/













































































































































































































































































































































































































































Автор: Мюссер Дэвид Р. Дердж Жилмер Дж. Сейни Атул.
Теги: компьютерные технологии программирование справочник
ISBN: 978-5-8459-1665-5
Год: 2010




Текст
C++ и STL
справочное
руководство
Второе издание Ife
Программирование на C++
с применением стандартной
библиотеки шаблонов
Дэвид Р. Мюссер
Жилмер Дж. Дердж
Атул Сейни
Предисловие Александра Степанова,
автора книги Elements of Programming и создателя STL
STL Tutorial
and
Reference Guide
Second Edition
C++ Programming with
the Standard Template Library
David R. Musser
GillmerJ. Derge
Atul Saini
Foreword by Alexander Stepanov
ADDISON-WESLEY
An imprint of Addison Wesley Longman, Inc.
Reading, Massachusetts • Harlow, England • Menlo Park, California
Berkeley, California • Don Mills, Ontario • Sydney
Bonn • Amsterdam • Tokyo • Mexico City
C++ и STL
справочное
руководство
Второе издание
Программирование на C++ с применением
стандартной библиотеки шаблонов
Дэвид Р. Мюссер
Жилмер Дж. Дердж
Атул Сейни
Предисловие Александра Степанова
вильямс
ш
Издательский дом "Вильямс"
Москва • Санкт-Петербург • Киев
2010
ББК 32.973.26-018.2.75
М98
УДК 681.3.07
Издательский дом "Вильяме"
Зав. редакцией С.Н. Тригуб
Перевод с английского и редакция канд. техн. наук И.В. Красикова
По общим вопросам обращайтесь в Издательский дом "Вильяме" по адресу:
info@williamspublishing.com, http://www.williamspublishing.com
Мюссер, Дэвид Р., Дердж, Жилмер Дж., Сейни, Атул.
М98 C++ и STL: справочное руководство, 2-е изд. (серия C++ in Depth).: Пер. с англ. —
М.: 000 "И.Д. Вильяме", 2010. — 432 с.: ил. — Парал. тит. англ.
ISBN 978-5-8459-1665-5 (рус.)
ББК 32.973.26-018.2.75
Все названия программных продуктов являются зарегистрированными торговыми марками
соответствующих фирм.
Никакая часть настоящего издания ни в каких целях не может быть воспроизведена в какой бы то ни было
форме и какими бы то ни было средствами, будь то электронные или механические, включая
фотокопирование и запись на магнитный носитель, если на это нет письменного разрешения издательства
Addison-Wesley Publishing Company, Inc.
Authorized translation from the English language edition published by Addison-Wesley Publishing Company, Inc,
Copyright © 1996,1998, 2001 by Modena Software, Inc.
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in
any form, or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written
permission of Modena Software, Inc.
This is a draft of the 2nd edition of STL Tutorial and Reference Guide — C++ Programming with the Standard
Template Library by David R. Musser, Atul Saini and Gillmer J. Derge, to be published by Addison-Wesley in 2001.
Copyright © 1998-2000 All rights reserved.
Russian language edition published by Williams Publishing House according to the Agreement with R&I
Enterprises International, Copyright © 2010
Научно-популярное издание
Дэвид Р. Мюссер, Жилмер Дж. Дердж, Атул Сейни
C++ и STL: справочное руководство, 2-е издание
(серия C++ in Depth)
Литературный редактор ЕЛ. Перестюк
Верстка О.В. Мишутина
Художественный редактор ЕЛ. Дынник
Корректор Л.А. Гордиенко
Подписано в печать 14.07.2010. Формат 70x100/16.
Гарнитура Times. Печать офсетная.
Усл. печ. л. 34,83. Уч.-изд. л. 23,4.
Тираж 1000 экз. Заказ № 23168.
Отпечатано по технологии CtP
в ОАО "Печатный двор" им. А. М. Горького
197110, Санкт-Петербург, Чкаловский пр., 15.
ООО "И. Д. Вильяме", 127055, г. Москва, ул. Лесная, д. 43, стр. 1
ISBN 978-5-8459-1665-5 (рус.) О Издательский дом "Вильяме", 2010
ISBN 978-0-321-70212-8 (англ.) © by Modena Software, Inc., 1996,1998, 2001
Предисловие 27
Предисловие к первому изданию 32
Введение 33
ЧАСТЬ I. ВВОДНЫЙ КУРС В STL 37
Глава 1. Введение 39
Глава 2. Обзор компонентов STL 51
Глава 3. Отличие STL от других библиотек 71
Глава 4. Итераторы 75
Глава 5. Обобщенные алгоритмы 93
Глава 6. Последовательные контейнеры 137
Глава 7. Отсортированные ассоциативные контейнеры 163
Глава 8. Функциональные объекты 181
Глава 9. Адаптеры контейнеров 189
Глава 10. Адаптеры итераторов 197
Глава 11. Функциональные адаптеры 201
ЧАСТЬ II. ПРИМЕРЫ ПРОГРАММ 207
Глава 12. Программа для поиска в словаре 209
Глава 13. Программа поиска всех групп анаграмм 217
Глава 14. Улучшенная программа поиска групп анаграмм 225
Глава 15. Ускорение программы поиска анаграмм: использование
мультиотображений 231
Глава 16. Определение класса итератора 237
Глава 17. STL и объекгно-ориентированное программирование 243
Глава 18. Программа вывода дерева ученых в области теории
вычислительных машин и систем 249
Глава 19. Класс для хронометража обобщенных алгоритмов 259
ЧАСТЬ III. СПРАВОЧНОЕ РУКОВОДСТВО ПО STL 271
Глава 20. Справочное руководство по итераторам 273
Глава 21. Справочное руководство по контейнерам 291
Глава 22. Справочное руководство по обобщенным алгоритмам 341
Глава 23. Справочное руководство по функциональным объектам
и адаптерам 377
Глава 24. Справочное руководство по аллока горам 385
Глава 25. Справочное руководство по утилитам 395
Приложение А. Заголовочные файлы STL 399
Приложение Б. Справочное руководство по строкам 401
Приложение В. Заголовочные файлы, используемые в примерах программ 413
Приложение Г. Ресурсы 419
Список литературы 420
Предметный указатель 421
Предисловие 27
Предисловие к первому изданию 32
Введение 33
Изменения во втором издании 33
Исторические сведения из предисловия к первому изданию 34
Что было потом 35
Благодарности из первого издания 36
Благодарности ко второму изданию 36
ЧАСТЬ I. ВВОДНЫЙ КУРС В STL 37
Глава 1. Введение 39
1.1. Для кого предназначена эта книга 40
1.2. Что такое обобщенное программирование 40
1.3. Обобщенное программирование и шаблоны C++ 42
1.3.1. Шаблоны классов 42
1.3.2. Шаблоны функций 44
1.3.3. Шаблоны функций-членов 45
1.3.4. Явное указание аргументов шаблонов 46
1.3.5. Параметры шаблона по умолчанию 47
1.3.6. Частичная специализация 47
1.4. Шаблоны и проблема "разбухания кода" 47
1.5. Гарантии производительности STL 48
1.5.1. 0-обозначения и связанные определения 48
1.5.2. Амортизированное время 49
1.5.3. Ограничения 0-обозначений 5 0
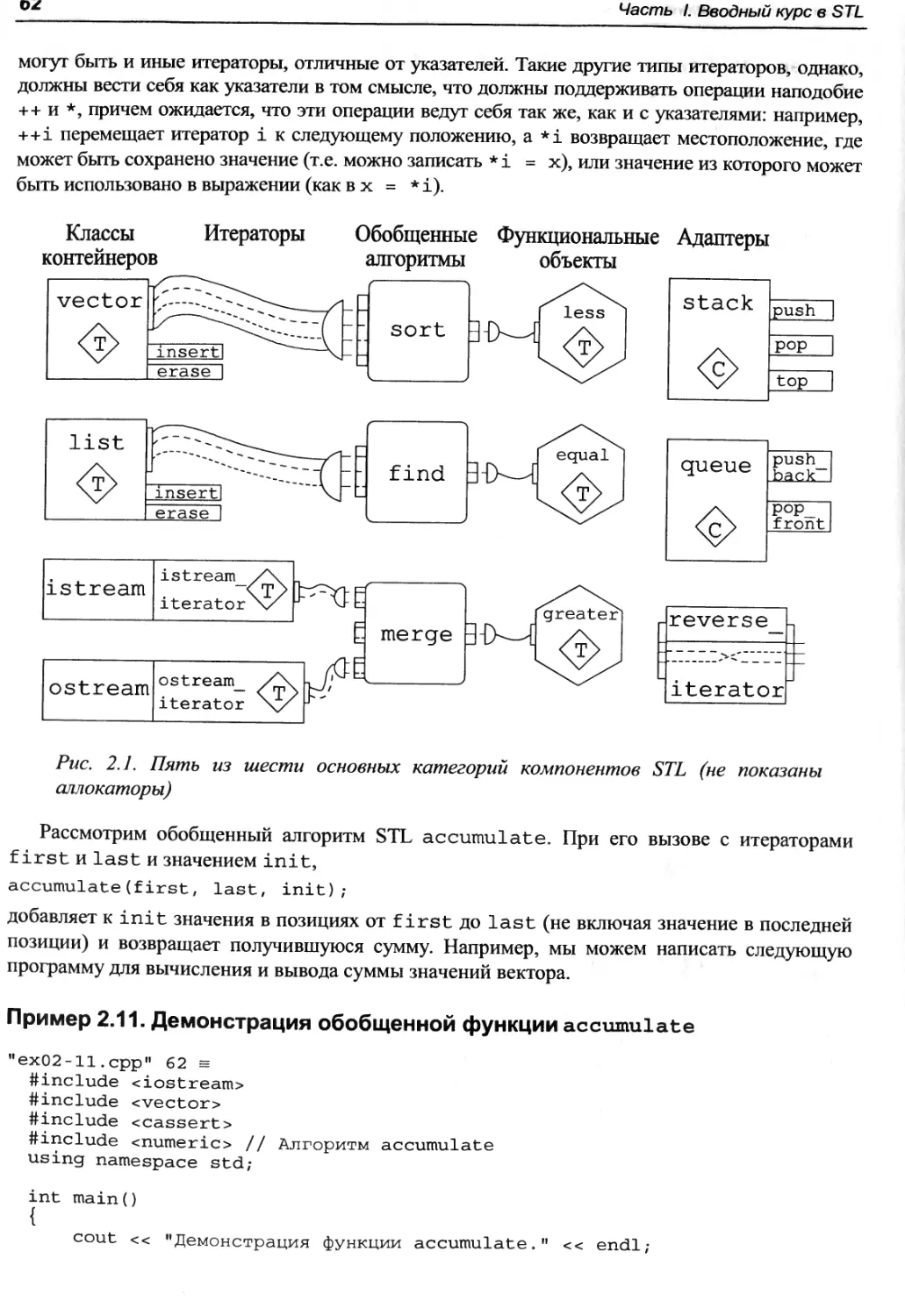
Глава 2. Обзор компонентов STL 51
2.1. Контейнеры 51
2.1.1. Контейнеры последовательностей 51
2.1.2. Отсортированные ассоциативные контейнеры 55
2.2. Обобщенные алгоритмы 56
2.2.1. Обобщенный алгоритм find 56
2.2.2. Обобщенный алгоритм merge 59
2.3. Итераторы 61
2.4. Функциональные объекты 64
2.5. Адаптеры 67
2.6. Аллокаторы 70
Глава 3. Отличие STL от других библиотек 71
3.1. Расширяемость 71
3.2. Взаимозаменяемость компонентов 72
3.3. Совместимость алгоритмов и контейнеров 73
Глава 4. Итераторы 75
4.1. Входные итераторы 75
4.2. Выходные итераторы 77
4.3. Однонаправленные итераторы 7 8
4.4. Двунаправленные итераторы 79
4.5. Итераторы с произвольным доступом 80
4.6. Иерархия итераторов STL: эффективная комбинация алгоритмов
и контейнеров 81
4.7. Итераторы вставки 83
4.8. Еще раз о входе и выходе: потоковые итераторы 84
4.9. Спецификация категорий итераторов, требуемых алгоритмами STL 86
4.10. Разработка обобщенных алгоритмов 87
4.11. Почему некоторые алгоритмы требуют более мощные итераторы 88
4.12. Выбор правильного алгоритма 89
4.13. Константные и изменяемые итераторы 89
4.14. Категории итераторов, предоставляемые контейнерами STL 91
Глава 5. Обобщенные алгоритмы 93
5.1. Базовая организация алгоритмов в STL 93
5.1.1. Версии "на месте" и копирующие версии 93
5.1.2. Алгоритмы с функциональными параметрами 95
5.2. Неизменяющие алгоритмы над последовательностями 96
5.2.1. find 96
5.2.2. adjacentfind 97
5.2.3. count 98
5.2.4. foreach 99
5.2.5. mismatch и equal 100
5.2.6. search 102
5.3. Изменяющие алгоритмы над последовательностями 104
5.3.1. сору и copybackward 104
5.3.2. fill 105
5.3.3. generate 106
5.3.4. partition 107
5.3.5. randomshuffle 109
5.3.6. remove 110
5.3.7. replace 111
5.3.8. reverse 111
5.3.9. rotate 111
5.3.10. swap 112
5.3.11. swapranges 113
5.3.12. transform 114
5.3.13. unique 114
5.4. Алгоритмы, связанные с сортировкой 116
5.4.1. Отношения сравнения 116
5.4.2. Неубывающее и невозрастающее упорядочения 118
5.4.3. sort, stable_sort и partial_sort 119
5.4.4. nth_element 122
5.4.5. binary_search, lower_bound, upper_bound и equal_range 123
5.4.6. merge 125
5.4.7. Теоретико-множественные операции над отсортированными
структурами 126
5.4.8. Операции над пирамидами 127
5.4.9. Минимум и максимум 129
5.4.10. Лексикографическое сравнение 130
5.4.11. Генераторы перестановок 130
5.5. Обобщенные числовые алгоритмы 131
5.5.1. accumulate 131
5.5.2. partialsum 132
5.5.3. adjacentdifference 133
5.5.4. inner_product 134
Глава 6. Последовательные контейнеры 137
6.1. Векторы 138
6.1.1. Типы 138
6.1.2. Конструирование последовательностей 139
6.1.3. Вставка 143
6.1.4. Удаление 147
6.1.5. Функции доступа 149
6.1.6. Отношения равенства и "меньше, чем" 150
6.1.7. Присваивания 151
6.2. Деки 152
6.2.1. Типы 154
6.2.2. Конструкторы 154
6.2.3. Вставка 154
6.2.4. Удаление 155
6.2.5. Аксессоры 155
6.2.6. Отношения равенства и "меньше, чем" 155
6.2.7. Присваивания 155
6.3. Списки 155
6.3.1. Типы 157
6.3.2. Конструкторы 157
6.3.3. Вставка 157
6.3.4. Удаление 157
6.3.5. Склейка 159
6.3.6. Функции-члены, связанные с сортировкой 160
6.3.7. Удаление 161
6.3.8. Аксессоры 161
6.3.9. Отношения равенства и "меньше, чем" 162
6.3.10. Присваивания 162
Глава 7. Отсортированные ассоциативные контейнеры 163
7.1. Множества и мультимножества 164
7.1.1. Типы 164
7.1.2. Конструкторы 165
7.1.3. Вставка 165
7.1.4. Удаление 168
7.1.5. Аксессоры 170
7.1.6. Отношения эквивалентности и "меньше, чем" 172
7.1.7. Присваивание 173
7.2. Отображения и мультиотображения 173
7.2.1. Типы 174
7.2.2. Конструкторы 174
7.2.3. Вставка 174
7.2.4. Удаление 178
7.2.5. Аксессоры 178
7.2.6. Отношения равенства и "меньше, чем" 179
7.2.7. Присваивания 179
Глава 8. Функциональные объекты 181
8.1. Передача функций через указатели 181
8.2. Преимущества передачи функциональных объектов как параметров
шаблонов 183
8.3. Функциональные объекты, предоставляемые STL 187
Глава 9. Адаптеры контейнеров 189
9.1. Адаптер стека 190
9.2. Адаптер очереди 191
9.3. Адаптер очереди с приоритетами 193
Глава 10. Адаптеры итераторов 197
Глава 11. Функциональные адаптеры 201
11.1. Связыватели 201
11.2. Инверторы 202
11.3. Адаптеры для указателей на функции 203
ЧАСТЬ II. ПРИМЕРЫ ПРОГРАММ 207
Глава 12. Программа для поиска в словаре 209
12.1. Поиск анаграмм данного слова 209
12.2. Работа со строками и потоками 211
12.3. Генерация перестановок и поиск в словаре 213
12.4. Полная программа 213
12.5. Насколько быстр разработанный код 214
Глава 13. Программа поиска всех групп анаграмм 217
13.1. Поиск групп анаграмм 217
13.2. Определение структуры данных для работы с STL 218
13.3. Создание функциональных объектов для сравнений 219
13.4. Полная программа поиска групп анаграмм 220
13.5. Чтение словаря в вектор объектов PS 220
13.6. Использование объекта сравнения для сортировки 221
13.7. Использование предиката эквивалентности для поиска равных
элементов 221
13.8. Использование функционального адаптера для получения объекта
предиката 222
13.9. Копирование группы анаграмм в выходной поток 222
13.10. Вывод программы 223
Глава 14. Улучшенная программа поиска групп анаграмм 225
14.1. Структура данных для хранения пар итераторов 225
14.2. Хранение информации в отображении списков 226
14.3. Упорядоченный по размерам вывод групп анаграмм 226
14.4. Улучшенная программа поиска анаграмм 227
14.5. Вывод программы 228
14.6. Причины использования отображения 229
Глава 15. Ускорение программы поиска анаграмм: использование
мультиотображений 231
15.1. Поиск групп анаграмм, версия 3 231
15.2. Объявление мультиотображения 234
15.3. Чтение словаря в мультиотображение 234
15.4. Поиск групп анаграмм в мультиотображений 234
15.5. Упорядоченный по размерам вывод групп анаграмм 236
15.6. Вывод программы 236
15.7. Скорость работы программы 236
Глава 16. Определение класса итератора 237
16.1. Новый вид итератора: подсчитывающий итератор 237
16.2. Класс подсчитывающего итератора 238
Глава 17. STL и объектно-ориентированное программирование 243
17.1. Использование наследования и виртуальных функций 244
17.2. Устранение "разбухания кода" 248
Глава 18. Программа вывода дерева ученых в области теории
вычислительных машин и систем 249
18.1. Сортировка аспирантов по датам 249
18.2. Связь аспирантов с руководителями 250
18.3. Поиск корней дерева 251
18.4. Чтение файла 254
18.5. Вывод результатов 255
18.6. Полный исходный текст программы 256
Глава 19. Класс для хронометража обобщенных алгоритмов 259
19.1. Препятствия точному хронометражу алгоритмов 259
19.2. Преодоление препятствий 260
19.3. Уточнение метода 262
19.4. Автоматизация анализа при помощи класса 263
19.4.1. Вывод результатов 265
19.5. Хронометраж алгоритмов сортировки STL 267
ЧАСТЬ III. СПРАВОЧНОЕ РУКОВОДСТВО ПО STL 271
Глава 20. Справочное руководство по итераторам 273
20.1. Требования ко входным итераторам 274
20.2. Требования к выходным итераторам 275
20.3. Требования к однонаправленным итераторам 276
20.4. Требования к двунаправленным итераторам 277
20.5. Требования к итераторам с произвольным доступом 277
20.6. Свойства итераторов 278
20.6.1. Базовый класс iterator 279
20.6.2. Стандартные дескрипторы итераторов 279
20.7. Операции с итераторами 280
20.8. istreamiterator 280
20.8.1. Файлы 281
20.8.2. Объявление класса 281
20.8.3. Примеры 281
20.8.4. Описание 281
20.8.5. Определения типов 281
20.8.6. Конструкторы 281
20.8.7. Открытые функции-члены 282
20.8.8. Операции сравнения 282
20.9. ostreamiterator 282
20.9.1. Файлы 282
20.9.2. Объявление класса 283
20.9.3. Примеры 283
20.9.4. Описание 283
20.9.5. Определения типов 283
20.9.6. Конструкторы 283
20.9.7. Открытые функции-члены 284
20.10. reverseiterator 284
20.10.1. Файлы 284
20.10.2. Объявление класса 284
20.10.3. Примеры 284
20.10.4. Описание 284
20.10.5. Конструктор 285
20.10.6. Открытые функции-члены 285
20.10.7. Глобальные операции 286
20.10.8. Предикаты равенства и упорядочения 286
20.11. backinsertiterator 287
20.11.1. Файлы 287
20.11.2. Объявление класса 287
20.11.3. Примеры 287
20.11.4. Описание 287
20.11.5. Конструкторы 287
20.11.6. Открытые функции-члены 287
20.11.7. Сопутствующие шаблоны функций 288
20.12. frontinsertiterator 288
20.12.1. Файлы 288
20.12.2. Объявление класса 288
20.12.3. Конструкторы 288
20.12.4. Открытые функции-члены 288
20.12.5. Сопутствующие шаблоны функций 289
20.13. insert_iterator 289
20.13.1. Файлы 289
20.13.2. Объявление класса 289
20.13.3. Примеры 289
20.13.4. Конструкторы 289
20.13.5. Открытые функции-члены 289
20.13.6. Сопутствующие шаблоны функций 290
Глава 21. Справочное руководство по контейнерам 291
21.1. Требования 291
21.1.1. Дизайн и организация контейнеров STL 291
21.1.2. Общие члены всех контейнеров 292
21.1.3. Требования к обратимым контейнерам 294
21.1.4. Требования к контейнерам последовательностей 294
21.1.5. Требования к отсортированным ассоциативным контейнерам 295
21.2. Описания организации классов контейнеров 298
21.2.1. Файлы 298
21.2.2. Объявление класса 299
21.2.3. Примеры 299
21.2.4. Описание 299
21.2.5. Определения типов 299
21.2.6. Конструкторы, деструкторы и связанные функции 299
21.2.7. Операции сравнения 299
21.2.8. Функции-члены для обращения к элементам 299
21.2.9. Функции-члены для вставки 299
21.2.10. Функции-члены для удаления 299
21.2.11. Раздел(ы) дополнительных примечаний 299
21.3. vector 300
21.3.1. Файлы 300
21.3.2. Объявление класса 300
21.3.3. Примеры 300
21.3.4. Описание 300
21.3.5. Определения типов 301
21.3.6. Конструкторы, деструкторы и связанные функции вектора 301
21.3.7. Операции сравнения 303
21.3.8. Функции-члены вектора для обращения к элементам 303
21.3.9. Функции-члены вектора для вставки 3 04
21.3.10. Функции-члены вектора для удаления 3 04
21.3.11. Замечания о функциях-членах вставки и удаления 305
21.4. deque 305
21.4.1. Файлы 305
21.4.2. Объявление класса 305
21.4.3. Примеры 306
21.4.4. Описание 306
21.4.5. Определения типов 306
21.4.6. Конструкторы, деструкторы и связанные функции дека 306
21.4.7. Операции сравнения 307
21.4.8. Функции-члены дека для обращения к элементам 307
21.4.9. Функции-члены дека для вставки 308
21.4.10. Функции-члены дека для удаления 308
21.4.11. Сложность вставки в дек 309
21.4.12. Замечания о функциях-членах удаления 309
21.5. list 309
21.5.1. Файлы 309
21.5.2. Объявление класса 309
21.5.3. Примеры 309
21.5.4. Описание 310
21.5.5. Определения типов 310
21.5.6. Конструкторы, деструкторы и связанные функции списка 311
21.5.7. Операции сравнения 311
21.5.8. Функции-члены списка для обращения к элементам 312
21.5.9. Функции-члены списка для вставки 313
21.5.10. Функции-члены списка для удаления 313
21.5.11. Специальные операции со списками 313
21.5.12. Замечания о функциях-членах вставки 315
21.5.13. Замечания о функциях-членах удаления 315
21.6. set 315
21.6.1. Файлы 315
21.6.2. Объявление класса 316
21.6.3. Примеры 316
21.6.4. Описание 316
21.6.5. Определения типов 316
21.6.6. Конструкторы, деструкторы и связанные функции множества 317
21.6.7. Операции сравнения 317
21.6.8. Функции-члены множества для обращения к элементам 318
21.6.9. Функции-члены множества для вставки 319
21.6.10. Функции-члены множества для удаления 319
21.6.11. Специализированные операции множества 320
21.7. multiset 320
21.7.1. Файлы 320
21.7.2. Объявление класса 320
21.7.3. Примеры 320
21.7.4. Описание 321
21.7.5. Определения типов 321
21.7.6. Конструкторы, деструкторы и связанные функции
мультимножества 321
21.7.7. Операции сравнения 322
21.7.8. Функции-члены мультимножества для обращения к элементам 322
21.7.9. Функции-члены мультимножества для вставки 323
21.7.10. Функции-члены мультимножества для удаления 323
21.7.11. Специализированные операции мультимножества 324
21.8. map 324
21.8.1. Файлы 324
21.8.2. Объявление класса 324
21.8.3. Примеры 325
21.8.4. Описание 325
21.8.5. Определения типов 325
21.8.6. Конструкторы, деструкторы и связанные функции отображения 326
21.8.7. Операции сравнения 326
21.8.8. Функции-члены отображения для обращения к элементам 327
21.8.9. Функции-члены отображения для вставки 328
21.8.10. Функции-члены отображения для удаления 328
21.8.11. Специализированные операции отображения 329
21.9. multimap 330
21.9.1. Файлы 330
21.9.2. Объявление класса 330
21.9.3. Примеры 330
21.9.4. Описание 330
21.9.5. Определения типов 330
21.9.6. Конструкторы, деструкторы и связанные функции
мультиотображения 330
21.9.7. Операции сравнения 331
21.9.8. Функции-члены мультиотображения для обращения к элементам 331
21.9.9. Функции-члены мультиотображения для вставки 332
21.9.10. Функции-члены мультиотображения для удаления 333
21.9.11. Специализированные операции мультиотображения 333
21.10. Адаптер контейнера stack 334
21.10.1. Файлы 334
21.10.2. Объявление класса 334
21.10.3. Примеры 334
21.10.4. Описание 334
21.10.5. Определения типов 335
21.10.6. Конструкторы 335
21.10.7. Открытые функции-члены 335
21.10.8. Операции сравнения 335
21.11. Адаптер контейнера queue 336
21.11.1. Файлы 336
21.11.2. Объявление класса 336
21.11.3. Примеры 336
21.11.4. Описание 336
21.11.5. Определения типов 336
21.11.6. Конструкторы 336
21.11.7. Открытые функции-члены 337
21.11.8. Операции сравнения 337
21.12. Адаптер контейнера priorityqueue 337
21.12.1. Файлы 337
21.12.2. Объявление класса 337
21.12.3. Примеры 337
21.12.4. Описание 338
21.12.5. Определения типов 338
21.12.6. Конструкторы 338
21.12.7. Открытые функции-члены 339
21.12.8. Операторы сравнения 339
Глава 22. Справочное руководство по обобщенным алгоритмам 341
22.1. Организация описаний алгоритмов 341
22.1.1. Прототипы 341
22.1.2. Примеры 342
22.1.3. Описание 342
22.1.4. Временная сложность 342
22.2. Неизменяющие алгоритмы над последовательностями 342
22.3. for_each 343
22.3.1. Прототип 343
22.3.2. Примеры 343
22.3.3. Описание 343
22.3.4. Временная сложность 344
22.4. find 344
22.4.1. Прототипы 344
22.4.2. Примеры 344
22.4.3. Описание 344
22.4.4. Временная сложность 344
22.5. fmdfirstof 344
22.5.1. Прототипы 344
22.5.2. Описание 345
22.5.3. Временная сложность 345
22.6. adjacentfmd 345
22.6.1. Прототипы 345
22.6.2. Примеры 345
22.6.3. Описание 345
22.6.4. Временная сложность 345
22.7. count 346
22.7.1. Прототипы 346
22.7.2. Примеры 346
22.7.3. Описание 346
22.7.4. Временная сложность 346
22.8. mismatch 346
22.8.1. Прототипы 346
22.8.2. Примеры 346
22.8.3. Описание 347
22.8.4. Временная сложность 347
22.9. equal 347
22.9.1. Прототипы 347
22.9.2. Примеры 347
22.9.3. Описание 347
22.9.4. Временная сложность 348
22.10. search 348
22.10.1. Прототипы 348
22.10.2. Примеры 348
22.10.3. Описание 348
22.10.4. Временная сложность 348
22.11. search_n 349
22.11.1. Прототипы 349
22.11.2. Описание 349
22.11.3. Временная сложность 349
22.12. fmd_end 349
22.12.1. Прототипы 349
22.12.2. Описание 350
22.12.3. Временная сложность 350
22.13. Обзор изменяющих алгоритмов над последовательностями 350
22.14. сору 351
22.14.1. Прототипы 351
22.14.2. Примеры 351
22.14.3. Описание 351
22.14.4. Временная сложность 351
22.15. swap 351
22.15.1. Прототипы 351
22.15.2. Примеры 352
22.15.3. Описание 352
22.15.4. Временная сложность 352
22.16. transform 352
22.16.1. Прототипы 352
22.16.2. Примеры 352
22.16.3. Описание 353
22.16.4. Временная сложность 353
22.17. replace 353
22.17.1. Прототипы 353
22.17.2. Примеры 353
22.17.3. Описание 354
22.17.4. Временная сложность 354
22.18. fill 354
22.18.1. Прототипы 354
22.18.2. Примеры 354
22.18.3. Описание 354
22.18.4. Временная сложность 354
22.19. generate 354
22.19.1. Прототипы 354
22.19.2. Примеры 355
22.19.3. Описание 355
22.19.4. Временная сложность 355
22.20. remove 355
22.20.1. Прототипы 355
22.20.2. Примеры 355
22.20.3. Описание 356
22.20.4. Временная сложность 356
22.21. unique 356
2221 Л. Прототипы 356
22.21.2. Примеры 356
22.21.3. Описание 357
22.21.4. Временная сложность 357
22.22. reverse 357
22.22.1. Прототипы 357
22.22.2. Примеры 357
22.22.3. Описание 357
22.22.4. Временная сложность 358
22.23. rotate 358
22.23.1. Прототипы 358
22.23.2. Примеры 358
22.23.3. Описание 358
22.23.4. Временная сложность 358
22.24. randomshuffle 358
22.24.1. Прототипы 358
22.24.2. Примеры 359
22.24.3. Описание 359
22.24.4. Временная сложность 359
22.25. partition 359
22.25.1. Прототипы 359
22.25.2. Примеры 359
22.25.3. Описание 359
22.25.4. Временная сложность 360
22.26. Обзор алгоритмов, связанных с сортировкой 360
22.27. sort 361
22.27.1. Прототипы 361
22.27.2. Примеры 362
22.27.3. Описание 362
22.27.4. Временная сложность 363
22.28. nthelement 363
22.28.1. Прототипы 363
22.28.2. Примеры 363
22.28.3. Описание 363
22.28.4. Временная сложность 364
22.29. Бинарный поиск 364
22.29.1. Прототипы 364
22.29.2. Примеры 365
22.29.3. Описание 365
22.29.4. Временная сложность 365
22.30. merge 365
22.30.1. Прототипы 365
22.30.2. Примеры 366
22.30.3. Описание 366
22.30.4. Временная сложность 366
22.31. Теоретико-множественные операции над отсортированными
структурами 366
2231 Л. Прототипы 367
22.31.2. Примеры 368
22.31.3. Описание 368
2231 А. Временная сложность 368
22.32. Операции с пирамидами 369
22.32.1. Прототипы 369
22.32.2. Примеры 370
22.32.3. Описание 370
22.32.4. Временная сложность 370
22.33. min и max 370
22.33.1. Прототипы 370
22.33.2. Примеры 371
22.33.3. Описание 371
22.33.4. Временная сложность 371
22.34. Лексикографическое сравнение 371
22.34.1. Прототипы 371
22.34.2. Примеры 371
22.34.3. Описание 372
22.34.4. Временная сложность 372
22.35. Генераторы перестановок 372
22.35.1. Прототипы 372
22.35.2. Примеры 372
22.35.3. Описание 373
22.35.4. Временная сложность 373
22.36. Обзор обобщенных численных алгоритмов 373
22.37. accumulate 373
22.37.1. Прототипы 373
22.37.2. Примеры 374
22.37.3. Описание 374
22.37.4. Временная сложность 374
22.38. inner_product 374
22.38.1. Прототипы 374
22.38.2. Примеры 374
22.38.3. Описание 374
22.38.4. Временная сложность 375
22.39. partialsum 375
22.39.1. Прототипы 375
22.39.2. Примеры 375
22.39.3. Описание 375
22.39.4. Временная сложность 376
22.40. adjacentdifference 376
22.40.1. Прототипы 376
22.40.2. Примеры 376
22.40.3. Описание 376
22.40.4. Временная сложность 376
Глава 23. Справочное руководство по функциональным объектам
и адаптерам 377
23.1. Требования 377
23.1.1. Функциональные объекты 377
23.1.2. Функциональные адаптеры 377
23.2. Базовые классы 378
