














































































































































































































































































































































































































































































































































































Автор: Вентцель Е.С.
Теги: теория вероятностей и математическая статистика теория вероятностей теория стрельбы
Год: 1969




Текст
Е. С. ВЕНТЦЕЛЬ
ТЕОРИЯ
ВЕРОЯТНОСТЕЙ
ИЗДАНИЕ ЧЕТВЕРТОЕ, СТЕРЕОТИПНОВ
Допущено Министерством
высшего и среднего специального образования СССР
в качестве учебника
для высших технических учебных заведений
ИЗДАТЕЛЬСТВО «НАУКА»
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ
МОСКВА 19 6 9
517.8
В 29
УДК 519.21 @75.8)
АННОТАЦИЯ
Книга представляет собой учебник, предназна-
предназначенный для лиц, знакомых с математикой в объеме
обычного втузовского курса и интересующихся тех-
техническими приложениями теории вероятностей,
в частности теорией стрельбы. Книга представляет
также интерес для инженеров других специально-
специальностей, которым приходится применять теорию вероят-
вероятностей в их практической деятельности.
От других учебников, предназначенных для
той же категории читателей, книга отличается боль-
шнм вниманием к важным для приложений новым
ветвям теории вероятностей (например, теории ве-
вероятностных процессов, теории информации, теории
массового обслуживания и др.).
Елена Сергеевна Вентцель
Теория вероятностей
М., 1969 с.» 57.6^стр. с илл.
Редакторы А. П. Баееа, В. В. Донченко
Техн. редактор Л. А. Пыжова Корректор К. В. Булатова
Печать с матриц. Подписано к печати 4/VII 1969 г. Бумага 60x90/16. Физ. печ. л. 36.
Услови, печ. л. 36. Уч.-изд. л. 33,80. Тираж 150 000 экз. Цена книги 1 р. 28 к. Заказ 196.
Издательство «Наука».
Главная редакция физико-математической литературы.
Москва, В-7 1, Ленинский проспект, 15.
Ордена Трудового Красного Знамени Первая Образцовая типография имени
А, А. Жданова Главполиграфпрома Комитета по печати при Совете Министров СССР
Москва, М-54, Валовая, 28
2-2-3
4-89
ОГЛАВЛЕНИЕ
Предисловие ко второму изданию ..,....,, О
Предисловие к первому изданию 9
Глава 1. Введение 11
1.1. Предмет тесани вероятностей И
1.2. Краткие исторические сведения 17
Глава 2. Основные понятия теорнн вероятностей 23
2.1. Событие. Вероятность события 23
2.2. Непосредственный подсчет вероятностей 24
2.3. Частота, или статистическая вероятность, события 28
2.4. Случайная величина 32
2.5. Практически невозможные и практически достоверные со-
события. Принцип практической уверенности 34
Глава 3. Основные теоремы теории вероитностей 37
3.1. Назначение основных теорем. Сумма и произведение событий 37
3.2. Теорема сложения вероятностей 40
3.3. Теорема умножения вероятностей 45
3.4. Формула полной вероятности 54
3.5. Теорема гипотез (формула Бейеса) 56
Глава 4. Повторение опытов 59
4.1. Частная теорема о повторении опытов 59
4.2. Общая теорема о повторении опытов 61
Глава 5. Случайные величины и их законы распределения. ... 67
5.1. Ряд распределения. Многоугольник распределения 67
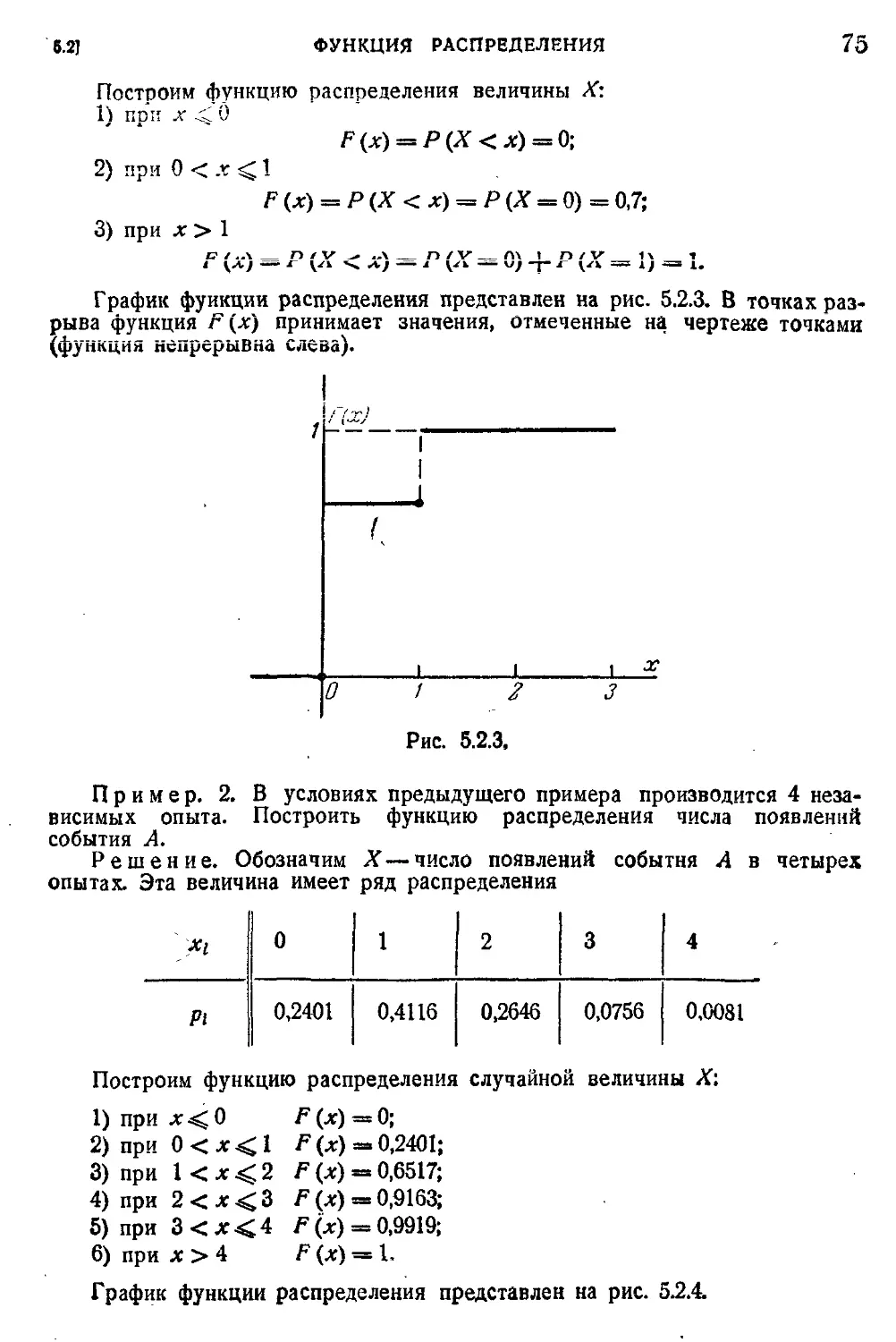
5.2. Функция распределения 72
5.3. Вероятность попадания случайной величины на заданный
участок 78
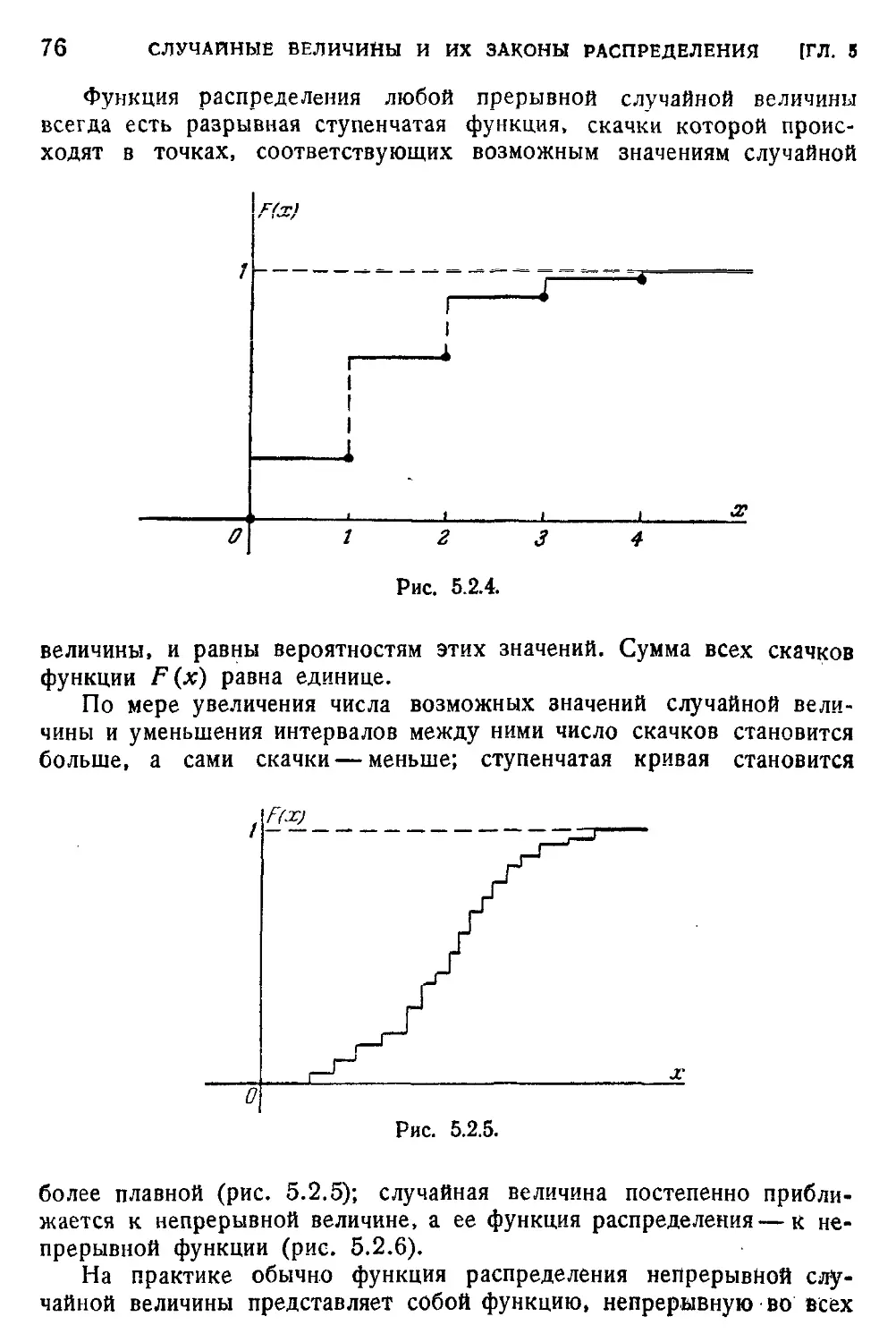
5.4. Плотность распределения 80
5.5. Числовые характеристики случайных величин. Их роль и на-
назначение 84
5.6. Характеристики положения (математическое ожидание, мода,
медиана) 85
5.7. Моменты. Дисперсия. Среднее квадратическое отклонение . . 92
5.8. Закон равномерной плотности 103
5.9. Закон Пуассона. 106
1*
4 ОГЛАВЛЕНИЕ
Глава 6. Нормальный закон распределения П>
6.1. Нормальный закон и его параметры 116
6.2. Моменты нормального распределения 120
6.3. Вероятность попадания случайной величины, подчиненной
нормальному закону, на заданный участок. Нормальная функ-
функция распределения 122
6.4. Вероятное (срединное) отклонение 127
Г л а в а 7. Определение законов распределения случайных вели-
величин на основе опытных данных 131
7.1. Основные задачи математической статистики 131
7.2. Простая статистическая совокупность. Статистическая функ-
функция распределения 133
7.3. Статистический ряд. Гистограмма 133
7.4. Числовые характеристики статистического распределения . . 139
7.5. Выравнивание статистических рядов 143
7.6. Критерии согласия 149
Глава 8. Системы случайных величин 159
8.1. Понятие о системе случайных величин 159
8.2. Функц,к« распределения системы двух случайных величин . . 163
8.3. Плотность распределения системы двух случайных величин 163
8.4. Законы распределения отдельных величин, входящих в си-
систему. УсУ/ные законы распределения 168
8.5. Зависимы? *i независимые случайные величины 171
8.6. Числовые характеристики системы двух случайных величии.
Корреляционный момент. Коэффициент корреляции 175
8.7. Система произвольного числа случайных величин 182
8.8. Числовые характеристики системы нескольких случайных
величин • 184
Глава 9. Нормальный закон распределения для системы случай-
случайных величин 188
9.1. Нормальный закон на плоскости 188
9.2. Эллипсы рассеивания. Приведение нормального закона к ка-
каноническому виду 193
9.3. Вероятность попадания в прямоугольник со сторонами, па-
параллельными главным осям рассеивания 196
9.4. Вероятность попадания в эллипс рассеивания 198
9.5. Вероятность попадания в область произвольной формы . . . 202
9.6. Нормальный закон в пространстве трех измерений. Общая
запись нормального закона для системы произвольного числа
случайных величин 205
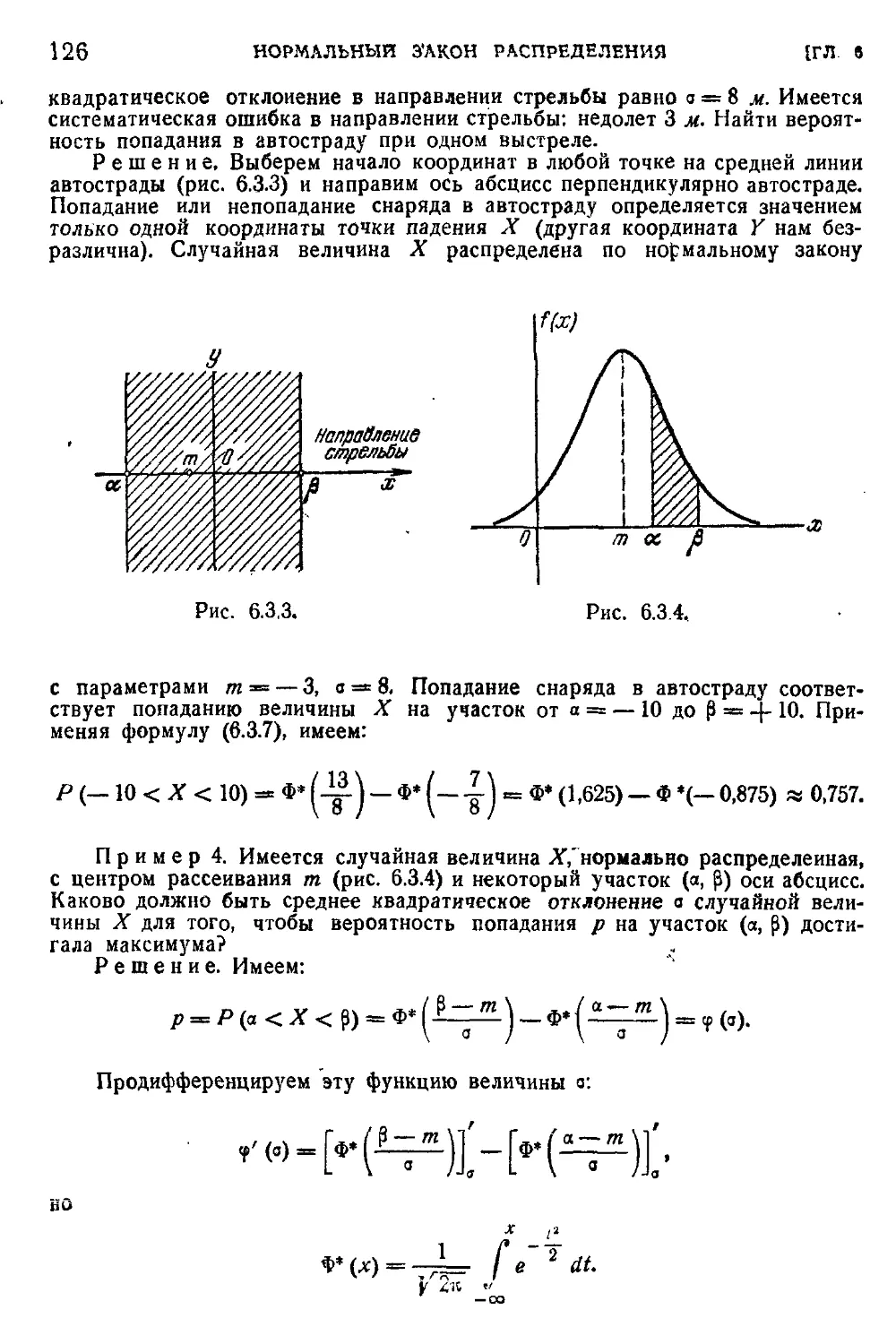
Глава 10. Числовые характеристики функций случайных величин 210
10.1. Математическое ожидание функции. Дисперсия функции . . 210
10.2. Теоремы о числовых характеристиках 219
,10.3. Применения теорем о числовых характеристиках 230
Глава 11. Линеаризация функций 252
11.1. Метод линеаризации функций случайных аргументов .... 252
11.2. Линеаризация функции одного случайного аргумента .... 253
11.3. Линеаризация функции нескольких случайных аргументов 255
11.4. Уточнение результатов, полученных методом линеаризации 259
ОГЛАВЛЕНИЕ 5
Гл
лава 12. Законы распределения функций случайных аргументов 263
12.1. Закон распределения монотонной функции одного случай-
случайного аргумента . . 943
12.2. Закон распределения линейной функции от аргумента, под-
подчиненного нормальному закону 266
12.3. Закон распределения немонотонной функции одного случай-
случайного аргумента 267
12.4. Закон распределения функции двух случайных величин . . . 269
12.5. Закон распределения суммы двух случайных величин. Ком-
Композиция законов распределения 271
12.6. Композиция нормальных законов 275
12.7. Линейные функции от нормально распределенных аргументов 279
12.8. Композиция нормальных законов на плоскости 280
Глава 13. Предельные теоремы теории вероятностей 286
13.1. Закон больших чисел и центральная предельная теорема . . 286
13.2. Неравенство Чебышева 287
13.3. Закон больших чисел (теорема Чебышева) 290
13.4. Обобщенная теорема Чебышева. Теорема Маркова 292
13.5. Следствия закона больших чисел: теоремы Бернулли и Пуас-
Пуассона 295
13.6. Массовые случайные явления и центральная предельная
теорема 297
13.7. Характеристические функции 299
13.8. Центральная предельная теорема для одинаково распреде-
распределенных слагаемых 302
13.9. Формулы, выражающие центральную предельную теорему и
встречающиеся при ее практическом применении 306
Глава 14. Обработка опытов 312
14.1. Особенности обработки ограниченного числа опытов. Оценки
для неизвестных параметров закона распределения 312
14.2. Оценки для математического ожидания и дисперсии .... 314
14.3. Доверительный интервал. Доверительная вероятность .... 317
14.4. Точные методы построения доверительных интервалов для
параметров случайной величины, распределенной по нор-
нормальному закону 324
14.5. Оценка вероятности по частоте 330
14.6. Оценки для числовых характеристик системы случайных
величин 339
14.7. Обработка стрельб 347
14.8. Сглаживание экспериментальных зависимостей по методу
наименьших квадратов 351
Глава 15. Основные понятия теории случайных функций .... 370
15.1. Понятие о случайной функции 370
15.2. Понятие о случайной функции как расширение понятия о си-
системе случайных величин. Закон распределения случайной
функции 374
15.3. Характеристики случайных функций 377
15.4. Определение характеристик случайной функции из опыта . . 383
15.5. Методы определения характеристик преобразованных слу-
случайных функций по характеристикам исходных случайных
функций . . 385
6 ОГЛАВЛЕНИЕ
15.6. Линейные и нелинейные операторы. Оператор динамической
системы 388
15.7. Линейные преобразования случайных функций 393
15.8. Сложение случайных функций 39Э
15.9. Комплексные случайные функции 402
Глава 16. Канонические разложения случайных функций .... 405
16.1. Идея метода канонических разложений. Представление слу-
случайной функции в виде суммы элементарных случайных
функций , 406
16.2. Каноническое разложение случайной функции , 410
16.3. Линейные преобразования случайных функций, заданных
каноническими разложениями ,. 411
Глава 17. Стационарные случайные функции 419
17.1. Понятие о стационарном случайном процессе 419
17.2. Спектральное разложение стационарной случайной функции
на конечном участке времени. Спектр дисперсий 427
17.3. Спектральное разложение стационарной случайной функции
на бесконечном участке времени. Спектральная плотность
стационарной случайной функции у . . 431
17.4. Спектральное разложение случайной функции в комплексной
форме I [ . . 438
17.5. Преобразование стационарной случайной функции стацио-
стационарной линейной системой 447
17.6. Применения теории стационарных случайных процессов
к решению задач, связанных с анализом и синтезом динами-
динамических систем 454
17.7. Эргодическое свойство стационарных случайных функций 457
17.8. Определение характеристик эртодическои стационарной слу-
случайной функции по одной реализации 462
Глава 18. Основные понятия теории информации 468
18.1. Предмет и задачи, теории информации 468
18.2. Энтропия как мера степени неопределенности состояния
физической системы 469
18.3. Энтропия сложной системы. Теорема сложения энтропии . . 475
15.4. Условная энтропия. Объединение зависимых систем .... 477
18.5. Энтропия н информация 481
18.6. Частная информация о системе, содержащаяся ~в сообщении
о событии. Частная информация о событии, содержащаяся
в сообщении о другом событии 489
18.7. Энтропия и информация для систем с непрерывным множест-
ством состояний 493
18.8. Задачи кодирования сообщений. Код Шеннона — Фэно . . . 502
18.9. Передача информации с искажениями. Пропускная способ-
способность канала с помехами • . 509
Глава 19. Элементы теории массового обслуживания 515
19.1. Предмет теории массового обслуживания . 515
19.2. Случайный процесс со счетным множеством состояний . . 517
19.3. Поток событий. Простейший поток и его свойства .... 520
19.4. Нестационарный пуассоновский поток 527
ОГЛАВЛЕНИЕ 7
19. 5. Поток с ограниченным последействием (поток Пальма) . , 529
1У. и. Ъремя обслуживания , 531
19. 7. Марковский случайный процесс 537
19. 8. Система массового обслуживания с отказами. Уравнения
Эрланга " 540
19. 9. Установившийся режим обслуживания. Формулы Эрланга . 544
19.10. Система массового обслуживания с ожиданием 548
19.11. Система смешанного типа с ограничением по длине очереди 557
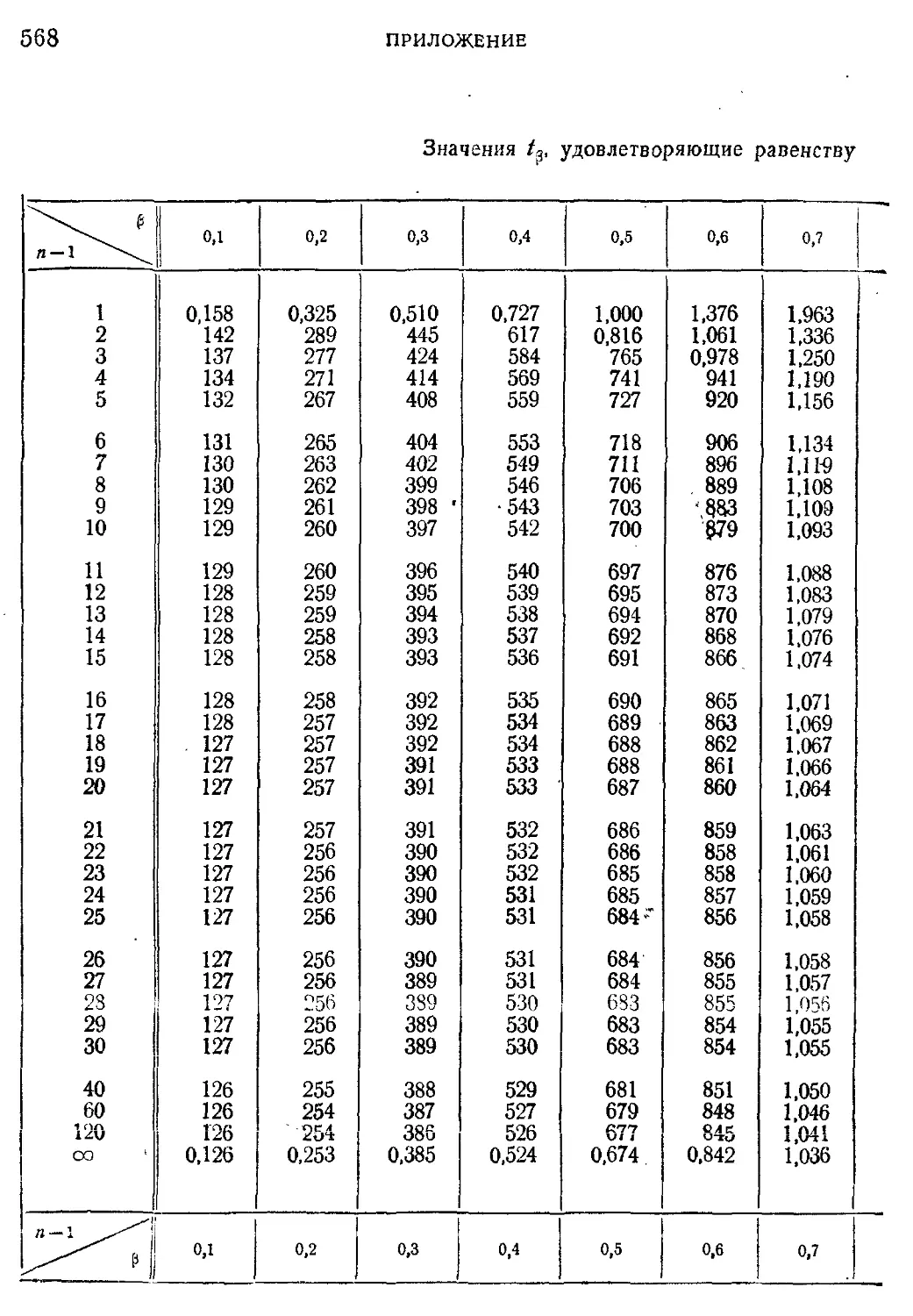
Приложение. Таблицы 561
Литература 573
Предметный указатель 574
ПРЕДИСЛОВИЕ КО ВТОРОМУ ИЗДАНИЮ
В настоящее издание по сравнению с первым внесены следующие
изменения и дополнения: материал, касающийся теоремы Ляпунова и
связанного с ней метода характеристических функций (прежние
пп° 13.7—13.11) сокращен и изложен в более простой форме в новых
пп° 13.7—13.9; изменено изложение вопросов, связанных с обработкой
опытов (глава 14), в связи с чем вместо прежних пп° 14.1 и 14.2
вставлены новые пп° 14.1—14.5, а прежние пп° 14.3—14.5 сохра-
сохранены под номерами 14.6—14.8 соответственно. Несколько изменен
п° 5.9, посвященный закону Пуассона. Добавлены две новые главы:
глава 18 «Основные понятия теории информации» и глава 19 «Эле-
«Элементы теории массового обслуживания» — касающиеся двух важных
ветвей теории вероятностей, до сих пор почти не освещавшихся
в учебной литературе. Изменен состав таблиц в «Приложении».
Изменены некоторые примеры.
Автор выражает глубокую благодарность академику АН УССР
Б. В. Гнеденко за ряд ценных указаний,
Е. Вентцель
В настоящем, третьем издании существенных изменений нет.
Произведены незначительные исправления и заменены некоторые
примеры и задачи. Некоторые таблицы заменены другими. Слегка
изменены в методическом отношении отдельные параграфы книги,
например п°п° 5.9, 6.3, 9.4, 9.5 и 9.6. Существенно обновлено
содержание п° 10.3.
ПРЕДИСЛОВИЕ К ПЕРВОМУ ИЗДАНИЮ
Настоящая книга написана на базе лекций по теории вероятностей,
читанных автором в течение ряда лет слушателям Военно-воздушной
инженерной академии им. Н. Е. Жуковского, а также учебника автора
по тому же предмету, изданного Академией ограниченным тиражом
в 1952 г.
В настоящем издании первоначальный текст учебника подвергся
весьма значительной перерабои?-
Книга рассчитана, в основном, на инженера, имеющего математи-
математическую подготовку в объеме обычного курса высших технических
учебных заведений. При составлении книги автор ставил себе задачу
изложить предмет наиболее просто и наглядно, не связывая себя
рамками полной математической строгости. В связи с этим отдельные
положения приводятся без доказательства (раздел о доверительных
границах и доверительных вероятностях; теорема А. Н. Колмогорова,
относящаяся к критерию согласия, и некоторые другие); некоторые
положения доказываются не вполне строго (теорема умножения зако-
законов распределения; правила преобразования математического ожидания
и корреляционной функции при интегрировании и дифференцировании
случайной функции и др.).
Применяемый математический аппарат, в основном, не выходит
за рамки нормального курса высшей математики, излагаемого в высших
технических учебных заведениях; там, где автору приходится поль-
пользоваться менее общеизвестными понятиями (например, понятием линей-
линейного оператора, матрицы, квадратичной формы и т. д.), эти понятия
поясняются.
Книга снабжена большим количеством примеров, в ряде случаев —
примерами расчетного характера, в которых применение излагаемых
методов иллюстрируется на конкретном практическом материале и
10 ПРЕДИСЛОВИЕ К ПЕРВОМУ ИЗДАНИЮ
доводится до численного результата. В связи с целевым назначением
курса зчяччтель-ая ч?сть пр:::,:срсз ззя.м иа области авиационной тех-
техники, воздушной стрельбы, бомбометания и теории боеприпасов.
Ряд приоров относится к общей теории стрельбы. С этой точки
зрения книга может быть особенно полезной для специалистов
в области наземной, зенитной и морской артиллерии. Однако, не-
несмотря на несколько специфический подбор примеров, иллюстративный
материал, помещенный в книге, вполне понятен и для инженеров,
работающих в других областях техники.
Автор выражает глубокую благодарность профессору Е. Б. Дын-
i.iiiiy и профессору В. С. Тича'ч.ву за ряд ценных указаний.
Е. Вент цель
ГЛАВА 1
ВВЕДЕНИЕ
1.1. Предмет теории вероятностей
Теория вероятностей есть математическая наука, изучающая законо-
закономерности в случайных явлениях.
Условимся, что мы будем понимать под «случайным явлением».
При научном исследовании различных физических и технических
задач часто приходится встречаться с особого типа явлениями, кото-
которые принято называть случайными. Случайное явление — это
такое явление, которое при неоднократном воспроизведении одного
и того же опыта протекает каждый раз несколько по-иному.
Приведем примеры случайных явлений.
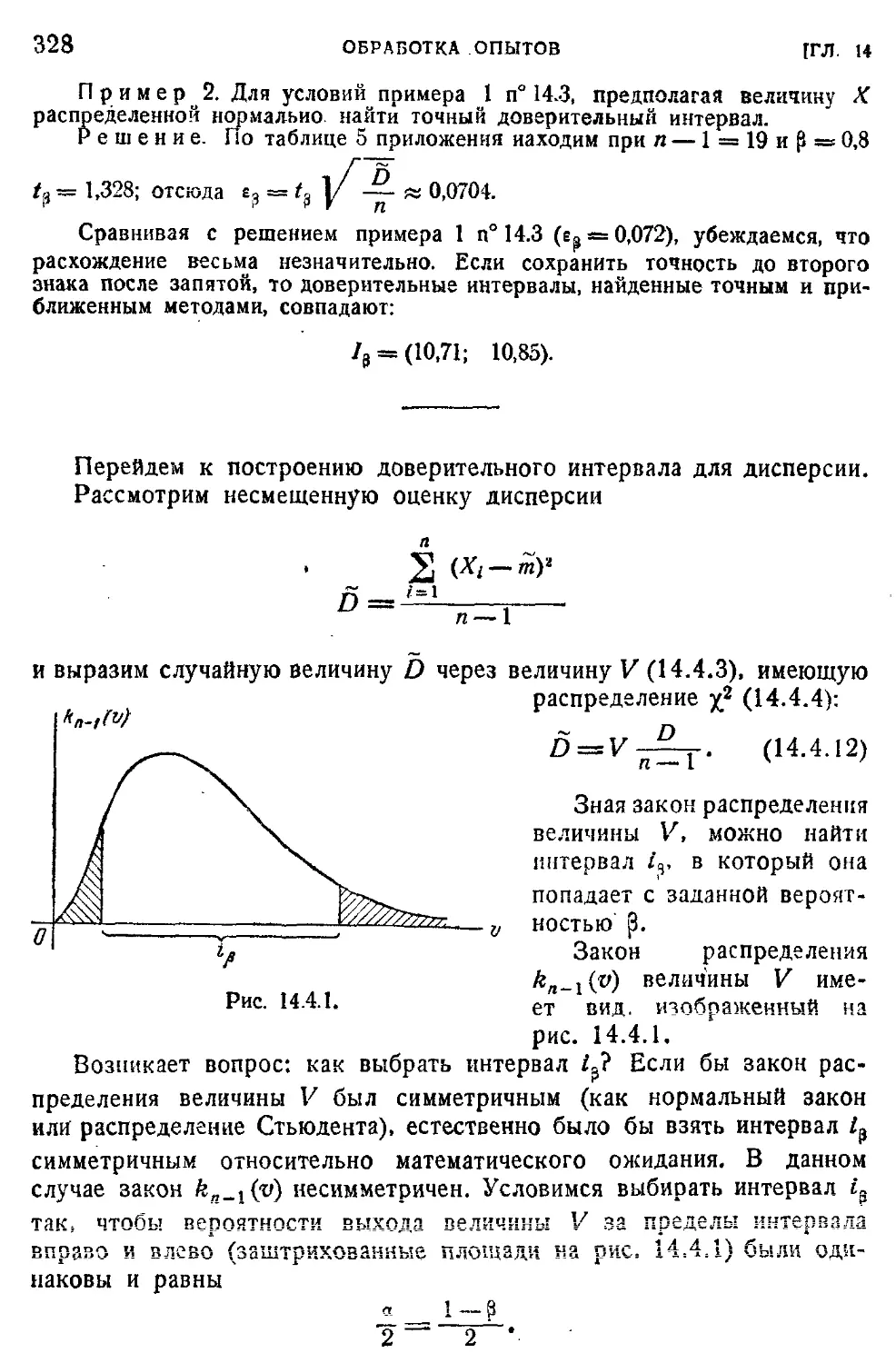
1. Производится стрельба из орудия, установленного под задан-
заданным углом к горизонту (рис. 1.1.1).
Пользуясь методами внешней баллистики (науки о движении сна-
снаряда в воздухе), можно найти теоретическую траекторию снаряда
(кривая К на рис. 1.1.1).
■А*.
Эта траектория вполне
определяется условиями
стрельбы: начальной ско-
скоростью снаряда vQ, углом
бросания 60 и баллисти-
баллистическим коэффициентом
снаряда с. Фактическая
траектория каждого отдельного снаряда неизбежно несколько откло-
отклоняется от теоретической за счет совокупного влияния многих факторов.
Среди этих факторов можно, например, назвать: ошибки изготовления
снаряда, отклонение веса заряда от номинала, неоднородность струк-
структуры заряда, ошибки установки ствола в заданное положение, метео-
метеорологические условия и т. д. Если произвести несколько выстрелов
при неизменных основных условиях (v0, 60, с), мы получим не одну
теоретическую траекторию, а целый пучок или «сноп» траекторий,
образующий так называемое «рассеивание снарядов».
2. Одно и то же тело несколько раз взвешивается на аналити-
аналитических весах; результаты повторных взвешиваний несколько отли-
отличаются друг от друга. Эти различия обусловлены влиянием многих
Рис. 1.1.1,
12 ВВЕДЕНИЕ [ГЛ. I
второстепенных фякторсв, сопровождающих операцию взвешивания,
таких как положение тела на чашке весов, случайные вибрации аппа-
аппаратуры, ошибки отсчета показаний прибора и т. д.
Ь. Самолет совершает полет на заданной высоте; теоретически
он летит горизонтально, равномерно и прямолчнейно. Фактически
полет сопровождается отклонениями центра массы самолета от тео-
теоретической траектории и колебаниями самолета около центра массы.
Эти отклонения и колебания являются случайными и связаны с турбу-
турбулентностью атмосферы; от раза к разу они не повторяются.
4. Производится ряд подрывов осколочного снаряда в определен-
определенном положении относительно цели. Результаты отдельных подрывов
несколько отличаются друг от друг?: меняются общее число осколков,
взаимное расположение их траекторий, вес, форма и скорость каждого
отдельного осколка. Эти изменения являются случайными и связаны
с влиянием таких факторов, как неоднородность металла корпуса
снаряда, неоднородность взрывчатого вещества, непостоянство ско-
скорости детонации и т. п. В связи с этим различные подрывы,
осуществленные, казалось бы, в одинаковых условиях, могут при-
приводить к различным результатам: в одних подрывах цель будет
поражена осколками, в других — нет.
Все приведенные примеры рассмотрены здесь под одним и тем же
углом зрения: подчеркнуты случайные вариации, неодинаковые резуль-
результаты ряда опытов, основные условия которых остаются неизменными.
Эти вариации всегда связаны с наличием каких-то второстепенных
факторов, влияющих на исход опыта, но не заданных в числе его
основных условий. Основные условия опыта, определяющие в общих
и грубых чертах его протекание, сохраняются неизменными; второ-
второстепенные— меняются от опыта к опыту и вносят случайные разли-
различия в их результаты.
Совершенно очевидно, что в природе нет ни одного физического
явления, в котором не присутствовали бы в той или иной мере
элементы случайности. Как бы точно и подробно ни были фиксиро-
фиксированы условия опыта, невозможно достигнуть того, чтобы при повто-
повторении опыта результаты полностью и в точности совпадали.
Случайные отклонения неизбежно сопутствуют любому законо-
закономерному явлению. Тем не менее в ряде практических задач этими
случайными элементами можно пренебречь, рассматривая вместо
реального явления его упрощенную схему, «модель», и предполагая,
что в данных условиях опыта явление протекает вполне определен-
определенным образом. При этом из бесчисленного множества факторов,
влияющих на данное явление, выделяются самые главные, основные,
решающие; влиянием остальных, второстепенных факторов просто
пренебрегают. Такая схема изучения явлений постоянно применяется
в физике, механике, технике. При пользовании этой схемой для
решения любой задачи прежде всего выделяется основной круг учи-
,1.1] ПРЕДМЕТ ТЕОРИИ ВЕРОЯТНОСТЕЙ 13
тываемых условий и выясняется, на какие параметры задачи они
влияют; затем применяется тот или иной математический аппарат
(например, составляются и интегрируются дифференциальные уравне-
уравнения, описывающие явление); таким образом выявляется основная
закономерность, свойственная данному явлению и дающая возможность
предсказать результат опыта по его заданным условиям. По мере
развития науки число учитываемых факторов становится все боль-
больше; явление исследуется подробнее; научный прогноз становится
точнее.
Однако для решения ряда вопросов описанная схема — классиче-
классическая схема так называемых «точных наук»—оказывается плохо при-
приспособленной. Существуют такие задачи, где интересующий нас исход
опыта зависит от столь большого числа факторов, что практически
невозможно зарегистрировать и учесть все эти факторы. Это — задачи,
в которых многочисленные второстепенные, тесно переплетающиеся
между собой случайные факторы играют заметную роль, а вместе
с тем число их так велико и влияние столь сложно, что применение
классических методов ис- <•
следования себя не оправ-
оправдывает.
Рассмотрим пример. и„у
Производится стрельба по
некоторой цели Ц из
орудия, установленного
под углом 60 к гори- Рис. 1.1.2.
зонту (рис. 1.1.2). Траек-
Траектории снарядов, как было указано выше, не совпадают между
собой; в результате точки падения снарядов на земле рассеиваются.
Если размеры цели велики по сравнению с областью рассеивания,
то этим рассеиванием, очевидно, можно пренебречь: при правильной
установке орудия любой выпущенный снаряд попадает в цель. Если же
(как обычно и бывает на практике) область рассеивания снарядов
превышает размеры цели, то некоторые из снарядов в связи с влия-
влиянием случайных факторов в цель не попадут. Возникает ряд вопро-
вопросов, например: какой процент выпущенных снарядов в среднем попадает
в цель? Сколько нужно потратить снарядов для того, чтобы доста-
достаточно надежно поразить цель? Какие следует принять меры для
уменьшения расхода снарядов?
Чтобы ответить на подобные вопросы, обычная схема точных
наук оказывается недостаточной. Эти вопросы органически связаны
со случайной природой явления; для того чтобы на них ответить,
очевидно, нельзя просто пренебречь случайностью, — надо изучить
случайное явление рассеивания снарядов с точки зрения закономер-
закономерностей, присущих ему именно как случайному явлению. Надо иссле-
исследовать закон, по которому распределяются точки падения снарядов;
'4 ВВЕДЕНИЕ [ГЛ. 1
нужно выяснить случайные причины, вызывающие рассеивание, срав-
сравнить их между собой по степени важности и т. д.
Рассмотрим другой пример. Некоторое техническое устройство,
например система автоматического управления, решает определенную
задачу в условиях, когда на систему непрерывно воздействуют слу-
случайные помехи. Наличие помех приводит к тому, что система решает
задачу с некоторой ошибкой, в ряде случаев выходящей за пределы
допустимой. Возникают вопросы: как часто будут появляться такие
ошибки? Какие следует принять меры для того, чтобы практически
исключить их возможность?
Чтобы ответить на такие вопросы, необходимо исследовать при-
природу и структуру случайных возмущений, воздействующих кя систему,
изучить реакцию системы на такие возмущения, выяснить влияние
конструктивных параметров системы на вид этой реакции.
Все подобные задачи, число которых в физике н технике чрезвы-
чрезвычайно велико, требуют изучения не только основных, главных зако-
закономерностей, определяющих явление в общих чертах, но и анализа
случайных возмущений и искажений, связанных с наличием второ-
второстепенных факторов и придающих исходу опыта при заданных усло-
условиях элемент неопределенности.
Какие же существуют пути и методы для исследования случай-
случайных явлений?
С чисто теоретической точки зрения те факторы, которые мы
условно назвали «случайными», в принципе ничем не отличаются от
других, которые мы выделили в качестве «основных». Теоретически
можно неограниченно повышать точность решения каждой задачи,
учитывая все новые и новые группы факторов: от самых существен-
существенных до самых ничтожных. Однако практически такая нопытка оди-
одинаково подробно и тщательно проанализировать влияние решительно
всех факторов, от которых зависит явление, привела бы только к тому,
что решение задачи, в силу непомерной громоздкости и сложности,
оказалось бы практически неосуществимым и к тому же не имело бы
никакой познавательной ценности.
Например, теоретически можно было бы поставить и решить
вадачу об определении траектории вполне определенного снаряда,
с учетом всех конкретных погрешностей его изготовления, точного
веса и конкретной структуры данного, вполне определенного поро-
порохового заряда при точно определенных метеорологических данных
(температура, давление, влажность, ветер) в каждой точке траектории.
Такое решение не только было бы необозримо сложным, но и не
имело бы никакой практической ценности, так как относилось бы
только к данному конкретному снаряду и заряду в данных конкрет-
конкретных условиях, которые практически больше не повторятся.
Очевидно, должна существовать принципиальная разница в мето-
методах учета основных, решающих факторов, определяющих в главных
1Л1 ПРЕДМЕТ ТЕОРИИ ВЕРОЯТНОСТЕЙ 15
чертах течение явленчя, н вторичных, второстепенных факторов,
влияющих на течение явления в качестве «погрешностей» или «воз-
«возмущений». Элемент неопределенности, сложности, многопричинности,
присущий случайным явлениям, требует создания специальных мето-
методов для изучения этих явлений.
Такие методы и разрабатываются в теории вероятностей. Ее
предметом являются специфические закономерности, наблюдаемые
в случайных явлениях.
Практика показывает, что, наблюдая в совокупности массы одно-
однородных случайных явлений, мы обычно обнаруживаем в них вполне
определенные закономерности, своего рода устойчивости, свой-
стве:!н:.:с nveinio мпссорым случайным явлениям.
Например, если много раз подряд бросать монету, частота по-
появления герба (отношение числа появившихся гербов к общему числу
бросаний) постепенно стабилизируется, приближаясь к вполне опре-
определенному числу, именно к -^. Такое же свойство «устойчивости
частот» обнаруживается и при многократком повторении любого дру-
другого опыта, исход которого представляется заранее неопределенным,
случайным. Так, при увеличении числа выстрелов частота попадания
в некоторую цель тоже стабилизируется, приближаясь к некоторому
постоянному числу.
Рассмотрим другой пример. В сосуде заключен какой-то объем
газа, состоящий из весьма большого числа молекул. Каждая моле-
молекула за секунду испытывает множество столкновений с другими
молекулами, многократно меняет скорость и направление движения;
траектория каждой отдельной молекулы случайна. Известно, что
давление газа на стенку сосуда обусловлено совокупностью ударов
молекул об эту стенку. Казалось бы, если траектория каждой от-
отдельной молекулы случайна, то и давление на стенку сосуда должно-
было бы изменяться случайным и неконтролируемым образом; однако
это не так. Если число молекул достаточно велико, то давление
газа практически не зависит от траекторий отдельных молекул и
подчиняется вполне определенней и очень простой закономерности.
Случайные особенности, свойственные движению каждой отдельной
молекулы, в массе взаимно компенсируются; в результате, несмотря
на сложность и запутанность отдельного случайного явления, мы
получаем весьма простую закономерность, справедливую для массы
случайных явлений. Отметим, что именно массовость случайных•
явлений обеспечивает выполнение этой закономерности; при ограни-
ограниченном числе молекул начинают сказываться случайные отклонения
от закономерности, так называемые флуктуации.
Рассмотрим еще один пример. По некоторой мишени произво-
производится один за другим ряд выстрелов; наблюдается распределение
точек попадания на мишени. При ограниченном числе выстрелов точки
! 6 ВВЕДЕНИЕ [ГЛ. Т
попадания распределяются по мишени в полном беспорядке, без какой-
ли&о видимой закономерности. По мере увеличения числа выстрелов
и расположении точек попадания начинает наблюдаться некоторая
закономерность; эта закономерность проявляется тем отчетливее, чем
Гольшее количеств выстрелов произведено. Расположение точек
попадания оказывается приблизительно симметричным относительно
некоторой центральной точки: в центральной области группы пробоин
они расположены гуще, чем по краям; при этом густота пробоин
убывает по вполне определенному закону (так называемый «нормаль-
«нормальный закон» или «закон Гаусса», которому будет уделено большое
внимание в данном курсе).
Подобные специфические, так называемые «статистические», за-
закономерности наблюдаются всегда, когда мы имеем дело с массой
однородных случайных явлений. Закономерности, проявляющиеся
« этой массе, оказываются практически независимыми от индиви-
индивидуальных особенностей отдельных случайных явлений, входящих
в массу. Эти отдельные особенности в массе как бы взаимно пога-
погашаются, нивелируются, и средний результат массы случайных явле-
явлений оказывается практически уже не случайным. Именно эта много-
многократно подтвержденная опытом устойчивость массовых случайных
явлений и служит базой для применения вероятностных (статистиче-
(статистических) методов исследования. Методы теории вероятностей по природе
приспособлены только для исследования массовых случайных явлений;
они не дают возможности предсказать исход отдельного случайного
явления, но дают возможность предсказать средний суммарный ре-
результат массы однородных случайных явлений, предсказать средний
исход массы аналогичных опытов, конкретный исход каждого из ко-
которых остается неопределенным, случайным.
Чем большее количество однородных случайных явлений участ-
участвует в задаче, тем определеннее и отчетливее проявляются прису-
присущие им специфические законы, тем с большей уверенностью и точ-
точностью можно осуществлять научный прогноз.
Во всех случаях, когда применяются вероятностные методы
исследования, цель их в том, чтобы, минуя слишком сложное
(и зачастую практически невозможное) изучение отдельного явления,
обусловленного слишком большим количеством факторов, обратиться
непосредственно к законам, управляющим массами случайных явле-
явлений. Изучение этих законов позволяет не только осуществлять науч-
научный прогноз в своеобразной области случайных явлений, но в ряде
случаев помогает целенаправленно влиять на ход случайных явлений,
контролировать их, ограничивать сферу действия случайности, су-
сужать ее влияние на практику.
Вероятностный, или статистический, метод в науке не про-
противопоставляет себя классическому, обычному методу точных
наук,. а является его дополнением, позволяющим глубже анали-
1.2} КРАТКИЕ ИСТОРИЧЕСКИЕ СВЕДЕНИЯ 17
зировать явление с учетом присущих ему элементов случай-
случайности.
Характерным для современного этапа развития естественных и
технических наук является весьма широкое и плодотворное приме-
применение статистических методов во всех областях знания. Это вполне
естественно, так как при углубленном изучении любого круга явле-
явлений неизбежно наступает этап, когда требуется не только выявление
основных закономерностей, но и анализ возможных отклонений от
них. В одних науках, в силу специфики предмета и исторических
условий, внедрение статистических методов наблюдается раньше,
в других — позже. В настоящее время нет почти ни одной есте-
естественной науки, в которой так или иначе не применялись бы ве-
вероятностные методы. Целые разделы современной физики (в част-
частности, ядерная физика) базируются на методах теории вероятностей.
Все шире применяются вероятностные методы в современной электро-
электротехнике и радиотехнике, метеорологии и астрономии, теории авто-
автоматического регулирования и машинной математике.
Обширное поле применения находит теория вероятностей в раз-
разнообразных областях военной техники: теория стрельбы и бомбоме-
бомбометания, теория боеприпасов, теория прицелов и приборов управления
огнем, аэронавигация, тактика и множество других разделов военной
науки широко пользуются методами теории вероятностей и ее мате-
математическим аппаратом.
Математические законы теории вероятностей — отражение реаль-
реальных статистических законов, объективно существующих в массовых
случайных явлениях природы. К изучению этих явлений теория ве-
вероятностей применяет математический метод и по своему методу
является одним из разделов математики, столь же логически точным
и строгим, как другие математические науки.
1.2. Краткие исторические сведения
Теория вероятностей, подобно другим математическим наукам,
развилась из потребностей практики.
Начало систематического исследования задач, относящихся к мас-
массовым случайным явлениям, и появление соответствующего математи-
математического аппарата относятся к XVII веку. В начале XVII века знаме-
знаменитый физик Галилей уже пытался подвергнуть научному исследованию
ошибки физических измерений, рассматривая их как случайные и
оценивая их вероятности. К этому же времени относятся первые
попытки создания общей теории страхования, основанной на анализе
закономерностей в таких массовых случайных явлениях, как заболе-
заболеваемость, смертность, статистика несчастных случаев и т. д. Необ-
Необходимость создания математического аппарата, специально приспособ-
приспособленного для анализа слу чайных явлений, вытекала и из потребностей
2 Е. С. Вентцель
18 ВВЕДЕНИЕ [ГЛ. I
обработки и обобщения обширного статистического материала во
всех областях науки.
Однако теория вероятностей как математическая наука сформи-
сформировалась, в основном, не на материале указанных выше практических
задач: эти задачи слишком сложны; в них законы, управляющие слу-
случайными явлениями, пооступ^ют недостаточно отчетливо и за^шеваны
многими осложняющими факторамя. Необходимо било сначала изу-
изучить закономерности случайных явлений на более простом материале.
Таким материалом исторически оказались так называемые «азартные
игры». Эти игры с незапамятных времен создавались рядом поколе-
поколений именно так, чтобы в них исход опыта был независим от под-
поддающихся наблюдению условий опыта, был чисто случайным. Самое
слово «азарт» (фр. «le hasard») означает «случай». Схемы азартных
игр дают исключительные по. простоте и прозрачности модели слу-
случайных явлений, позволяющие в наиболее отчетливой форме наблю-
наблюдать и изучать управляющие ими специфические законы; а возмож-
возможность неограниченно повторять один и тот же опыт обеспечивает
зксперименталькую проверку этих законов в условиях действитель-
действительной массовости явлений. Вплоть до настоящего времени примеры из
области азартных игр и аналогичные им задачи на «схему урн» ши-
широко употребляются при изучении теории вероятностей как упро-
упрощенные модели случайных явлений, иллюстрирующие в наиболее
простом и наглядном виде основные законы и правила теории ве-
вероятностей.
Возникновение теории вероятностей в современном смысле слова
относится к середине XVII века и связано с исследованиями Паскаля
A623—1662), Ферма A601—1665) и Гюйгенса A629—1695) в об-
области теории азартных игр. В этих работах постепенно сформирова-
сформировались такие важные понятия, как вероятность и математическое ожи-
ожидание; были установлены их основные свойства и приемы их вычи-
вычисления. Непосредственное практическое применение вероятностные
методы нашли прежде всего в задачах страхования. Уже с конца
XVII века страхование стало производиться на научной математи-
математической основе. С тех пор теория вероятностей находит все более
широкое применение в различных областях.
Крупный шаг вперед в развитии теории вероятностей связан
с работами Якова Бернулли A654—1705). Ему принадлежит первое
доказательство одного из важнейших положений теории вероят-
вероятностей— так называемого закона больших чисел.
Еще до Якова Бернулли многие отмечали как эмпирический факт
ту особенность случайных явлений, которую можно назвать «свой-
«свойством устойчивости частот при большом числе опытов». Было неод-
неоднократно отмечено, что при большом числе опытов, исход каждого
из которых является случайным, относительная частота появления
каждого данного исхода имеет тенденцию стабилизироваться, при-
1.2] КРАТКИЕ ИСТОРИЧЕСКИЕ СВЕДЕНИЯ 19
блгжгясь к некоторому спрсделегпому числу — вероятнгсти этого
исхода. Например, если много раз бросать монету, относительная
частота появления герба приближается к 1/2', при многократном бро-
бросании игральной кости частота появления грани с пятью очками при-
приближается к 7б и т. д. Яков Бернулли впервые дал теоретическое
обоснование этому эмпирическому факту. Теорема Якова Берпулла—-
простейшая форма закона больших чисел—устанавливает связь
между вероятностью события и частотой его появления; при доста-
достаточно большом числе опытов можно с практической достоверностью
ожидать сколь угодно близкого совпадения частоты с вероятностью.
Другой важный этап в развитии теории вероятностей связан
с именем Моавра A667—1754). Этот ученый впервые ввел в рас-
рассмотрение и для простейшего случая обосновал своеобразный закон,
очень часто наблюдаемый в случайных явлениях: так называемый
нормальный закон (иначе — закон Гаусса). Нормальный закон, как
мы увидим Далее, играет исключительно важную роль в случайных
явлениях. Теоремы, обосновывающие этот закон для тех или иных
условий, носят в теории вероятностей общее название «центральной
предельной теоремы».
Выдающаяся роль в развитии теории вероятностей принадлежит
знаменитому математику Лапласу A749—1827). Он впервые дал
стройное и систематическое изложение основ теории вероятностей,
дал доказательство одной из форм центральной предельной теоремы
(теоремы Моавра — Лапласа) и развил ряд замечательных приложе-
приложений теории вероятностей к вопросам практики, в частности к ана-
анализу ошибок наблюдений и измерений.
Значительный шаг вперед в развитии теории вероятностей связан
с именем Гаусса A777—1855), который дал еще более общее обо-
обоснование нормальному закону и- разработал метод обработки экспе-
экспериментальных данных, известный под названием «метода наименьших
квадратов». Следует также отметить работы Пуассона A781—1840),
доказавшего более 'общую, чем у Якова Бернулли, форму закона
больших чисел, а также впервые применившего теорию вероятностей
к задачам стрельбы. С именем Пуассона связан один из законов
распределения, играющий большую роль в теории вероятностей и ее
приложениях.
Для всего XVIII и начала XIX века характерны бурное развитие
теории вероятностей и повсеместное увлечение ею. Теория вероят-
вероятностей становится «модной» наукой. Ее начинают применять не только
там, где это применение правомерно, но и там, где оно ничем не
оправдано. Для этого периода характерны многочисленные попытки
применить теорию вероятностей к изучению общественных явлений,
к так называемым «моральным» или «нравственным» наукам. Во
множестве появились работы, посвященные вопросам судопроизвод-
судопроизводства, истории, политики, даже богословия, в которых применялся
2*
20 ВВЕДЕНИЕ [ГЛ. I
аппарат теории вероятностей. Для всех этих псевдонаучных исследо-
исследований характерен чрезвычайно упрощенный, мехлшспнесклй подход
к рассматриваемым в них общественным явлениям. В основу рас-
рассуждения полагаются некоторые произвольно заданные веролшоси!
(например, при рассмотрении вопросов судопроизводства склонность
каждого человека к правде или лжи оценивается некоторой постоян-
постоянной, одинаковой для всех людей вероятностью), и далее обществен-
общественная проблема решается как простая арифметическая задача. Естест-
Естественно, что все подобные попытки были обречены на неудачу и не
могли сыграть положительной роли в развитии науки. Напротив, их
косвенным результатом оказалось то, что примерно в 20-х — 30-х
годах XIX века в Западной Европе повсеместное увлечение теорией
вероятностей сменилось разочарованием и скептицизмом. На теорию
вероятностей стали смотреть как на науку сомнительную, второсорт-
второсортную, род математического развлечения, вряд ли достойный серьез-
серьезного изучения.
Замечательно, что именно в это время в России создается та
знаменитая Петербургская математическая школа, трудами которой
теория вероятностей была поставлена на прочную логическую и ма-
математическую основу и сделана надежным, точным и эффективным
методом познания. Со времени появления этой школы развитие тео-
теории вероятностей уже теснейшим образом связано с работами рус-
русских, а в дальнейшем — советских ученых.
Среди ученых Петербургской математической школы следует
назвать В. Я. Буняковского A804—1889) — автора первого курса
теории вероятностей на русском языке, создателя современной рус-
русской терминологии в теории вероятностей, автора оригинальных ис-
исследований в области статистики и демографии.
Учеником В. Я. Буняковского был великий русский математик
П. Л. Чебышев A821 —1894). Среди обширных и разнообразных
математических трудов П. Л. Чебышева заметное место занимают
его труды по теории вероятностей. П. Л. Чебышеву принадлежит
дальнейшее расширение и обобщение закона больших чисел. Кроме
того, П. Л. Чебышев ввел в теорию вероятностей весьма мощный и
плодотворный метод моментов.
Учеником П. Л. Чебышева был А. А. Марков A856—1922),
также обогативший теорию вероятностей открытиями и методами
большой важности. А. А. Марков существенно расширил область
применения закона больших чисел и центральной предельной теоремы,
распространив их не только на независимые, но и на зависимые
опыты. Важнейшей заслугой А. А. Маркова явилось то, что он за-
заложил основы совершенно новой ветви теории вероятностей—теории
случайных, или «стохастических», процессов. Развитие этой теории
составляет основное содержание новейшей, современной теории ве-
вероятностей.
1.2] КРАТКИЕ ИСТОРИЧЕСКИЕ СВЕДЕНИЯ 21
Учеником П. Л. Чебышсва был и А. М. Лкпуисп A857—1918),
с именем которого связано первое доказательство центральной пре-
предельной теоремы при чрезвычайно общих условиях. Для доказатель-
доказательства своей теоремы А. М. Ляпунов разработал специальный метод
характеристических функций, широко применяемый в современной
теории вероятностей.
Характерной особенностью работ Петербургской математической
и1 колы была исключительная четкость постановки задач, полная ма-
математическая строгость применяемых методов и наряду с этим тесная
связь теории с непосредственными требованиями практики. Трудами
ученых Петербургской математической школы теория вероятностей
была выведена с задворков науки и поставлена как полноправный
член в ряд точных математических наук. Условия применения ее ме-
методов были строго определены, а самые методы доведены до высокой
степени совершенства.
Современное развитие теории вероятностей характерно всеобщим
подъемом интереса к ней и резким расширением круга ее практи-
практических применений. За последние десятилетия теория вероятностей
превратилась в одну из наиболее быстро развивающихся наук, тес-
теснейшим образом связанную с потребностями практики и техники.
Советская школа теории вероятностей, унаследовав традиции Петер-
Петербургской математической школы, занимает в мировой науке веду-
ведущее место.
Здесь мы назовем только некоторых крупнейших советских уче-
ученых, труды которых сыграли решающую роль в развитии современ-
современной теории вероятностей и ее практических приложений.
С. Н. Бернштейн разработал первую законченную аксиоматику
теории вероятностей, а также существенно расширил область при-
применения предельных теорем.
А. Я. Хинчин A894—1959) известен своими исследованиями
в области дальнейшего обобщения и усиления закона больших чисел,
но главным образом своими исследованиями в области так называемых
стационарных случайных процессов.
Ряд важнейших основополагающих работ в различных областях
теории вероятностей и математической статистики принадлежит
А. Н. Колмогорову. Он дал наиболее совершенное аксиоматическое
построение теории вероятностей, связав ее с одним из важнейших
разделов современной математики—метрической теорией функций.
Особое значение имеют работы А. Н. Колмогорова в области теории
случайных функций (стохастических процессов), которые в настоящее
время являются основой всех исследований в данной области. Работы
At H. Колмогорова, относящиеся к оценке эффективности легли
в основу целого нового научного направления в теории стрельбы, пе-
переросшего затем в более широкую науку об эффективности боевых
действий.
22 ВВЕДЕНИЕ [ГЛ. I
В. И. Романовский A879—1954) и Н, В. Смирнов известны
своими работами в области математической статистики, Е. Е. Слуц-
Слуцкий A880 — 1948) — в теории случайных процессов, Б. В. Гнеденко—•
в области теории массового обслуживания, Е. Б. Дынкин — в об-
области марковских случайных процессов, В. С. Пугачев — в области
случайных процессов в применении к задачам автоматического упра-
управления.
Развитие зарубежной теории вероятностей б настоящее время
также идет усиленными темпами в связи с настоятельными требова-
требованиями практики. Преимущественным вниманием пользуются, как и
у нас, вопросы, относящиеся к случайным процессам. Значительные
работы в этой области принадлежат, например, Н. Винеру, В. Фсллсру,
Д. Дубу. Важные работы по теории вероятностей и математической
статистике принадлежат Р. Фишеру, Д. Нейману и Г. Крамеру.
За самые последние годы мы являемся свидетелями зарождения
новых и своеобразных методов прикладной теории вероятностей,
появление которых связано со спецификой исследуемых технических
проблем. Речь идет, в частности, о таких новых дисциплинах, как
«теория информации» и «теория массового обслуживания». Возник-
Возникшие из непосредственных потребностей практики, эти разделы тео-
теории вероятностей приобретают общее теоретическое значение, а круг
их приложений быстро увеличивается.
Г ЛАВА 2
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ВЕРОЯТНОСТЕЙ
2.!. Событие, Вероятность события
Каждая наука, развивающая общую теорию какого-либо круга
явлений, содержит ряд основных понятий, на которых она базируется.
Таковы, например, в геометрии понятия точки, прямой, линии; в ме-
механике— понятия силы, массы, скорости, ускорения и т. д. Есте-
Естественно, что не все основные понятия могут быть строго определены,
так как определить понятие — это значит свести его к другим, более
известным. Очевидно, процесс определения одних понятий через другие
должен где-то заканчиваться, дойдя до самых первичных понятий,
к которым сводятся все остальные и которые сами строго не опре-
определяются, а только поясняются.
Такие основные понятия существуют и в теории вероятностей.
В качестве первого из них введем понятие события.
Под «событием» в теории вероятностей понимается всякий факт,
который в результате опыта может произойти или не произойти.
Приведем несколько примеров событий:
А — появление герба при бросании монеты;
В — появление трех гербов при трехкратном бросании монеты;
С — попадание в цель при выстреле;
D—появление туза при вынимании карты из колоды;
Е— обнаружение объекта при одном цикле обзора радиолока-
радиолокационной станции;
F — обрыв нити в течение часа работы ткацкого станка.
Рассматривая вышеперечисленные события, мы видим, что каждое
из них обладает какой-то степенью возможности: одни — большей,
другие — меньшей, причем для некоторых из этих событий мы сразу же
можем решить, какое из них более, а какое менее возможно. Например,
сразу видно, что событие А более возможно, чем В и D. Относи-
Относительно событий С, Е и F аналогичных выводов сразу сделать нельзя;
для этого следовало бы несколько уточнить условия опыта. Так или
иначе ясно, что каждое, из таких событий обладает той или иной
степенью возможности. Чтобы количественно сравнивать между собой
события по степени их возможности, очевидно, нужно с каждым
24 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ 2
событием связать определенное число, которое тем больше, чем
иолеи возможно событие. Такое число мы назовем вероятностью
события.
Таким образом, мы ввели в рассмотрение второе основное по-
понятие теории вероятностей — понятие вероятности события. Вероят-
Вероятность события ecIJi^Si£^eHji_aj^i«pa_CTe2^2L^5^_ETillli;!5^ возможности
этого события!
Заметим, что уже при самом введении понятия вероятности со-
события мы связываем с этим понятием определенный практический
смысл, а именно: на основании опыта мы считаем более вероятными
те события, которые происходят чаще; менее вероятными —те события,
которые происходят реже; мало вероятными — те, которые почти
.никогда не происходят. Таким образом, понятие вероятности события
в самой своей основе связано с опытным, практическим понятием
частоты события.
Сравнивая между собой различные события по степени их воз-
возможности, мы должны установить какую-то единицу измерения.
В качестве такой единицы измерения естественно принять вероятность
достоверного события, т. е. такого события, которое в результате
опыта непременно должно произойти. Пример достоверного события —
выпадение не более 6 очков при бросании одной игральной кости.
Если приписать достоверному событию вероятность, равную еди-
единице, то все другие события — возможные, но не достоверные —
будут характеризоваться вероятностями, меньшими единицы, соста-
составляющими какую-то долю единицы.
Противоположностью по отношению к достоверному событию
является невозможное событие, т. е. такое событие, которое
в данном опыте не может произойти. Пример невозможного события —
появление 12 очков при бросании одной игральной кости. Естест-
Естественно приписать невозможному событию вероятность, равную нулю.
Таким образом, установлены единица измерения вероятностей —
вероятность достоверного события — и диапазон изменения вероятно-
вероятностей любых событий —. числа от 0 до 1.
2.2. Непосредственный подсчет вероятностей
Существует целый класс опытов, для которых вероятности их
возможных исходов легко оценить непосредственно из условий самого
опыта. Для этого нужно, чтобы различные исходы опыта обладали
симметрией и в силу этого были объективно одинаково возможными.
Рассмотрим, например, опыт, состоящий в бросании игральной
кости, т. е. симметричного кубика, на гранях которого нанесено раз-
различное число очков; от 1 до 6.
В силу симметрии кубика есть основания считать все шесть воз-
возможных исходов опыта одинаково возможными. Именно это дает нам
г.21
НЕПОСРЕДСТВЕННЫЙ ПОДСЧЕТ ВЕРОЯТНОСТЕЙ 25
право предполагать, что при многократном бросании кости все шесть
граней будут выпадать примерно одинаково часто. Это предположе-
предположение для правильно выполненной кости действительно оправдывается
на опыте; при многократном бросании кости каждая ее грань по-
появляется примерно в одной шестой доле всех случаев бросания,
причем отклонение этой доли от 4- тем меньше, чем большее число
опытов произведено. Имея в виду, что вероятность достоверного
события принята равной единице, естественно приписать выпадению
каждой отдельной грани вероятность, равную -g-. Это число харак-
характеризует некоторые объективные свойства данного случайного явле-
явления, а именно свойство симметрии шести возможных исходов опыта.
Для всякого опыта, в котором возможные исходы симметричны
и одинаково возможны, можно применить аналогичный прием, который
называется непосредственным подсчетом вероятностей.
Симметричность возможных исходов опыта обычно наблюдается
только в искусственно организованных опытах, типа азартных игр.
Так как первоначальное развитие теория вероятностей получила
именно на схемах азартных игр, то прием непосредственного под-
подсчета вероятностей, исторически возникший вместе с возникновением
математической теории случайных явлений, долгое время считался
основным и был положен в основу так называемой «классической»
теории вероятностей. При этом опыты, не обладающие симметрией
возможных исходов, искусственно сводились к «классической» схеме.
Несмотря на ограниченную сферу практических применений этой
схемы, она все же представляет известный интерес, так как именно
на опытах, обладающих симметрией возможных исходов, и на собы-
событиях, связанных с такими опытами, легче всего познакомиться с основ-
основными свойствами вероятностей. Такого рода событиями, допускаю-
допускающими непосредственный подсчет вероятностей, мы и займемся в первую
очередь.
Предварительно введем некоторые вспомогательные понятия.
1. Полная группа событий.
Говорят, что несколько событий в данном опыте образуют пол-
полную группу событий, если в результате опыта непременно должно
появиться хотя бы одно из них.
Примеры событий', образующих полную группу:
1) выпадение герба и выпадение цифры при бросании монеты;
2) попадание и промах при выстреле;
3) появление 1,2, 3, 4, 5, 6 очков при бросании игральной кости;
4) появление белого шара и появление черного шара при выни-
вынимании одного шара из урны, в которой 2 белых и 3 черных шара;
5) ни одной опечатки, одна, две, три и более трех опечаток при
проверке страницы напечатанного текста;
26 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 2
6) хотя бы одно попадание и хотя бы одни промах при двух
выстрелах.
2. Несовместные события.
Несколько событий называются несовместными в данном опыте,
если никакие два из них не мсгут появиться вместе.
Примеры несовместных событий:
1) выпадение герба и выпадение цифры при бросании монеты;
2) попадание и промах при одном выстреле;
3) лиииленне 1, 3, 4 очков при одном бросании игральной кости;
4) ровно один отказ, ровно два отказа, ровно три отказа тех-
технического устройства за десять часов работы.
3. Равновозможные события.
Несколько событий в данном опыте называются равновозмож-
ними, если по условиям Симметрии есть основание считать, что
ни одно из этих событий не является объективно более возможным,
чем другое.
Примеры равновозможных событий:
1) выпадение герба и выпадение цифры при бросании монеты;
2) появление 1, 3, 4, 5 очков при бросании игральной кости;
3) появление карты бубновой, червонной, трефовой масти при
вынимании карты из колоды;
4) появление шара с № 1, 2, 3 при вынимании одного шара
из урны, содержащей 10 перенумерованных шаров.
Существуют группы событий, обладающие всеми тремя свойствами:
они образуют полную группу, несовместны и равновозможны; на-
например: появление герба и цифры при бросании монеты; появление
1, 2, 3, 4, 5, 6 очков при бросании игральной кости. События,
образующие такую группу, называются случаями (иначе «шан-
«шансами»).
Если какой-либо опыт по своей структуре обладает симметрией
возможных исходов, то случаи представляют собой исчерпывающую
систему равновозможных и исключающих друг друга исходов опыта.
Про такой опыт говорят, что он «сводится к схеме случаев» (иначе —
к «схеме урн»).
Схема случаев по преимуществу имеет место в искусственно ор-
организованных опытах, в которых заранее и сознательно обеспечена
одинаковая возможность исходов опыта (как, например, в азартных
играх). Для таких опытов возможен непосредственный подсчет ве-
вероятностей, основанный на оценке доли так называемых «благопри-
«благоприятных» случаев в общем числе случаев.
Случай называется благоприятным (или «благоприятствующим»)
некоторому событию, если появление этого случая влечет за собой
появление данного события.
Например, при бросании игральной кости возможны шесть слу-
случаев: появление 1, 2, 3, 4, 5, 6 очков. Из них событию А—появ-
2.2] НЕПОСРЕДСТВЕННЫЙ ПОДСЧЕТ ВЕРОЯТНОСТЕЙ 27
лению четного числа очков — благоприятны три случая: 2, 4, б и не
благоприятны остальные три.
Если опыт сводится к схеме, случаев, то вероятность события А
в данном опыте можно оценить по относительной дело благоприят-
благоприятных случаев. Вероятность события А вычисляется как отношение
•тела благоприятных случаев к общему числу случаев:
Р {А)-—%■> B-2.1)
где Р (А) — вероятность события А; п — общее число случаев;
т — число случаев, благоприятных событию А.
Так как число благоприятных случаев всегда заключено между
О и п @—для невозможного и п—для достоверного события), то
вероятность события, вычисленная по формуле B.2.1), всегда есть
рациональная правильная дробь:
0<Р(Л)<1. B.2.2)
Формула B.2.1), так называемая «классическая формула» для вы-
вычисления вероятностей, долгое время фигурировала в литературе как
определение вероятности. В настоящее время при определении (по-
(пояснении) понятия вероятности обычно исходят из других принципов,
непосредственно связывая понятие вероятности с эмпирическим поня-
понятием частоты; формула же B.2.1) сохраняется лишь как формула
для непосредственного подсчета вероятностей, пригодная тогда и
только тогда, когда опыт сводится к схеме случаев, т. е. обладает
симметрией возможных исходов.
Пример 1. В урне находится 2 белых и 3 черных шара. Из урны на-
наугад вынимается один шар. Требуется найти вероятность того, что этот шар
будет белым.
Решение. Обозначим А событие, состоящее в появлении белого шара.
Общее число случаев п= 5; число случаев, благоприятных событию А, т =» 2.
Следовательно,
Пример 2. В урне а белых и Ъ черных шаров. Из урны вынимаются
два шара. Найти вероятность того, что оба шара будут белыми.
Решение. Обозначим В событие, состоящее в появлении двух белых
шаров. Подсчитаем общее число возможны* случаев п и число случаев т.
благоприятных событию В: 2 f - "
п — Са+Ь>
следовательно,
С'а
Знаком С1к обозначено число сочетаний из k элементов по I
2а основные понятия теория вероятностей [гл. 2
Пример 3. В партии из N изделий М бракованных. Из партии выби-
выбирается наугад п изделий. Определить вероятность того, что среди этих п
изделий будет ровно т бракованных.
Решение. Общее число случаев, очевидно, равно CnN; число благо-
благоприятных случаев C'J^C'lfJ'l,, откуда вероятность интересующего нас
Р(А)= '""-".
2.3. Частота, или статистическая вероятность, события
Формула B.2.1) для непосредственного подсчета вероятностей
применима только, когда опыт, в результате которого может по-
появиться интересующее нас событие, обладает симметрией возможных
исходов (сводится к схеме случаев). Очевидно, что далеко не всякий
опыт может быть сведен к схеме случаев, и существует обширный
класс событий, вероятности которых нельзя вычислить по формуле
B.2.1). Рассмотрим, например, неправильно выполненную, несимме-
несимметричную игральную кость. Выпадение определенной грани уже не
будет характеризоваться вероятностью -^; вместе с тем ясно, что
для данной конкретной несимметричной кости выпадение этой грани
обладает некоторой вероятностью, указывающей, насколько часто
в среднем должна появляться данная грань при многократном
бросании. Очевидно, что вероятности таких событий, как «попадание
в цель при выстреле», «выход из строя радиолампы в течение од-
одного часа работы» или «пробивание брони осколком снаряда», так-
также не могут быть вычислены по формуле B.2.1), так как соот-
соответствующие опыты к схеме случаев не сводятся. Вместе с тем ясно,
что каждое из перечисленных событий обладает определенной сте-
степенью объективной возможности, которую в принципе можно изме-
измерить численно и которая при повторении подобных опытов будет
отражаться в относительной частоте соответствующих событий. По-
Поэтому мы будем считать, что каждое событие, связанное с массой
однородных опытов,—сводящееся к схеме случаев или нет,—имеет
определенную вероятность, заключенную между нулем и единицей.
Для событий, сводящихся к схеме случаев, эта вероятность может
быть вычислена непосредственно по формуле B.2.1). Для событий,
не сводящихся к схеме случаев, применяются другие способы опре-
определения вероятностей. Все эти способы корнями своими уходят
в опыт, в эксперимент, и для того чтобы составить представление
об этих способах, необходимо уяснить себе понятие частоты собы-
события и специфику той органической связи, которая существует между
вероятностью и частотой.
[Если произведена серия из п опытов, в каждом из которых могло
появиться или не появиться некоторое событие А, то частотой
2.3] ЧАСТОТА, ИЛИ СТАТИСТИЧЕСКАЯ ВЕРОЯТНОСТЬ, СОБЫТИЯ 29
события А в данной серии опытов называется отношение числа опы-
опытов, в которых появилось событие А, к общему числу произведен-
произведенных ОПЫТОВ.
Частоту события часто называют его статистической вероят-
вероятностью (в отличие от ранее введенной «математической» вероятности).
' Условимся обозначать частоту (статистическую вероятность) со-
события А знаком Р* (А). Частота события вычисляется на основании
результатов опыта по формуле
Р\А) = ~, B.3.1)
где т — число появлений события А; п — общее число произведен-
произведенных опытов.
При небольшом числе опытов частота события носит в значи-
значительной мере случайный характер и может заметно изменяться от
одной группы опытов к другой. Например, при каких-то десяти бро-
бросаниях монеты вполне возможно, что герб появится только два раза
(частота появления герба будет равна 0,2); при других десяти бро-
бросаниях мы вполне можем получить 8 гербов (частота 0,8). Однако
при увеличении числа опытов частота события все более теряет свой
случайный характер; случайные обстоятельства, свойственные каж-
каждому отдельному опыту, в массе взаимно погашаются, и частота
проявляет тенденцию стабилизироваться, приближаясь с незначитель-
незначительными колебаниями к некоторой средней, постоянной величине. На-
Например, при многократном бросании монеты частота появления герба
будет лишь незначительно уклоняться от -<>-.
Это свойство «устойчивости частот», многократно проверенное
экспериментально и подтверждающееся всем опытом практической
деятельности человечества, есть одна из наиболее характерных за-
закономерностей, наблюдаемых в случайных явлениях. Математическую
формулировку этой закономерности впервые дал Я. Бернулли в своей
теореме, которая представляет собой простейшую форму закона
больших чисел. Я. Бернулли доказал, что при неограниченном уве-
увеличении числа однородных независимых опытов с практической до-
достоверностью можно утверждать, что частота события будет сколь
угодно мало отличаться от его вероятности в отдельном опыте.
Связь между частотой события и его вероятностью — глубокая,
органическая связь. Эти два понятия по существу неразделимы. Дей-
Действительно, когда мы оцениваем степень возможности какого-либо
события, мы неизбежно связываем эту оценку с большей или мень-
меньшей частотой появления аналогичных событий на практике. Характе-
Характеризуя вероятность события каким-то числом, мы не можем придать
этому числу иного реального значения и иного практического смысла,
чем относительная частота появления данного события при большом
числе опытов. Численная оценка степени возможности события
30 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ВЕРОЯТНОСТЕЙ (ГЛ. 2
посредством вероятности имеет практический смысл именно потому,
что более вероятные события происходят в среднем чаще, чем менее-
вероятные. И если практика определенно указывает на то, что при
увеличении числа опытов частота события имеет тенденцию выравни-
выравниваться, приближаясь сквозь ряд случайных уклонений к некоторому
постоянному числу, естественно предположить, что это число и есть
вероятность события.
Проверить такое предположение мы, естественно, можем только
для таких событий, вероятности которых могут быть вычислены не-
непосредственно, т. е. для событий, сводящихся к схеме случаев, так
как только для этих событий существует точный способ вычисления
математической вероятности. Многочисленные опыты, производившиеся
С- ~р ..*;..,. л bv^iiiiiwiuiii-iihri reupiiii вероятностей, действительно под-
подтверждают это предположение. Они показывают, что для события,
сводящегося к схеме случаев, частота события при увеличении числа
опытов всегда приближается к его вероятности. Вполне естественно
допустить, что и для события, не сводящегося к схеме случаев, тот
же закон остается в силе и что постоянное значение, к которому
при увеличении числа опытов приближается частота события, пред-
представляет собой не что иное, как вероятность события. Тогда частоту
события при достаточно большом числе опытов можно принять за
приближенное значение вероятности. Так и поступают на практике,
определяя из опыта вероятности событий, не сводящихся к схеме
случаев.
Следует отметить, что характер приближения частоты к вероят-
вероятности при увеличении числа опытов несколько отличается от «стрем-
«стремления к пределу» в математическом смысле слова.
Когда в математике мы говорим, что переменная х„ с возраста-
возрастанием я стремится к постоянному пределу а, то это означает, что
разность \х„— а\ становится меньше любого положительного числа е
для всех значений п, начиная с некоторого достаточно большого
числа.
Относительно частоты события и его вероятности такого кате-
категорического утверждения сделать нельзя. Действительно, нет ничего
физически невозможного в том, что при большом числе опытов ча-
частота события будет значительно уклоняться от его вероятности;
но такое значительное уклонение является весьма маловероятным,
тем менее вероятным, чем большее число опытов произведено. На-
Например, при бросании монеты 10 раз физически возможно (хотя и
маловероятно), что все 10 раз появится герб, и частота появления
герба будет равна 1; при 1000 бросаниях такое событие все еще
остается физически возможным, но приобретает настолько малую ве-
вероятность, что его смело можно считать практически неосуществи-
неосуществимым. Таким образом, при возрастании числа опытов частота прибли-
приближается к вероятности, но не с полной достоверностью, а с большой
ЧАСТОТА, ИЛИ СТАТИСТИЧЕСКАЯ ВЕРОЯТНОСТЬ, СОБЫТИЯ 31
вероятностью, которая при достаточно большом числе опытов может
рассматриваться как практическая достоверность.
В теории вероятностей чрезвычайно часто встречается такой ха-
характер приближения одних величин к другим, и для его описания
введен специальный термин: «сходимость по вероятности».
Говорят, что величина Хп сходится по вероятности к вели-
величине а, если при сколь угодно малом е вероятность неравенства
\Хп — а|< е с увеличением п неограниченно приближается к единице.
Применяя этот термин, можно сказать, что при увеличении числа
опытов, частота.хобытия не «стремится.» к вероятности события, а
«сходится к ней по вероятности»'?
ЭТ^'С'^о'Яст'пЬ" частот! s ;i~исро:гг;:ост:1, изложенное здесь пока без
достаточных математических оснований, просто на основании прак*
тики и здравого смысла, составляет содержание теоремы Бер«
ну л л и, которая будет доказана нами в дальнейшем (см. гл. 13).
Таким образом, вводя понятие частоты события и пользуясь
связью между частотой и вероятностью, мы получаем возможность
приписать определенные вероятности, заключенные между нулем и
единицей, не только событиям, которые сводятся к схеме случаев,
но и тем событиям, которые к этой схеме не сводятся; в последнем
случае вероятность события может быть приближенно определена
по частоте события при большом числе опытов.
В дальнейшем мы увидим, что для определения вероятности со-
события, не сводящегося к схеме случаев, далеко не всегда необхо-
необходимо непосредственно определять из опыта его частоту. Теория ве-'
роятностей располагает многими способами, позволяющими опреде-
определять вероятности событий косвенно, через вероятности других собы-
событий, с ними связанных. В сущности, такие косвенные способы и со-
составляют основное содержание теории вероятностей. Однако и при
таких косвенных методах исследования в конечном счете все же при-
приходится обращаться к экспериментальным данным. Надежность и
объективная ценность всех практических расчетов, выполненных
с применением аппарата теории вероятностей, определяется качеством
и количеством экспериментальных данных, на базе которых этот
расчет выполняется.
Кроме того, при практическом применении вероятностных ме-
методов исследования всегда необходимо отдавать себе отчет в том,
действительно ли исследуемое случайное явление принадлежит к ка-
категории массовых явлений, для которых, по крайней мере на неко-
некотором участке времени, выполняется свойство устойчивости частот.
Только в этом случае имеет смысл говорить о вероятностях собы-
событий, имея в виду не математические фикции, а реальные характери-
стики случайных явлений.
Например, выражение «вероятность поражения самолета в воз-
воздушном бою для данных условий равна 0,7» имеет определенный
32 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 2
конкретный смысл, потому что воздушные бон мыслятся как массо-
массовые операции, которые будут неоднократно повторяться в приблизи-
приблизительно аналогичных условиях.
Напротив, выражение «вероятность того, что данная научная про-
проблема решена правильно, равна 0,7» лишено конкретного смысла,
и было бы методологически нбправильно оценивать правдоподобие
научных положений метопами теории вероятностей.
2.4. Случайная величина
Одним из важнейших основных понятий теории вероятностей
является понятие о случайной величине.
Случайной величиной называется величина, которая в резуль-
результате опыта может принять то или иное значение, причем неизвестно
заранее, какое именно.
Примеры случайных величин:
1) число попаданий при трех выстрелах;
2) число вызовов, поступавших на телефонную станцию за сутки;
3) частота попадания при 10 выстрелах.
Во всех трех приведенных примерах случайные величины могут
принимать отдельные, изолированные значения, которые можно за-
заранее перечислить.
Так, в примере 1) эти значения:
0, 1, 2, 3;
в примере 2):
1, 2, 3, 4, ...;
в примере 3):
0; 0,1; 0,2; ...; 1,0.
Такие случайные величины, принимающие только отделенные друг
от друга значения, котор_уе_можнр_за£анее пе^анжл^тьГ^называются^
прерывными "или дискретными случайными величинами.^
Существуют случайные величины другого типа, например: -
1) абсцисса точки попадания при выстреле;
2) ошибка взвешивания тела на аналитических весах;
3) скорость летательного аппарата в момент выхода на заданную
высоту;
4) вес наугад взятого зерна пшеницы.
Возможные значения таких случайных величин не отделены друг
от друга; они непрерывно заполняют некоторый промежуток, кото-
который иногда имеет резко выраженные границы, а чаще — границы
неопределенные, расплывчатые.
Такие случайные величины, возможные значения которых непре-
непрерывно заполняют некоторый промежуток, называются непрерывными
случайными величинами.
2,41
СЛУЧАЙНАЯ ВЕЛИЧИНА
33
Понятие случайной величины играет весьма важную роль в тео-
теории вероятностей. Если «классическая» теория вероятностей опери-
оперировала по преимуществу с событиями, то современная теория вероят-
вероятностей предпочитает, где только возможно, оперировать со случай-
случайными величинами.
Приведем примеры типичных для теории вероятностей приемов
перехода от событий к случайным величинам.
Производится опыт, в результате которого может появиться или
не появиться некоторое событие А. Вместо события А можно -рас-
-рассмотреть случайную величину X, которая равна 1, если событие Л
происходит, и равна 0, если событие А не происходит. Случайная
величина Л', очевидно, является прерывной; она имеет два возмож-
возможных значения: 0 и 1. Эта случайная величина называется характе-
характеристической случайной величиной события А. На практике часто
вместо событий оказывается удобнее оперировать их характеристи-
характеристическими случайными величинами. Например, если производится ряд
опытов, в каждом из которых возможно появление события А, то общее
число появлений события равно сумме характеристических случайных
величин события А во всех опытах. При решении многих практиче-
практических задач пользование таким приемом оказывается очень удобным.
С другой стороны, очень часто для
вычисления вероятности события ока-
оказывается удобно связать это событие
с какой-то непрерывной случайной ве-
величиной (или системой непрерывных
величин).
Пусть, например, измеряются коор-
координаты какого-то объекта О для того,
чтобы построить точку М, изобра-
изображающую этот объект на панораме (раз-
(развертке) местности. Нас интересует со-
событие А, состоящее в том, что ошиб-
ошибка R в положении точки М не превзой-
превзойдет заданного значения г0 (рис. 2.4.1).
Обозначим X, Y случайные ошибки
в измерении координат объекта. Очевидно, событие А равносильно
попаданию случайной точки М с координатами X, Y в пределы круга
радиуса гй с центром в точке О. Другими словами, для выполнения собы-
события А случайные величины X и К должны удовлетворять неравенству
X2 + Y2<rl B.4.1)
Вероятность события А есть не что иное, как вероятность выпол-
выполнения неравенства B.4.1). Эта вероятность может быть определена,
если известны свойства случайных величин X, Y.
3 Е. С. Вентцель
Рис. 2.4.1,
34 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ВЕРОЯТНОСТЕЙ »ГЛ. 2
Такая органическая связь между событиями и случайными вели-
величинами весьма характерна для современной теории вероятностей,
которая, где только возможно, переходит от «схемы событий»
к «схеме случайных величин». Последняя схема сравнительно с пер-
первой представляет собой гораздо более гибкий и универсальный аппа-
аппарат для решения задач, относящихся к случайным явлениям.
2.5. Практически невозможные и практически достоверные
события. Принцип практической уверенности
В п° 2.2 мы познакомились с понятиями невозможного и досто-
достоверного события. Вероятность невозможного события, равная нулю,
к вероятность достоверного собтnv.r, равняя единице, занимают край-
крайние положения на шкале вероятностей.
На практике часто приходится иметь дело не с невозможными и
достоверными событиями, а с так называемыми «практически невоз-
невозможными» и «практически достоверными» событиями.
Практически невозможным событием называется событие,
вероятность которого не в точности равна нулю, но весьма близка
к нулю.
Рассмотрим, например, следующий опыт: 32 буквы разрезной
азбуки смешаны между собой; вынимается одна карточка, изображен-
изображенная на ней буква записывается, после чего вынутая карточка воз-
возвращается обратно, и карточки перемешиваются. Такой опыт произ-
производится 25 раз. Рассмотрим событие А, заключающееся в том, что
после 25 выниманий мы запишем первую строку «Евгения Онегина»:
«Мой дядя самых честных правил».
Такое событие не является логически невозможным; можно под-
считать его вероятность, которая равна f-™- > но ввиду того что
вероятность события А ничтожно мала, можно считать его практи-
практически невозможным.
Практически достоверным событием называется событие, ве-
вероятность которого не в точности равна единице, но весьма близка
к единице.
Если какое-либо событие А в данном опыте практически невоз-
невозможно, то противоположное ему событие А, состоящее в невыпол-
невыполнении события А, будет практически достоверным. Таким образом,
с точки зрения теории вероятностей все равно, о каких событиях
говорить: о практически невозможных или о практически достовер-
достоверных, так как они всегда сопутствуют друг''другу.
Практически невозможные и практически достоверные события
играют большую роль в теории вероятностей; на них основывается
все практическое применение этой науки.
2.51 ПРАКТИЧЕСКИ НЕВОЗМОЖНЫЕ И ДОСТОВЕРНЫЕ СОБЫТИЯ 35
В самом деле, если нам известно, что вероятность события в дан-
данном опыте равна 0,3, это еще не дает нам возможности предсказать
результат опыта. Но если вероятность события в данном опыте ни-
ничтожно мала или, наоборот, весьма близка к единице, это дает нам
возможность предсказать результат опыта; в первом случае мы не
будем ожидать появления события А; во втором случае будем ожи-
ожидать его с достаточным основанием. При таком предсказании мы
руководствуемся так называемым принципом практической уев"
ренности, который можно сформулировать следующим образом.
Если вероятность некоторого события А в данном опыте Е
весьма мала, то можно быть практически уверенным в том,
что при однократном выполнении опыта Е событие А не
произойдет.
Иными словами, если вероятность события А в данном опыте
весьма мала, то, приступая к выполнению опыта, можно организовать
свое поведение так, как будто это событие вообще невозможно,
т. е. не рассчитывал совсем на его появление.
В повседневной жизни мы непрерывно бессознательно пользуемся
принципом практической уверенности. Например, выезжая в путеше-
путешествие по железной дороге, мы все свое поведение организуем, не
считаясь с возможностью железнодорожной катастрофы, хотя неко-
некоторая, весьма малая, вероятность такого события все же имеется.
Принцип практической уверенности не может быть доказан мате-
математическими средствами; он подтверждается всем практическим опы-
опытом человечества.
Вопрос о том, насколько мала должна быть вероятность события,
чтобы его можно было считать практически невозможным, выходит
за рамки математической теории и в каждом отдельном случае ре-
решается из практических соображений в соответствии с той важностью,
которую имеет для нас желаемый результат опыта.
Например, если вероятность отказа взрывателя при выстреле
равна 0,01, мы еще можем помириться с этим и считать отказ взры-
взрывателя практически невозможным событием. Напротив, если вероят-
вероятность отказа парашюта при прыжке также равна 0,01, мы, очевидно,
не можем считать этот отказ практически невозможным событием и
должны добиваться большей надежности работы парашюта.
Одной из важнейших задач теории вероятностей является выявле-
выявление практически невозможных (или практически достоверных) собы-
событий, дающих возможность предсказывать результат опыта, и выявле-
выявление условий, при которых те или иные события становятся практи-
практически невозможными (достоверными). Существует ряд теорем теории
вероятностей — так называемых предельных теорем, в которых уста-
устанавливается существование, событий, становящихся практически
невозможными (достоверными) при увеличении числа опытов или
при увеличении числа случайных величин, участвующие в задаче.
36 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 2
Примером такой предельной теоремы является уже сформулированная
выше теорема Бернулли (простейшая форма закона больших чисел).
Согласно теореме Бсрн>лли при большом числе опытов событие,
заключающееся в том, что разность между частотой события и его
вероятностью сколь угодно мала, становится практически достоверным.
Наряду с практически невозможными (достоверными) событиями,
которые позволяют с уверенностью предсказывать исход опыта, не-
несмотря на наличие случайности, в теории вероятностей большую роль
играют особого типа случайные величины, которые, хотя и являются
случайными, но имеют такие незначительные колебания, что практи-
практически могут рассматриваться как не случайные. Примером такой
«почти не случайной» величины может служить частота события при
большом числе опытов. Эта величина, хотя и является случайной, но
при большом числе опытов практически может колебаться только
в очень узких пределах вблизи вероятности события.
Такие «почти не случайные» величины дают возможность пред-
предсказывать численный результат опыта, несмотря на наличие в нем
элементов случайности, оперируя с этим результатом столь же уве-
уверенно, как мы оперируем с данными, которые доставляются обыч-
обычными методами точных наук.
3.2] ТЕОРЕМА СЛОЖЕНИЯ ВЕРОЯТНОСТЕЙ 41
Предположим, что из этих случаев т благоприятны событию Л,
a k — событию В. Тогда
Так как события А и В несовместны, то нет таких случаев,
которые благоприятны я А, и В вместе. Следовательно, событию
А-\-В благоприятны т-\-k случаев и
Подставляя полученные выражения в формулу C.2.1), получим
тождество. Теорема доказана.
Обобщим теорему сложения на случай трех событий. Обозначал
событие А-\-В буквой D и присоединяя к сумме еще одно собы-
событие С, легко доказать, что
Очевидно, методом полной индукции можно обобщить теорему
сложения на произвольное число несовместных событий. Действи-
Действительно, предположим, что она справедлива для п событий:
А- А: Ar
и докажем, что она будет справедлива для ra-f- 1 событий:
А» ™2 А»» Ап+Х.
Обозначим:
/ А-ЬА-г- ■•• +а« = С.
Имеем:
Но так как для п событий мы считаем теорему уже доказанной, то
откуда
что и требовалось доказать.
Таким образом, теорема сложения вероятностей применима к лю-
любому числу несовместных событий. Ее удобно записать в виде:
a) JA ^ C-2.2)
42 ОСНОВНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ (ГЛ. 3
ОтметиМ следствия, вытекающие из теоремы сложения вероят-
вероятностей.
Следствие 1. Если события Ах, А2 Ап образуют, пол-
полную группу несовместных событий, то сумма их вероятностей
n/viwi/, пд к и и tip;
П
"Ч1 Г) / Л \ 1
i = l
Доказательство. Так как события Ах, А2 Ап образуют
полную группу, то появление хотя бы одного из них — достоверное
событие:
Тек как Л\> -^2 А»— несовместные события, то к ким приме-
применима теореМа сложения вероятностей
л)
i = 1
откуда
что и требовалось доказать.
Перед тем как вывести второе следствие теоремы сложения,
определим понятие о «противоположных событиях».
Противоположными событиями называются два несовместных
события, образующих полную группу.
Событие, противоположное событию А, принято обозначать А.
Примеры противоположных событий.
1) а попадание при выстреле,
А промах при выстреле;
2) в выпадение герба при бросании монеты,
"В выпадение цифры при бросании монеты;
3) С безотказная работа всех элементов технической системы,
С отказ хотя бы одного элемента;
4) о обнаружение не менее двух бракованных изделий в конт-
контрольной партии,
D обнаружение не более одного бракованного изделия.
Следствие 2. Сумма вероятностей противоположных
событий равна единице:
Это следствие есть частный случай следствия 1. Оно выделено
особо ввиду его большой важности в практическом применении теории
вероятностей- На практике весьма часто оказывается легче вычислить
8.21 ТЕОРЕМА СЛОЖЕНИЯ ВЕРОЯТНОСТЕЙ 43
вероятность противоположного события А, чем вероятность прямого
события А. В этих случаях вычисляют Р (Л) и находят Р(А) — 1 —Р (А).
Рассмотрим несколько примеров на применение теоремы сложения
и ее елсдетз^й.
Пример 1. В лотерее 1000 билетов; из них на один билет падает
выигрыш 500 рз^б., на 10 билетов^— выигрыши по 100 руб., на 50 билетов —
выигрыши по 20 руб., ка 100 билетов — выигрыши но 5 руб., остальные
билеты невыигрышные. Некто покупает один* билет. Найти вероятность
выиграть не менее 20 руб.
Решение. Рассмотрим События:
А —выиграть не менее 20 руб.,
А{—выиграть 20 руб.,
А2 — выиграть 100 руб.,
А3 — выиграть 500 руб.
Очевидно,
Л = ^1+Л2 + Аг.
По теореме сл&кения вероятностей
Р (А) = Р (А,) + Р (А2) + Р (Л3) = 0,050 + 0,010 + 0,001 = 0,061.
Пример 2. Производится бомбометание по трем складам боеприпасов,
причем сбрасывается одна бомба. Вероятность попадания в первый склад 0,01;
во второй 0,008; в третий 0,025. При попадании в один из складов взры-
взрываются все три. Найти вероятность того, что склады будут взорваны.
Решение. Рассмотрим события:
А —взрыв складов,
А{ — попадание в первый склад,
А2 — попадание во второй склад,
А3 — попадание в третий склад.
Очевидно,
Так как при сбрасывании одной бомбы события
А2, А$ несовместны, то
= 0,01+0,008 + 0,025 = 0,043. РИ°' 3'2Л<
Пример 3. Круговая мишень (рис. 3.2.1) состоит из трех зон: /, II
и ///. Вероятность попадания в первую зону при одном выстреле 0,15, во
вторую 0,23, в третью 0,17. Найти вероятность промаха.
Решение. Обозначим А — промах,
А — попадание.
Тогда
г + 2 + 3,
где Ait A2, As — попадание соответственно в первую, вторую и третью зоны
Р (J) = Р (J,) + Р (J2) + Р (!3) = 0,15 + 0,23 + 0,17 = 0,55,
откуда
P(A) = l — P (Л) = 0,45.
44 ОСНОВНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 9
Как уже указывалось, теорема сложения ^вероятностей C.2.1)
справедлива точько для несовместных событий. ' {3 случае, когда со-
события А и В совместны, вероятность суммы этизГсобытий выражается"
C.2.3)
В справедливости формулы C.2.3) можно наглядно убедиться- рас-
рассматривая рис. 3.2.2.
Рис. 3.2.2. Рис. 3.2.3.
Аналогично вероятность суммы трех совместных событий вы-
вычисляется по формуле
= Р(А)-{-Р(В) + Р (С) —Р(АВ) — Р(АС) — Р (ВС) + Р (ABC).
Справедливость этой формулы также наглядно следует из геометри-
геометрической интерпретации (рис. 3.2.3).
Методом полной индукции можно доказать общую формулу для
вероятности суммы любого числа совместных событий:
Е(^2ИЛ)+ S P(AiAjAk)- ...
t ■:■> it J '■ j, ft
s J ... А„), C.2.4)
где суммы распространяются на различные значения индексов /; /, j;
i, j, k, и т. д.
Формула C.2.4) выражает вероятность суммы любого числа собы-
событий через вероятности произведений этих событий, взятых по одному,
по два, по три и т. д.
Аналогичную формулу можно написать для произведения собы-
событий. Действительно, из рис. 3.2.2 непосредственно ясне, что
Р(АВ) = Р(А)-\-Р(В) — Р(А-\-В). C.2.5)
Из рис. 3.2.3 видно, что
Р (ABC) = Р (А) -+- Р (В) + Р (С) — Р (А + В) —
C.2.6)
Р (А,А2 ... Аа) = 2 Я (А} - 2 Р (А- +
i i, j
3,3) ТЕОРЕМА УМНОЖЕНИЯ ВЕРОЯТНОСТЕЙ 45
Общая формула, выражающая вероятность произведения произ-
произвольного числа событий через вероятности сумм этих событий, взя-
взятых по одному, по два, по три и т. д., имеет вид:
2т)-2-
i i, i
-f 2 P{Ai^rAj+Ak)+...-±i-irlP{Al+...+An). C.2.7;
', Л к
Формулы типа C.2.4) и C.2.7) находят практическое применение
при преобразовании различных выражений, содержащих вероятности
сумм и произведений событий. В зависимости от специфики задачи
в некоторых случаях удобнее бывает пользоваться только суммами,
а в других только произведениями событий: для преобразования
одних в другие и служат подобные формулы.
Пример. Техническое устройство состоит из трех агрегатов: двух
агрегатов первого типа—-Л[ и Л2 — и одного агрегата второго типа — В.
Агрегаты Л, и Л2 дублируют друг друга: при отказе одного из них про-
происходит автоматическое переключение на второй. Агрегат В не дублирован.
Для того 'чтобы устройство прекратило работу (отказало), нужно, чтобы
одновременно отказали оба агрегата А\ и Л2 или же агрегат В. Таким обра-
образом, отказ устройства — событие С — представляется в виде:
где j[i — отказ агрегата Alt A2 — отказ агрегата А2, В — отказ агрегата В.
Требуется выразить вероятность события С через вероятности событий,
содержащих только суммы, а не произведения элементарных событий Аи
А2к В.
Решение. По формуле C.2.3) имеем:
Р (С) = Р (Л,Л2) + Р(В)-Р (А^В); C.2.8)
по формуле C.2.5)
Р (Л, А2) = Р (Л,) + Р (А2) -Р(А{ + А,);
по формуле C.2.6)
Подставляя эти выражения в C.2.8) и производя сокращения, получим;
3.3. Теорема умножения вероятностей
Перед тем как излагать теорему умножения вероятностей, введем
еще одно важное понятие: понятие о независимых и зависимых со-
событиях.
Событие А называется независимым от события В, если ве-
вероятность события А не зависит от того, произошло событие В
или нет.
46 ОСНОВНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 3
Событие А называется зависимым от события В, если вероят-
вероятность события А меняется в зависимости от того, произошло собы-
событие В или нет/)
Рассмотрим примеры.
1) Опыт состоит в бросании двух монет; рассматриваются события:
А — появление герба на первой монете,
В — появление герба на второй монете.
В данном случае вероятность события А не зависит от того,
произошло событие В или нет; событие А независимо от со-
события В.
2) В урне два белых шара и один черный; два лица вынимают
из урны по одному шару; рассматриваются события:
А — появление белого шара у 1-го лица,
В — появление белого шара у 2-го лица.
Вероятность события А до того, как известно что-либо о собы-
2
тии В, равна у Если стало известно, что событие В произошло, то
вероятность события А становится равной -к-. из чего заключаем, что
событие А зависит от события В.
Вероятность события А, вычисленная при услозии, что имело место
другое событие В, называется условной вероятностью события А
и обозначается
Р(А\В).
Для условий последнего примера
Условие независимости события А от события В можно записать
в виде:
Р(А\В) = Р(А),
а условие зависимости — в виде:
Р{А\В)фР{А).
Перейдем к формулировке и доказательству теоремы умножения
вероятностей.
Теорема умножения вероятностей формулируется следующим
образом.
Вероятность произведения двух событий равна произведе-
произведению вероятности одного из них на условную вероятность
другого, вычисленную при условии, что первое имело место:
= Р(А)Р(В\А). C.3.1)
3.3] ТЕОРЕМА УМНОЖЕНИЯ ВЕРОЯТНОСТЕЙ 51
Пример 6. Происходит бой («дуэль») между двумя участниками (ле-
затедьными аппаратами, ганками, кораблями) А и В. У стороны А в запасе
два выстрела, у стороны В —одни. Начинает стрельбу А: он делает, по В
один выстрел и поражает его с вероятностью 0,2. Если В не поражен, он
отвечает противнику выстрелом н поражает его с вероятностью 0,3. Если А
этим выстрелом не поражен, то он делает по В свой последний выстрел;
которым поражает его с вероятностью 0,4. Найти вероятность того, что
в бою будет поражен: а) участник А, б) участник В.
Решение. Рассмотрим события:
А — поражение участника А,
В — поражение участника В.
Для выполнения события А необходимо совмещение (произведенне) двух
событий: 1) А не поразил В первым выстрелом и 2) В поразил А своим
ответным выстрелом. По теореме умножения вероятностей получим
Р (А) = 0,8 -0,3 = 024.
Перейдем к событию В. Оно, очевидно, состоит из двух несовместных
вариантов:
где Вх — поражение участника В первым выстрелом А,
В2 — поражение участника В вторым выстрелом А.
По теореме сложения вероятностей
По условию Р (В,) = 0,2. Что касается события В2, то оно представляет
собой совмещенне (произведение) трех событий, а именно:
1) первый выстрел стороны А не должен поразить В;
2) ответный выстрел стороны В не должен поразить А;
3) последний (второй) выстрел стороны А должен поразить В.
По теореме умножения вероятностей
Р (В2) = 0,8 • 0,7 • 0,4 = 0,224,
откуда
Р (В) = 0,2 + 0,224 = 0,424.
Пример 7. Цель, по которой ведется стрельба, состоит нз трех раз-
различных по уязвимости частей. Для поражения цели достаточно одного по-
попадания в первую часть, нли двух попаданий во вторую, или трех попаданий
в третью. Если снаряд попал в цель, то вероятность ему попасть в ту или
другую часть пропорциональна площади этой части. На проекции цели иа
плоскость, перпендикулярную направлению стрельбы, первая, вторая и
третья части занимают относительные площади 0,1, 0,2 н 0,7. Известно, что
в цель попало ровно два снаряда. Найти вероятность того, что цель будет
поражена.
Решение. Обозначим А — поражение цели; Р(А\2) — условную ве-
вероятность поражения цели прн условии, что в нее попало ровно два сна-
снаряда. Два снаряда, попавшие в цель, могут поразить ее двумя способами:
нли хотя бы один из них попадает в первую часть, илн же оба снаряда
попадут во вторую. Этн варианты несовместны, так как в цель попало всего
два снаряда; поэтому можно применить теорему сложения. Вероятность
того, что хотя бы один снаряд попадет в первую часть, может быть вычис-
вычислена через вероятность противоположного события (нн одни нз двух сна-
снарядов не попадет в первую часть) и равна 1 — 0.92. Вероятность того, что
оба снаряда попадут во вторую часть, равна 0,22. Следовательно,
Р (А12) = 1 — 0,92 + 0,22 = 0,23.
4»
52 ОСНОВНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 3
Пример 8. Для условий предыдущего примера найти вероятность
поражения цели, есля известно, что в псе попало три енлрядл.
Решение. Решим задачу двумя способами: через прямое и противо*
положное событие.
Прямое событие — порг::;°пие цели при трех попаданиях — распадается
на четыре несовместных варианта:
/lj — хотя бы одно попадание в первую часть,
А2 — два попадания во вторую часть и одно — в третью,
А3 — три попадания во вторую часть,
А4 — три попадания в третью часть.
Вероятность первого варианта находим аналогично предыдущему при-
примеру:
Р(Л) = 1—0,93 = 0,271.
Найдем вероятность второго варианта. Три попавших снаряда могут
распределиться по второй н третьей частям нужным образом (два во вторую
и один — в третью) тремя способами (Cl = 3). Следовательно,
Р (А2) = 3 • 0,22 ■ 0,7 = 0,084.
Далее находим:
Р (А3) = 0,23 = 0,008,
Р (А4) = 0,73 = 0,343.
Отсюда
Р (А 13) = 0,271 -f 0,084 -f 0,008 + 0,343 = 0,706.
Однако проще решается задача, если перейти к противоположному со-
событию— непоражению цели при трех попаданиях. Это событие может осу-
осуществиться только одним способом: если два снаряда нз трех попадут
в третью часть, а один — во вторую. Таких комбинаций может быть три
(С| = 3), следовательно, _
Р (А 13) = 3 - 0,72 ■ 0,2 = 0,294,
откуда
Р (А |3) = 1 — 0,294 = 0,706.
Пример 9. Монета бросается 6 раз. Найти вероятность того, что
выпадет больше гербов, чем цифр.
Решение. Для нахождения вероятности интересующего нас события А
(выпадет больше гербов, чем цифр) можно было бы перечислить все воз-
возможные его варианты, например:
Ах — выпадет шесть гербов и ни одной цифры,
А2 — выпадет пять гербов н одна цифра
и т. д.
Однако проще будет применить другой прием. Перечислим все возмож-
возможные исходы опыта:
А — выпадет больше гербов, чем цифр,
В— выпадет больше цифр, чем гербов,
С — выпадет одинаковое число цифр и гербов.
События А, В, С несовместны и образуют полную группу. Следова-
Следовательно,
8.3] ТЕОРЕМА УМНОЖЕНИЯ ВЕРОЯТНОСТЕЙ 53
Так как задача симметрична относительно «герба» н «цифры»,
Р(А)=Р(В),
откуда
Найдем вероятность события С, состоящего в том, что при шести бро-
бросаниях монеты появится ровно три герба (а значит, ровно три цифры). Веро-
Вероятность любого из вариантов события С (например, последовательности
г, ц, г, г, ц, ц при шести бросаниях) одна и та же и равна (-~ I . Число таких
комбинаций равно С| = 20 (числу способов, какими можно из шести броса-
бросаний выбрать три, в которых появился герб). Следовательно,
отсюда
32
Пример 10. Прибор состоит из четырех узлов: Аь А2, А3, А4, причем
узел А2 дублирует Ах, а узел At дублирует узел А3. При отказе (выходе из
строя) любого из основных узлов (At или А3) происходит автоматической
переключение на дублирующий узел. Надежность (вероятность безотказной
работы) в течение заданного времени каждого из узлов равна соответственно
Р\> Ръ Ра< Р\- Надежность каждого из переключающих устройств равна р.
Все элементы выходят из строя независимо друг от друга. Определить на-
надежность прибора.
Решение. Рассмотрим совокупность узлов Аи А2 и соответствующего
переключающего устройства как один «обобщенный узел» В, а совокупность
узлов А3, At и соответствующего переключающего устройства — как обоб-
обобщенный узел С. Рассмотрим события:
А — безотказная работа прибора,
В — безотказная работа обобщенного узла В,
С — безотказная работа обобщенного узла С.
/
Очевидно,
А = ВС,
откуда
Найдем вероятность события В. Оно распадается на два варианта:
Л, — исправно работал узел Ах
и
А2 — узел Ах отказал, но оказались исправными переключающее
устройство и узел А2.
Имеем:
Р (В) = Р(АХ) + Р (А'2) = Рх + A - Л) рр2,
аналогично
рр
откуда
Р (А) = [Pl + A — Pi) РРг] [рз+ A —
54 ОСНОВНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 3
■3.4. Формула полной вероятности
Следствием обеих основных теорем—теоремы сложения вероят-
вероятностей и теоремы умножения вероятностей — является так называемая
формула полной вероятности.
Пусть требуется определить вероятность некоторого события А,
которое может произойти вместе с одним из событий:
Hv Н2, .... Н„,
образующих полную группу несовместных событий. Будем эти собы-
события называть гипотезами.
Докажем, что в этом случае
%(i(\l) C.4.1)
т. е. вероятность события А вычисляется как сумма произведений
вероятности каждой гипотезы на вероятность события при этой ги-
гипотезе.
Формула C.4.1) носит название формулы полной вероятности.
Доказательство. Так как гипотезы Hv H2. .... Н„ обра-
образуют полную группу, то событие Л может появиться только в ком-
комбинации с какой-либо из этих гипотез:
А = Н1А-\-ЩА+ ... +НпА.
Так как гипотезы Нх, Н2, .... Н„ несовместны, той комбинации
НХА, Н2А, ..., НпА также несовместны; применяя к ним теорему
сложения, получим:
Применяя к событию HtA теорему умножения, получим:
что и требовалось доказать.
Пример 1. Имеются три одинаковые на вид урны; в первой урне два
белых и один черный шар; во второй — три белых и один черный; в третьей —
два белых и два черных шара. Некто выбирает наугад одну из урн и выни-~
мает нз иее шар. Найти вероятность того, что этот шар белый.
Решение. Рассмотрим трн гипотезы:
Hi — выбор первой урны,
//2 — выбор второй урны,
//3 — выбор третьей урны
и событие А — появление белого шара.
3.4] ФОРМУЛА ПОЛНОЙ ВЕРОЯТНОСТИ 55
Так как гипотезы, по условию задачи, равновозможны, то
~.
Условные вероятности события А при этих гипотезах соответственно равны:
Р (А | //,) = !; Р {А! Нл = 1; Р {А | Я3) = 1.
По формуле полной вероятности
„,,_! 1.1.1.1 .1.1-23
^4;~3 3~t~3 4i~3 2~36*
Пример 2. По самолету производится три одиночных выстрела. Ве-
Вероятность попадания при первом выстреле равна 0,4, при втором — 0,5, при
третьем—0,7. Для вывода самолета из строя заведомо достаточно трех по-
попаданий; прн одном попадании самолет выходит из строя е вероятностью 0,2,
при двух попаданиях с вероятностью 0,6. Найти вероятность того, что в ре-
результате трех выстрелов самолет будет выведен из строя.
Решение. Рассмотрим четыре гипотезы:
#0 — в самолет не попало ни одного снаряда,
Hi — в самолет попал один снаряд,
#2 — в самолет попало два снаряда,
Я3 — в самолет попало три снаряда.
Пользуясь теоремами сложения и умножения, найдем вероятности этих
гипотез:
Р(Н0) = 0,6- 0,5 -0,3 = 0,09;
Р (Я,) = 0,4 • 0,5 • 0,3 + 0,6 • 0,5 • 0,3 + 0,6 • 0,5 ■ 0,7 = 0,36;
Р (Я2) = 0,6 • 0,5 • 0,7 -f 0,4 ■ 0,5 • 0,7 -f 0,4 ■ 0,5 • 0,3 = 0,41;
Р (Я3) = 0,4 -0,5 -0,7 = 0,14.
Условные вероятности события А (выход самолета нз строя) при этих
гипотезах равны:
Р(А\Н0) = 0; Р(А\Н1) = 0,2; Я(Л|Я2) = 0,6; Я(Л|Я3) = 1,0.
Применяя формулу полной вероятности, получим:
Р (Л) = Р (Яо) Р (А | Яо) + Р (Я,) Р (А | Я,) + Р (Я2) Р {А | Н2) +
+ Р (Я3) Р (А | Я3) = 0,36 • 0,2 + 0,41 ■ 0,6 + 0,14 • 1,0 = 0,458.
Заметим, что первую гипотезу Яо можно было бы не вводить в рас-
рассмотрение, так как соответствующий член в формуле полной вероятности
обращается в нуль. Так обычно и поступают при применении формулы пол-
полной вероятности, рассматривая не полную группу несовместных гипотез,
а только те нз ннх, при которых данное событие возможно.
Пример 3. Работа двигателя контролируется двумя регуляторами.
Рассматривается определенный период временн t, в течение которого жела-
желательно обеспечить безотказную работу двигателя. При наличии обоих регу-
регуляторов двигатель отказывает с вероятностью qi,2, при работе только пер-
первого из них—с вероятностью qlt прн работе только второго — с вероят-
вероятностью qit при отказе обоих регуляторов — с вероятностью q0. Первый из
регуляторов имеет надежность Р1г второй—Р2. Все элементы выходят из
строя независимо друг от друга. Найти полную надежность (вероятность
безотказной работы) двигателя.
56 ОСНОВНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 3
Решение. Рассмотрим гипотезы:
Ни 2 — работают оба регулятора,
Hi —работает только первый регулятор (второй вышел из строя),
Н2 —работает только второй регулятор (первый вышел из строя),
#о —оба регулятора вышли из строя
и событие
А — безотказная работа двигателя.
Вероятности гипотез равны:
i. я) = РЛ; Р ("':) = Л A - Р»У.
= Я2 A - Р,); Р (Яо) = A - Р,) A _ Ра).
Условные вероятности события А при этих гипотезах заданы:
= l — qiJ; Р(А |//,)=1 —?,; Р (А | Я2) = 1 — q2;
По формуле полной вероятности получим:
Р (А) = Р,Я2 A - qu 2) + Я, A - Р2) A - ?,) +
+ р2 A - р,) A - ?,) + A - Л) A - р2) A - ft).
3.5. Теорема гипотез (формула Бейеса)
Следствием теоремы умножения и формулы полной вероятности
является так называемая теорема гипотез, или формула Бейеса.
Поставим следующую задачу.
Имеется полная группа несовместных гипотез Нх> Н2, .... Нп.
Вероятности этих гипотез до опыта известны и равны соответственно
Р(Н]). Р(Н2), .... РЩп)- Произведен опыт, в результате которого
наблюдено появление некоторого события А. Спрашивается, как сле-
следует изменить вероятности гипотез в связи с появлением этого со-
события?
Здесь, по существу, речь идет о том, чтобы найти условную
вероятность Рф^А) для каждой гипотезы.
Из теоремы умножения имеем:
P(AHi) = P(A)P(Hi\A) = P(Hl)P(A\HJ A = 1, 2 я),
или, отбрасывая левую часть,
P(A)P(Hi\A) = P(Hl)P(A\Hl) (/ = 1, 2 п),
откуда
A)= Р( А)——' ' — ''
Р( А)
Выражая Р(А) с помощью формулы полной вероятности C.4.1),
имеем:
J,P{Hi)P(A\Hi)
«.21
ОБЩАЯ ТЕОРЕМА О ПОВТОРЕНИИ ОПЫТОВ 61
причем в каждое произведение событие А должно входить т раз,
а А должно входить п — т ряз.
Число всех комбинаций такого рода равно С™, т. е. числу спо-
способов, каким;-: можно из п опытов выбрать т, в которых произошло
событие А. Вероятность каждой такой комбинации, по теореме умно-
умножения для независимых событий, равна p"'q"-'n. Так как комбинации
между собой несовместны, то, по теореме сложения, вероятность
события Вт равна
Pmn — mi | т п — т /~,т т п — т
т.а — Р, Я + • • ■ + Р Я —СпР Ч
С* раз
Таким образом, ми мо;:ссм лап, слгл\ ющ}ю формулировку частноЛ
теоремы о повторении опытов.
Если производится п независимых опытов, в каждом из которых
событие А появляется с вероятностью р, то вероятность того, что
событие А появится ровно т раз, выражается формулой
Я situ т п—го *л t *ч
и,л=С„р q , D.1.1)
где <7= 1 —р-
Формула D.1.1) описывает, как распределяются вероятности между
возможными значениями некоторой случайной величины — числа по-
появлений события А при п опытах.
В связи с тем, что вероятности Рт,п по форме представляют со-
собой члены разложения бинома (q-{-p)n, распределение вероятностей
вида D.1.1) называется биномиальным распределением.
4.2. Общая теорема о повторении опытов
Частная теорема о повторении опытов касается того случая, когда
вероятность события А во всех опытах одна и та же. На практике
часто приходится встречаться с более сложным случаем, когда опыты
производятся в неодинаковых условиях-, и вероятность события от
опыта к опыту меняется. Например, если производится ряд выстрелов
в переменных условиях (скажем, при изменяющейся дальности),
то вероятность попадания от выстрела к выстрелу может заметно
меняться.
Способ вычисления вероятности заданного числа появлений собы-
события в таких условиях дает общая теорема о повторении опытов.
Пусть производится п независимых опытов, в каждом из которых
может появиться или не появиться некоторое событие А, причем
вероятность появления события А в £-м опыте равна pt, а вероят-
вероятность непоявления qi—l —pL (t= 1 п). Требуется найти веро-
вероятность Рт_ а того, что в результате п опытов событие А появится
ровно т раз.
62 ПОВТОРЕНИЕ ОПЫТОВ [ГЛ. 4
Обозначим по-прежнему Вт событие, состоящее в том, что собы-
событие А появятся т раз в п опытах. По-прежнему представим Вт как
сумму произведений элементарных событий:
Зт = А\А2 • ' • АтАт+1 • • • Л "Г" • • • '
... + АхА2Аа ... Ап_хАа + ...
... + АХА2 ... Ап_тАп_т+х ... Ап,
причем в каждое из произведений событие А входит т раз, событие А
п — т раз. Число таких комбинаций по-прежнему будет С™, но сами
комбинации между собой будут уже неравновероятны.
Применяя теорему сложения и теорему умножения для независи-
независимых событий, получим:
Рт,п = Р\Ръ • • ' РтЯт+1 • • • Яп+ • • •
••• +Р1Я2Р3 ••■ Чп~1Рп+ ■"
•• Яп-тРп-т+1 ••• Рп>
т. е. искомая вероятность равна сумме всех возможных произведений,
в которые буквы р с разными индексами входят т раз, а буквы q
с разными индексами п — т раз.
Для того чтобы чисто механически составлять все возможные
произведения из т букв pan — т букв q с разными индексами,
применим следующий формальный прием. Составим произведение п
биномов:
<Рл(^) = <
или короче
9n() J\
1=1
где z — произвольный параметр.
Зададимся целью найти в этом произведении биномов коэффи-
коэффициент при zm. Для этого перемножим биномы и произведем приве-
приведение подобных членов. Очевидно, каждый член, содержащий zm.
будет иметь в качестве коэффициента произведение т букв р
с какими-то индексами и п—т букв q, а после приведения подоб-
подобных членов коэффициент при zm будет представлять собой сумму
всех возможных произведений такого типа. Следовательно, способ
составления этого коэффициента полностью совпадает со способом
вычисления вероятности Рт> п в задаче о повторении опытов.
Функция срд (z), разложение которой по степеням параметра г
дает в качестве коэффициентов вероятности Рт% „, называется про-
производящей функцией вероятностей Рт> п или просто производя-
производящей функцией.
J.2J ОБЩАЯ ТЕОРЕМА О ПОВТОРЕНИИ ОПЫТОВ 63
Пользуясь понятием производящей функции, можно сформулиро-
сформулировать общую теорему о повторении опытов в следующем пиле.
Вероятность того, что событие А в п независимых опытах поя-
появится ровно т раз, равна коэффициенту при zm в выражении произ-
производящей функции:
где Pi — вероятность появления события А в i-u опыте, <Ji~\—Pi.
Вышеприведенная формулировка общей теоремы о повторении
опытов в отличие от частной теоремы не дает явного выражения
для вероятности Рт< „. Такое выражение в принципе написать можно,
но оно является слишком сложным, и мы не будем его приводить.
Однако, не прибегая к такому явному выражению, все же можно
записать общую теорему о повторении опытов в виде одной
формулы:
£ля,л*т. D-2.1)
i = \ т=й
Левая и правая части равенства D.2.1) представляют собою одну
!ту же производящую функцию <prt(z), только слева она написана
виде одночлена, а справа — в виде многочлена. Раскрывая скобки
левой части и выполняя приведение подобных членов, получим все
$6роятности:
М>, Я> "l. It' • • • • °П, Я
как коэффициенты соответственно при нулевой, первой и т. д. сте-
§шях z.
Очевидно, частная теорема о повторении опытов вытекает из
Цбщей при
В этом случае производящая функция обращается в п-ю степень
инома (q-\-pz):
?«(*) = G+ />*)".
Раскрывая это выражение по формуле бинома, имеем:
m=0
Ь|(суда следует формула D.1.1),
°^ ПОВТОРЕНИЕ ОПЫТОВ (гл 4
Отметим, что как в общем, так и в частном случае сумма всех
вероятностей Рт п равна единице:
Р - . 1 (А 0
~0т,п
Это следует прежде всего из тою, что события Во, Вх Вп
образуют полную группу несовместных событий. Формально к равен-
равенству D.2.2) можно придти, полагая в общей формуле D.2.1) 2 = 1.
Во многих случаях практики, кроме вероятности Pmi n ровно т.
появлений события А, приходится рассматривать вероятность и е
менее т появлений события А.
Обозначим Ст событие, состоящее в том, что событие А поя-
появится не менее т раз, а вероятность события Ст обозначим кт п.
Очевидно,
откуда, по теореме сложения,
гт, п ~Т~ ^т + \, п ~Т~ • • • "г " п> п>
^т, п гт, п
или короче
п
D.2.3)
При вычислении Rm> n часто бывает удобнее не пользоваться не-
непосредственно формулой D.2.3), а переходить к противоположному
событию и вычислять вероятность Rm>n по формуле
m-l
Дт,л = 1-2Л,Я- D-2.4)
/=о
Пример 1. Производится 4 независимых выстрела по одной и той же
цели с различных расстояний; вероятности попадания при этих выстрелах
равны соответственно
р, = 0,1; р2 = 0,2; р3 = 0,3; р4 = 0,4.
Найти вероятности ии одного, одного, двух, трех и четырех попаданий:
^0,4! Pl,*> ^2,41 Pi,i> P*,f
Решение. Составляем производящую функцию:
4
= @,9 + 0,1*) @,8 + 0,2г) @,7 -f 0,Зг) @,6 -f 0.4г) =
= 0,302 + 0,440г + 0,215г2 + 0,040г3 -f 0,002г»,
откуда
Ро>4= 0,302; Рм = 0,440; Р2,4 = 0,215; Р3>4 = 0,040; Р4,4 = 0,002.
4.2] ОБЩАЯ ТЕОРЕМА О ПОВТОРЕНИИ ОПЫТОВ 65
Пример 2. Производится 4 независимых выстрела в одинаковых усло-
условиях, причем вероятность попадания р есть средняя из вероятностей рх, рг,
pit Pi предыдущего примера:
\ Pi) = 0,25.
Найти вероятности
'°0,4> ^1.4> jt>2,4> Pl,i> Р\Л-
Решение. По формуле D.1.1) имеем:
Рм = q* = 0,316;
Р1>4 == C\pq3 = 0,421;
^2,4 = <W = 0,211;
Я3,4 = С1Р6Ч = °>047:
Р4,4 = />« = 0,004.
Пример 3- Имеется 5 станций, с которыми поддерживается связь.
Время от времени связь прерывается из-за атмосферных помех. Вследствие
удаленности станций перерыв друг от друга связи с каждой из иих происхо-
происходит независимо от остальных с вероятностью р = 0,2. Найти вероятность
того, что в данный момент времени будет иметься связь не более чем с
двумя станциями.
Решение. Событие, о котором идет речь, сводится к тому, что будет
нарушена связь не менее чем с тремя станциями. По формуле D.2.3)
получим:
Дз,5 = ^3,5 + ^4,5 + Р5,5 = С\ ■ 0.23 • 0,82 + С\ ■ 0.24 • 0,8 + 0.25 =
= 0,0512 + 0,0064 + 0,0003 = 0,0579.
П р и м е р 4. Система радиолокационных станций ведет наблюдение за
группой объектов, состоящей из 10 единиц. Каждый из объектов может
быть (независимо от других) потерян с вероятностью 0,1. Найти вероят-
вероятность того, что хотя бы один из объектов будет потерян.
Решение. Вероятность потери хотя бы одного объекта /?1|]в можно
было бы найти по формуле >
но несравненно проще воспользоваться вероятностью противоположного со-
события — ни один объект ие потерян — и вычесть ее из единицы:
/?1>10 = 1 — pOilo = 1 — 0,9'° и 0,65.
Пример 5. Прибор состоит из 8 однородных элементов, но может
работать прн наличии в исправном состоянии не менее 6 из них. Каждый
из элементов за время работы прибора t выходит из строя независимо от
других с вероятностью 0,2. Найти вероятность того, что прибор откажет
за время t.
Решение. Для отказа прибора требуется выход из строя не менее
двух из восьми элементов. По формуле D.2.4) имеем:
*2,8 = 1 - (Л>,8 + Р1Л) = 1 - @>88 + С\ ■ 0,2 - 0.87) « 0,497.
Пример 6. Производится 4 независимых выстрела с самолета по са-
самолету. Вероятность попадания при каждом выстреле равна 0,3. Для
5 Е. С. Бентцель
66 ПОВТОРЕНИЕ ОПЫТОВ [ГЛ 4
поражения (выхода из строя) самолета заведомо достаточно двух попаданий;
при одном попадании самолет поражается с вероятнее г:,:л 0,6. Найти вероят-
вероятность того, что самолет будет поражен.
