/






























































































































































































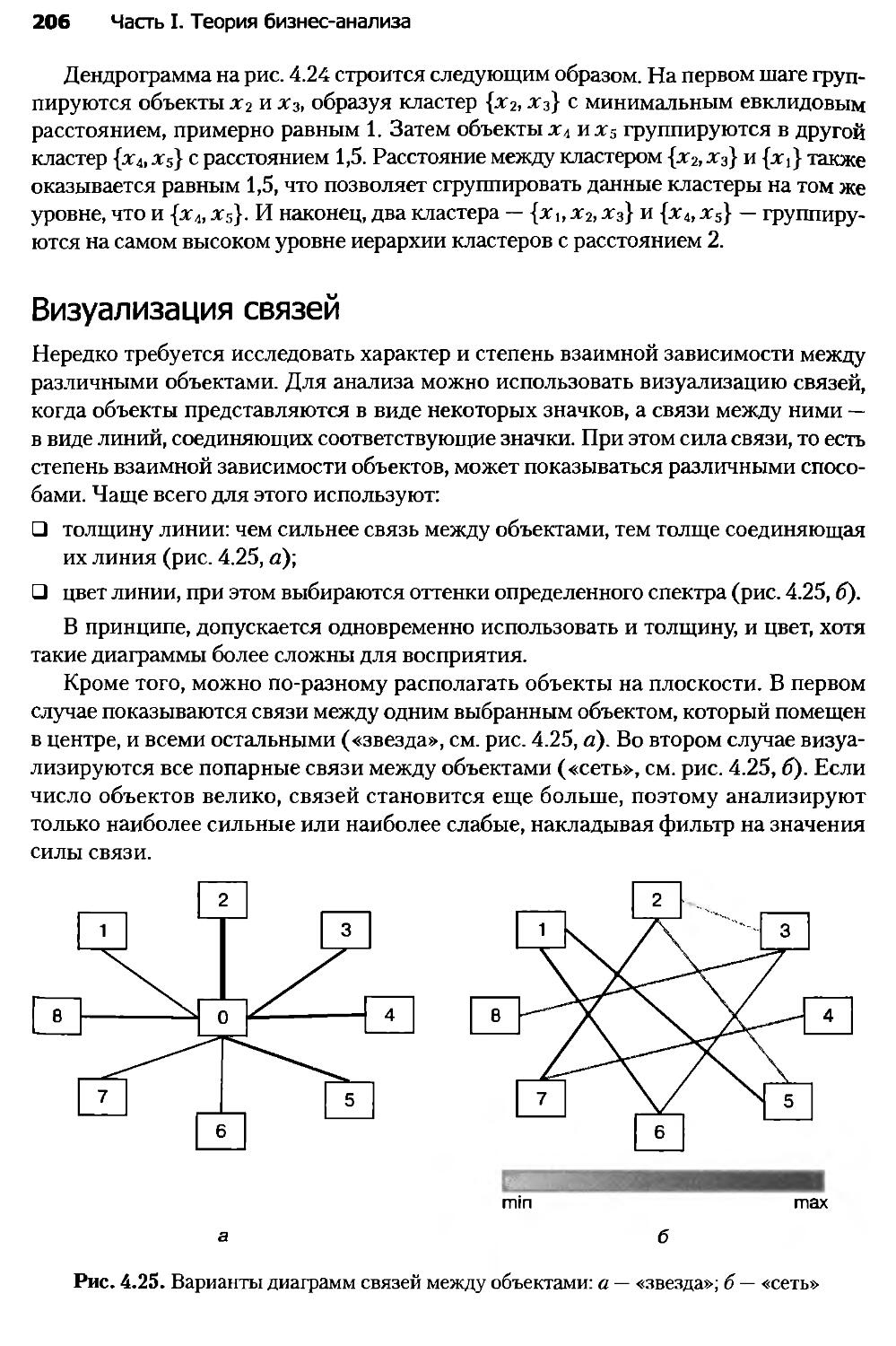


















































































































































































































































































































































































































































































Автор: Паклин Н.Б. Орешков В.И.
Теги: математическая экономика экономика экономические науки бизнес аналитика
ISBN: 978-5-459-00717-6
Год: 2013




Текст
Н. Паклин, В. Орешков
БИЗНЕС-
АНАЛИТИКА:
от данных к знаниям
Учебное пособие
2-е издание,
исправленное
/X BaseGroup Labs
7- ^ТЕХНОЛОГИИ АНАЛИЗА ДАННЫХ
СЕЛИГЕР'
Москва • Санкт-Петербург Нижний Новгород Воронеж
Ростов-на-Дону • Екатеринбург Самара Новосибирск
Киев Харьков Минск
2013
ББК 65. вб
УДК 330.43
П13
Рецензенты:
Завкафедрой информационных систем и технологий Нижегородского филиала
Государственного университета — Высшей школы экономики, канд. техн, наук,
профессор Э. А. Бабкин;
Директор научно-исследовательского института Российской экономической академии
им. Г. В. Плеханова, д-р техн, наук, профессор О. А. Косорукое.
Паклин Н. Б., Орешков В. И.
П13 Бизнес-аналитика: от данных к знаниям (+CD): Учебное пособие. 2-е изд.,
испр. — СПб.: Питер, 2013. — 704 с.: ил.
ISBN 978-5-459-00717-6
Книга представляет собой руководство для профессиональных бизнес-аналитиков, занимаю-
щихся внедрением корпоративных аналитических систем. В теоретической части последовательно
освещаются современные технологии сбора и анализа структурированной информации: хранили-
ща данных, ETL, OLAP, Data Mining, Knowledge Discovery in Databases. В практической части
приводятся примеры решения бизнес-задач на аналитической платформе Deductor Academic.
В данное, второе, издание включены разделы по последовательным шаблонам, байесовскому
классификатору, обучению в условиях несбалансированности классов, расширена практическая
часть.
Книга будет полезна всем интересующимся вопросами интеллектуального анализа данных
и методами автоматического поиска закономерностей в массивах информации.
Для специалистов в области анализа данных, студентов и аспирантов.
ББК65.В6
УДК 330.43
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было фор-
ме без письменного разрешения владельцев авторских прав.
ISBN 978-5Щ59-00717-6
© ООО Издательство «Питер», 2013
Краткое содержание
Предисловие авторов...............................................8
Об авторах.......................................................10
От издательства..................................................11
Вступительное слово..............................................12
Введение.........................................................14
ЧАСТЬ I. ТЕОРИЯ БИЗНЕС-АН АЛ ИЗА
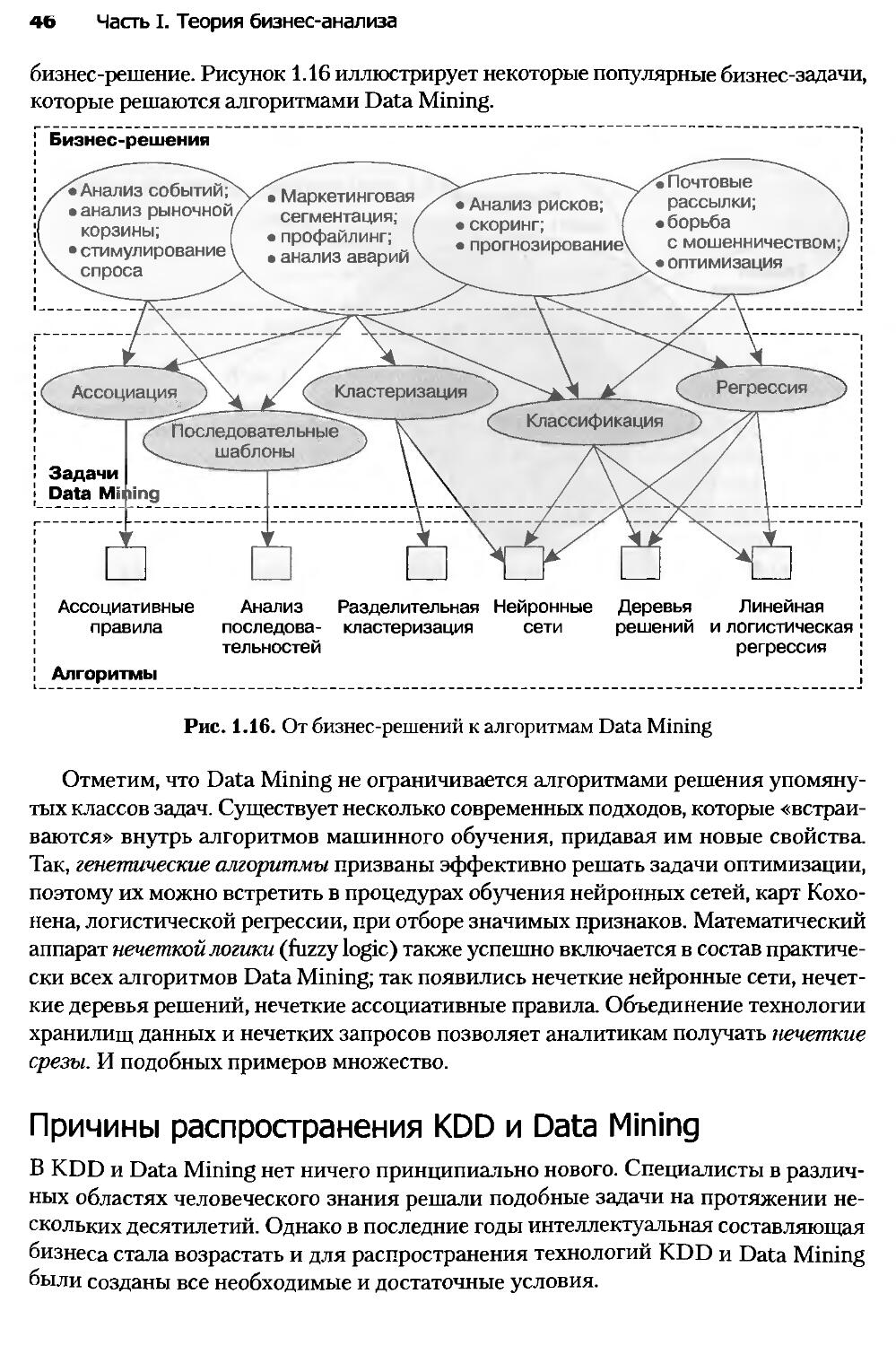
Глава 1. Технологии анализа данных...............................20
Глава 2. Консолидация данных.....................................61
Глава 3. Трансформация данных...................................138
Глава 4. Визуализация данных....................................173
Глава 5. Очистка и предобработка данных.........................211
Глава 6. Data Mining: задача ассоциации.........................281
Глава 7. Data Mining: кластеризация.............................308
Глава 8. Data Mining: классификация и регрессия.
Статистические методы...........................................342
Глава 9. Data Mining: классификация и регрессия.
Машинное обучение...............................................428
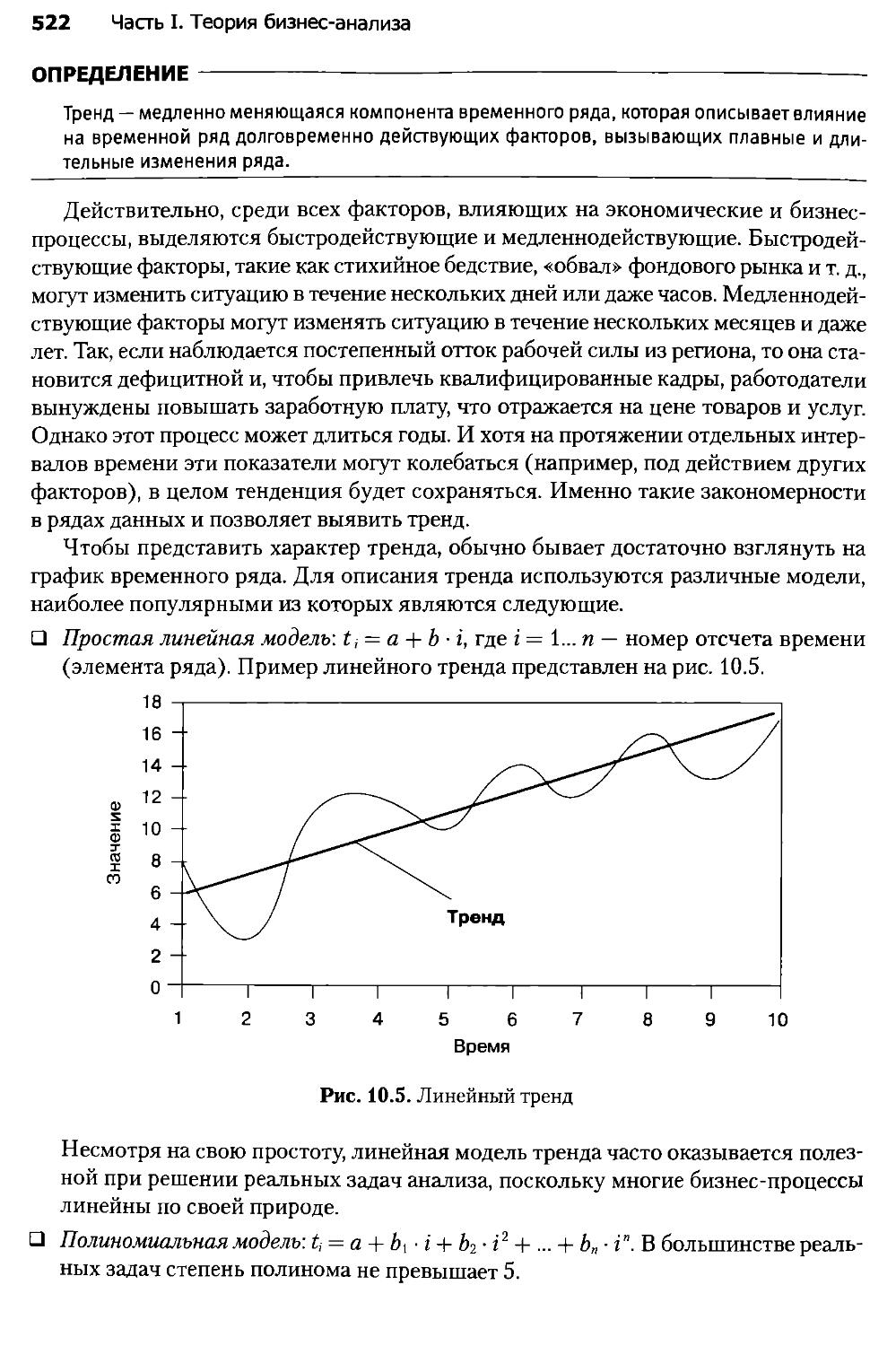
Глава 10. Анализ и прогнозирование временных рядов..............514
Глава 11. Ансамбли моделей......................................543
Глава 12. Сравнение моделей.....................................563
ЧАСТЬ II. БИЗНЕС-АНАЛИЗ В DEDUCTOR
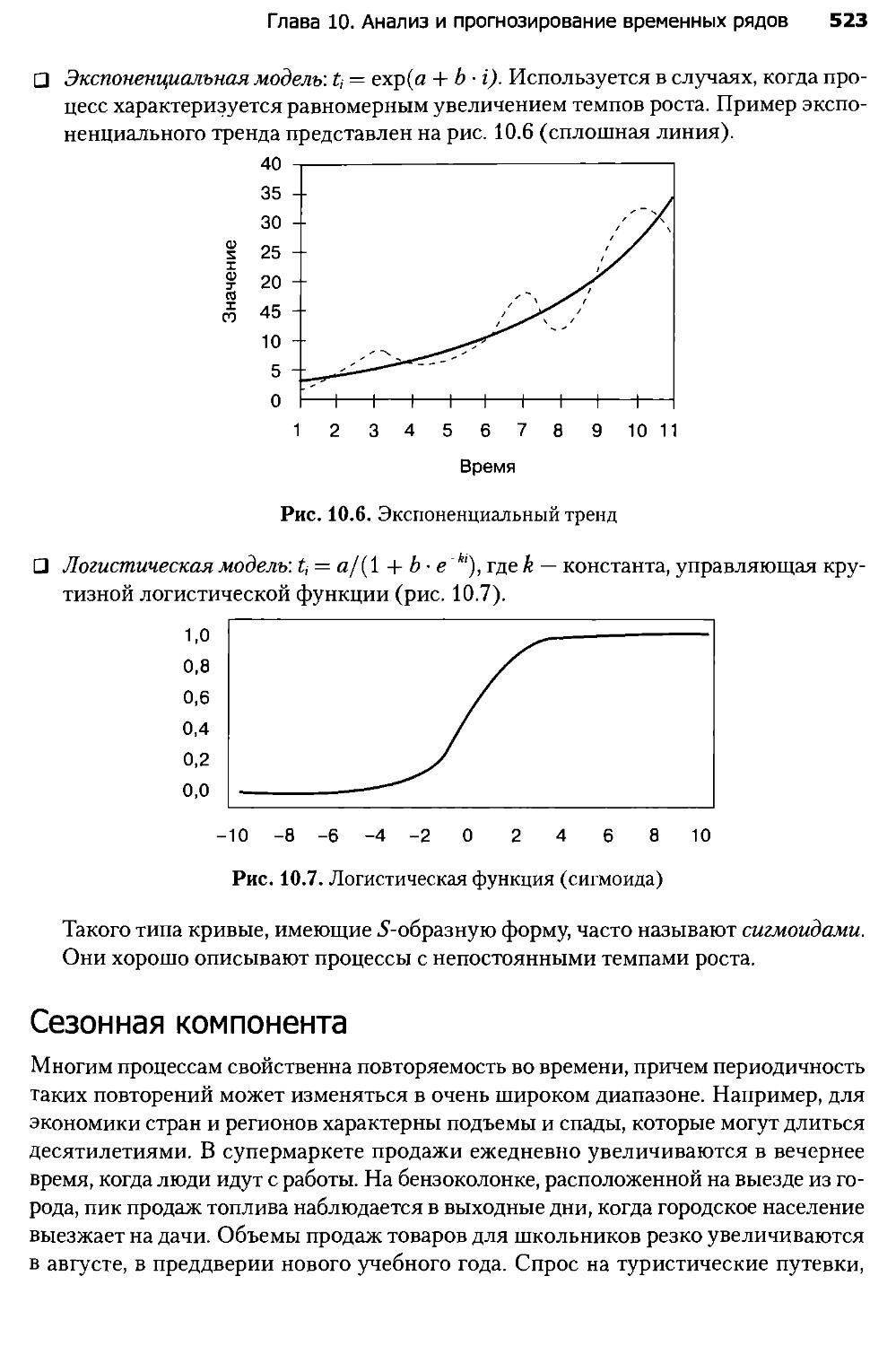
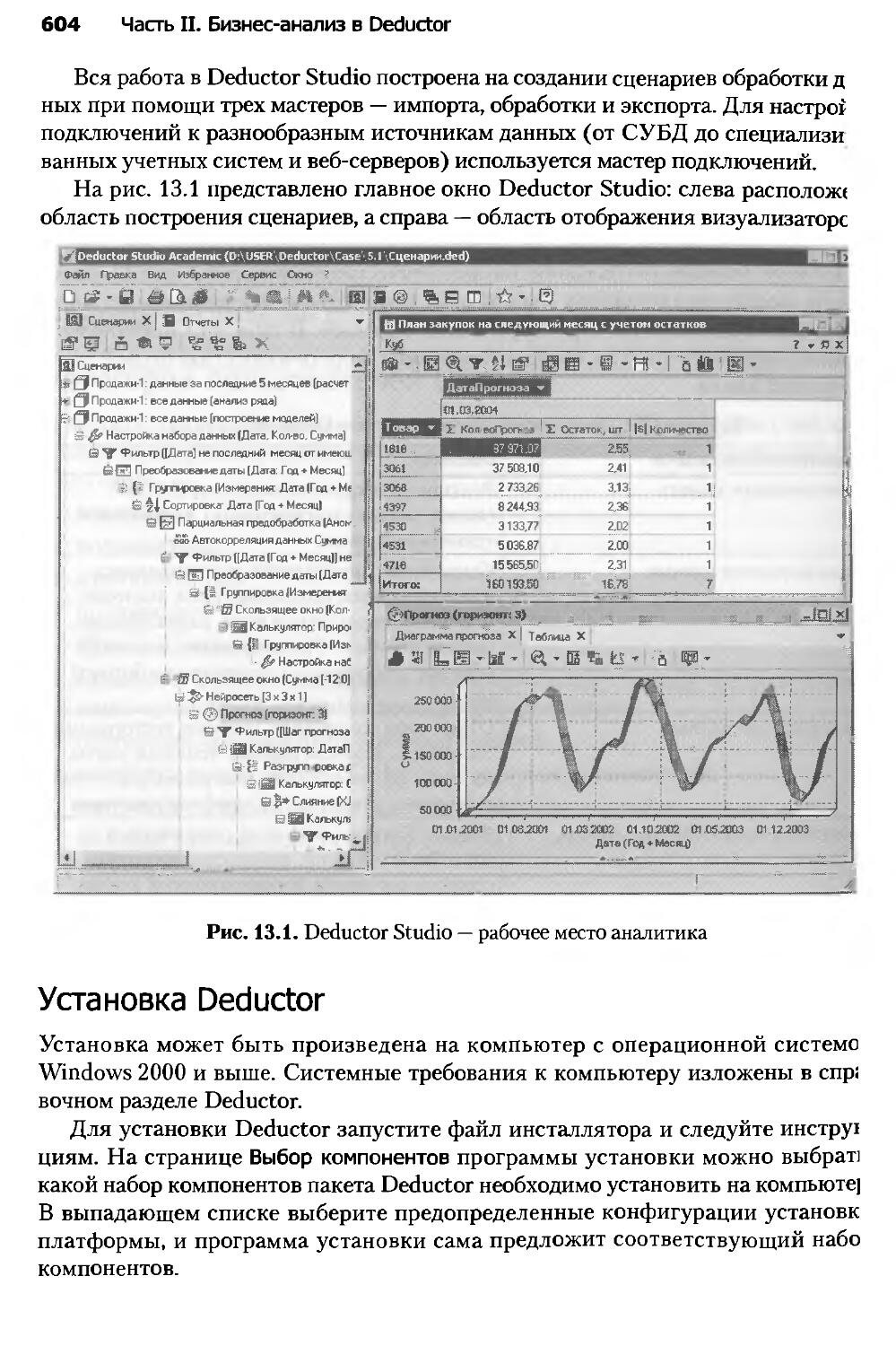
Глава 13. Аналитическая платформа Deductor......................600
Глава 14. Консолидация данных и аналитическая отчетность
аптечной сети...................................................606
Глава 15. Ассоциативные правила в стимулировании
розничных продаж................................................635
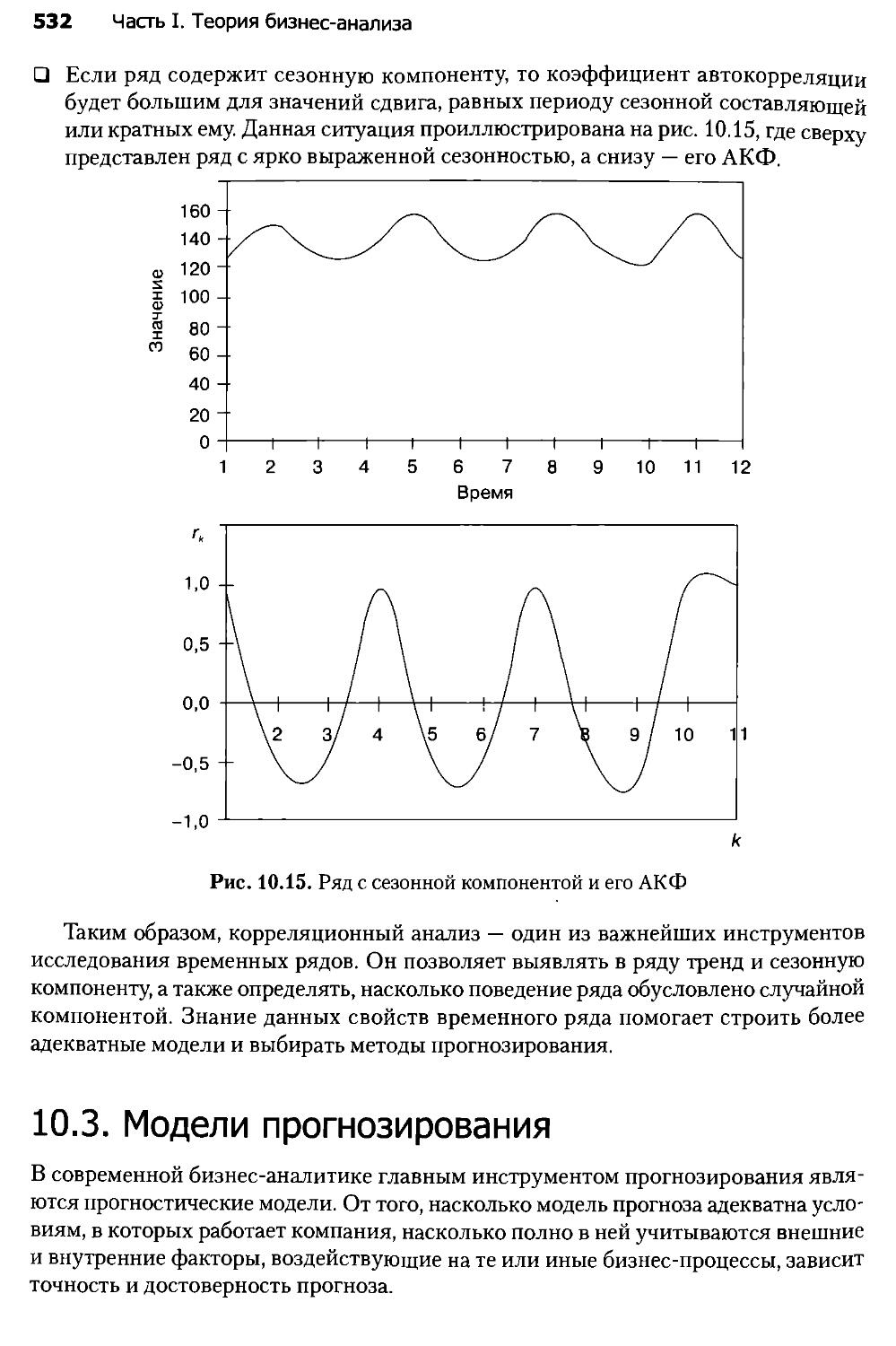
Глава 16. Сегментация клиентов телекоммуникационной компании....643
Глава 17. Скоринговые модели для оценки кредитоспособности
заемщиков.......................................................657
Глава 18. Прогнозирование продаж товаров в оптовой компании.....676
Глава 19. Повышение эффективности массовой рассылки клиентам....682
Заключение......................................................689
Литература......................................................690
Алфавитный указатель............................................693
Оглавление
Предисловие авторов.....................................................8
Об авторах..............................................................10
От издательства.........................................................11
Вступительное слово.....................................................12
Введение...............................................................14
Современная бизнес-аналитика............................................14
ЧАСТЬ I. ТЕОРИЯ БИЗНЕС-АНАЛИЗА
Глава 1. Технологии анализа данных.....................................20
1.1. Введение в анализ данных..........................................20
1.2. Принципы анализа данных...........................................25
1.3. Структурированные данные..........................................30
1.4. Подготовка данных к анализу.......................................34
1.5. Технологии KDD и Data Mining......................................40
1.6. Аналитические платформы...........................................47
1.7. Введение в алгоритмы Data Mining..................................51
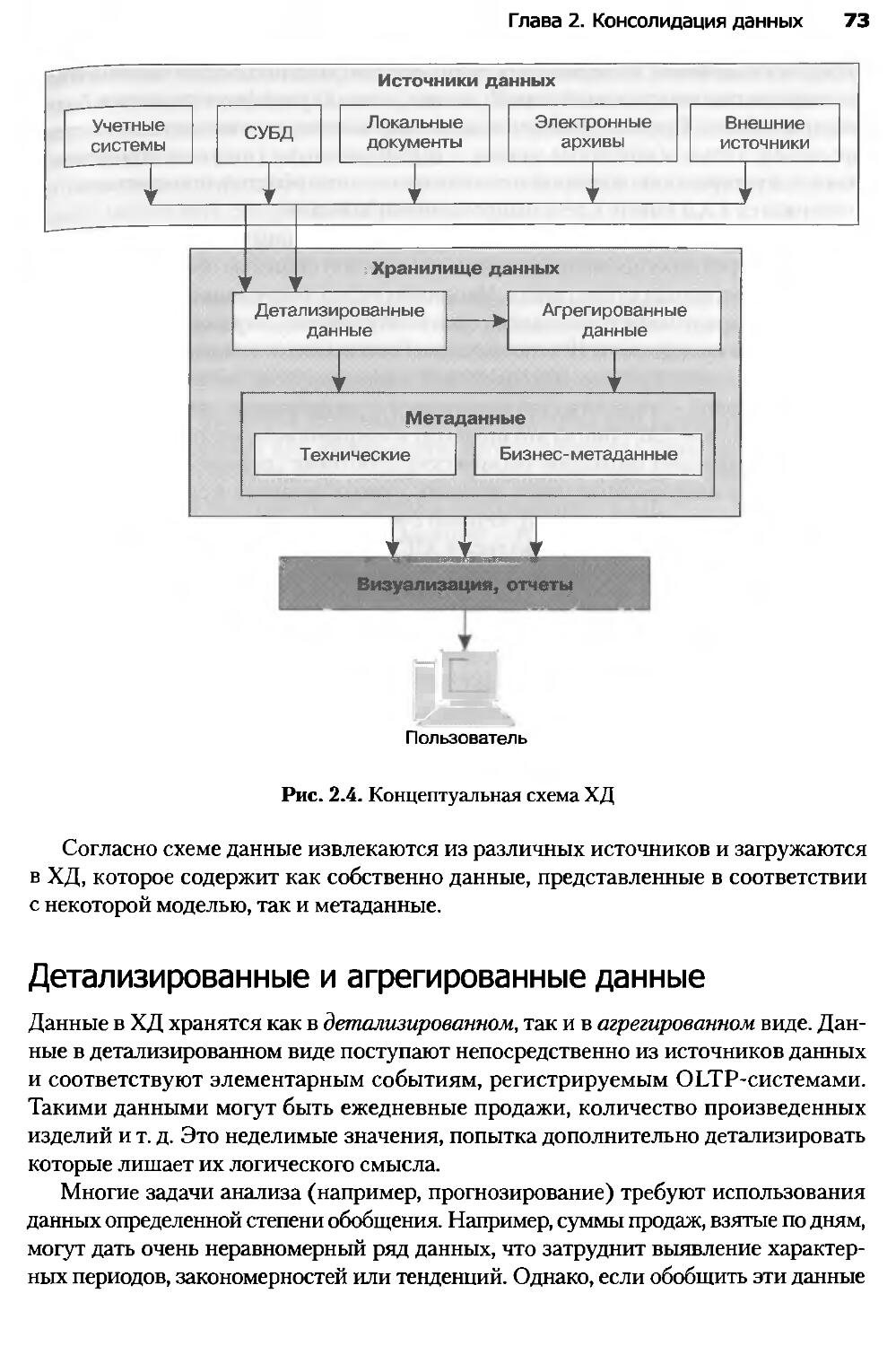
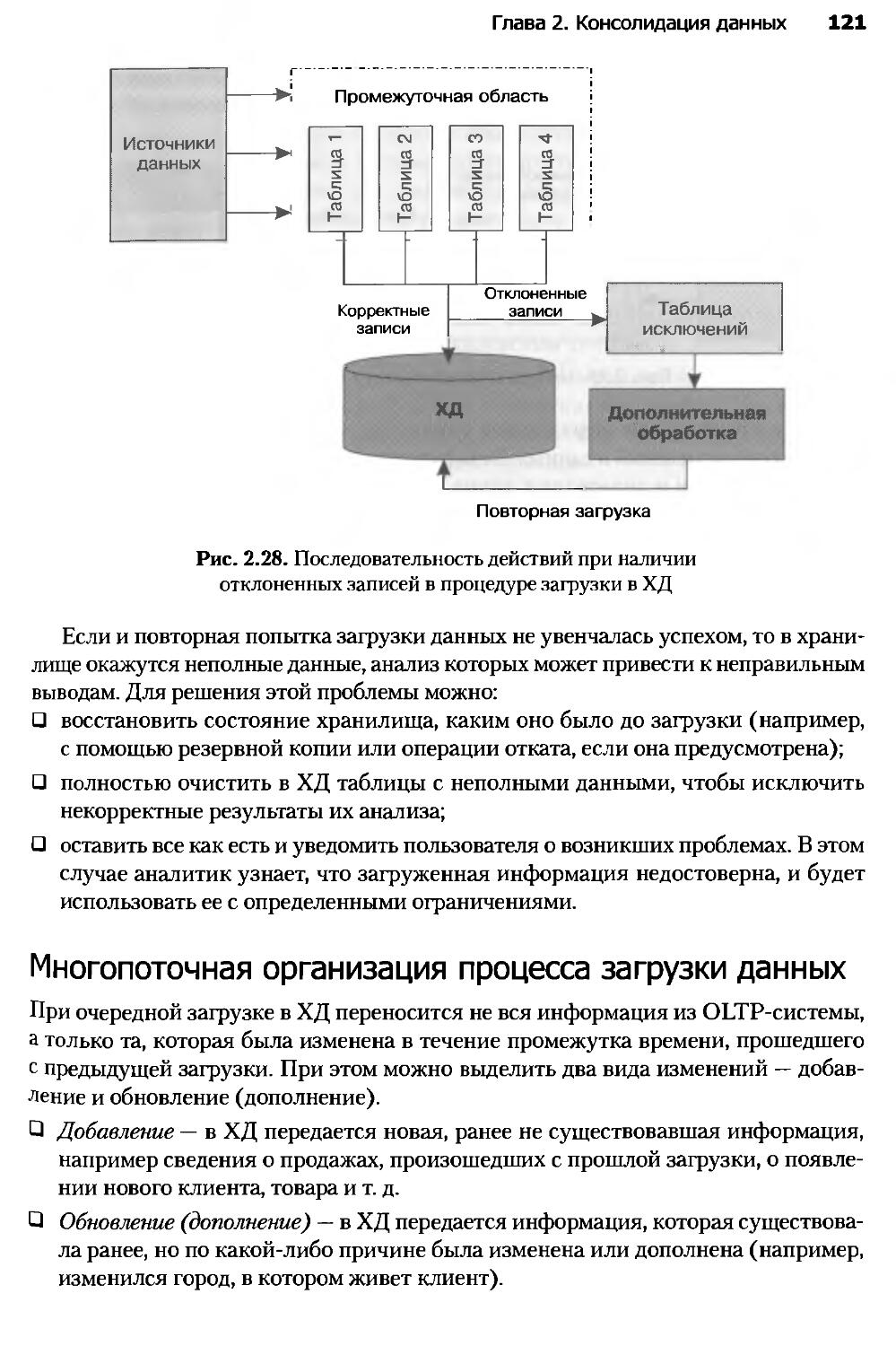
Глава 2. Консолидация данных...........................................61
2.1. Задача консолидации...............................................61
2.2. Введение в хранилища данных.......................................65
2.3. Основные концепции хранилищ данных................................71
2.4. Многомерные хранилища данных......................................76
2.5. Реляционные хранилища данных......................................82
2.6. Гибридные хранилища данных........................................86
Оглавление 5
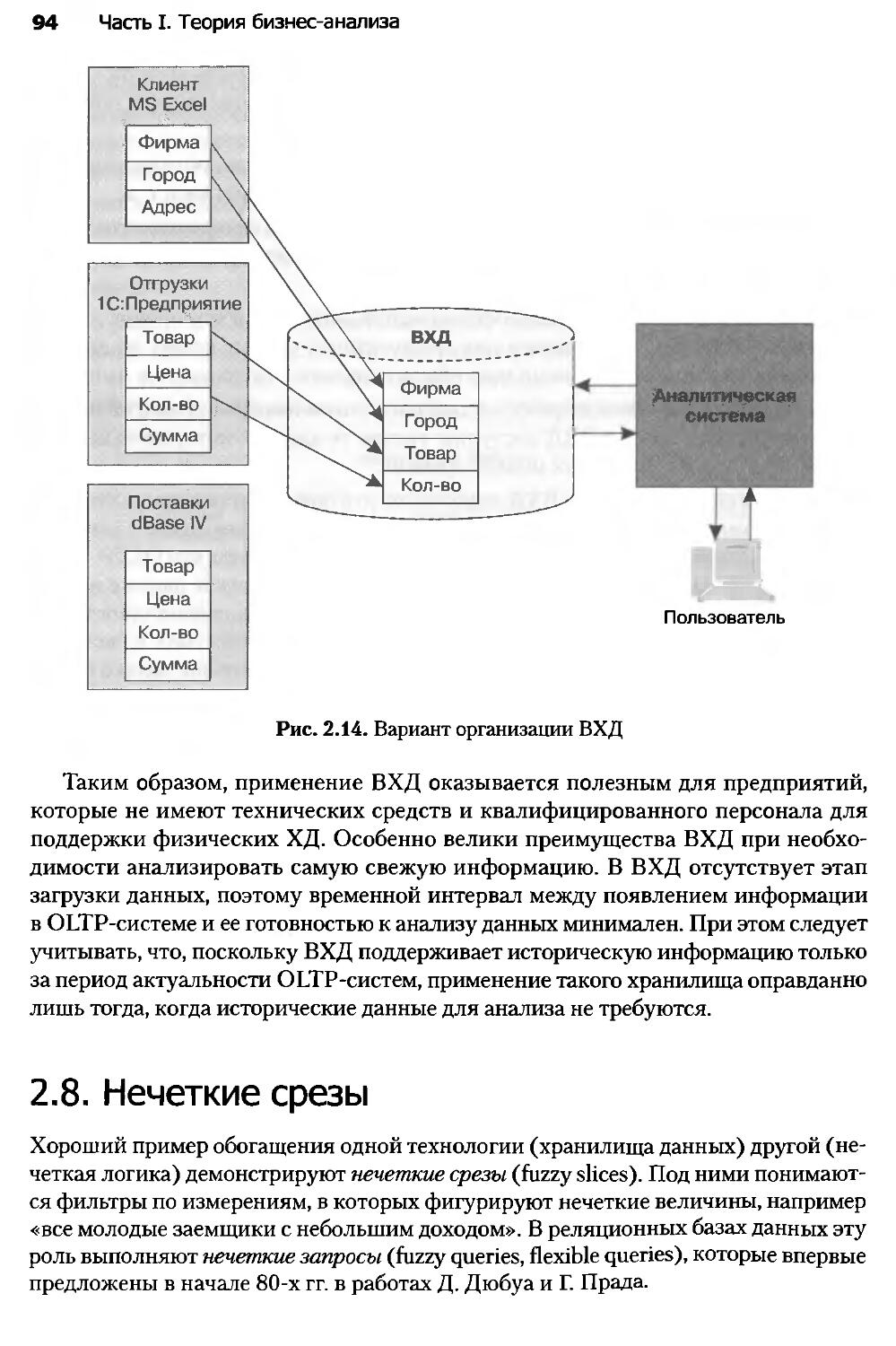
2.7. Виртуальные хранилища данных.......................................91
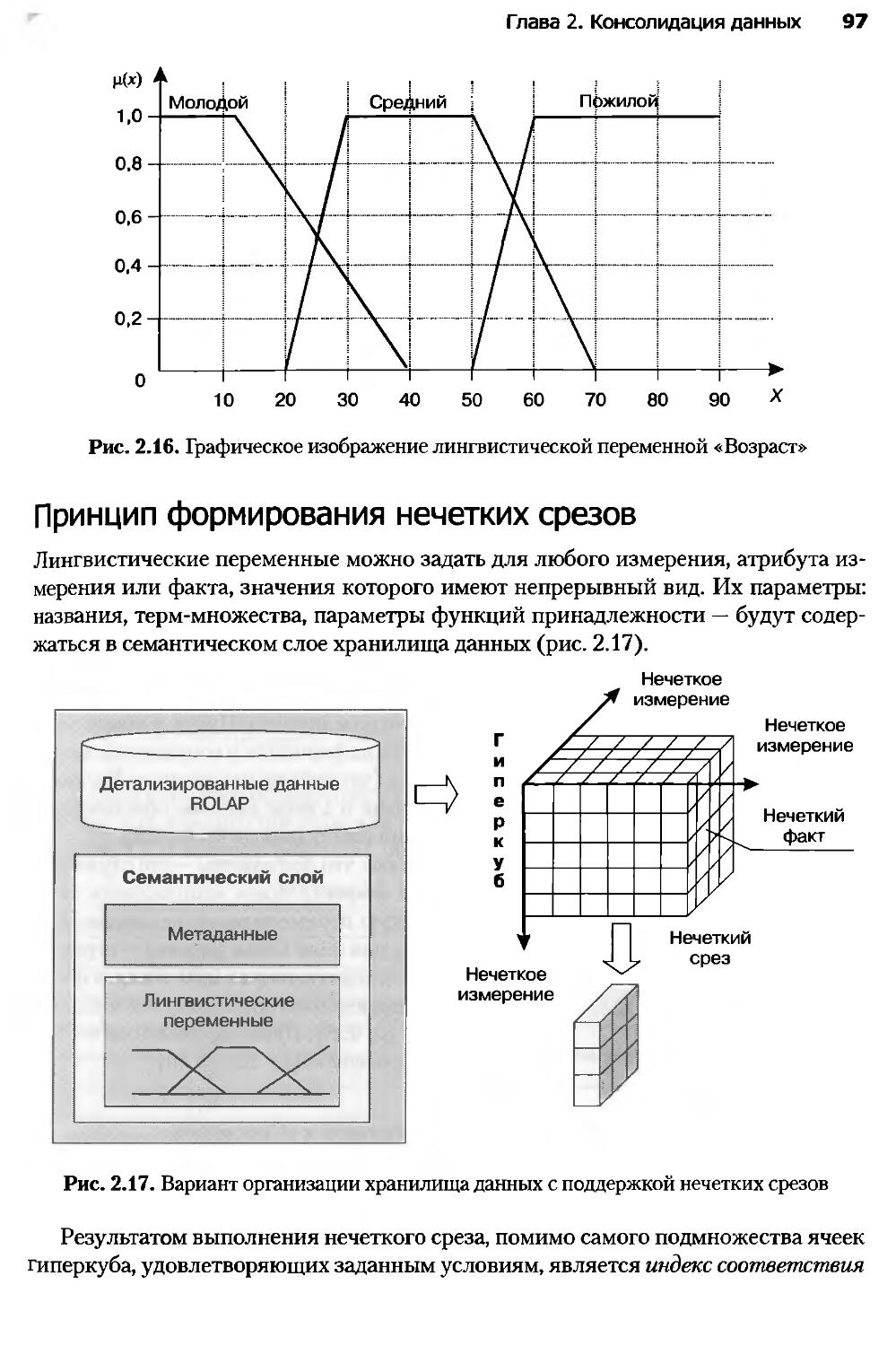
2.8. Нечеткие срезы.....................................................94
2.9. Введение в ETL....................................................100
2.10. Извлечение данных в ETL..........................................103
2.11. Очистка данных в ETL.............................................108
2.12. Преобразование данных в ETL......................................113
2.13. Загрузка данных в хранилище......................................119
2.14. Загрузка данных из локальных источников..........................123
2.15. Обогащение данных................................................131
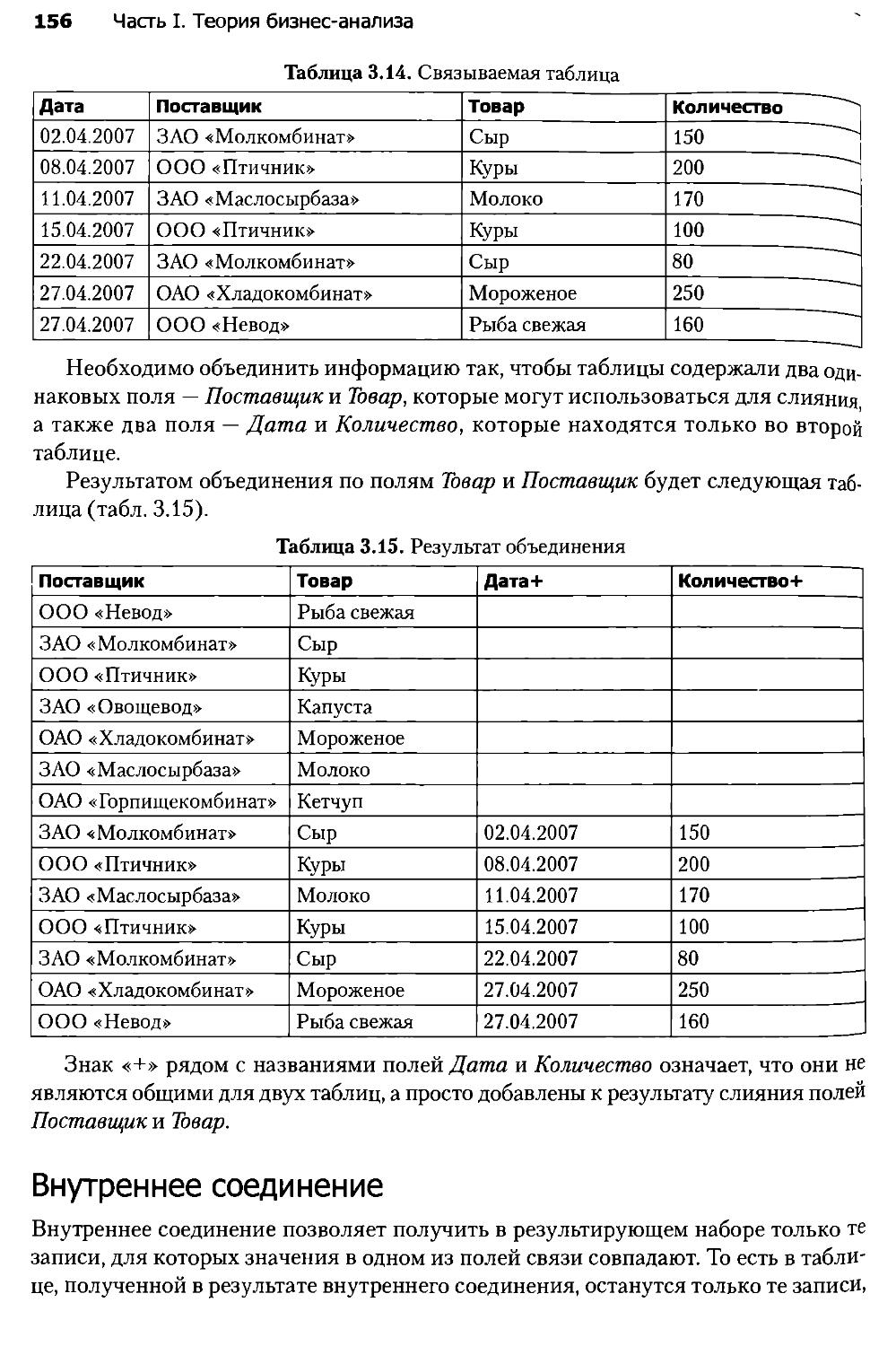
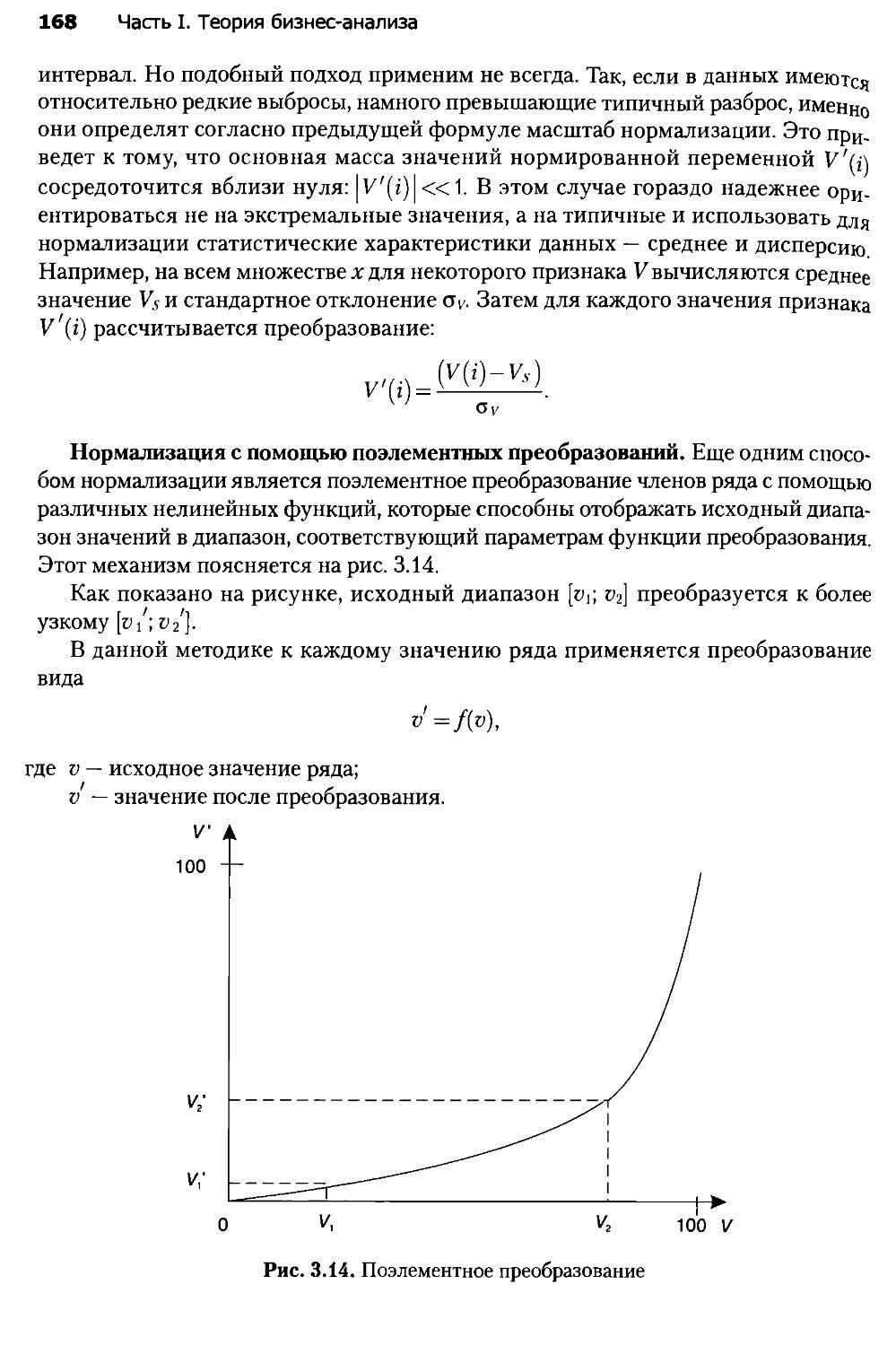
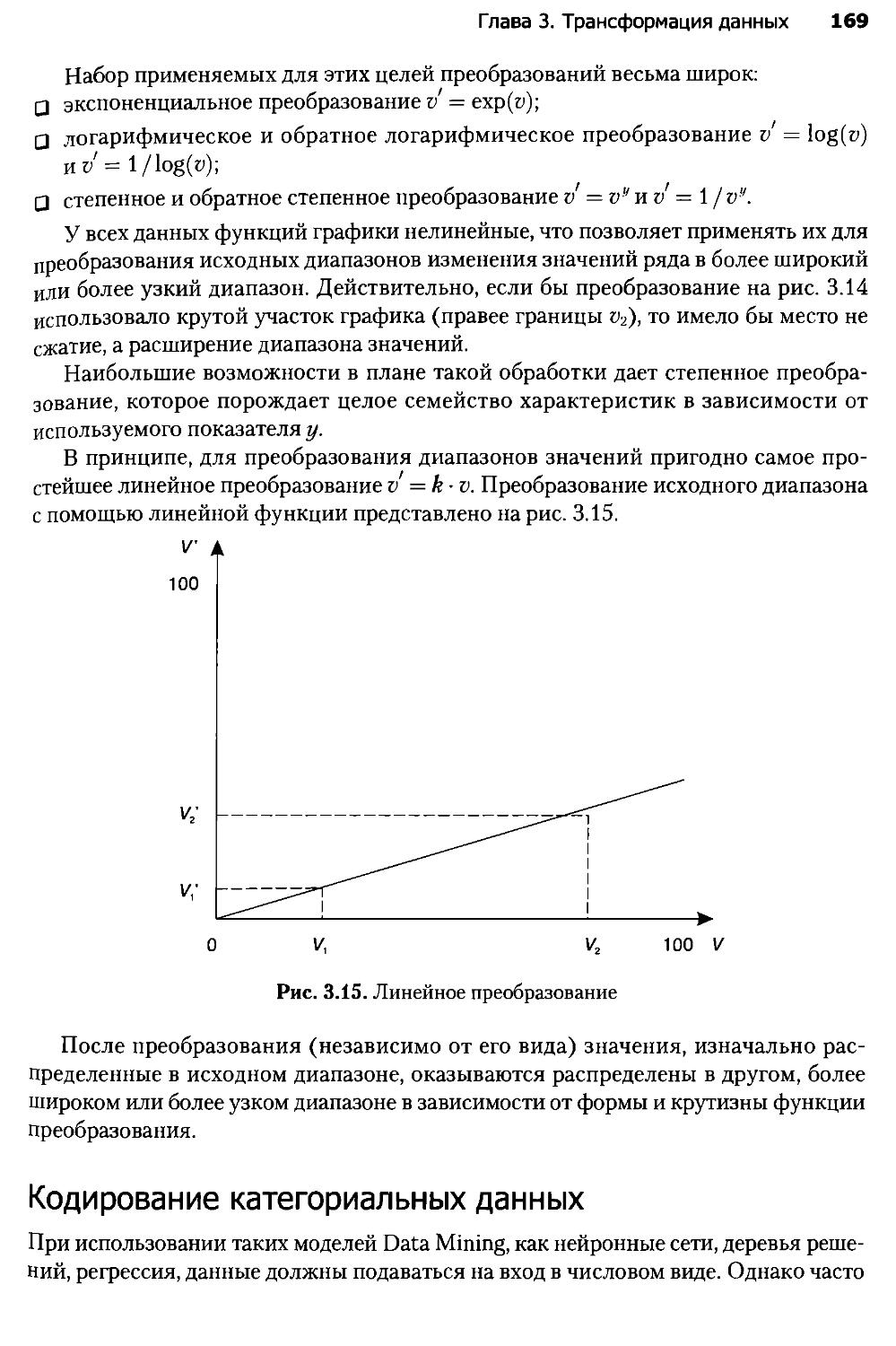
Глава 3. Трансформация данных..........................................138
3.1. Введение в трансформацию данных...................................138
3.2. Трансформация упорядоченных данных................................142
3.3. Группировка данных................................................151
3.4. Слияние данных....................................................154
3.5. Квантование.......................................................160
3.6. Нормализация и кодирование данных.................................166
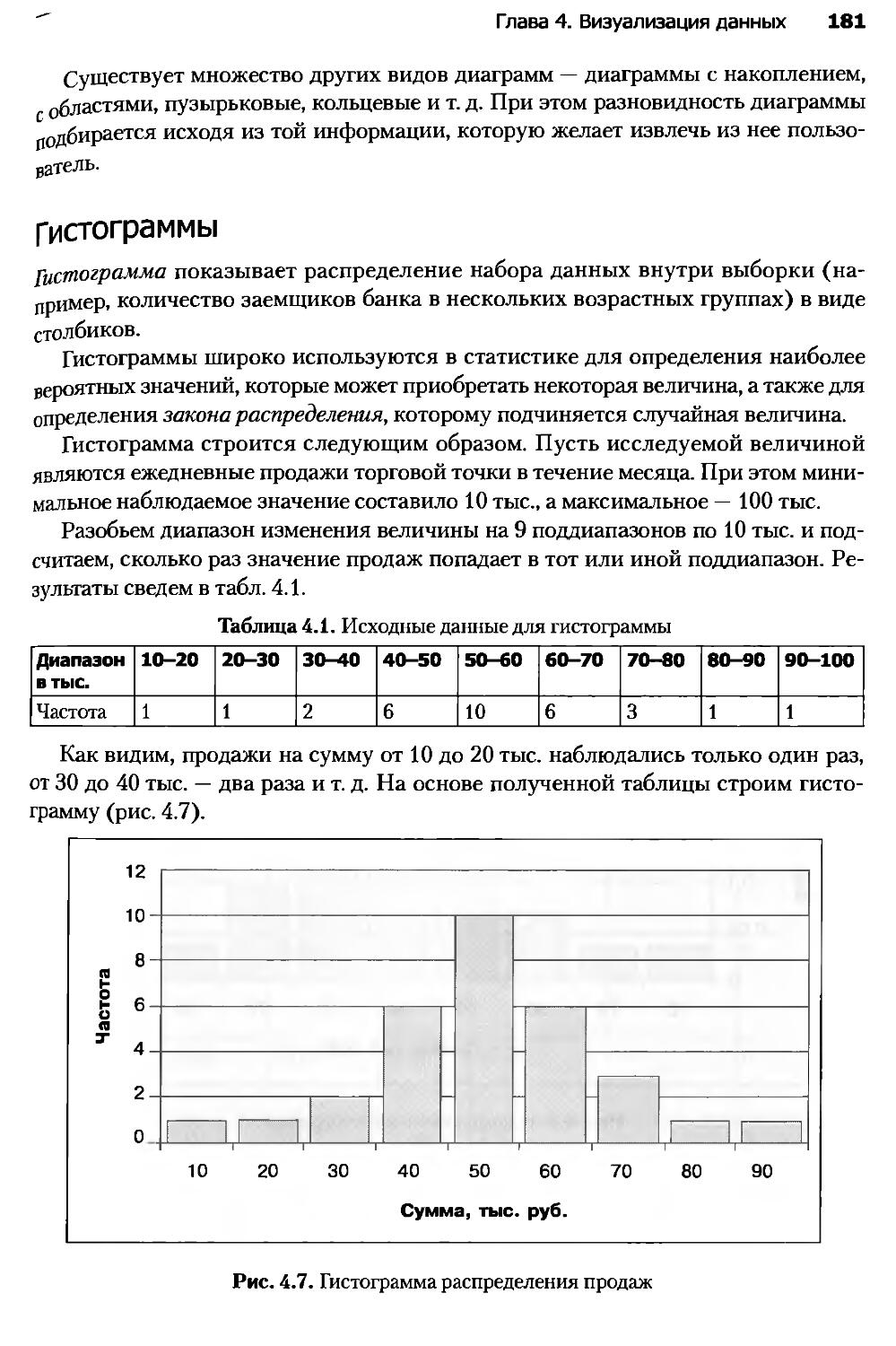
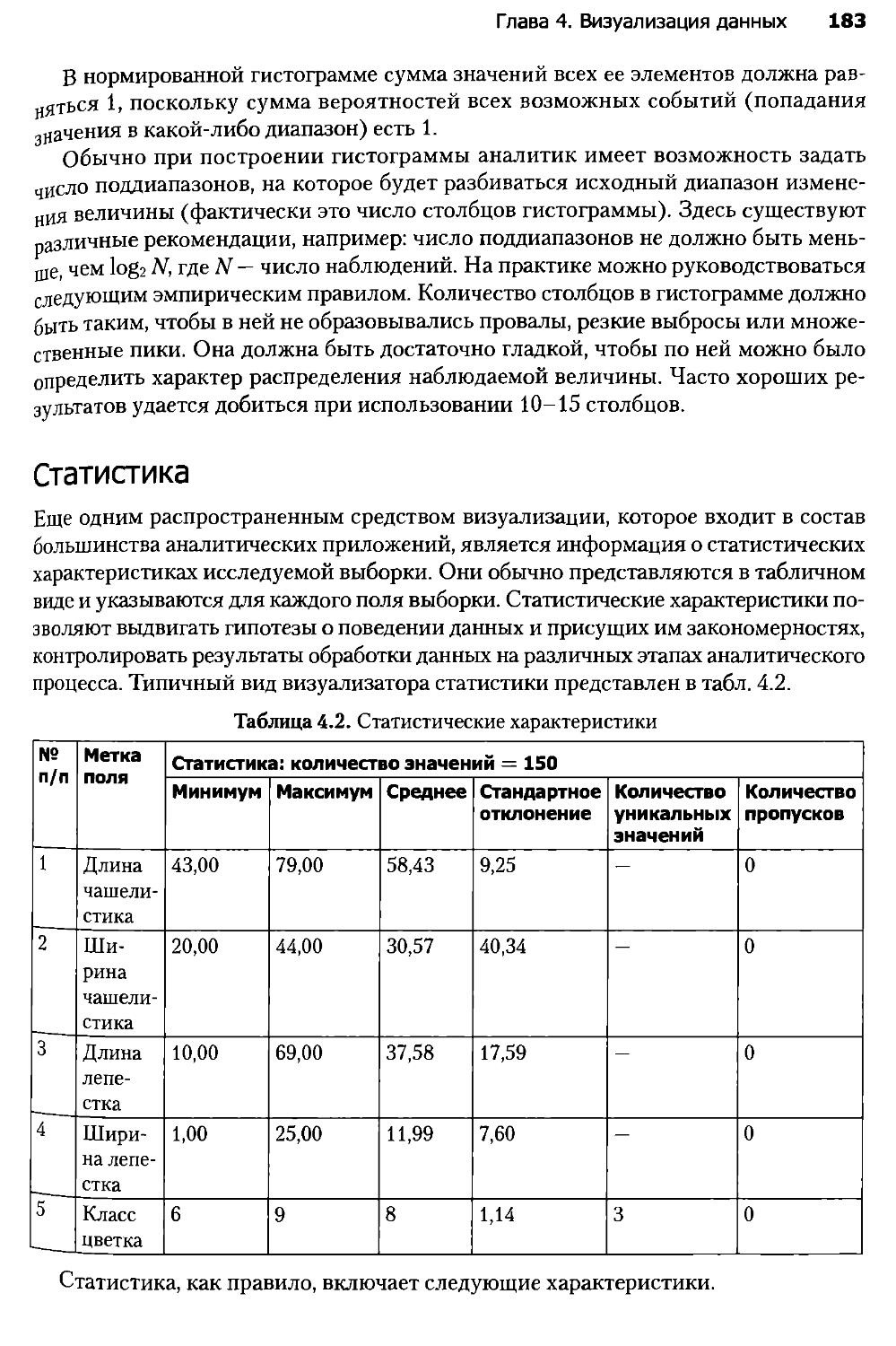
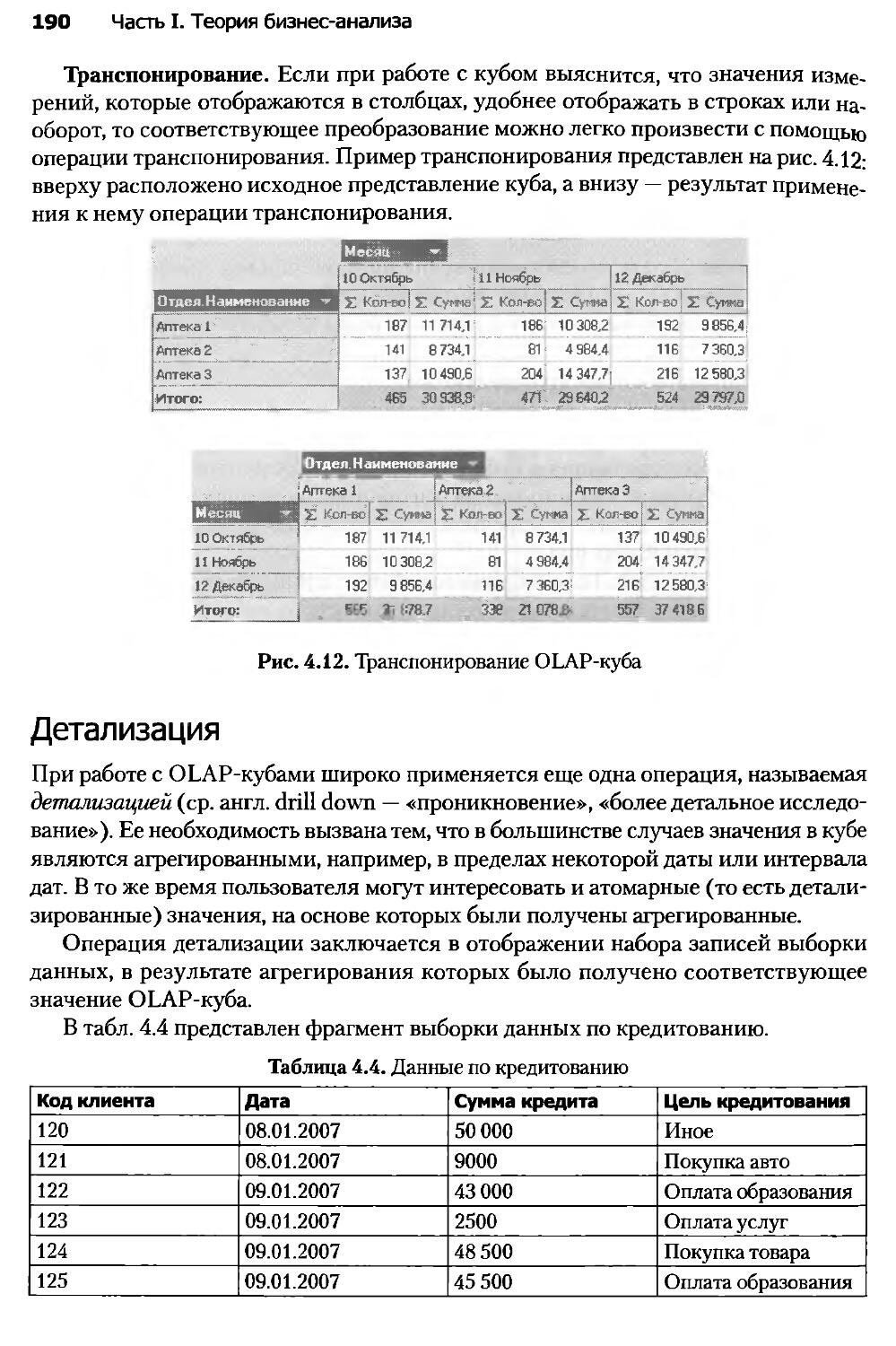
Глава 4. Визуализация данных...........................................173
4.1. Введение в визуализацию...........................................173
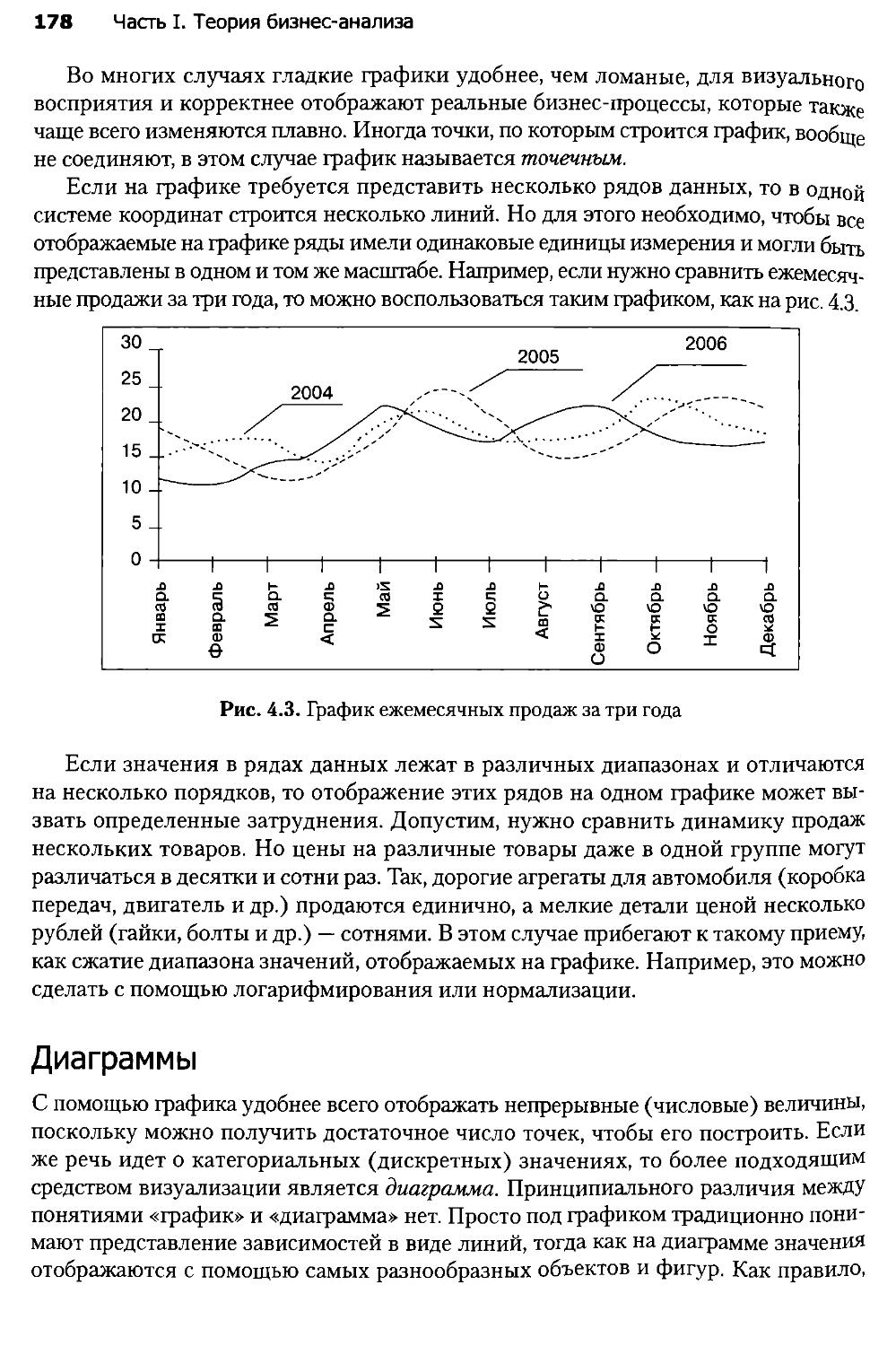
4.2. Визуализаторы общего назначения...................................177
4.3. OLAP-анализ.......................................................184
4.4. Визуализаторы для оценки качества моделей.........................192
4.5. Визуализаторы, применяемые для интерпретации результатов анализа..202
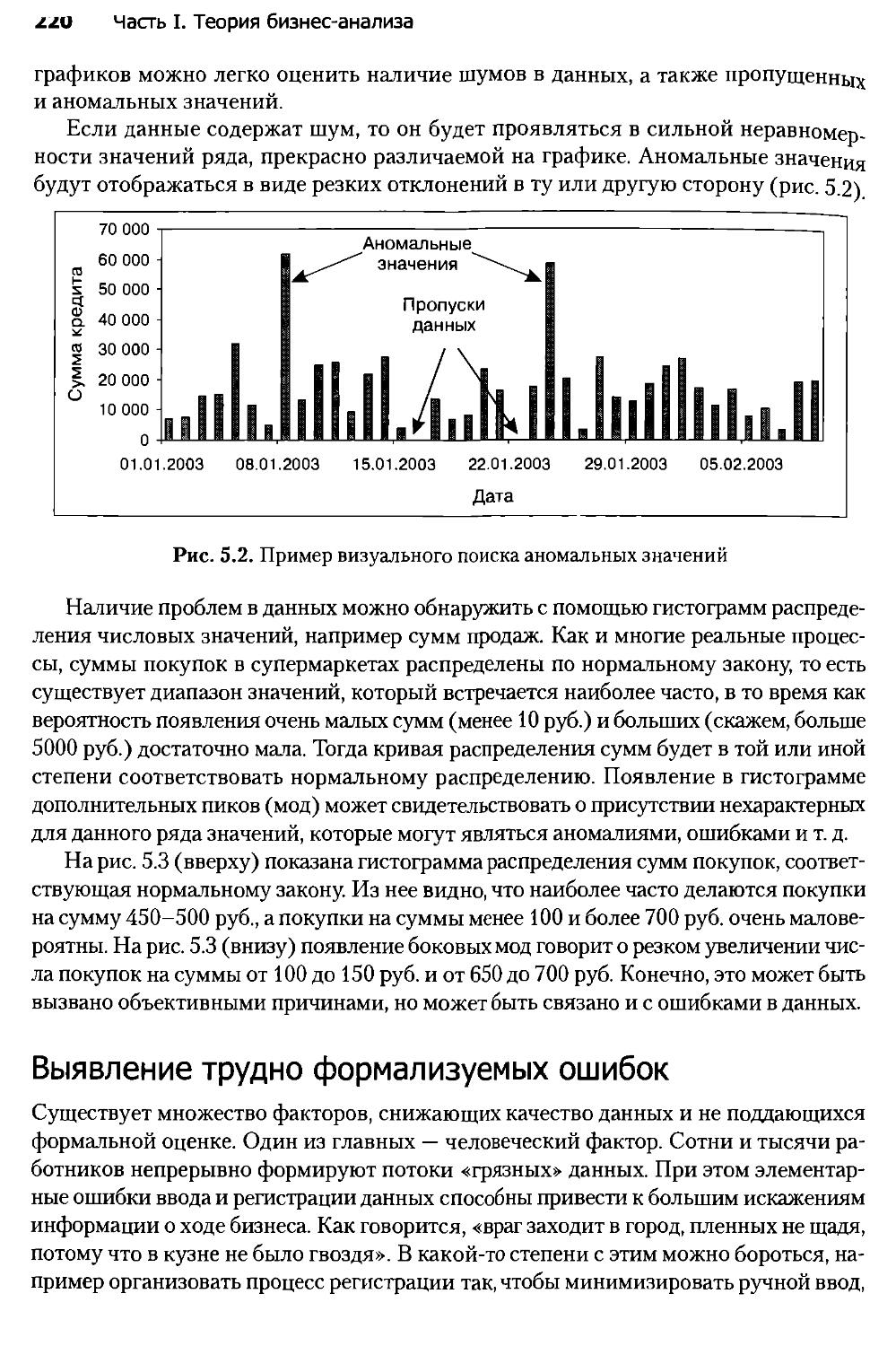
Глава 5. Очистка и предобработка данных................................211
5.1. Оценка качества данных............................................211
5.2. Технологии и методы оценки качества данных........................217
5.3. Очистка и предобработка...........................................224
5.4. Фильтрация данных.................................................232
5.5. Обработка дубликатов и противоречий...............................234
5.6. Выявление аномальных значений.....................................240
5.7. Восстановление пропущенных значений...............................247
5.8. Введение в сокращение размерности.................................253
5.9. Сокращение числа признаков........................................258
5.10. Сокращение числа значений признаков и записей....................270
5.11. Сэмплинг.........................................................273
Глава б. Data Mining: задача ассоциации................................281
6.1. Ассоциативные правила.............................................281
6.2. Алгоритм Apriori..................................................287
6.3. Иерархические ассоциативные правила...............................292
6.4. Последовательные шаблоны..........................................299
б Оглавление
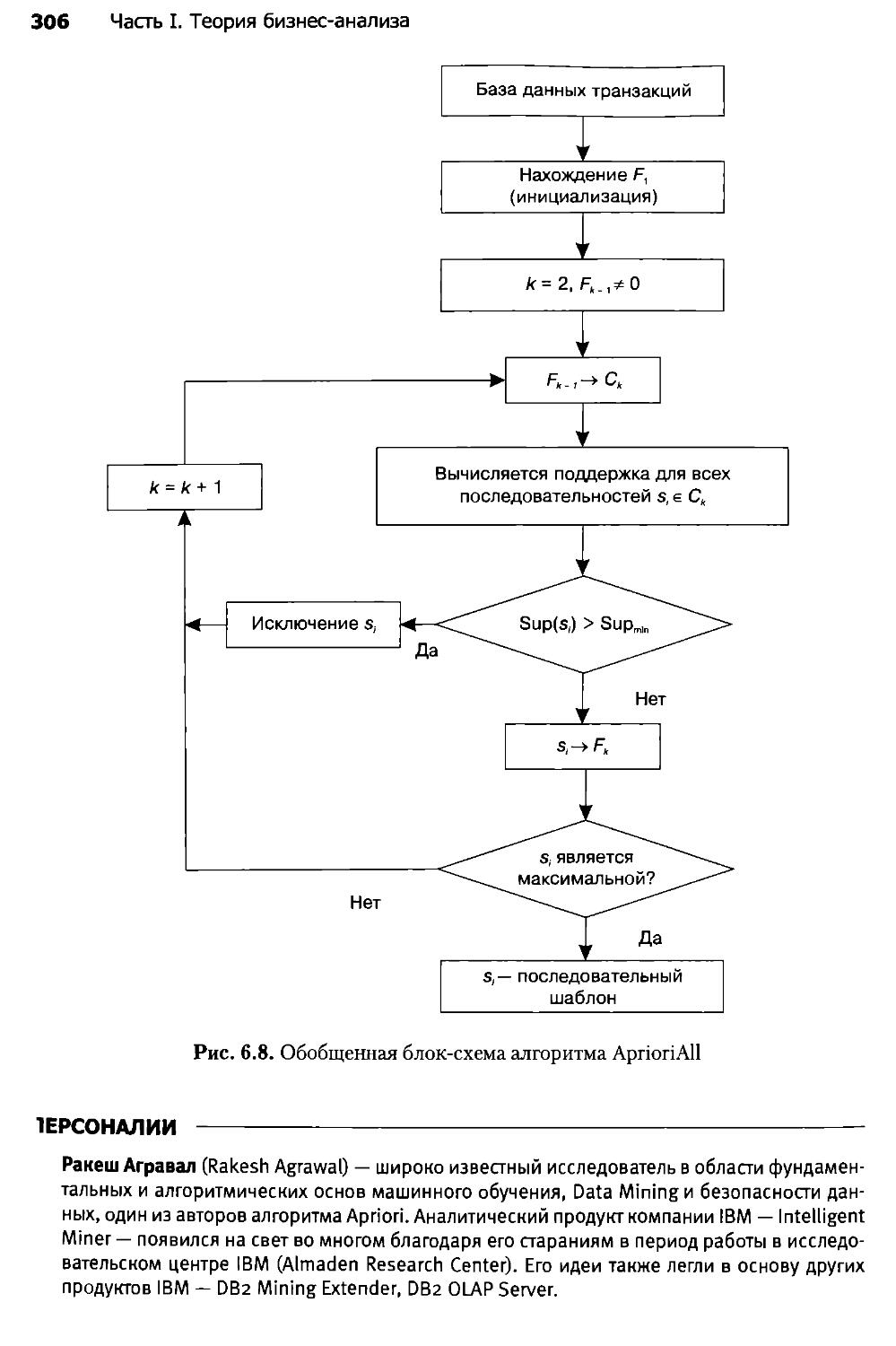
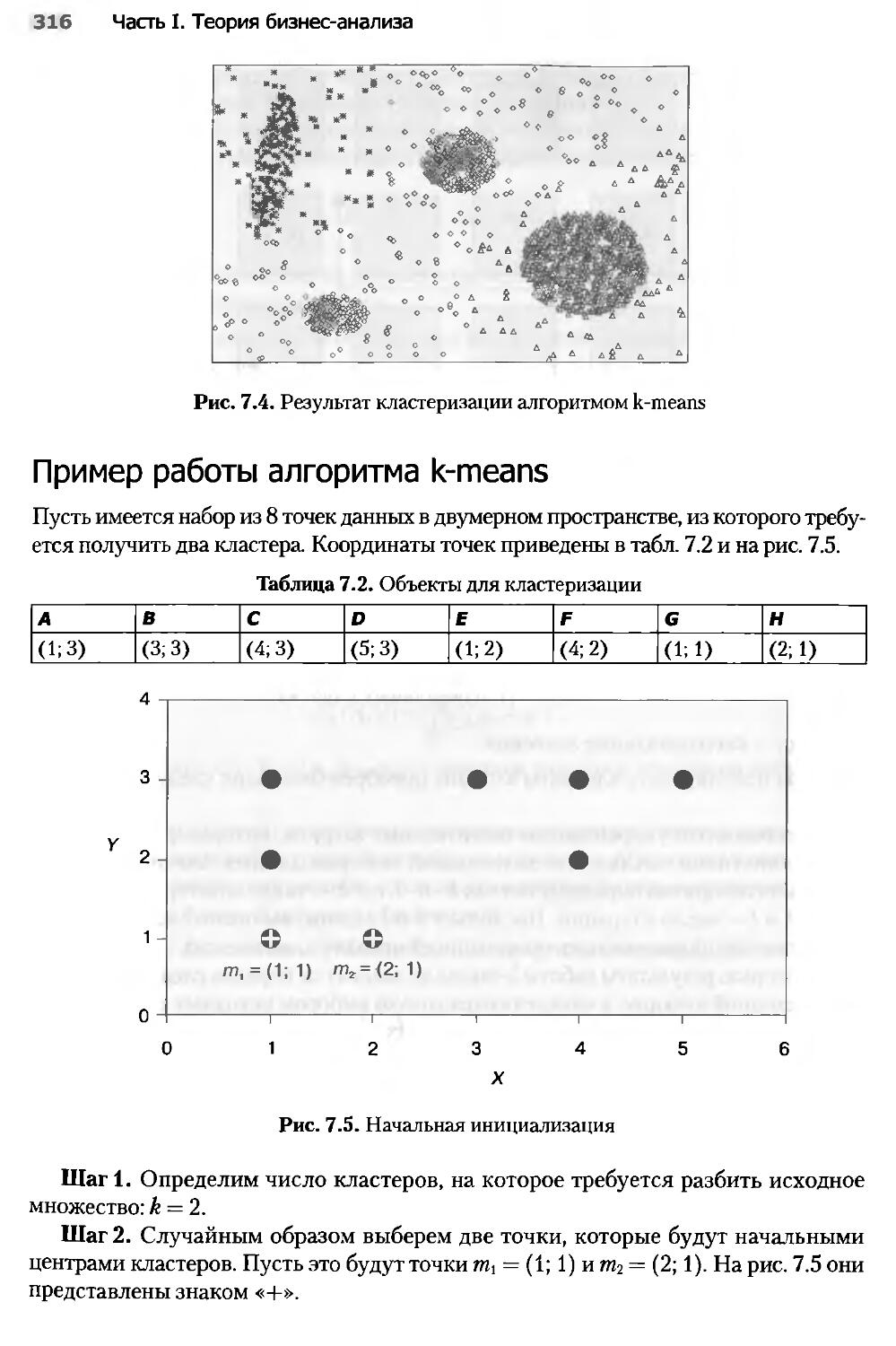
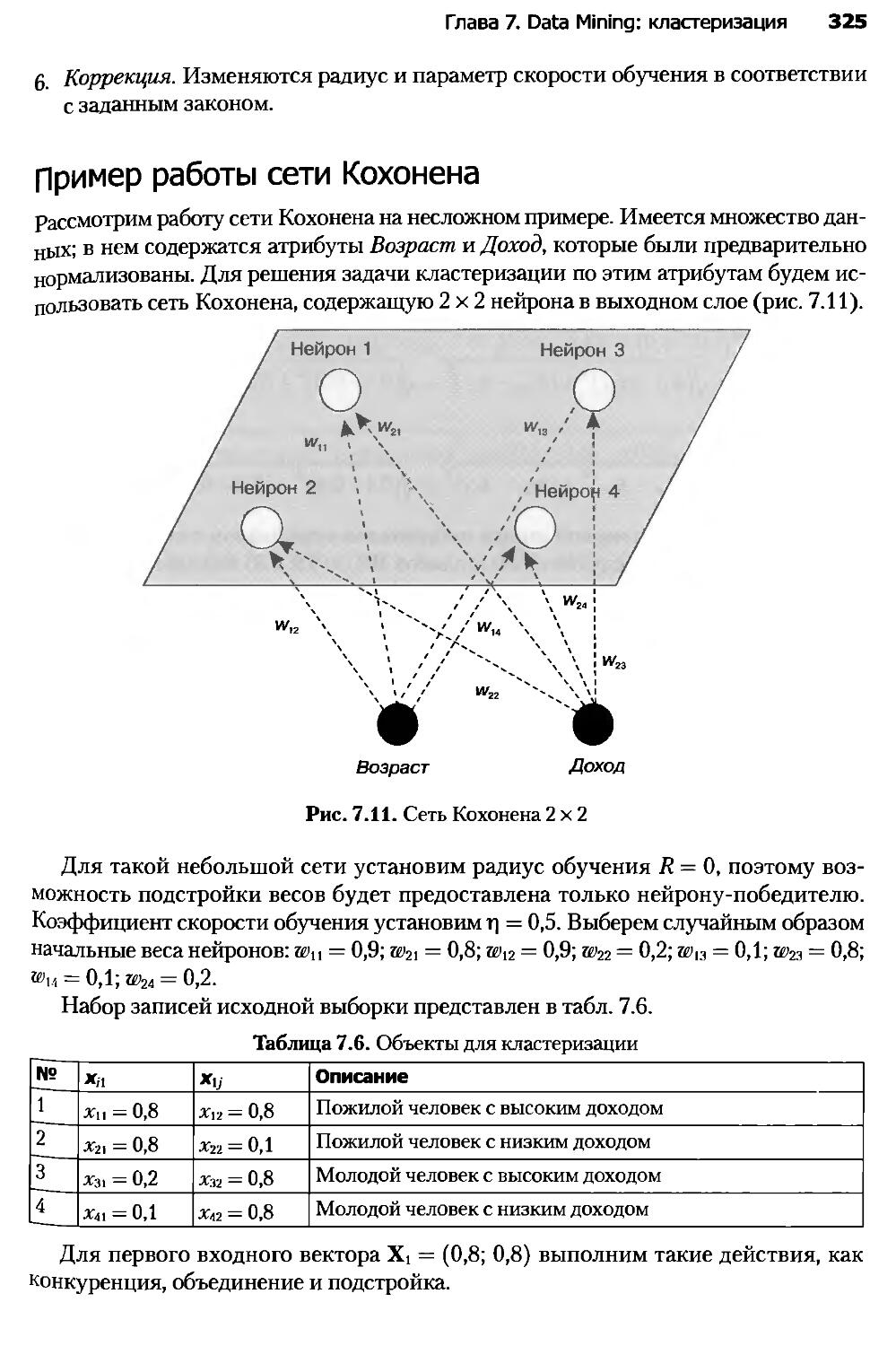
Глава 7. Data Mining: кластеризация.....................................308
7.1. Введение в кластеризацию...........................................308
7.2. Алгоритм кластеризации k-means.....................................311
7.3. Сети Кохонена......................................................322
7.4. Карты Кохонена.....................................................330
7.5. Проблемы алгоритмов кластеризации..................................337
Глава 8. Data Mining: классификация и регрессия.
Статистические методы...................................................342
8.1. Введение в классификацию и регрессию...............................342
8.2. Простая линейная регрессия.........................................351
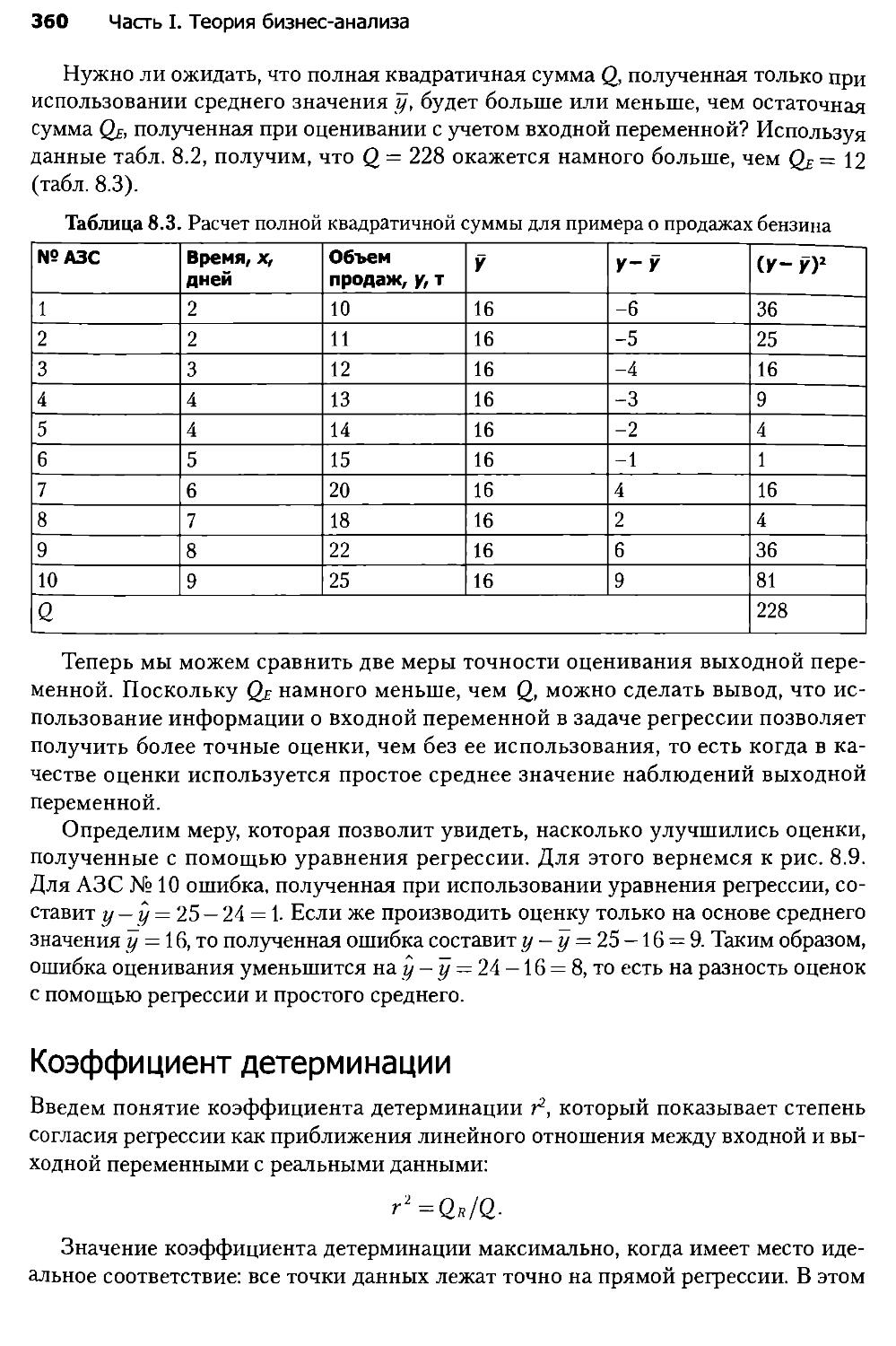
8.3. Оценка соответствия простой линейной регрессии реальным данным....356
8.4. Простая регрессионная модель.......................................363
8.5. Множественная линейная регрессия...................................370
8.6. Модель множественной линейной регрессии............................376
8.7. Регрессия с категориальными входными переменными...................380
8.8. Методы отбора переменных в регрессионные модели....................387
8.9. Ограничения применимости регрессионных моделей.....................396
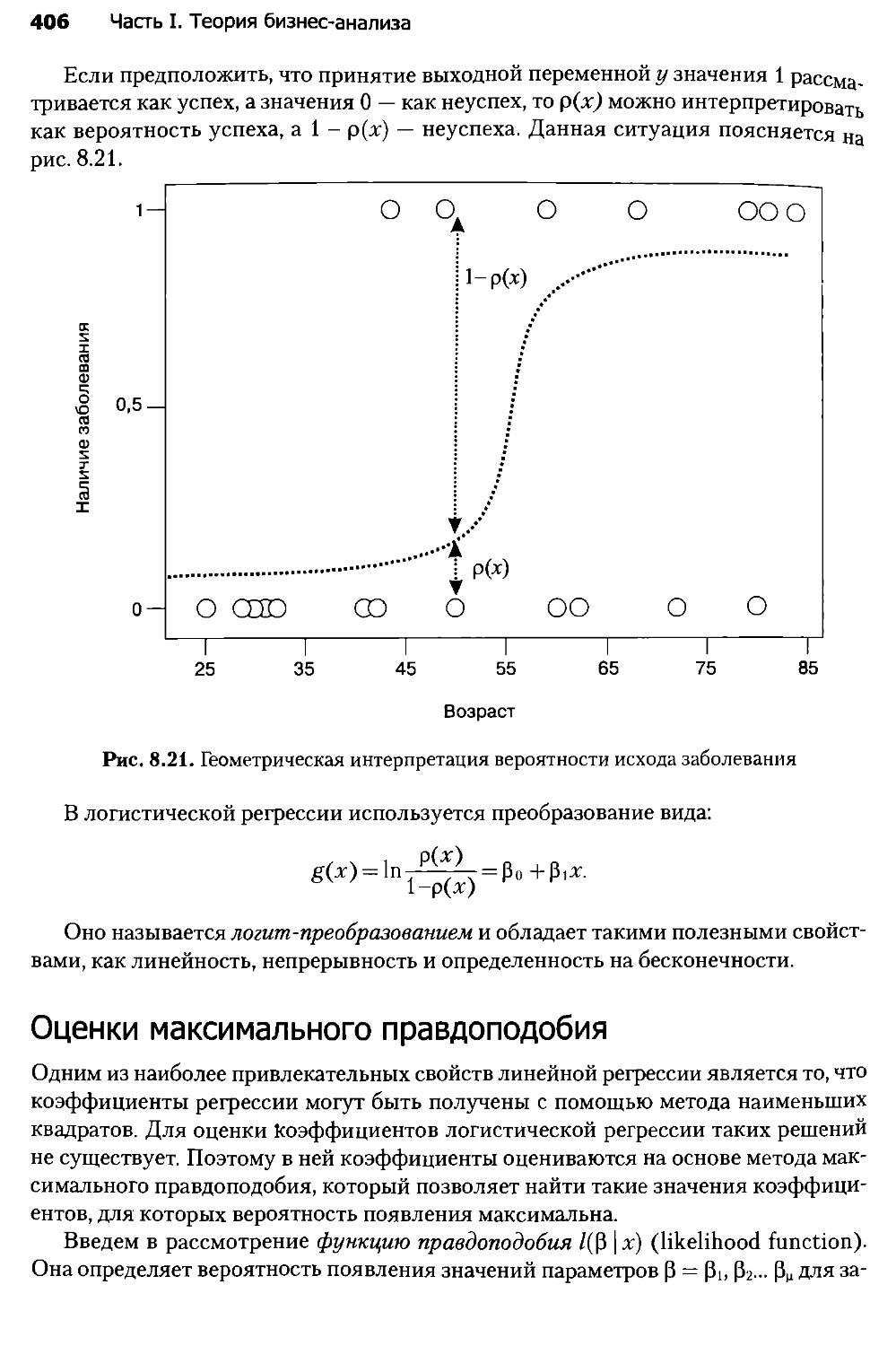
8.10. Основы логистической регрессии....................................403
8.11. Интерпретация модели логистической регрессии......................411
8.12. Множественная логистическая регрессия.............................421
8.13. Простой байесовский классификатор.................................423
Глава 9. Data Mining: классификация и регрессия.
Машинное обучение.......................................................428
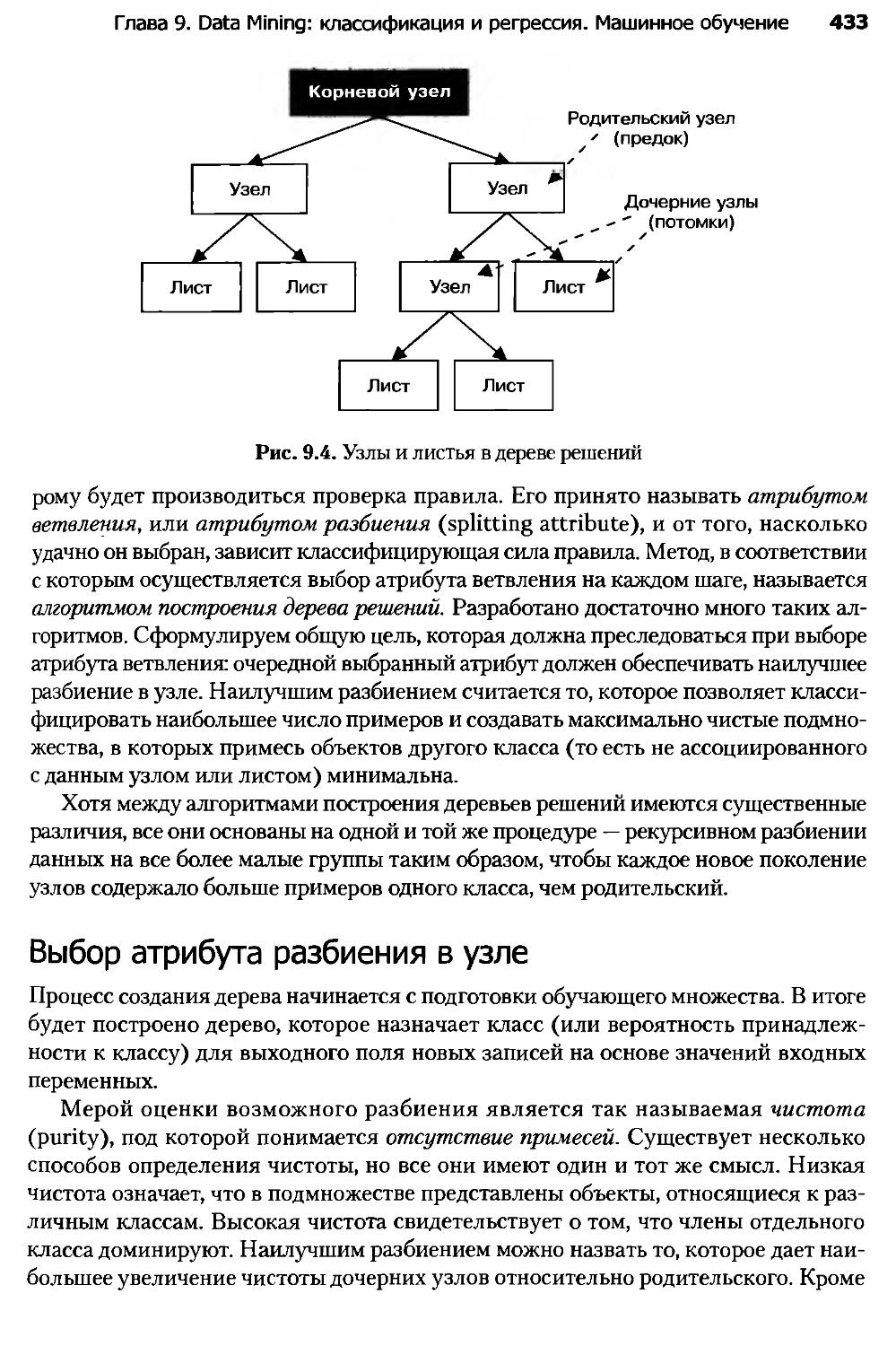
9.1. Введение в деревья решений.........................................428
9.2. Алгоритмы построения деревьев решений..............................437
9.3. Алгоритмы ID3 и С4.5...............................................444
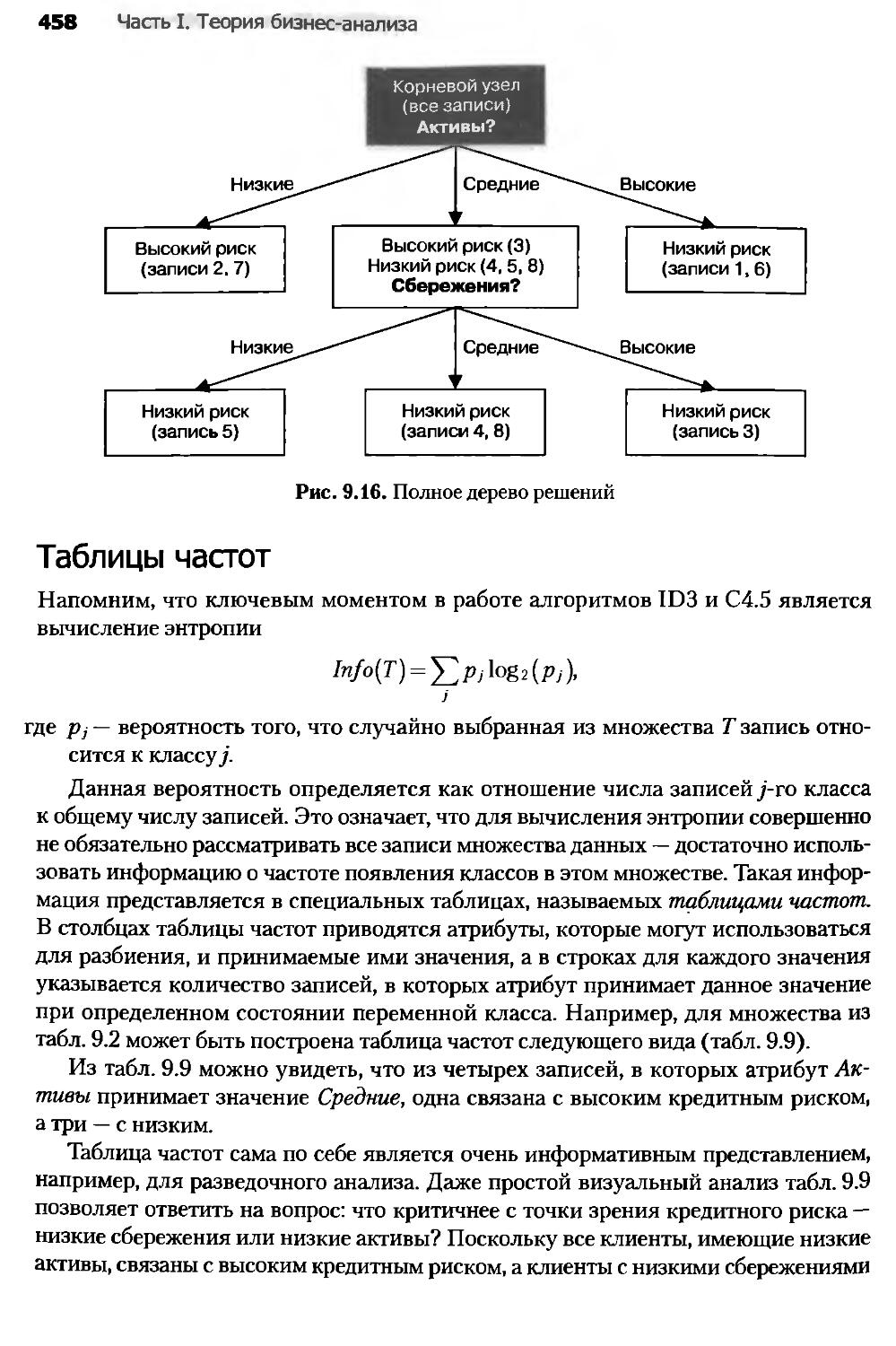
9.4. Алгоритм CART......................................................459
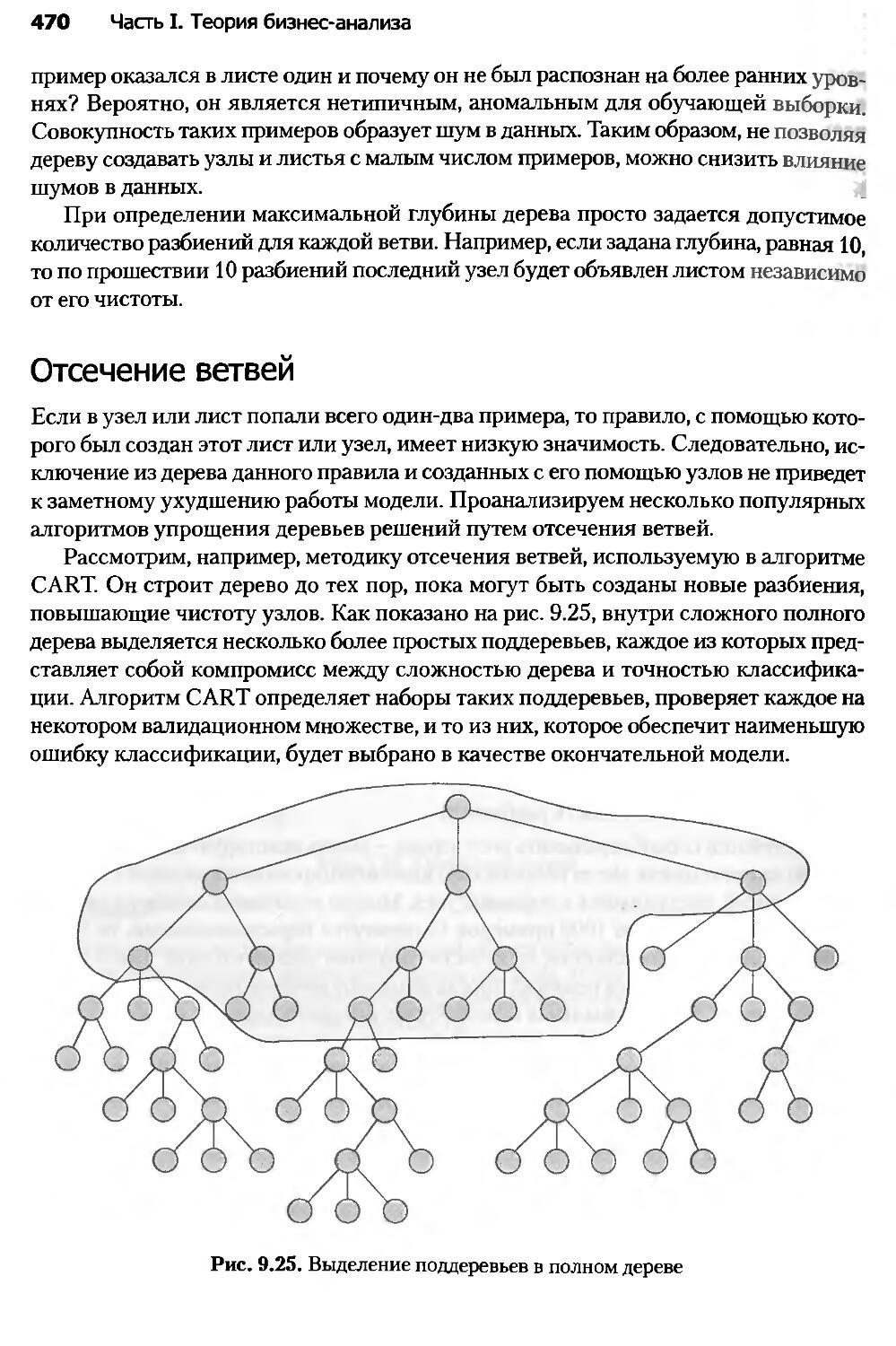
9.5. Упрощение деревьев решений.........................................465
9.6. Введение в нейронные сети..........................................472
9.7. Искусственный нейрон...............................................478
9.8. Принципы построения нейронных сетей................................484
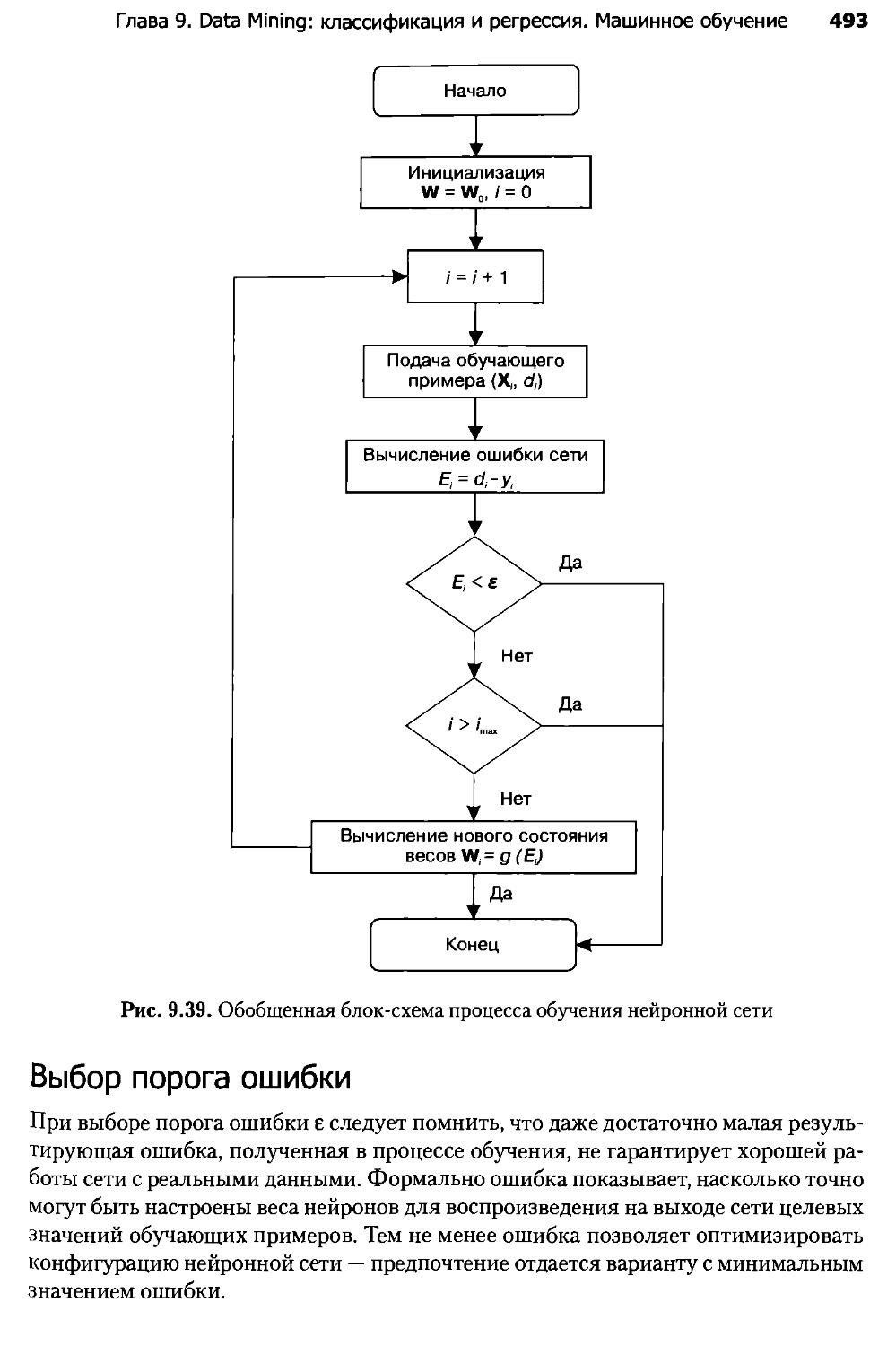
9.9. Процесс обучения нейронной сети....................................490
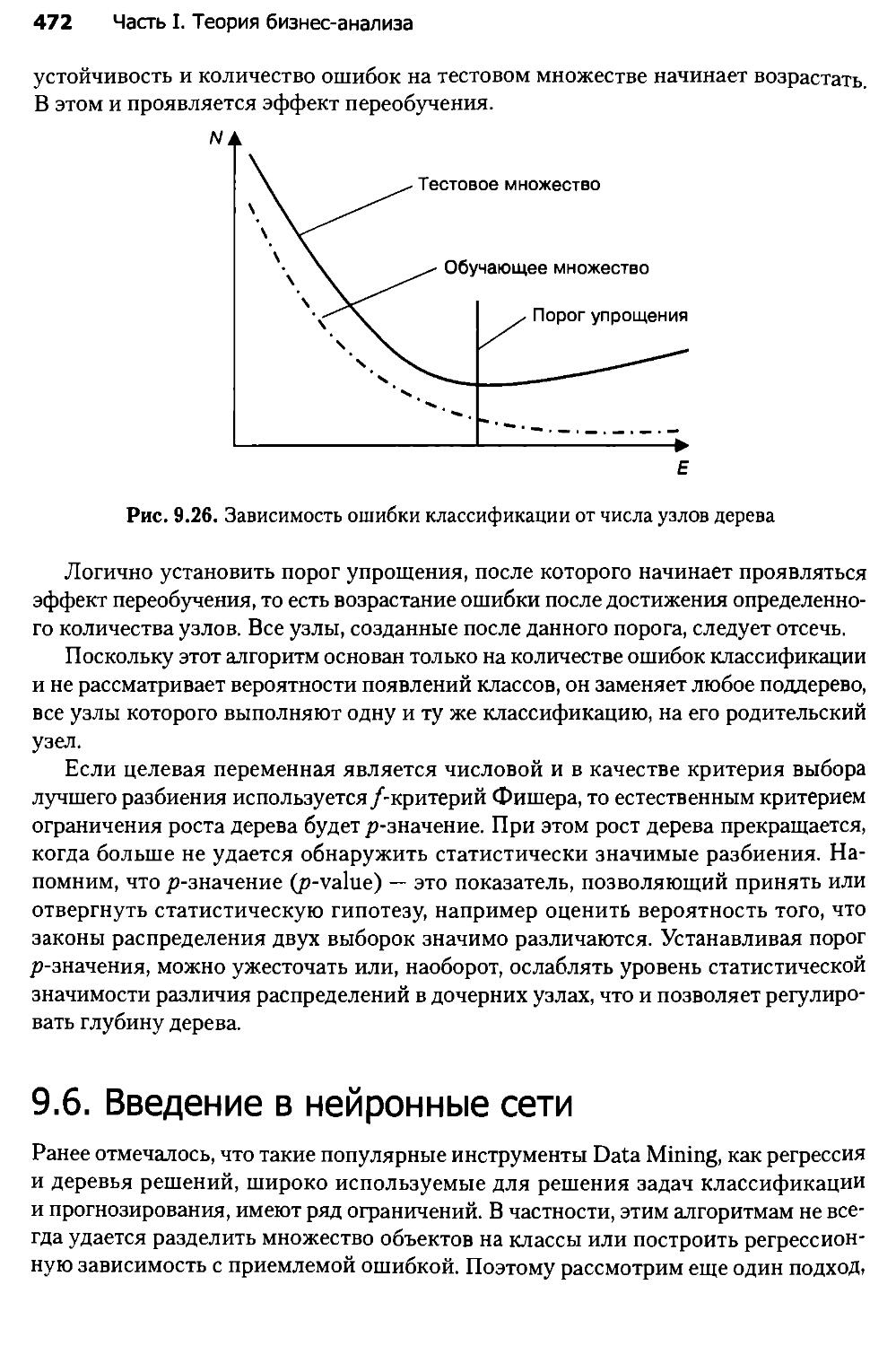
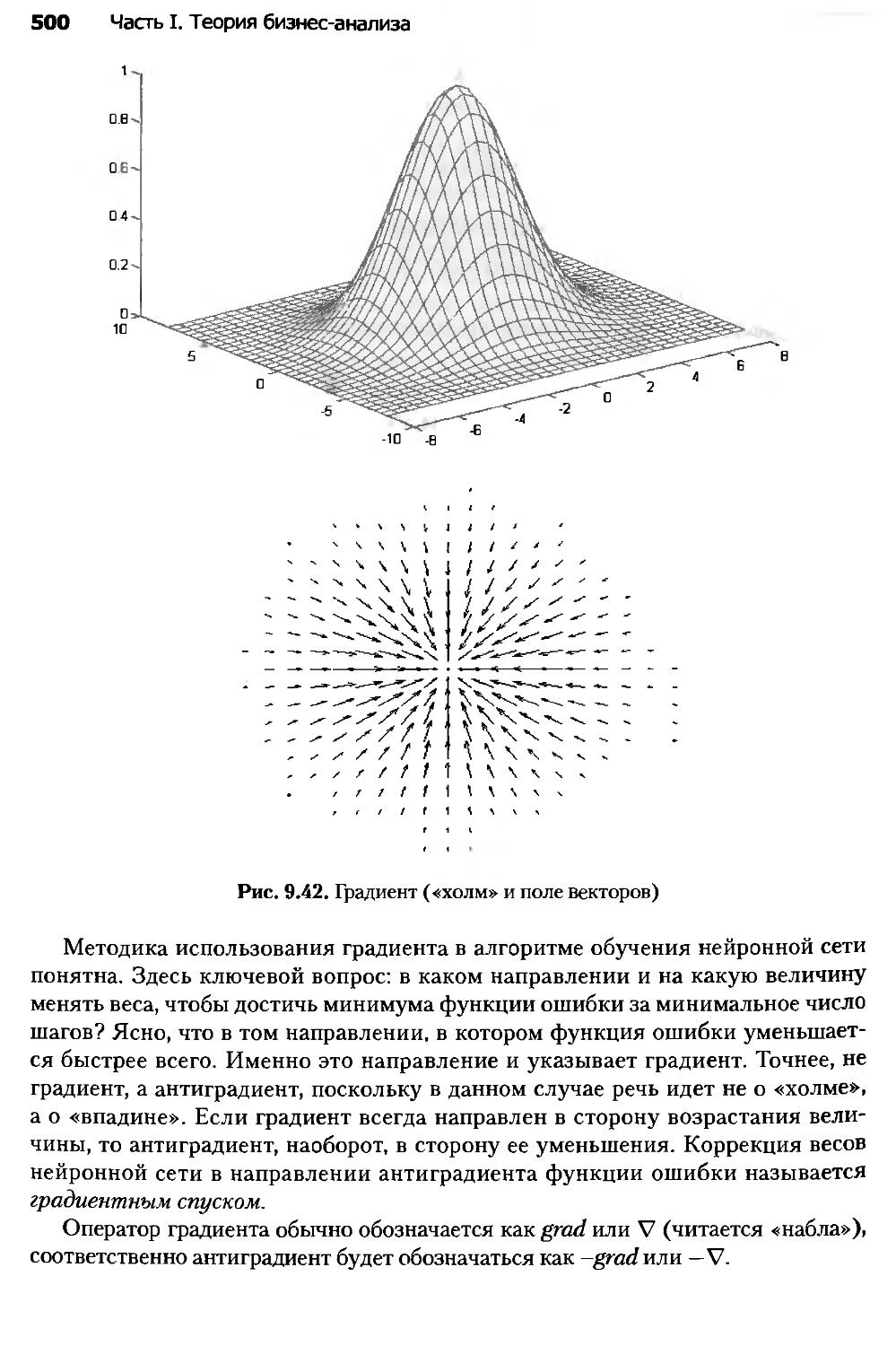
9.10. Алгоритмы обучения нейронных сетей................................498
9.11. Алгоритм обратного распространения ошибки.........................507
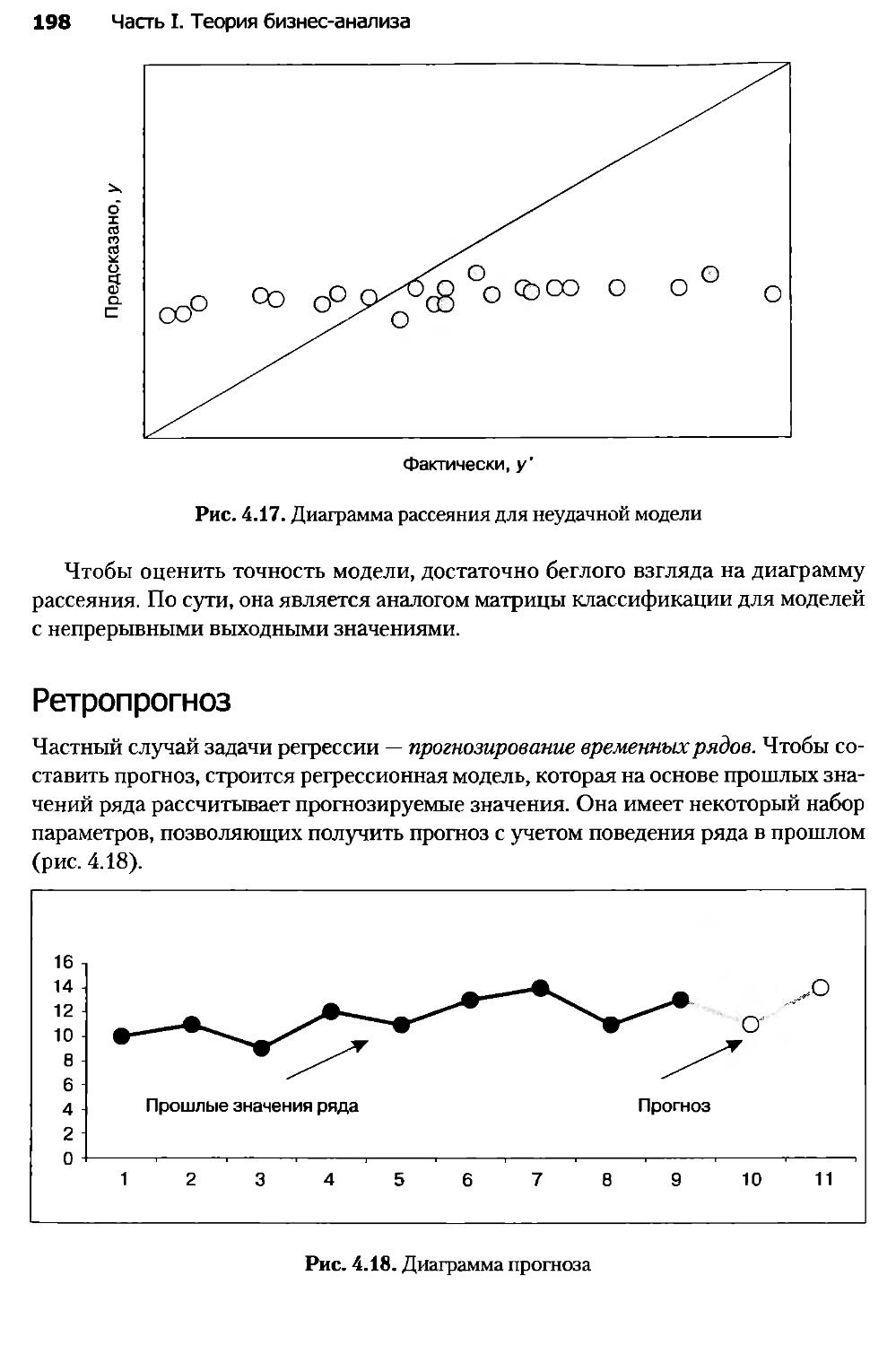
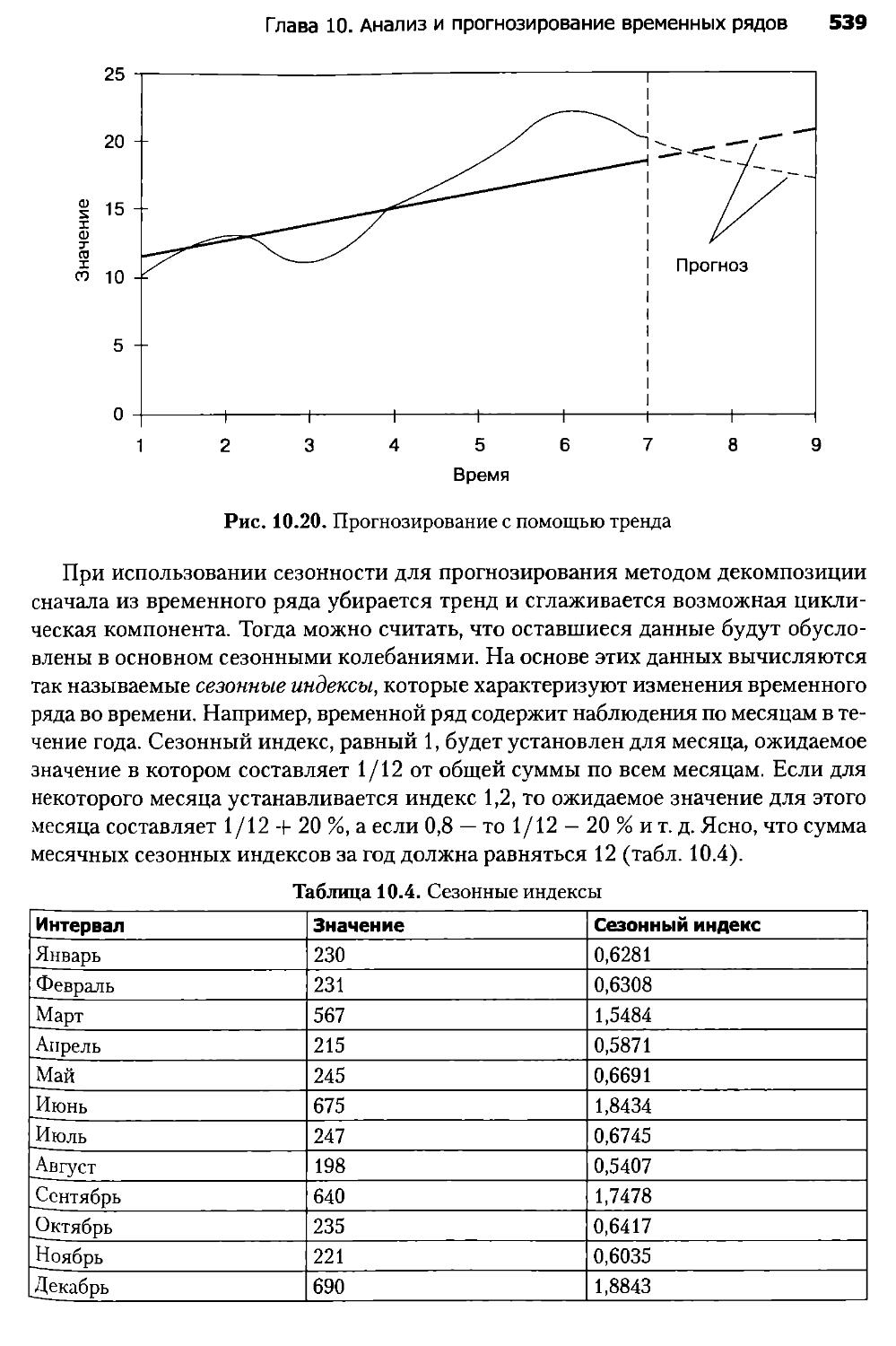
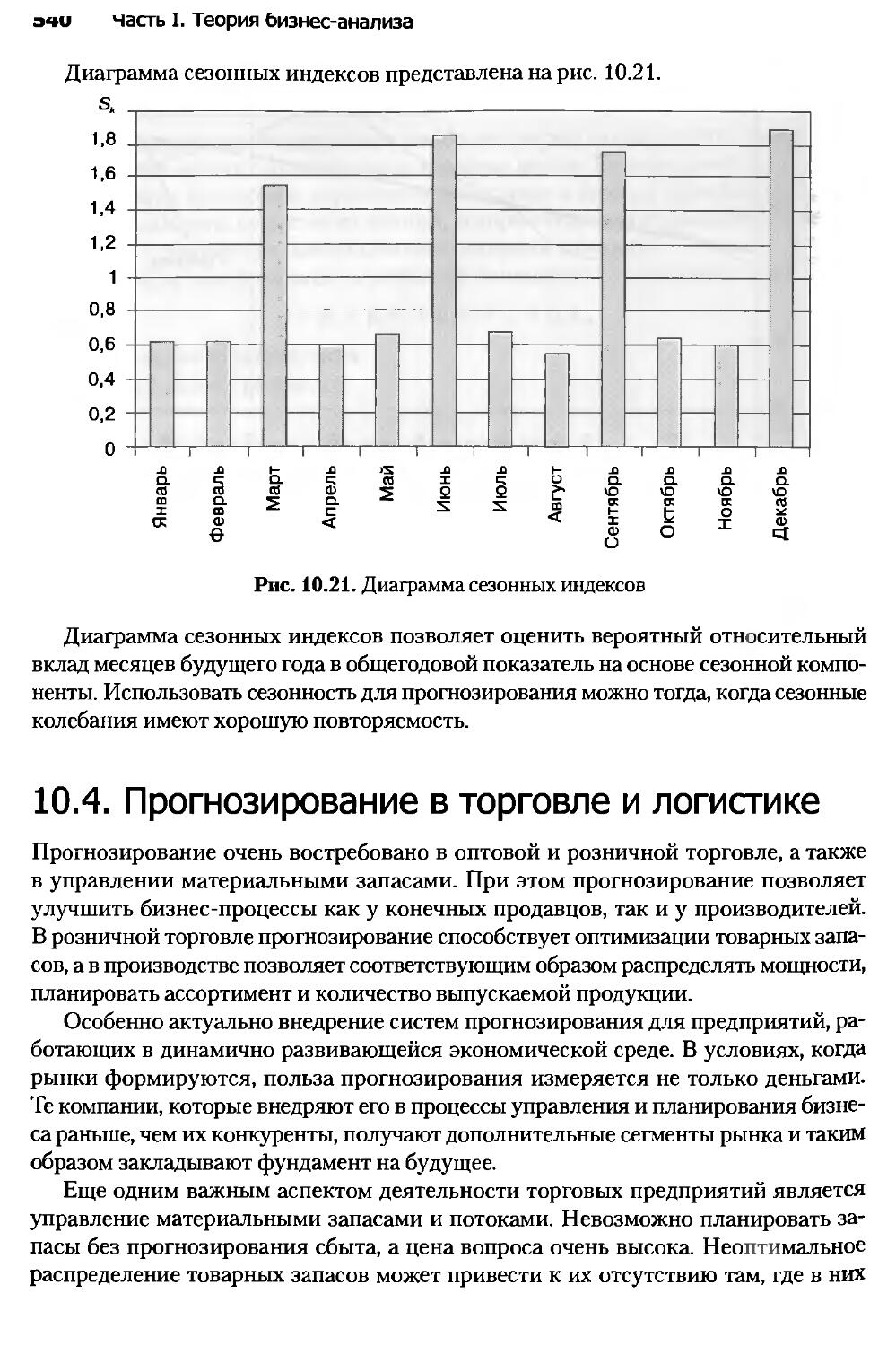
Глава 10. Анализ и прогнозирование временных рядов......................514
10.1. Введение в прогнозирование........................................514
10.2. Временной ряд и его компоненты....................................516
10.3. Модели прогнозирования............................................532
10.4. Прогнозирование в торговле и логистике............................540
Оглавление 7
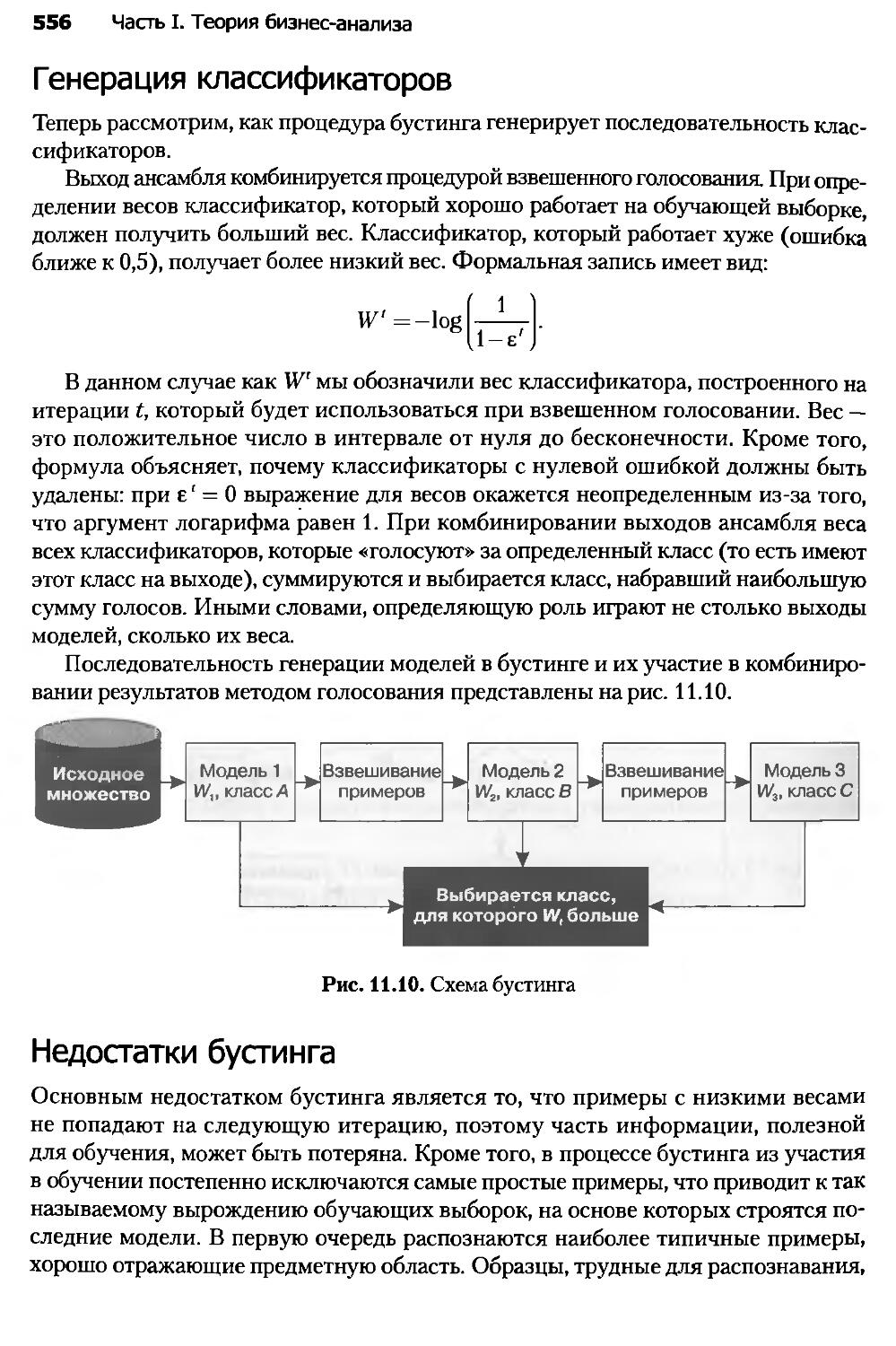
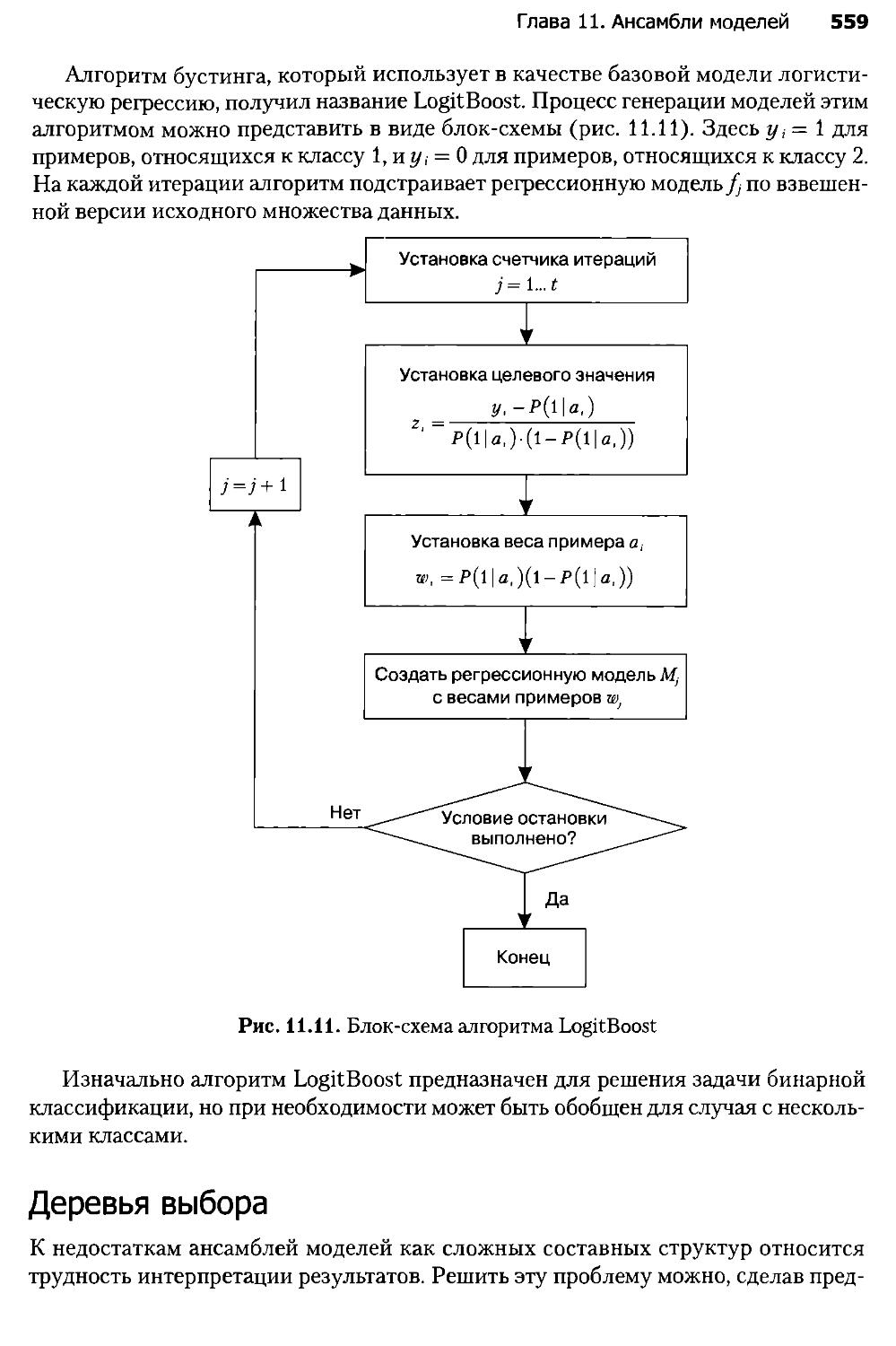
Глава 11. Ансамбли моделей........................................543
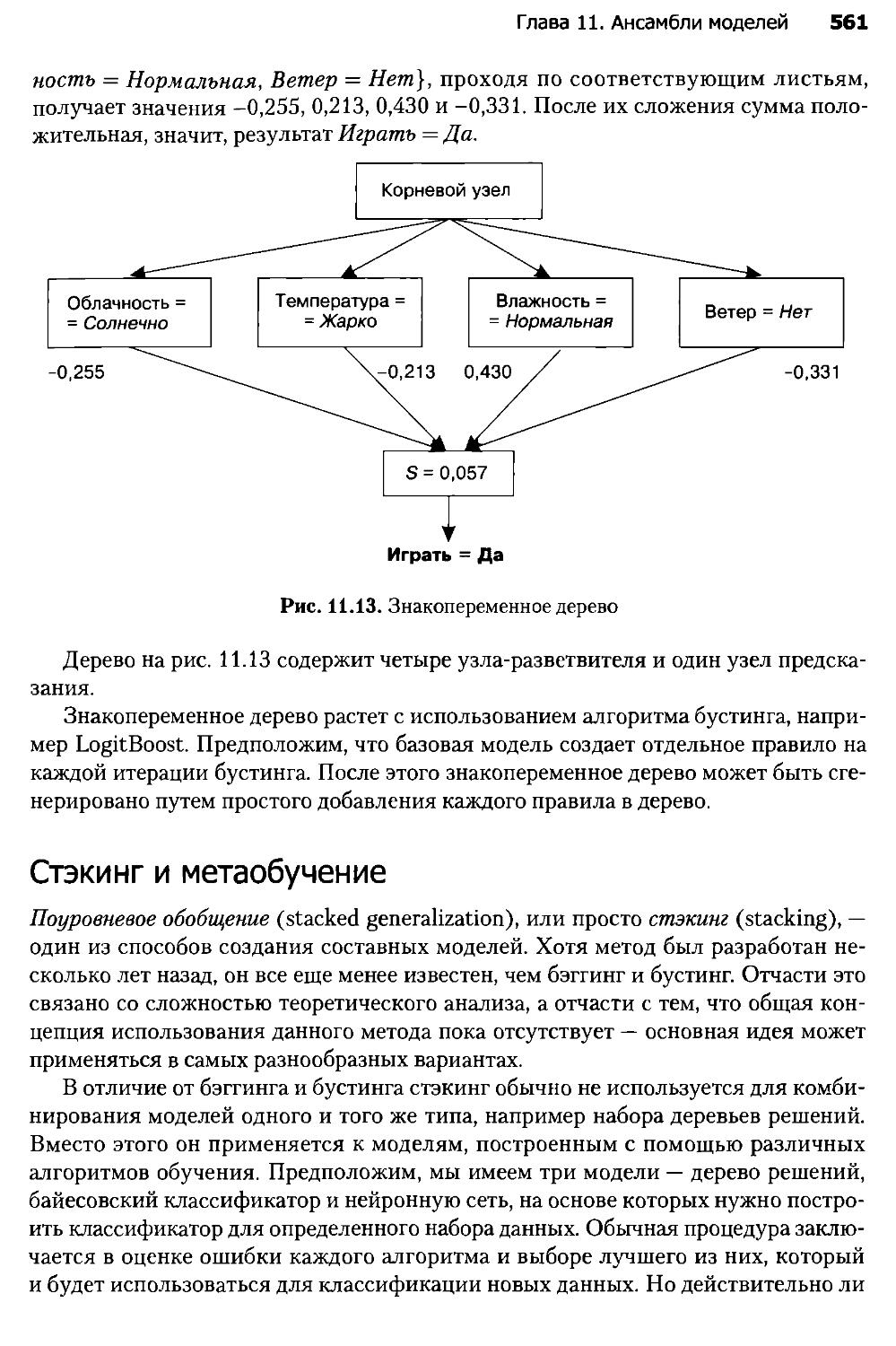
11.1. Введение в ансамбли моделей.................................543
11.2. Бэггинг.....................................................548
11.3. Бустинг.....................................................553
11.4. Альтернативные методы построения ансамблей..................557
Глава 12. Сравнение моделей.......................................563
12.1. Оценка эффективности и сравнение моделей....................563
12.2. Оценка ошибки модели........................................567
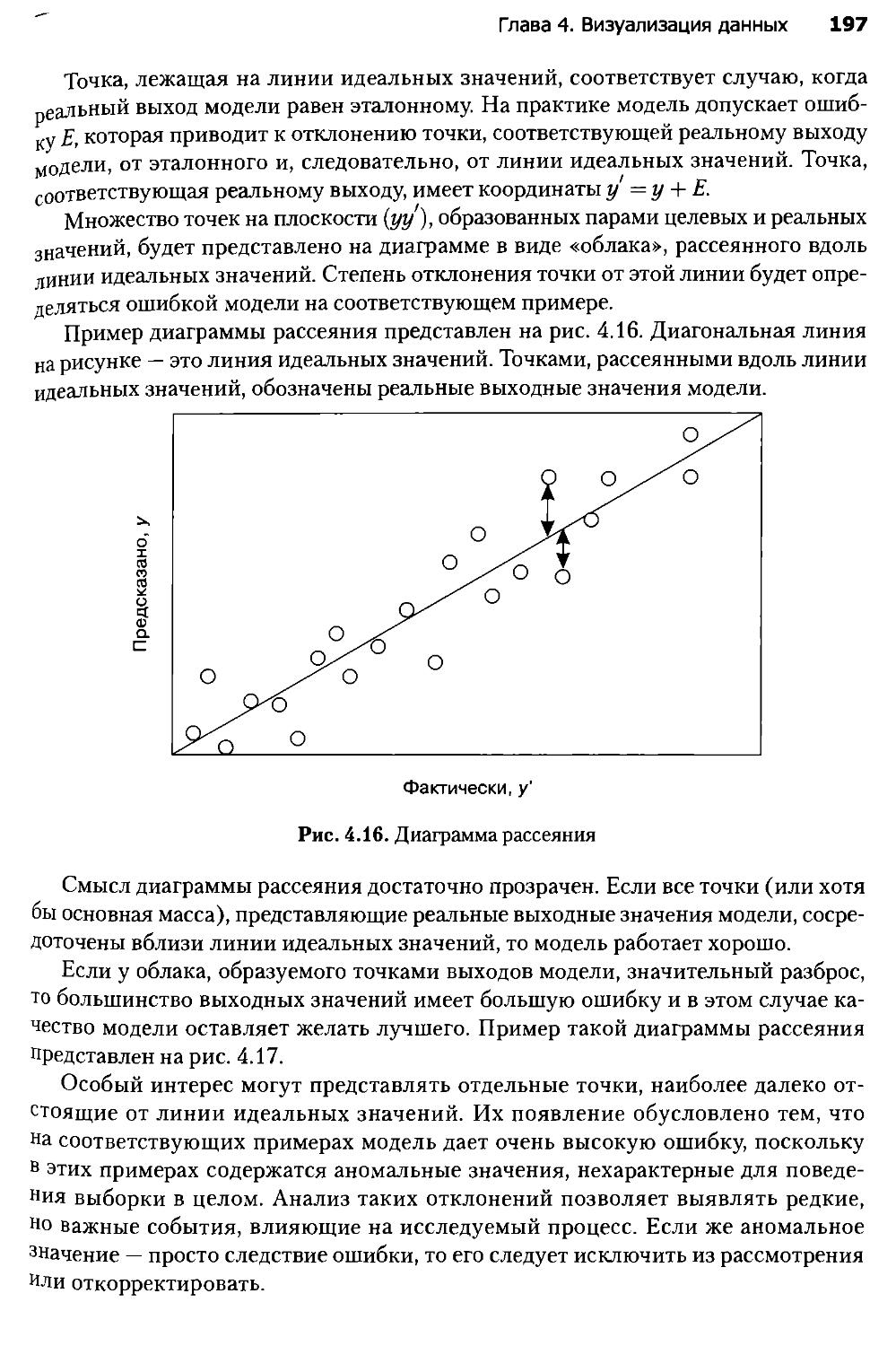
12.3. Издержки ошибочной классификации............................572
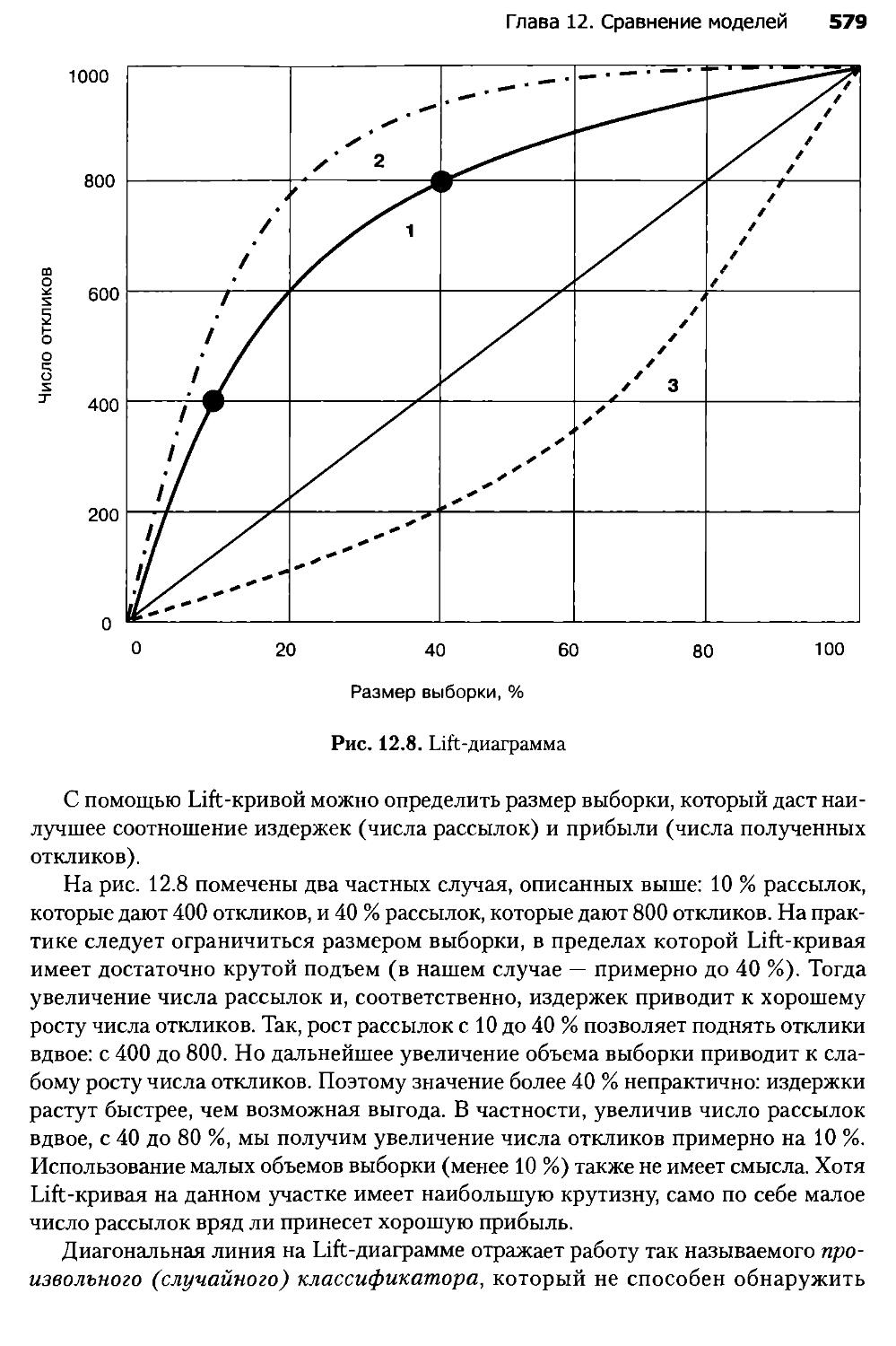
12.4. Lift- и Profit-кривые.......................................576
12.5. ROC-анализ..................................................586
12.6. Обучение в условиях несбалансированности классов............593
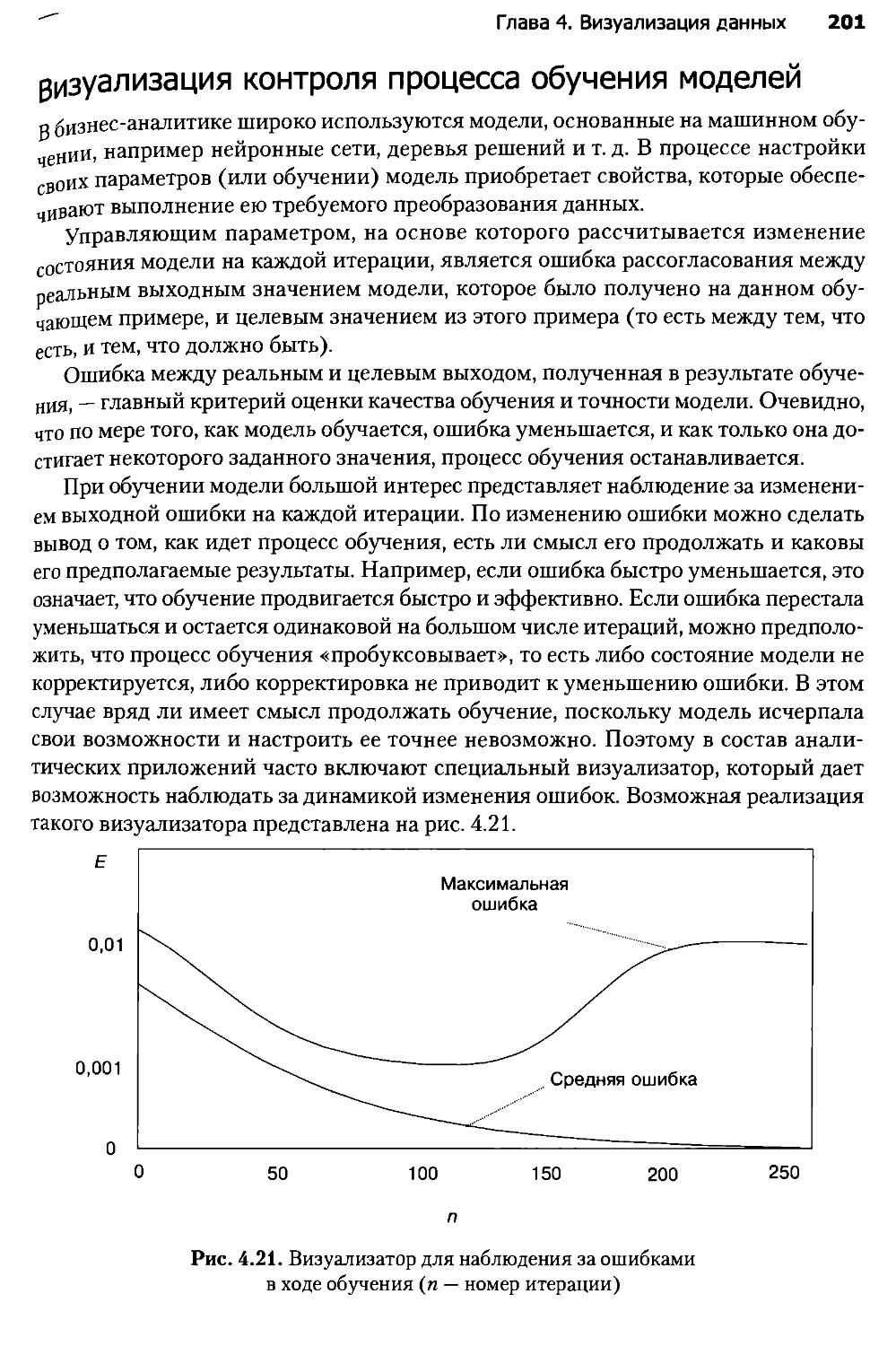
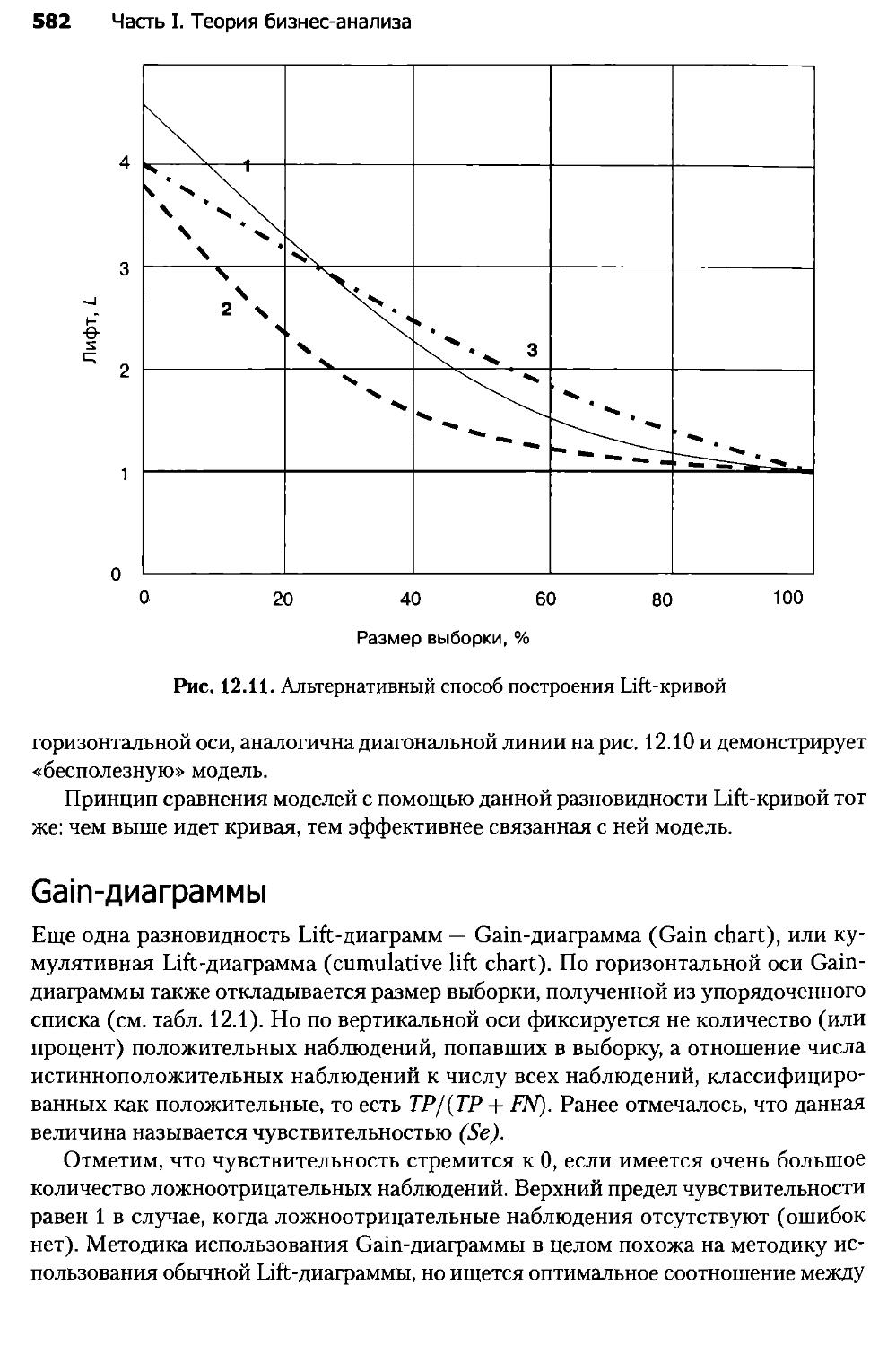
ЧАСТЬ II. БИЗНЕС-АНАЛИЗ В DEDUCTOR
Глава 13. Аналитическая платформа Deductor........................600
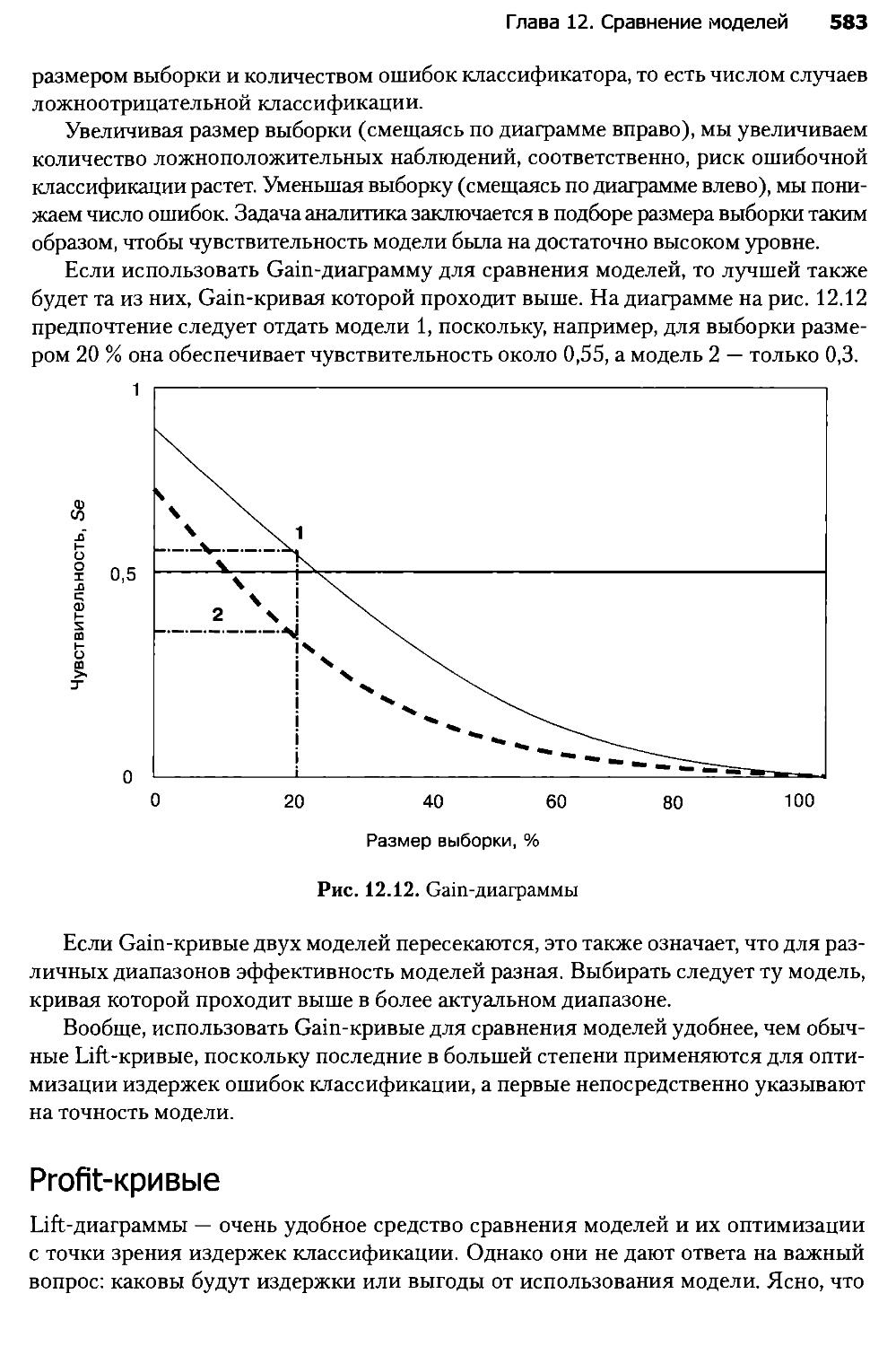
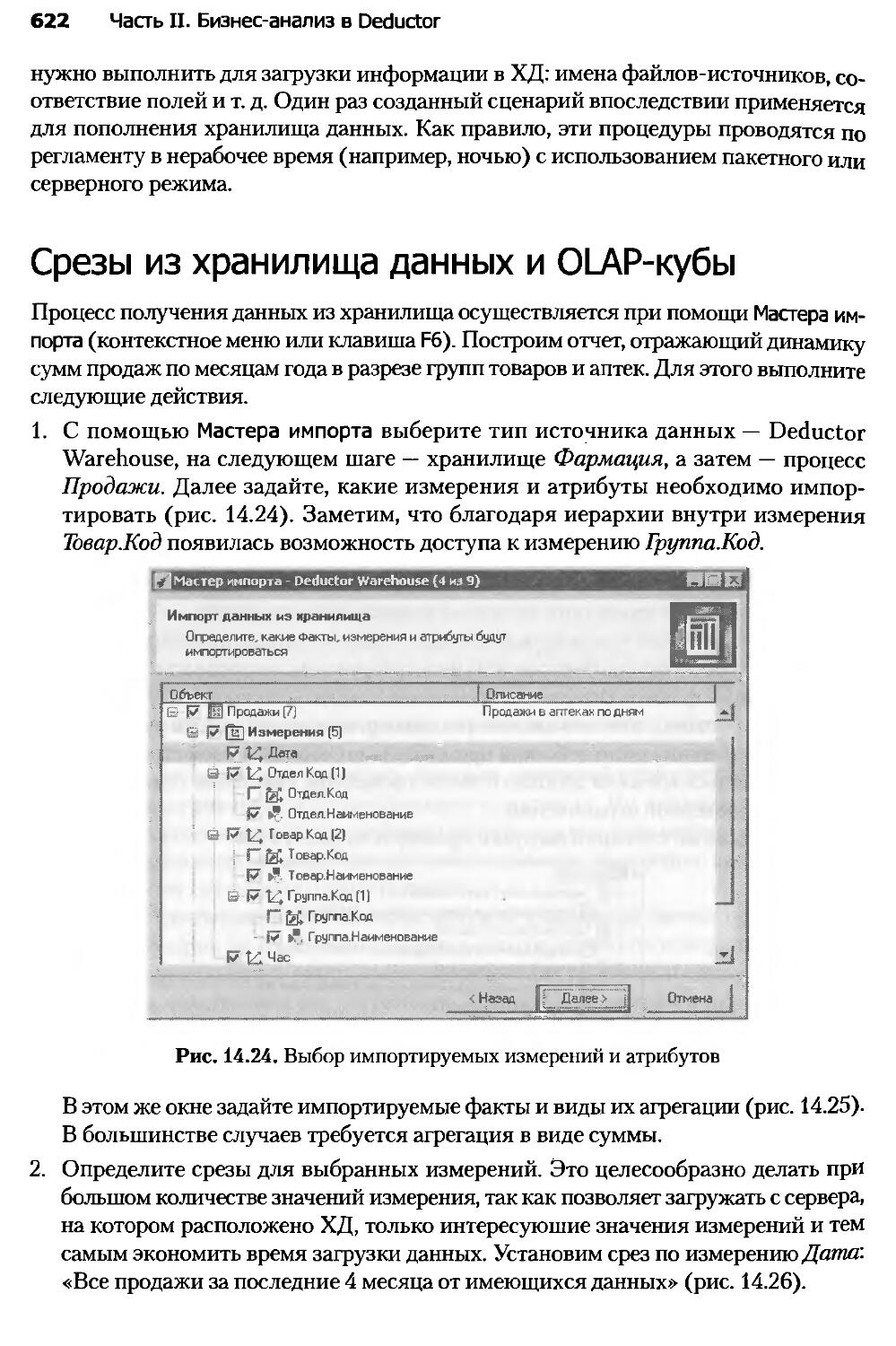
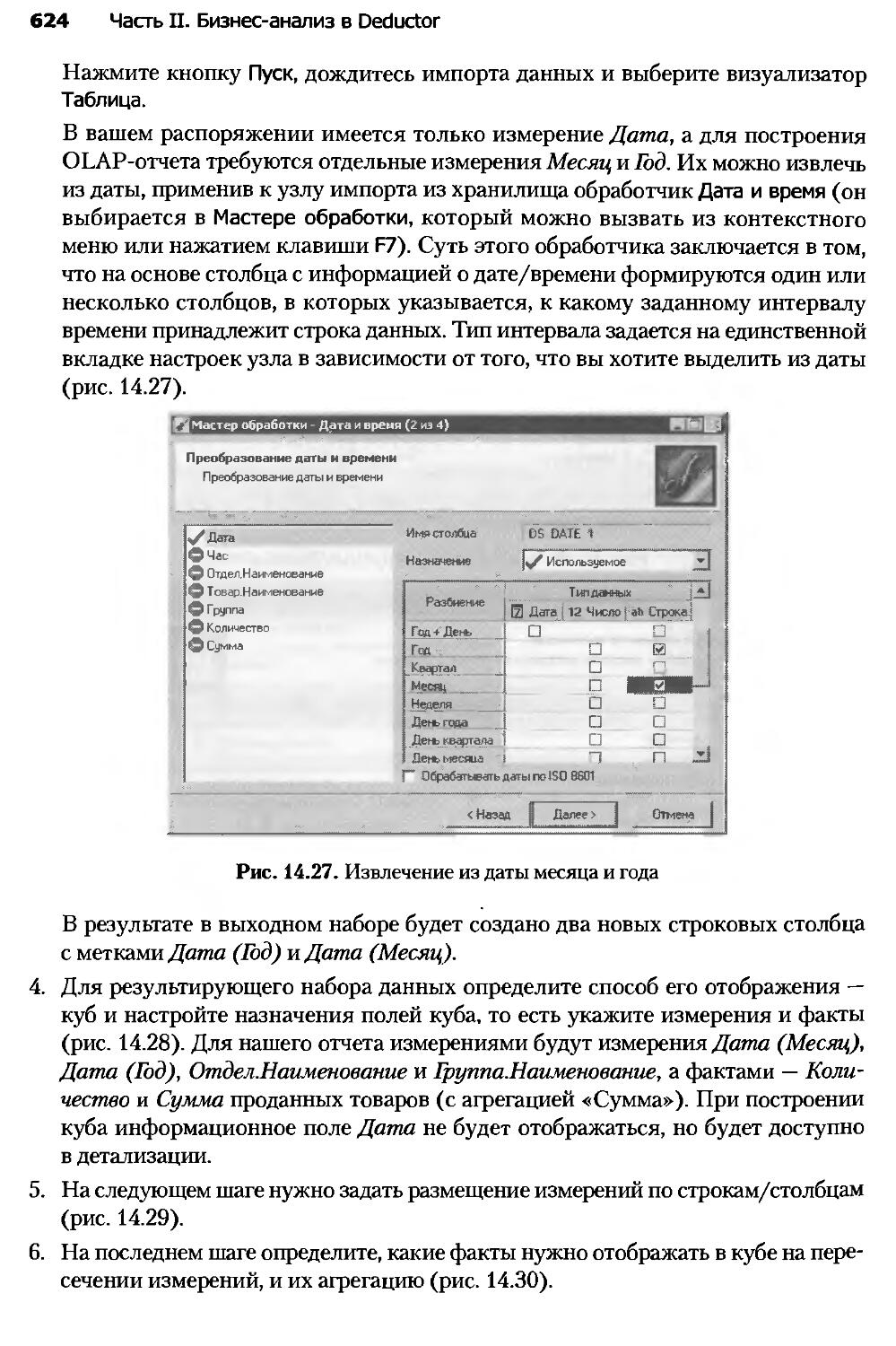
Глава 14. Консолидация данных и аналитическая отчетность
аптечной сети.....................................................606
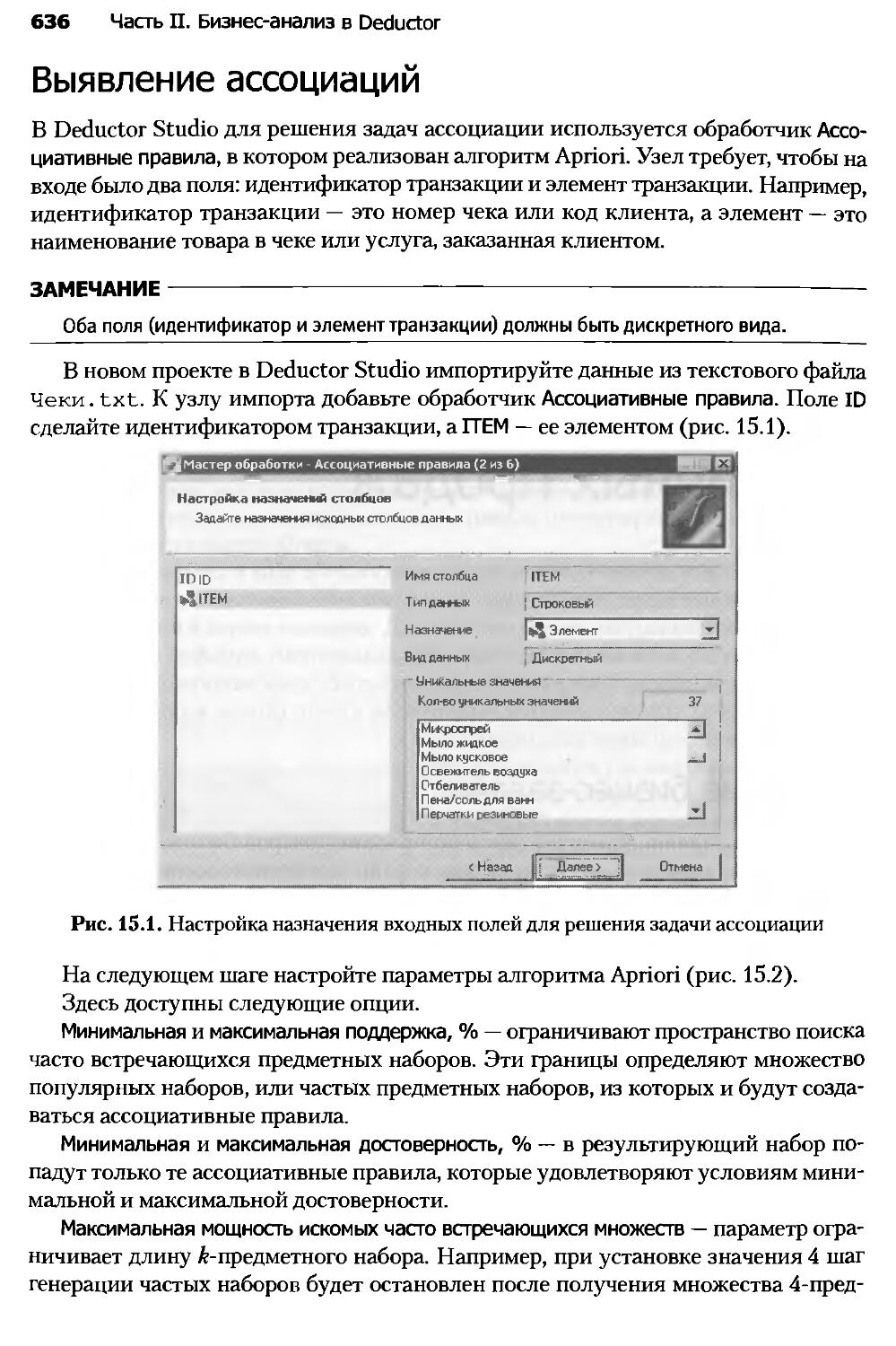
Глава 15. Ассоциативные правила в стимулировании
розничных продаж..................................................635
Глава 16. Сегментация клиентов телекоммуникационной компании......643
Глава 17. Скоринговые модели для оценки кредитоспособности
заемщиков.........................................................657
Глава 18. Прогнозирование продаж товаров в оптовой компании.......676
Глава 19. Повышение эффективности массовой рассылки клиентам......682
Заключение........................................................689
Литература........................................................690
Алфавитный указатель..............................................693
Предисловие авторов
Книга, которую вы держите в руках, в какой-то степени уникальна. Во-первых, ей
присущи системность и глубина изложения материала, чего так не хватает россий-
ским изданиям по бизнес-аналитике (да и самих книг, к сожалению, единицы). Во-
вторых, материал рассчитан не на разработчиков информационно-аналитических
систем (проще говоря, программистов), а на тех, кто этими системами пользует-
ся, — аналитиков. В-третьих, большинство рассмотренных технологий анализа
данных можно проверить в действии на примере решения актуальных бизнес-задач
(создание хранилищ данных, OLAP, скоринг, оптимизация массовой рассылки
и др.) на аналитической платформе Deductor Academic.
Несмотря на то что у книги два автора, за этим проектом стоит много талантли-
вых людей, и в первую очередь — коллектив российской компании BaseGroup Labs,
разработчика аналитической платформы Deductor. На протяжении многих лет ком-
пания целенаправленно занимается анализом данных, и сегодня ощутимы резуль-
таты этой кропотливой работы — десятки выполненных проектов, более 90 вузов-
партнеров, образовательный портал с e-learning-курсами по бизнес-аналитике,
накопленный опыт решения разнообразных бизнес-аналитических задач.
Книга в целом ориентирована на широкий круг читателей — от 1Т-специа-
листов до экономистов и медиков — то есть на всех желающих познакомиться
с современными технологиями анализа данных. Однако в значительной мере мы
ее писали для аналитиков, которые хотят, чтобы накопленные в компании данные
превратились в знания, а не лежали мертвым грузом.
Как учебное пособие книга в первую очередь предназначена для студентов на-
правлений и специальностей «Прикладная информатика», «Бизнес-информатика»,
а также других родственных направлений.
Области, которые затрагивает современная бизнес-аналитика, многочисленны.
Это математика, информатика, базы данных, статистика, методы визуализации
и многие другие. При написании глав, относящихся к теории бизнес-анализа, нам
часто приходилось искать баланс между полнотой и простотой изложения. Исполь-
зование Data Mining требует осторожности, поскольку некорректное применение
его методов и технологий, вызванное недостаточными знаниями и квалифика-
цией, может привести к ложным выводам и неправильно принятым на их основе
решениям. Поэтому профессиональный аналитик должен хорошо владеть этими
технологиями. Именно по этим причинам значительное внимание в книге уделено
вопросам сбора и консолидации, преобразования и очистки данных, алгоритмам,
а также методическим моментам процесса анализа — выдвижению гипотез, сбору
информации, типам и видам данных. Очень ценным мы считаем материал глав 11
и 12, так как вопросы сравнения моделей и их ансамблей в русскоязычных источ-
Предисловие авторов 9
никах освещены скудно, и мы искренне надеемся, что он будет полезен не только
начинающим, но и опытным бизнес-аналитикам.
Сюжеты некоторых из приведенных в учебном пособии примеров позаимствова-
ны из двух замечательных книг — Data Mining Methods and Models (2006) и Discovering
Knowledge in Data (2005) американского профессора Daniel T. Larose.
Интерес, проявленный к первому изданию настоящей книги (2009 г.), подвиг-
нул нас на подготовку второго. В текст были внесены изменения, направленные
на уточнение и углубление некоторых понятий и определений; исправлены обна-
руженные, в том числе с помощью читательских отзывов, опечатки, неточности
и ошибки. В книгу добавлены новые материалы по нечетким срезам, последова-
тельным шаблонам, байесовскому классификатору, кривым «точность — полнота»,
обучению в условиях несбалансированности классов. Как и в первом издании,
мы не ставили цель охватить все существующие в бизнес-аналитике алгоритмы
и методы, но то, что предлагается для изучения, рассказывается подробно и почти
всегда поясняется при помощи расчетного примера. Существенной переработке
подверглись глава 8 и материал о визуализации связей в главе 4. Кроме того,
в части II практическим примерам уделено больше внимания по сравнению с пре-
дыдущим изданием.
Общая концепция книги, введение, заключение, глава 1, разделы 2.8, 7.1, 7.5,
10.4 и все главы части II подготовлены Н. Паклиным; главы 2, 3,5,6,9-11 и разде-
лы 7.2-7.4,12.1-12.5 написаны В. Орешковым; главы 4,8 и раздел 12.6 представля-
ют собой итог совместного труда авторов. В разделе 8.8 использовались материалы,
предоставленные А. Сениным — сотрудником BaseGroup Labs.
Содержание многих глав пособия опробовано Н. Паклиным при чтении курсов
«Проектирование информационно-аналитических систем» и «Интеллектуальные
информационные системы» в Рязанском филиале Московского государственного
университета экономики, статистики и информатики.
Хочется выразить огромную благодарность: А. И. Арустамову — директору
и главному вдохновителю компании BaseGroup Labs; всем преподавателям вузов-
партнеров, активно использующих Deductor в учебном процессе; рецензентам
пособия — профессору Э. А. Бабкину и профессору О. А. Косорукову за ценные
замечания и рекомендации, которые были учтены авторами. Также выражаем
искреннюю признательность профессору МИРЭА Л. С. Болотовой за внимание
к нашей книге.
С авторами можно связаться по адресу edu@basegroup.ru. Ждем ваших пред-
ложений и замечаний.
Об авторах
Николай Паклин
Окончил Ижевский государственный технический университет по специаль-
ности «Информационные системы и технологии», в 2004 г. защитил диссертацию
на соискание ученой степени кандидата технических наук. С 2005 г. — сотрудник
компании BaseGroup Labs, в которой занимается внедрением информационно-
аналитических систем и разработкой корпоративных учебных курсов по бизнес-
аналитике. Опыт преподавательской деятельности более 5 лет. Область научных и
практических интересов связана с алгоритмами машинного обучения, Data Mining
и корпоративными информационно-аналитическими системами.
Вячеслав Орешков
Окончил Рязанскую государственную радиотехническую академию по специ-
альности «Радиоэлектронные системы и комплексы». В настоящее время — науч-
ный сотрудник кафедры радиоуправления и связи Рязанского государственного
радиотехнического университета. Сфера научных интересов — Data Mining, анализ
данных, цифровая обработка сигналов и изображений в системах телекоммуника-
ций. С 2002 г. сотрудничает с BaseGroup Labs в качестве технического писателя.
От издательства
Ваши замечания, предложения и вопросы отправляйте по адресу электронной
почты salnikova@msk.piter.com (издательство «Питер», редакция специальной ли-
тературы).
Мы будем рады узнать ваше мнение!
На сайте издательства http://www.piter.com вы найдете подробную информацию
о наших книгах.
Вступительное слово
Известно, что современное общество вступило в новый этап своего развития,
называемый информационным или постиндустриальным. Под этим обычно пони-
мается, что знания и информация стали главной движущей и производительной
общественной силой, определяющей как духовное, так и материальное состояние
личности, компании, государства в целом. От умения производить, искать, ана-
лизировать, классифицировать, обобщать, распознавать, перерабатывать, пред-
ставлять информацию и принимать решения сегодня напрямую зависят качество
жизни человека и общества, их информационная и общественная безопасность. Все
перечисленные процессы относятся к числу духовных, или идеальных. Примени-
тельно к ним справедлива прямая зависимость между уровнем духовного развития
человека, его способностями к творчеству и объемами информации, которые он
может усваивать и перерабатывать. Отсюда становится видимой стратегическая
направленность эволюции человечества в целом. Ее можно охарактеризовать как
тенденцию перехода от материального общества к духовному.
Вторая тенденция тоже проступает достаточно явно и состоит в том, что след-
ствием перехода к информационному обществу является его структурная и мате-
риальная трансформация: исчезают информационные барьеры между государст-
вами, корпорациями, языками. Глобализация — естественное следствие развития
информационного общества.
Это предъявляет новые требования к человеку, к уровню его подготовки, к его
информационной культуре. Если еще 10-15 лет назад под информационной куль-
турой личности, общества, корпорации и т. д. понималась просто компьютерная
грамотность (владение навыками работы с компьютером), то сегодня — владение
методами и технологиями работы с данными и знаниями, с базами данных и зна-
ний. Умение работать с информацией становится главным условием при приеме
на работу, при определении перспективного роста личности и компании.
Современное общество характеризуется еще одной важной деталью: оно по-
дошло к порогу, когда одновременно сконцентрировались огромные массивы
информации (в корпорациях, в государственных департаментах, в службах соци-
ального обеспечения и т. д.) в виде баз данных; значительно возросли мощности
вычислительной техники, систем и средств связи и передачи данных; Интернет
стал всеобщим единым хранилищем данных и знаний для человечества; четко
сформировалась потребность в новых возможностях взаимодействия с данными
и со средствами их обработки. Наконец, явственно сформировался социальный
заказ на достаточно полные и доступные отечественные издания, посвященные
информационно-аналитической обработке больших объемов данных, и на соответ-
ствующие программные средства. Выяснилось, например, что сведения о методах
Вступительное слово
13
и технологиях хранилищ данных и об интеллектуальном анализе данных содержат-
ся в основном в научных изданиях, в том числе в рамках тематики искусственного
интеллекта; практически отсутствуют издания, пригодные в качестве учебников
и учебных пособий для вузов.
Выход в свет такого полного и подробного издания, как «Бизнес-аналитика: от
данных к знаниям» в 2009 г., на мой взгляд, стал событием. Предлагаемое внима-
нию читателей второе издание, исправленное и дополненное новыми материалами
и примерами, является вполне логичным и необходимым.
Учебное пособие может быть использовано в первую очередь студентами и ас-
пирантами, обучающимися по специальностям, связанным с информационными
технологиями. Конечно, дисциплина под названием «Бизнес-аналитика» не входит
в вузовские учебные программы. Но многие вопросы, рассматриваемые в книге,
так или иначе включены в курсы по системам поддержки принятия решений,
искусственному интеллекту, интеллектуальным информационным технологиям.
Поэтому преподавателям будет несложно адаптировать материал пособия к чи-
таемым курсам.
Ориентация авторов на мировой уровень исследований в области бизнес-ана-
литики привела к тому, что в книге содержится довольно много англоязычных тер-
минов и аббревиатур наподобие Data Warehousing, Knowledge Discovery in Databases
и Data Mining, к которым российские читатели еще не привыкли. Да и в качестве
дополнительной литературы предлагаются в основном учебники на английском
языке. Это является определенным недостатком, хотя авторы старались сделать
пособие самодостаточным. Но достоинств у книги во много раз больше. Она
способствует формированию у читателя четкого представления о месте и роли
информационно-аналитических технологий (а также программных аналитических
платформ на их основе) в решении актуальных управленческих задач, изучению
сложившейся в этой области терминологии, освоению системных научных подхо-
дов к подготовке и анализу больших массивов данных. Важно, что присутствует
практическая часть, где на базе аналитической платформы Deductor показываются
бизнес-кейсы из различных прикладных областей: это ведет к усвоению получен-
ных теоретических знаний.
Современному бизнесу не обойтись без информационно-аналитической под-
держки, решения задач прогнозирования, управления рисками и пр. Помимо
программного обеспечения, нужны специалисты, которые будут внедрять анали-
тические проекты. Данное учебное пособие, безусловно, вносит вклад в решение
этих задач.
Л. С. Болотова,
доктор технических наук,
профессор Московского института
радиотехники, электроники и автоматики
Введение
Современная бизнес-аналитика
Еще несколько лет назад рынок корпоративных аналитических систем в России был
настолько мал, что вопросы и проблемы бизнес-аналитики обсуждались в узком
кругу профессионалов, а к запуску аналитических проектов относились с большим
недоверием.
Однако с тех пор, как компании получили возможность собирать и хранить
значительные объемы информации, ситуация коренным образом изменилась:
в стране начался экспоненциальный рост рынка систем бизнес-аналитики. Это-
му немало способствовали снижение сложности и стоимости внедрения таких
систем и примеры успешных решений в области корпоративных аналитических
систем.
Первыми возможности бизнес-аналитики оценили банки, а также страховые,
телекоммуникационные и торговые компании. Они научились извлекать полезные
знания и выгоду из огромного количества информации, собранной и хранящейся
в корпоративных базах данных. Сегодня очевидно, что без анализа данных в усло-
виях конкурентной борьбы не обойтись.
Что же скрывается за термином «бизнес-аналитика» (Business Intelligence)?
У него нет единого определения, слишком большой спектр технологий он включает
в себя. Можно признать удачным и емким определение авторитетной консалтинго-
вой компании IDC (http://idc.com/): бизнес-аналитика — это «инструменты и прило-
жения для поиска, анализа, моделирования и доставки информации, необходимой
для принятия решений». Бизнес-аналитика — мультидисциплинарная область,
находящаяся на стыке информационных технологий, баз данных, алгоритмов
интеллектуальной обработки информации, математической статистики и методов
визуализации.
Решения принимаются руководителями, и задача бизнес-аналитики — сделать
все, чтобы эти решения были оптимальными и своевременными. За готовыми
отчетами, которые, кстати, могут содержать не только цифры в различных разре-
зах, но и правила, зависимости, тенденции, прогнозы (то есть знания), скрывается
нелегкий труд бизнес-аналитика.
Эта книга адресована в первую очередь будущим бизнес-аналитикам, стремя-
щимся освоить современные технологии анализа данных или углубить имеющиеся
Введение 15
знания. Вам дается уникальная возможность не только изучить теоретические
аспекты хранилищ данных, их очистки и предобработки, Data Mining и др.,
но и приобрести навыки решения актуальных бизнес-задач на аналитической
платформе Deductor, которую уже свыше 90 вузов России, Беларуси и Украины
официально используют в учебном процессе для преподавания курсов по анализу
данных (разработчик — компания BaseGroup Labs). Книга, несомненно, будет также
интересна IT-специалистам, планирующим внедрение систем бизнес-аналитики
в компаниях и желающим поближе познакомиться с возможностями корпоратив-
ных информационно-аналитических систем.
Книга состоит из двух частей — теоретической и практической. Важно отметить,
что теория не привязана к конкретным программным продуктам, а значит, является
универсальной.
Путь от сырых данных к знаниям в бизнес-анализе довольно длинный. Поэтому
теоретическая часть книги — «Теория бизнес-анализа» — разбита на главы, каждая
из которых посвящена какой-либо одной задаче.
Первая глава «Технологии анализа данных» является вводной. В ней излага-
ются базовые сведения о принципах анализа, подготовке информации, струк-
турированных данных и технологиях Knowledge Discovery in Databases и Data
Mining.
Данные нередко хранятся в разрозненных источниках, поэтому могут иметь
различные форматы и типы. Решение задачи сбора информации, пригодной для
анализа в едином источнике, при помощи технологии многомерных и реляционных
хранилищ данных изложено в главе «Консолидация данных».
Для решения аналитических задач собранную воедино информацию часто
требуется группировать, фильтровать, кодировать и преобразовывать в опреде-
ленный вид при помощи специальных техник, о которых рассказывается в главе
«Трансформация данных».
Нерегламентированные запросы и аналитическая OLAP-отчетность — неотъ-
емлемые составляющие любого аналитического проекта по бизнес-анализу. Кроме
того, существует множество способов расширенной визуализации — от графиков
и диаграмм до специализированных визуализаторов — для оценки качества моде-
лей и интерпретации выявленных зависимостей. Все эти вопросы рассматриваются
в главе «Визуализация данных».
В условиях постоянного роста объемов информации критически важным ста-
новится качество данных. Пропуски, дубликаты, противоречия и аномалии — со
всеми этими проблемами необходимо бороться, используя специальные методы
и алгоритмы, чему посвящена глава «Очистка и предобработка данных».
Часто бизнес-аналитика ограничивается решением перечисленных выше задач.
Представленный в понятной форме отчет действительно помогает руководителю
оперативно принять решение. Но с повышением сложности задач одним только
визуальным анализом не обойтись. На помощь приходит прогнозное модели-
рование и извлечение знаний. Этим технологиям в книге уделено значительное
внимание.
16 Введение
В главах 6-9 под общим названием «Data Mining» последовательно изла-
гаются алгоритмы решения основных классов задач Data Mining: ассоциация,
кластеризация, классификация и регрессия. Рассматриваются алгоритмы ма-
шинного обучения и математической статистики, неоднократно показавшие свою
эффективность при решении практических задач в системах бизнес-аналитики:
нейронные сети, деревья решений, линейная, логистическая регрессия и др.
Алгоритмы описываются достаточно подробно: чтобы исключить опасность по-
явления недостоверных выводов и ложных тенденций, аналитик должен хорошо
понимать ограничения каждого метода и природу данных, с которыми работает
тот или иной алгоритм.
Многие процессы отражают динамику: продажи, поставки, заявки, трафик.
Поэтому в бизнес-аналитике важную роль играет прогнозирование, для чего необ-
ходимо владение методами анализа временных рядов. Эти вопросы раскрываются
в главе «Анализ и прогнозирование временных рядов».
Разнообразие алгоритмов Data Mining говорит о том, что не существует одного
универсального метода для решения всех задач. В то же время, если объединить
усилия нескольких методов, можно значительно повысить качество решения
аналитических задач. Поэтому в главе И «Ансамбли моделей» рассматриваются
современные подходы к комбинированию и объединению моделей: бустинг, бэг-
гинг и стэкинг.
Разнообразие алгоритмов порождает проблему выбора лучшей модели на основе
объективных критериев. Этому посвящена глава 12 «Сравнение моделей». В ней
рассматриваются Lift- и Profit-кривые, ROC-анализ и смежные темы. Знание мето-
дов сравнения моделей позволит при необходимости реализовать автоматический
перебор моделей, что важно при конвейерной обработке больших массивов данных
и промышленном прогнозировании.
Стоит сказать, что пособие ориентировано как на профессиональных читателей
и студентов старших курсов, так и на тех, кто только начал интересоваться анализом
данных. Можно следующим образом условно разделить читателей книги на кате-
гории:
□ специалисты в области хранилищ данных, OLAP и ETL — главы 1-5;
□ начинающие аналитики Data Mining — главы 1, 3, 4, 6 (кроме 6.3-6.5), 7, 9
(кроме 9.3, 9.4 и 9.10);
□ специалисты, занимающиеся прогнозированием временных рядов — главы 1,
3, 4,10;
□ профессиональные аналитики Data Mining — главы 1,3-12.
Глава 8 рассчитана на подготовленного читателя и требует присутствия у него
базовых знаний по теории вероятностей и математической статистике. При первом
чтении ее можно пропустить, освоив только тему «Введение в классификацию
и регрессию». Однако ценность всей главы заключается в наличии материала по
логистической регрессии, без знания которой невозможно овладеть технологиями
построения скоринговых карт оценки кредитоспособности, столь востребованными
в банковской бизнес-аналитике.
Введение 17
Те разделы по Data Mining, в которых подробно рассматриваются алгоритмы,
также рассчитаны на читателя, знающего основы вузовского курса высшей мате-
матики, и новичок может их пропустить.
Вторая часть — «Бизнес-анализ в Deductor» — содержит примеры решения за-
дач на базе аналитической платформы Deductor в различных областях: розничной
торговле, банкинге, телекоммуникациях, маркетинге. Эти разделы рекомендуются
для изучения всем читателям вне зависимости от уровня подготовки.
На прилагаемом компакт-диске содержатся дистрибутив Deductor Academic,
демонстрационные файлы с данными для примеров, приводимых в книге, а также
дополнительные материалы.
Часть
Теория
бизнес-анализа
Технологии
анализа данных
1.1. Введение в анализ данных
Методология анализа
Анализ данных — широкое понятие. Сегодня существуют десятки его определений.
В самом общем смысле анализ данных — это исследования, связанные с обсчетом
многомерной системы данных, имеющей множество параметров. В процессе анализа
данных исследователь производит совокупность действий с целью формирования
определенных представлений о характере явления, описываемого этими данными. Как
правило, для анализа данных используются различные математические методы.
Анализ данных нельзя рассматривать только как обработку информации после
ее сбора. Анализ данных — это прежде всего средство проверки гипотез и решения
задач исследователя.
Известное противоречие между ограниченными познавательными способностями
человека и бесконечностью Вселенной заставляет нас использовать модели и модели-
рование, тем самым упрощая изучение интересующих объектов, явлений и систем.
Слово «модель» (лат. inodeliuin) означает «мера», «способ», «сходство с какой-
то вещью».
Построение моделей — универсальный способ изучения окружающего мира,
позволяющий обнаруживать зависимости, прогнозировать, разбивать на группы
и решать множество других задач. Основная цель моделирования в том, что модель
должна достаточно хорошо отображать функционирование моделируемой системы.
ОПРЕДЕЛЕНИЕ--------------------------------------------------------------
Модель — объект или описание объекта, системы для замещения (при определенных усло-
виях, предположениях, гипотезах) одной системы (то есть оригинала) другой системой для
лучшего изучения оригинала или воспроизведения каких-либо его свойств.
Глава 1. Технологии анализа данных 21
ОПРЕДЕЛЕНИЕ
Моделирование — универсальный метод получения, описания и использования знаний.
Применяется в любой профессиональной деятельности.
По виду моделирования модели делят:
□ на эмпирические — полученные на основе эмпирических фактов, зависимостей;
□ теоретические — полученные на основе математических описаний, законов;
□ смешанные, полуэмпирические — полученные на основе эмпирических зависи-
мостей и математических описаний.
Нередко теоретические модели появляются из эмпирических, например, многие
законы физики первоначально были получены из эмпирических данных.
ПРИМЕР-----------------------------------------------------------------
Совокупность предприятий функционирует на рынке, обмениваясь товарами, сырьем,
услугами, информацией. Если описать экономические законы, правила взаимодействия
на рынке с помощью математических соотношений, например системы алгебраических
уравнений, где неизвестными будут величины прибыли, получаемые от взаимодействия
предприятий, а коэффициентами уравнения — значения интенсивности таких взаимодей-
ствий, то получится математическая модель экономической системы, то есть экономико-
математическая модель системы предприятий на рынке.
Таким образом, анализ данных тесно связан с моделированием.
Отметим важные свойства любой модели.
□ Упрощенность. Модель отображает только существенные стороны объекта
и, кроме того, должна быть проста для исследования или воспроизведения.
□ Конечность. Модель отображает оригинал лишь в конечном числе его отноше-
ний, и, кроме того, ресурсы моделирования конечны.
□ Приближенность. Действительность отображается моделью грубо или прибли-
женно.
□ Адекватность. Модель должна успешно описывать моделируемую систему.
□ Целостность. Модель реализует некоторую систему (то есть целое).
□ Замкнутость. Модель учитывает и отображает замкнутую систему необходимых
основных гипотез, связей и отношений.
□ Управляемость. Модель должна иметь хотя бы один параметр, изменениями
которого можно имитировать поведение моделируемой системы в различных
условиях.