23.3. Арифметические операции 378
23.4. Операции сравнения 379
23.5. Логические операции 379
23.6. Инверторы 380
23.7. Связыватели 380
23.8. Адаптеры для указателей на функции 381
23.9. Адаптеры для указателей на функции-члены 381
Глава 24. Справочное руководство по аллокаторам 385
24.1. Введение 385
24.1.1. Передача аллокаторов контейнерам STL 385
24.2. Требования к аллокаторам 385
24.3. Аллокатор по умолчанию 388
24.3.1. Файлы 388
24.3.2. Объявление класса 388
24.3.3. Описание 388
24.3.4. Определения типов 388
24.3.5. Конструкторы, деструкторы и связанные функции 388
24.3.6. Другие функции-члены 389
24.3.7. Операции сравнения 389
24.3.8. Специализация для void 390
24.4. Пользовательские аллокаторы 390
Глава 25. Справочное руководство по утилитам 395
25.1. Введение 395
25.2. Функции сравнения 395
25.3. pair 396
25.3.1. Файлы 396
25.3.2. Объявление класса 396
25.3.3. Примеры 396
25.3.4. Описание 396
25.3.5. Определения типов 396
25.3.6. Члены-данные 396
25.3.7. Конструкторы 396
25.3.8. Функции сравнения 397
Приложение А. Заголовочные файлы STL 399
Приложение Б. Справочное руководство по строкам 401
Б. 1. Классы строк 401
Б. 1.1. Файлы 401
Б. 1.2. Объявление класса 401
В. 1.3. Описание 401
Б. 1.4. Определения типов 402
Б. 1.5. Конструкторы, деструкторы и связанные функции 403
Б. 1.6. Операции сравнения 405
Б. 1.7. Функции-члены для доступа к элементам 407
Б. 1.8. Функции-члены для вставки 408
Б. 1.9. Функции-члены для удаления 408
Б. 1.10. Дополнительные примечания 409
Б.2. Свойства символов 409
Б.2.1. Файлы 409
Б.2.2. Описание 409
Б.2.3. Определения типов 409
Б.2.4. Функции для работы с символами 410
Приложение В. Заголовочные файлы, используемые в примерах программ 413
В. 1. Файлы, используемые в примере 17.1 413
Приложение Г. Ресурсы 419
Г. 1. Адрес реализации SGI STL 419
Г.2. Адрес для получения исходных текстов данной книги 419
Г.З. Использованные компиляторы 419
Список литературы 420
Предметный указатель 422
Пример 2.1. Использование обобщенного алгоритма STL reverse
со строкой и массивом 52
Пример 2.2. Применение обобщенного алгоритма STL reverse к вектору 53
Пример 2.3. Применение обобщенного алгоритма STL reverse к списку 54
Пример 2.4. Демонстрация STL map 55
Пример 2.5. Демонстрация работы обобщенного алгоритма find с массивом 56
Пример 2.6. Демонстрация работы обобщенного алгоритма find с вектором 57
Пример 2.7. Демонстрация работы обобщенного алгоритма find со списком 58
Пример 2.8. Демонстрация работы обобщенного алгоритма find с деком 59
Пример 2.9. Демонстрация работы обобщенного алгоритма merge
с массивом, списком и деком 60
Пример 2.10. Демонстрация работы обобщенного алгоритма merge
путем объединения частей массива и дека с помещением результата
в список 61
Пример 2.11. Демонстрация обобщенной функции accumulate 62
Пример 2.12. Использование обобщенного алгоритма accumulate
для вычисления произведения 65
Пример 2.13. Использование обобщенного алгоритма accumulate
для вычисления произведения с применением функционального объекта 65
Пример 2.14. Использование обобщенного алгоритма accumulate
для вычисления произведения с применением multiplies 67
Пример 2.15. Демонстрация обобщенного алгоритма accumulate
с обратным итератором 68
Вывод примера 2.15 69
Пример 4.1. Демонстрация обобщенного алгоритма find
со входными итераторами массивов, списков и входных потоков 77
Пример 5.1. Использование алгоритма сортировки "на месте" 93
Пример 5.2. Использование reversecopy, копирующей версии
обобщенного алгоритма reverse 94
Пример 5.3. Использование обобщенного алгоритма sort с бинарным предикатом 95
Пример 5.4. Иллюстрация применения обобщенного алгоритма findif 97
Пример 5.5. Иллюстрация применения обобщенного алгоритма adjacentfind 97
Пример 5.6. Демонстрация использования обобщенного алгоритма count 98
Пример 5.7. Демонстрация использования обобщенного алгоритма foreach 99
Вывод примера 5.7 100
Пример 5.8. Демонстрация использования обобщенных алгоритмов equal и mismatch 100
Вывод примера 5.8 101
Пример 5.9. Демонстрация обобщенного алгоритма search 102
Пример 5.10. Демонстрация использования обобщенных алгоритмов сору
и copybackward 104
Пример 5.11. Демонстрация использования обобщенных
алгоритмов fill и filln 106
Пример 5.12. Демонстрация использования обобщенного алгоритма generate 106
Пример 5.13. Демонстрация использования обобщенных алгоритмов partition
и stable_partition 107
Вывод примера 5.13 108
Пример 5.14. Демонстрация использования обобщенного алгоритма random_shuffle 109
Вывод примера 5.14 109
Пример 5.15. Демонстрация использования обобщенного алгоритма remove 110
Пример 5.16. Демонстрация использования обобщенного алгоритма replace 111
Пример 5.17. Демонстрация использования обобщенного алгоритма rotate 112
Пример 5.18. Демонстрация использования обобщенного алгоритма swap 112
Пример 5.19. Демонстрация использования обобщенного алгоритма swap_ranges 113
Пример 5.20. Демонстрация использования обобщенного алгоритма transform 114
Вывод примера 5.20 114
Пример 5.21. Демонстрация использования обобщенного алгоритма unique 115
Вывод примера 5.21 115
Пример 5.22. Демонстрация использования обобщенных алгоритмов
sort, stablesort и partialsort 121
Вывод примера 5.22 122
Пример 5.23. Демонстрация использования обобщенного алгоритма nthelement 122
Пример 5.24. Демонстрация использования обобщенных
алгоритмов бинарного поиска 124
Пример 5.25. Демонстрация использования обобщенных алгоритмов слияния 125
Пример 5.26. Демонстрация использования обобщенных операций над множествами 126
Пример 5.27. Демонстрация использования обобщенных операций над пирамидами 128
Пример 5.28. Демонстрация использования обобщенных алгоритмов minelement
и maxelement 129
Пример 5.29. Демонстрация использования обобщенного алгоритма
lexicographicalcompare 130
Пример 5.30. Демонстрация использования обобщенных алгоритмов перестановок 131
Пример 5.31. Демонстрация использования обобщенного алгоритма accumulate 132
Пример 5.32. Демонстрация использования обобщенного алгоритма partialsum 132
Вывод примера 5.32 133
Пример 5.33. Демонстрация использования
обобщенного алгоритма adj acentdifference 133
Пример 5.34. Демонстрация использования обобщенного алгоритма inner_product 134
Вывод примера 5.34 135
Пример 6.1. Демонстрация простейших конструкторов вектора STL 140
Пример 6.2. Демонстрация конструкторов вектора STL с пользовательским типом 141
Пример 6.3. Демонстрация конструкторов вектора STL с использованием
пользовательского типа и явным копированием 141
Вывод примера 6.3 142
Пример 6.4. Демонстрация копирующих конструкторов вектора STL 142
Пример 6.5. Демонстрация функций вектора STL pushback и insert 143
Пример 6.6. Демонстрация функций вектора STL capacity и reserve 145
Вывод примера 6.6 146
Пример 6.7. Демонстрация операций back и рор_Ьаск над вектором STL 147
Вывод примера 6.7 147
Пример 6.8. Демонстрация функции erase вектора STL 148
Пример 6.9. Демонстрация функций дека STL push_back и push_front 153
Пример 6.10. Демонстрация функций списков STL push_back и push_front 156
Пример 6.11. Демонстрация функции erase списков STL 158
Пример 6.12. Демонстрация функций splice списков STL 159
Пример 6.13. Демонстрация функций sort и unique списков STL 160
Пример 7.1. Демонстрация создания множества и вставки в него 165
Пример 7.2. Демонстрация создания мультимножества и вставки в него 166
Пример 7.3. Демонстрация функций erase мультимножества 168
Пример 7.4. Демонстрация функций-членов мультимножества для поиска 170
Пример 7.5. Вычисление скалярного произведения кортежей,
представленных векторами 176
Вывод примера 7.5 176
Пример 7.6. Вычисление скалярного произведения кортежей, представленных
отображениями 177
Вывод примера 7.6 178
Пример 8.1. Расширенное определение и вызов accumulate 182
Пример 8.2. Расширенное определение и вызов accumulate 183
Пример 8.3. Использование функционального объекта для подсчета операций,
первая версия 185
Вывод примера 8.3 185
Пример 8.4. Использование функционального объекта для подсчета операций,
вторая версия 186
Пример 9.1. Иллюстрация адаптера стека 190
Вывод примера 9.1 191
Пример 9.2. Иллюстрация адаптера очереди 192
Вывод примера 9.2 193
Пример 9.3. Иллюстрация адаптера очереди с приоритетами 194
Вывод примера 9.3 195
Пример 10.1. Демонстрация прямого и обратного обхода 197
Вывод примера 10.1 198
Пример 10.2. Использование find с обычными и обратными итераторами 198
Вывод примера 10.2 199
Пример 11.1. Сортировка вектора в возрастающем порядке членов id 203
Пример 11.2. Демонстрация применения адаптера для указателей на функции 204
Вывод примера 11.2 205
Вывод примера 12.1 209
Пример 12.1. Программа поиска анаграмм в словаре, считываемом из файла 210
вывод их в стандартный поток вывода 220
Пример 13.1. Поиск всех групп анаграмм в словаре и вывод их
в стандартный поток вывода 220
Вывод примера 13.1 223
Пример 14.1. Вывод всех групп анаграмм в порядке уменьшения размера 227
Вывод примера 14.1 228
Пример 15.1. Поиск всех групп анаграмм в заданном словаре 232
Пример 16.1. Демонстрация класса подсчитывающего итератора 237
Вывод примера 16.1 241
Пример 17.1. Комбинация компонентов STL с наследованием
и виртуальными функциями 244
Вывод примера 17.1 247
Вывод примера 18.1 250
Пример 18.1. Вывод дерева ученых в области теории вычислительных
машин и систем 256
Пример 19.1. Первая попытка хронометража алгоритма sort 260
Вывод примера 19.1 261
Вывод примера 19.1а 262
Пример 19.2. Хронометраж алгоритма sort со случайными векторами 267
Вывод примера 19.2 268
Вывод примера 19.2а 268
Вывод примера 19.26 269
Пример 24.1. Демонстрация применения пользовательского аллокатора 392
Вывод примера 24.1 393
Полю, Эрике и Марте.
Дэвид Р. Мюссер
Матери и отцу.
Жилмер Дж. Дердж
Айртону Сенне (1960-1994).
Атул Сейни
Предисловие
Когда Дэйв Мюссер попросил меня написать предисловие ко второму изданию этой
книги, я тут же откликнулся на его просьбу. Во-первых, Дэйв мой коллега — мы сотрудничали
более 20 лет, и без Дэйва не было бы STL. Так что я рассматриваю его просьбу как
привилегию. Кроме того, он дал мне возможность сказать несколько слов о том, о чем я думал при
разработке STL.
Чтобы использовать инструмент, полезно понимать не только инструкции по его
применению, но и принципы, которыми руководствовались его разработчики. Основная цель этого
предисловия — познакомить вас с принципами , лежащими в основе STL.
STL разработана с учетом четырех фундаментальных идей:
• обобщенное программирование;
• абстрактность без потери эффективности;
• вычислительная модель фон Неймана;
• семантика значений.
Обобщенное программирование. Некоторые из вас могли слышать, что STL
представляет собой пример технологии программирования, именуемой "обобщенным
программированием". Это так. Некоторые из вас могли слышать, что обобщенное программирование —
это стиль программирования с применением шаблонов C++. Это не так. Обобщенное
программирование не имеет никакого отношения к C++ и шаблонам. Обобщенное
программирование— это предмет, изучающий систематическую организацию полезных программных
компонентов. Его целью является разработка систематики алгоритмов, структур данных,
механизмов распределения памяти и прочих программных артефактов таким образом, чтобы
обеспечить максимальный уровень повторного использования, модульности и удобства.
Чтобы обеспечить наивысшую степень повторного использования, следует пытаться
анализировать все возможные расширения. Например, когда известный ученый-кибернетик увидел
мою реализацию алгоритма Евклида для поиска наибольшего общего делителя двух величин,
template <typename T> T gcd(T 01,711) {
while (n != 0) {
Т t = m % n;
m = n;
n = t;
}
return m;
}
он возразил, что данный алгоритм некорректен, так как возвращает -1 при передаче ему
аргументов 1 и -1, так что наибольший общий делитель не оказывается наибольшим. Он
предложил исправить ситуацию, заменив последнюю строку на
return m < 0 ? -m : m;
Предисловие
К сожалению, в этом случае алгоритм не будет работать для многих важных расширений,
таких как полиномы, комплексные целые числа и т.д. Требуется, чтобы множество элементов,
с которыми мы работаем, было вполне упорядоченным. Проблема исчезает, если мы
используем более абстрактное (и алгоритмически более осмысленное) определение наибольшего
общего делителя: это делитель, который делится на любой другой общий делитель. Такое
определение допускает неоднозначные решения: в случае целых чисел 24 и 30 наибольшими
общими делителями будут 6 и -6. Это соответствует тому, что математики делали несколько
последних столетий.
Классификация компонентов программного обеспечения должна работать только с
полезными компонентами. Было бы нелепо вводить концепцию полупоследовательности —
последовательности, у которой несколько начал, но только один конец — поскольку мы не знаем
ни каких-либо структур данных, имеющих подобный вид, ни алгоритмов, способных
работать с ними.
После систематизации вещей и явлений мы можем обеспечить согласованность их
интерфейсов, т.е. интерфейсы двух компонентов должны быть одинаковы при одинаковом их
поведении. Это позволит нам реализовать алгоритмы, которые смогут работать с несколькими
компонентами — обобщенные алгоритмы. Это также обеспечит возможность использования
библиотеки. Если программист овладел шаблоном STL vector, для него будет несложно
изучить шаблон STL list, а научиться пользоваться шаблоном deque — еще проще. Я
считаю, что интерфейсы, обеспечивающие наибольшую возможную степень абстрактного
программирования, наиболее просты в изучении (в предположении, что человек начинает
изучение с нуля. Трудно убедить программиста на Lisp, что сравнение с итератором за концом
последовательности лучше проверки на равенство nil).
Во многих отношениях идеи обобщенного программирования подобны идеям
абстрактной алгебры. Те из вас, кто прослушал курс, посвященный группам, кольцам и полям,
должны увидеть происхождение классификации итераторов.1
Как математика организует теоремы вокруг разных абстрактных теорий, так и
обобщенное программирование организует алгоритмы вокруг различных абстрактных концепций. Так
что задача проектировщика библиотеки заключается в том, чтобы определить все
интересующие алгоритмы и минимальные требования, которые надо удовлетворить для их работы.
В общем случае эти требования описываются посредством множества допустимых
выражений и их семантики. Например, STL не указывает, что ++ для итератора должно быть
определено как функция-член класса. Она просто указывает, что если i — итератор и если он может
быть разыменован, то ++i — корректное выражение.
Абстрактность без потери эффективности. Математикам, бывает, приходится работать
с объектами, которые не могут быть сконструированы вообще или могут быть
сконструированы только за произвольно большое время. В области же вычислительной техники
эффективность играет важную роль. Недостаточно знать, что некоторая операция может быть
выполнена— важно знать, что она может быть выполнена за разумное время. Чтобы это
гарантировать, STL предпринимает ряд мер.
Во-первых, она делает требование сложности частью каждого интерфейса. Когда опреде-
7ется некоторая концепция, такая как итераторы, задаются некоторые требования к сложно-
Вообще говоря, я считаю, что для хорошего программиста математическая культура совершенно
необходима. Достаточно грустно, что в наши дни программисты заканчивают колледжи (а часто и
магистратуру), так и не столкнувшись с реальной математикой. Я бы хотел посоветовать вам продолжать
изучение математики на всем протяжении вашей карьеры. Что касается конкретных книг, то я бы
рекомендовал трехтомник Джона Стивелла (John Stillwell) Numbers and Geometry, Mathematics and Its
History, и Elements of Algebra; после этого можно обратиться к Geometry: Euclid and Beyond Робина
Хартшорна (Robin Hartshorne) и Visual Complex Analysis Тристана Нидхэма (Tristan Needham).
Предисловие
29
сти. Программист может быть уверен, что применение операции ++ к итератору существенно
от его положения в последовательности не зависит. Разыменование должно выполняться
одинаково быстро — некорректно реализовывать итераторы списка при помощи структуры,
содержащей указатель на заголовок списка и целочисленный индекс. (Следует заметить, что
в то время как операционная семантика операций может быть строго определена при помощи
множества корректных выражений и их семантики, сложность определяется неформально;
требуется принципиально новое решение, чтобы найти способ для строгого, но практичного
указания требований сложности.)
Во-вторых, STL принимает особые меры к тому, чтобы не скрывать никакую часть
структуры данных, которая обеспечивает эффективный доступ. Вместо предоставления методов
доступа для чтения и записи для работы с контейнером — любимый метод авторов
учебников — используется указатель на значение, так что поля могут модифицироваться
непосредственно. Можно написать
i->second = 5;
вместо
pair<int/ int> tmp = my_vector.get(i);
tmp.second = 5;
my_vector.put(i, tmp);
Известно, что итераторы элементов вектора становятся некорректными после периодических
перераспределений памяти, так что предполагается, что пользователи STL знают, как быть —
заранее выделить достаточно памяти или хранить индексы, а не итераторы.
Были приняты меры для того, чтобы обобщенные алгоритмы в STL были технически
современны и эффективны, как и закодированные вручную (говоря точнее, эффективны, как
и закодированные вручную при наличии хорошего оптимизирующего компилятора).
Вычислительная модель фон Неймана. Хотя абстрактная математика использует
простые числовые факты в качестве основы для своих абстракций (не забывайте, что
математика — наука экспериментальная), что в качестве основы для абстракций должны использовать
мы? По мнению фирмы, где я работаю, единственной основой является архитектура
реальных компьютеров. Важно помнить, что архитектуры современных компьютеров являются
результатом многолетней эволюции, руководимой необходимостью решать все более и более
разнообразные задачи. Память с адресацией байтов и указатели не унаследованы нами от
некоего архаического аппаратного обеспечения (в нем вообще не было ни байтов, ни
указателей; циклы писались при помощи самомодифицирующегося кода), а явились результатом
"погони" архитектуры за потребностями приложений.2 Если вас интересует проектирование
обобщенных схем для числовых типов, важно не только знать математическую теорию целых
и действительных чисел, но и понимать, как работают встроенные числовые типы.
Наиболее важная концепция вычислительной техники, которой нет в математике, — это
концепция адреса. То, что не только значения, но и адреса стали частью вычислительной
модели, стало революционным шагом, обеспечившим путь от 72 адресов в ЭВМ Mark I к
миллионам Интернет-адресов. Во многих аспектах наиболее спорной частью STL является тот
факт, что "краеугольным камнем" всей ее доктрины стали адреса и их концептуальная клас-
2 Для того чтобы быть хорошим программистом, важно понимать, что в действительности
происходит "за кулисами" высокоуровневого языка программирования. Следует знать по крайней мере пару
разных архитектур. Я уже рекомендовал несколько математических книг; позвольте мне теперь
предложить вам пару компьютерных книг: книга Джона Хеннесси (John Hennessy) и Дэвида Паттерсона (David
Patterson) Computer Architecture: A Quantitative Approach является, по моему мнению, наиболее важной
книгой по вычислительной технике; она становится еще чудеснее, если сопровождается книгой
Computer Architecture: Concepts and Evolution Геррита Блаау (Gerrit Blaauw) и Фреда Брукса (Fred Brooks),
в особенности ее второй частью, освещающей вопросы исторического характера.
JU
Предисловие
сификация. (Это предложение может показаться странным практикующему программисту, но
академическая общественность затратила десятилетия на то, чтобы полностью удалить
адреса из того, что называется "функциональным программированием".) В математической
терминологии идея в основе STL состоит в том, что различные структуры данных
соответствуют различным адресным алгебрам, различным способам связывания адресов. Множество
операций, которые выполняют перемещение от одного адреса в структуре данных к
следующему, соответствуют итераторам. Множество операций, которые добавляют адреса в
структуру данных и удаляют их оттуда, соответствует контейнерам.
Классификации итераторов в STL (входные, выходные, однонаправленные,
двунаправленные, произвольного доступа) достаточно для всех фундаментальных алгоритмов,
работающих с последовательностями, но чтобы STL работала с многомерными структурами,
следует определить новые категории итераторов. (Неоспоримым фактом является то, что даже
для многих фундаментальных алгоритмов для последовательностей требуются двумерные
итераторы для ускорения этих алгоритмов в случаях (1) неравномерного доступа, как,
например, при итераторах дека или строках кэша, и (2) многопроцессорных реализаций.)
Семантика значений. STL рассматривает контейнеры как обобщение структур.
Контейнер, как и структура, владеет своими компонентами. При копировании структур копируются
все их компоненты. При уничтожении структуры уничтожаются все ее компоненты. То же
самое происходит и с контейнерами. Это важнейшие свойства, которые позволяют
структурам и контейнерам моделировать ключевой атрибут объектов реального мира —
взаимоотношения между целым и частью. Конечно, это не единственное взаимоотношение в реальном
мире, и остальные отношения должны моделироваться итераторами.3 По моему мнению,
путаница между частью и отношением, которая так распространена в объектно-
ориентированных языках и библиотеках, является основным источником неприятностей
в моделировании реального мира, а также основной причиной, по которой требуется сборка
мусора. STL не является объектно-ориентированной — не только по способу использования
глобальных обобщенных алгоритмов, но и по тому, что она разделяет понятия "иметь объект
в качестве части" и "указывать на объект". Она предполагает, что строка
Т а = Ь;
создает копию объекта со всеми индивидуальными частями, а не просто указатель на тот же
объект. Спецификации алгоритмов STL, использующих присваивание (sort, partition,
remove и т.д.), требуют такой семантики значений. Во вселенной STL объекты никогда не
используют свои части совместно с другими объектами (исключая, конечно, ситуацию, когда
один объект является частью другого).
В общем случае STL предполагает, что для любого типа, с которым он работает,
семантики копирующих конструкторов, деструкторов, присваивания и равенства и их взаимосвязи те
же, что и для встроенных типов. Кроме того, STL предполагает, что для этих объектов
определены операторы <, >, <= и >=, что их семантика та же, что и для встроенных типов, или,
говоря математически, они определяют полное упорядочение. (Один из недостатков C++, на
мой взгляд, заключается в том, что C++ не требует согласованности семантики
фундаментальных операций с семантикой встроенных типов; ничто не мешает определить оператор =
для выполнения умножения. Перегрузка операторов хороша только при высокой
самодисциплине; в противном случае она способна вызвать огромные неприятности.)
Например, моя нога является частью меня, а мой адвокат — нет. Если меня уничтожить, будет
уничтожена и моя нога; если меня скопировать — будет скопирована и моя нога. Мой адвокат — это
другой человек, и моя смерть может повлиять на него различными путями (например, он окажется
указателем на мертвого клиента, известным в программировании как висящий указатель), но не означает
его автоматического уничтожения.
Предисловие
31
Развитие. STL не проектировалась в качестве части стандартной библиотеки C++. Она
задумывалась как первая библиотека обобщенных алгоритмов и структур данных. Случилось
так, что C++ был единственным языком, на котором я мог реализовать такую библиотеку, —
тогда еще просто для собственного удовольствия. В течение пяти лет после того, как STL
стала широко доступна, многие люди заявили, что они могут сделать то же, что делает STL,
на своих любимых языках программирования: Ada-95, ML, Dylan, Eiffel, Java и т.д. Может
быть, так оно и есть. Насколько же я мог видеть, это не так. Я бы хотел, чтобы они смогли
это сделать. Я бы хотел, чтобы кто-то создал язык, в большей степени подходящий для
обобщенного программирования, чем C++. В конце концов, на C++ это получилось чудом.
Фундаментальные концепции STL, наподобие итераторов и контейнеров, нельзя описать на
C++, поскольку STL зависит от строго определенного множества требований, которые не
имеют никакого лингвистического представления на C++. (Они, конечно, определены в
стандарте, но это определение на естественном языке.)