Р с т е и к е Зя~ача решается по формуле полной вероятности. Можно
было бы рассмотреть гипотезы
н.—в самолет попал 1 снаряд,
Нц — в самолет попало 2 снаряда,
Н% — в самолет попало 3 снаряда.
Hi — в самолет попало 4 снаряда
и находить вероятность события А — поражения самолета — с помощью этих
четырех гипотез. Однако значительно проще рассмотреть всего две гипотезы:
//„ — в самолет не попало ни одного снаряда,
Hi — в самолет попал 1 снаряд,
я вычислять вероятность события А — непоражения самолета:
Р (А) = Р (На) Р (А ] Но) + Р (НДР (А | НО.
Имеем;
Р (Но) = Ро,4 = 0,7* = 0,240;
Р (Н{) = Р1Л = С\ ■ 0,3 • 0,73 = 0,412;
Р (Л |//„) = !;
Р(А |Я,)= 1 — 0,6 = 0,4.
Следовательно, _
Р (А) = 0,240 + 0,412 • 0,4 и 0,405,
откуда
Р( А) = 1—0,405 = 0,595.
ГЛАВА 3
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ
5.1. Ряд распределения. Многоугольник распределения
В разделе курса, посвященном основным понятиям теории вероят-
вероятностей, мы уже ввели в рассмотрение чрезвычайно важное понятие
случайной величины. Здесь мы дадим дальнейшее развитие этого
понятия и укажем способы, с помощью которых случайные величины
могут быть описаны и характеризованы.
Как уже было сказано, случайной величиной называется величина,
которая в результате опыта может принять то или иное значение,
неизвестно заранее — какое именно. Мы условились также различать
случайные величины прерывного (дискретного) и непрерывного
типа. Возможные значения прерывных величин ' могут быть заранее
перечислены. Возможные значения непрерывных величин не могут
быть заранее перечислены и непрерывно заполняют некоторый про-
промежуток.
Примеры прерывных случайных величин:
1) число появлений герба при трех бросаниях монеты (возможные
значения 0, 1, 2, 3);
2) частота появления герба в том же опыте (возможные значе-
значения о, i, J-, l);
3) число отказавших элементов в приборе, состоящем из пяти
элементов (возможные значения 0, 1, 2, 3, 4, 5);
4) число попаданий в самолет, достаточное для вывода его из
строя (возможные значения 1, 2, 3, .... га, ...);
5) число самолетов, сбитых в воздушном бою (возможные зна-.
чения 0, 1, 2 N, где N—общее число самолетов, участвую-
участвующих в бою).
Примеры непрерывных случайных величин:
1) абсцисса (ордината) точки попадания при выстреле;
2) расстояние от точки попадания до центра мишени;
3) ошибка измерителя высоты;
4) время безотказной работы радиолампы.
68
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
Условимся в дальнейшем случайные величины обозначать боль-
большими буквами, а их возможные значения— соответствующими малыми
буквами. Например, X — число попаданий при трех выстрелах; воз-
возможные значения: хх — Ъ\ х.2—\\ „v^ —2; .г4 = 3.
Рассмотрим прерывную случайную величину X с возможными зна-
х2,
х„. Каждое из этих значений возможно, но не
чениями х1
достоверно, и величина X может принять каждое из них с некото-
некоторой вероятностью. В результате опыта величина А" примет одно из
этих значений, т. е. произойдет одно из полной группы несовмест-
несовместных событий:
X = х„.
КОАЛ)
Обозначим вероятности этих событий буквами р с соответствую-
соответствующими индексами:
Так как несовместные события E.1.1) образуют полную группу, то
1 = 1
т. е. сумма вероятностей всех возможных значений случайной вели-
величины равна единице. Эта суммарная вероятность каким-то образом
распределена между отдельными значениями. Случайная величина
будет полностью описана с вероятностной точки зрения, если мы
зададим это распределение, т. е. в точности укажем, какой вероят-
вероятностью обладает каждое из событий E.1.1). Этим мы установим так
называемый закон распределения случайной величины.
Законом распределения случайной величины называется всякое
соотношение, устанавливающее связь между возможными значениями
случайной величины и соответствующими им вероятностями. Про слу-
случайную величину мы будем говорить, что она подчинена данному
закону распределения.
Установим форму, в которой может быть задан закон распреде-
распределения прерывной случайной величины X. Простейшей формой зада-
задания этого закона является таблица, в которой перечислены возмож-
возможные значения случайной величины и соответствующие им вероятности:
XI
Pi
хх
Рх
х2
Рг
. . .
. . .
хП
Рп
6.1]
РЯД РАСПРЕДЕЛЕНИЯ. МНОГОУГОЛЬНИК РАСПРЕДЕЛЕНИЯ
69
Такую таблицу мы будем называть рядом распределения слу-
случайной величины X.
Чтобы придать ряду распределения более наглядный вид* часто
прибегают к его графическому изображению: по оси абсцисс отклады-
откладываются возможные значения случайной величины, а по оси ординат —
вероятности этих значений. Для наглядности полученные точки со-
соединяются отрезками прямых. Такая фигура называется многоуголь-
многоугольником распределения (рис. 5.1.1). Многоугольник распределения,
I I I
х, хг х3 х4 х5
Рис. 5.1.1.
так же как и ряд распределения, полностью характеризует случай-
случайную величину; он является одной из форм закона распреде-
распределения.
Иногда удобной оказывается так называемая «механическая» интер-
интерпретация ряда распределения. Представим себе, что некоторая масса,
равная единице, распределена по оси абсцисс так, что в п отдельных
точках JC], х2,
хп сосредоточены соответственно массы рх.
р2, ..., рп. Тогда ряд распределения интерпретируется как система
материальных точек с какими-то массами, расположенных на оси
абсцисс.
Рассмотрим несколько примеров прерывных случайных величин
с их законами распределения.
Пример 1. Производится один опыт, в котором может появиться или
не появиться событие А. Вероятность события А равна 0,3. Рассматривается
случайная величина X—число появлений события А в данном опыте (т. е.
характеристическая случайная величина события А, принимающая значение 1,
если оно появится, и 0, если не появится). Построить ряд распределения и
многоугольник распределения величины X.
70
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ" [ГЛ. S
Р с тп е к и е. Величина X имеет всего два значения: 0 и 1, Ряд распре-
распределения величины X имеет вид:
О
Pi
0,7
0,3
0.7
Многоугольник распределения изображен на рис. 5.1.2.
Пример 2. Стрелок производит три вы-
\ стрела по мишени. Вероятность попадания в ми-
мишень при каждом выстреле равна 0,4. За каждое
попадание стрелку яасчмтыяпется 5 oirv<ra По-
Построить ряд распределения числа выбитых очков.
Решение. Обозначим X число выбитых
очков. Возможные значения величины X: х, = 0;
х2 = 5; хъ = 10; х4 — 15.
Вероятности этих значений находим по тео-
теореме о повторении опытов:
О
Щ
Рис, 5.1.2.
Pl = 0,63 = 0,216; р2 = С\ • 0,4 • 0,62 = 0,432;
рг=С\-0,42• 0,6 = 0,288; /»4 — 0,43 = 0,064.
Ряд распределения величины X имеет вид:
*1
Pi
0
0,216
5
0,432
10
0,288
15
0,064
0,4-
Многоугольник распределения изображен на рис. 5.1.3.
Пример 3. Вероятность появления события А в одном опыте
равна р. Производится ряд Незави-
Независимых опытов, которые продол-
продолжаются до первого появления собы-
события А, после чего опыты прекра-
прекращаются. Случайная величина Л—
число произведенных опытов. По-
Построить
чины X.
Решение. Возможные значе-
значения величины Х\ 1, 2, 3, ... (теорети-
(теоретически они ничем не ограничены). Для
того чтобы величина X приняла зна-
значение 1, необходимо, чтобы событие А
произошло в первом же опыте; ве-
вероятность этого равна р. Для того
чтобы величина X приняла значе-
ряд распределения вели-
10
Рис. 5,1.3,
15
иие 2, нужно, чтобы в' первом опыте событие
ром — появилось; вероятность этого равна др,
А не появилось, а во вто-
где q — 1 — р, и т. д. Ряд
6.1] РЯД РАСПРЕДЕЛЕНИЯ. МНОГОУГОЛЬНИК РАСПРЕДЕЛЕНИЯ
распределения величины X имеет вид: "*■-
i
РЯ2
Первые пять ординат многоугольника распределения для случая
p = q = 0,5 показаны на рис. 5.1.4.
Пример 4. Стрелок ведет стрельбу по мишени до первого попадания,
имея боезапас 4 патрона. Вероятность попадания при каждом выстреле
равна 0,6. Построить ряд распределения боезапаса, оставшегося неизрасхо-
неизрасходованным.
0,5
0,4
0,3
0,2
0,1
-
0
\
\
; h
i
i
> Z
3 4 5 Х1
Рис. 5.1,4.
Решение. Случайная величина X — число неизрасходованных натро»
нов — имеет четыре возможных значения: 0, 1, 2 и 3. Вероятности этих зна-
значений равны соответственно:
р0 = 0,43 = 0,064;
рх = 0.42 • 0,6 = 0,096;
рг = 0,4 • 0,6 = 0,240;
Рз = 0,600.
Ряд распределения величины X имеет вид:
Pi
0
0,064
1
0,096
2
0,240
3
0,600
Многоугольник распределения показан на рис. 5.1.5.
72
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
Пример 5. Техническое устройство может применяться в различных
условиях и в зависимости от этого время от времени требует регулировки.
При однократном применении устройства оио может случайным образом
попасть в благоприятный или неблагоприятный режим. В благоприятном
режиме устройство выдерживает три применения без регулировки; перед
четвертым его приходится регулировать. В неблагоприятном режиме устрой-
устройство приходится регулировать после первого же применения. Вероятность
того, что устройство попадает в бла-
благоприятный режим,— 0,7, что в не-
неблагоприятный, — 0,3. Рассматри-
Рассматривается случайная величина X—число
применений устройства до регули-
регулировки. Построить ее ряд распреде-
распределения.
Р е in e и и е. Случайная вели-
величина X имеет три возможных значе-
значения: 1, 2 и 3. Вероятность того, что
Х=\, равна вероятности того, что
при первом же применении устрой-
устройство попадет в неблагоприятный ре-
режим, т. е. pi = 0,3. Для того чтобы
величина X приняла значение 2,
нужно, чтобы при первом применении
Рис. 5.1.6.
устройство попало в благоприятный
режим, а при втором — в неблаго-
неблагоприятный; вероятность этого р% —
— 0,7 • 0,3 = 0,21. Чтобы величина X приняла значение 3, нужно, чтобы два
первых раза устройство попало в благоприятный режим (после третьего
раза его все равно придется регулировать). Вероятность этого равна
р3 = 0,72 = 0,49.
Ряд распределения величины X имеет вид:
Pi
1
0,30
2
0,21
3
0,49
Многоугольник распределения показан на рис. 5.1.6.
5.2. Функция распределения
В предыдущем п° мы ввели в рассмотрение ряд распределения
как исчерпывающую характеристику (закон распределения) прерыв-
прерывной случайной величины. Однако эта характеристика не является
универсальной; она существует только для прерывных случайных
величин. Нетрудно убедиться, что для непрерывной случайной вели-
величины такой характеристики построить нельзя. Действительно, непре-
непрерывная случайная величина имеет бесчисленное множество возмож-
возможных значений, сплошь заполняющих некоторый промежуток (так назы-
называемое «несчетное множество»). Составить таблицу, в которой были бы
перечислены все возможные значения такой случайной величины, не-1
5.2] ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ 73
возможно. Кроме того, как мы увидим в дальнейшем, каждое отдель-
отдельное значение непрерывной случайной величины обычно не обладает
никакой отличной от нуля вероятностью. Следовательно, для непре-
непрерывной случайной величины не существует ряда распределения в том
смысле, в каком он существует для прерывной величины. Однако
различные области возможных значений случайной величины все же
ке являются одинаково вероятными, и для непрерывкой величины
существует «распределение вероятностей», хотя и не в том смысле,
как для прерывной.
Для количественной характеристики этого распределения вероят-
вероятностей удобно воспользоваться не вероятностью события X = х,
а вероятностью события X < х, где х — некоторая текущая пере-
переменная. Вероятность этого события, очевидно, зависит от х, есть
некоторая функция от х. Эта функция называется функцией рас-
распределения случайной величины X и обозначается F(x):
F(x)=P(X<x). E.2.1)
Функцию распределения F(х) иногда называют также интеграль-
интегральной функцией распределения или интегральным законом рас-
распределения.
Функция распределения — самая универсальная характеристика
случайной величины. Она существует для всех случайных величин:
как прерывных, так и непрерывных. Функция распределения пол-
полностью характеризует случайную величину с вероятностной точки
зрения, т. е. является одной из форм закона распределения.
Сформулируем некоторые общие свойства функции распре-
распределения.
1. Функция распределения F(x) есть неубывающая функция своего
аргумента, т. е. при х2 > х1 F (x2) ^- F (хх).
2. На минус бесконечности функция распределения равна нулю:
F (— оо) == 0.
3. На плюс бесконечности 1 » ' х
Л УХ
функция распределения равна "
единице: Рис 52L
/7(+) 1
Не давая строгого доказательства этих свойств, проиллюстрируем
их с помощью наглядной геометрической интерпретации. Для этого
будем рассматривать случайную величину X как случайную
точку X на оси Ох (рис. 5.2.1), которая в результате опыта может
занять то или иное положение. Тогда функция распределения F (х)
есть вероятность того,-что случайная точка X в результате опыта
попадет левее точки х.
:. Будем увеличивать х, т. е. перемещать точку х- вправо по оси
абсцисс. Очевидно, при этом вероятность того, что случайная точка X
74
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
попадет левее х, не может уменьшиться; следовательно, функция
распределения F (х) с возрастанием х убывать не может.
Чтобы убедиться в том, что F (— сю) = 0, будем неограниченно
перемещать точку х влево по оси абсцисс. При этом попадание слу-
случайной точки X левее х в пределе становится невозможным собы-
событием; естественно полагать, что вероятность этого события стремится
к кулю, т. е. F(—оо) —0.
Аналогичным образом, неограниченно перемещая точку х вправо,
убеждаемся, что ,F(-f~oo)=l, так как событие X <i x становится
в пределе достоверным.
График функции распределения F (х) в общем случае представляет
собой график неубывающей функции (рис. 5.2.2), значения которой
начинаются от 0 и доходят
до 1, причем в отдельных
точках функция может иметь
скачки (разрывы).
Зная ряд распределения
прерывной случайной вели-
величины, можно легко построить
функцию распределения этой
величины. Действительно,
Рис. 5.2.2,
xi< *
. где неравенство xt < x под
знаком суммы указывает,
что суммирование распространяется на все те значения xt, которые
меньше х.
Когда текущая переменная х проходит через какое-нибудь из
возможных значений прерывной величины X, функция распределения
меняется скачкообразно, причем величина скачка равна вероятности
этого значения.
Пример 1. Производится один опыт, в котором может появиться
или не появиться событие А. Вероятность события А равна ОД Случайная
величина X—число появлений события А в опыте (характеристическая
случайная величина события А). Построить ее функцию распределения.
Решение. Ряд распределения величины л имеет вид:
Pi
0,7
0,3
6.2)
ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
75
Построим функцию распределения величины X:
I) при х 4О
2) при 0 < .г
3) при * > 1
F (*) = Р (X < х) =
= 0) = 0,7;
График фуикции распределения представлен на рис. 5.2.3. В точках раз-
разрыва функция F (X) принимает значения, отмеченные на чертеже точками
(функция непрерывна слева).
fix)
X
Рис. 5.2.3,
Пример. 2. В условиях предыдущего примера производится 4 неза-
независимых опыта. Построить функцию распределения числа появлений
события А.
Решение. Обозначим X—число появлений события А в четырех
опытах. Эта величина имеет ряд распределения
Pi
0
0,2401
1
0,4116
2
0,2646
3
0,0756
4
0,0081
Построим функцию распределения случайной величины X:
0,2401;
0,6517;
0,9163;
0,9919;
1.
1) при
2) при 0 < х < 1 F (х)
3) при 1 < х < 2 F (х)
4) при 2 < х < 3 F {х)
5) при 3 < х < 4 F (х)
6) при д: > 4 F (х)
График функции распределения представлен на рис. 5.2.4.
76
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 8
Функция распределения любой прерывной случайной величины
всегда есть разрывная ступенчатая функция, скачки которой проис-
происходят в точках, соответствующих возможным значениям случайной
1
0
Пх)
1
1
1
/
1
1
г
1 *
3 4
Рис. 5.2.4.
величины, и равны вероятностям этих значений. Сумма всех скачков
функции F(x) равна единице.
По мере увеличения числа возможных значений случайной вели-
величины и уменьшения интервалов между ними число скачков становится
больше, а сами скачки — меньше; ступенчатая кривая становится
F(X)
Рис. 5.2.5.
более плавной (рис. 5.2.5); случайная величина постепенно прибли-
приближается к непрерывной величине, а ее функция распределения—к не-
непрерывной функции (рис. 5.2.6).
На практике обычно функция распределения непрерывной слу-
случайной величины представляет собой функцию, непрерывную во всех
5.2]
ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
77
точках, как это показано на рис. 5.2.6. Однако можно построить
примеры случайных величин, возможные значения которых непрерывно
заполняют некоторый промежуток, но для которых функция распре-
распределения не везде является непрерывной, а в отдельных точках терпит
t-(x)
-X
Рис. 5.2.6.
разрывы (рис. 5.2.7). Такие случайные величины называются смешан*
ними. В качестве примера смешанной величины можно привести
площадь разрушений, наносимых цели бомбой, радиус разрушитель-
разрушительного действия которой равен /? (рис. 5.2.8). Значения этой случайной
величины непрерывно заполняют промежуток от 0 до я/?2, но при
F(x)
Рис. 5.2.7.
Рис. 5.2.8.
этом крайние значения промежутка 0 и я/?2, осуществляющиеся при
положениях бомбы типа / и //, обладают определенной конечной
вероятностью, и этим значениям соответствуют скачки функции рас-
распределения, тогда как в промежуточных значениях (положение типа III)
функция распределение непрерывна. Другой пример смешанной слу-
случайной величины — время Т безотказной работы прибора, испыты-
испытываемого в течение времени t. Функция распределения этой случайной
величины непрерывна всюду, кроме точки t.
78 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
5.3. Вероятность попадания случайной величины
на заданный участок
При решении практических задач, связанных со случайными вели-
величинами, часто оказывается необходимым вычислять вероятность того,
что случайная величина примет значение, заключенное в некоторых
^\Т^ Pt П '^ 1^ ^*<Т*^^ /^ *"\ ¥\ ¥ 1 Т^ / J f\ 111 т ^ьЧ * УТ Л "Щ й fid г^ w т r% f\ rr\t
у y ^
«попаданием случайной величины X на участок от а до р».
Условимся для определенности левый конец а включать в уча-
участок (a, P), а правый—не включать. Тогда попадание случайной
величины X на участок (а, р) равносильно выполнению неравенства:
Выразим вероятность этого события через функцию распределения
величины X. Для этого рассмотрим три события:
событие А, состоящее в том, что X < C;
событие В, состоящее в том, что X < а;
событие С, состоящее в том, что а ^ X < 0.
Учитывая, что А = В-\-С, по теореме сложения вероятностей
имеем:
Р(Х < $)=Р(Х < a) + P(a<X < р),
или
откуда
Р (а <*<£) =/Чр)— /=Ча), E.3.1)
т. е. вероятность попадания случайной величины на заданный
участок равна приращению функции распределения на этом
участке.
Будем неограниченно уменьшать участок (а, £1), полагая, что
f->a. В пределе вместо вероятности попадания на участок получим
вероятность того, что величина примет отдельно взятое значение а:
Р (X = а.)= limP (a *CX <$) = \im[F $) — F (а.)]. E.3.2)
Значение этого предела зависит от того, непрерывна ли функ-
функция F(x) в точке х — а или же терпит разрыв. Если в точке a
функция F (х) имеет разрыв, то предел E.3.2) равен значению скачка
функции F (х) в точке а. Если же функция F (х) в точке а непре-
непрерывна, то этот предел равен нулю.
В дальнейшем изложении мы условимся называть «непрерывными»
только те случайные величины, функция распределения которых везде
непрерывна. Имея это в виду, можно сформулировать следующее
положение:
5.3] ВЕРОЯТНОСТЬ ПОПАДАНИЯ НА ЗАДАННЫЙ УЧАСТОК 79
Вероятность любого отдельного значения непрерывной слу-
случайной -величины равна нулю.
Остановимся на этом положении несколько подробнее. В данном
курсе мы уже встречались с событиями, вероятности которых были
равны нулю: это были невозможные события. Теперь мы видим, что
обладать нулевой вероятностью могут не только невозможные, но и
возможные события. Действительно, событие X = а, состоящее в том,
что непрерывная случайная величина А" примет значение а, возможно;
однако вероятность его равна нулю. Такие события — возможные, но
с нулевой вероятностью—появляются только при рассмотрении опытов,
не сводящихся к схеме случаев.
Понятие о событии «возможном, но обладающем нулевой вероят-
вероятностью» кажется на первый взгляд парадоксальным. В действитель-
действительности оно не более парадоксально, чем представление о теле, имеющем
определенную массу, тогда как ни одна из точек внутри тела опре-
определенной конечной массой не обладает. Сколь угодно малый объем,
выделенный из тела, обладает определенной конечной массой; эта
масса приближается к нулю по мере уменьшения объема и в пределе
равна нулю для точки. Аналогично при непрерывном распределении
вероятностей вероятность попадания на сколь угодно малый участок
может быть отлична от нуля, тогда как вероятность попадания
в строго определенную точку в точности равна нулю.
Если производится опыт, в котором непрерывная случайная вели-
величина X должна принять одно из своих возможных значений, то до
опыта вероятность каждого из таких значений равна нулю; однако,
в исходе опыта случайная величина X непременно примет одно из
своих возможных значений, т. е. заведомо произойдет одно из собы-
событий, вероятности которых были равны нулю.
Из того, что событие Х = а имеет вероятность, равную нулю,
вовсе не следует, что это событие не будет появляться, т. е. что
частота этого события равна нулю. Мы знаем, что частота события
при большом числе опытов не равна, а только приближается к вероят-
вероятности. Из того, что вероятность события X =а равна нулю, следует
только, что при неограниченном повторении опыта это событие
будет появляться сколь угодно редко.
Если событие А в данном опыте возможно, но имеет вероятность,
равную нулю, то противоположное ему событие А имеет вероятность,
равную единице, но не достоверно. Для непрерывной случайной
величины X при любом а событие X Ф а. имеет вероятность, равную
единице, однако это событие не достоверно. Такое событие при
неограниченном повторении опыта будет происходить почти всегда,
но не всегда.
В п°5.1 мы познакомились с «механической» интерпретацией
прерывной случайной величины как распределения единичной массы,
сосредоточенной в нескольких изолированных точках на оси абсцисс.
80
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
В случае непрерывной случайной величины механическая интерпре-
интерпретация сводится к распределению единичной массы не по отдельным
точкам, а непрерывно по оси абсцисс, причем ни одна точка не
обладает конечной массой.
5.4. Плотность распределения
Пусть имеется непрерывная случайная величина X с функцией
распределения F(x), которую мы предположим непрерывной и диф-
дифференцируемой. Вычислим вероятность попадания этой случайной
величины на участок от х до х-\-Ах:
Р (х < X < х + Д*) = F (х + Дх) — F (х).
т. е. приращение функции распределения на этом участке. Рассмот-
Рассмотрим отношение этой вероятности к длине участка,- т. е. среднюю
вероятность, приходящуюся на единицу длины на этом участке,
и будем приближать Ддг к нулю. В пределе получим производ-
производную от функции распределения:
llm F(*+A?-FM =F'(x).
Ах
E.4.1)
Введем обозначение:
f(x) = F'(x). E.4.2)
Функция f (х) — производная функции распределения — характе-
характеризует как бы плотность, с которой распределяются значения
случайной величины в данной точке. Эта функция называется плот-
f(x)
ностью распределения (иначе—•
«плотностью вероятности») непре-
непрерывной случайной величины X.
Иногда функцию f(x) называют
также «дифференциальной функ-
функцией распределения» или «диффе-
«дифференциальным законом распределе-
распределения» величины X.
Термины «плотность распреде-
распределения», «плотность вероятности»
становятся особенно наглядными
при пользовании механической
интерпретацией распределения;
в этой интерпретации функция f(x) буквально характеризует
плотность распределения масс по оси абсцисс (так называемую
«линейную плотность»). Кривая, изображающая плотность распре-
распределения случайной величины, называется кривой распределения
(рис. 5.4.1),
Рис. 5.4.1.
5.4]
ПЛОТНОСТЬ РАСПРЕДЕЛЕНИЯ
81
ryxj
Плотность распределения, так же как и функция распределения,
есть одна из форм закона распределения. В противоположность
функции распределения эта форма не является универсальной: она
существует только для непрерыв-
непрерывных случайных величин.
Рассмотрим непрерывную слу-
цяйму!Г! р,рлииин\г X с плотнпгтью
распределения f (х) и элементар-
элементарный участок dx, примыкающий
к точке х (рис. 5.4.2). Вероят-
Вероятность попадания случайной вели-
величины X на этот элементарный
участок (с точностью до беско-
бесконечно малых высшего порядка) ^
равна f(x)dx. Величина f(x)dx О
называется элементом вероят- рис 542
поста. Геометрически это есть
площадь элементарного прямоугольника, опирающегося на отре-
отрезок dx (рис. 5.4.2).
Выразим вероятность попадания величины X на отрезок от а до р
(рис. 5.4.3) через плотность распределения. Очевидно, она равна
сумме элементов вероятности на всем этом участке, т. е. интегралу:
f(x)
P(a<AT<p) = J f(x)dxi).
E.4.3)
Геометрически вероятность
попадания величины X на
участок (a, P) равна площади
кривой распределения, опи-
опирающейся на этот участок
(рис. 5.4.3). ч
Формула E.4.2) выражает
плотность распределения через
функцию распределения. Зададимся обратной задачей: выразить функ-
функцию распределения через плотность. По определению
F (х) = Р (X < х) = Р (— оо < X < х),
откуда по формуле E.4.3) имеем:
F(x)= ff(x)dx.
E.4.4)
') Так как вероятность любого отдельного значения непрерывной слу-
случайной величины равна нулю, то можно рассматривать здесь отрезок (о, р),
не включая в него левый конец, т. е. отбрасывая знак равенства в а-^Х
6 Е. С. Вентцель
82
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ГГЛ. 5
Геометрически F(x) есть не что иное, как площадь кривой рас-
распределения, лежащая левее точки х (рис. 5.4.4).
Укажем основные свойства плотности распределения.
1. Плотность распределения есть неотрицательная функция:
Уто свойство непосредственно вытекает из того, что функция
распределения F {х) есть неубывающая функция.
2. Интеграл в бесконечных пределах от плотности распределения
равен единице:
Ю
J*/(*)</*= 1.
£- — оо
Это следует из формулы
E.4.4) и из того, что
х
Геометрически основные
свойства плотности распреде-
распределения означают, что:
1) вся кривая распределения
лежит не ниже оси абсцисс;
Рис. 5.4.4.
2) полная площадь, ограниченная кривой распределения и осью
абсцисс, равна единице.
Выясним размерности основных характеристик случайной вели-
величины — функции распределения и плотности распределения. Функция
распределения F(x), как всякая вероятность, есть величина безраз-
безразмерная. Размерность плотности распределения f(x), как видно из
формулы E.4.1), обратна размерности случайной величины.
Пример 1. Функция распределения непрерывной случайной величины X
задана выражением
( 0 при
F (л:) = \ ах2 при
( 1 при х > 1.
а) Найти коэффициент а.
б) Найти плотность распределения f (х).
в) Найти вероятность попадания величины X на участок от 0,25 до 0,5.
Решение, а) Так как функция распределения величины X непрерывиа,
то при х = 1 ахг = 1, откуда а = 1.
б) Плотность распределения величины X выражается формулой
10 при х < 0,
2х при 0 < х < 1,
0 при х > 1.
в) По формуле E.3.1) имеем:
Р @,25 < X < 0,5) = F @,5) — F @,25) = 0,52 — 0,252 = 0,1875.
6.41
ПЛОТНОСТЬ РАСПРЕДЕЛЕНИЯ
83
Пример 2. Случайная величина X подчинена закону распределения
с плотностью:
тс it
при Г) < *< >
f (*) = 0
п
при jf < ^- или jf > -=-
а) Найти коэффициент а.
б) Построить график плотности распределения / (х).
в) Найти функцию распределения F(x) и построить ее график.
г) Найти вероятность попадания ве-
величины X на участок от 0 до -jr.
Решение, а) Для определения
коэффициента а воспользуемся свойст-
свойством плотности распределения:
fix)
Г f (x) dx= I a cos х dx ■■
■-OD ТС
1
= 2а=1,
откуда а = -=■. Рис. 5.4.5.
б) График плотности /(j;) представлен на рис. 5.4.5.
■к
2
-я
2
7Г
2
О
Рис. 5.4.6.
в) По формуле E.4.4) получаем выражение функции распределения:
График функции
О При Х<— -д.;
при —-j
1 при х > -д-.
изображен на рис. 5.4.6.
84 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. Б
г) По формуле E,3,1) имеем:
по
Тот же результат, но несколько более сложным путем можно получить
\ff.r)
Пример 3. Плотность распределения случайной величины X задана
формулой:
а) Построить график плотности f (х).
б) Найти вероятность того, что величина X попадет на участок (—1, +')•
Решение, а) График плотности дан на рис. 5.4.7.
б) По формуле E.4.3) имеем:
-1
5.5. Числовые характеристики случайных величин.
Их роль и назначение
В данной главе мы познакомились с рядом полных, исчерпываю-
исчерпывающих характеристик случайных величин—так называемых законов
распределения. Такими характеристиками были:
для дискретной случайной величины
а) функция распределения;
б) ряд распределения (графически — многоугольник распределения);
для непрерывной величины
а) функция распределения;
б) плотность распределения (графически — кривая распределения).
') Так называемый закон Кошн.
5.6] ХАРАКТЕРИСТИКИ ПОЛОЖЕНИЙ
87
Каждый закон распределения представляет собой нёйложены
функцию, и указание этой функции полностью описывает слсоот-
ную величину с вероятностной точки зрения.
Однако во многих вопросах практики нет необходимости характ^»
ризовать случайную величину полностью, исчерпывающим образом.
Зачастую достаточно бывает указать только отдельные числовые
параметр"; лг> некоторой степени характеризующие, гутргткрнные
черты распределения случайной величины: например, какое-то сред-
среднее значение, около которого группируются возможные значения слу-
случайной величины; какое-либо число, характеризующее степень раз-
разбросанности этих значений относительно среднего, и т. д. Поль-
Пользуясь такими характеристиками, мы хотим все существенные све-
сведения относительно случайной величины, которыми мы располагаем,
выразить наиболее компактно с помощью минимального числа числовых
параметров. Такие характеристики, назначение которых — выразить
в сжатой форме наиболее существенные особенности распределения,
называются числовыми характеристиками случайной величины.
В теории вероятностей числовые характеристики и операции с ними
играют огромную роль. С помощью числовых характеристик суще-
существенно облегчается решение многих вероятностных задач. Очень
часто удается решить задачу до конца, оставляя в стороне законы
распределения и оперируя одними числовыми характеристиками. При
этом весьма важную роль играет то обстоятельство, что когда
в задаче фигурирует большое количество случайных величин, каждая
из которых оказывает известное влияние на численный результат опыта,
то закон распределения этого результата в значительной мере можно
считать независимым от законов распределения отдельных случайных ве-
величин (возникает так называемый нормальный закон распределения).
В этих случаях по существу задачи для исчерпывающего суждения
о результирующем законе распределения не требуется знать законов рас-
распределения отдельных случайных величин, фигурирующих в задаче; до-
достаточно знать лишь некоторые числовые характеристики этих величин.
В теории вероятностей и математической статистике применяется
большое количество различных числовых характеристик, имеющих
различное назначение и различные области применения. Из них
в настоящем курсе мы введем только некоторые, наиболее часто
применяемые.
5.6. Характеристики положения
(математическое ожидание, мода, медиана)
Среди числовых характеристик случайных величин нужно прежде
всего отметить те, которые характеризуют положение случайной
величины\ на числовой оси, т. е. указывают некоторое среднее,
ориентировочное значение, около которого группируются все возмож-
возможные значения случайной величины.
84 СЛУЧАЙНЫ' ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
_л ^д'нее значение случайной величины есть некоторое число,
/лцееся клс бы ее «представителем» н заменяющее ее при грубо
,л1ентировочных расчетах. Когда мы говорим: «среднее время работы
^ампы равно 100 часам» или «средняя точка попадания смещена от-
относительно цели на 2 м вправо», мы этим указываем определенную
числовую характеристику случайной величины, описывающую ее
местоположение на числовой оси, т. е. «характеристику положения».
Из характеристик положения в теории вероятностей важнейшую
роль играет математическое ожидание случайной величины, ко-
которое иногда называют просто средним ■ значением случайной
величины.
Рассмотрим дискретную случайную величину X, имеющую воз-
возможные значения хх, х2 хп с вероятностями рх, р2 рп. Мам
требуется охарактеризовать каким-то числом положение значений
случайной величины на оси абсцисс с учетом того, что эти значения
имеют различные вероятности. Для этой цели естественно воспользо-
воспользоваться так называемым «средним взвешенным» из значений xt, причем
каждое значение jc, при осреднении должно учитываться с «весом»,
пропорциональным вероятности этого значения. Таким образом, мы
вычислим среднее значение случайной величины X, которое мы обо-
обозначим М{Х]:
••• +Рп
или, учитывая, что 2j Pi==t-
E.6.1)
Это среднее взвешенное значение и называется математическим
ожиданием случайной величины. Таким образом, мы ввели в рас-
рассмотрение одно из важнейших понятий теории вероятностей — поня-
понятие математического ожидания. ,
Математическим ожиданием случайной величины называется
сумма произведений всех возможных значений случайной вели-
величины на вероятности этих значений.
Заметим, что в вышеприведенной формулировке определение мате-
математического ожидания справедливо, строго говоря, только для ди-
дискретных случайных величин; ниже будет дано обобщение этого по-
понятия на случай непрерывных величин.
Для того чтобы сделать понятие математического ожидания более
наглядным, обратимся к механической интерпретации распределения
6.61
ХАРАКТЕРИСТИКИ ПОЛОЖЕНИЯ
87
дискретной случайной величины. Пусть на оси абсцисс расположены
точки с абсциссами х1з х2 хп> в которых сосредоточены соот-
п
ветствешю массы рх, р%, .... рп, причем 2 р,-= *• Тогда, очевидно,
математическое ожидание М[Х\, определяемое формулой E.6.1),
есть не что иное, как абсцисса, центра тяжести данной системы
материальных точек.
Математическое ожидание случайной величины X связано свое-
своеобразной зависимостью со средним арифметическим наблю-
наблюденных значений случайной величины при большом числе опытов,.
Эта зависимость того же типа, как зависимость между частотой и
вероятностью,, а именно: при большом числе опытов среднее ариф-
арифметическое наблюденных значений случайной величины приближается
(сходится по вероятности) к ее математическому ожиданию. Из нали-
наличия связи между частотой и вероятностью можно вывести как след-
следствие наличие подобной же связи между средним арифметическим и
математическим ожиданием.
Действительно, рассмотрим дискретную случайную величину X,
характеризуемую рядом распределения:
Pi
где Pi = ( i)
Пусть производится N независимых опытов, в каждом из которых
величина X принимает определенное значение. Предположим, что
значение хг появилось т1 раз, значение х2 появилось т2 раз, вообще
значение xt появилось тг раз. Очевидно,
хх
Р\
х2
Р2
. . .
• • •
хп
Рп
Вычислим среднее арифметическое наблюденных значений вели-
величины X, которое в отличие от математического ожидания М [X] мы
обозначим М*[Х]:
М*[Х) =
... +хптп
N
N
2 N
" N ~ Lk x' N '
88 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
_ _ Tfll ,
Но -^ есть не что иное, как частота (или статистическая ве-
вероятность) события X = xt; эту частоту можно обозначить р\. Тогда
т. е. среднее арифметические наблюденных значений случайной вели-
величины равно сумме произведений всех возможных значений случайной
величины на частоты этих значений.
При увеличении числа опытов Л/ частоты р* будут приближаться
(сходиться по вероятности) к соответствующим вероятностям /?,-.
Следовательно, и среднее арифметическое наблюденных значений
случайной величины М* [X] при увеличении числа опытов будет при-
приближаться (сходиться по вероятности) к ее математическому ожида-
ожиданию М[Х\.
Сформулированная выше связь между средним арифметическим и
математическим ожиданием составляет содержание одной из форм
закона больших чисел. Строгое доказательство этого закона будет
дано нами в главе 13.
Мы уже знаем, что все формы закона больших чисел констати-
констатируют факт устойчивости некоторых средних при большом числе опы-
опытов. Здесь речь идет об устойчивости среднего арифметического из
ряда наблюдений одной и той же величины. При небольшом числе
опытов среднее арифметическое их результатов случайно; при доста-
достаточном увеличении числа опытов оно становится «почти не случай-
случайным» и, стабилизируясь, приближается к постоянной величине —
математическому ожиданию.
Свойство устойчивости средних при большом числе опытов легко
проверить экспериментально. Например, взвешивая какое-либо тело
в лаборатории на точных весах, мы в результате взвешивания полу-
получаем каждый раз новое значение; чтобы уменьшить ошибку наблю-
наблюдения, мы взвешиваем тело несколько раз и пользуемся средним
арифметическим полученных значений. Легко убедиться, что при
дальнейшем увеличении числа опытов (взвешиваний) среднее арифме-
арифметическое реагирует на это увеличение все меньше и меньше и при
достаточно большом числе опытов практически перестает меняться.
Формула E.6.1) для математического ожидания 'соответствует
случаю дискретной случайной величины. Для непрерывной величины X
математическое ожидание, естественно, выражается уже не суммой,
а интегралом:
оо
М[Х]= f x/(x)dx, E.6.2)
где f(x) — плотность распределения величины X.
5.6]
ХАРАКТЕРИСТИКИ ПОЛОЖЕНИЯ
89
Формула E.6.2) получается из формулы E.6.1). если в ней заме-
заменить отдельные значения xt непрерывно изменяющимся параметром х,
соответствующие вероятности pt — элементом вероятности f(x)dx,
конечную сумму — интегралом. В дальнейшем мы часто будем поль-
пользоваться таким способом распространения формул, выведенных для
прерывных величин, на случай непрерывных величин.
В механической интерпретации математическое ожидание непре-
непрерывной случайной величины сохраняет тот же смысл — абсциссы
центра тяжести в случае, когда масса распределена по оси абсцисс
непрерывно, с плотностью f(x). Эта интерпретация часто позволяет
найти математическое ожидание без вычисления интеграла E.6.2), из
простых механических соображений.
Выше мы ввели обозначение М [X] для математического ожида-
ожидания величины X. В ряде случаев, когда величина М [Х\ входит
в формулы как определенное число, ее удобнее обозначать одной
буквой. В этих случаях мы будем обозначать математическое ожида-
ожидание величины X через тх\
Обозначения тх и М [X] для математического ожидания будут
в дальнейшем применяться параллельно в зависимости от удобства
той или иной записи формул. Условимся также в случае надобности
сокращать слова «математическое ожидание» буквами м. о.
Следует заметить, что важнейшая характеристика положения —
математическое ожидание — существует не для всех случайных вели-
величин. Можно составить примеры таких случайных величин, для которых
математического ожидания не существует, так как соответствующая
сумма или интеграл расходятся.
Рассмотрим, например, прерывную случайную величину X с рядом
распределения:
Pi
2
1
2
1
22
. . .
2'
1
2<
. . .
Нетрудно убедиться в том, что
= 1, т. е. ряд распределе-
ния имеет смысл; однако сумма 2 xiPi B данном случае расходится
1-Х
и, следовательно, математического ожидания величины X не суще-
существует- Однако для практики такие случаи существенного интереса
не представляют. Обычно случайные величины, с которыми мы имеем
дело, имеют ограниченную область возможных значений и безусловно
обладают математическим ожиданием. <
90
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. S
Выше мы дали формулы E.6.1) и E.6.2), выражающие математи-
математическое ожидание соответственно для прерывной » пспне.пмшк;!; слу-
случайной величины X.
Если величина X принадлежит к величинам смешанного типа, то
ее математическое ожидание выражается формулой вида:
Pi
jf
I
+ f xF' (x) dx, E.6.3)
где сумма распространяется
на нее точки х{, в которых
функция распределения тер-
терпит разрыв, а интеграл — на
все участки, на которых
—х функция распределения не-
непрерывна.
Кроме важнейшей из ха-
характеристик положения—ма-
положения—математического ожидания, — на практике иногда применяются и другие
характеристики положения, в частности мода и медиана случайной
величины.
Модой случайной величины называется ее наиболее вероятное
значение. Термин «наиболее вероятное значение», строго говоря,
применим только к прерывным величинам; для непрерывной величины
М
Рис. 5.6.1<
ffx)
О
Рис. 5.6.2.
модой является то значение, в котором плотность вероятности макси-
максимальна. Условимся обозначать моду буквой о/И. На рис. 5.6.1 и
5.6.2 показана мода соответственно для прерывной и непрерывной
случайных величин.
S.8J ХАРАКТЕРИСТИКИ ПОЛОЖЕНИЯ 91
Веля многоугольник распределения (кривая распределения) имеет
(рис. 5.6.3 и 5.6.4).'
toQ ЛПНПГЛ \f ai/Г HXiWt 'J iiOr П 'Л Л Г1 Л пои КО
Рис. 5.6.3,
f(x)
Рис. 5.6.4.
Иногда встречаются распределения, обладающие посередине не
максимумом, а минимумом (рис. 5.6.5 и 5.6.6). Такие распределения
f(X)
О
Рис. 5.6.5.
Рис. 5.6.6.
называются «антимодальными». Примером антимодального распреде-
распределения может служить распределение, полученное в примере 5, п° 5.1.
92
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
В общем случае мода и математическое ожидание случайной вели-
величины не совпадают. В частном случае, когда распределение является
симметричным и модальным (т. е. имеет моду) и существует мате-
математическое ожидание, то оно совпадает с модой и центром симметрии
распределения.
Часто применяется еще одна характеристика положения — так на-
называемая медиана случайной величины. Этой характеристикой поль-
пользуются обычно только для
ffx) непрерывных случайных ве-
величин, хотя формально
можно ее определить и для
прерывной величины.
Медианой случайной ве-
величины X называется такое
ее значение o4te, для ко-
которого
—х Р (X < <Мё)=Р (X > <Ме),
О Me
т. е. одинаково вероятно,
Рис. 5.6.7. окажется ли случайная вели-
величина меньше или больше о/Яе.
Геометрическая медиана — это абсцисса точки, в которой площадь,
ограниченная кривой распределения, делится пополам (рис. 5.6.7).
В случае симметричного модального распределения медиана сов-
совпадает с математическим ожиданием и модой.
Б.7. Моменты. Дисперсия. Среднее квадратическое отклонение
Кроме характеристик положения — средних, типичных значений
случайной величины,—употребляется еще ряд характеристик, каждая
из которых описывает то или иное свойство распределения. В каче-
качестве таких характеристик чаще всего применяются так называемые
моменты.
Понятие момента широко применяется в механике для описания
распределения масс (статические моменты, моменты инерции и т. д.).
Совершенно теми же приемами пользуются в теории вероятностей для
описания основных свойств распределения случайной величины. Чаще
всего применяются на практике моменты двух видов: начальные и
центральные.
Начальным моментом s-го порядка прерывной случайной
величины X называется сумма вида:
2
5.7] МОМЕНТЫ. ДИСПЕРСИЯ 93
Очевидно, это определение совпадает с определением начального
момента порядка s в механике, если на оси абсцисс в точках
xv 'х2 хп сосредоточены массы рг, р2 рп-
Для непрерывной случайной величины X начальным моментом
s-ro порядка называется интеграл
а,[Х] = Jx*f(x)dx. E.7.2)
Нетрудно убедиться, что введенная в предыдущем п° основная
характеристика положения — математическое ожидание — представляет
собой не что иное, как первый начальный момент случайной ве-
величины X.
Пользуясь знаком математического ожидания, можно объединить
две формулы E.7.1) и E.7.2) в одну. Действительно, формулы E.7.1)
и E.7.2) по структуре полностью аналогичны формулам E.6.1) и
E.6.2), с той разницей, что в них вместо xt и х стоят, соответ-
соответственно, xst и Xs. Поэтому можно написать общее определение началь-
начального момента s-ro порядка, справедливое как для прерывных, так и
для непрерывных величин:
us[X) — M[X% E.7.3)
т. е. начальным моментом s-го порядка случайной величины X
называется математическое ожидание s-й степени этой слу-
случайной величины 1).
Перед тем как дать определение центрального момента, введем
новое понятие «центрированной случайной величины».
Пусть имеется случайная величина X с математическим ожида-
ожиданием тх. Центрированной случайной величиной, соответствующей
величине X, называется отклонение случайной величины X от ее
математического ожидания:
Х — Х — тх. E.7.4)
Условимся в дальнейшем везде обозначать центрированную слу-
случайную величину, соответствующую данной случайной величине, той
же буквой со значком ° наверху.
Нетрудно убедиться, что математическое ожидание центрирован-
центрированной случайной величины равно нулю. Действительно, для прерывной
') Понятие математического ожидания функции от случайной величины
будет уточнено далее (см. главу 10).
94 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
величины
М [X] = М [X — тх] = 2 (*, — тх)р, =
1
mx1i Pi = mx — mx = 0; E.7.5)
аналогично и для непрерывной величины.
Центрирование случайной величины, очевидно, равносильно пере-
переносу начала координат в среднюю, «центральную» точку, абсцисса
которой равна математическому ожиданию.
Моменты центрированной случайной величины носят название
центральных моментов. Они аналогичны моментам относительно
центра тяжести в механике.
Таким образом, центральным моментом порядка s случайной
величины X называется математическое ожидание s-й степени соот-
соответствующей центрированной случайной величины:
V.S[X] = M[XS) = M[(X — тх)% E.7.6)
Для прерывной случайной величины s-й центральный момент вы-
выражается суммой
■]£(**-'
Pi, E.7.7)
а для непрерывной — интегралом
(х - тхУ f (х) dx. E.7.8)
В дальнейшем в тех случаях, когда не возникает сомнений,
к какой случайной величине относится данный момент, мы будем
для краткости вместо <xslX] и ^ [X] писать просто as и p,s.
Очевидно, для любой случайной величины центральный момент
первого порядка равен нулю:
ц, = М [Х\ = М [Х — тх\ = 0, E.7.9)
так как математическое ожидание центрированной случайной вели-
величины всегда равно нулю.
Выведем соотношения, связывающие центральные и начальные
моменты различных порядков. Вывод мы проведем только для пре-
прерывных величин; легко убедиться, что точно те же соотношения
справедливы и для непрерывных величин, если заменить конечные
суммы интегралами, а вероятности — элементами вероятности.
5.71 МОМЕНТЫ. ДИСПЕРСИЯ
Рассмотрим второй центральный момент:
п
АЛ I V2^ i ^> {v *м "\2 и 11-
Ъ (=! ' ' '
л п п
— Zl^iPi— ^x^xi i х Ы1 i— а2 л - л
Аналогично для третьего центрального момента получим:
95
-
= % (xt -mxf p. = У x\Pi
t — 1 * = 1
2
- л» У
2m».
Выражения для {л4, р.5 и т. д. могут быть получены аналогич-
аналогичным путем.
Таким образом, для центральных моментов любой случайной ве-
величины К справедливы формулы:
E.7.1Q)
Вообще говоря, моменты могут рассматриваться не только отно-
относительно начала координат (начальные моменты) или математического
ожидания (центральные моменты), но и относительно произвольной
точки а:
1S = M{(X — af]. E.7.11)
Однако центральные моменты имеют перед всеми другими преиму-
преимущество: первый центральный момент, как мы видели, всегда равен
нулю, а следующий за ним, второй центральный момент при этой
системе отсчета имеет минимальное значение. Докажем это. Для
прерывной случайной величины X при s = 2 формула E.7.11) имеет вид:
E.7.12)
Преобразуем это выражение:
п
21( »* + »* —«У Pi
t=i
4- (тх — аJ = Р2 4- (^ — яJ-
96 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ГГЛ. 5
Очевидно, эта величина достигает своего минимума, когда тх = а,
т. е. когда момент берется относительно точки тх.
Из всех моментов в качестве характеристик случайной величины
чаще всего применяются первый начальный момент (математическое
ожидание) тх-=\ и второй центральный момент р.,.
Второй центральный момент называется дисперсией случайной
величины. Ввиду крайней^ важности этой характеристики среди других
моментов введем для нее специальное обозначение D[X]:
Согласно определению центрального момента
D[X] = M\X2\, E.7.13)
т. е. дисперсией случайной величины X называется математи-
математическое ожидание квадрата соответствующей центрированной
величины.
Заменяя в выражении E.7.13) величину X ее выражением, имеем
также:
D[X] = M[(X — тхJ\. E.7.14)
Для непосредственного вычисления дисперсии служат формулы:
D[X\=%{xl~mxfpi, E.7.15)
i = 1
оо
D [Х\ = J (х — тх? / (х) dx E.7.16)
—оо
— соответственно для прерывных и непрерывных величин.
Дисперсия случайной величины есть характеристика рассеива-
рассеивания, разбросанности значений случайной величины около ее мате-
математического ожидания. Само слово «дисперсия» означает «рассеивание».
Если обратиться к механической интерпретации распределения,
то дисперсия представляет собой не что иное, как момент инерции
заданного распределения масс относительно центра тяжести (матема-
(математического ожидания).
Дисперсия случайной величины имеет размерность квадрата слу-
случайной величины; для наглядной характеристики рассеивания удобнее
пользоваться величиной, размерность которой совпадает с размер-
размерностью случайной величины. Для этого из дисперсии извлекают ква-
квадратный корень. Полученная величина называется средним квадра-
тическим отклонением (иначе—«стандартом») случайной величины X.
Среднее квадратическое отклонение будем обозначать о[Х\:
E.7.J7)
5,7} МОМЕНТЫ. ДИСПЕРСИЯ 97
Для упрощения записей мы часто будем пользоваться сокращен-
сокращенными обозначениями среднего квадратического отклонения и диспер-
дисперсии: ах и Dx. В случае, когда не возникает сомнения, к какой
случайной величине относятся эти характеристики, мы будем иногда
опускать значок х у ок и Dx и писать просто о и D. Слова «среднее
квадратическое отклонение» иногда будем сокращенно заменять бук-
буквами с. к. о.
На практике часто применяется формула, выражающая дисперсию
случайной величины через ее второй начальный момент (вторая из
формул E.7.10)). В новых обозначениях она будет иметь вид:
D.< = *2 — m\- C.7. IS)
Математическое ожидание тх и дисперсия Dx (или среднее ква-
квадратическое отклонение ох) — наиболее часто применяемые характе-
характеристики случайной величины. Они характеризуют наиболее важные
черты распределения: его положение и степень разбросанности. Для
более подробного описания распределения применяются моменты
высших порядков.
Третий центральный момент служит для характеристики асим-
асимметрии (или «скошенности») распределения. Если распределение
симметрично относительно математического ожидания (или, в меха-
механической интерпретации, масса распределена симметрично относительно
центра тяжести), то все моменты нечетного порядка (если они суще-
существуют) равны нулю. Действительно, в сумме
V-,— 2* (ж, — mx
при симметричном относительно тх законе распределения и нечет-
нечетном * каждому положительному слагаемому соответствует равное ему
по абсолютной величине отрицательное слагаемое, так что вся сумма
равна нулю. То же, очевидно, справедливо и для интеграла
I*.
= J (x — mx)sf(x)dx,
который равен нулю, как интеграл в симметричных пределах от не-
нечетной функции.
Естественно поэтому в качестве характеристики асимметрии рас-
распределения выбрать какой-либо из нечетных моментов. Простейший
из них есть третий центральный момент. Он имеет размерность куба
случайной величины; чтобы получить безразмерную характеристику,
третий момент \х3 делят на куб среднего квадратического отклонения,
7 Е. С. Вентцель
98
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. S
Полученная величина носит название «коэффициента асимметрии»
или просто «асимметрии»; мы обозначим ее Sk:
E.7.19)
о
'"Ж
Рис. 5.7.1.
; другое (кри-
(криотрицательную
Ha рис. 5.7.1 показано два асимметричных распределения; одно
из них (кривая /) имеет
положительную асиммет-
асимметрию (S£>0
вая //) —
(S.k < 0).
Четвертый централь-
центральный момент служит для
характеристики так назы-
называемой «крутости», т. е.
островершинности
плосковершинности
или
рас-
распределения. Эти свойства
распределения описы-
описываются с помощью так
называемого эксцесса. Эксцессом случайной величины X называется
величина
Ех = ^-3. E.7.20)
Число 3 вычитается из отношения
ного и широко распростра-
распространенного в природе нормаль-
нормального закона распределения
(с которым мы подробно
познакомимся в дальнейшем)
i-^- = 3. Таким образом,
потому, что для весьма важ-
для нормального распреде-
распределения эксцесс равен нулю;
кривые, более островершин-
островершинные по сравнению с нор-
нормальной, обладают положи-
положительным эксцессом; кривые
более плосковершинные —
отрицательным эксцессом.
На рис. 5.7.2 представлены: нормальное распределение (кривая /),
распределение с положительным эксцессом (кривая //) и распреде-
распределение с отрицательным эксцессом (кривая ///).
Рис. 5.7.2.
5.71
МОМЕНТЫ. ДИСПЕРСИЯ 99
Кроме рассмотренных выше начальных и центральных моментов,
на практике иногда применяются так называемые абсолютные мо-
моменты (начальные и центральные), определяемые формулами
Очевидно, абсолютные моменты четных порядков совпадают с
обычными моментами.
Из абсолютных моментов наиболее часто применяется первый
абсолютный центральный момент
mx\]. E.7.21)
назь в.дСмыЛ с рее ним арп'рл'чпическа.м отклонением. Няг.'ду
с дисперсией и средним квадратическим отклонением среднее ариф-
арифметическое отклонение иногда применяется как характеристика рас-
рассеивания.
Математическое ожидание, мода, медиана, начальные и централь-
центральные моменты и, в частности, дисперсия, среднее квадратическое
отклонение, асимметрия и эксцесс представляют собой наиболее упо-
употребительные числовые характеристики случайных величин. Во многих
|$дачах практики полная характеристика случайной величины — закон
распределения — или не нужна, или не может быть получена. В этих
случаях ограничиваются приблизительным описанием случайной вели-
величины с помощью числовых характеристик, каждая из которых
выражает какое-либо характерное свойство распределения.
Очень часто числовыми характеристиками пользуются для при-
приближенной замены одного распределения другим, причем обычно
.стремятся произвести эту замену так, чтобы сохранились неизменными
несколько важнейших моментов.
Пример 1. Производится один опыт, в результате которого может
появиться или не появиться событие А, вероятность которого равна />. Рас-
Рассматривается случайная величина X — число Еоявлеиий события А (харак-
(характеристическая случайная величина события А). Определить ее характе-
характеристики: математическое ожидание, дисперсию, среднее квадратическое
'Отклонение.
Решение. Ряд распределения величины имеет вид:
0
1
Pi
где q as I — р — вероятность непоявления события А.
По формуле E.6.1) находим математическое ожидание величины X:
тх = М [X] = 0 • q -f-1 • р = р.
7*
100 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
Дисперсию величины X определим по формуле E.7.15):
откуда
(Предлагаем читателю получить тот же результат, выразив дисперсию через
второй начальный момент.)
Пример 2. Производится три независимых выстрела по мишенн, ве-
вероятность попадания при каждом выстреле равна 0,4. Случайная величина
X — число попаданий. Определить характеристики величины X — математи-
математическое ожидание, дисперсию, с. к. о., асимметрию.
Решение. Ряд распределения величины X имеет вид:
Pi II 0,216
0,432
0,288
0,064
Вычисляем числовые характеристики величины X:
т х = 0 • 0,216 -f 1 • 0,432 + 2 • 0,288 + 3 • 0,064 = 1,2;
D, = @ —1,2)* • 0,216 -f A —1,2J • 0,432 + B —1,2J.0,288 +
+ C —1,2J • 0,064 = 0,72;
«х = Y~D~X = УШ. = 0,848;
(х3 = @ — 1,2K • 0,216 + A - 1,2)' • 0,432 + B — 1,2)' • 0,288 +
+ C—1,2K.0,064 = 0,144;
с ** 0,144
0,72 • 0,848
0,236.
Заметим, что те же характеристики могли бы быть вычислены значи-
значительно проще с помощью теорем о числовых характеристиках функций
(см. главу 10).
Пример 3. Производится ряд независимых опытов до первого по-
появления события А (см. пример Зп°5.1). Вероятность события А в каждом
опыте равна р. Найти математическое ожидание, дисперсию и с. к. о. числа
опытов, которое будет произведено.
Решение. Ряд распределения величины X имеет вид:
Pi
1
р
2
ЧР
3
Ч'Р
. . .
. . .
q'-lp
• • •
. . .
Математическое ожидание величины X выражается суммой ряда
6.7]
МОМЕНТЫ. ДИСПЕРСИЯ 101
Нетрудно видеть, что ряд, стоящий в скобках, представляет собой ре-
результат дифференцирования геометрической прогрессии:
Следовательно,
откуда
Р 1
тх=~ = —.
Р2 Р
Для определения дисперсии величины X вычислим сначала ее второй
начальный момент:
Для вычисления ряда, стоящего в скобках, умножим на q ряд:
Получим:
Дифференцируя этот ряд по д, имеем:
1. + 2., + Зу+ ... +<V->+ ..
Умножая на р = 1 — <?> получим:
1
По формуле E.7.18) выразим дисперсию:
1 q q
-jc i —x (i — qy A —^p A — qy "^2"
откуда
Пример 4. Непрерывная случайная величина X подчинена закону
распределения с плотностью:
f(x) =^-1"
(рис. 5.7.3).
Найти коэффициент А. Определить м. о., дисперсию, с. к. о., асимме-
асимметрию, эксцесс величины X.
Решение. Для определения А воспользуемся свойством плотности
распределения:
со оо
jf(x)dx = 2A Jе-*dx = 2А = lj
102 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ {ГЛ. 5
отсюда
А>ш ~2'
Так как функция л^-'*1 нечетная, то м. о. величины Л* равно нулю:
х
а
Рис. 5.7.3.
Для вычисления эксцесса находим
со
откуда
га,
f-j xe~lx] dx = Q.
Дисперсия и с. к. о. равны,
соответственно:
, Г 1
A t. ' иЛ — 'J,
Так как распределение
симметрично, то Sk — 0.
Пример 5. Случайная величина X подчинена закону распределения,
плотность которого задана графически на рис. 5.7.4.
Написать выражение плотности распределения. Найти м. о., дисперсию,
с. к. о. и асимметрию распреде-
распределения. f(X)
Решение. Выражение плот-
плотности распределения имеет вид:
/(*)
' ах при 0 < х < \,
0 при х < 0 или х > 1.
Пользуясь свойством плог-
иости распределения, находим
а = 2.
Математическое ожидание ве-
величины X:
1
га. ' " " • 2
Рис. 5.7.4.
о
Дисперсию найдем через второй начальный момент:
1 „ _• 1 .
J
5 8] ЗАКОН РАВНОМЕРНОЙ ПЛОТНОСТИ 103
отсюда
1
Зу'2
Третий начальный момент равен
9
ч3 = ^ i л1 dx = ~.
б
Пользуясь третьей из формул E.7.10), выражающей Рз черел начальныз
моменты, имеем:
откуда
5А = -^ = -2)А2.
5.8. Закон равномерной плотности
В некоторых задачах практики встречаются непрерывные случай-
случайные величины, о которых заранее известно, что их возможные зна-
значения лежат в пределах некоторого определенного интервала; кроме
того, известно, что в пределах этого интервала все значения слу-
случайной величины одинаково вероятны (точнее, обладают одной и той же
плотностью вероятности). О таких случайных величинах говорят,
что они распределяются по закону равномерной плотности.
Приведем несколько примеров подобных случайных величин.
Пример 1. Произведено взвешивание тела на точных весах,
но в распоряжении взвешивающего имеются только разновески весом
не менее 1 г; результат взвешивания по-
показывает, что вес тела заключен между k
и (А-|-1) граммами. Вес тела принят
равным (k -\--%\ граммам. Допущенная
при этом ошибка X, очевидно, есть
случайная величина, распределенная
с равномерной плотностью на участке
Н
)
Пример 2. Вертикально поста- Рис' 5 8Ь
вленное симметричное колесо (рис. 5.8.1)
приводится во вращение и затем останавливается вследствие трения.
Рассматривается случайная величина 0 — угол, который после оста-
остановки будет составлять с горизонтом фиксированный радиус ко-
колеса ОА. Очевидно, величина 0 распределена с равномерной плот-
плотностью на участке @, 2тс).
104
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
Пример 3. Поезда метрополитена идут с интервалом 2 мин.
Пассажир выходит на платформу в некоторый момент времени.
Время Т, в течение которого ему придется ждать поезда, предста-
представляет собой случайную величину
распределенную с равномерной
плотностью на участке @, 2)
минут.
Рассмотрим случайную вели-
величину X, подчиненную закону
равномерной плотности на участке
от а до 3 (рис. 5.8.2), и напи-
напишем для нее выражение плотности
распределения / (х). Плотность
fix) постоянна и раваа с па от-
х резке (а, В); вне этого отрезка она
равна нулю:
Рис. 5.8.2.
/(*) =
с при а < х < В.
Так как
единице:
то
. О при х < а или х > В.
площадь, ограниченная кривой распределения, равна
и плотность распределения f (х) имеет вид:
1
при « < аг < р,
при х < а или х > p.
E.8.1)
Формула E.8.1) и выражает закон равномерной плотности на
участке (a, fl).
Напишем выражение для функции распределения F (х). Функция
распределения выражается площадью кривой распределения, лежащей
левее точки х. Следовательно,
при х < а,
0
1 при х > р.
График функции F(x) приведен на рис. 5.8.3.
Определим основные Числовые характеристики случайной вели-
величины А', подчиненной закону равномерной плотности на участке
от а до 3.
5.8]
ЗАКОН РАВНОМЕРНОЙ ПЛОТНОСТИ
Математическое ожидание величины X равно:
т
- f x dx-a + V
— J р_а UX— 2 -
105
E.8.2)
В силу симметричности равномерного распределения медиана ве-
величины X также равна —н— •
Моды закон равномерной плотности не имеет.
По формуле E.7,16) находим дисперсию величины X:
Ffxi
х —
12
E.8.3)
откуда среднее квадратическое
отклонение
о
а
х
Рис. 5.8.3.
В силу симметричности распределения его асимметрия равна нулю:
SA = -^ = 0. E.8.5)
ах
Для определения эксцесса находим четвертый центральный момент:
откуда
Ех = *$■'—'3=—1.2.
E.8.6)
Определяем среднее арифметическое отклонение:
Наконец, найдем вероятность попадания случайной величины X, рас-
распределенной по закону равномерной плотности, на участок (а, Ь),
106
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
представляющий собой часть участка (а, Р) (рис. 5.8.4). Геометри-
Геометрически эта вероятность представляет собой площадь, заштрихованную
на рис. 5.8.4. Очевидно, она равна:
Я(а
E.8.8)
т. е. отношению длины отрезка (а, Ь) ко всей длине участка (a, (J),
на котором задано равномерное
f(x) распределение.
а. а
Рис. 5.8.4.
5.9. Закон Пуассона
Во многих задачах практики
приходится иметь дело со слу-
случайными величинами, распреде-
распределенными по своеобразному за-
х кону, который называется за-
законом Пуассона.
Рассмотрим прерывную слу-
случайную величину X, которая
может принимать только целые, неотрицательные значения:
О, 1, 2 т
причем последовательность этих значений теоретически не ограничена.
Говорят, что случайная величина X распределена по закону
Пуассона, если вероятность того, что она примет определенное зна-
значение т, выражается формулой
Р = —е-
E.9.1)
где а — некоторая положительная величина, называемая параметром
закона Пуассона.
Ряд распределения случайной величины X, распределенной по
закону Пуассона, имеет вид:
0
1
а
21
т
ml
Убедимся прежде всего, что последовательность вероятностей,
вадаваемая формулой E.9.1), может представлять собой ряд распре-
8.91 ЗАКОН ПУАССОНА 107
деления, т. е. что сумма всех вероятностей Рт равна единице. Имеем:
Но
откуда
m! *
vi am
На рис. 5.9.1 показаны многоугольники распределения случайной
величины X, распределенной по закону Пуассона, соответствующие
различным значениям пара-
параметра а. В таблице 8 при-
ложения приведены значе-
значения Рт для различных с. V, =пч
Определим .основные ха- 0,5 ^ ~~'
рактГеристики — математиче-
математическое ожидание и диспер-
дисперсию—случайной величины X,
распределенной по закону
Пуассона. По определению
математического ожидания
о 1
2 3 4 5 6 7 8
Рис. 5.9. U
ш=0
Первый член суммы (соответствующий /и = 0) равен нулю, сле-
следовательно, суммирование можно начинать с ш = 1:
т-Ше-" = ае-а
т,
Обозначим т — 1 = k; тогда
00
та"
= ае~а £ (т — 1I '
т=1
= a.
F.9.2)
Таким образом, параметр а представляет собой не что иное, как
математическое ожидание случайной величины X.
108 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ {ГЛ. 5
Для опрр.лелекия дисперсии найдем сначала второй начальный
момент величины л:
т = 0 т~\
= а
. /п = 1 m = 1
По ранее доказанному
кроме того,
оо
\ p-a — p-apa i
Zi (m-l)| e ~e e —l-
m = l
следовательно,
a2== a (a 4-1).
Далее находим дисперсию величины X:
Dx = ai — m]. — a1^-a~ai— a. E.9.3)
Таким образом, дисперсия случайной величины, распределен-
распределенной по закону Пуассона, равна ее математическому ожи-
ожиданию а.
Это свт№ство распределения Пуассона часто применяется на прак-
практике для решения вопроса, правдоподобна ли гипотеза о том, что
случайная величина X распределена по закону Пуассона. Для этого
определяют из опыта статистические характеристики — математиче-
математическое ожидание и дисперсию — случайной величины ]). Если их значе-
значения близки, то это может служить доводом в пользу гипотезы
о пуассоновском распределении; резкое различие этих характеристик,
напротив, свидетельствует против гипотезы.
Определим для случайной величины X, распределенной по закону
Пуассона, вероятность того, что она примет значение не меньше
') О способах экспериментального определения этих характеристик
см. ниже, гл. 7 и 14.
5.91 ЗАКОН ПУАССОНА . 109
заданного k. Обозначим эту вероятность /?ft:
~v* —' \-'- «?-■--/■■
Очевидно, вероятность Rh может быть вычислена как сумма
R^pk+pk+1+ ... = i pm.
т =*
Однако значительно проще определить ее из вероятности проти-
противоположного события:
Rk=l-(Po + Pi+ ••• +^-i) = l- S Л»- F.9.4)
m =0
В частности, вероятность того, что величина К примет положи-
положительное значение, выражается формулой
/?! = I — /*о = 1 —**• E.9.5)
Мы уже упоминали о том, что многие задачи практики приводят
к распределению Пуассона. Рассмотрим одну из типичных задач
такого рода.
Пусть на оси абсцисс Ох случайным образом распределяются
точки (рис. 5.9.2). Допустим, что случайное распределение точек
удовлетворяет следующим условиям:
1. Вероятность попадания того или иного числа точек на отрезок I
зависит только от длины этого отрезка, но не зависит от его поло-
положения на оси абсцисс. Иными словами, точки распределены на оси
Рис. 5.9.2.
абсцисс с одинаковой средней плотностью. Обозначим эту плотность
(т. е. математическое ожидание числа точек, приходящихся на еди-
единицу длины) через X.
2. Точки распределяются на оси абсцисс независимо друг от друга,
т. е. вероятность попадания того или другого числа точек на задан-
заданный отрезок не зависит от того, сколько их попало на любой дру-
другой отрезок, не перекрывающийся с ним.
3. Вероятность попадания на малый участок Дл; двух или более
точек пренебрежимо мала по сравнению с вероятностью попадания
одной точки (это условие означает практическую невозможность
совпадения двух или более точек).
110 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 5
Выделим на оси абсцисс определенный отрезок длины / и рас-
рассмотрим дискретную случайную величину X — число точек, попа-
попадающих на этот отрезок. Возможные значения величины будут
0, 1, 2 т, ... E.Э.6)
Так как точки попадают на отрезок независимо друг от друга,
то теоретически не исключено, что их там окажется сколь угодно
много, т. е. ряд E.9.6) продолжается неограниченно.
Докажем, что случайная величина X имеет закон распределения
Пуассона. Для этого вычислим вероятность Рт того, что на отрезок /
попадет ровно т. точек.
Сначала решим более простую задачу. Рассмотрим на оси Ох
малый участок Дл: и вычислим вероятность того, что па этот участок
попадет хотя бы одна точка. Будем рассуждать следующим образом.
Математическое ожидание числа точек, попадающих на этот участок,
очевидно, равно ХДл; (т. к. на единицу длины попадает в среднем
X точек). Согласно условию 3 для малого отрезка Дл; можно прене-
пренебречь возможностью попадания на него двух или . больше точек.
Поэтому математическое ожидание ХДл; числа точек, попадающих на
участок Дл;, будет приближенно равно вероятности попадания на
него одной точки (или, что в наших условиях равнозначно, хотя бы
одной).
Таким образом, с точностью до бесконечно малых высшего
порядка, при Дл:—>0 можно считать вероятность того, что на уча-
участок Дл; попадет одна (хотя бы одна) точка, равной ХДлг, а вероят-
вероятность того, что не попадет ни одной, равной 1—ХДл;.
Воспользуемся этим для вычисления вероятности Рт попадания
на отрезок / ровно т. точек. Разделим отрезок I на п равных частей
длиной Дл:=—. Условимся называть элементарный отрезок Дл:
«пустым», если в него не попало ни одной точки, и «занятым», если
в него попала хотя бы одна. Согласно вышедоказанному вероятность
того, что отрезок Дл; окажется «занятым», приближенно равна ХДл; =
= —; вероятность того, что он окажется «пустым», равна 1 .
Так как, согласно условию 2, попадания точек в неперекрывающиеся
отрезки независимы, то наши п отрезков можно рассмотреть как п
независимых «опытов», в каждом из которых отрезок может быть
«занят» с вероятностью р ——. Найдем вероятность того, что среди
я отрезков будет ровно т «занятых». По теореме о повторении опы-
опытов эта вероятность равна
X/ \п-т
B.9J ЗАКОН ПУАССОНА 111
или, обозначая \1 — а,
При достаточно большом я эта вероятность приближенно равна
вероятности попадания на отрезок I ровно т точек, так как попада-
попадание двух или больше точек на отрезок Дл; имеет пренебрежимо малую
вероятность. Для того чтобы найти точное значение Рт, нужно в вы-
выражении E.9.7) перейти к пределу при »->оо:
E.9.8)
Преобразуем выражение, стоящее под знаком предела:
и (л — 1) ... (л —
ml nm I a
у—к
/,(/,-!)...(в-д + 1) д"
~ пт ml / а\т'
Первая дробь и знаменатель последней дроби в выражении E.9.9)
при п—уоо, очевидно, стремятся к единице. Выражение —р от п не
зависит. Числитель последней дроби можно преобразовать так:
При п—>оо >со, и выражение E.9.10) стремится к е~а.
Таким образом, доказано, что вероятность попадания ровно т точек
в отрезок I выражается формулой
т ТйТе '
где а = \1, т. е. величина X распределена по закону Пуассона с па-
параметром а = XI.
Отметим, что величина а по смыслу представляет собой среднее
число точек, приходящееся на отрезок I.
Величина Rx (вероятность того, что величина X примет положи-
положительное значение) в данном случае выражает вероятность того,
что на отрезок I попадет хотя бы одна точка:
Rx = \—e-a. E.9.11)
112 СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. 6
Таким образом, мы убедились, что распределение Пуассона воз-
някаст там, ме какие-то точки (или другие элементы) занимают слу-
случайное положение независимо друг от друга, и подсчитывается коли-
количество этих точек, попавших в какую-то область. В пашем случае та-
такой ^областью» был отрезок / на оси абсцисс. Однако наш вывод легко
распространить и на случай распределения точек на плоскости (слу-
(случайное плоское поле точек) и в пространстве (случайное простран-
пространственное поле точек). Нетрудно доказать, что если соблюдены условия:
1) точки распределены в поле "статистически равномерно со сред-
средней плотностью X;
2) точки попадают в неперекрывающиеся области независимым
образом;
3) точки появляются поодиночке, а не парами, тройками и т. д.,
то число точек X, попадающих в любую область D (плоскую' или
пространственную), распределяется по закону Пуассона:
где а — среднее число точек, попадающих в область D.
Для плоского случая
а = SDK
где SD — площадь области D;
для пространственного
a=VD-\,
где VD — объем области D.
Заметим, что для наличия пуассоновского распределения числа
точек, попадающих в отрезок или область, условие постоянной плот-
плотности (X = const) несущественно. Если выполнены два других условия,
то закон Пуассона все равно имеет место, только параметр а в нем
приобретает другое выражение: он получается не простым умноже-
умножением плотности X на длину, площадь или объем области, а инте-
интегрированием переменной плотности по отрезку, плошадй или объему.
(Подробнее об этом см. п° 19.4.)
Наличие случайных точек, разбросанных на линии, на плоскости
или объеме — не единственное условие, при котором возникает рас-
распределение Пуассона. Можно, например, доказать, что закон Пуас-
Пуассона является предельным для биномиального распределения:
Pm.u=ClZpm(\-p)n-n. E.9.12)
если одновременно устремлять число опытов п к бесконечности,
а вероятность р — к нулю, причем их произведение пр- сохраняет
постоянное значение:
пр = а. E.9.13)
S.9] ЗАКОН ПУАССОНА 113
Действительно, это предельное свойство биномиального распре-
распределения можно записать в виде:
lim C™pm(l—pf~m ==~т е~а' E.9.И)
п —^ оо
Но из условия E.9.13) следует, что
Р~^- E.9.15)
Подставляя E.9.15) в E.9.14), получим равенство
которое только что было доказано нами по другому поводу.
Это предельное свойство биномиального закона часто находит
применение на практике. Допустим, что производится большое коли-
количество независимых опытов «, в каждом из которых событие А имеет
очень малую вероятность р. Тогда для вычисления вероятности Рт< п
того, что событие А появится ровно т раз, можно воспользоваться
приближенной формулой
рт, п ~^[Г е~пр- E.9.17)
где пр = а—параметр того закона Пуассона, которым приближенно
заменяется биномиальное распределение.
От этого свойства закона Пуассона — выражать биномиальное
распределение при большом числе опытов и малой вероятности со-
события — происходит его название, часто применяемое в учебниках
статистики: закон редких явлений.
Рассмотрим несколько примеров, связанных с пуассоновским рас-
распределением, из различных областей практики.
Пример 1. На автоматическую телефонную станцию поступают вы-
вызовы со средней плотностью К вызовов в час. Считая, что число вызовов
на любом участке времени распределено по закону Пуассона, найти вероят-
вероятность того, что за две минуты на станцию поступит ровно три вызова.
Решение. Среднее число вызовов за две минуты равно:
-Ж'—JL
60 ~" 30 •
По формуле E.9.1) вероятность поступления ровно трех вызовов равна:
е
' 3~ 1-2-3
Пример 2. В условиях предыдущего примера найти вероятность того,
что за две минуты придет хотя бы один вызов.
8 Е. С. Вентцель
СЛУЧАЙНЫЕ ВЕЛИЧИНЫ И ИХ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ [ГЛ. S
Решение. По формуле E.9.4) имеем:
Пример 3. В тех же условиях найти вероятность того, что за две
минуты придет не менее трех вызовов.
Решение. По формуле E.9.4) имеем;
Пример 4. На ткацком стаже пить обрывается в среднем 0,375 раза
б течение часа работы станка. Найти вероятность того, что за смену (8 ча-
часов) число обрывов нити будет заключено в границах 2 и 4 (не менее 2 и
Решение. Очевидно,
а = 0,375 -8 = 3;
имеем:
РB< *< 4) = Р2 + Р, + /\-
По таблице 8 приложения при а — 3
Р2 = 0,224; Р3 = 0,224; Я4 = 0,168,
Р B < X < 4) = 0,616.
Пример 5. С накаленного катода за единицу времени вылетает в сред-
среднем q (t) электронов, где t — время, протекшее с начала опыта. Найти ве-
вероятность того, что за промежуток времени длительности х, начинающийся
в момент t0, с катода вылетит ровно т электронов.
Решение. Находим среднее число электронов а, вылетающих с ка-
катода за данный отрезок времени. Имеем:
«= J I(t)dt.
to
По вычисленному а определяем искомую вероятность:
„т
Пример 6. Число осколков, попадающих в малоразмерную цель при
заданном положении точки разрыва, распределяется по закону Пуассона.
Средняя плотность осколочного поля, в котором оказывается цель при дан-
данном положении точки разрыва, равна 3 оск./м2. Площадь цели равна S =
= 0,5 м2. Для поражения цели достаточно попадания в нее хотя бы одного
осколка. Найти вероятность поражения цели при данном положении точки
разрыва.
Решение. a = \S = 1,5. По формуле E.9.4) находим вероятность по-
попадания хотя бы одного осколка:
#! = 1 — е~х>ь = 1 — 0,223 = 0,777.
(Для вычисления значеиия показательной функции е~" пользуемся таблицей 2
приложения.)
6.91
ЗАКОН ПУАССОНА 115
Пример 7. Средняя плотность болезнетворных микробов в одном
кубическом метре воздуха равна 100. Берется на пробу 2 дм3 воздуха. Найти
вероятность того, что з нем будет обнаружен хотя би один микроб.
Решение. Принимая гипотезу о пуассоновском распределении числа
микробов в объеме, находим:
а = 0,1; Я, = 1— е'0'2 «1—0,819 я 0,18.
Пример 8. По некоторой цели производится 50 независимых выстрелов
Вероятность попадания в цель при одном выстреле равна 0,04. Пользуясь
предельным свойством биномиального распределения (формула E.9.17)),
найти приближенно вероятность тою, чло в делъ попадет: ни одного снаряда,
один снаряд, два снаряда. _
Решение. Имеем а — пр = 50 • 0,04 = 2. но таблице 8 приложения
находим вероятности:
Ро = 0,135; Л =0,271; Л-= 0,271.
ГЛАВА 6
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
6.!. Нормальный закон и его параметры
Нормальный закон распределения (часто называемый законом
Гаусса) играет исключительно важную роль в теории вероятностей
и занимает среди других законов распределения особое положение.
Это — наиболее часто встречающийся на практике закон распреде-
распределения. Главная особенность, выделяющая нормальный закон среди
других законов, состоит в том, что он является предельным
законом, к которому приближаются другие законы распределения
при весьма часто встречающихся типичных услэвиях.
Можно доказать, что сумма достаточно большого числа незави-
независимых (или слабо зависимых) случайных величин, подчиненных каким
угодно законам распределения (при соблюдении некоторых весьма
нежестких ограничений), приближенно подчиняется нормальному за-
закону, и это выполняется тем точнее, чем большее количество слу-
случайных величин суммируется. Большинство встречающихся на прак-
практике случайных величин, таких, например, как ошибки измерений,
ошибки стрельбы и т. д., могут быть представлены как суммы весьма
большого числа сравнительно малых слагаемых — элементарных оши-
ошибок, каждая из которых вызвана действием отдельной причины, не
зависящей от остальных. Каким бы законам распределения ни были
подчинены отдельные элементарные ошибки, особенности этих рас-
распределений в сумме большого числа слагаемых нивелируются, и сумма
оказывается подчиненной закону, близкому к нормальному. Основное
ограничение, налагаемое на суммируемые ошибки, состоит в том,
чтобы они все равномерно играли в общей сумме относительно малую
роль. Если это условие не выполняется и, например, одна из слу-
случайных ошибок окажется по своему влиянию на сумму резко прева-
превалирующей над всеми другими, то закон распределения этой прева-
превалирующей ошибки наложит свое влияние на сумму и определит
в основных чертах ее закон распределения.
Теоремы, устанавливающие нормальный закон как предельный для
суммы независимых равномерно малых случайных слагаемых, будут
подробнее рассмотрены в главе 13.
6.1]
НОРМАЛЬНЫЙ ЗАКОН И ЕГО ПАРАМЕТРЫ
117
Нормальный закон распределения характеризуется плотностью
вероятности вида:
/(*)=■
F.1.1)
f(x)
ный холмообразный вид (рис. 6.1.1). Максимальная ордината кривой,
равная —j=-, соответствует точке
х = т\ по мере удаления от точки т
плотность распределения падает, и
при х—> + оо кривая асимптоти-
асимптотически приближается к оси абсцисс.
Выясним смысл численных пара-
параметров т и о, входящих в выраже-
выражение нормального закона F.1.1); до-
докажем, что величина т есть не что
иное, как математическое ожи-
ожидание, а величина о — среднее
квадратическое отклонение вели-
О
Рис. 6.1.1.
чины X. Для этого вычислим основные числовые характеристики ве-
величины X — математическое ожидание и дисперсию.
Л!
KXJ CfJ
IX] = f xf{x)dx = —i=r f xe
202 dx.
Применяя замену переменной
имеем:
F.1.2)
Нетрудно убедиться, что первый из двух интервалов в формуле F.1.2)
равен нулю; второй представляет собой известный интеграл Эйлера —
Пуассона:
F.1.3)
118 Нормальный закон распределения (гл" в
Следовательно,
М[Х] = т,
т. е. параметр т представляет собой математическое ожидание вели-
величины X. Этот параметр, особенно в задачах стрельбы, часто назы-
называют центром рассеивания (сокращенно — ц. р.).
Вычислим дисперсию величины X:
(х-т?
х — отJ е~ 2"% dx.
Применив снова замену переменной
имеем:
— оо
Интегрируя по частям, получим:
со
D[X] = ^L ft-2te~
оо оо
е-" dt
Первое слагаемое в фигурных скобках равно нулю (так как е~р
ПрИ t->oo убывает быстрее, чем возрастает любая степень f), вто-
второе слагаемое по формуле F.1.3) равно \Лг, откуда
D\X\ = ai.
Следовательно, параметр о в формуле F.1.1) есть не что иное, как
среднее квддратическое отклонение величины X.
Выясним смысл параметров т и о нормального распределения.
Непосредственно из формулы F.1.1) видно, что центром симметрии
распределения является центр рассеивания т. Это ясно из того, что
при изменении знака разности (х — т) на обратный выражение F.1.1)
не меняется. Если изменять центр рассеивания т. кривая распреде-
распределения будет смещаться вдоль оси абсцисс, не изменяя своей формы
(рис. 6.1.2). Центр рассеивания характеризует положение распреде-
распределения на оси абсцисс.
Размерность центра рассеивания—та же, что размерность слу-
случайной величины X.
6.1]
нормальный закон и его параметры
119
Параметр о характеризует ке положение, а самую форму кривой
распределения. Это есть характеристика рассеивания. Наибольшая
ордината кривой распределения обратно пропорциональна о; при
увеличении о максимальная ордината уменьшается. Так как площадь
ffx)
-х
Рис. 6.1.2,
кривой распределения всегда должна оставаться равной единице, то
при увеличении о кривая распределения становится более плоской,
растягиваясь вдоль оси абсцисс; напротив, при уменьшении о кривая
распределения вытягивается вверх, одновременно сжимаясь с боков,
и становится более иглообразной. На рис. 6.1.3 показаны три нор-
нормальные кривые (/, //, ///) при т==0; из них кривая / соответствует
самому большому, а кривая /// — самому малому значению о. Изме-
Изменение параметра о равносильно изменению масштаба кривой распре-
распределения— увеличению масштаба по одной оси и такому же умень-
уменьшению по другой.
Размерность параметра о, естественно, совпадает с раамерноиью
случайной величины X.
120 нормальный закон распределения [гл. 6
В некоторых курсах теории вероятностей в качестве характери-
характеристики рассеивания для нормального закона вместо среднего квадра-
тического отклонения применяется так называемая мера точности.
Мерой точности называется величина, обратно пропорциональная
среднему квадратическому отклонению о:
Размерность меры точности обратна размерности случайной
величины.
Термин «мера точности» заимствован из теории ошибок измере-
измерений: чем точнее измерение, тем больше мера точности. Пользуясь
мерой точности h, можно записать нормальный закон в виде:
6.2. Моменты нормального распределения
Выше мы доказали, что математическое ожидание случайной вели-
величины, подчиненной нормальному закону F.1.1), равно т, а среднее
квадратическое отклонение равно о.
Выведем общие формулы для центральных моментов любого по-
порядка.
По определению:
n (x—mf
=—~- / (x — nife ^~dx.
— oo
Делая замену перемейной х~т
получим: со
—со
Применим к выражению F,2.1) формулу интегрирования по частям:
f
'у' г, J
—оэ
I U-J '-J--J
6.2] МОМЕНТЫ НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ 121
Имея в виду, что первый член внутри скобок равен нулю, получим:
-'e-'dt. F.2.2)
' —с»
Из формулы F.2.1) имеем следующее выражение для
—2
' -оо
Сравнивая правые части формул F.2.2) и F.2.3), видим, что они
отличаются между собой только множителем (s—1)з2; следовательно,
li, = (s—l)«V,-a. F.2.4)
Формула F.2.4) представляет собой простое рекуррентное соот-
соотношение, позволяющее выражать моменты высших порядков через
моменты низших порядков. Пользуясь этой формулой и имея в виду,
что [ло= 1 1) и [i.[ =0, можно вычислить центральные моменты всех
порядков. Так как ^ = 0, то из формулы F.2.4) следует, что все
нечетные моменты нормального распределения равны нулю. Это,
впрочем, непосредственно следует из симметричности нормального
закона.
Для четных s из формулы F.2.4) вытекают следующие выражения
дтя последовательных моментов:
1*2= в2!
и т. д.
Общая формула для момента s-ro порядка при любом четном s
имеет вид:
!*, = («-1L^.
где под символам E—1)!! понимается произведение всех нечетных
чисел от 1 до s— 1.
Так как для нормального закона м,3 = 0- то асимметрия его также
раиаа нулю:
с;, jfj. п
Из выражения четвертого момента
1*4 = За4
кмгсн:
£* = -£- —3 = 0.
') Нулевой момеш любой случайной величины равен единице как мате-
математическое ожидание нулевой степени этой величины.
122 нормальный закон распределения [гл 6
т. е. эксцесс нормального распределения равен нулю. Это и есте-
естественно, так как назначение эксцесса — характеризовать сравнитель-
сравнительную крутость данного закона по сравнению с нормальным.
6.3. Вероятность попадания случайной величины,
подчиненной нормальному закону, на заданный участок.
Нормальная функция распределения
Во многих задачах, связанных с нормально распределенными слу-
случайными величинами, приходится определять вероятность попадания
случайной величины X, подчиненной нормальному закону с пара-
параметрами т, о, на участок от а до р. Для вычисления этой вероят-
вероятности воспользуемся общей формулой
P(a<X<$) = F$)— F(a). F.3.1)
где F (х)— функция распределения величины X.
Найдем функцию распределения F(x) случайной величины X,
распределенной по нормальному закону с параметрами т, о. Плот-
Плотность распределения величины X равна:
Отсюда находим функцию распределения
/1 /* (х—тУ1
f{x)dx = —^ / е ™ dx. F.3.3)
—со —со
Сделаем в интеграле F.3.3) замену переменной
х— m ,
; t
в
и приведем его к виду:
-тк/ f[dL F-3-4)
Интеграл F.3.4) не выражается через элементарные функции,
но его можно вычислить через специальную функцию, выражающую
Л
определенный интеграл от выражения е~'г или е 2 (так называемый
интеграл вероятностей), для которого составлены таблицы. Суще-
Существует много разновидностей таких функций, например:
X а
6.3] НОРМАЛЬНАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ 123
и т. д. Какой из этих функций пользоваться — вопрос вкуса.
Мы выберем в качестве такой функции
Ф*(*) = г4= е 2 dt. F.3.5)
— со
Нетрудно видеть, что эта функция представляет собой не что
иное, как функцию распределения для нормально распределенной
случайной величины с параметрами от = 0, о=1.
Условимся называть функцию Ф*(л:) нормальной функцией
распределения. В приложении (табл. 1) приведены таблицы зна-
значений функции Ф'(хI).
Выразим функцию распределения F.3.3) величины X с пара-
параметрами от и о через нормальную функцию распределения Ф*(лг).
Очевидно,
(*11) F.3.6)
Теперь найдем вероятность попадания случайной величины X
на участок от а до р. Согласно формуле F.3.1)
^) F.3.7)
Таким образом, мы выразили вероятность попадания на участок
случайной величины X, распределенной по „нормальному закону
с любыми параметрами, через стандартную функцию распределе-
распределения Ф* (х), соответствующую простейшему нормальному . закону
с параметрами 0,1. Заметим, что аргументы функции Ф* в фор-
формуле F.3.7) имеют очень простой смысл: есть расстояние
от правого конца участка [3 до центра рассеивания, выраженное
а — т
в средних квадратических отклонениях; такое же расстоя-
расстояние для левого конца участка, причем это расстояние считается
положительным, если конец расположен справа от центра ряссеи-
санил, п отрицательным, если слева.
Как и всякая функция распределения,, функция Ф*(х) обладает
свойствами:
1. Ф*(—оо) = 0. 2. Ф*(+оо) = 1. 3. Ф* (х) — неубывающая
функция.
Кроме того, из симметричности нормального распределения
с параметрами от = 0, o=i относительно начала координат сле-
следует, что
ф* (— х)=1— Ф* (х). F.3.8)
!) Для облегчения интерполяции в таблицах рядом со значениями функ-
функции приведены ее приращения за один шаг таблиц Д.
124
НОРМАЛЬНЫЙ Э'АКОН РАСПРЕДЕЛЕНИЯ
[ГЛ в
f(x)
Пользуясь этим свойством, собственно говоря, можно было бы
ограничить таблицы функции Ф*(л:) только положительными значе-
значениями аргумента, но, чтобы избежать лишней операции (вычитание
из единицы), в таблице 1 приложения приводятся значения Ф*(лг)
как для положительных, так и для
отрицательных аргументов.
На практике часто встречается
задача вычисления вероятности по-
попадания нормально распределен-
распределенной случайной величины на уча-
участок, симметричный относительно
центра рассеивания т. Рассмотрим
такой участок длины 21 (рис. 6.3.1).
Вычислим вероятность попадания
на этот участок по формуле F.3.7):
Р {in — / <С X <^т —J— /) =
Ti-l m т+1
Рис. 6.3.1.
F-3;9>
Учитывая свойство F.3.8) функции Ф*(х) и придавая левой части
формулы F.3.9) более компактный вид, получим формулу для вероят-
вероятности попадания случайной вели-
величины, распределенной по нормаль-
нормальному закону, на участок, симме- .
тричный относительно центра рас-
рассеивания:
Р (| X — т |< I) = 2Ф* (-) — 1.
F.3.10)
Решим следующую задачу. От-
Отложим от центра рассеивания т
последовательные отрезки дли-
длиной о (рис. 6.3.2) и вычислим ве-
вероятность попадания случайной величины X в каждый из них. Так как
кривая нормального закона симметрична, достаточно отложить такие
отрезки только в одну сторону.
По формуле F.3.7) находим:
Р (т < X < т -+- о) = Ф* A) — Ф* @) =
= 0,8413 — 0,5000^0,341;
Р(т+ о< X <т + 2а) = Ф*B) — Ф'A)« 0,13бМ F.3.11)
I
Г) г у., 1 О- s* \ ^ у.. 1 rfll~\ (Т)* с\\ ф* {О\ '- П Л 1 '
Р(т + 3о < Х</и-)-4о) = Ф*D)— ф*C):
0,001.
6.31
НОРМАЛЬНАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ 125
Как видно из этих данных, вероятности попадания на каждый
из следующих отрезков (пятый, шестой и т. д.) с точностью до 0,001
равны нулю.
Округляя вероятности попадания в отрезки до 0,01 (до 1%).
получим три числа, которые легко запомнить:
0,34; 0,14; 0,02.
Сумма этих трех значений равна 0,5. Это значит, что для нор-
нормально распределенной случайной величины все рассеивание (с точ-.
ностью до долей процента) укладывается на участке т ± За.
Это позволяет, зная среднее квадратическое отклонение и мате-
математическое ожидание случайной величины, ориентировочно указать
интервал ее практически возможных значений. Такой способ оценки
диапазона возможных значений случайной величины известен в мате-
математической статистике под названием «.правило трех сигмаъ. Из
правила трех сигма вытекает также ориентировочный способ опреде-
определения среднего квадратического отклонения случайной величины: берут
максимальное практически возможное отклонение от среднего и делят
его на три. Разумеется, этот грубый прием может быть рекомен-
рекомендован, только если нет других, более точных способов определения о.
Пример 1. Случайная величина X, распределенная по нормальному
закону, представляет собой ошибку измерения некоторого расстояния. При
измерении допускается систематическая ошибка в сторону завышения на
1,2 (м)\ среднее квадратическое отклонение ошибки измереиия равно 0,8 (м).
Найти вероятность того, что отклонение измеренного значения от истинного
не превзойдет по абсолютной величине 1,6 (м).
Решение. Ошибка измерения есть случайная величина X, подчинен-
подчиненная нормальному закону с параметрами т = 1,2 и а = 0,8. Нужно найти
вероятность попадания этой величины на участок от а =—1,6 до р = + 1,6.
По формуле F.3.7) имеем:
= Ф* @,5) — Ф* (—3,5).
Пользуясь таблицами функции Ф* (х) (приложение, табл. 1), найдем:
Ф* @,5) = 0,6915; Ф* (—3,5) = 0,0002,
откуда
Р (—1,6 < X < 1,6) = 0,6915 — 0,0002 = 0,6913 « 0,691.
Пример 2. Найти ту же вероятность, что в предыдущем примере,
ри условии, что систематической ошибки нет.
Решение, По формуле F.3.10), полагая /=1.6, найдем:
Р (| X |< 1,6) = 2Ф- A|) - 1 « 0,955.
Пример 3. По цели, имеющей вид полосы (автострада), ширина кото-
которой равна 20 м, ведется стрельба в направлении, перпендикулярном авто-
автостраде, прицеливание ведется по средней линии автострады. Среднее
126
НОРМАЛЬНЫЙ Э'АКОН РАСПРЕДЕЛЕНИЯ
[ГЛ 9
квадратическое отклонение в направлении стрельбы равно а = 8 м. Имеется
систематическая ошибка в направлении стрельбы: недолет 3 м. Найти вероят-
вероятность попадания в автостраду при одном выстреле.
Решение, Выберем начало координат в любой точке на средней линии
автострады (рис. 6.3.3) и направим ось абсцисс перпендикулярно автостраде.
Попадание или непопадание снаряда в автостраду определяется значением
только одной координаты точки падения X (другая координата Y нам без-
безразлична). Случайная величина X распределена по нормальному закону
Рис. 6.3.3.
Рис. 6.3.4.
с параметрами те = —3, о = 8. Попадание снаряда в автостраду соответ-
соответствует попаданию величины X на участок от а = — 10 до Р = 4-10. При-
Применяя формулу F.3.7), имеем:
Р (- 10 < X < 10) - Ф* (-Н) - Ф* (-1) = Ф* A,625) - Ф *(- 0,875) я 0,757.
Пример 4. Имеется случайная величина А",'нормально распределенная,
с центром рассеивания т (рис. 6.3.4) и некоторый участок (а, Р) оси абсцисс.
Каково должно быть среднее квадратическое отклонение о случайной вели-
величины X для того, чтобы вероятность попадания р на участок (а, 6) дости-
достигала максимума?
Решение. Имеем:
р ш. Р (а < X <
Ф*
- Ф*
= V (а).
Продифференцируем эту функцию величины а:
но
л
dt.
g.41 ВЕРОЯТНОЕ (СРЕДИННОЕ) ОТКЛОНЕНИЕ 127
дящей в его предел, получим:
Применяя правило дифференцирования интеграла по переменной, вхо-
ей i
e 2 dt
- Г
е
— оо
(Р- т?
— ——- е ^"'
Аналогично
(а-/и)»
_ а — т 2о!
Для нахождения экстремума положим:
(a-mf _
1. F.3.12)
При а = со это выражение обращается в нуль и вероятность р достигает
минимума. Максимум р получим из условия
(a-mf C-m)'
(а — т)е~ 2l! —Q — m)e 2 =0. F.3.13)
Уравнение F.3.13) можно решить численно или графически.
6.4. Вероятное (срединное) отклонение
В ряде областей практических применений теории вероятностей
(в частности, в теории стрельбы) часто, наряду со средним квадрати-
ческим отклонением, пользуются еще одной характеристикой рассеи-
рассеивания, так называемым вероятным, или срединным, отклонением.
Вероятное отклонение обычно обозначается буквой Е (иногда В).
Вероятным (срединным) отклонением случайной величины X,
распределенной по нормальному закону, называется половина длины
участка, симметричного относительно центра рассеивания, вероятность
попадания в который равна половине.
Геометрическая интерпретация вероятного отклонения показана
на рис. 6.4.1. Вероятное отклонение Е — это половина длины
участка оси абсцисс, симметричного относительно точки т, на кото-
который опирается половина площади кривой распределения.
Поясним смысл термина «срединное отклонение» или «срединная
ошибка», которым часго пользуются в артиллерийской практике
вместо «вероятного отклонения».
128
НОРМАЛЬНЫЙ З'АКОН РАСПРЕДЕЛЕНИЯ
[ГЛ. в
Рассмотрим случайную величину X, распределенную по нормаль-
нормальному закону. Вероятность того, что она отклонится от центра рас-
рассеивания т меньше чем на Е, по определению вероятного откло-
отклонения Е, равна тг' i-.,, „ , -» 1
у 2 Р(\Х — /и|<£) = 1. F.4.1)
Вероятность того, что она отклонится от т больше чем на Е,
тоже равна \: p(lx-m\>E) = ±.
Таким образом, при большом числе опытов в среднем половина
значений случайной величины X отклонится от т больше чем на Е,
а половина — меньше. Отсюда и термины «срединная ошибка»,
«срединное отклонение».
Очевидно, вероятное отклонение, как характеристика рассеивания,
должно находиться в прямой зависимости от среднего квадратиче-
ского отклонения а. Установим
эту зависимость. Вычислим ве-
вероятность события | X — т | <
< Е в уравнении F.4.1) по
формуле F.3.10). Имеем:
Р(\Х-т\<Е) =
Отсюда
-х
-§"=0,75. F.4.2)
Рис. 6.4.1.
По таблицам функции Ф* (лг)
можно найти такое . значение
аргумента х, при котором она равна 0,75. Это значение аргумента
приближенно равно 0,674; отсюда
— = 0,674;
= 0,674о.
F.4.3)
Таким образом, зная значение о, можно сразу найти пропорцио-
пропорциональное ему значение Е. Часто пользуются еще такой формой записи
этой зависимости: __
Т F.4.4)
где р — такое значение аргумента, при котором одна из форм инте-
интеграла вероятностей — так называемая функция Лапласа
Ф (л) = -
6.4]
ВЕРОЯТНОЕ (СРЕДИННОЕ) ОТКЛОНЕНИЕ
129
— равна половине. Численное значение величины р приближенно
равно 0,477.
В настоящее время вероятное отклонение, как характеристика
рассеивания, все больше вытесняется более универсальной характе-
характеристикой о. В ряде областей приложений теории вероятностей она
сохраняется лишь по традиции.
Если в качестве характеристики рассеивания принято вероятное
отклонение Е, то плотность нормального распределения записывается
в виде:
/(*)==
Р
F.4.5)
а вероятность попадания на участок от а до р чаще всего записы-
записывается в виде:
Р(а<лг<В)= f(xj
где -
Ф
= -£=■ f e-'2
Kit .'
dt F.4.7)
— так называемая приведен-
приведенная функция Лапласа.
Сделаем подсчет, аналогич-
аналогичный выполненному в преды-
предыдущем п° для среднего квадратического отклонения о: отложим от
центра рассеивания т. последовательные отрезки длиной в одно
вероятное отклонение Е (рис. 6.4.2) и подсчитаем вероятности попа-
попадания в эти отрезки с точностью до 0,01. Получим:
Р (т < X < т -Ь Е) ж 0,25;
р (т 4- R < X < т + IE) <=* 0,! 6;
Р(т + ЧЕ < X < т -+- ЪЕ) я» 0,07;
Р(/и -f 3£ < А' < /и + АЕ) « 0,02.
Отсюда видно, что с точностью до 0,01 все значения нормально
распределенной случайной величины укладываются на участке т ± 4Е.
Пример. Самолет-штурмовик производит обстрел колонны войск
противника, ширина которой' равна 8 м. Полет — вдоль колонны, прицели-
прицеливание— по средней линии колонны; вследствие скольжения имеется систе-
систематическая ошибка: 2 м вправо но направлению полета. Главные вероятные
отклонения: по направлению полета Вж = 15 м, в боковом направлении
Q В. а. Бентцель
130 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ [ГЛ. в
В(, = 5 М. Не имея в своем распоряжении никаких таблиц интеграла
вероятностей, а зная только числа:
25%, 16%, 7%, 2%,
оценить грубо-приближенно вероятность попадания в колонну при одном
выстреле и вероятность хотя бы одного попадания при трех независимых
выстрелах.
Решение. Для решения задачи достаточно рассмотреть одну коорди-
координату точки попадания — абсциссу X в направлении, перпендикулярном
колонне. Эта абсцисса распределена по нормальному закону с центром
рассеивания т = 2 п вероятным отклонением В(, = Е = 5 (м). Отложим
мысленно от центра рассеивания в ту и другую сторону отрезки длиной
в 5 ж. Вправо от центра рассеивания цель занимает участок 2 м, который
составляет 0,4 вероятного отклонения. Вероятность попадания на этот
участок приближенно равна:
0,4-25% =0,1.
Влево от центра рассеивания цель занимает участок б м. Это — целое
вероятное отклонение E м), вероятность попадания в которое равна 25%
плюс часть длиной 1 м следующего (второго от центра) вероятного откло-
отклонения, вероятность попадания в которое равна 16%. Вероятность попадания
в часть длиной 1 м приближенно равна:
у. 16% =0,03.
Таким образом, вероятность попадания в колонну приближенно равна:
0,1+0,25 + 0,03 = 0,38.
Вероятность хотя бы одного попадания при трех выстрелах равна:
Л, = 1_A_ 0,38)'«0,76.
ГЛАВА 7
ОПРЕДЕЛЕНИЕ ЗАКОНОВ РАСПРЕДЕЛЕНИЯ
СЛУЧАЙНЫХ ВЕЛИЧИН НА ОСНОВЕ ОПЫТНЫХ ДАННЫХ
7.1. Основные задачи математической статистики
Математические законы теории вероятностей не являются беспред-
беспредметными абстракциями, лишенными физического содержания! они
представляют собой математическое выражение реальных закономер-
закономерностей, фактически существующих в массовых случайных явлениях
природы.
До сих пор, говоря о законах распределения случайных величин,
мы не затрагивали вопроса о том, откуда берутся, на каком осно-
основании устанавливаются эти законы распределения. Ответ на вопрос
вполне определенен — в основе всех этих характеристик лежит опыт;
каждое исследование случайных явлений, выполняемое методами тео-
теории вероятностей, прямо или косвенно опирается на эксперименталь-
экспериментальные данные. Оперируя такими понятиями, как события и их вероят-
вероятности, случайные величины, их законы распределения и числовые
характеристики, теория вероятностей дает возможность теоретиче-
теоретическим путем определять вероятности одних событий через вероятности
других, законы распределения и числовые характеристики одних
случайных величин через законы распределения и числовые характе-
характеристики других. Такие косвенные методы позволяют значительно
экономить время и средства, затрачиваемые на эксперимент, но отнюдь
не исключают самого эксперимента. Каждое исследование в области
случайных явлений, как бы отвлеченно оно ни было, корнями своими
всегда уходит в эксперимент, в опытные данные, в систему наблюдений.
Разработка методов регистрации, описания и анализа статисти-
статистических экспериментальных данных, получаемых в результате наблю-
наблюдения массовых случайных явлений, составляет предмет специальной
пауки — математической статистики.
Все задачи математической статистики касаются вопросов обра-
обработки наблюдений над массовыми случайными явлениями, но в зави-
зависимости от характера решаемого практического вопроса и от объема
9*
132 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 7
имеющегося экспериментального материала эти задачи могут прини-
принимать ту или иную форму.
Охарактеризуем вкратце некоторые типичные задачи математи-
математической статистики, часто встречаемые на практике.
1. Задача определения закона распределения
случайной величины (или системы случайных
величин) по статистическим данным
Мы уже указывали, что закономерности, наблюдаемые в массо-
массовых случайных явлениях, проявляются тем точнее и отчетливее, чем
больше объем статистического материала. При обработке обширных
по своему объему статистических данных часто возникает вопрос об
определении законов распределения тех или иных случайных величин.
Теоретически при достаточном количестве опытов свойственные этим
случайным величинам закономерности будут осуществляться сколь
угодно точно. На практике нам всегда приходится иметь дело с огра-
ограниченным количеством экспериментальных данных; в связи с этим
результаты наших наблюдений и их обработки всегда содержат боль-
больший или меньший элемент случайности. Возникает вопрос о том, какие
черты наблюдаемого явления относятся к постоянным, устойчивым
и действительно присущи ему, а какие являются случайными и про-
проявляются в данной серии наблюдений только за счет ограниченного
объема экспериментальных данных. Естественно, к методике обра-
обработки экспериментальных данных ■ следует предъявить такие требо-
требования, чтобы она, по возможности, сохраняла типичные, характерные
черты наблюдаемого явления и ртбрасывала все несущественног,
второстепенное, связанное с недостаточным объемом опытного мате-
материала. В связи с этим возникаем характерная для математической
статистики задача сглаживания или выравнивания стати-
статистических данных, представления их в наиболее компактном вида
с помощью простых аналитических зависимостей. '
2. Задача проверки правдоподобия гипотез
Эта задача тесно связана с предыдущей; при решении такого
рода задач мы обычно не располагаем настолько обширным стати-
статистическим материалом, чтобы выявляющиеся в нем статистические
закономерности были в достаточной мере свободны от элементов
случайности. Статистический материал может с ббльшим или меньшим
правдоподобием подтверждать или не подтверждать справедливость
той или иной гипотезы. Например, может возникнуть такой вопрос:
согласуются ли результаты эксперимента с гипотезой о том, что
данная случайная величина подчинена закону распределения F (jc)?
Другой подобный вопрос: указывает ли наблюденная в опыте тен-
7.2] СТАТИСТИЧЕСКАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ 133
денция к зависимости между двумя случайными величинами на нали-
наличие действительной объективной зависимости между ними или же
она объясняется случайными причинами, связанными с недостаточным
объемом наблюдений? Для решения подобных вопросов математи-
математическая статистика выработала ряд специальных приемов.
3. Задача нахождения неизвестных параметров
распределения
Часто при обработке статистического материала вовсе не возни-
возникает вопрос об определении законов распределения исследуемых слу-
случайных величин. Обыкновенно это бывает связано с крайне недоста-
недостаточным объемом экспериментального материала. Иногда же характер
закона распределения качественно известен до опыта, из теоретических
соображений; например, часто можно утверждать заранее, что случай-
случайная величина подчинена нормальному закону. Тогда возникает более
узкая задача обработки наблюдений — определить только некоторые
параметры (числовые характеристики) случайной величины или системы
случайных величин. При небольшом числе опытов задача более или
менее точного определения этих параметров не может быть решена;
в этих случаях экспериментальный материал содержит в себе неиз-
неизбежно значительный элемент случайности; поэтому случайными ока-
оказываются и все параметры, вычисленные на основе этих данных.
В таких условиях модет быть поставлена только задача об опреде-
определении так называемых «оценок» или «подходящих значений» для
искомых параметров, т. е. таких приближенных значений, которые
при массовом применении приводили бы в среднем к меньшим ошиб-
ошибкам, чем всякие другие. С задачей отыскания «подходящих значений»
числовых характеристик тесно связана задача оценки их точности
и надежности. С подобными задачами мы встретимся в главе 14.
Таков далеко не полный перечень основных задач математиче-
математической статистики. Мы перечислили только те из них, которые наиболее
важны для нас по своим практическим применениям. В настоящей
главе мы вкратце познакомимся с некоторыми, наиболее элементар-
'< "v.i згдачами математической статистики и с методами их решения.
7.2. Простая статистическая совокупность.
Статистическая функция распределения
Предположим, что изучается некоторая случайная величина X,
закон распределения которой в точности неизвестен, и требуется
определить этот .закон из опыта или проверить экспериментально
гипотезу о том, что величина X подчинена тому или иному закону.
•- атой целью над случайной величиной X производятся ряд незави-
независимых опытов (наблюдений). В каждом из этих опытов случайная
134
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ.-7
величина X принимает определенное значение. Совокупность наблю-
наблюденных значений величины и представляет собой первичный стати-
статистический материал, подлежащий обработке, осмыслению и научному
анализу. Такая совокупность называется «простой статистической
совокупностью» или «простым статистическим рядом». Обычно про-
простая статистическая совокупность оформляется в виде таблицы с од-
одним входом, в первом столбце которой стоит номер опыта i, а во
втором — наблюденное значение случайной величины.
Пример 1. Случайная величина р — угол скольжения самолета в мо-
момент сбрасывания бомбы '). Произведено 20 бомбометаний, в каждом из ко-
которых зарегистрирован угол скольжения р в тысячных долях радиана.
Результаты наблюдений сведены в простой статистический ряд:
1
2
3
4
5
6
7
h
—20
—60
-10
30
60
70
—10
(
8
9
10
11
12
13
14
h
—30
120
—100
—80
20
40
—60
i
15
16
17
18
19
20
h
—10
20
30
—80
60
70
Простой статистический ряд представляет собой первичную форму
записи статистического материала и может быть обработан различными
способами. Одним из способов такой обработки является построение
статистической функции распределения случайной величины.
Статистической функцией распределения случайной вели-
величины X называется частота события X < х в данном стати-
статистическом материале:
F* (х) = Р* (X < х). G.2.1)
Для того чтобы найти значение статистической функции распре-
распределения при данном х, достаточно подсчитать число опытов, в ко-
которых величина X приняла значение, меньшее чем х, и разделить
на общее число п произведенных опытов.
Tlj> и м е р 2. Построить статистическую функцию распределения для
случайной величины р, рассмотренной в предыдущем примере г).
') Под углом скольжения подразумевается угол, составленный вектором
скорости и плоскостью симметрии самолета.
2) З
р
2) Зд
ногих с
) лучаях далее, при рассмотрении конкретных прак-
практических примеров, мы не будем строго придерживаться правила — обозна-
обозначать случайные величины большими буквами, а их возможные значения —
соответствующими малыми буквами. Если это не может привести к недора-
недоразумения;.;, мы в ряде случаев будем обозначать случайную величину и ее
возможное значение одной и той же буквой.
7.21
СТАТИСТИЧЕСКАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
135
Решение. Так как наименьшее наблюденное значение величины равно
ЮО, то F(—100) = 0. Значение —100 наблюдено один раз, его частота
равна -щг] следовательно, в точке —100 F* ($) имеет скачок, равный -j-.
В промежутке от—100 до —80 функция F*ф) имеет значение-^; в точке
2
—80 происходит скачок функции F* (Р) на -щ, так как значение —80 на-
наблюдено дважды, и т. д.
График статистической функции распределения величины представлен
на рис. 7.2.1.
-50
50
100
Рис. 7.2.1.
Статистическая функция распределения любой случайной вели-
величины— прерывной или непрерывной — представляет собой прерывную
ступенчатую функцию, скачки которой соответствуют наблюденным
значениям случайной величины и по величине равны частотам этих
значений. Если каждое отдельное значение случайной величины X
было наблюдено только один раз, скачок статистической функции
распределения в каждом наблюденном значении равен —, где п —
число наблюдений.
При увеличении числа опытов ге, согласно теореме Бернулли, при
люОом х частота события X < х приближается (сходится по вероят-
вероятности) к вероятности этого события. Следовательно, при увеличе-
увеличении п статистическая функция распределения г* (х) приближается
(сходится по вероятности) к подлинной функции распределения F(x)
случайной величины X.
Ксли X — непрерывная случайная rpличина, то при увеличении
числа наблюдений п число скачков функции F* (х) увеличивается,
самые скачки уменьшаются и график функции F* (х) неограниченно
приближается к плавной кривой F(x) — функции распределения ве-
величины X.
136
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ 7
В принципе построение статистической функции распределения
уже решает задачу описания экспериментального материала. Однако
при большом числе опытов п построение F* (х) описанным выше
способом весьма трудоемко. Кроме того, часто бывает удобно —
в смысле наглядности — пользоваться другими характеристиками ста-
статистических распределений, аналогичными не функции распределе-
распределения F(x), а плотности /(*). С такими способами описания стати-
статистических данных мы познакомимся в следующем параграфе.
7.3. Статистический ряд. Гистограмма
При большом числе наблюдений (порядка сотен) простая стати-
статистическая совокупность перестает быть удобной формой записи
статистического материала — она становится слишком громоздкой и
мало наглядной. Для придания ему большей компактности и на-
наглядности статистический материал должен быть подвергнут до-
дополнительной обработке — строится так называемый «статистиче-
«статистический ряд».
Предположим, что в нашем распоряжении результаты наблюдений
над непрерывной случайной величиной X, оформленные в виде про-
простой статистической совокупности. Разделим весь диапазон наблю-
наблюденных значений X на интервалы или «разряды» и подсчитаем ко-
количество значений ю,, приходящееся на каждый i-й разряд. Это число
разделим на общее число наблюдений п и найдем частоту, соответ-
соответствующую данному разряду;
Сумма частот всех разрядов, очевидно, должна быть равна
единице,
Построим таблицу, в которой приведены разряды в порядке их
расположения вдоль оси абсцисс и соответствующие частоты. Эта
таблица называется статистическим рядом:
Pi
Pi
р\
Pi
Pk
Здесь // — обозначение 1-го разряда; xt, х,+% — его границы; />*
соответствующая частота; к — число разрядов.
7.31
СТАТИСТИЧЕСКИЙ РЯД. ГИСТОГРАММА
137
Пример 1. Произведено 500 измерений боковой ошибки наводки при
стрельбе с самолета по наземной цели. Результаты измерений (в тысячных
долях радиана) сведены в статистический ряд:
ггц
Pi
-4;-3
6
0,012
—3; —2
25
0,050
-2; -1
72
0,144
—1; 0
133
0,266
0; 1
120
0,240
i;2
88
0.176
2;3
46
0.092
3;4
10
0,020.
Здесь // обозначены интервалы значений ошибки наводки; /и/—число наб-
наблюдений в данном интервале, р\ = —1- — соответствующие частоты.
При группировке наблюденных значений случайной величины по
разрядам возникает вопрос о том, к какому разряду отнести значе-
значение, находящееся в точности на границе двух разрядов. В этих
случаях можно рекомендовать (чисто условно) считать данное зна-
значение принадлежащим в равной мере к обоим разрядам и прибав-
прибавлять к числам т1 того и другого разряда по -к .
Число разрядов, на которые следует группировать статистический
материал, не должно быть слишком большим (тогда ряд распреде-
распределения становится невыразительным, и частоты в нем обнаруживают
незакономерные колебания); с другой стороны, оно не должно быть
слишком малым (при малом числе разрядов свойства распределения
описываются статистическим рядом слишком грубо). Практика пока-
показывает, что в большинстве случаев рационально выбирать число
разрядов порядка 10 — 20. Чем богаче и однороднее статистический
материал, тем большее число разрядов можно выбирать при состав-
составлении статистического ряда. Длины разрядов могут быть как одина-
одинаковыми, так и различными. Проще, разумеется, брать их одинаковы-
одинаковыми. Однако при оформлении данных о случайных величинах, рас-
распределенных крайне неравномерно, иногда бывает удобно выбирать
в области наибольшей плотности распределения разряды более узкие,
чем в области малой плотности.
Статистический ряд часто оформляется графически в виде так
называемой гистограммы. Гистограмма строится следующим обра-
образом. По оси абсцисс откладываются разряды, и на каждом из раз-
разрядов как их основании строится прямоугольник, площадь которого
равна частоте данного разряда. Для построения гистограммы нужно
ччСт0Ту каждого разряда разделить на его длину и полученное число
взять в качестве высоты прямоугольника. В случае равных по длине
138
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ. 7
разрядов высоты прямоугольников пропорциональны соответствующим
частотам. Из способа построения гистограммы следует, что полная
площадь ее равна единице.
В качестве примера можно привести гистограмму для ошибки
наводки, построенную по данным статистического ряда, рассмотрен-
рассмотренного в примере 1 (рис. 7.3.1).
Очевидно, при увеличении числа опытов можно выбирать все
более и более мелкие разряды; при этом гистограмма будет все
более приближаться к некоторой кривой, ограничивающей площадь,
х
равную единице. Нетрудно убедиться, что эта кривая представляет
собой график плотности распределения величины X.
Пользуясь данными статистического ряда, можно приближенно
построить и статистическую функцию распределения величины X.
Построение точной статистической функции распределения с несколь-
несколькими сотнями скачков во всех наблюденных значениях X слишком
трудоемко и себя не оправдывает. Для практики обычно достаточно
построить статистическую функцию распределения по нескольким
точкам. В качестве этих точек удобно взять границы xv x%, ■ • ■
разрядов, которые фигурируют в статистическом ряде. Тогда,
очевидно,
1 = 1
к
G.3.2)
7.4]
ХАРАКТЕРИСТИКИ СТАТИСТИЧЕСКОГО РАСПРЕДЕЛЕНИЯ
139
Соединяя полученные точки ломаной линией или плавной кривой,
получим приближенный график статистической функции распреде-
распределения.
Пример 2. Построить приближенно статистическую функцию распре~
деления ошибки наводки по данным статистического ряда примера 1.
-4-3-2-1
0 1 2 3 4.
Рис. 7.3.2.
X
Решение. Применяя формулы G.3.2), имеем:
f*(—4) = 0; F* (—3) = 0,012; F* (—2) = 0,012 + 0,050 = 0,062;
F* (_1) = 0,206; F* @) = 0,472; F* A) = 0,712; F* B) = 0,888;
F* C) = 0,980; F* D) = 1,000.
Приближенный график статистической функции распределения дан на
рис. 7.3.2.
7.4. Числовые характеристики статистического
распределения
В главе 5 мы ввели в рассмотрение различные числовые харак-
характеристики случайных величин: математическое ожидание, дисперсию,
начальные и центральные моменты различных порядков. Эти число-
числовые характеристики играют большую роль в теории вероятностей.
Аналогичные числовые характеристики существуют и для статисти-
статистических распределений. Каждой числовой характеристике случайной
величины А" соответствует ее статистическая аналогия. Для основной
характеристики положения — математического ожидания случайной
величины—такой аналогией является среднее арифметическое наблю-
наблюденных значений случайной величины:
Ml[X\ = ^±—, G.4.1)
:ай:;сй величины, няблотиенное в t-ы опыте,
п — число опытов.
140 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 7
Эту характеристику мы будем в дальнейшем называть стати-
статистическим средним случайной величины.
Согласно закону больших чисел, при неограниченном увеличении
числа опытов статистическое среднее приближается (сходится по ве-
вероятности) к математическому ожиданию. При достаточно большом п
статистическое среднее может быть принято приближенно равным
математическому ожиданию. При ограниченном числе опытов стати-
статистическое среднее является случайной величиной, которая, тем не
менее, связана с математическим ожиданием и может дать о нем
известное представление.
Подобные статистические аналогии существуют для всех число-
числовых характеристик. Условимся в дальнейшем эти статистические
аналогии обозначать теми же буквами, что и соответствующие чис-
числовые характеристики, но снабжать их значком *.
Рассмотрим, например, дисперсию случайной величины. Она пред-
представляет собой математическое ожидание случайной величины
mJCJ]. G.4.2)
Если в этом выражении заменить математическое ожидание его
статистической аналогией — средним арифметическим, мы получим
статистическую дисперсию случайной величины X:
G.4.3)
где т*х — М*[Х] — статистическое среднее.
Аналогично определяются статистические начальные и централь-
центральные моменты любых порядков:
G.4.4)
G.4.5)
Все эти определения полностью аналогичны данным в главе 5
определениям числовых характеристик случайной величины, с той
разницей, что в них везде вместо математического ожидания фигу-
фигурирует среднее арифметическсе. При увеличении числа наблюдений,
очевидно, все статистические характеристики будут сходиться по
вероятности к соответствующим математическим характеристикам
и при достаточном п могут быть приняты приближенно равными им.
7.41
ХАРАКТЕРИСТИКИ СТАТИСТИЧЕСКОГО РАСПРЕДЕЛЕНИЯ
141
Нетрудно доказать, что для статистических начальных и цен-
центральных моментов справедливы те же свойства, которые были выве-
выведены в главе 5 для математических моментов. В частности, стати-
статистический первый центральный момент всегда равен нулю:
п
<«;-»;=о.
Соотношения между центральными и начальными моментами также
сохраняются:
V *-2
2
и т. д.
При очень большом количестве опытов вычисление характеристик
по формулам G.4.1) — G.4.5) становится чрезмерно громоздким,
и можно применить следующий прием: воспользоваться теми же
разрядами, на которые был расклассифицирован статистический
материал для построения статистического ряда или гистограммы, и
считать приближенно значение случайной величины в каждом разряде
постоянным и равным среднему значению, которое выступает в роли
«представителя» разряда. Тогда статистические числовые характе-
характеристики будут выражаться приближенными формулами:
тх
k
= М*\Х] = 2
k
Dx = D* [X] = 2 (*, — О2 Р\.
G.4.7)
G.4.8)
2
2
-4-1 о)
где xt — «представитель» /-го разряда, р* — частота /-го разряда,
к — ч
исло разрядов.
Как видно, формулы G.4.7) — G.4.10) полностью аналогичны
формулам псп° 5.6 и 5.7, определяющим математическое ожидание,
дисперсию, начальные и центральные моменты прерывной случайной
142 ," ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН 1ГЛ. 7
величины А', с той только разницей, что вместо вероятностей pt
в них стоят частоты /?*, вместо математического ожидания тх — ста-
статистическое среднее /и*, вместо числа возможных значений случайной
величины — число разрядов.
В большинстве руководств по теории вероятностей и математической
статистике при рассмотрении вопроса о статистических аналогиях для харак-
характеристик случайных величин применяется терминология, несколько отличная
от принятой в настоящей книге, а именно, статистическое среднее именуется
«выборочным средним», статистическая дисперсия—«выборочной дисперсией»
и т. д. Происхождение этих терминов следующее. В статистике, особенно
сельскохозяйственной и биологической, часто приходится исследовать распре-
распределение того или иного признака для весьма большой совокупности индиви-
индивидуумов, образующих статистический коллектив (таким признаком может
быть, например, содержание белка в зерне пшеницы, вес того же зерна,
длина или вес тела какого-либо из группы животных и т. д.). Данный
признак является случайной величиной, значение которой от индивидуума
к индивидууму меняется. Однако, для того, чтобы составить представление
о распределении этой случайной величины или о ее важнейших характери-
характеристиках, нет необходимости обследовать каждый индивидуум данной обширной
совокупности; можно обследовать некоторую выборку достаточно боль-
большого объема для того, чтобы в ней были выявлены существенные черты
изучаемого распределения. Та обширная совокупность, из которой произво-
производится выборка, носит в статистике название генеральной совокупности.
При этом предполагается, что число членов (иидивидуумов) N в генеральной
совокупности весьма велико, а число членов п в выборке ограничено.
При достаточно большом N оказывается, что свойства выборочных (статисти-
(статистических) распределений и характеристик практически не зависят от JV; отсюда
естественно вытекает математическая идеализация, состоящая в том, что
генеральная совокупность, из которой осуществляется выбор, имеет беско-
бесконечный объем. При этом отличают точные характеристики (закон распределе-
распределения, математическое ожидание, дисперсию и т. д.), относящиеся к генераль-
генеральной совокупности, от аналогичных им «выборочных» характеристик. Выбо-
Выборочные характеристики отличаются от соответствующих характеристик
генеральной совокупности за счет ограниченности объема выборки п;
при неограниченном увеличении п, естественно, все выборочные характери-
характеристики приближаются (сходятся по вероятности) к соответствующим характе-
характеристикам генеральной совокупности. Часто возникает вопрос о том, каков
должен быть объем выборки п для того, чтобы по выборочным характеристи-
характеристикам можно было с достаточной точностью судить о неизвестных характерис-
характеристиках генеральной совокупности или о том, с какой степенью точности при
заданном объеме выборки можно судить о характеристиках генеральной сово-
совокупности. Такой методический прием, состоящий в параллельном рассмотрении
бесконечной генеральной совокупности, из которой осуществляется выбор,
и ограниченной по объему выборки, является совершенно естественным
в тех областях статистики, где фактически приходится осуществлять выбор
из весьма многочисленных совокупностей индивидуумов. Для практических,
задач, связанных с вопросами стрельбы и вооружения, гораздо более
характерно другое положение, когда над исследуемой случайной величиной
(или системой случайных величин) производится ограниченное число
опытов с целью определить те или иные характеристики этой величины,
на:[имер, когда с целью исследования закона рассеивания при стрельбе
производится некоторое количество выстрелов, или с целью исследования
ошибки наводки производится серия опытов, в каждом из которых ошибка
наводки регистрируется с помощью фотопулемета, и т. д. При этом ограни-
7.5]
ВЫРАВНИВАНИЕ СТАТИСТИЧЕСКИХ РЯДОВ 143
ченное число опытов связано не с трудностью регистрации и обработки,
а со сложностью и дороговизной каждого отдельного опыта. В этом случае
с известной натяжкой можно также произведенные п опытов мысленно рас-
рассматривать как «выборку» из некоторой чисто условной «генеральной сово-
совокупности», состоящей из бесконечного числа возможных или мыслимых
опытов, которые можно было бы произвести в данных условиях. Однако
искусственное введение такой гипотетической «генеральной совокупности»
при данной постановке вопроса не вызвано необходимостью и вносит в рас-
рассмотрение вопроса, по существу, излишний элемент идеализации, не выте-
вытекающий из непосредственной реальности задачи.
Поэтому мы в данном курсе не пользуемся терминами «выборочное
среднее», «выборочная дисперсия», «выборочные характеристики» и т. д.,
заменяя их терминами «статистическое среднее», «статистическая дисперсия»,
«статистические характеристики».
7.5. Выравнивание статистических рядов
Во всяком статистическом распределении неизбежно присутствуют
элементы случайности, связанные с тем, что число наблюдений
ограничено, что произведены именно те, а не другие опыты, давшие
именно те, а не другие результаты. Только при очень большом числа
наблюдений эти элементы случайности сглаживаются, и случайное
явление обнаруживает в полной мере присущую ему закономерность.
На практике мы почти никогда не имеем дела с таким большим
числом наблюдений и вынуждены считаться с тем, что любому ста-
статистическому распределению свойственны в большей или меньшей,
мере черты случайности. Поэтому при обработке статистического
материала часто приходится решать вопрос о том, как подобрать для
данного статистического ряда теоретическую кривую распределения,
выражающую лишь существенные черты статистического материала,
но не случайности, связанные с недостаточным объемом эксперимен-
экспериментальных данных. Такая задача называется задачей выравнивания
(сглаживания) статистических рядов.
Задача выравнивания заключается в том, чтобы подобрать теоре-
теоретическую плавную кривую распределения, с той или иной точки
зрения наилучшим образом описывающую данное статистическое рас-
распределение (рис. 7.5.1).
Задача о наилучшем выравнивании статистических рядов, как и
вообще задача о наилучшем аналитическом представлении эмпири-
эмпирических функций, есть задача в значительной мере неопределенная,
и решение ее зависит от того, чтб условиться считать «наилучшим».
Например, при сглаживании эмпирических зависимостей очень часто
исходят из так называемого принципа или метода наименьших
квадратов (см. п° 14.5), считая, что наилучшим приближением к эмпи-
эмпирической зависимости в данном классе функций является такое, при
котором сумма квадратов отклонений обращается в минимум. При этом
ьиирос о том, в каком именно классе функций следует искать наи-
наилучшее приближение, решается уже не из математических сообра-
144
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
1ГЛ. 7
жений, а из соображений, связанных с физикой решаемой задачи,
с учетом характера полученной эмпирической кривой и степени точ-
точности произведенных наблюдений. Часто принципиальный характер
функции, выражающей исследуемую зависимость, известен заранее из
теоретических соображений, из опыта же требуется получить лишь
некоторые численные параметры, входящие в выражение функции;
именно эти параметры подбираются с помощью метода наименьших
квадратов.
Аналогично обстоит дело и с задачей выравнивания статистиче-
статистических рядов. Как правило, принципиальный вид теоретической кривой
выбирается заранее из соображений, связанных с существом задачи,
Рис. 7.5.1,
а в некоторых случаях просто с внешним видом статистического
распределения. Аналитическое выражение выбранной кривой распре-
распределения зависит от некоторых параметров; задача выравнивания ста-
статистического ряда переходит в задачу рационального выбора тех
значений параметров, при которых соответствие между статистиче-
статистическим и теоретическим распределениями оказывается наилучшим.
