip и bzip2. Последний сокращает размер ар-
хива на несколько мегабайтов, но не во все дистрибутивы входят утилиты для работы с ар-
хивами данного формата. Тем не менее желательно раздобыть эти утилиты, поскольку не-
которые проекты предлагаются только в виде Ьг1р2-файлов (например, пользователь-
ские программы системы Netfilter).
Получение утилиты bzip2
Утилита bzip2 реализует более быстрый и, как правило, более сильный алгоритм сжатия, чем
И GNU Gzip. Ее исходные коды можно найти по адресу http: //sources. redhat. com/bzip2/.
Загруженный архив следует поместить в каталог /usr/src. Для этого нужно предва-
рительно зарегистрироваться в системе под именем root (напомним, что только супер-
пользователь может компилировать и инсталлировать ядро). Выполните в указанном ка-
талоге команду Is -1, чтобы проверить, есть ли там каталог или символическая ссылка
linux. Если это так, удалите данный элемент файловой системы. Далее необходимо вы-
полнить команду tar -zxvf linux-2 . х. х. tar. gz, чтобы распаковать gzip- и tar-
архивы. Если архив был сжат в формате bzip2, воспользуйтесь командами bzip2 -d
linux-2.х.х.tar,bz2и tar -xvf linux-2.x.x.tar.
После распаковки архива перейдите в каталог linux и выполните команду make
mrproper, чтобы сформировать правильную среду компиляции:
$ cd linux
$ make mrproper
Далее начинается самое интересное: выбор компонентов пользовательского ядра. Для
этого нужно запустить одну из трех команд: make config, make menuconfig и make
xconfig. В первом случае будут последовательно перечислены все возможные опции яд-
ра, для каждой из которых будет выдаваться запрос Yes /No (иногда —Module). Это долгая
и утомительная процедура, поскольку переключаться между опциями нельзя.
Команда make menuconfig отображает систему меню, основанную на интерфейсе
ncurses. Если на компьютере работает протокол X, можно воспользоваться командой
make xconfig, которая отобразит меню, созданное на основе системы Tcl/Tk. Чаще
всего используется первая из этих двух команд, так как на большинстве Linux-маршрутиза-
торов не установлена среда XFree86.
Прежде чем переходить к данному этапу, необходимо проверить, какие аппаратные
устройства должны поддерживаться. Нет смысла включать все опции маршрутизации, ес-
ли не поддерживаются, к примеру, платы Ethernet или ГВС. Один из способов определить
(не вскрывая корпус), какие устройства подключены к компьютеру, заключается в провер-
ке специальных файлов, находящихся в файловой системе /ргос. Например, команда cat
/proc/pci | less выдаст список всех PCI-устройств, а команда cat /proc/dma — спи-
сок всех ISA-устройств, если таковые имеются. Информацию о SCSI-устройствах можно
получить с помощью команды cat /proc/scsi и т.д.
Ниже показан фрагмент результатов, выдаваемых командой cat /proc/pci. Как ви-
дите, на данном компьютере есть Ethernet-плата LiteOn:
192 Часть II. Средства и технологии маршрутизации в Linux
PCI devices found:
Bus 0, device 13, function 0:
Ethernet controller: LiteOn LNE100TX (rev 32).
Medium devsel. Fast back-to-back capable. IRQ 9. Master
^capable. Latency=32.
I/O at 0x8800 [0x8801] .
Non-prefetchable 32 bit memory at 0xdd800000 [0xdd800000] .
Если в дистрибутиве есть средства автоматического обнаружения устройств, Ethernet-
платы и другие сетевые устройства должны быть опознаны автоматически. В этом случае
можно запустить утилиту Ismod и посмотреть, какие модули ядра загружены.
Храните запасные платы
Между прочим, при компиляции ядра не помешает включить поддержку наиболее распростра-
ненных Ethernet-плат. Важно также держать под рукой запасные платы. Ethernet-платы имеют
“привычку” время от времени выходить из строя, поэтому гораздо проще будет в случае сбоя
просто выключить питание и заменить плату, чем перекомпилировать ядро, встраивая в него
поддержку нового устройства. Стоимость дублирования оборудования не идет ни в какое срав-
нение со стоимостью незапланированного простоя в течение одного-двух дней.
Конфигурирование ядра
Количество опций, которые нужно устанавливать в процессе конфигурирования ядра,
может показаться ошеломляющим. Но для компьютера, играющего роль маршрутизатора,
значение имеет лишь небольшое подмножество этих опций. Именно они будут рассмот-
рены ниже. Все остальные опции можно спокойно отменить.
Описываемые опции относятся к ядру версии 2.4, но большинство из них применимо и
в отношении ядер серии 2.2.x
Опции, определяющие уровень стабильности кода
(меню Code Maturity Level Options)
Несколько новых сетевых функций ядра Linux все еще считаются экспериментальными.
Если в меню Code Maturity Level Options установить опцию Prompt For Development and/or In-
complete Code/Drivers, то появится возможность выбирать эти функции при конфигуриро-
вании остальной части ядра. Включение самой опции не означает, что к ядру будет добавлен
“экспериментальный” код, или оно каким-то образом сделается нестабильным, или его раз-
мер увеличится. По этой причине рекомендуется устанавливать данную опцию.
Тип и характеристики процессора
(меню Processor Type and Features)
В основном опции меню Processor Type and Features относятся к процессорам Intel.
Здесь можно задать тип процессора, с которым будет работать система. Это позволит со-
ответствующим образом оптимизировать ядро. Но необходимо помнить, что ядро, ском-
пилированное для конкретного семейства процессоров, например PPro/6x86MX Processor
Family, может не загружаться при использовании других процессоров. Лучше всего ском-
пилировать “общее” ядро, установки которого останутся неизменными при последующей
замене материнской платы и процессора.
Если маршрутизирующая система является двухпроцессорной, то необходимо включить
поддержку’симметричной многопроцессорной обработки (symmetric multi-processing, SMP).
Эмуляция сопроцессора не нужна и должна быть отключена. Во всех современных
процессорах (старше i486) имеется встроенный сопроцессор.
Глава 13. Включение в ядро функций маршрутизации 193
Поддержка загружаемых модулей (меню Loadable Module Support)
При выборе опции Loadable Module Support в ядро будут встроены средства поддержки
загружаемых модулей. Включение опции Set Version Information позволит использовать
модули, скомпилированные для ядер более старых версий. Например, если скомпилиро-
вать ядро версии 2.4.3, а затем установить ядро версии 2.4.4, то можно будет продолжать
работать со всеми модулями старого ядра.
Опция Kernel Module Loader позволяет ядру автоматически загружать доступные моду-
ли. Эту опцию нужно установить, если применяется программа iptables.
Общая конфигурация (меню General Setup)
В меню General Setup нужно включить поддержку сетевых средств (опция Networking).
В остальном можно принять стандартные установки.
Сетевые опции (меню Networking Options)
В этом меню содержится множество всевозможных опций. Выбор поддерживаемых
сетевых протоколов (IPX, AppleTalk и др.) зависит от типа сети, в которой будет работать
маршрутизатор, и выполняемых им функций. Протоколы и функции, считающиеся
“экспериментальными”, явно помечены как таковые.
Опция Packet socket делает возможной работу программ пользовательского уровня,
например tcpdump, поэтому желательно включить ее. Необходимо активизировать стек
TCP/IP и сложные функции маршрутизации протокола IP (опции, названия которых на-
чинаются с IP:).
Поддержка сетевых устройств (меню Networking Device Support)
Опции, связанные с поддержкой сетевых устройств, вынесены в отдельное меню.
Здесь нужно найти опцию, соответствующую имеющейся сетевой плате.
Компиляция ядра
По завершении установки опций нужно запустить команду make dep, чтобы обеспе-
чить правильную сборку ядра. Если команда завершится успешно, последовательно вы-
полните команды make bzlmage,make modules ишаке modules_install.
Когда ядро будет скомпилировано, скопируйте файл /usr/src/linux/arch/i386/
boot/bzlmage под именем /vmlinuz или /boot/vmlinuz, в зависимости от того, куда
дистрибутив помещает образы ядра. Это лишь стандартное соглашение о наименовании
ядер. На самом деле ядро можно назвать как угодно; главное, чтобы запись в файле
/etc/lilo. conf соответствовала имени ядра.
После копирования ядра запустите программу lilo. Чтобы новое ядро вступило в си-
лу, нужно перезагрузить систему. Не забудьте убедиться в наличии резервного ядра.
Специальные дистрибутивы
Помимо дистрибутивов общего назначения, таких как Red Hat, Slackware, SuSE или
Debian, существуют сотни специализированных дистрибутивов. Некоторые из них, на-
пример EnGarde и Immunix, служат для создания безопасных систем, другие предназначе-
ны для решения более локальных задач. Для нас представляют интерес сетевые дистрибу-
тивы, обладающие дополнительными средствами маршрутизации и упрощенными опция-
ми конфигурирования. Ниже будут описаны некоторые из них.
194 Часть II. Средства и технологии маршрутизации в Linux
Проект Linux Router Project
Проект Linux Router Project (LRP) ориентирован на создание дистрибутива, специаль-
но предназначенного для целей маршрутизации. Результатом деятельности авторов про-
екта стало появление дистрибутива, умещающегося на одной дискете и называющегося
микродистрибутивом. Несмотря на крошечный размер, возможности его весьма велики.
С помощью дистрибутива LRP можно создать простой Linux-маршрутизатор, мост Т1,
вторичный DNS-сервер и даже маршрутизатор ГВС.
В настоящее время дистрибутив LRP поддерживает ядра версий 2.0 и 2.2. Есть ряд допол-
нительных пакетов, которые можно загрузить специально для этого дистрибутива, включая
Perl, Python, BIND и WANPIPE. Адрес Web-узла проекта таков: www. linuxrouter. org.
ZipSlack
Дистрибутив ZipSlack основан на системе Slackware Linux и помещается на одном диске
Iomega Zip. Вообще-то, его можно записать на любой раздел FAT или FAT32 емкостью не
менее 100 Мбайт, но наибольшую популярность этот дистрибутив имеет в системах, где
есть загрузочные Zip-дисководы.
Дистрибутив ZipSlack предназначен для пользователей, которые хотят поработать в
Linux, не меняя структуру разделов на жестком диске. Но с помощью этого дистрибутива
вполне можно создать маршрутизатор или брандмауэр, при условии, что сеть — небольшо-
го размера, а компьютер оснащен процессором Pentium и имеет не менее 32 Мбайт ОЗУ.
Дистрибутив ZipSlack можно найти на Web-узле Slackware Linux по адресу
www.slackware.com.
Встроенные Linux-системы
В ближайшем будущем наиболее важным сегментом компьютерного рынка станет сег-
мент встроенных систем. К ним относятся карманные компьютеры наподобие Palm Pilot и
встроенные интеллектуальные модули таких устройств, как автомобили, холодильники,
музыкальные центры, компьютерные приставки и др. ОС Linux практически отсутствова-
ла на этом рынке до 1999 г., но сумела прорваться на него в 2000 году.
Появление встроенных Linux-систем открыло дорогу к использованию традиционного
оборудования персональных компьютеров для создания маршрутизаторов. Впрочем, это
касается не только маршрутизаторов. Разрабатываются версии Linux для карманных ком-
пьютеров, сетевых видеокамер, устройств сетевого хранения данных и т.д. Компания IBM
даже выпустила часы, работающие под управлением Linux! Конечно, они не такие стиль-
ные, как Rolex, зато выполняют гораздо больше функций.
Зачем нужны встроенные системы
Термин “встроенная Linux-система” имеет достаточно широкий смысл. Им описывают
целый спектр аппаратно-программных решений. В основном под встроенным оборудовани-
ем понимаются устройства, для которых требуется операционная система, “встраиваемая” в
микросхему ПЗУ. В отличие от персональных компьютеров, такие устройства непросто мо-
дифицировать, и они предназначены для выполнения узкого круга функций.
В этом сегменте рынка традиционно доминировали патентованные операционные сис-
темы, например выпускаемые компаниями Wind River и Cisco. Но многие компании искали
более гибкие и открытые решения, поэтому неудивительно, что их выбор пал на Linux.
Оборудование, отличное от платформы Intel
Одной из причин, по которой Линус Торвальдс начал создавать Linux, была необходи-
мость изучить структуру процессора Intel 386. Автору Linux поначалу не приходила в голо-
Глава 13. Включение в ядро функций маршрутизации 195
ву мысль обеспечить переносимость системы, он не думал о том, что когда-нибудь она бу-
дет выполняться на какой-то другой платформе.
В большинстве случаев Linux и до сих пор работает на оборудовании Intel. Но деятель-
ность энтузиастов Linux привела к тому, что эта система оказалась перенесена на процес-
соры PowerPC, Alpha, SPARC и UltraSPARC, РА-RISC, StrongARM, MIPS и ряд других. Те-
перь сфера применения Linux простирается от карманных компьютеров до 64-разрядных
многопроцессорных станций. Как уже упоминалось, компания IBM даже выпустила наруч-
ные часы, работающие под управлением Linux.
Сетевые процессоры
Не так давно на рынке сетевых устройств появились сетевые процессоры. По сути, это обычный
ЦП, оптимизированный для выполнения сетевых функций. Раньше компаниям вроде Cisco
приходилось разрабатывать собственные процессоры для своих маршрутизаторов, так как эти
компании, в отличие от Intel с ее семейством х86, не располагали универсальными процессора-
ми. Любая компания, которая хотела освоить выпуск маршрутизаторов, вынуждена была
прилагать двойные усилия, пытаясь “прорваться’’ на рынок. Кроме проблемы с процессором
существовала еще одна: компании нужно было либо приобрести лицензию на чужую
операционную систему для маршрутизаторов, либо создать свою собственную ОС. Нетрудно
представить себе, сколь высокий барьер существовал на пути тех, кто пытался выйти на рынок
маршрутизаторов. Это одна из причин того, почему компания Cisco чувствовала себя так
вольготно в относительном одиночестве.