Самым главным в STL является то, что это расширяемая структура. Пока широко
применяется STL, мои надежды на создание нескольких библиотек обобщенных компонентов
неосуществимы. Насколько я могу определить, причина, по которой такие библиотеки не
созданы,— в отсутствии механизмов финансирования для поддержки такой работы.
Невозможно сделать деньги на фундаментальных алгоритмах. Такие библиотеки должны
быть разработаны для всей промышленности небольшими командами разработчиков
компонентов. Мне везло, и я пару раз получал средства от больших компьютерных компаний для
работы над STL. Такая работа не может быть выполнена без надежного способа ее
финансирования, и я надеюсь, что правительство США или ЕС создаст маленькую, но эффективную
организацию для работы над обобщенными программными компонентами (я имею в виду не
исследования, а реальное производство хорошо организованных, документированных,
обобщенных и эффективных компонентов). Не хотите ли вы обратиться с этим предложением
к своим парламентариям?
STL предполагает существенно отличный способ изучения. 99% программистов должны
знать, как использовать компоненты, и не должны знать, как они работают. STL предполагает
существенно отличный способ работы программистских компаний. Программисты, которые
пишут собственный код вместо использования стандартных компонентов, должны быть
похожи на людей, разрабатывающих собственные, нестандартные процессоры. Но сможет ли
программирование войти в промышленную стадию? Я сомневаюсь...
Александр Степанов (Alexander Stepanov),
январь, 2001 год
Предисловие к первому изданию
Что такое STL? STL, или Standard Template Library (стандартная библиотека шаблонов),
представляет собой библиотеку обобщенных алгоритмов и структур данных общего
назначения. Она делает работу программиста более производительной двумя способами: во-первых,
она содержит множество различных компонентов, которые могут быть собраны вместе и
использоваться в приложениях, а во-вторых, что более важно, она предоставляет способ
декомпозиции различных программных задач.
Схема, определяемая STL, очень проста: два ее фундаментальных измерения — это
алгоритмы и структуры данных. Причина успешной совместной работы структур данных и
алгоритмов достаточно парадоксальна: она заключается в том, что они ничего не знают друг
о друге. Алгоритмы написаны в терминах итераторов, которые представляет собой
абстрактные методы обращения к данным. Чтобы различные алгоритмы работали в терминах этих
концептуальных категорий, STL устанавливает строгие правила, которые управляют
поведением итераторов. Например, если любые два итератора равны, то и результаты их
разыменования должны быть равны. Только благодаря тому, что все эти правила явно указаны в STL,
можно написать код, который ничего не знает о конкретной реализации структуры данных.
Хотя мой опыт говорит о том, что применение STL может существенно повысить
производительность программирования, такое повышение возможно, только если программист
полностью осведомлен о структуре библиотеки и знаком с поддерживаемым ею стилем
программирования. Как программист может ознакомиться с этим стилем? Единственный способ
состоит в том, чтобы использовать и расширять ее. Однако для этого требуется с чего-то
начать, — например, с данной книги.
Авторы имеют квалификацию, достаточно высокую для написания такой книги. Дэйв
Мюссер более пятнадцати лет проводил исследования, которые привели к созданию STL.
Цитирую из руководства по STL: "Дэйв Мюссер ... внес свой вклад во все аспекты STL:
проектирование структуры, семантические требования, проектирование алгоритмов, анализ
сложности и измерения производительности". Атул Сейни был первым, кто разглядел
коммерческий потенциал STL и предложил свою компанию для продажи библиотеки, еще до
того как она была принята Комитетом по стандартизации C++.
Я надеюсь, что публикация этой книги поможет программистам получить от
использования STL такое же удовольствие, какое получаю я.
Александр Степанов (Alexander Stepanov),
октябрь, 1995 год
Введение
За пять лет, прошедших со времени первого издания этой книги был окончательно
формализован и принят стандарт языка программирования C++, производители компиляторов C++
сделали огромную работу по приведению своих компиляторов в соответствие со стандартом, и
появились десятки новых книг и статей, в которых описывались и пояснялись
стандартизованный язык и его библиотеки. Многие из этих книг и статей рассматривают стандартную
библиотеку шаблонов (Standard Template Library, STL) как наиболее важное добавление к стандарту.
Некоторые (как и мы в первом издании этой книги) считают, что у нее достаточный потенциал,
чтобы изменить само представление о программировании на C++. В первом издании мы указали
пять причин, по которым компоненты STL являются широко используемым программным
обеспечением.
• C++ становится одним из наиболее широко используемых языков программирования
(большей частью благодаря поддержке, которую он обеспечивает при построении
и применении библиотек компонентов).
• Поскольку STL инкорпорирован в стандарт ANSI/ISO C++ и его библиотек,
производители компиляторов делают его частью своих стандартных поставок.
• Все компоненты STL обобщенные, что означает их применимость (с помощью
поддерживаемых языком технологий компиляции) для многих различных целей.
• Обобщенность компонентов STL достигается без утраты эффективности.
• Компоненты STL спроектированы как малые, взаимозаменяемые строительные блоки,
делая их отличным фундаментом для создания компонентов для специализированных
областей, таких как базы данных, пользовательские интерфейсы и т.д.
Приятно, что наши предположения оправдались.
Изменения во втором издании
В это новое издание нами добавлен главным образом учебный материал: в главах части I,
"Вводный курс в STL", более подробно рассматриваются функциональные объекты,
контейнеры, итераторы и адаптеры функций; появились две совершенно новые главы части II,
"Примеры программ", содержащие в основном новые примеры. Мы также "прошлись" по
всем примерам и их обсуждениям, включая справочный материал части III, "Справочное
руководство по STL", чтобы привести их в соответствие с окончательной версией стандарта.
(Хотя со времени принятия стандарта в нем обнаружились некоторые неоднозначности, мы
полагаем, что в большинстве случаев оставшиеся неопределенности в спецификациях
компонентов STL не имеют важных последствий для практикующего программиста. В тех нескольких
Введение
34
случаях, где такие последствия возможны, мы явно это указываем.) Нами также добавлена глава
в часть III, "Справочное руководство по STL", описывающая вспомогательные компоненты,
такие как пары и классы сравнения, а также новое приложение с описанием связанных с STL
особенностей стандартного строкового класса.
В этом издании мы приняли для написания примеров и фрагментов кода стиль
"грамотного программирования". Читатели, не знакомые с этим подходом к одновременному
программированию и документированию, найдут краткое пояснение в главе 2, "Обзор
компонентов STL", и более детальное — в главе 12, "Программа для поиска в словаре".
Преимущество этого подхода заключается в том, что детали кодирования могут быть представлены
однократно, а затем на них можно ссылаться (по имени и номеру страницы) множество раз,
так что читателям не приходится постоянно читать об одних и тех же деталях. Другое
преимущество состоит в том, что мы можем более полно, чем ранее, проверять синтаксическую
и логическую корректность кода — поскольку этот подход позволяет легко получать код
непосредственно из рукописи, компилировать и тестировать его. Список компиляторов, при
помощи которых компилировался и тестировался код, приведен в приложении Г, "Ресурсы".
Исторические сведения из предисловия
к первому изданию
Почти все программисты на C++ знают, что этот язык был создан одним человеком,
Бьярном Страуструпом (Bjarne Stroustrup), который в 1979 году задумался над тем, как
расширить язык программирования С и добавить в него поддержку определений классов и
объектов. Так же и архитектура STL создана в основном одним человеком, Александром
Степановым (Alexander Stepanov).
Интересно, что это также произошло в 1979 году, примерно тогда же, когда свою работу
начал Страуструп. Именно тогда Александр начал выработку основных идей обобщенного
программирования и исследования его потенциала для революционизации разработки
программного обеспечения. Хотя Дэйв Мюссер (Dave Musser) разработал некоторые аспекты обобщенного
программирования еще в 1971 году, они были ограничены весьма специализированной
областью программного обеспечения, а именно компьютерной алгеброй. Александр увидел весь
потенциал обобщенного программирования и убедил своих коллег в General Electric (в первую
очередь Дэйва Мюссера и Дипака Капура (Deepak Kapur)) в том, что обобщенное
программирование должно рассматриваться в качестве базы для разработки программного обеспечения.
Однако в то время реальной поддержки обобщенного программирования не было ни в одном языке
программирования. Первым языком с такой поддержкой был язык программирования Ada с его
обобщенными модулями, и в 1987 Дэйв и Александр разработали и опубликовали библиотеку
Ada для обработки списков, которая вобрала в себяОрезультаты большинства их исследований
по обобщенному программированию. Однако язык программирования Ada не получил
распространения нигде за пределами оборонного ведомства, так что более подходящим для
поставленной задачи оказался язык программирования C++, который стал широко использоваться и
обеспечил неплохую поддержку обобщенного программирования, несмотря на относительную
незрелость (в тот момент в нем даже не было шаблонов, которые были добавлены в язык
позже). Еще одной причиной перехода на C++ была модель вычислений C/C++, которая
обеспечивала очень гибкое обращение к памяти (посредством указателей) и которая оказалась
решающим фактором для достижения обобщенности без потери эффективности.
При этом все еще требовалось большое количество исследований и экспериментов, причем
не только для разработки индивидуальных компонентов, но, что более важно, для разработки
всей архитектуры библиотеки, основанной на обобщенном программировании. Сначала в AT&T
35
Введение
Bell Laboratories, а позже в Hewlett-Packard Research Labs Александр экспериментировал со
многими архитектурными и алгоритмическими постановками задач, сначала на С, а позже на C++.
Дэйв Мюссер принимал участие в этой работе, а в 1992 году к проекту Александра в HP
присоединился Менг Ли (Meng Lee), вклад которого стал основным.
Несомненно, эта работа некоторое время продолжалась бы как исследовательский проект
или в лучшем случае оказалась бы частной собственностью HP, если бы Эндрю Кёниг
(Andrew Koenig) из Bell Labs не заинтересовался этой работой и не пригласил Александра
представить ее в ноябре 1993 года на заседании комитета ANSI/ISO по стандартизации C++.
Реакция комитета оказалась весьма положительной, что и привело к просьбе Эндрю
предоставить формальное предложение к заседанию в марте 1994 года. Несмотря на жесткие
временные рамки, Александр и Менг смогли подготовить черновик, получивший одобрение на
заседании комитета.
Комитет внес несколько предложений об изменениях и расширениях библиотеки
(некоторые из них существенные), и небольшая группа членов комитета встретилась с
Александром и Менгом, чтобы помочь им в разработке деталей. Решить вопрос с наиболее
значительным расширением (ассоциативные контейнеры) Александр поручил Дэйву Мюссеру,
который полностью их реализовал. Александр и Менг благополучно справились со всеми
трудностями и подготовили предложение, окончательно утвержденное на заседании комитета
в июле 1994 года. (Подробнее об этой истории можно прочесть в интервью, которое
Александр дал в марте 1995 года для Dr. Dobb 's Journal.)
Что было потом
Впоследствии документация от Степанова и Ли [17] была внесена в черновик стандарта
ANSI/ISO C++ [1]. Она повлияла и на другие части стандартной библиотеки C++ Standard
Library, такие как работа со строками. Были соответствующим образом пересмотрены и
некоторые более ранние стандарты в этой области.
Несмотря на успех STL у комитета, вопрос о распространении и принятии STL
программистами оставался открытым. Наличие части открытого черновика стандарта, посвященного
требованиям STL, позволяло производителям компиляторов и независимым производителям
библиотек разработать свои собственные реализации и продавать их в качестве отдельных
продуктов. Один из авторов первого издания, Атул Сейни (Atul Saini), был среди тех, кто сразу
рассмотрел коммерческий потенциал STL и воспользовался им в своей компании Modena
Software Incorporated, еще до того как STL была окончательно принята комитетом.
Шансы на распространенность библиотеки существенно выросли с решением Hewlett-
Packard в августе 1994 года сделать свою реализацию библиотеки, свободно доступной через
Интернет. Эта реализация Степанова, Ли и Мюссера, выполненная в процессе
стандартизации, стала основой всех реализаций, предлагаемых сегодня всеми производителями
компиляторов и библиотек.
В том же 1994 году Дэйв Мюссер и Атул Сейни создали STL++ Manual, первую полную
документацию пользователя по STL. Однако вскоре они убедились, что требуется еще более
полное руководство, которое бы охватывало все аспекты библиотеки. В попытках достичь
этой цели они написали первое издание данной книги (в чем немалую помощь им оказал их
редактор Майк Хендриксон (Mike Hendrickson)).
Во втором издании к авторскому коллективу присоединился Жилмер Дж. Дердж (Gillmer
J. Derge), президент и исполнительный директор консалтинговой фирмы Toltec Software
Services, Inc. Он имеет более чем десятилетний опыт разработки приложений на C++, в том
числе семь лет — в General Electric Corporate R&D.
Введение
36
Благодарности из первого издания
Бы благодарим за помощь многих. В первую очередь это Александр Степанов и Менг Ли,
которые постоянно ободряли нас и всегда были готовы помочь в исправлении всех ошибок.
Неоценимую помощь в написании и тестировании кода оказали многие сотрудники компании
Modena, включая Атула Гупту (Atul Gupta), Колахала Кальяна (Kolachala Kalyan) и Нарасимха
Рампалли (Narasimhan Rampalli). Ранние черновики просмотрели несколько людей, чье
мнение помогло нам добиться более ясного изложения основных идей. Это Майк Баллантайн
(Mike Ballantyne), Том Каргилл (Tom Cargill), Эдгар Хрисостомо (Edgar Chrisostomo), Брайан
Керниган (Brian Kernighan), Скотт Мейерс (Scott Meyers), Ларри Подмолик (Larry Podmolik),
Кэти Старк (Kathy Stark), Стив Виноски (Steve Vinoski) и Джон Влиссидес (John Vlissides).
Следует также упомянуть сделавших ценные предложения Дана Бенанава (Dan Benanav),
Боба Кука (Bob Cook), Боба Ингаллса (Bob Ingalls), Натана Шимке (Nathan Schimke), Кедара
Тупила (Kedar Tupil) и Рика Вильгельма (Rick Wilhelm). Наконец, мы благодарны команде
издательства Addison-Wesley за их отличную работу: Киму Доули (Kim Dawley), Кати Даффи
(Katie Duffy), Розе Гонзалес (Rosa Gonzalez), Майку Хендриксону (Mike Hendrickson), Симоне
Пэймент (Simone Payment), Аванде Питере (Avanda Peters), Джону Вейту (John Wait) и
Памеле Йи (Pamela Yee).
Благодарности ко второму изданию
В первую очередь мы благодарны всем, кто указал нам на ошибки, принимал участие
в обсуждении примеров и вносил предложения, улучшившие книгу. Особенно нам помогли
комментарии Макса Лебоу (Max A. Lebow), Лоуренса Раухвергера (Lawrence Rauchwerger)
и Яна Христиана ван Винкеля (Jan Christiaan van Winkel). Мы благодарим также наших
редакторов, Дебору Лафферти (Deborah Lafferty) и Жюли Де-Баггис (Julie De-Baggis). Нам
помогали и другие сотрудники Addison-Wesley, в том числе Жаклин Дюсетт (Jacquelyn Dou-
cette), Чанда Лири-Куту (Chanda Leary-Coutu), Керт Джонсон (Curt Johnson), Дженнифер Ла-
вински (Jennifer Lawinski) и Марти Рабиновиц (Marty Rabinowitz).
Д.Р.М.
Лудонвилль, штат Нью-Йорк
ЖДД.
Кохо, штат Нью-Йорк
А.С.
Лос Гатос, штат Калифорния,
октябрь, 2000 год
Часть I
Вводный курс в STL
В этой части вы познакомитесь с ключевыми идеями и
принципами стандартной библиотеки шаблонов и с описанием
большинства ее компонентов. Как правило, описание компонента
иллюстрируется небольшими примерами.
Глава 1
Введение
Стандартная библиотека шаблонов (Standard Template Library, STL) предоставляет набор
классов-контейнеров C++ и шаблонные алгоритмы, которые разработаны для совместной
работы и обеспечивают полезную функциональность в широком диапазоне. Хотя в библиотеке
представлено лишь небольшое количество классов-контейнеров, она включает все наиболее
часто применяемые и полезные контейнеры, такие как векторы, списки, множества и
ассоциативные множества. Множество алгоритмов включает широкий диапазон
фундаментальных алгоритмов для наиболее распространенных манипуляций с данными, таких как поиск,
сортировка или слияние.
Главное отличие STL от других библиотек классов контейнеров C++ заключается в том,
что алгоритмы STL являются обобщенными: каждый алгоритм работает с рядом контейнеров,
включая встроенные типы, а многие из них работают с любыми контейнерами. В части I,
"Вводный курс в STL", мы рассмотрим обобщенные алгоритмы и другие ключевые
концепции, которые дают STL преимущества по сравнению с другими программными библиотеками.
Одной из наиболее важных концепций STL является способ определения обобщенных
алгоритмов в терминах итераторов, которые обобщают указатели C/C++, вместе с определением
различных типов итераторов для обхода контейнеров разных видов. Помимо контейнеров,
обобщенных алгоритмов и итераторов, STL предоставляет функциональные объекты,
которые обобщают обычные функции C/C++ и позволяют эффективно адаптировать другие
компоненты для решения различных задач. Библиотека включает также различного вида
адаптеры для изменения интерфейсов контейнеров, итераторов или функциональных объектов.
Управление памятью в STL управляется еще одним типом компонентов — аллокаторами.
Все эти компоненты рассматриваются в обзоре STL в главе 2, "Обзор компонентов STL", и —
более детально — в остальных главах части I.
Просто почитать об STL — занятие интересное, но чтобы стать мастером в применении
этой библиотеки, просто необходим опыт ее реального применения на практике. Наши
описания в части I включают множество небольших примеров, показывающих, как работают
отдельные компоненты, а в части II представлен ряд более серьезных программ. Несмотря на их
малые размеры, эти примеры решают нетривиальные и полезные задачи, иллюстрируя мощь,
которую делает доступной хорошо организованная библиотека. Часть III содержит полное
справочное руководство по библиотеке.
STL — это только одна из частей большой стандартной библиотеки C++, утвержденной
комитетом ANSI/ISO C++ в международном стандарте C++ [5].4 Тем не менее, STL остается
логически связанным набором взаимозаменяемых компонентов, работа с которыми отделена
от остальных частей стандартной библиотеки C++. В этой книге мы попытаемся дать вам
4 Историю включения STL в стандарт языка программирования C++ можно прочесть в разделе
"Исторические сведения из предисловия к первому изданию".
40
Часть I. Вводный курс в STL
полное и точное описание STL на пользовательском уровне. (Полное описание одной широко
используемой реализации вы можете найти в [17].)
1.1. Для кого предназначена эта книга
Если вы не знакомы с другими библиотеками — это не должно вас останавливать. Хотя
в некоторых местах книги и имеется сравнение с другими библиотеками, основной материал
должен быть понятен без такого рода предварительных знаний. Все, что требуется от
читателя — это знакомство с основными концепциями C++: функциями, классами, объектами,
указателями, шаблонами и потоками ввода-вывода. Многие книги по C++ требуют от читателя
серьезной предварительной подготовки, но наша не входит в их число. Ключевые
возможности шаблонов, с которыми некоторые читатели могут быть недостаточно хорошо знакомы,
рассматриваются в разделе 1.3.
1.2. Что такое обобщенное программирование
STL — воплощение многолетних исследований в области обобщенного
программирования. Целью этих исследований было изучение методов разработки и организации библиотек
обобщенных — или повторно используемых — программных компонентов. Смысл термина
"повторно используемые" можно грубо передать как "легко приспосабливаемые в широком
диапазоне применений, но при этом остающиеся эффективными", где "приспосабливание"
осуществляется на уровне препроцессора или языка программирования, но не путем ручного
редактирования исходного текста. На тему повторного использования в области
программирования имелось немало других работ (часто с другой терминологией; например,
использовался термин "строительные блоки" или даже "интегральные схемы" программного
обеспечения), но STL отличают две очень важные характеристики— высокая адаптивность
и эффективность компонентов.
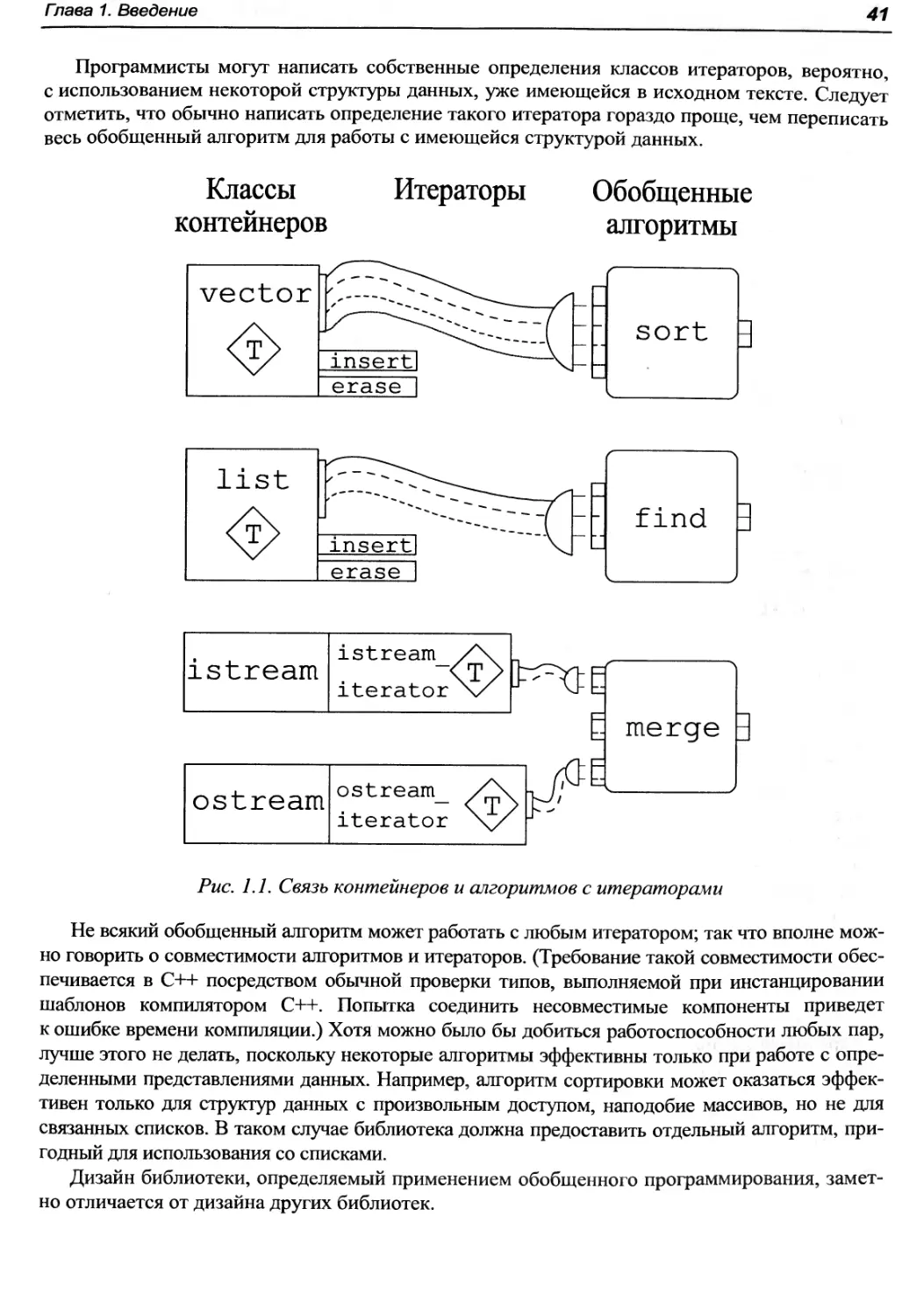
Главные идеи создания обобщенных компонентов показаны на рис. 1.1, где изображены
компоненты библиотеки и их "подключение друг к другу". Справа показаны компоненты,
которые называются обобщенными алгоритмами, служащие для таких операций, как слияние,
сортировка или копирование последовательностей. Однако эти алгоритмы не самодостаточны; они
реализованы в терминах операций обращения к контейнерам, которые предполагаются
внешними по отношению к алгоритмам. Обеспечением этих операций обращения к контейнерам
занимаются компоненты, именуемые итераторами (показанные на рис. 1.1 в виде шлейфов
подключения). Итератор каждого вида определяет операции обращения к контейнерам для
определенного представления данных, таких как связанный список или массив.
"Гнезда" в левой части компонентов обобщенных алгоритмов на рис. 1.1 представляют
вход или выход алгоритма. Так, например, в случае алгоритма merge имеются два входа,
представляющих собой входные итераторы, как, например, показанный на рисунке
istream_iterator, подключенный к первому гнезду, и один выход, который представляет
собой выходной итератор, такой как ostream_iterator, подключенный к третьему гнезду.
Чтобы такой "мелкозернистый" подход оказался работоспособен, требуется определенный
минимальный уровень поддержки со стороны базового языка программирования. К счастью,
C++ обеспечивает такую поддержку, главным образом путем механизма шаблонов. От
программистов, которые хотят использовать один из обобщенных алгоритмов, требуется только
выбрать алгоритм и контейнер, с которым он будет работать. Компилятор C++ примет меры по
соединению алгоритма, выраженного в виде шаблона функции, с итераторами, которые
представляют собой классы, связанные с классом контейнера.
Глава 1. Введение
41
Программисты могут написать собственные определения классов итераторов, вероятно,
с использованием некоторой структуры данных, уже имеющейся в исходном тексте. Следует
отметить, что обычно написать определение такого итератора гораздо проще, чем переписать
весь обобщенный алгоритм для работы с имеющейся структурой данных.
Классы
контейнеров
Итераторы
Обобщенные
алгоритмы
vector
<J?>
у ** ""»
insertl
erase I
sort
istream
istream_
iterator
ostream
ostream_
iterator
merge R
Рис. 1.1. Связь контейнеров и алгоритмов с итераторами
Не всякий обобщенный алгоритм может работать с любым итератором; так что вполне
можно говорить о совместимости алгоритмов и итераторов. (Требование такой совместимости
обеспечивается в C++ посредством обычной проверки типов, выполняемой при инстанцировании
шаблонов компилятором C++. Попытка соединить несовместимые компоненты приведет
к ошибке времени компиляции.) Хотя можно было бы добиться работоспособности любых пар,
лучше этого не делать, поскольку некоторые алгоритмы эффективны только при работе с
определенными представлениями данных. Например, алгоритм сортировки может оказаться
эффективен только для структур данных с произвольным доступом, наподобие массивов, но не для
связанных списков. В таком случае библиотека должна предоставить отдельный алгоритм,
пригодный для использования со списками.
Дизайн библиотеки, определяемый применением обобщенного программирования,
заметно отличается от дизайна других библиотек.
42
Часть I. Вводный курс в STL
• Четко организованные взаимозаменяемые строительные блоки, создаваемые при
таком подходе, допускают гораздо больше полезных комбинаций, чем в случае
применения традиционного дизайна компонентов.
• Описанный дизайн является хорошей основой для дальнейшей разработки
компонентов для специализированных областей программного обеспечения, таких как базы
данных, пользовательские интерфейсы и т.п.
• Применение механизмов времени компиляции и должное внимание к алгоритмам
позволяет достичь обобщенности компонентов без потери эффективности, в отличие от
неэффективности, часто наблюдающейся в других библиотеках C++, включающих
сложные иерархии наследования и обильное использование виртуальных функций.
В итоге оказывается, что обобщенные компоненты более полезны для программистов
и чаще применяются на практике, чем программирование каждого алгоритма или структуры
данных с нуля.
Но все это теория, и вы можете скептически отнестись к реализации обещанного на
практике. Однако мы уверены, что после прочтения книги, начав применять полученные знания
на практике, вы согласитесь с тем, что все сказанное здесь — правда, а не пустые слова, и что
все обещания обобщенного программирования действительно выполнены.
1.3. Обобщенное программирование
и шаблоны C++
Для обобщенного программирования очень важна адаптивность компонентов, так что
давайте рассмотрим, как шаблоны C++ ее обеспечивают. В C++ имеются шаблоны двух видов:
шаблоны классов и шаблоны функций.
1.3.1. Шаблоны классов
Шаблоны классов применяются для множества целей, но наиболее очевидно их
использование для создания адаптивных контейнеров. В качестве очень маленького примера
предположим, что мы хотим создавать объекты, которые могут хранить два значения — целое число
и символ. С этой целью мы можем определить класс:
class pair_int_char {
public:
int first;
char second;
pair_int_char(int x, char y)
: first(x), second(y) { }
Теперь можно, например, написать:
pair_int_char pairl(13, 'a');
cout << pairl.first << endl;
cout << pairl.second << endl;
Если вам нужны объекты для хранения, скажем, значений типа bool и double, можно
определить класс
class pair_bool_double {
public:
bool first;
double second;
pair_bool_double(bool x, double y)
Глава 1. Введение
43
: first(x), second(у){}
и написать, например, следующий код:
pair_bool_double pair2(true, 0.1);
cout << pair2.first << endl;
cout << pair2.second << endl;
Те же действия можно повторить для любых пар типов, но шаблон класса позволяет выразить
их все при помощи единственного определения:
template <typename Tl, typename T2>
class pair {
public:
Tl first;
T2 second;
pair(Tl x, T2 y) : first(x), second(y) { }
};
Здесь мы записали определение класса с применением двух произвольных имен типов Т1
и Т2, которые представляют собой параметры типа. Имена вводятся в определение в
качестве параметров типа с помощью конструкции
template <typename Tl, typename T2>
■
которая означает, что вместо Т1 и Т2 можно подставить фактические типы и таким образом
инстанцироватъ шаблон класса pair. Например, запись
pair<int, char> pair3(13, 'a');
pair<bool, double> pair4(true, 0.1);
объявляет pair3 и pair4 со структурами, эквивалентными структурам pairl и pair2
соответственно. Но теперь мы можем использовать pair в несметным количеством способов
с любыми комбинациями фактических типов, как, например:
pair<double/ long> pair5(3.1415, 999);
pair<bool, bool> pair6(false, true);
В качестве фактических типов могут использоваться и типы, определенные другими
классами, например:
pair<pair_int_char, float> pair7(pairl, 1.23);
или, что то же самое:
pair<pair<int, char>, float> pair8(pair3, 1.23);
Как видите, типы, полученные путем инстанцирования шаблонов классов, можно
использовать везде, где используются обычные типы.