Предположим, например, что исследуемая величина X есть ошибка
измерения, возникающая в результате суммирования воздействий
множества независимых элсмыиарных ошибок; тогда из теоретических
соображений можно считать, что величина X подчиняется нормаль-
нормальному закону:
f(x) = -4~e-J^r~, G.5.1)
и задача выравнивания переходит в задачу о рациональном выборе
параметров т и о в выражении G.5.1).
Бывают случаи, когда заранее известно, что величина X распре-
распределяется статистически приблизительно равномерно на некотором
7.5] ВЫРАВНИВАНИЕ СТАТИСТИЧЕСКИХ РЯДОВ 145
интервале; тогда можно поставить задачу о рациональном выборе
параметров того закона равномерной плотности
I
-а при а < х < В,
/(*) = Р~а
О при х < а или х > р.
которым можно наилучшим образом заменить (выровнять) заданное
статистическое распределение.
Следует при этом иметь в виду, что любая аналитическая функ-
функция / (х), с помощью которой выравнивается статистическое распреде-
распределение, должна обладать основными свойствами плотности распределения:
G.5.2)
ff(x)dx=l.
Предположим, что, исходя из тех или иных соображений, нами
выбрана функция f(x), удовлетворяющая условиям G.5.2), с помощью
которой мы хотим выровнять данное статистическое распределение;
в выражение этой функции входит несколько параметров а, Ь, ...;
требуется подобрать эти параметры так, чтобы функция / (х) наи-
наилучшим образом описывала данный статистический материал. Один
из методов, применяемых для решения этой задачи, — это так назы-
называемый метод моментов.
Согласно методу моментов, параметры а, Ь, ... выбираются с таким
расчетом, чтобы несколько важнейших числовых характеристик
(моментов) теоретического распределения были равны соответствующим
статистическим характеристикам. Например, если теоретическая кри-
кривая f (х) зависит только от двух параметров а и Ь, эти параметры
выбираются так, чтобы математическое ожидание тх и дисперсия Dx
теоретического распределения совпадали с соответствующими стати-
статистическими характеристиками тх и Dx- Если кривая f (х) зависит от
"рех параметров, можно полобрать их так, чтобы совпали первые
три момента, и т. д. При выравнивании статистических рядов может
оказаться полезной специально разработанная система кривых Пир-
Пирсона, каждая из которых зависит в общем случае от четырех пара-
параметров. При выравнивании эти параметры выбираются с тем расче-
расчетом, чтобы сохранить первые четыре момента статистического рас-
распределения (математическое ожидание, дисперсию, третий и четвертый
моменты)г). Оригинальный набор кривых распределения, построенных
') См., например, В. И. Романовский, Математическая статистика,
И, 1939.
10 Е. С. Вентцель
146 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 7
по иному принципу, дал Н. А. Бородачев:). Принцип, на котором
строится система кривых Н. А. Бородачева, заключается в том, что
выбор типа теоретической кривой основывается не на внешних
формальных признаках, а на анализе физической сущности случай-
случайного явления или процесса, приводящего к тому или иному закону
распределения.
Следует заметить, что при выравнивании статистических рядов
нерационально пользоваться моментами порядка выше четвертого,
так как точность вычисления моментов резко падает с увеличением
их порядка.
Пример. 1. В п° 7.3 (стр. 137) приведено статистическое распределе-
распределение боковой ошибки наводки X при стрельбе с самолета по наземной цели.
Требуется выровнять это распределение с помощью нормального закона:
Решение. Нормальный закон зависит от двух параметров: т и о.
Подберем эти параметры так, чтобы сохранить первые два момента—мате-
момента—математическое ожидание и дисперсию — статистического распределения.
Вычислим приближенно статистическое среднее ошибки наводки по фор-
формуле G.4.7), причем за представителя каждого разряда примем его середину:
гпх « — 3,5 • 0,012 — 2,5 • 0,050 —1,5 • 0,144 — 0,5 • 0,266 + 0,5 • 0,240 +
+ 1,5-0,176 + 2,5-0,092 + 3,5-0,020 = 0,168.
Для определения дисперсии вычислим сиачала второй начальный момент
по формуле G.4.9), полагая s = 2, к = 8
= 2,126.
Пользуясь выражением дисперсии через второй начальный момент (фор-
(формула G.4.6)), получим:
D* = а\ — (т*J = 2,126 — 0,028 = 2,098.
Выберем параметры m н о нормального закона так, чтобы выполнялись
условия:
то есть примем:
т = 0,168; а = 1,448.
Напишем выражение нормального закона:
1 (дг—0,168)*
1,448 V 2я
') Н. А. Бородачев, Основные вопросы теории точности произ-
производства, АН СССР, М. —Л., 1950.
7.5]
ВЫРАВНИВАНИЕ СТАТИСТИЧЕСКИХ РЯДОВ
147
Пользуясь в табл. 3 приложения, вычислим значения f(x) на границах
разрядов
X
fix)
—4
0,004
—3
0,025
2
0,090
—1
0,199
0
0,274
1
0,234
2
0,124
3
0,041
4
0,008
Построим на одном графике (рис. 7.5.2) гистограмму и выравнивающую
ее кривую распределения.
Из графика видно, что теоретическая кривая распределения f (х), сохра-
сохраняя, в основном существенные особенности статистического распределения,
свободна от случайных неправильностей хода гистограммы, которые, по-види-
по-видимому, могут быть отнесены за счет случайных причин; более серьезное
обоснование последнему суждению будет дано в следующем параграфе.
-4 -3 -2 -! От* 1
Рис. 7.5.2.
3
х
Примечание. В данном примере при определении D*x мы вос-
воспользовались выражением G.4.6) статистической дисперсии через
второй начальный момент. Этот прием можно рекомендовать только
в случае, когда математическое ожидание то* исследуемой случайной
величины X сравнительно невелико; в противном случае фор-
формула G.4.6) выражает дисперсию Dx как разность близких чисел
и дает весьма малую точность. В случае, когда это имеет место, ре-
рекомендуется либо вычислять Вх непосредственно по формуле G.4.3),
либо перенести начало координат в какую-либо точку, близкую к т*х,
и затем применить формулу G.4.6). Пользование формулой G.4.3)
равносильно перенесению начала координат в точку /в*; это может
10*
148
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
[Г Л 7
оказаться неудобным, так как выражение /м* может быть дробным,
и вычитание т*х из каждого xt при этом излишне осложняет вычис-
вычисления; поэтому рекомендуется переносить начало координат в ка-
какое-либо круглое значение х, близкое к то*.
Пример 2. С целью исследования закона распределения ошибки из-
измерения дальности с помощью радиодальномера произведено 400 измерений
дальности. Результаты опытов представлены в виде статистического ряда:
20; 30
21
0,052
30; 40
72
0,180
40; 50
66
0,165
50; 60
38
0,095
60; 70
51
0,128
70; 80
56
0,140
80; 90
64
0,160
90; 100
32
0,080
Выровнять статистический ряд с помощью закона равномерной плотности.
Решение. Закон равномерной плотности выражается формулой
I тг-гт при <*<•*<(*;
0
при х < а или х >
и зависит от двух параметров а и р. Эти параметры следует выбрать так,
Чтобы сохранить первые два момента статистического распределения — мате-
математическое ожидание тх и дисперсию Dx. Из примера п°5.8 имеем
выражения математического ожидания- и дисперсии для закона равномерной
Плотности:
12
Для того чтобы упростить вычисления, связанные с определением статисти-
статистических моыенюв, перенесем начало отсчета в точку А'а = 60 и нр:шем за
представителя каждого разряда его середину. Ряд распределения примет вид:
X,
*
Pi
-35
0,052
—25
0,180
—15
0,165
—5
0,095
5
0,128
15
0,140
25
0,160
35
0,080
где х\ — среднее для разряда значение ошибки радиодальномера X' при но-
новом начале отсчета.
7.6]
КРИТЕРИИ СОГЛАСИЯ
149
Приближенное значение статистического среднего ошибки X' равно:
к
т*х, = 2 "x'ip'i = 0,26.
Второй статистический момент величины X' равен:
4= £ №1 = 447,8,
откуда статистическая дисперсия:
Переходя к прежнему началу отсчета, получим новое статистическое
среднее:
m* = mx, -f 60 = 60,26
и ту же статистическую дисперсию:
^=^'=447,7.
Параметры закона равномерной плот-
плотности определяются уравнениями:
f(x)
_ 6о,26;
- 447,7.
Решая эти уравнения относительно а
и [J, имеем:
а я 23,6; р я; 96,9,
откуда
20 40 Б0 ВО 100
Рис. 7.5.3.
На рис. 7.5.3. показаны гистограмма и выравнивающий ее закон равномерной
плотности / (х).
7.6. Критерии согласия
В настоящем п° мы рассмотрим один из вопросов, связанных
с проверкой правдоподобия гипотез, а именно—вопрос о согласован-
согласованности теоретического и статистического распределения.
Допустим, что данное статистическое распределение выравнено
с помощью некоторой теоретической кривой / (х) (рис. 7.6.!). Кзк
бы хорошо ни была подобрана теоретическая кривая, между нею
и статистическим распределением неизбежны некоторые расхождения.
Естественно возникает вопрос: объясняются ли эти расхождения
только случайными обстоятельствами, связанными с ограниченным
числом наблюдений, или они являются существенными и связаны
с тем, что подобранная нами кривая плохо выравнивает данное ста-
статистическое распределение. Для ответа на такой вопрос служат так
называемые «критерии согласия».
150
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ. 7
Идея применения критериев согласия заключается в следующем.
На основании данного статистического материала нам предстоит
проверить гипотезу Н, состоящую в том, что случайная величина X
подчиняется некоторому определенному закону распределения. Этот
закон может быть задан в той или иной форме: например, в виде
функции распределения F(x) или в виде плотности распределения f(x),
или же в виде совокупности вероятностей р{, где pt— вероятность
того, что величина X попадет в пределы /-го разряда.
-.v
Рис. 7.6.1.
Так как из этих форм функция распределения F (х) является
наиболее общей и определяет собой любую другую, будем форму-
формулировать гипотезу Н, как состоящую в том, что величина X имеет
функцию распределения F (х).
Для того чтобы принять или опровергнуть гипотезу Н, рассмот-
рассмотрим некоторую величину U, характеризующую степень расхожде-
расхождения теоретического и статистического распределений. Величина U
может быть выбрана различными способами; например,, в качестве U
можно взять сумму квадратов отклонений теоретических вероятно-
вероятностей Pi от соответствующих частот р* или же сумму тех же квад-
квадратов с некоторыми коэффициентами («песями»), или же максимальное
отклонение статистической функции распределения F*(x) от теоре-
теоретической F(x) и т. д. Допустим, что величина U выбрана тем или
иным способом. Очевидно, это есть некоторая случайная величина.
Закон распределения этой случайной величины зависит от закона
распределения случайной величины X, над которой производились
опыты, и от числа опытов п. Если гипотеза Н верна, то закон рас-
распределения величины U определяется законом распределения вели-
величины X (функцией F(х)) и числом п.
Допустим, что этот закон распределения нам известен. В ре-
ультате данной серии опытов обнаружено, что выбранная нами мера
7.61
КРИТЕРИИ СОГЛАСИЯ
151
расхождения U приняла некоторое значение а. Спрашивается, можно
ли объяснить это случайными причинами или же это расхождение
слишком велико и указывает на наличие существенной разницы между
теоретическим и статистическим распределениями и, следовательно,
на непригодность гипотезы Н? Для ответа на этот вопрос предпо-
предположим, что гипотеза Н верна, и вычислим в этом предположении
вероятность того, что за счет случайных причин, связанных с недо-
недостаточным объемом опытного материала, мера расхождения U ока-
окажется не меньше, чем наблюденное нами в опыте значение и, т. е.
вычислим вероятность события:
Если эта вероятность весьма мала, то гипотезу Н следует отверг-
отвергнуть как мало правдоподобную; если же эта вероятность значительна,
следует признать, что экспериментальные данные не противоречат
гипотезе Н.
Возникает вопрос о том, каким же способом следует выбирать
меру расхождения £/? Оказывается, что при некоторых способах ее
выбора закон распределения величины U обладает весьма простыми
свойствами и при достаточно большом п практически не зависит от
функции F(x). Именно такими мерами расхождения и пользуются
в математической статистике в качестве критериев согласия.
Рассмотрим один из наиболее часто применяемых критериев со-
согласия— так называемый «критерий х2» Пирсона.
Предположим, что произведено п независимых опытов, в каждом
из которых случайная величина X приняла определенное значение.
Результаты опытов сведены в k разрядов и оформлены в виде ста-
статистического ряда:
#
Pi
X\, X2
#
Pi
X2r X$
*
P2
■ • •
• • •
xk' xh+i
*
Pk
Требуется проверить, согласуются ли экспериментальные данные
с гипотезой о том, что случайная величина X имеет данный закон
распределения (заданный функцией распределения F(x) или плот-
плотностью f(x)). Назовем этот закон распределения «теоретическим».
Зная теоретический закон распределения, можно найти теорети-
теоретические вероятности попадания случайной величины в каждый из
разрядов:
Pi. P2' •••> Pk'
Проверяя согласованность теоретического и статистического рас-
ппрдр пений, мн будем исходить из расхождений меж чу теоретиче-
теоретическими вероятностями pt и наблюденными частотами р*.. Естественно
152 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 7
выбрать в качестве меры расхождения между теоретическим и ста-
статистическим распределениями сумму квадратов отклонений (р* — рX
взятых с некоторыми «весами» ct:
^=S^K-^J' G.6.1)
Коэффициенты ct («веса» разрядов) вводятся потому, что в общем
случае отклонения, относящиеся к различным разрядам, нельзя счи-
считать равноправными по значимости. Действительно, одно и то же по
абсолютной величине отклонение р* — р( может быть мало значитель-
значительным, если сама вероятность р1 велика, и очень заметным, если она
мала. Поэтому естественно «веса» с{ взять обратно пропорциональ-
пропорциональными вероятностям разрядов pt.
Далее возникает вопрос о том, как выбрать коэффициент про-
пропорциональности.
К. Пирсон показал, что если положить
с, = ^, G.6.2)
то при больших п закон распределения величины U обладает весьма
простыми свойствами: он практически не зависит от функции рас-
распределения F (х) и от числа опытов п, а зависит только от числа
разрядов k, а именно, этот закон при увеличении я приближается
к так называемому «распределению х2» ')•
При таком выборе коэффициентов сс мера расхождения обычно
обозначается х2;
Для удобства вычислений (чтобы не иметь дела с дробными ве-
величинами с большим числом нулей) можно ввести п под знак суммы
1) Распределением у2 с г степенями свободы называется распределение
чинена нормальному закону с математическим ожиданием, равным нулю,
и дисперсией, равной единице. Это распределение характеризуется плотностью
ft, (и).
1 _!_! _JL
и2 е 2 при и > О,
22Г
\2.
л
4AJ
где Г(а)= I (l~le~idt — изьесгная гамма-функция.
7.61
КРИТЕРИИ СОГЛАСИЯ 153
и, учитывая, что /9^=—, где т, — число значений в /-м разряде,
привести формулу G.6.3) к виду:
Распределение х2 зависит от параметра г, называемого числом «сте-
«степеней свободы» распределения. Число «степеней свободы» г равно
числу разрядов k минус число независимых условий («связей»), на-
наложенных на частоты р\- Примерами таких условий могут быть
если мы требуем только того, чтобы сумма частот была равна еди-
единице (это требование накладывается во всех случаях);
Ъх1р]=тх,
если мы подбираем теоретическое распределение с тем условием,
чтобы совпадали теоретическое и статистическое средние значения;
если мы требуем, кроме того, совпадения теоретической и стати-
статистической дисперсий и т. д.
Для распределения х2 составлены специальные таблицы (см. табл. 4
приложения), Пользуясь этими таблицами, можно для каждого зна-
значения х2 и числа степеней свободы г найти вероятность р того, что
величина, распределенная по закону х2> превзойдет это значение.
В табл. 4 входами являются: значение вероятности р и число степе-
степеней свободы г. Числа, стоящие в таблице, представляют собой соот-
соответствующие значения х2-
Распределение v2 дает возможность оценить степень согласован-
согласованности теоретического и статистического распределений, Будем исхо-
исходить из того, что величина X действительно распределена по
закону F(x). Тогда вероятность р, определенная по таблице, есть
вероятность того, что за счет чисто случайных причин мера расхож-
расхождения теоретического и статистического распределений G.6.4) будет
не меньше, чем фактически наблюденное в данной серии опытов
ЗНЯЧРНир v2 Prim атз прпгштнпгть п Rpn.ua ия-я ,'ня-т," -!.;<■<-■ мя -я vrn
'* "~ г" г " — \ » ---
событие с такой вероятностью можно считать практически невозможным),
то результат огклта следует считать противоречащим гипотезе Н
о том, что закон распределения величины X есть F(x). Эту
154 ~ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 7
гипотезу следует отбросить как неправдоподобную. Напротив, если
вероятность р сравнительно велика, можно признать расхождения меж-
между теоретическим и статистическим распределениями несущественными
и отнести их за счет случайных причин. Гипотезу Н о том, что
величина X распределена по закону F(x), можно считать правдо-
правдоподобной или, по крайней мере, не противоречащей опытным
данным.
Таким образом, схема применения критерия у} к оценке согласо-
согласованности теоретического и статистического распределений сводится
к следующему:
1) Определяется мера расхождения у2 по формуле G.6.4).
2) Определяется число степеней свободы г как число разрядов k
минус число наложенных связей s:
r = k — s.
3) По г и f с помощью табл. 4 определяется вероятность того,
что величина, имеющая распределение у? с г степенями свободы, пре-
превзойдет данное значение у?. Если эта вероятность весьма мала, гипо-
гипотеза отбрасывается как неправдоподобная. Если эта вероятность
относительно велика, 4 гипотезу можно признать не противоречащей
опытным данным.
Насколько мала должна быть вероятность р для того, чтобы от-
отбросить или пересмотреть гипотезу,—вопрос неопределенный; он не
может быть решен из математических соображений, так же как и
вопрос о том, насколько мала должна быть вероятность события для
того, чтобы считать его практически невозможным. На практике,
если р оказывается меньшим чем 0,1, рекомендуется проверить экспе-
эксперимент, если возможно — повторить его и в случае, если заметные
расхождения снова появятся, пытаться искать более подходящий для
описания статистических данных закон распределения.
Следует особо отметить, что с помощью критерия у} (или любого
другого критерия согласия) можно только в некоторых случаях опро-
опровергнуть выбранную гипотезу Н и отбросить ее как явно несо-
несогласную с опытными данными; если же вероятность р велика, то этот
факт сам по себе ни в коем случае не может считаться доказатель-
доказательством справедливости гипотезы Н, а указывает только на то, что
гипотеза не противоречит опытным данным.
С первого взгляда может показаться, что чем больше вероят-
вероятность р, тем лучше согласованность теоретического и статистиче-
статистического распределений и тем более обоснованным следует считать
выбор функции F(x) в каче«Же закона распределения случайной
величины. В действительности это не так. Допустим, например, что,
оценивая согласие теоретического и статистического распределений
по критерию х?\ мы получили /? —0,99. Это значит, что с вероятно-
вероятностью 0,99 за счет чисто случайных причин при данном числе опытов
7.61
КРИТЕРИИ СОГЛАСИЯ
155
должны были получиться расхождения ббльшие, чем наблюденные.
Мы же получили относительно весьма малые расхождения, которые
слишком малы для того, чтобы признать их правдоподобными. Разум-
Разумнее признать, что столь близкое совпадение теоретического и стати-
статистического распределений не является случайным и может быть
объяснено определенными причинами, связанными с регистрацией и
обработкой опытных данных (в частности, с весьма распространенной
на практике «подчисткой» опытных данных, когда некоторые резуль-
результаты произвольно отбрасываются или несколько изменяются).
Разумеется, все эти соображения Применимы только в тех слу-
случаях, когда количество опытов п достаточно велико (порядка несколь-
нескольких сотен) и когда имеет смысл применять сам критерий, осно-
основанный на предельном распределении меры расхождения при п—>оо.
Заметим, что при пользовании критерием yj2 достаточно большим должно
быть не только общее число опытов п, но и числа наблюдений т.,
в отдельных разрядах. На практике рекомендуется иметь в каждом
разряде не менее 5—10 наблюдений. Если числа наблюдений в от-
отдельных разрядах очень малы (порядка 1 —2), имеет смысл объеди-
объединить некоторые разряды.
Пример 1. Проверить согласованность теоретического и статистического
распределений для примера 1 п° 7.5 (стр. 137, 146).
Решение. Пользуясь теоретическим нормальным законом распределе-
распределения с параметрами
т = 0,168, о=1,448,
находим вероятности попадания в разряды по формуле
Pi'
где х,, х,+1—границы i-ro разряда.
Затем составляем сравнительную таблицу чисел попаданий в разряды т,
и соответствующих значений npi {n = 500).
h
1
-4; -3
6
6,2
—3; —2
25
26,2
-2; -l
72
71,2
—1; 0
133
122,2
0; 1
120
131,8
1; 2
88
90,5
2;3
46
38,2
3; 4
10
10,5
По формуле G.6.4) определяем значение меры расхождения
з
1 ~ Ы1 llPl
Определяем число стрпрн^й свободы как число ргзрпдсз :.:;i;;yc число
наложенных связей s (в данном случае 5 = 3):
г = 8 — 3 = 5,
156
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ. 7
По табл. 4 приложения находим для г = 5:
при х2 = 3,00 р = 0,70;
при х2 = 4,35 р = 0,50.
Следовательно, искомая вероятность р при х2 =■= 3,94 приближенно равна
0,56. Эта вероятность малой не является; поэтому гипотезу о том, что ве-
величина X распределена по нормальному закону, можно считать правдоподобной.
Пример 2. Проверить согласованность теоретического и статистиче-
статистического распределений для условий примера 2 п° 7.5 (стр. 149).
Решение. Значения pi вычисляем как вероятности попадания на участки
B0; 30), C0; 40) и т. д. для случайной величины, распределенной по закону
равномерной плотности на отрезке B3,6; 96,9). Составляем сравнительную
таблицу значений mi и npi (л = 400):
h
пц
npi
20; 30
21
34,9
30; 40
72
54,6
40; 50
66
54,6
50; 60
38
54,6
60; 70
51
54,6
70; 80
56
54,6
80; 90
64
54,6
90; 100
32
38,0
По формуле G.6.4) находим х2:
iti
Число степеней свободы:
г = 8-3 = 5.
По табл. 4 приложения имеем:
при х2 = 20,5 и г = 5 р — 0,001,
Следовательно, наблюденное нами расхождение между теоретическим и
статистическим распределениями могло бы за счет чисто случайных причин
появиться лишь с вероятностью р» 0,001. Так как эта вероятность очень
мала, следует признать экспериментальные данные противоречащими
гипотезе о том, что величина X распределена по закрну равномерной
плотности.
Кроме критерия у}, для оценки степени согласованности теорети-
теоретического и статистического распределений на пряктике применяется
еще ряд других критериев. Из них мы вкратце остановимся на кри-
критерии А. Н. Колмогорова.
В качестве меры расхождения между теоретическим и статисти-
статистическим распределениями А. Н. Колмогоров рассматривает максималь-
максимальное значение модуля разности между статистической функцией рас-
распределения F* (х) и соответствующей теоретической функцией рас-
пределения: D = mnx\F*(x)-F(x)\.
Основанием для выбора в качестве меры расхождения величины D
является простота ее вычисления. Вместе с тем она имеет достаточно
7.6]
КРИТЕРИИ СОГЛАСИЯ
137
простой закон распределения. А. Н, Колмогоров доказал, что, какова
бы ни была функция распределения F (х) непрерывной случайной ве-
величины X, при неограниченном возрастании числа независимых на-
наблюдений п вероятность неравенства
стремится к пределу
= 1— 2) (— lfe-w*. G.6.5)
&= — со
Значения вероятности PQ-), подсчитанные по формуле G.6.5),
приведены в таблице 7.6.1.
Таблица 7.6.1
\ ■
0,0
од
0,2
0,3
0,4
0,5
0,6
Р(Ц
1,000
1,000
1,000
1,000
0,997
0,964
0,864
X
0,7
0,8
0,9
1,0
1,1
1,2
1,3
0,711
0,544
0,393
0,270
0,178
0,112
0,068
1,4
1,5
1,6
1,7
1,8
1,9
2,0
Ж»
0,040
0,022
0,012
0,006
0,003
0,002
0,001
Схема применения критерия А. Н. Колмогорова следующая: строят-
строятся статистическая функция распределения F* (х) и предполагаемая
Г*Ш
и
•Fix)
Рис. 7.6.2.
теоретическая функция распределения F (х), и определяется макси-
максимум D модуля разности между ними (рис. 7.6.2).
Ллл-с, ог.р-дгдяется величина
158 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 7
и по таблице 7.6.1 находится вероятность Р(Х), Это есть вероят-
вероятность того, что (если величина X действительно распределена по
закону F (х)) за счет чисто случайных причин максимальное расхож-
расхождение между F* (х) и F (х) будет не меньше, чем фактически наблю-
наблюденное. Если вероятность Р(к) весьма мала, гипотезу следует отверг-
отвергнуть как неправдоподобную; при сравнительно больших Р (X) ее можно
считать совместимой с опытными данными.
Критерий А. Н. Колмогорова своей простотой выгодно отличается
от описанного ранее критерия у}; поэтому его весьма охотно при-
применяют на практике. Следует, однако, оговорить, что этот критерий
можно применять только в случае, когда гипотетическое распреде-
распределение F (х) полностью известно заранее из каких-либо теоретиче-
теоретических соображений, т. е. когда известен не только вид функции рас-
распределения F (х), но и все входящие в нее параметры. Такой случай
сравнительно редко встречается на практике. Обычно из теоретиче-
теоретических соображений известен только общий вид функции F (х), а вхо-
входящие в нее числовые параметры определяются по данному стати-
статистическому материалу. При применении критерия х2 это обстоятельство
учитывается соответствующим уменьшением числа степеней свободы
распределения yj. Критерий А. Н. Колмогорова такого согласования
не предусматривает. Если все же применять этот критерий в тех
случаях, когда параметры теоретического распределения выбираются
по статистическим данным, критерий дает заведомо завышенные зна-
значения вероятности Р (к); поэтому мы в ряде случаев рискуем принять
как правдоподобную гипотезу, в действительности плохо согласую-
согласующуюся с опытными данными.
ГЛАВА 8
СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
8.1. Понятие о системе случайных величин
В практических применениях теории вероятностей очень часто
приходится сталкиваться с задачами, в которых результат опыта описы-
описывается не одной случайной величиной, а двумя или более случайными
величинами, образующими комплекс или систему. Например, точка
попадания снаряда определяется не одной случайной величиной, а
двумя: абсциссой и ординатой — и может быть рассмотрена как ком-
комплекс двух случайных величин. Аналогично точка разрыва дистан-
дистанционного снаряда определяется комплексом трех случайных величин.
При стрельбе группой из п выстрелов совокупность точек попада-
попадания на плоскости может рассматриваться как комплекс или система 2д
случайных величин: п абсцисс и п ординат точек попадания. Осколок,
образовавшийся при разрыве снаряда, характеризуется рядом случай-
случайных величин: весом, размерами, начальной скоростью, направлением
полета и т. д. Условимся систему нескольких случайных величин
X, Y W обозначать (X, Y W).
Свойства системы нескольких случайных величин не исчерпываются
свойствами отдельных величин, ее составляющих: помимо этого, они
включают также взаимные связи (зависимости) между случайными вели-
величинами.
Пf-'- рассмотрении вопросов, связанных с системами случайных ие~
личин, удобно пользоваться геометрической интерпретацией системы.
Например, систему двух случайных величин (X, Y) можно изобра-
изображать случайной точкой на плоскости с координатами X и Y
(рис. 8.1.1), Аналогично система трех случайных величин может быть
изображена случайной точкой в трехмерном пространстве. Часто бы-
бывает удобно говорить о системе п случайных величин как о «случай-
«случайной точке б пространстве п измерений». Несмотря на то, что послед-
последняя интерпретация не обладает непосредственной наглядностью, поль-
пользование ею дает некоторый выигрыш в смысле общности терминологии
и упрощения записей.
160
СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
{ГЛ. 8
Часто вместо образа случайной точки для геометрической
интерпретации системы случайных величин пользуются образом слу-
случайного вектора. Систему двух случайных величин при этом
рассматривают как случайный вектор на плоскости хОу, составляющие
которого по осям представляют собой случайные величины X, Y
(рис. 8.1.2). Система трех случайных величин изображается случайным
вектором в трехмерном пространстве, система п случайных величин —
У
Рис, 8.1.1.
Рис. 8.1.2,
случайным вектором в пространстве п измерений. При этом теория
систем случайных величин рассматривается как теория случайных
в е к т о р о в.
В данном курсе мы будем в зависимости от удобства изложения
пользоваться как одной, так и другой интерпретацией.
Занимаясь системами случайных величин, мы будем рассматривать
как полные, исчерпывающие вероятностные характеристики — законы
распределения, так и неполные — числовые характеристики.
Изложение начнем с наиболее простого случая системы двух слу-
случайных величин.
8.2. Функция распределения системы двух
случайных величин
Функцией распределения системы двух случайных величин (X, Y)
называется вероятность совместного выполнения двух неравенств
Х<х и У<у:
Если пользоваться для геометрической интерпретации системы
образом случайной точки, то функция распределения F(x, у) есть
не что иное, как вероятность попадании случайной точки (X, Y)
в бесконечный квадрант с вершиной в точке (х, у), лежащий левее
8.2]
ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ СИСТЕМЫ ДВУХ ВЕЛИЧИН
и ниже ее (рис. 8.2.1). В аналогичной интерпретации функция рас-
распределения одной случайной величины X — обозначим ее Fx(x)—■
представляет собой вероятность попада-
попадания случайной точки в полуплоскость,
ограниченную справа абсциссой х
(рис. 8.2.2); функция распределения од-
одной величины Y — F2(y)— вероятность
попадания в полуплоскость, ограничен-
ограниченную сверху ординатой у (рис. 8.2.3).
В п°5.2 мы привели основные свой-
свойства функции распределения F(х) для
одной случайной величины. Сформули-
Сформулируем аналогичные свойства для функ-
функции распределения системы случай-
случайных величин и снова воспользуемся
геометрической интерпретацией для
наглядной иллюстрации этих свойств.
1. Функция распределения F(x, у) есть неубывающая функция
обоих своих аргументов, т. е.
Рис. 8.2.1.
при х2 > хх F (х2, у) ;
при >J>у1 F(x, y2)>F(x, у,).
В этом свойстве функции F (х) можно наглядно убедиться, поль-
пользуясь геометрической интерпретацией. функции распределения как
вероятности попадания в квадрант
с вершиной (х, у) (рис. 8.2.1).
Действительно, увеличивая х (смещая
1
1
1
I
i
i
1
1
i
i
I
i
X
Рис. 8.2.2,
Рис. 8.2.3,
правую границу квадранта вправо) или увеличивая у (смешая верх-
верхнюю границу вверх), мы, очевидно, не можем уменьшить вероят-
вероятность попадания в этот квадрант.
ii E. С- вентцель
162 СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН 1ГЛ. 8
2. Повсюду на —оо функция распределения равна нулю:
F(x, —oo) = F(—оо, y) = F(—oo, —оо) = 0.
В этом свойстве мы наглядно убеждаемся, неограниченно отодви-
отодвигая влево правую границу квадранта (х—>— оо) или вниз его верх-
верхнюю границу (у —> — оо) или делая это одновременно с обеими гра-
границами; при этом вероятность попадания в квадрант стремится к нулю.
3. При одном из аргументов, равном -f-oo, функция распреде-
распределения системы превращается в функцию распределения случайной
величины, соответствующей другому аргументу:
F(x, -\-cxj) = F1(x), F(+oo, y)=*F2(y).
где Fl(x), F2(y) — соответственно функции распределения случайных
величин X и Y.
В этом свойстве функции распределения можно наглядно убе-
убедиться, смещая ту или иную из границ квадранта на -f- оо; при этом
в пределе квадрант превращается в полуплоскость, вероятность
попадания в которую есть функция распределения одной из величин,
входящих в систему.
4. Если оба аргумента равны -f-oo, функция распределения си-
системы равна единице:
Действительно, при х—>-\-оо, у—*--j-oo квадрант с вершиной
(х, у) в пределе обращается во всю плоскость хОу, попадание
в которую есть достоверное событие.
При рассмотрении законов распределе-
распределения отдельных случайных величин (глава 5)
мы вывели выражение для вероятности по-
попадания случайной величины в пределы
заданного участка. Эту вероятность мы выра-
выразили как через функцию распределения,
так и через плотность распределения.
О ———-х Аналогичным вопросом для системы двух
Рис. 8.2.4. случайных величин является вопрос о ве-
вероятности попадания случайной точки (X.Y)
в пределы заданной области D на плоскости лиу (рис. 8.2.4;.
Условимся событие, состоящее в попадании случайной точки (Л', Y)
в область D, обозначать символом (ЛГ, Y) с D.
Вероятность попадания случайной точки в заданную область вы-
выражается наиболее просто в том случае, когда эта область пред-
представляет собой прямоугольник со сторонами, параллельными коорди-
координатным осям.
Выразим через функцию распределения системы вероятность по-
попадания случайной точки (X, Y) в прямоугольник R, ограничен-
ограниченный абсциссами а и [J и ординатами ? и 8 (рис. 8.2.5).
8.3]
ПЛОТНОСТЬ РАСПРЕДЕЛЕНИЯ СИСТЕМЫ ДВУХ ВЕЛИЧИН
При этом следует условиться, куда мы будем относить границы
прямоугольника. Аналогично тому, как мы делали для одной случай-
случайной величины, условимся включать в прямоугольник R его нижнюю
и левую границы и не включать верхнюю и правую1). Тогда собы-
событие (X, Y)cR будет равносильно произведению двух событий:
и f <^ Y < 5. Выразим вероятность этого события через
У
U а.
(а.,8)
<-/U£*f#.A/L£Z
Рис. 8.2.5.
Рис. 8.2.6,
функцию распределения системы. Для этого рассмотрим на плоскости
хОу четыре бесконечных квадранта с вершинами в точках ф, 8); (а, 8);
(р. Т) и (а- Т) (Рис- 8.2.6).
Очевидно, вероятность попадания в прямоугольник R равна ве-
вероятности попадания в квадрант ф, 8) минус вероятность попадания
в квадрант (а, 8) минус вероятность попадания в квадрант ((J, f)
плюс вероятность попадания в квадрант (a, f) (так как мы дважды
вычли вероятность попадания в этот квадрант). Отсюда получаем
формулу, выражающую вероятность попадания в прямоугольник через
функцию распределения системы:
Р((Х. Y)<=R) = F$. b)-F (a. b)-F®, Т) + ^(а. Т). (8.2.2)
В дальнейшем, когда будет введено понятие плотности распреде-
-.-i;.jii !_;1С:емы, мы выведем формулу для вероятности попадания
случайной точки в область произвольной формы.
8.3. Плотность распределения системы двух случайных величин
Введенная в предыдущем п° характеристика системы — функция
распределения — существует для систем любых случайных величин,
как преривиых, так я непрерывных. Основное практическое значение
') На рис, 8=2,5 границы, включенные в поямо\толышк, даны жирными
линиями. * ■ .
Ц*
164
СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ 8
/ ff
У
имеют системы непрерывных случайных величин. Распределение
системы непрерывных величин обычно характеризуют не функцией
распределения, а плотностью рас-
распределения.
Вводя в рассмотрение плотность рас-
распределения для одной случайной вели-
величины, мы определяли ее как предел от-
отношения вероятности попадания на малый
участок к длине этого участка при ее
неограниченном уменьшении. Аналогично
определим плотность распределения си-
£ стемы двух величин.
Пусть имеется система двух непре-
непрерывных случайных величин (X, Y), кото-
которая интерпретируется случайной точкой
на плоскости хОу. Рассмотрим на этой
плоскости малый прямоугольник /?д со
сторонами ИкХ и Ду, примыкающий к точке с координатами (х, у)
(рис. 8.3.1). Вероятность попадания в этот прямоугольник по фор-
формуле (8.2.2) равна
Р((Х, У)с:11&) = Р(х-\-Ьх, у + Ду) —
— F(x-{-kx, у) — Р(х, У-\-&У)-\-F (х, у).
Разделим вероятность попадания в прямоугольник /?д на площадь
этого прямоугольника и перейдем к пределу при Дх—>0 и Ду—>0:
О
X 7>
Рис. 8.3.1.
Игл
■ Ду-*0
=- lfm
, y)-~F(x,
ду->о (8.3.1)
Предположим, что функция F(x, у) не только непрерывна, но и
дифференцируема; тогда правая часть формулы (8.3.1) представляет
собой вторую смешанную частную производную функции F (х, у)
по х и у. Обозначим эту производную /(.г. у):
Функция f (х, у) называется плотностью распределения системы.
Таким образом, плотность распределения системы представляет
собой предел отношения вероятности попадания в малый прямоуголь-
прямоугольник к площади этого прямоугольника, когда оба его размера стре-
стремятся к нулю; она может быть выражена как вторая смешанная
частная производная функции распределения системы по обоим аргу-
аргументам.
8.31
ПЛОТНОСТЬ РАСПРЕДЕЛЕНИЯ СИСТЕМЫ ДВУХ ВЕЛИЧИН
165
\f(x;y)
Если воспользоваться «механической» интерпретацией распреде-
распределения системы как распределения единичной массы по плоскости хОу,
функция f(x, у) представляет собой плотность распределения массы
в точке (х, у).
Геометрически функцию f(x, у) можно изобразить некоторой
поверхностью (рис. 8.3.2). Эта поверхность аналогична кривой рас-
распределения для одной случайной ве-
величины и называется поверхностью
распределения.
Если пересечь поверхность рас-
распределения f(x, у) плоскостью, па-
параллельной плоскости хОу, и спроек-
спроектировать полученное сечение на
плоскость хОу, получится кривая,
в каждой точке которой плотность
распределения постоянна. Такие кри-
кривые называются кривыми равной
плотности. Кривые равной плот-
плотности, очевидно, представляют собой
горизонтали поверхности распределения
задавать распределение семейством кривых
Рис. 8.3.2.
Часто бывает удобно
равной плотности.
Рассматривая плотность распределения / (х) для одной случайной
величины, мы ввели понятие «элемента вероятности» f(x)dx. Это
есть вероятность попадания случайной вели-
величины X на элементарный участок dx, приле-
прилежащий к точке х. Аналогичное понятие
«элемента вероятности» вводится и для си-
системы двух случайных величин. Элементом
вероятности в данном случае называется
выражение
f(x, y)dxdy.
Очевидно, элемент вероятности есть не
что иное, как вероятность попадания в эле-
элементарный прямоугольник со сторонами dx.
Рис 833 й?^1' пРимь;каюш'11*' к точке (х, у) (рис. 8.3.3).
Эта вероятность равна объему элементарного
параллелепипеда, ограниченного сверху поверхностью f(x, у) и опи-
опирающегося на элементарный прямоугольник dx dy (рис. 8.3.4).
Пользуясь понятием элемента вероятности, выведем выражение
для вероятности попадания случайной точки в произвольную область D.
Эта вероятность, очевидно, может быть получена суммированием
(интегрированием) элементов вероятности по всей области D:
P((X,Y)cD) = f J / {х, у) dx dy. (8.3.3)
@)
166
СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
1ГЛ. 8
Геометрически вероятность попадания в область D изображается
объемом цилиндрического тела С, ограниченного сверху поверхностью
распределения и опирающегося на область D (рис. 8.3.5).
■f(x,y)dxuy
f(x,y)
Рис. 8.3.4.
Рис. 8.3.5;
Из общей формулы (8.3.3) вытекает формула для вероятности
попадания в прямоугольник R, ограниченный абсциссами а и J3 и
ординатами -г и 8 (пис. 8.2.5):
Р((Х, К) с Я) = / f fix, y)dxdy. (8.3.4)
a T
Воспользуемся формулой (8.3.4) для того, чтобы выразить функ-
функцию распределения системы F(x, у) через плотность распределения
fix, у). Функция распределения F(x, у) есть вероятность попадания
в бесконечный квадрант; последний можно рассматривать как прямо-
прямоугольник, ограниченный абсциссами — оо и х и ординатами — оо и у.
По формуле (8.3.4) имеем:
х у
F(x,y)= J ff{x,y)dxdy. (8.3.5)
— оо —оо
Легко убедиться в следующих свойствах плотности распределения
системы:
1. Плотность распределения системы есть функция неотрица-
неотрицательная:
fix, y)>0.
Это ясно из того, что плотность распределения есть предел отно-
отношения двух неотрицательных величин: вероятности попадания в пря-
прямоугольник и площади прямоугольника — и, следовательно, отрица-
отрицательной быть не может.
8.31
ПЛОТНОСТЬ РАСПРЕДЕЛЕНИЯ СИСТЕМЫ ДВУХ ВЕЛИЧИН
167
2. Двойной интеграл в бесконечных пределах от плотности рас-
распределения системы равен единице:
(8.3.6)
Это видно из того, что интеграл (8.3.6) есть не что иное, как ве-
вероятность попадания во всю плоскость хОу,
т. е. вероятность достоверного события.
Геометрически это свойство означает, что
полный объем тела, ограниченного поверхностью
распределения и плоскостью хОу, равен единице^
Пример 1. Система двух случайных величин
(X, У) подчинена закону распределения с плотностью
»)
О
1
Рис. 8.3.6,
Найти функцию распределения F (х, у). Определить
вероятность попадания случайной точки (X, У) в квад-
квадрат R (рис. 8.3.6).
Решение. Функцию распределения F (х, у) находим по формуле (8.3.5).
X У
=^ f
— со —оо
Вероятность попадания в прямоугольник R находим по формуле (8.3.4):
11 11
dxdy L Г dx С йУ
i- С Г
Я2 J )
L Г dx С
0
Р((Х
Ц ' Я (|)(|y) +
0 0 0 0
Пример 2. Поверхность распределения системы (X, У) представляет
собой прямой круговой конус, основанием которого служит круг радиуса R
f(x,y)
Рис. 8.3.7.;
с центром в начале координат. Написать выражение плотности распределе-
-'-'"-". определить вероятность того, что случайная хсг;::а (х, у) попадет
в кРУг К радиуса а (рис. 8.3.7), причем а < R.
168 СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ 8
Решение. Выражение плотности распределения внутри круга К на-
находим из рис. 8.3.8:
где А — высота конуса. Величину h определяем так, чтобы объем конуса
был равен единице: -тг nR2h = 1, откуда
Н
Вероятность попадания в круг К определяем по формуле (8.3.4):
P((X,Y)aK)=f' f f (x, у) dxdy. (8.3.7)
(AT)
Для вычисления интеграла (8.3.7) удобио перейти к полярной системе коор-
координат г, <р:
Р{{Х, К)сК) =
/
0 0
8.4. Законы распределения отдельных величии,
входящих в систему. Условные законы распределения
Зная закон распределения системы двух случайных величин,
можно всегда определить законы распределения отдельных величин,
входящих в систему. В п° 8.2 мы уже вывели выражения для функ-
функций распределения отдельных величин, входящих в систему, через
функцию распределения системы, а именно, мы показали, что
F1(x) = F(x, oo); F2(y) = F(w, у): (8.4.1)
Выразим теперь плотность распределения каждой из величин,
входящих в систему, через плотность распределения системы. Поль-
Пользуясь формулой (S.6.O), выражающей функцию распределения через
плотность распределения, напишем:
X со
= F(x. oo)= f ff(x, y)dxdy.
— СО —OO
откуда, дифференцируя по х, получим выражение для плотности
распределения величины X:
со
/i (*) = F\ {x) = } f (x, у) dy. (8.4.2)
84J ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ОТДЕЛЬНЫХ ВЕЛИЧИН 169
Аналогично . . . . . . . „ . ,
/2 (У) = Р'% (У) = / / (*. У) dx. (8.4.3)
— оо
Таким образом, для того чтобы получить плотность распределе-
распределения одной из величин, входящих в систему, нужно плотность рас-
распределения системы проинтегрировать в бесконечных пределах по
аргументу, соответствующему другой случайной величине.
Формулы (8.4.1), (8.4.2) и (8.4.3) дают возможность, зная закон
распределения системы (заданный в виде функции распределения или
плотности распределения), найти законы распределения отдельных
величин, входящих в систему. Естественно, возникает вопрос об об-
обратной задаче: нельзя ли по законам распределения отдельных вели-
величин, входящих в систему, восстановить закон распределения системы?
Оказывается, что в общем случае этого сделать нельзя: зная только
законы распределения отдельных величин, входящих в систему, не
всегда можно найти закон распределения системы. Дли того чтобы
исчерпывающим образом охарактеризовать систему, недостаточно
знать распределение каждой из величин, входящих в систему; нужно
еще знать зависимость между величинами, входящими в систему.
Эта зависимость может быть охарактеризована с помощью так на-
называемых условных законов распределения.
Условным законом распределения величины X, входящей в си-
систему (X, Y), называется ее закон распределения, вычисленный при
условии, что другая случайная величина Y приняла определенное
значение у.
Условный закон распределения можно задавать как функцией
распределения, так и плотностью. Условная функция распределения
обозначается F (х \ у), условная плотность распределения / (х \ у). Так
как системы непрерывных величин имеют основное практическое зна-
значение, мы в данном курсе ограничимся рассмотрением условных за-
законов, заданных плотностью распределения.
Чтобы нагляднее пояснить понятие условного закона распреде-
распределения, рассмотрим пример. Система случайных величин L и Q пред-
представляет собой длину и вес осколка снаряда. Пусть нас интересует
Длина осколка L безотносительно к его весу; это есть случайная
величина, подчиненная закону распределения с плотностью Д (/).
Этот закон распределения мы можем исследовать, рассматривая все
без исключения осколки и оценивая их только по длине; fl(t) есть
безусловный закон распределения длины осколка. Однако нас может
интересовать и закон распределения длины осколка вполне опреде-
определенного веса, например 10 г. Для того чтобы его определить, мы
будем исследовать не все осколки, а только определенную весовую
группу, в которой вес приблизительно равен 10 г, и получим
условный закон распределения длины осколка при весе 10 г
170
СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ. 8
О
У
I
/////////У//
/////777 7Т
с плотностью f(l\q) при #=10. Этот условный закон распределе-
распределения вообще отличается от безусловного /j (/); очевидно, более тя-
тяжелые осколки должны в среднем обладать и большей длиной; сле-
следовательно, условный закон распре-
распределения длины осколка существенно
зависит от веса q.
Зная закон распределения одной
из величин, входящих в систему, и
условный закон распределения вто-
второй, можно составить закон распре-
распределения системы. Выведем формулу,
выражающую это соотношение, для
непрерывных случайных величин.
Для этого воспользуемся понятием
об элементе вероятности. Рассмотрим
прилежащий к точке (л;, у) элемен-
элементарный прямоугольник Rd со сто-
сторонами dx, dy (рис. 8.4.1). Вероят-
Вероятность попадания в этот прямоуголь-
прямоугольник— элемент вероятности f(x, у) dx dy — равна вероятности одно-
одновременного попадания случайной точки (X, Y) в элементарную полосу /,
опирающуюся на отрезок dx, и в полосу //, опирающуюся на от-
отрезок dy:
х
Рис. 8.4.1.
= P((x<X<x-\-dx)(y<Y<y-\-dy)).
Вероятность произведения этих двух событий, по теореме умно-
умножения вероятностей, равна вероятности попадания в элементарную
полосу /, умноженной на условную вероятность попадания в эле-
элементарную полосу //, вычисленную при условии, что первое событие
имело место. Это условие в пределе равносильно условию Х = х;
следовательно,
/ (х, у) dx dy = fx {x) dxf(y\ x) dy.
откуда
f(x, У) =
(8.4.4)
т. е. плотность распределения системы двух величин равна плот-
плотности распределения одной из величин, входящих в систему, умно-
умноженной на условную плотность распределения другой величины, вь:-
при условии, что пёовая величина лои
чение.
Формулу (8.4.4) часто называют теоремой умножения законов
распределения. Эта теорема в схеме случайных велнч;;;! аналогична
теореме умножения вероятностей в схеме событий.
85] ■ ЗАВИСИМЫЕ И НЕЗАВИСИМЫЕ СЛУЧАЙНЫЕ ВЕЛИЧИНЫ \J\
Очевидно, формуле (8.4.4) можно придать другой вид, если за-
задать значение не величины X, а величины Y:
\y). (8.4.5)
Разрешая формулы (8.4.4) и (8.4.5) относительно f(y\x) и f(x\y),
получим выражения условных законов распределения через без-
безусловные:
> =
fly) (8-4'6)
или, применяя формулы (8.4.2) и (8.4.3),
8.5. Зависимые и независимые случайные величины
При изучении систем случайных величин всегда следует обращать
внимание на степень и характер их зависимости. Эта зависимость
может быть более или менее ярко выраженной, более или менее
тесной. В некоторых случаях зависимость между случайными вели-
величинами может быть настолько тесной, что, зная значение одной
случайной величины, можно в точности указать значение другой.
В другом крайнем случае зависимость между случайными величинами
является настолько слабой и отдаленной, что их можно практически
считать независимыми.
Понятие о независимых случайных величинах — одно из важных
пт'ятий теории вероятностей.
Случайная величина Y называется независимой от случайной ве-
величины X, если закон распределения величины Y не зависит от того,
какое значение приняла величина X.
Для непрерывных случайных величин условие независимости К
от X может быть записано в виде;
при любом у.
Напротив, в случае, если Y зависит от А', то
172 ' СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН (ГЛ, S
Докажем, что зависимость или независимость случайных ве-
величин всегда взаимны: если величина Y не зависит от X, то и ве-
величина X не зависит от Y.
Действительно, пусть Y не зависит от X:
(8-5.1)
Из формул (8.4.4) и (8.4.5) имеем:
откуда, принимая во внимание (8.5.1), получим:
что и требовалось доказать.
Так как зависимость и независимость случайных величин всегда
взаимны, можно дать новое определение независимых случайных
величин.
Случайные величины X и Y называются независимыми, если
закон распределения каждой из них не зависит от того, какое
значение приняла другая. В противном случае величины X и Y
называются зависимыми.
Для независимых непрерывных случайных величин теорема умно-
умножения законов распределения принимает вид:
f{x, y) = fl(x)f,(y). (8.5.2)
т. е. плотность распределения системы независимых случайных
величин равна произведению плотностей распределения от-
отдельных величин, входящих в систему.
Условие (8.5.2) может рассматриваться как необходимое и до-
достаточное условие независимости случайных величин.
Часто по самому виду функции f(x, у) можно заключить, что
случайные величины X, Y являются независимыми, а именно, если
плотность распределения f(x, у) распадается на произведение двух
функций, из которых одна зависит только от х, другая — только
от у, то случайные величины независимы.
Пример. Плотность распределения системы (X, Y) имеет вид:
f(x)
Определить: зависимы или независимы случайные величины X и Y.
Решение. Разлагая знаменатель на множители, имеем:
Из того, чти функция /ух, у) распалась на произведение двух функций
из которых одна зависит только от х, а другая — только от у, заключаем)
g.5] ЗАВИСИМЫЕ И НЕЗАВИСИМЫЕ СЛУЧАЙНЫЕ ВЕЛИЧИНЫ 173
чго величины X и К должны быть независимы. Действительно, применяя
формулы (8.4.2) и (8.4.3), имеем:
7
J
аналогично
( +у2) '
откуда убеждаемся, что
f()
и, следовательно, величины X и Y независимы.
Вышеизложенный критерий суждения о зависимости или незави-
независимости случайных величин исходит из предположения, что закон
распределения системы нам известен. На практике чаще бывает на-
наоборот: закон распределения системы (Лг, К) не известен; известны
только законы распределения отдельных величин, входящих в систему,
и имеются основания считать, что величины А' и К независимы. Тогда
можно написать плотность распределения системы как произведение
плотностей распределения отдельных величин, входящих в систему.
Остановимся несколько подробнее на важных понятиях о «зави-
«зависимости» и «независимости» случайных величин.
Понятие «зависимости» случайных величин, которым мы пользу-
пользуемся в теории вероятностей, несколько отличается от обычного по-
понятия «зависимости» величин, которым мы оперируем в математике.
Действительно, обычно под «зависимостью» величин подразумевают
только один тип зависимости — полную, жесткую, так называемую
функциональную зависимость. Две величины X и Y называются
функционально зависимыми, если, зная значение одной из них, можно
точно указать значение другой.
В теории вероятностей мы встречаемся с другим, более общим,
типом зависимости — с вероятностной или «стохастической» зави-
зависимостью. Если величина Y связана с величиной X вероятностной
зависимостью, то, зная значение X, нельзя указать точно значение Y,
а можно указать только ее закон распределения, зависящий от того,
какое значение приняла величина X.
Вероятностная зависимость может быть более или менее тесной;
по мере увеличения тесноты вероятностной зависимости она все более
приближается к функциональной. Таким образом, функциональную
зависимость можно рассматривать как крайний, предельный случай
наиболее тесной вероятностной зависимости. Другой крайний случай —
полная независимость случайных величин. Между этими двумя край-
крайними случаями лежат все гпадании веооятностной зависимости — от
самой сильной до самой слабой. Те физические величины, которые
на практике мы считаем функционально зависимыми, в действитель-
действительности связаны весьма тесной вероятностной. зависимостью: при
174 СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 8
заданном значении одной из этих величин другая колеблется в столь
узких пределах, что ее практически можно считать вполне опреде-
определенной. С другой стороны, те величины, которые мы на практике
считаем независимыми, в действительности часто находятся в некоторой
взаимной зависимости, но эта зависимость настолько слаба, что ею
для практических целей можно пренебречь.
Вероятностная зависимость между случайными величинами очень
часто встречается на практике. Если случайные величины X и Y
находятся в вероятностной зависимости, это не означает, что с из-
изменением величины X величина Y изменяется вполне определенным
образом; это лишь означает, что с изменением величины X величина Y
имеет тенденцию также изменяться (например, возрастать или убывать
при возрастании X). Эта тенденция соблюдается лишь «в среднем», в об-
общих чертах, и в каждом отдельном случае от нее возможны отступления.
Рассмотрим, например, две такие случайные величины: X — рост
наугад взятого человека, Y — его вес. Очевидно, величины X и К
находятся в определенной вероятностной зависимости; она выражается
в том, что в общем люди с большим ростом имеют ббльший вес.
Можно даже составить эмпирическую формулу, приближенно заменяю-
заменяющую эту вероятностную зависимость функциональной. Такова, например,
общеизвестная формула, приближенно выражающая зависимость между
ростом и весом:
Y (кг) = Х (см)—100.
Формулы подобного типа, очевидно, не являются точными и вы-
выражают лишь некоторую среднюю, массовую закономерность, тенден-
тенденцию, от которой в каждом отдельном случае возможны отступления.
В вышеприведенном примере мы имели дело со случаем явно
выраженной зависимости. Рассмотрим теперь такие две случайные
величины: X — рост наугад взятого человека; Z — его возраст.
Очевидно, для взрослого человека величины X и Z можно считать
практически независимыми; напротив, для ребенка величины X и Z
являются зависимыми.
Приведем еще несколько примеров случайных величин, находя-
находящихся в различных степенях зависимости.
1. Из камней, составляющих кучу щебня, выбирается наугад
один камень. Случайная величина Q — вес камня; случайная величина
L — наибольшая длина камня. Величины Q и L находятся в явно
выраженной вероятностной зависимости.
2. Производится стрельба ракетой в заданный район океана.
Величина ДА — продольная ошибка точки попадания (недолет, пере-
перелет); случайная величина AV— ошибка в скорости ракеты в конце
активного участка движения. Величины АХ и AV явно зависимы,
так как ошибка AV являеюя одной из главных причин, порождаю-
порождающих продольную ошибку АХ.
8.6) ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ ДВУХ ВЕЛИЧИН 175
3. Летательный аппарат, находясь в полете, измеряет высоту над
поверхностью Земли с помощью барометрического прибора. Рас-
Рассматриваются две случайные величины: Д#— ошибка измерения вы-
высоты и G — вес топлива, сохранившегося в топливных баках к мо-
моменту измерения. Величины АН и G практически можно считать
независимыми.
В следующем п° мы познакомимся с некоторыми числовыми харак-
характеристиками системы случайных величин, которые дадут нам возмож-
возможность оценивать степень зависимости этих величин.
8.6. Числовые характеристики системы двух случайных величин.
Корреляционный момент. Коэффициент корреляции
В главе 5 мы ввели в рассмотрение числовые характеристики
одной случайной величины X— начальные и центральные моменты
различных порядков. Из этих характеристик важнейшими являются
две: математическое ожидание тх и дисперсия Dx.
Аналогичные числовые характеристики — начальные и центральные
моменты различных порядков — можно ввести и для системы двух
случайных величин.
Начальным моментом порядка k, s системы (Лг, К) называется
математическое ожидание произведения Хк на Ys:
4tS = M[XkYs\. (8.6.1)
Центральным моментом порядка k, s системы (X, Y) назы-
называется математическое ожидание произведения &-й и s-й степени
соответствующих центрированных величин:
^ l (8.6.2)
где Х = Х — тх, Y=Y~my.
Выпишем формулы, служащие для непосредственного подсчета
моментов. Для прерывных случайных величин
2^;^7, (8.6.3)
Си = 1111 <Л ~ Щ)к (У/ - т/ рф (8.6.4)
где p.j = P((X = X[)(Y = yj)) — вероятность того, что система (X, Y)
примет значения (xt, yj), а суммирование распространяется по всем
возможным значениям случайных величин X, Y.
176 СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН (ГЛ. 8
Для непрерывных случайных величин:
со
■«*.» = // * V/ (х. у) dx dy. (8.6.5)
— тх? (У — пуУ / (х. у) dx dy, (8.6.6)
где f(x, у) — плотность распределения системы.
Помимо чисел k и s, характеризующих порядок момента по от-
отношению к отдельным величинам, рассматривается еще суммарный
порядок момента k-\-s, равный сумме показателей степеней приХ и У.
Соответственно суммарному порядку моменты классифицируются на
первые, вторые и т. д. На практике обычно применяются только
первые и вторые моменты.
Первые начальные моменты представляют собой уже известные
нам математические ожидания величин X и У, входящих
в систему:
тх = о,, о = М [X* К°1 = М [X],
Совокупность математических ожиданий тх, ту представляет собой
характеристику положения системы. Геометрически это коор-
координаты средней точки на плоскости, вокруг которой происходит рас-
рассеивание точки (X, У).
Кроме первых начальных моментов, на практике широко при-
применяются еще вторые центральные моменты системы. Два из них
представляют собой уже известные нам дисперсии величин X и У:
Dy = (i0, a = M [X* К2) = М ф\ = D [У],
характеризующие рассеивание случайной точки в направлении осей
Ох и Оу.
Особую роль как характеристика системы играет второй сме-
смешанный центральный момент:
т. е. математическое ожидание произведения центрированных величин.
Ввиду того, что этот момент играет важную роль в теории
систем случайных величин, введем для него особое обозначение:
Кху = М [X У] = М l(X —mx)(Y — ту)\. (8.6.7)
Характеристика Кху называется корреляционным моментом
(иначе — «моментом связи») случайных величин X, У.
8.6] ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ ДВУХ ВЕЛИЧИН 177
Для прерывных случайных величин корреляционный момент вы-
выражается формулой
*,, = 2S(*i —»,)(Уу-«у)*у. (8-6.8)
« i
а для непрерывных — формулой
со
Кху = f f(x — тх)(у — my)f(x, y)dxdy. (8.6.9)
— 00
Выясним смысл и назначение этой характеристики.
Корреляционный момент есть характеристика системы случайных
величин, описывающая, помимо рассеивания величин X и Y, еще и
связь между ними. Для того чтобы убедиться в этом, докажем,
что для независимых случайных величин корреляционный момент
равен нулю.
Доказательство проведем для непрерывных случайных величин1).
Пусть А', У — независимые непрерывные величины с плотностью
распределения f(x, у). В п° 8.5 мы доказали, что для независимых
величин
У). (8-6.10)
где fi(x), /2(у) — плотности распределения соответственно величин
X к Y.
Подставляя выражение (8.6.10) в формулу (8.6.9), видим, что
интеграл (8.6.9) превращается в произведение двух интегралов:
00 00
Кху = f(x — тх) fx (х) dx f (y — my) /2 (у) dy.
— 00 —СО !
Интеграл
представляет собой не что иное, как первый центральный момент
величины X, и, следовательно, равен нулю; по той же причине равен
пулю и второй сомножитель; следовательно, для независимых слу-
случайных величин Кху = 0.
Таким образом, если корреляционный момент двух случайных
величин отличен от нуля, это есть признак наличия зависи-
зависимости между ними.
Из формулы (8.6.7) видно, что корреляционный момент характе-
характеризует не только зависимость величин, но и их рассеивание. Дей-
Действительно, если, например, одна из величин (X, Y) весьма мало
отклоняется от своего математического ожидания (почти не случайна),
J) Для прерывных оно может быть выполнено аналогичным способом.
12 £. С. Вентцель
178
СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ. 8
то корреляционный момент будет мал, какой бы тесной зависимостью
ни были связаны величины (X, К). Поэтому для характеристики связи
между величинами (X, Y) в чистом виде переходят от момента КхУ
к безразмерной характеристике
где ах, ау—средние квадратические отклонения величин X, Y. Эта
характеристика называется коэффициентом корреляции величин
X и К. Очевидно, коэффициент корреляции обращается в нуль
одновременно с корреляционным моментом; следовательно, для не-
независимых случайных величин коэффициент корреляции равен
нулю.
Случайные величины, для которых корреляционный момент (а зна-
значит, и коэффициент корреляции) равен нулю, называются некорре-
некоррелированными (иногда — «несвязанными»).
Выясним, эквивалентно ли понятие некоррелированности
случайных величин понятию независимости. Выше мы доказали,
что две независимые случайные величины
всегда являются некоррелированными.
Остается выяснить: справедливо ли обрат-
обратное положение, вытекает ли из некоррели-
некоррелированности величин их независимость?
х Оказывается — нет. Можно построить при-
примеры таких случайных величин, которые
являются некоррелированными, но зави-
зависимыми. Равенство нулю коэффициента
корреляции — необходимое, но не доста-
достаточное условие независимости случайных
величин. Из независимости случайных
величин вытекает их некоррелирован-
некоррелированность; напротив, из некоррелирован-
некоррелированности величин еще не следует их независимость. Условие неза-
независимости случайных величин — более жесткое, чем условие некор-
некоррелированности.
Убедимся с этом ка примере. Рассмотрим систему случайных
величин (X, Y), распределенную с равномерной плотностью внутри
круга С радиуса г с центром в начале координат (рис. 8.6.1).
Плотность распределения величин (X, Y) выражается формулой
с при лг2-|-у2 < г2,
О при jc2-f-y2>r2.
Из условия / / f(x, y)dxdy— / / с dx dy = \ находим с =—-2.
-«. (С)
Рис. 8.6.1,
8.6]
ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ ДВУХ ВЕЛИЧИН 179
Нетрудно убедиться, что в данном примере величины являются
зависимыми. Действительно, непосредственно ясно, что если ве-
величина X приняла, например, значение 0, то величина Y может
с равной вероятностью принимать все значения от — г до -f- г;
если же величина X приняла значение г, то величина Y может при-
принять только одно-единственное значение, в точности равное нулю;
вообще, диапазон возможных значений Y зависит от того, какое
значение приняла X.
Посмотрим, являются ли эти величины коррелированными. Вычис-
Вычислим корреляционный момент. Имея в виду, что по соображениям сим-
симметрии тх = ту = О, получим:
Кху = ffxyfix, y)dxdy = -±r f fxydxdy. (8.6.12)
"(С) (С)
Для вычисления интеграла разобьем область интегрирования (круг С)
на четыре сектора Cv C2, С3, С4, соответствующие четырем коор-
координатным углам. В секторах С1 и С3 подынтегральная функция
положительна, в секторах С2 и С4 — отрицательна; по абсолютной же
величине интегралы по этим секторам равны; следовательно, инте-
интеграл (8.6.12) равен нулю, и величины (А', К) не коррелированы.
Таким образом, мы видим, что из некоррелированности случай-
случайных величин не всегда следует их независимость.
Коэффициент корреляции характеризует не всякую зависимость,
а только так называемую линейную зависимость. Линейная вероятност-
вероятностная зависимость случайных величин заключается в том, что при
возрастании одной случайной величины другая имеет тенденцию
возрастать (или же убывать) по линейному закону. Эта тенденция
к линейной зависимости может быть более или менее ярко выражен-
выраженной, более или менее приближаться к функциональной, т. е. самой
тесной линейной зависимости. Коэффициент корреляции характе-
характеризует степень тесноты линейной зависимости между
случайными величинами. Если случайные величины X а У связаны
точной линейной функциональной зависимостью:
то гху= ±1, причем знак «плюс» или «минус» берется в зависимости
от того, положителен или отрицателен коэффициент а. В общем
случае, когда величины X и К связаны произвольной вероятностной
зависимостью, коэффициент корреляции может иметь значение в пре-
пределах:
- К гху < 1 >).
') Доказательство этих положений будет дано ниже, в п° 10.3, после того
как мы познакомимся с некоторыми теоремами теории вероятностей, кото-
которые позволят провести его очень просто.
12*
180
СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
[Г Л S
В случае гху > 0 говорят о положительной корреляции вели-
величин А' и К, в случае гху < 0 — об отрицательной корреляции.
Положительная корреляция между случайными величинами озна-
означает, что при возрастании одной из них другая имеет тенденцию
в среднем возрастать; отрицательная корреляция означает, что при
возрастании одной из случайных величин- другая имеет тенденцию
в среднем убывать.
В рассмотренном примере двух случайных величин (X, У), рас-
распределенных внутри круга с равномерной плотностью, несмотря на
наличие зависимости между X и К, линейная зависимость отсут-
отсутствует; при возрастании X меняется только диапазон изменения Y,
У
X
. X
Рис. 8.6.2.
Рис. 8.6.3.
а его среднее значение не меняется; естественно, вели-
величины (X, Y) оказываются некоррелированными.
Приведем несколько примеров случайных величин с положитель-
положительной и отрицательной корреляцией.
1. Вес и рост человека связаны положительной корреляцией.
2. Время,. потраченное на регулировку прибора при подготовке
его к работе, и время его безотказной работы связаны положитель-
положительной корреляцией (если, разумеется, время потрачено разумно).
Наоборот, время, потраченное на подготовку, и количество неисправ-
неисправностей, обнаруженное при работе прибора, связаны отрицательной
корреляцией.
3. При стрельбе залпом координаты точек попадания отдельных
снарядов- связаны положительной корреляцией (так как имеются
общие для всех выстрелов ошибки прицеливания, одинаково откло-
отклоняющие от цели каждый из них).
4. Производится два выстрела по цели; точка попадания первого
выстрела регистрируется, и в прицел вводится поправка, пропорцио-
пропорциональная ошибке первого выстрела с обратным знаком. Координаты
8.6]
ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ ДВУХ ВЕЛИЧИН
181
точек попадания первого и второго выстрелов будут связаны отри-
отрицательной корреляцией.
Если в нашем распоряжении имеются результаты ряда опытов
над системой двух случайных величин (X, У), то о наличии или
отсутствии существенной
корреляции между ними
легко судить в первом при-
приближении по графику, на
котором изображены в виде
точек все полученные из
опыта пары значений слу-
случайных величин. Например,
если наблюденные пары зна-
значений величин расположи-
расположились так, как показано на
рис. 8.6.2, то это указывает
на 'наличие явно выражен-
Рис. 8.6.4,
О
х
ной положительной корреля-
корреляции между величинами. Еще
более ярко выраженную положительную корреляцию, близкую к ли-
линейной функциональной зависимости, наблюдаем на рис. 8.6.3. На
рис. 8.6.4 показан случай сравнительно слабой отрицательной корре-
корреляции. Наконец, на рис. 8.6.5 иллюстрируется случай практически
У
х
Рис. 8.6.5.
некоррелированных случайных величин. На практике, перед тем как
исследовать корреляцию случайных величин, всегда полезно предвари-
предварительно построить наблюденные пары значений на графике для первого
качественного суждения о типе корреляции.
Способы определения характеристик системы случайных величин
из опыта будут освещены в гл. 14.
182 СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН ГГЛ. 8
8.7. Система произвольного числа случайных величин
На практике часто приходится рассматривать системы более чем
двух случайных величин. Эти системы интерпретируются как слу-
случайные точки или случайные векторы в пространстве того или иного
числа измерений.
Приведем примеры.
1. Точка разрыва дистанционного снаряда в пространстве харак-
характеризуется тремя декартовыми координатами (X, У, Z) или тремя
сферическими координатами (/?, Ф, в).
2. Совокупность п последовательных измерений изменяющейся
величины X — система п случайных величин (Xv Х2, .... Хп).
3. Производится стрельба очередью из п снарядов. Совокупность
координат п точек попадания на плоскости — система 2ге случайных
величин (абсцисс и ординат точек попадания):
(*,. X,, .... Хп, Yv К2, ..., Кя).
4. Начальная скорость осколка — случайный вектор, характери-
характеризуемый тремя случайными величинами: величиной скорости Vo и двумя
углами Фи 9, определяющими направление полета осколка в сфе-
сферической системе координат.
Полной характеристикой системы произвольного числа случайных
величин служит закон распределения системы, который может
быть задан функцией распределения или плотностью распределения.
Функцией распределения системы п случайных величин
(Xv Х2, ..., Хп) называется вероятность совместного выполнения п
неравенств вида X\ < xt:
F(xv x2 xJ = P((Xl<x{)(Xi<xJ ... (Хп<хп)). (8.7.1)
Плотностью распределения системы п непрерывных случайных
величин называется «-я смешанная частная производная функции
F (jtj, x2 хп), взятая один раз по каждому аргументу:
x2 х„) 8_2
f(x у 82
/(■*!• *2 Х»>— дххдх2...дхп • (8>7>2)
Зная закон распределения системы, можно определить законы
распределения отдельных величин, входящих в систему. Функция
распределения каждой из величин, входящих в систему, получится,
если в функции распределения системы положить все остальные
аргументы равными оо:
F1(xl) = F(xv оо оо). (8.7.3)
Если выделить из системы величин (X,. Х„ Х„) частную
систему (Xlt X2 Xk), то функция распределения этой системы
определяется по формуле
X2, .... хк, оо оо). (8.7.4)
8.7] СИСТЕМА ПРОИЗВОЛЬНОГО ЧИСЛА СЛУЧАЙНЫХ ВЕЛИЧИН 183
Плотность распределения каждой из величин, входящих в систему,
получится, если плотность распределения системы проинтегрировать
в бесконечных пределах по всем остальным аргументам:
со со
/(*!• Х2 xn)dx2 ... dxn. (8.7.5)
Плотность распределения частной системы (Xv Х2 Xk),
выделенной из системы (Хг, Х2, ... • Хп), равна:
Л, 2 k{xV Х2 хк)~
со со
= J ... f f (xv x2 хп) dxk+1 ... dxn. (8.7.6)
—со —со
Условным законом распределения частной системы {Хх, Х2, .... Хк)
называется ее закон распределения, вычисленный при условии, что
остальные величины Xй+1, ..., Хп приняли значения хк+1, .... хп.
Условная плотность распределения может быть вычислена по
формуле
^1 Xh\Xk + \ Хп) 7 JZ J-T> iP.t.l)
Jk+1, .... n{xk+V •••• хп)
Случайные величины (Xv X2. .... Хп) называются независимыми,
если закон распределения каждой частной системы, выделенной из
системы (Хг, Х2 Хп), не зависит от того, какие значения при-
приняли остальные случайные величины.
Плотность распределения системы независимых случайных вели-
величин равна произведению плотностей распределения отдельных вели-
величин, входящих в систему:
/(*1. х2 хп) = fx(Xl)f2(x2) ... fn(xn). (8.7.8)
Вероятность попадания случайной точки (Xv X2 Хп) в пре-
пределы я-мерной области D выражается «-кратным интегралом:
/ dx2 ... dxa. (8.7.9)
Ф)
Формула (8.7.9) по существу является основной формулой для
вычисления вероятностей событий, не сводящихся к схеме случаев.
Действительно, если интересующее нас событие А не сводится
к схеме случаев, то его вероятность не может быть вычислена непо-
непосредственно. Если при этом нет возможности поставить достаточное
число однородных опытов и приближенно определить вероятность
события Л по его частоте, то типичная схема вычисления вероятности
184 СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН _ [ГЛ. в
события сводится к следующему. Переходят от схемы событий к схеме
случайных величин (чаще всего — непрерывных) и сводят событие Л
к событию, состоящему в том, что система случайных величин
(Xv X2 Хп) окажется в пределах некоторой области D. Тогда
вероятность события Л может быть вычислена по формуле (8.7.9).
Пример 1. Самолет поражается дисТаиционным снарядом при условии,
если разрыв снаряда произошел не далее чем на расстоянии R от самолета
(точнее, от условной точки на оси самолета, принимаемой за его центр).
Закон распределения точек разрыва дистанционного снаряда в системе коор-
координат, связанной с целью, имеет плотность / (х, у, г). Определить вероят-
вероятность поражения самолета.
Решение. Обозначая поражение самолета буквой А, имеем:
(С)
где интегрирование распространяется по шару С радиуса R с центром
в начале координат.
Пример 2. Метеорит, встретившийся на пути искусственного спутника
Земли, пробивает его оболочку, если: 1) угол в, под которым метеорит
встречается с поверхностью спутника, заключен в определенных преде-
пределах (в,, в2); 2) метеорит имеет вес не менее qa (г) и 3) относительная ско-
скорость встречи метеорита со спутником не меньше va (м/сек). Скорость
встречи v, вес метеорита q и угол встречи О представляют собой систему
случайных величин с плотностью распределения / (v, q, 0). Найти вероят-
вероятность р того, что отдельный метеорит, попавший в спутник, пробьет его
оболочку.
Решение. Интегрируя плотность распределения / (v, q, 0) по трех-
трехмерной области, соответствующей пробиванию оболочки, получим:
' шах z
f f f (v, q, 0) dv dq db,
где qmtx — максимальный вес метеорита, vmat — максимальная скорость
встречи.
8.8. Числовые характеристики системы нескольких
О Л Г1IJ I»
Закон распределения системы (заданный функцией распределения
или плотностью распределения) является полной, исчерпывающей
характеристикой системы нескольких случайных величин. Однако
очень часто такая исчерпывающая характеристика не может быть
применена. Иногда ограниченность экспериментального материала не
дает возможности построить закон распределения системы. В других
случаях исследование вопроса с помощью сравнительно громоздкого
аппарата законов распределения не оправдывает себя в связи с не-
невысокими требованиями к точности результата. Наконец, в ряде
8.8] ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ НЕСКОЛЬКИХ ВЕЛИЧИН 185
задач примерный тип закона распределения (нормальный закон)
известен заранее и требуется только найти его характеристики.
Во всех таких случаях вместо законов распределения применяют
неполное, приближенное описание системы случайных величин с по-
помощью минимального количества числовых характеристик.
Минимальное число характеристик, с помощью которых может
быть охарактеризована система п случайиых величин Xv Х2, .... Х„,
сводится к следующему:
1) п математических ожиданий
mv m2, .... тп,
характеризующих средние значения величин;
2) п дисперсий
Dv D2 Da,
характеризующих их рассеивание;
3) п(п — 1) корреляционных моментов
где
о «
X i = X i — fitf, X1 = X1 —
характеризующих попарную корреляцию всех величин, входящих
в систему.
Заметим, что дисперсия каждой из случайных величин Xt есть,
по существу, не что иное, как частный случай корреля-
корреляционного момента, а именно корреляционный момент вели-
величины Х( и той же величины Xt:
Все корреляционные моменты и дисперсии удобно расположить в виде
прямоугольной таблицы (так называемой матрицы):
'V21 Л22 * • • /Ч2я
1 KnX К„2 • • • Кпп
Эта таблица называется корреляционной матрицей системы слу-
случайных величин (Xv Х2 Хп).
Очевидно, что ке все члены .корреляционной матрицы различны.
Из определения корреляционного момента ясно, что Kij = Kji, т. е.
элементы корреляционной матрицы, расположенные симме-
симметрично по отношению к главной диагонали, равны. В связи
186
СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
[ГЛ. 8
с этим часто заполняется не вся корреляционная матрица, а лишь ее
половина, считая от главной диагонали:
*Ч
Л12 • • • К i
/С22 • • • Къ
Корреляционную матрицу, составленную из элементов 1(^, часто
сокращенно обозначают символом ЦАГ^-Ц.
По главной диагонали корреляционной матрицы стоят дисперсии
случайных величин Xv Х2 Хп.
В случае, когда случайные величины Хг, Х2,
лированы, все элементы корреляционной матрицы
ных, равны нулю:
Э, О
., Хп не корре-
кроме диагональ-
диагональим =
О
о
Такая матрица называется диагональной.
В целях наглядности суждения именно о коррелирован-
коррелированно с т и случайных величин безотносительно к их рассеиванию часто
вместо корреляционной матрицы ||/С,у|| пользуются нормированной
корреляционной матрицей \\г1}\\, составленной не из корреляцион-
моментов, а из коэффициентов корреляции:
где
Все диагональные элементы этой матрицы, естественно, равны еди-
единице. Нормированная корреляционная матрица имеет вид:
II г.- ,11 =
1 '~12 •' !3 • • • ' I
1 /*9Ч • • • Гг>п
..
1 . . . Г„ II
8.8] ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ НЕСКОЛЬКИХ ВЕЛИЧИН 187
Введем понятие о некоррелированных системах случайных величин
(иначе — о некоррелированных случайных векторах). Рассмотрим
две системы случайных величин:
(Xv *2 *•„); (Vv Y2, .... Yn)
—>
или два случайных вектора в «-мерном пространстве: X с составляю-
составляющими (Xv Х2 Хп) и К с составляющими (Kj, K2 Yn).
Случайные векторы X и К называются некоррелированными, если
->
каждая из составляющих вектора ^Y не коррелирована с каждой из
составляющих вектора Y:
K*M[XlYj]=0 при /=sl. ...,я; /=1 п.
ГЛАВА 9
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ
ДЛЯ СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
9.1. Нормальный закон на плоскости
Из законов распределения системы двух случайных величин имеет
смысл специально рассмотреть нормальный закон, как имеющий наи-
наибольшее распространение на практике. Так как система двух слу-
случайных величин изображается случайной точкой на плоскости, нор-
нормальный закон для системы двух величин часто называют «нормальным
законом на плоскости».
В общем случае плотность нормального распределения двух слу-
случайных величин выражается формулой
1 2A
1 К*-",)» Ъ{*-"хI?-ту) (У уJ]
(9.1.1)
Этот закон зависит от пяти параметров: тх, ту, <зх, <зу и г.
Смысл этих параметров нетрудно установить. Докажем, что пара-
параметры тх, ту представляют собой математические ©жидания (центры
рассеивания) величин X и Y; ах, ау — их средние квадратические
отклонения; г — коэффициент корреляции величин X и Y.
Для того чтобы убедиться в этом, найдем прежде всего плот-
плотность распределения для каждой из величин, входящих в систему.
Согласно формуле (8.4.2)
е L
9П НОРМАЛЬНЫЙ ЗАКОН НА ПЛОСКОСТИ 189
Вычислим интеграл
1 \{х~тхУ 2'(х-тх)(у-ту) (у-туJ]
I—. I e V х * у -1 dy.
— 00
Положим:
х — т. у — mv
__£ = «, JL»=tr, (9.1.2)
тогда
1
J е *-'* dv.
— 00
Из интегрального исчисления известно, что
? Г— Ас~в%
j e-Ax*±2Bx+cdx==y JL е~ а 1). (9.1.3)
— 00
В нашем случае
А = —^—- В— т • С= "" ""'
Подставляя эти значения в формулу (9.1.3), имеем:
/ =
откуда
или, учитывая (9.1.2),
Таким образом, величина X подчинена нормальному закону
с центром рассеивания тх и средним квадратическим отклонением ах.
(У~туJ
f2(y) = —±=-e 2al , (9.1.5)
т. е. величина К подчинена нормальному закону с центром рассеи-
рассеивания ту и средним квадратическим отклонением оу.
') Для вычисления интеграла (9.1.3) достаточно дополнить показатель
степени до полного квадрата и после замены переменной воспользоваться
интегралом Эйлера—Пуассона F.1.3).
190 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН [ГЛ. 9
Остается доказать, что параметр г в формуле (9.1.1) предста-
представляет собой коэффициент корреляции величин X и У. Для этого
вычислим корреляционный момент:
Кху — j J (х — тх) (у — ту) f (х, у) dx dy,
— со
где тх, ту — математические ожидания величин X и У.
Подставляя в эту формулу выражение f (х, у), получим!
Кху =
где
2r(x~mx)(y-my) (y-
Произведем в двойном интеграле (9.1.6) замену переменных,
положив:
х — тх 1 /у — mv х—т
Якобиан преобразования равен
следовательно,
со
'^ и Л ^
— со
Учитывая, что
оо
■ )',
\—гг
со
» / О .' j
со
■ / ие~
— со
u'du
2c xc
ru
f\ — r2
CO
— CO
CO
— со
CO
-"-*du dw=
I ue~u dti = / we~w dw = 0', I ue~u du=^-L-^—j
J J J 2 1
CO
9.Ц НОРМАЛЬНЫЙ ЗАКОН НА ПЛОСКОСТИ 191
имеем:
Кху = гахау; г = -^-. (9.1.8)
Таким образом, доказано, что параметр г в формуле (9.1.1) пред-
представляет собой коэффициент корреляции величин X и Y.
Предположим теперь, что случайные величины X и Y, подчинен-
подчиненные нормальному закону на плоскости, не коррелированы; положим
в формуле (9.1.1) г = 0. Получим:
(х-тху (у-шу)»
1 9 2 9 2
/(*. У) = 2^Те ' (9Л'9)
Легко убедиться, что случайные величины (X, Y), подчиненные
закону распределения с плотностью (9.1.9), не только не коррели-
коррелированы, но и независимы. Действительно,
т. е. плотность распределения системы равна произведению плотно-
плотностей распределения отдельных величин, входящих в систему, а это
значит, что случайные величины (А', К) независимы.
Таким образом, для системы случайных величин, подчиненных
нормальному закону, из некоррелированности величин вытекает также
их независимость. Термины «некоррелированные» и «независимые»
величины для случая нормального распределения эквивалентны.
При г =£ 0 случайные величины (X, Y) зависимы. Нетрудно убе-
убедиться, вычисляя условные законы распределения по формулам (8.4.6),
что
1 Iх
g(i-rn
f(x\v),_l ,._g % :
- ■ ' - ' a, I/ 1 — r2 V 2k
Проанализируем однк из зтих условных законов распределения,
например f(y\x). Для этого преобразуем выражение плотности f{y\x)
к виду:
192 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН [ГЛ. 9
Очевидно, это есть плотность нормального закона с центром, рас-
рассеивания
^ (9.1.10)
и средним квадратическим отклонением
°y\* = °yVlZ:rr*- (9.1.11)
Формулы (9.1.10) и (9.1.11) показывают, что в условном законе
распределения величины У при фиксированном значении X = х от
этого значения зависит только математическое ожидание,
нонедисперсия.
Величина ту\х называется условным математическим ожи-
ожиданием величины Y при данном х. Зависимость (9.1.10) можно изо-
изобразить на плоскости хОу, откладывая условное математическое ожи-
ожидание tnyiJC по оси ординат. Получится прямая, которая называется
линией регрессии Y на X. Аналогично прямая
х = тх + г^(у — ту) (9.1.12)
есть линия регрессии X т Y.
Линии регрессии совпадают только при наличии линейной функ-
функциональной зависимости К от X. При независимых X и Y линии
регрессии параллельны координатным осям.
Рассматривая выражение (9.1.1) для плотности нормального рас-
распределения на плоскости, мы видим, что нормальный закон на плоскости
полностью определяется заданием пяти параметров: двух координат
центра рассеивания тх, ту, двух средних квадратических отклоне-
отклонений ах, <зу и одного коэффициента корреляции г. В свою очередь
последние -три параметра ох, ау и г полностью определяются эле-
элементами корреляционной матрицы: дисперсиями Dx, Dv и корреля-
корреляционным моментом КхГ Таким образом, минимальное количество
числовых характеристик системы — математические ожидания, диспер-
дисперсии и корреляционный момент — в случае, когда система подчинена
нормальному закону, определяет собой полностью закон распределе-
распределения, т. е. образует исчерпывающую систему характеристик.
Так как на практике нормальный закон весьма распространен,
то очень часто для полной характеристики закона распределения
системы оказывается достаточно задать минимальное число — всего
пять — числовых характеристик.
9.2] ЭЛЛИПСЫ РАССЕИВАНИЯ. ПРИВЕДЕНИЕ НОРМАЛЬНОГО ЗАКОНА 193
9.2. Эллипсы рассеивания. Приведение нормального закона
к каноническому виду
Рассмотрим поверхность распределения, изображающую функцию
(9.1.1). Она имеет вид холма, вершина которого находится над точ-
точкой (тх, ту) (рис. 9.2.1).
В сечении поверхности распределения плоскостями, параллельными
оси / (лг, у), получаются кривые, подобные нормальным кривым рас-
распределения. В сечении поверхности распределения плоскостями, парал-
параллельными плоскости хОу, получаются эллипсы. Напишем уравнение
проекции такого эллипса на плоскость хОу.
•+■
(х—тх)г
или, обозначая константу X2,
(х — тх)г 1г (х — тх) (у — ту)
• = const,
==Х2. (9.2л)
Уравнение эллипса (9.2.1) можно проанализировать обычными ме-
методами аналитической геометрии. Применяя их, убеждаемся, что центр
эллипса (9.2.1) находится в точке с координатами (тх, ту); что ка-
касается направления осей сим-
симметрии эллипса, то они со-
составляют с осью Ох углы,
определяемые уравнением
-1). (9.2.2)
f(x,y)
Это уравнение дает два зна-
значения углов: а и av разли-
различающиеся на y .
Таким образом, ориента-
ориентация эллипса (9.2.1) относи-
относительно координатных осей
находится в прямой зависи-
зависимости от коэффициента кор-
корреляции г системы (X. Y): если величины не коррелированы (т. в.
в данном случае и независимы), то оси Симметрия эллипса парал-
параллельны координатным осям; в противном случае они составляют
с координатными осями некоторый угол.
Рис, 9.2.1,
О Обоснование формулы (9.2.2) другим способом см. в п° 14.7.
13 Е. С. Бентцель
194 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН [ГЛ. 9
Пересекая поверхность распределения плоскостями, параллельными
плоскости хОу, и проектируя сечения на плоскость хОу, мы полу-
получим целое семейство подобных и одинаково расположенных эллипсов
с общим центром (тх, ту). Во всех точках каждого из таких эллип-
эллипсов плотность распределения / (х, у) постоянна. Поэтому такие эл-
эллипсы называются эллипсами равной плотности или, короче,
эллипсами рассеивания. Общие оси всех эллипсов рассеивания
называются главными осями рассеивания.
Известно, что уравнение эллипса принимает наиболее простой,
так называемый «канонический» вид, если координатные оси совпа-
совпадают с осями симметрии эллипса. Для того чтобы привести уравне-
уравнение эллипса рассеивания к каноническому виду, достаточно перенести
начало координат в точку (тх, ту) и повернуть координатные оси
на угол а, определяемый уравнением (9.2.2). При этом координатные
оси совпадут с главными осями рассеивания, и нормальный закон
на плоскости преобразуется к так называемому «каноническому» виду.
Каноническая форма нормального закона на плоскости имеет вид:
где о;, о —так называемые главные средние квадратические от-
отклонения, т. е. средние квадратические отклонения случайных величин
(S, Н), представляющих собой координаты случайной точки в системе
координат, определяемой главными осями рассеивания 0%, Ov\. Глав-
Главные средние квадратические отклонения <jj и о выражаются через
средние квадратические отклонения в прежней системе координат
формулами:
о2 = <з\ cos2 а -|- racv sin 2а + <s\ sin2 а, 1
с2 = а2 sin2 а — га с sin 2а + о2 cos2а.. | 1 '
Обычно, рассматривая нормальный закон на плоскости, стараются
заранее выбрать координатные оси Ох, Оу так, чтобы они совпали
с гласными осями рассеивания. При этом средние квадратичеекпг
отклонения по осям ах, оу и будут главными средними квадратиче-
скими отклонениями, и нормальный закон будет иметь вид:
■г* У2
/С У)-s^- ^ "*. (9-2-6)
В некоторых случаях координатные оси выбирают параллельно
главным осям рассеивания, но начало координат с центром рассеива-
') Вывод этих формул см. в главе 14, п° 14.7.
9.2] ЭЛЛИПСЫ РАССЕИВАНИЯ. ПРИВЕДЕНИЕ НОРМАЛЬНОГО ЗАКОНА 195
ния не совмещают. При этом случайные величины (X, Y) также ока-
оказываются независимыми, но выражение нормального закона имеет вид:
y)=^~e ^ 2i , (9.2.6)
где тх, Шу — координаты центра рассеивания.
Перейдем в канонической форме нормального закона (9.2.5) от
средних квадратических отклонений к вероятным отклонениям:
Величины Ех, Еу называются главными вероятными отклонениями.
Подставляя выражения сх, оу через Ех, Еу в уравнение (9.2.5), по-
получим другую каноническую форму нормального закона:
(9.2.7)
В такой форме нормальный закон часто применяется в теории
стрельбы.
Напишем уравнение эллипса рассеивания в каноническом виде:
где k — постоянное число.
Из уравнения видно, что полуоси эллипса рассеивания пропорцио-
пропорциональны главным средним квадратическим отклонениям (а значит, и
главным вероятным отклонениям).
Назовем «единичным» эллипсом рассеивания тот из эллипсов
равной плотности вероятности, полуоси которого равны главным
средним квадратическим отклонениям ах, оу. (Если пользоваться
и качестве характеристик рассеивания не главными средними квядря-
тическими, а главными вероятными отклонениями, то естественно
будет назвать «единичным» тот эллипс, полуоси которого равны Ех, Еу.)
Кроме единичного эллипса рассеивания иногда рассматривают еще
«полный» эллипс рассеивания, под которым понимают тот из эллип-
эллипсов равной плотности вероятности, в который с практической досто-
достоверностью укладывается все рассеивание. Размеры этого эллипса,
разумеется, зависят от того, что понимать под «практической досто-
достоверностью». В частности, если принять за «практическую достовер-
достоверность» вероятность порядка 0,99, то «полным эллипсом рассеива-
рассеивания» можно считать эллипс с полуосями Ъох, Зо?.
13*
196 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН 1ГЛ. 9
Рассмотрим специально один частный случай, когда главные
средние квадратические отклонения равны друг другу:
Тогда все эллипсы рассеивания обращаются в круги, и рассеива-
рассеивание называется круговым. При круговом рассеивании каждая из осей,
проходящих через центр рассеивания, может быть принята за главную
ось рассеивания, или, другими словами, направление главных осей
рассеивания неопределенно. При некруговом рассеивании случайные
величины X, Y, подчиненные нормальному закону на плоскости, не-
независимы тогда и только тогда, когда координатные оси параллельны
главным осям рассеивания; при круговом рассеивании случайные ве-
величины {X, К) независимы при любом выборе прямоугольной системы
координат. Эта особенность кругового рассеивания приводит к тому,
что оперировать с круговым рассеиванием гораздо удобнее, чем
с эллиптическим. Поэтому на практике, где только возможно, стре-
стремятся приближенно заменять некруговое рассеивание круговым.
9.3. Вероятность попадания в прямоугольник со сторонами,
параллельными главным осям рассеивания
Пусть случайная точка (Л", Y) на плоскости подчинена нормаль-
нормальному закону
(x-mx)i (У-туу
е
ОС
(9.3.1)
При этом главные оси рассеива-
рассеивания параллельны координатным осям
и величины X и ^независимы.
Требуется вычислить вероятность
попадания случайной точки (X, Y)
в прямоугольник R, стороны кото-
которого параллельны координатным
осям хОу, а следовательно и глав-
главным осям рассеивания (рис. 9.3.1). Согласно обшей формуле (8.3.4)
имеем:
9 5
Р[(.Х, Г) <=/?) = \ Г fix, y)dxdy =
fi
Рис, 9.3.1,
dx
[ 1
J cvV2T
dy.
8.3]
ВЕРОЯТНОСТЬ ПОПАДАНИЯ В ПРЯМОУГОЛЬНИК
197
откуда, применяя формулу F.3.3) для вероятности попадания на уча-
участок, находим:
Р((Х, Y)<=R) =
где Ф*(х) — нормальная функция распределения.
Если нормальный закон на плоскости дан в канонической форме,
то тх = ту = 0, и формула (9.3.2) принимает вид
Если стороны прямоугольника не параллельны координатным осям,
то формулы (9.3.2) и (9.3.3) уже неприменимы. Только при круговом
рассеивании вероятность попадания
в прямоугольник любой ориентации
вычисляется по формулам (9.3.2) или
(9.3.3).
Формулы (9.3.2) и (9.3.3) широко
применяются при вычислении вероят-
вероятностей попадания в цели: прямо-
прямоугольные, близкие к прямоуголь-
прямоугольным, составленные из прямоуголь-
прямоугольников или приближенно заменяемые
таковыми.
Пример. Производится стрельба -4,5
с самолета по прямоугольному щиту
размером 9 м X12 м, лежащему на
земле горизонтально. Главные вероят-
вероятные отклонения: в продольном напра-
направлении В, = 10 м, в боковом направле-
направлении Bq—Ъм. Прицеливание— по центру
мишени, заход — вдоль мишеии. Вслед-
Вследствие несовпадения дальности при-
пристрелки и дальности фактической стрель-
стрельбы средняя точка попадания смещается в сторону недолета на 4 м. Найти
п;рсятиость попадания в мишень при одном выстреле.
Решение. На чертеже (рис. 9.3.2) наносим мишень, точку прицелива-
прицеливания (т. п.) и центр рассеивания (ц. р.). Через ц. р. проводим главные осн
рассеивания: по направлению полета и перпендикулярно к нему.
Перейдем от главных вероятных отклонений Вл и В$ к главным сред-
средним квадратическим:
В6 В,
7,4 м; з« = -TTEwr « н.» -»•
Рис. 9.3.2<
г"~ 0,674
По формуле (9.3.3) имеем:
0,674
-а.»
198 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН [ГЛ. 9
9.4. Вероятность попадания в эллипс рассеивания
К числу немногих плоских фигур, вероятность попадания в кото-
которые может быть вычислена в конечном виде, принадлежит эллипс
рассеивания (эллипс равной плотности).
Пусть нормальный закон на плоскости задан в канонической
форме:
1ЛЛ
-~
1 ( )
* V* »' (9.4.1)
Рассмотрим эллипс рассеивания Bk, уравнение которого
где параметр k представляет собой отношение полуосей эллипса
рассеивания к главным средним квадратическим отклонениям. По общей
формуле (8.3.3) имеем:
Р{(Х, Y)cBk) = f f f(x, y)dxdy =
2 т 2
■е ^ х y'dxdy. (9.4.2)
(Bk)
Сделаем в интеграле (9.4.2) замену переменных
JL — u- J- = v
ах ау
Этой подстановкой эллипс Bk преобразуется в круг Ск радиуса k.
Следовательно,
Р((Х, Y)cBk) = ~ f J'e~^~~* dudv. (9.4.3)
Перейдем в интеграле (9.4.3) от декартовой системы координат
к полярной, положив
и = г cos 6; f = rsin6. (9.4.4)
Якобиан преобразования (9.4.4) равен г. Производя замену перемен-
ных, получим:
j
Р((Х, Y)aBk) = ~ f f re 2 drd%— / re 2 =1 —e
-л О О
9.4]
ВЕРОЯТНОСТЬ ПОПАДАНИЯ В ЭЛЛИПС РАССЕИВАНИЯ
199
Таким образом, вероятность попадания случайной точки в эллипс
рассеивания, полуоси которого равны k средним квадратическим
отклонениям, равна:
Р((Х.
(9.4.5)
В качестве примера найдем вероятность попадания случайной
точки, распределенной по нормальному закону на плоскости хОу,
в единичный эллипс рассеивания, полуоси которого равны средним
квадратическим отклонениям:
Для такого эллипса k=l. Имеем:
Р((Х, Y) с Вг) = 1-е".
Пользуясь таблицей 2 приложения, находим:
Р((Х, Y) с Я,) » 0,393.
Формула (9.4.5) чаще всего применяется для вычисления вероят-
вероятности попадания в круг при круговом рассеивании.
Пример. На пути быстро движущейся малоразмерной цели площади
1,2 м ставится осколочное поле в форме плоского диска радиуса Я = 30м.
Внутри диска плотность осколков постоянна и равна 2 оск./м2. Если цель на-
накрыта диском, то число осколков, попада-
попадающих в нее, можно считать распределен-
распределенным по закону Пуассона. В силу малости
цели можно рассматривать ее как точечную
и считать, что она или полностью накры-
накрывается осколочным полем (если ее центр
попадает в круг), или совсем не накры-
накрывается (если ее центр не попадает в круг).
Попадание осколка гарантирует поражение
цели. При прицеливании центр круга Oj
стремятся совместить в плоскости хОу
с началом координат О (центром цели),
но вследствие_ ошибок точка О\ рассеи-
■■" "тся около О (рис. 9.4.1). Закон рассеива-
рассеивания нормальный, рассеивание круговое,
а = 20 м. Определить вероятность Йораже-
ния цели Р(А).
Решение. Чтобы цель была пора-
поражена осколками, необходимо совмещение
двух событий: 1) попадание цели (точки О) в осколочное поле (круг
радиуса R) и 2) поражение цели при условии, что попадание произошло.
Вероятность попадания цели в круг, очевидно, равна вероятности того,
что центр круга (случайная точка Oj) попадет в круг радиуса R, описанный
вокруг начала координат. Применим формулу (9.4.5). Имеем:
1,5.
Рис 9.4.1.
= 1>0~
200 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН [ГЛ. 9
Вероятность попадания цели в осколочное поле равна:
1.5»
р=\—е 2 «0,675.
. Далее найдем вероятность поражения цели р* при условии, что она иа-
крыта осколочным диском. Среднее число осколков а, попадающих в на-
накрытую полем цель, равно произведению площади цели на плотность поля
осколков:
1,2-2 = 2,4.
Условная вероятность поражения цели р* есть не что иное, как вероят-
вероятность попадания в нее хотя бы одного осколка. Пользуясь формулой E.9.5)
главы 5, имеем:
/>• = /?, = 1— в-а«0,909.
Вероятность поражения цели равна:
Р (А) = 0,675 • 0,909 да 0,613.
Воспользуемся формулой (9.4.5) для вероятности попадания
в круг, чтобы вывести одно важное для практики распределение:
так называемое распределение Релея.
Рассмотрим на плоскости хОу (рис. 9.4.2) случайную точку (X, Y),
рассеивающуюся вокруг начала координат О по круговому нормаль-
нормальному закону со средним квадра-
тическим отклонением с. Найдем
закон распределения случайной ве-
величины R — расстояния от точки
(X, Y) до начала координат, т. е.
длины случайного вектора с соста-
составляющими X, Y.
Найдем сначала функцию распре-
распределения F(r) величины R. По опре-
определению
Рис. 9.4.2. Это есть не что иное, как ве-
вероятность попадания случайной точки
(X, Y) внутрь круга радиуса г (рис. 9.4.2). По формуле (9.4.5)
эта вероятность равна:
F(r)=l-e
где k — —
т. е.
' 2ч"
(9.4.6)
Данное выражение функции распределения имеет смысл только
при положительных значениях г; при отрицательных г нужно поло-
положить F(r)=0.
9.41
ВЕРОЯТНОСТЬ ПОПАДАНИЯ В ЭЛЛИПС РАССЕИВАНИЯ
20!
Дифференцируя функцию распределения F(r) по г, найдем плот-
плотность распределения **
г —
а2
О
при
при
г>0,
г<0.
(9.4.7)
Закон Релея (9.4.7) встречается в разных областях практики:
в стрельбе, радиотехнике, электротехнике и др.
График функции /(г) (плотности закона Релея) приведен на
рис. 9.4.3.
Найдем числовые характеристики величины R, распределенной по
закону Релея, а именно: ее моду <уН и математическое ожидание тг
Для того чтобы найти моду —
абсциссу точки, в которой плот-
плотность вероятности максимальна,
продифференцируем /(/•) и
приравняем производную нулю:
1-£-0; * = А
Корень этого уравнения и есть
искомая мода
аМ = о. (9.4.8)
О а тг
Таким образом, наивероятней- рИй д43
шее значение расстояния R случай-
случайной точки (X, К) от начала координат равно среднему квадратиче-
скому отклонению рассеивания.
Математическое ожидание тТ найдем по формуле
mr= / rf(r)dr =
о о
Производя замену переменной
г
получим:
г = оУ2 f 2Pe-'1dt = cSy~2 f
j-2te-pdt.
о о
Интегрируя по частям, найдем математическое ожидание расстоя-
расстояния /?:
= а|/|« 1,25а.
(9.4.9)
202 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН [ГЛ. S
9.5. Вероятность попадания в область произвольной формы
При стрельбе ударными снарядами вычисление вероятности по-
попадания в цель сводится к вычислению вероятности попадания слу-
случайной точки (X, Y) в некоторую область D. Пусть случайная
точка (X, Y) подчинена нормальному закону в каноническом виде. Ве-
Вероятность попадания точки (XI Y) в область D выражается интегралом
_£L У2
^ ^ dxdy. (9.5.1)
В отдельных частных случаях (например, когда область D есть
прямоугольник со сторонами, параллельными главным осям рас-
рассеивания, или эллипс рассеивания, а также в некоторых других,
имеющих меньшее практическое зна-
значение) интеграл (9.5.1) может быть
выражен через известные функции;
в общем же случае этот интеграл
через известные функции не выра-
выражается. На практике для вычисления
вероятности попадания в область
произвольной формы применяются
следующие приближенные способы.
1. Область D приближенно за-
заменяется областью, составленной из
х прямоугольников, стороны которых
параллельны главным осям рассеива-
рис 95 1,. ния (рис. 9.5.1). Вероятность по-
попадания в каждый из таких прямо-
прямоугольников вычисляется по формуле (9.3.3). Этот способ можно
рекомендовать тогда, когда число прямоугольников, щ которые при-
приближенно разбивается цель D, не слишком велико.
2. Вся плоскость хОу с помощью некоторой системы линий
(прямых или кривых) заранее разбивается на ряд ячеек, вероятности
попадания в которые могут быть выражены точно через известные
функции, и вычисляется вероятность попадания в каждую ячейку.
Такая система линий с соответствующими ей вероятностями попадания
в ячейки называется сеткой рассеивания. Работа с сеткой заклю-
заключается в том, что изображение сетки накладывается на изображение
цели, после чего производится суммирование вероятностей попадания
в ячейки, накрытые целью; если цель накрывает часть ячейки, то
берется часть вероятности попадания в ячейку, пропорциональная
накрытой площади.
Сетку рассеивания можно применять двояким образом: а) строить
цель в масштабе сетки, б) строить сетку в масштабе цели.
9.5] ВЕРОЯТНОСТЬ ПОПАДАНИЯ В ОБЛАСТЬ ПРОИЗВОЛЬНОЙ ФОРМЫ 203
Если цель имеет сложные очертания и, особенно, если она срав-
сравнительно невелика, бывает обычно удобнее построить на изображении
цели в том же масштабе ту часть сетки, которая занята целью.
Если же цель имеет сравнительно простые очертания и довольно
велика (занимает значительную часть полного эллипса рассеивания),
У
1
1
I
2
г
г
г
3
4
5
5
6
7
8
9
10
10
II
II
12
0
0
1
I
2
2
2
3
3
4
5
Б
7
8
9
9
10
II
11
II
0
1
0
1
1
г
2
2
3
4
5
6
6
7
8
9
10
10
II
II
1
0
1
1
1
1
2
2
3
4
5
5
6
7
8
8
10
10
10
10
0
1
0
1
1
1
2
2
3
3
4
5
6
6
7
8
8
9
9
10
0
0
1
1
1
1
2
2
3
3
4
5
5
6
7
7
8
8
9
9
0
0
0-
0
1
1
2
2
2
3
4
4
5
6
6
6
7
7
8
8
0
1
1
1
1
1
1
Счз
2
3
3
4
4
5
5
6
5
6
7
7
1
0
0
0
0
1
1
1
2
2
2
3
4
4
5
5
5
6
В
6
0
0
0
1
1
1
1
1
Счз
Счз
Счз
2
3
4
4
4
5
5
5
5
0
0
1
0
1
1
1
1
1
2
2
2
Счз
3
3
3
4
4
4
5
0
0
0
0
0
1
1
1
1
1
2
2
см
г
3
3
3
3
3
4
0
0
0
1
0
0
1
1
1
1
1
1
2
2
2
2
г
2
3
3
0
0
0
0
0
0
1
1
1
1
1
1
1
2
2
2
2
2
2
Счз
0
1
0
0
0
1
0
0
.1
1
1
1
1
1
1
1
1
2
2
1 Счз
0
0
0
0
1
1
0
1
1
1
1
2
/
2
Счз
0
0
1
0
0
1
0
1
0
1
1
1
1
1
Счз
0
0
0
0
1
0
0
1
0
I
0
1
0
1
1
1
0
0
0
0
0
0
1
0
0
1
0
1
0
I
0
0
0
0
0
0
1
0
0
0
0
1
0
0
1
-Рис. 9.5.2.
обычно удобнее построить цель в масштабе сетки. Так как стан-
стандартная сетка строится для кругового рассеивания, а на практике
рассеивание в общем случае круговым не является, при построении
Цели в масштабе сетки приходится в общем случае пользоваться
Двумя разными масштабами по осям Ох и Оу. При этом способе
удобно иметь в распоряжении сетку рассеивания, выполненную на
прозрачной бумаге, и накладывать ее на перестроенное изображение
иели. Прямолинейная сетка рассеивания для одного координатного
Угла дана на рис. 9.5.2. Сторона ячейки равна 0.-2Я» 0,1 ЗЗо.
204 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН [ГЛ. 9
В ячейках проставлены вероятности попадания в них, выраженные
в сороковых долях процента.
3. В случае, когда размеры области D невелики по сравнению со
средними квадратическими отклонениями (не превышают 0,5—1 с. к. о.
в направлении соответствующих осей), вероятность попадания в эту
область может быть приближенно
вычислена по формуле, не содер-
содержащей операции интегрирования.
Рассмотрим на плоскости хОу
малую цель D произвольной формы
(рис. 9.5.3). Допустим, что размеры
этой цели невелики по сравнению
х с вероятными отклонениями Ех, Еу,
По общей формуле (8.3.3) имеем:
Рис. 9.5.3. =fff(x,y)dxdy, (9.5.2)
(D)
где f(x, у) — плотность распределения системы (X, Y). Применим
к интегралу (9.5.2) теорему о среднем значении:
площадь
(О)
где (х0, у0) — некоторая точка внутри области D; SD ■
области D.
В случае, когда система (X, Y) подчинена нормальному закону
в каноническом виде, имеем: 2 2
*о Уо
/>(№K)cD) = ^8 2°' 2°у. (9.5.3)
При сравнительно малых размерах области D плотность распре-
распределения / (х, у) в пределах этой области изменяется мало и практи-
практически может быть принята постоянной. Тогда в качестве точки (х0, у0)
можно выбрать любую точку в пределах области D (например, при-
приблизительный центр цели).
Формулы типа (9.5.3) широко применяются на практике. Для
областей, наибольшие размеры которых не превышают 0,5 среднего
квадратического отклонения в соответствующем направлении, они
дают вполне приемлемые по точности результаты. В отдельных слу-
случаях их применяют и для более крупных областей (порядка одного
с. к. о.). При условии внесения некоторых поправок (а именно, за-
замены величин аг, ау несколько увеличенными значениями) область
применимости этой формулы может быть расширена на области раз-
размером порядка двух с. к, о.
9.6] НОРМАЛЬНЫЙ ЗАКОН В ПРОСТРАНСТВЕ ТРЕХ ИЗМЕРЕНИЙ 205
9.6. Нормальный закон в пространстве трех измерений.
Общая запись нормального закона для системы
произвольного числа случайных величин
При исследовании вопросов, связанных со стрельбой дистанцион-
дистанционными снарядами, приходится иметь дело с законом распределения
точек разрыва дистанционного снаряда в пространстве. При условии
применения обычных дистанционных взрывателей этот закон распре-
распределения может считаться нормальным.
В данном п° мы рассмотрим лишь каноническую форму нормаль-
нормального закона в пространстве:
_! /-£L+J!l+_£!_\
(9.6.1)
где <зх, <зу, аг — главные средние квадратические отклонения.
Переходя от средних квадратических отклонений к вероятным,
имеем:
При решении задач, связанных со стрельбой дистанционными
снарядами, иногда приходится вычислять вероятность разрыва ди-
дистанционного снаряда в пределах заданной области D. В общем
случае эта вероятность выражается тройным интегралом:
Р((Х, У, Z)cD)== f fff(x. У- z)dxdydz. (9.6.3)
(£0
Интеграл (9.6.3) обычно не выражается через элементарные
функции. Однако существует ряд областей, вероятность попадания
в которые вычисляется сравнительно просто.
1. Вероятность попадания в прямоугольный
параллелепипед со сторонами, параллельными
главным осям рассеивания
Пусть область R представляет собой прямоугольный параллелепи-
параллелепипед, ограниченный абсциссами а, [3, ординатами •{, 8 и аппликатами г, tj
(рис. 9.6.1). Вероятность попадания в область R, очезидно, равна:
Р{(Х, Y, Z)cR) =
(9.6.4)
206 нормальный закон распределения для системы величин [гл. 9
2. Вероятность попадания
в эллипсоид равной плотности
Рассмотрим эллипсоид равной плотности Bk, уравнение которого
j.2 V2 ~2
± |_ JL_1__ Ь2
2 "Г 2 "Г 2 — * '
ах °у °г
Полуоси этого эллипсоида пропорциональны главным средним
квадратическим отклонениям:
а =г kax; Ъ = kay; с = kaz.
Пользуясь формулой (9.6.1) для f(x, у, г), выразим вероятность
•г
Рис. 9.6,1,
попадания в эллипсоид Bk:
Р[{Л, Y.
^ 4D+4+4)
j е ч с* "* *•*'
' dx dy dz.
Перейдем от декартовых координат к полярным (сферическим)
заменой переменных
х
= /-cos8cos
-2- = г cos G sin cp,
— = rsin8.
(9.6.5)
9.6]
НОРМАЛЬНЫЙ ЗАКОН В ПРОСТРАНСТВЕ ТРЕХ ИЗМЕРЕНИЙ 207
Якобиан преобразования (9.6.5) равен:
/ = г2 cos Ьахауаг.
Переходя к новым переменным, имеем:
Р((Х, Y, Z)cBk) =
■к
k 2" 2* , k ,
= —Ц-у у у /-2cosee 2 drdbd<f= у ^J r2e 2 dr.
Интегрируя по частям, получим:
, Г.
dr =
= 2Ф*(А) — 1- ]/ 4*« 2 ' (9.6.6)
3. Вероятность попадания в цилиндрическую
область с образующей, параллельной одной
из главных осей рассеивания
Рассмотрим цилиндрическую область С, образующая которой
параллельна одной из главных осей рассеивания (например, оси Oz),
а направляющая есть контур произвольной области D на пло-
плоскости хОу (рис. 9.6.2). Пусть область С ограничена двумя плоско-
плоскостями г = г и z-=f\. Вычислим вероятность попадания в область С;
это есть вероятность произведения
двух событий, первое из которых
состоит в попадании точки (X, Y)
в область D, а второе — в попадании
величины Z на участок (г, rj). Так
как величины (X, Y, Z), подчинен-
подчиненные нормальному закону в канони-
канонической форме, независимы, то неза-
независимы и эти два события. Поэтому
Р((Х, Y, Z)cC) =
(9.6.7)
Рис. 9.6.2.
Вероятность Р((Х, Y)czD) в формуле (9.6.7) может быть вы-
вычислена любым из способов вычисления вероятности попадания
любым из
в плоскую область.
208 НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ ДЛЯ СИСТЕМЫ ВЕЛИЧИН [ГЛ. 9
На формуле (9.6.7) основан следующий способ вычисления ве-
вероятности попадания в пространственную область О произвольной
формы: область О приближенно разбивается на ряд цилиндрических
областей Ov Qp ... (рис. 9.6.3), и вероятность попадания в каждую
■G2
Рис. 9.6.3,
из них вычисляется по формуле (9.6.7). Для применения этого спо-
способа достаточно начертить ряд фигур, представляющих собой сечения
области О плоскостями, параллельными одной из координатных
плоскостей. Вероятность попадания в каждую из них вычисляется
по сетке рассеивания.
В заключение данной главы напишем общее выражение для нор-
нормального закона в пространстве любого числа измерений п.
Плотность распределения такого закона имеет вид:
~* 21
ii
где \С\ — определитель матрицы С, С= \\Си\\—матрица, обратная
корреляционной матрице /С, т. е. если корреляционная матрица
то
) -щ
где |АГ|—определитель корреляционной матрицы, a Mtj — минор
этого определителя, получаемый из него вычеркиванием 1-й строки
9.6] НОРМАЛЬНЫЙ" ЗАКОН В ПРОСТРАНСТВЕ ТРЕХ ИЗМЕРЕНИЙ
и У-го столбца. Заметим, что
209
Из общего выражения (9.6.8) вытекают все формы нормального
закона для любого числа измерений ц для любых видов зависимости
между случайными величинами. В частности, при я = 2 (рассеивание
на плоскости) корреляционная матрица есть
где г — коэффициент корреляции. Отсюда
1*1 ■=<**(!-^ icl=-
•>
Подставляя определитель матрицы \С\ и ее члены в (9.6.8), полу-
получим формулу (9.1.1) для нормального закона на плоскости, с которой
мы начали п°9.1.
ГЛАВА 10
ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ
СЛУЧАЙНЫХ ВЕЛИЧИН
10.1. Математическое ожидание функции.
Дисперсия функции
При решении различных задач, связанных со случайными явле-
явлениями, современная теория вероятностей широко пользуется аппара-
аппаратом случайных величин. Для того чтобы пользоваться этим аппара-
аппаратом, необходимо знать законы распределения фигурирующих в задаче
случайных величин. Вообще говоря, эти законы могут быть опреде-
определены из опыта, но обычно опыт, целью которого является определение
закона распределения случайной величины или системы случайных
величин (особенно в области военной техники), оказывается и слож-
сложным и дорогостоящим. Естественно возникает задача — свести объем
эксперимента к минимуму и составлять суждение о законах распре-
распределения случайных величин косвенным образом, на основании уже
известных законов распределения других случайных величин. Такие
косвенные методы исследования случайных величин играют весьма
большую роль в теории вероятностей. При этом обычно интересую-
интересующая нас случайная величина представляется как функция дру-
других случайных величин; зная законы распределения аргумен-
аргументов, часто удается установить закон распределения функции. С рядом
задач такого типа мы встретимся в дальнейшем (см. главу 12).
Однако на практике часто встречаются случаи, когда нет особой
надобности полностью определять закон распределения функции слу-
случайных величин, а достаточно только указать его числовые харак-
характеристики: математическое ожидание, дисперсию, иногда —некоторые
из высших моментов. К тому же очень часто самые законы распре-
распределения аргументов бывают известны недостаточно хорошо. В связи
с этим часто возникает задача об определении только числовых
характеристик функций случайных величин.
Рассмотрим такую задачу: случайная величина Y есть функция
нескольких случайных величин Xv Х2, .... Xл:
10.11 МАТЕМАТИЧЕСКОЕ ОЖИДАНИЕ ФУНКЦИИ ДИСПЕРСИЯ ФУНКЦИИ 211
Пусть нам известен закон распределения системы аргументов
(Xv Х2, .... Хп); требуется найти числовые характеристики вели-
величины К, в первую очередь — математическое ожидание и дисперсию.
Представим себе, что нам удалось тем или иным способом найти
закон распределения g(y) величины К. Тогда задача об определении
числовых характеристик становится тривиальной; они находятся по
формулам:
, = f yg (у) dy>
—оо
оо
и т. д.
Однако самая задача нахождения закона распределения g(y) ве-
величины Y часто оказывается довольно сложной. К тому же для
решения поставленной нами задачи нахождение закона распределения
величины Y как такового вовсе и не нужно: чтобы найти только
числовые характеристики величины К, нет надобности знать ее закон
распределения; достаточно знать закон распределения аргументов
(Xv X4 Хп). Более того, в некоторых случаях, для того чтобы
найти числовые характеристики функции, не требуется даже знать
закона распределения ее аргументов; достаточно бывает знать лишь
некоторые числовые характеристики аргументов.
Таким образом, возникает задача определения числовых характе-
характеристик функций случайных величин помимо законов распре-
распределения этих функций.
Рассмотрим задачу об определении числовых характеристик функ-
функции при заданном законе распределения аргументов. Начнем с самого
простого случая — функции одного аргумента — и поставим следую-
следующую задачу.
Имеется случайная величина X с заданным законом распределе-
распределения; другая случайная величина К связана с X функциональной за-
зависимостью: Y = o(X)
Требуется, не находя закона распределения величины К, опреде-
определить ее математическое ожидание:
ту=>М[<?(Х)]. A0.1.1)
Рассмотрим сначала случай, когда К есть прерывная случайная
величина с рядом распределения:
Xi II Х^
Л|Л|Л ••• Рп
14*
212 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. Iff
Выпишем возможные значения величины Y и вероятности этих
значений:
Pi
Pi
Pt
?(*„)
A0.1.2)
Pa
Таблица A0.1.2) не является в строгом смысле слова рядом распре-
распределения величины К, так как в общем случае некоторые из значений
?(*i). ?(**) ?(*») . A0.1.3)
могут совпадать между собой; к тому же эти значения в верхнем
столбце таблицы A0.1.2) не обязательно идут в возрастающем порядке.
Для того чтобы от таблицы A0.1.2) перейти к подлинному ряду
распределения величины К, нужно было бы расположить значения
A0.1.3) в порядке возрастания, объединить столбцы, соответствую-
соответствующие равным между собой значениям К, и сложить соответствующие
вероятности. Но в данном случае нас не интересует закон распре-
распределения величины Y как таковой; для наших целей — определения
математического ожидания — достаточно такой «неупорядоченной»
формы ряда распределения, как A0.1.2). Математическое ожидание
величины Y можно определить по формуле
,. A0.1.4)
Очевидно, величина ту = М[у(Х)], определяемая по формуле A0.1.4),
не может измениться от того, что под знаком суммы некоторые
члены будут объединены заранее, а порядок членов изменен.
В формуле A0.1.4) для математического ожидания функции не
содержится в явном виде закона распределения самой функции,
а содержится только закон распределения аргумента. Таким образом,
для определения математического ожидания функции вовсе не
требуется знать закон распределения этой функции, а доста-
достаточно знать закон распределения аргумента.
Заменяя в формуле A0.1.4) сумму интегралом, а вероятность pi—
элементом вероятности, получим аналогичную формулу для непрерыв-
непрерывной случайной величины:
=* j<?(x)f(x)dx.
A0.1.5)
где / (X) — плотность распределения величины X.
Аналогично может быть определено математическое ожидание
функции ср(Х, Y) от двух случайных аргументов X и Y. Для пре-
прерывных величин _, „,
М [ср {X, УI = £ S ср (*,, у,) ри. A0.1.6)
10.1] МАТЕМАТИЧЕСКОЕ ОЖИДАНИЕ ФУНКЦИИ, ДИСПЕРСИЯ ФУНКЦИИ 213
где рц = Р((Х = лгг) (К = у})) — вероятность того, что система {X, Y)
примет значения (xit yj).
Для непрерывных величин
М
= j ff(x, у) f{x, y)dxdy, A0.1.7)
где f{x, у) — плотность распределения системы (X, Y).
Совершенно аналогично определяется математическое ожидание
функции от произвольного числа случайных аргументов. Приведем
соответствующую формулу только для непрерывных величин:
M[<?{XV Х2 Хп)] =
(xi' х* •"• xn)f(*v X2 xn)dx1dx2 ... dxn,
-°° -00 A0.1.8)
где /(-"ч. х2, .... хп) —^плотность распределения системы
(Xv Ху, .... Хп).
Формулы типа A0.1.8) весьма часто встречаются в практическом
применении теории вероятностей, когда речь идет об осреднении
каких-либо величин, зависящих от ряда случайных аргументов.
Таким образом, математическое ожидание функции любого числа
случайных аргументов может быть найдено помимо закона распреде-
распределения функции. Аналогично могут быть найдены и другие числовые
характеристики функции — моменты различных порядков. Так как
каждый момент представляет собой математическое ожидание неко-
некоторой функции исследуемой случайной величины, то вычисление любого
момента может быть осуществлено приемами, совершенно аналогич-
аналогичными вышеизложенным. Здесь мы приведем расчетные формулы только
для дисперсии, причем лишь для случая непрерывных случайных
аргументов.
Дисперсия функции одного случайного аргумента выражается
формулой
00
D [<р (X)) = J [ср (лг) — т^ f (х) dx, A0.1.9)
— оо
где т^ = М [ср (х)] — математическое ожидание функции ср (X);
j \х) — плотность распределения величины X.
Аналогично выражается дисперсия функции двух аргументов:
00
D[cp(A-, Y)]=JJ[<t(x. у) — m^f{x, y)dxdy, A0.1.10)
—оо
214 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН 1ГЛ. 10
где т —математическое ожидание функции ср (A", Y);
/(■*• У) — плотность распределения системы (X, У).
Наконец, в случае произвольного числа аргументов, в аналогичных
обозначениях:
j, х2 xn)dx1dx2...dxn.
-°° -=° A0.1.11)
Заметим, что часто при вычислении дисперсии бывает удобно
пользоваться соотношением между начальным и центральным момен-
моментами второго порядка (см. главу 5) и писать:
со
D [ср (X)} = J [ср (х)? / (х) dx — n%
A0.1.12)
, y)?f(x,
A0.ЫЗ)
,. X2 Л-п)] =
00
1. х2,..., xn)dxldx2...dxn—
-00 -°° A0.1.14)
Формулы A0.1.12) — A0.1.14) можно рекомендовать тогда, когда
4 они не приводят к разностям близких чисел,
т. е. когда т сравнительно невелико.
Рассмотрим несколько примеров, иллюстри-
иллюстрирующих применение изложенных выше методов
для решения практических задач.
Пример 1. На плоскости задан отрезок дли-
длины / (рис. 10.1.1), вращающийся случайным образом
так, что все направления его одинаково вероятны.
Отрезок проектируется на неподвижную ось АВ.
Определить среднее значение длины проекции от-
отрезка.
Решение. Длина проекции равна:
Г = /1 cos а |,
Рис 10.1.1. где угол в —случайная величина, распределенная
_ с равномерной плотностью на участке 0,2я.
По формуле A0.1.5) имеем:
т = M[l \cosa\] =
==^ я 0,637,'.
10.11 'МАТЕМАТИЧЕСКОЕ ОЖИДАНИЕ ФУНКЦИИ ДИСПЕРСИЯ ФУНКЦИИ 215
Пример 2. Удлиненный осколок снаряда, который можно схемати-
схематически изобразить отрезком длины /, летит, вращаясь вокруг центра массы
таким образом, что все его ориентации в пространстве одинаково вероятны.
На своем пути осколок встречает плоский экран, перпендикулярный к напра-
направлению его движения, и оставляет в нем пробоину. Найти математиче-
математическое ожидание длины этой пробоины.
Решение, Прежде всего дадим
математическую формулировку утвер-
утверждения, заключающегося в том, что
«все ориентации осколка в простран-
пространстве одинаково вероятны». Направле-
Направление отрезка / будем характеризовать
единичным вектором г (рис. 10.1.2).
Направление вектора г в сферической
системе координат, связанной с плос-
плоскостью Р, на которую производится
проектирование, определяется двумя
углами: углом 9, лежащим в плоскости
Р, и углом <р, лежащим в плоскости,
вероятности всех направлений вектора г все положения его конца на поверх-
поверхности сферы единичного радиуса С должньГ обладать одинаковой плотностью
вероятности; следовательно, элемент вероятности
f {Ь, f) db d<f,
где / F, <р) — плотность распределения углов 0, у, должен быть пропорциона-
пропорционален элементарной площадке ds на сфере С; эта элементарная площадка равна
Рис, 10.1.2,
перпендикулярной к Р. При равной
откуда
/ (в, <f)
ds =
d<t = A cos
d<? cos
f (9, ?) = A cos <
где А — коэффициент пропорциональности.
Значение коэффициента А найдем из соотношения
//(в,
А =
J
Таким образом, плотность распределения углов в, у выражается формулой
0 < в < 2к,
(iO.i.lo)
/ (в> Ч) = XT cos ¥ ПРИ
■а
~2
2*
Спроектируем отрезок на плоскость Р; длина проекции равна:
Y = I cos tp.
216 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН 1ГЛ. 18
Рассматривая К как функцию двух аргументов в и <р « применяя фор-
формулу A0.1.7), получим:
■■М\
2* 2 2
-^- J db J cosJ9d? = i- I cos2 <?d<?=* ~ я 0,7851.
Таким образом, средняя длина пробоины, оставляемой осколком в экране,
равна 0,785 длины осколка.
Пример 3. Плоская фигура площади S беспорядочно вращается в про-
пространстве так, что все ориентации этой фигуры одинаково вероятны. Найти
среднюю площадь проекции фигуры S на неподвижную плоскость Р
(рис; 10.1.3).
Решение. Направление плоскости фигуры S в пространстве будем
характеризовать направлением нормали N к этой плоскости. С плоскостью Р
свяжем ту же сферическую систему координат, что в предыдущем примере.
Направление нормали N к площадке S характеризуется случайными углами в
■г и <р, распределенными с плотностью A0.1.5). Пло-
" щадь Z проекции фигуры S на плоскость Р равна
cos(-£- — H|=S| sin?l,
а средняя площадь проекции
mz = M[S \ sin<р\] =
2%
if-1
cos <р | sin у |rf? =»-£-.
Рис 10 13
Таким образом, средняя площадь проекции
произвольно ориентированной плоской фигуры
на неподвижную плоскость равна половине
площади этой фигуры.
Пример 4. В процессе слежения радиолокатором за определенным
объектом пятно, изображающее объект, все время удерживается в пределах
экрана. Экран представляет собой круг К радиуса R. Пятно занимает на
экране случайное положение с постоянной плотностью вероятности. Найти
среднее расстояние от пятна до центра экрана.
Решение. Обозначая расстояние D, имеем D — YX2 -]-- Уг , где
X, Y— координаты пятна; / (х, у) — ^j в пределах круга К и равна нулю
за его пределами. Применяя формулу A0.1.7) и переходя в ишеграле к ш>-
лярным координатам, имеем:
2u R
(К)
Пример 5. Надежность (вероятность безотказной работы) техниче-
технического устройства есть определенная функция р (X, Y, Z) трох параметров,
характеризующих работу регулятора. Параметры X, Y, Z представляют собой
случайные величины с известной плотностью распределения / (х, у. г).
10.1] МАТЕМАТИЧЕСКОЕ ОЖИДАНИЕ ФУНКЦИИ. ДИСПЕРСИЯ ФУНКЦИИ 217
Найти среднее значение (математическое ожидание) надежности устройства
и среднее квадратическое отклонение, характеризующее ее устойчивость.
Решение. Надежность устройства р (X, Y, Z) есть функция трех слу-
случайных величин (параметров) X, У, Z. Ее среднее значение (математическое
ожидание) найдется по формуле A0.1.8):
оо
тр = М [р (X, V,Z)] = JJJp {х, у, г) f (х, у, г) dx dy dz. A0.1.16)
— 00
По формуле A0.1.14) имеем:
оо
= J f J
{p{x,y,z)?f(x,y,z)dxdydz.
Формула A0.1.16), выражающая среднюю (полную) вероятность
безотказной работы устройства с учетом случайных величин, от ко-
которых зависит эта вероятность в каждом конкретном случае, пред-
представляет собой частный случай так называемой интегральной фор-
формулы полной вероятности, обобщающей обычную формулу полной
вероятности на случай бесконечного (несчетного) числа гипотез.
Выведем здесь эту формулу в общем виде.
Предположим, что опыт, в котором может появиться или не по-
появиться интересующее нас событие А, протекает в случайных, за-
заранее неизвестных условиях. Пусть эти условия характеризуются
непрерывными случайными величинами
Xv Х2 Хп, A0.1.17)
плотность распределения которых
Х2 Хп).
Вероятность РА появления события А есть некоторая функция
случайных величин A0.1.17):
PA(XV X2, .... Хп). A0.1.18)
Нам нуусю найти среднее значение этой вероятности или, другими
словами, полную вероятность события А:
РД = М[РА(Х1. Х2 ХЛ
Применяя формулу A0.1.8) для математического ожидания функ-
функции, найдем:
xn)dxxdx2 ... dxn.