Аналитический подход к моделированию
Модель в традиционном понимании представляет собой результат отображения
одной структуры (изученной) на другую (малоизученную). Так, отображая физи-
ческую систему (объект) на математическую (например, математический аппарат
22 Часть I. Теория бизнес-анализа
уравнений), получим физико-математическую модель системы, или математи-
ческую модель физической системы. Любая модель строится и исследуется при
определенных допущениях, гипотезах. Делается это обычно с помощью матема-
тических методов.
ПРИМЕР---------------------------------------------------------------------------
Рассмотрим экономическую систему. Величина ожидаемого спроса s на будущий месяц
(i + 1) рассчитывается на основе формулы s(t + 1) = [s(i) + s(t — 1) + s(t — 2)] / 3,
то есть как среднее от продаж за предыдущие три месяца. Это простейшая математиче-
ская модель прогноза продаж. При построении этой модели были приняты следующие
гипотезы.
Во-первых, годовая сезонность в продажах отсутствует.
Во-вторых, на величину продаж не влияют никакие внешние факторы: действия конкурен-
тов, макроэкономическая ситуация и т. д.
Использовать такую модель легко: имея данные о продажах за предыдущие
месяцы, по формуле мы получим прогноз на будущий месяц.
Такой подход к моделированию в литературе называют аналитическим.
Аналитический подход к моделированию базируется на том, что исследова-
тель при изучении системы отталкивается от модели (рис. 1.1). В этом случае
он по тем или иным соображениям выбирает подходящую модель. Как правило,
это теоретическая модель, закон, известная зависимость, представленная чаще
всего в функциональном виде (например, уравнение, связывающее выходной па-
раметр у с входными воздействиями xt, х2...). Варьирование входных параметров
на выходе даст результат, который моделирует поведение системы в различных
условиях.
Исследователь
Модель.
Рис. 1.1. Движение от модели к результату
ПРИМЕР-----------------------------------------------------------------------
Рассмотрим физическую систему. Тело массой т, на которое воздействует сила F, скаты-
вается по наклонной плоскости с ускорением а. Исследуя такие системы, Ньютон получил
математическое соотношение F= та. Это математическая модель физической систе-
мы. При построении этой модели были приняты следующие гипотезы.
1. Поверхность идеальна (то есть коэффициент трения равен нулю).
2. Тело находится в вакууме (то есть сопротивление воздуха равно нулю).
3. Масса тела неизменна.
4. Тело движется с одинаковым постоянным ускорением в любой точке.
При моделировании многих физических явлений мы используем закон Ньютона и дела-
ем выводы.
Глава 1. Технологии анализа данных 23
Результат моделирования может соответствовать действительности, а может
и не соответствовать. В последнем случае исследователю ничего не остается, кро-
ме как выбрать другую модель или другой метод ее исследования. Новая модель,
возможно, будет более адекватно описывать рассматриваемую систему.
При аналитическом подходе не модель «подстраивается» под действительность,
а мы пытаемся подобрать существующую аналитическую модель таким образом,
чтобы она адекватно отражала реальность.
Модель всегда исследуется каким-либо методом (численным, качественным
и т. и.). Поэтому выбор метода моделирования часто означает выбор модели.
Информационный подход к моделированию
При использовании в бизнесе традиционного аналитического подхода неизбежно
возникнут проблемы из-за несоответствия между методами анализа и реальностью,
которую они призваны отражать. Существуют трудности, связанные с формали-
зацией бизнес-процессов. Здесь факторы, определяющие явления, столь многооб-
разны и многочисленны, их взаимосвязи так «переплетены», что почти никогда не
удается создать модель, удовлетворяющую таким же условиям. Простое наложение
известных аналитических методов, законов, зависимостей на изучаемую картину
реальности не принесет успеха.
В сложности и слабой формализации бизнес-процессов главным образом «ви-
новат» человеческий фактор, поэтому бывает трудно судить о характере законо-
мерностей априори (а иногда и апостериори, после реализации какого-либо мате-
матического метода). С одинаковым успехом описывать эти закономерности могут
различные модели. Использование разных методов для решения одной и той же
задачи нередко приводит исследователя к противоположным выводам. Какой метод
выбрать? Получить ответ на подобный вопрос можно, лишь глубоко проанализи-
ровав как смысл решаемой задачи, так и свойство используемого математического
аппарата.
Поэтому в последние годы получил распространение информационный подход
к моделированию, ориентированный на использование данных. Его цель — освобож-
дение аналитика от рутинных операций и возможных сложностей в понимании
и применении современных математических методов.
При информационном подходе реальный объект рассматривается как «черный
ящик», имеющий ряд входов и выходов, между которыми моделируются некоторые
связи. Иными словами, известна только структура модели (например, нейрон-
ная сеть, линейная регрессия), а сами параметры модели «подстраиваются» под
данные, которые описывают поведение объекта. Для корректировки параметров
модели используется обратная связь — отклонение результата моделирования от
действительности, а процесс настройки модели часто носит итеративный (то есть
цикличный) характер (рис. 1.2).
Таким образом, при информационном подходе отправной точкой являются
данные, характеризующие исследуемый объект, и модель «подстраивается» под
действительность.
24 Часть I. Теория бизнес-анализа
Исследователь
Рис. 1.2. Построение модели от данных
Если при аналитическом подходе мы можем выбрать модель, даже не имея ни-
каких экспериментальных данных, характеризующих свойства системы, и начать ее
использовать, то при информационном подходе без данных невозможно построить
модель, так как ее параметры полностью определяются ими.
ПРИМЕР---------------------------------------------------------------------
В банковском риск-менеджменте широко известна модель Дюрана для расчета рей-
тинга кредитоспособности заемщика, которая получила распространение в 40-50-е гг.
XX в. На основе собственного опыта Дюран разработал балльную модель для оценки за-
емщика по совокупности его имущественных и социальных параметров (возраст, пол,
профессия ит. д.). Преодолев некоторый порог, заемщик считался кредитоспособным.
Эта модель представляет собой аналитическую зависимость у = f(X), где у — рейтинг,
X — набор признаков заемщика.
Если перед современным российским банком встанет задача рассчитать рейтинг заем-
щика, банк может воспользоваться моделью Дюрана. Однако будет ли адекватной для
современной российской действительности модель, разработанная в середине прошлого
века на Западе? Естественно, не будет, так как она не учитывает закономерности между
характеристиками российских заемщиков (возраст, образование, доход и т. д.) и дефолт-
ностью по кредитам. Если же банк возьмет собственные данные по кредитным историям
и на их основе построит модель, рассчитывающую рейтинг клиента, то, вполне вероятно,
она окажется работоспособной.
В первом случае, когда мы брали модель Дюрана, мы использовали аналитический подход.
Во втором — информационный; для построения модели нам понадобились данные — кре-
дитные истории заемщиков банка.
Модели, полученные с помощью информационного подхода, учитывают специфи-
ку моделируемого объекта, явления, в отличие от аналитического подхода. Для биз-
нес-процессов последнее качество очень важно, поэтому информационный подход лег
в основу большинства современных промышленных технологий и методов анализа
данных: Knowledge Discovery in Databases, Data Mining, машинного обучения.
Однако концепция «моделей от данных» требует тщательного подхода к ка-
честву исходных данных, поскольку ошибочные, аномальные и зашумленные
данные могут привести к моделям и выводам, не имеющим никакого отношения
к действительности. Поэтому в информационном моделировании важную роль
играют консолидация данных, их очистка и обогащение.
Глава 1. Технологии анализа данных 25
Модель, построенная на некотором множестве данных, описывающих реальный
объект или систему, может оказаться не работающей на практике, поэтому в ин-
формационном моделировании используются специальные приемы: разделение
данных на обучающее и тестовое множества, оценка обучающей и обобщающей
способностей модели, проверка предсказательной силы модели.
В дальнейшем, говоря об анализе данных, мы будем предполагать использование
именно информационного подхода. Поскольку данные могут быть представлены
в различной форме, круг рассмотрения будет ограничен областью структуриро-
ванных данных. Инструментальной поддержкой процесса построения моделей на
основе информационного подхода выступают современные технологии анализа
данных KDD и Data Mining, а средством построения прикладных решений в области
анализа — аналитические платформы.
1.2. Принципы анализа данных
Процесс анализа
В информационном подходе к анализу данных, помимо модели, присутствуют еще
три важные составляющие: эксперт, гипотеза и аналитик.
ОПРЕДЕЛЕНИЕ ------------------------------------------------------
Эксперт — специалист в предметной области, профессионал, который за годы обучения
и практической деятельности научился эффективно решать задачи, относящиеся к кон-
кретной предметной области.
Эксперт — ключевая фигура в процессе анализа. По-настоящему эффективные
аналитические решения можно получить не на основе одних лишь компьютерных
программ, а в результате сочетания лучшего из того, что могут человек и компью-
тер. Эксперт выдвигает гипотезы (предположения) и для проверки их достовер-
ности либо просматривает некие выборки различными способами, либо строит те
или иные модели.
ПРИМЕР------------------------------------------------------------
Гипотезой в анализе данных часто выступает предположение о влиянии какого-либо
фактора или группы факторов на результат. К примеру, при построении прогноза про-
даж допускается предположение, что на величину будущих продаж существенно влияют
продажи за предыдущие периоды и остатки на складе. При оценке кредитоспособности
потенциального заемщика выдвигается гипотеза, что на кредитоспособность влияют
социально-экономические характеристики клиента: возраст, образование, семейное
положение и т. п.
В крупных проектах по созданию прикладных аналитических решений участву-
ют, как правило, несколько экспертов, а также аналитик.
26 Часть I. Теория бизнес-анализа
ОПРЕДЕЛЕНИЕ
Аналитик — специалист в области анализа и моделирования. Аналитик на достаточном
уровне владеет какими-либо инструментальными и программными средствами анализа
данных, например методами Data Mining. Кроме того, в обязанности аналитика входят
функции систематизации данных, опроса мнений экспертов, координации действий всех
участников проекта по анализу данных.
Аналитик играет роль «мостика» между экспертами, то есть является связу-
ющим звеном между специалистами разных уровней и областей. Он собирает
у экспертов различные гипотезы, выдвигает требования к данным, проверяет
гипотезы и вместе с экспертами анализирует полученные результаты. Аналитик
должен обладать системными знаниями, так как помимо задач анализа на его пле-
чи часто ложатся технические вопросы, связанные с базами данных, интеграцией
с источниками данных и производительностью.
Поэтому в дальнейшем главным лицом в анализе данных мы будем считать анали-
тика, предполагая, что он тесно сотрудничает с экспертами предметных областей.
ПРИМЕР-------------------------------------------------------------------
В организации создается законченное аналитическое решение в области отчетности и про-
гнозирования продаж. Оно включает в себя консолидацию данных, настройку отчетов,
построение моделей прогнозирования и др. В реализации проекта участвуют специалисты
из нескольких подразделений предприятия: высшее руководство, экономисты, логистики,
программисты, администраторы баз данных. Аналитик обеспечивает связь между всеми
участниками проекта и координирует проект в целом.
Несмотря на то что существует множество аналитических задач, можно выде-
лить две основные группы методов их решения (рис. 1.3):
□ извлечение и визуализация данных;
□ построение и использование моделей.
Рис. 1.3. Общая схема анализа
Глава 1. Технологии анализа данных 27
Извлечение и визуализация данных
Чтобы получить новые знания об исследуемом объекте или явлении, не обязатель-
но строить сложные модели. Часто достаточно «посмотреть» на данные в нужном
виде, чтобы сделать определенные выводы или выдвинуть предположение о ха-
рактере зависимостей в системе, получить ответ на интересующий вопрос. Это
помогает сделать визуализация.
В случае визуализации аналитик некоторым образом формулирует запрос к ин-
формационной системе, извлекает нужную информацию из различных источников
и просматривает полученные результаты. На их основе он делает выводы, которые
и являются результатом анализа. Существует множество способов визуализации
данных:
□ многомерные кубы (кросс-таблицы и кросс-диаграммы);
□ таблицы;
□ диаграммы, гистограммы;
□ карты, проекции, срезы и т. п.
Проиллюстрируем вышесказанное. На рис. 1.4 приведены два способа визуали-
зации одних и тех же данных по продажам в аптечной сети: в виде таблицы и в виде
трафика.
Дата Is Отдел | Груте j Кш ясгео; Слима
_ „ 18.06.2007^ Аптека 1 Антисептики и дезинфицирующие средства ___ 3?_ 86,37
_j 18.06.2007 Аптека 1 Витамины и витаминоподоОные средства ‘ _____ 3; 512,23
18.06.2007 ^Аптека 1 Иммуномодуляторы= 2j_________________________ 56,26
18.06.2007 Аптека 1 ; Местные анестетики 1 4,93
18.06.2007 Аптека 2 Антисептики и дезинфицирующие средства 1 = 122,45
18.06.2007 Аптека 2 :Витамины и витаминоподобные средства _[__ 1J _ 68,5
L „ 19.06.2007 Аптека 1 ; Антисептики и дезинфицирующие средства 4] 52.4
1 19.06.2007 Аптека 1 -Витамины и витаминоподобные средства ,. 3 151,41
_ 19.06.2007 Аптека! Желчегонные средства и препараты желчи =_ 1|_ 31,3
19.06.2007 Аптека 1 Местные анестетики J 1 8,14
19.06.2007:Аптека 1 Микро-и макроэлементы 1 2,24
, 19.06.2007 Аптека 1 0бщетонизируюшие средства и адапгогены .1; 353,46
Рис. 1.4. Два способа представления данных: табличный и графический
28 Часть I. Теория бизнес-анализа
В первом случае, глядя на таблицу, нам трудно сделать какие-либо выводы
относительно динамики продаж.
Во втором варианте, представив те же данные в виде сумм продаж в разрезе
аптек и построив столбчатую диаграмму, мы видим, что самые большие продажи
приходятся на «Аптеку 1».
Несомненными достоинствами визуализации являются относительная про-
стота создания и введения в эксплуатацию подобных систем и возможность их
применения практически в любой сфере деятельности. Кроме того, в этом случае
по максимуму используются знания эксперта в предметной области и его способ-
ность принимать во внимание многие трудно формализуемые факторы, влияющие
на бизнес.
Недостатками визуализации являются неспособность людей обнаружить до-
статочно сложные и нетривиальные зависимости, а также невозможность отделить
знания от эксперта и тиражировать знания.
Этапы моделирования
Построение моделей — универсальный способ изучения окружающего мира, позво-
ляющий обнаруживать зависимости, прогнозировать, разбивать на группы и решать
множество других важных задач. Но самое главное: полученные таким образом
знания можно тиражировать.
ОПРЕДЕЛЕНИЕ ---------------------------------------------------------
Тиражирование знаний — совокупность методологических и инструментальных средств
создания моделей, которые обеспечивают конечным пользователям возможность исполь-
зовать результаты моделирования для принятия решений без необходимости понимания
методик, при помощи которых эти результаты получены.
Процесс построения моделей состоит из нескольких шагов (рис. 1.5).
Формулирование цели моделирования. При построении модели следует от-
талкиваться от задачи, которую можно рассматривать как получение ответа на
интересующий заказчика вопрос.
Например, в розничной торговле к таким вопросам относятся следующие.
□ Какова структура продаж за определенный период?
□ Какие клиенты приносят наибольшую прибыль?
□ Какие товары продаются или заказываются вместе?
□ Как оптимизировать товарные остатки на складах?
В этом случае можно говорить о создании модели прогнозирования продаж,
модели выявления ассоциаций и т. д. Данный этап также называют анализом про-
блемной ситуации.
Подготовка и сбор данных. Информационный подход к моделированию ос-
нован на использовании данных, подготовить и систематизировать которые — от-
дельная задача. Принципам подготовки данных, а также их очистке и обогащению
посвящены отдельные главы.
Глава 1. Технологии анализа данных 29
Рис. 1.5. Процесс построения модели
Поиск модели. После сбора и систематизации данных переходят к поиску моде-
ли, которая объясняла бы имеющиеся данные, позволила бы добиться эмпирически
обоснованных ответов на интересующие вопросы. В промышленном анализе дан-
ных предпочтение отдается самообучающимся алгоритмам, машинному обучению,
методам Data Mining.
Если построенная модель показывает приемлемые результаты на практике (на-
пример, в тестовой эксплуатации), ее запускают в промышленную эксплуатацию.
Так, при тестовой эксплуатации скоринговой модели, рассчитывающей кредитный
рейтинг клиента и принимающей решение о выдаче кредита, каждое решение
может подтверждаться человеком — кредитным экспертом. При запуске скоринга
в промышленную эксплуатацию человеческий фактор удаляется — теперь решение
принимает только компьютер.
Если качество модели неудовлетворительное, то процесс построения модели
повторяется, как это показано на рис. 1.5.
Моделирование позволяет получать новые знания, которые невозможно извлечь
каким-либо другим способом. Кроме того, полученные результаты представляют
собой формализованное описание некоего процесса, вследствие чего поддаются
автоматической обработке. Однако результаты, полученные при использовании
моделей, очень чувствительны к качеству данных, к знаниям аналитика и экспертов
30
Часть I. Теория бизнес-анализа
и к формализации самого изучаемого процесса. К тому же почти всегда имеются
случаи, не укладывающиеся ни в какие модели.
На практике подходы комбинируются. Например, визуализация данных на-
водит аналитика на некоторые идеи, которые он пробует проверить при помощи
различных моделей, а к полученным результатам применяются методы визуали-
зации.
Полнофункциональная система анализа не должна замыкаться на применении
только одного подхода или одной методики. Механизмы визуализации и построе-
ния моделей должны дополнять друг друга. Максимальную отдачу можно полу-
чить, комбинируя методы и подходы к анализу данных.
1.3. Структурированные данные
Данные, описывающие реальные объекты, процессы и явления, могут быть пред-
ставлены в различных формах и иметь разные тип и вид.
Формы представления данных
ОПРЕДЕЛЕНИЕ -----------------------------------------------------
Данные — сведения, которые характеризуют систему, явление, процесс или объект,
представленные в определенной форме и предназначенные для дальнейшего использо-
вания.
По степени структурированности выделяют следующие формы представления
данных:
□ неструктурированные;
□ структурированные;
□ слабоструктурированные.
К неструктурированным относятся данные, произвольные по форме, включаю-
щие тексты и графику, мультимедиа (видео, речь, аудио). Эта форма представления
данных широко используется, например, в Интернете, а сами данные представля-
ются пользователю в виде отклика поисковыми системами.
Структурированные данные отражают отдельные факты предметной области.
Структурированными называются данные, определенным образом упорядоченные
и организованные с целью обеспечения возможности применения к ним некоторых
действий (например, визуального или машинного анализа). Это основная форма
представления сведений в базах данных.
Организация того или иного вида хранения данных (структурированных или
неструктурированных) связана с обеспечением доступа к ним. Под доступом по-
нимается возможность выделения элемента данных (или множества элементов)
среди других элементов по каким-либо признакам с целью выполнения некоторых
действий над элементом.
Глава 1. Технологии анализа данных 31
Одной из самых распространенных моделей хранения структурированных дан-
ных является таблица. В ней все данные упорядочиваются в двумерную структуру,
состоящую из столбцов и строк (рис. 1.6).
Столбцы (поля, колонки, переменные, атрибуты, признаки)
Строки
(записи,
прецеденты,
примеры)
Рис. 1.6. Структурированный набор данных
В ячейках такой таблицы содержатся элементы данных: символы, числа, логи-
ческие значения.
Неструктурированные данные непригодны для обработки напрямую метода-
ми анализа данных, поэтому такие данные подвергаются специальным приемам
структуризации, причем сам характер данных в процессе структуризации может
существенно измениться.
Например, в анализе текстов (Text Mining) при структурировании из исходного
текста может быть сформирована таблица с частотами встречаемости слов, и уже
такой набор данных будет обрабатываться методами, пригодными для структури-
рованных данных.
Слабоструктурированные данные — это данные, для которых определены не-
которые правила и форматы, но в самом общем виде. Например, строка с адресом,
строка в прайс-листе, ФИО и т. п. В отличие от неструктурированных, такие дан-
ные с меньшими усилиями преобразуются к структурированной форме, однако без
процедуры преобразования они тоже непригодны для анализа На рис. 1.7 приведен
пример стандартизации строки с адресом.
32
Часть I. Теория бизнес-анализа
390045 г. Рязань, ул. Ленина, д. 45 корп. 1
Поле Значение
Индекс 390045
Город Рязань
Улица Ленина
Дом 45
Корпус 1
Рис. 1.7. Стандартизация слабоструктурированных данных
Подавляющее большинство методов анализа данных работает только с хоро-
шо структурированными данными, представленными в табличном виде, поэтому
дальнейшее изложение во всей книге ведется применительно к структурированным
данным.
Типы данных
Все структурированные данные делятся на пять типов:
□ целый (количество товара, код товара и т. п.);
□ вещественный (цена, скидка и т. п.);
□ строковый (фамилия, наименование, адрес, пол, образование и т. п.);
□ логический;
□ дата/время.
Среди строковых данных можно выделить два подтипа:
□ упорядоченные (ординальные);
□ категориальные.
В обоих случаях переменная относится к одному из значений дискретного на-
бора классов Ct... С/, и описывает некоторые качественные свойства объекта. Но если
в случае ординальных данных эти классы можно упорядочить, то в случае катего-
риальных данных — нельзя. При сравнении категориальных данных применимы
только две операции: «равно» (=) и «неравно» (^). В табл. 1.1 только одно поле
Образование является упорядоченным, а все остальные — категориальными.
Таблица 1.1. Множество данных одной системы
Код заявки Фамилия Образование Профессия Город
Z-01 Иванов Высшее Инженер Москва
Z-02 Кузнецова Среднее Бухгалтер Коломна
Значения в столбце Образование можно упорядочить по убыванию: Выс-
шее > Среднее > Начальное > ....
Со значениями полей Код заявки, Фамилия, Профессия, Город проделывать
упорядочение бессмысленно, применимы лишь операции «равно» и «не равно».
Глава 1. Технологии анализа данных 33
Виды данных
По виду данные делятся на непрерывные и дискретные.
ОПРЕДЕЛЕНИЕ---------------------------------------------------------
Непрерывные данные — данные, значения которых могут принимать какое угодно значение
в некотором интервале. Над непрерывными данными можно производить арифметические
операции сложения, вычитания, умножения, деления, и они имеют смысл.
Примерами непрерывных данных являются возраст, любые стоимостные
показатели, количественные оценки (количество товара, объем продаж, вес от-
грузки).
ОПРЕДЕЛЕНИЕ---------------------------------------------------------
Дискретные данные — значения признака, общее число которых конечно либо бесконечно,
но может быть подсчитано при помощи натуральных чисел от одного до бесконечности.
С дискретными данными не могут быть произведены никакие арифметические действия,
либо они не имеют смысла.
Дискретными данными являются все данные строкового и логического типа.
Дискретными могут быть и числовые данные. Например, поле Код товара, прини-
мающее значения целого типа, дискретно, так как операции сложения, вычитания,
умножения над Кодом товара не имеют смысла. Соответствие возможных видов
данных типам данных приведено в табл. 1.2.
Таблица 1.2. Соответствие между типами и видами данных
Тип данных Вид данных
Непрерывный Дискретный
Целый + +
Вещественный + +
Строковый +
Логический +
Дата/время + +
Аналитику важно понимать природу данных для выбора адекватных методов
их предобработки, очистки и построения моделей.
Представления наборов данных
По отношению к задаче анализа наборы данных могут быть упорядоченными
и неупорядоченными.
В упорядоченном наборе данных каждому столбцу соответствует один фактор,
а в каждую строку заносятся упорядоченные по какому-либо признаку события
с интервалом периода между строками. Часто таким признаком выступает время.
На рис. 1.8 приведены примеры упорядоченных наборов данных — временной ряд
34 Часть I. Теория бизнес-анализа
(слева, упорядочен по дате) и ряд показаний датчика зонда (справа, упорядочен
по глубине скважины).
i Дата Количество |; Сумма
j 01.01.2007 | 01.01 2007 4 283 31 Глубина > i DS
1 72,48 887,9 8.65 0,218 ‘
j 01.01 2007 1 173,32' 688.1 9.627 0.216
”1 02.01.2007 6 294,84 888,3 14,584 0,217
| 02 01 2007 2 405,76: 888,5 21 647! 0.215:
j 02.01.2007 12 303.1 з] 688.7 17.172 0,216
,j 02.01.2007 1 210,5; 688.9 6,118’ 0.215
j 03.01.2007 6 52116 889,1 2,886 0,217
,j 03.01.2007 3 <56.96.. _ 889,3 2.506 0,2191
Рис. 1.8. Примеры упорядоченных наборов данных
В неупорядоченном наборе каждому столбцу соответствует фактор, а в каждую
строку заносится пример (ситуация, прецедент), соответственно, упорядоченность
строк не требуется. Пример такого набора данных приведен на рис. 1.9.
Номер ’ Банк Филиалы | Город Собственные активы
2. Внешторгбанк 32 Москва 2323632’
3 Газпромбанк 27 Москва 925504I
4 ООО "Международный Промышленный банк' 4 Москва 26409116
5 Международный Московский Банк I 1 Москва 1176462
6 ОАО "АЛЬФАБАНК 17 Москва 12446936
7 ОАО "ПСБ" 44 Санкт-Петербург 1275859
8 Банк Москвы 34 Москва 3335734
9 АКБ "РОСБАНК" (ОАО) 13 Москва 46914^9
10 АКБ ДНЕ 0 Москва 2616993
Рис. 1.9. Пример неупорядоченного набора данных
Особо выделяют транзакционные данные. Под транзакцией подразумеваются
несколько объектов или действий, являющихся логически связанной единицей
(рис. 1.10). Очень часто данный механизм используется для анализа покупок
(чеков) в супермаркетах. Но в общем случае речь может идти о любых связанных
объектах или действиях.
Ко/ ранзакщ-.г. Товар
Одна транзакция 1020v 10200 10201 10201 Йогурт «Чудо» 0,4 Батон «Рязанский» Вода «Боржоми» 0,5 Сахарный песок
Рис. 1.10. Транзакционные данные
1.4. Подготовка данных к анализу
Информационный подход к анализу базируется на различных алгоритмах извлече-
ния закономерностей из исходных данных, результатом работы которых являются
Глава 1. Технологии анализа данных 35
модели. Таких алгоритмов довольно много, но они не способны гарантировать
качественное решение. Никакой, даже весьма изощренный, метод сам по себе не
даст хорошего результата, так как критически важным является качество исходных
данных. Чаще всего именно оно становится причиной неудачи. Несмотря на то
что существуют специальные методы очистки данных, понимание и соблюдение
принципов сбора и подготовки данных значительно облегчит построение моделей
и позволит получить хорошие результаты.
Особенности данных, накопленных в компаниях
Данные, которые накапливают предприятия и организации в базах данных и про-
чих источниках (так называемые бизнес-данные), имеют свои особенности. Рас-
смотрим их.
Бизнес-данные редко накапливаются специально для решения задач анализа.
Предприятия и организации собирают данные для коммерческих целей: ведения
учета, проведения финансового анализа, составления отчетности, принятия реше-
ний и т. п. Этим бизнес-данные отличаются от экспериментальных данных, которые
собираются для исследовательских целей. Основными потребителями бизнес-дан-
ных обычно являются лица, принимающие решения в компаниях.
Бизнес-данные, как правило, содержат ошибки, аномалии, противоречия и про-
пуски. Это следствие того, что компании не собирают данные с целью анализа.
В них появляются ошибки различной природы, что снижает качество данных.
С точки зрения анализа объемы хранимых данных очень велики. Современные
базы данных содержат мегабайты и гигабайты информации. Для ресурсоемких
алгоритмов анализа данных таблицу объемом 50 тыс. записей можно считать боль-
шой, поэтому при построении моделей важно применять процедуры сэмплинга,
сокращения записей и отбора информативных признаков либо использовать спе-
циальные масштабируемые алгоритмы, способные работать на больших наборах
данных.
Отмеченные особенности бизнес-данных влияют как на сам процесс анализа,
так и на подготовку и систематизацию данных.
Формализация данных
При сборе данных нужно придерживаться следующих принципов.
1. Абстрагироваться от существующих информационных систем и имеющихся
в наличии данных. Большие объемы накопленных данных совершенно не гово-
рят о том, что их достаточно для анализа в конкретной компании. Необходимо
отталкиваться от задачи и подбирать данные для ее решения, а не брать име-
ющуюся информацию. К примеру, при построении моделей прогноза продаж
опрос экспертов показал, что на спрос очень влияет цветовая характеристика
товара. Анализ имеющихся данных продемонстрировал, что информация о цве-
те товарной позиции отсутствует в учетной системе. Значит, нужно каким-то
ль часть I. Теория бизнес-анализа
образом добавить эти данные, иначе не стоит рассчитывать на хороший резуль-
тат использования моделей.
2. Описать все факторы, потенциально влияющие на анализируемый процесс/
объект. Основным инструментом здесь становится опрос экспертов и людей,
непосредственно владеющих проблемной ситуацией. Необходимо максимально
использовать знания экспертов о предметной области и, полагаясь на здравый
смысл, постараться собрать и систематизировать максимум возможных пред-
положений и гипотез.
3. Экспертно оценить значимость каждого фактора. Эта оценка не является
окончательной, она будет отправной точкой. В процессе анализа вполне может
выясниться, что фактор, который эксперты посчитали очень важным, таковым
не является, и наоборот, незначимый, с их точки зрения, фактор может оказы-
вать значительное влияние на результат.
4. Определить способ представления информации — число, дата, да/нет, категория
(то есть тип данных). Определить способ представления, то есть формализовать
некоторые данные, просто. Например, объем продаж в рублях — это определен-
ное число. Но довольно часто бывает непонятно, как представить фактор. Чаще
всего такие проблемы возникают с качественными характеристиками. Напри-
мер, на объемы продаж влияет качество товара. Качество — сложное понятие,
но если этот показатель действительно важен, то нужно придумать способ его
формализации. Скажем, качество можно определять по количеству брака на
тысячу единиц продукции либо оценивать экспертно, разбив на несколько ка-
тегорий — отлично/хорошо/удовлетворительно/плохо.
5. Собрать все легкодоступные факторы. Они содержатся в первую очередь в источ-
никах структурированной информации — учетных системах, базах данных и т. п.
6. Обязательно собрать наиболее значимые, с точки зрения экспертов, факторы.
Вполне возможно, что без них не удастся построить качественную модель.
7. Оценить сложность и стоимость сбора средних и наименее важных по значимо-
сти факторов. Некоторые данные легкодоступны, их можно извлечь из суще-
ствующих информационных систем. Но есть информация, которую непросто
собрать, например сведения о конкурентах, поэтому необходимо оценить, во что
обойдется сбор данных. Сбор данных не является самоцелью. Если информацию
получить легко, то, естественно, нужно ее собрать. Если сложно, то необходимо
соизмерить затраты на ее сбор и систематизацию с ожидаемыми результатами.
Рассмотрим эти принципы на примере формализации данных при решении
задачи прогнозирования спроса. На этапе описания факторов, влияющих на про-
дажи, и выдвижения гипотез полезно составить таблицу факторов и их значимости
(табл. 1.3).
При создании подобной таблицы следуют принципам 1-3 формализации
данных. Далее необходимо определить способ представления данных и оценить
стоимость их сбора. К таблице добавятся еще два столбца (табл. 1.4). И уже после
этого можно принимать решение о том, какие факторы включать в анализ, а ка-
Глава 1. Технологии анализа данных 37
кими пренебречь. Очевидно, что все легкодоступные показатели с высокой экс-
пертной значимостью требуется включать в рассмотрение. А фактором «Качество
продукции», например, можно пренебречь: по мнению экспертов, он малозначим,
а стоимость его сбора велика.
Таблица 1.3. Факторы, влияющие на продажи, и их значимость
Фактор Экспертная оценка значимости (1-100)
Сезон 100
День недели 80
Объем продаж за предыдущие недели 100
Объем продаж за аналогичный период прошлого года 95
Рекламная кампания 60
Маркетинговые мероприятия 40
Качество продукции 30
Рейтинг бренда 25
Отклонение цены от среднерыночной 60
Наличие данного товара у конкурентов 15
Таблица 1.4. Факторы, влияющие на продажи, с оценками экспертов
Фактор Экспертная оценка значимости (1-100) Способ представления Экспертная оценка сложности получения
Сезон 100 Число Низкая
День недели 80 Дата Низкая
Объем продаж за предыдущие недели 100 Число Низкая
Объем продаж за аналогичный пе- риод прошлого года 95 Число Низкая
Рекламная кампания 60 Число Средняя
Маркетинговый бюджет 40 Число Средняя
Качество продукции 30 Строка (плохое/хо- рошее / отличное) Высокая
Рейтинг бренда 25 Строка (известный/ малоизвестный и т. д.) Средняя
Отклонение цены от среднерыночной 60 Число Средняя
Наличие данного товара у конкурентов 15 Логическое (да/нет) Средняя
38 Часть I. Теория бизнес-анализа
Методы сбора данных
Есть несколько методов сбора необходимых для анализа данных.
1. Получение из учетных систем. Обычно в учетных системах есть различные ме-
ханизмы построения отчетов и экспорта данных, поэтому извлечение нужной
информации из них чаще всего относительно несложная операция.
2. Получение данных из косвенных источников информации. О многих показателях
можно судить по косвенным признакам, и этим нужно воспользоваться. Напри-
мер, можно оценить реальное финансовое положение жителей определенного
региона следующим образом. В большинстве случаев имеется несколько това-
ров, предназначенных для выполнения одной и той же функции, но отличаю-
щихся по цене: товары для бедных, средних и богатых. Если получить отчет
о продажах товара в интересующем регионе и проанализировать пропорции,
в которых продаются товары для бедных, средних и богатых, то можно предпо-
ложить, что чем больше доля дорогих изделий из одной товарной группы, тем
более состоятельны в среднем жители данного региона.
3. Использование открытых источников. Большое количество данных присут-
ствует в таких открытых источниках, как статистические сборники, отчеты
корпораций, опубликованные результаты маркетинговых исследований
и пр.
4. Приобретение аналитических отчетов у специализированных компаний.
На рынке работает множество компаний, которые профессионально зани-
маются сбором данных и представлением результатов клиентам для после-
дующего анализа. Собираемая информация обычно представляется в виде
различных таблиц и сводок, которые с успехом можно применять при ана-
лизе. Стоимость получения подобной информации чаще всего относительно
невысока.
5. Проведение собственных маркетинговых исследований и аналогичных меро-
приятий по сбору данных. Этот вариант сбора данных может быть достаточно
дорогостоящим, но в любом случае он существует.
6. Ввод данных вручную. Данные вводятся по различного рода экспертным
оценкам сотрудниками организации. Такой метод является наиболее трудо-
емким.
Методы сбора информации существенно отличаются по стоимости и необходи-
мому времени, поэтому следует соизмерять затраты с результатами. Возможно, от
сбора некоторых данных придется отказаться, но факторы, которые эксперты оце-
нили как наиболее значимые, нужно собрать обязательно, несмотря на стоимость
этих работ, либо вообще не проводить анализ.
Данные должны быть собраны в единую таблицу в формате Excel, DBase, в тек-
стовые файлы с разделителями или в набор таблиц в любой реляционной СУБД
(системе управления базами данных), то есть должны быть представлены в струк-
турированном виде. Кроме того, необходимо унифицировать представление данных:
один и тот же объект должен везде описываться одинаково.
Глава 1. Технологии анализа данных 39
Информативность данных
Одной из распространенных ошибок при сборе данных из структурированных
источников является стремление взять для анализа как можно больше признаков,
описывающих объекты. Между тем предварительная оценка данных, которая про-
водится визуально при помощи таблиц и базовой статистической информации по
набору данных, существенно помогает в определении информативности признаков
с точки зрения анализа.
Среди неинформативных признаков выделяется четыре типа:
□ признаки, содержащие только одно значение (рис. 1.11, а);
□ признаки, содержащие в основном одно значение (рис. 1.11,6);
□ признаки с уникальными значениями (рис. 1.11, в);
□ признаки, между которыми имеет место сильная корреляция, — в этом случае
для анализа можно взять один столбец (рис. 1.11, г).
Признак Признак № паспорта й Пол Gender
1 1 0936-866096 Жен 0
1 1 8355-512943 Жен 0
1 1 8017-098471 Жен 0
1 1 2762-945535 Муж 1
1 1 0459-997701 Муж 1
1 0 6291-817248 Жен 0
1 1 0094-883508 Жен 0
1 1 6385-082612 Муж 1
1 1 9290-732300 Муж 1
1 1 7022-736158 Жен 0
1 1 3127-709332 Жен 0
1 1 4179-171975 Муж 1
а б В
Рис. 1.11. Примеры неинформативных признаков
Признаки, содержащие в основном одно значение, не всегда могут быть неин-
формативными, многое зависит от целей анализа. Например, при решении задачи
анализа отклонений такие признаки могут существенно повлиять на построение
моделей.
Требования к данным
Аналитические инструменты пытаются построить модели на основе предложенных
данных, поэтому чем ближе данные к действительности, тем лучше. Необходимо
понимать: модель не может «знать» о том, что находится за пределами собранных
для анализа данных. Например, если при создании системы диагностики больных
40 Часть I. Теория бизнес-анализа
использовать только сведения о больных людях, то модель не будет знать о суще-
ствовании в природе здоровых людей.
Существуют требования к минимальным объемам данных для возможности
построения моделей на их основе. В зависимости от представления данных и ре-
шаемой задачи эти требования различны.
Для временных рядов, которые относятся к упорядоченным данным, требова-
ния следующие. Если для моделируемого бизнес-процесса (например, продажи)
характерна сезонность/цикличность, то необходимо иметь данные хотя бы за один
полный сезон/цикл с возможностью варьирования интервалов (понедельное,
помесячное и т. д.). Максимальный горизонт прогнозирования зависит от объема
данных: данные за 1,5 года — прогноз возможен максимум на 1 месяц; данные за
2-3 года — на 2 месяца.
Для неупорядоченных данных требования следующие.
□ Количество примеров (прецедентов) должно быть значительно больше коли-
чества факторов.
□ Желательно, чтобы данные покрывали как можно больше ситуаций реального
процесса.
□ Пропорции различных примеров (прецедентов) должны примерно соответ-
ствовать реальному процессу.
Транзакционные данные. Анализ транзакций целесообразно производить на
большом объеме данных, иначе могут быть выявлены статистически необоснован-
ные правила. Алгоритмы поиска ассоциативных связей способны быстро перера-
батывать огромные массивы данных. Примерное соотношение между количеством
объектов и объемом данных следующее:
□ 300-500 объектов — не менее 10 тыс. транзакций;
□ 500-1000 объектов — более 300 тыс. транзакций.
1.5. Технологии KDD и Data Mining
Информационный подход к анализу получил распространение в таких методиках
извлечения знаний, как KDD (Knowledge Discovery in Databases) и Data Mining.
Сегодня на базе этих методик создается большинство прикладных аналитических
решений в бизнесе и многих других областях.
Методика извлечения знаний
Несмотря на разнообразие бизнес-задач, почти все они могут решаться по единой
методике. Эта методика, зародившаяся в 1989 г., получила название Knowledge
Discovery in Databases — извлечение знаний из баз данных. Она описывает не кон-
кретный алгоритм или математический аппарат, а последовательность действий,
которую необходимо выполнить для обнаружения полезного знания. Методика
не зависит от предметной области; это набор атомарных операций, комбинируя
Глава 1. Технологии анализа данных 41
которые можно получить нужное решение. KDD включает в себя этапы подго-
товки данных, выбора информативных признаков, очистки, построения моделей,
постобработки и интерпретации полученных результатов. Ядром этого процесса
являются методы Data Mining, позволяющие обнаруживать закономерности и зна-
ния (рис. 1.12).
ОПРЕДЕЛЕНИЕ----------------------------------------------------------
Knowledge Discovery in Databases — процесс получения из данных знаний в виде зависимо-
стей, правил, моделей, обычно состоящий из таких этапов, как выборка данных, их очистка
и трансформация, моделирование и интерпретация полученных результатов.
Рассмотрим последовательность шагов, выполняемых в процессе KDD.
Выборка данных. Первым шагом в анализе является получение исходной вы-
борки. На основе отобранных данных строятся модели. Здесь требуется активное
участие экспертов для выдвижения гипотез и отбора факторов, влияющих на ана-
лизируемый процесс. Желательно, чтобы данные были уже собраны и консолиди-
рованы. Крайне необходимы удобные механизмы подготовки выборки: запросы,
фильтрация данных и сэмплинг. Чаще всего в качестве источника рекомендуется
использовать специализированное хранилище данных, консолидирующее всю
необходимую для анализа информацию.
Очистка данных. Реальные данные для анализа редко бывают хорошего каче-
ства. Необходимость в предварительной обработке при анализе данных возникает
независимо от того, какие технологии и алгоритмы используются. Более того, эта
задача может представлять самостоятельную ценность в областях, не имеющих
непосредственного отношения к анализу данных. К задачам очистки данных от-
носятся: заполнение пропусков, подавление аномальных значений, сглаживание,
исключение дубликатов и противоречий и пр.
42 Часть I. Теория бизнес-анализа
Трансформация данных. Этот шаг необходим для тех методов, при использо-
вании которых исходные данные должны быть представлены в каком-то опреде-
ленном виде. Дело в том, что различные алгоритмы анализа требуют специальным
образом подготовленных данных. Например, для прогнозирования необходимо
преобразовать временной ряд при помощи скользящего окна или вычислить агре-
гированные показатели. К задачам трансформации данных относятся: скользящее
окно, приведение типов, выделение временных интервалов, квантование, сорти-
ровка, группировка и пр.
Data Mining. На этом этапе строятся модели.
Интерпретация. В случае, когда извлеченные зависимости и шаблоны не-
прозрачны для пользователя, должны существовать методы постобработки,
позволяяющие привести их к интерпретируемому виду. Для оценки качества
полученной модели нужно использовать как формальные методы, так и знания
аналитика. Именно аналитик может сказать, насколько применима полученная
модель к реальным данным. Построенные модели являются, по сути, форма-
лизованными знаниями эксперта, а следовательно, их можно тиражировать.
Найденные знания должны быть применимы и к новым данным с некоторой
степенью достоверности.
ПРИМЕР----------------------------------------------------------------
Имеется сеть магазинов розничной торговли. Пусть требуется получить прогноз объемов
продаж на следующий месяц. Первым шагом будет сбор истории продаж в каждом мага-
зине и объединение ее в единый набор данных. Следующим шагом станет предобработка
собранных данных: их группировка по месяцам, сглаживание кривой продаж, исключение
из рассмотрения факторов, слабо влияющих на объемы продаж. Далее следует построить
модель зависимости объемов продаж от выбранных факторов, после чего можно получить
прогноз, подав на вход модели историю продаж. Зная прогнозное значение, его можно
использовать, например, в приложениях для оптимизации товарных запасов.
Data Mining
Термин Data Mining дословно переводится как «добыча данных» или «раскопка
данных» и имеет в англоязычной среде несколько определений.
ОПРЕДЕЛЕНИЕ---------------------------------------------------------
Data Mining — обнаружение в сырых данных ранее неизвестных, нетривиальных, практи-
чески полезных и доступных интерпретации знаний, необходимых для принятия решений
в различных сферах человеческой деятельности.
Зависимости и шаблоны, найденные в процессе применения методов Data
Mining, должны быть нетривиальными и ранее неизвестными, например, сведения
о средних продажах таковыми не являются. Знания должны описывать новые связи
между свойствами, предсказывать значения одних признаков на основе других.
Нередко KDD отождествляют с Data Mining. Однако правильнее считать Data
Mining шагом процесса KDD.
Глава 1. Технологии анализа данных 43
Data Mining — это не один метод, а совокупность большого числа различных
методов обнаружения знаний. Существует несколько условных классификаций
задач Data Mining. Мы будем говорить о четырех базовых классах задач.
। Классификация — это установление зависимости дискретной выходной перемен-
ной от входных переменных.
2 Регрессия — это установление зависимости непрерывной выходной переменной
от входных переменных.
3 Кластеризация — это группировка объектов (наблюдений, событий) на основе
данных, описывающих свойства объектов. Объекты внутри кластера должны
быть похожими друг на друга и отличаться от других, которые вошли в другие
кластеры.
4 . Ассоциация — выявление закономерностей между связанными событиями. При-
мером такой закономерности служит правило, указывающее, что из события
X следует событие Y. Такие правила называются ассоциативными. Впервые эта
задача была предложена для нахождения типичных шаблонов покупок, со-
вершаемых в супермаркетах, поэтому иногда ее называют анализом рыночной
корзины (market basket analysis). Если же нас интересует последовательность
происходящих событий, то можно говорить о последовательных шаблонах —
установлении закономерностей между связанными во времени событиями.
Примером такой закономерности служит правило, указывающее, что из собы-
тия X спустя время t последует событие Y.
Кроме перечисленных задач, часто выделяют анализ отклонений (deviation
detection), анализ связей (link alalysis), отбор значимых признаков (feature selection),
хотя эти задачи граничат с очисткой и визуализацией данных.
Задача классификации отличается от задачи регрессии тем, что в классифи-
кации на выходе присутствует переменная дискретного вида, называемая меткой
класса. Решение задачи классификации сводится к определению класса объекта
по его признакам, при этом множество классов, к которым может быть отнесен
объект, известно заранее. В задаче регрессии выходная переменная является непре-
рывной — множеством действительных чисел, например сумма продаж (рис. 1.13).
К задаче регрессии сводится, в частности, прогнозирование временного ряда на
основе исторических данных.
Класс
Рис. 1.13. Иллюстрация задачи классификации (слева) и задачи регрессии (справа)
Кластеризация отличается от классификации тем, что выходная переменная не
требуется, а число кластеров, в которые необходимо сгруппировать все множество
44 Часть I. Теория бизнес-анализа
данных, может быть неизвестным. Выходом кластеризации является не готовый
ответ (например, «плохо»/«удовлетворительно»/«хорошо»), а группы похожих
объектов — кластеры. Кластеризация указывает только на схожесть объектов,
и не более того. Для объяснения образовавшихся кластеров необходима их до-
полнительная интерпретация (рис. 1.14).
Рис. 1.14. Иллюстрация задачи кластеризации
Перечислим наиболее известные способы применения этих задач в экономике.
Классификация используется, если заранее известны классы, например при
отнесении нового товара к той или иной товарной группе, отнесении клиента
к какой-либо категории (при кредитовании — к одной из групп риска).
Регрессия используется для установления зависимостей между факторами. На-
пример, в задаче прогнозирования зависимая величина — объемы продаж, а фак-
торами, влияющими на нее, могут быть предыдущие объемы продаж, изменение
курсов валют, активность конкурентов и т. д. Или, например, при кредитовании
физических лиц вероятность возврата кредита зависит от личных характеристик
человека, сферы его деятельности, наличия имущества.
Кластеризация может использоваться для сегментации и построения профилей
клиентов. При достаточно большом количестве клиентов становится трудно под-
ходить к каждому индивидуально, поэтому их удобно объединять в группы — сег-
менты с однородными признаками. Выделять сегменты можно по нескольким
группам признаков, например по сфере деятельности или географическому распо-
ложению. После кластеризации можно узнать, какие сегменты наиболее активны,
какие приносят наибольшую прибыль, выделить характерные для них признаки.
Эффективность работы с клиентами повышается благодаря учету их персональных
предпочтений.
Ассоциативные правила помогают выявлять совместно приобретаемые то-
вары. Это может быть полезно для более удобного размещения товара на при-
лавках, стимулирования продаж. Тогда человек, купивший пачку спагетти, не
забудет купить к ней бутылочку соуса. Последовательные шаблоны могут исполь-
зоваться при планировании продаж или предоставления услуг. Они похожи на
ассоциативные правила, но в анализе добавляется временной показатель, то есть
важна последовательность совершения операций. Например, если заемщик взял
потребительский кредит, то с вероятностью 60 % через полгода он оформит
кредитную карту.
Для решения вышеперечисленных задач используются различные методы
и алгоритмы Data Mining. Ввиду того что Data Mining развивается на стыке таких
дисциплин, как математика, статистика, теория информации, машинное обучение,
Глава 1. Технологии анализа данных 45
теория баз данных, программирование, параллельные вычисления, вполне законо-
мерно, что большинство алгоритмов и методов Data Mining были разработаны на
основе подходов, применяемых в этих дисциплинах (рис. 1.15).
Рис. 1.15. Мультидисциплинарный характер Data Mining
В общем случае непринципиально, каким именно алгоритмом будет решаться
задача, главное — иметь метод решения для каждого класса задач. На сегодняшний
день наибольшее распространение в Data Mining получили методы машинного
обучения: деревья решений, нейронные сети, ассоциативные правила и т. д.
ОПРЕДЕЛЕНИЕ-------------------------------------------------------------
Машинное обучение (machine learning) — обширный подраздел искусственного интеллекта,
изучающий методы построения алгоритмов, способных обучаться на данных.
Общая постановка задачи обучения следующая. Имеется множество объектов
(ситуаций) и множество возможных ответов (откликов, реакций). Между ответа-
ми и объектами существует некоторая зависимость, но она неизвестна. Известна
только конечная совокупность прецедентов — пар вида «объект — ответ», — на-
зываемая обучающей выборкой. На основе этих данных требуется обнаружить
зависимость, то есть построить модель, способную для любого объекта выдать
достаточно точный ответ. Чтобы измерить точность ответов, вводится критерий
качества.
Решение подавляющего большинства бизнес-задач сводится к процессу KDD.
Ранее были описаны базовые блоки, из которых собирается практически любое
46
Часть I. Теория бизнес-анализа
бизнес-решение. Рисунок 1.16 иллюстрирует некоторые популярные бизнес-задачи,
которые решаются алгоритмами Data Mining.
Ассоциативные
правила
Анализ Разделительная Нейронные Деревья Линейная
последова- кластеризация сети решений и логистическая
тельностей регрессия
Алгоритмы
Рис. 1.16. От бизнес-решений к алгоритмам Data Mining
Отметим, что Data Mining не ограничивается алгоритмами решения упомяну-
тых классов задач. Существует несколько современных подходов, которые «встраи-
ваются» внутрь алгоритмов машинного обучения, придавая им новые свойства.
Так, генетические алгоритмы призваны эффективно решать задачи оптимизации,
поэтому их можно встретить в процедурах обучения нейронных сетей, карт Кохо-
нена, логистической регрессии, при отборе значимых признаков. Математический
аппарат нечеткой логики (fuzzy logic) также успешно включается в состав практиче-
ски всех алгоритмов Data Mining; так появились нечеткие нейронные сети, нечет-
кие деревья решений, нечеткие ассоциативные правила. Объединение технологии
хранилищ данных и нечетких запросов позволяет аналитикам получать нечеткие
срезы. И подобных примеров множество.
Причины распространения KDD и Data Mining
В KDD и Data Mining нет ничего принципиально нового. Специалисты в различ-
ных областях человеческого знания решали подобные задачи на протяжении не-
скольких десятилетий. Однако в последние годы интеллектуальная составляющая
бизнеса стала возрастать и для распространения технологий KDD и Data Mining
были созданы все необходимые и достаточные условия.
Глава 1. Технологии анализа данных 47
1 Развитие технологий автоматизированной обработки информации создало
основу для учета сколь угодно большого количества факторов и достаточного
объема данных.
2 Возникла острая нехватка высококвалифицированных специалистов в области
статистики и анализа данных. Поэтому потребовались технологии обработки
и анализа, доступные для специалистов любого профиля за счет применения
методов визуализации и самообучающихся алгоритмов.
3 . Возникла объективная потребность в тиражировании знаний. Полученные
в процессе KDD и Data Mining результаты являются формализованным описа-
нием некоего процесса, а следовательно, поддаются автоматической обработке
и повторному использованию на новых данных.
4 . На рынке появились программные продукты, поддерживающие технологии KDD
и Data Mining, — аналитические платформы. С их помощью можно создавать
полноценные аналитические решения и быстро получать первые результаты.
1.6. Аналитические платформы
Даже самые мощные технологии извлечения закономерностей и машинного обуче-
ния, такие как KDD и Data Mining, не представляют особой ценности без инстру-
ментальной поддержки в виде соответствующего программного обеспечения. Рынок
программных средств продолжает формироваться по сей день, однако в этой области
уже можно выделить некоторые стандарты де-факто.
Программное обеспечение в области анализа данных
Рынок программного обеспечения KDD и Data Mining делится на несколько сег-
ментов (рис. 1.17).
Рис. 1.17. Классификация ПО в области Data Mining и KDD
Статистические пакеты с возможностями Data Mining и настольные пакеты
Data Mining ориентированы в основном на профессиональных пользователей.
Их отличительные особенности:
48 Часть I. Теория бизнес-анализа
□ слабая интеграция с промышленными источниками данных;
□ бедные средства очистки, предобработки и трансформации данных;
□ отсутствие гибких возможностей консолидации информации, например, в спе-
циализированном хранилище данных;
□ конвейерная (поточная) обработка новых данных затруднительна или реали-
зуется встроенными языками программирования и требует высокой квалифи-
кации;
□ из-за использования пакетов на локальных рабочих станциях обработка боль-
ших объемов данных затруднена.
Плюсом статистических пакетов является их широкая распространенность. На-
стольные пакеты Data Mining могут быть ориентированы на решение всех классов
задач Data Mining или какого-либо одного, например кластеризации или класси-
фикации. Вместе с тем эти пакеты предоставляют богатые возможности в плане
алгоритмов, что достаточно для решения исследовательских задач. Существует
немало свободно распространяемых настольных пакетов Data Mining с открытыми
исходными кодами.
Однако создание эффективных прикладных решений промышленного уровня
с помощью таких пакетов затруднено, поэтому в бизнес-аналитике, как правило,
используются СУБД с элементами Data Mining и аналитические платформы.
Практически все крупные производители систем управления базами данных
включают в состав своих продуктов средства для анализа данных и поддержку
хранилищ данных. Эти инструменты как бы встраиваются в СУБД. Отличительные
особенности СУБД с элементами Data Mining:
□ высокая производительность;
□ алгоритмы анализа данных по максимуму используют преимущества СУБД;
□ жесткая привязка всех технологий анализа к одной СУБД;
□ сложность в создании прикладных решений, поскольку работа с СУБД ориен-
тирована на программистов и администраторов баз данных.
Аналитические платформы
В отличие от СУБД с набором алгоритмов Data Mining, аналитические платфор-
мы изначально ориентированы на анализ данных и предназначены для создания
готовых решений.
ОПРЕДЕЛЕНИЕ-----------------------------------------------------------
Аналитическая платформа — специализированное программное решение (или набор ре-
шений), которое содержит в себе все инструменты для извлечения закономерностей из сы-
рых данных: средства консолидации информации в едином источнике (хранилище данных),
извлечения, преобразования, трансформации данных, алгоритмы Data Mining, средства
визуализации и распространения результатов среди пользователей, а также возможности
конвейерной обработки новых данных.
Глава 1. Технологии анализа данных 49
В аналитической платформе, как правило, всегда присутствуют гибкие и разви-
тые средства консолидации, включающие богатые механизмы интеграции с промыш-
ленными источниками данных, инструменты очистки и преобразования структури-
рованных данных и их последующее хранение в едином источнике в многомерном
виде — в хранилище данных. Модели, описывающие выявленные закономерности,
правила и прогнозы, также хранятся в специальном источнике данных — репози-
тарии моделей.
На рис. 1.18 изображена типовая схема системы на базе аналитической плат-
формы.
Кубы, OLAP
Модели Data Mining
Отчеты, графики
Администрирование
*
Аналитическая платформа
Хранилище данных
в
и
Мониторинг
Извлечение, загрузка, очистка,
преобразование, обновление
Репозитарии моделей
Р
и
Рис. 1.18. Аналитическая платформа
Вообще говоря, приведенную на рис. 1.18 систему можно построить с ис-
пользованием нескольких программных решений, например разделить функции
извлечения/загрузки, OLAP-отчетности, хранилища данных, Data Mining между
различным программным обеспечением. Но чтобы эти отдельные компоненты
превратились в полноценную аналитическую систему, необходимо произвести ин-
теграцию между ними на уровне обмена данными, а еще лучше — метаданными.
50 Часть I. Теория бизнес-анализа
Языки визуального моделирования
Основным препятствием на пути все более широкого применения методов и про-
граммных средств анализа данных является сложность инструментов. Поэтому
важно освободить аналитика от необходимости углубленного понимания сложных
математических алгоритмов. Своеобразным ответом на это требование стало по-
явление языков визуального моделирования. Сегодня их наличие является стан-
дартом де-факто в полноценной аналитической платформе.
Язык моделирования позволяет аналитику в визуальной среде строить последо-
вательности шагов по обработке данных от получения сырых данных до конечного
результата. Шаги представляют собой набор атомарных по отношению к данным
операций, каждую из которых можно представить отдельным узлом. Примеры
таких операций: выборка данных, фильтрация, сортировка, добавление нового
столбца, построение модели Data Mining и т. п. Набор узлов образует графическую
диаграмму. Такой способ представления очень близок к рассуждениям и действиям
аналитика, которые он так или иначе проделывает. Существует две формы пред-
ставления диаграмм: в виде дерева и в виде графа (рис. 1.19).
Э (J хд [LOANS) извлечение процесса [Анкеты]
6 V Фильтр ([КодАнкеты] < 10ОО]
Q 3* Внешнее левое соединение (L0ANS5: Погашения}
G & Настройка набора данных (ДаватьКредиг)
В- сГе Замена значений. ДаватьКредит
Б SB Калькулятор: Возраст: СовокупДохед
ЙНастройка набора данных
Медель 1А - Дерево решений-1, все заемщики
Модель 1В Дерево решений-2, все заемщики
ЕЗ Замена значений: Пол, Автомобиль, ДавагьКредит
i && Настройка набора данных [Пол, Автомобиль, ДаватьКредит)
© Ж Медель 1С - Логистическая регрессия, все заемщики
Сортировка4 Рейтинг
© V Фильтр ЦСемвйноеПояожение] - 'Женат/замужем')
Рис. 1.19. Языки визуального моделирования:
в виде дерева (вверху), в виде графа (внизу)
Глава 1. Технологии анализа данных 51
Общие особенности языков моделирования в аналитических платформах
сЛедуюЩие-
□ Базовым узлом, с которого начинается диаграмма, является узел импорта,
поскольку в аналитических платформах обычно отсутствуют средства для
ручного ввода данных; предполагается, что данные уже имеются в каких-
либо источниках.
□ Графическое изображение, соответствующее какому-либо узлу, несет в себе
большой семантический смысл. Оно помогает аналитику различать узлы по
функциям и определять их активность (часто еще не выполненный узел поме-
чается значком серого цвета, а выполненный — цветным).
□ Диаграмма описывает формализованную последовательность действий над
данными, и эти действия можно повторить на совершенно других данных,
предварительно настроив соответствие колонок.
Каждая из форм представления имеет как достоинства, так и недостатки. У де-
ревьев более жесткая структура по сравнению с графами, поэтому, к примеру,
отображение двух узлов, сливающихся в один, затруднено. Вместе с тем дерево
более компактно (в графе обязательно присутствуют стрелки, которые занимают
место на диаграмме), что очень важно при большом количестве узлов, и позволяет
выполнять множество интуитивно понятных операций, связанных с манипулиро-
ванием ветвями (копирование, удаление, перенос и т. д.).
1.7. Введение в алгоритмы Data Mining
Цель применения моделей в методах Data Mining — выявление новых свойств
и закономерностей исследуемых объектов и процессов. Поэтому информационный
подход здесь очень кстати: модель должна самостоятельно обнаружить в данных
присущие им закономерности (в большинстве случаев ранее неизвестные и скры-
тые) и приобрести свойства, необходимые для отражения этих закономерностей.
Комплекс методов, используемых для создания таких моделей, называется машин-
ным обучением, а сами модели — обучаемыми. В дальнейшем мы будем рассматри-
вать модели именно в контексте машинного обучения.
В основе машинного обучения лежит обучающая выборка. Она может быть либо
получена как совокупность наблюдений за развитием объекта или процесса в про-
шлом, либо (что встречается реже) создана экспертом или аналитиком на основе
некоторых гипотез, аналогий, личного опыта и даже интуиции. Слово «выборка»
в данном случае означает, что, возможно, для обучения модели мы будем исполь-
зовать не все имеющиеся данные, а некоторое их подмножество, наиболее полно
отражающее искомые свойства и закономерности (методы получения выборок
будут изучаться в разделе 5.11).
Данные из обучающей выборки последовательно предъявляются модели, в ре-
зультате чего модель приобретает необходимые свойства. Этот процесс называет-
ся обучением. Он является итеративной процедурой, где на каждом шаге модели
52 Часть I. Теория бизнес-анализа
предъявляется объект данных из обучающей выборки и в соответствии с правилом,
называемым алгоритмом обучения, производится корректировка параметров мо-
дели до тех пор, пока она не придет в состояние, которое позволит ей выполнять
требуемое преобразование. После того как модель обучена и протестирована, ее
можно применять на практике.
Обучающая выборка
В машинном обучении любая модель отображает некоторое множество вход-
ных переменных X в множество выходных У. Поскольку в большинстве случаев
исследуемые объекты и процессы описываются несколькими признаками, то
правильнее говорить не о переменных, а о векторах: входном X = (хь х2... х„) и вы-
ходном Y = (//., уг... уп). Если модель работает корректно и выполняет требуемое
преобразование, то на каждое входное воздействие X модель всегда будет форми-
ровать на выходе правильный отклик Y, то есть всегда найдет для любой точки
множества X соответствующую ей точку множества У (рис. 1.20).
Рис. 1.20. Отображение, представляемое обучающей выборкой
Если модель не обучена и находится в некотором начальном состоянии, то на
каждое входное воздействие X* она будет формировать на выходе произвольное
значение Yz, которое может оказаться сколь угодно далеким от желаемого.
Для обучения модели необходимо использовать обучающие примеры, в каждом
из которых для заданного входного воздействия указывается соответствующий
ему правильный результат. Именно из таких обучающих примеров и состоит обу-
чающая выборка.
ОПРЕДЕЛЕНИЕ-------------------------------------------------------------
Обучающая выборка — набор данных, каждая запись которого представляет собой обуча-
ющий пример, содержащий заданное входное воздействие, и соответствующий ему пра-
вильный выходной результат.
Глава 1. Технологии анализа данных 53
Иными словами, обучающая выборка представляет собой функцию, заданную
таблично парами входных и выходных векторов [(XiYt), (X2Y2)...(X4Yt)]. Напри-
мер, обучающая выборка для обучения умножению и сложению будет содержать
четыре переменные — две входные и две выходные. Входными переменными будут
два числа (аргумента) xt и х2, которые требуется умножить или сложить, а выход-
ными — У\ и у2 — результаты сложения и умножения. Фрагмент такой обучающей
выборки представлен в табл. 1.5.
Таблица 1.5. Фрагмент обучающей выборки
Аргумент 1 Аргумент 2 Сумма Произведение
4 6 10 24
5 8 13 40
2 9 И 18
Поля обучающей выборки, содержащие входные переменные, обычно также
называются входными, а поля, в которых содержатся выходные переменные, то есть
заранее известный результат, — целевыми.
ЗАМЕЧАНИЕ -------------------------------------------------------------
Каждый, кто учился в школе, имел дело с различными обучающими выборками, простейшие
из которых — алфавит и таблица умножения. В алфавите входным воздействием является
графический образ буквы, а выходным — соответствующий звук или наоборот. При обу-
чении ребенку многократно предъявляют весь набор букв, а затем требуют повторить са-
мостоятельно. На начальной стадии обучения количество ошибок велико, но постепенно
уменьшается. В таблице умножения более сложное входное воздействие — два сомножи-
теля, выходное — результат умножения.
При формировании обучающей выборки неизбежно возникает вопрос о числе
примеров в ней. Единого и универсального правила здесь не существует. Все за-
висит от структуры модели, характера обучающих данных и сложности решаемой
задачи. Интуитивно понятно, что чем больше данных используется для обучения,
тем успешнее оно будет. Однако при этом не стоит забывать, что увеличение числа
примеров увеличивает также вычислительные и временные затраты на обучение
модели. Кроме того, чаще говорят не о количестве примеров, а о репрезентативности
выборки в целом. Под репрезентативностью понимается, насколько хорошо обу-
чающая выборка отражает характер преобразования, которое модель должна выпол-
нять после обучения. С одной стороны, чем сложнее преобразование, тем большее
число примеров потребуется. С другой — если примеры плохо подобраны и слабо
отражают зависимость между входными и выходными переменными, то даже очень
большое число примеров не гарантирует хороших результатов при обучении.
Чтобы обучение было эффективным, примеры обучающей выборки должны
отражать как можно больше разнообразных комбинаций «вход — выход», а сама вы-
борка — удовлетворять определенным критериям качества данных, то есть в ней не
должно быть дублирующих, противоречивых и недостоверных примеров. Представьте,
например, что таблица умножения, которая печатается на обложке школьных
54 Часть I. Теория бизнес-анализа
тетрадей, наполовину состоит из одинаковых примеров, а другая ее половина содер-
жит примеры типа 2-2 = 5 или 4 • 3 = 28 и т. д. Получится обучить ребенка умноже-
нию по такой таблице? Ответ очевиден. Если обучающая выборка содержит дубли-
каты, противоречия и просто неправильные примеры, то независимо от количества
используемых примеров ожидать хороших результатов вряд ли стоит.
Таким образом, чтобы набор данных можно было использовать для обучения
модели, он должен:
□ отражать правила и закономерности исследуемого процесса;
□ быть репрезентативным, то есть содержать достаточное количество уникаль-
ных примеров, как можно полнее отражающих закономерности исследуемого
процесса;
□ удовлетворять определенным критериям качества, а именно не содержать дуб-
ликаты и противоречия, пропуски и аномальные значения.
Как сформировать обучающую выборку? Для этого можно использовать два
метода:
□ естественный — обучающая выборка формируется на основе прошлых наблю-
дений за развитием исследуемого процесса. В этом случае примеры берутся из
базы данных предприятия, бухгалтерских документов, результатов научных
экспериментов и т. д. Например, при прогнозировании продаж чаще всего дос-
таточно иметь сведения о продажах за некоторый промежуток времени;
□ экспертный — обучающая выборка формируется специалистом в данной предмет-
ной области. Он определяет факторы, влияющие на решение задачи, и подбирает
примеры, отражающие правило, по которому ищется решение. Этот метод наибо-
лее эффективен для оригинальных, не имеющих типового решения задач.
Обучение с учителем и без учителя
При обучении моделей используются две методики (или, как иногда говорят, пара-
дигмы): с учителем (supervised learning) и без учителя (unsupervised learning).
Обучение с учителем предполагает, что модели предъявляются примеры, состо-
ящие из пар «известный вход — известный выход». То есть обучение производится
на основе заранее определенных (целевых) значений, с которыми сравниваются
реальные значения, сформированные моделью на выходе. Типичным приложением,
в котором необходимо обучение с учителем, является классификация, поскольку
классы предполагаются заданными заранее. В этом случае целевой переменной
будет метка класса.
При обучении без учителя настройка параметров модели производится ис-
ключительно на основе информации о ее текущем состоянии и значений входных
переменных в обучающих примерах. При этом целевые значения не используются.
Такие модели часто называют самоорганизующимися, а сам процесс обучения без
учителя — самоорганизацией. Одним из главных приложений обучения без учи-
теля является кластеризация, поскольку кластеры изначально не определяются,
Глава 1. Технологии анализа данных 55
формируются естественным образом на основе того, насколько близки значения
признаков объектов.
Обучающее и тестовое множества
Важнейшим свойством любой модели, которое она должна приобрести в процессе
обучения, является способность к обобщению. Если модель обучилась и приобрела
эту способность, то она будет выдавать правильный результат при подаче на ее вход
Не только данных, на которых она обучалась, но и новых данных, не участвовавших
в процессе обучения.
Чтобы проверить способность модели к обобщению, всю обучающую выборку
разделяют на два множества — обучающее и тестовое (рис. 1.21). Примеры из
обучающего множества используются непосредственно для обучения модели. При-
меры из тестового множества для обучения не применяются, а используются для
проверки обобщающей способности модели. Разделение примеров на обучающее
и тестовое множества производится обычно в случайном порядке или с примене-
нием различных методов сэмплинга.
Обучающая
выборка
Рис. 1.21. Обучающее и тестовое множества
Тогда в процессе обучения модели можно выделить две ошибки: ошибку обу-
чения и ошибку обобщения.
Ошибка обучения — это ошибка, допущенная моделью на обучающем множе-
стве. На каждой итерации обучения для непрерывной выходной переменной она
рассчитывается как среднеквадратичная ошибка:
E=^t^ -У?}*'
где N — число обучающих примеров;
у® — значение на выходе модели для i-ro примера;
— целевое (то есть желаемое) значение.
Если решается задача классификации, то ошибка вычисляется как k/N, где
k — число неправильно классифицированных примеров.
56 Часть I. Теория бизнес-анализа
Ошибка обобщения — это ошибка, полученная на тестовых примерах, то есть
вычисляемая по тем же формулам, но для тестового множества.
Если в результате обучения была получена достаточно малая ошибка как на
обучающем, так и на тестовом множестве, то можно заключить, что модель приоб-
рела обобщающую способность.
ЗАМЕЧАНИЕ -------------------------------------------------------------
Обобщающие свойства модель может приобрести только при обучении на большом числе
разнообразных примеров. При этом количество комбинаций «вход — выход» в примерах
обучающей выборки должно быть избыточным, то есть в несколько раз превышать число
параметров модели, настраиваемых в процессе обучения. В этом случае параметры моде-
ли будут адаптироваться не к отдельным комбинациям «вход — выход», а к закономерно-
стям и правилам исследуемого процесса. Если число комбинаций в обучающих примерах
будет не избыточным, а примерно равным числу параметров модели, то модель просто
«запомнит» все обучающие примеры и не приобретет способности к обобщению. Прак-
тическое применение модели, которая в процессе обучения не приобрела способности
к обобщению, не имеет смысла. Хотя существуют модели, целью которых служит именно
запоминание эталонных образов для решения задачи их распознавания, например ас-
социативная память. Но там возникают другие проблемы, связанные с максимальным
объемом памяти.
Размеры обучающего и тестового множеств зависят от особенностей конкретной
задачи. Обучающее множество обычно больше, чем тестовое, и содержит достаточ-
но примеров для качественного обучения модели. Размер тестового множества
определяется запасом примеров обучающей выборки. Если примеров едва хватает
на обучение, то тестовое множество придется взять поменьше — 5 % от общего
объема выборки. Если же обучающая выборка обладает достаточным запасом
примеров, тестовое множество можно выбрать и больше — 20-30 %.
Эффект переобучения
Процесс обучения модели можно рассматривать как задачу минимизации функции
выходной ошибки £(t), где t — номер итерации обучения. В процессе обучения
ошибки обучения и обобщения монотонно уменьшаются. В то же время после
определенной итерации может наблюдаться возрастание ошибки обобщения, что
говорит об ухудшении обобщающей способности модели (рис. 1.22).
На рис. 1.22 представлен характер поведения ошибки обучения Ео, и ошибки
обобщения Ет. Как видно, ошибка обучения постоянно снижается; ошибка обоб-
щения сначала снижается, а затем возрастает.
Этот эффект называется переобучением (overtraining, overfitting) и имеет место
в случае, когда количество итераций обучения превосходит некоторое оптимальное
значение. Обучающие данные, возможно, содержат шумоподобные изменения слу-
чайного характера. В процессе обучения параметры модели сначала адаптируются
к изменениям, отражающим закономерности в данных. Затем по мере более точной
настройки модели ее параметры начинают адаптироваться к незначительным флук-
туациям данных. Эффект переобучения вызван слишком детальной подстройкой
Глава 1. Технологии анализа данных 57
параметров модели, когда она начинает воспроизводить незначительные изменения
случайного характера. Данная ситуация поясняется на рис. 1.23.
Рис. 1.22. Поведение ошибки обучения и ошибки обобщения
Рис. 1.23. Иллюстрация эффекта переобучения
На рис. 1.23 сплошной линией представлен процесс, исследуемый с помощью
модели. Но поскольку отдельные наблюдения процесса подвержены случайным
флуктуациям, обучающая выборка содержит данные, отражаемые пунктирной
линией. В процессе обучения модель сначала адаптируется к «крупномасштабным»
данным, а затем — ко все более малым изменениям в них. Очевидно, что снизить
вероятность переобучения можно путем предобработки с целью сглаживания
данных и очистки их от шума.
58 Часть I. Теория бизнес-анализа
Контролировать появление переобучения можно с помощью ошибки обоб-
щения: как только ошибка на тестовом множестве начинает возрастать, процесс
обучения следует принудительно остановить.
Вычислительная сложность алгоритмов
как критерий их сравнения
Для различных классов задач Data Mining, а также для работы с данными различ-
ной природы и размерности в настоящее время разработано множество алгоритмов,
использующих самые разные математические подходы и методы.
При выборе алгоритма используют следующие критерии:
□ производительность (вычислительная сложность) — объем вычислений при
реализации алгоритма должен обеспечивать его выполнение за разумное время
и по возможности быть нетребовательным к ресурсам компьютера;
□ устойчивость — алгоритм должен обеспечивать достижение достоверных ре-
зультатов даже при низком качестве исходных данных, наличии в них шумов,
аномалий и противоречий;
□ точность — алгоритм должен обеспечивать работу модели на требуемом уровне
точности.
В большинстве случаев эти требования противоречат друг другу: чем точнее
и быстрее работает алгоритм, тем он сложнее в вычислительном плане и более
требователен к ресурсам компьютера. Поэтому каждый раз при выборе алгоритма
нужно оценить все его преимущества и недостатки, «примерить» их к особенно-
стям решаемой задачи. Так, если известно, что исходные данные низкого качества
(то есть содержат аномалии и шумы, являются неполными и противоречивыми
и т. д.), то предпочтение следует отдать более устойчивым методам, возможно,
в ущерб скорости и точности; если объем исходных данных очень велик, то на
первое место выходит производительность и т. д.
При выборе наилучшего алгоритма для решения конкретной задачи в первую
очередь учитывается вычислительная сложность. Это вполне оправданно, по-
скольку большинство задач в бизнес-аналитике имеет дело с большими объемами
данных и важно знать, как поведет себя алгоритм в условиях возрастания объемов
обрабатываемых данных, какие ресурсы (объем памяти, дисковое пространство
и т. д.) при этом потребуются.
Как основной критерий эффективности алгоритма используется трудоем-
кость — количество элементарных операций, которые необходимо выполнить
для решения задачи с помощью данного алгоритма. При анализе трудоемкости
рассматривается функция трудоемкости — отношение, связывающее объем вход-
ных данных алгоритма с количеством элементарных операций, которое требуется
для их обработки.
Трудоемкость алгоритма может по-разному зависеть от входных данных. Тру-
доемкость одних алгоритмов зависит от количества входных данных, других — от
Глава 1. Технологии анализа данных 59
х значений. В некоторых случаях на трудоемкость может повлиять и порядок
п0Ступления данных.
Одним из наиболее простых видов анализа, используемых при сравнении трудо-
емкости алгоритмов, является асимптотический. Используемая в асимптотическом
анализе оценка функции трудоемкости, называемая сложностью алгоритма, позволя-
ет оценить, насколько быстро растет трудоемкость алгоритма с увеличением объема
входных данных. Обычно эта оценка представляется в виде где f(N) — функ-
ция сложности, a N — число обрабатываемых наблюдений или примеров.
Можно выделить следующие функции сложности, которые позволяют оценить
ожидаемые вычислительные затраты и требуемые ресурсы при реализации того
или иного алгоритма. Наименее затратными являются алгоритмы, для которых
функция сложности имеет вид/(М) = С и f(N) = CN, где С — константа. В первом
случае вычислительные затраты не зависят от количества обрабатываемых данных,
а во втором — линейно возрастают с их увеличением. Встречаются функции слож-
ности с логарифмической или экспоненциальной зависимостью типа f(N) = log(N)
или f(N) = где С — константа. Самыми затратными являются алгоритмы, слож-
ность которых имеет степенную зависимость от числа обрабатываемых наблюдений
f(N) = CNи факториальную зависимость f(N) = №..
Понятие масштабируемых алгоритмов
Чтобы алгоритм машинного обучения мог работать с большими массивами данных,
он должен быть масштабируемым (scalable). Признаком этого качества является то,
что вычислительные затраты растут прямо пропорционально увеличению объема
обрабатываемых данных, то есть при увеличении объема данных в два раза число
вычислительных операций также увеличивается в два раза. В Data Mining масшта-
бируемость предполагает следующие свойства алгоритма:
□ однопроходность — алгоритм должен использовать минимально возможное ко-
личество сканирований набора данных, лучше, если сканирование будет одно;
□ возможность отсечения по времени — алгоритм должен быть способен выдать
наилучшее на данный момент решение в любое время, даже если процесс вы-
числений не доводится до естественной остановки;
□ прерываемость и продолжаемость — алгоритм должен предусматривать возмож-
ность временной приостановки и продолжения работы. Промежуточные ре-
зультаты должны сохраняться, при этом должна обеспечиваться возможность
продолжения вычислений, в том числе с использованием новых данных;
□ ограниченность по объему требуемой памяти — алгоритм должен работать
в пределах ограниченного объема памяти компьютера, выделяемого пользова-
телем;
□ однонаправленность — при проходе базы данных считывание записей произво-
дится только в одном направлении. Такой режим работы называется режимом
однонаправленного указателя: указатель движется только вперед без возмож-
ности обратного перемещения.
60 Часть I. Теория бизнес-анализа
Некоторые алгоритмы машинного обучения, изначально не являющиеся мас-
штабируемыми, могут быть доработаны и модифицированы для обеспечения
возможности их масштабирования. Основная цель масштабирования — предостав-
ление возможности обрабатывать большие объемы данных за приемлемое время.
Таким образом, при выборе алгоритма важно понимать его достоинства и недо-
статки, учитывать природу данных, с которыми он лучше работает, и способность
к масштабируемости.
ПЕРСОНАЛИИ --------------------------------------------------------------------
Григорий Пятецкий-Шапиро (Gregory Piatetsky-Shapiro) — основатель направлений Data Min-
ing и Knowledge Discovery in Databases, президент компании KDnuggets, исследователь
в области анализа данных и машинного обучения с мировым именем. Принимает участие
в работе многих организаций в сфере Data Mining, в конференциях по анализу данных,
консультирует компании по вопросам разработки и применения методов автоматического
извлечения закономерностей.
Получил степени магистра (1979) и доктора наук (1984) в Нью-Йоркском университете на
факультете компьютерных наук. До 1997 г. проработал в GTE Laboratories — исследовательском
центре крупной телекоммуникационной компании. Там Пятецкий-Шапиро реализовал первый
проект по применению в бизнесе методов Knowledge Discovery in Databases и Data Mining,
за которым последовали еще несколько успешных проектов.
До 2001 г. возглавлял компанию KSP (позже приобретена Xchange), специализирующуюся
в области консалтинга и разработки инструментов Data Mining. В последующие несколько
лет до создания компании KDnuggets работал профессором в американских и британских
университетах: преподавал и разрабатывал курсы по машинному обучению, Data Mining
в бизнесе и медицине.
Автор и соавтор более 50 публикаций, в том числе известной на весь мир статьи From Data
Mining to Knowledge Discovery in Databases. Схема процесса получения знаний из данных,
представленная в этой статье, сегодня приводится в любом учебнике no Data Mining. Соавтор
двух книг, ставших бестселлерами: Knowledge Discovery in Databases (1991) и Advances in
Knowledge Discovery in Databases (1996).
Усама Файад (Usama Fayyad) — один из идеологов технологий KDD и Data Mining, стоявший
у их истоков. В настоящее время работает в научно-исследовательском центре Yahoo Re-
search Labs в качестве исполнительного вице-президента.
В1991 г. получил степень доктора наук в области инженерии в Мичиганском университете
(США); также имеет степени магистра в области компьютерных наук (1986) и математики
(1989). Автор более 100 публикаций, посвященных интеллектуальным системам и Data
Mining; член американской ассоциации искусственного интеллекта. Под его редакцией
выпущено две книги no Data Mining. Регулярно принимает участие в научных конференциях
и симпозиумах по всему миру.
С1989 по 1996 г. Файад занимался анализом научных данных в лаборатории NASA, а затем
в течение пяти лет работал в исследовательском центре Microsoft по созданию и исследо-
ванию алгоритмов Data Mining. Многие его идеи и разработки получили развитие в Data
Mining-технологиях Microsoft.
В 2000 г. Файад основал собственную компанию DigiMine (сейчас — Revenue Science),
занимающуюся анализом веб-данных.
Консолидация
данных
2.1. Задача консолидации
Введение
Ценность и достоверность знаний, полученных в результате интеллектуального
анализа бизнес-данных, зависит не только от эффективности используемых ана-
литических методов и алгоритмов, но и от того, насколько правильно подобраны
и подготовлены исходные данные для анализа.
Обычно руководителям проектов по бизнес-аналитике с нуля приходится сталки-
ваться со следующей ситуацией. Во-первых, данные на предприятии расположены
в различных источниках самых разнообразных форматов и типов — в отдельных
файлах офисных документов (Excel, Word, обычных текстовых файлах), в учет-
ных системах («1С:Предприятие», «Парус» и др.), в базах данных (Oracle, Access,
dBase и др.). Во-вторых, данные могут быть избыточными или, наоборот, недоста-
точными. А в-третьих, данные являются «грязными», то есть содержат факторы,
мешающие их правильной обработке и анализу (пропуски, аномальные значения,
дубликаты и противоречия).
Поэтому, прежде чем приступать к анализу данных, необходимо выполнить
ряд процедур, цель которых — доведение данных до приемлемого уровня качества
и информативности, а также организовать их интегрированное хранение в струк-
турах, обеспечивающих их целостность, непротиворечивость, высокую скорость
и гибкость выполнения аналитических запросов.
ОПРЕДЕЛЕНИЕ-----------------------------------------------------
Консолидация — комплекс методов и процедур, направленных на извлечение данных из
различных источников, обеспечение необходимого уровня их информативности и качества,
преобразование в единый формат, в котором они могут быть загружены в хранилище данных
или аналитическую систему.
62 Часть I. Теория бизнес-анализа
Консолидация данных является начальным этапом реализации любой анали-
тической задачи или проекта. В основе консолидации лежит процесс сбора и ор-
ганизации хранения данных в виде, оптимальном с точки зрения их обработки на
конкретной аналитической платформе или решения конкретной аналитической
задачи. Сопутствующими задачами консолидации являются оценка качества дан-
ных и их обогащение.
Основные критерии оптимальности с точки зрения консолидации данных:
□ обеспечение высокой скорости доступа к данным;
□ компактность хранения;
□ автоматическая поддержка целостности структуры данных;
□ контроль непротиворечивости данных.
Источники данных
Ключевым понятием консолидации является источник данных — объект, содержа-
щий структурированные данные, которые могут оказаться полезными для решения
аналитической задачи. Необходимо, чтобы используемая аналитическая платформа
могла осуществлять доступ к данным из этого объекта непосредственно либо после
их преобразования в другой формат. В противном случае очевидно, что объект не
может считаться источником данных.
Аналитические приложения, как правило, не содержат развитых средств ввода
и редактирования данных, а работают с уже сформированными выборками. Таким
образом, формирование массивов данных для анализа в большинстве случаев ло-
жится на плечи заказчиков аналитических решений.
Основные задачи консолидации данных
В процессе консолидации данных решаются следующие задачи:
□ выбор источников данных;
□ разработка стратегии консолидации;
□ оценка качества данных;
□ обогащение;
□ очистка;
□ перенос в хранилище данных.
Сначала осуществляется выбор источников, содержащих данные, которые могут
иметь отношение к решаемой задаче, затем определяются тип источников и мето-
дика организации доступа к ним. В связи с этим можно выделить три основных
подхода к организации хранения данных.
Данные, хранящиеся в отдельных (локальных) файлах, например в текстовых
файлах с разделителями, документах Word, Excel и т. д. Такого рода источником
может быть любой файл, данные в котором организованы в виде столбцов и за-
писей. Столбцы должны быть типизированы, то есть содержать данные одного
Глава 2. Консолидация данных 63
типа, например только текстовые или только числовые. Преимущество таких ис-
точников в том, что они могут создаваться и редактироваться с помощью простых
и популярных офисных приложений, работа с которыми не требует от персонала
специальной подготовки. К недостаткам следует отнести то, что они далеко не
всегда оптимальны с точки зрения скорости доступа к ним, компактности пред-
ставления данных и поддержки их структурной целостности. Например, ничто не
мешает пользователю табличного процессора разместить в одном столбце данные
различных типов (числовые и текстовые), что впоследствии обязательно приведет
к проблемам при их обработке в аналитическом приложении.
Базы данных (БД) различных СУБД, таких как Oracle, SQL Server, Firebird,
dBase, FoxPro, Access и т. д. Файлы БД лучше поддерживают целостность струк-
туры данных, поскольку тип и свойства их полей жестко задаются при построении
таблиц. Однако для создания и администрирования БД требуются специалисты
с более высоким уровнем подготовки, чем для работы с популярными офисными
приложениями.
Специализированные хранилища данных (ХД) являются наиболее предпочти-
тельным решением, поскольку их структура и функционирование специально
оптимизируются для работы с аналитической платформой. Большинство ХД обес-
печивают высокую скорость обмена данными с аналитическими приложениями,
автоматически поддерживают целостность и непротиворечивость данных. Главное
преимущество ХД перед остальными типами источников данных — наличие семан-
тического слоя, который дает пользователю возможность оперировать терминами
предметной области для формирования аналитических запросов к хранилищу.
При разработке стратегии консолидации данных необходимо учитывать ха-
рактер расположения источников данных — локальный, когда они размещены на
том же ПК, что и аналитическое приложение, либо удаленный, если источники
доступны только через локальную или Глобальную компьютерные сети. Характер
расположения источников данных может существенно повлиять на качество
собранных данных (потеря фрагментов, несогласованность во времени их обнов-
ления, противоречивость и т. д.).
Другой важной задачей, которую требуется решить в рамках консолидации,
является оценка качества данных с точки зрения их пригодности для обработки
с помощью различных аналитических алгоритмов и методов. В большинстве
случаев исходные данные являются «грязными», то есть содержат факторы, не
позволяющие их корректно анализировать, обнаруживать скрытые структуры
и закономерности, устанавливать связи между элементами данных и выполнять
другие действия, которые могут потребоваться для получения аналитического
решения. К таким факторам относятся ошибки ввода, пропуски, аномальные зна-
чения, шумы, противоречия и т. д. Поэтому перед тем, как приступить к анализу
данных, необходимо оценить их качество и соответствие требованиям, предъ-
являемым аналитической платформой. Если в процессе оценки качества будут
выявлены факторы, которые не позволяют корректно применить к данным те или
иные аналитические методы, необходимо выполнить соответствующую очистку
данных.
64 Часть I. Теория бизнес-анализа
ОПРЕДЕЛЕНИЕ
Очистка данных — комплекс методов и процедур, направленных на устранение причин,
мешающих корректной обработке: аномалий, пропусков, дубликатов, противоречий, шу-
мов и т. д.
Еще одной операцией, которая может понадобиться при консолидации данных,
является их обогащение.
ОПРЕДЕЛЕНИЕ---------------------------------------------------------—
Обогащение — процесс дополнения данных некоторой информацией, позволяющей повы-
сить эффективность решения аналитических задач.
Обогащение позволяет более эффективно использовать консолидированные
данные. Его необходимо применять в тех случаях, когда данные содержат недо-
статочно информации для удовлетворительного решения определенной задачи
анализа. Обогащение данных позволяет повысить их информационную насыщен-
ность и, как следствие, значимость для решения аналитической задачи.
Обобщенная схема процесса консолидации
Место консолидации в общем процессе анализа данных может быть представлено
в виде структурной схемы (рис. 2.1).
Источники
данных
Локальные
документы
Электронные
архивы
Рис. 2.1. Процесс консолидации данных
Учетные
системы
СУБД
Внешние
источники
В основе процедуры консолидации лежит процесс ETL (extraction, transformation,
loading). Процесс ETL решает задачи извлечения данных из разнотипных источни-
ков, их преобразования к виду, пригодному для хранения в определенной структуре,
а также загрузки в соответствующую базу или хранилище данных. Если у аналитика
возникают сомнения в качестве и информативности исходных данных, то при не-
Глава 2. Консолидация данных 65
обходимости он может задействовать процедуры оценки их качества, очистки или
обогащения, которые также являются составными частями процесса консолидации
данных.
ПРИ М ЕР
Процесс сбора, хранения и оперативной обработки данных на типичном предприятии
обычно содержит несколько уровней. На верхнем уровне располагаются реляционные
SQL-ориентированные СУБД типа SQL Server, Oracle и т. д. На втором — файловые серверы
с некоторой системой оперативной обработки или сетевые версии персональных СУБД типа
R-Base, FoxPro, Access и т. д. И наконец, на самом нижнем уровне расположены локальные
ПК отдельных пользователей с персональными источниками данных. Чаще всего инфор-
мация на них собирается в виде файлов офисных приложений — Word, Excel, текстовых
файлов и т. д.
Из источников данных всех перечисленных уровней информация в соответ-
ствии с некоторым регламентом должна перемещаться в ХД. Для этого необходимо
обеспечить выгрузку данных из источников, провести их преобразование к виду,
соответствующему структуре ХД, а при необходимости выполнить их обогащение
и очистку.
Таким образом, консолидация данных является сложной многоступенчатой
процедурой и важнейшей составляющей аналитического процесса, обеспечива-
ющей высокий уровень аналитических решений.
2.2. Введение в хранилища данных
Введение
К середине 80-х гг. XX в. практически полностью завершился первый этап осна-
щения бизнеса и государственных структур средствами вычислительной техники
и начался период бурного развития информационных систем для организации
сбора и хранения больших массивов различного рода деловой и служебной ин-
формации. В основном это были корпоративные системы, предназначенные для
оперативной обработки информации, которые обслуживали бухгалтерию, ин-
формационные архивы, телефонные сети, регистрацию документов, банковские
операции и т. д. С появлением персональных компьютеров такие системы стали
доступными для множества мелких и средних фирм, предприятий и организаций.
Системы оперативной обработки информации получили название OLTP (On-Line
Transaction Processing — оперативная, то есть в режиме реального времени, обра-
ботка транзакций).
ОПРЕДЕЛЕНИЕ--------------------------------------------------------
Транзакция — некоторый набор операций над базой данных, который рассматривается как
единое завершенное, сточки зрения пользователя, действие над некоторой информацией,
обычно связанное с обращением к базе данных.
66 Часть I. Теория бизнес-анализа
Обобщенная структура системы OLTP представлена на рис. 2.2.
ПРИМЕР--------------------------------------------------------------------------
Типичным примером применения OLTP-систем является массовое обслуживание клиен-
тов, например бронирование авиабилетов или оплата услуг телефонных компаний. Обе
эти ситуации имеют два общих свойства: очень большое число клиентов и непрерывное
поступление информации.
При бронировании авиабилетов из многочисленных пунктов продажи непрерывно сте-
кается информация об уже проданных билетах, которую вводят со своих рабочих мест
операторы-продавцы. В той же БД формируется информация о свободных местах. С точки
зрения данной задачи транзакция включает в себя набор таких действий, как:
• запрос оператора о наличии свободных мест на тот или иной рейс;
• отклик БД с предоставлением соответствующей информации;
• ввод оператором информации о клиенте, номере заказанного места и оплаченной
сумме (возможно, будет присутствовать еще какая-либо служебная вспомогательная
информация);
• передача новой информации в базу данных и внесение в нее соответствующих изме-
нений;
• передача оператору подтверждения о том, что операция выполнена успешно.
Такие транзакции выполняются тысячи раз в день в сотнях пунктов продаж. Очевидно, что
основным приоритетом в данном случае является обеспечение минимального времени
отклика при максимальной загрузке системы.
Рассмотрим характерные черты данного процесса, свойственные в той или иной мере всем
OLTP-системам.
Глава 2. Консолидация данных 67
• Запросы и отчеты полностью регламентированы. Оператор не может сформировать соб-
ственный запрос, чтобы уточнить или проанализировать какую-либо информацию.
• Как только перелет завершился, информация об обслуживании данного клиента теряет
смысл, становится неактуальной и подлежит удалению по прошествии определенного
времени (то есть исторические данные не поддерживаются).
• Операции производятся над данными с максимальным уровнем детализации, то есть
по каждому клиенту в отдельности.
Ситуация коренным образом меняется, когда руководство авиакомпании прини-
мает решение об изучении пассажиропотоков с целью, например, их оптимизации.
Такие исследования могут быть реакцией на информацию о том, что в последнее
время во многих пунктах продаж участились случаи нехватки билетов на опре-
деленные маршруты, что позволяет сделать предположение о целесообразности
организации дополнительных рейсов.
Однако для проведения таких исследований необходимы как минимум три вещи.
Во-первых, нужны данные о продажах билетов за достаточно длительный период (не-
сколько месяцев или лет). Во-вторых, данные не должны содержать противоречий,
пропусков, аномальных значений и других факторов, которые не позволят выполнить
корректный анализ. В-третьих, необходима дополнительная информация о бизнес-
среде: о конкурентах, рыночных тенденциях, ценах на топливо и пр. Очевидно, что
типичная OLTP-система не может обеспечить ничего из перечисленного. Именно
с пониманием этих проблем приходит осознание необходимости использования
более развитых систем хранения данных, ориентированных на анализ.
Предпосылки появления ХД
Главное требование к OLTP-системам — быстрое обслуживание относительно
простых запросов большого числа пользователей, при этом время ожидания вы-
полнения типового запроса не должно превышать несколько секунд. Со временем
в таких системах начали аккумулироваться большие объемы данных — документы,
сведения о банковских операциях, информация о клиентах, заключенных сделках,
оказанных услугах и т. д.
Постепенно возникло понимание того, что сбор данных не самоцель. Собранная
информация может оказаться весьма полезной в процессе управления организацией,
поиска путей совершенствования деятельности и получения посредством этого кон-
курентных преимуществ. Но для этого нужны системы, которые позволяли бы вы-
полнять не только простейшие действия над данными: подсчитывать суммы, средние,
максимальные и минимальные значения. Появилась потребность в информационных
системах, которые позволяли бы проводить глубокую аналитическую обработку, для
чего необходимо решать такие задачи, как поиск скрытых структур и закономерностей
в массивах данных, вывод из них правил, которым подчиняется данная предметная
область, стратегическое и оперативное планирование, формирование нерегламенти-
рованных запросов, принятие решений и прогнозирование их последствий.
Понимание преимуществ, которые способен дать интеллектуальный анализ,
привело к появлению нового класса систем — информационных систем поддержки
68 Часть I. Теория бизнес-анализа
принятия решений (информационных СППР), ориентированных на аналитическую
обработку данных с целью получения знаний, необходимых для разработки реше-
ний в области управления. Дополнительным стимулом совершенствования этих
систем стали такие факторы, как снижение стоимости высокопроизводительных
компьютеров и расходов на хранение больших объемов информации, появление
возможности обработки больших массивов данных и развитие соответствующих
математических методов. Обобщенная структурная схема информационной СППР
представлена на рис. 2.3.
Оператор
Аналитик
Рис. 2.3. Структура информационной СППР
В основе работы с такой СППР лежат запросы, с которыми к ней обращается
пользователь (лицо, принимающее решение (ЛПР) — менеджер, эксперт или ана-
литик). При этом запросы, допустимые в традиционных системах оперативной
обработки данных, очень примитивны. Например, для банка это может быть запрос
типа «Сколько денег на счету клиента?» или «Сколько денег клиент потратил за
последний месяц?». Очевидно, что ценность информации, полученной с помощью
подобного запроса, невелика. В то же время аналитическая система может ответить
на гораздо более сложные запросы, например: «Определить среднее время между
выставлением и оплатой счета для каждой категории клиентов».
В процессе разработки систем анализа информации и методологии их приме-
нения обнаружилось, что для эффективного функционирования такие системы
должны быть организованы несколько иным способом, чем тот, который приме-
няется в OLTP-системах. Это обусловлено следующими причинами.
□ Для выполнения сложных аналитических запросов необходима обработка
больших массивов данных из разнообразных источников.
□ Для выполнения запросов, связанных с анализом тенденций, прогнозированием
протяженных во времени процессов, необходимы исторические данные, накоп-
ленные за достаточно длительный период, что не обеспечивается обычными
OLTP-системами.
□ Данные, используемые для целей анализа и обслуживания аналитических за-
просов, отличаются от используемых в обычных OLTP-системах. При аналити-
Глава 2. Консолидация данных 69
ческой обработке предпочтение отдается не детальным данным, а обобщенным
(агрегированным). Очевидно, что для анализа продаж крупного супермаркета
интерес представляет не информация об отдельных покупках, а скорее сведения
о продажах в течение определенных временных интервалов (например, недели
или месяца).
В связи с этим можно выделить ряд принципиальных отличий СППР и OLTP-
систем. Эти отличия представлены в табл. 2.1.
Таблица 2.1. Отличия СППР и OLTP-систем
Свойство OLTP-система СППР
Цели использования данных Быстрый поиск, простей- шие алгоритмы обработки Аналитическая обработка с целью поиска скрытых закономерностей, построения прогнозов и моде- лей и т. д.
Уровень обобще- ния (детализации) данных Детализированные Как детализированные, так и обоб- щенные (агрегированные)
Требования к каче- ству данных Возможны некорректные данные (ошибки регистра- ции, ввода и т. д.) Ошибки в данных не допускаются, поскольку могут привести к не- корректной работе аналитических алгоритмов
Формат хранения данных Данные могут храниться в различных форматах в зависимости от при- ложения, в котором они были созданы Данные хранятся и обрабатываются в едином формате
Время хранения данных Как правило, не более года (в пределах отчетного периода) Годы, десятилетия
Изменение данных Данные могут добавлять- ся, изменяться и удалять- ся Допускается только пополнение; ранее добавленные данные изменять- ся не должны, что позволяет обеспе- чить их хронологию
Периодичность обновления Часто, но в небольших объемах Редко, но в больших объемах
Доступ к данным Должен быть обеспечен доступ ко всем текущим (оперативным) данным Должен быть обеспечен доступ к историческим (то есть накоплен- ным за достаточно длительный период времени) данным с соблюдением их хронологии
Характер выполня- емых запросов Стандартные, настроен- ные заранее Нерегламентированные, формируе- мые аналитиком «на лету» в зависи- мости от требуемого анализа
Время выполнения запроса Несколько секунд До нескольких минут
70 Часть I. Теория бизнес-анализа
Как видно из табл. 2.1, требования к СППР и OLTP-системам существенно
отличаются. Поэтому в СППР используются специализированные базы данных
которые называются хранилищами данных (ХД). Хранилища данных ориентиро-
ваны на аналитическую обработку и удовлетворяют требованиям, предъявляемым
к системам поддержки принятия решений.
Основные особенности концепции ХД
В настоящее время однозначного определения ХД не существует, из-за того что
разработано большое количество различных архитектур и технологий ХД, а сами
хранилища используются для решения самых разнообразных задач. Каждый автор
вкладывает в это понятие свое видение вопроса. Обобщая требования, предъявля-
емые к СППР, можно дать следующее определение ХД, которое не претендует на
полноту и однозначность, но позволяет понять основную идею.
ОПРЕДЕЛЕНИЕ---------------------------------------------------------
Хранилище данных — разновидность систем хранения, ориентированная на поддержку про-
цесса анализа данных, обеспечивающая целостность, непротиворечивость и хронологию
данных, а также высокую скорость выполнения аналитических запросов.
Важнейшим элементом ХД является семантический слой — механизм, позволя-
ющий аналитику оперировать данными посредством бизнес-терминов предметной
области. Семантический слой дает пользователю возможность сосредоточиться на
анализе и не задумываться о механизмах получения данных.
Типичное ХД существенно отличается от обычных систем хранения данных.
Главным отличием являются цели использования. Например, регистрация про-
даж и выписка соответствующих документов — задача уровня OLTP-систем,
использующих обычные реляционные СУБД. Анализ динамики продаж и спроса
за несколько лет, позволяющий выработать стратегию развития фирмы и спла-
нировать работу с поставщиками и клиентами, удобнее всего выполнять при
поддержке ХД.
Другое важное отличие заключается в динамике изменения данных. Базы
данных в OLTP-системах характеризуются очень высокой динамикой изменения
записей из-за повседневной работы большого числа пользователей (откуда, кстати,
велика вероятность появления противоречий, ошибок, нарушения целостности
данных и т. д.). Что касается ХД, то данные из него не удаляются, а пополнение
происходит в соответствии с определенным регламентом (раз в час, день, неделю,
в определенное время).
Основные требования к ХД
Чтобы ХД выполняло функции, соответствующие его основной задаче — поддерж-
ке процесса анализа данных, — оно должно удовлетворять требованиям, сформу-
лированным Р Кимбаллом, одним из авторов концепции ХД:
Глава 2. Консолидация данных 71
д высокая скорость получения данных из хранилища;
д автоматическая поддержка внутренней непротиворечивости данных;
□ возможность получения и сравнения срезов данных;
д наличие удобных средств для просмотра данных в хранилище;
□ обеспечение целостности и достоверности хранящихся данных.
Чтобы соблюсти все перечисленные требования, для построения и работы
ХД, как правило, используется не одно приложение, а система, в которую входит
несколько программных продуктов. Одни из них представляют собой собственно
систему хранения данных, другие — средства их просмотра, извлечения, загрузки
ИТ. д.
В последние десятилетия технология ХД стремительно развивается. Десятки
компаний предлагают на рынке свои решения в области ХД, и тысячи организаций
уже используют это мощное средство поддержки аналитических проектов.
2.3. Основные концепции хранилищ данных
Основные положения концепции ХД
Принято считать, что у истоков концепции ХД стоял технический директор ком-
пании Prism Solutions Билл Инмон, который в начале 1990-х гг. опубликовал ряд
работ, ставших основополагающими для последующих исследований в области
аналитических систем.
В основе концепции ХД лежат следующие положения:
□ интеграция и согласование данных из различных источников, таких как обыч-
ные системы оперативной обработки, базы данных, учетные системы, офисные
документы, электронные архивы, расположенные как внутри предприятия, так
и во внешнем окружении;
□ разделение наборов данных, используемых системами выполнения транзакций
и СППР.
Инмон дал следующее определение ХД: предметно-ориентированный, интегри-
рованный, неизменяемый и поддерживающий хронологию набор данных, предназна-
ченный для обеспечения принятия управленческих решений.
Под предметной ориентированностью в данном случае подразумевается, что ХД
должно разрабатываться с учетом специфики конкретной предметной области, а не
аналитических приложений, с которыми его предполагается использовать. Струк-
тура ХД должна отражать представления аналитика об информации, с которой ему
приходится работать.
Интегрированность означает, что должна быть обеспечена возможность за-
грузки в ХД информации из источников, поддерживающих различные форматы
данных и созданных в различных приложениях — учетных системах, базах дан-
ных, электронных таблицах и других офисных приложениях, поддерживающих
72 Часть I. Теория бизнес-анализа
структурированность данных (например, текстовые файлы с разделителями).
При этом данные, допускающие различный формат (например, числа, дата и вре-
мя), в процессе загрузки должны быть преобразованы к единому представлению.
Кроме того, очень важно проверить загружаемые данные на целостность и не-
противоречивость, обеспечить необходимый уровень их обобщения (агрегирова-
ния). Объем данных в хранилище должен быть достаточным для эффективного
решения аналитических задач, поэтому в ХД может накапливаться информация
за несколько лет и даже десятилетий.
Принцип неизменчивости предполагает, что, в отличие от обычных систем опе-
ративной обработки данных, в ХД данные после загрузки не должны подвергаться
каким-либо изменениям, за исключением добавления новых данных.
И наконец, поддержка хронологии означает соблюдение порядка следования за-
писей, для чего в структуру ХД вводятся ключевые атрибуты Дата и Время. Кроме
того, если физически упорядочить записи в хронологическом порядке, например
в порядке возрастания атрибута Дата, можно уменьшить время выполнения ана-
литических запросов.
Использование концепции ХД в СППР и анализе данных способствует дости-
жению таких целей, как:
□ своевременное обеспечение аналитиков и руководителей всей информацией,
необходимой для выработки обоснованных и качественных управленческих
решений;
□ создание единой модели представления данных в организации;
□ создание интегрированного источника данных, предоставляющего удобный
доступ к разнородной информации и гарантирующего получение одинаковых
ответов на одинаковые запросы из различных аналитических приложений.
Задачи, решаемые ХД
Процесс разработки ХД весьма трудоемок, некоторые организации затрачивают на
него несколько месяцев и даже лет, а также вкладывают значительные финансовые
средства. Основными задачами, которые требуется решить в процессе разработки
ХД, являются:
□ выбор структуры хранения данных, обеспечивающей высокую скорость выпол-
нения запросов и минимизацию объема оперативной памяти;
□ первоначальное заполнение и последующее пополнение хранилища;
□ обеспечение единой методики работы с разнородными данными и создание
удобного интерфейса пользователя.
Круг задач интеллектуального анализа данных весьма широк, а сами задачи
существенно различаются по уровню сложности. Поэтому в зависимости от спе-
цифики решаемых задач и уровня их сложности архитектура ХД и модели данных,
используемых для их построения, могут различаться. Обобщенная концептуальная
схема ХД представлена на рис. 2.4.
Глава 2. Консолидация данных 73
Пользователь
Рис. 2.4. Концептуальная схема ХД
Согласно схеме данные извлекаются из различных источников и загружаются
в ХД, которое содержит как собственно данные, представленные в соответствии
с некоторой моделью, так и метаданные.
Детализированные и агрегированные данные
Данные в ХД хранятся как в детализированном, так и в агрегированном виде. Дан-
ные в детализированном виде поступают непосредственно из источников данных
и соответствуют элементарным событиям, регистрируемым OLTP-системами.
Такими данными могут быть ежедневные продажи, количество произведенных
изделий и т. д. Это неделимые значения, попытка дополнительно детализировать
которые лишает их логического смысла.
Многие задачи анализа (например, прогнозирование) требуют использования
данных определенной степени обобщения. Например, суммы продаж, взятые по дням,
могут дать очень неравномерный ряд данных, что затруднит выявление характер-
ных периодов, закономерностей или тенденций. Однако, если обобщить эти данные
74 Часть I. Теория бизнес-анализа
в пределах недели или месяца и взять сумму, среднее, максимальное и минимальное
значения за соответствующий период, то полученный ряд может оказаться более
информативным. Процесс обобщения детализированных данных называется агре-
гированием, а сами обобщенные данные — агрегированными (иногда — агрегатами).
Обычно агрегированию подвергаются числовые данные (факты), они вычисляются
и содержатся в ХД вместе с детализированными данными.
Поскольку один и тот же набор детализированных данных может породить не-
сколько наборов агрегированных данных с различной степенью обобщения, объем
ХД возрастает, иногда существенно. Например, набор, содержащий данные о про-
дажах по дням в течение года, помимо своих 360 значений, порождает 52 значения
с обобщением по неделям и 12 — по месяцам. Если при этом вычисляются все виды
агрегации — сумма, среднее, максимальное и минимальное значения за соответ-
ствующий период, — то количество хранящихся агрегированных значений составит
уже (52 + 12) • 4 = 256. Иногда это приводит к «взрывному», неконтролируемому
росту ХД и вызывает серьезные технические проблемы: хранилище «распухает»,
из-за того что непрерывный поток входных данных автоматически агрегируется
в соответствии с настройками ХД. Однако с этим приходится мириться: если бы
агрегированные данные не содержались в ХД, а вычислялись в процессе выполне-
ния запросов, время выполнения запроса увеличилось бы в несколько раз.
Метаданные
Слово «метаданные» (от греч. meta и лат. data) буквально переводится как «данные
о данных». Метаданные в широком смысле необходимы для описания значения
и свойств информации с целью лучшего ее понимания, использования и управле-
ния ею. Любой человек, который читал книги или пользовался библиотекой, в той
или иной мере имел дело с метаданными.
ПРИМЕР-------------------------------------------------------------
Всем хорошо известно, что в любой книге, помимо собственно текста, содержится значитель-
ное количество дополнительной информации. Цель ее заключается в том, чтобы, во-первых,
помочь читателю быстрее ознакомиться с содержимым книги и осмыслить его, во-вторых,
описать структуру книги для более эффективного поиска нужной информации. Для решения
первой задачи служат такие элементы, как аннотация, комментарии, глоссарий, приме-
чания ит. д. Для поиска нужной информации используются оглавление, названия глав,
параграфов и разделов, номера страниц, колонтитулы, предметный указатель ит. д. Кро-
ме этого, читателю могут понадобиться сведения об авторах или об издательстве. Вся эта
информация, которая не является частью книги, а служит для повышения эффективности
работы с ней, и представляет собой метаданные. В библиотеке метаданные применяются
для поиска нужных изданий и отслеживания их перемещений, например, систематический
или алфавитный каталоги, в которых используются названия книг, фамилии авторов, год
издания ит. д. Таким образом, метаданные имеют очень большое значение при работе
с различного рода информацией.
С точки зрения IT-технологий метаданные — любая информация, необходи-
мая для анализа, проектирования, построения, внедрения и применения ком-
Глава 2. Консолидация данных 75
пьютерной информационной системы. Одно из основных назначений метадан-
ных — повышение эффективности поиска. Поисковые запросы, использующие
метаданные, делают возможным выполнение сложных операций по фильтрации
и отбору данных.
Если рассматривать понятие «метаданные» в контексте технологии ХД, то его
можно определить следующим образом.
ОПРЕДЕЛЕНИЕ---------------------------------------------------------
Метаданные — высокоуровневые средства отражения информационной модели и опи-
сания структуры данных, используемой в ХД. Метаданные должны содержать описание
структуры данных хранилища и структуры данных импортируемых источников. Метаданные
хранятся отдельно отданных в так называемом репозитарии метаданных.
Метаданные являются ключевым фактором успеха при разработке и внедре-
нии ХД. Они содержат всю информацию, необходимую для извлечения, преобра-
зования и загрузки данных из различных источников, а также для последующего
использования и интерпретации данных, содержащихся в ХД.
Можно выделить два уровня метаданных — технический (административный)
и бизнес-уровень. Технический уровень содержит метаданные, необходимые для
обеспечения функционирования хранилища (статистика загрузки данных и их
использования, описание модели данных и т. д.). Бизнес-метаданные обеспечи-
вают пользователю возможность концентрироваться на процессе анализа, а не
на технических аспектах работы с хранилищем; они включают бизнес-термины
и определения, которыми привык оперировать пользователь.
Фактически бизнес-метаданные представляют собой описание предметной облас-
ти, для работы в которой создается аналитическая система или ХД. К формированию
бизнес-метаданных должны активно привлекаться эксперты и аналитики, которые
впоследствии и будут использовать систему для получения аналитических отчетов.
Бизнес-метаданные описывают объекты предметной области, информация о ко-
торых содержится в ХД, — атрибуты объектов и их возможные значения, соответ-
ствующие поля в таблицах и т. д. Бизнес-метаданные образуют так называемый
семантический слой. Пользователь оперирует близкими ему терминами предметной
области: товар, клиент, продажи, покупки и т. д., а семантический слой транслирует
бизнес-термины в низкоуровневые запросы к данным в хранилище.
Способы использования ХД
С помощью аналитического приложения, используемого совместно с ХД, можно
формировать запросы и получать по ним данные из хранилища. Данные могут
визуализироваться непосредственно либо подвергаться обработке средствами
аналитического приложения, тогда визуализируются результаты этой обработки.
Спектр аналитических задач очень широк. Соответственно, и методики при-
менения ХД для решения тех или иных задач весьма разнообразны. Тем не менее
можно выделить три основных подхода к использованию ХД:
76 Часть I. Теория бизнес-анализа
□ регулярные отчеты — подготовка отчетов стандартных форм, получаемых мно-
гократно с определенной периодичностью;
□ нерегламентированные запросы — возможность получать ответы на нестандарт-
ные, сформированные «по требованию» вопросы;
□ интеллектуальный анализ данных — поддержка процесса интеллектуального
анализа больших массивов данных с целью выявления скрытых закономерно-
стей, структур и объектов, построения моделей, прогнозов и т. д.
Краткий обзор архитектур ХД
Разработка и построение корпоративного ХД — это дорогостоящая и трудоемкая
задача. Успешность внедрения ХД во многом зависит от уровня информатизации
бизнес-процессов в компании, установившихся информационных потоков, объема
и структуры используемых данных, требований к скорости выполнения запро-
сов и частоте обновления хранилища, характера решаемых аналитических задач
и т. д. Чтобы приблизить ХД к условиям и специфике конкретной организации,
в настоящее время разработано несколько архитектур хранилищ — реляционные,
многомерные, гибридные и виртуальные.
Реляционные ХД используют классическую реляционную модель, характерную для
оперативных регистрирующих OLTP-систем. Данные хранятся в реляционных табли-
цах, но образуют специальные структуры, эмулирующие многомерное представление
данных. Такая технология обозначается аббревиатурой ROLAP — Relational OLAP.
Многомерные ХД реализуют многомерное представление данных на физическом
уровне в виде многомерных кубов. Данная технология получила название MOLAP —
Multidimensional OLAP.
Гибридные ХД сочетают в себе свойства как реляционной, так и многомерной
модели данных. В гибридных ХД детализированные данные хранятся в реляцион-
ных таблицах, а агрегаты — в многомерных кубах. Такая технология построения ХД
называется HOLAP — Hybrid OLAP.
Виртуальные ХД не являются хранилищами данных в привычном понимании.
В таких системах работа ведется с отдельными источниками данных, но при этом
эмулируется работа обычного ХД. Иначе говоря, данные не консолидируются фи-
зически, а собираются непосредственно в процессе выполнения запроса.
Кроме того, все ХД можно разделить на одноплатформенные и кросс-платфор-
менные. Одноплатформенные ХД строятся на базе только одной СУБД, а кросс-
платформенные могут строиться на базе нескольких СУБД.
2.4. Многомерные хранилища данных
Основное назначение многомерных хранилищ данных (МХД) — поддержка систем,
ориентированных на аналитическую обработку данных, поскольку такие хранилища
лучше справляются с выполнением сложных нерегламентированных запросов.
Глава 2. Консолидация данных 77
Многомерная модель данных, лежащая в основе построения многомерных хра-
нилищ данных, опирается на концепцию многомерных кубов, или гиперкубов. Они
представляют собой упорядоченные многомерные массивы, которые также часто
называют OLAP-кубами (аббревиатура OLAP расшифровывается как On-Line
Analytical Processing — оперативная аналитическая обработка). Технология OLAP
представляет собой методику оперативного извлечения нужной информации из
больших массивов данных и формирования соответствующих отчетов.
Основы многомерного представления данных
Сущность многомерного представления данных состоит в следующем. Большинство
реальных бизнес-процессов описывается множеством показателей, свойств, атрибу-
тов и т. д. Например, для описания процесса продаж могут понадобиться сведения
о наименованиях товаров или их групп, о поставщике и покупателе, о городе, где
производились продажи, а также о ценах, количествах проданных товаров и общих
суммах. Кроме того, для отслеживания процесса во времени должен быть введен
в рассмотрение такой атрибут, как дата. Если собрать всю эту информацию в таблицу,
то она окажется сложной для визуального анализа и осмысления. Более того, она
может оказаться избыточной: если, например, один и тот же товар продавался в один
и тот же день в различных городах, то придется несколько раз повторить одно и то же
соответствие «город — товар» с указанием различных суммы и количества. Все это
способно окончательно запутать и сбить с толку любого, кто попытается извлечь из
такой таблицы полезную информацию с целью анализа текущего состояния продаж
и поиска путей оптимизации процесса торговли. Указанные проблемы возникают по
одной простой причине: в плоской таблице хранятся многомерные данные.
Проясним суть вопроса с помощью геометрической аналогии. Представьте себе
трехмерную фигуру (например, тетраэдр или параллелепипед) и спроецируйте
его на плоскость, а затем по полученной плоской проекции попытайтесь оценить
форму и размеры исходной объемной фигуры. Сделать это будет трудно: во-первых,
потеряна информация об одном измерении, а во-вторых, фигура теперь представ-
лена в совершенно несвойственном ей плоском виде.
Примерно то же самое можно сказать об информации, представленной несколь-
кими рядами данных. Каждый такой ряд (поле таблицы) можно рассматривать как
своего рода информационное измерение, и тогда «плоская» таблица может быть
интерпретирована как результат преобразования многомерной информационной
структуры в совершенно несвойственную ей плоскую форму. Чтобы компенси-
ровать потерю информации от исключения одного или нескольких измерений,
приходится усложнять структуру таблицы, а это в большинстве случаев приводит
к тому, что разобраться в ней становится очень сложно.
Можно пойти другим путем — выполнить декомпозицию информации в не-
сколько более простых таблиц, связать их некоторым набором отношений и перейти
к реляционной модели, которую используют классические базы данных. Однако
доказано, что реляционная модель не является оптимальной с точки зрения задач
анализа, поскольку предполагает высокую степень нормализации, в результате чего
78 Часть I. Теория бизнес-анализа
снижается скорость выполнения запросов. Поэтому разработка многомерной мо-
дели представления данных, которая реализуется с помощью многомерных кубов,
стала естественным шагом.
ЗАМЕЧАНИЕ--------------------------------------------------------------
Не следует пытаться провести геометрическую интерпретацию понятия «многомерный
куб», поскольку это просто служебный термин, описывающий метод представления дан-
ных.
Измерения и факты — базовые понятия
многомерной модели данных
В основе многомерного представления данных лежит их разделение на две груп-
пы — измерения и факты.
Измерения — это категориальные атрибуты, наименования и свойства объ-
ектов, участвующих в некотором бизнес-процессе. Значениями измерений
являются наименования товаров, названия фирм-поставщиков и покупателей,
ФИО людей, названия городов и т. д. Измерения могут быть и числовыми, если
какой-либо категории (например, наименованию товара) соответствует числовой
код, но в любом случае это данные дискретные, то есть принимающие значения
из ограниченного набора. Измерения качественно описывают исследуемый
бизнес-процесс.
Факты — это данные, количественно описывающие бизнес-процесс, непрерыв-
ные по своему характеру, то есть они могут принимать бесконечное множество
значений. Примеры фактов — цена товара или изделия, их количество, сумма
продаж или закупок, зарплата сотрудников, сумма кредита, страховое вознаграж-
дение и т. д.
Структура многомерного куба
Многомерный куб можно рассматривать как систему координат, осями которой
являются измерения, например Дата, Товар, Покупатель. По осям будут откла-
дываться значения измерений — даты, наименования товаров, названия фирм-по-
купателей, ФИО физических лиц и т. д.
В такой системе каждому набору значений измерений (например, «дата — то-
вар — покупатель») будет соответствовать ячейка, в которой можно разместить
числовые показатели (то есть факты), связанные с данным набором. Таким обра-
зом, между объектами бизнес-процесса и их числовыми характеристиками будет
установлена однозначная связь.
Принцип организации многомерного куба поясняется на рис. 2.5.
В ячейке 1 будут располагаться факты, относящиеся к продаже цемента
ООО «Спецстрой» 3 ноября, в ячейке 2 — к продаже плит ЗАО «Пирамида» 6 но-
ября, а в ячейке 3 — к продаже плит ООО «Спецстрой» 4 ноября.
Глава 2. Консолидация данных 79
Многомерный взгляд на измерения Дата, Товар и Покупатель представлен
на рис. 2.6. Фактами в данном случае могут быть Цена, Количество, Сумма. Тогда
выделенный сегмент будет содержать информацию о том, сколько плит, на какую
сумму и по какой цене приобрела фирма ЗАО «Строитель» 3 ноября.
Рис. 2.6. Измерения и факты в многомерном кубе
80 Часть I. Теория бизнес-анализа
Таким образом, информация в многомерном хранилище данных является ло-
гически целостной. Это уже не просто наборы строковых и числовых значений
которые в случае реляционной модели нужно получать из различных таблиц, а це-
лостные структуры типа «кому, что и в каком количестве было продано на данный
момент времени». Преимущества многомерного подхода очевидны.
□ Представление данных в виде многомерных кубов более наглядно, чем сово-
купность нормализованных таблиц реляционной модели, структуру которой
представляет только администратор БД.
□ Возможности построения аналитических запросов к системе, использующей
МХД, более широки.
□ В некоторых случаях использование многомерной модели позволяет значи-
тельно уменьшить продолжительность поиска в МХД, обеспечивая выпол-
нение аналитических запросов практически в режиме реального времени.
Это связано с тем, что агрегированные данные вычисляются предварительно
и хранятся в многомерных кубах вместе с детализированными, поэтому
тратить время на вычисление агрегатов при выполнении запроса уже не
нужно.
В принципе, OLAP-куб может быть реализован и с помощью обычной ре-
ляционной модели. В этом случае имеет место эмуляция многомерного пред-
ставления совокупностью плоских таблиц. Такие системы получили название
ROLAP — Relational OLAP.
Использование многомерной модели данных сопряжено с определенными
трудностями. Так, для ее реализации требуется больший объем памяти. Это
связано с тем, что при реализации физической многомерности используется
большое количество технической информации, поэтому объем данных, который
может поддерживаться МХД, обычно не превышает нескольких десятков гига-
байт. Кроме того, многомерная структура труднее поддается модификации; при
необходимости встроить еще одно измерение требуется выполнить физическую
перестройку всего многомерного куба. На основании этого можно сделать вывод,
что применение систем хранения, в основе которых лежит многомерное представ-
ление данных, целесообразно только в тех случаях, когда объем используемых
данных сравнительно невелик, а сама многомерная модель имеет стабильный
набор измерений.
Работа с измерениями
В процессе поиска и извлечения из гиперкуба нужной информации над его изме-
рениями производится ряд действий, наиболее типичными из которых являются:
□ сечение (срез);
□ транспонирование;
□ свертка;
□ детализация.
Глава 2. Консолидация данных 81
Сечение заключается в выделении подмножества ячеек гиперкуба при фик-
сировании значения одного или нескольких измерений. В результате сечения
получается срез или несколько срезов, каждый из которых содержит информацию,
связанную со значением измерения, по которому он был построен. Например,
если выполнить сечение по значению ЗАО «Строитель» измерения Покупатель,
Ю полученный в результате срез будет содержать информацию об истории про-
даж всех товаров данного предприятия, которую можно будет свести в плоскую
таблицу. При необходимости ограничить информацию только одним товаром
(например, керамзитом) потребуется выполнить еще одно сечение, но теперь уже
по значению Керамзит измерения Товар. Результатом построения двух срезов бу-
дет информация о продажах одной фирме по одному товару. Манипулируя таким
образом сечениями гиперкуба, пользователь всегда может получить информацию
в нужном разрезе. Затем на основе построенных срезов может быть сформирована
кросс-таблица и с ее помощью очень быстро получен необходимый отчет. Данная
методика лежит в основе технологии OLAP-анализа.
На рис. 2.7 схематично представлены сечения гиперкуба. Слева сечение вы-
полнено при некотором фиксированном значении измерения Дата. Полученный
срез (светло-серая область) содержит информацию обо всех товарах и всех поку-
пателях на определенную дату. На правом фрагменте рисунка получено два среза,
пересечение которых будет содержать информацию обо всех покупателях, но на
определенный товар и на определенную дату.
Рис. 2.7. Сечения гиперкуба
Транспонирование (вращение) обычно применяется к плоским таблицам, полу-
ченным, например, в результате среза, и позволяет изменить порядок представле-
ния измерений таким образом, что измерения, отображавшиеся в столбцах, будут
отображаться в строках, и наоборот. В ряде случаев транспонирование позволяет
сделать таблицу более наглядной.
82 Часть I. Теория бизнес-анализа
Операции свертки (группировки) и детализации (декомпозиции) возможны
только тогда, когда имеет место иерархическая подчиненность значений измере-
ний. При свертке одно или несколько подчиненных значений измерений заменя-
ются теми значениями, которым они подчинены. При этом уровень обобщения
данных уменьшается. Так, если отдельные товары образуют группы, например
Стройматериалы, то в результате свертки вместо отдельных наименований то-
варов будет указано наименование группы, а соответствующие им факты будут
агрегированы. Проиллюстрируем результаты свертки: в табл. 2.2 представлена
исходная таблица, а в табл. 2.3 — результат ее свертки по измерению Товар.
Таблица 2.2. Исходная таблица
Группа Товар Сумма
Стройматериалы Кирпич 22 000
Цемент 12 000
Керамзит 4500
Доска 7400
Инструмент Отвертка 1200
Электропила 7600
Дрель 2450
Шпатель 780
Таблица 2.3. Результат свертки исходной таблицы по измерению «Товар»
Группа Сумма
Стройматериалы 45 900
Инструмент 12 030
Детализация — это процедура, обратная свертке; уровень обобщения данных
уменьшается. При этом значения измерений более высокого иерархического уровня
заменяются одним или несколькими значениями более низкого уровня, то есть вме-
сто наименований групп товаров отображаются наименования отдельных товаров.
2.5. Реляционные хранилища данных
В начале 1970-х гг. англо-американский ученый Э. Кодд разработал реляционную
модель организации хранимых данных, которая положила начало новому этапу
эволюции СУБД. Благодаря простоте и гибкости реляционная модель стала доми-
нирующей, а реляционные СУБД стали промышленным стандартом де-факто.
ОПРЕДЕЛЕНИЕ-----------------------------------------------------
Реляционная база данных (relational database) — совокупность отношений, содержащих
всю информацию, которая должна храниться в базе. Физически это выражается в том,
что информация хранится в виде двумерных таблиц, связанных с помощью ключевых
полей.
Глава 2. Консолидация данных 83
Применение реляционной модели при создании ХД в ряде случаев позволяет
получить преимущества над многомерной технологией, особенно в части эффектив-
ности работы с большими массивами данных и использования памяти компьютера.
Па основе реляционных хранилищ данных (РХД) строятся ROLAP-системы, и эта
идея тоже принадлежит Кодду.
В основе технологии РХД лежит принцип, в соответствии с которым измерения
хранятся в плоских таблицах так же, как и в обычных реляционных СУБД, а факты
(агрегируемые данные) — в отдельных специальных таблицах этой же базы данных.
При этом таблица фактов является основой для связанных с ней таблиц измерений.
Она содержит количественные характеристики объектов и событий, совокупность
которых предполагается в дальнейшем анализировать.
Схемы построения РХД
На логическом уровне различают две схемы построения РХД — «звезда» и «сне-
жинка».
При использовании схемы «звезда» центральной является таблица фактов,
с которой связаны все таблицы измерений. Таким образом, информация о каждом
измерении располагается в отдельной таблице, что упрощает их просмотр, а саму
схему делает логически прозрачной и понятной пользователю (рис. 2.8).
Рис. 2.8. Схема построения РХД «звезда»
84 Часть I. Теория бизнес-анализа
Однако размещение всей информации об измерении в одной таблице оказы-
вается не всегда оправданным. Например, если продаваемые товары объединены
в группы (имеет место иерархия), то придется тем или иным способом показать,
к какой группе относится каждый товар, что приведет к многократному повто-
рению названий групп. Это не только вызовет рост избыточности, но и повысит
вероятность возникновения противоречий (если, например, один и тот же т
ошибочно отнесут к разным группам).
Для более эффективной работы с иерархическими измерениями была разра-
ботана модификация схемы «звезда», которая получила название «снежинка».
Главной особенностью схемы «снежинка» является то, что информация об одном
измерении может храниться в нескольких связанных таблицах. То есть если
хотя бы одна из таблиц измерений имеет одну или несколько связанных с ней
других таблиц измерений, в этом случае будет применяться схема «снежин »
(рис. 2.9).
Рис. 2.9. Схема построения РХД «снежинка»
Основное функциональное отличие схемы «снежинка» от схемы «звезда» — это
возможность работы с иерархическими уровнями, определяющими степень дета-
лизации данных. В приведенном примере схема «снежинка» позволяет работать
с данными на уровне максимальной детализации, например с каждым товаром
Глава 2. Консолидация данных 85
отдельно, или использовать обобщенное представление по группам товаров с со-
ответствующей агрегацией фактов.
Выбор схемы для построения РХД зависит от используемых механизмов сбора
и обработки данных. Каждая из схем имеет свои преимущества и недостатки, ко-
торые, однако, могут проявляться в большей или меньшей степени в зависимости
от особенностей функционирования ХД в целом.
К преимуществам схемы «звезда» можно отнести:
□ простоту и логическую прозрачность модели;
□ более простую процедуру пополнения измерений, поскольку приходится рабо-
тать только с одной таблицей.
Недостатками схемы «звезда» являются:
□ медленная обработка измерений, поскольку одни и те же значения измерений
могут встречаться несколько раз в одной и той же таблице;
□ высокая вероятность возникновения несоответствий в данных (в частности,
противоречий), например, из-за ошибок ввода.
Преимуществами схемы «снежинка» являются следующие:
□ она ближе к представлению данных в многомерной модели;
□ процедура загрузки из РХД в многомерные структуры более эффективна и про-
ста, поскольку загрузка производится из отдельных таблиц;
□ намного ниже вероятность появления ошибок, несоответствия данных;
□ большая, по сравнению со схемой «звезда», компактность представления дан-
ных, поскольку все значения измерений упоминаются только один раз.
Недостатки схемы «снежинка»:
□ достаточно сложная для реализации и понимания структура данных;
□ усложненная процедура добавления значений измерений.
Кроме того, существует ряд технических особенностей, которые могут опреде-
лить предпочтения разработчиков РХД при выборе схемы его построения.
Преимущества и недостатки РХД
Основные преимущества РХД следующие:
□ практически неограниченный объем хранимых данных;
□ поскольку реляционные СУБД лежат в основе построения многих систем опе-
ративной обработки (OLTP), которые обычно являются главными источника-
ми данных для ХД, использование реляционной модели позволяет упростить
процедуру загрузки и интеграции данных в хранилище;
□ при добавлении новых измерений данных нет необходимости выполнять слож-
ную физическую реорганизацию хранилища, в отличие, например, от много-
мерных ХД;
86 Часть I. Теория бизнес-анализа
□ обеспечиваются высокий уровень защиты данных и широкие возможности
разграничения прав доступа.
Главный недостаток реляционных хранилищ данных заключается в том,
что при использовании высокого уровня обобщения данных и иерархичности
измерений в таких хранилищах начинают «размножаться» таблицы агрегатов.
В результате скорость выполнения запросов реляционным хранилищем замед-
ляется.
В то же время в многомерных хранилищах, где данные хранятся в виде много-
мерных кубов, эта проблема практически не возникает и в большинстве случаев
удается достичь более высокой скорости выполнения запросов.
Таким образом, выбор реляционной модели при построении ХД целесообразен
в следующих случаях.
□ Значителен объем хранимых данных (многомерные ХД становятся неэффек-
тивными).
□ Иерархия измерений несложная (другими словами, немного агрегированных
данных).
□ Требуется частое изменение размерности данных. При использовании реляци-
онной модели можно ограничиться добавлением новых таблиц, а для многомер-
ной модели придется выполнять сложную перестройку физической структуры
хранилища.
2.6. Гибридные хранилища данных
Многомерная и реляционная модели хранилищ данных имеют свои преимущества
и недостатки. Например, многомерная модель позволяет быстрее получить ответ
на запрос, но не дает возможности эффективно управлять такими же большими
объемами данных, как реляционная модель.
Логично было бы использовать такую модель ХД, которая представляла
бы собой комбинацию реляционной и многомерной моделей и позволяла бы
сочетать высокую производительность, характерную для многомерной модели,
и возможность хранить сколь угодно большие массивы данных, присущую ре-
ляционной модели. Такая модель, сочетающая в себе принципы реляционной
и многомерной моделей, получила название гибридной, или HOLAP (Hybrid
OLAP).
Хранилища данных, построенные на основе HOLAP, называются гибридными
хранилищами данных (ГХД) (рис. 2.10).
Главным принципом построения ГХД является то, что детализированные
данные хранятся в реляционной структуре (ROLAP), которая позволяет хранить
большие объемы данных, а агрегированные — в многомерной (MOLAP), которая
позволяет увеличить скорость выполнения запросов (поскольку при выполнении
аналитических запросов уже не требуется вычислять агрегаты).
Глава 2. Консолидация данных 87
Источники данных
Хранилище данных
Детализированные
данные
ROLAP
Агрегированные
данные
MOLAP
Метаданные
Технические
Бизнес-метаданные
Визуализация, *>тче~ы
Пользователь
Рис. 2.10. Гибридное ХД
ПРИМЕР-----------------------------------------------------------------
В супермаркете, ежедневно обслуживающем десятки тысяч покупателей, установлена
регистрирующая OLTP-система. При этом максимальному уровню детализации регистри-
руемых данных соответствует покупка по одному чеку, в котором указываются общая сумма
покупки, наименования или коды приобретенных товаров и стоимость каждого товара.
Оперативная информация, состоящая из детализированных данных, консолидируется
в реляционной структуре ХД. С точки зрения анализа представляют интерес обобщенные
данные, например, по группам товаров, отделам или некоторым интервалам дат. Поэтому
исходные детализированные данные агрегируются и вычисленные агрегаты сохраняются
в многомерной структуре гибридного ХД.
88
часть I. Теория бизнес-анализа
Если данные, поступающие из OLTP-системы, имеют большой объем (несколько десятков
тысяч записей в день и более) и высокую степень детализации, а для анализа использу-
ются в основном обобщенные данные, гибридная архитектура хранилища оказывается
наиболее подходящей.
Недостатком гибридной модели является усложнение администрирования
ХД из-за более сложного регламента его пополнения, поскольку при этом не-
обходимо согласовывать изменения в реляционной и многомерной структурах.
Однако существует и ряд преимуществ, делающих гибридную модель ХД при-
влекательной.
□ Хранение данных в реляционной структуре делает их в большей степени сис-
темно независимыми, что особенно важно при использовании в управлении
предприятием экономической информации (показателей).
□ Реляционная структура формирует устойчивые и непротиворечивые опорные
точки для многомерного хранилища.
□ Поскольку реляционное хранилище поддерживает актуальность и корректность
данных, оно обеспечивает очень надежный транспортный уровень для доставки
информации в многомерное хранилище.
Витрины данных
С гибридной архитектурой ХД обычно связывают еще одно важное понятие —
витрины данных (data marts). Ситуация, когда для анализа необходима вся инфор-
мация, содержащаяся в ХД, возникает крайне редко. В большинстве случаев под-
разделения предприятия или организации используют профильную информацию,
касающуюся только того направления деятельности, которое они обслуживают.
Как правило, объем такой тематической информации невелик по сравнению с об-
щим объемом хранилища и вполне эффективно может обслуживаться MOLAP-
системой. Концепция витрины данных заключается в выделении профильных
данных, чаще всего используемых по определенному направлению деятельности,
в отдельный набор и в организации его хранения в отдельной многомерной БД,
подключенной к централизованному РХД.
Глава 2. Консолидация данных 89
Чаще всего для построения витрин данных используется многомерная модель,
поскольку при небольших объемах данных она обеспечивает более быстрый отклик
на запросы, чем реляционная, хотя в некоторых случаях используется и реляцион-
ная модель.
ОПРЕДЕЛЕНИЕ-----------------------------------------------------------
Витрина данных — специализированное локальное тематическое хранилище, подключен-
ное к централизованному ХД и обслуживающее отдельное подразделение организации или
определенное направление ее деятельности.
На рис. 2.11 изображена система консолидации с использованием витрин данных.
Централизованное хранилище данных
ROLAP
Пользователь Пользователь
Пользователь Пользователь
Рис. 2.11. Консолидация с использованием витрин данных
Использование витрин данных имеет следующие преимущества, делающие их
ближе и доступнее конечному пользователю:
□ содержание данных, тематически ориентированных на конкретного пользова-
теля;
□ относительно небольшой объем хранимых данных, на организацию и поддерж-
ку которых не требуется значительных затрат;
□ улучшенные возможности в разграничении прав доступа пользователей, так как
каждый из них работает только со своей витриной и имеет доступ только к ин-
формации, относящейся к определенному направлению деятельности.
90 Часть I. Теория Оизнес-анализа
Использование витрин данных наиболее эффективно в крупных организа
циях с большим количеством независимых подразделений, каждое из которые
решает собственные аналитические задачи. В этом случае витрины данных могу]
применяться как самостоятельно, так и вместе с централизованным ХД. Однакс
использование самостоятельных витрин данных сопряжено с такой проблемой, Kai
многократное дублирование данных в различных витринах, что в конечном итоп
может привести к противоречивости данных.
Использование витрин данных вместе с централизованными ХД позволяет
повысить достоверность данных, получаемых пользователями витрин, поскольку
витрины «питаются» данными из хранилищ, где автоматически поддерживаете;
целостность и непротиворечивость данных и производится их очистка. Кроме того
корпоративная информационная система может эффективно наращиваться з<
счет добавления новых витрин данных. И наконец, использование витрин данны;
позволяет снизить нагрузку на централизованное ХД.
Примером организации централизованного ХД с витринами данных для пред-
приятия с большим количеством подразделений может служить схема, представ-
ленная на рис. 2.12.
Отдел закупок
Отдел продаж
Маркетинговый
отдел
Рекламный
отдел
Рис. 2.12. Централизованное ХД с витринами данных
В настоящее время концепция витрин данных находит очень широкое приме
нение при построении систем бизнес-аналитики, особенно для многопрофильны!
предприятий со сложной организационной структурой.
Глава 2. Консолидация данных 91
2.7. Виртуальные хранилища данных
При всех положительных сторонах хранилища данных как отдельного консолиди-
рованного источника встречаются ситуации, когда эта идея не работает. Дело в том,
чТо устоявшейся практикой является ночная загрузка собранных за день данных
из OLTP-систем в ХД. Такой регламент позволяет уменьшить нагрузку на OLTP-
систему в течение рабочего дня, то есть в период ее активного использования. Чаще
чем один раз в сутки пополнять ХД смысла не имеет. Однако подобное положение
вещей не обеспечивает возможности анализировать информацию в течение рабо-
чего дня сразу по мере ее поступления. Иногда это очень критично, и приходится
искать альтернативу традиционному (физическому) ХД.
Кроме того, неизбежной проблемой при использовании ХД в бизнес-аналитике
является избыточность. Она снижает эффективность использования дискового
пространства и оперативной памяти серверов, а при очень больших объемах хра-
нящейся и обрабатываемой информации может вызвать снижение производитель-
ности, возрастание времени ожидания отклика на запрос и даже привести к полной
неработоспособности системы. Избыточность в той или иной степени характерна
как для реляционных, так и для многомерных хранилищ.
Ситуация усугубляется еще и тем, что ХД хранят историческую информацию
и реализуют принцип неизменчивости данных. То есть в отличие от обычных
систем оперативной обработки (OLTP-систем), где хранятся лишь актуальные
данные, а данные, утратившие актуальность, уничтожаются, ХД могут только по-
полняться новыми данными, а удаление исторических данных не производится.
Кроме того, часто требуется хранить большие объемы агрегированных данных.
В совокупности эти факторы могут привести к «взрывному» росту объемов ХД.
Хотя ради справедливости заметим, что непрекращающееся развитие информа-
ционных технологий приводит к снижению стоимости хранения информации на
машинных носителях.
Преодолеть вышеперечисленные проблемы позволяет концепция виртуального
хранилища данных (ВХД). В ее основе лежит принцип, в соответствии с которым
данные из локальных источников, внешнего окружения, баз данных и учетных
систем не консолидируются в единое ХД физически, а извлекаются, преобразу-
ются и интегрируются непосредственно при выполнении запроса в оперативной
памяти компьютера. Фактически запросы адресуются непосредственно к источ-
никам данных.
ОПРЕДЕЛЕНИЕ----------------------------------------------------------
Виртуальным хранилищем данных называется система, которая работает с разрозненными
источниками данных и эмулирует работу обычного хранилища данных, извлекая, преобразуя
и интегрируя данные непосредственно в процессе выполнения запроса.
Преимущества такого подхода очевидны.
□ Появляется возможность анализа данных в OLTP-системе сразу после их по-
ступления без ожидания загрузки в хранилище.
92 Часть L Теория бизнес-анализа
□ Минимизируется объем требуемой дисковой и оперативной памяти, по-
скольку отсутствует необходимость хранения исторических данных и много-
численных агрегированных данных для различных уровней обобщения
информации.
□ Наличие в ВХД развитого семантического слоя позволяет аналитику полно-
стью абстрагироваться от проблем, связанных с процессом извлечения данных
из разнообразных источников, и сосредоточиться на решении задач анализа
данных.
При работе с ВХД пользователь, можно сказать, имеет дело с «иллюзией»
хранилища данных (рис. 2.13). Виртуальность предполагает, что ВХД существует
только до тех пор, пока работает соответствующее приложение. Как только оно
завершает работу, виртуальное хранилище прекращает существование.
Виртуальное хранилище данных
Пользователь
Рис. 2.13. Виртуальное ХД
Концепция ВХД имеет ряд недостатков по сравнению с ХД, где информация
консолидируется физически.
□ Увеличивается нагрузка на OLTP-систему, потому что, помимо обычных поль-
зователей, к ней обращаются аналитики с нерегламентированными запросами.
В результате производительность OLTP-системы падает.
□ Источники данных, информация из которых запрашивается в ВХД, могут
оказаться недоступными, если доступ к ним осуществляется по сети или если
Глава 2. Консолидация данных 93
изменилось место их локализации. Временная недоступность хотя бы одного
из источников может привести к невозможности выполнения запроса или к ис-
кажению представленной по нему информации.
□ Отсутствует автоматическая поддержка целостности и непротиворечивости
данных, могут быть утеряны отдельные фрагменты документов и т. д.
□ Данные в источниках хранятся в различных форматах и кодировках, что может
привести к ошибкам при их обработке и к искажению информации, полученной
в ответ на запрос.
□ Из-за возможной несогласованности моментов пополнения источников данных
и из-за отсутствия поддержки в них хронологии по одному и тому же запросу
в различные моменты времени могут быть получены отличающиеся данные.
□ Практически невозможна работа с данными, накопленными за долгий период
времени, поскольку в ВХД доступны только те данные, которые находятся
в источниках в конкретный момент времени.
Важнейшей особенностью ВХД является то, что они, работая непосредственно
с источниками, содержащими данные оперативного учета, имеют дело с данными
в пределах некоторого периода актуальности. Это связано с тем, что OLTP-систе-
мы не хранят исторические данные. Поэтому если исторические данные играют
важную роль при анализе, то предпочтительно применять разновидности ХД
с физической консолидацией данных. А ВХД следует использовать в системах,
ориентированных на анализ оперативной информации, актуальной только в тече-
ние ограниченного периода.
Довольно типична ситуация, когда оперативные регистрационные данные
заносятся в обычное офисное приложение, например в таблицы Excel. Это могут
быть сведения о поступлении или об отгрузке товара, о наличии его на складе
и т. д. Для такой информации характерна высокая скорость пополнения. Опе-
ративную деятельность, как правило, осуществляют менеджеры по продажам,
складские работники и т. д., то есть персонал, уровень компьютерной подготовки
которого соответствует офисным приложениям. Более стабильная информация,
например, о клиентах или поставщиках хранится в учетной системе, поддержи-
ваемой администратором. При необходимости проанализировать, например, эф-
фективность работы с клиентами на основе их покупательской активности система
самостоятельно обращается к соответствующим источникам (Excel, базы данных,
текстовые файлы и др.), собирая нужную информацию. При этом пользователь
работает с ними как с единым источником информации, несмотря на то что данные
получены из нескольких источников различных типов. Такая ситуация схематично
проиллюстрирована на рис. 2.14.
Даже когда одна и та же фирма выступает и в роли поставщика, и в роли по-
купателя, не происходит дублирования или противоречия. В одном случае запрос
связывает фирму с данными из таблицы «Поставки», а в другом — с данными из
таблицы «Отгрузки». Таким образом, виртуальное хранилище, формируя запрос
«налету», позволяет минимизировать избыточность и более эффективно исполь-
зует дисковое пространство.
94 Часть I. Теория бизнес-анализа
Рис. 2.14. Вариант организации ВХД
Таким образом, применение ВХД оказывается полезным для предприятий,
которые не имеют технических средств и квалифицированного персонала для
поддержки физических ХД. Особенно велики преимущества ВХД при необхо-
димости анализировать самую свежую информацию. В ВХД отсутствует этап
загрузки данных, поэтому временной интервал между появлением информации
в OLTP-системе и ее готовностью к анализу данных минимален. При этом следует
учитывать, что, поскольку ВХД поддерживает историческую информацию только
за период актуальности OLTP-систем, применение такого хранилища оправданно
лишь тогда, когда исторические данные для анализа не требуются.
2.8. Нечеткие срезы
Хороший пример обогащения одной технологии (хранилища данных) другой (не-
четкая логика) демонстрируют нечеткие срезы (fuzzy slices). Под ними понимают-
ся фильтры по измерениям, в которых фигурируют нечеткие величины, например
«все молодые заемщики с небольшим доходом». В реляционных базах данных эту
роль выполняют нечеткие запросы (fuzzy queries, flexible queries), которые впервые
предложены в начале 80-х гг. в работах Д. Дюбуа и Г. Прада.
Глава 2. Консолидация данных 95
Так как информация в ХД присутствует в четком виде, для использования
0 фильтрах нечетких понятий нужно предварительно формализовать их, что дела-
ется при помощи нечетких множеств, описание которых приводится ниже.
Нечеткие множества
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy
logic) являются обобщениями классической теории множеств и классической
формальной логики. Данные понятия были впервые предложены американским
ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой
теории стало наличие нечетких и приближенных рассуждений при описании че-
ловеком процессов, систем, объектов.
Характеристикой нечеткого множества выступает функция принадлежности
(membership function). Обозначим через р(х) степень принадлежности элемен-
та х к нечеткому множеству, представляющую собой обобщение понятия характери-
стической функции обычного множества. Тогда нечетким множеством С называется
множество упорядоченных пар вида С = {р(х) /х}, при этом р(х) может принимать
любые значения в интервале [0, 1], х G X. Значение |1(х) = 0 означает отсутствие
принадлежности к множеству, 1 — полную принадлежность.
Проиллюстрируем это на простом примере. Формализуем неточное определение
«неблагонадежный заемщик». В качестве X (область рассуждений) будет выступать
количество случаев просроченной задолженности по кредиту за последние 6 меся-
цев. Пусть оно изменяется от 0 до 6. Нечеткое множество, определенное экспертом,
может выглядеть следующим образом:
С = {0/0; 0,4/1; 0,7/2; 0,9/3; 1/4; 1/5; 1/6}.
Так, заемщик, совершивший две просрочки, принадлежит к множеству «неблаго-
надежный» со степенью принадлежности 0,7. Для одного банка такое число просро-
чек может быть крайне существенным, для другого — просто тревожным сигналом.
Именно в этом и проявляется нечеткость задания соответствующего множества.
Для переменных, относящихся к непрерывному виду данных, функцию при-
надлежности удобнее задать аналитической формулой и для наглядности изобра-
зить графически. Существует свыше десятка типовых форм кривых для задания
функций принадлежности. Рассмотрим самые популярные кусочно-линейные:
треугольную и трапецеидальную (рис. 2.15).
Рис. 2.15. Типовые функции принадлежности
96 Часть I. Теория бизнес-анализа
Треугольная функция принадлежности определяется тройкой чисел {а, Ь, с), и ее
значение в точке х вычисляется согласно выражению:
р(г) =
с — X ,
---, b < х < с,
с-Ь
О, в остальных случаях.
Аналогично для задания трапецеидальной функции принадлежности необхо-
дима четверка чисел (a, b, с, d):
х-а
Ь — а
И(*) =
d — c
О, в остальных случаях.
Для нечетких множеств, как и для обычных, определены основные логические
операции. Самыми необходимыми для расчетов являются пересечение, объедине-
ние и отрицание.
□ Пересечение двух нечетких множеств А п В (нечеткое «И»):
М(х) = min(pA(x), ps(x)).
□ Объединение двух нечетких множеств АиВ (нечеткое «ИЛИ»):
р(х) = тах(рА(х), Цв(х)).
□ Отрицание нечеткого множества -А:
ц(х) = 1 - цА(х),
где р(х) — результат операции;
Цл(х) — степень принадлежности элементах к множеству А;
Рв(х) — степень принадлежности элементах к множеству В.
Совокупность нечетких множеств, относящихся к одному объекту, образует
лингвистическую переменную. Например, лингвистическая переменная Воз-
раст может принимать значения Молодой, Средний, Пожилой (их еще называют
базовым терм-множеством, или термами). Зададим область рассуждений в виде
Х= {х| 0 <х<90} (годы). Теперь осталось построить функции принадлежности
для каждого терма (рис. 2.16).
Каждая функция принадлежности описывается четверкой чисел: Молодой =
= {0; 0; 12; 40}, Средний = {20; 30; 50; 70}, Преклонный = {50; 60; 90; 90}.
Глава 2. Консолидация данных 97
Принцип формирования нечетких срезов
Лингвистические переменные можно задать для любого измерения, атрибута из-
мерения или факта, значения которого имеют непрерывный вид. Их параметры:
названия, терм-множества, параметры функций принадлежности — будут содер-
жаться в семантическом слое хранилища данных (рис. 2.17).
Детализированные данные
ROLAP
Рис. 2.17. Вариант организации хранилища данных с поддержкой нечетких срезов
Результатом выполнения нечеткого среза, помимо самого подмножества ячеек
гиперкуба, удовлетворяющих заданным условиям, является индекс соответствия
98 Часть I. Теория бизнес-анализа
Рис. 2.18. Нечеткое множество
Рис. 2.19. Алгоритм получения
нечеткого среза
срезу С/е [0,1]. Он представляет собой итого-
вую степень принадлежности к нечетким мно-
жествам измерений и фактов, участвующих
в сечении куба, и рассчитывается для каждой
записи набора данных. Чтобы ускорить выпол-
нение запросов к ХД, часто задают верхнюю
границу индекса соответствия CI > а. Это по-
зволяет уже на уровне SQL-запроса отсеять
записи, которые заведомо не будут удовлет-
ворять минимальному порогу индекса соот-
ветствия (рис. 2.18).
На рисунке видно, что элементы нечет-
кого множества со значениями в интервале
[х(; х2] обеспечат степень принадлежности
не ниже а.
Алгоритм формирования нечеткого среза
иллюстрирует схема (рис. 2.19). На шаге 1
используется семантический слой храни-
лища данных. На шаге 3 в результирующий
SQL-запрос попадают границы с учетом ми-
нимального индекса соответствия а. Шаг 5
предполагает применение нечетких логиче-
ских операций.
Рассмотрим пример. Пусть в хранилище
содержится информация о соискателях вакан-
сий, и срез (четкий) по измерениям Код анке-
ты, Возраст и Стаж работы обеспечивает
следующий набор данных (табл. 2.4).
Очевидно, что Код анкеты — это служебное
поле. Для возраста будем использовать линг-
вистическую переменную, определенную на
рис. 2.16, а для поля Стаж работы — перемен-
ную, определенную на рис. 2.20. Каждая функ-
ция принадлежности описывается числами:
Малый = {0; 0; 6}, Продолжительный = {3; 6;
10; 20}, Большой = {15; 25; 40; 40}.
Таблица 2.4. Срез по измерениям «Возраст» и «Стаж работы»
Код анкеты Возраст Стаж работы
1 23 4
2 34 И
3 31 10
4 54 36
Глава 2. Консолидация данных 99
Код анкеты Возраст Стаж работы
1TL 46 26
6 38 15
7 21 1
23 2
9 30 8
кГ 30 12
цС^дМэлый Продолжительный Большой
Рис. 2.20. Графическое изображение лингвистической переменной «Стаж работы»
Сделаем нечеткий срез «Возраст = Средний и Стаж работы = Продолжитель-
ный». Например, для анкеты 4 получим:
CI = пйп(цСр1.Д|1111.1 (54), Pii|Wll,.1Am,1bllblii (36)) = min 7°2()54’1 = °>8-
Аналогично рассчитаем степени принадлежности к итоговому нечеткому мно-
жеству для каждого претендента, зададим минимальный индекс соответствия,
равный 0,3, и получим результат, показанный в табл. 2.5.
Таблица 2.5. Результат нечеткого среза
Код анкеты Возраст Стаж работы Индекс соответствия
3 31 10 1
9 30 8 1
6 38 15 1
2 34 11 0,9
10 30 12 0,8
8 23 2 0,3
1 23 4 0,3
Нечеткий поиск в хранилищах данных принесет аналитику максимальную поль-
зу в случаях, когда требуется не только извлечь информацию, оперируя нечеткими
понятиями, но и каким-то образом проранжировать ее по убыванию (возрастанию)
степени релевантности запроса. Это позволит ответить на следующие вопросы: каких
клиентов обзвонить в первую очередь, кому сделать рекламное предложение и т. д.
100 Часть I. Теория бизнес-анализа
2.9. Введение в ETL
Извлечение данных из разнотипных источников и перенос их в хранилище данных
с целью дальнейшей аналитической обработки связаны с рядом проблем, основны-
ми из которых являются нижеследующие.
□ Исходные данные расположены в источниках самых разнообразных типов
и форматов, созданных в различных приложениях, и, кроме того, могут ис-
пользовать различную кодировку, в то время как для решения задач анализа
данные должны быть преобразованы в единый универсальный формат, который
поддерживается ХД и аналитическим приложением.
□ Данные в источниках обычно излишне детализированы, тогда как для решения
задач анализа в большинстве случаев требуются обобщенные данные.
□ Исходные данные, как правило, являются «грязными», то есть содержат раз-
личные факторы, которые мешают их корректному анализу.
Поэтому для переноса исходных данных из различных источников в ХД следует
использовать специальный инструментарий, который должен извлекать данные из
источников различного формата, преобразовывать их в единый формат, поддер-
живаемый ХД, а при необходимости — производить очистку данных от факторов,
мешающих корректно выполнять их аналитическую обработку. Такой комплекс
программных средств получил обобщенное название ETL (от англ, extraction,
transformation, loading — «извлечение», «преобразование», «загрузка»). Сам про-
цесс переноса данных и связанные с ним действия называются ETL-процессом,
а соответствующие программные средства — ETL-системами.
ОПРЕДЕЛЕНИЕ--------------------------------------------------------
ETL — комплекс методов, реализующих процесс переноса исходных данных из различ-
ных источников в аналитическое приложение или поддерживающее его хранилище
данных.
Основные цели и задачи процесса ETL
Приложения ETL извлекают информацию из одного или нескольких источников,
преобразуют ее в формат, поддерживаемый системой хранения и обработки, которая
является получателем данных, а затем загружают в нее преобразованную информа-
цию. Изначально ETL-системы использовались для переноса информации из более
ранних версий различных информационных систем в новые. В настоящее время
ETL-системы все более широко применяются именно для консолидации данных
с целью их дальнейшего анализа. Очевидно, что поскольку ХД могут строиться на
основе различных моделей данных (многомерных, реляционных, гибридных), то
и процесс ETL должен разрабатываться с учетом всех особенностей используемой
в ХД модели. Кроме того, желательно, чтобы ETL-система была универсальной,
то есть могла извлекать и переносить данные как можно большего числа типов
и форматов.
Глава 2. Консолидация данных 101
Независимо от особенностей построения и функционирования ETL-система
должна обеспечивать выполнение трех основных этапов процесса переноса данных
(ETL-процесса).
□ Извлечение данных. На этом этапе данные извлекаются из одного или не-
скольких источников и подготавливаются к преобразованию. Следует отме-
тить, что для корректного представления данных после их загрузки в ХД из
источников должны извлекаться не только сами данные, но и информация,
описывающая их структуру, из которой будут сформированы метаданные
для хранилища.
□ Преобразование данных. Производятся преобразование форматов и кодировки
данных, а также их обобщение и очистка.
□ Загрузка данных — запись преобразованных данных в соответствующую сис-
тему хранения.
Перемещение данных в процессе ETL можно разбить на последовательность
процедур, представленных следующей функциональной схемой (рис. 2.21).
Рис. 2.21. Обобщенная структура процесса ETL
1. Извлечение. Данные извлекаются из источников и загружаются в промежуточ-
ную область.
2. Поиск ошибок. Производится проверка данных на соответствие спецификациям
и возможность последующей загрузки в ХД.
3. Преобразование. Данные группируются и преобразуются к виду, соответству-
ющему структуре ХД.
4. Распределение. Данные распределяются на несколько потоков в соответствии
с особенностями организации процесса их загрузки в ХД.
102 Часть I. Теория бизнес-анализа
5. Вставка. Данные загружаются в хранилище-получатель.
С точки зрения процесса ETL архитектуру ХД можно представить в виде трех
компонентов (рис. 2.22), таких как:
□ источник данных — содержит структурированные данные в виде отдельног
таблицы, совокупности таблиц или просто файла, данные в котором, например
упорядочены в типизированные столбцы, отделенные друг от друга некоторыми
символами-разделителями;
□ промежуточная область — содержит вспомогательные таблицы, создаваемые
временно и исключительно для организации процесса выгрузки;
□ получатель данных — ХД или просто БД, в которую должны быть помещень
извлеченные данные.
Поток данных
Рис. 2.22. Потоки данных в ETL
Перемещение данных от источника к получателю называется потоком данных
Требования к организации потоков данных описываются аналитиком.
ETL часто рассматривают как просто подсистему переноса данных из различ
ных источников в централизованное хранилище. Что касается самих хранилип
данных, то они, строго говоря, не связаны с решением какой-либо конкретно!
аналитической задачи. Задача хранилища — обеспечивать надежный и быстры!
доступ к данным, поддерживать их хронологию, целостность и непротиворечи
вость. Поэтому на первый взгляд ETL оказывается отделенным от собствен™
анализа данных. Однако такой взгляд на ETL не позволит добиться преимуществ
которые можно получить, если рассматривать его как неотъемлемую часть анали
тического процесса.
Опытный аналитик знает особенности и характер данных, циркулирующи:
на различных уровнях корпоративной информационной системы, частоту и:
обновления, степень «загрязненности», уровень их значимости и т. д. Это дае-
ему возможность с помощью комбинации различных методов преобразование
данных в ETL добиться достаточного уровня обобщения и качества данных
Глава 2. Консолидация данных 103
^опавших в хранилище, выбрать оптимальный регламент и технические требо-
вания его пополнения. Последнее особенно важно для организаций со сложной
многоуровневой филиальной структурой и большим количеством подразделе-
ний-
Например, если известно, что информация, поступающая из определенных
подразделений фирмы, является самой важной и полезной, а также часто анали-
зируется, то в регламент переноса данных в хранилище можно внести соответству-
ющие приоритеты.
Таким образом, ETL следует рассматривать не только как процесс переноса
данных из одного приложения в другое, но и как инструмент их подготовки к ана-
лизу
2.10. Извлечение данных в ETL
Введение
Начальным этапом процесса ETL является процедура извлечения записей из
источника данных и подготовка содержащейся в них информации к процессу
преобразования.
При разработке процедуры извлечения данных в первую очередь необходимо
определить регламент загрузки ХД и соответственно частоту выгрузки данных
из OLTP-систем или отдельных источников. Например, выгрузка может произ-
водиться по истечении заданного временного интервала (день, неделя, месяц или
квартал). В некоторых случаях предусматривается возможность внерегламентного
извлечения данных после завершения определенного бизнес-события (приобре-
тение нового бизнеса, открытие филиала, поступление большой партии товаров).
В зависимости от объема извлекаемых данных, сложности доступа к ним и скоро-
сти работы оборудования, выгрузка данных занимает определенное время, которое
так и называют — «окно выгрузки». Очевидно, что в течение «окна выгрузки» резко
увеличивается нагрузка на компьютерную сеть организации и ее работа может
оказаться частично или полностью парализованной. Особенно это актуально для
OLTP-систем, где в такие периоды может резко возрасти время ожидания откли-
ка. Поэтому «окно выгрузки» стараются выбрать так, чтобы оно в минимальной
степени влияло на рабочий процесс, например в обеденный перерыв, сразу по
завершении рабочего дня или ночью.
Если выгрузку данных производить более часто, то, с одной стороны, количе-
ство «окон загрузки» увеличивается, но поскольку за меньший период в OLTP-
системе накапливается меньше изменений, то «окна загрузки» становятся короче
и нагрузка на систему — ниже.
Процедуру извлечения можно реализовать двумя основными способами.
1. Извлечение данных с помощью специализированных программных средств
(рис. 2.23).
104 Часть I. Теория бизнес-анализа
OLTP-
система
Рис. 2.23. Первый способ извлечения данных в ETL
Преимущества данного способа заключаются в том, что использование спе-
циализированных программ позволяет, во-первых, избежать необходимости
оснащать OLTP-системы средствами выгрузки, во-вторых, учитывать особен-
ности всего ETL-процесса уже в процессе выгрузки. В случае, когда данные
извлекаются из локальных источников (отдельных документов, таблиц и т. д.),
альтернативы использованию специальных средств нет, поскольку такие виды
источников данных не содержат средств выгрузки данных.
2. Извлечение данных средствами той системы, в которой они хранятся (рис. 2.24).
OLTP-система
Рис. 2.24. Второй способ извлечения данных в ETL
Поскольку средства «самовыгрузки» разрабатываются с учетом особенностей
структуры данных OLTP-системы, это позволяет адаптировать процедуру из-
влечения к структуре извлекаемых данных, что в ряде случаев делает процесс
более эффективным.
После извлечения данные помещаются в так называемую промежуточную об-
ласть, где для каждого источника данных создается своя таблица или отдельный
файл (или и то и другое). В некоторых случаях, когда требуется выгрузить данные
из нескольких источников одного типа, для них создается общая таблица; одно из
ее полей указывает на источник, из которого были взяты данные. Пример подобной
схемы организации выгрузки приведен на рис. 2.25.
Чтобы начать процесс извлечения данных, в общем случае необходимо исполь-
зовать некоторую служебную информацию:
□ имя набора данных, из которого следует извлечь записи;
□ номер записи, с которой начинается извлечение;
Глава 2. Консолидация данных 105
Источники
Промежуточная
данных область
Рис. 2.25. Схема организации ETL
□ количество извлекаемых записей;
□ формат представления данных;
□ максимальная длина записи, доступная для извлечения, и т. д.
Выбор используемых источников данных
Перед тем как приступить к процессу извлечения данных, необходимо определить,
в каких именно источниках хранятся данные, которые должны попасть в храни-
лище. Все источники можно разделить на две группы — расположенные в корпо-
ративных информационных системах и на локальных компьютерах отдельных
пользователей. С точки зрения соблюдения регламента и периодичности загрузки
данных в ХД предпочтительны источники из первой группы, поскольку они также
функционируют в соответствии с определенным порядком, который проще согласо-
вать с периодичностью загрузки данных в хранилище. Что касается источников на
локальных ПК, то обычно никаких сколь-нибудь строгих правил работы с ними не
устанавливается: пользователи включают и выключают компьютеры, когда хотят;
постоянно возникают те или иные проблемы с сетью и т. д. Тем не менее именно на
локальных компьютерах часто собирается очень ценная для анализа информация.
Поэтому при выборе источников данных для загрузки в ХД необходимо учитывать
следующие факторы:
□ значимость данных с точки зрения анализа;
□ сложность получения данных из источников;
□ возможное нарушение целостности и достоверности данных;
□ объем данных в источнике.
Как правило, приходится искать компромисс между этими факторами. Напри-
мер, данные могут представлять несомненную ценность для анализа, но сложность
их извлечения или некорректность структуры может свести на нет все преимущества
106 Часть I. Теория бизнес-анализа
от их использования. В другом случае данные легкодоступны и не требуют допол-
нительной обработки при загрузке в ХД, но при этом практически не представляют
интереса с точки зрения анализа.
Особенности организации процесса извлечения данных
После того как источники, из которых будут извлекаться данные, выбраны, необ-
ходимо определить, все ли имеющиеся в источниках данные нужны в ХД.
Если извлекать нужно не все записи подряд, а только определенные, аналитик
может описать набор условий, которые позволят отобрать только записи, пред-
ставляющие интерес. Например, можно поставить условие, что записи, которые
содержат информацию о продажах на сумму меньше заданной, извлекать и поме-
щать в ХД не нужно, поскольку их ценность с точки зрения результатов анализа
ничтожна.
ПРИМЕР---------------------------------------------------------------
Легко представить, что посетитель супермаркета зашел туда случайно: не для покупки това-
ра, а чтобы переждать дождь, встретиться с кем-то, помочь донести сумки и т. д. При этом он
приобретает коробку спичек, авторучку или другую мелочь, которую мог купить и на обыч-
ном уличном лотке. Однако даже для спичечного коробка пробивается чек и создается со-
ответствующая запись в регистрирующей системе. И запись о покупке спичечного коробка
за 50 коп. требует места на диске или в памяти не меньше, чем о продаже бутылки коньяка
за 1000 руб. В результате после агрегирования данных о продажах за день по отделу выяс-
няется, что зарегистрировано 100 продаж, которые дали в сумме 300 руб., и 10 продажна
общую сумму 15 000 руб. Возникает вопрос: нужно ли тратить время на обработку и хра-
нение огромного количества записей, вклад которых в результат анализа будет ничтожен.
Более того, включение в анализ информации о мелких покупках, сделанных случайными
клиентами, может только помешать, например, построению модели поведения постоянных
клиентов. Поэтому аналитик может задать условие, что извлекаться должны лишь те записи,
в которых значение поля «Сумма» не менее 20 руб.
Другой важный момент — определение глубины выгрузки данных по времени.
Очевидно, что все записи понадобятся только при первичном заполнении хранили-
ща. В процессе его пополнения из источников должны извлекаться лишь те записи,
которые добавлялись или изменялись после прошлого извлечения. Иногда храни-
лища полностью очищают и перезагружают. Но это возможно только в случае, если
ХД не очень большое и процесс регенерации занимает не слишком много времени,
а также если регенерация происходит редко и за промежуток времени между ними
большая часть данных изменяется или утрачивает актуальность.
Вопрос определения глубины выгрузки актуален только при начальной за-
грузке хранилища, когда требуется определить, информация за какой период
времени является актуальной. В простейшем случае, когда никаких соображений
на этот счет нет, можно загрузить все имеющиеся записи. Однако этот подход не
всегда оптимален, поскольку в хранилище может оказаться много информации,
не представляющей ценности для анализа в связи с потерей актуальности. Та-
ким образом, выбор глубины выгрузки исторических данных должен обеспечить
Глава 2. Консолидация данных 107
компромисс между объемом выгружаемых данных и их ценностью с точки зрения
анализа.
Процедура определения глубины выгрузки облегчается, если в источнике дан-
ных присутствует поле, в котором указывается время создания и изменения каждой
записи. В этом случае отбирать извлекаемые записи по времени можно с помощью
несложного фильтра.
При повторных загрузках ХД важно не только определить глубину выгрузки,
но и организовать поиск измененных данных вообще. Для этой цели разработаны
различные методики, например использование меток времени. Для каждой изме-
ненной записи создается метка, указывающая на время изменения, и при очередной
выгрузке извлекаются только те записи, метки времени которых созданы позднее
прошлого извлечения.
Если источником данных является реляционная СУБД, то часто используются
так называемые триггеры (triggers) — специальные процедуры, запускаемые авто-
матически при выполнении операций вставки, обновления или удаления. Триггеры
позволяют сохранять измененные записи в специальной таблице (таблице изме-
нений), из которой они могут быть извлечены при следующей выгрузке. Однако
использование триггеров существенно увеличивает нагрузку на систему, поэтому,
если система уже работает с большой нагрузкой, к применению триггеров надо
подходить осторожно.
Особенности извлечения данных
из различных типов источников
Процесс извлечения данных в рамках ETL существенно зависит от типов и струк-
туры источников данных. Можно выделить три разновидности источников данных,
с которыми чаще всего сталкиваются организаторы аналитических проектов.
Базы данных (SQL Server, Oracle, Firebird, Access и т. д.). В большинстве слу-
чаев извлечение данных из баз данных не вызывает проблем, поскольку структура
данных в них жестко задана, соответствует определенным стандартам и общепри-
нятым требованиям. Кроме того, во многих СУБД предусмотрен автоматический
контроль за целостностью и непротиворечивостью данных.
Структурированные файлы различных форматов. Такие файлы очень широко
распространены, поскольку средства их создания (в большинстве случаев это ти-
повые офисные приложения) общедоступны и не требуют высокой квалификации
персонала и высокой производительности систем. К таким источникам относятся
текстовые файлы с разделителями, файлы электронных таблиц (например, Excel,
CSV-файлы, HTML-документы и т. д.). Здесь проблем больше, поскольку пользо-
ватель может допускать ошибки, пропуски, вводить противоречивые данные, те-
рять фрагменты данных и т. д. Пользователи офисных приложений часто понятия
не имеют о том, что такое тип данных, и уж тем более не связывают вводимые ими
данные с задачами будущего анализа. Очевидно, что в этой ситуации при извлече-
нии данных можно столкнуться с чем угодно. Единственным плюсом является то,
108 Часть I. Теория бизнес-анализа
что для доступа к типовым структурированным данным можно применять такие
стандартные средства, как ODBC и ADO.
Неструктурированные источники. Как правило, эта ситуация требует особого
внимания. Если избежать использования неструктурированных источников не
получается, нужно применить специальные средства их преобразования в струк.
турированный вид. Когда источник невелик, возможно, это удастся сделать
вручную. Но в большинстве случаев приходится разрабатывать специальный ин-
струментарий, учитывающий особенности организации данных в источнике и то,
какую структуру из них следует создать. Существуют также готовые программные
системы для решения этой задачи. Конечная цель структурирования — так упо-
рядочить данные в файле, чтобы их в том или ином виде можно было загрузить
в реляционную таблицу.
Таким образом, извлечение данных из OLTP-систем, СУБД и отдельных струк-
турированных источников в рамках ETL-процесса может оказаться задачей доста-
точно сложной в техническом плане и важной для эффективного анализа данных.
Поэтому разработкой и организацией процесса извлечения данных должны зани-
маться как технические специалисты, так и аналитики.
2.11. Очистка данных в ETL
Два уровня очистки данных
Наличие «грязных» данных — одна из важнейших и трудно формализуемых
проблем аналитических технологий вообще и ХД в частности. Очистка данных
обязательна при их перегрузке в хранилище, и при разработке стратегии ETL это-
му уделяется большое внимание. Следует отметить, что, помимо очистки данных
перед их загрузкой в хранилище, пользователь может выполнить дополнительную
очистку средствами аналитической системы уже после выполнения запроса к ХД.
Такое дублирование вполне оправданно по ряду причин.
□ В данных, извлекаемых из различных источников, могут содержаться проблемы,
из-за которых выполнить загрузку данных в ХД будет невозможно.
□ Конечный пользователь чаще всего не имеет представления обо всех особен-
ностях данных в источниках, из которых они извлекаются, и поэтому не может
(и не должен) разрабатывать стратегию очистки.
□ Вторичная очистка данных, предусмотренная в аналитической системе, по
своим методам и целям существенно отличается от очистки данных в процессе
ETL. Целесообразность применения того или иного метода очистки данных,
полученных в результате запроса из ХД, определяется пользователем, исходя из
особенностей конкретной задачи анализа. При этом часто используется субъ-
ективное мнение аналитика, основанное на личном опыте. Например, одному
специалисту гладкость ряда данных покажется недостаточной для решения
определенной задачи анализа и он применит процедуру сглаживания для
Глава 2. Консолидация данных 109
очистки от шумов или аномальных значений. В то же время другой аналитик
скажет, что в результате сглаживания вместе с шумом и аномалиями подавлены
изменения, несущие полезную информацию.
□ Некоторые виды ошибок (например, противоречия и аномальные значения)
могут быть обнаружены только после консолидации данных. Действительно,
нельзя сделать вывод, что некоторое значение является аномальным, пока не
произведено его сравнение с соседними значениями.
Таким образом, первичная очистка данных в процессе ETL носит в большей сте-
пени технический характер. Ее основная задача — подготовить данные к загрузке
в хранилище. Вторичная очистка в аналитической системе является пользователь-
ской, она направлена на подготовку данных к решению конкретной аналитической
задачи. Поэтому оба этапа очистки одинаково важны и необходимы.
Критерии оценки качества данных
Чтобы разработать методику очистки данных в процессе ETL, необходимо опре-
делить критерии оценки их качества. Одним из таких критериев является критич-
ность ошибок. В этой связи данные могут быть разделены на три категории:
□ данные высокого качества, не нуждающиеся в очистке;
□ данные, содержащие критичные ошибки, из-за которых они в принципе не мо-
гут быть загружены в ХД (например, буква или пробел в числовом значении,
неправильный разделитель целой и дробной частей числа и т. д.). То есть кри-
тичными являются ошибки, которые делают невозможной дальнейшую работу
с данными;
□ данные, содержащие некритичные ошибки, которые не мешают их загрузке
в ХД, но при этом данные являются некорректными с точки зрения их анализа
(аномальные значения, пропуски, дубликаты, противоречия и т. д.).
Некритичные ошибки могут быть исправлены в процессе анализа данных сред-
ствами аналитической системы.
Основные виды проблем в данных,
из-за которых они нуждаются в очистке
Существует несколько проблем, из-за которых данные нуждаются в очистке.
Наиболее широко распространены проблемы, связанные с нарушением структуры
данных:
□ корректность форматов и представлений данных;
□ уникальность первичных ключей в таблицах БД;
□ полнота и целостность данных;
□ полнота связей;
□ соответствие некоторым аналитическим ограничениям и т. д.
110 Часть I. Теория бизнес-анализа
Для каждого структурного уровня данных — отдельной ячейки, записи, целой
таблицы, отдельной БД или множества БД — характерны свои факторы, снижающие
качество данных. Наиболее типичные ошибки, соответствующие структурным
единицам БД, представлены в табл. 2.6.
Таблица 2.6. Типичные ошибки, соответствующие структурным единицам БД
Ячейка Запись Таблица Отдельная БД Множество БД
Орфографические ошибки Проти- воречия между ячейками Дублирова- ние записей Целостность данных Несоответствия структуры данных
Пропуски в данных
Фиктивные зна- чения Одинаковые наиме- нования различных атрибутов
Логические несоот- ветствия Противоречи- вые записи Противоречия Различное представ- ление однотипных данных
Закодированные значения Различная временная шкала
Составные значения
На уровне отдельной ячейки таблицы наиболее характерны следующие
ошибки.
Орфографические ошибки или опечатки могут привести к неправильному по-
ниманию или искажению данных. Например, ошибка в названии фирмы приведет
к появлению двух разных фирм с одинаковыми реквизитами, что вызовет проти-
воречия, ошибки в отчетах и т. д.
Пропуски данных — отсутствие данных в тех ячейках, где они должны быть.
Пропуски могут быть вызваны ошибкой оператора или отсутствием соответству-
ющей информации. Например, что означает отсутствие информации о продажах
в супермаркете на определенную дату? Если в этот день магазин был закрыт, то есть
продаж не было, в соответствующей ячейке должен стоять ноль. Если же магазин
работал, то, скорее всего, имеет место ошибка оператора. Однако при автоматиче-
ской загрузке огромного количества данных, что имеет место в большинстве кор-
поративных систем, разобраться с каждым отдельным случаем пропуска данных
невозможно. Поэтому на этапе очистки данных в ETL необходимо разработать
методику восстановления пропущенных данных, которая как минимум делала бы
их корректными с точки зрения совместимости со структурой хранилища. Что
касается корректности с точки зрения анализа, то большинство аналитических
систем содержит средства восстановления пропущенных данных способом, кото-
рый предпочтет аналитик (начиная от установки значения вручную до применения
сложных статистических методов).
Фиктивные значения — данные, не имеющие смысла, никак не связанные
с описываемым ими бизнес-процессом. Подобная ситуация возможна, если опе-
ратор системы OLTP, не располагая необходимой информацией, ввел в ячейку
произвольную последовательность символов. Оператор бывает вынужден это
Глава 2. Консолидация данных
111
сделать, когда система не позволяет продолжать работу, пока соответствующая
ячейка не будет заполнена. Так, если клиент забыл указать в анкете возраст, то
оператор может ввести значение 0 или 999. При этом лучше, если значение явно
«не лезет ни в какие ворота», поскольку в таком случае вероятность того, что оно
будет принято за реальное, уменьшается. Вообще, обнаружить и отфильтровать
фиктивные значения довольно трудно, поскольку понятие «смысл» является
субъективным и не поддается формализации. Поэтому на этапе очистки данных
средствами ETL можно выработать только общие формальные методы обна-
ружения фиктивных значений и борьбы с ними. Например, можно установить
правило: «Если возраст клиента больше 150, то заменить его на значение 0».
Когда при последующем анализе аналитик встретит такое значение, он поймет,
что значение фиктивное, и примет меры к его замене на более правдоподобное
(например, среднее по выборке). Существует и другой способ борьбы с фиктив-
ными значениями. Можно проинструктировать операторов OLTP-систем или
персонал, который занимается сводками данных в офисных приложениях, что
при отсутствии реальных данных должен вводиться специальный код, который
при обработке в процессе ETL распознавался бы как фиктивное значение. За-
тем к таким данным можно применить обработку, предписанную аналитиком.
Наконец, если фиктивные значения являются аномальными (что чаще всего
и имеет место), то они могут быть обнаружены и скорректированы средствами
аналитической системы.
Логические несоответствия возникают, если значение в ячейке не соответству-
ет логическому смыслу поля таблицы. Например, вместо наименования фирмы
указан ее банковский счет.
Закодированные значения — сокращения, аббревиатуры, замена наименований
числовыми кодами.
Составные значения появляются в файлах, где структура полей жестко не зада-
на, например в обычных текстовых файлах, электронных таблицах и т. д. Составное
значение может получиться, если оператор регистрационной системы ошибочно
ввел два отдельных значения или более в ячейку, предназначенную для одного зна-
чения. Например, в системе предусмотрены отдельные поля для фамилии, имени
и отчества клиента, а неопытный оператор ввел все эти значения в одно поле Фа-
милия. Другой вариант: для каждого из элементов адреса клиента предусмотрены
отдельные поля, а весь адрес оказался введен в поле Индекс.
На уровне записи возникают в основном проблемы противоречивости данных
в различных ячейках. Например, сумма, на которую был продан товар, не соответ-
ствует произведению цены за единицу и количества проданных единиц.
На уровне таблицы основными проблемами являются дублирующие и проти-
воречивые записи.
Дубликаты — это полностью идентичные записи. Сами по себе они не вызыва-
ют нарушений в структуре данных, и их наличие не является критичным. Однако
дубликаты также могут вызвать ряд проблем.
□ Увеличивается объем данных и, соответственно, время, требуемое на их загруз-
ку и обработку.
112 Часть I. Теория бизнес-анализа
□ Временные затраты при аналитической обработке дубликатов увеличиваются
при этом качество анализа не повышается.
□ Дубликаты могут ухудшить качество аналитических моделей, основанных на
обучении (нейронные сети, деревья решений). Если значительный процент
обучающей выборки для таких моделей будут составлять дублирующие записи
то результаты обучения могут ухудшиться.
Аналитические системы обычно содержат средства для обнаружения и удале-
ния дублирующих записей. Поэтому если в процессе ETL борьба с дубликатами
не была предусмотрена, это можно будет сделать при подготовке данных к ана-
лизу непосредственно в аналитической системе.
Противоречивыми являются записи, которые для двух различных объектов
содержат одинаковые значения уникальных атрибутов. Например, в базе дан-
ных клиентов для двух разных организаций указаны одинаковые банковские
реквизиты.
На уровне отдельной БД основной проблемой является нарушение целост-
ности данных, которое заключается в том, что происходит рассогласование
между различными объектами БД. Например, если в БД есть документ, со-
провождающий сделку с каким-либо клиентом, то, как правило, при создании
нового документа имя клиента не вводится вручную, а выбирается из списка
клиентов, содержащегося в другой таблице БД и открывающегося при запол-
нении соответствующего поля. В результате документ содержит не собственно
имя клиента, а ссылку на соответствующий объект другой таблицы. Если по
какой-либо причине объект (то есть запись о клиенте) будет удален, то доку-
мент не сможет быть сформирован, из-за того что объект, на который имеется
ссылка, оказывается недоступен.
На уровне множества БД возникают проблемы, связанные с отличиями струк-
туры данных в различных базах:
□ различные правила назначения имен полей (например, различное число сим-
волов, допустимых в имени поля, наличие пробелов, символов национальных
алфавитов и т. д.);
□ различия в используемых типах полей;
□ одинаковые названия полей для разных атрибутов (например, в одном источ-
нике данных поле Name содержит названия фирм, а в другом — наименования
товаров);
□ различная временная шкала (например, данные, описывающие один и тот же
бизнес-процесс, хранятся в двух разных файлах, но в одном из них представлена
ежедневная информация, а в другом — еженедельная).
Стратегия очистки данных должна разрабатываться с учетом особенностей
предметной области, функционирования OLTP-систем и порядка сбора данных.
Например, принимая решение о включении в процесс обработки данных ETL
средств для борьбы с дубликатами, аналитик должен выяснить, могут ли в бизнес-
процессе возникать идентичные объекты или события, происходящие в одном
Глава 2. Консолидация данных
113
временном интервале. Если да, то две одинаковые записи, определяемые как дуб-
ликаты, могут описывать разные объекты или события. Очевидно, что в этом случае
к обработке дубликатов следует подходить с осторожностью, чтобы не потерять
полезную информацию.
Кроме того, необходимо помнить, что полностью очистить данные удается
очень редко. Существуют проблемы, которые не получается решить независимо
от степени приложенных усилий. Бывают случаи, когда некорректное примене-
ние методов очистки данных только усугубляет ситуацию. Иногда использование
очень сложных алгоритмов очистки увеличивает время переноса данных в ХД до
неприемлемой величины. Поэтому не всегда следует стремиться к полной очистке
данных. Лучше обеспечить компромисс между сложностью используемых алгорит-
мов, затратами на вычисление, временем, требуемым на очистку, и ее результатами.
Если достоверность каких-то данных не влияет на результаты анализа, то от их
очистки, возможно, следует вообще отказаться.
2.12. Преобразование данных в ETL
Этап ETL-процесса, следующий за извлечением, — преобразование данных. Его
цель — подготовка данных к размещению в ХД и приведение их к виду, наиболее
удобному для последующего анализа. При этом должны учитываться некоторые
выдвигаемые аналитиком требования, в частности, к уровню качества данных.
Поэтому в процессе преобразования может быть задействован самый разнообраз-
ный инструментарий, начиная от простейших средств ручного редактирования
данных до систем, реализующих весьма сложные методы обработки и очистки
данных.
В процессе преобразования данных в рамках ETL чаще всего выполняются
следующие операции (рис. 2.26):
□ преобразование структуры данных;
□ агрегирование данных;
□ перевод значений;
□ создание новых данных;
□ очистка данных.
Извлеченные данные (промежуточные таблицы) Преобразо- вание структуры Преоб Агреги- рование ра зование Перевод значений дг 1ННЫХ Создание новых данных Очистка данных ► Загрузка данных в ХД
Рис. 2.26. Процесс преобразования данных в ETL
Рассмотрим каждую из этих операций более детально.
114 Часть I. Теория бизнес-анализа
Преобразование структуры данных
Во многих случаях данные поступают в хранилище, интегрируясь из множества ис-
точников, которые создавались с помощью различных программных средств, методо-
логий, соглашений, стандартов и т. д. Данные из таких источников могут отличаться
своей структурной организацией: соглашениями о назначении имен полей и таблиц
порядком их описания, форматами, типами и кодировкой данных, например точ-
ностью представления числовых данных, используемыми разделителями целой
и дробной частей, разделителями групп разрядов и т. д. Следовательно, во многих
случаях извлеченные данные непригодны для непосредственной загрузки в ХД из-за
отличия их структуры от структуры соответствующих целевых таблиц ХД.
При этом если таблицы фактов чаще всего соответствуют требованиям ХД,
то таблицы измерений нуждаются в дополнительной обработке и, может быть,
объединении.
Так, если в источнике, полученном из одного филиала, информация о покупа-
телях хранится в поле Customer_Id, а в источнике, полученном из другого филиа-
ла, — в поле Clients_Name, то для создания одного измерения Покупатель придется
решать задачу их объединения.
Дополнительная обработка структуры данных также требуется в ситуации,
когда одно подразделение фирмы представляет информацию о цене и количестве
проданных товаров, а другое — о количестве товаров и общей сумме продаж. В та-
ком случае потребуется привести информацию о продажах, полученную из обоих
источников, к общему виду.
Агрегирование данных
Как правило, в качестве источников данных для хранилищ выступают системы опе-
ративной обработки данных (OLTP-системы), учетные системы, файлы различных
СУБД, локальные файлы отдельных пользователей и т. д. Общим свойством всех
этих источников является то, что они содержат данные с максимальной степенью
детализации — сведения о ежедневных продажах или даже о каждом факте продажи
в отдельности, об обслуживании каждого клиента и т. д. Распространено мнение, что
такое детальное воспроизведение событий в исследуемом бизнес-процессе только
пойдет на пользу, поскольку данные никогда не бывают лишними и чем больше их
будет собрано, тем точнее окажутся результаты анализа.
Это не совсем так. Элементарные события, из которых состоит бизнес-процесс,
например обслуживание одного клиента, выполнение одного заказа и т. д., кото-
рые также называют атомарными (то есть неделимыми), по своей сути являются
случайными величинами, подверженными влиянию множества различных случай-
ных факторов — от погоды до настроения клиента. Следовательно, информация
о каждом отдельном событии в бизнес-процессе практически не имеет ценности.
Действительно, на основании информации о продажах за один день нельзя сделать
вывод обо всех особенностях торговли. Точно так же нельзя выработать стратегию
работы с клиентами на основе исследования поведения одного клиента.
Глава 2. Консолидация данных 115
Иными словами, для достоверного описания предметной области использо-
вание данных с максимальным уровнем детализации не всегда целесообразно,
поэтому наибольший интерес для анализа представляют данные, обобщенные по
некоторому интервалу времени, по группе клиентов, товаров и т. д. Такие обоб-
щенные данные называются агрегированными (иногда агрегатами), а сам процесс
их вычисления — агрегированием.
В результате агрегирования большое количество записей о каждом событии
в бизнес-процессе заменяется относительно небольшим количеством записей,
содержащих агрегированные значения. Например, вместо информации о каждой
из 365 ежедневных продаж в году в результате агрегирования будут храниться
52 записи с обобщением по неделям, 12 — по месяцам или 1 — за год. Если цель
анализа — разработка прогноза продаж, то для краткосрочного оперативного
прогноза достаточно использовать данные по неделям, а для долгосрочного стра-
тегического прогноза — по месяцам или даже по годам.
Фактически при атрегировании производится объединение нескольких записей
в одну с вычислением агрегированного значения на основе значений каждой запи-
си. При вычислении агрегатов может быть использовано несколько способов.
□ Среднее — для данных, расположенных в пределах интервала, в котором они
обобщаются, вычисляется среднее значение. Затем все записи из данного ин-
тервала заменяются одной, содержащей их среднее значение (рис. 2.27).
Дата Цена Кол-во Сумма
07.04 150,00 20 3000,00
08.04 135,00 10 1350,00
09.04 220,00 15 3300,00
10.04 173,00 5 865,00
11.04 245,00 24 5880,00
12.04 96,00 12 1152,00
13.04 110,00 320 3520,00
Дата Среднее кол-во Средняя сумма Максималь- ная сумма Минималь- ная сумма Кол-во сумм Медиана по сумме
07.04- 13.04 16,85 2723,85 5880 865 7 3000
Рис. 2.27. Пример агрегирования
□ Сумма — агрегируемые записи заменяются одной, в которой указывается сумма
агрегируемых значений.
□ Максимум — в результирующей записи остается максимальное значение из всех
объединяемых.
□ Минимум — в результирующей записи остается минимальное значение из всех
объединяемых.
116 Часть I. Теория бизнес-анализа
□ Количество уникальных значений — результатом агрегирования будет число
уникальных значений, появляющихся в ячейках одного и того же поля. Так
для поля, содержащего информацию о профессии клиента, данный способ аг-
регирования покажет, сколько раз та или иная профессия появлялась в списке
Например, если в 25 записях в поле профессия имело место значение Систем-
ный аналитик, а в 50 — Менеджер, то в результате агрегирования мы получим
число 2.
□ Количество — результатом агрегирования будет число записей, содержащихся
в поле. В приведенном выше примере с профессиями клиентов при этом вари-
анте агрегирования получим 75.
□ Медиана — вычисляется медиана агрегируемых значений. Медиана пред-
ставляет собой порядковую статистику, рассчитываемую следующим об-
разом. Набор агрегируемых значений, например продажи по дням недели,
сортируется в порядке возрастания. Тогда медианой будет центральный
элемент упорядоченного набора, если этот набор содержит нечетное количество
значений, или среднее двух центральных элементов, если число элементов
четное. Например, пусть каждый день в течение недели продажи составляли
{100, 120, 115, 119, 107, 131, 102}. Тогда для определения медианы нужно
выстроить эти значения по возрастанию: {100, 102, 107, 115, 119, 120, 131}.
Значение центрального элемента полученной последовательности, то есть
115, и будет медианой. Если продажи осуществлялись только 6 дней в неделю
(воскресенье — выходной), то будет получена последовательность из четного
числа значений {100, 107, 115, 119, 120, 131}. В этом случае медиана будет
равна: (115+ 119) /2 = 117.
Закономерен вопрос: нужно ли агрегировать все данные без разбору по всем
возможным уровням обобщения или к этому следует подходить внимательно?
Для ответа необходимо изучить наиболее вероятные направления использования
данных в ХД. Однако если хранилище находится на стадии разработки и вне-
дрения и методика его использования еще не до конца проработана, то сделать
это трудно. Тем не менее, если опросить потенциальных пользователей ХД, что
именно они хотят получить, возможно, некоторые сведения на этот счет удастся
разыскать.
Из всех возможных вариантов агрегирования следует выбрать наиболее значи-
мые с точки зрения планируемых направлений анализа, а от остальных отказаться.
Очевидно, можно отказаться от агрегатов, которые имеют малое число подчинен-
ных агрегированных значений (например, агрегирование ежемесячных продаж
за квартал), поскольку их легко вычислить в процессе анализа. Или, наоборот,
можно отказаться от агрегатов с максимальной степенью детализации (например,
агрегирование ежедневных продаж). Второй вариант наиболее предпочтителен,
поскольку на первый взгляд сулит существенную экономию, так как число дней
в году умножается на число товаров и продавцов. Однако если данные о продажах
являются разреженными, то есть не каждый товар продается ежедневно, то эконо-
мия может оказаться весьма незначительной.
Глава 2. Консолидация данных
117
Выбор нужных агрегатов всегда определяется особенностями бизнеса. При этом
сЛеДУет помнить, что агрегаты, требуемые для анализа, могут быть вычислены
л непосредственно при выполнении аналитического запроса к ХД, хотя тем самым
время его выполнения несколько увеличится. Подобный подход позволяет, напри-
мер, отказаться от агрегирования редко используемых данных.
Таким образом, выбор правильной стратегии агрегирования данных в ETL —
сложная и противоречивая задача. Увеличение числа агрегатов в ХД приводит
к увеличению его размеров и сложности структуры данных. Снижение числа агре-
гатов в ХД может привести к необходимости их вычисления в процессе выполнения
аналитических запросов, что увеличит время ожидания пользователя. Следова-
тельно, необходимо обеспечить разумный компромисс между этими факторами.
Существует и более простое правило, определяющее стратегию агрегирования:
создавайте только те агрегаты, которые с большой долей вероятности понадобятся
при анализе данных.
Перевод значений
Часто данные в источниках хранятся с использованием специальных кодировок,
которые позволяют сократить избыточность данных и тем самым уменьшить объ-
ем памяти, требуемой для их хранения. Так, наименования объектов, их свойств
и признаков могут храниться в сокращенном виде. В этом случае перед загрузкой
данных в хранилище требуется выполнить перевод таких сокращенных значений
в более полные и, соответственно, понятные.
Например, согласно заведенному в организации порядку идентификационный
номер операции может быть закодирован в виде 06-04-12-62, где 06-04 — число
и месяц, 12 — код товара, 62 — код региона. Такое представление позволяет хранить
данные очень компактно. Однако для заполнения соответствующих измерений
в многомерной модели запись необходимо декодировать.
Кроме того, часто возникает необходимость конвертировать числовые данные,
например преобразовать вещественные в целые, уменьшить избыточную точность
представления чисел, использовать экспоненциальный формат и т. д.
Создание новых данных
В процессе загрузки в ХД может понадобиться вычисление некоторых новых данных
на основе существующих, что обычно сопровождается созданием новых полей. На-
пример, OLTP-система содержит информацию только о количестве и цене проданного
товара, а в целевой таблице ХД есть поле Сумма. Тогда в процессе преобразования
необходимо вычислить сумму как произведение цены на количество проданных еди-
ниц товара. Таким образом, будет создано поле, содержащее новую информацию.
Еще одним возможным примером новых данных, создаваемых в процессе обра-
ботки, являются экономические, финансовые и другие показатели, которые могут
быть вычислены на основе имеющихся данных. Так, на основе данных о продажах
можно рассчитать рейтинг популярности товаров и создать новое поле, в котором
118 Часть I. Теория бизнес-анализа
для каждого товара будет указано соответствующее рейтинговое значение (напри.
мер, по пятибалльной системе).
Создание новой информации на основе имеющихся данных тесно связано с та-
ким важным процессом, как обогащение данных, которое может производиться
(частично или полностью) на этапе преобразования данных в ETL. Агрегирование
также может рассматриваться как создание новых данных.
Очистка данных
Сбор данных в процессе ETL производится из большого числа источников, многие
из которых не содержат автоматических средств поддержки целостности, непро-
тиворечивости и корректного представления данных. В связи с этим при переносе
информации в ХД приходится сталкиваться с потоками «грязных» данных, которые
могут стать причиной неправильных результатов анализа и даже сделать невозмож-
ным применение некоторых аналитических алгоритмов и методов. По этой причине
в процессе ETL применяется очистка — процедура корректировки данных, которые
в каком-либо смысле не удовлетворяют определенным критериям качества, то есть
содержат нарушения структуры данных, противоречия, пропуски, дубликаты, не-
правильные форматы и т. д.
Некоторые проблемы в данных являются критичными и даже не позволяют выпол-
нить загрузку данных в ХД (как правило, это нарушения структуры и некорректные
форматы данных). Другие проблемы менее критичны, не мешают переносу данных
в ХД, но не позволяют их корректно анализировать (пропуски, противоречия и дуб-
ликаты). Критичные проблемы в данных должны устраняться непосредственно в про-
цессе ETL. Некритичные факторы, снижающие качество данных, могут устраняться
как в процессе ETL, так и при подготовке их к анализу в аналитической системе.
Очистка данных — одна из наиболее важных и в то же время наиболее слож-
ных и трудно поддающихся формализации задач ETL-процесса, поскольку набор
факторов, снижающих качество данных, весьма разнообразен и может постоянно
меняться. Поэтому очистке данных при разработке ETL-процессов уделяют боль-
шое внимание.
Выбор места для выполнения преобразований данных
В принципе, преобразование данных может быть выполнено на любом этапе ETL-
процесса. Но иногда требуется выбрать оптимальное место для осуществления
преобразования. Некоторые виды преобразований удобнее выполнять «на лету»,
в процессе извлечения данных из источника, другие — в промежуточной области,
третьи — в процессе загрузки данных в ХД. Рассмотрим преимущества и недостат-
ки этих вариантов.
□ Преобразование в процессе извлечения данных. На данном этапе лучше всего
выполнять преобразование типов данных и производить фильтрацию записей,
представляющих интерес для ХД. В идеальном случае должны отбираться толь-
Глава 2. Консолидация данных
119
к0 те записи, которые изменялись или создавались после прошлой загрузки.
Недостаток — повышение нагрузки на OLTP-систему или БД.
□
Преобразование в промежуточной области перед загрузкой данных в хранили-
ще — наилучший вариант для интеграции данных из множества источников,
поскольку в процессе извлечения данных, очевидно, этого сделать нельзя. В про-
межуточной области целесообразно выполнять такие виды преобразований, как
сортировка, группировка, обработка временных рядов и т. п.
□ Преобразование в процессе загрузки данных в ХД. Отдельные простые преобра-
зования, например преобразование регистров букв в текстовых полях, могут
быть выполнены только после загрузки данных в хранилище.
Таким образом, все операции преобразования, которые могут потребоваться при
переносе данных в ХД, обычно не сосредотачиваются на одном шаге ETL-процес-
са, а распределяются по различным этапам в зависимости от того, где выполнение
преобразования более эффективно.
2.13. Загрузка данных в хранилище
После того как данные извлечены из различных источников и выполнены преоб-
разование, агрегация и очистка данных, осуществляется последний этап ETL — за-
грузка данных в хранилище. Процесс загрузки заключается в переносе данных из
промежуточных таблиц в структуры хранилища данных. От продуманности и оп-
тимальности процесса загрузки данных во многом зависит время, требуемое для
полного цикла обновления данных в ХД, а также полнота и корректность данных
в хранилище.