Определение шаблона класса pair представляет собой очень простой пример класса
обобщенного контейнера, поскольку он может быть адаптирован для многих различных
применений. Однако обычно для превращения обычного класса в обобщенный (в смысле полезности
и применимости в широком диапазоне приложений) требуется больше, чем просто добавление
ключевого слова template и списка параметров типов. Для того чтобы получающиеся
экземпляры класса были столь же эффективны, как и определенные обычными средствами, могут
оказаться необходимыми некоторые модификации. Даже в случае такого простого определения
шаблона класса, как pair, можно внести определенные усовершенствования. В определении
класса объявление конструктора имеет слишком простой вид:
pair(Tl х, Т2 у) : first(x), second(у) { }
Проблема в том, что х и у передаются по значению, а это означает, что если они
представляют собой большие объекты, при вызове конструктора будет выполняться излишнее
дорогостоящее копирование. Следует вместо этого передавать х и у как константные ссылки, с тем
44
Часть I. Вводный курс в STL
чтобы реально в конструктор передавались только их адреса. Именно так определен шаблон
pair в качестве компонента STL:
template <typename Tl, typename T2>
class pair {
public:
Tl first;
T2 second;
pairO : first (Tl()), second(T2()) { }
pair(const T1& x, const T2& y)
: first(x), second(y) { }
};
Здесь добавлен также конструктор по умолчанию, pair (), который полезен в ситуациях,
когда требуется инициализация объектов pair по умолчанию в определении другого класса.
В любом определении класса, где программистом не определен ни один конструктор,
компилятор сам определяет конструктор по умолчанию, но в данном случае мы уже определили
другой конструктор, поэтому правила языка программирования требуют от нас явного
определения конструктора по умолчанию.
В случае более сложных определений классов обычно имеется масса других факторов,
которые следует учесть, чтобы сделать классы хорошо приспосабливаемыми и эффективными.
В этой книге мы не будем глубоко изучать вопрос реализации STL, но ее авторы тщательно
рассматривали вопрос о том, как сохранить эффективность компонентов при придании им
обобщенности.
1.3.2. Шаблоны функций
Шаблоны функций могут использоваться для определения обобщенных алгоритмов.
Рассмотрим функцию для вычисления максимального из двух щгсых чисел:
int intmax(int х, int у)
{
if (x < у)
return у;
else
return x;
}
Эта функция может использоваться только для вычисления максимального из двух значений
типа int, но мы можем легко обобщить ее, сделав ее шаблоном функции:
template <typename T>
Т тах(Т х, Ту)
if (x < у)
return у;
else
return x;
}
Существенное отличие от шаблонов класса заключается в том, что вы не обязаны указывать
компилятору, какие типы используете; компилятор сам в состоянии вывести их из типов
аргументов:
int u = 3, v = 4;
double d = 4.7;
cout << max(u, v) << endl; // Используются типы int
cout << max(d, 9.3) << endl; // Используются типы double
Глава 1. Введение
45
Компилятор требует, чтобы в качестве х и у были переданы значения одного и того же типа,
поскольку в объявлении обоих аргументов использован один и тот же параметр типа Т. Таким
образом, приведенная далее строка ошибочна:
cout << max(u, d) << endl;
Кроме того, требуется наличие определения оператора <, принимающего два параметра
типа Т. Например, воспользуемся определением шаблона класса pair из предыдущего раздела:
pair<double# long> pair5(3.1415, 999);
Приведенная далее строка исходного текста не будет скомпилирована за отсутствием
определения operator< для двух объектов pair<double, long>:
return max(pairs, pair5);
Однако она скомпилируется без малейших проблем, если мы сначала определим operator<
для объектов указанного типа, например:
bool operator<(const pair<double/ long>& x,
const pair<double, long>& y)
// Сравниваем х и у по их первым членам:
{
return х.first < у.first;
}
То, что компилятор может вывести типы и вызвать соответствующий им оператор или
функцию, делает шаблоны функций в особенности полезными для обобщенного
программирования. Подтверждение этому вы увидите немного позже, в разделе 2.2, когда мы будем
рассматривать, как при помощи шаблонов функций определяются обобщенные алгоритмы STL.
Перед тем как закончить с примером max, мы все же должны заметить, что определение
этого шаблона функции может быть усовершенствовано так же, как был усовершенствован
конструктор шаблона класса pair, путем применения в качестве параметров константных
ссылок:
template <typename T>
const T& max(const T& х, const T& у) {
if (x < у)
return у;
else
return x;
}
По сути, именно это определение используется в STL.
1.3.3. Шаблоны функций-членов
В определениях классов — шаблонных или обычных — функции-члены могут иметь
шаблонные параметры (в дополнение к шаблонным параметрам на уровне класса). Эта
возможность C++ используется в шаблонах классов контейнеров STL. Например, класс вектора STL
имеет шаблонную функцию-член insert, чей шаблонный параметр определяет тип
используемого итератора:
template <typename T>
class vector {
// ...
public:
template <typename InputIterator>
void insert(iterator position,
Inputlterator first,
Inputlterator last);
// ...
};
46
Часть I. Вводный курс в STL
Здесь iterator представляет собой тип итератора вектора, определенный в классе vector,
a position является итератором, указывающим куда-то во внутрь объекта вектора, в
который выполняется вставка. Второй и третий аргументы также представляют собой итераторы,
но не обязательно итераторы вектора. Как вы увидите в разделе 6.1, эта функция-член
insert может использоваться для вставки элементов, копируемых из некоторого другого
контейнера, такого как список, с использованием итераторов, предоставленных этим другим
контейнером. Итераторы списков существенно отличны от итераторов векторов.
Определение функции типа insert в качестве шаблона функции-члена, с параметром типа
Input Iterator, делает ее существенно более обобщенной, чем если бы ее второй и третий
аргументы имели фиксированный тип итератора.
1.3.4. Явное указание аргументов шаблонов
Предположим, что мы хотим определить функцию для преобразования массива символов
в контейнер STL, такой как vector<char>. Мы намерены использовать вектор для
хранения той же последовательности символов, что и в данном массиве. Вот один из способов
написать такую функцию:
vector<char> vec(const char s[])
{
return vector<char>(&s[0], &s [strlen(s)]);
}
В теле этой функции мы использовали конструктор класса vec tor < char >, который,
подобно обсуждавшейся в разделе 1.3.3 функции insert, является шаблоном функции-члена:
template <typename InputIterator>
vector(Inputlterator first, Inputlterator last);
Точно так же мы можем определить функцию для преобразования символьного массива
в контейнер STL list:
list<char> 1st(const char s [])
{
return list<char>(&s [0] , &s[strlen(s)]);
}
поскольку list<char> также имеет конструктор, представляющий собой шаблон функции-
члена требуемого вида:
template <typename InputIterator>
list(Inputlterator first, Inputlterator last);
Основная цель обобщенного программирования заключается в написании максимально
обобщенных определений функций. Сейчас мы видим, что можно написать одну
обобщенную функцию преобразования, которая будет конвертировать строку в произвольный
контейнер STL. Фактически это можно сделать при помощи следующего определения:
template <typename Container>
Container make(const char s [])
{
return Container(&s [0], &s[strlen(s)]);
Этот способ сработает со всеми контейнерами STL, поскольку у всех классов контейнеров
есть шаблон конструктора наподобие показанного для векторов и списков. Проблема только
в том, что хотя определение и совершенно корректно, функция make не может быть инстан-
цирована так же, как и другие шаблоны функций. Если, например, мы напишем
list<char> L = make("Hello, world!"); // Неверно
Глава 1. Введение
47
то получим ошибку времени компиляции. Дело в том, что параметр шаблона, Container,
используется только в возвращаемом типе функции, но не в ее параметрах. Правила языка
программирования гласят, что в этом случае функция не может быть использована так, как мы
описывали. Поэтому мы должны явно указать, какое именно инстанцирование нам требуется:
list<char> L = make< list<char> >("Hello/ world!");
To есть, мы добавляем к имени функции выражение типа, которое будет подставлено вместо
параметра типа Container, заключенное в угловые скобки < и >, точно так же, как мы
поступали при инстанцировании шаблонов классов. Это действие называется явным указанием
аргумента шаблона.
Таким образом, мы можем записать преобразование массива символов в vector<char> так:
vector<char> V = make< vector<char> >("Hello/ world!");
и — как мы увидим впоследствии во многих примерах программ, иллюстрирующих работу
с контейнерами, — это преобразование массива символов в контейнер любого другого типа
выполняется при помощи единственной обобщенной функции make.
1.3.5. Параметры шаблона по умолчанию
Еще одной особенностью шаблонов C++, используемой в определениях классов
контейнеров и некоторых иных местах, является возможность указания параметров шаблонов по
умолчанию. Например, фактически определение шаблона класса STL vector имеет
следующий вид:
template <typename T, typename Allocator = allocator<T> >
class vector {
// ...
};
Второй параметр шаблона, Allocator, имеет значение по умолчанию, а именно— allo-
cator<T>. Все классы контейнеров STL используют для работы с памятью специальный класс
Allocator, и allocator представляет собой тип (определяемый классом),
предоставляющий стандартное управление памятью. Поскольку Allocator имеет значение по умолчанию,
мы не обязаны передавать аллокатор всякий раз при создании экземпляра vector; т.е. запись
vector<int> эквивалентна записи vector<int, allocator<int> >.
Аллокаторы будут кратко рассмотрены в разделе 2.6 и детально описаны в главе 24,
"Справочное руководство по аллокаторам".
1.3.6. Частичная специализация
Наконец, в определениях STL используется еще одна особенность шаблонов C++ —
частичная специализация. Эта возможность может быть использована для перекрытия
обобщенного шаблона класса или шаблона функции более специализированной версией (из
соображений эффективности), но тем не менее остающейся обобщенной (т.е. все еще имеющей
один или несколько параметров шаблона). Мы отложим рассмотрение и иллюстрацию этой
возможности до раздела 6.1.7, в котором рассматривается хороший пример обобщенного
алгоритма обмена двух контейнеров.
1.4. Шаблоны и проблема "разбухания кода"
При использовании в одной и той же программе различных инстанцировании шаблонов
классов или функций компилятор фактически создает различные версии исходного текста
и компилирует каждую из них в выполнимый код. (На самом деле различные версии обычно
40
Часть I. Вводный курс в STL
создаются не на уровне исходного текста, а на некотором промежуточном уровне
представления кода.) Главное преимущество при этом заключается в том, что каждая копия
специализирована для используемых ею типов данных, а потому она оказывается настолько
эффективна, насколько может быть эффективен написанный непосредственно специализированный
код. Но здесь же кроется и потенциально серьезный недостаток: при использовании
большого количества различных экземпляров шаблонов большое количество копий способно сделать
выполнимый код очень большим. Эта проблема "разбухания кода" усугубляется
обобщенностью шаблонов классов и функций в таких библиотеках, как STL, поскольку они
предназначены именно для получения рабочих экземпляров для использования в программе, и
программисты активно следуют этой тенденции, применяя компоненты библиотеки где это
только возможно.
К счастью, существуют методы для того, чтобы избежать наиболее серьезных
последствий разбухания кода, ценой некоторой (обычно небольшой) потери эффективности. Эти
методы будут рассмотрены в разделах 11.3 и 17.2.
1.5. Гарантии производительности STL
STL среди других библиотек отличается тем, что в требования ко всем ее компонентам
включены гарантии производительности. Эти гарантии являются ключевыми факторами при
выборе требуемых для программы компонентов, таком, например, как выбор между list,
vector или deque для представления последовательности в некотором приложении.
Характеристики производительности компонентов указываются с применением О-обозначений.
1.5.1. 0-обозначения и связанные определения
В большинстве случаев, говоря о времени вычислений алгоритма, для упрощения
используют классификацию всех входных данных алгоритмов, разбивая их на подмножества,
характеризуемые некоторым простым параметром или параметрами. Для алгоритмов, работающих
с контейнерами, обычно в качестве такого параметра выбирается размер контейнера N. Для
входных данных размера N рассматривается максимальное время работы алгоритма T(N).
Это время называется также временем наихудшего случая для входных данных размера N.
Для дальнейшего упрощения будем рассматривать поведение T(N) для больших
значений N, а вместо попытки записать точную формулу для T(N) будем искать простую
функцию для верхней границы функции. Например, может оказаться, что
T(N)<cN
для некоторой константы с и всех достаточно больших N. В этом случае мы говорим, что
"время в наихудшем случае линейно зависит от размера входных данных". Константа с может
оказаться разной для различных компиляторов и компьютеров, так что очередное, часто
делаемое упрощение заключается в выражении этой границы таким образом, чтобы скрыть эту
константу.
Это делается при помощи О-обозначений; например, написанное выше соотношение
переписывается как:
T(N) = 0(N).
В общем случае, если имеется некоторая функция/, такая, что
T{N)<cf(N)
для некоторой константы с и всех достаточно больших N, то можно записать
Глава 1 .Введение
49
T(N) = 0(f(N)).
В данной книге пятью основными встречающимися О-обозначениями являются следующие.
• T(n\=0(N). Этот случай был только что рассмотрен. Говорят, что такой алгоритм
имеет ушиеш/ое время работы, или что он просто линейный.
• T(N)*oIn J. Говорят, что такой алгоритм имеет квадратичное время работы, или
что он просто квадратичный.
• T(N) = 0(\ogN). Говорят, что такой алгоритм имеет логарифмическое время работы,
или что он просто логарифмический.
• T(N) = 0(N \og N). Говорят, что такой алгоритм имеет время работы N log N .
• T(N) = 0(\) . Говорят, что такой алгоритм имеет константное время работы, или что
он просто константный. Заметим, что в этом случае Ообозначение означает всего
всего лишь, что при всех достаточно больших N для некоторой константы с
выполняется соотношение T(N)<c.
В каждом из этих случаев важно помнить, что время выполнения алгоритма
характеризуется верхней границей для наихудшего случая. Это время может вводить в заблуждение, если
наихудший случай реализуется очень редко, как, например, в случае алгоритма быстрой
сортировки. Наихудшее время этого алгоритма— квадратичное, что существенно медленнее,
чем другие алгоритмы сортировки, такие как пирамидальная сортировка или сортировка
слиянием. Но для большинства ситуаций быстрая сортировка является наилучшим выбором,
поскольку в среднем она быстрее других алгоритмов. В таких случаях описание времени
вычисления выходит за рамки простого О-обозначения для худшего случая и включает описание
среднего времени вычисления. Среднее время работы алгоритма для входных данных
размера N обычно вычисляется в предположении, что все входные данные размера N имеют
одинаковую вероятность. Однако в некоторых ситуациях более подходящими могут оказаться
другие распределения вероятности.
1.5.2. Амортизированное время
В ряде случаев более полезной характеристикой времени работы алгоритма является не
наихудшее и не среднее время, а амортизированное время работы. Это понятие в чем-то
аналогично учету амортизации оборудования в промышленности, когда одноразовая стоимость
(такая как стоимость проектирования) делится на количество единиц произведенной
продукции и затем добавляется к каждой из них. Амортизированное время может быть полезным
способом описания времени операции над некоторым контейнером в случаях, когда это
время может существенно варьироваться в пределах последовательности операций, но общее
время для последовательности из N операций имеет существенно лучшую границу, чем
просто N времен для наихудшего случая.
Например, время вставки в конец вектора STL в наихудшем случае равно O(N) , где N—
размер контейнера, поскольку, если в нем больше нет места для вставляемого элемента,
требуется выделить новую память и переместить в нее все имеющиеся в контейнере элементы.
Однако при расширении вектора длины N выделяется память для 2N элементов, так что
такая операция перераспределения памяти и переноса элементов не потребуется при
следующих N -1 вставках. Каждая из этих N -1 вставок выполняется за константное время, т.е. за
общее время O(N) для N вставок (с учетом времени на перераспределение памяти и перенос
элементов), так что в среднем по всем N операциям на одну операцию вставки тратится
Часть I. Вводный курс в STL
время 0{\) . Таким образом, можно сказать, что амортизированное время вставки7
представляет собой константу, ими что время выполнения операции амортизированное
константное.5 В этом примере амортизированное константное время более точно отражает истинную
стоимость операции, чем линейное время в наихудшем случае. В общем
случае/амортизированное время операции представляет собой общее время, затраченное на выполнение
последовательности из N операций, деленное на N. Заметим, что хотя амортизированное время
и является усредненным, понятие вероятности здесь не используется, как это делается в
случае среднего времени вычисления.
1.5.3. Ограничения О-обозначений
У О-обозначений имеются хорошо известные ограничения. Время работы 0[N) -алгоритма
может расти медленнее, чем линейное, поскольку O(N) — это всего лишь верхняя граница;
или, напротив, при небольших N оно может расти быстрее, чем линейно — поскольку указанная
граница применима только для больших значений N. Два 0(7V) -алгоритма могут иметь
существенно различное время работы. Один из них может работать строго в 2, или в 10, или в 1000 раз
быстрее другого, но из О-обозначений это различие никак не видно.
В случае <9(logjV) -алгоритма огромные отличия могут вызвать еще меньшие различия
в постоянных множителях. Например, если алгоритмы 1 и 2 являются О (log N) -алгоритмами,
но у алгоритма 2 константа с в два раза превышает константу алгоритма 1, то время работы
алгоритма 2 для некоторого N окажется тем же, что и время работы алгоритма 1 для N2
(поскольку logN2 =2\ogN).
При переходе от компилятора к компилятору и от одного компьютера к другому скрытые
константы могут изменяться, возможно, в достаточной степени для того, чтобы программист
изменил свой выбор алгоритма.
По приведенным и многим другим причинам рекомендуется выполнять эмпирическое
тестирование производительности программ в условиях, приближенных к тем, которые будут
встречаться при реальной эксплуатации приложения.
В действительности реализация может увеличивать размер блока до 1.5N или умножать его на
иной множитель, отличный от 2. Однако если при увеличении блока используется умножение на
множитель, больший 1, а не увеличение блоков на некоторый постоянный размер, то для
амортизированного времени вставки можно провести аналогичные рассуждения и получить тот же вывод — об
амортизированной константности операции вставки.
\
Глава 2
Обзор компонентов STL
STL содержит компоненты шести основных видов: контейнеры, обобщенные алгоритмы,
итераторы, функциональные объекты, адаптеры и аллокаторы. В этой главе мы только
бегло ознакомимся с каждой из разновидностей, откладывая детали до следующих глав.
2.1. Контейнеры
Контейнеры в STL представляют собой объекты, которые хранят коллекции других объектов.
Имеется две категории контейнеров STL: контейнеры последовательностей и отсортированные
ассоциативные контейнеры.
2.1.1. Контейнеры последовательностей
Контейнеры последовательностей организуют набор объектов одного и того же типа Т
в строго линейную последовательность. В STL имеются следующие контейнеры
последовательностей.
• vector<T>. Обеспечивает произвольный доступ к последовательности переменной
длины (произвольный доступ означает, что время, требуемое для достижения /-го элемента,
представляет собой константу, т.е. оно не зависит от конкретного значения i), с
амортизированным константным временем вставки и удаления в конце последовательности.
• deque<Т>. Также обеспечивает произвольный доступ к последовательности
переменной длины, с амортизированным константным временем вставки и удаления с
обоих концов последовательности.
• list<T>. Обеспечивает линейное время доступа к последовательности переменной
длины (0[N), где N— текущая длина), но с константным временем вставки и
удаления в любом месте последовательности.
Перед рассмотрением этих типов контейнеров последовательностей заметим, что
обычный массив C++ Т a [N] может использоваться в качестве контейнера последовательности,
поскольку все обобщенные алгоритмы STL спроектированы для работы с массивами точно
так же, как и с другими типами последовательностей. Имеется еще один важный тип
string (из заголовочного файла <string>), представляющий последовательности
символов способом, совместимым с алгоритмами и соглашениями STL. Например, STL
предоставляет обобщенный алгоритм reverse, который может обратить последовательности
различного вида, включая объекты string и массивы. Вот пример его применения к string
и массиву символов.
Часть I. Вводный курс в STL
Пример 2.1. Использование обобщенного алгоритма STL reverse
со строкой и массивом
"ех02-01.срр" 52 =
#include <iostream>
#include <string>
#include <cassert>
#include <algorithm> // Алгоритм reverse
using namespace std;
int main()
{
cout << "Применение алгоритма reverse к строке"
<< endl;
string stringl = "mark twain";
reverse(stringl.begin(), stringl.end() ) ;
assert (stringl == "niawt kram");
cout << " Ok." << endl;
cout << "Применение алгоритма reverse к массиву"
<< endl;
char arrayl[] = "mark twain";
int N1 = strlen(arrayl);
reverse(fcarrayl[0], fcarrayl[Nl]);
assert (string(arrayl) == "niawt kram");
cout << " Ok." << endl;
return 0;
}
Аргументами первого вызова reverse, а именно stringl. begin () и stringl. end (),
являются вызовы функций-членов begin и end, определенных в классе string. Эти
функции-члены возвращают итераторы, которые представляют собой объекты наподобие
указателей, которые ссылаются на начало и конец строки stringl. Функция reverse обращает
порядок символов в указанном итераторами диапазоне "на месте" (т.е. результат замещает
исходное содержимое строки stringl). Макрос assert выполняет простую проверку того,
что результат в stringl ив самом деле представляет собой обращенную исходную строку.
(Во врезке "Макрос assert" имеется дополнительная информация об этом и других
применениях макроса assert.)
Во втором вызове reverse мы передаем указатель на начало и конец символьного
массива arrayl. Заметим, что на самом деле &arrayl [N1] представляет собой адрес ячейки
за последним сохраненным символом. В STL действует соглашение, согласно которому при
передаче алгоритму двух итераторов first и last ожидается, что они определяют
положения, где начинается обход последовательности (first) и где он заканчивается (last) — при
этом не делаются никакие попытки обратиться к элементу в позиции, на которую указывает
last. Таким образом, это точка за последним элементом последовательности. В случае
класса string и классов последовательных контейнеров STL функция-член end возвращает
итератор за пределами последовательности, а не указывает на ее последний элемент.
Векторы предоставляют все возможности обычных стандартных массивов, но при этом
они расширяемы и обладают рядом иных полезных свойств, которые будут рассматриваться
в разделах 2.1.1 и 6.1. Вот как выглядит применение алгоритма reverse к классу vector.
Глава 2. Обзор компонентов STL
оо
Макрос assert
В примере 2.1 мы проверяем результат вызова reverse при помощи макроса !
assert из заголовочного файла cassert (который соответствует заголовочному файлу
С assert.h). Этот макрос в качестве единственного аргумента получает выражение, !
| возвращающее значение логического типа, и ничего не делает, если вычисление выраже-
' ния возвращает значение true, но если выражение равно false, макрос выводит соот-
I ветствующее информативное сообщение и завершает работу программы. В первом при- !
\ менении макроса assert его аргумент— stringl == "niawt kram", в котором
I оператор ==, определенный в классе string, используется для сравнения двух объектов
| типа string символ за символом. Одна из строк — это stringl, а вторая — результат
j применения компилятором конструктора string к строке "niawt kram", в результате
I чего создается объект типа string.
Во втором вызове assert его аргументом является выражение string (arrayl) =
= "niawt kram", в котором использован явный вызов упомянутого конструктора
I string с передачей ему массива arrayl, чтобы можно было использовать оператор ==
класса string. Заметим, что если бы мы записали просто arrayl == "niawt kram",
то оператор == имел бы иной смысл (он бы проверял равенство указателей, а не строко-
! вых значений, на которые они указывают.)
Макрос assert используется аналогичным образом во многих примерах части I,
| чтобы показать, что получен именно тот результат, который мы ожидаем от алгоритма
I или операции над структурой данных.
Пример 2.2. Применение обобщенного алгоритма STL reverse к вектору
пех02-02.срр" 53а а
#include <iostream>
#include <vector>
#include <cassert>
#include <algorithm> // Алгоритм reverse
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Применение алгоритма reverse к вектору"
< < endl;
vector<char> vectorl =
make< vector<char> >("mark twain");
reverse(vectorl.begin(), vectorl.end() ) ;
assert (vectorl == make< vector<char> >("niawt kram"));
cout << "< Ok." << endl;
return 0; ■
}
В этот пример включена ссылка на часть программы, определенную отдельно:
<Функция make (создание контейнера символов) 53б> =
template <typename Container>
Container make(const char s[] )
{
return Container(&s[0], &s[strlen(s)]);
}
-шить I. явочный курс в 5/L
Используется в частях 53а, 54, 57, 58, 59, 60, 61, 113, 126, 130, 143,
147, 148, 153, 156, 158, 159, 160, 165, 166, 1686, 170, 198.
Это определение шаблона функции, которое мы уже встречали в разделе 1.3.3. Этот шаблон
функции будет использоваться нами во многих примерах программ в части I этой книги для
создания контейнеров из строк. О том, как определяются и используются части программ
в данной книге, рассказывается во врезке "Грамотное программирование".
Грамотное программирование
1
В определении части "Функция make (создание контейнера символов)" метка 536 I
I представляет собой присвоенный ей "номер части". Номер части представляет собой но- )
I мер текущей страницы. Цель такого номера состоит в том, чтобы помочь читателю быст- j
j ро найти определение части, увидев ссылку на нее на других страницах книги. Если вы 1
1 обратитесь к любой странице, указанной в строке "Используется в частях..." после опре- |
деления части, то встретите на ней ссылку на эту часть в тексте примера или определения j
| другой части. Это — простой случай стиля "грамотного программирования" Д.Э. Кнута j
j (D.E. Knuth), который объединяет программирование и документирование в единый про- j
I цесс. В части I книги мы ограниченно пользуемся этим стилем, но в части II грамотное j
j программирование будет использоваться более широко, а в главе 12, "Программа для по- j
иска в словаре", будет дано его более полное описание.
В вызове reverse программа использует функции-члены класса vector — begin и end,
которые возвращают начальную и конечную позиции объекта vector. Здесь также работает
соглашение, что конечная позиция — это первая позиция за концом содержимого вектора.
При выполнении проверки мы сравниваем содержимое вектора после вызова reverse
и вектора, полученного вызовом нашей обобщенной функции make,
make< vector<char> >("niawt kram");
Для сравнения двух векторов используется оператор ==, поскольку STL определяет этот
оператор как проверку на равенство векторов. Вообще говоря, STL определяет оператор = =
для всех своих классов контейнеров. (Мы уже использовали тот факт, что он определен для
объектов стандартного класса string.)
Наш пример с алгоритмом reverse можно записать с применением вместо vector
класса list.
Пример 2.3. Применение обобщенного алгоритма STL reverse к списку
■ех02-03.срр" 54 =
#include <iostream>
#include <cassert>
#include <list>
#include <algorithm> // Алгоритм reverse
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Применение алгоритма reverse к списку"
<< endl;
list<char> listl = make< list<char> >("mark twain");
reverse(listl.begin(), listl.end());
assert (listl == make< list<char> >("niawt kram"));
Глава 2. Обзор компонентов STL
ээ
cout << " Ок." << endl;
return 0;
}
Точно такой же пример может быть написан и для контейнера deque. Как вы увидите
в дальнейшем, векторы, списки и деки не являются полностью взаимозаменяемыми, но в
данном случае все они работают одинаково. Это связано с тем, что каждое определение функций-
членов begin и end имеет один и тот же абстрактный смысл, хотя их реализация существенно
различна: векторы представлены с применением массивов, списки — с использованием дважды
связанных узлов, а деки обычно реализуются при помощи двухуровневого массива.
Единственное отличие, которое может заметить пользователь при применении обобщенной функции
reverse — это производительность. В данном простом случае заметных отличий в
производительности быть не должно, но в других ситуациях, при использовании иных алгоритмов и
больших последовательностей, может обнаружиться существенное различие в производительности
при работе с разными контейнерами. (Однако ни один из них не будет "победителем" во всех
ситуациях — именно поэтому контейнеров в библиотеке несколько.)
2.1.2. Отсортированные ассоциативные контейнеры
Отсортированные ассоциативные контейнеры обеспечивают возможность быстрой
выборки объектов из коллекции на основе значения ключа. Размер коллекции может изменяться
во время работы программы. В STL имеется четыре типа отсортированных ассоциативных
контейнеров.
• set<Key>. Поддерживает уникальные ключи (содержит не более одного значения
каждого ключа) и обеспечивает быструю выборку искомого ключа.
• multiset<Key>. Поддерживает дублированные ключи (возможно наличие
нескольких копий одного и того же значения ключа) и обеспечивает быструю выборку
искомого ключа.
• map<Key, T>. Поддерживает уникальные ключи (типа Key) и обеспечивает
быструю выборку другого типа Т на основе ключа.