A0.1.19)
218 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
Формула A0.1.19) называется интегральной формулой полной
вероятности. Нетрудно заметить, что по своей структуре она сходна
с формулой полной вероятности, если заменить дискретный ряд ги-
гипотез непрерывной гаммой, сумму — интегралом, вероятность гипо-
гипотезы — элементом вероятности:
/ (хи х2 хп) dx1 dx2 ... dxn,
а условную вероятность события при данной гипотезе—условной
вероятностью события при фиксированных значениях случайных ве-
величин:
Pa(xV Х2> • • •• Хп)-
Не менее часто, чем интегральной формулой полной вероятности,
пользуются интегральной формулой полного математического
ожидания. Эта формула выражает среднее (полное) математическое
ожидание случайной величины Z, значение которой принимается в
опыте, условия которого заранее неизвестны (случайны). Если эти
условия характеризуются непрерывными случайными величинами
Хх, Хг Хп
с плотностью распределения
f (xv х2, .... хп),
а математическое ожидание величины Z есть функция от величин
Xv Х-г "■п'
тг(Х\< Х2 Хп),
то полное математическое ожидание величины Z вычисляется по
формуле
J/
!. х2 *«)/(*!, хг. .... xn)dxxdx2 ... dxn,
A0.1.20)
которая называется интегральной формулой полного матема-
математического ожидания.
Пример 6. Математическое ожидание расстояния D, на котором
будет обнаружен объект с помощью четырех радиолокационных станций,
зависит от некоторых технических параметров этих станций:
Xt, Х2, Xa, Xit
которые представляют собой независимые случайные величины с плотностью
распределения
/(*,, хг, лг3, х4) = /, (д:,) /2 (хг) /3 (х3) /4 U4)-
При фиксированных значениях параметров Хх = хи Х2 — хъ Хъ = х^>
А'4 = Xt математическое ожидание дальности обнаружения равно
10.2] ТЕОРЕМЫ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 219
Найти среднее (полное) математическое ожидание дальности обнару-
обнаружения.
Решение. По формуле A0.1.20) имеем:
10.2. Теоремы о числовых характеристиках
В предыдущем п° мы привели ряд формул, позволяющих нахо-
находить числовые характеристики функций, когда известны законы рас-
распределения аргументов. Однако во многих случаях для нахождения
числовых характеристик функций не требуется знать даже законов
распределения аргументов, а достаточно знать только некоторые их
числовые характеристики; при этом мы вообще обходимся без ка-
каких бы то ни было законов распределения. Определение числовых
характеристик функций по заданным числовым характеристикам ар-
аргументов широко применяется в теории вероятностей и позволяет
значительно упрощать решение ряда задач. По преимуществу такие
упрощенные методы относятся к линейным функциям; однако неко-
некоторые элементарные нелинейные функции также допускают подобный
подход.
В настоящем п° мы изложим ряд теорем о числовых характери-
характеристиках функций, представляющих в своей совокупности весьма про-
простой аппарат вычисления этих характеристик, применимый в широком
круге условий.
1. Математическое ожидание неслучайной величины
Если с — неслучайная величина, то
М[с\ — с.
Сформулированное свойство является достаточно очевидным; дока-
доказать его можно, рассматривая неслучайную величину с как частный
вид случайной, при одном возможном значении с вероятностью еди-
единица; тогда по общей формуле для математического ожидания:
М[с] = с-\=с.
2. Д и с п е р с и я н е с л у ч а й н о й величины
Если с — неслучайная величина, то
D[c] = 0.
Доказательство. По определению дисперсии
D [с] = М [с2] = М[(с — тс?\ = М[{с — с?\ = М [0] == 0.
220 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
3. Вынесение неслучайной величины
за знак математического ожидания
Если с — неслучайная величина, а X — случайная, то
М[сХ] = сМ[Х], A0.2.1)
т. е. неслучайную величину можно выносить за знак мате-
математического ожидания.
Доказательство.
а) Для прерывных величин
М [сХ] = 2 cxipt = с 2 XiPi = сМ [X].
б) Для непрерывных величин
оо оо
М[сХ\ = f сх/(х) dx = c f х/ (х) dx = сМ [X].
— оо —со
4. Вынесение неслучайной величины
за знак дисперсии и среднего квадратического
отклонения
Если с — неслучайная величина, а X — случайная, то
D[cX] = c2D[X], A0.2.2)
т. е. неслучайную величину можно выносить за знак диспер-
дисперсии, возводя ее в квадрат.
Доказательство. По определению дисперсии
п [сХ] — М \{сХ — М [сХ\ J] =
= М [(сХ — стх?\ = сШ l(X — tnxf\ = c*D \X\.
Следствие
с[сХ] = \с\о[Х],
т. е. неслучайную величину можно выносить за знак среднего квад-
ратического отклонения ее абсолютным значением. Доказательство
получим, извлекая корень квадратный из формулы A0.2.2) и учиты-
учитывая, что с.к.о.—существенно положительная величина.
10.21 ТЕОРЕМЫ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 221
5. Математическое ожидание суммы
случайных величин
Докажем, что для любых двух случайных величин X и К
A0.2.3)
т. е. математическое ожидание суммы двух случайных величин
равно сумме их математических ожиданий.
Это свойство известно под названием тео&еми сложения мате-
математических ожиданий.
Доказательство.
а) Пусть (X, Y) — система прерывных случайных величин. При-
Применим к сумме случайных величин общую формулу A0.1.6) для ма-
математического ожидания функции двух аргументов:
=2 2 х{ри+2 2 ytPij—
=2 •*< 2 рц+2 У] 2 рц-
Но 2/ty представляет собой не что иное, как полную вероят-
вероятность того, что величина X примет значение х{.
следовательно,
2*/2/^
Аналогично докажем, что
и теорема доказана.
б) Пусть (X, К) — система непрерывных случайных величин. По
формуле A0.1.7)
GO
М [X 4- У] = f f (-V + у) f (х, у) их йу =
—оо
оо оо
. y)dxdy + J fyf(x, y)dxdy. A0.2.4)
222 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ, 10
Преобразуем первый из интегралов A0.2.4):
f fxf(x, y)dxdy = f x\ f f{x, y)dy \dx=*
— oo —oo I —oo J
00
= / xfl(x)dx =
аналогично
00
f f
и теорема доказана.
Следует специально отметить, что теорема сложения математи-
математических ожиданий справедлива для любых случайных вели-
величин— как зависимых, так и независимых.
Теорема сложения математических ожиданий обобщается на про-
произвольное число слагаемых:
(Ю.2.5)
т. е. математическое ожидание суммы нескольких случайных
величин равно сумме их математических ожиданий.
Для доказательства достаточно применить метод полной ин-
индукции.
6. Математическое ожидание линейной функции
Рассмотрим линейную функцию нескольких случайных аргументов
*li *2 *я"
п
где ait Ъ — неслучайные коэффициенты. Докажем, что
/И
Г я 1 п
^ atXt + 0=2 а,А1 [КЛ -+- Ь, A0.2.6)
т. е." математическое ожидание линейной функции равно той же
линейной функции от математических ожиданий аргументов.
10.21 ТЕОРЕМЫ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 223
Доказательство. Пользуясь теоремой сложения м. о. и пра-
правилом вынесения неслучайной величины за знак м. о., получим:
= М [g OlX^ + M [b] =
7. Дисперсия суммы случайных величин
Дисперсия суммы двух случайных величин равна сумме их диспер-
дисперсий плюс удвоенный корреляционный момент:
Kxr A0.2.7)
Доказательство. Обозначим
Z = X-\-Y. A0.2.8)
По теореме сложения математических ожиданий
m2t=mx-\-mr A0.2.9)
Перейдем от случайных величин X, Y, Z к соответствующим
о о о
центрированным величинам X, Y, Z. Вычитая почленно из равенства
A0.2.8) равенство A0.2.9), имеем:
По определению дисперсии
D [X + К] = D [Z\ = М \Ъ\ =
= М [X2] + 2М [XY] Н- М [К2] = D [X] + 2Кху + D[Y],
что и требовалось доказать.
Формула A0.2.7) для дисперсии суммы может быть обобщена на
любое число слагаемых:
| £Ки, A0.2.10)
где К1} — корреляционный момент величин Xt, Xf, знак i</ под
суммой обозьачаег, что суммирование распространяется на все воз-
возможные попарные сочетания случайных величин (Xlt Х2, .... Хп).
224 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИИ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
Доказательство аналогично предыдущему и вытекает из формулы
для квадрата многочлена.
Формула A0.2.10) может быть записана еще в другом виде:
где двойная сумма распространяется на все элементы корреляцион-
корреляционной матрицы системы величин (Xv Х2 Хп), содержащей как
корреляционные моменты, так и дисперсии.
Если все случайные величины (Xlt Х2 Хп), входящие в си-
систему, некоррелированы (т. е. Кц = Ъ при l=f=J). формула A0.2.10)
принимает вид:
[я и я
D[Xt]. A0.2.12)
т. е. дисперсия суммы некоррелированных случайных величин
равна сумме дисперсий слагаемых.
Это положение известно под названием теоремы сложения
дисперсий.
8. Дисперсия линейной функции
Рассмотрим линейную функцию нескольких случайных величин.
2
где аь, Ь — неслучайные величины.
Докажем, что дисперсия этой линейной функции выражается
формулой
[п Л п
A0.2.13)
[п Л п
2<*j*i + * =2 <4D\X,
ы\ J i=i l
где Ку — корреляционный момент величин Хг, Xj.
Доказательство. Введем обозначение:
Тогда
2 2 A0.2,14)
Применяя к правой части выражения A0.2.14) формулу A0.2.10)
для дисперсии суммы и учитывая, что В [и] — 0, получим:
Z)f 2 fl,*i + * I = 2 ЯМ + 2 2 Щ= 2 a\D [ХЛ+ 2 2 К?),
A0.2.15)
,10.21 ТЕОРЕМЫ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 229
где К($ — корреляционный момент величин Ylt Yji
Вычислим этот момент. Имеем:
о
аналогично
о
Отсюда
Подставляя это выражение в A0.2.15), приходим к формуле
A0.2.13).
В частном случае, когда все величины (Xv X2, .... Ха) некор-
некоррелированны, формула A0.2.13) принимает вид:
(Ю.2.16)
т. е. дисперсия линейной функции некоррелированных случай-
случайных величин равна сумме произведений квадратов коэффициен-
коэффициентов на дисперсии соответствующих аргументов').
9. Математическое ожидание произведения
случайных величин
Математическое ожидание произведения двух случайных величин
равно произведению их математических ожиданий плюс корреляцион-
корреляционный момент: ^
M{XY\ = M[X}M{Y\ + Kxr A0.2.17)
Доказательство. Будем исходить из определения корреля-
корреляционного момента:
Кху = MlXY] = M[(X—mx)(Y — my)],
где
тх = М[Х\; my = M[Y].
Преобразуем это выражение, пользуясь свойствами математиче-
математического ожидания:
= М [XY] — тхМ [Y] — туМ [X] + тхту = М [XY] — М [X] М [Y],
что, очевидно, равносильно формуле A0.2.17),
') Так как независимые величины всегда являются некоррелированными,
то ясе свойства, доказываемые в данном п° для некоррелированных величин,
справедливы для независимых величин.
15 Е, С, Вснтцгл
226 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
Если случайные величины (X, Y) некоррелированны (Кху = 0), то
формула A0.2.17) принимает вид:
M{XY\ = M{X\M[Y\, A0.2.18)
т. е. математическое ожидание произведения двух некоррели-
некоррелированных случайных величин равно произведению их матема-
математических ожиданий.
Это положение известно под названием теоремы умножения
математических ожиданий.
Формула A0.2.17) представляет собой не что иное, как выраже-
выражение второго смешанного центрального момента системы через второй
смешанный начальный момент и математические ожидания:
^ = 1*11 = «u — т*тг A0.2.19)
Это выражение часто применяется на практике при вычислении
корреляционного момента аналогично тому, как для одной случайной
величины дисперсия часто вычисляется через второй начальный мо-
момент и математическое ожидание.
Теорема умножения математических ожиданий обобщается и на
произвольное число сомножителей, только в этом случае для ее при-
применения недостаточно того, чтобы величины были некоррелированны,
а требуется, чтобы обращались в нуль и некоторые высшие смешан-
смешанные моменты, число которых зависит от числа членов в произведении.
Эти условия заведомо выполнены при независимости случайных вели-
величин, входящих в произведение. В этом случае
-1 я
, -п
A0.2.20)
т. е. математическое ожидание произведения независимых
случайных величин равно произведению их математических
ожиданий.
Это положение легко доказывается методом полной индукции.
10. Дисперсия произведения независимых
случайных величин
Докажем, что для независимых величин X. У
Доказательство. Обозначим XY = Z. По определению
дисперсии
D [XY\ = D[Z\ = M [Z21 = M [(Z — тгJ].
10-2] ТЕОРЕМЫ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 227
Так как величины X, У независимы, тг — тхту и
D [XY] = М [(ХУ—тхтуJ] = М [Х2У2] — 2тхтуМ [XV] + т2хт2.
При независимых X, У величины X2, Y2 тоже независимы5);
следовательно,
М[Х2У2) = М[Х2]М[У2], М[ХУ] — тхту
и
D \XY\ = М [X2] М [Y2] — т\т2 A0.2.22)
х у
Но М [X2] есть не что иное, как второй начальный момент вели-
величины X, и, следовательно, выражается через дисперсию:
аналогично
Подставляя эти выражения в формулу A0.2.22) и приводя подоб-
подобные члены, приходим к формуле A0.2.21).
В случае, когда перемножаются центрированные случайные вели-
величины (величины с математическими ожиданиями, равными нулю), фор-
формула A0.2.21) принимает вид:
D[XY] = D[X]D[Y], A0.2.23)
т. е. дисперсия произведения независимых центрированных
случайных величин равна произведению их дисперсий:
11. Высшие моменты суммы случайных
величин
В некоторых случаях приходится вычислять высшие моменты
суммы независимых случайных величин. Докажем некоторые относя-
относящиеся сюда соотношения.
1) Если величины X, Y независимы, то
ЫЛ-Ч-П = ЫЛ-] + ЫП. A0.2.24)
Доказательство.
\ = M\{X +Y ~ тх — myf] =
+ ЪМ [{X - тх) (У — ту)Ц + М [(У - myf},
') Можно доказать, что любые функции от независимых случайных
величин также независимы.
15*
228 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЯ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
откуда по теореме умножения математических ожиданий
Но первый центральный момент jij для любой величины равен
нулю; два средних члена обращаются в нуль, и формула A0.2.24)
доказана.
Соотношение A0.2.24) методом индукции легко обобщается на
произвольное число независимых слагаемых:
[л "j п
~х Л. j I = ^j [1, [Л jj. (Hj.Z.Zo)
i=\ J i=l
2) Четвертый центральный момент суммы двух независимых слу-
случайных величин выражается формулой
DxDy. A0.2.26;
где Dx, Dy— дисперсии величин X и Y.
Доказательство совершенно аналогично предыдущему.
Методом полной индукции легко доказать обобщение формулы
A0.2.26) на произвольное число независимых слагаемых:
N [2"*/] = 2 14\Xt\ + 6 2 DxpXj. A0.2.27)
Аналогичные соотношения в случае необходимости легко вывести
и для моментов более высоких порядков.
12. Сложение некоррелированных случайных
векторов
Рассмотрим на плоскости хОу два некоррелированных случайных
->
вектора: вектор V1 с составляю-
составляющими (Xv Kj) и вектор V2 с соста-
составляющими (Х2, Y2) (рис. 10.2.1).
Рассмотрим их векторную
сумму:
т. е. вектор с составляющими:
2\ == 2\ j —J— 2\ 2*
Рис. 10.2.1. Требуется определить число-
числовые характеристики случайного
■у
вектора V — математические ожидания тх, ту, дисперсии и корреля-
корреляционный момент составляющих: Dx, Dv> Kxy.
10.2J ТЕОРЕМЫ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 229
По теореме сложения математических ожиданий:
По теореме сложения дисперсий
Докажем, что корреляционные моменты также складываются:
где К , К — корреляционные моменты составляющих каждого из
векторов V\ и V2.
Доказательство. По определению корреляционного момента:
Кху = М [XY] = М [(X, + Х2) (Y\ + Y$\ =
= М (^КПЧ- М [X2Yx]-i-M [ХгУ2] -\- М [Х2У2]. A0.2.29)
> >
Так как векторы Vv V2 некоррелированны, то два средних члена
в формуле A0.2.29) равны нулю; два оставшихся члена представляют
собой /e,v и /( : формула A0.2.28) доказана.
Формулу A0.2.28) иногда называют «теоремой сложения корре-
корреляционных моментов».
Теорема легко обобщается на произвольное число слагаемых.
Если имеется две некоррелированные системы случайных величин,
т. е. два и-мерных случайных вектора:
X с составляющими Xv Х2 Хп,
->
Y с составляющими Yv Y2, ,,., У„,
то их векторная сумма _>_>_>
Z = X+Y
имеет корреляционную матрицу, элементы которой получаются сум-
суммированием элементов корреляционных матриц слагаемых:
Kfj = Kf)-rK?j, A0.2.30)
где Kf), K^fj, К?] обозначают соответственно корреляционные мо-
моменты величин B;, Zj); (Xit Xj), (Kf> Yj).
Формула A0.2.30) справедлива как при /==/, так и при
Действительно; составляющие вектора Z равны:
z2 == х2 -f-
230 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
По теореме сложения дисперсий
или в других обозначениях
t\ii = Д и ~г а г/.
По теореме сложения корреляционных моментов при
rs(z) isW i iffy)
В математике суммой двух матриц называется матрица, элементы
которой получены сложением соответствующих элементов этих мат-
матриц. Пользуясь этой терминологией, можно сказать, что корреля-
корреляционная матрица суммы двух некоррелированных случайных
векторов равна сумме корреляционных матриц слагаемых:
\\Kfj\\ =11^11 + 11^11. A0.2.31)
Это правило по аналогии с предыдущими можно назвать «теоре-
«теоремой сложения корреляционных матриц».
10.3. Применения теорем о числовых характеристиках
В данном п° мы продемонстрируем применение аппарата числовых
характеристик к решению ряда задач. Некоторые из этих задач
имеют самостоятельное теоретическое значение и найдут применение
в дальнейшем. Другие задачи носят характер примеров и приводятся
для иллюстрации выведенных общих формул на конкретном цифровом
материале.
Задача 1. Коэффициент корреляции линейно за-
зависимых случайных величин.
Доказать, что если случайные величины X и Y связаны линейной
функциональной зависимостью :>
то их коэффициент корреляции равен -j-1 или —1, смотря по знаку
коэффициента а.
Решение. Имеем:
Кху = М [XY] = M[(X — mx)(Y — my)] =
— М [(X — тх) (аХ -\-Ь — атх — и)} = am \{Х — тхJ] = айх,
где Dx — дисперсия величины X.
Для коэффициента корреляций имеем выражение:
% <10-зл>
10.3] ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ
Для определения оу найдем дисперсию величины К:
231
°у = \а\ вх
Подставляя в формулу A0.3.1), имеем:
aD,c a
Величина -j—г равна +1, когда а положительно, и —1, когда а от-
отрицательно, что и требовалось доказать.
Задача 2. Границы коэффициента корреляции.
Доказать, что для любых слу-
случайных величин у
Решение. Рассмотрим слу-
случайную величину:
Z = oyX±oxY,
где ах, оу — средние квадратиче-
ские отклонения величин X, Y.
Определим дисперсию величины Z.
По форму vie A0.2.13) имеем:
(XJ)
Dz =
или
o2xDy ±
Рис. 10.3.1.
Так как дисперсия любой случайной величины не может быть
отрицательна, то
ИЛИ
откуда
следовательно.
' ху I
что и требовалось доказать.
Задача 3. Проектирование случайной точки на
плпгипгти ня nnnu3Rn.nbHVin nnanvn.
Дана случайная точка на плоскости с координатами (X, Y)
(рис. 10.3.1). Спроектируем эту точку на ось Oz, проведенную через
начало координат под углом а к оси Ох. Проекция точки (X, У)
на ось Oz также есть случайная точка; ее расстояние Z от начала
координат есть случайная величина. Требуется найти математическое
ожидание и дисперсию величины Z.
232 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
Решение. Имеем:
Z = X cos a + Y sin а.
Так как Z есть линейная функция аргументов X и Y, то
тг = /«_,. cos a -f- тяу sin а;
Ог = D_,. cos2 а + Dy sin2 а + 2/С^у sin а cos а =
= Dr cos2 а + Dv sin2 а -f- /f г„ sin 2а,
где D_,., Dy, /C^.y—дисперсии и корреляционный момент величин (X, Y).
Переходя к средним квадратическим отклонениям, получим:
о2 = 02 cos2а + ау sin2а + rxyaxoy sin 2а. A0.3.2)
В случае некоррелированных случайных величин (при гху — 0)
o2=o2cos2a + a2sin2a. A0.3.3)
Задача 4. Математическое ожидание числа по-
появлений события при нескольких опытах.
Производится п опытов, в каждом из которых может появиться
или не появиться событие А. Вероятность появления события А
р /-м опыте равна pt. Найти математическое ожидание числа появле-
появлений события.
Решение. Рассмотрим прерывную случайную величину X —
число появлений события во всей серии опытов. Очевидно.
Л = Л1 -)- Л 2 -f- ... -^-Лп,
где ЛГг — число появлений события в первом опыте,
Х2 — число появлений события во втором опыте,
Хп — число появлений события в л-м опыте,
или, короче, f
где Ki—число появлений события в i~n опыте1).
Каждая из величин Xt есть прерывная случайная величина с двумя
возможными значениями: 0 и 1. Ряд распределения величины Х1
имеет вид:
0
1
A0.3.4;
где ff? = l — р, — вероятность непоявления события А в £-м опыте.
') Иначе — характеристическая случайная величина события А в г-м опыте.
10.3] ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 233
По теореме сложения математических ожиданий
я
т, = М [X] = 2 и, • A0.3.5)
где т —математическое ожидание величины X,.
xi
Вычислим математическое ожидание величины Xt. По определе-
определению математического ожидания
Подставляя это выражение в формулу A0.3.5), имеем
л
т. е. математическое ожидание числа появлений события при
нескольких опытах равно сумме вероятностей события в от-
отдельных опытах.
В частности, когда условия опытов одинаковы и
Р\ = Ръ— ••• =Рп — Р'
формула A0.3.5) принимает вид
тх—пр. A0.3.7)
Так как теорема сложения математических ожиданий применима
к любым случайным величинам — как зависимым, так и независимым,
формулы A0.3.6) и A0.3.7) применимы к любым опытам—зависи-
опытам—зависимым и независимым.
Выведенная теорема часто применяется в теории стрельбы, когда
требуется найти среднее число попаданий при нескольких выстре-
выстрелах— зависимых или независимых. Математическое ожидание
числа попаданий при нескольких выстрелах равно сумме ве-
вероятностей попадания при отдельных выстрелах.
Задача 5. Дисперсия числа появлений события
при нескольких независимых опытах.
Производится п независимых опытов, в каждом из которых мо-
может появиться событие А, причем вероятность появления события А
в /-м опыте равна p-t. Найти дисперсию и среднее квадратическое
отклонение числа появлений события А.
Решение, Рассмотрим случайную величину X — число появле-
появлений события А. Так же как б предыдущей задаче, представим вели-
величину X в виде суммы:
где Xt — число появлений события в 1-й опыте.
234 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
В силу независимости опытов случайные величины Xv Х2 Хп
независимы и к ним применима теорема сложения дисперсий:
Найдем дисперсию случайной величины Xt. Из ряда распределе-
распределения A0.3.4) имеем:
D*t = (° ~ Pif 1i + О -Pi? Pi = Pfli-
откуда
O,= .|j№ (Ю.3.8)
т. е. дисперсия числа появлений события при нескольких независимых
опытах равна сумме вероятностей появления и непоявления события
в каждом опыте.
Из формулы A0.3.8) находим среднее квадратическое отклонение
числа появлений события А:
A0.3.9)
При неизменных условиях опытов, когда рх = р2 = ... = рп = р,
формулы A0.3.8) и A0.3.9) упрощаются и принимают вид:
A0.3.10)
Задача 6. Дисперсия числа появлений события
при зависимых опытах.
Производится п зависимых опытов, в каждом из которых может
появиться событие А, причем вероятность события А в i-м опыте
равна рг(/=1, 2, ..., п). Определить дисперсию числа появлений
события.
Решение. Для того чтобы решить задачу, снова представим
число появлений события X в виде суммы:
■л =2*,. (ю.з.П)
где
""'
< 1, если в i-u опыте событие А появилось,
{
{ 0, если в /-м опыте событие А не появилось.
Так как опыты зависимы, то нам недостаточно задать вероятности
pv Р2> ••.. Рп
10.3] ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 235
того, что событие А произойдет в первом, втором, третьем и т. д.
опытах. Нужно еще задать характеристики зависимости опытов.
Оказывается, для решения нашей задачи достаточно задать вероят-
вероятности Рц совместного появления события А как в г-м, так и в /-м
опыте: Р((Х1 = \)(Х}= 1) =Рц- Предположим, что эти вероят-
вероятности заданы. Применим к выражению A0.3.11) теорему о дисперсия
суммы (формулу A0.2.10)):
ijAr,4 2/Cv. A0.3.12)
где К if — корреляционный момент величин Xt,
KtJ = M[XtXj\.
По формуле A0.2.19)
A0.3.13)
Рассмотрим случайную величину XtXj. Очевидно она равна нулю,
если хотя бы одна из величин Xit Xj равна нулю, т. е. хотя бы
в одном из опытов (/-м или у-м) событие А не появилось. Для того
чтобы величина XtXj была равна единице, требуется, чтобы в обоих
опытах A-й и /-м) событие А появилось. Вероятность этого равна Рц.
Следовательно,
M[XtX,]=Plf,
Подставляя это выражение в формулу A0.3.12), получим:
л
^ ^ A0.3.14)
Формула A0.3.14) и выражает дисперсию числа появлений собы-
события при зависимых опытах. Проанализируем структуру этой формулы.
Первый член в правой части формулы представляет собой дисперсию
числа появлений события при независимых опытах, а второй дает
«поправку на зависимость». Если вероятность Рц равна PiP>, то эта
поправка равна нулю. Если вероятность Рц больше, чем PiP>, это
значит, что условная вероятность появления события А в /-м опыте
при условии, что в /-м опыте оно появилось, больше, чем простая
(безусловная) вероятность появления события в _/-м опыте р, (между
появлениями события в 1-й и J-м опытах имеется положительная кор-
корреляция). Если это так для любой пары опытов, то поправочный
член в формуле A0.3.14) положителен и дисперсия числа появлений
события при зависимых опытах больше, чем при независимых.
236 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
Если вероятность Plf меньше, чем ptPj (между появлениями
события в /-м и /-м опытах существует отрицательная корреляция),
то соответствующее слагаемое отрицательно. Если это так для любой
пары опытов, то дисперсия числа появлений события при зависимых
опытах меньше, чем при независимых.
Рассмотрим частный случай, когда ру = р2 = • • • =Ра==Р'
Рп = РХ2 = • •. = Р, т. е. условия всех опытов одинаковы. Фор-
Формула A0.3.14) принимает вид:
Аг = »/»? +2 2-(Я — р"*) = прЧ + п(п — 1)(Р— J>2), A0.3.15)
1<J
где Р — вероятность появления события А сразу в паре опытов (все
равно каких).
В этом частном случае особый интерес представляют два подслучая:
1. Появление события А в любом из опытов влечет за собой
с достоверностью его появление в каждом из остальных. Тогда Р = р,
и формула A0.3.15) принимает вид:
Dx = npq~\-n(n— l)(p — P2) = npq-\- n(n — 1) pq = n2pq.
2. Появление события А в любом из опытов исключает его
появление в каждом из остальных. Тогда Я = 0, и формула A0.3.15)
принимает вид:
Dx = npq — п (п — 1) р2 = пр [q — (и — 1) р] = пр A — пр).
Задача 7. Математическое ожидание числа объек-
объектов, приведенных в заданное состояние.
На практике часто встречается следующая задача. Имеется не-
некоторая группа, состоящая из п объектов, по которым осуществляется
какое-то воздействие. Каждый из объектов в результате воздействия
может быть приведен в определенное состояние S (например, поражен,
исправлен, обнаружен, обезврежен и т. п.). Вероятаость того, что
/-й объект будет приведен в состояние S, равна pt. Найти матема-
математическое ожидание числа объектов, которые в результате воздействия
ло группе будут приведены в состояние 5.
Решение. Свяжем с каждым из объектов случайную величину Xt,
которая принимает значения 0 или 1:
A, если /-й объект приведен в состояние S,
0, если /-Й объект не приведен в состояние 5.
Случайная величина X — число объектов, приведенных в состоя-
состояние 3, — может быть представлена в виде суммы;
л
Л. === ^j i*
1=1
10.3) ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 237
Отсюда, пользуясь теоремой сложения математических ожиданий,
получим:
х 2 х(
Математическое ожидание каждой из случайных величин Xt известно:
mXl = р^
Следовательно,
л
«,= 2/^. A0.3.16)
/=1
т. е. математическое ожидание числа объектов, приведенных в состоя-
состояние 5, равно сумме вероятностей перехода в это состояние для
каждого из объектов.
Особо подчеркнем, что для справедливости доказанной формулы
вовсе не нужно, чтобы объекты переходили в состояние S независимо
друг от друга. Формула справедлива для любого вида воздействия.
Задача 8. Дисперсия числа объектов, приведен-
приведенных в заданное состояние.
Если в условиях предыдущей задачи переход каждого из объектов
в состояние S происходит независимо от всех других, то, применяя
теорему сложения дисперсий к величине
получим дисперсию числа объектов, приведенных в состояние S:
?* = 1-/V (Ю.3.17)
Если же воздействие по объектам производится так, что переходы
в состояние S для отдельных объектов зависимы, то дисперсия числа
объектов, переведенных в состояние S, выразится формулой (см.
задачу 6)
J A0.3.18)
где Рц — вероятность того, что в результате воздействия i-R
и /-й объекты вместе перейдут в состояние S.
Задача 9. Математическое о ж к д а к к е числа опытов
ия.
Производится ряд независимых опытов, в каждом из которых
может с вероятностью р появиться событие А. Опыты проводятся
до тех пор, пока событие А не появится k раз, после чего опыты
238 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
прекращаются. Определить математическое ожидание, дисперсию
и с. к. о. числа опытов X, которое будет произведено.
Решение. В примере 3 п° 5.7 были определены математическое
ожидание и дисперсия числа опытов до первого появления события А:
где р— вероятность появления события в одном опыте,
g = 1 — р — вероятность непоявления.
Рассмотрим случайную величину X — число опытов до й-ro по-
появления события А. Ее можно представить в виде суммы:
где Хх — число опытов до первого появления события А,
Х2 — число опытов от первого до второго появления события А
(считая второе).
Xk — число опытов от (й— 1)-го до й-ro появления события Л
(считая й-е).
Очевидно, величины Xv X2 Xk независимы; каждая из них
распределена по тому же закону, что и первая из них (число опытов
до первого появления события) и имеет числовые характеристики
Применяя теоремы сложения математических ожиданий и дисперсий,
получим:
~~ т" ~~Р
A0.3.19)
Р '
Задача 10. Средний расход средств до достижения
заданного результата.
В предыдущей задаче был рассмотрен случай, когда предпри-
предпринимается ряд опытов с целью получения вполне определенного ре-
результата — k появлений события А, которое в каждом опыте имеет
одну и ту же вероятность. Эта задача является частным случаем
другой, когда производится ряд опытов с целью достижения любого
результата В, вероятность которого с увеличением числа опытов п.
возрастает по любому закону Р(п). Предположим, что на каждый
oiiui расходуется определенное количество средств а. Требуется
10.31 ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 239
найти математическое ожидание количества средств, которое будет
израсходовано.
Решение. Для того чтобы решить задачу, сначала предположим,
что число производимых опытов ничем не ограничено, и что они
продолжаются и после достижения результата В. Тогда некоторые
из этих опытов будут излишними. Условимся называть опыт «не-
«необходимым», если он производится при еще не достигнутом резуль-
результате В, и «излишним», если он производится при уже достигнутом
результате В.
Свяжем с каждым (/-м) опытом случайную величину Xt, которая
равна нулю или единице в зависимости от того, «необходимым» или
«излишним» оказался этот опыт. Положим
1. если опыт оказался «необходимым»,
0, если он оказался «излишним».
Рассмотрим случайную величину X — число опытов, которое
придется произвести для получения результата В. Очевидно, ее можно
представить в виде суммы:
А' = А'14-А'2+ ... +A",+ ... A0.3.20)
Из величин в правой части A0.3.20) первая (A'j) является неслу-
неслучайной и всегда равна единице (первый опыт всегда «необходим»).
Каждая из остальных — случайная величина с возможными значе-
значениями 0 и 1. Построим ряд распределения случайной величины Xt
(i > 1). Он имеет вид:
1
• A0.3.21)
Р 0-1)
где P(i — 1)—вероятность достижения результата В после / — 1
опытов.
Действительно, если результат В уже был достигнут при пре-
предыдущих t — 1 опытах, то Xt = Q (опыт излишен), если не достигнут,
то X, — 1 (опыт необходим).
Найдем математическое ожидание величины Xt. Из ряда распре-
распределения A0.3.21) имеем:
, • [1— Р(} — 1)] = 1—РA—1).
Нетрудно убедиться, что та же формула будет справедлива и
при !=1, так как Р@) —0.
Применим к выражению A0.3.20) теорему сложения математи-
математических ожиданий. Получим:
2^ 2
240 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
или, обозначая /—l = k,
со
" A0.3.22)
»х«2.[1-
Каждый опыт требует затраты средств а. Умножая полученную
величину тх на а, определим среднюю затрату средств на достиже-
достижение результата В:
*=о
A0.3.23)
Данная формула выведена в предположении, что стоимость каждого
опыта одна и та же. Если это не так, то можно применить другой
прием — представить суммарную затрату средств SB как сумму затрат
на выполнение отдельных опытов, которая принимает два значения:
Др если /-й опыт «необходим», и нуль, если он «излишен». Средний
расход средств SB представится в виде:
SB=Iiak[l-P(k)\.
A0.3.24)
Задача 11. Математическое ожидание суммы слу-
случайного числа случайных слагаемых.
В ряде практических приложений теории вероятностей приходится
встречаться с суммами случайных величин, в которых число слагаемых
заранее неизвестно, случайно.
Поставим следующую задачу. Случайная величина Z представляет
собой сумму Y случайных величин:
у
Z=2IX,, A0.3.25)
причем Y — также случайная величина. Допустим, что нам известны
математические ожидания тх, всех слагаемых:
и что величина Y не зависит ни от одной из величин Xt.
Требуется найти математическое ожидание величины Z.
Решение. Число слагаемых в сумме есть дискретная случайная
величина. Предположим, что нам известен ее ряд распределения:
Уь
Рь
1
Pi
2
Рг
. . .
. . .
k
Рь
. . .
• • •
где pk — вероятность того, что величина У приняла значение k.
Зафиксируем значение Y = k и найдем при этом условии математи-
10.3] ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 2,41
ческое ожидание величины Z (условное математическое ожидание):
AI[Z|*1=»S«,.. A0.3.26)
j=i *
Теперь применим формулу полного математического ожидания,
для чего умножим каждое условное математическое ожидание на
вероятность соответствующей гипотезы pk и сложим:
AHZ]=2p»2«,. A0.3.27)
ft ~1 •
Особый интерес представляет случай, когда все случайные вели-
величины Xlt Х2, ... имеют одно и то же математическое ожидание:
тХ1 = тХг= ... = тх.
Тогда формула A0.3.26) принимает вид:
^x x
i=\
И
M[Z] = mx2ikpk. A0.3.28)
Сумма в выражении A0.3.28) представляет собой не что иное, как
математическое ожидание величины Y:
my=*2ikpk.
°ТСЮда m2 = MlZ] = mx-my, A0.3.29)
т. е. математическое ожидание суммы случайного числа случайных
слагаемых с одинаковыми средними значениями (если только число
слагаемых не зависит от их значений) равно произведению среднего
значения каждого из слагаемых на среднее число слагаемых.
Снова отметим, что полученный результат справедлив как для
независимых, так и для зависимых слагаемых Хх, Хг, .... лишь бы
число слагаемых Y не зависело от самих слагаемых.
Ниже мы решим ряд конкретных примеров из разных областей
практики, на которых продемонстрируем конкретное применение
общих методов оперирования с числовыми характеристиками, выте-
вытекающих из доказанных теорем, и специфических приемов, связанных
с решенными выше общими задачами.
Пример 1. Монета бросается 10 раз. Определить математическое ожи-
ожидание и среднее квадратическое отклонение числа X выпавших гербов.
Решение. По формулам A0.3.7) и A0.3.10) найдем:
тх = 10 • 0,5 = 5; Dx= 10 -0,5 -0,5 = 2,5; 0^=1,58.
Пример 2. Производится 5 независимых выстрелов по круглой мишени
диаметром 20 см. Прицеливание — по центру мишени, систематическая
16 Е, С. Вентцель
242 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИИ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
ошибка отсутствует, рассеивание — круговое, среднее квадратическое откло-
отклонение а = 16 см. Найти математическое ожидание и с. к. о. числа попаданий.
Решение. Вероятность попадания в мишень при одном выстреле
вычислим по формуле (9.4.5):
р = 1 -Г = 1 -е-0-625 я 0,465.
Пользуясь формулами A0.3.7) и A0.3.10), получим:
Dx= 5рA —/>) « 1,25; ях « 1,12.
Пример 3. Производится отражение воздушного налета, в котором
участвует 20 летательных аппаратов типа 1 и 30 летательных аппаратов
типа 2. Летательные аппараты типа 1 атакуются истребительной авиацией.
Число атак, приходящееся на каждый аппарат, подчинено закону Пуассона
с параметром ах = 2,5. Каждой атакой истребителя летательный аппарат
типа 1 поражается с вероятностью рх = 0,6. Летательные аппараты типа 2 ата-
атакуются зенитными управляемыми ракетами. Число ракет, направляемых иа каж-
каждый аппарат, подчинено закону Пуассона с параметром а2 = 1,8, каждая ракета
поражает летательный аппарат типа 2 с вероятностью рг = 0,8. Все аппараты,
входящие в состав налета, атакуются и поражаются независимо друг от друга.
Найти:
1) математическое ожидание, дисперсию и с. к. о. числа пораженных
летательных аппаратов типа 1;
2) математическое ожидание, дисперсию и с. к. о. числа пораженных
летательных аппаратов типа 2;
3) математическое ожидание, дисперсию и с. к. о. числа пораженных
летательных аппаратов обоих типов.
Решение. Рассмотрим вместо «числа атак» на каждый аппарат типа I
«число поражающих атак», тоже распределенное по закону Пуассона, но
с другим параметром:
а* = рхах = 0,6 • 2,5 = 1,5.
Вероятность поражения каждого из летательных аппаратов типа 1 будет
равна вероятности того, что на него придется хотя бы одиа поражаю-
поражающая атака:
fl^l—*-1'5» 0,777.
Вероятность поражения каждого из летательных аппаратов типа 2 найдем
аналогично:
Rf = 1 _е-08-1.8= ! _,-М4 ю Oi763.
Математическое ожидание числа пораженных аппаратов типа 1 будет:
«1=20-0,777=15,5.
Дисперсия к с. к. о. этого числа:
Z>! = 20 ■ 0,777 • 0,223 = 3,46, в, и 1,86.
Математическое ожидание, дисперсия числа и с. к. о. пораженных аппа-
аппаратов типа 2:
тг = 30 • 0,763 = 22,8, D2 = 5,41, з2 » 2,33.
Математическое ожидание, дисперсия и с. к. о. общего числа поражен-
пораженных аппаратов обоих типов:
m=m,-f«2 = 38,3, D = D1 + D2 = 8,87, a2 « 2,97.
10.3]
ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ
243
Пример 4. Случайные величины X и Y представляют собой элемен-
элементарные ошибки, возникающие на входе прибора. Они имеют математические
2 4 £> 4 D 9 фф
ожидания тх = — 2
корреляции этих
р
и ту = 4, дисперсии
р
ошибок равен гху = — 0,5.
м н фай
рр р ху
связана с ошибками на входе функциональной зависимостью:
— 2XY+Y2 — 3.
и Dy = 9; коэффициент
Ошибка иа выходе прибора
Найти математическое ожидание ошибки на выходе прибора.
Решение.
тг = М [Z] = Ш [X*] — 2М [XY] + М [Y2] — 3.
Пользуясь связью между начальными и центральными моментами и
формулой A0.2.17), имеем:
M[X2] = a2[X] = Dx + m2=S;
= mxmy -
т\ = 25;
= —11,
откуда
= 3-8 — 2-(-11)+ 25 — 3 = 68.
Пример 5. Самолет производит бом-
бомбометание по автостраде, ширина которой
30 м (рис. 10.3.2). Направление полета со-
составляет угол 30° с направлением авто-
автострады. Прицеливание — по средней линии
автострады, систематические ошибки отсут-
отсутствуют. Рассеивание задано главными ве-
вероятными отклонениями: по направлению
полета Вл = 50 м и в боковом направлении
В(, = 25 м. Найти вероятность попадания
в автостраду при сбрасывании одной бомбы.
Решение. Спроектируем случайную точку попадания на ось Ог, пер-
перпендикулярную к автостраде и применим формулу A0.3.3). Она, очевидно,
остается справедливой, если в нее вместо средних квадратических подста-
подставить вероятные отклонения:
Е2г = Е2Х cos 60° -f El sin 60° = 502 • 0,25 -f- 252
Рис. 10.3.2,
• 0,75 «1093.
Отсюда
Ег х 33, z, =
0,674
48,9.
Вероятность попадания в автостраду найдем по формуле F.3.10):
— 1 и 0,238.
П р и м е ч а н и е. Примененный здесь прием пересчета рассеивания
к другим осям пригоден только для вычисления вероятности попадания
в область, имеющую вид полосы; для прямоугольника, стороны которого
повернуты под углом к осям рассеивания, он уже не годится. Вероятность
попадания в каждую из полос, пересечением которых образован прямоуголь-
прямоугольное, может быть вычислена с помощью этого приема, однако вероятность
16*
244 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
попадания в прямоугольник уже не равна произведению вероятностей по-
попадания в полосы, так как эти события зависимы.
Пример 6. ^Производится наблюдение с помощью системы радиоло-
радиолокационных станций за группой объектов в течение некоторого времени;
группа состоит из четырех объектов; каждый нз них за время t обнаружи-
обнаруживается с вероятностью, равной соответственно:
^ />4 = 0,42.
/>1=0,2,
0,25, />з =
Найти математическое ожидание числа объектов, которые будут обна-
обнаружены через время t.
Решение. По формуле (Ю.3.16) имеем:
4
тх = 2 Pi = 0,2 -f 0,25 + 0,35 -f 0,42 = 1,22.
Пример 7. Предпринимается ряд мероприятий, каждое из которых,
если оно состоится, приносит случайный чистый доход X, распределенный
по нормальному закону со средним значением т = 2 (условных единиц).
Число мероприятий за данный период времени случайно и распределено
по закону
Pi
1
0.2
2
0,3
3
0.4
4
0,1
причем не зависит от доходов, приносимых мероприятиями. Определить
средний ожидаемый доход за весь период.
Решение. На основе задачи 11 данного п° находим математическое
ожидание полного дохода Z:
тг = tnx- Шу,
где ffljt—средний доход от одного мероприятия, ту — среднее ожидаемое
число мероприятий.
Имеем:
/7^ = 2-2,4 = 4,8.
Пример 8, Ошибка прибора выражается функцией
U=3Z + 2X—Y—4, A0.3.30)
где X, Y, Z — так называемые «первичные ошибки», представляющие собой
систему случайных величин (случайный вектор).
Случайный вектор {X, Y, Z) характеризуется математическими ожида-
ожиданиями
/тг*- = — 4; /л у = 1; tnz := 1
и корреляционной матрицей:
II Dx К.
лгу
у
1-1' i
Аг I
—1 I
1
4
10.3] ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 245
Определить математическое ожидание, дисперсию и среднее квадратиче-
ское отклонение ошибки прибора.
Решение. Так как функция A0.3.30) линейна, применяя формулы A0.2.6)
и A0.2.13), находим:
ти = Ътг-\-2тх — ту — 4 = —10,
а„ =5.
Пример 9. Для обнаружения источника неисправности в вычислитель-
вычислительной машине проводятся пробы (тесты). В каждой пробе неисправность неза-
независимо от других проб локализуется с вероятностью /7 = 0,2. На каждую
пробу в среднем уходит 3 минуты. Найти математическое ожидание времени,
которое потребуется для локализации неисправности.
Решение. Пользуясь результатом задачи 9 данного п° (математическое
ожидание числа опытов до А-го появления события А), полагая к = 1, най-
найдем среднее число проб
т* = ~р ~ Щ
На эти пять проб потребуется в среднем
5 • 3 = 15 (минут).
Пример 10. Производится стрельба по резервуару с горючим. Вероят-
Вероятность попадания при каждом выстреле равна 0,3. Выстрелы независимы.
При первом попадании в резервуар появляется только течь горючего, при
втором попадании горючее воспламеняется. После воспламенения горючего
стрельба прекращается. Найти математическое ожидание числа произведен-
произведенных выстрелов.
Решение. Пользуясь той же формулой, что и в предыдущем примере,
найдем математическое ожидание числа выстрелов до 2-го попадания:
_ 2
Пример 11. Вероятность обнаружения объекта радиолокатором сро-
сростом числа циклов обзора растет по закону:
/>(л) = 1—0,8",
где п — число циклов, начиная с начала наблюдения.
Найти математическое ожидание числа циклов, после которого объект
будет обнаружен.
Решение. Пользуясь результатами задачи 10 данного параграфа
получим:
ft=0 ft=0
Пример 12. Для того чтобы выполнить определенную задачу по сбору
информации, в заданный район высылается несколько разведчиков. Каждый
посланный разведчик достигает района назначения с вероятностью 0,7. Для
выполнения' задачи достаточно наличия в районе трех разведчиков. Одни
разведчик с задачей вообще справиться не может, а два разведчика выпол-
выполняют ее с вероятностью 0,4. Обеспечена непрерывная связь с районом, и до-
дополнительные разведчики посылаются, только если задача еще не выполнена.
246 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ-ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
Требуется найти математическое ожидание числа разведчиков, которые будут
посланы.
Решение. Обозначим X — число прибывших в район разведчиков,
которое оказалось достаточным для выполнения задачи. В задаче 10 дан-
данного п° было найдено математическое ожидание числа опытов, которое нужно
дяя того, чтобы достигнуть определенного результата, вероятность которого
с увеличением числа опытов возрастает по закону Р (п). Это математическое
ожидание равно:
В нашем случае:
= 0; />B) = 0,4; ЯC) =
. =1.
Математическое ожидание величины X равно:
Итак, для того чтобы задача была выполнена, необходимо, чтобы
в район прибыло в среднем 2,6 разведчика.
Теперь решим следующую задачу. Сколько разведчиков придется в сред-
среднем выслать в район для того, чтобы их в среднем прибыло тх?
Пусть послано Y разведчиков. Число прибывших разведчиков можно
представить в виде
где случайная величина Zi принимает значение 1, если i-й разведчик при-
прибыл, и 0, если не прибыл. Величина X есть не что иное, как сумма случай-
случайного числа случайных слагаемых (см. задачу 11 данного п°). С учетом этого
имеем:
М [X] = М [Zt] M [У],
откуда
2,6
M[Zt]
во M[Zi\ = р, где р — вероятность прибытия отправленного разведчика
(в нашем случае р = 0,7). Величина тх нами только что найдена и равна 2,6.
Имеем:
Пример 13. Радиолокационная станция просматривает область про-
пространства, в которой находится N объектов. За один цикл обзора она обна-
обнаруживает каждый из объектов (независимо от других циклов) с вероят-
вероятностью р. На один цикл требуется время т. Сколько времени потребуется
на то, чтобы из N объектов обнаружить в среднем к?
Решение. Найдем прежде всего математическое ожидание числа
сбнаружеиных объектов после п циклов обзора. За п циклов один (любой)
вз объектов обнаруживается с вероятностью
Р„=1-A -/>)".
10.3] ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 247
руженных за п цик
задачу 5 данного п°
= N[l — (I — p)n].
а среднее число объектов, обнаруженных за п циклов, по теореме сложения
математических ожиданий (см. задачу 5 данного п°) равно:
Полагая
N[\ — (l — p)n]=k,
получим необходимое число циклов п из уравнения
решая которое, найдем:
откуда время, необходимое для обнаружения в среднем k объектов, будет
равно:
tb = ХП = X , ' ^- .
Пример 14. Изменим условия примера 13. Пусть радиолокационная
станция ведет наблюдение за областью только до тех пор, пока не будет
обнаружено к объектов, после чего наблюдение прекращается или продол-
продолжается в новом режиме. Найти математическое ожидание времени, которое
для этого понадобится.
Для того чтобы решить эту задачу, недостаточно задаться вероятностью
обнаружения одного объекта в одном цикле, а надо еще указать, как растет
с увеличением числа циклов вероятность того, что из N объектов будет
обнаружено не менее к. Проще всего вычислить эту вероятность, если пред-
предположить, что объекты обнаруживаются независимо друг от друга. Сделаем
такое допущение и решим задачу.
Решение. При независимых обнаружениях можно наблюдение за N
объектами представить как N независимых опытов. После п циклов каждый
из объектов обнаруживается с вероятностью
Рп=\-(\-р)п.
Вероятность того, что после п циклов будет обнаружено не менее k объек-
объектов из N, найдем по теореме о повторении опытов: _
т-= k
Среднее число циклов, после которых будет обнаружено не менее к
объектов, определится по формуле A0.3.22):
сю N Г ЛГ
л=0 л=0L т=к
Пример 15. На плоскости хОу случайная точка М с координа-
координатами (л, Y) отклоняется от требуемого положения (начало координат) под
■>->->
влиянием трех независимых векторных ошибок Vit V2 и Уз- Каждый из век-
векторов характеризуется двумя составляющими:
h{X» Г,), V2(X2, Y2), V3(X3, Yd
248 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
(рис. 10.3.3). Числовые характеристики этих трех векторов равны:
т.
= 2,
тг = — 1
= 0,2.
Найти характеристики суммарной ошибки (вектора, отклоняющего
точку М от начала координат).
Решение. Применяя теоремы сложения математических ожиданий,
дисперсий и корреляционных моментов, получим:
= 0,5 • 4 • 1 = 2,0,
= 0,2 • 2 • 2 = 0,8,
1,0
Рис. 10.3.3.
4,90-3,75
и 0,054.
Пример 16. Тело, которое имеет форму прямоугольного параллелепи-
параллелепипеда с размерами а, Ь, с, летит в пространстве, беспорядочно вращаясь
вокруг центра массы так, что все его ориентации одинаково вероятны. Тело
находится в потоке частиц, и среднее число частиц, встречающихся с телом,
пропорционально средней площади, которую тело подставляет потоку.
Найти математическое ожидание площади проекции тела на плоскость, пер-
перпендикулярную направлению его движения. ••
Решение. Так как все ориентации тела в пространстве одинаково
вероятны, то направление плоскости проекций безразлично. Очевидно, пло-
площадь проекции тела равна половине суммы проекций всех граней паралле-
параллелепипеда (так как каждая точка проекции представляет собой проекцию
двух точек на поверхности тела). Применяя теорему сложения математи-
математических ожиданий и формулу для средней площади проекции плоской фигуры
(см. пример 3 п° 10.1), получим:
_ £* I. ас | Ьс — ^°
т$ 2 2 2 4 '
где Sn — полная площадь поверхности параллелепипеда.
Заметим, что выведенная формула справедлива не только для паралле-
параллелепипеда, но и для любого выпуклого тела: средняя площадь проекции та-
такого тела при беспорядочном вращении равна одной четверти полной его
поверхности. Рекомендуем читателю в качестве упражнения доказать это
положение.
10.3] ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 249
Пример 17. На оси абсцисс Ох движется случайным образом точка х
по следующему закону. В начальный момент она находится в начале коор-
координат и начинает двигаться с вероятностью -=- вправо и с вероятностью -^
влево. Пройдя единичное расстояние, точка с вероятностью р продолжает
двигаться в том же направлении, а с вероятностью q = 1 — р меняет его
на противоположное. Пройдя единичное расстояние, точка снова с вероят-
вероятностью р продолжает движение в том направлении, в котором двигалась,
а с вероятностью 1 — р меняет его иа противоположное и т. д.
В результате такого случайного блуждания по оси абсцисс точка х
после п шагов займет случайное положение, которое мы обозначим Хп.
Требуется найти характеристики случайной величины Хп: математическое
ожидание и дисперсию.
Решение. Прежде всего, из соображений симметрии задачи ясно, что
М [Хп] = 0. Чтобы найти D [Хп], представим Хп в виде суммы п слагаемых:
Xn=Ul + U2+ ... + Un-j$Ul> A0.3.31)
; = i
где Ui — расстояние, пройденное точкой иа <-м шаге, т. е. -f-1, если точка
двигалась на этом шаге вправо, и —1, если она двигалась влево.
По теореме о дисперсии суммы (см. формулу A0.2.10)) имеем:
/ = 1 i<j lJ
Ясно, что D [U(] = 1, так как величина Ui принимает значения -\А
и —1 с одинаковой вероятностью (из тех же соображений симметрии). Най-
Найдем корреляционные моменты
Начнем со случая / = /4-1, когда величины Ui и Uj стоят рядом
в сумме A0.3.31). Ясно, что UiUi+\ принимает значение +1 с вероятностью р
и значение —1 с вероятностью д. Имеем:
Рассмотрим, далее, случай / = г" + 2. В этом случае произведение UtU)
равно +1, если оба перемещения — на г'-м и /-{-2-м шаге — происходят
в одном и том же направлении. Это может произойти двумя способами.
Или точка х все три шага — г-й, (г-(-1)-й и (г -J- 2)-й — двигалась в одном
и том же направлении, или же она дважды изменила за эти три шага свое
направление. НаДдем вероятность того, что UiUi+г = 1:
Найдем теперь вероятность того, что U-JJ-l+i — — 1. Это тоже может
произойти двумя способами: или точка изменила свое направление пои пеое-
ходе от /"-го шага к (/-)- 1)-му, а при переходе от у+ 1)-го шага к (Л}-2)-му
сохранила его, или наоборот. Имеем:
250 ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ФУНКЦИЙ СЛУЧАЙНЫХ ВЕЛИЧИН [ГЛ. 10
Таким образом, величина UfJi+i имеет два возможных значения +1
и —1, которые она принимает с вероятностями соответственно p2-\-q2 и 2pq.
Ее математическое ожидание равно:
= M [
Легко доказать по индукции, что для любого расстояния к между ша-
шагами в ряду Uи Uг, .... Un справедливы формулы:
и, следовательно,
Таким образом, к
Uи иг,..., Un будет
Таким образом, корреляционная матрица системы случайных величин
и U б иметь вид:
\\К„
p — q ... (p — q)"~*
1 ... (p — q)n-3
Дисперсия случайной величины Хп будет равна:
KU)U =«
или же, производя суммирование элементов, стоящих на одном расстоянии
от главной диагонали,
л-1
D[Xn] = n + 2^ (n-k){p-q)K
k=i
Пример 18. Найти асимметрию биномиального распределения
Р(Х=т) = C™pmqn-m (q = 1 — р). A0.3.32)
Решение. Известно, что биномиальное распределение A0.3.32) пред-
представляет собой распределение числа появлений в п независимых опытах не-
некоторого события, которое в одном опыте имеет вероятность р. Представим
случайную величину X — число появлений события в п опытах — как сумму п
случайных величин:
л
Х= ^ Xi,
2=1
где
(
= \
1, если б г-м опыте событие появилось,
0, если в г-м опыте событие не появилось.
По теореме сложения третьих центральных моментов
[X] =
[xt\.
2
1=1
(ю.азз)
10.3] ПРИМЕНЕНИЯ ТЕОРЕМ О ЧИСЛОВЫХ ХАРАКТЕРИСТИКАХ 251
Найдем третий центральный момент случайной величины Х^ Она имеет
ряд распределения
Я I Р
Третий центральный момент величины Xi равен:
@ — рK ч+A — рK р = — р3д+д3р = рд (д — р).
Подставляя в A0.3.33), получим:
п
Ы-Х"] = 2- />0 (? — />) = пР9 (д-р)-
i = l
Чтобы получить асимметрию, нужно разделить третий центральный мо-
момент величины X на куб среднего квадратического отклонения:
<?,._. npq(q — p) q — p
о/с ' — - •
Vnpq
Пример 19. Имеется я положительных, одинаково распределенных
независимых случайных величин:
Xlt Хг<..., Хп.
Найти математическое ожидание случайной величииы
... +Хп'
Решение. Ясно, что математическое ожидание величины Z, суще-
существует, так как оиа заключена между нулем и единицей. Кроме того, легко
видеть, что закон распределения системы величин (Xt, X2, ..., Хп), каков бы
он ни был, симметричен относительно своих переменных, т. е. не меняется
при любой их перестановке. Рассмотрим случайные величины:
_ _ Xi Х2
Очевидно, их закон распределения тоже должен обладать свойством сим-
симметрии, т. е. не меняться при замене одного аргумента любым другим и
наоборот. Отсюда, в частности, вытекает, что
М [Z,] = М [Z,] = ... =Af[Zn].
Вместе с тем нам известно, что в сумме случайные величины Zb Z2, ..., Zn
образуют единицу, следовательно, по теореме сложения математических
ожиданий,
М [ZA + М [Z2] + ... + М [Zn] = U [1] = 1,
откуда
М [Z,] = М [Z2] = ... = М [Zn] = ~.
ГЛАВА 11
ЛИНЕАРИЗАЦИЯ ФУНКЦИЙ
11.1. Метод линеаризации функций случайных аргументов
В предыдущей главе мы познакомились с весьма удобным мате-
математическим аппаратом теории вероятностей — с аппаратом числовых
характеристик. Этот аппарат во многих случаях позволяет находить
числовые характеристики функций случайных величин (в первую оче-
очередь — математическое ожидание и дисперсию) по числовым харак-
характеристикам аргументов, оставляя совершенно в стороне законы рас-
распределения. Такие методы непосредственного определения числовых
характеристик применимы главным образом к линейным функциям.
На практике очень часто встречаются случаи, когда исследуемая
функция случайных величин хотя и не является строго линейной, но
практически мало отличается от линейной и при решении задачи
может быть приближенно заменена линейной. Это связано с тем, что
во многих практических задачах случайные изменения фигурирующих
в них величин выступают как незначительные «погрешности», накла-
накладывающиеся на основную закономерность. Вследствие сравнительной
малости этих погрешностей обычно фигурирующие в задаче функции,
не будучи линейными во всем диапазоне изменения своих аргументов,
оказываются почти линейными в узком диапазоне их случайных
изменений.
Действительно, из математики известно, что любая непрерывная
дифференцируемая функция в достаточно узких пределах изменения
аргументов может быть приближенно заменена линейной (линеаризо-
(линеаризована). Ошибка, возникающая при этом, тем меньше, чем уже границы
изменения аргументов и чем ближе функция к линейной. Если область
практически возможных значений случайных аргументов настолько
мала, что в этой области функция может быть с достаточной для
практики точностью линеаризована, то, заменив нелинейную функцию
линейной, можно применить к последней тот аппарат числовых харак-
характеристик, который разработан для линейных функций. Зная числовые
характеристики аргументов, можно будет найти числовые характе-
характеристики функции. Конечно, при этом мы получим лишь приближен-
11.2] ЛИНЕАРИЗАЦИЯ ФУНКЦИИ ОДНОГО СЛУЧАЙНОГО АРГУМЕНТА 253
ное решение задачи, но в большинстве случаев точного решения и
не требуется.
При решении практических задач, в которых случайные факторы
сказываются в виде незначительных возмущений, налагающихся на
основные закономерности, линеаризация почти всегда оказывается
возможной именно в силу малости случайных возмущений.
Рассмотрим, например, задачу внешней баллистики о движении
центра массы снаряда. Дальность полета снаряда X определяется как
некоторая функция условий стрельбы — угла бросания 60, начальной
скорости v0 и баллистического коэффициента с:
X = <р(80, v0, с). A1.1.1)
Функция A1.1.1) нелинейна, если рассматривать ее на всем диа-
диапазоне изменения аргументов. Поэтому, когда речь идет о решении
основной задачи внешней баллистики, функция A1.1.1) выступает
как нелинейная и никакой линеаризации не подлежит. Однако есть
задачи, в которых такие функции линеаризуются; это — задачи, свя-
связанные с исследованием ошибок или погрешностей. Пусть
нас интересует случайная ошибка в дальности полета снаряда X,
связанная с наличием ряда случайных факторов: неточностью уста-
установки угла 80, колебаниями ствола при выстреле, баллистической
неоднородностью снарядов, различными весами зарядов и т. д. Тогда
мы зафиксируем определенные номинальные условия стрельбы и будем
рассматривать случайные отклонения от этих условий. Диапазон таких
случайных изменений, как правило, невелик, и функция ф, не будучи
линейной во всей области изменения своих аргументов, может быть
линеаризована в малой области их случайных изменений.
Метод линеаризации функций, зависящих от случайных аргументов,
находит самое широкое применение в различных областях техники.
Очень часто, получив решение задачи обычными методами «точных
наук», желательно оценить возможные погрешности в этом решении,
связанные с влиянием не учтенных при решении задачи случайных
факторов. В этом случае, как правило, задача оценки погрешности
успешно решается методом линеаризации, так как случайные изме-
изменения фигурирующих в задаче величин обычно невелики. Если бы
это было не так, и случайные изменения аргументов выходили за
пределы области примерной линейности функций, следовало бы счи-
считать техническое решение неудовлетворительным, так как оно содер-
содержало бы слишком большой элемент неопределенности.
11.2. Линеаризация функции одного случайного аргумента
На практике необходимость в линеаризации функции одного слу-
случайного аргумента встречается сравнительно редко: обычно прихо-
приходится учитывать совокупное влияние нескольких случайных факторов.
Однако из методических соображений удобно начать с этого наиболее
254 ЛИНЕАРИЗАЦИЯ ФУНКЦИЯ [ГЛ. !Г
простого случая. Пусть имеется случайная величина X и известны
ее числовые характеристики: математическое ожидание тх и диспер-
дисперсия Dx.
Допустим, что практически возможные значения случайной вели-
величины X ограничены пределами а, р, т. е.,
Имеется другая случайная величина У, связанная с X функцио-
функциональной зависимостью:
К = <р (*)'). (И.2.1)
причем функция <р хотя не является линейной, но мало отличается
от линейной на участке (a, fi).
Требуется найти числовые характеристики величины Y— матема-
математическое ожидание ту и. дисперсию Dr
Рассмотрим кривую у = <р(х) на участке (а, Р) (рис. 11.2.1) и за-
заменим ее приближенно касательной, проведенной в точке М с абс-
абсциссой тх. Уравнение касательной имеет вид:
у = ср {тх) + ср' (тх) (х — тх). A1.2.2)
Предположим, что интервал практически возможных значений
аргумента (а, Р) настолько узок, что в пределах этого интервала
кривая и касательная различаются мало,
так что участок кривой практически
.y=f(x) можно заменить участком касательной;
короче, на участке (a, fJ) функция
у = <р(х) почти линейна. Тогда
случайные величины X и Y прибли-
приближенно связаны линейной зависимостью:
или, обозначая X — тх = X,
а т* г У = <?(тх) + <р'(тх)Х. A1.2.3)
Рис. 11.2.1, К линейной функции A1.2.3) можно
применить известные приемы определе-
определения числовых характеристик линейных функций (см. п° 10.2). Л1ате-
матическое ожидание этой линейной функции найдем, подставляя
о
в ее выражение A1.2.3) математическое ожидание аргумента X,
равное нулю. Получим:
(П.2.4)
') Функцию <? на участке (я, [J) предполагаем непрерывной и дифферен-
дифференцируемой.
11.3] ЛИНЕАРИЗАЦИЯ ФУНКЦИИ НЕСКОЛЬКИХ СЛУЧАЙНЫХ АРГУМЕНТОВ 255
Дисперсия величины К определится по формуле
Dy = [cp'(O№. (П.2.5)
Переходя к среднему квадратическому отклонению, имеем:
о, = | ?'(»,)] °,- (П.2.6)
Формулы A1.2.4), A1.2.5), A1.2.6), разумеется, являются прибли-
приближенными, поскольку приближенной является и сама замена нелиней-
нелинейной функции линейной.
Таким образом, мы решили поставленную задачу и пришли к сле-
следующим выводам.
Чтобы найти математическое ожидание почти линейной функции,
нужно в выражение функции вместо аргумента подставить его мате-
математическое ожидание. Чтобы найти дисперсию почти линейной функ-
функции, нужно дисперсию аргумента умножить на квадрат производ-
производной функции в точке, соответствующей математическому ожиданию
арумента.
11.3. Линеаризация функции нескольких случайных
аргументов
Имеется система п случайных величин:
(*,. *2 Хп)
и заданы числовые характеристики системы: математические ожидания
лц. тХ2..... т.хп
и корреляционная матрица
кп кп... к
1л
Случайная величина У есть функция аргументов Xv X2, ...» Хп:
У = ?(Хи Х2 Хп), A1.3.1)
причем функция ф не линейна, но мало отличается от линейной
в области практически возможных значений всех аргументов (короче,
«почти линейная.» функция). Требуется приближенно найти числовые
характеристики величины У — математическое ожидание /и., и дис-
дисперсию Dy.
Для решения задачи подвергнем линеаризации функцию
*2 *„)• (I I.3.2)
256 ЛИНЕАРИЗАЦИЯ ФУНКЦИЙ [ГЛ. II
В данном случае нет смысла пользоваться геометрической интер-
интерпретацией, так как за пределами трехмерного пространства она уже
не обладает преимуществами наглядности. Однако качественная сто-
сторона вопроса остается совершенно той же, что и в предыдущем п°.
Рассмотрим функцию y = y(xv х2. •••. х„) в достаточно малой
окрестности точки mXl, mX2, .... тх . Так как функция в этой окре-
окрестности почти линейна, ее можно приближенно заменить линейной.
Это равносильно тому, чтобы в разложении функции в ряд Тейлора
около точки (mXl, tnXj, ..., тх) сохранить только члены первого
порядка, а все высшие отбросить:
х2 *„)»
я
LХ,Дтд.1> mv .... тх^(xt — тх^.
:Х
Значит, и зависимость A1.3.1) между случайными величинами
можно приближенно заменить линейной зависимостью:
Зф^О, ,x)(i ^ A1.3.3)
/= 1
Введем для краткости обозначение:
Учитывая, что Xi—tnXl = Xl, перепишем формулу A1.3.3) в виде:
у=т («V **«• • • • ■ т
К линейной функции A1.3.4) применим способы определения чи-
числовых характеристик линейных функций, выведенные в п° 10.2.
о о о
Имея в виду, что центрированные аргументы (Хи Х2, ..., Хп) имеют
математические ожидания, равные нулю, и ту же корреляционную
матрицу \\Kij\\, получим:
my=<f(mXj, тх% тх^, A1.3.5)
&^
11.3] ЛИНЕАРИЗАЦИЯ ФУНКЦИИ НЕСКОЛЬКИХ СЛУЧАЙНЫХ АРГУМЕНТОВ 257
Переходя в последней формуле от дисперсий к средним квадра-
тическим отклонениям, получим:
i=l
где Гц — коэффициент корреляции величин Xt, Xг
Особенно простой вид принимает формула A1.3.7), когда вели-
велиХп не коррелированы, т. е. Гц = 0 при i ф J.
чины Aj, Х2, .
В этом случае
1=\
A1.3.8)
Формулы типа A1.3.7) и A1.3.8) находят широкое применение
в различных прикладных вопросах: при исследовании ошибок раз-
разного вида приборов и механизмов, а также при Va
анализе точности стрельбы и бомбометания. —~
Пример 1. Относ бомбы X (рис. 11.3.1) выра- |
жается приближенной аналитической формулой: i
]/"
Ж d-1,8.
g
10сЯ), A1.3.9)
Н\
X
Рис. 11.3.1.
где 0О — скорость самолета (м/сек), Н— высота сбра-
сбрасывания (м), с— баллистический коэффициент.
Высота Н определяется по высотомеру, скорость
самолета 0О — по указателю скорости, баллистиче-
баллистический коэффициент с принимается его номинальным
значением с = 1,00. Высотомер показывает 4000 м,
указатель скорости 150 м/сек. Показания высотомера
характеризуются систематической ошибкой -|- 50 м
и средним квадратическим отклонением а== 40 ж;
показания указателя скорости — систематической
ошибкой—2 м/сек и средним квадратическим откло-
отклонением 1 м/сек; разброс возможных значений бал-
баллистического коэффициента с, обусловленный неточностью изготовления
бомбы, характеризуется средним квадратическим отклонением <зс — 0,05.
Ошибки приборов независимы между собой.
Найти систематическую ошибку и среднее квадратическое отклонение
точки падения бомбы вследствие неточности в определении параметров Н,
0О и с. Определить, какой из этих факторов оказывает наибольшее влияние
на разброс точки падения бомбы.
Решение. Величины Н, v0 и с представляют собой некоррелирован-
некоррелированные случайные величины с числовыми характеристиками:
тн = 3950 м; °н = 4° ■*'.
mVts = 152 м/сек;
ml=\,№;
= 1 м/сек:
= 0,05.
Так как диапазон возможных изменений случайных аргументов сравни-
сравнительно невелик, для решения задачи можно применить метод линеаризации.
17 Е. С. Вентцель
258 ЛИНЕАРИЗАЦИЯ ФУНКЦИЙ [ГЛ. 11
Подставляя в формулу A1.3.9) вместо величин ft с, и с их математические
ожидания, найдем математическое ожидание величины X:
т, = 4007 (ж).
Для сравнения вычислим номинальное значение:
*ш>м = 150 у -—■ A — 1,8 • 10~5 • 1 • 4000) = 3975 (м).
Разность между математическим ожиданием и номинальным значением
и представляет собой систематическую ошибку точки падения:
Ах = тх — Хноы = 4007 — 3975 = 32 (м).
Для определения дисперсии величины X вычислим частные производные:
|£.= j/ .£!(!_ 1,8. КГ5сЯ),
дХ^ ,/М
и подставим в эти выражения вместо каждого аргумента его математиче-
математическое ожидание:
/ дХ\ ~ .л-. / дХ \ пп . ( оХ\ ___
тг? = О-429; -а— = 26>4; гз-1 = —307.
\дН]т ' \dva)m \дс)т
По формуле A1.3.8) вычислим среднее квадратическое отклонение вели-
величины X:
а2 = 0.4292 • 402 + 26,42 • I2 + 3072 ■ 0.052 = 294,4 + 697,0 + 235,5 = 1126,9,
откуда
ах « 33,6 (м).
Сравнивая слагаемые, образующие <з2х, приходим к заключению, что наи-
наибольшее из них F97,0) обусловлено наличием ошибок в скорости va\ следо-
следовательно, в данных условиях из рассмотренных случайных факторов, обуслов-
обусловливающих разброс точки падения бомбы, наиболее существенной является
ошибка указателя скорости.
Пример 2. Абсцисса точки попадания (в метрах) при стрельбе по са-
самолету выражается формулой
A1.3.10)
где Хн— ошибка наводки (м), »> — угловая скорость цели (рад/сек), D — даль-
дальность стрельбы (м), Xf, — ошибка, связанная с баллистикой снаряда (м).
Величины Хв, ft), D, Xf, представляют собой случайные величины с ма-
математическими ожиданиями:
тХа = 0; тщ = 0,1; т. = 1000; «^ = 0
и средними квадратическими отклонениями:
"жн = 4; °ш = 0,005; од = 50; ^6 = 3.
11.4] УТОЧНЕНИЕ РЕЗУЛЬТАТОВ 259
Нормированная корреляционная матрица системы (Х1{, а>, D, Х$ (т. е. матрица,
составленная из коэффициентов корреляцни) имеет вид:
i 0,5 0,3 0
1 0,4 0
1 0
1
Требуется найти математическое ожидание и среднее квадратическое
отклонение величины X.
Решение. Подставляя в формулу A1.3.10) математические ожидания
аргументов, имеем:
тх = 1,8 • 0,1.1000 = 180 (м).
Для определения среднего квадратического отклонения величины X най-
найдем частные производные:
■й-)--1' (-^)т=1'8ид=180°;
Л,8тш = 0,18; D^-) =1.
Применяя формулу A1.3.7), имеем:
1-0,18-0,3-4-50 + 2-1800-0,18.0,4-0,005-50 =
= 164-81+81+9 + 36 + 21,6 + 64,8=309,4,
откуда
ах « 17,6 (м).
11.4. Уточнение результатов, полученных методом
линеаризации
В некоторых задачах практики возникает сомнение в применимости
метода линеаризации в связи с тем, что диапазон изменений случай-
случайных аргументов не настолько мал, чтобы в его пределах функция
могла быть с достаточной точностью линеаризована.
В этих случаях для проверки применимости метода линеаризации
и для уточнения полученных результатов может быть применен ме-
метод, основанный на сохранении в разложении функции не только
линейных членов, но и некоторых последующих членов более высо-
высоких порядков и оценке погрешностей, связанных с этими членами.
Для того чтобы пояснить этот метод, рассмотрим сначала наибо-
наиболее простой случай функции одного случайного аргумента. Случай-
Случайная величина У есть функция случайного аргумента X:
У = Ч(Х). A1.4.1)
причем функция <р сравнительно мало отличается от линейной на
участке практически возможных значений аргумента X, но все же
17*
260 ЛИНЕАРИЗАЦИЯ ФУНКЦИЙ [ГЛ. И
отличается настолько, что возникает сомнение в применимости ме-
метода линеаризации. Для проверки этого обстоятельства применим
более точный метод, а именно: разложим функцию <р в ряд Тей-
Тейлора в окрестности точки тх и сохраним в разложении первые три
члена:
у = ср (х)« ср {тх) -f-ср' (тх) (х - тх) + ~ <?"\тх) (х -тх)\ A1.4.2)
Та же формула будет, очевидно, приближенно связывать случайные
величины Y и X:
Y = Ф (тх) + ср' (тх) (X -тх) + \ <р" (т,) (* - mxf =
Пользуясь выражением A1.4.3), найдем математическое ожидание
и дисперсию величины К. Применяя теоремы о числовых характери-
характеристиках, имеем:
ту = ср (И;г) + \ ср" («,) М Ф\ = ср (ях) + i ср"(я,) D,. A1.4.4)
По формуле A1.4.4) можно найти уточненное значение матема-
математического ожидания и сравнить его с тем значением ср(т^), которое
получается методом линеаризации; поправкой, учитывающей нелиней-
нелинейность функции, является второй член формулы A1.4.4).
Определяя дисперсию правой и левой части формулы A1.4.3),
имеем:
= [Ф' (тх)? Dx + \ [ср" (
A1.4.5)
о о о о
где К [X, Х*\ — корреляционный момент величин X.JC2.
Выразим входящие в формулу A1.4.5) величины через централь-
центральные моменты величины X:
К[Х, Х*\ = М\хф~
Окончательно имеем:
Dy - W (да,)]2 D, + \ W (/тОг (|*4 [А'] - ul) -f
Y (mx) <f (тх) |л3 [Х\. A1.4.6)
Формула A1.4.6) дает уточненное значение дисперсия по сравне-
сравнению с методом линеаризации; ее второй и третий члены представ-
11.4] УТОЧНЕНИЕ РЕЗУЛЬТАТОВ 261
ляют собой поправку на нелинейность функции. В формулу, кроме
дисперсии аргумента Dx, входят еще третий и четвертый централь-
центральные моменты р3[^П' [^[•Л']. Если эти моменты известны, то по-
поправка к дисперсии может быть найдена непосредственно по фор-
формуле A1.4.6). Однако зачастую нет необходимости в ее точном
определении; достаточно лишь знать ее порядок. На практике часто
встречаются случайные величины, распределенные приблизительно по
нормальному закону. Для случайной величины, подчиненной нормаль-
нормальному закону,
£ & A1.4.7)
и формула A1.4.6) принимает вид:
Dy = [ср' (тх)\* Dx+1 [/ (тх) f D\. A1.4.8)
Формулой A1.4.8) можно пользоваться для приближенной оценки
погрешности метода линеаризации в случае, когда аргумент распре-
распределен по закону, близкому к нормальному.
Совершенно аналогичный метод может быть применен по отно-
отношению к функции нескольких случайных аргументов:
Х2 Хп). A1.4.9)
Разлагая функцию
х% хп)
в ряд Тейлора в окрестности точки яц, тх тХп и сохраняя
в разложении члены не выше второго порядка, имеем приближенно:
или, вводя центрированные величины,
где индекс т по-прежнему обозначает, что в выражение частной
производной вместо аргументов Xt подставлены их математические
ожидания тх..
262 ЛИНЕАРИЗАЦИЯ ФУНКЦИЯ [ГЛ. II
Применяя к формуле A1.4.10) операцию математического ожида-
ожидания, имеем:
л»у = ?(«*,. тх% «*„) +
где Кц — корреляционный момент величин Xt, Xj.
В наиболее важном для практики случае, когда аргументы Xv
Х2 Хп некоррелированны, формула A1.4.11) принимает вид:
и, = ?(»,,. тх mXn) + ^\(jr\ Dx. A1.4.12)
AaX I
х
Второй член формулы A1.4.12) представляет собой поправку на
нелинейность функции.
Перейдем к определению дисперсии величины Y. Чтобы получить
выражение дисперсии в наиболее простом виде, предположим, что
величины Xv X2 Хп не только некоррелированны, но и неза-
независимы. Определяя дисперсию правой и левой части A1.4.10) и поль-
пользуясь теоремой о дисперсии произведения (см. п° 10.2), получим:
Для величин, распределенных по закону, близкому к нормальному,
можно воспользоваться формулой A1.4.7) и преобразовать выраже-
выражение A1.4.13) к виду:
Последние два члена в выражении A1.4.14) представляют собой
«поправку на нелинейность функции» и могут служить для оценки
точности метода линеаризации при вычислении дисперсии.
ГЛАВА 12
ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЙ СЛУЧАЙНЫХ
АРГУМЕНТОВ
12.1. Закон распределения монотонной функции
одного случайного аргумента
В предыдущих главах мы познакомились с методами определения
числовых характеристик функций случайных величин; главное удоб-
удобство этих методов в том, что они не требуют нахождения законов
распределения функций. Однако иногда возникает необходимость
в определении не только числовых характеристик, но и законов рас-
распределения функций.
Начнем с рассмотрения наиболее простой задачи, относящейся
к этому классу: задачи о законе распределения функции одного
случайного аргумента. Так как для практики наибольшее значение
имеют непрерывные случайные величины, будем решать задачу именно
для них.
Имеется непрерывная случайная величина X с плотностью рас-
распределения /(х). Другая случайная величина Y связана с нею функ-
функциональной зависимостью:
Требуется найти плотность распределения величины Y.
Рассмотрим участок оси абсцисс (а, Ь), на котором лежат все
возможные значения величины X, т. е.
В частном случае, когда область возможных значений X ничем но
ограничена. а= — оо: Ь=-\-оо.
Способ решения поставленной задачи зависит от поведения функ-
функции ср на участке (а, Ь): возрастает ли она на этом участке или убывает,
или колеблется.
') Функцию <р предполагаем непрерывной и дифференцируемой.
264 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИИ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
В данном п° мы рассмотрим случай, когда функция у = <р(х) на
участке (а, Ь) монотонна1). При этом отдельно проанализируем два
случая: монотонного возрастания и монотонного убывания функции.
1. Функция у = ср(х) на участке (а, Ь) монотонно возрастает
(рис. 12.1.1). Когда величина X принимает различные значения на
участке '(а, Ь), случайная точка
у (X, Y) перемещается только по
*-i=<p{x) кривой у = ср(х); ордината этой
случайной точки полностью опре-
определяется ее абсциссой.
Обозначим g(y) плотность
распределения величины Y. Для
I того чтобы определить g(y), най-
У
j дем сначала функцию 'распреде-
_1 х ления величины У:
0 а х Ь
ис' 2Л' ' Проведем прямую АВ, парал-
параллельную оси абсцисс на расстоя-
расстоянии у от нее (рис. 12.1.1). Чтобы выполнялось условие К < у, случайная
точка (X, Г) должна попасть на тот участок кривой, который лежит
ниже прямой АВ; для этого необходимо и достаточно, чтобы слу-
случайная величина X попала на участок оси абсцисс от а до х, где
х — абсцисса точки пересечения кривой у = «р (х) и прямой ' АВ.
Следовательно,
у)=*Р(а<Х <*)== f f{x)dx.
а
Верхний предел интеграла х можно выразить через у:
где ф — функция, обратная функции ср. Тогда
= / f(x)dx. A2.1.1)
Дифференцируя интеграл A2.1.1) по переменной у, входящей в верх-
верхний предел, получим:
(У). A2.1.2)
') Случай немонотонной функции будет рассмотрен в п° 12.3.
12.1] ЗАКОН РАСПРЕД. МОНОТОННОЙ ФУНКЦИИ ОДНОГО АРГУМЕНТА 265
2. Функция у = ср(х) на участке (а, Ь) монотонно убывает
(рис. 12.1.2). В этом случае
ь ь
Q(y) = P(Y<y) = P(x<X <b) = f f(x)dx = J f{x)dx,
откуда
g(y)~ G'(У)— —/(ф (У))ф'(У)- A2.1.3)
Сравнивая формулы A2.1.2) и A2.1.3), замечаем, что они могут
быть объединены в одну:
£г(У) = /(ф(У))|ф/(УI- A2.1.4)
Действительно, когда ср возрастает, ее производная (а значит, и ф')
положительна. При убывающей функции ср производная ф' отрица-
отрицательна, но зато перед ней в формуле A2.1.3) стоит минус. Следо-
Следовательно, формула A2.1.4), в которой производная берется по модулю,
верна в обоих случаях. Таким
образом, задача о законе рас- У
пределения монотонной функции
решена.
Пример. Случайная величина X
подчинена закону Коши с плотностью Д
распределения".
Величина Y связана с X зависимостью
Г=1— X3.
Рис. 12.1.2.
Найти плотность распределения ве-
величины Y.
Решение. Так как функция у = 1 — х3 монотонна на участке
(—оо, +со), можно применить формулу A2.1.4). Решение задачи оформим
в виде двух столбцов: в левом будут помещены обозначения функций, при-
принятые в общем решении задачи, в правом — конкретные функции, соответ-
соответствующие данному примеру:
I 1
fix)
У = Ч (■*)
х = ф (у)
Ф'(У)
\Y(y)\
у=1—
— 1
3/A-УJ
1
266 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЙ СЛУЧАЙНЫХ АРГУМЕНТОВ {ГЛ. 12
12.-2. Закон распределения линейной функции
от аргумента, подчиненного нормальному закону
Пусть случайная величина X подчинена нормальному закону
с плотностью:
A2.2.1)
а случайная величина Y связана с нею линейной функциональной за-
зависимостью:
Y = aX-\-b, A2.2.2)
где а и b — неслучайные коэффициенты.
Требуется найти закон распределения величины К.
Оформим решение в виде двух столбцов, аналогично примеру
предыдущего п°:
/(*)
IfOOl
3» = ах -\-Ь
у — Ь
а
\_
а
1
1«1
Преобразуя выражение g(y), имеем:
а I "л
2la|V
е х
а это есть не что иное, как нормальный закон с параметрами:
ау = атх-\- Ь,
A2.2.3)
Если перейти от средних квадратических отклонений к пропор-
пропорциональным им вероятным отклонениям, получим:
х- A2.2.4)
12.31 ЗАКОН РАСПРЕД. НЕМОНОТОННОЙ ФУНКЦИИ ОДНОГО АРГУМЕНТА 267
Таким образом мы убедились, что линейная функция от аргу-
аргумента, подчиненного нормальному закону, также подчинена
нормальному закону. Чтобы найти центр рассеивания этого закона,
нужно в выражение линейной функции вместо аргумента подставить
его центр рассеивания. Чтобы найти среднее квадратическое откло-
отклонение этого закона, нужно среднее квадратическое отклонение аргу-
аргумента умножить на модуль коэффициента при аргументе в выражении
линейной функции. То же правило справедливо и для вероятных
отклонений.
12.3. Закон распределения немонотонной функции
одного случайного аргумента
Имеется непрерывная случайная величина X с плотностью распре-
распределения / (х); другая величина Y связана с X функциональной за-
зависимостью:
причем функция у=ср(д:) на участке (а, Ь) возможных значений
аргумента не монотонна (рис. 12.3.1).
О Л,(у)
Рис. 12.3.1.
Найдем функцию распределения G(y) величины К. Для этого снопа
проведем прямую АВ, параллельную оси абсцисс, на расстоянии у
от нее и выделим те участки кривой у = ср(х), на которых выпол-
выполняется условие Y < у. Пусть этим участкам соответствуют участки
оси абсцисс: Ь.х (у), Д2 (у), . ..
Событие Y < у равносильно попаданию случайной величины X
на один из участков А, (у), Д2(у), • •. —безразлично, на какой именно.
Поэтому
268 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЙ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
Таким образом, для функции распределения величины У=
имеем формулу:
О (У) = 2 /f{x)dx. A2.3.1)
Границы интервалов Д/(у) зависят от у "и при заданном конкрет-
конкретном виде функции у = (р(лг) могут быть выражены как явные функ-
функции у. Дифференцируя О (у) по величине у, входящей в пределы
интегралов, получим плотность
распределения величины Y:
g(y)=G'(y). A2.3.2)
Пример. Величина X подчи-
подчинена закону равномерной плотности
на участке от — у до у:
/(•*) =
I при \х\<\\
О при | х\ > у.
Рис. 12.3.2.
Найтн закон распределения величины
K=cosA'.
Решение. Строим график функции у = cos x (рис. 12.3.2). Очевидно,
= —S" > * = "о" > и в интервале (я, Ь) функция у = cos x немонотонна.
Применяя формулу A2.3.1), имеем:
*1 2
ff(x)dx+ff(x)dx.
Выразим пределы Xi и хг через у:
Xi= — arccos у; х2 = arccos у.
Отсюда
— arccos у 2
f(x)dx+ j f(x)dx.
arccos у
A2,3.3)
Чтобы найти плотность g{y), не будем вычислять интегралы в фор-
формуле A2.3.3), а непосредственно продифференцируем это выражение по пере-
переменной у, входящей в пределы интегралов:
g {У) = О' (у) = / (— arccos у) -—=_.-!- / (arccos у) —____.
12.4] ЗАКОН РАСПРЕДЕЛЕНИЯ ФУНКЦИИ ДВУХ СЛУЧАЙНЫХ ВЕЛИЧИН 269
Имея в виду, что /(л) = —, получим:
A2.3.4)
Указывая для К закон распределения A2.3.4), следует оговорить, что
он действителен лишь в пределах от 0 до 1, т.е.
в тех пределах, в которых меняется y=cosX
при аргументе л, заключенном между — -^ и "о"
Вне этих пределов плотность g (у) равна
нулю.
График функции g (у) дан на рис. 12.3.3.
При у — 1 кривая g (у) имеет ветвь, уходящую
на бесконечность.
12.4. Закон распределения функции
двух случайных величин
Задача определения закона распределения
функции нескольких случайных аргументов
значительно сложнее аналогичной задачи
для функции одного аргумента. Здесь мы изложим общий метод
решения этой задачи для
наиболее простого случая
функции двух аргументов.
Имеется система двух
непрерывных случайных ве-
величин (X, Y) с плотностью
распределения / (х, у). Слу-
Случайная величина Z связана
с X и Y функциональной
зависимостью:
Рис. 12.3.3.
Рис. 12.4. L
в случае одного аргумента. Функция
не кривой, а поверхностью (рис. 12.4.1).
Найдем функцию распределения величины Z:
Требуется найти закон
распределения величины Z.
Для решения задачи вос-
воспользуемся геометрической
интерпретацией, аналогичной
той, которую мы применяли
= f(x, у) изобразится уже
)
A2.4.1)
270 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЯ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
Проведем плоскость Q, параллельную плоскости хОу, на расстоя-
расстоянии z от нее. Эта плоскость пересечет поверхность г = <р(х, у) по
некоторой кривой К г)- Спроектируем кривую К на плоскость хОу.
Эта проекция, уравнение которой ср(лс, y) = z, разделит плоскость хбу
на две области; для одной из них высота поверхности над пло-
плоскостью хОу будет меньше, а для другой—больше z. Обозначим D
ту область, для которой эта высота меньше z. Чтобы выполнялось
неравенство A2.4.1), случайная точка (X, К), очевидно, должна по-
попасть в область D; следовательно,
= J J
y)dxdy. A2.4.2)
(D)
В выражение A2.4.2) величина z входит неявно, через пределы
интегрирования.
Дифференцируя 0{z) no z, получим плотность распределения
величины Z:
Зная конкретный вид функции z = <?(x, у), можно выразить пре-
пределы интегрирования через z и написать выражение g(z) в явном виде.
Для того чтобы найти закон распределения функции двух аргу-
аргументов, нет необходимости каждый раз строить поверхность
z = y(x, у), подобно тому, как
это сделано на рис. 12.4.1, и пе-
пересекать ее плоскостью, парал-
параллельной хОу. На практике доста-
достаточно построить на плоскости
хОу кривую, уравнение которой
z = cp (x, у), отдать себе отчет
в том, по какую сторону этой
: кривой Z < z, а по какую Z > z,
и интегрировать по области D,
для которой Z < Z.
Пример. Система величин (X, Y)
подчинена закону распределения с
плотностью f (х, у). Величина Z есть
произведение величин X, Y:
Z=XY.
Рис. 12.4.2, Шйти плотность распределения ве-
величины Z.
Решение. Зададимся некоторым значением г и построим на пло-
плоскости xOv кривую, уравнение которой ху = г (рис. 12.4.2). Это — гипербола,
асимптоты" ко'торой совпадают с осями координат. Область D на рис. 12.4.2
заштрихована.
') На нашем чертеже кривая К замкнута; вообще она может быть и не-
незамкнутой, а может состоять и из нескольких ветвей.
12.51 ЗАКО» РАСПРЕДЕЛЕНИЯ СУММЫ ДВУХ СЛУЧАЙНЫХ ВЕЛИЧИН 271
Функция распределения величины Z имеет вид:
О со
2
ОТ ~Х
= J ff(x,y)dxdy = J j f(x,y)dxdy +J j f(x,y)dxdy.
Ф)
— CO 2
0 _
Дифференцируя это выражение по z, имеем:
и
<12-4-з>
12.5. Закон распределения суммы двух случайных величин.
Композиция законов распределения
Воспользуемся изложенным выше общим методом для решения
одной важной для практики частной задачи, а именно для нахожде-
нахождения закона распределения суммы
двух случайных величин.
Имеется система двух случай-
случайных величин {X, Y) с плотностью
распределения f(x, у). Рассмот-
Рассмотрим сумму случайных величин
X и Y:
и найдем закон распределения
величины Z. Для этого построим на
плоскости хОу линию, уравнение
которой x-\~y=z (рис. 12.5.1).
Это — прямая, отсекающая на
осях отрезки, равные z. Прямая
х-\~у = z делит плоскость хОу
на две части; правее и выше ее рис. 12.5.L
X -\-Y y> Z', левее и ниже X ~\-
-j- Y < z. Область D в данном случае — левая нижняя часть пло-
плоскости хОу, заштрихованная на рис. 12.5.1. Согласно формуле
A2.4.2) имеем:
f ff(x,
(D)
/ / /(*. y)dxdy= f < J f{x, y)dy>
— 00 —QO —OO I — CO j
dx.
272 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЙ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
Дифференцируя это выражение по переменной z, входящей в верх-
верхний предел внутреннего интеграла, получим:
оо
g{z)= f /(*, z — x)dx. A2.5.1)
— оо
Это — общая формула для плотности распределения суммы двух
случайных величин.
Из соображений симметричности задачи относительно X и К
можно написать другой вариант той же формулы:
оо
//(* —У. У)«*У. 02.5.2)
— оо
который равносилен первому и может применяться вместо него.
Особое практическое значение имеет случай, когда складываемые
случайные величины (X, К) независимы. Тогда говорят о компози-
композиции законов распределения.
Произвести композицию двух законов распределения это значит
найти закон распределения суммы двух независимых случайных вели-
величин, подчиненных этим законам распределения.
Выведем формулу для композиции двух законов распределения.
Имеются две независимые случайные величины X и К, подчиненные
соответственно законам распределения fi(x) и /2(у); требуется про-
произвести композицию этих законов, т. е. найти плотность распределе-
распределения величины
Так как величины X и К независимы, то
и формулы A2.5.1) и A2.5.2) принимают вид:
оо
g(*) = / /, (х)/2 (z — х)dx. A2.5.3)
—ОО
СО
g{z)= f /, (z — у) /а (у) dy. A2.5.4)
—оо
Для обозначения композиции законов распределения часто при-
применяют символическую запись:
g = fi*fi>
где * — символ композиции.
12.5] ЗАКОН РАСПРЕДЕЛЕНИЯ СУММЫ ДВУХ СЛУЧАЙНЫХ ВЕЛИЧИН 273
Формулы A2.5.3) и A2.5.4) для композиции законов распределе-
распределения удобны только тогда, когда законы распределения /, (х) и /2 (у)
(или, по крайней мере, один из них) заданы одной формулой на
всем диапазоне значений аргумента (от —со до со). Если же оба
закона заданы на различных участках различными уравнениями (на-
(например, два закона равномерной плотности), то удобнее пользоваться
непосредственно общим методом, изложенным в п° 12.4, т. е. вы-
вычислить функцию распределения О (z) величины Z = X -\- Y и про-
продифференцировать эту функцию.
Пример 1. Составить композицию нормального закона:
Oc-mf
, , . 1 2о2
и закона равномерной плотности:
/г (У)
при
Решение. Применим формулу композиции законов распределения
в виде A2.5.4):
ty-jL-J*, 2Л dy. A2.5.5)
Подынтегральная функция в выражении A2.5.5) есть не что иное, как нор-
нормальный закон с центром рассеивания z — m и средним квадратическим
отклонением о, а интеграл в выражении A2.5.5) есть вероятность попадания
случайной величины, подчиненной этому закону, на участок от а до C; сле-
следовательно,
^1
Графики законов /j (х), /2 (у) и g (г) при ос = — 2, Р = 2, т
приведены на рис. 12.5.2.
18 Е. С. Вентцель
0, а=1
274 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЙ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
Пример 2. Соста вить композицию двух законов равномерной плот-
плотности, заданных на одном и том же участке @, 1):
/, (х) = 1
/» (У) = 1
при
при
О < у < 1.
Решение. Так как законы /t (х) и /2 (у) заданы только на опреде-
определенных участках осей Ох и Оу, для решення этой задачи удобнее восполь-
воспользоваться не формулами A2.5.3)' и A2.5.4), а общим методом, изложенным
в п° 12.4, и найти функцию распределения G (г) величины Z = X -j- Y.
Рассмотрим случайную точку (X, Y) на плоскости хОу. Область ее воз-
возможных положении — квадрат Н со стороной, равной 1 (рис. 12.5.3). Имеем:
G(z) = jjf(x, у)dxdy = j jdxdy,
(D) (D)
где область D — часть квадрата R, лежащая левее и ниже прямой х-\-у ==г.
Очевидно,
G
где SD — площадь области £>.
Составим выражение для площади области D при .различных значе-
значениях г, пользуясь рис. 12.5.3 и 12.5.4:
1) при z < О G (г) == 0;
2) при 0 < г < 1 G (г) = 4
3) при 1 < г < 2 G (г) = 1 ^-
4) при г > 2 G (г) = 1.
Дифференцируя этн выраження, получим:
1) при z < 0 g (г) = 0;
2) прн 0 < г < 1 £ (г) = г;
Рис. 12.5.5. 3)при1<г<2 ^(г) = 2 — г;
4) при г > 2 g- (г) = 0.
График закона распределения g (z) дан на рис. 12.5.5. Такой закон носит
название «закона Симпсона» или «закона треугольника».
12.6] КОМПОЗИЦИЯ НОРМАЛЬНЫХ ЗАКОНОВ 275
12.6. Композиция нормальных законов
Рассмотрим две независимые случайные величины X и Y, подчи-
подчиненные нормальным законам:
(У
Требуется произвести композицию этих законов, т. е. найти закон
распределения величины:
Применим общую формулу A2.5.3) для композиции законов рас-
распределения:
UU
= fMx)/2(z-x)dx =
со
1 Г
=ъЬ; J
2«2 0 2
х у dx- <12-6-3)
—оо
Если раскрыть скобки в показателе степени подынтегральной
функции и привести подобные члены, получим:
со
f е-
где
2
т
24
Подставляя эти выражения б уже встречавшуюся нам формулу
(9.1.3):
18*
— ас-&
J e-jw±2Bx-cdx = y ^e a t A2.6.4)
276 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЙ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
после преобразований получим:
<12-6-5)
а это есть не что иное, как нормальный закон с центром рассеи-
рассеивания
тг = тх -f- ту A2.6.6)
и средним квадратическим отклонением
Ц A2-6.7)
К тому же выводу можно прийти значительно проще с помощью
следующих качественных рассуждений.
Не раскрывая скобок и не производя преобразований в подынте-
подынтегральной функции A2.6.3), сразу приходим к выводу, что показатель
степени есть квадратный трехчлен относительно х вида
ср (х) = — Ах2 -t- 2Вх — С,
где в коэффициент А величина z не входит совсем, в коэффициент В
входит в первой степени, а в коэффициент С — в квадрате. Имея
это в виду и применяя формулу A2.6.4), приходим к заключению,
что g(z) есть показательная функция, показатель степени которой —
квадратный трехчлен относительно z, а плотность распределения
такого вида соответствует нормальному закону. Таким образом, мы
приходим к чисто качественному выводу: закон распределения вели-
величины z должен быть нормальным.
Чтобы найти параметры этого закона — тг и ог — воспользуемся
теоремой сложения математических ожиданий и теоремой сложения
дисперсий. По теореме сложения математических ожиданий
mz = tnx-\~mr A2.6.8)
По теореме сложения дисперсий
или
О2 = О2 -4~ S2. II О К ОЛ
откуда следует формула A2.6.7).
Переходя от средних квадратических отклонений к пропорцио-
пропорциональным им вероятным отклонениям; получим:
A2.6.10)
12.61 КОМПОЗИЦИЯ НОРМАЛЬНЫХ ЗАКОНОВ 277
Таким образом, мы пришли к следующему правилу: при компо-
композиции нормальных законов получается снова нормальный за-
закон, причем математические ожидания и дисперсии {или квад-
квадраты вероятных отклонений) суммируются.
Правило композиции нормальных законов может быть обобщено
на случай произвольного числа независимых случайных величин.
Если имеется п независимых случайных величин:
Xv Х2 Хп,
подчиненных нормальным законам с центрами рассеивания
и средними квадратическими отклонениями
"■V "*»• •••• °v
то величина
я
z = 2j xt
j = l
также подчинена нормальному закону с параметрами
A2.6.11)
л
|Д О2-6.12)
Вместо формулы A2.6.12) можно применять равносильную ей
формулу.
п
4=2£V A2.6.13)
Если система случайных величин (X, Y) распределена по нор-
нормальному закону, но величины X, Y зависимы, то нетрудно доказать,
так же как раньше, исходя из общей формулы A2.5.1), что закон
распределения величины
Z = X-\-Y
есть тоже нормальный закон. Центры рассеивания по-прежнему скла-
складываются алгебраически, но для средних квадратических отклонений
правило становится более сложным:
A2.6.14)
где г — коэффициент корреляции величин X и У.
278 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЙ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
При. сложении нескольких зависимых случайных величин, подчи-
подчиненных в своей совокупности нормальному закону, закон распреде-
распределения суммы также оказывается нормальным с параметрами
я
тг=Ътх., A2.6.15)
°\ = 2 «' + 2 2 гиохох A2.6.16)
1 = 1 xl i<j ' '
или в вероятных отклонениях
4 = 2 El + 2 S Г'АД. A2-6.17)
i=l ' i<j
где г;у—коэффициент корреляции величин Xt, Xj, а суммирование
распространяется на все различные попарные комбинации величин
Xv Х2 Хп.
Мы убедились в весьма важном свойстве нормального закона: при
композиции нормальных законов получается снова нормальный закон.
Это — так называемое «свойство устойчивости». Закон распределения
называется устойчивым, если при композиции двух законов этого
типа получается снова закон того же типа1). Выше мы показали,
что нормальный закон является устойчивым. Свойством устойчивости
обладают весьма немногие законы распределения. В предыдущем п°
(пример 2) мы убедились, что, например, закон равномерной плот-
плотности неустойчив: при композиции двух законов равномерной плот-
плотности на участках от 0 до 1 мы
получили закон Симпсона.
Устойчивость нормального зако-
закона—одно из существенных условий
его широкого распространения на
практике. Однако свойством устой-
устойчивости, кроме нормального, обла-
обладают и некоторые другие законы
распределения. Особенностью нор-
нормального закона является то, что
Рис. 12.6.1. при композиции достаточно боль-
большого числа практически произволь-
произвольных законов распределения суммарный закон оказывается сколь угодно
близок к нормальному вне зависимости от того, каковы были законы
распределения слагаемых. Это можно проиллюстрировать, например,
составляя композицию трех законов равномерной плотности на уча-
участках от 0 до 1. Получающийся при атом закон распределения g(z)
изображен на рис. 12.6.1. Как видно из чертежа, график функции glz)
весьма напоминает график нормального закона.
') Под «законами одного и того же типа» мы подразумеваем законы, раз-
различающиеся только масштабами по осям и началом отсчета по оси абсцисс.
0J5
12.7] ФУНКЦИИ ОТ НОРМАЛЬНО РАСПРЕДЕЛЕННЫХ АРГУМЕНТОВ 279
12.7. Линейные функции от нормально распределенных
аргументов
Дана система случайных величин (Xv Х2, .... Хп), подчиненная
нормальному закону распределения (или, короче, «распределенная
нормально»); случайная величина Y представляет собой линейную
функцию этих величин:
К= 2 «!*, + &• A2.7.1)
i=i
Требуется найти закон распределения величины Y.
Нетрудно убедиться, что это нормальный закон. Действительно,
величина Y представляет собой сумму линейных функций, каждая из
которых зависит от одного нормально распределенного аргумента X,
а выше было доказано, что такая линейная функция также распре-
распределена нормально. Складывая несколько нормально распределенных
случайных величин, мы снова получим величину, распределенную
нормально.
Остается найти параметры величины Y — центр рассеивания ту
и среднее квадратическое отклонение оу. Применяя теоремы о мате-
математическом ожидании и дисперсии линейной функции, получим:
ту = 2 «,»»,.+ Ь A2.7.2)
S
atajrijaXloXi, A2.7.3)
где r{j—коэффициент корреляции величин Xt, Xj.
В случае, когда величины (Xv Х2 Хп) некоррелированы
(а значит, при нормальном законе, и независимы), формула A2.7.3)
принимает вид:
л
о2=У, а2а2 . A2.7.4)
,, __ , х.
Средние квадратические отклонения в формулах A2.7.3) и A2.7.4)
могут быть заменены пропорциональными им вероятными отклонениями.
На практике часто встречается случай, когда законы распределе-
распределения случайных величин Xv X2. .... Х„, входящих в формулуA2.7.1),
в точности не известны, а известны только их числовые характери-
характеристики: математические ожидания и дисперсии. Если при этом вели-
величины Xv Х2, ..., Хп независимы, а их число п достаточно велико,
то, как правило, можно утверждать, что, безотносительно к виду
законов распределения величин Xt, закон распределения величины Y
280 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИЙ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
близок к нормальному. На практике для получения закона распре-
распределения, который приближенно может быть принят за нормальный,
обычно оказывается достаточным наличие 5-*- 10 слагаемых в выра-
выражении A2.7.1). Следует оговориться, что это не относится к слу-
случаю, когда дисперсия одного из слагаемых в формуле A2.7.1) пода-
подавляюще велика по сравнению со всеми другими*; предполагается, что
случайные слагаемые в сумме A2.7.1) по своему рассеиванию имеют
примерно один и тот же порядок. Если эти условия соблюдены, то
для величины Y может быть приближенно принят нормальный закон
с параметрами, определяемыми формулами A2.7.2) и A2.7.4).
Очевидно, все вышеприведенные соображения о законе распре-
распределения линейной функции справедливы (разумеется, приближенно)
и для того случая, когда функция не является в точности линейной,
но может быть линеаризована.
12.8. Композиция нормальных законов на плоскости
Пусть в системе координат хОу заданы два независимых слу-
чайных вектора: Vj с составляющими (Хх, Yx) и V2 с составляющими
(Х2, Y2). Допустим, что каждый из них распределен нормально,
причем параметры пер-
первого вектора равны
т*? ту? a*f °у«» Г*|У|'
а параметры второго —
Требуется определить за-
закон распределения случай-
■*-■>*■
ного вектора V — Vx-\-V%
х (рис. 12.8.1), составляю-
~~р '—т—' щие которого равны:
Рис. 12.8.1. Х = Хх-\-Х2;
Y = Y.~\- У у
Не представляет трудности качественно доказать (аналогично тому,
как мы это сделали для случая композиции двух нормальных зако-
законов в п° 12.6), что вектор V также распределен нормально. Мы при-
примем это положение без специального доказательства.
Определим параметры закона распределения вектора V.
По теореме сложения математических ожиданий
■ -' \ A2.8.1)
12.8] КОМПОЗИЦИЯ НОРМАЛЬНЫХ ЗАКОНОВ НА ПЛОСКОСТИ
По теореме сложения дисперсий
По теореме сложения корреляционных моментов
1\ХУ = А xtfi -р" A Jfjy2.
или, переходя к коэффициентам корреляции,
Гху0х0у == /■^1y1ojf,°y1 ~Г" гл'2Уго-гаоУ2>
откуда
rjry —
281
A2.8.2)
A2.8.3)
Таким образом, задача композиции нормальных законов на пло-
плоскости решается формулами A2.8.1), A2.8.2) и A2.8.3).
Эти формулы выведены для того случая, когда оба исходных
■> •>
нормальных закона (для векторов V1 и V2) заданы в одной и той же
координатной системе хОу. На практике иногда встречается случай,
когда нужно произвести композицию двух нормальных законов на
плоскости, каждый из которых задан в своей системе координат,
а именно в своих главных осях рассеивания. Дадим способ компо-
композиции нормальных законов для этого случая.
Пусть на плоскости хОу (рис. 12.8.2) даны два нормально рас-
распределенных некоррелированных случайных вектора Vl и Vv Каждый
Рис. 12.8.2.
из векторов характеризуется своим единичным эллипсом рассеивания:
вектор V'j — эллипсом с центром в точке mXl, тУх с полуосями с;,, о^^
из которых первая образует с осью Ох угол а,; аналогичные
282 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИИ СЛУЧАЙНЫХ АРГУМЕНТОВ ГГЛ. !2
характеристики для вектора V2 будут: tnXi, ntya, c5s, о,,, а2. Требуется
найти параметры единичного эллипса рассеивания, характеризующего
->■■>->-
вектор V = V1-Jf-V2. Обозначим их
тх' ту ах>- °у <*•
Так как положение центра рассеивания не зависит от выбора
системы координат, очевидно, по-прежнему будут справедливы соот-
соотношения:
тх = тХх + /MJs,
my = myi -f- Оту2.
Для того чтобы найти элементы корреляционной матрицы век-
вектора V, спроектируем случайные точки, соответствующие векторам
V! и V2. на оси Од; и Оу. Пользуясь формулой A0.3.3), получим:
O =
A2.8.4)
Коэффициенты корреляции составляющих векторов V-y и VV, в
системе координат хОу найдем из соотношения (9.2.2):
_ tg2a1(<£i —<~
1 2о,о„
A2.8.5)
' Х2У2 cjZ Z •
X V
Далее задача композиции нормальных законов на плоскости сво-
сводится к предыдущей. Зная ах, оу, г^, можно найти углы, составлен-
составленные осями суммарного эллипса с осью абсцисс, по формуле (9.2.2):
A2.8.6)
и главные средние квадратические отклонения — по формулам (9.2.4):
о, = У a2 cos2 a -f- r a a sin 2a -\- o^sin2 a, 1
У У У ' A2.8.7)
^ = I' cr sin2 a — Гхуохъ„ sin 2а -f- о! cos2 a.
') Так как тангенс имеет период я, то значения ое, определяемые по
формуле A2.8.6), могут различаться на —. что соответствует двум главным
осям эллипса.
12.8] КОМПОЗИЦИЯ НОРМАЛЬНЫХ ЗАКОНОВ НА ПЛОСКОСТИ 283
Последние соотношения справедливы не только для средних
квадратических отклонений, но и для пропорциональных им вероят-
вероятных отклонений:
. У ' A2.8.8)
Еп = /^ sin2 а — rxyExEy sin 2а + Ву cos2 а.
Перейдем к композиции произвольного числа нормальных законов
на плоскости.
С наиболее простым случаем композиции произвольного числа
нормальных законов мы встречаемся тогда, когда главные оси рас-
рассеивания для всех законов, подлежащих композиции, параллельны
друг другу. Тогда, выбирая координатные оси параллельно этим
главным осям рассеивания, мы будем иметь дело с системами неза-
независимых случайных величин, и композиция нормальных законов вы-
выполняется по простым формулам:
п л
A2.8.9)
где ах, aXl, оу, оУ|—главные средние квадрэтические отклонения
соответствующих законов.
В случае, когда направления главных осей не совпадают, можно
составить композицию нескольких нормальных законов тем же мето-
методом, которым мы пользовались выше для двух законов, т. е. проек-
проектируя складываемые случайные векторы на оси одной и той же си-
системы координат.
На практике часто встречаются случаи, когда в числе законов,
подлежащих композиции, встречаются так называемые «вырожденные»
законы, т. е. законы, характеризующиеся эллипсом рассеивания, имею-
имеющим только одну полуось (другая равна нулю). Такие «вырожден-
«вырожденные» законы дают рассеивание только в одном направлении. При
композиции таких законов нужно поступать так же, как при ком-
композиции обычных законов, полагая некоторые параметры (средние
квадратические или вероятные отклонения) равными нулю.
Пример 1. Ошибка бомбометания вызвана совместным действием
следующих факторов:
1) техническое рассеивание бомб;
2) неточность прицеливания по дальности;
3) неточная наводка в боковом направлении.
Все эти факторы независимы. Техническое рассеивание бомб дает единич-
единичный эллипс рассеивания в виде круга радиусом 20 м. Ошибка прицеливания
284 ЗАКОНЫ РАСПРЕДЕЛЕНИЯ ФУНКЦИИ СЛУЧАЙНЫХ АРГУМЕНТОВ [ГЛ. 12
по дальности действует только в направлении полета и имеет среднее квад-
рзтическое отклонение 40 м; центр рассеивания сдвинут вперед по полету
на 5 м. Ошибка боковой наводки действует только в направлении, перпен-
перпендикулярном к полету, н имеет среднее квадратическое отклонение 30 м;
центр рассеивания смещен вправо на 10 м. Найти параметры нормального
закона, которому подчинена суммарная ошибка бомбометания, вызванная сов-
совместным действием всех перечисленных факторов.
Решение. Так как главные оси всех перечисленных в задаче эллип-
эллипсов (из которых второй и третий вырождены) параллельны, то можно при-
применить правило композиции нормальных законов с независимыми составляю-
составляющими (формулы A2.8.9)). Выбирая ось Оу по направлению полета, ось Ох —
перпендикулярно к нему, имеем:
тх =
= 202 + 302:
= 202 + 402:
10, т
= 1300,
= 2000,
1У = 5,
о, = 36,1
о, = 44,7
(м),
(м).
Пример 2. Производится воздушная стрельба с самолета по само-
самолету; рассеивание точек попадания рассматривается на вертикальной пло-
плоскости, перпендикулярной к направлению стрельбы. Причины рассеивания
точек попадания состоят в следующем:
1) ошибки, связанные с неоднородностью баллистики снарядов и коле-
колебаниями установки;
2) ошибки наводки;
3) ошибки, вызванные неточностью определения дальности;
4) инструментальные ошибки прицела.
Главные оси рассеивания, вызванного первой причиной, расположены гори-
горизонтально н вертикально, и главные средние квадратическне отклонения
равны соответственно 1 и 2 м\ ошибка наводки дает круговое рассеивание
со средним квадратическнм отклонением 3 м; ошибка, вызванная неточно-
неточностью определения дальности, дает рассеивание только вдоль оси, наклонен-
наклоненной к горизонту под углом 30°, со с. к. о. 4 м; инструментальные ошибки при-
прицела дают круговое" рассеивание со с. к. о. 2 м. Систематические ошибки
равны нулю.
Требуется найтн параметры закона распределения суммарной ошибки,
вызванной всеми перечисленными факторами.
Решение. Выбираем систему координат с горизонтальной осью Ох
и вертикальной Оу. Эти оси являются главными осями рассеивания для всех
законов, кроме третьего (ошибки вследствие неточности определения даль-
дальности). Обозначим составляющие каждой ошибки в системе координат хОу
соответственно:
XbY,- Xt. Y2; Х3, Г3; Х„ К,.
Параметры этих составляющих равны соответственно:
тх, = "*х, = *х, = тх, = '7гу, = тъ = тУ, = тУ< = 0;
Что касается величин аХа и sy, то их мы определяем, проектируя случай-
случайную точку (Jf3. Уз) на оси Ох и Оу по формулам A2.8.4):
<£ = 42 cos2 30° = 12;
12.8] КОМПОЗИЦИЯ НОРМАЛЬНЫХ ЗАКОНОВ НА ПЛОСКОСТИ 285
Коэффициент корреляции величин (Х3, Y3) найдем по формуле A2.8.5)
_ tg6O°A2-4)
ад 2/48
что и естественно, так как рассеивание сосредоточено на одной прямой и,
следовательно, величины Х3 и У3 зависимы функционально.
Применяя теорему сложения дисперсий, имеем:
°у = °у, + °у, + °п + °Ъ = 21г °у = 4-58 (*)■
Коэффициент корреляции гху найдем, применяя теорему сложения кор-
корреляционных моментов:
откуда
г** = 2р2-5,09-4,58 = °>297-
Определим угол а, который составляет с осью первая главная ось рас-
рассеивания:
. „ 2-0,297-5,09-4,58
* 2а = 5,09' -4,58» = ll340>
2ая69°30'; а«34°45'.
По формулам A2.8.8) имеем:
cos2a + r^ayiy sin 2a + oj sin2 a = 5,55 (ж);
n2 a ~~ rjryajt°y sln 2a + °y cos2a = 4>22 (ж)-
ГЛАВА 13
ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ
13.1. Закон больших чисел и центральная предельная теорема
В начале курса мы уже говорили о том, что математические
законы теории вероятностей получены абстрагированием реальных
статистических закономерностей, свойственных массовым случайным
явлениям. Наличие этих закономерностей связано именно с массо-
массовостью явлений, то есть с большим числом выполняемых однородных
опытов или с большим числом складывающихся случайных воздей-
воздействий, порождающих в своей совокупности случайную величину, под-
подчиненную вполне определенному закону. Свойство устойчивости мас-
массовых случайных явлений известно человечеству еще с глубокой
древности. В какой бы области оно ни проявлялось, суть его сводится
к следующему: конкретные особенности каждого отдельного случай-
случайного явления почти не сказываются на среднем результате массы
таких явлений; случайные отклонения от среднего, неизбежные в каж-
каждом отдельном явлении, в массе взаимно погашаются, нивелируются,
выравниваются. Именно эта устойчивость средних и пред-
представляет собой физическое содержание «закона больших чисел», пони-
понимаемого в широком смысле слова: при очень большом числе случай-
случайных явлений средний их результат практически перестаёт бытьслучай-
ным и может рыть _гпэедсказан~с^Вольшой степенью определенности.
" В узком" 'смыслёслова под~«законом больших чисел» в теории
вероятностей понимается ряд математических теорем, в каждой из
которых для тех или иных условий устанавлиьается факт приближе-
приближения средних характеристик большого числа опытов к некоторым
определенным постоянным.
В п° 2.3 мы уже формулировали простейшую из этих теорем —
теорему Я. Бернулли. Она утверждает, что при большом числе опы-
опытов частота события приближается (точнее — сходится по вероятно-
вероятности) к вероятности этого события. С другими, более общими фор-
формами закона больших чисел мы познакомимся в данной главе. Все
они устанавливают факт и условия сходимости по вероятности тех
или иных случайных величин к постоянным, не случайным величинам.
13.2] НЕРАВЕНСТВО ЧЕБЫШЕВА 287
Закон больших чисел играет важную роль в практических приме-
применениях теории вероятностей. Свойство случайных величин при опре-
определенных условиях вести себя практически как не случайные позволяет
уверенно оперировать с этими величинами, предсказывать резуль-
результаты массовых случайных явлений почти с полной определенностью.
Возможности таких предсказаний в области массовых случайных
явлений еще больше расширяются наличием другой группы предель-
предельных теорем, касающихся уже не предельных значений случайных
величин, а предельных законов распределения. Речь идет о группе
теорем, известных под названием «центральной предельной теоремы».
Мы уже говорили о том, что при суммировании достаточно большого
числа случайных величин закон распределения суммы неограниченно
приближается к нормальному при соблюдении некоторых условий.
Эти условия, которые математически можно формулировать различным
образом — в более или менее общем виде, — по существу сводятся
к требованию, чтобы влияние на сумму отдельных слагаемых было
равномерно малым, т. е. чтобы в состав суммы не входили члены,
явно преобладающие над совокупностью остальных по своему влия-
влиянию на рассеивание суммы. Различные формы центральной предельной
теоремы различаются между собой теми условиями, для которых
устанавливается это предельное свойство суммы случайных величин.
Различные формы закона больших чисел вместе с различными
формами центральной предельной теоремы образуют совокупность
так называемых предельных теорем теории вероятностей. Предель-
Предельные теоремы дают возможность не только осуществлять научные
прогнозы в области случайных явлений, но и оценивать точность
этих прогнозов.
В данной главе мы рассмотрим только некоторые, наиболее про-
простые формы предельных теорем. Сначала будут рассмотрены теоремы,
относящиеся к группе «закона больших чисел», затем—теоремы,
относящиеся к группе «центральной предельной теоремы».
13.2. Неравенство Чебышева
U качестве леммы, необходимой для доказательства теорем, отно-
относящихся к группе «закона больших чисел», мы докажем одно весьма
общее неравенство, известное под названием неравенства Чебышева.
Пусть имеется случайная величина X с математическим ожида-
ожиданием тх и дисперсией Dx. Неравенство Чебышева утверждает, что.
каково бы ни было положительное число а, вероятность того, что
величина X отклонится от своего математического ожидания не меньше
чем на а, ограничена сверху величиной —f '•
—я*1>«)<% • A3.2.1)
288 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 13
Доказательство. 1. Пусть величина X прерывная, с рядом
распределения
Xt\\Xi\X2\...\xn
Pl\\P\\Pt\---\Pn'
Изобразим возможные значения величины X и ее математическое
ожидание тх в виде точек на числовой оси Ох (рис. 13.2.1).
Зададимся некоторым значением а > 0 и вычислим вероятность
того, что величина X отклонится от своего математического ожида-
ожидания не меньше чем на а:
Р(\Х — /их|>а). A3.2.2)
Для этого отложим от точки тх вправо и влево по отрезку дли-
длиной а; получим отрезок АВ. Вероятность A3.2.2) есть не что иное,
как вероятность того, что
а. т а случайная точка X попадет
7)—» ■ я. не внутрь отрезка АВ, а
В XlM x» вовне его:
Рис. 13.2.1.
Для того чтобы найти эту вероятность, нужно просуммировать
вероятности всех тех значений xlt которые лежат вне отрезка АВ.
Это мы запишем следующим образом:
Р(\Х — тх\>о)= ^ 2 ^Pl, A3.2.3)
где запись \xt — тх\^-а под знаком суммы означает, что суммиро-
суммирование распространяется на все те значения /, для которых точки xt
лежат вне отрезка АВ.
С другой стороны, напишем выражение дисйерсии величины X
По определению:
п п
л = М[(Х — m,J]=2 (-V;— mjcrpi = '% \х,~тх\*р,. A3.2.4)
Так как все члены суммы A3.2.4) неотрицательны, она может
только уменьшиться, если мы распространим ее не на все значения х(,
а только на некоторые, в частности на те, которые лежат вне
отрезка АВ:
Dx> 2 |**-»*18/>|. A3-2.5)
\*Гтх\>а
') Концы отрезка АВ мы в него не включаем.
13.2] НЕРАВЕНСТВО ЧЕБЫШЕВА 289
Заменим под знаком суммы выражение \xt— тх\ через а. Так как
для всех членов суммы \х(— тх\^а, то от такой замены сумма
тоже может только уменьшиться; значит,
Dx> S «2/>( = «2 2 Pt- A3.2.6)
\хгтх}>* \*Гтх\>'
Но согласно формуле A3.2.3) сумма, стоящая в правой части A3.2.6),
есть не что иное, как вероятность попадания случайной точки вовне
отрезка АВ; следовательно,
откуда непосредственно вытекает доказываемое неравенство.
2. В случае, когда величина X непрерывна, доказательство про-
проводится аналогичным образом с заменой вероятностей />, элементом
вероятности, а конечных сумм — интегралами. Действительно,
Р(\Х — тх\>а) = f /(x)dx1), A3.2.7)
\х—тх\>л
где /(х)— плотность распределения величины X. Далее, имеем:
СО GO
Dx = J(x — mx?f(x)dx = f\x—
~ oo —oo
J \x-tnx\*f{x)dx.
J
где знак \х—mx\^>a под интегралом означает, что интегрирова-
интегрирование распространяется на внешнюю часть отрезка АВ.
Заменяя \х—тх\ под знаком интеграла через а, получим:
J
\х-тх\>а
откуда и вытекает неравенство Чебышева для непрерывных величин.
Пример. Дана случайная величина X с математическим ожида-
ожиданием тх и дисперсией о2. Оценить сверху вероятность того, что
величина X отклонится от своего математического ожидания не
меньше чем на Зож.
Решение. Полагая в неравенстве Чебышева а = 3ож, имеем:
') Знак > заменен знаком >, так как для непрерывной величины вероят-
вероятность точного равенства равна нулю.
19 Е. С. Вентцель
290 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 13
т. е. вероятность того, что отклонение случайной величины от ее
математического ожидания выйдет за пределы трех средних квадра-
тических отклонений, не может быть больше -^ .
Примечание. Неравенство Чебышева дает только верхнюю
границу вероятности данного отклонения. Выше этой границы
вероятность не может быть ни при каком законе распределения.
На практике в большинстве случаев вероятность того, что величина X
выйдет за пределы участка тх ± ?>ох, значительно меньше -д-. Напри-
Например, для нормального закона эта вероятность приблизительно
равна 0,003. На практике чаще всего мы имеем дело со случайными
величинами, значения которых только крайне редко выходят за пре-
пределы ^,.±30^. Если закон распределения случайной величины неиз-
неизвестен, а известны только тх и ах, на практике обычно считают
отрезок тх + Ъах участком практически возможных значений случайной
величины (так называемое «правило трех сигма»).
13.3. Закон больших чисел (теорема Чебышева)
В данном п° мы докажем одну из простейших, но вместе с тем
наиболее важных форм закона больших чисел — теорему Чебышева.
Эта теорема устанавливает связь между средним арифметическим
наблюденных значений случайной величины и ее математическим
ожиданием.
Предварительно решим следующую вспомогательную задачу.
Имеется случайная величина X с математическим ожиданием тх
и дисперсией Dx. Над этой величиной производится п независимых
опытов и вычисляется среднее арифметическое всех наблюденных
значений величины X. Требуется найти числовые характеристики
этого среднего арифметического — математическое ожидание и диспер-
дисперсию — и выяснить, как они изменяются с увеличением п.
Обозначим:
Хх — значение величины X в первом опыте;
А— значение величины X во втором опыте, и т. д.
Очевидно, совокупность величин A'lf А*2, .... А'„ предстиляег
собой п независимых случайных величин, каждая из которых распре-
распределена по тому же закону, что и сама величина X. Рассмотрим
среднее арифметическое этих величин:
л
'' ™ п '
Случайная величина Y есть линейная функция независимых слу-
случайных величин Xv АГ2. •... Хп. Найдем математическое ожидание
13.3)
ЗАКОН БОЛЬШИХ ЧИСЕЛ (ТЕОРЕМА ЧЕБЫШЕВА)
291
и дисперсию этой величины. Согласно правилам п° 10 для определения
числовых характеристик линейных функций получим:
ту
М [Y] = i-
М [Xt] =Д птх = тх;
Итак, математическое ожидание величины Y не зависит от числа
опытов п и равно математическому ожиданию наблюдаемой вели-
величины X; что касается дисперсии величины Y, то она неограниченно
убывает с увеличением числа опытов и при достаточно большом п.
может быть сделана сколь угодно малой. Мы убеждаемся, что среднее
арифметическое есть случайная величина со сколь угодно малой дис-
дисперсией и при большом числе опытов ведет себя почти как не
случайная.
Теорема Чебышева и устанавливает в точной количественной
форме это свойство устойчивости среднего арифметического. Она
формулируется следующим образом:
При достаточно большом числе независимых опытов среднее
арифметическое наблюденных значений случайной величины
сходится по вероятности к ее математическому ожиданию.
Запишем теорему Чебышева в виде формулы. Для этого напомним
смысл термина «сходится по вероятности». Говорят, что случайная
величина Xп сходится по вероятности к величине а, если при увели-
увеличении п вероятность того, что Хп и а будут сколь угодно близки,
неограниченно приближается к единице, а это значит, что при
достаточно большом п
Р(\Хп-а\<е)>1 — Ь,
где s, 8 — произвольно малые положительные числа.
Запишем в аналогичной форме теорему Чебышева. Она утверждает,
что при увеличении п среднее арифметическое
вероятности к тх, т. е.
%
— т.
Докажем это неравенство.
19*
сходится по
A3.3.1)
292 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 13
Доказательство. Выше было показано, что величина
Y '-1
имеет числовые характеристики
Применим к случайной величине К неравенство Чебышева, полагая
Как бы мало ни было число е, можно взять п таким большим,
чтобы выполнялось неравенство
2*
<§.
где 8 — сколь угодно малое число.
Тогда
откуда, переходя к противоположному событию, имеем:
п х
что и требовалось доказать.
13.4. Обобщенная теорема Чебышева. Теорема Маркова
Теорема Чебышева легко может быть обобщена на оолее слож-
сложный случай, а именно когда закон распределения случайной вели-
величины X от опыта к опыту не остается одним и тем же, а изменяется.
Тогда вместо среднего арифметического наблюденных значений одной
и той же величины X с постоянными математическим ожиданием и
дисперсией мы имеем дело со средним арифметическим п различных
случайных величин, с различными математическими ожиданиями и
дисперсиями. Оказывается, что и в этом случае при соблюдении
некоторых условий среднее арифметическое является устойчивым и
сходится по вероятности к определенной неслучайной величине.
13.4] ОБОБЩЕННАЯ ТЕОРЕМА ЧЕБЫШЕВА. ТЕОРЕМА МАРКОВА 293
Обобщенная теорема Чебышева формулируется следующим образом.
Если
независимые случайные величины с математическими ожида-
ожиданиями
и дисперсиями
D D* D*
a
и если все дисперсии ограничены сверху одним и тем же
числом L:
DXi<L (/=1, 2 и),
то при возрастании п среднее арифметическое наблюденных
значений величин Xv X2 Хп сходится по вероятности
к среднему арифметическому их математических ожиданий').
Запишем эту теорему в виде формулы. Пусть е, 8 — сколь угодно
малые положительные числа. Тогда при достаточно большом п
/га.
<е/>1— 8. A3.4.1)
Доказательство. Рассмотрим величину
Г п
Ее математическое ожидание равно:
а дисперсия
') То есть разность между тем и другим средним арифметическим
сходится по вероятности к нулю.
294 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ
Применим к величине К неравенство Чебышева:
1ГЛ. 13
или
X,
= 1
2
1=1
A3.4.2)
Заменим в правой части неравенства A3.4.2) каждую из вели-
величин Dx большей величиной L. Тогда неравенство только усилится:
Р]
п
2*,
i=i *
Как бы мало ни было е, можно,выбрать п настолько большим,
чтобы выполнялось неравенство
L
тогда
Л1
>4<ь,
откуда, переходя к противоположному событию, получим доказываемое
неравенство A3.4.1).
Закон больших чисел может быть распространен и на зависимые
случайные величины. Обобщение закона больших чисел на случай
зависимых случайных величин принадлежит А. А. Маркову.
Теорема Маркова. Если имеются зависимые случайные
величины Xv Х2 Хп и если при п—>оо
D
■о,
то среднее арифметическое наблюденных значений случайных
величин Xv X2, ..., Хп сходится по вероятности к среднему
арифметическому их математических ожиданий.
Доказательство. Рассмотрим величину
13.5] ТЕОРЕМА БЕРНУЛЛИ И ПУАССОНА 295
Очевидно,
£>« =
у п2
Применим к величине К неравенство Чебышева:
Так как по условию теоремы при я—>-оо Dy-*■(), то при доста-
достаточно большом п
или, переходя к противоположному событию,
я я
2л xi 2j т*
п п
что и требовалось доказать.
13.5. Следствия закона больших чисел:
теоремы Бернулли и Пуассона
Известная теорема Я. Бернулли, устанавливающая связь между
частотой события и его вероятностью, может быть доказана как пря-
прямое следствие закона больших чисел.
Пусть производится п независимых опытов, в каждом из которых
может появиться или не появиться некоторое событие А, вероятность
которого в каждом опыте равна р. Теорема Я. Бернулли утверждает,
что при неограниченном увеличении числа опытов п частота
события А сходится по вероятности к его вероятности р.
Обозначим частоту события Л в я опытах через Р* и запишем
теорему Я. Пернулли в виде формулы
Р(\Р*~р\ <е)> 1—8. A3.5.1)
где е, 8—сколь угодно малые положительные числа.
Требуется доказать справедливость этой формулы при достаточно
большом п.