Организация процесса загрузки
Первыми в процессе загрузки данных в ХД обычно загружаются таблицы измере-
ний, которые содержат суррогатные ключи и другую описательную информацию,
необходимую для таблиц фактов.
При загрузке таблиц измерений требуется и добавлять новые записи, и из-
менять существующие. Например, измерение Клиент может содержать десятки
тысяч клиентов, при этом информация меняется только для незначительного их
числа (не более 10 %). Нужно добавить данные о новых клиентах и одновременно
Модифицировать информацию о существующих.
При добавлении новых данных в таблицу измерений требуется определить, не
существует ли в ней соответствующая запись. Если нет, то она добавляется в таб-
лицу. В противном случае могут использоваться различные способы обработки
изменений в зависимости от того, нужно ли поддерживать старую информацию
в хранилище с целью ее последующего анализа. Например, если изменился только
адрес клиента, то в большинстве случаев нет необходимости хранить старый адрес,
Поэтому запись может быть просто обновлена.
120 Часть I. Теория бизнес-анализа
У быстро растущих компаний часто возникают новые регионы продаж. Напрц.
мер, если сначала регионом продаж была только Рязанская область, то впослед.
ствии он может расшириться на весь Центральный федеральный округ (Цфф)
и далее на всю Российскую Федерацию. Если в ХД требуется хранить как старую
географическую иерархию, так и обновленную, можно создать дополнительную
таблицу измерений, записи которой будут содержать и старые географические
данные, и новые. В качестве альтернативы можно добавить дополнительные поля
в существующие таблицы, чтобы сохранить старую информацию и добавить но-
вую.
При загрузке таблицы фактов новая информация обычно добавляется в конец
таблицы, чтобы не изменять существующие данные.
Неполная загрузка данных
Одной из основных проблем данного этапа ETL является то, что далеко не всегда
данные загружаются полностью: в загрузке некоторых записей может быть отка-
зано. Отклонение записей происходит по следующим причинам.
□ На этапе преобразования данных не удалось исправить все критичные ошибки,
которые блокируют загрузку записей в ХД.
□ Некорректный порядок загрузки данных. Например, предпринимается попыт-
ка загрузить факты для значения измерения, которое еще не было загружено.
Причиной этого является неправильная разработка ETL-процесса.
□ Внутренние проблемы ХД, например недостаток места в нем.
□ Прерывание процесса загрузки или остановка его пользователем.
Независимо от причин результатом всегда оказывается наличие определенного
количества записей, которые не попали в хранилище. Как правило, предусмотрена
система извещения пользователя о том, что хранилище содержит не полностью
загруженные данные. Это необходимо потому, что если неполные данные будут
использованы для анализа (при этом аналитик пребывает в уверенности, что дан-
ные достоверны), то последствия могут быть непредсказуемыми. Например, если
не до конца загрузились данные о продажах по определенным товарным позициям
и последующий анализ выявит падение продаж, то руководство компании может
ошибочно исключить такие товары из ассортимента как не пользующиеся спросом,
хотя на самом деле это не так.
При появлении данных, попытка загрузки которых потерпела неудачу, необхо-
димо предусмотреть следующие действия (рис. 2.28):
□ сохранить данные, не попавшие в ХД, в виде таблицы или файла того же фор-
мата, что и исходная таблица или файл (такие таблицы обычно называют таб-
лицами исключений)-,
□ провести анализ отклоненных данных для выявления причин, по которым они
не были загружены;
□ при необходимости произвести дополнительную обработку и очистку данных,
после чего предпринять повторную попытку их загрузки.
Глава 2. Консолидация данных 121
Повторная загрузка
Рис. 2.28. Последовательность действий при наличии
отклоненных записей в процедуре загрузки в ХД
Если и повторная попытка загрузки данных не увенчалась успехом, то в храни-
лище окажутся неполные данные, анализ которых может привести к неправильным
выводам. Для решения этой проблемы можно:
□ восстановить состояние хранилища, каким оно было до загрузки (например,
с помощью резервной копии или операции отката, если она предусмотрена);
□ полностью очистить в ХД таблицы с неполными данными, чтобы исключить
некорректные результаты их анализа;
□ оставить все как есть и уведомить пользователя о возникших проблемах. В этом
случае аналитик узнает, что загруженная информация недостоверна, и будет
использовать ее с определенными ограничениями.
Многопоточная организация процесса загрузки данных
При очередной загрузке в ХД переносится не вся информация из OLTP-системы,
а только та, которая была изменена в течение промежутка времени, прошедшего
с предыдущей загрузки. При этом можно выделить два вида изменений — добав-
ление и обновление(дополнение).
□ Добавление — в ХД передается новая, ранее не существовавшая информация,
например сведения о продажах, произошедших с прошлой загрузки, о появле-
нии нового клиента, товара и т. д.
□ Обновление (дополнение) — в ХД передается информация, которая существова-
ла ранее, но по какой-либо причине была изменена или дополнена (например,
изменился город, в котором живет клиент).
122 Часть I. Теория бизнес-анализа
Для обеспечения этих функций загружаемые данные распределяются по Дву^
параллельным потокам (data flow) — потоку добавления и потоку обновлен^
(рис. 2.29).
Источники
данных
Рис. 2.29. Поток добавления и поток обновления
Для распределения загружаемых данных на потоки используются средства
мониторинга изменений в данных. Они фиксируют состояние данных в некоторые
моменты времени и определяют, какие данные были изменены или дополнены.
Применяются следующие методы:
□ полное сравнение загружаемых записей со всей информацией, которая уже
содержится в хранилище. Данный способ является самым простым и в то же
время самым трудоемким в плане вычислительных затрат;
□ использование признаков модифицированных данных или полей Дата/Время
для определения последнего изменения записи (если такие поля предусмотрены
в источнике данных).
Распределение загружаемых данных на поток добавления и поток обновления
позволяет выполнять перенос данных в хранилище с помощью обычных запросов, не
используя какие-либо фильтры для разделения данных на новые и обновляющие.
Обновление данных должно производиться строго в соответствии с требова-
ниями к обеспечению истории данных, то есть не должно приводить к потере уже
существующих данных, за исключением особых случаев.
Следует отметить, что при разработке методики загрузки данных в ХД нет
общего подхода к тому, как модифицировать таблицы измерений. Например, если
изменилось описание некоторого продукта, придется создать новое поле в табли-
це, чтобы сохранить старое описание и добавить новое. Если требуется сохранить
все старые описания продукта, то придется создавать новую запись для каждого
изменения и назначать соответствующие ключи.
Постзагрузочные операции
После завершения загрузки выполняются дополнительные операции над дан-
ными, только что загруженными в ХД, перед тем как сделать их доступными для
пользователя. Такие операции называются постзагрузочными. К ним относятся
переиндексация, верификация данных и т. д.
С точки зрения аналитика, наиболее важной задачей является верификация
данных. Прежде чем использовать новые данные для анализа, полезно убедиться
Глава 2. Консолидация данных 123
в их надежности и достоверности. Для этих целей можно предусмотреть комплекс
верификационных тестов. Например:
□ при суммировании продаж по одному измерению результат должен совпадать
с соответствующей суммой, полученной по другому, связанному с ним измере-
нию, то есть сумма продаж по всем товарам за месяц должна соответствовать
сумме сделок, заключенных со всеми клиентами за тот же период;
□ итоговый показатель за месяц должен соответствовать сумме ежедневных или
еженедельных показателей в этом месяце;
□ суммарная выручка по всем регионам за текущий месяц должна соответствовать
сумме продаж по всем региональным дилерским центрам.
Кроме того, может оказаться полезным сравнивать данные не только в различ-
ных разрезах после их загрузки в ХД, но и с источниками данных. Так, если зна-
чения какого-либо показателя в источнике и хранилище равны, то все нормально,
в противном случае данные, возможно, некорректны.
Если тестирование показало, что несоответствия, позволяющие заподозрить
потерю или недостоверность данных, отсутствуют, то можно считать загрузку
данных в ХД успешной и приступать к анализу новой информации.
2.14. Загрузка данных из локальных источников
Довольно часто возникают ситуации, когда данные для анализа приходится им-
портировать непосредственно из источников, минуя хранилища данных и другие
промежуточные системы. Это может потребоваться в случае, когда организация
отказалась от использования ХД или когда хранилище имеется, но данные из не-
которых источников не могут быть в него загружены по техническим причинам,
из-за несоответствия моделям и форматам данных, используемым в ХД.
Таким образом, часть данных поступает в аналитическую систему через ХД
с соответствующей очисткой и подготовкой, а другая часть — непосредственно из
источников (рис. 2.30).
Рис. 2.30. Загрузка данных из локальных источников
124 Часть I. Теория бизнес-анализа
Извлечение данных напрямую из источников имеет свои преимущества и недо-
статки, а также порождает ряд проблем, связанных как непосредственно с про-
цессом извлечения, так и с качеством полученных данных.
Преимущества и недостатки отказа
от хранилищ данных
Главным преимуществом, которое дает использование хранилищ данных в ана-
литических технологиях, является повышение эффективности и достоверности
анализа данных, особенно для поддержки принятия стратегических решений.
Это достигается за счет оптимизации скорости доступа к данным, возможности
интеграции данных различных форматов и типов, автоматической поддержки
целостности и непротиворечивости, обеспечения хронологии и истории дан-
ных.
Тем не менее некоторые организации не используют хранилища данных для
консолидации анализируемой информации. При необходимости выполнения
анализа данные загружаются в аналитическое приложение непосредственно из
источников, где они содержатся, а семантический слой обеспечивается средства-
ми самого аналитического приложения.
Причины отказа от использования ХД могут быть следующими.
1. Организация не располагает достаточными ресурсами (финансовыми, техни-
ческими, кадровыми) для разработки, приобретения и поддержки ХД.
2. Унаследованная система аналитической обработки эффективно функциони-
рует с использованием обычной реляционной СУБД, и руководство не видит
смысла в дорогостоящем и трудоемком процессе внедрения ХД.
3. Объем анализируемых данных невелик, а применяемые технологии анализа
данных несложны. В частности, не требуется поддержка хронологии данных,
для анализа используются только данные за актуальный период и т. д.
4. Роль анализа в деятельности организации невысока, администрация не осо-
знала его значимость в получении конкурентных преимуществ.
Таким образом, причин для отказа от использования ХД в аналитическом
процессе достаточно много и все они могут быть по-своему аргументированы.
В некоторых случаях отказ от ХД дает определенные преимущества: аналитиче-
ский процесс становится проще и дешевле; нет необходимости разрабатывать кон-
цепцию его внедрения; не нужны сложный процесс ETL и другие сопутствующие
затраты. Кроме того, процессы, связанные с поддержкой ХД, — интегрирование
данных из различных источников и ETL, — если они недостаточно продуманы
и некачественно реализованы, способны не только свести на нет все преимущест-
ва, которые дает ХД, но и ухудшить ситуацию, породив массу ошибок и проблем
с получением данных. Возможно также, что лучше быстро реализовать аналити-
ческий процесс в упрощенном варианте, чем годами отлаживать взаимодействие
OLTP-систем с ХД.
Глава 2. Консолидация данных 125
проблемы, возникающие при прямом доступе
к источникам данных
0Тказ от использования ХД для консолидации и интегрирования данных не только
нлэкает эффективность анализа, достоверность и значимость его результата, но
п0рождает ряд дополнительных проблем как технического, так и методического
Ппана. Конечно, они присутствуют и при использовании ХД, но в этом случае они
автоматически решаются самим хранилищем и поддерживающими его програм-
мНыми средствами. При осуществлении прямого доступа к источникам данных
пользователь (эксперт, аналитик) вынужден сталкиваться с этими проблемами
непосредственно. К таким проблемам относятся следующие.
Необходимость самостоятельно определять тип и формат источника данных.
Узнать тип и формат файла можно по его расширению. Однако, если приходится
иметь дело с экзотическим форматом или типом файла, этот вопрос может потребо-
вать дополнительного исследования. Например, если речь идет о текстовом файле
с разделителями, то ТХТ-формат известен любому, кто работал на компьютере, по-
скольку его освоение обычно начинается с создания простейших текстовых файлов.
В то же время формат CSV в повседневной работе используется достаточно редко
и поэтому большинству пользователей неизвестен. Кроме того, при загрузке данных
из СУБД пользователь сталкивается с поиском нужной таблицы, что само по себе
не очень сложно, но может занять определенное время.
Отсутствие полноценного семантического слоя того уровня, который имеется
в ХД. При работе с ХД, которое обеспечивает семантический слой, преобразующий
высокоуровневые запросы пользователей в низкоуровневые запросы к источникам
данных, пользователь оперирует такими бизнес-терминами предметной области,
как наименования товаров и клиентов, цена, количество, сумма, наценка, скидка
и т. д. При работе с источниками данных напрямую аналитик вынужден иметь
дело непосредственно с именами полей источника, которые в большинстве случаев
вводятся на латинице и не всегда понятны, поэтому приходится тратить время на
то, чтобы разобраться, в каком поле содержатся нужные данные.
Отсутствие жесткой поддержки структуры и форматов данных. При непосред-
ственной работе с источниками данных часто приходится иметь дело с файлами,
в которых структура и формат данных жестко не заданы. Типичный пример — тек-
стовый файл с разделителями, в котором данные упорядочены в столбцы, отделен-
ные друг от друга однотипными символами-разделителями. В таких файлах могут
быть любые нарушения структуры и форматов данных. В них могут содержаться
неполные поля и записи, использоваться различные символы — разделители столб-
цов, произвольные разделители целой и дробной частей и групп разрядов в чис-
лах. В одном и том же столбце могут оказаться и строковые, и числовые данные,
различные форматы даты и т. д. Особенно это характерно для файлов, которые
создавались без учета перспективы анализа данных. В подобной ситуации ничего
не остается, кроме как попытаться выполнить корректировку данных средствами,
Имеющимися в аналитическом приложении. Иногда структура данных в файле
126 Часть I. Теория бизнес-анализа
оказывается настолько искаженной, что его загрузка в аналитическую систему це,
возможна. Тогда редактировать данные приходится непосредственно в источнике
И в том и в другом случае ручная корректировка данных является очень трудоемкой
и затратной по времени. Если затраты на подготовку данных превышают их ценность
с точки зрения анализа, то, возможно, от работы с ними следует вообще отказаться
Отсутствие автоматических средств поддержки целостности, непротиворе-
чивости и уникальности данных. Эта проблема главным образом возникает при
работе с локальными файлами. При извлечении данных может произойти разрыв
связей между атрибутами и, как следствие, потеря целостности данных.
Отсутствие средств автоматического агрегирования и создания новых дан-
ных. При использовании ХД предусмотрены автоматические агрегирование дан-
ных и расчет вычисляемых значений (обычно в процессе ETL). Эти новые данные
сохраняются и остаются доступными в любой момент, что ускоряет выполнение
аналитических запросов. Когда загрузка данных производится напрямую из ис-
точников, агрегирование и вычисление новых данных приходится делать непо-
средственно в ходе выполнения запросов либо вручную, что существенно снижает
скорость работы.
Отсутствие средств автоматического контроля ошибок и очистки данных. Это
приводит к тому, что в аналитическую систему загружаются «грязные» данные,
зачастую непригодные для анализа, поэтому пользователь должен самостоятельно
(визуально и с помощью статистических характеристик или специальных средств,
если они доступны) оценить качество данных, степень их пригодности для анализа
и применить необходимые методы очистки.
Необходимость настройки механизмов доступа к источникам данных. Для осу-
ществления непосредственного доступа к различным источникам данных обычно
используются стандартные механизмы доступа — ODBC, ADO и OLE DB. Чтобы
указанные компоненты функционировали правильно, они должны быть соответ-
ствующим образом настроены, что также зачастую ложится на плечи пользователя
или системного администратора.
Преимущества использования непосредственного
доступа к источникам данных
Помимо недостатков, использование непосредственного доступа к источникам
данных имеет ряд преимуществ.
□ Отсутствие ETL-процесса снимает проблему «окна загрузки», то есть промежут-
ка времени, в течение которого производятся загрузка ХД и сопутствующие ей
операции. Обычно во время «окна загрузки» нагрузка на систему предприятия
резко возрастает, а производительность работы пользователей, наоборот, падает,
при этом само ХД может оказаться частично или полностью недоступным.
□ Возможность внерегламентного использования источников данных. Обычно
обновление данных в хранилище производится в соответствии с определенным
регламентом. Это в некоторой степени связывает руки пользователю. Например,
Глава 2. Консолидация данных 127
если загрузка новой информации в ХД осуществляется раз в неделю, а непо-
средственный доступ к источникам данных не предусмотрен, то пользователю
приходится ждать, пока данные не появятся в ХД и не станут доступными.
g Возможность получать для анализа данные, которые почему-либо не попали
в хранилище (например, по техническим причинам как не представляющие
ценности). Кроме того, у сотрудников организаций часто накапливаются дан-
ные, собранные ими для собственного использования. На первый взгляд такие
данные кажутся свалкой информационного мусора (чем чаще всего и являются),
поскольку при их сборе и организации используются нестандартные методы,
отличные от тех, которые применяются при сборе и консолидации данных через
хранилище. Однако именно благодаря этому на основе таких данных можно
получить очень интересные и нестандартные аналитические решения.
□ Пользователь имеет возможность работать с данными в их «первозданном»
виде, что представляет особый интерес, поскольку при загрузке данных в ХД
в них вносятся изменения, которые в некоторых случаях влияют на их изна-
чальный смысл.
Таким образом, необходимость в организации непосредственного доступа к раз-
личным источникам данных из аналитического приложения возникает даже при
наличии ХД.
Особенности непосредственной загрузки данных
из наиболее распространенных типов источников
Наиболее часто встречающимися видами источников данных, доступ к которым
производится напрямую, являются:
□ текстовые файлы с разделителями (TXT, CSV);
□ файлы электронных таблиц Excel;
□ файлы плоских таблиц БД, например dBase, FoxPro и т. д. (DBF-файлы);
□ реляционные СУБД настольного уровня, например Access и т. д.;
□ корпоративные базы данных и учетные системы (Oracle, Informix, Sybase, DB2
и т. д.).
Текстовые файлы с разделителями (TXT, CSV). Файлы в ТХТ-формате хорошо
известны большинству пользователей (даже непрофессиональных) еще со времен
MS-DOS. Для создания таких файлов достаточно использовать простейший тексто-
вый редактор, например Блокнот из набора стандартных программ Windows. Однако
эти файлы имеют произвольную структуру данных, поэтому они наиболее уязвимы
с точки зрения нарушения структуры, использования некорректных форматов
и представлений данных. Так что загрузка и очистка ТХТ-файлов могут вызвать са-
мые серьезные проблемы, несмотря на то что эти файлы очень просты в создании.
Чтобы создать структурированный текстовый файл, который может быть за-
гружен в аналитическую систему, достаточно упорядочить в нем данные в виде
128 Часть I. Теория бизнес-анализа
вертикальных столбцов и горизонтальных строк, из которых будут сформированы
поля и записи соответственно. Для разделения столбцов должны использоваться од.
нотипные символы-разделители, например табуляция, точка с запятой и др. Можно
использовать как один символ, так и несколько идущих подряд символов.
При создании файла следует придерживаться нескольких правил.
1. В первой строке файла нужно указать заголовки столбцов в произвольной
форме, при этом используются кириллица и пробелы. При загрузке в аналити-
ческую систему заголовки столбцов будут преобразованы в метки полей, что
позволит аналитику быстрее разобраться с содержимым источника. Посколь-
ку в ТХТ-файлах имена полей (в том виде, как они представлены в таблицах
файлов БД) отсутствуют, при загрузке в аналитическую систему они будут
установлены автоматически в соответствии с правилами, принятыми в данной
системе. Например, им по умолчанию могут быть присвоены метки COL1, COL2
или FIELD1, FIELD2 и т. д. Если в первой строке текстового файла над каждым
столбцом указано его название, то система при загрузке сможет преобразовать
эти названия в имена полей, если каким-либо образом указать, что первая строка
содержит заголовки. Однако это возможно только при условии, что названия
столбцов не противоречат правилам назначения имен полей в данной анали-
тической системе, то есть не содержат недопустимых символов, не превышают
заданную длину и т. д. Это следует учитывать при создании текстовых файлов
с разделителями, которые планируется использовать в качестве источников
данных для аналитических систем.
2. Необходимо соблюдать регулярность структуры данных, то есть каждые строка
и столбец должны содержать одинаковое число элементов. Если некоторые зна-
чения были утеряны, то их можно заменить средними значениями по столбцу
для числовых атрибутов. Для строковых атрибутов можно указать наиболее
вероятное значение или значение по умолчанию, которое впоследствии может
быть соответствующим образом обработано (например, NONAME). Оставлять
пустые или фиктивные значения нежелательно: пропущенное значение может
заблокировать работу аналитических алгоритмов, а фиктивное (например,
$999,999) может быть обработано как истинное.
3. Столбцы должны быть типизированы, то есть содержать данные только одного
типа (например, только строковые или только числовые). Кроме того, внутри
каждого столбца формат представления чисел или дат должен быть одинако-
вым. Например, использование в одном столбце краткого (12.07.06) и полного
(12 июля 2006 г.) форматов даты способно вызвать серьезные проблемы при
загрузке данных. Также нежелательно использовать в одном поле числа в экс-
поненциальном формате (1,2Е + 3) и в обычном (12 000), поскольку это может
вызвать проблемы при загрузке значений из данного поля.
4. Строковые значения желательно приводить в соответствие унифицированным
шаблонам. Например, нежелательно смешивать представление ФИО, указывая
инициалы то справа, то слева от фамилии или вообще не указывая, использовать
в инициалах то одну, то две буквы и т. д. При указании названий организаций
Глава 2. Консолидация данных 129
также нужно использовать единое представление. Например, форма собствен-
ности должна во всех строках указываться только после названия (это упростит
сортировку названий по алфавиту). Несоблюдение этого требования, скорее
всего, не вызовет проблем при загрузке, но может привести к неправильной
обработке таких данных аналитическим приложением.
5 Символы-разделители и их количество во всех строках и между столбцами
должны быть одинаковыми.
6 Необходимо использовать одинаковые разделители целой и дробной частей
чисел и групп разрядов. Например, если по умолчанию в качестве разделите-
ля целой и дробной частей используется точка, а в каком-то значении будет
обнаружена запятая, это значение будет рассматриваться системой как стро-
ковое.
При загрузке в ХД все эти проблемы автоматически корректируются на этапе
ETL. А при непосредственной загрузке пользователю приходится отслеживать эти
проблемы самому. Если данных в источнике немного, то они могут быть откоррек-
тированы вручную. В противном случае приходится использовать средства очистки
данных, предусмотренные в аналитической системе (например, восстановление
пропущенных значений, трансформация типов и т. д.).
Чтобы настроить процесс импорта текстового файла с разделителями, обычно
требуется указать:
□ имя файла и путь к нему;
□ символ-разделитель, используемый для разделения столбцов;
□ используемый формат даты (времени);
□ используемые разделители целой и дробной частей чисел и групп разрядов;
□ номер строки файла, с которой требуется начать извлечение данных (если все
данные извлекать не нужно или нужно извлечь только те данные, которыми
файл был пополнен с прошлой загрузки);
□ является ли первая строка строкой заголовков. Если да, то содержимое первой
строки будет преобразовано в метки полей, а данные начнут загружаться со
второй строки.
Таким образом, чтобы правильно настроить параметры импорта текстового
файла, нужно иметь информацию о файле, которая в большинстве случаев может
быть получена только опытным путем. Для этого достаточно открыть файл с по-
мощью текстового редактора, просмотреть структуру файла и при необходимости
откорректировать ее (например, присвоить столбцам заголовки).
Текстовые файлы в формате CSV менее известны пользователям, поскольку
Используются реже, чем обычные ТХТ-файлы. CSV (от англ, comma separated
values — «значения, разделенные запятыми») — это специальный текстовый фор-
мат, предназначенный для представления табличных данных. Каждая строка в таком
файле соответствует одной строке таблицы. Значения отдельных столбцов разде-
ляются специальным символом — запятой или точкой с запятой. Используемый
130 Часть I. Теория бизнес-анализа "
символ-разделитель зависит от настроек региональных стандартов. В США ЭТ()
запятая, а в России — точка с запятой, поскольку у нас запятая используется
разделения целой и дробной частей чисел (в отличие от США, где для этого служцт
точка). Файлы такого типа могут быть получены путем конвертации из любого
табличного процессора.
Все свойства обычных текстовых файлов с разделителями, описанные выще
и рекомендации по их подготовке и загрузке в полной мере относятся к CSV-фай’
лам. Но у CSV-файлов есть и ряд преимуществ.
□ Использование унифицированного символа-разделителя (запятой) позволяет
избежать разночтений и связанных с этим проблем.
□ Поскольку CSV-файлы в большинстве случаев являются результатом преобра-
зования файлов Excel, в них более жестко задана структура строк и столбцов.
Файлы «плоских* таблиц СУБД семейства dBase, FoxBase, FoxPro и т. д.
Файлы данного типа имеют расширение DBF (database file). Как и файлы любых
СУБД, DBF-файлы имеют жестко заданную структуру. В них строго определены
имена и типы полей, структура полей и записей, используемые форматы представ-
ления данных. Следовательно, проблем с загрузкой данных из таких источников
намного меньше по сравнению с текстовыми файлами, поскольку все возможные
проблемы контролируются в процессе создания файла. СУБД не позволит при-
своить полю некорректное имя, ввести в поле данные, не соответствующие его
типу или использующие неправильный разделитель групп разрядов в числе, и т. д.,
поэтому ожидаемое качество данных, загружаемых из DBF-файлов, является более
высоким, чем для текстовых.
При загрузке данных из DBF-файлов в аналитическую систему, как правило,
достаточно указать их имя. В некоторых случаях требуется дополнительно указать
версию СУБД (dBase III или dBase IV), а также кодовую страницу для корректного
отображения символов.
Файлы электронных таблиц Excel. Excel — одно из наиболее популярных
офисных приложений, применяемых пользователями всех уровней, поэтому
возможность загрузки данных из файлов в формате XLS предусмотрена практи-
чески в любой аналитической системе. Однако следует учитывать, что в одном
столбце таблицы Excel могут содержаться данные различных типов и форматов,
допускаться неправильное использование разделителей целой и дробной частей
чисел и групп разрядов в них. В этом плане к ним следует относиться так же вни-
мательно, как и к данным из текстовых файлов.
Файлы реляционных СУБД. Источники этого типа самые «желанные» для
пользователей аналитических систем, поскольку с ними меньше всего проблем.
Структура данных в файлах реляционных СУБД жестко задана, поля строго ти-
пизированы, форматы данных соответствуют стандартам. В большинстве СУБД
поддерживается автоматический контроль целостности, непротиворечивости
и уникальности данных. Для загрузки данных, например, из файла Access доста-
точно указать имя файла и таблицу, из которой нужно взять данные.
Глава 2. Консолидация данных 131
2.15. Обогащение данных
g большинстве случаев хранилища данных создаются и поддерживаются для обес-
печения эффективного анализа данных на предприятии.
Очевидно, что данные, собираемые для задач анализа, должны быть полными
достоверными, поскольку на основе неполных или недостоверных данных нельзя
сделать правильные выводы о состоянии бизнеса и путях его совершенствования.
Неполные данные могут появиться, например, если часть сведений о прода-
жах филиала фирмы была утеряна в процессе их переноса в ХД. Аналитик может
прийти к выводу, что продажи в этом филиале катастрофически низкие, филиал
работает неэффективно и его следует закрыть, хотя на самом деле деятельность
филиала вполне успешна, а его сотрудники хорошо справляются со своими зада-
чами. Недостоверные данные, которые при этом могут быть полными, содержат
искаженную информацию, не позволяющую провести качественный анализ. По-
этому в процессе загрузки в ХД, а также при подготовке к анализу в аналитическом
приложении данные проверяются на полноту, целостность, непротиворечивость,
наличие ошибок, пропусков, аномальных значений и других факторов, которые
могут привести к некорректным результатам анализа.
Данные и информация
Помимо достоверности и полноты данных, существует еще один фактор, непосред-
ственно влияющий на эффективность их анализа, — информационная насыщен-
ность. Вообще говоря, данные и информация не совсем одно и то же. Каждый стал-
кивался с ситуацией, когда, несмотря на наличие данных, извлечь из них какую-либо
информацию оказывалось невозможно. Например, если вывести на экран компью-
тера текст с неправильной кодировкой шрифта, мы увидим вместо букв непонятные
закорючки, фигурки, спецсимволы и т. д. Данные есть — информации нет. То же
самое произойдет, если вы попытаетесь читать текст на иностранном языке, которого
не знаете и символы которого вам неизвестны, например на китайском. При этом мы
понимаем, что информация есть, но мы не можем ее распознать и осмыслить.
Для извлечения информации из данных может потребоваться их обработка —
корректировка представления значений (символов), упорядочение и т. д. Примера-
ми такой обработки служат перевод с неизвестного языка на известный, изменение
кодировки символов и т. д. На практике подобная обработка с целью получить
из произвольных данных информацию является очень трудоемкой, отнимающей
много времени и не гарантирующей результатов. Действительно, если изначально
при создании данных в них не закладывалась никакая информация, то и извлечь
ее будет невозможно. Попробуйте закрыть глаза и случайно набрать на клавиатуре
несколько строк, а затем отнесите набранный фрагмент криптографу, скажите, что
это код, и попросите расшифровать его. Скорее всего, усилия специалиста будут
напрасны. Если же ему случайно и удастся выявить некоторую закономерность
и извлечь какую-то информацию, то о ее достоверности и говорить не приходится.
132 Часть I. Теория бизнес-анализа
Таким образом, информация — это не любые данные, а только те, которые со.
ответственным образом представлены и упорядочены, то есть имеют структурцЬ1е
закономерности, которые, кроме всего прочего, должны распознаваться и осмыс-
ливаться пользователем. Так, если мы видим текст на языке, символы которого
нам незнакомы, мы сталкиваемся с ситуацией, когда упорядоченность данных есть
а соответствующего представления нет. Напротив, если в тексте на известном языке
случайным образом переставить буквы, то получится правильное представление
но отсутствие упорядоченности. И в том и в другом случае воспользоваться этими
данными мы не сможем, до тех пор пока они не будут соответствующим образом
преобразованы.
Данные — понятие объективное. Они либо реально существуют как изменения
некоторого физического процесса, либо нет. А информация в большинстве случаев
субъективна. Если один эксперт с определенным уровнем компетентности, знаний
и опыта увидит в некотором наборе данных полезную информацию, то другой
эксперт с другим уровнем опыта и знаний отыщет совсем другую информацию
или не найдет ее вовсе.
Приступая к анализу данных с целью поиска скрытых закономерностей и из-
влечения знаний, мы должны задаться рядом вопросов.
□ Имеют ли эти данные вообще какой-нибудь смысл? Присутствует ли в них
какая-либо информация?
□ Если да, то насколько эта информация надежна и достоверна?
□ Достаточно ли этой информации для генерирования надежных и достоверных
знаний, на основе которых можно принимать ответственные управленческие
решения?
Ответ на первый вопрос во многом определяется происхождением набора данных.
Если данные были получены из надежного источника: от подразделения предпри-
ятия, из учетной системы, органов госстатистики и т. д., скорее всего, в том или ином
виде информация в них имеется. Правда, иногда для ее извлечения требуется неко-
торая обработка данных — перекодировка, преобразование форматов и т. д.
Таким образом, если поставщик данных хорошо известен, то и смысл данных
определен. Например, если источником данных является бухгалтерия, то они, скорее
всего, содержат информацию финансового или учетного характера. Если источни-
ком является какая-либо техническая служба предприятия, то и предоставляемая
ею информация в большинстве случаев носит технический характер.
Надежность и достоверность проверяются практически на всех этапах аналити-
ческого процесса: сначала на этапе загрузки данных в ХД (в процессе ETL), затем
в самом ХД (автоматический контроль) и, наконец, в аналитическом приложении
при подготовке данных к анализу.
Третий вопрос является самым неоднозначным. Достаточно или недоста-
точно информации для решения той или иной аналитической задачи, каждый
аналитик определяет сам на основании весьма субъективных критериев. Один
аналитик даже из минимума информации выжмет максимум полезных знаний
с помощью личного опыта, навыков аналитической работы, умелого применения
Глава 2. Консолидация данных 133
аналитических методов и алгоритмов. Специалисту с меньшей квалификацией,
возможно, не удастся решить задачу с любым количеством данных. Кроме того,
сами аналитические задачи различаются по уровню сложности и требованиям
к информативности исходных данных.
Необходимость обогащения данных
Часто возникают ситуации, особенно при решении нестандартных аналитических
задач, когда для анализа требуется информация, которой почему-то не оказалось
в наличии. Это может произойти из-за непродуманного процесса сбора данных.
Порой базы данных оказываются забиты чем угодно, только не данными, имеющи-
ми прямое отношение к основным бизнес-процессам на предприятии. Например,
в регистрирующую систему заносят номер автомобиля, на котором вывозят то-
вар, номер путевого листа, ФИО водителя и т. д. А непосредственное отношение
к бизнес-процессу имеют только наименование товара, его количество и цена за
единицу. Очевидно, что большая часть информации, содержащейся в БД, может
заинтересовать разве что начальника охраны, но никак не аналитика по продажам.
Складывается ситуация, проиллюстрированная левой частью рис. 2.31, когда
в огромном массиве данных имеется только небольшое их подмножество, реально
описывающее исследуемый процесс.
Рис. 2.31. Обогащение данных
Когда же наконец приходит время анализировать данные, выясняется, что
анализировать, в общем-то, и нечего. В этот момент осознается необходимость
обогащения данных. Оно может выполняться за счет реорганизации самих данных:
введения каких-то кодировок, признаков состояний объектов, подразделения их на
категории (например, товары распределяются по группам товаров) и т. д. Может
привлекаться дополнительная внешняя информация, например история курсов
валют на день продажи, информация о продажах конкурентов за тот же период
и др. И постепенно ситуация примет вид, представленный в правой части схемы
(см. рис. 2.31), когда полезная информация составляет большую часть имеющихся
в распоряжении аналитика данных.
134 Часть I. Теория бизнес-анализа
ОПРЕДЕЛЕНИЕ
Обогащение данных — процесс насыщения данных новой информацией, которая позволяет
сделать их более ценными и значимыми с точки зрения решения той или иной аналити-
ческой задачи.
Можно выделить два основных метода обогащения данных — внешнее обога-
щение и внутреннее.
Внешнее обогащение предполагает привлечение дополнительной информации
из внешних источников, что позволит повысить ценность и значимость данных
с точки зрения их анализа. Под повышением значимости данных подразумева-
ется, что на основе их анализа можно будет принимать управленческие решения
принципиально нового уровня. Например, обычные данные о текущей работе
предприятия позволяют оптимизировать товарные потоки, работу с клиентами,
политику скидок, гарантий и т. д. Уже немало, но, поскольку у конкурентов тоже
созданы аналитические службы, больших конкурентных преимуществ анализ
только оперативной информации не принесет.
Другое дело — стратегический анализ, на основании результатов которого
можно поднять работу предприятия на качественно новый уровень и существенно
увеличить продажи, а соответственно, и прибыль. Как правило, подобные проры-
вы связаны с освоением новых рынков, технологий, номенклатуры выпускаемых
изделий и т. д. Такие бизнес-проекты в случае успеха сулят большие дивиденды,
но требуют очень больших временных и финансовых затрат. Поэтому, если при
разработке и реализации масштабных бизнес-проектов допускаются просчеты,
не учитываются какие-то факторы, делаются неверные прогнозы и проект закан-
чивается неудачей, для любого предприятия это очень серьезный удар, грозящий
полным крахом.
Для поддержки успешного решения стратегических бизнес-задач необходимо
использовать соответствующий уровень анализа данных. Данных из обычных
OLTP или учетных систем предприятия для такого анализа, как правило, не-
достаточно. В этом случае следует привлекать дополнительную информацию из
внешних источников. Она позволит обогатить внутренние данные, имеющиеся
в распоряжении аналитиков фирмы, до уровня информативности и значимости,
который позволит решать задачи стратегического анализа с соответствующим
уровнем достоверности.
Внешними источниками могут быть:
□ другие предприятия и организации, работающие в этой же сфере деятельности
или в смежных сферах, причем как партнеры, так и конкуренты;
□ финансово-кредитные учреждения, банки, страховые компании;
□ государственные налоговые и статистические службы;
□ органы государственного и муниципального управления;
□ различные службы социальной сферы: миграционная служба, органы труда
и занятости, система здравоохранения, пенсионные фонды и т. д.
Глава 2. Консолидация данных 135
расточником информации для обогащения данных могут быть любые органи-
ацИИ, которые в процессе своей деятельности собирают, структурируют и хранят
3 „формацию, необходимую им для осуществления своих целей.
11 внутреннее обогащение не предполагает привлечения внешней информации,
g этом случае повышение информативности и значимости данных может быть
достигнуто за счет изменения их организации. Не следует путать внутреннее обога-
щение с обычным преобразованием данных, выполняемым в процессе их загрузки
в ХД или при подготовке к анализу в аналитическом приложении. Преобразование
данных изначально связано с оптимизацией занимаемого ими объема, скорости
доступа к ним, удобства представления для пользователя, обеспечения целостности
и непротиворечивости данных, удаления факторов, которые мешают их корректно
обрабатывать, и т. д. Такая обработка не преследует цель обогатить данные инфор-
мацией, а только решает определенные технические проблемы.
Внутреннее обогащение обычно связано с получением и включением в набор
данных полезной информации, которая отсутствует в явном виде, но может быть
тем или иным способом получена с помощью манипуляций с имеющимися дан-
ными. Затем эта информация встраивается в виде новых полей или даже таблиц
в ХД и может быть использована для дальнейшего анализа. Для обогащения
данных также может использоваться информация, полученная в процессе их
анализа.
ПРИМЕР---------------------------------------------------------------------
Рассмотрим пример внутреннего обогащения. Руководство предприятия поставило за-
дачу выработать новую политику взаимодействия с поставщиками в зависимости от их
надежности. Были разработаны критерии, в соответствии с которыми определялась степень
надежности поставщиков, в результате чего все поставщики разбивались на три катего-
рии — надежные, средние и ненадежные. Степень надежности конкретного поставщика
определялась как отношение общего числа дней задержки поставок за квартал к стоимости
поставок. То есть поставщик, часто задерживающий мелкие поставки, но в целом соблю-
дающий график серьезных поставок, будет рассматриваться как надежный партнер. В то же
время поставщик, который задерживает крупные поставки, пусть даже и редко, но соблюда-
ет график мелких поставок, будет рассматриваться как потенциально ненадежный партнер.
Информацию о задержках и суммах поставок можно получить из документов о поступлении
товара в учетной системе. После соответствующих вычислений и сравнений в таблицу ХД,
где находится информация о поставщиках, будет добавлено новое поле, в котором для каж-
дого из них будет указана категория надежности. Дальнейший анализ в области поставок
может производиться с использованием новых данных.
Таким же образом можно создавать рейтинги сотрудников для их поощрения
и продвижения по службе, рейтинги популярности товаров и т. д.
Применение обогащения данных из внешних источников обычно связано со
сбором информации об объектах предметной области, участвующих в исследуемом
бизнес-процессе. Для предприятий и организаций это могут быть экономические
показатели (прибыль, численность работников, объем продаж и др.). При исследо-
вании клиентов — физических лиц наибольший интерес представляют признаки,
136 Часть I. Теория бизнес-анализа
позволяющие распределить их по группам, например с точки зрения их активности
как покупателей или потребителей каких-либо услуг. В этом случае выясняются
пол, возраст, род занятий и увлечений, наличие семьи и детей, медиапредпочтещ^
и т. д.
ПРИМЕР--------------------------------------------------------------——_
Сеть магазинов, торгующих недорогой повседневной одеждой, решила провести реклам-
ную кампанию с целью привлечения большего числа покупателей. При этом организаторы
кампании посчитали, что реклама должна быть направлена на те категории населения
которые являются самыми активными клиентами. Чтобы узнать, представители каких слоев
общества наиболее активно приобретают товары этой сети магазинов, были проведены
следующие мероприятия. Клиентам предлагалась дисконтная карта, при получении которой
нужно было заполнить анкету и указать пол, возраст, профессию, семейное положение, род
занятий, увлечения, наличие детей, предпочтения в стилях одежды. Затем по номеру дис-
контной карты отслеживались продажи. По итогам квартала были сопоставлены анкетные
данные и собранная информация о продажах. В результате выяснилось, что более 70 % кли-
ентов сети магазинов составляют студенты и молодые специалисты в возрасте до 25-27 лет,
предпочитающие современный стиль в одежде и ведущие активный образ жизни. Поэтому
рекламную кампанию было решено направить именно на эту категорию клиентов.
Обогащение — один из важнейших этапов подготовки данных к анализу. Ис-
пользование этой процедуры во многих случаях позволяет поднять качество анали-
за на принципиально новый уровень, особенно при решении нестандартных задач,
даже в условиях недостаточной информативности данных, поступающих из OLTP
и учетных систем. Кроме того, обогащение данных в какой-то мере позволяет ком-
пенсировать просчеты в стратегии сбора и консолидации аналитических данных.
ПЕРСОНАЛИИ----------------------------------------------------------------
Билл Инмон (Bill Inmon) — автор концепции хранилищ данных, обнародованной в 1989 г.,
крупнейший в мире специалист в этой области. Его идея вызвала настоящий переворот
в методах использования при управлении бизнесом гигантских массивов данных, накоп-
ленных компаниями. Тем самым был дан мощный толчок дальнейшему развитию технологий
Business Intelligence, прежде всего построению информационных витрин. Билл Инмон — со-
автор концепций корпоративной информационной фабрики (Corporate Information Factory)
и ее аналога для государственных структур (Government Information Factory). В его модели
атомарные данные организованы в реляционные базы и находятся в нормализованном
хранилище данных.
Из-под пера Инмона вышло более боо статей, а также 46 книг, переведенных на девять язы-
ков мира. Среди них — бестселлер Building the Data Warehouse, суммарный тираж которого
уже превысил полмиллиона экземпляров.
Билл Инмон является основателем Prism Solutions — первой в мире компании, которая
занялась разработкой инструментария ETL— средств извлечения, преобразования и за-
грузки данных.
Ральф Кимболл (Ralph Kimball) — широко известный специалист в области хранилищ дан-
ных и бизнес-аналитики. Он предложил использовать пространственную организацию баз
данных (dimensional data bases) с так называемой архитектурой «звезда».
Глава 2. Консолидация данных 137
Кимболл известен как автор бестселлера «Инструменты для хранилища данных: полное
руководство пространственного моделирования» (The Data Warehouse Toolkit: The Complete
Guide to Dimensional Modeling) и др.
Карьера Кимболла складывалась следующим образом. В1972 г., после окончания постдока
Стэндфордского университета в области электротехники (специализация — человеко-ма-
шинное взаимодействие), он попал в исследовательский центр Xerox Palo Alto, где принял
участие в разработке коммерческого программного продукта Xerox StarWorkStation. Затем
Кимболл становится вице-президентом компании Metaphor Computer Systems, занима-
ющейся разработкой систем принятия решений и консалтингом. В 1986 г. он основывает
компанию Red Brick Systems и занимает пост ее генерального директора до 1992 г. Red Brick
System, сейчас принадлежащая IBM, известна своими разработками в области производи-
тельной реляционной СУБД, оптимизированной под хранилища данных.
В1992 г. зарегистрирована ассоциация Ральфа Кимболла, оказывающая услуги консалтин-
га и обучения в области хранилищ данных. Сайт ассоциации: http://ralphkimball.com/.
Трансформация
данных
3.1. Введение в трансформацию данных
Помимо предобработки, целью которой является приведение данных в соответ-
ствие с определенными критериями качества, процесс подготовки данных к ана-
лизу обычно включает в себя еще один этап — трансформацию.
Каждая выборка исходных данных, загружаемая в аналитическое приложение,
характеризуется набором свойств, которые могут повлиять на эффективность
работы модели и снизить достоверность результатов анализа. Даже если данные
очищены от таких факторов, ухудшающих их качество, как дубликаты, противо-
речия, шумы, аномальные значения, пропуски и др., они все еще мотут не соответ-
ствовать методике и целям анализа. Это связано не с содержанием данных, а с их
представлением и внутренней организацией. Может возникнуть парадокс: данные
совершенно корректны с точки зрения качества, а их информационного содержания
вполне достаточно для решения аналитической задачи, но представление и орга-
низация данных затрудняют анализ или вообще делают его невозможным. Данные
могут быть разобщены, не упорядочены, представлены в форматах, с которыми не
работает тот или иной алгоритм. Трансформация данных, то есть их преобразование
к определенному представлению, формату или виду, оптимальному с точки зрения
решаемой задачи, и призвана решить эту проблему.
В то время как очистка данных занимается только их содержанием, транс-
формация — это процесс оптимизации их представления и организации с точки
зрения определенного метода анализа. Трансформация данных зависит от задач,
алгоритмов и целей анализа. То есть для одной задачи могут потребоваться одни
виды трансформации, а для другой — другие.
Несоответствие представления и организации данных методике и целям ана-
лиза может проявляться как на уровне моделей, так и на уровне отдельных задач
анализа. Несоответствие на уровне моделей означает, что даже если данные в их
Глава 3. Трансформация данных 139
нынешнем представлении пригодны для использования в нейронной сети, то впол-
не возможно, что их использование с другими моделями Data Mining, например
с деревьями решений, окажется затруднено либо вообще невозможно. Что касается
уровня задач, то, скажем, для прогнозирования достаточно иметь одномерный ряд
наблюдений за прогнозируемым параметром исследуемого процесса или объекта,
тогда как для решения задачи классификации требуется выборка, содержащая
несколько признаков классифицируемых объектов. Если для решения задачи
регрессии выходные данные должны быть числовыми, то при классификации — ка-
тегориальными. В то же время все три задачи Data Mining: классификация, регрес-
сия и прогнозирование — могут быть решены в рамках одной модели (например,
нейросетевой).
Трансформация данных — очень широкое понятие, не имеющее четко очерчен-
ных границ. В различных направлениях обработки данных термин «трансформа-
ция» иногда распространяют на любые манипуляции с данными независимо от их
целей и методов. Однако в контексте бизнес-аналитики трансформация данных
имеет вполне конкретные цели и задачи, а также использует достаточно стабиль-
ный набор методов.
ОПРЕДЕЛЕНИЕ ---------------------------------------------------------
Трансформация данных — комплекс методов и алгоритмов, направленных на оптимиза-
цию представления и форматов данных с точки зрения решаемых задач и целей анализа.
Трансформация данных не ставит целью изменить информационное содержание данных.
Ее задача — представить эту информацию в таком виде, чтобы она могла быть использована
наиболее эффективно.
Трансформация данных не обязательно связана только с аналитическим при-
ложением — в том или ином виде она выполняется на всех этапах аналитического
процесса: в регистрирующих системах (OLTP-системах), в процессе переноса
и загрузки данных в ХД (ETL-процесс) и непосредственно при подготовке данных
к анализу в аналитическом приложении. Такая распределенность процесса транс-
формации обусловлена тем, что на каждом этапе он преследует различные цели.
В системах первичной регистрации данных (OLTP-системах) трансформация
может производиться для обеспечения технической и логической совместимости
Данных, их подготовки к извлечению, переносу в хранилище данных и т. д. Напри-
мер, адреса часто вводят одной строкой. В то же время для анализа могут представ-
лять интерес отдельные компоненты адреса, которые имеют как текстовый формат
(улица, город), так и числовой (номер дома, офиса). С помощью трансформации
можно распределить соответствующие элементы по отдельным полям и преобра-
зовать их в нужный формат. Приведем еще один пример. Различные системы реги-
страции (сканер штрихкодов, контрольно-кассовый аппарат и т. п.) мшут выдавать
однотипные данные в разных форматах. Так, в одном случае в качестве разделителя
целой и дробной частей чисел может использоваться точка, а в другом — запятая.
Попытка вставить такие данные в одно поле базы данных может привести к серьез-
ным техническим проблемам, а трансформация, то есть преобразование к единому
формату, поможет решить этот вопрос.
140 Часть I. Теория бизнес-анализа
Основными целями трансформации данных на этапе процесса ETL являются
приведение их в соответствие с моделью данных, используемой в хранилище, осу.
ществление корректной консолидации и собственно загрузка в хранилище.
Возникает вопрос: если трансформации данных так много внимания уделяется
на этапе сбора и организации хранения данных, то зачем включать средства транс-
формации в аналитическое приложение (что, несомненно, усложняет и делает более
дорогим его разработку)? Ответ прост. Не все данные поступают в аналитическое
приложение из систем, где они прошли предварительную подготовку, таких как
OLTP-системы и хранилища данных. Но главная причина заключается в том, что
трансформация данных в этих системах в большей степени носит технический ха-
рактер и слабо связана с возможными методами, алгоритмами и целями анализа.
Основные отличия применения трансформации данных на разных этапах ана-
литического процесса представлены в табл. 3.1.
Таблица 3.1. Трансформация данных на разных этапах аналитического процесса
OLTP-системы ETL-процесс Аналитическое приложение
Обеспечение поддержки корректности форматов и типов данных. Оптими- зация процессов доступа и выгрузки данных Обеспечение поддержки корректности форматов и типов данных. Преобра- зование данных с целью приведения в соответствие с моделью данных, которая используется в хранилище. Обеспечение процесса кон- солидации данных и их за- грузки в хранилище Непосредственная подго- товка данных к анализу, объединение и выделение наиболее ценной инфор- мации, обеспечение кор- ректной работы аналити- ческих алгоритмов, методов и моделей
Хотя и OLTP-системы, и хранилища данных во многих случаях разрабатыва-
ются с учетом перспективных направлений анализа, предусмотреть все возмож-
ные ситуации очень трудно. В условиях динамики современного бизнеса нельзя
предсказать, какой набор аналитических решений понадобится в ближайшем
будущем. Именно процесс подготовки данных в аналитическом приложении непо-
средственно перед выполнением анализа, когда его цели и методы ясны, позволяет
аналитику наилучшим образом подготовить данные, выделить и подчеркнуть в них
необходимую информацию для наиболее эффективного ее использования. Эту
задачу и решает трансформация данных.
Необходимость использования методов трансформации данных в аналити-
ческом приложении обусловлена еще и их доступностью аналитику. Действитель-
но, в процессе подготовки данных пользователь аналитического приложения имеет
возможность по своему усмотрению применять те или иные методы трансформации
данных, настраивать их параметры, проводить эксперименты, позволяющие опре-
делить влияние трансформации на результаты анализа. Что касается хранилищ
данных и ETL-процессов, то, как правило, выполняемые в них преобразования дан-
ных заданы жестко, их адаптация в зависимости от характера данных и решаемых
задач анализа не предусмотрена и аналитик не может вмешиваться в эти процессы.
Глава 3. Трансформация данных
141
Системы оперативной регистрации данных (OLTP) обычно вообще недоступны
аналитику.
Основные методы трансформации данных
Прежде чем приступить к подробному рассмотрению методов, алгоритмов и целей
отдельных направлений трансформации данных, проведем краткий обзор типич-
ных средств трансформации, которыми оснащается большинство аналитических
платформ.
Преобразование упорядоченных данных. Позволяет оптимизировать пред-
ставление таких данных с целью обеспечения дальнейшего анализа, например
решения задачи прогнозирования временного ряда или группировки по времен-
ному периоду.
Квантование. Позволяет разбить диапазон возможных значений числового
признака на заданное количество интервалов и присвоить номера интервалов или
иные метки попавшим в них значениям.
Сортировка. Позволяет изменить порядок следования записей исходной выбор-
ки данных в соответствии с алгоритмом, определенным пользователем. В некоторых
случаях сортировка дает возможность упростить визуальный анализ выборки, опе-
ративно определить наибольшие и наименьшие значения признаков и т. д.
Слияние. Позволяет объединить две таблицы по одноименным полям или до-
полнить одну таблицу записями из другой, которые отсутствуют в дополняемой.
Слияние применяется в тех случаях, когда информацию в анализируемой выборке
данных необходимо дополнить информацией из другой выборки. При объединении
к записям исходной выборки добавляются все записи другой. В случае дополне-
ния к исходной выборке добавляются только те данные, которые отсутствовали
в исходной. Операция слияния является одним из способов обогащения данных:
если выборка содержит недостаточно данных для анализа, то ее можно дополнить
недостающей информацией из другой выборки.
Группировка и разгруппировка. Очень часто информация, интересующая ана-
литика, в таблице оказывается «разбавлена» посторонними данными, разобщена,
разбросана по отдельным полям и записям. Используя группировку, можно обоб-
щить нужную информацию, объединить ее в минимально необходимое количество
полей и значений. Обычно предусматривают возможность выполнения и обратной
операции — разгруппировки.
Настройка набора данных. Позволяет изменять имена, типы, метки и назначе-
ния полей исходной выборки данных. Например, если поле, содержащее числовую
информацию, в источнике данных по какой-либо причине имеет строковый тип,
значения этого поля не могут обрабатываться как числа. Чтобы работа с числовы-
ми данными этого поля стала возможной, их следует преобразовать к числовому
типу.
Табличная подстановка значений. Позволяет производить замену значений
в исходной выборке данных на основе так называемой таблицы подстановки.
Таблица подстановки содержит пары «исходное значение — новое значение».
142 Часть I. Теория бизнес-анализа
Каждое значение выборки данных проверяется на соответствие исходному значе
нию таблицы подстановки, и если такое соответствие найдено, то значение выбору
изменяется на соответствующее новое значение из таблицы подстановки. Это очець
удобный способ для автоматической корректировки значений.
Вычисляемые значения. Иногда для анализа требуется информация, которая
отсутствует в явном виде в исходных данных, но может быть получена на основе
вычислений над имеющимися значениями. Например, если известны цена и ко-
личество товара, то сумма может быть рассчитана как их произведение. Для этих
целей в аналитическое приложение включается своего рода калькулятор, который
позволяет выполнять над данными исходной выборки различные вычисления. По-
скольку анализируемые данные могут быть различных типов (строковый, числовой
дата/время, логический), то механизм расчетов должен поддерживать работу не
только с числовыми данными, но и с данными других типов, например выделять
подстроку, выполнять логические операции и т. д.
Нормализация. Нормализация позволяет преобразовать диапазон изменения
значений числового признака в другой диапазон, более удобный для применения
к данным тех или иных аналитических алгоритмов, а также согласовать диапазо-
ны изменений различных признаков. Часто используется приведение к единице,
когда весь имеющийся диапазон данных «сжимается» в интервал [0; 1] или [—1; 1].
Особенно важно произвести правильную нормализацию данных в алгоритмах Data
Mining, которые основаны на измерении расстояния между векторами объектов
в многомерном пространстве признаков (например, в кластеризации).
3.2. Трансформация упорядоченных данных
Многие аналитические задачи, например прогнозирование, анализ продаж, динами-
ки спроса, состояния бизнес-объектов и других протяженных во времени процес-
сов, связаны с обработкой данных, зависящих от времени. Такие данные называют
упорядоченными, или временными рядами. В процессе обработки временных рядов
требуется специальная подготовка данных, чтобы оптимизировать их представле-
ние для решения определенных аналитических задач: прогнозирования, классифи-
кации состояний объектов, выявления закономерностей, объясняющих динамику
бизнес-процессов, и т. д. — для всех возможных интервалов даты и времени.
Временной ряд состоит из последовательности наблюдений за состоянием
параметров (признаков) исследуемых объектов или процессов. Если наблюдения
содержат один признак, то ряд является одномерным, а если два или более — мно-
гомерным. Поскольку значения временного ряда определены только в фикси-
рованные моменты времени, так называемые отсчеты, последовательность его
значений может быть представлена в следующем виде:
X = {х(1),х(2)... х(и)},
где х(и) — последнее значение рассматриваемой временной последовательности.
При этом отсчеты времени полагаются равноотстоящими друг от друга.
Глава 3. Трансформация данных 143
ЗАМЕЧАНИЕ
Временной ряд всегда представляет собой упорядоченные во времени данные. Однако
обратное не всегда верно: не все упорядоченные данные могут образовывать временной
ряд. Скажем, при снятии показаний из скважины измерения характеристик производятся
с некоторым шагом глубины. Это тоже упорядоченные данные, но их нельзя назвать вре-
менным рядом, так как фиксируется не время, а глубина. Тем не менее многие рассуждения
о временных рядах распространяются на любые упорядоченные данные.
Целью трансформации временных рядов является не изменение их содержания,
а представление информации таким образом, чтобы обеспечивалась максимальная
эффективность решения определенной задачи анализа. Можно выделить два основ-
ных типа преобразования, которые наиболее часто используются при подготовке
временных рядов к анализу.
□ Скользящее окно применяется при решении задач прогнозирования и классифи-
кации состояний бизнес-объектов, чтобы преобразовывать последовательность
значений ряда в таблицу, которую можно использовать для построения моделей
или какой-либо другой обработки.
□ Преобразование даты и времени заключается в приведении даты и времени
к виду, наиболее удобному для визуального анализа и обработки временного
ряда. При этом результаты преобразования даты уже не являются значениями
типа Дата/Время и могут обрабатываться как обычные числа и строки.
Рассмотрим эти преобразования более подробно.
Скользящее окно
Широко применяется при обработке временных рядов, например, чтобы построить
модель прогноза временного ряда. Целью прогнозирования значений временного
ряда является предсказание значения х(п + 1) на основе предыдущих значений
признака. Решение задачи прогнозирования возможно только в том случае, если
значения временного ряда связаны между собой.
ПРИМЕР-----------------------------------------------------------------
При регистрации заявок, поступивших от клиентов, среди прочего фиксируются дата пода-
чи заявки и адрес клиента. Из базы данных системы регистрации заявок можно извлечь
временной ряд с последовательностью номеров квартир, указанных в адресах. Очевидно,
что пытаться предсказать номер квартиры следующего клиента на основе знания номеров
квартир клиентов, чьи заявки были зарегистрированы ранее, бессмысленно.
Для построения прогностической модели необходимо знать три параметра.
Интервал прогноза — временной интервал, на котором будет осуществляться
прогнозирование: день, неделя, месяц, квартал или год.
Горизонт прогноза — на какое количество интервалов (дней, недель и т. д.) мы
хотим получить прогноз.
Глубина погружения — количество значений интервалов прогноза в прошлом, ко-
торое мы будем использовать для предсказания значений интервалов в будущем.
144
Часть I. Теория бизнес-анализа
При выборе интервала прогноза, возможно, понадобится агрегирование данных
внутри интервала. Например, если в базе данных информация о продажах пред,
ставлена по дням, то для построения прогноза по неделям придется объединить
информацию за отдельные дни, вычислив сумму, среднее значение или испольэуя
другую функцию агрегации.
Если в качестве интервала прогноза выбрана неделя, то глубина погружения -
количество недель в прошлом, значения продаж за которые мы будем использовать
в качестве исходных данных для предсказания.
Горизонт прогноза в этом случае — количество недель, значения продаж за
которые мы хотим предсказать.
При выборе глубины погружения и горизонта прогноза следует руководство-
ваться следующими соображениями.
□ Модель прогноза функционирует по принципу обобщения, то есть вывод о воз-
можном значении в будущем делается на основе анализа большого числа значе-
ний из прошлого. Следовательно, глубина погружения должна в несколько раз
превышать горизонт прогноза.
□ Чем большее число значений из прошлого используется для прогнозирования,
тем выше степень обобщения и тем достовернее результаты предсказания. Од-
нако при этом есть два ограничения. Во-первых, глубина погружения должна
быть такой, чтобы значения из прошлого, используемые для прогнозирования,
оставались актуальными, то есть правильно отражали текущее поведение ис-
следуемого процесса. Использование для построения модели прогноза слишком
старых данных, утративших актуальность, приведет к снижению достоверности
или к получению некорректных результатов. Во-вторых, слишком большая
глубина погружения увеличит размерность выборки данных, полученной в ре-
зультате обработки ряда скользящим окном, что повлечет за собой усложнение
модели. Кроме того, возрастут временные и вычислительные затраты на анализ
данных.
□ Чем дальше простирается горизонт прогноза, тем ниже достоверность резуль-
татов.
Обобщенная модель прогноза имеет следующий вид (рис. 3.1).
Рис. 3.1. Обобщенная модель прогноза
Глава 3. Трансформация данных 145
В данной модели глубина погружения составляет d = 5, а горизонт прогно-
__ h — 2. Сама модель может представлять собой скользящее среднее, нейронную
сеть, регрессию и т. д. Значение х (и) — текущее состояние исследуемого параметра,
которое также включается в набор исходных данных для прогноза.
Выборка данных для такой модели должна содержать 6 входных полей, соот-
ветствующих входным переменным модели, и 2 выходных поля, соответствующих
выходным переменным. Преобразование ряда последовательно идущих значе-
ний в набор записей для модели прогноза выполняется с помощью скользящего
окна.
Пусть имеется ряд данных, содержащий 10 наблюдений:
X = {х(0), х(1), х(2), х(3), х(4), х(5), х(6), х(7), х(8), х(9), х(10)}.
Если глубину погружения задать равной 5, то с помощью скользящего окна
можно преобразовать исходный ряд данных в табличную форму, состоящую из
6 записей, которая может быть использована для работы с моделью, представ-
ленной на рис. 3.1. Преобразованный ряд будет выглядеть следующим образом
(табл. 3.2).
Таблица 3.2. Преобразованный ряд данных
№ х(л-5) х(л —4) х(л-З) х(л-2) х(л-1) х(л) х(л + 1) х(л + 2)
1 х(0) х(1) х(2) х(3) х(4) х(5) х(6) х(7)
2 х(1) х(2) х(3) х(4) х(5) х(6) х(7) х(8)
3 х(2) х(3) х(4) х(5) х(6) х(7) х(8) х(9)
4 х(3) х(4) х(5) х(6) х(7) х(8) х(9) х(10)
5 х(4) х(5) х(6) х(7) х(8) х(9) х(10) х(11)
6 х(5) х(6) х(7) х(8) х(9) х(10) х(11) х(12)
Рассмотрим еще пример. Пусть имеется ряд наблюдений, отражающий коли-
чество клиентов, обслуженных за месяц (табл. 3.3). Задача состоит в том, чтобы
построить модель прогноза числа клиентов на будущий месяц. При этом глубина
погружения задается равной 2, горизонт прогнозирования — 1, то есть на основе
Двух предыдущих месяцев прогнозируется следующий.
Таблица 3.3. Ряд наблюдений
Дата начала месяца Число клиентов
01.01.2006 1540
01.02.2006 960
01.03.2006 1150
01.04.2006 1230
01.05.2006 1056
01.06.2006 995
Выборка, полученная в результате обработки данных скользящим окном,
будет содержать в начале и в конце неполные записи, количество которых равно
146 Часть I. Теория бизнес-анализа
глубине погружения (табл. 3.4). Неполные записи можно исключить из рассмот
рения. Если это сделать, то результирующая выборка будет иметь следующ^
вид (табл. 3.5).
Таблица 3.4. Скользящее окно с неполными записями для ряда из табл. 3.3
Дата начала месяца х(л-2) х(л-1) х(л) х(л + 1) ~~|
1540
01.01.2006 1540 960 "
01.02.2006 1540 960 1150
01.03.2006 1540 960 1150 1230 '
01.04.2006 960 1150 1230 1056
01.05.2006 1150 1230 1056 995
01.06.2006 1230 1056 995
1056 995
995
Таблица 3.5. Скользящее окно с полными записями для ряда из табл. 3.3
Дата начала месяца х(л-2) х(л-1) х(л) х(л + 1)
01.03.2006 1540 960 1150 1230
01.04.2006 960 1150 1230 1056
01.05.2006 1150 1230 1056 995
На рис. 3.2 поясняется принцип формирования последней таблицы. Первое
положение окна соответствует строке таблицы с датой 01.03.2006, когда в него
попадают три значения — 1540, 960 и 1150. Значение, соответствующее горизон-
ту прогноза для данного положения окна, выделено темно-серым цветом и рав-
но 1230. Затем окно смещается, формируя таким же образом вторую строку для
даты 01.04.2006, а затем и третью.
Положения окна на рис. 3.2 соответствуют набору полных записей. Нетрудно
заметить, что если начальное положение окна будет левее, то одно или два места
в окне окажутся пустыми, что и порождает неполные записи в начале табл. 3.4.
Смещение окна до крайнего правого положения, когда в него попадет только
последнее значение ряда, приведет к появлению неполных строк в конце таб-
лицы.
Если временной ряд образован не одним, а двумя параметрами и более, то он
является многомерным. Например, для двумерного ряда можно записать:
X = {a(i),b(i)},
где i — номер временного отсчета, в который было зафиксировано наблюдение,
то есть i = 1, 2... п.
Процедура преобразования многомерного ряда в табличную форму выполняет-
ся по тому же алгоритму, что и преобразование одномерного (табл. 3.6, 3.7).
Глава 3. Трансформация данных 147
01.03.2006
01.04.2006
------------------►
01.05.2006
Рис. 3.2. Принцип работы скользящего окна
148 Часть I. Теория бизнес-анализа
Таблица 3.6. Ряд наблюдений
i а Ь
1 8 111 "
2 5 112
3 4 106 —-
4 10 114 .
5 12 96 .
6 9 116
Таблица 3.7. Скользящее окно с полными записями для ряда из табл. 3.6
№ записи а(л-2) а(л-1) а (л) Ь(л-2) Ь(л-1) Ь(л)
1 8 5 4 111 112 106
2 5 4 10 112 106 114
3 4 10 12 106 114 96
4 10 12 9 114 96 116
Таблицы, полученные в результате преобразования многомерных рядов данных,
как правило, содержат большое число признаков, что может потребовать сокраще-
ния размерности данных (см. главу 5 «Очистка и предобработка данных»).
Преобразование даты и времени
Обычно каждый элемент временного ряда представляет собой соответствие «дата —
значение», а в случае многомерного ряда — «дата — значение 1, значение 2...». Все
методы обработки, рассмотренные ранее, были направлены на преобразование
значений, сами же даты обычно оставались без изменений. Однако, как показывает
практика, при решении различных задач анализа может быть полезным и преобра-
зование даты.
Чаще всего даты в исходных данных представлены в определенном формате,
обычно «ЧЧ.ММ.ГГ», то есть число, месяц и год, при этом на отображение каждого
элемента даты отводятся две цифры. Возможны некоторые вариации: указывается
полностью год (02.10.2006) или (и) месяц (12 сентября 2006) и т. д. С точки зрения
анализа наибольший интерес представляют собой не детализированные данные за
каждый день, а агрегированные по неделям, месяцам, кварталам или годам. В этой
связи может оказаться полезным извлекать из даты дополнительную информацию
о временных интервалах, на которых производится анализ.
Так, если базовый интервал, по которому осуществляется анализ деятельности
предприятия, — неделя, то в некоторых случаях может представлять интерес ото-
бражение даты не на каждый день, а на первый или последний день недели. Иными
словами, все данные за неделю определяются по первому или последнему ее дню.
Пример такого преобразования представлен на рис. 3.3.
Аналогично строится преобразование Год + Квартал, когда все даты в пределах
квартала отображаются его первым числом, или Год + Месяц, когда все даты в пре-
делах месяца отображаются его первым числом.
Глава 3. Трансформация данных 149
Дата 02 01 -2006 количество 250 Дата Г02701.2006 Дата (год -н «деля) 02.01.2006 02.01.2006 Количество. 250 230
ОЗДГ2006 230 Год + + неделя 03.01.2006
04ДГ2006 345 04.01.2006 02.01.2006 345
05ДК2006 215 05.01.2006 02.01.2006 215
оТоГгооб 312 06.01.2006 02.01.2006 312
"оТдГзООб 124 07.01.2006 02.01.2006 124
0&01-2006 321 08.01.2006 02.01.2006 321
09ЛуГ.2ОО6 234 09.01.2006 09.01.2006 234
щи.2006 243 10.01.2006 09.01.2006 243
ТГ01.2006 312 11.01.2006 09.01.2006 312
12.01.2006 321 12.01.2006 09.01.2006 321
"l3.01.2006 267 13.01.2006 09.01.2006 267
14.01.2006 351 14.01.2006 09.01.2006 351
15.01.2006 П 216 15.01.2006 09.01.2006 216
16.01.2006 187 16.01.2006 16 01.2006 187
17.01.2006 179 17.01.2006 16.01.2006 179
18.01.2006 261 18.01.2006 16.01.2006 261
19.01.2006 305 19.01.2006 16.01.2006 305
20.01.2006 156 20.01.2006 16.01.2006 156
Рис. 3.3. Пример трансформации поля с датой
Представляет интерес извлечение из даты номеров временных интервалов —
недель, месяцев и кварталов — как в числовом, так и в текстовом виде. Тогда зна-
чения этих временных интервалов сами могут использоваться в качестве исходных
данных для дальнейшего анализа.
Приведение даты к различным видам представления позволяет упростить
визуальный анализ исходных данных, зависящих от времени, а также использо-
вать значения времени в качестве исходных данных для решения разнообразных
аналитических задач.
Следует отметить, что после преобразования даты являются уже не значениями
типа Дата, а обычными строковыми и числовыми значениями. Поэтому их боль-
ше нельзя обрабатывать как даты, но можно использовать в моделях как обычные
строковые или числовые переменные.
Могут быть интересны данные, полученные для различных интервалов времени
в пределах одной даты, то есть представленные в масштабе часов, минут и секунд.
Обычный формат для представления времени — «ЧЧ:ММ:СС»: для отображения
каждого элемента времени отводится по два знако-места, а символом-разделителем
служит двоеточие. Для трансформации времени часы, минуты и секунды извлекают-
ся в отдельные поля. Результаты такого преобразования представлены в табл. 3.8.
150 Часть I. Теория бизнес-анализа
Таблица 3.8. Преобразование поля с временем
Время Время, ч Время, мин Время, с ~~~
12:10:39 12 10 39 ''
13:15:20 13 15 20
16:20:44 16 20 44 ~~
18:09:56 18 9 56 "
19:15:30 19 15 30 ~~
21:22:50 21 22 50 '
23:12:40 23 12 40 '
ПРИМЕР-----------------------------------------------—-
Информация, важная для оптимизации бизнес-процесса, может заключаться в почасовых
данных. Например, в сети розничных магазинов было решено провести исследование того,
правильно ли выбран режим работы. Для этого в течение каждого часа фиксировалось
количество чеков. Затем были построены графики, отражающие нагрузку на кассовые
пункты в течение рабочего дня для каждого магазина. При этом рабочее время всех мага-
зинов — с 9:00 до 20:00 с перерывом на обед с 13:00 до 14:00. Результаты исследований
представлены на рисунке.
Исследования показали, что в первом магазине пиковые нагрузки приходятся на обеденное
и вечернее время. Это может быть обусловлено наличием вблизи магазина крупных предпри-
ятий или организаций, сотрудники которых покупают продукты в обеденный перерыв, время
которого колеблется oti2:oo до 15:00. Вечерние нагрузки могут быть связаны с тем, что магазин
расположен в спальном районе, жители которого приобретают продукты после работы. Для оп-
тимизации режима работы первого магазина можно сделать следующие рекомендации.
• Сместить время работы на один час позже, поскольку основная нагрузка приходится на
вечернее время, а утром магазин практически «простаивает».
• Организовать обеденный перерыв сотрудников магазина таким образом, чтобы в течение
дневного пика продаж большинство сотрудников находились на своих рабочих местах.
• В интервалы пиковых нагрузок задействовать дополнительные кассовые пункты, а в ин-
тервалы спада сокращать число работающих кассовых пунктов.
Аналогичные рекомендации можно выработать и для других магазинов. Например, во вто-
ром магазине пиковые нагрузки приходятся на утреннее и вечернее время, поэтому, воз-
можно, имеет смысл увеличить рабочее время на два часа, то есть открываться на час
раньше, а закрываться на час позже.
Глава 3. Трансформация данных
151
3.3- Группировка данных
Иногда высокая степень детализации данных может ухудшить результаты анализа.
Следствием ее является слишком большое количество записей в исходной выборке
данных, а также низкая значимость каждого отдельного значения. Кроме того, ин-
формация оказывается «размазанной» по всей выборке и ее трудно использовать
для анализа. Ежедневные показатели некоторого бизнес-процесса, например продаж,
подвержены колебаниям под действием различных случайных факторов, поэтому
значения продаж, взятые по отдельности за каждый день, вряд ли дадут надежную
оценку, характеризующую развитие процесса. Но если сгруппировать ежедневные
показатели за неделю или месяц, то такая оценка будет более обоснованной. То же
самое можно сказать и о признаках объектов (например, товаров). Если объекты
похожи между собой, то будут близки и их одноименные признаки. Однако значе-
ния признаков также могут быть подвержены случайным вариациям. Поэтому если
объединить признаки по группе похожих объектов, то можно получить показатель,
более надежно характеризующий свойства совокупности в целом.
Таким образом, группировка данных — полезный инструмент, применение
которого в процессе подготовки данных к анализу позволяет более эффективно
использовать содержащуюся в данных информацию.
Перед тем как приступать к группировке, необходимо определить в исходной вы-
борке данных поля измерений и фактов. Измерения — это данные, характеризующие
исследуемый процесс качественно, а факты — количественно. Например, процесс
продаж описывается количественными и качественными данными. Качественные
данные — наименования товаров и клиентов. Очевидно, что просто указать эти па-
раметры недостаточно. С каждым проданным товаром или клиентом связан набор
числовых показателей — фактов: цены, количества, суммы, скидки, наценки и т. д.
Каждое наименование товара или клиента, содержащееся в поле измерения,
называется значением измерения. Суть группировки заключается в том, что все
записи, содержащие одноименные значения измерения, по которому производится
группировка, объединяются в одну, а соответствующие факты агрегируются.
Рассмотрим выборку данных, отражающих продажу стройматериалов (табл. 3.9).
Она содержит измерения Дата, Клиент и Товар, а также факты Цена, Количество
и Сумма.
Таблица 3.9. Продажа стройматериалов
Дата Клиент Товар Цена Количество Сумма
01.03.2007 ООО «Полигон» Цемент 150 20 3000
01.03.2007 ЗАО «Монтажник» Керамзит 100 60 6000
01.03.2007 ООО «Тандем» Кирпич 1500 5 7500
£2.03.2007 ООО «Шплинт» Плиты 1100 10 11000
£2.03.2007 ЗАО «Монтажник» Блоки 900 20 18 000
£2.03.2007 ООО «Полигон» Кирпич 1500 10 15 000
£3.03.2007 ООО «Агрострой» Плиты 1100 8 8800
Продолжение
152 Часть I. Теория бизнес-анализа
Таблица 3.9 (продолжение)
Дата Клиент Товар Цена Количество Сумма ~~~
03.03.2007 ЗАО «Монтажник» Керамзит 100 30 3000 "
03.03.2007 ООО «Тандем» Блоки 900 10 9000 "
03.03.2007 ООО «Полигон» Плиты 1100 30 33 ООО "
04.03.2007 ООО «Шплинт» Керамзит 100 100 10 ООО '
04.03.2007 ООО «Тандем» Кирпич 1500 10 15 000
04.03.2007 ЗАО «Монтажник» Цемент 150 20 3000 '
04.03.2007 ООО «Полигон» Блоки 900 15 13 500
05.03.2007 ООО «Агрострой» Плиты 1100 20 22 000 '
05.03.2007 ООО «Шплинт» Керамзит 100 50 5000
05.03.2007 ЗАО «Монтажник» Цемент 150 40 6000
05.03.2007 ООО «Тандем» Блоки 900 15 13 500
06.03.2007 ООО «Полигон» Кирпич 1500 6 9000
06.03.2007 ООО «Агрострой» Керамзит 100 70 7000
06.03.2007 ЗАО «Монтажник» Цемент 150 30 4500
Группировка может производиться по одному из трех фактов. Если в качестве
факта для группировки выбирается Дата, то все записи, содержащие одинаковые
даты, будут объединены в одну (табл. 3.10).
Таблица 3.10. Вариант группировки 1
Дата Цена Количество Сумма
01.03.2007 583,33 85 16 500
02.03.2007 1166,67 40 44 000
03.03.2007 800,00 78 53 800
04.03.2007 662,50 145 41500
05.03.2007 562,50 125 46 500
06.03.2007 583,33 106 20 500
При этом для измерения Цена была выбрана функция агрегации с вычислением
среднего значения, для измерений Количество и Сумма — с вычислением суммы.
Таким образом, этот вариант группировки позволяет получить информацию о том,
какое количество единиц товара, по какой средней цене и на какую сумму было
продано в пределах каждой даты.
Группировка по измерению Клиент позволяет получить те же агрегированные
факты, что и в предыдущем примере, но уже не для каждой даты, а для каждого
клиента (табл. 3.11).
Таблица 3.11. Вариант группировки 2
Клиент Цена Количество Сумма
ЗАО «Монтажник» 258,33 200 40 500
ООО «Агрострой» 766,67 98 37 800
ООО «Полигон» 1030,00 81 73 500
Глава 3. Трансформация данных 153
Гкдиёнт Цена Количество Сумма
7)00 «Тандем» 1200,00 40 45 000
qqO «Шплинт» 433,33 160 26 000
Наконец, группировка по измерению Товар позволяет получить информацию
0 том, по какой цене, в каком количестве и на какую сумму был продан каждый из
товаров (табл. 3.12).
Таблица 3.12. Вариант группировки 3
[Товар Цена Количество Сумма
Блоки 900 60 54 000
_—-— Керамзит 100 310 31 000
Кирпич 1500 31 46 500
Плиты 1100 68 74 800
Цемент 150 110 16 500
Полученная в результате группировки информация может использоваться для
различных задач. Так, распределение сумм продаж по датам позволит проанали-
зировать динамику продаж, выявить тенденции и т. д.; группировка по полю Кли-
ент — оптимизировать работу с клиентами, например предоставить наиболее актив-
ным из них скидки; группировка по полю Товар — определить наиболее и наименее
продаваемые товары, оценить вклад конкретного товара в общий объем продаж.
При группировке данных могут использоваться различные функции агрегации.
К наиболее типичным относятся: сумма, среднее, количество, максимум, минимум,
медиана (их смысл уже раскрывался в главе 2 при рассмотрении преобразования
данных в ETL).
Для строковых значений в качестве функций агрегации могут использоваться
только максимум, минимум, количество, первый, последний. При этом макси-
мум (минимум) нескольких строковых значений рассчитывается посимвольным
сравнением. Сначала сравниваются два первых символа строк. Если их коды
одинаковы, сравниваются вторые символы и т. д. Как только в строках появляется
первый несовпадающий символ, функция агрегации принимает значение строки,
код символа в которой оказался больше (меньше).
Разгруппировка данных
В процессе группировки данных происходит объединение фактов по значениям не-
которого измерения с применением той или иной функции агрегации, но при этом
теряется информация, связанная с другими измерениями, то есть связь фактов со
значениями других измерений. И если у нас есть прогноз, построенный на основе
сгруппированных данных, то по нему мы ничего не можем сказать о значениях,
На основе которых он был получен. При необходимости эту информацию можно
восстановить с помощью разгруппировки данных. Строго говоря, она не является
операцией, обратной группировке, то есть при разгруппировке не происходит вос-
становления исходного состояния выборки. Факты восстанавливаются не точно,
154 Часть I. Теория бизнес-анализа
а пропорционально их известному вкладу в значения, полученные в результат
агрегирования. В общем, разгруппировка может быть никак не связана с грущ^
ровкой.
Разгруппировка может выполняться для всех видов обработки данных, ког
да имеет место преобразование некоторого набора
значений в одно значение с помощью какого-либо
алгоритма, например, когда на основе нескольких
членов ряда формируется прогнозируемое значение.
При этом значения, полученные при разгруппиров-
ке, будут отображать долю каждого исходного зна-
чения в результате.
Рассмотрим модель, преобразующую набор зна-
Рис. 3.4. Модель
чений в одно с помощью операции суммирования
(рис. 3.4).
Каждое значение, полученное в результате разгруппировки, может быть опре-
делено как доля в результате, выраженная, например, в процентах, то есть {19; 28;
22; 31}. На круговой диаграмме представлены группируемые значения и соответ-
ствующие им доли, которые будут получены при разгруппировке (рис. 3.5).
10; 19%
12; 22 % 15; 28 %
Рис. 3.5. Информация для разгруппировки
3.4. Слияние данных
В практике анализа достаточно часто встречается ситуация, когда требуемые дан-
ные приходится собирать из нескольких таблиц. Необходимость в этом обычно
возникает в следующих случаях.
□ Данные, которые нужны для анализа, «разбросаны» по нескольким таблицам.
□ Данные в исходной таблице несут недостаточно информации для качественного
анализа, и поэтому требуется процедура их обогащения, которая обычно связана
с добавлением в таблицу данных из сторонних источников.
Ситуация, когда анализируемые данные оказываются в нескольких таблицах
или берутся из отдельных источников, а не из централизованного хранилища
данных, может быть следствием непродуманного процесса консолидации и инте-
грирования данных на этапе ETL. Недостаточно информативная выборка также
Глава 3. Трансформация данных 155
всТречается довольно часто. И дело здесь даже не столько в самой выборке, сколько
в методике анализа, для которой она используется. Например, изначально множе-
ство данных предполагалось применять как обучающую выборку для построения
модели прогноза, но впоследствии возникла необходимость в ее использовании
дЛя классификации объектов множества. Возможно, для решения задачи прогно-
зирования в множестве использовались один или два выходных признака, тогда
как для надежной классификации требуется не менее трех или четырех. В этом
случае недостающие признаки можно будет взять из другой таблицы. Таким обра-
зом, если для решения одной аналитической задачи информативность множества
данных может быть достаточна или даже избыточна, то для другой она окажется
недостаточной и потребует обогащения.
При необходимости объединить данные выполняется процедура слияния
(merge). Таблица, к которой в процессе слияния добавляются данные из другой,
называется исходной, или входящей', вторую таблицу, данные из которой добавля-
ются к исходной, часто называют связываемой. Исходная и связываемая таблицы
должны иметь одно или несколько одинаковых полей, на основе которых будет
производиться связывание двух таблиц, — это поля связи. Остальные поля, уни-
кальные для каждой из таблиц, могут быть присоединены к результирующему
набору после слияния.
Существует несколько способов слияния, которые применяются в зависимости
от того, какие данные и в каком виде должны быть объединены в результирующей
таблице. Рассмотрим их.
Объединение
Объединение применяется в тех случаях, когда к строкам
исходной таблицы требуется добавить все строки связы-
ваемой, при этом строки добавляются снизу. Принцип
объединения двух таблиц поясняется на рис. 3.6.
Рассмотрим пример. Пусть имеется исходная выборка
данных, в которой содержатся сведения о поставляемых
товарах — наименования и поставщики (табл. 3.13), а так-
же выборка данных, содержащая историю продаж этих
товаров (табл. 3.14).
Исходная таблица
------------------
Связываемая таблица
Рис. 3.6. Объединение
таблиц
Таблица 3.13. Входящая таблица
Поставщик Товар
ООО «Невод» Рыба свежая
ЗАО «Молкомбинат» Сыр
ООО «Птичник» Куры
ЗАО «Овощевод» Капуста
ОАО «Хладокомбинат» Мороженое
ЗАО «Маслосырбаза» Молоко
ОАО «Горпищекомбинат» Кетчуп
156 Часть I. Теория бизнес-анализа
Таблица 3.14. Связываемая таблица
Дата Поставщик Товар Количество
02.04.2007 ЗАО «Молкомбинат» Сыр 150 "
08.04.2007 ООО «Птичник» Куры 200
11.04.2007 ЗАО «Маслосырбаза» Молоко 170 "
15.04.2007 ООО «Птичник» Куры 100
22.04.2007 ЗАО «Молкомбинат» Сыр 80 "
27.04.2007 ОАО «Хладокомбинат» Мороженое 250
27.04.2007 ООО «Невод» Рыба свежая 160 '
Необходимо объединить информацию так, чтобы таблицы содержали два оди-
наковых поля — Поставщик и Товар, которые могут использоваться для слияния
а также два поля — Дата и Количество, которые находятся только во второй
таблице.
Результатом объединения по полям Товар и Поставщик будет следующая таб-
лица (табл. 3.15).
Таблица 3.15. Результат объединения
Поставщик Товар Дата+ Количество-1-
ООО «Невод» Рыба свежая
ЗАО «Молкомбинат» Сыр
ООО «Птичник» Куры
ЗАО «Овощевод» Капуста
ОАО «Хладокомбинат» Мороженое
ЗАО «Маслосырбаза» Молоко
ОАО «Горпищекомбинат» Кетчуп
ЗАО «Молкомбинат» Сыр 02.04.2007 150
ООО «Птичник» Куры 08.04.2007 200
ЗАО «Маслосырбаза» Молоко 11.04.2007 170
ООО «Птичник» Куры 15.04.2007 100
ЗАО «Молкомбинат» Сыр 22.04.2007 80
ОАО «Хладокомбинат» Мороженое 27.04.2007 250
ООО «Невод» Рыба свежая 27.04.2007 160
Знак «+» рядом с названиями полей Дата и Количество означает, что они не
являются общими для двух таблиц, а просто добавлены к результату слияния полей
Поставщик и Товар.
Внутреннее соединение
Внутреннее соединение позволяет получить в результирующем наборе только те
записи, для которых значения в одном из полей связи совпадают. То есть в табли-
це, полученной в результате внутреннего соединения, останутся только те записи,
Глава 3. Трансформация данных 157
которые содержат одинаковые значения в заданном
доле (или заданных полях). Принцип внутреннего
соединения схематично представлен на рис. 3.7.
Продолжим предыдущий пример. Теперь
результирующая таблица содержит только те за-
писи, для которых значения в полях связи Товар
и Поставщик одинаковые. При этом ЗАО «Овоще-
вод» и ОАО «Горпищекомбинат», присутствующие
в общем списке поставщиков, в результирующую
таблицу внесены не были, поскольку в таблице
истории продаж записи с их участием отсутствуют
(табл. 3.16).
Рис. 3.7. Внутреннее
соединение
Таблица 3.16. Результат внутреннего соединения
Поставщик Товар Дата+ Поставщики- Товар-1- Количество-1-
ООО «Невод» Рыба свежая 27.04.2007 ООО «Невод» Рыба свежая 160
ЗАО «Мол- комбинат» Сыр 02.04.2007 ЗАО «Мол- комбинат» Сыр 150
ЗАО «Мол- комбинат» Сыр 22.04.2007 ЗАО «Мол- комбинат» Сыр 80
ООО «Птич- ник» Куры 08.04.2007 ООО «Птич- ник» Куры 200
ООО «Птич- ник» Куры 15.04.2007 ООО «Птич- ник» Куры 100
ОАО «Хладо- комбинат» Мороженое 27.04.2007 ОАО «Хладо- комбинат» Мороженое 250
ЗАО «Масло- сырбаза» Молоко 11.04.2007 ЗАО «Масло- сырбаза» Молоко 170
Таким образом, внутреннее объединение позволило из всех поставщиков ото-
брать только тех, закупка у которых производилась за наблюдаемый период вре-
мени.
Внешнее соединение
При внешнем соединении все записи одной таблицы дополняются значениями из
другой, если значения этих записей по ключевым полям совпадают. То есть табли-
цы связываются по полю Товар, и если существуют записи, где значения данного
поля в обеих таблицах идентичны, то записи будут дополнены значениями, которые
отсутствуют в одной таблице и присутствуют в другой. Фактически этот механизм
позволяет добавлять поля из одной таблицы в другую, но не по всем записям,
а только по тем, значения которых в поле связи совпадают для обеих таблиц.
Кроме того, различают левое и правое внешнее соединение. При левом записи
исходной таблицы дополняются значениями из связанной таблицы, а при правом —
наоборот. Схематично принцип внешнего соединения поясняется на рис. 3.8.
158 Часть I. Теория бизнес-анализа
Внешнее
правое соединение
Внешнее
левое соединение
Рис. 3.8. Внешнее соединение
Рассмотрим пример. Пусть к табл. 3.13, где содержится только информация
о товарах и поставщиках, требуется добавить поля, которые отражают историю
закупок (Дата и Количество). Для этого в качестве поля связи будет применяться
поле Товар. При использовании левого внешнего соединения получим следующее
(табл. 3.17).
Таблица 3.17. Результат внешнего левого соединения
Поставщик Товар Дата+ Поставщик-!- Количеством-
ООО «Невод» Рыба свежая 27.04.2007 ООО «Невод» 160
ЗАО «Молкомбинат» Сыр 02.04.2007 ЗАО «Молкомбинат» 150
ЗАО «Молкомбинат» Сыр 22.04.2007 ЗАО «Молкомбинат» 80
ООО «Птичник» Куры 08.04.2007 ООО «Птичник» 200
ООО «Птичник» Куры 15.04.2007 ООО «Птичник» 100
ЗАО «Овощевод» Капуста
ОАО «Хладокомби- нат» Мороженое 27.04.2007 ОАО «Хладокомби- нат» 250
ЗАО «Маслосырбаза» Молоко 11.04.2007 ЗАО «Маслосырбаза» 170
ОАО «Горпищеком- бинат» Кетчуп
Теперь рассмотрим ситуацию, когда имеется информация о наименовании
товаров и истории закупок, а информация о поставщике отсутствует. Получить ее
можно через поле связи Товар, поскольку в одной таблице каждый товар связан
со своим поставщиком, а в таблице, где содержится история закупок, — с датой
и количеством. Пусть исходной будет таблица с историей закупок (табл. 3.18),
а связываемой — с информацией о поставщике (табл. 3.19).
Таблица 3.18. Исходная таблица
Дата Товар Количество
02.04.2007 Сыр 150
08.04.2007 Куры 200
Глава 3. Трансформация данных 159
[Дата Товар Количество
7704.2007 Молоко 170
15М2007 Куры 100
22.04.2007 Сыр 80
2704-2007 Мороженое 250
'2704-2007 Рыба свежая 160
Таблица 3.19. Связываемая таблица
"поставщик Товар
ООО «Невод» Рыба свежая
ЗАО «Молкомбинат» Сыр
ООО «Птичник» Куры
ЗАО «Овощевод» Капуста
ОАО «Хладокомбинат» Мороженое
ЗАО «Маслосырбаза» Молоко
ОАО «Горпищекомбинат» Кетчуп
При правом внешнем соединении получим следующий результат (табл. 3.20).
Таблица 3.20. Результат правого внешнего соединения
Товар Дата+ Поставщик*- Количество*
Сыр 02.04.2007 ЗАО «Молкомбинат» 150
Куры 08.04.2007 ООО «Птичник» 200
Молоко 11.04.2007 ЗАО «Маслосырбаза» 170
Куры 15.04.2007 ООО «Птичник» 100
Сыр 22.04.2007 ЗАО «Молкомбинат» 80
Мороженое 27.04.2007 ОАО «Хладокомбинат» 250
Рыба свежая 27.04.2007 ООО «Невод» 160
Полное внешнее соединение. В результирующий набор включаются все строки
и поля как исходной, так и связываемой таблиц. При этом, если в некоторой за-
писи значения поля связи для обеих таблиц совпадают, то все поля этой записи
заполняются соответствующими значениями.
Если совпадение по полю связи отсутствует, то
остальные поля такой записи будут заполнены
пустыми значениями. Фактически это означает,
что для значений исходной таблицы отсутству-
ют соответствующие значения в связываемой.
Принцип работы полного внешнего соединения
поясняется на рис. 3.9.
Таким образом, для исходной и связываемой
таблиц из предыдущего примера (см. табл. 3.18,
3.19) применение полного внешнего соединения рис> 3 9 Полное внешнее
даст следующий результат (табл. 3.21). соединение
160 Часть I. Теория бизнес-анализа
Таблица 3.21. Результат полного внешнего соединения
Поставщик Товар Дата+ Поставщик-1- Количество+С
ООО «Невод» Рыба свежая 02.04.2007 ООО «Невод» 160 "
ЗАО «Молкомби- пат» Сыр 08.04.2007 ЗАО «Молкомбинат» 150 "
ЗАО «Молкомби- нат» Сыр 11.04.2007 ЗАО «Молкомбинат» 80 '
ООО «Птичник» Куры 15.04.2007 ООО «Птичник» 200 '
ООО «Птичник» Куры 22.04.2007 ООО «Птичник» 100 '
ЗАО «Овощевод» Капуста
ОАО «Хладоком- бинат» Мороженое 27.04.2007 ОАО «Хладокомби- нат» 250
ЗАО «Маслосыр- база» Молоко 11.04.2007 ЗАО «Маслосырбаза» 170
ОАО «Горпищеком- бинат» Кетчуп
Если информация по определенному товару и поставщику присутствует в обеих
таблицах, то она полностью объединяется. Однако для товаров «капуста» и «кет-
чуп» отсутствует информация о закупках, а значит, о дате и количестве. Поэтому
соответствующие ячейки должны остаться пустыми. Полное внешнее соединение
позволяет полностью связать информацию таблиц.
3.5. Квантование
Одним из преобразований, которые часто используются при подготовке данных
к анализу, является квантование. В основе операции квантования лежит проце-
дура, состоящая из двух шагов.
□ Диапазон значений, в пределах которого изменяется некоторая числовая вели-
чина (признак, показатель и т. д.), разбивается на заданное количество интерва-
лов, каждому из которых присваивается определенный номер. Эти интервалы
называются интервалами квантования, а присвоенные им номера — уровнями
квантования.
□ Каждое значение заменяется номером интервала квантования, в который по-
пало данное значение.
ЗАМЕЧАНИЕ----------------------------------------------------------
При необходимости вместо номера интервала квантования используются другие значения,
связанные с этим интервалом. Это могут быть верхняя или нижняя границы интервала, его
срединное значение или произвольная метка, выбранная пользователем.
Графически процесс квантования может быть представлен в следующем виде
(рис. 3.10).
Глава 3. Трансформация данных 161
Рис. 3.10. Процесс квантования
Пусть наблюдаемый на рис. 3.10 ряд значений представляет собой суммы
выданных кредитов. При этом минимальная сумма составляет 7000 руб., а макси-
мальная — 65 000 руб. Если диапазон значений ряда от 0 до 70 000 руб., его можно
разбить на 7 равных интервалов, взятых через 10 000, по которым и будет произ-
водиться квантование. Для этого каждому интервалу будет присвоен порядковый
номер, после чего все наблюдаемые значения будут заменены номерами интер-
валов квантования, в которые они попали. То есть вместо значения 23, которое
принадлежит третьему интервалу квантования, в результирующем наборе данных
будет 3, вместо значения 35 будет 4 и т. д.
На рис. 3.10 штрихпунктирными линиями представлены границы интервалов
квантования, справа расположены номера интервалов, а внизу — результирующие
значения, которые будут присвоены наблюдениям в результате квантования. Таб-
При квантовании необходимо определить, какую из границ интервала следует
включить в этот интервал. Поскольку нижняя граница диапазона всегда принад-
лежит нижнему интервалу, то и для других интервалов есть смысл условиться
0 включении нижней границы. Единственным исключением является самый верх-
ний интервал, который включает в себя как верхнюю, так и нижнюю границу.
162 Часть I. Теория бизнес-анализа
Цели использования квантования
Квантование широко используется во всех областях, где возникает необходимость
в обработке, передаче и хранении данных. Квантование — неотъемлемая часть
процесса преобразования аналоговых (то есть непрерывных по времени и ам-
плитуде) сигналов в цифровые (то есть дискретные по времени и квантованные
по амплитуде). Квантование позволяет представлять и хранить данные в более
компактном и защищенном от искажений виде. Процесс дискретизации заключа-
ется в представлении непрерывной функции в виде набора отдельных значений
взятых в определенные моменты времени — отсчеты. В результате квантования
значения отсчетов преобразуются в номера интервалов квантования, в которые
эти значения попали. Принцип преобразования аналоговых данных в цифровые
представлен на рис. 3.11.
Рис. 3.11. Иллюстрация принципа преобразования
В бизнес-аналитике квантование способствует достижению следующих целей.
□ Изменяется вид данных: из непрерывных они могут быть преобразованы в дис-
кретные.
□ Квантование может использоваться для сокращения размерности данных,
а именно для уменьшения числа разнообразных значений признака. Например,
если для анализа клиентов банка, получающих кредит, интерес представляют
не отдельные клиенты и суммы кредитов, а группы, объединяющие клиентов по
интервалам сумм, то в результате квантования можно получить более удобный
для анализа ряд данных. Уменьшение разнообразия значений признаков в не-
которых случаях позволяет сделать работу моделей более эффективной. Дей-
ствительно, если с точки зрения анализа нет разницы между суммами кредита
15 и 17 тыс., то нет смысла рассматривать эти величины отдельно.
В некоторых случаях представляет интерес использование в качестве результатов
квантования не самих номеров интервалов, а других значений, связанных с ними.
□ Нижняя граница интервала — вместо значения, попавшего в интервал, устанав-
ливается значение его нижней границы.
□ Верхняя граница интервала — вместо значения, попавшего в интервал, устанав-
ливается значение его верхней границы.
□ Середина интервала — вместо значения, попавшего в интервал, устанавливается
его срединное значение.
Глава 3. Трансформация данных 163
□ Метка интервала — пользователь может задать произвольное значение, обозна-
чающее интервал, например наименование категории, к которой будет относить-
ся объект классификации.
Границы и середину интервала удобно применять в тех случаях, когда кван-
тованный ряд значений должен сохранять количественное выражение исходных
данных. Однако при этом результирующее поле по-прежнему останется непрерыв-
ным и не сможет быть использовано в качестве выходного в классификационной
модели. Преимуществом от использования данного метода будет сокращение
разнообразия значений признака.
Использование меток интервалов дает возможность сделать результаты
квантования более наглядными и сразу определить метки классов, если целью
квантования является разбиение признака по категориям. Так, если цель кван-
тования поля Сумма кредита — разделить всех клиентов на категории в зависи-
мости от взятой ими суммы, то можно использовать соответствующие метки
(табл. 3.23).
Таблица 3.23. Пример квантования с меткой интервала
Срок кредита Возраст Пол Образование Сумма кредита Категория клиента
6 37 Жен. Специальное 7000 Категория 1
6 38 Муж. Среднее 7500 Категория 1
12 60 Муж. Высшее 14 500 Категория 2
6 28 Муж. Специальное 15 000 Категория 2
12 59 Жен. Специальное 32 000 Категория 4
6 25 Жен. Специальное И 500 Категория 1
6 57 Муж. Специальное 5000 Категория 1
30 29 Муж. Высшее 61 500 Категория 7
12 37 Муж. Специальное 13 500 Категория 2
18 36 Муж. Специальное 25 000 Категория 3
24 68 Муж. Высшее 25 500 Категория 3
6 20 Жен. Высшее 9500 Категория 1
На практике этот набор данных можно использовать как обучающую выборку
для построения классификационной модели, где в качестве целевого поля будет
использоваться Категория клиента.
Выбор числа интервалов квантования
В квантовании важно правильно выбрать число интервалов. В результате кван-
тования осуществляется переход от точных данных к некоторой интервальной
оценке, и при этом неизбежна потеря информации. Фактически ряд значений,
полученных в результате квантования, просто выражает отношения между исход-
ными значениями признака. То, что два значения расположены в двух соседних
164 Часть I. Теория бизнес-анализа
интервалах квантования, не позволяет точно определить, насколько одно из щц
больше или меньше другого. Можно сказать только, что они не различаются
больше чем на две ширины интервала. Следовательно, чем больше интервалов
используется при квантовании, тем точнее представление исходных значений
данных. При уменьшении ширины интервала в пределе мы получим исходный
набор значений. Увеличение интервала, напротив, огрубляет описание данных
и в пределе дает один интервал для всего диапазона значений, которые меняются
на метку интервала (например, 0).
Иными словами, меняя число интервалов квантования, можно перейти от точ-
ного воспроизведения исходных значений данных к полной потере информации
об изменчивости значений признака. На практике выбрать количество интервалов
квантования можно, исходя из следующих соображений.
□ Если квантование выполняется для преобразования непрерывных данных
в дискретные, то число интервалов будет определяться числом уникальных
значений (меток, категорий), которое используется при решении задачи ана-
лиза.
□ Необходимо учитывать требуемую точность описания данных. Например, мо-
жет быть поставлено условие, что количество интервалов квантования должно
быть таким, чтобы ширина интервала не превышала 10 % от полного диапазона
изменения исходных значений.
Иногда может потребоваться проведение экспериментов, чтобы определить
лучшие параметры квантования с точки зрения решения конкретной задачи ана-
лиза.
Методы квантования
Помимо выбора числа интервалов, при выполнении операции квантования требу-
ется выбрать ее метод. Выбор метода квантования зависит от характера данных.
Различают два основных метода квантования:
□ равномерное (однородное) квантование;
□ неравномерное (неоднородное) квантование.
При равномерном квантовании диапазон изменения значений признака разде-
ляется на интервалы одинаковой ширины, а при неравномерном ширина интерва-
лов может быть различной.
Первый метод используется, если данные равномерно распределены по всему
диапазону их изменения, то есть в результате квантования не будет интервалов,
в которых значения почти отсутствуют или заполнены очень плотно. В противном
случае лучшие результаты даст второй метод.
Например, рассмотрим набор значений {2,4,3,1,4, 22, 24, 23,21, 24}. Диапазон
изменения его значений составит 23. Разделим диапазон значений на 5 равных ин-
тервалов квантования, каждый из которых будет содержать 5 значений. Интервал
с номером 0 будет содержать значения от 0 до 4, с номером 1 — от 5 до 9, с номе-
ром 2 — от 10 до 14 и т. д. На рис. 3.12 видно, что значения в указанном диапазоне
Глава 3. Трансформация данных 165
распределены неравномерно: в нулевом интервале квантования расположено
5 значений, а остальные значения — в диапазоне 20-24, который соответствует
интервалу квантования с номером 4. При этом в диапазон 5-20, которому соот-
ветствуют интервалы квантования с номерами 1,2 и 3, не попало ни одного значе-
ния. Следовательно, квантованные значения также распределятся неравномерно:
интервалы 0 и 4 будут заполнены очень плотно, в то время как интервалы 1, 2 и 3
окажутся пустыми. Если квантование производится для преобразования непре-
рывных данных в набор категорий, это приведет к тому, что все объекты выборки
окажутся отнесенными всего к двум категориям — 0 и 4 (табл. 3.24).
Рис. 3.12. Неравномерное заполнение интервалов квантования
Таблица 3.24. Результат квантования для случая
неравномерного заполнения интервалов
Исходное значение 2 4 3 1 4 22 24 23 21 24
Квантованное значение 0 0 0 0 0 4 4 4 4 4
Преодолеть данную проблему позволяет неравномерное квантование, когда
используются интервалы разной ширины. Ширину интервалов выбирают таким
образом, чтобы в каждый из них попало примерно одинаковое количество значе-
ний. Такое квантование назовем квантильным. Если применить квантование по
квантилям к приведенному выше примеру, то получатся следующие интервалы
(табл. 3.25).
Таблица 3.25. Выбор интервалов в квантильном квантовании
№ Диапазон значений Метка
0 От 0 до 2 0
2 От 3 до 4 1
2 От 5 до 21 2
3 От 22 до 22 3
4 От 23 до 23 4
5 От 24 5
166 Часть I. Теория бизнес-анализа
Результат квантования будет следующим (табл. 3.26).
Таблица 3.26. Результат квантования
Исходное значение 2 4 3 1 4 22 24 23 21 2Г"
Квантованное значение 0 1 1 0 1 3 5 4 2
Как видно из табл. 3.26, заполнение интервалов квантования получилось более
равномерным, чем при обычном равноинтервальном квантовании.
3.6. Нормализация и кодирование данных
Алгоритмы Data Mining (они будут подробно изучаться в последующих главах)
работают только с числами, поскольку их работа базируется на математических
операциях. Между тем не всякая входная или выходная переменная изначально
представлена в виде числа. Прежде чем подавать такие переменные на вход
алгоритма, их нужно преобразовать к числовому представлению. Этот процесс
называется кодированием.
Как входами, так и выходами алгоритмов могут быть совершенно разнородные
величины. Очевидно, что результаты моделирования не должны зависеть от еди-
ниц измерения этих величин. Чтобы аналитический метод трактовал их значения
единообразно, все входные и выходные величины должны быть приведены к еди-
ному масштабу. Такой процесс называется нормализацией (или нормированием).
Она заключается в преобразовании исходного диапазона, в пределах которого
распределены значения некоторого признака, к другому, обычно меньшему диапа-
зону, например [-1; 1] или [0; 1]. Кроме того, для повышения скорости и качества
настройки параметров модели полезно провести дополнительную предобработку
данных, выравнивающую распределение значений еще до начала этапа настройки
параметров.
ЗАМЕЧАНИЕ-------------------------------------------------------
Далеко не все алгоритмы требуют нормализации. Например, деревья решений или линей-
ная регрессия не нуждаются в приведении входов и выходов к единому масштабу, а вот
в нейронной сети без этой процедуры не обойтись. В большинстве случаев нормализация
и кодирование «зашиты» внутри алгоритмов, однако аналитик должен разбираться в их
разновидностях, так как выбор схемы кодирования и нормализации существенно влияет
на результат.
Основные методы нормализации
Существует несколько методов нормализации данных. Рассмотрим ниже четыре из
них, которые, с одной стороны, достаточно просты, а с другой — эффективны.
Десятичное масштабирование. Производится путем перемещения десятичной
точки на количество цифр в числе, которое определяется исходя из максималь-
Глава 3. Трансформация данных 167
лого значения признака. При этом преобразование каждого исходного значения
Признака V(i) в нормализованное значение V'(i) производится с помощью выра-
жения:
V'(i) = V(z)/10*.
В то же время k выбирается так, что max(V'(z)) < 1. Например, если наибольшее
значение в наборе данных составляет 455, а наименьшее — (—834), то максимальное
абсолютное значение признака будет 0,834 и, следовательно, k = 3 для всех V(z)
(то есть деление производится на 1000).
Минимаксная нормализация. Предположим, что значения некоторого при-
знака Улежат в диапазоне от 150 до 250. Предыдущий метод даст все значения
нормализованного признака в интервале от 0,15 до 0,25, что не вполне удачно,
поскольку они оказываются сконцентрированными в очень небольшом диапа-
зоне.
Чтобы получить лучшее распределение значений в пределах интервала [0; 1],
можно воспользоваться так называемой минимаксной формулой:
= V(i)-min(V(i))
max( V (Г)1) — min( V (z)) ’
где минимальное и максимальное значения вычисляются автоматически или вы-
бираются аналитиком.
Похожее преобразование используется и для нормализации в интервале [—1; 1].
Хотя поиск минимального и максимального значений в большом множестве дан-
ных может занять некоторое время, в целом вычислительная процедура очень
проста. Кроме того, выбор минимального и максимального значения аналитиком
позволит оптимизировать диапазон, в котором будут распределены нормализован-
ные значения с точки зрения решаемой задачи.
На рис. 3.13 слева представлен график исходного ряда данных, а справа — ре-
зультирующий ряд, полученный в результате применения минимаксной норма-
лизации.
Рис. 3.13. Пример нормализации
Нормализация с помощью стандартного отклонения. Минимаксная норма-
лизация оптимальна, когда значения признака Vплотно заполняют определенный
168 Часть I. Теория бизнес-анализа
интервал. Но подобный подход применим не всегда. Так, если в данных имеются
относительно редкие выбросы, намного превышающие типичный разброс, именно
они определят согласно предыдущей формуле масштаб нормализации. Это при.
ведет к тому, что основная масса значений нормированной переменной V'ty
сосредоточится вблизи нуля: | V'(i)|«1. В этом случае гораздо надежнее ори-
ентироваться не на экстремальные значения, а на типичные и использовать для
нормализации статистические характеристики данных — среднее и дисперсию
Например, на всем множестве х для некоторого признака V вычисляются среднее
значение Vs и стандартное отклонение Сту. Затем для каждого значения признака
Ух(г) рассчитывается преобразование:
r(i)=(r«zM
Пу
Нормализация с помощью поэлементных преобразований. Еще одним спосо-
бом нормализации является поэлементное преобразование членов ряда с помощью
различных нелинейных функций, которые способны отображать исходный диапа-
зон значений в диапазон, соответствующий параметрам функции преобразования.
Этот механизм поясняется на рис. 3.14.
Как показано на рисунке, исходный диапазон [гц v2] преобразуется к более
узкому [р/; v2'].
В данной методике к каждому значению ряда применяется преобразование
вида
v =/(<>),
где v — исходное значение ряда;
v — значение после преобразования.
Рис. 3.14. Поэлементное преобразование
Глава 3. Трансформация данных 169
Набор применяемых для этих целей преобразований весьма широк:
□ экспоненциальное преобразование v = ехр(п);
□ логарифмическое и обратное логарифмическое преобразование v = log(n)
ир'= l/log(t>);
□ степенное и обратное степенное преобразование v = v'1 и v = 1 / vv.
У всех данных функций графики нелинейные, что позволяет применять их для
преобразования исходных диапазонов изменения значений ряда в более широкий
или более узкий диапазон. Действительно, если бы преобразование на рис. 3.14
использовало крутой участок графика (правее границы <у2), то имело бы место не
сжатие, а расширение диапазона значений.
Наибольшие возможности в плане такой обработки дает степенное преобра-
зование, которое порождает целое семейство характеристик в зависимости от
используемого показателя у.
В принципе, для преобразования диапазонов значений пригодно самое про-
стейшее линейное преобразование v = k • v. Преобразование исходного диапазона
с помощью линейной функции представлено на рис. 3.15.
Рис. 3.15. Линейное преобразование
После преобразования (независимо от его вида) значения, изначально рас-
пределенные в исходном диапазоне, оказываются распределены в другом, более
широком или более узком диапазоне в зависимости от формы и крутизны функции
преобразования.
Кодирование категориальных данных
При использовании таких моделей Data Mining, как нейронные сети, деревья реше-
ний, регрессия, данные должны подаваться на вход в числовом виде. Однако часто
170 Часть I. Теория бизнес-анализа
в качестве исходных данных для анализа используются категориальные данные.
В этом случае может понадобиться применение к ним преобразования, аналогич-
ного нормализации для числовых признаков, то есть приведение категориальных
значений к числовым. При этом набор уникальных категориальных значений дол-
жен быть преобразован в определенный диапазон числовых кодов. Для этих целей
применяется несколько способов.
Преобразование в уникальные числовые коды. В простейшем случае осущест-
вляется преобразование к порядковым номерам. Данный метод используется, если
значения признака допускают порядковую интерпретацию (малый/средний/круп-
ный; медленный/быстрый/скоростной и т. д.), то есть позволяют указать, какое из
них больше, а какое меньше (так называемый упорядоченный, или ординальный,
тип данных). При этом числовые значения также будут отражать соответствующие
порядковые отношения исходных значений (табл. 3.27).
Таблица 3.27. Кодирование уникальными кодами
Возраст клиента Код возраста
Подросток 0
Молодой 1
Средних лет 2
Пожилой 3
В принципе, все дискретные значения переменных можно закодировать таким
способом, пронумеровав их произвольным образом. Однако навязывание несу-
ществующей упорядоченности только затруднит решение задачи. Оптимальное
кодирование не должно искажать структуру соотношений между классами. Если
классы не упорядочены, такова же должна быть и схема кодирования: здесь при-
меняется двоичное кодирование.
Двоичное кодирование. Способ применяется для кодирования категориальных
неупорядоченных признаков с помощью маски из двоичных цифр (битов). В этом
случае каждому уникальному значению ставится в соответствие двоичное число,
называемое маской.
Пусть признак А исходной выборки содержит т уникальных значений {А ь
А2...Ат). Тогда при кодировке признака каждому значению Д нужно поставить в со-
ответствие битовую маску. Самый простой способ — кодирование т —> т, причем
первое значение кодируется как (1,0,0, 0... 0), второе соответственно — (0,1,0,0... 0)
и т. д. вплоть до ти-й позиции (табл. 3.28).
Таблица 3.28. Двоичное кодирование по маске
№ состояния Значение признака Маска [0; 1] Маска [-1; 1]
1 Ai 1,0, 0, 0, 0, 0, 0,0 1,-1,-1,-1,-1,-1,-1,-1
2 а2 0,1, 0, 0, 0, 0, 0, 0 -1,1,-1,-1,-1,-1,-1,-1
3 Аз 0, 0, 1, 0, 0, 0, 0, 0 -1,-1,1,-1,-1,-1,-1,-1
4 Аз 0, 0, 0, 1, 0, 0, 0, 0 -1,-1,-1,1,-1,-1,-1,-1
Глава 3. Трансформация данных 171
'^^ОСТОЯНИЯ Значение признака Маска [0; 1] Маска [-1; 1]
—— 5 а5 0, 0, 0, 0, 1, 0, 0, 0 -1,-1,-1,-1,1,-1,-1,-1
_ б Аг, 0, 0, 0, 0, 0,1, 0, 0 -1,-1,-1,-1,-1,1,-1,-1
.— 7 А- 0, 0, 0, 0, 0, 0,1, 0 -1,-1,-1,-1,-1,-1, 1,-1
8 — Ац 0, 0, 0, 0, 0, 0, 0, 1 -1,-1,-1,-1,-1,-1,-1, 1
В таблице представлены два варианта кодировки. Если требуется использовать
диапазон [0; 1], то можно взять значения, полученные в результате кодирования
непосредственно. Если в результате требуется получить диапазон [-1; 1], то можно
применить дополнительное преобразование, заменив нули на -1.
Однако такое кодирование неоптимально, когда классы представлены сущест-
венно различающимся числом примеров. Тогда имеет смысл использовать более
компактный, но симметричный код, когда имена т классов кодируются и-битным
двоичным кодом. При этом количество битов (то есть нулей и единиц) должно
быть достаточным для обеспечения такого количества состояний маски, чтобы их
хватило для кодирования всех уникальных значений признака. Маска, состоящая
из п двоичных цифр, способна дать 2” уникальных состояний, то есть должно
соблюдаться равенство 2" = т. Поэтому, например, если требуется закодировать
8 уникальных значений признака, нужно использовать маску из трех цифр, по-
скольку 23 = 8. Данная ситуация поясняется в табл. 3.29.
Таблица 3.29. Кодирование компактным кодом
№ состояния Значение признака Маска [0; 1] Маска [-1; 1]
1 At 0, 0,0 -1,-1,-1
2 А? 0, 0,1 -1,-1, 1
3 Аз о, 1,0 -1,1,-1
4 Ад 1,0,0 1, -1, -1
5 а5 0, 1,1 -1,1,1
6 Аг, 1, 1,0 1,1,-1
7 А7 1,0,1 1,-1, 1
8 Ав 1,1,1 1,1,1
Обратим внимание: если в данном случае использовать маску из двух цифр, то
она обеспечит всего 22 = 4 уникальных состояния, которых не хватит для коди-
рования всех уникальных значений признака. Если в маске использовать четыре
цифры, то получим 24 = 16 уникальных состояний, что породит избыточность,
то есть один бит окажется лишним (неиспользуемым). Это неэффективно с точки
зрения вычислительных затрат и используемой памяти.
В математической статистике существует еще один способ двоичного кодирова-
ния — введение фиктивных переменных. Он подробно рассматривается в главе 8.
Кодирование с использованием дополнительной информации. Перечисленные
методы кодирования, к сожалению, малоинформативны для рядового пользова-
теля, поскольку никак не связаны со свойствами исследуемых объектов. Поэтому
172 Часть I. Теория бизнес-анализа
представляет интерес кодирование на основе некоторой информации об объекте,
важной с точки зрения решаемой задачи. Например, при анализе перевозок с це-
лью их оптимизации важным является не название населенного пункта, в который
производится доставка, а расстояние до него по определенному маршруту. Тогда
названия населенных пунктов можно закодировать с помощью соответствующих
расстояний. Аналогично ФИО сотрудников можно закодировать с помощью их
окладов или стажа работы, наименования товаров — с помощью их цены и т. д.
Очевидно, что такой метод кодирования будет более информативным, чем просто
присвоение номеров. Кроме того, мы получаем новый признак, который можно
использовать в процессе анализа.
Визуализация данных
4.1. Введение в визуализацию
Одной из важнейших составляющих бизнес-аналитики является визуализация —
представление данных в виде, который обеспечивает наиболее эффективную ра-
боту пользователя. Способ визуализации должен максимально полно отражать
поведение данных, содержащуюся в них информацию, тенденции, закономерности
и т. д. При этом выбор способа визуализации зависит от характера исследуемых
данных и от задачи анализа, а также от предпочтений пользователя.
Многие связывают визуализацию только с интерпретацией, оценкой качества
и достоверности результатов анализа. Однако это в корне неверно. Визуализацию
необходимо применять на всех этапах аналитического процесса без исключения.
На практике в процессе анализа данных пользователь непрерывно работает с раз-
личными визуализаторами.
Цели и задачи визуализации на разных этапах аналитического процесса иллю-
стрируются на рис. 4.1.
Рис. 4.1. Цели и задачи визуализации данных
174 Часть I. Теория бизнес-анализа
Цели и задачи визуализации на разных этапах
аналитического процесса
Визуализация используется на разных этапах аналитического процесса для дости-
жения следующих целей и решения следующих задач.
Визуализация источников данных. В источнике данных перед их загрузкой
в аналитическую систему аналитику требуется визуально оценить:
□ характер, тип и поведение данных;
□ динамический диапазон значений;
□ степень гладкости;
□ наличие факторов, снижающих качество данных, таких как шумы, аномальные
и пропущенные значения.
Визуальный анализ источника данных позволяет:
□ увидеть, соответствуют ли данные ожидаемым;
□ оценить степень пригодности данных к анализу;
□ выдвинуть гипотезы о закономерностях процессов, описываемых данными;
□ определить, какие виды очистки и предобработки необходимо применить
к данным.
Кроме того, визуализация источников данных позволяет определить метод за-
грузки данных в аналитическое приложение и параметры, которые при этом долж-
ны быть использованы. Например, для корректной загрузки данных из текстового
файла с разделителями необходимо правильно определить символ-разделитель, ис-
пользуемый формат даты и времени, расположение заголовков столбцов и т. д. Не-
правильный выбор любого из этих параметров приведет к некорректной загрузке,
что не позволит выполнять обработку данных в аналитическом приложении.
ЗАМЕЧАНИЕ-------------------------------------------------------------
Особенно важно правильно настроить параметры загрузки при импорте больших массивов
данных, тем более при загрузке по сети. Если источник имеет большой объем, то процесс за-
грузки данных из него в аналитическое приложение может оказаться очень длительным. А по-
сле долгого ожидания может выясниться, что данные были загружены некорректно, поскольку
в параметрах загрузки текстового файла был неправильно указан символ-разделитель.
Для визуализации источников данных можно использовать приложения,
в которых они были созданы (текстовые редакторы, СУБД, электронные таблицы
и т. д.). Кроме того, большинство аналитических приложений содержат собствен-
ные средства предварительного просмотра источников данных.
Визуализация данных, загруженных в аналитическое приложение. После
загрузки данных из источника в аналитическое приложение работа с выборкой
также начинается с визуального анализа. Однако теперь цели, задачи и методы
визуального анализа будут несколько другими.
Нужно убедиться, что данные загрузились правильно: не появились пропуски,
сохранилась структура строк и столбцов и т. д. Искажение данных при загрузке
Глава 4. Визуализация данных 175
может произойти из-за несоответствия их типов, неправильной настройки пара-
меТров загрузки и т. д.
Если данные загружены корректно, то, как правило, стараются оценить степень
их гладкости, наличие шумов и аномальных выбросов. Интерес представляет по-
иск фрагментов данных с некоторыми особенностями. Кроме того, большинство
аналитических систем предлагают пользователю возможность получить стати-
стические характеристики — минимальное и максимальное значения, дисперсию
и среднеквадратическое отклонение и др.
По результатам визуального анализа исходной выборки делаются выводы
о целесообразности применения тех или иных видов очистки и трансформации
данных, вырабатывается методика и стратегия их анализа.
Визуализация данных в процессе их аналитической обработки. Сложные анали-
тические процедуры являются многошаговыми. Это означает, что в процессе анализа
к данным последовательно применяется несколько алгоритмов или моделей. Напри-
мер, сначала данные подвергаются предобработке с целью сглаживания и нормали-
зации, затем к результирующей выборке применяется та или иная модель. При этом
выборка, формируемая на выходе каждого алгоритма или модели, может подаваться
на вход следующего этапа обработки. Очевидно, что если данные, поступившие с пре-
дыдущего этапа, окажутся некорректными, то дальнейшая обработка теряет смысл.
Поэтому очень важно предусмотреть визуализацию промежуточных результатов
анализа с целью проверки корректности используемых моделей и алгоритмов.
Визуализация результатов анализа. После получения конечных результатов
аналитической обработки на первый план выходит задача их интерпретации
и оценки достоверности. И здесь не обойтись без визуализации. Следует заметить,
что, даже если в процессе анализа были получены достоверные и ценные резуль-
таты, неудачный выбор визуализации не позволит их интерпретировать, увидеть
в них зависимости и закономерности.
Группы методов визуализации
В настоящее время в бизнес-аналитике используется несколько десятков методов
визуализации. Выбор метода определяется особенностями и характером данных,
спецификой решаемой задачи и, наконец, предпочтениями пользователя. Рассмот-
рим основные методы визуализации.
Табличные и графические. Как правило, таблицы применяются в том случае,
когда пользователю необходимо работать с отдельными значениями данных, вносить
изменения, контролировать форматы данных, пропуски, противоречия и т. д. Графи-
ческие методы позволяют лучше увидеть общий характер данных — закономерности,
тенденции, периодические изменения. Кроме того, графические методы более эффек-
тивно сопоставляют данные: достаточно построить графики двух исследуемых про-
цессов в одной системе координат, чтобы оценить степень их сходства и различия.
Одномерные и многомерные. Одномерные визуализаторы представляют инфор-
мацию только об одном измерении данных, в то время как многомерные — о двух
или более. Если график показывает зависимость суммы продаж от даты, то он будет
одномерным, поскольку на нем будет отображаться только одно измерение — Дата,
176 Часть I. Теория бизнес-анализа
значениям которого будет соответствовать факт Цена. Если же информация о про-
дажах приводится по датам и наименованиям товаров, то появляется еще одно
измерение — Товар, и тогда для корректного представления данных используется
многомерный визуализатор. Популярные многомерные визуализаторы: OLAP-куб
многомерная диаграмма, карта Кохонена и др.
Общего назначения и специализированные. Методы визуализации общего
назначения не связаны с каким-либо определенным видом задач анализа или
типом данных и могут использоваться на любом этапе аналитического процесса.
Это своего рода типовые визуализаторы: графики и диаграммы, графы, гисто-
граммы и их разновидности, статистические характеристики и др. В то же время
существует ряд задач, специфика которых требует применения специализиро-
ванных визуализаторов. Например, карты Кохонена специально разработаны для
визуализации результатов кластеризации, матрицы классификации используются
в основном для проверки состоятельности классификационных моделей, а с по-
мощью диаграмм рассеяния оценивается корректность работы регрессионных
моделей.
При изучении различных видов визуализации удобнее рассматривать их не по
отдельности, а в контексте задач, для которых они наиболее часто применяются.
В связи с этим выделяются следующие группы методов визуализации:
□ общего назначения — применяются для решения типовых задач анализа дан-
ных: визуальной оценки качества и характера данных, распределения значений
признаков, статистических характеристик и т. д.;
□ OLAP-анализ — комплекс методов для визуализации многомерных данных;
□ оценка качества моделей — позволяет оценивать различные характеристики
моделей, такие как точность, эффективность, достоверность результатов, ин-
терпретируемость, устойчивость и т. д.;
□ интерпретация результатов анализа — служит для представления конечных
результатов анализа в виде, наиболее удобном с точки зрения их интерпретации
пользователем.
Подсистемы визуализации данных содержатся не только в специализирован-
ных аналитических платформах, но и практически во всех программных средствах,
которые связаны с обработкой данных, — от офисных приложений до систем
компьютерной математики. Однако в аналитических платформах визуализации
данных уделяется особое внимание, поскольку она является одной из состав-
ляющих аналитического процесса, без которой невозможно эффективно решить
поставленные задачи.
Наилучших результатов можно добиться, если считать визуализацию не отдель-
ной подсистемой, а такой же частью аналитического процесса, как, например, моде-
лирование, очистка и трансформация. Это позволит получить максимум полезной
информации в случаях, когда применение других методов неэффективно.
Даже если для построения качественной модели данных недостаточно, визуали-
зация позволяет выдвигать гипотезы, делать выводы на основе экспертных оценок,
разрабатывать способы повышения информативности данных.
Глава 4. Визуализация данных 177
4.2- Визуализаторы общего назначения
]у[ожно выделить набор средств визуализации, которые включаются в состав любого
аналитического приложения и применяются на всех этапах KDD. Такие средства
визуализации называются визуализаторами общего назначения. К ним относятся:
□ графики;
□ диаграммы;
□ гистограммы;
□ статистика.
Кратко рассмотрим каждый из перечисленных типов визуализаторов.
Графики
Графики представляют собой линии, отображающие зависимость между несколь-
кими переменными в некоторой системе координат. Линия на графике состоит из
множества точек, положение каждой из которых определяется значениями зависи-
мой и независимой переменной (переменных). Чаще всего используется декартова
система координат (X, Y, Z). Также может применяться полярная система коорди-
нат (г, 0), где положение точки на координатной плоскости зависит от расстояния
до начала координат z и угла 0.
Несмотря на свою относительную простоту, графики являются эффективным
средством визуального анализа данных, ведь часто именно с построения графи-
ка и начинается работа с данными. С помощью графиков оценивается степень
гладкости данных, наличие в них шумовой составляющей, аномальных выбросов
и пропусков. Особенно полезны они при анализе временных рядов. Иногда одного
взгляда на график достаточно, чтобы выявить наличие тренда, сезонной компонен-
ты, оценить степень влияния случайной составляющей на исследуемый процесс.
Чтобы построить график, достаточно задать таблично значения зависимой
и независимой переменной, отметить соответствующие точки на координатной
плоскости и соединить их линиями. Линии, соединяющие узлы графика, могут
быть прямыми или сглаженными. На рис. 4.2 представлены примеры обычного
Рис. 4.2. Ломаный и гладкий графики
178 Часть I. Теория бизнес-анализа
Во многих случаях гладкие графики удобнее, чем ломаные, для визуального
восприятия и корректнее отображают реальные бизнес-процессы, которые также
чаще всего изменяются плавно. Иногда точки, по которым строится график, вообще
не соединяют, в этом случае график называется точечным.
Если на графике требуется представить несколько рядов данных, то в одной
системе координат строится несколько линий. Но для этого необходимо, чтобы все
отображаемые на графике ряды имели одинаковые единицы измерения и могли быть
представлены в одном и том же масштабе. Например, если нужно сравнить ежемесяч-
ные продажи за три года, то можно воспользоваться таким графиком, как на рис. 4.3.
Рис. 4.3. График ежемесячных продаж за три года
Если значения в рядах данных лежат в различных диапазонах и отличаются
на несколько порядков, то отображение этих рядов на одном графике может вы-
звать определенные затруднения. Допустим, нужно сравнить динамику продаж
нескольких товаров. Но цены на различные товары даже в одной группе могут
различаться в десятки и сотни раз. Так, дорогие агрегаты для автомобиля (коробка
передач, двигатель и др.) продаются единично, а мелкие детали ценой несколько
рублей (гайки, болты и др.) — сотнями. В этом случае прибегают к такому приему,
как сжатие диапазона значений, отображаемых на графике. Например, это можно
сделать с помощью логарифмирования или нормализации.
Диаграммы
С помощью графика удобнее всего отображать непрерывные (числовые) величины,
поскольку можно получить достаточное число точек, чтобы его построить. Если
же речь идет о категориальных (дискретных) значениях, то более подходящим
средством визуализации является диаграмма. Принципиального различия между
понятиями «график» и «диаграмма» нет. Просто под графиком традиционно пони-
мают представление зависимостей в виде линий, тогда как на диаграмме значения
отображаются с помощью самых разнообразных объектов и фигур. Как правило,
Глава 4. Визуализация данных 179
а диаграммах по горизонтальной оси X откладываются категории, а по вертикальной
осИ У — значения.
Самые простые и часто используемые диаграммы — столбиковые. На них значение
нуждой категории представляется в виде столбика, высота которого пропорциональна
соответствующему значению (рис. 4.4, а). Разновидностью столбиковой диаграммы
является линейчатая диаграмма, которая отличается от столбиковой тем, что ось
категорий откладывается вертикально, а ось значений — горизонтально (рис. 4.4, б).
б
Рис. 4.4. Столбиковая (а) и линейчатая (б) диаграммы
Еще одним распространенным видом диаграмм является круговая диаграмма.
Ее очень удобно использовать, если нужно показать долю, которую вносит то или
Иное значение в общую сумму. Эта доля может быть выражена как в абсолютных
180 Часть I. Теория бизнес-анализа
единицах, так и в процентах (например, процент от выручки, который обеспечил
товар А). Пример круговой диаграммы распределения месячных продаж бытовой
техники и электроники по категориям товаров представлен на рис. 4.5.
12 %
11 %
22%
Аудио- и видеотехника В Бытовая техника Встраиваемая техника
□ Компьютеры Телефоны □ Другое
Рис. 4.5. Круговая диаграмма
Хорошую наглядность обеспечивают лепестковые диаграммы. На них каж-
дая категория данных представлена в виде отдельной оси (лепестка), на которой
отображается соответствующее значение. Затем значения на всех осях соединя-
ются линиями. Если в ряду данных все точки имеют одинаковые значения, то
лепестковая диаграмма приобретает вид круга. Наличие на диаграмме нескольких
рядов позволяет сравнивать, например, динамику изменения структуры продаж
в группах товаров по месяцам (рис. 4.6).
Рис. 4.6. Лепестковая диаграмма
Глава 4. Визуализация данных 181
Существует множество других видов диаграмм — диаграммы с накоплением,
с областями, пузырьковые, кольцевые и т. д. При этом разновидность диаграммы
подбирается исходя из той информации, которую желает извлечь из нее пользо-
ватель.
Гистограммы
Гистограмма показывает распределение набора данных внутри выборки (на-
пример, количество заемщиков банка в нескольких возрастных группах) в виде
столбиков.
Гистограммы широко используются в статистике для определения наиболее
вероятных значений, которые может приобретать некоторая величина, а также для
определения закона распределения, которому подчиняется случайная величина.
Гистограмма строится следующим образом. Пусть исследуемой величиной
являются ежедневные продажи торговой точки в течение месяца. При этом мини-
мальное наблюдаемое значение составило 10 тыс., а максимальное — 100 тыс.
Разобьем диапазон изменения величины на 9 поддиапазонов по 10 тыс. и под-
считаем, сколько раз значение продаж попадает в тот или иной поддиапазон. Ре-
зультаты сведем в табл. 4.1.
Таблица 4.1. Исходные данные для гистограммы
Диапазон в тыс. 10-20 20-30 30-40 40-50 50-60 60-70 70-80 80-90 90-100
Частота 1 1 2 6 10 6 3 1 1
Как видим, продажи на сумму от 10 до 20 тыс. наблюдались только один раз,
от 30 до 40 тыс. — два раза и т. д. На основе полученной таблицы строим гисто-
грамму (рис. 4.7).
Рис. 4.7. Гистограмма распределения продаж
182 Часть I. Теория бизнес-анализа
По горизонтальной оси гистограммы откладываются значения продаж, а по
вертикальной — количество или частота наблюдений, значения которых попали
в заданный диапазон (поэтому иногда гистограмму называют частотным поли-
гоном).
Гистограмма на рис. 4.7 показывает, что наибольшее число наблюдений попало
в диапазон 50—60 тыс. Таким образом, значения из данного диапазона можно рас-
сматривать как наиболее вероятные. Эту информацию используют для восстанов-
ления пропущенных значений при очистке данных, для планирования денежных
поступлений, закупок и т. д.
Что касается крайних элементов гистограммы, то они представляют редкие со-
бытия — экстремально высокие или экстремально низкие значения продаж. Видно,
что в диапазон 10-20 тыс. попало всего одно значение, следовательно, вероятность
такого события мала и его не стоит включать в рассмотрение. Экстремально низкие
продажи могут быть вызваны исключительной ситуацией, например погодными
условиями, отключением электроэнергии и т. п.
Иногда используют нормированную гистограмму, что позволяет оперировать
не значениями наблюдений, а их вероятностями. Для этого каждый элемент гис-
тограммы делится на количество наблюдений, то есть в нашем случае на 31 (число
дней в месяце). Рассмотрим рис. 4.8.
Рис. 4.8. Нормированная гистограмма
Теперь высота столбца определяется не количеством наблюдений, попавших
в соответствующий диапазон, а вероятностью попадания в него. На рисунке видно,
что вероятность попадания значения в диапазон 50-60 тыс. составляет примерно
0,32, или 32 %. Соответственно вероятность появления значений в диапазоне
10-20 тыс. не превышает 0,03, или 3 %.
Глава 4. Визуализация данных 183
В нормированной гистограмме сумма значений всех ее элементов должна рав-
няться 1, поскольку сумма вероятностей всех возможных событий (попадания
значения в какой-либо диапазон) есть 1.
Обычно при построении гистограммы аналитик имеет возможность задать
яисло поддиапазонов, на которое будет разбиваться исходный диапазон измене-
ния величины (фактически это число столбцов гистограммы). Здесь существуют
различные рекомендации, например: число поддиапазонов не должно быть мень-
ше, чем log2 N, где N — число наблюдений. На практике можно руководствоваться
следующим эмпирическим правилом. Количество столбцов в гистограмме должно
быть таким, чтобы в ней не образовывались провалы, резкие выбросы или множе-
ственные пики. Она должна быть достаточно гладкой, чтобы по ней можно было
определить характер распределения наблюдаемой величины. Часто хороших ре-
зультатов удается добиться при использовании 10-15 столбцов.
Статистика
Еще одним распространенным средством визуализации, которое входит в состав
большинства аналитических приложений, является информация о статистических
характеристиках исследуемой выборки. Они обычно представляются в табличном
виде и указываются для каждого поля выборки. Статистические характеристики по-
зволяют выдвигать гипотезы о поведении данных и присущих им закономерностях,
контролировать результаты обработки данных на различных этапах аналитического
процесса. Типичный вид визуализатора статистики представлен в табл. 4.2.
Таблица 4.2. Статистические характеристики
№ п/п Метка поля Статистика: количество значений = 150
Минимум Максимум Среднее Стандартное отклонение Количество уникальных значений Количество пропусков
1 Длина чашели- стика 43,00 79,00 58,43 9,25 — 0
2 Ши- рина чашели- стика 20,00 44,00 30,57 40,34 — 0
3 Длина лепе- стка 10,00 69,00 37,58 17,59 — 0
4 Шири- на лепе- стка 1,00 25,00 11,99 7,60 — 0
5 Класс цветка 6 9 8 1Д4 3 0
Статистика, как правило, включает следующие характеристики.
184
Часть I. Теория бизнес-анализа
Минимум и максимум позволяют определить диапазон изменения значений
величины. Знание минимального и максимального значений дает возможность
увидеть, лежит ли величина в диапазоне, допустимом для применения в той или
иной аналитической модели, выбрать корректную методику сравнения величин
ит. д.
Среднее значение и математическое ожидание позволяют выдвигать гипотезы
о наиболее вероятных значениях, которые может принимать исследуемая вели-
чина.
Стандартное (среднеквадратическое) отклонение и дисперсия показывают
степень разброса значений величины относительно среднего. Знание этих харак-
теристик позволяет оценивать гладкость рядов данных, наличие в них шумов,
контролировать степень сглаживания данных в процессе их предобработки и т. д.
Распределение — указывается соответствие исследуемой выборки некоторому
статистическому распределению (нормальному, равномерному, экспоненциаль-
ному и т. д.). Знание распределения исследуемой величины позволяет объяснить
особенности ее поведения, например определить, какие значения являются наи-
более вероятными.
Кроме того, в набор определяемых статистических характеристик могут вклю-
чаться медиана, коэффициенты асимметрии и эксцесса и др. Также визуализатор
статистики часто содержит количество уникальных значений для дискретных ве-
личин и количество пропущенных значений, обнаруженное в выборке.
Визуализатор статистики — одно из самых востребованных средств при ре-
шении большинства задач анализа; применяется на всех этапах аналитического
процесса для предварительного исследования свойств данных, для выдвижения
гипотез о присущих им закономерностях, а также для контроля результатов об-
работки.
4.3. OLAP-анализ
Большинство реальных бизнес-процессов являются сложными, поскольку в них
участвует много объектов, которые находятся в самых разнообразных отношениях
и с каждым из которых может быть связано несколько числовых характери-
стик. Поэтому при визуализации данных часто встает вопрос: как представить
сложные данные в таком виде, чтобы человек мог их осмыслить и интерпрети-
ровать?
Например, если исследуемым процессом являются продажи, то приходится
иметь дело с наименованиями товаров и групп товаров, с городами, в которых
они продавались, с датами продаж, с информацией о поставщиках, покупателях,
местах хранения и т. д. На первый взгляд, данная проблема стоит не так уж остро.
Если необходимо отслеживать несколько объектов (продажу нескольких това-
ров), то достаточно построить соответствующее количество линий на графике
для каждого товара или таблицу. Но товары могут различаться по цене и объ-
емам продаж в сотни и даже тысячи раз, что вызовет проблему при построении
Глава 4. Визуализация данных 185
скольких графиков в одной системе координат. Кроме того, данные могут
f|VieTb различную степень детализации, что также затрудняет их табличное или
' яфическое представление. И наконец, ситуацию заводит в тупик огромное
количество записей, которые накапливаются в корпоративных базах и храни-
лищах данных.
Предположим, требуется визуализировать с помощью таблицы продажу не-
скольких наименований товаров по нескольким датам и городам (табл. 4.3).
Таблица 4.3. Продажи товаров
Дата Товар Город Цена Количество Сумма
OL02.07 Пылесос Михайлов 3500 10 35 000
OL02.07 Стиральная машина Михайлов 6700 5 33 500
01.02.07 Утюг Михайлов 1200 3 3600
01.02.07 Пылесос Касимов 3500 2 7000
’оГо2.О7 Стиральная машина Касимов 6700 4 26 800
01.02.07 Пылесос Касимов 1200 5 6000
02.02.07 Пылесос Михайлов 3500 4 35 000
02.02.07 Утюг Михайлов 1200 10 12 000
02.02.07 Телевизор Михайлов 7800 2 15 600
Даже такой сравнительно простой фрагмент демонстрирует сложности, с ко-
торыми можно столкнуться при визуализации бизнес-процессов. Если продажи
велись одновременно по множеству наименований товаров в нескольких городах,
то таблица, содержащая соответствующие наблюдения, неизбежно окажется из-
быточной: в ней много раз будут повторяться одни и те же данные. А оперативно
получить нужную информацию из такой таблицы будет весьма проблематично
из-за огромного количества наблюдений.
Возможным выходом из ситуации является декомпозиция сложной таблицы
на множество более простых, где содержится информация о продажах отдельных
товаров и групп товаров по городам, интервалам дат, поставщикам и т. д. Но такой
подход позволяет лишь отчасти решить проблему. Дело в том, что процесс анализа
Данных требует сравнения и сопоставления данных (например, по различным го-
родам или группам товаров), вычисления различных показателей и характеристик
И т. д. Если данные о продажах распределены по нескольким таблицам, каждая из
которых составлена для одного города, то как найти, например, товар, продажи
которого были максимальными в каждом городе? Для этого придется сформиро-
вать сводный отчет и выявить соответствующие максимумы. С учетом огромных
объемов данных каждая такая операция может занять очень много времени и по-
требовать больших вычислительных затрат.
Все эти трудности, возникающие при обработке больших и сложных массивов
Данных, создали предпосылки для появления метода визуализации многомерных
табличных данных — OLAP-анализа.
В основе OLAP лежит многомерное представление данных (принцип многомер-
н°го хранения данных подробно рассматривался в главе 2), которые могут быть
186 Часть I. Теория бизнес-анализа
разделены на количественные и качественные. Качественные данные представляют
собой значения, выраженные в категориальной форме. Обычно это наименования
товаров, групп товаров, организаций, названия городов, ФИО сотрудников и т. д.
С каждым объектом связаны признаки, количественно описывающие его. Для то-
вара это может быть цена, количество или сумма; для города, в котором располо-
жено торговое представительство, — расстояние до него и количество жителей; для
сотрудника — заработная плата и стаж работы.
С каждым качественным значением анализируемого бизнес-процесса связаны
один или несколько количественных показателей. В рамках многомерной модели
данные, качественно описывающие исследуемый бизнес-процесс, называются
измерениями. Измерениями могут быть Товар, Город, Клиент, Организация и др.
К ним относят и дату. Данные, количественно описывающие процесс или объект,
называются фактами. Примеры фактов: Количество, Сумма, Возраст, Доход,
Торговая наценка и др. Другими словами, с каждым измерением связаны один
или несколько фактов.
Измерения несут смысловую нагрузку, а факты — количественную. Чтобы
достоверно отделить измерения от фактов, достаточно сопоставить значение
с вопросом. Измерения позволяют ответить на вопросы «Что?» (товар), «Кто?»
(клиент), «Когда?» (дата) и «Где?» (город). Факты отвечают на единственный
вопрос — «Сколько?».
Каждое измерение содержит ограниченный набор значений (категорий). Для из-
мерения Товар значениями будут наименования товаров: Холодильник, Утюг, Пы-
лесос и т. д. Каждому значению измерения в многомерной модели соответствуют
одно или несколько значений фактов. Так, для значений измерения Товар могут
указываться цена и количество на складе.
ЗАМЕЧАНИЕ----------------------------------------------------------------
Аббревиатура OLAP таже встречается в теории хранилищ данных. Но если там она упо-
требляется в контексте моделей хранения данных (многомерной, реляционной), то здесь
под OLAP подразумевается метод визуализации, при этом модель хранения данных может
быть любой.
Чтобы построить OLAP-куб, пользователь должен указать системе следующие
параметры:
□ какие измерения и факты включать в куб;
□ методы агрегации значений фактов.
Визуализация OLAP-куба производится с помощью специального вида таблиц,
которые строятся на основе срезов OLAP-куба, содержащих необходимую пользо-
вателю информацию. Срезы, в свою очередь, являются результатом выполнения
соответствующего запроса к базе данных.
Как правило, в процессе построения срезов пользователь с помощью мыши
и клавиатуры манипулирует заголовками измерений, добиваясь наиболее инфор-
мативного представления данных в кубе. В зависимости от положения заголовков
измерений в таблице автоматически формируется запрос к базе или хранилищу
Глава 4. Визуализация данных 187
данных. Запрос извлекает данные из базы или хранилища, после чего OLAP-ядро
системы визуализирует их.
Процесс построения OLAP-куба может быть пояснен с помощью схемы, пред-
ставленной на рис. 4.9.
Рис. 4.9. Построение OLAP-куба
На рис. 4.10 показан пример визуализации данных с помощью OLAP-куба, где
представлена информация о количестве и суммах продаж по аптекам в разрезе года
и месяца. Эти сведения могут оказаться полезными при определении наиболее
загруженных аптек.
Измерения Фа кты
1 Отдея-Намменованме
Аптека 1 . Аптека 2 / Дпт вкаЗ — - Итого:
1 -+ Гад |Месяц X Ксп-во X Сумма. X Кол-во | X Сумма X Сол-во 'X Сумма X Кол-во | X Сумма
01 Январь 573 33 284,1 573 33287 1
02 Февраль 623 33889,2 623 33809.2:
03 Март 534 32241,2 534 32241.2
04 Апрель 527 33 488Г 353 19 370,6 880 52858.6;
05 Май 449 22 377.6 224 10 759,3 673 33 1 36.9
06 Июнь 425 21 364,1 186 8 160,5 611 29 524.5
:#2004 07 Июль 373 13 536,4 1 64 8 1 58,1 537 21 694"
08 Август 312 14 324 6 227 1 0 764,9 539 25089.5
09 Сентябр! 453 23 436.4 278 1 5 008.1 731 38 444 6
10 Октябрь 536 31 328.3 361 21 777,8 566 35 965 4 1 463 89071,5
11 Ноябрь 588 33413.9 281 16 416,8 603 46 399,3 1 472 96229.9
12 Декабрь 591 32 596.5 350 21 365.7 655 43121.3 1 596' 970835
Итого: . 5.98Й 325 200,1 2 424 1 31 781 8 1824 125 486 9 10 232 582 468.0
Итого: 5 984 325 200.1 2424*131781,8 1824 1254860 10232 582466.0
Рис. 4.10. Пример OLAP-куба
В кубе на рис. 4.10 для каждого месяца и года перечислены все продажи, кото-
рые были сделаны в пределах этого периода, с указанием количества проданных
единиц товара и их общей суммы. Визуальный анализ позволяет увидеть, что
больше всего продаж пришлось на «Аптеку 1».
188 Часть I. Теория бизнес-анализа
Для более детального анализа представляют интерес продажи по дням. Чтобы
преобразовать куб в соответствующий вид, достаточно добавить еще одно измере-
ние — День месяца, как показано на рис. 4.11.
I С!Л-Нлмм* >'
Аптека 1 Тдитека 2 —~ Итого:
I-+ Год ЧТ | - ♦ Месяц Лен» месяца * Г Кол-во 52 Сумма] 52 Кол-во, 52 Сумма! 52 Кол-во IX Сумгш
Sot Январь 9942.2 202 9942.2
S02 Февраль 221 13 544.3 221 13544 3
g?03Март 183 10 951 5 183 10951 5
Апрель 206 13363,5 122 9 908.2 328 22671 7
(В 05 Май 141 5670 5 73 3 762,4 214 94330
К 06 Июнь 183 9 965.7 84 3 822,1 267 137878
^07 Июль 136 55285 55 3 314.7 191 8842,7
ЗВ 08 Август 130 4 928.6 57 25764 187 7 5050
®09 Сентябрь 137 7 072.7 70 4 300.3 207 11 373,0
01 15 8853 25 647,0 40 1 532.3
02 10 971,2 21 9377 31 1 908,9
BZ004 03 25 8275 12 453.1 37 1 280,5
04 16 950 2 14 1 161,7 30 2111.9
05 17 1 309.6 18 1 305,0 35 2 614 7
Q10 Октябрь 06 31 1 289,6 16 1 330 4 47 2620 9
07 20 1 580? 12 932.1 32 2512.8
08 14 719,3 9 656.2 23 1 375,5
09 21 2099.9 5 389.5 26 2 489,4
10 18 1 060.9 9 921 4 27 2 002.3
Итого: 187 11 7141 141 8 734.1 328 20 448.3
Lft? 11 Ноябрь 186 10 308 2 81 4 984 4 267 15 2925
®1Z Декабрь 192 9 856,4 116 7 660.3 308 17216,7,
Итого: 2104 112845.7 799 48162.9 2903 161 008.6
Итого: 2104 112 845,7 799 48162,9 2 903 161 008 9
Рис. 4.11. OLAP-куб с добавленным измерением «День месяца»
Таким образом, OLAP-куб можно использовать не только как метод визуали-
зации, но и как средство оперативного формирования отчетов и представления
информации в нужном разрезе (так называемая аналитическая отчетность).
Наибольший интерес OLAP-куб представляет с точки зрения визуального
анализа данных, поиска особенностей и закономерностей в данных. При этом су-
ществует два подхода.
□ Аналитик может задаться несколькими вопросами: «Какой товар самый попу-
лярный?», «Где продажи были наилучшими и с чем это связано?» и т. д. Затем
с помощью манипуляций заголовками измерений выбирается такое представ-
ление куба, которое позволяет ответить на поставленные вопросы.
□ Можно подойти к проблеме и с другой стороны — последовательно перебирать
возможные варианты представления данных, которые обеспечивает куб, и с их
помощью сопоставлять данные, выявлять закономерности и связи между эле-
ментами данных, выдвигать гипотезы и т. д.
Глава 4. Визуализация данных 189
Умелое использование OLAP-анализа и работа с кубом порой позволяют
полУчить результаты даже в тех случаях, когда методы Data Mining оказыва-
ется малоэффективными (например, из-за недостатка или низкого качества
данных).
Манипуляции с измерениями
Для того чтобы сделать процесс извлечения информации из куба более гибким
И эффективным, в OLAP-системах обычно предусматривается набор операций
с измерениями, позволяющих получить максимум возможных представлений
данных.
К таким операциям относятся следующие.
Замена и добавление измерений. Любые измерения куба можно заменить
другими, присутствующими в исходном множестве данных. Например, если ранее
нас интересовала информация о продажах в разрезе каждого отдельного клиен-
та, а позже — в разрезе каждого города, где производились продажи, то можно
заменить измерение Клиент измерением Город. При необходимости в куб могут
встраиваться новые измерения.
Удаление измерений. Если в процессе работы с кубом какое-либо измерение
утратило информативность, то его можно исключить из куба. Оставлять в кубе
лишние измерения нежелательно: чем выше размерность куба, тем сложнее для
понимания и осмысления представленная в нем информация. Кроме того, чем
больше измерений в кубе, тем выше временные и вычислительные затраты на его
обработку.
Скрытие измерений. Пользователь может выбрать в кубе несколько наиболее
информативных представлений и работать с ними. Но часто возникает ситуация,
когда какое-либо измерение для одного из представлений является лишним,
то есть не несет полезной информации, а только усложняет визуальное воспри-
ятие, в то время как для других представлений оно нужно. Временно удалять,
а затем встраивать это измерение в куб непрактично, поскольку перестройка
куба при большом объеме данных может занять много времени. Поэтому преду-
сматривается возможность временного скрытия измерений без удаления их из
куба. Тогда при необходимости можно вновь отобразить скрытое измерение без
перестройки всего куба.
Изменение порядка следования измерений. При работе с несколькими
измерениями в кубе закладывается возможность выбрать порядок их отобра-
жения.
Отбор значений измерений. Часто необходимость в отображении всех возмож-
ных значений измерения (например, дат, товаров и т. д.) отсутствует. Поэтому,
Чтобы не загромождать куб ненужными данными, лишние значения измерений
Могут быть временно скрыты, а если понадобится — отображены снова. При этом
выбирать отображаемые значения измерений можно или непосредственно из спис-
ка, или с помощью фильтрации по какому-либо условию.
190 Часть I. Теория бизнес-анализа
Транспонирование. Если при работе с кубом выяснится, что значения изме-
рений, которые отображаются в столбцах, удобнее отображать в строках или на-
оборот, то соответствующее преобразование можно легко произвести с помощью
операции транспонирования. Пример транспонирования представлен на рис. 4.12:
вверху расположено исходное представление куба, а внизу — результат примене-
ния к нему операции транспонирования.
Месяц
10 01 тябрь
11 Ноябрь
12 Декабрь
X К-уъ-о I X Сумма
11 714.1
8 734.1
10 480.6
187
141
137
465 30938.8
X Кол-во] X Сунна X Kofr-во | X С/има
18к 10 308,2
81- 4 984.4
132 8856,4,
116 7 360.3
216 12 580.3
524 29787,0
204 14 347,7-
471 29640’
Отдел. Наименование
Аптека 1 I Аптека 2 Аптека 3
| Месяц X Кол-во! X Сумма! X Кол-во! X Сумма X Кол-во X Сумма
10 Октябрь 187 11 714.1 141 8 734.1 137 10 480.6
11 Ноябрь 186 10 306,2 81 4 984,4 204 14 347 7
12 Декабрь 192 8856,4 116 7 380,3 216 12 580 3
Итого: 565 ,01878.7 338 21 076:'. 557 37 4186
Рис. 4.12. Транспонирование OLAP-куба
Детализация
При работе с OLAP-кубами широко применяется еще одна операция, называемая
детализацией (ср. англ, drill down — «проникновение», «более детальное исследо-
вание»), Ее необходимость вызвана тем, что в большинстве случаев значения в кубе
являются агрегированными, например, в пределах некоторой даты или интервала
дат. В то же время пользователя могут интересовать и атомарные (то есть детали-
зированные) значения, на основе которых были получены агрегированные.
Операция детализации заключается в отображении набора записей выборки
данных, в результате агрегирования которых было получено соответствующее
значение OLAP-куба.
В табл. 4.4 представлен фрагмент выборки данных по кредитованию.
Таблица 4.4. Данные по кредитованию
Код клиента Дата Сумма кредита Цель кредитования
120 08.01.2007 50 000 Иное
121 08.01.2007 9000 Покупка авто
122 09.01.2007 43 000 Оплата образования
123 09.01.2007 2500 Оплата услуг
124 09.01.2007 48 500 Покупка товара
125 09.01.2007 45 500 Оплата образования
Глава 4. Визуализация данных 191
^лдклиентз Дата Сумма кредита Цель кредитования
Ттб 09.01.2007 32 000 Оплата услуг
"57 09.01.2007 2500 Оплата услуг
128__ 09.01.2007 6500 Оплата услуг
129_ 09.01.2007 13 500 Оплата услуг
130_ 09.01.2007 31500 Оплата образования
131__ 09.01.2007 6000 Иное
7з12__ 09.01.2007 28 000 Покупка авто
Тй 09.01.2007 13 500 Покупка товара
tfTL 09.01.2007 19 500 Оплата образования
135 10.01.2007 18 000 Покупка товара
7зб~3 10.01.2007 45 000 Турпоездки
На рис. 4.13 представлен фрагмент куба, построенного на основе этой выборки.
Данные о кредитах агрегированы по датам: в кубе мы видим не суммы отдельных
кредитов, а значения, полученные их суммированием по отдельным целям кредито-
вания в пределах одной даты. Другими словами, из куба можно почерпнуть только
информацию о том, на какую общую сумму было выдано кредитов на ту или иную
цель в пределах определенной даты, а суммы, выданные отдельным клиентам,
остаются неизвестными.
ЦиЖ К, • ДМ1ОВдНИЯ
| Дата Иное Оплата образован Оплата услуг = Итого: 204 0009
04.01.2007 135 000.0 23 40,0 45 500.0,
05.01.2007 34 500.0 38 0000 40 500.0- 113000,0
06.01.2007 48 000.0 48 000.3
07.01.2007 51 000,0 31 000.0 82 000,0
=08.01.2007 100 000.0 100 01.0.0
09.01.2007 42 000.0 139 500,0| 114 000,0 295 500,0
Итого: 311 500,0 300000.0 231 ОООДЯШ W5w-°
V
Дата | Сумма кредита Цель кредитования
> 09.01.2007 43000 Оплата образования
09.01.2007 45500 Оплата образования
09.01.2007 31500 Оплата образования
09.01.2007 19500 Оплата образования
Рис. 4.13. Детализация значений фактов в кубе
Предположим, аналитика заинтересовала аномально высокая сумма кредитов,
ВЬ1данных 09.01.2007 на оплату образования, которая составила 139 500 и в не-
сколько раз превысила аналогичные значения на другие даты. Для более детального
^следования может понадобиться информация о сумме каждого кредита в отдель-
н°сти. Получить такую информацию поможет операция детализации.
Результатом применения детализации к соответствующей ячейке куба будет
Таблица, в которой представлены записи, содержащие данные, связанные с этой
ячейкой (путем агрегирования которых она была получена) (см. рис. 4.13).
192 Часть I. Теория бизнес-анализа
Существует и другой вариант детализации — в виде последовательно разво-
рачивающихся и сворачивающихся измерений, как мы это видели на рис. 4.11.
4.4. Визуализаторы для оценки
качества моделей
В процессе решения задач в бизнес-аналитике приходится создавать одну или не-
сколько моделей. Они могут быть основаны на машинном обучении, как нейронные
сети, деревья решений, самоорганизующиеся карты признаков и т. д., или жестко
заданы путем непосредственного программирования преобразований, которые дан-
ная модель должна выполнять. Независимо от вида построенной модели, прежде
чем применять ее на практике, необходимо оценить ее качество, то есть определить,
насколько правильно и точно она решает поставленную задачу.
Можно выделить две составляющие качества модели:
□ адекватность — насколько точно модель описывает исследуемый объект или
процесс;
□ корректность — насколько правильно модель может работать со всеми возмож-
ными входными данными.
Достичь абсолютно точного описания моделью реального бизнес-процесса или
объекта практически невозможно, поскольку в таком случае модель окажется очень
сложной и труднореализуемой. Чаще всего ищут разумный компромисс между
точностью и сложностью. Например, задается допустимая точность 10 %, которую
должна соблюдать построенная модель. То есть требуется, чтобы классификацион-
ная модель из 100 примеров неправильно классифицировала не более 10.
Но даже если сама по себе модель обладает достаточной степенью точности
и адекватности, при поступлении на ее вход некорректных данных она может по-
вести себя непредсказуемо.
Чтобы свести к минимуму вероятность выявления несуществующих законо-
мерностей при анализе, необходимо исследовать качество работы моделей. Такие
исследования должны проводиться как в процессе построения модели, так и после
его завершения. Так, при обучении нейронной сети с целью создания классифика-
тора обычно требуется несколько этапов обучения. После каждого этапа контро-
лируется точность модели (например, число неправильно распознанных примеров
или выходная ошибка), после чего корректируются конфигурация сети, обучающая
выборка или параметры обучения. И это происходит до тех пор, пока модель не
станет удовлетворять заданным требованиям (рис. 4.14).
После того как модель доведена до требуемого уровня точности, проверяется ее
устойчивость к некорректным данным. Например, если нейронная сеть обучалась
на данных, значения которых лежали в диапазоне от 0 до 100, то как она поведет
себя при подаче на вход значения 105? Если при появлении некорректных данных
модель выдает неправильные результаты, то, возможно, изменять ее не потребует-
ся, так как окажется достаточным применить те или иные методы трансформации
и очистки данных, что позволит обеспечить корректность исходных данных.
Глава 4. Визуализация данных 193
Рис. 4.14. Итерационный характер моделирования
Для исследования адекватности и корректности моделей в состав аналитических
приложений включаются специальные визуализаторы, которые позволяют оценить
точность модели и ее реакцию на те или иные входные данные.
Типичный набор визуализаторов для оценки качества моделей следующий:
□ матрица классификации;
□ диаграмма рассеяния;
□ ретропрогноз;
□ графики контроля хода обучения.
Рассмотрим их более подробно.
Матрица классификации
Матрица классификации, или таблица сопряженности (confusion matrix), приме-
няется для оценки качества классификационных моделей. Как известно, задача
классификации заключается в отнесении предъявленного объекта к одному из
заранее определенных классов на основе набора признаков данного объекта. Таким
образом, входные данные для классификационной модели представляют собой
признаки (атрибуты) классифицируемых объектов, а на выходе классификаци-
онной модели должна формироваться метка класса, к которому относится объект
с Данным набором признаков. При этом она должна быть категориального вида.
194 Часть I. Теория бизнес-анализа
Для каждого примера классификационная модель формирует на выходе метку
класса, к которой относится объект с набором признаков, указанных в примере.
Если метка класса, сформированная моделью, совпадает с целевой меткой класса
из примера, то такой пример (объект) является правильно распознанным, в про-
тивном случае — неправильно распознанным.
Фрагмент классификационной выборки представлен в табл. 4.5, где имеется
четыре признака: Длина чашелистика, Ширина чашелистика, Длина лепестка
и Ширина лепестка. На основе значений данных признаков модель должна от-
нести каждый предъявленный экземпляр цветка к одному из трех видов (клас-
сов) — Versicolo, Virginica или Setosa (данная задача классификации известна как
«ирисы Фишера»),
Таблица 4.5. Ирисы Фишера
Длина чашелистика Ширина чашелистика Длина лепестка Ширина лепестка Класс цветка Класс цветка (модель)
50 33 14 2 Setosa Setosa
64 28 56 22 Virginica Virginica
65 28 46 15 Versicolo Versicolo
67 31 56 24 Virginica Virginica
63 28 51 15 Virginica Versicolo
46 34 14 3 Setosa Setosa
69 31 51 23 Virginica Virginica
62 22 45 15 Versicolo Versicolo
59 32 48 18 Versicolo Virginica
46 36 10 2 Setosa Setosa
61 30 46 14 Versicolo Versicolo
60 27 51 16 Versicolo Versicolo
Поле Класс цветка является целевым и содержит эталонную метку класса, по
которой производится настройка параметров модели. Поле Класс цветка (мо-
дель) содержит метку класса, выданную моделью на данном примере. В табл. 4.5
выделены примеры, в которых модель допустила ошибку, выдав метку класса, не
соответствующую эталонной.
Соотношение числа правильно и неправильно распознанных объектов служит
критерием качества модели. Чем больше объектов выборки было распознано пра-
вильно, тем лучше работает модель.
Однако с точки зрения оценки качества модели интерес представляет не только
общее количество правильно и неправильно распознанных объектов, но и их число
в каждом классе. Если в одном из классов число неправильно распознанных при-
меров существенно больше, чем в других, есть повод задуматься о том, правильно
ли подобраны примеры в обучающей выборке, и разработать соответствующие
меры для оптимизации модели. Для оперативной визуализации числа правильно
и неправильно распознанных примеров в каждом классе исходной выборки служит
матрица классификации. Поясним принцип ее построения.
Глава 4. Визуализация данных 195
Пусть выборка данных содержит 150 объектов, относящихся к трем классам — А,
каждому из классов относятся 50 объектов. В процессе распознавания каж-
дого объекта с помощью модели возможны два случая: объект распознан правильно
или объект распознан неправильно.
Таким образом, после обработки всей выборки будет получено некоторое ко-
личество правильно и неправильно распознанных объектов, при этом известно,
к какому классу будет ошибочно отнесен тот или иной пример. Тогда можно будет
построить таблицу, каждый столбец и строка которой будут соответствовать од-
нОму из классов А, В или С. При этом заголовок строки указывает на фактическую
принадлежность объекта к определенному классу, а заголовок столбца — на то, как
объект был распознан. На пересечении каждых строки и столбца можно указать
количество объектов, которые относятся к классам, указанным в строках, но при
этом были распознаны как класс, указанный в столбце.
Следовательно, в ячейках, расположенных на главной диагонали таблицы ука-
зывается количество объектов, которые были распознаны правильно. Если неко-
торое количество объектов указывается в ячейке, расположенной на пересечении
разноименных строк и столбцов, эти объекты распознаны неправильно: объект
класса, указанного в строке, распознан как объект класса, указанного в столбце.
ПРИМЕР--------------------------------------------------------------------
Пусть исходная выборка содержит 100 объектов двух классов Больной и Здоровый по
50 объектов в каждом. Результаты классификации находятся в матрице классификации.
Классифицировано
Фактически Больной Здоровый Итого
Больной 36 14 50
Здоровый 9 41 50
Итого 45 55 100
Чтобы оценить результаты классификации и, следовательно, работоспособность классифи-
кационной модели, достаточно беглого взгляда на матрицу. Из 50 пациентов, принадлежа-
щих к классу Больной, таковыми были признаны моделью только 36 человек. 14 больных
человек модель ошибочно отнесла к здоровым. Аналогично из 50 пациентов, принадлежа-
щих к классу Здоровый, 41 человек был отнесен моделью к этому классу. 9 здоровых людей
модель ошибочно отнесла к больным. Этот классификатор реже ставит неверный диагноз
здоровым людям, или, другими словами, модель склонна к пропуску больных.
Общая ошибка классификации составит: (14 + 9) / 100 х 100 % = 23 %.
Аналитик может сделать следующие выводы о качестве модели.
□ Матрица классификации показывает, какая доля от общего числа примеров
распознана неправильно. В зависимости от особенностей решаемой задачи
и требуемой точности допускается определенный процент неправильно распо-
знанных примеров. Например, если обнаружилось, что число неправильно рас-
познанных примеров не превышает 10 %, то модель считается работоспособной.
В противном случае необходимо откорректировать параметры модели.
196 Часть I. Теория бизнес-анализа
□ Матрица классификации позволяет определить классы, для которых допущено
самое большое число ошибок классификации.
Главным преимуществом этого визуализатора является наглядное и оператив-
ное представление результатов работы модели. Если бы аналитик пытался извлечь
эту информацию из обычной таблицы, где представлена результирующая выборка,
то при большом числе объектов это заняло бы много времени.
Диаграмма рассеяния
Другая важнейшая задача Data Mining (наряду с классификацией) — регрессия.
Формальное отличие регрессии от классификации заключается в том, что выходная
переменная является непрерывной (подробнее классы задач Data Mining рассмат-
ривались в главе 1), поэтому использование матриц классификации для оценки
качества регрессионных моделей неприемлемо. Регрессия просто устанавливает
взаимную связь между значениями входных и выходных переменных модели.
Визуализатором, который применяется для оценки качества моделей в случае
непрерывной выходной переменной, является диаграмма рассеяния. Диаграмма
рассеяния представляет собой график, по одной оси которого откладываются целе-
вые значения выходной переменной (то есть те, которые заданы в качестве эталона
для обучения), а по другой — реальные значения, полученные на выходе модели.
На таком графике можно построить линию идеальных значений: у = у. На этой
линии будет лежать любая точка, для которой реальное выходное значение у,
сформированное моделью, будет равно целевому значению у (при этом ошибка
Е = у - у = 0). Такая линия, очевидно, будет выходить из начала координат и пе-
ресекать координатную плоскость по диагонали.
В то же время любая точка, для которой реальное выходное значение будет
отлично от эталонного целевого значения, отклонится от линии идеальных значе-
ний. При этом величина отклонения будет равна ошибке, допущенной моделью на
данном примере (рис. 4.15).
Рис. 4.15. Принцип построения диаграммы рассеяния
Глава 4. Визуализация данных 197
Точка, лежащая на линии идеальных значений, соответствует случаю, когда
реальный выход модели равен эталонному. На практике модель допускает ошиб-
ку Е, которая приводит к отклонению точки, соответствующей реальному выходу
модели, от эталонного и, следовательно, от линии идеальных значений. Точка,
соответствующая реальному выходу, имеет координаты у = у + Е.
Множество точек на плоскости (уу), образованных парами целевых и реальных
значений, будет представлено на диаграмме в виде «облака», рассеянного вдоль
линии идеальных значений. Степень отклонения точки от этой линии будет опре-
деляться ошибкой модели на соответствующем примере.
Пример диаграммы рассеяния представлен на рис. 4.16. Диагональная линия
на рисунке — это линия идеальных значений. Точками, рассеянными вдоль линии
идеальных значений, обозначены реальные выходные значения модели.
Смысл диаграммы рассеяния достаточно прозрачен. Если все точки (или хотя
бы основная масса), представляющие реальные выходные значения модели, сосре-
доточены вблизи линии идеальных значений, то модель работает хорошо.
Если у облака, образуемого точками выходов модели, значительный разброс,
то большинство выходных значений имеет большую ошибку и в этом случае ка-
чество модели оставляет желать лучшего. Пример такой диаграммы рассеяния
представлен на рис. 4.17.
Особый интерес могут представлять отдельные точки, наиболее далеко от-
стоящие от линии идеальных значений. Их появление обусловлено тем, что
На соответствующих примерах модель дает очень высокую ошибку, поскольку
в этих примерах содержатся аномальные значения, нехарактерные для поведе-
ния выборки в целом. Анализ таких отклонений позволяет выявлять редкие,
но важные события, влияющие на исследуемый процесс. Если же аномальное
значение — просто следствие ошибки, то его следует исключить из рассмотрения
Или откорректировать.
198 Часть I. Теория бизнес-анализа
Рис. 4.17. Диаграмма рассеяния для неудачной модели
Чтобы оценить точность модели, достаточно беглого взгляда на диаграмму
рассеяния. По сути, она является аналогом матрицы классификации для моделей
с непрерывными выходными значениями.
Ретропрогноз
Частный случай задачи регрессии — прогнозирование временных рядов. Чтобы со-
ставить прогноз, строится регрессионная модель, которая на основе прошлых зна-
чений ряда рассчитывает прогнозируемые значения. Она имеет некоторый набор
параметров, позволяющих получить прогноз с учетом поведения ряда в прошлом
(рис. 4.18).
Рис. 4.18. Диаграмма прогноза
Глава 4. Визуализация данных 199
Неизбежно возникает вопрос: насколько корректна построенная модель прогно-
насколько она точна и адекватна поведению исследуемого ряда? Для проверки
качества прогностической модели используется специальный тип визуализатора —
^^оп/’огноз. Слово «ретропрогноз» буквально означает «прогноз в прошлом»,
Прогноз прошлых значений». Его сущность заключается в том, чтобы применить
построенную модель к подмножеству данных из прошлого и оценить, насколько
полученный прогноз соответствует реальным значениям ряда, имевшим место
в прошлом.
Для построения ретропрогноза нужно выбрать некоторое подмножество данных
из прошлого, чтобы использовать их в качестве исходных. Затем к этому подмно-
жеству применяется прогностическая модель с заданными параметрами. Модель
формирует набор прогнозных значений, которые затем сравниваются с данными,
реально имевшими место в прошлом. Если в результате такого сравнения обнару-
жится, что между значениями ретропрогноза и реальными данными существует
большое расхождение, это даст повод усомниться в корректности прогностической
модели. Сам характер расхождения (его величина, знак и т. д.) позволяет выработать
методику коррекции модели.
Принцип работы ретропрогноза поясняется с помощью диаграммы на рис. 4.19.
Ретропрогноз направлен не в будущее ряда, а формируется параллельно его
прошлым значениям и сравнивается с ними. На рис. 4.19 можно наблюдать хорошее
согласование значений ретропрогноза и реальных значений ряда, что позволяет
предположить высокое качество прогностической модели, с помощью которой
был построен ретропрогноз. На рис. 4.20 представлен противоположный случай:
Ретропрогноз оказывается существенно завышенным или заниженным, что говорит
о недостаточной точности модели.
200 Часть I. Теория бизнес-анализа
Рис. 4.20. Ретропрогноз с большим отклонением прогнозируемых значений от реальных
При выборе множества значений временного ряда, которые будут использо-
ваться в качестве исходных данных для ретропрогноза, следует учитывать его
актуальность. Во временном ряду можно выделить два вида данных — актуальные
и устаревшие. Первые сформированы под действием текущих условий, влияющих
на процесс, который описывается временным рядом. Со временем условия могут
меняться, и тогда данные, сформированные под действием утративших силу усло-
вий, оказываются устаревшими, а данные, сформированные под действием новых
условий, — актуальными. Обычно актуальными являются самые свежие данные.
Если модель прогноза была построена на основе актуальных данных, то и ретро-
прогноз должен строиться на основе свежих данных. Если же ретропрогноз будет
построен на основе устаревших данных, то, скорее всего, его значения будут сильно
расходиться с реальностью. Но это будет связано не с низким качеством модели,
а с тем, что она используется для данных, подчиняющихся другим закономерно-
стям, которые в этой модели не учитываются. С учетом изложенных обстоятельств
к интерпретации результатов ретропрогноза следует подходить с известной долей
осторожности.
Глава 4. Визуализация данных 201
Визуализация контроля процесса обучения моделей
g бизнес-аналитике широко используются модели, основанные на машинном обу-
чении, например нейронные сети, деревья решений и т. д. В процессе настройки
своих параметров (или обучении) модель приобретает свойства, которые обеспе-
чивают выполнение ею требуемого преобразования данных.
Управляющим параметром, на основе которого рассчитывается изменение
состояния модели на каждой итерации, является ошибка рассогласования между
реальным выходным значением модели, которое было получено на данном обу-
чающем примере, и целевым значением из этого примера (то есть между тем, что
есть, и тем, что должно быть).
Ошибка между реальным и целевым выходом, полученная в результате обуче-
ния, — главный критерий оценки качества обучения и точности модели. Очевидно,
что по мере того, как модель обучается, ошибка уменьшается, и как только она до-
стигает некоторого заданного значения, процесс обучения останавливается.
При обучении модели большой интерес представляет наблюдение за изменени-
ем выходной ошибки на каждой итерации. По изменению ошибки можно сделать
вывод о том, как идет процесс обучения, есть ли смысл его продолжать и каковы
его предполагаемые результаты. Например, если ошибка быстро уменьшается, это
означает, что обучение продвигается быстро и эффективно. Если ошибка перестала
уменьшаться и остается одинаковой на большом числе итераций, можно предполо-
жить, что процесс обучения «пробуксовывает», то есть либо состояние модели не
корректируется, либо корректировка не приводит к уменьшению ошибки. В этом
случае вряд ли имеет смысл продолжать обучение, поскольку модель исчерпала
свои возможности и настроить ее точнее невозможно. Поэтому в состав анали-
тических приложений часто включают специальный визуализатор, который дает
возможность наблюдать за динамикой изменения ошибок. Возможная реализация
такого визуализатора представлена на рис. 4.21.
п
Рис. 4.21. Визуализатор для наблюдения за ошибками
в ходе обучения (и — номер итерации)
202 Часть I. Теория бизнес-анализа
4.5. Визуализаторы, применяемые
для интерпретации результатов анализа
Как на входе, так и на выходе аналитического процесса присутствуют некоторые
данные. Данные на входе обычно называются исходными. Предполагается, что
они обладают свойствами, содержат закономерности, структуры и особенности,
выявление и понимание которых позволяет получить новые знания об исследуемых
объектах. На выходе также имеются данные, которые называются результатами.
На их основе делаются выводы и принимаются решения.
К сожалению, аналитическая обработка данных не дает готовых ответов на
вопросы, которые интересуют аналитика, исследователя или лицо, принимающее
решения. В процессе анализа происходит лишь преобразование данных к представ-
лению, позволяющему увидеть в них нечто важное с точки зрения исследования
и управления некоторым объектом или процессом. Поэтому между результатами
анализа и полученными на их основе знаниями и решениями лежит процедура
интерпретации результатов, которая может оказаться не менее сложной и про-
блемной, чем сам анализ.
Неправильная интерпретация может не только обесценить самые удачные ре-
зультаты анализа, но и привести к ложным выводам и заключениям, что повлечет
за собой неверные управленческие решения. Именно поэтому в бизнес-аналитике
так много внимания уделяется визуализации результатов анализа, позволяющей
сделать их интерпретацию как можно более эффективной и свести к минимуму
возможность ошибочных выводов.
Помимо визуализаторов общего назначения, в состав аналитических прило-
жений включается набор специализированных средств визуализации, которые
связаны с используемыми в процессе анализа моделями, формой представления
результатов и целями анализа.
Основная сложность в интерпретации результатов анализа заключается в том,
что наборы данных, как правило, имеют большую размерность. Здесь наиболее
приемлем подход, применяющий моделирование данных большой размерности
с помощью вложенного в многомерное пространство многообразия данных малой
размерности. Например, для изображения данных на экране монитора наиболее ес-
тественно использовать два измерения. Вообще говоря, человек способен наглядно
представить себе не более двух-трех измерений.
Существует два основных способа описания данных. Первый заключается в по-
строении иерархической структуры данных, то есть в разбиении данных на классы,
подклассы и т. д., второй — в сокращении размерности исходного пространства
данных. Рассмотрим несколько наиболее распространенных типов визуализаторов,
применяемых для интерпретации результатов анализа:
□ древовидные визуализаторы;
□ визуализаторы связей;
□ карты.
Глава 4. Визуализация данных 203
древовидные визуализаторы
Многие методы и алгоритмы Data Mining имеют дело с различными объектами
и структурами, организованными в упорядоченную иерархию. К таким методам
и алгоритмам относятся деревья решений, ассоциативные правила, некоторые
методы кластеризации и т. д. В принципе, древовидные визуализаторы могут
использоваться везде, где результаты аналитической обработки данных образуют
иерархические уровни и могут быть разделены на предков и потомков. Кратко
рассмотрим основные виды применения деревьев.
Деревья. Одной из наиболее популярных классификационных моделей являют-
ся деревья решений. Они представляют собой иерархическую последовательность
правил вида «если... то...». Например, классифицирующее правило может быть
сформулировано следующим образом: «Если значение признаках > 10, то объект
относится к классу Л». В процессе построения модели генерируется иерархическая
последовательность правил, которые применяются к исследуемой выборке и рас-
пределяют все входящие в нее объекты по заранее определенным классам.
Для интерпретации результатов классификации с помощью дерева решений
используются визуализаторы, показывающие структуру дерева, а также сформули-
рованные в нем правила. Пример дерева решений для классификационной задачи
об ирисах Фишера представлен на рис. 4.22. Для компактности классификационные
признаки цветков обозначены следующим образом: SL — длина лепестка, 5W— ши-
рина лепестка, CL — длина чашелистика, CW— ширина чашелистика. При таком
способе визуализации дерева решений узлы и листья представлены в виде пря-
моугольников и расположены в порядке их иерархической подчиненности. В узле
указывается действующее в нем правило.
Рис. 4.22. Дерево решений
204 Часть I. Теория бизнес-анализа
Ценность метода не только в том, что он позволяет классифицировать объекты, но
и в том, что он описывает их свойства. Так, по дереву решений можно оценить степень
сходства классов. Если для распознавания классов достаточно одного или двух правил,
то объекты этих классов хорошо различимы: их признаки (или хотя бы один из них)
сильно отличаются. Если же для распознавания классов требуется несколько правил,
классы различаются хуже: признаки их объектов более близки (объекты похожи). Кро-
ме того, правила не только классифицируют объекты, но и описывают их обобщенные
свойства, объясняют, по какому признаку объект отнесен к тому или иному классу.
Применение деревьев для визуализации ассоциативных правил. Деревья ре-
шений часто называют индуктивными, поскольку правила, из которых они состоят,
разбивают исходное множество данных на подмножества, соответствующие классам.
Наряду с индуктивными правилами в Data Mining широко используются так назы-
ваемые ассоциативные правила. При этом в отличие от индуктивных правил, которые
служат для распознавания объектов по принадлежности к определенному классу,
ассоциативные правила устанавливают взаимную связь между двумя событиями.
Например, если событием А является продажа товара X, а событием В — прода-
жа товара Y, то ассоциация между данными событиями записывается в виде А—» В
и читается следующим образом: «Из А следует В». При этом событие А называется
условием, а событие В — следствием. Если ассоциация между Л и В является прави-
лом, это означает, что раз произошло событие А, то с большой вероятностью наступит
событие В (то есть продажа товара X в большинстве случаев влечет за собой продажу
товара У). Является ли та или иная ассоциация правилом, определяется путем анали-
за их достаточно большого количества. Так, если было установлено, что из 100 тран-
закций, в которых появлялось событие А, 90 транзакций содержат событие В (то есть
вероятность совместного появления Л и В будет 0,9, или 90 %), то такую ассоциацию
с высокой степенью достоверности можно считать правилом.
Основное применение ассоциативные правила находят в розничной торговле.
Если известно, что продажа товара X с большой вероятностью влечет за собой про-
дажу товара Y, то логично клиенту, купившему товар X, предложить и товар Y
Поиск ассоциативных правил позволяет выявлять группы товаров, которые час-
то продаются вместе, а это, в свою очередь, помогает оптимизировать ассортимент
товаров, закупки, размещение товаров в торговом зале, на витрине и т. д.
Для интерпретации результатов поиска ассоциативных правил (как и индуктив-
ных) часто используют представление в виде деревьев. Но в отличие от индуктив-
ных правил в деревьях решений ассоциативные правила не используют иерархию,
поскольку правила ищутся независимо для всех возможных ассоциаций.
Один из возможных вариантов визуализации ассоциативных правил с помощью
дерева представлен на рис. 4.23. Каждый узел образован условием, которому соот-
ветствует одно или несколько следствий, ассоциации с которыми были обнаружены
в исходном наборе транзакций. Как условие, так и следствие могут быть образованы
одним предметом («Макаронные изделия») или набором предметов («Кетчупы,
соусы, аджика»),
В каждом узле может быть предусмотрен вывод значений поддержки или досто-
верности связанной с ним ассоциации.
Глава 4. Визуализация данных 205
Продукты |
—| Кетчупы, соусыГаджика (52 %) | —| Макаронные изделия (54 %)
>| Макаронные изделия (45 %) |
Кетчупы, соусы, аджика (45 %)
> Сыры (22 %)
> Мед (22 %)
-► Сыры (22 %)
Рис. 4.23. Дерево ассоциативных правил
Кластеризация. Одной из важнейших задач Data Mining является кластери-
зация — объединение объектов в группы на основе сходства их признаков. Такие
группы называются кластерами. Попадание двух объектов в один кластер позво-
ляет предположить высокую степень схожести их свойств, и наоборот, если объ-
екты в результате кластеризации попали в разные кластеры, то они существенно
отличаются друг от друга по своим признакам.
В результате кластеризации некоторого множества данных формируется опреде-
ленное количество кластеров. Одним из популярных видов кластеризации является
иерархическая кластеризация, которая, в свою очередь, содержит два метода:
□ агломеративную кластеризацию — кластеры формируются путем слияния кла-
стеров меньшего размера в кластеры большего размера;
□ разделительную кластеризацию — кластеры большего размера разделяются на
несколько кластеров меньшего размера.
Для визуализации результатов иерархической кластеризации используют спе-
циальную разновидность диаграмм, называемую дендрограммой. Дендрограмма
показывает степень близости отдельных объектов и кластеров, а также наглядно
представляет в графическом виде последовательность их объединения или разде-
ления. Количество уровней дендрограммы соответствует числу шагов слияния или
разделения кластеров. Пример дендрограммы представлен на рис. 4.24. В нижней
части рисунка расположена шкала, на которой откладывается расстояние между
объектами в пространстве признаков.
1.5 2,0 2,5
Рис. 4.24. Дендрограмма
206 Часть I. Теория бизнес-анализа
Дендрограмма на рис. 4.24 строится следующим образом. На первом шаге груп-
пируются объекты х2 и х3, образуя кластер {х2, х3} с минимальным евклидовым
расстоянием, примерно равным 1. Затем объекты хл их5 группируются в другой
кластер {х4, х5} с расстоянием 1,5. Расстояние между кластером {х2, х3} и {xj} также
оказывается равным 1,5, что позволяет сгруппировать данные кластеры на том же
уровне, что и {хл, х5}. И наконец, два кластера — {хь х2, х3} и {х4, х5} — группиру-
ются на самом высоком уровне иерархии кластеров с расстоянием 2.
Визуализация связей
Нередко требуется исследовать характер и степень взаимной зависимости между
различными объектами. Для анализа можно использовать визуализацию связей,
когда объекты представляются в виде некоторых значков, а связи между ними —
в виде линий, соединяющих соответствующие значки. При этом сила связи, то есть
степень взаимной зависимости объектов, может показываться различными спосо-
бами. Чаще всего для этого используют:
□ толщину линии: чем сильнее связь между объектами, тем толще соединяющая
их линия (рис. 4.25, а);
□ цвет линии, при этом выбираются оттенки определенного спектра (рис. 4.25, б).
В принципе, допускается одновременно использовать и толщину, и цвет, хотя
такие диаграммы более сложны для восприятия.
Кроме того, можно по-разному располагать объекты на плоскости. В первом
случае показываются связи между одним выбранным объектом, который помещен
в центре, и всеми остальными («звезда», см. рис. 4.25, а). Во втором случае визуа-
лизируются все попарные связи между объектами («сеть», см. рис. 4.25, б). Если
число объектов велико, связей становится еще больше, поэтому анализируют
только наиболее сильные или наиболее слабые, накладывая фильтр на значения
силы связи.
Рис. 4.25. Варианты диаграмм связей между объектами: а — «звезда»; б — «сеть»
Глава 4. Визуализация данных 207
Объекты сравниваются между собой на основе какого-либо признака. Если
признаков несколько, выбирается способ расчета критерия связи. Чаще всего
это метрика — правило вычисления расстояния в многомерном пространстве
признаков — евклидово расстояние, расстояние Манхэттена и др. (подробнее меры
расстояний рассматриваются в главе 7).
Пример диаграммы связей между несколькими регионами РФ представлен на
рис. 4.26. В качестве признаков используются:
□ численность постоянного населения;
□ удельный вес городского населения;
□ зафиксированное за последний период число умерших на 1000 человек.
Критерий связи: рассток Манхэттена
0,50
0,85
Рис. 4.26. Пример диаграммы связей между регионами РФ
Критерий связи рассчитывался с использованием манхэтенновского расстояния.
Видно, что Владимирская и Ярославская области очень близки по сравниваемым
208 Часть I. Теория бизнес-анализа
признакам (расстояние равно 0,85), а между Калужской и Тульской областями
наоборот, различие самое большое (расстояние — 0,14).
Карты
Карты позволяют наглядно представить данные, связанные с географическим рас-
положением исследуемых объектов и процессов. Это могут быть демографические
данные (например, распределение показателей смертности или рождаемости по
различным регионам), а также данные, отражающие миграцию населения и рабо-
чей силы, обеспечение регионов энергоносителями, динамику распространения
эпидемий и т. д. В бизнес-аналитике это информация, связанная с уровнем потреб-
ления в регионах, характером спроса и предложения по различным видам товаров,
сведения о продажах, осуществляемых региональными дилерами, о логистических
и транспортных потоках и т. д.
Рассмотрим пример. В табл. 4.6 содержатся данные об отгрузках продукции,
произведенных компаней мелким оптовикам из различных субъектов Центрального
федерального округа (ЦФО).
Таблица 4.6. Объем продаж по субъектам ЦФО РФ
№ п/п Область Продажи, млн руб.
1 Белгородская 162
2 Брянская 61
3 Владимирская 54
4 Воронежская 154
5 Ивановская 209
6 Калужская 117
7 Костромская 90
8 Курская 57
9 Липецкая 50
10 Г. Москва 664
И Московская 328
12 Орловская 54
13 Рязанская 151
14 Смоленская 137
15 Тамбовская 29
16 Тверская 178
17 Тульская 186
18 Ярославская 120
Имея карту ЦФО, можно в соответствии с палитрой раскрасить области и по-
лучить сравнительный отчет о продажах по регионам (рис. 4.27).
Видно, что максимальные значения продаж приходятся на Москву и Москов-
скую область, а минимальные — на Тамбовскую. При этом может использоваться
Глава 4. Визуализация данных 209
Рис. 4.27. Отчет о продажах по регионам
многомерное представление данных. Например, если требуется показать на карте не
только суммы продаж, но и прибыль, то последнюю можно отобразить рельефным
выделением соответствующей области на карте. Также на карты можно наносить
значки, форма, цвет, размер и взаимное положение которых соответствуют свой-
ствам исследуемых объектов.
Впрочем, карты не обязательно должны быть связаны с географией. В бизнес-
аналитике почти всегда приходится иметь дело с объектами, которые описываются
Двумя признаками и более. То есть выборки, образованные такими объектами,
являются многомерными. В этом случае может возникнуть проблема с визуали-
зацией результатов, поскольку представление многомерных объектов на плоских
визуализаторах (графиках, диаграммах) не всегда удобно и корректно отображает
Результаты. Поэтому актуальны визуализаторы, позволяющие адекватно представ-
лять многомерные данные. В частности, распространение получили двумерные
пепловые карты (heat maps), где каждому значению признака соответствует один
из оттенков в заранее выбранной цветовой гамме.
На рис. 4.28 можно наблюдать пример тепловой карты, построенной по двум
измерениям — Топливо и Город. Цвет каждой прямоугольной ячейки карты фор-
мируется на основе цены топлива: чем темнее оттенок, тем она выше.
210 Часть I. Теория бизнес-анализа
Город
Цена, руб.
16
31
Рис. 4.28. Пример тепловой карты
К разновидности тепловых карт относят карты Кохонена. Принцип этого мето-
да визуализации основан на том, что многомерные данные представляются в виде
плоских карт, при построении которых комбинируются информация о расстоянии
между векторами объектов в многомерном пространстве признаков и раскраска,
порожденная значениями признаков. Данные тематически раскрашиваются и ото-
бражаются в ячейках. При этом достигается соглашение о том, каким образом рас-
крашивается ячейка (например, в зависимости от того, сколько или каких данных
в нее попало, — круговой раскраской, наложением и т. д.). Карты всех интересующих
признаков собираются воедино, и получается топографический атлас, дающий
интегральное представление о структуре многомерных данных. Подробнее карты
Кохонена изучаются в главе 7.
Очистка
и предобработка
данных
5.1. Оценка качества данных
Качество данных, которые собираются и консолидируются для анализа из различ-
ных источников, является одной из самых больших проблем бизнес-аналитики.
Недостаточное внимание к ней способно свести на нет все преимущества самых
современных и мощных методов анализа, все усилия аналитиков и экспертов по
созданию аналитических решений. А сами аналитические решения, полученные
на основе некачественных данных, могут оказаться сколь угодно далекими от
действительности, исказить истинную картину исследуемых бизнес-процессов,
показать ложные закономерности, тенденции и связи между объектами бизнеса.
Следствием этого может стать выработка неверных управленческих решений, кото-
рые нанесут бизнесу ущерб. Именно поэтому мониторинг качества данных, а также
их преобразование с целью исключения факторов, служащих причиной снижения
качества данных, производятся на всех этапах аналитического процесса — от из-
влечения данных из источников до их обработки в аналитической системе. Более
того, если важность этого направления осознается и аналитическим технологиям
на предприятии уделяется должное внимание, то контроль и поддержка качества
производятся на этапе сбора данных в самих источниках: OLTP-системах, учетных
системах и корпоративных БД предприятия.
Понятие «качество данных» очень широкое, не имеет четко очерченных границ
и строгого определения, даже может трактоваться несколько по-разному в зависи-
мости от того, в какой области информационных технологий оно употребляется.
Термин «качество данных» появился задолго до IT-технологий. Изначально под
качеством данных понималось количество ошибок при вводе и форматировании
212 Часть I. Теория бизнес-анализа
данных. В контексте современных аналитических технологий качество данных —
совокупность их свойств и характеристик, определяющих степень пригодности
для анализа.
С целью повышения качества данных используется комплекс методов и ал-
горитмов, получивших название «очистка данных» (cleaning, refinement). Чтобы
правильно подготовить данные к анализу, необходимо иметь стратегию их очист-
ки, разрабатываемую на основе знания структуры и особенностей источников,
из которых поступают данные, характера самих данных, методики и цели их
анализа.
Однако использовать очистку данных вслепую неэффективно. Перед приме-
нением тех или иных методов очистки необходимо выполнить оценку качества
данных (Assessment Data Quality, ADQ) с целью выявления наиболее характерных
проблем и уровня их сложности, а также для выработки стратегии очистки. В ре-
зультате такой оценки, возможно, будет принято решение отказаться от очистки
некоторых данных, поскольку это слишком сложно, дорого или не приведет к же-
лаемым результатам. Кроме того, следует помнить, что некорректное применение
методов очистки может ухудшить ситуацию, а предварительная оценка качества
данных позволит по возможности избежать этого;
Очень часто проекты по очистке данных в компаниях создаются только тогда,
когда кризис уже наступил, то есть когда данные стали настолько «грязными»,
что их анализ сделался невозможным по техническим причинам или из-за низкой
достоверности получаемых результатов. Чтобы избежать подобной ситуации,
необходимо подходить к проблеме качества данных комплексно, а именно разра-
батывать стратегию сбора, консолидации и анализа данных параллельно с оценкой
и мониторингом их качества, выявлением факторов, влияющих на их качество,
и выработкой стратегии исключения таких факторов. Лозунг «Предотвратить
проще, чем исправить!» здесь полностью оправдан. Дешевле и легче изначально
застраховаться от проблем с качеством данных, чем потом судорожно и в спешке
исправлять ситуацию, теряя время, конкурентные преимущества, доходы, клиен-
тов и т. д.
В результате развития комплексного подхода к поддержанию качества данных
на предприятии на должном уровне в IT-технологиях появилась новая дисцип-
лина — управление качеством данных на предприятии (Enterprise Data Quality
Management, EDQM). Развитие EDQM стимулировалось осознанием того факта,
что многие инновационные проекты потерпели неудачу именно из-за низкого каче-
ства данных и невозможности принимать на их основе правильные управленческие
решения. Более того, EDQM де-факто стало частью общего процесса управления
качеством на предприятии (Total Quality Management, TQM).
Ключевым звеном EDQM является оценка качества данных, которая может
быть реализована тремя способами.
□ Единовременная оценка качества проводится для некоторого массива данных
(файла или таблицы) один раз, после чего, в зависимости от ее результатов,
к данным применяются те или иные методы очистки, иногда же данные при-
знаются качественными и остаются без изменений.
Глава 5. Очистка и предобработка данных 213
д/оншпо/шнг: поток данных, поступающих из различных источников в ХД и далее
в аналитическую систему, непрерывно сканируется специальными программами
поиска ошибок в данных.
□ Визуальная оценка используется в исключительных случаях, когда специали-
зированным программным средствам не удалось повысить качество данных
до приемлемого уровня. Чаще всего применяется при предобработке данных,
загруженных в аналитическую систему: аналитик или эксперт с помощью
имеющихся средств визуализации (таблиц, графиков и диаграмм) определяет
наличие в данных аномальных значений, пропусков, шумов и т. д. Этот метод
оценки качества применим только к небольшим объемам данных при решении
отдельных нетиповых задач. Кроме того, визуально выявлять противоречия
и дубликаты весьма проблематично.
При разработке методики оценки качества данных также необходимо решить,
где именно ее следует производить. Существуют следующие варианты:
□ непосредственно в источниках данных — можно эффективно выполнять поиск
орфографических ошибок (путем сравнения со словарем), пропущенных, ано-
мальных, логически неверных и фиктивных значений, противоречий и дубли-
катов на уровне записей и таблиц. Преимущество этого варианта в том, что по
результатам оценки соответствующие методы очистки могут быть задейство-
ваны уже на этапе ETL и в ХД поступят очищенные данные. При этом следует
учитывать, что в процессе ETL качество данных может вновь ухудшиться:
появятся новые дубликаты и противоречия, несоответствия форматов, пред-
ставлений данных и т. д. Это случается, потому что в процессе ETL происходит
интегрирование данных из нескольких отдельных источников. Следовательно,
записи, которые являются уникальными и непротиворечивыми для одной
таблицы или одного источника, могут потерять уникальность и непротиворе-
чивость после слияния или объединения источников. Несоответствие форматов
при интеграции данных может появиться, если в разных файлах или таблицах
использовались различные форматы представления данных (например, даты
или денежных сумм). Тогда в результирующих таблицах окажутся одни и те же
данные, представленные в различных форматах;
□ в процессе ETL — можно выявлять проблемы в данных и по результатам оцен-
ки качества оперативно задействовать те или иные методы очистки, чтобы
обеспечить загрузку в хранилище уже очищенных данных. Недостаток этого
варианта заключается в том, что использование средств оценки качества данных
в процессе их переноса в ХД увеличивает так называемое «загрузочное окно»,
в течение которого резко увеличивается нагрузка на информационную систему
предприятия;
0 в аналитической системе — используется в процессе предобработки данных
перед применением к ним различных методов Data Mining. Оценка может про-
изводиться аналитиком визуально с помощью таблиц, графиков и диаграмм
или на основе статистических оценок и характеристик. Например, дисперсия
позволяет определить степень неравномерности ряда значений. Большая
214 Часть I. Теория бизнес-анализа
дисперсия обычно свидетельствует о шумоподобном характере данных, что
может потребовать применения их сглаживания. С помощью гистограммы
распределения можно выявить аномальные значения.
Скорее всего, применять те или иные средства оценки качества данных и выяв-
лять характерные проблемы придется на всех перечисленных этапах. В источниках
данных удобно оценивать наличие ошибок, связанных с вводом данных. В процессе
ETL выявляются факторы, связанные с нарушениями структуры, целостности
и полноты данных, поскольку они просто не позволят загрузить данные в ХД.
И наконец, в аналитической системе данные оцениваются с точки зрения их соот-
ветствия конкретной задаче Data Mining и возможности применения тех или иных
алгоритмов анализа.
Следует помнить, что цель оценки качества данных — только обнаружение
проблем в данных, определение степени их «загрязненности» и пригодности для
анализа. Выявлением источников проблем и борьбой с ними занимается другая
дисциплина — очистка данных.
Уровни качества данных
Чтобы систематизировать проблемы, связанные с качеством данных, и определить
основные аспекты оценки качества, выделим несколько уровней. На каждом из
них существуют свои специфические проблемы, цели, методы и критерии оценки
качества данных.
□ Технический уровень. На качество данных влияют в основном факторы, связан-
ные с нарушением их структуры, целостности и полноты, некорректные форма-
ты и представления данных. Проблемы технического плана мешают корректно
выполнить консолидацию и интегрирование данных, загрузку их в хранилище,
применение к ним тех или иных алгоритмов обработки.
□ Аналитический уровень. Предполагает наличие факторов, мешающих выпол-
нить корректный анализ данных и получить достоверные результаты. К таким
факторам относятся шумы в данных, аномальные значения, противоречивые
и дублирующие записи, фиктивные значения, пропуски и т. д. Для этого уровня
характерна субъективность оценки качества данных. Так, шум обычно проявля-
ется в виде быстрых изменений значений ряда данных (например, ежедневных
продаж), которые мешают обнаружить общие закономерности и тенденции. То,
что для одного аналитика будет шумом, для другого — ценные с точки зрения
анализа данные. Что касается аномальных значений, то нельзя заранее сказать,
является определенная аномалия ошибкой оператора или реальным событием,
исключив которое мы, возможно, потеряем важную информацию. Рассматривая
две одинаковые записи, нельзя сказать, дубликаты это или информация о двух
идентичных событиях. С противоречивыми записями тоже не все так просто.