В настоящее время компании Intel, Motorola, IBM и Lucent начали выпускать “универсальные”
ЦПУ, оптимизированные для сетевого применения. Это означает, что компании, стремящиеся
выйти на рынок сетевых устройств, могут приобрести готовые процессоры, не тратя деньги на
разработку собственных решений. Еще большую финансовую выгоду сулит наличие свободно
распространяемой операционной системы с надежным стеком сетевых протоколов, поэтому уже
стали появляться сетевые устройства, функционирующие на базе Linux.
Lineo SecureEdge
Компания Lineo, Inc. первоначально была подразделением фирмы Caldera Systems, ос-
нованной бывшими сотрудниками Novell с целью выпуска Linux-продуктов. В настоящее
время компания Lineo сосредоточена на создании встроенных систем, операционных
систем реального времени и продуктов повышенной надежности. Она распространяет ди-
стрибутивы Embeddix и uClinux.
SecureEdge представляет собой настраиваемое сетевое устройство, которое функцио-
нирует на основе дистрибутива uClinux и может быть сконфигурировано как маршрутиза-
тор, брандмауэр и даже полноценный Web-сервер. Это один из примеров применения
встроенных Linux-систем в коммерческих целях.
Hard Hat Linux
Компания MontaVista предлагает ряд продуктов, основанных на дистрибутиве Hard
Hat Linux. Это встроенный дистрибутив, работающий на целом ряде платформ, включая
сетевые процессоры Intel. Он оснащен ядром, поддерживающим режим реального време-
ни. Дистрибутив Hard Hat Linux может также выполняться на обычных компьютерах се-
мейства х86, чтобы разработчикам было проще создавать продукты, которые впоследст-
вии будут перенесены во встроенные системы.
uClinux
Дистрибутив uClinux рассчитан для применения с процессорами, в которых отсутствует
блок управления памятью. Этот дистрибутив создан на базе ядер серии 2.0.x, а его ядро и ин-
струментальные средства могут поместиться в пределах 900 Кбайт оперативной памяти. Ди-
196 Часть II. Средства и технологии маршрутизации в Linux
стрибутив способен выполняться на процессорах Motorola Dragonball, ETRAX, Intel i960 и
некоторых других. Он был также перенесен на маршрутизаторы Cisco серий 2500, 3000 и
4000. Информацию о дистрибутиве можно получить на Web-узле www.ucli.nux. огд.
Резюме
В этой главе рассказывалось о том, как удалить из ядра Linux ненужные функции,
должным образом настроить его и скомпилировать так, чтобы систему можно было ис-
пользовать в качестве выделенного маршрутизатора. Был также описан ряд специализи-
рованных дистрибутивов, как коммерческих, так и некоммерческих, предназначенных
для выполнения сетевых функций и функций маршрутизации.
Сконфигурировать Linux-систему в качестве маршрутизатора несложно. Нужно лишь
научиться компилировать ядро. Компании, разрабатывающие системы маршрутизации
для коммерческого или внутреннего применения, могут даже создавать собственные ди-
стрибутивы на базе Linux.
Глава 13. Включение в ядро функций маршрутизации 197
f.
Безопасность и система NAT
В этой главе...
Фильтрация и обработка пакетов маршрутизатором 199
1Р-маскирование 204
Система NAT 205
Резюме 206
В этой главе мы вкратце остановимся на вопросах безопасности, возникающих в про-
цессе конфигурирования Linux-маршрутизатора, и покажем, как с помощью маршру-
тизатора улучшить безопасность сети. Это достаточно обширная тема, поэтому глава яв-
ляется скорее обзорной, чем углубленной. Некоторые из рассматриваемых концепций
выходят за рамки маршрутизации и касаются больше создания брандмауэров.
Одно из преимуществ использования Linux-станции в качестве маршрутизатора за-
ключается в том, что в Linux есть сетевые функции, редко или вообще не встречающиеся
в аппаратных маршрутизаторах. Но это же делает задачу конфигурирования Linux-систем
более сложной.
Стоит ли говорить о том, что в мире компьютерной безопасности все меняется очень
быстро. Новые виды атак выявляются чуть ли не ежедневно, и почти также быстро выпус-
каются всевозможные “заплаты”. Независимо от того, какой дистрибутив Linux использу-
ется для создания маршрутизатора, удостоверьтесь в том, что разработчики системы
своевременно анонсируют о выявлении брешей в системе защиты и публикуют соответст-
вующие исправления. Авторы большинства дистрибутивов ведут специальные списки рас-
сылки, посвященные вопросам безопасности, а также Web-архивы, в которых хранятся
сообщения о выявленных проблемах. Когда обнаруживается новая “дыра”, разработчики
рассылают инструкции по поводу’ ее устранения или минимизации возможных проблем.
Если компьютер служит исключительно целям маршрутизации и все ненужные серви-
сы на нем отключены, то риск уже сведен к минимуму. Можно также установить LIDS
(Linux Intrusion Detection System — система обнаружения вторжений в Linux) или какую-
нибудь другую систему выявления взломов. Кроме того, желательно хотя бы раз в месяц
полностью проверять безопасность системы, даже если никаких нарушений зафиксирова-
но не было.
Разумеется, удаленное управление маршрутизатором следует осуществлять только по
шифрованным каналам, например по протоколу SSH (Secure Shell). Передавать пароли и
даже имена учетных записей через сеанс Telnet не рекомендуется.
Слабые места протокола SSH
Недавно обнаружилось, что некоторые реализации протокола SSH не полностью защищены от
анализаторов пакетов. Раньше долгое время считалось, что даже если злоумышленник сумеет
перехватить трафик SSH-сеанса, то он не сможет получить никакой полезной информации, так
как данные окажутся зашифрованными. Но обе версии — и SSH-1, и SSH-2 — могут раскрывать
длину используемого пароля и имени пользователя, а также длину команд интерпретатора и
даже настоящие имена этих команд. Конечно, это вряд ли поможет взломщику узнать пароль
сеанса, зато облегчит задачу программе взлома, работающей методом последовательного
перебора, ведь ей станет известна настоящая длина пароля.
В пакете OpenSSH, являющемся наиболее популярной реализацией протокола SSH в Linux, эта
проблема решена в версии 2.5.2. Более старые версии использовать не рекомендуется.
Фильтрация и обработка пакетов
маршрутизатором
Linux-машину можно настроить не только на выполнение функций маршрутизации, но
и на осуществление некоторых видов фильтрации пакетов. Для этих целей предназначены
две программы, обе из которых описываются ниже: ipchains и iptables. Первая из них
обладает более ограниченными возможностями, но именно она используется в ядрах се-
рии 2.2.x. В ядрах серии 2.4.x есть модуль совместимости с программой ipchains.
Что такое фильтрация пакетов
Как известно, поток информации, передаваемой в сеть, разбивается на пакеты. Сбор
пакетов и извлечение из них информации осуществляются принимающей стороной.
У каждого пакета есть заголовок, по которому определяется коммуникационный протокол
(HTTP, FTP, SSH, Telnet и т.д.). Благодаря заголовку отправитель и получатель пакетов
выясняют их назначение и выбирают соответствующий способ обработки.
Злоумышленники могут намеренно фальсифицировать пакеты или же пытаться пере-
хватить их, чтобы самостоятельно извлечь из них интересующую информацию, зная ко-
торую можно будет атаковать компьютер. В арсенале хакеров есть и такие атаки, как
“отказ от обслуживания” (denial of service, DoS) и “распределенный отказ от обслужива-
ния” (distributed denial of service, DDoS), при которых атакуемый компьютер перегружает-
ся пакетами определенного вида.
Таким образом, фильтрация пакетов — это процедура проверки пакетов, проходящих че-
рез компьютер, с целью определения способа их обработки на основании протокола, порта,
исходного и/или целевого IP-адресов, а также процедура проверки заголовков пакетов на
предмет того, не являются ли они фрагментами более крупных пакетов или же опасными по
какой-то другой причине. Путем фильтрации пакетов можно запретить нежелательные вхо-
дящие и исходящие соединения, блокируя пакеты некоторых типов или пакеты, адресован-
ные известным портам. Например, если нужно запретить передачу почтовых сообщений от
внешних компьютеров в локальную сеть, достаточно активизировать фильтр входящих со-
единений порта 25. Подобного рода фильтры часто создаются на почтовых серверах, кото-
рые предназначены исключительно для отправки почты из внутренней сети. Дело в том, что
многие спамеры специально ищут неправильно сконфигурированные почтовые серверы,
используя их в качестве шлюзов открытой ретрансляции спама.
Глава 14. Безопасность и система NAT 199
Любая правильно сконфигурированная Linux-система способна выполнять фильтра-
цию пакетов, но если сеть подключена к Internet через маршрутизатор/брандмауэр, луч-
ше настроить фильтрацию всех входящих и исходящих пакетов на одной машине (шлюзе).
Если же одиночная станция подключается к глобальной сети напрямую, придется органи-
зовать на ней простейший брандмауэр, чтобы защитить ее от потенциальных угроз со
стороны хакеров.
Программа ipchains
Начиная с версии 1.1 каждое следующее поколение ядер Linux оснащалось новым меха-
низмом фильтрации пакетов. К ядрам версии 2.0 прилагалась программа ipfwadm, а в ядрах
версии 2.2 появилась программа ipchains, которая считается улучшением своей предшест-
венницы. Программа ipchains в настоящее время распространена наиболее широко.
Принципы использования
Для правильной работы программы ipchains требуется поддержка со стороны ядра.
Нужно включить в ядре функции ipchains, а также скомпилировать одноименную про-
грамму пользовательского уровня. В большинстве дистрибутивов Linux эти действия уже
выполнены.
Программы пользовательского уровня
Возможно, не все читатели понимают, что скрывается под термином “программа пользователь-
ского уровня". Разработчики кодов ядра называют так программы, с которыми пользователи
непосредственно взаимодействуют, в то время как ядро незаметно работает в фоновом режиме,
никак не проявляя себя до тех пор, пока не произойдет какая-нибудь ошибка. Новичков Linux
иногда сбивает с толку то, что программа пользовательского уровня и модуль ядра называются
одинаково, как в случае программ ipchains и iptables.
Если программа ipchains отсутствует в системе или нужно убедиться в наличии самой
свежей версии, обратитесь по адресу http://netfilter.saniba.org/ipchains. Разра-
ботка программы резко замедлилась с появлением серии ядер 2.4.x На момент написания
книги последняя версия программы датировалась 5 октября 2000 года и имела номер 1.3.10.
Синтаксис
Прежде всего напомним, что любые изменения, относящиеся к настройкам ядра, раз-
решено делать только пользователю root. Что касается синтаксиса программы ipchains,
то он выглядит следующим образом:
ipchains [-команда] имя_цепочки [опции]
С помощью программы ipchains можно создавать в ядре цепочки правил фильтрации
пакетов, а также модифицировать и удалять эти цепочки. Прежде чем начинать что-то ме-
нять, проверим, какие цепочки в настоящий момент загружены. Это делает команда
ipchains -L:
rootShost:/ > ipchains -L
Chain input (policy ACCEPT):
Chain forward (policy ACCEPT):
Chain output (policy ACCEPT):
В данном случае никакие правила еще не заданы.
200 Часть II. Средства и технологии маршрутизации в Linux
Добавление правила в цепочку
По умолчанию существуют три цепочки: input, output и forward. В первой из них
обрабатываются входящие пакеты, во второй — исходящие, в третьей — пакеты, которые
поступают в один интерфейс и перенаправляются в другой. Синтаксис добавления прави-
ла в цепочку таков:
ipchains -А имя_цепочки опции
Правило может добавляться только в существующую цепочку. В противном случае бу-
дет получено сообщение об ошибке.
Предположим, к примеру, что нужно запретить все входящие пакеты, разрешив лишь
некоторые из них. Сначала определим политику обработки стандартной цепочки input:
root@host:/ > ipchains -Р input REJECT
Директива REJECT задает отмену всех пакетов. Это слишком жесткое правило, поэтому
разрешим часть трафика:
root@host:/ > ipchains -A input -i ethO -s 10.0.0.0/24 -j ACCEPT
Опция -i задает интерфейс, из которого поступают пакеты. Опция -s определяет от-
правителя пакетов. В данном случае это пакеты локальной сети 10.0.0.0/24. При необхо-
димости можно указать получателя пакетов (опция -d). Флаг ! инвертирует смысл про-
верки. Например, выражение -s ! 10.0.0.0/24 означает “все исходные адреса, кроме
указанного”.
Опция - j задает действие, которое должно выполняться над пакетами, соответствую-
щими данному правилу. В рассматриваемом случае пакеты принимаются (директива
ACCEPT). Существуют следующие стандартные директивы: ACCEPT, DENY (немедленное
удаление пакета), REJECT (удаление пакета с выдачей ICMP-сообщения), MASQ (включение
режима IP-маскирования), REDIRECT (перенаправление пакета прокси-серверу) и RETURN
(конец пользовательской цепочки). Вместо директивы может стоять имя пользователь-
ской цепочки.