Доказательство, Рассмотрим независимые случайные ие-
личины:
Хх — число появлений события Л в первом опыте;
Х2 — число появлений события Л во втором опыте, и т. д.
296 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ 13
Все эти величины прерывны и имеют один и тот же закон рас-
распределения, выражаемый рядом вида:
О 1
где q=l—р. Математическое ожидание каждой из величин Хг
равно р, а ее дисперсия pq (см. п° 10.3).
Частота Р* представляет собой не что иное, как среднее ариф-
арифметическое величин Xv Х2, .... Хп:
и, согласно закону больших чисел, сходится по вероятности к общему
математическому ожиданию этих случайных величин. Отсюда и сле-
следует справедливость неравенства A3.5.1).
Теорема Я. Бернулли утверждает устойчивость частоты при
постоянных условиях опыта. Но при изменяющихся условиях опыта
аналогичная устойчивость также существует. Теорема, устанавливаю-
устанавливающая свойство устойчивости частот при переменных условиях опыта,
называется теоремой Пуассона и формулируется следующим
образом:
Если производится п независимых опытов и вероятность
появления события А в i-м опыте равна р1% то при увеличе-
увеличении п частота события А сходится по вероятности к сред-
среднему арифметическому вероятностей pt.
Теорема Пуассона выводится из обобщенной теоремы Чебышева
точно так же, как теорема Бернулли была выведена из закона
больших чисел.
Теорема Пуассона имеет большое принципиальное значение для
практического применения теории вероятностей. Дело в том, что
зачастую вероятностные методы применяются для исследования явле-
явлений, которые в одних и тех же условиях не имеют шансов повто-
повториться достаточно много раз, но повторяются многократно при весьма
разнообразных условиях, причем вероятности интересующих нас собы-
событий сильно зависят от этих условий. Например, вероятность пораже-
поражения цели в воздушном бою существенно зависит от дальности
стрельбы, ракурса цели, высоты полета, скорости стреляющего
самолета и цели и т. д. Комплекс этих условий слишком многочислен
для того, чтобы можно было рассчитывать на многократное осуще-
осуществление воздушного боя именно в данных фиксированных условиях.
И все же, несмотря на это, в данном явлении налицо определенная
}С1ойчивость частот, а именно частота поражения цели в реальных
воздушных боях, осуществляемых в самых разных условиях, будет
13.61 МАССОВЫЕ СЛУЧАЙНЫЕ ЯВЛЕНИЯ 297
приближаться к средней вероятности поражения цели, харак-
характерной для данной группы условий. Поэтому те методы организации
стрельбы, которые основаны на максимальной вероятности поражения
цели, будут оправданы и в данном случае, несмотря на то, что
нельзя ожидать подлинной массовости опытов в каждом определен-
определенном комплексе условий.
Аналогичным образом обстоит дело в области опытной проверки
вероятностных расчетов. На практике очень часто встречается слу-
случай, когда требуется проверить на опыте соответствие вычисленной
вероятности какого-либо события А его фактической частоте. Чаще
всего это делается для того, чтобы проверить правильность той или
иной теоретической схемы, положенной в основу метода вычисления
вероятности события. Зачастую при такой экспериментальной про-
проверке не удается воспроизвести достаточно много раз одни и те же ,
условия опыта. И все же эта проверка может быть осуществлена,
если сравнить наблюденную в опыте частоту события не с его
вероятностью для фиксированных условий, а со средним ариф-
арифметическим вероятностей, вычисленных для различных условий.
13.6. Массовые случайные явления и центральная
предельная теорема
В предыдущих п°п° мы рассмотрели различные формы закона
больших чисел. Все эти формы, как бы они ни были различны,
утверждают одно: факт сходимости по вероятности тех или иных
случайных величин к определенным постоянным. Ни в одной из форм
закона больших чисел мы не имеем дела с законами распре-
распределения случайных величин. Предельные законы распределения
составляют предмет другой группы теорем — центральной предельной
теоремы, которую иногда называют «количественной формой закона
Оольших чисел».
Все формы центральной предельной теоремы посвящены устано-
установлению условий, при которых возникает нормальный закон распреде-
распределения. Так как эти условия на практике весьма часто выполняются,
нормальный закон является самым распространенным из законов рас-
распределения, наиболее часто встречающимся в случайных явлениях
природы. -Он возникает во всех случаях, когда исследуемая слу-
случайная величина может быть представлена в виде суммы достаточ-
достаточно большого числа независимых (или слабо зависимых) элементар-
элементарных слагаемых, каждое из которых в отдельности сравнительно мало
влниет на сумму.
В теории стрельбы нормальный закон распределения играет особо
важную роль, так как в большинстве случаев практики координаты
гочек попадания и точек разрыва снарядов распределяются по нор-
нормальному закону. Объяснить это можно на следующем примере.
298 . ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 13
Пусть производится стрельба по некоторой плоской мишени,
с центром которой (точкой прицеливания) связано начало координат.
Точка попадания характеризуется двумя случайными величинами: X и К.
Рассмотрим одну из них, например отклонение X точки попадания
от цели в направлении оси Ох. Это отклонение вызвано совокупным
действием очень большого количества сравнительно малых факторов,
как-то: ошибка наводки, ошибка в определении дальности до цели,
вибрации орудия и установки при стрельбе, ошибки изготовления
снаряда, атмосферные условия и т. д. Каждая из этих причин создает
элементарную ошибку — отклонение снаряда от цели, и координата
снаряда X может быть представлена как сумма таких элементарных
отклонений:
Х = ХХ + Х2+ ... +Хп+ .... A3.6.1)
где Xv X2, ...—отклонения, вызванные отдельными факторами.
Так как этих факторов очень много, между собой они являются
в основном независимыми и по влиянию на сумму отдельные слагае-
слагаемые можно считать приблизительно равномерно малыми, то налицо
условия применимости центральной предельной теоремы, и вели-
величина A3.6.1) должна подчиняться закону распределения, близкому
к нормальному.
Остановимся несколько подробнее на нашем утверждении о при-
приблизительно равномерно малом влиянии каждого из слагаемых на
сумму. Смысл его в том, что среди элементарных ошибок стрельбы
нет ни одной резко превалирующей над суммой всех остальных.
Действительно, если бы такая ошибка была, нужно думать, что,
составляя правила стрельбы или конструируя прицельный прибор, мы
постарались бы ликвидировать эту ошибку и учесть заранее самую
значительную причину, отклоняющую снаряд от цели. Неучтенные
случайные факторы, создающие рассеивание, обычно характерны
своей равномерной малостью и отсутствием среди них резко преоб-
преобладающих. Именно поэтому закон распределения точек попадания
снарядов (или закон распределения точек разрыва* снарядов при
дистанционной стрельбе) обычно принимается нормальным ]).
Нормальный закон распределения является доминирующим не
голики в теирлн стрельбы, по и во многих ipyritx осл^стнх, напри-
например в теории ошибок измерения. Именно исходя из теории ошибок
измерения нормальный закон и был впервые обоснован Лапласом и
Гауссом. Действительно, в большинстве случаев ошибки, возникаю-
'•) В некоторых случаях стрельбы фактическое распределение точек по-
попадания на плоскости может сильно отличаться от нормального, например,
при стрельбе в рэзко переменных условиях, когда центр рассеивания и ве-
вероятное отклонение в процессе стрельбы заметно меняются. Однако в таких
случаях мы фактически имеем дело не с законом распределения координат
точки попадания при одном выстреле, а со средним из таких законов для
различных выстрелов.
13.7]
ХАРАКТЕРИСТИЧЕСКИЕ ФУНКЦИИ
299
щие при измерении тех или иных физических величин, распреде-
распределяются именно по нормальному закону; причина этого в том, что
такие ошибки, как правило, складываются из многочисленных незави-
независимых элементарных ошибок, порождаемых различными причинами.
Долгое время нормальный закон считался единственным и универ-
универсальным законом ошибок. В настоящее время взгляд на нормальный
закон как на единственный и универсальный должен быть пересмотрен
(опыт показывает, что в ряде процессов измерения и производства
наблюдаются законы распределения, отличные от нормального), но
все же нормальный закон остается самым распространенным и самым
важным для практики законом ошибок.
13.7. Характеристические функции
Одна из наиболее общих форм центральной предельной теоремы
была доказана А. М. Ляпуновым в 1900 г. Для доказательства этой
теоремы А. М. Ляпунов создал специальный метод характери-
характеристических функций. В дальнейшем этот метод приобрел само-
самостоятельное значение и оказался весьма мощным и гибким методом,
пригодным для решения самых различных вероятностных задач.
Характеристической функцией случайной величины X назы-
называется функция
M[e"X], A3.7.1)
где I — мнимая единица. Функция g (t) представляет собой математи-
математическое ожидание некоторой комплексной случайной величины
U = ettx,
функционально связанной с величиной X. При решении многих задач
теории вероятностей оказывается удобнее пользоваться характеристи-
характеристическими функциями, чем законами распределения.
Зная закон распределения случайной величины X, легко найти
ее характеристическую функцию.
Если X — прерывная случайная величина с рядом распределения
XI
Pi
Xi
Pi
хг
Р2
...
...
х„
Ра
то ее характеристическая функция
А—I
A3.7.2)
300 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 13
Если X— непрерывная случайная величина с плотностью распреде-
распределения / (х), то ее характеристическая функция
00
= fe"*f(x)dx. A3.7.3)
Пример 1. Случайная величина X — число попаданий при одном
выстреле. Вероятность попадания равна р. Найти характеристическую функ-
функцию случайной величины X.
Решение. По формуле A3.7.2) имеем:
где q = 1 — р.
Пример 2. Случайная величина А" имеет нормальное распределение:
£1
/<*)---^# 2 . A3.7.4)
Определить ее характеристическую функцию.
Решение. По формуле A3.7.3) имеем:
00 -— °° Их —
'@ - fe"x ?W *2 dx - ?W /• ~2 dx-
-оо -оо
Пользуясь известной формулой
АС-&
и имея в виду; что /2 = — 1, получим: .
р_
g(t) = e 2 • A3.7.6)
Формула A3.7.3) выражает характеристическую функцию g(t)
непрерывной случайной величины X через ее плотность распределе-
распределения /(х). Преобразование A3.7.3), которому нужно подвергнуть /(х),
чтобы получить g(t), называется преобразованием Фурье. В курсах
математического анализа доказывается, что если функция g(t) выра-
выражается через / (х) с помощью преобразования Фурье, то, в свою
очередь, функция f (х) выражается через g{t) с помощью так назы-
называемого обратного преобразования Фурье:
оо
==~ f e-'txg(t)dtl). A3.7.7)
') В n°n° 17.3, 17.4 будут выведены те же преобразования Фурье, свя-
связывающие корреляционную функцию и спектральную плотность.
13.7] ХАРАКТЕРИСТИЧЕСКИЕ ФУНКЦИИ 301
Сформулируем и докажем основные ев ойств а характери-
характеристических функций.
1. Если случайные величины X и У связаны соотношением
где а — неслучайный множитель, то их характеристические
функции связаны соотношением:
gyit) = Sxi.at). A3.7.8)
Доказательство:
gy (t) = M [eitY] = M [eltaX] = M \el W>x] = gx (at).
2, Характеристическая функция суммы независимых слу-
случайных величин равна произведению характеристических функ-
функций слагаемых.
Доказательство. Даны Xv Х2 Хп -—независимые слу-
случайные величины с характеристическими функциями
гЛО. g.(t) ёх (О
и их сумма
Требуется доказать, что
я
й-у @ == П ЙГХ (О- A3.7.9)
Имеем
gv(t)
[It S Xk"] Г я -I
Так как величины Xk независимы, то независимы и их функции в"х*.
По теореме умножения математических ожиданий получим:
gy(t) = i\M{elt^] = ilgx (t),
что и требовалось доказать.
Аппарат характеристических функций часто применяется для ком-
композиции законов распределения. Пусть, например, имеются две не-
независимые случайные величины А" и К с плотностями распределе-
распределения /j (л;) и /2 (у). Требуется найти плотность распределения величины
Это можно выполнить следующим образом: найти характеристиче-
характеристические функции gx(t) и gy(t) случайных величин X и У и, перемножив
302 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 13
их, получить характеристическую функцию величины Z:
после чего, подвергнув gz(t) обратному преобразованию Фурье, найти
плотность распределения величины Z:
со
= Г fe-"'g,(t)dt.
Пример 3. Найти с помощью характеристических функций компози-
композицию двух нормальных законов:
/[ (.*) с характеристиками тх = 0; ах,
/2 (у) с характеристиками ту = 0; оу.
Решение. Находим характеристическую функцию пеличины X. Для
этого представим ее в виде
где ти = 0; ои = 1.
Пользуясь результатом примера 2, найдем
Л
Согласно свойству 1 характеристических функций,
Аналогично
(У)'
^у @ = е 2 •
Перемножая g^. (/) и ^у (/)> имеем:
а это есть характеристическая функция нормального закона с параметрами
тг --- 0; аг— \ ix-\-с . Таким образом, получена композиция нормальных
законов гораздо более простыми средствами, чем в п" 12.6.
13.8. Центральная предельная теорема для одинаково
распределенных слагаемых
Различные формы центральной предельной теоремы отличаются
между собой условиями, накладываемыми на распределения образую-
образующих сумму случайных слагаемых. Здесь мы сформулируем и докажем
одну из самих простых форм центральной предельной теоремы, отно-
относящуюся к случаю одинаково распределенных слагаемых.
Т3.8] ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА 303
Теорема. Если Хх, Х2 Хп, ... —независимые случай-
случайные величины, имеющие один и тот же закон распределения
с математическим ожиданием т и дисперсией о2, то при не-
неограниченном увеличении п закон распределения суммы
Yn = ^Xb A3.8.1)
k=i
неограниченно приближается к нормальному.
Доказательство.
Проведем доказательство для случая непрерывных случайных ве-
величин Хх Хп (для прерывных оно будет аналогичным).
Согласно второму свойству характеристических функций, дока-
доказанному в предыдущем п°, характеристическая функция величины К„
представляет собой произведение характеристических функций слага-
слагаемых. Случайные величины Хх, ..., Хп имеют один и тот же закон
распределения с плотностью f(x) и, следовательно, одну и ту же
характеристическую функцию
оо
gx<t)= fe«*f(x)dx. (I3.8.2)
-оо v
Следовательно, характеристическая функция случайной величины Кя
будет
*,„(') = [*, (О]"- A3.8.3)
Исследуем более подробно функцию gx(t). Представим ее в окрест-
окрестности точки t = 0 по формуле Маклорена с тремя членами:
= Вх (°) + В'х @) t + \fiP~ + «(о] t\
P ] A3.8.4)
где a (t) -> 0 при t -> 0.
Найдем величины gr@), #'.@), g"@). Полагая в формуле A3.8.2)
t = 0, имеем:
Sx(°i = / /(х) dx=\. A3.8.5)
-oq
Продифференцируем A3.8.2) no t:
оо оо
g'x (t) =■ | txeltx / (x) dx — / f xeltxf (x) dx. A3.8.6)
304 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. U
Полагая в A3.8.6) £ = 0, получим:
оо
g'x@) = l f xf(x)dx = lM[X} = tm. A3.8.7)
— оо
Очевидно, не ограничивая общности, можно положить т = 0 (для
этого достаточно перенести начало отсчета в точку т). Тогда
£@) = 0.
Продифференцируем A3.8.6) еще раз:
оо
£(') = - / x2eUxf.(x)dx.
— ОО
отсюда
со
£@) = — / x*f(x)dx. A3.8.8)
При wt = O интеграл в выражении A3.8.8) есть не что иное, как
дисперсия величины X с плотностью f (х), следовательно
£@) = -А A3.8.9)
Подставляя в A3.8.4) gx @) = 1. g'x @) = 0 и g"x @) == — о2, получим:
Обратимся к случайной величине Yп. Мы хотим доказать, что ее
закон распределения при увеличении га приближается к нормальному.
Для этого перейдем от величины Yn к другой («нормированной»)
случайной величине у
*« = -£-• Aз:8.п)
Эта величина удобна тем, что ее дисперсия не зависит от га и равна
единице при любом га. В этом нетрудно убедиться, рассматривая
величину Zn как линейную функцию независимых случайных величин
Xv Х2 Хп, каждая из которых имеет дисперсию о2. Если мы
докажем, что закон распределения величины Zn приближается к нор-
нормальному, то, очевидно, это будет справедливо и для величины К„,
связанной с Zn линейной зависимостью A3.8.11).
Вместо того чтобы доказывать, что закон распределения величины
Zn при увеличении га приближается к нормальному, покажем, что ее
характеристическая функция приближается к характеристической функ-
функции нормального законаJ).
') Здесь мы принимаем без доказательства, что из сходимости характе-
характеристических функций следует сходимость- законов распределения. Доказа-
Доказательство см., например, Б. В. Гнедеико, Курс теории вероятностей, 1961.
13.8] ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА 305
Найдем характеристическую функцию величины Zn. Из соотноше-
соотношения A3.8.11), согласно первому свойству характеристических функций
A3.7.8), получим
^) A3-8Л2)
где gyn(f) — характеристическая функция случайной величины Кя.
Из формул A3.8.12) и A3.8.3) получим
или. пользуясь формулой A3.8.10),
Прологарифмируем выражение A3.8.14):
Введем обозначение
Г л>2 г 4 \ -I /2
х. A3.8.15)
Тогда
In £г„ @ = га'п I1 — *}• A3.8.16)
■ Будем неограниченно увеличивать п. При этом величина х, согласно
формуле A3.8.15), стремится к нулю. При значительном п ее можно
считать весьма малой. Разложим In {1 — %} в ряд и ограничимся
одним членом разложения (остальные при п —> оо станут пренебре-
пренебрежимо малыми):
In {1 —xj гк — х.
Тогда получим
lim In в, (t) = lim n • (— х) =
i ->с
По определению функция а(^) стремится к нулю при t->0; следо-
следовательно,
@ = — -н-
306 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ {ГЛ. 13
откуда
-JL
Um gZn(t) = e~ 2. A3.8.17)
Я->оо
Это есть не что иное, как характеристическая функция нормального
закона с параметрами т — 0, о = 1 (см. пример 2, п° 13.7).
Таким образом, доказано, что при увеличении п характеристиче-
характеристическая функция случайной величины Zn неограниченно приближается
к характеристической функции нормального закона; отсюда заключаем,
что и закон распределения величины Zn (а значит и величины Yn)
неограниченно приближается к нормальному закону. Теорема доказана.
Мы доказали центральную предельную теорему для частного, но
важного случая одинаково распределенных слагаемых. Однако в до-
достаточно широком классе условий она справедлива и для неодинаково
распределенных слагаемых. Например, А. М. Ляпунов доказал цен-
центральную предельную теорему для следующих условий:
ft*
»ш . *=I ,„. =0, A3.8.18)
Л->оо
где Ьк—третий абсолютный центральный момент величины Хк:
Ьк = ЫХк\ = М1\Хк\«\ (k = l п).
Dk—дисперсия величины Хк.
Наиболее общим (необходимым и достаточным) условием спра-
справедливости центральной предельной теоремы является условие
Линдеберга: при любом х > О
где mk — математическое ожидание, f k (x) — плотность распре-
' п
деления случайной величины X' к, Вп=у 2 Dft .
13.9. Формулы, выражающие центральную предельную теорему
и встречающиеся при ее практическом применении
Согласно центральной предельной теореме, закон распределения
суммы достаточно большого числа независимых случайных величин
(при соблюдении некоторых нежестких ограничений) сколь угодно
близок к нормальному.
13.9] ФОРМУЛЫ, ВЫРАЖАЮЩИЕ ЦЕНТРАЛЬНУЮ ПРЕДЕЛЬНУЮ ТЕОРЕМУ 307
Практически центральной предельной теоремой можно пользо-
пользоваться и тогда, когда речь идет о сумме сравнительно небольшого
числа случайных величин. При суммировании независимых случайных
величин, сравнимых по своему рассеиванию, с увеличением числа сла-
слагаемых закон распределения суммы очень скоро становится прибли-
приблизительно нормальным. На практике вообще широко применяется при-
приближенная замена одних законов распределения другими; при той
сравнительно малой точности, которая требуется от вероятностных
расчетов, такая замена тоже может быть сделана крайне приближенно.
Опыт показывает, что когда число слагаемых порядка десяти (а часто
и меньше), закон распределения суммы обычно может быть заменен
нормальным.
В практических задачах часто применяют центральную предельную
теорему для вычисления вероятности того, что сумма нескольких
случайных величин окажется в заданных пределах.
Пусть Л\, Х2 Х„— независимые случайные величины с ма-
математическими ожиданиями
и дисперсиями
m,.
Dv
т2, .,
D2...
••• тп
Предположим, что условия центральной предельной теоремы вы-
выполнены (величины Хь Х2, .... Хп сравнимы по порядку своего
влияния на рассеивание суммы) и число слагаемых п достаточно для
того, чтобы закон распределения величины
Y—%Xt A3.9.1)
можно было считать приближенно нормальным.
Тогда вероятность того, что случайная величина Y попадает в пре-
пределы участка (а, C), выражается формулой
A3.9.2)
где ту, оу — математическое ожидание и среднее квадратическое от-
отклонение величины V, Ф* — нормальная функция распределения.
Согласно теоремам сложения математических ожиданий и дисперсий
ту = 2 »*,:.
V
A3.9.3)
20*
308 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ [ГЛ. 13
Таким образом, для того чтобы приближенно найти вероятность
попадания суммы большого числа случайных величин на заданный
участок, не требуется знать законы распределения этих величин; до-
достаточно знать лишь их характеристики. Разумеется, это относится
только к случаю, когда выполнено основное условие центральной
предельной теоремы — равномерно малое влияние слагаемых на рас-
рассеивание суммы.
Кроме формул типа A3.9.2), на практике часто применяются фор-
формулы, в которых вместо суммы случайных величин Xt фигурирует
их нормированная сумма
Очевидно,
M[Z] = 0; D[Z] = o, = l.
Если закон распределения величины Y близок к нормальному
с параметрами A3.9.3), то закон распределения величины Z близок
к нормальному с параметрами mz = 0, ог = 1. Отсюда
Р(а<г<Р) = Ф*(р) — Ф*(а). A3.9.5)
Заметим, что центральная предельная теорема может применяться
не только к непрерывным, но и к дискретным случайным величинам
при условии, что мы будем оперировать не плотностями, а функциями
распределения. Действительно, если величины Xv Х2. ■••> Х„ дис-
дискретны, то их сумма X — также дискретная случайная величина
и поэтому, строго говоря, не может подчиняться нормальному закону.
Однако все формулы типа A3.9.2), A3.9.5) остаются в силе, так
как в них фигурируют не плотности, а функции распределения. Можно
доказать, что если дискретные случайные величины Удовлетворяют
условиям центральной предельной теоремы, то функция распределе-
распределения их нормированной суммы Z (см. формулу A3.9.4)) при увеличе-
увеличении п неограниченно приближается к нормальной функции распреде-
распределения с параметрами тг = 0, <зг=\.
Частным случаем центральной предельной теоремы для дискрет-
ьых случайных величин является теорема Лапласа.
Если производится п независимых опытов, в каждом из
которых событие А появляется с вероятностью р, то спра-
справедливо соотношение
Р (а < 1-=Ш- < р) = Ф* (р) - Ф* («). A3.9.6)
V У пря г
где К — число появлений события А в п опытах, q=l—р.
13.9] ФОРМУЛЫ, ВЫРАЖАЮЩИЕ ЦЕНТРАЛЬНУЮ ПРЕДЕЛЬНУЮ ТЕОРЕМУ 309
Доказательство. Пусть производится п независимых опытов,
в каждом из которых с вероятностью р может появиться событие А.
Представим случайную величину Y — общее число появлений события
в п опытах — в виде суммы
Y =2 *i. A3.9.7)
где Xt — число появлений события А в t-u опыте.
Согласно доказанной в п° 13.8 теореме, закон распределения
суммы одинаково распределенных слагаемых при увеличении их числа
приближается к нормальному закону. Следовательно, при достаточно
большом л справедлива формула A3.9.5), где
Y— тч
Z = —J—2-. A3.9.8)
В п° 10.3 мы доказали, что математическое ожидание и дисперсия
числа появлений события в п независимых опытах равны:
ту = пр\ Dy = npq (q=l—p).
Подставляя эти выражения в A3.9.8), получим
7
Vnpq
и формула A3.9.5) примет вид:
Теорема доказана.
Пример 1. По полосе укреплений противника сбрасывается 100 серий
бомб. При сбрасывании одной такой серии математическое ожидание числа
попаданий равно 2, а среднее квадратическое отклонение числа попаданий
равно 1,5. Найти приближенно вероятность того, что при сбрасывании
100 серий в полосу попадает от 180 до 220 бомб.
Решение. Представим общее число попаданий как сумму чисел по-
попаданий бомб в отдельных сериях:
100
X — Xi + Х2 + .. 2
где Xi — число попаданий <-й серии.
Условия центральной предельной теоремы соблюдены, так как величины
X,, Х2, ..., А'1ОО распределены одинаково. Будем считать число п = 100 до-
достаточным для того, чтобы можно было применить предельную теорему (на
практике она обычно применима и при гораздо меньших л), имеем:
100 я 100
тх = ^ пи = 200, У />/=2
;i
310 ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ
Применяя формулу A3.9.6), получим:
Р A80 < X < 220) = Ф* /22"~f°'j - Ф* ( """" ) » 0,82,
[ГЛ. 13
т. е. с вероятностью 0,82 можно утверждать, что общее число попаданий
в полосу не выйдет за пределы 180-s-220.
Пример 2. Происходит групповой воздушный бой, в котором уча-
участвуют 50 бомбардировщиков и 100 истребителей. Каждый бомбардировщик
атакуется двумя истребителями; таким образом, воздушный бой распадается
на 50 элементарных воздушных боев, в каждом из которых участвует один
бомбардировщик и два истребителя. В каждом элементарном бою вероят-
вероятность сбития бомбардировщика равна 0,4; вероятность того, что в элемен-
элементарном бою будут сбиты оба истребителя, равна 0,2; вероятность того, что
будет сбит ровно один истребитель, равна 0,5. Требуется: 1) найти вероят-
вероятность того, что в воздушном бою будет сбито не менее 35% бомбардиров-
бомбардировщиков; 2) оценить границы, в которых с вероятностью 0,9 будет заключено
число сбитых истребителей.
Решение. 1) Обозначим X— число сбитых бомбардировщиков;
50
1=1
где Xi — число бомбардировщиков, сбитых в 1-м элементарном бою.
Ряд распределения величины А/ имеет вид:
0,6
0,4
Отсюда
тх =0,4; D, =0,4-0,6 = 0,24; тх = 50- 0,4 = 20;
3,464.
Применяя формулу A3.9.6) и полагая р = 50 (или, что в данном случае равно-
равносильно, jl = оо), а = 17, находим:
0,807.
2) Обозначим У число сбитых истребителей:
50
(=1
Где yt — число истребителей, сбитых в г-м элементарном бою.
Ряд распределения величины К; имеет вид:
0 1
0,3 0,5 0,2
13.91 ФОРМУЛЫ, ВЫРАЖАЮЩИЕ ЦЕНТРАЛЬНУЮ ПРЕДЕЛЬНУЮ ТЕОРЕМУ 311
Отсюда находим математическое ожидание и дисперсию величины У(.
ту =0,9; Dy =0,49.
Для величины У:
ту = 50 • 0,9 = 45; Dy = 24,5; <sy = 4,96.
Определим границы участка, симметричного относительно ту = 45, в ко-
который с вероятностью 0,9 попадет величина У. Обозначим половину длины
этого участка /. Тогда
Р(\У— ту\ < 1) = 2Ф*(-±-) — 1=0,9,
Ф*( -L =0,95»
\°у/
По таблицам функции Ф* I — | находим то значение аргумента, для ко-
торого Ф* (х) = 0,95; это значение приближенно равио
х = 1,645,
т. е.
— = 1,645,
откуда
/ = 8,Н«8.
Следовательно, с вероятностью около 0,9 можно утверждать, что число
сбитых истребителей будет заключено в пределах mv ± I, т. е. в пределах
от 37 до 53.
ГЛАВА 14
ОБРАБОТКА ОПЫТОВ
14.1. Особенности обработки ограннченного числа опытов.
Оценки для неизвестных параметров закона распределения
В главе 7 мы уже рассмотрели некоторые задачи математической
статистики, относящиеся к обработке опытных данных. Это были
главным образом задачи о нахождении законов распределения случай-
случайных величин по результатам опытов. Чтобы найти закон распределе-
распределения, нужно располагать достаточно обширным статистическим мате-
материалом, порядка нескольких сотен опытов (наблюдений). Однако на
практике часто приходится иметь дело со статистическим материалом
весьма ограниченного объема — с двумя-тремя десятками наблюдений,
часто даже меньше. Это обычно связано с дороговизной и сложностью
постановки каждого опыта. Такого ограниченного материала явно не-
недостаточно для того, чтобы найти заранее неизвестный закон распре-
распределения случайной величины; но все же этот материал может быть
обработан и использован для получения некоторых сведений о слу-
случайной величине. Например, на основе ограниченного статистического
материала можно определить—хотя бы ориентировочно — важнейшие
числовые характеристики случайной величины: математическое ожида-
ожидание, дисперсию, иногда — высшие моменты. На практике часто бывает,
что вид закона распределения известен заранее, а требуется найти
только некоторые параметры, от которых он зависит. Например,
если заранее известно, что закон распределения случайной величины
нормальный, то задача обработки сводится к определению двух его
параметров т и о. Если заранее известно, что величина распределена
по закону Пуассона, то подлежит определению только один его пара-
параметр: математическое ожидание а. Наконец, в некоторых задачах вид
закона распределения вообще несуществен, а требуется знать только
его числовые характеристики.
В данной главе мы рассмотрим ряд задач об определении неиз-
неизвестных параметров, от которых зависит закон распределения случай-
случайной величины, по ограниченному числу опытов.
14.1] ОСОБЕННОСТИ ОБРАБОТКИ ОГРАНИЧЕННОГО ЧИСЛА ОПЫТОВ 313
Прежде всего нужно отметить, что любое значение искомого
параметра, вычисленное на основе ограниченного числа опытов, всегда
будет содержать элемент случайности. Такое приближенное, случай-
случайное значение мы будем называть оценкой параметра. Например, оцен-
оценкой для математического ожидания может служить среднее арифме-
арифметическое наблюденных значений случайной величины в- п независимых
опытах. При очень большом числе опытов среднее арифметическое
будет с большой вероятностью весьма близко к математическому
ожиданию. Если же число опытов п невелико, то замена математиче-
математического ожидания средним арифметическим приводит к какой-то ошибке.
Эта ошибка в среднем тем больше, чем меньше число опытов. Так же
будет обстоять дело и с оценками других неизвестных параметров.
Любая из таких оценок случайна; при пользовании ею неизбежны
ошибки. Желательно выбрать такую оценку, чтобы эти ошибки были
по возможности минимальными.
Рассмотрим следующую общую задачу. Имеется случайная вели-
величина X, закон распределения которой содержит неизвестный параметр а.
Требуется найти подходящую оценку для параметра а по результа-
результатам п независимых опытов, в каждом из которых величина X при-
приняла определенное значение.
Обозначим наблюденные значения случайной величины
Xv Xa Хп. A4.1.1)
Их можно рассматривать как п «экземпляров» случайной величины X,
то есть п независимых случайных величин, каждая из которых рас-
распределена по тому же закону, что и случайная величина X.
Обозначим а оценку для параметра а. Любая оценка, вычисляемая
на основе материала A4.1.1), должна представлять собой функцию
величин Xv Х2 Хп:
S=a(Xv X2 Хп) A4.1.2)
и, следовательно, сама является величиной случайной. Закон распре-
распределения а зависит, во-первых, от закона распределения величины X
(и, в частности, от самого неизвестного параметра а); во-вторых, от
M::c,ia опытов п. В принципе этот закон распределения может быть
найден известными методами теории вероятностей.
Предъявим к оценке а ряд требований, которым она должна удо-
удовлетворять, чтобы быть в каком-то смысле «доброкачественной»
оценкой.
Естественно потребовать от оценки а, чтобы при увеличении числа
опытов п она приближалась (сходилась по вероятности) к параметру а.
Оценка, обладающая таким свойством, называется состоятельной.
Кроме того, желательно, чтобы, пользуясь величиной а вместо а,
мы по крайней мере не делали систематической ошибки в сторону
314 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
завышения или занижения, т. е. чтобы выполнялось условие
М[а] — а. A4.1.3)
Оценка, удовлетворяющая такому условию, называется несмещенной.
Наконец, желательно, чтобы выбранная несмещенная оценка обла-
обладала по сравнению с другими наименьшей дисперсией, т. е.
D[a] = mln. A4.1.4)
Оценка, обладающая таким свойством, называется эффективной.
На практике не всегда удается удовлетворить всем этим требо-
требованиям. Например, может оказаться, что, даже если эффективная
оценка существует, формулы для ее вычисления оказываются слишком
сложными, и приходится удовлетворяться другой оценкой, дисперсия
которой несколько больше. Иногда применяются — в интересах про-
простоты расчетов — незначительно смещенные оценки. Однако выбору
. оценки всегда должно предшествовать ее критическое рассмотрение
со всех перечисленных выше точек зрения.
14.2. Оценки для математического ожидания и дисперсии
Пусть имеется случайная величина X с математическим ожида-
ожиданием т и дисперсией D; оба параметра неизвестны. Над величиной X
произведено п независимых опытов, давших результаты Xlt Х% Xп.
Требуется найти состоятельные и несмещенные оценки для парамет-
параметров т. и D.
В качестве оценки для математического ожидания естественно
предложить среднее арифметическое наблюденных значений (ранее мы
его обозначали т*)\
A4.2.1)
Нетрудно убедиться, что эта оценка является состоятельной:
согласно закону больших чисел, при увеличении а величина т. схо-
сходится по вероятности к т. Оценка т является также и несмещенной,
так как
л
М\т]=-^±— = т. A4.2.2)
Дисперсия этой оценки равна:
\о. A4.2.3)
14.2] ОЦЕНКИ ДЛЯ МАТЕМАТИЧЕСКОГО ОЖИДАНИЯ И ДИСПЕРСИИ 315
Эффективность или неэффективность оценки зависит от вида
закона распределения величины X. Можно доказать, что если вели-
величина X распределена по нормальному закону, дисперсия A4.2.3) будет
минимально возможной, т. е. оценка т. является эффективной. Для
других законов распределения это может быть и не так.
Перейдем к оценке для дисперсии D. На первый взгляд наиболее
естественной оценкой представляется статистическая дисперсия:
D'^i^l— , A4.2.4)
где
£*.
» = -Ь1_. , A4.2.5)
Проверим, является ли эта оценка состоятельной. Выразим ее
через второй начальный момент (по формуле G.4.6) гл. 7):
£*?
D* = ^ in2. A4.2.6)
Первый член в правой части есть среднее арифметическое п на-
наблюденных значений случайной величины X2; он сходится по вероят-
вероятности к М [Х2\ =а2 [X]. Второй член сходится по вероятности к т2;
вся величина A4.2.6) сходится по вероятности к величине
a2[X]—tn2 = D.
Это означает, что оценка A4.2.4) состоятельна.
Проверим, является ли оценка D* также и несмещенной. Подста-
Подставим в формулу A4.2.6) вместо т его выражение A4.2.5) и произ-
произведем указанные действия:
Л*
п
\ п
£ а £ а? ^
1 = 1 l^J. о i<j
п п2
316 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
Найдем математическое ожидание величины A4.2.7):
л
М [О*] = ^! 2 М [А'?] - А £ Ж [*,*,]. A4.2.8)
Так как дисперсия D* не зависит от того, в какой точке выбрать
начало координат, выберем его в точке т. Тогда
]]=: Ж [!,] = £; ^M[X2i\==nD, A4.2.9)
i
j^MlXtXjl^Ktj^O. A4.2.10)
Последнее равенство следует из того, что опыты независимы.
Подставляя A4.2.9) и A4.2.10) в A4.2.8), получим:
M[D*]=~^-D. A4.2.11)
Отсюда видно, что величина D* не является несмещен-
несмещенной оценкой для D: ее математическое ожидание не равно D,
а несколько меньше. Пользуясь оценкой D* вместо дисперсии D,
мы будем совершать некоторую систематическую ошибку в меньшую
сторону. Чтобы ликвидировать это смещение, достаточно ввести по-
поправку, умножив величину D* на ——у. Получим:
2 J£
„, (=1 П 1=1
п—\ п п — 1 ~~ п — \
Такую «исправленную» статистическую дисперсию мы и выберем
в качестве оценки для D; r
Д= i=1 „_! • A4.2.12)
Так как множитель ——Г стремится к единице при п->оо,
а оценка D* состоятельна, то оценка D также будет состоятельной ').
На практике часто вместо формулы A4.2.12) бывает удобнее
применять другую, равносильную ей, в которой статистическая
!) Оценка D для дисперсии не является эффективной. Однако в случае
нормального распределения она является «асимптотическн эффективной», то
есть при увеличении п отношение ее дисперсии к минимально возможной
неограниченно приближается к единице.
14.3) ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ. ДОВЕРИТЕЛЬНАЯ ВЕРОЯТНОСТЬ 317
дисперсия выражена через второй начальный момент:
.. Г2*5 1 „
я—1 •
A4.2.13)
При больших значениях п, естественно, обе оценки — смещенная
D* и несмещенная D — будут различаться очень мало и введение
поправочного множителя теряет смысл.
Таким образом, мы пришли к следующим правилам обработки
ограниченного по объему статистического материала.
Если даны значения xv х2, .... х„..принятые в п независимых
опытах случайной величиной X с неизвестными математическим ожи-
ожиданием т и дисперсией D, то для определения этих параметров сле-
следует пользоваться приближенными значениями (оценками):
/я — •
2 (** -
я —1
или
A4.2,14)
14.3. Доверительный интервал. Доверительная вероятность
В предыдущих п°п° мы рассмотрели вопрос об оценке неизвест-
неизвестного параметра а одним числом. Такая оценка называется «точечной».
В ряде задач требуется не только найти для параметра а подходя-
подходящее численное значение, но и оценить его точность и надежность.
Требуется знать—к каким ошибкам может привести замена пара-
параметра а его точечной оценкой а и с какой степенью уверенности
можно ожидать, что эти ошибки не выйдут за известные пределы?
Такого рода задачи особенно актуальны при малом числе наблю-
наблюдений, когда точечная оценка а в значительной мере случайна и
приближенная замена а на а может привести к серьезным ошибкам.
Чтобы дать представление о точности и надежности оценки а,
в математической статистике пользуются так называемыми дове-
доверительными интервалами и доверительными вероят-
вероятностями.
318 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
Пусть для параметра а получена из опыта несмещенная оценка а.
Мы хотим оценить возможную при этом ошибку. Назначим некоторую
достаточно большую вероятность р (например, р=гО,9, 0,95 или 0,99)
такую, что событие с вероятностью р можно считать практически
достоверным, и найдем такое значение е, для которого
Р(\а~ а | < е) == р." A4.3.1)
Тогда диапазон практически возможных значений ошибки, возникаю-
возникающей при замене а на а, будет +е; большие по абсолютной величине
ошибки будут появляться только с малой вероятностью а — 1 — р.
Перепишем A4.3.1) в виде:
Р(а— 8<а<а-)-е) = р. A4.3.2)
Равенство A4.3.2) означает, что с вероятностью Р неизвестяое зна-
значение параметра а попадает в интервал
/р = (о — е; a-f-e). A4.3.3)
При этом необходимо отметить одно обстоятельство. Ранее мы не-
неоднократно рассматривали вероятность попадания случайной величины
в заданный неслучайный интервал. Здесь дело обстоит иначе: вели-
величина а не случайна, зато случаен интервал Д. Случайно его
положение на оси абсцисс, определяемое его центром а; случайна
вообще и длина интервала 2s, так как величина е вычисляется, как
правило, по опытным данным. Поэтому в данном случае лучше будет
толковать величину [j не как вероятность «попадания» точки а в ин-
интервал /р, а как вероятность того, что случайный интервал /? на-
накроет точку а (рис. 14.3.1).
ь
////S///S///7///////77A
Рис. 14.3.1.
Вероятность р принято называть доверительной вероятностью,
а интервал L—доверительным интервалом 1). Границы интервала L:
ах—а—е и а2 —a-f-г называются доверительными границами.
Дадим еще одно истолкование понятию доверительного интервала:
его можно рассматривать как интервал значений параметра а, совме-
совместимых с опытными данными и не противоречащих им.
Действительно, если условиться считать событие с вероятностью
') На рис. 14.3.1 рассматривается доверительный интервал, симметрич-
симметричный относительно а. Вообще, как мы увидим дальше, это не обязательно.
14.3) ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ, ДОВЕРИТЕЛЬНАЯ ВЕРОЯТНОСТЬ 319
а = 1 — р практически невозможным, то те значения параметра а,
для которых | а — а | > е, нужно признать противоречащими опыт-
опытным данным, а те, для которых \ а — а\ < е, —совместимыми с ними.
Перейдем к вопросу о нахождении доверительных границ ах и а2.
Пусть для параметра а имеется несмещенная оценка а. Если бы
нам был известен закон распределения величины а, задача нахожде-
нахождения доверительного интервала была бы весьма проста: достаточно
было бы найти такое значение е, для которого
Затруднение состоит в том, что закон распределения оценки а
зависит от закона распределения величины X и, следовательно,
от его неизвестных параметров (в частности, и от самого пара-
параметра а).
Чтобы обойти это затруднение, можно применить следующий грубо
приближенный прием: заменить в выражении для е неизвестные пара-
параметры их точечными оценками. При сравнительно большом числе
опытов п (порядка 20 -ь 30) этот прием обычно дает удовлетвори-
удовлетворительные по точности результаты.
В качестве примера рассмотрим задачу о доверительном интервале
для математического ожидания.
Пусть произведено п независимых опытов над случайной величи-
величиной X, характеристики которой — математическое ожидание т и дис-
дисперсия D — неизвестны. Для этих параметров получены оценки:
п п
т = ^; б-i^-j . A4.3.4)
Требуется построить доверительный интервал /., соответствующий
доверительной вероятности р, для математического ожидания т. вели-
величины X.
При решении этой задачи воспользуемся тем, что величина т
представляет собой сумму п независимых одинаково распределенных
случайных величин X\, и, согласно центральной предельной теореме,
при достаточно большом п ее закон распределения близок к нормаль-
нормальному. На практике даже при относительно небольшом числе слагае-
слагаемых (порядка 10-^-20) закон распределения суммы можно прибли-
приближенно считать нормальным. Будем исходить из того, что величина т.
распределена по нормальному закону. Характеристики этого закона —
математическое ожидание и дисперсия — равны соответственно т к —
(см. гл. 13 п°13.3). Предположим, что величина D нам известна,
320 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
и найдем такую величину sp, для которой
Р(\т — т|<в(!)=р. A4.3.5)
Применяя формулу F.3.5) главы 6, выразим вероятность в левой
части A4.3.5) через нормальную функцию распределения
Р(\т~ т\<Ве) = 2Ф*(^А — 1, A4.3.6)
/ТУ
среднее квадратическое отклонение оценки т.
Из уравнения
находим значение ер:
ер = о~ arg<5*(-^t£), A4.3.7)
где argO*(Jc) — функция, обратная Ф*(л:), т. е. такое значение аргу-
аргумента, при котором нормальная функция распределения равна х.
Дисперсия D, через которую выражена величина о~, нам в точ-
точности не известна; в качестве ее ориентировочного значения можно
воспользоваться оценкой D A4.3.4) и положить приближенно:
- . A4.3.8)
Таким образом, приближенно решена задача построения доверитель-
доверительного интервала, который равен:
/p = (m_ Sj); w + ep), A4.3.9)
где ер определяется формулой A4.3.7).
Чтобы избежать при вычислении sp обратного интерполирования
в таблицах функции Ф* (х), удобно составить специальную таблицу
(см. табл. 14.3.1), где приводятся значения величины
в зависимости от р. Величина ^ определяет для нормального закона
число средних квадраткческих отклонений; которое нужно отложить
вправо и влево от центра рассеивания для того, чтобы вероятность
попадания в полученный участок была равна р.
Через величину /р доверительный интервал выражается в виде:
14.3! ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ. ДОВЕРИТЕЛЬНАЯ ВЕРОЯТНОСТЬ 321
Таблица 14.3.1
0,80
0,81
0,82
0,83
0,84
0,85
1,282
1,310
1,340
1,371
1,404
1,439
0,86
0,87
0,88
0,89
0,90
1,475
1,513
1,554
1,597
1,643
0,91
0,92
0,93
0,94
&Э5
1),%'
1,694
1,750
1,810
1,880
1,960
" 2ДШ
р
0,97
0,98
0,99
0,9973
0,999
н
2,169
2,325
2,576
3,000
3,290
Пример 1. Произведено 20 опытов над величиной X; результаты
приведены в таблице 14.3.2.
\ Таблица 14.3.2
1
2
3
4 ■
5
Х1
10,5
10,8
11,2
10,9
10,4
1
6
7
8
9
10
Х1
10,6
10,9
11,0
10,3
10,8
11
12
13
14
15
Х1
10,6
11,3
10,5
10,7
10,8
i
16
17
18
19
20
10,9
10,8
10,7
10,9
11,0
Требуется найти оценку т для математического ожидания т величины X
и построить доверительный интервал, соответствующий доверительной ве-
вероятности р = 0,8.
Решение. Имеем:
20
т = -
Выбрав за начало отсчета
несмещенную оценку D:
х —10, по третьей формуле A4.2.14) находим
, = 1 / — = 0,0564.
По таблице 14.3.1 находим
Доверительные границы:
ДоверительнЫй интервал:
$ == 1,282;
£В = tBa~ = 0,072.
х = гк — 0,072=10,71;
j = т 4- 0,072 ^- 10,85.
/р = A0,71; 10,85).
р
Значения параметра т, лежащие в этом интервале, являются совмести-
совместимыми с опытными данными, приведенными в таблице 14.3.2.
21 Е. С. Еентцель
322 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
Аналогичным способом может быть построен доверительный
интервал и для дисперсии.
Пусть произведено п независимых опытов над случайной величи-
величиной X с неизвестными параметрами т и D, и для дисперсии D по-
получена несмещенная оценка:
Д='=1П_! . A4.3.11)
где
Требуется приближенно построить доверительный интервал для
дисперсии.
Из формулы A4.3.11) видно, что величина D представляет собой
сумму п случайных величин вида г . ' ■» Эти величины не
являются независимыми, так как в любую из них входит величина т,
зависящая от всех остальных. Однако можно показать, что при уве-
увеличении п закон распределения их суммы тоже приближается к нор-
нормальному. Практически при п = 20 ч- 30 он уже может считаться
нормальным.
Предположим, что это так, и найдем характеристики этого закона:
математическое ожидание и дисперсию. Так как оценка D — несме-
несмещенная, то
M[D] — D.
Вычисление дисперсии D [D] связано со сравнительно сложными
выкладками, поэтому приведем ее выражение без вывода:
где [*4 — четвертый центральный момент величины X.
Чтобы воспользоваться этим выражением, нужно подставить
в него значения \ь4 и D (хотя бы приближенные). Вместо D можно
воспользоваться его оценкой D. В принципе четвертый централь-
центральный момент [а4 тоже можно заменить его оценкой-, например вели-
величиной вида:
A4.3.13)
H.3J ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ. ДОВЕРИТЕЛЬНАЯ ВЕРОЯТНОСТЬ' 323
но такая замена даст крайне невысокую точность, так как вообще
при ограниченном числе опытов моменты высокого порядка опреде-
определяются с большими ошибками. Однако на практике часто бывает,
что вид закона распределения величины X известен заранее: неиз-
неизвестны лишь его параметры. Тогда можно попытаться выразить \х4
через D.
Возьмем наиболее часто встречающийся случай, когда величина А"
распределена по нормальному закону. Тогда ее четвертый централь-
центральный момент выражается через дисперсию (см. гл. 6 п° 6.2):
и формула A4.3.12) дает
или
D[D] = 7r|TD2. A4.3.14)
Заменяя в A4.3.14) неизвестное D его оценкой D, получим:
T A4.3.15)
откуда
в5 = /тГ=Т6- A4.3.16)
Момент |а4 можно выразить через D также и в некоторых других
случаях, когда распределение величины X не является нормальным,
но вид его известен. Например, для закона равномерной плотности
(см. главу 5) имеем:
Р* ~~ 80 ' U ~~ 12 '
где (а, Р) — интервал, на котором задан закон. Следовательно,
По формуле A4.3.12) получим:
откуда находим приближенно
21*
324 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
В случаях, когда вид закона распределения величины X неизве-
неизвестен, при ориентировочной оценке величины о^ рекомендуется все же
пользоваться формулой A4.3.16), если нет специальных оснований
считать, что этот закон сильно отличается от нормального (обладает
заметным положительным или отрицательным эксцессом).
Если ориентировочное значение <jg тем или иным способом полу-
получено, то можно построить доверительный интервал для дисперсии,
аналогично тому, как мы строили его для математического ожидания:
I^ = {D~tfB; D + tfz), A4.3.18)
где величина t$ в зависимости от заданной вероятности f5 находится
по таблице 14.3.1.
Пример 2. Найти приближенно 80%-й доверительный интервал для
дисперсии случайной величины X в условиях примера 1, если известно, что
величина X распределена по закону, близкому к нормальному.
Решение. Величина ^ остается той же, что в примере 1:
*[, = 1,282.
По формуле A4.3.16)
*s=]/-~ 0,064 = 0,0207.
По формуле A4.3.18) находим доверительный интервал:
/[, = @,043; 0,085).
Соответствующий интервал значений среднего квадратического отклонения:
@,21; 0,29).
14.4. Точные методы построения доверительных интервалов
для параметров случайной величины, распределенной
по нормальному закону
В предыдущем п° мы рассмотрели грубо приближенные методы
построения доверительных интервалов для математического ожидания
и дисперсии. В данном п° мы дадим представление о точных мето-
методах решения той же задачи. Подчеркнем, что для точного нахожде-
нахождения доверительных интервалов совершенно необходимо знать заранее
вид закона распределения величины X, тогда как для применения
приближенных методов это не обязательно.
Идея точных методов построения доверительных интервалов сво-
сводится к следующему. Любой доверительный интервал находится из
условия, выражающего вероятность выполнения некоторых неравенств,
в которые входит интересующая нас оценка а. Закон распределения
оценки а в общем случае зависит от самих неизвестных параметров
величины X. Однако иногда удается перейти в неравенствах от слу-
14.4]
МЕТОДЫ ПОСТРОЕНИЯ ДОВЕРИТЕЛЬНЫХ ИНТЕРВАЛОВ
326
чайной величины а к какой-либо другой функции наблюденных зна-
значений Xv X2. .... Хп, закон распределения которой не зависит
от неизвестных параметров, а зависит только от числа
опытов га и от вида закона распределения величины X. Такого
рода случайные величины играют большую роль в математической
статистике; они наиболее подробно изучены для случая нормального
распределения величины X.
Например, доказано, что при нормальном распределении вели-
величины X случайная величина
™-т , A4.4.1)
где
■т)г
D —
2
1=1
п— 1
подчиняется так называемому закону распределения Стъюдента
с я — 1 степенями свободы; плотность этого закона имеет вид
—\
A4.4.2)
где Г(д;) — известная гамма-функция:
со
Г(дг)= Г ux-le~adu.
о
Доказано также, что случайная величина
5
A4.4.3)
имеет «распределение х2» с п — 1 степенями свободы (см. гл. 7,
стр. 145), плотность которого выражается формулой
*„-!(«) =
1
я-1
п-\
V
при v > О,
О
A4.4.4)
при v < 0. ^
Не останавливаясь на выводах распределений A4.4.2) и A4.4.4),
покажем, как их можно применить при построении доверительных
интервалов для параметров т и D.
326 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
Пусть произведено п независимых опытов над случайной вели-
величиной X. распределенной по нормальному закону с неизвестными
параметрами т и D. Для этих параметров получены оценки
" п—\ '
Требуется построить доверительные интервалы для обоих параметров,
соответствующие доверительной вероятности р.
Построим сначала доверительный интервал для математического
ожидания. Естественно этот интервал взять симметричным относи-
относительно т; обозначим ер половину длины интервала. Величину е»
нужно выбрать так, чтобы выполнялось условие
Р(\т — /ге| < еэ)==р. A4.4.5)
Попытаемся перейти в левой части равенства A4.4.5) от случай-
Ной величины т к случайной величине Т, распределенной по закону
Стьюдента. Для этого умножим обе части неравенства \m — tn\ < е«
На положительную величину ■ ■■ ?— 2
/Ж
У п
или, пользуясь обозначением A4.4.1),
Pi \Т\ <—-J=-\ = p. A4.4.6)
\ VI?)
Найдем такое число tp что
P(.\T\<t$ = §. A4.4.7)
В1' rn'iy.na tp найдется из условия
'я
A4.4.8)
Из формулы A4.4.2) видно, что Sn_x(f) — четная функция; по-
поэтому A4.4.8) дает
$. A4.4.9)
14.4]
МЕТОДЫ ПОСТРОЕНИЯ ДОВЕРИТЕЛЬНЫХ ИНТЕРВАЛОВ
Равенство A4.4.9) определяет величину t9 в зависимости от
иметь в своем распоряжении таблицу значений интеграла
327
3. Еслц
то величину t9 можно найти обратным интерполированием в этой
таблице. Однако удобнее составить заранее таблицу значений t^.
Такая таблица дается в приложении (см. табл. 5). В этой таблице
приведены значения t$ в зависимости от доверительной вероятности [}
и числа степеней свободы п — 1. Определив t9 по таблице 5 и по-
полагая
A4.4.10)
мы найдем половину ширины доверительного интервала /» и сам
интервал
( /"^ й/4) A4.4.11)
Пример 1. Произведено 5 независимых опытов над случайной вели-
величиной X, распределенной нормально с неизвестными параметрами т и я.
Результаты опытов приведены в таблице 14.4.1.
Таблица 14.4.1
i
xt
I
—2,5
2
3,4
3
—2,0
4
1,0
5
2,1
Найти оценку т. для математического ожидания и построить для
него 90%-й доверительный интервал /^ (т. е. интервал, соответствующий
доверительной вероятности [1 = 0,9).
° о пт е и и е. Имеем
т = 0,4; В = 6,6.
По таблице 5 приложения для п —Л = 4 и J3 = 0,9 находим
to = ^,lv,
откуда
Доверительный интервал будет
-lT «2,45.
е3) = (—2,05; 2,85).
328 ОБРАБОТКА ОПЫТОВ ГГЛ. 14
П р и м е р ^ 2. Для условий примера 1 п° 14.3, предполагая величину X
распределенной нормально найти точный доверительный интервал.
Решение. По таблице 5 приложения находим при и — 1 = 19 и р = 0,8
Ц — 1,328; отсюда е, == to 1/ — « 0,0704.
Сравнивая с решением примера 1 п° 14.3 (е^ = 0,072), убеждаемся, что
расхождение весьма незначительно. Если сохранить точность до второго
знака после запятой, то доверительные интервалы, найденные точным и при-
приближенным методами, совпадают:
/3 = A0,71; 10,85).
Перейдем к построению доверительного интервала для дисперсии.
Рассмотрим несмещенную оценку дисперсии
D
л — 1
и выразим случайную величину D через величину V A4.4.3), имеющую
распределение у? A4.4.4):
®~VT~\- (Н.4.12)
Зная закон распределения
величины V, можно найти
интервал 1Ч, в который она
попадает с заданной вероят-
вероятностью р.
Закон распределения
kn_1(v) величины V име-
Рис. 14.4.1. ет вид изображенный на
рис. 14.4.1.
Возникает вопрос: как выбрать интервал /?? Если бы закон рас-
распределения величины V был симметричным (как нормальный закон
или распределение Стьюдента), естественно было бы взять интервал /?
симметричным относительно математического ожидания. В данном
случае закон kn_l(v) несимметричен. Условимся выбирать интервал t,
так, чтобы вероятности выхода величины V за пределы интервала
вправо и влево (заштрихованные площади на рис. 14.4.1) были оди-
одинаковы и равны
а __ 1—3
2 ~" 2 *■
14.4] МЕТОДЫ ПОСТРОЕНИЯ ДОВЕРИТЕЛЬНЫХ ИНТЕРВАЛОВ 329
Чтобы построить интервал /э с таким свойством, воспользуемся
таблицей 4 приложения: в ней приведены числа yj такие, что
для величины V, имеющей ^-распределение с г степенями свободы.
В нашем случае г = п — 1. Зафиксируем г = п — 1 и найдем в со-
соответствующей строке табл. 4 два значения у}; одно, отвечающее
вероятности Pi —у! другое — вероятности р2 — 1—<у. Обозначим
эти значения у^ и у^. Интервал L имеет у^ своим левым, а у^ —
правым концом.
Теперь найдем по интервалу /? искомый доверительный интер-
интервал /р для дисперсии с границами Dx и Dv который накрывает
точку D с вероятностью р:
Построим такой интервал /g = (£I, D2), который накрывает точку D
тогда и только тогда, когда величина V попадает в интервал /?.
Покажем, что интервал
удовлетворяет этому условию. Действительно, неравенства
равносильны неравенствам
а эти неравенства выполняются с вероятностью 3. Таким образом,
доверительный интервал для дисперсии найден и выражается форму-
формулой A4.4.13).
Пример 3. Найти доверительный интервал для дисперсии в условиях
примера 2 п° 14.3, если известно, что величина X распределена нормально.
Решение. Имеем р = 0,8; а = 0,2; -к- = ОД. По таблице 4 приложения
находим при г — п — 1 = 19
Апя Pl = у = 0,1 х! = 27,2;
для р2 = 1 — £ = 0,9 Х2 = п>65.
330 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
По формуле A4.4.13) находим доверительный интервал "для дисперсии
/р = @,045; 0,104).
Соответствующий интервал для среднего квадратического отклонения:
@,21; 0,32). Этот интервал лишь незначительно превосходит полученный
в примере 2 п° 14.3 приближенным методом интервал @,21; 0,29).
14.5. Оценка вероятности по частоте
На практике часто приходится оценивать неизвестную вероят-
вероятность р события А по его частоте р* в п независимых опытах.
Эта задача близко примыкает к рассмотренным в предыдущих п°п°.
Действительно, частота события А в п независимых опытах есть не
что иное, как среднее арифметическое наблюденных значений вели-
величины X, которая в каждом отдельном опыте принимает значение 1,
если событие А появилось, и 0, если не появилось:
Р* = ~ A4.5.1)
Напомним, что математическое ожидание величины X равно р;
ее дисперсия pq, где q=\—р. Математическое ожидание среднего
арифметического также равно р
М[р*] = р, A4.5.2)
т. е. оценка р* для р является несмещенной.
Дисперсия величины р* равна
A4.5.3)
Можно доказать, что эта дисперсия является минимально возмож-
возможной, т. е. оценка р* для р является эффективной.
Таким образом, в качестве точечной оценки для неизвестной ве-
вероятности р разумно во всех случаях принимать частоту «*. Возни-
Возникает вопрос о точности и надежности такой оценки, т. е. о построе-
построении доверительного интервала для вероятности р.
Хотя эта задача и представляет собой частный случай ранее
рассмотренной задачи о доверительном интервале для математического
ожидания, все же целесообразно решать ее отдельно. Специфика
здесь в том, что величина X — прерывная случайная величина только
с двумя возможными значениями: 0 и 1. Кроме того, ее математи-
математическое ожидание р и дисперсия pq — p(l—р) связаны функцио-
функциональной зависимостью. Это упрощает задачу построения доверитель-
доверительного интервала.
14.5] ОЦЕНКА ВЕРОЯТНОСТИ ПО ЧАСТОТЕ 331
Рассмотрим сначала наиболее простой случай, когда число опы-
опытов п сравнительно велико, а вероятность р не слишком велика и
не слишком мала. Тогда можно считать, что частота события р*
есть случайная величина, распределение которой близко к нормаль-
нормальному1). Расчеты показывают, что этим допущением можно пользо-
пользоваться даже при не очень больших значениях п: достаточно, чтобы
обе величины пр и щ были больше четырех. Будем исходить из
того, что эти условия выполнены и частоту р* можно считать рас-
распределенной по нормальному закону. Параметрами этого закона будут!
тр* = р; ар, = ]/■&■, A4.5.4)
Предположим сначала, что величина р нам известна. Назначим дове-
доверительную вероятность C и найдем такой интервал (р—е», р-\~е<д,
чтобы величина р* попадала в этот интервал с вероятностью В:
Р(\Р* — /»|<в„) = р. A4.5.5)
Так как величина р* распределена нормально, то
откуда, как и в п° 14.3,
где arg Ф* — функция, обратная нормальной функции распределения Ф*.
Для определения {3, как и в п° 14,3, можно обозначить
Тогда
е? = /рар*, A4.5.6)
где t9 определяется из таблицы 14.3.1.
Таким образом, с вероятностью В можно утверждать, что
\Р'—Р\<^У~- A4.5.0
Фактически величина р нам неизвестна; однако неравенство A4.5.7)
будет иметь вероятность В независимо от того, известна нам или
неизвестна вероятность р. Получив из опыта конкретное значение
частоты р*, можно, пользуясь неравенством A4.5.7), найти интервал /»,
который с вероятностью 8 накрывает точку р. Действительно,
') Частота события при п опытах представляет собой прерывную слзг-
чайную величину; говоря о близости ее закона распределения к нормаль-
нормальному, мы имеем в виду функцию распределения, а не плотность.
332
ОБРАБОТКА ОПЫТОВ
1ГЛ. 14
преобразуем это неравенство к виду
(Р* — Р? < -f Р A — р)
A4.5.8)
м
и дадим ему геометрическую интерпретацию. Будем откладывать по
оси абсцисс частоту р*. а по оси ординат — вероятность р (рис. 14.5.1).
Геометрическим местом точек, координаты которых р* и р удовле-
удовлетворяют неравенству A4.5.8). будет внутренняя часть эллипса, про-
проходящего через точки @, 0)
и A, 1) и имеющего в этих
точках касательные, параллель-
параллельные оси Ор*. Так как вели-
величина р* не может быть ни
отрицательной, ни большей
единицы, то область D, со-
соответствующую неравенству
A4.5.8), нужно еще ограни-
ограничить слева и справа прямыми
р* — 0 и р* = 1. Теперь можно
для любого значения р*, полу-
~Р* ченного из опыта, построить
доверительный интервал /«, ко-
который с вероятностью 3 накроет
неизвестное значение р. Для
этого проведем через точку р* прямую, параллельную оси ординат; на
этой прямой границы области D отсекут доверительный интервал
/р = (у71# р2). Действительно, точка М со случайной абсциссой р* и
неслучайной (но неизвестной) ординатой р с вероятностью ^ попадет
внутрь эллипса, т. е. интервал /р с вероятностью C накроет точку р.
Размеры и конфигурация «доверительного эллипса» вависят от
числа опытов п. Чем больше и, тем больше вытянут эллипс и тем
^же доверительный интервал. г
Доверительные границы рх и р2 можно найти из соотношения
A4.5.8), заменив в нем знак неравенства равенством. Решая получен-
полученное квадратное уравнение относительно р, получим два корня:
0
/
Рис. 14.5.1,
Р\
Рг —
1 *Р_Ь, 1/ ''
ттг+'р V —
A4.5.9)
14.51 ОЦЕНКА ВЕРОЯТНОСТИ ПО ЧАСТОТЕ 338
Доверительный интервал для вероятности р будет
Пример 1. Частота события А в серии из 100 опытов оказалась
/?* = 0,78. Определить 90%-й доверительный интервал для вероятности р со-
события А.
Решение. Прежде всего проверяем применимость нормального закона;
для этого оценим величины пр и nq. Полагая ориентировочно р ~ р*, получим
пр я пр* = 78; nq я п A — р*) = 22.
Обе величины зиачительно больше четырех; нормальный за кап применим.
Из таблицы 14.3.1 для Р=0,9 находим ^ = 1,643. По формулам A4.5.9)
имеем
Рг = 0,705; рг = 0,840; /? — @.705; 0,840).
t2 I t2
Заметим, что при увеличении п величины — и -г — в формулах
A4.5.9) стремятся к нулю; в пределе формулы принимают вид
A4.5.10)
Эти формулы могут быть получены и непосредственно, если
воспользоваться приближенным способом построения доверительного
интервала для математического ожидания, данным в п° 14.3. Форму-
Формулами A4.5.10) можно пользоваться при больших п (порядка сотен),
если только вероятность р не слишком велика и не слишком мала
(например, когда обе величины пр и nq порядка 10 или более).
Пример 2. Произведено 200 опытов; частота события А оказалась
/>* = 0,34. Построить 85%-й доверительный интервал для вероятности собы-
события приближенно (по формулам A4.5.10)). Сравнить результате точным,
соответствующим формулам A4.5.9).
Решение, р = 0,85; по таблице 14.3.1 находим ^ = 1,439. Умножая
с. о ;:а
l/ Г( п Г) к. 0,0335,
получим
"*A — р*) й 0 048_
откуда находим приближенно доверительный интервал
/р « @,292; 0,388).
ilo формулам A4.5.9) найдем более точные значения />i = 0,294; р2 = 0,389,
которые почти не отличаются от приближенных.
334 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
Выше мы рассмотрели вопрос о построении доверительного интер-
интервала для случая достаточно большого числа опытов, когда частоту
можно считать распределенной нормально. При малом числе опытов
(а также если вероятность р очень велика или очень мала) таким
допущением пользоваться нельзя. В этом случае доверительный ин-
интервал строят, исходя не из приближеняого, а из точного закона
распределения частоты. Нетрудно убедиться, что это есть биномиаль-
биномиальное распределение, рассмотренное в главах 3 и 4. Действительно, число
появлений события А в п опытах распределено по биномиальному
закону: вероятность того, что событие А появится ровно т раз, равна
Pm,n = C™pmf-m, A4.5.11)
а частота р* есть не что иное, как число появлений события, делен-
деленное на число опытов.
Исходя из этого распределения, можно построить доверительный
интервал /р аналогично тому, как мы строили его, исходя из нор-
нормального закона для больших п (стр. 331).
Предположим сначала, что вероятность р нам известна, и найдем
интервал частот р*, р*. в который с вероятностью |3= 1 —а попадет
частота события р*.
Для случая большого п мы пользовались нормальным законом рас-
распределения и брали интервал симметричным относительно математиче-
математического ожидания. Биномиальное распределение A4.5.11) не обладает
симметрией. К тому же (в связи с тем, что частота — прерывная
случайная величина) интервала, вероятность попадания в который в точ-
точности равна р, может и не существовать. Поэтому выберем в качестве
интервала р*, /?* самый малый интервал, вероятность попадания левее
которого и правее которого будет больше 4-.
Аналогично тому, как мы строили область D для нормального
закона (рис. 14.5.1), можно будет для каждого п и* заданного fi по-
построить область, внутри которой значение вероятности р совместимо
с наблюденным в опыте значением частоты р*.
На рис. 14.5.2 изображены кривые, ограничипяющир такие облает::
для различных п при доверительной вероятности р = 0,9. По оси
абсцисс откладывается частота р*, по оси ординат — вероятность р.
Каждая пара кривых, соответствующая данному п, определяет довери-
доверительный интервал вероятностей, отвечающий данному значению частоты.
Строго говоря, границы областей должны быть ступенчатыми (ввиду
прерывности частоты), но для удобства они изображены в виде
плавных кривых.
Для того чтобы, пользуясь такими кривыми, найти доверительный
интервал/р, нужно произвести следующее построение (см. рис. 14.5.2):
по оси абсцисс отложить наблюденное в опыте значение частоты р*.
T4.5J
ОЦЕНКА ВЕРОЯТНОСТИ ПО ЧАСТОТЕ
335
провести через эту точку прямую, параллельную оси ординат, и
отметить точки пересечения прямой с парой кривых, соответствующих
данному числу опытов п; проекции этих точек на ось ординат и
дадут границы рх, р2 доверительного интервала /р.
О 0,10 0.20 0.30 OfiD Ц50 0,60 0,70 0.80 ОМ I.OOp*
Рис. 14.5.2.
При заданном п кривые, ограничивающие «доверительную область»,
определяются уравнениями:
Стпрт(\ -р)"-т = ^;
т = к
A4.5.12)
A4.5.13)
m=0
где k — число появлений события:
k = пр".
Разрешая уравнение A4.5.12) относительно р, можно найти нижнюю
Границу рх «доверительной области»; аналогично из A4.5.13) можно
найти р2.
Чтобы не решать эти уравнения каждый раз заново, удобно заранее
эатабулировать (или представить графически) решения для нескольких
336
ОБРАБОТКА ОПЫТОВ
[ГЛ,- 14
типичных значений доверительной вероятности f). Например, в
книге И. В. Дунина-Барковского и Н. В. Смирнова «Теория вероят-
вероятностей и математическая статистика в технике» имеются таблицы рх
и р2 для р = 0,95 и р = 0,99. Из той же книги заимствован график
рис. 14.5.2.
Пример 3. Найти доверительные границы р, и р2 для вероятности
события, если в 50 опытах частота его оказалась р* = 0,4. Доверительная
вероятность £ = 0,9.
Решение. Построением (см. пунктир на рис. 14.5.2) для /?* = 0,4и
п = 50 находим: />( и 0,28; р2 к, 0,52.
Пользуясь методом доверительных интервалов, можно приближенно
решить и другой важный для практики вопрос: каково должно быть
число опытов п для того, чтобы с доверительной вероятностью f3
ожидать, что ошибка от замены вероятности частотой не превзойдет
заданного значения?
При решении подобных задач удобнее не пользоваться непосред-
непосредственно графиками типа рис. 14.5.2, а перестроить их, представив
доверительные границы как функции от числа опытов п.
Пример 4. Проведено 25 опытов, в которых событие А произошло
12 раз. Найти ориентировочно число опытов п, которое понадобится для
1.00 ■
0 50 W0
Рис 14.53.
того, чтобы с вероятностью р = 0,9 ошибка от замены вероятности частотой
не превзошла 20%.
Решение. Определяем предельно допустимую ошибку:
Д = 0,2 - 0,48 = 0,096 х ОД.
Пользуясь кривыми рис. 14.5.2, построим новый график: по оси абсцисс
отложим число опытов п, по оси ординат — доверительные границы для вероят-
вероятности (рис. 14.5,3). Средняя прямая, параллельная оси абсцисс, соответствует
14.6] ОЦЕНКА ВЕРОЯТНОСТИ ПО ЧАСТОТЕ 337
12
наблюденной частоте события />* = ^ = 0,48. Выше и ниже прямой р = р* =
= 0,48 проведены кривые р, (л) и р2 (л), изображающие нижнюю и верхнюю
доверительные границы в зависимости от п. Область между кривыми, опре-
определяющая доверительный интервал, заштрихована. В непосредственной бли-
близости от прямой р = 0,48 двойной штриховкой показана более узкая область
20%-й допустимой ошибки. Из рис. 14.5.3 видно, что ошибка падает до
допустимой величины при числе опытов п порядка 100.
Заметим, что после выполнения потребного числа опытов может
понадобиться новая проверка точности определения вероятности по
частоте, так как будет получено в общем случае уже другое значение
частоты р*, "отличное от наблюденного в ранее проведенных опытах.
При этом может оказаться, что число опытов все еще недостаточно
для обеспечения необходимой точности, и его придется несколько
увеличить. Однако первое приближение, полученное описанным выше
методом, может служить для ориентировочного предварительного пла-
планирования серии опытов с точки зрения требуемого на них времени,
денежных затрат и т. д.
На практике иногда приходится встречаться со своеобразной зада-
задачей определения доверительного интервала для вероятности события,
когда полученная из опыта частота равна нулю. Такая задача обычно
связана с опытами, в которых вероятность интересующего нас события
очень мала (или, наоборот, очень велика — тогда мала вероятность
противоположного события).
Пусть, например, проводятся испытания какого-то изделия на без-
безотказность работы. В результате испытаний изделие не отказало ни
разу. Требуется найти максимальную практически возможную вероят-
вероятность отказа.
Поставим эту задачу в общем виде. Произведено п независимых
опытов, ни в одном из которых событие А не произошло. Задана
доверительная вероятность р; требуется построить доверительный
интервал для вероятности р события А, точнее — найти его верхнюю
границу р2, так как нижняя pv естественно, равна нулю.
Поставленная задача является частным случаем общей задачи
О доверительном интервале для вероятности, но ввиду своих особен-
особенностей заслуживает отдельного рассмотрения. Прежде всего, прибли-
приближенный метод построения доверительного интервала (на основе замены
закона распределения частоты нормальным), изложенный в начале
данного п°, здесь неприменим, так как вероятность р очень мала.
Точный метод построения доверительного интервала на основе бино-
биномиального распределения в данном случае применим, по может быть '
существенно упрощен.
Будем рассуждать следующим образом, В результате я опытов
наблюдено событие В, состоящее в том, что А не появилось ни
разу. Требуется найти максимальное значение р = р2, которое
«совместимо» с наблюденным в опыте событием В, если считать
22 Е. С. Вентцель
338 ОБРАБОТКА ОПЫТОВ [ГЛ. И
«несовместимыми» с В те 'значения р, для которых вероятность
события В меньше, чем <х=1—f3.
Очевидно, для любой вероятности р события А вероятность
наблюденного события В равна
/>(Я) = 0—/0". ..
Полагая Р(В) = а, получим уравнение для р2:
A— р2)°==\—$, A4.5.14)
откуда
р2 = \— УГ^р. A4.5.15)
Пример 5. Вероятность р самопроизвольного срабатывания взрыва-
взрывателя при падении снаряда с высоты h неизвестна, но предположительно
весьма мала. Произведено 100 опытов, в каждом из которых снаряд роняли
с высоты Л, но ни в одном опыте взрыватель не сработал. Определить
верхнюю границу р2 90% -го доверительного интервала для вероятности р.
Решение. По формуле A4.5.15)
100 100
pt=l— /1 — 0,9 = 1— /0,1,
100
\g /0,1 = 0,01 \g 0,1 = 1,9900;
100
/0,1 « 0,977; рг = 1 — 0,977 = 0,023.
Рассмотрим еще одну задачу, связанную с предыдущей. Событие А
с малой вероятностью р не наблюдалось в серии из п опытов
ни разу. Задана доверительная вероятность fi. Каково должно быть
число опытов п для того, чтобы верхняя доверительная граница для
вероятности события была равна заданному значению /?2?
Решение сразу получается из формулы A4.5.14):
Пример 6. Сколько раз нужно убедиться в безотказной работе изде-
изделия для того, чтобы с гарантией 95% утверждать, что в практическом при-
менеятга опо будет отказывать не более чем и 5% всех случаев"
Решение. По формуле A4.5.16) при р=0,95, ^2 = 0,05 имеем;
Округляя в большую сторону, получим:
и = 59.
Имея в виду ориентировочный характер всех расчетов подобного
рода, можно предложить вместо формул A4.5.15) и A4.5.16) более
простые приближенные формулы. Их можно получить, предполагая,
14.61 ОЦЕНКИ ДЛЯ ЧИСЛОВЫХ ХАРАКТЕРИСТИК СИСТЕМЫ ВЕЛИЧИН 339
что число появлений события А при п опытах распределено по закону
Пуассона с математическим ожиданием а = пр. Это предположение
приближенно справедливо в случае, когда вероятность р очень мала
(см. гл. 5, п° 5.9). Тогда
и вместо формулы A4.5.15) получим:
а вместо формулы A4.5.16)
Пример 7. Найти приближенно значение р2 для условий примера 5.
Решение. По формуле A4.5.14) имеем:
-1пО,1 2,303
^2 = —loo— = "Too-
т. е. тот же результат, который получен по точной формуле в примере 5.
Пример 8. Найти приближенно значение п для условий примера 6.
Решение. По формуле A4.5.18) имеем:
п_,-1п0,05_ 2,996
~ ~0ДО "W ~
Округляя в ббльшую сторону, находим п = 60, что мало отличается от ре-
результата п — 59, полученного в примере 6.
14.6. Оценки для числовых характеристик
системы случайных величин
В n°n° I4.1—14.4 мы рассмотрели задачи, связанные с оценками
для числовых характеристик одной случайной величины при ограни-
ограниченном числе опытов и построением для этих характеристик дове-
доверительных интервалов.
Аналогичные вопросы возникают и при обработке ограниченного
числа наблюдений над двумя и более случайными нел^чкпамп.
Здесь мы ограничимся рассмотрением только точечных оценок
для характеристик системы.
Рассмотрим сначала случай двух случайных величин.
Имеются результаты п независимых опытов над системой случай-
случайных величин (X, Y), давшие результаты:
{xv у!>; (х2, у2); ...; (хп, у„).
Требуется найти оценки для числовых характеристик системы;
математических ожиданий тх, ту, дисперсий Dx, Dy и корреляцией
ного момента К„...
22*
340
ОБРАБОТКА ОПЫТОВ
[Г Л 14
Этот вопрос решается аналогично тому, как мы решили его для
одной случайной величины. Несмещенными оценками для математи-
математических ожиданий будут средние арифметические:
п
2*/
tnr =
n • у n
а для элементов корреляционной матрицы —
л
A4.6.1)
л
л
2
Л-
(*
(*|
-1
-т
— т
и-
,J
-1
«у)
A4.6.2)
Доказательство может быть проведено аналогично п° 14.2.
При непосредственном вычислении оценок для дисперсий и кор-
корреляционного момента часто бывает удобно воспользоваться связью
между центральными и начальными статистическими моментами:
A4.6.3)
, = а*,[^. К]-т>;,
где
2
A4,6.4)
Вычяслив статистические моменты по формулам C 4.6.3), можно
затем найти несмещенные Оценки для элементов корреляционной
и
2
п
п
у\
1
V,
14.61 ОЦЕНКИ ДЛЯ ЧИСЛОВЫХ ХАРАКТЕРИСТИК СИСТЕМЫ ВЕЛИЧИН
матрицы по формулам:
341
A4.6.5)
Пример. Произведены стрельбы с самолета по земле одиночными
выстрелами. Зарегистрированы координаты точек попадаиия и одиовремеиио
записаны соответствующие значения угла скольжения самолета. Наблюден-
Наблюденные значения угла скольжения р (в тысячиых радиана) н абсциссы точки
попадаиия X (в метрах) приведены в таблице 14.6.1.
Таблица 14.6.1
1
1
2
3
4
5
6
7
8
9
10
h
—8
+10
4-22
-4-55
+2
-30
—15
+5
+10
+18
h
—10
2
+4
+7о
-1
-16
—8
—2
+с
+8
1
11
12
13
14
15
16
17
18
19
20
h
+з
-2
+28
+62
—10
—8
+22
+з
-32
+8
хг
J
-и
+12
+20
—И
+2
+14
+6
—12
+1
Найти оценки для числовых характеристик системы (f), X).
Решение. Для наглядности наносим все пары значений (Р, X) на
график (рис. 14.6.1). Расположение точек на графике уже свидетельств
вует о наличии определенной зависимости (положительной корреляции)
между р и 1.
По формулам A4.6.1) вычисляем средние зиачения величии [) н X—оценка
для математических ожиданий:
т^ — 7,15; и, = 0,5.
Далее находим статистические вторые начальные моменты:
20
w
■■ 581,8;
20
20
= 85,4,
342 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
По формулам A4.6.3) находим статистические дисперсии:
Dp = 581,8 — 51,0 = 530,8;
D* = 85,4 — 0,2= 85,2.
Для нахождения несмещенных оценок умножим статистические дис-
п 20
персни на Г==То'> получим:
Dp = 559,
Соответственно средние квадратические отклонения равны:
ар = УВ? = 23,6; ож = 9,46.
По последней формуле A4.6.4) находим статистический начальный момент:
х
20
Ю
10
-to
-го
Рис. 14.6.1,
и статистический корреляционный
момент:
= 190,8 — 3,6=187,2.
Для определения несмещен-
несмещенной оценки умножаем его на
п 20
=- = -уд-; получаем:
/^=197,0,
откуда оценка для коэффициента
корреляции равна:
197,0
3,6 • 9,46
: 0,88.
Полученное сравнительно большое значение г^х указывает на наличие
существенной связи между р и X; на этом основании можно предполагать,
чт^ скольжение является основной причиной боковых отклонений снаряюп.
Перейдем к случаю обработки наблюдений над системой произ-
произвольного числа случайных величин.
Имеется система т случайных величин
Над системой произведено п независимых наблюдений; резуль-
результаты этих наблюдений оформлены в виде таблицы, каждая строка
которой содержит т значений, принятых случайными величинами
Aj, X2, .... Хт в одном наблюдении (табл. 14.6.2).
14.6] ОЦЕНКИ ДЛЯ ЧИСЛОВЫХ ХАРАКТЕРИСТИК СИСТЕМЫ ВЕЛИЧИН 343
Таблица 14.6.2
i
1
2
;
i
п
х\
ХП
Х\2
■
ХЧ
'•
х\п
ч
хг\
Хгг
•
Х2п
...
...
...
...
...
...
...
Xk
Xftl
Xk2
'•
xki
xkn
...
...
...
...
...
...
хт
хт\
хт2
•
хт1
•
хтп
Числа, стоящие в таблице и занумерованные двумя индексами,
представляют собой зарегистрированные результаты наблюдений; пер-
первый индекс обозначает номер случайной величины, второй—номер
наблюдения, так что хи — это значение, принятое величиной Хк
в (м наблюдении.
Требуется найти оценки для числовых характеристик системы:
математических ожиданий тх , тх тх и элементов корреля-
корреляционной матрицы:
KuKi2 •. • Klm
\\К„\\ = К*
По главной диагонали корреляционной матрицы, очевидно, стоят
дисперсии случайных величин Xv X2, ..., Хт:
Оценки для математических ожиданий найдутся как средние ариф-
арифметические:
т.
(А=1. 2 т).
A4.6.6)
344 , ОБРАБОТКА ОПЫТОВ ГГЛ. 14
Несмещенные оценки для дисперсий определятся по формулам
Р*= п_1 A4.6.7)
а для корреляционных моментов — по формулам
По этим данным определяются оценки для элементов нормиро-
нормированной корреляционной матрицы:
~гн = ^Ш-. ' A4.6.9)
где
oft=/Zv, %t = VWi. A4.6.10)
Пример. Сброшено 10 серий бомб, по 5 бомб в каждой, и зарегистри-
зарегистрированы точки попадания. Результаты опытов сведены в таблицу 14.6.3.
В таблице буквой / обозначен номер серии; k — номер бомбы в серии.
Требуется определить подходящие значения числовых характеристик —
математических ожиданий и элементов корреляционных матриц — для системы
пяти случайных величин
(Xlt Хь Х3, Xt, Х$)
и системы пяти случайных величин
Решение. Оценки для математических ожиданий найдутся как сред-
средние арифметические по столбцам:
тг= — 74,3; тх= —19,9; тх =27,7; тх = 85,8; «.
myi = — 3,9; ту2 = —1,6; ту> = 12,2; иу< = 13,3; /^ = 9,9.
При вычислении элементов корреляционной матрицы мы не будем, как
в прежних примерах, пользоваться соотношениями между начальными и
центральными моментами; в данном случае ввиду сильно изменяющихся ма-
математических ожиданий пользование этим приёмом ие даст преимуществ.
Будем вычислять оценки для моментов непосредственно по формулам A4.6.2).
Для этого вычтем из каждого элемента таблицы 14.6.3 среднее значение
соответствующего столбца. Результаты сведем в таблицу 14.6.4.
t4.61 ОЦЕНКИ ДЛЯ ЧИСЛОВЫХ ХАРАКТЕРИСТИК СИСТЕМЫ ВЕЛИЧИН 345
Таблица 14.6.3
Абсцисса X
1
2
3
4
5
6
7
8
9
10
1
—120
—108
—200
—55
5
—240
10
-40
—100
105
2
—20
—75
—120
—2
60
—202
65
0
—40
135
з
2
—20
—80
40
100
—140
120
65
—10
190
60
20
—20
120
165
—88
160
103
55
280
5
180
80
10
200
220
—30
205
170
105
330
1
—20
40
—25
—100
—40
80
14
80
—70
2
Ордината
2
—15
60
—30
—75
—30
30
25
75
-60
4
3
— 8
120
—20
—35
—25
25
25
60
—30
10
у
4
—6
125
—10
2
—30
10
30
10
—10
12
5
—2
130
2
2
—45
2
10
—*
0
4
х
1
2
3
4
5
6
7
8
9
10
l
—45,7
-33,7
-125,7
19,3
79,3
—165,7
84,3
34,3
—25,7
179,3
1
—0,1
—55,1
—100,1
17,9
79,9
—182,1
84,9
19,9
—20,1
154,9
3
—25,7
—37,7
—107,7
12,3
72,3
—167,7
92,3
37,3
—37,7
162,3
4
—25,8
—65,8
—105,8
34,2
79,2
—173,8
74,2
17,2
—30,8
194,2
33,0
—67,0
—137,0
53,0
73,0
—177,0
58,0
23,0
—42,0
183,0
Таблица
14.6.4
\~™У>
—16,1
43,9
—21,1
—96,1
—36,1
83,9
17,9
83,9
—66,1
5,9
2
—13,4
61,6
—28,4
—73,4
—28,4
31,6
26,6
76,6
—58,4
5,6
3
—20,2
107,8
-32,2
-47,2
-37,2
12,8
12,8
47,8
—42,2
—2,2
4
—19,3
111,7
—23,3
—11,3
—43,3
-3,3
16,7
—3,3
—23,3
—1,3
5
—11,9
120,1
-7,9
—7,9
—54,9
—7,9
0,1
—13,9
-9,9
—5,9
Возводя эти числа в квадрат, суммируя по столбцам и деля на п — 1=9,
получим оценки для дисперсий н средних квадратических отклонений:
DXi = 104,2 • 102; DXi = 94,4 • 102; бХз — 94,3 ■ 103;
5^ = 110,2-10'; /5^ = 114,4-102;
£,.=102; оЖ2 = 97; а х> = 97; 5^ = 105; 2^ = 107.
Dyi = 35,5 • Ю2; Dy2 = 24,4 • 102; Z>yj = 23,4 • Ю2;
Dyi = 19,6 • 102; Dy_ = 20,1 • 102;
= 60; •„=.
= 48; а =44; а =45.
Чтобы найти оценку для корреляционного момента, например, меж-
между величинами Xt и ль составим столбец попарных произведений чисел,
346
ОБРАБОТКА ОПЫТОВ
ГГЛ !4
стоящих в первом и втором столбцах таблицы 14.6.4'). Сложив все эти
произведения и разделив сумму на п — 1, получим:
KXiX% = 0,959-10*.
Деля Кх Xi на ах aXi, получим:
: 0,97.
Аналогично находим все остальные элементы корреляционных матриц.
Для удобства умножим все элементы обеих матриц моментов на 10~2. По-
Получим:
104,2 96,0 98,4 105,1 106,9
94,4 93,2 107,0 101,1
94,3 102,0 99,2
110,2 108,2
111,4
35,5 27,8 22,9 11,0 8,3
24,4 21,4 13,0 10,2
23,4 17,4 17,2
19,6 19,3
20,1
(Ввиду симметричности матриц они заполнены только иаполовииу.)
Нормированные корреляционные матрицы имеют вид:
1,00 0,97 0,99 0,98 0,98
1,00 0,99 0,99 0,97
1,00 0,98 0,96
1,00 0,97
1,00
1,00 0,94 0,76 0,42 0,31
1,00 0,89 0,59 0,46
|г„„||= 1,00 0,81 0,80
1,00 0,97
II 1.00 |
Рассматривая эти матрицы, убеждаемся, что величины {Хх, Х2, Х2, Xit X5)
находятся в весьма тесной зависимости, приближающейся к функциональной;
величины (К,, К2, Y3l Y,, У5) связаны менее тесно, и коэффициенты корре-
корреляции между ними убывают по мере удаления от главной диагонали корре-
корреляционной матрицы.
') Если вычисление производится на арифмометре или клавишной счет-
счетной машине, то нет смысла выписывать отдельные произведения, а следует
непосредственно вычислять суммы произведений, не останавливаясь на про-
промежуточных результатах.
14.7] ОБРАБОТКА СТРЕЛЬБ 347
14.7. Обработка стрельб
Одной из важных практических задач, возникающих при изучении
вопросов стрельбы и бомбометания, является задача обработки резуль-
результатов экспериментальных стрельб (бомбометаний).
Здесь мы будем различать два случая: стрельбу ударными сна-
снарядами и стрельбу дистанционными снарядами.
При стрельбе ударными снарядами рассеивание характеризуется
законом распределения системы двух случайных величин: абсциссы
и ординаты точки попадания на некоторой плоскости (реальной или
воображаемой). При стрельбе дистанционными снарядами рассеивание
носит пространственный характер
и описывается законом распреде-
распределения системы трех координат
точки разрыва снаряда.
Рассмотрим сначала задачу
обработки стрельб ударными сна-
снарядами. Пусть произведено п не- *
зависимых выстрелов по некото- ■
рой плоской мишени и зареги-
зарегистрированы координаты п точек &а,уя)
попадания (рис. 14.7.1): *
(*1. У:У> (х3, у2); ...; (*„. yeV Рис. 14.7.1,
Предполагая, что закон распределения системы (X, Y) нормаль-
нормальный, требуется найти оценки для его параметров: координат центра
рассеивания тх, ту, угла а, определяющего направление главных
осей рассеивания £, ij, и главных с.к.о. ое, о .
Начнем с рассмотрения самого простого случая, когда направле-
направление главных осей рассеивания известно заранее. Этот случай часто
встречается на практике, так как обычно направление главных осей
рассеивания определяется самими условиями стрельбы (например,
при бомбометании — направление полета и перпендикулярное к нему;
при воздушной стрельбе — направление поперечной скорости цели и
перпендикулярное к нему и т. д,). В этом случае задача обработки
стрельб сильно упрощается. Зная заранее хотя бы ориентировочно
направление главных осей, можно выбрать координатные оси парал-
параллельно им; в такой системе координат абсцисса и ордината точки
попадания представляют собой независимые случайные величины, и.
их закон распределения определяется всего четырьмя параметрами:
координатами центра рассеивания и главными средними квадра-
тическими отклонениями ах, о . Оценки для этих параметров
348
ОБРАБОТКА ОПЫТОВ
[ГЛ. 14
определяются формулами
n
,/
f
,/
n
2
л
2
v
(xt-
n —
<*-
«
1
2
n
,J
\2
A4.7.1)
n —1
Рассмотрим более сложный случай, когда направление главных
осей рассеивания заранее неизвестно и тоже должно быть опреде-
определено из опыта. В этом случае определению подлежат оценки всех
пяти параметров: координат
центра рассеивания тх, т ,
угла а и главных средних квад-
ратических отклонений о£, о
(рис. 14.7.2).
Оценки для координат
центра рассеивания в этом слу-
случае определяются так же, как
в предыдущем случае, по фор-
формулам
Рис. 14.7.2, ■* п у п
A4.7.2)
Перейдем к оценке угла а. Предположим, что направления глав-
главных осей рассеивания известны, и проведем через точку (тх, ту)
главные оси 0%, Ог\ (рис. 14.7.2). В системе lO-q координаты слу-
случайной точки (Л', У) будут:
S = (X — тх) cos a -f (У — ту) sin а,
Н = — {X — тх) sin а -|- (У — ту) cos а.
или
S = ^cosa-f Ksina, ^^
Н = — X Sin a -j- У cos a.
Очевидно, величины S, Н будут иметь математические ожидания,
равные нулю:
14.7) ОБРАБОТКА СТРЕЛЬБ 349
Так как оси О\, Ot\ — главные оси рассеивания, величины S, Н
независимы. Но для величин, подчиненных нормальному закону, не-
независимость эквивалентна некоррелированности; следовательно, нам
достаточно найти такое значение угла а, при котором величины S, Н
не коррелированы. Это значение и определит направление главных
осей рассеивания.
Вычислим корреляционный момент величин (S, Н). Перемножая
равенства A4.7.3) и применяя к их произведению операцию матема-
математического ожидания, получим:
/Сц == М [SH] = — М [fr] sin a cos a -+■ M [XY] (cos2 а —sin2 а) +
-\- M[Y2] sin а cos а = — -^ sin 2а фх — Dy) -f- КХу cos 2а.
Приравнивая это выражение нулю и деля обе части на cos 2ot,
имеем:
1К
Уравнение A4.7.4) даст два значения угла а: а, и а^, различаю-
различающиеся на -к. Эти два угла и определяют направления главных осей
рассеивания1).
Заменяя в равенстве A4.7.4) Кху, Dx, Dy их оценками, получим
оценку для угла а:
Найдем оценки для главных средних квадратических отклоне-
отклонений оЕ, о . Для этого найдем дисперсии величин S, Н, заданных
формулами A4.7.3), по теореме о дисперсии линейной функции:
D^ = Dx cos2 a -j- Dy sin2 а + ^Kxy sin a cos а;
Dn = Dx sin2 а + Dy cos2 а — 2Kxy sin a cos a,
откуда находим оценки для главных дисперсий:
n2al J
j
') Заметим, что выражение A4.7.4) совпадает с приведенным в главе 9
выражением (9.2.2) для угла а, определяющего направление осей симметрии
эллипса рассеивания.
350
ОБРАБОТКА ОПЫТОВ
1ГЛ. 14
Оценки для главных средних квадратических отклонений выра-
выразятся формулами;
A4.7.6)
Выпишем отдельно полную сводку формул для обработки стрельб
по плоской мишени в случае, когда направление главных осей рас-
рассеивания заранее неизвестно. Оценки искомых параметров опре-
определяются формулами:
а = — arctg ■
. = V Dx cos2а -\-Кху sin
sin2 a;
v-У
где
л—1
|2а+ D cos2a,
2 (Уi- «,)
л^1
A4.7.7)
S (,xi — mx){yi — i
и —1
A4.7.8)
В заключение следует заметить, что обработку-стрельб по пол-
полным формулам A4.7.7) имеет смысл предпринимать только тогда,
когда число опытов достаточно велико (порядка многих десятков);
только в этом случае угол а может быть оценен с достаточной
точностью. При малом числе наблюдений значение а, полученное
обработкой, является в значительной мере случайным.
* Задачу обработки стрельб дистанционными снарядами мы здесь
рассмотрим только в простейшем случае, когда направление главных
осей рассеивания (хотя бы ориентировочно) известно заранее. Как
правило, встречающиеся в практике стрельбы дистанционными сна-
снарядами задачи обработки опытов относятся к этому типу. Тогда
можно выбрать координатные оси параллельно главным осям рас-
рассеивания и рассматривать три координаты точки разрыва снаряда
как независимые случайные величины.
14.8]
СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
351
Пусть в результате п независимых выстрелов зарегистрированы
координаты п точек разрыва дистанционных снарядов
в системе координат с осями, параллельными главным осям рассеи-
рассеивания. Оценки для параметров нормального закона определятся
формулами:
ту =
п
п
»=1
п —
v-
п —
1
"у
1
J
J
A4.7.9)
На решении задачи обработки стрельб дистанционными снарядами
в случае, когда направления главных осей рассеивания заранее не-
неизвестны, мы останавливаться не будем, так как на практике эта
задача встречается сравнительно редко.
14.8. Сглаживание экспериментальных зависимостей
по методу наименьших квадратов
К вопросам, связанным с обработкой опытов, разобранным в дан-
данной главе, близко примыкает вопрос о сглаживании эксперименталь-
экспериментальных ??.в::с!!мостой.
Пусть производится опыт, целью которого является исследование
зависимости некоторой физической величины у от физической вели-
величины х (например, зависимости пути, пройденного телом, от времени;
начальной скорости снаряда от температуры заряда; подъемной силы
от угла атаки и т. д.). Предполагается, что величины хну связаны
функциональной зависимостью:
у = ?(*).
A4.8.1)
Вид этой зависимости и требуется определить из опыта.
352
ОБРАБОТКА ОПЫТОВ
[ГЛ. Г4
Предположим, что в результате опыта мы получили ряд экспери-
экспериментальных точек и построили график зависимости у от л; (рис. 14.8.1).
Обычно экспериментальные точки на таком графике располагаются
не совсем правильным образом — дают некоторый «разброс», т. е.
обнаруживают случайные отклонения от видимой общей закономер-
•о
-X
Рис. 14.8.1,
Рис, 14.8.2,
ности. Эти уклонения связаны с неизбежными при всяком опыте
ошибками измерения.
Возникает вопрос, как по этим экспериментальным данным наи-
наилучшим образом воспроизвести зависимость у от х?
Известно, что через любые п точек с координатами (xt, y{)
всегда можно провести кривую, выражаемую аналитически полино-
полиномом степени (п — 1), так, чтобы она в точности прошла через каж-
каждую из точек (рис. 14.8.2). Однако такое решение вопроса обычно не
является удовлетворительным: как правило, нерегулярное поведение
экспериментальных точек, подобное изображенному на рис. 14.8.1
и 14.8.2, связано не с объективным характером зависимости у от х,
а исключительно с ошибка-
ошибками измерения. Это легко
^■^ обнаружить, сравнивая на-
-* блюденные уклонения (раз-
(разброс точек) с примерно из-
известными ошибками H3iv5e-
ригельной аппаратуры.
Тогда возникает весьма
типичная для практики зада-
задача сглаживания экспе-
х риментальной зависимости.
Желательно обработать
экспериментальные данные
так, чтобы по возможности точно отразить общую тенденцию зависимости
у от х, но вместе с тем сгладить незакономерные, случайные уклоне-
уклонения, связанные с неизбежными погрешностями самого наблюдения.
О
Рис. 14.8.3.
14.8J
СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
353
Для решения подобных задач обычно применяется расчетный метод,
известный под названием «метода наименьших квадратов». Этот метод
дает возможность при заданном типе зависимости у = <р(л;) так
выбрать ее числовые параметры, чтобы кривая у — ? (х) в известном
смысле наилучшим образом отображала экспериментальные данные.
Скажем несколько слов о том, из каких соображений может быть
выбран тип кривой у == ср (х). Часто этот вопрос решается непосред-
непосредственно по внешнему виду экспериментальной зависимости. Например,
экспериментальные точки, изображенные на рис. 14.8.3, явно наводят
на мысль о прямолинейной зависимости вида у = ах-\-Ь. Зависи-
Зависимость, изображенная на рис. 14.8.4, хорошо может быть предста-
представлена полиномом второй сте-
степени у = ах2 -\-bx-\~c. Если
речь идет о периодической
функции, часто можно вы-
выбрать для ее изображения
несколько гармоник триго-
тригонометрического ряда и т, д.
Очень часто бывает так,
что вид зависимости (линей-
(линейная, квадратичная, показа-
показательная и т. д.) бывает из-
известен из физических сооб-
соображений, связанных с су-
0
V
\
ч
Рис. 14.8.4,
Таблица 14.8.1
ществом решаемой задачи, а из опыта требуется установить только
некоторые параметры этой зависимости.
Задачу о рациональном выборе та-
таких числовых параметров при данном
виде зависимости мы и будем решать
в настоящем п°.
Пусть имеются результаты п неза-
независимых опытов, оформленные в виде
простой статистической таблицы (табл.
14,8,1), где / — номер опыта; х, — зна-
значение аргумента; у,-—соответствующее
значение функции.
Точки (хР уг) нанесены на график
(рис. 14.8.5).
Из теоретических или иных соо-
соображений выбран принципиальный вид
зависимости у=ф (х). Функция у—ср (х)
содержит ряд числовых параметров
а, Ь, с, ... Требуется так выбрать эти параметры, чтобы кривая
у = у(х) в каком-то смысле наилучшим образом изображала зави-
зависимость, полученную в опыте.
(
1
2
*i
дг,
х2
...
п
У\
Уг
...
1 1 *' 1 »
...
...
п | хп
...
Уп
23 Е. С. Вентцель
354 ОБРАБОТКА ОПЫТОВ [ГЛ. 14
Решение этой задачи, как и любой задачи выравнивания или
сглаживания, зависит от того, что именно мы условимся считать
«наилучшим». Можно, например, считать «наилучшим» такое взаим-
взаимное расположение кривой и экспериментальных точек, при котором
максимальное расстояние между ними обращается в минимум; можно
потребовать, чтобы в минимум обращалась сумма абсолютных величин
отклонений точек от кривой и т. д. При каждом из этих требований
мы получим свое решение задачи, свои значения параметров а, Ь, с, ...
Однако общепринятым при
решении подобных задач
является так называемый ме-
метод наименьших квадра-
квадратов, при котором требова-
,л ние наилучшего согласо-
* вания кривой у = <р(д:) и
экспериментальных точек
сводится к тому, чтобы
сумма квадратов откло-
отклонений эксперименталь-
экспериментальных точек от сглаживаю-
' г " щей кривой обращалась
Рис. 14.8.5. в минимум. Метод наимень-
наименьших квадратов имеет перед
другими методами сглаживания существенные преимущества: во-пер-
во-первых, он приводит к сравнительно простому математическому способу
определения параметров а, Ь, с, ...; во-вторых, он допускает до-
довольно веское теоретическое обоснование с вероятностной точки
зрения.
Изложим это обоснование. Предположим, что истинная зависи-
зависимость у от л в точности выражается формулой у = ср (л;); экспери-
экспериментальные точки уклоняются от этой зависимости вследствие неиз-
неизбежных ошибок измерения. Мы уже упоминали о том, что
ошибки измерения, как правило, подчиняются нормальному закону.
Допустим, что это так. Рассмотрим какое-нибудь значение аргумента х(.
Результат опыта есть случайная величина Yr распределенная по
нормальному закону с математическим ожиданием фО;) и со сред-
средним квадратическим отклонением at, характеризующим ошибку из-
измерения. Предположим, что точность измерения во всех точках оди-
одинакова:
°1 = °2= ••■ =О„ = О.
Тогда нормальный закон, по которому распределяется величина Ylt
можно записать, б виде:
14.8] СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ 355
В результате нашего опыта — ряда измерений — произошло следую-
следующее событие: случайные величины (Кх, К2, .. •, К„) приняли сово-
совокупность значений (yt, у2, .... у„). Поставим задачу: так подобрать
математические ожидания <?(хх), f(x2), .... <р(#л)> чтобы вероят-
вероятность этого события была максимальна1).
Строго говоря, вероятность любого из событий Yl = yl, так же
как и их совмещения, равна нулю, так как величины Yt непре-
непрерывны; поэтому мы будем пользоваться не вероятностями событий
Уt = yt, а. соответствующими элементами вероятностей:
в-_1_.Г 2за dyt. A4.8.3)
Найдем вероятность того, что система случайных величин
Yv Y2, .... Yn примет совокупность значений, лежащих в пределах
(У|. yt + dyj (у=1. 2 п).
Так как опыты независимы, эта вероятность равна произведению
элементов вероятностей A4.8.3) для всех значений /:
2!
dyt=Ke i=l , A4.8.4)
iVT " r ""
где К — некоторый коэффициент, не зависящий от <?(хр.
Требуется так выбрать математические ожидания <?(х{),
..., <?(х„), чтобы выражение A4.8.4) обращалось в максимум.
Величина „
всегда меньше единицы; очевидно, она имеет наибольшее значение,
когда показатель степени по абсолютной величине минимален:
1
2q*
1=1
Отсюда, отбрасывая постоянный множитель -fpr • получаем трс«
вание метода наименьших квадратов: для того чтобы данная сово-
совокупность наблюденных значений
была наивероятнейшей, нужно выбрать функцию <f(x) так, чтобы
сумма квадратов отклонений наблюденных значений у( от <р(*<)
была минимальной: „
ебо-
ебо23*
356
ОБРАБОТКА ОПЫТОВ
ГГЛ. М
Таким образом обосновывается метод наименьших квадратов,
исходя из нормального закона ошибок измерения и требования макси-
максимальной вероятности данной совокупности ошибок.
Перейдем к задаче определения параметров а, Ь, с исходя
из принципа наименьших квадратов. Пусть имеется таблица экспери-
экспериментальных данных (табл. 14.8.1) и пусть из каких-то соображений
(связанных с существом явления или просто с внешним видом наблю-
наблюденной зависимости) выбран общий вид функции у — у(х), завися-
зависящей от нескольких числовых параметров а, Ъ, с, ...; именно
эти параметры и требуется выбрать согласно методу наименьших
квадратов так, чтобы сумма квадратов отклонений yt от <f(Xf) была
минимальна. Запишем у как функцию не только аргумента х, но и
параметров а, Ь, с, ...:
y = cp(jr, a, b, с, ...)• A4.8.5)
так, чтобы выполнялось условие:
Требуется выбрать а, Ь, с,
с, ...)]2 =
A4.8.6)
Найдем значения а, Ь, с обращающие левую часть выражения
A4.8.6) в минимум. Для этого продифференцируем ее по а, Ь, с, ...
и приравняем производные нулю:
n
i — <f(xt\ a, b, c, ...)](-^ = 0.
где
A4.8.7)
1' а' Ь' с' '' 0 — значение частной производной функ-
функции <р по параметру а в точке дг^ i-^|-i , i-^-i . ...—аналогично.
Система уравнений A4.8.7) содержит столько же уравнений,
сколько неизвестных а, Ъ, с, ...
Решить систему A4.8.7) в общем виде нельзя; для этого необхо-
необходимо задаться конкретным видом функции <р.
Рассмотрим два часто встречающихся на практике случая: когда
функция ср линейна и когда она выражается полиномом второй сте-
степени (параболой).
14.8J
СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
357
1. Подбор параметров линейной функции
методом наименьших квадратов
В опыте зарегистрирована совокупность значений (лгг, yj
(/=1. 2, .... п\ см. рис. 14.8.6).
Требуется подобрать по методу наименьших квадратов пара-
параметры a, b линейной функции
у = ах ~\-Ь,
изображающей данную экспери-
экспериментальную зависимость.
Решение. Имеем:
A4.8.8)
Дифференцируя выражение
A4.8.8) по а и Ь, имеем:
... *
~да Х> \daji *1'
d<f I d<f \ Рис 14.8.6.
Подставляя в формулы A4.8.7), получим два уравнения для опре-
определения а и Ь:
п
или, раскрывая скобки и производя суммирование,
п п п
2;
(=1
21
1=1
11
1=1
п п
У] V,- — а 2 х,- — £>я = 0.
Разделим оба уравнения A4.8.9) на а:
п
I
п
а
п
Я
п
V 2
Zj xi
п
1
а
п
я
п
п
1
= 0.
A4.8.9)
A4.8.10)
S58
ОБРАБОТКА ОПЫТОВ
[ГЛ. 14
Суммы, входящие в уравнения A4.8.10), представляют собой не что
иное, как уже знакомые нам статистические моменты:
п п
< = 1
п
= тх;
У
1=\
. П-
Подставляя эти выражения в систему A4.8.10), получим:
< i\X.Y\ — av*2[X) — bmx = 0, \
m* — атх — b = Q.
A4.8.11)
Выразим Ь из второго уравнения A4.8.11) и подставим в первое:
= т*у — ат*х\
у х
а* , [X. Y) - а**21Х] -(т'у - атх) т\ = 0.
Решая последнее уравнение относительно а, имеем:
_
а
■ У) —
A4.8.12)
Выражение A4.8.12) можно упростить, если ввести в него не началь-
начальные, а центральные моменты. Действительно,
откуда
где
D
2*1
у х<
п
A4.8.13)
„* «=1 . „,• ---
** Г"' ту-~~7Г
Таким образом, поставленная задача решена, и линейная зависи-
зависимость, связывающая у и х, имеет вид:
к* к*
о:
14.8]
СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
359
или, перенося т в левую часть,
A4.8.15)
Мы выразили коэффициенты линейной зависимости через централь-
центральные, а не через начальные вторые моменты только потому, что в таком
виде формулы имеют более компактный вид. При практическом примене-
применении выведенных формул может оказаться удобнее вычислять моменты
КХу и Dx не по формулам A4.8.14), а через вторые начальные моменты:
A4.8.16)
2
(=1
Для того чтобы формулы A4.8.16) не приводили к разностям
близких чисел, рекомендуется перенести начало отсчета в точку, не
слишком далекую от математи-
математических ожиданий т\, т*у.
2. Подбор параметров
параболы второго
порядка методом
наименьших квадратов
В опыте зарегистрированы зна-
значения (xt, у;) (i = 1. 2, ..., п;
см. рис. 14.8.7). Требуется мето-
методом наименьших квадратов подо-
подобрать параметры квадратичной
функции — параболы второго по-
V;?,£\i2.: P:!C. H S 7.
у = ax2-\-bx -f- с,
соответствующей наблюденной экспериментальной зависимости. Имеем:
\) = у(х; а, Ь, с) = ах2-4-Ьх-{-с,
А-д.2. (±L\ —Х2.
да ~~ ' \da)i~ *'
09 ( д<р \
ж—х'> \w)i — хс'
дс -' \дс )i~
360 ОБРАБОТКА ОПЫТОВ
Подставляя в уравнения A4.8.7), имеем:
Я"Л.
[У/- (fl*!+Ч-ИИ=о.
2 [у, - (ах] + Ьх, + с)} xt = 0.
2
2
i — 1
или, раскрывая скобки, производя суммирование и деля на п.
24
24
Ct-
Ctrl п
г п
= 0,
= 0.
2
A4.8.17)
Коэффициенты этой системы также представляют собой статисти-
статистические моменты системы двух величин X, У, а именно:
2
±_ = я,; =
1 = 1
24
Пользуясь этими выражениями для коэффициентов через началь-
начальные моменты одной случайной величины и системы двух величин,
М.8] СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ 361
можно придать системе уравнений A4,8.7) достаточно компактный
вид. Действительно, учитывая, что а*[А"] = 1; а* г [X, Y] = a*[Y\
и перенося члены, не содержащие неизвестных, в правые части, при-
приведем систему A4.8.17) к виду:
о.\\Х\а-\-а.1[Х\Ь-\-*1\Х]с=я*21[Х, К].
а*2[Х\а+а\[Х]Ь-\-а'01Х]с=^1[Х, К].
A4.8.18)
Закон образования коэффициентов в уравнениях A4.8.18) нетрудно
подметить: в левой части фигурируют только моменты величины X
в убывающем порядке; в правой части стоят моменты системы (X, Y),
причем порядок момента по X убывает от уравнения к уравнению,
а порядок по Y всегда остается перзым1).
Аналогичными по структуре уравнениями будут определяться
коэффициенты параболы любого порядка.
Мы видим, что в случае, когда экспериментальная зависимость
выравнивается по методу наименьших квадратов полиномом некото-
некоторой степени, то коэффициенты этого полинома находятся решением
системы линейных уравнений. Коэффициенты этой системы линейных
уравнений представляют собой статистические моменты различных
порядков, характеризующие систему величин (X, Y), если ее рас-
рассмотреть как систему случайных величин.
Почти так же просто решается задача сглаживания эксперимен-
экспериментальной зависимости методом наименьших квадратов в случае, когда
сглаживающая функция представляет собой не полином, а сумму про-
произвольных заданных функций <pi (■*)< Ъ (■*)• • • • • ?*(■*) с коэффици-
коэффициентами alt а2, ... ■ ak:
у.-=ср(лг; ах, а2, .... «ft)=^=
= a!<Pi(Jf)-f- а2ср2 (лг) —}- ... +aft(pft(j:)= S вЛ(*)> A4-8.19)
и когда требуется определить коэффициенты а,.
') Решения системы A4.8.18) относительно неизвестных а, Ь, с в общем
виде мы не приводим, так как это решение слишком громоздко, а на прак-
практике обычно удобнее решать систему A4.8.18) не с помощью определителей,
а последовательным исключением неизвестных.
362 ОБРАБОТКА ОПЫТОВ [ГЛ. Ч
Например, экспериментальную зависимость можно сглаживать
тригонометрическим полиномом
ср(х; alt a2, аъ, а4) =
= a1cos<i)X + a2sin<i)X + a3cos2<i)X+ a4sin2u)x.
или линейной комбинацией показательных функций
ср(х; alt a2, ag^a^' + fi^' + ageT',
и т. д.
В случае, если функция задается выражением типа A4.8.19), коэф-
коэффициенты av a2> .... ak находятся решением системы к линейных
уравнений вида:
л
2
l
S
а2Ъ (xt) + ... + akyk (X;)]} <fx (*,) = О,
Выполняя почленное суммирование, имеем:
ял я
а1 2 [?i (^)]2+ «2 2 <РаUi) ?i (хг) + • • • + ак 2
2
я
i) + «2 2 [?2 (^i)l2 + • • • + «* 2 9k (Xi)
*md Tl \"D - - . - . ..
n
yi
1=1
14.8] СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
или, короче,
ft л п
2 2 2 (*/)•
363
2 a, 2 <Pi (*,) ?,-(*/) = 2
; = 1 Ы1 »= 1
k п
2 «у 2 ?2 (*/
jl 11
у 2
1=1
»= 1
п
= 2
A4.8.20)
я
)=2
Систему линейных уравнений A4.8.20) всегда можно решить
и определить таким образом коэффициенты av ay ..., ак.
Сложнее решается задача о сглаживании методом наименьших
квадратов, если в выражение функции у = ср(х; а, Ь, с, ...) число-
числовые параметры а, Ь, с, ... входят нелинейно. Тогда решение си-
системы A4.8.7) может оказаться сложным и трудоемким. Однако и в
этом случае часто удается получить
решение задачи с помощью сравни-
сравнительно простых приемов.
Проиллюстрируем идею этих
приемов на самом простом примере
функции, нелинейно зависящей толь-
только от одного параметра а (напри-
(например, у = е~ах' или y = sinax, или
у = —). Имеем:
J ax ]
у = ср(х, а), A4.8.21)
где а — параметр, подлежащий под-
подбору методом наименьших квадратов
для наилучшего сглаживания задан-
заданной экспериментальной зависимости
(рис. 14.8.8).
Будгм решить задачу следующим образом. Зададимся рядом зна-
значений параметра а и для каждого из них найдем сумму квадратов
отклонений yt от <р(х/> а)- Эта сумма квадратов есть некоторая
функция а; обозначим ее £(а):
л
2, (а) = Д. [yt — <р {xt, а)У,
Нанесем значение S(a) на график (рис. 14.8.9).
То значение а, для которого кривая S(a) имеет минимум, и вы-
выбирается как подходящее значение параметра а в выражении A4.8.21).
Рис. 14.8.8.
ОБРАБОТКА ОПЫТОВ
[ГЛ. 14
Совершенно так же, в принципе, можно, не решая уравнений A4.8.7),
подобрать совокупность двух параметров (а, Ь), удовлетворяющую
№
ЩЬ)
Рис. 14.8.9.
Рис. 14.8.10.
принципу наименьших квадратов; работа при этом лишь незначительно
усложнится и сведется к построению не одного, а нескольких гра-
графиков (рис. 14.8.10); при
этом придется искать со-
совокупность значений а, Ь,
обеспечивающую мини-
минимум минимального зна-
значения суммы квадратов
40
Л?
го
10
отклонений S (а, Ь).
Пример 1. В опыте
исследована зависимость
глубины проникания Л тела
в преграду от удельной энер-
энергии $ (энергии, приходя-
приходящейся на квадратный сан-
сантиметр площади соударе-
соударения). Экспериментальные
данные приведены в табли-
таблице 14.8.2 и на графике
(рис. 14.8.11).
Требуется по методу наименьших квадратов подобрать и построить пря-
прямую, изображающую зависимость h от $.
Решение. Имеем:
*' _ 2137_ лрлл <_ i 1_274
13 ~^>к
300
Рис, 14.S.H.
13
13
\
13
Для обработки по начальным моментам переносим начало координат
в близкую к средней точку:
g0 = 150; Ло = 20.
H.8J СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
Получаем новую таблицу значений величин:
36S
(табл. 14.8.3).
Определяем моменты:
: 6869;
D* = 6869 — (mg, J = 6869 — A64,4 — 150J = 6662;
i
1
2
3
4
5
6
7
8
9
10
11
12
13
41
50
81
104
120
139
154
180
208
241
250
269
301
h, (мм)
4
8
10
14
16
20
19
23
26
30
31
36
37
Таблица 14.8.2
ю 842;
Таблица 14.8.3
1
2
3
4
5
6
7
8
9
10
11
12
13
8^ = ^-150
—109
—100
—69
—46
—30
-11
4
30
58
91
100
119
151
—16
—12
—10
—6
—4
0
—1
3
6
10
и
16
17
К*,, = а* 2 [$', h'\ — mt
Уравнение прямой имеет вид:
=*842 — A64,4 — 150)B1,1 — 20) «
«842—16 = 826.
или
h — 21,1 = 0,124 (S —164,4).
A4.8.22)
Прямая A4.8.22) показана на рис. 14.8.11.
Пример 2. Произведен ряд опытов по измерению перегрузки авиа-
авиационной бомбы, проникающей в грунт, при различных скоростях встречи.
Полученные значения перегрузки N в зависимости от скорости v приведены
в таблице 14.8.4.
Построить по методу наименьших квадратов квадратичную завися-
мость вида:
N — av% + bv -j- с,
наилучшим образом согласующуюся с экспериментальными данными.
366
ОБРАБОТКА ОПЫТОВ
1ГЛ. 14
Решение. В целях удобства обработки удобно изменить единицы из-
измерения так, чтобы не иметь дела с многозначными числами; для этого можно
значения v выразить в сотнях м/сек (умножить на 10~2), а N — в тысячах
единиц (умножить на 10~*3) и всю обработку провести в этих условных
единицах.
Находим коэффициенты уравнений A4.8.18).
В принятых условных единицах:
2Х
Таблица 14.8.4
1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
v (м/сек)
120
131
140
161
174
180
200
214
219
241
250
268
281
300
540
590
670
760
850
970
1070
1180
1270
1390
1530
1600
1780
2030
14
148,36
14
63,49
14
= 10,60;
= 4,535;
= 2,056;
9 Ъ
а*0, 1 [v, Щ = a* [N] = m*N = '14
16'23
14
= 1,159;
^
<lh «,_-!___ «L_w
88,02
14
= 6,287.
Система уравнений A4.8.18) имеет вид:
25,92а + 10-606 -j- 4,535с = 6,287,
10,60а -j- 4,5356 + 2,056с = 2,629,
4,535а + 2,0566 + с =1,159.
Решая эту систему, находим:
а к, 0,168; 6 и 0,102; с и 0,187.
На рис. 14.8.12 нанесены экспериментальные точки и зависимость
N — at'2 -}- bv 4- с,
построенная по методу наименьших квадратов.
Примечание. В некоторых случаях может потребоваться провести
кривую >' = ¥(-«) так, чтобы она точно проходила через некоторые заданные
заранее точки. Тогда некоторые из числовых параметров а, Ь,''С, ..., входя-
входящих s функцию у — '7" (х), могут быть определены из зтпх тслознй.
14.8]
СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
367
Например, в условиях примера 2 может понадобиться проэкстраполиро-
вать зависимость N(v) на малые значения v; при этом естественно провести
параболу второго порядка так, чтобы она проходила через начало координат
(т. е. нулевой скорости встречи соответствовала нулевая перегрузка). Тогда,
естественно, с = 0 и зависимость N (и) приобретает вид:
N = av2 -f- bv,
а система уравнений для определения a a b будет иметь вид:
25,92а + 10,606 = 6,287,
10,60а + 4,5356 = 2,629.
Пример 3. Конденсатор, заряженный до напряжения Uo — 100 вольт,
разряжается через некоторое сопротивление. Зависимость напряжения и
N10
-з
-v/0-3
Рис. 14.8.12.
между обкладками конденсатора от времени t зарегистрирована на участке
времени 10 сек с интервалом 1 сек. Напряжение измеряется с точностью
до 5 вольт. Результаты измерений приведены в таблице 14.8.5.
Согласно теоретическим данным, зависимость напряжения от времени
должна иметь вид:
Основываясь на опытных данных, подобрать методом наименьших квадратов
значение параметра а.
Решение. По таблицам функции е~х убеждаемся, что е~х доходит при-
приблизительно до 0,05 при х к, 3; следовательно, коэффициент а должен иметь
368
ОБРАБОТКА ОПЫТОВ
Таблица 14.8.5
1
2
3
4
5
6
tt (сек)
0
1
2
3
4
5
Ui (в)
100
75
55
40
30
20
1
7
8
9
10
11
tt (сек)
6
7
8
9
10
15
10
10
5
5
[ГЛ, 14
порядок 0,3. Задаемся в районе а = 0,3 несколькими значениями а:
а = 0,28; 0,29; 0,30; 0,31; 0,32; 0,33
и вычисляем для них значения функции
в точках tt (табл. 14.8.6). В нижней строке таблицы 14.8.6 помещены значе-
значения суммы квадратов отклонений 2 (а) в зависимости от а.
50
I
I
0,30 ос=0,307
Рис. 14.8.13.
График функции У, (а) приведен на рис. 14.8.13. Из графика видно, что
значение а, отвечающее минимуму, приближенно равно 0,307. Таким образом,
14.8]
СГЛАЖИВАНИЕ ЭКСПЕРИМЕНТАЛЬНЫХ ЗАВИСИМОСТЕЙ
369
по методу наименьших квадратов наилучшим приближением к опытным дан-
данным будет функция U = £/ое~°'зо7/. График этой функции вместе с экспери-
экспериментальными точками дан на рис. 14.8.14.
Ult)
Рис. 14.8.14.
Таблица 14.8.6
1
1
2 |
3
4
5
6
7
8
9
10
11
Н
0
1
2
3
4
5
6
7
8
9
10
S(a)
а = 0,28
100.0
75,5
57,1
43,2
32,6
24.6
18,6
14,1
10,7
8,0
6,1
83,3
а = 0,29
100.0
74,8
56,0
41,9
31,3
23.5
17,6
13,1
9,8
7,4
5,5
40,3
7 = 0,30
100.0
74,1
54,9
40,7
30,1
22,3
16,5
12,2
9,1
6,7
5,0
17,4
о = 0,31
100,0
73,3
53,8
39,5
28,9
21,2
15,6
11,4
8,4
6,1
4,5
13,6
о = 0,32
100,0
72,6
52,7
38,3
27,8
20,2
14,7
10,6
7,7
5,6
4,1
25,7
а = 0,33
100,0
71,9
51,7
37,2
26,7
19,2
13,8
QQ
7,1
5,1
3,7
51,4
24 Е. С. Вентдель
ГЛАВА 15
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ
15.1. Понятие о случайной функции
До сих пор в нашем курсе теории вероятностей основным пред-
предметом исследования были случайные величины. Случайная величина
характерна тем, что она в результате опыта принимает некоторое
одно, заранее неизвестное, но единственное значение. Примерами
таких случайных величин могут служить: абсцисса точки попада-
попадания при выстреле; ошибка радиодальномера при одном, единичном
измерении дальности; горизонтальная ошибка наводки при одном
выстреле и т. д.
Ограничиваясь рассмотрением подобных отдельных случайных ве-
величин, мы изучали случайные явления как бы «в статике», в ка-
каких-то фиксированных постоянных условиях отдельного опыта.
Однако такой элементарный подход к изучению случайных явле-
явлений в ряде практических задач является явно недостаточным. На
практике часто приходится иметь дело со случайными величинами,
непрерывно изменяющимися в процессе опыта. Примерами таких слу-
случайных величин могут служить: ошибка радиодальномера при непре-
непрерывном измерении меняющейся дальности; угол упреждения при не-
непрерывном прицеливании по движущейся цели; отклонение траекто-
траектории управляемого снаряда от теоретической в процессе управления
или самонаведения.
Такие случайные величины, изменяющиеся в процессе опыта, мы
будем в отличие от обычных случайных величин называть случай-
случайными функциями.
Изучением подобных случайных явлений, в которых случайность
проявляется в форме процесса, занимается специальная отрасль тео-
теории вероятностей—теория случайных функций (иначе —теория слу-
случайных или стохастических процессов). Эту науку можно образно
назвать «динамикой случайных явлений».
Теория случайных функций — новейший раздел теории вероятно-
вероятностей, развившийся, в основном, за последние два-три десятилетия.
15.11 ПОНЯТИЕ О СЛУЧАЙНОЙ ФУНКЦИИ 371
В настоящее время эта теория продолжает развиваться и совершен-
совершенствоваться весьма быстрыми темпами. Это связано с непосредственными
требованиями практики, в частности с необходимостью решения ряда
технических задач. Известно, что за последнее время в технике все
большее распространение получают системы с автоматизированным
управлением. Соответственно все ббльшие требования предъявляются
к теоретической базе этого вида техники — к теории автоматиче-
автоматического управления. Развитие этой теории невозможно без анализа
ошибок, неизбежно сопровождающих процессы управления, которые
всегда протекают в условиях непрерывно воздействующих случайных
возмущений (так называемых «помех»). Эти возмущения по своей
природе являются случайными функциями. Для того чтобы рацио-
рационально выбрать конструктивные параметры системы управления,
необходимо изучить ее реакцию на непрерывно воздействующие слу-
случайные возмущения, а единственным аппаратом, пригодным для
такого исследования, является аппарат теории случайных функций.
В данной главе мы познакомимся с основными понятиями этой
теории и с общей постановкой ряда практических задач, требующих
применения теории случайных функций. Кроме того, здесь будут
изложены общие правила оперирования с характеристиками случайных
функций, аналогичные правилам оперирования с числовыми характе-
характеристиками обычных случайных величин.
Первым из основных понятий, с которыми нам придется иметь
дело, является само понятие случайной функции. Это понятие на-
настолько же шире и богаче понятия случайной величины, насколько
математические понятия переменной величины и функции шире и
богаче понятия постоянной величины.
Вспомним определение случайной величины. Случайной величиной
называется величина, которая в результате опыта может принять то
или иное значение, неизвестно заранее — какое именно. Дадим ана-
аналогичное определение случайной функции.
Случайной функцией называется функция, которая в результате
опыта может принять тот или иной конкретный вид, неизвестно за-
заранее— какой именно.
Конкретный вид, принимаемый случайной функцией в результате
опыта, называется реализацией случайной функции. Если над слу-
случайной функцией произвести группу опытов, то мы получим группу
или «семейство» реализаций этой функции.
Приведем несколько примеров случайных функций.
Пример 1. Самолет-бомбардировщик на боевом курсе имеет
теоретически постоянную воздушную скорость V. Фактически его
скорость колеблется около этого среднего номинального значения
и представляет собой случайную функцию времени. Полет на боевом
курсе можно рассматривать как опыт, в котором случайная функция
V(f) принимает определенную реализацию (рис= 15.1,1)= От опьпа
24*
372
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ
[ГЛ. 15
Рис. 15.1.1.
к опыту вид реализации меняется. Если на самолете установлен
самопишущий прибор, то он в каждом полете запишет новую, отлич-
'ную от других реализа-
реализацию случайной функции.
В результате нескольких
полетов можно получить
семейство реализаций слу-
случайной функции V(t)
(рис. 15.1.2).
Пример 2. При на-
наведении управляемого сна-
снаряда на цель ошибка на-
наведения /? (t) представ-
представляет собой отклонение
центра массы снаряда от
теоретической траекто-
траектории, т. е. случайную функ-
функцию времени (рис. 15.1.3).
В том же опыте слу-
случайными функциями вре-
... t мени являются, например,
перегрузка снаряда N(t),
угол атаки а(^) и т. д.
Рис- 151-2- Пример 3. При
стрельбе с самолета по
самолету перекрестие прицела в течение некоторого времени должно
непрерывно совмещаться с целью — следить за ней. Операция слежения
Рис. 15.1.3,
Рис. 15.1.4,
за целью сопровождается ошибками—так называемыми ошибками на-
наводки (рис. 15.1.4). Горизонтальная и вертикальная ошибки наводки
в процессе прицеливания непрерывно меняются и представляют собой
две случайные функции X (t) и Y (t). Реализации этих случайных функ-
15.1]
ПОНЯТИЕ О СЛУЧАЙНОЙ ФУНКЦИИ
373
ций можно получить в результате дешифровки снимков фотопулемета,
фотографирующего цель в течение всего процесса слежения.
Число примеров случайных функций, встречающихся в технике,
можно было бы неограниченно увеличивать. Действительно, в любом
случае, когда мы имеем дело с непрерывно работающей системой
(системой измерения, управления, наведения, регулирования), при
анализе точности работы этой системы нам приходится учитывать
наличие случайных воздействий (помех). Как сами помехи, так и
вызванная ими реакция системы представляют собой случайные функ-
функции времени.
До сих пор мы говорили только о случайных функциях, аргу-
аргументом которых является время t. В ряде задач практики встречаются
случайные функции, зависящие не от времени, а от других аргумен-
аргументов. Например, характеристики прочности неоднородного стержня
могут рассматриваться как случайные функции абсциссы сечения х.
Температура воздуха в различных слоях атмосферы может рассмат-
рассматриваться как случайная функция высоты Н.
На практике встречаются также случайные функции, зависящие
не от одного аргумента, а от нескольких. Например, аэрологические
данные, характеризующие состояние атмосферы (температура, давле-
давление, ветер), представляют собой в общем случае случайные функции
четырех аргументов: трех координат х, у, z и времени t.
X(t) i
Рис. 15.1.5.
В данном курсе мы будем рассматривать только случайные функ-
функции одного аргумента. Так как этим аргументом чаще всего является
время, будем обозначать его буквой t. Кроме того, условимся,
как правило, обозначать случайные функции большими буквами
(X (t), Y(t), ...) в отличие от неслучайных функций (x(t), y(t), ...).
Рассмотрим некоторую случайную функцию X [t). Предположим,
что над ней произведено п независимых опытов, в результате кото-
которых получено п реализаций (рис. 15.1.5). Обозначим их соотвег=
ственно номеру опыта х, (t), x2 (t) xn (t).
374 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
Каждая реализация, очевидно, есть обычная (неслучайная) функ-
функция. Таким образом, в результате каждого опыта случайная функция
X @ превращается в обычную, неслучайную функцию.