• multimap<Key, T>. Поддерживает дублированные ключи (типа Key) и
обеспечивает быструю выборку другого типа Т на основе ключа.
Примером отсортированного ассоциативного контейнера является map<string, long>,
который может использоваться для хранения имен и телефонных номеров, т.е. для
представления телефонного справочника. По данному имени такое отображение обеспечивает
быструю выборку телефонного номера, как в приведенном ниже примере.
Пример 2.4. Демонстрация STL шар
"ех02-04.срр" 55 =
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main()
{
map<string, long> directory;
directory["Bogart"] = 1234567;
directory["Bacall"] = 9876543;
directory["Cagney"] = 3459876;
часть I. Вводный курс в STL
// И т.д.
// Чтение имен и поиск номеров телефонов:
string name;
while (cin >> name)
if (directory.find(name) != directory.end())
cout << "Номе телефона " << name
<< " - " << directory[name] << "\n";
else
cout << "Извините, в каталоге нет "
<< name << "\n";
return 0;
}
В этой программе использован класс string стандартной библиотеки C++
(заголовочный файл string). Переменная directory объявлена как тар со string в качестве
ключа и long в качестве связанного типа значения Т.
Затем мы вставляем в каталог несколько имен и номеров телефонов, используя
присваивание в стиле массивов: directory [ "Bogart" ] = 1234567. Такая запись возможна
благодаря тому, что тип тар определяет operator [] аналогично соответствующему оператору
для массивов. Если нам известно имя name в каталоге, то соответствующий ему телефонный
номер можно получить при помощи выражения directory [name]. В этой программе мы
сначала проверяем, имеется ли ключ name в directory (для чего используем функцию-
член find контейнера тар (и всех прочих отсортированных ассоциативных контейнеров)).
Функция find возвращает итератор, который указывает на запись каталога с именем name
в качестве ключа, если таковая запись в каталоге имеется; в противном случае она
возвращает итератор "за концом", тот самый, который возвращает функция-член end. Таким образом,
сравнивая итератор, возвращенный функцией find, с итератором, возвращенным функцией
end, мы выясняем, имеется ли в таблице запись с ключом name.
Подход STL к контейнерам отличается от подхода других библиотек классов контейнеров
C++: контейнеры STL не предоставляют множества операций над содержащимися в них
объектами данных. Вместо этого STL предоставляет обобщенные алгоритмы, которые и
являются нашей следующей темой.
2.2. Обобщенные алгоритмы
Два простейших обобщенных алгоритма STL — find и merge.
2.2.1. Обобщенный алгоритм find
В качестве простого примера гибкости алгоритмов STL рассмотрим алгоритм find,
использующийся для поиска определенного значения в последовательности. Алгоритм find можно
использовать с любыми контейнерами STL. В следующем примере продемонстрирована работа
алгоритма с массивами.
Пример 2.5. Демонстрация работы обобщенного алгоритма find с массивом
пех02-05.срр» 56 =
#include <iostream>
#include <cassert>
#include <algorithm> // Алгоритм find
using namespace std;
Глава 2. Обзор компонентов STL
57
int main()
{
cout << "Демонстрация работы обобщенного алгоритма "
<< "find с массивом." << endl;
char s[] = "C++ is a better C";
int len = strlen(s);
// Ищем первое вхождение символа 'е1:
const char* where = find(&s[0], &s [len], ' e1);
assert (*where == 'e1 && *(where+l) == 't1);
cout << " Ok." << endl;
return 0;
}
В этой программе обобщенный алгоритм find используется для поиска среди элементов
массива s[0],..., s[len-l] элемента, содержащего символ ■ е '. Если символ ' е ' имеется
в массиве s, указатель where указывает на первое вхождение символа в массив, так что
* where == ■ е ■. В нашем случае такой символ в массиве есть, но если бы его не было, то
алгоритм find вернул бы значение &s [len]. Это значение— местоположение за
последним элементом массива.
Теперь вместо массива сохраним наши данные в объекте типа vector, контейнере,
обеспечивающем произвольный доступ к своим элементам, так же, как и массив, но который
к тому же может динамически изменять свой размер. Чтобы найти элемент в векторе,
используется тот же алгоритм find.
Пример 2.6. Демонстрация работы обобщенного алгоритма find с вектором
"ех02-0б.срр" 57 =
#include <iostream>
#include <cassert>
#include <vector>
#include <algorithm> // Алгоритм find
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация работы обобщенного алгоритма "
<< "find с вектором." << endl;
vector<char> vectorl =
make< vector<char> >("C++ is a better C");
// Ищем первое вхождение символа 'е':
vector<char>::iterator
where = find(vectorl.begin(), vectorl.end(), 'e');
assert (*where == 'e1 && *(where + 1) == ' t');
cout << " Ok." << endl;
return 0;
}
В этот раз мы создаем вектор, содержащий те же символы, что и массив s, применяя
конструктор класса vector, который инициализирует вектор с использованием последователь-
58
Часть I. Вводный курс в STL
ности значений из массива. Типом where вместо char* в данном случае является тип
vector<char> : : iterator. Итераторы представляют собой указателеобразные объекты,
которые можно использовать для обхода последовательности объектов. Когда
последовательность хранится в массиве char, итераторы являются указателями C++ (типа char*), но
когда последовательность хранится в контейнере, таком как vector, мы получаем от класса
контейнера соответствующий итератор. Каждый контейнер STL типа С определяет тип
итератора С: : iterator, который может использоваться с контейнерами типа С.
В любом случае при вызове алгоритма find, как в строке
where = find(first, last, value);
предполагается следующее:
• итератор first указывает позицию последовательности, где должен начаться поиск;
• итератор last указывает позицию последовательности, где поиск должен завершиться.
Эти начальная и конечная позиции в точности совпадают с тем, что возвращают функции-
члены begin и end класса vector (и всех прочих классов STL, определяющих контейнеры).
Если элементы данных находятся в списке, мы опять можем применить тот же алгоритм find.
Пример 2.7. Демонстрация работы обобщенного алгоритма find со списком
"ех02-07.срр" 58 =
#include <iostream>
#include <cassert>
#include <list>
#include <algorithm> // Алгоритм find
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация работы обобщенного алгоритма "
<< "find со списком." << endl;
list<char>
listl = make< list<char> >("C++ is a better C");
// Ищем первое вхождение символа ' е':
list<char>::iterator
where = find(listl.begin(), listl.end(), ' e');
list<char>::iterator next = where;
++next;
assert (*where == 'e' && *next = = »t');
cout << " Ok." << endl;
return 0;
}
Между этой и предыдущей программой имеется одно тонкое отличие, связанное с тем,
что итератор, связанный со списком, не поддерживает оператор +, который в версии для
вектора был использован в выражении * (where + 1). Причина этого поясняется в главе 4,
"Итераторы". Однако все итераторы STL поддерживают оператор ++, поэтому для
обращения к позиции, следующей за той, на которую указывает итератор where, мы использовали
еще один итератор next.
Глава 2. Обзор компонентов STL
59
Если данные хранятся в контейнере deque, который является контейнером с
произвольным доступом, аналогичным массивам и векторам, но обеспечивает еще большую гибкость
при увеличении и уменьшении размера, мы вновь можем прибегнуть к обобщенному
алгоритму find.
Пример 2.8. Демонстрация работы обобщенного алгоритма find с деком
"ех02-08.сррп 59 =
#include <iostream>
#include <cassert>
#include <deque>
#include <algorithm> // Алгоритм find
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация работы обобщенного алгоритма "
<< "find с деком." << endl;
deque<char> dequel =
make< deque<char> >("C++ is a better C");
// Ищем первое вхождение символа 'е1:
deque<char>::iterator
where = find(dequel.begin(), dequel.end(), ' e1);
assert (*where == *e' && *(where + 1) == 't');
cout << " Ok." << endl;
return 0;
}
Эта программа идентична версии с использованием вектора, за исключением того, что
везде vector заменен на deque (итераторы деков, в отличие от итераторов списков,
поддерживают оператор +).
Фактически алгоритм find может использоваться для поиска во всех контейнерах STL.
Главное, что следует сказать о find и всех других обобщенных алгоритмах STL— это то,
что поскольку они могут использоваться со многими или даже со всеми контейнерами,
отпадает необходимость в определении соответствующих функций-членов у отдельных
контейнеров, что снижает размер кода и упрощает интерфейсы контейнеров.
2.2.2. Обобщенный алгоритм merge
Гибкость обобщенных алгоритмов STL даже больше, чем демонстрируют примеры с
алгоритмом find. Рассмотрим такой алгоритм, как merge, который объединяет две
отсортированные последовательности в единую (отсортированную же) последовательность. В общем
случае merge вызывается следующим образом:
merge(firstl, lastl, first2/ last2, result);
где предполагается следующее.
• f irstl и lastl представляют собой итераторы, указывающие начало и конец
первой входной последовательности элементов некоторого типа Т.
• first2nlast2 представляют собой итераторы, указывающие начало и конец
второй входной последовательности элементов того же типа Т.
60
Часть I. Вводный курс в STL
• Эти две входные последовательности упорядочены в возрастающем порядке в
соответствии с оператором < для типа Т.
• result указывает начало последовательности, в которой будет сохранен результат
слияния входных последовательностей.
При указанных условиях результат содержит все элементы из двух входных
последовательностей, и они также отсортированы в порядке возрастания. Этот интерфейс
достаточно гибок, чтобы входные и выходная последовательности находились в контейнерах разного
типа, как видно из приведенного далее примера.
Пример 2.9. Демонстрация работы обобщенного алгоритма merge
с массивом, списком и деком
мех02-09.срр" 60 =
#include <iostream>
#include <cassert>
#include <list>
#include <deque>
#include <algorithm> // Алгоритм merge
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация работы обобщенного алгоритма "
<< "merge с массивом, списком и деком. " << endl;
char s[] = "aeiou";
int len = strlen(s);
list<char> listl =
make< list<char> >("bcdfghjklmnpqrstvwxyz");
// Инициализация dequel 26 символами х:
deque<char> dequel(26, 'x');
// слияние массива s и listl,
// размещение результата в dequel:
merge (&s[0], &s [len] , listl .begin () , listl.endO,
dequel.begin());
assert (dequel ==
make<deque<char> >("abcdefghijklmnopqrstuvwxyz"));
cout << " Ok." << endl;
return 0;
}
В этой программе мы создаем дек для хранения результата слияния массива s и списка
listl. Обратите внимание, что как в s, так ив listl, символы находятся в возрастающем
порядке, как и результат работы merge в dequel.
Можно объединять часть одной последовательности с частью другой. Например, можно
модифицировать программу в примере 2.9 так, чтобы в ней выполнялось слияние первых
пяти символов s с первыми десятью символами dequel, а результат помещался в listl
(обратите внимание на то, что мы поменяли роли listl и dequel).
Глава 2. Обзор компонентов STL
61
Пример 2.10. Демонстрация работы обобщенного алгоритма merge путем
объединения частей массива и дека с помещением результата в список
"ех02-10.срр" 61 =
#include <iostream>
#include <string>
#include <cassert>
#include <list>
#include <deque>
#include <algorithm> // Алгоритм merge
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация работы обобщенного алгоритма "
<< "merge путем объединения частей массива и "
<< "дека с помещением результата в список."
<< endl;
char s[] = "acegikm";
deque<char> dequel =
make< deque<char> >("bdfhjlnopqrstuvwxyz");
// Инициализация списка 26 символами х:
list<char> listl (26, 'x');
// Слияние первых 5 символов массива s с первыми
// 10 символами из dequel, с размещением результата
// в списке listl:
merge(&s[0], &s [5], dequel.begin(),
dequel.begin() + 10, listl.begin());
assert (listl ==
make< list<char> >("abcdefghijlnopqxxxxxxxxxxx"));
cout << " Ok." << endl;
return 0;
}
Это простые примеры, но они показывают большой диапазон возможных применений таких
обобщенных алгоритмов.
2.3. Итераторы
Понимание итераторов является ключом к пониманию STL и тому, как наилучшим
образом работать с этой библиотекой. Обобщенные алгоритмы STL написаны с применением
в качестве параметров итераторов, а контейнеры STL предоставляют итераторы, которые
затем могут "включаться" в алгоритмы, как это было показано на рис. 1.1. На рис. 2.1 вновь
показано это взаимоотношение, а также отношения между другими важными категориями
компонентов STL. Эти очень обобщенные компоненты спроектированы для "подключения" друг
к другу несметным количеством разных способов для получения больших и более
специализированных компонентов, которые можно найти в других библиотеках. Основным типом
"проводов" для соединения компонентов является категория, именуемая итераторами (на рис. 1.1 и 2.1
эта категория схематически показана в виде соединительных шлейфов, а иерархия самих
итераторов показана на рис. 2.2). Одним из видов итераторов является обычный указатель C++, но
oz
Часть I. Вводный курс в STL
могут быть и иные итераторы, отличные от указателей. Такие другие типы итераторов, однако,
должны вести себя как указатели в том смысле, что должны поддерживать операции наподобие
++ и *, причем ожидается, что эти операции ведут себя так же, как и с указателями: например,
++i перемещает итератор i к следующему положению, a *i возвращает местоположение, где
может быть сохранено значение (т.е. можно записать * i = x), или значение из которого может
быть использовано в выражении (как в х = * i).
Классы
контейнеров
Итераторы
Обобщенные Функциональные Адаптеры
алгоритмы объекты
sort H-D—4
list
<(т>
l^v^
insertl
erase 1
н^
istream
istream_
iterator
P merge H-|>—П
ostream
ostream_
iterator
№
stack
<(c>
push |
pop |
top |
queue
push
back
pop j
front!
reverse
iterator
Рис. 2.1. Пять из шести основных категорий компонентов STL (не показаны
аллокаторы)
Рассмотрим обобщенный алгоритм STL accumulate. При его вызове с итераторами
first и last и значением init,
accumulate(first, last, init);
добавляет к init значения в позициях от first до last (не включая значение в последней
позиции) и возвращает получившуюся сумму. Например, мы можем написать следующую
программу для вычисления и вывода суммы значений вектора.
Пример 2.11. Демонстрация обобщенной функции accumulate
"ех02-11.срр" 62 =
#include <iostream>
#include <vector>
#include <cassert>
#include <numeric> // Алгоритм accumulate
using namespace std;
int main()
{
cout << "Демонстрация функции accumulate." << endl;
Глава 2. Обзор компонентов STL
63
int х[5] = {2, 3, 5, 7, 11};
// Инициализация вектора элементами от х[0] до х[4]:
vector<int> vector1(&х[0], &х[5]);
int sum = accumulate(vectorl.begin(), vectorl.end(), 0);
assert (sum == 28);
cout << " Ok." << endl;
return 0;
}
Эта программа использует функцию accumulate для суммирования целых чисел из
контейнера vectorl, который указывается с применением итераторов vectorl .begin () и
vectorl. end (). Можно воспользоваться функцией accumulate для работы
непосредственно с массивом х, записав
sum = accumulate(&x[0], &х[5], 0);
или, например, со списком чисел с плавающей точкой double, как в следующем фрагменте:
double у[5] = {2.0, 3.0, 5.0, 7.0, 11.0};
list<double> listl(&у[0], &у[5]);
double sum = accumulate (list 1 .begin () , list Lend (), 0.0);
В каждом случае смысл действий один и тот же — прибавление к начальному значению
значений из диапазона, указанного итераторами, однако типы итераторов и тип начального
значения определяют, каким образом функция accumulate будет настроена для решения
конкретной задачи.
Давайте рассмотрим, как функция accumulate использует итераторы. Она может быть
определена следующим образом:
template <typename InputIterator, typename T>
T accumulate(InputIterator first, Inputlterator last, T init)
while (first != last) {
init = init + *first;
++first;
}
return init;
}
Операции, выполняемые над итераторами, включают проверку неравенства итераторов
с помощью оператора ! =, разыменование с применением оператора *, и инкремент с
применением префиксного оператора ++. Эти операции, вместе с постфиксным оператором ++
и проверкой равенства ==, составляют все множество операций, поддержка которых
требуется категорией входных итераторов. Другая характеристика входных итераторов (из-за
которой они, собственно, и получили свое имя) — это то, что от операции разыменования *
требуется только возможность чтения из указанной позиции контейнера, но не записи в нее.
В случае выходных операторов, наоборот, от операции разыменования * требуется только
возможность записи в указанную позицию контейнера, но не чтения из нее; кроме того,
поддержка проверок равенства и неравенства в этом случае не требуются.
STL определяет три другие категории итераторов — однонаправленные, двунаправленные
итераторы и итераторы с произвольным доступом. За исключением входных и выходных
итераторов, соотношения между итераторами образуют иерархию, показанную на рис. 2.2;
т.е. каждая категория добавляет новые требования к требованиям, предъявляемым
предыдущей категорией, что означает, что итераторы более поздней категории в иерархии
одновременно являются членами более ранней. Например, двунаправленные итераторы
одновременно являются однонаправленными, а итераторы с произвольным доступом одновременно
являются двунаправленными и однонаправленными.
64
Часть I. Вводный курс в STL
Входные Выходные
== I = • ЧУ
++
+=-=+-<><=>=
> Однона- ^ п \
правленные I Двунаправ-
г ленные
Произвольного
доступа
Рис. 2.2. Иерархия категорий итераторов STL
Алгоритмы, такие как accumulate, find или merge, которые спроектированы для
работы со входными итераторами, являются более обобщенными, чем алгоритмы, требующие
более мощных итераторов, — как, например, sort, который требует итераторов с
произвольным доступом. Например, sort не может использоваться со списками STL, так как
итераторы списков являются всего лишь двунаправленными, а не итераторами с произвольным
доступом. Вместо этого STL предоставляет функцию-член, которая эффективно работает
с двунаправленными итераторами. Как вы увидите в главе 4, "Итераторы", задача достичь
высокой эффективности накладывает в STL ограничения на обобщенность некоторых
алгоритмов, а организация итераторов в категории является основным средством достижения
поставленной цели.
2.4. Функциональные объекты
Рассматривавшаяся в предыдущем разделе функция accumulate является весьма
обобщенной в смысле использования ею итераторов, но не настолько обобщена, как могла бы
быть, в смысле действий с типами значений, на которые указывают итераторы (эти типы
называются просто типами значений итераторов). Определение accumulate предполагает,
что имеется определенный для типа значения оператор +, используя его в выражении
init = init + *first;
Таким образом, функция может работать с любыми встроенными числовыми типами C++
или с любыми пользовательскими типами Т, в которых определен такой оператор. Однако
абстрактное понятие накопления (accumulation) применимо не только к суммированию;
можно точно так же накапливать, например, произведение значений последовательности. Потому
STL предоставляет еще одну, более обобщенную версию accumulate:
template <typename Inputlterator, typename T,
typename BinaryOperation>
T accumulate(InputIterator first, Inputlterator last,
T init, BinaryOperation binary_op)
while (first != last) {
init = binary_op(init, *first);
++first;
return init;
}
Вместо записи с оператором + в этом определении вводится еще один параметр — binary_op,
представляющий собой бинарную операцию, используемую для объединения значений.
Глава 2. Обзор компонентов STL
65
Как воспользоваться этой более обобщенной версией accumulate для вычисления
произведения? Если мы определим функцию mult так, как это сделано в следующей программе,
то сможем использовать ее в качестве параметра binary_op функции accumulate.
Пример 2.12. Использование обобщенного алгоритма accumulate для
вычисления произведения
"ех02-12.срр" 65а =
#include <iostream>
#include <vector>
#include <cassert>
#include <numeric> // Алгоритм accumulate
using namespace std;
int mult(int x, int y) { return x * y; }
int main()
{
cout << "Использование обобщенного алгоритма "
<< "accumulate для вычисления произведения."
<< endl;
int x[5] = {2, 3, 5, 7, 11};
// Инициализация вектора элементами от х[0] до х[4]:
vector<int> vectorl(&x[0], &х[5]);
int product = accumulate(vectorl.begin(),
vectorl.end(), 1, mult);
assert (product == 2310);
cout << " Ok." << endl;
return 0;
}
(Обратите внимание, что мы заменили начальное значение с 0 на 1, которое является
правильным "единичным элементом" для умножения.) В приведенном примере мы передаем
аргументу accumulate обычную функцию mult. В действительности передается адрес
функции, так что мы можем записать аргумент явно, как &mult. Но это только один из способов
поддержки в C++ передачи функций другим функциям. Более общей является передача
функциональных объектов, представляющих собой произвольные сущности, которые могут быть
применены к нулю или большему количеству аргументов, чтобы получить значение и/или
модифицировать состояние вычислений. Кроме обычных функций, функциональными объектами
являются объекты типа, определенного как класс или структура с перегруженным
оператором вызова функции. Вот пример определения и передачи такого функционального объекта.
Пример 2.13. Использование обобщенного алгоритма accumulate для
вычисления произведения с применением функционального объекта
"ех02-13.срр" 656 =
#include <iostream>
#include <vector>
#include <cassert>
#include <numeric> // Алгоритм accumulate
using namespace std;
66
Часть I. Вводный курс в STL
class multiply {
public:
int operator()(int x, int y) const { return x * y; }
};
int main()
{
cout << "Использование обобщенного алгоритма "
<< "accumulate для вычисления произведения."
<< endl;
int x[5] = {2, 3, 5, 7, 11};
// Инициализация вектора элементами от х[0] до х[4]:
vector<int> vectorl(&x[0], &х[5]);
int product = accumulate(vectorl.begin(),
vectorl.end(), 1,
multiply());д
assert (product == 2310);
cout << " Ok." << endl;
return 0;
}
Путем определения оператора вызова функции operator () в классе multiply мы
определяем тип объекта, который может быть применен к списку аргументов, так же, как
и функция. Обратите внимание, что объект, переданный accumulate, получается путем
вызова конструктора класса по умолчанию multiplyO, который автоматически создается
компилятором, так как явно определенного конструктора в определении класса нет. Заметим
также, что этот объект не требует для хранения памяти, так как представляет собой только
определение функции (хотя в некоторых случаях хранение данных в функциональных
объектах оказывается удобным).
В чем же преимущество, если таковое имеется, функциональных объектов перед
обычными функциями? Детально этот вопрос будет рассмотрен в главе 8, "Функциональные
объекты", но одно из главных преимуществ заключается в том, что объекты, в отличие от обычных
функций, могут хранить дополнительную информацию, которая затем может использоваться
обобщенными алгоритмами или контейнерами, которым требуется более сложные знания
о функции, чем алгоритму accumulate. Имеются также преимущества, связанные с
эффективностью и обобщенностью.
Перед тем как завершить рассмотрение этой темы, мы должны упомянуть, что в
примере 2.13 в действительности нет необходимости определять класс multiply, поскольку STL
уже содержит такое определение, хотя и в более обобщенной форме:
template <typename T>
class multiplies : public binary_function<T, T, T> {
public:
T operator()(const T& x, const T& y) const {
return x * y;
}; }
Этот класс наследует другой компонент STL, бинарную функцию, назначение которой —
хранить дополнительную информацию о функции (этот вопрос будет рассматриваться в
главе 8, "Функциональные объекты"). Используя это определение, программу можно переписать
следующим образом.
Глава 2. Обзор компонентов STL
67
Пример 2.14. Использование обобщенного алгоритма accumulate для
вычисления произведения с применением multiplies
«ех02-14.срр" 67 =
#include <iostream>
#include <vector>
#include <cassert>
#include <numeric> // Алгоритм accumulate
#include <functional> // Класс multiplies
using namespace std;
int main()
{
cout << "Использование обобщенного алгоритма "
<< "accumulate для вычисления произведения."
<< endl;
int x[5] = {2, 3, 5, 7, 11};
// Инициализация вектора элементами от х[0] до х[4]:
vector<int> vectorl(&х[0], &х[5]);
int product = accumulate(vectorl.begin(),
vectorl.end(),
1, multiplies<int>() ) ;
assert (product == 2310);
cout << " Ok." << endl;
return 0;
}
Выражение multiplies<int> () представляет собой вызов конструктора по
умолчанию класса multiplies, инстанцированного с типом int. Несколько других
функциональных объектов показано в четвертом столбце на рис. 2.1.
2.5. Адаптеры
Компонент, который изменяет интерфейс другого компонента, называется адаптером.
Адаптеры изображены в последнем столбце на рис. 2.1. Например, reverse_iterator
представляет собой компонент, который адаптирует тип итератора в новый тип итератора с
теми же возможностями, что и у исходного, но с обратным направлением прохода. Это
оказывается полезным, так как для ряда задач требуется именно такой проход. Например,
алгоритм find возвращает итератор, указывающий на первое найденное в последовательности
значение, но может оказаться, что нас интересует последнее значение. Мы можем обратить
порядок элементов в последовательности, применяя алгоритм reverse, а затем применить
алгоритм find, но мы можем добиться того же, не изменяя и не копируя исходную
последовательность, воспользовавшись адаптером reverse_iterator. На рис. 2.1 этот адаптер
изображен как шлейф, в котором перекрещиваются проводники для ++ и
Продолжая использовать в качестве примера алгоритм accumulate, можно не увидеть
никакой пользы в обращении порядка накапливаемых значений, поскольку сумма не должна
изменяться при изменении порядка суммирования. Это справедливо для последовательности
целых чисел и + в качестве функции накопления, поскольку для целочисленного сложения
выполняются закон ассоциативности (x + y\ + z = x + (y + z} и закон коммутативности
х + У = У + х • Однако эти законы не выполняются при сложении чисел с плавающей точкой, что
00
Часть I. Вводный курс в STL
связано с ошибками округления и переполнения (из-за переполнения ассоциативность может
нарушиться даже для чисел типа int). В случае чисел с плавающей точкой ошибки округления
обычно оказываются меньшими, если числа суммируются в порядке возрастания; в противном
случае значения, оказывающиеся слишком малыми по сравнению с текущей суммой, могут
вообще никак на нее не повлиять. Предположим, что у нас имеется вектор значений в порядке
убывания, и мы хотим вычислить их сумму. Чтобы выполнить сложение в порядке возрастания,
мы можем воспользоваться алгоритмом accumulate с обратными итераторами.
Пример 2.15. Демонстрация обобщенного алгоритма accumulate
с обратным итератором
"ех02-15.срр" 68 =
#include <iostream>
#include <vector>
#include <cassert>
#include <numeric> // Алгоритм accumulate
using namespace std;
int main()
{
cout << "Демонстрация обобщенного алгоритма\п"
<< "accumulate с обратным итератором."
< < endl;
float small = (float)1.О/(1 << 27);
float x[5] = {l.O, 3*small/ 2*small, small, small};
// Инициализация вектора элементами от х[0] до х[4]:
vector<float> vectorl(&x[0], &х[5]);
cout << "Суммируемые значения: " << endl;
vector<float>::iterator i;
cout.precision(10);
for (i = vectorl.begin(); i != vectorl.end(); ++i)
cout << *i << endl;
cout << endl;
float sum = accumulate(vectorl.begin(),
vectorl.end(),
(float)0.0);
cout << "Сумма слева направо = " << sum << endl;
float suml = accumulate(vectorl.rbegin(),
vectorl.rend(),
(float)O.O);
cout << "Сумма справа налево = "
<< (double)suml << endl;
return 0;
}
Для вычисления suml для получения итераторов типа vector<f loat>: :rever-
se_iterator мы используем функции-члены vector— rbegin и rend. Итератор
vector<f loat> : : reverse_iterator, подобно итератору vector<float>: :
iterator, определен как часть интерфейса vector. Вывод представленной программы зависит
Глава 2. Обзор компонентов STL
69
от точности типа float, но значение small выбрано достаточно малым, чтобы разница
между sum и suml обнаружилась при точности около десяти десятичных знаков.6 Вывод
программы при использовании компилятора VC++ имеет следующий вид.
Вывод примера 2.15
Демонстрация обобщенного алгоритма
accumulate с обратным итератором.
Суммируемые значения:
1
2.235174179е-008
1.490116119е-008
7.450580597е-009
7.450580597е-009
Сумма слева направо = 1
Сумма справа налево = 1.000000052
Сумма, накопленная при суммировании справа налево, начиная с малых значений,
оказывается более точной.
Тип vector<float>: :reverse_iterator в действительности определен с
использованием адаптера итератора. Мы можем использовать этот адаптер непосредственно в
нашей программе, записав
reverse_iterator<vector<float>::iterators
start(vector1.end()), finish(vectorl.begin());
float suml = accumulate(start, finish, (float)O.O);
Здесь start и finish объявлены как переменные типа
reverse_iterator<vector<float>::iterator>
в котором параметр шаблона vector<f loat> : : iterator представляет собой тип
итератора. Этот тип reverse_iterator предоставляет операторы ++ и --, так же как и тип
vector<f loat>: : iterator, но их смысл меняется на обратный. Для удобства каждый из
типов контейнеров STL предоставляет определенный таким образом тип reverse_iterator,
а также функции-члены rbegin и rend, которые возвращают итераторы указанного типа.
STL определяет также несколько видов адаптеров контейнеров и функций. Адаптер
стека преобразует последовательный контейнер в контейнер с ограниченным интерфейсом стека
"последний вошел — первый вышел". Адаптер очереди преобразует последовательный
контейнер в контейнер с ограниченным интерфейсом очереди "первый вошел — первый вышел",
а адаптер очереди с приоритетами создает очередь, в которой значения доступны в порядке,
управляемом сравниваемым параметром. Эти адаптеры будут более полно описаны в главе 9,
"Адаптеры контейнеров".