Очистка цепочки правил
Опция -F позволяет удалить все правила из цепочки. Например, команда ip-
chains -F input полностью очищает входную цепочку. С другой стороны, имеется оп-
ция -D, которая служит для удаления отдельных правил, а не всех сразу. Все правила в це-
почке нумеруются последовательно, начиная с единицы, поэтому следующая команда уда-
лит первое правило цепочки input:
root@host:/ > ipchains -D input 1
Проверить содержимое полученной цепочки позволяет команда ipchains -L
имя_цепо яки.
Сохранение и восстановление конфигурации
Правила, задаваемые в программе ipchains, не сохраняются автоматически. Всякий
раз после перезагрузки системы их нужно восстанавливать. Авторы программы создали
два сценария, ipchains-save и ipchains-restore, упрощающих данный процесс. По-
лучив требуемую конфигурацию, введите ipchains-save > router_conf ig, чтобы со-
хранить текущие правила в файле router__conf ig, из которого они могут быть загруже-
ны по команде ipchains-restore router__config.
Глава 14. Безопасность и система NAT 201
Система Netfilter и программа iptables
Система Netfilter представляет собой расположенный в стеке сетевых протоколов ядра
Linux набор механизмов, позволяющих различным модулям работать с сетевыми пакета-
ми. Пакет, проходящий через стек протоколов, перехватывается модулем, который может
удалить пакет, перенаправить его, поместить в очередь внешней программы или каким-то
образом изменить.
Программа пользовательского уровня iptables предназначена для добавления пра-
вил в сетевые таблицы. С технической точки зрения это не единственная программа, по-
средством которой можно взаимодействовать с системой Netfilter.
Программа iptables является прямым потомком программы ipchains, т.е. у них много
общего. В основном они имеют одинаковый синтаксис и опции, отличаясь лишь деталями.
Netfilter— это не просто синоним программы iptables. В Netfilter поддерживается
система NAT, имеются модули совместимости с программами ipchains и ipfwadin и сис-
тема отслеживания соединений.
Различия между ядрами версий 2.2.x и 2.4.x
Изменения, произошедшие при переходе от ядер серии 2.2.x к ядрам серии 2.4.x и ка-
сающиеся фильтрации пакетов, IP-маскирования и системы NAT, довольно существенны,
если анализировать внутреннюю структуру ядра. Появились новые мощные возможности,
например фильтрация с учетом состояния сеанса. Но в то же время различия синтаксиса
программ ipchains и iptables далеко не столь велики. Любой, кому доводилось рабо-
тать с программой ipchains, без проблем освоится с программой iptables.
Использование программы iptables
Как и в случае программы ipchains, нужно скомпилировать или включить соответст-
вующие модули ядра и инсталлировать саму программу iptables. Ее исходные коды мож-
но загрузить с Web-узла проекта Netfilter по адресу http: / /netfilter. samba . org.
Самая свежая версия
Даже если в имеющемся дистрибутиве уже инсталлирована программа iptables, все равно
желательно убедиться в наличии самой последней ее версии. На момент написания книги тако-
вой была версия 1.2.2. Все версии, более ранние чем 1.2.1а, имеют проблемы безопасности в
модуле ip_conntrack_ftp. Вряд ли нужно напоминать о том, как важно вовремя обновлять
программы наподобие iptables. Иногда обновления выпускаются с целью исправления не-
больших ошибок и добавления новых возможностей, но чаще всего они связаны с устранением
проблем безопасности и действительно серьезных ошибок. Лучше потратить несколько часов в
месяц на проверку и инсталляцию обновлений, чем несколько дней на восстановление системы
после взлома или несколько месяцев на поиск новой работы.
Синтаксис программы iptables
Как уже говорилось, синтаксис программ iptables и ipchains во многом одинаков.
Программа iptables позволяет добавлять к таблицам правил фильтрации IP-пакетов но-
вые правила, а также модифицировать существующие правила и удалять их.
Правила, цепочки и таблицы
Новичок легко может запутаться, пытаясь понять, чем отличаются друг от друга правила, цепочки и
таблицы. Поясним. Под правилом понимается способ описания критерия, по которому отбирается и
обрабатывается пакет. Цепочка— это набор правил, применяющихся к одной и той же группе
пакетов. Наконец, таблица представляет собой совокупность цепочек. В ядрах серии 2.4.x есть
£. таблица filter, содержащая цепочки input, output и forward, а также таблицы nat и mangle.
202 Часть II. Средства и технологии маршрутизации в Linux
Просмотр цепочек правил
Прежде чем добавлять правила к цепочке, желательно просмотреть, какие правила в
ней уже есть. Вот как это делается:
rootShost: > iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Команда iptables -L имя_цепочки отображает список правил, входящих в задан-
ную цепочку.
Добавление правила к цепочке
По команде -А программа iptables добавляет правило в указанную цепочку. Можно
задать исходный адрес пакета (опция -s), целевой адрес (опция -d), протокол (-р) и вы-
полняемое действие (опция -j). В следующем примере блокируются telnet-соединения,
устанавливаемые не из локальной сети:
root@host: > iptables -A INPUT -s I 10.0.0.0 -p tcp
^--destination-port telnet -j REJECT
Здесь также используется опция --destination-port, определяющая порт, в кото-
рый направляются пакеты. А вот как можно запретить исходящие telnet-соединения:
root@host: > iptables -A OUTPUT -р tcp --destination-port telnet
REJECT
Создание новой цепочки правил
Программа iptables допускает создание пользовательских цепочек. Это делается
следующим образом:
root@host: > iptables -N NEW_CHAIN_NAME
Проверим результат:
root@host: > iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain NEW_CHAIN_NAME (o references)
target prot opt source destination
Удаление правил
Как и в случае программы iptables, опция -F вызывает удаление всех правил из це-
почки. Например, команда iptables -F OUTPUT очищает цепочку OUTPUT.
Глава 14. Безопасность и система NAT 203
Где найти дополнительную информацию
На man-странице, посвященной программе iptables, приведено достаточно подробное
описание программы. Рекомендуем также посетить Web-узел проекта Netfilter, где содержит-
ся ряд прекрасных обучающих пособий, написанных автором системы Netfilter Расти Рас-
селлом (Rusty Russell). Их можно найти по адресу http://netfilter.samba.org/
unreliable-guides.
1Р-маскирование
Во многих случаях требуется, чтобы маршрутизатор выполнял IP-маскирование (IP Masquer-
ading). Обычно оно необходимо, когда закрытая сеть с “неправильными” IP-адресами соединя-
ется с внешним миром, особенно через одиночный канал с одним открытым IP-адресом
(коммутируемое соединение, DSL, кабельный модем). Весь трафик, приходящий на шлюз от
локальных компьютеров и направляемый во внешний мир через один и тот же интерфейс, д ля
стороннего наблюдателя кажется поступающим исключительно от шлюза. Суть механизма в
том, чтобы несколько компьютеров совместно пользовались общим каналом доступа в Internet.
Это и дешевле, и безопаснее. Ведь если сеть скрыта за маршрутйзатором/брандмауэром, зло-
умышленнику нужно сначала взломать шлюз, затем определить структуру локальной сети и
только после этого он сможет приступить к атаке внутреннего узла.
Для многих пользователей конфигурирование ядра Linux выглядит сложной и утоми-
тельной задачей. Это далеко не всегда так. Ниже будет показано, как можно быстро на-
строить механизм 1Р-маскирования.
IP-маскирование с помощью программы ipchains
Если в ядре разрешены функции ipchains, а сама программа скомпилирована, то ре-
жим IP-маскирования включается почти'мгновенно (естественно, у компьютера должно
быть два сетевых интерфейса: один — для локальной сети, а другой — для внешнего соеди-
нения). В первую очередь необходимо активизировать перенаправление IP-пакетов:
# echo 1 > /proc/sys/net/ipv4/ip_forward
Чтобы проверить результат, введите
# cat /proc/sys/net/ipv4/ip_forward
Если на экране будет отображено “1”, значит, ядро сделало то, что нам нужно. Но это
еще не все. Нужно задать правило, разрешающее перенаправление пакетов в цепочке
forward. Тут следует поступить от обратного. Нельзя, чтобы по умолчанию было разре-
шено перенаправление всех пакетов, поэтому сначала запретим его:
# ipchains -Р forward DENY
А теперь ослабим это ограничение, сделав исключение для интерфейса ethl, который
обычно используется для внешних соединений:
# ipchains -A forward -i ethl -j MASQ
IP-маскирование с помощью программы iptables
В ядрах серии 2.4.x включить режим IP-маскирования тоже несложно. Но теперь за это
отвечает не цепочка forward, а таблица nat (IP-маскирование является упрощенной раз-
новидностью системы NAT). Сначала следует убедиться в том, что модуль iptable_nat
загружен (напоминаем: для этого нужно быть зарегистрированным в системе под именем
root). Загрузку модуля выполняет команда modprobe:
# modprobe iptable_nat
204 Часть II. Средства и технологии маршрутизации в Linux
Следующая команда загружает все правила таблицы nat:
# iptables -N nat
Ядро не выдаст никаких сообщений в случае успешного завершения этих операций,
поэтому нужно также вызвать команду Ismod и проверить, какие модули загружены.
Как и в случае программы ipchains, перенаправление IP-пакетов включается такой
командой:
# echo 1 > /proc/sys/net/ipv4/ip_forward
Теперь уже можно с помощью программы iptables создать нужное нам правило:
# iptables -t nat -A POSTROUTING -о ethl -j MASQUERADE
Опция -t задает имя таблицы, в которую добавляется правило, а опция -о — интер-
фейс, через который отправляются пакеты. В системе Netfilter маскирование пакетов
осуществляется иначе, чем в ядрах серии 2.2.x. Эта операция выполняется после всех ос-
тальных (потенциальных) операций над пакетами, что вполне резонно, так как с перена-
правленным пакетом уже очень трудно работать. Цепочка POSTROUTING содержит прави-
ла, которые применяются к пакетам, собирающимся покинуть брандмауэр.
Система NAT
Выше рассматривалась простейшая разновидность системы NAT (Network Address Trans-
lation— трансляция сетевых адресов), которая называется IP-маскированием. Она использу-
ется во множестве ситуаций, при которых несколько компьютеров эксплуатируют общее се-
тевое соединение. Ниже будут описаны более общие случаи применения системы NAT.
В чем разница между системой NAT и 1Р-маскированием
IP-маскирование, как уже говорилось, является одной из форм системы NAT. Необхо-
димость в нем появляется тогда, когда группа компьютеров локальной сети вынуждена де-
лить один открытый IP-адрес, чаще всего назначаемый динамически. В этом случае ло-
кальные пакеты, идущие через шлюз во внешний мир, подвергнутся автоматической заме-
не исходных адресов, чтобы можно было получать ответные пакеты. Подставляемый
адрес не указывается в правиле и вычисляется динамически.
Это не единственный способ трансляции сетевых адресов. Во-первых, подставляемый
исходный адрес можно задавать явно, если он известен заранее. Во-вторых, может суще-
ствовать несколько допустимых исходных адресов; в таком случае они указываются в виде
диапазона. Наконец, разрешается менять не только исходные, но и целевые адреса, если
из соображений безопасности нужно перенаправлять поступающие пакеты в другое место.
Конфигурирование системы NAT с помощью
программы iptables
Для работы системы NAT также необходимо наличие загруженного модуля iptable_nat.
Замечание по поводу имен модулей
Все модули имеют расширение .о. Например, файл упомянутого выше модуля iptable_nat на
самом деле называется iptable_nat. о. Однако команда modprobe принимает имя модуля без
расширения. Об этом следует помнить, так как в случае ошибки команда выдаст сообщение
“Can't locate module iptable_nat.o” (“He могу обнаружить модуль...”). Те, кто не знакомы с
подобной особенностью работы команды, оказываются сбитыми с толку: "Как же так? — говорят
они. — Ведь этот модуль есть. Вот же он!” Подобные вопросы периодически встречаются в
телеконференциях.
Глава 14. Безопасность и система NAT 205
Трансляция исходных адресов
Первый вариант системы NAT, который мы рассмотрим, называется SNAT (Source
Network Address Translation — трансляция исходных сетевых адресов). Как и в случае IP-
маскирования, в SNAT происходит замена исходных адресов отправляемых пакетов. Под-
ставляемый адрес должен быть задан явно, причем это может быть как один адрес, так и
группа адресов. Данная замена осуществляется на самом последнем этапе прохождения
пакета через брандмауэр, чтобы к пакету можно было предварительно применить различ-
ные правила обработки.
Предположим, что организация располагает группой открытых IP-адресов от 194.2.3.4
до 194.2.3.10 и требуется, чтобы маршрутизатор подставлял один из них вместо исходных
адресов отправляемых пакетов. Вот команда, задающая соответствующее правило:
# iptables -t nat -A POSTROUTING -о ethl -j SNAT --to-source
4>195.2.3.4-195.2.3.10
После опции —to-source указываются подставляемые адреса.
Трансляция целевых адресов
Второй вариант NAT называется DNAT (Destination Network Address Translation —
трансляция целевых сетевых адресов). В DNAT замена целевого адреса входящего пакета
происходит перед началом обработки пакета, чтобы можно было задавать правила обра-
ботки на основании того, каким внутренним узлам адресован пакет.
Приведем пример:
# iptables -t nat -A PREROUTING -i ethO -j DNAT —to-destination
MO. 0.0.4-10.0.0.14
В данном случае все пакеты, поступающие через интерфейс ethO, будут направляться
на узлы с IP-адресами 10.0.0.4-10.0.0.14.