Например, для двух одинаковых наименований клиентов могут быть указаны
различные адреса и банковские реквизиты. Но при этом вполне вероятно, что
речь идет о двух разных фирмах с одинаковыми названиями, то есть никакого
противоречия на самом деле нет.
Глава 5. Очистка и предобработка данных 215
0
Концептуальный уровень. Отражает проблемы, связанные с тем, что стратегия
сбора данных на предприятии была изначально неверной. Собранные данные
не содержат достаточно информации для всестороннего описания предметной
области и основных бизнес-процессов. Например, в результате анализа может
быть обнаружено, что данных мало или данные не те. В этом случае для реше-
ния проблемы используют обогащение данных. Иногда оказывается, что дан-
ных очень много, но реально полезной является только определенная их часть.
Тогда приходится принимать меры к определению наиболее информативных
атрибутов и признаков.
Сравнительная характеристика различных уровней качества данных приво-
дится в табл. 5.1.
Таблица 5.1. Уровни качества данных
уровень Факторы Проявление Место борьбы
Техни- ческий — Нарушения в структуре данных; — некорректное наименование таблиц и полей; — некорректные форматы и коди- ровки данных; — нарушение полноты и целостно- сти данных; — противоречия и дубликаты на уровне таблиц и файлов БД Мешают интегри- рованию данных, их загрузке в ХД и в аналитические системы ETL
Аналити- ческий — Пропуски; — аномальные и фиктивные значе- ния, опечатки; — шумы; — противоречия и дубликаты на уровне записей Снижают досто- верность данных и искажают резуль- таты их анализа, не позволяют ис- пользовать некото- рые аналитические методы Источники дан- ных, ETL, анали- тические системы
Концеп- туальный Собранные и консолидирован- ные данные в недостаточной мере отражают исследуемые бизнес-про- цессы Отсутствие или не- достаток данных для анализа Стадия разработки аналитических проектов и про- цессов
При оценке качества данных и разработке стратегии его повышения необхо-
димо уделять внимание всем трем уровням. Попытка сосредоточиться на чем-то
одном, когда предполагается, что с остальными уровнями все в порядке, может
привести к эффекту тришкина кафтана: здесь исправили — там потеряли. Дей-
ствительно, какую бы ценную информацию ни содержали данные, наличие в них
технических проблем просто не позволит донести их до пользователя (эксперта,
аналитика) — интегрировать, загрузить в ХД или аналитическую систему. Данные,
Некорректные с точки зрения анализа, хотя и не содержащие технических проблем,
Дойдут до пользователя, но вряд ли обеспечат значимые и достоверные результаты
анализа. И наконец, если данные собраны неправильно на концептуальном уровне,
216 Часть I. Теория бизнес-анализа
их анализ оказывается полностью бессмысленным независимо от того, насколько
данные корректны.
Таким образом, оценка качества данных — это сложная и трудоемкая задача
часто не поддающаяся формализации. Она требует привлечения всех, кто участвует
в процессе сбора и анализа данных, начиная от операторов, осуществляющих ввод
данных в OLTP, и заканчивая конечными пользователями.
Оценка пригодности данных к анализу
Оценка качества данных преследует две цели: контроль их пригодности к ана-
лизу и выявление проблем в функционировании систем сбора и консолидации
данных. Впрочем, обе цели взаимосвязаны: качество данных, консолидируемых
для анализа, в большинстве случаев является индикатором качества функциони-
рования соответствующих информационных систем как на аппаратном, так и на
программном уровнях. Если аналитику стабильно поставляются качественные
данные независимо от их происхождения и характера, значит, система их сбора
и консолидации функционирует на высоком организационно-техническом уровне.
Если качество данных стабильно низкое, то, возможно, дело не только в том, что их
очистке уделяется мало внимания, но и в проблемах, связанных с функциониро-
ванием OLTP-систем, с просчетами в процессе разработки ETL и т. д. Например,
известен случай, когда в сети супермаркетов обнаружилось резкое увеличение
ошибок при регистрации торговых операций. При этом никакие усилия по очистке
данных не давали желаемого результата. Причина оказалась банальной: сканеры
штрихкодов из новой партии были низкого качества и давали большой процент
ошибок.
Тем не менее приоритетной целью контроля качества данных является оценка
степени их пригодности к анализу. По результатам аудита качества данных могут
быть сделаны следующие выводы.
□ Данные полностью пригодны к анализу и не нуждаются в очистке. Такие данные
не содержат ошибок, либо количество ошибок незначительно и не способно по-
влиять на результаты анализа. Это крайне редкая ситуация, которая указывает
на очень качественную и продуманную стратегию сбора и консолидации данных
как на логическом, так и на техническом уровне.
□ Данные пригодны к анализу без очистки, но с определенными ограничениями.
Такие данные содержат ошибки, которые могут повлиять на достоверность ре-
зультатов анализа, поэтому анализ возможен, но с учетом вероятного влияния
ошибок.
□ Данные пригодны к анализу после применения методов очистки и предобработ-
ки. Проблемы в данных не являются критическими, поэтому после применения
соответствующих процедур очистки качество данных может быть поднято до
приемлемого уровня.
□ Данные совершенно непригодны к анализу, и никакие методы очистки ситуа-
цию не исправят.
Глава 5. Очистка и предобработка данных 217
Оценка качества данных по их происхождению
Приступая к оценке качества анализируемых данных (которая вместе с их очист-
кой может занимать до 80 % времени всего процесса анализа), можно выдвинуть
некоторые предположения относительно их качества.
Во-первых, необходимо учитывать информацию о происхождении данных.
Выделяют два типа источников:
□ источники, которые автоматически поддерживают определенную структуру,
целостность и непротиворечивость данных, — OLTP-системы, корпоративные
БД, некоторые учетные системы и т. д.;
□ локальные файлы отдельных пользователей (текстовые файлы, файлы офис-
ных приложений), где не предусмотрена поддержка структуры, целостности
и непротиворечивости данных.
При использовании данных, поступивших из источников 1-го типа, следует быть
готовыми к проблемам, связанным с ошибками ввода, пропусками, фиктивными
и аномальными значениями, то есть с проблемами, характерными для аналитиче-
ского уровня (см. табл. 5.1). Что касается источников 2-го типа, то в них можно
встретить факторы технического уровня, связанные с нарушением структуры
данных, использованием некорректных форматов, противоречия и т. д. Поэтому
качеству данных из таких источников нужно уделять повышенное внимание.
Во-вторых, необходимо учитывать, организован ли процесс сбора данных на
предприятии с прицелом на их будущий анализ. Если этому уделялось должное
внимание, то можно ожидать приемлемого качества данных, в противном случае
предположения об их качестве и пригодности к анализу будут весьма пессими-
стическими.
Выводы
Оценка качества данных — необходимый этап процесса подготовки к анализу. Она
дает возможность своевременно выявлять проблемы, которые не позволяют кор-
ректно анализировать данные, снижают значимость и достоверность результатов
анализа. Контроль качества данных должен проводиться на всех этапах аналити-
ческого процесса, поскольку для каждого этапа характерны свои проблемы.
5.2. Технологии и методы оценки
качества данных
в настоящее время технологии оценки качества данных широко используются не
только в процессе анализа данных, но и в информационных системах самого раз-
личного назначения, а реализующие их программные средства стали привычным
явлением на рынке программного обеспечения. Рассмотрим несколько практи-
ческих аспектов оценки качества данных.
218 Часть I. Теория бизнес-анализа
Профайлинг данных
Одним из наиболее распространенных методов оценки качества данных и вы-
явления проблем является профайлинг. В процессе профайлинга определяется
информация о некотором атрибуте (поле) источника данных и проверяется ее
соответствие заданным ограничениям. Если параметры атрибута удовлетворяют
этим ограничениям, то данные соответствуют определенному уровню качест-
ва, в противном случае необходимо принимать меры к приведению параметров
к соответствующим ограничениям. Профайлинг выполняется на основе анализа
метаданных, описывающих структуру данных.
В процессе профайлинга анализируется следующая информация.
□ Тип атрибута (поля). Если тип атрибута (поля) определен как числовой, а при
проверке обнаружено, что он имеет другой тип (строковый или дата/время), то
выясняются причины и производится соответствующее преобразование данных.
Причиной искажения типа может быть неправильное использование символа —
разделителя целой и дробной частей числа, когда вместо точки используется
запятая, или наоборот. Кроме того, достаточно распространено несоответствие
разделителей групп разрядов в числах — пробела, точки и запятой — или их
отсутствие. Например, как прочитать строку 99,999.99? Если предположить,
что запятая разделяет группы разрядов, а точка — целую и дробную часть, то
это 99 тыс. 999 руб. и 99 коп. Но также можно предположить, что это 99 руб.
и 999 коп., а точка и следующие цифры — ошибка ввода.
□ Длина значения. Определяется максимально допустимое количество символов
в значении атрибута (поля), и, если длина значения превышает максимальную,
необходимо принимать меры к ее ограничению.
□ Дискретные значения. Обычно проверяется частота их появления и уникаль-
ность (в процентном или абсолютном виде).
□ Диапазон допустимых значений. Задаются минимальное и максимальное зна-
чения, которые может принимать атрибут. Еслй значение атрибута выходит
за ограничения, то оно может меняться на некоторое значение по умолчанию.
Например, можно ограничить возраст клиента 18 и 70 годами, тогда любое
значение, не попавшее в данный диапазон, будет определено как недопустимое
и изменено на значение по умолчанию.
□ Анализ строковых шаблонов (например, почтовых индексов или номеров
карт социального страхования). Если строка в ячейке соответствует шаблону
(например, ХХХ-ХХХ-ХХХ), то ошибки нет. В противном случае включается
обработка строки в соответствии с некоторым заранее определенным правилом
(строка символов приводится в соответствие с шаблоном).
Профайлинг — достаточно развитый метод выявления проблем в данных. Од-
нако он рассчитан на анализ «штатных», технических проблем, которые относятся
к наиболее типичным и хорошо формализуемым. Поэтому профайлинг — это ско-
рее метод предварительной оценки качества данных с целью выявления типичных
проблем.
Глава 5. Очистка и предобработка данных 219
Визуальная оценка качества данных
Если объем данных не слишком велик, то для оценки их качества можно с успехом
применять визуальные методы. Для этого используются как встроенные средства
визуализации аналитической платформы, так и сторонние программные средства,
в которых можно просматривать данные в табличной и графической форме, рас-
считывать статистические характеристики.
Оценка качества данных с помощью таблиц. Табличное представление позво-
ляет делать общие выводы о наличии в данных структурных нарушений, пропус-
ков, аномальных и фиктивных значений. Беглого взгляда на таблицу в большин-
стве случаев достаточно, чтобы оценить количество неполных строк и столбцов,
пустых ячеек. Аномальные числовые значения могут резко выделяться на фоне
окружающих данных количеством цифр. Даже простая сортировка по возраста-
нию позволит собрать предполагаемые аномальные значения в начале или конце
столбца и легко обнаружить их.
На общем фоне хорошо выделяются несоответствия типов данных в одном
столбце. Числовые данные обычно выравниваются по правому краю ячейки таб-
лицы, чтобы обеспечить расположение соответствующих разрядов чисел друг под
другом (например, рубли под рублями, а копейки под копейками). Строковые
данные, как правило, выравниваются по левому краю. Поэтому, если в столбце
с числовыми данными окажется строковое значение, его можно легко обнаружить
по выравниванию (рис. 5.1).
Некорректный
номер чека
Номер чека Товар Сумма
160888 КЕТЧУП, СОУС, АДЖИКА 0,25 р.ч
160698 МАКАРОНЫ 24,80 р.
160698 ЧАЙ, ХЛЕБ 18,90 р.
160747 МАКАРОНЫ, СОУС, ХЛЕБ 74,20 р.
1607 МЕД, МОЛОКО 89,65 р.
160747 ЧАЙ, СОК
161217 КЕТЧУП, МАКАРОНЫ, СОК 79,98 р.
161217 ЯБЛОКИ, БАНАНЫ, КОЛБАСА 156,40 р.
161217 СЫР, ХЛЕБ, КОЛБАСА 124,65 р.
161243 СОСИСКИ, ХЛЕБ, САХАР 145.90
V 161243 ЯБЛОКИ, СОК, ЙОГУРТ Я 96,70 p.J
* 12161243 СЫР, КОЛБАСА, МАСЛО / 25 450,45 р/
Аномальные
значения
Строковое значение
Пропущенное
значение
Рис. 5.1. Пример визуального поиска аномальных значений
Ясно, что визуально в таблице можно обнаружить несоответствия в данных,
если они резко выделяются на общем фоне. Труднее выявить такие проблемы, как
Дубликаты и противоречия, поскольку на фоне окружающих данных они выглядят
вполне правдоподобно.
В некоторых случаях дублирующие записи удается обнаружить путем сортиров-
ки по возрастанию или убыванию, когда идентичные записи оказываются рядом.
Оценка качества данных с помощью графиков. Графики и диаграммы — эф-
фективные средства для выявления проблем в данных. Например, с помощью
Часть I. Теория бизнес-анализа
графиков можно легко оценить наличие шумов в данных, а также пропущенных
и аномальных значений.
Если данные содержат шум, то он будет проявляться в сильной неравномер-
ности значений ряда, прекрасно различаемой на графике. Аномальные значения
будут отображаться в виде резких отклонений в ту или другую сторону (рис. 5.2)
70 000
60 000
га
S 50 000
Ч
о. 40 000
Я 30 000
I. 20 000
О
10 000
о
01.01.2003 08.01.2003 15.01.2003 22.01.2003 29.01.2003 05.02.2003
Дата
Рис. 5.2. Пример визуального поиска аномальных значений
Наличие проблем в данных можно обнаружить с помощью гистограмм распреде-
ления числовых значений, например сумм продаж. Как и многие реальные процес-
сы, суммы покупок в супермаркетах распределены по нормальному закону, то есть
существует диапазон значений, который встречается наиболее часто, в то время как
вероятность появления очень малых сумм (менее 10 руб.) и больших (скажем, больше
5000 руб.) достаточно мала. Тогда кривая распределения сумм будет в той или иной
степени соответствовать нормальному распределению. Появление в гистограмме
дополнительных пиков (мод) может свидетельствовать о присутствии нехарактерных
для данного ряда значений, которые могут являться аномалиями, ошибками и т. д.
На рис. 5.3 (вверху) показана гистограмма распределения сумм покупок, соответ-
ствующая нормальному закону. Из нее видно, что наиболее часто делаются покупки
на сумму 450-500 руб., а покупки на суммы менее 100 и более 700 руб. очень малове-
роятны. На рис. 5.3 (внизу) появление боковых мод говорит о резком увеличении чис-
ла покупок на суммы от 100 до 150 руб. и от 650 до 700 руб. Конечно, это может быть
вызвано объективными причинами, но может быть связано и с ошибками в данных.
Выявление трудно формализуемых ошибок
Существует множество факторов, снижающих качество данных и не поддающихся
формальной оценке. Один из главных — человеческий фактор. Сотни и тысячи ра-
ботников непрерывно формируют потоки «грязных» данных. При этом элементар-
ные ошибки ввода и регистрации данных способны привести к большим искажениям
информации о ходе бизнеса. Как говорится, «враг заходит в город, пленных не щадя,
потому что в кузне не было гвоздя». В какой-то степени с этим можно бороться, на-
пример организовать процесс регистрации так, чтобы минимизировать ручной ввод,
Глава 5. Очистка и предобработка данных 221
6000
5000
К
О
Е
4000
О
с
о 3000
а
н
о
0) 2000
т
S
Е
о 1000
50 1 00 150 200 250 300 350 400 450 500 550 600 650 700 750
руб.
Сумма покупок
Рис. 5.3. Гистограммы сумм покупок
когда наименования клиентов и товаров выбираются из списка. Можно дать работ-
никам четкие инструкции по вводу данных, поощрять сотрудников, допустивших
наименьшее число ошибок, дублировать ввод данных и т. д. Это поможет добиться
некоторого улучшения качества данных, но вряд ли решит проблему кардинально.
ПРИМЕР-------------------------------------------------------------------
Проблема накопления «грязных» данных актуальна для Интернета. Начиная с 2005 г. стали
развиваться так называемые социальные сети. Авторы одного такого русскоязычного ин-
тернет-проекта дали пользователям право «создавать» города, улицы, институты и другие
объекты. В результате в течение нескольких месяцев база данных оказалась засорена дуб-
ликатами, опечатками и различными вариантами наименований одних и тех же объектов.
Например, в городе присутствуют «школа 29» и одновременно «шк. 29», «гимназия 29»,
что на самом деле означает один и тот же объект.
222 Часть I. Теория бизнес-анализа
Главная задача оценки качества данных заключается в том, чтобы отличить
«грязные» данные от «чистых», то есть выявить, какие данные содержат ошибки
и оценить, какую долю «грязные» данные составляют в общем объеме данных
В ряде случаев эту задачу удается решить типовыми методами, например с помо-
щью профайлинга. Однако для глубокого анализа причин «загрязнения» данных
как правило, требуются более изощренные методы, основанные на знаниях о том
какими должны быть качественные данные. Такие знания содержат правила
и шаблоны, которым должны отвечать качественные данные. Чем больше данных
не соответствует шаблонам и правилам, тем сильнее они «загрязнены» и тем боль-
ше внимания требуется уделять очистке данных.
Инструментальные средства анализа качества данных содержат десятки тысяч
шаблонов и правил для выявления «грязных» данных. Например, чтобы проана-
лизировать правильность ввода наименований клиентов, можно задать шаблон,
в котором сначала указывается организационно-правовая форма предприятия
в сокращенном виде (ООО, ЗАО, ПБОЮЛ и т. д.). Затем следует собственно на-
именование предприятия в кавычках. То есть правильным наименованием будет
считаться ООО «Рога и копыта», а не «Рога и копыта» ООО или просто «Рога
и копыта». Если содержание ячейки поля «Клиент» не соответствует заданному
шаблону, значит, оно не соответствует заданным критериям качества.
Широко распространено использование шаблонов для выявления ошибок
в почтовых адресах, картах социального страхования, банковских реквизитах
организаций и т. д.
Одна из областей, где особенно остро стоит проблема «грязных» данных, — сети
розничной торговли. Это обусловлено такими причинами, как:
□ территориальная распределенность — множество филиалов, разбросанных на
большой территории;
□ большие объемы консолидируемых данных — отражаются сотни тысяч торго-
вых операций в день;
□ высокая степень детализации данных — сумма каждой отдельной торговой
операции ничтожна по сравнению с общими объемами продаж.
Все это порождает множество ошибок в данных, которые способны существен-
но снизить достоверность результатов анализа. Выделяются следующие основные
классы ошибок:
□ ошибки ввода — возникают в процессе ввода данных на торговых терминалах
и в кассовых пунктах. Конечно, в большинстве современных супермаркетов кас-
совые пункты максимально автоматизированы, чтобы избежать ручного ввода
данных и связанных с этим ошибок. Специальный сканер считывает штрихкод,
наклеенный на упаковку товара, и вводит информацию в кассовую машину, ко-
торая подсчитывает сумму по каждому товару и выбивает чек. Информация по
каждому чеку вводится в БД. Однако полностью исключить ошибки не удается,
поскольку невозможно избежать ручного ввода, когда не читается или отсут-
ствует штрихкод, товар поступил в продажу, но не занесен в БД и т. д. Кроме
того, сканер может неправильно считать штрихкод;
Глава 5. Очистка и предобработка данных 223
□
□
о
ошибки в программном обеспечении торгового терминала;
ошибки в базе данных системы учета торговых операций;
ошибки консолидации данных, которые возникают в процессе переноса данных
Из филиалов в централизованное ХД торговой организации.
Задача оценки качества данных заключается в выявлении ошибок и определе-
нии их критичности по отношению к результатам анализа. Обнаружение ошибок
производится с помощью специальных процедур, каждая из которых разрабаты-
вается для выявления определенного рода ошибок. При этом необходимо выбрать
приоритет ошибок и обеспечить соответствующий порядок работы процедур.
Очевидно, что, пока не установлено, присутствует ли некоторое значение вообще,
бессмысленно выяснять, допустимо ли оно. Пока допустимость значения не под-
тверждена, нет смысла проверять его на аномальность; если же значение само по
себе недопустимо, то, аномально оно или нет, уже роли не играет. Его нужно либо
удалять, либо приводить в соответствие с заданными ограничениями.
Результатом работы такой системы будет отчет об обнаруженных ошибках
и оценке уровня загрязненности данных. Отчет может использоваться аналитиками
для разработки комплекса мер, направленных на повышение качества данных.
Контроль качества данных должен производиться непрерывно в процессе их
сбора и консолидации. Для этого целесообразно организовать мониторинг данных,
одна из возможных схем которого представлена на рис. 5.4.
Рис. 5.4. Организация мониторинга качества данных
224 Часть I. Теория бизнес-анализа
Согласно схеме контроль качества данных и выявление возможных проблем
осуществляются как на этапе сбора данных в OLTP-системе, так и при их кон-
солидации и преобразовании в процессе ETL. Когда установлено, что данные не
содержат ошибок, они беспрепятственно загружаются в ХД. Если в ходе проверки
были выявлены ошибки, то производится оценка их критичности относительно
анализа данных. Если ошибки некритичны, то данные также загружаются в хра-
нилище. Если обнаружено, что ошибки критичны, то вырабатывается комплекс
мер по очистке данных, которая также может производиться как непосредственно
в OLTP-системе, так и в процессе консолидации и ETL.
Оценка качества данных, контроль ошибок и анализ обнаруженных проблем —
необходимые звенья любого проекта по бизнес-аналитике. Оценка качества данных
не только позволяет определить степень их пригодности к анализу, но и служит
индикатором оптимальности и продуманности работы таких систем сбора и консо-
лидации данных, как OLTP-системы, ETL и ХД.
5.3. Очистка и предобработка
Несмотря на многоступенчатую процедуру очистки данных (в OLTP-системах,
в процессе ETL, в ХД), даже на этапе их непосредственного анализа возникают
серьезные проблемы, препятствующие эффективному и корректному анализу
данных. Эти проблемы далеко не всегда связаны только с загрязненностью дан-
ных — имеются и другие причины, которые не позволяют эффективно использо-
вать данные для конкретного вида аналитической обработки.
Что такое предобработка и чем она отличается
от очистки данных?
С точки зрения анализа «качество данных» и «чистота» — это не одно и то же.
Если чистота данных подразумевает отсутствие в них ошибок ввода, структурных
нарушений, некорректных форматов и других причин, которые мешают анализу
данных вообще, то качество данных тесно связано с конкретными целями и зада-
чами анализа, используемыми моделями, методами и алгоритмами. Это значит,
что данные, которые можно считать качественными с точки зрения одной задачи
анализа (например, прогнозирования), окажутся малопригодными для решения
другой (например, классификации). Действительно, для построения прогноза
может быть вполне достаточно наблюдений за развитием исследуемого процесса
в некотором временном интервале. А для классификации объекта, скорее всего,
потребуется его всестороннее описание. Очевидно, что даже критерии качества
данных для этих задач могут оказаться различными.
Проще говоря, нельзя достоверно утверждать, являются ли данные качествен-
ными, пока они не будут связаны с конкретной аналитической задачей. Поэтому,
как только выборка данных загружается в аналитическое приложение с целью
решения конкретной задачи, аналитик должен оценить степень их соответствия
Глава 5. Очистка и предобработка данных 225
□
□
бованиям, которые позволят получить качественное аналитическое решение.
я данные этим требованиям не соответствуют, нужно либо применить к ним
опеДУРУ для повышения уровня качества, либо отказаться от анализа. Успех
обработки зависит от таких факторов, как:
количество проблем, «унаследованных» от предыдущих этапов жизненного
цикла данных (OLTP-систем, ETL-процесса, ХД и др.);
набор инструментальных средств обработки, предоставляемых аналитической
платформой;
□ умение аналитика использовать эти средства для приведения данных в соответ-
ствие с требованиями конкретной задачи анализа.
С целью подготовки данных к решению конкретной задачи анализа использу-
ется комплекс средств, получивший название «предобработка данных».
ОПРЕДЕЛЕНИЕ------------------------------------------------------------
Предобработка данных — комплекс методов и алгоритмов, применяемых в аналитическом
приложении с целью подготовки данных к решению конкретной задачи и приведения их в со-
ответствие с требованиями, определяемыми спецификой задачи и способами ее решения.
Очистка данных в аналитическом приложении — лишь один из аспектов
предобработки, хотя эти два процесса часто отождествляются. Однако очистка
не является синонимом предобработки. Более того, если в данных, загруженных
в аналитическое приложение, отсутствуют проблемы, требующие очистки, или
их влияние на качество решения оценивается как минимальное, то очистка дан-
ных в процессе их предобработки может вообще не проводиться. В то же время
предобработка осуществляется в любом случае.
Почему борьба за качество данных ведется
на всех этапах аналитического процесса?
Возникает закономерный вопрос: с чем связана такая распределенность, почему
нельзя решить все проблемы с качеством данных в одном месте? Причин для этого
несколько.
О Некоторые проблемы появляются и могут быть обнаружены только на опреде-
ленном этапе сбора и консолидации данных. Например, нельзя выявить проти-
воречия между данными, находящимися в двух разных источниках, до тех пор,
пока оба источника не будут интегрированы в процессе ETL.
□ Характер влияния отдельных аспектов качества данных на процесс анализа раз-
личен. Одни проблемы в данных могут вызывать только технические сложности,
например невозможность интегрирования данных или загрузки их в хранилище.
Другие не позволяют выполнять корректный анализ данных и препятствуют по-
лучению достоверных результатов, например шумы, дубликаты и противоречия.
Технические проблемы в основном выявляются и по возможности устраня-
ются при консолидации данных. Аналитические проблемы доминируют на этапе
226 Часть I. Теория бизнес-анализа
непосредственной обработки данных, когда данные уже привязаны к определен-
ной методике и задаче анализа.
ПРИМЕР----------------------------------------------------------------—
Данные о продажах, получаемые из OLTP-системы сети придорожных кафе и магазинов, содер-
жатаномальные значения, когда показатели ежедневных продаж в три-четыре раза превышают
средние. Аномальные значения могут быть искусственными или естественными. Искусственное
аномальное значение является следствием ошибки оператора, сбоя в работе системы, то есть
оно отражает событие, которое в действительности не имело места и только искажает описание
предметной области. Естественная аномалия, напротив, отражает реальное событие, вызванное
исключительными обстоятельствами. Например, аномальный подъем спроса в придорожном
кафе или магазине может быть вызван проходящим неподалеку массовым мероприяти-
ем — музыкальным фестивалем, ярмаркой и т. д. — или ремонтом параллельной автострады.
При разработке ETL-процедур аналитик может указать в техническом задании, что все значе-
ния продаж, превышающие среднее в два раза и более, должны рассматриваться как ано-
мальные и подавляться. Однако, решая одну проблему, можно породить несколько других.
Во-первых, подавляя аномальные значения, аналитик лишает себя возможности в будущем
анализировать работу предприятия в условиях резкого возрастания и падения спроса, их
предсказания. Во-вторых, при добавлении в ETL-процесс дополнительных преобразований
данных увеличивается время загрузки ХД и связанное с этим падение производительности
корпоративной информационной системы («загрузочное окно»).
Аномальные значения не являются технической проблемой, поскольку это про-
сто числа, которые в несколько раз больше, чем соседние значения. В то же время
в зависимости от специфики анализа данных их наличие или отсутствие может
повлиять на качество анализа и достоверность полученных результатов, поэтому
проблема аномальных значений является чисто аналитической. Оптимальным
является перенос обработки аномальных значений в аналитическое приложение,
где пользователь может самостоятельно принимать решение о том, какие значения
в контексте выполняемого анализа следует считать аномальными, нужно ли их
подавлять, если да, то в какой степени и т. д.
Технические проблемы влияют как на процесс консолидации данных, так и на
результаты анализа. Аналитические проблемы влияют только на анализ данных.
Если данные в том или ином виде удалось загрузить в аналитическое приложе-
ние, то, скорее всего, в них остались только проблемы аналитического плана.
Главное отличие очистки данных при предобработке от очистки в OLTP-систе-
мах и в процессе ETL заключается в том, что она проводится с учетом планируемой
методики анализа, его целей, требуемой достоверности результатов и может кор-
ректироваться в зависимости от полученных предварительных результатов.
В то время как разработка очистки данных в OLTP-системах и в процессе
ETL является результатом совместной деятельности программиста и аналитика,
очистка данных при их непосредственной подготовке к анализу полностью ло-
жится на плечи пользователя аналитического приложения и не должна требовать
вмешательства технических работников. Цели и методы предварительной обра-
ботки данных должны полностью определяться пользователем и ограничиваться
лишь комплексом средств, которые предоставлены ему системой.
Глава 5. Очистка и предобработка данных 227
почему «грязные» данные доходят
до аналитической системы?
дакономерен вопрос: почему, несмотря на все усилия разработчиков OLTP-систем,
g-fL-nP0Ilecc0B и хранилищ данных, «грязные» данные попадают в выборки для
построения моделей? Существует несколько причин.
а
Некоторые ошибки не удается выявить. Чтобы система могла обнаружить
ошибку, необходимо указать правило или шаблон, которому должны соответ-
ствовать «правильные» данные. Ошибкой будет считаться все, что не соответст-
вует определенному шаблону или правилу. Предусмотреть шаблоны и правила
для всех возможных проблем в данных невозможно.
□ Не все обнаруженные проблемы удается устранить. Существуют проблемы,
устранить которые можно, только удалив сами данные. Поэтому принимается реше-
ние, что использовать данные в «грязном» виде лучше, чем вообще лишиться их.
□ Отказ от устранения ошибки. Процесс устранения некоторых обнаруженных
ошибок очень трудоемок, поэтому если затраты на устранение ошибки превы-
шают выгоду от него, то может быть принято решение отказаться от очистки.
□ Программы очистки данных сами могут являться источниками ошибок. Напри-
мер, корректируя одну запись, программа очистки данных может превратить ее
в дубликат или противоречие другой. Это может произойти, если вместо пропу-
щенного значения программа подставляет значение, выбираемое в соответствии
с некоторым правилом (например, среднее по столбцу). Иногда процедуры очист-
ки данных только усугубляют ситуацию. Если оператор OLTP-системы создает не
так уж и много ошибок, то алгоритм очистки может преобразовать одновременно
многие тысячи записей в попытке исправить несуществующую ошибку.
Все ошибки, связанные с качеством данных, делятся на два типа. Ошибки
l-ro типа имеют место в том случае, когда программа очистки данных обнаружи-
вает ошибку там, где ее нет.
ПРИМЕР 1-------------------------------------------------------------------
В ларек, в котором продается мороженое, было завезено товара на 5000 руб. До обеда
мороженое было продано, и продавец запросил еще одну партию на такую же сумму.
До закрытия ларька она также была распродана. На складе торговой фирмы в систему
регистрации заказов были введены две записи об отпуске одинаковых товаров на одну и ту
же сумму и одну и ту же дату. Процедура очистки данных, если при ее разработке данная
ситуация не была предусмотрена, посчитает записи дубликатами и удалит одну из них.
пример 2------------------------------------------------------------------
К распространенным ошибкам относится ввод всех элементов адреса клиента в одну ячейку.
Чтобы получить из адреса город, в котором находится клиент, применяют разделение адреса
на отдельные элементы в соответствии с шаблоном «Индекс_Город_Улица_Дом_№офиса».
При этом оказалось не предусмотрено, что названия городов могут состоять из двух слов —
Нижний Новгород, Великие Луки и т. д. Программа просто удаляла вторую часть названия
Часть I. Теория бизнес-анализа
после пробела или пыталась преобразовать его в название улицы. В итоге появлялись
названия городов Нижний, Великие и улиц Новгород, Луки и т. д.
Ошибки 2-го типа называют «утраченными». Они появляются, если процедура
очистки данных не смогла выявить проблему, то есть данные, содержащие ошибку,
были распознаны как правильные. Это происходит тогда, когда данные выглядят прав-
доподобно, даже если содержат ошибку. Также пропуск ошибки возможен, если соот-
ветствующее правило или шаблон не были предусмотрены в программе очистки.
ПРИМЕР-------------------------------------------------------------------—
Вместо отсутствующей информации о возрасте клиента оператор указывает последователь-
ность цифр 00, полагая, что система распознает ее как фиктивное значение и применит
соответствующую обработку. Однако, если набор символов соответствует заданному шаблону,
у системы нет формального повода подозревать ошибку и эти данные могут беспрепятственно
проникнуть в ХД или аналитическую систему.
Таким образом, очистка данных как часть их предобработки в аналитическом
приложении является «последней инстанцией», где аналитик может провести
оценку качества данных и принять необходимые меры к их очистке на основе соб-
ственного мнения с учетом конкретных целей и задач анализа.
Предобработка данных как важнейшая часть
процесса их анализа
Предобработку данных можно рассматривать как комбинацию методов очистки
и специальных методов оптимизации данных для решения конкретной задачи.
Чтобы лучше понять, как соотносятся между собой очистка и предобработка, обра-
тимся к следующей схеме (рис. 5.5).
Очистка
Предобработка
Нарушения структуры
данных
( Аномальные
значения
Нарушения
целостности и полноты
Некорректные форматы
Фиктивные значения
Пропуски
Противоречия
OLTP, ETL, ХД
Пропуски
Противоречия
Дубликаты
Шумы
Понижение
размерности
входных данных
Устранение
незначащих признаков
Аналитическое приложение
Рис. 5.5. Связь между очисткой и предобработкой
Глава 5. Очистка и предобработка данных 229
В OLTP-системах, в процессе ETL и в ХД производится очистка данных от
Ощибок, которые в большей степени носят технический характер. Нарушения
структУР1*1’ целостности, полноты и некорректные форматы данных необходимо
постараться исправить до загрузки в ХД, поскольку данные с такими проблемами
могут вообще не загрузиться в хранилище. Фиктивные значения тоже проще рас-
познать и исправить в OLTP-системе: как только данные выйдут за ее пределы,
обнаружить, что значение ошибочное, будет гораздо труднее, особенно если оно
выглядит правдоподобно и имеет корректный формат. Что касается пропусков,
то выяснить их причину и восстановить пропущенные значения также легче в той
системе, где они были созданы.
Проблемы, связанные с качеством данных, удобнее распознавать и устранять
в первоисточнике. Здесь проще узнать причины и закономерности появления про-
блем, доступен для консультаций персонал, работавший с данными, а также пер-
вичные бухгалтерские и другие документы, из которых можно взять правильные
и недостающие значения. Если организация имеет значительную территориальную
и структурную распределенность, большое количество филиалов и дочерних ком-
паний, а отдел, где данные консолидируются для анализа, расположен в централь-
ном офисе, то, когда данные доберутся до него, найти первопричины появления
многих проблем будет очень сложно.
Типичный набор инструментов предобработки
в аналитическом приложении
В блок предобработки аналитического приложения, как отмечалось выше, входит
набор методов очистки и оптимизации данных для конкретной задачи анализа. Если
организация использует информационно-аналитическую подсистему собственной
разработки, то комплекс средств предобработки данных в ней может быть создан с уче-
том специфики решаемых задач. Однако разработать собственную аналитическую
платформу имеют возможность только крупные предприятия, большинство же при-
меняет продукты сторонних производителей, поэтому выполнять подготовку данных
к анализу приходится теми средствами, которые заложены разработчиками системы.
Типичный набор инструментов предобработки и подготовки данных к анализу,
поставляемый с большинством аналитических платформ, содержит следующие
средства.
Очистка от шумов и сглаживание рядов данных. Часто ряды данных содержат
быстрые случайные изменения значений, которые можно рассматривать как шум.
Шум мешает выполнять анализ данных, делает неустойчивой работу алгоритмов,
не позволяет обнаруживать в данных скрытые закономерности, структуры, тен-
денции и т. д. Сглаживание необходимо в том случае, когда ряд данных оказыва-
ется неравномерным, содержит большое количество мелких структур (которые не
являются шумом в обычном понимании), препятствующих исследованию более
значительных объектов и закономерностей. Хотя сглаживание и очистка от шумов
По своим целям похожи, это различные методы обработки данных, использующие
Различные математические подходы.
230
Часть I. Теория бизнес-анализа
Восстановление пропущенных значений. Пустые значения вызывают не-
определенность при работе многих алгоритмов Data Mining. Даже одно пропу-
щенное значение может привести к невозможности моделирования. Если же
пропущенных данных много, объема информации в выборке может оказаться
недостаточно.
Редактирование аномальных значений. Аномальные значения также требуют
внимания при подготовке данных к анализу. В большинстве случаев они являются
просто ошибками ввода. Если же аномальные значения — действительные события
вызванные исключительными обстоятельствами, то они все равно являются вред-
ными, поскольку мешают обнаружению закономерностей в исследуемом процессе.
Однако исследование аномального поведения данных позволит прогнозировать
условия, вызывающие аномальные события, и их последствия, изучать реакцию
бизнес-систем на аномальные изменения условий. Следовательно, ответы на во-
просы, какие значения считать аномальными, принимать ли меры к их подавлению,
каковы должны быть степень и методика подавления, далеко не однозначны и тре-
буют дополнительных исследований в контексте целей и методов анализа.
Обработка дубликатов и противоречий. Дубликаты и противоречия в данных —
весьма распространенные явления, особенно когда данные поступают не из ХД, где
выполняется автоматическая поддержка их уникальности и непротиворечивости,
а напрямую из разнообразных источников. При этом подходы к обработке дубли-
катов и противоречий существенно различаются. Дубликаты — одинаковые данные
(записи). Они могут дублировать информацию об одном и том же событии, а могут
содержать идентичную информацию о двух различных, но похожих событиях.
В первом случае дубликаты должны быть удалены, а во втором требуется более
тонкая обработка. С противоречиями тоже не все так просто. Они возникают там,
где нарушается логика причинно-следственной связи. Например, два одинаковых
события являются следствием различных исходных условий или одинаковые усло-
вия породили различные события. Противоречия существенно мешают анализу
данных, особенно при их использовании для построения моделей, основанных на
обучении: нейронных сетей, деревьев решений и т. д. Использование противоречи-
вых данных резко ухудшает процесс настройки параметров моделей.
Снижение размерности входных данных. В основе работы большинства мо-
делей Data Mining лежит принцип обобщения. То есть, чтобы получить на выходе
модели даже единственное значение, нужно подать на ее вход некоторый набор
значений, на основе соотношений между которыми и будет определено выходное.
При построении модели изначально стараются привлечь максимум собранной
информации об исследуемом объекте: клиенте, поставщике, товаре и т. д. В резуль-
тате набор входных переменных разрастается, что приводит к усложнению модели,
делает ее уязвимой для некачественных данных, увеличивает время, требуемое на
ее построение. Поэтому одной из важных задач подготовки данных к анализу яв-
ляется снижение их размерности (data reduction). Для этого производится поиск
входных признаков (атрибутов, показателей), которые обладают высокой степенью
статистической взаимозависимости. Такие данные могут быть исключены из рас-
смотрения без существенного ущерба для результатов анализа.
Глава 5. Очистка и предобработка данных 231
Устранение незначащих факторов. Не все имеющиеся в распоряжении ана-
литика данные одинаково важны с точки зрения целей анализа. Фактор (бизнес-
показатель), включаемый в рассмотрение, должен вносить достаточный вклад
0 решение задачи, участвовать в объяснении причинно-следственной связи между
исходными данными и результатом, то есть между входными и выходными факто-
рами должна быть высокая степень взаимозависимости. Если между каким-либо
входным фактором и выходным результатом такая связь мала или отсутствует, то
использование этого входного фактора бессмысленно или даже вредно, поскольку
может увести решение в ложном направлении. Поэтому при подготовке данных
к анализу необходимо выявить входные факторы, слабо или совсем не связанные
с искомым аналитическим решением, и исключить их из пространства входных
факторов. Чаще всего критерием для определения значимости входных факторов
является некоторый уровень (показатель) значимости, который согласовывается
со степенью зависимости (корреляции) искомого решения от данного фактора.
Если показатель значимости входного фактора меньше некоторого порога, то
этот фактор может быть определен как слабо влияющий на решение и исключен
из рассмотрения без существенного ухудшения качества анализа. Однако такой
подход скрывает в себе определенный риск, поскольку порог значимости задается
аналитиком на основе субъективных оценок и может быть ошибочным.
В целом последние две задачи похожи: из анализа исключаются данные, которые
в контексте решаемой задачи являются лишними (избыточными) и только влекут
дополнительные вычислительные затраты, усложняют используемую модель.
Принципиальная разница заключается в следующем.
□ В первом случае в качестве критерия для исключения факторов используется
степень взаимной зависимости (корреляции) между входными факторами. То есть
чем выше эта степень, тем больше оснований для исключения факторов.
□ Во втором случае используется степень связи между входными факторами
и результатом. То есть чем ниже эта степень, тем больше оснований для ис-
ключения фактора.
Следует отметить, что уменьшение размерности анализируемых данных не
связано с их очисткой, поскольку данные могут рассматриваться как избыточные
только в контексте решаемой задачи. В свою очередь, эта избыточность никак
не связана с наличием в данных пропусков, аномалий, шумов и других проблем,
традиционно связываемых с очисткой. Именно поэтому понижение размерности
входных данных является неотъемлемой частью предобработки данных и должно
выполняться в аналитическом приложении. Делать это на этапе сбора и консоли-
дации данных в отрыве от условий конкретной аналитической задачи (например,
в процессе ETL) бессмысленно.
Выводы
Предобработка и очистка данных в аналитическом приложении — важнейшие эта-
пы, «последняя инстанция» при подготовке данных к анализу. В процессе предоб-
работки аналитик преобразует данные так, как он видит их в контексте решаемой
232 Часть I. Теория бизнес-анализа
задачи, используемых моделей и методов. При этом обеспечивается неформальный
подход, который не может заменить ни одна автоматическая машинная процедура
Это достигается за счет того, что стратегию подготовки данных аналитик разраба-
тывает и реализует на основе собственного опыта, знаний и даже интуиции. Именно
субъективный компонент позволяет в ряде случаев добиться наиболее значимых
аналитических решений.
Возможность непосредственного управления подготовкой данных важна для
аналитика еще и потому, что в некоторых случаях характер его вмешательства
может идти вразрез с формальными процедурами.
5.4. Фильтрация данных
При подготовке выборки данных к анализу часто возникает ситуация, когда неко-
торые записи нужно исключить из выборки и не использовать. Это может потребо-
ваться в следующих случаях.
□ Значения, содержащиеся в записи, могут негативно повлиять на результаты
анализа.
□ Значения записи нежелательно использовать в данной аналитической задаче.
□ Запись связана с каким-либо объектом или событием, которое нежелательно
рассматривать при анализе.
□ Запись содержит незначащую информацию и т. д.
Для исключения записей, присутствие которых в исходной выборке по какой-либо
причине нежелательно, используется фильтрация. Фильтрация является многоцеле-
вым средством, которое позволяет выполнять очистку данных от факторов, снижа-
ющих качество анализа, понижать размерность исходного множества данных, отбирать
наиболее важные данные, упрощать визуальный анализ исходной выборки и т. д.
В основе фильтрации лежит использование условий, которые играют роль фильт-
ров, позволяющих оставлять в выборке одни данные и исключать другие. В неко-
торых случаях применение фильтрации в качестве альтернативы таким методам
подготовки данных, как очистка и снижение размерности, может дать определенные
преимущества. Во-первых, фильтрация достаточно проста с вычислительной точки
зрения, поэтому в ситуациях, когда обработка более сложными алгоритмами зани-
мает слишком много времени, фильтрация позволяет справиться с проблемой зна-
чительно быстрее. Во-вторых, решение о целесообразности фильтрации и настройка
ее параметров производятся непосредственно пользователем, что дает возможность
действовать более тонко, чем некоторые алгоритмы очистки и сокращения размер-
ности, а также избегать проблем, иногда создаваемых этими алгоритмами. Кроме
того, результаты фильтрации более предсказуемы и легче интерпретируются.
Алгоритмы фильтрации существенно отличаются по своей сложности. В про-
стейшем случае это может быть отбор записей, значение определенного признака
в которых не превышает заданного. Однако при необходимости используются
сложные многоступенчатые алгоритмы фильтрации по нескольким полям и не-
скольким условиям одновременно.
Глава 5. Очистка и предобработка данных 233
В основе технологии фильтрации лежат три базовых понятия: условие, значение
й отношение.
g Условие. Определяется порядок отбора данных, например «больше или равно»,
«меньше» и т. д.
□ Значение. С помощью заданного условия проверяется конкретное значение.
□ Отношение. Используется при фильтрации с помощью нескольких условий
и устанавливает логические отношения между этими полями.
Набор условий, используемых при фильтрации, может быть разным для данных
различного типа. Для числовых данных используются следующие условия.
□ «Равно», «неравно», «больше», «меньше», «меньше или равно», «больше или равно».
Отбираются только те записи, в которых значение некоторого признака удовле-
творяет заданному условию. Таким простым способом можно исключать аномаль-
ные значения либо значения, величина которых не соответствует целям анализа.
□ «Пустое»/«не пустое». Отбираются только те записи, которые в данном поле
содержат пустое (или, наоборот, непустое) значение. Этот метод фильтрации
позволяет исключить из рассмотрения записи с пропусками данных или, на-
оборот, отобрать из всего множества только полные записи. Значение при этом
не задается.
□ «Содержит»/«не содержит». Включаются (исключаются) все записи, которые
содержат или, наоборот, не содержат некоторое заданное значение.
□ «В интервале»/«вне интервала». Отбираются только те записи, значения которых
для определенного поля лежат в некотором заданном диапазоне или вне его.
□ «В списке»/«вне списка». Отбираются только те записи, значение фильтруемого
поля которых содержится или, наоборот, не содержится в заданном пользова-
телем списке.
Данное условие фильтрации, как правило, доступно только для полей дискрет-
ного вида.
□ «Начинается на»/«не начинается на». Отбираются записи, в которых значение
определенного признака начинается (или, наоборот, не начинается) с заданного
набора символов. Условие применяется только к строковым данным.
□ «Заканчивается на»/«не заканчивается на». Отбираются записи, в которых значе-
ние определенного признака заканчивается (или, наоборот, не заканчивается) на
заданный набор символов. Условие применяется только к строковым данным.
При необходимости можно использовать сложные алгоритмы фильтрации, со-
держащие несколько условий, проверяющих данные по нескольким полям. Главное
в этом случае — правильно установить отношения между условиями. Отношения
устанавливаются с помощью логических операций «И» и «ИЛИ».
Если между двумя условиями установлено отношение «И», то в результиру-
ющий набор данных войдут записи, удовлетворяющие всем условиям, связанным
этим отношением. Если между условиями устанавливается отношение «ИЛИ»,
то будут отобраны записи, удовлетворяющие хотя бы одному из условий.
234 Часть I. Теория бизнес-анализа
5.5. Обработка дубликатов и противоречий
Наличие в данных дубликатов и противоречий часто снижает эффективность рабо-
ты моделей и достоверность результатов анализа. Поэтому при подготовке данных
к анализу большое внимание уделяется устранению дубликатов и противоречий,
а инструментарий для этого включен в комплекс средств предобработки многих
аналитических платформ.
В большинстве случаев выборка данных, на основе которой строится модель, со-
держит некоторый набор признаков (атрибутов, показателей), описывающих иссле-
дуемый бизнес-процесс или объект. Эти признаки можно разделить на две группы:
□ входные — подаются на вход модели, и на основе их значений модель рассчи-
тывает выходной результат. Входные признаки играют роль независимых пе-
ременных;
□ выходные (целевые) — их значения формируются на выходе модели как отклик
на подачу на ее вход набора входных признаков. Выходные признаки играют
роль зависимых переменных модели.
Введем определения дубликатов и противоречий.
ОПРЕДЕЛЕНИЕ --------------------------------------------------------
Две записи или более называются дубликатами, если они содержат идентичные наборы
значений всех признаков.
ОПРЕДЕЛЕНИЕ --------------------------------------------------------
Две записи или более являются противоречивыми, если они содержат одинаковые наборы
значений входных признаков и различные наборы значений выходных.
Проще говоря, дубликаты — это одинаковые записи. А в противоречивых записях
нарушается однозначность причинно-следственной связи: одинаковым исходным
данным соответствуют различные результаты.
ПРИМЕР--------------------------------------------------------------
Пусть имеется задача классификации, где на основе набора признаков X, Y, /требуется
определить принадлежность объектов к одному из классов А, В, С. Тогда выборка для
построения классификационной модели будет иметь следующий вид.
№ записи X Y Z Метка класса
1 Х[ У2 Z4 А
2 х2 У1 22 В
3 х2 3/1 22 В
4 Xi У1 24 С
При этом 1-я и д-я записи будут противоречивыми, поскольку двум одинаковым наборам
признаков соответствуют различные метки классов, а 2-я и з-я — дубликатами, поскольку
все их значения одинаковы.
Глава 5. Очистка и предобработка данных 235
В том, что в процессе предобработки данных необходимо выполнять поиск
обработку дубликатов и противоречий, сомнений нет. Сомнения возникают то-
гда когда записи, формально являющиеся дублирующими и противоречивыми,
с точки зрения логики данных таковыми не являются. Например, объекты, которые
в 1-й и 4-й записях, несмотря на одинаковые значения признаков, классифици-
руются как относящиеся к различным классам (что и порождает противоречие),
могут и на самом деле характеризоваться этими значениями и тем не менее отно-
ситься к различным классам. Это возможно в том случае, если существуют еще
какие-то признаки, позволяющие различить эти объекты, которые не были учтены
при формировании выборки или были исключены в процессе снижения размер-
ности данных. Иными словами, существует гипотетический признак Т, который
позволил бы объяснить, почему, несмотря на одинаковый набор значений призна-
ков X, Y, Z, объекты в 1-й и 4-й записях относятся к различным классам.
С дубликатами тоже не все просто. Каждая запись выборки данных фактически
представляет собой наблюдение за состоянием некоторого объекта или процесса.
Поэтому, когда аналитик обнаруживает, что в анализируемых данных присутству-
ют одинаковые записи, у него возникает закономерный вопрос: являются ли дуб-
ликаты ошибочно введенными копиями одной записи либо отражают различные
наблюдения за идентичными событиями и наблюдениями?
Таким образом, при обработке дубликатов и противоречий нужен неформаль-
ный подход, который учитывает их происхождение и логику анализируемых
данных. Во многих случаях это позволяет избежать потери информации из-за
неправильной интерпретации дублирующих и противоречивых записей.
ПРИМЕР-----------------------------------------------------------------
На склад в течение одного дня были завезены две одинаковые партии одноименных това-
ров, что привело к появлению двух идентичных записей в регистрирующей системе. Если
при обработке дубликатов предполагается, что из двух одинаковых записей только одна
правильная, а другая — следствие ошибки, то одна из записей будет удалена, а вместе
с ней будетпотеряна информация о поступлениитовара. Применив неформальный подход,
аналитик постарается выяснить причину появления двух одинаковых записей: позвонит на
склад или запросит в бухгалтерии первичные документы. Если выяснится, что обе записи
отражают реальные события, то аналитик примет решение либо оставить обе записи, либо
объединить их с агрегированием числовых значений.
Очевидно, что неформальный подход удастся применить только в том случае,
когда объем данных и количество дубликатов и противоречий в них невелики.
В случае, описанном в последнем примере, дублирующие записи могут обра-
зовываться из-за того, что при регистрации поступления товаров на склад в базу
данных заносится только информация о дате поставки, фирме-поставщике, ко-
личестве, цене и сумме товара. Поэтому, если поступают две одинаковые партии
товара в пределах одного дня, в базе данных оказываются две идентичные записи.
Знание модели формирования дубликатов позволяет выработать единый подход
к их обработке или принять меры к устранению причины их появления. Для этого
достаточно добавить в базу данных системы регистрации признак, уникальный
zjo часть I. Теория бизнес-анализа
для каждой операции приемки товара, например время регистрации или номер
соответствующего первичного документа.
Непродуманная методика обработки дубликатов и противоречий может привес-
ти к потере информации, что окажет негативное влияние на результаты анализа.
Обобщенная модель дубликатов
и противоречий данных
При обработке дубликатов и противоречий могут возникнуть разночтения в том,
что считать дублирующими и противоречивыми данными. Например, если все
признаки числовые, можно ли считать дубликатами записи в табл. 5.2?
Таблица 5.2. Пример набора данных
№ записи Цена Количество Сумма Наценка
1 1000 250 250 000 120,02
2 1000 250 250 000 120,01
3 999,9 249,8 249 775,02 120,05
4 1100 255 280 500 122,2
Формально три первые записи не являются дубликатами, но с точки зрения
логики бизнеса отражают идентичные данные. При этом неважно, откуда взялась
«лишняя копейка» (возможно, это просто ошибка округления).
Чтобы определить, следует ли считать формально различные записи дубликата-
ми с точки зрения логики бизнеса, можно воспользоваться их представлением в мно-
гомерном пространстве признаков, а в качестве меры различия выбрать расстояние
(например, евклидово) между точками, соответствующими каждой записи.
На рис. 5.6 показано, что первые три записи достаточно близки и порождают
в многомерной системе координат точки, расположенные внутри области. При этом
размер области выбирается из допустимой меры близости, в пределах которой
записи можно считать дубликатами. Четвертая запись находится на значительном
расстоянии от других и не попадает внутрь области, поэтому она дубликатом
остальных записей не считается.
Рис. 5.6. Дубликаты в многомерном пространстве признаков
Таким образом, если две записи или более попали внутрь области, в пределах
которой расстояние между ними не превышает заданного значения (меры бли-
Глава 5. Очистка и предобработка данных 237
Зости), то с точки зрения логики бизнеса они могут считаться дубликатами, хотя
Нормально таковыми и не являются.
Теперь рассмотрим аналогичную меру для противоречий. Например, проти-
воречивы ли следующие записи, если предположить, что цена, количество и сум-
ма — входные признаки, а наценка — выходной (табл. 5.3)?
Таблица 5.3. Пример набора данных
№ записи Цена Количество Сумма Наценка
1 1001 250 250 250 120,02
2 1000 250 250 000 120,01
- 3 1000 250 250 000 130,05
Если две записи являются дубликатами, то значения всех их признаков должны
быть идентичны (или почти идентичны), а соответствующие точки в пространстве
признаков должны совпадать или располагаться на достаточно малом расстоянии
друг от друга (расстояние R2 на рис. 5.7). Если же значения выходных признаков
будут различаться и записи будут противоречивыми, то, несмотря на близость
входных значений, их точки в пространстве признаков окажутся на большом рас-
стоянии (расстояние Ri).
Рис. 5.7. Дубликаты и противоречия
в многомерном пространстве признаков
Таким образом, если записи имеют одинаковые значения входных и выходных
полей и, следовательно, являются дубликатами, то их точки в пространстве призна-
ков совпадают или близки друг к другу. Если записи противоречивы, то, несмотря
на одинаковые значения входных полей, их точки в многомерном пространстве
признаков окажутся удаленными из-за различия значений выходных полей. Если
расстояние между записями, имеющими одинаковые значения входных полей
и различные значения выходных, достаточно мало, то это дубликаты. Если рас-
стояние между ними значительно, то это противоречия.
Влияние дубликатов и противоречий
на эффективность анализа
Наличие в данных дубликатов и противоречий может вызвать следующие про-
блемы.
Часть I. Теория бизнес-анализа
□ Дубликаты вызывают избыточность данных, увеличивают объем выборки,
при этом совершенно не повышая информативность данных. Так, одинаковые
примеры в обучающей выборке не способствуют процессу обучения, поскольку
в них содержится одна и та же информация. Вместе с тем они увеличивают объем
выборки и время, требуемое для обучения. Кроме того, если объем выборки огра-
ничен, дубликаты «отнимают» в ней место у полезных примеров, что ухудшает ре-
зультаты обучения. Для пояснения проведем следующую аналогию. Представим
себе таблицу умножения, в которой некоторые примеры дублируются несколько
раз. Очевидно, что с точки зрения изучения правил умножения это бессмысленно,
к тому же набор примеров разрастается, что ухудшает их восприятие учеником.
□ Противоречия приводят к искажению результатов анализа и снижают качество
моделей, поскольку нарушают общие закономерности в данных, обнаружение
которых и является целью анализа.
ЗАМЕЧАНИЕ-----------------------------------------------------------------
При решении некоторых задач Data Mining дубликаты и противоречия добавляются в дан-
ные искусственно. Добавление противоречий позволяет внести в данные неопределен-
ность, что в ряде случаев стимулирует процесс настройки параметров модели к более
тщательной «проработке» данных. Добавление в выборку дубликатов повышаетзначимость
дублируемой информации.
Противоречия, выбивающиеся из общей модели данных, могут также способствовать об-
наружению отклонений. Например, если два разных шаблона расходования средств со
счета или с кредитной карты в данных оказываются связанными с одним клиентом, то такое
противоречие позволяет заподозрить мошенничество.
Обработка дубликатов и противоречий
Обработка дубликатов и противоречий должна производиться с учетом особенно-
стей исходных данных и логики решаемой задачи. Существует несколько подходов
к решению проблемы наличия в данных дубликатов и противоречий.
Обработка дубликатов и противоречий не производится вообще. Это воз-
можно в следующих случаях. Во-первых, когда формально дубликаты и проти-
воречия присутствуют, но при этом корректность описания динамики иссле-
дуемых процессов не нарушается. Во-вторых, если дубликаты и противоречия
были введены в данные искусственно. Наконец, в некоторых задачах дубликаты
и противоречия могут быть индикаторами отклонений, поиск которых и является
целью анализа.
Удаление дублирующихся и противоречивых записей. Подход применяется
в том случае, если установлено, что из набора дублирующихся и противоречивых
записей только одна отражает действительное наблюдение или событие, а осталь-
ные являются следствием ошибок. Тогда из всех дублирующих друг друга запи-
сей оставляют только одну, а остальные удаляют. С противоречиями сложнее,
поскольку требуется определить, какая из противоречивых записей правильная,
а какие — следствия ошибок.
Глава 5. Очистка и предобработка данных 239
Объединение (слияние) дублирующихся и противоречивых записей. Этот
метод применяется тогда, когда дубликаты и противоречия отражают действитель-
ные события. Например, если регистрация поступления двух одинаковых партий
товара привела к появлению двух одинаковых записей, то можно либо удалить
одну запись, либо оставить все без изменений. В первом случае будет потеряна
информация о реальном событии, во втором — появится избыточность в данных,
поэтому оптимальным будет объединить две записи в одну, выполнив агрегацию
количества поступивших единиц товара и соответствующих сумм. При этом цены,
очевидно, агрегировать не следует (рис. 5.8).
Товар Цена Кол-во, кг Сумма
Бананы 35,00 500 17 500 ,
Бананы 35,00 500 17 500
Товар Цена Кол-во, кг Сумма |
| Бананы 35,00 1000 35 000 |
Рис. 5.8. Объединение дубликатов
Ситуация, когда может потребоваться объединение противоречивых записей,
выглядит следующим образом. Допустим, обнаружилось, что одному и тому же
наименованию товара в разных записях были присвоены различные идентифи-
кационные коды. В результате это привело к возникновению противоречия. Если
вследствие удаления одной из записей данные будут потеряны, то записи можно
объединить под одним кодом, а числовые значения — агрегировать (рис. 5.9).
Товар Код товара Кол-во, м Цена за 1 м Сумма
Швеллер Ns 15 2365 100 180 18 000
Швеллер № 15 2395 150 180 27 000
I
Товар Код товара Кол-во, м Цена за 1 м Сумма
| Швеллер Ns 15 | 2365 | 250 180 | 45 000 |
Рис. 5.9. Объединение противоречий
В зависимости от ситуации при объединении записей могут использоваться
различные функции агрегирования: суммирование, выбор среднего, максималь-
ного или минимального значений и т. д.
Из всех видов предобработки данных обработка дубликатов и противоречий
в наименьшей степени поддается формальному подходу. Это связано с тем, что при
наличии противоречивых или дублирующих друг друга записей невозможно выбрать
метод их обработки, пока не будут выяснены их характер и происхождение. Анали-
тику приходится разбираться с каждым случаем дублирования и противоречивости
240 Часть I. Теория бизнес-анализа
данных, чтобы выяснить, являются ли они следствием ошибки либо обусловлены
особенностями данных. При большом объеме выборки данных и наличии значи-
тельного числа дубликатов и противоречий их обработка может стать длительной
и трудоемкой процедурой.
5.6. Выявление аномальных значений
Часто в больших наборах данных встречаются значения, которые не укладываются
в общую модель поведения анализируемого процесса. Такие значения, которые
сильно отличаются от окружающих данных или несовместимы с ними, называются
аномальными значениями (outlier value). Аномалии могут быть вызваны ошибками
измерений или ввода данных, однако могут являться и результатом сильной измен-
чивости данных. Если, например, в базе данных указан возраст клиента, равный 1,
это значение некорректно. Ошибка может быть связана с тем, что компьютерная
программа по умолчанию установила это значение, если возраст клиента не был
указан вообще (то есть имеет место фиктивное значение, которое также является
аномальным). Но если в базе данных указано, что у клиента 15 детей, это значение
будет скорее подозрительным и его следует проверить.
При подготовке данных к анализу необходимо выполнять поиск и корректиров-
ку аномальных значений, поскольку они являются одним из факторов, существенно
снижающих качество данных и достоверность результатов их анализа. Аномальные
данные способны значительно ухудшить работу моделей Data Mining.
Все аномальные значения можно разделить на два класса:
□ искусственные — связаны с ошибками ввода данных, некорректной работой
программ или систем регистрации (например, сканера штрихкода);
□ естественные — отражают факты и события, имевшие место в действительно-
сти, но вызванные исключительными обстоятельствами, которые встречаются
очень редко или в единичных случаях.
Так, аномально большая сумма выручки придорожного кафе может быть вы-
звана ошибкой оператора, который при вводе указал лишний ноль (искусственная
аномалия). Но возможно, что параллельная дорога была закрыта из-за ремонта
и поток машин (а следовательно, и число клиентов) возрос в несколько раз. В этом
случае имеет место естественная аномалия.
Отличить искусственное аномальное значение от естественного, кроме очевид-
ных случаев (типа Возраст = 250), практически невозможно. Но если возникают
сомнения, то лучше произвести дополнительную проверку, например связаться
с менеджером подразделения, которое показало аномально высокую выручку,
позвонить клиенту, чтобы уточнить его возраст, и т. д.
Впрочем, такие действия возможны только тогда, когда объем выборки данных
и число аномальных значений невелики и с каждым из них можно разобраться
отдельно. Если же объем выборки составляет десятки и сотни тысяч записей и она
содержит сотни аномальных значений, то для их обработки приходится использо-
вать автоматические процедуры обнаружения и корректировки.
Глава 5. Очистка и предобработка данных 241
Таким образом, задача обработки аномальных значений состоит из двух этапов,
j Обнаружение. Производится поиск аномальных значений, и, если возможно,
проверяется, является аномалия искусственной или естественной. Если ано-
малия искусственная, то необходимо удалить соответствующую запись либо
произвести корректировку значений одним из доступных методов. Если ано-
малия естественная (то есть отражает естественную изменчивость данных), то
ее, возможно, следует оставить, но дальнейший анализ производить с соответ-
ствующими поправками.
2. Корректировка. Обнаруженные аномальные значения исключаются или кор-
ректируются в зависимости от логики и особенностей задачи анализа.
Аналитик должен осторожно подходить к автоматическому исключению ано-
мальных значений, поскольку, если результаты, кажущиеся аномальными, на самом
деле корректны, это может привести к потере важной информации. Кроме того,
следует учитывать, что некоторые алгоритмы анализа направлены именно на обна-
ружение аномалий. Например, в процессе выявления мошенничеств с кредитными
картами аномальные значения являются индикаторами мошеннических действий,
и тогда аномальные значения будут не препятствующим фактором, а целью анали-
за. Но чаще всего, особенно при больших объемах данных, аномальные значения
снижают качество анализа, поскольку, как правило, являются результатом ошибок,
а не действительными характеристиками исследуемого процесса.
Обнаружение аномальных значений
Если исходное множество не очень велико и не содержит большого числа изме-
рений данных, то эффективным способом обнаружения аномалий является визу-
альный анализ таблицы или графика. В таблице аномальное значение может быть
обнаружено по количеству цифр в числе или по первой цифре. Более наглядным,
конечно, служит графическое представление.
Наиболее простым является визуальный анализ одномерных рядов данных. В них
аномалии выглядят как выбросы значений в ту или иную сторону (рис. 5.10).
Сумма кредита
80 000
70 000
60 000
50 000
40 000
30 000
20 000
10 000
о
ffltriffltrifflda.Q.Q.22 2 2?dddddS5Sf5
Z Z Z Z Z ffl ffi ffi ffi Q.Q.Q.Q.C C C c C S § S 5
(хккккф ф Ф ф m ca co ca nJ co co co co 2222
’-CMCMinC4|O)tD Ч-СМСМ T“ OJ OJ
— r\i
Рис. 5.10. Ряд данных
242 Часть I. Теория бизнес-анализа
На рисунке представлен ряд данных о суммах выданных кредитов. Два зна-
чения, помеченные цифрами 1 и 2, могут рассматриваться как потенциальные
аномалии. Действительно, в то время как сумма кредита в основном не превышает
50 тыс., а средняя — около 20 тыс., суммы 70 тыс. выглядят подозрительно. Это
как раз тот пограничный случай, когда значения несколько отклоняются от общей
модели поведения данных, но в целом не противоречат ей. Вот если бы вместо
70 тыс. стояло 700 тыс., был бы повод задуматься.
Информация, полученная с помощью данного графика, может использоваться
двояко. С точки зрения анализа имеет смысл либо исключить аномальные значе-
ния, либо привести их в соответствие с общей моделью данных, чтобы они не влия-
ли на результаты анализа. С точки зрения руководства кредитного учреждения,
эти два значения — повод к проверке. Лица, взявшие большой кредит, могут быть
либо перспективными клиентами, к которым нужен особый подход (например,
специальные условия кредитования), чтобы повысить их лояльность к банку, либо
мошенниками. Следует отметить, что если бы система автоматически подавляла
аномальные значения, то потенциально ценная информация была бы утрачена.
Визуальный анализ аномалий в двумерных рядах данных несколько сложнее.
Рассмотрим выборку, в которой указываются суммы кредитов и возраст клиентов.
Очевидно, что наибольшее количество клиентов — это люди в самом трудоспособном
возрасте, от 25 до 50 лет, которые берут кредиты на покупку теле- и видеоаппаратуры,
холодильника, мебели и т. д. Сумма кредитов при этом составляет от 20 до 40 тыс.
Люди помоложе, которые еще не имеют стабильного заработка, подходят к кредитам
осторожнее (если они не мошенники и мыслят здраво), и их доля в общем числе
клиентов меньше. Что касается пожилых людей, то они также пользуются креди-
тами меньше, поскольку их финансовая стабильность под вопросом, да и запросы
скромнее, чем у молодежи. Поэтому графическое представление соответствующей
двумерной выборки будет выглядеть приблизительно так (рис. 5.11).
На рисунке обозначены два типа аномалий. Буквой «О» помечены очевидные
ошибки, когда сумма 80 тыс. была выдана 12-летнему ребенку и людям в возрасте
около 100 лет. Эти значения нужно сразу исключать или корректировать. Бук-
вой «П» помечены подозрительные значения, которые в целом не противоречат
логике данных, но отклоняются от общей модели их поведения. Такие значения
должны быть подвергнуты дополнительной проверке.
Поиск аномалий и их потенциальное удаление из наборов данных могут быть
описаны как процесс отбора значений, которые сильно отличаются от окружающих
данных, выбиваются из общего ряда значений или несовместимы с остальными
данными. Задача обнаружения аномалий, особенно в многомерных наблюдениях,
является сложной. Методы визуализации, полезные при поиске аномальных зна-
чений в случае использования 1-3 измерений, оказываются несостоятельными
в случае многомерных данных, поскольку отсутствует адекватная методология
визуализации таких пространств.
Наиболее простым подходом к обнаружению аномалий в одномерных рядах
данных является статистический. Если предположить, что распределение значений
ряда известно, нужно определить такие основные статистические параметры, как
Глава 5. Очистка и предобработка данных 243
90
80
70
60
50
40
30
20
10
(О)
(П) (П)
© © ©
© © ® ® @
© • © ® ®
© •• ®® ©
© © а в • о
© • • ® © ®
0 10 20 30 40 50 60 70 80
(О)
(О)
90 100
1
Возраст клиента, лет
Рис. 5.11. Очевидные и подозрительные аномальные значения
среднее значение и дисперсия. На основе этих характеристик можно установить
некоторый порог, величина которого зависит от дисперсии ряда. Все элементы
ряда, значения которых превысили данный порог, могут рассматриваться как по-
тенциальные аномалии.
Основной проблемой при реализации этого метода является априорное предпо-
ложение относительно закона распределения значений ряда, которое в большин-
стве случаев неизвестно.
ПРИМЕР----------------------------------------------------------------------
Пусть атрибут Возраст представлен следующими двадцатью значениями: {3, 56, 23, 39,
156, 52, 41, 22, 9, 28, 139, 31, 55, 20, -67, 37, И, 55, 45, 37}.
Для данной выборки значений среднее будет
х = -Ух,= 39,6
и среднеквадратическое отклонение (СКО)
о= -У(х/-х)2 =45,89,
уп / = 1
где п — количество элементов выборки;
х, — i-й элемент выборки.
Если предположить, что распределение данных нормальное, то порог можно задать как
Т — х ± 2о. Это значит, что любые значения ряда, отличающиеся от среднего больше чем
244 Часть I. Теория бизнес-анализа
на два СКО (то есть вышедшие за диапазон [—52,2; 131,3]), являются потенциальными
аномалиями. Знание о характере данных (возраст не может быть отрицательным) позволяет
ввести дополнительное ограничение: данные будут считаться корректными в диапазоне
[0; 131,2].
В приведенном ряде присутствуют три значения, которые могут рассматриваться как по-
тенциальные аномалии: 156, 139 и -67. Это ошибки ввода. При этом в значениях 156
и 139, скорее всего, введена лишняя цифра (возможно, единица), а в значении -67 весьма
вероятен ошибочный ввод знака «—».
Обнаружение аномальных значений
на основе меры расстояния
Данный метод позволяет преодолеть некоторые ограничения, присущие статисти-
ческому подходу. Основное его преимущество заключается в том, что он применим
к многомерным данным, в то время как статистический метод применим только
в случае одномерного ряда или к каждому измерению по отдельности. В основе
метода лежит оценка мер расстояния между всеми наблюдениями в и-мерном
пространстве данных. Следовательно, значение s, множества данных 5 является
аномальным, если хотя бы часть из р значений множества S расположена на боль-
шем расстоянии, чем d, от остальных значений. Иными словами, аномалии — это
значения, которые не имеют достаточного числа соседей, где соседи — это значе-
ния, расстояния d до которых не превышают заданного в многомерной системе
координат. Данный критерий обнаружения аномальных значений основывается
на двух параметрах — d и р, то есть на расстоянии и количестве соседей. Эти пара-
метры могут быть заданы более обоснованно, если использовать априорные знания
о данных, или путем итеративной подстройки методом проб и ошибок для поиска
наиболее ярко выраженных аномалий.
Для иллюстрации метода проанализируем множество двумерных наблюдений
S, где требованием для аномальности является значение порогов р > 4 и d > 3.
5-{S),s2,s3,s4,s3,s6,s7} = {(2; 4), (3; 2), (1; 1), (4; 3), (1; 6), (5; 3), (4; 2)}.
Таблица евклидовых расстояний d = -^(х\ - х2 )2 + (//,- У2 )2 представлена следу-
ющим образом (табл. 5.4).
Таблица 5.4. Таблица евклидовых расстояний
Si s2 S3 S4 S5 S4 s7
Si 2,236 3,162 2,236 2,236 3,162 2,828
S1 2,236 1,414 4,472 2,236 1,000
S3 3,605 5,000 4,472 3,162
S4 4,242 1,000 1,000
S5 5,000 5,000
S6 1,414
Глава 5. Очистка и предобработка данных 245
Например, для наблюдений Si = (2; 4) и S2 = (3; 2) евклидово расстояние рас-
считывается следующим образом: di2 = ^/(2-3)2 + (4-2)2 = >/1 + 4 = 2,236.
На основе табл. 5.4 мы можем вычислить значение параметра р при заданном
гроговом расстоянии d = 3. Результаты представлены в табл. 5.5, то есть указано
число точек р с расстоянием, большим чем d, для каждой заданной точки из мно-
жества 5.
Таблица 5.5. Результаты вычисления параметра/?
Значение Si s2 S3 s4 Ss se
Параметр р 2 1 5 2 5 3
Значение р = 2 для элемента S\ означает, что существует только два элемента,
53 и 5б (см. табл. 5.4), расстояние до которых больше заданного порога d > 3; для
элемента 52 — только один элемент, S5, и т. д.
Используя полученные результаты и заданные пороговые значения, можно
выбрать элементы 53 и 55 как кандидаты в аномальные, поскольку для них значение
р = 5 превышает заданный порог/? > 4.
Данные результаты могут быть подтверждены путем визуального анализа
(рис. 5.12).
Рис. 5.12. Аномальные значения,
вычисленные на основе меры расстояния
Конечно, визуальный анализ возможен, если множество не очень велико и со-
держит всего одно или два измерения. В противном случае поиск аномалий при-
ходится проводить только аналитическими методами.
246 Часть I. Теория бизнес-анализа
Методы корректировки аномальных значений
Если обнаруженное аномальное значение действительно искажает информацию об
исследуемом бизнес-процессе и может повлиять на качество модели и достовер-
ность результатов анализа, то необходимо выполнить его корректировку. Для этого
в зависимости от логики и особенностей решаемой задачи можно использовать
несколько способов.
□ Удаление записи с аномальным значением. Если число записей в выборке данных
существенно превышает минимум, требуемый для анализа, то записи, содержа-
щие аномальные значения, можно просто удалить.
□ Ручная замена аномальных значений. Применяется, если количество аномальных
значений невелико и они могут быть обработаны вручную. При этом аналитик
заменяет аномальные значения на другие, более соответствующие модели пове-
дения данных.
□ Сглаживание и фильтрация данных. Для обработки аномальных значений
можно использовать методы частотной или пространственной фильтрации,
применяемые при сглаживании данных и очистке от шумов (впрочем, это
отдельный класс алгоритмов). При этом следует учитывать, что в результате
обработки будут изменены не только аномальные значения, но и все значения
ряда.
□ Интерполяция данных. Аномальные значения заменяются другими, вычислен-
ными на основе нескольких ближайших соседей.
□ Замена на наиболее вероятное значение. Строится гистограмма распределения
значений ряда, и по ней определяется значение, соответствующее моде гисто-
граммы, которое и будет являться статистически наиболее вероятным.
ПРИМЕР-------------------------------------------------------------
Пусть имеется выборка данных {8, 10, 9, 24, 11, 8, 13, 12}. Визуальный анализ легко
позволяет выявить аномалию.
Сгладим аномалию путем усреднения по некоторой окрестности. Если для этого использо-
вать окно, в которое попадут два значения слева и два значения справа от аномального,
то получим: (10 + 9 + 24 + 11 + 8)/5 = 12,4. То есть аномальное значение ряда, рав-
ное 24, будет заменено 12,4.
Кроме того, для корректировки выброса можно использовать медиану нескольких соседних
значений. Для этого значения выбранной окрестности (в данном случае {10, 9, 24, 11, 8})
Глава 5. Очистка и предобработка данных 247
ранжируются по возрастанию, то есть {8,9,10,11,24}. Тогда медианой будет центральное
значение упорядоченного набора, то есть 10.
Результаты применения данной обработки представлены на рисунке.
5.7. Восстановление пропущенных значений
Одним из тех факторов, которые снижают качество анализируемых данных
и достоверность результатов анализа, является наличие в них пропущенных
значений. Пропущенное значение выглядит как пустая ячейка в таблице, где
в соответствии с логикой и структурой данных должно находиться некоторое
значение.
Сами по себе пропущенные значения (если их не очень много) не угрожают
информативности данных и не искажают их. Наоборот, к искажению может при-
вести некорректное применение процедур заполнения пропущенных значений.
Тем не менее восстанавливать пропущенные значения необходимо. Главная
причина этого заключается в том, что многие алгоритмы Data Mining не могут
обрабатывать пропуски.
В большинстве случаев разработчики аналитических платформ предусмат-
ривают автоматическую обработку пустых значений путем исключения записей,
содержащих пропуски, или подстановки вместо пропуска некоторого значения по
умолчанию. Но это не всегда приводит к желаемым результатам и может породить
другие проблемы. Например, если исключить неполные записи, оставшихся может
оказаться недостаточно для качественного анализа.
Подстановка значений по умолчанию тоже не всегда решает проблему, посколь-
ку при этом не учитываются особенности данных. Допустим, в качестве значения,
подставляемого вместо пропущенных данных, по умолчанию использовались
средние продажи за месяц. Но если в силу внешних факторов объемы продаж стали
подвергаться частым изменениям, то подставляемые по умолчанию значения могут
не соответствовать реальному поведению данных.
Из сказанного можно сделать следующий вывод: необходимо уделять большое
внимание восстановлению пропущенных значений, а используемые для этого
подходы должны выбираться исходя из особенностей самих данных и решаемой
задачи анализа.
248 Часть I. Теория бизнес-анализа
Происхождение пропусков в данных
Чтобы выработать методику борьбы с пропусками в данных, сначала нужно понять
откуда они берутся. В этой связи можно выделить два основных момента появления
пропущенных значений.
□ В процессе ввода данных, если нужные значения отсутствовали изначально. Так,
если оператор вводит данные из анкет клиентов, а анкета заполнена неверно
и некоторые данные (возраст, адрес и т. д.) в ней отсутствуют или указаны не-
разборчивым почерком, то оператору ничего не остается, кроме как пропустить
отсутствующие значения в надежде, что позднее об этом кто-нибудь позаботит-
ся. Кроме того, пропуски в данных могут появляться из-за сбоев в работе авто-
матических систем регистрации, например при работе сканера штрихкода.
□ В процессе ETL или загрузки данных в аналитическое приложение. В этом случае
пропуски могут возникать на месте значений, имеющих некорректный тип или
формат. При загрузке такие значения могут быть просто отброшены. Например,
если исходные данные находятся в текстовом файле с разделителями, то при им-
порте данных из него требуется указать, что считать разделителем целой и дроб-
ной частей числа — точку или запятую. Если выбрать запятую, то все числовые
значения, в которых целая и дробная части числа разделены точками, будут иметь
некорректный формат. Тогда после загрузки данных в аналитическое приложение
на месте значений с некорректными форматами окажутся пропуски (рис. 5.13).
Сумма Сумма
24,5 24,5
32.6
23,4 23,4
24.6 ►
12,6 12,6
15,8 15,8
19,2 19,2
Источник Аналитическое приложение
Рис. 5.13. Пример появления пропусков в данных на этапе загрузки
Методы восстановления пропущенных значений
Выбор методов восстановления пропусков зависит от того, являются ли данные
упорядоченными. Под упорядоченностью в этом случае следует понимать степень
взаимной зависимости значений данных. Если можно предположить, что несколько
соседних значений данных связаны между собой, то такие данные будут считаться
упорядоченными. Наиболее характерна упорядоченность для временных рядов,
которые состоят из наблюдений за изменением параметров некоторого объекта
или процесса.
Как правило, реальные бизнес-процессы не подвержены резким изменениям.
Зная одно из значений ряда, можно предположить, что предыдущее и последу-
Глава 5. Очистка и предобработка данных 249
ющее значения будут примерно такими же. То есть в упорядоченных данных со-
седние значения в определенной степени «объясняют» друг друга. Так, на вопрос;
«Какой курс доллара к рублю вы предполагаете завтра?» — можно с достаточной
степенью уверенности ответить: «Примерно такой же, как и сегодня, плюс-минус
5 копеек».
Если данные не упорядочены, то их значения никак не связаны. В этом случае
пытаться оценить некоторое значение ряда на основе его соседей бессмысленно.
Например, зная, что клиент получил в банке кредит на сумму 15 тыс., мы не можем
сделать вывод о сумме, которую запросит следующий клиент. Это может быть
и 10 тыс., и 50 тыс., поскольку значения никак не связаны.
Причины, по которым методики восстановления пропущенных значений в упо-
рядоченных и неупорядоченных данных будут различаться, достаточно очевидны.
Если данные упорядочены, то получить хорошую оценку значения для восстанов-
ления пропуска можно на основе соседних значений. При неупорядоченных дан-
ных это сделать невозможно и приходится применять более сложные алгоритмы.
Впрочем, существует ряд методов, которые могут использоваться как для упоря-
доченных данных, так и для неупорядоченных. Если у аналитика есть возможность
выбора, то преимущество следует отдавать методам, которые удовлетворяют сле-
дующим требованиям.
□ Метод должен быть понятным и прозрачным для пользователей, что снижает
вероятность его некорректного применения.
□ Восстановленные с помощью метода значения должны максимально соответ-
ствовать общей модели поведения данных.
□ Вычислительная сложность метода не должна увеличивать время предобра-
ботки данных до неприемлемой величины, что особенно важно при анализе
больших массивов данных.
Обычно эти требования оказываются противоречивыми. Действительно, про-
стые, понятные и незатратные в вычислительном отношении методы часто не
обеспечивают корректных результатов и наоборот. В силу этого выбор метода,
используемого для восстановления пропущенных значений, — поиск компромисса
между перечисленными требованиями.
В любом случае при восстановлении пропущенных значений следует учитывать,
что автоматические процедуры, реализующие этот процесс, генерируют новые
значения данных. Это может привести к возникновению других проблем: дублика-
тов, противоречий и аномальных значений. Например, если две записи в выборке
отличались только значением одного признака, который в одной из записей был
пропущен, то нет гарантии, что после его восстановления записи не станут иден-
тичными (дубликатами). Поэтому восстановление пропусков должно быть первым
этапом предобработки данных.
Рассмотрим наиболее популярные методы восстановления пропущенных зна-
чений при подготовке данных к анализу.
Ручная обработка пропусков. Это самый простой и эффективный способ
восстановления пропущенных значений, который может использоваться как для
250 Часть I. Теория бизнес-анализа
упорядоченных, так и для неупорядоченных данных. Аналитик совместно с экспер-
том в предметной области проверяет наличие пропусков в данных и подставляет
наиболее вероятные или правдоподобные значения, основываясь на личных зна-
ниях и опыте. Недостаток подхода очевиден: он применим только для небольших
выборок данных (не более нескольких сотен записей) с малым количеством про-
пущенных значений. Поэтому в реальных случаях чаще всего приемлемы только
автоматические процедуры восстановления пропущенных данных.
Подстановка констант. Вместо пропущенных значений подставляются неко-
торые фиксированные значения (константы). Этот метод тоже позволяет работать
как с упорядоченными, так и с неупорядоченными данными. Хотя в случае упо-
рядоченных данных результат может быть несколько лучше. Если можно пред-
положить, что значения признака как-то связаны между собой, то, зная значения,
соседние с пропущенным, считаем, что подставляемая константа не должна сильно
от них отличаться.
Значения констант определяются следующими методами.
□ Замена пропущенного значения некоторой глобальной константой, которая
выбирается исходя из специфики данных и решаемой задачи анализа. Гло-
бальность подразумевает, что соответствующее значение подставляется вместо
всех пропусков вне зависимости от конкретной ситуации. Например, если
отсутствуют данные о суммах продаж, аналитик может использовать наиболее
типичное значение из ранее сделанных наблюдений, которое поддерживает
достоверность результатов анализа. Недостаток метода заключается в том, что
если под воздействием некоторых факторов типичные объемы продаж изменят-
ся, а значения, используемые для подстановки вместо пропущенных, не будут
вовремя скорректированы, то они могут оказаться противоречащими общему
поведению данных и отрицательно повлиять на результаты анализа.
□ Замена отсутствующего значения наиболее характерным для данного класса.
Метод применим только при решении задач классификации, где классы для
каждого набора значений признаков в записи заранее известны. В этом случае
производится замена не глобальным значением для всего признака (или всех
признаков), а несколькими значениями, каждое из которых связано с опреде-
ленным классом.
В случае, когда данные не упорядочены, для повышения достоверности оцен-
ки пропущенных значений можно выполнить предварительную группировку
данных по классам. Поскольку внутри каждого класса значения признаков будут
сходными, в изначально неупорядоченном множестве данных появится несколько
подмножеств, в каждом из которых значения можно будет считать упорядочен-
ными. Аналогично товары можно разложить по полкам: на одной — дорогие, а на
другой — дешевые. Если известно, что рядом с товаром, на котором не указана цена,
лежат дорогие товары, логично и на него установить высокую цену.
В табл. 5.6 представлены данные, позволяющие классифицировать все товары
на дорогие, средние и дешевые. Если товар стоит менее 100 ед., то он считается
дешевым, если от 100 до 1000 ед. — средним, свыше 1000 ед. — дорогим.
Глава 5. Очистка и предобработка данных 251
Таблица 5.6. Данные о товарах
'Наименование Цена (ед.) Класс товара
Утюг 500 Средний
Пылесос 3500 Дорогой
Зубная щетка 25 Дешевый
Стиральная машина Дорогой
.—— Электрочайник 670 Средний
Будильник 90 Дешевый
Холодильник 7400 Дорогой
Миксер Средний
Пассатижи Дешевый
Если выполнить группировку записей по классу товара, то среднее значение по
каждой группе даст вполне состоятельную оценку пропущенного значения цены.
Результаты такой обработки представлены в табл. 5.7. Средние значения цены по
каждому классу, подставленные вместо пропусков, выделены.
Таблица 5.7. Результаты группировки записей по классу товара
Наименование Цена (ед.) Класс товара
Зубная щетка 25 Дешевый
Пассатижи 57 Дешевый
Будильник 90 Дешевый
Утюг 500 Средний
Миксер 585 Средний
Электрочайник 670 Средний
Пылесос 3500 Дорогой
Холодильник 7400 Дорогой
Стиральная машина 5450 Дорогой
Предсказание пропущенных значений. Еще одним методом восстановления
пропущенных значений является построение модели их предсказания. Для этого
может использоваться какая-либо модель Data Mining, основанная на машинном
обучении, — нейронная сеть, дерево решений и т. д. Обучающая выборка будет
сформирована из полных записей, где присутствуют все значения признаков, а це-
левым будет признак, значения которого требуется предсказать.
Например, если значения признаков Л, В и С в некоторой записи заданы, то значе-
ние признака D может быть сгенерировано моделью. И чем выше корреляция между
известными и искомыми признаками, тем более достоверно предсказание. Однако на
практике к этому методу нужно относиться с осторожностью. Если отсутствующее
значение признака может быть предсказано с высоким уровнем достоверности на
основе имеющихся значений других признаков, то признак является избыточным
и его ценность с точки зрения анализа минимальна. Такие признаки должны исклю-
чаться из рассмотрения при сокращении размерности исходных данных.
252 Часть I. Теория бизнес-анализа
Подстановка среднего значения. Еще одним часто используемым подходом
к восстановлению пропущенных значений в упорядоченных данных является
подстановка вместо пропущенного значения среднего по ряду данных или по не-
скольким его ближайшим соседями.
ПРИМЕР---------------------------------------------------------------------—-
Пусть требуется восстановить отсутствующее значениех ряда данных. Для этого нужно вы-
брать интервал, центральным значением которого и будетх„ состоящий из k его ближайших
соседей. Например, для k = 4:
х,_2 = 10, Х,_1 = 12, х, = ? ...Х, + 2 = И.
Тогда среднее значение по выбранной окрестности будет:
Xi =(х,_! +Xi-t +Х;+1 +Xi_2)/£ = (10 + 12 + 9 + ll)/4 = 10,5.
Естественно задаться вопросом, сколько соседей пропущенного значения следу-
ет использовать при его восстановлении. С одной стороны, чем больше значений,
тем более обоснованной будет полученная оценка. С другой — нужно учитывать,
что значения различных интервалов ряда могли формироваться под действием
разных факторов и условий внешней среды. Следовательно, попытка использо-
вать для восстановления пропусков в данных значения всего ряда может привести
к появлению аномалий.
ПРИМЕР
Пусть имеется ряд наблюдений за процессом продаж мороженого и прохладительных
напитков во втором полугодии. Тогда, учитывая вероятный спад продаж по окончании
жаркого сезона, можно предположить, что значения продаж в конце наблюдаемого ин-
тервала (ноябрь, декабрь) окажутся в несколько раз меньше, чем в начале интервала
(июль, август).
30 000
25 000
20 000
15 000
10 000
5000
О
Июль
Август Сентябрь Октябрь Ноябрь Декабрь
Попытка использовать среднее по всему ряду для восстановления пропуска в июле породит
аномально низкое значение, а в декабре — аномально высокое. Поэтому для восстановле-
ния пропущенного значения на основе среднего его соседей следует использовать только
интервал ряда, значения в пределах которого примерно одинаковы и предположительно
сформированы под действием одинаковых факторов и условий внешней среды. То есть при
восстановлении пропущенного значения из интервала июль — сентябрь следует использо-
вать усреднение по этому же интервалу.
Глава 5. Очистка и предобработка данных 253
Подстановка наиболее вероятных значений. Одним из популярных методов
восстановления пропусков является подстановка вместо них наиболее вероятных со
статистической точки зрения значений. Данный метод применим как к упорядочен-
ным, так и к неупорядоченным данным. В его основе лежит построение гистограммы
распределения значений признака, и для подстановки выбирается значение из интер-
вала, соответствующего моде распределения. То есть фактически для подстановки вы-
бирается значение из подмножества наиболее часто встречающихся значений ряда.
На рис. 5.14 приведена гистограмма распределения сумм кредитов, выданных
банком за неделю.
Сумма, тыс. руб.
Рис. 5.14. Гистограмма распределения сумм кредитов
Визуальный анализ гистограммы показывает, что наибольшее число кредитов
было выдано на суммы в интервале от 10 до 18 тыс. Подстановка значения из
данного интервала вместо пропущенного даст его самую правдоподобную оценку.
Хотя полной корректности восстановленного значения метод не гарантирует, его
использование часто дает хорошие результаты. Кроме того, данный метод имеет
два неоспоримых преимущества:
□ понятность пользователю и хорошую визуальную интерпретируемость резуль-
татов (по гистограмме сразу видно, какие значения наиболее правдоподобны,
а какие — нет);
□ адаптивность к данным — для каждой выборки можно построить свою гисто-
грамму и определить наиболее вероятное значение.
5.8. Введение в сокращение размерности
При решении задач анализа часто приходится сталкиваться с двумя полярными
проблемами — избыточностью и недостаточностью данных. Следует отметить,
что избыточность и недостаточность далеко не всегда связаны с количеством
имеющихся данных. Вполне возможно, что объем исходных данных велик, но для
решения конкретной задачи анализа их все равно недостаточно из-за отсутствия
254 Часть I. Теория бизнес-анализа
в них необходимой информации. Возможен и прямо противоположный случай,
когда объем исходных данных небольшой, но они подобраны настолько удачно, что
обеспечивают высокую эффективность анализа. Таким образом, информативность
данных не всегда пропорциональна их объему.
Тем не менее многие аналитики считают, и практика это показывает, что лучше
иметь данные с запасом, то есть собирать для анализа как можно больше данных,
описывающих предметную область. Действительно, в больших массивах данных
есть вероятность «наскрести» достаточное количество информации для решения
той или иной задачи. Кроме того, технический уровень современных носителей
информации, которые могут хранить сотни гигабайт данных, снимает проблему
размещения данных.
Когда дело доходит до анализа, встает проблема: из всего имеющегося множест-
ва данных, которое может содержать десятки признаков, атрибутов и показателей,
описывающих анализируемый процесс или объект, необходимо выбрать подмно-
жество, которое обеспечит оптимальные результаты анализа.
Целью анализа является поиск закономерностей и структур в данных, поэтому
перед его проведением следует выделить только те данные, которые могут описы-
вать эти закономерности и структуры. Это довольно трудная и неочевидная задача.
Ее выполнение можно разделить на два этапа (рис. 5.15).
Аналитическое приложение
Предварительный
отбор
(опыт и знания
аналитика)
Сокращение размерности
(статистический,
корреляционный анализ
ит. д.)
Локальные
источники
данных
Запрос
Признак 1
Признак 2
Признак 3
Признак 4
Признак 5
Признак 6
Признак 7
Признаке
Признак 9
Признак 10
Признак 2
Признак 3 ->
Признак 4
Признак 6
Исходное
множество
Признак 2
Признак 4
Признаке
Анализ '
данных ;
Сокращенное
множество
Рис. 5.15. Сокращение размерности
1. Предварительный отбор данных. Осуществляется вручную, когда аналитик
выбирает данные для решения конкретной задачи на основе личного опыта,
знаний и интуиции. Основная цель этого этапа — отсеять данные, которые не
способствуют получению решения. Например, при анализе продаж бесполез-
ны данные о номерах машин, вывозивших товар, номерах накладных и счетов,
Глава 5. Очистка и предобработка данных
255
ФИО складских работников, отпустивших товар, и другая вспомогательная
информация, которая заносится в базу данных, но описывает анализируемый
процесс лишь косвенно. Номера машин нужны только охране, чтобы организо-
вать допуск транспорта клиентов на территорию; ФИО складских работников
нужны бухгалтерии для формирования документов и отчетов и т. д.
2 Сокращение объема исходной выборки. Как правило, при первичном отборе дан-
ных аналитики перестраховываются. Если отсутствие или наличие связи между
какими-либо данными и целями анализа неочевидно, то в большинстве случаев
аналитики включают эти данные в исходное множество, считая, что потеря важ-
ной информации обойдется дороже, чем привлечение излишней. И в этом есть
своя логика. Но в результате даже после предварительного отбора исходное мно-
жество оказывается избыточным, содержит очень много данных, в том числе сла-
бо или вообще не связанных с целями анализа. Это способно вызвать серьезные
проблемы — не меньшие, чем при потере релевантной информации. Сущность
этих проблем будет рассмотрена ниже. Пока же отметим, что объем исходной
выборки сокращается уже не вручную, а с помощью определенных методов,
процедур и алгоритмов, специально разработанных для снижения размерности
исходных данных. Эти методы основаны на статистических оценках и критериях,
корреляционном анализе и других математических подходах, которые позволя-
ют более точно оценить степень взаимосвязи данных с целями анализа с точки
зрения конкретной задачи. Тот или иной набор инструментов для сокращения
размерности данных включается в состав практически любого аналитического
приложения. Использование этих инструментов позволяет найти оптимальный
баланс между качеством полученных решений, сложностью модели, а также вы-
числительными и временными затратами на обработку данных.
Постановка задачи
В разделе 1.7 мы уже познакомились с тем, что в машинном обучении и Data Mining
большинство моделей работает по принципу обобщения. На вход модели подается
некоторый набор входных (независимых) переменных, связанных с какими-либо
признаками, атрибутами или показателями, описывающими исследуемый объект
или процесс. Модель производит над входными данными преобразование, опре-
деляемое некоторой целевой функцией, и формирует на выходе набор выходных
(зависимых) переменных. При этом для успешного решения задачи чаще всего
необходимо, чтобы число входных переменных было больше либо равно числу
выходных, в чем и состоит принцип обобщения.
Обычно для классификации реального объекта недостаточно знать один его
признак — требуется исчерпывающее описание. То есть, чтобы получить на выходе
модели только одно значение — класс, к которому относится объект, — на ее вход
нужно подать несколько признаков и атрибутов объекта. Конечно, в отдельных
случаях удается классифицировать объекты по одному признаку, но это очень
простые объекты, задача их распознавания тривиальна и не представляет практи-
ческого интереса.
256 Часть I. Теория бизнес-анализа
Большинство реальных объектов и бизнес-процессов, которые нужно проана-
лизировать, достаточно сложны, и для их исчерпывающего описания требуется
множество признаков и наблюдений (записей). Поэтому размерность входного
вектора может оказаться высокой — несколько десятков и сотен признаков.
Это вызывает ряд серьезных проблем при анализе данных:
□ рост вычислительных затрат и времени, требуемого на обработку данных, до
совершенно неприемлемых значений;
□ сложность построения модели, трудность понимания ее пользователем;
□ сложность интерпретации результатов анализа и оценки их достоверности;
□ снижение качества результатов анализа. В исходном наборе могут содержаться
данные, не связанные с исследуемым процессом или объектом. Если такие дан-
ные не будут исключены перед анализом, то они могут увести решение задачи
в неверном направлении.
Чтобы исключить эти проблемы, в процессе предобработки данных в аналити-
ческом приложении выполняется снижение их размерности (data reduction).
ОПРЕДЕЛЕНИЕ-------------------------------------------------------------
Снижение размерности входных данных— процесс сокращения объема исходного мно-
жества, загруженного для анализа в аналитическое приложение, таким образом, чтобы
результирующее множество имело оптимальную размерность с точки зрения решаемой
задачи и используемой модели.
Исходные множества данных представляются в аналитическом приложении
в виде «плоских» таблиц, поэтому, когда говорят о снижении размерности данных,
подразумевают сокращение данных по таким трем направлениям, как:
□ сокращение количества признаков (столбцов таблицы);
□ сокращение числа наблюдений (записей таблицы);
□ сокращение числа значений измерения (при этом само количество значений не
меняется, уменьшается только число различных вариаций значения).
Сокращение данных может производиться в двух режимах.
1. Режим отбора. Определяется значимость каждого признака исходного мно-
жества для решения конкретной задачи. Затем признаки отбираются в поряд-
ке уменьшения их значимости. Как только попадается признак, значимость
которого меньше некоторого порога, отбор прекращается. Порог значимости
устанавливается или на основе статистического анализа исходного множества,
или опытным путем (рис. 5.16).
2. Режим исключения. Размер исходной выборки сокращается путем отбрасывания
незначащих и избыточных данных. Например, для каждого признака исходной вы-
борки определяется коэффициент значимости, а затем исключаются все признаки,
значимость которых ниже некоторого порога. Возможен и другой вариант. По мере
исключения признаков результирующая выборка становится все менее похожа на
исходную. Задается условие, что выборка, полученная в результате сокращения
исходной, не должна отличаться от нее более чем на 70 %. Затем все признаки
Глава 5. Очистка и предобработка данных 257
исходной выборки ранжируются по уровню их значимости и начинается процесс
исключения наименее значимых. Он будет продолжаться до тех пор, пока отличие
исходной выборки от сокращенной не превысит допустимое значение (рис. 5.17).
Rn — значимость признака,
Т — порог значимости
Рис. 5.16. Сокращение признаков
в режиме отбора
Исходное множество
Признак 1
Признак 2
Признак 3
Признак 4
Признак 5
Признак 6
(R,>D
(R, < Г)
(ЯЭ>П
(Я6>п
R, — значимость признака,
Т — порог значимости
Рис. 5.17. Сокращение признаков
в режиме исключения
Требования к алгоритмам снижения размерности данных
В настоящее время используется большое количество различных подходов к сокра-
щению размерности данных. Одни из этих подходов относятся к эвристическим,
другие основаны на строгом статистическом анализе данных, третьи сочетают
в себе и то и другое. Тем не менее можно выделить ряд общих требований ко всем
алгоритмам снижения размерности данных.
□ Подмножество данных, образованное в результате сокращения размерности ис-
ходного множества, должно унаследовать от него столько информации, сколько
необходимо для получения решения с заданной точностью.
□ Вычислительные и временные затраты на обработку данных с целью сокра-
щения их размерности не должны обесценивать преимущества, полученные
в результате сокращения размерности.
□ Модель, полученная на основе множества данных со сниженной размерностью,
должна быть проще для разработки, реализации и понимания, чем модель, по-
строенная на исходном множестве.
□ Признаки, оставшиеся после процедуры сокращения размерности, должны
иметь высокий уровень значимости для решения задачи и не должны быть
258 Часть I. Теория бизнес-анализа
коррелированы между собой, а также содержать закономерности, которые могут
увести аналитический процесс в сторону от правильных результатов.
В идеальном случае в результате сокращения размерности данных удается
уменьшить время анализа, повысить его точность и упростить модель одновремен-
но. Однако чаще всего приходится искать баланс между этими преимуществами.
Не существует метода снижения размерности, который одинаково хорошо
работал бы для всех задач анализа и видов исходных данных. Решение о выборе
метода основывается на априорном знании о поставленной задаче и ожидаемых
результатах с учетом временных ограничений.
Выделим следующие рекомендуемые характеристики методов снижения раз-
мерности данных, которые могут применяться как при выборе алгоритмов, так
и при разработке стратегии сокращения размерности данных в целом.
□ Алгоритм должен предоставлять пользователю возможность контролировать
ход процесса, а также оценивать влияние сокращения признаков, записей
и отдельных значений на ожидаемые результаты анализа. При большом объ-
еме данных процедура их обработки с целью сокращения размерности может
занять довольно продолжительное время, поэтому пользователь должен полу-
чать информацию о результатах работы, чтобы при необходимости остановить
алгоритм, не дожидаясь его завершения.
□ Наибольшая эффективность должна достигаться на первых итерациях алго-
ритма и со временем уменьшаться (то есть сначала должны отбрасываться
наименее значимые данные или отбираться наиболее значимые). Это позволит
не ждать окончания работы алгоритма, а остановить его, как только будут до-
стигнуты приемлемые результаты.
□ Алгоритм должен обеспечивать возможность приостановки в любой момент
времени с сохранением промежуточных результатов, их оценки, а также возоб-
новления работы.
Таким образом, сокращение размерности — одна из важнейших задач подготов-
ки исходных данных к анализу.
5.9. Сокращение числа признаков
Основных преимуществ от сокращения размерности исходного множества данных
можно добиться, уменьшив количество признаков, используемых для анализа.
При этом качество результатов анализа не должно существенно снизиться, а в не-
которых случаях удается его повысить. Когда говорят о снижении размерности
исходных данных, в первую очередь имеют в виду сокращение числа признаков.
Уменьшение числа наблюдений (записей) и отдельных значений признаков обычно
рассматривается как вспомогательный элемент. Это вполне справедливо, поскольку
именно сокращение признаков позволяет:
□ сразу исключить из рассмотрения большое количество данных (десятки и сотни
тысяч значений);
Глава 5. Очистка и предобработка данных 259
д упростить будущую модель, сделать ее более понятной, а также повысить ин-
терпретируемость результатов анализа;
д исключить избыточные и незначащие данные, которые способны увести реше-
ние в сторону, снизить достоверность результатов анализа.
фактически, сокращая количество используемых для анализа признаков,
мы снижаем размерность векторов наблюдений, которыми являются все записи
исходной выборки данных. Это позволяет повысить эффективность решения
таких задач Data Mining, как классификация и кластеризация, основанных на
определении степени близости векторов наблюдений. Кроме того, уменьшая число
признаков, можно снизить размерность OLAP-кубов. Известно, что многомерные
модели с размерностью больше 7-9 очень плохо поддаются визуальному анализу
и осмыслению пользователем. Поэтому, если размерность модели удается сокра-
тить без существенной потери и искажения информации, работа с моделью будет
более эффективной.
Все сокращаемые признаки можно разделить на две группы.
1. Незначащие — признаки, которые слабо или никак не связаны с результатами
анализа. Использовать такие признаки нецелесообразно по двум причинам. Во-
первых, они не несут в себе информации, которая может быть использована при
анализе, не содержат закономерностей и структур, которые могут представлять
интерес при решении задачи. Во-вторых, использование незначащих данных
может нанести ущерб результатам анализа. Такие данные могут содержать
закономерности, которые не имеют отношения к решаемой задаче, но которые
могут быть обнаружены моделью вместо искомых. Например, если в обучающую
выборку для модели включить поле, где содержатся номера доставлявших товар
транспортных средств, то вместо того, чтобы искать закономерность поступления
или отгрузки товара, модель будет пытаться выявить закономерность движения
транспортных средств, которой может и не быть.
2. Избыточные — признаки, которые содержат полезную информацию, но без которых
могут быть получены хорошие результаты анализа. То есть информация, которую
несут такие признаки, является лишней. Вся необходимая информация содержится
в одном или нескольких других входных признаках, которые также используются
для анализа, а избыточный признак в том или ином виде дублирует ее.
ПРИМЕР------------------------------------------------------------------
В организациях, помимо наименований товаров, используются их числовые коды. Это,
в частности, связано с удобством манипулирования числовыми кодами в базах данных.
Но если использовать на входе модели как наименования товаров, так и их коды, то один
из этих признаков окажется избыточным: для идентификации товара достаточно или его
наименования, или кода.
Основное отличие незначащих признаков от избыточных заключается в том,
что незначащие признаки имеют низкую степень связи с результатами анализа,
а избыточные — высокую степень связи с другими входными полями исходного
множества данных.
260 Часть I. Теория бизнес-анализа
Алгоритмы и методы сокращения числа признаков
Большинство алгоритмов и методов сокращения числа признаков используют
статистические или эвристические критерии, на основе которых принимаются
решения о включении того или иного признака в модель. С сокращением набора
признаков связаны две стандартные задачи:
□ отбор признаков — основывается на знании предметной области и целей анали-
за. Аналитик может выбрать подмножество признаков из исходного множества
вручную или с помощью некоторых автоматических процедур;
□ композиция признаков — происходит формирование одного признака на основе
слияния нескольких других с использованием некоторого преобразования.
Хотя такие алгоритмы сокращения признаков весьма сложны, они позволяют
получить новые признаки, которые существенно влияют на результаты анализа.
Например, вместо двух признаков Рост клиента и Вес клиента можно исполь-
зовать единый показатель Рост/вес, который в некоторых случаях окажется
более эффективным, чем два исходных признака.
Разные методы отбора признаков обеспечивают различную степень сокра-
щения исходного множества данных. Можно классифицировать эти методы на
две группы: алгоритмы упорядочения признаков (ранжирования) и алгоритмы
минимального подмножества.
Алгоритмы упорядочения признаков основаны на вычислении для каждого
признака некоторого оценочного показателя (коэффициент корреляции, показа-
тель значимости и т. д.). Затем признаки ранжируются в порядке возрастания или
убывания этого показателя. В большинстве случаев эти алгоритмы не использу-
ются непосредственно для формирования множеств сокращенной размерности,
они только показывают значимость данного признака по сравнению с другими, что
позволяет аналитику принять решение об их сокращении.
Алгоритмы минимального подмножества, напротив, после их запуска выдают
минимальное подмножество признаков, необходимых для эффективного анализа
данных. Признаки, попавшие в подмножество, являются значимыми для анализа,
остальные — нет.
В обоих видах алгоритмов важно установить схему оценки признака, то есть
способ, с помощью которого признаки оцениваются, ранжируются и добавляются
в результирующее подмножество.
Отбор признаков можно рассматривать как поиск в пространстве, каждая точка
которого соответствует определенной комбинации признаков.
ПРИМЕР----------------------------------------------------------------
Исходное множество данных содержит три признака {Аь Аг, Аэ}, и в процессе выбора
присутствие признака кодируется как 1, а отсутствие — как 0. Таким образом, можно
получить (23 — 1) подмножества признаков: {1, 0, 0}, {0, 1, 0}, {0, 0, 1}, {1, 1, 0},
{1, 0,1}, {0,1,1} и {1,1,1}. Задача выбора признаков относительно проста, если про-
странство поиска невелико, поскольку мы можем проанализировать все подмножества
в любом порядке и поиск занимает короткое время. Однако в большинстве практических
Глава 5. Очистка и предобработка данных 261
задач анализа пространство поиска достаточно велико. Оно составляет (2'v — 1), где
N— количество анализируемых признаков, которое для типичных аналитических задач
может достигать 20 и более. Поэтому поиск всех подмножеств признаков часто заменя-
ется эвристической процедурой, в процессе которой ищется подмножество, наиболее
близкое к оптимальному.
Отбор признаков на основе
статистических показателей
Одна из методик отбора признаков основана на сравнении их средних значений
и дисперсий. Недостаток данного подхода в том, что распределение значений
признаков не всегда известно. Если оно предполагается нормальным, то стати-
стические оценки могут работать очень хорошо, но если характер распределе-
ния неизвестен, то на основе статистических оценок нельзя построить точную
модель.
Если один признак содержит значения, описывающие разные классы объектов,
то должны быть исследованы примеры из разных классов. Для этого значения при-
знака распределяются по классам, вычисляются их средние значения и дисперсия.
Затем средние значения нормализуются дисперсией и сравниваются. Если средние
значения для разных классов существенно различаются, то интерес к признаку,
содержащему такие значения, с точки зрения разделения классов увеличивается.
Если средние значения различаются мало, то ожидаемая эффективность признака
с точки зрения разделения классов невелика. Этот эвристический подход не явля-
ется оптимальным при отборе признаков, но он вполне состоятелен при решении
некоторых задач анализа.
Рассмотрим уравнение:
Е (А — В) = 1J|var(A)/wt — var(A —В)/п2|,
где А и В — множества значений признака, измеренных для двух различных клас-
сов;
П{ и п2 — соответствующие количества примеров;
var(A) и var(B) — дисперсии значений соответствующих подмножеств.
Чтобы проверить степень значимости признака с точки зрения разделения
классов А и В, можно выполнить следующий тест:
|Я-в|
где Т — некоторый порог, часто называемый порогом значимости;
А и В — средние значения соответствующих множеств.
В данном случае предполагается, что признаки являются статистически неза-
висимыми. Сравнение средних значений — естественный шаг при решении задач
классификации.
262 Часть I. Теория бизнес-анализа
ПРИМЕР
Рассмотрим простую выборку данных, содержащую два входных признака X и Y, а также
метку класса С. Требуется определить, какой из признаков является кандидатом на сокра-
щение. Установим значение порога Т = 0,5.
X Y C
0,3 0,7 A
0,2 0,9 В
0,6 0,6 A
0,5 0,5 A
0,7 0,7 В
0,4 0,9 В
Графически это можно интерпретировать следующим образом.
Сначала необходимо вычислить среднее значение и дисперсию для обоих признаков. Анали-
зируемые подмножества значений признаков: Хл = {0,3; 0,6; 0,5}, Хн = {0,2; 0,7; 0,4},
Ул = {0,7; 0,6; 0,5}, Уй = {0,9; 0,7; 0,9}.
Е(ХА -Xв) = 5/|var(JT^)/«, — var(A'e)/z72| = 7|0,025/3-0,042/3| = 0,078.
E(Ya -YB) = 5y|var(yJ)/n] -var(ys)/n2| = ^|0,067/3-0,009/3| =0,138.
|Z< - Xb\/e(Xa -XbS) = |0,467-0,433|/0,078 = 0,436 < 0,5.
|Ул-Yb\/e(Ya — rB)) = |0,6 — 0,833|/0,138 = 1,688 > 0,5.
Глава 5. Очистка и предобработка данных 263
Установлено, что кандидатом на сокращение является признак X, поскольку средние его
значения для различных классов оказываются ближе и их разность не превышает заданного
порога. В то же время для признака Yзначение порога превышено, следовательно, этот
признак не является кандидатом на сокращение, так как потенциально содержит ценную
информацию для различения классов.
Описанный метод достаточно прост, он исследует признаки по отдельности.
р{о таким образом можно определить только значимость признака с точки зрения
различия классов. Чтобы узнать, является ли признак избыточным для решения за-
дачи в целом, необходимо провести его анализ совместно с другими признаками.
Сокращение числа признаков на основе оценки
их информационного содержания
Несмотря на разнообразие подходов, применяемых для сокращения числа призна-
ков в множестве данных, можно сформулировать единый критерий, в соответствии
с которым будет оцениваться любой метод: в результате сокращения размерности
данных информационное содержание результирующего множества не должно
существенно измениться относительно исходного. Но это не более чем благое по-
желание, к тому же достаточно очевидное. Тем не менее оно служит отправной точ-
кой для целой группы методов сокращения избыточных и незначащих признаков.
Действительно, если выразить информационное содержание исходного множества
в виде системы характеристик (например, статистических) и в процессе исключе-
ния признаков наблюдать за динамикой изменения этих характеристик, то можно
выработать соответствующие критерии, позволяющие оптимизировать процесс
сокращения размерности. Проще говоря, сокращать количество признаков нужно
таким образом, чтобы характеристики, отражающие информационное содержание
исходной выборки, изменились не более чем на заданную величину.
Для оценки информационного содержания данных может служить специальная
мера теории информации — энтропия. Это понятие впервые было введено К. Шен-
ноном как мера разнообразия значений данных. Чем более гладким является ряд
данных, тем меньше его энтропия. Если ряд данных состоит из одинаковых зна-
чений, его энтропия равна 0. Очевидно, что ни о какой информативности данных
в этом случае говорить не приходится. С увеличением разнообразия значений
признака возрастают его энтропия и ожидаемое информационное содержание.
Таким образом, энтропия может служить мерой информационной насыщенно-
сти данных. Чем выше энтропия набора, тем выше ожидаемая информационная
насыщенность, и наоборот.
В основе методики лежит сравнение энтропии исходного множества данных
и энтропии множества, полученного после снижения размерности. Если энтропия
результирующего множества близка к энтропии исходного, то оно по своему ин-
формационному содержанию близко к исходному.
Метод, основанный на энтропии, относительно прост, но с ростом числа при-
знаков его вычислительная сложность существенно возрастает. В соответствии
с данным методом все примеры исходной выборки рассматриваются как и-ком-
264 Часть I. Теория бизнес-анализа
понентные векторы значений признаков, где п равно числу признаков. Нужно
удалить столько признаков, чтобы при этом все еще поддерживался уровень
различия между примерами в множестве данных, как и при исходном количестве
признаков.
В основе алгоритма лежит вычисление коэффициента подобия S, который
обратно пропорционален расстоянию D между векторами примеров в и-мерном
пространстве признаков. Расстояние D является малым для похожих векторов
и большим, если векторы сильно различаются. Ситуация проиллюстрирована на
рис. 5.18 для п = 3 и набора признаков (р, q, z), где расстояние D вычисляется между
двумя векторами Xi и х2.
Для числовых признаков мера сходства векторов примеров может быть опре-
делена следующим образом:
5,, =ехр(-а£>,7), (5.1)
где Dy — расстояние между двумя примерами х,- и х/
а — параметр, заданный как а = - In (0,5) / D, при этом D — среднее расстояние
между примерами в наборе данных. Следовательно, коэффициент а зависит
от характера исходных данных. На практике хороших результатов удается до-
биться при а = 0,5.
Для вычисления расстояния D:J между примерами х и х; можно использовать
нормированное евклидово расстояние:
Dy = /^((х» -х;1)/(тах*-тт*))2, (5.2)
У *=i
где п — число измерений;
min* и шах* — минимальное и максимальное значения, используемые для нор-
мировки k-то признака.
Глава 5. Очистка и предобработка данных 265
В случае если признаки не являются числовыми, степень их близости опреде-
ляется с помощью расстояния Хемминга:
1 "
Sij-xjh\, (5.3)
п k=t
где Xik - Xjk — 1, если Хц, = х#, и xik - xjk = 0 в остальных случаях.
Общее число значений равно п.
Если данные смешанные, то перед вычислением степени близости можно
выполнить квантование числовых значений и преобразовать числовые признаки
в категориальные.
Для простого набора данных, состоящего из трех категориальных признаков,
степень близости может быть представлена в табличном виде (табл. 5.8, 5.9).
Таблица 5.8. Исходный набор данных
Пример Признак
Ft F2 F,
Я, А X 1
R3 В Y 2
R3 С Y 2
R 4 В X 1
R-, с Z 3
Таблица 5.9. Меры расстояний, вычисленные для примеров из табл. 5.8
Пример Rt Rz R, Rt Rs
Ri 0/3 0/3 2/3 0/3
Ri 2/3 1/3 0/3
R3 0/3 1/3
R< 0/3
R3
В табл. 5.8 содержится исходный набор данных, а в табл. 5.9 — меры расстоя-
ния между примерами. Три в знаменателе дроби соответствует числу признаков,
а значение в числителе — количеству совпадений значений в примерах, рас-
стоянием между которыми оно определяется. Например, для пары примеров /?2
и Д3 установлено число 2, потому что в них совпадают значения двух измерений:
F2- УиЕз-2.
Распределение всех расстояний между векторами примеров в наборе данных
характеризует расположение данных в и-мерном пространстве. При сокращении
отдельных признаков распределение меняется, и это изменение будет главным
критерием принятия решения о сокращении признака. Как уже говорилось ранее,
мерой таких изменений и является энтропия.
Шаги алгоритма основаны на последовательном убывающем ранжировании,
а затем на проверке результатов с помощью различных практических задач.
1. Берется исходное множество признаков F.
266 Часть I. Теория бизнес-анализа
2. Из множества £удаляется один из признаков f е F, в результате чего получается
подмножество Fi = F- f.
3. Для Fи Ft определяется энтропия E(F) и E(Fi~), затем полученные значения
сравниваются.
4. Данная процедура итеративно повторяется, и на каждой итерации вычисляет-
ся разность энтропии Д£* исходного множества F и множества Fk, полученного
в результате исключения k-ro признака.
5. Из полученной последовательности выбирается минимальный элемент AEk
и устанавливается, для какого подмножества Fk он был получен, то есть обнару-
живается, исключение какого признака fk&F обеспечивает минимум разности
энтропии исходного множества признаков F и множества, полученного путем
исключения данного признака /*.
6. Формируется новое исходное множество £(1), которое образуется с помощью
исключения из начального множества F подмножества Л, выбранного на пятом
шаге, то есть £0) = F - Fk.
7. Шаги 2-5 итеративно повторяются, пока не будет получено множество призна-
ков F'"', состоящее всего из одного признака.
В результате будет получена последовательность подмножеств F(k> (k = 1,2... ri)
исходного множества признаков F, ранжированная в порядке увеличения разности
энтропии множества Ди подмножеств Fw, то есть в порядке уменьшения близости
к исходному множеству. Таким образом, в начале последовательности окажутся
подмножества, которые наиболее близки к исходному.
ПРИМЕР-----------------------------------------------------------------------
Пусть исходное множество данных Дсодержитд признака } Тогда алгоритм
будет работать следующим образом:
f = {h, h, Л}; Ft = }; = {/, }; F< = {/, ,/2,/3 }•
bEi = E(F) - E(Fi); Д£2 = E(F) - E(F2); Д£. t = E(F) - E(F3); Д£< = E(F) - £(Д).
Предположим, что Д£3 = пнп(Д£), тогда £(1) = F - j\.
F Ja}; £,(,) = {h }; f2(1) = {/i ,/•>}; f3(,) = {/. }•
Д£, = £(£(,)) - £(£/”); Д£2 = £(£(l)) - £(£2(l)); A£3 = £(£(,)) - E{F^).
Предположим, что Д£2 = min(A£),тогда f(2) = £(l) -/2.
F^ = {f.,h}-,F^ = {f,}-F^ = {/,}.
A£i = £(£<2)) - £(£t(2>); Д£2 = £(£(2)) - E(F^).
Предположим, что Д£1 = пйп(Д£), тогда £(3) = £(1) - /3 = {/,}.
Глава 5. Очистка и предобработка данных 267
Итак, мы установили, что при сокращении одного признака результирующим подмноже-
ством, наиболее близким к начальному, будет {/ь/2,/ч}, при сокращении двух призна-
ков — {/i ,Уз}, при сокращении трех — {/, }. То есть оптимальный порядок сокращения
признаков следующий: ft, fi, ft.
Данный алгоритм можно использовать в двух режимах — в режиме сокращения
п в режиме отбора признаков. В режиме сокращения определяется, какие признаки
можно сократить с минимальной потерей информации относительно исходного
множества. Нужно выполнить алгоритм полностью (пока в результирующем
подмножестве не останется один признак), а затем сократить столько признаков,
сколько возможно без существенного ухудшения результатов анализа. Определять
степень влияния сокращения признаков на результаты анализа в большинстве
случаев приходится экспериментально.
Режим сокращения имеет существенный недостаток, поскольку необходима пол-
ная проверка всех подмножеств, полученных в результате сокращения признаков.
Если число признаков и записей исходного множества велико, то могут потребовать-
ся значительные вычислительные и временные затраты, что не всегда приемлемо.
Режим отбора предполагает, что анализируются не все подмножества, полу-
ченные в результате сокращения признаков, а только те, разность энтропии кото-
рых по сравнению с исходным множеством не превышает заданного порога. Как
только порог будет достигнут, выполнение алгоритма остановится, а отобранные
в результате признаки, как ожидается, будут нести в себе достаточно информации
для проведения анализа с приемлемым качеством. Значение порога в большинстве
случаев также определяется экспериментально.
Корреляционный анализ
Для количественной оценки связи между двумя случайными величинами исполь-
зуется корреляционный анализ. В математике зависимость между двумя вели-
чинами х и у выражается с помощью функции у = f(x), где каждому возможному
значению X ставится в соответствие не более одного значения Y (так называемая
функциональная зависимость).
Важным частным случаем зависимости является корреляционная. Корреляци-
онная связь чаще всего характеризуется выборочным коэффициентом корреля-
ции г, который отражает степень линейной функциональной зависимости между
случайными величинами X и Y. Для двух случайных величин X и Y коэффициент
корреляции имеет следующие свойства:
□ -1<г<1;
□ если г = ±1, то между X и Y существует функциональная линейная зависи-
мость;
□ если г = 0, то X и У не коррелированы, что не означает независимости вообще
(может иметь место нелинейная зависимость);
□ коэффициенты корреляции Y на X и X на Y совпадают.
268 Часть I. Теория бизнес-анализа
Как корреляционный анализ может помочь в сокращении признаков? Принцип
корреляционного анализа состоит в поиске таких факторов, которые в наименьшей
степени коррелированы (взаимосвязаны) с выходным результатом. Эти факторы
могут быть исключены из результирующего набора данных практически без потери
полезной информации. Метод также применяется для поиска среди входных при-
знаков таких пар, между которыми существует функциональная линейная зависи-
мость. В этом случае из двух признаков целесообразно оставить только один.
На практике считается, что если корреляция больше 0,6, то связь между двумя
признаками очень высока, если меньше 0,3 — зависимость отсутствует, промежу-
точные значения констатируют наличие определенной связи.
Метод главных компонент
Другим популярным методом сокращения размерности исходных данных является
метод главных компонент (principal component analysis). Он заключается в преоб-
разовании исходного множества данных X, представленных векторами значений
признаков, в другое множество У, где данные будут представлены векторами мень-
шей размерности. То есть метод можно рассматривать как сокращение размерно-
сти векторов признаков, описывающих объекты классификации, кластеризации
и других задач анализа. Цель данного преобразования — сконцентрировать всю
информацию о различиях между наблюдениями в небольшом числе признаков.
Преобразование из X в У основано на предположении, что самыми информатив-
ными являются признаки, обеспечивающие наибольшую изменчивость исходных
данных. Мерой изменчивости служит дисперсия векторов признаков. Необходимо
найти признак, который «берет» на себя большую часть дисперсии набора данных.
При этом предполагается, что он унаследует и большую часть информации, содер-
жащейся в наборе. Такой признак называется главной компонентой.
Задача заключается в последовательном поиске главных компонент, макси-
мальное количество которых равно числу признаков исходного множества. Тогда
первая главная компонента будет занимать первое место по информационной
нагрузке, вторая — второе и т. д. Таким образом, последние главные компоненты
будут наименее информативны и могут быть исключены из рассмотрения как
незначимые, что приведет к сокращению пространства признаков с минимальной
потерей информации.
ЗАМЕЧАНИЕ---------------------------------------------------------------
Каждая главная компонента представляет собой новый признак, который не связан ни с од-
ним из исходных признаков, а является их линейной комбинацией. Поэтому при дальнейшем
анализе может потребоваться интерпретировать новые признаки, полученные на основе
главных компонент, наполнить их новой логикой и смыслом. Например, интерпретация новых
признаков может быть проведена на основе их корреляции с исходными признаками.
Процесс определения главных компонент заключается в построении новой оси
многомерного пространства признаков, совпадающей с направлением, вдоль которо-
го дисперсия векторов признаков максимальна. Как только эта ось будет построена,
Глава 5. Очистка и предобработка данных 269
базовая система координат поворачивается таким образом, чтобы одна из ее осей
совпала с новой осью. Она и образует первую главную компоненту (рис. 5.19).
Рис. 5.19. Метод главных компонент
На рисунке система координат (х, у, z) соответствует исходному пространству
признаков. После того как будет найдено направление, совпадающее с максималь-
ной дисперсией векторов признаков, система координат повернется так, чтобы
ось у стала ориентирована вдоль этого направления, образуя первую главную ком-
поненту. При этом образуется новая система координат (х7, у', z'). Затем процедура
повторяется до тех пор, пока все оси не окажутся ориентированы в направлении
соответствующих главных компонент.
Закономерен вопрос: сколько главных компонент понадобится для исчерпы-
вающего описания исходных данных? Для ответа проще всего проанализировать
долю дисперсии, которую вносит каждая компонента в общую дисперсию набо-
ра признаков. Выразив долю дисперсии в процентах, можно установить порог,
называемый порогом значимости. Все признаки, доля которых в общей дисперсии
меньше порога значимости, считаются имеющими низкую значимость и подлежат
сокращению.
На практике порог значимости выбирается экспериментально исходя из необхо-
димой точности результатов. Увеличивая значение порога, мы тем самым ужесточа-
ем требования к модели. При этом модель становится более точной, но возрастают
вычислительные затраты и время на обработку данных. Обычно ищут компромисс
между уровнем снижения размерности исходных данных, адекватностью аналити-
ческой модели, а также вычислительными и временными затратами на обработку.
270 Часть I. Теория бизнес-анализа
5.10. Сокращение числа значений
признаков и записей
При сокращении размерности исходных данных основное внимание уделяется умень-
шению числа признаков, используемых для анализа. И это оправданно, поскольку
именно исключение избыточных и незначащих признаков позволяет наиболее эф-
фективно упростить аналитическую модель, сделать ее понятной для пользователя
и повысить интерпретируемость результатов анализа. Но иногда уменьшить число
признаков без существенного ухудшения результатов анализа не удается. Или же, не-
смотря на то что незначащие и избыточные признаки были исключены, размерность
данных все еще остается очень большой с точки зрения вычислительных и времен-
ных затрат на аналитическую обработку и требований к доступному объему памяти.
В этом случае проблему большой размерности исходных данных можно попытаться
решить, сократив разнообразие значений признаков и записей (примеров).
Сокращение числа значений признака
Сокращение числа разнообразных значений признаков обычно связано с измене-
нием интервала дискретизации значений. Задача заключается в уменьшении числа
значений исходного набора данных за счет их объединения в пределах некоторого
интервала и присвоения этому интервалу определенного символа или значения.
В результате такого преобразования число значений признака, которые нужно
обработать в процессе анализа, должно уменьшиться без существенного ущерба
для информативности данных. Во многих случаях дополнительным выигрышем
от такой обработки является упрощение описания исследуемых объектов.
Обратим внимание, что уменьшается не само количество значений признака,
а количество его уникальных значений. Например, если признак содержал 1000 зна-
чений в диапазоне от 9,5 до 10,4, то простое округление позволит преобразовать
все эти значения к 10. То есть само количество значений признака останется без
изменений, а вот количество уникальных значений уменьшится.
Обычно такая операция производится вручную на основе некоторых априор-
ных знаний об исследуемом объекте или процессе. Например, возраст человека,
заданный как непрерывный ряд в интервале от 0 до 100, может быть разделен на
интервалы по категориям: ребенок, подросток, зрелый возраст, средний возраст,
пожилой возраст и т. д. (рис. 5.20).
Рис. 5.20. Квантование значений признака
Глава 5. Очистка и предобработка данных 271
Без некоторого априорного знания о признаке, значения которого требуется со-
кратить, выбор интервалов является проблемой. Например, если речь идет о возрасте
человека, то нужно иметь представление о точках (возрасте), когда происходит
смена возрастного статуса. Границы возрастных переходов условны.
Сокращение количества значений признаков обычно не вредит практическим
задачам анализа и в то же время позволяет добиться существенного уменьшения
вычислительных и временных затрат на аналитическую обработку данных.
Если количество различных значений признака может быть уменьшено, то ка-
чество анализа, проводимого с помощью некоторых методов Data Mining, особенно
основанных на выявлении логических правил (например, деревья решений), может
улучшиться.
Предположим, что признак ограничен некоторым диапазоном числовых значе-
ний, которые могут быть упорядочены по возрастанию с использованием обычных
операторов «больше чем» или «меньше чем». Это естественным образом ведет
к концепции объединения соседних значений в группы, или интервалы объедине-
ния, называемые винами (bin).
Все значения объединяются в интервалы по единому правилу, а именно:
заменяются значениями верхней или нижней границ интервала, модой (ста-
тистически наиболее вероятное значение), средней или медианой, категорией
и т. д. Использование среднего значения или моды наиболее эффективно при
среднем или большом количестве интервалов объединения, а значений границ
интервала — при малом.
ПРИМЕР--------------------------------------------------------------------
Пусть имеется множество значений некоторого признака {3,2,1,5,4,3,1,7,5,3}. После
упорядочения последовательность примет вид {1,1, 2,3,3,3,4,5,5, 7}.
Сначала можно разбить все множество на три группы по степени близости значений.
1, 1, 2
3, 3, 3
4, 5, 5, 7
BIN,
BIN,
BIN,
На следующем этапе для каждой группы выбирается представление. Например, можно
использовать наиболее вероятное значение в группе (моду).
1,1,1 3, 3,3 5, 5, 5, 5
BIN, BIN, BIN, Можно использовать среднее значение и т. д.
1,33, 1,33,1,33 3 3,3 5,25, 5,25, 5,25, 5,25
BIN,
BIN.
BIN.
Hl
часть I. Теория бизнес-анализа
Главная проблема данного метода — поиск точек среза для групп. Теоретически
разбиение на группы не может быть выполнено независимо от других признаков
Тем не менее эвристическое решение для каждого признака в отдельности во мно-
гих задачах анализа дает хорошие результаты.
Задача сокращения числа значений может рассматриваться как задача опти-
мизации в выборе k групп: дано число групп k, которое должно распределять зна-
чения в группах таким образом, чтобы минимизировать расстояние от значения
до среднего или медианы группы, в которую это значение попало. Это расстояние
обычно определяется как квадрат расстояния для среднего по группе и как модуль
расстояния для медианы. Упрощенная модификация такого алгоритма содержит
следующие шаги.
1. Сортируются все значения данного признака.
2. Задается приблизительно равное количество смежных значений о, для каждой
группы; число групп задано заранее.
3. Граничный элемент о, перемещается из своей группы в следующую или преды-
дущую, если это уменьшает общую ошибку расстояния — сумму расстояний от
значения до средней или моды соответствующей группы.
ПРИМЕР-------------------------------------------------------------------------
Пусть задан набор значений f— {5, 1, 8, 2, 2, 9, 2, 1, 8, 6}. Разделим их на три группы
(k = 3). На первой итерации алгоритма будут выполнены следующие вычисления.
1. Множество / сортируется в порядке возрастания: {1, 1, 2, 2, 2, 5, 6,8, 8,9}.
2. Упорядоченное множество разделяется на три группы: {(1,1,2); (2,2, 5); (6, 8, 8,9)}.
3. Определяются моды групп (в данном случае это наиболее часто встречающиеся
значения): {1, 2, 8}. Тогда общая ошибка расстояния рассчитывается следующим
образом:
£ = |1-1| + |1-1| + |2-1| + |2-2| + |2-2|+|5-2| + |6-8| + |8-8| +
+|8-8| + |8-9| = 0 + 0 + 14-0 + 0 + 3 + 2 + 0 + 0 + 1 = 7.
Как видно, большую долю в общей ошибке расстояния вносят значение 5 во второй
группе, где мода равна 2, и значение 6 в третьей группе, где мода равна 8, что в итоге
дает долю ошибки 5 из 7. Для уменьшения ошибки очевидной является следующая пе-
рестановка:
{(1,1, 2); (2, 2, 5); (6, 8, 8, 9)} -> {(1,1, 2, 2, 2); (5, 6); (8, 8, 9)}.
Она даст набор мод {2, 5, 8} и обеспечит ошибку Е = 2 +1 + 1 = 4. Любое дополни-
тельное перемещение значений между группами вызовет увеличение ошибки. Таким
образом, указанное распределение значений по группам и будет оптимальным для дан-
ной задачи.
{1,1,2 2, 2, 5 6, 8, 8, 9)
// /
{1, 1, 2, 2, 2 5, 6 8, 8, 9}
Глава 5. Очистка и предобработка данных 273
5.11. Сэмплинг
Сущность сэмплинга
При сборе и консолидации данных в хранилищах данных могут накапливаться
огромные массивы информации. Обычно она касается бизнес-процессов, протека-
ющих в компании и иногда во внешнем ее окружении. Когда возникает необходи-
мость выполнить анализ некоторых данных с целью получения новых знаний о свя-
занном с этими данными процессе или объекте, аналитик сталкивается с проблемой
выбора: что именно использовать для анализа. Здесь возможны два варианта:
□ использовать для анализа все имеющиеся данные;
□ выбрать из всего множества имеющихся данных некоторое подмножество и на
основе анализа этого подмножества попытаться сделать выводы о свойствах
исследуемого процесса или объекта.
Оба подхода имеют свои преимущества и недостатки. Использование всего
множества имеющихся данных позволит обеспечить максимальную достоверность
результатов анализа, поскольку при этом будет учтена вся доступная информация.
Но на практике этот подход реализовать проблематично, поскольку объем анали-
зируемых данных может оказаться настолько большим, что время и вычислитель-
ные ресурсы, требуемые для анализа, выйдут за все мыслимые рамки. В итоге пре-
имущества, полученные в результате анализа данных, будут обесценены. Никому
не понравится, если информационная система компании окажется парализована
на несколько часов из-за того, что сервер, на котором установлена аналитическая
платформа, занимается анализом набора данных, состоящего из сотен миллионов
записей. Однако следует отметить, что если ценность ожидаемых результатов ана-
лиза очень высока, а временные ограничения на его проведение некритичны, то,
возможно, следует использовать все доступные данные, не считаясь с затратами.
Главное преимущество второго подхода заключается в том, что анализируется
относительно небольшое подмножество данных. При этом временные и вычисли-
тельные затраты невысоки, что особенно важно для оперативного управления и пла-
нирования, когда управленческие решения, генерируемые на основе результатов
анализа, требуется получать практически в режиме реального времени. Недостаток
подхода в том, что, поскольку при анализе используется только часть доступной
информации, весьма вероятно снижение достоверности результатов анализа.
ПРИМЕР--------------------------------------------------------------
Аналогией, поясняющей данную ситуацию, является опрос общественного мнения с целью
получения информации для принятия решений в социально-политической сфере. Можно
провести опрос всего населения, но это очень долго и затратно. Поэтому чаще всего про-
водится выборочный опрос определенного числа респондентов и на основе их мнения
делаются выводы о настроении всего населения. Хотя если принимается очень важное
социально-политическое решение, которое может повлиять на все общество, прибегают
к опросу всего населения (референдуму), поскольку затраты в этом случае оправданны.
274 Часть I. Теория бизнес-анализа
На практике в бизнес-аналитике применяется второй метод, когда анализу
подвергаются не все имеющиеся данные, а только некоторое их подмножество. Это
обусловлено следующими причинами.
□ Стратегические решения, для обоснования которых необходимо привлечь мак-
симальное количество информации, принимаются достаточно редко. Намного
более востребованы решения в области оперативного управления и планиро-
вания, для которых нужна информация об отдельных аспектах и временных
интервалах деятельности компании. Поэтому для анализа с целью поддержки
принятия таких решений должны быть выбраны только данные, непосредствен-
но касающиеся исследуемой проблемы.
□ С точки зрения анализа решающую роль играет не количество данных, а их
информационная насыщенность. Например, можно проанализировать очень
большой массив данных, затратив на это много времени. Но если эти данные
слабо отражают искомые закономерности, то результаты анализа окажутся бес-
полезными. Напротив, анализируемое подмножество может быть компактным,
но при этом хорошо отражать поведение исследуемого процесса. В таком случае
анализ не займет много времени и даст хорошие результаты.
□ При решении некоторых задач анализа использование всех накопленных дан-
ных неприемлемо. Особенно это характерно для прогнозирования, когда долж-
ны использоваться только актуальные данные, а устаревшие — отбрасываться.
□ Трудоемкость некоторых алгоритмов Data Mining экспоненциально возрастает
с увеличением объема данных, поэтому обработка даже относительно небольших
выборок такими алгоритмами требует неприемлемо высоких временных затрат.
Существуют различные стратегии извлечения подмножеств наблюдений из
исходных множеств данных. Комплекс таких методов получил название «сэм-
плинг» (sampling). Приемлемый размер подмножества определяется исходя из
вычислительных затрат, доступного объема памяти, требуемой точности и других
характеристик алгоритма и данных.
Место сэмплинга в общем процессе анализа данных можно пояснить с помощью
схемы, представленной на рис. 5.21.
Рис. 5.21. Место сэмплинга в процессе анализа данных
Глава 5. Очистка и предобработка данных 275
Таким образом, в большинстве случаев при подготовке данных к анализу из
вСего имеющегося в распоряжении аналитика множества данных выбирается не-
которое подмножество, на основе которого и пытаются получить нужное решение.
Сэмплинг обеспечивает оперативность выполнения анализа при приемлемых
вычислительных затратах.
Проблема репрезентативности
Используемое для анализа подмножество данных должно быть репрезентатив-
ным, то есть в достаточной мере отражать свойства всего множества данных
и, соответственно, связанного с ним процесса или объекта.
Вернемся к аналогии с опросом общественного мнения. Достаточно ли при
опросе на тему «Как вы оцениваете уровень жизни в стране?» ограничиться
респондентами, живущими в элитном поселке или, наоборот, имеющими доход
ниже прожиточного минимума? Очевидно, что и в том и в другом случае, не-
зависимо от числа опрошенных, мы получим искаженную картину, поскольку
исследуемая выборка окажется нерепрезентативной. При опросе общественного
мнения респондентов отбирают по специальной методике, которая позволяет
охватить все социальные слои населения и сферы деятельности. И только то-
гда результаты опроса будут отражать мнения и настроения большинства, что
позволит принимать обоснованные решения в социально-политической и госу-
дарственной сфере.
Точно так же обстоит дело и с выбором подмножества данных для анализа.
При этом необходимо соблюдать следующий принцип: анализируемое подмно-
жество должно быть выбрано таким образом, чтобы результаты его анализа не
сильно отличались от результатов, которые были бы получены при анализе всего
множества доступных данных. Добиться этого можно только путем применения
соответствующих методов сэмплинга.
Цели и задачи сэмплинга
Понятие «сэмплинг» выходит за рамки технологий анализа. В более общем смысле
под сэмплингом понимают отбор некоторого набора объектов (товаров, продук-
тов, изделий, респондентов и т. д.), выделяемых в отдельную группу с какой-либо
целью. Например, респонденты отбираются с целью опроса, товары — в группу
наиболее популярных и т. д.
Чтобы применить понятие сэмплинга к анализу данных, введем несколько
сопутствующих терминов.
ОПРЕДЕЛЕНИЕ-------------------------------------------------------
Совокупность (population) — множество всех данных, описывающих некоторый объект или
процесс, которые могут быть использованы для анализа с целью получения новых знаний
об этом объекте или процессе.
276 Часть I. Теория бизнес-анализа
ОПРЕДЕЛЕНИЕ
Выборка (sample) — подмножество данных, формируемое путем отбора из совокупности
с целью анализа. Для обеспечения достоверности результатов анализа полученная выборка
должна быть репрезентативной, то есть в достаточной мере отражать свойства и характе-
ристики совокупности.
ОПРЕДЕЛЕНИЕ
Сэмплинг (sampling) — процесс отбора из исходной совокупности данных выборки, пред-
ставляющей интерес для анализа. При реализации сэмплинга используются специальные
методы отбора, которые должны обеспечить репрезентативность выборки с точки зрения
решаемой задачи.
Итак, в контексте нашего рассмотрения сэмплинг представляет собой процесс
отбора из исходного множества данных (совокупности) некоторого подмножест-
ва (выборки) для анализа. Конечной целью сэмплинга является сведение задачи
анализа всех доступных данных, что требует больших (часто неприемлемых) вре-
менных и вычислительных затрат, к анализу ограниченной выборки, в достаточной
мере отражающей свойства всей исследуемой совокупности. Для обеспечения ре-
презентативности выборки сэмплинг использует специальные методы и алгоритмы
отбора, способствующие обеспечению ее информационной насыщенности.
Методы сэмплинга
Равномерный случайный сэмплинг (uniform random sampling). Все записи ис-
ходной совокупности разделяются на группы, в каждой из которых содержится
одинаковое число записей (например, 100). Затем из каждой группы случайным
образом выбирается одна запись и помещается в результирующую выборку. Вы-
борка, полученная в результате сэмплинга, будет состоять из записей, случайным
образом отобранных из каждой группы.
Эта методика проиллюстрирована на рис. 5.22. Слева представлена исходная
совокупность данных, разбитая на группы по пять записей, справа — выборка,
составленная из записей, случайным образом выбранных из каждой группы.
Количество групп, на которые следует разбить исходную совокупность, зависит
от общего числа записей в ней и числа записей, из которых должна состоять резуль-
тирующая выборка. Размер результирующей выборки, в свою очередь, зависит от
особенностей решаемой задачи.
Иногда применяется более простой вариант случайного сэмплинга, когда исход-
ная совокупность не разбивается на подгруппы, а выборка производится случай-
ным образом из всей совокупности (но в ряде случаев это делает результирующую
выборку менее равномерной).
Основные преимущества данного метода — простота и эффективность. Главный
его недостаток заключается в том, что, если исходная совокупность не является
гомогенной, то есть содержит разного размера группы, в каждой из которых данные
имеют различное распределение, это может привести к получению смещенной
Глава 5. Очистка и предобработка данных 277
Сумма Срок
род Дата кредита кредита
1 01.02.2003 7000 6
2 01.02.2003 7500 6
3 01.02.2003 14 500 12
4 01.02.2003 15 000 6 \
5 01.02.2003 32 000 12
6 01.02.2003 11 500 6
7 01.02.2003 5000 6 Я Код Дата Сумма Срок
8 01.02.2003 61 500 30 кфВл А М кредита кредита
9 01.02.2003 13 500 12 ~-^Л2 ч1 02.2003 7500 6
Ю 01.02.2003 25 000 18 ^9 01.02.2003 13 500 12
11 01.02.2003 25 500 24 J13 01.02.2003 53 000 24
12 01.02.2003 9500 6 19 02.02.2003 8500 6
13 01.02.2003 53 000 24
14 02.02.2003 27 500 18
15 02.02.2003 4000 6
16 02.02.2003 40 500 26
17 02.02.2003 51 500 36
18 02.02.2003 7000 6
19 02.02.2003 8500 6
20 02.02.2003 23 500 12
Рис. 5.22. Равномерный случайный сэмплинг
выборки. Смещенной называется выборка, которая представляет исходную сово-
купность не вполне достоверно. Например, если в исходной совокупности объекты
классов А, В и С содержатся в приблизительно одинаковых пропорциях и, соот-
ветственно, имеют одинаковую вероятность быть выбранными, то в смещенной
выборке могут преобладать объекты класса А, что неминуемо приведет к некор-
ректным результатам анализа.
Если исходная совокупность существенно неоднородна, случайный сэмплинг
работает плохо и лучших результатов удается добиться, если использовать другие
методы сэмплинга, такие как стратификационный и кластерный.
Стратификационный сэмплинг. Название метода происходит от английского
слова stratified, что в переводе означает «слоистый». Когда исходная совокупность
существенно неоднородна, наилучших результатов удается добиться, если про-
изводить выборку из каждой группы независимо от других групп. Такие группы
называются стратами, или слоями (от англ, strata — «слой»).
Стратификационный сэмплинг выполняется в два этапа.
□ Стратификация — группировка элементов исходной совокупности в относи-
тельно однородные подгруппы, которые и называются слоями.
□ Случайный сэмплинг — случайная выборка из каждого слоя по отдельности.
Слои должны быть взаимоисключающими, то есть каждый элемент исходной
совокупности включается только в один слой. Кроме того, слои должны быть исчер-
пывающими: ни один из элементов совокупности не должен быть пропущен.
278 Часть I. Теория бизнес-анализа
Схематично процесс стратификацион-
ного сэмплинга показан на рис. 5.23.
Основной проблемой стратификаци-
онного сэмплинга является определение
состава слоев и размера выборки, извле-
каемой из каждого слоя.
Как правило, для определения состава
слоев необходимо использовать некото-
рую априорную информацию об исходной
совокупности, а также учитывать характер
задачи, для решения которой формиру-
ется выборка. Например, если речь идет
о товаре, то в качестве слоев могут быть
выбраны группы товаров, категории по
степени популярности, местам хранения
и т. д. При анализе сотрудников фирмы
критериями могут быть пол, возраст, стаж
и характер выполняемой работы. В боль-
шинстве случаев при таком построении
слоев достигается главная цель стратифи-
кации: в каждом слое содержатся равно-
мерно распределенные данные. Действи-
тельно, товары в пределах одной группы
обычно характеризуются одним ценовым
диапазоном и схожими потребительски-
Исходная совокупность
Рис. 5.23. Схема стратификационного
сэмплинга
ми свойствами, поэтому распределение их
признаков в пределах группы (слоя) будет, скорее всего, достаточно равномерным.
Что касается размеров выборок, извлекаемых из каждого слоя, то здесь возмож-
ны две стратегии.
□ Пропорциональное распределение. В каждом из слоев используется так называ-
емая выборочная доля, пропорциональная составу всей исходной совокупности.
Например, если совокупность содержит 60 % товаров группы А и 40 % товаров
группы В, то относительный объем двух слоев должен отражать эту пропорцию
(три товара группы А, два товара группы В).
□ Оптимальное распределение. Размер выборки, извлекаемой из слоя, пропорцио-
нален стандартному отклонению распределения некоторой переменной (напри-
мер, цены). Наибольшие выборки берутся в слое с большей вариабельностью.
ПРИМЕР----------------------------------------------------------------
Размер выборки, извлекаемой из каждого слоя, пропорционален размеру этого слоя. Это
и называется пропорциональным распределением. Предположим, что требуется проана-
лизировать совокупность, состоящую из 500 наименований товаров, которые разбиты на
4 группы (слоя):
Глава 5. Очистка и предобработка данных 279
• мясные продукты — 250 наименований;
• молочные продукты — 125 наименований;
• соки и прохладительные напитки — 50 наименований;
• морепродукты — 75 наименований.
Пусть требуется получить выборку, состоящую из 40 товаров, стратифицированных по ука-
занным выше категориям. На первом шаге определим общее число товаров (500) и вычис-
лим процентную долю, которую составляет каждая группа:
• мясные продукты — (250/500) 100 = 50 %;
• молочные продукты — (125/500) • 100 = 25 %;
• соки и прохладительные напитки — (50/500) • 100 = 10 %;
• морепродукты — (75/500) • 100 = 15 %.
Тогда в результирующей выборке из 40 товаров указанные группы должны быть представ-
лены следующим образом:
• мясные продукты — 50 %, или 20 наименований;
• молочные продукты — 25 %, или 10 наименований;
• соки и прохладительные напитки — 10 %, или 4 наименования;
• морепродукты — 15 %, или 6 наименований.
Таким образом, при использовании пропорционального распределения выборка,
полученная в результате стратификационного сэмплинга, оказывается уменьшенной
копией исходной совокупности.
Иногда исследователи сталкиваются с ситуацией, когда важные с точки зрения
решаемой задачи объекты или события представлены очень небольшим числом
наблюдений, что не позволяет выполнить их достоверный анализ. В рассмотренном
выше примере в подобной ситуации оказывается группа товаров «Морепродукты»,
представленная после сэмплинга всего шестью наименованиями. В таких случаях
применяется искусственное усиление представительства редких событий или
объектов выборки с помощью диспропорционального сэмплинга. Например, если
потребуется усилить представительство товаров группы морепродуктов в два раза,
то соответствующие данные можно добавить из исходной совокупности. Но ис-
кусственная диспропорция может исказить результаты анализа выборки. Чтобы
этого не произошло, остальным группам товаров можно назначить веса, которые
позволят сбалансировать диспропорцию и скорректировать результаты анализа.
ПЕРСОНАЛИИ -----------------------------------------------------------------
Шеннон Клод Элвуд (Shannon Claude Elwood (1916-2001)) — американский математик
и электротехник, один из создателей математической теории информации. Результаты его
работы в значительной мере предопределили развитие общей теории дискретных автома-
тов, которые являются важными составляющими кибернетики.
В 1936 г. окончил Мичиганский университет. После защиты диссертации (1940) в 1941 г.
поступил на работу в знаменитые лаборатории Белла. С1956 г. преподавал в МТИ.
В1948 г. опубликовал фундаментальный труд A Mathematical Theory of Communication, в кото-
ром сформулированы основы теории информации. Ввел понятие энтропии — количественной
280 Часть I. Теория бизнес-анализа
характеристики меры информации. На энтропии основаны многие алгоритмы анализа данных,
особенно методы Data Mining. Примером служит известный алгоритм ID3, применяемый для
построения деревьев решений.
Даниэль Т. Ларос (Daniel Т. Larose) — профессор, защитил докторскую диссертацию в 1996 г.
Ларос возглавляет направление Data Minings Центральном университете штата Коннектикут
(Central Connecticut State University, CCSU), в том числе руководит первой в мире маги-
стерской онлайн-программой по Data Mining. Занимается консультированием в области
анализа данных, статистического анализа и Data Mining. Автор нескольких книг: Discovering
Knowledge In Data (2005), Data Mining Methods And Models (2006), Data Mining The Web
(2007).
Домашняя страница Даниэля Лароса: http://www.math.ccsu.edu/larose.
Николай Григорьевич Загоруйко — доктор технических наук, профессор, один из ведущих
отечественных специалистов по машинному обучению, методам автоматической очистки
данных. Его работы в области анализа данных и распознавания образов имеют всемир-
ную известность. Более 30 лет ведет активную педагогическую деятельность: читает курсы
лекций по искусственному интеллекту и анализу данных в Новосибирском государственном
университете и ряде зарубежных университетов. Участвует в международных и всероссий-
ских научных конференциях, является членом советов по защите диссертаций. Н. Г. Заго-
руйко — автор более 190 научных работ, в том числе и монографий.
С i960 г. работает в Институте математики СО РАН (Новосибирск). В СССР и РФ большую извест-
ность получили его книги «Прикладные методы анализа данных и знаний» (1999), «Алгоритмы
обнаружения эмпирических закономерностей» (1985, соавторы Л. Б. Елкина и Г. С. Лбов).
Data Mining:
задача ассоциации
6.1. Ассоциативные правила
Аффинитивный анализ (affinity analysis) — один из распространенных методов Data
Mining. Его название происходит от английского слова affinity, которое в переводе
означает «близость», «сходство». Цель данного метода — исследование взаимной
связи между событиями, которые происходят совместно. Разновидностью аффи-
нитивного анализа является анализ рыночной корзины (market basket analysis), цель
которого — обнаружить ассоциации между различными событиями, то есть найти
правила для количественного описания взаимной связи между двумя или более
событиями. Такие правила называются ассоциативными правилами (association
rules).
Примерами приложения ассоциативных правил могут быть следующие задачи:
□ выявление наборов товаров, которые в супермаркетах часто покупаются вместе
или никогда не покупаются вместе;
□ определение доли клиентов, положительно относящихся к нововведениям в их
обслуживании;
□ определение профиля посетителей веб-ресурса;
□ определение доли случаев, в которых новое лекарство оказывает опасный по-
бочный эффект.
Базовым понятием в теории ассоциативных правил является транзакция — не-
которое множество событий, происходящих совместно. Типичная транзакция —
приобретение клиентом товара в супермаркете. В подавляющем большинстве
случаев клиент покупает не один товар, а набор товаров, который называется ры-
ночной корзиной. При этом возникает вопрос: является ли покупка одного товара
282 Часть I. Теория бизнес-анализа
в корзине следствием или причиной покупки другого товара, то есть связаны ли
данные события? Эту связь и устанавливают ассоциативные правила. Например,
может быть обнаружено ассоциативное правило, утверждающее, что клиент, ку-
пивший молоко, с вероятностью 75 % купит и хлеб.
Следующее важное понятие — предметный набор. Это непустое множество
предметов, появившихся в одной транзакции.
Анализ рыночной корзины — это анализ наборов данных для определения ком-
бинаций товаров, связанных между собой. Иными словами, производится поиск
товаров, присутствие которых в транзакции влияет на вероятность наличия других
товаров или комбинаций товаров.
Современные кассовые аппараты в супермаркетах позволяют собирать информа-
цию о покупках, которая может храниться в базе данных. Затем накопленные данные
могут использоваться для построения систем поиска ассоциативных правил.
В табл. 6.1 представлен простой пример, содержащий данные о рыночной
корзине. В каждой строке указывается комбинация продуктов, приобретенных за
одну покупку. Хотя на практике приходится иметь дело с миллионами транзакций,
в которых участвуют десятки и сотни различных продуктов, пример ограничен
10 транзакциями, содержащими 13 видов продуктов: чтобы проиллюстрировать
методику обнаружения ассоциативных правил, этого достаточно.
Таблица 6.1. Пример набора транзакций
№ Транзакция
1 Сливы, салат, помидоры
2 Сельдерей, конфеты
3 Конфеты
4 Яблоки, морковь, помидоры, картофель, конфеты
5 Яблоки, апельсины, салат, конфеты, помидоры
6 Персики, апельсины, сельдерей, помидоры
7 Фасоль, салат, помидоры
8 Апельсины, салат, морковь, помидоры, конфеты
9 Яблоки, бананы, сливы, морковь, помидоры, лук, конфеты
10 Яблоки, картофель
Визуальный анализ примера показывает, что все четыре транзакции, в которых
фигурирует салат, также включают помидоры и что четыре из семи транзакций,
содержащих помидоры, также содержат салат. Салат и помидоры в большинстве
случаев покупаются вместе. Ассоциативные правила позволяют обнаруживать
и количественно описывать такие совпадения.
Ассоциативное правило состоит из двух наборов предметов, называемых усло-
вием (antecedent) и следствием (consequent), записываемых в виде X —> Y, что чита-
ется так: «Из Xследует У». Таким образом, ассоциативное правило формулируется
в виде: «Если условие, то следствие».
Условие может ограничиваться только одним предметом. Правила обычно
отображаются с помощью стрелок, направленных от условия к следствию, напри-
Глава 6. Data Mining: задача ассоциации 283
^ер, помидоры —> салат. Условие и следствие часто называются соответственно
левосторонним (left-hand side — LHS) и правосторонним (right-hand side — RHS)
компонентами ассоциативного правила.
Ассоциативные правила описывают связь между наборами предметов, соответ-
ствующими условию и следствию. Эта связь характеризуется двумя показателя-
ми — поддержкой (support) и достоверностью (confidence).
Обозначим базу данных транзакций как D, а число транзакций в этой базе —
как N. Каждая транзакция Z), представляет собой некоторый набор предметов.
Обозначим через S поддержку, через С — достоверность.
Поддержка ассоциативного правила — это число транзакций, которые содержат
как условие, так и следствие. Например, для ассоциации А —> В можно записать:
,, ,. т количество транзакций, содержащих А и В
S (А В) = Р(А Г\В) =--------------------------------з------.
общее количество транзакции
Достоверность ассоциативного правила А —> В представляет собой меру точ-
ности правила и определяется как отношение количества транзакций, содержащих
и условие, и следствие, к количеству транзакций, содержащих только условие:
С(А^В)^Р(В\А') = Р{АпВ)/Р(А) =
количество транзакций, содержащих А и В
количество транзакций, содержащих только А'
Если поддержка и достоверность достаточно высоки, можно с большой веро-
ятностью утверждать, что любая будущая транзакция, которая включает условие,
будет также содержать и следствие.
Вычислим поддержку и достоверность для ассоциаций из табл. 6.1.
Возьмем ассоциацию салат —> помидоры. Поскольку количество транзакций,
содержащих как салат, так и помидоры, равно 4, а общее число транзакций — 10,
то под держка данной ассоциации будет:
S (салат —> помидоры) = 4/10 = 0,4.
Поскольку количество транзакций, содержащих только салат (условие), рав-
но 4, то достоверность данной ассоциации будет:
(Дсалат —> помидоры) = 4/4 = 1.
Иными словами, все наблюдения, содержащие салат, также содержат и поми-
доры, из чего делаем вывод о том, что данная ассоциация может рассматриваться
как правило. С точки зрения интуитивного поведения такое правило вполне
объяснимо, поскольку оба продукта широко используются для приготовления
растительных блюд и часто покупаются вместе.
Теперь рассмотрим ассоциацию конфеты —> помидоры, в которой содержатся,
в общем-то, слабо совместимые в гастрономическом плане продукты: тот, кто ре-
шил приготовить растительное блюдо, вряд ли станет покупать конфеты, а тот, кто
желает приобрести что-нибудь к чаю, скорее всего, не станет покупать помидоры.
284 Часть I. Теория бизнес-анализа
Поддержка данной ассоциации: 5= 4/10 = 0,4, а достоверность: С= 4/6 = 0,67.
Таким образом, сравнительно невысокая достоверность данной ассоциации дает
повод усомниться в том, что она является правилом.
Аналитики могут отдавать предпочтение правилам, которые имеют только вы-
сокую поддержку или только высокую достоверность либо, что является наиболее
частым, оба этих показателя. Правила, для которых значения поддержки или до-
стоверности превышают определенный, заданный пользователем порог, называются
сильными правилами (strong rules). Например, аналитика может интересовать, какие
товары, покупаемые вместе в супермаркете, образуют ассоциации с минимальной
поддержкой 20 % и минимальной достоверностью 70 %. А при анализе с целью
обнаружения мошенничеств может потребоваться уменьшить поддержку до 1 %,
поскольку с мошенничеством связано сравнительно небольшое число транзакций.
Значимость ассоциативных правил
Методики поиска ассоциативных правил обнаруживают все ассоциации, которые
удовлетворяют ограничениям на поддержку и достоверность, наложенным поль-
зователем. Это приводит к необходимости рассматривать десятки и сотни тысяч
ассоциаций, что делает невозможным обработку такого количества данных вруч-
ную. Число правил желательно уменьшить таким образом, чтобы проанализировать
только наиболее значимые из них. Значимость часто вычисляется как разность
между поддержкой правила в целом и произведением поддержки только условия
и поддержки только следствия.
Если условие и следствие независимы, то поддержка правила примерно соот-
ветствует произведению поддержек условия и следствия, то есть SAB « SASB. Это
значит, что, хотя условие и следствие часто встречаются вместе, не менее часто они
встречаются и по отдельности. Например, если товар А встречался в 70 транзакци-
ях из 100, а товар В — в 80 и в 50 транзакциях из 100 они встречаются вместе, то,
несмотря на высокую поддержку (SAB = 0,5), это не обязательно правило. Просто
эти товары покупаются независимо друг от друга, но в силу их популярности часто
встречаются в одной транзакции. Поскольку произведение поддержек условия
и следствия SASB = 0,7 0,8 = 0,56, то есть отличается от SAB = 0,5 всего на 0,06,
предположение о независимости товаров А и В достаточно обоснованно.
Однако если условие и следствие независимы, то правило вряд ли представляет
интерес независимо от того, насколько высоки его поддержка и достоверность. На-
пример, если статистика дорожно-транспортных происшествий показывает, что из
100 аварий в 80 участвуют автомобили марки ВАЗ, то на первый взгляд это выгля-
дит как правило «если авария, то ВАЗ». Но если учесть, что парк автомобилей ВАЗ
составляет, скажем, 80 % от общего числа легковых автомобилей, то такое правило
вряд ли можно назвать значимым.
ПРИМЕР---------------------------------------------------------------
Рассмотрим проект Data Mining в области продаж, который призван объяснить связь между
покупками женского белья и других товаров. Простой ассоциативный анализ (рассматри-
Глава 6. Data Mining: задача ассоциации 285
вающий отдельные корзины закупок всех клиентов за год) обнаруживает с очень высокой
степенью поддержки и достоверности, что женское белье ассоциировано с конфетами.
Сначала это вызывает некоторое недоумение, но последующий анализ показывает, что все
основные категории товаров ассоциированы с конфетами с высоким уровнем достовер-
ности. Большинство клиентов покупают конфеты в любом случае. Ассоциации с конфетами
как следствием с поддержкой S = 0,87 оказываются малоинтересны, поскольку 87 % по-
купателей всегда приобретают конфеты. Чтобы быть значимой, ассоциация с конфетами
в качестве следствия должна иметь поддержку, большую чем 0,87.
По этой причине при поиске ассоциативных правил используются дополни-
тельные показатели, позволяющие оценить значимость правила. Можно выделить
объективные и субъективные меры значимости правил. Объективными являются
такие меры, как поддержка и достоверность, которые могут применяться незави-
симо от конкретного приложения. Субъективные меры связаны со специальной
информацией, определяемой пользователем в контексте решаемой задачи. Такими
субъективными мерами являются лифт (lift) и левередж (от англ, leverage — «пле-
чо», «рычаг»).
Лифт (оригинальное название — интерес) вычисляется следующим образом:
ЦАВ) = С(АB)/S(B).
Лифт — это отношение частоты появления условия в транзакциях, которые
также содержат и следствие, к частоте появления следствия в целом. Значения
лифта, большие чем 1, показывают, что условие чаще появляется в транзакциях,
содержащих следствие, чем в остальных. Можно сказать, что лифт является обоб-
щенной мерой связи двух предметных наборов: при значениях лифта больше 1
связь положительная, при 1 она отсутствует, а при значениях меньше 1 — отри-
цательная.
Рассмотрим ассоциацию помидоры —> салат из табл. 6.1.
А(салатп) = 4 /10 = 0,4; Цпомидоры —> салат) = 4/7 = 0,57.
Следовательно, Цпомидоры —> салат) = 0,57/0,4 = 1,425.
Теперь рассмотрим ассоциацию помидоры —> конфеты.
S (конфеты) — 0,6; Цпомидоры —> конфеты) = 4/7 = 0,57.
Тогда Цпомидоры —> конфеты) = 0,57/0,6 = 0,95.
Большее значение лифта для первой ассоциации показывает, что помидоры
больше влияют на частоту покупок салата, чем конфет.
Хотя лифт используется широко, он не всегда оказывается удачной мерой зна-
чимости правила. Правило с меньшей поддержкой и большим лифтом может быть
менее значимым, чем альтернативное правило с большей поддержкой и меньшим
лифтом, потому что последнее применяется для большего числа покупателей.
Значит, увеличение числа покупателей приводит к возрастанию связи между усло-
вием и следствием.
Другой мерой значимости правила, предложенной Г. Пятецким-Шапиро, явля-
ется левередж: Т(А —> В) = 5(Л —> В) — S(A)S(B).
Левередж — это разность между наблюдаемой частотой, с которой условие
и следствие появляются совместно (то есть поддержкой ассоциации), и произве-
дением частот появления (поддержек) условия и следствия по отдельности.
286 Часть I. Теория бизнес-анализа
Рассмотрим ассоциации морковь —> помидоры и салат —> помидоры, которые
имеют одинаковую поддержку С = 1, поскольку салат и морковь всегда прода-
ются вместе с помидорами (см. табл. 6.1). Лифты для данных ассоциаций так-
же будут одинаковыми, поскольку в обеих ассоциациях поддержка следствия
S (по мидоры) = 7/10 = 0,7.
Тогда Цморковь —> помидоры) = Цсалат —> помидоры) = 1 /0,7 = 1,43.
Последняя ассоциация представляет больший интерес, так как она встречается
чаще, то есть применяется для большего числа покупателей.
S (морковь —> помидоры) = 3/10 = 0,3; S (морковь) = 0,3; 5(помидоры) = 0,7.
Таким образом, Т(морковь —> помидоры) = 0,3 - 0,3 • 0,7 = 0,09.
5(салат —> помидоры) = 0,4; S (салат) = 0,4; 5(помидоры) = 0,7.
Следовательно, Т(салат —> помидоры) = 0,4 — 0,4 • 0,7 = 0,12.
Итак, значимость второй ассоциации больше, чем первой.
Иногда лифт, представляющий собой меру полезности ассоциативного прави-
ла, называют улучшением (improvement) и вычисляют подобно левереджу, только
берется не разность, а отношение наблюдаемой частоты и частот появления по от-
дельности:
’'А ° 5(Л)-5(»)'
Улучшение (лифт) показывает, полезнее ли правило случайного угадывания.
Если КА —> В) > 1, это значит, что вероятнее предсказать наличие набора В с по-
мощью правила, чем угадать случайно.
Такие меры, как лифт и левередж, могут использоваться для последующего огра-
ничения набора рассматриваемых ассоциаций путем установки порога значимости,
ниже которого ассоциации отбрасываются.
Поиск ассоциативных правил
В процессе поиска ассоциативных правил может производиться обнаружение
всех ассоциаций, поддержка и достоверность для которых превышают заданный
минимум. Простейший алгоритм поиска ассоциативных правил рассматривает
все возможные комбинации условий и следствий, оценивает для них поддержку
и достоверность, а затем исключает все ассоциации, которые не удовлетворяют
заданным ограничениям. Число возможных ассоциаций с увеличением числа
предметов растет экспоненциально. Если в базе данных транзакций присутствует
k предметов и все ассоциации являются бинарными (то есть содержат по одному
предмету в условии и следствии), то потребуется проанализировать k • 2к‘1 ассоци-
аций. Поскольку реальные базы данных транзакций, рассматриваемые при анализе
рыночной корзины, обычно содержат тысячи предметов, вычислительные затраты
при поиске ассоциативных правил огромны. Например, если рассматривать вы-
борку, содержащую всего 100 предметов, то количество ассоциаций, образуемых
этими предметами, составит 100 • 2" « 6,4 1031. Поиск ассоциативных правил
Глава 6. Data Mining: задача ассоциации 287
г1утем вычисления поддержки и достоверности для всех возможных ассоциаций
й сравнения их с заданным пороговым значением малоэффективен из-за больших
вычислительных затрат.
Поэтому в процессе генерации ассоциативных правил широко используются
методики, позволяющие уменьшить количество ассоциаций, которое требуется
проанализировать. Одной из наиболее распространенных является методика, ос-
нованная на обнаружении так называемых частых наборов, когда анализируются
только те ассоциации, которые встречаются достаточно часто. На этой концепции
основан известный алгоритм поиска ассоциативных правил Apriori.
6.2. Алгоритм Apriori
При практической реализации систем поиска ассоциативных правил используют
различные методы, которые позволяют снизить пространство поиска до размеров,
обеспечивающих приемлемые вычислительные и временные затраты, например
алгоритм Apriori (Agrawal и Srikant, 1994).
Частые предметные наборы и их обнаружение
В основе алгоритма Apriori лежит понятие частого набора (frequent itemset), ко-
торый также можно назвать частым предметным набором, часто встречающимся
множеством (соответственно, он связан с понятием частоты). Под частотой пони-
мается простое количество транзакций, в которых содержится данный предметный
набор. Тогда частыми наборами будут те из них, которые встречаются чаще, чем
в заданном числе транзакций.
ОПРЕДЕЛЕНИЕ--------------------------------------------------------
Частый предметный набор — предметный набор с поддержкой больше заданного порога
либо равной ему. Этот порог называется минимальной поддержкой.
Методика поиска ассоциативных правил с использованием частых наборов со-
стоит из двух шагов.
1. Следует найти частые наборы.
2. На их основе необходимо сгенерировать ассоциативные правила, удовлетво-
ряющие условиям минимальной поддержки и достоверности.
Чтобы сократить пространство поиска ассоциативных правил, алгоритм Apriori
использует свойство антимонотонности. Свойство утверждает, что если пред-
метный набор Z не является частым, то добавление некоторого нового предме-
та А к набору Z не делает его более частым. Другими словами, если Z не является
частым набором, то и набор Z и А также не будет являться таковым. Данное
полезное свойство позволяет значительно уменьшить пространство поиска ассо-
циативных правил.
288 Часть I. Теория бизнес-анализа
Пусть имеется множество транзакций, представленное в табл. 6.2.
Таблица 6.2. Множество транзакций
№ транзакции Предметные наборы —-—_
1 Капуста, перец, кукуруза
2 Спаржа, кабачки, кукуруза
3 Кукуруза, помидоры, фасоль, кабачки
4 Перец, кукуруза, помидоры, фасоль
5 Фасоль, спаржа, капуста
6 Кабачки, спаржа, фасоль, помидоры
7 Помидоры, кукуруза
8 Капуста, помидоры, перец
9 Кабачки, спаржа, фасоль
10 Фасоль, кукуруза
И Перец, капуста, фасоль, кабачки
12 Спаржа, фасоль, кабачки
13 Кабачки, кукуруза, спаржа, фасоль
14 Кукуруза, перец, помидоры, фасоль, капуста
Будем считать частыми наборы, которые встречаются в D более чем f = 4 раза.
Сначала найдем частые однопредметные наборы. Для этого представим базу дан-
ных транзакций из табл. 6.2 в нормализованном виде, который демонстрируется
в табл. 6.3.
Таблица 6.3. Нормализованный вид множества транзакций
№ транзакции Спаржа Фасоль Капуста Кукуруза Перец Кабачки Помидоры
1 0 0 1 1 1 0 0
2 1 0 0 1 0 1 0
3 0 1 0 1 0 1 1
4 0 1 0 1 1 0 1
5 1 1 0 0 0 0 1
6 1 1 0 0 0 1 1
7 0 0 0 1 0 0 1
8 0 0 1 0 1 0 1
9 1 1 0 0 0 1 0
10 0 1 0 1 0 0 0
11 0 1 1 0 1 1 0
12 1 1 0 0 0 1 0
13 1 1 0 1 0 1 0
14 0 1 1 1 1 0 1
На пересечении строки транзакции и столбца предмета ставится 1, если данный
предмет присутствует в транзакции, и 0 — в противном случае. Тогда, просуммиро-
вав значения в каждом столбце, мы получим частоту появления каждого предмета.
Глава 6. Data Mining: задача ассоциации 289
Поскольку все суммы равны или превышают 4, все предметы можно рассматривать
как частые однопредметные наборы. Обозначим их в виде множества Л = {спаржа,
фасоль, капуста, кукуруза, перец, кабачки, помидоры}.
Теперь переходим к поиску частых 2-предметных наборов. Вообще, для поиска
fk, то есть ^-предметных наборов, алгоритм Apriori сначала создает множество Л
кандидатов в ^-предметные наборы путем связывания множества Fk _ ( с самим
собой. Затем Fk сокращается с использованием свойства антимонотонности. Пред-
метные наборы множества Fk, которые остались после сокращения, формируют Fk.
Множество F2 содержит все комбинации предметов, представленные в табл. 6.4.
Таблица 6.4. Предметные наборы
Набор Количество Набор Количество
Спаржа, фасоль 5 Капуста, кукуруза 2
Спаржа, капуста 1 Капуста, перец 4
Спаржа, кукуруза 2 Капуста, кабачки 1
Спаржа, перец 0 Капуста, помидоры 2
Спаржа, кабачки 5 Кукуруза, перец 3
Спаржа, помидоры 1 Кукуруза, кабачки 3
Фасоль, капуста 3 Кукуруза, помидоры 4
Фасоль, кукуруза 5 Перец, кабачки 1
Фасоль, перец 3 Перец, помидоры 3
Фасоль, кабачки 6 Кабачки, помидоры 2
Фасоль, помидоры 4
Поскольку / = 4, из табл. 6.4 в множество F2 (то есть множество 2-предметных
наборов) войдут только те наборы, которые встречаются в исходной выборке 4 раза
или более. Таким образом:
{спаржа, фасоль}',
{спаржа, кабачки}',
{фасоль, кукуруза}-,
F2 = {фасоль, кабачки}',
{фасоль, помидоры}',
{капуста, перец}',
{кукуруза, помидоры}.
Далее мы используем частые 2-предметные наборы из множества F2 для гене-
рации множества F2 3-предметных наборов. Для этого нужно связать множество
F2 с самим собой, где предметные наборы являются связываемыми, если у них
первые k — 1 предметов общие (предметы должны следовать в алфавитном по-
рядке). Например, наборы {спаржа, фасоль} и {спаржа, кабачки}, для которых
k — 2, чтобы быть связываемыми, должны иметь k — 1 = 1 общий первый элемент,
которым и является спаржа. В результате связывания пары 2-предметных наборов
мы получим:
{спаржа, фасоль} + {спаржа, кабачки} = {спаржа, фасоль, кабачки}.
290 Часть I. Теория бизнес-анализа
Аналогично {фасоль, кукуруза} и {фасоль, кабачки} могут быть объединены
в 3-предметный набор {фасоль, кукуруза, кабачки}. И наконец, так же формируются
остальные 3-предметные наборы {фасоль, кабачки, помидоры} и {фасоль, кукуруза
помидоры}. Таким образом:
{спаржа, фасоль, кабачки}',
Р _ {фасоль, кукуруза, кабачки}',
3 {фасоль, кабачки, помидоры}-,
{фасоль, кукуруза, помидоры}.
Затем F3 также сокращается с помощью свойства антимонотонности. Для каждого
предметного набора $ из множества F3 создаются и проверяются поднаборы размером
k — 1. Если любой из этих поднаборов не является частым и, следовательно, наборы
5 также не могут быть частыми (в соответствии со свойством антимонотонности), то
он должен быть исключен из рассмотрения. Например, пусть s = {спаржа, фасоль,
кабачки}. Тогда поднаборы размера £—1=2, сгенерированные на основе набора
s, — {спаржа, фасоль}, {спаржа, кабачки} и {фасоль, кабачки}.
Из табл. 6.4 можно увидеть, что все эти поднаборы являются частыми, значит,
и набор 5 = {спаржа, фасоль, кабачки} будет частым и сокращению не подлежит.
Таким же образом можно убедиться, что и набор 5 = {фасоль, кукуруза, помидоры}
является частым.
Рассмотрим набор $ = {фасоль, кукуруза, кабачки}. Поднабор {кукуруза, кабач-
ки} появляется всего три раза (см. табл. 6.4), поэтому не является частым. Тогда
в соответствии со свойством антимонотонности и набор 5 = {фасоль, кукуруза,
кабачки} не будет частым — мы должны его отбросить.
Теперь рассмотрим набор {фасоль, кабачки, помидоры}. Поскольку поднабор
{кабачки, помидоры} не является частым (частота его появления — всего 2), набор
{фасоль, кабачки, помидоры} также не является частым и вследствие этого будет
исключен из рассмотрения.
Таким образом, в множество F3 3-предметных частых наборов попадают два на-
бора — {спаржа, фасоль, кабачки} и {фасоль, кукуруза, помидоры}. Их уже нельзя
связать, поэтому задача поиска частых предметных наборов на исходном множестве
транзакций решена.
Генерация ассоциативных правил
После того как все частые предметные наборы найдены, можно переходить к гене-
рации на их основе ассоциативных правил. Для этого к каждому частому предмет-
ному набору 5, нужно применить процедуру, состоящую из двух шагов.
1. Генерируются все возможные поднаборы $.
2. Если поднабор 55 является непустым поднабором 5, то рассматривается ассоци-
ация R: $$—>($ — ss), где $ — 55 представляет собой набор $ без поднабора 55.
R считается ассоциативным правилом, если удовлетворяет условию заданного
минимума поддержки и достоверности. Данная процедура повторяется для
каждого подмножества 55 из 5.
Глава 6. Data Mining: задача ассоциации 291
Рассмотрим предметные наборы — кандидаты в ассоциативные правила, содер-
жащие два предмета в условии, например набор 5 = {спаржа, фасоль, кабачки} из
множества 3-компонентных предметных наборов Е3, полученных на этапе поиска
частых наборов. Соответствующими поднаборами s являются: {спаржа}, {фасоль},
{кабачки}, {спаржа, фасоль}, {спаржа, кабачки}, {фасоль, кабачки} (табл. 6.5).
Таблица 6.5. Ассоциативные правила с двумя предметами в условии
Если условие, то следствие Поддержка Достоверность
Если {спаржа и фасоль}, то {кабачки} 4/14 = 28,6 % 4/5 = 80%
Если {спаржа и кабачки}, то {фасоль} 4/14 = 28,6% 4/5 = 80%
Если {фасоль и кабачки}, то {спаржа} 4/14 = 28,6 % 4/6 = 66,7%
Для первого ассоциативного правила в табл. 6.5 предположим, что ss = {спаржа,
фасоль}, и тогда (s - ss) — {кабачки}.
Рассмотрим правило R: {спаржа, фасоль} —> {кабачки}.
Поддержка, показывающая долю транзакций, которые содержат как условие
{спаржа, фасоль}, так и следствие {кабачки}, в общем наборе транзакций, имеющихся
в базе данных, составляет 28,6 % (4 из 14 транзакций). Чтобы найти достоверность,
мы должны учесть, что набор {спаржа, фасоль} появляется в 5 из 14 транзакций, 4 из
которых также содержат {кабачки}. Тогда достоверность будет 4/5 = 80 %. Аналогич-
но определяются поддержка и достоверность для остальных правил в табл. 6.5.
Если предположить, что минимальная достоверность для правила составляет
60 %, то все ассоциации, представленные в табл. 6.5, будут правилами. Если порог
установить равным 80 %, то правилами будут считаться только первые две ассо-
циации.
Наконец, рассмотрим кандидатов в правила, содержащих одно условие и одно
следствие. Для этого применим описанную выше методику генерации ассоциатив-
ных правил к множеству F2 2-компонентных предметных наборов, и результаты
представим в табл. 6.6.
Таблица 6.6. Ассоциативные правила с одним предметом в условии
Если условие, то следствие Поддержка Достоверность
Если {спаржа}, то {фасоль} 5/14 = 35,7% 5/6 = 83,3%
Если {фасоль}, то {спаржа} 5/14 = 35,7% 5/10 = 50%
Если {спаржа}, то {кабачки} 5/14 = 35,7% 5/6 = 83,3%
Если {кабачки}, то {спаржа} 5/14 = 35,7% 5/7 = 71,4%
Если {фасоль}, то {кукуруза} 5/14 = 35,7% 5/10 = 50%
Если {кукуруза}, то {фасоль} 5/14 = 35,7% 5/8 = 62,5%
Если {фасоль}, то {кабачки} 6/14 = 42,9% 6/10 = 60%
Если {кабачки}, то {фасоль} 6/14 = 42,9% 6/7 = 85,7%
Если {фасоль}, то {помидоры} 4/14 = 28,6% 4/10 = 40%
Если {помидоры}, то {фасоль} 4 /14 = 28,6 % 4/6 = 66,7%
Продолжение &
292 Часть I. Теория бизнес-анализа
Таблица 6.6 (продолжение)
Если условие, то следствие Поддержка Достоверность
Если {капуста}, то {перец} 4/14 = 28,6% 4/5 = 80%
Если {перец}, то {капуста} 4/14 = 28,6% 4/5 = 80%
Если {кукуруза}, то {помидоры} 4/14 = 28,6% 4/8 = 50% ~
Если {помидоры}, то {кукуруза} 4/14 = 28,6% 4/6 = 66,7%
Чтобы проверить значимость сгенерированных правил, обычно перемножают
их значения поддержки и достоверности, что позволяет аналитику ранжировать
правила в соответствии с их значимостью и достоверностью. В табл. 6.7 представ-
лен список правил, сгенерированных на основе исходного множества транзак-
ций (см. табл. 6.2) при заданном уровне минимальной достоверности 80 %.
Таблица 6.7. Ассоциативные правила
Если условие, то следствие Поддержка, S Достоверность, С CS
Если {кабачки}, то {фасоль} 6/14 = 42,9% 6/7 = 85,7% 0,3677
Если {спаржа}, то {фасоль} 5/14 = 35,7% 5/6 = 83,3% 0,2974
Если {спаржа}, то {кабачки} 5/14 = 35,7% 5/6 = 83,3% 0,2974
Если {капуста}, то {перец} 4/14 = 28,6% 4/5 = 80% 0,2288
Если {перец}, то {капуста} 4/14 = 28,6% 4/5 = 80% 0,2288
Если {спаржа и фасоль}, то {кабачки} 4/14 = 28,6% 4/5 = 80% 0,2288
Если {спаржа и кабачки}, то {фасоль} 4/14 = 28,6% 4/5 = 80% 0,2288
Таким образом, в результате применения алгоритма Apriori нам удалось обна-
ружить 7 ассоциативных правил, с достоверностью не менее 80 % показывающих,
какие продукты из исходного набора чаще всего продаются вместе. Это знание по-
зволит разработать более совершенную маркетинговую стратегию, оптимизировать
закупки и размещение товара на прилавках и витринах.
6.3. Иерархические ассоциативные правила
Если производить поиск ассоциативных правил среди отдельных предметов (на-
пример, товаров в магазине), то можно обнаружить, что во многих случаях ассо-
циации с высокой поддержкой для отдельных товаров практически отсутствуют.
Особенно это характерно для супермаркетов, где ассортимент товаров каждого
вида очень велик. Например, в продаже могут иметься десятки разновидностей
таких товаров, как кетчуп и макароны. Поэтому, несмотря на то что в целом под-
держка ассоциации макароны —> кетчуп может быть очень высока, поддержка
ассоциаций между отдельными видами этих товаров, скорее всего, будет низкой.
Следовательно, такие ассоциации, хотя и могут представлять интерес, окажутся
исключенными из рассмотрения, поскольку не будут удовлетворять некоторому
минимальному порогу поддержки 5min.
Глава 6. Data Mining: задача ассоциации 293
Для решения данной проблемы при поиске ассоциативных правил рассмат-
пйвают не отдельные предметы, а их иерархию. Если на нижних иерархических
уровнях интересные ассоциации отсутствуют, то на более высоких они могут иметь
место. Иными словами, поддержка отдельного предмета всегда будет меньше, чем
поддержка группы, в которую он входит:
5(7)>5(Ъ),
где I — группа в иерархии;
ij — предмет, входящий в данную группу.
Причины этого очевидны: общая поддержка группы равна сумме поддержек
всех входящих в нее предметов:
где N — число предметов в группе.
Например, рассмотрим иерархию продуктов, представленную на рис. 6.1.
Рис. 6.1. Иерархия продуктов
В этой иерархической схеме кетчуп и макаронные изделия имеют множество
подвидов. Транзакции в базе данных являются результатом сканирования штрих-
кодов в контрольно-кассовых пунктах, поэтому содержат информацию только
о конкретных товарах. Следовательно, при анализе таких максимально детализи-
рованных данных интересные ассоциации могут отсутствовать.
Если структура базы данных транзакций позволяет отражать иерархию товаров,
то можно исследовать все образованные ими иерархические уровни. Ассоциатив-
ные правила, обнаруженные для предметов, расположенных на различных иерар-
хических уровнях, получили название иерархические ассоциативные правила. В за-
рубежной литературе они также известны как многоуровневые правила (multilevel
rules) или обобщенные правила (generalized rules).
Пусть имеется множество транзакционных данных о продажах компьютерной
фирмы (табл. 6.8).
294 Часть I. Теория бизнес-анализа
Таблица 6.8. Пример транзакций
№ транзакции Предметные наборы
1 Настольный компьютер Acer, лазерный принтер HP
2 OS MS Windows XP, ПО MS Office
3 Мышь Genius, коврик для мыши Logitech
4 Портативный компьютер Dell, ПО MS Office
5 Настольный компьютер Compaq
Иерархия предметов, связанных с компьютерной техникой, представлена на
рис. 6.2. Она содержит 4 уровня. Обычно иерархические уровни нумеруются сверху
вниз, начиная с нулевого. Узел, соответствующий нулевому уровню, называется
корневым (root node). В нашей иерархической схеме уровень 2 включает виды
компьютерного обеспечения, уровень 3 — конкретные предметы (товары), а уро-
вень 4 — фирму-производителя.
Рис. 6.2. Иерархия товаров, связанных с компьютерной техникой
Предметы из табл. 6.8 принадлежат самому низкому уровню иерархии, то есть
содержат конкретные товары конкретных производителей. Обнаружить интерес-
ные модели покупок на столь низком уровне трудно. Например, если каждый из
предметов настольный компьютер Compaq и лазерный принтер Canon появляется
в очень небольшом числе транзакций, то трудно будет обнаружить ассоциацию
настольный компьютер Compaq —> лазерный принтер Canon с высоким уровнем
поддержки и достоверности, так как лишь небольшое количество клиентов приоб-
ретают их совместно. Хотя в целом поддержка ассоциации компьютер —> принтер,
скорее всего, будет достаточно высока.
Иными словами, ассоциации, которые содержат предметы более высоких
уровней иерархии, будут с большей вероятностью удовлетворять условию ми-
Глава 6. Data Mining: задача ассоциации 295
нимальной поддержки и достоверности, чем предметы уровня с максимальной
детализацией. Следовательно, искать интересные ассоциации в многоуровневой
иерархии удобнее, чем только среди предметов самого низкого уровня. Более
того, можно ожидать, что чем выше уровень иерархии, тем больше вероятность
обнаружить ассоциации с высокой поддержкой.
Таким образом, иерархия предметов может использоваться для сокращения
числа рассматриваемых предметных наборов.
1. Сначала ищутся ассоциации с высокой поддержкой для верхних уровней иерар-
хии.
2. Анализируются потомки только тех предметов верхних уровней, которые удов-
летворяют заданному минимуму поддержки 5П11П. Анализ потомков тех предме-
тов, которые сами по себе являются редкими, не имеет смысла, поскольку они
будут встречаться еще реже, чем их предки.
Перемещаясь вверх или вниз по иерархии, мы можем регулировать количе-
ство данных, которое нужно обработать. Так, при поиске на высоких уровнях
иерархии уменьшается объем обрабатываемых данных, но увеличивается степень
обобщенности полученных результатов. При спуске на нижние уровни количест-
во обрабатываемых данных увеличивается, но при этом увеличивается и степень
детальности анализа.
В качестве недостатка иерархического подхода к поиску ассоциативных правил
иногда указывают на то, что полученные правила в большинстве случаев относятся
не к отдельным предметам, а к их группам, что не всегда соответствует требованиям
анализа. Следует заметить, что в некоторых приложениях количество отдельных
предметов может быть так велико, что обнаружение ассоциативных правил даже на
некотором уровне обобщения — это уже удача. Кроме того, бизнес-аналитические
технологии в большей мере ориентированы на обобщенные данные, поэтому во
многих случаях использование иерархий предметов при поиске ассоциативных
правил открывает принципиально новые возможности, делает анализ более гибким
и позволяет получать дополнительные знания.
Методы поиска иерархических ассоциативных правил
Существует несколько подходов к поиску иерархических ассоциативных правил.
Большинство из них, как и классический алгоритм Apriori, основаны на вычислении
поддержки и достоверности. Чаще всего используются нисходящие методы, когда
частые предметные наборы исследуются на каждом иерархическом уровне, начиная
с первого и заканчивая уровнем с наибольшей детализацией. Проще говоря, как
только обнаруживаются все популярные предметные наборы на первом уровне, на-
чинается поиск популярных предметных наборов на втором и т. д. На каждом уровне
для открытия популярных наборов может использоваться любой алгоритм, напри-
мер Apriori и его модификации. Приведем несколько вариантов таких подходов.
Вариант 1 — использование одинакового порога минимальной поддержки Smin
на всех иерархических уровнях. При поиске правил на каждом уровне иерархии
задается некоторый порог минимальной поддержки. Если поддержка предмета
296 Часть L Теория бизнес-анализа
превышает данный порог, то он появляется достаточно часто, чтобы для него имело
смысл искать ассоциации с другими предметами. Можно указать некоторый порог
поддержки (например, 5 %) и использовать его на всех иерархических уровнях.
На рис. 6.3 приведен пример, где однопредметные наборы компьютер и настольный
компьютер будут обнаружены как популярные, а портативный компьютер — нет
поскольку он не преодолел заданный порог поддержки.
Уровень 1 (Smln = 0,05)
Уровень 2 (S,ni„ = 0,05)
Рис. 6.3. Иллюстрация первого варианта
При использовании одинаковой минимальной поддержки на всех уровнях проце-
дура поиска частых наборов упрощается. Ее можно дополнительно оптимизировать,
если известно, что родительский узел иерархии не содержит частых наборов. В этом
случае проверка дочерних узлов может не производиться, поскольку они также не
будут содержать частых наборов. Например, если известно, что компьютеры прода-
ются редко, то отдельные их разновидности будут продаваться еще реже.
Однако подход, при котором для поиска кандидатов используется одинаковый
порог поддержки на всех уровнях иерархии, имеет ряд недостатков. Так, маловеро-
ятно, что предметы нижних уровней продаются так же часто, как предметы более
высоких уровней. Если порог минимальной поддержки слишком большой, это может
привести к потере полезных ассоциаций между предметами низких уровней. Если
порог слишком низкий, это может породить много неинтересных ассоциаций между
предметами высоких уровней. Чтобы избежать данных проблем, используется мето-
дика адаптивного порога, который будет отличаться для разных уровней иерархии.
Вариант 2 — использование пониженного порога минимальной поддержки
для нижних уровней иерархии. Данный подход предполагает, что на каждом
иерархическом уровне задается свой порог минимальной поддержки для отбора
кандидатов. При этом чем ниже уровень, тем ниже порог. Например, на рис. 6.4
порог минимальной поддержки для уровней 1 и 2 составляет 0,5 и 0,3 соответ-
ственно. Таким образом, и компьютер, и настольный компьютер, и портативный
компьютер окажутся популярными.
Уровень 1 (Smin = 0,05)
Уровень 2 (Sm„ = 0,03)
Рис. 6.4. Иллюстрация второго варианта
Глава 6. Data Mining: задача ассоциации 297
Для поиска иерархических ассоциативных правил с уменьшением минимальной
ПОДДеРжки на нижних уровнях можно использовать несколько альтернативных
стратегий поиска.
Вариант 3 — независимая установка порога. Осуществляется полный поиск,
когда отсутствуют априорные сведения, которые могут использоваться для сокра-
щения числа рассматриваемых предметных наборов. Проверяется каждый узел
независимо от того, содержит ли его родительский узел частые предметные наборы.
Здесь возможны следующие ситуации.
□ Межуровневая (cross-level) фильтрация по одному предмету. Предмет на г-м
уровне проверяется тогда и только тогда, когда его родительский узел на уровне
г — 1 содержит частые наборы. Например, на рис. 6.5 потомки узла компьютер
(то есть настольный компьютер и портативный компьютер) не проверяются,
поскольку узел компьютер не является частым: его поддержка S = 0,1, а порог
5,„in = 0,12.
Уровень 1 (Smln = 0,12)
Уровень 2 (S„ln = 0,03)
Рис. 6.5. Межуровневая фильтрация по одному предмету
□ Межуровневая фильтрация по ^-предметному набору, ^-предметный набор на
z-м уровне проверяется тогда и только тогда, когда его родительский ^-предмет-
ный набор на уровне i — 1 является частым. Например, на рис. 6.6 2-предметный
набор {компьютер, принтер} является частым, а предметные наборы {порта-
тивный компьютер, струйный принтер}, {портативный компьютер, лазерный
принтер}, {настольный компьютер, струйный принтер} и {настольный компь-
ютер, лазерный принтер} должны проверяться.
Уровень 1
(Sml„ = 0,05)
Уровень 2
(Sm,„ = 0,02)
Рис. 6.6. Межуровневая фильтрация по к предметам
Стратегия, когда минимальная поддержка устанавливается для каждого уровня
независимо, может привести к проверке огромного количества редко встречающихся
298 Часть I. Теория бизнес-анализа
предметов на нижних уровнях с обнаружением ассоциаций между предметами
с низкой значимостью. Например, если -компьютерная мебель сама по себе по-
купается редко, то проверка, является ли частым набор {компьютерное кресло,
портативный компьютер}, не имеет смысла. В то же время если аксессуары для
компьютера покупаются часто, то проверка ассоциаций настольный компью-
тер —> мышь имеет смысл.
Стратегия межуровневой фильтрации по ^-предметному набору позволяет огра-
ничить число проверяемых наборов теми, которые являются потомками частых
^-предметных наборов. Данное ограничение весьма эффективно, поскольку обычно
не существует большого количества частых ^-предметных наборов (особенно при
k > 2). Следовательно, этот подход дает возможность значительно сократить число
рассматриваемых наборов.
Одна из проблем такой стратегии заключается в том, что предметные наборы,
которые на нижних уровнях иерархии могли бы оказаться частыми, «выпадут» из
рассмотрения, поскольку их предки не смогли преодолеть более высокий порог,
применяемый на верхних уровнях. Например, если предмет монитор 17" на уров-
не i является частым в соответствии с порогом минимальной поддержки для данного
уровня, то его предок монитор на уровне i - 1 может не быть частым, так как порог
на этом уровне будет выше. В результате такие часто встречающиеся ассоциации,
как настольный компьютер монитор 17", могут быть утеряны.
Модифицированной версией межуровневой фильтрации по одному предмету
является управляемая межуровневая фильтрация. В этом методе вводится еще один
порог, называемый уровнем прохода (level passage). Он может быть установлен для
относительно часто встречающихся предметов на нижних уровнях. Иными словами,
данный подход позволяет потомкам предметов, которые не удовлетворяют основ-
ному порогу минимальной поддержки, подвергаться проверке, но только если эти
предметы удовлетворяют проходному порогу. Каждый уровень может иметь свой
собственный проходной порог. Он обычно выбирается между значениями порогов
минимальной поддержки для следующего и данного уровня.
Например, на рис. 6.7 установка на уровне 1 проходного порога, равного 0,08,
позволяет проверить и отнести к частым узлы портативный компьютер и на-
стольный компьютер на уровне 2 даже в том случае, если их родительский узел
сомпъютер не является таковым. Эта методика дает возможность сделать процесс
гоиска иерархических ассоциативных правил более гибким, а также уменьшить
гисло ассоциаций с низкой значимостью.
Рис. 6.7. Управляемая межуровневая фильтрация
Глава 6. Data Mining: задача ассоциации 299
6.4. Последовательные шаблоны
Ассоциативные правила имеют ряд ограничений, из-за которых не могут охва-
тывать отдельные аспекты анализа транзакционных данных, представляющие
большой практический интерес.
Дело в том, что ассоциативные правила учитывают только факты совместного
появления товаров в транзакциях, но не учитывают временной аспект, а именно
последовательность появления товаров и динамику продаж. Если мы рассмотрим
рост или спад продаж определенных товаров или услуг за несколько последователь-
ных периодов времени, то сможем получить полезные знания, скажем, о готовности
клиентов к покупке нового товара или услуги, о целесообразности стимулирования
спроса и т. д. Для ввода в рассмотрение времени и последовательности появления
товаров достаточно фиксировать в транзакции ее дату и время, что легко реализу-
ется современными OLTP-системами.
Кроме того, ассоциативные правила не являются клиентоориентированными,
поскольку не связывают наборы предметов в транзакции с определенным клиен-
том. В то же время может представлять интерес исследование динамики продаж
в разрезе конкретных клиентов. С этой целью в транзакцию, кроме предметного
набора, необходимо ввести идентификатор клиента, который может быть получен
при оплате по кредитным картам, клиентским картам, дающим право на скидку,
и т. д. Такие транзакции называются клиентскими и образуют клиенто-ориен-
тированные транзакционные базы данных, которые обязательно содержат поле
идентификатора клиента.
Чтобы расширить возможности анализа транзакционных данных с учетом
времени, последовательности появления предметов и ориентированности на кон-
кретного клиента, разработаны последовательные шаблоны (sequential patterns).
Теория последовательных шаблонов во многом базируется на ассоциативных
правилах и, по сути, является их расширением. Базовые понятия здесь те же: транз-
акция, предметный набор, частота набора, поддержка и т. д. Кроме того, для поиска
последовательных шаблонов используются адаптированный алгоритм Apriori и его
модификации.
Итак, если в ассоциативных правилах важен только факт совместного присут-
ствия товаров в одной транзакции, то в последовательных шаблонах рассматрива-
ется и последовательность их появления. Интуитивно понятно, что последователь-
ным шаблоном может быть только такая последовательность, которая встречается
в базе данных достаточно часто. Поэтому здесь возникает та же проблема, что и для
ассоциативных правил: большое число рассматриваемых предметов порождает
огромное количество возможных последовательностей, что приводит к серьез-
ным вычислительным затратам при использовании полного перебора. Но и здесь
применим принцип антимонотонности: последовательности, содержащие редкие
предметы, не могут быть частыми, что позволяет существенно снизить простран-
ство поиска.
Применение последовательных шаблонов выходит за рамки анализа рыноч-
ной корзины. Они позволяют выявлять типичные последовательности событий
300 Часть I. Теория бизнес-анализа
в самых разнообразных предметных областях. Например, последовательность
может включать такие события, как взятие нескольких фильмов клиентом в видео-
прокате. Если фильм представляет собой трилогию (скажем, «Звездные войны»),
то типичная последовательность, в которой клиент будет брать эти фильмы, —
1-я часть, 2-я часть и 3-я часть. При этом последовательность не обязательно
должна быть непрерывной. В промежутке клиент может взять и другой фильм, но
типичная последовательность при этом сохранится. Анализ всех последователь-
ностей фильмов, взятых напрокат определенными клиентами, может выявить
наиболее типичные шаблоны, знание которых поможет стимулировать клиентов,
предлагая им фильмы в соответствующем порядке.