Функциональные адаптеры, предоставляемые STL, включают инверторы, связыватели
и адаптеры для указателей на функции. Инвертор (negator) представляет собой
функциональный адаптер, используемый для обращения смысла предиката, который представляет собой
функциональный объект, возвращающий значение типа bool. Связыватель (binder)
применяется для преобразования бинарного функционального объекта в унарный путем связывания
аргумента с некоторым определенным значением. Адаптер для указателя на функцию
преобразует указатель на функцию в функциональный объект; он может использоваться для
придания компилируемому коду большей гибкости, чем при применении стандартных
функциональных объектов (что помогает избежать "разбухания кода", являющегося результатом
Вывод содержит десять значащих цифр, но это зависит от подпрограммы вывода.
70
Часть I. Вводный курс в STL
слишком большого количества компилируемых комбинаций алгоритмов и функциональных
объектов в одной программе). Подробно эти функциональные адаптеры рассматриваются
в главе 11, "Функциональные адаптеры".
2.6. Аллокаторы
Каждый класс контейнера STL использует класс аллокатора для инкапсуляции
информации о модели распределения памяти, используемой программой. Различные модели
распределения памяти используют разные способы получения памяти от операционной системы.
Класс аллокатора инкапсулирует информацию об указателях, константных указателях,
ссылках, константных ссылках, размерах объектов, типах разности между указателями, функции
выделения и освобождения памяти и некоторые другие. Все операции аллокаторов имеют
константное амортизированное время работы.
Поскольку модель распределения памяти может быть инкапсулирована в аллокаторе,
контейнеры STL могут работать с разными моделями распределения памяти, просто используя
разные аллокаторы.
В этой книге мы не будет детально рассматривать аллокаторы, поскольку класса
аллокатора по умолчанию, предоставляемого реализациями STL, вполне достаточно для
удовлетворения большинства потребностей программистов. Те программисты, которым требуется
определение новых аллокаторов, найдут в главе 24, "Справочное руководство по аллокаторам",
описание информации, которую должен предоставлять аллокатор.
Глава 3
Отличие STL от других библиотек
Перед тем как перейти к более детальному рассмотрению компонентов STL в следующей
главе, кратко рассмотрим основные отличия между STL и другими библиотеками C++.
Во-первых, большинство библиотек C++ содержит контейнеры, которые требуют, чтобы
содержащиеся в них объекты были производными от некоторого общего предка. Контейнеры
STL не опираются ни на какие предположения о наследовании; они могут хранить что
угодно, включая встроенные типы.
Во-вторых, в традиционных библиотеках контейнерных классов все алгоритмы связаны
с определенными классами и реализованы в качестве функций-членов. Если класс списка
в такой библиотеке имеет алгоритм поиска наподобие find, то такой алгоритм будет
отличаться от алгоритма поиска в классе вектора. Основная проблема такой организации
заключается в том, что каждый класс библиотеки должен содержать огромное количество
исходного текста и документации. При наличии т контейнеров и определенных над ними п операций
(наподобие find) вам потребуется определить и документировать тп операций. В
противном случае классы библиотеки просто не будут иметь многие операции, которые они должны
выполнять. В этом случае придется либо жертвовать одним классом в пользу другого, либо
выполнять преобразования туда и обратно между двумя представлениями данных для
выполнения некоторой операции. Такие преобразования не только увеличивают количество
классов, с которыми мы должны уметь работать, но часто приводят к серьезным проблемам,
связанным с падением производительности.
Подход STL прошел длинный путь в поисках решения этой проблемы. Вместо т
контейнеров и тп операций, которые следует определить и документировать, мы имеем дело только
с т контейнерами и п обобщенными операциями. Так мы получаем гораздо более высокую
степень гибкости в выборе алгоритмов и контейнеров, чем в случае традиционных библиотек
классов, а кроме того, количество интерфейсов, которые следует изучить, и общее
количество кода, которое следует поддерживать, остается достаточно небольшим.
3.1. Расширяемость
Ни одна программная библиотека не делает все, и STL — не исключение. Но по
сравнению с традиционными библиотеками классов STL сравнительно легко расширить, если
в этом возникнет необходимость.
В традиционных библиотеках, где алгоритмы связаны с конкретными классами, можно
добавлять алгоритмы путем наследования новых классов из библиотечных. У этого подхода
есть некоторые недостатки.
• Он работает, только если проектировщик исходных классов предвидит такие
расширения и предоставляет специальные средства для них (например, делает некоторые
72
Часть I. Вводный курс в STL
данные-члены защищенными, а не закрытыми, или некоторые функции виртуальными,
а не обычными).
• Чаще, чем этого хотелось бы, приходится прибегать к внесению изменении в
исходный текст библиотеки (конечно, в предположении, что он доступен), что может
привести к внесению ошибок или возникновению новых проблем при тестировании,
сопровождении и управлениями версиями.
С другой стороны, STL имеет открытую и ортогональную структуру, которая позволяет
программисту разработать собственные алгоритмы для работы с контейнерами библиотеки
или собственные контейнеры для работы с алгоритмами библиотеки, никак не затрагивая
(или даже не читая) исходный текст библиотеки.
3.2. Взаимозаменяемость компонентов
Каким же образом достигнута эта открытость и ортогональность компонентов STL?
Оказывается, решение давно известно во многих промышленных отраслях: взаимозаменяемость
компонентов, достигаемая путем максимально возможного упрощения и унификации
интерфейсов.
Мы все знакомы с преимуществами взаимозаменяемости в промышленности, и в области
программного обеспечения делались такие же попытки. Начавшись с первых набросков STL,
подход, нацеленный на достижение максимальной взаимозаменяемости программных
компонентов, достиг таких высот, как ни в одной другой библиотеке.
Мы уже знакомы с некоторыми аспектами взаимозаменяемости компонентов STL в
алгоритмах find и merge (в разделах 2.2.1 и 2.2.2). Эти алгоритмы работают с таким
множеством контейнеров, потому что их интерфейсы спроектированы для обращения к
последовательностям только очень ограниченными способами, посредством указателеобразных
объектов, называющихся итераторами.
Основная цель заключается в том, чтобы сделать алгоритмы STL не зависящими от
структур данных, с которыми они работают. Вместо этого алгоритмы и контейнеры STL
комбинируются следующим образом.
• Для каждого контейнера мы указываем, какие категории итераторов он предоставляет.
• Для каждого алгоритма мы указываем, с какими категориями итераторов он работает.
Определение алгоритмов в терминах итераторов, а не непосредственно структур данных,
делает возможной независимость алгоритмов от последних. Так алгоритмы становятся
особенно "обобщенными", способными работать с большим количеством разных структур
данных. Ни одна другая библиотека не способна на такое расширение, как STL.
Кроме того, наблюдается единообразное использование соглашения об указании начала
и конца данных. Рассмотрим алгоритм sort, который, подобно алгоритму find, работает
с данными в одной последовательности (он сохраняет результаты работы в той же
последовательности). Как и find, sort получает доступ к последовательности при помощи двух
итераторов, указывающих начальную и конечную точки:
long a [10000] ;
vector<int> v;
deque<double> d;
// ... Код для вставки значений в a, v и d
// Сортировка всех элементов массива а:
sort(&а[0], &а[10000]);
Глава 3. Отличие STL от других библиотек
73
II Сортировка всех элементов вектора v:
sort (v.begin () , v.endO);
// Сортировка всех элементов дека d:
sort (d.begin () , d.endO);
// Сортировка первых 100 элементов дека d:
sort (d.beginO , d.beginO + 100);
Одним словом, алгоритмы единообразны в своем обращении к данным, а контейнеры
предоставляют доступ к данным согласно требованиям алгоритмов.
Концепция итераторов более детально разъясняется в главе 4, "Итераторы".
3.3. Совместимость алгоритмов и контейнеров
Теперь перейдем к одному из наиболее важных моментов в понимании STL. Хотя
некоторые алгоритмы STL, наподобие find и merge, полностью обобщенные, — т.е. они
работают с контейнерами любого типа — невозможно соединить любой контейнер с любым
алгоритмом библиотеки.
Теоретически все алгоритмы и контейнеры STL можно было бы сделать совместимыми,
но это было бы не так просто, поскольку некоторые алгоритмы не могут достаточно
эффективно работать с теми или иными контейнерами.
Хорошим примером является алгоритм sort. Используемый алгоритм (вариация
алгоритма быстрой сортировки) эффективен только тогда, когда возможен произвольный доступ
к данным. Такой произвольный доступ обеспечивают массивы, векторы и деки, но не списки
или иные контейнеры STL. Поэтому невозможно написать следующий код:
list<int> listl;
// ... Код вставки значений в listl
sort(listl.begin(), listl.end О); // Неверно!
Класс list предоставляет функцию-член sort, которая эффективно сортирует списки.
Например, в приведенном коде эффективно отсортировать listl можно при помощи вызова
listl.sort().
Сейчас вы можете начать подозревать, что STL может не так уж сильно отличаться от
традиционных библиотек классов — быть может, у нее тоже используются разные алгоритмы
для разных классов. Но по ряду причин это не так. Во-первых, многие алгоритмы STL
(наподобие find и merge) совершенно обобщенные. В STL имеется только несколько
алгоритмов (наподобие функции-члена sort класса list), специфичных для определенного
класса контейнера. Многие алгоритмы, подобно обобщенному алгоритму sort, работают
с контейнерами некоторых видов, хотя и не со всеми.
Во-вторых, для тех алгоритмов, которые работают только с итераторами контейнеров
определенных видов, нетрудно указать, с какими именно контейнерами они могут
использоваться. Нам надо только разобраться, как алгоритмы и контейнеры комбинируются друг
с другом с применением итераторов — именно это и будет темой очередной главы.
Глава 4
Итераторы
Итераторы представляют собой указателеобразные объекты, которые алгоритмы STL
используют для обхода последовательности объектов, хранящихся в контейнере. Итераторы
занимают центральное место в дизайне STL благодаря их роли посредников между контейнерами и
обобщенными алгоритмами. Они позволяют создавать обобщенные алгоритмы без учета того,
как именно хранятся последовательности данных, а контейнеры — без необходимости
написания большого количества исходного текста работающих с ними алгоритмов. Однако, как
говорилось в предыдущей главе, по причинам эффективности невозможно обеспечить возможность
работы каждого обобщенного алгоритма с каждым контейнером. Но как тогда узнать, какие
комбинации возможны? Для ответа на этот вопрос мы должны изучить одну из ключевых
технических идей, лежащую в основе STL — разделение итераторов на пять категорий: входные,
выходные, однонаправленные, двунаправленные и произвольного доступа (см. рис. 2.1). Мы
начнем эту главу с точного определения этих категорий, а затем покажем, как они используются
для определения того, какие алгоритмы могут использоваться теми или иными контейнерами.
Перед тем как мы перейдем к категориям, следует упомянуть еще одну важную
концепцию, связанную с тем, как алгоритмы STL используют итераторы, — а именно диапазоны
итераторов. Все алгоритмы STL получают доступ к последовательностям через итераторы,
обычно посредством пары итераторов first и last, которые указывают начало и конец
последовательности. Для того чтобы разобраться, как такая пара итераторов определяет
последовательность, используется концепция диапазона итераторов. Диапазон от first до last
состоит из итераторов, которые получаются, начиная с итератора first, путем применения
оператора operator++ до тех пор, пока не будет достигнут итератор last, но не включая
его. Этот диапазон записывается в виде7
[first; last)
и называется корректным тогда и только тогда, когда итератор last достижим из итератора
first. Все алгоритмы STL полагают, что все диапазоны, с которыми они работают,
корректны; результат применения алгоритма к некорректному диапазону не определен.
Важным частным случаем является пустой диапазон, когда first == last. Пустой
диапазон корректен, но не содержит итераторов, указывающих на корректные данные.
4.1. Входные итераторы
Определение категорий итераторов STL связано с рассмотрением требований конкретных
алгоритмов. Как было сказано в главе 2, "Обзор компонентов STL", обобщенный алгоритм
STL find может использоваться для поиска значений во множестве структур данных, вклю-
Эта запись основана на аналогичной записи [a,b) в математике, которая для действительных
чисел а и Ъ означает множество всех действительных чисел х таких, что а < х < Ъ . Такое множество
называется полуоткрытым интервалом.
часть i. ьвооныи курс в SIL
чая массивы, векторы и списки. Он может использоваться даже для сканирования входного
потока при помощи специальных итераторов, именуемых итераторами входных потоков,
которые будут рассмотрены позже в данной главе. Алгоритм find имеет простое определение
как шаблон функции:
template <typename InputIterator, typename T>
Inputlterator find(Inputlterator first,
Inputlterator last,
const T& value)
while (first 1= last && *first != value)
++first;
return first;
}
Вот выражения в коде, в которых участвуют объекты Inputlterator:
• first != last
• ++first
• *first
Чтобы алгоритм find работал корректно, эти выражения должны быть определены
и иметь следующий смысл:
• выражение first != last должно возвращать true, если first не равно last,
в противном случае оно должно возвращать false;
• ++f i r s t должно выполнять инкремент f i r s t и возвращать новое значение итератора;
• * f i r s t должно возвращать значение, на которое указывает first.
Кроме того, чтобы алгоритм find работал эффективно, каждая из этих операций должна
выполняться за константное время.
Эти требования почти в точности совпадают с требованиями, налагаемыми определением
категории входных итераторов. Основные дополнительные требования, налагаемые
определением категории: чтобы был определен оператор ==, выполняющий проверку на равенство,
и чтобы был также определен постфиксный оператор ++ с тем же действием, что и
префиксный оператор ++, но возвращающий значение итератора до увеличения (как и в случае
встроенных типов указателей).
Этим требованиям, само собой, отвечают встроенные типы указателей. Заметим, однако,
что встроенные типы указателей обладают рядом других свойств, которые определение
входных итераторов не требует. В частности, от входных итераторов не требуется поддержка
записи в указанную позицию при помощи выражения * first = .... Конкретный входной
итератор, конечно, может поддерживать данную операцию, но она не является необходимой.
(Как вы увидите в следующем разделе, к выходным итераторам предъявляется
противоположное требование: они должны обеспечивать возможность записи посредством оператора
operator*, но не обязаны обеспечивать чтение.)
Заметим, что термин "входной итератор" не означает тип. Он указывает семейство типов,
каждый из которых удовлетворяет описанным ранее базовым требованиям. Чтобы убедиться,
что требованиям ко входным итераторам удовлетворяют одновременно несколько разных
типов, рассмотрим следующий пример.
В первой части этой программы мы применяем алгоритм find с обычными указателями,
которые ведут себя как массивы C++. Во второй части find используется с итераторами
списка, которые также удовлетворяют поставленным требованиям. Наконец, STL
предоставляет специальные входные итераторы, которые называются итераторами istream и которые
используются для чтения значений из входного потока. В последней части программы
Глава 4. Итераторы
77
выполняется чтение из стандартного входного потока с in до тех пор, пока в нем не будет
найден символ х или пока не будет достигнут конец потока. Затем выполняется инкремент
итератора для получения очередного непробельного символа и его вывод.
Пример 4.1. Демонстрация обобщенного алгоритма find со входными
итераторами массивов, списков и входных потоков
»ех04-01.срр" 77 з
#include <iostream>
#include <cassert>
#include <algorithm>
#include <list>
#include <iterator>
using namespace std;
int main()
{
// Инициализация массива 10 целыми числами:
int a[10] = {12, 3, 25, 7, 11, 213, 7, 123, 29, -3l};
// Поиск в массиве первого элемента, равного 7:
int* ptr = find(&a[0], &a[10], 7);
assert (*ptr == 7 && *(ptr+l) == 11);
// Инициализация списка теми же числами, что и массива:
list<int> listl(&a[0], &a[10]);
// Поиск в списке первого элемента, равного 7:
list<int>::iterator i = find(listl.begin(),
listl.endO ,7) ;
assert (*i == 7 && *(++i) == 11);
cout << "Введите некоторые символы, включая •x',\n"
<< "за которым следует как минимум один\п"
<< "непробельный символ: " << flush;
istream_iterator<char> in(cin);
istream_iterator<char> eos,-
find(in, eos, 'x');
cout << "Первый непробельный символ, следующий за\п"
<< "первым 'х1 - '" << *(++in) << "'." << endl;
}
return 0;
В случае итераторов массива и списка поддерживаются и другие операции, такие как
сохранение значений в позиции, указываемой итератором. Однако в случае итераторов istream
единственными поддерживаемыми операциями являются операции входных итераторов.
Более подробно входные итераторы рассматриваются в разделе 4.8.
4.2. Выходные итераторы
В предыдущем разделе мы видели, что входные итераторы могут использоваться для
чтения значений последовательности, но запись при помощи входных итераторов возможна не
всегда. Выходные итераторы обладают противоположной функциональностью: они
позволяют записывать значения в последовательность, но не гарантируют возможность их чтения.
То есть, если first — выходной итератор, то мы можем написать *f irst = ..., но не га-
78
Часть I. Вводный курс в STL
рантируется возможность применения *f irst в выражении для получения значения, на
которое указывает итератор. Еще одно отличие от требований для входных итераторов состоит
в отсутствии обязательной поддержки операторов == и ! = для выходных итераторов. Что
касается префиксного и постфиксного операторов ++, то здесь выходные итераторы идентичны
входным. Как и в случае входных итераторов, термин "выходные итераторы" сам по себе не
представляет никакой тип. Он может быть применен к любому типу, который удовлетворяет
соответствующим требованиям.
Рассмотрим, например, алгоритм STL copy, который выполняет копирование из одной
последовательности в другую:
template <typename Inputlterator, typename Outputlterator>
Outputlterator copy(InputIterator first,
Inputlterator last,
Outputlterator result)
{
while (first != last) {
*result = *first;
++first;
++result;
}
return result;
}
И опять, обычные указатели могут выступать в роли выходных итераторов для
встроенных массивов C++:
int а[100] , Ь[100] ;
// ... Код для сохранения значений в а[0], . . ., а[99]
сору(&а[0], &а[100], &Ь[0]);
Здесь выполняется копирование значений а [0], ..., а [99] в b [0], ..., b [99].
STL предоставляет специальные выходные операторы, которые называются
итераторами ostream, и используются для записи значений в выходной поток. Например, в
приведенном далее фрагменте исходного текста элементы списка выводятся в выходной поток cout:
list<int> listl;
// ... Код для вставки значений в listl
// Объявление объекта итератора ostream:
ostream_iterator<int> out(cout, "\n");
copy(listl.begin(), listl.end(), out);
Аргументами конструктора ostream_iterator являются объект выходного потока и
строка, которая записывается между значениями в выходном потоке; в нашем случае символ
новой строки обеспечивает вывод каждого значения в отдельной строке. Итераторы ostream
более детально будут рассмотрены в разделе 4.8.
Указатели на элементы массива, использованные в первом примере сору, позволяют
выполнять чтение из позиций, на которые они указывают, но итераторы ostream этого не
позволяют, так что мы не можем использовать их в качестве первых двух аргументов сору.
4.3. Однонаправленные итераторы
Мы уже видели, что входные итераторы могут использоваться для чтения значений
последовательности, а выходные — для их записи. Однонаправленный итератор (forward iterator) — это
итератор, который объединяет в себе и входной, и выходной итераторы, тем самым обеспечивая
возможность чтения и записи и обхода последовательности в одном направлении.
Однонаправленные итераторы обладают также свойством, которое не требуется ни для входных, ни для вы-
Глава 4. Итераторы
79
ходных итераторов: возможностью сохранить однонаправленный итератор и использовать
сохраненное значение для повторного прохода из того же положения. Это свойство позволяет
однонаправленным итераторам использоваться в многопроходных алгоритмах, в отличие от
однопроходных алгоритмов, таких как find и merge.
В качестве примера алгоритма, который выполняет и чтение, и запись
последовательности, рассмотрим алгоритм STL replace, который заменяет все значения х в диапазоне
[first; last) другим значением у:
template <typename Forwardlterator, typename T>
void replace(Forwardlterator first, Forwardlterator last,
const T& x, const T& y)
{
while (first != last) {
if (*first == x)
*first = y;
++first;
}
}
Этот алгоритм может использоваться для замены значений в различных структурах данных,
которые в состоянии предоставить однонаправленные итераторы для доступа к данным.
Встроенные указатели, использующиеся с массивами, удовлетворяют соответствующим
требованиям и могут использоваться с алгоритмом replace:
int a[100] ;
// ... Код для сохранения значений в а[0], . .., а[99]
// Замена всех элементов массива, равных 5, на 6:
replace(&а[0], &а[100], 5, 6);
Поскольку тип deque<T>: : iterator также удовлетворяет всем требованиям к
однонаправленным итераторам, этот алгоритм можно использовать и для замены элементов в деке:
deque<char> dequel;
// ... Код для вставки символов в dequel
// Замена всех 'е1 в dequel на 'о1:
replace(dequel.begin(), dequel.end(), 'e', 'o');
4.4. Двунаправленные итераторы
В последнем разделе мы видели, что однонаправленные итераторы позволяют нам читать
значения из структуры данных и записывать их в нее при проходе по структуре данных в
одном направлении. Двунаправленный итератор аналогичен однонаправленному итератору, за
исключением того, что он допускает обход в обоих направлениях. То есть, двунаправленные
итераторы должны поддерживать все операции однонаправленных итераторов, а кроме
них — операцию - -, делая возможным обход последовательности в обратном направлении.
Требуется наличие и префиксной, и постфиксной версий operator--; префиксная
версия выполняет декремент итератора и возвращает новое его значение, а постфиксная —
выполняет декремент итератора и возвращает его старое значение. И префиксный, и
постфиксный operator- - должны выполняться за константное время.
Возможность обхода структуры данных в обратном порядке важна потому, что в
противном случае некоторые алгоритмы не в состоянии эффективно работать. Например, алгоритм
STL reverse может использоваться для обращения порядка элементов в
последовательности при наличии двунаправленных итераторов. Например, встроенные типы указателей,
80
Часть I. Вводный курс в STL
использующиеся с массивами, удовлетворяют всем требованиям к двунаправленным
итераторам, так что мы можем написать
int a [100];
// ... Код для сохранения значений в а[0], . . . , а[99]
// Обращение порядка значений в массиве:
reverse(&а[0] , &а [100]);
Контейнер STL list также предоставляет двунаправленные итераторы, так что его тоже
можно использовать с алгоритмом reverse:
list<int> listl;
// ... Код для вставки значений в listl
// Обращение порядка значений в списке:
reverse(listl.begin(), listl.end());
Как можно ожидать, требование поддержки двунаправленных итераторов к классу list
приводит к тому, что представление списка должно быть двусвязным. В случае односвязного
списка эффективно реализовать operator- - (с константным временем работы) невозможно.
Таким образом, требования к двунаправленным итераторам позволяют гарантировать
эффективность работы таких алгоритмов, как reverse, которым требуется обход
последовательности в любом направлении.
4.5. Итераторы с произвольным доступом
В предыдущих разделах мы рассмотрели четыре категории итераторов, которые
позволяют нам выразить различные ограничения, которые разные алгоритмы накладывают на
структуры данных, чтобы эффективно с ними работать. Мы видели примеры алгоритмов,
требующие, чтобы структуры данных, с которыми они работают, могли как минимум быть:
• прочитаны и обойдены в одном направлении (иначе говоря, алгоритм принимает
входные итераторы);
• записаны и обойдены в одном направлении (иначе говоря, алгоритм принимает
выходные итераторы);
• прочитаны, записаны и обойдены в одном направлении с дополнительной
возможностью сохранения итератора и повторного сканирования с сохраненной позиции (иначе
говоря, алгоритм принимает однонаправленные итераторы);
• прочитаны, записаны и пройдены в любом направлении (иначе говоря, алгоритм
принимает двунаправленные итераторы).
Оказывается, этих четырех категорий структур данных недостаточно для всех алгоритмов.
Имеются некоторые алгоритмы, которые предъявляют к итераторам еще более высокие
требования. Для эффективной работы эти алгоритмы требуют, чтобы любой элемент
последовательности был достижим из любого другого за константное время.
Рассмотрим, например, обобщенный алгоритм STL binary_search. Будучи вызван как
binary_search(first, last, value)
где first и last ограничивают последовательность, хранящуюся в порядке возрастания,
алгоритм возвращает true, если в последовательности имеется позиция, в которой хранится
значение value, и false в противном случае. Это описание похоже на описание алгоритма
find, но binary_search использует факт упорядоченности последовательности для сокра-
Глава 4. Итераторы
81
щения времени работы с O(N) до O(logiV), где N— длина последовательности. Этого можно
достичь, сравнивая значение в средине последовательности с value и продолжая поиск в левой
половине, если значение в средине больше value, или в правой половине, если оно меньше. То
есть, при каждом сравнении пространство поиска сокращается вдвое, поэтому требуется
выполнить не более \og2N сравнений. Но чтобы общее время вычислений было OCiogN),
требуется, чтобы элемент в средине последовательности был достижим за константное время.
Ясно, что списки таким свойством не обладают. Имея указатели на начало и конец списка,
единственный способ добраться до элемента посредине — это обойти элементы один за
другим. Это займет время, пропорциональное длине списка.
С другой стороны, векторы и массивы позволяют обратиться к любому элементу
контейнера за константное время. Таким образом, алгоритм binary_search эффективно работает
с векторами и массивами:
vector<int> vectorl;
// ... Код для вставки значений в vectorl
// Сканирование vectorl в поисках значения 5; если оно
// найдено, возвращает true; в противном случае — false:
bool found = binary_search(vectorl.begin(),
vectorl.end(), 5);
Из этого примера видна необходимость еще одной категории итераторов — итераторов
с произвольным доступом.
Итераторы с произвольным доступом должны поддерживать все операции
двунаправленных итераторов, плюс следующие (здесь г и s — итераторы с произвольным доступом,
an — целочисленное выражение):
• прибавление и вычитание целых чисел, выражаемые r + п, п + гиг-п;
• доступ к n-му элементу при помощи выражения г [п], которое означает * (г + п);
• двунаправленные "большие переходы", выражаемые как г += пиг -= п;
• вычитание итераторов, выражаемое как г - s и дающее целочисленное значение;
• сравнения, выражаемые как г < s,r > s,r <= s и г >= sh дающие значения
типа bool.
От структур STL с произвольным доступом, таких как векторы и деки, требуется, чтобы
их итераторы удовлетворяли перечисленным требованиям, так что любая позиция в такой
структуре данных может быть достигнута за константное время.
4.6. Иерархия итераторов STL: эффективная
комбинация алгоритмов и контейнеров
Ключом к пониманию итераторов и их роли в STL является понимание того, почему
следует разбивать итераторы на категории входных/выходных, одно- и двунаправленных, а
также произвольного доступа. Эта классификация образует иерархию итераторов, т.е.:
• однонаправленные итераторы одновременно являются входными и выходными
итераторами;
• двунаправленные итераторы одновременно являются однонаправленными
итераторами, а следовательно, входными и выходными итераторами;
oz
Часть I. Вводный курс в STL
• итераторы с произвольным доступом являются двунаправленными итераторами, а
следовательно, и однонаправленными итераторами, и входными и выходными итераторами.
Эта иерархия приводит к следующему:
• алгоритмы, требующие для работы входные или выходные итераторы, могут также
работать с однонаправленными итераторами, двунаправленными итераторами и
итераторами с произвольным доступом;
• алгоритмы, требующие для работы однонаправленные итераторы, могут также
работать с двунаправленными итераторами и итераторами с произвольным доступом;
• алгоритмы, требующие для работы двунаправленные итераторы, могут также работать
с итераторами с произвольным доступом.
Таким образом, категории итераторов используются в спецификациях контейнеров и
алгоритмов следующим образом:
• описание классов контейнеров включает категорию предоставляемых ими итераторов;
• описание обобщенных алгоритмов включает категории итераторов, с которыми они
работают.
Вот несколько примеров.
• list предоставляет двунаправленные итераторы, а алгоритм find требует входные
итераторы; следовательно, find можно использовать с list.
• list предоставляет двунаправленные итераторы, а алгоритм sort требует итераторы
с произвольным доступом. Поскольку двунаправленные итераторы в общем случае не
обладают свойствами итераторов с произвольным доступом, алгоритм sort не может
использоваться с контейнерами list. Код наподобие
list<int> listl;
// ... Код для вставки значений в listl
sort(listl.begin(), listl.end());
компилироваться не будет.
• deque предоставляет итераторы с произвольным доступом, которые требует алгоритм
sort. Это означает, что sort будет работать с deque; более того, эта комбинация
будет работать эффективно.
• Итераторы set двунаправленные, а алгоритм merge требует входные итераторы или
более высокие. Поскольку двунаправленные итераторы в иерархии находятся выше
входных, понятно, что алгоритм merge может быть применен к контейнерам set.
Такая комбинация допустима и эффективна.
Иерархия итераторов подчеркивает фундаментальную идею в основе дизайна STL:
интерфейсы контейнеров и алгоритмов STL спроектированы так, чтобы поддерживать
эффективные комбинации и препятствовать неэффективным. Поддержка означает, что
эффективные комбинации компилируются без ошибок. Хотя компилируются и некоторые
неэффективные комбинации, в большинстве случаев они приводят к ошибкам компиляции и требуют
больших усилий, поскольку программист вынужден писать дополнительный код для
компенсации отсутствующих операторов.
Категории итераторов и вопросы эффективности рассматриваются дальше, в разделе 4.11.