Можно задать более конкретное правило, по которому будет проверяться порт, куда
направляется пакет. Например, следующая команда включает систему DNAT только для
HTTP-запросов, адресованных порту 80:
# iptables -t nat -A PREROUTING -i ethO -p tcp --destination-port
4>80 -j DNAT --to-destination 10.0.0.13
Если узел с IP-адресом 10.0.0.13— это Web-сервер, скрытый за маршрутизато-
ром/брандмауэром, то все HTTP-запросы будут направляться только ему. Удобно разгра-
ничивать трафик таким образом, чтобы пакеты протокола HTTP шли на один компьютер,
протокола HTTPS — на другой и т.д. Это позволит незаметно для пользователей распреде-
лять нагрузку между разными машинами.
Резюме
В этой главе были описаны средства, позволяющие повышать безопасность сети и вы-
полнять различные типы фильтрации пакетов в ядрах серий 2.2.x и 2.4.x.
206 Часть II. Средства и технологии маршрутизации в Linux
Мониторинг,
анализ и управление
сетевым трафиком
В этой главе...
Средства мониторинга и анализа
Качество обслуживания
Резюме
207
224
226
В этой главе речь пойдет об имеющихся в Linux средствах мониторинга, анализа и
управления качеством трафика. Все рассматриваемые утилиты свободно распро-
страняются и доступны сетевым администраторам. Программы мониторинга могут рабо-
тать с машинами самых разных типов, начиная от серверов и маршрутизаторов Linux и
заканчивая высококлассными маршрутизаторами ядра Internet.
Средства мониторинга и анализа
В Linux, как и в других разновидностях UNIX, есть большой набор команд, предназна-
ченных для поиска неисправностей и мониторинга сети в режиме реального времени.
Основные из них рассматривались в главе 9, “Сетевые команды”. В сочетании с описывае-
мыми ниже утилитами анализа сети они составляют основной инструментарий сетевого
администратора.
Протокол SNMP
Протокол SNMP (Simple Network Management Protocol — простой протокол управления
сетью) проектировался как открытый протокол конфигурирования и мониторинга сете-
вых станций. Существуют три реализации протокола, различаемые по номерам: 1, 2 и 3.
Первые две поддерживаются достаточно широко, тогда как версия 3 была принята в каче-
стве чернового стандарта лишь в марте 1999 года.
Топология
В SNMP определена топология, называемая системой управления сетью. В эту систему
входит станция-менеджер, которая взаимодействует со станцией управления сетью и се-
тевыми узлами. Последние называются управляемыми устройствами.
Управляемое устройство содержит стек приложений SNMP, называемый агентом
(служит интерфейсом доступа к сетевым объектам данного устройства), а также стек про-
токола IP. Логическая схема такой модели приведена на рис. 15.1.
менеджера сети
Маршрутизатор Linux
Управляемое устройство
Рис. 15.1. Система управления сетью
Управляемое устройство
В SNMP-сообщениях, передаваемых между менеджером й агентами, содержатся иден-
тификаторы сетевых объектов, описанных в так называемой базе управляющей информации
(Management Information Base, MIB). В настоящее время наиболее широко распростране-
на база MIB-П, определение которой дано в документе RFC1213.
База MIB представляет собой древовидную структуру, которая охватывает все данные о
состоянии конкретного устройства, доступные по протоколу SNMP. На рис. 15.2 изобра-
жена высокоуровневая структура базы MIB-II.
208 Часть II. Средства и технологии маршрутизации в Linux
Каждый узел дерева, называемый SNMP-объектом, пронумерован в рамках своего
уровня иерархии. Полная ссылка на объект с указанием всех вышестоящих узлов (для раз-
деления номеров используется точка) называется идентификатором объекта (Object Identi-
fier, OID). Для облегчения ссылок узлам присваиваются также текстовые имена, но схема
именования определяется на высоком уровне, а не в самой базе. Например, интерфейс
ethO Linux-узла в текстовом виде задается так:
.iso.org.dod.internet.mgmt.mib-2.interfaces.ifTable.ifEntry.ifIndex.2
Числовой эквивалент будет следующим:
.1.3.6.1.2.1.2.ifTable.ifEntry.ifIndex.2
Если используется база MIB-II, то большинство SNMP-пакетов допускает сокращенную
запись идентификаторов в рамках дерева MIB-II:
interfaces.ifTable.ifEntry.ifIndex.2
Сообщения
В SNMP определены пять сообщений, посредством которых организуется общение
между менеджером и агентом: GET, GET NEXT, SET, RESPONSE и TRAP. Первые три пере-
даются от менеджера агенту. Сообщение GET запрашивает конкретный атрибут конкрет-
ного объекта, описанного в базе MIB агента. Сообщение GET NEXT запрашивает следую-
щее значение из базы MIB. С помощью сообщения SET менеджер информирует агента о
необходимости соответствующим образом установить заданный атрибут указанного объ-
екта. В ответ на любое из этих трех сообщений возвращается сообщение RESPONSE.
Единственное сообщение, посылаемое по инициативе агента, — это TRAP. Оно предна-
значено для передачи менеджеру срочного асинхронного уведомления (называемого пре-
рыванием'). Например, если какой-то интерфейс теряет физическое соединение с сетью,
агент генерирует сообщение TRAP, включая в него идентификатор OID интерфейса.
Аутентификация
Поскольку посредством протокола SNMP можно наблюдать за сетевыми узлами и
управлять ими, необходимы какие-то способы защиты узлов от несанкционированного
доступа. В SNMP определены два уровня доступа: открытый и частный. На открытом
уровне к узлу возможен только доступ для чтения, тогда как на частном уровне возможны и
чтение, и запись SNMP-данных. К сожалению, на обоих уровнях пароли передаются в тек-
стовом виде.
Безопасность протокола SNMP
Рабочая группа организации IETF, занимающаяся проектированием протокола SNMP, искала
способы повышения безопасности второй версии протокола, но члены группы так и не смогли
прийти к единому мнению, в результате чего появились два варианта протокола: V2u и V2c. Оба
они не лишены недостатков с точки зрения безопасности. Делаются попытки устранить их в
версии 3. Информацию об этом можно получить по адресу http://www.ietf.org/html.
charters /snmpv3-charter. html.
SNMP в Linux (пакет NET-SNMP)
Раньше в Linux существовали две реализации протокола SNMP: одна — университета
Карнеги-Меллона (CMU), а вторая — Калифорнийского университета в Дэвисе (UCD). Оба
этих пакета по-прежнему можно найти в Internet, но в настоящее время все разработки со-
средоточены в рамках пакета NET-SNMP.
Пакет NET-SNMP, ранее известный как UCD-SNMP, доступен по адресу http: / /
sourceforge.net/projects/net-snmp/. Текущая версия дистрибутива, 4.2.1, все еще
Глава 15. Мониторинг, анализ и управление сетевым трафиком 209
называется по-старому, но все последующие дистрибутивы уже будут носить новое имя.
В состав пакета входят SNMP-агент, библиотека функций SNMP, а также утилиты команд-
ной строки, предназначенные для выдачи сообщений.
Агент NET-SNMP не только работает с базой MIB-II, но и напрямую контролирует за-
полнение жесткого диска и работу процессов. Агент пошлет управляющей станции сооб-
щение о прерывании, если заполнение диска достигнет критической отметки или задан-
ный процесс перестанет выполняться. Поддерживаются также сценарии, посредством ко-
торых генерируются дополнительные прерывания.
Инсталляция
Чтобы иметь возможность инсталлировать пакет NET-SNMP, нужно загрузить текущую
версию дистрибутива (на момент написания книги она имела номер 4.2.1) с Web-узла
sourceforge. net. Поместите дистрибутив в каталог, где хранятся исходные коды. В нашем
случае это /usr/src. Инсталляцию пакета может выполнить только пользователь root.
Распакуйте архив с помощью команды
[rootSlefty src]# gunzip ucd-snmp-4.2.1.tar.gz
а затем раскройте его:
[rootSlefty src]# tar xvf ucd-snmp-4.2.1. tar
Теперь перейдите в созданный каталог и прочтите файлы README и INSTALL, в кото-
рых приведены уточнения, касающиеся процедуры инсталляции. Желательно также за-
глянуть в файлы FAQ и NEWS.
На следующем шаге нужно запустить сценарий конфигурации, который запросит у сис-
темы различные установки, например, какой компилятор языка С используется, какие
библиотеки присутствуют, и т.д.:
[rootSlefty ucd-snmp-4.2.1]# ./configure
Сценарий запросит у пользователя адрес контактного лица, ответственного за работу
SNMP-агента. Эта информация возвращается Linux-станцией в ответ на SNMP-запрос, ес-
ли агент функционирует. Далее сценарий поинтересуется географическим местоположе-
нием Linux-станции, а также именем журнального файла (по умолчанию— /var/log/
snmpd.log). В конце будет выдан запрос по поводу имени конфигурационного каталога
(по умолчанию — / var/ucd).
После этого сценарий создаст файл сборки проекта, и можно вызывать команду make:
[rootSlefty ucd-snmp-4.2.1]# make
Убедитесь в том, что права доступа заданы правильно:
[root@lefty ucd-snmp-4.2.1]# umask 022
Остается с помощью команды make install выполнить инсталляцию пакета:
[root@lefty ucd-snmp-4.2.1]# make install
Пакет будет помещен в структуру каталога /usr/local. Выйдите из системы и снова
зайдите под именем root, чтобы было восстановлено прежнее значение umask. Если не-
обходима поддержка протокола SNMPvS, потребуется инсталлировать пакет OpenSSL
(www. openssl. org).
Агент NET-SNMP работает в виде демона и называется snmpd. Он обращается к конфи-
гурационному файлу /usr/local/share/snmp/snmpd. conf, в котором хранятся строки
паролей (официальное название такой строки — “community name”, т.е. имя сообщества) и
параметры прерываний. Разрешается задавать расширенные установки, например назна-
210 Часть II. Средства и технологии маршрутизации в Linux
чать пароли для доступа к конкретным объектам и ограничивать запросы менеджера кон-
кретными IP-адресами.
Прежде чем запускать демон, создайте конфигурационный файл следующего вида:
#
# snmpd.conf
# Пример.
#
# Параметры контроля доступа.
# rwcommunity: пароль для доступа на частном уровне
# (чтение/запись).
rwcommunity fullaccess
# rocommunity: пароль для доступа на открытом уровне
# (только чтение).
rocommunity readaccess
Это очень простой файл, в котором определены только пароли. Переменная rwcommunity
содержит пароль, позволяющий получить полный доступ к узлу. В данном случае он равен
fullaccess. В переменной rocommunity содержится пароль доступа только для чтения
(равен readaccess). Если запустить демон, не задав эти пароли, любой пользователь сможет
послать данному узлу SNMP-запрос по сети.
Запуск демона осуществляется следующим образом:
[root@lefty /root]# snmpd
Если все пройдет успешно, демон перейдет в режим ожидания запросов, добавив за-
пись в журнальный файл:
[root@lefty /root]# cat /var/log/snmpd.log
UCD-SNMP version 4.2.1
Чтобы лучше понять, как работает SNMP-агент, нужно поближе познакомиться с ути-
литами, входящими в пакет NET-SNMP. Они не являются собственно менеджерами, а
лишь генерируют сообщения, поддерживаемые менеджерами: GET, GET NEXT и SET.
Команды
В пакет NET-SNMP входят утилиты командной строки snmpget, snmpgetnext и
snmpset, генерирующие сообщения GET, GET NEXT и SET соответственно. Есть также
команда snmpwalk, которая с помощью сообщения GET NEXT собирает значения всех пе-
ременных, относящихся к указанному идентификатору объекта.
Ниже показаны примеры использования всех четырех команд, посылающих запросы
запущенному выше демону.
snmpget агент пароль OID. Команда snmpget запрашивает у заданного агента
значение, соответствующее указанному идентификатору объекта. Вот как, к приме-
ру, можно узнать общее время работы системы:
[root@lefty /root]# snmpget 192.168.1.254 readaccess system.sysUpTime. О
system. sysUp'Time . 0 = Timeticks: (76980) 0 : 12:49.80
Демон snmpd распознает идентификаторы практически всех объектов базы MIB-II,
так что подобным образом можно получить очень много полезной информации. На-
пример, в ветви icmp накапливаются сведения о трафике протокола ICMP. Следующая
команда определяет число ping-пакетов (эхо-запросов), полученных данным узлом:
Глава 15. Мониторинг, анализ и управление сетевым трафиком 211
[root@lefty /root]# snmpget 192.168.1.254 readaccess icmp.icmpInEchos.0
icmp.icmpInEchos.0 = Counter32: 43
Как видите, таких запросов было 43.