Постановка задачи
Рассмотрим поиск последовательных шаблонов, используя задачу анализа рыноч-
ной корзины. Пусть имеется база данных, в которой каждая запись представляет
собой клиентскую транзакцию, содержащую следующие поля: идентификатор
клиента, дата/время транзакции и набор купленных товаров. Введем ограничение:
ни один клиент не может иметь двух или более транзакций, совершенных в один
и тот же момент времени.
Последовательность — это упорядоченный список предметных наборов.
Будем записывать последовательность в треугольных скобках, а предметный
набор — в круглых. Тогда, если обозначать предметы целыми числами, пред-
метные наборы будут записаны в виде (2, 4, 5), (1, 3), а последовательность,
содержащая эти наборы, — в виде <(2, 4, 5); (1, 3)>. Если предметы являются
товарами и появились в одном наборе, это значит, что они были приобретены
одновременно.
Обозначим предметный набор I = (ib i2- i„), где i, — предмет. Обозначим после-
довательность S = (71,12... 1т), где 7, — предметный набор.
Последовательность 5) содержится в последовательности S2, если все предмет-
ные наборы 51 содержатся в предметных наборах 52. Например, последовательность
<(3); (4, 5); (8)> содержится в последовательности <(7); (3, 8); (9); (4, 5, 6); (8)>,
поскольку (3) С (3, 8), (4, 5) С (4, 5, 6) и (8) С (8). Однако <(3); (5)> £ <(3, 5)>
и наоборот, поскольку в первой последовательности предметы 3 и 5 были куплены
один за другим, а во второй — совместно.
ОПРЕДЕЛЕНИЕ-------------------------------------------------------------
Последовательность 5 называется максимальной, если она не содержится в какой-либо
другой последовательности.
ОПРЕДЕЛЕНИЕ
Последовательность 5 называется клиентской, если она, кроме набора предметов, даты
и времени, содержит также идентификатор клиента.
Глава 6. Data Mining: задача ассоциации 301
Пусть клиент совершил несколько транзакций — 7), Тг... Tk. Тогда каждый
предметный набор в транзакции 7} обозначим 7(7]), а каждую клиентскую последо-
вательность для данного клиента запишем как 7(7)), 7(Т2)... I(Tk). Иными словами,
клиентская последовательность — это последовательность предметных наборов,
содержащихся во всех транзакциях, совершенных данным клиентом.
Последовательность S называется поддерживаемой клиентом, если она содер-
жится в его клиентской последовательности. Тогда поддержка последовательности
определяется как число поддерживающих ее клиентов, которое обычно выражается
в процентах от общего числа клиентов. Таким образом, понятие поддержки для
последовательных шаблонов несколько отличается от аналогичного понятия для
ассоциативных правил.
Для базы данных клиентских транзакций задача поиска последовательных
шаблонов заключается в обнаружении максимальных последовательностей среди
всех, имеющих поддержку выше заданного порога. Каждая такая максимальная
последовательность и есть последовательный шаблон. Далее будем называть
последовательности, удовлетворяющие ограничению минимальной поддержки,
частыми (по аналогии с часто встречающимися наборами в теории ассоциатив-
ных правил).
Рассмотрим набор транзакций, представленный в табл. 6.9. Они упорядочены
по кодам клиентов, а для каждого клиента — по дате транзакции.
Таблица 6.9. Пример набора транзакций
ID клиента Дата транзакции Купленные предметы
1 25.06.2008 3
1 30.06.2008 9
2 10.06.2008 1,2
2 15.06.2008 3
2 20.06.2008 4, 6,7
3 25.06.2008 3, 5,7
4 25.06.2008 3
4 30.06.2008 4,7
4 25.07.2008 9
5 12.06.2008 9
После преобразования базы данных в набор клиентских последовательностей
получим табл. 6.10.
Таблица 6.10. Клиентские последовательности
№ Клиентская последовательность
1 <(3); (9)>
2 <(1,2); (3); (4, 6, 7)>
3 <(3, 5, 7)>
4 <(3); (4, 7); (9)>
5 <(9)>
302 Часть I. Теория бизнес-анализа
Зададим уровень минимальной поддержки 25 %. В нашем примере ему будет
удовлетворять любая последовательность, поддерживаемая как минимум двумя
клиентами, то есть <(3); (9)> и <(3); (4, 7)>, которые также являются максималь-
ными. В данном примере они и будут искомыми шаблонами.
Последовательный шаблон <(3); (9)> поддерживается клиентами 1 и 4. Кли-
ент 4 купил предметы (4, 7) между предметами 3 и 9, но поддерживает шаблон <(3);
(9)>, поскольку шаблоны не обязательно являются непрерывными последователь-
ностями. Шаблон <(3); (4, 7)> поддерживается клиентами 2 и 4. Клиент 2 купил
предмет 6 между 4 и 7, но поддерживает данный шаблон, поскольку набор (4, 7)
является подмножеством (4, 6, 7).
Не удовлетворяет уровню минимальной поддержки последовательность <(1,2);
(3)>, поскольку она поддерживается только клиентом 2. Последовательности
<(3)>, <(4)>, <(7)>, <(9)>, <(3); (4)>, <(3); (7)> и <(4, 7)>, хотя и удовле-
творяют минимальной поддержке, но не являются максимальными, поскольку
содержатся в более длинных последовательностях.
Поиск последовательных шаблонов
Дополнительно введем несколько понятий.
Длина последовательности — это число содержащихся в ней предметных набо-
ров. Последовательность длины k будем называть ^-последовательностью (чита-
ется: ^-элементная последовательность). Поддержка предметного набора / равна
числу клиентов, которые приобрели входящие в него предметы в одной тран-
закции. Таким образом, предметный набор In 1-последовательность <1> имеют
одну и ту же поддержку. Напомним, что в ассоциативных правилах предметный
набор, удовлетворяющий уровню минимальной поддержки, называется частым.
Обратим внимание, что любой предметный набор в частой последовательности
также должен быть частым, на что указывает свойство антимонотонности. Сле-
довательно, любая частая последовательность будет состоять только из частых
предметных наборов. Частые предметные наборы из табл. 6.10 представлены
в табл. 6.11.
Таблица 6.11. Частые предметные наборы
Частые наборы Поддерживается клиентом Представление
(3) 1,2,3, 4 А
(4) 2,4 В
(7) 2, 3,4 С
(4, 7) 2,4 D
(9) 1,4,5 Е
Процесс поиска последовательных шаблонов содержит следующие шаги.
1. Сортировка. Транзакции исходной базы данных сортируются по кодам кли-
ентов, а транзакции каждого клиента — по дате, времени или номеру визита.
Глава 6. Data Mining: задача ассоциации 303
Таким образом, исходная база данных преобразуется в базу данных клиентских
последовательностей.
2 Поиск частых предметных наборов. Ищется множество всех частых пред-
метных наборов F. Одновременно ищется множество всех частых 1-последо-
вательностей, поскольку это просто множество {</> | f € F}. Задача поиска
частых предметных наборов на множестве клиентских транзакций использует
несколько другое определение поддержки, а именно: число транзакций, в ко-
торых представлен данный предметный набор, в то время как в задаче поиска
последовательных шаблонов это число клиентов, купивших данный набор
хотя бы в одной из транзакций. Затем множество частых предметных наборов
преобразуется в альтернативное представление в виде букв, целых чисел или
двоичных последовательностей. Ранее мы установили, что частыми предметны-
ми наборами будут (3), (4), (7), (4, 7) и (9). Возможное представление в виде
отдельных значений (табл. 6.12) позволяет упростить алгоритмическую реали-
зацию задачи.
3. Преобразование. Нужно определить, какие из частых последовательностей
содержатся в клиентской последовательности. Для этого каждая транзакция
клиентской последовательности замещается множеством ее частых предметных
наборов. Если транзакция не содержит ни одного частого предметного набора,
то в результате преобразования она вообще исключается из рассмотрения. Если
клиентская последовательность не содержит ни одного частого предметного на-
бора, то вся эта последовательность также исключается. После преобразования
каждая клиентская последовательность будет представлена в виде множества
частых наборов /ь/г-Л-
Обозначим такой преобразованный набор транзакций DT. В зависимости от
объема доступной памяти преобразование может быть выполнено полностью
над всеми данными, или «на лету» при чтении каждой клиентской последова-
тельности в процессе прохода по набору данных. Преобразование данных из
табл. 6.10 представлено в табл. 6.12.
Таблица 6.12. Преобразованные клиентские последовательности
Код клиента Исходная клиентская последовательность Преобразованная клиентская последовательность Результат альтернативного представления
1 <(3); (9)> <{(3)}; {(9)}> <{А, Е}>
2 <(1,2); (3); (4, 6, 7)> <{(3)}; {(4), (7), (4, 7)}> <{А), {В, С, D}>
3 <(3,5, 7)> <{(3); (7)}> <{А, С}>
4 <(3); (4, 7); (9)> <{(3)};{(4), (7), (4,7)}, {(9)}> <{А}, {В, С, D}, {Е}>
5 <(9)> <{(9)}> <{Е}>
Например, в процессе преобразования клиентской последовательности 2 набор
(1,2) был исключен, поскольку не является частым, а набор (4,6, 7) был заменен
множеством частых предметных наборов {(4); (7); (4, 7)}.
304 Часть I. Теория бизнес-анализа
4. Поиск частых последовательностей. На множестве частых предметных наборов
производится поиск частых последовательностей.
5. Поиск максимальных последовательностей. Среди частых последовательно-
стей ищутся максимальные. Иногда данный этап совмещают с предыдущим
чтобы уменьшить затраты времени на вычисление немаксимальных последо-
вательностей.
Самым проблемным этапом поиска последовательных шаблонов является
обнаружение частых последовательностей, поскольку большое число предметных
наборов требует рассмотрения огромного количества возможных комбинаций
и многократного прохода по набору транзакций. Каждый проход начинается с ис-
ходного набора последовательностей, который используется для генерации новых
потенциальных частых последовательностей, называемых последовательностями-
кандидатами, или просто кандидатами. Для этого вычисляется их поддержка и по
завершении прохода определяется, являются ли обнаруженные кандидаты в дей-
ствительности частыми. Обнаруженные частые последовательности-кандидаты
станут исходными для нового прохода.
На первом проходе ищутся все 1-последовательности, удовлетворяющие усло-
вию минимальной поддержкой, полученные на этапе поиска частых предметных
наборов. При этом возможно использование двух алгоритмов полного и частич-
ного поиска. Первый ищет все частые последовательности, включая те, которые
не являются максимальными (впоследствии они будут исключены). Одним из
таких алгоритмов полного поиска является AprioriАП, основанный на алгоритме
Apriori.
Алгоритм AprioriАН
В алгоритме AprioriAll (Agrawal и Srikant, 1995) на каждом проходе сканируются
частые последовательности, найденные на предыдущем, и формируются новые по-
следовательности-кандидаты, а затем вычисляется их поддержка в процессе нового
прохода. В дальнейшем она используется для определения частых последователь-
ностей. Частые предметные наборы, найденные на первом проходе, являются, по
сути, частыми 1 -последовательностями, поэтому иногда этот процесс называют
инициализацией.
Рассмотрим набор клиентских последовательностей, представленный в табл. 6.13.
Таблица 6.13. Клиентские последовательности
Последовательность_____________________________________________________________
<{1,5}; (2}; {3};{4}>__________________________________________________________
<{1};{3};{4};{3, 5}>___________________________________________________________
<{!}; (2}; {3}; (4}>___________________________________________________________
<{!}; {3};{5}; {4}>____________________________________________________________
<{4}; {5}>
Глава 6. Data Mining: задача ассоциации 305
Клиентские последовательности получены путем замены транзакций содержа-
щимися в них частыми предметными наборами. Минимальная поддержка опреде-
лена 40 % (две клиентские последовательности).
На первом проходе производится поиск частых предметных наборов и, соответ-
ственно, частых 1-последовательностей. Результаты, а именно частые последова-
тельности длин 2, 3, и 4 и их поддержки, представлены в табл. 6.14.
Таблица 6.14. Частые последовательности
1-последова- тельность 2-последователь- ность 3-последователь- ность 4-последовательность
Я Поддержка f2 Поддержка Гз Поддержка Ft Поддержка
1 4 <1, 2> 2 <1,2, 3> 2 <1,2,3, 4> 2
2 2 <1,3> 4 <1,2, 4> 2
3 4 <1, 4> 3 <1,3, 4> 3
4 4 <1,5> 3 <1,3, 5> 2
5 4 <2, 3> 2 <2,3, 4> 2
<2, 4> 2
<3, 4> 3
<3, 5> 2
<4, 5> 2
На пятом проходе новых кандидатов получено не было. Таким образом, макси-
мальными частыми последовательностями являются <1,2, 3,4>, <1,3,5> и <4, 5>,
поскольку они не содержатся в последовательностях бблыпей длины. Они и будут
искомыми последовательными шаблонами. Обобщенная блок-схема алгоритма
AprioriAll представлена на рис. 6.8, где Fk ( — множество всех частых (k - ^-по-
следовательностей, k — длина последовательности, Q, — множество последователь-
ностей кандидатов длины k, s, — последовательности-кандидаты, входящие в Ск,
Sup — оператор вычисления поддержки.
Главный недостаток алгоритма AprioriAll заключается в том, что он обрабаты-
вает последовательности всех возможных длин, а это не является оптимальным
с точки зрения временных и вычислительных затрат. Среди последовательностей
определенных длин может быть мало частых. Такие длины можно пропустить без
особого ущерба, поскольку вероятность появления для них последовательных
шаблонов очень мала. Алгоритм, реализующий данный подход, получил название
AprioriSome (от англ, some — «некоторые»). Если обозначить номер прохода t, то
можно записать, что k(t + 1) = k(t) + р. Это означает, что на следующем проходе
будут анализироваться последовательности, длина которых на р больше, чем на
предыдущем. В случае еслир = 1, алгоритм идентичен AprioriAll, то есть будут
анализироваться все последовательности. Необходимо определить, какие длины
последовательностей могут быть пропущены без ущерба для качества решения
задачи. Основное преимущество AprioriSome перед AprioriAll заключается в том,
что он позволяет избежать вычисления большого числа немаксимальных после-
довательностей.
306 Часть I. Теория бизнес-анализа
Рис. 6.8. Обобщенная блок-схема алгоритма AprioriАП
1ЕРС0НАЛИИ ------------------------------------------------------------
Ракеш Агра вал (Rakesh Agrawal) — широко известный исследователь в области фундамен-
тальных и алгоритмических основ машинного обучения, Data Mining и безопасности дан-
ных, один из авторов алгоритма Apriori. Аналитический продукт компании IBM — Intelligent
Miner — появился на свет во многом благодаря его стараниям в период работы в исследо-
вательском центре IBM (Almaden Research Center). Его идеи также легли в основу других
продуктов IBM — DB2 Mining Extender, DB2 OLAP Server.
Глава 6. Data Mining: задача ассоциации 307
В1983 г. защитил магистерскую и докторскую диссертации в университете Висконсин-Мэди-
сон (Wisconsin-Madison). Начиная с марта 2006 г. Агравал — сотрудник Microsoft Technical,
глава Search Labs в исследовательском центре Microsoft Research.
Агравал имеет более 6о патентов и 150 научных публикаций. Его работы по базам данных
и Data Mining одни из самых упоминаемых в научной среде: они процитированы более
6500 раз.
В 2003 г. американский журнал Scientific American внес Агравала в топ-50 ученых и иссле-
дователей.
Домашняя страница Ракеша Агравала: http://rakesh.agrawal-family.com/.
Data Mining:
кластеризация
7.1. Введение в кластеризацию
Кластеризация — одна из задач Data Mining, а кластер — группа похожих объек-
тов (постановка задачи кластеризации рассматривалась в разделе 1.5 «Техноло-
гии KDD и Data Mining»). Существует много определений кластеризации, поэтому
приведем несколько.
ОПРЕДЕЛЕНИЕ--------------------------------------------------------
Кластеризация — 1) группировка объектов на основе близости их свойств; каждый кластер
состоит из схожих объектов, а объекты разных кластеров существенно отличаются; 2) про-
цедура, которая любому объекту х е X ставит в соответствие метку кластера у G У.
Кластеризацию используют, когда отсутствуют априорные сведения относи-
тельно классов, к которым можно отнести объекты исследуемого набора данных,
либо когда число объектов велико, что затрудняет их ручной анализ.
Постановка задачи кластеризации сложна и неоднозначна, так как:
□ оптимальное количество кластеров в общем случае неизвестно;
□ выбор меры «похожести» или близости свойств объектов между собой, как
и критерия качества кластеризации, часто носит субъективный характер.
На рис. 7.1 показан пример кластеризации объектов, которые описываются
двумя числовыми признаками, поэтому объекты легко изобразить на плоскости.
К сожалению, в реальных приложениях количество признаков объектов измеря-
ется десятками и такой способ их представления не подходит.
Естественно, приведенный вариант разбиения не является единственным.
ЗАМЕЧАНИЕ----------------------------------------------------------
Задача кластеризации известна давно, и специалисты в различных областях оперируют
рядом других терминов — таксономия, сегментация, группировка, самоорганизация. В Data
Mining употребляется термин «кластеризация».
Глава 7. Data Mining: кластеризация 309
Остановимся на целях кластеризации и на ее применении в бизнес-аналитике.
Цели кластеризации в Data Mining могут быть различными и зависят от кон-
кретной решаемой задачи. Рассмотрим эти задачи.
□ Изучение данных. Разбиение множества объектов на группы помогает выявить
внутренние закономерности, увеличить наглядность представления данных,
выдвинуть новые гипотезы, понять, насколько информативны свойства объ-
ектов.
□ Облегчение анализа. При помощи кластеризации можно упростить дальнейшую
обработку данных и построение моделей: каждый кластер обрабатывается ин-
дивидуально, и модель создается для каждого кластера в отдельности. В этом
смысле кластеризация может рассматриваться как подготовительный этап перед
решением других задач Data Mining: классификации, регрессии, ассоциации,
последовательных шаблонов.
□ Сжатие данных. В случае, когда данные имеют большой объем, кластеризация
позволяет сократить объем хранимых данных, оставив по одному наиболее
типичному представителю от каждого кластера.
Q Прогнозирование. Кластеры используются не только для компактного пред-
ставления объектов, но и для распознавания новых. Каждый новый объект
относится к тому кластеру, присоединение к которому наилучшим образом
удовлетворяет критерию качества кластеризации. Значит, можно прогнози-
ровать поведение объекта, предположив, что оно будет схожим с поведением
других объектов кластера.
□ Обнаружение аномалий. Кластеризация применяется для выделения нетипич-
ных объектов. Эту задачу также называют обнаружением аномалий (outlier
detection). Интерес здесь представляют кластеры (группы), в которые попадает
крайне мало, скажем один-три, объектов.
310 Часть I. Теория бизнес-анализа
Первые две задачи наиболее популярны в бизнес-аналитике. В табл. 7.1 приве-
дены практические примеры применения кластеризации в разных областях.
Таблица 7.1. Примеры кластеризации в различных областях
№ При- кладная область Цель кластери- зации Описание
1 Роз- ничная торговля Облег- чение анализа Построение в сети розничных магазинов ассоциативных правил, выявляющих совместно покупаемые продукты, при- водило к громоздким результатам с большим числом правил. При помощи кластеризации все покупатели были разделены на несколько сегментов, и ассоциативные правила выявля- лись в каждом сегменте отдельно. Это позволило разбить задачу на подзадачи и найти ассоциативные правила для каждого сегмента покупателей в отдельности
2 Банкинг Изучение данных, облег- чение анализа Отдел продаж коммерческого банка, работающего на рынке розничного кредитования, задался целью изучить профили потенциальных клиентов, подающих заявки на потребитель- ский кредит. Очень малочисленным оказался кластер под названием «Молодежь» — работающие студенты и молодые люди в возрасте до 23 лет. Оказалось, что у банка не было то- чек продаж кредитов в тех районах города, где сосредоточены университеты и институты. Данный факт был учтен службой продаж и службой развития бизнеса банка
Прогно- зирование Исследование клиентов банка, взявших автокредит, при по- мощи инструментов кластеризации выделило кластер, в ко- торый попали мужчины в возрасте от 23 до 28 лет, прожи- вающие в Московской области менее года. Их объединяло то, что практически все они имели длительные просрочки по кредиту. Скорее всего, это молодые люди, переоценившие свои возможности, либо мошенники. Эта информация была учтена банком при разработке скоринговых карт
3 Телеком- муни- кации Изучение данных Анализ базы данных клиентов крупной сети сотовой связи позволил выделить несколько кластеров. Самым малочислен- ным кластером оказались пожилые женщины, совершающие звонки в весенне-летнее время. С большой долей вероятно- сти это пенсионерки-дачницы, значительную часть теплого времени года проживающие за городом. Для увеличения численности этого кластера был разработан соответствующий тарифный план, который наилучшим образом устраивал бы абонентов этой группы
4 Страхо- вание Обнару- жение аномалий Кластеризация клиентов страховой компании, застрахован- ных от несчастных случаев, выявила небольшой по объему кластер, в котором фигурировали одни и те же фамилии врачей; суммы страховых выплат тоже варьировались незна- чительно. Проверка показала, что в 90 % таких случаев имел место сговор с врачом
Глава 7. Data Mining: кластеризация 311
№ При- кладная область Цель кластери- зации Описание
5 Государ- ственные службы Изучение данных В ходе исследования базы данных миграционной службы, в которой содержалась информация о людях, переехавших из села в город (возраст, образование, семейное положение и т. д.), с помощью алгоритма кластеризации было выделено несколько сегментов, характеристики которых позволили дать им содержательную интерпретацию. Например, выде- лился кластер, куда вошли женщины в возрасте более 60 лет, дети которых живут в городе. С большой вероятностью это бабушки, которые едут в город нянчить своих внуков. Вы- делились также кластеры «Демобилизованные солдаты», «Невесты» и др.
Ранее в определении кластеризации встречалось словосочетание «похожесть
свойств». Термины «похожесть», «близость» можно понимать по-разному, поэтому
в зависимости от того, какой вариант оценки близости между свойствами объектов
мы выберем, получим тот или иной вариант кластеризации.
В Data Mining распространенной мерой оценки близости между объектами
является метрика, или способ задания расстояния. Проблема выбора той или иной
метрики в моделях всегда остро стоит перед аналитиком. Наиболее популярные
метрики — евклидово расстояние и расстояние Манхэттена — рассматриваются
далее при изложении конкретных алгоритмов.
Важно понимать, что сама по себе кластеризация не приносит каких-либо ре-
зультатов анализа. Для получения эффекта необходимо провести содержательную
интерпретацию каждого кластера. Такая интерпретация предполагает присвоение
каждому кластеру емкого названия, отражающего его суть, например «Разведенные
женщины с детьми», «Дачники», «Работающие студенты» и т. д. Для интерпретации
аналитик детально исследует каждый кластер: его статистические характеристики,
распределение значений признаков объекта в кластере, оценивает мощность кла-
стера — число объектов, попавших в него. Интерпретация значительно облегчается,
если имеются способы представления результатов кластеризации в специализиро-
ванном виде: дендрограммы, кластерограммы, карты.
На сегодня предложено несколько десятков алгоритмов кластеризации и еще
больше их разновидностей. Несмотря на это, в Data Mining в первую очередь при-
меняются алгоритмы, которые понятны и просты в использовании. Это алгоритм
k-means и сети Кохонена. Рассмотрим их.
Z2. Алгоритм кластеризации k-means
Одной из широко используемых методик кластеризации является разделительная
кластеризация (partitioning clustering), в соответствии с которой для выборки
Данных, содержащей п записей (объектов), задается число кластеров k, которое
312 Часть I. Теория бизнес-анализа
должно быть сформировано. Затем алгоритм разбивает все объекты выборки на
k групп (k < п), которые и представляют собой кластеры.
К наиболее простым и эффективным алгоритмам кластеризации относится
k-means (Mac-Queen, 1967), или в русскоязычном варианте ^-средних (от англ
mean — «среднее значение»). Он состоит из четырех шагов.
1. Задается число кластеров k, которое должно быть сформировано из объектов
исходной выборки.
2. Случайным образом выбирается k записей, которые будут служить начальными
центрами кластеров. Начальные точки, из которых потом вырастает кластер,
часто называют «семенами» (от англ, seeds — «семена», «посевы»). Каждая такая
запись представляет собой своего рода «эмбрион» кластера, состоящий только
из одного элемента.
3. Для каждой записи исходной выборки определяется ближайший к ней центр
кластера.
ПРИМЕР-------------------------------------------------------------------
Для лучшего понимания методики воспользуемся геометрической интерпретацией определе-
ния того, к какому из центров кластеров ближе всего расположената или иная запись. Границей
между двумя кластерами является точка, равноудаленная от четырех центров. Из геометрии
известно, что множество точек, равноудаленных от двух точек А и В, образует прямую, пер-
пендикулярную отрезку АВ и пересекающую его середину. Принцип поиска границ будущих
кластеров поясняется на рисунке. Для простоты рассматривается двумерный случай, когда
пространство признаков содержит всего два измерения (Х1(Х2)- Пусть на первом шаге были
отобраны три точки — А, В и С. Тогда линия 1, проходящая перпендикулярно отрезку АВ
через его середину, будет состоять из точек, равноудаленных от точек А и В. Аналогично
строится прямая 2 для точек А и С, а также прямая 3 для точек В и С. С помощью данных
линий можно определить, к какому из центров оказывается ближе та или иная точка.
Глава 7. Data Mining: кластеризация 313
Однако такая геометрическая интерпретация полезна только для лучшего понимания.
На практике, чтобы определить, в «сферу влияния» какого центра кластера входит та или
иная запись, вычисляется расстояние от каждой записи до каждого центра в многомерном
пространстве признаков и выбирается то «семя», для которого данное расстояние мини-
мально (более подробно это рассматривается ниже).
4 Производится вычисление центроидов — центров тяжести кластеров. Это дела-
ется путем определения среднего для значений каждого признака всех записей
в кластере.
Например, если в кластер вошли три записи с наборами признаков (хь г/i),
(х2, у г), (Хз, Уз), то координаты его центроида будут рассчитываться следующим
образом:
((%) + х2 +х:)) (г/1 + у2 +Уз\
(Х’У)= -------5------------5------•
Затем старый центр кластера смещается в его центроид. На рис. 7.2 центры
тяжести кластеров представлены в виде крестиков.
Рис. 7.2. Определение центров тяжести кластеров (центроидов)
и новых границ кластеров
Таким образом, центроиды становятся новыми центрами кластеров для следу-
ющей итерации алгоритма.
Шаги 3 и 4 повторяются до тех пор, пока выполнение алгоритма не будет пре-
рвано либо пока не будет выполнено условие в соответствии с некоторым крите-
рием сходимости.
Остановка алгоритма производится, когда границы кластеров и расположение
центроидов перестают изменяться, то есть на каждой итерации в каждом кластере
314 Часть I. Теория бизнес-анализа
остается один и тот же набор записей. Алгоритм k-means обычно находит набор
стабильных кластеров за несколько десятков итераций.
Что касается критерия сходимости, то чаще всего используется сумма квадратов
ошибок между центроидом кластера и всеми вошедшими в него записями:
£=ЕЕ(р-т02>
i = i рее,
где р & Ci — произвольная точка данных, принадлежащая кластеру С,;
т, — центроид данного кластера.
Иными словами, алгоритм остановится тогда, когда ошибка Е достигнет доста-
точно малого значения.
Меры расстояний
Ключевой момент алгоритма k-means: на каждой итерации вычисляется расстояние
между объектами и центрами кластеров, чтобы определить, к какому из кластеров
принадлежит данная запись. Правило, по которому вычисляется расстояние в мно-
гомерном пространстве признаков, называется метрикой. Наиболее часто в практи-
ческих задачах кластеризации используются следующие метрики.
□ Евклидово расстояние, или метрика Ь2. Использует для вычисления расстояний
следующее правило:
= (7.1)
где X = (xi, х2... хт), Y = (г/i, у2... ут) — векторы значений признаков двух запи-
сей.
Поскольку множество точек, равноудаленных от некоторого центра, при исполь-
зовании евклидовой метрики будет образовывать сферу (или круг в двумерном
случае), кластеры, полученные с использованием евклидова расстояния, также
будут иметь форму, близкую к сферической.
□ Расстояние Манхэттена (Manhattan distance), или метрика Llt вычисляется
по формуле:
</м(Х,У) = £>-гл|.
Фактически это кратчайшее расстояние между двумя точками, пройденное по
линиям, параллельным осям прямоугольной системы координат (рис. 7.3).
Преимущество метрики Ц заключается в том, что использование прямоугольной
системы координат позволяет снизить влияние аномальных значений на работу
алгоритмов. Кластеры, построенные на основе расстояния Манхэттена, стремятся
к кубической форме. Иногда расстояние Манхэттена называют «расстоянием го-
родских кварталов» (city-block distance) из-за ассоциаций, возникающих с прямо-
угольными формами застройки, которая характерна для современных городов.
Глава 7. Data Mining: кластеризация 315
d(xi,yi) =
Рис. 7.3. Расстояние Манхэттена (метрика Ц)
□ Для категориальных признаков в качестве меры расстояния можно исполь-
зовать функцию отличия (different function), которая задается следующим
образом:
О, если Xi = y t
1, в остальных случаях,
где Xi nyi — категориальные значения.
Свою популярность алгоритм k-means приобрел благодаря следующим свой-
ствам.
Во-первых, это умеренные вычислительные затраты, которые растут линей-
но с увеличением числа записей исходной выборки данных. Вычислительная
сложность алгоритма определяется как k-n-l, где k — число кластеров, п — число
записей и I — число итераций. Поскольку k и I заданы, вычислительные затраты
возрастают пропорционально числу записей исходного множества.
Во-вторых, результаты работы k-means не зависят от порядка следования запи-
сей в исходной выборке, а определяются только выбором исходных точек.
Один из основных недостатков, присущих алгоритму k-means, — отсутствие
четких критериев выбора числа кластеров, целевой функции их инициализации
и модификации. Кроме того, он очень чувствителен к шумам в данных и ано-
мальным значениям, поскольку они способны существенно повлиять на среднее
значение, используемое при вычислении положений центроидов. Чтобы снизить
влияние таких факторов, как шумы и аномальные значения, иногда на каждой
итерации используют не среднее значение признаков, а их медиану. Данная мо-
дификация алгоритма называется ^-mediods (^-медиан).
Пример работы алгоритма k-means, разбивающего объекты на 4 кластера, при-
веден на рис. 7.4 (каждому кластеру соответствует свой тип точек).
316 Часть I. Теория бизнес-анализа
Рис. 7.4. Результат кластеризации алгоритмом k-means
Пример работы алгоритма k-means
Пусть имеется набор из 8 точек данных в двумерном пространстве, из которого требу-
ется получить два кластера. Координаты точек приведены в табл. 7.2 и на рис. 7.5.
Таблица 7.2. Объекты для кластеризации
А в С D Е F G н
(1;3) (3; 3) (4;3) (5;3) (1;2) (4; 2) (1;1) (2; 1)
Рис. 7.5. Начальная инициализация
Шаг 1. Определим число кластеров, на которое требуется разбить исходное
множество: k = 2.
Шаг 2. Случайным образом выберем две точки, которые будут начальными
центрами кластеров. Пусть это будут точки mt = (1; 1) и тп2 = (2; 1). На рис. 7.5 они
представлены знаком «+».
Глава 7. Data Mining: кластеризация 317
ШагЗ, проход 1. Для каждой точки определим ближайший к ней центр кла-
стера в евклидовой метрике. В табл. 7.3 представлены вычисленные с помощью
формулы (7.1) расстояния между центрами кластеров mi = (1; 1), т2 = (2; 1)
и каждой точкой исходного множества и указано, к какому кластеру принадлежит
та или иная точка.
Таблица 7.3. Нахождение ближайшего центра для каждой точки (первый проход)
Точка Расстояние от mi Расстояние от ли Принадлежит кластеру
А 2,00 2,24 1
В 2,83 2,24 2
С 3,61 2,83 2
D 4,47 3,61 2
Е 1,00 1,41 1
F 3,16 2,24 2
G 0,00 1,00 1
~Н 1,00 0,00 2
Таким образом, кластер 1 содержит точки А, Е, G, а кластер 2 — точки В, С,
D, F, Н. Как только определятся члены кластеров, может быть рассчитана сумма
квадратов ошибок:
£ = ^^(р-т,)2 = 22 +2,242 + 2,832 +
1 = 1 ре С,
+ 3,612 +12 4-2,242 +02 +02 =36.
Шаг 4, проход 1. Для каждого кластера вычисляется центроид, и в него пере-
мещается центр кластера.
Центроид для кластера 1: [(1 + 1 + 1)/3; (3 + 2 + 1)/3] = (1; 2).
Центроид для кластера 2: [(3 + 4 + 5 -I- 4 + 2) / 5; (3 + 3 + 3 + 2 + 1) / 5] = (3,6; 2,4).
Расположение кластеров и центроидов после первого прохода алгоритма пред-
ставлено на рис. 7.6.
Шаг 3, проход 2. После того как найдены новые центры кластеров, для каждой
точки снова определяется ближайший к ней центр и ее отношение к соответству-
ющему кластеру. Для это еще раз вычисляются евклидовы расстояния между точ-
ками и центрами кластеров. Результаты вычислений приведены в табл. 7.4.
Относительно большое изменение тг привело к тому, что запись Н оказалась
ближе к центру пц, что автоматически сделало ее членом кластера 1. Все осталь-
ные записи остались в тех же кластерах, что и на предыдущем проходе алгоритма.
Таким образом, кластер 1 будет содержать точки А, Е, G, Н, а кластер 2 — В, С, D, F.
Новая сумма квадратов ошибок составит:
£ = ^^(р-т;)2 = 12 +0,852 +0,722 +
г=1peG
+ 1,522 +02 +0,572 +12 +1,412 =7,86.
318 Часть I. Теория бизнес-анализа
X
Рис. 7.6. Расположение кластеров и центроидов после первого прохода алгоритма
Таблица 7.4. Нахождение ближайшего центра для каждой точки (второй проход)
Точка Расстояние от mi Расстояние от т2 Принадлежит кластеру
А 1,00 2,67 1
В 2,24 0,85 2
С 3,16 0,72 2
D 4,12 1,52 2
Е 0,00 2,63 1
F 3,00 0,57 2
G 1,00 2,95 1
Н 1,41 2,13 1
Вычисление показывает уменьшение ошибки относительно начального состоя-
ния центров кластеров (на первом проходе она составляла 36). Это говорит об
улучшении качества кластеризации, то есть о более высокой «кучности» объектов
относительно центра кластера.
Шаг 4, проход 2. Для каждого кластера вновь вычисляется центроид, и центр
кластера перемещается в него.
Новый центроид для кластера 1: [(1 + 1 + 1 + 2)/4, (3 -I-2 + 1 + 1)/4] = (1,25; 1,75).
Новый центроид для кластера 2: [(3 + 4 + 5 + 4) /4, (3 + 3 + 3 + 2) /4] = (4; 2,75).
Расположение кластеров и центроидов после второго прохода алгоритма пред-
ставлено на рис. 7.7.
По сравнению с предыдущим проходом центры кластеров изменились незна-
чительно.
Шаг 3, проход 3. Для каждой записи вновь ищется ближайший к ней центр
кластера. Полученные на данном проходе расстояния представлены в табл. 7.5.
Глава 7. Data Mining: кластеризация 319
X
Рис. 7.7. Расположение кластеров и центроидов после второго прохода алгоритма
Таблица 7.5. Нахождение ближайшего центра для каждой точки (третий проход)
Точка Расстояние от mi Расстояние от пь Принадлежит кластеру
А 1,27 3,01 1
В 2,15 1,03 2
С 3,02 0,25 2
D 3,95 1,03 2
Е 0,35 3,09 1
F 2,76 0,75 2
G 0,79 3,47 1
Н 1,06 2,66 1
Следует отметить, что записей, сменивших кластер на третьем проходе алгорит-
ма, не было. Новая сумма квадратов ошибок составит:
£ = £ £2 (р - от, )2 = 1,272 +1,032 + 0,252 +
j=1реС,
+1,032 +0,352 + 0,752 +0,792 +1,062 = 6,23.
Таким образом, сумма квадратов ошибок изменилась незначительно по сравне-
нию с предыдущим проходом.
Шаг 4, проход 3. Для каждого кластера вновь вычисляется центроид, и центр
кластера перемещается в него. Но поскольку на данном проходе ни одна запись
не изменила своего членства в кластерах и положение центроидов не поменялось,
алгоритм завершает работу.
320 Часть I. Теория бизнес-анализа
Алгоритм G-means
Одним из недостатков алгоритма k-means является отсутствие ясного критерия для
выбора оптимального числа кластеров. Действительно, пусть множество данных
содержит 5 групп, внутри которых объекты похожи, а в различных группах суще-
ственно отличаются. Тогда логично задать k = 5, чтобы каждая группа оказалась
ассоциирована с отдельным кластером. Но, как правило, такая априорная инфор-
мация отсутствует и аналитику приходится действовать методом проб и ошибок
Если будет выбрано k = 3, то какие-то две из 5 групп окажутся «распылены» по
«чужим» кластерам и не будут обнаружены. Это может привести к потере потен-
циально ценных знаний. Кроме того, в общем-то, мало похожие объекты могут
оказаться в одном кластере, что затруднит интерпретацию результатов анализа.
Если выбрать большее число кластеров, например k = 7, то будут сформированы
«лишние» кластеры. При этом получится, что достаточно похожие объекты ока-
жутся в различных кластерах. Это проиллюстрировано на рис. 7.8, где знаком «+»
отмечены центры кластеров, сформированные обычным алгоритмом k-means.
На рис. 7.8, а, где для 5 групп сформировано всего 3 кластера, можно увидеть,
что группы 1 и 5, а также 2 и 3 оказались ассоциированы с одним центром, то есть
попали в общий кластер. В результате аналитик может сделать ошибочный вывод
о сходстве объектов из групп, объединенных в один кластер. На рис. 7.8, б, гае
число кластеров было задано слишком большим, наблюдается обратная ситуация.
Группы 3 и 5 оказались ассоциированы с двумя центрами, и, следовательно, каждая
из них разбросана по двум кластерам.
Чтобы решить данную проблему, было разработано большое количество ал-
горитмов, позволяющих производить автоматический выбор числа кластеров,
оптимального с точки зрения того или иного критерия. Обычно в них строится
несколько моделей для различных значений k, а затем выбирается наиболее под-
ходящая. Примерами могут служить алгоритм X-means, в основе которого лежат
байесовские оценки логарифмического правдоподобия; алгоритм, основанный на
принципе минимальной длины описания (MDL) и др.
Одним из самых популярных алгоритмов кластеризации с автоматическим
выбором числа кластеров является G-means. В его основе лежит предположение
о том, что кластеризуемые данные подчиняются некоторому унимодальному
закону распределения, например гауссовскому (откуда и название алгоритма).
Тогда центр кластера, определяемый как среднее значений признаков попавших
в него объектов, может рассматриваться как мода соответствующего распределения.
Если исходные данные описываются унимодальным гауссовским распределением
с заданным средним, то можно предположить, что все они относятся к одному кла-
стеру. Если распределение данных не гауссовское, то можно попробовать выпол-
нить разделение на два кластера. Если в этих кластерах распределения окажутся
близки к гауссовскому, то можно в первом приближении считать, что k = 2 будет
оптимальным. В противном случае будут построены новые модели с большим
числом кластеров, и так до тех пор, пока распределение в каждом из них не ока-
жется достаточно близким к гауссовскому. Такая модель и, соответственно, число
кластеров в ней будут считаться оптимальными.
Глава 7. Data Mining: кластеризация 321
Рис. 7.8. Разбиение алгоритмом k-means: а — 3 кластера; 6 — 7 кластеров
Алгоритм G-means является итеративным, где на каждом шаге с помощью обыч-
ного k-means строится модель с определенным числом кластеров. Обычно G-means
начинает работу с небольшого значения k, и на каждой итерации оно увеличивает-
ся. Как правило, начальное значение k выбирается равным 1. На каждой итерации
увеличение k производится за счет разбиения кластеров, в которых данные не
соответствуют гауссовскому распределению.
Алгоритм «принимает решение» о дальнейшем разбиении на основе статистиче-
ского теста данных, связанных с каждым центроидом. Если при этом будет обнару-
жено, что они распределены по гауссовскому закону, то дальнейшего смысла в их
разбиении нет. Фактически в процессе работы G-means алгоритм k-means будет
повторен k раз, поэтому сложность алгоритма составит O(k).
322 Часть I. Теория бизнес-анализа
7.3. Сети Кохонена
Термин «сети Кохонена» (Kohonen clastering network — KCN) был введен
в 1982 г. финским ученым Тойво Кохоненом. Хотя изначально сети Кохонена
применялись для обработки изображений и звука, они также являются эффек-
тивным средством кластерного анализа. Сети Кохонена представляют собой
разновидность самоорганизующихся карт признаков, которые, в свою очередь
являются специальным типом нейронных сетей (базовые понятия о нейронах
и нейронных сетях вводятся в главе 9).
Основная цель сетей Кохонена — преобразование сложных многомерных дан-
ных в более простую структуру малой размерности. Таким образом, они хорошо
подходят для кластерного анализа, когда требуется обнаружить скрытые законо-
мерности в больших массивах данных.
Сеть Кохонена состоит из узлов, которые объединяются в кластеры. Наиболее
близкие узлы соответствуют похожим объектам, а удаленные друг от друга — не-
похожим. Можно рассматривать сеть Кохонена как обобщение метода главных
компонент — другой методики, применяемой для сокращения размерности дан-
ных.
В основе построения сети Кохонена лежит конкурентное обучение, когда вы-
ходные узлы (нейроны) конкурируют между собой за право стать «победителем».
Говорят, что нейроны избирательно настраиваются для различных входных
примеров или классов входных примеров в ходе соревновательного процесса
обучения.
Пример сети Кохонена представлен на рис. 7.9.
Возраст
Доход
Рис. 7.9. Структура простой сети Кохонена
для кластеризации клиентов по возрасту и доходу
Глава 7. Data Mining: кластеризация 323
Входные нейроны образуют входной слой сети, который содержит по одному
^ейрону для каждого входного поля. Как и в обычной нейронной сети, входные
нейроны не участвуют в процессе обучения. Их задача — передать значения вход-
нух полей исходной выборки на нейроны выходного слоя. Каждая связь между
нейронами сети имеет определенный вес, который в процессе ее инициализации
устанавливается случайным образом в интервале от 0 до 1. Процесс обучения за-
ключается в подстройке весов.
Однако в отличие от большинства нейронных сетей других видов сеть Кохонена
не имеет скрытых слоев: данные с входного слоя передаются непосредственно на
выходной, нейроны которого упорядочены в одномерную или двумерную решетку
прямоугольной или шестиугольной формы.
Значения каждого признака объекта поступают через входные нейроны на
каждый нейрон выходного слоя. Предположим, что нормированные значения
возраста и дохода составляют 0,58 и 0,69 соответственно. Значение 0,58 поступает
в сеть через входной нейрон Возраст и передается на все нейроны выходного
слоя. Аналогично значение 0,69 поступает через нейрон Доход и также распро-
страняется на все нейроны выходного слоя.
В процессе обучения и функционирования сеть KCN выполняет три процедуры.
1. Конкуренция (competition). Выходные нейроны конкурируют между собой за
то, чтобы векторы их весов оказались как можно ближе к вектору признаков
объекта. Выходной нейрон, вектор весов которого имеет наименьшее расстояние
до вектора признаков объекта, объявляется победителем.
2. Объединение (cooperation). Победивший нейрон становится центром некото-
рой группы соседних нейронов. В KCN все нейроны такого соседства называют
награжденными правом подстройки весов. Следовательно, несмотря на то что
нейроны в выходном слое не соединяются непосредственно, они имеют похо-
жие наборы весов благодаря соседству с нейроном-победителем.
3. Подстройка весов (adaptation). Нейроны, соседствующие с нейроном-победи-
телем, участвуют в подстройке весов, то есть в обучении.
Обучение сети Кохонена
Рассмотрим набор из т значений полей n-й записи исходной выборки, который
будет служить входным вектором Х„ = (х„ь х„2... хпт)Т, и текущий вектор весов
j-vo выходного нейрона W, = (w{j, w2j... wmjy. В обучении по Кохонену нейроны, ко-
торые являются соседями нейрона-победителя, подстраивают свои веса, используя
линейную комбинацию входных векторов и текущих векторов весов:
wij, новое wij, текущее Л\xni wij, текущее]’ (7-2)
гДе 0 < Т) < 1 — коэффициент скорости обучения.
Согласно Кохонену, скорость обучения должна быть уменьшающейся функцией
от числа его итераций. Поэтому процесс обучения сети можно разделить на две
фазы — грубой подстройки и точной подстройки. В первой фазе скорость обучения
324 Часть I. Теория бизнес-анализа
велика и веса нейронов корректируются значительно, что позволяет примерно
настроить их в соответствии с распределением значений признаков объектов в ис-
ходной выборке. Во второй фазе скорость обучения уменьшается, что позволяет
подстраивать веса более точно.
При инициализации сети начальные веса нейронов назначаются случайно, если
отсутствуют априорные знания о характере распределения признаков в исходной
выборке. Также при инициализации задаются начальная скорость обучения ц и ра-
диус обучения R, то есть количество нейронов, которые будут считаться соседями
для нейрона-победителя и подстраивать свои веса вместе с ним. Радиус максимален
в начале процесса и по мере обучения уменьшается.
Алгоритм Кохонена включает следующие шаги.
1. Инициализация. Для нейронов сети устанавливаются начальные веса, а также
задаются начальная скорость обучения ц и радиус обучения R.
2. Возбуждение. На входной слой подается вектор воздействия Х„, содержащий
значения входных полей записи обучающей выборки.
3. Конкуренция. Для каждого выходного нейрона вычисляется расстояние Z)(W7, Х„)
между векторами весов всех нейронов выходного слоя и вектором входного
воздействия. Если в качестве меры близости двух векторов выбрано евклидо-
во расстояние, то получим: Z>(W;,X„) — —х,,/)2. Иными словами, рас-
считывается расстояние между векторами весов всех нейронов выходного слоя
и вектором входного воздействия. Тот нейрону, для которого расстояние
окажется наименьшим, и будет победителем.
4. Объединение. Определяются все нейроны, расположенные в пределах радиуса
обучения относительно нейрона-победителя.
5. Подстройка. Производится подстройка весов нейронов в пределах радиуса
обучения в соответствии с формулой (7.2). При этом веса нейронов, ближай-
ших к нейрону-победителю, подстраиваются в сторону его вектора весов. Это
иллюстрирует рис. 7.10, на котором координаты входного вектора отмечены
знаком «+», а вид сети после модификации — штриховыми линиями.
Рис. 7.10. Подстройка нейронов в соседстве с нейроном-победителем
Глава 7. Data Mining: кластеризация 325
6. Коррекция. Изменяются радиус и параметр скорости обучения в соответствии
с заданным законом.
Пример работы сети Кохонена
Рассмотрим работу сети Кохонена на несложном примере. Имеется множество дан-
ных; в нем содержатся атрибуты Возраст и Доход, которые были предварительно
нормализованы. Для решения задачи кластеризации по этим атрибутам будем ис-
пользовать сеть Кохонена, содержащую 2x2 нейрона в выходном слое (рис. 7.11).
Для такой небольшой сети установим радиус обучения R = 0, поэтому воз-
можность подстройки весов будет предоставлена только нейрону-победителю.
Коэффициент скорости обучения установим ц = 0,5. Выберем случайным образом
начальные веса нейронов: ®tl = 0,9; w2l = 0,8; ®i2 = 0,9; w22 = 0,2; wl3 = 0,1; ®23 = 0,8;
»и = 0,1; ®24 = 0,2.
Набор записей исходной выборки представлен в табл. 7.6.
Таблица 7.6. Объекты для кластеризации
№ Х,1 Описание
7 Хн = 0,8 Х12 = 0,8 Пожилой человек с высоким доходом
2 x2i = 0,8 х2г = 0,1 Пожилой человек с низким доходом
3 %31 = 0,2 хм = 0,8 Молодой человек с высоким доходом
4 %41 = 0,1 Ха = 0,8 Молодой человек с низким доходом
Для первого входного вектора Xi = (0,8; 0,8) выполним такие действия, как
конкуренция, объединение и подстройка.
326 Часть I. Теория бизнес-анализа
Конкуренция. Вычислим евклидово расстояние между входным вектором Xj
и векторами весов всех четырех нейронов выходного слоя.
Нейрон 1:
D(W,, X,) = 7(®ц-хц)2 + (®21-х12)2 = 7(°’9-°-8)2 + (0,8~0,8)2 =0,1.
Нейрон 2:
D (W2, X!) = ^(ж12-х11)2+(ж22-Х12)2 = J(0,9-0,8)2 + (0,2-0,8)2 =0,61.
Нейрон 3:
D(W;>, X,) = 7(®i3-^ti)2 +(®2.з-х12)2 = ^(О’1 -°'8)2 -|-(0’8-0’8)2 = °’7-
Нейрон 4:
O(W4, Х1) = 7(да14-х11)2+(ж24-х12)2 = 7(0,1-0,8)2 + (0,2-0,8)2 = 0,92.
Таким образом, для первой записи победителем стал нейрон с номером 1, для
которого расстояние между вектором его весов Wi = (0,9; 0,8) и входным вектором
Xi = (0,8; 0,8) оказалось минимальным среди всех нейронов. По этой причине мы мо-
жем предполагать, что нейрон 1 «близок» записям, в которых фигурируют пожилые
люди с высоким доходом, и открывает кластер, в который будут включены пожилые
люди с высоким доходом.
Объединение. В данном примере установлен радиус обучения R = 0, поэтому
только нейрон-победитель будет «награжден» возможностью подстройки своего
вектора весов. В связи с этим мы не будем рассматривать этот этап в дальнейшем.
Подстройка. Поскольку для первого нейрона у = 1, для первой записи п = 1
при коэффициенте скорости обучения г) = 0,5 в соответствии с формулой (7.2)
получим:
<®ii, новое = <®ii, текущее + 0,5-(хн — Wn, текущее)-
Тогда для признака Возраст-.
®и, новое = <®и, текущее + 0,5 • (Хц — <®it, текущее) = 0,9 + 0,5 • (0,8 — 0,9) = 0,85.
Для признака Доход'.
®21, новое = ®21, текущее + 0,5 (xt2 — ®21, текущее ) = 0,8 + 0,5 (0,8 — 0,8) = 0,8.
Обратим внимание на то, как происходит подстройка весов. Они «подталкива-
ются» в направлении значений входных полей записи, то есть связи нейрона-
победителя, соответствующей признаку Возраст, изначально был равен 0,9, но
в результате подстройки изменился в сторону нормализованного значения Возраст
первой записи, равного 0,8. Поскольку коэффициент скорости обучения г) = 0,5, ве-
личина подстройки равна половине расстояния между текущим весом и значением
Глава 7. Data Mining: кластеризация 327
роля. Данная подстройка позволит нейрону 1 стать более успешным в «захвате»
записей, содержащих информацию о пожилых людях с высоким доходом.
Произведем аналогичные действия для второго входного вектора Х2 = (0,8; 0,1).
Конкуренция.
Нейрон 1:
O(Wt, Х2) = j(wlt-x2i)2+(w2i-x-n)2 = 7(0,85-0,8)2+(0,8-0,1)2 =0,71.
Нейрон 2:
O(W2,Х2) = 7(^12 -х2,)2 + (ж22-х22)2 = 7(0,9-0,8)2+(0,2-0,1)2 = 0,14.
Нейрон 3:
О( W.3, Х2) = 7(®1.з-х21)2 +(®23-х22)2 = 7(0,1-0,8)2+(0,8-0,1)2 = 0,99.
Нейрон 4:
D(W4, Х2) = 7(®u-x21)2 + (®24-х22)2 = ^О'1-0-8)2 + (0,2-0,1)2 = 0,71.
Таким образом, для второй записи победителем стал нейрон 2. Обратим вни-
мание на то, что он выиграл соревнование, поскольку вектор его весов W2 = (0,9;
0,2) ближе к входному вектору второй записи Х2 = (0,8; 0,1), чем векторы весов
других нейронов. Можно предположить, что второй нейрон «захватывает» записи,
в которых содержится информация о пожилых людях с низким доходом.
Подстройка весов. Поскольку победил второй нейрон, то у = 2, и для второй
записи п = 2 при коэффициенте скорости обучения г) = 0,5 в соответствии с фор-
мулой (7.2) получим:
<®,2, новое —Wi2, текущее + 0,5 (х2, — ®/2, текущее )•
Тогда для признака Возраст'.
12, новое = й-т 2, текущее + 0,5 (х2| — ®Л2, текущее) = 0,9 + 0,5 • (0,8 — 0,9) = 0,85.
Для признака Доход'.
<®22, новое = 8’22, текущее + 0,5 (х22 — ® 22, текущее) = 0,2-|-0,5 - (0,1 — 0,2) = 0,15.
Как можно увидеть, веса вновь корректируются в направлении значений вход-
ных полей записи. Вес <®i2 подстраивается так же, как и вес и>ц для первой записи,
поскольку текущие веса и значения поля Возраст для обеих записей одни и те же.
Вес да22 для признака Возраст уменьшился, поскольку значение поля Доход для
второй записи ниже, чем текущий вес связи Доход нейрона-победителя. Благодаря
данной подстройке нейрон 2 сможет лучше «захватывать» записи, содержащие
информацию о пожилых людях с низким доходом.
328 Часть I. Теория бизнес-анализа
Теперь выполним ту же последовательность действий для третьей записи, где
входной вектор Х3 = (0,2; 0,9).
Конкуренция.
Нейрон 1:
£)( W,, Х3) = 7(®Ц-^31)2 +(®21-^:>2)2 = 7(0,85-0,2)2 +(0,8-0,9)2 = 0,66.
Нейрон 2:
£>( W2, Хз) = 7(®i2-^3i)2 +(®22-^з2)2 = 7(0,85-0,2)2 +(0,15-0,9)2 = 0,99.
Нейрон 3:
D (W.3, X з) = 7(®i3-^3i)2 +(®2з-х32)2 = 7(0,1-0,2)2+(0,8-0,9)2 =0,14.
Нейрон 4:
О( W,, Хз) = 7(®и-^<|)2+(к'24-Хз2)2 = 7(0,1-0,2)2 + (0,2-0,9)2 = 0,71.
Теперь победителем стал нейрон 3, поскольку вектор его весов W3 = (0,1; 0,8)
оказался ближе к входному вектору третьей записи Х3 = (0,2; 0,9), чем векторы
весов остальных нейронов. Поэтому можно ожидать, что нейрон 3 станет началом
кластера для молодых людей с высоким доходом.
Подстройка весов. Поскольку победил третий нейрон, то у = 3, и для третьей
записи п = 3 при коэффициенте скорости обучения ц = 0,5 в соответствии с фор-
мулой (7.2) получим:
®i,3, новое = ®;з, текущее + 0,5 • (х3, — 8.’,з, текущее )
Тогда для признака Возраст'.
®|3, новое — ® 13, текущее + 0,5 (х3, — ИЛз, текущее ) = 0,1 + 0,5 (0,2 — 0,1) = 0,15.
Для признака Доход:
®2.з, новое = ®23, текущее + 0,5 • (х32 — ®23, текущее) — 0,8 + 0,5 • (0,9 — 0,8) = 0,85.
И наконец, выполним ту же последовательность действий для входного вектора
четвертой записи Х4 = (0,1; 0,1).
Конкуренция.
Нейрон 1:
О( W,, Х4) = 7(®11-л+)2+(®21-М2 = 7(0’85-0’1)2 +(°’8 —0,1)2 = 1,03.
Глава 7. Data Mining: кластеризация 329
Нейрон 2:
P(W2, Х4) = = >,85-ОД)2+(0,15-0,1)2 = 0,75.
Нейрон 3:
D (W.), X 4) = — х4,) + (®2з — х,12) = 7(0,1 —0,1) +(0,8 —0,1) =0,7.
Нейрон 4:
D(W4, X4) = 7(®и-^1)2 +(®24-Х42)2 = 7(0,1-0,1)2+(0,2-ОД)2 =0,1.
Теперь победителем стал нейрон 4, поскольку вектор его весов W4 = (ОД; 0,2)
оказался ближе к входному вектору 3-й записи Х4 = (ОД; ОД), чем векторы весов
остальных нейронов. Поэтому можно ожидать, что нейрон 4 станет основой кла-
стера для молодых людей с низким доходом.
Подстройка весов. Поскольку победил четвертый нейрон, то у = 4, и для чет-
вертой записи п = 4 в соответствии с формулой (7.2) получим:
й-’,4, новое — й-+, текущее + 0,5 • (х4,- — , текущее)-
Тогда для признака Возраст'.
®14, новое — ®-'14, текущее + 0,5 • (x4i — ffc’n, текущее ) = ОД + 0,5 • (ОД — 0,1) = ОД.
Для признака Дохой:
й-+, новое = ® 24, текущее + 0,5 • (х42 — <®24, текущее ) = 0,2 + 0,5 • (ОД — 0,2) = 0,15.
Таким образом, можно увидеть, что четыре выходных нейрона представляют
четыре различных кластера, если выборка данных содержит записи, схожие с за-
писями из табл. 7.6. Эти кластеры представлены в табл. 7.7.
Таблица 7.7. Получившиеся кластеры
№ кластера № нейрона Описание
1 1 Пожилой человек с высоким доходом
2 2 Пожилой человек с низким доходом
3 3 Молодой человек с высоким доходом
4 4 Молодой человек с низким доходом
Число выходных нейронов сети Кохонена должно соответствовать числу кла-
стеров, которые должны быть построены.
Конечно, кластеры, открытые сетью Кохонена в данном примере, достаточ-
но очевидны. Однако здесь хорошо проиллюстрированы основы работы KCN
с использованием конкуренции между нейронами и алгоритма обучения Кохо-
нена.
330 Часть I. Теория бизнес-анализа
7.4. Карты Кохонена
Самоорганизующиеся карты признаков (self organizing map — SOM) позволяют
представлять результаты кластеризации в виде двумерных карт, где расстояния
между объектами соответствуют расстояниям между их векторами в многомерном
пространстве, а сами значения признаков отображаются различными цветами
и оттенками. Можно провести аналогию между SOM и обычной географической
картой, где размещение объектов и расстояния между ними соответствуют их
расположению на земной поверхности. Однако, кроме горизонтальных координат,
необходимо показать и рельеф — высоту гор, холмов, а также глубину водоемов.
Для этого используется специальная цветовая гамма. Так, высота местности ото-
бражается с помощью оттенков коричневого, глубина морей и океанов — синего:
чем выше или глубже объект, тем более темным цветом он окрашивается. Таким
образом, двумерная карта позволяет представлять трехмерные данные.
Если размерность пространства признаков набора данных, на котором строится
SOM, равна 2 (например, Возраст иДоход), то и векторы весов нейронов также будут
двухкомпонентными и отображение результатов кластеризации в этом случае проблем
не вызовет. Но в большинстве практических приложений приходится иметь дело с дан-
ными, для которых размерность пространства признаков больше чем 2 (рис. 7.12).
Рис. 7.12. Нарушение топологического подобия при проецировании
На первый взгляд, если мы хотим отобразить многомерное пространство на пло-
скую карту, достаточно выполнить соответствующую проекцию. Однако при этом
неизбежно нарушится топологическое подобие, то есть объекты, которые были суще-
ственно удалены друг от друга (и следовательно, обладали малой степенью сходства)
в исходном пространстве признаков, могут оказаться рядом друг с другом на карте.
На рис. 7.12 представлено трехмерное пространство признаков с двумя векторами
V, (х,, yi, Zi) и V2 (х2, у г, z2), евклидово расстояние между которыми равно:
Глава 7. Data Mining: кластеризация 331
De (Vi, V2) — — x2) +(z/i — z/2) +(zi — z2) .
j(aK видно, реальное расстояние между векторами в исходном пространстве при-
знаков намного больше, чем расстояние между их проекциями, то есть имеет место
нарУшеНИе топологического подобия. В этом случае при визуальном анализе из-за
потери информации об одном или нескольких измерениях (признаках) может быть
сделан неверный вывод о схожести объектов по их свойствам, что станет причиной
ошибочного отнесения объектов к одному классу.
Например, требуется выполнить классификацию объектов, признаками которых
являются размеры — длина, ширина и высота. При этом имеются две группы объектов,
отличающихся по длине, но примерно одинаковых по ширине и высоте. Тогда, если
исключить из рассмотрения длину, эти группы окажутся практически неразличимы,
что не позволит выполнить корректную кластеризацию объектов (рис. 7.13).
Поэтому при отображении многомер-
ных векторов на плоской карте необходи-
мо выполнять проекцию с сохранением
топологического подобия. Этого можно
добиться, если проецировать на карту
не сами векторы (объекты), а расстоя-
ния между ними, вычисленные в соответ-
ствии с определенной метрикой (на-
пример, евклидовой).
Таким образом, чем больше расстояние
между объектами на карте, тем больше
расстояние между векторами их призна-
ков и, следовательно, тем больше разли-
чаются их свойства.
Рис. 7.13. Неразличимость объектов
из-за потери информации об одном
из признаков
Методика построения карты
Чем отличаются понятия «сеть Кохонена» и «карта Кохонена»? Во-первых, сеть
Кохонена используется только для кластеризации объектов, а визуализация ре-
зультатов будет производиться традиционными способами, то есть с помощью
таблиц или диаграмм. В то же время карта Кохонена позволяет визуализировать
результаты кластеризации, в том числе многомерные. Во-вторых, в сети число
выходных нейронов соответствует количеству кластеров, которое должно быть
получено, а в карте — количеству сегментов, из которого будет состоять карта,
или, иными словами, размеру карты. Из вышесказанного можно сделать вывод,
что карта Кохонена — это частный случай сети Кохонена, когда число выходных
нейронов намного превышает число кластеров..
Размер карты определяется степенью ее детальности: чем выше число сегмен-
тов, тем подробнее представлено распределение признаков объектов. К обычной
сети Кохонена можно вернуться, уменьшив число сегментов карты до нужного
количества кластеров.
332
Часть I. Теория бизнес-анализа
Карта Кохонена состоит из сегментов прямоугольной или шестиугольной
формы, называемых ячейками (рис. 7.14). Каждая ячейка связана с опреде-
ленным выходным нейроном и представляет собой «сферу влияния» данного
нейрона: в нее попадают объекты, «захваченные» нейроном в процессе класте-
ризации. Распределение векторов весов нейронов карты происходит так же, как
и в обычной сети Кохонена, то есть на основе конкурентного обучения (см. раз-
дел 7.3). Объекты, векторы которых оказываются ближе к вектору весов данного
нейрона, попадают в ячейку, связанную с ним. Тогда распределение объектов на
карте в целом будет соответствовать распределению векторов весов ее нейронов.
Следовательно, если объекты на карте расположены близко друг к другу, то их
векторы будут близки. Напротив, если объекты на карте находятся далеко друг
от друга, то и векторы их признаков различаются сильно.
Рис. 7.14. Структура карты Кохонена размером 10 х 10 ячеек
Хотя расстояние между объектами позволяет сделать выводы о степени их сход-
ства или различия, также важна информация о том, в чем проявляется это сходство
и различие, по каким признакам объекты различаются в наибольшей степени, а по
каким — в наименьшей и т. д. Именно специальная раскраска помогает получить
ответы на эти вопросы, выполняя функцию третьего измерения. Идея состоит
в том, что каждой ячейке на карте назначается цвет в соответствии со значениями
признаков объектов в ней.
Таким образом, есть два важных фактора: положение объекта на карте (рас-
стояние до других объектов) и цвет ячейки, в которой он расположен. При данном
способе визуализации на одной карте можно использовать расцветку только по
одному признаку. Это значит, что для визуализации значений нескольких призна-
ков требуется строить отдельные карты. Например, если объекты имеют признаки
Возраст а Доход, то для получения полной информации о значениях этих призна-
ков необходимо построить две карты (рис. 7.15).
Теперь рассмотрим вопрос о том, как связаны цвета ячеек на карте и значения
признаков попавших в них объектов. Пусть в некоторую ячейку попали всего два
объекта с признаками Возраст и Доход, значения которых образуют векторы (45;
Глава 7. Data Mining: кластеризация 333
Доход, тыс. ед.
Возраст, лет
Рис. 7.15. Примеры карт размером 16 х 12
21) и (34; 14). Строятся две карты, и цвет ячейки будет определяться по среднему
значению признака в них. Для признака Возраст оно будет равно: (45 + 34) /2 = 39,5,
то есть серому оттенку (в цветной палитре — зеленому), а для признака Доход —
(21 + 14)/2 = 17,5, то есть белому оттенку (в цветной палитре — желто-зеленому).
Заметим, что можно не усреднять значения признака, а брать минимальное или
максимальное из них.
Если в ячейку попал только один объект, то ее цвет будет определяться по одно-
му значению признака. Если центр ячейки — «мертвый» нейрон, для которого при
обучении карты не нашлось ни одного достаточно близкого объекта, то ячейка ока-
жется пустой и ее расцветка будет формироваться только на основе весов нейрона.
Но в большинстве случаев из-за «подтягивания» его вектора весов в процессе обу-
чения мы не увидим резкого различия между цветом пустой ячейки и соседних.
Ячейки бывают прямоугольной и шестиугольной формы. Шестиугольные ячей-
ки более корректно отражают расстояния между объектами на карте, поскольку
в этом случае расстояния между центрами смежных ячеек одинаковы. В случае
же прямоугольных ячеек расстояния между центрами смежных ячеек зависят
от их взаимного расположения (рис. 7.16). С точки зрения логики работы карты
расстояния Г1 и г2 равны. Однако, как видно на рисунке, при использовании ячеек
Рис. 7.16. Шестиугольные и прямоугольные ячейки
334 Часть I. Теория бизнес-анализа
прямоугольной формы диагональное расстояние г2 всегда больше, чем rt, что при-
водит к некорректному представлению расстояний на карте.
Вернемся к рис. 7.15 и проанализируем карту по признаку Доход. На ней вы-
деляются три области с ячейками одного цвета, в каждой из которых собраны
клиенты с примерно одинаковым уровнем дохода. Так, темная область содержит
объекты со значением данного признака, не превышающим 5-7 тыс. ед. (низкий
доход), серая область — от 7 до 15 тыс. ед. (средний доход), а область со светло-
серыми и белыми ячейками — от 20 до 25 тыс. ед. (высокий доход). Проще говоря,
хорошо видна группировка клиентов по уровню их доходов.
Раскраска карты позволяет оценивать и сами результаты кластеризации. Если
ячейки с примерно одинаковой расцветкой образуют обособленные области, как
показано на рис. 7.15, то результаты кластеризации хорошие: алгоритму удалось вы-
делить группы объектов с похожими признаками.
Если ячейки разных цветов разбросаны вперемеш-
ку по всей карте, то результаты плохие: алгоритму
не удалось обнаружить группы похожих объектов.
Данная ситуация представлена на рис. 7.17. Хотя
возможна ситуация, когда по одним признакам объ-
екты различаются хорошо, а по другим хуже. Это
может привести к тому, что карты, построенные
по одним признакам, которые для разных групп
объектов различаются хорошо, покажут хорошую
кластеризацию, а по другим, которые различаются
хуже, — плохую.
Рис. 7.17. Пример неудачной
кластеризации
Выбор числа нейронов карты
Как отмечалось выше, карта Кохонена состоит из ячеек, центром каждой из которых
является нейрон выходного слоя. В ячейку попадают один или несколько объектов,
векторы признаков которых оказываются ближе к вектору весов данного нейрона.
В этом смысле ячейки карты можно рассматривать как своего рода микрокластеры.
Рассмотрим два крайних случая. Пусть в карте только один нейрон и, соот-
ветственно, одна ячейка. Тогда все объекты попадут в нее и кластеризации не
произойдет. По мере увеличения числа нейронов объекты начнут распределяться
по ячейкам в зависимости от того, к нейрону какой ячейки они окажутся ближе.
Однако, пока количество ячеек мало, в каждой из них будет собираться много
объектов, в том числе и сильно отличающихся по своим признакам. По мере уве-
личения числа нейронов все большее количество объектов будет «расселяться»
по своим ячейкам, и в пределе мы получим второй крайний случай, когда число
ячеек будет равно числу объектов. То есть каждый объект получит шанс занять
отдельную ячейку.
В первом случае карта имеет наибольший масштаб, когда даже далекие друг
от друга объекты представлены рядом. Во втором случае — наименьший, когда
близкие объекты оказываются в разных частях карты. Фактически выбор числа
Глава 7. Data Mining: кластеризация 335
ячеек в карте признаков аналогичен выбору масштаба обычной карты: детальность
представления данных зависит от особенностей решаемой задачи.
Таким образом, число нейронов в карте Кохонена выбирается в зависимости
от того, какую информацию мы хотим получить. Если нужна детальная инфор-
мация о каждом объекте и его признаках, то количество нейронов карты должно
приближаться к числу объектов выборки. Но при этом следует помнить две
вещи. Во-первых, увеличение числа нейронов карты приводит к росту вычисли-
тельных и временных затрат на ее обучение. Во-вторых, чаще всего для анализа
представляют интерес обобщенные данные, когда сделанные на основе карты
выводы и заключения можно распространить на группы объектов. В этом случае
нужно, чтобы число нейронов было в несколько раз меньше числа кластеризуе-
мых объектов.
Можно провести такую аналогию.
Если мы идем в турпоход, то нам по-
надобится карта с малым масштабом
(например, 1 км в 1 см), детально
представляющая местность. Если
мы отправляемся в путешествие на
автомобиле к морю, то потребует-
ся карта с большим масштабом, на
которой представлены регион или
область. А для заблудившихся в лесу
туристов карта мира бесполезна.
Поэтому не существует строгих
правил для выбора числа нейро-
нов в карте Кохонена. Каждый раз
аналитик должен сам определять
(возможно, методом проб и ошибок)
оптимальное количество нейронов,
исходя из решаемой задачи и осо-
бенностей данных. Например, если
разброс значений признаков в обу-
чающей выборке сильный (то есть
векторы объектов в пространстве
признаков разрежены), то, воз-
можно, следует уменьшить число
нейронов карты, чтобы избежать
большого количества пустых ячеек.
И наоборот, если векторы объектов
расположены в пространстве при-
знаков плотно, то для получения
лучших результатов можно увели-
чить число нейронов. Эти ситуации
проиллюстрированы на рис. 7.18.
У
Рис. 7.18. Выбор числа нейронов карты
336 Часть I. Теория бизнес-анализа
Недостатки карт Кохонена
Карты Кохонена — мощное средство визуализации и разведочного анализа дан-
ных, отличающееся от классических статистических процедур, в ходе которых
проверяется некоторый набор выдвинутых гипотез. Но у карт Кохонена есть ряд
недостатков и ограничений. Хотя минусы не умаляют его достоинств, в некоторых
случаях требуется осторожное отношение как к самому процессу построения карт
так и к интерпретации его результатов.
Одна из самых серьезных претензий, предъявляемых некоторыми исследовате-
лями в области Data Mining к картам Кохонена, заключается в том, что сами по себе
карты задачу кластеризации не решают, а лишь позволяют выдвинуть гипотезы
о наличии кластерной структуры и зависимостей в наборе данных. Выдвинутые
гипотезы нужно подтверждать другими методами, потому что они могут оказаться
ложными.
Остановимся также на таком недостатке, как эвристический характер метода.
В большинстве случаев инициализация карты, то есть задание начальных векторов
весов нейронов, является произвольной, при этом возможна потеря однозначно-
сти результата. Если обучать карту несколько раз, то мы всегда будем получать
непохожие итоги, поскольку устанавливаемые случайным образом начальные веса
нейронов будут различны и обучение каждый раз будет идти несколько иначе.
Кроме того, может возникнуть такая проблема, как «мертвые» нейроны — ней-
роны, веса которых были проинициализированы таким образом, что их векторы
оказались в той части пространства признаков, где отсутствуют или почти отсут-
ствуют векторы объектов.
На рис. 7.19 скопление светлых точек соответствует области, где сгруппированы
веса нейронов объектов исходной выборки.
Рис. 7.19. «Мертвые» нейроны
Глава 7. Data Mining: кластеризация 337
«Мертвые» нейроны практически не имеют шансов стать победителями и при-
нять участие в обучении и коррекции весов. Это может привести к обработке
входных данных меньшим числом нейронов, что ухудшит результаты кластери-
зации. Другими словами, нейронов в карте может просто-напросто не хватить для
интерпретации объектов из выборки.
Чтобы решить эту проблему, то есть вовлечь в процесс обучения максимальное
число нейронов, используются различные подходы и методы. Например, можно
инициализировать карту не случайными весами, а векторами признаков объектов
обучающей выборки или, как вариант, подсчитывать количество «побед» каждого
нейрона с целью учета его активности. Если это число превышает некоторое значе-
ние, то есть нейрон слишком активен, то, чтобы дать другим нейронам возможность
«побеждать», налагается «штраф» искусственным завышением расстояния между
вектором весов активного нейрона и векторами признаков объектов. При этом
величина «штрафа» пропорциональна числу побед нейрона. После того как в про-
цесс обучения вовлекается достаточное количество нейронов, продолжается их
«честная» конкуренция.
ПРИМЕР--------------------------------------------------------------------------
В бизнес-аналитике часто возникает необходимость исследовать степень лояльности кли-
ентов. В этой связи можно попытаться выделить группы клиентов, которые:
• полностью лояльны — будут пользоваться товарами и услугами фирмы при любых обстоя-
тельствах;
• частично лояльны — предпочитают пользоваться товарами и услугами компании, но в лю-
бой момент готовы отказаться от них ради более выгодных условий;
• нелояльны — пользуются товарами и услугами компании от случая к случаю, когда под
рукой нет ничего более доступного.
Если построить карту Кохонена, содержащую кластеры для каждой группы клиентов по сте-
пени их лояльности, то с ее помощью можно предсказывать ожидаемое поведение клиентов
и применять к ним соответствующую маркетинговую политику.
Так, если клиент попал в кластер, где преимущественно находятся лояльные клиенты, то можно
рассчитывать на долгое сотрудничество с ним. Если клиент попал в кластер для частично лояль-
ных клиентов, это значит, что особенно полагаться на него как на потребителя товаров и услуг
не стоит: он в любой момент переключится на более выгодное предложение. Если объект попал
в кластер для нелояльных клиентов, то его вообще не следует встраивать в маркетинговые
планы компании, хотя и нужно подумать о том, как повысить уровень его лояльности.
Иными словами, зная свойства объектов, сгруппированных в кластере, мы можем распро-
странить эти свойства на любой новый объект, который попал в данный кластер, и приме-
нить к нему соответствующие подходы, в частности другие методы Data Mining.
7.5. Проблемы алгоритмов кластеризации
Ранее уже отмечалось, что одно и то же множество объектов можно разбить на не-
сколько кластеров по-разному. Это привело к изобилию алгоритмов кластеризации.
338 Часть I. Теория бизнес-анализа
Пожалуй, ни одна другая задача Data Mining не имеет в своем арсенале столько
алгоритмов и методов решения.
Причинами сложившейся ситуации является несколько факторов, имеющих
общее объяснение: не существует одного универсального алгоритма кластеризации
Перечислим эти факторы и остановимся на каждом подробнее.
Неопределенность в выборе критерия
качества кластеризации
В Data Mining при решении задач кластеризации популярны алгоритмы, которые
ищут оптимальное разбиение множества данных на группы. Критерий оптималь-
ности определяется видом целевой функции, от которой зависит результат кла-
стеризации.
Например, семейство алгоритмов k-means показывает хорошие результаты,
когда данные в пространстве образуют компактные сгустки, четко отличимые друг
от друга. Поэтому и критерий качества основан на вычислении расстояний точек
до центров кластера.
На рис. 7.20 приведен пример неуспеха алгоритма k-means. При использовании
евклидовой метрики кластеры в k-means имеют сферическую форму, поэтому та-
кой алгоритм никогда не разделит на кластеры вложенные друг в друга множества
объектов.
ООО
О о о
о°о°
Чоо
§°о°о?Ро
°о°°оо%°
°О%°%
° ОО
о оо
ООО
°°о°
3°° оо°оо>.
0°<ь%°0^°о00
о ОО °О° ОсР?,
о о о о 2
о О °оо°оОоо
°ОО(₽ОоОО
Op
Оо°
°о
° о°о°о
о о
О
Рис. 7.20. Здесь не справится k-means
Главная трудность в выборе критерия качества кластеризации заключается
в том, что на практике в условиях, когда объекты описываются десятками и сот-
нями свойств, становится сложно оценить взаимное расположение объектов и по-
добрать адекватный алгоритм.
Глава 7. Data Mining: кластеризация 339
d(x, у) =
Трудность выбора меры близости,
обусловленная различной природой данных
Особенность бизнес-данных такова, что в таблицах, описывающих свойства объек-
тов, могут присутствовать различные типы данных (типы данных рассматривались
в разделе 1.3 «Структурированные данные»). Для задачи кластеризации это чаще
всего числовые и строковые данные. Строковый тип, в свою очередь, делится на
упорядоченный и категориальный.
Присутствие тех или иных типов данных в наборе определяет его природу. На-
зовем набор данных числовым, если он состоит только из целых и вещественных
признаков. Для вычисления расстояний между объектами таких наборов чаще
всего применяется популярная метрика евклидово расстояние.
Назовем набор данных строковым, если он состоит из упорядоченных и кате-
гориальных признаков (сюда же относятся логические признаки). Для упорядо-
ченных можно также использовать евклидово расстояние, закодировав значения
признака целыми числами. А вот к категориальным типам эта мера не подходит.
Здесь нужно применять специальную меру расстояния, например функцию отли-
чия (difference function), которая задается следующим образом:
О, еслих=г/
1, в остальных случаях,
где х и у — категориальные значения.
Наборы данных, содержащие признаки, к которым нельзя применять одну и ту
же меру расстояния, называются смешанными (mixed datasets).
Проиллюстрируем вышесказанное на примере. Пусть требуется вычислить
попарные расстояния между следующими объектами с атрибутами Возраст, Цвет
глаз, Образование: (1) {23, карий, высшее}; (2) {25, зеленый, среднее}; (3) {26, серый,
среднее}.
Первый атрибут является числовым, остальные — строковыми, причем признак
Цвет глаз имеет категориальный тип, а Образование — упорядоченный. Если для
вычисления расстояний мы выберем одну метрику — евклидову, то возникнут
проблемы с признаком Цвет глаз. Для него подходит только функция отличия.
Главная трудность в выборе меры близости состоит в том, что необходимость
использования комбинации метрик ухудшает работу алгоритма, а эффективных
алгоритмов кластеризации для смешанных наборов данных мало.
Различные требуемые машинные ресурсы
(память и время)
Алгоритмы кластеризации, как и любые другие, имеют различную вычислитель-
ную сложность. Вопрос масштабируемости в кластеризации стоит особенно остро,
так как эта задача Data Mining часто выступает первым шагом в анализе: после
выделения схожих групп применяются другие методы, для каждой группы строится
340 Часть I. Теория бизнес-анализа
отдельная модель. В частности, именно из-за больших вычислительных затрат
в Data Mining не получили распространение иерархические алгоритмы, которые
строят полное дерево вложенных кластеров.
Для кластеризации больших массивов данных, содержащих миллионы строк
разработаны специальные алгоритмы, позволяющие добиваться приемлемого каче-
ства за несколько проходов по набору данных. Такие задачи, к примеру, актуальны
при сегментации покупателей супермаркета по их чекам.
Получение масштабируемых алгоритмов основано на идее отказа от локальной
функции оптимизации. Парное сравнение объектов между собой в алгоритме
k-means есть не что иное, как локальная оптимизация: на каждом шаге необходимо
рассчитывать расстояние от центра кластера до каждого объекта. Это ведет к боль-
шим вычислительным затратам. При задании глобальной функции оптимизации
добавление новой точки в кластер не требует больших вычислений: расстояние
рассчитывается на основе старого значения, нового объекта и параметров кластера.
К сожалению, ни k-means, ни сеть Кохонена не используют глобальную функцию
оптимизации.
Выбор числа кластеров
Хоть и редко, но встречаются случаи, когда точно известно, сколько кластеров
нужно выделить. Но чаще всего перед процедурой кластеризации этот вопрос
остается открытым. Если алгоритм не поддерживает автоматическое определение
оптимального количества кластеров (как, например, G-means), есть несколько эм-
пирических правил, которые можно применять при условии, что каждый кластер
будет в дальнейшем подвергаться содержательной интерпретации аналитиком.
□ Двух или трех кластеров, как правило, недостаточно: кластеризация будет
слишком грубой, приводящей к потере информации об индивидуальных свой-
ствах объектов.
□ Больше десяти кластеров не укладываются в «число Миллера 7±2»': аналитику
трудно держать в кратковременной памяти столько кластеров.
Поэтому в подавляющем большинстве случаев число кластеров варьируется
от 4 до 9.
При взгляде на изобилие алгоритмов кластеризации возникает вопрос, суще-
ствует ли объективная, естественная кластеризация, или она всегда носит субъ-
ективный характер? Не существует. Любая кластеризация субъективна, потому
что выполняется на основе конечного подмножества свойств объектов. А выбор
этого подмножества всегда субъективен, как и выбор критерия качества и меры
близости.
Популярные алгоритмы k-means и сеть Кохонена изначально разрабатывались
для числовых данных, и, хотя впоследствии появились их модификации, приме-
1 В 1956 г. Дж. Миллер обобщил имевшиеся данные об объеме кратковременной памяти
человека и показал, что этот объем определяется не числом слов в предложении, а числом
объектов и обычно равен 7 ± 2.
Глава 7. Data Mining: кластеризация
341
няемые к смешанным наборам данных, они все равно лучше решают задачи кла-
стеризации на числовых признаках.
Чтобы применять кластеризацию корректно и снизить риск получения ре-
зультатов моделирования, не имеющих никакого отношения к действительности,
необходимо придерживаться следующих правил.
Правило 1. Перед кластеризацией четко обозначьте цели ее проведения: облег-
чение дальнейшего анализа, сжатие данных и т. п. Кластеризация сама по себе не
представляет особой ценности.
Правило 2. Выбирая алгоритм, убедитесь, что он корректно работает с теми
данными, которыми вы располагаете для кластеризации. В частности, если при-
сутствуют категориальные признаки, удостоверьтесь, что та реализация алгоритма,
которую вы используете, умеет правильно обрабатывать их. Это особенно актуаль-
но для алгоритмов k-means и сетей Кохонена (впрочем, и для других, основанных
на метриках), в большинстве случаев применяющих евклидову меру расстояния.
Если алгоритм не умеет работать со смешанными наборами данных, постарайтесь
сделать набор данных однородным, то есть отказаться от категориальных или
числовых признаков.
Правило 3. Обязательно проведите содержательную интерпретацию каждого
полученного кластера: постарайтесь понять, почему объекты были сгруппирова-
ны в определенный кластер, что их объединяет. Для этого можно использовать
визуальный анализ, графики, кластерограммы, статистические характеристики
кластеров, карты. Полезно каждому кластеру дать емкое название, состоящее из
нескольких слов. Встречаются ситуации, когда алгоритм кластеризации не вы-
делил никаких особых групп. Возможно, набор данных и до кластеризации был
однороден, не расслаивался на изолированные подмножества, а кластеризация
подтвердила эту гипотезу.
Таким образом, не существует единого универсального алгоритма кластери-
зации. При использовании любого алгоритма важно понимать его достоинства,
недостатки и ограничения. Только тогда кластеризация будет эффективным ин-
струментом в руках аналитика.
ПЕРСОНАЛИИ ------------------------------------------------------------------
Тойво Кохонен (Teuvo Kohonen) — финский ученый и исследователь, профессор технологи-
ческого университета г. Хельсинки. Внес большой вклад в развитие теории искусственных
нейронных сетей, ассоциативной памяти и распознавания образов. Однако всемирную
известность ему принесли сети и карты Кохонена, решающие задачи кластеризации и мно-
гомерной визуализации. В последние годы Кохонен развивает проект WEBSOM — приме-
нение самоорганизующихся карт в Text Mining.
Автор более 300 научных статей. В 2001 г. вышло третье издание его книги «Самооргани-
зующиеся карты».
Кохонен имеет множество почетных титулов в университетах Европы.
Веб-страница Тейво Кохонена: http://www.cis.hut.fi/teuvo/.
Data Mining:
классификация
и регрессия.
Статистические
методы
8.1. Введение в классификацию и регрессию
Классификация и регрессия являются одними из важнейших задач анализа данных.
Их объединение в одной главе не случайно, поскольку в самой постановке задач
классификации и регрессии много общего. Действительно, как классификационная,
так и регрессионная модель находят закономерности между входными и выход-
ными переменными. Но если входные и выходные переменные модели непрерыв-
ные — перед нами задача регрессии. Если выходная переменная одна и она является
дискретной (метка класса), то речь идет о задаче классификации.
Применение классификации и регрессии
Задачи классификации и регрессии возникают практически во всех областях че-
ловеческой деятельности. Приведем несколько примеров.
В банковском деле классификация применяется для решения задач скоринга,
определения кредитного рейтинга клиентов с целью минимизации рисков при
выдаче кредитов, выявления мошенничества с кредитными картами.
В розничной торговле классификация может использоваться для выделения
групп покупателей с определенными предпочтениями, что позволит более полно
Глава 8. Data Mining: классификация и регрессия. Статистические методы 343
спрос и гибко реагировать на его изменения, прогнозировать со-
стояние рынков.
В военной технике с помощью классификации можно распознавать тип цели,
обнаруженной радиолокатором (пассажирский лайнер, бомбардировщик, истре-
битель и т. д.), по параметрам отраженного от цели сигнала.
В биомедицине с помощью классификации и регрессии можно диагностировать
заболевания на основе наблюдаемых симптомов (температура, давление, состав
крови и т. д.), оценивать ожидаемые результаты лечения.
В правоохранительной деятельности классификация используется для выявле-
ния мошеннических действий, при расследовании и предотвращении преступлений
на основе анализа ранее совершенных, организации систем безопасности и т. д.
В большинстве приведенных примеров упоминалась задача классификации.
Что касается регрессии, то она может использоваться при решении тех же задач, но
в несколько другой постановке. Например, при определении кредитного рейтинга
все клиенты банка могут быть распределены по трем классам: высокому, сред-
нему и низкому Если эту же задачу поставить как регрессионную, то в качестве
выходной переменной можно выбрать оценку вероятности возврата кредита. Как
и вероятность любого события, она будет изменяться от 0 до 1. Высокая веро-
ятность возврата (0,8-1) соответствует высокому кредитному рейтингу, низкая
вероятность (0,1-0,3) — низкому, промежуточные значения (0,3-0,7) — среднему
При обеих постановках задачи сохраняется главная цель — минимизация рисков
при кредитовании.
ЗАМЕЧАНИЕ -------------------------------------------------------------
В ряде источников, особенно зарубежных, задачу, в которой присутствуют непрерывные
выходные переменные, называют предсказанием (prediction) и рассматривают не пару
«классификация — регрессия», а пару «классификация — предсказание». Логика использо-
вания термина «предсказание» понятна. Действительно, если при классификации каждый
новый объект или наблюдение относится к одному из заранее определенных классов, то
в случае регрессии фактически предсказываются значения параметров новых объектов.
Иногда термин «предсказание» трактуют еще шире и распространяют как на классифика-
цию, так и на регрессию. То есть при классификации для новых, ранее неизвестных объектов
предсказываются их классы, а при регрессии — значения отдельных параметров. Знание
класса, к которому относится объект, а также его важных характеристик позволяет выра-
ботать стратегию работы с ним (например, предоставить особые условия кредитования
состоятельному клиенту). В такой постановке классификация и регрессия — методы решения
задачи предсказания.
Классификацию данных можно рассматривать как процесс, состоящий из двух
этапов. На первом этапе (рис. 8.1) строится модель, описывающая предварительно
определенный набор классов или категорий. Модель строится на основе анализа
записей множества данных, содержащих признаки (атрибуты) объектов и соот-
ветствующую им метку класса. Такое множество называется обучающей выборкой.
В контексте классификации записи могут упоминаться как наблюдения, примеры,
прецеденты или объекты.
344 Часть I. Теория бизнес-анализа
Обучающая выборка
ФИО клиента Возраст Доход Кредитный рейтинг
Иванов И. И. 28 Низкий Низкий
Сидоров С. А. 26 Низкий Низкий
Петров В. М. 35 Высокий Высокий
Кузнецов П. И. 42 Средний Высокий
Васильев И. К. 44 Средний Высокий
Николаев А. И. 34 Высокий Высокий
Рис. 8.1. Построение классификационной модели
Поскольку метка класса для каждого примера обучающей выборки предвари-
тельно задана, построение классификационной модели часто называют обучением
с учителем. В процессе обучения формируются правила, по которым производится
отнесение объекта к одному из классов (см. рис. 8.1).
На втором этапе модель применяется для классификации новых, ранее неиз-
вестных объектов и наблюдений (рис. 8.2). Перед этим оценивается точность
построенной классификационной модели. Одним из наиболее простых способов
такой проверки является использование тестового множества. Из доступного
набора данных случайным образом выбирается подмножество примеров (5-10 %
от общего объема), которые не используются для настройки параметров модели,
а подаются на ее вход для проверки результатов обучения. Заданный класс
каждого тестового примера сравнивается с классом, к которому пример был
отнесен моделью. Точность модели, оцененная с помощью тестового множест-
ва, будет определяться процентом правильно классифицированных тестовых
примеров.
Тестовый набор
ФИО клиента Возраст Доход Кредитный рейтинг Классификационное правило
Сидоров С. А. 26 Низкий Низкий
Петров В. М. 35 Высокий Высокий
Васильев И. К. 44 Средний Высокий V
Новое наблюдение:
Возраст = 36
Доход = Высокий,
=> Кредитный рейтинг = Высокий
Рис. 8.2. Классификация новых данных
Глава 8. Data Mining: классификация и регрессия. Статистические методы 345
Если установлено, что модель обладает приемлемой точностью и достаточной
обобщающей способностью, то ее можно использовать для классификации новых
соблюдений или объектов, для которых класс еще неизвестен.
Обзор методов классификации и регрессии
В настоящее время для разнообразных прикладных областей, использующих данные
различных природы и объемов, разработано огромное количество методов и алго-
ритмов решения задач классификации и регрессии и еще больше их модификаций.
В контексте бизнес-аналитики все методы можно разделить на статистические
и методы машинного обучения.
Статистические методы основаны на математической статистике. К ним,
в частности, относятся:
□ линейная регрессия;
□ логистическая регрессия;
□ байесовская классификация и др.
Методы машинного обучения используют модели, основанные на обучении,
такие как:
□ деревья решений;
□ решающие правила;
□ нейронные сети;
□ метод k ближайших соседей и др.
К базовому набору методов, которые входят в состав большинства аналитиче-
ских платформ, относятся множественные регрессионные модели, деревья решений
и искусственные нейронные сети. В последние годы резко возрос интерес к маши-
нам опорных векторов. Кратко рассмотрим суть каждого алгоритма.
Статистические методы
Линейная и логистическая регрессия
Задача линейной регрессии заключается в нахождении коэффициентов урав-
нения линейной регрессии, которое имеет вид:
у = Ьп + Ь2х2 +... + Ь„х„, (8.1)
гДе у — выходная (зависимая) переменная модели;
Х\,х2...хп — входные (независимые) переменные;
bi — коэффициенты линейной регрессии, называемые также параметрами мо-
дели (Ьо — свободный член).
Задача линейной регрессии заключается в подборе коэффициентов 6, уравне-
ния (8.1) таким образом, чтобы на заданный входной вектор X = (хь х2... х„) рег-
рессионная модель формировала желаемое выходное значение у.
346 Часть I. Теория бизнес-анализа
Одним из наиболее востребованных приложений линейной регрессии является
прогнозирование. В этом случае входными переменными модели х, являются на-
блюдения из прошлого (предикторы), а у — прогнозируемое значение. Несмотря
на свою универсальность, линейная регрессионная модель не всегда пригодна для
качественного предсказания зависимой переменной. Когда для решения задачи
строят модель линейной регрессии, на значения зависимой переменной обычно
не налагают никаких ограничений. Но на практике такие ограничения могут
быть весьма существенными. Например, выходная переменная может быть кате-
гориальной или бинарной. В таких случаях приходится использовать различные
специальные модификации регрессии, одной из которых является логистическая
регрессия, предназначенная для предсказания зависимой переменной, принима-
ющей значения в интервале от 0 до 1. Такая ситуация характерна для задач оценки
вероятности некоторого события на основе значений независимых переменных.
Кроме того, логистическая регрессия используется для решения задач бинарной
классификации, в которых выходная переменная может принимать только два
значения — 0 или 1, «Да» или «Нет» и т. д.
ПРИМЕР --------------------------------------------------------------------
Пусть требуется спрогнозировать исход операции на сердце. Такие операции очень слож-
ны, и их результаты труднопредсказуемы. При построении модели в качестве независимых
переменных (предикторов) используются медицинские показатели, характеризующие со-
стояние пациента, например возраст, наличие других заболеваний, состав крови, давление
и т. д. Что касается зависимой (предсказываемой) переменной, то она должна указывать
на вероятность успеха или неуспеха операции. В случае успеха больной выживает, в случае
неуспеха — летальный исход. Возможны два варианта.
• Выходная переменная бинарная, то есть на выходе модели могут появляться только два
значения: 1 — успех, 0 — неуспех. Тогда задача прогнозирования фактически сводится
к классификации, а именно к разделению пациентов на две группы. К первой группе
будут отнесены пациенты, для которых прогноз результатов операции положительный,
а ко второй группе — пациенты, для которых прогноз отрицательный.
• Выходная переменная непрерывная в диапазоне [0, 1]. Тогда задача будет заклю-
чаться в оценке вероятности появления определенного события, например успеха
операции. Если переменная на выходе модели приметзначение 0,75, это означает,
что вероятность успеха операции (событие 1) составляет 75 %, а неуспеха (собы-
тие 0) — 25 %.
Таким образом, логистическая регрессия служит не для предсказания значе-
ний зависимой переменной, а скорее для оценки вероятности того, что зависимая
переменная примет заданное значение.
Предположим, что выходная переменная у может принимать два возможных
значения — 0 и 1. Основываясь на доступных данных, можно вычислить вероятно-
сти их появления: Р(у = 0) = 1 - р; Р(у = 1) =р. Иными словами, вероятность появ-
ления одного значения равна 1 минус вероятность появления другого, поскольку
одно из них появится обязательно и их общая вероятность равна 1. Для опереде-
ления этих вероятностей используется логистическая регрессия:
Глава 8. Data Mining: классификация и регрессия. Статистические методы 347
log(p/(l — р)) — ₽() + Р1 X] + Р2Х2 + ... + рпт„. (8.2)
Правая часть формулы (8.2) эквивалентна обычному уравнению линейной
агрессии (8.1). Однако вместо непрерывной выходной переменной у в левой
части отношения вероятностей двух взаимоисключающих событий (в нашем при-
мере — вероятность появления 0 и вероятность появления 1).
функция вида log(р/ (1 — р)) называется логит-преобразованием и обозначается
|ogit(/>)- Использование логит-преобразования позволяет ограничить диапазон
изменения выходной переменной в пределах [0; 1].
ПРИМЕР
Предположим, что регрессионная модель задана уравнением:
logit(p) = 1,5 —0,6-Х) 4-0,4-хг — 0,3-хз.
Имеется наблюдение (хъ х2, Хз) = (1,0,1)- Используя логистическую модель, можно оце-
нить вероятность появления выходного значения 1, то есть P(Y = 1).
Для этого сначала вычислим соответствующее логит-преобразование:
logit (р) = 1,5 - 0,6 • 1 + 0,4 • 0 - 0,3 • 1 = 0,6.
То есть log(py /(1 - р})) = 0,6.
Затем можно вычислить вероятность появления значения 1:
е°'6
Р(У = 1) = Т7^ = 0’65-
Таким образом, можно заключить, что выходное значение Y = 1 более вероятно, чем Y = 0.
Даже этот несложный пример показывает, что, несмотря на относительную простоту, логи-
стическая регрессия может быть очень полезной при решении задачи предсказания, если
наилучшим прогнозом считается наиболее вероятное значение.
Применение регрессионных методов в анализе данных активно развивается при-
мерно с середины XX в. В настоящее время регрессия является одним из наиболее
мощных и универсальных методов, успешно используемых для решения широкого
круга бизнес-задач, в том числе прогнозирования.
Байесовская классификация
Байесовский подход объединяет группу алгоритмов классификации, осно-
ванных на принципе максимума апостериорной (условной) вероятности: для
объекта с помощью формулы Байеса определяется апостериорная вероятность
принадлежности к каждому классу и выбирается тот класс, для которого она
максимальна.
Особое место в данной области занимает простая байесовская классификация,
в основе которой лежит предположение о независимости признаков, описываю-
щих классифицируемые объекты. Это предположение значительно упрощает
задачу, поскольку вместо сложной процедуры оценки многомерной плотности
вероятности требуется оценка нескольких одномерных.
348 Часть I. Теория бизнес-анализа
Линейная, логистическая регрессия и простой байесовский классификатор
подробно рассматриваются далее в этой главе.
Методы, основанные на обучении
Деревья решений
Деревья решений (деревья классификаций) — популярная классификационная
методика, в которой решающие правила извлекаются непосредственно из исходных
данных в процессе обучения. Дерево решений — это древовидная иерархическая
модель, где в каждом узле производится проверка определенного атрибута (при-
знака) с помощью правила. По результатам проверки формируются два или более
дочерних узла, в которые попадают объекты, для которых значения данного атри-
бута удовлетворяют (или не удовлетворяют) правилу в родительском узле. Каждый
конечный узел дерева (лист) содержит объекты, относящиеся к одному классу.
Пример простого дерева решений приведен на рис. 8.3.
Рис. 8.3. Пример дерева решений
Классический алгоритм построения деревьев решений использует стратегию
«разделяй и властвуй». Начиная с корневого узла, где присутствуют все обучающие
примеры, происходит их разделение на два или более подмножества на основе
значений атрибута, выбранных в соответствии с критерием (правилом) разделения.
Для каждого из полученных подмножеств создается дочерний узел. Затем процесс
ветвления повторяется для каждого дочернего узла до тех пор, пока не будет вы-
полнено одно из условий остановки алгоритма.
В настоящее время разработано большое количество алгоритмов построения
деревьев решений. Они отличаются способом отбора атрибутов для разбиения
в каждом узле, условиями остановки и методикой упрощения построенного дерева.
Упрощение дерева заключается в том, что после его построения удаляются те узлы,
правила в которых имеют низкую ценность, поскольку относятся к небольшому
числу примеров. Упрощение позволяет сделать дерево решений компактней.
Искусственные нейронные сети
Нейронные сети, или искусственные нейронные сети, представляют собой
модели, которые в процессе функционирования имитируют работу головного
мозга. Нейронная сеть состоит из простейших вычислительных элементов — ис-
Глава 8. Data Mining: классификация и регрессия. Статистические методы 349
кусственных нейронов, связанных между собой. Каждый нейрон имеет несколько
входных и одну выходную связь. Каждая входная связь обладает весом, на кото-
рый умножается сигнал, поступающий по ней с выхода другого нейрона. Каждый
нейрон выполняет простейшее преобразование — взвешенное суммирование своих
входов (рис. 8.4).
Рис. 8.4. Искусственный нейрон
В нейронных сетях нейроны объединяются в слои, при этом выходы нейронов
предыдущего слоя являются входами нейронов следующего слоя. В каждом слое
нейроны выполняют параллельную обработку данных. Пример нейронной сети
представлен на рис. 8.5.
Рис. 8.5. Пример нейронной сети
Первый слой называется входным, его нейроны обеспечивают ввод в сеть
входного вектора X = (хь х2, х3) и распределяют его по нейронам следующего
слоя. Нейроны последнего слоя, обеспечивающие вывод результатов, называются
выходными и образуют выходной слой. Между входным и выходным нейронами
расположены один или несколько промежуточных слоев, называемых скрытыми.
Именно в скрытых слоях производится основная обработка данных.
В процессе работы нейронной сети значения входных переменных т, передаются
по межнейронным связям и умножаются на весовые коэффициенты вд, полученные
значения суммируются в нейроне. Также в каждом нейроне выполняется простое
преобразование с помощью активационной функции/(5), обычно нелинейной.
В результате преобразования значений входного вектора всеми нейронами сети на
ее выходе формируется вектор результата (выходной вектор) Y = (г/i, г/2)-
Деревья решений и нейронные сети подробно рассматриваются в главе 9.
ээи часть 1. Теория бизнес-анализа
Метод к ближайших соседей
Этот алгоритм относит любой новый пример к классу, которому принадлежит
большинство его ближайших соседей в обучающем множестве. Под соседством
в данном случае подразумевается не расположение объектов или наблюдений
рядом в обучающем множестве, а то, что их многомерные векторы в пространстве
признаков близки друг к другу. Сосед классифицируемого объекта считается
ближайшим в пространстве признаков, если евклидово расстояние между ними
является наименьшим. Если k = 1, то новый объект относится к тому же классу,
что и его ближайший сосед.
Разнообразие подходов
Не существует универсального метода для решения задач классификации и ре-
грессии, дающего наилучший результат во всех случаях. На рис. 8.6 схематически
представлено решение задачи классификации деревом решений и нейронной сетью.
Так, дерево решений осуществляет последовательное дробление пространства
входных признаков на прямоугольные области (см. рис. 8.6, а). Нейронная сеть
формирует области более сложной формы, чем прямоугольники (см. рис. 8.6, б).
Рис. 8.6. Решение задачи классификации различными методами:
а — дерево решений; б — нейронная сеть
Глава 8. Data Mining: классификация и регрессия. Статистические методы 351
Дальнейший материал этой главы ориентирован на опытного читателя, зна-
комого с базовыми понятиями теории вероятностей и математической статисти-
KfI такими как вероятность, случайная величина, случайное событие, среднее,
дисперсия, среднеквадратическое отклонение, математическое ожидание, ста-
тистическая гипотеза, статистический тест, статистическая значимость, распре-
деление вероятностей, нормальное распределение, выборочное распределение.
Те кого статистические методы не интересуют, могут сразу перейти к изучению
главы 9.
8.2. Простая линейная регрессия
В Data Mining существует большой класс задач, где требуется установить зависи-
мость между признаками (атрибутами, показателями), которые описывают иссле-
дуемый процесс или объект предметной области. Для этого строятся различные
модели, в которых данные признаки выступают в качестве переменных. Если
модель будет корректно отражать зависимость между входными и выходными
переменными, то с помощью такой модели можно будет предсказывать значения
выходной переменной по заданным значениям входных.
Как правило, реальные процессы в науке, технике, экономике и бизнесе до-
статочно сложны, и для их описания требуется большое количество переменных,
которое может насчитывать и несколько сотен в зависимости от сложности объекта
исследования.
Начнем рассмотрение с простого примера. Владелец овощной лавки планирует
оптимизировать закупки и для этого собирает статистику, отражающую зависи-
мость объемов продаж от цены, устанавливаемой на продукты. Предполагается,
что розничная цена меняется ежемесячно в зависимости от цены, устанавливаемой
поставщиком, на которую, в свою очередь, влияют сезонность, качество товара,
ситуация на рынке и т. д. Для розничного продавца оценка того, сколько товара
он сможет продать за определенную цену, представляет большой интерес. Если
такая оценка будет получена, то станет ясно, сколько и каких продуктов потребу-
ется закупить, например, на месяц при определенной ценовой ситуации на рынке.
Результатом собранных наблюдений явилась зависимость ежемесячных продаж
картофеля от установленной цены (табл. 8.1).
Таблица 8.1. Зависимость объема продаж от цены
№ месяца Цена за 1 кг, х Количество проданного картофеля, у, кг Количество проданного картофеля, оцененное с помощью регрессии, у, кг
1 13 1000 1323,4
2 20 600 305,6
3 17 500 741,8
4 15 1200 1032,6
Продолжение
352
Часть I. Теория бизнес-анализа
Таблица 8.1 (продолжение)
№ месяца Цена за 1 кг, х Количество проданного картофеля, у, кг Количество проданного картофеля, оцененное с помощью регрессии, у, кг
5 16 1000 887,2
6 12 1500 1468,8 '
7 16 500 887,2 ’
8 14 1200 1178,0
9 10 1700 1759,6
10 И 2000 1614,2
Цель анализа — оценка ожидаемых объемов продаж картофеля в зависимости
от установленной цены. Построим модель продаж, где в качестве входной перемен-
ной будет использоваться цена, а в качестве выходной — объем продаж. На рис. 8.7
представлена диаграмма рассеяния исходных данных. Даже простой визуальный
анализ показывает наличие обратной зависимости между ценой и объемами про-
даж: с увеличением цены продажи падают. Само по себе это не является неожи-
данным. Однако с практический точки зрения наибольший интерес представляет
количественное описание этой зависимости, а именно — какого падения спроса
следует ожидать при увеличении цены за единицу.
Если предположить, что зависимость между переменными линейная, то для по-
строения модели достаточно провести прямую линию, проходящую через «облако»
точек, соответствующих наблюдениям. Тогда наклон линии покажет, насколько
уменьшатся продажи при увеличении цены.
2500
2000
* 1500
Й
Ct
о
с 1000
500
ОО
О
0 5 10
J____________I__________L
15 20 25
Цена
Рис. 8.7. Наблюдаемая зависимость объемов продаж
от установленной цены
Глава 8. Data Mining: классификация и регрессия. Статистические методы 353
Если мы хотим смоделировать зависимость объемов продаж картофеля от
цены за килограмм, то нужно построить прямую, каждая точка которой будет
представлять собой оценку объемов продаж для заданной цены. Но таких линий
можно построить бесконечно много, и только одна из них обеспечит оптимальную
оценку объемов продаж. Естественным было бы провести линию таким образом,
чтобы рассеяние вдоль нее точек, соответствующих реальным наблюдениям, было
минимальным. На практике линию строят так, чтобы сумма квадратов отклонений
наблюдаемых значений от оцененных с помощью данной линейной зависимости
была минимальной, то есть
—yt)2 ~^min,
/=1
где п — число наблюдений;
у-, — оценка выходного значения для г-го наблюдения, полученная с помощью
модели;
у — реально наблюдаемое значение объема продаж.
Данный метод приближения линейной зависимости между входными и выход-
ными переменными известен как метод наименьших квадратов (МНК), а линия,
построенная с его помощью, называется линией регрессии.
Линия регрессии — это прямая наилучшего приближения для множества пар
значений входной и выходной переменной (х, у), выбираемая таким образом, чтобы
сумма квадратов расстояний от точек (х„ г/,) до этой прямой, измеренных верти-
кально (то есть вдоль оси у), была минимальна. Уравнение, описывающее линию
регрессии, называется уравнением регрессии-.
у = Ьп+Ь\х, (8-3)
где у — оценка значения выходной переменной;
Ьо — коэффицент, определяющий точку пересечения линии с осью у, называ-
емый также свободным членом. Коэффициент Ь, определяет наклон линии отно-
сительно оси х (иногда его называют угловым коэффициентом). Проще говоря,
Ь, — это величина, на которую изменяется значение выходной переменной у при
изменении входной переменной х на единицу. Коэффициенты линейного уравне-
ния Ьо и 61 называются коэффициентами регрессии.
Как упоминалось ранее, в зарубежной литературе регрессию часто называют
предсказанием (prediction). При этом входную переменную называют предсказы-
вающей переменной, или предиктором (predictor variable), а выходную перемен-
ную — предсказываемой (predicted variable).
Таким образом, задача построения модели линейной регрессии сводится к нахож-
дению таких коэффициентов Ьй и h-., для которых сумма квадратов ошибок, то есть
разностей между реально наблюдаемыми значениями выходной переменной у, и их
оценками у, была бы минимальна. Уравнение регрессии с учетом ошибки между
наблюдаемым и оцененным значениями будет
у = Ьй +Ь'Х + г,
354 Часть I. Теория бизнес-анализа
где е — ошибка.
Тогда сумму квадратов ошибок по всем наблюдениям можно вычислить сле-
дующим образом:
£ = £е2 = i(yi-bo-b'Xi)2. (8.4)
i=\ i=1 i=l
л
Мы можем найти значения Ьо и bh которые минимизируют У^е,2, путем диффе-
г = 1
ренцирования уравнения (8.3) по Ьо и Ь,. Частные производные для уравнения (8.4)
по Ьо и bi соответственно будут:
д F н Л ri Л
^ = -2-J2(pi-bo -biXi);-^ = -2-Y^Xi(yi-bo-bix,). (8.5)
Как известно, в точке, где функция минимальна, ее производная обращается
в ноль. Поэтому нас интересуют значения Ьо и bi, которые обращают (8.5) в ноль,
то есть
'* 2 л
— Ьо -Ь,х^ = 0; '{.У’ — bo -biX^ — 0.
i=l i=l
Опустив некоторые промежуточные выкладки, сразу запишем результат:
п л W п /
Иу‘ п
i=l 1=1 Дг=1 )!
(8-6)
1 _л h _л
z’o=-E^+d-£x=^-Z’1^
П г=1 П 1 = 1
где п — общее число наблюдений;
у— среднее значение выходной переменной;
X — среднее значение входной переменной.
Уравнения (8.6) — это полученные методом МНК для значений bt) и Ь, оценки,
которые минимизируют сумму квадратов ошибок.
Разности между наблюдаемыми значениями выходной переменной и значения-
ми, оцененными с помощью регрессии, называются остатками. Справедливо:
наблюдение = оценка + остаток.
Используя МНК, вычислим оценки коэффициентов регрессии для данных из
табл. 8.1.
bi =
1493 000-1612 800
21560-20 735
=-145,4; Z>o =1120 + 2093,6 = 3213,6.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 355
Соответствующее уравнение регрессии будет иметь вид
у = 3213,6-145,4г.
Смысл коэффициентов уравнения регрессии следующий: Ьо — это значение
выходной переменной у при значении входной переменной х = 0. Значит, при цене
картофеля, равной нулю, оценка объемов продаж составит 3213,6 кг. Однако данная
формальная интерпретация явно противоречит здравому смыслу, поскольку если
раздавать картофель бесплатно, то купят любое его доступное количество. Такая
ситуация возникла из-за того, что в исходной выборке наблюдений отсутствуют
значения х, близкие к нулю. Отсюда вытекает одно из ограничений линейной
регрессии: линию регрессии (и, соответственно, описывающее ее уравнение)
следует считать подходящей аппроксимацией некоторой реальной функции
только в том диапазоне изменений входной переменной х, в котором распреде-
лены исходные наблюдения. В противном случае результаты могут оказаться
непредсказуемыми.
Значение коэффициента наклона линии регрессии hi можно интерпретировать
как среднюю величину изменения значения выходной переменной при изменении
значения входной переменной на единицу. В нашем примере это означает, что
при увеличении цены за один килограмм картофеля на одну денежную единицу
можно ожидать уменьшения спроса в среднем на 145,4 кг. Линия регрессии для
найденного нами уравнения представлена на рис. 8.8.
Рис. 8.8. Линия регрессии для примера из табл. 8.1
Для линии регрессии сумма квадратов вертикальных расстояний между точка-
ми данных (светлые точки) и линией должна быть меньше, чем аналогичная сумма
квадратов для любой другой прямой.
356 Часть I. Теория бизнес-анализа
8.3. Оценка соответствия простой линейной
регрессии реальным данным
Линия регрессии должна аппроксимировать линейную зависимость между входной
и выходной переменными модели. Однако при этом возникает вопрос, насколько
линейная аппроксимация соответствует наблюдаемым данным. Чтобы определите
это, введем в рассмотрение два показателя — стандартную ошибку оценивания Есг
и коэффициент детерминации, обозначаемый г1.
В статистике мерой разброса случайной величины относительно среднего
значения является стандартное отклонение. Аналогично в качестве меры раз-
броса точек наблюдений относительно линии регрессии можно использовать
стандартную ошибку оценивания, которая показывает среднюю величину
отклонения точек исходных данных от линии регрессии вдоль оси у. Стандарт-
ная ошибка равна корню квадратному среднеквадратической ошибки (ЕСко),
то есть сумме квадратов разностей между реальным и оцененным значениями,
вычисленной по всем наблюдениям и отнесенной к числу степеней свободы
выборки:
±(х-5>)2
С — 2=1_______
где т — количество независимых переменных, которое для простой линейной рег-
рессии равно 1.
Еско можно рассматривать как меру изменчивости выходной переменной,
объясняемую регрессией. Тогда стандартная ошибка оценивания определится
следующим образом:
Дч = а/Еско •
Значение стандартной ошибки Ест позволяет оценить степень рассогласования
оценок, полученных с помощью регрессии, и реальных наблюдений аналогично
тому, как стандартное отклонение позволяет оценить в статистическом анализе
степень разброса случайной величины относительно среднего. Чем меньше стан-
дартная ошибка оценивания, тем лучше работает модель.
Рассмотрим пример. Пусть требуется оптимизировать закупку бензина для сети
автозаправочных станций (АЗС). Для этого была исследована выборка, в которой
представлены данные, описывающие объемы продаж бензина определенной марки
десятью АЗС. В ней представлено количество бензина в тоннах, проданное АЗС
за определенное число дней. На основе наблюдений было получено уравнение ре-
грессии у = 6 + 2х. Объем продаж оценивается как 6 т плюс удвоенное количество
дней, в течение которых осуществлялись продажи. Уравнение позволяет оценить
количество тонн бензина, которое может быть продано за заданный интервал вре-
мени. Полученные оценки представлены в табл. 8.2.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 357
Таблица 8.2. Расчет среднеквадратической ошибки
для примера о продажах бензина
№ АЗС Время, х, дней Объем продаж, у, т Оцененное количество, у = 6 + 2х Ошибка оценивания, у— у (У“ У)2
Т 2 10 10 0 0
2 2 И 10 1 1
3 3 12 12 0 0
4 4 13 14 -1 1
5 4 14 14 0 0
6 5 15 16 -1 1
7 6 20 18 2 4
8 7 18 20 -2 4
9 8 22 22 0 0
10 9 25 24 1 1
Р)2 12
Из табл. 8.2 видно, что сумма квадратов ошибок оценивания У~^(г/ — у)2 =12.
Эта величина представляет собой общую меру ошибки оценивания значения вы-
ходной переменной с помощью данного уравнения регрессии. Если она велика, то
модель работает неудовлетворительно. Является ли полученное значение суммы
квадратов ошибок, равное 12, большим? Этого достоверно сказать нельзя, посколь-
ку на данном этапе мы не имеем других мер для сравнения.
Для примера, который представлен в табл. 8.2, стандартная ошибка будет
I 12
= J ——-—- = 1,2. Следовательно, при оценке объема продаж АЗС с помощью
уравнения у = 6 + 2х ожидаемая ошибка равна 1,2 т.
Теперь предположим, что информация о времени, в течение которого осу-
ществлялись продажи, отсутствует, то есть использовать переменную х для оце-
нивания переменной у невозможно. Полученные в этом случае оценки объемов
продаж окажутся менее точными, поскольку количество исходной информации
уменьшится. Тогда единственно возможной оценкой для у будет простое среднее
значение г/ = 16. Рассмотрим рис. 8.9, где оценка объемов продаж, не учитывающая
информацию о времени, за которое они были сделаны, представлена горизонталь-
ной линией у = 16.
Отсутствие информации о времени приводит к оценке объемов продаж
16 т для всех АЗС независимо от отработанного времени. Очевидно, что цен-
ность такой оценки сомнительна. Действительно, одни АЗС расположены на
оживленных трассах, а другие — на второстепенных, плотность транспортного
потока меняется под действием различных факторов. Поэтому ожидать, что
АЗС, отработавшие 1-2 дня и 5-7 дней, продадут одинаковое количество бен-
зина, наивно.
358 Часть I. Теория бизнес-анализа
Рис. 8.9. Геометрическая интерпретация линий регрессии
Точки на рис. 8.9 сосредоточены вдоль линии регрессии, а не вдоль линии
г/ = 16. То есть предполагается, что суммарная ошибка оценивания будет меньше,
если использовать информацию о времени. Например, рассмотрим АЗС № 10, на
которой было продано у = 25 т бензина за 9 дней. Если игнорировать информацию
о времени и предположить, что на ней, как и на остальных АЗС, продано только
16 т, то ошибка оценивания составит Е10 = у — у = 9 т.
Мы можем сравнить стандартную ошибку Е„ =1,2 и ошибку относительно
среднего значения у = 16, когда информация о предсказывающей переменной
игнорируется:
— I 1 ~1
£~=^£(у.-у)2=5,0.
Таким образом, типичной ошибкой предсказания для случая, когда инфор-
мация о значениях предсказывающей переменной не используется, будет 5,0 т.
Следовательно, применение регрессии вместо оценки на основе простого среднего
значения позволяет уменьшить ошибку с 5,0 до 1,2 т, то есть более чем в 4 раза.
Это позволяет сделать вывод о значимости полученной регрессионной моде-
ли. Если бы значения стандартной ошибки, полученные для оценок регрессии
и простого среднего значения, были примерно одинаковы, это говорило бы о том,
что регрессия практически не дает выигрыша в точности оценки по сравнению
с обычным средним наблюдаемых значений, то есть о низкой значимости регрес-
сионной модели.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 359
Изменчивость выходной переменной
Чтобы оценить степень соответствия регрессии реальным данным, полезно ввести
меры, количественно характеризующие поведение выходной переменной. В каче-
стве таких мер используются три квадратичные суммы: общая (полная) Q, регрес-
сионная Qr и ошибки (остаточная) Qr. Чтобы пояснить смысл данных величин,
представим наблюдаемое значение выходной переменной в виде у = у + (г/ — у),
то есть наблюдаемое значение равно сумме его оценки и ошибки оценивания. Дан-
ное выражение может быть записано в виде y — {b0 + bix') + (y — b0 — bix\ Здесь
у — наблюдаемое значение, (hi, + Ь\х) — член, описывающий долю изменчивости вы-
ходной переменной, объясняемой регрессией, (y — bQ —btx) — член, описывающий
отклонение выходной переменной от линии регрессии (остаток). Если все точки
данных лежат непосредственно на линии регрессии (идеальное соответствие), то
остатки будут равны 0. Если из обеих частей предыдущего выражения вычесть
среднее значение у, то есть
у-у = (у-у)+(у-у\
то можно показать, что суммы квадратов складываются следующим образом:
-^)2-*/)2+ЕЬ‘ - Я2’
/=| ?=1 /=1
или, используя введенные выше обозначения для квадратичных сумм:
<2 = <2«+Q/:'.
Таким образом,
О. = £,(У’ -y)2;Q« = ~у} ’Qi: = ~У’)2-
i=l i=l i=l
Следовательно, полная изменчивость выходной переменной складывается из
части, объясняемой регрессией (линейной зависимостью), и ошибки, то есть части,
не объясненной регрессией.
ЗАМЕЧАНИЕ -----------------------------------------------------------
С каждой из квадратичных сумм связано определенное число степеней свободы, кото-
рое используется при статистическом анализе регрессионных моделей. Сумма квадратов
Qr, обусловленная уравнением регрессии, имеет число степеней свободы dfK = т, где
т — количество независимых переменных модели, поскольку участвующая в ней величина
у определяет т линейных связей для Wнаблюдений, так как в нее входят т оценок коэф-
фициентов bi, b2... Ьт . Остаточная сумма квадратов Qr, отражающая долю изменчивости
выходной переменной, которая не может быть объяснена уравнением регрессии, имеет
число степеней свободы dfr = n-m - 1. И наконец, с полной суммой Q связано df =п- 1
степеней свободы, поскольку в нее входят ЛГнаблюдений, на которые наложена одна ли-
нейная связь у. Легко увидеть, что df= dfR + dfE.
360 Часть I. Теория бизнес-анализа
Нужно ли ожидать, что полная квадратичная сумма Q, полученная только при
использовании среднего значения у, будет больше или меньше, чем остаточная
сумма Qe, полученная при оценивании с учетом входной переменной? Используя
данные табл. 8.2, получим, что Q = 228 окажется намного больше, чем Qe = 12
(табл. 8.3).
Таблица 8.3. Расчет полной квадратичной суммы для примера о продажах бензина
№ АЗС Время, х, дней Объем продаж, у, т И У~ У (X- У)1
1 2 10 16 -6 36
2 2 И 16 -5 25
3 3 12 16 -4 16
4 4 13 16 -3 9
5 4 14 16 -2 4
6 5 15 16 -1 1
7 6 20 16 4 16
8 7 18 16 2 4
9 8 22 16 6 36
10 9 25 16 9 81
Q 228
Теперь мы можем сравнить две меры точности оценивания выходной пере-
менной. Поскольку Qe намного меньше, чем Q, можно сделать вывод, что ис-
пользование информации о входной переменной в задаче регрессии позволяет
получить более точные оценки, чем без ее использования, то есть когда в ка-
честве оценки используется простое среднее значение наблюдений выходной
переменной.
Определим меру, которая позволит увидеть, насколько улучшились оценки,
полученные с помощью уравнения регрессии. Для этого вернемся к рис. 8.9.
Для АЗС № 10 ошибка, полученная при использовании уравнения регрессии, со-
ставит у — у = 25 — 24 = 1. Если же производить оценку только на основе среднего
значения г/ = 16, то полученная ошибка составит у- у = 25 —16 = 9. Таким образом,
ошибка оценивания уменьшится на у — у = 24 — 16 = 8, то есть на разность оценок
с помощью регрессии и простого среднего.
Коэффициент детерминации
Введем понятие коэффициента детерминации г2, который показывает степень
согласия регрессии как приближения линейного отношения между входной и вы-
ходной переменными с реальными данными:
r2=QR/Q.
Значение коэффициента детерминации максимально, когда имеет место иде-
альное соответствие: все точки данных лежат точно на прямой регрессии. В этом
Глава 8. Data Mining: классификация и регрессия. Статистические методы 361
случае квадратичная сумма Qf оценки, полученной с помощью регрессии, равна 0.
Тогда <2 = Qr nr2 = Qr/Q = ‘\.. Максимальное значение коэффициента детерми-
нации, равное 1, имеет место только тогда, когда уравнение регрессии идеально
описывает связь между входной и выходной переменными.
ОПРЕДЕЛЕНИЕ-------------------------------------------------------------
Коэффициент детерминации (coefficient of determination), называемый также коэффици-
ентом смешанной корреляции или статистикой /?-квадрат, — статистический показатель,
отражающий объясняющую способность уравнения регрессии. Он также является стати-
стической мерой согласия, с помощью которой можно определить, насколько уравнение
регрессии соответствует реальным данным.
Чтобы определить минимальное значение коэффициента детерминации, пред-
положим, что регрессия совсем не улучшает точность оценки по сравнению с ис-
пользованием среднего значения, то есть не объясняет изменчивость выходной
переменной. В этом случае QR = 0, а значит, и г2 — 0. Таким образом, коэффициент
детерминации может изменяться от 0 до 1 включительно. При этом чем выше
значение г2, тем больше регрессионная модель соответствует реальным данным.
Значения г2, близкие к 1, означают очень хорошее соответствие регрессионной
модели реальным данным, а значения, близкие к 0, — очень плохое.
Вычислим значение коэффициента детерминации для примера из табл. 8.3:
г2 = Q/./Q = 216/228 = 0,9474.
Можно сделать вывод, что регрессионная модель работает хорошо.
Коэффициент корреляции
Еще одной мерой, используемой для количественного описания линейной зависи-
мости между двумя числовыми переменными, является коэффициент корреляции,
который определяется следующим образом:
^2(x-x)(z/-z/)
(п-1)сттст„
(8.7)
где ог и — стандартные отклонения соответствующих переменных. Значение
коэффициента корреляции всегда расположено в диапазоне от -1 до 1 вклю-
чительно и может быть интерпретировано следующим образом.
□ Если коэффициент корреляции близок к 1, то между переменными имеет место
сильная положительная корреляция. Иными словами, наблюдается высокая
степень зависимости входной и выходной переменных (если значения входной
переменной х возрастают, то и значения выходной переменной у также будут
увеличиваться).
□ Если коэффициент корреляции близок к -1, это означает, что между перемен-
ными наблюдается отрицательная корреляция: поведение выходной переменной
362 Часть I. Теория бизнес-анализа
будет противоположным поведению входной (когда значение х возрастает
у уменьшается, и наоборот).
□ Промежуточные значения указывают на слабую корреляцию между пере-
менными и, соответственно, на низкую зависимость между ними: поведение
входной переменной х совсем (или почти совсем) не будет влиять на пове-
дение у.
Зависимость степени связи между переменными от конкретных значений коэф-
фициента корреляции в большинстве задач можно определить с помощью прибли-
женной оценки. Но следует отметить, что в технических приложениях, например,
при обнаружении целей в радиолокации на фоне шумов и помех необходимо при-
менять более строгие подходы. Для приближенной оценки можно воспользоваться
следующей шкалой (табл. 8.4).
Таблица 8.4. Шкала соответствия для коэффициента корреляции
Коэффициент корреляции, г Корреляция
0,6 <г< 1 Высокая положительная
0,3<г<0,6 Средняя положительная
-0,3<г<0,3 Корреляция отсутствует
-0,6 < г< -0,3 Средняя отрицательная
-1 < г< -0,6 Сильная отрицательная
Вычисление коэффициента корреляции по формуле (8.7) может быть несколь-
ко громоздким, поскольку в знаменателе требуется найти стандартные отклонения'
для х и у. Поэтому при вычислении коэффициента корреляции для примера из
табл. 8.2 воспользуемся упрощенным выражением:
г=E^~(ExE7/w=
7е*2 -(Ех)7п 7е^ -(Е77и
= t ^-(50-60)/10 = 0 9733
V304-502/10-/2788-1602/10
Видно, что между временем, в течение которого производились продажи,
и количеством проданного бензина существует сильная корреляция (чего,
впрочем, и следовало ожидать): с увеличением времени продаж, количество
проданного бензина увеличивается. Чтобы вычислить коэффициент корре-
ляции, можно использовать коэффициент детерминации г2, то есть г = ±4г2.
Если коэффициент уравнения регрессии bt > 0 (линия регрессии возрастает),
то и коэффициент корреляции также будет положительным, то есть г = 4г2.
В противном случае коэффициент корреляции будет отрицательным, то есть
г = —442. Поскольку в нашем примере Ь, = 2, коэффициент корреляции будет
положительным и равным г = 4г2 = ^0,9474 = 0,9733.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 363
8.4. Простая регрессионная модель
ддя многих практических приложений найти уравнение регрессии и построить
соответствующую линейную зависимость недостаточно. Чтобы решить задачу,
требуется построить регрессионную модель. В чем же отличие простой линейной
регрессии от регрессионной модели? Дело в том, что уравнение регрессии в боль-
шинстве случаев строится на основе выборочных данных. При этом из множества
наблюдений, называемого генеральной совокупностью, выделяется некоторая
выборка, на основе свойств которой предполагается делать выводы о свойствах
всей совокупности. Для данной выборки и строится уравнение регрессии. Затем
производится попытка обобщить полученную линейную зависимость на всю ге-
неральную совокупность.
То есть простая линейная регрессия строится на основе выборки наблюдений,
каждое из которых содержит соответствие х —> г/, а регрессионная модель предпо-
лагает, что обнаруженная линейная зависимость имеет место для всех возможных
пар х—>у, содержащихся в генеральной совокупности. Однако при построении
регрессионной модели возникает ряд проблем, выходящих за рамки построения
уравнения регрессии. Во-первых, нужно определить, справедливо ли предположе-
ние о том, что линейная зависимость, обнаруженная для выборочных наблюдений,
будет истинна для всей совокупности. Во-вторых, ситуация осложняется тем, что
регрессия, вообще говоря, не является детерминированной задачей, поскольку для
реальных данных зависимость изменения выходной переменной от изменения
входной носит случайный характер. Следовательно, коэффициенты регрессии
могут рассматриваться как статистики, описывающие распределение выходной
переменной.
Простая линейная регрессионная модель задается следующим образом. Пусть
имеется выборка данных, содержащая п наблюдений, в каждом из которых значе-
нию независимой переменной х,- соответствует значение зависимой переменной г/;,
связанных с помощью линейной зависимости:
у — Ро + Р1Х + £,
где Ро и Pi — параметры модели, определяющие точку пересечения линии регрессии
с осью у и наклон линии регрессии соответственно;
Е — член, определяющий ошибку отклонения реального наблюдения от оценки,
полученной с помощью данной модели.
ЗАМЕЧАНИЕ ---------------------------------------------------------
Если для обозначения коэффициентов уравнения регрессии мы использовали латинские
буквы Ьо и Ь[, то при рассмотрении регрессионной модели соответствующие параметры мы
будем обозначать греческими буквами р0 и рь
Поскольку для реальных данных отношение между входной переменной х и вы-
ходной переменной у носит случайный характер, любое его линейное приближение
будет характеризоваться некоторой ошибкой. Для учета этой ошибки в модель
364 Часть I. Теория бизнес-анализа
необходимо ввести соответствующий элемент, также представляющий собой слу-
чайную переменную. При этом допускается несколько предположений.
□ Предположение о нулевом среднем. Член, учитывающий ошибку, является слу-
чайной переменной с математическим ожиданием, равным 0, то есть щ(е) = 0.
□ Предположение о постоянной дисперсии. Дисперсия е (обозначим ее а2) по-
стоянна.
□ Предположение о независимости. Отдельные значения е являются независи-
мыми.
□ Предположение о нормальности. Ошибка Е является нормально распределенной
случайной переменной.
Иными словами, ошибка Е, является независимой нормально распределенной
случайной переменной с нулевым математическим ожиданием и дисперсией a j.
На основе этих предположений можно сделать выводы о поведении зависимой
переменной. Статистическая модель простой линейной регрессии предполагает,
что для каждого значения входной переменной х наблюдаемое значение выход-
ной переменной у является нормально распределенной случайной величиной
со средним £(z/) = Po + 0|Х и постоянной дисперсией о2. Данное предположение
иллюстрируется на рис. 8.10 для случаев х = 5, х = 10 и х = 15. Видно, что все кри-
вые нормального распределения имеют одну и ту же форму, из чего следует, что
дисперсия постоянна для всех х.
Рис. 8.10. Для каждого значения х значение у есть нормально
распределенная случайная величина
Если при решении задачи регрессии строить модель не требуется, то проверять
состоятельность данных предположений не обязательно, поскольку они касаются
Глава 8. Data Mining: классификация и регрессия. Статистические методы 365
только ошибки е. Если ошибка не учитывается, то и предположения не нужны. Од-
нако если нужно построить модель, то предположения должны быть проверены.
Поясним смысл предположений о поведении зависимой переменной у.
□ На основе предположения о нулевом среднем имеем:
E(z/) = E(Po + PiX + £) = E(Po) + E(Pt^) + E(£) = Po + Pt%.
Для каждого значения х среднее значение у лежит на линии регрессии.
□ На основе предположения о постоянстве дисперсии D(y) имеем
D(y) = £)(р0 +Pix + e) = £)(e) = o2.
Независимо от того, какое значение принимает переменная х, дисперсия пере-
менной у всегда является постоянной величиной.
□ Из предположения о независимости следует, что для любого х значения у также
будут независимыми.
□ Из предположения о нормальности следует, что у также является нормально
распределенной случайной переменной.
Таким образом, выходная переменная у является независимой нормально рас-
пределенной случайной переменной со средним, равным Ро + Рь и дисперсией ст2.
Гипотезы в регрессии
Пусть для уравнения линейной регрессии, построенного на некоторой выборке,
мы определили коэффициент детерминации г1 — 0,2. Это значение показывает,
что соответствующая модель вряд ли является значимой, то есть линейная зави-
симость между входной и выходной переменными отсутствует. Но отсутствует
ли она полностью? Возможно, линейная зависимость между переменными имеет
место даже при очень малых значениях коэффициента детерминации. Существует
ли системный подход, позволяющий определить наличие линейной зависимости
между входной и выходной переменными? Методическую основу для оценки зна-
чимости таких зависимостей создают гипотезы линейной регрессии.
Рассмотрим модель простой линейной регрессии:
У — Ро + Р1 х + Е.
Данная модель утверждает, что между выходной переменной у и входной пере-
менной х существует линейная зависимость. Здесь Pi — параметр модели, констан-
та, значение которой неизвестно. Существует ли такое значение Pi, при котором
линейная зависимость между переменными х и у будет отсутствовать?
Рассмотрим случай Pi = 0. Тогда регрессионная модель примет вид
У = Ро + 0 • X + £ = Ро + £.
Следовательно, линейная зависимость между переменными х и у перестанет
существовать. Но если Pi примет любое отличное от нуля значение, то она будет
366 Часть I. Теория бизнес-анализа
наблюдаться. Отсюда следует важный вывод: линейная зависимость между пере-
менными х и у зависит от параметра рь
Возможна ситуация, когда регрессия, построенная на основе выборки, обнару-
жит линейную зависимость между входной и выходной переменными, в то время
как регрессионная модель, построенная для всей совокупности, нет. Таким образом,
если между переменными некоторой выборки существует линейная зависимость
из этого не обязательно следует существование линейной зависимости для всей
совокупности. Это значит, что даже если коэффициент уравнения регрессии bi * О,
то коэффициент регрессионной модели Pi может оказаться равным 0 и линия ре-
грессии, вычисленная с использованием всех наблюдений совокупности, окажется
горизонтальной. Поясним данную ситуацию (рис. 8.11).
Рис. 8.11. Отсутствие линейной зависимости во всей совокупности
На рис. 8.11 светлыми кругами обозначены точки, соответствующие наблюде-
ниям генеральной совокупности. Визуальный анализ показывает, что такой набор
точек даст горизонтальную линию регрессии (Р! = 0), представленную на рисунке
сплошной линией. В то же время линия регрессии, построенная по выборочным
наблюдениям (темные круги), может иметь некоторый наклон (штрихпунктирная
линия), и в этом случае Ь, * 0, что указывает на наличие положительной линейной
зависимости между переменными х и у.
Поскольку зависимость выходной переменной от входной носит случайный
характер, то и оценки параметра наклона линии регрессии b являются статисти-
ческими. Как и все такие оценки, они имеют распределение с некоторым средним
значением и стандартным отклонением. Стандартное отклонение для оценки bi
определяется следующим образом:
а
где ст — стандартное отклонение, вычисленное для всей совокупности.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 367
Как предположение о среднем значении генеральной совокупности может быть
сделано на основе выборочного среднего х, так и предположение о значении Pi
мОжет быть сделано на основе выборочной оценки Ь,.
На основе о/,, мы можем получить показатель (обозначим его А’*,), отражающий
меру изменчивости bt. Определим его следующим образом:
Ест
Sl1' ~ I- о / ’
VE%2-(Ex) /п
где Ес, — стандартная ошибка оценивания. Большие значения s/,t показывают, что
оценка параметра неустойчива, нестабильна.
Во многих задачах интерес представляет не оценка значения параметра модели
|3: для генеральной совокупности, а некоторое утверждение о нем. В этом случае
задача сводится к проверке гипотезы, по результатам которой гипотеза будет либо
подтверждена, либо отклонена.
Введем в рассмотрение две гипотезы — нулевую (основную) и альтернативную.
Нулевая гипотеза Но предполагает, что линейные связи между переменными от-
сутствуют, в то время как альтернативная гипотеза На утверждает, что такие связи
имеют место. Таким образом:
□ Но: 0! = 0 — линейные связи между переменными отсутствуют;
□ На: 0t * 0 — линейные связи между переменными имеют место.
Если верна гипотеза Но, то линия регрессии будет расположена горизонталь-
но и построенная регрессионная модель бесполезна. С таким же успехом можно
использовать для оценки простое среднее значение выходной переменной, вы-
численное по всем имеющимся наблюдениям. Наоборот, если удастся отвергнуть
нулевую гипотезу, подтвердится значимость модели, то есть наличие линейной
зависимости между входной и выходной переменными. Но чтобы сделать окон-
чательное заключение о пригодности модели к решению той или иной задачи,
необходимо определить степень ее значимости. Для этого можно использовать
силу отклонения нулевой гипотезы. Для подтверждения или отклонения гипо-
тезы используется некоторый статистический показатель, значение которого
должно быть вычислено на основе имеющихся наблюдений. Например, если зна-
чение, принятое показателем, очень маловероятно в предположении истинности
гипотезы, то истинность гипотезы также маловероятна и ее следует отклонить.
При этом уверенность в отклонении гипотезы тем сильнее, чем меньше веро-
ятность появления данного значения показателя. Такое проверочное значение
часто называют ^-значением. Чем меньше р-значение, тем выше ожидаемая зна-
чимость модели и сильнее линейная зависимость между входными и выходной
переменными.
Для проверки истинности нулевой и альтернативной гипотез существуют
различные критерии. Например, гипотеза Но может утверждать, что наблюдаемое
выборочное распределение значений переменной является нормальным, а альтер-
нативная гипотеза — что оно таковым не является. Тогда вероятность значения
368 Часть I. Теория бизнес-анализа
проверочной статистики либо подтвердит, что данные имеют нормальное распре-
деление, либо покажет степень его отклонения от нормального.
Одними из наиболее популярных критериев оценки значимости регрессионных
моделей являются /-критерий, построенный на основе /-распределения Стьюдента
и F-критерий, использующий /^-распределение Фишера.
Оценка значимости регрессионной модели:
t-критерий и F-критерий
Для проверки истинности гипотезы Но /-критерий использует статистику t = bi/shl,
подчиняющуюся /-распределению с (п - 2) степенями свободы. При проверке ги-
потез возможно появление двух видов ошибок, представленных в табл. 8.5.
Таблица 8.5. Виды ошибок, возникающих при проверке гипотез
Действительное состояние Но принимается Но отвергается
Но справедлива Верное решение Ошибка I рода: вероят- ность а
Но несправедлива Ошибка II рода: вероят- ность р Верное решение
Ошибка I рода заключается в отклонении верной нулевой гипотезы, а ошибка
II рода — в принятии неверной нулевой. Вероятности данных событий обозначим
а и Р соответственно, причем вероятность а называется уровнем значимости крите-
рия. Он определяет вероятность того, что справедливая гипотеза Но будет ошибочно
отвергнута. Задав значение а и вычислив значение проверочной статистики /, по
таблице /-распределения можно установить, насколько вероятно появление полу-
ченного значения статистики /, если нулевая гипотеза будет ошибочно отвергнута
(таблицу /-распределения см. в приложении на CD).
В качестве примера возьмем данные о продажах картофеля, для которых было
получено уравнение регрессии у = 3213,6 —145,4 • х. Тогда
7e*'-(E-/ /»~ /Е(*~г)!
t = b\/sbl =-145,4/30 =-4,85.
Чтобы оценить вероятность справедливости гипотезы Но при значении ста-
тистики / = -4,85, воспользуемся методом ^-значения. Под ^-значением в кри-
терии проверки гипотезы понимается вероятность получения значения стати-
стики /, большего или равного значению выборочной статистики, вычисленной
исходя из предположения о справедливости гипотезы Но. Следовательно, р-зна-
чение представляет собой часть выборочного распределения, расположенную
правее значения выборочной статистики /, выраженную в процентах. Иными
словами, чем меньше ^-значение, тем больше вероятность того, что гипотеза
Глава 8. Data Mining: классификация и регрессия. Статистические методы 369
несправедлива, и если вычисленное р-значение будет очень малым, то гипотезу
следует отвергнуть.
ОПРЕДЕЛЕНИЕ---------------------------------------------------------------
p-значением, или значимой вероятностью, называют вероятность получения (в предположе-
нии о справедливости гипотезы) значения выборочной i-статистики, большего или равного
вычисленному, то есть р — Р(| 11> t'\ где t' — значение распределения i-статистики для
выбранного уровня значимости. Иначе говоря, ^-значение — зто наименьшее значение
показателя уровня значимости а (то есть вероятности отказа от справедливой гипотезы),
для которого вычисленная i-статистика ведет к отказу от гипотезы Но.
--------------------------------------------------------------------------
Из таблицы i-распределения можно увидеть, что для и-2 = 10-2 = 8 степе-
ней свободы значение 3,55 соответствует р = 0,005. Это указывает на вероятность
справедливости гипотезы, равную 0,5 %. Значение статистики 111 = 4,85, полученное
на основе регрессии, существенно больше, чем 3,55. Следовательно, для данного
значения вероятность справедливости гипотезы еще меньше. Можно сделать вы-
вод о высокой вероятности несостоятельности гипотезы Но, поскольку появление
значения 111 = 4,8 очень маловероятно, если гипотеза Но истинна. Тогда предполо-
жение о том, что Pi = 0 и линейная зависимость между переменными отсутствует,
также несостоятельно.
Другим возможным методом определения значимости регрессионной модели
является Е-критерий. В этом случае используются два показателя — средний
квадрат регрессионной квадратичной суммы (в случае простой линейной регрес-
сии т — 1):
и средний квадрат ошибок регрессии:
s. е.
п-т-\ п-2
С их помощью можно вычислить значение, называемое Е-статистикой. От-
ношение F — s2K/s2E подчиняется Е-распределению с (1, п - т - 1) степенями
свободы. Если гипотеза Но: Pi = 0 истинна и линейная связь между перемен-
ными отсутствует, то ошибка оценивания возрастает и ее средний квадрат $2Г,
соответственно, тоже. Поэтому если нулевая гипотеза справедлива, то значе-
ние Е-статистики будет мало из-за увеличения знаменателя s2;. Напротив, если
справедлива альтернативная гипотеза На: Pt * 0, то ошибка оценивания падает,
а значение F возрастает. Таким образом, большее значение F согласуется с ис-
тинностью альтернативной гипотезы.
Например, значение Е-статистики, рассчитанное для данных о продажах кар-
тофеля, будет Е= 1 742 032 / 74 280 = 23,5. По таблице Е-распределения можно
370 Часть I. Теория бизнес-анализа
установить, что для чисел степеней свободы числителя и знаменателя, равных
соответственно 1ип — т—1 = 10 — 1 — 1 = 8, рассчитанное по наблюдаемым дан-
ным значение F= 23,5 намного превышает теоретическое Fa = F0,01 = 11,26. Таким
образом, вероятность того, что гипотеза Н»: Pi = 0 истинна для рассчитанного
значения F-статистики, будет менее 0,01. Поэтому мы вынуждены отвергнуть
нулевую гипотезу, что позволяет сделать вывод о высокой значимости нашей
регрессионной модели.
Основные формулы, рассмотренные в разделе, сведены в табл. 8.6.
Таблица 8.6. Основное разложение для простой линейной регрессии
Источник вариации Число степеней свободы Квадратичные суммы Средние квадраты ?расч. ^КР.
Обусловленный регрессией 1 е«=Е(£--.^)2 2 1 е2 Г __ Ш#-2)
Относительно регрес- сии (остаток) п - 2 <24=Е(г/1-У,)2 ;=1 s1 = -0±- к п-2
Общий п - 1 Q = Q» + Qr.
8.5. Множественная линейная регрессия
В простой линейной регрессии устанавливается линейная зависимость между
одной входной переменной и одной выходной. Но на практике в задачах анализа
часто возникает необходимость привлечь для решения больше исходной инфор-
мации. Поэтому представляет интерес исследование зависимости выходной пе-
ременной от нескольких входных. Многие задачи Data Mining имеют достаточно
большую размерность и содержат десятки и сотни переменных. Для установления
таких связей служит множественная регрессия (иногда ее называют многомерной
линейной регрессией). Как правило, она обеспечивает более высокую точность
оценки, чем простая.
Если простая линейная регрессия использует приближение в виде прямой
линии, то множественная линейная регрессия для моделирования линейных свя-
зей между выходной переменной и набором входных — плоскость (если входных
переменных две) или гиперплоскость (если входных переменных более, чем две).
Обычно входные переменные являются непрерывными, но в некоторых задачах
могут содержаться и категориальные входные переменные. В этом случае приме-
няется специальный подход, основанный на введении так называемых фиктивных
переменных, хотя в Data Mining пользуются другой терминологией (она рассмат-
ривалась в разделе 3.6).
Для изучения множественной регрессии нам понадобится набор данных, в кото-
ром присутствует несколько входных переменных. Наборы наблюдений, на основе
Глава 8. Data Mining: классификация и регрессия. Статистические методы 371
оТорых рассматривалась простая линейная регрессия, не подходят, поскольку
одержат только одну входную и одну выходную переменную. Поэтому в качестве
примера возьмем еще один набор данных, содержащий информацию о пищевой
ценности продуктов — завтраков из сухих злаков. Каждый вид продукта описы-
вается признаками, в зависимости от значений которых рассчитывается пищевая
ценность продукта. Набор данных содержит 77 наблюдений. В табл. 8.7 приведен
его фрагмент (данные взяты из источника Cereals data set, http://lib.stat.cmu.edu/DASL;
они доступны в приложении на CD, файл cereals . xls).
Таблица 8.7. Фрагмент набора данных «Пищевая ценность продуктов»
Наименование продукта Произво- дитель Сахар, г Калорий- ность Белок, г Жиры, г Угле- воды, г Пищевая ценность
100 % Bran N 6 70 4 1 130 68,4030
100 % Natural Bran Q 8 120 3 5 15 33,9837
All-Bran к 5 70 4 1 260 59,4255
All-Bran Extra Fiber к 0 50 4 0 140 93,7049
Almond Delight R 8 110 2 2 200 34,3848
Apple Cinnamon Cheerios G 10 110 2 2 180 29,5095
Apple Jacks К 14 110 2 0 125 33,1741
Basic 4 G 8 130 3 2 210 37,0386
Bran Chex R 6 90 2 1 200 49,1203
Bran Flakes P 5 90 3 0 210 53,3138
Cap’n crunch Q 12 120 1 2 220 18,0429
Cheerios G 1 110 6 2 290 50,7650
Cinnamon Toast Crunch G 9 120 1 3 210 19,8236
Clusters G 7 110 3 2 140 40,4002
Cocoa Puffs G 13 110 1 1 180 22,7364
Выборка в полном ее варианте содержит следующие признаки:
□ наименование — наименование продукта;
□ производитель — производитель продукта;
□ тип — заливается холодной или горячей водой;
□ калорийность — содержание калорий в одной порции продукта;
□ белок — содержание белка, г;
□ жиры — содержание жиров, г;
□ натрий — содержание натрия, мг;
□ волокна — содержание пищевых волокон, г;
372 Часть I. Теория бизнес-анализа
□ углеводы — содержание углеводов, г;
□ сахар — содержание сахара, г;
□ калий — содержание калия, мг;
□ витамины — содержание ежедневной рекомендуемой дозы витаминов (0,25
или 100 %);
□ вес одной порции;
□ вода — количество чашек воды на порцию;
□ № витрины — витрина, на которой расположен продукт;
□ пищевая ценность продукта.
Приступая к анализу, предполагаем, что признаки, описывающие каждый про-
дукт, каким-то образом влияют на его пищевую ценность, которая, в свою очередь,
определенным образом связана с этими признаками. Цель анализа — обнаружить
закономерности в этих связях. Если закономерности будут найдены, то с их помо-
щью можно определять пищевую ценность новых продуктов, описываемых тем
же набором признаков, разрабатывать новые рецептуры с требуемой пищевой
ценностью.
В процессе анализа возникает масса вопросов.
□ Все ли признаки влияют на пищевую ценность продукта?
□ Какие из признаков влияют сильнее, а какие — слабее?
□ Какие из признаков способствуют повышению пищевой ценности продукта,
а какие — уменьшению?
□ Как влияет изменение отдельного признака на пищевую ценность?
Пусть требуется смоделировать линейную зависимость между выходной пере-
менной и двумя входными. Это можно сделать с помощью плоскости, которая
является линейной в двух измерениях (по каждой входной переменной). Пред-
положим, нас интересует оценка пищевой ценности продукта на основе двух
признаков — содержания сахара и пищевых волокон. Графическая интерпретация
множественной линейной регрессии для двух входных переменных представлена
на рис. 8.12.
Увеличение содержания пищевых волокон связано с повышением пищевой
ценности, а увеличение содержания сахара — с уменьшением. Данное отношение на
рисунке представлено с помощью плоскости, которая имеет наклон вниз и вправо
(в сторону увеличения содержания сахара), а также в сторону переднего фронта
(в сторону уменьшения содержания пищевых волокон). Таким образом, чем выше
содержание сахара и ниже содержание пищевых волокон, тем меньше ожидаемая
оценка выходной переменной и наоборот.
Уравнение множественной линейной регрессии для двух входных переменных
и одной выходной имеет вид:
у = Ь0 +ЬуХу + Ь2х2.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 373
Сахар
Волокно
Рис. 8.12. Диаграммы разброса данных
для переменных «сахар» и «волокно»
Обобщив его на произвольное число входных переменных, получим:
у = b{} + btxt + b2x> +... + Ь,„х,„.
Запишем уравнение множественной регрессии с рассчитанными коэффици-
ентами, где в качестве входных переменных используется содержание сахара (xi)
и пищевых волокон (х2), а в качестве выходной — наблюдаемое значение пищевой
ценности:
у = 51,787 - 2,2090xi + 2,8408х2.
Высокое содержание сахара уменьшает пищевую ценность, и коэффициент
при соответствующей переменной имеет отрицательный знак. Содержание пи-
щевых волокон увеличивает пищевую ценность, и коэффициент для данного
показателя в уравнении регрессии положительный. Построим отдельные диа-
граммы рассеяния данных для каждой входной переменной, где коэффициент
наклона прямой для сахара будет 2,2090, а для пищевых волокон — 2,8408
(см. рис. 8.12).
Интерпретация коэффициентов bi и Ь2, определяющих положение плоскости
множественной регрессии, несколько отличается от простой линейной регрессии.
Например, при интерпретации bt = -2,2090 можно сказать, что оцененное умень-
шение пищевой ценности на единицу увеличения содержания сахара составляет
2,2090 при фиксированном значении второй входной переменной, то есть содержания
374 Часть I. Теория бизнес-анализа
пищевых волокон. Аналогично коэффициент Ь-г = 2,8408 говорит о том, что при-
рост пищевой ценности на единицу увеличения содержания волокон составляет
2,8408 при фиксированном содержании сахара. Таким образом, для множественной
линейной регрессии с т входных переменных коэффициенты регрессии следует ин-
терпретировать по следующему правилу: оценка изменения выходной переменной
у на единицу изменения входной переменной х, составляет Ь, при фиксированном
значении остальных переменных.
В простой линейной регрессии остаток у — у представляется вертикальным рас-
стоянием между реальным значением и соответствующей точкой на линии регрессии.
В множественной регрессии остаток представляется в виде расстояния между точкой
данных и плоскостью (или гиперплоскостью) регрессии. Пусть некоторый продукт
имеет содержание сахара Xi = 0 г и содержание пищевых волокон х3 = 3 г, а его пище-
вая ценность составляет 72,8018. В соответствии с нашим уравнением регрессии оце-
ненная пищевая ценность будет у = 51,787 — 2,2090 - 0 + 2,8408 • 3 = 60,3094 и остаток
у — у = 72,8018 — 60,3094 = 12,4924. Данная ситуация показана на рис. 8.13.
С помощью этих остатков так же, как и в случае простой линейной регрессии,
могут быть вычислены квадратичные суммы Q, Qr и Qr- При этом Q — Qr + Qr>
где Q — полная изменчивость, Qr — доля изменчивости, объясняемая регрессией,
и Qe — доля изменчивости, определяемая ошибкой (см. раздел 8.3).
Для множественной регрессии мы также можем ввести множественный ко-
эффициент детерминации г2 = Qr/Q, который определяет относительную долю
изменчивости, объясненную регрессией, в полной изменчивости выходной пере-
Глава 8. Data Mining: классификация и регрессия. Статистические методы 375
елной. Чем выше доля изменчивости, объясненная регрессией, тем больше зна-
ецце коэффициента детерминации. В идеальном случае, когда все имеющиеся
наблюдения попадут на плоскость регрессии (изменчивость, обусловленная ре-
цессией, окажется равной полной изменчивости выходной переменной), г2 = 1.
Л наоборот, чем меньше доля изменчивости выходной переменной, объясненная
регрессией, тем меньше значение г2. Таким образом, как и в случае простой линей-
ной регрессии, значения коэффициента детерминации, близкие к 1, указывают на
хорошее соответствие регрессии исходным данным, а значения, близкие к 0, — на
плохое.
Если г2 = Qr/Q = 0,808, это означает, что 80,8 % изменчивости выходной пере-
менной определяются ее линейной зависимостью от набора входных переменных.
Можно ли ожидать, что г2 будет больше для простой линейной регрессии, если
н качестве входной использовать только одну переменную — содержание сахара?
Всякий раз, когда в модель добавляется новая входная переменная, коэффициент
детерминации увеличивается. При этом если новая переменная является полезной,
то есть существенно увеличивает долю изменчивости, объясненную регрессией,
то коэффициент детерминации увеличивается значительно, в противном случае
увеличение может быть едва заметным.
Например, если использовать для оценки пищевой ценности только содержание
сахара (х), то уравнение простой линейной регрессии будет иметь вид:
z/ = 59,4 —2,42х.
Для этого случая коэффициент детерминации г2 = 58 %. После добавления
новой переменной, то есть содержания пищевых волокон, коэффициент увели-
чился до 80,8 %. Таким образом, введение новой переменной в модель добавило
80,8 - 58 = 22,8 % изменчивости выходной переменной, объясненной с помощью
регрессии. Следовательно, в целом можно утверждать, что соответствие регрессии
реальным данным улучшилось. Увеличение кажется значительным, но оценим
его позже.
Обычно в качестве показателя точности оценок, получаемых с помощью ре-
грессии, используется среднеквадратическая ошибка ЕСко, которая в случае оценки
содержания сахара и пищевых волокон равна 6,24. Следует ли ожидать, что данная
ошибка будет больше или меньше, если использовать только одну входную пере-
менную (содержание сахара)? Это зависит от степени полезности новой перемен-
ной. Если переменная полезна, то есть способствует повышению точности оценки,
то ошибка уменьшается, в противном случае — увеличивается. Такое поведение
Делает среднеквадратическую ошибку оценивания более привлекательным показа-
телем целесообразности добавления в модель новой переменной, чем коэффициент
Детерминации, который всегда увеличивается при добавлении новых переменных
в модель независимо от степени их полезности.
Значение среднеквадратической ошибки £Ско в случае простой линейной ре-
грессии, то есть при оценивании рейтинга продукта только на основе содержания
сахара, составляет 9,16. Таким образом, введение в модель дополнительной входной
переменной (содержания пищевых волокон) уменьшает ошибку оценивания с 9,16
до 6,24, то есть на 2,92.
376 Часть I. Теория бизнес-анализа
8.6. Модель множественной линейной регрессии
Как и в случае простой линейной регрессии, в множественной требуется опре-
делить, можно ли распространить линейную зависимость между набором вход-
ных переменных и выходной переменной, построенную на основе выборочных
наблюдений, на всю имеющуюся совокупность данных. Необходимо не только
вычислить коэффициенты уравнения множественной регрессии, но и построить
соответствующую регрессионную модель и определить ее значимость.
При построении такой модели можно использовать те же подходы, что и для
простой линейной регрессионной модели. Множественная регрессионная модель
представляет собой прямое расширение простой линейной регрессионной модели
для заданного числа переменных:
У = Р о + Р1 Х\ + p2^2 + --- + Р/пЛ:т + е,
где Ро, Pi— Рт ~ параметры модели, представляющие собой константы, значения
которых оцениваются с помощью метода наименьших квадратов.
Как и в случае простой линейной регрессии, об ошибке е высказываются сле-
дующие предположения.
□ Предположение о нулевом среднем. Ошибка е представляет собой случайную
переменную со средним, равным 0, то есть Е(е) = 0.
□ Предположение о постоянстве дисперсии. Дисперсия ошибки ст,2 является по-
стоянной величиной для всех значений переменных х2... хт.
□ Предположение о независимости. Значения переменной е являются статисти-
чески независимыми.
□ Предположение о нормальности. Значения ошибки е распределены по нор-
мальному закону.
Иными словами, значения ошибки е, представляют собой независимые случай-
ные переменные с нулевым средним и постоянной дисперсией ст.
Как и в случае простой линейной регрессии, мы можем сделать четыре вывода
о поведении выходной переменной у.
□ На основе предположения о нулевом среднем имеем:
^(?/)= £(₽о + Р1 Х\ +... + р,„х,„ + е) =
— £(Р<>) + Д(Р1Х]) +... + Е(р,„х,„) +
+Д(е) = Ро + Р t Xi +... + p,nx,n.
Для каждого набора входных переменных х2... среднее значение выходной
переменной у лежит на плоскости регрессии.
□ На основе предположения о постоянной дисперсии имеем дисперсию D(y'), за-
данную следующим образом:
D(y) = D&0 + Р1 Х\ + р 2 х> + ... + Ротхга + е) = £)(€) = ст2.
Иными словами, независимо от того, какие значения принимают переменные
xt, х2... хт, дисперсия D(y) всегда постоянна.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 377
g Из предположения о независимости следует, что для любого набора значений
Xi, Х2— хт значения у также являются независимыми.
□ Из предположения о нормальности следует, что у также является нормально
распределенной случайной переменной.
Таким образом, выходная переменная у является независимой нормально
распределенной случайной переменной со среднимр0 + рtx, + р2х2 + ... + pmxm +е
и дисперсией ст2.
Оценка значимости множественной
регрессионной модели
Как и в случае простой регрессионной модели, для оценки значимости множе-
ственной регрессии используются гипотезы о наличии или отсутствии линей-
ной зависимости между набором входных переменных и выходной переменной.
Для проверки этих гипотез также можно применять t-критерий и F-критерий.
Но в случае множественной линейной регрессии применение данных критериев
несколько иное. Если t-критерий исследует линейную зависимость между каждой
отдельной входной переменной х, и выходной переменной у, то F-критерий иссле-
дует линейную зависимость для всей модели, то есть между набором входных
переменных Х\, х2... хт и переменной у (рис. 8.14).
Рис. 8.14. Различие между F-критерием и t-критерием
для множественной линейной регрессии
Начнем рассмотрение с t-критерия, который оказывается особенно полезным
в том случае, когда требуется оценить значимость каждой отдельной входной пере-
менной. Гипотезы для t-теста о наличии связи между выходной переменной у и не-
которой входной переменной х, задаются следующим образом:
□ //(1^р,=0;
378 Часть I. Теория бизнес-анализа
Модели, вытекающие из этих гипотез, представляются в следующем виде:
О Но > у = Ро + р 11 + ... + Р,-1Х,_| + Р,Х; + Р;+|Х/+1 + ... + p,„xm + EJ
□ На —> У = Ро + Р1-Т1 + ... + Р,_)Х,_| + Р/+|Х!+, + ... + P,„Xm + Е.
Обратим внимание на то, что разница между двумя моделями заключается
только в присутствии или отсутствии г-го члена, а остальные члены присутствуют
в обеих моделях. Следовательно, при интерпретации результатов t-теста для дан-
ной переменной значения остальных переменных должны фиксироваться.
При нулевой гипотезе статистика t = bt/sb: подчиняется ^-распределению
с т - п - 1 степенями свободы, где sb — среднеквадратическая ошибка оценки
коэффициента bi для z-й выходной переменной (метод ее расчета излагался в раз-
деле, посвященном оценке значимости простой регрессионной модели).
Рассмотрим примеры выполнения t-теста для выявления линейных зависи-
мостей между содержанием сахара и пищевой ценностью продукта, содержанием
пищевых волокон и пищевой ценностью, а также при использовании обеих входных
переменных.
□ Выполним t-тест для определения зависимости между содержанием сахара
и пищевой ценностью.
• Определим модели, соответствующие нулевой и альтернативной гипотезам:
Но ->Pi =0; ,z/ = p0 +р,(сахар)+ е;
На —> Pi *0; z/ = p0 +Pi(caxap) + P2(волокно)+ е.
• = 2,2090.
• 5Л|=0,1633.
. t = bjshi =-2,2090/0,1633 = -13,53.
• Вычислим p-значения для t-статистики. Напомним, что р-значение — это
вероятность появления значения t-статистики, большего, чем наблюда-
емого по результатам регрессии t', то есть p = P(|t|>tQ. Следовательно,
P = P(|t|>t') = P(|t|>13,5).
Из таблицы t-распределения можно увидеть, что вероятность появления значе-
ния t, большего 13,5, не превышает 0,05 %. Это с достаточной долей уверенности
позволяет отклонить нулевую гипотезу и сделать вывод о наличии линейной
зависимости между пищевой ценностью продукта и содержанием сахара в нем
при фиксированном содержании пищевых волокон.
□ Выполним t-тест для определения зависимости между пищевой ценностью
и содержанием волокон.
• Определим модели, соответствующие нулевой и альтернативной гипоте-
зам:
Но ->р2 =О;р = ро +р2(сахар) + Е;
Н„ -^р2 = 0; г/ = р() +р((сахар)+ р2(волокно) + е.
• Ь2 = 2,8408.
• 5/,2 =0,032.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 379
• t = b2/sbl =2,8408/0,3032 = 9,37.
• р < 0,05 %.
Нулевая гипотеза вновь отклоняется, и наличие линейной зависимости между
пищевой ценностью продукта и содержанием пищевых волокон в нем при фик-
сированном содержании сахара можно считать доказанным.
F-тест для оценки значимости полной
регрессионной модели
Гипотезы F-теста в случае множественной линейной регрессии задаются следую-
щим образом:
□ Но ->р, =р2 = ... = ₽„ =0;
□ Н„—> как минимум одна из Р/0.
Нулевая гипотеза предполагает, что линейная зависимость между выходной
переменной у и набором входных переменных хь х2... хт отсутствует. Таким образом,
она утверждает, что коэффициент р, для каждой входной переменной х,- равен 0
и модель сводится к виду у = Ьо + е.
Альтернативная гипотеза не утверждает, что все коэффициенты регрессии
отличны от нуля. Для истинности альтернативной гипотезы достаточно, чтобы
только один из коэффициентов был отличен от 0. Напомним, что используемая
в F-тесте F-статистика представляет собой отношение двух среднеквадратических
величин F = s,e/s/, где s2K — средний квадрат регрессии, s2- — средний квадрат
ошибки.
При оценке значимости простой регрессионной модели (см. раздел 8.4) мы сде-
лали вывод, что высокие значения F-статистики соответствуют малой вероятности
того, что нулевая гипотеза истинна, и наоборот. Данное правило справедливо и для
множественной регрессии.
Проведем F-тест для проверки наличия линейных связей между пищевой цен-
ностью продукта и содержанием в нем сахара и пищевых волокон.
□ Определим нулевую и альтернативную гипотезы:
• Но —* Р J = Р г == 0;
• Н„ —> как минимум одна из р, 0.
□ Модель, соответствующая альтернативной гипотезе, определена неоднозначно
и может быть представлена в одном из трех видов:
• у = Ро + Р1Х1 +е;
• г/= Ро + Ргх2 + е;
* 2/ = Ро + Р1Х1 + Р2Х2 + Е.
□ Вычислим оценку среднего квадрата регрессии = 6058,9.
□ Вычислим средний квадрат ошибок регрессии si = 38,9.
380 Часть I. Теория бизнес-анализа
□ Вычислим значение статистики F = 6058,9/38,9 = 155,76.
□ Число степеней свободы F-статистики будет п - т - 1 = 74, где т = 2 — число
входных переменных, п = П — число наблюдений исходной выборки.
□ По таблице F-распределения для ^-значения определим:
P(Fm,„_m., >F) = P(F2.7i > 155,76) « 0.
Данное p-значение меньше, чем любое допустимое значение порога значи-
мости, поэтому нулевую гипотезу следует отвергнуть. Таким образом, между
пищевой ценностью продукта и набором из двух входных переменных — со-
держанием сахара и содержанием пищевых волокон — существует линейная
зависимость. Это позволяет говорить о высокой значимости регрессионной
модели в целом.
8.7. Регрессия с категориальными
входными переменными
В Data Mining часто приходится иметь дело с задачами, содержащими не только
количественные, но и качественные данные, когда входные переменные являют-
ся категориальными. Существуют способы выразить значения категориальных
переменных в виде числовых величин. В разделе 3.6 приводились различные
схемы кодирования категориальных переменных: уникальные коды и двоичное
кодирование. Все это справедливо и для регрессионного анализа, однако в нем
принято оперировать терминологией фиктивных переменных (dummy variables),
что напоминает кодирование по битовой маске. Не нарушая традиций, в данном
разделе будем использовать эту терминологию.
Чтобы исследовать особенности применения категориальных переменных в ли-
нейной регрессии, рассмотрим переменную Номер витрины из набора данных о су-
хих завтраках, которая показывает, на какой витрине располагается тот или иной
продукт. Пусть из 77 продуктов 20 размещается на витрине 1, 21 — на витрине 2
и 36 — на витрине 3. На рис. 8.15 представлен точечный график, показывающий
пищевую ценность продуктов, размещенных на соответствующих витринах, при
этом среднее значение по каждой витрине отмечено треугольником.
Нас интересует применение категориальной переменной Номер витрины
совместно с непрерывными переменными: содержанием сахара и пищевых
волокон. Придется использовать множественную регрессию с фиктивными
переменными.
На основе сравнения элементов точечного графика зададимся вопросом, как
связан номер витрины, на которой расположен продукт, с его пищевой ценностью?
Казалось бы, продукты, расположенные на витрине 2 и имеющие среднее значение
пищевой ценности 34,97, отстают от продуктов, расположенных на витринах 1 и 3
и имеющих среднюю пищевую ценность 46,15 и 45,22 соответственно. Но является
ли эта разница значительной? Кроме того, данный точечный график не рассма-
Глава 8. Data Mining: классификация и регрессия. Статистические методы 381
Рис. 8.15. Точечный график пищевой ценности продуктов,
размещенных на витринах
тривает такие переменные, как содержание сахара и пищевых волокон. Поэтому
непонятно, как расположение продукта на определенной витрине будет проявлять
себя в присутствии других переменных.
Для использования в регрессии категориальная переменная, содержащая k ка-
тегорий, вначале должна быть преобразована в k - 1 фиктивных переменных.
Фиктивная переменная — это бинарная переменная, которая принимает зна-
чение 1, если наблюдение соответствует данной категории, и значение 0 — в про-
тивном случае.
Для нашего примера определим следующие переменные.
□ Витрина 1 = 1 — если продукт расположен на витрине 1.
□ Витрина 1 = 0 — в противном случае.
□ Витрина 2=1 — если продукт расположен на витрине 2.
□ Витрина 2 = 0 — в противном случае.
В табл. 8.8 приводятся значения фиктивных переменных для продуктов, рас-
положенных на витринах 1, 2 и 3. Обратите внимание, что нет необходимости
определять 3-ю фиктивную переменную Витрина 3, потому что оба ее состояния
окажутся нулевыми, поскольку продукты, размещенные на 3-й витрине, естест-
венно, не будут располагаться на 1-й и 2-й. Поэтому оба состояния фиктивной
переменной Витрина 3 будут нулевыми, и нам достаточно будет рассмотреть только
первые две.
382 Часть I. Теория бизнес-анализа
Таблица 8.8. Использование фиктивных переменных
Расположение продукта Значение переменной Витрина 1 Значение переменной Витрина 2
Витрина 1 1 0 ~~
Витрина 2 0 1
Витрина 3 0 0 '
Категория, для которой фиктивная переменная не назначается, называется
опорной категорией, и в нашем примере это Витрина 3. Позднее мы оценим влия-
ние размещения продукта на его пищевую ценность относительно этой опорной
категории.
Рассмотрим модель множественной регрессии для линейных отношений между
выходной переменной — пищевой ценностью продукта — и содержанием сахара,
содержанием пищевых волокон и размещением продукта на витрине, используя
две фиктивные переменные из табл. 8.8. Общая модель выглядит следующим
образом:
г/ = 0о +Pi -(сахар) + 02 (волокна) + 0.3 -(витрина 1) + 04 -(витрина 2) + е.
Тогда соответствующее уравнение регрессии будет:
у = h0 + h\ (сахар) + h2 (волокна) + h3 • (витрина 1) + hA • (витрина 2).
Для продуктов, расположенных на витрине 1, модель и уравнение регрессии
выглядят следующим образом:
г/ = 0о + 0i • (сахар)+ 02-(волокна)+ 0з-3,1 + 04 -0 + е =
= (0о + 0.1) + 0i • (сахар) + 02 • (волокна) + е;
у = ha + by • (сахар) + h2 (волокна) + b3 • 3,1 + hA • 0 =
= (ho + h3) + />, (сахар) + h2 (волокна).
Для продуктов, расположенных на витрине 2, модель и уравнение регрессии
выглядят следующим образом:
у = 0о +01 -(сахар)+ 02-(волокна)+ 0з-0 + 04-3,1+е =
= (0о + 04) + 0i • (сахар) + 02 • (волокна) + е;
у — bo +Z>i • (сахар) + Ь2 - (волокна) + Ь3 -0 + /ц -3,1 =
= (ho +bA) + hr(сахар) + h2 • (волокна).
Для продуктов, расположенных на витрине 3, модель и уравнение регрессии
выглядят следующим образом:
у = 0о +01 - (сахар)+ 02 - (волокна)+ 0з - 0 + 04 - 0 + е =
= 0о +0i - (сахар)+ 02 • (волокна) + е;
Глава 8. Data Mining: классификация и регрессия. Статистические методы 383
у — Ьп + Ь\ • (сахар) + Ь2 (волокна) + Ь3 • 0 + Ьл - 0 =
= Ьо + Ь\ • (сахар) + Ь2 (волокна).
Обратим внимание на связь уравнений для моделей друг с другом. Три модели
представляют собой параллельные плоскости, как показано на рис. 8.16.
Рис. 8.16. Представление моделей для продуктов на различных витринах
в виде параллельных плоскостей
Уравнение для исходной выборки будет иметь вид:
у — 50,433 — 2,2554 (сахар) + 3,0856 • (волокна) +
+ 1,446-(витрина 1) +3,828-(витрина 2).
Таким образом, получим следующие уравнения регрессии для продуктов, рас-
положенных на различных витринах.
□ Витрина 1:
у = 50,433 — 2,2954 - (сахар) 4- 3,0856- (волокна) +1,446-1 = 51,879 —
—2,2954 • (сахар) + 3,0856 • (волокна).
□ Витрина 2:
у = 50,433 — 2,2954 (сахар) + 3,0856-(волокна) + 3,828-1 =
= 54,261 — 2,2954 • (сахар) + 3,0856 • (волокна).
384 Часть I. Теория бизнес-анализа
□ Витрина 3:
у = 50,433 — 2,2954 (сахар) + 3,0856 (волокна).
Заметим, что данные уравнения регрессии одинаковы, за исключением сво-
бодного члена Ьо, то есть точки пересечения плоскости с осью у. Это означает, что
для продуктов на каждой витрине имеет место один и тот же наклон плоскости
регрессии, определяемый содержанием сахара (-2,2954) и волокон (3,0856), что
дает три параллельные плоскости. Разница заключается только в коэффициенте
Ьо. Опорная категория в данном случае — Витрина 3- Как выразить вертикальное
расстояние между Витриной 3 и, скажем, Витриной 1?
Исходя из приведенных выше выводов уравнение регрессии для продуктов на
витрине 1:
у = (Ьо +/>:)) + &, • (сахар)+ />2 - (волокна).
Поэтому значение точки пересечения с осью у есть Ьо + Ь3.
В то же время уравнение регрессии для продуктов на витрине 3:
у = bo + • (сахар) + (волокна).
Таким образом, расстояние между точками пересечения с осью у для соответ-
ствующих плоскостей регрессии будет (б0 + бз) - Ъ = 1,44.
Пересечение плоскости с осью у показывает пищевую ценность продукта,
если содержание сахара и волокон равно 0. Однако, поскольку плоскости па-
раллельны, разность точек пересечения для разных витрин остается постоян-
ной во всем диапазоне изменений содержания сахара и волокон. Следователь-
но, вертикальное расстояние между параллельными плоскостями, измеренное
с помощью коэффициента при фиктивной переменной, представляет собой
оценку влияния отдельной фиктивной переменной на выходную переменную
(рис. 8.17).
В примере />3 = 1,446 означает оценку разности между пищевой ценностью
продуктов, расположенных на витрине 1, и пищевой ценностью продуктов, распо-
ложенных на витрине 3. Поскольку значение Ь3 положительное, оценка пищевой
ценности продуктов с витрины 1 будет более высокой. Коэффициент Ь3 можно
интерпретировать следующим образом: оценка увеличения пищевой ценности
продуктов, расположенных на витрине 1, по сравнению с продуктами, располо-
женными на витрине 3, составит Ь3 = 1,446 при постоянном содержании сахара
и волокон.
Аналогичные рассуждения можно использовать и для витрины 2. Уравнение
регрессии в этом случае будет иметь вид:
У — (Ьо + ) + Ь\ • (сахар) + Ь3 (волокна).
Тогда разность между точками пересечения с осью у плоскостей для витрин 2
и 3 составит(Ьо +Ь^)-Ь0 =Ь3 = 54,261 -50,433 = 3,828. Это значит, что расстояние
Глава 8. Data Mining: классификация и регрессия. Статистические методы 385
Сахар
Рис. 8.17. Оценка влияния фиктивной переменной
на целевую переменную
между плоскостями для витрин 2 и 3 равно 3,828 (рис. 8.17).Тогда коэффициент
Ь> можно интерпретировать так: оценка увеличения пищевой ценности продуктов,
расположенных на витрине 2, по сравнению с продуктами на витрине 3 составит
Ь3 = 3,828 при постоянном содержании сахара и пищевых волокон.
Таким же образом определяется разность пищевой ценности продуктов, распо-
ложенных на витринах 1 и 2:
(Йо + й4) -(й0 + йз) = й4 - йз = 3,828 -1,446 = 2,382.
Оценка увеличения пищевой ценности продуктов, расположенных на витрине 2,
по сравнению с продуктами, расположенными на витрине 1, составляет 2,382 при
постоянном содержании сахара и волокон.
Вернемся к рис. 8.15, на котором видно, что продукты, расположенные на
витрине 2, имеют среднюю пищевую ценность 35. Это существенно ниже, чем
пищевая ценность продуктов, размещенных на витринах 1 и 3, где она составляет
соответственно 46 и 45. Как это согласуется с результатами, полученными с по-
мощью фиктивных переменных, которые показали, что наибольшую пищевую
ценность имеют товары, размещенные на витрине 2? Расхождение вызвано тем,
что результаты были получены с учетом двух других переменных — содержания
сахара и волокон. Действительно, продукты на витрине 2 имеют самую низкую
386 Часть I. Теория бизнес-анализа
пищевую ценность. Но, как видно из табл. 8.9, эти продукты также имеют высокое
содержание сахара (в среднем 9,62 г по сравнению с 4,65 и 6,53 г для витрин 1 и 3
соответственно) и самое низкое содержание пищевых волокон (0,92 г против 1 75
и 3,17 г для продуктов на витринах 1 и 3 соответственно). Поскольку имеет место
отрицательная корреляция между пищевой ценностью продукта и содержанием
сахара и положительная корреляция между пищевой ценностью и содержанием
пищевых волокон, продукты на витрине 2 должны иметь более низкую пищевую
ценность, чем продукты на других витринах. В табл. 8.9 представлены средние
значения содержания сахара и пищевых волокон, пищевой ценности и ее оцен-
ки, полученной с помощью регрессии, для случая, когда в качестве входных
переменных модели использовалось только содержание сахара и волокон (без
использования номеров витрин).
Таблица 8.9. Средние значения и оценки регрессии
№ витрины Среднее содержание сахара Среднее содержание волокон Средняя пищевая ценность Средняя оценка пищевой ценности Средняя ошибка
1 4,85 1,75 46,15 46,04 -0,11
2 9,62 0,92 34,97 33,11 -1,86
3 6,53 3,17 45,22 46,36 1,14
Видно, что среднее значение пищевой ценности для продуктов на витрине 2
занижено на 1,86, в то время как оценка для витрины 3 завышена на 1,14. Следо-
вательно, когда в модель вводится расположение продуктов, оценки завышаются
или занижаются. Заметим, что разность ошибок оценки для витрин 2 и 3 состав-
ляет 1,86 + 1,14 = 3. Таким образом, следует ожидать, что, если использование
переменной Номер витрины привело к занижению оценки пищевой ценности
продуктов, размещенных на витрине 2 относительно продуктов на витрине 3, это
и является фа’ктором, определившим суммарную ошибку, равную 3. Вспомним,
что коэффициент bi = 3,828, что сопоставимо с суммарной ошибкой, равной 3.
Также обратим внимание, что относительная ошибка оценки выходной перемен-
ной между витринами 1 и 3 составляет 1,14 -4-0,11 = 1,25. Следует ожидать, что
фиктивная переменная Номер витрины не изменит ошибку намного более чем
на 1,25. И действительно, мы имеем похожий коэффициент й3 = 1,446.
Данный пример иллюстрирует особенность множественной регрессии, ко-
торая заключается в том, что линейная зависимость между набором входных
переменных и выходной переменной не обязательно определяется отношениями
между отдельными входными переменными и выходной переменной. Например,
рис. 8.17 позволяет увидеть, что если в качестве фиктивной переменной использу-
ется витрина 2, то оценка пищевой ценности продукта снижается. В то же время
в регрессионной модели, которая включает содержание сахара, волокон и место
расположения продукта, пищевая ценность увеличивается из-за влияния других
переменных.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 387
8.8. Методы отбора переменных
0 регрессионные модели
Введение
большинство реальных анализируемых процессов и объектов являются сложны-
ми, для их описания требуется много признаков и показателей. Поэтому типична
ситуация, когда аналитику при построении регрессионных моделей приходится
иметь дело с десятками переменных и, соответственно, производить отбор пере-
менных для построения модели. Данная задача совсем не так проста, как кажется.
На первый взгляд, нужно отобрать только те переменные, которые непосредственно
связаны с решаемой задачей. Однако даже после того, как посторонние переменные
будут отсеяны, нет гарантии успешного решения.
Действительно, из ранее рассмотренного материала по регрессии мы увидели,
что:
□ входные переменные могут иметь низкую значимость, то есть линейная зави-
симость между ними и выходной переменной может либо отсутствовать, либо
быть очень слабой. Такие переменные не способствуют повышению точности
полученных оценок, а только усложняют модель;
□ входные переменные могут коррелировать между собой, что приводит к муль-
тиколлинеарности и, как следствие, к снижению точности и устойчивости
модели, к противоречивости результатов и т. д.
Как показывает практика, визуально выявить эти проблемы в исходных данных
и результатах регрессии практически невозможно. Чтобы оптимизировать процесс
отбора переменных для использования в регрессионной модели, разработаны
различные методы, которые позволяют учесть указанные факторы и выбрать наи-
лучшую модель.
Существует общая рекомендация, которая в первом приближении дает воз-
можность построить хорошую регрессионную модель: необходимо включить
в рассмотрение все переменные, которые позволяют повысить точность оценок,
получаемых с помощью регрессии. Но возникает дилемма: как реализовать модель
с приемлемыми точностью и затратами? На практике приходится соблюдать два
противоречивых требования.
□ В регрессионной модели нужно использовать как можно больше входных пере-
менных, содержащих новую информацию о выходной переменной.
□ Поскольку включение в модель каждой новой переменной увеличивает вре-
менные и вычислительные затраты на ее реализацию, нужно стремиться, чтобы
модель содержала как можно меньше входных переменных.
Выбор лучшей регрессионной модели заключается в поиске компромисса
между данными требованиями.
388 Часть I. Теория бизнес-анализа
Обычно после того, как составлен список переменных — потенциальных канди-
датов для использования в модели, переходят ко второму этапу отбора — исклю-
чению переменных, которые по тем или иным причинам неадекватны решаемой
задаче. Это могут быть коррелированные переменные; переменные, характери-
зующиеся большими ошибками измерений; переменные, трудно поддающиеся
измерению, и т. д.
После того как нежелательные переменные будут исключены, среди остав-
шихся производится поиск тех, набор которых обеспечит лучшую регрессионную
модель. Однако и на этом этапе возникает ряд проблем. Во-первых, понятие «луч-
шая модель» не имеет строгих критериев и во многом субъективно. Во-вторых, ни
один из известных методов отбора не гарантирует получение набора переменных,
позволяющих достичь наилучшего результата. Зачастую такого набора просто не
существует. В-третьих, различные методы отбора приводят к различным резуль-
татам. Поэтому на практике аналитики чаще всего ставят целью получить не наи-
лучший, а приемлемый набор входных переменных, который позволит соблюсти
баланс между противоречивыми требованиями.
Рассмотрим наиболее популярные методы отбора входных переменных в ре-
грессионные модели:
□ метод прямого отбора (forward selection);
□ метод обратного исключения (backward elimination);
□ метод последовательного отбора (stepwise selection);
□ метод лучших подмножеств (best subsets).
Частный F-критерий
Перед изучением перечисленных методов отбора переменных рассмотрим част-
ный F-критерий. Предположим, мы уже отобрали для использования в модели
набор из k переменных: xt, х2... xk. Теперь нас интересует, имеет ли смысл включать
в модель некоторую дополнительную переменную х'. Рассмотрим квадратичную
сумму регрессии Q^1'1 =Qs(xl,x2...xt), которую дают ранее введенные в модель
переменные, а также дополнительную сумму Q™" =&(* | хх,х2... xk), обуслов-
ленную только новой переменной х\ Очевидно, что если сложить эти две суммы,
то можно получить полную квадратичную сумму по модели, включающей как
ранее введенные переменные, так и новую, то есть Q”"" = QK (х,,х2... Тогда
можно записать:
Qr = егн - Qr = qk (*’ I ,х2... xk)=QK (*, ,х2... xt,x)-QK (Х],х2... Хь).
Поскольку, как отмечено ранее, квадратичная сумма Qr описывает долю измен-
чивости выходной переменной, объясненную регрессией, то чем больше QR", тем
больше ожидаемый вклад новой переменной в объясняющую способность модели.
Таким образом, чтобы сделать вывод о целесообразности включения новой пере-
менной в модель, достаточно оценить статистическую значимость ее вклада. Это
и позволяет сделать частный F-критерий.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 389
Нулевая гипотеза для частного F-критерия определяется следующим образом.
Но: нет, квадратичная сумма Q«"', связанная с дополнительной переменной х,
не вносит значительного вклада в квадратичную сумму регрессии для модели,
которая уже содержит переменные хъ х2...хк. Следовательно, включать в модель
дополнительную переменную х’ не имеет смысла.
Тогда альтернативная гипотеза будет формулироваться следующим образом.
На: да, квадратичная сумма Q«’", связанная с дополнительной переменной х',
вносит значительный вклад в квадратичную сумму регрессии Q))'1'1 для модели,
которая уже содержит переменные xlt х2... xk. Следовательно, включение в модель
дополнительной переменной х" имеет смысл.
Статистика для частного F-критерия рассчитывается по формуле:
где Fioni — среднеквадратическая ошибка для полной модели, включающей как
xi,x2...xk, так их*.
Данное соотношение известно также как частная F-статистика для переменной х
с числами степеней свободы (1, п - k - 2), где k — число независимых переменных
в исходной модели.
ЗАМЕЧАНИЕ --------------------------------------------------------------
Можно выделить два типа квадратичных сумм, связанных с определенными комбина-
циями входных переменных в регрессионной модели: последовательные и частные.
Последовательные квадратичные суммы соответствуют порядку включения переменных
в модель. Частные — это просто квадратичные суммы для моделей, содержащих опре-
деленный набор входных переменных, никак не связанные с порядком их включения
в модель.
В таблице показывается различие между последовательной и частной квадратичными
суммами для модели, содержащей четыре входных переменныхх1( х2, Хд, х4.
Переменная Последовательная квадратичная сумма Частная квадратичная сумма
Х1 5(xi) 5(xi | х2, х3, х4)
х2 5(xi|x2) 5(х2|Х],Хз,Х;)
Хз 5(х3|х1,х2) 5(хз|х1,х2, х4)
%4 S(x41 Xi, Х2, Хз) 5(х4 I х2, х2, Хз)
Метод прямого отбора
Прямой отбор начинается с пустой модели, в которую еще не включена ни одна
переменная, и содержит следующие шаги.
1. Вычисляется корреляция между выходной переменной и каждой из потен-
циальных входных. По результатам выбирается та входная переменная, для
390 Часть I. Теория бизнес-анализа
которой корреляция с выходной наибольшая. Для этой переменной вычис-
ляется последовательная квадратичная сумма и оценивается значимость при
помощи частного F-критерия. Если по его результатам переменная признается
значимой, то она добавляется в модель, в противном случае начинается анализ
следующей переменной.
2. Для каждой из остальных переменных вычисляются последовательные квадра-
тичные суммы с учетом добавленной на 1-м шаге переменной, и рассчитывается
частный F-критерий. Например, сначала могут вычисляться последовательные
F-статистики F(x21 х(), F(x31 Xi), F(x41 Xi), то есть производится выбор между пе-
ременными х2, х3 и х4 при условии, что переменная х, уже включена в модель.
Затем вычисляются F(x31 хь х2) и F(x41 хь х2). При этом каждый раз выбирается та
переменная, для которой значение F-статистики будет наибольшим (обозначим
ее F
3. Для всех переменных в порядке убывания связанного с ними значения F-ста-
тистики выполняется расчет частного F-критерия, и те из них, которые по его
результатам признаются значимыми, добавляются в модель.
Процесс продолжается до тех пор, пока все значимые переменные не будут
включены в модель.
Метод обратного исключения
В отличие от метода прямого отбора в методе обратного исключения процесс на-
чинается с полной модели, в которую включаются все доступные переменные. Эта
процедура также содержит три шага.
1. Решается задача регрессии с помощью полной модели, в которой присутствуют
все доступные переменные. В нашем примере их четыре — xt, х2, х3, х4.
2. Для каждой переменной в модели вычисляется частная F-статистика, то есть
F(x[ | х2, х3, х4), F(x21Xi, х3, х4), F(x31 х(, х2, х4) и F(x41 хь х2, х3). Предпочтение отдает-
ся переменной, для которой значение частной F-статистики будет наименьшим
(обозначим его Finin).
3. Проводится тест значимости Fmin. Если статистика Fmin не указывает на дос-
таточно высокую значимость, то связанная с ней переменная исключается из
модели и происходит возврат к шагу 2. Если статистика Frai„ указывает на высо-
кую значимость, то алгоритм останавливается и формируется отчет о текущем
состоянии модели, которое и будет считаться наилучшим.
Метод последовательного отбора
Метод последовательного отбора представляет собой модификацию метода пря-
мого отбора. Переменные, которые были введены в модель ранее на основе теста
их значимости, могут стать незначащими после введения новых переменных, кото-
рые могут взять на себя «объяснение» части дисперсии независимой переменной.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 391
Чтобы выявить данную ситуацию, алгоритм последовательного отбора использует
частный F-критерий для каждой переменной, ранее включенной в модель, после
включения каждой новой переменной. Если обнаруживается, что Е-статистика
для переменной, которая ранее рассматривалась как значимая, стала меньше «на
фоне» новой переменной, то переменная, потерявшая значимость, исключается из
модели. Процедура прекращается, когда переменные, которые могут быть введены
в модель или удалены из нее, заканчиваются.
Поиск лучших подмножеств
Для наборов данных, в которых количество переменных не очень велико, процедура
поиска лучших подмножеств является наиболее привлекательным методом отбора
переменных для регрессионной модели. Однако если число потенциальных вход-
ных переменных составляет несколько десятков и более, то использование этого
метода может привести к большим вычислительным затратам. Метод наилучших
подмножеств работает следующим образом.
□ Аналитик определяет количество моделей N, которое должно быть проанали-
зировано, а также максимальное количество переменных k, которое он хочет
использовать в модели.
□ Строятся все модели с одной переменной: у = Ьо + бг х(, у = Ьо + Ьг х2 и т. д.
Затем для всех моделей вычисляются коэффициенты детерминации R2, и соз-
дается отчет о лучших N моделях.
□ Строятся все модели с двумя переменными: у = b0 + bfXi + b2- х2, у = Ьо + Ьх-х2 +
+ Ь2- х3 и т. д. Затем для всех моделей с двумя переменными вычисляются R2,
и вновь создается отчет о лучших N моделях.
Данная процедура повторяется до тех пор, пока не будет достигнуто макси-
мальное количество входных переменных k. Затем аналитик рассматривает список
лучших моделей каждой размерности, чтобы из них выбрать самую лучшую. Не-
достаток этого метода в том, что окончательный выбор субъективен.
Метод перебора всех возможных наборов
Четыре рассмотренных выше метода, по сути, являются алгоритмами оптими-
зации на большом пространстве наблюдений. По этой причине отсутствует га-
рантия, что будет найдена наилучшая модель из всех возможных, то есть модель,
обеспечивающая минимальную ошибку и максимальную значимость. Един-
ственным способом, гарантирующим, что будет построена наилучшая модель,
является перебор всех возможных комбинаций входных переменных, то есть
метод глобального поиска.
К сожалению, аналитические задачи часто содержат очень большое число
потенциальных входных переменных, что делает метод глобального поиска
нереализуемым на практике. Действительно, если имеется k потенциальных
392 Часть I. Теория бизнес-анализа
входных переменных, то для глобального поиска потребуется перебрать 2* - 1
комбинаций.
Однако если число потенциальных входных переменных не очень велико, то за-
дача глобального поиска вполне разрешима. Например, при k = 5 для выбора лучшей
модели потребуется перебрать всего 25 -1=31 комбинацию входных переменных.
Но когда число входных переменных начинает возрастать, задача глобального по-
иска резко усложняется. Так, для 10 потенциальных входных переменных нужно
перебрать уже 210 - 1 = 1023 комбинации, для двадцати — 220 - 1 = 1 048 575 и т. д.
Поэтому для большинства типичных задач метод глобального поиска неприемлем.
Таким образом, хотя перечисленные методы и не гарантируют построения наи-
лучшей модели, они позволяют за приемлемое время выбрать достаточно значимые
переменные и получить хорошие результаты.
Пример использования алгоритма прямого отбора
Рассмотрим набор данных, в котором представлена информация о заемщиках банка
(табл. 8.10).
Таблица 8.10. Кредитные истории клиентов
№ клиента Стаж на последнем месте работы (Xi), лет Срок кредита (х2), мес. Сумма кредита (хэ), тыс. ед. Количество просрочек (у)
1 7,5 12 170 0
2 4,5 12 120 0
3 6,5 12 85 0
4 2,5 12 160 1
5 3,5 24 105 1
6 6,5 12 90 0
7 2,0 24 80 3
8 3,5 24 395 2
9 6,0 36 150 2
10 2,0 60 70 4
Переменные xt, х2 и х3 являются независимыми, а у — зависимой. Задача заклю-
чается в отборе переменных прямым методом (forward) для построения модели,
предсказывающей значения независимой переменной.
Первым кандидатом на включение в модель является переменная, которая
в наибольшей степени коррелирована с независимой. Рассчитав коэффициенты
корреляции для каждой из независимых переменных, получим: г (xj = -0,721,
г(х2) = 0,871 и г(х3) = 0,018. Значит, наибольшую корреляцию с зависимой пе-
ременной у имеет независимая переменная х2, которая и оказывается первым
кандидатом на включение в модель. Рассчитаем оценки у значения зависимой
переменной, полученные с помощью модели, содержащей только х2, а также их
среднее у и соответствующие квадратичные суммы. Уравнение простой линейной
Глава 8. Data Mining: классификация и регрессия. Статистические методы 393
пегрессии для независимой переменной х2 будет у = -0,523 + 0,080х2. Результаты
промежуточных расчетов представлены в табл. 8.11.
Таблица 8.11. Исходные и расчетные данные, необходимые
для проверки значимости переменной х2
№ клиента хг У У У II s'—*. 1* XI м Qc= (У- У?
1 12 0 0,436 1,3 0,746 0,190
2 12 0 0,436 1,3 0,746 0,190
3 12 0 0,436 1,3 0,746 0,190
4 12 1 0,436 1,3 0,746 0,318
5 24 1 1,396 1,3 0,009 0,157
6 12 0 0,436 1,3 0,746 0,190
7 24 3 1,396 1,3 0,009 2,573
8 24 2 1,396 1,3 0,009 0,365
9 36 2 2,356 1,3 1,115 0,127
10 60 4 4,275 1,3 8,852 0,076
S 13,724 4,376
Рассчитаем значение частного F-критерия для переменной х2.
Е = ^ = С. = 4'376 = 0.547,
df п-к-2 10-0-2
где df =n-k-2— число степеней свободы выборки, связанное с остаточной сум-
мой;
k — число переменных начальной модели, то есть модели без дополнительной
переменной.
Теперь рассчитаем значение статистики F-критерия:
Qaon л полн _ /~)iia'i л пол.г _ л 1 о '794
г - R = ^R ^R = —- = 1724 = 25 089
Е Е Е 0,547
ПОЛИ ПОЛИ ПОЛИ ’
Очевидно, что поскольку начальная модель в данном случае не содержит пере-
менных (х2 добавляется в пустую модель), то " = 0.
Зададим уровень значимости а = 0,05 и по таблице F-распределения определим,
что теоретическое значение статистики критерия FT для чисел степеней свободы
df1 = 1 и df2 = 8 составляет 5,318, что намного меньше, чем 25,089 — ее значение,
рассчитанное для реальных данных. Это с вероятностью ошибки 0,05 позволяет
отклонить нулевую гипотезу и сделать вывод о значимости переменной х2 и целе-
сообразности включения ее в модель.
После включения в модель переменной х2 остается решить вопрос о целесооб-
разности включения переменных xt и х3. Рассчитаем прирост значения квадратич-
ной суммы Q'f" при поочередном включении в модель переменных xt и х3 с учетом
того, что она уже содержит переменную х2.
394 Часть I. Теория бизнес-анализа
Для модели, содержащей переменные Xt и х2, уравнение регрессии будет
у = 1,112 -0,279 -х, + 0,063 х2. Данные, необходимые для расчета F-статистики
представлены в табл. 8.12.
Таблица 8.12. Таблица с исходными
и расчетными данными для оценки F(xt | х2)
№ клиента Xi х2 У У У Qr qe
1 7,5 12 0 -0,228 1,3 2,335 0,052 ~
2 4,5 12 0 0,607 1,3 0,478 0,371
3 6,5 12 0 0,051 1,3 1,560 0,003
4 2,5 12 1 1,167 1,3 0,018 0,028
5 3,5 24 1 1,640 1,3 0,116 0,410
6 6,5 12 0 0,051 1,3 . 1,560 0,003
7 2,0 24 3 2,059 1,3 0,578 0,886
8 3,5 24 2 1,640 1,3 0,114 0,129
9 6,0 36 2 1,695 1,3 0,156 0,093
10 2,0 60 4 4,316 1,3 9,096 0,010
I 16,011 1,985
Число степеней свободы для вычисления среднеквадратической ошибки соста-
вит df = п — k — 2 = 10 — 1 — 2 = 7. Тогда
Е =^L=.^ = I985 =0284.
df n-k-2 10-1-2 ’ ’
, 16,011-13,724
F^x'^ =------0Д84----= 8’°53-
Вновь задавшись уровнем значимости а = 0,05, для чисел степеней свободы
dfi = 1 и df2 = 7 по таблицам F-распределения определим теоретическое значение
статистики FT = 5,591. Поскольку 5,591 < 8,053, мы с вероятностью ошибки 0,05
вновь должны отклонить нулевую гипотезу и сделать вывод о целесообразности
добавления переменной xt в модель, которая уже содержит переменную х2.
Проведем аналогичные рассуждения для переменной х3. Уравнение регрессии
будет:
у = -0,768 + 0,081 • х2 + 0,002 • х3.
Соответствующие результаты представлены в табл. 8.13.
Е = & = Qe =_±1.5_1_ _
"°"" df n-k-2 10-1-2 ’ ’
Т(х3|х2) =
13,940-13,724
0,593
= 0,364-
Глава 8. Data Mining: классификация и регрессия. Статистические методы 395
Таблица 8.13. Таблица с исходными
и расчетными данными для оценки F(x31 х2)
№ клиента Xi х2 У У У Qr Qt
Т" 12 170 0 0,515 1,3 0,616 0,265
2 12 120 0 0,415 1,3 0,783 0,172
3 12 85 0 0,345 1,3 0,912 0,119
4 12 160 1 0,495 1,3 0,648 0,255
5 24 105 1 1,357 1,3 0,003 0,127
6 12 90 0 0,355 1,3 0,893 0,126
7 24 80 3 1,307 1,3 0 2,866
8 24 395 2 1,937 1,3 0,406 0,004
9 36 150 2 2,419 1,3 1,252 0,176
10 60 70 4 4,203 1,3 8,427 0,041
S 13,940 4,151
Поскольку значение F-статистики, полученное на реальных данных, меньше
теоретического, то есть 0,364 < 5,591, добавление в модель, содержащую перемен-
ную х2, новой переменой х3 не является целесообразным.