Зафиксируем теперь некоторое значение аргумента t и посмотрим,
во что превратится при этом случайная функция X (t). Очевидно,
она превратится в случайную величину в обычном смысле слова.
Условимся называть эту случайную величину сечением случайной
функции, соответствующим данному t. Если провести «сечение» се-
семейства реализаций при данном t (рис. 15.1.5), мы получим п зна-
значений, принятых случайной величиной X (/) в и опытах.
Мы видим, что случайная функция совмещает в себе черты слу-
случайной величины и функции. Если зафиксировать значение аргумента,
она превращается в обычную случайную величину; в результате
каждого опыта она превращается в обычную (неслучайную)
функцию.
В ходе дальнейшего изложения мы часто будем попеременно рас-
рассматривать одну и ту же функцию X(() то как случайную функцию,
то как случайную величину, в зависимости от того, рассматри-
рассматривается ли она на всем диапазоне изменения t или при его фиксиро-
фиксированном значении.
15.2. Понятие о случайной функции как расширение понятия
о системе случайных величин. Закон распределения
случайной функции
Рассмотрим некоторую случайную функцию X (t) на определенном
отрезке времени (рис. 15.2.1).
Строго говоря, случайную функцию мы не можем изобра-
изображать с помощью кривой на графике: начертить мы можем лишь ее
ХШ
ч\ ,--\
ъ ь 4 \ / \ / V/ ta
Рис. 15.2.1.
конкретные реализации. Однако в целях наглядности можно позволить
себе условно изобразить ка чертеже случайную функцию Л" (f) в виде
кривой, понимая под этой кривой не конкретную реализацию^ а всю
15.Z) ЗАКОН РАСПРЕДЕЛЕНИЯ СЛУЧАЙНОЙ ФУНКЦИИ 375
совокупность возможных реализаций X (t). Эту условность мы будем
отмечать тем, что кривую, символически изображающую случайную
функцию, будем проводить пунктиром.
Предположим, что ход изменения случайной функции регистри-
регистрируется с помощью некоторого прибора, который не записывает слу-
случайную функцию непрерывно, а отмечает ее значения через определен-
определенные интервалы — в моменты времени tr, t2, ..., tm.
Как было указано выше, при фиксированном значении t случай-
случайная функция превращается в обычную случайную величину. Следо-
Следовательно, результаты записи в данном случае представляют собой
систему т случайных величин:
) X{tm). A5.2.1)
Очевидно, при достаточно высоком темпе работы регистрирующей
аппаратуры запись случайной функции через такие интервалы даст
достаточно точное представление о ходе ее изменения. Таким обра-
образом, рассмотрение случайной функции можно с некоторым прибли-
приближением заменить рассмотрением системы случайных величин A5.2.1).
По мере увеличения т такая замена становится все более и более
точной. В пределе число значений аргумента — и соответственно
число случайных величин A5.2.1) — становится бесконечным. Таким
образом, понятие случайной функции можно рассматривать как
естественное обобщение понятия системы случайных величин на слу-
случай бесконечного (несчетного) множества величин, входящих в
систему.
Исходя из такого толкования случайной функции попытаемся от-
ответить на вопрос: что же должен представлять собой закон рас-
распределения случайной функции?
Мы знаем, что закон распределения одной случайной величины
есть функция одного аргумента, закон распределения системы двух
величин — функция двух аргументов и т. д. Однако практическое
пользование в качестве вероятностных характеристик функциями
многих аргументов настолько неудобно, что даже для систем трех-
четырех величин мы обычно отказываемся от пользования законами
распределения и рассматриваем только числовые характеристики.
Что касается закона распределения случайной функции, который пред-
представляет собой функцию бесчисленного множества аргументов, то
такой закон в лучшем случае можно чисто формально записать
в какой-либо символической форме; практическое же пользование
подобной характеристикой, очевидно, совершенно исключено.
Можно, однако, для случайной функции построить некоторые
вероятностные характеристики, аналогичные законам распределения.
Идея построения этих характеристик заключается в следующем.
Рассмотрим случайную величину X (t)— сечение случайной функ-
функции в момент t (рис. 15.2.2). Эта случайная величина, очевидно,
376 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
обладает законом распределения, который в общем случае зависит
от t. Обозначим его f(x, t). Функция f(x, t) называется одномер-
одномерным законом распределения случайной функции X (t).
Очевидно, функция f(x, t) не является полной, исчерпывающей
характеристикой случайной функции X (t). Действительно, эта функ-
функция характеризует только закон распределения X (t) для данного,
хш
/
1
1
t
/
\
ч
t
\
\
V
\
Рис.
/
/
15.2.2.
/
хотя и произвольного t; она не отвечает на вопрос о зависи-
зависимости случайных величин X (t) при различных t. С этой точки зре-
зрения более полной характеристикой случайной функции X (t) является
так называемый двумерный закон распределения:
/(*,, х2; tv t2). A5.2.2)
Это — закон распределения системы двух случайных величин X (ft),
X (t2), т. е. двух произвольных сечений случайной функции X (t).
Однако и эта характеристика в общем случае не является исчерпы-
исчерпывающей; еще более полной характеристикой был бы трехмерный закон:
/(*!• х2, х3; tv t2, fj). A5.2.3)
Очевидно, теоретически можно неограниченно увеличивать число
аргументов и получать при этом все более подробную, все более
исчерпывающую характеристику случайной функции, но опе.рировять
со столь громоздкими характеристиками, зависящими от многих аргу-
аргументов, крайне неудобно. Поэтому при исследовании законов рас-
распределения случайных функций обычно ограничиваются рассмотрением
частных случаев, где для полной характеристики случайной функции
достаточно, например, знания функции A5.2.2) (так называемые «про-
«процессы без последействия»).
Б пределах настоящего элементарного изложения теории случайных
функций мы вовсе не будем пользоваться законами распределения, а
ограничимся рассмотрением простейших характеристик случайных
функций, аналогичных числовым характеристикам случайных величин.
15.3]
ХАРАКТЕРИСТИКИ СЛУЧАЙНЫХ ФУНКЦИЙ
377
15.3. Характеристики случайных функций
Мы имели много случаев убедиться в том, какое большое значе-
значение в теории вероятностей имеют основные числовые характеристики
случайных величин: математическое ожидание и дисперсия — для
одной случайной величины, математические ожидания и корреляцион-
корреляционная матрица — для системы случайных величин. Искусство пользо-
пользоваться числовыми характеристиками, оставляя по возможности в сто-
стороне законы распределения,—основа прикладной теории вероятно-
вероятностей. Аппарат числовых характеристик представляет собой весьма
гибкий и мощный аппарат,
позволяющий сравнительно
просто решать многие прак-
практические задачи.
Совершенно аналогичным
аппаратом пользуются и в
теории случайных функций.
Для случайных функций
также вводятся простейшие
основные характеристики,
аналогичные числовым ха-
характеристикам случайных ве-
величин, и устанавливаются
правила действий с этими
характеристиками. Такой
аппарат оказывается доста-
достаточным для решения мно-
многих практических задач.
В отличие от числовых характеристик случайных величин, пред-
представляющих собой определенные числа, характеристики случайных
функций представляют собой в общем случае не числа, а функции.
Математическое ожидание случайной функции X (() определяется
следующим образом. Рассмотрим сечение случайной функции X (t)
при фиксированном t. В этом сечении мы имеем обычную случайную
величину, Определим ее ма^еыаШЧёСкОё Ожидание. ичеййДнО. В О&Щём
случае оно зависит от t, т. е. представляет собой некоторую функ-
Рис. 15.3.1,
mx{t)=M[X(t)\.
A5.3.1)
Таким образом, математическим ожиданием случайной
лА * ■ •! •' 11 ill* V I r\ »i n r\t i n f гычл п п «г п п п ■■* лЛилгт *« .1.1 .»*# т* »-i «л '^\ *я *-• ллм г* ю п гш
iif \' «1, i\, и 1Л u# j \ \ У } i^ *A*lJ *~н> *' п' iJ //£■ l- /i i g,i^ iy ^X l~ *i* eX лл*ё и lL /L u/ \j I Li ь* /н<г iL /и iii* -_ t i* f • /«' \/ it Lit ir iJ, n»
при каждом значении аргумента t равна математическому
ожиданию соответствующего сечения случайной функции.
По смыслу математическое ожидание случайной функции есть
некоторая средняя функция, около которой различным образом
варьируются конкретные реализации случайной функции.
378
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
На рис. 15.3.1 тонкими линиями показаны реализации случайной
функции, жирной линией — ее математическое ожидание.
Аналогичным образом определяется дисперсия случайной функции.
Дисперсией случайной функции X (t) называется неслучай-
неслучайная функция Dx{t), значение которой для каждого t равно
дисперсии соответствующего сечения случайной функции:
Dx(t) — D[X(Jt)]. A5.3.2)
Дисперсия случайной функции при каждом t характеризует раз-
разброс возможных реали-
X,(t) заций случайной функции
относительно среднего,
иными словами, «степень
случайности» случайной
функции.
Очевидно, Dx(t) есть
неотрицательная функция.
Извлекая из нее квадрат-
квадратный корень, получим
функцию <зх (t) — среднее
квадратяческое отклоне-
отклонение случайной функции:
x,(t)
Рис. 15.3.2.
V
Рис. 15.3.3.
У случайных функций Хх (t) и
матические ожидания и дисперсии;
A5.3.3)
Математическое ожи-
ожидание и дисперсия пред-
представляют собой весьма
важные . характеристики
случайной функции; од-
однако для описания основ-
основных особенностей слу-
случайной функции этих
характеристик недоста-
недостаточно. Чтобы убедиться
в этом, рассмотрим две
случайные функции Хх (f)
и X2(t), наглядно изо-
изображенные семействами
реализаций на рис. 15.3.2
и 15.3.3.
X2(t) примерно одинаковые мате-
однако характер этих случайных
15.3] ХАРАКТЕРИСТИКИ СЛУЧАЙНЫХ ФУНКЦИЙ 3F9
функций резко различен. Для случайной функции Xl(f) (рис. 15.3.2)
характерно плавное, постепенное изменение. Если, например, в точке t
случайная функция Хх (t) приняла значение, заметно превышающее
среднее, то весьма вероятно, что и в точке t' она также примет
значение больше среднего. Для случайной функции Хл (t) характерна
ярко выраженная зависимость между ее значениями при различных /.
Напротив, случайная функция X2(t) (рис. 15.3.3) имеет резко коле-
колебательный характер с неправильными, беспорядочными колебаниями.
Для такой случайной функции характерно быстрое затухание, зави-
зависимости между ее значениями по мере увеличения расстояния по t
между ними.
Очевидно, внутренняя структура обоих случайных процессов со-
совершенно различна, но это различие не улавливается ни математи-
математическим ожиданием, ни дисперсией; для его описания необходимо
ввести специальную характеристику. Эта характеристика называется
корреляционной функцией (иначе — автокорреляционной функ-
функцией). Корреляционная функция характеризует степень зависимости
между сечениями случай-
случайной функции, относящи-
относящимися к различным t.
Пусть имеется слу- ^ , -
чайная функция X{t) (--' | j ~ч\ X(ti+
(рис. 15.3.4); рассмотрим
два ее сечения, относя-
относящихся к различным мо- ~ о\ t T' \ ? 7^
ментам: t и У, т. е. две J
случайные величины X (t)
и X (У). Очевидно, что рис 153.4.
при близких значениях t
и У величины X (t) и X (У) связаны тесной зависимостью: если
величина X (t) приняла какое-то значение, то и величина X (У)
с большой вероятностью примет значение, близкое к нему. Очевидно
также, что при увеличении интервала между сечениями i, У зависи-
зависимость величин X (t) и X (У) вообще должна убывать.
Степень зависимости величин X (t) и X (У) может быть в зна-
значительной мере охарактеризована их корреляционным моментом;
очевидно, он является функцией двух аргументов t и У. Эта функ-
функция и называется корреляционной функцией.
Таким образом, корреляционной функцией случайной функ-
функции X (t) называется неслучайная функция двух аргументов
Kx{t, У), которая при каждой паре значений t, У равна
корреляционному моменту соответствующих сечений случай-
случайной функции:
A5.3.4)
\
380
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАННЫХ ФУНКЦИИ
[ГЛ. 15
где
X @ = X (t) - тх (t), X (О = X (?) — тх (f).
Вернемся к примерам случайных функций Х1 (f) и Х2 (t)
(рис. 15.3.2 и 15.3.3). Мы видим теперь, что при одинаковых мате-
математических ожиданиях н дисперсиях случайные функции Х1 (() и
X2(t) имеют совершенно различные корреляционные функции. Кор-
Корреляционная функция случайной функции Xt (t) медленно убывает по
мере увеличения промежутка (t, ?); напротив, корреляционная функ-
функция случайной функции X2(t) быстро убывает с увеличением этого
промежутка.
Выясним, во что обращается корреляционная функция Кх (t, t'),
когда ее аргументы совпадают. Полагая ? = t, имеем:
Kx(t, f) = M[(X(t)f\ = Dx(t), A5.3.5)
т. е. при ? = t корреляционная функция обращается в дис-
дисперсию случайной функции.
Таким образом, необходимость в дисперсии как отдельной харак-
характеристике случайной функции отпадает: в качестве основных харак-
характеристик случайной функции
достаточно рассматривать ее
математическое ожидание и
корреляционную функцию.
Так как корреляционный
момент двух случайных вели-
величин X (t) и X(?) не зависит
от последовательности, в кото-
I рой эти величины рассматри-
рассматриваются, то корреляционная
функция симметрична относи-
относительно своих аргументов, т. е.
не меняется при перемене аргу-
аргументов местами:
\t--t
Kx{t, O=Kx(t'. t).
A5.3.С)
Если изобразить корреляционную функцию Kx(t. t') в виде по-
поверхности, то эта поверхность будет симметрична относительно вер-
вертикальной плоскости Q, проходящей через биссектрису угла tOt'
(рис. 15.3.5).
Заметим, что свойства корреляционной функции естественно
вытекают из свойств корреляционной матрицы системы случайных
величин. Действительно, заменим приближенно случайную функ-
функцию X (t) системой т случайных величин X (t{), X (/2) X (tm).
При увеличении т и соответственном уменьшении промежутков между
15.3] ХАРАКТЕРИСТИКИ СЛУЧАЙНЫХ ФУНКЦИЙ 381
аргументами корреляционная матрица системы, представляющая собой
таблицу о двух входах, в пределе переходит в функцию двух не-
непрерывно изменяющихся аргументов, обладающую аналогичными свой-
свойствами. Свойство симметричности корреляционной матрицы относи-
относительно главной диагонали переходит в свойство симметричности
корреляционной функции A5.3.6). По главной диагонали корреля-
корреляционной матрицы стоят дисперсии случайных величин; аналогично
при ?' — t корреляционная функция Кх (t, t') обращается в диспер-
дисперсию Dx(t).
На практике, если требуется построить корреляционную функцию
случайной функции X (t), обычно поступают следующим образом:
задаются рядом равноотстоящих значений аргумента и строят корре-
корреляционную матрицу полученной системы случайных величин. Эта
матрица есть не что иное, как таблица значений корреляционной
функции для прямоугольной сетки значений аргументов на пло-
плоскости (t, t'). Далее, путем интерполирования или аппроксимации
можно построить функцию двух аргументов Кх (t, t').
Вместо корреляционной функции Kx(t, t') можно пользоваться
нормированной корреляционной функцией:
r*(tn = ^7W)' A5-3'7)
которая представляет собой коэффициент корреляции величин X (t),
X (t'). Нормированная корреляционная функция аналогична норми-
нормированной корреляционной матрице системы случайных величин. При
t'=t нормированная корреляционная функция равна единице:
-J^W-x- A538)
Выясним, как меняются основные характеристики случайной
функции при элементарных операциях над нею: при прибавлении не-
неслучайного слагаемого и при умножении на неслучайный множитель.
Эти неслучайные слагаемые и множители могут быть как постоян-
постоянным;! величинами, так в обшем случае и функциями t.
Прибавим к случайной функции X (/) неслучайное слагаемое <?(t).
Получим новую случайную функцию:
A5.3.9)
По теореме сложения математических ожиданий:
/и, @ =/и, (/) + <р(/). A5.3.10)
т. е. при прибавлении к случайной функции неслучайного
слагаемого к ее математическому ожиданию прибавляется
то же неслучайное слагаемое.
382 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
Определим корреляционную функцию случайной функции Y(t):
= М [(К @ — ту @ ) (К (О — ту (О)] =»
= М [(X @ + 9 @ - я», @ - <р @) (А" (О + 9 (О — тх (*0-<Р (<0I =
— mx{t))(X(t') — mx(t'))] = Kx(t, t'), A5.3.11)
т. е. от прибавления неслучайного слагаемого корреляцион-
корреляционная функция случайной функции не меняется.
Умножим случайную функцию X (t) на неслучайный множи-
множитель y(t):
= <?(t)X(t). A5.3.12)
Вынося неслучайную величину <?(t) за знак математического ожида-
ожидания, имеем:
my(t)=:Ml<?(t)X(t)}=<?(t)mx(t), A5.3.13)
т. е. при умножении случайной функции на неслучайный мно-
множитель ее математическое ожидание умножается на тот one
множитель.
Определяем корреляционную функцию:
Ку(t, t') = M\Y(О У(?)] = M\{Y{t) — my(t))(Y(С) — ту(?))] =
= М [? @ <р {tr) (X (О - тх @) {X (О - тх {t'))] =
*,(*. *0. A5.3.14)
т. е. при умножении случайной функции на неслучайную фунК'
цию <?(t) ее корреляционная функция умножается на <?(t)<f(t').
В частности, когда y(t) = c (не зависит от t), корреляционная
функция умножается на с2.
Пользуясь выведенными свойствами характеристик случайных
функций, можно в ряде случаев значительно упростить операции
с ними. В частности, когда требуется исследовать корреляционную
функцию или дисперсию случайной функции, можно заранее перейти
от нее к так называемой центрированной функции:
X(t) = X(f) — mx(t). A5.3.15)
Математическое ожидание центрированной функции тождественно
равно нулю, а ее корреляционная функция совпадает с корреляцион-
15.41 ОПРЕДЕЛЕНИЕ ХАРАКТЕРИСТИК СЛУЧАЙНОЙ ФУНКЦИИ ИЗ ОПЫТА 383
ной функцией случайной функции X (t):
Ko(t, t') = M\X{t)X(t')\^=Kx(t, t'). A5.3.16)
При исследовании вопросов, связанных с корреляционными свой-
свойствами случайных функций, мы в дальнейшем всегда будем перехо-
переходить от случайных функций к соответствующим центрированным
функциям, отмечая это значком ° вверху знака функции.
Иногда, кроме центрирования, применяется еще нормирование
случайных функций. Нормированной называется случайная функция
вида:
A5.3.17)
Корреляционная функция нормированной случайной функции XN(t)
равна
**««• *°д «*&(?) дГ«(/- п A5-ЗЛ8)
а ее дисперсия равна единице.
15.4. Определение характеристик случайной функции из опыта
Пусть над случайной функцией X (t) произведено п независимых
опытов (наблюдений) и в результате получено п реализаций случай-
случайной функции (рис. 15.4.1).
Рис. 15.4.1.
Требуется найти оценки для характеристик случайной функции:
ее математического ожидания тх (f), дисперсии Dx (t) и корреля-
корреляционной функции Кх (t, t').
Для этого рассмотрим ряд сечений случайной функции для мо-
моментов времени
384
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ
1ГЛ. 15
и зарегистрируем значения, принятые функцией X(t) в эти моменты
времени. Каждому из моментов tv t2, ..., tm будет соответствовать п
значений случайной функции.
Значения tv t^, •••• tm обычно задаются равноотстоящими; вели-
величина интервала между соседними значениями выбирается в зависи-
зависимости от вида экспериментальных кривых так, чтобы по выбранным
точкам можно было восстановить основной ход кривых. Часто бывает
так, что интервал между соседними значениями t задается независимо
от задач обработки частотой работы регистрирующего прибора (на-
(например, темпом киноаппарата).
Зарегистрированные значения X{t) заносятся в таблицу, каждая
строка которой соответствует определенной реализации, а число столб-
столбцов равно числу опорных значений аргумента (табл. 15.4.1).
Таблица 15.4.1
^N. t
x,{t)
tl
*i (*,)
x»{tt)
XI (*,)
■■•!■•■
xn(t) 1 *„<*,)
**
xx (tt)
x2 (t2)
Xl {U)
xniU)
. . .
. . .
. . .
. . .
. . .
<k
Xx (tk)
*i (tk)
*i (h)
xn(tk)
• • •
. . .
. . .
. . .
. . .
h
x, (t,)
Xi«l)
Xl(f,)
Xn (tl)
. . .
. . .
. . .
. . .
. . .
Xi (tm)
x2 (tm)
Xi (tm)
Xn (tm)
В таблице 15.4.1 в /-й строке помещены значения случайной
функции, наблюденной в /-й реализации (/-м опыте) при значениях
аргумента tv t2. .... tm. Символом xt{tk) обозначено значение, соот-
ветствуюшее г-й реализации в момент t,r
Полученный материал представляет собой не что иное, как ре-
результаты п опытов над системой т случайных величин
и обрабатывается совершенно аналогично (см. п° 14.3). Прежде
всего находятся оценки для математических ожиданий по формуле
i \
A5.4.1)
W.51 МЕТОДЫ ОПРЕДЕЛЕНИЯ ХАРАКТЕРИСТИК
затем — для дисперсий "
и, наконец, для корреляционных моментов
п
2 \xl (fft) — ™* (f*)l f-^i (fг) — ™x
n—\
385
A5.4.2)
A5.4.3)
В ряде случаев бывает удобно при вычислении оценок для ди-
дисперсий и корреляционных моментов воспользоваться связью между
начальными и центральными моментами и вычислять их по формулам;
2
— [«,('*) I2
rt —1 '
A5.4.4)
*/ ft)
— Щ (tk) mx (tt)
тг^т- A5-4-5>
При пользовании последними вариантами формул, чтобы избежать
разности близких чисел, рекомендуется заранее перенести начало
отсчета по оси ординат поближе к математическому ожиданию.
После того, как эти характеристики вычислены, можно, пользуясь
рядом значений тх (^), тх (/2) тх (tm), построить зависимость
тх@ (Рис> 15.4.1). Аналогично строится зависимость Dx(t). Функция
двух аргументов Kx(t, t') воспроизводится по ее значениям в прямо-
прямоугольной сетке точек. В случае надобности все эти функции аппро-
аппроксимируются какими-либо аналитическими выражениями.
15.5. Методы определения характеристик
преобразованных случайных функций по характеристикам
исходных случайных функций
Б предыдущем п° мы познакомились с истодом непосредственного
определения характеристик случайной функции из опыта. Такой метод
применяется далеко не всегда. Во-первых, постановка специальных
опытов, предназначенных для исследования интересующих нас слу-
случайных функций, может оказаться весьма сложной и дорогостоящей.
Во-вторых, часто нам требуется исследовать случайные функции,
характеризующие ошибки приборов, прицельных приспособлений, си-
систем управления и т. д., еще не существующих, а только проекти-
проектируемых или разрабатываемых. При этом обычно исследование этих
ошибок и предпринимается именно для того, чтобы рационально вы-
выбрать конструктивные параметры системы так, чтобы они приводили
25 Е. С. Вентцель
386
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЯ
[ГЛ. IS
к минимальным ошибкам. Ясно, что при этом непосредственное иссле-
исследование случайных функций, характеризующих работу системы, неце-
нецелесообразно, а в ряде случаев вообще невозможно. В таких случаях
в качестве основных рабочих методов применяются не прямые, а кос-
косвенные методы исследования случайных функций. Подобными кос-
косвенными методами мы уже пользовались при исследовании случайных
величин: ряд глав нашего курса — гл. 10, 11, 12 — был посвящен
нахождению законов распределения и числовых характеристик слу-
случайных величин косвенно, по законам распределения и числовым ха-
характеристикам других случайных величин, с ними связанных. Поль-
Пользуясь совершенно аналогичными методами, можно определять харак-
характеристики случайных функций косвенно, по характеристикам других
случайных функций\ с ними связанных. Развитие таких косвенных
методов и составляет главное содержание прикладной теории случай-
случайных функций.
Задача косвенного исследования случайных функций на практике
обычно возникает в следующей форме.
Имеется некоторая динамическая система А; под «динамической
системой» мы понимаем любой прибор, прицел, счетно-решающий
механизм, систему автоматического управления и т. п. Эта система
может быть механической, электрической или содержать любые дру-
другие элементы. Работу системы будем представлять себе следующим
образом: на вход системы непрерывно поступают какие-то входные
данные; система перерабатывает их и непрерывно выдает некоторый
результат. Условимся называть поступающие на вход системы данные
«воздействием», а выдаваемый результат «реакцией» системы на это
воздействие. В качестве воздействий могут фигурировать изменяю-
изменяющиеся напряжения, угловые и линейные координаты каких-либо объек-
объектов, сигналы или команды, подаваемые на систему управления, и
т. п. Равным образом и реакция системы может вырабатываться в той
или иной форме: в виде напряжений, угловых перемещений и т. д.
Например, для прицела воздушной стрельбы воздействием является
угловая координата дви-
Реокция жущейся цели, непре-
непрерывно измеряемая в про-
процессе слежения, реак-
реакцией— угол упреждения.
Рассмотрим самый
простой случай: когда на
вход системы А подается
только одно воздействие, представляющее собой функцию времени х (t);
реакция системы на это воздействие есть другая функция времени y(t).
Схема работы системы А условно изображена на рис. 15.5.1.
Будем говорить, что система А осуществляет над входным воз-
воздействием некоторое преобразование, в результате которого
Рие. 15.5.1.
I5.S1
МЕТОДЫ ОПРЕДЕЛЕНИЯ ХАРАКТЕРИСТИК
387
функция x(t) преобразуется в другую функцию у @* Запишем это
преобразование символически в виде:
у (О =
A5.5.1)
Преобразование А может быть любого вида и любой сложности.
В наиболее простых случаях это, например, умножение на заданный
множитель (усилители, множительные механизмы), дифференцирование
или интегрирование (дифференцирующие или интегрирующие устрой-
устройства). Однако на практике системы, осуществляющие в чистом виде
такие простейшие преобразования, почти не встречаются; как правило,
работа системы описывается дифференциальными уравнениями, и пре-
преобразование А сводится к решению дифференциального уравнения,
связывающего воздействие x(t) с реакцией у(/).
При исследовании динамической системы в первую очередь решается
основная задача: по заданному воздействию х (t) определить реакцию
системы y(t). Однако для полного исследования системы и оценки ее
технических качеств такой элементарный подход является недоста-
недостаточным. В действительности воздействие х (t) никогда не поступает на
вход системы в чистом виде: оно всегда искажено некоторыми слу-
случайными ошибками (воз-
(возмущениями), в результате .„., У ft)
которых на систему фак-
фактически воздействует не
заданная функция х (/)•
а случайная функция X{t)\
соответственно этому си-
система вырабатывает в ка-
качестве реакции случайную функцию Y(t), также отличающуюся от
теоретической реакции у (О (рис. 15.5.2).
Естественно возникает вопрос: насколько велики будут случайные
искажения реакции системы при наличии случайных возмущений на
ее входе? И далее: как следует выбрать параметры системы для того,
чтобы эти искажения были минимальными?
Решение подобных задач не может быть получено методами клас-
классической теории вероятностей; единственным подходящим математи-
математическим аппаратом для этой цели является аппарат теории случайных
функций.
Из двух поставленных выше задач, естественно, более простой
является первая — прямая — задача. Сформулируем ее следующим
образом.
На вход динамической системы А поступает случайная функ-
функция X (t); система подвергает ее известному преобразованию, в ре-
результате чего на выходе системы появляется случайная функция:
A5.5.2)
Рис 15.5.2.
25»
388 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
Известны характеристики случайной функции X (t): математиче-
математическое ожидание и корреляционная функция. Требуется найти анало-
аналогичные характеристики случайной функции Y(t). Короче: по задан-
заданным характеристикам случайной функции на входе динамической си-
системы найти характеристики случайной функции на выходе.
Поставленная задача может быть решена совершенно точно в одном
частном, но весьма важном для практики случае: когда преобразо-
преобразование А принадлежит к классу так называемых линейных преобразо-
преобразований и соответственно система А принадлежит к классу линейных
систем.
Содержание этих понятий будет пояснено в следующем п°.
15.6. Линейные и нелинейные операторы.
Оператор динамической системы
При изложении теории преобразования случайных функций мы
будем пользоваться широко применяемым в математике и технике
понятием оператора.
Понятие оператора является обобщением понятия функции. Когда
мы устанавливаем функциональную связь между двумя переменными у
и х и пишем: у = /(*). A5.6.1)
то под символом / мы понимаем правило, по которому заданному
значению х приводится в соответствие вполне определенное значе-
значение у. Знак / есть символ некоторого преобразования, которому
нужно подвергнуть величину х, чтобы получить у. Соответственно
виду этого преобразования функции могут быть линейными и нели-
нелинейными, алгебраическими, трансцендентными и т. д.
Аналогичные понятия и соответствующая символика применяются
в математике и в тех случаях, когда преобразованию подвергаются
не величины, а функции.
Рассмотрим некоторую функцию х(t) и установим определенное
правило А, согласно которому функция х (t) преобразуется в другую
функцию у ({)• Запишем это преобразование в следующем виде:
y(t) = A[x(t)}. A5.6.2)
Примерами подобных преобразований могут быть, например, диф-
ференцирование: у@=а<Щ0, A5.6.3)
интегрирование:
y{t)= 'j x{i)di, A5.6.4)
и т. д.
Правило А, согласно которому функция х (t) преобразуется
в функцию y(t), мы будем называть оператором; например, мы
15.6] ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ ОПЕРАТОРЫ 389
будем говорить: оператор дифференцирования, оператор интегриро-
интегрирования, оператор решения дифференциального уравнения и т. д.
Определяя оператор, мы рассматривали только преобразование
функции x(t) в другую функцию .у того же аргумента t. Следует
заметить, что такое сохранение аргумента при определении опера-
оператора вовсе не является обязательным: оператор может преобразовы-
преобразовывать функцию x(t) в функцию другого аргумента у (s), например:
y(s)= ff(t, s)x(t)dt, A5.6.5)
а
где y(t, s) — некоторая функция, зависящая, помимо аргумента t,
еще и от параметра s.
Но так как при анализе ошибок динамических систем наиболее
естественным аргументом является время t, мы здесь ограничимся рас-
рассмотрением операторов, преобразующих одну функцию аргумента t
в другую функцию того же аргумента.
Если динамическая система преобразует поступающую на ее вход
функцию х (t) в функцию у (t):
то оператор А называется оператором динамической системы.
В более общем случае на вход системы поступает не одна,
а несколько функций; равным образом на выходе системы могут
появляться несколько функций; в этом случае оператор системы пре-
преобразует одну совокупность функций в другую. Однако в целях
простоты изложения мы рассмотрим здесь лишь наиболее элементар-
элементарный случай преобразования одной функции в другую.
Преобразования или операторы, применяемые к функциям, могут
быть различных типов. Наиболее важным для практики является
класс так называемых линейных операторов.
Оператор L называется линейным однородным, если он обла-
обладает следующими свойствами:
1) к сумме функций оператор может применяться почленно:
L {Xl(t) + x2(t)} =L{xx(t)) -+-L [x2(f)}; A5.6.6)
2) постоянную величину с можно выносить за знак оператора:
L[cx(t)}=cL{x(t)}. A5.6.7)
Из второго свойства* между прочим, следует, что для линейного
однородного оператора справедливо свойство
L{0} = 0, A5.6.8)
т. е. при нулевом входном воздействии реакция системы равна нулю.
390 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
Примеры линейных однородных операторов:
1) оператор дифференцирования:
2) оператор интегрирования:
о
3) оператор умножения на определенную функцию
4) оператор интегрирования с заданным «весом»
t
о
и т. д.
Кроме линейных однородных операторов, существуют еще линей-
линейные неоднородные операторы.
Оператор L называется линейным неоднородным, если он со-
состоит из линейного однородного оператора с прибавлением некото-
некоторой вполне определенной функции <?(t):
Ч* (*)}=£<> {*(*)} + ¥(*). 05.6.9)
где £0 — линейный однородный оператор.
Примеры линейных неоднородных операторов:
1)" >'(') = ^
3) зЧО=4г(О()тР2(О.
где y(t), r-pl(t), cpsW — вполне определенные функция, a x(t) — пре-
преобразуемая оператором функция.
В математике и технике широко применяется условная форма
записи операторов, аналогичная алгебраической символике. Такая
символика в ряде случаев позволяет избегать сложных преобразова-
преобразований и записывать формулы в простой и удобной форме.
Например, оператор дифференцирования часто обозначают буквой р:
_ d
помещаемой в виде множителя перед выражением, подлежащим диф-
дифференцированию. При этом запись
15.6] ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ ОПЕРАТОРЫ 391
равносильна записи
Двойное дифференцирование обозначается множителем р2:
и т. д.
Пользуясь подобной символикой, в частности, очень удобно за-
записывать дифференциальные уравнения.
Пусть, например, работа динамической системы А описывается
линейным дифференциальным уравнением с постоянными коэффи-
коэффициентами, связывающими реакцию системы у (t) с воздействием х (t).
В обычной форме записи это дифференциальное уравнение имеет вид:
at at ut
В символической форме это уравнение может быть записано
в виде:
(anpn-\-an_lpn-i+ ... + ахр + aQ) у (t) =
где р = ~7т — оператор дифференцирования.
Обозначая для краткости полиномы относительно р, входящие
в правую и левую части,
А„ (р) == апрп + ап_хрп-1 + ... +alP-\-a0,
Bm(p)^bmpm+bm_,pm-i+ ... +blP-{-b0.
запишем уравнение в еще более компактной форме:
An(p)y{t) = Bm(p)x{t). A5.6.11)
Наконец, формально разрешая уравнение A5.6.11) относи-
относительно y(t), можно символически записать оператор решения линей-
линейного дифференциального уравнения в «явном» виде:
Пользуясь аналогичной символикой, можно записать в оператор-
операторной форме и линейное дифференциальное уравнение с переменными
392 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
коэффициентами. В обычной форме это уравнение имеет вид:
A5.6.13)
Обозначая многочлены относительно р, коэффициенты которых
зависят от t,
AJp, t) = an(t)p» +an_l(t)p«-i+ ... +ai(t)p + a0(t).
Bm{p, f) = ba(.f)pm-{-bm_1(t)p'*-i+ ... +bl(f)p-\-b0(t).
можно записать оператор дифференциального уравнения в виде:
У(*)= ВАтп{р,?)Х {t)- A5.6.14)
В дальнейшем мы по мере надобности будем пользоваться такой
символической формой записи операторов.
Встречающиеся в технике динамические системы часто описываются
линейными дифференциальными уравнениями. В этом случае, как
нетрудно убедиться, оператор системы является линейным.
Динамическая система, оператор которой является линейным, назы-
называется линейной динамической системой.
В противоположность линейным операторам и системам рассматри-
рассматриваются системы и операторы нелинейные. Примерами нелинейных
операторов могут служить
t
у (9 = /*8 СО Л.
о
а также решение нелинейного дифференциального уравнения, хотя бы
« cos у (9 =*(*)•
Динамическая система, оператор которой не является /шпгйпыч,
называется нелинейной системой.
На практике линейные системы встречаются очень часто. В связи
с линейностью этих систем к анализу их ошибок может быть
с большой эффективностью применен аппарат теории случайных
функций. Подобно тому как числовые характеристики линейных функ-
функций обычных случайных величин могут быть получены по числовым
характеристикам аргументов, характеристики случайной функции на
выходе линейной динамической системы могут быть определены, если
известны оператор системы и характеристики случайной функции на
ее входе.
15.7] ЛИНЕЙНЫЕ ПРЕОБРАЗОВАНИЯ СЛУЧАЙНЫХ ФУНКЦИЙ 393
Еще чаще, чем линейные системы, на практике встречаются системы
не строго линейные, но в известных пределах допускающие линеари-
линеаризацию. Если случайные возмущения на входе системы достаточно
малы, то практически любая система может рассматриваться — в пре-
пределах этих малых возмущений — как приближенно линейная, подобно
тому как при достаточно малых случайных изменениях аргументов
практически любая функция может быть линеаризована.
Прием приближенной линеаризации дифференциальных уравнений
широко применяется в теории ошибок динамических систем.
В дальнейшем мы будем рассматривать только линейные (или
линеаризуемые) динамические системы и соответствующие им линей-
линейные операторы.
15.7. Линейные преобразования случайных функций
Пусть на вход линейной системы с оператором L воздействует
случайная функция X (t), причем известны ее характеристики: мате-
математическое ожидание mx{t) и корреляционная функция Kx(t, t').
Реакция системы представляет собой случайную функцию
Y{t) = L{X(f)). A5.7.1)
Требуется найти характеристики случайной функции Y(t) на
выходе системы: my{t) и Ky{t, t'). Короче: по характеристикам слу-
случайной функции на входе линейной системы найти характеристики
случайной функции на выходе.
Покажем сначала, что можно ограничиться решением этой задачи
только для однородного оператора L. Действительно, пусть опера-
оператор L неоднороден и выражается формулой
05-7.2)
где Lo—линейный однородный оператор, ср(£)— определенная неслу-
неслучайная функция. Тогда
;??.., (Л = М [/.,, {X (t)}] + ? (')- A5.7.3)
т. е. функция ср(^) просто прибавляется к математическому ожида-
ожиданию случайной функции на выходе линейной системы. Что же касается
корреляционной функции, то, как известно, она не меняется от при-
прибавления к случайной функции неслучайного слагаемого.
Поэтому в дальнейшем изложении под «линейными операторами»
будем разуметь только линейные однородные операторы.
Решим задачу об определении характеристик на выходе линей-
линейной системы сначала для некоторых частных видов линейных
операторов.
S94 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
1. Интеграл от случайной функции
Дана случайная функция X (t) с математическим ожиданием тх (t)
и корреляционной функцией Kx(t, t'). Случайная функция Y (t) свя-
связана с X (t) линейным однородным оператором интегрирования:
(t)dt'. A5.7.4)
о
Требуется найти характеристики случайной функции Y (t): my{t)
и Ky(t, Г).
Представим интеграл A5.7.4) как предел суммы:
i
Y(t) = ( X(x)di— Iim S\ X (xt) fa A5.7.5)
и применим к равенству A5.7.5) операцию математического ожида-
ожидания. По теореме сложения математических ожиданий имеем:
= Iim
Дт-»0
t
= Iim У «jr(x/)Ax= fmx(z)dxi). A5.7.6)
At-Ю >f J
Итак,
t
my(t) — Jmx(x)dx, A5.7.7)
о
т. е. математическое ожидание интеграла от случайной функ-
функции равно интегралу от ее математического ожидания. Иными
словами: операцию интегрирования и операцию математического ожи-
ожидания можно менять местами. Это и естественно, так как операция
интегрирования по своей природе не отличается от операции сум-
суммирования, которую, как мы раньше убедились, можно менять местами
с операцией математического ожидания.
Найдем корреляционную функцию Ку (t, t'). Для этого перейдем
к центрированным случайным функциям:
Xit) = X @ - тх @; К @ - Y (t) - ту (/).
Нетрудно убедиться, что
К (г)— | Л'(-)йЧ. A5.7.8)
') При эхом мы предполагаем, что математическое ожидание предела
равно пределу от математического ожидания. На практике мы, как правило,
имеем дело с функциями, для которых такая перестановка возможна.
15.7J ЛИНЕЙНЫЕ ПРЕОБРАЗОВАНИЯ СЛУЧАЙНЫХ ФУНКЦИЯ 395
По определению корреляционной функции,
Ky(t, t') = M[Y(t)Y(t%
где
t f
Y(t) = f X (x) dx; Y {?) = f X (x') dx' »)• A5.7.9)
0 9
Перемножим выражения A5.7.9):
t f
Y(f)Y(t) = fx(x)dxf X(x')dxf. A5.7.10)
о о
Нетрудно убедиться, что произведение двух интегралов в правой
части формулы A5.7.10) равно двойному интегралу
t V
j j X{x)X(x')dxdx'. A5.7.11)
о о
Действительно, в связи с тем, что подынтегральная-функция в инте-
интеграле A5.7.11) распадается на два множителя, из которых первый
зависит только от х, второй — только от х', двойной интеграл A5.7.11)
распадается на произведение двух однократных интегралов A5.7.10).
Следовательно,
i г
A5.7.12)
о о
Применяя к равенству A5.7.12) операцию математического ожи-
ожидания и меняя ее в правой части местами с операцией интегрирова-
интегрирования, получим:
t г
Ку (t, f) — M[Y (t) Y (/')] = / / M [X (x) X (x')] dx dx'.
о о
или окончательно:
t t'
Ky\t. t') = J J Kx (x, x') dx dx'. A5.7.13)
о о
Таким образом, для того чтобы найти корреляционную функцию
интеграла от случайной функции, нужно дважды проинтегри-
проинтегрировать корреляционную функцию исходной случайной функции:
сначала по одному аргументу, затем — по другому.
') Как известно, в определенно;.! интеграле переменная интегрирования
может быть обозначена любой буквой; в данном случае удобно обозначить
ее 1 к ".' соответственно.
396 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
2. Производная от случайной функции
Дана случайная функция X (t) с математическим ожиданием тх (t)
и корреляционной функцией Кх {t, t'). Случайная функция Y (t) свя-
связана со случайной функцией X (t) линейным однородным оператором
дифференцирования:
Y{t) = ^P-. A5.7.14)
Требуется найти ту (f) и Ку (t, tr).
Представим производную в виде предела:
; A5.7.15)
Применяя к равенству A5.7.15) операцию математического ожи-
ожидания, получим:
Итак,
»,(О=^^. A5.7Л6)
т. е. математическое ожидание производной от случайной
функции равно производной от ее математического ожидания.
Следовательно, операцию дифференцирования, как и операцию инте-
интегрирования, тоже можно менять местами с операцией математического
ожидания.
Для определения Ky(t, ?) перейдем к центрированным случайным
функциям Y (t) и X (t); очевидно,
^P A5.7.17)
По определению
Ky(t,t')^=M[Y{t)Y(t')\.
о о
Подставим вместо Y (t) и Y (f) их выражения:
Представим выражение под знаком математического ожидания
в виде второй смешанной частной производной:
*xju.ЁМ2. = д*ху)Х(?) ,15 7 ,8)
dt dt' dtdt' ' \ ■ ■ )
Мы доказали, что математическое ожидание производной случай-
случайной функции равно производной от математического ожидания, т. е.
') См. сноску1) на стр. 394.
15.71 ЛИНЕЙНЫЕ ПРРОБРАЗОВАНИЯ СЛУЧАЙНЫХ ФУНКЦИЙ 397
знаки дифференцирования и математического ожидания можно менять
местами. Следовательно,
= ТПГ
Таким образом,
Итак, чтобы найти корреляционную функцию производной, нужно
дважды продифференцировать корреляционную функцию
исходной случайной функции: сначала по одному аргументу, затем —
по другому.
Сравнивая правила нахождения математического ожидания и кор-
корреляционной функции для двух рассмотренных нами линейных одно-
однородных операторов, мы видим, что они совершенно аналогичны,
а именно: для нахождения математического ожидания преобразованной
случайной функции тот же линейный оператор применяется к мате-
математическому ожиданию исходной случайной функции; для нахождения
корреляционной функции тот же линейный оператор применяется
дважды к корреляционной функции исходной случайной функции.
В первом частном случае это было двойное интегрирование, во вто-
втором — двойное дифференцирование.
Можно доказать, что такое правило является общим для всех
линейных однородных операторов1). Мы здесь сформулируем это
общее правило без доказательства.
Если случайная функция X(jt) с математическим ожиданием mx(f)
и корреляционной функцией Kx(t, t') преобразуется линейным одно-
однородным оператором L в случайную функцию
Y(t) = L{X(t)},
то для нахождения математического ожидания случайной функции Y(f)
нужно применить тот же оператор к математическому ожиданию
случайной функции X (J):
my(t)=*L{mx(t)). A5.7.21)
а для нахождения корреляционной функции нужно дважды применить
тот же оператор к корреляционной функции случайной функции X (t),
сначала по одному аргументу, затем — по другому:
KM,t') = W){Kjt,t')}. A5=7,22)
В формуле A5.7.22) значки (t), {t') у знака оператора L указы-
указывают, по какому аргументу он применяется.
') См., например, В. С. Пугачев, Теория случайных функций и ее
применение к задачам автоматического управления, Физматгиз, 1960.
398 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
Во многих задачах практики нас, в конечном счете, интересует
не корреляционная функция Ky(t, t') на выходе линейной системы,
а дисперсия Dy (t), характеризующая точность работы системы в усло-
условиях наличия случайных возмущений.- Дисперсию Dy (t) можно найти,
зная корреляционную функцию:
Dy(t) = Ky(t,t). A5.7.23)
При этом нужно подчеркнуть, что, как правило, для определения
дисперсии на выходе линейной системы недостаточно знать дисперсию
на ее входе, а существенно важно знать корреляционную функцию.
Действительно, линейная система может совершенно по-разному
реагировать на случайные возмущения, поступающие на ее вход,
в зависимости от того, какова внутренняя структура этих случайных
возмущений; состоят ли они, например, по преимуществу из высоко-
высокочастотных или низкочастотных колебаний. Внутренняя же структура
случайного процесса описывается не его дисперсией, а корреляцион-
корреляционной фукцией.
Пример. На вход дифференцирующего механизма поступает случайная
функция X(t) с математическим ожиданием mt(t) — s\nt и корреляционной
функцией
где Dx—постоянная дисперсия случайной функции X{t).
Определить математическое ожидание и дисперсию на выходе системы.
Решение. Случайная функция Y (t) на выходе системы (реакция)
связана с воздействием X(t) оператором дифференцирования: "
Применяя общие правила, имеем:
г @ =-^-«ДО = cos <;
Ку (t, f) = -g^r Kx (t, П = 2D&-V-» [1 - 2* (f - О2]-
Полагая t' = t, имеем:
£>., (t) = 2DX«,
или, замечая, что Dy (jt) не зависит от t,
Dy = 2Dxa.
Итак, дисперсия на выходе дифференцирующего механизма зависит не
только от дисперсии Dx на входе, но также и от коэффициента а, характе-
характеризующего быстроту затухания корреляционной связи между сечениями
случайной функции ~X(t) при возрастании промежутка между ними. Если
коэффициент а мал, корреляционная связь затухзет медленно, случайная
функция изменяется со временем сравнительно плавно, и, естественно, диф-
дифференцирование такой функции приводит к сравнительно малым ошибкам.
Напротив, если коэффициент а велик, корреляционная функция убывает
быстро; в составе случайной функции преобладают резкие, беспорядочные
15.8] СЛОЖЕНИЕ СЛУЧАЙНЫХ ФУНКЦИИ * 399
высокочастотные колебания; естественно, дифференцирование такой функции
приводит к большим случайным ошибкам. В таких случаях обычно прибе-
прибегают к сглаживанию дифференцируемой функции, т. е. так меняют
оператор системы, чтобы он давал меньшие случайные ошибки на выходе.
15.8. Сложение случайных функций
Во многих задачах практики мы встречаемся с тем, что на вход
динамической системы поступает не одна случайная функция X\t),
а две или более случайные функции, каждая из которых связана
с действием отдельного возмущающего фактора. Возникает задача
сложения случайных функций, точнее — задача определения характе-
характеристик суммы по характеристикам слагаемых.
Эта задача решается элементарно просто, если две складываемые
случайные функции независимы (точнее, некоррелированны) между
собой. В общем же случае для ее решения необходимо знание еще
однсй характеристики — так называемой взаимной корреляционной
функции (иначе — корреляционной функции связи).
Взаимной корреляционной функцией двух случайных функций X(t)
и У (t) называется неслучайная функция двух аргументов t и У,
которая при каждой паре значений t, t' равна корреляционному
моменту соответствующих сечений случайной функции X(t) и слу-
случайной функции У (t)i
Rxy(t. O = M[X(t)y(t% A5.8.1)
Взаимная корреляционная функция, так же как и обычная кор-
корреляционная функция, не изменяется при прибавлении к случайным
функциям любых неслучайных слагаемых, а следовательно, и при
центрировании случайных функций.
Из определения взаимной корреляционной функции вытекает сле-
следующее ее свойство:
Rxy(t.n = RyX(?tf). A5.8.2)
Вместо функции Rxy (t, t') часто пользуются нормированной
взаимной корреляционной функцией:
RxAt,t') -
г^- О==момп' A5-8-3)
Если взаимная корреляционная функция равна нулю при всех значе-
значениях t, t', то случайные функции X(t) и К @ называются некорре-
некоррелированными (несвязанными).
На практике обычно суждение о некоррелированности случайных
функций составляют не на основании равенства нулю взаимной кор-
корреляционной функции, а, наоборот, взаимную корреляционную функцию
полагают равной нулю на основании физических соображений, свиде-
свидетельствующих о независимости случайных функций.
400 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
Пусть, например, два самолета обстреливают наземную цель;
обозначим X (t), Y (t) углы пикирования первого и второго самолетов
в процессе выполнения боевой операции. Если самолеты заходят на
цель поодиночке, естественно считать случайные функции X(t) и Y(t)
некоррелированными; если же маневр выполняется самолетами сов-
совместно, причем один из них является ведущим, а другой — ведомым,
очевидно наличие корреляционной связи между функциями X (t) и Y (t).
Вообще, если из физических соображений, связанных с существом
решаемой задачи, вытекает наличие зависимости между фигурирую-
фигурирующими в задаче случайными функциями, то их взаимные корреляционные
функции должны быть обследованы.
Зная математические ожидания и корреляционные функции двух
случайных функций X {t) и Y (t), а также их взаимную корреляцион-
корреляционную функцию, можно найти характеристики суммы этих двух слу-
случайных функций:
Z(t) = X (t)+Y(t). A5.8.4)
По теореме сложения математических ожиданий:
mz(t) = mx{t)-\-my{t), A5.8.5)
т. е. при сложении двух случайных функций их математи-
математические ожидания складываются.
Для определения корреляционной функции Kz(t, t') перейдем
к центрированным случайным функциям Z(t), X (t), У (t). Очевидно,
A5.8.6)
По определению корреляционной функции
= М [X(t) X (t')]+М [У (t) ПП\ + М [Хф У {t')\ + M [Х(С) Y(t)].
Или
KM, t') = Kx(t. П-i-KJt ОН-/?,.., С, !')-;-Rsy(t\ t). A5.8.7)
Формула A5.8.7) аналогична формуле A0.2.7) для дисперсии
суммы случайных величин.
В случае, когда случайные функции X (t) и К (t) некоррелиро-
некоррелированны, Rxy(t, tf)^0, и формула A5.8.7) принимает вид:
Kza, t') = Kx{t, t')-\-Ky(t, f), A5.8.8)
т. е. при сложении некоррелированных случайных функций
их корреляционные функции складываются.
Выведенные формулы могут быть обобщены на случай произволь-
произвольного числа слагаемых. Если случайная функция X (t) есть сумма «
15.8] СЛОЖЕНИЕ СЛУЧАЙНЫХ ФУНКЦИЙ 401
случайных функций:
я
*■(*)•= 2!*, (9, A5.8.9)
то ее математическое ожидание выражается формулой
я
mx(t)=%imx.{t), A5.8.10)
а ее корреляционная функция — формулой
К* ('■ П = 2 KXl (t. f) + S Л^. (Л О. A5.8.11)
где суммирование распространяется на все возможные размещения
индексов / и J попарно.
В случае, когда все случайные функции X\ (t) некоррелированны,
формула A5.8.11) превращается в теорему сложения корреляцион-
корреляционных функций: „
Kx{t. П=^КГМ, t'), A5.8.12)
i = l '
т. е. корреляционная функция суммы взаимно некоррелирован-
некоррелированных случайных функций равна сумме корреляционных функций
слагаемых.
Формула A5.8.12) аналогична теореме сложения дисперсий для
обычных случайных величин.
Частным случаем сложения случайных функций является сложение
случайной функции со случайной величиной.
Рассмотрим случайную функцию X(t) с характеристиками mx(t)
и Kx{t, ?) и случайную величину Y с математическим ожиданием пгу
и дисперсией Dy. Предположим, что случайная функция X (t) и слу-
случайная величина К некоррелированны, т. е. при любом t
M[X(t)Y] = 0.
Сложим случайную функцию X(f) со случайной величиной К;
получим случайную функцию
Z(t) = X(t)+Y. A5.8.13)
Определим ее характеристики. Очевидно,
тг it) = mx (t) + my. A5.8.14)
Чтобы найти Kz(t, l'), пользуясь теоремой сложения корреляцион-
корреляционных функций A5.8.8), рассмотрим случайную величину К как частный
случай случайной функции, не меняющейся во времени, и найдем ее
корреляционную функцию:
Ку (t. t') = Л! [Y {t) Y{t')] .-= М [К2] = Dr A5.8.15)
26 Е. С. Вентцель
402 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 15
Применяя формулу A5.8.8), получим!
Kt(t. t') = Kx(t.
т. е. при прибавлении к случайной функции некоррелированной
с нею случайной величины к корреляционной функции при-
прибавляется постоянное слагаемое, равное дисперсии этой слу-
случайной величины.
15.9. Комплексные случайные функции
При практическом применении математического аппарата теории
случайных функций часто оказывается удобным записывать как сами
случайные функции, так и их характеристики не в действительной,
а в комплексной форме. В свя-
у зи с этим необходимо дать
определение комплексной слу-
2 чайной величины и комплекс-
комплексной случайной функции.
Комплексной случайной ве-
величиной называется случайная
величина вида:
где X,Y — действительные слу-
q jf -— чайные величины; i — Y—* —
мнимая единица.
Рис. 15.9.1, Комплексную случайную ве-
величину можно геометрически
интерпретировать как случайную точку Z на плоскости хОу
(рис. 15.9.1).
Для того чтобы аппарат числовых характеристик был применим
и к комплексным случайным величинам, необходимо обобщить основ-
основные понятия математического ожидания, дисперсии и корреляционного
момента на случай комплексных случайных величпл. Очевидно, эш
обобщения должны быть сделаны так, чтобы в частном случае, когда
К = 0 и величина Z действительна, они сводились к обычным опре-
определениям характеристик действительных случайных величин.
Математическим ожиданием комплексной случайной вели-
величины Z — X-\-iY называется комплексное число
т. = т, -A- im... A5.9.2)
Это есть некоторое среднее значение величины Z или, геометрически,
средняя точка тг, вокруг которой происходит рассеивание случайной
точки Z (рис. 15.9.1).
15.9] КОМПЛЕКСНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ 403
Дисперсией комплексной случайной величины называется
математическое ожидание квадрата модуля соответствующей
центрированной величины'.
DZ = M[\Z\Z\, A5.9.3)
где
о
Z = Z — mz.
Геометрически дисперсия комплексной случайной величины есть
не что иное, как среднее значение квадрата расстояния от случайной
точки Z до ее математического ожидания тг (рис. 15.9.1). Эта вели-
величина характеризует разброс случайной точки Z около ее среднего
положения.
Выразим дисперсию комплексной случайной величины через дис-
дисперсии ее действительной и мнимой частей. Очевидно,
Z = Z — mz = X + iY — mx — lmy =
отсюда
или
DZ = DX + Dr A5.9.4)
т. е. дисперсия комплексной случайной величины равна сумме
дисперсий ее действительной и мнимой частей.
Из самого определения дисперсии следует, что дисперсия ком-
комплексной случайной величины всегда действительна и существенно
положительна. Обращаться в нуль она может только в случае, если
величина Z не случайна.
Данные выше определения математического ожидания и дисперсии,
очевидно, удовлетворяют поставленному требованию: при К = 0
и Z — X они превращаются в обычные определения математического
ожидания и дисперсии действительной случайной величины.
Попытаемся построить аналогичное определение корреляционного
момента двух комплексных случайных величин Zl и Z2:
Z1 = X1 + tYl; Z2 = X2-\-iY2. A5.9.5)
Это определение, очевидно, должно быть построено так, чтобы
при Z1 = Z2 — Z корреляционный момент обращался в дисперсию
величины Z. Оказывается, этому требованию нельзя было бы удо-
удовлетворить, если бы мы, как в случае действительных величин,
назвали корреляционным моментом математическое ожидание произ-
произведения ZjZ2. Нетрудно убедиться, что при ZX = Z2 = Z математиче-
математическое ОЖИДаНИс ТАКОГО ПрСнЗВсДёпИл чуДсТ Не ДсйСТБИТсЛЬНЫм,
а комплексным, т. е. уже не дает дисперсии, которая, согласно
определению, действительна и существенно положительна. Этого
не будет, если назвать корреляционным моментом математическог
26*
404 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИИ [ГЛ. IS
ожидание произведения /Ll не на самую величину Z2, а на соответ-
соответствующую ей комплексную сопряженную величину:
Z2 = X2—iY2. A5.9.6)
Тогда при Zj = Z2 = Z корреляционный момент, очевидно, обратится
в дисперсию величины Z:
Kzz — М {(X + tY) (X — iY)} = М [ХЦ + М [Y2] = Dz. A5.9.7)
Таким образом, целесообразно дать следующее определение кор-
корреляционного момента двух комплексных случайных величин Zx и Z2:
К*л = И4[ад1, A5.9.8)
где чертой наверху обозначается комплексная сопряженная величина.
Выразим корреляционный момент двух комплексных случайных
величин через корреляционные моменты их действительных и мнимых
частей. Имеем:
= М lZ,Za] = M [(i, + iYd (X2 — IY2)] =
= КХЛ + КУ1У14- i (К,Л - Кхл). A5.9.9)
где Кх,хг> ^y,y2> Kytx2> Кх,у2 — соответственно корреляционные мо-
моменты величин (ЛГ,, Х2), (У,, К2); (КР А'г), (ATj, Y2).
Очевидно, в случае, когда все эти величины между собой не кор-
релированы, корреляционный момент величин Zv Z2 также равен
нулю.
Таким образом, определения основных характеристик комплексных
случайных величин отличаются от обычных определений аналогичных
характеристик для действительных величин только тем, что:
1) в качестве дисперсии рассматривается не математическое ожи-
ожидание квадрата центрированной случайной величины, а математи-
математическое ожидание квадрата ее модуля;
2) в качестве корреляционного момента рассматривается не мате-
математическое ожидание произведения центрированных величин, а мате-
математическое ожидание произведения одной центрированной величины
па комплексную сопряженную другой.
Перейдем к определению комплексной случайной функции и ее
характеристик.
Комплексной случайной функцией называется функция вида:
Z(t) = X{t) + iY(t), A5.9.10)
где X(t), Y(t)—действительные случайные функции.
Математическое ожидание комплексной случайной функции A5.9.10)
равно;
) (<Ну(9. A5.9.11)
15.91 КОМПЛЕКСНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ 405
Дисперсия комплексной случайной функции Z(t) определяется как
математическое ожидание квадрата модуля соответствующей центри-
центрированной функции:
Dz{t) = M[\Z(t)\4, A5.9.12)
где
Z(t) = Z (t) — тг (t) = AT (/) + IV @- A5.9.13)
Из определения A5.9.12) видно, что дисперсия комплексной случай-
случайной функции действительна и неотрицательна.
Из формулы A5.9.4) следует, что дисперсия комплексной слу-
случайной функции равна сумме дисперсий ее действительной и мнимой
частей:
t). A5.9.14)
Корреляционная функция комплексной случайной функции опре-
определяется как корреляционный момент ее сечений t и t'\
Kz(t, t') = M[Z(t)Z(t% A5.9.15)
где
— комплексная величина, сопряженная величине Z(t').
При t' = t корреляционная функция, очевидно, обращается в дис-
дисперсию:
Kt(t. t) = Dz(t). A5.9.16)
Пользуясь формулой A5.9.9), можно выразить корреляционную
функцию комплексной случайной функции через характеристики ее
действительной и мнимой частей. Рассматривая в качестве случайных
величин Zx и Z2, фигурирующих в этой формуле, сечения случайной
функции Z (t) и Z(t'), получим:
K,(t. t') = Kx(t, f) + Ky<t. f) + t[Rxy(t', t) — Rxy(t, t% A5.9.17)
где Rxy(t, t') — взаимная корреляционная функция случайных функ-
i;"!1 X(t) н К (?) (дсПстантелыю" 'л :.;;шмои uacicit случайно;! фрак-
фракции Z{t)).
В случае, когда действительная и мнимая части случайной функ-
функции не коррелированы (/?(/, /')==QY формула A5.9.17) имеет вид:
Кг (t. f) = Кх (t, f) + Ку {t, I')- A5.9. i 8)
В дальнейшем изложении мы будем пользоваться как действи-
действительной, так и комплексной формой записи случайных функций.
В последнем случае мы будем всегда оговаривать это.
ГЛАВА Щ
КАНОНИЧЕСКИЕ РАЗЛОЖЕНИЯ СЛУЧАЙНЫХ ФУНКЦИЙ
16.1. Идея метода канонических разложений.
Представление случайной функции в виде
суммы элементарных случайных функций
В п° 15.7 мы познакомились с общими правилами линейных пре-
преобразований случайных функций. Эти правила сводятся к тому, что
при линейном преобразовании случайной функции ее математическое
ожидание подвергается тому же линейному преобразованию, а кор-
корреляционная функция подвергается этому преобразованию дважды:
по одному и другому аргументу.
Правило преобразования математического ожидания очень просто
и при практическом применении затруднений не вызывает. Что ка-
касается двойного преобразования корреляционной функции, то оно
в ряде случаев приводит к чрезвычайно сложным и громоздким опе-
операциям, что затрудняет практическое применение изложенных общих
методов.
Действительно, рассмотрим, например, простейший интегральный
оператор: f ?
Y (t) = f X (х) dx. A6.1.1)
о
Согласно общему правилу корреляционная функция преобразуется
тем же оператором дважды:
t v
Ку (t. *') = // Кх (*. т') dx dx'. A6.1.2)
о о
Очень часто бывает, что полученная из опыта корреляционная
функция Kx(t, tr) не имеет аналитического выражения и задана
таблично; тогда интеграл A6.1.2) приходится вычислять численно,
определяя его как функцию обоих пределов. Это — задача очень
16.1]
ПРЕДСТАВЛЕНИЕ СЛУЧАЙНОЙ ФУНКЦИИ В ВИДЕ СУММЫ
407
x(t)'
громоздкая и трудоемкая. Если даже аппроксимировать подынте-
подынтегральную функцию каким-либо аналитическим выражением, то и в этом
случае чаще всего интеграл A6.1.2) через известные функции не
выражается. Так обстоит дело даже при простейшей форме опера-
оператора преобразования. Если же, как часто бывает, работа динами-
динамической системы описывается дифференциальными уравнениями, реше-
решение которых не выражается в явной форме, задача об определении
корреляционной функции на вы-
выходе еще более осложняется:
она требует интегрирования диф-
дифференциальных уравнений с част-
частными производными.
В связи с этим на практике
применение изложенных общих
методов линейных преобразова- ?,
ний случайных функций, как
правило, оказывается слишком
сложным и себя не оправдывает.
При решении практических задач
значительно чаще применяются
другие методы, приводящие к бо-
более простым преобразованиям.
Один из них — так называемый метод канонических разложе-
разложений, разработанный В. С. Пугачевым, и составляет содержание
данной главы.
Идея метода канонических разложений состоит в том, что слу-
случайная функция, над которой нужно произвести те или иные преоб-
преобразования, предварительно представляется в виде суммы так назы-
называемых элементарных случайных функций.
Элементарной случайной функцией называется функция вида:
A6.1.3)
Рис. 16.1.1,
где V — обычная случайная величина, w (t) — обычная (неслучайная)
функция.
Элементарная c^vin^as^ ф^акг.-'ч яялтется нч.чболее простым ти-
типом случайной функции. Действительно, в выражении A6.1.3) слу-
случайным является только множитель V, стоящий перед функцией f(t);
сама же зависимость от времени случайной не является.
Все возможные реализации элементарной случайной функции X (t)
могут быть получены из графика функции х = ср (J) простым изме-
изменением масштаба по оси ординат (рис. 16.1.1). При этом ось абсцисс
(л --= 0) также представляем собой одну из возможных реализаций
случайной функции X (t), осуществляющуюся, когда случайная вели-
величина V принимает значение 0 (если это значение принадлежит к числу
возможных значений величины V).
408
КАНОНИЧЕСКИЕ РАЗЛОЖЕНИЯ СЛУЧАЙНЫХ ФУНКЦИЙ
[ГЛ. 16
В качестве примеров элементарных случайных функций приведем
функции X(t) — Vsint (рис. 16.1.2) и X(t) = Vt2 (рис. 16.1.3).
Элементарная случайная функция характерна тем, что в ней раз-
разделены две особенности случайной функции: случайность вся сосре-
сосредоточена в коэффициенте V, а зависимость от времени — в обычной
функции ср (t).
Рис. 16.1.2.
Рис. 16.1.3.
Определим характеристики элементарной случайной функции
A6.1.3). Имеем:
V
где mv — математическое ожидание случайной величины V.
Если mv — Q, математическое ожидание случайной функции X (t)
также равно нулю, причем тождественно:
mx(t)==0.
Мы знаем, что любую случайную функцию можно центрировать,
т. е. привести к такому виду, когда ее математическое ожидание
равно нулю. Поэтому в дальнейшем мы будем рассматривать только
центрированные элементарные случайные функции.
для которых mv = 0; К—F; mx(/) = 0.
Определим корреляционную функцию элементарной случайной
функции X (t). Имеем:
Кх (t, П = м [X (t) х (t')\ = ср @ 9 (О м [V2] = <р С) ? (*') d,
где D — дисперсия величины V.
Над элементарными случайными функциями весьма просто вы-
выполняются всевозможные линейные преобразования.
Например, продифференцируем случайную Функцию A6.1.3). Слу-
Случайная величина V, не зависящая от t, выйдет за знак производной,
и мы получим:
16.11 ПРЕДСТАВЛЕНИЕ СЛУЧАЙНОЙ ФУНКЦИИ В ВИДЕ СУММЫ 409
Аналогично t t
f X(x)dx = V f <?(x)dx.
0 0
Вообще, если элементарная случайная функция A6.1.3) преобра-
преобразуется линейным оператором L, то при этом случайный множитель V,
как не зависящий от t, выходит за знак оператора, а неслучайная
функция <р@ преобразуется тем же оператором L:
L{X{t)}=VL{^(t)\. A6.1.4)
Значит, если элементарная случайная функция поступает на вход
линейной системы, то задача ее преобразования сводится к простой
задаче преобразования одной неслучайной функции ср (t). Отсюда
возникает идея: если на вход динамической системы поступает неко-
некоторая случайная функция общего вида, то можно ее представить —
точно или приближенно — в виде суммы элементарных случайных
функций и только затем подвергать преобразованию. Такая идея
разложения случайной функции на сумму элементарных случайных
функций и лежит в основе метода канонических разложений.
Пусть имеется случайная функция:
X {t) — mx (t) + X(t). A6.1.5)
Допустим, что нам удалось — точно или приближенно — предста-
представить ее в виде суммы
*(*) = «, @+2^(9. A6.1.6)
где Vl — случайные величины с математическими ожиданиями, рав-
равными нулю, ср,. (t)—неслучайные функции, тх (t) — математическое
ожидание функции X (t).
Условимся называть представление случайной функции в форме
A6.1.6) разложением случайной функции. Случайные величины
V,, V2 Vm будем называть коэффициентами разложения, а не-
неслучайные функции <fi @< ъ@> •••> <Рт@ — координатными функ-
функциями.
Определим реакцию линейной системы с оператором L на слу-
случайную функцию X (t), заданную в виде разложения A6.1.6). Известно,
что линейная система обладает так называемым свойством супер-
суперпозиции, состоящим в том, что реакция системы на сумму несколь-
нескольких воздействий равна сумме реакций системы на каждое отдельное
воздействие. Действительно, оператор системы L, будучи линейным,
может, по определению, применяться к сумме почленно.
Обозначая Y (t) реакцию системы на случайное воздействие X (Г),
имеем: т
2 A6.1.7)
410 КАНОНИЧЕСКИЕ РАЗЛОЖЕНИЯ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 16
Придадим выражению A6.1.7) несколько иную форму. Учитывая
общее правило линейного преобразования математического ожидания,
убеждаемся, что
Обозначая
имеем:
т
к (о=/я, @+21^,^@- A6.1.8)
Выражение A6.1.8) представляет собой не что иное, как раз-
разложение случайной функции Y(t) по элементарным функциям. Коэф-
Коэффициентами этого разложения являются те же случайные величины
Vj, V2 Vm, а математическое ожидание и координатные функ-
функции получены из математического ожидания и координатных функций
исходной случайной функции тем же линейным преобразованием L,
какому подвергается случайная функция X(t).
Резюмируя, получаем следующее правило преобразования случай-
случайной функции, заданной разложением.
Если случайная функция X (t), заданная разложением по
элементарным функциям, подвергается линейному преобра-
преобразованию L, то коэффициенты разложения остаются неизмен-
неизменными, а математическое ожидание и координатные функции
подвергаются тому же линейному преобразованию L.
Таким образом, смысл представления случайной функции в виде
разложения сводится к тому, чтобы свести линейное преобразование
случайной функции к таким же линейным преобразованиям несколь-
нескольких неслучайных функций — математического ожидания и коорди-
координатных функций. Это позволяет значительно упростить решение
задачи нахождения характеристик случайной функции Y (t) по срав-
сравнению с общим решением,' данным в п° 15.7. Действительно, каждая
из неслучайных функций тх (t), <fi @- Ъ W ?«@ в данном
случае преобразуется только один раз в отличие от корреляцион-
корреляционной функции Кх (t, t'), которая, согласно общим правилам, преоб-
преобразуется дважды.
16.2. Каноническое разложение случайной функции
Рассмотрим случайную функцию X (t), заданную разложением
УЦ), 06.2.1)
1
где коэффициенты V,, V2 Vm представляют собой систему
случайных величин с математическими ожиданиями, равными нулю и
с корреляционной матрицей Ц/СЦ
16.2) КАНОНИЧЕСКОЕ РАЗЛОЖЕНИЕ СЛУЧАЙНОЙ ФУНКЦИИ 411
Найдем корреляционную функцию и дисперсию случайной функ-
функции X(t).
По определению
Kx(t, t')~ M[X(t)X(t% A6.2.2)
где
1
A6.2.3)
A6.2.4)
j=i
В формуле A6.2.4) индекс суммирования обозначен буквой J,
чтобы подчеркнуть его независимость от индекса суммирования I
в формуле A6.2.3).
Перемножая выражения A6.2.3) и A6.2.4) и применяя к произ-
произведению операцию математического ожидания, получим:
Kx{t, *O = JW[jS ^y?/@?/(O] = t2.^n^/.]^@?y(O. A6.2.5)
где суммирование распространяется на все пары значений I, j—как
равные, так и неравные. В случае, когда t = j.
где Di — дисперсия случайной величины Vt. В случае, когда I Ф J,
где Ку—корреляционный момент случайных величин Vt, Vj.
Подставляя эти значения в формулу A6.2.5), получим выражение
для корреляционной функции случайной функции X (t), заданной
разложением A6.2.1):
A6.2.6)
Полагая в выражении A6.2.6) t' = t, получим дисперсию случай-
случайной функции X (t):
2 ?i m i£,
412 КАНОНИЧЕСКИЕ РАЗЛОЖЕНИЯ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 16
Очевидно, выражения A6.2.6) и A6.2.7) приобретают особенно
простой вид, когда все коэффициенты^ разложения A6.2.1) некор-
некоррелированны, т. е. Кц~0 при i Ф j. В этом случае разложение
случайной функции называется «каноническим».
Таким образом, каноническим разложением случайной функ-
функции X (t) называется ее представление в виде:
*@ = m,(')+Sl'M(9. A6.2.8)
i—i
где тх (t) — математическое ожидание случайной функции; cpz (t),
<p2(f), ..., <Pm(O — координатные функции, a Vv V2, ..., Vm—не-
Vm—некоррелированные случайные величины с математическими ожиданиями,
равными нулю.
Если задано каноническое разложение случайной функции, то ее
корреляционная функция Kx(t, t') выражается весьма просто. Пола-
Полагая в формуле A6.2.6) Kij = 0 при l=j=j, получим:
К At- П = %ъФъ(?г)О1. 06.2.9)
Выражение A6.2.9) называется каноническим разложением кор-
корреляционной функции.
Полагая в формуле A6.2.9) t' = t, получим дисперсию случайной
функции
Аг2?«(№ A6.2.10)
Таким образом, зная каноническое разложение случайной функ-
функции X (t), можно сразу найти каноническое разложение ее корре-
корреляционной функции. Можно доказать, что обратное положение тоже
справедливо, а именно: если задано каноническое разложение кор-
корреляционной функции A6.2.9), то для случайной функции X(t) спра-
справедливо каноническое разложение вида A6.2.8) с координатными
функциями 9ДО 'Л коэффициентами v'i с дисперсиями £)г. Мы при-
примем это положение без специального доказательства1).
Число членов канонического разложения случайной функции может
быть не только конечным, но и бесконечным. Примеры канонических
разложений с бесконечным числом членов встретятся нам в главе 17.
Кроме того, в ряде случаев применяются так называемые инте-
интегральные канонические представления случайных функций, в кото-
которых сумма заменяется интегралом.
') Доказательство см.: В. С. Пугачев, Теория случайных функций и
ее применение в задачах автоматического управления, Флзматгиз, 19S2.
16.2] КАНОНИЧЕСКОЕ РАЗЛОЖЕНИЕ СЛУЧАЙНОЯ ФУНКЦИИ 413
Канонические разложения применяются не только для действи-
действительных, но и для комплексных случайных функций. Рассмотрим
обобщение понятия канонического разложения на случай комплексной
случайной функции.
Элементарной комплексной случайной функцией называется функ-
функция вида:
A6.2.11)
где как случайная величина V, так и функция y(t) комплексны.
Определим корреляционную функцию элементарной случайной
функции A6.2.11). Пользуясь общим определением корреляционной
функции комплексной случайной функции, имеем:
Kx(Jt, ?) = M\yf(t)V<f(f)]. A6.2.12)
где чертой вверху, как и ранее, обозначена комплексная сопряжен-
сопряженная величина. Имея в виду, что
и вынося неслучайные величины ср(^) и <р(О за знак математиче-
математического ожидания, получим:
Kx(t, *0 =
Но, согласно п° 15.9, M[|V|2] есть не что иное, как дисперсия
комплексной случайной величины V:
следовательно,
Kx(t. t') = '?(t)<?(t')D. A6.2.13)
Каноническим разложением комплексной случайной функции назы-
называется ее представление в виде:
m
X(t) = mx(t)-\-J^Vffl(t), A6.2.14)
i = l
где V}1 V*>, ,,,, Vm — некоррелированные комплексные случайные
величины с математическими ожиданиями, равными нулю, а тх (t),
ср.(t), w2(f), .... cpm(O — комплексные неслучайные функции.
Если комплексная случайная функция представлена каноническим
разложением A6.2.14), то ее корреляционная функция выражается
формулой
KX(U O=S?/(')?7(OA. A6.2.15)
1-Х
где Dj — дисперсия величины V,;
Dl = M[lVl\2]. A6.2.16)
414
КАНОНИЧЕСКИЕ РАЗЛОЖЕНИЯ СЛУЧАЙНЫХ ФУНКЦИЯ
1ГЛ. W
Формула A6.2.15) непосредственно следует из выражения A6.2.13)
для корреляционной функции элементарной комплексной случайной
функции.
Выражение A6.2.15) называется каноническим разложением кор-
корреляционной функции комплексной случайной функции.
Полагая в A6.2.15) t' = t, получим выражение для дисперсии
комплексной случайной функции, заданной разложением A6.2.14):
A6.2.17)
2
16.3. Линейные преобразования случайных функций,
заданных каноническими разложениями
Пусть на вход некоторой линейной системы L поступает случай-
случайная функция X (t) (рис. 16.3.1).
Г-Ylt)
Рис. 16.3.1.
Система преобразует функцию X (f) посредством линейного опе-
оператора L, и на выходе мы получаем случайную функцию
Y{t) — L\X(f)). A6.3.1)
Предположим, что случайная функция X(t) задана ее канониче-
каноническим разложением: :;
к
A6.3.2)
Определим реакцию системы на это воздействие. Так как опера-
оператор системы является линейным, то
{T|(Q]. A6.3.3)
Рассматривая выражение A6.3.3), легко убедиться, что оно пред-
представляет собой не что иное, как каноническое разложение слу-
случайной функции Y(t) с математическим ожиданием
m,(t)=:L{mr(J)\ A6,3.4)
re.sj линейные преобразования случайных функций 415
и координатными функциями
<h@ = M'f/№b A6.3.5)
Таким образом, при линейном преобразовании канонического
разложения случайной функции X(t) получается каноническое
разложение случайной функции Y(t), причем математическое
ожидание и координатные функции подвергаются тому же
линейному преобразованию.
Если случайная функция Y(t) на выходе линейной системы пол/»
чена в виде канонического разложения
к (*) = «,@+1^@. A6.3.6)
то ее корреляционная функция и дисперсия находятся весьма просто1
Ky(t. О = 2^@^@^. 06.3.7)
k
Dy(t) = ^i(t)]2Dl. A6.3.8)
Это делает особенно удобными именно канонические разло-
разложения по сравнению с любыми другими разложениями по элементар-
элементарным функциям.
Рассмотрим несколько подробнее применение метода канонических
разложений к определению реакции динамической системы на слу-
случайное входное воздействие, когда работа системы описывается линей-
линейным дифференциальным уравнением, в общем случае — с перемен-
переменными коэффициентами. Запишем это уравнение в операторной форме:
Ая(р. t)Y{t) = Bm{p, t)X{t). A6.3.9).
Согласно вышеизложенным правилам линейных преобразований
случайных функций математические ожидания воздействия и реакции
должны удовлетворять тому же уравнению:
Аа(р. t)my{t) = Bm{p, t)mx(jt)- A6.3.10)
Аналогично каждая из координатных функций должна удовлет-
удовлетворять тому же дифференциальному уравнению:
К(Р, t)^{t) = Bmip, .')?,('}. A6.3.!!)
(i = I. 2 k).
Таким образом, задача определения реакции линейной динамиче-
динамической системы на случайное воздействие свелась к обычной математи-
математической задаче интегрирования ft-f-1 обыкновенных дифференциальных
416 КАНОНИЧЕСКИЕ РАЗЛОЖЕНИЯ СЛУЧАЙНЫХ ФУНКЦИЙ [ГЛ. 16'
уравнений, содержащих обычные, не случайные функции. Так как
при решении основной задачи анализа динамической системы — опре-
определения ее реакции на заданное воздействие — задача интегриро-
интегрирования дифференциального уравнения, описывающего работу системы,
тем или Другим способом решается, то при решении уравнений A6.3.10)
и A6.3.11) новых математических трудностей не возникает. В част-
частности, для решения этих уравнений могут быть с успехом применены
те же интегрирующие системы или моделирующие устройства, которые
применяются для анализа работы системы без случайных возмущений.
Остается осветить вопрос о начальных условиях, при которых
следует интегрировать уравнения A6.3.10) и A6.3.11).
Сначала рассмотрим наиболее простой случай, когда начальные
условия для данной динамической системы являются неслучайными,
В этом случае при ^ = 0 должны выполняться условия:
A6.3.12)
где у0, у{, ..., Ул_1 — неслучайные числа.
Условия A6.3.12) можно записать более компактно:
К(г)(О) = ;уг (/- = 0, 1, .... я —1), A6.3.13)
понимая при этом под «производной нулевого порядка» Р'(t) саму
функцию Y (t).
Выясним, при каких начальных условиях должны интегрироваться
уравнения A6.3.10) и A6.3.11). Для этого найдем r-ю производную
функции Y (t) и положим в ней ^ = 0:
п
Y{r) @) = т(р @) + У, У^р @).
Учитывая A6.3.12), имеем:
<@)+ S^'r)@)-yr. A6.3.14)
i=\
Так как величина уг не случайна, то дисперсия левой части
равенства A6.3.14) должна быть равна нулю:
ilDiWP @)\2 = 0. A6.3.15)
16,3]
ЛИНЕЙНЫЕ ПРЕОБРАЗОВАНИЯ СЛУЧАЙНЫХ ФУНКЦИЙ
417
Так как все дисперсии Dl величин Vt положительны, то равен-
равенство A6.3.15) может осуществиться только, когда
^г)@)==0 A6.3.16)
для всех /.
Подставляя ф@@) = 0 в формулу A6.3.14), получим:
= У,- A6.3.17)
Из равенства A6.3.17) следует, что уравнение A6.3.10) для ма-
математического ожидания должно интегрироваться при заданных на-
начальных условиях A6.3.12):
A6.3.18)
Что касается уравнений A6.3.11), то они должны интегрироваться
при нулевых начальных условиях:
ф. @) == ф; @) = ... =<i>w @)== ... =<!4">(О)=о
(/ = 1. 2 k). A6.3.19)
Рассмотрим более сложный случай, когда начальные условия
случайны:
A6.3.20)
где Ко, Yv .... Ya_x — случайные величины.
В этом случае реакция на выходе системы может быть найдена
в виде суммы:
Y It) = К,@ + К„ (О, A6.3.21)
где Y\(t) — решение дифференциального уравнения A6.3.9) при нуле-
нулевых начальных условиях; Yn(t) — решение того же дифференциаль-
дифференциального уравнения, но с нулевой правой частью при заданных начальных
условиях A6.3.20). Как известно из теории дифференциальных
27 Е. С. Вентцель
418 КАНОНИЧЕСКИЕ РАЗЛОЖЕНИЯ СЛУЧАЙНЫХ ФУНКЦИЯ [ГЛ, 18
уравнений, это решение представляет собой линейную комбинацию
начальных условий:
Yn(t) = "±Yfff(t), A6.3.22)
где fj(t) — неслучайные функции.
Решение Yy(t) может быть получено изложенным выше методом
в форме канонического разложения. Корреляционная функция случай-
случайной функции Y (t) = Kj (t) -f- Yn (t) может быть найдена обычными
приемами сложения случайных функций j[cm. n°15.8).
Следует заметить, что на практике весьма часто встречаются
случаи, когда для моментов времени, достаточно удаленных от начала
случайного процесса, начальные условия уже не оказывают влияния
на его течение: вызванные ими переходные процессы успевают за-
затухнуть. Системы, обладающие таким свойством, называются асимп-
асимптотически устойчивыми. Если нас интересует реакция асимптотически
устойчивой динамической системы на участках времени, достаточно
удаленных от начала, то можно ограничиться исследованием реше-
решения Ki(O> полученного при нулевых начальных условиях. Для доста-
достаточно удаленных от начального моментов времени это решение будет
справедливым и при любых начальных условиях.
ГЛАВА 17
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
17.1. Понятие о стационарном случайном процессе
На практике очень часто встречаются случайные процессы, про-
протекающие во времени приблизительно однородно и имеющие вид
непрерывных случайных колебаний вокруг некоторого среднего зна-
значения, причем ни средняя амплитуда, ни характер этих колебаний не
обнаруживают существенных изменений с течением времени. Такие
случайные процессы называются стационарными.
В качестве примеров стационарных случайных процессов можно
привести: 1) колебания самолета на установившемся режиме горизон-
горизонтального полета; 2) колебания напряжения в электрической освети-
осветительной сети; 3) случайные шумы в радиоприемнике; 4) процесс
качки корабля и т. п.
Каждый стационарный процесс иожио рассматривать как продол-
продолжающийся во времени неопределенно долго; при исследовании стацио-
стационарного процесса в качестве начала отсчета можно выбрать любой мо-
момент времени. Исследуя стационарный процесс иа любом участке вре-
времени, мы должны получить одни и те же его характеристики. Образно
выражаясь, стационарный процесс «не имеет ни начала, ни конца».
Рис. 17.1.1.
Примером стационарного случайного процесса может служить из-
изменение высоты центра тяжести самолета на установившемся режиме
горизонтального полета (рис. 17.1.1).
В противоположность стационарным случайным процессам можно
указать другие, явно нестационарные, случайные процессы, например:
27*
420 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. 17
колебания самолета в режиме пикирования; процесс затухающих
колебаний в электрической цепи; процесс горения порохового заряда
в реактивной камере и т. д. Нестационарный процесс характерен
тем, что он имеет определенную тенденцию развития во
времени; характеристики такого процесса зависят от начала от-
отсчета, зависят от времени.
На рис. 17.1.2 изображено семейство реализаций явно нестацио-
нестационарного случайного процесса — процесса изменения тяги двигателя
реактивного снаряда во времени.
Заметим, что далеко не все нестационарные случайные процессы
являются существенно нестационарными на всем протяжении своего
развития. Существуют неста-
ционарные процессы, которые
(на известных отрезках вре-
времени и с известным приближе-
приближением) могут быть приняты за
стационарные.
Например, процесс наводки
перекрестия авиационного при-
i цела на цель есть явно неста-
Рис. 17.1.2. ционарный процесс, если цель
за короткое время с большой
и резко меняющейся угловой скоростью проходит поле зрения
прицела. В этом случае колебания оси прицела относительно цели
не успевают установиться в некотором стабильном режиме; про-
процесс начинается и заканчивается, не успев приобрести стационар-
стационарный характер. Напротив, процесс наводки перекрестия прицела на
неподвижную или движущуюся с постоянной угловой скоростью
цель через некоторое время после начала слежения приобретает
стационарный характер.
Вообще, как правило, случайный процесс в любой динамической
системе начинается с нестационарной стадии — с'так называемого
«переходного процесса». После затухания переходного процесса
система обычно переходит на установившийся режим, и тогда слу-
случайные процессы, протекающие в пей. moivt считаться стационарными.
Стационарные случайные процессы очень часто встречаются в фи-
физических и технических задачах. По своей природе эти процессы
проще, чем нестационарные, и описываются более простыми характе-
характеристиками. Линейные преобразования стационарных случайных про-
процессов также обычно осуществляются проще, чем нестационарных.
В связи с этим на практике получила широкое применение специаль-
специальная теория стационарных случайных процессов, или, точнее,
теория стационарных случайных функций (так как аргументом
стационарной случайной функции в общем случае может быть и не
время). Элементы этой теории и будут изложены в данной главе.
17.11 ПОНЯТИЕ О СТАЦИОНАРНОМ СЛУЧАЙНОМ ПРОЦЕССЕ 421
Случайная функция X(t) называется стационарной, если все ее
вероятностные характеристики не зависят от t (точнее, не меняются
при любом сдвиге аргументов, от которых они зависят, по оси /).
В данном элементарном изложении теории случайных функций
мы совсем не пользуемся такими вероятностными характеристиками,
как законы распределения: единственными характеристиками, кото-
которыми мы пользуемся, являются математическое ожидание, дисперсия
и корреляционная функция. Сформулируем определение стационарной
случайной функции в терминах этих характеристик.
Так как изменение стационарной случайной функции должно
протекать однородно по времени, то естественно потребовать, чтобы
для стационарной случайной функции математическое ожидание было
постоянным: mx{t) — mx —const. A7.1.1)
Заметим, однако, что это требование не является существенным: мы
знаем, что от случайной функции X (t) всегда можно перейти к цен-
о
трированной случайной функции X (t), для которой математическое
ожидание тождественно равно нулю и, следовательно, удовлетворяет
условию A7.1.1). Таким образом, если случайный процесс нестацио-
нестационарен только за счет переменного математического ожидания, это не
помешает нам изучать его как стационарный процесс.
Второе условие, которому, очевидно, должна удовлетворять ста-
стационарная случайная функция,—это условие постоянства дисперсии:
Dx (t) = Dx = const. A7.1.2)
Установим, какому условию должна удовлетворять корреляцион-
корреляционная функция стационарной случайной функции. Рассмотрим случай-
случайную функцию X(() (рис. 17.1.3). Положим в выражении Kx{t, t')
t'=-t~\-t и рассмотрим
Кх (t, t -f- т) — корреляцион-
корреляционный момент двух сечений слу-
случайной функции, разделен-
разделенных интервалом времени t.
Очевидно, если случайный
процесс X (t) действительно
с~ [г-'юмлрем, тс* этот корре-
корреляционный момент не должен ^11С' ''-1-3-
зависеть от того, где именно
на оси Ot мы взяли участок т, а должен зависеть только от длины
этого участка. Например, для участков / и // на рис. 17.1.3, имею-
имеющих одну и ту же длину х, значения корреляционной функции
Kx(t, t~\-t) и Kx{tv /j-f-t) должны быть одинаковыми. Вообще,
корреляционная функция стационарного случайного процесса должна
зависеть не от положения t первого аргумента на оси абсцисс, а
только от промежутка х между первым и вторым аргументами:
Kx(t, t-\-x) = kx(x). A7.1.3)
Ш)
1
1
1
1 1
1
\
Г х
\
\
• \
А
i /Л t-t-T f
1 il \ if* I /
422 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. IT
Следовательно, корреляционная функция стационарного случайного
процесса есть функция не двух,, а- всего адного аргумента. Это
обстоятельство в ряде случаев, сильно упрощает операции над ста-
стационарными случайными, функциями-
Заметим, что условие (L7.1.2), требующее от стационарной слу-
случайной функции поетовнств-а дисперсии, является частным случаем
условия A7.3.3). Действительно, налагая в формуле A7.1.3) t-\-x^=-.t
х v), имеем Dx(t) = Кx(t, t) = kx($) = const. A7.1.4)
Таким образом, условие A7.1.3) есть единственное существенное усло-
условие, которому должна удовлетворять стационарная случайная функция.
Поэтому в дальнейшем мы под стационарной случайной функцией
будем понимать такую случайную функцию, корреляционная функция
которой зависит не от обоих своих аргументов / и г', а только от
разности х между ними. Чтобы не. накладывать специальных условий
на математическое ожидание;
мы> будем рассматривать
только центрированные слу-
случайные функции.
Мы знаем, что корреля-
корреляционная функция любой слу-
случайной функции обладает
свойством симметрии:
"^^ • is a ff\. if t+f 4-\
Отсюда для стационарного
процесса, полагая t' — t = х,
имеем:
Рис- 17Л4- kx(i)^kx(— т). A7.1.5)
т. е. корреляционная функция kx(x) есть четная функция своего
аргумента. Поэтому обычно корреляционную функцию определяют
только для положительных значений аргумента (рис. 17.1.4).
На практике, вместо корреляционной функции kx(x), часто поль-
пользуются нормированной корреляционной функцией
Р,« = ^#- A7-1.6)
Г\
где Dx — kx@) — постоянная дисперсия стационарного процесса.
Функция- рх (%) есть не что иное, как коэффициент корреляции между
сечениями случайной функции, разделенными интервалом х по времени.
Очевидно, что рх (@>= 1.
В качестве примеров рассмотрим два образца приблизительно
стационарных случайных процессов и построим их характеристики.
Пример 1. Случайная функция X(t) задана совокупностью 12 реали-
реализаций (рис. 17.1.5). а) Найти ее характеристики mx(t), Kx(t, t'), Dx(t) и
17.
ПОНЯТИЕ' О СТАЦИОНАРНОМ СЛУЧАЙНОМ ПРОЦЕССЕ
423
нормированную корреляционную функцию rx (t, t'). б) Приближенно рассмат-
рассматривая случайную функцию X (t) как стационарную, найти ее характеристики.
Решение. Так как случайная функция X (t) меняется сравнительно
плавно, можно брать сечения не очень часто, например через 0,4 сек. Тогда
хш
W
Рис. 17Л5.
случайная функция будет сведена « системе семи случайных величин,
отвечающих сечениям <=0;0,4; 0,8; 1,2; 1,6; 2,'О; 2,4. Намечая »ти сечения
на графике н снимая с графика значения случайной функции в этих сече-
сечениях, получим таблицу (табл. 17.1.1).
Таблица 17.1.1
^~\-_ t
зации ~^*J
1 !
2 :
3 i
4
5
6
7
8
9
10
11
12
0
0j64
(№4:
0,34
0,23
0,12
—0Д6
—0,22
—0,26
—0,50
—0,30
-0,69
0,18
0;4
0,74
0,37
0,50
0,26
0,20
-0,12
—0,29
-4),69 '
—0,60
0,13
—0,40
—0,79 >
0,8
0,62
0,06
0,37
0,35
0,24
—0,15
—0,38
—0,70
—0,68
0,75
0,08 ■
—0,56
1,2
0,59
—0,32
0,26
0,55
0,18
0,05
—0,24
--0,€1
—0,62
0,84
0,16
—0,39
l;6
0,35
—0,60
—0,52
0,69
—0,20
0,29
—0,06
—0,43
—0,68
0,78
0,12
-4>,42
—0,09
—0,69
—0,72
0,75
—0,42
0,43
0,07
—0,22
—0,56
0,73
0,18
-0,58
2,4
—0,39
—0,67
0,42
0,80
—0,46
0,63
—0,16
0,29
—0,54
0,71
0,33
—0,53
Таблицу рекомендуется заиол«ятъ ио -строчкам, передвигаясь ®ое время вдоль
ОДНОЙ прялияяпии.
Далее ^находим оценки дм характеристик случайны* величин X (С),
Х@,4) ^B,4). Суммируя значении по столбцам и деля сумму иа число
424
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
[ГЛ 17
0
—0,007
0,4
—0,057
0,8
0,000
1.2
0,037 ■
1.6
—0,057
2,0
-0,093
2,4
0,036
реализаций п = 12, найдем приближенно зависимость математического ожи-
ожидания от времени:
t
mx{t)
На графике рис. 17.1.5 математическое ожидание показано жирной линией.
Далее находим оценки для элементов корреляционной матрицы: диспер-
дисперсий и корреляционных моментов. Вычисления удобнее всего производить по
следующей схеме. Для вычисления статистической дисперсии суммируются
квадраты чисел, стоящих в соответстзующем столбце; сумма делится на п = 12;
из результата вычитается квадрат соответствующего математического ожи-
ожидания. Для получения несмещенной оценки результат множится на поправку
——г = -j-;-. Аналогично оцениваются корреляционные моменты. Для вы-
п — 1 п
числения статистического момента, отвечающего двум заданным сечениям,
перемножаются числа, стоящие в соответствующих столбцах; произведения
складываются алгебраически; полученная сумма делится на п = 12; из резуль-
результата вычитается произведение соответствующих математических ожиданий;
для получения несмещенной оценки корреляционного момента результат мно-
множится на г-. При выполнении расчетов на счетной машине или ариф-
арифмометре промежуточные результаты умножений не записываются, а непо-
непосредственно суммируются'). Полученная таким способом корреляционная
матрица системы случайных величин Хф), X(ОД), ,.., X B,4)— она
же таблица значений корреляционной функции Kx'(t, ?) — приведена
в таблице 17.1.2.
Таблица 17.1.2
0
0,4
0,8
1,2
1,6
2,0
2,4
0
0,1632
0,4
0,1379
0,2385
0,8
0,0795
0,2029
0,2356
1,2
0,0457
0,1621
0,2152
0,2207
1,6
—0,0106
0,0827
0,1527
0,1910
0,2407
2,0 •
—0,0642
0,0229
. 0,0982
0,1491
0,2348
0,2691
2,4
—0,0648
0,0251
0,0896
0,1322
0,1711
0,2114
0.2878
По главной диагонали таблицы стоят оценки дисперсий:
' II •
Dx(t) К 0,1632
0,4
0,2385
0,8
0,2356
1,2
0,2207
1,6
0,2407
2,0
0,2691
2,4
0,2878
1) В данном случае оказалось возможным непосредственно вести обработку
через начальные моменты, так как математическое ожидание функции X (t)
близко к пулю. Если это не так, то перед обработкой необходимо перенести
начало отсчета поближе к математическому ожиданию.
17.1]
ПОНЯТИЕ О СТАЦИОНАРНОМ СЛУЧАЙНОМ ПРОЦЕССЕ
425
Извлекая из этих величин квадратные корни, найдем зависимость сред-
среднего квадратического отклонения ах от времени:
t
0
0,404
0,4
0,488
0,8
0,485
1,2
0,470
1,6
0,491
2,0
0,519
2,4
0,536
Деля значения, стоящие в табл. 17.1.2, на произведения соответствующих
средних квадратичесхих отклонений, получим таблицу значений нормирован-
нормированной корреляционной функции rx (t, t') (табл. 17.1.3).
Таблица 17.1.3
\ч t
<'\.
0
0,4
0,8
1,2
1,6
2,0
2,4
0
1
0,4
0,700
1
0,8
0,405
0,856
1
1,2
0,241
0,707
0,943
1
1,6
—0,053
0,345
0,643
0,829
1
2,0
—0,306
0,090
0,390
0,612
0,923
1
2,4
—0,299
0,095
0,344
0,524
0,650
0,760
1
Проанализируем полученные данные под углом зрения предполагаемой
стационарности случайной функции X (t). Если судить непосредственно по
данным, полученным в результате обработки, то можно прийти к выводу, что
случайная функция X (t) стационарной не является: ее математическое ожи-
ожидание не вполне постоянно; дисперсия также несколько меняется со време-
временем; значения нормированной корреляционной функции вдоль параллелей
главной диагонали также не вполне постоянны. Однако, принимая во внима-
внимание весьма ограниченное число обработанных реализаций (я = 12) ив связи
с этим наличие большого элемента случайности в полученных оценках, эти
видимые отступления от стационарности вряд ли можно считать значимыми,
тем более, что они не носят сколько-нибудь закономерного характера. По-
Поэтому вполне целесообразной будет приближенная замена функции X (t)
стационарной. Для приведения функции к стационарной прежде всего осред-
ним по времени оценки для математического ожидания:
тхB,А)
— 0,02.
Аналогичным образом осредним оценки для дисперсии:
0,236.
Извлекая корень, найдем осредненную оценку с. к. о.:
о*. » 0,486.
Перейдем к построению нормированной корреляционной функции того
стационарного процесса, которым можно заменить случайную функцию X(t).
Для стационарного процесса корреляционная функция (а значит, и нормиро-
нормированная корреляционная функция) зависит только от т = *'—t; следовательно,
426
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
[ГЛ. 17
при постоянном т корреляционная функция должна быть постоянной. В таб-
таблице 17.1.3 постоянному т соответствуют: главная диагональ (т = 0) и парал-
параллели этой диагонали (х = 0,4; т = 0,8; х = 1,2 и т. д.). Осредняя оценки нор-
нормированной корреляционной функции вдоль этих параллелей главной диагонали,
получим значения функции р^. (х):
t
0
1,00
0,4
0,84
0,8
0,60
1,2
0,38
1,6
0,13
2,0
—0,10
2,4
—0,30
График функции рх (х) представлен на рис. 17.1.6.
При рассмотрении рис. 17.1.6 обращает на себя внимание наличие для
некоторых т отрицательных значений корреляционной функции. Это указывает
на то, что в структуре случайной функции имеется некоторый элемент пе-
периодичности, в связи с чем на расстоянии ло времени, равном примерно
половине периода основных коле-
рхП) баиий, наблюдается отрицательная
корреляция между значениями слу-
случайной функции: положительным
отклонениям от среднего в одном
сечении соответствуют отрица-
отрицательные отклонения через опре-
определенный промежуток времени, и
наоборот.
Такой характер корреляцион-
корреляционной функции, с переходом на отри-
отрицательные значения, очень часто
встречается на практике. Обычно
в таких случаях по мере увеличе-
увеличения т амплитуда колебаний корре-
корреляционной функции уменьшается
и при дальнейшем увеличении т
корреляционная функция стре-
стремится к нулю.
Пример 2. Случайная функция X(t) задана совокупностью 12 своих
реализаций (рис. 17.1.7). Приближенно заиеиив функцию X (t) стационарной,
сравнить ее нормированную корреляционную функцию с фуйкцией рх (х) пре-
предыдущего примера.
Решение.' Так как случайная функция X{t) отличается значительно
менее плавным ходом по сравнению с функцией X(t) предыдущего примера,
промежуток между сечениями уже ис.-м.?я брать равпиы 0,4 сек, как в пре-
предыдущем примере, а следует взять по крайней мере вдвое меньше (напри-
(например, 0,2 сек, как на рис. 17.1.7). В результате обработки получаем Оценку
для нормированной корреляционной функции рд-(т):
Рис. 17.1.6.
0
0,2
0,4 0,6
0,8 1,0 1,2
1,4
1,6
1,8
2,0
2,2
2,4
1,00
0,73
0,41 0,22 —0,01 j—O^Jf—0,19
1
—0,10j—0,06
—0,15J0,08
I
)
0,19
0,05
График функции fx(t) представлен на рис. 17.1.8. Из сравнения графиков
рис. 17.1.8 и 17.1.6 видно, что корреляционная функция, изображенная
17.2J
СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ НА КОНЕЧНОМ УЧАСТКЕ
427
на рис. 17.1.8, убывает значительно быстрее. Это и естественно, так
как характер изменения функции X(t) в примере 1 гораздо более
плавный и постепенный, чем в примере 2; в связи с этим корреляция
между значениями случайной функции в примере 1 убывает медленнее.
Прл рассмотрении рис. 17.1.8
бросаются в глаза незакономерные
колебания функции pt, (т) для боль- ),0
ших значений т. Так как при боль-
большие значениях z точки графика
получены осреднением сравни-
сравнительно очень небольшого числа
данных, их нельзя считать надеж-
надежными. В подобных случаях имеет
смысл сгладить корреляционную
функцию, как, например, показано
пунктиром на рис 17.1.8.
17.2. Спектральное разложе-
разложение стационарной случайной
функции на конечном участке
времени. Спектр дисперсий
Рис. 17.1.8.
На двух примерах, приве-
приведенных в предыдущем п°, мы
наглядно убедились в том, что существует связь между характером кор-
корреляционной функции и внутренней структурой соответствующего
ей случайного процесса. В зависимости от того, какие частоты и
423
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
[ГЛ. 17
в каких соотношениях преобладают в составе случайной функции, ее
корреляционная функция имеет тот или другой вид. Из таких сооб-
соображений мы непосредственно приходим к понятию о спектральном
составе случайной функции.
Понятие «спектра» встречается не только в теории случайных
функций; оно широко применяется в математике, физике и технике.
x(t)
Г
\J \
v/ \
Рис. 17.2.1.
i
Если какой-либо колебательный процесс представляется в виде
суммы гармонических колебаний различных частот (так называемых
«гармоник»), то спектром колебательного процесса называется функ-
функция, описывающая распределение амплитуд по различным частотам.
Спектр показывает, какого рода колебания преобладают в данном
процессе, какова его внутренняя структура.
Совершенно аналогичное спектральное описание можно дать и
стационарному случайному процессу; вся разница в том, что для слу-
случайного процесса ампли-
НХ(Х) туды колебаний будут
случайными величинами.
Спектр стационарной слу-
случайной функции будет
описывать распределе-
распределение дисперсий по раз-
различным частотам.
Подойдем к понятию
о спектре стационарной
С.1!}';U,'iilO.'S функции 1:3
следующих соображений.
о
Рассмотрим стационарную случайную функцию X (t), которую мы
наблюдаем на интервале (О, Т) (рис. 17.2.1).
Задана корреляционная функция случайной функции X (t)
Функция kx (x) есть четная функция:
ft, @ = М-О
и, следовательно, на графике изобразится симметричной кривой
(рис. 17.2.2).
Рле. 17.2 2.
17.2]
СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ НА КОНЕЧНОМ УЧАСТКЕ
429
При изменении t и ? от 0 до Т аргумент x = t'—t изменяется
от —Т до +Г.
Мы знаем, что четную функцию на интервале (—Т, Т) можно
разложить в ряд Фурье, пользуясь только четными (косинусными)
гармониками:
где
kx (х) = 2 Dk cos (oftx,
ft 0
1 2Г Г '
A7.2.1)
A7.2.2)
а коэффициенты Dk определяются формулами:
г
1
-T
Dk-y J i
-г
cos
при
A7.2.3)
Имея в виду, что функции kx (x) и cos wftx четные, можно пре-
преобразовать формулы A7.2.3) к виду:
г
2 f
Dk — yl kx (x) cos шкх dx при k
0.
A7.2.4)
Перейдем в выражении A7.2.1) корреляционной функции kx(x)
от аргумента х снова к двум аргументам t и t'. Для этого положим
'sin(oft^ A7.2.5)
cosio^t = cos (o,; (f — f) = cos (oftf cos (
и подставим выражение A7.2.5) в формулу A7.2.1):
Кх((, 0 = 2 (D k cos ш ktr cos ш k't-\-D „sin (о ktr sin (о kt). A7.2.6)
Мы видим, что выражение A7.2.6) есть ке что иное, как кано-
каноническое разложение корреляционной функции Kx(t, по-
покоординатными функциями этого канонического разложения являются
попеременно косинусы и синусы частот, кратных шх:
cos
(k=0,
430 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. 17
Мы знаем, что по каноническому разложению корреляционной
функции можно построить каноническое разложение самой случайной
функции с теми же координатными функциями и с дисперсиями,
равными коэффициентам Dk в каноническом разложении корреля-
корреляционной функции!).
Следовательно, случайная функция X (t) может быть представлена
в виде канонического разложения:
со
Ar(*)=2(t/*cos<eftf + VftsinV). A7.2.7)
ft = 0
где Uk, Vk — некоррелированные случайные величины с математи-
математическими ожиданиями, равными нулю, и дисперсиями, одинаковыми для
каждой пары случайных величин с одним и тем же индексом k:
D[Uk\ = D[Vk] = Dk. A7.2.8)
Дисперсии Db при различных k определяются формулами A7.2.4).
Таким образом, мы получили на интервале @, Т) каноническое
разложение случайной функции X (/), координатными функциями
которого являются функции cos u>ht, sin u>tt при различных ws. Раз-
Разложение такого рода называется спектральным разложением ста-
стационарной случайной функции. На представлении случайных функций
в виде спектральных разложений основана так называемая спект-
спектральная теория стационарных случайных процессов.
Спектральное разложение изображает стационарную случайную
функцию разложенной на гармонические колебания различных частот:
причем амплитуды этих колебаний являются случайными величинами.
о
Определим дисперсию случайной функции X (t), заданной спек-
спектральным разложением A7.2.7). По теореме о дисперсии линейной
функции некоррелированных случайных величин
со со
£>, = /> [Л" (*)] = 2 (cos2«y + sin2<V)Di* = 2£>ft- A7.2.9)
Таким образом, дисперсия стационарной случайной функции
равна сумме дисперсий всех гармоник ее спектрального разло-
разложения. Формула A7.2.9) показывает, что дисперсия функции X (t)
') Можно доказать, что для любой корреляционной функции йЛ (х) коэф-
коэффициенты D/j, выражаемые формулами A7.2.4), неотрицательны.
Г <•>,
17.3] СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ НА БЕСКОНЕЧНОМ УЧАСТКЕ 431
известным образом распределена по различным частотам: одним часто-
частотам соответствуют большие дисперсии, другим — меньшие. Распреде-
Распределение дисперсий по частотам
можно проиллюстрировать
графически в виде так назы-
называемого спектра стационар-
стационарной случайной функции (точ-
(точнее — спектра дисперсий).
Для этого по оси абсцисс от-
откладываются частоты (о0 = 0, —^—J-—^ ^
Шр ш2, ..., а>£, ..., а по ' 3
оси ординат—соответствую- Рис. 17.2.3.
щие дисперсии (рис. t7.2.3).
Очевидно, сумма всех ординат построенного таким образом
спектра равна дисперсии случайной функции.
17.3. Спектральное разложение стационарной
случайной функции на бесконечном участке времени.
Спектральная плотность стационарной случайной функции
Строя спектральное разложение стационарной случайной функ-
о
ции X (t) на конечном участке времени (О, Г), мы получили спектр
дисперсий случайной функции в виде ряда отдельных дискретных
линий, разделенных равными промежутками (так называемый «пре-
«прерывистый» или «линейчатый» спектр).
Очевидно, чем ббльший участок времени мы будем рассматривать,
тем полнее будут наши сведения о случайной функции. Естественно
поэтому в спектральном разложении попытаться перейти к пределу
при Г->оо и посмотреть, во что при этом обратится спектр случай-
случайной функции. При Г—>оо (Oj=: ~W~>®> поэтому расстояния между
частотами ws, на которых строится спектр, будут при Т-*оо не-
неограниченно уменьшаться. При этом дискретный спектр будет при-
приближаться к непрерывному, в котором каждому сколь угодно малому
Mine риа.;у час от Дш будет соответстпоргль элементарная диспер-
дисперсия Ad ((о).
Попробуем изобразить непрерывный спектр графически. Для
этого мы должны несколько перестроить график дискретного спектра
при конечном Т. А именно, будем откладывать по оси ординат уже
не самую дисперсию Dk (которая безгранично уменьшается при
Г->оо), а среднюю плотность дисперсии, т. е. дисперсию, при-
приходящуюся на единицу длины данного интервала частот. Обозначим
расстояние между соседними частотами Д,ш:
2к
<°1 = ГГ = Лш
432
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
[ГЛ. IT
и на каждом отрезке Дш, как на основании, построим прямоугольник
с площадью Dk (рис. 17.3.1). Получим ступенчатую диаграмму,
напоминающую по принципу построения гистограмму статистического
распределения.
Высота диаграммы на участке Дш, прилежащем к точке шк, равна
^(щ*) = -ё- A7-3.1)
и представляет собой среднюю плотность дисперсии на этом участке.
Суммарная площадь всей
Sx(wK) диаграммы, очевидно, рав-
равна дисперсии случайной
.Л,, функции.
Будем неограниченно
увеличивать интервал Т.
При этом Дш->0, и сту-
ступенчатая кривая будет не-
неограниченно приближать-
приближаться к плавной кривой Sx (о>)
(рис. 17.3.2). Эта кривая
_ изображает плотность
°к распределения дисперсий
Рис 17 3 1 по частотам непрерывного
спектра, а сама функция
Sx ((о) называется спектральной плотностью дисперсии, или, короче,
спектральной плотностью стационарной случайной функции X (t).
Очевидно, площадь, огра-
ограниченная кривой Sx ((о), по-
прежнему должна равняться
дисперсии Dx случайной
функции X (t):
Dx= f Sx((o)dw. A7.3.2)
Формула A7.3.2) есть не
что иное, как разложение
дисперсии Dx на сумму
О)
Рис. 17.3.2.
элементарных слагаемых О
Sx(tu)dw, каждое из кото-
которых представляет собой
дисперсию, приходящуюся на элементарный участок частот dw,
прилежащий к точке w (рис. 17.3,2),
Таким образом, мы ввели в рассмотрение новую дополнительную
характеристику стационарного случайного процесса — спектральную
17.3] СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ НА БЕСКОНЕЧНОМ УЧАСТКЕ 433
плотность, описывающую частотный состав стационарного процесса.
Однако эта характеристика не является самостоятельной; она пол-
полностью определяется корреляционной функцией данного процесса.
Подобно тому, как ординаты дискретного спектра Dk выражаются
формулами A7.2.4) через корреляционную функцию kx(x), спектраль-
спектральная плотность Sx (to) также может быть выражена через корреляцион-
корреляционную функцию.
Выведем это выражение. Для этого перейдем в каноническом
разложении корреляционной функции к пределу при Т —>оо и посмот-
посмотрим, во что оно обратится. Будем исходить из разложения A7.2.1)
корреляционной функции в ряд Фурье на конечном интервале (—Т, Т):
оо
Mt)=2a*cos<eftT. A7.3.3)
где дисперсия, соответствующая частоте шл, выражается формулой
т
= ^J kx(x)cosak%d%. A7.3.4)
kx
о
Перед тем как переходить к пределу при Г->оо, перейдем
в формуле A7.3.3) от дисперсии Dk к средней плотности дисперсии
~-. Так как эта плотность вычисляется еще при конечном значе-
значении Т и зависит от Т, обозначим ее:
^ о**) = -§*-• A7-3-5>
Разделим выражение A7.3.4) на Д(й^=^; получим:
т
4 / К (х) cos («4г dx. A7.3.6)
о
Из A7.3.5) следует, что
Dk = Sj\u>k) Дм. A7.3.7)
Подставим выражение A7.3.7) в формулу A7.3.3); получим:
оо
kx (т) = 2 8{Г(шк) cos (Oftt Дш. A7.3.8)
* = о
Посмотрим, во что превратится выражение A7.3.8) при Т—>оо.
Очевидно, при этом Д(о->0; дискретный аргумент wt переходит
в непрерывно меняющийся аргумент и>; сумма переходит в интеграл
по переменной о»; средняя плотность дисперсии 5^'(со*) стремится
28 Е. С. Вентдель
434 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИЙ [ГЛ. 17
к плотности дисперсии Sx(u>), и выражение A7.3.8) в пределе при-
принимает вид:
оо
kx (х) = f Sx (<о) cos (ox dv>, A7.3.9)
о
где Sx (ш) — спектральная плотность стационарной случайной функции'.
Переходя к пределу при Г->оо в формуле A7.3.6), получим
выражение спектральной плотности через корреляционную функцию:
оо
Sx(<a) = 2- i kx(t)cosmd-z. A7.3.10)
о
Выражение типа A7.3.9) известно в математике под названием
интеграла Фурье. Интеграл Фурье есть обобщение разложения
в ряд Фурье для случая непериодической функции, рассматриваемой
на бесконечном интервале, и представляет собой разложение функции
на сумму элементарных гармонических колебаний с непрерывным
спектром *).
Подобно тому как ряд Фурье выражает разлагаемую функцию
через коэффициенты ряда, которые в свою очередь выражаются через
разлагаемую функцию, формулы A7.3.9) и A7.3.10) выражают функ-
функции kx(x) и Sx(u>) взаимно: одна через другую. Формула A7.3.9)
выражает корреляционную функцию через спектральную плотность;
формула A7.3.10), наоборот, выражает спектральную плотность через
корреляционную функцию. Формулы типа A7.3.9) и A7.3.10),
связывающие взаимно две функции, называются преобразованиями
Фурье2).
Таким образом, корреляционная функция и спектральная плот-
плотность выражаются одна через другую с помощью преобразований
Фурье.
Заметим, что из общей формулы A7.3.9) при x=feO получается
ранее полученное разложение дисперсии по частотам A7.3.2).
На практике вместо спектральной плотности Sx((») часто поль-
пользуются нормированной спектральной плотностью:
М<») = ^-. A7.3.11)
где Dx — дисперсия случайной функции.
!) Формула A7.3.9) является частным видом интеграла Фурье, обобщаю-
обобщающим разложение в ряд Фурье четной функции по косинусным гармоникам.
Аналогичное выражение .может быть написано и для более.общего случая.
2) В данном случае мы имеем дело с частным случаем преобразований
Фурье — с так называемыми «косинус-преобразованиями Фурье».
17.3) СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ НА БЕСКОНЕЧНОМ УЧАСТКЕ 435
Нетрудно убедиться, что нормированная корреляционная функция
рх (Ч) и нормированная спектральная плотность sx (w) связаны теми же
преобразованиями Фурье:
со
рх (т) = I sx (ш) cos (ox da,
cos шт й?т.
A7.3.12)
Полагая в первом из равенств A7.3.12) т = 0 и учитывая, что
=: 1, имеем:
f sx ((о) dm = 1,
A7.3.13)
т. е. полная площадь, ограниченная графиком нормированной спект-
спектральной плотности, равна единице.
Пример 1. Нормированная корреляционная функция ?х (х) случайной
функции X if) убывает по линейному закону от единицы до нуля при 0 < % < т0;
Рис. 17.3.3.
Рис. 17.3.4.
при х > х0 pj (т) = 0 (рис. 17.3.3). Определить нормированную спектральную
плотность случайной функции X (t).
Решение. Нормированная корреляционная функция выражается фор-
при 0 < г < t0,
при х > т„.
Из формул A7.3.12) имеем:
оо
2 С
sx (*>) = — J П
1/"(»--
я ./ \ х0
cos шт dx =
ЯХ0(й'
A — COS <йХ0).
28*
436
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
[ГЛ. 17
График нормированной спектральной плотности представлен на рис. 17.3.4.
Первый — абсолютный — максимум спектральной плотности достигается
при о> = 0; раскрытием неопределенности в этой точке убеждаемся, что он
равен —2-. Далее при возрастании ш спектральная плотность достигает ряда
относительных максимумов, высота которых убывает с возрастанием <в;
при <л -*■ со sx («) -> 0.
Характер изменения спектральной плотности sx («) (быстрое или медлен-
медленное убывание) зависит от параметра v Полная площадь, ограниченная кри-
кривой s^w), постоянна и равна единице. Изме-
Изменение т0 равносильно изменению масштаба кри-
кривой 5г(ш) по обеим осям при сохранении ее
площади. При увеличении т0 масштаб по оси
ординат увеличивается, по оси абсцисс —
уменьшается; преобладание в спектре случай-
случайной функции нулевой частоты становится бо-
более ярко выраженным. В пределе при т0->оо
случайная функция вырождается в обычную
случайную величину; при этом qx (т) ==1, а
спектр становится дискретным с одной-един-
одной-единственной частотой и>0 = 0.
Пример 2. Нормированная спектральная
плотность sx(w) случайной функции X (t) по-
постоянна на некотором интервале частот <0[, <в2
и равна нулю вне этого интервала (рис. 17.3,5).
Определить нормированную корреляционную функцию случайной функ-
функции X (t).
Решение. Значение sx (щ) при a>s < о> < <о2 определяем из условия,
что площадь, ограниченная кривой sx (o>), равна единице:
о>>=1 s («)==—L_
о
ы
OJ,
Рис. 17.3.5,
Из A7.3.12) имеем:
'-/
Sx (is) COS <ot rfw
ш2
i Г
0>2 — <i>i ,/
cos (
Т((й2
- (sin (й2т — sin ш/ т) =
"С (чJ <
■ cos
Общий вид функции рд- (") изображен на рис. 17.3.6. Она носит характер
убывающих по амплитуде колебаний с рядом узлов, в которых функция обра-
обращается в нуль. Конкретный вид графика, очевидно, зависит от значений а>,, и>2-
Представляет интерес предельный вид функции рх (т) при ш, -> <at. Оче-
Очевидно, при <й2 = <«! = «и спектр случайной функции обращается в дискретный
с одной-единственной линией, соответствующей частоте м; при этом корре-
корреляционная функция обращается в простую косинусоиду:
9л (х) — COS «t.
Посмотрим, какой вид в этом случае имеет сама случайная функция А'(().
При дискретном спектре с одной-единственной линией спектральное разложе-
разложение стационарной случайной функции X (t) имеет вид:
X{t) — U cos at+V sin at,
A7.3.14)
17.31
СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ НА БЕСКОНЕЧНОМ УЧАСТКЕ
437
где U и V — некоррелированные случайные величины с математическими
ожиданиями, равными нулю, и равными дисперсиями:
Покажем, что случайная функция типа A7.3.14) может быть предста-
представлена как одно гармоническое колебание частоты а со случайной ампли-
амплитудой и случайной фазой. Обозначая
cos Ф = - —, 8!пФ =
приводим выражение A7.3.14) к виду:
X @ = VU2 + V2 (cos Ф cos at + sin Ф sin at) = yu*-\-V2 cos (at — Ф).
В этом выражении У~и2-\-У2 — случайная амплитуда; Ф — случайная фаза
гармонического колебания.
До сих пор мы рассматривали только тот случай, когда распре-
распределение дисперсий по частотам является непрерывным, т. е. когда
на бесконечно малый участок частот приходится бесконечно малая
дисперсия. На практике иногда встречаются случаи, когда случайная
Рис. 17.3.6.
функция имеет в своем составе чисто периодическую составляющую
частоты ч>к со случайной амплитудой. Тогда в спектральном разло-
разложении случайной функции, помимо, непрерывного спектра частот,
будет фигурировать еще отдельная частота и>к с конечной диспер-
дисперсией Dk. В общем случае таких периодических составляющих может
быть несколько. Тогда спектральное разложение корреляционной
функции будет состоять из двух частей: дискретного и непрерывного
спектра:
оо
kx{x) — ^ Dk cos шйт: -f- J Sx (ш) cos tot du>. A7.3.15)
438 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. I?
Случаи стационарных случайных функций с таким «смешанным»
спектром на практике встречаются довольно редко. В этих случаях
всегда имеет смысл разделить случайную функцию на два слагае-
слагаемых— с непрерывным и дискретным спектром — и исследовать эти
слагаемые в отдельности.
Относительно часто приходится иметь дело с частным случаем,
когда конечная дисперсия в спектральном разложении случайной
функции приходится на нулевую частоту ((о = 0). Это значит, что
в состав случайной функции в качестве слагаемого входит обычная
случайная величина с дисперсией Do. В подобных случаях также имеет
смысл выделить это случайное слагаемое и оперировать с ним отдельно.
17.4. Спектральное разложение случайной функции
в комплексной форме
В ряде случаев с точки зрения простоты математических пре-
преобразований оказывается удобным пользоваться не действительной,
а комплексной формой записи как спектрального разложения слу-
случайной функции, так и ее характеристик: спектральной плотности
и корреляционной функции. Комплексная форма записи удобна,
в частности, потому, что всевозможные линейные операции над функ-
функциями, имеющими вид гармонических колебаний (дифференцирование,
интегрирование, решение линейных дифференциальных уравнений
и т. д.), осуществляются гораздо проще, когда эти гармонические
колебания записаны не в виде синусов и косинусов, а в комплекс-
комплексной форме, в виде показательных функций. Комплексная форма записи
корреляционной функции и спектральной плотности применяется и
в тех случаях, когда сама случайная функция (а следовательно, и ее
корреляционная функция и спектральная плотность) действительна.
Покажем, как можно в спектральном разложении случайной функ-
функции чисто формально перейти от действительной формы к комплексной.
Рассмотрим спектральное разложение A7.2.8) случайной функции
X (t) на участке (О, Г):
со
A' (t) = xj l^'fc cos iD^-f-Va sin u>fc£)t A7.4.1)
ft = 0
где Uk, V\—некоррелированные случайные величины, причем для
каждой пары Uk, Vk с одинаковыми индексами дисперсии равны:
Учитывая, что ич=£ш,; wo = O, перепишем выражение A7.4.1)
в виде".
X {t) = Uo + 2j {Uk cos V + Vk sin <V)- A7.4.2)
k i
17.4] СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ В КОМПЛЕКСНОЙ ФОРМЕ 439
Придадим спектральному разложению A7.4.2) комплексную форму.
Для этого воспользуемся известными формулами Эйлера:
sin V= Ji — — *■ §
Подставляя эти выражения в формулу A7.4.2), имеем:
т. е. разложение с координатными функциями е "*', е"
Преобразуем разложение A7.4.3) так, чтобы в нем в качестве
координатных функций фигурировали только функции е'"У; для
этого распространим условно область частот шк на отрицательные
значения шив качестве частот спектрального разложения будем
рассматривать значения
(^«ft»! (ft=±l, ±2, ...),
т. е. будем считать, что k принимает не только положительные, но
и отрицательные значения. Тогда формулу A7.4.3) можно переписать
в виде:
uk + ivk <<Vt A7>4<4)
*=1 к=-1
если положить
Формула A7.4.4) представляет собой разложение случайной функ-
функции X (f), в котором в качестве координатных функций фигурируют
комплексные функции с""*', а коэффициенты представляют собой
комплексные случайные величины. Обозначая эти комплексные слу-
форму:
X(t)= 2 Wfte'V, A7.4.5)
где
при к = 1
При к > I
„ри
A7.4.6)
440 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. 17
Докажем, что разложение A7.4.5) является каноническим раз-
ложением случайной функции X (t). Для этого достаточно показать,
что случайные коэффициенты этого разложения не коррелированы
между собой.
Рассмотрим сначала коэффициенты двух различных членов раз-
разложения в положительной части спектра W'k и Wt при k Ф I, k > 0,
I > 0 и определим корреляционный момент этих величин. Согласно
определению корреляционного момента для комплексных случайных
величин (см. п° 15.9) имеем:
где Wt — комплексная сопряженная величина для Wt.
При k>0, />0
2 2 J-^L 2 2 J =
= I [M \UkUx\ + Ш [£/вК,1 - Ш [UtVk\ + M [V^]} = 0,
так как случайные величины Uk, Vk, фигурирующие в разложении
A7.4.1), все не коррелированы между собой.
Совершенно так же докажем некоррелированность величин Wk, Wl
при любых знаках индексов k и I, если кф+1.
Остается доказать только некоррелированность коэффициентов
при симметричных членах разложения, т. е. величин Wk и W_/l при
любом k. Имеем:
\- M[v\l-2iM[UkVk]).
Учитывая, что величины Uk, Vk, входящие в один и тот же член
разложения A7.4.1), не коррелированы и имеют одинаковые диспер-
дисперсии Ок, получим:
Таким образом, доказано, что разложение A7.4.5) представляет
собой не что иное, как каноническое разложение случай-
случайной функции X(/) с комплексными координатными
функциями е'ш*' и комплексными коэффициентами!^.
Найдем дисперсии этих коэффициентов. При k = Q дисперсия Do
осталась, очевидно, такой же, как была при действительной форме
17.4]
СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ В КОМПЛЕКСНОЙ ФОРМЕ
441
спектрального разложения. Дисперсия каждой из комплексных вели-
величин Wk (при кфО) равна сумме дисперсий ее действительной и мни-
мнимой частей:
I
Введем обозначение:
D* = -^ при
=D0 при k =
и построим дискретный спектр случайной функции X (t), распро-
распространенный на частоты от —со до -j-co (рис. 17.4.1).
-Ц -Ы2 -У, Q й/, Ы2 W3 (i)h
Рис. 17.4.1.
Этот спектр симметричен относительно оси ординат; от ранее
построенного спектра (рис. 17.2.3) он отличается тем, что определен
не только для положительных, но и для отрицательных частот, но
зато его ординаты при k Ф 0 вдвое меньше соответствующих орди-
ординат прежнего спектра; сумма всех ординат по-прежнему равна дис-
дисперсии случайной функции X (t):
k = - o
A7.4.7)
Определим корреляционную функцию случайной функции X (f),
представленной в виде комплексного спектрального разложения A7.4.5).
Применяя формулу A6.2.15) для корреляционной функции комплекс-
комплексной случайной функции, заданной каноническим разложением, имеем;
*=-оо
442 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ (ГЛ. 17
или, переходя к аргументу i = t' — t,
М*)= 2 D\eu*\ A7.4.8)
k = —со
где
г
Dft = ^ Dk ~ f J kx (T) cos coftT rf-: при & =£ 0. A7.4.9)
Придадим выражению A7.4.9) также комплексную форму. По-
Полагая
cos (oftT = ■
получим:
J kx (t) e~ гшАт dx + j kx (t) e'e*T
о .
г г
_ 1
— 2Г
в б
Полагая во втором интеграле т = — и, имеем:
г -г о
Г кх (т) е'ш*т di = — Г Аж (и) е~ '*"*" «Ги = f Аж (т) <
откуда
/rW«"/v^' '" A7.4.10)
-V
Таким образом, мы построили комплексную форму спектрального
разложения случайной функции на конечном интервале @, 71). Далее
естественно перейти к пределу при Т—>оо, как мы делали для
действительной формы, т. е. ввести в рассмотрение спектральную
плотность
и получить в пределе из формул A7.4.8), A7.4.10) интегральные соот-
соотношения, связывающие корреляционную функцию и спектральную плот-
плотность в комплексной форме, В пределе при Г—>-оо формулы A7.4.8)
17.4]
СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ В КОМПЛЕКСНОЙ ФОРМЕ
443
и A7.4.10) принимают вид:
оо
A7.4.11)
A7.4.12)
Формулы A7.4.11) и A7.4.12) представляют собой комплексную
форму преобразований Фурье, связывающих корреляционную функ-
функцию и спектральную плотность ]).
Формулы A7.4.11) и A7.4.12) могут быть и непосредственно
получены из формул A7.3.9) и A7.3.10), если произвести в них
замену ,«
COS (ОТ =
положить Sx (и) — 2SX(со) и расширить область интегрирования на
интервал от —оо до -(-оо.
Полагая в формуле A7.4.11) т = 0, получим выражение диспер-
дисперсии случайной функции X (t):
Dx = jSx(io)dm.
A7.4.13)
Формула A7.4.13) выражает дисперсию случайной функции в виде
суммы элементарных дисперсий, распределенных с некоторой плот-
плотSx(u»
Sxlui)
S/faJ
ностью по всему диапазону
частот от — оо до -\- оо.
Сравнивая формулу
A7.4.13) и ранее выведен-
выведенную (для действительной
формы спектрального раз-
разложения) формулу A7.3.2),
мы видим, что они разли-
различаются лишь тем, что в фор-
формуле A7.4.13) стоит не-
несколько иная функция спе-
спектральной плотности Sx(w),
опредеденная ке от 0 до
оо, а от —оо до оо, но зато с вдвое меньшими ппдиня-
тамк. Если изобразить обе функции спектральной плотности на
0
Рис. 17.4.2.
') Заметим, что в главе 13, рассматривая характеристические функции,
мы уже встречались с преобразованиями такого тйпз: а именно: характеристи-
характеристическая функция и плотность вероятности выражаются одна через другую
с помощью преобразований Фурье.
444
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
[ГЛ. 17
графике, они различаются только масштабом по оси ординат и тем,
что функция Sx (со) для отрицательных частот не определена
(рис. 17.4.2). На практике в качестве спектральной плотности при-
применяются как та, так и другая функции.
Иногда в качестве аргумента спектральной плотности рассмат-
рассматривают не круговую частоту (со), а частоту колебаний /, выражен-
выраженную в герцах:
(О
/ =
В этом случае подстановкой
водится к виду:
или, вводя обозначение
> = 2i:/ формула A7.4.11) при-
A7.4.14)
Функция Gx(f) также может применяться как спектральная
плотность дисперсии. Ее выражение через корреляционную функцию,
очевидно, имеет вид:
■тЮ
GX(J)
A7.4.15)
Рис. 17.4.3.