Команда snmpget не может заменить полноценную станцию управления сетью, но
она во много раз увеличивает возможности существующих средств автоматизации,
контролирующих деятельность системы.
snmpgetnext агент пароль OID. Команда snmpget запрашивает у заданного аген-
та значение следующего объекта базы MIB, например:
[root@lefty /root]# snmpget 192.168.1.254 readaccess icmp.icmpInEchos.О
icmp.icmpInEchoReps.0 = Counter32: 3
Показанная команда возвращает число эхо-ответов, полученных системой.
snmpwalk агент пароль OID. Команда snmpwalk посылает сообщения GET NEXT
до тех пор, пока не будут получены все переменные, относящиеся к объекту с задан-
ным идентификатором. Таким способом можно узнавать имена имеющихся иден-
тификаторов. Например, следующая команда сообщает всю информацию о прото-
коле ICMP:
[root@lefty /root]# snmpget 192.168.1.254 readaccess icmp
icmp.icmpInMsgs.0 = Counter32: 12
icmp.icmpInErrors.0 = Counter32: 0
icmp.icmpInDestUnreachs.0 = Counter32: 6
icmp.icmpInTimeExcds.0 = Counter32: 0
icmp.icmpInParmProbs.0 - Counter32: 0
icmp.icmpInSrcQuenchs.0 = Counter32: 0
icmp.icmpInRedirects.0 = Counter32: 0
icmp.icmpInEchos.0 = Counter32: 3
icmp.icmpInEchoReps.0 = Counter32: 3
icmp.icmpInTimestamps.0 - Counter32: 0
icmp.icmpInTimestampReps.0 = Counter32: 0
icmp.icmpInAddrMasks.0 - Counter32: 0
icmp.icmpInAddrMaskReps.0 = Counter32: 0.
icmp.icmpOutMsgs.0 = Counter32: 9
icmp.icmpOutErrors.0 = Counter32: 0
icmp.icmpOutDestUnreachs.0 = Counter32: 6
icmp.icmpOutTimeExcds.0 = Counter32: 0
icmp.icmpOutParmProbs.0 = Counter32: 0
icmp.icmpOutSrcQuenchs.0 = Counter32: 0
icmp.icmpOutRedirects.0 = Counter32: 0
icmp.icmpOutEchos.0 = Counter32: 0
icmp.icmpOutEchoReps.0 = Counter32: 3
icmp.icmpOutTimestamps.0 = Counter32: 0
icmp.icmpOutTimestampReps.0 = Counter32: 0
icmp.icmpOutAddrMasks.0 = Counter32: 0
icmp.icmpOutAddrMaskReps.0 = Counter32: 0
А вот как можно получить все данные, составляющую таблицу маршрутизации прото-
кола IP:
[root@lefty /root]# snmpget 192.168.1.254 readaccess ip. ipRouteTable
ip.ipRouteTable.ipRouteEntry.ipRouteDest.0.0.0.0 = IpAddress: 0.0.0.0
ip.ipRouteTable.ipRouteEntry.ipRouteDest.127.0.0.0 = IpAddress: 127.0.0.0
ip.ipRouteTable.ipRouteEntry.ipRouteDest.192.168.1.0 = IpAddress: 192.168.1.0
ip.ipRouteTable.ipRouteEntry.ipRouteDest.192.168.1.254 = IpAddress:
^192.168.1.254
ip.ipRouteTable.ipRouteEntry.ipRoutelfIndex.0.0.0.0 = 2
ip.ipRouteTable.ipRouteEntry.ipRoutelfIndex.127.0.0.0 = 3
ip.ipRouteTable.ipRouteEntry.ipRoutelfIndex.192.168.1.0 = 2
ip.ipRouteTable.ipRouteEntry.ipRoutelfIndex.192.168.1.254 = 2
212 Часть II. Средства и технологии маршрутизации в Linux
ip.ipRouteTable.ipRouteEntry.ipRouteMetricl.О.О.О.О = 1
ip.ipRouteTable.ipRouteEntry.ipRouteMetricl.127.О.О.О - О
ip.ipRouteTable.ipRouteEntry.ipRouteMetricl.192.168.1.О = 0
ip.ipRouteTable.ipRouteEntry.ipRouteMetricl.192.168.1.254 = 0
ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.0.0.0.0 = IpAddress: 192.168.1.1
ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.127.0.0.0 = IpAddress: 0.0.0.0
ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.192.168.1.0 = IpAddress: 0.0.0.0
ip.ipRouteTable.ipRouteEntry.ipRouteNextHop.192.168.1.254 = IpAddress: 0.0.0.0
ip.ipRouteTable.ipRouteEntry.ipRouteType.0.0.0.0 = indirect(4)
ip.ipRouteTable.ipRouteEntry.ipRouteType.127.0.0.0 = direct(3)
ip.ipRouteTable.ipRouteEntry.ipRouteType.192.168.1.0 = direct(3)
ip.ipRouteTable.ipRouteEntry.ipRouteType.192.168.1.254 = direct(3)
ip.ipRouteTable.ipRouteEntry.ipRouteProto.0.0.0.0 = local(2)
ip.ipRouteTable.ipRouteEntry.ipRouteProto.127.0.0.0 = local(2)
ip.ipRouteTable.ipRouteEntry.ipRouteProto.192.168.1.0 = local(2)
ip.ipRouteTable.ipRouteEntry.ipRouteProto.192.168.1.254 = local(2)
ip.ipRouteTable.ipRouteEntry.ipRouteMask.0.0.0.0 = IpAddress: 0.0.0.0
ip.ipRouteTable.ipRouteEntry.ipRouteMask.127.0.0.0 = IpAddress: 255.0.0.0
ip.ipRouteTable.ipRouteEntry.ipRouteMask.192.168.1.0 = IpAddress: 255.255.255.0
ip.ipRouteTable.ipRouteEntry.ipRouteMask.192.168.1.254 = IpAddress: 255.255.255.255
ip.ipRouteTable.ipRouteEntry.ipRoutelnfо.0.0.0.0 = OID: . ccitt.zeroDotZero
ip.ipRouteTable.ipRouteEntry.ipRoutelnfо.127.0.0.0 = OID: .ccitt.zeroDotZero
ip.ipRouteTable.ipRouteEntry.ipRoutelnfo.192.168.1.0 = OID: .ccitt. zeroDotZero
ip.ipRouteTable.ipRouteEntry.ipRoutelnfo.192.168.1.254 = OID: .ccitt.zeroDotZero
snmpset агент пароль_частного_уровня OID тип значение. Команда snmpset
посылает агенту сообщение SET с указанием нового значения требуемого объекта. На-
пример, следующая команда меняет контактный адрес:
[rootSlefty /root]# snmpset 192.168.1.254 fullaccess system.sysContact.0
1>s root@testme.net
Задаваемый тип должен соответствовать типу существующего объекта. В данном
случае тип объекта — s (строка). Возможные типы перечислены в табл. 15.1.
Таблица 15.1. Типы данных, поддерживаемые командой snmpset
Сокращение Тип
а IP-адрес в формате ххх.ххх.ххх.ххх
ь Цепочка битов
d Десятичное число
1 Целое число
п Пустой объект
о Идентификатор объекта
S Строка
t Число интервалов времени
U Беззнаковое целое
X Шестнадцатеричное целое
Команде snmpset требуется “частный” доступ к SNMP-агенту, так как она меняет конфигу-
рацию системы. Эти изменения принимаются агентом, но они могут не сохраняться при пере-
загрузке системы. По крайней мере, пакет NET-SNMP, как и другие SNMP-пакеты UNIX-систем,
практически не поддерживает возможность сохранения изменений. Например, заданный вы-
ше новый контактный адрес не будет сохранен в результате перезагрузки.
Глава 15. Мониторинг, анализ и управление сетевым трафиком 213
Программа MRTG
Программа MRTG (Multi-Router Traffic Grapher — многомаршрутный визуальный ана-
лизатор трафика) является, наверное, наиболее популярным свободно распространяемым
инструментом сетевого анализа. Она посылает SNMP-сообщения GET, собирая информа-
цию о статистике функционирования сетевых интерфейсов. Результаты сохраняются в
файле, и на их основании создаются графики работы сети, по которым можно выявить
периоды высокой и низкой загруженности, определить среднюю загруженность сети и т.д.
Программа MRTG доступна для большинства вариантов UNIX, включая Linux (есть
даже версия для Windows). Ее исходные коды можно получить по адресу http: //people .
ее.ethz.ch/~oetiker/webtools/mrtg. Программа получает SNMP-данные посредст-
вом пакета NET-SNMP, который, следовательно, должен быть заранее инсталлирован в
системе.
Программа MRTG написана на языке Perl, интерпретатор которого тоже должен при-
сутствовать в системе. Желательно, чтобы он имел версию 5.05 или выше. Более деталь-
ные требования, касающиеся инсталляции программы, приведены в файле doc/unix-
guide . txt (находится в исходном каталоге программы).
Инсталляция
На момент написания книги текущая версия программы имела номер 2.9.12. Именно ее
инсталляция описывается ниже.
После загрузки дистрибутива необходимо выполнить следующую последовательность
действий.
1. Войдите в систему под именем root и перейдите в каталог, куда был загружен пакет:
[rootSlefty /root]# cd /usr/src
2. Распакуйте gzip-архив:
[rootSlefty src)# gunzip mrtg-2.9.12.tar.gz
3. Раскройте tar-архив:
[rootSlefty src]# tar xvf mrtg-2.9.12.tar
4. Перейдите в созданный каталог:
[root@lefty src]# cd mrtg-2.9.12
5. Выполните сценарий конфигурации:
[rootSlefty mrtg-2.9.12]# ./configure
6. Выполните команду make:
[rootSlefty mrtg-2.9.12 ] # make
7. Наконец, выполните команду make install:
[rootSlefty mrtg-2.9.12]# make install
В результате будет создан инсталляционный каталог /usr/local/mrtg-2, в который
будут помещены все двоичные и прочие необходимые файлы. Перейдите в этот каталог:
[root@lefty mrtg-2.9.12]# cd /usr/local/mrtg-2
Программе MRTG нужен каталог, доступный Web-серверу. Обычно Web-сервер Apache
помещает HTML-документы в каталог /home/httpd/html. Создадим в нем подкаталог для
файлов программы MRTG:
[root@lefty mrtg-2]# mkdir /home/httpd/html/mrtg
214 Часть II. Средства и технологии маршрутизации в Linux
Нужно также создать каталог для конфигурационных файлов:
[root@lefty mrtg-2]# mkdir cfg
Конфигурирование
Теперь можно приступать к конфигурированию программы MRTG с помощью сцена-
рия cfgmaker:
[root@lefty mrtg-2]# bin/cfgmaker --global 'WorkDir:
'Ъ/home/httpd/html/mrtg' --output /usr/local/mrtg-2/cfg/mrtg.cfg
4>readaccess@192.168.1.254
Опция --global с параметром WorkDir сообщает сценарию, в каком каталоге про-
грамма MRTG должна сохранять создаваемые файлы. Опция —output сообщает о том,
куда нужно записывать конфигурационную информацию. Последний параметр — это па-
роль для открытого доступа и адрес опрашиваемого агента.
После завершения'сценария в каталоге /usr/local/mrtg-2/cfg будет создан файл
mrtg . cfg. С его помощью можно проверить конфигурацию программы:
[root@lefty mrtg-2]# /usr/local/mrtg-2/bin/mrtg /usr/local/mrtg-2/cfg/mrtg.cfg
Rateup WARNING: /usr/local/mrtg-2/bin/rateup could not read the
'^primary log file for 192.168.1.254_2
Rateup WARNING: /usr/local/mrtg-2/bin/rateup The backup log file
4>for 192.168.1.254_2 was invalid as well
Rateup WARNING: /usr/local/mrtg-2/bin/rateup Can’t remove
Ъ192.168.1.254_2. old updating log file
Rateup WARNING: /usr/local/mrtg-2/bin/rateup Can’t rename
^192.168.1.254_2 . log to 192.168.1.254_2.old updating log file
Показанные предупреждения всегда появляются при первом запуске программы, так
как журнальные файлы еще не были созданы. Выполним команду еще раз:
[rootSlefty mrtg-2]# /usr/local/mrtg-2/bin/mrtg /usr/local/mrtg-2/cfg/mrtg.cfg
Rateup WARNING: /usr/local/mrtg-2/bin/rateup Can’t remove
1>192.168.1.254_2 . old updating log file
Осталось только одно предупреждение. После третьего запуска и оно исчезнет:
[rootSlefty mrtg-2]# /usr/local/mrtg-2/bin/mrtg /usr/local/mrtg-2/cfg/mrtg.cfg
В результате выполненных действий программа MRTG получила данные, которые
можно просмотреть. Если ввести в броузере адрес каталога mrtg (http://192.168.
1.254/mrtg/), будет выдан список подготовленных файлов (рис. 15.3).
Щелкните на файле с расширением . html, чтобы увидеть графическое представление ра-
боты сетевого интерфейса. В данном примере файл называется 192.168.1.254_2. html.
Адрес 192.168.1.254— это IP-адрес интерфейса, а 2— его индекс (индекс 1 закреплен за интер-
фейсом обратной связи). Результат будет примерно таким, как на рис. 15.4 (если график создан,
но данных на нем нет, выполните показанную выше команду mrtg еще несколько раз).
Глава 15. Мониторинг, анализ и управление сетевым трафиком 215
Index of /mrtg
N-ч н
30-Kay-2001 02:08
ЗО-Мау-2001 02:10 ilk.
30-May-2001 02:08 Bk.
30-Иау-2001 02:00 8k
30-May-2001 02:08 9k
30-May-2001 02:10 8k
30-May~2001 02:10 45k
30-May-2001 02:09 45k
Apachell.3.12 Server al localhosi Port 80
' Document Done
Рис. 15.3. Web-каталог программы MRTG
л.тПёТх!
, _g £o't yiew fio Cornrrunicator tje:p
w J z3 .л -4 I J’ ‘1 li |W
Dock Hebad Home Search Ne'scape Ft* jerurify Shop Stop
ii«-»ra i * <*.awrli »"j j* w*jrC«aM
' IndjrtMetvaae g WebMai Eg Rajq g M: gVaHat-Pages g. Рои^ j> Cetendai jjj СЬмтяЬ
Traffic Analysis for 2 — lefty ~
System lefty in Anywhere USA
Mamtamer root@tesfcne net Ж
Description ethO
iflype ethemetCsrnacd (6)
ifName.