И наконец, осталось рассмотреть целесообразность включения в модель пере-
менной х3 при условии, что она уже содержит переменные xt и х2, то есть иссле-
довать случай (х31 х, ,х2). Для полной модели, содержащей все три переменные,
уравнение множественной регрессии будет у = 0,875-0,273 • х, + 0,064 • х2 + 0,001 • х3.
Данные, необходимые для расчета F(x31 х, ,х2), представлены в табл. 8.14.
Таблица 8.14. Таблица с исходными
и расчетными данными для оценки F(x3 | х, ,х2)
№ клиента X Х2 Хэ У У У Qr Qe
1 7,5 12 170 0 -0,235 1,3 2,355 0,054
2 4,5 12 120 0 0,534 1,3 0,586 0,286
3 6,5 12 85 0 -0,047 1,3 1,813 0,002
4 2,5 12 160 1 1,121 1,3 0,032 0,015
5 3,5 24 105 1 1,561 1,3 0,068 0,314
6 6,5 12 90 0 -0,042 1,3 1,800 0,002
7 2,0 24 80 3 1,945 1,3 0,416 1,113
8 3,5 24 395 2 1,851 1,3 0,303 0,0.22
9 6,0 36 150 2 1,691 1,3 0,152 0,095
10 2,0 60 70 4 4,239 1,3 8,638 0,057
I 16,163 1,960
Поскольку теперь исходная модель содержит две независимые перемен-
ные (k = 2), число степеней свободы, связанное с остаточной суммой, составит
n-k-2 = 10-2-2 = 6.
396 Часть I. Теория бизнес-анализа
= 0^ = _0е_
df n — k — 2
1,960
10-2-2
= 0,327;
F(x:i |xi,x2) =
16,163-16,011
0,327
= 0,465.
По таблицам /"-распределения для чисел степеней свободы df, = 1 и df2 = 6, при
уровне значимости а = 0,05 определим, что теоретическое значение статистики FT =
= 5,987. Поскольку F < FT, мы вынуждены принять нулевую гипотезу и сделать
вывод о низкой значимости вклада переменной х3 в объясняющую способность
модели и нецелесообразности ее включения.
Таким образом, используя метод прямого отбора, мы выяснили, что целесооб-
разно включить в модель переменные Х[ и х2, поскольку именно они вносят наибо-
лее значимый вклад в объясняющую способность модели. Включение переменной
х3 нецелесообразно.
8.9. Ограничения применимости
регрессионных моделей
В настоящее время регрессионные модели являются одним из наиболее попу-
лярных методов решения различных классов задач бизнес-аналитики. Эта попу-
лярность обусловлена тем, что регрессия сочетает в себе как высокую эффектив-
ность и универсальность, так и относительную простоту реализации, понимания
и интерпретации пользователем. Кроме того, аппарат регрессионного анализа
включает множество методов оценивания точности и достоверности полученных
результатов.
Однако, как и большинство других статистических методов, линейную ре-
грессию нельзя применять без учета особенностей конкретной задачи. Такие
особенности могут порождать ограничения применимости регрессионных мо-
делей, игнорирование которых часто приводит к снижению точности результа-
тов и даже к их полной недостоверности. Поэтому каждый раз при построении
регрессионной модели и особенно при ее практическом применении необходимо
удостовериться в ее корректности с точки зрения условий самой задачи и исполь-
зуемых данных.
Приведем несколько основных ограничений, которые следует учитывать при
построении регрессионных моделей.
□ Никакая единственная независимая переменная за редкими исключениями не
в состоянии хорошо объяснить изменения зависимой переменной.
□ Могут существовать несколько одинаково хороших и в то же время противо-
речивых регрессионных моделей.
□ Линейная форма связи примитивна.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 397
□ Наличие на входе модели переменных, сильно коррелированных друг с другом,
приводит к проблеме мультиколлинеарности.
В процессе регрессионного анализа оценивается качество модели, определяется,
насколько данный набор входных переменных объясняет поведение выходной.
Для этих целей вычисляется коэффициент детерминации г2, который показывает,
какую долю информации о поведении выходной переменной можно объяснить
входными переменными. Коэффициенты Ь, определяют силу зависимости выход-
ной переменной от г-й входной.
Метод линейной регрессии имеет несколько методологических недостатков,
которые при ее неосторожном применении способны существенно исказить
результаты. Основным недостатком является то, что регрессионная модель стро-
ится на основе выборки, формируемой из имеющегося множества наблюдений.
Затем зависимость между входными и выходной переменными, заданная в виде
уравнения регрессии, распространяется на все наблюдаемые данные. В большин-
стве случаев хранилища данных, в которых консолидируется анализируемая
информация, предоставляют пользователю весьма объемные наборы данных, со-
держащие тысячи, десятки и сотни тысяч наблюдений. Проблема кроется в том,
что большие наборы данных часто не являются однородными и могут включать
группы наблюдений, для которых зависимости между входными и выходной
переменными различны. Например, такая ситуация может сложиться при ис-
пользовании линейной регрессии для предсказания значений временного ряда.
Так, спрос на некоторый товар может изменяться в соответствии с сезонными
колебаниями: возрастать весной и падать осенью. Поэтому если мы используем
для построения модели наблюдения за весь год, то получим две противоречивые
тенденции.
Другим примером является построение скоринговой модели, которая на основе
некоторого набора характеристик должна определить кредитный рейтинг клиента.
Известно, что к полезным переменным, тесно связанным с вероятностью возврата
или невозврата кредита, относится возраст клиента. Ясно, что молодые люди, не
имеющие жизненного опыта, не всегда адекватно оценивают свои финансовые
возможности, находятся на этапе профессионального становления, обзаводятся
семьей, что, вообще говоря, не делает их привлекательными заемщиками. Поэтому
следует ожидать, что в уравнении регрессии коэффициент при переменной Возраст
будет положительным, то есть с возрастом кредитный рейтинг возрастает. Однако
по достижении клиентом определенного возраста ситуация коренным образом ме-
няется. Так, человек в возрасте более подвержен риску заболеваний, из-за которых
можно потерять работу, при потере работы ему труднее найти новую и т. д. Поэто-
му очевидно, что начиная с некоторого возраста (например, с 50 лет) кредитный
рейтинг будет снижаться, а коэффициент уравнения регрессии при переменной
Возраст станет отрицательным.
Данный пример поясняется на рис. 8.18. До 45 лет кредитный рейтинг клиента
увеличивается с возрастом, поэтому прямая линейной регрессии, построенная для
возрастной группы 20-45 лет, будет возрастающей. После 45 лет наблюдается
398 Часть I. Теория бизнес-анализа
обратная тенденция, и регрессионная модель для возрастной группы 45-70 лет
будет описываться убывающей линией. Однако если не выделять эти две воз-
растные группы, то линия регрессии (пунктирная линия) для всей выборки
будет показывать некоторую общую тенденцию, которая не отражает реальную
ситуацию.
Возраст
Рис. 8.18. Нелинейная зависимость возраста от кредитного рейтинга
Попытка использовать одну регрессионную модель для клиентов всех возраст-
ных категорий будет давать очень недостоверные оценки, а коэффициенты урав-
нения регрессии будут отражать «среднюю температуру по больнице».
Очевидно, что при наличии в наборе данных групп наблюдений, для которых
характер связи между входными и выходной переменными различен, разум-
нее строить несколько моделей, то есть отдельную модель для каждой группы.
Но такой подход не вполне конструктивен, поскольку количество моделей будет
ограничиваться только фантазией аналитика. Тем не менее существует ряд кри-
териев, позволяющих применить формальный подход к разбиению совокупности
на группы.
Пусть для примера с кредитным рейтингом модель имеет вид:
рейтинг = 12,5 + 0,25 • (возраст).
Иными словами, минимальный наблюдаемый рейтинг составляет 12,5 и для
каждого дополнительного года увеличивается на 0,25. При этом данное увели-
чение будет одинаковым как для клиента в возрасте 25 лет, так и для клиента
в возрасте 70 лет. Модель дает единый механизм влияния возраста на вероятность
возврата кредита. Здравый смысл и жизненный опыт подсказывают нам, что это
не так. Если же мы предположим, что в наборе данных присутствуют возрастные
группы, для которых поведение выходной переменной различно, то возникает
вопрос, где проходит граница между этими возрастными группами. С точки
зрения регрессионной модели эту проблему можно сформулировать следующим
Глава 8. Data Mining: классификация и регрессия. Статистические методы 399
образом: «Если построить регрессионные модели для двух возрастных групп, то
как определить, в каком случае эти две модели будут отличными друг от друга
и где это различие максимально?»
Для решения данной проблемы используется статистический метод, называ-
емый тестом Чоу, который показывает, является ли значимым улучшение модели
после разделения исходной совокупности наблюдений на однородные группы
и построения отдельной модели для каждой группы. Тест Чоу вычисляется как
/-статистика вида:
fjQr-Q'-Q^k + V
(Qi +Q2)/(h — 2k — 2)
где Qt — остаточная сумма квадратов для модели, построенной на неразделенном
наборе данных;
Q, — остаточная сумма квадратов для модели, построенной по первой под-
группе;
Q, — остаточная сумма квадратов для модели, построенной по второй под-
группе;
£+1ип-2#-2 — число степеней свободы Е-распределения.
Иными словами, тест Чоу позволяет определить статистическую значимость
повышения качества модели при переходе от одного уравнения к двум.
Таким образом, в нашем примере можно разделить возрастную шкалу на два
интервала, для каждого из них построить уравнение регрессии и с помощью теста
Чоу определить, улучшились ли результаты работы модели, то есть увеличилась
ли точность получаемых с ее помощью оценок. Однако остается открытым вопрос,
какое именно значение возраста следует выбрать в качестве граничного при раз-
делении исходной совокупности наблюдений на группы. Действительно, можно
выбрать 45 лет, а можно — 50, при этом в обоих случаях тест Чоу, скорее всего,
покажет улучшение качества модели. Более того, иногда тест Чоу оказывается
значимым практически для любых разумных разбиений исходной совокупности на
группы. Но это лишь позволяет сделать вывод, что два уравнения регрессии почти
всегда более точно описывают связь между входными и выходной переменными,
чем единственное уравнение.
Проблему выбора граничного значения входной переменной при разбиении
исходной совокупности данных на группы можно решить следующим обра-
зом.
1. Реализовать все разумные с точки зрения решаемой задачи разбиения. Очевид-
но, что в рассмотренном примере нелогично выбирать в качестве граничных
значений возраст 25 или 65 лет. Скорее всего, граница будет лежать между 40
и 55 годами.
2. Перебрать все реализованные на предыдущем шаге варианты разбиения
и для каждого из них с помощью теста Чоу определить степень улучшения
качества модели, полученной в результате разбиения.
3. Выбрать то разбиение, которое покажет наиболее значимое улучшение ка-
чества.
400 Часть I. Теория бизнес-анализа
Использование фиктивных переменных
Еще одним способом повысить точность модели, построенной на основе совокуп-
ности наблюдений, которая содержит разнородные группы, является применение
фиктивных переменных. Предположим, что граничный возраст — 45 лет. Тогда
мы можем ввести фиктивную переменную G, которая определяется следующим
образом (табл. 8.15).
Таблица 8.15. Фиктивная переменная G
Возраст G
20-45 С = 0
46-70 G = 1
Уравнение регрессии может быть записано в виде:
рейтинг = 6,4 +12,5 • G — 2,24 • G • (возраст).
Здесь с помощью одного уравнения удается объединить в рамках одной модели
две тенденции, прослеживающиеся в исходных данных. Действительно, для клиен-
тов, возраст которых менее 45 лет, то есть когда G = 0, имеем, что рейтинг от возрас-
та не зависит и равен значению свободного члена (коэффициента Ьо = 6,4). В то же
время для клиентов старше 45 лет, когда G = 1, уравнение преобразуется к виду:
рейтинг = 6,4 +12,5 — 2,24 • 1 • (возраст) = 18,9 — 2,24 (возраст),
что отражает убывающую зависимость между возрастом и кредитным рейтингом
для данной возрастной категории.
Конечно, отражение обеих тенденций в наблюдаемых данных с помощью од-
ного уравнения обеспечивает более компактное и интерпретируемое представ-
ление. Очевиден и недостаток этого подхода: для одной из двух групп значимая
зависимость от возраста вообще отсутствует. Тем не менее в некоторых случаях
использование фиктивных переменных вполне себя оправдывает.
Г етероскедастичность
Еще одной проблемой, которая может привести к ограниченности применения
регрессионной модели, является гетероскедастичность. Одним из ограничений,
накладываемых на регрессионную модель, является то, что разброс точек реаль-
ных значений данных относительно линии регрессии должен быть равномерным
во всем диапазоне изменения независимой переменной — дисперсия наблюдений
вдоль линии регрессии должна быть постоянной. Это требование называется гомо-
скедастичностъю. Если для различных диапазонов изменения входной переменной
дисперсия точек данных непостоянна, то имеет место гетероскедастичность. Эта
ситуация поясняется с помощью рис. 8.19.
Возвращаясь к примеру с оценкой кредитного рейтинга, предположим, что
в качестве входной переменной будет использоваться не возраст, а доход. Наличие
Глава 8. Data Mining: классификация и регрессия. Статистические методы 401
Рис. 8.19. Иллюстрация случая гомоскедастичности (а)
и гетероскедастичности (б)
гетероскедастичности имеет простое логическое объяснение: при больших зна-
чениях дохода (переменная х) их вариабельность также увеличивается. Пере-
фразируя известную поговорку, можно сказать, что все бедные бедны одинаково,
а богатые богаты по-своему. Действительно, в диапазоне значений, связанных
с низким доходом (например, 5000 ед.), значимыми будут изменения и в 1000 ед.
Тем не менее и клиент с доходом 4000 ед., и клиент с доходом 6000 ед. относятся
к категории малообеспеченных. В то же время клиенты, имеющие доход 100 000
и 500 000 ед., являются высокообеспеченными, хотя их доходы различаются
в 5 раз. Таким образом, линия регрессии отражает одинаковый рост кредитного
рейтинга как при изменении дохода на 10 % для клиентов с низким доходом, так
и при изменении на 500 % для клиентов с высоким доходом.
При гетероскедастичности значение выходной переменной зависит не только
от величины изменения входной переменной, но и от того, относительно какой
402 Часть I. Теория бизнес-анализа
величины это изменение происходит. Для борьбы с гетероскедастичностью
часто используется простой прием. В наборе переменных ищется такая, которая
имеет сильную связь как с входной переменной х, так и с выходной у. Например,
если выходная переменная — кредитный рейтинг, а входная — доход, то вспо-
могательной переменной может быть стоимость автомобиля, которым владеет
клиент, поскольку вероятность наличия дорогого автомобиля у человека с низ-
ким достатком весьма мала. Затем входную, и выходную переменную делят на
вспомогательную и строят модель на основе новых полученных переменных.
Низкий доход одного клиента окажется разделенным на низкую стоимость его
автомобиля, и наоборот, высокий доход другого — на высокую стоимость его
автомобиля. Иногда такое «масштабирование» позволяет избавиться от гетеро-
скедастичности.
Мультиколлинеарность
В множественной регрессии не исключена ситуация, когда некоторые из входных
переменных будут коррелировать между собой. Например, если агент по недвижи-
мости оценивает дом, то он использует такие показатели, как число комнат, жилая
площадь, год постройки дома, его техническое состояние и т. д. Однако чем больше
комнат в доме, тем больше его ожидаемая площадь, и наоборот. Чем меньше возраст
дома, тем лучше (как правило) его техническое состояние. Иначе говоря, между
указанными показателями наблюдается высокая корреляция.
Наличие на входе регрессионной модели коррелированных переменных на-
зывается мультиколлинеарностью. Это явление в большинстве случаев вызывает
серьезные проблемы при построении регрессионных моделей, их неустойчивость
и неоднозначность. Например, в наборе данных с сильной мультиколлинеарностью
F-тест может показать высокую значимость модели в целом, тогда как i-тест не
покажет наличия в модели значимых переменных. Неустойчивость модели при
мультиколлинеарности заключается в высокой дисперсии оценок коэффициентов
регрессии. Даже небольшие вариации исходных данных могут вызывать сильное
изменение коэффициентов.
Существуют различные методы, направленные на снижение мультиколли-
неарности. Некоторые из них предлагают выбрать одну из коррелированных
переменных и исключить ее из модели. Однако это крайнее средство, поскольку
исключенная переменная может нести важную информацию. Также для иссле-
дования корреляционных отношений между переменными и выделения неболь-
шого набора независимых переменных с успехом используется метод главных
компонент. Эффективным способом борьбы с мультиколлинеарностью служит
и комбинирование переменных, когда две коррелированные переменные объеди-
няются в одну.
Рассмотренные выше ограничения, связанные с применением регрессионных
моделей, являются только небольшой частью проблем, которые поджидают анали-
тика при серьезном подходе к анализу данных. Широкое распространение различ-
Глава 8. Data Mining: классификация и регрессия. Статистические методы 403
нЬ1Х аналитических систем, пакетов статистического анализа и обработки данных
убеждает пользователя в том, что для решения определенной задачи достаточно
загрузить выборку данных и щелкнуть на соответствующем значке на экране. Од-
нако, столкнувшись с решением практических задач, большинство начинающих
аналитиков быстро понимают, что для эффективного анализа данных в любой
сфере необходимы как знание специфики используемых методов, так и хорошая
подготовка в самой предметной области. Не является исключением и регрессион-
ный анализ. Знание особенностей применения регрессионных моделей, связан-
ных с ними ограничений и условий, при которых эти ограничения возникают,
позволяет строить более совершенные модели и получать с их помощью более
достоверные результаты.
8.10. Основы логистической регрессии
Линейная регрессия используется для моделирования линейных зависимостей
между непрерывной выходной переменной и набором входных переменных.
При анализе данных часто встречаются задачи, где выходная переменная является
категориальной и тогда использование линейной регрессии затруднено. Поэтому
при поиске связей между набором входных переменных и категориальной выход-
ной переменной получила распространение логистическая регрессия. Ниже мы
рассмотрим применение логистической регрессии для случая бинарной выходной
переменной (переменной, которая может принимать только два значения), хотя
можно использовать данный метод и в случае, когда выходная переменная прини-
мает более чем два значения.
Простой пример логистической регрессии
Предположим, что врача интересует зависимость между возрастом пациента и на-
личием (1) или отсутствием (0) некоторого заболевания. Данные, собранные по
20 пациентам, представлены в табл. 8.16, а соответствующий график — на рис. 8.20.
Таким образом, в задаче используется бинарная выходная переменная у, которая
может принимать только два значения: 0 и 1. Иногда такие переменные называют
дихотомическими.
Таблица 8.16. Данные о пациентах
№ пациента Возраст, х Наличие заболевания, у
1 25 0
2 29 0
3 30 0
4 31 0
5 32 0
Продолжение &
404 Часть I. Теория бизнес-анализа
Таблица 8.16 (продолжение)
№ пациента Возраст, х Наличие заболеванйяТу"
6 41 0
7 41 0
8 42 0
9 44 1
10 49 1 ~~
И 50 0
12 59 1 "
13 60 0
14 62 0
15 68 1
16 72 0
17 79 1
18 80 0
19 81 1
20 84 1
1
СК
S
I
СО
03
ф
i 0,5
со
ф
S
у
S
§
т
О
Рис. 8.20. Диаграмма «Возраст — заболевание»,
линия регрессии и кривая логистической регрессии
На рисунке сплошной линией представлена прямая простой линейной регрес-
сии, построенная для данных из табл. 8.16, а пунктиром — кривая логистической
Глава 8. Data Mining: классификация и регрессия. Статистические методы 405
регрессии. Также для обеих кривых показана ошибка оценивания для пациента
j^o И (х = 50, у = 0). Линия логистической регрессии, в отличие от линейной, не
является прямой.
Рассмотрим ошибки оценивания, полученные для пациента №11. Расстояние
между точкой данных для пациента № 11 и линией регрессии показано сплошной
вертикальной стрелкой, а для кривой логистической регрессии — пунктирной. Вид-
но, что расстояние будет больше для линейной регрессии, а это означает, что она
дает худшую оценку выходной переменной, чем логистическая. Это утверждение
также является истинным для большинства других пациентов.
Построение линии логистической регрессии
Введем в рассмотрение условное среднее Е(у | х) значений выходной переменной
у для заданного значения х входной переменной X. Е(у | х) представляет собой ожи-
даемое значение выходной переменной при заданном значении входной. Напом-
ним, что выходная переменная в линейной регрессии — это случайная переменная,
определяемая как у = р() + Piх + е. Поскольку ошибка е имеет нулевое среднее, для
линейной регрессии мы получим, что Е(у | х) — р0 + PiX (так же как и в линейной
регрессии, буквой b будем обозначать коэффициенты уравнения регрессии, а 0 —
параметры соответствующей модели).
Для краткости введем обозначение Е(у | х) = р(х). Условное среднее для логи-
стической регрессии имеет вид:
gPo+Pl.r
Р(х)=1+еро+р..г-
(8-8)
Функцию, описываемую уравнением (8.8), называют логистической, а соответ-
ствующие кривые — сигмоидами, поскольку они имеют характерную 5-образную
форму. Эта функция определена на бесконечности и изменяется в диапазоне от 0
до 1. Диапазон изменения р(х) также будет от 0 до 1, поэтому данную функцию
можно интерпретировать как вероятность того, что выходная переменная при-
обрела значение 1 (заболевание имеет место), а 1 - р(х) — как вероятность по-
явления значения 0 (заболевание отсутствует).
Как уже говорилось при обсуждении модели линейной регрессии, ошиб-
ка е является нормально распределенной случайной величиной с нулевым средним
и постоянной дисперсией. Предположения, используемые для логистической
регрессии, несколько отличаются. Выходная переменная является бинарной,
и принятие выходной переменной одного из двух возможных значений назы-
вается исходом.
ОПРЕДЕЛЕНИЕ------------------------------------------------------------
Исход — явление, показатель или признак, который служит объектом исследования. На-
пример, при проведении клинических испытаний в медицине вероятность исхода служит
критерием оценки эффективности лечебного или профилактического воздействия.
406 Часть I. Теория бизнес-анализа
Если предположить, что принятие выходной переменной у значения 1 рассма-
тривается как успех, а значения 0 — как неуспех, то р(х) можно интерпретировать
как вероятность успеха, а 1 - р(х) — неуспеха. Данная ситуация поясняется на
рис. 8.21.
В логистической регрессии используется преобразование вида:
«<Л) = |пТ=Ш> = ₽"+₽’^
Оно называется логит-преобразованием и обладает такими полезными свойст-
вами, как линейность, непрерывность и определенность на бесконечности.
Оценки максимального правдоподобия
Одним из наиболее привлекательных свойств линейной регрессии является то, что
коэффициенты регрессии могут быть получены с помощью метода наименьших
квадратов. Для оценки коэффициентов логистической регрессии таких решений
не существует. Поэтому в ней коэффициенты оцениваются на основе метода мак-
симального правдоподобия, который позволяет найти такие значения коэффици-
ентов, для которых вероятность появления максимальна.
Введем в рассмотрение функцию правдоподобия /(0 |х) (likelihood function).
Она определяет вероятность появления значений параметров 0 = 0Ь 02... 0Ц для за-
Глава 8. Data Mining: классификация и регрессия. Статистические методы 407
данного значения х. Задача заключается в поиске таких значений этих параметров,
которые максимизируют функцию правдоподобия: строятся оценки максимального
правдоподобия (maximum likelihood estimates), для которых значения параметров
являются наиболее подходящими для наблюдаемых данных.
Вероятность того, что выходная переменная у приобретет значение 1 для задан-
ного значения х (вероятность успеха), будет р(х) = Р(у = 11 х), а вероятность того,
чт0 у = 0 при заданном х, будет 1 - р(х) = Р(у = 0 | х). Таким образом, поскольку
у,=:0или 1, вклад г-го наблюдения может быть выражен как [р(х,)],л • [1 — р(х,-)]*''
Предположение, что наблюдения являются независимыми, позволяет представить
функцию правдоподобия как произведение двух отдельных членов:
/(₽ I *) = П[р(*<)]'" • [! - p(*i)](W,)-
i = l
В вычислительном плане более удобна логарифмическая функция правдопо-
добия £(Р | х) = 1п[/(Р | х)]:
Z(P | х) = In [/(р | х)| = {zln [p(x, )] + (1 — Z) ln t1 - P(Z )]}• (8-9)
»=l
Оценки максимального правдоподобия могут быть найдены путем дифферен-
цирования i(P | х) относительно каждого параметра и приравниванием результи-
рующих выражений к 0.
Проверим результаты логистической регрессии для данных из табл. 8.16. Коэф-
фициенты, то есть оценки максимального правдоподобия неизвестных параметров
Ро и pt, определятся как Ро = -4,372, a Pi = 0,067. С учетом уравнения (8.8) можно
записать:
i(.r) —4,372+0,067(иозраст)
где g(x) = —4,372 + 0,067- х есть логит-преобразование.
Эти уравнения могут использоваться, чтобы оценить вероятность наличия за-
болевания у пациентов определенного возраста. Например, для пациента в возрасте
50 лет имеем:
eS(X) е-1,022
g(x) = -4,372 + 0,067• 50 = -1,022; Р(*) = —= °’26-
В итоге вероятность того, что пациент 50 лет страдает заболеванием, со-
ставляет 26 %. Соответственно, вероятность отсутствия заболевания будет
100 - 26 = 74 %. Если провести такую же оценку для пациента в возрасте 72 лет,
то можно увидеть, что вероятность наличия заболевания составит 61 %, а его
отсутствия — 39 %.
408 Часть I. Теория бизнес-анализа
Значимость входных переменных
Напомним, что в простой линейной регрессии модель считалась значимой, если
средний квадрат значений оценок регрессии был больше, чем средний квадрат
ошибки оценивания. Средний квадрат регрессии представляет собой меру улучще.
ния оценки выходной переменной, если для оценивания мы используем не среднее
значение, а входную переменную. Если входная переменная является «полезной»
для оценивания значения выходной, то средний квадрат регрессии будет больше
и статистика F= Qr/ Q также будет больше. Тогда соответствующую линейную
регрессионную модель можно будет рассматривать как значимую.
Значимость коэффициентов логистической регрессии определяется аналогично
В сущности, мы проверяем, обеспечивает ли использование в модели определенной
входной переменной лучшую оценку выходной переменной.
Введем понятие насыщенной модели (saturated model), то есть модели, в кото-
рой количество входных переменных равно числу наблюдений данных. Очевидно,
что такая модель будет предсказывать значения выходной переменной с абсо-
лютной точностью. Затем мы можем посмотреть на наблюдаемые значения вы-
ходной переменной, которые были предсказаны с помощью насыщенной модели.
Для сравнения оценок, полученных с помощью обычной модели и насыщенной
модели, введем понятие отклонения D:
Z> = —21п . (8.10)
MPI*)
Здесь мы имеем отношение двух значений функции правдоподобия, поэтому про-
верка результирующей гипотезы называется проверкой отношения правдоподобия.
ОПРЕДЕЛЕНИЕ----------------------------------------------------------
Отношение правдоподобия — отношение вероятности получить положительный результат
для положительного исхода к вероятности получить положительный результат для отрица-
тельного исхода.
Например, для выборки из табл. 8.16 отношение правдоподобия — это отно-
шение вероятности обнаружить болезнь у больного к вероятности обнаружить
болезнь у здорового.
Кроме этого, введем еще два понятия.
ОПРЕДЕЛЕНИЕ----------------------------------------------------------
Отношение правдоподобия положительного результата — отношение вероятности получить
истинноположительный результат к вероятности получить ложноположительный результат.
ОПРЕДЕЛЕНИЕ----------------------------------------------------------
Отношение правдоподобия отрицательного результата теста — отношение вероятности получить
истинноотрицательный результат к вероятности получить ложноотрицательный результат.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 409
Обозначим оценку р(х), полученную с помощью обычной модели, как р(х). За-
тем, используя уравнение (8.10), для случая логистической регрессии мы можем
записать отклонение D в следующем виде:
1=1
у;йД + (1-у,.)1п^—£-
У,- 1 - У,
Чтобы определить, является ли переменная значимой, нужно найти разность
двух отклонений — вычисленного для модели без данной входной переменной D
и найденного для всей модели D', то есть
G = D~-D+ = -21n
правдоподобие без переменной
правдоподобие с переменной
Введем обозначения и, = г/, и п0 = У~^(1_ У\ } Тогда для случая единственной
входной переменной можно записать:
{п
^[у, Inp, + (1 - у, ) • In (1 - р, )] - [«! In Wj +п01пи0 - п In п]
1=1
Для примера из табл. 8.16 логарифмическое правдоподобие будет -10,101,
тогда:
G = 2{-10,101-[71п(7) + 131п(13)-201п(20)]} = 5,696.
При справедливости нулевой гипотезы, состоящей в предположении Pi =
= 0, статистика G имеет распределение %2 с одной степенью свободы. Следо-
вательно, результирующее p-значение для проверки данной гипотезы будет
Р(^2 > 5,696) = 0,017. Благодаря весьма малому p-значению становится очевидно,
что возраст — очень значимая переменная при определении вероятности наличия
заболевания.
Другим методом для проверки значимости определенной входной переменной
ь. Y
---1-- соот-
является тест Вальда. При нулевой гипотезе Pi = 0 отношение Zw
ветствует распределению хи-квадрат с одной степенью свободы, где £"„(6,) — стандарт-
ная ошибка оценивания коэффициента регрессии на основе наблюдаемых данных.
Напомним, что стандартная ошибка оценивания коэффициентов регрессии £),
использовалась ранее для оценки значимости коэффициентов линейной регрессии.
В логистической регрессии она также используется для этих целей. О том, как
вычисляются стандартные ошибки оценивания коэффициентов логистической
регрессии будет рассказано дальше, а пока возьмем готовые цифры. Посколь-
ку Ъ. = 0,067, a £(£,) = 0,0322, то Zw = 0,0672 / 0,03222 = 4,33 и Р(г > 4,33) = 0,038.
Это неравенство означает, что вероятность справедливости нулевой гипотезы не
превышает 3,8 %. Данное p-значение также достаточно мало, хотя и не настолько,
как полученное с помощью отношения правдоподобия. Следовательно, результаты
410 Часть I. Теория бизнес-анализа
обоих тестов совпадают, и переменная возраста является статистически значимой
для оценки вероятности заболевания.
Введем в рассмотрение понятие доверительного интервала.
ОПРЕДЕЛЕНИЕ------------------------------------------------------------
Доверительный интервал — наиболее вероятный диапазон изменения наблюдений случай-
ной величины. Величины, полученные в исследованиях на выборке данных, отличаются
от истинных (наблюдаемых) величин вследствие влияния случайной составляющей. Так
95%-й доверительный интервал означает, что истинное значение величины с вероятностью
95 % лежит в пределах данного интервала. Доверительные интервалы помогают опреде-
лить, соответствует ли данный диапазон значений представлениям аналитика о значимости
связи между переменными. Величина доверительного интервала характеризует степень
доказательности данных, в то время как p-значение указывает на вероятность отклонения
нулевой гипотезы.
Определим границы доверительных интервалов для оценок коэффициента Ьх
логистической регрессии (1 - а) • 100 % в следующем виде:
bt ±z-Enfy'),
где z определяется с использованием t-критерия Стьюдента для двусторонней об-
ласти при заданном уровне значимости а и с п - k степенями свободы (для
а = 0,05 z « 1,96, таблицу критических точек t-распределения смотрите в прило-
жении на компакт-диске). В нашем примере 95%-ный доверительный интервал
для коэффициента Ьх определится так:
СТ (6,) = 0,06696 ±1,96-0,03223 = 0,06696 ± 0,06317 = [0,00379; 0,13013].
Поскольку 0 не входит в данный интервал, мы можем заключить, что с ве-
роятностью 95 % Ь, 0 и, следовательно, возраст пациента является значимой
переменной.
Использование логистической регрессии для решения
задач классификации
Постановка задач классификации и регрессии отличается характером выходной
переменной. Если выходная переменная является непрерывной, то имеет место
задача регрессии, а если дискретной (метка класса) — то классификации. Как
было показано выше, логистическая регрессия позволяет работать с дихотомиче-
ской выходной переменной, что предполагает возможность использования этого
метода для решения задач бинарной классификации. В бинарной классификации
каждое наблюдение или объект должны быть отнесены к одному из двух классов
(например, А и Б). Тогда с каждым исходом связано событие: объект принадлежит
к классу А и объект принадлежит к классу Б. Результатом будет оценка вероятно-
сти соответствующего исхода.
Если в процессе анализа будет установлено, что вероятность Р(А) принадлеж-
ности объекта с заданным набором значений признаков (входных переменных)
Глава 8. Data Mining: классификация и регрессия. Статистические методы 411
jc классу А больше, чем вероятность Р(Б) его принадлежности к классу Б, то он
будет классифицирован как объект класса А. Очевидно, что поскольку события
взаимоисключающие, то Р(Б) = 1 - Р(А). Может быть задан порог вероятности,
при превышении которого вероятность, связанная с определенным классом, «пере-
вешивает» и объект относится к этому классу В простейшем случае это может
быть порог равной вероятности, то есть 0,5. Как только вероятность Р(Б) стано-
вится 0,51, а Р(А) — 0,49, объект относится к классу Б. Иногда порог определяется
более сложным образом, например исходя из надежности решения. Так, решение
о принадлежности объекта к определенному классу может быть принято только
тогда, когда вероятность данного события, оцененная с помощью логистической
регрессии, превысит 0,7.
Бинарная классификация на основе логистической регрессии широко применя-
ется при решении задач в медицине, технической диагностике, социальной сфере
и других предметных областях.
8.11. Интерпретация модели логистической
регрессии
Очень важно не только математически описать модель, но и правильно интерпре-
тировать ее с точки зрения анализа, то есть извлечь всю необходимую информацию
об исследуемых объектах и процессах.
Напомним, что в простой линейной регрессии коэффициент Ь\ интерпретиру-
ется как изменение значения выходной переменной при изменении входной на 1.
В логистической регрессии его интерпретация аналогична, но применительно к ло-
гистической функции. То есть коэффициент bi может быть интерпретирован как
изменение значения логистической функции при изменении входной переменной
на 1. Формально это можно записать в виде:
6, =g(x + l)-g(x).
Рассмотрим интерпретацию коэффициента Ь> в простой логистической регрес-
сии для трех случаев:
□ когда входная переменная принимает только два значения (дихотомическая
входная переменная);
□ когда входная переменная может принимать несколько значений (полихотоми-
ческая входная переменная);
□ для случая непрерывной входной переменной.
Шансы и отношение шансов
Введем в рассмотрение понятие «шанс», который определяется как вероятность
того, что событие произошло (шанс успеха), разделенная на вероятность того,
412 Часть I. Теория бизнес-анализа
что событие не произошло (шанс неуспеха). Шансы и вероятности содержат
одну и ту же информацию, но по-разному выражают ее. Если вероятность того
что событие произойдет, обозначить р, то шансы этого события будут равны р/
(1 - р). Например, если вероятность выздоровления составляет 0,3, то шансы вы-
здороветь равны 0,3/(1 - 0,3) = 0,43. Если вероятность вытащить любую карту
пиковой масти из колоды составляет 0,25, то шансы этого события равны 0,25 /
(1 -0,25) = 0,33. ’ '
Ранее мы обнаружили, что вероятность наличия заболевания у 72-летнего паци-
ента составляет 61 %, соответственно, вероятность отсутствия заболевания — 39 %
Таким образом, если обозначить шанс как О (Odds), то О = 0,61/0,39 = 1,56. Мы
также нашли, что вероятность наличия или отсутствия заболевания у 50-летнего
пациента составляет 26 и 74 % соответственно, тогда О = 0,26/0,74 = 0,35.
Заметим, что когда вероятность появления события выше, чем вероятность
его отсутствия, то О > 1, а когда наоборот — О < 1. Когда вероятности появления
и отсутствия события равны, 0=1.
В бинарной логистической регрессии с дихотомической входной переменной
вероятность того, что выходная переменная принимает значение у = 1 (событие
произошло) прих = 1, может быть записано в виде:
р(1) ?[<>|
1-р(1) 1/(1 + еРп+р')
Аналогично вероятность того, что выходная переменная принимает значение
у = 1 (событие произошло) для наблюдений, в которых х = 0, будет:
р(0) е'-ДИ-е-)-
1-р(0) !/(! + <!')
Введем в рассмотрение так называемое отношение шансов, или отношение
несогласия (odds ratio — OR), являющееся отношением шансов того, что событие
произойдет, к шансам того, что событие не произойдет. В нашем случае это от-
ношение шанса того, что выходная переменная примет значение 1 (событие про-
изошло), к шансу того, что переменная примет значение 0 (событие не произошло).
То есть:
од.рт/о-рд)-)^.^, (8.И)
р<0>/1-р<0> Л
Данное отношение достаточно широко используется аналитиками, поскольку
с его помощью хорошо выражается взаимосвязь между OR и коэффициентом Ь\.
Очевидно, что если отношение шансов равно 1, то есть шансы благоприятного
и неблагоприятного исхода равны, то модель оказывается бесполезной, поскольку
коэффициент Pt = 0 и выход модели будут определяться только константой р0. Та-
ким образом, чем сильнее отношение шансов отличается от 1, тем более значимой
Глава 8. Data Mining: классификация и регрессия. Статистические методы 413
будет модель. Если OR < 1, шансы благоприятного исхода меньше, чем шансы не-
благоприятного (событие не произойдет), а если больше 1, то наоборот. Значения
отношения шансов, близкие к 0, указывают на очень низкую вероятность благо-
приятного исхода.
Чтобы определить точность полученной оценки отношения шансов, используют
стандартную ошибку отношения шансов, которая для случая дихотомической вы-
ходной переменной вычисляется с помощью выражения
£ст (OR) = OR £ст (h) = OR • I—+ — + — + —' (8-12>
п12 п2, п22
где Ест — стандартная ошибка оценивания соответствующего коэффициента рег-
рессии, а значения Иц, n12f п21 и п22 — элементы четырехклеточной таблицы
сопряженности признаков, отражающей все возможные состояния входной
и выходной переменных.
Например, для задачи, в которой исследуется зависимость наличия некоторого за-
болевания от возраста пациента, таблица будет иметь следующий вид (табл. 8.17).
Таблица 8.17. Четырехклеточная таблица сопряженности признаков
Наличие заболевания, у Возраст, х
х< 50 (0) х>50 (1)
Да(0) Иц = 21 И12 = 22
Нет(1) И21 = 6 п22 = 51
Тогда Ест (OR) = OR-J—+—+- + —= 0,529 OR.
V 21 22 6 51
Границы доверительного интервала отношения шансов будут вычисляться по
формулам:
exp(Z>0 ±z-Е„(Z>0)); exp(Z>, ±z-Ест (Z>,)),
где z — критическое значение коэффициента Стьюдента, связанное с уровнем до-
стоверности (1 - а) • 100 % (для а = 0,05 z « 1,96);
E„(b0), E,,(b<) — стандартные ошибки оценивания коэффициента регрессии на
основе наблюдаемых данных. Если данный интервал не содержит е° = 1, то от-
ношение шансов с достоверностью 95 % является статистически значимым.
Ошибка Е„(ЬХ) для непрерывной переменной определяется как квадратный
корень дисперсии оценки и вычисляется в процессе оценки максимального прав-
доподобия. Ручные вычисления трудоемки и громоздки, поэтому значения ошибки
берут из соотвествующей компьютерной программы.
Часто отношение шансов используется для определения понятия относитель-
ного риска-.
р(1)
относительный риск = —гт-
Р(0)
414 Часть I. Теория бизнес-анализа
При низкой частоте событий значение отношения шансов приблизительно
равно относительному риску.
Интерпретация модели для дихотомической
переменной
Рассмотрим еще один пример. В сфере телекоммуникаций и предоставления услуг
связи существует понятие «текучести» абонентской базы. Текучесть показывает
насколько часто клиенты отказываются от услуг данной компании и переходят
к другим поставщикам услуг связи. Очевидно, что высокая текучесть — проблема для
компании. Поэтому представляют интерес исследования, цель которых заключается
в выявлении причин ухода клиентов и в оценке вероятности ухода клиента с задан-
ными показателями. На основе результатов таких исследований можно разработать
методы работы с клиентами, позволяющие повысить их лояльность компании.
Фрагмент множества данных, собранных для такого исследования, представлен
в табл. 8.18 (данные взяты из источника Churn data set, UCI Repository of Machine
Learning Databases, http://archive.ics.uci.edu/ml; доступны в приложении на CD, файл
churn. xls).
Таблица 8.18. Фрагмент набора данных «Текучесть абонентской базы»
Международные звонки Голосовая почта Количество голосо- вых сообщений Использовано дневных минут Количество звонков днем Использовано вечерних минут Количество звонков вечером Использование ночных минут Количество ночных звонков Между го род н их разговоров, мин Число международных звонков Обращений |В сервисную службу Уход
Нет Да 25 265,10 110 197,4 99 244,7 91 10,0 3 1 Нет
Нет Да 26 161,60 123 195,5 103 254,4 103 13,7 3 1 Нет
Нет Нет 0 243,40 114 121,2 110 162,6 104 12,2 5 0 Нет
Да Нет 0 299,40 71 61,9 88 196,9 89 6,6 7 2 Нет
Да Нет 0 166,70 ИЗ 148,3 122 186,9 121 10,1 3 3 Нет
Да Нет 0 223,40 98 220,6 101 203,9 118 6,3 6 0 Нет
Нет Да 24 218,20 88 348,5 108 212,6 118 7,5 7 3 Нет
Да Нет 0 157,00 79 103,1 94 211,8 96 7,1 6 0 Нет
Нет Нет 0 184,50 97 351,6 80 215,8 90 8,7 4 1 Нет
Да Да 37 258,60 84 222,0 111 326,4 97 11,2 5 0 Нет
Нет Нет 0 129,10 137 228,5 83 208,8 111 12,7 6 4 Да
Нет Нет 0 187,70 127 163,4 148 196,0 94 9,1 5 0 Нет
Нет Нет 0 128,80 96 104,9 71 141,1 128 11,2 2 1 Нет
Нет Нет 0 156,60 88 247,6 75 192,3 115 12,3 5 3 Нет
Глава 8. Data Mining: классификация и регрессия. Статистические методы 415
Для описания признаков клиента, которые предположительно влияют на
вероятность его ухода в другую компанию, используются следующие пере-
менные:
□ международные звонки — использует ли клиент международный тариф;
□ голосовая почта — использует ли клиент службу отправки голосовых сообще-
ний;
□ количество голосовых сообщений — число отправленных голосовых сообще-
ний;
□ использовано минут днем — количество минут дневных разговоров, использо-
ванных клиентом;
□ количество звонков днем — количество дневных звонков, сделанных клиен-
том;
□ использовано вечерних минут — количество минут вечерних разговоров, исполь-
зованных клиентом;
□ количество звонков вечером — количество вечерних звонков, сделанных кли-
ентом;
□ использовано ночных минут — количество минут ночных разговоров, исполь-
зованных клиентом;
□ количество ночных звонков — количество ночных звонков, сделанных клиен-
том;
□ минут междугородних разговоров — количество минут междугородних разгово-
ров, использованных клиентом;
□ число международных разговоров — число международных разговоров, сделан-
ных клиентом;
□ число обращений в сервисную службу — число обращений клиента в абонентскую
сервисную службу.
Выходная переменная уход показывает, ушел ли клиент в другую компанию.
Обозначим данную переменную как С.
Предположим, нужно оценить, как влияет использование или неиспользование
клиентом службы голосовых сообщений (обозначим эту переменную VoiceMail)
на вероятность его ухода к другому оператору связи. В табл. 8.19 указано, какое
количество клиентов, использующих и не использующих голосовую почту, ушло
и осталось.
Таблица 8.19. Сводная таблица ухода клиентов в зависимости от VoiceMail
VoiceMail = Нет, х= 0 VoiceMail = Да, х= 1 Всего
С = Нет, у = 0 2008 842 2850
С = Да,у= 1 403 80 483
Всего 2411 922 3333
416 Часть I. Теория бизнес-анализа
Из таблицы видно, что из 2411 клиентов, не использующих голосовую почту
2008 клиентов остались, а 403 ушли в другую компанию. Из 922 клиентов, ис-
пользующих голосовую почту, 80 клиентов ушли, а 842 остались. Оценим влияние
использования голосовой почты на вероятность ухода клиента.
ЗАМЕЧАНИЕ -------------------------------------------------------------
При использовании логистической регрессии сначала необходимо определить, какое собы-
тие и состояние выходной переменной связано с положительным исходом, а какое — с отри-
цательным. Например, если целью медицинского обследования является проверка наличия
заболевания, то положительным исходом будет обнаружение болезни, а отрицательным — ее
отсутствие. Напротив, если обследование пациента производится после лечения, то целью
является подтвердить результаты лечения. Тогда положительным исходом будет отсутствие
заболевания, а отрицательным — его наличие. В каждом случае положительный и отрица-
тельный исход определяется логикой задачи. Для положительного исхода вероятность будет
р(х), а для отрицательного — 1 - р(х). Что касается состояния бинарной выходной перемен-
ной, то 1 обычно связывают с положительным исходом, а 0 — с отрицательным.
Функция правдоподобия задается следующим образом:
/(р|х) = [р(0)]^+[(1-р(0))]2008-[Р(1)]8"-[(1-р(1))]^
На основе данных, приведенных в табл. 8.19, вычислим шансы и отношения
шансов. При этом, если клиент ушел, исход считается положительным, а если
остался — отрицательным.
□ Шанс ухода клиента, использующего голосовую почту: О = р(1)/(1 —р(1)) =
= 80/842 = 0,095.
□ Шанс ухода клиента, не использующего голосовую почту: О = 403/2008 = 0,201.
Тогда отношение шансов будет:
р(0)/(1 —р(0)) 403/2008
Значения коэффициентов регрессии для модели с одной независимой переменной
VoiceMailбудут Ьо = -1,606 и bi — -0,748. Тогда OR = exp(bi) = ехр(-0,748) = 0,47,
что совпадает с ранее вычисленным значением. Вероятность ухода клиента, исполь-
зующего (х = 1) или не использующего (х = 0) голосовую почту, будет равна:
exp(g(x))
р(х) =----- , „ .,
l + exp(g(x))
а соответствующее логит-преобразование — g(x) = -1,606-0,748-х.
Тогда для клиентов, использующих голосовую почту, вероятность ухода со-
ставит:
А/ . а, . ехр(-2,354)
= -1,606 - 0,748.1 = -2.354; р(х) = ,+ Jp(_., 3/4) = 0.087.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 417
Иными словами, вероятность того, что клиент, использующий голосовую почту,
откажется от услуг компании, составляет всего 8,7 %. Это меньше, чем общая доля
клиентов, которые отказались от услуг компании, в исходном множестве данных,
составившая 14,5 %. Следовательно, тот факт, что клиент использует голосовую
почту, снижает вероятность его ухода.
Вероятность ухода также может быть вычислена непосредственно с помощью
табл. 8.19:
Р(С | VoiceMail) = 80/922 = 0,087.
Для клиентов, не использующих голосовые сообщения, вероятность ухода
оценивается как
Л Л/ . ехр(—1,606)
g(x) = -l,606 - 0,748 0 = -!,606; р(х)=1 + ^(^1(.0;б) = 0,167.
Это немного выше 14,5 %. Следовательно, если клиент не использует голосовую
почту, вероятность его ухода несколько увеличивается.
Вероятность ухода также может быть вычислена непосредственно с помощью
табл. 8.19:
Р(С | VoiceMail) = 403/2411 = 0,167.
Интерпретация модели для полихотомической
входной переменной
Введем в рассмотрение переменную, которая указывает на количество обращений
клиентов в абонентскую сервисную службу. Число обращений за поддержкой
в сервисную службу зависит от числа проблем. А чем больше проблем, тем выше
вероятность того, что клиент откажется от услуг компании. Чтобы использовать
данную переменную, определим, какое число обращений в сервисную службу
(обозначим эту переменную через CSC) можно рассматривать как низкое, среднее
и большое. Для этого введем фиктивные переменные (табл. 8.20).
Таблица 8.20. Квантование переменной CSC
CSC1 CSC2
Низкое (0 или 1 вызов), CSC = Низкое 0 0
Среднее (2 или 3 вызова), CSC = Среднее 1 0
Высокое (> 4 вызовов), CSC = Высокое 0 1
Таким образом, мы квантовали переменную, указывающую на количество
обращений клиентов в сервисную службу. При этом использовалась новая пере-
менная CSC, которая порождает три фиктивные переменные. Выберем в качестве
опорной категории CSC = Низкое.
418 Часть I. Теория бизнес-анализа
В табл. 8.21 представлена зависимость значения выходной переменной от пере-
менной CSC.
Таблица 8.21. Сводная таблица для переменной CSC
CSC = Низкое CSC= Среднее CSC = Высокое Всего —
С = Нет, у = 0 1664 1057 129 2850
С = Да, у = 1 214 131 138 483
Всего 1878 1188 267 3333
Вычислим отношения шансов.
Для CSC = Среднее:
138-1664
214-1057
131-1664
Для CSC = Высокое:
Коэффициенты уравнения логистической регрессии будут равны Ьо = -2,051,
bi = -0,037 и />2 = 2,118.
Вероятность ухода клиента:
exp(g(x)j
pW = :------
l + exp(g(x))
с логит-преобразованием g(x) = -2,051 - 0,037 -CSC] + 2,118- CSC>.
Оценим вероятность ухода для клиентов с низким числом обращений в сер-
висный центр:
л . ехр(—2,051)
g(x) = -2,051 - 0,0369891-0 + 2,11844-0 = -2,051; р х = -— v = 0,114.
1+ехр(-2,051)
Таким образом, вероятность того, что клиент с низким числом обращений
в сервисный центр откажется от услуг компании, составляет 11,4 %. Это меньше,
чем доля таких клиентов по всему исходному набору данных, которая составляет
14,5 %. Следовательно, клиенты, которые редко обращаются в сервисный центр,
менее склонны к уходу из компании.
Данная вероятность также может быть рассчитана непосредственно с помощью
табл. 8.21:
Р(С | CSC = Низкое) = 214 /1878 = 0,114.
Для клиентов со средним числом обращений:
g(x) = -2,051 - 0,037 • 1 + 2,118 • 0 = -2,088; £(г) = . еХр(~2’°88) = °’11 °’
1 +ехр(—2,088)
Оцененное значение показывает, что вероятность ухода клиентов, число обра-
щений которых в сервисный центр мы определили как среднее, примерно та же,
что и для клиентов, редко обращающихся в сервисный центр.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 419
Наконец, определим вероятность ухода клиентов, для которых зафиксировано
большое число обращений в сервисный центр:
ехр(-0,003)
g(x) = -2,051 - 0,037 • 1 + 2,118 • 1 = -О,003; р(х) = 1 + = 0-500.
Таким образом, вероятность ухода клиентов с большим числом обращений
в сервисный центр составляет около 52 %, а это более чем в три раза превышает
вероятность ухода по выборке в целом. Очевидно, что компании необходимо выде-
лять клиентов, которые 4 и более раза обращались в сервисный центр, и проводить
с ними определенную работу.
Чтобы определить значимость переменной CSC = Среднее, выполним тест
Вальда. Вычислим стандартную ошибку оценивания для данного коэффициента.
Расчеты выполняются по той же схеме, что и для случая дихотомической входной
переменной, но относительно опорной переменной. Это можно сделать, взяв дан-
ные непосредственно из табл. 8.21:
Er.(b(CSC = Среднее)) = J——I——н——+—— = 0,118;
v v !! V1664 1057 214 131
b, -0,037
Zw = —ТТЛ- =---= -0,314.
Ecr(bt) 0,118
В данном случае ^-значение P(|z| > 0,314) = 0,753 указывает на низкую зна-
чимость переменной. Поэтому в плане предсказания ухода клиента перемен-
ная CSC = Среднее ненамного полезнее, чем CSC = Низкое. В то же время для
CSC — Высокое имеем, что bi — -2,118, a E„(bi) = 0,1424, поэтому:
2 ц/
Ь} 2,118
£„(/>,)" 0,1424
14,87.
В этом случае ^-значение Р (|z| > 14,87)« 0. Очевидно, что переменная CSC = Вы-
сокое намного полезнее с точки зрения предсказания, чем переменная CSC = Низ-
кое.
Доверительный интервал для отношения шансов между CSC = Высокое
и CSC = Низкое вычислится следующим образом:
С1= ехр[2,118 ± 1,96 • 0,1424] = (е183, е240) = (6,23; 11,0).
Интервал не содержит значение е° = 1, поэтому отношение является статисти-
чески значимым.
Однако если рассмотреть доверительный интервал между CSC = Среднее
и CSC = Низкое, получим:
CI = ехр[-0,037 ± 1,96 0,118] = (е’0'268 ,е0|!М) = (0,77; 1,21).
Интервал содержит единицу, следовательно, отклонение отношения шансов от
единицы является статистически незначимым на уровне а = 5 %.
420 Часть I. Теория бизнес-анализа
Интерпретация логистической модели
для непрерывной переменной
В рассмотренном в самом начале примере с предсказанием вероятности наличия
заболевания для пациентов различных возрастов используется непрерывная вход-
ная переменная Возраст. В наборе данных по текучести абонентской базы также
присутствуют непрерывные переменные. Предположим, что нас интересует оценка
вероятности ухода клиентов на основе информации о том, сколько времени клиент
разговаривал в дневные часы. Обозначим эту переменную DayMin.
Визуально проанализировав статистические характеристики, рассчитанные для
поля DayMin (табл. 8.22), можно заметить, что клиенты, отказавшиеся от услуг
компании, в среднем использовали в дневное время несколько большее количество
минут. Это позволяет предположить, что данная переменная может использоваться
в качестве входной переменной регрессионной модели для оценки вероятности
ухода клиента.
Таблица 8.22. Статистические характеристики для переменной DayMin
Уход Число, № Среднее Ст. откл. Минимум Максимум Медиана
Нет 2850 175,18 50,18 0,00 315,60 177,20
Да 483 206,91 69,0 0,00 350,80 217,6
Здесь можно показать, что Ьо = -3,929 и bt = 0,011. Вероятность ухода р(х) для
клиента с заданным числом минут, использованным в дневное время, будет иметь
логит-преобразование g(x) = —3,929 + 0,011 • DayMin.
Так, вероятность ухода клиента, который использовал 100 минут разговора
в дневное время, можно оценить следующим образом:
g(x) = -3,929 + 0,011 100 = -2,802; р(х) = = 0,057.
1 + ехр(—2,802)
Таким образом, оцененная вероятность того, что клиент, использовавший
100 минут в дневное время, уйдет, составляет менее 6 %. Это меньше, чем общая
доля ушедших в исходной выборке (14,5 %). Значит, малое число минут, исполь-
зованных днем, каким-то образом снижает вероятность ухода клиента.
Это позволит нам интерпретировать коэффициент bt как изменение логарифма
отношения шансов при увеличении на единицу значения входной переменной. В дан-
ном примере Ь[ = 0,011. Это означает, что для каждой дополнительной минуты,
которую использует клиент, логарифм отношения шансов увеличивается на 0,011-
Значение для отношения шансов, найденное выше, — OR = е0011 = 1,01 — может
быть интерпретировано как отношение шансов для клиента с х + 1 минутами от-
носительно клиента с х минутами. Например, для клиента с 201 минутой разговора
уход в 1,01 раза более вероятен, чем для клиента с 200 минутами. Но поединичное
увеличение значения входной переменной не всегда соответствует особенностям
решаемой задачи. В примере мы видим, что увеличение времени, используемого
клиентом, на одну минуту, не окажет существенного влияния на шанс его ухода.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 421
Поэтому вместо единицы обычно используют константу с. При этом отношение
щансов станет OR = е'ь'. Таким образом, можно обобщить интерпретацию коэффи-
циентов логистической регрессии с помощью следующего правила.
Для некоторой константы с произведение с • bi представляет собой оценку
изменения логарифма отношения шансов при увеличении входной переменной на
с единиц.
Пусть с = 60, то есть нас интересует, как изменится логарифм отношения
шансов, если клиент увеличит время использования на 60 дневных минут. Это
оценивается как с • Ь\ = 60 • 0,011 = 0,66. Рассмотрим клиента А, у которого время
использования на 60 дневных минут больше, чем у клиента Б. Тогда мы можем оце-
нить отношение шансов ухода клиента А по сравнению с клиентом Б как е°67 = 1,95.
Таким образом, увеличение времени использования в дневное время на 60 минут
почти удваивает вероятность того, что клиент уйдет.
8.12. Множественная логистическая регрессия
До сих пор мы рассматривали логистическую регрессию только для случая с од-
ной входной переменной. По аналогии с множественной линейной регрессией
существует множественная логистическая регрессия, в которой значение бинар-
ной выходной переменной предсказывается на основе более чем одной входной
переменной.
Вернемся к набору данных «Текучесть абонентской базы» и проверим, су-
ществует ли зависимость между выходной переменной и следующим набором
входных:
□ использование международных звонков (IntCall)-,
□ использование голосовой почты (VoiceMail)-,
□ обращения в сервисную службу (CSC) — бинарная переменная, указывающая,
является ли количество обращений в сервисный центр большим (истинна при
С5С>4);
□ количество минут, использованных в вечернее время (EveMin);
□ количество минут, использованных в дневное время (DayMin)-,
□ количество минут, использованных в ночное время (NightMin)-,
□ количество минут международных разговоров (IntMin).
Параметры модели множественной логистической регрессии представлены
в табл. 8.23.
Проинтерпретируем полученные результаты. Отметим, что отрицательные ко-
эффициенты регрессии дают отношения шансов меньше 1. Для дихотомической
переменной это означает, что шансы положительного исхода (то есть ухода клиента)
меньше, чем отрицательного. Данную ситуацию мы можем наблюдать для перемен-
ной VoiceMail, которая указывает на использование или неиспользование клиентом
сервиса голосовой почты. Ранее мы увидели, что клиенты, использующие голосовую
422 Часть I. Теория бизнес-анализа
Таблица 8.23. Параметры модели множественной регрессии
Переменная Z„ Р-значение OR 95 % CI
Константа -8,074 — — — — —
IntCall = Да 2,036 0,1468 13,86 0,000 7,66 5,74-10,21 ~~
Voice Mail = Да -1,044 0,1501 -6,59 0,000 0,35 0,26-0,47 ’
С8С>4=Да 2,677 0,1592 16,82 0,000 14,54 10,64-19,86~~
DayMin 0,014 0,0011 12,04 0,000 1,01 1,01-1,02 ~~
EveMin 0,007 0,0012 6,24 0,000 1,01 1,01-1,01 ~
NightMin 0,004 0,0011 3,68 0,000 1,00 1,00-1,01
IntMin 0,085 0,0210 4,06 0,000 1,09 1,05-1,13
почту, почти в 2 раза меньше склонны к уходу по сравнению с не использующими
ее. Аналогичную ситуацию показывает и множественная модель. Отношение шан-
сов 0,35 демонстрирует, что в данном случае шанс ухода примерно в 3 раза меньше.
Значительно выделяется среди остальных отношение шансов для дихотомической
переменной CSC = Да, которая указывает на факт большого числа обращений (боль-
ше 4) в сервисную службу компании. Отношение шансов 14,54 показывает, что если
клиент обращался в сервисную службу больше 4 раз, то шанс его ухода в 14,54 раза
выше, чем клиента, имеющего малое число обращений.
Отношение шансов, значительно отличающееся от нуля OR = 7,66, связано так-
же с бинарной переменной IntCall, которая отражает факт использования клиентом
международного тарифа. Оно позволяет сделать вывод, что клиенты, использу-
ющие международный тариф, уходят из компании примерно в 7,5 раза чаще, чем
клиенты, не использующие его.
Теперь рассмотрим непрерывные переменные DayMin, IntCall, EveMin, NightMin
и IntMin, которые показывают количество минут, использованное клиентом в раз-
личное время суток. Общим свойством этих переменных является то, что связанные
с ними коэффициенты модели близки к нулю, а их отношения шансов, поскольку
OR, = ехр(р,), — к единице.
Поскольку для непрерывной выходной переменной коэффициент /ц интерпре-
тируется как изменение логарифма отношения шансов при увеличении на единицу
значения входной переменной для каждой дополнительной минуты, которую ис-
пользует клиент, логарифм отношения шансов, например, для переменной DayMin
увеличивается на 0,01347. Если взять 60 минут, то получим отношение шансов
OR = ехр(60 • 0,01347) = 2,24. Значит, каждый дополнительный час разговоров
повышает вероятность ухода в 2,24 раза.
Логит-преобразование для модели множественной логистической регрессии
будет иметь вид:
g(x) = — 8,074 + 0,014 • DayMin + 0,007 • EveMin + 0,004 • NightMin +
+0,085 • IntMin + 2,036 • {IntCall = Да) — 1,044 • (VoiceMail — Да) +
2,677 • (C5C > 4 = Да).
Глава 8. Data Mining: классификация и регрессия. Статистические методы 423
С помощью преобразования р(х) можно оценить вероятность ухода опреде-
ленного клиента для заданных значений входной переменной. Вычислим ее для
следующих категорий клиентов.
j Клиенты с малым количеством использованного времени и небольшим числом
обращений в абонентскую сервисную службу, не использующие голосовую
почту.
Типичный клиент данной категории использует 100 мин. дневных, вечерних
и ночных разговоров и не ведет международных разговоров. Подставив значе-
ния в логит-преобразование, получим g(x) — -5,574.
В итоге вероятность того, что клиент данной категории сменит оператора, со-
ставит:
ехр(—5,574)
р(х) = £1—’---' = о,ОО4,
н 7 1 + ехр(—5,574)
что менее 1 %.
2 . Клиенты с умеренным количеством использованного времени и небольшим чис-
лом обращений в абонентскую службу, не использующие голосовую почту.
Такой клиент может использовать 180 мин. в дневное время, 200 мин. — в ве-
чернее и ночное, а также 10 мин. международных разговоров. В этом случае
g(x) = -0,468. Соответствующая вероятность ухода р(х) = 0,385.
3 . Клиенты с большим количеством использованного времени, имеющие меж-
дународные звонки, но не использующие голосовую почту, с большим числом
обращений в абонентскую службу.
Такой клиент может использовать 300 дневных, вечерних и ночных минут и 20 мин.
международных разговоров. Получим: g(x) = -5,84; р(х) = 0,997.
Клиенты с этими параметрами имеют очень высокую склонность к уходу: вероят-
ность события составляет 99,7 %.
Очевидно, что во многих случаях использование нескольких входных пере-
менных позволяет сделать модель более информативной и повысить точность
оценивания. Однако в наборах данных, на основе которых строятся регрессион-
ные модели, может содержаться большое количество переменных (до нескольких
десятков). Поэтому при построении моделей множественной регрессии аналитик
неизбежно сталкивается с проблемой выбора наиболее значимых переменных,
которые имеют самую сильную связь с выходной переменной. Для отбора пере-
менных в логистической регрессии применяются те же пошаговые процедуры, что
и в линейной (см. раздел 8.8).
8.13. Простой байесовский классификатор
Байесовский подход представляет собой группу алгоритмов классификации, осно-
ванных на принципе максимума апостериорной вероятности. Сначала определя-
424 Часть I. Теория бизнес-анализа
ется апостериорная вероятность отношения объекта к каждому из классов, а затем
выбирается тот класс, для которого она максимальна. Как и в логистической
регрессии, алгоритм предсказывает вероятность того, что объект или наблюдение
относится к определенному классу.
Этот подход к классификации является одним из старейших и до сих пор
сохраняет прочные позиции в технологиях анализа данных. Кроме того, он ле-
жит в основе многих удачных алгоритмов классификации. Рассмотрим один из
них — так называемый простой, или наивный, байесовский классификатор (naive
Bayesian classifier). Это специальный случай байесовского классификатора, в ко-
тором используется предположение о статистической независимости признаков
описывающих классифицируемые объекты. Такое предположение существенно
упрощает задачу, поскольку вместо одной многомерной плотности вероятности
по всем признакам достаточно оценить несколько одномерных (маргинальных)
плотностей. К сожалению, на практике предположение о независимости призна-
ков редко выполняется, является «наивным», что и дало название методу.
Основные преимущества наивного байесовского классификатора — легкость
программной реализации и низкие вычислительные затраты при обучении и клас-
сификации. В тех редких случаях, когда признаки действительно независимы
(или близки к этому), он почти оптимален. Главный его недостаток — относительно
низкое качество классификации в большинстве реальных задач. Поэтому чаще
всего его используют либо как примитивный эталон для сравнения различных
моделей, либо как блок для построения более сложных алгоритмов.
Рассмотрим базовые принципы работы простого байесовского классификатора.
Формула Байеса
Пусть имеется объект или наблюдение X, класс которого неизвестен. Пусть также
имеется гипотеза Н, согласно которой X относится к некоторому классу С. Для за-
дачи классификации можно определить вероятность Р(Н\ X), то есть вероятность
того, что гипотеза Н для X справедлива. Р(Н\Х) называется условной вероятностью
того, что гипотеза Н верна при условии, что классифицируется объект X, или апо-
стериорной вероятностью.
Предположим, что объектами классификации являются фрукты, которые
описываются их цветом и размером. Определим объект X как красный и круглый
и выдвинем гипотезу Н, что это яблоко. Тогда условная вероятность Р(Н | X) отра-
жает меру уверенности в том, что объект X является яблоком при условии, что он
красный и круглый. Кроме условной (апостериорной) вероятности, рассмотрим
так называемую априорную вероятность Р(Н). В нашем примере это вероятность
того, что любой наблюдаемый объект является яблоком, безотносительно к тому,
как он выглядит. Таким образом, апостериорная вероятность основана на боль-
шей информации, чем априорная, не предполагающая зависимость от свойств
объекта X.
Аналогично Р(Х | Н) — апостериорная вероятность X при условии Н, или веро-
ятность того, что X является красным и круглым, если известно, что это яблоко.
Глава 8. Data Mining: классификация и регрессия. Статистические методы 425
р(Х) — априорная вероятность X. В нашем примере это просто вероятность того,
что объект является красным и круглым. Вероятности Р(Х), Р(Н) и Р(Х\Н) могут
быть оценены на основе наблюдаемых данных.
Для вычисления апостериорной вероятности Р(Н\ X) на основе Р(Х), Р(Н)
и Р(Н | X) используется формула Байеса:
(8.13)
Алгоритм работы простого байесовского классификатора содержит следующие
шаги.
1. Пусть исходное множество данных S содержит атрибуты А,, А2... А„. Тогда
каждый объект или наблюдение X 6 S будет представлено своим набором зна-
чений этих атрибутов xt, х2... х„, где х,- — значение, которое принимает атрибут
А, в данном наблюдении.
2. Предположим, что задано т классов С = {С,, С2... Ст} и наблюдение X, для ко-
торого класс неизвестен. Классификатор должен определить, что X относится
к классу, который имеет наибольшую апостериорную вероятность Р(Н | X). Про-
стой байесовский классификатор относит наблюдение X к классу Q (k = 1... т)
тогда и только тогда, когда выполняется условие P(G | X) > Р(СУ- | X) для любых
1 <7 <m,k ^j.
По формуле Байеса:
(8.14)
3. Поскольку вероятность Р(Х) для всех классов одинакова, максимизировать
требуется только числитель формулы (8.14). Если априорная вероятность
класса P(Q) неизвестна, то можно предположить, что классы равновероятны,
Р(С1) = Р(С2) = ... = Р(С„,), и, следовательно, мы должны выбрать максимальную
вероятность Р(Х | Q).
Заметим, что априорные вероятности классов могут быть оценены как P(Q) =
= Sk / s, где Sk — число наблюдений обучающей выборки, которые относятся
к классу Q, a s — общее число обучающих примеров.
4. Если исходное множество данных содержит большое количество атрибутов, то
определение Р(Х | Q) может потребовать значительных вычислительных затрат.
Чтобы их уменьшить, используется «наивное» предположение о независимости
признаков. То есть для набора атрибутов X = (хь х2... х„) можно записать:
P(X|G) = P(xi|G)-P(x2|G)-...-P(x„|Q). (8.15)
Вероятности, стоящие в правой части формулы (8.15), могут быть определены
из обучающего набора данных для следующих случаев.
426 Часть I. Теория бизнес-анализа
• Атрибут А: является категориальным, тогда Р(Х | Q) = sik / sk, где sik — число
наблюдений класса С„ в которых А, принимает значение х„ a sk — общее число
наблюдений, относящихся к классу Ск.
• Атрибут А,- является непрерывным, тогда предполагается, что его значения
подчиняются закону распределения Гаусса:
Р(у 1С*) = _/=ехР
< /ЯП
2о2
где тио2- математическое ожидание и дисперсия значений атрибута А, для
наблюдений, относящихся к классу Q.
При классификации неизвестного наблюдения объект X будет относиться
к классу, для которого Р(Х| С,) • Р(С,) принимает наибольшее значение.
Пример работы простого байесовского
классификатора
Рассмотрим пример работы наивного байесовского классификатора на основе уже
знакомой задачи предсказания текучести абонентской базы, только в качестве на-
бора данных возьмем упрощенный вариант Churn data set, содержащий 14 записей
с квантованными входными полями (табл. 8.24).
Таблица 8.24. Набор данных «Текучесть абонентской базы»
№ Количество звонков SMS-активность Internet- активность Международные звонки Уход
1 < 100 Высокая Средняя Нет Да
2 < 100 Высокая Высокая Нет Да
3 100-150 Высокая Средняя Нет Нет
4 > 150 Средняя Средняя Нет Да
5 > 150 Низкая Средняя Да Нет
6 >150 Низкая Высокая Да Нет
7 100-150 Низкая Высокая Да Да
8 < 100 Средняя Средняя Нет Нет
9 < 100 Низкая Средняя Да Да
10 > 150 Средняя Средняя Да Да
И < 100 Средняя Высокая Да Да
12 100-150 Средняя Высокая Нет Да
13 100-150 Высокая Средняя Да Да
14 >150 Средняя Высокая Нет Нет
Обозначим как G класс клиентов, для которых Уход = Да. К классу С2 будем
относить клиентов, которые сохраняют лояльность компании. Для них метка класса
будет Нет. Пусть новый клиент, вероятность ухода которого мы хотим оценить,
обладает следующими параметрами:
Глава 8. Data Mining: классификация и регрессия. Статистические методы 427
X = (Количество звонков = < 100, SMS-активность =
= Средняя, Internet-активность = Средняя, Международные звонки = Да).
Согласно простому алгоритму Байеса нужно максимизировать Р(Х| Q)P(Q) для
£=1,2 (поскольку классов всего два). Априорная вероятность появления каждого
класса P(G) может быть вычислена с помощью обучающего множества из таблицы
как отношение числа примеров k-ro класса к общему числу примеров. Поскольку
всего примеров 14, наблюдений с меткой класса Да — 9, а с меткой Нет — 5, то
P(G) = 9 / 14 = 0,643; Р(С2) = 5 / 14 = 0,357.
Для вычисления Р(Х | Q), k = 1, 2 определим следующие условные вероятности
(табл. 8.25).
Таблица 8.25. Расчет условных вероятностей
Р(Число звонков = < 100 | Уход = Да) = 4 / 9 = 0,444________________
Р(Число звонков = < 100 | Уход = Нет) = 1 / 5 = 0,200
Р(5М5-активность = Средняя | Уход = Да) = 4 /9 = 0,444
P(SMS-aKTHBHOCTb = Средняя | Уход = Нет) = 2 / 5 = 0,400____________
Р(Internet-активность = Средняя | Уход = Да) = 5 / 9 = 0,555________
P(Internet-aKTHBHOCTb = Средняя | Уход — Нет) = 3 / 5 = 0,600_______
Р(Международные звонки = Да | Уход = Да) = 5 / 9 = 0,555____________
Р(Международные звонки =Да | Уход = Нет) = 2 / 5 = 0,400
Используя рассчитанные условные вероятности, получим (табл. 8.26).
Таблица 8.26. Расчет условных вероятностей
Р(Х| Уход = Да) = 0,444 • 0,444 0,555 • 0,555 = 0,061_____________
Р(Х| Уход = Нет) = 0,600 0,400 0,200 0,400 = 0,019____________
Р(Х | Уход = Да) • Р(Уход = Да) = 0,061 0,643 = 0,039_____________
Р(Х | Уход = Нет) • Р(Уход = Нет) = 0,019 • 0,357 = 0,007
Таким образом, для наблюдения X произведение вероятностей для класса С,
то есть Р(Х| С,) • P(Ci) = 0,039, а для класса С2 - Р(Х| С2) • Р(С2) = 0,007. Поэтому
выбирается класс Сь для которого оно больше. Можно нормализовать эти вероят-
ности, тогда получим: Р'(Х| C,)P(Ci) = 0,039 / (0,039 + 0,007) = 0,848 и Р'(Х | С2)Р
(С2) = 0,007 / (0,039 + 0,007) = 0,152.
Следовательно, для наблюдения X метка класса будет Да, а клиент, характери-
зуемый соответствующими признаками, должен рассматриваться как склонный
к уходу.
Хотя предположение о статистической независимости признаков на практике
выполняется достаточно редко, в Data Mining существуют различные методы,
которые позволяют отбирать наименее коррелированные из них. Использование
таких методов позволяет повысить эффективность байесовских классификаторов
до уровней, сравнимых с эффективностью нейронных сетей и деревьев решений.
Data Mining:
классификация
и регрессия.
Машинное обучение
9.1. Введение в деревья решений
Деревья решений (decision trees) относятся к числу самых популярных и мощных
инструментов Data Mining, позволяющих эффективно решать задачи классифи-
кации и регрессии. В отличие от методов, использующих статистический подход,
таких как классификатор Байеса, линейная и логистическая регрессия, деревья
решений основаны на машинном обучении и в большинстве случаев не требуют
предположений о статистическом распределении значений признаков. В основе
деревьев решений лежат решающие правила вида «если... то...», которые могут
быть сформулированы на естественном языке. Поэтому деревья решений являются
наиболее наглядными и легко интерпретируемыми моделями.
Для удобства приведем базовые понятия теории деревьев решений в табл. 9.1.
Таблица 9.1. Понятия, встречающиеся в теории деревьев решений
Название Описание
Объект Пример, шаблон, наблюдение, запись
Атрибут Признак, независимая переменная, свойство, входное поле
Метка класса Зависимая переменная, целевая переменная, выходное поле
Узел Внутренний узел дерева
Лист Конечный узел дерева, узел решения
Проверка Условие в узле
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 429
Атрибутами в теории деревьев решений называются признаки, описывающие
классифицируемые объекты.
В основе работы деревьев решений лежит процесс рекурсивного разбиения ис-
ходного множества наблюдений или объектов на подмножества, ассоциированные
с классами. Разбиение производится с помощью решающих правил, в которых осу-
ществляется проверка значений атрибутов по заданному условию. Рекурсивными
называются алгоритмы, которые работают в пошаговом режиме, при этом на каждом
последующем шаге используются результаты, полученные на предыдущем шаге.
Рассмотрим главную идею алгоритмов построения деревьев решений на приме-
ре. Пусть требуется предсказать возврат или невозврат кредита с помощью набора
решающих правил на основе единственного атрибута Возраст клиента. Для этого бу-
дем использовать множество наблюдений, в каждом из которых указывается возраст,
а также факт возврата/невозврата кредита. Графически такое множество наблюде-
ний представлено на рис. 9.1. Условно примем, что объект в форме круга указывает
на дефолт, в форме прямоугольника — на возврат по кредиту, а внутри каждого
объекта указан возраст. Необходимо разбить множество объектов на подмножества
таким образом, чтобы в каждое из них попали объекты только одного класса.
Рис. 9.1. Разделение на классы
Выберем некоторое значение возрастного порога, например равное 50, и разобьем
исходное множество на два подмножества в соответствии с условием Возраст > 50.
В результате разбиения в одном подмножестве окажутся все записи, для которых
значение атрибута Возраст больше 50, а во втором — меньше 50. На рис. 9.1 данные
подмножества обозначены номерами 1 и 2 соответственно. Легко увидеть, что выбор
возрастного порога 50 не позволил получить подмножества, содержащие только
объекты одного класса, поэтому для решения задачи применяется разбиение полу-
ченных подмножеств. Поскольку для этого имеется только один атрибут — Возраст,
мы будем использовать его и в дальнейшем, но в условиях выберем другой порог.
Например, для подмножества 1 применим порог 60, а для подмножества 2 — 30.
Результаты повторного разбиения представлены на рис. 9.2.
430 Часть I. Теория бизнес-анализа
Рис. 9.2. Продолжение деления на классы
На рис. 9.2 можно увидеть, что задача решена: исходное множество удалось
разбить на чистые подмножества, содержащие только наблюдения одного класса.
Дерево, реализующее данную процедуру, представлено на рис. 9.3.
Рис. 9.3. Сформированное дерево решений
Сопоставление рис. 9.2 и 9.3 показывает, что подмножества 4 и 6 ассоциированы
с классом добросовестных клиентов, а 3 и 5 — с классом клиентов, не погасивших
кредит. Применяя построенную модель к новым клиентам, мы можем предсказать
риск, связанный с выдачей им кредита, на основе того, в какое из подмножеств
модель поместит соответствующую запись.
Конечно, приведенный пример тривиален. В реальности задача классификации
по одному атрибуту встречается очень редко, поскольку для эффективного разде-
ления на классы требуется несколько атрибутов. Но даже этот пример позволяет
увидеть причину привлекательности деревьев решений. Они не только класси-
фицируют объекты и наблюдения, но и объясняют, почему объект был отнесен
к данному классу. Так, если с помощью дерева решений было предсказано, что
Глава 9. Data Mining: классификация и регрессия. Машинное обучение
431
вероятность возврата кредита данным клиентам слишком мала и на этом осно-
вании в выдаче кредита было отказано, то можно не только принять решение, но
и объяснить его причину. В нашем случае это возраст клиента.
Обладая высокой объясняющей способностью, деревья решений могут исполь-
зоваться и как эффективные классификаторы, и как инструмент исследования
предметной области.
Таким образом, мы получили систему правил вида «если... то...», которые позво-
ляют принять решение относительно принадлежности объекта к определенному
классу. Решающие правила образуют иерархическую древовидную структуру,
дающую возможность выполнять классификацию объектов и наблюдений. Эта
структура и называется деревом решений.
ОПРЕДЕЛЕНИЕ-----------------------------------------------------------
Деревья решений — иерархические древовидные структуры, состоящие из решающих
правил вида «если... то...» и позволяющие выполнять классификацию объектов. В дереве
каждому объекту соответствует единственный узел, дающий решение.
Деревья решений стали одним из наиболее популярных методов Data Mining,
используемых при решении задач классификации. Это обусловлено следующими
факторами.
□ Деревья решений — это модели, основанные на обучении. Процесс обучения
сравнительно прост в настройке и управлении.
□ Процесс обучения деревьев решений быстр и эффективен.
□ Деревья решений универсальны — способны решать задачи как классификации,
так и регрессии.
□ Деревья решений обладают высокой объясняющей способностью и интерпре-
тируемостью.
ЗАМЕЧАНИЕ-------------------------------------------------------------
Термин «дерево решений» используется не только в Data Mining, но и в смежных областях
анализа и обработки данных, искусственном интеллекте. Например, в задачах алгоритми-
зации дерево решений — это способ представления процесса принятия решения, имеющий
вид ответов на серию вопросов, образующих древовидную структуру, каждая конечная вер-
шина которой представляет элементарное решение. В менеджменте поддеревом решений
понимают графическое изображение альтернативных действий и их последствий. Однако
между всеми этими толкованиями термина много общего.
Для эффективного построения дерева решений должны выполняться следу-
ющие условия.
□ Описание атрибутов. Анализируемые данные должны быть представлены
в виде структурированного набора, в котором вся информация об объекте или
наблюдении должна быть выражена совокупностью атрибутов.
□ Предварительное определение классов. Категории, к которым относятся на-
блюдения (метки классов), должны быть заданы предварительно, то есть имеет
место обучение с учителем.
432 Часть I. Теория бизнес-анализа
□ Различимость классов. Должна обеспечиваться принципиальная возможность
установления факта принадлежности или непринадлежности примера к опреде-
ленному классу. При этом количество примеров должно быть намного больше,
чем количество классов.
□ Полнота данных. Обучающее множество должно содержать достаточно большое
количество различных примеров. Необходимая численность зависит от таких
факторов, как количество признаков и классов, сложность классификационной
модели и т. д.
Структура дерева решений
Как можно увидеть на рис. 9.3, структура деревьев решений проста и в целом
аналогична древовидным иерархическим структурам, используемым в других об-
ластях Data Mining, например деревьям ассоциативных правил. В состав деревьев
решений входят два вида объектов — узлы (node) и листья (leaf). В узлах содержат-
ся правила, с помощью которых производится проверка атрибутов и множество
объектов в данном узле разбивается на подмножества. Листья — это конечные
узлы дерева, в которых содержатся подмножества, ассоциированные с классами.
Основным отличием листа от узла является то, что в листе не производится про-
верка, разбивающая ассоциированное с ним подмножество и, соответственно, нет
ветвления. В принципе, листом может быть объявлен любой узел, если принято
решение, что множество в узле достаточно однородно в плане классовой при-
надлежности объектов и дальнейшее разбиение не имеет смысла, поскольку не
приведет к значимому увеличению точности классификации, а только усложнит
дерево.
В дереве, представленном на рис. 9.3, объекты с номерами 1 и 2 — узлы, а с но-
мерами 3, 4, 5 и 6 — листья. Обратим внимание на то, что в дереве имеется по два
листа, ассоциированных с одним классом. В этом нет никакого противоречия,
просто для классификации объектов в них использовались различные способы
проверки. Для каждого листа в дереве имеется уникальный путь. Начальный
узел дерева является входным: через него проходят все объекты, предъявляемые
дереву. Обычно входной узел называют корневым узлом (root node). Следователь-
но, дерево растет сверху вниз. Узлы и листья, подчиненные узлу более высокого
иерархического уровня, называются потомками, или дочерними узлами, а тот узел
по отношению к ним — предком, или родительским узлом. Обобщенная структура
дерева проиллюстрирована на рис. 9.4.
Как и любая модель Data Mining, дерево решений строится на основе обу-
чающего множества. Атрибуты могут быть как числовыми (непрерывными), так
и категориальными (дискретными). Одно из полей обязательно должно содержать
независимую переменную — метку класса. Иными словами, для каждой записи
в обучающем множестве должна быть задана метка класса, определяющая классо-
вую принадлежность связанного с ней объекта.
В процессе построения дерева решений формируются решающие правила и для
каждого из них создается узел. Для каждого узла нужно выбрать атрибут, по кото-
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 433
Рис. 9.4. Узлы и листья в дереве решений
рому будет производиться проверка правила. Его принято называть атрибутом
ветвления, или атрибутом разбиения (splitting attribute), и от того, насколько
удачно он выбран, зависит классифицирующая сила правила. Метод, в соответствии
с которым осуществляется выбор атрибута ветвления на каждом шаге, называется
алгоритмом построения дерева решений. Разработано достаточно много таких ал-
горитмов. Сформулируем общую цель, которая должна преследоваться при выборе
атрибута ветвления: очередной выбранный атрибут должен обеспечивать наилучшее
разбиение в узле. Наилучшим разбиением считается то, которое позволяет класси-
фицировать наибольшее число примеров и создавать максимально чистые подмно-
жества, в которых примесь объектов другого класса (то есть не ассоциированного
с данным узлом или листом) минимальна.
Хотя между алгоритмами построения деревьев решений имеются существенные
различия, все они основаны на одной и той же процедуре — рекурсивном разбиении
данных на все более малые группы таким образом, чтобы каждое новое поколение
узлов содержало больше примеров одного класса, чем родительский.
Выбор атрибута разбиения в узле
Процесс создания дерева начинается с подготовки обучающего множества. В итоге
будет построено дерево, которое назначает класс (или вероятность принадлеж-
ности к классу) для выходного поля новых записей на основе значений входных
переменных.
Мерой оценки возможного разбиения является так называемая чистота
(purity), под которой понимается отсутствие примесей. Существует несколько
способов определения чистоты, но все они имеют один и тот же смысл. Низкая
чистота означает, что в подмножестве представлены объекты, относящиеся к раз-
личным классам. Высокая чистота свидетельствует о том, что члены отдельного
класса доминируют. Наилучшим разбиением можно назвать то, которое дает наи-
большее увеличение чистоты дочерних узлов относительно родительского. Кроме
434 Часть I. Теория бизнес-анализа
того, хорошее разбиение должно создавать узлы примерно одинакового размера
или как минимум не создавать узлы, содержащие всего несколько записей. Рас-
смотрим рис. 9.5.
Хорошее разбиение
Рис. 9.5. Различные варианты разбиений
В исходном множестве представлена смесь объектов различной формы (треу-
гольники и круги) в пропорции 1 : 1 (10 кругов и 10 треугольников). Разбиение
слева признано плохим, потому что оно не увеличивает чистоту результирующих
узлов: пропорция объектов обоих классов в них сохраняется и также составляет 1:1
(5 кругов и 5 треугольников). Во втором случае плохого разбиения (справа) с помо-
щью условия в родительском узле удалось добиться доминирования класса в одном
из дочерних узлов (круги), но к классу было отнесено только два объекта. Такое
разбиение неудачно по двум причинам. Во-первых, правило, с помощью которого
было получено это разбиение, имеет очень низкую значимость, то есть относится
к малому числу примеров. Во-вторых, чистота другого узла осталась низкой: соот-
ношение объектов в нем — 0,8:1 (8 кругов и 10 треугольников). И хотя в целом чи-
стота относительно родительского узла улучшилась (класс треугольников стал слабо
доминирующим), это не позволяет говорить о положительном результате. Наконец,
случай хорошего разбиения обеспечивает абсолютную чистоту обоих дочерних узлов,
поскольку в каждый из них распределены объекты только одного класса.
Алгоритмы построения деревьев решений являются «жадными». Они раз-
виваются путем рассмотрения каждого входного атрибута по очереди и оцени-
вают увеличение чистоты, которое обеспечило разбиение с помощью данного
атрибута.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 435
ЗАМЕЧАНИЕ
«Жадными» называются алгоритмы, которые на каждом шаге делают локально оптималь-
ный выбор, допуская, что итоговое решение также окажется оптимальным. Для большо-
го числа алгоритмических задач «жадные» алгоритмы действительно дают оптимальное
решение. Однако вопрос о применимости «жадного» алгоритма в каждом классе задач
решается отдельно. При построении деревьев решений «жадность» алгоритма заключается
в следующем: для каждого узла ищется оптимальный атрибут разбиения и предполагается,
что дерево в целом также будет оптимальным.
После того как все потенциальные атрибуты будут проверены, тот из них, кото-
рый обеспечит наилучшее разбиение, будет использован для начального разбиения
в корневом узле, в результате чего будут созданы дочерние узлы. Если дальнейшее
разбиение невозможно (например, из-за того, что в узле осталось всего два приме-
ра) или ни одно возможное разбиение не может увеличить чистоту дочерних узлов,
то алгоритм завершит работу, а текущий узел будет объявлен листом.
ЗАМЕЧАНИЕ--------------------------------------------------------------
Еще одним важным свойством деревьев решений является ацикличность. Выбрав атрибут
разбиения в определенном узле и выполнив соответствующее разбиение, алгоритм не мо-
жет вернуться назад, если оно оказалось неоптимальным, и выполнить новое разбиение на
основе другого атрибута. Иными словами, если по какой-либо причине на определенном
шаге построения дерева решений было получено неудачное разбиение, алгоритм все рав-
но будет продолжать строить дерево. Чтобы компенсировать неудачный выбор, алгоритму
потребуется создать дополнительные узлы, что приведет к увеличению сложности дерева
и временных затрат на его построение.
Г(С,)
С,
Рис. 9.6.
Иллюстрация
первого случая
Принцип «разделяй и властвуй»
Процесс рекурсивного разбиения подмножеств в узлах дерева решений получил
название «разделяй и властвуй» (divide and conquer). В его основе лежит следующий
принцип. Пусть задано множество Т, в котором определены классы {Cb С2... С*.}.
Тогда существуют три возможных варианта разбиения.
1. Множество Т содержит два примера или более, которые отно-
сятся к одному классу Cj. Деревом решений для множества Тбу-
дет лист, идентифицирующий класс Q. Это тривиальный слу-
чай, который на практике не представляет интереса. Графически
он может быть интерпретирован, как показано на рис. 9.6.
2. Множество Тне содержит примеров, то есть является пустым.
Деревом решений также будет лист, но класс, ассоциирован-
ный с данным листом, должен быть определен из другого
множества, например родительского. Этот случай иллюстриру-
ется на рис. 9.7. После разбиения по атрибуту Доход ветвление
продолжилось по атрибуту Образование.
Как должен вести себя алгоритм, если в обучающем множестве нет ни одного
наблюдения, где Доход = Высокий и Образование = Среднее? Алгоритм должен
436 Часть I. Теория бизнес-анализа
создать три дочерних узла, и в 7\ окажется пустое множество. Тогда сгенериру-
ется узел, который будет ассоциирован с классом, наиболее часто встречающим-
ся в родительском множестве.
Су — наиболее часто встречающийся класс
Рис. 9.7. Иллюстрация второго случая
3. Множество Т содержит примеры, относящиеся к различным классам. Задача
заключается в разделении Т на подмножества, ассоциированные с классами.
Выбирается один из входных атрибутов, принимающий два отличных друг от
друга значения щ, о2- v„ или более, после чего Тразбивается на подмножества
{И (щ), Т> (п2 )-• Т„ (п„)}, где каждое подмножество Т, содержит все примеры из
исходного множества, в которых выбранный атрибут принимает значение п;.
Данная процедура будет рекурсивно повторяться до тех пор, пока подмножества
не будут содержать примеры только одного класса. Этот случай проиллюстри-
рован на рис. 9.8.
Рис. 9.8. Иллюстрация третьего случая
Пусть требуется определить класс риска, связанный с выдачей кредита клиенту,
на основе двух атрибутов — Доход и Имущество. Атрибуты принимают по два
значения — Высокий и Низкий. На первом шаге алгоритм разобьет исходное
множество на два подмножества, в одно из которых будут помещены клиенты
с высокими доходами, а в другое — с низкими. Предположим, что все клиенты
с высокими доходами относятся к классу низкого кредитного риска, поэтому со-
ответствующее подмножество будет объявлено листом и дальнейшее разбиение
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 437
в нем остановится. Другое подмножество, в котором остались клиенты с низ-
ким доходом, подвергается проверке с помощью атрибута Имущество. Логика
проста: если клиент не имеет высокого дохода, но имеет достаточно имущества,
чтобы покрыть кредит при невозможности его выплатить, то кредитный риск
может быть определен как низкий.
Данный случай является наиболее распространенным и практически важным
в процессе построения деревьев решений.
Процесс построения дерева решений не является однозначно определенным.
Для различных атрибутов и даже для различного порядка их применения могут
быть сгенерированы различные деревья решений. В идеальном случае разбиения
должны быть такими, чтобы результирующее дерево оказалось наиболее компакт-
ным. Встает вопрос: почему бы тогда не исследовать все возможные деревья и не
выбрать самое компактное? К сожалению, во многих реальных задачах перебор
всех возможных деревьев решений приводит к комбинаторному взрыву. Даже для
небольшой базы данных, содержащей всего 5 атрибутов и 15 примеров, возможное
число деревьев превышает 106 в зависимости от количества значений, принима-
емых каждым атрибутом.
Эффективность разбиения оценивается по чистоте полученных дочерних узлов
относительно целевой переменной. От ее типа и будет зависеть выбор предпоч-
тительного критерия разбиения. Если выходная переменная является категори-
альной, то необходимо использовать такие критерии, как индекс Джини, прирост
информации или тест хи-квадрат. Если выходная переменная является непрерыв-
ной, то для оценки эффективности разбиения используются метод уменьшения
дисперсии или Е-тест (рис. 9.9).
Рис. 9.9. Критерии разбиения
9.2. Алгоритмы построения деревьев решений
Если обратиться к истокам деревьев решений, то можно увидеть, что одни методы
их построения были разработаны в рамках теории машинного обучения, а другие
пришли из математической статистики. Все они имеют определенные преимущества
438 Часть I. Теория бизнес-анализа
и недостатки: одни могут работать только с категориальной выходной переменной
а другие — с непрерывной; одни работают медленнее, а другие — быстрее; одни
методы более точны, чем другие, и т. д. Аналитик выбирает тот или иной алгоритм
исходя из особенностей конкретной задачи анализа.
Прежде чем приступить к обзору распространенных алгоритмов построения
деревьев решений, введем в рассмотрение несколько важных понятий.
Полное дерево решений
Процесс роста дерева решений начинается с разбиения корневого узла на два
потомка или более, каждый из которых рекурсивно подвергается дальнейшему
разбиению. При этом каждый раз все входные атрибуты рассматриваются как по-
тенциальные атрибуты разбиения, даже те, что уже использовались ранее, кроме
атрибутов, все значения в которых одинаковы. Такие атрибуты исключаются из
рассмотрения, поскольку с их помощью нельзя разделить примеры различных
классов. Когда больше не удается обнаружить разбиения, значимо повышающие
чистоту дочерних узлов, или когда число примеров в узле достигает некоторого
заданного минимума, процесс разбиения для данной ветви заканчивается. Узел
объявляется листом.
Когда найти в дереве какие-либо новые разбиения, повышающие его точность,
не удается и разбиение прекращается по всем ветвям, это значит, что построено
полное дерево. Как мы увидим позднее, полное дерево не является оптималь-
ным.
Если существуют полностью детерминистические отношения между входными
и выходной переменными, то рекурсивное разбиение в конечном итоге дает дерево
с абсолютно чистыми листьями. В реальности такое встречается редко.
Меры эффективности деревьев решений
В целом эффективность деревьев решений определяется с помощью тестового
множества — набора примеров, которые не использовались при построении дерева.
Дереву предъявляется набор тестовых примеров и вычисляется, для какого про-
цента примеров класс был определен правильно. Это позволяет оценить ошибку
классификации, а также качество решения задачи классификации или регрессии
отдельных ветвей в дереве.
Каждый узел или лист дерева обладает следующими характеристиками:
□ количество примеров, попавших в узел (лист);
□ доли примеров, относящихся к каждому из классов;
□ число классифицированных примеров (для листьев);
□ процент примеров, верно классифицированных данным узлом (листом).
Особый интерес представляет количество правильно классифицированных
записей в данном узле или листе. Поэтому для оценки качества классификации
вводятся два показателя — поддержка (support) и достоверность (confidence).
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 439
Поддержка определяется как отношение числа правильно классифицированных
примеров в данном узле или листе к общему числу попавших в него примеров,
то есть:
с_ N«'
N, ’
* * общ
Очевидно, что значение поддержки может изменяться от 0 до 1.
Достоверность определяется как отношение числа правильно классифициро-
ванных примеров к числу ошибочно классифицированных, то есть:
с
N он.
Значит, чем больше число правильно классифицированных примеров в узле,
тем выше достоверность.
Поддержка и достоверность могут использоваться в качестве параметров по-
строения дерева решений. Например, можно задать, что разбиение должно произ-
водиться до тех пор, пока в узле не будет достигнут заданный порог поддержки.
Критерии выбора наилучших атрибутов ветвления
Существует множество различных подходов к оценке потенциальных разбиений.
При этом методы, разработанные в рамках теории машинного обучения, в основном
сосредотачиваются на повышении чистоты результирующих подмножеств, в то
время как статистические методы фокусируются на статистической значимости
различий между распределением значений выходной переменной в узлах. Аль-
тернативные методы разбиения часто приводят к построению совершенно разных
деревьев, которые, впрочем, функционируют примерно одинаково. Различные меры
оценки чистоты ведут к выбору различных атрибутов разбиения, но, поскольку все
меры основаны на одной и той же идее, полученные с их помощью модели будут
похожи.
Для выбора атрибута ветвления в случае категориальной целевой переменной
используются такие методы, как:
□ индекс Джини, или метод разнообразия выборки (Gini-index);
□ энтропия, или прирост информации (information gain);
□ отношение прироста информации (gain-ratio);
□ тест хи-квадрат (chi-square test).
Данные методы применимы и тогда, когда целевая переменная является непре-
рывной, но в этом случае необходимо предварительно выполнить ее квантование.
Индекс Джини
Один из популярных критериев разбиения получил название индекса Джини
в честь итальянского статистика и экономиста. Эта мера основана на исследовании
разнообразия совокупности. Она определяет вероятность того, что два объекта,
440 Часть I. Теория бизнес-анализа
случайным образом выбранные из одной совокупности, относятся к одному классу.
Очевидно, что для абсолютно чистой выборки данная вероятность равна 1.
Мера Джини для узла представляет собой простую сумму квадратов долей
классов в узле. В случае, представленном на рис. 9.10, родительский узел содержит
одинаковое количество светлых и темных кругов.
Рис. 9.10. Пример разбиения
Для узла, в котором содержится равное число объектов, относящихся к двум
классам, можно записать: 0,52 + 0,52 = 0,5. Такой результат вполне ожидаем, по-
скольку вероятность того, что случайно дважды будет выбран пример, относящий-
ся к одному классу, равна 1/2. Индекс Джини для любого из двух результирующих
узлов будет 0,12 + 0,92 = 0,82. Идеально чистый узел имеет значение индекса
Джини, равное 1. Узел, в котором содержится равное число объектов двух классов,
будет иметь значение индекса 0,5. Таким образом, предпочтение следует отдать
тому атрибуту, который обеспечит максимальное значение индекса Джини.
Уменьшение энтропии, или прирост информации
Из теории информации известно, что чем больше состояний может принимать
некоторая система, тем сложнее ее описать и тем больше информации для этого
потребуется. Примером может служить кодирование цифровых изображений.
Для представления каждой точки черно-белого изображения достаточно одного
бита. Если он принимает значение 1, точка черная, а если 0 — белая. Когда нужно
описать изображение, содержащее 256 оттенков, для задания каждой его точки
потребуется k = log2 256 — 8 бит и т. д.
Аналогичный подход можно применить к описанию подмножества в некото-
ром узле дерева решений. Если лист совершенно чистый, то все попавшие в него
примеры относятся к одному классу и его описание будет очень простым. Но если
лист содержит смесь объектов различных классов, то его описание усложнится
и для этого потребуется большее количество информации. В теории информации
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 441
существует мера количества информации — энтропия. Она отражает степень не-
упорядоченности системы.
В контексте нашего рассмотрения энтропия — это мера разнообразия классов
в узле. Проще говоря, будем считать, что это мера, определяющая количество во-
просов «да/нет», на которые нужно ответить, чтобы определить состояние системы.
Если существует 16 возможных состояний, это даст log2 (16), или 4 бита, необходи-
мых для описания всех состояний.
Целью разбиения узла в дереве решений является получение дочерних узлов
с более однородным классовым составом. В результате разбиения должны образо-
вываться узлы с меньшим разнообразием состояний выходной переменной. Сле-
довательно, энтропия падает, а количество внутренней информации в узле растет.
Уменьшение энтропии эквивалентно приросту информации.
Известно, что значение энтропии для некоторого множества максимально тогда,
когда все классы в этом множестве равновероятны, то есть с точки зрения класси-
фикации имеет место полная неопределенность. Когда вероятность появления од-
ного из классов увеличивается, энтропия множества уменьшается. При разбиении
целесообразно выбрать атрибут, который позволит разбить множество так, чтобы
в результирующих подмножествах определенный класс стал доминирующим,
то есть алгоритм должен минимизировать энтропию.
Формально энтропия определенного узла Тдерева решений определяется фор-
мулой
Info^^^pjlogipj (9.1)
7 = 1
и представляет собой сумму всех вероятностей появления примеров, относящихся
кj-му классу, умноженную на логарифм этой вероятности. Поскольку вероятность
меньше или равна 1, значение логарифма всегда будет отрицательным. На практике
эта сумма обычно умножается на — 1 для получения положительного числа.
Энтропия всего разбиения — это сумма энтропий всех узлов, умноженных на
долю записей каждого узла в числе записей исходного множества.
Пусть в некотором узле дерева решений содержится множество Т, которое
состоит из N примеров. При этом неважно, является ли данный узел корневым
или потомком. Тогда по формуле (9.1) для него может быть рассчитана энтропия
Info (Г). В результате разбиения S для данного узла были созданы k потомков 7),
Т2... Тк, каждый из которых содержит число записей У, N2 и АД. Для потомков рас-
считывается энтропия по формуле (9.1}: InfofTf, Info{Tf)... Info{Tk). Тогда общая
энтропия разбиения 5:
Info^S} = Info(Tt) + ^ • Info(T2) + ... + • Infoflf) = YrjT-In-MTi). (9.2)
IV IV IV • j x V
Для бинарной целевой переменной, показанной на рис. 9.10, формула энтропии
отдельного узла будет:
Info(T') = (-!)• (Р(темные) • log 2 Р(темные) + Р(светлые) • log2 Р(светлые)).
442 Часть I. Теория бизнес-анализа
Здесь Р(темные) — вероятность того, что случайно выбранная из подмножества
запись имеет значение целевой переменной Темные. В нашем примере вероятности
Р(темные) и Р(светлые) равны 0,5. Подставив значение 0,5 в предыдущую формулу,
получим:
7n/o(T) = -l-(0,54og20,5 + 0,5Uog20,5) = -Mog2(0,5) = l.
Что собой представляет энтропия узлов, полученных в результате разбиения?
Один из них содержит 1 темный и 9 светлых объектов, в то время как другой —
1 светлый и 9 темных. Очевидно, что оба узла имеют одинаковую энтропию:
Info(T, ) = lnfo(T2} = —1 - (0,1 - log2 0,1 + 0,9-log20,9) = 0,33 + 0,14 = 0,47.
Для вычисления общей энтропии разбиения воспользуемся формулой (9.2):
/лЯ5) = ^./лЯГ,) + ^-/л/о(Г2) = ^.0,47 + ^.0,47 = 0,47.
В результате разбиения уменьшение полной энтропии, или прирост инфор-
мации, составит Gain(S) = 1 — 0,47 = 0,53. Это показывает, что данное разбиение
является эффективным.
Отношение прироста информации
Энтропия как мера эффективности разбиения в узле может использоваться совмест-
но с методологией разбиения путем создания отдельной ветви для каждого значения
атрибута. Это так называемый алгоритм ID3 (Iterative Dihotomizer 3), разработанный
австралийским ученым Дж. Р. Куинленом (J. Ross Quinlan). Практическое приме-
нение данного алгоритма сопряжено с большой проблемой, а именно: только при
разбиении набора данных на достаточное число небольших подмножеств количество
классов, представленное в каждом узле, имеет тенденцию сокращаться и их энтропия,
следовательно, тоже. Поэтому деревья решений, которые строятся с использованием
критерия уменьшения энтропии, предрасположены к сильной ветвистости.
Сложные деревья с большим числом ветвей имеют узлы с малым количеством
примеров, трудно интерпретируются, ведут к снижению устойчивости модели
в целом. Для решения этой проблемы были разработаны модификации алгоритма
ID3, такие как алгоритмы С4.5, С5.0 и др. В них используется отношение полного
прироста информации, полученного в результате данного разбиения, к приросту
информации в данном узле. Такой метод называется отношением прироста инфор-
мации (gain-ratio). Он уменьшает ветвистость деревьев.
Тест хи-квадрат
Тест хи-квадрат — это тест статистической значимости различия между распреде-
лениями значений двух выборок, разработанный К. Пирсоном. Тест представляет
собой оценку вероятности того, что статистические законы распределения для двух
неупорядоченных совокупностей наблюдений значимо различаются. При использо-
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 443
Бании чистоты в качестве меры эффективности разбиения большое значение теста
хи-квадрат говорит о том, что различие значимо.
На основе критерия хи-квадрата построен популярный алгоритм CHAID (Chi-
square Automatic Interaction Detector). Принцип его работы основан на обнаруже-
нии статистических связей между переменными. Критерий хи-квадрат применяется
для категориальных переменных, поэтому и в CHAID входные переменные должны
быть категориальными. Непрерывные переменные должны быть подвергнуты кван-
тованию. Иногда критерий хи-квадрат используется для построения разбиений на
основе категориальных переменных, в то время как для непрерывных переменных
применяются другие статистические тесты, например F-тест.
Уменьшение дисперсии
Все рассмотренные выше меры используются только для категориальных целевых
переменных. Когда целевая переменная числовая, удачное разбиение должно умень-
шать ее дисперсию. Напомним, что дисперсия представляет собой меру разброса
значений случайной переменной относительно ее среднего значения. В выборке с ма-
лой дисперсией все значения переменной сосредоточены вблизи среднего значения,
а в выборке с большой дисперсией они имеют существенный разброс относительно
среднего. Хотя метод уменьшения дисперсии применяется для разбиения по число-
вым переменным, его работу можно проиллюстрировать с помощью рис. 9.10 для
светлых (0) и темных (1) кружков. Среднее значение в родительском узле будет:
тпх = (1/А)-£> =0,5,
/ = 1
где х, — наблюдаемое значение целевой переменной;
N — число наблюдений.
Каждое наблюдение, то есть 0 или 1, отличается от среднего также на 0,5, то есть
|х, — т| = 0,5. Следовательно, дисперсия будет:
4 .V -I N
О=,уЕ^-»-.)2 = 2ёХ0-51 = 0’25-
После разбиения левый узел содержит 9 темных и 1 светлый кружок, поэтому
среднее значение для данного узла составит тх = 0,9. Тогда для 9 наблюдений
значения целевой переменной будут отличаться от среднего значения на 0,1 и для
1 наблюдения — на 0,9. Значит, дисперсия в данном узле составит D — 0,09. По-
скольку оба узла, полученные в результате разбиения, будут иметь дисперсию
D = 0,09, общая дисперсия составит 0,09. Тогда уменьшение дисперсии по сравне-
нию с родительским узлом будет 0,25 — 0,09 = 0,16.
F-критерий Фишера
Еще одним статистическим критерием, который может оказаться полезным при
построении разбиений для случая числовой целевой переменной, является критерий
444 Часть I. Теория бизнес-анализа
Фишера (Ronald A. Fisher), или F-критерий. Он позволяет оценить вероятность того
что выборки наблюдений, имеющие различные среднее и дисперсию, принадлежат
одной и той же совокупности. Иными словами, F-критерий показывает, являются ли
различия статистических свойств выборок, полученных при разбиении совокупно-
сти в родительском узле, значимыми. Если это так, то разбиение является удачным.
В противном случае хорошо разделить объекты различных классов не удалось.
Существует связь между дисперсией выборки и дисперсией совокупности, из
которой данная выборка была извлечена. Фактически если выборка формируется
случайным отбором и имеет приемлемый размер, то ее дисперсия может служить
хорошей оценкой дисперсии всей совокупности. Если выборка слишком мала,
например 30 или менее наблюдений, то ее дисперсия обычно оказывается выше,
чем дисперсия исходной совокупности. F-тест проверяет связь между двумя оцен-
ками дисперсии совокупности и выборки из нее. Первая оценка получается путем
объединения всех выборок и вычисления на их основе общей дисперсии. Вторая
оценка вычисляется как дисперсия по отдельным выборкам, полученным из сово-
купности. Если различные выборки случайным образом извлечены из одной и той
же совокупности, эти две оценки должны быть хорошо согласованы.
Отношение этих двух оценок называется F-статистикой. Чем больше значе-
ние F-статистики, тем меньше вероятность того, что выборки принадлежат одной
совокупности. Следовательно, в дереве решений большое значение F-статистки
показывает, что разбиение позволило успешно разделить совокупность примеров
в узле на подмножества, которые имеют значимо различающиеся распределения.
9.3. Алгоритмы ID3 и С4.5
Одними из наиболее популярных алгоритмов построения деревьев решений явля-
ются алгоритм ID3 и его модификация С4.5.
Алгоритм ID3 начинает работу со всеми обучающими примерами в корневом
узле дерева. Для разделения множества примеров корневого узла выбирается один
из атрибутов, и для каждого значения, принимаемого этим атрибутом, строится
ветвь и создается дочерний узел. Затем все примеры распределяются по дочерним
узлам в соответствии со значением атрибута.
Поясним это на рис. 9.11. Пусть атрибут X принимает три значения: А,ВиС. То-
гда при разбиении исходного множества Т по атрибуту X алгоритм создаст три
дочерних узла Tj(A), Т2(В) и Т3(С), в первый из которых будут помещены все записи
со значением А, во второй — со значением В, а в третий — со значением С.
Рис. 9.11. Разбиение по атрибуту
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 445
Алгоритм повторяется рекурсивно до тех пор, пока в узлах не останутся только
примеры одного класса, после чего узлы будут объявлены листами и разбиение
прекратится. Наиболее проблемным этапом алгоритма является выбор атрибута,
по которому будет производиться разбиение в каждом узле.
Для выбора атрибута разбиения ID3 использует критерий, называемый при-
ростом информации (information gain), или уменьшением энтропии (entropy
reduction).
Введем в рассмотрение меру прироста информации, вычисляемую как:
Gain(S) = Info (Д) - Infos (Д), (9.3)
где Info (Д) — энтропия множества Т до разбиения;
Infos(T) — энтропия после разбиения S.
Данная мера представляет собой прирост количества информации, получен-
ный в результате разделения множества Т на подмножества Д, Д... Д с помощью
разбиения S. В качестве наилучшего атрибута для использования в разбиении
S выбирается тот атрибут, который обеспечивает наибольший прирост информа-
ции Gam (5).
Рассмотрим пример. Пусть имеется набор данных Д содержащий 14 записей
и 3 входных атрибута — Alt Аг, А3, а также выходной атрибут (метку класса) С, ко-
торый принимает два значения — С> и С2 (табл. 9.2).
Таблица 9.2. Набор данных для иллюстрации работы алгоритма ID3
№ п/п А1 Аг Аз С
1 А 70 Да с,
2 А 90 Да Сг
3 А 85 Нет С2
4 А 95 Нет Сг
5 А 70 Нет с.
6 В 90 Да С,
7 В 78 Нет с,
8 В 65 Да с,
9 в 75 Нет с,
10 с 80 Да Сг
И с 70 Да Сг
12 с 80 Нет с,
13 с 80 Нет с,
14 с 96 Нет с,
В данном примере 9 записей относится к классу Сь а пять — к классу С2. Энтропия
множества Тбудет Infо(Т) — — (9/14) • log2 (9/14) — (5/14) • log2 (5/14) = 0,94 бит.
После использования атрибута А, для разбиения исходного множества на три
подмножества: Д(А), Д(В) и Т3(С) — общая энтропия разбиения составит (условно
полагаем, что log2 (0) = 0):
446 Часть I. Теория бизнес-анализа
Info,, (Г) = 5/14(-2/5-log2 (2/5)-3/5- log2 (3/5)) +
+4/14(-4/4-log2(4/4) — 0/4-log2(0/4)) +
+5/14(—3/5-log2(3/5) —2/5-log2(2/5)) = 0,694 бит.
Таким образом, прирост информации при использовании атрибута At для раз-
биения исходного подмножества составит:
GainfSt) = 0,94 - 0,694 = 0,246 бит.
При использовании разбиения на основе атрибута А3, проведя аналогичные
вычисления, получим:
F.s„(7’) = 6/14(-3/6-log2(3/6)-3/6-log2(3/6)) +
+8/14(-6/8- log2 (6/8) — 2/8 • log 2 (2/8)) = 0,892 бит.
Тогда прирост информации, обеспечиваемый разбиением исходного множества
на основе атрибута А:), будет
Gain(S3) — 0,94 — 0,892 = 0,048 бит.
Итак, для начального разделения множества Г алгоритм выберет разбиение S-,
с использованием атрибута At как обеспечивающее наибольший прирост инфор-
мации. Для нахождения оптимальной проверки необходимо также рассмотреть
атрибут А2.
Ранее рассматривались разбиения по категориальным атрибутам. Но в текущем
примере мы столкнулись с необходимостью проверки по числовому атрибуту Аг-
Проверки по таким атрибутам сложнее, поскольку требуется установка порогов
для разбиения, которая в общем случае может быть произвольной. Существует
алгоритм для определения оптимального значения порога z. Сначала обучающие
примеры сортируются в том порядке, в котором будут рассматриваться значения
атрибута: (и,, v2... v„). Тогда существует только т — 1 порогов из возможных раз-
биений, каждое из которых должно быть проверено на предмет максимального
прироста информации. При этом в качестве порога могут выбираться срединные
точки между соседними значениями (и, , п,ч |)/2 или наименьшие значения из ка-
ждого интервала (г?, , n(+i).
Для иллюстрации данного способа нахождения порога возьмем числовой атри-
бут Л2. После сортировки примеров множества по возрастанию значений атрибута
получим следующий порядок: {65, 70, 75, 78, 80,85, 90,95, 96} — и множество воз-
можных пороговых значений z = {65, 70, 75, 78, 80, 85, 90, 95}. Из девяти значений
оптимальным будет то, которое обеспечивает наибольший прирост информации.
Если для каждого потенциального порога определить прирост информации по-
добно тому, как ранее это делалось для значений категориальной переменной, то
можно обнаружить, что лучшим значением порога будет z = 80. Соответствующий
процесс вычисления прироста информации для разбиения 52 (А2 < 80 или А2 > 80),
производится следующим образом:
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 447
InfoSl (T) = 9/14(-7/9-log2(7/9)-2/9-log2(2/9)) +
+5/14(-2/5-log2(2/5) —3/5-log2(3/5)) = 0,837 6nT;
Gain(X3) = 0,94 - 0,837 = 0,103 бит.
Теперь можно сравнить прирост информации для всех трех атрибутов иллю-
стративного примера. Видим, что атрибут Л] по-прежнему обеспечивает наиболь-
ший прирост информации — 0,246 и, следовательно, он должен быть выбран для
использования в первом разбиении дерева решений.
Корневой узел произведет проверку для атрибута Ах, в результате чего будут
созданы три ветви — по одной для каждого значения атрибута (рис. 9.12).
Рис. 9.12. Разбиение по первому атрибуту для примера из табл. 9.2
После начального разбиения все узлы-потомки будут содержать по нескольку
наблюдений из исходного множества, и для каждого узла затем будет повторен
процесс выбора атрибута разбиения и оптимизации порога (если для разбиения
используется числовой атрибут). Поскольку узел-потомок Т2, полученный в ветви
для значения В, содержит 4 наблюдения, которые относятся к одному классу, то
энтропия равна 0, узел объявляется листом и дальнейшее ветвление для него не
проводится.
Для узла Г], включающего 5 наблюдений, может быть сделана проверка по
оставшимся атрибутам. Опуская промежуточные расчеты, констатируем, что опти-
мальное разбиение будет достигнуто с помощью атрибута Л2 для альтернативных
вариантов А2 < 70 или А2 > 70. Поскольку множество 1\ содержит 5 наблюдений,
из которых два относятся к классу Съ а три — к классу С2, то в соответствии с фор-
мулой энтропии можно записать:
Infos-i (Л) = — 2/5- log2 (2/5)—3/5- log2 (3/5) = 0,97 бит.
При использовании атрибута А2 для разбиения Тх с порогом 70 получим чистые
узлы, поэтому InfoSt (Тх) = 0. Прирост информации, обеспеченный данным разбие-
нием, составит Gain(X3) — 0,94 —0 = 0,94 бит и будет максимальным.
448 Часть I. Теория бизнес-анализа
Аналогичным образом могут быть выполнены расчеты и для подмножества Т3
В нем оптимальна проверка по значениям атрибута А3. Следовательно, будут созда-
ны две новые ветви, соответствующие значениям А3 = Да и А3 = Нет. В результате
получим два однородных подмножества, содержащих наблюдения одного класса.
Результирующее дерево представлено на рис. 9.13.
Рис. 9.13. Сгенерированное алгоритмом ID3 дерево решений
ЗАМЕЧАНИЕ----------------------------------------------------------------
Если в процессе работы алгоритма получен пустой узел, не содержащий ни одного примера,
то он объявляется листом, с которым ассоциирован класс, наиболее часто встречающийся
в родительском узле.
Практическое применение классического алгоритма ID3 сопряжено с рядом
проблем, характерных для моделей, основанных на обучении вообще и деревьев ре-
шений в частности. Основными из них являются переобучение и наличие пропус-
ков в данных. Для их эффективного преодоления ID3 был доработан, в результате
чего появилось его расширение, названное С4.5. Рассмотрим его подробнее.
Проблема переобучения
Основной недостаток алгоритма ID3 — тенденция к переобучению. Например,
если данные содержат шум, то число уникальных значений атрибутов увеличит-
ся, а в крайнем случае для каждого примера обучающего множества значения
атрибутов окажутся уникальными. Следуя логике ID3, можно предположить, что
при разбиении по такому атрибуту будет создано количество узлов, равное числу
примеров, так как в каждом узле окажется по одному примеру. После этого каждый
узел будет объявлен листом и дерево даст число правил, равное числу примеров
обучающего набора. С точки зрения классифицирующей способности такая модель
бесполезна.
В качестве примера описанной ситуации возьмем случай, когда атрибут А] в вы-
борке, представленной в табл. 9.2, содержит не три значения — А, В и С, а 14 зна-
чений — от А до N. Тогда в результате разбиения будет сформировано 14 узлов,
в каждый из которых попадет только один пример, и на этом построение дерева
закончится. Дополнительно усложняет проблему тот факт, что критерий прироста
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 449
информации всегда будет приводить к выбору атрибутов с наибольшим количе-
ством уникальных значений. Действительно, если в результате разбиения будут
получены множества, содержащие по одному объекту, образующему один класс, то
частота появления этого класса окажется равной числу примеров, то есть 1. Таким
образом, в выражении для оценки количества информации появится log2( 1) = 0.
Следовательно, и все выражение обратится в ноль, то есть Infos(T) = 0. Всегда бу-
дет обеспечен максимальный прирост информации Gain (5) = шах, что приведет
к выбору алгоритмом соответствующего атрибута.
Данная проблема решается введением нормировки. В рассмотрение включается
дополнительный показатель, который представляет собой оценку потенциальной
информации, созданной при разбиении множества Г на п подмножеств Д:
5рМ/О(5) = -Е((|Д|/|Д|)-1о§2(|Д|/|Д|)).
; = 1
С помощью этого показателя можно модифицировать критерий прироста ин-
формации, перейдя к отношению:
Split-Info(S) = Gain(T)/Split-Infо(Т).
Новый критерий позволяет оценить долю информации, полученной при разби-
ении, которая является полезной, то есть способствует улучшению классификации.
Использование данного отношения обычно приводит к выбору более удачного
атрибута, чем обычный критерий прироста. Вычисление отношения прироста
проиллюстрируем с помощью примера из табл. 9.2.
Найдем прирост информации для разбиения Sc
Split-Info(Si) = -5/14 • log2 (5/14) -4/14 log2 (4/14) -5/14 • log2 (5/14) = 1,577.
Тогда отношение прироста будет:
Split-Info^ = 0,246/1,577 = 0,156.
Аналогичная процедура должна быть выполнена для остальных разбиений
в дереве решений.
Смысл этой модификации прост. Д/Д — отношение числа примеров в г-м под-
множестве, полученном в результате разбиения S, к числу примеров в родительском
множестве Д. Если в результате разбиения получается большое число подмножеств
с небольшим числом примеров, что характерно для переобучения, то параметр Split-
Info растет. Поскольку он стоит в знаменателе выражения, то Gain-ratio есть обычный
прирост информации, «оштрафованный» с помощью параметра Split-Info. Благодаря
этому атрибут, для которого параметр Split-Info растет, имеет меньше шансов быть
выбранным для разбиений, чем при использовании обычного Gain-критерия.
Неизвестные значения атрибутов
Рассматривая алгоритмы ID3 и С4.5, мы предполагали, что все значения атрибутов,
используемых при разбиении, известны. Но типичной проблемой реальных наборов
450 Часть I. Теория бизнес-анализа
данных является отсутствие значений атрибутов в отдельных наблюдениях. При-
чины появления отсутствующих значений и связанные с этим сложности излагались
в разделе 2.10. Если в наборе данных, для которого строится дерево решений, име-
ют место отсутствующие значения, то можно выбрать один из вариантов решения
данной проблемы:
□ исключить все наблюдения, содержащие пропущенные значения;
□ создать новый или модифицировать существующий алгоритм таким образом
чтобы он мог работать с пропусками в данных.
Первое решение простое, но оно часто неприемлемо из-за того, что в наборе
данных может присутствовать большое количество записей с пропущенными зна-
чениями. И если все такие записи будут исключены из рассмотрения, то оставшихся
записей окажется недостаточно для формирования обучающего множества.
При выборе альтернативного подхода необходимо ответить на следующие во-
просы.
□ Как сравнивать два наблюдения при отсутствующих значениях атрибутов?
□ Обучающие примеры с пропущенными значениями не могут использоваться
в разбиении по атрибуту, значение которого отсутствует, и поэтому не могут
быть отнесены ни к одному из полученных подмножеств. Как такие наблюдения
должны обрабатываться при разбиении?
□ Как работать с отсутствующим значением при классификации, если проверка
в узле производится по атрибуту, значение которого отсутствует?
Эти и многие другие вопросы возникают при попытке найти решение проблемы
пропущенных данных.
Различные классификационные алгоритмы обычно основаны на заполнении
пропусков наиболее вероятными значениями.
В алгоритме С4.5 предполагается, что наблюдения с неизвестными значениями
имеют статистическое распределение соответствующего атрибута согласно относи-
тельной частоте появления известных значений. Например, рассмотрим множество
наблюдений из табл. 9.2, в котором отсутствует значение атрибута Л] в строке 6.
Введем в рассмотрение параметр F, который представляет собой число наблю-
дений в наборе данных с известным значением данного атрибута, отнесенное к об-
щему числу наблюдений. Тогда модифицированный для работы с пропущенными
значениями критерий прироста информации будет иметь вид:
Gain(S) = F(lnfo(T) - Infos (Т)).
Аналогично параметр Split-Info(S) может быть видоизменен путем отнесения
числа наблюдений, содержащих пропущенные значения, к отдельным дополни-
тельно создаваемым подмножествам. Если разбиение S дает п подмножеств, его
параметр Split-Info(S) вычисляется, как если бы в результате разбиения было
получено п +1 подмножество.
Рассмотрим работу алгоритма С4.5, модифицированного для обработки пропу-
щенных значений, на примере из табл. 9.3.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 451
Таблица 9.3. Набор данных для иллюстрации работы алгоритма С4.5
№п/П Ai л2 Аз С
7 А 70 Да Cl
7 А 90 Да с2
7 А 85 Нет с2
Т А 95 Нет с2
7 А 70 Нет Cl
6 90 Да Cl
7 В 78 Нет Cl
8 В 65 Да Cl
9 В 75 Нет Cl
10 с 80 Да c2
11 с 70 Да c2
12 с 80 Нет Cl
13 с 80 Нет Cl
14 с 96 Нет Cl
Из 13 наблюдений, в которых значения атрибута Ai известны, 8 относятся
к классу Ci и 5 — к классу С2. Поэтому в результате разбиения по атрибуту At
получим:
Infos, (E) = -8/13-log2(8/13) —5/13-log2 (5/13) = 0,961 бит.
После разделения исходного множества Тс помощью атрибута Ai на подмноже-
ства в соответствии со значениями атрибутах, Ви С результирующая информация
определяется следующим образом:
Info.,, (E) = 5/13(-2/5-log2(2/5)-3/5-log2(3/5)) +
+3/13(-3/3-log2(3/3)-0/3-log2(0/3)) +
-|-5/14(—3/5-log2 (3/5) — 2/5-log2 (2/5)) = 0,747 бит.
Прирост информации, полученный в результате данного разбиения, корректи-
руется с помощью фактора F= 13/14 = 0,93. Тогда:
Gain($i) = F • (0,961 - 0,747) = 0,93 • (0,961 - 0,747) = 0,199 бит.
Прирост, полученный в результате данного разбиения, несколько ниже, чем для
множества из табл. 9.2 (то есть без пропусков), где он составлял 0,246:
5p/it-7n/o(X1) = -5/13-log2(5/13)-3/13-log2(3/13)-
-5/13-log2(5/13) — l/13-log2(l/13) = 1,876.
Когда наблюдение с известным значением атрибута переходит из множест-
ва Т в подмножество Т„ вероятность его отношения к Tt равна 1, а ко всем остальным
подмножествам — 0. Если в примере имеется пропущенное значение, то относительно
452 Часть I. Теория бизнес-анализа
данного примера может быть сделано только некоторое вероятностное предположе-
ние. При этом очевидно, что вероятность принадлежности примера ко всем подмно-
жествам, полученным в результате разбиения, будет равна 1 (то есть к какому-либо
из них он будет отнесен обязательно).
После разбиения множества Т на подмножества по атрибуту At запись, содер-
жащая пустое значение, будет распределена во все три полученных подмножества.
Данная ситуация проиллюстрирована на рис. 9.14.
Рис. 9.14. Пример разбиения множества
Веса Wi для примеров с пропусками будут равны вероятностям 5/13,3/13 и 5/13
соответственно. Теперь 7} может быть интерпретировано алгоритмом не как число
записей в соответствующем подмножестве, а как сумма весов w для данного под-
множества.
Практический пример работы алгоритма С4.5
Чтобы проиллюстрировать работу алгоритма С4.5, рассмотрим задачу кредитного
скоринга. Воспользуемся набором данных для оценки кредитного риска, представ-
ленным в табл. 9.4.
Таблица 9.4. Кредитные истории клиентов
№ кли- ента Сбере- жения Другие активы (недви- жимость, автомобиль и т. д.) Годовой доход, тыс. у. е. Кредитный риск
1 Средние Высокие 75 Низкий
2 Низкие Низкие 50 Высокий
3 Высокие Средние 25 Высокий
4 Средние Средние 50 Низкий
5 Низкие Средние 100 Низкий
6 Высокие Высокие 25 Низкий
7 Низкие Низкие 25 Высокий
8 Средние Средние 75 Низкий
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 453
Уровень риска, связанный с выдачей кредита клиенту, определяется на основе
трех признаков: количества имеющихся у него сбережений, наличия собственности
(автомобиль, недвижимость и т. д.), а также годового дохода. Первые два показате-
ля представлены в модели категориальными переменными Сбережения и Другие
активы, которые могут принимать три значения — Высокие, Низкие и Средние.
Доход клиента представлен числовой переменной Годовой доход.
Поскольку в 5 из 8 записей целевая переменная указывает на низкий кредитный
риск, а в оставшихся 3 записях — на высокий, энтропия исходного множества до
разбиения составит:
Info(T) = -YJPAo^iP]
j
5, (51 3,
-glog. s -5log2
= 0,954 бит.
Рассмотрим разбиение по атрибуту Сбережения. Две записи имеют значение
данного атрибута Высокие, три — Средние и три — Низкие. Тогда соответствующие
вероятности будут: Р„ыс„кие =2/8, Д релпис = 3/8 и Р„гакие = 3/8. Из двух записей, в ко-
торых присутствуют высокие сбережения, одна имеет значение целевой переменной,
указывающее на высокий кредитный риск, а вторая — на низкий. Тогда при случай-
ном выборе из этих двух записей вероятность появления каждого класса составит 0,5.
Следовательно, энтропия для значения Высокие атрибута Сбережения составит:
Info
DblCOKHC
(r) = _ll°g2[l -llog2
= 1 бит.
Три записи, в которых имеют место средние сбережения, содержат целевую
переменную, указывающую на низкий кредитный риск, поэтому соответствующая
энтропия будет:
/и/осредние (г) — д log 2 д
о, (о)
3 og2 3
= 0,
где условно полагаем, что log2 (0) = 0.
В технических приложениях информация рассматривается как аналог полез-
ного сигнала, а энтропия — как аналог шума. Отсюда понятно, почему энтропия
для средних сбережений равна 0: мы получили чистый сигнал без шума. Таким
образом, если потенциальный заемщик имеет средние сбережения, то кредитный
риск будет низким с поддержкой 100 %.
Теперь приведем аналогичные рассуждения для значения Низкие атрибута
Сбережения. Соответствующая энтропия будет:
e(T)-|10g2[|
21
2 (2)
--log2 - =0,918 бит.
г г 1
/Ylj О низкие
Затем, используя выражение (9.2), рассчитаем полную энтропию разбиения:
2 3 3
/и/ос6срсжс,1ИЯ (Г) = - • 1 + - • 0 + - 0,183 = 0,594 бита.
ООО
3
454 Часть I. Теория бизнес-анализа
Тогда прирост информации, полученный в результате разбиения по атрибуту
Сбережения, будет:
Gain(T) = Info(T')- /и/осбчкЖ1.,,Ия(Т) = 0,954 - 0,594 = 0,36 бит.
Как интерпретировать полученное значение? Во-первых, Info(T) — 0,954 озна-
чает, что в среднем потребуется 0,954 бита для представления кредитного риска
для 8 клиентов из табл. 9.4. Во-вторых, Infoc(Kpemm„ (Г) = 0,594 говорит о том, что
разделение клиентов на три подмножества понизило среднее количество бит, тре-
буемых для представления кредитного риска. Уменьшение энтропии после разбие-
ния указывает на то, что в целом разбиение является полезным, то есть повышает
чистоту дочерних узлов. В результате разбиения по переменной Сбережения мы
получили прирост информации на 0,36 бита.
Теперь мы должны вычислить прирост информации для остальных возможных
разбиений, представленных в табл. 9.5, и выбрать то из них, которое даст наиболь-
ший прирост информации (или, что одно и то же, уменьшение энтропии).
Таблица 9.5. Все варианты первого разбиения
№ разби- ения Дочерние узлы
1 Сбережения = Низкие Сбережения = Средние Сбережения = Высокие
2 Активы = Низкие Активы = Средние Активы = Высокие
3 Доход < 25 тыс. у. е. Доход > 25 тыс. у. е.
4 Доход < 50 тыс. у. е. Доход > 50 тыс. у. е.
5 Доход < 75 тыс. у. е. Доход > 75 тыс. у. е.
Потенциальное разбиение под номером 2 из табл. 9.5 использует атрибут Акти-
вы. В исходном множестве данных (см. табл. 9.4) две записи имеют значения дан-
ного атрибута Высокие, четыре записи — Средние и две — Низкие. Вероятности по-
явления соответствующих значений будут следующие: РВЫС0Кие = 2/8, РСреЛ1,ие = 4/8,
Риизкис = 2/8. Обе записи, в которых атрибут Активы принимает значение Высокие,
имеют значение целевой переменной, указывающее на низкий кредитный риск.
В результате будет получен совершенно чистый узел с нулевой энтропией. Анало-
гичная ситуация ранее имела место для значения Высокие атрибута Сбережения.
Три записи из четырех, в которых Активы = Средние, указывают на низкий
кредитный риск и одна запись — на высокий. Энтропия соответствующего потомка
рассчитывается как:
/и/Ьсрсдпнс (Г) — log2
= 0,811 бит.
4
В обеих записях, в которых клиенты имеют низкие активы, целевая переменная
указывает на высокий кредитный риск, поэтому соответствующий дочерний узел
также будет чистым с нулевой энтропией.
На основе результатов, полученных для каждого из трех узлов, вычислим пол-
ную энтропию разбиения по переменной Активы:
Глава 9. Data Mining: классификация и регрессия. Машинное обучение
455
2 4 2
Infom (Г) = — • 0 +—• 0,811 +=• 0 = 0,406бит.
О О О
Энтропия, полученная после разбиения по атрибуту Активы, меньше, чем по-
сле разбиения по атрибуту Сбережения, что указывает на более эффективное раз-
деление записей различных классов. Чтобы убедиться в этом, вычислим прирост
информации, полученный в результате разбиения по атрибуту Активы:
Gain(T) = Info (Г) - /н/оактивь, (Г) = О,954-0,406 = 0,548 бит.
Таким образом, прирост информации в результате разбиения по атрибуту Ак-
тивы больше, чем при разбиении по атрибуту Сбережения, что выдвигает его на
первое место среди возможных кандидатов.
При разбиении по числовому атрибуту Доход используются четыре порога —
25, 50, 75 и 100 тыс. Для возможного разбиения под номером 3 (см. табл. 9.5) три
записи содержат значение переменной Доход меньше 25 тыс., а остальные пять
записей — больше 25 тыс. Тогда соответствующие вероятности будут: Р<25ооо =3/8
И Р>25000 = 5 / 8.
Для одной из записей, в которых доход менее 25 тыс., указан низкий кредитный
риск, а для двух других — высокий. Тогда энтропия узла, в который будут помеще-
ны клиенты с доходом, меньше или равным 25 тыс., составит:
1 (1)2 (21
= (T)--log2к hI = 0,918бит.
Четыре из пяти записей с доходом более 25 тыс. имеют низкий кредитный риск,
и только одна запись — высокий. Тогда энтропия узла, куда попадут записи, сумма
дохода клиента в которых превышает 25 тыс., составит:
4 (4
/и/о>25000 = —з 10g 2 -j,
-•^logj-^ =0,722 бит.
Теперь вычислим энтропию для всего разбиения по условию Доход < 25 тыс.:
3 5
Info доходно» (Г) = -• 0,918 + -• 0,722 = 0,796 бит.
о О
Прирост информации, полученный в результате разбиения по атрибуту Доход
с порогом 25 тыс.:
баш(Т) =/и/о(Т)-/и/оДОХОД(25ооо) (Г) = 0,954 - 0,796 = 0,159 бит.
Эти расчеты показывают, что наименее эффективным является разбиение 3.
Далее рассмотрим потенциальное разбиение 4 (см. табл. 9.5), в котором исполь-
зуется атрибут Доход с порогом 50 тыс. Вычислим энтропию для него:
7и/одОх<>д(50000)
(7>|Ulog2
3,
-jlog,
31 3 3, (31 о,
5 +8‘ 3 °g2 3 "3 °g2
= 0,607 бит.
2
5
0
3
456 Часть I. Теория бизнес-анализа
Прирост информации составит:
Gam(T) = Info(T ') - Info лахол{ЖШУ) (Г) = 0,954 - 0,607 = 0,347 бит.
Данное значение прироста также существенно ниже, чем для атрибута Активы.
И наконец, рассмотрим разбиение 5 по атрибуту Доход с использованием поро-
га 75 тыс.:
InfOftoxodilMW) (Г) ~ о" — yl°g2
з, (з
у log 2 у
1
+ 8'
1. f1) °i
-jl°g2 J -jl0g2
= 0,862 бит;
4
7
Gain(T) = Info(T)- 1п/олтт(7МЮ) (Г) = 0,954 - 0,862 = 0,092 бит,
что является самым низким показателем среди всех потенциальных разбиений.
Таким образом, мы вычислили прирост информации, который обеспечивают все
возможные разбиения корневого узла. Полученные результаты в компактной форме
представлены в табл. 9.6.
Таблица 9.6. Варианты разбиений корневого узла с энтропией
№ разбиения Дочерние узлы Прирост информации
1 Сбережения = Низкие 0,36
Сбережения = Средние
Сбережения = Высокие
2 Активы = Низкие 0,548
Активы = Средние
Активы = Высокие
3 Доход < 25 тыс. у. е. 0,159
Доход > 25 тыс. у. е.
4 Доход < 50 тыс. у. е. 0,347
Доход > 50 тыс. у. е.
5 Доход < 75 тыс. у. е. 0,092
Доход > 75 тыс. у. е.
Видно, что разбиение по атрибуту Активы обеспечило наибольший прирост
информации, поэтому оно выбирается в качестве начального разбиения в корневом
узле дерева. Схема начального разбиения представлена на рис. 9.15.
Рис. 9.15. Результат первого шага алгоритма С4.5
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 457
Получилось два листа для значений Низкие и Высокие атрибута Активы, даль-
нейшее разбиение которых производиться не будет. Для значения Средние получен
узел, содержащий одну запись со значением целевой переменной Высокий и три
записи со значением Низкий. Поскольку в данном узле содержится смесь классов,
алгоритм будет выполнять дальнейшее разбиение подмножества в нем (обозначим
это подмножество Г). Для этого вновь будет произведен поиск оптимального раз-
биения. Множество Г] представлено в табл. 9.7.
Таблица 9.7. Множество Г(
№ кли- ента Сбережения Другие активы Годовой доход, тыс. долл. Кредитный риск
3 Высокие Средние 25 Высокий
4 Средние Средние 50 Низкий
5 Низкие Средние 100 Низкий
8 Средние Средние 75 Низкий
Три из четырех записей в узле имеют значение целевой переменной Низкий,
и одна — Высокий. Энтропия узла до разбиения составит:
/п/о(Г( ) =-^^ log2 =-|log2 |j-|log2 |j = 0,8116HT. Возможные разбиения в узле показаны в табл. 9.8. Таблица 9.8. Все варианты второго разбиения
№ разби- ения Дочерние узлы
1 Сбережения = Низкие Сбережения = Средние Сбережения = Высокие
2 Доход < 25 тыс. у. е. Доход > 25 тыс. у. е.
3 Доход < 50 тыс. у. е. Доход > 50 тыс. у. е.
4 Доход <75 тыс. у. е. Доход >75 тыс. у. е.
Для разбиения одна-единственная запись с низкими сбережениями имеет и низ-
кий кредитный риск наряду с двумя записями, содержащими средние сбережения.
Единственная запись с высокими сбережениями имеет высокий кредитный риск.
Поэтому энтропия узлов, полученных с помощью всех трех значений атрибута Сбе-
режения, равна 0, то есть /и/осберсжеиия (Г) = 0. Все три потомка, полученные в резуль-
тате разбиения, будут абсолютно чистыми. Ясно, что такое разбиение обеспечивает
максимальный прирост информации:
Gain(T\) = Info(T\) - Infoc(,^mm (Г ) = 0,811 - 0 = 0,811 бит.
Аналогично можно показать, что энтропия для разбиения по атрибуту Доход
с порогом 25 тыс. также равна 0 и такое разбиение обеспечивает максимальный
прирост информации. Но остановим выбор на разбиении по атрибуту Сбереже-
ния. Полное дерево, полученное в результате данного разбиения, представлено на
рис. 9.16.
458 Часть I. Теория бизнес-анализа
Рис. 9.16. Полное дерево решений
Таблицы частот
Напомним, что ключевым моментом в работе алгоритмов ID3 и С4.5 является
вычисление энтропии
Info{T) = £>,log2(py),
j
где pj — вероятность того, что случайно выбранная из множества Т запись отно-
сится к классу/.
Данная вероятность определяется как отношение числа записей /-го класса
к общему числу записей. Это означает, что для вычисления энтропии совершенно
не обязательно рассматривать все записи множества данных — достаточно исполь-
зовать информацию о частоте появления классов в этом множестве. Такая инфор-
мация представляется в специальных таблицах, называемых таблицами частот.
В столбцах таблицы частот приводятся атрибуты, которые могут использоваться
для разбиения, и принимаемые ими значения, а в строках для каждого значения
указывается количество записей, в которых атрибут принимает данное значение
при определенном состоянии переменной класса. Например, для множества из
табл. 9.2 может быть построена таблица частот следующего вида (табл. 9.9).
Из табл. 9.9 можно увидеть, что из четырех записей, в которых атрибут Ак-
тивы принимает значение Средние, одна связана с высоким кредитным риском,
а три — с низким.
Таблица частот сама по себе является очень информативным представлением,
например, для разведочного анализа. Даже простой визуальный анализ табл. 9.9
позволяет ответить на вопрос: что критичнее с точки зрения кредитного риска —
низкие сбережения или низкие активы? Поскольку все клиенты, имеющие низкие
активы, связаны с высоким кредитным риском, а клиенты с низкими сбережениями
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 459
Таблица 9.9. Пример таблицы частот
Сбережения Активы Годовой доход, тыс. у. е. Кредитный риск
Высокие L. Средние Низкие Высокие Средние Низкие <25 25-50 50-75 >75
1 0 2 0 1 2 2 1 1 0 Высокий
1 3 1 2 3 0 1 1 2 1 Низкий
распределились поровну, можно предположить, что низкие активы более важны.
Но риск зависит от состояний нескольких входных атрибутов, поэтому выводы,
которые могут быть сделаны на основе визуального анализа таблицы частот, явля-
ются приближенными. Чтобы получить более достоверные результаты, необходимо
использовать формальный подход.
Кроме того, таблица частот дает возможность сразу оценить эффективность
разбиений по тому или иному атрибуту. Так, если в столбце для определенного
значения атрибута присутствует 0, то соответствующее разбиение позволит по-
лучить максимальный прирост информации и чистый узел с нулевой энтропией,
который будет объявлен листом.
9.4. Алгоритм CART
CART (Classification and Regression Tree) — популярный алгоритм построения
деревьев решений, предложенный в 1984 г. (L. Breiman, J. Friedman, R. Olshen
и Ch. Stone).
Деревья решений, построенные с помощью CART, являются бинарными,
то есть содержат только два потомка в каждом узле.
Пусть задано обучающее множество, содержащее К примеров и У классов.
Введем в рассмотрение показатель, который позволит оценить эффективность
разбиения, полученного на основе конкретного атрибута. Обозначим его Q(s 1t),
где $ — идентификатор разбиения, t — идентификатор узла. Тогда можно запи-
сать:
Q(s 11) = 2-Л • РЛ£(Р(у | | ^)), (9.4)
7 = 1
где tL и tR — левый и правый потомки узла t соответственно;
Pi. — К /. /К — отношение числа примеров в левом потомке узла t к общему числу
примеров;
PR —KR/K — отношение числа примеров в правом потомке узла t к общему
числу примеров;
Р(; 1= К.'; /Кг — отношение числа примеров у'-го класса в tL к общему числу
примеров в tR,
460 Часть I. Теория бизнес-анализа
P(j'IМ = К?/К< — отношение числа примеровj-ro класса в tR к общему числу
примеров в tR.
Тогда наилучшим разбиением в узле t будет то, которое максимизирует пока-
затель Q(s 1t).
Рассмотрим ту же задачу предсказания кредитного риска потенциального кли-
ента банка, что и в примере на алгоритм С4.5 (см. табл. 9.4).
Все восемь примеров обучающего множества поступают в корневой узел дерева.
Поскольку алгоритм CART создает только бинарные разбиения, возможные кан-
дидаты, которые будут оцениваться на начальном этапе, представлены в табл. 9.10.
Непрерывный атрибут Доход был предварительно квантован с использованием
порогов 25, 50 и 75 тыс.
Таблица 9.10. Потенциальные разбиения
Разбиение Левый потомок, tL Правый потомок, tK
1 Сбережения = Низкие Сбережения е {Высокие, Средние}
2 Сбережения = Средние Сбережения 6 {Высокие, Низкие}
3 Сбережения = Высокие Сбережения G (Средние, Низкие}
4 Активы = Низкие Активы G {Высокие, Средние}
5 Активы = Средние Активы 6 {Высокие, Низкие}
6 Активы = Высокие Активы 6 {Средние, Низкие}
7 Доход < 25 Доход > 25
8 Доход < 50 Доход > 50
9 Доход <75 Доход > 75
Для каждого потенциального разбиения вычислим значения составляющих
выражения (9.4) и исследуем их влияние на значение всего показателя Q.
Можно увидеть, что Q(s увеличивается, когда оба сомножителя в выраже-
N
нии 9.4:2 • Р/. PR и | tL) - P(j 11R)) — также увеличиваются.
7 = 1
Обозначим сумму в выражении 9.4 через W (s 1t), то есть:
iv(s|t) = £(p(;K)-P(jM-
Компонент | будет расти при увеличении разности в скобках. Данная сум-
ма максимальна, когда количество примеров, относящихся к одному классу, в обоих
потомках максимально различается. Следовательно, значение окажется наиболь-
шим тогда, когда оба потомка вообще не будут содержать примеров одинаковых
классов. В частности, если классов только два, то оба потомка будут чистыми.
Теоретически максимальное значение W(s | ?) равно числу классов в обучающем
множестве. Поскольку в нашем примере только два класса — Высокий и Низкий,
максимальное значение W(s | равно 2. В табл. 9.11 приведены результаты расчета
компонентов выражения (9.4).
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 461
Таблица 9.11. Расчет значений меры Q для потенциальных разбиений
№ Pl Pr ₽(Л to Р( J1 to 2-PlPr W(s | t) Q(s 1 0
Низкий Высокий Низкий Высокий
1 0,375 0,625 0,333 0,667 0,8 0,2 0,46875 0,934 0,4378
2 0,375 0,625 1 0 0,4 0,6 0,46875 1,2 0,5625
3 0,25 0,75 0,5 0,5 0,667 0,333 0,375 0,334 0,1253
4 0,25 0,75 0 1 0,833 0,167 0,375 1,667 0,6248
5 0,5 0,5 0,75 0,25 0,5 0,5 0,5 0,5 0,25
6 0,25 0,75 1 0 0,5 0,5 0,375 1 0,375
7 0,375 0,625 0,333 0,667 0,8 0,2 0,46875 0,934 0,4378
8 0,625 0,375 0,4 0,6 1 0 0,46875 1,2 0,5625
9 0,875 0,125 0,571 0,429 1 0 0,21875 0,858 0,1877
Произведение Pl-Pr возрастает с увеличением значений сомножителей. Это
происходит, когда доли записей одного класса в левом и правом потомках оказы-
ваются равны. Следовательно, MepaQ(s|f) имеет тенденцию давать сбалансиро-
ванные разбиения, которые будут делить исходное множество на подмножества,
содержащие примерно одинаковое количество записей. Теоретически максималь-
ное значение 2- PL PR = 2-0,5-0,5 = 0,5.
В нашем примере только потенциальное разбиение 5 (см. табл. 9.11) дает произ-
ведение Pl Pr, достигающее теоретического максимума 0,5, поскольку в результате
записи были разделены на две равные группы по четыре в каждой.
Наибольшее из наблюдаемых значений 11) было получено для разбиения 4
(см. табл. 9.11), rfleQ(s|t) = 0,6248. Значит,для начального разбиения CART выбе-
рет условие, являются ли активы клиента низкими. Тогда в результате разбиения
будут созданы два потомка: в одном окажутся записи, в которых атрибут Активы
принимает значение Низкие, во втором — записи, в которых этот же атрибут при-
нимает значения Высокие и Средние. Полученное в результате данного разбиения
дерево представлено на рис. 9.17.
Рис. 9.17. Дерево после первого разбиения
Обе записи, в которых активы клиента являются низкими и по этой причине
оказавшиеся в левом узле, содержат одну и ту же целевую переменную, указы-
вающую на высокий кредитный риск. Таким образом, узел является чистым. Узел
462 Часть I. Теория бизнес-анализа
будет объявлен листом, и дальнейшее разбиение по данной ветви производиться
не будет. Записи в правом узле относятся к различным классам. Потребуется даль-
нейшее разбиение, поэтому мы снова рассчитаем Q(s | f) и представим полученные
результаты в табл. 9.12. Обратим внимание на то, что ранее использованное раз-
биение 4 больше не рассматривается.
Таблица 9.12. Второй этап расчета значений меры Q
№ Pl Р„ Р(Л М Р(Л t„) W(s|t) Q(s| t)
Низкий Высокий Низкий Высокий
1 0,167 0,833 1 0 0,8 0,2 0,2782 0,4 0,1112~
2 0,5 0,5 1 0 0,667 0,333 0,5 0,6666 0,3333~
3 0,333 0,667 0,5 0,5 1 0 0,4444 1 0,4444~
4 0,667 0,333 0,75 0,25 1 0 0,4444 0,5 0,2222
5 0,333 0,667 1 0 0,75 0,25 0,4444 0,5 0,2222
6 0,333 0,667 0,5 0,5 1 0 0,4444 1 0,4444
7 0,5 0,5 0,667 0,333 1 0 0,5 0,6666 0,3333
8 0,167 0,833 0,8 0,2 1 0 0,2782 0,4 0,1112
Наибольшее значение меры | £) = 0,4444 было получено для разбиений 3 и 7.
Произвольным образом выберем разбиение 3 Сбережения = Высокие. В результате
дерево будет дополнено двумя новыми узлами. В левом потомке окажутся запи-
си, в которых атрибут Сбережения принимает значение Высокие. Таких записей
в исходном множестве всего две (см. табл. 9.4, записи 3 и 6). Однако они имеют
разное значение целевой переменной: для записи 2 кредитный риск высокий,
а для записи 3 — низкий. Следовательно, данный узел содержит два класса и в нем
возможно дальнейшее ветвление. Во второй узел этого разбиения будут отобраны
оставшиеся записи — 1, 4, 5 и 8. Как можно увидеть из табл. 9.4, все они имеют
одну и ту же метку класса, указывающую на низкий риск кредитования заемщи-
ков. Поскольку записи, попавшие в данный узел, относятся к одному классу, узел
объявляется листом. Результирующее дерево представлено на рис. 9.18.
Рис. 9.18. Дерево после второго разбиения
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 463
Новое разбиение возможно только для узла, содержащего записи 3 и 6, отно-
сящиеся к различным классам. Для разбиения можно использовать два ранее не
применявшихся атрибута — Доход и Другие активы. Однако, поскольку в обеих
записях сумма дохода одна и та же (25 000 у. е.), это ничего не даст. В то же время
значения атрибута Другие активы различаются: для записи 3 — Средние, а для
записи 6 — Высокие, поэтому его можно использовать для разбиения. Результи-
рующее дерево представлено на рис. 9.19.
Рис. 9.19. Дерево после третьего разбиения
В общем случае алгоритм будет рекурсивно продолжаться, пока в дереве оста-
ются узлы, содержащие примеры, которые относятся к различным классам. Когда
узлов, для которых можно выполнить разбиение, не останется (то есть все подветви
будут заканчиваться листьями), будет построено полное дерево. Но при работе
с реальными наборами данных часто возникает ситуация, когда получить абсолют-
но чистые узлы не удается, что ведет к возникновению ошибки классификации.
Рассмотрим набор данных, представленный в табл. 9.13.
Таблица 9.13. Набор данных
№ клиента Сбережения Другие активы (недвижимость, автомобиль и т. д.) Годовой доход, тыс. у. е. Кредитный риск
1 Высокие Низкие <30 Низкий
2 Высокие Низкие <30 Низкий
3 Высокие Низкие <30 Высокий
4 Высокие Низкие <30 Высокий
5 Высокие Низкие <30 Высокий
464 Часть I. Теория бизнес-анализа
Визуальный анализ табл. 9.13 показывает, что все представленные в ней по-
тенциальные заемщики характеризуются высокими сбережениями, но низкими
(менее 30 тыс. у. е.) доходами. В то же время, несмотря на одинаковые значения
атрибутов, целевые переменные для идентичных записей окажутся разными. Как
известно, записи, где одному и тому же набору значений входных переменных
соответствуют разные значения выходных, называются противоречивыми и от
них стремятся избавиться путем очистки данных. На практике подобная ситуация
может сложиться, если атрибуты Сбережения и Другие активы получены путем
квантования соответствующих непрерывных атрибутов.
Очевидно, что в данном случае невозможно получить чистые узлы, так как
одинаковые значения независимых атрибутов не позволят разделить объекты по
классам. В результате в листьях окажутся «смеси» нескольких классов. В такой си-
туации можно отнести всех клиентов к категории высокого кредитного риска. Тогда
вероятность того, что случайно выбранная из данного набора запись будет отнесена
к соответствующему классу, составит 3/5 = 0,6, или 60 %. В то же время вероятность
неправильной классификации составит 0,4, или 40 %. Данное значение называется
ошибкой классификации (classification error rate). Если узлов, в которых допущена
ошибка классификации, несколько, то полная ошибка дерева есть средневзвешенная
ошибка по всем узлам. При этом в качестве весов используются доли записей в каж-
дом листе относительно общего количества записей в обучающем множестве.
Регрессионное дерево решений
Как следует из названия алгоритма CART — классификационные и регрессионные
деревья решений, — он позволяет строить не только классификационные, но и регрес-
сионные модели. В основном процесс построения регрессионного дерева аналогичен
процессу построения классификационного, но вместо меток классов в листьях будут
расположены числовые значения. Фактически регрессионные деревья реализуют
кусочно-постоянную функцию входных переменных (рис. 9.20).
Рис. 9.20. Регрессионное дерево решений
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 465
На рис. 9.20, а представлено дерево решений, построенное для двух входных
переменных — Xi и Х2 и содержащее 5 листьев. На рис. 9.20, б показано разбие-
ние (кусочно-постоянная функция двух переменных), которое реализует данное
дерево.
В результате построения регрессионного дерева в каждом листе должны ока-
заться примеры с близкими значениями выходной переменной. Чем ближе будут
эти значения, тем меньше — их дисперсия. Поэтому дисперсия является хорошей
мерой чистоты узла.
Для минимизации квадратичной ошибки на обучающем множестве результат
в листе определяется как среднее значений выходных переменных обучающих
примеров, распределенных в данный лист. При этом мера «загрязненности» лис-
та I пропорциональна дисперсии Dy значений выходной переменной примеров
в узле:
I^Dy = £{(г/„-£,,)2}.
Тогда наилучшим разбиением в узле будет то, которое обеспечит максимальное
уменьшение дисперсии выходной переменной.
Следует отметить, что для регрессионных деревьев решений упрощение важ-
нее, чем для классификационных. Это связано с тем, что регрессионные деревья,
как правило, получаются более сложными, чем классификационные, поскольку
количество значений непрерывной целевой переменной намного разнообразнее,
чем категориальной. Например, если значения непрерывной целевой переменной
уникальны для каждого примера обучающего множества, то полное дерево будет
содержать число листьев, равное числу примеров. Процедура упрощения дерева
путем отсечения ветвей основана на анализе квадратичной ошибки на тестовом
множестве: отсекаются все узлы, удаление которых не приводит к росту ошибки,
превышающему заданное значение.
9.5. Упрощение деревьев решений
Если не принять определенных мер, то дерево решений будет строиться до тех
пор, пока могут быть найдены новые разбиения, которые на последующем шаге
дают более чистые узлы, чем на предыдущем. В результате будет построено так
называемое полное дерево с абсолютно чистыми листьями. Полное классифика-
ционное дерево дает нулевую ошибку классификации, а полное регрессионное
дерево — нулевую ошибку регрессии, но только на обучающем множестве. Каж-
дое дерево строится на конкретном обучающем множестве, поэтому исключение
каких-либо ветвей увеличивает ошибку дерева. Значит ли это, что полное дерево,
то есть дерево, правильно распознавшее все примеры и содержащее только абсо-
лютно чистые листья, является наилучшим с точки зрения задачи классифика-
ции? Определенно нет.
Вообще говоря, полное дерево — почти всегда результат переобучения мо-
дели.
466 Часть I. Теория бизнес-анализа
Переобучение и сложность моделей
Для деревьев решений сложность модели пропорциональна количеству узлов
разбиений и листьев. Как уже упоминалось, дерево решений может выполнять
разбиения до тех пор, пока не будут получены абсолютно чистые листья или пока
листья не будут содержать только одно наблюдение. Такие деревья будут показы-
вать прекрасные результаты на обучающем множестве, но не на новых данных.
Другая крайность: дерево решений имеет только один лист, совпадающий
с корневым узлом, и любое наблюдение будет всегда относиться к одному и тому
же классу. В результате недообучения (underfitting) дерево получается слишком
простым и содержит недостаточно разбиений, чтобы обеспечить приемлемую
точность классификации. Основной признак недообучения — большая общая
ошибка дерева.
Очень важно найти баланс между точностью и сложностью дерева. С этой целью
был разработан комплекс подходов и методов под общим названием упрощение (де-
ревьев решений), в англоязычной литературе известный как pruning или reduction.
Поиск компромисса между точностью и сложностью дерева решений проиллю-
стрирован на рис. 9.21. Здесь точками представлены наблюдения, которые должна
воспроизвести (аппроксимировать) модель. Легко увидеть, что данные содержат
закономерную составляющую (плавный спад и подъем) и шум (разброс точек).
Сплошной линией представлена аппроксимация, полученная на основе переобу-
ченной модели, — она моделирует не только закономерности в данных, но и шум,
что выражается в большой дисперсии модели. Пунктирная линия дает более грубое
приближение, что ведет к увеличению суммарной ошибки модели.
16 - 14 1 12 . 10 - 8 - 6 - 4 - 2 - 0
Illi ) 5 10 15 20
Рис. 9.21. Переобучение и недообучение
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 467
Процесс упрощения деревьев решений можно рассматривать как поиск опти-
мальной модели с точки зрения ошибки и дисперсии.
С позиции точности классификации эффект переобучения может быть проиллю-
стрирован следующим образом. На рис. 9.22, а представлена переобученная модель,
разделяющая объекты на два класса — круги и треугольники. Как видно, на обуча-
ющем множестве она не допустила ни одной ошибки. Однако если эту же переобу-
ченную модель применить к новым (тестовым) данным, то будет допущено семь оши-
бок: четыре треугольника и три круга будут распознаны неправильно (рис. 9.22, б).
Ца рис. 9.22, в представлена более удачная модель: хотя на обучающем множестве
она и допустила две ошибки, зато на тестовом множестве благодаря более высокой
обобщающей способности количество ошибок снизилось до трех (рис. 9.22, г).
Обучающее множество
Тестовое множество
Рис. 9.22. Иллюстрация эффекта переобучения
Критерии оптимизации деревьев решений
Существуют два основных подхода к выбору оптимальной сложности дерева ре-
шений.
1. Принудительная остановка алгоритма с помощью условия, при выполнении
которого рост дерева автоматически остановится. Этот метод называется раннем
остановкой (prepruning) (рис. 9.23). Здесь могут использоваться такие параметры,
468 Часть I. Теория бизнес-анализа
ограничивающие рост дерева, как минимальное количество примеров в узЛе
глубина дерева, статистическая значимость разбиений и т. д.
Рис. 9.23. Ранняя остановка построения дерева решений
2. Сначала строится полное дерево, затем производится его упрощение путем
отсечения ветвей (postprunning) (рис. 9.24). В данном случае создается после-
довательность поддеревьев в порядке увеличения их сложности. После этого
при помощи определенного критерия выбирается лучшее поддерево. Обычно
в качестве такого критерия используется эффективность работы дерева на ва-
лидационном множестве.
Полное дерево
Рис. 9.24. Отсечение ветвей
Дерево после отсечения ветвей
ЗАМЕЧАНИЕ---------------------------------------------------------------
Обычно процесс построения дерева решений делится на две фазы: фазу роста и фазу упро-
щения. Если упрощение производится первым способом, то говорят, что имеет место ранняя
остановка, и используют термин prepruning. Для упрощения вторым способом используют
термин «отсечение ветвей», или postprunning.
Предварительная остановка менее затратна в вычислительном плане, но воз-
никает риск потери хороших разбиений, которые могут следовать за плохими.
Поэтому отсечение ветвей, как правило, позволяет получить лучшие результаты
и пользуется большей популярностью.
Алгоритм дерева решений строит лучшее разбиение в корневом узле, где при-
сутствует вся выборка записей. На более низких уровнях, по мере того как записи
распределяются по узлам, узлы становятся меньше и в них преобладают примеры
с близкими значениями атрибутов. С уменьшением числа примеров в узлах па-
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 469
дает ценность связанных с ними правил. И если на некотором уровне разбиение
дало узлы, содержащие один-два примера, то такие разбиения не имеют смысла,
поскольку обобщающая способность модели оказывается слабой.
Данный фактор обычно связывают с переобучением — адаптацией модели
к частным случаям, нетипичным примерам, шумам в данных и т. д. Вследствие
переобучения модель оказывается неустойчивой, а ее поведение при работе с ре-
альными данными — непредсказуемым. Способом решения проблемы является
удаление неустойчивых разбиений путем объединения узлов с небольшим числом
примеров.
Подытожив, можно сказать, что упрощение деревьев решений преследует такие
цели:
□ уменьшить сложность дерева и извлеченных из него правил, повысить интер-
претируемость классификационной модели;
□ повысить устойчивость и обобщающую способность модели;
□ сократить вычислительные затраты, связанные с работой модели.
Рассмотрим основные подходы, применяемые в обеих методиках.
Ранняя остановка
Ранняя остановка процесса построения дерева решений связана с некоторым
ограничением, по достижении которого поиск новых разбиений прекращается.
Наиболее типичными ограничениями являются:
□ ошибка дерева;
□ минимальное допустимое количество примеров в узле;
□ глубина дерева;
□ статистическая значимость разбиений.
Простейший способ ограничить рост дерева — задать некоторую ошибку, опреде-
ляемую как отношение числа неправильно классифицированных записей к общему
числу записей, поступивших в корневой узел. Можно установить ошибку в размере
1 %, полагая, что если из 1000 примеров 10 останутся нераспознанными, то это не
окажет существенного влияния на качество решения задачи в целом. Такой метод
ограничения роста дерева решений иногда называют оптимистическим, поскольку
предполагается, что минимальная ошибка будет у полного дерева, а у любого подде-
рева ошибка будет больше. Однако при работе с новыми данными это не всегда так
из-за переобучения. Поэтому при отсечении ветвей используется пессимистический
подход, который предполагает, что в результате переобучения полное дерево даст
худшие результаты, чем упрощенное.
При задании минимально допустимого количества примеров в узле исходят из
того, что листья, в которые попало очень мало записей (например, один или два),
являются следствием переобучения модели и ухудшают качество классификации
при работе с новыми данными, хотя наличие таких узлов и листьев формально
увеличивает точность дерева на обучающем множестве. Возникает вопрос: почему
470 Часть I. Теория бизнес-анализа
пример оказался в листе один и почему он не был распознан на более ранних уров-
нях? Вероятно, он является нетипичным, аномальным для обучающей выборки.
Совокупность таких примеров образует шум в данных. Таким образом, не позволяя
дереву создавать узлы и листья с малым числом примеров, можно снизить влияние
шумов в данных.
При определении максимальной глубины дерева просто задается допустимое
количество разбиений для каждой ветви. Например, если задана глубина, равная 10,
то по прошествии 10 разбиений последний узел будет объявлен листом независимо
от его чистоты.
Отсечение ветвей
Если в узел или лист попали всего один-два примера, то правило, с помощью кото-
рого был создан этот лист или узел, имеет низкую значимость. Следовательно, ис-
ключение из дерева данного правила и созданных с его помощью узлов не приведет
к заметному ухудшению работы модели. Проанализируем несколько популярных
алгоритмов упрощения деревьев решений путем отсечения ветвей.
Рассмотрим, например, методику отсечения ветвей, используемую в алгоритме
CART. Он строит дерево до тех пор, пока могут быть созданы новые разбиения,
повышающие чистоту узлов. Как показано на рис. 9.25, внутри сложного полного
дерева выделяется несколько более простых поддеревьев, каждое из которых пред-
ставляет собой компромисс между сложностью дерева и точностью классифика-
ции. Алгоритм CART определяет наборы таких поддеревьев, проверяет каждое на
некотором валидационном множестве, и то из них, которое обеспечит наименьшую
ошибку классификации, будет выбрано в качестве окончательной модели.
Рис. 9.25. Выделение поддеревьев в полном дереве
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 471
CART обнаруживает поддеревья-кандидаты путем последовательного отсе-
чения ветвей от полного дерева решений. Цель — отсечь ветви, имеющие наи-
меньшую классифицирующую способность, то есть ветви, которые классифици-
руют малое число примеров в расчете на лист. Для этого используется понятие
скорректированной ошибки (adjusted error rate). Это мера, которая увеличивает
показатель, отражающий количество ошибок классификации каждого узла на
обучающем множестве, налагая штраф, учитывающий сложность дерева на основе
количества листьев в нем. Она используется для определения самых «слабых»
ветвей, то есть тех, в которых количество неправильно классифицированных
примеров недостаточно мало, чтобы компенсировать штраф. Затем такие ветви
помечаются как удаляемые.
Выражение для вычисления скорректированной ошибки имеет вид:
Я = £ + а-(У),
где a — корректирующий параметр, который постепенно увеличивается по мере
создания новых поддеревьев;
N — количество поддеревьев;
Е — показатель количества ошибок (в простейшем случае это количество оши-
бок классификации, допущенных деревом в данном узле).
Когда a = 0, скорректированная ошибка равна показателю ошибки, то есть R = E.
Чтобы найти первое поддерево, вычисляются скорректированные показатели
ошибок для всех поддеревьев, включая корневой узел. Когда скорректированный
показатель ошибки становится меньше или равен соответствующему показателю
для полного дерева, это значит, что обнаружено первое поддерево-кандидат a,. Все
ветви, которые не являются частью at, отсекаются, и процесс повторяется. Затем
из поддерева at аналогичным образом получается аг и т. д. до тех пор, пока все де-
рево не будет «острижено» до корневого узла. Каждое из полученных в результате
поддеревьев а, является потенциальным кандидатом, чтобы стать окончательной
моделью. Обратим внимание на то, что все кандидаты содержат корневой узел,
а самый большой кандидат — это полное дерево.
После того как определены все поддеревья-кандидаты, из них нужно выбрать
то, которое лучше остальных работает с новыми данными. Для этого через каждое
поддерево пропускается валидационный набор данных, и поддерево, допустившее
наименьшее число ошибок, объявляется победителем. Фактически поддерево-по-
бедитель — это часть полного дерева, от которого было отсечено достаточно ветвей
для того, чтобы компенсировать эффект переобучения, но недостаточно для того,
чтобы потерять полезную информацию.
Влияние упрощения дерева на точность классификации качественно иллю-
стрируется с помощью графика на рис. 9.26. Здесь представлена зависимость
количества ошибок классификации Е от числа узлов N в дереве. На обучающем
множестве увеличение числа узлов ведет к постоянному уменьшению ошибки
классификации. На тестовом множестве ошибка снижается только до опреде-
ленного числа узлов. Когда дерево становится слишком сложным, модель теряет
472 Часть I. Теория бизнес-анализа
устойчивость и количество ошибок на тестовом множестве начинает возрастать.
В этом и проявляется эффект переобучения.
Рис. 9.26. Зависимость ошибки классификации от числа узлов дерева
Логично установить порог упрощения, после которого начинает проявляться
эффект переобучения, то есть возрастание ошибки после достижения определенно-
го количества узлов. Все узлы, созданные после данного порога, следует отсечь.
Поскольку этот алгоритм основан только на количестве ошибок классификации
и не рассматривает вероятности появлений классов, он заменяет любое поддерево,
все узлы которого выполняют одну и ту же классификацию, на его родительский
узел.
Если целевая переменная является числовой и в качестве критерия выбора
лучшего разбиения используется /-критерий Фишера, то естественным критерием
ограничения роста дерева будет p-значение. При этом рост дерева прекращается,
когда больше не удается обнаружить статистически значимые разбиения. На-
помним, что p-значение (p-value) — это показатель, позволяющий принять или
отвергнуть статистическую гипотезу, например оценить вероятность того, что
законы распределения двух выборок значимо различаются. Устанавливая порог
p-значения, можно ужесточать или, наоборот, ослаблять уровень статистической
значимости различия распределений в дочерних узлах, что и позволяет регулиро-
вать глубину дерева.
9.6. Введение в нейронные сети
Ранее отмечалось, что такие популярные инструменты Data Mining, как регрессия
и деревья решений, широко используемые для решения задач классификации
и прогнозирования, имеют ряд ограничений. В частности, этим алгоритмам не все-
гда удается разделить множество объектов на классы или построить регрессион-
ную зависимость с приемлемой ошибкой. Поэтому рассмотрим еще один подход,
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 473
основанный на машинном обучении, — искусственные нейронные сети (artificial
neural network), или просто нейронные сети. В основе их функционирования лежит
принцип обработки информации мозгом человека, и они привлекательны тем, что
могут моделировать практически любые, в том числе нелинейные, зависимости.
Оговоримся сразу, что речь дальше пойдет только о таких нейронных сетях, в ко-
торых применяются алгоритмы обучения с учителем. Сети Хопфилда и подобные
им модификации не рассматриваются.
Структура и принцип работы нейронных сетей
Мозг обрабатывает информацию образами, которые ассоциируются в сознании
с определенными действиями, выводами, символами и т. д. Человеческий мозг
может распознавать весьма сложные образы за несколько миллисекунд. Высокая
эффективность обработки информации человеческим мозгом всегда привлекала
внимание специалистов. Создание вычислительных систем, действующих по
аналогичному принципу, открывает путь к созданию систем искусственного ин-
теллекта и обработки сложной информаций в реальном времени. Очевидно, что
обычные цифровые вычислительные машины для этого непригодны, поскольку
они оперируют не образами, а элементарными единицами данных — битами. Толь-
ко для того, чтобы создать образ с помощью обычного компьютера, требуется ряд
сложных операций, занимающих много времени.
Вывод напрашивается сам собой: необходимо разработать вычислительную
систему, в основе которой лежал бы тот же принцип обработки данных, что и в че-
ловеческом мозге. Интуитивно понятно, что такая система должна выполнять
параллельную обработку данных. Образ должен восприниматься одновременно
и полностью.
Любой образ формально описывается набором признаков, таких как размеры,
цвет, форма и т. д. (рис. 9.27). Поэтому для формирования образа нужно ввести
в систему набор (вектор) значений соответствующих признаков. В теории нейрон-
ных сетей входной вектор часто так и называют — образ внешней среды. На выходе
система должна сформировать значение, указывающее на класс объекта.
Класс
Рис. 9.27. Распознавание образа по набору его признаков
474 Часть I. Теория бизнес-анализа
Остается ответить на вопрос: какими должны быть структура и принцип работы
системы, чтобы наиболее эффективно решать задачу распознавания образов? Есте-
ственным было бы построить систему, моделирующую процесс обработки данных
человеческим мозгом. Так возникла теория нейронных сетей.
Появлению и развитию нейронных сетей во многом способствовали достижения
медицины и биологии в области знаний о функционировании нервной системы
живых существ. В настоящее время с нейронными сетями связана целая отрасль
знаний — нейроинформатика. Это междисциплинарная сфера, объединяющая
в себе элементы биокибернетики, электроники, статистики, прикладной математики
и даже биомедицины.
Искусственная нейронная сеть — это вычислительная модель человеческого
мозга. Человеческий мозг состоит из примерно 1011 простейших клеток, называ-
емых нейронами, которые способны обрабатывать информацию. Нейроны связаны
между собой, и количество связей оценивается как 10ь. Каждый нейрон в отдель-
ности выполняет только простейшие преобразования, но параллельная работа
большого числа нейронов и огромное количество связей между ними приводят
к тому, что нейронная сеть в целом может выполнять очень сложные преобразова-
ния сигналов в реальном времени. Кроме того, большое количество связей делает
нейронную сеть устойчивой к ошибкам, возникающим в отдельных связях, — ра-
бота всей сети не претерпевает существенных изменений.
Визуально нейронные сети обычно представляются в виде графов, в которых
нейроны — узлы, а связи — линии. Достаточно часто нейронные сети упоминают-
ся как нейрокомпьютеры. Структурная схема типичной нейронной сети с тремя
входами и двумя выходами изображена на рис. 9.28.
Рис. 9.28. Пример нейронной сети
Введем следующее формальное определение, которое отражает главное свойство
нейронной сети как адаптивной системы.
ОПРЕДЕЛЕНИЕ---------------------------------------------------------------
Искусственная нейронная сеть представляет собой параллельно-распределенную систему
процессорных элементов (нейронов), способных выполнять простейшую обработку данных,
которая может настраивать свои параметры в ходе обучения на эмпирических данных.
Накопленные знания нейронной сети сосредоточены в весах межэлементных связей.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 475
Основные свойства нейронных сетей
Нейронные сети обладают большой вычислительной мощностью по ряду причин.
Во-первых, нейронная сеть — это параллельно-распределенная структура. Во-
вторых, она способна к обучению и, следовательно, к обобщению. Кроме того,
нейронным сетям присущ ряд полезных свойств и возможностей, делающих их
привлекательными при решении многих задач обработки информации и сигна-
лов.
□ Нелинейность. Нейронная сеть в целом является нелинейной системой. Данное
свойство особенно важно для моделирования процессов, которые нелинейны
по своей природе.
□ Обучение на примерах. Нейронная сеть способна изменять веса связей между
нейронами с помощью наборов обучающих примеров. Результатом обучения
является настройка параметров сети таким образом, что они в неявном виде
хранят информацию об объектах, о решаемой задаче и предметной области.
□ Параллельная обработка данных. Поступающие сигналы распараллеливаются,
что значительно ускоряет обработку информации.
□ Адаптивность. Нейронная сеть способна адаптировать веса связей между
нейронами к изменениям во внешнем окружении. В частности, сеть, ранее
обученная для решения одной задачи, может быть адаптирована (переобучена)
для другой задачи.
□ Отказоустойчивость. При большом количестве связей между нейронами
потеря или искажение данных в отдельных связях не ведет к существенному
ухудшению качества работы сети в целом.
В последние несколько десятилетий наблюдается огромный интерес к нейросе-
тевым технологиям и значительный прогресс в их исследовании, а также в разра-
ботке на их основе различных систем обработки информации и сигналов.
В Data Mining нейронные сети применяются для решения двух классов задач:
классификации и регрессии. Кроме того, с помощью специального вида нейронной
сети Кохонена можно решать и задачу кластеризации (см. главу 7 «Data Mining:
кластеризация»).
Сегодня теория нейронных сетей хорошо развита, а на практике они нашли ши-
рокое применение в науке и технике, экономике и бизнесе, медицине и социальной
сфере. Поэтому алгоритмы нейронных сетей содержатся в любой коммерческой
аналитической платформе. Знание базовых принципов функционирования ней-
ронных сетей открывает перед аналитиком перспективы эффективного решения
практических задач.
Пример нейронной сети для оценки недвижимости
Нейронные сети способны обучаться на примерах точно так же, как эксперт при-
обретает опыт в процессе изучения предметной области и практической работы
в ней. Продемонстрируем это на примере.
476 Часть I. Теория бизнес-анализа
Почему автоматическая оценка недвижимости представляет такой интерес?
Во-первых, она дает агентам по недвижимости возможность эффективнее находить
соответствия между желаниями потенциальных покупателей и объектами продаж
что позволяет улучшить работу даже неопытных агентов. Во-вторых, нейронные
сети могут применяться при создании веб-страниц, где возможные покупатели
могли бы задавать параметры дома, который они хотели бы купить, и немедленно
получать ответ на вопрос, сколько стоит дом их мечты.
Нейронные сети работают аналогично эксперту, который оценивает стои-
мость объекта недвижимости на основе его признаков. Очевидно, что квартиры
в различных частях города будут стоить по-разному. Тип дома, район, количество
и площадь комнат и другие признаки являются факторами, которые участвуют
в формировании цены. Эксперт не применяет каких-либо формул, а делает оценку
на основе личного опыта и знания цен на аналогичные дома. При этом его знание
не статично: он может распознавать и оценивать тенденции на рынке недвижи-
мости, приводя оценку в соответствие с ситуацией.
Итак, объекты недвижимости описываются определенным набором стандарт-
ных признаков, рассматриваемых экспертом и формирующих цену. Поэтому
оценка недвижимости хорошо формализуется для решения методами регрес-
сии, в том числе нейросетевыми. На вход сети подаются значения признаков
определенного объекта недвижимости, а на выходе формируется оценка его
стоимости.
С получением входных данных обычно проблем не возникает, поскольку ис-
черпывающую информацию о рынке недвижимости можно получить с помощью
различных агентств. Помимо этого, существуют стандарты описания объектов
недвижимости для ипотеки и вторичных рынков. Желаемый выход также хо-
рошо определен — цена. Кроме того, имеется богатый опыт в виде предыдущих
продаж.
Нейронные сети — эффективный инструмент для решения задач классифика-
ции и предсказания, если задача хорошо формализована. Задача является хорошо
формализованной, если выполняются три требования.
1. Входные данные хорошо интерпретируются. Дана задача, для решения которой
требуется исследовать набор признаков, но неясно, как именно их использовать,
чтобы получить желаемые результаты моделирования.
2. Желаемые результаты также хорошо интерпретируются. Аналитик знает,
чему нейронная сеть должна научиться.
3. Доступный опыт. Имеется достаточно примеров, в которых присутствуют как
заданный вход, так и заранее известный выход.
Первым шагом в построении нейросетевой модели, позволяющей рассчи-
тывать стоимость недвижимости, является определение набора признаков,
влияющих на эту стоимость (вопросы сбора и подготовки данных к анализу
рассматривались в главе 1). Пусть возможный набор таких признаков выявлен
(табл. 9.14).
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 477
Таблица 9.14. Входные признаки, влияющие на стоимость жилья
№ Наименование Тип значений
1 Микрорайон Строковый
2 Число комнат в квартире Целый
3 Тип дома Строковый
4 Возраст дома Целый
5 Этаж Целый
6 Этажность дома Целый
7 Общая площадь Вещественный
8 Жилая площадь Вещественный
9 Площадь кухни Вещественный
На практике перечисленные признаки работают только для определенных
географических и климатических областей. Более полный набор будет включать
сведения о демографической ситуации, показатели уровня жизни и транспортной
инфраструктуры, а также другие признаки, которые интересуют клиента при по-
купке недвижимости.
Затем строится модель, которая впоследствии будет использоваться для оценки
целевых значений новых примеров. В процессе обучения ей предъявляются приме-
ры — данные о прошлых сделках. Обучающие примеры должны содержать два допол-
нительных признака — цену объекта и дату продажи. Цена нужна в качестве значения
целевой переменной, а дату можно использовать для группировки продаж.
Взаимодействие нейронных сетей
с другими методами Data Mining
Регрессионные модели, деревья решений и нейронные сети — своего рода «три
кита» Data Mining: они входят в состав практически любой серьезной аналити-
ческой платформы. Решение многих бизнес-задач с помощью методов Data Mining
представляет собой достаточно сложную и многоэтапную процедуру, а результаты
применения той или иной модели не всегда однозначно интерпретируемы. Имен-
но поэтому использование не одной, а нескольких моделей может способствовать
более эффективному решению задач. И регрессионные модели, и деревья решений
имеют свои преимущества и недостатки. Не лишены недостатков и нейронные сети.
В частности, они не обладают объясняющей способностью деревьев решений, по-
скольку сами по себе веса нейронов, настраиваемые в процессе обучения, не несут
Для пользователя никакой смысловой нагрузки. Кроме того, выбор оптимальной
конфигурации нейронной сети для решения конкретной задачи не всегда очевиден,
а сам процесс обучения может оказаться весьма затратным как по объемам вычис-
лений, так и по времени.
Однако нельзя сказать заранее, без проб и ошибок, без детального исследо-
вания исходных данных, когда та или иная модель проявит свои преимущества
478 Часть I. Теория бизнес-анализа
либо недостатки. Во многих случаях регрессионные модели, деревья решений
и нейронные сети дополняют друг друга и их комбинация дает наилучшее ре-
шение.
Иногда удается произвести декомпозицию сложной задачи на несколько бо-
лее простых этапов, на каждом из которых применяется определенная модель
Например, на первом этапе выделяются объекты с общими свойствами, затем
внутри полученной группы устанавливается связь между входными и выходны-
ми переменными и т. д. Модели применяются последовательно, в соответствии
с некоторым заранее настроенным сценарием. При этом результаты, полученные
одной моделью, являются исходными данными для другой.
При параллельном использовании моделей один и тот же обучающий набор
данных «прогоняется» одновременно через несколько моделей, которые затем
сравниваются на основе полученных результатов. Модель, признанная наилучшей
выбирается в качестве рабочей.
В отличие от деревьев решений, нейронные сети изначально не развивались
внутри технологий Data Mining. Исследования нейронных сетей стимулирова-
лись разработками в областях искусственного интеллекта, машинного зрения,
обработки изображений и сигналов и др. Поэтому нейронные сети, пришедшие
в Data Mining из научно-технической сферы, стоят особняком. Несмотря на это,
они оказались эффективным методом решения бизнес-задач, применяемые как
в отдельности, так и совместно с другими моделями.
9.7. Искусственный нейрон
Ключевую роль в понимании принципов функционирования нейронных сетей
играет знание того, как работает искусственный нейрон. В основе его действия
лежат те же принципы, по которым работает его биологический прототип. Поэтому
начнем с краткого рассмотрения свойств биологического нейрона.
Биологический нейрон
Биологический нейрон — это нервная клетка, являющаяся основным элементом
нервной системы живых организмов. Именно нейроны, взаимодействуя между
собой, обеспечивают протекающие в нервной системе процессы поиска, передачи
и обработки информации.
Биологический нейрон состоит из тела клетки, или сомы, — оболочки, со-
держащей вещества, необходимые для обеспечения жизнедеятельности клетки.
Размер тела клетки составляет от 3 до 100 мкм. Внутри расположено ядро. Нейрон
соединяется с другими нейронами через отростки двух видов: многочисленные
тонкие, сильно ветвящиеся дендриты и единственный аксон, более толстый и раз-
ветвляющийся на конце. Сигналы от других нейронов поступают в клетку через так
называемые синапсы, образующиеся в местах контакта дендритов одного нейрона
с телом другого, а передаются через аксон (рис. 9.29).
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 479
Рис. 9.29. Строение биологического нейрона
Передача сигналов внутри нервной системы представляет собой сложный
электрохимический процесс. Нервные импульсы передаются между нейронами
с помощью специальных биохимических веществ, называемых нейромедиато-
рами, которые служат раздражителями, заставляющими нейрон переходить
в возбужденное состояние. Если рассматривать процесс упрощенно, то под
воздействием нейромедиаторов синапсы могут изменять способность переда-
вать сигнал. Иными словами, каждой межнейронной связи (синапсу) можно
поставить в соответствие некоторый коэффициент или вес, на который должно
умножаться значение сигнала, поступающего через синапс. Эти веса могут при-
нимать как отрицательные, так и положительные значения. Связи, имеющие
положительные веса, называются возбуждающими, а имеющие отрицательные
веса — тормозящими.
Сигналы, принятые через синапсы, поступают в тело нейрона, где происходит
их суммирование. При этом одни связи являются возбуждающими, а другие —
тормозящими. В зависимости от баланса возбуждающих и тормозящих связей
нейрон сам может перейти в возбужденное состояние: как только суммарное воз-
буждение превышает некоторый порог активации, нейрон начинает через аксон
передавать сигналы другим нейронам. Интенсивность сигнала роли не играет,
так как работает принцип «всё или ничего». Если соотношение возбуждающих
и тормозящих связей таково, что порог активации превышен, нейрон переходит
в возбужденное состояние, если нет — то в тормозящее.
Данная ситуация поясняется на рис. 9.30, где иллюстрируется так называ-
емая активационная функция нейрона. Она имеет вид ступеньки. Если сумма
возбуждающих и тормозящих сигналов, поступающих на вход нейрона через
синапсы, не превышает некоторого порога Т, то сигнал на выходе нейрона
в соответствии с активационной функцией равен 0. Если сумма превышает
этот порог, то нейрон переходит в состояние возбуждения и передает сигналы
Другим нейронам.
480 Часть I. Теория бизнес-анализа
Область торможения Область
(ничего) I возбуждения
। (все)
-------------------------1---------►
Т------------------------Г---------S
Рис. 9.30. Ступенчатая активационная функция
Несмотря на огромное количество нейронов в мозге, они составляют лишь не-
сколько процентов от его объема; остальное место занято межнейронными связями
при этом число связей каждого нейрона не имеет аналогов в электронной техни-
ке. Исследования показали, что именно строго организованное взаимодействие
огромного количества синаптических связей обеспечивает высокую производи-
тельность мозга в плане обработки информации.
Таким образом, нейрон выполняет простейшее преобразование: суммирует
входные сигналы, взвешенные с помощью весов синаптических связей, и сравни-
вает полученные значения с порогом активации. Каждый нейрон обладает своим
набором весов и порогом, значения которых могут рассматриваться аналогично
содержимому памяти компьютера.
Благодаря огромному количеству работающих параллельно нейронов и числу
связей между ними (каждый нейрон имеет до 20 000 связей) ошибки в работе от-
дельных нейронов теряются в массе взаимодействующих клеток и не оказывают
практически никакого влияния на результаты деятельности всей системы.
Огромные способности к обработке информации, исключительная устойчи-
вость и стабильность работы нейронной сети мозга не могли не привести к попыт-
кам создать вычислительные системы, действующие по аналогичным принципам.
Но, к сожалению, современные технологии не позволяют создавать нейронные
сети, сопоставимые по масштабам с нейронной сетью мозга.
Искусственный нейрон
Искусственный нейрон является процессорным элементом, на основе которого
строятся искусственные нейронные сети. Подобно биологическому прототипу
искусственный нейрон выполняет взвешенное суммирование своих входов с по-
следующим нелинейным преобразованием результата, аналогичным сравнению
с порогом активации.
Искусственный нейрон состоит из таких основных элементов, как:
□ набор входных связей (синапсов) х„ каждая из которых имеет вес wt. Значения
весов нейронов могут быть как положительными, так и отрицательными;
□ сумматор для суммирования входных сигналов взвешенных весами w;,
□ активационная функция/(5), выполняющая преобразование (обычно нелиней-
ное) значений с выхода сумматора.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 481
Модель искусственного нейрона схематично представлена на рис. 9.31.
Рис. 9.31. Обобщенная модель искусственного нейрона
В математическом смысле искусственный нейрон — это абстрактная модель био-
логического нейрона. Каждое значение xt, поступающее по г-й синапсической связи,
умножается на вес связи да,. Тогда взвешенная сумма входов нейрона будет:
S = W\ -xt + да2 -х-2 + ... + да„ -х„ + bn + Ь». (9.5)
1 = 1
Свободный член Ьо в выражении (9.5) называется смещением (bias). Оно позво-
ляет дополнительно управлять уровнем активации нейрона, сдвигая активацион-
ную функцию вправо или влево вдоль горизонтальной оси. Увеличивая смещение,
мы повышаем порог активации и искусственно вводим некоторое торможение
нейрона, а уменьшая, как бы «подталкиваем» нейрон, заставляем его выдавать
большее значение на выходе для меньших значений S.
В некоторых случаях используется матричная запись выражения (9.5): смеще-
ние Ьо также рассматривается как дополнительный вес да0 при фиктивном входном
значении х0 = 1. Тогда выражение (9.5) записывается как:
п
S — да0 • х0 + да( Xi + да2 • х2 +... + w„ • хл + b0 = t • х,.
i = 0
После того как полученная сумма будет преобразована с помощью активацион-
ной функции, выход нейрона у составит у = f(S).
Графически преобразование данных искусственным нейроном можно проил-
люстрировать следующим образом (рис. 9.32).
Рис. 9.32. Логистическая активационная функция
482 Часть I. Теория бизнес-анализа
По горизонтальной оси графика откладывается результат взвешенного сумми-
рования входных значений нейрона, а по вертикальной — его выходное значение
Оно полностью определяется видом активационной функции. На рисунке пред-
ставлена так называемая логистическая активационная функция с насыщением
или сигмоида. При увеличении S происходит ограничение выходного значения
нейрона между 0 и 1. Если S изменяется вблизи 0, то выход нейрона меняется
существенно, а область изменения определяется крутизной активационной функ-
ции. При уходе S в область насыщения выходное значение нейрона у стремится
к 0 или 1.
Активационная функция нейрона
Активационная функция играет очень важную роль в работе как отдельного
нейрона, так и нейронной сети в целом. При построении нейронных сетей могут
использоваться различные виды активационных функций, основные из которых
представлены в табл. 9.15.
Таблица 9.15. Распространенные активационные функции
Название График функции Формула
Логистическая функция (сигмоида) _1 У ^0 1 у= l + e-“
S
Гиперболический тангенс 1 У 0 е'“ -е-“ у= е'л + е “
-1 S
Жесткий порог (функция единичного скачка) 1 0 У У = 1, 5>0 0, 5<0
S
Симметричный жесткий порог 1 Q У У = 1, 5>0 -1, 5<0
-1 S
Выбор активационной функции зависит от характера преобразования, который
должна выполнять нейронная сеть, а также от применяемого метода обучения.
Например, логистическая функция и гиперболический тангенс имеют полезное
свойство непрерывности и дифференцируемости на всей числовой оси, что позво-
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 483
дяет использовать их в методах обучения, в которых присутствует производная
активационной функции (так называемые градиентные методы). Жесткий порог
и симметричный жесткий порог удобно применять в бинарных нейронных сетях,
где выход нейрона может принимать только два состояния.
Сигмоидальный нейрон
Одной из наиболее часто применяемых моделей нейрона является так называемый
сигмоидальный нейрон, использующий сигмоидальную активационную функ-
цию — логистическую или гиперболический тангенс (см. табл. 9.15). Структура
сигмоидального нейрона представлена на рис. 9.33.
Рис. 9.33. Сигмоидальный нейрон
Основное преимущество сигмоидального нейрона — непрерывность и диф-
ференцируемость активационной функции на всей числовой оси, что позволяет
использовать для обучения нейронных сетей, построенных на таких нейронах,
градиентные алгоритмы обучения. Модели нейронов, применяющие разрывные
активационные функции, такие как линейный и жесткий пороги, не позволяют
использовать при обучении информацию об изменении значения у, поскольку
производная в точках разрыва функции не существует. К таким нейронным сетям
возможно применение только неградиентных методов обучения, что приводит
к возрастанию длительности обучения и не гарантирует его успех.
Существуют и другие модели искусственных нейронов, такие как модель
Маккаллока — Питтса и пр. Но мы ограничим рассмотрение сигмоидальным
нейроном, поскольку большинство задач Data Mining могут быть эффективно
решены с помощью сетей, построенных на нейронах данного типа.
Пример вычисления выхода нейрона
Чтобы обеспечить лучшее понимание принципов работы искусственного нейрона,
покажем, как вычисляется результат на его выходе. Рассмотрим нейрон с логисти-
ческой активационной функцией.
Пусть на вход нейрона поступает 4 сигнала х, (i = 1... 4), где xt = 0,4, х2 = 0,7,
= 0,6 и Xt = 0,2 (рис. 9.34). Значения входов нейронов нормируются к 1. Каждая
связь обладает некоторым весом ®,. Значения весов зададим следующим образом:
= 0,8, = —1,2, w3 = 1,5 и Wt = 0,35. Смещение пусть будет Ьп = 0,5.
484 Часть I. Теория бизнес-анализа
В соответствии с формулой (9.5) рассчитаем взвешенную сумму входов ней-
рона:
S^^wrXi+bv = 0,4 • 0,8 + 0,7-(—1,2) + 0,6-1,5 +
i = 1
+0,2-0,35 + 0,5 = 0,32 - 0,84 + 0,9 + 0,07 + 0,5 = 0,95.
Теперь вычислим результат преобразования полученной суммы с помощью
сигмоидальной активационной функции, полагая крутизну а = 1:
У = —-— =----Цтпг = °-72-
Из графика логистической функции можно увидеть, что выходные значения
нейрона всегда лежат в диапазоне от 0 до 1. Кроме того, значения у < 0,5 соответ-
ствуют отрицательным суммам S, а у > 0,5 — положительным. Следует отметить,
что при использовании сигмоидальной активационной функции не выполняется
принцип «все или ничего», реализуемый моделью, использующей ступенчатую
активационную функцию единичного скачка. В сигмоидальном нейроне зависи-
мость выхода от взвешенной суммы его входов является плавной и непрерывной
с насыщением для больших отрицательных и положительных 5. Иными словами,
можно выделить интервал [—5; 5], в котором выход нейрона будет существенно
зависеть от 5. Этот интервал определяется параметром крутизны а активацион-
ной функции. Подбирая параметр крутизны в процессе обучения нейронной сети,
можно оптимизировать его результаты, поэтому крутизна активационной функции
является одним из настраиваемых параметров.
9.8. Принципы построения нейронных сетей
Функционирование нейронной сети определяется не только тем, какие модели
нейронов в ней используются, и видом их активационных функций, но и ко-
личеством нейронов, а также способом их соединения внутри сети. Параметры
выбираются исходя из особенностей решаемой с помощью нейронной сети зада-
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 485
чи, уровня ее сложности и трудоемкости, количества используемых переменных,
характера исходных данных.
При реализации нейронной сети и определении ее параметров необходимо
выбрать нейросетевую архитектуру и конфигурацию. При этом под архитектурой
понимаются общие принципы построения нейронных сетей для определенного
класса задач, а под конфигурацией — параметры конкретной нейросетевой модели.
Если решаемая задача является типовой и хорошо известной, что характерно для
задач Data Mining, то при создании нейронной сети можно воспользоваться одной
из готовых конфигураций. В научных и технических приложениях, где сложность
и разнообразие задач намного выше, в некоторых случаях приходится синтези-
ровать нестандартные нейросетевые конфигурации, что может оказаться весьма
трудоемким и длительным процессом.
Построение и обучение нейронных сетей часто называют искусством, поскольку
выбор конфигурации сети и параметров ее обучения не всегда однозначен, он во
многом определяется опытом и даже интуицией аналитика. Конечно, в данной об-
ласти существуют теория и общие рекомендации, но сильная зависимость работы
нейронных сетей от особенностей входных данных и характера искомых законо-
мерностей делает процесс построения классификационных и регрессионных моде-
лей на их основе неоднозначным: при поиске оптимального решения приходится
использовать метод проб и ошибок.
Прежде чем приступить к рассмотрению основных нейросетевых архитектур
и конфигураций, а также рекомендаций по выбору соответствующих параметров,
введем некоторые базовые понятия.
Основные группы нейронов в сети
В зависимости от расположения в сети и выполняемых функций все нейроны могут
быть разбиты на группы.
1. Входные нейроны. На них поступают значения переменных вектора входного
воздействия X = (хь х2... х„)г, где п — число компонентов вектора, равное числу
входных переменных модели; соответственно ему же будет равно число входных
нейронов. Совокупность входных нейронов образует вход нейронной сети. Входные
нейроны не выполняют обработку информации: их задача — принять компоненты
вектора входного воздействия и распределить по другим нейронам сети.
2. Выходные нейроны. Служат для вывода результатов обработки нейронной сетью
входного вектора. На их выходах формируются компоненты выходного вектора
Y = (у 1, у2... ут)Т, где т — число выходных нейронов, которое соответствует числу
выходных переменных модели. В общем случае т п. Выходной вектор Y часто
называют откликом, или реакцией, сети на заданное входное воздействие, а сеть
в процессе функционирования реализует функцию многих переменных Y = /(X).
3. Скрытые нейроны. Расположены внутри сети. Если у входных нейронов с дру-
гими нейронами сети связаны только выходы, а у выходных нейронов — только
входы, то скрытыми можно назвать все нейроны, не имеющие связи с внешним
486 Часть I. Теория бизнес-анализа
окружением сети. Именно скрытые нейроны выполняют преобразование дан-
ных в нейронной сети.
Архитектуры нейронных сетей
Функциональные возможности нейронной сети возрастают с увеличением числа
нейронов и связей между ними. Чем больше связей, тем больше количество весов,
настраиваемых в процессе обучения нейронной сети. При увеличении числа весо-
вых коэффициентов возрастает число возможных состояний нейросетевой модели,
а значит, и количество возможных функциональных преобразований. Однако
усложнение модели неизбежно приводит к росту вычислительных затрат, связан-
ных с ее обучением и работой. Кроме того, уровень сложности задач Data Mining
не требует применения нейронных сетей с большим числом связей, поэтому при
выборе конфигурации нейронной сети всегда следует искать компромисс.
Единственное жесткое требование, предъявляемое к конфигурации сети, — это
соответствие размерности вектора входного воздействия числу входов нейронной
сети и размерности вектора отклика числу выходных нейронов.
Искусственную нейронную сеть прямого распространения, в которой при-
сутствует хотя бы один скрытый слой, называют многослойным персептроном
(multilayer perceptron, MLP). Из всех архитектур нейронных сетей именно он
с сигмоидной функцией активации является базовым для решения задач класси-
фикации и регрессии. Существуют нейронные сети, в которых сигнал проходит не
только в прямом направлении, но и в обратном, в структуре их связей присутству-
ют замкнутые циклы, однако такие сети реже применяются в Data Mining.
Принципы функционирования
многослойного персептрона
Рассмотрим сначала несложную конфигурацию многослойного персептрона, со-
держащую один скрытый слой (рис. 9.35, смещением пренебрегли).
Слой 1 Слой 2
Рис. 9.35. Многослойный персептрон
Нейроны выходного слоя обрабатывают данные и выполняют вывод результата.
Обозначим каждую связь внутри сети как ?»,*, где г — номер нейрона входного слоя,
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 487
с выхода которого выходит связь; j — номер нейрона выходного слоя, на вход ко-
торого поступает связь (полагаем, что нейроны в слоях нумеруются сверху вниз).
Индекс k указывает на слой сети, к которому относится данная связь. Например,
^0) _ это первая связь первого нейрона первого слоя сети.
При подаче на вход вектора X = (хь хг... хл)т сеть сформирует на выходе двух-
компонентный вектор Y = (г/ ь г/2)г, значения элементов которого вычисляются по
формуле:
У;=/
п
i = \
(9-6)
где f ~ активационная функция нейрона.
Рассмотрим пример, который иллюстрирует процесс формирования выхода
в многослойном персептроне, содержащем три входных нейрона, три нейрона
скрытого слоя и два нейрона выходного слоя (рис. 9.36).