Все приведенные нами и некоторые
другие применяемые на практике вы-
выражения спектральной плотности, оче-
очевидно, отличаются друг от другя
только масштабом. Каждую из них
можно нормировать, деля соответству-
соответствующую функцию спектральной плот-
плотности на дисперсию случайной функции.
Пример 1. Корреляционная функция случайной функции X(t) задана
формулой:
kx(x) = De-A%\ A7.4.16)
где а > 0 (рис. 17.4.3).
Пользуясь комплексной формой преобразования Фурье, определить
спектральную плотность 5„(«).
17.4] СПЕКТРАЛЬНОЕ РАЗЛОЖЕНИЕ В КОМПЛЕКСНОЙ ФОРМЕ
Решение. По формуле A7.4.12) находим:
445
2^ L a — i(
График спектральной плотности
Л (a2
представлен на рис. 17.4.4.
Посмотрим, как будут вести себя корреляционная функция и спектраль-
спектральная плотность при изменении а.
При уменьшении а корреляционная функция будет убывать медленнее;
характер изменения случайной функции становится более плавным; соответ-
соответственно в спектре случайной функции больший удельный вес приобретают
малые частоты: кривая спектральной плотности вытягивается вверх, одновре-
одновременно сжимаясь с боков; в пределе при <х->0 случайная функция выродится
в обычную случайную величину с дискретным спектром, состоящим из един-
единственной линии с частотой а>0 = 0.
При увеличении а. корреляционная функция убывает быстрее, характер
колебаний случайной функции становится более резким и беспорядочным;
соответственно этому в спектре
случайной функции преобладание
малых частот становится все /
Рис. 17.4.4.
Рис. 17.4.5.
менее, дыраженным; при а -> со спектр случайной функции приближается к
равномерному (так называемому «белому») спектру, в котором нет преоб-
преобладания каких-либо частот.
446
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИЙ
[ГЛ. 17
Пример 2. Нормированная корреляционная функция случайной функ-
функции X(t) имеет вид:
(рис. 17.4.5).
Определить нормированную спектральную плотность.
Решение. Представляем рх (т) в комплексной форме:
Р.Г (Ч = «
Нормированную спектральную плотность sx (ш) находим по формуле A7.4.12),
подставляя в нее рх (т) вместо kx (т):
откуда после элементарных преобразований получаем:
Вид графика спектральной плотности зависит от соотношения парамет-
. ров а и р, т. е. от того, что преобладает в корреляционной функции: убывание
по закону «~* I' или колеба-
колебание но закону cos fte. Очевидно,
яри сравнительно малых а пре-
преобладает колебание, при срав-
сравнительно больших а — убыва-
убывание. В первом случае случайная
функция близка к периодиче-
периодическим колебаниям частоты р со
случайной амплитудой и фазой;
соответственно в спектре слу-
случайной функция преобладают
частоты, близкие к частоте р.
Во втором случае спектраль-
р ный состав случайной функции
fhc. нал. более равномерен, преоблада-
преобладания тех или иных частот не
наблюдается; в пределе при а->оэ спектр случайной функции приближается
к «белому» спектру.
В качестве иллюстрации на рис. 17.4.6 изображены нормированные
спектральные плотности для случаев:
I) р == 2, а = 1 (кривая /); 2) Р = 2, а — 3 (кривая //). Как видно из
чертежа, при а = 1 спектр случайной функции обнаруживает ярко выраженный
максимум в области частот ш=±р. При <х = 3 (кривая //) спектральная
плотность в значительном диапазоне частот остается почти постоянной.
17.5] ПРЕОБРАЗОВАНИЕ СТАЦИОНАРНОЙ ЛИНЕЙНОЙ СИСТЕМОЙ 447
17.5. Преобразование стационарной случайной функции
стационарной линейной системой
В главе 16 мы познакомились с общими правилами линейных пре-
преобразований случайных функций, представленных в виде канони-
канонических разложений. Эти правила сводятся к тому, что при линейных
преобразованиях случайных функций их математические ожидания и
координатные функции подвергаются тем же линейным преобразо-
преобразованиям. Таким образом, задача линейного преобразования случайной
функции сводится к задаче такого же линейного преобразования
нескольких неслучайных функций.
В случае, когда речь идет о линейных преобразованиях стацио-
стационарных случайных функций, задачу удается упростить еще больше.
Если и входное воздействие X (t) и реакция системы Y (t) стацио-
стационарны, задачу преобразования случайной функции можно свести
к преобразованию одной-единственной неслучайной функции — спек-
спектральной плотности Sx(w).
Для того чтобы при стационарном воздействии реакция системы
могла быть тоже стационарной, очевидно необходимо, чтобы пара-
параметры системы (например, входящие в нее сопротивления, емкости,
индуктивности и т. п.) были постоянными, а не переменными. Усло-
Условимся называть линейную систему с постоянными параметрами
стационарной линейной системой^ Обычно работа стационарной
линейной системы описывается
линейными дифференциальными /ft) Y////////////X уМ
уравнениями с постоянными коэф- ,'"\ ,'\ / уу/у/ l уу///~\ Г /
фициентами. *"' ч' '^у/ууу///ууУ/ ^-' ''
Рассмотрим задачу о преоб- Ях^хЮ Y////////////A ту,ку(т)
разовании стационарной случай- *- *-
ной функции стаитнарнюй линей- Рис 1751
ной системой. Пусть на аход ли-
линейной системы L наступает стационарная случайная функция X (t);
пеакчи-з с:<стеч:3: есть СР-члЯная функция Y(t) рис. П7.5.1). Известны
характеристики случайной функции X (t): математическое ожи-
ожидание тх и коррелягшоонгя функция kx (т). Требуется опреде-
определить характеристики случайной функции Y(t) на выходе линейной
системы.
Так как для решения задач» нам придется преобразовывать не-
неслучайные функции— математическое ожидание и координатные функ-
функции, рассмотрим прежде всего задачу об определении реакции
системы L на неслучайное воздействие x{t).
Напишем в операторной форме линейное дифференциальное
уравнение с постоянными коэффициентами, связывающее реакцию
448 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. 17
системы у (t) с воздействием х (t):
A7-5.1)
) = Bm(p)x(t), A7.5.2)
или, наконец, условно разрешая уравнение A7.5.2) относительно y(t),
записать оператор системы в «явном» виде:
^5^* Ю- (I7-5-3)
где p-=z-~ оператор дифференцирования.
Уравнение A7.5.1) короче можно записать в виде:
Реакцию системы L на воздействие х (t) можно найти путем ре-
решения линейного дифференциального уравнения A7.5.1). Как известно
из теории дифференциальных уравнений, это решение состоит из
двух слагаемых: У[ (t) и уп (t). Слагаемое уи (t) представляет собой
решение уравнения без правой части и определяет так называемые
свободные или собственные колебания системы. Это — колебания,
совершаемые системой при отсутствии входного воздействия, если
система в начальный момент как-то была выведена из состояния
равновесия. На практике чаще всего встречаются так называемые
устойчивые системы; в этих системах свободные колебания с тече-
течением времени затухают.
Если ограничиться рассмотрением участков времени, достаточно
удаленных от начала процесса, когда все переходные процессы
в системе можно считать законченными, и система работает в устано-
установившемся режиме, можно отбросить второе слагаемое yn(t) и огра-
ограничиться рассмотрением только первого слагаемого yl (t). Это первое
слагаемое определяет так называемые вынужденные колебания си-
системы под влиянием воздействия на нее заданной функции x(t).
В случае, когда воздействие х (t) представляет собой достаточно
простую аналитическую функцию, часто удается найти реакцию
системы также в виде простой аналитической функции. В частности,
когда воздействие представляет собой гармоническое колебание опре-
определенной частоты, система отвечает на него также гармоническим
колебанием той же частоты, но измененным по амплитуде и фазе.
Так как координатные функции спектрального разложения стацио-
стационарной случайной функции X (t) представляют собой гармонические
колебания, то нам прежде всего необходимо научиться определять
реакцию системы на гармоническое колебание заданной частоты с».
Эта задача решается очень просто, особенно если гармоническое
колебание представлено в комплексной форме.
175] ПРЕОБРАЗОВАНИЕ СТАЦИОНАРНОЙ ЛИНЕЙНОЙ СИСТЕМОЙ 449
Пусть на вход системы поступает гармоническое колебание вида:
x(t) = elat. A7.5.4)
Будем искать реакцию системы y(t) также в виде гармонического
колебания частоты а>, но умноженного на некоторый комплексный
множитель Ф (/(»):
уУ) = Ф(Ш)ем. A7.5.5)
Множитель Ф(Ы) найдем следующим образом. Подставим функ-
функцию A7.5.4) в правую, а функцию A7.5.5) в левую часть уравнения
A7.5.1). Получим:
ап -^ [Ф (/ш) *<«'] + ап_, -^ [Ф (/ш) «'«<] + ...
... + с, -^ [Ф (to) ег<»<] + а0 [Ф (to) в'»'] =
Имея в виду, что при любом k
— e == (to) e , — [Ф (/(в) e J = (/o>) e Ф (/a
и деля обе части уравнения A7.5.6) на еш, получим:
07-5.7)
Мы видим, что множитель при Ф (tio) представляет собой не что
иное, как многочлен Ап (р) = апрп-}-ап_1рп-1 +... -\-агр-^-а0,
в который вместо оператора дифференцирования р подставлено (to);
аналогично правая часть равенства A7.5.7) есть не что иное, как
ВтAш). Уравнение A7.5.7) можно записать в виде:
откуда
Функция Ф (/ш) носит специальное название частотной характе-
характеристики линейной системы. Для определения частотной характери-
характеристики достаточно в оператор системы, записанный в явной форме
A7.5.3), вместо оператора дифференцирования р подставить ш.
Таким образом, если на вход линейной системы с постоян-
постоянными параметрами поступает гармоническое колебание
вида еш, то реакция системы представляется в виде того же
гармонического колебания, умноженного на частотную харак-
характеристику системы. Ф(Ло). Пусть на вход системы поступает воз-
воздействие вида x(t) = UeM. A7.5.9)
29 Е. С. Вентцель
450 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ (ГЛ. 17
где U — некоторая величина, не зависящая от t. В силу линейности
системы величина U выходит за знак оператора, и реакция системы
на воздействие A7.5.9) будет равна:
у(Г) = и${Ш)еш. A7.5.10)
Очевидно, это свойство сохранится и в том случае, когда вели-
величина U будет случайной (лишь бы она не зависела от t).
Применим изложенные приемы преобразования гармонических ко-
колебаний линейной системой к математическому ожиданию случайной
функции X (t) и координатным функциям ее спектрального разло-
разложения.
Представим математическое ожидание тх стационарной случайной
функции X (t) как гармоническое колебание нулевой частоты ш = 0
и положим в формуле A7.5.8) ш = 0:
<17-5Л1>
откуда получаем математическое ожидание на выходе системы:
1ву = -^тх. A7.5.12)
Перейдем к преобразованию линейной системой существенно слу-
случайной части функции X (t), а именно функции
ДГ(9 = Х@ — тх. A7.5.13)
Для этого представим функцию X (/) на участке @, Т) в виде
спектрального разложения:
i@= £ У» «'"*'. A7.5.14)
к = — оо
где Uk — некоррелированные случайные величины, дисперсии кото-
которых образуют спектр случайной функции X (t). •'
Рассмотрим отдельное слагаемое этой суммы:
X,(t) = Uhelwkt. A7.5.15)
Реакция системы на это воздействие будет иметь вид:
Гл @ - UH Ф (/т4) е'V. A7.5.16)
Согласно принципу суперпозиции реакция системы на сумму воз-
воздействий равна сумме реакций на отдельные воздействия. Слелова-
телыю, реакцию системы на воздействие A7.5.14) можно предста-
представить в виде спектрального разложения:
17.5) ПРЕОБРАЗОВАНИЕ СТАЦИОНАРНОЙ ЛИНЕЙНОЙ СИСТЕМОЙ 451
или, обозначая икФ (Шк) = Wk,
Y{t) = 2 W» «'"*'. A7.5.17)
ft=-oo
где Wk — некоррелированные случайные величины с математическими
ожиданиями, равными нулю.
Определим спектр этого разложения. Для этого найдем диспер-
дисперсию комплексной случайной величины Wk в разложении A7.5.17).
Имея в виду, что дисперсия комплексной случайной величины равна
математическому ожиданию квадрата ее модуля, имеем:
D [WJ = М [| иьФ (/шй)|*] = М [|UkР|Ф (/u,ft)|2] =
A7.5.18)
Мы приходим к следующему выводу: при преобразовании ста-
ционарной случайной функции стационарной линейной систе-
мой каждая из ординат ее спектра умножается на квадрат
модуля частотной характеристики системы для соответ.'
ствующей частоты.
Таким образом, при прохождении стационарной случайной функ-
функции через линейную стационарную систему ее спектр определенным
образом перестраивается: некоторые частоты усиливаются, некоторые,
напротив, ослабляются (фильтруются). Квадрат модуля частотной ха-
характеристики (в зависимости от ш^,) и показывает, как реагирует
система на колебания той или иной частоты.
Аналогично тому, как это делалось раньше, перейдем в спек-
спектральном представлении случайной функции к пределу при Г—>со
и от дискретного спектра — к спектральной плотности. Очевидно,
спектральная плотность на выходе линейной системы получается из
спектральной плотности на входе тем же умножением на )Ф(/а>)|2,
как и ординаты дискретного спектра:
5у(ш) = |Ф(/ш)|*5х(ш). A7.5.19)
Таким образом, получено весьма простое правило:
При преобразовании стационарной случайной функции
стационарной линейной системой ее спектральная плотность
умножается на квадрат модуля частотной характеристика
системы.
Пользуясь этим правилом, мы легко можем решить поставленнз'ю
выше задачу: по характеристикам случайной функции на входе линей-
линейной системы найти характеристики случайной функции на ее выходе.
Пусть на вход стационарной линейной системы с оператором
A7.5.3) поступает стационарная случайная функция X(t) с матема-
математическим ожиданием тх и корреляционной функцией ^^(х). Требуется
Пийти математическое ожидание т., и корреляционную функцию А,,(т)
случайной функции Y(t) на выходе системы.
452 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. 17
Задачу будем решать в следующем порядке.
1. Находим математическое ожидание на выходе:
A7.5.20)
2. По корреляционной функции kx (%) находим спектральную плот-
плотность на входе (см. формулу A7.4.12)):
x(z)e-"»dxi). A7.5.21)
3. По формуле A7.5.8) находим частотную характеристику си-
системы и квадрат ее модуля:
ra$f- A7i5-22)
4. Умножая спектральную плотность на входе на квадрат моду-
модуля частотной характеристики, находим спектральную плотность на
выходе:
ш). A7.5.23)
5. По спектральной плотности Sy (со) находим корреляционную
функцию ky (%) на выходе системы:
оо
ky (%) = J Sy (u>) e<°" dio. A7.5.24)
— со
Таким образом, поставленная задача решена.
Во многих задачах практики нас интересует не вся корреляци-
корреляционная функция ky(r) на выходе системы, а только дисперсия Dy,
равная
Тогда из формулы A7.5.24) получаем при т = 0 гораздо более
простую формулу:
или, учитывая четность функции 5 (ш),
оо
Dy = 2J*5y(<o)da>. A7.5.25)
') Для простоты записи мы здесь опускаем знак * в обозначении спек-
спектральной плотности.
17 5] ПРЕОБРАЗОВАНИЕ СТАЦИОНАРНОЙ ЛИНЕЙНОЙ СИСТЕМОЙ 453
Пример. Работа линейной динамической системы описывается линей-
линейным дифференциальным уравнением первого порядка:
(<»i/> + во) У @ = (*!/>+ Ьо) х @, A7.5.26)
или
На вход системы поступает стационарная случайная функция X (t) с ма-
математическим ожиданием тх и корреляционной функцией
fcx(t) = Dxe-a^^ A7.5.27)
где а — положительный коэффициент (см. пример 1 п° 17.4). Найти матема-
математическое ожидание ту и дисперсию Dy на выходе системы ').
Решение. По формуле A7.5.20) имеем:
Очевидно, величина ту не зависит от параметра а, растет при возра-
возрастании Ьо и убывает при возрастании аа.
Спектральную плотность на входе определяем как в примере 1 п° 17.4;
о / \ __
те (а2 -)- со2)
(см. рис. 17.4.4).
По ф
формуле A7.5.8) находим частотную характеристику системы:
Ф (/о>) = ———
ait<a + аа
и квадрат ее модуля:
Затем определяем спектральную плотность на выходе системы:
Dr bV + bl a
,() |()|r() 52TT2r2
Далее по формуле A7.5.25) определяем дисперсию на выходе:
те '' йЛсо А-пп о. -]-
О 110 I
) Выбирая для корреляционной функции случайной функции X (t) выра-
выражение типа A7.5.27), широко применяемое из практике ввиду его простоты,
необходимо иметь в виду следующее. Строго говоря, случайная функция X (t),
имеющая корреляционную функцию такого вида, педифференцируема, и, сле-
следовательно, для нее нельзя писать дифференциальные уравнения в обычном
смысле слова. Это затруднение можно обойти, если рассматривать выраже-
выражение A7.5.27) для корреляционной функции только как приближенное.
454 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. 17
Для вычисления интеграла разложим подынтегральное выражение на
простые дроби:
Ь\ы2-\-Ь1 а А В
0 0 О >
аУ-а20
и определим коэффициенты:
А = а-
/} = а "'"" ""
После интегрирования получим:
В заключение данного п° упомянем о том, как преобразуется
линейной системой стационарная случайная функция, содержащая в
качестве слагаемого обычную случайную величину: •■
Xl(t) = Uu-{-X(t), A7.5.28)
где Uo — случайная величина с дисперсией Do, X (t) — стационарная
случайная функция.
Реакция системы на воздействие Xx(t) найдется как сумма реак-
реакций на отдельные воздействия в правой части A7.5.28). Реакцию на
воздействие X (t) мы уже умеем находить. Воздействие £/0 мы рас-
рассмотрим как гармоническое колебание нулевой частоты а> = 0; со-
согласно формуле A7.5.11) реакция на него будет равна
vo = ~uo- A7.5.29)
Слагаемое Vo просто прибавится к реакции системы на воздей-
воздействие X (t).
17.6. Применения теории стационарных случайных процессов
к решению задач, связанных с анализом
II СКПТсЗОМ ДПП!лМ1|Ч£СКП/С CiiCTc.U
В предыдущем п° был рассмотрен вопрос о преобразовании ста-
стационарной случайной функции стационарной линейной системой и
получены простые математические приемы решения этой задачи.
Преобразование случайной функции свелось к простейшему пре-
преобразованию (умножению на квадрат модуля частотной характеристи-
характеристики) одной-едипствепной функции: сиекчральпой плотности. Такая про-
простота спектральной теории стационарных случайных процессов делает
ее незаменимым аппараюм при исследовании линейных динамических
систем, работающих в условиях наличия случайных возмущений (помех).
17.61 ПРИМЕНЕНИЯ ТЕОРИИ СТАЦИОНАРНЫХ ПРОЦЕССОВ 455
Обычно при решении практических задач нас интересует не сама
по себе корреляционная функция ky (i) на выходе системы, а связан-
связанная с нею дисперсия
D, = *,@).
которая характеризует ошибки системы, вызванные поступающими на
нее случайными возмущениями, и во многих случаях может служить
критерием точности работы системы.
При исследовании динамических систем методами теории случай-
случайных функций решаются два вида задач, которые можно назвать «пря-
«прямыми» и «обратными».
Прямая задача состоит в следующем. Анализируется заданная
линейная динамическая система с вполне определенными параметрами,
работа которой описывается линейным дифференциальным уравнением:
(m ai l o)x(f). A7.6.1)
Требуется исследовать точность работы системы при наличии на
ее входе стационарного случайного воздействия — так называемой
«стационарной помехи». Для этого прежде всего исследуется случай-
случайная помеха, определяются ее корреляционная функция и спектральный
состав. Далее, описанными выше методами находятся спектр и дис-
дисперсия случайной функции на выходе системы. Дисперсия на выходе,
очевидно, зависит как от характеристик случайного воздействия на
входе, так и от коэффициентов уравнения. Решая "такую задачу,
можно оценить точность работы заданной системы в условиях раз-
различного рода помех.
Обратная задача состоит в том, чтобы так выбрать коэффициенты
уравнения A7.6.1), чтобы при заданном спектральном составе помехи
ошибки на выходе системы были минимальными. При заданных ха-
характеристиках случайной функции (помехи) на входе системы диспер-
дисперсия на выходе зависит от всей совокупности коэффициентов урав-
уравнения:
Dy=Dy(an, an_i av д0, bm, bm_x bv b0).
Клэфф>:,;;;емтн уравнения зуй;:счг от конструктивных параметров
системы, и некоторыми из них при проектировании системы можно
в достаточно широких пределах распоряжаться. Задача выбора рацио-
рациональных значений этих параметров может быть решена исходя из
того требования, чтобы дисперсия Dy была минимальна.
Следует оговориться, что на практике часто не удается пол»
ностью удовлетворить этому требованию. Действительно, выведенные
нами выражения для корреляционной функции и дисперсии на выходе
системы справедливы только для значений времени t, достаточно
удаленных от начала случайного процесса, когда все переходные
процессы в системе, связанные с ее свободными колебаниями, успели
456 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. 17
уже затухнуть. В действительности же часто приходится применять
линейные динамические системы (прицелы, счетно-решающие меха-
механизмы, следящие системы и т. п.) на ограниченном участке времени;
при этом быстрота затухания переходных процессов в системе суще-
существенно зависит от ее конструктивных параметров, т. е. от тех же
коэффициентов уравнения A7.6.1). Если выбрать эти коэффициенты
так, чтобы они обращали в минимум дисперсию на выходе (для
достаточно удаленных моментов времени), это, как правило, приво-
приводит к тому, что на выходе системы появляются другие ошибки, свя-
связанные с тем, что переходные процессы в системе еще не успели
затухнуть. Эти ошибки обычно называют динамическими ошибками.
В связи с ограниченностью времени применения линейных систем
и наличием динамических ошибок на практике обычно приходится
решать задачу о рациональном выборе параметров системы не на
чистом принципе минимума дисперсии, а с учетом динамических оши-
ошибок. Рациональное решение задачи находится как компромиссное, при
котором, с одной стороны, дисперсия на выходе системы достаточно
мала, с другой стороны—динамические ошибки не слишком велики.
В случае, когда ищутся оптимальные параметры системы с учетом
как дисперсии, так и систематических динамических ошибок, часто
в качестве критерия точности работы системы выбирают второй на-
начальный момент а2 на выходе системы:
a2 = Dy + ^, A7.6.2)
где Dy — дисперсия, ту — систематическая ошибка на выходе системы.
При этом параметры системы выбирают так, чтобы они обращали
в минимум величину а2.
Иногда в качестве критерия для оценки системы выбирают не
дисперсию и не второй начальный момент, а какую-либо другую
величину, связанную с целевым назначением системы. Например, при
исследовании прицельных устройств и систем управления, предназна-
ченнных для стрельбы, к выбору их параметров часто подходят,
исходя из максимума вероятности поражения цели.
Упомянем еще об одной типичной задаче, связанной с рациональ-
рациональным конструированием динамических систем. До сих пор мы рассмат-
рассматривали только задачу о рациональном выборе коэффициентов урав-
уравнения A7.6.1), самый же вид уравнения считался заданным. При
решении задач, связанных с так называемым синтезом динамических
систем, задача ставится более широко. В частности, ставится во-
вопрос о рациональном выборе самого вида уравнения или, еще шире,
задача об определении оптимального оператора динамической
системы. Такого рода задачи в настоящее время успешно решающи
методами теории случайных функций.
При решении практических задач, связанных с анализом и син-
синтезом динамических систем, часто не удается ограничиться кругом
17.7] ЭРГОДИЧЕСКОЕ СВОЙСТВО СТАЦИОНАРНЫХ ФУНКЦИЙ 457
стационарных случайных процессов и относящимся к нему аппаратом
спектральной теории. Однако в ряде случаев, несколько видоизменив
этот аппарат, можно применить его и для нестационарных процессов.
На практике часто встречаются так называемые «квазистационарные»
случайные функции и «квазистационарные» динамические системы;
они характерны тем, что изменения характеристик случайных функ-
функций и параметров системы со временем протекают сравнительно мед-
медленно. Для таких случайных процессов В. С. Пугачевым разработан
метод, по структуре мало отличающийся от спектрального, но при-
применимый в более широком диапазоне условий ')•
17.7. Эргодическое свойство стационарных
случайных функций
Рассмотрим некоторую стационарную случайную функцию 'X (f)
и предположим, что требуется оценить ее характеристики: матема-
математическое ожидание тх и корреляционную функцию kx(x). Выше
(см. п° 15.4) были изложены способы получения этих характеристик
из опыта. Для этого нужно располагать известным числом реализа-
реализаций случайной функции X (t). Обрабатывая эти реализации, можно
найти оценки для математического ожидания mx(t) и корреляционной
функции Кх (t, t'). В связи с ограниченностью числа наблюдений
функция mx{t) не будет строго постоянной; ее придется осреднить
и заменить некоторым постоянным тх; аналогично, осредняя значе-
значения Kx(t, t') для разных x = t'—/, получим корреляционную функ-
функцию kx (х).
Этот метод обработки, очевидно, является довольно сложным
и громоздким и к тому же состоит из двух этапов: приближенного
определения характеристик случайной функции и также приближен-
приближенного осреднения этих характеристик. Естественно возникает вопрос:
нельзя ли для стационарной случайной функции этот сложный, двух-
двухступенчатый процесс обработки заменить более проствш, который
заранее базируется на предположении, что математическое ожидание
не зависит от времени, а корреляционная функция — от начала отсчета?
Кроме того, возникает вопрос: при обработке наблюдений над
стационарной случайной функцией является ли существенно необхо-
необходимым располагать несколькими реализациями? Поскольку случай-
случайный процесс является стационарным и протекает однородно по времени,
естественно предположить, что о дк д-с д и и ств е :: и а я р е а л и з а-
ц и я достаточной продолжительности может служить достаточным опыт-
опытным материалом для получения характеристик случайной функции.
') См. В. С. Пугачев. Теория случайных функций и ее применение
к задачам автоматического управления, Физматгиз, 1962.
458
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
[ГЛ. 17
При более подробном рассмотрении этого вопроса оказывается,
что такая возможность существует не для всех случайных процессов:
не всегда одна реализация достаточной продолжительности оказы-
оказывается эквивалентной множеству отдельных реализаций.
Для примера рассмотрим две стационарные случайные функции
Xx(f) и X2(t), представленные совокупностью своих реализаций на
рис. 17.7.1 и 17.7.2.
Рис, 17.7.1.
Для случайной функции Х} (t) характерна следующая особенность:
каждая из ее реализаций обладает одними и теми же характерными
признаками: средним значением, вокруг которого происходят колеба-
колебания, и средним размахом этих колебаний. Выберем произвольно одну
из таких реализаций и продолжим мысленно опыт, в результате
которого она получена, на некоторый участок времени Т. Очевидно,
Рис. 17.7.2.
при дсстптс-:::о cc.":.:::c:i 7" ■;■
достаточно хорошее представление о свойствах случайной функции
в целом. В частности, осредняя значения этой реализации вдоль оси
абсцисс — по времени, мы должны получить приближенное значение
математического ожидания случайной функции; осредняя квадраты
отклонений от этого среднего, мы должны получить приближенное
значение дисперсии, и т. д.
Про такую случайную функцию говорят, что она обладает эрго-
дическим свойством. Эргодическое свойство состоит в том, что каж-
каждая отдельная реализация случайной функции является как бы «пол-
«полномочным представителем» всей совокупности возможных реализаций;
17.7J ЭРГОДИЧЕСКОЕ СВОЙСТВО СТАЦИОНАРНЫХ ФУНКЦИЯ 459
одна реализация достаточной продолжительности может заменить при
обработке множество реализаций той же общей продолжительности1).
Рассмотрим теперь случайную функцию X2{t). Выберем произ-
произвольно одну из ее реализаций, продолжим ее мысленно на доста-
достаточно большой участок времени и вычислим ее среднее значение по
времени на всем участке наблюдения. Очевидно, это среднее значе-
значение для каждой реализации будет свое и может существенно отли-
отличаться от математического ожидания случайной функции, построенного
как среднее из множества реализаций. Про такую случайную функ-
функцию говорят, что она не обладает эргодическим свойством.
Если случайная функция X (t) обладает эргодическим свойством, ■
то для нее среднее по времени (на достаточно большом участке на-
наблюдения) приближенно равно среднему по множеству наблю-
наблюдений. То же будет верно и для X2(t), X (t) ■ X (t-\-ъ) и т. д. Сле-
Следовательно, все характеристики случайной функции (математическое
ожидание, дисперсию, корреляционную функцию) можно будет при-
приближенно определять по одной достаточно длинной реализации.
Какие же стационарные случайные функции обладают, а какие
не обладают эргодическим свойством?
Поясним этот вопрос наглядно, исходя из примера. Рассмотрим
случайную функцию а(^) — колебания угла атаки самолета на уста-
установившемся режиме горизонтального полета. Предположим, что по-
полет происходит в каких-то типичных средних метеорологических усло-
условиях. Колебания угла атаки вызваны случайными возмущениями, свя-
связанными с турбулентностью атмосферы. Среднее значение угла атаки,
около которого происходят колебания, зависит от высоты полета Н.
Зависит от этой высоты и размах колебаний: известно, что в нижних
слоях атмосферы турбулентность сказывается сильнее, чем в верхних.
Рассмотрим случайную функцию a.{t)— колебания угла атаки на
заданной высоте Н. Каждая из реализаций этой случайной функ-
функции осуществляется в результате воздействия одной и той же группы
случайных факторов и обладает одними и теми же вероятностными
характеристиками; случайная функция а(^) обладает эргодическим
свойством (рис. 17.7.3).
Представим себе теперь, что рассматривается случайная функция
a (t) не для одной высоты Н, а для целого диапазона, внутри кото-
которого задан какой-то закон распределения высот (например, закон
равномерной плотности). Такая случайная функция, оставаясь стацио-
стационарной, очевидно, уже не будет обладать эргодическим свойством; ее
возможные реализации, осуществляющиеся с какими-то вероятностями,
имеют различный характер (рис. 17.7.4).
') Строго говоря, следовало бы сказать не «каждая отдельная реализа-
реализация», а «почти каждая». Дело в том, что в отдельных случаях могут по-
появляться реализации, не обладающие таким свойством, но вероятность по-
яилзиня такой ргзлизац.'и раз;и нулю.
460
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ
[ГЛ. ]?
Для этого случайного процесса характерно то, что он как бы
«разложим» на более элементарные случайные процессы; каждый из
них осуществляется с некоторой вероятностью и имеет свои индиви-
индивидуальные характеристики. Таким образом, разложимость,
Рис. 17.7.3.
внутренняя неоднородность случайного процесса, протекающего с не-
некоторой вероятностью по тому или другому типу, есть физическая
причина неэргодичности этого процесса.
Рис. 17.7.4.
В частности, неэргодичность случайного процесса может быть
связана с наличием в его составе слагаемого в виде обычной случай-
случайной величины (т. е. наличие в спектре случайного процесса, помимо
непрерывной части, конечной дисперсии при частоте 0).
Действительно, рассмотрим случайную функцию
Z(f) = X{t)-\-Y. A7.7.1)
где X (t) — эргодическая стационарная случайная функция с характе-
характеристиками тх, kx(t), V — случайная величина с характеристиками ту
и Dy\ предположим к тому же, что X (t) и К некоррелированны.
Определим характеристики случайной функции Z{t). Согласно
общим правилам сложения случайных функций (см. п° 15.8) имеем:
т—-т^ -i-mvI A7,7,2)
Mt) = Mt)-KV A7.7.3)
Из формул A7.7.2) и A7.7.3) видно, что случайная функция Z(f)
является стационарной. Но обладает ли она эргодическим свойством?
Очевидно, нет. Каждая ее реализация будет по характеру отличаться
от других, будет обладать тем или иным средним по времени зна-
17.7]
ЭРГОДИЧЕСКОЕ СВОЙСТВО СТАЦИОНАРНЫХ ФУНКЦИЯ
461
чением в зависимости от того, какое значение приняла случайная
величина У (рис. 17.7.5).
Об эргодичности или неэргодичности случайного процесса может
непосредственно свидетельствовать вид его корреляционной функции.
Действительно, рассмотрим корреляционную функцию неэргодической
случайной функции A7.7.1). Она отличается от корреляционной функ-
функции случайной функции X (t) наличием постоянного слагаемого Dy
Рис. 17.7.5.
(рис. 17.7.6). В то время как корреляционная функция kx(x) стре-
стремится к нулю при т—>-эо (корреляционная связь между значениями
случайной функции неограниченно убывает по мере увеличения рас-
расстояния между ними), функция kz(x) уже не стремится к нулю при
t->oo, а приближается
к постоянному значе-
значению Dy.
На практике мы не j)y-
имеем возможности иссле-
исследовать случайный процесс
и его корреляционную
функцию на бесконечном
участке времени; участок
значений т, с которым мы „
имеем дело, всегда огра- у
ничен. Если при этом
корреляционная функция
стационарного случайного
процесса при увеличении х рис 17.7.6.
не убывает, а, начиная с
некоторого z, остается приблизительно постоянной, зто обычно есть
признак того, что в составе случайной функции имеется слагаемое
в виде обычной случайной величины и что процесс не является эрго-
дичееккм. Стремление же корреляционной функции к нулю при t-^oo
говорит в пользу эргодичности процесса. Во всяком случае оно
О
462 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ, 17
достаточно для того, чтобы математическое ожидание функции можно
было определять как среднее по времени.
При решении практических задач часто суждение об эргодичности
случайного процесса выносится не на основе исследования поведения
корреляционной функции при т->оо, а на основании физических
соображений, связанных с существом процесса (его предположительной
«разложимостью» или «неразложимостью» на элементарные процессы
различного типа, появляющиеся с некоторыми вероятностями).
17.8. Определение характеристик эргодической
стационарной случайной функции по одной реализации
Рассмотрим стационарную случайную функцию X (t), обладающую
эргодическим свойством, и предположим, что в нашем распоряжении
имеется всего одна реализация этой случайной функции, но зато на
достаточно большом участке времени Т. Для эргодической стационар-
стационарной случайной функции одна реализация достаточно большой про-
продолжительности практически эквивалентна (в смысле объема сведений
о случайной функции) множеству реализаций той же общей продол-
продолжительности; характеристики случайной функции могут быть прибли-
приближенно определены не как средние по множеству наблюдений, а как
средние по времени t. В частности, при достаточно большом Т
математическое ожидание шх может быть приближенно вычислено
по формуле
~ f
6
A7.8.1)
6
Аналогично может быть приближенно найдена корреляционная
функция ^(х) при любом х. Действительно, корреляционная функция,
по определению, представляет собой не что иное, как математиче-
математическое ожидание случайной функции X (t) X (t-f-т):
]. A7.8.2)
Это математическое ожидание тякжс. очевидно, может быт;, прибли-
приближенно вычислено как среднее по времени.
Фиксируем некоторое значение х и вычислим указанным способом
корреляционную функцию kx(i). Для этого удобно предварительно
«центрировать» данную реализацию x(t), т. е. вычесть из нее мате-
математическое ожидание A7.8.1):
x(t)~x(f)—mx. A7.8.3)
') Для простоты записи мы здесь опускаем знак ~> при характеристиках
случайной функции, означающий, что мы имеем дело не с самими характе-
характеристиками, а с их оценками.
17.8]
ОПРЕДЕЛЕНИЕ ХАРАКТЕРИСТИК ЭРГОДИЧЕСКОЙ ФУНКЦИИ
463
Вычислим при заданном х математическое ожидание случайной
функции X (t) X {t -f- т) как среднее по времени. При этом, очевидно,
нам придется учитывать не весь участок времени от 0 до Т, а не-
сколько меньший, так как второй сомножитель X(t-\-z) известен нам
не для всех t, а только для тех, для которых t-\-x^T.
Вычисляя среднее по времени указанным выше способом, получим:
A7.8.4)
Вычислив интеграл A7.8.4) для ряда значений т, можно прибли-
приближенно воспроизвести по точкам весь ход корреляционной функции.
На практике обычно интегралы A7.8.1) и A7.8.4) заменяют
конечными суммами. Покажем, как это делается. Разобьем интервал
xfO
1
1
1
1
ti
•AtJ
i
4
!
г'
1
1
1
1
1
1
ill
Vtv/
j
1
1
1
^ Ч7-/ r/7
Рис. 17.8.1.
записи случайной функции на п равных частей длиной Д^ и обозна-
обозначим середины полученных участков tv t2, .... tn (рис. 17.8.1). Пред-
Представим интеграл A7.8.1) как сумму интегралов по элементарным
участкам Д£ и на каждом из них вынесем функцию х (t) из-под знака
интеграла средним значением, соответствующим центру интервалах (tt).
Получим приближенно: л
или
A7.8.5)
Аналогично можно вычислить корреляционную функцию для значе-
значений х, равных О, Д£, 2 ДЛ ... Придадим, например, величине т значение
? = т Дг = —-
и вычислим интеграл A7.8.4). деля интервал интегрирования
_ j, гпТ_ п — tn j,
464 СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ [ГЛ. 17
на п — т равных участков длиной Д^ и вынося на каждом из них
функцию х (() х (i -\- т) за знак интеграла средним значением. Получим:
или окончательно
п-т
(^) S °° A7-8.6)
Вычисление корреляционной функции по формуле A7.8.6) произ-
производят для /я = 0, 1, 2, ... последовательно вплоть до таких значе-
значений т, при которых корреляционная функция становится практически
равной нулю или начинает совершать небольшие нерегулярные коле-
колебания около нуля. Общий ход функции Ад-(т) воспроизводится по
отдельным точкам (рис. 17.8.2).
Для того чтобы математическое ожидание тх и корреляционная
функция kx (x) были определены с удовлетворительной точностью,
нужно, чтобы число точек п было
достаточно велико (порядка сотни,
а в некоторых случаях даже не-
нескольких сотен). Выбор длины эле-
элементарного участка Ы опреде-
ляется характером изменения слу-
случайной функции. Если случайная
функция изменяется сравнительно
< ^ плавно, участок Ы можно выби-
At 2At Nv S^~ ~~~T Рать ббльшим, чем когда она со-
>■—*S вершает резкие и частые колеба-
Рис. 17.8.2. ния- Чем более высокочастотный
состав имеют колебания, образую-
образующие случайную функцию, тем чаще нужно располагать опорные
точки при обработке. Ориентировочно можно рекомендовать выбирать
элементарный участок hi так, чтобы на полный период самой высо-
высокочастотной гармоники в составе случайно" функции приходилось
порядка 5—10 опорных точек.
Часто выбор опорных точек вообще не зависит от обрабатываю-
обрабатывающего, а диктуется темпом работы записывающей аппаратуры. В этом
случае следует вести обработку непосредственно полученного из опыта
материала, не пытаясь вставить между наблюденными значениями про-
промежуточные, так как это не может повысить точности результата,
а излишне осложнит обработку.
П р и м е р. В условиях горизонтального полета самолета произведена
запись вертикальной перегрузки, действующей на самолет. Перегрузка ре-
регистрировалась на участке времени 200 сек с интервалом 2 сек. Результаты
17.8]
ОПРЕДЕЛЕНИЕ ХАРАКТЕРИСТИК ЭРГОДИЧЕСКОЙ ФУНКЦИИ
465
приведены в таблице 17.8.1. Считая процесс изменения перегрузки стационар-
стационарным, определить приближенно математическое ожидание перегрузки т„,
дисперсию DN и нормированную корреляционную функцию р^ (т). Аппрокси-
Аппроксимировать р^. (t) какой-либо аналитической функцией, найти и построить
спектральную плотность случайного процесса.
Таблица 17.8.1
(сек)
0
2
4
6
8
10
12
14
16
18
20
22
24
26
28
30
32
34
36
38
40
42
44
46
48
Перегрузка
N{t)
1,0
1,3
1,1
0,7
0,7
U
1,3
0,8
0,8
0,4
0,3
0,3
0,6
0,3
0,5
0,5
0,7
0,8
0,6
1,0
0,5
1,0
0,9
1,4
1,4
(сек)
50 .
52
54
56
58
60
62
64
66
68
70
72
74
76
78
80
82
84
86
88
90
92
94
96
98
Перегрузка
Nit)
1,0
1,1
1,5
1,0
0,8
1Д
1,1
1,2
1,0
0,8
0,8
1,2
0,7
0,7
Ы
1,5
1,0
0,6
0,9
0,8
0,8
0,9
0,9
0,6
0,4
t
(сек)
100
102
104
106
108
110
112
114
116
118
120
122
124
126
128
130
132
134
136
138
140
142
144
146
148
Перегрузка
N(t)
1,2
1,4
0,8
0,9
1,0
0,8
0,8
1,4
1,6
1,7
1,3
1,6
0,8
1,2
0,6
1,0
0,6
0,8
0,7
0,9
1,3
1,5
1,1
0,7
1,0
t
(сек)
150
152
154
156
158
160
162
164
166
168
170
172
174
176
178
180
182
184
186
188
190
192
194
196
198
Перегрузка
N(t)
0,8
0,6
0,9
1,2
1,3
0,9
1,3
1,5
1,2
1,4
1,4
0,8
0,8
1,3.
1,0
0,7
1,1
0,9
0,9
1,1
1,2
1,3
1,3
1,6
1,5
Решение. По формуле A7.8.5) имеем:
N
100
а 0,98.
Центрируем случайную функцию (табл. 17.8.2).
Возводя в квадрат все значения N(t) и деля сумму па п = 100, получим
приближенно дисперсию случайной функции N (t):
100
2
100
» 0,1045
30 Е. С. Веитаель
466
СТАЦИОНАРНЫЕ СЛУЧАЙНЫЕ ФУНКЦИИ {ГЛ. 17
Таблица 17.8.2
t
(сек)
0
2
4
6
8
10
12
14
16-
18
20
22
24
26
28
30
32
34
36
38
40
42
44
46
48
N(t)
0,02
0,32
0,12
— 0,28
-0,28
0,12
0,32
— 0,18
— 0,18
— 0,58
— 0,68
— 0,68
— 0,38
— 0,68
— 0,48
— 0,48
— 0,28
— 0,18
— 0,38
0,02
-0,48
0,02
— 0,08
0,42
0,42
(сек)
50
52
54
55
58
60
62
64
66
68
70
72
74
76
78
80
82
84
86
88
90
92
94
96
98
N((\
0,02
0,12
0,52
0,02
— 0,18
0,12
0,12
0,22
0,02
— 0,18
-0,18
0,22
— 0,28
— 0,28
0,12
0,52
0,02
— 0,38
— 0,08
— 0,18
— 0,18
— 0,08
— 0,08
— 0,38
— 0,53
t
(сек)
100
102
104
106
108
ПО
112
114
116
118
120
122
124
126
128
130
132
134
136
138
140
142
144
146
148
N(t)
0,22
0,42
— 0,18
— 0,08
0,02
— 0,18
— 0,18
0,42
0,62
0,72
0,32
0,62
-0,18
0,22
— 0,38
0,02
-0,38
— 0,18
— 0,28
— 0,08
0,32
0,52
0,12
— 0,28
0,02
(сек)
150
152
154
156
158
160
162
164
166
168
170
172
174
176
178
180
182
184
186
188
190
192
194
196
198
N(t)
— 0,18
— 0,38
— 0,08
0,22
0,32
— 0,08
0,32
0,52
0,22
0,42
0,42
— 0,18
— 0,18
0,32 .
0,02
— 0,28
0,12
— 0,08
— 0,08
0,12
0,22
0,32
0,32
0,62
0,52
и среднее квадратическос отклонение:
« 0,323.
Перемножая значения N (t), разделенные интервалом t =
сумму произведений
2, 4, 6, ..., и деля
соответственно на
п— 1" = 99; л —2 = 98; п — 3 = 97
получим значения корреляционной функ-
функции ^V(T)- Нормируя корреляционную
функцию делением на D—0,1045, по-
получим таблицу значений функции р^ (т)
(табл. 17.8.3).
График функции р^ (х) представлен
на рис. 17.8.3 в виде точек, соединенных
пунктиром. Не вполне гладкий ход кор-
корреляционной функции может быгь объ-
объяснен недостаточным объемом экспери-
экспериментальных данных (недостаточной про-
продолжительностью опыта), в связи с чем
случайные неровности в ходе функции
не успевают сгладиться. Вычисление рл„ (-) продолжено до таких значений т,
при которых фактически корреляционная связь пропадает.
17.8]
ОПРЕДЕЛЕНИЕ ХАРАКТЕРИСТИК ЭРГОДИЧЕСКОИ ФУНКЦИИ
467
Для того чтобы сгладить явно незакономерные колебания эксперимен-
экспериментально найденной функции р^ (т), заменим ее приближенно функцией вида:
где параметр а подберем методом наименьших квадратов (см. пс 14.5).
Таблица 17.8.3
т
0
2
4
6
8
10
12
14
1,000
0,505
0,276
0,277
0,231
—0,015
0,014
0,071
1,000
0,598
0,358
0,214
0,128
0,077
0,046
0,027
Применяя этот метод, находим а = 0,257. Вычисляя значения функции pN(t)
яри т = 0, 2, 4, ..., построим график сглаживающей кривой. На рис. 17.8.3
он проведен сплошной линией. В последнем столбце таблицы 17.8.3 приве-
приведены значения функции р^(т).
1
/Ту/.
J/
Ж
А
У/УУ/К
-1
о
Рис. 17.8.4.
Пользуясь приближенным выражением корреляционной функции A7.8.6),
получим (см. п° 17.4, пример 1) нормированную спектральную плотность слу-
случайного процесса в виде:
-* < * _ g = 0.257
°ж 1-ш-' — я („г _|_ Ш2у - @,257а {- а2) *
График нормированной спектральной плотности представлен на рис, 17.8,4,
30*
ГЛАВА 18
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ
18.1. Предмет и задачи теории информации
Теорией информации называется наука, изучающая количествен-
количественные закономерности, связанные с получением, передачей, обработкой
и хранением информации. Возникнув в 40-х годах нашего века из
практических задач теории связи, теория информации в настоящее
время становится необходимым математическим аппаратом при изуче-
изучении всевозможных процессов управления.
Черты случайности, присущие процессам передачи информации,
заставляют обратиться при изучении этих процессов к вероятностным
методам. При этом не удается ограничиться классическими методами
теории вероятностей, и возникает необходимость в создании новых
вероятностных категорий. Поэтому теория информации представляет
собой не просто прикладную науку, в которой применяются вероят-
вероятностные методы исследования, а должна рассматриваться как раздел
теории вероятностей.
Получение, обработка, передача и хранение^ различного рода ин-
информации — непременное условие работы любой управляющей системы.
В этом процессе всегда происходит обмен информацией между раз-
различными звеньями системы. Простейший случай—передача информа-
информации от управляющего устройства к исполнительному органу (передача
команд). Более сложный случай—замкнутый контур управления, в ко-
котором информация о результатах выполнения команд передается уп-
управляющему устройству с помощью так называемой «обратной связи».
Любая информация для того, чтобы быть переданной, должна
быть соответственным образом «закодирована», т. е. переведена на
язык специальных символов или сигналов. Сигналами, передающими
информацию, могут быть электрические импульсы, световые или зву-
звуковые колебания, механические перемещения и т. д.
Одной из задач теории информации является отыскание наиболее
экономных методов кодирования, позволяющих передать заданную
информацию с помощью минимального количества символов. Эта
задача решается как при отсутствии, так и при наличии искаженна
(помех) в канале связи.
18.2] ЭНТРОПИЯ 469
Другая типичная задача теории информации ставится следующим
образом: имеется источник информации (передатчик), непрерывно вы-
вырабатывающий информацию, и канал связи, по которому эта инфор-
информация передается в другую инстанцию (приемник). Какова должна
быть пропускная способность канала связи для того, чтобы канал
«справлялся» со своей задачей, т. е, передавал всю поступающую
информацию без задержек и искажений?
Ряд задач теории информации относится к определению объема
запоминающих устройств, предназначенных для хранения информации,
к способам ввода информации в эти запоминающие устройства и вы-
вывода ее для непосредственного использования.
Чтобы решать подобные задачи, нужно прежде всего научиться
измерять количественно объем передаваемой или хранимой информа-
информации, пропускную способность каналов связи и их чувствительность
к помехам (искажениям). Основные понятия теории информации, из-
излагаемые в настоящей главе, позволяют дать количественное описа-
описание процессов передачи информации и наметить некоторые матема-
математические закономерности, относящиеся к этим процессам.
18.2. Энтропия как мера степени неопределенности
состояния физической системы
Любое сообщение, с которым мы имеем дело в теории .информа-
.информации, представляет собой совокупность сведений о некоторой физи-
физической системе. Например, на вход автоматизированной системы
управления производственным цехом может быть передано сообщение
о нормальном или повышенном проценте брака, о химическом со-
составе сырья или температуре в печи. На вход системы управления
средствами противовоздушной обороны может быть передано сооб-
сообщение о том, что в воздухе находятся две цели, летящие на опре-
определенной высоте, с определенной скоростью. На тот же вход может
быть передано сообщение о том, что на определенном аэродроме
в данный момент находится такое-то количество истребителей в бое-
боевой готовности, или что аэродром выведен из строя огневым воз-
воздействием противника, si.iii 4iu Первая ::,с.:ь с^г.та, о "vhw-i продол-
продолжает полет с измененным курсом. Любое из этих сообщений опи-
описывает состояние какой-то физической системы.
Очевидно, если бы состояние физической системы было известно
заранее, не было бы смысла передавать сообщение. Сообщение при-
приобретает смысл только тогда, когда состояние системы заранее ке-
пзвестпо, случайно.
Поэтому в качестве объекта, о котором передается информация,
г.ш будем рассматривать некоторую физическую систему X, которая
случайным образом может оказаться в том или ином состоянии,
т. с. систему, которой заведомо присуща какая-то степень
470 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ [ГЛ. 18
неопределенности. Очевидно, сведения, полученные о системе,
будут, вообще говоря, тем ценнее и содержательнее, чем больше была
неопределенность системы до получения этих сведений («априори»).
Возникает естественный вопрос: что значит «ббльшая» или «мень-
«меньшая» степень неопределенности и чем можно ее измерить?
Чтобы ответить на этот вопрос, сравним между собой две си-
системы, каждой из которых присуща некоторая неопределенность.
В качестве первой системы возьмем монету, которая в результате
бросания может оказаться в одном из двух состояний: 1) выпал герб
к 2) выпала цифра. В качестве второй — игральную кость, у которой
шесть возможных состояний: 1, 2, 3, 4, 5 и 6. Спрашивается, не-
неопределенность какой системы больше? Очевидно, второй, так как
у нее больше возможных состояний, в каждом из которых она мо-
может оказаться с одинаковой вероятностью.
Может показаться, что степень неопределенности определяется
числом возможных состояний системы. Однако в общем случае это
не так. Рассмотрим, например, техническое устройство, которое мо-
может быть в двух состояниях: 1) исправно и 2) отказало. Предполо-
Предположим, что до получения сведений (априори) вероятность исправной
работы устройства 0,99, а вероятность отказа 0,01. Такая система
обладает только очень малой степенью неопределенности: почти на-
наверное можно предугадать, что устройство будет работать исправно.
При бросании монеты тоже имеется два возможных состояния, но
степень неопределенности гораздо больше. Мы видим, что степень
неопределенности физической системы определяется не только
числом ее возможных состояний, но и вероятностями
состояний.
Перейдем к общему случаю. Рассмотрим некоторую систему X,
которая может принимать конечное множество состояний: xv дг2, ...
.... хп с вероятностями pv р2 рп, где
p.=zP(X~Xl) ; A8.2.1)
— вероятность того, что система X примет состояние xt (символом
A"~je; обозначается событие: система находится в состоянии х;).
п
Очевидно, 2 />/ = 1 •
t=t
Запишем эти данные в виде таблицы, где в верхней строке пе-
перечислены возможные состояния системы, а в нижней — соответствую-
соответствующие вероятности:
| хг | . .
Pi \ Р\ Pi • • • Рп
18.2] ЭНТРОПИЯ 471
Эта табличка по написанию сходна с рядом распределения пре-
прерывной случайной величины X с возможными значениями дгр дг2 ха,
имеющими вероятности pv р2, • ■.. рп- И действительно, между
физической системой X с конечным множеством состояний и пре-
прерывной случайной величиной много общего; для того чтобы свести
первую ко второй, достаточно приписать каждому состоянию какое-то
числовое значение (скажем, номер состояния). Подчеркнем, что для
описания степени неопределенности системы совершенно неважно,
какие именно значения хх, x2, ■■■> хп записаны в верхней строке
таблицы; важны только количество этих значений и их ве-
вероятности.
В качестве меры априорной неопределенности системы (или пре-
прерывной случайной величины X) в теории информации применяется
специальная характеристика, называемая энтропией. Понятие об
энтропии является в теории информации основным.
Энтропией, системы называется сумма произведений вероятностей
различных состояний системы на логарифмы этих вероятностей, взя-
взятая с обратным знаком:
tt(;0 = -i;^iogV). A8.2.2)
Энтропия Н(Х), как мы увидим в дальнейшем, обладает рядом
свойств, оправдывающих ее выбор в качестве характеристики степени
неопределенности. Во-первых, она обращается в нуль, когда одно из
состояний системы достоверно, а другие — невозможны. Во-вторых,
при заданном числе состояний она обращается в максимум, когда
эти состояния равновероятны, а при увеличении числа состояний —
увеличивается. Наконец, и это самое главное, она обладает свойством
аддитивности, т. е. когда несколько независимых систем объеди-
объединяются в одну, их энтропии складываются.
Логарифм в формуле A8.2.2) может быть взят при любом осно-
основании а > 1. Перемена основания равносильна простому умножению
энтропии на постоянное число, а выбор основания равносилен вы-
выбору определенной единицы измерения энтропии. Если за основа-
основание выбрано число iO, ;o ;oisop-if о десятмчгнк единицах» энтро-
энтропии, если 2— о «двоичных единицах». На практике удобнее всего
пользоваться логарифмами при основании 2 и измерять энтропию
в двоичных единицах; это хорошо согласуется с применяемой в эле-
электронных цифровых вычислительных машинах двоичной системой
счисления.
В дальнейшем мы будем везде, если не оговорено противное,
под символом log понимать двоичный логарифм.
') Знак минус перед суммой поставлен для того, чтобы энтропия была
лс;:е:к;:тедь;:ой (числя /?,- меньше единицы и их логарифмы отрицательны).
472
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ
{ГЛ. 18
В приложении (табл. 6) даны двоичные логарифмы целых чисел
от 1 до 1001).
Легко убедиться, что при выборе 2 в качестве основания лога-
логарифмов за единицу измерения энтропии принимается энтропия про-
простейшей системы X, которая имеет два равновозможных состояния:
Pi
1
т
Действительно, по формуле A8.2.2) имеем:
= -A log i-r-Ilo
Определенная таким образом единица энтропии называется «дво-
«двоичной единицей» и иногда обозначается bit (от английского «binary
digit» — двоичный знак). Это энтропия одного разряда двоичного
числа, если он с одинаковой вероятностью может быть нулем или
единицей.
Измерим в двоичных единицах энтропию системы X, которая
имеет п равновероятных состояний:
Имеем:
или
xt
Pi
Xi
1
п
х2
1
п
. . .
Хп
1
п
log
H(X)~logn,
A8.2.3)
т. е. энтропия системы с равновозможными состояниями равна
логарифму числа состояний.
Например, для системы с восемью состояниями Н(X) — !og 8 = 3.
Докажем, что в случае, когда состояние системы в точности из-
известно заранее, ее энтропия равна нулю. Действительно, в этом слу-
случае все вероятности р,, р.,, ..., р„ в формуле A8.2.2) обращаются
') Логарифмы дробей находятся вычитанием, например:
log 0,13 = log 13 — log 100.
Для нахождения логарифмов чисел с тремя значащими цифрами можно поль-
пользоваться линейной интерполяцией.
18.21 .. ЭНТРОПИЯ , 473
в нуль, кроме одной — например pk, которая равна единице. Член
pk\ogpk обращается в нуль, так как log 1=0. Остальные члены
тоже обращаются в нуль, так как
lim plog p = 0.
Докажем, что энтропия системы с конечным множеством состоя-
состояний достигает максимума, когда все состояния равновероятны. Для
этого рассмотрим энтропию системы A8.2.2) как функцию вероят-
вероятностей pv p2, .... рп и найдем условный экстремум этой функции
при условии:
п
Z/>< = !• A8.2.4)
Пользуясь методом неопределенных множителей Лагранжа, будем
искать экстремум функции:
п п
F^—iiPilogPi+lZpr A8.2.5)
i=i i=i
Дифференцируя A8.2.5) по р, р„ и приравнивая производные
нулю, получим систему уравнений:
или
logpt — — X — logs (/=1 п), A8.2.6)
откуда видно, что экстремум (в данном случае максимум) достигается
при равных между собой значениях pt. Из условия A8.2.4) видно,
что при этом
А = />2= •••=/>„ = ■■;-. A8.2.7)
а максимальная энтропия системы равна:
#maxW = logn. A8.2.8)
т. е. максимальное значение энтропии системы с конечным числом
состояний pauiio логарифму числа состояний и достигается, когда
все состояния равновероятны.
Вычисление энтропии по формуле A8.2.2) можно несколько упро-
упростить, если ввести в рассмотрение специальную функцию:
I (/») = — Plogp, A8.2.9)
где логарифм берется по основанию 2.
Формула A8.2.2) принимает вид:
1=1
474
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ
(ГЛ. 18
Функция flip) затабулирована; в приложении (табл. 7) приведены
ее значения для р от 0 до 1 через 0,01.
Пример 1. Определить энтропию физической системы, состоящей из двух
самолетов (истребителя и бомбардировщика), участвующих в воздушном бою.
В результате боя система может оказаться в одном из четырех возможных
состояний:
1) оба самолета не сбиты;
2) истребитель сбит, бомбардировщик не сбит;
3) истребитель не сбит, бомбардировщик сбит;
4) оба самолета сбиты.
Вероятности этих состояний равны соответственно 0,2; 0,3; 0,4 и 0,1.
Решение. Записываем условия в виде таблицы:
Pi
Х\
0,2
х%
0,3
0,4
xk
0,1
По формуле A8.2.10) имеем:
Н (X) = т) @,2) + 1) @,3) +1) @,4) + -Ч @,1).
Пользуясь таблицей 7 приложения, находим
1 Н(X) = 0,4644 + 0,5211+0,5288 + 0,3322 « 1,85 (дв. ед.).
Пример 2. Определить энтропию системы, состояние которой описы-
описывается прерывной случайной величиной X с рядом распределения
Xl
Pi
X,
0,01
х»
0,01
х3
0,01
х4
0,01
0,96
Решение.
Н (X) = 4т) @,01) +ц @,96) я 0,322 (дв. ед.).
Пример 3. Определить максимально возможную энтропию системы,
состоящей из трех элементов, каждый из которых может быть в четырех
возможных состояниях.
Решение. Общее число возможных состояний системы равно я=4- 4- 4=64.
Мт-'С'.^ЯЛЫЮ ЗОЗМО"!С1.".Я 0!!'!'рОЛЧП С"СТСЧ';Т p.".Ij;i" \cig 84 - = С (ZJ. сД.).
Пример 4. Определить максимально возможную энтропию сообщения,
состоящего из пяти букв, причем общее число букв в алфавите равно 32.
Решение. Число возможных состояний системы п = 325. Максимально
возможная энтропия равна 5 log 32 = 25 (дв. ед).
Формула A8.2.2) (или равносильная ей A8.2.10)) служит для
непосредственного вычисления энтропии. Однако при выполнении
преобразований часто более удобной оказывается другая форма записи
энтропии, а именно, представление ее в виде математического ожи-
ожидании;
A8.2.11)
18.3]
ЭНТРОПИЯ СЛОЖНОЙ СИСТЕМЫ
475
где logP(X) — логарифм вероятности любого (случайного) состояния
системы, рассматриваемый как случайная величина.
Когда система X принимает состояния xv .... хп, случайная
величина log/5(А') принимает значения:
l0g/»i. l0g/>2
A8.2.12)
Среднее значение (математическое ожидание) случайной величины
■—logP(X) и есть, как нетрудно убедиться, энтропия системы X.
Для ее получения значения A8.2.12) осредняются с «весами», равными
соответствующим вероятностям pv p2, ..., рп.
Формулы, подобные A8.2.11), где энтропия представляется в виде
математического ожидания, позволяют упрощать преобразования, свя-
связанные с энтропией, сводя их к применению известных теорем
о математических ожиданиях.
18.3. Энтропия сложной системы.
Теорема сложения энтропии
На практике часто приходится определять энтропию для сложной
системы, полученной объединением двух или более простых систем.
Под объединением двух систем А" и К с возможными состояниями
хх хп; У1 ут понимается сложная система (А", К), состоя-
состояния которой (xt, yj) представляют собой все возможные комбинации
состояний JCj, y>j систем X и Y.
Очевидно, число возможных состояний системы (X, Y) равно
л X гп. Обозначим Рц вероятность того, что система (А", К) будет
в состоянии (х,-, уу):
PG = P((A-~*J)(K~y7)). A8.3.1)
Вероятности Ptj удобно расположить в виде таблицы (матрицы)
У\
У2
Ут
|
Рп
Рп
к.
Ргг
•
Ргт .
■ ■ ■
Р«х
Рп,
■
Рпт
476 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ ■ [ГЛ. 18
Найдем энтропию сложной системы. По определению она равна
сумме произведений вероятностей всех возможных ее состояний на их
логарифмы с обратным знаком:
п т
Я (*. К) = - 2 2 *V°g ^ A8-3-2)
или, в других обозначениях:
п т
Н(Х. К)=2 2ч(Я„). A8.3.2')
Энтропию сложной системы, как и энтропию простой, тоже можно
записать в форме математического ожидания:
Н{Х. Y) = M[—\ogP(X, У)}, A8.3.3)
где logP(X, У)—логарифм вероятности состояния системы, рас-
рассматриваемый как случайная величина (функция состояния).
Предположим, что системы X и У независимы, тле. принимают
Свои состояния независимо одна от другой, и вычислим в этом пред-
предположении энтропию сложной системы. По теореме умножения
вероятностей для независимых событий
Р(Х, У)—Р(Х)Р(У),
откуда
log Я (А", У) = log Р (X) + log P (У).
Подставляя в A8.3.3), получим
Н(Х. Y)=M[—logP(X)~logP(Y)].
или
Н(Х, У) = Н{Х)-\-Н(У), A8.3.4)
т. е. при объединении независимых систем их энтропии скла-
складываются,
Доказанное положение называется теоремой сложения
энтропии.
Теорема сложения энтропии может бить легко обобщена па про-
произвольное число независимых систем:
H(XV X2 А>2//Щ. A8.3.5)
Если объединяемые системы зависимы, простое сложение энтропии
уже неприменимо. В этом случае энтропия сложной системы меньше,
чем сумма энтропии ее составных частей. Чтобы найти энтропию
системы, составленной из зависимых элементов, нужно ввести новое
понятие условнойэнтропии.
18.4] УСЛОВНАЯ ЭНТРОПИЯ. ОБЪЕДИНЕНИЕ ЗАВИСИМЫХ СИСТЕМ 477
18.4. Условная энтропия. Объединение зависимых систем
Пусть имеются две системы А" и К, в общем случае зависимые.
Предположим, что система X приняла состояние хг Обозначим Р (у;-1х{)
условную вероятность того, что система Y примет состояние у;- при
условии, что система X находится в состоянии х/.
у/|*~*/). A8.4,1)
Определим теперь условную энтропию системы Y при условии,
что система X находится в состоянии xt. Обозначим ее Н{Y\xt).
По общему определению, имеем:
jJi) A8.4.2)
или
A8.4.2')
2
Формулу A8.4.2) можно также записать в форме математического
ожидания: H(X\xl) = MX([—\ogP(Y\xl)\, A8.4.3)
где знаком Мх обозначено условное математическое ожидание вели-
величины, стоящей в скобках, при условии X ~ xt.
Условная энтропия зависит от того, какое состояние xt приняла
система X; для одних состояний она будет больше, для других —
меньше. Определим среднюю, или полную, энтропию системы Y
с учетом того, что система может принимать разные состояния. Для
этого нужно каждую условную энтропию A8.4.2) умножить на
вероятность соответствующего состояния pt и все такие произведе-
произведения сложить. Обозначим полную условную энтропию H{Y\X):
п
X)=IiPtH(Y\xt) A8.4.4)
или, пользуясь
и
Внося р, под
н,
или
формулой
(У\Х) = -
знак второй
(К 1 А') = —
H(Y\X)
i =
A8.4.2),
п rtt
2 pt 2
суммы,
п т
Zt Z, Pi
i=\ j=l
n m
= 2j Zi
1=1 1=1
1
Р(У}\хд
получим:
P(yf\Xi)
V
\\0g P (у j\Xi).
\ogP{yj\xj)
j\xp)-
A8
A8.
.4
4.
.5)
50
Но по теореме умножения вероятностей рь Р{у^\х{) =
478
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ
[ГЛ. 18
следовательно,
Н(У | X) = - i S Рц log P {у, \Xl).
A8.4.6)
Выражению A8.4.6) тоже можно придать форму математического
ожидания:
= M[—\ogP(Y\X)]. A8.4.7)
Величина Н(У\Х) характеризует степень неопределенности си-
системы У, остающуюся после того, как состояние системы X пол-
полностью определилось. Будем называть ее полной условной энтро-
энтропией системы У относительно X.
Пример 1. Имеются две системы X н Y, объединяемые в одну (X, Y);
вероятности состояний системы (X, Y) заданы таблицей
У\
У2
Уг
Pi
х,
0,1
0
0
0,1
0,2
0,3
0,2
0,7
0
0
0,2
0,2
0,3
0,3
0,4
Определить полные условные энтропии Н(У\ X) и Н{Х\ У).
Решение. Складывая вероятности Рц по столбцам, получим вероят-
вероятности р, = Р (X /~ х^:
р,=0,1; рг = 0,7; рг = 0,2.
Записываем их в нижней, добавочной строке таблицы. Аналогично, склады-
складывая Ptj по строкам, найдем:
г, = 0,3; r2 = 0,3; r3 = 0,4 (rf = P(r~yj))
и запишем справа дополнительным столбцом. Деля Р{. на pt, получим таб-
таблицу условных вероятностей Р(у|л):
У\
■ У 2
Уз
Х\
1
0
0
Х2
0,2
0,7
0,3
0,7
0,2
0,7
0
0
1
18.4] УСЛОВНАЯ ЭНТРОПИЯ. ОБЪЕДИНЕНИЕ ЗАВИСИМЫХ СИСТЕМ 479
По формуле A8.4.5') находим H(Y\X). Так как условные энтропии при
X ~> Xi и л ~ х3 равны нулю, то
Пользуясь таблицей 7 приложения, находим
Я(КЦГ)и1,09 (дв. ед.).
Аналогично определим Н{Х\ Y). Из формулы A8.4.5'). меняя местами X
и Y, получим
Составим таблицу условных вероятностей Р(х^у.). Деля Р{. на г., получим:
У1
Уг
Уг
х,
01
0,3
0
0
х%
02
0,3
1
02
0,4
Хг
0
0
0^2
0,4
Отсюда
Пользуясь понятием условной энтропии, можно определить энтро-
энтропию объединенной системы через энтропию ее составных частей.
Докажем следующую теорему:
Если две системы X и Y объединяются в одну, то энтро-
энтропия объединенной системы равна энтропии одной из ее со-
стаспых частей i: i-^c условная энтропия второй части отно-
относительно первой:
Н(Х, V) = H(X)-\-H(Y\X).
A8.4.8)
Для доказательства запишем Н{Х, Y) в форме математического ожк«
дания A8.3.3):
Н(Х, Y)=,M[—logР(Х, У)}.
По теореме умножения вероятностей
Р{Х, Y) = P(X)P(Y\X),
480 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ [ГЛ. 18
следовательно,
logP.(X, Y) = logP (X) + logP(Y\ X),
откуда
Н(X, Y) = М [— logР(X)] + М [- logP(Y\X)]
или, по формулам A8.2.11), A8.3.3)
Н(Х, Y)
что и требовалось доказать.
В частном случае, когда системы X и Y независимы, H{Y\ X) —
= H(Y), и мы получаем уже доказанную в предыдущем п° теорему
сложения энтропии:
Н(Х, Y) = H(X) + H(Y).
В общем случае
Н(Х, Y)*CH(X)-{-H(Y). A8.4.9)
Соотношение A8.4.9) следует из того, что полная условная энтро-
энтропия H{Y\ X) не может превосходить безусловной:
H(Y\ X)*CH(Y). A8.4.10)
Неравенство A8.4.10) будет доказано в п° 18.6. Интуитивно оно
представляется довольно очевидным: ясно, что степень неопределен-
неопределенности системы не может увеличиться оттого, что состояние какой-то
другой системы стало известным.
Из соотношения A8.4.9) следует, что энтропия сложной системы
достигает максимума в крайнем случае, когда ее составные части
независимы.
Рассмотрим другой крайний случай, когда состояние одной из
систем (например X) полностью определяет собой состояние дру-
другой (Y). В этом случае H{Y\ X) = 0, и формула A8.4.7) дает
Н (X, Y) = H{X).
Если состояние, каждой из систем X, Y однозначно определяет
сосюмние другой (или, как 1оворлг, системы X и Y эквивалентны), то
Н{Х, Y) = H{X) = H{Y).
Теорему об энтропии сложной системы легко можно распростра-
распространить на любое число объединяемых систем:
... +H(XS\XV Xv .... Xs_x), A8.4.11)
где энтропия каждой последующей системы вычисляется при условии,
что состояние всех предыдущих известно.
18.5J ЭНТРОПИЯ И ИНФОРМАЦИЯ 481
18.5. Энтропия и информация
В предыдущих п°п° была определена энтропия как мера неопре-
неопределенности состояния некоторой физической системы. Очевидно, что
в результате получения сведений неопределенность системы может
быть уменьшена. Чем больше объем полученных сведений, чем они
более содержательны, тем больше будет информация о системе, тем
менее неопределенным будет ее состояние. Естественно поэтому коли-
количество информации измерять уменьшением энтропии той си-
системы, для уточнения состояния которой предназначены сведения.
Рассмотрим некоторую систему X, над которой производится
наблюдение, и оценим информацию, получаемую в результате того,
что состояние системы X становится полностью известным. До полу-
получения сведений (априори) энтропия системы была Н(Х); после полу-
получения сведений состояние системы полностью определилось, т. е.
энтропия стала равной нулю. Обозначим I x информацию, получаемую
в результате выяснения состояния системы X. Она равна уменьше-
уменьшению энтропии:
или
1Х = Н(Х), A8.5.1)
т. е. количество информации, приобретаемое при полном
выяснении состояния некоторой физической системы, равно
энтропии этой системы.
Представим формулу A8.5.1) в виде:
л
Ix = -^Pi^SPi' A8.5.2)
где pi=P(X'-^xl).
Формула A8.5.2) означает, что информация 1Х есть осредненное
по всем состояниям системы значение логарифма вероятности состоя-
состояния с обратным знаком.
Действительно, для получения Ix каждое значение log p, (лога-
ркфм вероятности 1-го сосюяник) со заткем г.пшус множится на
вероятность этого состояния и все такие произведения складываются.
Естественно каждое отдельное слагаемое —log" /Jj- рассматривать как
частную информацию, получаемую от отдельного сообщения,
состоящего в том, что система X находится в состоянии xt. Обо-
Обозначим эту информацию 1Х.\
Ix. = —logPl. A8.5.3)
Тогда информация 1Х представится как средняя (или полная)
информация, получаемая от всех возможных отдельных сообщений
31 Е. С. Вснтцель
482 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ [ГЛ. 18
с учетом их вероятностей. Формула A8.5.2) может быть переписана
в форме математического ожидания:
Ix = M\~\ogP{X)], A8.5.4)
где буквой X обозначено любое (случайное) состояние системы X.
Так как все числа pt не больше единицы, то как частная инфор-
информация /*., так и полная /х не могут быть отрицательными.
Если все возможные состояния системы априори одинаково ве-
вероятны |/?, = /?2= ... —р„ = ~), то, естественно, частная инфор-
информация 1Х от каждого отдельного сообщения
lx. —
равна средней (полной) информации
В случае, когда состояния системы обладают различными вероят-
вероятностями, информации от разных сообщений неодинаковы: наибольшую
информацию несут сообщения о тех событиях, которые априори были
наименее вероятны. Например, сообщение о том, что 31 декабря
в г. Москве выпал снег, несет гораздо меньше информации, чем
аналогичное по содержанию сообщение, что 31 июля в г. Москве
выпал снег.
Пример 1. На шахматной доске в одной из клеток произвольным об-
образом поставлена фигура. Априори все положения фигуры на доске одинаково
вероятны. Определить информацию, получаемую от сообщения, в какой
именно клетке находится фигура.
Решение. Энтропия системы X с п равновероятными состояниями
равна log n; в данном случае
1Х = Н {X) = log 64 = 6 (дв. ед.), "
т. е. сообщение содержит б двоичных единиц информации. Так как все со-
состояния системы равновероятны, то ту же информацию несет и любое кон-
конкретное сообщение^ типа: фигура находится в квадрате е2.
Пример 2. В условиях примера 1 определить частную информацию от
сообщения, что фигура находится в одной из угловых клеток доски.
Решение. Априорная вероятность состояния, о котором сообщается,
равна
4 _ 1
P~W"W
Частная информация равна
/ = _ log — = 4 (да. ед.).
Пример 3. Определить частную информацию, содержащуюся в сооб-
сообщении впервые встреченного лица А: «сегодня мой день рождения».
J8.5]
ЭНТРОПИЯ И ИНФОРМАЦИЯ
483
Решение. Априори все дни в году с одинаковой вероятностью могут
быть днями рождения лица А. Вероятность полученного сообщения р = ggg •
Частная информация от данного сообщения
/ = — log
8,51 (дв. ед.).
Пример 4. В условиях примера 3 определить полную информацию от
сообщения, выясняющего, является ли сегодняшний день днем рождения
впервые встреченного лица А.
Решение. Система, состояние которой выясняется, имеет два возмож-
возможных состояния: хх — день рождения и хг — не день рождения. Вероятности
1 364
этих состоянии ft = ggg-; p2 =
Полная информация равна:
-™-.
!х = Н(Х) = , ( gig-) + ч (Ц) * 0,063 (дв. ед.).
Пример 5. По цели может быть произведено п независимых выстре-
выстрелов; вероятность поражения цели при каждом выстреле равна р. После ft-f©
выстрела A ■< k < п) производится разведка, сообщающая, поражена или не
поражена цель; если она поражена, стрельба по ней прекращается. Опреде-
Определить k из того условия, чтобы количество информации, доставляемое развед-
разведкой, было максимально ').
Решение. Рассмотрим физическую систему Хц — цель после ft-ro вы-
выстрела. Возможные состояния системы Хк будут
Xi — цель поражена;
х2 — цель не поражена.
Вероятности состояний даны в таблице:
Pi
1-A-/>)* (!-/>)*
Очевидно, информация, доставляемая выяснением состояния системы
будет максимальна, когда оба состояния хх и хг равновероятны:
1-<!-/>)* = (!-/>)*,
откуда
А== Iog(l —/»>'
где log — знак двоичного логарифма.
Например, при р = 0,2 получаем (округляя до ближайшего целого числа)
') Пример заимствован у И. Я. Динера.
31*
484 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ ГГЛ. 18
Если информация выражена в двоичных единицах, то ей можно
дать довольно наглядное истолкование, а именно: измеряя информа-
информацию в двоичных единицах, мы условно характеризуем ее числом
ответов «да» или «нет», с помощью которых можно приобрести
ту же информацию. Действительно, рассмотрим систему с двумя со-
состояниями:
Pi
Pi
Рг
Чтобы выяснить состояние этой системы, достаточно задать один
вопрос, например: находится ли система в состоянии xt? Ответ «да»
или «нет» на этот вопрос доставляет некоторую информацию, кото-
которая достигает своего максимального значения 1, когда оба состояния
априори равновероятны: рх = р2~ — . Таким образом, максимальная
информация, даваемая ответом «да» или «нет», равна одной двоич-
двоичной единице.
Если информация от какого-то сообщения равна п двоичным еди-
единицам, то она равносильна информации, даваемой п ответами «да»
или «нет» на вопросы, поставленные так, что «да» и «нет» одина-
одинаково вероятны.
В некоторых простейших случаях для выяснения содержания сооб-
сообщения действительно удается поставить несколько вопросов так, чтобы
ответы «да» и «нет» на эти" вопросы были равновероятны. В таких
случаях полученная информация фактически измеряется числом таких
вопросов.
Если же поставить вопросы точно таким образом не удается,
можно утверждать только, что минимальное число вопросов, необхо-
необходимое для выяснения содержания данного сообщения, не меньше, чем
информация, заключенная в сообщении. Чтобы число вопросов было
минимальным, нужно формулировать их так, чтобы вероятности отве-
ответов «да» и «нет» были как можно ближе к -^>
Пример 6. Некто задумал любое целое число X от единицы до восьми:
а нам предлагается угадать его. поставив минимальное число вопросов, на
каждый из которых дается ответ «да» или «нет».
Решение. Определяем информацию, заключенную в сообщении, какое
число задумано. Априори все значения А' от 1 до 8 одинаково вероятны:
Pi — Pi= ... = р% = -ft-» и формула A8.5.2) дает
1Х = log 8 = 3.
Минимальное число uonpoeos, которые нужно поставить для выдсигиил
задуманного числа, не меньше трек.
18.5] ЭНТРОПИЯ И ИНФОРМАЦИЯ . 485
В данном случае можно, действительно, обойтись тремя вопросами, если
сформулировать их так, чтобы вероятности ответов «да» и «нет» были равны.
Пусть, например, задумано число «пять», мы этого не знаем и задаем'
вопросы:
Вопрос 1. Число X меньше пяти?
Ответ. Нет.
(Вывод: X— одно из чисел 5, 6, 7, 8.)
Вопрос 2. Число X меньше семи?
Ответ. Да.
(Вывод: X—одно из чисел 5, 6.)
Вопрос 3. Число X меньше шести?
Ответ. Да.
(Вывод: число X равно пяти.)
Легко убедиться, что тремя такими (или аналогичными) вопросами можно
установить любое задуманное число от-1 до 8 ').
Таким образом, мы научились измерять информацию о системе X,
содержащуюся как в отдельных сообщениях о ее состоянии, так и
в самом факте выяснения состояния. При этом предполагалось, что
наблюдение ведется непосредственно за самой системой X. На прак-
практике это часто бывает не так: может оказаться, что система X непо-
непосредственно недоступна для наблюдения, и выясняется состояние не
самой системы X, а некоторой другой системы К, связанной с нею.
Например, вместо непосредственного наблюдения за воздушными
целями на посту управления средствами противовоздушной обороны
ведется наблюдение за планшетом или экраном отображения воздуш-
воздушной обстановки, на котором цели изображены условными значками.
Вместо непосредственного наблюдения за космическим кораблей
ведется наблюдение за системой сигналов, передаваемых его аппара-
аппаратурой. Вместо текста X отправленной телеграммы получатель наблю-
наблюдает текст У принятой, который не всегда совпадает с X.
Различия между непосредственно интересующей нас системой X
и поддающейся непосредственному наблюдению У вообще могут быть
двух типов:
1) Различия за счет того, что некоторые состояния системы X
не находят отражения в системе К, которая «беднее подробностями»,
чем система X.
2) Различия за счет ошибок: неточностей измерения параметров
системы X и ошибок при передаче сообщений.
Примером различий первого типа могут служить различия, воз-
возникающие при округлении численных данных и вообще при грубой
описании свойств системы X отображающей ее системой У. При-
Примерами различий второго типа могут быть искажения сигналов,
возникающие за счет помех (шумов) в каналах связи, за счет
) Читателю рекомендуется самостоятельно поставить шесть вопросов,
необходимых для выяснения положения фигуры на шахматной доске (см. при-
пример !), и определить число вопросов, достаточное для выяснения задуманной
нарты в колоде из 3d карт.
486 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ (ГЛ. 18
неисправностей передающей аппаратуры, за счет рассеянности
людей, участвующих в передаче информации, и т. д.
В случае, когда интересующая нас система X и наблюдаемая У
различны, возникает вопрос: какое количество информации о си-
системе X дает наблюдение системы У?
Естественно определить эту информацию как уменьшение энтро-
энтропии системы X в результате получения сведений о состоянии
системы У:
). A8.5.5)
Действительно, до получения сведений о системе У энтропия
системы А' была Н (X); после получения сведений «остаточная» эн-
энтропия стала Н(Х\ У); уничтоженная сведениями энтропия и есть
информация /г->х«
Величину A8.5.5) мы будем называть полной (или средней)
информацией о системе X, содержащейся в системе У.
Докажем, что
т. е. из двух систем каждая содержит относительно другой одну и
ту же полную информацию.
Для доказательства запишем энтропию системы (X, У) согласно
теореме на стр. 479, двумя равносильными формулами:
Н(Х, У) — Н(Х)-\-Н(У\Х),
Н(Х, У)=Н{У) -\-Н{Х\У),
откуда
\
или
h+x = lx+Y. A8.5.6)
что и требовалось доказать.
Введем обозначение:
1y++x = 1y-*x — 1x+y A8.5.7)
и будем называть информацию /к«->х полной взаимной информа-
информацией, содержащейся в системах X и У.
Посмотрим, во что обращается полная взаимная информация
в крайних случаях полной независимости и полной зависимости систем.
Если X и У независимы, то Н(У\Х) = Н<У), и
т, е, полная взаимная информация, содержащаяся з независимых си-
системах, равна нулю. Это вполне естественно, так как нельзя полу-
получить сведений о системе, наблюдая вместо нее другую, никак с нею
не связанную.
18.5] ЭНТРОПИЯ И ИНФОРМАЦИЯ . 487
Рассмотрим другой крайний случай, когда состояние системы X
полностью определяет состояние системы Y и наоборот (системы
эквивалентны). Тогда H{X)—H{Y):
A8.5.9)
т. е. получается случай, уже рассмотренный нами выше (формула
A8.5.2)), когда наблюдается непосредственно интересующая нас си-
система X (или, что то же, эквивалентная ей Y).
Рассмотрим случай, когда между системами X и Y имеется жест-
жесткая зависимость, но односторонняя: состояние одной из систем
полностью определяет состояние другой, но не наоборот. Условимся
называть ту систему, состояние которой полностью определяется
состоянием другой, «подчиненной системой». По состоянию подчи-
подчиненной системы вообще нельзя однозначно определить состояние
другой. Например, если система X представляет собой полный текст
сообщения, составленного из ряда букв, a Y — его сокращенный
текст, в котором для сокращения пропущены все гласные буквы,
то, читая в сообщении Y слово «стл», нельзя в точности быть уве-
уверенным, означает оно «стол», «стул», «стал» или «устал».
Очевидно, энтропия подчиненной системы меньше, чем энтропия
той системы, которой она подчинена.
Определим полную взаимную информацию, содержащуюся в си-
системах, из которых одна является подчиненной.
Пусть из двух систем X и У подчиненной является X. Тогда
Н(Х\У) = 0, и
1у++х = Н{Х), A8.5.10)
т. е. полная взаимная информация, содержащаяся в системах,
из которых одна является подчиненной, равна энтропии под-
подчиненной системы.
Выведем выражение для информации /у^._ух не через условную
энтропию, а непосредственно через энтропию объединенной системы
Н(Х, Y) и энтропии ее составных частей Н (X) и Н (Y).
Пользуясь теоремой об энтропии объединенной системы (стр. 479),
получим: Н(Х\У) = Н(Х, У)— И (У)- A8.5.11)
Подставляя это выражение в формулу A8.5.5), получим:.
Iy+->x*=H(X) + H(Y)—H(X. У), A8.5.12)
т. с. полная взаимная информация, содержащаяся в двух си-
системах., равна сумме. энтропии составляющих систем минус-
энтропия объединенной системы.
На основе полученных зависимостей легко вывести общее выра-
выражение для полной взаимной информации в виде математического
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ
[ГЛ. 18
ожидания. Подставляя в A8.5.12) выражения для энтропии:
Н(Х) = М[— logP(X)], H(Y)=M[— logP(K)],
получим
Iу<.+х = Мl~logP(X)—logP(YX+logР(Х. К)]
или
Р(Х, У)
x = M [log-
■]•
Т>СХ)Р(Г)У A8.5.13)
Для непосредственного вычисления полной взаимной информации
формулу A8.5.13) удобно записать в виде
A8.5.14)
где
Пример 1. Найти полную взаимную информацию, содержащуюся в си-
системах X и Y в условиях примера 1 л" 18.4.
Решение. Из примера 1 п° 18.4 с помощью таблицы 7 приложения
получим:
Н (X, Y) = 2,25; Я(Х) = 1Д6; Я(К) = 1,57;
(К) — // (X, К) = 0,48 (дв. ед.).
Пример 2. Физическая система X может находиться в одном из четы-
рех состояний xit хъ х3, хА; соответствующие вероятности даны в таблице
Pi
ОД
0,2
0,4 0,3
При наблюдении за системой X состояния хх и х2 неразличимы; состояния хз
и хА также неразличимы. Сообщение о системе X указывает, находится ли'
она в одном из состояний х{, х2 или же в одном из состояний х3, xf. Полу-
Получено сообш?;!"!?. VKa"biBaroiii,ee. ч ка;;ом из состолп;;п; ::х. Л\ :\.v,i x3, xt - ;i.i-
ходится система X. Определить информацию, заключенную в этом сообщении.
Решение. В данном примере мы наблюдаем не саму систему X,
а подчиненную ей систему Y, которая принимает состояние уь когда система X
оказывается в одном т состояний хь х2, и состояние у2, когда X оказы-
оказывается в одном из состояний х3, х4- Имеем:
г-. = Р (Y -Уд =0,1+0,2 = 0,3;
г2 = Р(У~ у2) = 0,3 -f 0,4 = 0,7.
Находим взаимную информацию, т. е. энтропию подчиненной системы:
— Гх
°'88
18.6] ЧАСТНАЯ ИНФОРМАЦИЯ О СИСТЕМЕ 489
13.6. Частная информация о системе, содержащаяся в сообщении
о событии. Частная информация о событии, содержащаяся
в сообщении о другом событии
В предыдущем п° мы рассмотрели полную (или среднюю) инфор-
информацию о системе X, содержащуюся в сообщении о том, в каком
состоянии находится система Y. В ряде случаев представляет интерес
оценить частную информацию о системе X, содержащуюся в от-
отдельном сообщении, указывающем, что система Y находится в кон-
конкретном состоянии у,. Обозначим эту частную информацию 1у,-+х-
Заметим, что полная (или, иначе, средняя) информация /г->х должна
представлять собой математическое ожидание частной информации для
всех возможных состояний, о которых может быть передано сообщение:
т
A8.6.1)
Придадим формуле A8.5.14), по которой вычисляется 1у-*х (она же
/к^_»л). такой вид, как у формулы A8.6.1):
1 = 1 j=\
j=\ i=\ l
откуда, сравнивая с формулой A8.6.1), получим выражение частной
информации:
Л p{xi\yt)
—-р- A8-6-3)
l
Выражение A8.6.3) и примем за определение частной информации.
Проанализируем структуру этого выражения. Оно представляет собой не
что иное, как осредненное по всем состояниям х1 значение величины
log -—. A8.0.4)
Осреднение происходит с учетом различных вероятностей значений
xv х2, .... х„. Так как система Y уже приняла состояние y/t то
при осреднении значения A8.6.4) множатся не на вероятности pt
состояний хг, а на условные вероятности -р(*г|.Уу).
Таким образом, выражение для частной информации можно запи-
записать в виде условного математического ожидания:
Г р{к\^Л
(х{ \- A8.Ь.5>
490 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ {ГЛ. 18
Докажем, что частная информация /у.->х> так же как и полная,
не может быть отрицательна. Действительно, обозначим;
^Яц A8-6.6)
и рассмотрим выражение
log j—1- ~ log qtJ.
Легко убедиться (см. рис. 18.6.1), что при любом х > 0
lnx<jc —1. A8.6.7)
Полагая в A8.6.7) # = —г, получим:
откуда
На основании A8.6.3) и A8.6.6) имеем:
hj+x = 2 р (xi I
Но
и выражение в фигурной скобке равно нулю; следовательно /у.^х^- 0.
Таким образом, мы доказали, что частная информация о си-
системе -V, заключенная в сообщении о любом состоянии у, си-
системы Y, не может быть отрицательной. Отсюда следует, что
неотрицательна и полная взаимная информация ly^^x (к^к матема-
математическое ожидание неотрицательной случайной величины):
Лч.>х>0. A8.6.9)
Из формулы A8.5.5) для информации: Iy^.^,x = H(л) — Н(Х\Т)
СПРД\/Р"_г\ utq
H(X) — H{X\Y)>0 A8.6,10)
18.6]
ЧАСТНАЯ ИНФОРМАЦИЯ О СИСТЕМЕ
491
т. е. полная условная энтропия системы не превосходит ее
безусловной энтропии1).
Таким образом, доказано положение, принятое нами на веру
в п°18.3.
Рис. 18.6.1.
Для непосредственного вычисления частной информации фор-
формулу A8.6.3) удобно несколько преобразовать, введя в нее вместо
условных вероятностей Р (х,-1 уу) безусловные. Действительно,
P
и формула A8.6.3) принимает вид
1 = 1
Pfj
A8.6.11)
Пример 1. Система (X, Y) характеризуется таблицей вероятностей
У.
ft
од
0,3
0,4
I
0,2
0,4
0,6
Ч
0,3
0,7
Найти частную информацию о системе X, заключенную в сообщении Г
') Заметим, что это справедливо только в отношении полной условней
энтропии; что касаегся частной условной энтропии Н(Х)у,), то она для от-
отдельных yj может быть как больше, так и меньше Н\Х). '
492 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ 1ГЛ. 18
Решение. По формуле A8.6.11) имеем:
_0Л, 0,1 0,2 0,2
'у^х— о3 og 04-03 + 03 g
о,3 og 0,4-0,3 + 0,3 g 0,6-0,3 *
По таблице 6 приложения находим
log oj^g = 1о8 10 -10«12 w - °-263-
02
'og -щ^ = log 20 - log 18 «0,152,
/у +х х — °-333 ' °'2
— °-333 ' °'263 + °-667 " 0.152s;0,013 (дв. ед.).
Мы определили частную информацию о системе X, содержащуюся
в конкретном событии У~у;; т. е. в сообщении «система У нахо-
находится в состоянии ур. Возникает естественный вопрос: а нельзя ли
пойти еще дальше и определить частную информацию о событии
Х'~^х[, содержащуюся в событии У~у(? Оказывается, это можно
сделать, только получаемая таким образом информация «от события
к событию» будет обладать несколько неожиданными свойствами:
она может быть как положительной, так и отрицательной.
Исходя из структуры формулы A8.6.3), естественно определить
информацию «от события к событию» следующим образом:
Р(х,\у>)
V.*, = l°g -~-> A8.6.12)
т. е. частная информация о событии, получаемая в резуль-
результате сообщения о другом событии, равна логарифму отно-
отношения вероятности первого события после сообщения к его же
вероятности до сообщения {априори).
Из формулы A8.6.12) видно, что если вероятность события
X — X; в результате сообщения У—у} увеличивается, т. е.
то информация 1У,+Х. положительна; в противном случае она отри-
отрицательна. В частности, когда появление события V — у,- полностью
исключает есзможкость появления соСшня Л"<—'Л'{ ^. ё. когда эти
события несовместны), то
Информацию 'у.+х. можно записать в виде:
Р (xi) у/) Pif -
/yj^=log -12-= iOg-JL, A8.6.13)
из чего следует, что она симметрична относительно xt и yj, и
h h 1 A8.6.14)
18.7) ЭНТРОПИЯ ДЛЯ СИСТЕМ С НЕПРЕРЫВН. МНОЖЕСТВОМ СОСТОЯН. 493
Таким образом, нами введены три вида информации:
1) полная информация о системе X, содержащаяся в системе Y:
2) частная информация о системе X, содержащаяся в событии
(сообщении) Y ~ yf.
3) частная информация о событии X~xt, содержащаяся в со-
событии (сообщении) К ~ у у.
Первые два типа информации неотрицательны; последняя может
быть как положительной, так и отрицательной.
Пример 2. В урне 3 белых и 4 черных шара. Из урны вынуто 4 шара,
три из них оказались черными, а один —белым. Определить информацию
заключенную в наблюденном событии В по отношению к событию А — сле-
следующий вынутый из урны шар будет черным.
Решение.
Г» / Л 1 Г>\ 1 /О
— 0,779 (дв. ед.).
" * Р (А) ~ ""б 4/7
18.7. Энтропия и информация для систем с непрерывным
множеством состояний
До сих пор мы рассматривали физические системы, различные
состояния которых xv x2 хп можно было все перечислить;
вероятности этих состояний были какие-то отличные от нуля вели-
величины pv p2, ..., рп. Такие системы аналогичны прерывным (диск-
(дискретным) случайным величинам, принимающим значения xv x2 хл
с вероятностями ру р2 рп. На практике часто встречаются
физические системы другого типа, аналогичные непрерывным случай-
случайным величинам. Состояния таких систем нельзя перенумеровать: они
непрерывно переходят одно в другое, причем каждое отдельное со-
состояние имеет вероятность, равную нулю, а распределение вероят-
вероятностей характеризуется некоторой плотностью. Такие системы,
по аналогии с непрерывными случайными величинами, мы будем на-
зь,:;з:ь ".^-"pjp'.irivb'-M1». в отличие от ранее рассмотренных, кото-
которые мы будем называть «дискретными». Наиболее простой пример
непрерывной системы — это система, состояние которой описывается
одной непрерывной случайной величиной X с плотностью распре-
распределения {(х). В более сложных случаях состояние системы описы-
описывается несколькими случайными величинами Xv Х2 Xs с плот-
плотностью распределения f {xv x2 xs). Тогда ее можно рассматри-
рассматривать как объединение (A'j, X 2- ■ ■ ■ • Х3) простых систем Xt, Х2, .,., X л.
Рассмотрим простую систему X, определяемую одной непрерыв-
непрерывной случайной величиной X с пдошосгью распределения / (х)
494
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ
[ГЛ. 18
Рис. 18.7.1,
(рис. 18.7.1). Попытаемся распространить на эту систему введенное
в п° 18.1 понятие энтропии.
Прежде всего отметим, что понятие «непрерывной системы», как
и понятие «непрерывной случайной величины», является некоторой
идеализацией. Например,
I f(x) когда мы считаем величину
X — рост наугад взятого че-
человека— непрерывной слу-
случайной величиной, мы отвле-
отвлекаемся от того, что факти-
фактически никто не измеряет
рост точнее, чем до 1 см,
и что различить между собой
два значения роста, разня-
разнящиеся, скажем, на 1 мм,
практически невозможно.
Тем не менее данную слу-
случайную величину естественно описывать как непрерывную, хотя можно
было бы описать ее и как дискретную, считая совпадающими те зна-
значения роста, которые различаются менее чем на 1 см.
Точно таким образом, установив предел точности измерений, т. е.
некоторый отрезок кх, в пределах которого состояния системы X
практически неразличимы,
можно приближенно свести
непрерывную систему X к
дискретной. Это равносильно
замене плавной кривой f(x)
ступенчатой, типа гисто-
гистограммы (рис. 18.7.2); при
этом каждый участок (раз-
(разряд) длины Дх заменяется
одной точкой-представите-
точкой-представителем. Площади прямоуголь-
прямоугольников изображают вероят-
вероятности попадания в соответ-
соответствующее разряди: f{xL)lx. Если услог,::;хсл считать неразли-
неразличимыми состояния системы, относящиеся к одному разряду, и объе-
объединить их все в одно состояние, то можно приближенно определить
энтропию системы X, рассматриваемой с точностью до Lxx
И,х (X) = - S / (*,) Д* log 1/ (*<) Ах) =
= - 2 / <*;) Дат {log / (х,) + log Дх} =*
= - 2 {/(*,) tog/(x,)] Ax —log Ax 2/"(*,) Ах. A8-7.1)
Рис. 18.7.2.
18.7] ЭНТРОПИЯ ДЛЯ СИСТЕМ С НЕПРЕРЫВН. МНОЖЕСТВОМ СОСТОЯН. 495
При достаточно малом Дх
ff(x)dx = l,
i -oo
и формула A8.7.1) принимает вид:
оо
= — ff(x)logf(x)dx — logbx. A8.7.2)
Заметим, что в выражении A8.7.2) первый член получился совсем
не зависящим от Дх— степени точности определения состояний си-
системы. Зависит от Дх только второй член (—logAje), который стре-
стремится к бесконечности при Дх—>0. Это и естественно, так как чем
точнее мы хотим задать состояние системы X, тем большую степень
неопределенности мы должны устранить, и при неограниченном умень-
уменьшении Дх эта неопределенность растет тоже неограниченно.
Итак, задаваясь произвольно малым «участком нечувствительно-
нечувствительности» Дх наших измерительных приборов, с помощью которых опре-
определяется состояние физической системы X, можно найти энтропию
Ньх(Х) по формуле A8.7.2), в которой второй член неограниченно
растет с уменьшением кх. Сама энтропия Н^х (X) отличается
от этого неограниченно растущего члена на независимую от Дх
величину
оо
= — ff(x)logf(x)dx. A8.7.3)
Эту величину можно назвать «приведенной энтропией» непрерывной
системы X. Энтропия Н^Х(Х) выражается через приведенную энтро-
энтропию Я* (А') формулой
1о%Ьх. A8.7.4)
Соотношение A8.7.4) можно истолковать следующим образом:
от точности измерения Дх зависит только начало отсчета, при
котором вычисляется энтропия.
В дальнейшем для упрощения записи мы будем опускать ин-
индекс Д# в обозначении энтропии и писать просто Н{Х)\ наличие Дл
в правой части всегда укажет, о какой точности идет речь.
Формуле A8.7.2) для энтропии можно придать более компактный
вид, если, как мы это делали для прерывных величин, записать ее
в виде математического ожидания функции. Прежде всего перепишем
496 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ [ГЛ. 18
A8.7.2) в виде
ОО
Н(Х)= — f f(x)\og{f(x)Ax\dx. A8.7.5)
— ОО
Это есть не что иное, как математическое ожидание функции
— log {/(,Y) Дх} от случайной величины X с плотностью f(x):
= M[-\og{f(X)Ax}]. A8.7.6)
Аналогичную форму можно придать величине Н*(Х):
H*(X) = M[-\ogf(X)]. A8.7.7)
Перейдем к определению условной энтропии. Пусть имеются две
непрерывные системы: X и У. В общем случае эти системы зави-
зависимы. Обозначим f{x, у) плотность распределения для состояний
объединенной системы (X, К); fl(x) — плотность распределения си-
системы X; /2(У)—плотность распределения системы У; f (у\х),
f{x\y) — условные плотности распределения.
Прежде всего определим частную условную энтропию
Н(У\х), т. е. энтропию системы У при условии, что система X при-
приняла определенное состояние х. Формула для нее будет аналогична
A8.4.2), только вместо условных вероятностей Р(У;|*г) будут стоять
условные законы распределения f(y\x) и появится слагаемое A
= — ff(y\x)logf(y\x)dy — loghy. A8.7.8)
— ОО
Перейдем теперь к полной (средней) условной энтропии Н (У\Х);
для этого нужно осреднить частную условную энтропию Н(У\х)
по всем состояниям х с учетом их вероятностей, характеризуемых
плотностью /) (х):
ОО
H(Y\X) = — f f f1(x)f(y\x)logf(y\x)dxdy — log£Ly A8.7.9)
— ОО
или, учитывая, что
/(*, у) = /,(*)/(уИ.
ОО
H(Y\X) = — f f f(x, y)logf(y\x)dxdy~logby. A8.7.10)
— ОО
Иначе эта формула может быть записана в виде
H{Y\X)= M[—\ogf{Y\X)] — \ogby A8.7.1I)
или
A8.7.12)
18.7] ЭНТРОПИЯ ДЛЯ СИСТЕМ С НЕПРЕРЫВН. МНОЖЕСТВОМ СОСТОЯН. 497
Определив таким образом условную энтропию, покажем, как она
применяется при определении энтропии объединенной системы.
Найдем сначала энтропию объединенной системы непосредственно.
Если «участками нечувствительности» для систем X и У будут Ах и
Ду, то для объединенной системы (X, Y) роль их будет играть эле-
элементарный прямоугольник Ах Ду. Энтропия системы (X, Y) будет
Н(Х, Y) == М [— log (/ (X, Н)Д*Ду}]. A8.7.13)
Так как
f(x, y) = f,(x)f(y\x),
то и
f(X,Y) = fl(X)f(Y\X). A8.7.14)
Подставим A8.7.14) в A8.7.13):
Н (X, У) = М [— log fx (X) — log / (У | X) — log Дат — log Ay] =
= M[~log(fl(X)Ax)]-i-M[-log(f(y\X)Ay)]t
или, по формулам A8.7.6) и A8.7.12),
H(X, Y) = H(X)-+H{Y\X), A8.7.15)
т. е. теорема об энтропии сложной системы остается в силе и для
непрерывных систем.
Если X и У независимы, то энтропия объединенной системы
равна сумме энтропии составных частей:
И(Х, Y) = H(X)+H(Y). A8.7.16)
Пример 1. Найти энтропию непрерывной системы X, все состояния
которой на каком-то участке (а, Р) одинаково вероятны:
при х < а или х > р.
Н*(Х) = - f j~ log -gJL- dx = log (P - a);
//(*) = tog ((*-<*)-log 4*
или
= !og-b^-. A8.7.17)
Пример 2. Найти энтропию системы X, состояния которой распреде-
распределены по нормальному закону:
9*2
32 Е. С. Бентцель
498 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ [ГЛ. 18
Решение.
Н*{Х) = М {- log / (*)] = М [- log ( —L- е~^ j J =
log e] = fog (У 2£ а) + ^Я!1 log e.
Ho
M [JV2] = D [X] = cr2,
//* (X) = log <У 2S cr) + I loge = lo
= log (У2Й a) - log Д* = log [^r1] • A8.7.18)
Пример З. Состояние самолета характеризуется тремя случайными
величинами: высотой Н, модулем скорости V и углом 8, определяющим
направление полета. Высота самолета распределена с равномерной плотностью
на участке (Лр Л2); скорость V — по нормальному закону с м.о. va и с.к.о. av;
угол в — с равномерной плотностью на участке @, it). Величины Н, V, в не-
независимы. Найти энтропию объединенной системы.
Решение.
Из примера 1 (формула A8.7.17)) имеем
tf(tf)=Iog ftft
ДЛ
где ДЛ — «участок нечувствительности» при определении высоты.
Так как энтропия случайной величины не зависит от ее математического
ожидания, то для определения энтропии величины V воспользуемся формулой
A8.7.18):
Энтропия величины 6:
Окончательно имеем:
„{Н, у, 0} = log *L=*L + !og Щ^ + Iog JL
или
{^>qg^} A8.7.19)
Заметим, что каждый из сомножителей под знаком фигурной скобки имеет
один и тот же смысл: он показывает, сколько «участков нечувствительности»
укладывается в некотором характерном для данной случайной величины от-
отрезке. В случае распределения с равномерной плотностью этот участок пред-
представляет собой просто участок возможных значений случайной величины;
в,случае нормального распределения этот участок равен У2пе я, где а — сред-
среднее квадратическое отклонение.
18.7] ЭНТРОПИЯ ДЛЯ СИСТЕМ С НЕПРЕРЫВН. МНОЖЕСТВОМ СОСТОЯН. 499
Таким образом, мы распространили понятие энтропии на случай
непрерывных систем. Аналогично может быть распространено и поня-
понятие информации. При этом неопределенность, связанная с наличием
в выражении энтропии неограниченно возрастающего слагаемого, отпа-
отпадает: при вычислении информации, как разности двух энтропии, эти
члены взаимно уничтожаются. Поэтому все виды информации, связан-
связанные с непрерывными величинами,
оказываются не зависящими от
«участка нечувствительности» Lx. -г£Е
Выражение для полной взаим-
взаимной информации, содержащейся
в двух непрерывных системах X
и К, будет аналогично выражению A8.5.4), но с заменой вероятностей
законами распределения, а сумм — интегралами:
и
Рис. 18.7.3.
ЖШ
A8-7>20)
или, применяя знак математического ожидания,
К, Y)
:М
[log7I
A8.7.21)
Полная взаимная информация /к<_>х> как и в случае дискретных си-
систем, есть неотрицательная величина, обращающаяся в нуль только
тогда, когда системы X и Y
независимы.
Пример 4. На отрезке @, 1)
выбираются случайным образом,
независимо друг от друга, две
точки U и V; каждая из них рас-
распределена на этом отрезке с равно-
равномерной плотностью. В результате
опыта одна из точек легла правее,
другая — левее. Сколько информа-
информации о положении правой точки
дает значение положения левой?
Решение. Рассмотрим две
C."vii;!Hi;№- ТОЧКИ U И V iia ОСИ
абсцисс Ох (рис. 1о.7.о). Обозна-
Обозначим Y абсциссу той из них, ко-
которая оказалась слева, а Х-т-абс-
Х-т-абсциссу той, которая оказалась
справа (на рис. 18.7.3 слева оказа-
оказалась точка U, но могло быть и
о
■xdz
Рис, 18.7.4.
наоборот). Величины X и Y определяются через U и V следующим o6pa3oni
Y = min {U, V)i X = max {U, V).
Найдем закон распределения системы (X, Y). Так как Y < X, то он будет
существовать только в области D, заштрихованной на рис. 18.7.4. Обозначим
32*
500
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ
[ГЛ 18
/ (х, у) плотность распределения системы (X, Y) и найдем элемент вероятности
f(x, y)dxdy, т. е. вероятность того, что случайная точка (X, Y) попадет
в элементарный прямоугольник (х, х -\- dx; у, у -f- dy). Это событие может
произойти двумя способами: либо слева окажется точка U, а справа V, либо
наоборот. Следовательно,
/ (х, у) dx dy = 9 (х, у) dx dy -f- ? (у, x) dx dy,
где <f (и, f) обозначена плотность распределения системы величин (if, V).
В данном случае
следовательно,
ч> С*, у) = ? (у. -v) = 1;
/ (х, у) dx dy = 2 dx dy
-J
О при (х, у) ф D.
Найдем теперь законы распределения отдельных величин, входящих
в систему:
X
Idy = 2х при 0 < х < 1;
-оо О
аналогично
оо 1
2 dx = 2 A — у) при 0 < )
— оо У
Графики плотностей fl (x) и /2 (у) изображены на рис. 18.7.5.
Подставляя / (х, у), /i (x) и /2 (у) в формулу A8.7.20), получим
(О)
-щ
(О)
18.7] ЭНТРОПИЯ ДЛЯ СИСТЕМ С НЕПРЕРЫВН. МНОЖЕСТВОМ СОСТОЯН. 501
В силу симметрии задачи последние два интеграла равны, и
1 х 1
1п *dx f d* = ~! - ш 12х ln *dx
=-1 —ш 11п *dx f d* = ~! - ш 1
0 0 0
= -г—2 — 1 ~ °.44 (дв. ед.).
Пример 5. Имеется случайная величина X, распределенная по нор-
нормальному закону с параметрами тх = 0, ах. Величина X измеряется с ошиб-
ошибкой Z, тоже распределенной по нормальному закону с параметрами тг = 0, аг.
Ошибка Z не зависит от X. В нашем распоряжении — результат измерения,
т. е. случайная величина
Определить, сколько информации о величине X содержит величина К.
Решение. Воспользуемся для вычисления информации формулой
A8.7.21), т. е. найдем ее как математическое ожидание случайной величины
т- <ш-22>
Для этого сначала преобразуем выражение
log
og
/i (*) Л (У) ~ 6 /. <*) Л (У) ~ * Л (у) '
В нашем случае
У
Л(У) = -7=- 1
-Jf)'
(у--«-):
2
1
f(y\x)= e (см. главу 9).
V 2я °г
Выражение A8.7.22) равно:
Отсюда
/Л+7 1 \ м\гЦ м[гЦ 1
A8.7,3)
602 основные понятия теории информации [гл. ia
Но tnz— ffiy = 0, следовательно,
М [Z2] = D [Z] = a», j
Подставляя A8.7.24) в A8.7.23), получим
1/ 2 _i 2
■- log (дв. ед.)').
Например, при ix = vz
Iy<~>x= log/^=2" (дв. ед.).
Если о =4; ог = 3, то /j,^x= log-х- а 0,74 (дв. ед.).
18.8. Задачи кодирования сообщений. Код Шеинона — Фэно
При передаче сообщений по линиям связи всегда приходится
пользоваться тем или иным кодом, т. е. представлением сообщения
в виде ряда сигналов. Общеизвестным примером кода может слу-
служить принятая в телеграфии для передачи словесных сообщений азбука
Морзе. С помощью этой азбуки любое сообщение представляется
в виде комбинации элементарных сигналов: точка, тире, пауза (про-
(пробел между буквами), длинная пауза (пробел между словами).
Вообще кодированием называется отображение состояния одной
физической системы с помощью состояния некоторой другой. Напри-
Например, при телефонном разговоре звуковые сигналы кодируются в виде
электромагнитных колебаний, а затем снова декодируются, превра-
превращаясь в звуковые сигналы на другом конце линии. Наиболее простым
случаем кодирования является случай, когда обе системы X к У
(отображаемая и отображающая) имеют конечное число возможных
состояний. Так обстоит дело при передаче записанных буквами сооб-
сообщений, например, при телеграфировании. Мы ограничимся рассмотре-
рассмотрением этого простейшего случая кодирования.
Пусть имеется некоторая система X (например, буква русского
алфавита), которая может случайным образом принять одно из состоя-
состояний xv x2 ха. Мы хотим отобразить ее (закодировать) с пи-
мощью другой системы К, возможные состояния которой уу, у2, ..., ут.
Если т <Сп (число состояний системы У меньше числа состояний
системы X), то нельзя каждое состояние системы X закодировать с по-
помощью одного-единственного состояния системы Y. В таких случаях
одно состояние системы X приходится отображать с помощью опре-
определенной комбинации (последовательности) состояний системы Y. Так,
в азбуке Морзе буквы отображаются различными комбинациями эле-
') Применяя формулу (Ш.7.20), можно было бы прийти к тому же ре-
результату, но более громоздким способом.
IS.8] ЗАДАЧИ КОДИРОВАНИЯ СООБЩЕНИЙ. КОД ШЕННОНА — ФЭНО 503
ментарных символов (точка, тире). Выбор таких комбинаций и уста-
установление соответствия между передаваемым сообщением и этими ком-
комбинациями и называется «кодированием» в узком смысле слова.
Коды различаются по числу элементарных символов (сигналов),
из которых формируются комбинации, иными словами — по числу воз-
возможных состояний системы Y. В азбуке Морзе таких элементарных
символов четыре (точка, тире, короткая пауза, длинная пауза). Пере-
Передача сигналов может осуществляться в различной форме: световые
вспышки, посылки электрического тока различной длительности, зву-
звуковые сигналы и т. п. Код с двумя элементарными символами @ и 1)
называется двоичным. Двоичные коды широко применяются на прак-
практике, особенно при вводе информации в электронные цифровые вы-
вычислительные машины, работающие по двоичной системе счисления.
Одно и то же сообщение можно закодировать различными спосо-
способами. Возникает вопрос об оптимальных (наивыгоднейших) способах
кодирования. Естественно считать наивыгоднейшим такой код, при
котором на передачу сообщений затрачивается минимальнее время,
Если на передачу каждого элементарного символа (например 0 или 1)
тратится одно и то же время, то оптимальным будет такой код,
при котором на передачу сообщения заданной длины будет затрачено
минимальное количество элементарных символов.
Предположим, что перед нами поставлена задача: закодировать
двоичным кодом буквы русской азбуки так, чтобы каждой букве
соответствовала определенная комбинация элементарных символов 0 и 1
и чтобы среднее число этих символов на букву текста было мини-
минимальным.
Рассмотрим 32 буквы русской азбуки: а, б, в, г, д, е, ж, з, и,
й, к, л, м, н, о, п, р, с, т, у, ф, х, ц, ч, ш, щ, ъ, ы, ь, э, ю, я
плюс промежуток между словами, который мы будем обозначать «—».
Если, как принято в телеграфии, не различать букв ъ и ь (это не
приводит к разночтениям), то получится 32 буквы: а, б, в, г, д, е,
ж, з, и, й, к, л, м, н, о, п, р, с, т, у, ф, х, ц, ч, ш, щ, (ъ, ь),
ы, э, ю, я, «—».
Первое, что приходит в голову — это, не меняя порядка букв,
занумеровать их подряд, приписав им номера от 0 до 31, и затем
перевести нумерацию в двоичную систему счисления. Двоичная си-
система — это такая, в которой единицы разных разрядов представляют
собой разные степени двух. Например, десятичное число 12 изобра-
изобразится в виде
12 = 1 -23H-i •224-0-2I-j-0-2°
и в двоичной системе запишется как 1100. ■
Десятичное число 25 —
оя ^ 1 . 24-f 1 • 23-4- 0 ■ 22-f- 0 • 23 -4- 1 • 2°
— запишется в двоичной системе как, 11001,,
504
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ
[ГЛ 18
Каждое из чисел 0, 1, 2 31 может быть изображено пяти-
пятизначным двоичным числом. Тогда получим следующий код:
а
б
в
г
я
»
~00000
— 00001
— 00010
— 00011
— НПО
~ 11111
В этом коде на изображение каждой буквы тратится ровно 5
элементарных символов. Возникает вопрос, является ли этот простей-
простейший код оптимальным и нельзя ли составить другой код, в котором
на одну букву будет в среднем приходиться меньше элементарных
символов?
Действительно, в нашем коде на изображение каждой буквы —
часто встречающихся «а», «е», «о» или редко встречающихся «щ»,
«э», «ф»—тратится одно и то же число элементарных символов.
Очевидно, разумнее было бы, чтобы часто встречающиеся буквы были
закодированы меньшим числом символов, а реже встречающиеся —
ббльшим.
Чтобы составить такой код, очевидно, нужно знать частоты букв
в русском тексте. Эти частоты приведены в таблице 18.8.1. Буквы
в таблице расположены в порядке убывания частот.
Таблица 18.8.1
Буква
«—•»
О
е
а
и
1
н
с
Частота
0,145
0,095
0,074
0,064
0,064
0,0оо
0,056
0,047
Буква
р
В
л
к
м
д
п
У
Частота
0,041
0,039
0,036
0,029
0,02E
0,0*0
0,024
0,021
Буква
я
ы
3
ъ, ь
б
г
ч
и
Частота
0,019
0,016
0,015
0,015
0,015
0,014
0,013
0,010
Буква
- х
Ж
ю
ш
ц
щ
э
ф
Частота
0,009.
0,008
0,007
0,006
0,00 \
0,003
0,003
0,002
Пользуясь такой таблицей, можно составить наиболее экономич-
экономичный код на основе соображений, связанных с количеством информа-
информации Очевидно код бггдрт сямым экономичным, когда каждый эле-
элементарный символ будет передавать максимальную информацию.
Раи;мо1рим элементарный символ (т. e. изображающий его сигнал)
как физическую систему с двумя возможными состояниями: 0 и 1.
18.81 ЗАДАЧИ КОДИРОВАНИЯ СООБЩЕНИЙ. КОД ШЕННОНА - ФЭНО
505
Информация, которую дает этот символ, равна энтропии системы
и максимальна в случае, когда оба состояния равновероятны; в этом
случае элементарный символ передает информацию 1 (дв. ед.).
Поэтому основой оптимального кодирования будет требование, чтобы
элементарные символы в закодированном тексте встречались в сред-
среднем одинаково часто.
Таблица 18.8.2
Изложим здесь способ построения кода, удовлетворяющего по-
поставленному условию; этот способ известен под названием «кода
Шеннона — Фзно». Идея его сонои* в том,что кодируемы; символы
(буквы или комбинации букв) разделяются на две приблизительно
равновероятные группы: для первой группы символов на первом месте
комбинации ставится 0 (первый знак двоичного числа, изображающего
символ); для второй группы — 1. Далее каждая группа снова делится
на две приблизительно равновероятные подгруппы; для символов пер-
первой подгруппы на втором месте ставится нуль; для второй подгруппы —
единица и т. д.
Продемонстрируем принцип построения кода Шеннона—Фэно на
материале русского алфавита (табл. 18.8.1). Отсчитаем первые шесть
506
ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ -ИНФОРМАЦИИ
[гл. щ
букв (от «—» до «т»); суммируя их вероятности (частоты), получим
0,498; на все остальные буквы (от «н» до «ф») придется приблизи-
приблизительно такая же вероятность 0,502. Первые шесть букв (от «—» до
«т») будут иметь на первом месте двоичный знак 0. Остальные буквы
(от «н» до «ф») будут иметь на первом месте единицу. Далее снова
разделим первую группу на две приблизительно равновероятные под-
подгруппы: от «—» до «о» и от «е» до «т»; для всех букв первой
подгруппы на втором месте поставим нуль, а второй подгруппы —
единицу. Процесс будем продолжать до тех пор, пока в каждом
подразделении не останется ровно одна буква, которая и будет за-
закодирована определенным двоичным числом. Механизм построения
кода показан на таблице 18.8.2, а сам код приведен в таблице 18.8.3.
Таблица 18.8.3
Буква
«—*
О
е
а
и
т
н
с
о
Y
В
л
Двоичное
число
000
001
0100
0101
оно
0111
1000
1001
10100
10101
10110
Буква
к
м
д
п
у
я
ы
3
ъ, ь
б
г
Двоичное
число
10111
11000
110010
110011
110100
110110
110111
111000
111001
111010
111011
Буква
ч
й
X
ж
ю
ш
ц
Щ
э
Ф
Двоичное
число
111100
1111010
1111011
1111100
1111101
11111100
11111101
11111110
111111110
111111111
С помощью таблицы 18.8.3 можно закодировать и декодировать
любое сообщение.
В виде примера запишем двоичным кодом фразу: «теория ин-
информации» -*
01110100001101000110110110000
0110100011111111100110100
110000101111П101П1100110
Заметим, что здесь нет необходимости отделять друг от друга
буквы специальным знаком, так как и без этого декодирование вы-
выполняется однозначно. В этом можно убедиться, декодируя с по-
помощью таблицы 18.8.2 следующую фразу:
10011100110011001001111010000
1011100111001001101010000110101
010110000110110110
(«способ кодирования»).
J8.8] ЗАДАЧИ КОДИРОВАНИЯ СООБЩЕНИЙ. КОД ШЕННОНА - ФЭНО 507
Однако необходимо отметить, что любая ошибка при кодирова-
кодировании (случайное перепутывание знаков 0 и 1) при таком коде губи-
губительна, так как декодирование всего следующего за ошибкой текста
становится невозможным. Поэтому данный принцип кодирования может
быть рекомендован только в случае, когда ошибки при кодировании
и передаче сообщения практически исключены.
Возникает естественный вопрос: а является ли составленный нами
код при отсутствии ошибок действительно оптимальным? Для того
чтобы ответить на этот вопрос, найдем среднюю информацию, при-
приходящуюся на один элементарный символ @ или 1), и сравним ее
с максимально возможной информацией, которая равна одной двоич-
двоичной единице. Для этого найдем сначала среднюю информацию, содер-
содержащуюся в одной букве передаваемого текста, т. е. энтропию на
одну букву:
32 32
Н (б) = - 2 Pi log Pi = 2 Ч (Л).
i=i i=i
где р( — вероятность того, что буква примет определенное состояние
(«—», о, е, а ф).
Из табл. 18.8.1 имеем
И (б) = т] @,145) -(- г] @,095) -f ■•• 4- П @.003)+ tj @,002) « 4,42
(дв. единиц на букву текста).
По таблице 18.8.2 определяем среднее число элементарных сим-
символов на букву
пср = 3-0,1454-3-0,095 4-4-0,074 4- ...
... 4-9-0.003 4-9-0,002=4,45.
Деля энтропию Н (б) на пср, получаем информацию на один эле-
элементарный символ
!§ дв- ед->-
Таким образом, информация на один символ весьма близка к сво-
своему верхнему пределу 1, а выбранный нами код весьма близок
к оптимальному. Оставаясь в пределах задачи кодирования по
буквам, мы ничего лучшего получить не сможем.
Заметим, что в случае кодирования просто двоичных номеров
букв мы имели бы изображение каждой буквы пятью двоичными зна-
знаками и информация на один символ была бы
4 42
^= 0884 (дв- ед-)!
т. е. заметно меньше, чем при оптимальном буквенном кодировании.
Однако надо заметить, что кодирование «по буквам» вообще не
является экономичным. Дело в том, что между соседними буквами
508 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ [ГЛ. 18
любого осмысленного текста всегда имеется зависимость. Напри-
Например, после гласной буквы в русском языке не может стоять «ъ»
или «ь»; после шипящих не могут стоять «я» или «ю»; после не-
нескольких согласных подряд увеличивается вероятность гласной и т. д.
Мы знаем, что при объединении зависимых систем суммарная
энтропия меньше суммы энтропии отдельных систем; следовательно,
информация, передаваемая отрезком связного текста, всегда меньше,
чем информация на один символ, умноженная на число символов.
С учетом этого обстоятельства более экономный код можно построить,
если кодировать не каждую букву в отдельности, а целые «блоки»
из букв. Например, в русском тексте имеет смысл кодировать цели-
целиком некоторые часто встречающиеся комбинации букв, как «тся»,
«ает», «ние» и т. п. Кодируемые блоки располагаются в порядке
убывания частот, как буквы в табл. 18.8.1, а двоичное кодирование
осуществляется по тому же принципу.
В ряде случаев оказывается разумным кодировать даже не блоки
из букв, а целые осмысленные куски текста. Например, для разгрузки
телеграфа в предпраздничные дни целесообразно кодировать условными
номерами целые стандартные тексты, вроде:
«поздравляю новым годом желаю здоровья успехов работе».
Не останавливаясь специально на методах кодирования блоками,
ограничимся тем, что сформулируем относящуюся сюда теорему
Шеннона.
Пусть имеется источник информации X и приемник К, связанные
каналом связи К (рис. 18.8.1).
Известна производительность источника информации И1 (X),
т. е. среднее количество двоичных единиц информации, поступающее
от источника в единицу времени (численно
К
оно равно средней энтропии сообщения,
производимого источником в единицу вре-
времени). Пусть, кроме того, известна про-
Рис. 18.8.1. пускная способность канала Са, т. е.
максимальное количество информации (на-
(например, двоичных знаков 0 или 1), которое способен передать канал
в ту же единицу времени. Возникает вопрос: какова должна быть
пропускная uiOLcGiiociL канала, чтоби он «справлялся» со своей за-
задачей, т. е. чтобы информация от источника X к приемнику V по-
поступала без задержки?
Ответ на этот вопрос дает первая теорема Шеннона. Сформули-
Сформулируем ее здесь без доказательства.
1-я теорема Шеннона
Если пропускная способность канала связи С1 больше энтро-
энтропии источника информации в единицу времени
18.9) ПЕРЕДАЧА ИНФОРМАЦИИ С ИСКАЖЕНИЯМИ 509
то всегда можно закодировать достаточно длинное сообще-
сообщение так, чтобы оно передавалось каналом связи без задержки.
Если же, напротив,
С /
то передача информации без задержек невозможна.
18.9. Передача информации с искажениями.
Пропускная способность канала с помехами
В предыдущем п° мы рассмотрели вопросы, связанные с кодиро-
кодированием и передачей информации по каналу связи в идеальном случае,
когда процесс передачи информации осуществляется без ошибок.
В действительности этот процесс неизбежно сопровождается ошиб-
ошибками (искажениями). Канал передачи, в котором возможны искаже-
искажения, называется каналом с помехами (или шумами). В частном
случае ошибки возникают в процессе самого кодирования, и тогда
кодирующее устройство может рассматриваться как канал с помехами.
Совершенно очевидно, что наличие помех приводит к потере
информации. Чтобы в условиях наличия помех получить на прием-
приемнике требуемый объем информации, необходимо принимать специаль-
специальные меры. Одной из таких мер является введение так называемой
«избыточности» в передаваемые сообщения; при этом источник ин-
информации выдает заведомо больше символов, чем это было бы нужно
при отсутствии помех. Одна из форм введения избыточности — про-
простое повторение сообщения. Таким приемом пользуются, например,
при плохой слышимости по телефону, повторяя каждое сообщение
дважды. Другой общеизвестный способ повышения надежности пере-
передачи состоит в передаче слова «по буквам» — когда вместо каждой
буквы передается хорошо знакомое слово (имя), начинающееся с этой
буквы.
Заметим, что все живые языки естественно обладают некоторой
избыточностью. Эта избыточность часто помогает восстановить пра-
правильный текст «по смыслу» сообщения. Вот почему встречающиеся
вообще нередко искажения отдельных букв телеграмм довольно редко
приводят к действительной потере информации: обычно удается
исправить искаженное слово, пользуясь одними только свойствами
языка. Этого не было бы при отсутствии избыточности. Мерой избы-
избыточности языка служит величина
£/ —l_j^ie_, A8.9.1)
log га v '
где Hlc— средняя фактическая энтропия, приходящаяся на один пе-
передаваемый символ (букву), рассчитанная для достаточно длинных
отрывков текста, с учетом зависимости между символами, п—число
л
к
1 t 1 '
flatuu
Рис. 18.9.1.
Y
510 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ {ГЛ. 18
применяемых символов (букв), log n — максимально возможная в дан-
данных условиях энтропия на один передаваемый символ, которая была
бы, если бы все символы были равновероятны и независимы.
Расчеты, проведенные на материале наиболее распространенных
европейских языков, показывают, что их избыточность достигает 50%
и более (т. е., грубо говоря, 50% передаваемых символов являются
лишними и могли бы не передаваться, если бы не опасность иска-
искажений).
Однако для безошибочной передачи сведений естественная избы-
избыточность языка может оказаться как чрезмерной, так и недостаточ-
недостаточной: все зависит от того, как велика опа-
опасность искажений («уровень помех») в ка-
канале связи.
С помощью методов теории информа-
информации можно для каждого уровня помех
найти нужную степень избыточности источ-
источника информации. Те же методы помо-
помогают разрабатывать специальные помехоустойчивые коды (в частности,
так называемые «самокорректирующиеся» коды). Для решения этих
задач нужно уметь учитывать потерю информации в канале, связан-
связанную с наличием помех.
Рассмотрим сложную систему, состоящую из источника информа-
информации X, канала связи К и приемника У (рис. 18.9.1). Источник ин-
информации представляет собой физическую систему X, которая
имеет п возможных состояний
Х1> Х2> • • •' ХП
с вероятностями
" ' PV Р* ••>> Prf
Будем рассматривать эти состояния как элементарные символы, кото-
которые может передавать источник X через канал К к приемнику К.
Количество информации на один символ, которое да*т источник, бу-
будет равно энтропии на один символ:
п
Н(Х) = -^ Р: log p,.
Если бы передача сообщений не сопровождалась ошибками, то коли-
количество информации, содержащееся в системе Y относительно X, было
бы равно самой энтропии системы X. При наличии ошибок оно бу-
будет меньше:
Естественно рассматривать условную энтропию Н (X j Y) как
потерю информации на один элементарный символ, связанную
с наличием помех.
18.9] ПЕРЕДАЧА ИНФОРМАЦИИ С ИСКАЖЕНИЯМИ 511
Умея определять потерю информации в канале, приходящуюся на
один элементарный символ, переданный источником информации,
можно определить пропускную способность канала с поме-
помехами, т. е. максимальное количество информации, которое способен
передать канал в единицу времени.
Предположим, что канал может передавать в единицу времени к
элементарных символов. В отсутствие помех пропускная способ-
способность канала была бы равна
C — k\ogn, A8.9.2)
так как максимальное количество информации, которое может содер-
содержать один символ, равно log я, а максимальное количество инфор-
информации, которое могут содержать k символов, равно k logn, и оно
достигается, когда символы появляются независимо друг от друга.
Теперь рассмотрим канал с помехами. Его пропускная способ-
способность определится как
(rUx. A8.9.3)
где тах/у-^х — максимальная информация на один символ, которую
может передать канал при наличии помех.
Определение этой максимальной информации в общем случае —
дело довольно сложное, так как она зависит от того, как и с какими
вероятностями искажаются символы; происходит ли их перепутывание,
или же простое выпадение некоторых символов; происходят ли
искажения символов независимо друг от друга и т. д.
Однако для простейших случаев пропускную способность канала
удается сравнительно легко рассчитать.
Рассмотрим, например, такую задачу. Канал связи К передает от
источника информации X к приемнику Y элементарные символы 0 и 1
в количестве k символов в единицу времени. В процессе передачи
каждый символ, независимо от других, с вероятностью [л может быть
искажен (т. е. заменен противоположным). Требуется найти про-
пропускную способность канала.
Определим сначала максимальную информацию на один символ,
которую может передавать канал. Пусть источник производит сим-
символы 0 и 1 с вероятностям'.! р и 1 —pt
Тогда энтропия источника будет
Н (X) = - р log р — A — р) log A — р).
Определим информацию /$1>.х на один элементарный символ{
Чтобы найти полную условную энтропию H(Y\X), найдем сна-
сначала частные условные энтропии: H{Y\x^) (энтропию системы К
при условии, что система X приняла состояние хг) и H(Y\x)
512 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ [ГЛ. 18
(энтропию системы У при условии, что система X приняла состоя-
состояние х2). Вычислим H(Y\xx)\ для этого предположим, что передан
элементарный символ 0. Найдем условные вероятности того, что при
этом система К находится в состоянии у, = 0 и в состоянии у2=1.