Max Speed 1250 0 kBytes/s О
Ip 192 168 1 254 (lefty mcwnte net)
The statistics were last updated Wednesday, 30 May 2001 at 2:10,
at which tune 'lefty' had been up for 3:41:03
Daily* Graph (5 Minute Average)
: _ 1200.0 ---7”!--7-!----!---!-•--; ! •---!----1---------П----ГТ
g soo.o 444444...;I ь 44.44-444
g З00.0 . .{...i.-i-.i -I. .....
т o.« .ч И H ;
2 0 22 20 1B 16 14 12 10 8 6 4 2 0 20 18
Max 1W.OB/»(00%) Averaga 1590В/б(00%) Cunent . 1390B/s(00%)
Мм Out J187 0 B/s (01%) Average J j1, 1187 0 B/s (P 1%) Cunent 41 1187 0 B/s (0 1%)
Weekly* Graph (30 Minute Average)
Рис. 15.4. Статистика работы сетевого интерфейса, отображаемая программой MRTG
216 Часть II. Средства и технологии маршрутизации в Linux
Теперь нужно сконфигурировать систему так, чтобы команда mrtg вызывалась регу-
лярно. Вызовите команду crontab с флагом -е:
[root@lefty mrtg-2]# crontab -е
и добавьте в crontab-файл запись, задающую запуск команды mrtg каждые пять минут:
0,5,10,15,20,25,30,35,40,45,50,55 * * * * /usr/local/mrtg-2/bin/mrtg
(b/usr/local/mrtg-2 cfg/mrtg.cfg
Программа MRTG пока что отображает данные в несколько неудобном формате. Но в
пакет MRTG входит специальная утилита indexmaker, которая формирует индексную
страницу со ссылками на все контролируемые узлы (рис. 15.5). В нашем примере индекс
создается с помощью такой команды:
[root@lefty mrtg-2]# bin/indexmaker /usr/local/mrtg-2/cfg/mrtg.cfg
'Ъ /home/ht tpd/html /mrtg/index. h tml
Права доступа к файлу index. html
Возможно, придется вручную поменять права доступа к файлу index.html, чтобы к нему мог
обращаться владелец процесса Web-сервера.
file Edit View Go Communicator Help
W J О *>* Ы • t if Й
л Beck Reload- Homn SaMtih HetK-apo PwK Seeurfy Shop Slop
ПС>ЙГ 11 - >
J*i. Indent Menage }ч. <WebMei Iji Radn Pecple 4, YafcwReget Oowfoed 4 Calende, '~*i Chsnnelr
MRTG Index Page
Traffic Analytic for 2 — lefty
22 20 18 16 14 12 10
2 0 22
sf *Ф"' Occumett Done _____________________________ *“•* •
Рис. 15.5. Индексная страница
Глава 15. Мониторинг, анализ и управление сетевым трафиком 217
Если с помощью сценария cfgmaker будет добавлено еще несколько проверяемых уз-
лов, не забудьте повторно запустить утилиту indexmaker. Со временем наполнение ин-
дексной страницы станет более содержательным (рис. 15.6).
Ч! IndentMettage 3 WebMri U1 Ratio People 4, YetowPege* JJj Downbad Calender Омплей
MRTG Index Page
Traffic Analysis for ethO - lefty
Traffic Analysis for ethO - righty
TraffieAnalysis for setO - gateway
16 14 12 10 6 6 4 2 0 22 20 18 16 14 12 10 8
J-HSMULT! ROWER TRAEFlGiGRAPHERi
version 2 9 12 Tobias Qeliker <oetikerffiee ethz.ch»
and Dave Rant? <dlrffibungi.com>
Document Done
I
k
Рис. 15.6. Заполненная индексная страница
Программа IPTraf
IPTraf — это программа мониторинга сети, ориентированная на сбор данных в реаль-
ном времени. В отличие от сетевых анализаторов, например tcpdump, программа IPTraf
сообщает статистические данные, известные сетевому драйверу Linux. Но в то же время
ей необходимо, чтобы интерфейс работал в беспорядочном режиме, следовательно, про-
грамму может запускать только пользователь root.
Инсталляция программы очень проста: нужно лишь раскрыть и распаковать архив, а
затем запустить сценарий настройки. По этой причине мы не описываем здесь данный
процесс. Программа помещается в каталог/usr/local/bin.
Знакомство
Управление программой IPTraf осуществляется с помощью меню, что делает програм-
му особенно ценной для сетевых администраторов (рис. 15.7). Перемещаться по меню
можно с помощью клавиш управления курсором; кроме того, с каждым элементом меню
связана клавиша быстрого вызова (выделена).
218 Часть II. Средства и технологии маршрутизации в Linux
file Edit Setup Central Window Help
El
IPTraf
|P traffic E°nitor
General interface statistics
Detailed interface statistics
Statistical breakdowns
LAN station monitor
1CP display filters
Other protocol filters
Configure
Exit
Displays current IP traffic information
Д-Move selector ДпИа-execute
Рис. 15.7. Основное меню программы IPTraf
Ниже описаны функции, поддерживаемые программой IPTraf.
Монитор трафика
Модуль мониторинга IP-трафика позволяет следить за работой сетевых интерфейсов,
распознаваемых ядром Linux (рис. 15.8). В верхней половине окна отображаются ТСР-
соединения. На рис. 15.8 представлено telnet-соединение (порт 23) между узлами
192.168.1.254 и 192.168.1.101. Программа сообщила о том, что узел 192.168.1.254 отправил
372 пакета, аузел 192.168.1.101 — 366.
file Edit . getup Central- window Help
IPTraf
TCP Connections (Source Host:Port)
192.168.1.254:23
192.168.1.101:1298
Packets
372
366
— Bytes Flags
67711 -PA-
14640 —A-
Iface
ethO
ethO
X|
TCP: 1 entries
Active —
ICHP echo req (60 bytes) from 192.168.1.101 to 192.168.1 .2511 on ethO
ICMP echo rply (60 bytes) from 192.168.1 .2511 to 192.168.1.101 on ethO
ICMP echo req (60 bytes) from 192.168.1.101 to 192.168.1 .2511 on ethO
ICMP echo rply (60 bytes) from 192.168.1.2511 to 192.168.1.101 on ethO
ARP request for 192.168.1 .252 (46 bytes) from 0020?8cf3d66 to fffITffI If ГI о
Bottom ------ Elapsed time: 0:01 ----------------------------------------------
IP: 82831 TCP: 82851 UDP: . fl ICMP: 48fl Hon-IP: 46|
||1с1/Ьп/Роио/Ра0пДЯ1ПМДпЯЯо»н1»«11а!^М1ДЯ|ТЖПД1Я|»Да118»1а.ЖХИаз1^М
Рис. 15.8. Окно монитора IP-трафика
Глава 15. Мониторинг, анализ и управление сетевым трафиком 219
В колонке Flags сообщается о том, какие флаги были установлены в последнем
TCP-пакете. Возможные флаги перечислены в табл. 15.2.
Таблица 15.2. TCP-флаги в программе IPTraf
Сокращение IPTraf Сокращение TCP Назначение
А АСК Подтверждение
Р PSH “Проталкивание” всех данных в очередь
и URG Пакет помечается как срочный
S SYN Синхронизация в процессе квитирования
Программа IPTraf сообщает также о сбросе соединения по флагу RST, получении не-
подтвержденных пакетов FIN (сообщение DONE) и корректном закрытии соединения
(сообщение CLOSED). Нажав клавишу <т>, можно просмотреть размер пакета и окна в ка-
ждом соединении.
В нижней половине окна показаны самые последние пакеты, не относящиеся к трафику
протокола TCP. На рис. 15.8 это эхо-запросы ICMP (команда ping) и запросы протокола ARP.
В нижней части экрана отображаются две строки. В первой из них содержатся счетчики
числа пакетов для протоколов IP, TCP, UDP и ICMP, а также трафика протоколов, не входя-
щих в стек IP. Вторая строка — это меню программы IPTraf. С помощью клавиш управления
курсором можно прокручивать содержимое окна вверх и вниз, если есть более одного экрана
информации. После нажатия клавиши <w> происходит переключение фокуса между верхней
и нижней половинами окна. О назначении клавиши <т> уже говорилось выше.
После нажатия клавиши <s> список TCP-соединений будет отсортирован по числу па-
кетов. В результате соединения с наибольшим трафиком окажутся в верхней части списка.
Клавиша <х> служит для возврата в основное меню программы IPTraf.
Общая статистика интерфейсов
В окне общей статистики интерфейсов дан базовый отчет об объемах трафика, прохо-
дящего через все сетевые интерфейсы (рис. 15.9). Отображаются счетчики IP-пакетов, па-
кетов, не относящихся к протоколу IP (например, IPX), а также пакетов, которые были
распознаны как IP-пакеты, но содержали неправильный заголовок.
File Edit Setup Csntrol Window Help -
Рис. 15.9. Окно общей статистики интерфейсов
220 Часть II. Средства и технологии маршрутизации в Linux
Статистика отдельных интерфейсов
В окне статистики отдельных интерфейсов администратор может просмотреть более
детальный отчет о структуре трафика, проходящего через тот или иной интерфейс. На
рис. 15.10 представлен отчет по интерфейсу ethO. В нижней части окна показана пропу-
скная способность, как общая, так и входящая/исходящая.
file Edit Setup Control Window Help
IPTraF
Statistics for ethfl -----------------------------------------------------------
Total Total Incoming Incoming Outgoing Outgoing
Packets Bytes Packets Bytes Packets Bytes
Total: 1962 1923211 972 879S92 990 10'13319
IP: 19S9 1093361 970 863930 989 1029031
TCP: UDP: ICMP: Other IP: Non-IP: 787 0 1172 0 3 196305 0 1697056 0 162
Total rates: 21. Й 10.3 kbits/sec packets/sec
Incoming rates 2.5 5.1 kbits/sec packets/sec
Outgoing rates Elapsed time: 0:00 18.5 5.1 kbits/sec packets/sec
| 0-exit
384 154 02 *103 1809031
0 0 0 0
586 848528 586 8*18528
0 0 0 U
2 120 1 42
Broadcast packets: 1
Broadcast bytes: 60
IP checksum errors 0
Рис. 15.10. Статистика интерфейса ethO
По статистике отдельных интерфейсов можно быстро находить источники проблем
при отладке сети. Например, если повнимательнее присмотреться к рис. 15.10, то можно
заметить, что число ICMP-пакетов очень велико в сравнении с общим числом пакетов. Это
последствия работы команды ping.
Статистический анализ
В окне статистического анализа для конкретного интерфейса приводится сводка паке-
тов, составленная по одному из двух критериев: распределение по портам TCP/UDP или
размеры пакетов (рис. 15.11).
Монитор станции ЛВС
В окне монитора станции ЛВС отображается статистическая информация канального
уровня (рис. 15.12). Благодаря этой информации можно выявлять проблемы в работе Eth-
ernet-платы.
Фильтры TCP и другие фильтры
В процессе статистического анализа может потребоваться проверить только опреде-
ленные виды трафика. С помощью команд меню TCP display filters и Other protocol filters
можно уточнить, трафик каких протоколов нужно или не нужно учитывать. ТСР-фильтры
применимы только по отношению к ТСР-трафику.
Для создания фильтра нужно выполнить несложную последовательность действий.
Выберите в меню TCP display filters команду Define new filter. Будет выдан запрос на ввод
описания фильтра. Введите строку “Telnet Traffic Only” (рис. 15.13).
Глава 15. Мониторинг, анализ и управление сетевым трафиком 221
file Edit Setup Cantrol Window Help
IPTraf
г Packet Distribution by Size Elapsed tine: 0:00 Elapsed time: 0:00 Elaps*
e 0
0 Packet size brackets For interface ethO m
е c
Packet Size (bytes) Count Packet bize (bytes) Count
1 to 75: m| 751 to 825: 0
76 to 150: 279 826 to 900: 2448
151 to 225: 116 901 to 975: 1555
226 to 300: 23 976 to 1050: 1
301 to 375: 6 1051 to 1125: 1692
376 to 450: 1 1126 to 1200: U
451 to 525: 0 1201 to 1275: 0
526 to 600: 1552 1276 to 1350: 3856
601 to 675: 1886 1351 to 1425: 0
676 to 750: 0 1426 to 1500: 485
Interface MTU is 1500 bytes
Рис. 15.11. Статистический анализ: размеры пакетов
file Edit Setup Cantrol Window Help
ВЛВЯМВ^МНВ^М11^Н1ННМНН1ИИ11111^ННМИВИННИМНННГа]'
---- Pktsln - IP In - Bytesln - InRate PktsBut — IP Out BytesOut OutRate —'
Ethernet HU addr: OBeO294bac0c on ethO
L 85 85 5100 2.0 88 88 26382 10.11
Ethernet HU addr: 0B4Bd00B6a72 on ethO
L 88 88 26382 10.8 85 85 510([ 2.«i
Ethernet HU addr: 002B78cF3d66 on ethO
>0 0 0 0.0 1 О 60 0.0
Ethernet HU addr: FFFFFFFFFFFF on ethO
1 1 0 60 0.0 О О 0 0.0
I 4 entries ---- Elapsed tine: 0:00 ---- InRate and OutRate are
|Up/bo»n/PgUp/PgOn-scroll window
in kbits/sec —
Рис. 15.12. Окно монитора станции ЛВС
222 Часть II. Средства и технологии маршрутизации в Linux
file Edit Setup Control Window Help
IPTraf
I IP traffic monitor
Enter a description for this filter
[BnSffl-accpnt AOIbM-cancpl
Configure
Exit
j|Up/Down|
l-Moue selector
lEnter
-execute
s
cs
Detach filter
Edit filter..