Глава 4. Итераторы
83
4.7. Итераторы вставки
Итератор вставки переводит обобщенный алгоритм в "режим вставки", а не в "режим
перезаписи". Это означает, что присваивание *i = ... приводит не к перезаписи объекта
в позиции i, а к вставке его в эту позицию с применением функции-члена контейнера для
вставки. Итераторы вставки особенно полезны при пересылке последовательности данных из
входного потока или контейнера в другой контейнер, когда длина последовательности
заранее неизвестна. STL предоставляет три типа итераторов вставки, каждый из которых
параметризован типом Container:
• back_insert_iterator<Container> — использует функцию-член push back
класса Container;
• f ront_insert_iterator<Container> — использует функцию-член push_f ront
класса Container;
• insert_iterator<Container> — использует функцию-член insert класса
Container.
Такие вставки заставляют контейнер увеличивать выделенную память, в отличие от
присваиваний, при которых в контейнере должно быть зарезервировано достаточное количество
памяти. Например, следующий код некорректен, так как в vector 1, куда выполняется
копирование, недостаточно места для хранения данных:
vector<int> vectorl; // vectorl пуст
deque<int> dequel(200/ 1); // В dequel хранится 200 единиц.
copy(dequel.begin(), dequel.end(),
vectorl.begin()); // ОШИБКА!
В процессе копирования возникает ошибка времени выполнения в инструкции
*(vectorl.begin()) = *(dequel.begin())
Однако при использовании в качестве третьего аргумента итератора вставки алгоритм сору
работает корректно, поскольку функция push_back вектора vectorl выполняет при
необходимости перераспределение памяти:
copy(dequel.begin(), dequel.end(),
back_insert_iterator< vector<int> >(vectorl));
Здесь back_insert_iterator<vector<int> > (vectorl) вызывает конструктор
шаблона класса
template <typename Container>
class back_insert_iterator;
инстанцированный с vector<int> в качестве типа Container. Чтобы было удобнее
использовать итератор вставки, STL определяет шаблон обобщенной функции back_inserter.
template <typename Container>
inline
back_insert_iterator<Container> // Возвращаемый тип
back_inserter(Container& x) {
return back_insert_iterator<Container>(x);
}
Таким образом, вызов copy можно записать более кратко:
copy(dequel.begin(), dequel.end(), back_inserter(vectorl));
Компилятор автоматически инстанцирует функцию back_inserter с параметром типа
Container, равным vector<int>. Инстанцированный экземпляр функции back_inserter
вернет нам back_insert_iterator<Container>.
84
Часть I. Вводный курс в STL
Итератор back_insert_iterator, а значит, и функция back_inserter, могут
использоваться с контейнерами vector, list и deque, поскольку все они имеют функцию-
член pushback. Этот итератор вставки принимает любой контейнер С1, имеющий
функцию-член push_back, и создает итератор с определенными в нем операторами * и = таким
образом, что код
*i = х;
при выполнении делает вызов
Cl.push_back(x);
Кроме того, итератор i, по сути, всегда указывает на конец связанного с ним контейнера,
а операции ++ini++He выполняют никаких действий.
Аналогично, front_insert_iterator и связанный с ним шаблон функции
f rontinserter осуществляют вставку в начало контейнера. Они могут использоваться
с контейнерами list и deque, поскольку эти контейнеры имеют функцию-член push_f ront:
int array1[100];
deque<int> dequel;
// Присваивание значений arrayl[0] , ..., arrayl[99]:
copy(&arrayl[0], fcarrayl[100], front_inserter(dequel));
Элементы arrayl будут находиться в начале dequel (в порядке, обратном порядку этих
элементов в arrayl).
Контейнер vector функции-члена push_f ront не имеет, поскольку такая операция
имела бы линейное время работы (то же относится и к функции popf ront, как вы увидите
при рассмотрении адаптера очереди в разделе 9.2). Таким образом, f ront_inserter
не может работать с контейнером vector.
Наиболее общим итератором вставки является insert_iterator, который имеет
соответствующий шаблон функции inserter и обеспечивает вставку в любое место текущей
последовательности элементов контейнера, указываемое аргументом-итератором.
В этом случае элементы arrayl будут вставлены после первого элемента dequel и
будут находиться в том же порядке, что и в arrayl (т.е. после каждой вставки к итератору
будет применяться операция инкремента ++, так что он будет перемещаться в позицию за
только что вставленным элементом).
Итератор insert_iterator и функция inserter используют функцию-член
контейнера insert (iterator, value). Поскольку такая функция имеется у всех типов
контейнеров STL, inserter может применяться к контейнеру любого типа (включая отсортированные
ассоциативные контейнеры).
Другие примеры использования итераторов вставки вы встретите в следующем разделе
и в главах 5, "Обобщенные алгоритмы", и 12, "Программа для поиска в словаре".
4.8. Еще раз о входе и выходе: потоковые
итераторы
Сейчас мы немного детальнее рассмотрим категории входных и выходных итераторов. Важной
причиной включения этих категорий в STL является возможность указания алгоритмов, которые
могут использоваться с итераторами, связанными с потоками ввода-вывода. Такие итераторы
предоставляются классами STL istream_iterator (для ввода) и ostream_iterator (для
вывода). Итераторы, создаваемые istream_iterator, являются входными, но не выходными
итераторами. Это означает, что объекты istream_iterator могут читать данные только в
одном направлении и что запись данных при помощи этого объекта итератора невозможна.
Глава 4. Итераторы
85
Конструктор istream_iterator (istream&) типа istream_iterator<T> создает
входной итератор для значений типа Т из данного входного потока (такого, как стандартный
поток ввода с in в приведенном далее примере).
Конструктор istream_iterator<T> () генерирует входной итератор, который
работает в качестве маркера конца для итераторов istream. Это просто значение, которому
итераторы istream становятся равны, когда связанный с ними входной поток сообщает о достижении
конца потока.
С итераторами istream могут использоваться такие алгоритмы, как merge, поскольку им
требуется единственный проход по данным, и только их чтение, но не запись. Вот пример
такого использования:
vector<int> vectorl;
list<int> listl;
// ... Код вставки значений в vectorl
merge(vectorl.begin(), vectorl.end(),
istream_iterator<int>(cin),
istream_iterator<int>(),
back_inserter(listl));
Здесь выполняется слияние целых чисел из vectorl с числами из стандартного потока
ввода cin и размещение получающейся последовательности в listl при помощи итератора
вставки, построенного с помощью вызова back_inserter.
Итераторы istream из предыдущего примера могут быть использованы и в качестве первой
пары итераторов алгоритма merge:
merge(istream_iterator<int>(cin), istream_iterator<int>(),
vectorl.begin(), vectorl.end(),
back_inserter(listl));
но мы не можем использовать итератор istream в качестве последнего аргумента, поскольку
merge требуется возможность записи новых значений посредством этого итератора, что,
конечно же, невозможно сделать посредством итератора istream_iterator.
Итераторы, созданные с применением вызова ostream_iterator, представляют собой
выходные итераторы, не являющиеся входными. Такой алгоритм, как merge, может
использовать такие итераторы, но только в качестве последнего аргумента:
vector<int> vectorl;
list<int> listl;
// ... Код для вставки значений в vectorl
// ... Код для вставки значений в listl
merge(vectorl.begin(), vectorl.end(),
listl.begin(), listl.end(),
ostream_iterator<int>(cout, " "));
В этом примере выполняется слияние целых чисел из вектора vectorl с целыми
числами из списка listl, и передача получившейся в результате последовательности в
стандартный поток вывода cout, со вставкой пробелов между значениями при выводе (для этого
служит второй аргумент конструктора ostream_iterator).
Итератор ostream нельзя использовать в качестве ни одного из первых четырех аргументов
merge, так как алгоритму merge требуется возможность читать данные посредством
разыменования этих итераторов, a ostream_iterator такой функциональности не предоставляет.
ьь
Часть I. Вводный курс в SIL
4.9. Спецификация категорий итераторов,
требуемых алгоритмами STL
Давайте подробнее рассмотрим, как из спецификаций интерфейсов алгоритмов STL
определить, какие итераторы могут использоваться конкретным алгоритмом. В главе 22,
"Справочное руководство по обобщенным алгоритмам", приведен следующий интерфейс
алгоритма merge:
template <typename Inputlteratorl,
typename InputIterator2,
typename Outputlterator>
Outputlterator merge(Inputlteratorl firstl,
Inputlteratorl lastl,
InputIterator2 first2/
InputIterator2 last2,
Outputlterator result);
В главе 22, "Справочное руководство по обобщенным алгоритмам", используются
следующие соглашения.
• Имена параметров шаблона класса, заканчивающиеся на Iterator или Iterators,
для некоторого целого N означают, что параметры этого типа должны быть итераторами.
• Первая часть имени используется для описания категории, которой должен
принадлежать итератор.
Приведенное выше описание интерфейса гласит, что алгоритм merge требует, чтобы два
первых его параметра были входными итераторами одного типа, третий и четвертый
параметры также должны быть входными итераторами одинакового типа (который может быть
отличен от типа первых двух параметров); а последний параметр алгоритма должен быть
выходным итератором.
Только из приведенной спецификации, без знания, что именно делает алгоритм merge
и как он реализован, мы можем заключить, что все приведенные выше примеры корректны,
включая примеры с использованием объектов istream_iterator и ostream_iterator.
Алгоритм find имеет следующий интерфейс:
template <typename InputIterator, typename T>
Inputlterator find(InputIterator first,
Inputlterator last,
const T& value);
Таким образом, алгоритм find требует, чтобы его первые два аргумента были входными
итераторами, как и возвращаемое алгоритмом значение. Это означает, что find работает
почти со всеми итераторами — входными, одно- и двунаправленными, а также
произвольного доступа. Исключение составляют только выходные итераторы.
Спецификация еще одного алгоритма, search, указывает, что он более ограничивающий,
чем алгоритм find. Алгоритм search ищет подпоследовательность в другой
последовательности; он обобщает алгоритмы поиска подстрок наподобие strstr:
template<typename Forwardlteratorl, typename ForwardIterator2>
Forwardlteratorl search(Forwardlteratorl firstl,
Forwardlteratorl lastl,
ForwardIterator2 first2,
ForwardIterator2 last2);
Эта спецификация гласит, что аргументами должны быть однонаправленные итераторы, но
почему они не могут быть входными итераторами? Причина в том, что алгоритм search
многопроходный: он сохраняет итераторы и использует их для повторного сканирования,
поэтому он не будет работать, если попробовать применить его с istream_iterator.
Глава 4. Итераторы
Ы
4.10. Разработка обобщенных алгоритмов
Теперь, когда мы понимаем, как спецификация интерфейса говорит нам о том, какие
итераторы могут быть использованы, нам не требуется знать реализации алгоритмов. Однако
давайте углубим наше понимание категорий итераторов, рассмотрев "начинку" одного
алгоритма и изучив некоторые из проектных решений, диктуемых целью достичь максимальной
обобщенности при сохранении эффективности. Ниже в очередной раз приведено определение
обобщенного алгоритма STL find:
template <typename Inputlterator, typename T>
Inputlterator find(Inputlterator first,
Inputlterator last,
const T& value) {
while (first != last && *first != value)
++first;
return first;
}
Мы видим, что такая реализация будет работать с любым входным итератором.
• Она применяет к итераторам-параметрам только лишь операции ! =, * и ++.
• Она не пытается присваивать значения объектам с применением разыменования *.
• Это однопроходный алгоритм.
Такая реализация find делает алгоритм максимально обобщенным, но это не так при
других возможных реализациях. Предположим, что мы сделаем одно маленькое изменение,
воспользовавшись < вместо ! = для сравнения итераторов:
while (first < last && *first != value)
++first;
Если мы воспользуемся таким модифицированным алгоритмом f indl, то увидим, что
алгоритм будет работать для многих контейнеров, таких как обычные массивы, векторы и деки.
Но если попытаться использовать его со списками, например
list<int> listl;
// ... Код для вставки значений в in listl
list<int>::iterator
where = findl(listl.begin(),listl.end(),7);
то у нас ничего не получится, потому что новая реализация алгоритма пытается вычислить
выражение
listl .beginO < listl. end ()
но оператор < для итераторов list не определен (так как оператор < был бы очень
неэффективным, как вы вскоре убедитесь). Это приводит к ошибке времени компиляции.
Поскольку наличие оператора < гарантируется только для итераторов с произвольным
доступом, интерфейс алгоритма f indl должен иметь следующий вид:
template <typename RandomAccessIterator, typename T>
RandomAccessIterator findl(RandomAccessIterator first,
RandomAccessIterator last,
const T& value);
Одним из ключевых достижений при проектировании STL является то, что множество
алгоритмов наподобие find может быть закодировано с минимальными требованиями к обраще-
8 Сообщение об ошибке будет иметь вид наподобие "не могу найти list<int>::itera-
tor: :operator<(list<int>: :iterator) ".
оо
часть I. Вводный курс в STL
нию к данным, что делает их максимально обобщенным. Все реализации наподобие f indl,
которые предъявляют излишне строгие требования, были тщательно пересмотрены, а их
требования снижены до совершенно необходимых, как в случае find, так что в STL остались
алгоритмы с минимально возможными допущениями (и тем самым— с максимально
возможной обобщенностью).
4.11. Почему некоторые алгоритмы требуют
более мощные итераторы
Некоторые алгоритмы в библиотеке требуют от итераторов большего, чем минимальные
возможности входных, выходных или однонаправленных итераторов. Такие алгоритмы
требуют от передаваемых им итераторов принадлежности к категории двунаправленных
итераторов или итераторов с произвольным доступом; в противном случае они просто не
компилируются. Например, алгоритм sort имеет следующий интерфейс:
template <typename RandomAccessIterator>
void sort(RandomAccessIterator first,
RandomAccessIterator last);
означающий, что sort требует передачи двух итераторов, принадлежащих категории
итераторов с произвольным доступом. Именно их он и получает, когда мы пишем
vector<int> vectorl;
// ... Код для вставки значений в vectorl
sort(vectorl.begin(), vectorl.end());
Как и в случае "не совсем обобщенной" реализации f indl, мы получим проблемы, пытаясь
применить алгоритм sort к контейнеру list:
list<int> listl;
// ... Код для вставки значений в listl
sort(listl.begin(), listl.end()); // Неверно
Поскольку listl .begin() и listl.end() всего лишь двунаправленные итераторы,
они не предоставляют всю необходимую функциональность, используемую реализацией
sort, такую как оператор +=, так что такой код компилироваться не будет.
Почему бы не расширить итераторы list и подобные до другой категории, добавив им
операции +=, < и прочие, которыми обладают итераторы с произвольным доступом? Похоже,
это бы упростило задачу написания обобщенных алгоритмов, так как нам бы не пришлось
столько беспокоиться о том, какие операции могут быть применены к итераторам. И вновь
причина в эффективности. В случае списков нет никакой возможности вычислить выражение
наподобие listl.begin () + п за константное время; есть только очевидный способ
прохода по узлам списка один за другим, требующий время, пропорциональное п (т.е. имеющий
линейное время работы). Поэтому даже если мы запрограммируем метод и назовем его +, то
все равно не достигнем истинного произвольного доступа. Такие алгоритмы, как sort, будут
работать существенно медленнее, чем алгоритмы, использующие возможности списков
(такой, как алгоритм, использующийся классом list в функции-члене sort).
Глава 4. Итераторы
89
4.12. Выбор правильного алгоритма
Одно из последних замечаний о совместимости алгоритм/контейнер: хотя схема
классификации итераторов STL способствует созданию эффективных комбинаций и препятствует
неэффективным, она не в состоянии полностью исключить комбинации, неэффективные
в некоторых случаях. То есть можно применить тот или иной алгоритм к контейнеру, но
делать это — неразумно.
Пожалуй, наиболее простым примером является алгоритм find в комбинации с
контейнерами с произвольным доступом, такими как массивы, векторы и деки. Как мы уже видели,
find просто проходит по объектам последовательности один за другим, так что это
алгоритм с линейным временем работы (т.е. время, необходимое алгоритму find для поиска
значения в контейнере размера N пропорционально N). Если объекты последовательности не
упорядочены каким-либо образом, такой поиск может быть лучшим. Однако если объекты
в контейнере с произвольным доступом находятся в отсортированном виде, то другой
алгоритм STL, binary_search, выполнит ту же работу гораздо эффективнее (за
логарифмическое время, т.е. время работы алгоритма пропорционально логарифму размера контейнера).
Немного более "хитрый" случай представляет собой поиск в ассоциативном контейнере.
Здесь также может быть применен обобщенный алгоритм find, поскольку ассоциативные
контейнеры предоставляют двунаправленные итераторы, но внутренняя организация
ассоциативных контейнеров STL обеспечивает возможность поиска за логарифмическое время.
Поэтому все они предоставляют функцию-член (с тем же именем find, но принимающую
один аргумент — искомое значение), которая выполняет такой эффективный поиск. Так что
для больших ассоциативных контейнеров неэффективно использовать обобщенный алгоритм
find для всего диапазона позиций контейнера:
set<int> setl;
// ... Код для вставки значений в setl
set<int>::iterator where;
where = find(setl.begin(), setl.end О * 7);
Этот способ работает, но время его работы — линейное. Гораздо эффективнее написать
следующее выражение, выполняющееся за логарифмическое время:
where = setl.find(7);
4.13. Константные и изменяемые итераторы
Имеется еще одно дополнительное различие, применимое к однонаправленным
итераторам, двунаправленным итераторам и итераторам с произвольным доступом,— они могут
быть изменяемыми (mutable) или константными (constant) в зависимости от того, является
результат operator* ссылкой или константной ссылкой.
Все типы контейнеров STL определяют не только идентификатор iterator, но и
const_iterator. Например, vector<T>: : iterator— это изменяемый итератор
с произвольным доступом, a vector<T>: :const_iterator— соответствующий
константный итератор с произвольным доступом.
Когда результат применения operator* к итератору i представляет собой ссылку,
можно выполнить присваивание * i = .... Такое присваивание, однако, невозможно в случае
ссылки константной (как в случае, когда итератор в действительности является константным
итератором). Компилятор воспринимает такие попытки присваивания как ошибки.
90
Часть I. Вводный курс в STL
Прочие применения разыменования, которые могут привести к изменению объекта, на
который ссылается *i, такие как передача *i в функцию вместо параметра, являющегося
неконстантной ссылкой (Т&, а не const T&), также не разрешаются.
В большинстве случаев можно использовать тип iterator контейнера при объявлении
итераторных переменных:
vector<int> vectorl;
// ... Код для вставки значений в vectorl
vector<int>::iterator i = vectorl.begin(); // OK
Это вполне корректно, так как функция-член begin возвращает iterator при
применении к изменяемому контейнеру (т.е. к контейнеру, не объявленному как константный). В
действительности можно записать и следующее:
vector<int>::const_iterator j = vectorl.begin(); // OK
поскольку имеется преобразование iterator в const_iterator.
Однако если у нас имеется константный контейнер, то с ним мы должны использовать
константные итераторы:
// Инициализация vector2 100 нулями:
const vector<int> vector2(100/ 0);
vector<int>::iterator i = vector2.begin(); // Неверно
Вместо этого следует использовать объявление
vector<int>::const_iterator i = vector2.begin();
В первом случае применение iterator некорректно, так как функция-член begin
возвращает const_iterator при применении к контейнеру, объявленному как const.
Преобразования от const_iterator к iterator нет, так что попытка инициализировать
переменную i значением const_iterator, возвращаемым begin, приводит при компиляции
к сообщению об ошибке.
Зачастую мы не хотим непосредственно объявлять контейнер константным, поскольку
обычно требуется выполнять вставку или удаление элементов после его создания. Но всякий
раз, когда мы передаем контейнер в функцию посредством параметра, являющегося
константной ссылкой, контейнер рассматривается как объявленный константным:
template <typename T>
void print(const vector<T>& v)
{
for (vector<T> : : const_iterator i = v.beginO;
i != v.end(); ++i)
cout << *i << endl;
}
Попытка использовать vector<T>: : iterator в этом примере приведет при компиляции
к сообщению об ошибке, так же как и попытка воспользоваться функциями-членами
контейнера insert или erase.
Если у нас есть функция с параметром-итератором, то этот параметр должен быть по
возможности объявлен как const_iterator:
template <typename T>
void foo(list<T>::const_iterator i,
deque<T>& d, deque<T>::iterator j)
if (*i > *j++)
*j = *i++;
d.insert(j, *i);
Глава 4. Итераторы
91
Здесь * используется только для чтения значения, на которое указывает i, но не для
присваивания посредством этого итератора, так что объявление i как const_iterator вполне
допустимо. Он может быть объявлен и как iterator, но тогда соответствующий
фактический параметр должен принимать только значения типа iterator. С другой стороны,
переменная j должна быть объявлено как iterator, поскольку с помощью этого итератора
выполняется присваивание, и он используется как параметр функции insert.
Заметим, что в этом примере и с i, и с j выполняется операция инкремента ++. Часть
"const" в const_iterator не означает, что сам итератор не может изменяться—
запрещается только изменение значения, на которое указывает итератор.
4.14. Категории итераторов, предоставляемые
контейнерами STL
В табл. 4.1 показаны категории каждого типа итераторов, которые предоставляют
контейнеры STL. Обратите внимание, что для set и multiset как iterator, так и const_ite-
rator представляют собой константные двунаправленные итераторы — т.е. фактически это
один и тот же тип. Причина этого в том, что единственный разрешенный метод изменения
ключа— это его удаление (при помощи функции-члена erase), а затем вставка другого ключа
(посредством функции-члена insert). Если бы итераторы множеств и мультимножеств были
неконстантными, то было бы можно модифицировать ключи без участия функций-членов
erase и insert, и такое изменение могло бы привести к нарушению свойства размещения
элементов в отсортированном порядке. Приведенный ниже пример иллюстрирует сказанное:
#include <set>
set<int> s;
s.insert(3);
s.insert(5);
s.insert(7);
set<int> :: iterator i = s.beginO;
*i = 4; // Неверно
Эта программа не будет компилироваться, поскольку i представляет собой константный
итератор, а элементы не могут быть изменены посредством константного итератора. Вместо
этого мы должны записать
s.erase(i);
s.insert(4);
Аналогичное ограничение действует и для отображений и мультиотображений. Объект
типа тар<Кеу/ Т> хранит значения типа pair<const Key, T>. Ключ данной пары не
может быть модифицирован непосредственно, но можно модифицировать значение типа Т.
Эта идея иллюстрируется приведенным ниже примером:
#include <map>
typedef multimap<int, double> multimap_l;
multimap_l m;
m.insert(pair<const int, double>(3, 4.1));
multimap_l:: iterator i = m.beginO;
*i = pair<const int, double>(3/ 5.1); // Неверно
Это неверный метод изменения значений, и компилироваться такой код не будет.
Корректный метод состоит в удалении значения, на которое указывает i, и вставке новой пары:
92
Часть I. Вводный курс в STL
m.erase(i);
m.insert(pair<const int, double>(3/ 5.1));
Можно также записать
i->second = 5.1;
поскольку значения, связанные с ключами, могут быть изменены с помощью неконстантного
итератора. Такой метод предпочтительнее, поскольку он эффективнее, чем era sen insert.
Однако он не будет работать, если объявить i как multimap_l: :const_iterator,
поскольку константные итераторы не допускают изменения значений, на которые они указывают.
Таблица 4.1. Категории итераторов, предоставляемые контейнерами STL
Контейнер
Итератор
Категория итератора
Т а[п]
Т а[п]
vector<T>
vector<T>
deque<T>
deque<T>
list<T>
list<T>
set<T>
set<T>
multiset<T>
multiset<T>
map<Key,T>
map<Key,T>
multimap<Key,T>
multimap<Key,T>
T*
const T*
vector<T>::iterator
vector<T>::const_iterator
deque<T>::iterator
deque<T>::const_iterator
list<T>::iterator
list<T>::const_iterator
set<T>::iterator
set<T>::const_iterator
multiset<T>::iterator
multiset<T>::const_iterator
map<Key,T>::iterator
map<Key,T>::const_iterator
multimap<Key,T>::iterator
multimap<Key,T>::const_iterator
Изменяемый
доступом
Константный
доступом
Изменяемый
доступом
Константный
доступом
Изменяемый
доступом
Константный
доступом
Изменяемый
Константный
Константный
Константный
Константный
Константный
Изменяемый
Константный
Изменяемый
Константный
с произвольным
с произвольным
с произвольным
с произвольным
с произвольным
с произвольным
двунаправленный
двунаправленный
двунаправленный
двунаправленный
двунаправленный
двунаправленный
двунаправленный
двунаправленный
двунаправленный
двунаправленный
Глава 5
Обобщенные алгоритмы
STL предоставляет программистам богатый набор алгоритмов, работающих со
структурами данных, определенными в рамках схемы STL. Как мы видели в разделе 2.2, алгоритмы
STL являются обобщенными: каждый алгоритм может работать не с одной, а с
разнообразными структурами данных.
Обобщенные алгоритмы STL разделяются на четыре большие категории в соответствии
с их семантикой. Неизменяющие алгоритмы над последовательностями работают с
контейнерами без модификации их содержимого, в то время как изменяющие алгоритмы над
последовательностями обычно модифицируют содержимое контейнеров, с которыми они имеют
дело. Связанные с сортировкой алгоритмы включают алгоритмы сортировки и слияния,
алгоритмы бинарного поиска и операции над множествами, работающие с упорядоченными
последовательностями. Наконец, имеется небольшой набор обобщенных числовых алгоритмов.
Из предыдущей главы вы узнали, как итераторы позволяют различным классам
алгоритмов работать с разнообразными структурами данных. В этой главе вы изучите разные
категории алгоритмов и познакомитесь с их использованием на конкретных примерах. Детальную
информацию по каждому алгоритму можно найти в главе 22, "Справочное руководство
по обобщенным алгоритмам".
5.1. Базовая организация алгоритмов в STL
Перед тем как детальнее познакомить вас с четырьмя основными категориями алгоритмов
STL, приведем краткий обзор различных вариаций, которые может иметь конкретный
алгоритм. Эти вариации включают версии, работающие без дополнительной памяти и
копирующие, а также версии, принимающие в качестве параметров предикаты.
5.1.1. Версии "на месте" и копирующие версии
Ряд алгоритмов STL имеет версию, работающую "на месте", и копирующую. Версия "на
месте " помещает результат в тот же контейнер, с которым работает.
Пример 5.1. Использование алгоритма сортировки "на месте"
"ех05-01.срр" 93 з
#include <iostream>
#include <algorithm>
#include <cassert>
using namespace std;
int main() {
94
Часть I. Вводный курс в STL
cout << "Использование алгоритма сортировки "
<< "\"на месте\"." << endl;
int a[1000];
int i ;
for (i = 0; i < 1000; ++i)
a[i] = 1000 - i - 1;
sort(&a[0] , &a[1000] ) ;
for (i = 0; i < 1000; + + i)
assert (a[i] == i) ;
cout << " Ok." << endl;
return 0;
}
Эта программа сортирует массив а и помещает отсортированную последовательность
обратно в а, т.е. массив заменяется отсортированной версией самого себя, поскольку
обобщенный алгоритм sort является алгоритмом, работающим "на месте".
Копирующая версия алгоритма копирует результат работы в другой контейнер или в
неперекрывающуюся часть того же контейнера, из которого берутся исходные данные.
Например, в приведенной далее программе алгоритм reverse_copy оставляет массив а
неизменным, помещая обращенную копию в массив Ь.
Пример 5.2. Использование reverse_copy, копирующей версии
обобщенного алгоритма reverse
"ех05-02.срр" 94 в
#include <iostream>
#include <algorithm>
#include <cassert>
using namespace std;
int main() {
cout << "Использование reverse_copy, копирующей "
<< "версии обобщенного алгоритма reverse."
<< endl;
int a[1000] , b[1000] ;
int i ;
for (i = 0; i < 1000; ++i)
a[i] = i;
reverse_copy(&a[0], &a[1000], &b[0]);
for (i = 0; i < 1000; ++i)
assert (a[i] == i && b[i] == 1000 - i - 1);
cout << " Ok." << endl;
return 0;
Решение о том, включать ли копирующую версию алгоритма в STL, основано на
рассмотрении сложности алгоритмов. Например, алгоритма sort_copy в библиотеке нет, поскольку
стоимость сортировки существенно выше стоимости копирования, так что пользователи
могут просто воспользоваться алгоритмом сору, а после него— алгоритмом sort. С другой
стороны, reverse_copy включен в библиотеку, поскольку стоимость копирования с
последующим обращением примерно в два раза выше стоимости одной операции копирования
в обратном порядке.
Глава 5. Обобщенные алгоритмы
95
Если в STL имеется копирующая версия алгоритма algorithm, то она имеет имя
algorithm_copy. Например, копирующая версия алгоритма replace называется
replace_copy.
5.1.2. Алгоритмы с функциональными параметрами
Многие обобщенные алгоритмы STL имеют версии, которые принимают в качестве
параметров функции. В большинстве случаев эти функции являются предикатами (предикат
представляет собой функцию, которая возвращает значение типа bool). Например, все
алгоритмы, связанные с сортировкой, принимают бинарный предикат и используют его для
сравнения двух значений х и у для выяснения, является ли значение х меньше значения у при
некотором упорядочении. Используя в качестве этого параметра различные функции, мы
можем получить по разному упорядоченную результирующуюпоследовательность.9
Удобным способом получения функции для передачи обобщенному алгоритму является
использование функционального объекта в виде класса, вкратце рассматривавшегося в
разделе 2.4 и более детально — в главе 8, "Функциональные объекты". Такой функциональный
объект является формой представления функции, которая делает передачу функции особенно
эффективной, так как она выполняется во время компиляции. В приведенном далее примере
функциональный объект greater<int> (), созданный с использованием конструктора по
умолчанию шаблонного класса greater, передается в качестве бинарного предиката
обобщенному алгоритму sort для сортировки массива в убывающем порядке. Этот класс
функционального объекта определен в заголовочном файле STL functional. Массив
инициализируется с использованием обобщенного алгоритма STL random_shuffle, который
выполняет случайную перестановку элементов массива в произвольном порядке.