Скрытый слой
Пусть на вход нейронной сети поступает вектор X = (0,4; 0,6; 0,8)г, а веса связей
установлены в соответствии с табл. 9.16.
Таблица 9.16. Начальные веса нейронов
1-й СЛОЙ 2-й СЛОЙ
= 0,25 w® =0,17
= 1,2 w® -1,25
®1(з = -1,5 = - 0,25
= 0,5 =2,25
= 0,75 =0,65
Г0 23 = -0,7 w$ = 0,76
Продолжение &
488 Часть I. Теория бизнес-анализа
Таблица 9.16 (продолжение)
1-й слой
2-й слой
№<7 =0,45
®зз =0,9
На каждый нейрон скрытого слоя поступает один и тот же входной вектор,
распределяемый нейронами входного слоя. Тогда на выходах сумматоров нейро-
нов скрытого слоя будут получены следующие значения:
= Xt +x2-W2f +х.з -w$ = 0,4-0,25 +
+ 0,6-1,2 + 0,8-0,45 = 0,1 + 0,72 + 0,36 = 1,18;
5^ =х, -w^2 + x2-w22 + -Тз-®32 =0,4-1,2 + 0,6-0,75 +
+ 0,8-1,9 = 0,48 + 0,45 +1,52 = 2,45;
5^ —xt -w^j +х2-®2з +хз -®зз = 0,4-(-1,5) + 0,6-(-0,7) +
+ 0,8-0,9 = -0,6-0,42 + 0,72 = -0,30.
Если используется логистическая активационная функция с параметром кру-
тизны, равным 1, то выходы нейронов 1-го слоя будут:
У? = /(s,(,)) = l/(l + e1,lfi) = 0,86;
У? = /(4')) = 1/(1 + е-2Л,) = 0,92;
= /(4’> 1/(1 + е°-3) = 0,42.
Таким образом, вектор входов для нейронов скрытого слоя составит Xi =
= (0,86; 0,92; 0,42). Тогда
s(2) = xt -wff +x2-w^t +x-j -wff =0,86-0,17 + 0,92-(-0,25) +
+ 0,42-0,65 = 0,15-0,23 + 0,27 = 0,9;
= xt -w$ +x2 -w$ +x3 -w$ — 0,86-1,25 + 0,92- 2,25 +
+ 0,42-0,76 = 1,08 + 2,07 + 0,32 = 3,47.
Выходы нейронной сети будут иметь следующие значения:
l/i(2) =/(5i(2)) = 1/(1 +е“0,19) = 0,54;
^)=/(5(2)j = i/(i + e-3,^ = 0)97.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 489
Выбор числа нейронов в многослойном персептроне
При выборе конфигурации нейронной сети для решения конкретной задачи очень
важно правильно определить оптимальное число нейронов. Строгих соотношений,
позволяющих точно рассчитать его, не существует. Тем не менее можно привести ряд
рекомендаций (отчасти эмпирических), которые помогут оценить приемлемое для ре-
шения той или иной задачи число нейронов. Вообще, интерес представляет не столько
количество нейронов сети, сколько число связей между ними, так как именно настрой-
ка весов связей определяет выполняемое сетью функциональное преобразование.
Чтобы исключить переобучение нейронной сети, нужно придерживаться сле-
дующих рекомендаций.
□ Число нейронов во входном и выходном слоях жестко определяется числом
входных и выходных переменных модели соответственно.
□ Число нейронов в скрытых слоях и число скрытых слоев выбираются таким обра-
зом, чтобы количество образованных ими связей было меньше числа обучающих
примеров как минимум в два-три раза.
Рассмотрим конкретный случай. Пусть обучающее множество содержит 150 при-
меров. Полагая, что число связей в нейронной сети должно быть в три раза меньше
числа примеров, получаем общее число связей в сети С = 150/3 = 50. Пусть обуча-
ющий набор данных содержит четыре входных переменных и одну выходную.
Тогда нейронная сеть должна иметь четыре входных нейрона и один выходной.
Рассмотрим две возможные конфигурации — с одним скрытым слоем и с двумя.
В случае одного скрытого слоя можно составить соотношение 4 • t + 1 • t = 50, где
t — число нейронов в скрытом слое. Можно записать: 4-£+1-£ = £-(4 + 1) = 5- £
= 50, откуда t = 10. Следовательно, для обеспечения 50 связей нейронная сеть с че-
тырьмя входными нейронами, одним выходным и одним скрытым слоем должна
содержать в нем 10 нейронов (рис. 9.37, а). Аналогично определяем, что в случае
двух скрытых слоев можно использовать варианты по 5 нейронов в слое; в первом
слое 7 нейронов, во втором — 3 и т. д. (рис. 9.37, б).
a б
Рис. 9.37. Возможные конфигурации сетей с 50 связями
490 Часть I. Теория бизнес-анализа
9.9. Процесс обучения нейронной сети
В процессе работы нейронная сеть реализует преобразование данных, которое в об-
щем виде может быть описано функцией многих переменных Y = /(X). Это преоб-
разование определяется конфигурацией сети (числом нейронов, способом их со-
единения, количеством связей, видом активационной функции и смещениями),
а также весами межнейронных связей. Поэтому после того как конфигурация сети
задана, необходимо выполнить соответствующую настройку весов, то есть произ-
вести обучение нейронной сети, чтобы она могла выполнять требуемую обработку
данных.
Пусть F — множество всех функций, которые возможно реализовать при
помощи нейронной сети с данной конфигурацией. Тогда это множество будет
содержать и функцию g: Y = g(X), которую должна выполнять нейронная сеть
после обучения. Функцию g часто называют целевой функцией. При этом для
обучения нейронной сети целевая функция должна быть задана в табличном
виде парами значений «известный вход — известный выход». Каждая пара
(X;,Y,) образует обучающий пример. Очевидно, что связь между входным и це-
левым вектором в каждом примере обучающего множества должна определяться
функцией g.
Таким образом, процесс обучения нейронной сети будет сводиться к подбору ее
весовых коэффициентов так, чтобы из всех возможных функций f &F нейронная
сеть реализовывала функцию максимальное близкую к функции g. Степень
близости функции f, которую реализует нейронная сеть с данным состоянием
весов, и целевой функции g определяется ошибкой Е — f'-g. Следовательно,
обучить нейронную сеть — значит настроить веса ее нейронов так, чтобы для всех
пар (X,, Y,) функция ошибки Е принимала минимальное значение.
Задачи, в которых требуется минимизировать или максимизировать неко-
торую функцию, называются задачами оптимизации. В случае нейронной сети
задачу оптимизации можно интерпретировать с помощью рис. 9.38. На нем схе-
матически представлено пространство F функций, которые могут быть реализо-
ваны нейронной сетью с данной конфигурацией. Тогда каждая из этих функций
может быть представлена точкой в пространстве F. Обучение нейронной сети
является итерационной процедурой, где на каждой итерации производится
подстройка весов нейронов. Следовательно, после завершения каждой итера-
ции сеть будет принимать некоторое новое состояние и реализовывать новую
функцию. Например, на рис. 9.38 точка f соответствует начальному состоянию
сети, которое она приобрела в результате инициализации — задания начальных
значений весов нейронов (обычно небольшими случайными значениями). После
первой итерации веса нейронов меняются и сеть переходит в состояние, в ко-
тором реализуется функция /1, после второй итерации сеть реализует функцию
/2 И т. д.
Так продолжается до тех пор, пока рассогласование между целевой функци-
ей g и функцией fi, реализуемой нейронной сетью после г-й итерации, не станет
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 491
Рис. 9.38. Обучение нейронной сети как задача оптимизации
меньше заданной величины. Поскольку рассогласование определяется ошибкой
Е, то обучение будет продолжаться до тех пор, пока не будет найдено состояние
сети, обеспечивающее минимальную ошибку £min, или ошибка не станет меньше
некоторого порога е. Могут использоваться и другие условия остановки обучения,
например достижение заданного числа итераций.
Роль выходной ошибки сети в процессе обучения
Возникает вопрос: как менять веса нейронов на каждой итерации, чтобы достичь
требуемого состояния весов за приемлемое число итераций? Само собой напра-
шивается решение перебрать все возможные состояния весов сети и выбрать то из
них, которое даст минимальную ошибку. На практике такой подход нереализуем
из-за огромного числа возможных комбинаций весов — в процессе обучения сеть
может бесконечно «блуждать» по пространству F.
Более удачным решением является управление процессом обучения с помощью
ошибки Е. Действительно, при каждом изменении состояния весов сети ошибка
будет или уменьшаться, или увеличиваться. Тогда естественным решением будет
принимать только те корректировки весов, которые приводят к уменьшению ошиб-
ки. Хотя данный метод и позволит придать процессу обучения нужное направле-
ние, но все еще может потребовать слишком большого числа итераций. Поэтому
на практике для вычисления коррекций весов на каждой итерации используют
различные методы, позволяющие достичь нужного состояния нейронной сети за
минимальное число итераций. Эти методы позволяют определить правила, по
492 Часть I. Теория бизнес-анализа
которым производится вычисление новых значений весов. Такое правило называ-
ется алгоритмом обучения нейронной сети.
В настоящее время разработано много алгоритмов обучения нейронных се-
тей, в основе которых лежат различные методы решения задач оптимизации
(некоторые из них будут рассмотрены в следующем разделе). Выбор алгоритма
зависит от особенностей решаемой задачи, в частности от количества данных, ис-
пользуемых для обучения, их качества и требования к уровню точности решения
задачи. Например, одни алгоритмы работают очень быстро, но являются крайне
неустойчивыми при наличии в данных шумов и аномальных значений. Другие,
наоборот, требуют для обучения большего числа итераций, но позволяют достичь
хороших результатов даже при низком качестве данных. Поэтому выбор алгоритма
обучения для конкретной задачи может быть неочевидным, требовать исследова-
ния особенностей данных, использовать метод проб и ошибок, опираться на опыт
и интуицию аналитика.
Независимо от алгоритма, обучение с использованием ошибки (с учителем)
производится по схеме, представленной на рис. 9.39. Поясним ее по шагам,
а для упрощения выкладок будем рассматривать сеть с одним выходным ней-
роном.
1. Инициализация — задание начального состояния сети путем установления ее
весов небольшими случайными значениями. Для обобщенного состояния весов
сети введем обозначение W, тогда начальное состояние будет Wo. Также введем
счетчик итераций i.
2. Начинаем первую итерацию и увеличиваем г на 1.
3. Подаем на вход сети первый обучающий пример (Х„ </,), на который сеть реаги-
рует выходным значением у.
4. Вычисляется ошибка, допущенная сетью на данном примере, как разность
между целевым выходом 4 и реальным выходом сети г/„
Если ошибка меньше некоторого достаточно малого порога е или число ите-
раций превышает некоторое заданное значение то обучение завершается.
Эти ограничения часто используются, потому что достижение малого порога
ошибки гарантировано не всегда. Это может быть связано с неудачным выбором
конфигурации сети, алгоритма обучения, с проблемами в обучающих данных
ит. д.
Если порог ошибки сети и (или) максимальное число итераций не достигнуты,
то в соответствии с заданным алгоритмом обучения на основе ошибки, полученной
на четвертом шаге, вычисляются новые веса нейронов сети и делается их коррек-
ция. Далее производится возврат к пункту 2, счетчик итераций увеличивается на 1
и начинается следующая итерация.
После изучения данной процедуры возникнет два вопроса.
□ Как выбрать значение порога ошибки е, по достижении которого можно завер-
шать процедуру обучения и считать процесс обучения успешным?
□ Как выбрать количество итераций гтах, по достижении которого процесс обуче-
ния будет остановлен автоматически?
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 493
Рис. 9.39. Обобщенная блок-схема процесса обучения нейронной сети
Выбор порога ошибки
При выборе порога ошибки е следует помнить, что даже достаточно малая резуль-
тирующая ошибка, полученная в процессе обучения, не гарантирует хорошей ра-
боты сети с реальными данными. Формально ошибка показывает, насколько точно
могут быть настроены веса нейронов для воспроизведения на выходе сети целевых
значений обучающих примеров. Тем не менее ошибка позволяет оптимизировать
конфигурацию нейронной сети — предпочтение отдается варианту с минимальным
значением ошибки.
494 Часть I. Теория бизнес-анализа
Что касается порога е, то выбрать его оптимальное значение можно только
опытным путем в зависимости от особенностей решаемой задачи, возможностей
сети, качества обучающих данных и от того, что вообще хочет получить аналитик
Так, ошибка 10 7 может оказаться в принципе недостижимой, а ошибку 10 3 мож-
но получить за малое число итераций, и построенная в результате модель будет
прекрасно работать. Однако определить это можно только после многократных
экспериментов.
Выбор числа итераций
Точно так же выбрать предельное число итераций можно лишь путем многократ-
ных экспериментов. С одной стороны, оно должно быть достаточным для полу-
чения малой выходной ошибки. С другой — слишком большое число итераций
требует много времени на обучение сети. На практике сначала число итераций
устанавливают достаточно большим, затем осуществляют пробный «прогон»
сети и контролируют динамику изменения выходной ошибки. По достижении
некоторого числа итераций ошибка перестает уменьшаться и стабилизируется.
Это говорит о том, что сеть в данной конфигурации достигла предела своих воз-
можностей и дальнейшее обучение не приведет к увеличению точности. Поэтому
максимальное число итераций должно быть примерно таким, которое необходимо
для обеспечения минимальной ошибки.
Режимы обучения
В приведенной на рис. 9.39 схеме коррекция весов нейронов производится после
предъявления сети каждого примера обучающей выборки. Данный режим обу-
чения называется online, или «обучение по шагам». Здесь на каждой итерации
коррекция весов рассчитывается на основе ошибки, которую сеть показала на
одном примере. Таким образом, шаг обучения — это цикл, в котором на вход
сети подается один случайно выбранный пример из обучающего множества и на
основе ошибки, допущенной сетью на этом примере, производится коррекция
весов сети.
Широко используется другой режим обучения, называемый offline, или «обу-
чение по эпохам». В этом случае коррекция весов нейронной сети производится
после подачи на вход всех примеров обучающего множества. Тогда эпоха — это
цикл обучения, в котором на вход сети подаются все примеры обучающего мно-
жества, рассчитывается среднеквадратическая ошибка по всем примерам и на ее
основе корректируются веса.
Преимуществом режима online является быстрота обучения. Поскольку под-
стройка весов производится после каждого примера, то желаемое состояние весов
сети может быть достигнуто относительно быстро. Но данный подход имеет недо-
статок — чувствительность к наличию в обучающих данных шумов и аномальных
значений. Действительно, если какой-либо пример содержит аномально большое
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 495
значение, скорее всего, сеть на данном примере даст большую ошибку, что может
вызвать сбой в процессе обучения. Поэтому при использовании алгоритмов обу-
чения, работающих в режиме online, необходимо уделять повышенное внимание
очистке данных.
Алгоритмы, использующие режим обучения offline, более устойчивы, поскольку
среднеквадратическая ошибка по всем примерам обучающего множества — более
состоятельная оценка рассогласования текущего состояния сети и желаемого.
Таким образом, если заранее известно, что обучающие данные имеют низкое
качество, то предпочтение следует отдать алгоритмам, реализующим обучение по
эпохам. Если обучающие данные достаточно равномерны и не содержат аномалий,
противоречий и шумов, то использование алгоритмов, реализующих обучение по
шагам, ускорит процесс обучения.
Обучающая выборка
Настройка весов нейронной сети производится с помощью обучающего набора
данных, или обучающей выборки. Определение, структура, требования и особен-
ности формирования обучающих выборок для построения аналитических моделей,
основанных на машинном обучении, подробно рассматривались в разделах 1.7,
3.6 и 5.11. Поэтому остановимся только на тех особенностях обучающих выборок,
которые характерны для нейронных сетей.
Одной из особенностей функционирования нейронных сетей является необ-
ходимость нормализации значений входных полей, причем как числовых, так
и категориальных (для дерева решений, к примеру, такая процедура не нужна).
У числовых полей распространена обычная минимаксная нормализация, причем
принято входные признаки нормировать в диапазон [-1; 1], а выходные — [0; 1].
Кодирование категориальных переменных — обязательная процедура. Здесь
используются любые известные методы: уникальные числовые коды (для упо-
рядоченных признаков) либо двоичное кодирование по маске или компактным
кодом (для неупорядоченных признаков).
Продемонстрируем это на примере с оценкой недвижимости, рассматривав-
шемся в разделе 9.6. Пусть требуется обучить нейронную сеть для предсказания
оценочной стоимости квартиры и пусть обучающая выборка содержит четыре
входных поля и одно выходное. Используя один скрытый слой с тремя нейронами
в нем, получим конфигурацию нейронной сети, представленную на рис. 9.40.
Данная конфигурация содержит 15 межнейронных связей, веса которых
будут настраиваться в процессе обучения (связь, отвечающая за смещение, не
показана). Следовательно, полагая, что число примеров обучающей выборки
должно быть как минимум в два раза больше, чем число межнейронных связей,
для обучения потребуется не менее 30 примеров. А если предположить, что
для повышения достоверности предсказания целесообразно учитывать еще
и площадь кухни, то во входной слой сети будет добавлен еще нейрон. Тогда
количество связей сети увеличится до 18, что потребует использования как
минимум 36 примеров.
496 Часть I. Теория бизнес-анализа
Рис. 9.40. Структура многослойного персептрона
для решения задачи о недвижимости
Проблема переобучения
Так же как и для других моделей, основанных на машинном обучении, для нейрон-
ных сетей актуальна проблема переобучения. Переобучение нейронной сети заклю-
чается в слишком точной подстройке весов, в результате чего сеть адаптируется не
к общим закономерностям в данных, а к изменениям, обусловленных случайной
составляющей. Как и во всех подобных случаях, переобучение нейронной сети
приводит к ухудшению ее обобщающей способности, то есть способности работать
с новыми данными, не участвовавшими в процессе обучения.
Как говорилось в разделе 1.7, чтобы избежать переобучения сети, нужно ис-
пользовать тестовое множество, содержащее примеры, которые не использова-
лись в процессе обучения. Если сеть по результатам обучения покажет низкую
ошибку как на обучающем, так и на тестовом множестве, то переобучения не
произошло. Если на обучающем множестве ошибка низкая, а на тестовом — вы-
сокая, имеет место переобучение сети и ее обобщающая способность будет ниже,
чем ожидалось.
Некоторые особенности формирования обучающей
выборки
Чтобы построить хорошую нейросетевую модель, аналитику приходится затра-
чивать много усилий, идти методом проб и ошибок, использовать весь свой опыт
и интуицию. Ключевым моментом при построении модели является удачное
формирование обучающей выборки. В определенном смысле все рекомендации,
касающиеся формирования обучающей выборки, эвристические. Тем не менее
их применение на практике во многих случаях позволяет добиться хороших ре-
зультатов. Кратко рассмотрим дополнительные рекомендации, помимо тех, что
обсуждались в разделе 5.11.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 497
Покрытие значений всех признаков
Обучающая выборка должна быть разнообразной. В примере об оценке недвижи-
мости это означает, что в рассмотрение должны включаться квартиры всех ценовых
категорий — от экономкласса до элитных, с большой и малой общей площадью
и т. д. Желательно, чтобы обучающее множество содержало несколько примеров
для каждого значения категориального признака, а также для всех диапазонов
значений упорядоченных признаков.
Кроме того, желательно, чтобы значения признаков были распределены равно-
мерно, то есть ни один диапазон не доминировал в процессе обучения. Например,
если в обучающей выборке будет рассматриваться 90 % квартир на первом этаже,
то нейронная сеть вряд ли распознает закономерность того, как этажность влияет
на стоимость.
Выбор количества признаков
Количество входных признаков воздействует на нейронную сеть в двух аспектах.
Во-первых, чем больше входных признаков, тем больше число входных нейронов
и тем больше весов будет в сети, что приведет к росту риска переобучения и увели-
чению размера обучающего множества. Во-вторых, чем больше входных признаков,
тем больше требуется итераций для оптимизации весов.
Проблема отбора признаков, которые будут использоваться в качестве вход-
ных при построении различных аналитических моделей, выходит далеко за рамки
нейронных сетей. Часто хорошие результаты дает интуитивный подбор признаков,
метод проб и ошибок. Работу начинают с набора признаков, которые, как ожидает-
ся, влияют на результат. Затем экспериментально проверяют, исключение каких
признаков ухудшает модель. Во многих случаях представляет интерес комбини-
рование признаков.
Размер обучающей выборки
Чем больше входных признаков используется при обучении нейронной сети, тем
больше примеров потребуется включить в обучающую выборку для достаточного
покрытия всех значений признаков. К сожалению, правила, позволяющего выра-
зить связь между числом входных признаков и числом обучающих примеров, не
существует.
Если обучающее множество невелико, нейронная сеть имеет тенденцию к пере-
обучению. Переобучение может возникнуть, если число обучающих примеров
соизмеримо с числом весов сети.
Конечно, обратной стороной увеличения числа обучающих примеров являет-
ся рост затрат на обучение. За время, требуемое для обучения модели с большим
числом признаков и на большой обучающей выборке, можно построить несколько
более простых и компактных моделей, комбинируя различные признаки и конфи-
гурации нейронной сети, и в конце концов добиться лучших результатов.
498 Часть I. Теория бизнес-анализа
9.10. Алгоритмы обучения нейронных сетей
Обучение нейронных сетей как задача оптимизации
Процесс обучения нейронной сети заключается в подстройке весов ее нейронов.
Целью обучения является поиск состояния весов, которое минимизирует выходную
ошибку сети в обучающем и тестовом множествах. Задачи поиска оптимального
состояния систем по минимуму или максимуму некоторой функции образуют
отдельный класс и называются задачами оптимизации. В случае нейронной сети
оптимизация ведется по функции ошибки, зависящей от состояния весов нейро-
нов. Состояние системы, при котором обеспечивается минимум целевой функции
(в данном случае — выходной ошибки сети), называется оптимальным.
Задачи оптимизации для обучения нейронных сетей достаточно сложны. Это
связано со следующими причинами.
□ Нейронная сеть может содержать очень большое количество связей, поэтому
пространство возможных состояний нейронной сети огромно и рассмотреть их
все практически невозможно. Например, сеть, которая содержит 28 связей, при
условии, что вес каждой связи является бинарным, будет иметь 228, или примерно
250 млрд комбинаций весов.
□ Нейронные сети, которые содержат более чем один нейрон в скрытом слое,
имеют не одно, а несколько оптимальных состояний, обусловленных наличием
у функции ошибки нескольких минимумов. Однако истинно оптимальным со-
стоянием является только одно, где обеспечивается «наименьший», или, как
говорят, глобальный, минимум. Остальные минимумы функции ошибки назы-
ваются локальными. Наличие множества минимумов существенно затрудняет
поиск глобального оптимума. На рис. 9.41 представлена зависимость ошибки
сети Е от некоторого обобщенного состояния вектора весов сети W, которая
имеет три локальных минимума.
В настоящее время для решения задач оптимизации разработано большое
количество различных методов. На их основе создаются алгоритмы обучения
нейронных сетей.
Рис. 9.41. Локальные
и глобальный минимумы
Каждый раз, приступая к постро-
ению нейросетевой модели, аналитик
должен не только задать конфигура-
цию сети и сформировать обучающий
набор данных, но и выбрать алгоритм
обучения, наиболее соответствующий
конкретной задаче. Очевидно, что раз-
личные алгоритмы обучения обладают
И/ своими достоинствами и недостатками,
поэтому неудачный выбор алгоритма
может свести на нет все преимущества,
полученные на первых двух шагах.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение
499
В общем случае предпочтение следует отдать тому алгоритму, который:
□ позволяет достичь оптимального состояния модели за меньшее число итера-
ций;
□ обладает приемлемыми трудоемкостью и объемом требуемых вычислительных
затрат;
□ обеспечивает наименьшую результирующую ошибку сети;
□ обладает устойчивостью к низкому качеству данных — наличию в них аномалий,
шумов, противоречий и т. д.
Перечисленные требования часто противоречат друг другу, и приходится искать
компромисс.
Обзор алгоритмов обучения нейронных сетей
Методы оптимизации, применяемые при обучении нейронных сетей, делятся на
два основных направления:
□ методы локальной оптимизации, использующие анализ производной функции
ошибки (градиентные методы);
□ методы глобальной оптимизации.
Нахождение оптимального состояния весов сети можно сравнить с поиском
экстремума на выпуклой поверхности. Алгоритм начинает работу со случайного
набора весов, а затем делает небольшие коррекции весов в разных направлени-
ях. После этого выбирается та коррекция, которая дает наибольшее сокращение
ошибки, а затем процедура повторяется. Можно провести аналогию с нахождением
наивысшей точки в холмистой местности. При этом нет гарантии, что вершина, на
которой будет остановлен поиск, является самой высокой.
Градиентные методы
Введем в рассмотрение одно из важнейших понятий, используемых при решении
задач оптимизации, — градиент (от лат. gradientis — «шагающий»). Это харак-
теристика, показывающая направление наискорейшего возрастания некоторой
величины, значение которой меняется от одной точки пространства к другой.
Например, если взять высоту поверхности земли над уровнем моря (двумерное
пространство), то ее градиент в каждой точке поверхности будет показывать вверх
(рис. 9.42).
Таким образом, операция градиента преобразует «холм», если смотреть на него
сверху, в поле векторов, направление которых в каждой точке совпадает с направ-
лением наиболее крутого подъема, а длина пропорциональна крутизне подъема.
Видно, что все векторы направлены к вершине. На пологом участке у «подножия
холма» длина векторов небольшая. На самом крутом участке векторы имеют мак-
симальную длину. И наконец, там, где вершина «холма» образует купол, длина
векторов уменьшается.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 501
Формально градиент определяется следующим образом:
дЕ . дЕ . дЕ ,
V. =—1 + — J+ — k,
дх ду дг
где Е — некоторая скалярная величина, обозначающая ошибку сети.
Методы оптимизации, которые в том или ином виде используют градиент,
называются градиентными методами. Их применение в алгоритмах обучения
нейронных сетей позволяет добиться очень хороших результатов, что делает эти
методы весьма распространенными при создании нейросетевых моделей.
Методы глобальной оптимизации
Большинство методов обучения нейронных се-
тей являются локальными, то есть выполняют _ >----
поиск локальных минимумов функции ошибки. \ / \ /
Обучение производится до тех пор, пока алго- е —\V . ...V--- L ...
ритм не достигнет минимума, значение ошибки д \ J
в котором окажется меньше некоторого задан- \
ного порога е. При этом глобальный минимум, ' w
, Обучение остановится здесь
то есть оптимальное состояние сети, не будет
достигнут (рис. 9.43). Рис. 9.43. Остановка алгоритма
Если предположить, что начальное состо- в локальном минимуме
яние вектора весов Wo совпадает с началом
координат, то, поскольку локальный минимум, значение ошибки в котором
падает ниже е, «встретится» алгоритму первым, глобальный минимум не будет
обнаружен.
Вообще говоря, если значение глобального минимума заранее неизвестно,
то невозможно сказать, насколько близко к нему находится текущее состояние
весов сети. Для поиска глобального минимума используются следующие ме-
тоды.
□ Метод перебора всех возможных значений целевой функции гарантированно
позволит обнаружить глобальный минимум, но в большинстве случаев этот
способ неприменим на практике из-за огромного количества состояний весов,
которое потребуется рассмотреть.
□ Можно несколько раз последовательно произвести процесс оптимизации,
каждый раз изменяя начальное состояние модели в надежде, что какое-то из
них окажется в «области притяжения» глобального минимума. Этот способ не
гарантирует обнаружения глобального оптимума, но позволяет задать поиску
более определенное направление.
Кроме того, разработаны специальные методы глобальной оптимизации, напри-
мер метод имитации отжига, генетические алгоритмы, метод виртуальных частиц
и др.
500 Часть I. Теория бизнес-анализа
Рис. 9.42. Градиент («холм» и поле векторов)
Методика использования градиента в алгоритме обучения нейронной сети
понятна. Здесь ключевой вопрос: в каком направлении и на какую величину
менять веса, чтобы достичь минимума функции ошибки за минимальное число
шагов? Ясно, что в том направлении, в котором функция ошибки уменьшает-
ся быстрее всего. Именно это направление и указывает градиент. Точнее, не
градиент, а антиградиент, поскольку в данном случае речь идет не о «холме»,
а о «впадине». Если градиент всегда направлен в сторону возрастания вели-
чины, то антиградиент, наоборот, в сторону ее уменьшения. Коррекция весов
нейронной сети в направлении антиградиента функции ошибки называется
градиентным спуском.
Оператор градиента обычно обозначается как grad или V (читается «набла»),
соответственно антиградиент будет обозначаться как -grad или —V.
502 Часть I. Теория бизнес-анализа
Градиентные алгоритмы обучения
нейронных сетей
Наибольшую популярность при обучении многослойных персептронов получили
градиентные алгоритмы. В их основе лежат метод градиентного (наискорейшего)
спуска, метод сопряженных градиентов и пр. Причины распространенности гра-
диентных алгоритмов заключаются в том, что они требуют относительно неболь-
шого числа итераций для обучения сети, обеспечивают достаточно малый уровень
ошибки и устойчивы к аномальным значениям входных признаков. Недостатком
градиентных методов является то, что они обнаруживают только локальные ми-
нимумы целевой функции.
Метод градиентного спуска
Градиентный спуск — это метод нахождения локального минимума функции
с помощью движения вдоль антиградиента. В случае обучения нейронных сетей
целевой функцией является функция выходной ошибки сети £(W). Напомним,
что градиент представляет собой сумму производных функции по трем коорди-
натам. График целевой функции в трехмерных координатах (х, у, z) напоминает
рельеф земной поверхности. Минимумы функции образуют «впадины», а макси-
мумы — «холмы» (рис. 9.44).
Рис. 9.44. Градиентный рельеф
Процесс оптимизации, то есть поиск оптимального состояния весов нейронной
сети, начинается со случайного выбора точки на рельефе, которая получается
в результате инициализации весов небольшими случайными значениями. Затем
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 503
в данной точке вычисляется градиент функции, и на его основе определяется
точка, соответствующая новому состоянию весов. При этом согласно рассмот-
ренному выше свойству градиента новая точка формируется с определенным
шагом в направлении максимального убывания функции. Далее вычисляется
следующая точка, и процесс повторяется, пока не будет достигнут ближайший
минимум. Можно провести следующую аналогию: если на поверхности устано-
вить шарик, он скатится в ближайшую впадину по направлению наибольшей
крутизны спуска.
Направление коррекции весов мы определили, но остается открытым вопрос
о величине этой коррекции, или, как говорят, о шаге коррекции. Влияет ли величи-
на коррекции весов на результаты обучения, и если да, то как ее выбрать? Влияние
шага коррекции на каждой итерации очевидно. Если шаг коррекции окажется
слишком большим, то алгоритм может «перешагнуть» через «впадину» на рель-
ефе и не обнаружить соответствующего минимума. Если шаг коррекции будет
слишком малым, то для достижения минимума потребуется большое количество
итераций, что приведет к очень долгой процедуре обучения.
При практической реализации градиентных алгоритмов обучения величину
шага коррекции делают переменной, и в процессе обучения она адаптируется к си-
туации. Для этого желательно, чтобы на начальных этапах обучения шаг коррекции
весов был наибольшим, а к концу процесса постепенно уменьшался, как показано
на рис. 9.45.
Рис. 9.45. Градиентный спуск
504 Часть I. Теория бизнес-анализа
На рисунке представлена «впадина» градиентного рельефа. При градиентном
спуске осуществляется переход из точки в точку в направлении антиградиента.
При этом расстояние между двумя соседними точками х, и х,_, меняется в зави-
симости от номера шага. Начальные шаги самые большие, а последующие умень-
шаются по мере приближения к минимуму.
Рассмотрим вопрос о том, как менять величину шага в процессе обучения.
Характер градиентного рельефа может быть различным: «впадины» могут быть
«глубже» или «мельче», их склоны — «круче» или «более пологими», область точ-
ки минимума может иметь разную кривизну. Если просто задать некоторый коэф-
фициент изменения шага в зависимости от номера итерации обучения, желаемого
эффекта достичь не получится. Длина шага должна подстраиваться к конкретным
особенностям поведения целевой функции.
Удачным решением является использование для определения величины шага
значения производной функции в данной точке, ведь производная позволяет по-
лучить всю необходимую информацию о поведении функции. Производная опре-
деляется как отношение приращения функции к приращению аргумента, поэтому
чем быстрее изменяется функция, тем выше значение ее производной. Кроме того,
значение производной функции в данной точке численно равно тангенсу угла
касательной к графику функции в этой точке. Следовательно, в тех точках, где
функция убывает, ее производная имеет отрицательный знак, а в тех, где возрас-
тает, — положительный. При проходе через экстремум производная меняет свой
знак: в точке минимума — с отрицательного на положительный (функция сначала
убывает, а потом возрастает); в точке максимума, наоборот, с плюса на минус
(функция сначала возрастает, а потом убывает). Экстремум расположен в точке,
где производная равна 0.
Следует отметить, что при приближении к экстремуму функция становится
более пологой, поэтому значение производной в области экстремума уменьшается
и стремится к нулю.
Эти свойства производной функции делают ее удобным инструментом для
управления процессом обучения нейронных сетей с использованием градиентных
алгоритмов. Величина шага коррекции на каждой итерации определяется выра-
жением:
4, = -,^. (9.7)
OW
где w — текущее состояние веса;
А® — шаг коррекции состояния веса;
E(w) — текущее значение ошибки;
т] — константа, называемая коэффициентом скорости обучения.
Знак «минус» в правой части выражения (9.7) учитывает, что движение осуще-
ствляется в направлении антиградиента.
Методика использования производной функции ошибки для управления шагом
коррекции весов нейронов иллюстрируется на рис. 9.46.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 505
Рис. 9.46. Управление шагом коррекции весов
На рисунке представлен график функции ошибки £(ю). На начальных итераци-
ях ошибка падает интенсивно, поэтому значение ее производной велико и имеет от-
рицательный знак (область 1). В соответствии с формулой (9.7) шаг коррекции Д®!
также велик: пока ошибка падает быстро, веса корректируются с большой скоро-
стью. По мере приближения алгоритма к минимуму скорость падения функции
уменьшается, следовательно, уменьшается и шаг коррекции, что позволяет более
точно настроиться на минимум функции ошибки.
При коррекции весов методом наискорейшего спуска возможна ситуация, когда
алгоритм попадет в точку экстремума, где производная равна 0. Тогда по формуле
(9.7) величина коррекции весов также будет Дк- = 0. На следующем шаге алго-
ритм останется в точке, где производная равна 0, поэтому ситуация повторится
и т. д. Проще говоря, алгоритм «забуксует» в точке экстремума, и коррекция весов
остановится. Чтобы выйти из этого состояния, можно запустить обучение заново.
Предположим, имеется вектор весов W = (w0, wit w2... wm)T, которые требуется
настроить таким образом, чтобы минимизировать выходную ошибку сети. Для этого
можно использовать метод градиентного спуска, который определит направление
коррекции весов. Градиент функции ошибки относительно вектора весов запишется
как вектор производных:
дЕ дЕ дЕ дЕ
dw0 ’ dw\ ’ dw-i dw,„
то есть вектор частных производных функции ошибки по каждому весу.
Рассмотрим отдельно вес Wt. На рис. 9.47 представлен график зависимости
функции ошибки от этого веса.
Наша задача — выбрать такое значение которое минимизирует ошибку.
Пусть оптимальным значением будет W\ = wopt. Нужно выбрать правило, которое
переместит Wi в положение, максимально близкое к wopt:
ю(А + 1) = ®(&) + Д®(&),
гДе k — номер итерации.
506 Часть I. Теория бизнес-анализа
Рис. 9.47. Зависимость функции ошибки Е от веса да.
Теперь предположим, что W\ лежит слева от минимума. Тогда текущий вес
следует увеличить, чтобы он стал ближе к оптимальному. Если текущий вес выше
оптимума, то мы должны уменьшать его. В первом случае производная ошибки от-
рицательная, а во втором — положительная. Следовательно, настройка весов всегда
должна выполняться в направлении, противоположном знаку производной.
Коэффициент скорости обучения
Величину шага коррекции веса на каждой итерации обучения часто называют
скоростью обучения. В соответствии с формулой (9.7) она определяется значением
производной функции ошибки. Однако, кроме производной, на скорость обучения
влияет дополнительный параметр — коэффициент скорости обучения ц & (0;1].
Он подбирается экспериментально.
Если коэффициент скорости обучения велик (г| « 1), то скорость обучения
определяется только производной функции ошибки. При уменьшении коэффи-
циента возникает эффект «торможения» процесса: шаг коррекции уменьшается
в соответствии со значением коэффициента. Например, при г] = 0,5 каждый шаг
коррекции уменьшается в два раза.
При подборе г] руководствуются следующей логикой. Если задать его значение
большим, например 0,8 или 0,9, то такой шаг коррекции весов приведет к ускорению
процесса обучения — для достижения оптимума потребуется меньшее число итера-
ций, но при этом несколько снизится точность настройки на оптимум. Если задать
малый коэффициент скорости обучения (0,1-0,2), то время, требуемое для обучения,
возрастет, но увеличится и ожидаемая точность настройки на оптимум (рис. 9.48).
На верхнем графике, где шаг обучения мал, для достижения точки оптимума
требуется шесть шагов, но при этом точность настройки на оптимум будет высокой.
На нижнем графике, где шаг большой, оптимум будет достигнут всего за три шага,
но точность при этом уменьшится.
Наиболее распространенным градиентным алгоритмом обучения для нейрон-
ной сети является алгоритм обратного распространения ошибки.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 507
Рис. 9.48. Подбор коэффициента скорости обучения
9.11. Алгоритм обратного распространения ошибки
Алгоритм обратного распространения ошибки (error backpropagation, BackProp)
представляет собой градиентный алгоритм обучения многослойного персептрона,
основанный на минимизации среднеквадратической ошибки выходов сети. Алго-
ритм был предложен в 1974 г. П. Дж. Вербосом, а в 1986 г. его развили Д. Румель-
харт и Р. Вильямс. Появление алгоритма дало дополнительный толчок развитию
нейросетевых технологий.
Основная идея алгоритмов обучения с учителем, к которым относится и Back-
Prop, заключается в том, что на основе разности между желаемым и целевым выхо-
дами сети можно вычислить выходную ошибку сети. Цель определения выходной
ошибки — управление процессом обучения нейронной сети, то есть корректировки
весов ее межнейронных связей для минимизации функции ошибки.
Корректировка весов сети делается по правилу Видроу — Хоффа. Каждый
нейрон в сети получает возбуждение от вектора входных значений, производит
их взвешенное суммирование и преобразует полученную сумму с помощью ак-
тивационной функции. Выходная ошибка сети формируется на нейронах выход-
ного слоя. Но это не означает, что погрешность работы сети обусловлена только
выходными нейронами. Свой вклад в результирующую ошибку вносит каждый
скрытый нейрон. Тогда для него может быть указана ошибка 5 = d — у, где d — же-
лаемое выходное значение, а у — реальное выходное значение.
Правило Видроу — Хоффа, называемое также 5-правилом, подразумевает кор-
ректировку весов в соответствии с выражением:
Aw, = r]8r„ (9-8)
где т] — коэффициент скорости обучения;
Xi — значения, поступающие по входным связям.
Зная величину коррекции веса /-связи, мы можем вычислить ее новый вес по
формуле:
Wi(k + 1) = wdjt) + Ад-,, (9.9)
где k — номер итерации обучения.
508 Часть I. Теория бизнес-анализа
Непосредственно применять правило (9.9) для многослойного персептрона невоз-
можно: ошибки на выходах нейронов скрытых слоев неизвестны. Возникает вопрос:
нельзя ли рассчитать ошибку 5 на выходах скрытых нейронов как вклад в общую
ошибку сети? Иначе говоря, чтобы вычислить ошибки на выходе каждого скрытого
нейрона и на их основе рассчитать соответствующую коррекцию весов по форму-
ле (9.8), нужно передавать значение выходной ошибки от выходного слоя к входно-
му через все скрытые слои. Тогда, зная веса связей, виды активационных функций
и входные значения каждого нейрона, можно рассчитать их выходные ошибки.
Пусть выходная ошибка сети определяется по формуле:
f = (9.10)
В соответствии с выражением для коррекции весов алгоритма градиентного
спуска запишем:
дЕ
= <911>
где Wjj — текущий вес z-й связи у-го нейрона.
Можно показать, что:
дЕ ; дЕ дУ> (912)
dwn ду j dwtj'
Подставим выражение (9.12) в формулу (9.11):
= —г]
дЕ dyj
ду, dwy ’
(9.13)
Тогда в соответствии с формулой (9.7) получим: дЕ/ду; = —8,, a dyj/dwi, =
илидЕ/dWij =8jXj.
Выражение (9.12) справедливо только для линейного нейрона, у которого выходное
значение равно взвешенной сумме входов. В случае, когда выход нейрона формируется
с помощью активационной функции/(5), выражение (9.12) запишется в виде:
дЕ дЕ dyj dSj
dw:j dyj dSj dwtj ’
Тогда и выражение дЕ/dyj = —3, примет вид:
й = ЭЕ ду}
J dyjdSj'
Продифференцировав выражение (9.10), получим:
дЕ
wr{y'~ lY
(9.14)
(9.15)
(9.16)
Поскольку реальный выход г/; = f (5), то производная dyj/dS, = С уче-
том формул (9.15) и (9.16) получим:
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 509
(9Л7)
б/Z/ j j
В соответствии с принципом функционирования искусственного нейрона
5 = и dS/dwy = Xi. Таким образом, нам удалось выразить все сомножители
в правой части выражения (9.14) в виде известных значений и определить величину
коррекции веса:
dF
fVU,.
С учетом того, что вес должен изменяться в направлении, противоположном
знаку производной функции ошибки, получим:
AWjj—Sj-Xi. (9.18)
Ошибка 8; была получена для выходного нейрона. Что касается ошибки на выхо-
дах скрытых нейронов, то она не имеет непосредственной связи с выходной ошиб-
кой. Поэтому вес скрытых нейронов в соответствии с формулой (9.18) приходится
корректировать по его вкладу в величину ошибки следующего слоя. В сети с одним
скрытым слоем при распространении сигнала ошибки в обратном направлении
ошибка выходного нейрона также вносит вклад в ошибку каждого нейрона скры-
того слоя. Этот вклад зависит от значения ошибки выходного нейрона и веса связи,
соединяющей его со скрытым нейроном, ошибку которого требуется определить.
Чем больше ошибка на выходном нейроне и больше вес связи, соединяющей его со
скрытым нейроном, тем больше ошибка на выходе скрытого нейрона.
Тогда для произвольного нейрона скрытого слоя выходная ошибка может быть
получена в следующем виде:
5; =/'(5)-£8^-, (9.19)
k
где k — номер слоя, по ошибке которого производится корректировка весов преды-
дущего слоя. Если сеть имеет только один скрытый слой, то k — выходной слой.
Поскольку в формуле (9.19) присутствует производная активационной функ-
ции, становится понятно, почему к ней предъявляется требование дифференци-
руемости на всей числовой оси. В алгоритме обратного распространения ошибки
наиболее часто используется логистическая активационная функция, производная
которой равна:
/'(5) = /(5)(1 - /(5)) = У1 (1 - У]). (9.20)
На основе формул (9.19) и (9.20) можно вычислить ошибку для нейронов как
выходного 8""', так и скрытого 5*!,/ слоев:
5Г =^(1-^)-«(9-21)
(9.22)
k
510 Часть I. Теория бизнес-анализа
Блок-схема алгоритма обратного распространения ошибки для нейронной сети
с одним скрытым слоем представлена на рис. 9.49. Если нейронная сеть содержит
несколько скрытых слоев, то шаги с 6-го по 8-й повторяются для каждого скрытого
слоя (пунктирная линия на блок-схеме).
Рис. 9.49. Блок-схема алгоритма обратного распространения ошибки
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 511
ПРИМЕР-------------------------------------------------------------------
Имеется сеть, состоящая из трех нейронов входного слоя, одного скрытого слоя из двух
нейронов и одного выходного нейрона Сеть 3x2x1. Смещением для упрощения пре-
небрегли.
Предположим, что начальные веса связей были установлены следующим образом: wIA = 0,6;
да2л =0,8;®зл = 0,4; W\R = Q,T,w2b =0,9; =0,5; юлс = 0,9; wBc =0,2.
Коэффициент скорости обучения зададим т] = 0,1.
Пусть для некоторого обучающего примера выход сети у = 0,87, а целевое значение
d = 0,80, а также при прямом проходе алгоритма уже рассчитаны значения выходов уА
и ув для нейронов скрытого слоя. Проделаем одну итерацию алгоритма BackProp в об-
ратном направлении.
По формуле (9.21) найдем ошибку для выходного нейрона 5с:
5с = yj (у-y^.^d,- yj) = 0,87• (1 - 0,87)• (0,8 - 0,87) = -0,0079.
Теперь на основе полученной ошибки вычислим величины коррекции весов А®Лс и Аювс.
Для этого сначала рассчитаем ошибки на выходах нейронов А и В скрытого слоя. Слой,
следующий за скрытым, является выходным и содержит только один нейрон С, поэтому
формула (9.22) примет вид:
Зи = г/л • (1 — г/и)-8с • ге’лс-
Пустьу,, = 0,78. Имеем:
5л =0,78-(1 — 0,78)-(—0,0079)-0,9 = —0,0012.
Зная ошибку 5с нейрона С, с помощью формулы 9.18 вычислим коррекцию веса связи
А®лс:
Awac = т]’Зс • Ул — 0,1'(—0,0079)-0,78 = —0,00062.
После выполним коррекцию веса:
= ж’лс + Ак-ис = 0,9 - 0,00062 = 0,89938.
512 Часть I. Теория бизнес-анализа
Теперь для вычисления коррекции веса А® дс рассчитаем ошибку на входе нейрона В (пусть
г/д = 0,82):
5 „ = у „ - (1 - у „) • 5С • wпс = 0,82 • (1 - 0,82) • (-0,0079) 0,2 = -0,0002.
Тогда
Ада/)с = т] • 5с • у в = 0,1 • (-0,0079)- (0,82) = -0,00065;
=w'bI + А® „с =0,2-0,00065 = 0,19935.
Аналогичным образом рассчитываются коррекции для весов нейронов скрытого слоя,
в формулах которых будут использоваться ранее вычисленные ошибки 5Л и 5В и оставши-
еся веса связей.
Момент
Алгоритм обратного распространения ошибки можно сделать более эффективным,
если ввести в него дополнительный элемент, называемый моментом. Момент обо-
значается а и вводится следующим образом:
дЕ
Иными словами, при вычислении коррекции веса на итерации k к значению
коррекции, вычисленному в соответствии с методом градиентного спуска, дела-
ется добавка, равная значению коррекции веса на предыдущей итерации (то есть
итерации k — 1), умноженному на некоторый коэффициент 0 < а < 1.
Использование момента позволяет придать некоторую инерционность процессу
обучения. При больших значениях параметра а момент будет сдвигать текущую кор-
рекцию веса в направлении предыдущей коррекции. Включение момента в алгоритм
ведет к тому, что подстройка весов на текущей итерации становится экспоненциаль-
ным средним значений подстроек весов на всех предыдущих итерациях, то есть:
°° dF
Аж(^) = -л^а*—-г.
k = 0 dw\k)
Член а* показывает, что более поздние итерации, поскольку им соответствуют
бблыпие значения k, оказывают большее влияние. Большие значения а позволяют
алгоритму запоминать больше значений подстроек весов, имевших место на более
ранних итерациях. Малые значения а, наоборот, уменьшают эффект инерцион-
ности. При а = 0 инерционность алгоритма полностью исчезает.
Момент ослабляет колебания алгоритма около оптимума, поддерживая подстрой-
ку весов в одном и том же направлении. Но если коэффициент а слишком большой,
то алгоритм приобретает чрезмерно большую инерционность и может пропустить
минимум функции ошибки из-за суммарного влияния предыдущих итераций.
Глава 9. Data Mining: классификация и регрессия. Машинное обучение 513
Рассмотрим рис. 9.50. На обоих графиках присутствуют локальные минимумы
в точках Л и С, а также глобальный минимум в точке В. Движение алгоритма по
поверхности функции ошибки можно представить в виде перемещения шарика
с определенной массой. Если масса шарика и, соответственно, его инерция низкие,
то он не сможет преодолеть локальный минимум А и остановится в нем (этот слу-
чай соответствует малым значениям а). Если значения а велики (правый график),
то гипотетический шарик будет обладать слишком большими массой и инерцией,
вследствие чего «проскочит» оптимум и остановится только в точке С.
Рис. 9.50. Влияние момента на обучение сети
Таким образом, введение момента позволяет алгоритму преодолевать локаль-
ные минимумы и задерживаться только в более глубоких и значимых «впадинах»
поверхности ошибки. Экспериментально подбирая момент а и коэффициент
скорости обучения Т), можно добиться эффективной работы алгоритма обратного
распространения ошибки.
ПЕРСОНАЛИИ--------------------------------------------------------------------
Лео Брейман (Leo Breiman) (1928-2005) — выдающийся ученый, профессор, работавший
в Калифорнийском университете в Беркли, член Национальной академии наук США, один
из авторов алгоритма CART и подходов под названием «случайные леса» (random forests).
Брейман занимался вопросами на стыке математической статистики и машинного обучения,
исследованиями в области многомерного статистического анализа, в том числе нелинейны-
ми методами распознавания образов. Активно развивал идеи ансамблей деревьев решений
и связанных с ними технологий бутстрэп-анализа (bootstrap) и бэггинга (bagging).
Росс Куинлан (Ross Quinlan) — один из ведущих мировых специалистов в области машин-
ного обучения. Data Mining и деревьев решений, автор алгоритмов ID3 и С4.5 и их коммер-
ческой модификации — С5.0.
Долгое время работал в Сиднейском университете, Сиднейском технологическом универси-
тете, а в 1997 г. основал собственную компанию RuleQuest Research (http://rulequest.com/)
по разработке и поставке коммерческого ПО в области машинного обучения. Известность
получили такие программные решения компании, как пакеты Sees (деревья решений)
и Magnum Opus (ассоциативные правила).
Анализ
и прогнозирование
временных рядов
10.1. Введение в прогнозирование
Прогнозирование — одна из самых востребованных задач бизнес-аналитики. И это
неудивительно: зная, пусть даже с определенной погрешностью, характер разви-
тия событий в будущем, можно принимать более обоснованные управленческие
решения, планировать деятельность, разрабатывать соответствующие комплексы
мероприятий, эффективно распределять ресурсы и т. д.
С точки зрения технологий анализа данных прогнозирование может рассмат-
риваться как определение некоторой неизвестной величины по набору связанных
с ней значений. Поэтому прогнозирование выполняется с помощью таких задач
Data Mining, как регрессия, классификация и кластеризация.
Продажи, поставки, заказы — это процессы, распределенные во времени.
Данные, собираемые и используемые для разработки прогнозов, чаще всего
представляют собой временные ряды, то есть описывают развитие того или иного
бизнес-процесса во времени. Следовательно, прогнозирование в области продаж,
сбыта и спроса, управления материальными запасами и потоками обычно связано
именно с анализом временных рядов. Это объясняет, почему обработке временных
рядов в бизнес-аналитике и Data Mining уделяется такое большое внимание.
Все методы прогнозирования можно разделить на три большие группы — фор-
мализованные, эвристические и комплексные.
Формализованные методы позволяют получать в качестве прогнозов количе-
ственные показатели, описывающие состояние некоторого объекта или процесса.
При этом предполагается, что анализируемый объект или процесс обладает свой-
ством инерционности, то есть в будущем он продолжит развиваться в соответствии
Глава 10. Анализ и прогнозирование временных рядов 515
с теми же законами, по которым развивался в прошлом и существует в настоящем.
Недостатком формализованных методов является то, что для прогноза они могут
использовать только исторические данные, находящиеся в пределах эволюци-
онного цикла развития объекта или процесса. Поэтому такие методы пригодны
лишь для оперативных и краткосрочных прогнозов. К формализованным методам
относятся экстраполяционные и регрессионные методы, методы математической
статистики, факторный анализ и др.
Эвристические методы основаны на использовании экспертных оценок. Экс-
перт (группа экспертов), опираясь на свои знания в предметной области и прак-
тический опыт, способен предсказать качественные изменения в поведении
исследуемого объекта или процесса. Эти методы особенно полезны в тех случаях,
когда поведение объектов и процессов, для которых требуется дать прогноз, харак-
теризуется большой степенью неравномерности. Если формализованные методы
в силу присущих им ограничений используются для оперативных и краткосроч-
ных прогнозов, то эвристические методы чаще применяются для среднесрочных
и перспективных.
Комплексное прогнозирование использует комбинацию формализованного под-
хода с экспертными оценками, что в некоторых случаях позволяет добиться наи-
лучшего результата.
Независимо от методики на эффективность прогноза в наибольшей степени
влияет то, насколько он полезен для планирования и ведения бизнеса. Прогноз
полезен только тогда, когда его компоненты тщательно продуманы и ограничения,
содержащиеся в нем, представлены явно. Чтобы понять, будет ли прогноз полезен,
необходимо ответить на несколько вопросов.
□ Для чего нужен прогноз, какие решения будут на нем основаны? Этим опреде-
лится требуемая точность прогноза. Например, одни решения принимать опас-
но, даже если возможная погрешность прогноза менее 10 %. Другие решения
можно безбоязненно принимать и при значительно более высокой допустимой
ошибке.
□ Какие изменения должны произойти, чтобы прогноз оказался достоверным?
Другими словами, следует оценить вероятность событий, которые должны
случиться, чтобы прогноз сбылся. Например, если таким событием будет озе-
ленение Луны, от прогноза в ближайшей перспективе следует отказаться.
□ Насколько структурированным должен быть прогноз? Например, при про-
гнозировании продаж может оказаться целесообразным выделение отдельных
сегментов рынка (развивающиеся клиенты, стабильные клиенты, крупные
и мелкие клиенты, вероятность появления новых клиентов и т. п.).
Кроме того, необходимо подумать об источниках информации; определить, на-
сколько ценен опыт прошлого и не настолько ли быстры изменения, что основанный
на опыте прогноз окажется бесполезным; выяснить, какие финансовые, временные
и прочие затраты потребуются, чтобы получить надежную информацию, и др.
Условия функционирования рыночной экономики делают невозможным эф-
фективное управление бизнесом без прогнозирования. От того, насколько прогноз
516 Часть I. Теория бизнес-анализа
будет точным и своевременным, а также от его соответствия поставленным задачам
будет зависеть успех деятельности предприятия.
Прогнозирование — очень широкое понятие. Как отмечалось ранее, в боль-
шинстве случаев оно связывается с предвидением во времени, с предсказанием
дальнейшего развития событий. В таком контексте прогнозирование понимается
и в системах бизнес-аналитики. Поэтому далее при изложении аспектов прогно-
зирования речь будет идти именно о прогнозировании временных рядов; с этих
позиций будут рассматриваться основные модели и методы прогнозирования.
10.2. Временной ряд и его компоненты
Аналитику часто приходится иметь дело с данными, представляющими собой ис-
торию изменения различных объектов во времени. Такого рода данные называются
временными рядами (time series data). Именно они вызывают наибольший интерес
с точки зрения множества задач анализа, а особенно прогнозирования.
Временной ряд представляет собой последовательность наблюдений за измене-
ниями во времени значений параметров некоторого объекта или процесса. Строго
говоря, каждый процесс непрерывен во времени, то есть некоторые значения па-
раметров этого процесса существуют в любой момент времени. Например, если
вы запросите в банке текущий курс валют, вам никогда не ответят, что в настоя-
щее время курса валют нет. Возможно, новый курс установился минуту назад,
возможно, через час он изменится, но в настоящее время какое-то его значение
непременно существует.
Для задач анализа не нужно знать значения параметров объектов в лю-
бой момент времени. Интерес представляют временные отсчеты — значения,
зафиксированные в некоторые, обычно равноотстоящие моменты времени.
Отсчеты могут браться через различные промежутки: через минуту, час, день,
неделю, месяц или год — в зависимости от того, насколько детально должен
быть проанализирован процесс. В задачах анализа временных рядов мы имеем
дело с дискретным временем, когда каждое наблюдение за параметром образует
временной отсчет. Непрерывный и дискретный временные ряды иллюстриру-
ются на рис. 10.1.
ЗАМЕЧАНИЕ----------------------------------------------------------
Не следует путать такие понятия, как непрерывный или дискретный ряд и непрерывные
или дискретные данные. Непрерывный ряд — это процесс, значения которого известны
в любой момент времени, а дискретный ряд — процесс, значения которого известны только
в заданные моменты времени (временные отсчеты). Непрерывные данные — зто данные,
которые могут принимать бесконечное множество значений. Непрерывными могут быть
только числовые данные. Дискретные данные могут принимать ограниченный набор зара-
нее определенных значений (категорий).
Все временные отсчеты нумеруются в порядке возрастания. Тогда временной
ряд будет представлен в следующем виде: X = {хь х2... х„}.
Глава 10. Анализ и прогнозирование временных рядов 517
Рис. 10.1. Непрерывный и дискретный временные ряды
Временные ряды бывают одномерные и многомерные. Одномерные ряды содер-
жат наблюдения за изменением только одного параметра исследуемого процесса
или объекта, а многомерные — за двумя параметрами или более. Трехмерный
временной ряд, содержащий наблюдения за тремя параметрами — X, Y и Z — про-
цесса F, можно записать в следующем виде:
F = {(*), у); (х2, у2, z2)...(х„, у„, ?„)}.
Пример многомерного временного ряда представлен на рис. 10.2.
Время
Рис. 10.2. Многомерный временной ряд
518 Часть I. Теория бизнес-анализа
Значения временного ряда получаются путем регистрации соответствующе-
го параметра исследуемого процесса через определенные промежутки времени.
При этом в зависимости от природы данных и характера решаемых задач регист-
рируется либо текущее значение (например, температура или курс валюты), либо
сумма значений, накопленная за определенный интервал времени (например,
сумма продаж за день, количество клиентов за неделю и т. д.). В последнем случае
может использоваться не только суммирование, но и среднее значение за интервал
минимальное, максимальное значения или медиана. Так, исследователя может ин-
тересовать средний объем продаж за неделю, максимальный курс доллара к рублю,
минимальная температура за месяц и т. д.
Цели и задачи анализа временных рядов
При изучении временного ряда аналитик должен на основе некоторого отрезка
ряда конечной длины сделать выводы о характере и закономерностях процесса,
который описывается данным рядом. Наиболее часто в ходе анализа временных
рядов решаются следующие задачи:
□ описание характеристик и закономерностей ряда. На основе этого описания
могут быть выявлены свойства соответствующих бизнес-процессов;
□ моделирование — построение модели исследуемого процесса;
□ прогнозирование — предсказание будущих значений временного ряда;
□ управление. Зная свойства временных рядов, можно выработать методы воздей-
ствия на соответствующие бизнес-процессы для управления ими.
Наиболее востребованными в бизнес-аналитике являются задачи моделиро-
вания и прогнозирования. Они взаимосвязаны: чтобы составить прогноз, сначала
нужно построить соответствующую модель, проверить степень ее адекватности
и правильно применить к имеющимся наблюдениям.
При решении данных задач можно столкнуться с такими проблемами, как:
□ недостаточное количество наблюдений, содержащихся во временном ряду;
□ статистическая изменчивость ряда, которая приводит к тому, что прошлые зна-
чения ряда устаревают и обесцениваются с точки зрения выявления текущих
закономерностей и возможности прогнозирования.
Детерминированная и случайная составляющая
временного ряда
Любой бизнес-процесс разрабатывается и направляется осмысленно в соответ-
ствии с теми или иными целями, поэтому в его поведении должны присутствовать
определенные закономерности. Некоторые процессы протекают равномерно, не
отклоняясь от намеченных показателей. Например, завод должен производить
ровно столько изделий, сколько требуется заказчикам, поэтому, если спрос ста-
бильный, то и производство необходимо поддерживать на одном уровне. Увели-
чивать или снижать его нет смысла, поскольку в первом случае будет иметь место
Глава 10. Анализ и прогнозирование временных рядов 519
работа «на склад», а во втором — упущенная прибыль и потерянные заказчики.
Если спрос устойчиво возрастает с течением времени, то и производство должно
наращиваться пропорционально. Если спрос характеризуется периодичностью,
вызванной сезонными колебаниями, то и производство должно подстраиваться
под них. Возьмем пиво и шипованные автопокрышки: первое лучше продается
в теплое время, а вторые — в зимнее. Попытка пойти против данной закономер-
ности вряд ли будет способствовать коммерческому успеху.
Таким образом, в любом бизнес-процессе присутствует определенная законо-
мерность, способствующая достижению его целей. Она прослеживается и в соответ-
ствующих временных рядах. Но любой бизнес сталкивается с воздействием различ-
ных случайных факторов. Диапазон таких факторов очень широк — от стихийных
бедствий и пожаров до банального хищения на складе готовой продукции. При этом
случайные факторы могут как препятствовать, так и способствовать бизнесу. Напри-
мер, аномально холодная зима будет способствовать взлету продаж отопительных
приборов, а аномально теплая испортит бизнес продавцам зимних автопокрышек.
Общим свойством всех случайных факторов является то, что они не поддаются
прогнозированию и вносят во временные ряды изменения, не соответствующие их
основным закономерностям.
Можно выделить две составляющие временного ряда — закономерную (детер-
минированную) и случайную (стохастическую).
ОПРЕДЕЛЕНИЕ-------------------------------------------------------------
Закономерная (детерминированная) составляющая временного ряда — последователь-
ность значений, элементы которой могут быть вычислены в соответствии с определенной
функцией. Закономерная составляющая временного ряда отражает действие известных
факторов и величин.
Зная функцию, описывающую закономерность, в соответствии с которой раз-
вивается исследуемый процесс, мы можем вычислить значение детерминированной
составляющей в любой момент времени. Например, если спрос на товары и услуги
фирмы имеет устойчивую тенденцию к росту по линейному закону, то его можно
приближенно описать функцией d(f) = а + b t, где а и b — константы. Подставляя
в эту формулу время, для которого требуется определить значение процесса, мы
можем вычислить нужное значение. Конечно, это упрощенная ситуация и обычно
реальные процессы описываются более сложными законами.
ОПРЕДЕЛЕНИЕ-------------------------------------------------------------
Случайная (стохастическая) составляющая временного ряда — последовательность зна-
чений, которая является результатом воздействия на исследуемый процесс случайных
факторов. Случайная составляющая и ее влияние на временной ряд могут быть оценены
только с помощью статистических методов.
Пример соотношения детерминированной и случайной составляющих пред-
ставлен на рис. 10.3. Здесь детерминированная составляющая изображена плавной
темной линией, а случайная — быстро изменяющейся светлой линией.
520 Часть I. Теория бизнес-анализа
Рис. 10.3. Детерминированная и случайная составляющие
Вообще говоря, случайная составляющая не существует отдельно от детерми-
нированной. Она проявляется только как результат воздействия набора случайных
факторов на исследуемый процесс и обычно выражается в повышенной измен-
чивости временного ряда, а также в отклонении значений детерминированной
составляющей. Проще говоря, результирующее значение временного ряда — это
результат взаимодействия детерминированной и случайной составляющих. Про-
стейшим видом такого взаимодействия является случай, когда каждое значение
временного ряда можно рассматривать как сумму (разность) двух значений, одно
из которых обусловлено детерминированной составляющей, а другое — случай-
ной, то есть х, = dj + pt. Графически это иллюстрируется на рис. 10.4, где нижняя
часть каждого столбика (светлая) обусловлена детерминированной составляющей,
а верхняя (темная) — случайной составляющей.
Значение
Время
Рис. 10.4. Аддитивное взаимодействие детерминированной и случайной составляющих
Глава 10. Анализ и прогнозирование временных рядов 521
Модели временных рядов
Итак, наблюдаемые значения временного ряда представляют собой результат
взаимодействия детерминированной и случайной составляющих. Различают два
вида такого взаимодействия:
□ аддитивное — значения временного ряда получаются как результат сложения
детерминированной и случайной составляющих;
□ мультипликативное — значения временного ряда получаются как результат
умножения детерминированной и случайной составляющих.
Соответственно модели временных рядов также бывают аддитивные и муль-
типликативные.
Аддитивная модель имеет вид:
Xt = di + p i или X = D + Р,
где i = 1... п — номер временного отсчета.
Мультипликативная модель имеет вид:
х, = d,- р i или Х = D • Р.
Очень важно знать характер взаимодействия детерминированной и случайной
составляющих, поскольку методика анализа временных рядов зависит от исполь-
зуемой модели.
Компоненты временного ряда
Количество разнообразных процессов в экономике, управлении, бизнесе, социаль-
ной и государственной сфере весьма велико, и поведение временных рядов, опи-
сывающих эти процессы, может существенно различаться. Поэтому для описания
поведения временных рядов были введены три компоненты, своего рода типовые
структуры, которые можно выделить во временном ряду, — тренд, сезонная ком-
понента и циклическая компонента.
С учетом указанных компонент детерминированная составляющая ряда может
быть записана в виде:
d, = t i -|- 5 i -|- с ;r
где ti — тренд;
s, — сезонная компонента;
с, — циклическая компонента;
i = 1... п — номер временного отсчета.
Тренд
Тренд — наиболее важная компонента временного ряда. Именно с выделения
тренда чаще всего и начинается анализ временного ряда.
522 Часть I. Теория бизнес-анализа
ОПРЕДЕЛЕНИЕ
Тренд — медленно меняющаяся компонента временного ряда, которая описывает влияние
на временной ряд долговременно действующих факторов, вызывающих плавные и дли-
тельные изменения ряда.
Действительно, среди всех факторов, влияющих на экономические и бизнес-
процессы, выделяются быстродействующие и медленнодействующие. Быстродей-
ствующие факторы, такие как стихийное бедствие, «обвал» фондового рынка и т. д.,
могут изменить ситуацию в течение нескольких дней или даже часов. Медленнодей-
ствующие факторы могут изменять ситуацию в течение нескольких месяцев и даже
лет. Так, если наблюдается постепенный отток рабочей силы из региона, то она ста-
новится дефицитной и, чтобы привлечь квалифицированные кадры, работодатели
вынуждены повышать заработную плату, что отражается на цене товаров и услуг.
Однако этот процесс может длиться годы. И хотя на протяжении отдельных интер-
валов времени эти показатели могут колебаться (например, под действием других
факторов), в целом тенденция будет сохраняться. Именно такие закономерности
в рядах данных и позволяет выявить тренд.
Чтобы представить характер тренда, обычно бывает достаточно взглянуть на
график временного ряда. Для описания тренда используются различные модели,
наиболее популярными из которых являются следующие.
□ Простая линейная модель: tt = а + b i, где i = 1... п — номер отсчета времени
(элемента ряда). Пример линейного тренда представлен на рис. 10.5.
Рис. 10.5. Линейный тренд
Несмотря на свою простоту, линейная модель тренда часто оказывается полез-
ной при решении реальных задач анализа, поскольку многие бизнес-процессы
линейны по своей природе.
□ Полиномиальная модель: i, = а + Ь-, • i + Ьг • i2 + ... + b„ • г". В большинстве реаль-
ных задач степень полинома не превышает 5.
Глава 10. Анализ и прогнозирование временных рядов 523
□ Экспоненциальная модель: Г, = ехр(а + b • i). Используется в случаях, когда про-
цесс характеризуется равномерным увеличением темпов роста. Пример экспо-
ненциального тренда представлен на рис. 10.6 (сплошная линия).
Рис. 10.6. Экспоненциальный тренд
□ Логистическая модель: t,= а/(1 + b • е k'~), где k — константа, управляющая кру-
тизной логистической функции (рис. 10.7).
Такого типа кривые, имеющие 5-образную форму, часто называют сигмоидами.
Они хорошо описывают процессы с непостоянными темпами роста.
Сезонная компонента
Многим процессам свойственна повторяемость во времени, причем периодичность
таких повторений может изменяться в очень широком диапазоне. Например, для
экономики стран и регионов характерны подъемы и спады, которые могут длиться
десятилетиями. В супермаркете продажи ежедневно увеличиваются в вечернее
время, когда люди идут с работы. На бензоколонке, расположенной на выезде из го-
рода, пик продаж топлива наблюдается в выходные дни, когда городское население
выезжает на дачи. Объемы продаж товаров для школьников резко увеличиваются
в августе, в преддверии нового учебного года. Спрос на туристические путевки,
524 Часть I. Теория бизнес-анализа
авиа- и железнодорожные билеты существенно возрастает в сезон отпусков. По-
добных примеров можно привести множество.
Очевидно, что для описания таких периодических изменений, присутствующих
во временных рядах, тренд непригоден. Поэтому вводится еще одна компонента,
называемая сезонностью, или сезонной компонентой.
ОПРЕДЕЛЕНИЕ-----------------------------------------------------------
Сезонная компонента — составляющая временного ряда, описывающая регулярные изме-
нения его значений в пределах некоторого периода и представляющая собой последова-
тельность почти повторяющихся циклов.
Сезонная компонента может быть привязана к определенному календарному
временному интервалу: дню, неделе, кварталу, месяцу или году — либо к какому-
нибудь событию, которое прямо не соотносится с конкретными календарными
интервалами.
ПРИМЕР----------------------------------------------------------------
Ажиотажный спрос на цветы перед 8 Марта всегда связан с определенной датой и неза-
висимо от погоды и других факторов наблюдается в одно и то же время. В данном случае
имеет место годовая периодичность.
Резкий рост спроса на услуги пунктов шиномонтажа наблюдается дважды в год — при
ухудшении дорожных условий из-за выпадения снега и гололеда, когда водители меняют
летние шины на зимние, и весной, когда дороги очищаются от снега и льда. Изменение
спроса связано не с конкретной датой (все бросились менять резину 1 декабря), а с ре-
альными погодными условиями. Например, условия, которые сделают необходимым
переход на зимние покрышки, могут сложиться и в конце октября, и в начале января.
Очиститься ото льда и снега дороги могут уже в начале марта, а могут и в конце апре-
ля. Следовательно, в данном случае имеет место сезонная компонента с переменным
периодом.
Сезонную компоненту с изменяющимся периодом иногда называют «плава-
ющей».
Утверждать, что сезонная компонента описывается периодической функци-
ей, было бы неверно. Понятно, что регулярно повторяющиеся всплески продаж,
образующие сезонную компоненту, не будут воспроизводиться абсолютно точно
(как, например, значения функций синуса или косинуса). Тем не менее сезон-
ная компонента обычно хорошо прослеживается на графике временного ряда
(рис. 10.8).
Представленный временной ряд содержит наблюдения за числом автомобилей,
заправляющихся на бензоколонке. Он включает наблюдения за 3 недели. На гра-
фике видно, что в рабочие дни количество заправляющихся автомобилей почти
в два раза меньше, чем в выходные. Рост числа клиентов начинается с пятницы,
когда жители города выезжают на дачу, и завершается в воскресенье, когда они
возвращаются назад. Таким образом, имеется сезонная компонента с недельной
периодичностью.
Глава 10. Анализ и прогнозирование временных рядов 525
Рис. 10.8. Сезонная компонента временного ряда
Циклическая компонента
Часто временные ряды содержат изменения, слишком плавные и заметные для слу-
чайной составляющей. В то же время такие изменения нельзя отнести ни к тренду,
поскольку они не являются достаточно протяженными, ни к сезонной компоненте,
поскольку они не являются регулярными. Подобные изменения называются цик-
лической компонентой временного ряда. Она занимает промежуточное положение
между детерминированной и случайной составляющими временного ряда.
ОПРЕДЕЛЕНИЕ-------------------------------------------------------
Циклическая компонента временного ряда — интервалы подъема или спада, которые
имеют различную протяженность, а также различную амплитуду расположенных в них
значений.
Наличие в рядах данных циклических компонент связано с тем, что в пределах
интервалов более глобальных изменений (например, сезонных) могут наблюдаться
не имеющие периодичности временные подъемы и спады, которые, в отличие от
случайной компоненты, не вызваны действием случайных факторов, а являются
особенностями бизнеса и обусловлены общеэкономической ситуацией. На графике
циклическая компонента выглядит как плавные волнообразные флуктуации вокруг
тренда. На рис. 10.9 представлен временной ряд с ярко выраженным возрастающим
трендом и циклической компонентой.
Выделить во временных рядах циклическую компоненту формальными мето-
дами довольно сложно. Обычно для этого используют информацию из других вре-
менных рядов, которые связаны с исследуемым. Например, объяснить колебания
ряда в пределах сезонных интервалов можно инфляцией, изменениями на рынке
трудовых ресурсов и т. д. Но для этого необходимо привлечь соответствующую
информацию.
526 Часть I. Теория бизнес-анализа
Рис. 10.9. Циклическая компонента
Изучение циклической компоненты часто оказывается полезным для прогно-
зирования, особенно краткосрочного.
Таким образом, временной ряд можно представить как композицию, состоящую
из двух составляющих — случайной и детерминированной. Детерминированная
составляющая, в свою очередь, содержит три компоненты — тренд, сезонную и ци-
клическую. Структура временного ряда поясняется на рис. 10.10.
Рис. 10.10. Композиционная структура временного ряда
Исследование временных рядов и автокорреляция
Цель анализа временного ряда — построение его математической модели, с помо-
щью которой можно обнаружить закономерности поведения ряда, а также постро-
ить прогноз его дальнейшего развития.
Глава 10. Анализ и прогнозирование временных рядов 527
Главной проблемой при построении таких моделей является нестационарность
ряда.
Временной ряд называется стационарным, если его статистические свой-
ства (математическое ожидание и дисперсия) одинаковы на всем протяжении
ряда.
Если статистические свойства для различных интервалов ряда существенно
различаются, то такой ряд называется нестационарным. Применение к нестацио-
нарным рядам различных методов анализа, в том числе статистических, затруд-
нено. Поэтому, прежде чем приступать к построению модели ряда, его стараются
свести к стационарному. В верхней части рис. 10.11 представлен стационарный
ряд, а в нижней — нестационарный.
Рис. 10.11. Визуальная оценка стационарности временного ряда
При исследовании временного ряда, как правило, ищут ответы на несколько
вопросов.
□ Является ли ряд данных случайным?
□ Содержит ли временной ряд тренд и сезонную компоненту?
□ Является ли временной ряд стационарным?
528 Часть I. Теория бизнес-анализа
Для ответа используется аппарат корреляционного анализа. Корреляция — это
понятие математической статистики, которое характеризует степень статисти-
ческой взаимосвязи между элементами данных. Если взаимосвязь между эле-
ментами данных присутствует, то такие данные называются коррелированными,
в противном случае — некоррелированными (корреляционный анализ рассмат-
ривался в главе 5).
Если определяется корреляция между двумя временными рядами, то говорят
о взаимной корреляции. Когда устанавливается степень статистической зависи-
мости между значениями одного временного ряда, имеет место автокорреляция.
В этом случае вычисляется корреляция между временным рядом и его копией,
сдвинутой на один или несколько временных отсчетов.
Смысл корреляционного анализа заключается в следующем. Детерминиро-
ванная составляющая временного ряда, которая описывает закономерности,
присущие связанному с ним процессу, характеризуется плавными изменениями
значений ряда. То есть соседние значения ряда не должны сильно отличаться,
и, следовательно, между ними присутствует взаимная зависимость (элементы
ряда коррелированы между собой). Если значения ряда в большей степени
обусловлены случайной составляющей и соседние значения могут существенно
отличаться друг от друга, то степень их взаимозависимости и, следовательно,
корреляция будут меньше.
Рассмотрим понятие автокорреляции на следующем примере. Пусть дан ряд,
который содержит последовательность ежемесячных наблюдений за продажами
(табл. 10.1).
Таблица 10.1. Продажи по месяцам
Месяц Продажи
Январь 125
Февраль 130
Март 140
Апрель 132
Май 145
Июнь 150
Июль 148
Август 155
Сентябрь 157
Октябрь 160
Ноябрь 158
Декабрь 165
График ряда представлен на рис. 10.12.
Для того чтобы вычислить автокорреляцию ряда, будем использовать его ко-
пию, сдвинутую в сторону запаздывания на определенное количество отсчетов
(табл. 10.2).
Глава 10. Анализ и прогнозирование временных рядов 529
Рис. 10.12. График продаж по месяцам
Таблица 10.2. Данные для расчета автокорреляционной функции (АКФ)
X 125 130 140 132 145 150 148 155 157 160 158 165
Х,-1 125 130 140 132 145 150 148 155 157 160 158
Xi—2 125 130 140 132 145 150 148 155 157 160
...
Х,-„ 125
Тогда ряд Xi 1 будет представлять собой копию исходного ряда, сдвинутую на
один временной отсчет, X,.. 2 — на два временных отсчета и т. д. Для определения
степени взаимной зависимости элементов ряда используется величина, называ-
емая коэффициентом автокорреляции rk, где k — количество отсчетов, на которое
был сдвинут временной ряд при вычислении данного коэффициента. Коэффици-
ент автокорреляции вычисляется в соответствии с формулой
^2 -х)(х,_* -х)
г = * + 1
r‘=------;--------------
£(х,-х)
i = 1
где х, — значение z-ro отсчета;
Xi _k — наблюдение х, со сдвигом на k временных отсчетов;
х — среднее значение ряда.
Коэффициент корреляции изменяется в диапазоне [-1; 1], где rk = 1 указывает
на полную корреляцию. Если рассчитать коэффициенты автокорреляции для
каждого сдвига, то получим последовательность коэффициентов, называемую
автокорреляционной функцией (АКФ).
530 Часть I. Теория бизнес-анализа
Результат расчета АКФ для ряда X представлен в табл. 10.3.
Таблица 10.3. Результаты расчета АКФ для ряда X
к 0 1 2 3 4 5 6 7 8 9 10
Гь 1 0,87 0,86 0,84 0,79 0,71 0,64 0,53 0,02 0 0 ~
Соответствующий график представлен на рис. 10.13.
Значение коэффициента автокорреляции при нулевом сдвиге г0 равно 1, по-
скольку определяется автокорреляция двух одинаковых копий временного ряда,
а ряд полностью коррелирован сам с собой. Также наблюдается высокая степень
корреляции гк > 0,8 при сдвиге менее чем на 4 временных отсчета и умеренная при г*,
изменяющемся на 5-7 отсчетов. При сдвиге более чем на 7 отсчетов коэффициент
корреляции быстро падает. Такой результат вполне объясним. Значения ряда, рас-
положенные близко друг к другу, имеют высокую степень взаимной зависимости,
что обеспечивает высокий коэффициент автокорреляции при малом сдвиге (в пре-
делах 4 отсчетов). По мере удаления значений степень их взаимной зависимости
падает, что приводит к уменьшению коэффициента автокорреляции при сдвиге бо-
лее чем на 5 отсчетов. И наконец, при сдвиге более чем на 7 отсчетов коэффициент
автокорреляции устремляется к нулю, что говорит о резком уменьшении взаимной
зависимости точек, отстоящих друг от друга более чем на 7 отсчетов.
Для ряда на рис. 10.12 на основе АКФ, представленной на рис. 10.13, можно сде-
лать вывод, что в нем наблюдается высокая степень взаимной зависимости между
соседними значениями. Данный вывод подтверждается визуальным исследованием
ряда: в нем присутствует небольшой линейный положительный тренд, отсутствует
сезонная компонента, а достаточно высокая гладкость позволяет выдвинуть пред-
положение о малой величине случайной составляющей. Все это хорошо согласуется
с выводами, сделанными на основе корреляционного анализа.
Кроме того, корреляционный анализ позволяет прийти к следующим заключе-
ниям о поведении временного ряда.
Глава 10. Анализ и прогнозирование временных рядов 531
□ Если ряд содержит тренд, то степень взаимной зависимости между последова-
тельными значениями ряда и корреляция между ними очень высоки. При этом
коэффициент автокорреляции значителен для первых нескольких сдвигов
ряда, а в дальнейшем убывает до нуля. Данная ситуация иллюстрируется на
рис. 10.12 и 10.13.
□ Если действие случайной компоненты велико, то коэффициенты автокорреля-
ции для любого значения сдвига будут близки к нулю. Высокая изменчивость
ряда, являющаяся следствием воздействия случайной компоненты, приводит
к уменьшению взаимной связи между последовательными значениями ряда
и, соответственно, к уменьшению коэффициента автокорреляции. Данная си-
туация поясняется на рис. 10.14. Сверху представлен график временного ряда,
который обладает большей изменчивостью, чем ряд на рис. 10.12. Снизу приведе-
на его автокорреляционная функция. Видим, что коэффициент автокорреляции
равен 1 только при нулевом сдвиге, когда ряд коррелирован сам с собой. Даже
при сдвиге на 1 отсчет коэффициент автокорреляции равен почти 0. В данном
ряду превалирует случайная компонента, что приводит к низкой степени взаим-
ной зависимости последовательных значений ряда.
Рис. 10.14. Случайный ряд и его АКФ
532 Часть I. Теория бизнес-анализа
□ Если ряд содержит сезонную компоненту, то коэффициент автокорреляции
будет большим для значений сдвига, равных периоду сезонной составляющей
или кратных ему. Данная ситуация проиллюстрирована на рис. 10.15, где сверху
представлен ряд с ярко выраженной сезонностью, а снизу — его АКФ.
-1,0 -1-------------------------------------------------------
к
Рис. 10.15. Ряд с сезонной компонентой и его АКФ
Таким образом, корреляционный анализ — один из важнейших инструментов
исследования временных рядов. Он позволяет выявлять в ряду тренд и сезонную
компоненту, а также определять, насколько поведение ряда обусловлено случайной
компонентой. Знание данных свойств временного ряда помогает строить более
адекватные модели и выбирать методы прогнозирования.
10.3. Модели прогнозирования
В современной бизнес-аналитике главным инструментом прогнозирования явля-
ются прогностические модели. От того, насколько модель прогноза адекватна усло-
виям, в которых работает компания, насколько полно в ней учитываются внешние
и внутренние факторы, воздействующие на те или иные бизнес-процессы, зависит
точность и достоверность прогноза.
Глава 10. Анализ и прогнозирование временных рядов 533
Обобщенная модель прогноза
Рис. 10.16. Обобщенная
модель прогноза
Структура прогностической модели похожа на структуры моделей, используемых
для решения других задач анализа, например распознавания, идентификации
и т. Д- Модель прогноза отличается только характером используемых данных
и алгоритмами их обработки. Обобщенная структура
прогностической модели представлена на рис. 10.16.
Здесь набор входных переменных х, (i = 1... п), образу-
ющих вектор X, — исходные данные для прогноза. Набор
выходных переменных у} (j = 1... т), образующих вектор
результата Y, есть набор прогнозируемых величин.
Когда решается задача прогнозирования значений
временного ряда, описывающего динамику изменения
некоторого бизнес-процесса, входные значения — наблю-
дения за развитием процесса в прошлом, а выходные —
прогнозируемые значения процесса в будущем. При этом временные интервалы
прошлых наблюдений и временные интервалы, по которым требуется получить
прогноз, должны соответствовать друг другу. Например, требуется получить прогноз
по продажам на будущую неделю. Наблюдения, на основе которых будет строиться
прогноз, также должны быть взяты за неделю. Если в базе данных история продаж
представлена по дням, то получить данные по неделям можно с помощью соответ-
ствующего агрегирования. Обучающая выборка строится путем преобразования
временного ряда с помощью скользящего окна.
Кроме того, количество наблюдений за историей развития процесса в прошлом,
на основе которого строится прогноз, должно быть больше, чем число прогнозиру-
емых интервалов, то есть п > т. Иначе говоря, если мы хотим получить прогноз на
неделю, то для этого должны взять наблюдения за несколько прошедших недель.
Рассмотрим основные модели прогнозирования.
«Наивная» модель прогнозирования
«Наивная» модель предполагает, что последний период прогнозируемого времен-
ного ряда лучше всего описывает будущее этого ряда. В таких моделях прогноз, как
правило, является довольно простой функцией от наблюдений прогнозируемой
величины в недалеком прошлом.
Простейшая модель описывается выражением:
3/(*+1)=з/(£),
где y(t) — последнее наблюдаемое значение;
y(t + 1) — прогноз.
В основу этой модели заложен принцип: «Завтра будет как сегодня».
Ждать от такой примитивной модели точного прогноза не стоит. Она не
только не учитывает закономерности прогнозируемого процесса (что в той или
иной степени свойственно многим статистическим методам прогнозирования), но
534 Часть I. Теория бизнес-анализа
и не защищена от случайных изменений в данных, а также не отражает сезонные
колебания и тренды.
Чтобы модель учитывала наличие возможных трендов, ее можно несколько
усложнить, например преобразовав к виду y(t + 1) = y(t) + [y(t) — y(t - 1)1 Или
y(t+ 1) =y(t) • [y(t)/y{t- 1)].
При необходимости учета сезонных колебаний «наивная» модель модифици-
руется следующим образом:
где $ — показатель, учитывающий сезонные изменения прогнозируемого времен-
ного ряда.
Экстраполяция
Экстраполяция представляет собой попытку распространить закономерность
поведения некоторой функции из интервала, в котором известны ее значения, за
его пределы. Иными словами, если значения функции/(х) известны в некотором
интервале [х<>; хп], то целью экстраполяции является определение наиболее веро-
ятного значения в точке х„ т i-
На рис. 10.17 представлен возможный результат экстраполяции устойчивой
тенденции роста в первом полугодии на первые два месяца второго полугодия
(последние два столбца).
Рис. 10.17. Экстраполяция значений временного ряда
Экстраполяция применима только в тех случаях, когда функция /(х) (а соот-
ветственно, и описываемый с ее помощью временной ряд) достаточно стабильна
и не подвержена резким изменениям. Если это требование не выполняется, скорее
всего, поведение функции в различных интервалах будет подчиняться разным
закономерностям.
К существенным факторам, определяющим эффективность применения метода
экстраполяции, относится надежность данных, лежащих в основе анализа.
Экстраполяция тенденций получила широкое применение в нормативном про-
гнозировании. В частности, с помощью этого метода устанавливается, можно ли,
Глава 10. Анализ и прогнозирование временных рядов 535
используя существующие технологии, достичь заданных производственных или
других бизнес-показателей.
Наиболее популярным методом экстраполяции в настоящее время является
экспоненциальное сглаживание. Основной его принцип заключается в том, чтобы
учесть в прогнозе все наблюдения, но с экспоненциально убывающими весами.
Метод позволяет принять во внимание сезонные колебания ряда и предсказать
поведение трендовой составляющей.
Прогнозирование методом среднего
и скользящего среднего
Наиболее простая модель этой группы — обычное усреднение набора наблюдений
прогнозируемого ряда:
y^t += (z/G) +г/(^-1) + г/(^-2) + .- +г/(1))
Принцип модели простого среднего: «Завтра будет как в среднем за последнее
время». Преимущество такого подхода по сравнению с «наивной» моделью оче-
видно: при усреднении сглаживаются резкие изменения и выбросы данных, что
делает результаты прогноза более устойчивыми к изменчивости ряда. Но в целом
эта модель прогноза столь же примитивна, как и «наивная», и ей присущи те же
недостатки.
В формуле прогноза на основе среднего предполагается, что ряд усредняется по
достаточно длительному интервалу времени (в пределе — по всем наблюдениям).
С точки зрения прогноза это не вполне корректно, так как старые значения вре-
менного ряда могли формироваться на основе иных закономерностей и утратить
актуальность. Поэтому свежие наблюдения из недалекого прошлого лучше описы-
вают прогноз, чем более старые значения того же ряда. Чтобы повысить точность
прогноза, можно использовать скользящее среднее'.
(y(t) + y(t -1) + y(t - 2) +... + y(t-ту
T + i
Смысл данного метода заключается в том, что модель «видит» только ближай-
шее прошлое на Т отсчетов по времени и прогноз строится только на этих наблю-
дениях.
Например, при скользящем среднем за три месяца прогнозом на май будет
среднее значение показателей за февраль, март и апрель, а при скользящем сред-
нем за четыре месяца майский показатель можно оценить как среднее значение
показателей за январь, февраль, март и апрель (рис. 10.18).
Метод скользящего среднего весьма прост, и его результаты довольно точно
отражают изменения основных показателей предыдущего периода. Иногда он
оказывается даже эффективнее, чем методы, основанные на долговременных на-
блюдениях.
536 Часть I. Теория бизнес-анализа
Рис. 10.18. Прогноз по скользящему среднему
Допустим, требуется составить прогноз объема продаж продукции предприяти-
ем, если средний показатель объема продаж за последние несколько лет — 1000 ед.
При этом прогноз должен учитывать планируемое сокращение дилерской сети, что,
очевидно, повлечет за собой временное снижение объемов продаж.
Если для прогнозирования объема продаж в следующем месяце воспользовать-
ся средним значением этого показателя за четыре последних месяца, то, скорее
всего, полученный результат окажется несколько завышенным по сравнению
с фактическим. Но если прогноз будет составлен на основании данных за два
последних месяца, то он более точно отразит последствия сокращения штата тор-
говых агентов. В этом случае прогноз будет отставать по времени от фактических
результатов всего на один-два месяца.
Итак, чем меньшее количество наблюдений используется для вычисления
скользящего среднего, тем точнее будут отражены изменения показателей, на ос-
нове которых строится прогноз. Однако, если для прогнозируемого скользящего
среднего используется только одно или два наблюдения, такой прогноз может
быть слишком упрощенным. Чтобы определить, сколько наблюдений желательно
включить в скользящее среднее, нужно исходить из предыдущего опыта и име-
ющейся информации о наборе данных. Необходимо соблюдать равновесие между
повышенным откликом скользящего среднего на несколько самых поздних наблю-
дений и большой изменчивостью скользящего среднего. Одно отклонение в наборе
данных для трехкомпонентного среднего может исказить весь прогноз.
Более хороших результатов удается добиться при использовании метода экспо-
ненциальных средних. Соответствующая модель записывается с помощью формулы:
y(t + 1) = а • y{t) + (1 - а) • y'(t),
где у{t + 1) — прогнозируемое значение;
y(t) — текущее наблюдаемое значение;
у'(f) — прошлый прогноз текущего значения;
а — параметр сглаживания (0 < а < 1). Параметр а позволяет определять
степень участия прошлых значений ряда в формировании прогноза. Видно, что
с удалением значений ряда от текущего момента в прошлое их вклад в прогноз
экспоненциально убывает, а скорость этого убывания регулируется параме-
Глава 10. Анализ и прогнозирование временных рядов 537
тром а. В пределе, когда а = 1, мы получим обычный «наивный» прогноз, а при
а = 0 прогнозируемая величина всегда будет равна предыдущему прогнозу.
Метод экспоненциальных средних можно пояснить с помощью диаграммы,
представленной на рис. 10.19.
Рис. 10.19. Прогнозирование методом экспоненциальных средних
Как видно на рисунке, при больших а увеличивается вклад самых свежих значе-
ний ряда, а с удалением в прошлое вклад значений резко уменьшается. При малых
значениях а вклад значений ряда в результат прогнозирования распределяется
более равномерно.
Обычно при использовании модели экспоненциального сглаживания строятся
прогнозы на некотором тестовом наборе при а = {0,01; 0,02... 0,98; 0,99}. Затем
определяется, при каком а обеспечивается наиболее высокая точность прогнози-
рования, и это значение применяется в дальнейшем.
Описанные выше модели («наивный» метод, методы, основанные на средних,
скользящих средних и метод экспоненциального сглаживания) используются
при решении несложных задач прогнозирования, например при прогнозировании
продаж на устоявшихся рынках. Но ввиду примитивности этих моделей следует
очень осторожно подходить к их использованию на практике.
Регрессионные модели
К числу наиболее мощных, развитых и универсальных моделей прогнозирования
относятся регрессионные модели. Регрессия — это технология статистического
анализа, целью которой является определение лучшей модели, устанавливающей
взаимосвязь между выходной (зависимой) переменной и набором входных (неза-
висимых) переменных (в Data Mining регрессией называют класс задач).
Применение регрессионных моделей оказывается особенно полезным в сле-
дующих случаях.
Q Входные переменные задачи известны или легко поддаются измерению, а вы-
ходные — нет.
Q Значения входных переменных известны изначально, и на их основе требуется
предсказать значения выходных переменных.
538 Часть I. Теория бизнес-анализа
□ Требуется установить причинно-следственные связи между входными и выход-
ными переменными, а также силу этих связей.
В технологиях прогнозирования наиболее широко используется такой вид
регрессионной модели, как обобщенная линейная модель. Ее популярность вызвана
тем, что многие процессы в управлении, экономике и бизнесе линейны по своей
природе. Кроме того, существуют методы, которые позволяют привести нелиней-
ную модель к линейной с минимальными потерями точности.
Обобщенная линейная модель регрессии описывается уравнением:
У = Ро + Pi Xi + Р2Х2 + ... + [3„х„, (10.1)
где Xi — значение г-го наблюдения;
Р, — коэффициент регрессии.
Метод декомпозиции временного ряда
Одним из методов прогнозирования временных рядов является определение
факторов, которые влияют на каждое значение временного ряда. Для этого вы-
деляется каждая компонента временного ряда, вычисляется ее вклад в общую
составляющую, а затем на его основе прогнозируются будущие значения времен-
ного ряда. Данный метод получил название декомпозиции временного ряда.
Термин «декомпозиция» означает, что исходный временной ряд представляет-
ся как композиция компонент — тренда, сезонной и циклической. Для построения
прогноза выполняется выделение этих компонент из ряда, то есть декомпозиция,
или разложение ряда по компонентам. Методы декомпозиции могут использовать-
ся для построения как краткосрочных, так и долгосрочных прогнозов.
Фактически декомпозиция — это выделение компонент временного ряда и их
проекция на будущее с последующей комбинацией для получения прогноза. Метод
был разработан довольно давно, однако сейчас его использует все реже и реже из-за
присущих ему ограничений. Проблема заключается в том, что обеспечить достаточ-
но высокую точность прогноза для отдельных компонент очень затруднительно.
Рассмотрим прогнозирование методом декомпозиции с помощью тренда
(рис. 10.20). Если тренд линейный, что типично для многих реальных временных
рядов, то он представляет собой прямую линию, описываемую уравнением:
у = а + b • t,
где у — значение ряда;
а и b — коэффициенты, определяющие расположение и наклон линии тренда;
t — время.
Если уравнение линии тренда известно, с его помощью можно рассчитать зна-
чения тренда в любой, в том числе будущий, момент времени. Достаточно восполь-
зоваться уравнением:
yl+k = a + b- (t' + k),
где t' — начало прогноза;
k — горизонт прогноза.
Глава 10. Анализ и прогнозирование временных рядов 539
Рис. 10.20. Прогнозирование с помощью тренда
При использовании сезонности для прогнозирования методом декомпозиции
сначала из временного ряда убирается тренд и сглаживается возможная цикли-
ческая компонента. Тогда можно считать, что оставшиеся данные будут обусло-
влены в основном сезонными колебаниями. На основе этих данных вычисляются
так называемые сезонные индексы, которые характеризуют изменения временного
ряда во времени. Например, временной ряд содержит наблюдения по месяцам в те-
чение года. Сезонный индекс, равный 1, будет установлен для месяца, ожидаемое
значение в котором составляет 1/12 от общей суммы по всем месяцам. Если для
некоторого месяца устанавливается индекс 1,2, то ожидаемое значение для этого
месяца составляет 1 /12 + 20 %, а если 0,8 — то 1/12 - 20 % и т. д. Ясно, что сумма
месячных сезонных индексов за год должна равняться 12 (табл. 10.4).
Таблица 10.4. Сезонные индексы
Интервал Значение Сезонный индекс
Январь 230 0,6281
Февраль 231 0,6308
Март 567 1,5484
Апрель 215 0,5871
Май 245 0,6691
Июнь 675 1,8434
Июль 247 0,6745
Август 198 0,5407
Сентябрь 640 1,7478
Октябрь 235 0,6417
Ноябрь 221 0,6035
Декабрь 690 1,8843
34U
часть I. Теория бизнес-анализа
Диаграмма сезонных индексов представлена на рис. 10.21.
Рис. 10.21. Диаграмма сезонных индексов
Диаграмма сезонных индексов позволяет оценить вероятный относительный
вклад месяцев будущего года в общегодовой показатель на основе сезонной компо-
ненты. Использовать сезонность для прогнозирования можно тогда, когда сезонные
колебания имеют хорошую повторяемость.
10.4. Прогнозирование в торговле и логистике
Прогнозирование очень востребовано в оптовой и розничной торговле, а также
в управлении материальными запасами. При этом прогнозирование позволяет
улучшить бизнес-процессы как у конечных продавцов, так и у производителей.
В розничной торговле прогнозирование способствует оптимизации товарных запа-
сов, а в производстве позволяет соответствующим образом распределять мощности,
планировать ассортимент и количество выпускаемой продукции.
Особенно актуально внедрение систем прогнозирования для предприятий, ра-
ботающих в динамично развивающейся экономической среде. В условиях, когда
рынки формируются, польза прогнозирования измеряется не только деньгами.
Те компании, которые внедряют его в процессы управления и планирования бизне-
са раньше, чем их конкуренты, получают дополнительные сегменты рынка и таким
образом закладывают фундамент на будущее.
Еще одним важным аспектом деятельности торговых предприятий является
управление материальными запасами и потоками. Невозможно планировать за-
пасы без прогнозирования сбыта, а цена вопроса очень высока. Неоптимальное
распределение товарных запасов может привести к их отсутствию там, где в них
Глава 10. Анализ и прогнозирование временных рядов 541
возникает острая необходимость, или к переполнению складов в противоположной
ситуации. Расходы, связанные с перемещением и хранением товара, могут «съесть»
львиную долю прибыли. В идеальном случае товар должен поступать именно туда
и именно тогда, когда в нем есть необходимость. Только прогнозирование спроса
и сбыта позволит отделу логистики спланировать процесс управления запасами
так. чтобы минимизировать связанные с ним затраты.
Отказ от ручной работы и использование специализированных инструментов
для оптимизации складских запасов актуален в следующих случаях:
□ большой ассортимент (от 1000 позиций и более), частое обновление номенк-
латуры;
□ сложный алгоритм планирования, учитывающий прогнозы спроса, способы
доставки, планы выпуска продукции;
□ большая трудоемкость — влияние множества факторов, необходимость обмена
данными с различными системами, малое количество менеджеров по закупкам.
Оптимизация складских запасов начинается с прогнозирования. Продажи и пе-
ремещения товаров являются процессами, распределенными во времени, поэтому
здесь применимы все рассмотренные выше методы анализа временных рядов.
Но решение этой задачи не сводится к построению моделей временных рядов: часто
это сложная многоступенчатая процедура, включающая предварительные этапы
консолидации, очистки и предобработки данных (рис. 10.22). В процессе очистки
и предобработки выполняются действия, которые могут существенно повлиять на
качество прогноза и расчета требуемых запасов, такие как редактирование анома-
лий, заполнение пропусков, сглаживание и пр. Например, аномальные всплески
продаж либо их провалы, связанные с техническими проблемами или отсутствием
товара на складе, серьезно искажают объективную картину и не позволяют точно
рассчитать потребность в товарах.
Источник
данных
____________ 4 ____________
Очистка данных (аномалии, противоречия...)
Группировка данных
Приемники данных Приемники данных
Рис. 10.22. Типовая схема оптимизации товарных запасов
542 Часть I. Теория бизнес-анализа
Сам по себе анализ временных рядов при решении бизнес-задач в торговле
и логистике применяется редко. В готовом аналитическом решении используются
многие технологии бизнес-аналитики: хранилища данных, очистка и трансформа-
ция данных, группировка и разгруппировка, ABC-XYZ-анализ, OLAP и, конечно,
методы прогнозирования временных рядов, а также элементы логистики. Подроб-
нее это показывается в главах 14 и 18.
Ансамбли
моделей
11.1. Введение в ансамбли моделей
При создании алгоритмов машинного обучения разработчики сталкиваются
с такими проблемами, как вычислительные затраты на реализацию алгоритма,
прозрачность построенных моделей для пользователя, а также точность резуль-
татов. Большинство исследователей сосредотачиваются на повышении точности
классификации и предсказания, поэтому производительность новых систем часто
рассматривается именно с этой точки зрения. И это легко понять: точность играет
решающую роль во всех приложениях машинного обучения и может быть легко
оценена, в то время как прозрачность для пользователя субъективна. Что касается
вычислительных затрат, то с прогрессом вычислительной техники они во многих
случаях вообще отошли на задний план.
В последние несколько лет значительно возрос интерес к вопросу увеличения
точности моделей Data Mining, основанных на обучении, за счет создания и аг-
регирования набора классификаторов. В результате появились новые подходы
к анализу на базе ансамблей классификаторов, которые применимы к широкому
кругу систем машинного обучения и основаны на теоретическом исследовании
поведения составных классификаторов.
Комбинирование решений
Принимая важное решение, опытный руководитель не только полагается на соб-
ственные знания и интуицию, но и старается привлечь экспертов в конкретных
предметных областях. Считается, что выводы экспертов, полученные на основе
анализа данных, связанных с решаемой задачей, позволят сделать оптимальный
выбор.
544 Часть I. Теория бизнес-анализа
Например, когда предприятие планирует выпуск нового продукта, взвешива-
ются все «за» и «против», привлекаются специалисты в сферах экономики, мар-
кетинга, производства, рекламы и т. д., и каждый из них высказывает свое мнение.
Выслушав всех, руководитель приходит к окончательному решению.
Однако выводы, сделанные разными экспертами, могут противоречить друг дру-
гу. Поэтому неизбежно встает вопрос: как скомбинировать несколько экспертных
оценок, чтобы на их основе принять правильное решение? В простейших случаях
руководитель может, не прибегая к формальным методам, просто воспользоваться
своими опытом и интуицией.
Существуют методы, которые позволяют принять более обоснованное решение.
Допустим, в качестве оценки определенного решения эксперт указывает число бал-
лов: 100 баллов соответствуют положительному решению («выпускать продукт»),
0 баллов — отрицательному («не выпускать продукт»). Указывая промежуточные
значения, эксперты оценивают вероятность успеха или провала проекта. Получен-
ные оценки суммируется, и если сумма превысит заданный порог, то решение будет
положительным, а если нет — отрицательным. При желании можно произвести
усреднение оценок, то есть разделить сумму баллов на число экспертов.
Хорошие результаты часто дает взвешивание оценок: в зависимости от важно-
сти предметной области, профессионального уровня эксперта и т. д. экспертной
оценке присваивается определенный вес. Чем опытнее эксперт и важнее оценка,
тем больше ее вес.
Наконец, самым простым, хотя и не всегда эффективным методом является
голосование: выбирается решение, принятое большинством голосов.
Остановимся еще на одном важном моменте — доверии к эксперту. Действитель-
но, эксперты отличаются уровнем подготовки, опытом и т. д. В этой связи их можно
разделить на сильных и слабых. Например, слабым может считаться эксперт, который
участвовал в 10 проектах, причем в 7 случаях его мнение оказалось ошибочным.
Используются два варианта экспертных оценок: параллельные и дополняющие.
В первом случае каждый эксперт высказывает мнение по всему спектру проблем,
связанных с решаемой задачей. Во втором каждый эксперт дает заключение только
по одному аспекту задачи. Тогда выводы экспертов дополняют друг друга, вместе
покрывая весь спектр проблем.
Таким образом, выбирая методы извлечения экспертных оценок и комбинируя
полученные результаты, можно найти наилучшее решение.
Аналогичная ситуация складывается при использовании моделей, основанных
на машинном обучении, — деревьев решений, нейронных сетей и т. д. Эти модели
фактически играют роль экспертов и в явном или неявном виде предоставляют
информацию, необходимую для обоснованного принятия решений.
Можно ограничиться результатами, полученными единственной моделью.
Но, так же как и эксперты, модели бывают слабыми и сильными. Если обученной
модели хорошо удается разделить классы и она допускает мало ошибок класси-
фикации, то такая модель может рассматриваться как сильная. Слабая модель,
напротив, не позволяет надежно разделять классы или давать точные предсказа-
ния, допускает в работе большое количество ошибок.
Глава 11. Ансамбли моделей 545
Если в результате обучения мы получили слабую модель, то ее необходимо
усовершенствовать, подбирая тип классификатора, алгоритмы и параметры обу-
чения. Но часто встречаются ситуации, когда все возможности совершенствования
единственной модели исчерпаны, а качество ее работы по-прежнему неудовлетво-
рительно. Это может быть связано со сложностью решаемой задачи и искомых
закономерностей, с низким качеством обучающих данных и другими факторами.
Пример такой ситуации представлен на рис. 11.1.
Рис. 11.1. Иллюстрация сложной разделимости классов
На рис. 11.1, я изображено множество объектов, содержащее два класса — кру-
ги и квадраты. В результате обучения построена модель, разделившая классы по
линии 1. Поскольку классы пересекаются, они являются трудноразделимыми,
из-за чего значительное количество квадратов оказалось распознано как круги.
Ожидать от такой модели хорошей работы с новыми данными не следует, при
этом ее возможности уже исчерпаны: как бы мы ни провели линию 1, всегда будет
присутствовать значительная ошибка классификации.
Неизбежно возникает вопрос: как усилить слабую модель, что сделать для по-
вышения эффективности классификации? Вполне логичным выходом из ситуации
является попытка применить к неудачным результатам работы первой модели еще
одну модель, задача которой — классифицировать те примеры, что остались нерас-
познанными. Результаты работы второй модели представлены на рис. 11.1,6. Как
видно, ей удалось почти полностью разделить круги и квадраты. Если и после этого
результаты неудовлетворительны, можно применить третью модель и так далее до
тех пор, пока не будет получено достаточно точное решение.
Таким образом, для решения одной задачи классификации или регрессии мы
применили несколько моделей, при этом нас интересует не результат работы каждой
отдельной модели, а результат, который дает весь набор моделей. Такие совокуп-
ности моделей называются ансамблями моделей.
546 Часть I. Теория бизнес-анализа
ОПРЕДЕЛЕНИЕ------------------------------------------------------------
Набор моделей, применяемых совместно для решения единственной задачи, называется
ансамблем (комитетом) моделей.
Цель объединения моделей очевидна — улучшить (усилить) решение, которое
дает отдельная модель. При этом предполагается, что единственная модель никогда
не сможет достичь той эффективности, которую обеспечит ансамбль.
Использование ансамблей вместо отдельной модели в большинстве случаев по-
зволяет повысить качество решений, однако такой подход связан с рядом проблем,
основными из которых являются:
□ увеличение временных и вычислительных затрат на обучение нескольких мо-
делей;
□ сложность интерпретации результатов;
□ неоднозначный выбор методов комбинирования результатов, выдаваемых от-
дельными моделями.
Перечисленные проблемы аналогичны тем, что возникают при работе несколь-
ких людей-экспертов. Действительно, приходится собирать группу экспертов,
предоставлять им необходимую информацию, обсуждать задачу и т. д. — все это
отнимает намного больше времени, чем принятие решения одним человеком.
Сложность интерпретации результатов экспертных оценок также имеет место,
ведь каждый эксперт оперирует терминами своей предметной области, форму-
лирует выводы на уровне своего понимания проблемы. И наконец, выбор метода
обобщения отдельных заключений экспертов, позволяющего получить наилучшие
результаты, не является однозначным.
Виды ансамблей
В последнее десятилетие ансамбли моделей стали областью очень активных
исследований в машинном обучении, что привело к разработке большого числа
разнообразных методов формирования ансамблей.
Первым вопросом при формировании ансамбля ярляется выбор базовой модели
(base model). Ансамбль в целом может рассматриваться как сложная, составная
модель (multiple model), состоящая из отдельных (базовых) моделей. Здесь воз-
можны два случая.
1. Ансамбль состоит из базовых моделей одного типа, например только из деревь-
ев решений, только из нейронных сетей и т. д. (рис. 11.2).
2. Ансамбль состоит из моделей различного типа — нейронных сетей, деревьев
решений, регрессионных моделей и т. д. (рис. 11.3).
Рис. 11.2. Однородный ансамбль
Глава 11. Ансамбли моделей 547
Обучающее
множество
Дерево
решений
Нейронная
сеть
Логистическая
регрессия
Рис. 11.3. Ансамбль, состоящий из моделей различного типа
Каждый подход имеет свои преимущества и недостатки. Использование мо-
делей различных типов дает классификатору дополнительную гибкость. Но, по-
скольку выход одной модели применяется для формирования обучающего множе-
ства для другой, возможно, потребуются дополнительные преобразования, чтобы
согласовать входы и выходы моделей.
Второй вопрос: как использовать обучающее множество при построении ан-
самбля? Здесь также существуют два подхода.
1. Перевыборка (resampling). Из исходного обучающего множества извлекается
несколько подвыборок, каждая из которых используется для обучения одной
из моделей ансамбля. Данный подход иллюстрируется с помощью рис. 11.4.
Если ансамбль строится на основе моделей различных типов, то для каждого
типа будет свой алгоритм обучения.
Рис. 11.4. Перевыборка
2. Использование одного обучающего множества для обучения всех моделей ансамб-
ля (рис. 11.5).
Рис. 11.5. Использование одного обучающего множества
для всех моделей ансамбля
548 Часть I. Теория бизнес-анализа
И наконец, третий вопрос касается метода комбинирования результатов, вы-
данных отдельными моделями: что будет считаться выходом ансамбля при опреде-
ленных состояниях выходов моделей? Обычно используются следующие способы
комбинирования.
1. Голосование. Применяется в задачах классификации, то есть для категориаль-
ной целевой переменной. Выбирается тот класс, который был выдан простым
большинством моделей ансамбля. Пусть, например, решается задача бинарной
классификации с целевыми переменными Да и Нет, для чего используется
ансамбль, состоящий из трех моделей. Если две модели выдали выход Нет
и только одна — Да, то общий выход ансамбля будет Нет.
2. Взвешенное голосование. В ансамбле одни модели могут работать лучше, а дру-
гие — хуже. Соответственно, к результатам одних моделей доверия больше,
а к результатам других — меньше. Чтобы учесть уровень достоверности резуль-
татов, для моделей ансамбля могут быть назначены веса (баллы). Например,
в случае, рассмотренном в предыдущем пункте, для моделей, выдавших резуль-
тат Нет, установлены веса 30 и 40, указывающие на невысокую достоверность
этих результатов. В то же время единственная модель, которая выдала Да,
имеет вес 90. Тогда голосование будет производиться с учетом весов моделей:
30 (Нет) + 40 (Нет) — 70 (Нет) < 90 (Да). Таким образом, модель с выходом Да
перевесила обе модели с выходом Нет и общий выход ансамбля будет Да.
3. Усреднение (взвешенное или невзвешенное). Если с помощью ансамбля решается за-
дача регрессии, то выходы его моделей будут числовыми. Выход всего ансамбля мо-
жет определяться как простое среднее значение выходов всех моделей. Например,
если в ансамбле три модели и их выходы равны yit у г и г/3, то выход ансамбля будет
У= (z/i + у2 + г/з) / 3 (для произвольного числа моделей У = (у, + у2 + ... + г/к) /К,
где К — число моделей в ансамбле). Если производится взвешенное усреднение,
то выходы моделей умножаются на соответствующие веса.
Исследования ансамблей моделей в Data Mining стали проводиться относитель-
но недавно. Тем не менее к настоящему времени разработано множество различных
методов и алгоритмов формирования ансамблей. Среди них наибольшее распро-
странение получили такие методы, как бэггинг, бустинг и стэкинг. Рассмотрим их
подробнее.
11.2. Бэггинг
Наряду с бустингом бэггинг является одним из самых современных методов по-
вышения эффективности моделей. Бэггинг формирует набор классификаторов,
которые комбинируются путем голосования или усреднения. Термин «бэггинг»
(bagging) происходит от английского словосочетания bootstrap aggregating, которое
можно перевести как «улучшающее объединение».
В основе работы баттинга лежит технология, получившая название «возмущение
и комбинирование» (perturb and combine).
Глава 11. Ансамбли моделей 549
«Возмущение и комбинирование»
Модели, которые в процессе обучения адаптируют свое состояние в соответствии
с обучающим множеством, такие как деревья решений и нейронные сети, неустой-
чивы: даже небольшие изменения в обучающем множестве (замена или удаление
одного примера) могут привести к существенным изменениям в состоянии модели —
в структуре дерева решений или в распределении весов нейронной сети. Иными сло-
вами, внося даже незначительные изменения в обучающие данные, мы всегда будем
получать другую модель. Но исходная и измененная модели будут функционировать
примерно одинаково и со сравнимой точностью: незначительные изменения в обуча-
ющих данных не приведут к изменению основных закономерностей, которые должны
быть обнаружены моделью. Сказанное можно пояснить с помощью рис. 11.6.
Рис. 11.6. Изменение одного примера отражается на конечной модели
Слева представлено разбиение объектов двух классов (светлых и темных точек)
с помощью дерева решений. Изменение всего лишь одной точки (помеченной
стрелкой) приведет к совершенно другому разбиению и другой структуре дерева
решений, но в целом точность модели останется примерно на том же уровне. Не-
устойчивость деревьев решений во многом обусловлена конкурирующими узлами,
то есть узлами, работающими примерно одинаково. Поэтому даже небольшое из-
менение в данных может привести к тому, что процесс обучения пойдет по другому
узлу и будет построено другое дерево решений.
Неустойчивость моделей, особенно деревьев решений, используется для созда-
ния ансамблей моделей с помощью технологии «возмущения и комбинирования».
Под возмущением понимается внесение некоторых изменений, часто случайного
характера, в обучающие данные и построение нескольких альтернативных моделей
на измененных данных с последующим комбинированием результатов. Для возму-
щения используются следующие приемы:
Q извлечение выборок из обучающего множества. В этом случае путем сэмплин-
га из исходного обучающего множества извлекается несколько выборок, и на
каждой из них обучается отдельная модель;
550 Часть I. Теория бизнес-анализа
□ выборка из выборок, формирование внутри выборок подгрупп;
□ добавление шума;
□ адаптивное взвешивание;
□ случайный выбор между конкурирующими узлами (разбиениями).
Добавление в процесс обучения элемента случайности часто называют рандо-
мизацией (randomization).
Основная идея
Идея бэггинга проста. Сначала на основе исходного множества данных путем
случайного отбора формируется несколько выборок. Они содержат такое же ко-
личество примеров, что и исходное множество. Но, поскольку отбор производится
случайно, набор примеров в этих выборках будет различным: одни примеры могут
быть отобраны по нескольку раз, а другие — ни разу. Затем на основе каждой вы-
борки строится классификатор и выходы всех классификаторов комбинируются
(агрегируются) путем голосования или простого усреднения. Ожидается, что
полученный результат будет намного точнее любой одиночной модели, построен-
ной на основе исходного набора данных. Обобщенная схема процедуры бэггинга
представлена на рис. 11.7 (на примере дерева решений).
Рис. 11.7. Схема процедуры бэггинга
Таким образом, бэггинг включает следующие шаги.
1. Из обучающего множества извлекается заданное количество выборок одинако-
вого размера.
2. На основе каждой выборки строится модель.
3. Определяется общий результат путем голосования или усреднения выходов
моделей.
Предположим, что задан набор из N обучающих примеров, каждый из которых
относится к одному из k = kt, k2... К классов, а также алгоритм обучения, стро-
ящий классификаторы. Бэггинг представляет собой итерационную процедуру,
Глава 11. Ансамбли моделей 551
где количество итераций (испытаний) Т задается как константа (хотя иногда для
автоматического определения числа итераций рекомендуется использовать те-
стовое множество, чтобы избежать переобучения). Классификатор, полученный
на итерации Г, обозначим С', а итоговый классификатор, полученный с помощью
бэггинга, — С'. Для каждого примерах С'(х) и С\х) являются классами, предска-
занными классификаторами С1 и С' соответственно.
Пусть на каждой итерации t = t2... Т из исходного обучающего множества
производится выборка, состоящая из Nпримеров. Она имеет тот же размер, что
и исходное множество, но некоторые примеры могут в нее не попасть, а некоторые
попадут несколько раз. Система обучения создает классификаторы С1 из выборок,
а конечный классификатор С’ создается путем агрегирования Тклассификаторов.
При классификации примера х голоса для класса k записываются каждым класси-
фикатором, для которого С'(х) = k, и затем для С’(х) назначается класс, получивший
большинство голосов.
Схема бэггинга, представленная на рис. 11.7, применяется и к регрессионным
моделям. В этом случае результат — среднее значение, рассчитанное по выходам
всех моделей ансамбля.
Остановка процедуры бэггинга производится на основе следующих критериев.
□ На некоторой итерации t ошибка е' классификатора С становится равной 0 или
больше либо равной 0,5. В этом случае процедура бэггинга останавливается,
а последний классификатор удаляется: T=t— 1. Таким образом, бэггинг не
пускает в ансамбль «плохие» классификаторы.
□ Число итераций достигло заданного пользователем предела Т. Как и для боль-
шинства других итеративных алгоритмов Data Mining, однозначного ответа на
вопрос, каково достаточное число итераций, не существует. Оно подбирается
эмпирическим путем.
□ Бэггинг, хотя и в меньшей степени, чем отдельные модели, склонен к переобуче-
нию. Поэтому критерием для остановки процедуры может служить возрастание
ошибки на тестовом множестве.
Почему бэггинг работает?
Результаты бэггинга часто удивляют аналитиков: точность предсказания по-
строенных с его помощью комбинированных классификаторов оказывается зна-
чительно выше, чем точность отдельных моделей. Причины этого неочевидны.
Действительно, если все выборки извлечены из одного обучающего множества,
то можно ожидать, что построенные на их основе модели будут практически
идентичными. Однако данное предположение ошибочно. Причина заключается
все в той же неустойчивости моделей, особенно деревьев решений: даже неболь-
шие изменения в обучающих данных легко могут привести к выбору различных
атрибутов в определенном узле дерева, что вызовет существенные изменения при
дальнейшем ветвлении. В результате одни и те же тестовые примеры будут распо-
знаваться различными деревьями по-разному.
ЭЭ2
Часть I. Теория бизнес-анализа
В основе эффективности методов комбинирования моделей, в том числе
бэггинга, лежит идея декомпозиции ошибки ансамбля на смещение и дисперсию.
Предположим, что имеется бесконечное число независимых обучающих множеств
одинакового размера, которые используются для построения бесконечного числа
классификаторов. Обучающие примеры обрабатываются всеми классификатора-
ми, и их общий выход определяется большинством голосов. В данной ситуации
ошибки все еще имеют место, поскольку идеальных обучающих процедур не су-
ществует. Значение ошибки зависит от того, насколько хорошо метод машинного
обучения соответствует решаемой задаче, а также от качества самих данных.
Допустим, ожидаемая ошибка оценивается как средняя ошибка комбиниро-
ванного классификатора на бесконечном числе независимо выбранных тестовых
примеров. Значение ошибки конкретного обучающего алгоритма называется сме-
щением (систематической ошибкой) е*. Смещение есть мера стабильности ошибки
данного алгоритма обучения, которая не может быть исключена даже применением
бесконечного числа обучающих множеств. Конечно, на практике такая ошибка не
может быть вычислена точно, а только оценивается приблизительно.
Вторым источником ошибки при обучении модели является то, что обучающее
множество используется частично — оно всегда конечно — и, следовательно, не
полностью представляет реальную популяцию наблюдений. Ожидаемое значение
этого компонента ошибки по всем возможным обучающим наборам заданного раз-
мера и всем возможным тестовым наборам называется дисперсией метода обучения
для этой задачи е0.
Таким образом, общая ожидаемая ошибка классификатора состоит из суммы
дисперсии и смещения: е = Eh + ед. В этом и заключается смысл декомпозиции
ошибки на дисперсию и смещение. Комбинирование нескольких классификаторов
позволяет уменьшить ошибку за счет дисперсии. При этом чем больше классифи-
каторов используется, тем меньше дисперсия.
Смещение определяется как среднеквадратическая ошибка, ожидаемая при
усреднении по моделям, построенным на основе всех обучающих множеств одного
размера, а дисперсия — это компонент ожидаемой ошибки отдельной модели, кото-
рая была построена с помощью отдельного обучающего множества. Теоретически
можно показать, что усреднение по множеству моделей, построенных на основе
независимых обучающих множеств, всегда уменьшает ожидаемое значение сред-
неквадратической ошибки.
На практике возникает проблема: где взять большое количество обучающих
множеств. Бэттинг решает эту задачу, используя единственное обучающее множе-
ство, а именно «тасует» его, как колоду карт (рис. 11.8).
Разница между бэггингом и идеальной процедурой, описанной выше, заклю-
чается в способе формирования обучающих множеств. Вместо получения незави-
симых множеств из предметной области бэггинг просто производит перевыборку
исходного множества данных. Такие множества отличаются друг от друга, но не
являются независимыми, поскольку все они основаны на одном и том же множе-
стве. Тем не менее бэггинг позволяет создавать комбинированные модели, которые,
как правило, работают значительно лучше, чем отдельная модель.
Глава 11. Ансамбли моделей 553
Рис. 11.8. Отбор примеров с заменой, используемый в бзггинге
11.3. Бустинг
По сравнению с бэггингом бустинг (boosting) несколько более сложная процедура,
но во многих случаях работает эффективнее. Как и бэггинг, бустинг использует
неустойчивость алгоритмов обучения и начинает создание ансамбля на основе един-
ственного исходного множества. Но если в бэггинге модели строятся параллельно
и независимо друг от друга, то в бустинге каждая новая модель строится на основе
результатов ранее построенных моделей, то есть модели создаются последовательно.
Бустинг создает новые модели таким образом, чтобы они дополняли ранее постро-
енные, выполняли ту работу, которую другие модели сделать не смогли на предыду-
щих шагах. И наконец, последнее отличие бустинга от бэггинга заключается в том,
что всем построенным моделям в зависимости от их точности присваиваются веса
(бэггинг, напомним, использует взвешенное голосование или усреднение).
В настоящее время разработано большое количество различных модификаций
бустинга. Рассмотрим один из наиболее популярных алгоритмов — AdaBoost.Ml,
который предназначен для решения задач классификации. Будем использовать
обозначения, ранее введенные для бэггинга.
Вместо извлечения выборок из исходного множества данных бустинг в качестве
«возмущающего» фактора применяет взвешивание примеров. Вес каждого приме-
ра устанавливается в соответствии с его влиянием на обучение классификатора.
На каждой итерации вектор весов подстраивается таким образом, чтобы отражать
эффективность данного классификатора. В результате вес неправильно классифи-
цированных примеров увеличивается. Итоговый классификатор также агрегирует
обученные классификаторы путем голосования, но теперь голос классификатора
является функцией его точности.
554 Часть I. Теория бизнес-анализа
Обозначим вес примера х на итерации t как w-, при этом вес на первой итерации
задается как = 1/Л/для каждого х (N— число примеров). На каждой итерации
t = 1, 2... Тклассификатор Сс конструируется из данных примеров в соответствии
с распределением их весов w‘ (то есть как будто вес w's отражает вероятность по-
явления примерах). Ошибка е' классификатора tтакже измеряется относительно
весов и представляет собой сумму весов примеров, которые были классифици-
рованы неправильно. Когда е( становится больше 0,5, итерации прекращаются
последний классификатор удаляется и Т изменяется на t - 1. Наоборот, если
е' = 0 (классификатор С ' правильно классифицировал все примеры), итерации
останавливаются и Т = t. В остальных случаях вектор весов w'^1 для следующей
итерации генерируется путем умножения текущих весов примеров, которые были
правильно распознаны классификатором С, на коэффициент Р' = е е/(1 - е')> а за-
тем нормируется так, чтобы = 1. Тогда:
£1
w'+'=O)'-------г. (11.1)
(!-е )
Итоговый классификатор С‘ получается путем суммирования голосов классифи-
каторов С1, С2... Ст, где голос классификатора С‘ определяется как log (1/Р') единиц.
Было показано, что если ошибка отдельного классификатора е‘ всегда мень-
ше 0,5, то значение ошибки итогового классификатора С* экспоненциально стре-
мится к 0 с увеличением числа итераций t. Последовательность слабых классифи-
каторов С\ С2... С1 может быть усилена до классификатора С, который обычно
получается более точным, чем отдельные классификаторы. Конечно, при этом
нельзя гарантировать высокую обобщающую способность С'.
Процедура бустинга включает следующие шаги.
1. Для всех примеров исходного множества данных устанавливаются равные на-
чальные веса Wq.
2. На основе взвешенного набора примеров строится классификатор С1, вычисля-
ется и запоминается выходная ошибка данного классификатора ес.
3. Рассчитывается коррекция весов примеров обучающего множества, и веса кор-
ректируются по формуле (11.1).
4. Если ошибка е‘ = 0 или е' > 0,5, то классификатор С1 удаляется и процедура
бустинга останавливается.
5. В противном случае осуществляется переход на шаг 2 и начинается следующая
итерация.
Процедура поясняется с помощью блок-схемы на рис. 11.9.
Таким образом, параметрами, настраиваемыми на каждой итерации, являются
веса примеров. При этом чем больше раз пример был неправильно распознан пре-
дыдущими моделями, тем выше его вес. Вес можно рассматривать как вероятность
попадания примера на следующую итерацию.
В построении первой модели будут участвовать все примеры, в построении
второй — только те, которые были неправильно распознаны первой, в построении
Глава 11. Ансамбли моделей 555
третьей — примеры, неправильно распознанные двумя предыдущими моделями,
и т. д. Модели будут дополнять друг друга — работать с теми примерами, от кото-
рых «отказались» другие модели. Из теории машинного обучения известно, что
именно трудные для распознавания примеры толкают процесс обучения вперед,
заставляя модель классифицировать их, в то время как простые примеры распозна-
ются быстро и для дальнейшей тренировки бесполезны.
Веса примеров увеличиваются или уменьшаются в зависимости от выхода
каждого нового классификатора. В результате некоторые трудные примеры могут
стать еще труднее, а легкие — еще легче. После каждой итерации веса отражают,
насколько часто тот или иной пример классифицировался неправильно.
Рис. 11.9. Блок-схема алгоритма AdaBoost.Ml
556 Часть I. Теория бизнес-анализа
Генерация классификаторов
Теперь рассмотрим, как процедура бустинга генерирует последовательность клас-
сификаторов.
Выход ансамбля комбинируется процедурой взвешенного голосования. При опре-
делении весов классификатор, который хорошо работает на обучающей выборке,
должен получить больший вес. Классификатор, который работает хуже (ошибка
ближе к 0,5), получает более низкий вес. Формальная запись имеет вид:
W' =- log
Г 1
1,1-е'.
В данном случае как IV' мы обозначили вес классификатора, построенного на
итерации t, который будет использоваться при взвешенном голосовании. Вес —
это положительное число в интервале от нуля до бесконечности. Кроме того,
формула объясняет, почему классификаторы с нулевой ошибкой должны быть
удалены: при е' = 0 выражение для весов окажется неопределенным из-за того,
что аргумент логарифма равен 1. При комбинировании выходов ансамбля веса
всех классификаторов, которые «голосуют» за определенный класс (то есть имеют
этот класс на выходе), суммируются и выбирается класс, набравший наибольшую
сумму голосов. Иными словами, определяющую роль играют не столько выходы
моделей, сколько их веса.
Последовательность генерации моделей в бустинге и их участие в комбиниро-
вании результатов методом голосования представлены на рис. 11.10.
Рис. 11.10. Схема бустинга
Недостатки бустинга
Основным недостатком бустинга является то, что примеры с низкими весами
не попадают на следующую итерацию, поэтому часть информации, полезной
для обучения, может быть потеряна. Кроме того, в процессе бустинга из участия
в обучении постепенно исключаются самые простые примеры, что приводит к так
называемому вырождению обучающих выборок, на основе которых строятся по-
следние модели. В первую очередь распознаются наиболее типичные примеры,
хорошо отражающие предметную область. Образцы, трудные для распознавания,
Глава 11. Ансамбли моделей 557
часто являются нетипичными, аномальными и пр. Обучение классификаторов на
поздних итерациях может почти полностью вестись на таких примерах, что в ко-
нечном итоге приводит к переобучению. В силу вышесказанного бустинг более
склонен к переобучению, чем бэггинг.
Чтобы избежать переобучения, количество итераций Тдолжно быть настолько
малым, насколько это возможно без потери точности. Алгоритм останавливается,
когда на некотором С ошибка приближается к 0, невзирая на то что С' может
распознать все обучающие примеры, а С1 — нет. Дальнейшие итерации в данной
ситуации, скорее всего, не приведут к приросту точности. Вместо этого увеличится
сложность С", но его эффективность не повысится.
Наконец, общей проблемой бустинга и бэггинга является низкая прозрачность
модели для аналитика и сложность интерпретации результатов, что в целом харак-
терно для всех ансамблей моделей.
11.4. Альтернативные методы
построения ансамблей
Применение ансамблей моделей к решению различных задач анализа открывает
широкие возможности для повышения эффективности моделей Data Mining.
Поэтому в последние несколько лет в данной области проводятся активные ис-
следования, в результате чего появилось большое количество методов.
Не все методы работают одинаково хорошо в разных ситуациях, а возмож-
ность выбора позволяет аналитику добиться наилучших результатов. Например,
бустинг и бэггинг изначально возникли как методы повышения эффективности
классификационных моделей, особенно деревьев решений, и не могли напрямую
использоваться для регрессионных моделей. Поэтому для решения задач регрес-
сии были разработаны варианты бустинга, получившие название аддитивной
регрессии, в частности алгоритм LogitBoost. Распространены и такие методы
комбинирования моделей, как деревья выбора и стэкинг. Рассмотрим основы
их работы.
Аддитивная регрессия
Появление бустинга вызвало большой интерес в Data Mining, поскольку он по-
зволяет обеспечить очень высокую эффективность моделей. Одним из вариантов
бустинга стало построение так называемых аддитивных регрессионных моделей.
Понятие «аддитивная регрессия» относится к любым методам предсказания, осно-
ванным на комбинировании (суммировании) вкладов от нескольких регрессионных
моделей.
В основе идеи аддитивной регрессии лежит прямое ступенчатое аддитивное
моделирование (forward stagewise additive modeling), алгоритм которого содержит
следующие шаги.
558 Часть I. Теория бизнес-анализа
1. Сначала строится обычная регрессионная модель, например регрессионное
дерево решений.
2. Вычисляются ошибки, полученные на обучающем множестве, как разность
между желаемым и наблюдаемым значениями. Эти ошибки называются остат-
ками (residuals).
3. Производится минимизация остатков с помощью второй модели (другого де-
рева решений), которая пытается предсказать наблюдаемые остатки. Для этого
исходные целевые значения заменяются соответствующими остатками перед
обучением второй модели.
4. Поскольку и вторая модель не является идеальной, она также даст остатки на
некоторых примерах. Поэтому процесс продолжится: строится третья модель,
которая обучается предсказывать остатки от остатков, и т. д.
Если каждая модель минимизирует квадратическую ошибку предсказания, как
делает обычная линейная регрессионная модель, то алгоритм прямого ступенчатого
моделирования минимизирует ошибку ансамбля в целом. Фактически при исполь-
зовании обычной линейной регрессии как базовой модели для аддитивной регрес-
сии сумма линейных регрессионных моделей также будет линейной регрессионной
моделью и регрессионный алгоритм сам минимизирует квадратическую ошибку.
Для удобства создание ступенчатой аддитивной регрессии обычно начинается
с построения модели нулевого уровня, которая просто предсказывает среднее зна-
чение выхода на обучающем множестве, а каждая следующая модель подстраивает
остатки.
Аддитивная регрессия подвержена переобучению, поскольку каждая модель,
добавленная в ансамбль, делает его настройку все более точной. Чтобы определить
момент остановки, используется ошибка на тестовом множестве и выбирается то
число итераций, которое ее минимизирует.
Аддитивная логистическая регрессия
Аддитивная регрессия может применяться для решения задач бинарной классифи-
кации. Но поскольку для этого больше подходит логистическая регрессия, аддитив-
ная модель должна быть соответствующим образом модифицирована. С помощью
логит-преобразования производится оценка вероятности каждого класса, а затем
задача регрессии решается с использованием ансамбля моделей, например регрес-
сионных деревьев, так же, как и в случае аддитивной регрессии. На каждом шаге
добавляется модель, которая максимизирует вероятность одного из классов.
Предположим, что / - j-я регрессионная модель в ансамбле, a f (а) — ее пред-
сказание для примера а. Рассмотрим задачу бинарной классификации, используя
аддитивную модель (а) для получения оценки вероятности первого класса:
Р(1|«) =-----р--------р
1 + exp -VMa)
Глава 11. Ансамбли моделей 559
Алгоритм бустинга, который использует в качестве базовой модели логисти-
ческую регрессию, получил название LogitBoost. Процесс генерации моделей этим
алгоритмом можно представить в виде блок-схемы (рис. 11.11). Здесь г/, = 1 для
примеров, относящихся к классу 1, и у, = 0 для примеров, относящихся к классу 2.
На каждой итерации алгоритм подстраивает регрессионную модель fj по взвешен-
ной версии исходного множества данных.
Рис. 11.11. Блок-схема алгоритма LogitBoost
Изначально алгоритм LogitBoost предназначен для решения задачи бинарной
классификации, но при необходимости может быть обобщен для случая с несколь-
кими классами.
Деревья выбора
К недостаткам ансамблей моделей как сложных составных структур относится
трудность интерпретации результатов. Решить эту проблему можно, сделав пред-
560 Часть I. Теория бизнес-анализа
ставление ансамбля более компактным. Одним из вариантов является исполь-
зование структур, называемых деревьями выбора (option tree). Они отличаются
от обычных деревьев решений тем, что содержат два типа узлов: узлы решений
и узлы выбора. Простой пример такого дерева с одним узлом выбора представлен
на рис. 11.12. В узел решений, как и в обычном дереве решений, входит только одна
ветвь, а в узел выбора — две. Таким образом, в узел выбора поступают решения из
двух предыдущих узлов. Тогда выход узла выбора — это комбинация поступивших
в него решений. Выбор может быть сделан обычным голосованием.
Класс Класс
Рис. 11.12. Дерево выбора
Когда узел выбора содержит два входа и более, результат будет зависеть от
того, являются ли они категориальными или числовыми. Если входы категори-
альные, то используется голосование, а если числовые — полученные различ-
ными способами вероятностные оценки, взвешенное среднее или байесовский
подход.
Деревья выбора можно создавать с помощью модификации обычных деревьев
решений путем встраивания в них узлов выбора.
Другая возможность построить дерево выбора — пошагово добавлять в него
узлы. При этом используется алгоритм бустинга. Полученное дерево называет-
ся знакопеременным деревом, узлы решений — узлами-разветвителями, а узлы
выбора — узлами предсказания. Узлы предсказания являются листьями, если из
них больше не выходят узлы-разветвители. Обычные знакопеременные деревья
применяются при решении задач бинарной классификации, и с каждым узлом
предсказания ассоциировано положительное или отрицательное числовое значе-
ние. Чтобы предсказать класс определенного примера, его пропускают через все
возможные ветви, после чего значения, полученные на выходах всех узлов пред-
сказания, суммируются. Класс выбирается в зависимости от того, положительной
или отрицательной оказалась сумма.
Схема знакопеременного дерева представлена на рис. 11.13, где положитель-
ное значение соответствует классу Играть — Да, а отрицательное — классу Иг-
рать = Нет. Пример {Облачность = Солнечно, Температура = Жарко, Влаж-
Глава 11. Ансамбли моделей 561
ноешь = Нормальная, Ветер = Нет}, проходя по соответствующим листьям,
получает значения —0,255, 0,213, 0,430 и -0,331. После их сложения сумма поло-
жительная, значит, результат Играть = Да.
Играть = Да
Рис. 11.13. Знакопеременное дерево
Дерево на рис. 11.13 содержит четыре узла-разветвителя и один узел предска-
зания.
Знакопеременное дерево растет с использованием алгоритма бустинга, напри-
мер LogitBoost. Предположим, что базовая модель создает отдельное правило на
каждой итерации бустинга. После этого знакопеременное дерево может быть сге-
нерировано путем простого добавления каждого правила в дерево.
Стэкинг и метаобучение
Поуровневое обобщение (stacked generalization), или просто стэкинг (stacking), —
один из способов создания составных моделей. Хотя метод был разработан не-
сколько лет назад, он все еще менее известен, чем бэггинг и бустинг. Отчасти это
связано со сложностью теоретического анализа, а отчасти с тем, что общая кон-
цепция использования данного метода пока отсутствует — основная идея может
применяться в самых разнообразных вариантах.
В отличие от бэггинга и бустинга стэкинг обычно не используется для комби-
нирования моделей одного и того же типа, например набора деревьев решений.
Вместо этого он применяется к моделям, построенным с помощью различных
алгоритмов обучения. Предположим, мы имеем три модели — дерево решений,
байесовский классификатор и нейронную сеть, на основе которых нужно постро-
ить классификатор для определенного набора данных. Обычная процедура заклю-
чается в оценке ошибки каждого алгоритма и выборе лучшего из них, который
и будет использоваться для классификации новых данных. Но действительно ли
562 Часть I. Теория бизнес-анализа
этот способ лучший? Если доступны три модели, то нельзя ли их все применять
для классификации, комбинируя выходы?
Одной из техник комбинирования выходов является голосование (та же мето-
дика, что и в бэггинге). Но оно имеет смысл только тогда, когда обучающие схемы
работают сравнительно хорошо. Если два из трех классификаторов работают
плохо, то ожидать хороших результатов от всего ансамбля не приходится. Вместо
этого стэкинг вводит концепцию метаобучения, которая заменяет процедуру
голосования. Проблема голосования заключается в том, что неясно, какому клас-
сификатору следует доверять. Стэкинг пытается обучить каждый классификатор,
используя алгоритм метаобучения, который позволяет обнаружить лучшую ком-
Базовые модели образуют уровень 0. На вход метамодели, которая также на-
зывается моделью уровня 1, подаются результаты с выходов базовых моделей.
Пример уровня 1 имеет столько атрибутов, сколько существует моделей уровня 0,
а сами значения атрибутов — выходы моделей нулевого уровня. Затем на основе
результатов, полученных моделью уровня 1, строится модель уровня 2 и т. д., пока
не будет выполнено какое-либо из условий остановки обучения.
Сравнение
моделей
12.1. Оценка эффективности
и сравнение моделей
Бизнес-аналитические проекты с применением технологий Data Mining в боль-
шинстве своем дорогостоящи и трудоемки. Поэтому предприятия и организации,
выступающие в качестве заказчиков таких проектов, ожидают получить от них
соответствующую отдачу. По этой причине аналитики, которые ведут проект, стре-
мятся «выжать» из находящихся в их распоряжении данных максимум пользы. Это
и само по себе непросто, поскольку данных может быть недостаточно, они могут
иметь низкое качество, плохо отражать предметную область и т. д.
Так что же делать аналитику, чтобы не разочаровать заказчика и не нанести
вред его бизнесу из-за использования некорректных моделей? Ответить на этот
вопрос позволяет специальный раздел Data Mining, который объединяет в себе
методы оценивания эффективности и сравнения различных моделей.
Действительно, после того, как модель построена, естественным образом воз-
никают два вопроса.
□ Насколько построенная модель полезна, эффективна и точна?
□ Нельзя ли построить модель, которая будет работать лучше имеющейся?
Ясно, что модель нельзя применять на практике до тех пор, пока не будут прове-
рены ее эффективность и точность, поэтому на завершающем этапе ее построения
эти показатели всегда оцениваются. Что касается второго вопроса, часто строят
несколько моделей, затем оценивают эффективность каждой из них и выбирают
лучшую, для чего требуется решить задачу сравнения моделей.
Мы затронули два ключевых понятия — эффективность и точность. Но как их
соотнести? Интуитивно понятно, что модель, обладающая низкой точностью, не
может быть эффективной. Если вероятность того, что модель даст неправильные
564 Часть I. Теория бизнес-анализа
результаты, велика, скорее всего, мы откажемся от нее и попытаемся построить но-
вую, более точную модель или изменим параметры существующей таким образом,
чтобы повысить ее точность. Но увеличение точности модели, как правило, ведет
к тому, что она усложняется и ее прозрачность для пользователя снижается. В итоге
мы можем получить очень точную модель, которая окажется неэффективной из-за
своей сложности и плохой интерпретируемости.
Проведем аналогию. Докладчик выступает с научно-популярной лекцией.
Он может точно описать предметную область, используя при этом специальные
термины, но тогда слушатели ничего не поймут. Можно удариться в другую край-
ность — объяснить все «на пальцах», но в этом случае информация окажется не-
полной и недостоверной и желаемый результат снова не будет достигнут. Хороший
докладчик всегда найдет компромисс между сложностью и точностью изложения
материала и приведет их в соответствие с уровнем аудитории. Эффективная мо-
дель также получается на основе компромисса между такими показателями, как
точность, сложность и интерпретируемость.
Если мы построили несколько моделей и хотим выбрать наиболее эффектив-
ную, то сначала придется оценить эффективность каждой из них, а затем сравнить
полученные результаты. При этом возможны два варианта.
□ В первом случае все сравниваемые модели однотипны, например три дерева
решений, построенные с различными параметрами на одном и том же наборе
данных. Здесь может оказаться достаточным выбрать ту модель, которая дает
меньшую ошибку при заданном уровне сложности модели.
□ Во втором случае требуется оценить эффективность моделей различных типов,
например регрессионной модели, нейронной сети и дерева решений, и сделать
между ними выбор. Данная задача сопряжена с серьезными проблемами, глав-
ная из которых — различные меры точности моделей. Действительно, точность
дерева решений определяется на основе числа правильно и неправильно клас-
сифицированных примеров, регрессионной модели — на основе среднеквадрати-
ческой ошибки. Кроме того, мерой точности может быть вероятность правильной
или неправильной классификации. Использование различных мер для оценки
точности моделей требует применения специальных методов сравнения.
ПРИМЕР--------------------------------------------------------------------
Сферой, в которой востребованы оценка эффективности и сравнение моделей, является
директ-маркетинг — прямая почтовая рассылка рекламы. Главная задача здесь — миними-
зация количества рассылок клиентам, которые не откликаются на рекламу. Если проводить
рассылку без предварительного анализа клиентской базы, то затраты на такую рассылку
могут оказаться выше прибыли, полученной от продажи рекламируемых товаров. Обычно
фирмы, занимающиеся директ-маркетингом, имеют так называемый список контактов,
то есть список клиентов, которым уже производилась рекламная рассылка. Некоторые из
клиентов реагировали активно, откликаясь, скажем, на 7 рассылок из ю, другие — менее
активно (2-3 отклика), а третьи — вообще никак.
Желание человека приобрести тот или иной товар зависит от множества признаков, описы-
вающих его как потенциального клиента. Ими могут быть возраст, пол, доход, семейное по-
ложение, количество детей, наличие или отсутствие собственного дома и автомобиля, кли-
Глава 12. Сравнение моделей 565
мат местности проживания и др. Действительно, никому не придете голову рекламировать
теплую одежду жителям тропических районов или предлагать банковские карты обитателям
бедных кварталов. Но если известно, что потенциальный клиент имеет собственный дом,
то можно попробовать предложить ему средства для ухода за садом (газонокосилку и др.),
а если у потенциального клиента есть автомобиль, то вполне возможно, что он откликнется
на рекламу автохимии (полироли, автошампуни, масло для двигателя и др.).
Аналитик может выделить набор таких признаков для каждого вида товаров и построить
модель, которая будет определять, стоит ли включать в список рекламной рассылки кли-
ента, имеющего определенный набор значений признаков.
С точки зрения оценки эффективности можно выделить два типа моделей Data
Mining, основанных на обучении.
□ К первому типу относятся модели, для описания точности которых можно
использовать количественные меры: ошибку, среднеквадратическую ошибку,
показатель ошибки и др. Это классификационные (предсказательные) и регрес-
сионные (оценочные) модели.
□ Оценка точности моделей второго типа трудно поддается формализации, по-
скольку они не имеют выходов как таковых (в том смысле, в каком их имеют
классификационные и регрессионные модели). Такие модели называются деск-
риптивными (описательными), и к ним относятся, например, ассоциативные пра-
вила. С помощью ассоциативных правил можно выделить группы товаров, часто
продаваемых вместе. Так, может оказаться, что большинство клиентов, которые
ранее приобрели полироль и шампунь для автомобиля, с высокой вероятностью
откликнутся на рекламу нового моторного масла.
Классификационные модели позволяют, например, определить категорию получа-
теля рассылки в директ-маркетинге — высокоактивный получатель, низкоактивный
и неактивный. После разделения получателей на категории можно принять решение
о том, что рассылку следует производить только первым двум категориям клиентов,
а от работы с третьей категорией отказаться.
Одной из важнейших задач Data Mining, наиболее востребованной в бизнесе,
экономике, маркетинге, медицине и технике, является бинарная классификация,
когда нужно определить принадлежность объекта к одному из двух классов. В ме-
дицине это может быть наличие или отсутствие заболевания, в директ-маркетин-
ге — наличие или отсутствие отклика респондента, в военной технике — наличие
или отсутствие цели. Бинарную классификацию часто называют вероятностной
(probability classification): в такой постановке удобно определять не сам класс,
а вероятность того, что данное наблюдение относится к этому классу. Тогда на
выходе модели будет числовое значение в диапазоне от 0 до 1. Для решения задачи
вероятностной классификации используются модели логистической регрессии.
Чтобы оценить их эффективность и сравнить, широко применяются такие методы,
как Lift- и Profit-кривые, ROC-анализ, матрицы классификаций.
Регрессионные модели по определению имеют непрерывную выходную пере-
менную. В контексте задачи директ-маркетинга модель должна определять веро-
ятность того, что клиент откликнется на рекламную рассылку. В качестве меры
566 Часть I. Теория бизнес-анализа
точности модели используется среднеквадратическая ошибка между наблюдаемыми
и предсказанными значениями для каждого примера. Также могут использоваться
относительные и абсолютные ошибки и коэффициент корреляции между входными
и выходными переменными.
Поскольку дескриптивные модели не выполняют классификацию, регрессию или
оценивание, методика оценки их эффективности и сравнения трудно формализуема
и основана скорее на здравом смысле. Эффективность дескриптивных моделей опреде-
ляется их простотой и понятностью для пользователя. Если есть две модели, имеющие
одинаковую точность и эффективность, но разный уровень сложности, то при прочих
равных условиях следует отдавать предпочтение более простой из них. Данный прин-
цип известен как «бритва Оккама» (Occam’s razor). Он заключается в том, что лучшей
будет модель, которая обладает достаточным уровнем объясняющей способности, но
при этом является наиболее простой. Вспомним слова А. Эйнштейна: «Все должно
делаться настолько просто, насколько это возможно, но не проще».
В качестве количественной меры оценки дескриптивных моделей можно при-
менить принцип минимума длины описания (minimum descriptive length, MDL).
Согласно ему лучшим представлением (описанием) будет то, которое минимизи-
рует информацию (в битах), требуемую для кодирования модели.
Методы сравнения дескриптивных моделей выходят за рамки нашего рас-
смотрения. В дальнейшем мы сосредоточимся на методах оценки эффективности
и точности классификационных и регрессионных моделей, а также на методах их
сравнения (рис. 12.1).
Рис. 12.1. Подходы к сравнению моделей
Глава 12. Сравнение моделей 567
12.2. Оценка ошибки модели
Процесс построения модели не ограничивается ее обучением. Прежде чем исполь-
зовать модель на практике, необходимо оценить ее эффективность и способность
к работе с новыми данными.
В чем заключается задача оценки эффективности? На первый взгляд, доста-
точно взять обучающее множество и посмотреть, насколько отличается работа на
нем различных моделей. Однако эффективность модели на обучающем множестве
определенно не отражает результативность ее работы с новыми данными. Для кор-
ректной оценки модели необходимо использовать методы, которые не зависят от
происхождения данных.
Если данных для построения модели достаточно, можно проверить ее на боль-
шом тестовом множестве. Но проблема кроется в другом: хотя задачи Data Mining
обычно связаны с огромными объемами данных, особенно в маркетинге, торговле
и работе с клиентами, часто оказывается, что качество данных низкое. Поэтому
оценка эффективности моделей представляет интерес прежде всего в контексте
ограниченного объема доступных данных. Ниже мы рассмотрим несколько мето-
дов, которые наиболее часто используются при оценке моделей в таких условиях:
перекрестную проверку (cross-validation), бутстрэп-оценку (bootstrap) и исключе-
ние по одному примеру (leave-one-out).
Сравнение эффективности различных моделей — непростая процедура. Даже
если модели показывают разную эффективность, возникает два вопроса.
□ Не является ли это следствием воздействия на работу моделей случайных
факторов?
□ Достаточно ли значимы различия, чтобы сделать вывод о превосходстве одной
модели над другой?
Чтобы быть уверенными в том, что различия не являются результатом влияния
случайных факторов, необходимо использовать статистические тесты.
Необходимо также рассмотреть вопрос издержек (cost) классификации. В боль-
шинстве ситуаций издержки неправильной классификации зависят от типа ошиб-
ки. Например, при отборе получателей рекламной рассылки в директ-маркетинге
положительным считается пример, в котором имеет место отклик клиента, а отри-
цательным — тот, в котором реакция клиента отсутствует (возможно и наоборот).
Тогда издержками неправильной классификации положительного примера станет
отказ от рассылки клиенту, который на самом деле откликнулся бы с высокой
долей вероятности. В одном случае издержками являются затраты на рассылку,
в другом — упущенная прибыль от потери потенциального клиента. При оценива-
нии эффективности используемых моделей необходимо обязательно учитывать
такие издержки.
Обучение и тестирование
Эффективность модели, предназначенной для решения задачи классификации,
обычно оценивается с помощью коэффициента ошибки (error rate). Классификатор
568 Часть I. Теория бизнес-анализа
должен предсказать класс каждого наблюдения. Если это сделано правильно, то
имеет место успех, в противном случае — ошибка.
Коэффициент ошибки — это количество ошибок, допущенных на всем множест-
ве, отнесенное к общему числу наблюдений. Он показывает общую эффективность
классификатора.
Конечно, в первую очередь представляет интерес эффективность работы модели
на новых данных. Поскольку классы обучающих примеров известны заранее, их
можно использовать для вычисления ошибки обучения. Но, как упоминалось ра-
нее, она не отражает эффективность работы модели на новых данных. Потребуется
определить величину ошибки на множестве данных, которое не использовалось для
обучения, то есть ошибку обобщения. Для этого применяется тестовое множество.
Очень важно, чтобы тестовые данные никак не использовались при построении
классификатора. Например, некоторые методы обучения включают два этапа:
сначала создается первое приближение модели, а потом ее параметры оптимизиру-
ются. Для каждого из этих этапов могут потребоваться отдельные наборы данных.
Существует и другой подход: на обучающих данных строятся различные модели,
затем они оцениваются на тестовом множестве и выбирается та, которая работает
лучше.
В этом случае часто говорят о трех множествах данных: обучающем, валидаци-
онном и тестовом (рис. 12.2). Обучающее множество используется для создания од-
ной модели или более, валидационное — для оптимизации их параметров, а тесто-
вые данные — для определения ошибки конечной, оптимизированной модели. Все
три множества выбираются независимо друг от друга. Валидационное множество
должно быть отличным от обучающего для эффективной оптимизации. Тестовое
множество должно отличаться от двух других, чтобы с его помощью можно было
получить достоверную оценку ошибки модели.
Рис. 12.2. Разбиение исходного множества данных
на обучающее, валидационное и тестовое
После того как ошибка обобщения на тестовом множестве будет определена,
примеры из него могут быть добавлены в обучающее множество, чтобы создать
новый классификатор. Аналогично поступают и с валидационными данными.
Глава 12. Сравнение моделей 569
В общем случае чем больше объем обучающего множества, тем лучше будет
работать классификатор. Чем больше тестовое множество, тем точнее оценка
ошибки обобщения.
Нередки случаи, когда достаточного количества данных нет. Ограничение ко-
личества данных, которые могут использоваться для обучения, валидации и тес-
тирования, ставит вопрос: как создать необходимые множества из ограниченного
набора данных? Возникает дилемма: для построения лучшего классификатора
нужно использовать как можно больше обучающих данных, для получения более
точной оценки ошибки — тестовых.
Перекрестная проверка
Что делать, когда количество данных для обучающего и тестового множеств ограни-
ченно? Можно использовать тот или иной метод сэмплинга при отборе данных для
тестового множества и, возможно, для валидации, а остальные данные применять
для обучения. Обычно одна треть данных отбирается для тестового множества, а две
трети — для обучающего.
Но выборка, используемая для обучения или тестирования, может оказаться
нерепрезентативной, то есть не все классы в ней будут представлены в достаточном
объеме. Здесь существует одно простое правило: все классы исходного множества
данных должны быть представлены в обучающем и тестовом множествах примерно
в одинаковой пропорции. Если в худшем случае все примеры определенного класса
отсутствовали в обучающем множестве (были отобраны в тестовое множество), то
с примерами этого класса классификатор будет работать плохо. Ситуация, скорее
всего, усугубится тем, что в тестовом множестве этот класс окажется представлен
слишком сильно.
Наиболее общим способом уменьшить перекосы, вызванные неудачным сэм-
плингом, является повторение всего процесса обучения и тестирования несколько
раз при различных случайных выборках. На каждой итерации определенная доля
данных (например, 2/3) случайно отбирается для обучения, а оставшиеся исполь-
зуются для тестирования. Ошибки, полученные на различных итерациях, усред-
няются, и определяется общая ошибка. Этот метод оценивания ошибки получил
название ^повторяющийся захват» (repeated holdout).
При одиночном захвате обучающее и тестовое множество меняются ролями:
обучение ведется на данных, которые использовались ранее как тестовые, и наобо-
рот. Затем полученные результаты усредняются. Это позволяет снизить влияние
неравномерного представления классов в обучающем и тестовом множествах.
К сожалению, такой способ приемлем только при разбиении данных на обучающие
и тестовые в равной пропорции (50 : 50), что, вообще говоря, не является удачным
решением, поскольку обучающее множество должно быть больше тестового.
Существует простой и эффективный способ формирования этих множеств
в условиях недостаточности данных, который называется перекрестной проверкой,
или кросс-валидацией. Выбирается фиксированное число слоев (folds) или блоков
(partitions) данных, например 3. Затем данные разбиваются на три приблизительно
570 Часть I. Теория бизнес-анализа
равных блока, и каждый из них по очереди применяется для тестирования, а оста-
вшиеся — для обучения (используется разбиение 2 : 3 для обучения и 1 : 3 ддя
тестирования). Процедура повторяется трижды так, чтобы каждое наблюдение
хотя бы один раз использовалось для тестирования. В данном случае имеет место
трехблочная перекрестная проверка (рис. 12.3).
1-й проход
2-й проход
3-й проход
т
О
о
Рис. 12.3. Трехблочная перекрестная проверка
(О — обучающая выборка, Т — тестовая)
Для определения ошибки принято делать десятиблочную перекрестную провер-
ку (tenfold cross-validation). Данные случайным образом разделяются на 10 блоков,
в каждом из которых классы представлены приблизительно так же, как и в исходном
множестве. Затем модель обучается на 9/10 данных и тестируется на оставшейся
1/10 части. Полученные 10 значений ошибки усредняются, и результат рассматри-
вается как общая ошибка модели.
Следует отметить, что перекрестная проверка не требует точного разделения
на 10 равных блоков — оно может быть приблизительным. Главное, чтобы классы
в блоках представлялись примерно в равных пропорциях.
Почему рекомендуется использовать именно 10 блоков? Экспериментальные
исследования, проведенные на различных множествах данных при различных ме-
тодах обучения, показали, что 10 — то число блоков, которое позволяет получить
наилучшую оценку ошибки. Существуют и некоторые теоретические доказатель-
ства в пользу этого. Впрочем, эти аргументы отнюдь не являются определяющими
(окончательными): среди исследователей продолжаются споры относительно оп-
тимального числа блоков для перекрестной проверки. Тем не менее десятиблочная
схема стала стандартом де-факто в практических приложениях.
В то же время 10 блоков может оказаться недостаточно для получения досто-
верной оценки ошибки. Эксперименты по десятиблочной перекрестной проверке
для одних и тех же множеств данных и методов обучения часто дают различные
результаты из-за случайного отбора блоков. Поэтому, когда требуется получить
более точную ошибку, используется десятикратная перекрестная проверка, то есть
10 раз по 10 блоков с последующим усреднением результатов. Полученная мера
эффективности модели является очень хорошей, но затратной в вычислительном
плане.
Глава 12. Сравнение моделей 571
Перекрестная проверка с исключением
Альтернативой десятиблочной перекрестной проверке является метод перекрест-
ной проверки с исключением одного примера (leave-one-out cross-validation). В целом
это обычная «-блочная перекрестная проверка, где п — число наблюдений в наборе
данных. На каждом из проходов по очереди исключается один пример, и обучение
производится на оставшихся п — 1 примерах, а тестирование — на исключенном.
Если при тестировании результат, выданный моделью, совпадает с фактическим
(целевым) значением этого примера, то имеет место успех и данному проходу
присваивается значение 1, в противном случае — 0. Затем результаты, полученные
при тестировании на всех п примерах, усредняются и это значение рассматривается
как ошибка модели.
Процедура привлекательна по двум причинам. Во-первых, для обучения ис-
пользуется наибольшее количество данных, что повышает точность модели. Во-
вторых, процедура полностью детерминирована — отсутствует случайный отбор.
Поэтому ее не нужно повторять несколько раз: результаты для одного и того же
метода обучения и одного и того же множества данных всегда будут одинаковыми
(если в самом алгоритме обучения отсутствует случайность, например случайная
инициализация начальных весов нейронной сети). Недостаток подхода — высо-
кие вычислительные затраты, что делает его непригодным для использования
на больших множествах данных. Тем не менее на небольших множествах метод
эффективен и дает хорошую оценку ошибки.
Бутстрэп-оценки (самонастройка)
Получение бутстрэп-оценок основано на процедуре сэмплинга, называемой сэм-
плингом с замещением. В обычном сэмплинге каждая запись исходного множества
данных отбирается только один раз. Это похоже на отбор игроков для футбольного
матча: нельзя включить в команду одного и того же игрока дважды. Сэмплинг с за-
мещением позволяет выбирать одни и те же наблюдения несколько раз.
В основе идеи бутстрэп-оценок лежит выборка с замещением набора данных
для обучающего множества. Рассмотрим частный случай, который называется
0,632-бутстрэпом. Множество данных из п наблюдений выбирается с замещением,
чтобы сформировать другое множество данных, также состоящее из п наблюдений.
Поскольку некоторые элементы во втором множестве будут повторяться, а исход-
ное и полученное множества содержат одинаковое число примеров, то окажется,
что некоторые примеры не будут отобраны во второе множество. Они и будут ис-
пользоваться как тестовые.
Какова вероятность того, что некоторое наблюдение не будет включено в обу-
чающее множество? Вероятность выбора наблюдения равна 1 /п. Соответственно
вероятность того, что наблюдение не будет выбрано, — 1 — 1/п. Умножив эти ве-
роятности друг на друга п раз, получим (1 — 1/п)" « е1 = 0,368. Это дает оценку
вероятности того, что определенное наблюдение вообще не будет выбрано. Таким
образом, если исходное множество данных достаточно большое, тестовое множество
572 Часть I. Теория бизнес-анализа
будет содержать примерно 36,8 % наблюдений, а обучающее — оставшиеся 63,2 %.
Некоторые примеры в обучающем множестве будут повторяться, благодаря чему
результирующее множество будет равно исходному.
Результаты, полученные в процессе обучения модели на обучающем множестве
и вычисления ошибки на тестовом, дадут пессимистическую оценку, поскольку обу-
чающее множество, хотя и имеет размер п, содержит только 63 % наблюдений, что
немного по сравнению, например, с 90 %, которые используются в десятиблочной
перекрестной проверке. Чтобы компенсировать это, можно комбинировать ошибку
на тестовом множестве etot с ошибкой обучения ег,и,„. С помощью бутстрэпирования
получаем итоговую ошибку е:
Е = 0,632 Etes( + 0,368 • Е train.
Затем процедура бутстрэпа повторяется несколько раз при различных выборках
с замещением, и полученные ошибки усредняются.
12.3. Издержки ошибочной классификации
Ошибки, допускаемые моделью при ее практическом применении к новым данным,
могут приводить к ложным выводам, что влечет за собой материальные и, следо-
вательно, финансовые потери от неправильно принятых решений. Такие потери
в Data Mining часто называются издержками ошибки классификации (classification
cost error, misclassification cost). Действительно, при разработке модели кредитного
скоринга ставится цель разделить всех клиентов на добросовестных и недобросо-
вестных. Закономерен вопрос: «Что лучше — принять добросовестного клиента за
недобросовестного или наоборот?» Ответ на него очевиден даже неспециалисту:
в первом случае мы теряем только проценты по кредиту, который не был выдан,
а во втором — всю сумму, выданную недобросовестному заемщику. То есть издерж-
ки ошибок второго вида больше. При построении модели необходимо минимизи-
ровать вероятность появления ошибок, которые вызывают наибольшие издержки
классификации. Такая методика называется классификацией с учетом издержек
(cost-sensitive classification).
Приведем еще типичные примеры ситуаций, когда издержки для разных типов
ошибок различны:
□ директ-маркетинг — издержки отправки тематической почты клиентам, которые
не отвечают на нее, существенно меньше, чем потери из-за пропуска потенци-
альных клиентов;
□ поиск очагов нефтяного загрязнения — издержки пропуска реального нефтя-
ного пятна существенно выше, чем издержки ложной тревоги;
□ техническая диагностика — издержки неправильной идентификации проблемы
существенно меньше, чем издержки пропуска проблемы.
Вообще, трудно найти область, в которой издержки различных типов ошибок
были бы одинаковыми.
Глава 12. Сравнение моделей 573
В бинарной классификации каждое отдельное предсказание может иметь четыре
исхода:
□ истинноположительный (true positive, TP);
□ истинноотрицательный (true negative, TN);
□ ложноположительный (false positive, FP);
□ ложноотрицательный (false negative, FN).
Пусть в качестве положительного исхода выбрано значение Да, а в качестве
отрицательного — Нет. Истинноположительным исход будет, когда фактический
класс данного примера Да и модель на выходе выдаст Да. Истинноотрицательным
исход будет, когда фактический класс наблюдения Нет и модель выдаст Нет. Лож-
ноположительное значение имеет место, когда класс наблюдения Нет, а модель
для него сформирует выход Да. При ложноотрицательном выходе целевая пере-
менная принимает значение Да, а на выходе модель выдаст Нет (рис. 12.4).
Введем в рассмотрение два основных показателя, позволяющих оценить точ-
ность бинарной классификационной модели.
Общий показатель успеха (overall success rate, OSR), или просто точность
(accuracy), — это число правильно классифицированных наблюдений, отнесенное
к общему числу наблюдений:
OSR =
TP + TN
TP + TN + FP + FN'
Иногда данную величину называют точностью классификатора.
Общий показатель ошибки (overall error rate, OVR) составит:
OVR =
FP + FN
TP + TN + FP + FN'
Для дальнейшего рассмотрения вопросов, связанных с оценкой эффективности
и сравнением моделей бинарной классификации, введем еще два показателя — чув-
ствительность (sensitivity, Se) и специфичность (specificity, Sp).
Чувствительность определяется как отношение числа истинноположительных
наблюдений к числу фактически положительных наблюдений:
574 Часть I. Теория бизнес-анализа
с ТР
TP + FN'
Специфичность определяется как отношение числа истинноотрицательных
наблюдений к числу фактически отрицательных наблюдений:
TN
Р TN + FP'
Классификация с учетом издержек
При бинарной классификации два типа ошибок — ложноположительные и ложно-
отрицательные — будут иметь различные издержки, а два типа корректной клас-
сификации — истинноположительный и истинноотрицательный — будут давать
различную прибыль (profit).
В случае двух классов издержки ошибок могут быть сведены в таблицу разме-
ром 2 х 2, в которой диагональные элементы представляют два типа правильной
классификации, недиагональные — два типа ошибок. Такие таблицы называются
матрицами издержек (cost matrix). В случае нескольких классов матрица издержек
будет представлять собой квадратную таблицу, размер которой по вертикали и го-
ризонтали равен числу классов, а диагональные элементы представляют издержки
правильной классификации. Ниже представлены матрицы издержек для случая
двух (рис. 12.5) и трех (рис. 12.6) классов. Издержки для всех типов ошибок
приняты равными 1: то есть 0 — издержки отсутствуют, 1 — присутствуют. Если
издержки известны, то в соответствующих ячейках могут напрямую указываться
связанные с ними суммы.
Учет матриц издержек позволяет заменить показатель успеха классификации
средними издержками (или, более позитивно, прибылями).
Минимизировать издержки ошибок классификации можно с помощью выбора
точки отсечения (cut-off point) — порогового значения вероятности, разделяющего
классы. Поднимая порог (приближая его к 1), мы увеличиваем вероятность лож-
ноположительных исходов и уменьшаем вероятность ложноотрицательных. Сни-
жая порог, мы, наоборот, уменьшаем вероятность ложноположительных исходов
и увеличиваем вероятность ложноотрицательных. Если известно, какие из этих
Глава 12. Сравнение моделей 575
ошибок обходятся дороже, то можно подобрать порог так, чтобы минимизировать
связанные с ними издержки.
Классифицировано
мм
S X О D
т S
си 9
Рис. 12.6. Матрица издержек 3x3
С помощью матрицы издержек и матрицы классификации можно вычислить
издержки обученной модели на данном тестовом множестве. Для этого достаточ-
но перемножить соответствующие количества ошибочно классифицированных
наблюдений, взятые из матрицы классификации, на значения связанных с ними
издержек из матрицы издержек (рис. 12.7).
Полные
издержки
Матрица издержек
Классифицировано
S *
Q
Ф
7 S
СО
Матрица
классификации
4-6 +
+ 2 • 4 = 32
Рис. 12.7. Вычисление полных издержек ошибок классификации
Одним из широко используемых методов оценивания оптимального порога
является правило Байеса. Пусть положительным исходом классификации является
класс 1. Тогда полные издержки Сrotai будут:
С Ма1 = (1 — Р) ' СрР,
где Р — вероятность отнесения наблюдения к классу 1.
Если положительным исходом классификации является класс 0, то:
С total — Р ' С ну.
Следовательно, оптимальное правило отнесет наблюдение к классу 1, если:
(1 — Р) • CFP < Р CFN.
В противном случае наблюдение будет отнесено к классу 0. Вероятность Р оце-
нивается как отношение числа примеров соответствующего класса к общему числу
примеров.
576 Часть I. Теория бизнес-анализа
На практике правило Байеса используется в следующем виде: если вероятность,
определенная моделью для г-го наблюдения удовлетворяет неравенству
Pi>_____!_____,
1 + (С т /С /.-р)
то наблюдение относится к классу 1, в противном случае — к классу 0.
Обратим внимание на то, что правило Байеса зависит только от отношения
издержек, а не от их фактических значений. Значит, если издержки обоих типов
ошибок равны, то правило Байеса даст порог отсечения 0,5. Можно показать, что
когда отношение издержек равно 1, то ожидаемые издержки пропорциональны
показателю ошибки.
Если событие, связанное с положительным исходом классификации, является
редким, то издержки ложноотрицательных ошибок обычно больше, чем ложнопо-
ложительных. Например, издержки от пропусков потенциального клиента в директ-
маркетинге больше, чем издержки от рассылки тем, кто не реагирует на нее. Из-
держки от проведения мошеннической транзакции по кредитной карте больше, чем
издержки от невыполнения законной транзакции (хотя всегда есть исключения).
Для таких случаев порог отсечения должен задаваться существенно ниже, чем 0,5.
12.4. Lift- и Profit-кривые
Lift-кривые и диаграммы
Наличие издержек классификации делает актуальной задачу не только оценки
эффективности модели, но и оптимизации ее с точки зрения издержек. Достаточ-
но часто издержки классификации точно не заданы, а известно только, какой тип
ошибок ведет к большим издержкам, исходя из постановки задачи. Аналитику
ничего не остается, кроме как рассмотреть все возможные варианты и выбрать
оптимальный.
Вернемся к примеру с директ-маркетингом. Пусть фирма производит рассыл-
ку 1 миллиону потенциальных клиентов. Предположим, что обычно откликается
0,1 %, то есть 1000 человек. Таким образом, отклик можно рассматривать как редкое
событие. Ранее говорилось, что если положительный исход есть редкое событие, то
ложноотрицательные ошибки связаны с большими издержками, чем ложнополо-
жительные. Иными словами, пропуск вероятного клиента (ложноотрицательный
исход) ведет к большим потерям, чем рассылка респонденту, от которого не после-
довало отклика (ложноположительная ошибка). Логика очевидна: один отклик-
нувшийся респондент способен принести прибыль, которая покроет издержки от
тысячи «пустых» отправлений.
С точки зрения оптимизации издержек имеет смысл отобрать подмножество из
100 тысяч респондентов, в котором число откликов больше, чем во всем множестве,
например 0,4 %, или 400. Если ограничиться рассылкой только этим респондентам,
Глава 12. Сравнение моделей 577
то издержки на рассылку станут в 10 раз меньше, в то время как количество откли-
ков уменьшится всего в 2,5 раза. Увеличение числа откликов относительно числа
почтовых отправлений известно как лифт-фактор, или коэффициент лифта, или
просто лифт. В данном случае коэффициент лифта равен 4. Если известны издерж-
ки, то можно определить прибыль, полученную при данном значении лифта L.
Обозначим исходное число рассылок У (в нашем примере У = 1 000 000), а чис-
ло откликов — п (и = 1000). Также обозначим размер выборки, для которой коли-
чество откликов ожидается более значительным, К (то есть К = 400 000), а число
откликов в выборке — k (k = 800). Тогда прирост доли положительных исходов,
то есть коэффициент лифта, составит:
k/K_ 800/400 000 _ 0,002
“ n/N ~ 1000/1000 000 “ 0,001 “ '
Рассмотрим вариант с моделью, учитывающей рассылку 400 тысячам респон-
дентов, для которой процент отклика — 0,2 %, или 800 человек. Это соответствует
коэффициенту лифта, равному 2. Что лучше: разослать рекламу 100 тысячам
респондентов и получить 400 откликов или сделать рассылку 400 тысячам рес-
пондентов и получить 800 откликов? Повысив издержки в 4 раза, мы получаем
увеличение числа откликов всего вдвое.
Обобщим методику расчета лифта для произвольной модели бинарной класси-
фикации. Пусть имеется множество из У примеров, из которых п положительных.
Для каждого примера модель выдает вероятность его принадлежности к опреде-
ленному классу. Задача аналитика заключается в выборе подмножества примеров,
которые имеют наибольшую вероятность положительного исхода. Для этого от-
сортируем примеры в порядке уменьшения вероятности положительного исхода
(табл. 12.1) и извлечем некоторое число наблюдений К из полученного списка, на-
чиная сверху. Тогда, чтобы рассчитать коэффициент лифта, достаточно вычислить
отношение доли положительных примеров в выборке k/K к доле положительных
примеров в исходном множестве n/N.
Таблица 12.1. Фрагмент набора данных, отсортированных по убыванию
вероятности положительной классификации
№ п/п Предсказанная вероятность Фактический класс
1 0,95 Да
2 0,93 Да
3 0,93 Нет
4 0,88 Да
5 0,86 Да
6 0,85 Да
7 0,82 Да
8 0,80 Да
9 0,80 Нет
Продолжение &
578 Часть I. Теория бизнес-анализа
Таблица 12.1 (продолжение)
№ п/п Предсказанная вероятность Фактический класс
10 0,79 Да ~~
И 0,77 Нет
12 0,76 Да
13 0,73 Да
14 0,65 Нет
15 0,63 Да
16 0,58 Нет
17 0,56 Да
18 0,49 Нет
19 0,48 Да
В табл. 12.1 представлен фрагмент набора данных, содержащего N = 150 на-
блюдений, из которых п = 50 являются положительными (-0,33). Наблюдения от-
сортированы в порядке уменьшения вероятности положительной классификации,
то есть класса Да. Модель правильно классифицировала наблюдения 1 и 2: они
действительно положительны. Для наблюдения 3, скорее всего, была допущена
ошибка, поскольку оно оказалось отрицательным. Теперь, если мы хотим найти
подмножество из К = 10 наблюдений, которые с наибольшей вероятностью явля-
ются положительными, нужно взять 10 первых наблюдений из упорядоченного
списка. Восемь из них положительные (k = 8), поэтому их доля для выборки рав-
на 0,8. Тогда коэффициент лифта составит L = 0,8/0,33 = 2,42.
Таким образом, чтобы минимизировать издержки, или максимизировать при-
быль, достаточно, изменяя объем выборки, подобрать такое количество наблю-
дений из упорядоченного списка, которое обеспечит оптимальное соотношение
числа рассылок (а соответственно, и затрат на нее) и числа откликов. Для решения
данной задачи может быть построено несколько моделей, после чего потребуется
проверить, какая из них более эффективна.
Чтобы выбрать модель, которая позволяет найти оптимальное соотношение
между издержками и прибылью, для каждой модели-кандидата строится график,
называемый Lift-кривой (Lift curve). Семейство Lift-кривых образует Lift-диаграм-
му (Lift chart). Поведение Lift-кривых и их взаимное расположение на диаграмме
позволяют сделать вывод о том, какая из моделей работает лучше.
По горизонтальной оси Lift-диаграммы откладывается размер выборки в про-
центах от общего числа наблюдений в упорядоченном списке (в нашем случае это
получатели рассылки), а по вертикальной — число полученных откликов. Каждая
точка Lift-кривой показывает ожидаемое число откликов для выборки заданного
размера. Точка с координатами (0; 0) соответствует нулевому числу рассылок
и, следовательно, откликов. Точка с координатами (100; 1000) соответствует
максимальному числу наблюдений (рассылок) с откликом от 1000 респондентов
(рис. 12.8).
Глава 12. Сравнение моделей 579
Рис. 12.8. Lift-диаграмма
С помощью Lift-кривой можно определить размер выборки, который даст наи-
лучшее соотношение издержек (числа рассылок) и прибыли (числа полученных
откликов).
На рис. 12.8 помечены два частных случая, описанных выше: 10 % рассылок,
которые дают 400 откликов, и 40 % рассылок, которые дают 800 откликов. На прак-
тике следует ограничиться размером выборки, в пределах которой Lift-кривая
имеет достаточно крутой подъем (в нашем случае — примерно до 40 %). Тогда
увеличение числа рассылок и, соответственно, издержек приводит к хорошему
росту числа откликов. Так, рост рассылок с 10 до 40 % позволяет поднять отклики
вдвое: с 400 до 800. Но дальнейшее увеличение объема выборки приводит к сла-
бому росту числа откликов. Поэтому значение более 40 % непрактично: издержки
растут быстрее, чем возможная выгода. В частности, увеличив число рассылок
вдвое, с 40 до 80 %, мы получим увеличение числа откликов примерно на 10 %.
Использование малых объемов выборки (менее 10 %) также не имеет смысла. Хотя
Lift-кривая на данном участке имеет наибольшую крутизну, само по себе малое
число рассылок вряд ли принесет хорошую прибыль.
Диагональная линия на Lift-диаграмме отражает работу так называемого про-
извольного (случайного) классификатора, который не способен обнаружить
580 Часть I. Теория бизнес-анализа
подмножества, где процент откликов больше, чем в целом по выборке. Модель,
которой соответствует диагональная линия, бесполезна.
Любая модель, Lift-кривая которой проходит выше диагональной прямой,
дает прирост числа откликов относительно случайной модели и обеспечивает
лифт. Классификатор, представленный на рис. 12.8 кривой 3, проходящей ниже
диагональной прямой, дает отрицательный лифт и будет хуже «бесполезного»,
поэтому применение таких моделей с точки зрения оптимизации издержек бес-
смысленно.
Подытожим: чем выше проходит Lift-кривая, тем эффективнее модель. При про-
чих равных условиях предпочтение следует отдать той модели, для которой Lift-
кривая проходит выше других или, что одно и то же, максимально приближается
к точке с координатами (0; 1000).
Рассмотрим два крайних случая (рис. 12.9). Слева показана идеальная, но не-
вероятная ситуация, когда количество откликов всегда равно 100 % независимо от
числа рассылок, даже если вообще ничего никому не отправлялось. Кривая справа
отображает наихудшую ситуацию: сколько бы рассылок мы ни отправляли, ни один
респондент не откликнется.
Рис. 12.9. Граничные случаи для Lift-кривой
Что касается промежуточных вариантов, сравним линии 1 и 2 на рис. 12.8. Хо-
рошо видно, что при объеме выборки, равном 40 % обучающего множества, модель,
которой соответствует линия 1, дает ожидаемое число откликов, равное 800. Мо-
дель, описываемая линией 2, для того же количества рассылок дает 950 откликов.
Действительно, чем точнее классификация и чем меньше ошибок допускает модель,
тем быстрее и до большего значения возрастет количество истинноположительных
классификаций в табл. 12.1.
Для сравнения эффективности моделей, описываемых Lift-кривыми, часто
используется площадь под ними (area under curve, AUC). Чем выше проходит
график, тем больше площадь под кривой. Этот числовой показатель удобен, когда
Lift-кривые двух моделей проходят близко друг к другу и визуально оценить раз-
ницу между ними трудно.
При оценивании эффективности моделей с помощью показателя AUC можно
столкнуться со следующей проблемой: одна модель лучше работает в одном диа-
Глава 12. Сравнение моделей 581
пазоне (например, при объемах выборки 70-100 %), а вторая — в другом (скажем,
0-50 %). Следствием этого будет пересечение кривых (рис. 12.10).
Рис. 12.10. Lift-кривые с одинаковыми показателями AUC
На рисунке видно, что, хотя площади под Lift-кривыми одинаковы, однозначно
сказать, какая из моделей лучше, нельзя. Если планируется малый объем рассыл-
ки, например 10-30 % общего количества респондентов, то лучших результатов
можно добиться с помощью модели 1: в этом интервале ее Lift-кривая проходит
выше, чем кривая второй модели. Однако, запланировав большой объем рассылки
(50-90 % общего числа респондентов), мы обнаружим, что большую эффектив-
ность показывает модель 2. Таким образом, эффективность моделей, оцениваемая
с помощью Lift-кривых, и выбор лучшей модели зависят от особенностей реша-
емой задачи.
Иногда по вертикальной оси Lift-диаграммы откладывают не количество поло-
жительных наблюдений, а собственно значения лифта. Очевидно, что в этом случае
Lift-кривая будет убывать (рис. 12.11). Максимальный лифт будет при объеме вы-
борки, равном 1, поскольку для первого наблюдения вероятность положительной
классификации самая большая. По мере увеличения объема выборки в нее начи-
нает попадать все больше отрицательных исходов и лифт уменьшается. В пределе,
когда размер выборки — 100 %, лифт стремится к 1. Прямая L = 1, параллельная
Рис. 12.11. Альтернативный способ построения Lift-кривой
горизонтальной оси, аналогична диагональной линии на рис. 12.10 и демонстрирует
«бесполезную» модель.
Принцип сравнения моделей с помощью данной разновидности Lift-кривой тот
же: чем выше идет кривая, тем эффективнее связанная с ней модель.
Gain-диаграммы
Еще одна разновидность Lift-диаграмм — Gain-диаграмма (Gain chart), или ку-
мулятивная Lift-диаграмма (cumulative lift chart). По горизонтальной оси Gain-
диаграммы также откладывается размер выборки, полученной из упорядоченного
списка (см. табл. 12.1). Но по вертикальной оси фиксируется не количество (или
процент) положительных наблюдений, попавших в выборку, а отношение числа
истинноположительных наблюдений к числу всех наблюдений, классифициро-
ванных как положительные, то есть ТР/{ТР + FN). Ранее отмечалось, что данная
величина называется чувствительностью (Se).
Отметим, что чувствительность стремится к 0, если имеется очень большое
количество ложноотрицательных наблюдений. Верхний предел чувствительности
равен 1 в случае, когда ложноотрицательные наблюдения отсутствуют (ошибок
нет). Методика использования Gain-диаграммы в целом похожа на методику ис-
пользования обычной Lift-диаграммы, но ищется оптимальное соотношение между
Глава 12. Сравнение моделей 583
размером выборки и количеством ошибок классификатора, то есть числом случаев
ложноотрицательной классификации.
Увеличивая размер выборки (смещаясь по диаграмме вправо), мы увеличиваем
количество ложноположительных наблюдений, соответственно, риск ошибочной
классификации растет. Уменьшая выборку (смещаясь по диаграмме влево), мы пони-
жаем число ошибок. Задача аналитика заключается в подборе размера выборки таким
образом, чтобы чувствительность модели была на достаточно высоком уровне.
Если использовать Gain-диаграмму для сравнения моделей, то лучшей также
будет та из них, Gain-кривая которой проходит выше. На диаграмме на рис. 12.12
предпочтение следует отдать модели 1, поскольку, например, для выборки разме-
ром 20 % она обеспечивает чувствительность около 0,55, а модель 2 — только 0,3.
Рис. 12.12. Gain-диаграммы
Если Gain-кривые двух моделей пересекаются, это также означает, что для раз-
личных диапазонов эффективность моделей разная. Выбирать следует ту модель,
кривая которой проходит выше в более актуальном диапазоне.
Вообще, использовать Gain-кривые для сравнения моделей удобнее, чем обыч-
ные Lift-кривые, поскольку последние в большей степени применяются для опти-
мизации издержек ошибок классификации, а первые непосредственно указывают
на точность модели.
Profit-кривые
Lift-диаграммы — очень удобное средство сравнения моделей и их оптимизации
с точки зрения издержек классификации. Однако они не дают ответа на важный
вопрос: каковы будут издержки или выгоды от использования модели. Ясно, что
584 Часть I. Теория бизнес-анализа
для этого необходимы числовые показатели, связанные с решаемой бизнес-задачей.
Например, в задаче кредитного скоринга нужно знать, в какие суммы обойдутся
необоснованный отказ добросовестному заемщику и ошибочно выданный кредит
неплатежеспособному лицу. В задаче директ-маркетинга требуется информация
о том, во сколько обходится одно почтовое отправление с рекламой и какая при-
быль ожидается от каждого потенциального клиента.
Чтобы точно узнать, прибыль или убытки принесет использование той или
иной модели, недостаточно просто сравнить их эффективность — необходимо ис-
пользовать числовые значения издержек и прибыли. Для этих целей используется
еще один графический метод, называемый Profit-кривой (Profit curve), или кривой
дохода. Проиллюстрируем его на примере массовой рассылки.
Введем следующие обозначения:
□ Р — доход;
□ R — выручка (от англ, revenue — «прибыль», «выручка»);
□ С — издержки (от англ, cost — «издержки», «затраты»);
□ NR — общее число полученных откликов;
□ RR — выручка с одного отклика (revenue per response);
□ CR — издержки одного отклика (cost per response);
□ NM — число отправлений (number mailed);
□ CM — издержки на одно отправление (cost per mailing);
□ PR — прибыль с каждого отклика, равная разнице между затратами на продажу
и прибылью от продажи, то есть PR = RR — CR.
Тогда доход будет определен следующим образом:
р = R-C = NR-RR-(NR-CR + NM-СМ).
Пусть рекламная рассылка производилась 10 тысячам потенциальных клиентов
(то есть NM = 10 000), из которых откликнулись NR = 250. Предположим, что вы-
ручка, полученная от каждого откликнувшегося.клиента, составляет RR =100 ед.,
издержки на обслуживание клиента — CR = 60 ед., а затраты на каждое отправле-
ние — СМ = 2 ед.
Общая выручка R определяется как произведение числа истинноположитель-
ных исходов (TP = NR) и выручки, полученной от каждого откликнувшегося
клиента RR. Тогда полные издержки С будут равняться произведению издержек
на одно отправление и числа положительных исходов, предсказанных моделью,
то есть сумме истинноположительных и ложноположительных исходов. Следо-
вательно:
Р = Я-С = (ТРЮ0)-(7Р-60 + (7Р + РР)-2) =
= (7Р100)-ТР-60 + 2ТР + 2-РР = 42ТР + 2РР.
Введем в рассмотрение показатель отклика (response rate) как процент
истинноположительных исходов от общего числа положительных исходов —
Глава 12. Сравнение моделей 585
(ТР/(ТР + FP)) 100 %, иными словами, долю откликов от общего числа рассылок
для каждой выборки. Пусть первая выборка составляет 10 %, или 1000 рассылок,
а показатель отклика — 5 %. Это значит, что из 1000 респондентов откликну-
лись 50 (ТР), а 950 рассылок (FP) остались без ответа. Тогда для первой выборки
прибыль составит 42 • 50 - 2 • 950 = 2100 - 1900 = 200. Таким образом, мы по-
лучили отрицательный доход. Проведем аналогичные расчеты для 10 выборок
с возрастанием каждой последующей на 10 % (табл. 12.2).
Таблица 12.2. Расчет прибыли
Объем выборки, % Объем выборки, количество Показатель отклика, % Прибыль, ед.
0 0 0 0
10 1000 5 42 • 50 - 2 • 950 = 200
20 2000 4,5 42-90-2-1100 = = 1580
30 3000 4 42 -120 - 2 - 2880 = -720
40 4000 3,5 42 • 140 - 2 • 3860 = -1840
50 5000 3 42 -150 - 2 - 4850 = -3400
60 6000 2,5 42-150-2 5850 = -5400
70 7000 2 42 • 140 - 2 6860 = -7840
80 8000 1,5 42 • 120 - 2 • 7880 = -10 720
90 9000 1 42•90 - 2 • 8910 = = -14 040
100 10 000 0,5 42 50 - 2 • 9500 = = -16 900
Наибольшая прибыль получается при объеме выборки 20 %. Однако поскольку
с увеличением числа рассылок издержки растут быстрее, чем выручка, при даль-
нейшем увеличении размера выборки прибыль падает и даже становится отрица-
тельной. На основе данной таблицы легко построить график зависимости прибыли
от объема выборки (рис. 12.13).
Рис. 12.13. Зависимость маржи от объема выборки
586 Часть I. Теория бизнес-анализа
12.5. ROC-анализ
Помимо Lift-кривых, широко используемых в маркетинге, кредитном скоринге
и других областях, где применяется бинарная вероятностная классификация
существует еще одна графическая методика оценивания эффективности моделей
которая называется RO С-анализом.
Как отмечалось ранее, в задачах бинарной классификации, когда модель пред-
сказывает вероятность того, что наблюдение относится к одному из двух классов
очень важен выбор точки отсечения, то есть порога вероятности, разделяющего два
класса. Точка отсечения показывает, после какого значения вероятности на выходе
модели один класс сменяется другим. Например, в задаче кредитного скоринга мы
можем установить точку отсечения для положительного исхода 70 %. Если модель
для некоторого потенциального заемщика выдаст значение вероятности ниже 0,7,
то он будет признан некредитоспособным и ему откажут в выдаче займа, а если
выше 0,7, то заемщик признается кредитоспособным и будет принято положитель-
ное решение о выдаче ему кредита.
Выбирая точку отсечения, мы управляем вероятностью правильного распо-
знавания положительных и отрицательных примеров. При уменьшении порога
отсечения увеличивается вероятность ошибочного распознавания положительных
наблюдений (ложноположительных исходов), а при увеличении возрастает веро-
ятность неправильного распознавания отрицательных наблюдений (ложноотрица-
тельных исходов). Цель заключается в том, чтобы подобрать такое значение точки
отсечения, которое дает наибольшую точность распознавания заданного класса,
а какого именно — определяется постановкой задачи.
Именно для этого используется ROC-анализ. Методика была перенесена в Data
Mining из области обработки сигналов в радиолокации, а сама аббревиатура ROC
расшифровывается как receiver operating characteristic, что переводится с англий-
ского как «рабочая характеристика приемного устройства». В радиотехническом
приложении задача заключается в обнаружении с помощью приемного устройства
(радиолокатора) некоторой цели (морской, воздушной и т. д.). При этом положи-
тельный исход — цель обнаружена, отрицательный исход — цель не обнаружена.
В настоящее время ROC-анализ широко применяется в экономике и бизнесе,
медицине и биологии, научных исследованиях.
Перед рассмотрением методики введем понятия ошибок I и II рода. Если би-
нарная классификационная модель строится на основе обучающей выборки, то
все входящие в нее примеры соответствуют либо положительному, либо отрица-
тельному исходам. Тогда в процессе работы модели могут возникнуть следующие
ошибки.
□ Пример соответствует положительному исходу, но был распознан как отри-
цательный: заемщик кредитоспособен, но модель распознает его как некреди-
тоспособного; пациент болен, но модель распознает его как здорового; радио-
локационная система не смогла обнаружить цель по ее сигналу, принятому
локатором (пропуск цели), и т. д. Иными словами, интересующее событие
ошибочно не обнаружено. Такие ошибки называются ошибками Ipoda.
Глава 12. Сравнение моделей 587
□ Пример соответствует отрицательному исходу, но был распознан как поло-
жительный: заемщик некредитоспособен, но модель определяет его как кре-
дитоспособного; пациент здоров, но модель определяет его как больного; ра-
диолокационная цель отсутствует, но система определяет ее наличие (ложная
тревога) и т. д. Иными словами, интересующее событие не произошло, но было
обнаружено. Такие ошибки называются ошибками Проба.
Ранее мы сказали, что для оценки качества любой бинарной классификацион-
ной модели можно использовать два показателя — чувствительность (Se) и спе-
цифичность (Sp).
Обратим внимание: если отсутствуют ложноотрицательные исходы, чувстви-
тельность равна 1; если отсутствуют ложноположительные исходы, специфичность
равна 1. Модель, которая способна идеально точно классифицировать как поло-
жительные, так и отрицательные примеры, будет иметь 100-процентную чувстви-
тельность и специфичность.
Чтобы минимизировать ошибки I рода, нужно использовать модель с высокой
чувствительностью. Чтобы минимизировать ошибки II рода, нужно использовать
модель с высокой специфичностью.
Идеальных моделей не бывает, и на практике приходится искать компромисс
между чувствительностью и специфичностью. Он достигается за счет выбора
порогового значения вероятности, или точки отсечения. Как следует из фор-
мулы расчета чувствительности, для ее повышения необходимо уменьшить
количество ложноотрицательных исходов, а это достигается путем снижения
порога. Для увеличения специфичности нужно снизить число ложноположи-
тельных исходов (см. формулу расчета Sp). С этой целью увеличивается порог
отсечения — так модели будет сложнее перепутать отрицательный исход с по-
ложительным.
В общем случае задача ROC-анализа заключается в том, чтобы выбрать
такую точку отсечения, которая обеспечит максимум чувствительности и спе-
цифичности. Но всегда ли нужна модель, которая одинаково хорошо распознает
как положительные, так и отрицательные примеры? Если издержки обоих ти-
пов ошибок примерно одинаковы, то такая модель нас устроит. Но на практике
подобных задач мало. Чаще встречаются ситуации, в которых издержки одного
типа ошибок больше, чем издержки другого (см. раздел 12.3). Так, издержки
ложной тревоги намного меньше, чем пропуска цели. Поэтому понятие «опти-
мальный порог» относительно: все зависит от задачи.
ПРИМЕР-----------------------------------------------------------------
Одним из первых практических приложений ROC-анализа стал скрининг, когда на основе не-
которого ограниченного набора медицинских показателей (возраст, состав крови, уровень
холестерина, температура, кровяное давление и т. д.) определяется наличие или отсутствие
заболевания у пациента. Задача сводится к бинарной классификации, причем положитель-
ным исходом чаще всего выбирается наличие заболевания, а отрицательным — его отсут-
ствие. Классификационная модель выдает вероятность отнесения каждого наблюдения
588 Часть I. Теория бизнес-анализа
к одному из классов. При этом выход 1 указывает на стопроцентную вероятность наличия
заболевания, а 0 — на достоверное его отсутствие.
В простейшем случае, если издержки ошибок диагностики безразличны, следует выбрать
такую точку отсечения, чтобы максимизировать и чувствительность, и специфичность
Но, к сожалению, задачи медицинской диагностики чувствительны к издержкам ошибок
классификации как никакие другие. Сделав порог слишком низким, мы рискуем получить
так называемую передиагностику, когда модель допускает слишком много ложноположи-
тельных ошибок. А ведь перестраховка может оказаться опасной: лечение пациента от
несуществующего заболевания бывает связано с необоснованным хирургическим вме-
шательством, применением болезненных методов и лекарств, вызывающих побочные эф-
фекты, не говоря уже о финансовых издержках. Однако, сделав порог отсечения слишком
высоким, мы рискуем пропустить заболевание.
Тем не менее в скрининге де-факто используется правило, смещающее диагностическое
решение в сторону снижения вероятности пропуска заболевания, то есть передиагностики.
В частности, во многих диагностических тестах требуется, чтобы чувствительность была
не менее 90 %: вовремя выявить болезнь важнее любых затрат.
В основе ROC-анализа лежат так называемые ROC-кривые. Чтобы построить
ROC-кривую, нужно изменять порог отсечения в интервале от 0 до 1 с заданным
шагом Ах, например 0,01. В результате при каждом значении порога будет меняться
количество правильно и неправильно распознанных примеров, а соответственно,
чувствительность и специфичность модели. Если рассчитать чувствительность
и специфичность для каждого значения порога, а затем построить график, по вер-
тикальной оси которого откладывается чувствительность, а по горизонтальной —
величина S = 100 % — Sp, это и будет ROC-кривая.
Типичный вид ROC-кривой представлен на рис. 12.14. Увеличение значения по
горизонтальной оси соответствует уменьшению специфичности модели: точках = 0
соответствует максимальной специфичности (Sp = 100 %), а точках = 100 — мини-
мальной (Sp = 0).
Формы ROC- и Lift-кривых во многом схожи, как и методики их анализа.
И это не случайно, поскольку принцип их построения примерно один и тот же.
Кривые обоих видов строятся на основе отсечения: в случае Lift-кривых отсече-
нию подвергается часть выборки, оптимальная с позиции издержек ошибочной
классификации, а в случае ROC-кривой отсечению подвергается вероятность
принадлежности объекта к классу для обеспечения требуемого соотношения
Se и Sp.
Каждая точка ROC-кривой соответствует определенному значению поро-
га отсечения. При этом оптимальным будет значение, соответствующее точке
ROC-кривой с координатами, максимально близкими к (0; 100), для которой
и чувствительность, и специфичность равны 100 %, то есть как положительные,
так и отрицательные примеры распознаны правильно. Таким образом, если бы
удалось построить модель, ROC-кривая которой проходила бы через точку с ко-
ординатами (0; 100), мы получили бы идеальный классификатор (пунктирная
линия на рис. 12.14).
На практике модели допускают ошибки. Поэтому о качестве бинарной класси-
фикационной модели можно судить по степени кривизны ROC-кривой, то есть по
Глава 12. Сравнение моделей 589
Рис. 12.14. ROC-кривые
тому, насколько близко к точке, соответствующей идеальному классификатору,
она проходит. И здесь, как и в случае Lift-кривой, диагональная линия соответ-
ствует «бесполезному» классификатору.
Площадь под кривой (AUC) говорит о прогностической силе модели, причем
AUC — 1 соответствует идеальному классификатору. Что же касается реальных
случаев, то, если площадь под ROC-кривой больше 0,7-0,8, соответствующая
модель демонстрирует достаточно высокую точность.
С помощью выбора порога отсечения добиваются оптимального соотношения
между чувствительностью и специфичностью модели. Для этого применяются раз-
личные стратегии. Например, часто порог выбирают таким образом, чтобы сумма
чувствительности и специфичности была максимальна (то есть чтобы обеспечи-
валось максимальное количество как положительных, так и отрицательных пра-
вильно распознанных примеров). Иногда порог выбирают так, чтобы соблюдался
баланс между чувствительностью и специфичностью, то есть Se = Sp.
Чувствительность и специфичность представляют собой доли истинноположи-
тельных и истинноотрицательных исходов классификации. Обычно такие исходы
распределяются неравномерно.
В матрице классификации на один положительный исход может приходиться
несколько отрицательных, и наоборот. Поэтому в реальности линия ROC-кривой
будет не гладкой, как показано на рис. 12.14, а изрезанной (рис. 12.15).
590 Часть I. Теория бизнес-анализа
100 - Sp, %
Рис. 12.15. Ломаный характер ROC-кривой
На рисунке видно, что из начала координат кривая возрастает на два положи-
тельных наблюдения и одно отрицательное, затем на пять положительных и одно
отрицательное и т. д.
Изрезанность ROC-кривой существенно зависит от особенностей выборки данных.
Эту зависимость можно уменьшить путем перекрестной проверки за счет усреднения
по блокам. Хотя, как правило, идеальной степени сглаживания достичь не удается.
Диаграмма «точность — полнота»
Понятия чувствительности и специфичности, применяемые в ROC-анализе, приш-
ли из медицины и лабораторной диагностики заболеваний. В Data Mining вместо
них часто используют понятия точности и полноты.