Первая из них равна вероятности того, что сигнал не перепутан:
Р(у1\х1)=1-р;
вторая — вероятности того, что сигнал перепутан:
Условная энтропия H(Y\xl) будет:
= —A — (i)iog(l — |x)—
Найдем теперь условную энтропию системы Y при условии, что
А' — х2 (передан сигнал единица):
откуда
Н (Y| х2) = - р log (л - A — [л) log A — р).
Таким образом,
2) = — fx log ^ — A— j*)log(l— |*). A8.9.4)
Полная условная энтропия H{Y\X) получится, если осреднить услов-
условные энтропии H(Y\x{) и //(К(х2) с учетом вероятностей р и 1—р
значений xv x2. Так как частные условные энтропии равны, то
И {Y | X) = — (х log р — A — (х) log A — (х).
Мы получили следующий вывод: условная энтропия H(Y\X)
совсем не забасит от того, с какими вероятностями р, 1 — р
встречаются символы 0; 1 в передаваемом сообщении, а зави-
зависит только от вероятности ошибки о..
Вычислим полную информацию, передаваемую одним символом:
— H(Y\X) =
= {— г log г — A — г) log A — г)] —
— {— (A lOg (А — A — fl) lOg A — |Х)} --=
= [1 (О + Ч О — г)\ - h (р) -г- ТA - ?)].
18.9] ПЕРЕДАЧА ИНФОРМАЦИИ С ИСКАЖЕНИЯМИ 513
где г — вероятность того, что на выходе появится символ 0. Оче-
Очевидно, при заданных свойствах канала информация на один символ /р'-*х
достигает максимума, когда i\{f)-\-i\(\—г) максимально. Мы знаем,
что такая функция достигает максимума при г = 1/2, т. е. когда на
приемнике оба сигнала равновероятны. Легко убедиться, что это
достигается, когда источник передает оба символа с одинаковой
вероятностью р = 1/2. При том же значении р = 1/2 достигает
максимума и информация на один символ. Максимальное значение
равно
/'Лх = Н (К) - [7J (Ц) +. 7) A — ,1I = 1 - [7J ([*) + 7J A - (Л)].
Следовательно, в нашем случае
max $UX = 1 — h (|») + -П A -1*)].
и пропускная способность канала связи будет равна
C = ft{l —h(|*) + ij(l —v-)]}. A8.9.5)
Заметим, что Tj([A) + irj(l—[*) есть не что иное, как энтропия
системы, имеющей два возможных состояния с вероятностями \х и
1—[л. Она характеризует потерю информации на один
символ, связанную с наличием помех в канале.
Пример. 1. Определить пропускную способность канала связи, способ-
способного передавать 100 символов 0 или 1 в единицу времени, причем каждый из
символов искажается (заменяется противоположным) с вероятностью |л = 0,01.
Решение. По таблице 7 приложения находим
■ц (ji) = 0,0664,
1)A—ц) = 0,0144,
4(W + 4(l-ri = 0,0808.
На один символ теряется информация 0,0808 (дв. ед). Пропускная способ-
способность канала равна
С = 100 A — 0,0808) = 91,92 « 92
двоичные единицы в единицу времени.
С помощью аналогичных расчетов может быть определена про-
пропускная способность канала и в более сложных случаях: когда число
элементарных символов более двух и когда искажения отдельных
символов зависимы. Зная пропускную способность канала, можно
определить верхний предел скорости передачи информации по каналу
с помехами. Сформулируем (без доказательства) относящуюся к этому
случаю вторую теорему Шеннона.
2-я теорема Шеннона
Пусть имеется источник информации X, энтропия кото-
которого в единицу времени равна Н (X), и канал с пропускной
способностью С. Тогда если
Н(Х) > С,
33 Е. С. Вентцель
514 ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ИНФОРМАЦИИ [ГЛ. IS
то при любом кодировании передача сообщений без задержек
и искажений, невозможна, Если же
Й (X) < С,
то всегда можно достаточно длинное сообщение закодировать
так, чтобы оно было передано без задержек и искажений
с вероятностью, сколь угодно близкой к единице.
Пример 2. Имеются источник информации с энтропией в единицу
времени И (X) = 100 (дв. ед.) и два канала связи; каждый из них может
передавать в единицу времени 70 двоичных знаков @ или 1); каждый двоич-
двоичный знак заменяется противоположным с вероятностью it = 0,1. Требуется
выяснить: достаточна ли пропускная способность этих каналов для передачи
информации, поставляемой источником?
Решение. Определяем потерю информации на один символ:
Ч (V) + Ч <\ — V-) = 0.332 -f 0,137 = 0,469 (дв. ед.).
Максимальное количество информации, передаваемое по одному каналу
в единицу времени:
С = 70 A—0,469) = 37,2.
Максимальное количество информации, которое может быть передано
по двум каналам в единицу времени:
37,2-2 = 74,4 (дв. ед.),
чего недостаточно для обеспечения передачи информации от источника.
ГЛАВА 19
ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ
19.1. Предмет теории массового обслуживания
За последние десятилетия в самых разных областях практики
возникла необходимость в решении своеобразных вероятностных
задач, связанных с работой так называемых систем массового
обслуживания. Примерами таких систем могут служить: телефон-
телефонные станции, ремонтные мастерские, билетные кассы, справочные
бюро, парикмахерские и т. п. Каждая такая система состоит из
какого-то числа обслуживающих единиц, которые мы будем назы-
называть «каналами» обслуживания. В качестве каналов могут фигури-
фигурировать: линии связи; лица, выполняющие те ли иные операции; раз-
различные приборы и т. п. Системы массового обслуживания могут быть
как одно-.так и многоканальными.
Работа любой системы массового обслуживания состоит в выпол-
выполнении поступающего на нее потока требований или заявок. Заявки
поступают одна за другой в некоторые, вообще говоря, случайные,
моменты времени. Обслуживание поступившей заявки продолжается
какое-то время, после чего канал освобождается и снова готов для
приема следующей заявки. Каждая система массового обслуживания,
в зависимости от числа каналов и их производительности, обладает
какой-то пропускной способностью, позволяющей ей более или менее
успешно справляться с потоком заявок. Предмет теории массового
обслуживания — установление зависимости между характером потока
заявок, производительностью отдельного канала, числом каналов и
успешностью (эффективностью) обслуживания. В качестве характе-
характеристик эффективности обслуживания — в зависимости от условий
задачи и целей исследования — могут применяться различные вели-
величины и функции, например: средний процент заявок, получающих
отказ и покидающих систему необслуженными; среднее время «простоя»
отдельных каналов и системы в целом; среднее время ожидания
в очереди; вероятность того, что поступившая заявка немедленно
будет принята к обслуживанию; закон распределения длины очереди
и т. д. Каждая из этих характеристик описывает, с той или другой
стороны, степень приспособленности системы к выполнению потока
заявок, иными словами — ее пропускную способность.
33*
516 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. 19
Под «пропускной способностью» в узком смысле слова обычно
понимают среднее число заявок, которое система может обслужить
в единицу времени. Наряду с нею часто рассматривают относительную
пропускную способность — среднее отношение числа обслуженных
заявок к числу поданных. Пропускная способность (как абсолютная,
так и относительная) в общем случае зависит не только от пара-
параметров системы, но и от характера потока заявок. Если бы заявки
поступали регулярно, через точно определенные промежутки времени,
и обслуживание каждой заявки тоже имело строго определенную
длительность, расчет пропускной способности системы не предста-
представлял бы никакой трудности. На практике обычно моменты поступления
заявок случайны; по большей части случайна и длительность обслу-
обслуживания заявки. В связи с этим процесс работы системы протекает
нерегулярно: в потоке заявок образуются местные сгущения и разре-
разрежения. Сгущения могут привести либо к отказам в обслуживании,
либо к образованию очередей. Разрежения могут привести к непроиз-
непроизводительным простоям отдельных каналов или системы в целом.
На эти случайности, связанные с неоднородностью потока заявок,
накладываются еще случайности, связанные с задержками обслужи-
обслуживания отдельных заявок. Таким образом, процесс функционирования
системы массового обслуживания представляет собой случайный
процесс. Чтобы дать рекомендации по рациональной организации
системы, выяснить ее пропускную способность и предъявить к ней
требования, необходимо изучить случайный процесс, протекающий
в системе, и описать его математически. Этим и занимается теория
массового обслуживания.
Заметим, что за последние годы область применения математи-
математических методов теории массового обслуживания непрерывно расши-
расширяется и все больше выходит за пределы задач, связанных с «обслу-
«обслуживающими организациями» в буквальном смысле слова. Многие
задачи автоматизации производства оказываются близкими к теории
массового обслуживания: потоки деталей, поступающих для выполнения
над ними различных операций, могут рассматриваться как «потоки
заявок», ритмичность поступления которых нарушается за счет слу-
случайных причин. Своеобразные задачи теории массового обслуживания
возникают в связи с проблемой организации транспорта и системы
сообщений. Близкими к теории массового обслуживания оказываются
и задачи, относящиеся к надежности технических устройств: такие
их характеристики, как среднее время безотказной работы, потребное
количество запасных деталей, среднее время простоя в связи с ре-
ремонтом и т. д., определяются методами, непосредственно заимство-
заимствованными из теории массового обслуживания.
Проблемы, родственные задачам массового обслуживания, постоянно
возникают в военном деле. Каналы наведения, линии связи, аэродромы,
устройства для сбора и обработки информации представляют собой
19.2] СЛУЧАЙНЫЙ ПРОЦЕСС СО СЧЕТНЫМ МНОЖЕСТВОМ СОСТОЯНИЙ 517
своеобразные системы массового обслуживания со своим режимом
работы и пропускной способностью.
Трудно даже перечислить все области практики, в которых нахо-
находят применение методы теории массового обслуживания. За последние
годы она стала одной из самых быстро развивающихся ветвей теории
вероятностей.
В настоящей главе будут изложены некоторые элементарные све-
сведения по теории массового обслуживания, знание которых необходимо
любому инженеру, занимающемуся вопросами организации в области
промышленности, народного хозяйства, связи, а также в военном деле.
19.2. Случайный процесс со счетным множеством состояний
Случайный процесс, протекающий в системе массового обслужива-
обслуживания, состоит в том, что система в случайные моменты времени пере-
переходит из одного состояния в другое: меняется число занятых каналов,
число заявок, стоящих в очереди, и т. п. Такой процесс существенно
отличается от случайных процессов, которые мы рассматривали в гла-
главах 15—17. Дело в том, что система массового обслуживания пред-
представляет собой физическую систему дискретного типа с конеч-
конечным (или счетным) множеством состояний'), а переход системы из
одного состояния в другое происходит скачком, в момент, когда осу-
осуществляется какое-то событие (приход новой заявки, освобождение
канала, уход заявки из очереди и т. п.).
Рассмотрим физическую систему X со счетным множеством со-
состояний v v v
XV X2 хп< • • •
В любой момент времени t система X может быть в одном из этих
состояний. Обозначим pk(t) (k=l, 2 п, .. .) вероятность того,
что в момент t система будет находиться в состоянии xk. Очевидно,
для любого г 2^@=1. A9.2.1)
k
Совокупность вероятностей рк (t) для каждого момента времени t ха-
характеризует данное сечение случайного процесса, протекающего в сн-
ст.:-:с. Эт," грв^ю'пиос-ь не япляетсч нгчерпчнающей характеристик -!А
процесса (она, например, совсем не отражает зависимости между се-
сечениями), но все же достаточно хорошо описывает процесс и для ряда
практических применений оказывается достаточной.
Случайные процессы со счетным множеством состояний бывают
двух типов: с дискретным или непрерывным временем. Первые отлича-
отличаются тем, что переходы из состояния в состояние могут происходить
') В математике «счетным» называется конечное или бесконечное множе-
множество, члены которого можно перенумеровать, т. е. записать в виде после-
последовательности аи аг, ..,, ап, ...
518
ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ
[ГЛ 19
только в строго определенные, разделенные конечными интервала-
интервалами моменты времени ty t2, ... Случайные процессы с непрерывным
временем отличаются тем, что переход системы из состояния в со-
состояние возможен в любой момент времени t.
В качестве примера дискретной системы X, в которой протекает
случайный процесс с непрерывным временем,-рассмотрим группу из я
самолетов, совершающих налет на территорию противника, обороняе-
обороняемую истребительной авиацией. Ни момент обнаружения группы, ни
моменты подъема по ней истребителей заранее не известны. Различ-
Различные состояния системы соответствуют различному числу пораженных
самолетов в составе группы:
х0 — не поражено ни одного самолета,
Xj —поражен ровно один самолет,
xk — поражено ровно k самолетов,
хп — поражены все п самолетов.
Схема возможных состояний системы и возможных переходов из
состояния в состояние показана на рис. 19.2.1.
Стрелками показаны возможные переходы системы из состояния
в состояние. Закругленная стрелка, направленная из состояния хк
в него же, означает, что система может не только перейти в соседнее
хп
—
—
СЛ
хг
х*
-
хкн
х„
Рис. 19.2.1.
состояние xk+v но и остаться в прежнем. Для данной системы
характерны необратимые переходы (пораженные самолеты
не восстанавливаются); в связи с этим из состояния л„?никакие пере-
переходы в другие состояния уже невозможны.
Отметим, что на схеме возможных переходов (рис. 19.2.1) пока-
показаны только переходы из состояния в соседнее состояние и не пока-
Заны «перескоки» через состояние: эти перескоки отброшены как
практически невозможные. Действительно, для того чтобы система
«перескочила» через состояние, нужно, чтобы строго одновременно
были поражены два или более самолета, а вероятность такого собы-
события равна нулю.
Случайные процессы, протекающие в системах массового обслужи-
обслуживания, как правило, представляют собой процессы с непрерывным
временем. Это связано со случайностью потока заявок. В противопо-
противоположность системе с необратимыми переходами, рассмотренной в пре-
предыдущем примере, для системы массового обслуживания характерны
t9.2] СЛУЧАЙНЫЙ ПРОЦЕСС СО СЧЕТНЫМ МНОЖЕСТВОМ СОСТОЯНИЙ 519
обратимые переходы: занятый канал может освободиться, оче-
очередь может «рассосаться».
В качестве примера рассмотрим одноканальную систему массового
обслуживания (например, одну телефонную линию), в которой заявка,
заставшая канал занятым, не становится в очередь, а покидает си-
систему (получает «отказ»). Это — дискретная система с непрерывным
временем и двумя возможными состояниями:
х0— канал свободен,
хг— канал занят.
Переходы из состояния в состояние обратимы. Схема возможных
переходов показана на рис. 19.2.2.
Рис, 19.2.2.
Рис. 19.2.3.
Для я-канальной системы такого же типа схема возможных пере-
переходов показана на рис. 19.2.3. Состояние д:0 — все каналы свободны;
jc, — занят ровно один канал, х2— занято ровно два канала и т. д.
Рассмотрим еще один пример дискретной системы с непрерывным
временем: одноканальную систему массового обслуживания, которая
может находиться в четырех состояниях:
х0—канал исправен и свободен,
хх — канал исправен и занят,
х2 — канал неисправен и ждет ремонта,
х3 — канал неисправен и ремонтируется.
Схема возможных переходов для этого случая показана на рис. 19.2.4!).
Переход системы из х3 непосредственно в xv минуя х0, можно счи-
считать практически невозможным, так как для этого
нужно, чтобы окончание ремонта и приход оче-
очередной заявки произошли строго в один и тот
же момент времени.
Для того чтобы описать случайный процесс,
протекающий в дискретной системе с непрерывным
временем, прежде всего нужно проанализировать
причины, вызывающие переход системы из состоя-
состояния в состояние. Для системы массового обслужи-
С \
•Л
"V.
хг
X
Рис. 19.2.4.
вания основным фактором, обусловливающим протекающие в ней про-
процессы, является поток заявок. Поэтому математическое описание любой
системы массового обслуживания начинается с описания потока заявок.
•) Схема составлена в предположении,, что неработающий канал выйти
из строя не может. ■
620 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. 19
19.3. Поток событий. Простейший поток и его свойства
Под потоком событий в теории вероятностей понимается после-
последовательность событий, происходящих одно за другим в какие-то мо-
моменты времени. Примерами могут служить: поток вызовов на телефон-
телефонной станции; поток включений приборов в бытовой электросети; поток
заказных писем, поступающих в почтовое отделение; поток сбоев
(неисправностей) электронной вычислительной машины; поток выстре-
выстрелов, направляемых на цель во время обстрела, и т. п. События, обра-
образующие поток, в общем случае могут быть различными, но здесь мы
будем рассматривать лишь поток однородных событий, различаю-
различающихся только моментами появления. Такой поток можно изобразить
как последовательность точек tv t2 tk, ... на числовой оси
(рис. 19.3.1), соответствующих моментам появления событий.
Рис. 19.3.1.
Поток событий называется регулярным, если события следуют
одно за другим через строго определенные промежутки времени. Та-
Такой поток сравнительно редко встречается в реальных системах, но
представляет интерес как предельный случай. Типичным для системы
массового обслуживания является случайный поток заявок.
В настоящем п° мы рассмотрим потоки событий, обладающие
некоторыми особенно простыми свойствами. Для этого введем ряд
определений.
1. Поток событий называется стационарным, если вероятность
попадания того или иного числа событий на участок времени длиной х
(рис. 19.3.1) зависит только от длины участка и не зависит от
того, где именно на оси Ot расположен этот участок.
2. Поток событий называется потоком без последействия, если
для любых неперекрывающихся участков времени число событий, по-
попадающих на один из них, не зависит от числа событий, попадающих
на другие.
3. Поток событий называется ординарным, если вероятность по-
попадания на элементарный участок &.t двух или более событий прене-
пренебрежимо мала по сравнению с вероятностью попадания одного события.
Если поток событий обладает всеми тремя свойствами (т. е. ста-
стационарен, ординарен и не имеет последействия), то он называется
простейшим (или стационарным пуассоновским) потоком. Название
«пуассоновский» связано с тем, что при соблюдении условий 1-т-З
число событий, попадающих на любой фиксированный интервал вре-
времени, будет распределено по закону Пуассона (см. п° 5.9).
19.3] ПОТОК СОБЫТИЙ. ПРОСТЕЙШИЙ ПОТОК И ЕГО СВОЙСТВА 521
Рассмотрим подробнее условия 1 -н- 3, посмотрим, чему они соот-
соответствуют для потока заявок и за счет чего они могут нару-
нарушаться.
1. Условию стационарности удовлетворяет поток заявок, вероят-
вероятностные характеристики которого не зависят от времени. В частности,
для стационарного потока характерна постоянная плотность
(среднее число заявок в единицу времени). На практике часто встре-
встречаются потоки заявок, которые (по крайней мере, на ограниченном
отрезке времени) могут рассматриваться как стационарные. Например,
поток вызовов на городской телефонной станции на участке времени
от 12 до 13 часов может считаться стационарным. Тот же поток в те-
течение целых суток уже не может считаться стационарным (ночью
плотность вызовов значительно меньше, чем днем). Заметим, что так
обстоит дело и со всеми физическими процессами, которые мы назы-
называем «стационарными»: в действительности все они стационарны лишь
на ограниченном участке времени, а распространение этого участка
до бесконечности — лишь удобный прием, применяемый в целях упро-
упрощения анализа. Во многих задачах теории массового обслуживания
представляет интерес проанализировать работу системы при постоян-
постоянных условиях; тогда задача решается для стационарного потока
заявок.
2. Условие отсутствия последействия — наиболее существенное для
простейшего потока — означает, что заявки поступают в систему не-
независимо друг от друга. Например, поток пассажиров, входящих на
станцию метро, можно считать потоком без последействия потому,
что причины, обусловившие приход отдельного пассажира именно
в тот, а не другой момент, как правило, не связаны с аналогичными
причинами для других пассажиров. Однако условие отсутствия после-
последействия может быть легко нарушено за счет появления такой зави-
зависимости. Например, поток пассажиров, покидающих станцию
метро, уже не может считаться потоком без последействия, так как
моменты выхода пассажиров, прибывших одним и тем же поездом,
зависимы между собой.
Вообще нужно заметить, что выходной поток (или поток обслу-
обслуженных заявок), покидающий систему массового обслуживания, обычно
имеет последействие, даже если входной поток его не имеет. Чтобл
убедиться в этом, рассмотрим одноканальную систему массового обслу-
обслуживании, для которой время обслуживания одной заявки вполне опре-
определено и равно tO(,. Тогда в потоке обслуженных заявок минимальный
интервал времени между заявками, покидающими систему, будет ра-
равен to6. Нетрудно убедиться, что наличие такого минимального интер-
интервала неизбежно приводит к последействию. Действительно, пусть стало
известно, что в какой-то момент tt систему покинула обслуженная
заявка. Тогда можно утверждать с достоверностью, что на любом
участке времени х, лежащем в пределах (tv ^ + ^об). обслуженной
522 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. 19
заявки не появится; значит, будет иметь место зависимость между чи-
числами событий на неперекрывающихся участках.
Последействие, присущее выходному потоку, необходимо учитывать,
если этот поток является входным для какой-либо другой системы
массового обслуживания (так называемое «многофазовое обслуживание»,
когда одна и та же заявка последовательно переходит из системы
в систему).
Отметим, между прочим, что самый простой на первый взгляд ре-
регулярный поток, в котором события отделены друг от друга равными
интервалами, отнюдь не является «простейшим» в нашем смысле слова,
так как в нем имеется ярко выраженное последействие: моменты появ-
появления следующих друг за другом событий связаны жесткой, функцио-
функциональной зависимостью. Именно из-за наличия последействия анализ
процессов, протекающих в системе массового обслуживания при регу-
регулярном потоке заявок, гораздо сложнее, чем при простейшем.
3. Условие ординарности означает, что заявки приходят пооди-
поодиночке, а не парами, тройками и т. д. Например, поток атак, которому
подвергается воздушная цель в зоне действия истребительной авиа-
авиации, будет ординарным, если истребители атакуют цель поодиночке,
и не будет ординарным, если истребители идут в атаку парами. Поток
клиентов, входящих в парикмахерскую, может считаться практически
ординарным, чего нельзя сказать о потоке клиентов, направляющихся
в ЗАГС для регистрации брака.
Если в неординарном потоке заявки поступают только парами,
только тройками и т. д., то неординарный поток легко свести к орди-
ординарному; для этого достаточно вместо потока отдельных заявок рас-
рассмотреть поток пар, троек и т. д. Сложнее будет, если каждая заявка
случайным образом может оказаться двойной, тройной и т. д. Тогда
уже приходится иметь дело с потоком не однородных, а разнород-
разнородных событий.
В дальнейшем мы для простоты ограничимся рассмотрением орди-
ординарных потоков. *
Простейший поток играет среди потоков событий вообще особую
роль, до некоторой степени аналогичную роли нормального закона
среди других законов распределении. jWhi знаем, чго прн суммирова-
суммировании большого числа независимых случайных величин, подчиненных
практически любым законам распределения, получается величина,
приближенно распределенная по нормальному закону. Аналогично
можно доказать, что при суммировании (взаимном наложении) большого
числа ординарных, стационарных потоков с практически любым по-
последействием получается поток, сколь угодно близкий к простейшему.
Условия, которые должны для этого соблюдаться, аналогичны условиям
центральной предельной теоремы, а именно — складываемые потоки
должны Оказыьа1ь иа с) мму приблизительно равномерно малое
влияние.
19.31
ПОТОК СОБЫТИЙ. ПРОСТЕЙШИЙ ПОТОК И FXO СВОЙСТВА
523
Не доказывая этого положения и даже не формулируя математи-
математически условия, которым должны удовлетворять потоки1), проиллюстри-
проиллюстрируем его элементарными рассуждениями. Пусть имеется ряд незави-
независимых потоков Пр П2. • • •• Пя (рис. 19.3.2). «Суммирование» потоков
состоит в том, что все моменты появления событий сносятся на одну
и ту же ось Ot, как показано на рис. 19.3.2.
\°п
/7 с \в\\ 11
-14-
-U-L
tn-t
to
Рис. 19.3.2.
Предположим, что потоки П^ ГЬ> • • • сравнимы по своему влиянию
на суммарный поток (т. е. имеют плотности одного порядка), а число
их достаточно велико. Предположим, кроме того, что эти потоки
стационарны и ординарны, но каждый из них может иметь после-
последействие, и рассмотрим суммарный поток
П = 2ПЛ A9.3.1)
на оси Ot (рис. 19.3.2). Очевидно, что поток П должен быть ста-
стационарным и ординарным, так как каждое слагаемое обладает этим
свойством и они независимы. Кроме того, достаточно ясно, что при
увеличении числа слагаемых последействие в суммарном потоке, даже
если оно значительно в отдельных потоках, должно постепенно сла-
слабеть. Действительно, рассмотрим «а оси Ot два неперекрывающихся
отрезка -с, и т, (рис. 19.3.2). Каждая из точек, попадающих в эти
') См. А. Я. X и п ч и н, «Математические методы теории массового обслу-
обслуживания», 1955.
524 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. 19
отрезки, случайным образом может оказаться принадлежащей тому
или иному потоку, и по мере увеличения п удельный вес точек, при-
принадлежащих одному и тому же потоку (и, значит, зависимых), должен
уменьшаться, а остальные точки принадлежат разным потокам и
появляются на отрезках Xj, х2 независимо друг от друга. Достаточно
естественно ожидать, что при увеличении н суммарный поток будет
терять последействие и приближаться к простейшему.
Рис. 19.3.3.
, На практике оказывается обычно достаточно сложить 4 ч- 5 пото-
потоков, чтобы получить поток, с которым можно оперировать как
с простейшим.
Простейший поток играет в теории массового обслуживания осо-
особенно важную роль. Во-первых, простейшие и близкие к простейшим
потоки заявок часто встречаются на практике (причины этого изло-
изложены выше). Во-вторых, даже при потоке заявок, отличающемся
от простейшего, часто можно получить удовлетворительные по точ-
точности результаты, заменив поток любой структуры простейшим
с той же плотностью. Поэтому займемся подробнее простейшим
потоком и его свойствами.
Рассмотрим на оси Ot простейший поток событий П (рис. 19.3.3)
как неограниченную последовательность случайных точек.
Выделим произвольный участок времени длиной х. В главе 5
(п°5.9) мы доказали, что при условиях 1, 2 и 3 (стационарность,
отсутствие последействия и ординарность) число точек, попадающих
на участок х, распределено по закону Пуассона с математическим
ожиданием
а=Хх, ,- A9.3.2)
где X— плотность потока (среднее число событий, приходящееся на
единицу времени).
равна
В частности, вероятность того, что участок окажется пустым (не произой-
произойдет ни одного события), будет
= е-Ч A9.3.4)
Важной характеристикой потока является закон распределения
длины промежутка между соседними событиями. Рассмотрим случай-
19.31
ПОТОК СОБЫТИЙ. ПРОСТЕЙШИЙ ПОТОК И ЕГО СВОЙСТВА
525
ную величину Г — промежуток времени между произвольными двумя
соседними событиями в простейшем потоке (рис. 19.3.3) и найдем
ее функцию распределения
Перейдем к вероятности противоположного события
Это есть вероятность того, что на участке времени длиной t, начи-
начинающемся в момент tk появления одного из событий потока, не появится
ни одного из последующих событий. Так как простейший поток
не обладает последействием, то наличие в начале участка (в точке tk)
какого-то события никак не влияет на вероятность появления тех или
других событий в дальнейшем. По-
Поэтому вероятность P(T~^>t) можно
вычислить по формуле A9.3.4)
откуда
F(t) = l—e-xt (/> 0). A9.3.5)
Дифференцируя, найдем плотность
распределения
f(f) = \e-Kt (t>0). A9.3.6)
Закон распределения с плот- Рис 19-3,4,
ностью A9.3.6) называется показа-
показательным законом, а величина х — его параметром. График плот-
плотности / (t) представлен на рис. 19.3.4.
Показательный закон, как мы увидим в дальнейшем, играет боль-
большую роль в теории дискретных случайных процессов с непрерывным
временем. Поэтому рассмотрим его подробнее.
Найдем математическое ожидание величины Г, распределенной
по показательному закону:
UO 00
mt — М [71] = J t/ (t) dt = X J ts ->•■' dt
или, интегрируя по частям,
Дисперсия величины Т равна
Dt~ D(T) —
A9.3.7)
i
526 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. 19
откуда
Dt = ±, A9.3.8)
ot — j> A9.3.9)
Докажем одно замечательное свойство показательного закона.
Оно состоит в следующем: если промежуток времени, рас-
распределенный по показательному за ко ну, уже дли л с я
некоторое время х, то это никак не влияет на за-
закон распределения оставшейся части промежутка: он
будет таким же, как и закон распределения всего промежутка Т.
Для доказательства рассмотрим случайный промежуток времени Т
с функцией распределения
F{t)=\—e-u A9.3.10)
и предположим, что этот промежуток уже продолжается некоторое
время х, т. е. произошло событие Т > х. Найдем при этом предпо-
предположении условный закон распределения оставшейся части промежутка
Г, = 7 — х; обозначим его /^@
i<t\T>x). A9.3.11)
Докажем, что условный закон распределения F (f) не зависит
от х и равен F (t). Для того чтобы вычислить /^т)(/), найдем сна-
сначала вероятность произведения двух событий
Г>х и Т — х<*.
По теореме умножения вероятностей
х)/>(Г — х<г|Г>т) =
откуда
' кч~ />G'>т)
Но событие (Г > t)(T — х < t) равносильно событию х < Т < t + х,
вероятность которого равна
Р(х <Г <
С другой стороны,
х)==1— F(x).
следовательно,
19.4] НЕСТАЦИОНАРНЫЙ ПУАССОНОВСКИЙ ПОТОК 527
откуда, согласно формуле A9.3.10), получим
что и требовалось доказать.
Таким образом, мы доказали, что если промежуток времени Т
распределен по показательному закону, то любые сведения о том,
сколько времени уже протекал этот промежуток, не влияют на закон
распределения оставшегося времени. Можно доказать, что показатель-
показательный закон — единственный, обладающий таким свойством. Это свой-
свойство показательного закона представляет собой, в сущности, другую
формулировку для «отсутствия последействия», которое является
основным свойством простейшего потока.
19.4 Нестационарный пуассоновский поток
Если поток событий нестационарен, то его основной характери-
характеристикой является мгновенная плотность Х(£). Мгновенной
плотностью потока называется предел отношения среднего числа
событий, приходящегося на элементарный участок времени (t, t-{-kt),
к длине этого участка, когда последняя стремится к нулю:
Х@= lim m(* + *g-m(*>- = m'(Q. 09.4.1)
где т (t) — математическое ожидание числа событий на участке @, t).
Рассмотрим поток однородных событий, ординарный и без после-
последействия, но не стационарный, с переменной плотностью Х(£). Такой
поток называется нестационарным пуассоновским потоком.
Это — первая ступень обобщения по сравнению с простейшим пото-
потоком. Легко показать методом, аналогичным примененному в п° 5.9,
что для такого потока число событий, попадающих на участок
длины т, начинающийся в точке tQ, подчиняется закону -Пуассона
ат
Рт(х, tQ) = —те~а (/и = 0, 1, 2, ...). A9.4.2)
где а—математическое ожидачне числа событий на участке от /0
до ^о + 1. равное
а= J \(t)dt. A9.4.3)
Здесь величина а зависит не только от длины т участка, но и
от его положения на оси Ot.
Найдем для нестационарного потока закон распределения проме-
промежутка времени Т между соседними событиями. Ввиду нестационар-
нестационарности потока этот закон будет зависеть от того, где на оси Ot
528
ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ
[ГЛ 19
расположено первое из событий. Кроме того, он будет зависеть
от вида функции X(t). Предположим, что первое из двух соседних
1.0
0.5 1.0 15
Рис. 19.4.1.
г,о
событий появилось в момент tQ, и найдем при этом условии закон
распределения времени Т между этим событием и последующим:
Найдем P(T^t) — вероятность того, что на участке от t0 до t0 -+-1
не появится ни одного события:
-J
откуда
- j l(t)dt
F,,(f) = l—e '« A9.4.4)
Дифференцируя, найдем плотность распределения
ta+t
- J х«) dt
Этот закон распрсдслспи" уже не Суде; показательным. Вид и о
зависит от параметра ^0 и вида функции Х(/). Например, при линей-
линейном изменении Х
~at~ 0<" 2
плотность П9.4.5} имеет вид
h A9.4.6)
График этого закона при о = 0,4, Ь = 2 и £0 = 0,3 представлен
на рис. 19.4.1.
19.5) ПОТОК С ОГРАНИЧЕННЫМ ПОСЛЕДЕЙСТВИЕМ (ПОТОК ПАЛЬМА) 529
Несмотря на то, что структура нестационарного пуассоновского
потока несколько сложнее, чем простейшего, он очень удобен в прак-
практических применениях: главное свойство простейшего потока — отсут-
отсутствие последействия — в нем сохранено. А именно, если мы зафикси-
зафиксируем на оси Ot произвольную точку t0, то закон распределения
f t (t) времени Т, отделяющего эту точку от ближайшего по времени
будущего события, не зависит от того, что происходило на участке
времени, предшествующем t0, и в самой точке tQ (т. е. появлялись ли
ранее другие события и когда именно).
19.5. Поток с ограниченным последействием
(поток Пальма)
В предыдущем п° мы познакомились с естественным обобщением
простейшего потока — с нестационарным пуассоновским потоком.
Обобщением простейшего потока в другом направлении является
поток с ограниченным последействием.
Рассмотрим ординарный поток однородных событий (рис. 19.5.1).
Этот поток называется потоком с ограниченным последействием
Т,
Рис. 19.5.1.
(или потоком Пальма), если промежутки времени между последо-
последовательными событиями ГР Г2, ... представляют собой независимые
случайные величины.
Очевидно, простейший поток является частным случаем потока
Пальма: в нем расстояния ТЛ, Г2, ... представляют собой неза-
независимые случайные величины, распределенные по показательному за-
закону. Что касается нестационарного пуассоновского потока, то он не
является потоком Пальма. Действительно, рассмотрим два соседних
при.мсжу 1ка Tk п Тй+1 и нестационарном пуассоноислом иишке. как
мы видели в предыдущем п°, закон распределения промежутка между
событиями в нестационарном потоке зависит от того, где этот про-
промежуток начинается, а начало промежутка Tk+1 совпадает с концом
промежутка Tk\ значит, длины этих промежутков зависимы.
Рассмотрим примеры потоков Пальма.
1. Некоторая деталь технического устройства (например, радио-
радиолампа) работает непрерывно до своего отказа (выхода из строя),
после чего она мгновенно заменяется новой. Срок безотказной работы
детали случаен; отдельные экземпляры выходят из строя независимо
34 Е. С. Вентцель
530 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ ГГЛ. !9
друг от друга. При этих условиях поток отказов (или поток «восста-
«восстановлений») представляет собой поток Пальма. Если, к тому же, срок
работы детали распределен по показательному закону, то поток
Пальма превращается в простейший.
2. Группа самолетов идет в боевом порядке «колонна» (рис. 19.5.2)
с одинаковой для всех самолетов скоростью V. Каждый самолет,
кроме ведущего, обязан выдерживать строй, т. е. держаться на задан-
заданном расстоянии L от впереди идущего. Это расстояние, вследствие
погрешностей радиодальномера, выдерживается с ошибками. Моменты
Рис. 19.5.2.
пересечения самолетами заданного рубежа образуют поток Пальма,
так как случайные величины Т1 = ~; Г2 = -~-; ... независимы. За-
Заметим, что тот же поток не будет потоком Пальма, если каждый из
самолетов стремится выдержать заданное расстояние не от соседа,
а от ведущего.
Потоки Пальма часто получаются в виде выходных потоков си-
систем массового обслуживания. Если на какую-либо систему поступает
какой-то поток заявок, то он этой системой разделяется на два: по-
поток обслуженных и поток необслуженных заявок.
Поток необслуженных заявок часто поступает на какую-либо дру-
другую систему массового обслуживания, поэтому представляет интерес
изучить его свойства.
Основной в теории выходных потоков является тесфема Пальма,
которую мы сформулируем без доказательства.
Пусть на систему массового обслуживания поступает по-
поток заявок типа Пальма, причем заявка, заставшая все ка-
каналы занятыми, получает отказ {не обслуживается). Если при
этом время обслуживания имеет показательный закон рас-
распределения, то поток необслуженных заявок является также
потоком типа Пальма.
В частности, если входной поток заявок будет простейшим, то
поток необслуженных заявок, не будучи простейшим, будет все же
иметь ограниченное последействие.
Интересным примером потоков с ограниченным последействием
являются так называемые потоки Эрланга. Они образуются «про-
«просеиванием» простейшего потока.
19.51 ПОТОК С ОГРАНИЧЕННЫМ ПОСЛЕДЕЙСТВИЕМ (ПОТОК ПАЛЬМА) 531
Рассмотрим простейший поток (рис. 19.5.3) й выбросим из него
каждую вторую точку (на рисунке выброшенные точки отмечены
крестами). Оставшиеся точки образуют поток; этот поток называется
потоком Эрланга первого порядка (Эх). Очевидно, этот поток
Рис. 19.5.3.
есть поток Пальма: поскольку независимы промежутки между со-
событиями в простейшем потоке, то независимы и величины 7\, Т2, ....
получающиеся суммированием таких промежутков по два.
Поток Эрланга второго порядка получится, если сохранить
в простейшем потоке каждую третью точку, а две промежуточные
выбросить (рис. 19.5.4).
Рис. 19.5.4.
Вообще, потоком Эрланга k-го порядка Ck) называется по-
поток, получаемый из простейшего, если сохранить каждую (&-|-1)-ю
точку, а остальные выбросить. Очевидно, простейший поток можно
рассматривать как поток Эрланга нулевого порядка (Эо)-
Рис. 19.5.5.
Найдем закон распределения промежутка времени Т между сосед-
соседними событиями в потоке Эрланга А-го порядка Oft). Рассмотрим
на оси Ot (рис. 19.5.5) простейший поток с интервалами 7\, Г2, ...
Величина Т представляет собой сумму ft-|-i независимых случайных
величин
Т=%Т1, . A9.5.1)
34*
532 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. 19
где Tv Т2 Гй+, — независимые случайные величины, подчинен-
подчиненные одному и тому же показательному закону
/(/) = Х«-« (/>0). A9.5.2)
Можно было бы найти закон распределения величины Т как компо-
композицию (k-\-l) законов A9.5.2). Однако проще вывести его элемен-
элементарными рассуждениями.
Обозначим fk(,t) плотность распределения величины Т для по-
потока 3ftl fn(t)dt есть вероятность того, что величина Г примет зна-
значение между t и t-{-dt (рис. 19.5.5). Это значит, что последняя
точка промежутка Т должна попасть на элементарный участок
(t, t-{-dt), а предыдущие k точек простейшего потока — на учас-
участок @, t). Вероятность первого события равна \dt; вероятность вто-
второго, на основании формулы A9.3.2), будет
Перемножая эти вероятности, получим
откуда
/*@ = -^-«-" ■(*><>). A9.5.3)
Закон распределения с плотностью A9.5.3) называется законом
Эрланга h-zo порядка. Очевидно, при ft = 0 он обращается в пока-
показательный
/о(О = Хв-" (*>0). A9.5.4)
Найдем характеристики закона Эрланга f k(t): математическое ожи-
ожидание mk и дисперсию Dk. По теореме сложения математических
ожиданий
где niQ = -r математическое ожидание промежутка между Событи-
Событиями в простейшем потоке.
Отсюда
^± A9.5.5)
Аналогично по теореме сложения дисперсий
-р-. -* —г^-. A9.5.6)
19.5] ПОТОК С ОГРАНИЧЕННЫМ ПОСЛЕДЕЙСТВИЕМ (ПОТОК ПАЛЬМА) 533
Плотность Ак потока Э^ будет обратна величине mk
л- A9-5-7)
Таким образом, при увеличении порядка потока Эрланга увеличи-
увеличиваются как математическое ожидание, так и дисперсия промежутка
времени между событиями, а плотность потока падает.
Выясним, как будет изменяться поток Эрланга при &->оо, если
его плотность будет сохраняться постоянной? Пронормируем вели-
величину Т так, чтобы ее математическое ожидание (и, следовательно,
плотность потока) оставалось неизменным. Для этого изменим мас-
масштаб по оси времени и вместо Т рассмотрим величину
Т-т—-. A9.5.8)
Назовем такой поток нормированным потоком Эрланга k-го по-
порядка. Закон распределения промежутка 7" между событиями этого
потока будет
ffi ). A9.5.9)
где Ak—\(k-\-l), или
1) * (/>0). A9.5.10)
Математическое ожидание величины Т, распределенной по закону
A9.5.10), не зависит от ft и равно
m m
где X — плотность потока, совпадающая при любом k с плотностью
исходного простейшего потока. Дисперсия величины Т равна
^d 09.5.11)
и неограниченно убывает с возрастанием k.
Таким образом, мы приходим к выводу: при неограниченном
увеличении k нормированный поток Эрланга приближается
к регулярному потоку с постоянными интервалами, рав-
равными у.
Зто свойство потоков Эрланга удобно в практических примене-
применениях: оно дает возможность, задаваясь различными k, получить любую
степень последействия: от полного отсутствия (k = 0) до жесткой
функциональной связи между моментами появления событий (k = сю)»
Таким образом, порядок потока Эрланга может служить как бы «ме-
«мерой 'последействия», имеющегося в потоке. В целях упрощения часто
534 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. 19
бывает удобно заменить реальный поток заявок, имеющий последей-
последействие, нормированным потоком Эрланга с примерно теми же характе-
характеристиками промежутка между заявками: математическим ожиданием
и дисперсией.
Пример. В результате статистической обработки промежутков между
заявками в потоке получены оценки для математического ожидания и дис-
дисперсии величины Т:
), Dt = 0,8 (минг).
Заменить этот поток нормированным потоком Эрланга с теми же характе-
характеристиками.
Решение. Имеем
I = Л- = 0,5.
mt
Из формулы A9.5.11) получим
ъ * 4
Поток можно приближенно заменить нормированным потоком Эрланга чет-
четвертого порядка.
19.6. Время обслуживания
Кроме характеристик входного потока заявок, режим работы си-
системы зависит еще от характеристик производительности самой си-
системы: числа каналов п и быстродействия каждого канала. Одной из
важнейших величин, связанных с системой, является время обслу-
обслуживания одной заявки Тоб. Эта величина может быть как не-
неслучайной, так и случайной. Очевидно, более общим является слу-
случайное время обслуживания.
Рассмотрим случайную величину Гоб и обозначим O(t) ее функ-
функцию распределения:
= P(To6<t). A9.6.1)
a g (t) — плотность распределения:
g(t) = Q'(t). A9.6.2)
Для практики особый интерес представляет случай, когда вели-
величина 7 Об имеет показательное распределение
pe-iH (t>0), A9.6.3)
где параметр (л — величина, обратная среднему времени обслуживания
одной заявки:
Рв-£7-' т-'об = М1Гоб1- A9-6.4)
•об
Особая роль, которую играет в теории массового обслуживания
показательный закон распределения величины Гоб, связана с тем
19.6] ВРЕМЯ ОБСЛУЖИВАНИЯ 535
свойством этого закона, которое было доказано в п° 19.4. В приме-
применении к данному случаю оно формулируется так: если в какой-то
момент t0 происходит обслуживание заявки, то за-
закон распределения оставшегося времени обслужива-
обслуживания не зависит от того, сколько времени обслужи-
обслуживание уже продолжалось.
На первый взгляд допущение о том, что время обслуживания
распределено по показательному закону, представляется довольно
искусственным. В ряде практических задач кажется естественнее пред-
предположить его либо совсем не случайным, либо распределенным по
нормальному закону. Однако существуют условия, в которых время
обслуживания действительно распределяется по закону, близкому
к показательному.
Это, прежде всего, все задачи, в которых обслуживание сводится
к ряду «попыток», каждая из которых приводит к необходимому
результату с какой-то вероятностью р.
Пусть, например, «обслуживание» состоит в обстреле какой-то
цели и заканчивается в момент ее поражения. Обстрел ведется неза-
независимыми выстрелами с некоторой средней скорострельностью X вы-
выстрелов в единицу времени. Каждый выстрел поражает цель с вероят-
вероятностью р. Чтобы не связывать себя необходимостью точного учета
момента каждого выстрела, предположим, что они происходят в слу-
случайные моменты времени и образуют простейший поток П с плот-
плотностью X (рис. 19.6.1).
Рис. 19.6.1,
Выделим мысленно из этого потока другой — поток «успешных»,
или «поражающих», выстрелов (они отмечены кружками на рис. 19.6.1).
Выстрел будем называть «успешным», если он приводит к поражению
цели (если только цель не оыла поражена ранее). Нетрудно убедиться,
что успешные выстрелы тоже образуют простейший поток П* с плот-
плотностью Л —Хр (исходный поток П — простейший, а каждый выстрел
может стать поражающим, независимо от других, с вероятностью р).
Вероятность того, что цель будет поражена до момента t, будет равна
откуда плотность распределения времени «обслуживания»
а это есть показательный закон с параметром |л = Л.
536
ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ
[ГЛ. 19
Рис. 19.6.2.
Показательным законом распределения времени обстрела до пора-
поражения цели можно приближенно пользоваться и в случае, когда вы-
выстрелы не образуют простейшего потока, а отделены, например,
строго определенными промежутками времени tv если только ве-
вероятность поражения одним выстрелом р не очень велика. Для ил-
иллюстрации приведем на одном и том же графике (рис. 19.6.2) функ-
функцию распределения момента поражающего выстрела (ступенчатая
линия) для случая р = 0,4, ^=1 и функцию распределения показа-
показательного закона с парамет-
qm ром у- = р = 0,4 (плавная
кривая). Как видно на
рис. 19.6.2, непрерывное
показательное распределе-
распределение хорошо соответствует
характеру нарастания функ-
функции распределения для ди-
дискретного случая. Есте-
Естественно, если моменты вы-
выстрелов не будут строго
t определенными, соответст-
соответствие с показательным законом
будет еще лучше.
Случай стрельбы — не
единственный, когда обслу-
обслуживание осуществляется рядом «попыток». К такому типу часто можно
отнести обслуживание по устранению неисправностей технических
устройств, когда поиски неисправной детали или узла осуществляются
рядом тестов или проверок. К такому же типу можно отнести задачи,
где «обслуживание» заключается в обнаружении какого-либо объекта
радиолокатором, если объект с какой-то вероятностью может быть
обнаружен при каждом цикле обзора.
Показательным законом хорошо описываются и те случаи, когда
плотность распределения времени обслуживания по тем или иным
причинам убывает при возрастании аргумента t. Это бывает, когда
основная масса заявок обслуживается очень быстро, а значительные
задержки в обслуживании наблюдаются редко. Рассмотрим, например,
окно почтового отделения, где продаются марки и конверты, а также
принимаются почтовые отправления и переводы. Основная масса по-
посетителей покупает марки или конверты и обслуживается очень
быстро. Реже встречаются заявки на отправление заказных писем,
они обслуживаются несколько дольше. Переводы посылаются еще
реже и обслуживаются еще дольше. Наконец, в самых редких слу-
случаях представители организаций отправляют сразу большое коли-
количество писем. Гистограмма распределения времени обслуживания
имеет* вид, представленный на рис. 19.6.3. Так как плотность рас-
19.7]
МАРКОВСКИЙ СЛУЧАЙНЫЙ ПРОЦЕСС
537
Рис. 19.6.3.
пределения убывает с возрастанием t, можно без особой погрешности
выровнять распределение с помощью показательного закона, подобрав
соответствующим образом его параметр [)..
Разумеется, показательный закон не является универсальным
законом распределения времени обслуживания. Часто время обслу-
обслуживания лучше описывается, например, законом Эрланга. Однако,
к счастью, пропускная спо-'
собность и другие характе-
характеристики системы массового
обслуживания сравнительно
мало зависят от вида закона
распределения, времени об-
обслуживания, а зависят, глав-
главным образом, от его среднего
значения tnto6. Поэтому в
теории массового обслужи-
обслуживания чаще всего пользуются
допущением, что время об-
обслуживания распределено по
показательному закону. Эта
гипотеза позволяет сильно
упростить математический
аппарат, применяемый для решения задач массового обслуживания,
и, в ряде случаев, получить простые аналитические формулы для ха-
характеристик пропускной способности системы.
19.7. Марковский случайный процесс
Допущения о пуассоновском характере потока заявок и о пока-
показательном распределении времени обслуживания ценны тем, что
позволяют применить в теории массового обслуживания аппарат так
называемых марковских случайных процессов.
Процесс, протекающий в физической системе, называется мар-
марковским (или процессом без последействия), если для каждого мо-
момента времени вероятность любого состояния системы в бу-
будущем зависит только от состояния системы в настоящий
момент (t0) и не зависит от того, каким образом система
пришла в это состояние.
Рассмотрим элементарный пример марковского случайного про-
процесса. По оси абсцисс Ох случайным образом перемещается точка X.
В момент времени t =О точка X находится в начале координат
(-* = 0) и остается там в течение одной секунды. Через секунду
бросается монета; если выпал герб — точка X перемещается на одну
единицу длины вправо, если цифра — влево. Через секунду снова
бросается монета и производится такое же случайное перемещение,
538
ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ
[ГЛ. 19
и т. д. Процесс изменения положения точки (или, как говорят,
«блуждания») представляет собой случайный процесс с дискретным
временем (^ = 0, 1, 2 ) и счетным множеством состояний
хо — О; лгх = 1; *_, = — 1; х2 = 2; х_2 =—2; ...
Схема возможных переходов для этого процесса показана на
рис. 19.7.1.
Покажем, что этот процесс — марковский. Действительно, пред-
представим себе, что в какой-то момент времени t0 система находится,
например, в состоянии л:, — на одну единицу правее начала коорди-
координат. Возможные положения точки через единицу времени будут х0
и х2 с вероятностями 1/2 и 1/2; через две единицы — x_v xv x3
с вероятностями 1/4, 1/2, 1/4 и так далее. Очевидно, все эти ве-
вероятности зависят только от того, где находится точка в данный
момент tQ, и совершенно не зависят от того, как она пришла туда.
—
I.
1
—
л.
-^ — 1.
—
Рис. 19.7.1,
Рассмотрим другой пример. Имеется техническое устройство X,
состоящее из элементов (деталей) типов а и Ь, обладающих разной
долговечностью. Эти элементы в случайные моменты времени и неза-
независимо друг от друга могут выходить из строя. Исправная работа
каждого элемента безусловно необходима для работы устройства
в целом. Время безотказной работы элемента — случайная величина,
распределенная по показательному закону; для элементов типа а и b
параметры этого закона различны и равны соответственно \а и \.
В случае отказа устройства немедленно принимаются меры для вы-
выявления причин и обнаруженный неисправный элемент немедленно
заменяется новым. Время, потребное для восстановления (ремонта)
устройства, распределено по показательному закону с параметром \ia
(если вышел из строя элемент типа а) и [А6 (если вышел из строя
элемент типа и).
В данном примере случайный процесс, протекающий в системе,
есть марковский процесс с непрерывным временем и конечным мно-
множеством состояний:
лг0 — все элементы исправны, система работает,
х1—неисправен элемент типа а, система ремонтируется1),
х2—неисправен элемент типа Ь, система ремонтируется.
Схема возможных переходов дана на рис. 19.7.2.
') Предполагается, что детали могут выходить из строя только во время
работы системы; выход из строя одновременно двух или более деталей прак-
практически невозможен. .
t
It,
хг
хг
19.71 МАРКОВСКИЙ СЛУЧАЙНЫЙ ПРОЦЕСС 539
Действительно, процесс обладает марковским свойством. Пусть
например, в момент tQ система находится в состоянии х0 (исправна).
Так как время безотказной работы каждого элемента — показатель-
показательное1), то момент отказа каждого элемента в будущем не зависит от
того, сколько времени он уже работал (когда поставлен). Поэтому
вероятность того, что в будущем система останется в состоянии х0
или уйдет из него, не зависит' от «предыстории» процесса. Пред-
Предположим теперь, что в момент t0 система находится в состоянии хг
(неисправен элемент типа а). Так как время ремонта тоже показа-
показательное, вероятность окончания ремонта в любое время после t0 не
зависит от того, когда начался ремонт и когда
были поставлены остальные (исправные) элементы.
Таким образом, процесс является марковским.
Заметим, что показательное распределение вре-
времени работы элемента и показательное распреде-
распределение времени ремонта — существенные условия, ,
без которых процесс не был бы марковским. Дей- С
ствительно, предположим, что время исправной
работы элемента распределено не по показатель- Рис. 19.7.2.
ному закону, а по какому-нибудь другому —
например, по закону равномерной плотности на участке (tv t2). Это
значит, что каждый элемент с гарантией работает время tv а нэ
участке от tl до t2 может выйти из строя в любой момент с одина-
одинаковой плотностью вероятности. Предположим, что в какой-то момент
времени t0 элемент работает исправно. Очевидно, вероятность того,
что элемент выйдет из строя на каком-то участке времени в будущем,
зависит от того, насколько давно поставлен элемент, т. е. зависит
от предыстории, и процесс не будет марковским.
Аналогично обстоит дело и с временем ремонта Тр; если оно не
показательное и элемент в момент t0 ремонтируется, то оставшееся
время ремонта зависит от того, когда он начался; процесс снова не
будет марковским.
Вообще показательное распределение играет особую роль в теории
марковских случайных процессов с непрерывным временем. Легко убе-
диться, что г! стацигчторчом мпрковском процессе врсм^. в течение
которого система остается в каком-либо состоянии, распределено
всегда по показательному закону (с параметром, зависящим, вообще
говоря, от этого состояния). Действительно, предположим, что в мо-
момент t0 система находится в состоянии xk и до этого уже находилась
в нем какое-то время. Согласно определению марковского процесса,
вероятность любого события в будущем не зависит от предыстории;
в частности, вероятность того, что система уйдет из состояния хк
') Так говорят кратко вместо «имеет показательный закон распреде-
распределения».
540
ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ
[ГЛ. 19
в течение времени t, не должна зависеть от того, сколько времени
система уже провела в этом состоянии. Следовательно, время пребы-
пребывания системы в состоянии xk должно быть распределено по показа-
показательному закону.
В случае, когда процесс, протекающий в физической системе со
счетным множеством состояний и непрерывным временем, является
марковским, можно описать этот процесс с помощью обыкновенных
дифференциальных уравнений, в которых неизвестными функциями
являются вероятности состояний p1(t), p2{i)> ••• Составление и ре-
решение таких уравнений мы продемонстрируем в следующем п° на
примере простейшей системы массового обслуживания.
19.8. Система массового обслуживания с отказами.
Уравнения Эрланга
Системы массового обслуживания делятся на два основных типа:
а) системы с отказами, б) системы с ожиданием.
В системах с отказами заявка, поступившая в момент, когда
все каналы обслуживания заняты, немедленно получает отказ, поки-
покидает систему и в дальнейшем процессе обслуживания не участвует.
В системах с ожиданием заявка, заставшая все каналы заня-
занятыми, не покидает систему, а становится в очередь и ожидает, пока
не освободится какой-нибудь канал. В настоящем п° мы рассмотрим
систему с отказами как наиболее простую.
—
X,
—
—
х„
Рис. 19.8.1.
Пусть имеется я-канальная система массового обслуживания
с отказами. Рассмотрим ее как физическую систему X с конечным
множеством состояний:
х0 — свободны все каналы,
хк —занято ровно k каналов,
х„—заняты все п каналов.
Схема возможных переходов дана на рис. 19.8.1.
Поставим задачу: определить вероятности состояний системы
pk(t) (fe = 0, 1 и.) для любого момента времени t. Задачу будем
решать при следующих допущениях:
1) поток заявок — простейший, с плотностью X;
19.8] СИСТЕМА МАССОВОГО ОБСЛУЖИВАНИЯ С ОТКАЗАМИ 541
2) время обслуживания Тоб — показательное, с параметром и.=
g(f) = v*-v* (t>0). A9.8.1)
Заметим, что параметр \>. в формуле A9.8.1) полностью аналогичен
параметру X показательного закона распределения промежутка Т между
соседними событиями простейшего потока:
= ke~M (t>0). A9.8.2)
Параметр к имеет смысл «плотности потока заявок». Аналогично,
величину (а можно истолковать как «плотность потока освобождений»
занятого канала. Действительно, представим себе канал, непрерывно
занятый (бесперебойно снабжаемый заявками); тогда, очевидно, в этом
канале будет идти простейший поток освобождений .с плотностью \х.
Так как оба потока — заявок и освобождений — простейшие, про-
процесс, протекающий в системе, будет марковским.
Рассмотрим возможные состояния системы и их вероятности
PoV). Pi (О Л.(9- A9.8.3)
Очевидно, для любого момента времени
в
2/>*(*)=!• A9.8.4)
Составим дифференциальные уравнения для всех вероятностей A9.8.3),
начиная с po{t). Зафиксируем момент времени t и найдем вероятность
po(t-\-kt) того, что в момент t-\-kt система будет находиться в со-
состоянии х0 (все каналы свободны). Это может про-
произойти двумя способами (рис. 19.8.2):
щ
А — в момент t система находилась в состоя-
состоянии х0, а за время Ы не перешла из нее в х, (не
пришло ни одной заявки), Рис. 19.8.2,
В — в момент t система находилась в состоя-
состоянии Хр а за время b.t канал освободился, и система перешла в со-
состояние Xq1).
Возможностью «перескока» системы через состояние (например, из
x.j, и л'о через х±) за ма.ши промежуток времени можно пренебречь,
как величиной высшего порядка малости по сравнению с Р (А) и Р (ВJ).
По теореме сложения вероятностей имеем
A9.8.5)
') На рис. 19.8.2 возможные способы появления состояния х0 в момент
t -f- M показаны стрелками, направленными в ха\ стрелка, направленная из
х0 в хи перечеркнута в знак того, что система не должна выйти из состоя-
состояния Л'о-
2) В дальнейшем мы все время будем пренебрегать слагаемыми высших
порядков малости по сравнению с At. В пределе при Д^->0 приближенные
равенства перейдут в точные.
542 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. J9
Найдем вероятность события А по теореме умножения. Вероят-
Вероятность того, что в момент t система была в состоянии х0, равна po(f).
Вероятность того, что за время Д£ не придет ни одной заявки, равна
0-х д^ q точностью до величин высшего порядка малости
е-хд'«1— ХД*. A9.8.6)
Следовательно,
P(A)~po(t)(l~ ХМ).
Найдем Р(В). Вероятность того, что в момент t система была
в состоянии xv равна р1 (f). Вероятность того, что за время Д£ канал
освободится, равна 1 — е~*и; c точностью до малых величин выс-
высшего порядка
Следовательно,
Отсюда
р0 (t+ДО « /»0 (/) A — X М) + цр, (О А/.
Перенося po(f) в левую часть, деля на Д£ и переходя к пределу
при Д£—>0, получим дифференциальное уравнение для pQ(t)\
A9.8.7)
ш
Аналогичные дифференциальные уравнения могут быть составлены
и для других вероятностей состояний.
Возьмем любое £@<£<л) и найдем вероятность pk(t-\-ht)
того, что в момент f + Д^ система будет в состоянии xk (рис. 19.8.3).
Эта вероятность вычисляется как вероят-
вероятность суммы уже не двух, а трех событий (по
числу стрелок, направленных в состояние xk):
А—в момент t система была в состоянии xk
(занято k каналов), а за время Д£ не перешла
Рис. 19.8.3. из Него ни в xk+1, ни в xk_l (ни одна заявка
не поступила, ни один канал не освободился);
В — в момент t система была в состоянии xk_i (занято к—1
каналов), а за время Д£ перешла в xk (пришла одна заявка);
С — в момент t система была в состоянии xk+l (занято fe-j-1
каналов), а за время Д^ один из каналов освободился.
Найдем Р(А). Вычислим сначала вероятность того, что за время
Д£ не придет ни одна заявка и не освободится ни один из каналов:
0-х и (£-[>*
Пренебрегая малыми величинами высших порядков, имеем
1 _ (I _)- ftp) д*.
19.8] СИСТЕМА МАССОВОГО ОБСЛУЖИВАНИЯ С ОТКАЗАМИ
откуда
P(A)~pk(t)[l-
Аналогично
*/>*-! (ОХАЛ
543
-i (OX A* +
Отсюда получаем дифференциальное уравнение для pk (t) (О < k < п):
Составим уравнение для последней вероятности pn(t) (рис. 19.8.4).
Имеем
рп (/ + АО » рп @ A — Ч ДО + рл_! (О X АЛ
/
щ
где 1 — К(аД£ — вероятность того, что за время Д^ рис
не освободится ни один канал; \ht — вероятность
тэго, что за время Д^ придет одна заявка. Получаем дифференциаль-
ног уравнение для pn(t):
Таким образом, получена система дифференциальных уравнений
для вероятностей рх (t), p2 (t) рп (t):
at
рк it) + (A + 1) ]xpk+l (t)
@<k< я),
A9.8.8)
Уравнения A9.8.8) называются уравнениями Эрланга. Интегри-
Интегрирование системы уравнений A9.8.8) при начальных условиях
544 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ 19
(в начальный момент все каналы свободны) дает зависимость pk {t)
для любого ft. Вероятности pk (t) характеризуют среднюю загрузку
системы и ее изменение с течением времени. В частности, pn(t) есть
вероятность того, что заявка, пришедшая в момент t, застанет все
каналы занятыми (получит отказ):
Величина q(t)=\—pn (t) называется относительной пропу-
пропускной способностью системы. Для данного момента t это есть отно-
отношение среднего числа обслуженных за единицу времени заявок
к среднему числу поданных.
Система линейных дифференциальных уравнений A9.8.8) сравни-
сравнительно легко может быть проинтегрирована при любом конкретном
числе каналов и.
Заметим, что при выводе уравнений A9.8.8) мы нигде не пользо-
пользовались допущением о том, что величины X и (а (плотности потока
заявок и «потока освобождений») постоянны. Поэтому уравнения
A9.8.8) остаются справедливыми и для зависящих от времени ~k(t).
\>.(t), лишь бы потоки событий, переводящих систему из состояния
в состояние, оставались пуассоновскими (без этого процесс не будет
марковским).
19.9. Установившийся режим обслуживания. Формулы Эрланга
Рассмотрим я-канальную систему массового обслуживания с отка-
отказами, на вход которой поступает простейший поток заявок с плот-
плотностью X; время обслуживания — показательное, с параметром [х. Воз-
Возникает вопрос: будет ли стационарным случайный процесс, протекаю-
протекающий в системе? Очевидно, что в начале, сразу после включения
системы в работу, протекающий в ней процесс еще не будет стацио-
стационарным: в системе массового обслуживания (как и в любой динами-
динамической системе) возникнет так называемый «переходный», нестацио-
нестационарный процесс. Однако, спустя некоторое время, этот переходный
процесс затухнет, и система перейдет на стационарный, так называе-
называемый «установившийся» режим, вероятностные харгктергстики кото-
которого уже не будут зависеть от времени.
Во многих задачах практики нас интересуют именно характери-
характеристики предельного установившегося режима обслуживания.
Можно доказать, что для любой системы с отказами такой пре-
предельный режим существует, т. е. что при t—>oo все вероятности
Рч'\ч< Pi(f) Рп(О стремятся к постоянным пределам рй, рх, ...
..., рп, а все их производные — к нулю.
Чтобы найти предельные вероятности р0, pv ..., рп (вероятности
соыииний chlIcMdi в у становившемся режиме), заменим в уравнениях
A9.8.8) все вероятности pk(t) @ </%<«) их пределами рк, а все
19.9] УСТАНОВИВШИЙСЯ РЕЖИМ ОБСЛУЖИВАНИЯ. ФОРМУЛЫ ЭРЛАНГА 545
производные положим равными нулю. Получим систему уже не диф-
дифференциальных, а алгебраических уравнений
= 0,
@<А<я).
„-2 — [X + (Я — 1) Jl] /Jn_! + Я|1/»я = 0,
К этим уравнениям необходимо добавить условие
4 = 0
A9.9.2)
• Разрешим систему A9.9.1) относительно неизвестных р0, рх, ...
..., рп. Из первого уравнения имеем
A9.9.3)
Из второго, с учетом A9.9.3),
Рч — 2JT [— Хри
рх\ =
= ^-Ро; 09.9.4)
аналогично из третьего, d учетом A9.9.3) и A9.9.4),
и вообще, для любого k
Введем обозначение
09.9.5)
A9.9.6)
и назовем величину а, приведенной плотностью потока заявок.
Это есть не что иное, как среднее число заявок, приходя-
приходящееся на среднее время обслуживания одной заявки.
Действительно,
7.-- — — Km, ,
(A UQ
35 Е. С. Еслтцель
646 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ 19
где mto6 = M[To6] — среднее время обслуживания одной заявки*
В новых обозначениях формула A9.9.5) примет вид
Р"~Т[Ро- A9.9.7)
Формула A9.9.7) выражает все вероятности рк через р0. Чтобы вы-
выразить их непосредственно через а и и, воспользуемся условием
A9.9.2). Подставив в него A9.9.7), получим
откуда
Ро=-г • A9.9.8)
Подставляя A9-9.8) в A9.9.7), получим окончательно
Р* = -^— @<*<л). A9.9.9)
Формулы A9.9.9) называются формулами Эрланга. Они дают
предельный закон распределения числа занятых каналов в зависимости
от характеристик потока заявок и производительности системы обслу-
обслуживания. Полагая в формуле A9.9.9) k = n, получим вероятность
отказа (вероятность того, что поступившая заявка найдет все ка-
каналы занятыми):
а"
"' A9.9.10)
Sa*
В частности, для одноканальной системы (п = 1)
Рт = Р1 = Т^' A9.9.11)
а относительная пропускная способность
9=1-^0^ = ^. A9.9.12)
Формулы Эрланга A9.9.9) и их счедствия A9.Ч. 10) — A9.9.12)
выведены нами для случая показательного распределения времени
19.9] УСТАНОВИВШИЙСЯ РЕЖИМ ОБСЛУЖИВАНИЯ. ФОРМУЛЫ ЭРЛАНГА 547
обслуживания. Однако исследования последних лет1) показали, что
эти формулы остаются справедливыми и при любом законе распре-
распределения времени обслуживания, лишь бы входной поток был про-
простейшим.
Пример 1. Автоматическая телефонная станция имеет 4 линии связи.
На станцию поступает простейший поток заявок с плотностью X = 3 (вызова
в минуту). Вызов, поступивший в момент, когда все линии заняты, получает
отказ"). Средняя длительность разговора 2 минуты. Найти: а) вероятность
отказа; б) среднюю долю времени, в течение которой телефонная станция
вообще не загружена.
Решение. Имеем т,о6 = 2 (мин);
|а = 0,5 (рааг/мин), о = — = 6.
а) По формуле A9.9.10) получаем
а*
Р°™ = Р* = «■ а*' «э g< « °'47-
1 + ТТ+ 21 + ЗТ + ТГ
б) П© формуле A9.9.8)
1 + ТТ"|"Т" ЗТ + 1Г
Несмотря на то, что формулы Эрланга в точности справедливы
только при простейшем потоке заявок, ими можно с известным при-
приближением пользоваться и в случае, когда поток заявок отличается
от простейшего (например, является стационарным потоком с огра-
ограниченным последействием). Расчеты показывают, что замена произ-
произвольного стационарного потока с не очень большим последействием
простейшим потоком той же плотности X, как правило, мало влияет
на характеристики пропускной способности системы.
Наконец, можно заметить, что формулами Эрланга можно при-
приближенно пользоваться и в случае, когда система массового обслу-
обслуживания допускает ожидание заявки в очереди, но когда срок ожи-
ожидания мал по сравнению со средним временем обслуживания одной
заявки.
Пример 2. Станция наведения истребителей имеет 3 канала. Каждый
канал может одновременно наводить один истребитель на одну цель. Среднее
время наведения истребителя на цель mto6 — 2 мин. Поток целей — простей-
простейший, с плотностью X = 1,5 (самолетов в минуту). Станцию можно считать
«системой с отказами», так как цель, по которой наведение не началось
в момент, когда она вошлавзону действия истребителей, вообще остается не
') См. Б. А. Севастьянов, Эргодическая гсорсма для марковских
процессов и ее приложение к телефонным системам с отказами. Теория ве-
вей 2 1 1^7
рц р ф
роятностей !! ев ПР!ТМ?НРН!!Я, т. 2, ЕМП 1,
2) Предполагается, что вторичные вызовы абонентов, получивших отказ,
не нарушают пуассоновского характера потока заявок.
35*
548 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ 19
атакованной. Найти среднюю долю целей, проходящих через зону действия
не обстрелянными.
Решение. Имеем [а = -^- = 0,5: X = 1,5; « =— = 3.
По формуле A9.9.10)
ii
ч i
р „ ~ 0 446
* отк — Pi — о<p оТГ ~ v,&tv.
1+ТТ + '2Т+ ЗУ
Вероятность отказа « 0,346; она же выражает среднюю долю необстрелян-
необстрелянных целей.
Заметим, что в данном примере плотность потока целей выбрана такой,
что при их регулярном следовании одна за другой через определенные интер-
интервалы и при точно фиксированном времени наведения Таъ = 2 мин номиналь-
номинальная пропускная способность системы достаточна для того, чтобы обстрелять
все без исключения цели. Снижение пропускной способности происходит из-за
наличия случайных сгущений и разрежений в потоке целей, которые нельзя
предвидеть заранее.
19.10. Система массового обслуживания с ожиданием
Система массового обслуживания называется системой с ожида-
ожиданием, если заявка, заставшая все каналы занятыми, становится в оче-
очередь и ждет, пока не освободится какой-нибудь канал.
Если время ожидания заявки в очереди ничем не ограничено, то
система называется «чистой системой с ожиданием». Если оно огра-
ограничено какими-то условиями, то система называется «системой сме-
смешанного типа». Это промежуточный случай между чистой системой
с отказами и чистой системой с ожиданием.
Для практики наибольший интерес представляют именно системы
смешанного типа.
Ограничения, наложенные на ожидание, могут быть различного
типа. Часто бывает, что ограничение накладывается на время ожи-
ожидания заявки в очереди; считается, что оно Ограничено сверху
каким-то сроком Гож, который может быть как строго определенным,
так и случайным. При этом ограничивается только срок ожидания
в очеречи а начатое обслуживание доводится до конца, незявмсммо
от того, сколько времени продолжалось ожидание (например, клиент
в парикмахерской, сев в кресло, обычно уже не уходит до конца
обслуживания). В других задачах естественнее наложить ограниче-
ограничение не на время ожидания в очереди, а на общее время пребы-
пребывания заявки в системе (например, воздушная цель может
пробыть в зоне стрельбы лишь ограниченное время и покидает ее
независимо от того, кончился обстрел или нет). Наконец, можно рас-
рассмотреть и такую смешанную систему (она ближе всего к типу тор-
торговых предприятий, торгующих предметами не первой необходимости),
когда заявка становится в очередь только в том случае, если длина
19.10] СИСТЕМА МАССОВОГО ОБСЛУЖИВАНИЯ С ОЖИДАНИЕМ 549
очереди не слишком велика. Здесь ограничение накладывается на
число заявок в очереди.
В системах с ожиданием существенную роль играет так назы-
называемая «дисциплина очереди». Ожидающие заявки могут вызываться
на обслуживание как в порядке очереди (раньше прибывший раньше
и обслуживается), так и в случайном, неорганизованном порядке.
Существуют системы массового обслуживания «с преимуществами»,
где некоторые заявки обслуживаются предпочтительно перед другими
(«генералы и полковники вне очереди»).
Каждый тип системы с ожиданием имеет свои особенности и свою
математическую теорию. Многие из них описаны, например, в книге
Б. В. Гнеденко «Лекции по теории массового обслуживания».
Здесь мы остановимся только на простейшем случае смешанной
системы, являющемся естественным обобщением задачи Эрланга для
системы с отказами. Для этого случая мы выведем дифференциаль-
дифференциальные уравнения, аналогичные уравнениям Эрланга, и формулы для
вероятностей состояний в установившемся режиме, аналогичные фор-
формулам Эрланга.
Рассмотрим смешанную систему массового обслуживания X
с п каналами при следующих условиях. На вход системы поступает
простейший поток заявок с плотностью X. Время обслуживания одной
заявки ГОб — показательное, с параметром ц =-——.Заявка, застав-
'об
шая все каналы занятыми, становится в очередь и ожидает обслужи-
обслуживания; время ожидания ограничено некоторым сроком Гож; если до
истечения этого срока заявка не будет принята к обслуживанию, то
она покидает очередь и остается необслуженной. Срок ожидания ТиА
будем считать случайным и распределенным по показательному
закону
h (t) = ve-*< (t > 0),
где параметр v—величина, обратная среднему сроку ожидания:
1 = ; т, =М[Т„Ж\.
„,ож> /о»
Параметр v полностью аналогичен параметрам X и jj. потока за-
заявок и «потока освобождений». Его можно интерпретировать, как
плотность «потока уходов» заявки, стоящей в очереди. Действительно,
представим себе заявку, которая только и делает, что становится
в очередь и ждет в ней, пока не кончится срок ожидания Гож, после
чего уходит и сразу же снова становится в очередь. Тогда «ноток
уходов» такой заявки из очереди будет иметь плотность ч.
Очевидно, при v—>oo система смешанного типа превращается
В ЧИСТУЮ СИСТС!1Г С О^КЗЗЗМИ' ПРИ V > 0 0112 ПП-3ПЯЩВ6ТСЯ В ЧИСТОЮ
систему с ожиданием.
550 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ Ю
Заметим, что при показательном законе распределения срока ожи-
ожидания пропускная способность системы не зависит от того, обслужи-
обслуживаются ли заявки в порядке очереди или в случайном порядке: для
каждой заявки закон распределения оставшегося времени ожидания не
зависит от того, сколько времени заявка уже стояла в очереди.
Благодаря допущению о пуассоновском характере всех потоков
событий, приводящих к изменениям состояний системы, процесс, про-
протекающий в ней, будет марковским. Напишем уравнения для вероят-
вероятностей состояний системы. Для этого, прежде всего, перечислим эти
состояния. Будем их нумеровать не по числу занятых каналов, а ло
числу связанных с системой заявок. Заявку будем называть
«связанной с системой», если она либо находится в состоянии обслу-
обслуживания, либо ожидает очереди. Возможные состояния системы будут:
х0 — ни один канал не занят (очереди нет),
хх — занят ровно один канал (очереди нет),
xk — занято ровно k каналов (очереди нет),
хп — заняты все п каналов (очереди иет),
хп-\\—заняты все п каналов, одна заявка стоит в очереди,
xn+s — заняты все п каналов, s заявок стоят в очереди,
Число заявок s, стоящих в очереди, в наших условиях может
быть сколь угодно большим. Таким образом, система X имеет беско-
бесконечное (хотя и счетное) множество состояний. Соответственно, число
описывающих ее дифференциальных уравнений тоже будет беско-
бесконечным.
Очевидно, первые п дифференциальных уравнений ничем не будут
отличаться от соответствующих уравнений Эрлангр:
Отличие новых уравнений от уравнений Зрланга начнется при
rt. Действительно, в состояние хп система с отказами может
19.101 СИСТЕМА МАССОВОГО ОБСЛУЖИВАНИЯ С ОЖИДАНИЕМ 551
перейти только из состояния ха_1; что касается системы с ожида-
ожиданием, то она может перейти в состояние хп не только из xn_v но
и из хп+1 (все каналы заняты, одна заявка стоит в очереди).
Составим дифференциальное уравнение для pn(t)- Зафиксируем мо-
момент t и найдем pn(t-±-kt)— вероятность того, что система в момент
t-{-kt будет в состоянии х„. Это может осуществиться тремя спо-
способами:
1) в момент t система уже была в состоянии хп, а за время Д£
не вышла из него (не пришла ни одна заявка и ни один из каналов
не освободился);
2) в момент t система была в состоянии xn_i, а за время М
перешла в состояние х„ (пришла одна заявка);
3) в момент t система была в состоянии хп+х (все каналы заняты,
одна заявка стоит в очереди), а за время Lt перешла в хп (либо
освободился один канал и стоящая в очереди заявка заняла его, либо
стоящая в очереди заявка ушла в связи с окончанием срока).
Имеем:
Рп ц + до « рп (о A — X м — цр, Ы) -н
+ Рп-1 (*) Х** + Рп+1 @ (ЯР + *) Д t.
откуда
Вычислим теперь pn+s(t-\-M) при любом 5>0 — вероятность
того, что в момент t-\-M все п каналов будут заняты и ровно
s заявок будут стоять в очереди. Это событие снова может осуще-
осуществиться тремя способами:
1) в момент t система уже была в состоянии xn+s, а за время Д£
это состояние не изменилось (значит, ни одна заявка не пришла,
ни один канал не освободился и ни одна из 5 стоящих в очереди
заявок не ушла);
2) в момент t система была в состоянии xn+s_v а за время Д£
перешла в состояние xn+s (т. е. пришла одна заявка);
3) в момент t система была в состоянии xn+s+1, а за время Д^
перешла в состояние xn+s (для этого либо один из каналов должен
освободиться, и тогда одна из 5-4-1 стояших в очереди заявок зай-
займет его, либо одна из стоящих в очереди заявок должна уйти в связи
с окончанием срока).
Следовательно:
) ~ pn+s(t)(l —XU — npU—S4 ДО-Ь
+ ря+,_! (/) X М + ра+3+1 ф [пр. + (s + 1) v] At,
откуда
552
ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ
[ГЛ. 19
Таким образом, мы получили для вероятностей состояний систему
бесконечного числа дифференциальных уравнений:
/г —1),
A9.10.1)
Уравнения A9.10.1) являются естественным обобщением уравнений
Эрланга на случай системы смешанного типа с ограниченным време-
временем ожидания. Параметры X, [i, v в этих уравнениях могут быть как
постоянными, так и переменными. При интегрировании системыA9.10.1)
нужно учитывать, что хотя теоретически число возможных состояний
системы бесконечно, но на практике вероятности pn+s(t) при возра-
возрастании s становятся пренебрежимо малыми, и соответствующие урав-
уравнения могут быть отброшены.
Выведем формулы, аналогичные формулам Эрланга, для вероятно-
вероятностей состояний системы при установившемся режиме обслуживания
(при *->со). Из уравнений A9.10.1), полагая все рк (& = 0 п, ...)
постоянными, а все производные—равными нулю^ получим систему
алгебраических уравнений:
XРс — (X + ,х) p. -U 2№ = 0,
A<*<я —1).
Рп
0,
+ L»t* -I-1* 4-
A9.10.2)
19.10] СИСТЕМА МАССОВОГО ОБСЛУЖИВАНИЯ С ОЖИДАНИЕМ 553
К ним нужно присоединить условие:
со
2/>* = !• A9.10.3)
6=0
Найдем решение системы A9.10.2).
Для этого применим тот же прием, которым мы пользовались
в случае системы с отказами: разрешим первое уравнение относи-
относительно pv подставим во второе, и т. д. Для любого k^.n, как
и в случае системы с отказами, получим:
- A9ЛО4)
Перейдем к уравнениям для k > п (& = ra + s, s^-1). Тем же спо-
способом получим:
рд ур
собом получим:
л! [*"
и вообще при любом 5 >-1
Pn+s= Г^ • A9Л0.5)
n! [J.n JJ {пр -\- тч)
m=i
В обе формулы A9.10.4) и A9.10.5) в качестве сомножителя
входит вероятность р0. Определим ее из условия A9.10.3). Под-
Подставляя в него выражения A9.10.4) и A9.10.5) для k^.n и s^-lf
получим:
откуда
ро = ~ -s-J _ A9.10.6)
|J
m=l
554
ЭЛЕМЕНТЫ. ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ
[ГЛ. 19
Преобразуем выражения A9.10.4), A9.10.5) и-A9.10.6), вводя в них
вместо плотностей X и v «приведенные» плотности:
— = \т, , = а,
(А '00
— = чт, . ==
(А 'Об
A9.10.7)
Параметры аир выражают соответственно среднее число заявок
и среднее число уходов заявки, стоящей в очереди, приходящиеся
на среднее время обслуживания одной заявки.
В новых обозначениях формулы A9.10.4), A9.10.5) и A9.10.6)
примут вид:
/>А = 4тРо @ <&<«); A9.10.8)
пТ
'Ро
A9.10.9)
П
0=1
~k\
*=о
т=\
A9.10.10)
Подставляя A9.10.10) в A9.10.8) и A9.10.9), получим оконча-
окончательные выражения для вероятностей состояний системы:
о"
ТУ
л); A9.10.11)
у а»
.4=0
(s>l). A9.10.12)
19101 СИСТЕМА МАССОВОГО ОБСЛУЖИВАНИЯ С ОЖИДАНИЕМ 555
Зная вероятности всех состояний системы, можно легко опреде-
определить другие интересующие нас характеристики, в частности, вероят-
вероятность Рн того, что заявка покинет систему необслуженной. Опреде-
Определим ее из следующих соображений: при установившемся режиме
вероятность Р„ того, что заявка покинет систему необслуженной,
есть не что иное, как отношение среднего числа заявок, уходя-
уходящих из очереди в единицу времени, к среднему числу заявок, по-
поступающих в единицу времени. Найдем среднее число заявок.-
уходящих из очереди в единицу времени. Для этого сначала вычи-
вычислим математическое ожидание ms числа заявок, находящихся
в очереди:
о"
ИГ
; A9.10.13)
1=1 Vfl^4- — V
2^kw п\2л'
k=0 s-l
Чтобы получить Рн, нужно т3 умножить на среднюю «плотность
уходов» одной заявки м и разделить на среднюю плотность заявок X,
т. е. умножить на коэффициент
Получим:
4
T
a"
n\
V-
x —
00
r '
•
a
Sas
Vn + mV
A9.10.14)
a* , o"
т—\
Относительная пропускная способность системы характеризуется
вероятностью того, что заявка, попавшая в систему, будет обслужена:
Очевидно, что пропускная способность системы с ожиданием, при
тех же X и [а, будет всегда выше, чем пропускная способность
системы с отказами: в случае наличия ожидания неоослуженными
556 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. 19
уходят не все заявки, заставшие п каналов занятыми, а только не-
некоторые. Пропускная способность увеличивается при увеличении
среднего времени ожидания т/ож= —.
Непосредственное пользование формулами A9.10.11), A9.10.12)
и A9.10.14) несколько затруднено тем, что в них входят бесконеч-
бесконечные суммы. Однако члены этих сумм быстро убывают *).
Посмотрим, во что превратятся формулы A9.10.11) и A9.10.12)
при р->оо и р—>-0. Очевидно, что при j3->oo система с ожида-
ожиданием должна превратиться в систему с отказами (заявка мгновенно
уходит из очереди). Действительно, при р-э-со формулы A9.10.12)
дадут нули, а формулы A9.10.11) превратятся в формулы Эрланга
для системы с отказами.
Рассмотрим другой крайний случай: чистую систему с ожиданием
(р->0). В такой системе заявки вообще не уходят из очереди, и
поэтому Ра — 0: каждая заявка рано или поздно дождется обслужи-
обслуживания. Зато в чистой системе с ожиданием не всегда имеется пре-
предельный стационарный режим при t—э-оо. Можно доказать, что
такой режим существует только при а < п, т. е. когда среднее
число заявок, приходящееся на время обслуживания одной заявки,
не выходит за пределы возможностей /г-канальной системы. Если же
<х^-я, число заявок, стоящих в очереди, будет с течением времени
неограниченно возрастать.
Предположим, что а < п, и найдем предельные вероятности pk
@ <;&<]«) для чистой системы с ожиданием. Для этого положим
в формулах A9.9.10), A9.9.11) и A9.9.12) р~>0. Получим:
1
п
a
п
1\+~п\ 2л~п?
*=0
или, суммируя прогрессию (что возможно только при а < п),
Ро=—п • A9.10.15)
k\r'n\{n— ~a)
') Для грубой оценки ошибки, происходящей от отбрасывания всех чле-
членов сумм, начиная с r-го, можно воспользоваться формулами:
П
m=l
19.111 СИСТЕМА СМЕШАННОГО ТИПА 557
Отсюда, пользуясь формулами A9.10.8) и A9.10.9), найдем
Pk=—n ~ • @<Л<я). A9.10.16)
2
и аналогично для k = п -\- s (s ^- 0)
Рп+.= п A9.10.17)
1(л-«)
Среднее число заявок, находящихся в очереди, определяется из фор-
формулы A9.10.13) при В->0:
■ !i ^ A9.10.18)
~l
k\ ' n!(n —а)
ft = 0
Пример 1. Ha вход трехканальнои системы с неограниченным време-
временен ожидания поступает простейший поток заявок с плотностью \ = 4
(заявки в час). Среднее время обслуживания одной заявки гп(об = 30 мин.
Определить, существует ли установившийся режим обслуживания; если да,
то найти вероятности ра, рх, р2, Рг, вероятность наличия очереди и среднюю
длину очереди ms.
Решение. Имеем р. = =2; а = — = 2. Так как а < п, установив-
шийся режим существует. По формуле A9.10.16) находим
Л=1« 0,111; Pl = |^0,222; й = |-я 0,222; Л = ^« 0,148.
Вероятность наличия очереди:
Л>ч = 1 — (Ро + Р1+Р2 + Pi) = 0,297.
Средняя длина очереди ио форм}лз A9.10.18) Суде г
т, w 0,89 (заявки).
19.11. Система смешанного типа с ограничением
по длине очереди
В предыдущем п° мы рассмотрели систему массового обслужива-
обслуживания с ограничением по времени пребывания в очереди. Здесь мы
рассмотрим систему смешанного типа с другим видом ограничения
ожидания — по числу заявок, стоящих в очереди. Предположим, что
558 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ (ГЛ 19
заявка, заставшая все каналы занятыми, становится в очередь, только
если в ней находится менее т заявок; если же число заявок в оче-
очереди равно т (больше т оно быть не может), то последняя при-
прибывшая заявка в очередь не становится и покидает систему необ-
служенной. Остальные допущения — о простейшем потоке заявок и
о показательном распределении времени обслуживания—оставим
прежними.
Итак, имеется я-канальная система с ожиданием, в которой коли-
количество заявок, стоящих в очереди, ограничено числом т. Составим
дифференциальные уравнения для вероятностей состояний системы.
Заметим, что в данном случае число состояний системы будет
конечно, так как общее число заявок, связанных с системой, не
может превышать п -\- т (п обслуживаемых и т стоящих в очереди).
Перечислим состояния системы:
хп — все каналы свободны, очереди нет,
х] — занят один канал. » » ,
хк — занято k каналов, » » •
• ■ . . •
хп_х—занято п — 1 каналов, » » ,
хп — заняты все п каналов, » » ,
jcn+1 — заняты все п каналов, одна заявка стоит в очереди,
• • • • •
хп+т — заняты все я каналов, т заявок стоит в очереди.
Очевидно, первые п уравнений для вероятностей po(t), ... Pa-\(t)
будут совпадать с уравнениями Эрланга A9.8.8). Выведем остальные
уравнения. Имеем
Рп (/ + U) = />„_! {() ЪЫ + Рп (t) A — X М - ЛA А/) + ра+1 @ п? At,
откуда *•
iE^L = */>„-1 (О - (Ь + «10 Рп @ + 4w>B+i @.
Далее выведем уравнение для pn+iit) A-^s</k)
откуда
^^- = b/Wi @ ~ <*■ + я& Pa+S it) 4- прр
Последнее уравнение будет
^"^@ = >.Рп+т-1 @ -
СИСТЕМА СМЕШАННОГО ТИПА
559
Таким образом, получена система (п-\-т-\-1) дифференциальных
уравнений:
dt
=^Pk-x (о -
р* да+
dt
@
-l — nV-Pn+m
A9.11.1)
Рассмотрим предельный случай при t->oo. Приравнивая все про-
производные нулю, а все вероятности считая постоянными, получим Си-
стему алгебраических уравнений
= 0
я —1).
= о
A < s < m),
A9.11.2)
и добавочное условие:
л+m
(I9.I1.3)
Уравнения A9,11.2) могут быть решены так же, как мы решили
аналогичные алгебраические уравнения в предыдущих п°п°. Не оста-
560 ЭЛЕМЕНТЫ ТЕОРИИ МАССОВОГО ОБСЛУЖИВАНИЯ [ГЛ. И
навливаясь на этом решении, приведем только окончательные формулы:
^ЧA9.11.4)
л! jU \ n
k=0 i=l
(l<5<m). A9.11.5)
Вероятность того, что заявка покинет систему необслуженной,
равна вероятности рп+т того, что в очереди уже стоят т заявок.
Нетрудно заметить, что формулы A9.11.4) и A9.11.5) получаются
из формул A9.10.11), A9.10.12), если положить в них р = 0 и огра-
ограничить суммирование по 5 верхней границей т.
Пример. На станцию текущего ремонта автомашин поступает простей-
простейший поток заявок с плотностью А = 0,5 (машины в час). Имеется одно поме-
помещение для ремонта. Во дворе станции могут одновременно находиться, ожи-
ожидая очереди, не более трех машин. Среднее время ремонта одной машины
mto6 = — =2 (часа). Определить: а) пропускную способность системы;
б) среднее время простоя станции; в) определить, насколько изменятся эти
характеристики, если оборудовать второе помещение для ремонта.
Решение. Имеем: X = 0,5; ц. = 0,5; а = 1; т = 3.
а) По формуле A9.11.5), полагая л=1, находим вероятность того, что
пришедшая заявка покинет систему необслуженной:
Ри = Рг + ,= 1 + } + 3=°-20-
Относительная пропускная способность системы 9=1—Ян = 0,80. Абсолют-
Абсолютная пропускная способность: Q = Хд = 0,4 (машины в час).
б) Средняя доля времени, которое система будет простаивать, найдем по
формуле A9.11.4): р0 = ~ = 0,20.
О
в) Полагая п = 2, найдем:
Ян = Л+8 = , Ш, 1 г = i- я 0,021,
l + l-f-o+X-h-g -fig"
q = 1 — Ян и 0,979 (т. е. удовлетворяться будет около 98% всех заявок).
Q = l.q к 0,49 (машины в час).
Относительное время простоя: р0 — -^ » 0,34.
т. с. обог>^лояяние 6virt простячрять по-ччпстью око то 34°/0 рс°го рремеки.
«з
=Г
Я
осо рзсоросососососчсчсч сч ?) сч сч cn сч сч сч сч сч
ТОО? (ОТО—i ooc
о
CSC4C
0>—СЦТО*Ю«2@005
CD CD CD CD CD CO CO CO CO CO
Ы
5
X
ш
ft.
0>
о.
с
я
X
я
о
X
о.
о
В!
S
X
X
со
1111111111 1111111111 11111111V
_ _ - _ _-- _. _,-_ эсч aoio — оотрг-N^rHf-
COt^t^^CDCOiOiOlO^t1 Tf^TOTOTOCNtM—i^-ir— 0000H10100»» t~-
tocototototototototo tocotototocotototoco tototocsc4C4cmc-)csci
о" о о"
S^SSSS8S5SS§ ЗЗЗЗЗЗ.д^З ss3fse5-"*etet=i5ffl
ffffffffff 1111111111
QOOOOTOOOOOi OOOTOOTOOTOTOTO OlOlGJOOOlOMaoOM
glgig.^ico^^'^'^TO -*^to^>to-*tototo-* сотососотосотосЪсогз
§0000'-*^н^н CNCMCSTOTO^TflOCOC^- SaOOOWCO'tOSC)
cpOlOOTfOCOCNCOTf OCOCNCOTfOCOCSlCO^r ОСО^МОЮ'-ЬОФЮ
OlOTCOCOOOt^-t^-cpcO СОЮЮ'^'Т'тГ'СОТОСЧСЧ CN -—i -и О О О O) C7i Ю *
ю^-*-*-*-*-*-*^-* ■*-*'*-*-*-*-^"Tt1-*-* •ф-ф-ф^-ф^тотосоМ'
о о' о"
Ort СЧР0-*ЮСОГ~СОО5 Ot-iCNTO-^iOCD^COOI О i—' СЧ СО ■* 1О СО |~- СО О^
ОООООООООО янягч^н^чпг- СМ(МГ~4СЧСЧСЧСЧС\|СЧСЧ
ffffffffff ffffffffff ffffffffff
562
ПРИЛОЖЕНИЕ
—0,90
—0,91
—0,92
-0,93
—0.94
-о;э5
-0,96
-0,97
—0,98
—0,99
—1,00
—1,01
—1,02
—1,03
—1,04
—1,05
—1,06
—1,07
—1,08
—1,09
—1,10
—1,11
-1,12
—1,13
-1,14
-1,15
—1,16
—1,17
-1,18
—1,19
—1,20
1 -1,21
—1,22
—1,23
-1,24
-1,25
—1,26
—1,27
-1,28
, —1,29
1
0,1841
1814
1788
1762
1736
1711
1685
1660
1635
1611
0,1587
1563
1539
1515
1492
1469
1446
1423
1401
1379
0,1357
1335
1314
1292
1271
1251
1230
1210
1190
1170
0,1151
1131
1112
1093
1075
1056
1038
1020
1003
0985
А
27
26
26
26
25
26
25
25
24
24
24
24
24
23
23
23
23
22
22
22
22
21
22
21
20
21
20
20
20
19
20
19
19
18
19
18
18
17
18
17
X
—1,30
—1,31
—1,32
—1,33
—1,34
-1,35
—1,36
—1,37
—1,38
—1,39
—1,40
—1,41
—1,42
—1,43
—1,44
-1,45
—1,46
—1,47
—1,48
—1,49
—1,50
—1,51
-1,52
—1,53
—1,54
—1,55
—1,56
—1,57
-1,58
—1,59
—1,60
—1,61
—1,62
—1,63
—1,64
—1,65
—1,66
—1,67
—1,68
—1,69
Ф*(х)
0,0968
0951
0934
0918
0901
0885
■ 0869
0853
0838
0823
0,0808
0793
0778
0764
0749
0735
0721
0708
0694
0681
0,0668
0655
0643
0630
0618
0606
0594
0582
0571
0559
0,0548
0537
0526
0516
0505
0495
0485
0475
0465
0455
17
17
16
17
16
16
16
15
•15
15
15
15
14
15
14
14
13
14
13
13
13
12
13
12
12
12
12
11
12
11
И
11
10
11
10
10
10
10
10
9
Продолжение
X
—1,70
—1,71
—1,72
—1,73
—1,74
—1,75
—1,76
-1,77
—1,78
—1,79
—1,80
—1,81
-1,82
—1,83
—1,84
—1,85
—1,86
—1,87
—1,88
—1,89
—1,90
-1,91
—1,92
—1,93
—1,95
—1,96
—1,97
—1,98,
—1,99*
—2,00
—2,10
—2,20
—2,30
—2,40
—2,50
—2,60
—2,70
—2,80
—2,90
0,0446
0436
0427
0418
0409
0401
0392
0384
0375
0367
0,0359
0351
0344
0336
0329
0322
0314
0307
0301
0294
0,0288
0281
0274
0268
0262
0256
0250
0244
0239
0233
0,0228
0179
0139
0107
0082
0062
0047
0035
0026
0019
табл. 1
А
10
9
9
9
8
9
8
9
8
8
8
7
8
7 '
7
8
7
6
7
6
7
7
6
6
6
6
6
5
6
5
49
40
32
25
20
15
12
9
7
5
ПРИЛОЖЕНИЕ
563
Продолжение табл. 1
Ф*(Х)
—3,00
-3,10
-3,20
-3,30
-3,40
-3,50
-3,60
-3,70
-3,80
-3,90
0,00
0,01
0,02
0,03
0,04
0,05
0,06
0,07
0,08
0,09
0,10
0,11
0,12
0,13
0,14
0,15
0,16
0,17
0,18
0,19
0,20
0,21
0,22
0,23
0,24
0,25
0,26
0.27
0,28
0,29
0,0014
0010
0007
0005
0003
0002
0002
0001
0001
0000
0,5000
5040
5080
5120
5160
5199
5239
5279
5319
5359
0,5398
5438
5478
5517
5557
5596
5636
5675
5714
5753
0,5793
5832
5871
5910
5948
5987
6026
6064
6103
6141
4
3
2
2
1
0
1
0
1
40
40
40
40
39
40
40
40
40
39
40
40
39
40
39
40
39
39
39
40
39
39
39
38
39
39
38
39
38
38
0,30
0,31
0,32
0,33
0,34
0,35
0,36
0,37
0,38
0,39
0,40
0,41
0,42
0,43
0,44
0,45
0,46
0,47
0,48
0,49
0,50
0,51
0,52
0,53
0,54
0,55
0,56
0,57
0,58
0,59
0,60
0,61
0,62
0,63
0,64
0,65
0,66
0,67
0,68
0,69
0,6179
6217
6255
6293
6331
6368
6406
6443
6480
6517
0,6554
6591
6628
6664
6700
6736
6772
6808
6844
6879
0,6915
6950
6985
7019
7054
7088
7123
7157
7190
7224
0,71>57
7291
7324
7357
7389
7422
7454
7486
7517
7549
38
38
38
38
37
38
37
37
37
37
37
37
36
36
36
36
36
36
35
36
35
35
34
35
34
35
34
33
34
33
31
33
аз
32
33
32
32
31
32
31
0,70
0,71
0,72
0,73
0,74
0,75
0,76
0,77
0,78
0,79
0,80
0,81
0,82
0,83
0,84
0,85
0,86
0,87
0,88
0,89
0,90
0,91
0,92
0,93
0,94
0,95
0,96
0,97
0,98
0,99
!,00
1,01
1,02
1,03
1,04
1,05
1,06
1,07
1,08
1,09
0,7580
7611
7642
7673
7703
7734
7764
7794
7823
7852
0,7881
7910
7939
7967
7995
8023
8051
8078
8106
8133
0,8159
8186
8212
8238
8264
8289
8315
8'340
8365
8389
0,8-513
8437
8461
8485
8508
8531
8554
8577
8599
8621
31
31
31
30
31
30
30
29
29
29
29
29
28
28
28
28
27
28
27
26
27
26
26
26
25
26
25
25
24
24
24
24
24
23
23
23
23
22
22
22
36*
564
ПРИЛОЖЕНИЕ
X
1,10
1,11
1,12
1,13
1.14
1,15
1,16
1,17
1,18
1,19
1,20
1,21
1,22
1,23
1,24
1,25
1,26
1,27
1,28
1,29
1,30
1,31
1,32
1,33
1,34
1,35
1,36
1,37
1,38
1,39
1,40
1.41
1,42
1,43
1,44
1,45
1,46
1,47
1,48
1,49
Ф* (X)
0,8643
8665
8686
8708
8729
8749
8770
8790
8810
8830
0,8849
8869
8888
8907
8925
8944
8962
8980
8997
9015
0,9032
9049
9066
9082
9099
9115
9131
9147
9162
9177
0,9192
9207
9222
9236
9251
9265
9279
9292
9306
9319
А
22
21
22
21
20
21
20
20
20
19
20
19
19
18
19
18
18
17
18
17
17
17
16
17
16
16
16
15
15
15
15
15
14
15
14
14
13
14
13
13
X
1,50
1,51
1,52
1,53
1,54
1,55
1,56
1,57
1,58
1,59
1,60
1,61
1.62
1,63
1,64
1,65
1,66
1,67
1,68
1,69
1,70
1,71
1,72
1,73
1,74
1,75
1,76
1,77
1,78
1,79
1,80
1,81
1,82
1,83
1,84
1,85
1,86
1,87
1,88
1,89
Ф* (лг)
0,9332
9345
9357
9370
9382
9394
9406
9418
9429
9441
0,9452
9463
9474
9484
9495
9505
9515
9525
9535
9545
0,9554
9564
9573
9582
9591
9599
9608
9616
9625
9633
0,9641
9649
9656
9664
9671
9678
9686
9693
9699
970S
л
13
12
13
12
12
12
12
11
12
11
11
И
10
И
10
10
10
10
10
9
10
9
9
9
8
9
8
9
8
8
8
7
8
7
7
7
6
7
7
Продолжение
Х-
1,90
1 П1
1,91
1,92
1 ПО
1,9о
1,94
1 ПК
1,90
1,96
1,97
1,98
1 ПП
1,99
2,00
2,10
2,20
2,30
2,40
2,50
2,60
2,70
2,80
2,90
3,00
3,10
3,20
3,30
3,40
3,50
3,60
3,70
3,80
3,90
Ф* (X,
0,9713
9719
9726
9732
9738
9744
9750
9756
9761
CY7CH
9767
0,9772
9821
9861
9893
9918
9938
9953
9965
9974
9981
l 0,9986
9990
9993
9995
9997
9998
9998
9999
9999
1,0000
табл 1
6
7
6
6
6
6
6
5
6
5
49
40
32
25
20
15
12
9
7
5
4
3
2
2
1
0
1
0
1
о
©■
© р р
J"S"^r^QPOooo оорооэсосоороосососр сососрсрсосососос
" СЛ О5 ~-1 -} 00 СО О —ч— ЮСОЛСЛСЛСП-^ООСОО ►-'ЮСОФСЛСП-^С
> О5 СО ►-' СО -} СЛ СО >— СО -3 СЛ 4* Ю 1—' СО 00 -~} OJ Сл *■ СО Ю Ю "-"—' О <
~J 00 ~J 00 00 00 00 00 00 00 00 00 СО 00 СО 00 СО СО СО СО СОСОСООСООСООО О
р о о о
ё
СЛСлСлСлСлСлС71СЛСДО5
С^ ^Э ^^ ^Э СЭ ^Э ^^ С5 С С5 С5 ^Э ^Э ^? ^^ ^Э ^Э С5 ^5 ^Э tO QO **4 Oi Сл ь^ СО Ю ^~* ^Э fp 00 ~^1 Oi СД *^ Со Ю •—*
о р
СОСООЗСОСОСОСОСО4*-4ь
- ■ --о оо со со с
Сл Сл Сл Сл Сл Сл Сл Сл Сл Сл
о ооооооооо
8S3
8S'SS858
СО СО СО СО СО СО СО СО СО СО
"gSgegg 8
> to с/
о
о
о
"8
£:Ц §
Значения f? в зависимости от г и р
Таблица 4
1
2
з
4
5
6
7
8
9
10
11
12
13
14
15
Т6~
17
18
19
20
21
22
23
24
25
26
27
28
29
30
0,99
0,000
0,020
0,115
0,297
0,554
0,872
1,239
1,646
2,09
•2,56
3,05
3,57
4,11
4,66
5,23
5,81"
6,41
7,0?
7,63
8,26
8,90
9,54
10,20
10,86
11,52
12,20
12,88
13,56
14,26
14,95
0,98
СОМ
0,0 0
0.U 5
0,4 )
0,7.) 2
1.134
1,5D
2,0о
2,53
3,0()
3,61
4,18
4,70
5,37
5,9Ь
' 6,61
7,2f
7,91
8,57
9,24
9,92
10,60
11,29
11,99
12,70
13,41
14.12
14,85
15,57
16,31
0.95
0,004
0,103
0,352
0,711
1,145
1,635
2,17
2,73
3,32
3,94
4,58
5,23
5,89
6,57
7,26
7,96
8,67
9,39
10,11
10,85
11.59
12,34
13,09
13,85
14,61
15,38
16,15
16,93
17,71
18,49
0,90
0,016
0,211
0,584
1,064
1,610
2,20
2.83
3,49
4.17
4,86
5,58
6,30
7,04
7,79
5,55.
9,31
10,08
10,86
11,65
12,44
13,24
14,04
14,85
15,66
16,47
17,29
18,11
18.94
19,77
20,6
0,80
0,064
0.446
1,005
1,649
2,34
3,07
3,82
4,59
5,38
6,18
6,99
7,81
8,63
9,47
.Щ31_
11,15
12,00
12,86
13,72
14,58
15,44
16,31
17,19
18,08
18,94
19,82
20,7
21,6
22,5
23,4
0,70
0,148
0,713
1,424
2,20
3,00
3,83
4,67
5,53
6,39
7,27
8,15
9,03
9,93
10,82
11.72
12,62
13,53
14,44
15,35
16,27
17,18
18.10
19,02
19,94
20,9
21,8
22,7
23,6
24,6
25,5
0,50
0,455
1,386
2,37
3,36
4,35
5,35
6,35
7,34
8.34
9,34
1034
11,34
12,34
1334
14 34
15,34
16 34
17 34
18?34
19,'34
20,3
21,3
22,3
23,3
24,3
25,3
26,3
27,3
28,3
29,3
0,30
1,074
2,41
3,66
4,88
6,06
7,23
8,38
9,52
10,66
11,78
12,90
14,01
15,12
16,22
_LL32
18,42
19,51
20,6
21,7
22,8
23,9
24,9
26,0
27,1
28,2
29,2
30,3
31,4
32,5
33,5
0,20
1,642
3,22
4,64
5,99
7,29
8,56
9,80
11,03
12,24
13,44
14,63
15,81
16,98
18,15
1&3L-
20,5
21,6
22,8
23,9
25,0
26,2
27,3
28,4
29,6
30,7
31,8
32,9
34,0
35,1
36,2
0,10
2,71
4,60
6,25
7,78
9,24
10,64
12,02
13,36
14,68
15,99
17,28
18.55
19,81
21.1
_22Д. -
23,5
24,8
26.0
27.2
28,4
29,6
30,8
32,0
33.2
34,4
35,6
36,7
'37,9
39,1
40,3
0,05
3.84
5,99
7,82
9.49
11,07
12.59
14,07
15,51
16.92
18,31
19,68
21,0
22,4
23,7
-2&Q
26,3-
27,6
28,9
30,1
31,4
32,7
33,9
35.2
36,4
37,7
38,9
40,1
41,3
42,6
43,8
0,02
5,41
7,82
9,84
11,67
13,39
15,03
16,62
18,17
19,68
21,2
22,6
24,1
25,5
26,9
_т_
29.6
31,0
32,3
33,7
35,0
36,3
37,7
39,0
40,3
41,7
42.9
44,1
45,4
46,7
48,0
0,01
6,64
9,21
11,34
13,28
15,09
16,81
18,48
20,1
21Л
23Д,
24,7 -
26,2
27,7
29,1
.J0J3-
12Д)
33,4
34,8
36,2
37,6
38,9
40,3
41,6
43,0
44,3
45,6
47,0
48,3
49,6
50,9
0,001
10,83
13,82
16,27
18,46
20,5
22,5
24,3
26,1
27,9 .
29Г6
1,3
32,9
34,6
36,1
39,3
40,8
42.3
43,8
45,3
46,8
48,3
49.7
51.2
52,6
54,1
55,5
56,9
58,3
59,7
566
ПРИЛОЖЕНИЕ
Таблица 3
X
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0.7
0,8
0,9
1,0
1.1
1,2
1.3
1,4
1.5
1.6
1.7
1.8
1.9
2,0
2.1
2,2
2,3
2,4
2.5
2,6
2,7
2,8
2.9
3,0
3,1
3,2
3.3
3.4
3.5
3.6
3.7
3.8
3.9
X
0
0,3989
3970
3910
3814
3683
3521
3332
3123
2897
2661
0.2420
2179
1942
1714
1497
1295
1109
0940
0790
0656
0,0540
0440
0355
0283
0224
0175
0136
0104
0079
0060
0,0044
0033
0024
0017
0012
0009
0006
0004
0003
0002
и
l
3989
3965
3902
3802
3668
3503
3312
3101
2874
2637
2396
2155
1919
1691
1476
1276
1092
0925
cO775j
и644
0529
0431
0347
0277
0219
0171
0132
0101
0077
0058
0043
0032
0023
0017
0012
0008
0006
0004
0003
0002
l
Значения функции
2
3989
3961
3894
3790
3653
3485
3292
3079
2850
2613
2371
2131
1895
1669
1.456
1257
1074
0909
07.61
0632
0519
0422
0339
0270
0213
0167
0129
0099
0075
0056
0042
0031
0022
0016
0012
0008
0006
0004
0003
0002
3
3988
3956
3885
3778
3637
3467
3271
3056
2827
2589
2347
2107
1872
1647
1435
1238
1057
0893
0748
0620
0508
0413
0332
0264
0208
0163
0126
0096
0073
0055
0040
0030
0022
0016
ООП
0008
0005
0004
0003
0002
■ з
4
3986
3951
3876
3765
3621
3448
3251
3034
2803
2565
2323
2083
1849
1626
1415
1219
1040
0878
0734
0608
0498
0404
0325
0258
0203
0158
0122
0093
0071
0053
0039
0029
0021
0015
ООП
0008
0005
0004
0003
0002
4
/(•*) =
5
3984
3945
3867
3752
3605
3429
3230
ЗОН
2780
2541
2299
2059
1826
1604
1394
1200
1023
0863
0721
0596
0488
0396
0317
0252
0198
0154
0119
0091
0069
0051
0038
0028
0020
0015
0010
0007
0005
0004
0002
0002
5
6
3982
3939
3857
3739
3589
3410
3209
2989
2756
2516
2275
2036
1804
1582
1374
1182
1006
0848
0707
0584
0478
0388
0310
0246
0194
0151
0116
0088
0067
0050
0037
0027
0020
0014
0010
0007
0005
0003
0002
0002
6
е *
7
3980
3932
3847
3726
3572
,3391
ЗТВТ
2966
2732
2492
2251
2012
1781
1561
1354
1163
0989
0833
0694
0573
0468
0379
0303
0241
0189
0147
0113
0086
0065
0048
0036
0025
0019
0014
0010
0007
0005
0003
0002
0002
7
8
3977
3925
3836
3712
3555
3372
3166
2943
2709
2468
2227
1989
1758
1539
1334
1145
0973
0818
0681
0562
0459
0371
0297
0235
0184
0143
ОНО
«0084
0063
0047
0035
0025
0018
0013
0009
0007
0005
0003
0002
0001
8
9
3973
3918
3825
3697
3538
3352
3144
2920
2685
2444
2203
1965
1736
1518
1315
1127
0957
0804
0669
0551
0449
0363
0290
0229
0180
0139
0107
0081
0061
0046
0034
0025
0018
0013
0009
0006
0004
0003
0002
0001
X
0,0
0,1
0,2
0,3
0,4
0,5
0,6.
0.7
0,8
0,9
1.0
1.1
1.2
1.3
1,4
1.5
1.6
1.7
1,8
1.9
2.0
2.1
2.2
2,3
2,4
2,5
2.6
2.7
2,8
2,9
3.0
3 '
32
3.3
3.4
3.5
3,6
3,7
3.8
3,9
9 '
008
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
23
29
30
40
60
120
оо '
0,1
0,158
142
137
134
132
131
130
130
129
129
129
128
128
128
128
128
128
. 127
127
127
127
127
127
127
127
127
127
127
127
127
126
126
126
0,126
0,1
0,2
0,325
289
277
271
267
265
263
262
261
260
260
259
259
258
258
258
257
257
257
257
257
256
256
256
256
256
256
256
256
256
255
254
254
0,253
0,2
ПРИЛОЖЕНИЕ
Значения tq,
0,3
0,510
445
424
414
408
404
402
399
398 ■
397
396
395
394
393
393
392
392
392
391
391
391
390
390
390
390
390
389
339
389
389
388
387
386
0,385
0,3
0,4
0,727
617
584
569
559
553
549
546
•543
542
540
539
538
537
536
535
534
534
533
533
532
532
532
531
531
531
531
530
530
530
529
527
526
0,524
0,4
удовлетворяющие равенству
0,5
1.000
0,816
765
741
727
718
711
706
703
700
697
695
694
692
691
690
689
688
688
687
686
686
685
685
684"
684
684
633
683
683
681
679
677
0,674
0,5
0,6
1,376
1,061
0,978
941
920
906
896
. 889
',8,83
879
876
873
870
868
866
865
863
862
861
860
859
858
858
857
856
856
855
855
854
854
851
848
845
0.842
0,6
0,7
1.963
1,336
1,250
1,190
1,156
1,134
1 1 Н)
1Д08
1,109
1,093
1,088
1,083
1,079
1.076
1,074
1.071
1.069
1,067
1.066
1.064
1.063
1.061
1,060
1.059
1.058
1,058
1,057
1,056
1,055
1,055
1,050
1.046
1,041
1,036
0,7
ПРИЛОЖЕНИЕ
569
Таблица 5
- г-
2 1 Sn-t{t)dt = $, в зависимости от р и п—1
0,8
3,03
1,886
1,638
1,533
1,476
1,440
1.415
1,397
1,383
1,372
1,363
1,356
1,350
1,345
1,341
1,337
1,333
1,330
1,328
1,325
1,323
1,321
1,319
1,318
1,316
1.315
1,314
1,313
1,311
1,310
1,303
1,296
1,289
1,282
0,8
0,9
6,31
2,92
2,35
2,13
2,02
1,943
1,895
1,860
1,833
1.812
1,796
1,782
1,771
1,761
1,753
1,746
1,740
1,734
1,729
1.725
1,721
1,717
1,714
1,711
1.708
1,706
1,703
1,701
1,699
1.697
1.684
1,671
1,658
1,645
0,9
0,95
12,71
' 4,30
i3,18
2,77
2,57
2,45
2,36
2,31
2,26
2,23
2.20
2.18
2,16
2,14
2,13
2,12
2,11
2,10
2.09
2,09
2.08
2.07
2,07
2,06
2.06
2,06
2,05
2,05
2,04
2,04
2,02
2,00
1,980
1,960
0,95
0,98
31,8
6,96
4,54
3,75
3,36
3,14
3,00
2,90
2,82
2,76
2,72
2,68
2,65
2.62
2,60
2.58
2,57
2,55
2,54
2,53
2,52
2,51
2,50
2.49
2,48
2.48
2,47
2,47
2,46
2,46
2,42
2,39
2,36
2,33
0,98
0,99
63,7
9,92
5,84
4,60
4,03
3,71
3,50
3,36
3,25
3,17
3,11
3,06
3,01
2,98
2,95
2,92
2,90
2,88
2,86
2,84
2,83
2,82
2,81
2,80
2,79
2,78
2,77
2,76
2,76
2.75
2,70
2,66
2,62
2.58
0,99
0,999
636,6
31,6
12,94
8,61
6,86
5,96
5,40
5,04
4,78
4,59
4,49
4,32
4,22
4,14
4,07
4,02
3,96
3,92
3,88
3,85
3,82
3.79
3,77
3,74
3,72
3,71
3,69
3,и7
3,66
3,65
3,55
3,46
3,37
3,29
0,999
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
40
60
120
оо
570 ПРИЛОЖЕНИЕ
Таблица 6
Таблица двоичных логарифмов целых чисел от 1 до 100
X
1
2
3
4
5
6
7
8
9
10
И
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
log*
0,00000
1,00000
1,58496
2,00000
2,32193
2,58496
2,80735
3,00000
3,16993
3,32193
3,45943
3,58496
3,70044
3,80735
3,90689
4,00000
4,08746
4,16993
4,24793
4,32193
4,39232
4,45943
4,52356
4,58496
4,64386
4,70044
4,75489
4,80735
4,85798
4,90689
4,95420
5,00000
5,04439
5,08746
5,12028 '
X
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52 ..
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
log X
5,16993
5,20945
5,24793
5,28540
5,32193
5,35755
5,39232
5,42626
5,45943
5,49185
5,52356
5,55459
5,58496
5,61471
5,64386
5,67242
5,70044
5,72792
5,75489
5,78136
5,80735
5,83289
5,85798
5,88264
5,90689
5,93074
5,95-120
5,97728
6,00000 I
6,02237
6,04439
6,06609
6,08746
6,10852
6,12928 j
X
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
GA
УО
97
98
99
100
log X
6,14975
6,16992
" 6,18982
6,20945
6,22882
6,24793
6,26679
6,28540
6,30378
6,32193
6,33985
6,35755
6,37504
6,39232
6,40939
6,42626
6,44294
6,45943
6,47573
6,49185
t
6,50779
6,52356
653916
6,55459
6,56986
0,О04У0
6,59991
6,61471
6,62936
6,64386
ПРИЛОЖЕНИЕ
571
*
0
0,01
0,02
0.03
0,04
0,05
0,06
0,07
0,08
0.09
0,10
0,11
0.12
0,13
0.14
0,15
0,16
0,17
0.18
0.19
0,20
0.21
0.22
0,23
0,24
0,25
0,26
0,27
0,28
0,29
0,30
0,31
0,32
0,33
0,34
0,35
0,36
0,37
0 38
0,39
0,40
0,41
0,42
0,43
0,44
0.45
0,46
0,47
0.48
0,49
0,50
ч</>)
0
0,0664
1128
1518
1858
2161
2435
2686
2915
3126
3322
3503
3671
3826
3971
4105
4230
4346
4453
4552
4644
4728
4806
4877
4941
5000
5053
5100
5142
5179
5211
5238
5260
5278
5292
5301
5306
5307
5405
5298
5288
5274
5256
5236
5210
5184
5153
5120
5083
5043
0,5000
.аблица значений функции Т
1 (/>)= — /> log2 Р
L ■ II р
664
464
"" 390
340
303
274
251
229
211
196
181
168
155
145
134
125
116
107
99
92
84
78
71
67
59
53
47
42
37
32
27
22
18
14
9
5
1
—2
—7
—10
—14
—18
—20
—24
—26
—29
-33
—37
—40
—43
0,50
0,51
0.52
0,53
0,54
0,55
0,56
0,57
0,58
0.59
0,60
0.61
0.62
0,63
0,64
0.65
0.66
0,67
0,68
0,69
0,70
0,71
0,72
0.73
0,74
0.75
0.76
0,77
0,78
0,79
0,80
0,81
0,82
0,83
0,84
0,85
0,86
0,87
0,88
0.89
0,90
0,91
0.92
0.93
0.94
0,95
0,96
0,97
0,98
0,99
1,00
0,5000
4954
4906
4854
4800
4744
4685
4623
4558
4491
4422
4350
4276
4199
4121
4040
3957
3871
3784
3694
3602
3508
3412
3314
3215
3113
3009
2903
2796
2687
2575
2462
2348
2231
2112
1992
1871
1748
1623
1496
1368
1238
0,1107
00974
839
703
565
426
286
144
0
аблица 7
Д
—46
—48
—52
—54
—55
—59
—62
—65
—67
—69
—72
—74
—77
—78
—81
—83 ■
—86
—87
—90
—92
—94
—96
—98
—99
— 102
— 104
— 106
— 107
— 109
—112
— 113
— 114
— 117
— 119
—120
—121
—123
-125
— V17
—128
—130
— 131
—133
—135
—136
—138
—139
—140
—142
—144
572
Значения Рт =
ПРИЛОЖЕНИЕ
Таблица 8
—г- е~а (распределение Пуассона)
т
0'
1
2
3
4
5
6
т
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1G
17
18
19
20
21
22
23
24
а=0,1
0,9048
0,0905
0,0045
0,0002
о = 1
0,3679
0,3679
0,1839
0,0613
0,0153
0,0031
0,0005
0,0001
о = 0,2
0,8187
0,1638
0,0164
0,0019
0,0001
я=2
0,1353
0,2707
0,2707
0,1804
0,0902
0,0361
0,0120
0,0037
0,0009
0,0002
о = 0,3
0,7408
0,2222
0,0333
0,0033
0,0002
а=3
0,0498
0,1494
0,2240
0,2240
0.1680
0,1008
0,0504
0,0216
0,0081
0,0027
0,0008
0,0002
0,0001
о = 0,4
0,6703
0,2681
0,0536
0,0072
0,0007
0,0001
о = 4
0,0183
0,0733
0,1465
0,1954
0,1954
0,1563
0,1042
0,0595
0,0298
0,0132
0,0053
0,0019
0,0006
0,0002
0,0001
о = 0,5
0,6065
0,3033
0,0758
0,0126
0,0016
0,0002
а=5
0,0067
0,0337
0,0842
0,1404
0,1755
0,1755
0,1462
0,1044
0,0653
0,0363
0,0181
0,0082
0,0034
0,0013
0,0005
0,0002
о = 0,6
0,5488
0,3293
0,0988
0,0198
0,0030
0,0004
о=6
0,0025
0,0149
0,0446
0,0892
0,1339
0,1606
0,1606
0,1377
0,1033
0,0688
0,0413
0,0225
0,0126
0,0052
0,0022
0,0009
0,0003
0,0001
а = 0,7
0,4966
0,3476
0,1217
0,0284
0,0050
0,0007
0,0001
о = 7
0,0009
0,0064
0,0223
0,0521
0,0912
0,1277
0,1490
0,1490
0,1304
0,1014
0,0710
0,0452
0,0263
0,0142
0,0071
0,0033
0,0014
0,0006
0,0002
0,0001
а=0,8
0,4493
0,3595
0,1438
0,0383
0,0077
0,0012
0,0002
а=8
0,0003
0,0027
0,0107
0,0286
0,0572
0,0916
0,1221
0,1396
0,1396
0,1241
0,0993
0,0722
0,0481
0,0^96
0,0169
0,0090
0,0045
0,0021
0,0009
0,0004
0,0002
0,0001
о = 0,9
0,4066
0,3659
0,1647
0,0494
0,0111
0,0020
0,0003
о = 9
0,0001
0,0011
0,0050
0,0150
0,0337
0,0607
0,0911
0,1171
0,1318
0,1318
0,1186
0,0970
0,0728
0,0504
0,0324
0,0194
0,0109
0,0058
0,0029
0,0014
0,0006
0,0003
0,0001
i
0,0000
0.С005
0,0023
0,0076
0,0189
0,0378
0,0631
0,0901
0,1126
0,1251
0,1251
0,1137
0,0948
0,0729
0,0521
0,0347
0,0217
0,0128
0,0071
0,0037
0.С019
0,0009
0,0004
0,0002
0,0001
ЛИТЕРАТУРА
1. Б. В. Г н е д е н к о, Курс теории вероятностей, Физматгиз, 1961.
2. В. С. Пугачев, Теория случайных функций и ее применение к задачам
автоматического управления, Физматгиз, 1962.
3. В. С. Пугачев, Статистическая теория систем автоматического упра-
управления (лекции), вып. 1 и 2, изд. ВВИА, 1961,
4. Г. К р а м е р, Математические методы статистики, ИЛ, 1948.
5. И. В. Ду н и н-Б ар к о в с к ий и Н. В. Смирнов, Теория вероятно-
вероятностей и математическая статистика в технике, Гостехиздат, 1955.
6. А. М. Я г л о м и И. М. Я г л о м, Вероятность и информация, Гостех-
Гостехиздат, 1960.
7. С. Н. Б е р н ш т е й н, Теория вероятностей, Гостехиздат, 1946.
8. А. А. Свешников, Прикладные методы теории случайных функций,
Судпромиздат, 1961.
9. А. М. Я г я о м, Введение в теорию стационарных случайных функций,
Успехи матем. наук, т. VII, вып. 5, 1952.
10. Б. В. Г н е д е н к о, Лекции по теории массового обслуживания, изд.
КВИРТУ, 1960.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Асимметрия 97
Вероятностная зависимость 173
Вероятнесть доверительная 318
— события 24
— — условная 46
— статистическая 29
Выборка 142
Выравнивание статистических ря-
рядов 143
Генеральная совокупность 142
Гистограмма 137
Главные оси рассеивания 194
— средние квадратические отклоне-
отклонения 194
Группа событий полная 25
Дисперсия 96, 403
— случайной функции 378
Доверительные границы 318
Доверительный интервал 318
Зависимость случайных величин ли-
линейная 179
— стохастическая 173
Закон больших чисел 88, 286, 290
— Гаусса 116
— Пуассона 106
— рг:'смГ-.оГ.,(;л ^.т-:-нести ЮЗ
— распределения 68, 182, 376
— — дифференциальный 80
— — интегральный 73
— — предельный 287
— — случайной функции 375
суммы 271
условный 169
устойчивый 278
— редких явлений 113
— Симпсона 274
— треугольника 274
— Эрланга 532
Интеграл вероятностей 122
— Фурье 434
Информация 481
— полная взаимная 486
•— — (средняя) 486
— частная 489
Код 502
— двоичный 503
— Шеннона — Фено 505
Кодирование 502
Комплекс 159
Композиция законов распределения
272
— нормальных законов 275
— на плоскости 280
Корреляция отрицательная 180
— положительная 180
Коэффициент корреляции 178
Кривая распределения 80
Кривые Пирсона 145
— равной плотности 165
Критерии согласия 149
Критерий Колмогорова 156
-%* 151
Круговое рассеивание 196
Линеаризация функций 252
Линия регрессии 192
Магматическая стилистика 131
Математическое ожидание 86, 218,
402
— — случайной функции 377
— — условное 192
Матрица корреляционная 185
■ нормированная 186
Медиана 92
Мера точности 120
Метод моментов 145
— наименьших квадратов 354
Многоугольник распределения 69
Мода 90
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
575
Момент 92
— абсолютный 99
— корреляционный 176
— начальный 92, 93, 175
— нормального распределения 120
■— связи 176
— системы случайных величин 175
— статистический 140
— центральный 94, 175, 176
Непосредственный подсчет вероят-
вероятностей 25
Неравенство Чебышева 287
Нормальный закон 116, 280, 297
■ в пространстве 205
— — — теории стрельбы 297
— —, каноническая форма 194
на плоскости 188
, параметры 117
Обработка стрельб 347
Объединение двух систем 475
Опыты независимые 59
Отклонение вероятное 127
главное 195
— срединное 127
— среднее арифметическое 99
квадратическое 96, 97
Оценка 313
— несмещенная 314
— состоятельная 313
— эффективная 314
Оценки для характеристик системы
339
Плотность вероятности 80
— дисперсии средняя 431
— потока мгновенная 527
заявок приведенная 545
— распределения 80, 164
системы двух величин 163
— — — нескольких величин 182
— спектральная 432
нормированная 434
Поверхность распределеиня 165
Поте:; Па-!,уз 52*9
— событий 520
без последействия 520, 521
нестационарный пуассоновский
527
• однородных 520
ординарный 520, 522
простейший 520
регулярный 520
с ограниченным последействи-
последействием 529
■ стационарный 520, 521
— Эрланга 530—533
Правило трех сигма 125, 290
Преобразование Фурье 300, 434
обратное 300
Принцип практической уверенности
35
Произведение событий 39
Производительность источника ин-
информации 508
Пропускная Способность канала 508,
511
системы абсолютная 516
относительная 516, 544
Простая статистическая совокуп-
совокупность 133, 134
Процесс без последействия 537
— марковский 537
— стохастический 20
Разложение корреляционной функ*
ции каноническое 412
— случайной функции 409
каноническое 412
— спектральное 430, 431
— — в комплексной форме 438
Распределение антимодальное 91
1— биномиальное 61
— полимодальное 91
— Пуассона 106
— Релея 200
— Стьюдента 325
Рассеивание 96, 176
Реализация случайной функции 371
Ряд распределения 69
1— статистический 136
■ простой 134
Свойство суперпозиции 409
Сетка рассеивания 202
Сечение случайной функции 374
Система случайных величин 159
Системы величин некоррелирован»
ные 187
<— массового обслуживания 515
Скошенность 97
Случаи 26
■— благоприятные 26
Случайная величина 32, 67
дискретная 32
комплексная. 4S2
непрерывная 32
прерывная 32
■ смешанная 77
• характеристическая 33
центрированная 93
— точка 159
•— функция 370, 371
• ■ комплексная 404
576
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Случайная функция нормированная
383
— —, разложение 409
— — центрированная 382
-- — элементарная 407
Случайное явление 11
Случайные векторы некоррелирован-
некоррелированные 187
— величины зависимые 172
независимые 172, 183
«— — некоррелированные 178
~- — несвязанные 178
— функции, сложение 399
Случайный вектор 160
— процесс нестационарный 419
стационарный 419
Событие 23
■— достоверное 24
— невозможное 24
События зависимые 46
— независимые 45, 48
— несовместные 26
— практически достоверные 34
невозможные 34
— противоположные 42
— равновозможные 26
Спектр дисперсий 431
— стационарной случайной функции
431
Стандарт 96
Статистическое среднее 140
Степень неопределенности системы
469, 470
Сумма событий 38
Сходимость по вероятности 31
Теорема Бернулли 31, 36, 286, 295
— гипотез 56
— Лапласа 308
— Маркова 294
— о повторении опытов 61, 63
— Пальма 530
— Пуассона 296
— сложения вероятностей 40
— — дисперсий 224
— — корреляционных матриц 230
— — — моментов 229
математических ожиданий 221
— — энтропии 476
— умножения вероятностей 46
■ законов распределения 170
— — математических ожиданий 226
— центральная поедельная 2S7 W7,
302, '303
— Чебышева обобщенная 293
Георема Шеннона вторая 513
первая 508
Теоремы предельные 287
Теория информации 468
Уравнения Эрланга 543
Условие Линдеберга 306
Устойчивость средних 88, 286
— частот 28, 29
Формула Бейеса 56
— полной вероятности 54
— — — интегральная 217, 218
Формулы Эрланга 546
Функция автокорреляционная 379
— корреляционная 379
взаимная 399
нормированная 381, 422
— Лапласа 128
— — приведенная 129
— производящая 62
— распределения 73
нормальная 123
— — системы двух величин F0
— нескольких величин 182
— — статистическая 134
— связи корреляционная 399
— характеристическая 299, 301
Характеристика частотная 449
Характеристики выборочные 142
— комплексной случайной величины
402
— положения 85
— рассеивания 96
— системы величин 184
— случайной функции 377
— числовые 85
— — функций случайных величин
210..
Центр рассеивания 118
Частота события 24, 28
Эксцесс 98
Элемент вероятности 81, 165
Эллипс равной плотности 194
— рассеивания 194
— единичный 195
полный 195
Энтропия 471, 481
— приведенная 495
— условная 477
— частная условная 496
Эргодическое свойство 458