Delete filter
Exit menu
filter...
er...
d
Рис. 15.13. Будет фильтроваться только трафик telnet
Далее будет отображено окно, в котором необходимо ввести IP-адреса и порты
(рис. 15.14). В первых двух полях задаются адреса отправителя и получателя (в произволь-
ном порядке). В полях, расположенных под ними, вводятся сетевые маски, определяющие
диапазон адресов. В нашем случае все эти поля равны 0.0.0.0, так как нам нужен весь трафик
telnet. Номер порта telnet равен 23. Перемещение между полями осуществляется с по-
мощью клавиши <ТаЪ>, а не <Enter> (после нажатия этой клавиши будет создана запись).
file Edit Setup Control Window Help
IPTraf
First
Second
Host name/IP address:
Wildcard mask:
Port:
Include/Exclude (I/E):
D
ffiffl-npxt field ШПЯ-accpDt ШШ&Я-сапсе!
|Up/Down|
-Move selector am
-execute
Рис. 15.14. Окно задания фильтра
Глава 15. Мониторинг, анализ и управление сетевым трафиком 223
Созданный фильтр нужно применить. Для этого предназначена команда Apply filter ме-
ню TCP display filters. После выбора этой команды будет отображен список имеющихся
фильтров. Активизируйте нужный фильтр и нажмите <Enter>, а затем выйдите из меню
TCP display filters и выберите нужную функцию программы IPTraf, к которой должен при-
меняться фильтр. На рис. 15.15 представлены результаты работы фильтра совместно с
функцией мониторинга 1Р-трафика.
file Edit Setup Control Window Help
Packets ---- Bytes Flags
54 12263 -PR-
52 2080 —A-
IPTraF
TCP Connections (Source Host:Port)
И92.168.1.254:23
492.168.1.101:1036
I face
ethO
ethO
TCP: 1 entries
ftctiue —
Рис. 15.15. Мониторинг IP-трафика с учетом фильтра telnet
И
Если фильтруемый протокол не относится к семейству TCP, нужно воспользоваться
меню Other protocol filters. Эти фильтры создаются точно так же, как и ТСР-фильтры.
Качество обслуживания
Полоса пропускания сетей передачи данных, хоть и является ограниченным ресурсом,
обычно используется без каких-либо ограничений, а задача повторной передачи данных
возлагается на приложение или, в случае TCP, на сам протокол. Однако коммерциализа-
ция сети Internet и появление класса приложений, которым требуется доступ к сети в ре-
жиме реального времени, вызвали необходимость в средства^, обеспечивающих гаранти-
рованное предоставление требуемой полосы пропускания.
Например, многие организации отдают входящим Web-запросам более высокий при-
оритет по сравнению с остальным трафиком: посетитель Web-узла не должен ощущать за-
медление соединения с Web-сервером из,за того, что кто-то другой посылает электронную
почту. Почта может и подождать!
В качестве еще одного примера можно привести приложения передачи голосовых
данных. В основном именно они привели к улучшению средств поддержки технологии,
называемой качеством обслуживания (Quality of Service, QoS).
Существуют четыре основных метода управления IP-трафиком: по исходным и/или це-
левым адресам, по исходным или целевым портам, по значению сервисных битов заголовка
IP-пакета и путем совместного использования этих методов. Сервисные биты обычно назы-
вают битами типа обслуживания (Type of Service, TOS). Правила задания этих битов опреде-
224 Часть II. Средства и технологии маршрутизации в Linux
лены в документах RFC791 и RFC1349. Существуют еще методы дифференцированного обслужи-
вания, тоже основанные на анализе сервисных битов (http://www.ietf.org/html.
charters/diffserv-charter.html).
Типы обслуживания
Исходный метод управления IP-трафиком на основании типа обслуживания описан в
документах RFC791 и RFC795. Поле TOS IP-пакета состоит из восьми битов: три бита оп-
ределяют приоритет, один — режим минимальной задержки, один — режим максимальной
пропускной способности, один — режим максимальной надежности, один — режим мини-
мальной стоимости. Еще один бит не используется и равен нулю.
Поддержка в Linux
В Linux биты поля TOS можно задавать с помощью любой из утилит фильтрации паке-
тов: ipfwadm, ipchains и iptables. Допускается также использование ICMP-сообще-
ний, указывающих на то, что данная сеть или узел недоступны для требуемого типа обслу-
живания. Но их следует применять лишь в пределах одной автономной системы, посколь-
ку многие сетевые фильтры отбрасывают ICMP-сообщения.
Примеры задания поля TOS
Ниже показано, как повысить приоритет трафика, адресованного Web-серверу:
# sbin/ipchains -A output -р tcp -d 0/0 80 -j 0x10
В табл. 15.3 приведены значения числовых констант, соответствующих различным ти-
пам обслуживания (определены в документе RFC1349). В Linux этот механизм реализован
таким образом, что после четырех битов TOS должен следовать обязательный нулевой
бит. Об этом обязательно нужно помнить при выборе числовых значений.
В качестве еще одного примера возьмем протокол FTP и попытаемся повысить надеж-
ность его трафика:
# sbin/ipchains -A output -р tcp -d 0/0 21 -j 0x04
В табл. 15.3 показаны также мнемонические константы, соответствующие числовым зна-
чениям. Если воспользоваться ими, то предыдущий пример можно будет переписать так:
# sbin/ipchains -A output -р tcp -d 0/0 21 -j Maximize-Reliability
Таблица 15.3. Константы типа обслуживания
Мнемоника Шестнадцате- ричное значение Двоичное значение (RFC1349) Двоичное значение плюс обязательный нулевой бит Десятичное значение
Normal-Service 0x00 0000 00000 0
Minimize-Cost 0x02 0001 00010 2
Maximize-Reliability 0x04 0010 00100 4
Maximize-Throughput 0x08 0100 01000 8
Minimize-Delay 0x10 1000 10000 16
С помощью программы ipchains можно также проверять поле TOS поступающих па-
кетов. Соответствующая опция называется -т:
# sbin/ipchains -A output -р tcp -d 0/0 21 -т 0x00 -j 0x04
# sbin/ipchains -A output -р tcp -d 0/0 21 -m 0x02 -j 0x04
Глава 15. Мониторинг, анализ и управление сетевым трафиком 225
В данном случае пакеты протокола FTP, биты поля TOS которых равны 0000 и 00001
(т.е. 0x00 и 0x02— помните о последнем нулевом бите), будут изменены таким образом,
что поле TOS станет равным 0x04. Пакеты с полем TOS, равным 0x08 или 0x10, не под-
вергнутся изменениям согласно этому правилу.
Резюме
В этой главе рассматривались две важные темы: сетевой анализ и качество сетевого
обслуживания. Были описаны программы сетевого управления (NET-SNMP, MRTG и
IPTraf), играющие важную роль в арсенале сетевого администратора. С помощью этих
программ можно узнать, что происходит в сети и какие в ней существуют “узкие места”.
Что касается качества обслуживания, то в настоящее время это одна из наиболее перспек-
тивных областей сетевого рынка.
226 Часть II. Средства и технологии маршрутизации в Linux
ш
Приложения
В этой части...
Приложение А. Ресурсы, посвященные маршрутизации в Linux
Приложение Б. Аппаратные решения
Ресурсы, посвященные
маршрутизации в Linux
В этом приложении...
Демоны маршрутизации 228
Программы маршрутизации и управления трафиком 229
Дополнительные ресурсы 230
Официальные справочные документы 230
В этом приложении содержатся ссылки на многочисленные Internet-ресурсы, имею-
щиеся в распоряжении администратора Linux.
Демоны маршрутизации
В книге рассказывалось о целом ряде демонов маршрутизации, а некоторые демоны
только упоминались. В табл. А. 1 приведен список многопротокольных демонов, доступных
пользователям Linux. Символьные обозначения расшифровываются следующим образом:
д (да) — функция поддерживается хотя бы в одной версии программы;
н (нет) — функция не поддерживается ни в одной из версий программы;
ч (частично) — поддержка, возможно, еще не реализована, но находится в стадии
разработки.
Таблица А.1. Многопротокольные демоны маршрутизации в Linux и их возможности
Демон Web-узел Одноадресная маршрутиз ация Многоадресная маршрутизация IPv4 IPv6
bird bird.network.cz д н д д
gated www.gated.org д Д -д д
mrtd www.mrtd.net д Д д д
zebra www.zebra.org д ч д д
В табл. А.2 перечислены однопротокольные демоны маршрутизации.
Таблица А.2. Однопротокольные демоны маршрутизации в Linux и их возможности
Демон Источник Протокол
mrouted ftp://parcftp.xerox.com/pub/net-research/ipmulti DVMRP
pimd http://catarina.use.edu/pim/pimd PIM-SM
pimd-dense http://ante.uoregon.edu/PIMDM/pimd-dense.html PIM-DM
routed Входит во все основные дистрибутивы Linux RIP-2,
Программы маршрутизации и управления
трафиком
Сетевым администраторам всегда важно знать стоимость и эффективность передачи
данных по сетевым соединениям, знать, насколько безопасны такие соединения. Ниже пе-
речислена группа сетевых утилит, применение которых тесно связано с маршрутизацией.
Таблица А.З. Утилиты, связанные с маршрутизацией
Программа Web-узел Описание
CIPE http://sites.inka.de/sites/ bigred/devel/cipe.html Пакет CIPE (Crypto IP Encapsula- tion) работает на маршрутизато- рах, которые шифруют IP-пакеты при отправке их конкретным ад- ресатам
Edge Fireplug http: / /edge.fireplug.net Специализированный дистрибу- тив, превращающий компьютер в маршрутизатор/брандмауэр
heartbeat http://www.linux-ha.org/ download/ Утилита мониторинга, динами- чески отображающая сетевую информацию при ее появлении
IPTraf http://cebu.mozcom.com/ riker/iptraf/index.html Утилита мониторинга 1Р-трафика и определения сетевой статистики
lerzoex http://www.laurentconstantin.com/ en/lcrzoex/ Пакет тестирования сети
Linux Router Project http://www.linuxrouter.org Микродистрибутив, умещающийся на одной дискете и превращающий компьютер в маршрутизатор
MRTG http://people.ee.ethz.ch/ -oetiker/webtools/mrtg/ Программа, накапливающая и динамически анализирующая данные, характеризующие про- изводительность сети
VisualRoute http : / /www. visualware . com/ visualroute/index.html Графический аналог утилиты traceroute
Приложение А. Ресурсы, посвященные маршрутизации в Linux 229
Дополнительные ресурсы
Маршрутизация — это лишь один аспект сетей TCP/IP. В табл. А.4 приведены ссылки
на другие полезные сетевые ресурсы.
Таблица А.4. Полезные сетевые ресурсы
Ресурс Web-узел Описание
Организация IETF http://www.ietf.org Хранилище документов и стан- дартов, выпускаемых рабочими группами организации IETF
Хранилище RFC-доку- ментов http://www.faqs.org/rfcs Архив RFC-документов с воз- можностью поиска
Stardust http://www.stardust.com На этом узле есть ряд каналов, посвященных технологиям маршрутизации, например групповому’ вещанию, качеству обслуживания, беспроводным сетям и стандарту IPv6
Типы DSL-соединений http://www.efficient.com/ tlc/dsltypes.html Здесь можно найти описание существующих вариантов техно- логии DSL
Проект USAGI http://www.Iinux-ipv6.org На этом узле можно найти ново- сти и утилиты, связанные с реа- лизацией стека IPv6 в Linux
Официальные справочные документы
В книге неоднократно упоминались различные справочные документы, в основном из
серии RFC. В табл. А.5 перечислены документы и стандарты, которые мы считаем особен-
но полезными.
Таблица А.5. Полезные официальные документы
Название Местоположение
Assigned Network Numbers http://www.faqs.org/rfcs/rfc770.html
Border Gateway Protocol (BGP) http://www.faqs.org/rfcs/rfell05.html
Border Gateway Protocol 4 (BGP-4) http://www.faqs.org/rfcs/rfcl771.html
Distance Vector Multicast Routing Protocol (DVMRP) http://search.ietf.org/internet-drafts/ draft-ietf-idmr-dvmrp-v3-10.txt
Exterior Gateway Protocol (EGP) http://www.faqs.org/rfcs/rfc904.html
Internet Protocol (IP) version 4 http://www.faqs.org/rfcs/rfc760.html
Internet Protocol (IP) version 6 http://www.faqs.org/rfcs/rfc2373.html
Open Shortest Path First version 2 (OSPF-2) http://www.faqs.org/rfcs/rfcl247.html
Protocol Independent Multicast Sparse Mode (PIM-SM) http://www.faqs.org/rfcs/rfc2362.html
Routing Information Protocol (RIP) http://www.faqs.org/rfcs/rfcl058.html
RIP version 2 (RIP-2) http://www.faqs.org/rfcs/rfcl723.html
Simple Network Management Protocol (SNMP) http://www.faqs.org/rfcs/rfcll57.html
Transmission Control Protocol (TCP) http://www.faqs.org/rfcs/rfc761.html
230 Часть III. Приложения
Аппаратные решения
В этом приложении...
Выделенные маршрутизаторы 231
Linux-совместимые платы маршрутизации 231
Не у каждого найдется время создавать собственные программные маршрутизаторы.
Да это и не всегда требуется. Данное приложение посвящено коммерческим Linux-
маршрутизаторам.