Полнота (recall) классификатора есть не что иное, как ранее рассмотренная
чувствительность: R — ТР/(ТР + FN\
Точность классификатора определяется как:
Р- ТР
TP + FP
Основное применение этих показателей — оценка качества работы информа-
ционно-поисковых систем. Рассмотрим, например, процесс поиска информации
Глава 12. Сравнение моделей 591
в Интернете. Реагируя на запрос, поисковая система дает список найденных до-
кументов, предположительно важных с точки зрения запроса. Сравним систему,
находящую 100 документов, 40 из которых являются важными, и систему, нахо-
дящую 400 документов, 80 из которых являются важными. Какая из них лучше?
Ответ очевиден: это зависит от относительных издержек ложноположительных
исходов (числа документов, которые найдены, но не являются важными) и лож-
ноотрицательных исходов (числа документов, которые являются важными, но не
обнаружены). Тогда информацию, извлеченную в процессе поиска, определяют два
параметра: полнота и точность.
В контексте решаемой задачи полнота определяется как отношение числа важных
найденных документов к общему числу важных документов Ng: R = NBHINB.
Точность есть отношение числа важных найденных документов NgH к общему
числу найденных документов NH: Р = NgH / NH.
Например, если список найденных документов проранжировать по убыванию
вероятности того, что документ является важным, то полнота для первых 10 запи-
сей, 8 из которых истинноположительные, а две — ложноположительные, будет
(8 / 40) • 100 % = 20 %, в то время как точность — (8 / 10) • 100 = 80 %.
На основе этих двух показателей строят диаграммы «точность — полнота»
(Precision-Recall curve). Как и в случаях с Lift- и ROC-кривыми, это делается для
различного числа найденных документов.
Продолжим пример. Пусть в результате выполнения запроса и классификации
релевантности найденных документов было получено множество, представленное
в табл. 12.1. Общее число важных документов равно 19, но из них правильно клас-
сифицировано только 13. Тогда по формулам рассчитаем данные табл. 12.3 и на ее
основе построим две кривые (рис. 12.16).
Таблица 12.3. Набор данных, отсортированный по убыванию вероятности
положительной классификации текстовых документов
№ п/п Предсказанная вероятность Фактический класс Точность Полнота
1 0,95 Да 1,00 0,05
2 0,93 Да 1,00 0,11
3 0,93 Нет 0,66 0,11
4 0,88 Да 0,75 0,16
5 0,86 Да 0,80 0,21
6 0,85 Да 0,83 0,26
7 0,82 Да 0,86 0,32
8 0,80 Да 0,87 0,37
9 0,80 Нет 0,77 0,37
10 0,79 Да 0,80 0,42
И 0,77 Нет 0,73 0,42
12 0,76 Да 0,75 0,47
Продолжение £'
592 Часть I. Теория бизнес-анализа
Таблица 12.3 (продолжение)
№ п/п Предсказанная вероятность Фактический класс Точность Полнота
13 0,73 Да 0,77 0,52 '
14 0,65 Нет 0,71 0,52
15 0,63 Да 0,73 0,58
16 0,58 Нет 0,68 0,58 ~~
17 0,56 Да 0,71 0,63
18 0,49 Нет 0,66 0,63
19 0,48 Да 0,68 0,68
Рис. 12.16. Диаграмма «точность — полнота»
Поведение кривых полноты и точности на рис. 12.16 хорошо объяснимо. По ме-
ре того как мы смещаем точку отсечения вправо, включая в рассмотрение все
больше наблюдений, полнота как относительная доля обнаруженных релевантных
документов увеличивается, причем тем быстрее, чем меньше ошибок. Но посколь-
ку наблюдения упорядочены по убыванию вероятности класса, то увеличивается
и число ложноположительных наблюдений и, соответственно, падает точность.
Точность падает тем быстрее, чем больше число ошибок классификации и чем хуже
работает модель.
Итак, при прочих равных условиях лучшей будет модель, для которой кривые
точности и полноты идут выше. В идеальном случае, когда все наблюдения явля-
ются истинноположительными, график точности будет представлять собой прямую
линию на уровне 1, а график полноты — диагональную линию, идущую из начала
координат в правую верхнюю точку диаграммы.
Глава 12. Сравнение моделей 593
12.6. Обучение в условиях
несбалансированности классов
Если при решении задачи кредитного скоринга выбрать, например, дерево ре-
шений, то обнаружится, что итоговая модель содержит очень мало правил, а то
и совсем «пустое» дерево (особенно если применялась процедура упрощения
дерева). Причина в том, что в обучающей выборке присутствует несбалансирован-
ность классов, то есть классы представлены неравномерно (imbalanced dataset).
Например, в кредитных историях доля «плохих» заемщиков редко превышает
15 %, а в большинстве случаев и того меньше — на уровне 3-6 %. В директ-марке-
тинге при массовой рассылке всем респондентам процент отклика также невысок
и сопоставим с приведенными цифрами для скоринга. В медицинском скрининге
больных людей значительно меньше, чем здоровых, если только мы не проводим
обследование в какой-то специально отобранной группе людей. И таких примеров
много, то есть на практике оказывается, что несбалансированность классов — нор-
мальное явление.
Однако это оборачивается трудностями для аналитика. Классификаторы,
построенные на основе выборки, в которой репрезентативность классов несба-
лансирована, в процессе практического использования склонны с большей ве-
роятностью относить новые наблюдения к классам, представленным большим
числом обучающих примеров. Для многих приложений, особенно применяемых
при медицинской диагностике, обнаружении мошенничеств и др., это совершенно
неприемлемо, поскольку наименее представленный класс является самым интерес-
ным. При этом издержки ошибок неправильной классификации для него больше,
чем для доминирующих классов. Например, в задаче обнаружения мошенничеств
«честные» транзакции не представляют никакого интереса, хотя их намного боль-
ше, чем «мошеннических». Действительно, если рассмотреть тысячу транзакций,
то «мошенническими» могут оказаться только несколько из них. Построенный на
таких данных классификатор будет «оптимистическим», то есть станет с большей
вероятностью относить любые представленные ему транзакции к «честным».
Основная причина здесь в том, что в процессе обучения модели не было доступно
достаточно информации об обоих классах.
ЗАМЕЧАНИЕ -------------------------------------------------------
Для краткости класс (ограничимся случаем с двумя классами), представленный в обуча-
ющих данных меньшим числом примеров, будем называть миноритарным (от англ, minor-
ity — «меньшинство»), а представленный большим числом примеров — мажоритарным (от
англ, majority — «большинство»).
Кроме несбалансированности классов, большой проблемой при построении
и практическом использовании классификационных моделей являются издержки
ошибок классификации, точнее, их неодинаковость для различных классов. Обычно
издержки ошибок классификации для миноритарного класса существенно выше,
чем для мажоритарного. Действительно, ошибочный пропуск факта мошенничества
594 Часть I. Теория бизнес-анализа
приведет к большим издержкам, чем ложный сигнал тревоги для «честной» транз
акции. В этих случаях важно минимизировать общую ошибку классификатора
Существуют разнообразные подходы, позволяющие компенсировать влияние
несбалансированности классов и минимизировать издержки ошибок классифика-
ции в процессе использования алгоритмов машинного обучения. Мы рассмотрим
два основных подхода — специальные стратегии сэмплинга и модификацию алго-
ритма обучения так, чтобы сделать его чувствительным к издержкам (cost-sensitive
algorithm).
Выше мы использовали понятие матрицы издержек, в которой показываются
издержки, связанные со всеми четырьмя возможными исходами СГр, С№, С^ и Сп
(см. раздел 12.3). Когда издержки в случае правильной классификации отсутству-
ют, величины СТр и Cfn полагают равными 0. Также в силу того, что миноритарный
класс представляет больший интерес, CFP < Ст.
Если издержки ошибочной классификации известны, то лучшей оценкой эф-
фективности модели служат полные издержки:
G=(FN-CW) + (FP-CW.).
Издержки обычно выражаются в единицах, соответствующих области, в которой
решается задача. Это могут быть денежные суммы, затраты времени, сырья и мате-
риалов и т. д. Отрицательные издержки интерпретируются как прибыль, выгода.
Говоря о двух новых подходах, напомним, что ранее мы уже упоминали метод оце-
нивания оптимального порога при помощи правила Байеса. К сожалению, его при-
менение ограничено только алгоритмами классификации, которые выдают степень
уверенности в своем решении, например логистическая регрессия и простой байе-
совский классификатор. Поэтому альтернативные методы также востребованы.
Изменение репрезентативности классов
Данный подход использует сэмплинг для изменения распределения классов и на-
зывается восстановлением равновесия (rebalancing) с целью получения более сба-
лансированного обучающего множества. Здесь существует два специальных метода
сэмплинга: выборка с дублированием миноритарного класса (oversampling) и выбор-
ка с удалением примеров мажоритарного класса (undersampling).
Предполагается, что смещение, внесенное в обучающие данные, позволит
алгоритму обучения получить модель, которая минимизирует издержки при
классификации новых наблюдений. Для простоты рассмотрим задачу бинарной
классификации со следующей матрицей издержек (в качестве положительного
исхода предсказания выбрано значение 1) (рис. 12.17).
Предположим, что правильная классификация не имеет издержек, то есть Соо
и Си равны 0. Издержки ложноотрицательных и ложноположительных классифи-
каций запишем как С10 и С01 соответственно, и пусть С10 » COt. Цель восстановле-
ния равновесия заключается в том, чтобы соотношение примеров, принадлежащих
классам 0 и 1, в обучающем множестве было как-то связано с отношением Сю / Coi-
Глава 12. Сравнение моделей 595
Рис. 12.17. Матрица издержек 2x2
Этого можно достичь путем дублирования примеров миноритарного класса либо
удалением «лишних» примеров, относящихся к мажоритарному классу. В данном
случае это означает, что нужно просто случайным образом продублировать не-
которое количество положительных примеров или удалить некоторое количество
отрицательных.
Возникает вопрос: на сколько конкретно нужно увеличивать число примеров
миноритарного (редкого) класса или сколько удалять из мажоритарного класса?
Ответ на этот вопрос дает следующее утверждение, связывающее правило Байеса
для определения оптимального порога и число примеров обоих классов1.
При использовании в классификаторе порога отсечения 0,5 и при условии,
что Соо = Си = 0, число примеров миноритарного класса нужно увеличить
в Сю / С01 раз.
Данное утверждение позволяет понять, как нужно изменить соотношение при-
меров в обучающем множестве, чтобы это было равносильно изменению порога
отсечения для принятия решения о принадлежности к классу. Можно пойти другим
путем — уменьшить число записей мажоритарного класса в Cl0 / COi раз.
ПРИМЕР ---------------------------------------------------------------
Пусть имеется обучающее множество с кредитными историями заемщиков, в котором
содержится 900 записей о хороших заемщиках и 100 — о плохих (редкий класс). Пусть
известно, что отношение издержек равно 5 :1. Тогда по правилу Байеса оптимальным
порогом в логистической регрессии будет величина р' > 1 / (1 + 5) = 0,167 при усло-
вии, что мы не изменяем баланс классов и за положительный исход принимаем плохого
клиента. Если мы оставляем порог, равный 0,5, то согласно процедуре oversampling необ-
ходимо продублировать еще 400 записей, относящихся к плохим клиентам (общий объем
выборки составит 1000 + 400 = 1400 примеров), а согласно процедуре undersampling —
уменьшить число хороших до 900 / 5 = 180 клиентов (общий объем выборки составит
180 + 100 = 280 примеров).
Альтернативным подходом, используемым для манипуляции обучающими
данными, является изменение весов примеров. Значение веса отражает влияние
Теоретическое обоснование этого утверждения изложено в работе: Elchan Ch. The Foun-
dations of Cost-Sensitive Learning// In Proc, of the 17th International Joint Conference on
Artificial Intelligence, 2001. — P. 973-978.
596 Часть I. Теория бизнес-анализа
ошибки классификации. Наблюдению назначается тем больший вес, чем выше
связанные с ним ожидаемые издержки классификации.
Метод восстановления равновесия классов применяется практически для всех
типов классификаторов, обучаемых на основе ошибок, а взвешивание примеров —
только для алгоритмов, в которых предусмотрена обработка весов примеров.
Главное преимущество сэмплинга и взвешивания заключается в том, что они не
требуют модификации алгоритма обучения, достаточно просты и могут применяться
к любым типам классификаторов. Их использование позволяет строить модели, опти-
мальные с точки зрения издержек классификации. Но есть и недостатки. Так, выборка
с удалением примеров мажоритарного класса может вызвать потерю потенциально по-
лезной информации, которая содержится в исключаемых примерах. А «клонирование»
большого числа одинаковых примеров способно привести к переобучению модели.
Несмотря на это, многие исследователи отдают предпочтение процедурам вос-
становления равновесия, а не модифицированным алгоритмам обучения. Для этого
есть несколько причин. Во-первых, не для всех алгоритмов машинного обучения
разработаны модифицированные варианты, учитывающие издержки ошибок
классификации. Во-вторых, число примеров с доминирующим классом часто даже
избыточно, и тогда выборка с удалением примеров мажоритарного класса кажется
наиболее привлекательной стратегией.
Кроме того, издержки ошибок классификации часто неизвестны, что затрудняет
использование методов обучения, чувствительных к издержкам. Если информация
об издержках отсутствует, то для оценки эффективности бинарного классификато-
ра можно использовать другие методы, например графики «чувствительность —
специфичность», больше известные как ROC-кривые.
Модификация алгоритмов обучения
Алгоритм построения классификатора можно модифицировать таким образом,
чтобы он учитывал издержки ошибок классификации. В настоящее время такие
модификации существуют для многих алгоритмов машинного обучения. Например,
при построении дерева решений одним из наиболее популярных методов является
использование информации об издержках неправильной классификации при вы-
боре атрибута ветвления в каждом узле строящегося дерева.
Кратко рассмотрим несколько вариантов модификации алгоритмов ID3 и С4.5
для деревьев решений (EG2, CS-ID3, IDX) и для многослойного персептрона
(CSBP), учитывающих издержки классификации.
Алгоритм EG2 использует для выбора атрибута комбинированный критерий,
учитывающий как приращение информации, так и ошибки издержек классифика-
ции. Для этого вводится функция, несущая информацию об издержках классифи-
кации. Для k-ro атрибута эта функция определяется как:
ICFh=(2^ -1)/(Су+1)“,
где 0 < а < 1;
А/* — прирост информации, связанный с разбиением по k-му атрибуту;
Глава 12. Сравнение моделей 597
Су — издержки, связанные с классами, примеры которых участвовали в разбие-
нии.
Напомним, что уже известный нам алгоритм С4.5 максимизирует отношение
приращения информации АД. Таким образом, EG2 можно рассматривать как вари-
ант алгоритма С4.5, измененный для работы с несбалансированными классами.
Параметр а позволяет варьировать степенью «стремления» алгоритма к вы-
бору атрибутов, с которыми связаны меньшие издержки. Если а = 0, a ICF = 1,
то издержки не учитываются. Если а = 1, то имеет место максимальное влияние
издержек на процесс построения дерева. Регулируя значение данного параметра,
аналитик добивается оптимальной чувствительности алгоритма к издержкам
классификации.
Алгоритм CS-ID3. Как следует из названия, он представляет собой модифика-
цию алгоритма ID3. В нем в процессе выбора атрибута разбиения минимизируется
эвристическая функция:
ICFk=Ml/Ctj.
Алгоритм IDX также является разновидностью ID3 и использует минимизацию
функции:
= А 7* / Cij.
Алгоритм CSBP. Исследования показали, что несбалансированность классов
в обучающем множестве негативно влияет и на качество обучения нейронных
сетей. Причина этого достаточно очевидна: неравномерно представленные классы
вносят различный «вклад» в выходную ошибку сети, на основе которой рассчиты-
вается корректировка весов нейронов на каждом шаге обучения.
Рассмотрим случай несбалансированности классов для многослойного персеп-
трона. Пусть в обучающей выборке, состоящей из N примеров, представлены
т
т классов, то есть N = где N — число примеров, относящихся к г-му классу.
/=1
Предположим, что доля выходной ошибки сети, определяемая каждым классом,
может быть выражена формулой:
1 .V, К
£Ч«)=^ЕЕ(»"-«•")
П=1 «•=!
где W — матрица состояния весов нейронной сети;
К — число выходных нейронов сети;
у'ь — фактическое значение на выходе k-vo нейрона для и-го примера.
Тогда для случая бинарной классификации (т = 2) полную ошибку сети пред-
ставим в виде:
Е( w) = ^Ё1 (W) = Е, (W) + Е2 (W).
Пусть «N2, тогда Et «Е2. Следовательно, можно утверждать: VEi «\7Е2
и VE « VE2. То есть ошибка будет минимизироваться с учетом информации об
одном классе, а информация о другом будет практически игнорироваться.
598 Часть I. Теория бизнес-анализа
Чтобы исправить ситуацию, в алгоритм обучения методом обратного распро-
странения ошибки вводятся величины а(1) и а(2);
E(W) = l(a(l)£1(W) + a(2)£2(W)).
Для случая двух классов а(1) и а(2) должны быть выбраны таким образом чтобы
a(l)V£\ (W)» a(2) V£2 (W). На практике используются различные виды функций
например:
□ a(l) = y2/N1,a(2) = l;
a a(l) = N/yi,a(2) = y/y2;
a a(l) = V£2(W)/V£1(W),a(2) = l.
Следует отметить, что, хотя проблемы несбалансированности классов в обу-
чающем множестве и неравенство издержек ошибочной классификации часто
связаны между собой, их решение может представлять собой различные, вполне
самостоятельные задачи. Выделим три случая.
1. Классы представлены в обучающем множестве неравномерно, но издержки
для различных типов ошибок классификации одинаковы или различаются
несущественно. Здесь задача сводится только к балансировке множества таким
образом, чтобы все классы в нем были представлены примерно одинаковым
числом примеров.
2. Множество несбалансированно и издержки ошибок классификации неодина-
ковы. Тогда изменение равновесия должно производиться так, чтобы миними-
зировать издержки ошибок классификации. При этом увеличивают число при-
меров класса, ошибка определения которого грозит наибольшими издержками,
чтобы классификатор «научился» лучше распознавать именно данный класс.
Альтернативным способом является введение в алгоритм обучения параметров,
учитывающих издержки.
3. Множество сбалансировано, но издержки ошибок классификации неодинако-
вы. В этом случае также требуется изменить равновесие в множестве с учетом
издержек либо учитывать их в алгоритме обучения.
Таким образом, изменение репрезентативности классов и классификация с уче-
том издержек являются независимыми приемами, но иногда их совместное приме-
нение позволяет добиться лучших результатов. Использование этих приемов при
решении бизнес-задач показывается во второй части книги.
II
Часть
Бизнес-анализ
в Deductor
Аналитическая
платформа
Deductor
Развитие и назначение Deductor
Deductor — это аналитическая платформа, основа для создания законченных
прикладных решений в области анализа данных. Реализованные в Deductor тех-
нологии позволяют на базе единой архитектуры пройти все этапы построения
аналитической системы: от консолидации данных до построения моделей и ви-
зуализации полученных результатов.
До появления аналитических платформ анализ данных осуществлялся в ос-
новном в статистических пакетах. Их применение требовало от пользователя вы-
сокой квалификации. Большинство алгоритмов, реализованных в статистических
пакетах, не позволяло эффективно обрабатывать большие объемы информации.
Для автоматизации рутинных операций приходилось использовать встроенные
языки программирования.
В конце 80-х гг. произошел стремительный рост объемов информации, накап-
ливаемой на машинных носителях, и увеличились потребности бизнеса в приме-
нении анализа данных. Ответом стало появление новых парадигм в анализе, таких
как хранилища данных, машинное обучение, Data Mining, Knowlegde Discovery
in Databases. Это позволило популяризировать анализ данных, поставить его на
промышленную основу и решить огромное число бизнес-задач с большим эконо-
мическим эффектом.
Венцом развития анализа данных стали специализированные программные
системы — аналитические платформы, которые полностью автоматизировали все
этапы анализа от консолидации данных до эксплуатации моделей и интерпретации
результатов.
Глава 13. Аналитическая платформа Deductor 601
Первая версия Deductor увидела свет в 2000 г., и с тех пор идет непрерывное
развитие платформы. В 2007 г. выпущена пятая по счету версия системы (5.0 и 5.1),
в 2009 г. — версия 5.2. Разработчик — компания BaseGroup Labs (Россия).
Сегодня Deductor — яркий представитель как настольной, так и корпоративной
системы анализа данных последнего поколения.
Общие сведения о Deductor
Аналитическая платформа Deductor состоит из пяти частей:
□ Warehouse — хранилище данных, консолидирующее информацию из разных
источников;
□ Studio — приложение, позволяющее пройти все этапы построения прикладного
решения, рабочее место аналитика;
□ Viewer — рабочее место конечного пользователя, одно из средств тиражирова-
ния знаний (то есть построенные аналитиком модели применяют пользователи,
не владеющие технологиями анализа данных);
□ Server — служба, обеспечивающая удаленную аналитическую обработку дан-
ных;
□ Client — клиент доступа к Deductor Server. Обеспечивает доступ к серверу
и управление его работой из сторонних приложений.
Существует три варианта поставки платформы Deductor:
□ Enterprise;
□ Professional;
□ Academic.
В зависимости от типа поставки набор доступных компонентов может разли-
чаться.
Версия Enterprise предназначена для корпоративного использования. В ней
присутствуют:
□ серверные компоненты Deductor Server и Deductor Client;
□ интерфейс доступа к Deductor через механизм OLE Automation;
□ традиционное хранилище данных Deductor Warehouse на основе трех СУБД:
Firebird, SQL, Oracle;
□ виртуальное хранилище данных Deductor Virtual Warehouse.
Версия Professional предназначена для небольших компаний и однопользова-
тельской работы. В ней отсутствуют серверные компоненты, поддержка OLE, вир-
туальное хранилище, а традиционное хранилище данных можно создавать только
на базе СУБД FireBird. Автоматизация выполнения сценариев обработки данных
осуществляется только через пакетный режим.
Версии Professional и Enterprise требуют установки драйверов Guardant для
работы с лицензионным ключом.
602 Часть II. Бизнес-анализ в Deductor
Версия Academic (бесплатно распространяемая) предназначена для образо-
вательных и обучающих целей. С точки зрения функций она аналогична версии
Professional за исключением того, что:
□ отсутствует пакетный запуск сценариев, то есть работа в программе может ве-
стись только в интерактивном режиме',
□ отсутствует импорт из промышленных источников данных: 1 С, СУБД, файлы
Excel (имеется возможность импорта только из текстовых файлов и Deductor
Warehouse на базе Firebird);
□ отсутствуют некоторые другие возможности.
Категории пользователей Deductor
В процессе развертывания и использования аналитической платформы с ней взаи-
модействуют различные типы пользователей. Можно выделить четыре основные
категории:
□ аналитик;
□ пользователь;
□ администратор;
□ программист.
Функции аналитика'.
□ создание в Deductor сценария — последовательности шагов, которую необхо-
димо осуществить для получения нужного результата;
□ построение, оценка и интерпретация моделей;
□ настройка панели отчетов Deductor Viewer для пользователей;
□ настройка сценария на пакетную обработку новых данных.
Функции пользователя: просмотр отчетов в Deductor Viewer.
Функции администратора:
□ установка компонентов Deductor на рабочих местах и сервера ключей Guardant
при необходимости;
□ развертывание традиционного хранилища данных на сервере;
□ контроль процедур регулярного пополнения хранилища данных;
□ конфигурирование сервера Deductor Server;
□ настройка пакетной и/или серверной обработки сценариев Deductor;
□ оптимизация доступа к источникам данных, в том числе к хранилищу данных.
Функции программиста:
□ интеграция Deductor с источниками и приемниками данных;
□ вызов Deductor из внешних программ различными способами, в том числе
взаимодействие с Deductor Server.
Такая работа, как проектирование и наполнение хранилища данных, часто вы-
полняется коллективно аналитиком, администратором и программистом. Аналитик
проектирует семантический слой хранилища данных, то есть определяет, какие
Глава 13. Аналитическая платформа Deductor 603
данные необходимо иметь в хранилище. Администратор создает хранилище данных
и наполняет его данными. Программист при необходимости создает программные
модули, выполняющие выгрузку информации из учетных систем в промежуточные
источники (так называемые транспортные таблицы).
Аналитические технологии, реализованные в Deductor
В Deductor реализовано большинство аналитических технологий — от ETL и хра-
нилищ данных до алгоритмов Data Mining. В качестве языка визуального моде-
лирования используются структуры в виде деревьев. В табл. 13.1 перечислены
возможности Deductor 5.2 в порядке следования теоретических глав первой части
настоящей книги.
Таблица 13.1. Технологии, реализованные в Deductor 5.1 (5.2)
Аналитические задачи Deductor
Консолидация данных Реляционное хранилище данных ROLAP (схемы «звезда» и «снежинка»), виртуальное хранилище данных
Трансформация данных Фильтрация, группировка, разгруппировка и замена данных, скользящее окно, квантова- ние, слияние, расчетные поля, нормализация, свертка столбцов. Разнообразные схемы коди- рования: уникальными значениями и битовой маской
Визуализация данных OLAP-кубы, диаграммы, графики, гистограммы, статистика, правила, деревья, тепловые карты, матрицы классификации, диаграммы рассеяния, статистика, ретропрогноз, профили кластеров
Очистка и предобработка данных Фильтр Калмана, вейвлеты, равномерный случайный сэмплинг, заполнение пропусков средним значением, корреляционный анализ, метод главных компонент
Data Mining: задача ассоциации Алгоритм Apriori
Data Mining: кластеризация Сети и карты Кохонена, алгоритмы k-means и G-means
Data Mining: классификация и регрессия Линейная и логистическая регрессия, дерево решений (алгоритм С4.5), многослойный пер- септрон (алгоритмы ВРгор и RProp)
Анализ и прогнозирование временных рядов «Наивные» и базовые эконометрические мо- дели, пользовательские модели, расчет АФК, выделение тренда, регрессионные и нейросете- вые модели
Ансамбли моделей Сценарный подход, поддерживающий создание однородных ансамблей и ансамблей на основе различных типов моделей, стэкинг и бэггинг
Сравнение моделей ROC-анализ, Lift-кривые
604 Часть II. Бизнес-анализ в Deductor
Вся работа в Deductor Studio построена на создании сценариев обработки д
ных при помощи трех мастеров — импорта, обработки и экспорта. Для настрот
подключений к разнообразным источникам данных (от СУБД до специализи
ванных учетных систем и веб-серверов) используется мастер подключений.
На рис. 13.1 представлено главное окно Deductor Studio: слева расположу
область построения сценариев, а справа — область отображения визуализаторс
Рис. 13.1. Deductor Studio — рабочее место аналитика
Установка Deductor
Установка может быть произведена на компьютер с операционной системе
Windows 2000 и выше. Системные требования к компьютеру изложены в спр<
вочном разделе Deductor.
Для установки Deductor запустите файл инсталлятора и следуйте инстру!
циям. На странице Выбор компонентов программы установки можно выбрат:
какой набор компонентов пакета Deductor необходимо установить на компыоте]
В выпадающем списке выберите предопределенные конфигурации установк
платформы, и программа установки сама предложит соответствующий набо
компонентов.
Глава 13. Аналитическая платформа Deductor 605
После установки версий Professional и Enterprise дополнительно потребуется
настроить работу с электронным ключом защиты от копирования. Установку
и подсоединение электронного ключа осуществляет администратор.
На прилагаемом к книге компакт-диске находится дистрибутив Deductor
Studio Academic 5.2 (его и последнюю версию Deductor Academic также можно
загрузить с веб-ресурса http://www.basegroup.ru/download/deductor; программа рас-
пространяется бесплатно). Установите его на компьютер и скопируйте файлы
с демопримерами на локальный диск (они понадобятся при изучении дальней-
шего материала).
Deductor имеет интуитивно понятный дружественный пользовательский
интерфейс. Тем не менее для быстрого освоения основных принципов работы
в Deductor Studio (импорт файлов, создание проекта, операции со сценариями,
простые манипуляции с набором данных, настройка среды) рекомендуется изу-
чить занятия практикума «Базовые навыки работы в Deductor Studio», который
расположен на прилагаемом компакт-диске, а также просмотреть демонстраци-
онные видеоролики.
В следующих главах мы покажем, как решаются конкретные бизнес-задачи
с использованием аналитических технологий, рассмотренных в первой части.
При этом мы прибегаем к двум упрощениям. Во-первых, в реальности анали-
тический проект может включать многоступенчатую процедуру, в ходе которой
применяется несколько аналитических технологий — от консолидации до моделей
Data Mining, мы же рассматриваем отдельные случаи. Во-вторых, поскольку для
демонстрации примеров используется Deductor Academic, в качестве источника
данных выступает текстовый файл с разделителями, тогда как на практике боль-
шая часть информации хранится в учетных системах и базах данных.
Консолидация
данных
и аналитическая
отчетность
аптечной сети
Описание бизнес-задачи
Постановка задачи. Компания, владеющая небольшой аптечной сетью, занимается
розничной продажей лекарственных препаратов. Руководство компании приняло
решение о внедрении системы аналитической OLAP-отчетности, в которой его
интересует информация о динамике продаж, загруженности торговых точек, са-
мых продаваемых товарах в различных разрезах. Так как существующая учетная
система испытывает нагрузки (компания постоянно расширяет свою сеть), было
решено создать единый консолидированный источник — хранилище данных, ко-
торое послужит базой для OLAP-отчетности.
Предварительно программисты компании создали процедуру выгрузки данных
из учетной системы в структурированные текстовые файлы (в качестве пробы
сформирована «пачка» данных за несколько месяцев). Требуется:
□ спроектировать структуру реляционного хранилища данных (ХД);
□ наполнить ХД первичной информацией;
□ разработать процедуры пополнения ХД и контроль непротиворечивости содер-
жащихся в нем данных;
□ предложить набор OLAP-отчетов.
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 607
Исходные данные. Представлены в четырех файлах: Группы товаров . txt,
Товары.txt, Отделы.txt, Продажи.txt.
Покажем последовательность решения задачи в аналитической платформе
Deductor.
Deductor Warehouse
Хранилище данных Deductor Warehouse — это специально организованная база
данных, ориентированная на решение задач анализа данных и поддержки принятия
решений, обеспечивающая максимально быстрый и удобный доступ к информации.
ХД Deductor Warehouse соответствует модели ROLAP (схема «снежинка») и мо-
жет быть развернуто на одной из следующих СУБД: Firebird, SQL Server, Oracle
(в версии Academic — только на Firebird). С Deductor Warehouse на базе Firebird
имеется возможность работать локально при помощи динамической библиотеки
fbclient. dll (поставляется вместе с Deductor).
Хранилище данных Deductor Warehouse включает в себя потоки данных, посту-
пающие из различных источников, и специальный семантический слой, содержа-
щий так называемые метаданные (данные о данных). Семантический слой и сами
данные хранятся в одной СУБД.
Запрос к хранилищу осуществляется непосредственно сквозь семантический
слой, который через внутреннюю систему команд (скрытую от пользователя и ана-
литика) подбирает запрашиваемую информацию из многообразия хранимых дан-
ных. Работу семантического слоя можно сравнить с деятельностью библиотекаря,
который по просьбе читателя достает с разрозненных полок книги и раскрывает
их на нужных страницах.
Все данные в Deductor Warehouse хранятся в структурах типа «снежинка», где
в центре расположены таблицы фактов, а «лучами» являются измерения, причем
каждое измерение может ссылаться на другое измерение. Именно эта схема чаще
всего встречается в реляционных хранилищах данных (рис. 14.1).
Рис. 14.1. Структура Deductor Warehouse
608 Часть II. Бизнес-анализ в Deductor
В Deductor Warehouse имеются следующие типы объектов.
Измерение — последовательность значений одного из анализируемых парамет-
ров. Например, для параметра Время это последовательность календарных дней,
для параметра Регион — список городов. Каждое значение измерения может быть
представлено координатой в многомерном пространстве процесса, например Товар,
Клиент, Дата.
Атрибут — свойство измерения (то есть точки в пространстве). Атрибут как
бы скрыт внутри другого измерения и помогает пользователю полнее описать
исследуемое измерение. Атрибутами измерения Товар могут выступать Цвет, Вес,
Габариты.
Факт — значение, соответствующее измерению. Факты — это данные, отра-
жающие сущность события. Как правило, фактами являются численные значения,
например сумма и количество отгруженного товара, скидка.
Ссылка на измерение — установленная связь между двумя и более измерениями.
Дело в том, что некоторые бизнес-понятия (соответствующие измерениям в хра-
нилище данных) могут образовывать иерархии, например, Товары могут включать
Продукты питания и Лекарственные препараты, которые, в свою очередь, подраз-
деляются на группы продуктов и лекарств и т. д. В этом случае первое измерение
содержит ссылку на второе, второе — на третье и т. д.
Процесс — совокупность измерений, фактов и атрибутов. По сути, процесс и есть
«куб», «снежинка». Процесс описывает определенное действие, например продажи
товара, отгрузки, поступления денежных средств и пр.
Атрибут процесса — свойство процесса. Атрибут процесса, в отличие от измере-
ния, не определяет координату в многомерном пространстве. Это справочное значе-
ние, относящееся к процессу, например № накладной, Валюта документа и т. д. Зна-
чение атрибута процесса, в отличие от измерения, не всегда может быть определено.
В Deductor Warehouse может одновременно храниться множество процессов
(«звезд» или «снежинок»), имеющих общие измерения, например измерение Товар,
фигурирующее в процессах Поступления и Отгрузка.
Все загружаемые в ХД данные обязательно должны быть определены как изме-
рение, атрибут либо факт (рис. 14.2).
Рис. 14.2. Проектирование структуры хранилища
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети
609
Информация о принадлежности данных к тому или иному типу (измерение,
ссылка на измерение, атрибут или факт) содержится в семантическом слое храни-
лища. Обратим внимание на то, что:
□ таблицы измерений содержат только справочную информацию (коды, наимено-
вания и т. п.) и ссылки на другие измерения при необходимости;
□ таблица процесса содержит только факты и коды измерений (без их атрибутов).
Проектирование хранилища «Фармация»
Первая подзадача — спроектировать структуру хранилища нашей аптечной сети.
Все данные представлены в четырех таблицах. Их фрагменты приведены ниже
(табл. 14.1-14.4).
Таблица 14.1. Группы товаров (фрагмент)
Код группы Наименование группы
33 Иммуномодуляторы
48 Общетонизирующие средства и адаптогены
50 Местные анестетики
108 Микро- и макроэлементы
198 Витамины и витаминоподобные средства
223 Желчегонные средства и препараты желчи
Таблица 14.2. Товары (фрагмент)
Код товара Наименование товара Код группы
774 Альмагель 1
810 Иммунорм 33
824 Ревит 198
898 Настойка пустырника 48
Таблица 14.3. Отделы
Код отдела Наименование отдела
1 Аптека 1
2 Аптека 2
3 Аптека 3
Таблица 14.4. Продажи (фрагмент)
Дата Код отдела Код товара Час покупки Количество Сумма
01.01.2009 1 3382 15 1 293,92
01.01.2009 1 18346 17 1 22,15
Продолжение &
610 Часть II. Бизнес-анализ в Deductor
Таблица 14.4 (продолжение)
Дата Код отдела Код товара Час покупки Количество Сумма
01.01.2009 2 85600 16 1 32,16
01.01.2009 3 62535 14 4 202,72 '
01.01.2009 2 40315 15 3 47,52 ’
Покажем, какие данные являются измерениями, какие — атрибутами, а ка-
кие — фактами и что представляет собой процесс.
В табл. 14.1 Код группы является измерением, а Наименование группы — его
атрибутом.
В табл. 14.2 Код товара является измерением, Наименование товара — его ат-
рибутом, а Код группы — ссылкой на одноименное измерение.
В табл. 14.3 Код отдела является измерением, а Наименование отдела — его
атрибутом.
В табл. 14.4 Дата является измерением, Код отдела и Код товара, как было ска-
зано выше, — измерения, Час покупки — измерение, Количество и Сумма — факты.
То есть табл. 14.4 представляет собой описание процесса продаж в трех аптеках.
При такой структуре ХД мы предполагаем, что уникальность точки в простран-
стве определяется совокупностью измерений Дата + Товар + Код отдела + Час
покупки. То есть если в одной и той же аптеке в один и тот же день и час будет
совершено несколько покупок, скажем, препарата «анальгин», то в хранилище
данных будет отражена только одна запись.
Взаимоотношение измерений, атрибутов и фактов внутри процесса продаж
в трех аптеках показано на рис. 14.3 (см. выделенную строку в табл. 14.4). В силу
того, что визуально можно представить только трехмерное пространство, на ри-
сунке показано взаимодействие трех измерений (Дата, Код отдела и Код товара).
В рассмотренном примере измерений гораздо больше. Каждое новое может быть
представлено новой осью.
Факты:
сумма (202,72);
количество (4)
Продажи
Рис. 14.3. Измерения, атрибуты и факты внутри процесса продаж
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 611
Создание хранилища
Запустите программу Deductor Studio Academic. Для создания нового пустого
хранилища данных или подключения к существующему перейдите на вкладку
Подключения меню Вид, щелкните правой кнопкой мыши и запустите Мастер под-
ключений (рис. 14.4).
I 151 Сценарии X © Подключения X
'г 4 >' © к, XI %
ЙЧ., ......
Ctrl I Enter
Сохранить настройки подключений
Рис. 14.4. Создание (подключение) хранилища данных
На первом шаге мастера следует выбрать тип источника (приемника) — Deductor
Warehouse (рис. 14.5).
Рис. 14.5. Окно выбора типа подключения
612 Часть II. Бизнес-анализ в Deductor
На следующем шаге из единственно доступного в списке типа базы данных
выберите Firebird. Задайте параметры базы данных, в которой будет создана фи-
зическая и логическая структура хранилища данных (рис. 14.6):
□ база данных — D:\farma.gdb (или любой другой путь);
□ логин — sysdba, пароль — masterkey,
□ установите флажок Сохранять пароль.
Рис. 14.6. Установка параметров базы данных
На следующей вкладке выберите последнюю версию для работы с ХД Deductor
Warehouse 6 (предыдущие версии необходимы для совместимости с предыдущими
хранилищами). Нажмите кнопку Создать файл базы данных с необходимой структурой
метаданных 'Д •и по указанному ранее пути будет создан файл f arma. gdb (появит-
ся сообщение о его успешном создании). Это и есть пустое хранилище данных.
Осталось выбрать визуализатор для подключения (здесь это Сведения и Мета-
данные) и задать имя, метку и описание нового .хранилища (рис. 14.7).
Рис. 14.7. Настройка семантики имен для узла подключения
'денарии X (§? Подключения X |
Г W » ! ® * i X ,
В (§) Подключения
В Г~1 Хранилища данных
□ Фармация
Рис. 14.8. Хранилище
данных «Фармация»
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 613
Имя хранилища может быть введено только ла-
тинскими буквами.
После нажатия кнопки Готово на дереве узлов под-
ключений появится метка хранилища (рис. 14.8).
Для проверки доступа к новому хранилищу дан-
ных воспользуйтесь кнопкой Тестирование соедине-
ния . Если спустя некоторое время появится сообще-
ние «Тестирование соединения прошло успешно»,
то хранилище готово к работе. Сохраните настройки
подключений, нажав соответствующую кнопку •
Если соединение по какой-либо причине установить не удалось, то будет выдано
сообщение об ошибке. В этом случае нужно проверить параметры подключения
хранилища данных и при необходимости внести в них изменения (используйте для
этого кнопку Настроить подключение gf).
Таким образом, создано пустое хранилище, в котором нет ни одного объекта
(процесса, измерения, факта). Ранее мы спроектировали структуру хранилища
данных аптечной сети. Осталось отразить ее в хранилище. Для этого предназначен
редактор, который вызывается нажатием кнопки Открыть редактор метаданных...
на вкладке Подключения.
Для перехода в режим внесения изменений в структуру хранилища нажмите
кнопку Разрешить редактировать . Появится диалоговое окно с предупреждением
о том, что это небезопасная операция. Выберите узел Измерения, щелкните правой
кнопкой мыши, затем нажмите кнопку Добавить и создайте первое измерение Код
группы со следующими параметрами:
□ имя — GRID',
□ метка — Группа.Код',
□ тип данных — целый.
Метка — это семантическое название объекта хранилища данных, которое уви-
дит пользователь, работающий с ХД.
Проделайте аналогичные действия для создания всех остальных измерений,
взяв параметры из табл. 14.5. Зафиксируйте изменение структуры ХД, нажав
кнопку Принять изменения .
Таблица 14.5. Параметры измерений
Измерение Имя Метка Тип данных
Код группы GR ID Группа. Код Целый
Код товара TV_ID Товар.Код Целый
Код отдела PARTID Отдел.Код Целый
Дата SDATE Дата Дата/время
Час покупки S HOUR Час Целый
В результате структура метаданных хранилища будет содержать пять измере-
ний (рис. 14.9).
614 Часть II. Бизнес-анализ в Deductor
Рис. 14.9. Структура метаданных хранилища
К каждому измерению, кроме Дата и Час, добавьте текстовый атрибут (это
также делается нажатием кнопки Добавить). Для измерения Группа.Код это будет
Группа.Наименование, для измерения Товар.Код — Товар.Наименование, для изме-
рения Отпдел.Код — Отпдел.Наименование. Старайтесь не делать имя измерения
зарезервированным ключевым словом языка SQL.
Каждое измерение может ссылаться на другое измерение, реализуя тем самым
иерархию измерений. В нашем случае измерение Товар.Код ссылается на Ipynna.
Код. Эту ссылку и установите путем простого добавления (ссылка на измерение
отображается значком ££), а имя ссылки задайте GRID1. Результат работы ил-
люстрирует рис. 14.10.
ъ/ Редактор метаданных [Фармация]
МИР
-1 О X :
Объект
Q Фармация
Пв]Кцбы
|В] Процессы
^Измерения
й 14 Группа.Код
Й [^Атрибуты
^Измерения
лй Т4 Товар.Код
J ^Атрибуты
Товар.Наименование
* Имя
FARMA
12 GRJD
12 TVJD
Имя ®GRJD_1
Метка {Группа.Код
Списание
Т ип данных ‘ Целый
^Видимый
Вид данных лДись.ретцьай
Назначение данных Измерение
Измерение I [GRJD] Группа.Код
Измерения
ab TV_NAME
Ш 14 Отдел. Код
й 14 Дата
51-14 Час
12 GRJDJ
12 PARTJD
й S.DATE
аЪ SJ4OUR
Рис. 14.10. Формирование ссылки на измерение
После того как все измерения и ссылки на измерения созданы, приступайте
к формированию процесса («снежинки»). Назовите его Продажи и добавьте в него
ссылки на четыре существующих измерения: Дата, Отдел.Код, Товар.Код, Час
(кнопка Ф ). Кроме них, в процессе участвуют два факта: Количество и Сумма,
причем первый — целочисленный, а второй — вещественный (рис. 14.11).
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 615
is.' Редактор метаданных [Фармация]
=; “а: ♦ х ; а-; # ’: й
Объект _ __
Q Фармация
(в|Кчбы
И [в] Процессы
ё В EJ Продажи
[ТГ| Атрибуты
В -ПП Измерения
£4 Дггга
Отдел. Код
Товар.Код
К Час
© fu]Факты
[^3]ДД
|ТН Сумма
W ^Измерения
ffi- Х4 Группа.Код
ffi Т4 Товар.Код
ffi t4 Отдел. Код
® Дэта
ffi И Час
Имя
FARMA
SALES
0 S_DATE_1
12 PARTJDJ
12 TV_ID_1
ab S_HOUR_1
12 F_COUNT
9.0 F_SUM
12 GR_ID
12 TVJD
12 PARTJD
0 S-DATE
ab S_HOUR
н ~Имя _ iFjsouNT
Метка 8 Количество
Описание________________________
Тип данных «Целый ’
Видимый
Размер ноги М
Вид данных 1Н ©прерывный
Назначение данных i Факт
Рис. 14.11. Создание метаданных процесса
На этом проектирование структуры и метаданных ХД закончено.
Наполнение хранилища данных
После создания структуры хранилища данных оно представляет с собой пустой
файл с настроенным семантическим слоем. В таком виде ХД готово к загрузке
в него данных из внешних структурированных источников. Для этого необходимо
написать соответствующий сценарий в Deductor Studio. Он должен выполнять
следующие функции:
□ импорт данных в Deductor Studio из базы данных, учетной системы или предо-
пределенных файлов;
□ опциональную предобработку данных, например очистку или преобразование
формата;
□ загрузку данных в измерения и процессы хранилища Deductor Warehouse.
В нашем примере исходными данными для ХД служат четыре текстовых фай-
ла: Группы товаров . txt, Товары. txt, Отделы. txt, Продажи. txt. Поэтому
сценарий загрузки должен быть настроен на использование этих файлов в качестве
источников данных (рис. 14.12).
При создании сценария необходимо строго придерживаться следующих правил.
□ Первыми загружаются все измерения, имеющие атрибуты. Только после загруз-
ки всех измерений загружаются данные в процесс(-ы).
□ Измерения нужно загружать, начиная с самого верхнего уровня иерархии и спус-
каясь ниже. Это крайне важно: в противном случае иерархия не будет создана.
616 Часть II. Бизнес-анализ в Deductor
Каталог
Рис. 14.12. Схема сценария загрузки
□ Допускается не загружать отдельно измерения, не имеющие атрибутов и не со-
стоящие в иерархии измерений. Значения таких измерений можно создавать
во время загрузки в процесс с помощью специальной опции.
Поясним второе правило (рис. 14.13). Измерение Группа находится в иерархии
выше измерения Товар, поэтому последовательность загрузки измерений будет
следующая: Группа, Товар.
Рис. 14.13. Иерархия измерений
Импортируйте все четыре текстовых файла в Deductor в том порядке, как это
показано на рис. 14.14. Для этого перейдите на вкладку Сценарии и из контекстного
меню или нажатием клавиши F6 вызовите Мастер импорта, выберите тип источни-
ка — текстовый файл и настройте параметры импорта. Последовательность создания
узлов импорта должна быть такой, чтобы первыми следовали узлы импорта из фай-
лов с таблицами измерений, и только в конце — таблица процесса Продажи. txt.
Менять порядок веток сценария можно при помощи кнопок CTRL + ? и CTRL + X.
Покажем последовательность загрузки данных в измерение на примере первого
измерения Группа.Код. Встав на первом узле, вызовите Мастер экспорта (контекстное
меню или клавиша F8). Из списка типа приемников выберите Deductor Warehouse
(рис. 14.15).
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 617
OS’S нйй fjna'w ®
П Сценарии X ) (§) Подключения X
ЕГ & ар, ь у
Сценарии
[ё] Текстовый Файл (Груты товаров, txtl
(U Текстовый Файл (Товары-txtj
ЛЗ Текстовый Файл (Отделы.txt)
Текстовый файл (Продажи-txt)
J Тебя, ца______________________________
Ю*-^£1*Д’’т1м «; 32/6
I Товарная I т
груяяаЖод °®
33 Иммуномодуляторы
34 Иммунодепрессанты
38 Секретолитики и стимуляторы к
39 Противокашлевые средства
41 Стимуляторы дыхания
46 Психостимуляторы и ноотропы
Рис. 14.14. Сценарий в Deductor
Рис. 14.15. Экспорт в хранилище данных
На следующей вкладке из списка доступных хранилищ выберите нужное под
названием «Фармация». Далее требуется указать, в какое именно измерение будет
загружаться информация. Это Ipynna.Kod (рис. 14.16).
Рис. 14.16. Выбор объекта для экспорта
618 Часть П. Бизнес-анализ в Deductor
Осталось установить соответствие элементов объекта в хранилище данных
с полями входного источника данных (то есть таблицы Группы товаров. txt)
В случае, когда имена полей и (или) метки в семантическом слое хранилища дан-
ных совпадают, делать ничего не нужно (рис. 14.17).
Рис. 14.17. Настройка соответствия полей
Нажатие кнопки Пуск на следующем шаге загрузит в измерение данные. При этом
старые данные, если они были, обновятся.
Проделав аналогичные действия еще для двух измерений — Отдел.Код, Товар.
Код, получим следующий сценарий (рис. 14.18).
a IS Сценарии
G Т екстовый файл (Группы TOBapoB.txt)
I 9 Загрузка данных в Хранилище данных - FARМА:GRJD
G Sn Текстовый Файл (Товары.txt]
g Загрузка данных в Хранилище данных - FARMA: TVJD
© (D Текстовый Файл (Отделы txt)
g Загрузка данных в Хранилище данных FAR МА: PARTJD
[^Текстовый файл (Продажи, txt]
Рис. 14.18. Незаконченный сценарий загрузки данных в ХД
Загрузка измерений на этом заканчивается, несмотря на то что остались еще два
измерения — Дата и Час. Но они не имеют атрибутов и не участвуют в иерархии,
поэтому их значения можно загрузить на этапе экспорта в процесс.
Загрузите данные в процесс Продажи. В отличие от загрузки измерений, в Мас-
тере экспорта появляются два специфических шага.
На одном из них нужно задать параметры контроля непротиворечивости дан-
ных в хранилище — указать измерения, по которым следует удалять данные из
хранилища (рис. 14.19).
Выбирается действие, выполняемое в ситуации, когда в процесс загружается
информация, которая совпадает по значениям из нескольких измерений. Может
быть два варианта: удалить старые данные и загрузить новые или запретить уда-
ление и оставить то, что было загружено ранее.
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 619
Рис. 14.19. Параметры для контроля непротиворечивости информации
Поясним операцию удаления на примере (рис. 14.20). Допустим, в хранилище
имеется процесс с двумя измерениями: Клиент и Дата. Необходимо загрузить
в хранилище данные о продажах за последние два дня. Если в наборе данных, ко-
торый мы загружаем, имеются все сведения о продажах за эти два дня, то можно
указать: «Удалять данные по измерению и выбрать таким измерением Дата».
Программа определит, что по измерению Дата в исходных данных всего два зна-
чения, а потом удалит из хранилища в процессе Продажи всю информацию за эти
два дня и загрузит новую.
Исходное состояние
данных
После удаления
данных за 2 дня
Новое состояние
данных
Рис. 14.20. Иллюстрация контроля непротиворечивости
620 Часть II. Бизнес-анализ в Deductor
Подобный способ загрузки удобен еще и тем, что позволяет избежать коллизий
например, когда в хранилище имеются некорректные данные за какой-то период
В таком случае лучше все данные за этот период удалить, а после загрузить новые
корректные сведения.
На последней странице Мастера экспорта лучше оставить настройки по умолча-
нию (рис. 14.21).
Рис. 14.21. Дополнительные параметры загрузки в процесс
Флажок Автоматически добавлять значения измерений позволяет «на лету» до-
бавлять новые значения в существующие измерения. Но пользоваться опцией
нужно с осторожностью. В случае бездумного ее применения можно очень быстро
засорить хранилище данных, так как любое значение измерения, даже неверное,
будет занесено как реально существующее.
Флажок Группировать данные перед загрузкой в хранилище данных полезен в сле-
дующей ситуации: вы до конца не уверены, что совокупность измерений процесса
обеспечит уникальность точки в многомерном пространстве, и одновременно та-
кой уровень детализации вас устраивает. В нашей задаче, если в таблице продаж
встретятся две записи с одинаковыми значениями измерений (табл. 14.6), то при
отсутствии установленного флажка Группировать данные... в хранилище попадет
только вторая запись (последняя встретившаяся). Получится, что одна запись
фактически потеряется, хотя нужно просуммировать значения полей Количество
и Сумма.
Таблица 14.6. Случай, при котором совокупность измерений не дает уникальности
Дата Код отдела Код товара Час покупки Количество Сумма
16.12.2008 1 3381 18 2 196,0
16.12.2008 1 3381 18 1 98,0
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 621
В Мастере экспорта можно задать любой вариант агрегации данных (рис. 14.22).
Рис. 14.22. Дополнительные параметры загрузки в процесс
При загрузке с установленным флажком Обновить кубы «пересчитаются» все
кубы, построенные в хранилище на основе данного процесса (кубы «обсчитывают-
ся» заранее и хранятся в отдельных таблицах, поэтому операция импорта из куба
выполняется значительно быстрее, чем непосредственно из процесса).
Включенный флажок Отключить ограничения и индексы полезен в случае экспор-
та в процесс больших объемов данных (например, при первичной загрузке). Тогда
во время выполнения этого действия при добавлении каждой новой строки данных
не будет тратиться время на дополнительные процедуры, связанные с перестройкой
индексов и проверкой ограничений.
Окончательный сценарий загрузки приведен на рис. 14.23.
₽ Сценарии
В gj Т екстовый Файл (Группы товаров, txl)
0 Загрузка данных в Хранилище данных - FARMA : GRJD
В Текстовый Файл (I овары-txt)
fj Загрузка данных в Хранилище данных - FARMA : TV_ID
Й Текстовый Файл (Отделы.txl)
9 Загрузка данных в Хранилище данных - FARMA: PARTJH
В Текстовый Файл (Продажи, txt]
____g Загрузка данных в Хранилище данных FARMA. SALES |
Рис. 14.23. Окончательный сценарий загрузки
В результате всех вышеописанных действий будет:
□ создано и наполнено хранилище данных;
□ написан сценарий загрузки (пополнения) информации из источников в ХД;
□ продуман контроль непротиворечивости данных в ХД.
Заметим, что сценарий загрузки привязан не к данным непосредственно, а к их
структуре, то есть в нем смоделирована последовательность действий, которые
622 Часть II. Бизнес-анализ в Deductor
нужно выполнить для загрузки информации в ХД: имена файлов-источников, со-
ответствие полей и т. д. Один раз созданный сценарий впоследствии применяется
для пополнения хранилища данных. Как правило, эти процедуры проводятся по
регламенту в нерабочее время (например, ночью) с использованием пакетного или
серверного режима.
Срезы из хранилища данных и OLAP-кубы
Процесс получения данных из хранилища осуществляется при помощи Мастера им-
порта (контекстное меню или клавиша F6). Построим отчет, отражающий динамику
сумм продаж по месяцам года в разрезе групп товаров и аптек. Для этого выполните
следующие действия.
1. С помощью Мастера импорта выберите тип источника данных — Deductor
Warehouse, на следующем шаге — хранилище Фармация, а затем — процесс
Продажи. Далее задайте, какие измерения и атрибуты необходимо импор-
тировать (рис. 14.24). Заметим, что благодаря иерархии внутри измерения
Товар.Код появилась возможность доступа к измерению Группа.Код.
Рис. 14.24. Выбор импортируемых измерений и атрибутов
В этом же окне задайте импортируемые факты и виды их агрегации (рис. 14.25).
В большинстве случаев требуется агрегация в виде суммы.
2. Определите срезы для выбранных измерений. Это целесообразно делать при
большом количестве значений измерения, так как позволяет загружать с сервера,
на котором расположено ХД, только интересуюшие значения измерений и тем
самым экономить время загрузки данных. Установим срез по измерению Дата'.
«Все продажи за последние 4 месяца от имеющихся данных» (рис. 14.26).
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 623
Мастер импорта - Deductor Warehouse (4 из 9)
Рис. 14.25. Выбор импортируемых фактов
Рис. 14.26. Выбор срезов
3. В этом же окне внизу выберите тип фильтра — Пользовательский фильтр. Это
означает, что при каждом выполнении узла импорта будет выводиться окно, ана-
логичное окну настройки среза, в котором он сможет указать требуемые разрезы
по этому измерению. Опция позволяет строить динамические отчеты, в которых
пользователю предоставляется только интересующая его информация, а кон-
кретные условия фильтрации он выбирает в момент импорта данных.
624 Часть П. Бизнес-анализ в Deductor
Нажмите кнопку Пуск, дождитесь импорта данных и выберите визуализатор
Таблица.
В вашем распоряжении имеется только измерение Дата, а для построения
OLAP-отчета требуются отдельные измерения Месяц и Год. Их можно извлечь
из даты, применив к узлу импорта из хранилища обработчик Дата и время (он
выбирается в Мастере обработки, который можно вызвать из контекстного
меню или нажатием клавиши F7). Суть этого обработчика заключается в том,
что на основе столбца с информацией о дате/времени формируются один или
несколько столбцов, в которых указывается, к какому заданному интервалу
времени принадлежит строка данных. Тип интервала задается на единственной
вкладке настроек узла в зависимости от того, что вы хотите выделить из даты
(рис. 14.27).
Мастер обработки Дата и время (2 из 4)
Преобразование даты и времени
Преобразование даты и времени
^’Да>а
Q Час
© Зтд ел. Наименование
О Т овар.Наименование
О "руппа
О количество
О Зумма
Имя столбца
DS DATE I
Назначение
Используемое
Г” Обрабатывать даты по ISO 8S01
< Назад | Далее > J
Отмена
Рис. 14.27. Извлечение из даты месяца и года
В результате в выходном наборе будет создано два новых строковых столбца
с метками Дата (Год) и Дата (Месяц).
4. Для результирующего набора данных определите способ его отображения —
куб и настройте назначения полей куба, то есть укажите измерения и факты
(рис. 14.28). Для нашего отчета измерениями будут измерения Дата (Месяц),
Дата (Год), Отдел.Наименование и Группа.Наименование, а фактами — Коли-
чество и Сумма проданных товаров (с агрегацией «Сумма»). При построении
куба информационное поле Дата не будет отображаться, но будет доступно
в детализации.
5. На следующем шаге нужно задать размещение измерений по строкам/столбцам
(рис. 14.29).
6. На последнем шаге определите, какие факты нужно отображать в кубе на пере-
сечении измерений, и их агрегацию (рис. 14.30).
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 625
Рис. 14.28. Настройка назначений полей куба
Рис. 14.29. Настройка размещения полей куба
Рис. 14.30. Настройка отображения фактов
626 Часть II. Бизнес-анализ в Deductor
Таким образом, наш сценарий будет включать два узла (рис. 14.31).
Ш Сценарии
□ Фармация. Продажи
_____ПГ1 Преобразование даты (Дата: Г од. Месяц]
Рис. 14.31. Фрагмент сценария
В результате получим следующий многомерный отчет (рис. 14.32).
Скрытые
измерения
Измерения в столбцах Значения фактов
Измерения
в строках
Рис. 14.32. OLAP-отчет о продажах в разрезе месяца, года и аптеки
Фильтрация данных в кубе может производиться двумя способами:
□ по значениям фактов;
□ по значениям измерений.
Для фильтрации данных в кубе необходимо во всплывающем меню или на па-
нели инструментов нажать кнопку Селектор... Y > после чего откроется диалоговое
окно (рис. 14.33).
Пусть нужно определить товарные группы, приносящие 80 % выручки. Выбери-
те измерение Группа, условие —Доля от общего, значение — 80 и настройте в кубе
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 627
одно активное измерение, добавив вывод относительных долей и отсортировав по
убыванию (рис. 14.34).
Рис. 14.33. Окно селектора
[Дата (Год) [Дата (Месяц) Ю- .л?
Х= Кол-во
X Сумма
Г рчппа
X Процент по Вертикал X Значениеf
Антиконгестанты
91831
Витамины и витаминоподобные средства
: Сердечные гликозиды и негликозидные кардиотоничес
2D7O;BT
Антисептики и дезинфицррующие средства______
! Спазмолитики инотропные
| Секретолитики и гп#1уляторы моторной функции дыха-
Детоксицирующие средства
^Противорвотные средства
Итого:
3020 Я22
5277 ИГ
1 728t
49695
I 18,485?
"1 417?.
45.65?
1 5.31?
ZJ 15,бз?;
6.08?
ZJ 10.62?
2] 3,48?
1 2 10000?
292482,0
292 471Л
282 604.6
275 730.3
210812.5
196707,8
25649.5
14482,9
1 590341 0
Рис. 14.34. Куб с группами препаратов, дающих 80 % выручки
Такую выборку можно получить по любому факту. В данном примере это сумма.
Если выбрать измерение Товар и отфильтровать по количеству, то получим лекар-
ственные препараты, пользующиеся наибольшим спросом.
Одновременно с кубом всегда строится кросс-диаграмма. Ее отличие от обыч-
ной диаграммы в том, что она однозначно соответствует текущему состоянию куба
и при любых его изменениях (транспонировании, вращении) тоже модифицируется.
Например, построим отчет и кросс-диаграмму загруженности аптек (по количеству
проданных единиц товаров) за последние 7 дней (рис. 14.35).
628 Часть П. Бизнес-анализ в Deductor
Рис. 14.35. Загруженность аптек по дням недели
ABC-XYZ-анализ
В аналитической отчетности очень полезным часто оказывается ABC-XYZ-ана-
лиз — распределение объектов, например товаров, клиентов, поставщиков, по
стабильности продаж и доходности (это уже упоминалось в разделе 10.4). Если в
качестве объекта анализа взять лекарственные препараты, а в качестве критерия
анализа — объем продаж, то в результате получим:
□ при ABC-анализе продаж — наиболее и наименее пользующиеся спросом то-
вары;
□ при XYZ-анализе продаж — группировку товарных позиций в зависимости от
стабильности продаж (количество проданных единиц).
Результатом ABC-анализа является группировка объектов по трем катего-
риям:
□ категория А — наиболее ценные объекты, сумма долей с накопительным итогом
которых составляет первые 75 % общей суммы параметров;
□ категория В — промежуточные объекты, следующие за группой А, сумма до-
лей с накопительным итогом которых составляет от 75 до 90 % общей суммы
параметров;
□ категория С — оставшиеся наименее ценные объекты, сумма долей с накопи-
тельным итогом которых составляет от 90 до 100 % обшей суммы парамет-
ров.
Существуют и другие варианты процентного распределения объектов внутри
категорий АВС, например: А — 80 %, В — 15 %, С — 5 % или А — 50 %, В — 30 %,
С-20 %.
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 629
Алгоритм ABC-анализа состоит из следующих шагов.
1. Определить объект анализа: клиент, поставщик, товарная группа, товарная
позиция. Для ABC-анализа продаж это, как правило, товарная позиция.
2. Определить параметр анализа: объем продаж, доход, количество проданных
единиц, частота покупок товара, количество заказов, средний товарный запас
и т. д. Для ABC-анализа продаж это, как правило, объем продаж в денежном
выражении.
3. Определить период, за который будет проводиться ABC-анализ, и подготовить
агрегированные данные по продажам за этот период. Так, если период равен
кварталу, то нужно для каждой товарной позиции получить сумму квартальных
продаж.
4. Отсортировать объекты анализа в порядке убывания значения параметра.
5. Чтобы определить принадлежность выбранного объекта к группам А, В и С,
необходимо:
• рассчитать долю параметра от общей суммы параметров выбранных объек-
тов;
• рассчитать эту долю с накопительным итогом;
• присвоить значения групп выбранным объектам.
ABC-анализ рекомендуется проводить периодически, особенно если в ассорти-
менте есть товарные позиции со значительными сезонными перепадами продаж.
Периодичность анализа определяется экспертным путем и зависит от бизнес-
процессов организации. Оптимальные периоды проведения ABC-анализа: год,
полугодие, сезон (квартал), помесячно в течение года. Периодическое проведение
ABC-анализа позволяет отследить перемещение товарных позиций из группы в
группу (например, нового товара из группы А в группу С, а также контролировать
жизненный цикл товара).
Результат XYZ-анализа — группировка ресурсов по трем категориям на основе
предварительно рассчитанного коэффициента вариации:
□ категория X— объекты, коэффициент вариации которых не превышает 10 %.
Характеризуются стабильной величиной потребления;
□ категория У — объекты, коэффициент вариации которых составляет 10-25 %.
Потребность в них зависит от известных тенденций, например от сезонных
колебаний;
□ категория Z— объекты, коэффициент вариации которых превышает 25 %. По-
требление ресурсов нерегулярное, какие-либо тенденции отсутствуют.
Существуют и другие варианты процентного распределения объектов внутри
категорий XYZ (например, 15-50 %). Коэффициент вариации рассчитывается по
формуле: __________
fe(x'-Y)2
v = А---=?-----100%,
X
630 Часть II. Бизнес-анализ в Deductor
где х. — значение параметра по оцениваемому объекту за г'-й период;
х — среднее значение параметра по оцениваемому объекту анализа;
п — число периодов.
Прибегать к данному методу анализа имеет смысл, если количество анализи-
руемых периодов больше трех. Чем больше количество периодов, тем более пока-
зательными будут результаты. При этом сам период должен быть не меньше, чем
горизонт планирования, принятый в компании, иначе велика вероятность того, что
все товары попадут в категорию Z.
Алгоритм XYZ-анализа также состоит из нескольких шагов.
1. Определить объект анализа: клиент, поставщик, товарная группа, товарная
позиция. Для XYZ-анализа продаж это, как правило, товарная позиция.
2. Определить параметр анализа: объем продаж, доход, количество проданных
единиц, частота покупок товара, количество заказов, средний товарный запас
и т.д. Для XYZ-анализа продаж это, как правило, количество проданных единиц
товара или частота покупок.
3. Определить период, за который будет проводиться XYZ-анализ, и подготовить
агрегированные данные по продажам за этот период.
4. Рассчитать коэффициент вариации.
5. Отсортировать объекты анализа по возрастанию значения коэффициента ва-
риации.
6. Определить группы X, YnZ.
Результаты АВС- и XYZ-анализа обычно представляются в виде матрицы, со-
стоящей из трех строк и трех столбцов (табл. 14.7), и позволяют дать практически
полную характеристику эффективности ассортиментной политики.
Таблица 14.7. ABC-XYZ-матрица
Категория X Y Z
А АХ AY AZ
В ВХ BY BZ
с СХ CY CZ
Прогнозирование по группам такой ассортиментной матрицы позволит диф-
ференцировать усилия: одни позиции прогнозировать, другие планировать, чему-
то уделять максимум внимания, а что-то рассчитывать по жестким методикам
(рис. 14.36). Поэтому для торговых компаний матрица ABC-XYZ является эффек-
тивным инструментом при подборе стратегий управления товарными запасами.
Товарам групп АХ, AY и ВХ следует уделять повышенное внимание, поскольку
отсутствие этих товаров может привести к серьезным убыткам. У группы АХ самая
высокая степень надежности прогноза, поэтому здесь пригодны сложные модели
временных рядов с учетом сезонности, регрессионные и нейросетевые модели.
Вследствие стабильности потребления попозиционные прогнозы будут обеспе-
чивать хорошее качество. Остальные группы — AY и ВХ — возможно, следует про-
гнозировать по товарным группам.
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 631
Хаотичная
Динамика продаж
Стабильная
ф
а
ч
о
L0
Особое внимание,
желательно
проводить
попозиционный
прогноз
Повышенное
внимание,
прогнозировать
по группам
или по позициям
Повышенное
внимание,
желательно
прогнозировать
по группам
Прогнозировать
по группам
Рассчитывать
по бизнес-правилам,
контролировать
наличие
минимального запаса
Рассчитывать
по бизнес-правилам,
предлагать
товары-заменители
Качественный
прогноз невозможен,
желательно назна-
чить персонального
менеджера
Качественный
прогноз невозможен,
рассчитывать
потребность
по «жестким» правилам
Хаотичные продажи
и маленькая маржа,
приобретать товары
только при нулевом
количестве на складе
Рис. 14.36. Прогнозирование по группам в ABC-XYZ-анализе
Товары групп СХ и CY характеризуются низкой потребительской стоимостью
и средней надежностью прогноза. Здесь хорошо подходят несложные расчетные
модели, например скользящее среднее с контролем страхового запаса. Вообще, для
товаров группы СХ можно построить качественный прогноз, однако ввиду низкой
потребительской стоимости тратить дополнительное время на него не нужно.
Наименьшее внимание уделяют позициям, попавшим в группы BZ и CZ. Если
в этих товарах нет острой необходимости, от них можно вообще отказаться. Поэто-
му здесь говорить о каких-либо моделях временных рядов не имеет смысла — в ход
идут простые «жесткие» правила. Товары группы CZ стоит приобретать по мере
необходимости.
Сценарий ABC-анализа продаж для хранилища данных Фармация изображен
на рис. 14.37. В качестве периода взяты последние 3 месяца; параметром выбрана
сумма продаж в денежном выражении. Доли с накопительным итогом рассчиты-
вались в узле Калькулятор с использованием функции CumulativeSum().
@ Фармация: Продажи (последние 3 месяца для АВС)
= лу Фильтр ([Дата] не последний месяц от имеющихся данных)
В & АВС-аиализ
Группировка (Сумма продаж по товарам)
В *1 Сортировка: Сумма
Ы &В Калькулятор: Доля от общей суммы
В [£j Калькулятор: Доля с накопительным итогом
Ы 8Ш1 Калькулятор: Группа АВС
Рис. 14.37. Сценарий ABC-анализа продаж для ХД «Фармация»
Результат ABC-анализа в виде отчета с OLAP-кубом представлен на рис. 14.38.
632 Часть II. Бизнес-анализ в Deductor
Рис. 14.38. Результат ABC-анализа в OLAP-кубе
Сценарий XYZ-анализа продаж для хранилища данных Фармация изображен
на рис. 14.39.
3 Q Фармация: Продажи эа последние 3 месяца [дляХ/ZJ
В V Фильтр ((Дата] не последний месяц от имеющихся данных)
Э [71 Преобразование даты (Дата: Год ♦ Месяц)
Ы {1 Группировка по периоду (месяц)
3 XYZ анализ
Q {1 Группировка (Измерения: Товар.Код; Факты: Количество.
И Калькулятор: X среднее
Fl 3* Внутреннее соединение (Калькулятор: X среднее)
& И Калькулятор: (Х-Хср)^2
0- {1 Группировка: сумьагруем (Х-Хср)л2
В ЙЙ Калькулятор: Вариация
S zl Сортировка: Вариация
_________________________ ЙЯ Ка/ькулятор; XYZ группа______________
Рис. 14.39. Сценарий XYZ-анализа продаж для ХД «Фармация»
ЗАМЕЧАНИЕ -----------------------------------------------------------
Значение квадратного корня в формуле для расчета v есть не что иное, как стандартное
отклонение. Его (как и среднее количество продаж товара за рассматриваемые периоды)
можно было бы рассчитать, взяв функции Среднее и Стандартное отклонение у агрегаций
факта в узле Группировка. Но данный способ пригоден только в случае, когда каждый товар
продавался хотя бы один раз в каждый период. В реальности этого может не быть. Поэтому
в сценарии предварительно рассчитывается х так, чтобы количество проданных единиц
всегда делилось на п = 3. Затем оно внутренним соединением «прикрепляется» к каждому
товару и рассчитываются суммы квадратов отклонений от среднего (х- х ). Дальше по
формуле вычисляются коэффициент вариации и группы XYZ. Если изменяется период
анализа п, то нужно подправить формулы расчета в соответствующих узлах.
Глава 14. Консолидация данных и аналитическая отчетность аптечной сети 633
Результат XYZ-анализа в виде отчета с OLAP-кубом представлен на рис. 14.40.
Рис. 14.40. Результат XYZ-анализа в OLAP-кубе
Теперь, чтобы получить ABC-XYZ-матрицу, осталось добавить узел Слияние1
для соединения АВС- и XYZ-групп и настроить OLAP-куб (рис. 14.41).
Рис. 14.41. ABC-XYZ-матрица в OLAP-кубе
1 См. раздел 3.4 и «Руководство аналитика» в поставке Deductor.
634 Часть II. Бизнес-анализ в Deductor
Настройка отчетов
В процессе работы специалист-аналитик выполняет множество операций над ана-
лизируемыми данными. Результаты его работы могут быть интересны широкому
кругу лиц — так называемым конечным пользователям, которым не обязательно
вникать в последовательность действий аналитика, знать особенности математи-
ческого аппарата и методов, применяемых при анализе данных. Чтобы представить
результаты анализа конечным пользователям, можно использовать аналитическую
отчетность.
Аналитическая отчетность (отчеты) — это одно из средств визуализации и кон-
солидации результатов анализа данных для конечного пользователя. Аналити-
ческая отчетность обеспечивает быстрый доступ к результатам анализа, не требуя
от пользователя навыков анализа данных и работы в пакете Deductor. При работе
с отчетами пользователь не видит сценария анализа данных, ему доступны только
конечные результаты (выдержки) из работы аналитика.
Для создания аналитической отчетности в меню Вид выберите пункт Отчеты
или нажмите соответствующую кнопку на панели инструментов. В рабочей части
экрана появится панель Отчеты.
Отчеты строятся в виде древовидного иерархического списка, каждым узлом ко-
торого является отдельный отчет или папка. Каждый узел дерева отчетности связан
со своим узлом в дереве сценария. Для каждого отчета настраивается свой способ
отображения (таблица, гистограмма, куб, кросс-диаграмма и т. п.). Это удобно, так
как несколько отчетов могут быть связаны с одним узлом дерева сценария.
Для создания нового отчета необходимо выбрать команду Добавить узел из
всплывающего меню или нажать соответ-
ствующую кнопку на панели инструментов.
В результате откроется окно Выбор узла,
в котором следует выделить узел дерева
сценария, где содержится нужная выборка
данных, и щелкнуть на кнопке Выбрать.
В результате выполнения перечислен-
ных операций получим дерево отчетов
(рис. 14.42).
На прилагаемом к книге компакт-диске
вы найдете исходные файлы для наполне-
ния хранилища данных, готовое хранилище
данных «Фармация» (f arma. gdb), а также
сценарии Deductor для загрузки и отобра-
„ ., „ жения отчетов load. ded и reports . ded
Рис. 14.42. Панель отчетов
ffl Сценарии X В Отчеты X J
W Biф Л X
Э В Отчеты
• Я Продажи по месяцам и аптекам
’ Э ГРуппы препаратов, дающие 802: прибыли
3) Препараты, дающие 80% прибыли
И Загруженность аптек по дням
® 20 самых продавав» 1ыг товаров
Д Загруженность отделов по часам
ЭО ABC-XrZ-анализ (период: 3 мес)
ЕД АВС-анализ
fFI XrZ-анализ
(3| ABC-XTZ-матрица
соответственно.
Ассоциативные ,
правила
в стимулировании
розничных продаж
Описание бизнес-задачи
Постановка задачи. Розничная сеть по продаже товаров бытовой химии по-
ставила задачу анализа покупательских корзин для оптимизации размещения
товаров на витринах и проведения кросс-продаж. Отдел маркетинга представил
5000 чеков, в которых отражены покупки, сделанные клиентами магазинов.
Требуется:
□ предсказать, какие товары покупатели могут выбрать в зависимости от того, что
уже есть в их корзинах;
□ выявить наиболее популярные товарные наборы, состоящие из более чем одно-
го предмета.
Исходные данные. Представлены в файле Чеки. txt двумя полями — Номер
транзакции и Товар. Поскольку номенклатура товаров бытовой химии очень
разнообразна, решено ограничиться представлением товаров в обобщенной
форме без торговых марок: порошки, моющие средства и т. д. (всего 37 наиме-
нований).
Используя алгоритм Apriori, извлечем ассоциативные правила и проинтерпре-
тируем их.
636 Часть II. Бизнес-анализ в Deductor
Выявление ассоциаций
В Deductor Studio для решения задач ассоциации используется обработчик Ассо-
циативные правила, в котором реализован алгоритм Apriori. Узел требует, чтобы на
входе было два поля: идентификатор транзакции и элемент транзакции. Например,
идентификатор транзакции — это номер чека или код клиента, а элемент — это
наименование товара в чеке или услуга, заказанная клиентом.
ЗАМЕЧАНИЕ
Оба поля (идентификатор и элемент транзакции) должны быть дискретного вида.
В новом проекте в Deductor Studio импортируйте данные из текстового файла
Чеки. txt. К узлу импорта добавьте обработчик Ассоциативные правила. Поле ID
сделайте идентификатором транзакции, а ГТЕМ — ее элементом (рис. 15.1).
Рис. 15.1. Настройка назначения входных полей для решения задачи ассоциации
На следующем шаге настройте параметры алгоритма Apriori (рис. 15.2).
Здесь доступны следующие опции.
Минимальная и максимальная поддержка, % — ограничивают пространство поиска
часто встречающихся предметных наборов. Эти границы определяют множество
популярных наборов, или частых предметных наборов, из которых и будут созда-
ваться ассоциативные правила.
Минимальная и максимальная достоверность, % — в результирующий набор по-
падут только те ассоциативные правила, которые удовлетворяют условиям мини-
мальной и максимальной достоверности.
Максимальная мощность искомых часто встречающихся множеств — параметр огра-
ничивает длину ^-предметного набора. Например, при установке значения 4 шаг
генерации частых наборов будет остановлен после получения множества 4-пред-
Глава 15. Ассоциативные правила в стимулировании розничных продаж 637
метных наборов. В конечном итоге это позволяет избежать появления длинных
ассоциативных правил, которые трудно интерпретируются.
Все настройки оставьте предлагаемыми по умолчанию. Нажатие кнопки Пуск
запустит работу алгоритма поиска ассоциативных правил, по окончании которой
справа в полях появится следующая информация (рис. 15.3):
□ Кол-во множеств — число частых наборов, удовлетворяющих заданным условиям
минимальной поддержки и достоверности (93 набора);
□ Кол-во правил — число сгенерированных ассоциативных правил (найдено
18 правил).
Рис. 15.2. Параметры алгоритма Apriori
Рис. 15.3. Процесс выявления ассоциаций
638 Часть II. Бизнес-анализ в Deductor
Далее выбираете все доступные специализированные визуализаторы и визуа-
лизатор Таблица (рис. 15.4).
Рис. 15.4. Доступные визуализаторы
Все эти визуализаторы, кроме Что-если, отображают результаты работы алго-
ритма в различных формах.
Часто встречающиеся наборы в Deductor называются популярными. На вклад-
ке Популярные наборы, как следует из названия, в виде списка отображается
множество найденных популярных предметных наборов, которые можно от-
фильтровать и отсортировать. Например, задав в фильтре минимальное значение
поддержки 6 % и отсортировав записи по ее убыванию, получим следующие
16 популярных наборов (рис. 15.5). Два из них имеют мощность 2, то есть со-
держат по 2 элемента.
На вкладке Дерево правил предлагается еще один удобный способ отображения
множества ассоциативных правил. При построении дерева по условию на первом
(верхнем) уровне находятся узлы с условиями, а на втором — узлы со следствием.
В дереве, построенном по следствию, наоборот, на первом уровне располагаются
узлы со следствием.
Справа от дерева расположен список правил, построенный по выбранному узлу
дерева (рис. 15.6).
Для каждого правила отображаются поддержка, достоверность и лифт. Если
дерево построено по условию, то вверху списка находится условие правила, а спи-
сок состоит из его следствий. Тогда правила отвечают на вопрос: что будет при
таком условии?
Если же дерево построено по следствию, то вверху списка отображается след-
ствие правила, а список состоит из его условий. Эти правила отвечают на вопро-
Глава 15. Ассоциативные правила в стимулировании розничных продаж 639
сы: что нужно для того, чтобы получилось заданное следствие, или какие товары
нужно продать для того, чтобы продать товар из следствия?
Рис. 15.5. Популярные наборы с поддержкой более 6 %
Рис. 15.6. Дерево ассоциативных правил
Интерпретация ассоциативных правил
Теперь остановимся на наиболее важном этапе — интерпретации ассоциативных
правил. Дело в том, что ассоциативные правила сами по себе, как результат работы
некоторого алгоритма, еще не готовы к использованию. Их нужно проинтерпре-
тировать, то есть понять, какие из ассоциативных правил представляют интерес,
действительно ли правила отражают закономерности или, наоборот, являются
640 Часть II. Бизнес-анализ в Deductor
артефактом. Это требует от аналитика тщательной работы и понимания предмет-
ной области, в которой решается задача ассоциации.
Все множество ассоциативных правил можно разделить на три вида.
□ Полезные правила содержат действительную информацию, которая ранее была
неизвестна, но имеет логичное объяснение. Такие правила могут быть исполь-
зованы для принятия решений, приносящих выгоду.
□ Тривиальные правила содержат действительную и легко объяснимую ин-
формацию, которая уже известна. Такие правила, хотя и объяснимы, но не
могут принести какой-либо пользы, так как отражают или известные законы
в исследуемой области, или результаты прошлой деятельности. При анализе
рыночных корзин в правилах с самой высокой поддержкой и достоверностью
окажутся товары — лидеры продаж. Практическая ценность таких правил
крайне низка.
□ Непонятные правила содержат информацию, которая не может быть объяснена.
Такие правила получаются на основе или аномальных значений, или глубоко
скрытых знаний. Напрямую эти правила нельзя использовать для принятия
решений, так как их необъяснимость может привести к непредсказуемым ре-
зультатам. Для лучшего понимания требуется дополнительный анализ.
Варьируя верхний и нижний пределы поддержки и достоверности, можно из-
бавиться от очевидных и неинтересных закономерностей. Как следствие, правила,
генерируемые алгоритмом, принимают приближенный к реальности вид. Значения
верхнего и нижнего пределов сильно зависят от предметной области, поэтому не
существует четкого алгоритма их выбора. Но есть ряд общих рекомендаций.
□ Большая величина максимальной поддержки означает, что алгоритм будет
находить правила, хорошо известные или же настолько очевидные, что в них
нет никакого смысла. Поэтому ставить порог максимальной поддержки очень
высоким (более 20 %) не рекомендуется.
□ Большинство интересных правил находится именно при низком значении поро-
га поддержки, хотя слишком низкое значение ведет к генерации статистически
необоснованных правил. Поэтому правила, которые кажутся интересными, но
имеют низкую поддержку, нужно дополнительно анализировать, рассчитывая
для них лифт.
□ Уменьшение порога достоверности приводит к увеличению количества правил.
Значение минимальной достоверности не должно быть слишком низким, так
как ценность правила с достоверностью 5 % чаще всего настолько мала, что это
и правилом считать нельзя.
□ Правило с очень большой достоверностью (> 85-90 %) практической ценности
в контексте решаемой задачи не имеет, так как товары, входящие в следствие,
покупатель, скорее всего, уже приобрел.
Вернемся к задаче. Снова обратимся к вкладке Правила, где, помимо самих
ассоциативных правил, приводятся их расчетные характеристики: поддержка, до-
стоверность и лифт (рис. 15.7).
Глава 15. Ассоциативные правила в стимулировании розничных продаж 641
[Правила
V • £1 ’ ' ▼ 1 ш ’
Фильтр: Без Фильтрации
Правил. 17 из 17
№ Номе Условие Следствие й Поддержк Достов ^Лиф
Кол-во %
1 Нц Стиральный порошок-автомат Кондиционер для белья 79 3,86 54,86 12,064
Г" 1 1 3 Кондиционер для б» пья Стиральный порошок-авт( 79 3,86 84,95 12,Об4
ь э 2 Запасной баллон для освежите Освежитель воздуха 53 2,59 59,55 5,855
4 1 Бумага туалетная Освежитель воздуха 53 2,59 58,89 5,790
5 9 Сода кальцинированная Чистящий порошок универ 96 4,69 72,18 5,055
6 Зубная паста 14 Сода кальцинированная Чистящий порошок униве; 28 1,37 71,79 5,028
7 Гель для туалетов 13 Сода кальцинированная Чистящий порошок универ 34 1,66 70,83 4,961
8 11. Средство от накипи Чистящий порошок ужвер 76 3,72 69,72 4,883=
9 15 Мыло кусковое Отбеливатель Мыло жидкое 25 1,22 46,30 4,734
10 8 Салфетки бумажные Освежитель воздуха 50 2,44 47,17 4,638
11 7 Средство для мытья посуды Мыло кусковое 131 6,41 86,18 4,496
12 £ Гель для туалетов Мыло жидкое Мыло кусковое 56 2,74 84,85 4,426-
13 Средство для мытья посуды 17 Средство для чистки плит Мыло кусковое 37 1,81 84,09 4,387
14 6 Мыло кусковое Мыло жидкое 167 8,17 42,60 4,356
15 5 Мыло жидкое Мыло кусковое 167 8,17 83,50 4,356
16 ЯЧыло жидкое 16 Стиральный порошок ручной Мыло кусковое 29 1,42 76,32 3,981
i 17 10 Средство для чистки кафеля Чистящий порошок универ 42 2,05 48,28 3,381
Рис. 15.7. Ассоциативные правила, отсортированные по убыванию лифта
Например, правило № 3 кондиционер для белья —> стиральный порошок-автомат
имеет S = 3,86 %; С = 84,95 % и L = 12,06. Это означает следующее.
□ Ожидаемая вероятность покупки набора кондиционер для белья + стиральный
порошок-автомат равна 3,86 %.
□ Если клиент положил в корзину кондиционер для белья, то с вероятностью
84,95 % он купит и стиральный порошок-автомат.
□ Клиент, купивший кондиционер для белья, в 12,06 раза чаще выберет стираль-
ный порошок-автомат, нежели любой другой товар.
Анализ правил позволяет прийти к выводу, что многие из них тривиальны,
так как это лидеры продаж магазина (см. популярные наборы, рис. 15.5), хотя есть
и интересные правила (например, средство от накипи —> чистящий порошок уни-
версальный). И тот факт, что при достоверности 42-43 % встречаются тривиальные
ассоциативные правила (например, мыло кусковое —> мыло жидкое), говорит о том,
что можно найти интересные правила при меньших значениях достоверности.
642 Часть II. Бизнес-анализ в Deductor
Сделаем следующее:
□ запустим алгоритм Apriori с интервалом допустимой достоверности от 25
до 40 %;
□ не будем рассматривать правила с лидерами продаж: это снова будут тривиаль-
ные правила.
В итоге получим как вариант следующие дополнительные правила (рис. 15.8).
Как видно, все эти правила можно назвать полезными: они неочевидны, но
понятны и имеют высокий лифт.
Рис. 15.8. Полезные правила с достоверностью меньше 40 %
Как компания может применять на практике результаты ассоциативного ана-
лиза? Перечислим лишь некоторые варианты:
□ осуществление кросс-продаж;
□ рациональное размещение совместно покупаемых товаров на полках;
□ применение ассоциативных правил совместно с ABC-анализом для выявления
наиболее доходных товарных позиций.
Сегментация
клиентов
телекоммуникационной
компании
Описание бизнес-задачи
В такой высокотехнологичной отрасли, как телекоммуникации, методы и подходы
Data Mining получили широкое применение. Решаемые задачи прежде всего свя-
заны с программами лояльности и удержанием существующей клиентской базы,
а также с привлечением новых потребителей услуг.
В биллинговых системах телекоммуникационных компаний накапливаются
большие объемы данных. В первую очередь это информация об абонентах и стати-
стика использованных услуг. Анализ такой информации ручными и полуручными
методами малоэффективен.
Постановка задачи. Руководство филиала региональной телекоммуникаци-
онной компании, предоставляющей услуги мобильной связи, поставило задачу
сегментации абонентской базы. Ее целями являются:
□ построение профилей абонентов путем выявления их схожего поведения в пла-
не частоты, длительности и времени звонков, а также ежемесячных расходов;
□ оценка наиболее и наименее доходных сегментов.
Эта информация может в дальнейшем использоваться для:
□ разработки маркетинговых акций, направленных на определенные группы
клиентов;
□ разработки новых тарифных планов;
644 Часть II. Бизнес-анализ в Deductor
□ оптимизации расходов на адресную SMS-рассылку о новых услугах и тарифах'
□ предотвращения оттока клиентов в другие компании.
Данные за последние несколько месяцев, взятые из биллинговой системы
представляют собой таблицу со следующими полями (табл. 16.1).
Таблица 16.1. Данные по абонентам из биллинговой системы
№ Поле Описание Тип
1 Возраст Возраст клиента Целый
2 Среднемесячный расход Сколько в среднем денег в ме- сяц тратит абонент на мобиль- ную связь Вещественный
3 Средняя продолжитель- ность разговора Сколько в среднем минут на исходящие звонки тратит абонент за месяц Вещественный
4 Звонков днем за месяц Количество исходящих звонков в утреннее и дневное время Целый
5 Звонков вечером за месяц Количество исходящих звонков в вечернее время Целый
6 Звонков ночью за месяц Количество исходящих звонков в ночное время Целый
7 Звонки в другие города Количество исходящих звонков в другие города Целый
8 Звонки в другие страны Число исходящих международ- ных звонков Целый
9 Доля звонков на стацио- нарные телефоны — Вещественный
10 Количество SMS Число исходящих SMS-сооб- щений в месяц Целый
Исходные данные. Были отобраны только активные абоненты, которые регуляр-
но пользовались услугами сотовой связи в течение последних нескольких месяцев.
Данные находятся на прилагаемом к книге компакт-диске в файле mobile. txt.
Решение задачи
Покажем последовательность решения бизнес-задачи сегментации абонентов
с помощью подхода, который основан на алгоритме Кохонена. Решение состоит
из двух шагов:
□ кластеризации объектов алгоритмом Кохонена;
□ построения и интерпретации карты Кохонена.
В программе Deductor сети и карты Кохонена реализованы в обработчике Кар-
та Кохонена, где содержатся сам алгоритм Кохонена и специальный визуализатор
Карта Кохонена.
Глава 16. Сегментация клиентов телекоммуникационной компании 645
В Deductor канонический алгоритм Кохонена дополнен рядом возможностей.
□ Алгоритм Кохонена применяется к сети Кохонена, состоящей из ячеек, упоря-
доченных на плоскости. По умолчанию размер карты равен 16x12, что соответ-
ствует 192 ячейкам. В выходном наборе данных алгоритм Кохонена формирует
поля Номер ячейки и Расстояние до центра ячейки.
□ Ячейки карты с помощью специальной дополнительной процедуры объединя-
ются в кластеры. Эта процедура — алгоритмы k-means и G-means. В результате
в выходном наборе данных формируются поля Номер кластера и Расстояние до
центра кластера.
□ Каждый входной признак может иметь весовой коэффициент от 0 до 100 %,
который влияет на расчет евклидова расстояния между векторами.
Импортируйте в Deductor набор данных из файла mobile .txt. Запустите
Мастер обработки и выберите узел Карта Кохонена. Установите все поля, кроме Код,
входными (рис. 16.1).
Рис. 16.1. Установка входных полей в алгоритме Кохонена
На этой же вкладке при нажатии кнопки Настройка нормализации откроется
окно, где можно задать значимость каждого входного поля. Оставьте значимость
всех полей без изменений.
Поскольку любой метод кластеризации, в том числе алгоритм Кохонена, субъ-
ективен, смысл в выделении отдельного тестового множества, как правило, отсут-
ствует. Оставьте в обучающем множестве 100 % записей (рис. 16.2).
На третьей вкладке задаются размер и форма карты Кохонена (рис. 16.3).
Увеличьте размер карты до 24 х 18 (соотношение рекомендуется делать крат-
ным 4:3).
646 Часть II. Бизнес-анализ в Deductor
(^Мастер обработки - Харта Кохонена (2 иэ в)
Разбиение исходного набора данных на подмножества
Настройте разбиение исходного множества данных на обучающее и
тестовое множества
Отмена
Рис. 16.2. Разбиение набора данных на обучающее
и тестовое множества
< Назад
Q Мастер обработки - Карта Кохонена (3 из 8)
Настройка параметров карты Кохонена
Укажите значения параметров карты Кохонена
< Назад ] Далее > 1 Отмена
Рис. 16.3. Параметры будущей карты Кохонена
На следующем шаге оставьте все без изменений (рис. 16.4).
Наконец, на последнем шаге, предшествующем обучению, настраиваются пара-
метры обучения алгоритма Кохонена (рис. 16.5).
Здесь задаются следующие опции.
Способ начальной инициализации карты определяет, как будут установлены на-
чальные веса нейронов карты. Удачно выбранный способ инициализации может
Глава 16. Сегментация клиентов телекоммуникационной компании 647
Рис. 16.4. Параметры остановки алгоритма Кохонена
Рис. 16.5. Параметры обучения сети Кохонена
существенно ускорить обучение и привести к получению более качественных ре-
зультатов. Доступны три варианта.
□ Случайными значениями — начальные веса нейронов будут инициированы слу-
чайными значениями.
□ Из обучающего множества — в качестве начальных весов будут использоваться
случайные примеры из обучающего множества.
648 Часть II. Бизнес-анализ в Deductor
□ Из собственных векторов — начальные веса нейронов карты будут проинициали-
зированы значениями подмножества гиперплоскости, через которую проходят
два главных собственных вектора матрицы ковариации входных значений
обучающей выборки.
При выборе способа начальной инициализации нужно руководствоваться сле-
дующей информацией:
□ объемом обучающей выборки;
□ количеством эпох, отведенных для обучения;
□ размером карты.
Между указанными параметрами и способом начальной инициализации суще-
ствует много зависимостей. Выделим несколько главных.
□ Если объем обучающей выборки значительно (в 100 раз и более) превышает
число ячеек карты и время обучения не играет первоочередной роли, то лучше
выбрать инициализацию случайными значениями.
□ Если объем обучающей выборки не очень велик, время обучения ограничен-
но или если необходимо уменьшить вероятность появления после обучения
пустых ячеек, в которые не попало ни одного экземпляра обучающей вы-
борки, то следует использовать инициализацию примерами из обучающего
множества.
□ Инициализацию из собственных векторов можно использовать при любом
стечении обстоятельств. Именно этот способ лучше выбирать при первом озна-
комлении с данными. Единственное замечание: вероятность появления пустых
ячеек после обучения выше, чем при инициализации примерами из обучающего
множества.
Скорость обучения — задается скорость обучения в начале и в конце обу-
чения сети Кохонена. Рекомендуемые значения: 0,1-0,3 в начале обучения
и 0,05-0,005 в конце.
Радиус обучения — задается радиус обучения в начале и в конце обучения сети
Кохонена, а также тип функции соседства. Вначале радиус обучения должен
быть достаточно большим — примерно половина размера карты (максимальное
линейное расстояние от любого нейрона до другого любого нейрона) или мень-
ше, а в конце — достаточно малым, 1 или меньше. Начальный радиус в Deductor
подбирается автоматически в зависимости от размера карты.
В этом же блоке задается вид функции соседства: гауссова или ступенчатая.
Если функция соседства ступенчатая, то «соседями» нейрона-победителя будут
считаться все нейроны, линейное расстояние до которых не больше текущего
радиуса обучения. Если применяется гауссова функция соседства, то «соседями»
нейрона-победителя будут считаться все нейроны карты, но в разной степени.
При использовании гауссовой функции соседства обучение проходит более плавно
и равномерно, так как одновременно изменяются веса всех нейронов, что может
дать немного лучший результат, чем если бы использовалась ступенчатая функ-
Глава 16. Сегментация клиентов телекоммуникационной компании 649
ция. Однако и времени на обучение требуется больше, поскольку в каждой эпохе
корректируются все нейроны.
Кластеризация — в этой области указываются параметры алгоритма k-means,
который запускается после алгоритма Кохонена для кластеризации ячеек карты.
Здесь нужно либо позволить алгоритму автоматически определить число класте-
ров, либо сразу зафиксировать его. Следует знать, что автоматически подбираемое
число кластеров не всегда приводит к желаемому результату: оно может быть
слишком большим, поэтому рассчитывать на эту опцию можно только на этапе
исследования данных.
Нажмите кнопку Пуск — в следующем окне можно будет увидеть динамику про-
цесса обучения сети Кохонена (рис. 16.6). По умолчанию алгоритм делает 500 ите-
раций (эпох). Если предварительно установить флажок Рестарт, то веса нейронов
будут проинициализированы согласно выбранному на предыдущем шаге способу
инициализации, иначе обучение начнется с текущих весовых коэффициентов (это
справедливо только при повторной настройке узла).
? sp _ эд! Титки Карта Коконена (6 из В)
Построение карты Кохонена
Запуск процесса построения карты Кохонена
-I I х|
" Обучающее множество — —| Тестовое множество
S Р Макс, ошибка | 1.15Е+01 ®П
ЕЭ Р Средн, ошибка 3.81Е-01 ЕЬ"*
Распознано И 01,14
| Эпоха
I.............. до|
Время обучения
М| 00.00.461
Рис. 16.6. Обучение сети Кохонена
Для обученной сети Кохонена предлагается специализированный визуали-
затор — Карта Кохонена. Параметры ее отображения задаются на одноименной
вкладке мастера (рис. 16.7).
Область Список допустимых отображений карты содержит три группы — Входные
столбцы, Выходные столбцы и Специальные. Последние не связаны с каким-либо
полем набора данных, а служат для анализа всей карты.
□ Матрица расстояний применяется для визуализации структуры кластеров,
полученных в результате обучения карты. Большое значение говорит о том,
650 Часть II. Бизнес-анализ в Deductor
Рис. 16.7. Параметры карты Кохонена
что данный нейрон сильно отличается от окружающих и относится к другому
классу
□ Матрица ошибок квантования отображает среднее расстояние от расположения
примеров до центра ячейки. Расстояние считается как евклидово. Матрица
ошибок квантования показывает, насколько хорошо обучена сеть Кохонена.
Чем меньше среднее расстояние до центра ячейки, тем ближе к ней располо-
жены примеры и тем лучше модель.
□ Матрица плотности попадания отображает количество объектов, попавших
в ячейку.
□ Кластеры — ячейки карты Кохонена, объединенные в кластеры алгоритмом
k-means.
□ Проекция Саммона — матрица, являющаяся результатом проецирования мно-
гомерных данных на плоскость. При этом данные, расположенные рядом
в исходной многомерной выборке, будут расположены рядом и на плоско-
сти.
Дополнительно справа имеется еще ряд настроек.
□ Способ раскрашивания ячеек — цветная палитра или градация серого. Цветная
палитра нагляднее, однако если потребуется встраивать карту Кохонена в отчет
с последующей распечаткой на бумажном носителе, то лучше выбрать серую
цветовую схему.
□ Сглаживание цветов карты — цвета на картах будут сглажены, то есть будет
обеспечен более плавный переход цветов. Это поможет устранить случайные
выбросы.
Глава 16. Сегментация клиентов телекоммуникационной компании 651
□ Границы ячеек — установка данного флажка позволит включить отображение
границ ячеек на карте.
□ Границы кластеров — установка данного флажка позволит включить отображе-
ние границ кластеров на всех картах. Этот режим удобен для анализа струк-
туры кластеров.
□ Размер ячейки по умолчанию — указывается размер ячейки на карте в пикселах
(по умолчанию 16).
Текущая ячейка отображается на карте маленькой окружностью черного цвета.
Изменить текущую ячейку просто: щелкнуть кнопкой мыши на нужном участке
карты. Внизу каждой карты на градиентной шкале в желтом прямоугольнике отобра-
жается числовое значение признака, соответствующее цвету ячейки.
На рис. 16.8 приведены получившиеся карты Кохонена. По матрице плотности
попадания видно, что в одной ячейке сосредоточилось 259 объектов. Эта ячейка
выделяется белым цветом. Можно приступать к интерпретации результатов кла-
стеризации.
Рис. 16.8. Карты Кохонена для сегментации абонентов сети сотовой связи
Попробуем выделить на карте изолированные области самостоятельно (без
использования встроенного метода группировки ячеек алгоритмом k-means).
Анализируя карту Возраст (рис. 16.9), видим, что четко выделяются три возраст-
ные группы: молодежь, люди среднего возраста и люди старше 45 лет.
Остановимся подробнее на молодежи. Она неоднородна — здесь можно выде-
лить несколько кластеров. Первый расположен в правом нижнем углу (рис. 16.10).
Абоненты этой условной зоны активно и продолжительно разговаривают по
652 Часть II. Бизнес-анализ в Deductor
и пенсионный
возраст
Молодежь
Средневозрастная
группа
Рис. 16.9. Деление по возрастным группам
Рис. 16.10. Кластер «Активная молодежь»
телефону вечером и ночью, отправляют много SMS-сообщений, соответственно,
и тратят на разговоры больше денег, чем другие представители возрастной группы.
Обратите внимание, что в этот кластер попала львиная доля тех, кто увлекается
ночными разговорами. Можно предположить, что это студенты и молодежь, часто
проводящие вечера вне дома.
Вверху (рис. 16.11) сосредоточилась небольшая по числу ячеек группа молоде-
жи, которая не отличается активностью разговоров и пользования SMS-услугами
ни днем, ни вечером, ни тем более ночью, и, как следствие, ежемесячные расходы
на связь у представителей этого кластера невелики.
Остальные люди в этой возрастной группе ничем особенным не выделяются:
умеренные расходы на связь и преимущественно вечерние разговоры. Можно
I лава 16. Сегментация клиентов телекоммуникационной компании
653
предположить, что сюда попала наибольшая часть молодежи. Таким образом,
в молодежной возрастной группе мы обнаружили три кластера.
Рис. 16.11. Кластер молодежи с пониженным потреблением услуг связи
Продолжим интерпретацию карты Кохонена и теперь остановимся на людях
зрелого и пенсионного возраста. Обратим внимание на ярко выраженный сгу-
сток в нижней области, в котором практически по всем признакам, кроме SMS,
наблюдаются высокие значения, в том числе по звонкам в другие города и стра-
ны (рис. 16.12). Это так называемые VIP-клиенты: бизнесмены, руководители,
топ-менеджеры. Они преимущественно зрелого возраста, очень много разгова-
ривают днем и вечером (скорее всего, по работе) и практически не пользуются
SMS-услугами. Месячные расходы на связь у этой категории абонентов самые
высокие.
Сг^еднемесячнь». расхо, д л! I Средняя продолжитемьнис.х
Самые высокие
расходы
QC ' । :fl f
3,18 257| 3344,91 5142,8
1 250 5|34f ZS| 500
Продолжительные
разговоры
Звонки в другие страны w
Частые
международные
/ звонки
Рис. 16.12. Кластер «VIP-клиенты»
654 Часть II. Бизнес-анализ в Deductor
Чуть выше в небольшом кластере наблюдается противоположная картина:
люди практически не пользуются услугами сотовой сети (рис. 16.13). Вероятнее
всего, это пенсионеры, которым мобильная связь нужна преимущественно для
приема входящих звонков, сами же они почти не звонят. Их расходы на связь
самые низкие, возможно, из-за того, что единственным их доходом является
пенсия.
Изучим статистические характеристики этой группы людей.
Нажмите кнопку Показать/скрыть окно данных й , затем — кнопку Изменить
способ фильтрации и установите Фильтр по выделенному ▼ . Там же переключитесь
в режим статистики (кнопка Способ отображения). Колонка Среднее даст следующие
вычисленные значения (табл. 16.2).
Остальных людей в возрастной группе «Зрелый и пенсионный возраст» объ-
единяет то, что они в основном звонят вечером и не используют SMS-сервис.
С большой долей вероятности можно утверждать, что сюда входят работающие
пенсионеры, дачники, родители совершеннолетних детей.
Рис. 16.13. Пенсионеры, практически не делающие исходящих звонков
Таблица 16.2. Статистические характеристики кластера 5
№ Признак Среднее значение
1 Возраст 64,5
2 Среднемесячный расход 49,7
3 Средняя продолжительность разговоров, мин 2,1
4 Звонков днем за месяц 13,4
5 Звонков вечером за месяц 7,4
6 Звонков ночью за месяц 0,3
7 Звонки в другие города 0,5
Глава 16. Сегментация клиентов телекоммуникационной компании 655
№ Признак Среднее значение
8 Звонки в другие страны 0,05
9 Доля звонков на стационарные телефоны, % 5,7
10 Количество SMS в месяц 1,6
Осталась последняя, средневозрастная группа. Это кластер работающих лю-
дей. В нем можно отметить группу тех, кто совершает мало звонков вечером.
Теперь включите автоматическую группировку ячеек в кластеры: Настроить
отображения — Кластеры. При установленном флажке Автоматически определить ко-
личество кластеров (с уровнем значимости 1,00) будет работать алгоритм G-means
и получится И кластеров (рис. 16.14, а). Это очень много, поэтому следует при-
нудительно установить, скажем, 6 кластеров (рис. 16.14, б).
Рис. 16.14. Варианты группировки ячеек:
а — алгоритм G-means; б — алгоритм k-means
Видно, что алгоритм k-means при 6 кластерах выделил целиком кластер «Зре-
лый и пенсионный возраст», раздробились группы «Молодежь» и «Люди среднего
возраста». Не были явно выделены кластеры 2, 4 и 5 из табл. 16.3. Тем не менее
автоматическая группировка ячеек в Deductor имеет одно важное преимущество:
в наборе данных появляется столбец Кластер с номером, который можно исполь-
зовать в дальнейшем, в частности «прогонять» новые объекты и получать для них
номер кластера.
Кроме того, через визуализатор Профили кластеров можно изучить статистиче-
ские характеристики кластеров: мощность (число записей, попавших в кластер),
среднее и др. (рис. 16.15). Это очень полезно, так как карты Кохонена не позволяют
увидеть все детали. Кластерам можно дать краткие названия.
В этом визуализаторе особый интерес представляют две характеристики — зна-
чимость и доверительный интервал. Значимость выражается в процентах, и для
непрерывных полей используется t-критерий Стьюдента. 95%-ный доверительный
интервал представляется в виде графического изображения для среднего значения
кластера.
656 Часть II. Бизнес-анализ в Deductor
Рис. 16.15. Профили кластеров
На прилагаемом к книге компакт-диске данный сценарий в Deductor для сег-
ментации абонентов соответствует файлу som. ded.
Скоринговые
модели для оценки
17
кредитоспособности
заемщиков
Описание бизнес-задачи
Технологии кредитного скоринга — автоматической оценке кредитоспособности
физического лица — в банковской среде традиционно уделяется повышенное
внимание. Сегодня можно сказать, что экспертные методы уходят в прошлое, и все
чаще при разработке скоринговых моделей обращаются к алгоритмам Data Mining.
Классическую скоринговую карту можно построить при помощи логистической
регрессии на основе накопленной кредитной истории, применив к ней ROC-ана-
лиз для управления рисками. Кроме того, хорошие и легко интерпретируемые
модели можно получить, используя деревья решений.
Постановка задачи. В коммерческом банке имеется продукт «Нецелевой
потребительский кредит»: кредиты предоставляются на любые цели с принятием
решения в течение нескольких часов. За это время проверяются минимальные
сведения о клиенте, в основном такие, как отсутствие криминального прошлого
и кредитная история в других банках.
В банке накоплена статистическая информация о заемщиках и качестве об-
служивания ими долга за несколько месяцев. Руководство банка, понимая, что
отсутствие адекватных математических инструментов, позволяющих оптими-
зировать риски, не способствует расширению розничного бизнеса в области
потребительского кредитования, поставило перед отделом розничных рисков
658 Часть II. Бизнес-анализ в Deductor
задачу разработать скоринговые модели с различными стратегиями кредитова-
ния, которые позволили бы управлять рисками, настраивая уровень одобрений,
и минимизировать число «безнадежных» заемщиков.
Исходные данные. Вообще говоря, информация о заемщиках — физических лицах
и кредитных договорах хранится в банковской информационной системе. Там же со-
держатся графики и даты погашений кредита, сведения о просрочках, об их суммах,
о процентах и т. д. Получить для построения скоринговой модели таблицу с параме-
трами заемщиков и информацию о наличии просрочек — отдельная задача. Будем
считать, что она уже выполнена и результат представлен в виде текстового файла.
Важным также является вопрос о том, что понимать под параметрами заемщика.
Здесь уместно обратиться к главе 1, где рассматривались методические аспекты
подготовки и сбора данных для анализа, и вспомнить, что на этом этапе требуется
активное взаимодействие с экспертами: они с высоты своего опыта ограничат круг
входных переменных, которые потенциально могут влиять на кредитоспособность
будущего заемщика. Кроме того, следует учитывать аспекты бизнеса и технические
вопросы (например, сложно проверить в короткий срок достоверность признака
«Сфера деятельности компании», а потому полагаться на него не стоит).
Скоринговые модели часто строятся на категориальных переменных, и для
этого непрерывные признаки квантуются при помощи ручного выбора точек
разрыва (или полуручного, см., например, подраздел «Тест Чоу» в разделе 8.9).
Скажем, переменная Стаж работы разбивается на три категории: «до 1 года»,
«от 1 до 3 лет», «свыше 3 лет». Такую модель легче интерпретировать, но она ме-
нее гибкая при моделировании связей: горизонтальные «ступени» дают плохую
аппроксимацию при наличии частых крутых «склонов».
В банковской практике перед скорингом заемщик, как правило, проходит
процедуру андеррайтинга — проверку на удовлетворение жестким требованиям:
соответствие возрасту, отсутствие криминального прошлого и, конечно, наличие
определенного дохода. При этом выдвигаются требования к минимальному уров-
ню дохода и рассчитывается возможный лимит кредита. При его расчете участвует
один из двух коэффициентов — П/Д либо О/Д.
Коэффициент «Платеж/Доход» (П/Д) — отношение ежемесячных платежей
по кредиту заемщика к его доходу за тот же период. Считается, что значительная
величина этого коэффициента (свыше 40 %) свидетельствует о повышенном риске
как для кредитора, так и для заемщика.
Коэффициент «Обязательства/Доход» (О/Д) — отношение ежемесячных
обязательств заемщика к его доходу за тот же период с учетом удержаний налогов.
В обязательства включаются расходы, связанные с выплатой планируемого кре-
дита, а также имеющиеся другие долгосрочные обязательства (выплаты по иным
кредитам, на содержание иждивенцев, семьи, алиментов, обязательные налоговые
платежи и пр.). Считается, что размер ежемесячных обязательств заемщика не
должен превышать 50-60 % его совокупного чистого дохода.
Заявки клиентов, не прошедшие андеррайтинг, получат отказ и даже не попадут
на скоринг. Поэтому на вход скоринговой процедуры выгоднее подавать не доход
клиента, а отношение О/Д или П/Д.
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 659
В нашей задаче представлено 2709 кредитов (файл loans . txt) с известными
исходами платежей на протяжении нескольких месяцев после выдачи кредита. На-
бор данных уже разбит на два множества — обучающее (80 %) и тестовое (20 %) —
при помощи процедуры стратифицированного сэмплинга так, чтобы в каждом мно-
жестве доля плохих кредитов была примерно одинаковой. В табл. 17.1 отображены
структура и описание полей текстового файла с кредитными историями.
Таблица 17.1. Данные по заемщикам и качеству обслуживания ими долга
№ Поле Описание Тип
1 Код Служебный код заявки Целый
2 Дата Дата выдачи кредита Дата/время
3 о/д, % Коэффициент О/Д («Обязательства/До- ход»)в % Вещественный
4 Возраст Возраст заемщика (полных лет) на момент принятия решения о выдаче кредита Целый
5 Проживание Основание для проживания: собственник; муниципальное жилье; аренда Строковый
6 Срок проживания в регионе Менее 1 года; от 1 года до 5 лет; свыше 5 лет Строковый
7 Семейное положение Холост/не замужем; женат/замужем; разве- ден (-а)/вдовство; другое Строковый
8 Образование Среднее; среднее специальное; высшее Строковый
9 Стаж работы на по- следнем месте Менее 1 года; от 1 года до 3 лет; свыше 3 лет Строковый
10 Уровень должности Сотрудник; руководитель среднего звена; руководитель высшего звена Строковый
И Кредитная история Информация берется из бюро кредитных историй. Если имеется негативная инфор- мация о клиенте (просрочки по прошлым кредитам), то ему присваивается категория «отрицательная» Строковый
12 Просрочки свыше 60 дней Факт наличия просрочек свыше 60 дней: 0 — отсутствовали, 1 — имели место Целый
13 Тестовое множество Служебный признак, отвечающий за то, к ка- кому множеству относится запись. TRUE соответствует тестовому множеству Логический
Скоринговая карта на основе
логистической регрессии
Базовым статистическим алгоритмом, который строит аналог традиционной балль-
ной скоринговой карты, является логистическая регрессия (см. главу 8). С нее
и начнем решение задачи.
660 Часть II. Бизнес-анализ в Deductor
Импортируйте файл с кредитными историями в Deductor. Скоринг представляет
собой задачу бинарной классификации, которая относит заемщика к одному из двух
классов — «плохой» или «хороший». Если заемщик «хороший» — кредит выдается,
если «плохой» — выносится отрицательное решение. Разделение заемщиков на
«плохих» и «хороших» осуществляется на основе качества обслуживания ими дол-
га, проще говоря — наличия просрочек. В банковском деле существуют различные
шкалы перехода от числа просрочек к классу заемщика, и это тема для отдельного
обсуждения. Примем следующее правило: если у клиента была хотя бы одна про-
срочка свыше 60 дней, то он относится к классу неблагонадежных. Запустите Мастер
обработки, в категории Прочие выберите Калькулятор, запишите это условие, в резуль-
тате чего появится новое вычисляемое поле — Класс заемщика (рис. 17.1).
Рис. 17.1. Создание нового поля Класс заемщика
Далее с помощью визуализатора Статистика можно узнать, что имеется 500 запи-
сей с «плохими» кредитами, что составляет 18,5 % всех выданных кредитов. Это
не так уж и мало: в практике кредитного скоринга число записей миноритарного
класса может быть и меньше, вплоть до 1-3 %. Поэтому задача классификации
заемщиков всегда решается в условиях сильной несбалансированности классов
(см. раздел 12.6).
Таким образом, выходная бинарная переменная — Класс заемщика — у нас уже
имеется. В качестве входных имеет смысл оставить все, кроме Код иДата: очевид-
но, что они никак не влияют на кредитоспособность.
Поля Возраст и О/Д, % оставьте непрерывными.
Построим модель логистической регрессии, которая рассчитает соответству-
ющие коэффициенты регрессии. Для этого в сценарий после узла квантования
добавьте обработчик Логистическая регрессия. Установите входные и выходные поля,
как это показано на рис. 17.2.
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 661
Рис. 17.2. Задание входных и выходных полей
В этом же окне нажмите кнопку Настройка нормализации. Для выходного поля
Класс заемщика порядок сортировки уникальных значений (которых в логисти-
ческой регрессии всегда два) определяется типом события: первое — отрица-
тельное, второе — положительное (рис. 17.3). В скоринге принято, что чем выше
рейтинг заемщика, тем выше кредитоспособность, поэтому значение «хороший»
будет положительным исходом события (второе по счету), а «плохой» — отри-
цательным (первое по счету).
Рис. 17.3. Задание типов событий выходного поля
В следующем окне мастера будет предложено настроить обучающие и тестовые
множества. Поскольку у нас есть специальное поле, в котором хранится информа-
ция о разбиении на множества, укажем его, установив соответствующие настройки
(рис. 17.4).
662 Часть II. Бизнес-анализ в Deductor
Рис. 17.4. Настройка разбиения набора данных
На третьем шаге мастера предлагается изменить параметры алгоритма логисти-
ческой регрессии (рис. 17.5). По умолчанию порог классификации равен 0,5. Пока
оставьте его без изменений.
Р Максимальное число итераций |б00
Алгоритм расчета коэффициентов завершится, когда очередное значение
логарифмической Функции правдоподобия -2KLog[Likehood) прекратит
изменяться в пределах заданной точности.
Точность Функции оценки |1Е-7
Оценочной функцией является значение логарифма Функции правдоподобия
-S^LogfLikehood].
Порог отсечения |Ш5
Задача бинарной классификации будет решена на основе заданного порога
отсечения для поля со значением рейти-га
Считать пример распознанным, если ошибка меньше СБ
Рис. 17.5. Настройки алгоритма логистической регрессии
На последнем шаге нажмите кнопку Пуск — будет построена модель и мастер
предложит выбрать визуализаторы узла. Укажите следующие: ROC-анализ, Коэф-
фициенты регрессии, Что-если, Таблица сопряженности, Таблица.
В визуализаторе Таблица видно, что добавились две новые колонки: Класс заем-
щика Рейтинг и Класс заемщика_ОиТ (рис. 17.6). Рейтинг представляет собой рассчи-
танное значение у по уравнению логистической регрессии, а второе поле определяет
принадлежность к тому или иному классу в зависимости от порога округления.
Визуализатор Коэффициенты регрессии наглядно показывает рассчитанные коэф-
фициенты логистической регрессии, которые являются прототипом скоринговой
карты, и соответствующие им отношения шансов (рис. 17.7).
Проинтерпретируем отношение шансов для признака Стаж работы. Если стаж
работы на последнем месте от 1 до 3 лет, то шансы стать благонадежным заемщи-
ком при фиксированных значениях других переменных в OR =1,71 раза выше
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 663
по сравнению с тем, у кого стаж менее 1 года. А если стаж свыше 3 лет, то шансы
увеличиваются в 2,67 раза.
из - Й’ Ю А ▼ ч 22 / 2709 ►
Класс Класс J Класс заемщика
заемщика . заемщика_ОПТ j Рейтинг
Плохой Плохой 0.3896
Хороший Хороший 0.9976
Хороший Хороший 0.9253
Плохой .Хороший 0,5858
Хороший .Хороший 0,8516
Плохой Плохой 0,4219
Хороший Хороший 0,7817
Хороший Хороший 0.9160
Хороший .Хороший 0.9979
Хороший Хороший 0.9222
Плохой ’Плохой 0.3101
Хороший : ХОРОШИЙ 0.9963
Хороший Хороший 0.9806
Плохой Хсрсшай 0,9818
Рис. 17.6. Выходные поля
Рис. 17.7. Коэффициенты логистической регрессии
Проинтерпретируем теперь отношение шансов для поля ОД, %: OR = 0,96.
Оно меньше единицы, значит, увеличение кредитной нагрузки снижает итоговый
скоринговый балл клиента. Рассмотрим потенциального заемщика А, у которого
доля выплат по кредиту в структуре дохода на 10 % меньше, чем у заемщика Б.
664 Часть П. Бизнес-анализ в Deductor
Тогда можно сказать, что снижение ежемесячных выплат на 10 % приводит к тому,
что вероятность стать хорошим заемщиком вырастает в ехр (10 • 0,041506) =
= 1,52 раза.
Визуализатор ROC-кривая выводит график ROC-кривой, на котором по умол-
чанию отображаются положение текущего порога отсечения, а также значения
чувствительности и специфичности, показатель AUC и типы событий (рис. 17.8).
Площадь под кривой равна 0,894 на обучающем множестве и 0,905 — на тесто-
вом, что говорит об очень хорошей предсказательной способности построенной
модели.
Рис. 17.8. График ROC-кривой скоринговой модели
Однако оптимальная точка для данной модели не равна 0,5. Максимальная
суммарная чувствительность и специфичность достигается в точке 0,78 (для рас-
чета и отображения оптимальной точки необходимо в меню кнопки Тип оптималь-
ной точки выбрать пункт Максимум). Для установки нового порога отсечения,
равного 0,78, следует перенастроить узел-обработчик логистической регрессии.
В этой точке Se = 85 %, Sp = 86 %, что означает: 85 % благонадежных заемщиков
будут выявлены классификатором, а 100 — 86 = 14 % недобросовестных заемщиков
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 665
получат кредит. На тестовом множестве наблюдается похожая картина: Se = 84 %,
Sp = 86 %.
В общем случае, проецируя определения чувствительности и специфичности
на скоринг (и учитывая, что класс заемщика «хороший» соответствует положи-
тельному исходу), можно заключить, что скоринговая модель с высокой специ-
фичностью соответствует консервативной кредитной политике (чаще происходит
отказ в выдаче кредита), а с высокой чувствительностью — политике рискованных
кредитов. В первом случае минимизируется кредитный риск, связанный с потерями
ссуды и процентов и с дополнительными расходами на возвращение кредита, а во
втором — коммерческий риск, связанный с упущенной выгодой. Это хорошо иллю-
стрирует визуализатор Таблица сопряженности (рис. 17.9), которая есть не что иное,
как матрица классификации (см. раздел 4.4).
a
Рис. 17.9. Таблицы сопряженности: а — рабочая выборка, б — тестовая выборка
Из таблицы видно, что на обучающем множестве модель чаще отказывала
в выдаче кредита «хорошим» заемщикам (271 ошибочный случай), чем выдавала
кредит «плохим» (см. рис. 17.9, а). Точность классификации составила 85 %. На те-
стовом множестве наблюдается примерно та же картина (точность классификации
84,7 %), а уровень одобренных кредитов (Approval Rate, AR) здесь составляет
AR = (387 / 542) • 100 % = 72 % при уровне дефолтных кредитов (Bad Rate, BR)
равном BR = (14/387) • 100 % = 3,62 % (см. рис. 17.9, б). Если такая ситуация не
устраивает, можно снизить порог отсечения и добиться того, чтобы модель чаще
выдавала положительное решение. Процент отказов уменьшится, но возрастет
и кредитный риск. Поэтому выбор точки отсечения зависит от поставленных
целей — снизить долю «плохих» кредитов или увеличить кредитный портфель,
чаще вынося положительное решение по клиенту.
Предположим, нам известны издержки ошибочной классификации (см. раз-
дел 12.3): CFN/CFP = i/i, то есть выдача кредита недобросовестному заемщику
обходится в 4 раза дороже, чем отказ добросовестному. Тогда мы можем, используя
правило Байеса, оценить оптимальный скоринговый балл Р:
„ 1
= 0,80.
1 + 1/4
Визуализатор Что-если позволяет увидеть, как будет вести себя построенная
модель при подаче на ее вход тех или иных данных. Иначе говоря, проводится
666 Часть II. Бизнес-анализ в Deductor
эксперимент, в котором, изменяя значения входных полей логистической регрес-
сии, аналитик наблюдает за изменением значений на выходе. Возможность ана-
лиза по принципу «Что, если» особенно ценна, поскольку позволяет исследовать
правильность работы системы, достоверность полученных результатов, а также ее
устойчивость. Визуализатор Что-если включает табличное и графическое представ-
ления, которые формируются одновременно (рис. 17.10).
Рис. 17.10. Визуализатор «Что-если»
В верхней части табличного представления отображаются входные поля,
а в нижней — выходные и расчетные. Изменяя значения входных полей, аналитик
дает команду выполнить расчет и наблюдает рассчитанные значения выходов
логистической регрессии.
В графическом представлении визуализатора Что-если по горизонтальной оси
диаграммы откладывается весь диапазон значений текущего поля выборки, а по
вертикальной — значения соответствующих выходов модели. На диаграмме Что-
если видно, при каком значении входа изменяется значение на соответствующем
выходе. Если, например, во всем диапазоне входных значений выходное значение
для данного поля не изменялось, то диаграмма будет представлять собой горизон-
тальную прямую линию. В нашем случае установлена графическая зависимость
изменения кредитного рейтинга конкретного клиента от коэффициента О/Д (все
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 667
остальные входы — константы). Видно, что с увеличением О/Д рейтинг практи-
чески линейно падает.
При желании от модели логистической регрессии несложно перейти к скорин-
говой карте, для чего нужно перевести коэффициенты логистической регрессии
в линейную шкалу.
Итак, подбирая порог отсечения, мы можем установить желаемое соотношение
уровня одобрений AR и ожидаемой величины просроченной задолженности BR.
Интересует вопрос, как сравнить несколько скоринговых карт между собой.
Для этого строят различные отчеты и графики. Например, подвергают анализу
кривые распределения кумулятивных процентов для хороших и плохих кредитов.
По оси ох откладывают диапазоны скорингового балла, а по оу — накапливающую-
ся долю плохих (хороших) кредитов.
Сформируем такой отчет в Deductor. Нам понадобятся несколько узлов из
группы Трансформация данных'. Квантование, Группировка, Кросс-таблица, Замена
данных и Калькулятор (преобразования, выполняемые ими, описывались в гла-
ве З)1, а также визуализатор Диаграмма. На рис. 17.11 можно наблюдать график,
отражающий кумулятивный процент хороших и плохих кредитов нашей скорин-
говой карты.
Рис. 17.11. Распределения кумулятивных процентов в скоринговой модели
Видно, что кривая для плохих кредитов проходит выше и обладает более кру-
тым подъемом, чем кривая для хороших, поскольку в области низких значений
' См. также документ «Руководство аналитика» в составе Deductor.
668 Часть П. Бизнес-анализ в Deductor
сосредоточено больше плохих кредитов. Если скоринговая карта неэффективна
эти кривые будут похожи, а в пределе — налагаться друг на друга.
Окончательный сценарий будет иметь следующий вид (рис. 17.12).
Сцена.
г в; р Ж ? i В X _
т- Сценарии
да Ц] Текстовый Файл (loans.txt)
Калькулятор: Класс заемщика
& ёИ- Логистическая регрессия (порог 0,78)
•5 Фильтр ([Тестовое множество] ложь]
3 Э Калькулятор: Скоринговый балл
& == КРИВЫЕ РАСПРЕДЕЛЕНИЯ СКОРИНГОВОГО БАЛЛА ==
Ч !►[□ Квантование (Класс заемщика Рейтинг)
ё {= Группировка [Измерения: Балл, класс; Факт: число кредитов]
s |Й| Кросс-таблица (Строки: балл; Колонки: класс)
Ы * Замена значений
э 2Ц Калькулятор: % от общего числа
- Настройка набора данных
ИЗ Калькулятор: Кумулятивные %
ёВ- Логистическая регрессия (порог ОДО)
Рис. 17.12. Сценарий построения скоринговой модели на основе логистической регрессии
Скоринговая модель на основе дерева решений
Теперь воспользуемся другим инструментом — деревом решений (см. главу 9).
Добавьте в сценарий одноименный узел через Мастер обработки (рис. 17.13).
Рис. 17.13. Окно выбора нового узла обработки
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 669
Следующие два шага мастера аналогичны описанным ранее для узла Логи-
стическая регрессия. На четвертом шаге откроется окно выбора параметров алго-
ритма С4.5 (рис. 17.14). Здесь не меняйте настройки, принятые по умолчанию,
за исключением минимального количества примеров в узле, при котором будет
создаваться новый. Задайте этот параметр равным примерно 1 % от объема обу-
чающего множества; меньшее значение может привести к появлению недостовер-
ных правил, большее — к почти полному отсутствию таковых.
Рис. 17.14. Настройка алгоритма дерева решений
На следующем шаге в качестве желаемого способа построения дерева оставь-
те режим автоматического построения — это и есть алгоритм С4.5. Запустив его
нажатием кнопки Пуск, пройдите по шагам мастера дальше и выберите нужные
визуализаторы, как показано на рис. 17.15.
В результате работы алгоритма было выявлено 18 правил; точность классифи-
кации на обучающем множестве составила 85 %, на тестовом — 87 %. Визуализатор
Дерево решений позволяет увидеть полученный набор правил в схематическом
виде, а также выводит показатели достоверности и поддержки для каждого узла
(рис. 17.16). Это и есть скоринговая модель. Она менее привычна, поскольку здесь
не начисляются баллы за характеристики заемщика, но тоже объясняет результат
классификации того или иного заемщика.
В принципе, достоверность каждого правила можно воспринимать как итоговый
скоринговый балл с той оговоркой, что для плохих заемщиков он равен величине,
полученной вычитанием из 100%-ного значения достоверности.
Теперь откройте таблицы сопряженности этого дерева решений (рис. 17.17).
Оказывается, в сравнении с моделью на основе логистической регрессии здесь
совершенно другая ситуация. Дерево решений значительно чаще одобряет неблагона-
дежных заемщиков, потому что его построение идет в условиях несбалансированности
670 Часть II. Бизнес-анализ в Deductor
Рис. 17.15. Выбор визуализаторов узла
Рис. 17.16. Скоринговая модель — дерево решений
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 671
а
Рис. 17.17. Таблицы сопряженности: a — рабочая выборка; б — тестовая выборка
б
классов. В результате доля дефолтных кредитов на тестовом множестве равна BR =
= 51 /475 100 % = 10,7 %, что в 3 раза выше этого же показателя в логрегресионной
модели (правда, уровень одобрений вырастает до 87,6 %). Что делать, если такая си-
туация не устраивает? В логистической регрессии для решения этой проблемы мы
варьировали порогом отсечения, а в дереве решений такой возможности нет.
Нам помогут специальные стратегии сэмплинга для уравновешивания обучающего
множества, которые подробно изучались в разделе 12.6: выборка с дублированием
миноритарного класса (oversampling) и выборка с удалением примеров мажоритар-
ного класса (undersampling). Поскольку примеров не так много (400 — с плохими
клиентами и 1767 — с хорошими) и информация о каждом заемщике представляет
ценность, имеет смысл использовать первый вариант — с дублированием. Пусть
отношение издержек ошибочной классификации останется прежним: 1:4. Тогда,
согласно правилу, к обучающей выборке нужно добавить 3 • 400 = 1200 примеров,
и общее число записей составит 3367, а доля плохих увеличится до 47 %.
ЗАМЕЧАНИЕ ---------------------------------------------------------
Процедуру дублирования записей, принадлежащих к миноритарному классу, нужно осуще-
ствлять только на обучающем множестве.
Для этой операции снова привлечем несколько узлов из группы Трансформация
данных'. Фильтр и Слияние данных (рис. 17.18, выделенный блок).
Сценарии
|С-ценарм»1|
Б1 [Й] Т екстовый файл (loans, txt)
£3 Я Калькулятор: Класс заемщика
> Дерево решений (автоматическое)________________________
f && == ПРОЦЕДУРА OVERSAMPLING == \
BY Фильтр - обучающее множество
V Фильтр ([Класс заемщика] = 'Плохой'}
• Объединение (Фильтр ([Класс заемщика] = 'Плохой'))
Объединение (Фильтр ([Класс заемщика] = 'Плохой')] j
К_____________ез» Объединение (Фильтр ([Класс заемщика] = 'Плохой'])
№ Дерево решений (oversampling. Фактор 4]
& V" Фильтр ([Тестовое множество] истина)
S Скрипт (2Б-26): ("Дерево решений (oversampling. Фактор 4J")
Рис. 17.18. Сценарий построения скоринговой модели на основе дерева решений
672 Часть II. Бизнес-анализ в Deductor
Рис. 17.19. Таблица сопряженности
для тестовой выборки (процедура
oversampling)
Построив дерево решений на сба-
лансированной выборке, убедитесь, что
ситуация улучшилась: теперь на тесто-
вом множестве модель чаще отказывает
в выдаче хорошим заемщикам, нежели
одобряет плохих (рис. 17.19). Эти ре-
зультаты сравнимы с теми, которые вы-
дает модель логистической регрессии.
Таким образом, мы получили несколь-
ко скоринговых моделей. Варьируя поро-
гами отсечения и применяя специальные
приемы борьбы с несбалансированностью классов, можно подобрать ту модель, кото-
рая отвечает заданным потребностям кредитного учреждения по уровню одобрений
заявок и ожидаемой доле просроченной задолженности. Проверять новых клиентов
можно при помощи обработчика Скрипт.
Интерактивное дерево решений
До этого мы получали дерево, которое строилось автоматическим способом, то есть
алгоритм на каждом шаге выбирал атрибут для разбиения по заданному критерию.
В главе 9 также говорилось о том, что алгоритмы построения деревьев «жадные»,
поэтому не факт, что итоговое дерево будет наилучшим. В то же время иногда
имеются экспертные знания, которые позволяют «вмешаться» в процесс форми-
рования дерева и выбора атрибутов, а также порогов для разбиения. Возможно,
это и не повысит точность модели, но правила станут более логичными, с точки
зрения экспертов.
Кредитный скоринг представляет собой тот самый случай, когда банковские
аналитики имеют определенные знания и хотят, чтобы в модели ветвление по
атрибутам осуществлялось в определенном порядке. Например, если имеются
атрибуты Наличие квартиры и Стоимость квартиры, то разумно сразу после
первого рассмотреть второй. Еще пример: после суммы кредита сразу желательно
проанализировать первоначальный взнос.
В аналитической платформе Deductor имеется возможность построения
интерактивных деревьев решений. Зададимся целью построить скоринговую
модель на прежней выборке, приняв во внимание следующие пожелания экс-
пертов.
□ Первым атрибутом, по которому анализируют заемщика, должен быть атрибут
Кредитная история.
□ Далее необходимо рассмотреть коэффициент О/Д. Всех клиентов нужно
разбить на три категории: заемщики с низким О/Д (до 20 %), с умеренным
(от 20 до 40 %) и высоким (от 40 %).
Добавьте в сценарий новый узел дерева решений и на пятом шаге мастера по-
ставьте переключатель в позицию Интерактивный режим (рис. 17.20).
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 673
Мастер обработки - Дерево решений (5 из 8)
Способ построения
Укажите желаемый способ построения дерева решения
Г* Автоматическое построение
Дерево решений будет построено автоматически по нажатию на кнопку '’Пуск*' на
следующей странице "Построение дерева решения" мастера обработки.
Интерактивное построение,-
Дерево решений необходимо будет в дальнейшем строить полуавтоматически с помощью
элементов управлениявизуализатора "Дерево решений", находящегося в интерактивном
режиме. После окончания построения, необходимо выйти из интерактивного режима.
< Назад I Далее > 1 Отмена
Рис. 17.20. Выбор способа построения дерева решений
В результате открывшийся визуализатор Дерево решений не будет содержать ни
одного узла. На панели инструментов нажмите кнопку Разбить текущий узел на
подузлы..., откроется соответствующее окно (рис. 17.21).
Рис. 17.21. Окно выбора атрибута для разбиения в интерактивном режиме: первый шаг
674 Часть II. Бизнес-анализ в Deductor
Слева в списке выводятся все атрибуты вместе с рассчитанными значения-
ми прироста информации Gain Ratio (см. раздел 9.3), а справа — диаграммы
распределения классов по подузлам. По умолчанию предлагается атрибут
с максимальным значением Gain Ratio, но его можно переопределить. В дан-
ном случае ничего делать не нужно, поскольку разбиение и так начнется по
атрибуту Кредитная история. Нажатие кнопки Ок приведет к тому, что в дерево
добавится три узла этого атрибута со значениями нет данных, отрицательная,
положительная.
Продолжим разбиение дальше, выбрав узел Кредитная история = нет данных
(рис. 17.22).
уз«
Параметры разбиения I Информация о разбиваемом узле |
< № '6 . ® ’
0k j Отмена
Рис. 17.22. Окно выбора атрибута для разбиения в интерактивном режиме: второй шаг
Здесь в качестве оптимального с точки зрения прироста информации пред-
лагается атрибут Проживание. Переопределите его на ОД, %, указав в нижней
части окна порог, равный 20. Затем для узла ОД, % >20 снова выберите раз-
биение по ОД, %, но уже с порогом 40, после чего нажмите кнопку Л Построить
дерево, начиная с текущего узла. В результате ветвь дерева будет полностью готова
(рис. 17.23).
Аналогичным образом достраивается дерево для оставшихся узлов. Качество
классификации, как и прежде, можно оценивать через таблицы сопряженности.
Сценарии Deductor, рассмотренные в главе, называются scorecardl .ded
и scorecard2 . ded и находятся на прилагаемом к книге компакт-диске.
Глава 17. Скоринговые модели для оценки кредитоспособности заемщиков 675
"3 *5 .кдЛ х а ® *
Рис. 17.23. Дерево решений, построенное в интерактивном режиме
Прогнозирование
продаж товаров
в оптовой компании
18
Описание бизнес-задачи
Постановка задачи. Оптовая компания занимается сбытом строительных материа-
лов. Ассортимент насчитывает несколько тысяч товарных позиций, объединенных
в группы (сухие смеси, грунтовка, напольные покрытия, плитка и т. д.). Менедже-
рам отдела логистики постоянно приходится решать задачи прогнозирования
спроса, но большой ассортимент продукции не позволяет уделять каждой позиции
должное внимание. Руководство поставило цели: снизить логистические затраты,
повысить стабильность запасов и оптимизировать их структуру. Более конкретно
требования формулируются следующим образом:
□ автоматизировать ежемесячный расчет потоварного прогноза на следующие
три периода;
□ обеспечить аналитикам компании доступ, к рассчитанным прогнозам для пла-
нирования запасов и формирования заказов.
Для этого было принято решение о внедрении системы автоматического расчета
потребности в товарах.
Исходные данные. В наполненном хранилище данных о продажах товаров
(начиная с 2004 г.) имеется единственный процесс Продажи с измерениями Дата
продажи, Товар, Товарная группа и фактами Количество и Сумма.
Решение задачи
Нужно сразу оговориться, что задача прогнозирования спроса не имеет единой
методики решения (см. раздел 10.4 и главу 14). Не существует надежного способа
количественной оценки наиболее существенных факторов, влияющих на спрос,
Глава 18. Прогнозирование продаж товаров в оптовой компании
677
что еще сильнее проявляется в условиях рыночных отношений. Хороший анали-
тик, прогнозирующий спрос, использует все имеющиеся факты — количественные
и качественные, а также интуицию, в основе которой лежит опыт работы на данном
рынке. Но проблема заключается в том, что при большом ассортименте и частом
обновлении спроса ручная обработка каждой товарной позиции не представля-
ется возможной. Необходимо максимально автоматизировать эти процедуры.
Например, можно построить несколько прогнозных моделей временных рядов для
каждой товарной группы, выбрать из них оптимальную при помощи какого-либо
критерия качества и перейти к позиционным прогнозам (рис. 18.1).
Рис. 18.1. Автоматизированный процесс получения прогноза спроса
Это не единственный вариант: можно отказаться от группировки и обрабаты-
вать каждую позицию по отдельности или сгруппировать товары по ABC-XYZ-
категориям и т. д.
Описанный общий подход не обеспечивает идеального результата и не гаранти-
рует высокую точность прогнозов: это невозможно в принципе. Но гарантируется,
что будет получен лучший из возможных вариантов прогноза. А поддерживаемые
аналитическими платформами механизмы очистки, группировки и подстройки
678 Часть II. Бизнес-анализ в Deductor
под новые данные позволят постепенно повышать качество прогнозов, быстро до-
бавлять или изменять прогностические модели.
С помощью сценариев в Deductor несложно реализовать такую схему. По-
кажем этапы создания сценария на примере товарной группы «Грунтовка».
Построим несколько моделей временных рядов, затем выберем наилучшую
и рассчитаем по ней прогноз, проделаем разгруппировку по товарным позици-
ям, а результат прогноза сохраним в хранилище данных. В качестве моделей
прогноза выберем:
□ «наивную» модель скользящего среднего за предыдущие три месяца;
□ линейную регрессию с периодами: (1,2,3), (1,2, 6) и (1, 2,12) месяцев.
Соответствующий сценарий обработки данных приведен на рис. 18.2.
га Ш Сценарии
В □ 11 ] Стройматериалы: Продажи (1 группа)
Ss === Переименование столбцов ===
В ПГ1 [2] П реобразование даты (Дата: Год + Месяц)
В {1 [3) Группировка по месяцам
Р {4) Скользящее окно (Кол-во (-12:0))
В®™ МОДЕЛЬ! ===
© [А! ]М одель "Скользящее среднее 3 мес"
В @ [А2] Прогноз (горизонт: 3)
© [АЗ] Прогноз по модели 1
В Э* [А4] Объединение (Прогноз по модели 2)
©#* | А5] Объединение (Прогноз по модели 3)
U р* [А6] Объединение (Прогноз по модели 4)
’3 [А7] Выбор прогноза с мин. ошибкой
Ё Я [А8) Калькулятор: Дата прогноза
В <Ш [А9] Разгруппировка данных (Товар.Код)
3 [А10] Загрузка вХД - Прогноз
SJ {« (В 1 ] Группировка (Факты. Кол-во_ЕЯЯ)
Я®=== МОДЕЛЬ 2 ===
Ё40: [С! ] Линейная регрессия (2x1)
© [С2] Прогноз [горизонт: 3)
[СЗ] Модель 2
©{« [04] Группировка (Факты: Кол-во_ЕПВ)
Н [05] Калькулятор: Ошибка модели 2
ЙИ=== МОДЕЛЬ 3===
Ей И —МО ДЕ ЛЬ 4^
Рис. 18.2. Сценарий получения прогноза в Deductor
В первом узле из хранилища импортируются данные о продажах, после чего они
группируются по месяцам и строится диаграмма, представляющая собой временной
ряд продаж позиций товарной группы «Грунтовка» (рис. 18.3).
В узле под номером 4 ряд приводится к специальному виду для построения
моделей при помощи скользящего окна (см. раздел 3.2). Дальше сценарий делится
на четыре практически идентичные ветви, в каждой из которых строится та или
иная модель временного ряда.
Для «наивной» модели скользящего среднего используется обработчик Поль-
зовательская модель, для остальных — Линейная регрессия. После каждого такого
обработчика при помощи узла Прогнозирование (например, узлы А2, С1) рассчиты-
вается прогноз на заданное число периодов.
Глава 18. Прогнозирование продаж товаров в оптовой компании 679
Рис. 18.3. Временной ряд продаж товаров из группы «Грунтовка»
В качестве критерия качества выберем среднеквадратическую ошибку, рассчи-
тываемую на ретропрогнозе:
•I ; — 1
где pi, р2... р„ — значения ряда, предсказанные моделью;
Xi, х2... х„ — фактические значения.
В специальной ветви сценария (рис. 18.4) сливаются в один набор данных ошиб-
ки для каждой из моделей (узлы Bl — В5) и среди них выбирается минимальная
(В6 - В7).
S {i (В1) Группировка (Факты: Кол-во_ЕВВ)
В Н [В 2] Калькулятор: Ошибка
Э-а» [ВЗ] Объединение (Калькулятор: Ошибка модели 2)
Й [В4] Объединение (Калькулятор: Ошибка модели 3)
В [В5] Объединение (Калькулятор: Ошибка модели 4]
В zl РВ] Сортировка: Ошибка
[В 7] Группировка (минимальная ошибка)
Рис. 18.4. Ветвь сценария, сравнивающая прогностические модели
В узлах А4 — А6 все прогнозы объединяются в один набор данных, и на основе
информации из узла В7 о номере модели с минимальной ошибкой выбирается
оптимальный прогноз. В нашем случае таким оказался прогноз на основе линейной
регрессии с месяцами 1,2 и 12 (рис. 18.5).
680 Часть II. Бизнес-анализ в Deductor
Рис. 18.5. Диаграмма рассеяния для модели 4
После получения прогнозной цифры по группе прогнозирования производится
так называемая разгруппировка. Наиболее простой способ распределения квот — сде-
лать предположение о том, что если продукция рассматриваемой прогнозной группы
товаров в определенный период продавалась в известных пропорциях, то какое-то вре-
мя данные товары будут продаваться в тех же пропорциях с поправкой на новый про-
гноз (этот период называется периодом актуальности). Для этой операции в Deductor
имеется готовый обработчик Разгруппировка (рис. 18.6, см. также раздел 3.3).
Рис. 18.6. Разгруппировка
Глава 18. Прогнозирование продаж товаров в оптовой компании 681
Рассчитанный прогноз необходимо сохранить. Для этого откроем Редактор ме-
таданных и создадим новый процесс Прогноз с измерениями Дата прогноза и Товар.
Код и единственным фактом Количество (рис. 18.7).
Ъ/ Редактор метаданных [Стройматериалы]
ЧП * X & * ’
Объект И г-.я Имя ••JS DATE 2
hi iWl Процессы ffi Продажи ; S Прогноз ? SALES ? FORECAST Метка Описание Тип данных : Дата прогноза ,Дата/Время
|^] Атрибуты О-(txl Измерения = -^4 Товар.Код ab GOOD_ID_2 Видимый Измерение и (S-DATElUara
Дата прогнозе! 0 S_DATE_2 ’
Э TTf] Факты [ГН Кол-во Я ^Измерения ffi 14 Товар.Код ЕЙ 14 Группа товара 12 KOL 0 S-DATE ab GOODJD ab GOOD_GROUP
Рис. 18.7. Добавление процесса «Прогноз» в хранилище
Если запустить выполнение этого сценария в пакетном или серверном режиме
для всех товарных групп, то мы получим прогноз, рассчитываемый автоматически без
участия человека, который удобно просматривать в виде OLAP-куба (рис. 18.8).
Рис. 18.8. Прогноз в виде OLAP-куба
На компакт-диске сценарий прогноза называется forecast. ded, а хранилище
данных — materials . gdb.
Повышение
эффективности
19
массовой рассылки
клиентам
Описание бизнес-задачи
В главе 12 мы познакомились с формулировкой бизнес-задачи о прямой почтовой
рассылке рекламы, где главной целью ставилась минимизация рассылок клиентам,
которые не откликаются на рекламу. Вместе с тем классификация с учетом издер-
жек в директ-маркетинге имеет свои особенности, на которые мы обратим особое
внимание при разборе примера.
Постановка задачи. Торговая компания, осуществляющая продажу товаров,
располагает информацией о своих клиентах и их покупках. Компания провела рек-
ламную рассылку 13 504 клиентам и получила отклик в 14,5 % случаев. Необходи-
мо построить модели отклика и проанализировать результаты, чтобы предложить
способы минимизации издержек на новые почтовые рассылки.
Исходные данные. Набор данных содержит информацию о 13 504 клиентах,
включая известные отклики на рекламную рассылку и такие сведения, как пол;
возраст; сколько лет данный человек является клиентом компании; суммарная
стоимость всех заказов клиента; общее число покупок; факты обращений в службу
поддержки и др. Всего для анализа доступно 9 независимых и 1 зависимая пере-
менная. Имеется также следующая информация (будем использовать обозначения,
аналогичные принятым в разделе 12.4):
□ расходы на одну рассылку СМ =1,0 ед.;
□ издержки на обслуживание клиента CR = 9,0 ед.;
□ ожидаемая выручка с 1 заказа R = 20,0 ед.
Глава 19. Повышение эффективности массовой рассылки клиентам 683
Решение задачи
Сформулированная выше бизнес-задача сводится к бинарной классификации.
Но сначала разберемся в типах ошибок классификации применительно к массовой
рассылке (табл. 19.1).
Таблица 19.1. Доход-издержки в массовой рассылке
Исход Предсказано моделью Фактически Доход, ед. Комментарий
TN Нет отклика Нет отклика 0 Нет контакта, нет издержек
ТР Есть отклик Есть отклик (R-CM-CR) = = 10,0 Ожидаемая выруч- ка минус расходы на обслуживание и рассылку
FN Нет отклика Есть отклик 0 Нет контакта, нет издержек
FP Есть отклик Нет отклика СМ=-1,0 Печать, упаковка и доставка по почте рассылки
Заметим, что в столбце «Доход, ед.» издержки записаны как отрицательный
доход.
Формула для расчета дохода будет иметь вид:
Р=ТР-(R-CM-CR)-FP-СМ.
Чтобы оценить прогностическую силу классификационной модели, необхо-
димо с чем-то сравнить эффективность ее работы — в данном случае с моделью
«разослать всем». То есть мы рассчитаем, какую прибыль получим, если проведем
рассылку всем клиентам (при этом моделирования не потребуется). Более того,
такой расчет нужно выполнять не на обучающем, а на тестовом множестве. Объем
тестового множества обычно варьируется от 10 до 50 %; мы выберем 40 % (5402 за-
писи, из которых в 781 случае есть отклик, в 4621 — отклик отсутствует). Тогда
доход составит (781 • 10,0 - 4621 • 1,0) = 3189 ед.
Нам нужна модель, которая будет давать доход больше этой величины.
Импортируем в Deductor два текстовых файла — responsesl.txt
и responses2 . txt с обучающим и тестовым множествами соответственно. Открыв
статистические характеристики, обнаружим, что доля клиентов с положительным
откликом в обучающем множестве составляет 14,5 %. Иначе говоря, распределение
классов в выходной переменной неравномерное. В таких случаях нежелательно стро-
ить модель на всем доступном множестве примеров, а рекомендуется предварительно
уравновесить их (см. раздел 12.6).
В главе 17, рассматривая бизнес-задачу о кредитном скоринге, мы уже стал-
кивались с несбалансированностью классов, для борьбы с которой использовали
правило Байеса для расчета порога в логистической регрессии и процедуру отбора
684 Часть II. Бизнес-анализ в Deductor
с дублированием миноритарного класса (oversampling) в дереве решений. В за-
даче о массовой рассылке мы построим предсказательные модели двумя метода-
ми — снова с помощью логистической регрессии и нейронной сети (многослойный
персептрон, алгоритм ВаскРгор). Для этого в Deductor имеются соответствующие
узлы-обработчики. Число примеров в нашем случае достаточное, так что для ней-
ронной сети уравновесим их с помощью процедуры удаления примеров мажори-
тарного класса (undersampling). Отметим еще раз, что при проверке модели урав-
новешивать тестовое множество ни в коем случае нельзя, поскольку мы смотрим,
как будет вести себя модель в реальных условиях.
Перед моделированием полезно оценить влияние входных переменных на вы-
ходную. Воспользуемся обработчиком Корреляционный анализ и откроем визуали-
затор Матрица корреляции (рис. 19.1). Там мы, в частности, видим, что количество
покупок и потраченные суммы сильно влияют на отклик на рассылку и демонст-
рируют положительную связь.
Рис. 19.1. Корреляция с полем «Отклик»
Приступим к построению моделей Data Mining. Импортируйте в сценарий
текстовые файлы responses 1. txt и responses2 . txt и постройте модель логи-
стической регрессии на данных первого файла, задав входные и выходное поля, как
показано на рис. 19.2. Положительным исходом будет считаться наличие отклика.
Из табл. 19.1 следует, что отношение издержек обоих типов ошибок равно 10:1. Со-
гласно правилу Байеса порог отсечения нужно установить равным 10 / И = 0,909.
На следующем шаге добавьте обработчик Скрипт к узлу импорта второго файла.
Скрипт должен ссылаться на модель логистической регрессии. В результате вы полу-
чите вероятности отклика для каждой записи из тестового множества (рис. 19.3).
В задачах массовой рассылки не обойтись без анализа Lift-диаграммы (см. раз-
дел 12.4). Для ее построения необходимо отсортировать примеры в порядке уменьше-
ния вероятности положительного исхода. Это легко сделать, так как в выходном набо-
ре данных узла Логистическая регрессия присутствует поле Отклик Рейтинг. Для других
алгоритмов машинного обучения вопрос, по какому полю сортировать, решается
каждый раз отдельно. Построим Lift-кривую, когда по оси оу откладывается кумуля-
тивный процент откликов. Фрагмент сценария, реализующий формирование лифт-
таблицы, состоит из пяти узлов (с учетом сортировки) и представлен на рис. 19.3.
Глава 19. Повышение эффективности массовой рассылки клиентам 685
И
Мастер обработки - Логистическая регрессия (1 из Б)
Настройка назначений столбцов
Задайте назначения исходных столбцов данных
ЯЯпи
© Код клиента
Возраст
колько лет клиент
Имя столбца COL5
Количество позиции товаров
Доход с клиента, тыс. ед.
Общее число покупок
^Обращений в службу поддержки
Задержки платежей
Дисконтная карта
X Дата отклика
^•Отклик
Тип данных
Назначение
Вид данных
Вещественный
Настройка нормализации...
Статистика
Минимум
Максимум
Среднее
Стандартнее откл.
Непрерывный
1
6
1,88780548012836
1,32940383310238
а------------1
Далее > I Отмена
Рис. 19.2. Установка назначения столбцов
а Ш Сценарии
Э fi) Текстовый Файл (responsesl .1x1)
: 1Н- Логистическая регрессия (9; порог 1/11)
58? Корреляционный анализ [устранение незначащих Факторов)
й П|] Текстовый файл [responses2.txt]
□ S Скрипт (159-159): ("Логистическая регрессия (9; порог 1/11)")
Л S х ПОСТРОЕНИЕ LIFT-КРИВОЙ *
Н zl Сортировка: Отклик Рейтинг
В 1§1 Калькулятор: Номер записи
Ё Калькулятор: Размер выборки
В {1 Группировка (Измерения: Размер выборки; Факты: Отклик)
V Калькулятор: % Отклика; Лифт-значение
Формирование
лифт-таблицы
Рис. 19.3. Сценарий к задаче о массовой рассылке
На рис. 19.4 изображена получившаяся Lift-кривая. Диагональная линия отра-
жает работу бесполезного классификатора, то есть ситуацию, когда списки полу-
чателей рассылки формируются случайным образом. График кривой, соответству-
ющей нашей модели, проходит достаточно высоко, что говорит о хорошем качестве
прогнозирования клиентского отклика. Видим, что при объеме рассылки, равном
25 % от тестового множества, мы получим около 75 % всех возможных откликов.
Если бы мы проводили рассылку по принципу случайности, то для получения
такого же отклика нам пришлось бы отправить письма 74 % клиентов. Разница
в 49 % и есть эффект, который даст нам стратегия рассылки, с использованием мо-
дели логистической регрессии, когда в первую очередь письма будут отправляться
респондентам с максимальными вероятностями отклика.
686 Часть II. Бизнес-анализ в Deductor
Рис. 19.4. Lift-кривая для модели отклика на основе логистической регрессии
Теперь представьте, что компания ранее использовала правило, согласно кото-
рому рассылка производилась в первую очередь тем клиентам, которые принесли
наибольшие доходы. Отсортируем записи по убыванию значений поля Доход с кли-
ента, повторим расчеты и построим Lift-кривую (рис. 19.5). Она окажется гораздо
хуже Lift-кривой для логистической регрессии, но при малых объемах рассылки
(до 6 %) не уступит ей в эффективности.
Рис. 19.5. Lift-кривая для случая рассылки по убыванию
значений поля «Доход с клиента»
Глава 19. Повышение эффективности массовой рассылки клиентам 687
Теперь построим модель нейронной сети. Процедура undersampling предпола-
гает, что придется пожертвовать примерно 9/10 примеров с клиентами, от которых
не было отклика. В сценарии Deductor это реализуется с помощью обработчиков
Фильтр, Калькулятор и Слияние (рис. 19.6).
S & " ПРОЦЕДУРА UNDERSAMPLING
6 Y Фильтр ([Отклик] = 0)
-j OI Калькулятор: СЛЧИС()
S Настройка набора данных (СЛЧИСО)
▼ Фильтр ((СЛЧИСШ > 0,89)
% Y Фильтр ((Отклик] = 1)
i£- Обучающее множество (Фактор 10]
’ Нейросеть [9x4x1]
Рис. 19.6. Фрагмент сценария, выполняющий процедуру undersampling
При настройке обработчика Нейросеть первые два шага аналогичны шагам узла
Логистическая регрессия. Третий шаг мастера отвечает за архитектуру многослой-
ного персептрона и параметры активационной функции (рис. 19.7).
Рис. 19.7. Настройка структуры нейронной сети
Для нашей задачи достаточно одного скрытого слоя с четырьмя нейронами.
Для обучения выберем алгоритм ВаскРгор, после обучения — визуализатор Граф
нейросети. Он позволяет графически представить нейронную сеть со всеми ее ней-
ронами и синаптическими связями. При этом можно увидеть не только структуру
многослойного персептрона, но и значения весов, которые принимают те или иные
нейроны. В зависимости от веса нейрона он отображается определенным цветом,
а соответствующее значение можно определить по цветовой шкале, расположенной
внизу окна (рис. 19.8).
688 Часть II. Бизнес-анализ в Deductor
Рис. 19.8. Граф нейросети
В табл. 19.2 сведены воедино результаты классификации и издержки для двух
моделей на тестовом множестве и для модели «разослать всем».
Таблица 19.2. Результаты классификации
Модель TN ТР FN FP Общая ошибка Доход, ед.
Логистическая ре- грессия (порог 0,909) 3119 643 138 1502 30,3% 4928
Нейронная сеть (undersampling, 10:1) 3295 744 37 1326 25,2% 6114
«Разослать всем» 0 781 0 4621 — 3189
Наши усилия привели к тому, что на тестовом множестве классификаторы
чаще ошибаются в сторону ложноположительных случаев, и это хорошо, так как
отношение издержек обоих типов ошибок большое.
Из табл. 19.2 видно, что лучшей моделью для предсказания отклика клиента
становится нейронная сеть, дающая доход 6114 ед. С ее помощью эффективность
рассылки увеличивается в 6114 / 3189 = 1,92 раза.
На компакт-диске сценарий этой бизнес-задачи называется responses . ded.
Издержки классификации занесены в переменные проекта (Сервис — Перемен-
ные — Проект).
Заключение
Аналитики нередко рассуждают о том, какой алгоритм лучше, а какой хуже. Од-
нако, прочитав эту книгу, вы поймете, что она не об алгоритмах. Наверное, в этом
и заключается привлекательность бизнес-аналитики: она позволяет сформировать
целостный взгляд на анализ данных и моделирование, предложить последователь-
ность действий для решения управленческих задач на основе накопленной в компа-
нии информации. И неважно, все алгоритмы Data Mining рассмотрены в книге или
нет. Главное — уметь собирать данные в единый источник, производить их очистку
и предобработку, строить и сравнивать модели и интерпретировать результаты.
Хотя почему мы постоянно говорим о бизнесе? Подходы, изложенные в книге,
можно без каких-либо оговорок применять и в медицине, и в технических науках,
словом, в любых областях, где требуется обработка данных.
Как показывают мировые тенденции, рынок аналитических платформ будет сильно
расти еще долго. Но какие бы программные средства, облегчающие труд аналитика,
ни были разработаны, нужно еще знать, как их применить для решения той или
иной задачи. Этому мы посвятили всю вторую часть книги.
Мы надеемся, что, прочитав и проработав материалы пособия, студенты и пре-
подаватели, опытные практикующие консультанты и читатели, только недавно
столкнувшиеся с современными технологиями анализа данных, захотят испытать
свои силы на ниве бизнес-аналитики. Желаем вам больших успехов!
Литература
Основная
1. Архипенков С. Я., Голубев Д. В., Максименко О. Б. Хранилища данных. — М.:
Диалог-МИФИ, 2002.
2. Барсегян А. А. и др. Технологии анализа данных: Data Mining, Visual Mining,
Text Mining, OLAP. 2-е изд., перераб. и доп. — СПб.: БХВ-Петербург, 2007.
3. Ва?.ин В. Н., Головина Е. Ю., Загорянская А. А. Достоверный и правдоподобный
вывод в интеллектуальных системах. — М.: Физматлит, 2004.
4. Кацко И. А., Паклин Н. Б. Практикум по анализу данных на компьютере. — М.:
КолосС, 2009.
5. Косорукое И. А. Методы количественного анализа в бизнесе: Учебник. — М.:
Инфра-М, 2005.
6. Загоруйко Н. Г. Прикладные методы анализа данных и знаний. — Новосибирск:
Изд-во Ин-та математики, 1999.
7. Зиновьев А. Ю. Визуализация многомерных данных. — Красноярск: Изд-во
КГТУ, 2000.
8. Писарева О. М. Методы прогнозирования развития социально-экономических
систем. — М.: Высшая школа, 2007.
9. Прикладная информатика: справочник: Учеб, пособие / Под ред. В. Н. Волковой
и В. Н. Юрьева. — М.: Финансы и статистика; Инфра-М, 2008.
10. Спирли Э. Корпоративные хранилища данных. Планирование, разработка
и реализация. — М.: Вильямс, 2001. Т. 1.
И. Berry M.J. A., Linoff G. S. Data Mining Techniques for Marketing, Sales and Cus-
tomer Relationship Management. — Wiley Publishing, Inc., 2004.
12. Hosmer D. W., Lemeshow S. Applied Logistic Regression (Second Edition). — Wiley
Publishing, Inc., 2000.
13. Inmon W. H. Building the Data Warehouse. — Wiley Publishing, Inc., 2005.
14. Larose D. T. Discovering Knowledge in Data: An Introduction in Data Mining. —
Wiley Publishing, Inc., 2005.
Литература 691
15. Larose D. T. Data Mining Methods and Models. — Wiley Publishing, Inc., 2006.
16. Vercellis C. Business Intelligence: Data Mining and Optimization for Decision Mak-
ing. — Wiley Publishing, Inc., 2009.
17. Wang L., Fu X. Data Mining with Computational Intelligence. — Berlin; Heidelberg:
Springer-Verlag, 2005.
Дополнительная
1. Круглов В. В., Борисов В. В. Нейронные сети: теория и практика. — М.: Горячая
линия Телеком, 2001.
2. Руководство по кредитному скорингу / Под ред. Э. Мейз. — Минск: Гревцов
Паблишер, 2008.
3. Хайкин С. Нейронные сети: полный курс. 2-е. изд. / Пер. с англ. — М.: Вильямс,
2006.
4. ХанкД. Э., УичернД. У., Райте А. Дж. Бизнес-прогнозирование. 7-е изд. / Пер.
с англ. — М.: Вильямс, 2003.
5. Хьюз А. Маркетинг на основе баз данных / Пер. с англ. — М.: Издательский дом
Гребенникова, 2008.
6. Abbass Н. A., SarkerR. A., Newton С. S. Data Mining: A Heuristic Approach. — Uni-
versity of New South Wales, Australia. Idea Group Publishing, 2002.
7. Adamson C. Mastering Data Warehouse Aggregates: Solutions for Star Schema
Performance. — Wiley Publishing, Inc., 2006.
8. Agrawal R., Srikant R. Mining Sequential Patterns //Journal Intelligent Systems,
1997. Vol. 9. - № 1. - P. 33-56.
9. Agrawal R., Mannila H., Srikant R., Toivonen H., Verkamo A. I. Fast Discovery of As-
sociations Rules // Advances in Knowledge Discovery and Data Mining. — Ameri
can Association for Artificial Intelligence, 1996. — P. 307-328.
10. Anderson R. The Credit Scoring Toolkit // Theory and Practice for Retail Credit
Risk Management and Decision Automation. — OXFORD University Press, 2007.
11. Berthold M., Hand D. J. (Eds.) Intelligent Data Analysis. — Berlin; Heidelberg:
Springer-Verlag, 2007.
12. Chiu S., Tavella D. Data Mining and Market Intelligence for Optimal Marketing
Returns. — Elsevier Inc., 2003.
13. Hamerly G., Elkan C. Learning the К in K-Means // Neural Information Processing
Systems. — MIT Press, 2003.
14. Han J., KamberM. Data Mining: Concepts and Techniques. — Elsevier Inc., 2006.
15. Data Mining for Business Applications / Edited by L. Cao, Philip S. Yu, C. Zhang,
H. Zhang. — Springer Science; Business Media, 2008.
692 Литература
16. Encyclopedia of Data Warehousing and Mining. — Idea Group Inc., 2006.
17. Fabrice G., Hamilton H.J. (Eds.) Quality Measures in Data Mining. — Berlin; Hei-
delberg: Springer-Verlag, 2007.
18. GiudiciP. Applied Data Mining: Statistical Methods for Business and Industry. —
Wiley Publishing, Inc., 2003.
19. Kantardzic M. Data Mining: Concepts, Models, Methods, and Algorithms. — Wiley
Publishing, Inc., 2003.
20. Kovalerchuk B., Vityaev E. Data Mining in Finance. Advances in Relational and
Hybrid Methods. — New York: Kluwer Academic Publishers, 2002.
21. Mitra S., Acharya T. Data Mining: Multimedia Soft Computing, and Bioinformat-
ics. — Wiley Publishing, Inc., 2003.
22. Olsen J. E. Data Quality: The Accuracy Dimension. — Morgan Kaufmann Publishers,
2003.
23. Powers D. A., Xie Y. Statistical Methods for Categorical Data Analysis. — Academic
Press, Inc., 1999.
24. Pyle D. Business Modeling and Data Mining. — Morgan Kaufmann Publishers,
2003.
25. Siddiqi N. Credit Risk Scorecards: Developing and Implementing Intelligent Credit
Scoring. — Wiley Publishing, Inc., 2006.
26. Soukup T., Davidson I. Visual Data Mining: Techniques and Tools for Data Visualiza-
tion and Mining. — Wiley Publishing, Inc., 2002.
27. The Handbook of Data Mining / Edited by Nong Ye. — Lawrence Erlbaum Associ-
ates, Inc., 2003.
28. The Top Ten Algorithms in Data Mining / Edited by Xindong Wu. — Chap-
man & Hall, 2009.
29. Weiss G. M., McCarthy K., ZabarB. Cost-Sensitive Learning vs. Sampling: Which
is Best for Handling Unbalanced Classes with Unequal Error Costs? // Proc, of
the 2007 International Conference on Data Mining. — CSREA Press, 2007. —
P. 35-41.
30. Williams G.J., Simoff S.J. (Eds.) Data Mining: Theory, Methodology, Techniques,
and Applications. — Berlin; Heidelberg: Springer-Verlag, 2006.
31. Witten 1. H., Frank E. Data Mining: Practical Machine Learning Tools and Tech-
niques. — Elsevier Inc., 2005.
32. Zhao Hui Tang, MacLennanJ. Data Mining with SQL Server 2005. — Wiley Publish-
ing, Inc., 2005.
Алфавитный указатель
А
AdaBoost, 553,555
Affinity analysis, 281
Antecedent, 282
Apriori, 287,289,292,295,299,603,635-636,
642
Apriori All, 304-306
AprioriSome, 305
Artificial neural network, 473
AUC, Area under Curve, 580,589, 664
В
Backward elimination, 388
Bagging, 548
Base model, 546
Best subsets, 388
Boosting, 553
Bootstrap, 567
c
C4.5, 442,444, 448-450, 452,596, 603, 669
C5.0, 442
CART, Classification and Regression Tree,
459-461, 464, 470,471
CHAID, Chi-square Automatic Interaction
Detector, 443
City-block distance, 314
Classification cost error, 572
Classification error rate, 464
Cleaning, 212
Competition, 323
Confusion matrix, 193
Consequent, 282
Cooperation, 323
Cost, 567,584
Cost matrix, 574
Cost-sensitive algorithm, 594
Cost-sensitive classification, 572
Cross-validation, 567,570,571
Cut-off point, 574
D
Data mart, 88
Data Mining, 42-47
Decision trees, 428
Different function, 315
Divide and conquer, 435
Drill down, 190
E
Error backpropagation, 507
Error rate, 567
ETL, 64, 100-105, 107-113, 117-120, 140,
213-216,224-227,229,248
F
Folds, 569
Forward selection, 388
Frequent itemset, 287
Fuzzy logic, 46,95
Fuzzy queries, 94
Fuzzy sets, 95
G
Gain chart, 582
Gain-ratio, 439
Generalized rules, 293
Gini-index, 439
G-means, 320-321,340, 603, 645, 655
H
Heat map, 209
Hybrid OLAP, 76, 86
I
ID3, Iterative Dihotomizer, 442,444,445,448,
449,458,596,597
Imbalanced dataset, 593
Information gain, 439, 445
К
KDD, Knowledge Discovery in Databases, 25,
40, 41, 42, 45,46, 47, 177
k-means, 311-312, 314-316, 320-321, 338,
340-341, 603, 645, 649-651, 655
k-mediods, 315
Kohonen clustering network, 322
694 Алфавитный указатель
L
Leaf, 432
Leave-one-out, 567,571
Leverage, 285
Lift, 565, 576, 578-583, 586, 588-589, 591,
603, 684-686
chart, 578,582
curve, 578
Likelihood function, 406
M
Machine learning, 45, 414
Manhattan distance, 314
Market basket analysis 43,281
Maximum likelihood estimates, 407
Minimum descriptive length, 566
Misclassification cost, 572
Multidimensional OLAP, 76
Multilevel rules, 293
Multilayer perceptron, 486
Multiple model, 546
N
Naive Bayesian classifier, 424
Node, 432
0
Occam’s razor, 566
Odds ratio, 412
OLAP, On-line Analytical Processing, 77
OLAP, On-Line Transaction Processing, 65
Option tree, 560
Outlier detection, 309
Outlier value, 240
Overall error rate, 573
Overall success rate, 573
Oversampling, 594,595, 671, 684
P
Partitions, 569
Perturb and combine, 548
Population, 275
Postpruning, 468
Precision-Recall curve, 591
Predicted variable, 353
Prediction, 343,353
Predictor variable, 353
Prepruning, 467,468
Principal component analysis, 268
Profit curve, 584
Pruning, 466
Purity, 433
R
Randomization, 550
Rebalancing, 594
Relational database, 82
Relational OLAP, 76, 80
Repeated holdout, 569
Resampling, 547
ROC, Receiver Operating Characteristic, 565,
586,587,588,589,590,591,596, 603, 662,
664
Root node, 294, 432
s
Sample, 276
Sampling, 276
Scalable Algorithm, 59
Self organizing map, 330
Sensitivity, 573
Specificity, 573
Splitting attribute, 433
Stacking, 561
Stepwise selection, 388
Supervised learning, 54
T
Tenfold cross-validation, 570
Time series data, 516
u
Undersampling, 594,595, 671, 684, 687, 688
A
Автокорреляционная функция временного
ряда, 530
Агломеративная кластеризация, 205
Агрегирование, 114, 118
Аддитивная регрессия, 557-558
Активационная функция нейрона, 482
Алгоритм
AdaBoost, 553,555
Алфавитный указатель 695
Apriori, 287, 289, 292, 295, 299, 603,
635-636, 642
AprioriAll, 304-306
AprioriSome, 305
C4.5, 444, 451-452, 456, 458, 460, 513,
596-597, 603, 669
CART, 459-461, 464,470-471
G-means, 320-321,340, 603, 645, 655
ID3, 280, 442, 444-445, 448-449, 458,
596-597
k-means, 311-312, 314-316, 320-321,
338,340-341, 603, 645, 649-651, 655
к-медиан, 3/5
масштабируемый, 59-60,340
обратного распространения ошибки,
506-507,509-510,512-513,598
обучения, 24-25,45-47,51-60, 112, 137,
192-193, 196,201,238,306,322-329,
332-333,337,344-345,348, 431, 437,
439,473-475,477,482-486,490-504,
506-507, 511-513, 543, 545, 547,
549-553,555-556,561-562,568-572,
593-594,596-598,646-649,684, 687
Альтернативная гипотеза, 379
Анализ АВС, 628-633, 677
Анализ XYZ, 628-633, 677
Анализ данных, 20
Аналитик, 26, 131, 188, 195, 241, 250, 260,
391, 438,476,565, 602
Аналитическая платформа, 48-49, 601
Аналитический подход, 21-22,24
Аналитическое приложение, 140
Аномальные значения, 220, 226, 230,
245-246
корректировка, 52,126,131,201,241,507,
509,597
обнаружение, 42, 214,223, 238, 241, 244,
286-287,295,304,309-310,416
Ансамбль моделей, 16, 603
Антимонотонность, 287,289,290,299,302
Апостериорная вероятность, 347, 423-425
Априорная вероятность, 427
Ассоциативные правила, 44, 281-283,
291-293,299,636,641
достоверность, 61,90, 113, 125, 132, 138,
144, 176, 215-217, 222, 226, 234, 240,
246-247, 250, 259, 273, 283-286,
291-292, 438-439,532, 548, 636, 638,
640, 658, 666, 669
значимость, 285-286
иерархические, 203,292-294,340, 431
непонятные, 131, 640, 695
поддержка, 283, 640-641
полезные, 14,242,299, 640, 642
следствие, 12, 35, 64, 126, 197, 204, 235,
282-285, 291-292, 387, 638-640,
652
тривиальные, 640-642
условие, 233,282-283,428
частый предметный набор, 287
Ассоциация, 43
Атрибут, 426, 428, 608
ветвления, 348, 432-433,439, 596
Аффинитивный анализ, 281
Ацикличность деревьев решений, 435
Б
База данных
реляционная, 77, 82, 86, 88-89, 107
транзакционная, 299
Бизнес-данные, 35
Бритва Оккама, 566
Бустинг, 553
Бутстрэп-оценки, 571
Бэггинг, 548,550-552
В
Визуализаторы, 177, 192,202
OLAP-куб, 80, 176, 186, 188, 633
графические, 175
древовидные, 202-203,431
карты, 27, 176, 192, 202, 208-210, 311,
330-336, 341, 565, 603, 644-646,
648-651, 653, 655
общего назначения, 176-177,202
оценки качества моделей, 193, 196
связей, 206-208
табличные, 175
что-если, 638, 662, 665-666
Визуализация, 173-175, 186,201,206, 603
Виртуальное ХД, 92
Витрина данных, 89
Восстановление равновесия классов, 594
Временной отсчет, 516
696 Алфавитный указатель
Временной ряд, 142- 143, 145, 148, 241, 516,
527,532,679
дискретный, 33,516-517
многомерный, 78-79, 176,517, 626
непрерывной, 43, 55, 162, 196, 300, 347,
403, 410-411, 413, 420, 422, 437-439,
465, 484
нестационарный, 527
стационарный, 527
Выборка, 4/, 145,276,371
исходная, 82, 120, 155, 158,195,276-277,
303,395,549
обучающая, 51-54, 56-57, 192, 251, 495,
497,533,570
тестовая, 570, 665, 671
Г
Гетероскедастичность, 400
Гибридное ХД, 87
Гипотеза, 25
альтернативная, 367,369,379,389
нулевая, 367-369,379,389
Гистограмма, 181-182,253
Глубина погружения, 143
Горизонт прогноза, 143-144
Градиентные методы обучения, 501
метод градиентного спуска, 502,505
Группировка данных, 151
д
Данные
агрегированные, 42,69, 73- 74,80,86,115,
148, 152, 190, 629-630
аномальные, 24, 54, 61, 63, 109, 138, 174,
197,214-215, 219-220, 226, 230,233,
240-243,245-246,315,541
вещественные, 117
дата/время, 32-33, 122, 142-143, 218,
300, 613, 659
детализированные, 69, 73, 76,86-87,148,
190
дискретные, 33, 78, 162, 164, 170, 218,
516
избыточные, 231,259,270
исторические, 67-68,93-94,515
категориальные, 32, 78,170,265,315,339,
341,370,560
логические, 31, 96, 110-111, 142, 233,
339
неполные, 120-121, 125, 131, 145-146,
247
непрерывные, 33, 78, 178, 342-343, 420,
422, 443,516, 658
неструктурированные, 30-31, 108
ординальные, 32
пропущенные, 174,229,247,450
противоречивые, 107, 110-111,214,397
слабоструктурированные, 30-31
строковые, 125, 128, 149,219,339
структурированные, 30, 32, 62, 102, 107,
339, 606
транзакционные, 34, 40,299
упорядоченные, 30,32-33, 77, 143
целые, 117
числовые, 33,63, 74, 78,117, 125,128,149,
170, 178, 219,236, 239, 248, 259, 265,
339,464,495,516,560,584
Дерево решений, 203,348, 669, 673, 675
интерактивное, 672
полное 122, 137, 159-160, 340, 438,
457-458, 463,465, 468-469, 471
регрессионное, 464-465,558
Деревья выбора, 559-560
Диаграмма рассеяния, 196-198, 680
Диаграмма связей, 206-207
Диаграмма «точность — полнота», 591
Доверительный интервал, 410, 419
Достоверность, 61,90,113, 125,132,138,144,
176,215-217,222,226,234,240,246-247,
250,259,273,283-286,291-292,438-439,
532,548, 636,638, 640,658, 666, 669
ассоциативного правила, 283,286,291
Дубликат, 230,234-235,237-239
Ж
«Жадный» алгоритм, 434-435, 672
3
Зависимая переменная, 428
Загрузка данных, 101, 119, 123
из локальных источников, 91, 104, 123
многопоточная, 121
неполная, 120
Запрос, 187, 607
Алфавитный указатель 697
аналитический, 21-22, 24, 124, 166,
214-215,258,306, 605
к базе данных, 65, 186
нерегламентированный, 69, 76,92, 103
нечеткий, 99
Значения
пропущенные, 174,229,247, 450
закодированные, 110-111
составные, 110-111, 128,214-215,229,
382, 417
аномальные, см. Аномальные значения
Значимость, 284, 408, 655
модели, 367,368,377,378
переменной, 419
Иерархические ассоциативные правила,
292
Избыточность, 91
Извлечение данных , 100-101, 103-104,
124
Издержки классификации, 688
Измерение, 78-82, 608, 613, 616
Индекс Джини, 439-440
Индекс соответствия, 99
Интервал прогноза, 143
Информативность данных, 39
Информационный подход, 23,28,34,40,51
Исторические данные, 68-69
Источник данных
локальные, 65, 114,217,498,502,513
неструктурированные, 30-31, 108
структурированные, 30, 32, 62, 102, 107,
339, 606
Исход, 405, 683
истинноотрицательный, 408,573,576
истинноположительный, 408,573-574
ложноотрицательный, 408,573-574
ложноположительный, 408,573
Кары, 332, 644-645, 649
самоорганизующаяся, 322,330
тепловая, 209-210
Карта Кохонена, 46, 176, 210,311,322-325,
329-332, 334-337, 340-341, 475, 603,
644-651, 653, 655
инициализация, 316,324,336, 492,571
обучение, 54,323,475,490-491,498,501,
557,567,593,649
Категориальные данные, см. Данные кате-
гориальные
Качество данных, 211
визуальная оценка, 213,219,527
оценка, 25,36-37,39,59, 62-63, 151,176,
211-213, 216-217,219,224,244, 252,
347,351-357,367-368,372,374,377,
384-386, 410, 420, 444, 476, 495, 527,
544, 558,563-565,567,569, 590, 602,
643
профайлинг, 218
уровни, 203,214-215,293-295
Квадратичная сумма
остаточная, 359-360,399
полная, 267,359-360,374,441, 464
последовательная, 389-390
регрессионная, 198, 342, 345-347, 359,
361,363,365-367,376,397-398,558
частная, 389-390
Квантование, 141, 160, 162,270, 417, 667
интервал, 94,142-143, 148,161-164,167,
252,356, 410, 413, 419, 484, 518, 539,
655
неравномерное, 164-165,683
равномерное, 164
Класс, 183, 194,251,560, 660-662
миноритарный, 594
мажоритарный, 594
Классификация, 43-44, 47,342,344,574
байесовская, 345,347
бинарная, 346, 381, 403, 411, 421, 565,
586, 660
с учетом издержек, 572,598, 682
Кластер, 652-653, 655
Кластеризация, 43-44, 205, 308-310, 341,
649
агломеративная, 205
разделительная, 205,311
Кодирование, 169-171,495
двоичное, 170,380, 495
дополнительная информация, 67
уникальные числовые коды, 170, 495
Компоненты временного ряда, 521
сезонная компонента, 521,523-525,530
тренд, 521-524, 526-527, 530-532,
538-539
698 Алфавитный указатель
циклическая компонента, 521,525-526
Конкурентное обучение, 322
Консолидация данных, 15, 62, 603
Корневой узел, 447
Корреляция, 362,528, 684
Коэффициент детерминации, 360-361
Коэффициент корреляции, 361-362,529
Коэффициент регрессии, 353
Коэффициент скорости обучения, 325, 506,
511
Кривая дохода, 584
Критерий, 207,338, 443
разбиения в дереве решений, 439
Стьюдента, 368, 410, 655
Фишера, 194,203,368, 443-444,472
Куб, 627
OLAP, 49, 76-77,80-81,86,176,184-190,
259, 306, 542, 603, 606, 622, 624, 626,
631-633, 681
многомерный, 78-79, 176,517, 626, 703
Л
Левередж, 285
Линия регрессии, 353,355-356
Лист, 428
Лифт ассоциативного правила, 283, 286,
291
Лифт-кривая, 578
Логит-преобразование, 422
м
Матрица издержек, 574-575,595
Матрица классификации, 193, 195-196,
573
Машинное обучение, 44-45
Метаданные, 74-75, 612
Метод наименьших квадратов, 353
Метод обратного исключения, 390
Метод перебора всех возможных набо-
ров, 391
Метод поиска лучших подмножеств, 391
Метод последовательного отбора, 390
Метод прямого отбора, 389
Метрика
евклидова, 314, 645
Манхэттена, 207,311,314-315
Многомерное ХД, 76, 80, 88, 185, 202, 209,
330
Многомерный куб, 78
детализация, 80, 82, 190-191
сечение, 80-81
свертка, 80, 603
транспонирование, 80-81, 190
Многослойный персептрон, 486
Множество, 32, 110, 197, 272, 288-289,
435-436,457,571,598
валидационное, 568
обучающее, 25,55-56, 432,459, 489, 497,
547,552,567-569,571-572,595, 646,
659
тестовое, 25, 55-56, 496, 551, 568-569,
571, 646, 659, 684
Моделирование, 21,29
аналитический подход, 21-22,24
информационный подход, 23-24,28,34,
40,51
Модель, 20-21,23,25,144, 154,199,255,257,
343,376,379,398,478,481,533,578,580,
587,688
полная, 267,359-360,374, 441,464
Модель временного ряда
аддитивная, 521,557-558
мультипликативная, 521
Модель прогноза, 532
декомпозиция временного ряда, 538
метод среднего и скользящего среднего
наивная, 533-535
обобщенная, 64, 66, 68, 72, 101, 144, 236,
305-306,432, 481, 493,533,538,550
регрессионная, 198, 342, 345-347, 361,
363,365-367,376,397-398,558
экстраполяция, 534
Модель смешанная, 21
Модель теоретическая, 21
Модель эмпирическая, 21
Момент, 512
Мультиколлинеарность, 402
н
Наивный прогноз, 533
Недообучение, 466
Независимая переменная, 297,392,396, 428
Нейрон, 326-329,478
биологический, 478
входной, 485
выходной, 485
Алфавитный указатель 699
искусственный, 349, 478, 480-481
«мертвый», 333
победитель, 326, 471
сигмоидальный, 483
скрытый, 485
Нейронная сеть, 348,350, 475,498, 688
Непрерывные данные, 33, 516
Несбалансированность классов, 593
Нечеткая логика, 46,95
Нечеткие запросы, 94
Нечеткие срезы, 94
Нечеткое множество, 95,98
Нормализация, 142, 166-168, 495, 603
десятичное масштабирование, 166
минимаксная, 167, 495
поэлементное преобразование, 168
стандартным отклонением, 366
Нулевая гипотеза, 367,379,389
О
Область промежуточная, 102
Обобщающая способность, 55,345, 467,469
Обогащение данных, 64, 131, 133-134
внешнее, 134, 157-160
внутреннее, 134-135, 156-157
Обработка дубликатов и противоречий, 230,
238
Обучающая выборка, 52,251, 495, 497,533
Обучающее множество, 56,432,568
Обучение, 54, 323, 475, 490-491, 498, 501,
557,567,593, 649
без учителя, 54
деревьев решений, 230,280,348,427-435,
437-438, 444, 448, 459, 465-467,
469-470, 477-478, 513, 544, 546, 549,
551,557,560-561,596,672
конкурентное, 322
машинное, 44-45, 137, 428, 600
нейронных сетей, 46, 230, 322-323, 341,
427,473-475,477-478, 482-486,492,
495-499,501-502,504,544,546,597
с учителем, 54,344, 431, 473, 492,507
Обучение сети Кохонена, 323, 649
конкуренция, 323-328,337
объединение, 42,46, %, 115,140,153,155,
157,205,239,323-326,342,548
подстройка весов, 323-324,326-329,490,
494,512
Окно выгрузки, 103
Ординальные данные, 32
Остатки регрессии, 354
Отношение правдоподобия, 468
отрицательного результата, 408
положительного результата, 408
Отношение шансов, 422
Оценка качества данных, 211,216-217,219,
224
Оценка максимального правдоподобия
Очистка данных, 41, 64, 108, 118, 225
Ошибка, 55-56, 201, 240, 357,364,368,376,
413,509,554
второго рода, 586-587
обобщения, 55-58, 69, 72-74, 82, 86,
92, 102, 116, 144, 230, 255, 295, 546,
568-569
обучения, 55
первого рода, 586
п
Перекрестная проверка, 569,571
Переменная, 389, 422
бинарная, 346, 381, 403, 411, 421, 565,
586, 660
зависимая, 44,345-346, 428, 682
лингвистическая, 96
независимая, 297,392,396, 428
фиктивная, 381-382,386, 400
Переобучение, 466, 496-497
Поддержка, 283-284, 291-292, 302, 305,
439
ассоциативного правила, 283,286,291
минимальная, 161,291,297,305,469,518,
636, 679
Последовательность, 121,300-302,304,554,
556,616
клиентская, 301,303
максимальная, 105, 143, 161, 301, 636,
664
частая, 302
Последовательный шаблон, 44,299
Постзагрузочные операции, 122
Правило Байеса, 575-576
Правило Видроу — Хоффа, 507
Предобработка данных, 225,228
Принцип «разделяй и властвуй», 435
Прогноз, 515,536, 681
700 Алфавитный указатель
Прогнозирование, 309-310, 514, 516, 535,
537,539-540, 630-631, 676, 678
Проекция, 650
с сохранение топологического подобия,
330
Пропущенные данные, 174,229,247,450
восстановление, 129,230,247,249
Простой классификатор Байеса, 423
Профайлинг данных, 218
Р
Радиус обучения, 648
Разделительная кластеризация, 205,311
Расстояние, 206,264,314-315,317-319,405,
645, 650
евклидово, 207, 236, 245, 264, 311, 314,
324,326,330,339,350, 650
Манхэттена, 207,311,314-315
Регрессионная модель, 198, 342, 345-347,
361,363,365-367,376,397-398,558
множественная, 370,376,421-422
простая, 219,347,351,363,370-371,522,
535
Регрессия, 43-44, 196,380,537
линейная, 23, 166, 267-268, 345-346,
348,351-352,356,359,363,365-367,
369-371,379-380,386-387,396,403,
428,522,538,558, 603, 678
логистическая, 345-348, 403, 405, 410,
421, 428, 481-482, 488, 509, 523, 558,
594, 603,659-660,669, 684, 687-688
множественная, 370,376, 421-422
простая, 219,347,351,363,370-371,522,
535
Реляционное ХД, 76, 83, 608
Ретропрогноз, 198-200
С
Самоорганизация, 54,308
Сбор данных, 36, 118
Сглаживание, 229,246, 650
временных рядов, 16,40, 119, 142-143,
177, 198, 248, 514, 516, 518, 521,
525-526, 532, 538, 541-542, 603,
630-631, 677-678
Сезонная компонента, 521,523-525,530
Семантический слой, 70, 607
Сеть Кохонена, 322,325
Система, 551
аналитическая, 48-49, 62, 68-69, 75, 77,
188,202,273, 600-601, 606, 634
оперативной обработки (OLTP), 85
поддержки принятия решений, 67, 70,
607
Скользящее окно, 42, 143, 146, 148, 603
Скоринг кредитный, 342,397, 452,572, 584,
586, 657-658
Скоринговая карта, 310, 659
Скорость обучения, 648
Слияние данных, 154, 671
внешнее соединение, 157-160
внутреннее соединение, 156-157
объединение, 155
Сокращение размерности, 254
записей, 270-272
значений, 270-272
числа признаков, 258,260,263,270
Сортировка данных, 141
Составное значение, 111
Специфичность, 574
Сравнение моделей, 563-566, 603
Срез, 80,98, 186, 622
нечеткий, 99
Стэкинг, 561-562
СУБД, 38, 48, 63, 65, 70, 76, 82-83, 85,
107-108,114, 124-125,127, 130,137,174,
601-602, 604, 607
Схема «звезда», 83
Схема «снежинка», 84
Сэмлинг
равномерный случайный, 276-277, 603
стратификационный, 277
т
Таблица сопряженности, 662, 665, 672
Таблица фактов, 83
Тест Вальда, 409,419
Тест Чоу, 399, 658
Тип данных
вещественный, 32-33,477, 614, 644, 659
дата/время, 32-33, 122, 142-143, 218,
300, 613, 659
логический, 32-33, 142, 659
строковый, 32-33,141-142,218,339,477,
659
целый, 32-33, 477, 613, 644, 659
Алфавитный указатель 701
числовой, 78,139,142,218,443,446-447,
453, 472, 482-483,509,580
Тиражирование знаний, 28
Точка отсечения, 586
Транзакционные данные, 34, 40
Транзакция, 65,282
клиентская, 301,303
Трансформация, 138
временных рядов, 40, 119, 142-143, 177,
198,248,514, 516,518, 521, 525-526,
532, 538, 541-542, 603, 630-631,
677-678
группировка, 42-43, 119, 141, 151-153,
277,308,334, 542, 603, 628-629, 632,
655, 667
квантование, 42, 141, 160-162, 164-165,
265,270,417, 439, 603, 667
нормализация, 142, 166-168,495, 603
разгруппировка, 141, 153-154, 542, 603,
680
скользящее окно, 42, 143, 146, 148, 603
слияние, 141, 154,239, 603, 633, 671, 687
сортировка, 42,50, 119, 141,219,302
табличная подстановка, 141
Тренд, 521-522
Трудоемкость алгоритма, 58
У
Узел, 294,428, 438,440,461, 636
дочерний, 348, 444, 454
корневой, 447, 460, 469, 471
родительский, 296-298, 433, 440, 472
Упрощение деревьев решений, 465
отсечение ветвей, 468, 470
ранняя остановка, 468-469
Уравнение регрессии, 353,384,394,400
Ф
Формула Байеса, 424
Функция отличия, 315
Функция правдоподобия, 416
логарифмическая, 407
Функция принадлежности
трапецеидальная, 96
треугольная, 96
X
Хранилище данных, 70, 607, 613
виртуальное, 92-93, 601, 603
гибридное, 87
кросс-платформенное, 76
многомерное, 76, 80, 88, 185, 202, 209,
330
реляционное, 88, 603
ц
Целостность данных, 110
Центроид, 317
Циклическая компонента, 521, 525-526,
539
ч
Частный F-критерий, 388
Черный ящик, 23
Числовые данные, 219
Чувствительность, 573,589
ш
Шанс, 416
Шум, 229
Факт, 78-79, 608, 659 л
Фактор, 37,231
Фильтрация, 232, 603, 626 Ячейка карты Кохонена, 332
Паклин Николай Борисович, Орешков Вячеслав Игоревич
Бизнес-аналитика: от данных к знаниям (+CD)
Учебное пособие
2-е издание, исправленное
Заведующая редакцией
Ведущий редактор
Художник
Корректор
Верстка
И. Сальникова
Е. Власова
Л. Аду веская
А. Павлович
О. Махлина
ООО «Мир книг», 198206, Санкт-Петербург, Петергофское шоссе, 73, лит. А29.
Налоговая льгота — общероссийский классификатор продукции ОК 005-93, том 2; 95 3005 — литература учебная.
Подписано в печать 12.06.12. Формат 70x100/16. Усл. п. л. 56,760. Тираж 1500. Заказ 6029.
Отпечатано по технологии CtP в ИПК ООО «Ленинградское издательство»
194044, Санкт-Петербург, ул.Менделеевская, д. 9
Телефон/факс: (812)495-56-10.
BaseGroup Labs
ТЕХНОЛОГИИ АНАЛИЗА ДАННЫХ
BaseGroup Labs — профессиональный поставщик продуктов и решений в области анализа дан-
ных. Мы имеем многолетний опыт работы в области разработки аналитических алгоритмов и
создания законченных систем. BaseGroup Labs предлагает полностью интегрированные продук-
ты, объединяющие все необходимые инструменты анализа: хранилища данных, аналитическую
отчетность, механизмы поиска закономерностей и построения моделей, средства интеграции
аналитических систем с платформами сторонних производителей.
Системы от BaseGroup Labs выполнены с применением самых современных информаци-
онных технологий.
Технологии
Data Warehouse
хранилище данных
Data Mining
добьгча'данных
□ Консолидация анализируемых данных,
обеспечение непротиворечивости данных.
□ Быстрый доступ к необходимой инфор-
мации.
□ Автоматическое обновление данных.
□ Богатый семантический слой
□ Прогнозирование.
□ Поиск закономерностей и зависимостей.
□ Извлечение правил.
□ Оптимизация процессов.
□ Анализ по принципу «что-если»
OLAP
многомерный анализ данных
Knowledge Discovery in DB
обнаружение знаний в базах данных
□ Многомерная отчетность, позволяющая
извлечь максимум полезной информации
из имеющихся данных.
□ Гибкие механизмы навигации и манипу-
лирования данными.
□ Анализ тенденций.
□ Простота применения конечным поль-
зователем
□ Механизмы улучшения качества исход-
ных данных (очистка, преобразование
и трансформация данных).
□ Построение сценариев обработки дан-
ных.
□ Механизмы построения моделей.
□ Интеграция моделей в информационные
системы
Наши системы базируются на собственном аналитическом ядре, что обеспечивает беспреце-
дентную гибкость при выборе способов анализа и создании прикладных решений. Применение
самообучающихся механизмов дает возможность быстрой адаптации решения под постоянно
изменяющиеся условия.
Россия, 390046, г. Рязань,
ул. Введенская, д. 115, оф. 447.
Тел./факс: +7 (4912) 24-09-77.
Россия, г. Москва, ул. Садовническая,
д. 82, стр. 2, подъезд 6.
Тел./факс: +7 (495) 222-71-17.
info@basegroup.ru
www.basegroup.ru
Ж Deductor
ПАРТНЕРСКАЯ ПРОГРАММА ДЛЯ ВУЗОВ
Deductor — флагманский продукт BaseGroup Labs, концентрирующий многолетний опыт ком-
пании и вобравший в себя самые удачные архитектурные идеи и современный математический
аппарат. В Deductor реализованы технологии анализа структурированных данных: нейронные
сети, деревья решений, хранилища данных и OLAP, ассоциативные правила, карты Кохонена
и многое другое. Использование Deductor в учебном процессе поможет студентам освоить
алгоритмы машинного обучения и системы интеллектуальной обработки информации на прак-
тике, решая актуальные задачи по консолидации, очистке, прогнозированию, классификации,
кластеризации, скорингу.
Образование
Для высших учебных заведений BaseGroup Labs предлагает специальные условия. Заключив
с нами соглашение о сотрудничестве, преподаватели и сотрудники учебного заведения получают
следующие возможности.
□ Аналитическую платформу Deductor Academic для проведения практикумов по дисци-
плинам, связанным с информационно-аналитическими системами, интеллектуальными
информационными системами, системами поддержки принятия решений и другим курсам
для прикладных информатиков и экономистов.
□ Бесплатное e-leaming-обучение преподавателей на образовательном портале edu.basegroup.ru
в полноценной системе дистанционного обучения и сертификацию по результатам обучения,
обсуждение возникающих вопросов на форуме.
□ Мероприятия для вузов-партнеров: очные конференции для преподавателей, конкурсы сту-
денческих работ.
□ Программы повышения квалификации по корпоративным аналитическим системам при
институте экономики и финансов «Синергия».
□ Большое число методических разработок для проведения практических занятий со студен-
тами по всем современным технологиям анализа данных.
Участие в программе полностью бесплатное. Образовательная инициатива действует
с 2005 года, и за это время более 90 вузов России, Украины и Беларуси стали нашими партнерами
и используют аналитическую платформу Deductor в учебном процессе. Вот некоторые из них:
□ Высшая школа экономики;
□ Российский государственный аграрный университет;
□ Томский государственный университет;
□ Санкт-Петербургский государственный политехнический университет;
□ Одесский национальный университет имени И. И. Мечникова;
□ Белорусский государственный университет информатики и радиоэлектроники.
Форму и условия партнерства, полный список вузов-партнеров и другую дополнительную
информацию можно получить на образовательном портале http://edu.basegroup.ru.
Россия, 390046, г. Рязань,
ул. Введенская, д. 115, оф. 447.
Тел./факс: +7 (4912) 24-09-77;
+7 (4912) 24-06-99.
edu@basegroup.ru
S э я
□ □□
БИЗНЕС
АНАЛИТИКА:
от данных к знаниям
2-е издание, исправленное
> Хранилища данных и OLAP
> Очистка и предобработка данных
) Основные алгоритмы Data Mining
> Сравнение и ансамбли моделей
> Решение бизнес-задач
на аналитической платформе Deductor
CD-ROM
Аналитическая платформа
Deductor Academic
^ППТЕР
Недостаток квалифицированных специалистов - главная проблема на пути
распространения методов анализа данных в бизнесе, производстве, технике.
В ближайшие годы спрос на таких специалистов будет только расти.
Вы хотите идти в ногу со временем?
Тогда ваш выбор — дистанционные курсы BaseGroup Labs. Окунитесь в мир
современных технологий анализа данных, скрывающийся за аббревиатурами
и словами OLAP, KDD, Data Warehouse, Data Mining и Business Intelligence.
> Полный курс по корпоративным аналитическим системам
► Обучение не выходя из дома, офиса
► Закрепление навыков на практике
> Опытные преподаватели
> Аттестация и сертификация
► Выгодные предложения о работе
> Совместные с вузами программы
повышения квалификации
Образовательный портал http://www.edu.basegroup.ru
К изданию прилагается компакт-диск с дистрибутивом свободно распространяемой версии аналити-
ческой платформы Deductor Academic, файлы с демопримерами ко второй части книги, а также
дополнительные материалы по Deductor.
В первой части учебного пособия раскрываются основные технологии, используемые при создании и внедрении
корпоративных информационно-аналитических систем и объединяемые термином «бизнес-аналитика»: хранилища
данных и OLAP, преобразование и очистка данных, базовые алгоритмы Data Mining, анализ временных рядов
сравнение и ансамбли моделей.
Во второй части авторы демонстрируют, как можно решать задачи консолидации, составления аналитической
отчетности, кредитного скоринга, кросс-продаж, прогнозирования спроса и многие другие средствами бизнес-
аналитики, на примере аналитической платформы Deductor.
Книга предназначена для бизнес-аналитиков специалистов в области анализа данных, а также для студентов вузов,
обучающихся по направлениям и специальностям «Прикладная информатика», «Бизнес-информатика» и другим
экономическим специальностям.
Тема: Экономическая литература Экономико-математические методы Уровень пользователя: опытный
С^ППТЕР
| 197198, Санкт-Петербург, а/я 127; тел.: (812) 703-73-74, postbook@prter.com
| 61093, Харьков-93, а/я 9130; тел.: (057) 758-41 -45,751 -10-02, prter@kharkov.piter.com
ISBN: 978-5-459-00717-6
www.piter.com — вся информация о книгах и веб-магазин