Выделенные маршрутизаторы
Мы не будем комментировать те или иные семейства продуктов, которые постоянно
модернизируются, а просто приведем набор ссылок на Web-узлы компаний, в настоящее
время предлагающих готовые Linux-маршрутизаторы.
www.rocksolidbox.de
www.cyclades.com
www.imagestream-is.com
www.datapro.net
www.digi.com
www.equinox.com
www.stallion.com
www.eicon.com
www.emacinc.com
Linux-совместимые платы маршрутизации
Еще одна интересная область — это платы с интерфейсами ГВС, которые могут быть
размещены в Linux-системе и выполнять функции маршрутизации. Если есть многофунк-
циональный сервер, такая плата послужит средством снижения нагрузки, поскольку она
возьмет на себя функции маршрутизации, предоставив процессору возможность зани-
маться фильтрацией пакетов и решать другие специализированные задачи.
Ниже перечислен список Web-узлов производителей таких плат:
www.sangoma.com
www.cyclades.com
www.eicon.com
www.stallion.com
www.LanMedia.com
www.gcom.com
www.imagestream-is.com
www.etinc.com
232 Часть III. Приложения
Предметный указатель
D
DSL,технология
ADSL, 32; 181
HDSL, 32; 181
HDSL-2, 181
IDSL, 32
SDSL, 32; 181
модем,181
устройство DSLAM, 182
E
Ethernet
параметр MTU, 139
разновидности, 142
I
IP-маскирование, 204
отличия от системы NAT, 205
ISDN, технология
BRI, 183
В-канал, 184
D-канал, 184
PRI, 183
N
NAT, система
DNAT, 134; 206
SNAT, 134; 206
конфигурирование, 205
отличия от IP-маскирования, 205
Netfilter, 134; 202
Автономная система
магистраль, 43
область, 35
Анализатор пакетов, 143; 152
Б
Безопасность, 160
демилитаризованная зона, 161
зоны, 161
В
Виртуальный канал, 43
д
Демон
bird, 116
gated, 29; 31; 43; 56; 57; 62; 64; 65; 66
агрегированные маршруты, 113
версии, 87
взаимодействие с серверами
SNMP, 106
импортируемые маршруты, 108
инструкция aggregate, 113
инструкция autonomoussystem, 92
инструкция bgp, 102
инструкция egp, 99
инструкция export, 111
инструкция import, 108
инструкция interfaces, 89
инструкция martians, 92
инструкция options, 89
инструкция ospf, 97
инструкция rip, 93
инструкция routerid, 92
инструкция snmp, 106
инструкция static, 107
конфигурирование, 88
конфигурирование интерфейсов, 89
многоадресная версия, 117
параметры трассировки, 96
принцип работы, 87
протокол BGP, 102
протокол EGP, 99
протокол OSPF,97
протокол RIP, 93
статические маршруты, 107
тестирование, 114
типы инструкций, 88
экспортируемые маршруты, 111
mrouted, 45; 53
запуск, 121
конфигурирование, 120
pimd, 117
Предметный указатель 233
запуск, 119 конфигурирование, 118 pppd,123 запуск, 129 компиляция, 128 конфигурирование, 128 pptpd, 136 routed, 29 запуск, 87 конфигурирование, 85 принцип работы, 84 snmpd, 210 zebra, 29; 31; 43; 64; 116 Дерево TRPB, 48 кратчайших путей, 36; 45; 53 точки встречи, 53 опция -f, 145 опция -i, 146 опция -I, 146 опция -s, 146 гагр, 148 route, 21; 78; 143 добавление маршрутов, 145 опция-С, 144 опция -п, 144 опция-V, 144 опция -V, 144 флаги, 144 tcpdump, 152; 157 выражения, 155 имена сервисов, 155 опция -i, 153 опция -п, 153
К опция-q, 154 опция-г, 154
Канал DS0, 175; 183 DS1, 175 DS3, 183 Е1, 183 ЕЗ, 183 Т1, 175; 183 ТЗ, 175 Качество обслуживания, 224 поле TOS, 225 задание, 225 Команда агр, 146 опция -а, 147 опция -d, 148 опция -Н,147 опция -i, 147 опция -п, 147 ifconfig, 138 конфигурирование интерфейсов, 141 отчет о состоянии интерфейсов, 139 типы адресов, 141 типы интерфейсов, 140 netstat опция -а, 150 опция-1, 151 опция-р, 151 опция -г, 150 ping опция -d, 145 опция -t, 154 опция-v, 154 опция -w, 154 traceroute, 148 анализ работы,157 опция -d, 149 опция -f, 149 опция -F, 149 опция -i, 149 опция-I, 149 опция -т,149 опция -п, 149 опция-t, 150 м Маршрутизатор, 16 зависимый, 50 конфигурирующий, 55 назначенный, 35; 54 пограничный, 39 точки встречи, 53 Маршрутизация бесклассовая, 77 в виртуальных частных сетях, 172 в глобальных сетях, 171 в локальных сетях, 169 динамическая, 165 лавинная, 65 многоадресная, 44 протокольно-независимая, 53
234 Предметный указатель
одноадресная, 16
пограничная, 59
статическая, 20; 163
таблица
в протоколе DVMRP, 49
в протоколе OSPF,42
в протоколе RIP-1, 25
размер, 36
статическая, 20
Метрика стоимости, 23
Модем, 174
DSL, 181
WinModem, 176
внешний, 176
внутренний, 176
кабельный, 180
скорость работы, 33
стандартные команды, 177
Программа
chat, 130
gdc
управляющие команды, 115
флаги, 114
ipchains
IP-маскирование, 204
включение поддержки в ядре, 135
добавление правила, 201
изменение поля TOS, 225
синтаксис, 200
сохранение конфигурации, 201
удаление правил, 201
ipfwadm, 135
iptables, 135
IP-маскирование, 204
добавление правила, 203
просмотр цепочек, 203
синтаксис, 202
система NAT, 205
создание новой цепочки, 203
удаление правил, 203
IPTraf, 218
монитор станции ЛВС,221
монитор трафика, 219
общая статистика интерфейсов, 220
статистика отдельных интерфейсов, 221
статистический анализ, 221
фильтры, 221
MRTG
инсталляция, 214
конфигурирование, 215
net-snmp, 209
инсталляция, 210
команды, 211
РоРТоР, 136
rip2ad, 123
инсталляция, 131
wan pipe, 172
Протокол
ARP, 146
BGMP, 64
BGP, 62
база Adj-RIB-In, 63
база Adj-RIB-Out, 63
база Loc-RIB, 63
база PIB, 63
идентификатор, 62
многоканальный доступ, 167
настройка в демоне gated, 102
таймер удержания, 62
СПАР, 125
CIDR
агрегирование маршрутов, 77
адресация подсетей, 74
битовая маска, 73
поддержка в ядре Linux, 78
CSLIP, 140
DHCP, 148; 170
DVMRP, 45
алгоритм RPM, 46; 48
алгоритм TRPB, 46
зависимые маршрутизаторы, 50
метод обратного исправления, 50
назначенный ретранслятор, 50
настройка в демоне mrouted, 120
номер поколения, 50
отсечение ветвей, 48
прививание ветвей, 52
принцип работы, 49
таблица маршрутизации, 49
туннели, 51
EGP, 29; 60
настройка в демоне gated, 99
GRE, 51
HDLC, 123
HELLO, 38
ICMP, 109
IGMP, 45; 46; 54
Предметный указатель 235
IGP, 59
IPCP, 126
IPIP, 141
IPv4, 67
адреса частных сетей, 69
адресация подсетей, 70
бесклассовая адресация, 73
бесклассовая маршрутизация, 77
классы адресов, 69
маршрутизация, 73
сетевая маска, 69
IPv6, 166
агрегат верхнего уровня (TLA), 80
агрегат второго уровня (NLA), 80
агрегат уровня организации (SLA), 81
агрегированный адрес, 80
адрес обратной связи, 78
групповой адрес, 78; 80
идентификатор интерфейса, 81
локальный канальный адрес, 80
маршрутизация, 81
неуточненный адрес, 78
однонаправленный адрес, 78; 80
префикс формата, 78
производный адрес, 80
совмещенный адрес, 78
структура адресов, 80
ISIS, 106
LCP, 124
MOSPF, 45
MP, 128; 183
MSDP, 65
NCP, 126
OSPF
алгоритм Дейкстры, 31
аутентификация, 39
виртуальный канал, 43
внешние канальные анонсы, 41
дерево кратчайших путей, 36
настройка в демоне gated, 97
область, 35
переменная HelioInterval, 38
переменная RouterDeadlnterval, 38
принцип работы, 35
распределение нагрузки, 34
таблица маршрутизации, 42
РАР, 125
PIM
насыщенный режим, 56
разреженный режим, 53
PIM-DM, 56
PIM-SM
дерево кратчайших путей, 53
дерево точки встречи, 53
конфигурирующий маршрутизатор, 55
настройка в демоне pimd, 117
принцип работы, 54
точка встречи, 53; 55
хеш-функция, 55
РРР
настройка в демоне pppd, 128
поддерживаемые протоколы, 123
применение, 126
схема работы,124
фаза аутентификации, 125
фаза организации канала, 124
фаза отсутствия канала, 124
фаза протокола сетевого уровня, 126
фаза разрыва канала, 126
РРТР, 136; 173
RADIUS, 179
RARP, 148
RIP-1
алгоритм Беллмана-Форда, 21
настройка в демоне gated, 93
принцип работы, 26
простое сужение обзора, 27
сужение обзора с обратным
исправлением,28
таблица маршрутизации, 26
RIP-2, 29
аутентификация, 30
многоадресные обновления, 44
настройка в демоне gated, 93
SLIP, 140
SNMP, 207
аутентификация, 209
база MIB, 208
идентификатор объекта, 209
имя сообщества, 210
настройка сеанса в демоне gated, 106
пакет NET-SNMP, 209
прерывание, 209
сообщения, 209
топология, 208
SSH, 199
внутреннего шлюза, 59
дистанционно-векторный, 21
многоадресной маршрутизации, 44
одноадресной маршрутизации, 16
236 Предметный указатель
пограничной маршрутизации, 59
состояния канала, 31
топологический, 31
Р,С
Ретрансляция кадров, 184
Сервер
терминальный, 178
удаленного доступа, 179
Сетевое планирование, 159
Транк, 175
Туннель, 51; 166
создание, 121
Файл
/etc/gated.conf, 88
проверка, 115
/etc/gateways, 85
/etc/lilo.conf, 190
/etc/mrouted.conf, 120
/etc/pimd.conf, 118
Фильтрация пакетов, 199
ш,я
Шлюз, 60
Ядро
выбор,191
компиляция, 194
конфигурирование, 193
получение исходных кодов, 192
создание, 190
Предметный указатель 237
Научно-популярное издание
Джо Брокмайер, Ди-Энн Лебланк, Рональд У. Маккарти
Маршрутизация в Linux
Литературный редактор
Верстка
Художественный редактор
Корректоры
И.А. Попова
А.В. Плаксюк
С.А. Чернтсозинский
О.В. Мишутина
Издательский дом “Вильямс”.
101509, Москва, ул. Лесная, д. 43, стр. 1.
Изд. лиц. ЛР № 090230 от 23.06.99
Госкомитета РФ по печати.
Подписано в печать 25.03.2002. Формат 70x100/16.
Гарнитура NewBaskerville. Печать офсетная.
Усл. печ. л. 19,6. Уч.-изд. л. 14,0.
Тираж 3500 экз. Заказ № 188.
Отпечатано с диапозитивов в ФГУП “Печатный двор”
Министерства РФ по делам печати,
телерадиовещания и средств массовых коммуникаций.
197110, Санкт-Петербург, Чкаловский пр., 15.
Маршрутизация
в Linux®
Книга Маршрутизация в Linux предназначена для
опытных пользователей и администраторов Linux,
а также для всех сетевых администраторов, которых
интересует не только создание простейших сетей
и подсетей, но и реализация более сложных решений,
связанных с различными протоколами маршрутизации.
В данной книге излагаются теоретические сведения
и методики, знакомство с которыми позволит
читателям научиться правильно выбирать протоколы
маршрутизации, конфигурировать демоны
маршрутизации, защищать сети и компьютеры,
настраивать системное ядро и даже контролировать
сетевой трафик. Описываются сетевые утилиты Linux,
популярные протоколы маршрутизации и принципы
реализации маршрутизатора на Linux-машине в самых
разных ситуациях.
Джо Брокмайер работает в Linux с 1996 года. Он
является автором и соавтором ряда книг по Linux
и другим открытым технологиям, а также пишет
статьи для изданий Linux Magazine
и UnixReview.com.
Ди-Энн Лебланк работает в Linux с 1994 года.
Будучи преподавателем, она научилась понимать,
какими знаниями владеют среднестатистические
пользователь и администратор Linux, и ее задачей
является помочь людям перейти на следующий
уровень знаний.
Рональд Маккарти, мл. работает в Linux с 1994
года. Он имеет опыт установки маршрутизаторов,
брандмауэров и сетевых серверов Linux.
Если вы ищете решения,
связанные с маршрутизацией
в Linux, эта книга
поможет вам:
• Научиться конфигурировать
gated, сложный, но много-
функциональный демон
маршрутизации
• Освоить принципы
бесклассовой адресации
в стандарте IPv4
• Понять основы стандарта IPv6
• Изучить принципы
маршрутизации в локальных,
глобальных и виртуальных
частных сетях
• Научиться работать
с множеством сетевых утилит
Linux
• Узнать об инструментах
анализа сетевого трафика
• Понять принципы
функционирования
протоколов одноадресной,
многоадресной и пограничной
маршрутизации
• Познакомиться со средствами
защиты сетей, имеющимися
в Linux
Linux / сети
Иеш\
Riders 1
Вильямс
www.newriders.com
www.williamspublishing.com