Пример 5.3. Использование обобщенного алгоритма sort с бинарным
предикатом
"ех05-03.срр" 95 =
#include <iostream>
#include <algorithm>
#include <cassert>
#include <functional>
using namespace std;
int main() {
cout << "Использование обобщенного алгоритма "
<< "sort с бинарным предикатом."
<< endl;
int a [1000] ;
int i;
for (i = 0; i < 1000; ++i)
a[i] = i;
random_shuffle(&a [0] , &a [1000]);
// Сортировка в возрастающем порядке:
sort(&a[0], &a[1000]);
for (i = 0; i < 1000; + + i)
assert (a [i] == i) ;
9 Функции, использующиеся для сравнения в алгоритмах, связанных с сортировкой, должны
подчиняться определенным правилам, рассматривающимся в разделе 5.4.
УО
Часть I. Вводный курс в STL
random_shuffle(&a[0] , &а [1000]);
// Сортировка в убывающем порядке:
sort(&a[0], &а[1000], greater<int>());
for (i = 0; i < 1000; ++i)
assert (a[i] == 1000 - i - 1) ;
cout << " Ok." << endl;
return 0;
}
Версия sort с двумя параметрами-итераторами выполняет сравнение значений с помощью
оператора <, определенного для типа значений. Версия с двумя параметрами-итераторами
и бинарным предикатом выполняет сравнение с использованием этого бинарного предиката.
Для алгоритма в обоих случаях используется одно и то же имя sort, поскольку эти версии
отличаются списками аргументов. Однако в некоторых случаях возникает неоднозначность,
которая не может быть разрешена, и тогда используются различные имена. Например, версия
find с предикатом называется find_if, чтобы не возникало неоднозначности при выборе
одного из двух интерфейсов:
template <typename InputIterator, typename T>
Inputlterator
find(InputIterator first, Inputlterator last,
const T& value);
template <typename Inputlterator, typename Predicate>
Inputlterator
find_if(Inputlterator first, Inputlterator last,
Predicate pred);
В примерах в этой главе мы рассматриваем либо версию алгоритма с предикатом, либо
без него, и только в некоторых случаях — обе. Версия с предикатом, имя которой
завершается на if, рассматривается в подразделе с базовым именем алгоритма; например, алгоритм
f ind_if рассматривается в разделе 5.2.1.
5.2. Неизменяющие алгоритмы над
последовательностями
Неизменяющие алгоритмы над последовательностями— это алгоритмы, которые
непосредственно не модифицируют контейнеры, с которыми работают. Они включают алгоритмы
для поиска элементов в последовательностях, проверки равенства и пересчета элементов
последовательности. Это алгоритмы find, adjacent_find, count, for_each, mismatch,
equal и search.
5.2.1. find
В разделе 2.2 мы встречались с несколькими примерами обобщенного алгоритма find.
Его версия с предикатом, f ind_if, выполняет сканирование последовательности в поисках
первого элемента, для которого данный предикат истинен.
Глава 5. Обобщенные алгоритмы
97
Пример 5.4. Иллюстрация применения обобщенного алгоритма findif
"ех05-04. срр" 97а =
#include <iostream>
#include <algorithm>
#include <cassert>
#include <vector>
using namespace std;
// Определение типа унарного предиката:
class GreaterThan50 {
public:
bool operator()(int x) const { return x > 50; }
};
int main()
{
cout << "Иллюстрация применения обобщенного "
<< "алгоритма find_if." << endl;
// Создание вектора со значениями
// 0, 1, 4, 9, 16, . . . , 144:
vector<int> vectorl;
for (int i = 0; i < 13; ++i)
vectorl.push_back(i * i);
vector<int>::iterator where;
where = find_if(vectorl.begin(), vectorl.end(),
GreaterThan50());
assert (*where == 64) ;
cout << " Ok." << endl;
return 0;
}
В этой программе мы определили тип объекта унарного предиката GreaterThan50
и передали объект, созданный его конструктором по умолчанию, алгоритму f ind_if.
(Вместо определения GreaterThanSO в качестве нового класса можно было скомпоновать
эквивалентный тип функционального объекта с использованием функциональных объектов
и функциональных адаптеров STL, как описано в главе 8, "Функциональные объекты".)
Временная сложность алгоритмов find и f ind_if — линейная.
5.2.2. adjacent_f ind
Алгоритм adj acent_f ind выполняет сканирование последовательности в поисках пары
смежных одинаковых элементов. Когда такая пара найдена, алгоритм возвращает итератор,
указывающий на первый элемент пары.
Пример 5.5. Иллюстрация применения обобщенного алгоритма
adj acentfind
"ех05-05.срр" 976 s
#include <iostream>
#include <string>
#include <algorithm>
#include <cassert>
#include <functional>
98
Часть I. Вводный курс в STL
#include <deque>
using namespace std;
int main()
{
cout << "Иллюстрация применения обобщенного "
<< "алгоритма adjacent_find." << endl;
deque<string> player(5);
deque<string>::iterator i;
// Инициализация дека:
player[0] = "Pele";
player[1] = "Platini";
player[2] = "Maradona";
player[3] = "Maradona";
player[4] = "Rossi";
// Поиск первой пары одинаковых последовательных имен:
i = adjacent_find(player.begin(), player.end());
assert (*i == "Maradona" && *(i+l) == "Maradona");
// Поиск первого имени, лексикографически большего,
// чем следующее за ним:
i = adjacent_find(player.begin О, player.end(),
greater<string>());
assert (*i == "Platini" && *(i+l) == "Maradona");
cout << " Ok." << endl;
return 0;
}
Сначала в программе используется непредикативная версия алгоритма adjacent_f ind,
которая использует для сравнения string: :operator==, так что она находит первую пару
равных элементов. Затем проводится еще один поиск, в этот раз при помощи предикативной
версии алгоритма adjacent_f ind и бинарного предиката greater<string> () для
выполнения сравнения. Таким образом, этот алгоритм находит первую пару строк в деке, такую,
что первая строка пары лексикографически больше второй.
Временная сложность алгоритма adj acent_f ind — линейная.
5.2.3. count
Алгоритм count представляет собой неизменяющий алгоритм, сканирующий
последовательность для подсчета количества элементов, равных определенному значению.
Пример 5.6. Демонстрация использования обобщенного алгоритма count
"ех05-06.срр" 98 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <functional>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма count." << endl;
int a[] = {0, 0, 0, 1, 1, 1, 2, 2, 2};
Глава 5. Обобщенные алгоритмы
99
// Подсчет количества единиц в массиве а:
int final_count = count(&a[0], &а[9], 1);
assert (final_count == 3) ;
// Определение количества элементов массива а, которые
// не равны 1:
final_count =
count_if(&a[0] , &а [9] ,
bind2nd(not_equal_to<int>(), 1));
// Имеется б таких элементов,
assert (final_count == 6) ;
cout << " Ok." << endl;
return 0;
}
Первый вызов count определяет количество элементов массива а, которые равны 1.
Второй— вызов алгоритма count_if, предикативной версии алгоритма, использующей
унарный предикат для выяснения количества элементов массива, не равных 1. Унарный
предикат строится путем передачи бинарного предиката not_equal_to<int>
функциональному адаптеру bind2nd вместе с аргументом 1:
bind2nd(not_equal_to<int>(), 1)
И not_equal_to, и bind2nd определены в заголовочном файле functional.
Обратите внимание, что путем простого изменения аргументов предиката мы легко
можем выполнить совершенно другую задачу. Например, чтобы найти все элементы массива,
которые больше 5, можно использовать предикат
bind2nd(greater<int>(), 5)
Временная сложность алгоритмов count и count_if — линейная.
5.2.4. f or_each
Обобщенный алгоритм f or_each применяет функцию f к каждому элементу
последовательности.
Пример 5.7. Демонстрация использования обобщенного алгоритма
foreach
"ех05-07.срр" 99 а
#include <iostream>
#include <cassert>
#include <algorithm>
#include <string>
#include <list>
#include <iostream>
using namespace std;
void print list(string s)
{
cout << s << endl;
}
int main()
{
cout << "Демонстрация использования обобщенного "
100
Часть I. Вводный курс в STL
<< "алгоритма for_each." << endl;
list<string> dlist;
dlist.insert(dlist.end(), "Clark");
dlist.insert(dlist.end(), "Rindt");
dlist.insert(dlist.end(), "Senna");
// Вывод каждого элемента списка:
for_each(dlist.begin(), dlist.end(), print_list);
return 0;
}
Вывод примера 5.7
Clark
Rindt
Senna
В этом примере алгоритм f or_each используется для вывода всех элементов списка.
Функция print_list применяется к результату разыменования каждого итератора из диапазона
[dlist.begin () /dlist. end () ) .10 Результат, возвращаемый функцией, применяемой
алгоритмом f or_each к элементам контейнера, игнорируется.
Временная сложность алгоритма f or_each — линейная.
5.2.5. mismatch и equal
Алгоритмы mismatch и equal используются для сравнения двух диапазонов. Каждый
из них получает три параметра-итератора: f irstl, lastl и f irst2. Алгоритм equal
возвращает true, если элементы в соответствующих позициях firstl + /и first2 + /
равны для всех позиций firstl + i из диапазона [firstl; lastl), и false в противном
случае. Алгоритм mismatch возвращает пару итераторов (тип pair),11 firstl + i
nfirst2 + i, которые представляют собой первые позиции последовательностей, где
найдены неодинаковые элементы. Если неодинаковых элементов в соответствующих позициях
не обнаружено, возвращается пара итераторов lastl и first2 + (lastl - firstl).
Таким образом, запись
equal(firstl, lastl, first2)
эквивалентна записи
mismatch(firstl, lastl, first2).first == lastl
Пример 5.8. Демонстрация использования обобщенных алгоритмов equal
и mismatch
"ех05-08.срр" 100 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <string>
#include <list>
#include <deque>
Концепция диапазонов итераторов и соответствующая запись рассматриваются во введении
к главе 4, "Итераторы".
Шаблон класса pair рассматривался в разделе 1.3.1; он имеет два члена-данных, first
и second, типы которых могут быть отличны друг от друга
Глава 5. Обобщенные алгоритмы
101
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенных '
<< "алгоритмов equal и mismatch." << endl;
list<string> driver_list;
vector<string> vec;
deque<string> deq;
driver_list.insert(driver_list.end(), "Clark")
driver_list.insert(driver_list.end(), "Rindt")
driver_list.insert(driver_list.end(), "Senna")
vec.insert(vec.end(), "Clark")
vec.insert(vec.end(), "Rindt")
vec.insert(vec.end(), "Senna")
vec.insert(vec.end(), "Berger");
deq.insert(deq.end(), "Clark");
deq.insert(deq.end(), "Berger");
// Демонстрация того, что driver_list и первые три
// элемента vec одинаковы во всех соответствующих
// позициях:
assert (equal(driver_list.begin(),
driver_list.end() ,
vec.begin0 ) ) ;
// Демонстрация того, что deq и первые 2 элемента
// driver_list отличаются во всех соответствующих
// позициях:
assert (! equal (deq.begin () , deq.endO,
driver_list.begin()));
// Поиск соответствующих позиций deq и driver_list, в
// которых впервые встречаются несовпадающие элементы:
pair<deque<string>::iterator, list<string>::iterator>
pairl = mismatch (deq. begin () , deq.endO,
driver_list.begin());
if (pairl. first != deq.endO)
cout << "Первое несовпадение элементов "
<< "deq и driver_list:\n "
<< *(pairl.first) << " и "
<< *(pairl.second) << endl;
return 0;
Вывод примера 5.8
Первое несовпадение элементов deq и driver_list:
Berger and Rindt
В этом примере, хотя список driver_list полностью не совпадает с вектором vec,
первый вызов assert показывает, что алгоритм equal определяет, что driver_list
совпадает с первыми тремя элементами vec. Второй вызов assert показывает, что equal
возвращает false, поскольку deq и driver_list не совпадают во второй позиции. Вызов
102
Часть I. Вводный курс в STL
equal не содержит никакой информации о том, где именно имеется несовпадение, так что
в последней части примера показано, как можно использовать вызов алгоритма mismatch
и возвращаемое им значение для вывода несовпадающих элементов.
Заметим, что ни один из этих алгоритмов не может служить для полной проверки
равенства двух контейнеров, поскольку проверка равенства контейнеров в алгоритмах отсутствует.
Чтобы убедиться, что контейнеры cl и с 2 имеют одинаковое содержимое, можно записать
cl.sizeO == c2.size() &&
equal (cl. begin () , cl.endO, c2.begin())
Этот способ работает, даже если cl и с2 представляют собой контейнеры разных типов;
если это контейнеры одного типа, то можно просто записать
cl == с2
поскольку, как вы узнаете в разделе 6.1.6, оператор == определен для контейнеров одного
итого же типа именно так, как было показано во фрагменте с применением вызовов size
и equal.
Следует сделать еще одно замечание по поводу размеров диапазонов, передаваемых
алгоритмам equal и mismatch. Количество разыменуемых позиций, начиная с f irst2, должно
быть как минимум равно размеру диапазона [firstl ,-lastl) или должно наблюдаться
отличие между некоторой достижимой разыменуемой позицией и соответствующей позицией
в диапазоне [firstl;lastl). Если не выполняется ни одно из указанных условий,
результат работы алгоритмов equal и mismatch не определен. Например, было бы неверным
записать первый вызов equal в примере 5.8 как
equal (vec . begin () , vec.endO, driver_list .begin () )
поскольку конец списка driver_list достигается без выявления несовпадения.
Оба алгоритма имеют предикативные версии, в которых понятие эквивалентности
заменяется бинарным предикатом, передаваемым в качестве четвертого аргумента.
Временная сложность алгоритмов equal и mismatch — линейная.
5.2.6. search
Для двух данных диапазонов обобщенный алгоритм search находит первую позицию
в первом диапазоне, с которой вторая позиция входит в первую в качестве
подпоследовательности. Этот алгоритм обобщает функции поиска подстрок наподобие библиотечной функции
С strstr. Ее интерфейс имеет вид
template <typename Forwardlteratorl,
typename ForwardIterator2>
Forwardlteratorl
search(Forwardlteratorl firstl, Forwardlteratorl lastl,
ForwardIterator2 first2, ForwardIterator2 last2);
где указанные две последовательности определяются диапазонами [firstl;lastl)
и [first2;last2). Если второй диапазон входит в первый в качестве
подпоследовательности, возвращается начальная позиция первого его вхождения в [firstl;lastl); в
противном случае возвращается lastl.
Пример 5.9. Демонстрация обобщенного алгоритма search
"ех05-09.срр" 102 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
Глава 5. Обобщенные алгоритмы
103
#include <deque>
using namespace std;
int main()
{
cout << "Демонстрация обобщенного алгоритма search."
<< endl;
vector<int> vectorl(20);
deque<int> dequel(5);
// Инициализация вектора значениями 0, 1, . .., 19:
int i ;
for (i = 0; i < 20; ++i)
vectorl [i] = i;
// Инициализация дека значениями 5, 6, 7, 8, 9:
for (i = 0; i < 5; ++i)
dequel[i] = i + 5;
// Поиск первого вхождения содержимого dequel в
// качестве подпоследовательности в содержимое
// вектора:
vector<int>::iterator k =
search(vectorl.begin(), vectorl.end(),
dequel.begin(), dequel.end());
// Проверка того, что 5, 6, 7, 8, 9 находятся в
// vectorl начиная с позиции, на которую указывает
// итератор к:
for (i = 0; i < 5; + + i)
assert (*(k + i) == i + 5);
cout << " Ok." << endl;
return 0;
}
Вызов алгоритма search ищет первую позицию в векторе, где в качестве поддиапазона
содержатся элементы дека (5, 6, 7, 8, 9). Он возвращает итератор типа vector<int>: :
iterator, указывающий на элемент 5 вектора.
Алгоритм имеет также предикативную версию, в которую в качестве пятого аргумента
передается бинарный предикат, используемый в качестве средства проверки эквивалентности.
Временная сложность алгоритма search должна не превышать О(тп), где т — размер
первого диапазона, а п — размер второго диапазона. Это требование можно удовлетворить
простейшим алгоритмом, который начинает поиск второго диапазона с первой позиции
первого диапазона: если все элементы второго диапазона совпадают с элементами первого,
поиск успешен; в противном случае новый поиск начинается со второй позиции первого
диапазона, и т.д. до тех пор, пока либо будет найдено совпадение, либо будет достигнут конец
первого диапазона. В большинстве случаев время работы этого наивного алгоритма
оказывается существенно лучше 0(тп), составляя всего лишь 0{т + п). Время 0{т + п) в
действительности может быть наихудшим временем работы более сложного алгоритма, но когда
решался вопрос о требованиях к временной сложности алгоритма search, сочли, что для
большинства входных данных такой сложный алгоритм окажется медленнее наивного
алгоритма. Однако с последними достижениями в области алгоритмов стало возможным
реализовать алгоритм search со временем работы в наихудшем случае 0(т + п), и при этом
в среднем такой алгоритм оказывается быстрее наивного [13]. Так что было бы лучше, если
бы в будущих версиях стандарта C++ Standard для алгоритма search было указано время
7(/4
Часть I. Вводный курс в STL
работы 0(т + п) . (Другие ситуации, когда прогресс в области алгоритмов делает указанные
в стандарте временные границы устаревшими, рассмотрены в разделе 5.4.)
5.3. Изменяющие алгоритмы над
последовательностями
Изменяющие алгоритмы модифицируют содержимое контейнеров, с которыми работают.
Например, алгоритм unique удаляет все последовательные дублирующиеся элементы из
последовательности. Другие алгоритмы из этой категории копируют, заполнят, генерируют,
замещают и т.п. элементы последовательных контейнеров, с которыми работают.
5.3.1. сору и copy_backward
Обобщенные алгоритмы сору и copy_backward используются для копирования
элементов из одного диапазона в другой. Вызов
copy(firstl, lastl, first2)
копирует элементы из диапазона [firstl; lastl) в [first2;last2) и возвращает
итератор last2, где last2 == first2 + (lastl - firstl). Алгоритм работает в
прямом направлении, копируя исходные элементы в порядке firstl, firstl+1, ..., lastl-1,
так что целевой диапазон может перекрываться с исходным, если последний не содержит
first2. Так, например, сору может использоваться для сдвига диапазона на одну позицию
влево, но не вправо. Обратное верно для алгоритма copy_backward:
copy_backward(firstl, lastl, last2)
который копирует элементы из диапазона [firstl; lastl) в диапазон [first2;last2)
и возвращает f irst2, где f irst2 == last2 - (lastl - firstl). Он работает в
обратном направлении, копируя исходные элементы в порядке lastl-1, lastl-2, ...,
firstl. Таким образом, копирование выполняется корректно, если исходный диапазон не
содержит last2.
Например, для сдвига диапазона влево на одну позицию используется вызов
copy(firstl, lastl, firstl - 1)
который копирует firstl в firstl-1, firstl + 1 в firstl, ..., lastl-1 в lastl-2
и возвращает lastl-1. Для сдвига диапазона на одну позицию вправо используется вызов
copy_backward(firstl, lastl, lastl + 1)
который копирует lastl-1 в lastl, lastl-2 в lastl-1, ..., firstl в firstl + 1 и
возвращает firstl+1.
Пример 5.10. Демонстрация использования обобщенных алгоритмов сору
и copybackward
"ех05-10.сррм 104 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
#include <string>
#include <iostream>
using namespace std;
Глава 5. Обобщенные алгоритмы
105
int main()
{
cout << "Демонстрация использования обобщенных "
<< "алгоритмов сору и copy_backward." << endl;
string s("abcdefghihklmnopqrstuvwxyz");
vector<char> vectorl(s.begin(), s.end());
vector<char> vector2(vectorl.size());
// Копирование vectorl в vector2:
copy(vectorl.begin(), vectorl.end(),
vector2.begin() ) ;
assert (vectorl == vector2);
// Сдвиг содержимого vectorl влево на 4 позиции:
copy(vectorl.begin() + 4, vectorl.end(),
vectorl.begin() ) ;
assert (string(vectorl.begin(), vectorl.end()) ==
string("efghihklmnopqrstuvwxyzwxyz"));
// Сдвиг его же вправо на 2 позиции:
copy_backward(vectorl.begin(), vectorl.end() - 2,
vectorl.end());
assert (string(vectorl.begin(), vectorl.end()) ==
string("efefghihklmnopqrstuvwxyzwx"));
cout << " Ok." << endl;
return 0;
}
Первый пример copy выполняет копирование содержимого vectorl Bvector2.
Второй пример иллюстрирует копирование перекрывающихся диапазонов, сдвигая содержимое
vectorl влево на четыре позиции. Обратите внимание, что после копирования первые
четыре символа, abed, оказываются потеряны, а последние четыре, wxyz, повторяются
в конце дважды.
Пример copy_backward выполняет сдвиг на две позиции вправо; такой сдвиг нельзя
выполнить при помощи алгоритма сору. В этом случае первые два символа, ef,
повторяются в начале строки, а последние два, yz, будут утеряны.
Временная сложность алгоритмов сору и copy_backward — линейная.
5.3.2. fill
Алгоритмы fill и fill_n помещают копии данного значения во все позиции
диапазона. Вызов
fill(first, last, value)
помещает last - first копий value в [first; last). Вызов
fill_n(first, n, value)
помещает п копий value в [first;first+n).
106
Часть I. Вводный курс в STL
Пример 5.11. Демонстрация использования обобщенных алгоритмов
fill и filln
"ех05-11.срр" 106a =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенных "
<< "алгоритмов fill и fill_n." << endl;
string s("Hello there");
vector<char> vectorl(s.begin(), s.end());
// Заполнение первых 5 позиций vectorl символами X:
fill(vectorl.begin(), vectorl.begin() + 5, 'X');
assert (string(vectorl.begin() , vectorl.end()) ==
string("XXXXX there"));
// Заполнение следующих З позиций символами Y:
fill_n(vectorl.begin() + 5, 3, 'Y');
assert (string(vectorl.begin(), vectorl.end()) ==
string("XXXXXYYYere" ) ) ;
cout << " Ok." << endl;
return 0;
Временная сложность алгоритмов fill и f ill_n — линейная.
5.3.3. generate
Алгоритм generate заполняет диапазон [first; last) значениями, которые
возвращают last - first последовательных вызовов функции gen (третий параметр алгоритма
generate). Предполагается, что gen не получает никаких аргументов.
Пример 5.12. Демонстрация использования обобщенного алгоритма
generate
"ех05-12.срр" 1066 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
template <typename T>
class calc_square {
T i;
public:
calc_square(): i(0) {}
T operator()() { ++i; return i * i; }
Глава 5. Обобщенные алгоритмы
107
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма generate." << endl;
vector<int> vectorl(10);
// Заполнение vectorl значениями
// 1, 4, 9, 16, . . . , 100:
generate(vectorl.begin(), vectorl.end(),
calc_square<int>());
for (int j = 0; j < 10; ++j )
assert (vectorl [j] == (j+1)*(j+1));
cout << " Ok." << endl;
return 0;
}
Вызов generate заполняет вектор vectorl значениями, возвращаемыми десятью
последовательными вызовами функционального объекта calc_square<int> (). Обратите
внимание, что эти вызовы представляют собой
calc_square<int>()()
поскольку вызываемая функция определена как operator () в классе calc_square<int>.
Хотя всякий раз вызов имеет один и тот же вид, он возвращает разные значения, потому что
данные-член i увеличивается при каждом вызове. Функциональные объекты, используемые
с алгоритмом generate, обычно определяются так, что при вызове изменяются некоторые
данные-члены, от которых зависит возвращаемое значение; таким образом,
последовательные вызовы возвращают разные значения.
Временная сложность алгоритма generate — линейная.
5.3.4. partition
Для данного диапазона [first /last) и унарного предиката pred обобщенный
алгоритм partition перегруппировывает элементы диапазона таким образом, чтобы все
элементы, удовлетворяющие предикату pred, находились перед элементами, не
удовлетворяющими ему. Имеется версия этого алгоритма с названием stable_partition, которая
гарантирует сохранение в каждой группе относительного порядка элементов. Каждый из этих
алгоритмов возвращает итератор, указывающий конец первой группы и начало второй.
Пример 5.13. Демонстрация использования обобщенных алгоритмов
partition и stable_partition
"ех05-13.срр" 107 в
#include <algorithm>
#include <vector>
#include <string>
#include <iostream>
#include <iterator>
using namespace std;
bool above40(int n) { return (n > 40); }
int main()
{
cout << "Демонстрация использования обобщенных "
108
Часть I. Вводный курс в STL
<< "алгоритмов partition и stable_partition."
< < endl;
const int N = 7;
int arrayO[N] = {50, 30, 10, 70, 60, 40, 20};
int arrayl[N];
copy(&array0[0] , &array0[N] , &arrayl[0]) ;
ostream_iterator<int> out(cout, " ");
cout << "Исходная последовательность : " ;
copy(&arrayl[0], &arrayl[N], out); cout << endl;
// Разбиение arrayl, при котором вначале размещаются
// элементы, большие 40, а за ними следуют элементы,
// меньшие или равные 40:
int* split = partition(&arrayl[0], &arrayl[N],
above4 0);
cout << "Результат (неустойчивого) разбиения: ";
copy(&arrayl[0], split, out); cout << "| ";
copy(split, &arrayl[N], out); cout << endl;
// Восстанавливаем в arrayl содержимое массива arrayO:
copy(&array0[0], &array0[N], fcarrayl[0]);
// Вновь выполняем разбиение arrayl, при котором
// вначале размещаются элементы, большие 40, а за ними
// следуют элементы, меньшие или равные 40, в этот раз
// с сохранением относительного порядка в каждой
// группе:
split = stable_partition(&arrayl[0], &arrayl[N],
above4 0);
cout << "Результат устойчивого разбиения: ";
copy(&arrayl[0] , split, out); cout << "| ";
copy(split, &arrayl [N] , out); cout << endl;
return 0;
Вывод примера 5.13
Исходная последовательность: 50 30 10 70 60 40 20
Результат (неустойчивого) разбиения: 50 60 70 | 10 30 40 20
Результат устойчивого разбиения: 50 70 60 | 30 10 40 20
В этой программе вызов partition разбивает значения в arrayl на две группы: в первой
находятся все значения, большие 40, а во второй — значения, не превышающие 40. Алгоритм
partition не гарантирует сохранение относительного порядка элементов в каждой группе,
что видно из вывода примера 5.13, где числа 70 и 60 поменялись местами. Точный порядок,
создаваемый алгоритмом partition, может изменяться в зависимости от конкретной
реализации STL. В случае же алгоритма stable_partition элементы в каждой группе в
результирующей последовательности находятся в том же порядке, что и в исходной
последовательности.
Временная сложность алгоритмов partition и stable_jpartition — линейная.
Глава 5. Обобщенные алгоритмы
109
5-3.5. randomshuf f le
Обобщенный алгоритм random_shuf f le случайным образом переставляет элементы из
диапазона [first; last), используя для этого функцию, генерирующую псевдослучайные
числа. Перестановки, получающиеся при применении алгоритма random_shuf f le, имеют
приблизительно равномерное распределение, т.е. вероятность каждой из N\ перестановок
диапазона размером N приблизительно равна \/N\.
Пример 5.14. Демонстрация использования обобщенного алгоритма
random_shuffle
»ех05-14.cpp" 109 =
#include <algorithm>
#include <vector>
#include <functional>
#include <iostream>
#include <iterator>
using namespace std;
int main() {
cout << "Демонстрация использования обобщенного "
<< "алгоритма random_shuffle." << endl;
const int N = 20;
vector<int> vectorl(N);
for (int i = 0; i < N; ++i)
vectorl [i] = i;
for (int j = 0; j < 3; ++j) {
// Случайное перемешивание целых чисел в vectorl:
random_shuffie(vectorl.begin(), vectorl.end());
// Вывод содержимого vectorl:
copy(vectorl.begin(), vectorl.end(),
ostream_iterator<int>(cout, " "));
cout << endl;
}
return 0;
}
Вывод примера 5.14
б 11 9 2 18 12 17 7 0 15 4 8 10 5 1 19 13 3 14 16
14 19 18 12 0 2 3 5 4 13 15 8 17 11 1 16 9 б 10 7
15 10 5 14 б 11 17 9 13 8 16 4 1 19 7 12 2 18 3 0
Порядок вывода, само собой разумеется, зависит от используемого конкретного генератора
псевдослучайных чисел.
Имеется также версия random_shuf f le, которая в качестве третьего аргумента
принимает функцию, так что с этим алгоритмом можно использовать собственный генератор
псевдослучайных чисел. Функция, передаваемая алгоритму random_shuf f le, должна получать
целочисленный аргументе и возвращать псевдослучайное число в диапазоне [0,N) .
Временная сложность алгоритма random_shuf f le — линейная.
110
Часть I. Вводный курс в STL
5.3.6. remove
Обобщенный алгоритм remove удаляет из диапазона те элементы, которые равны
определенному значению. Этот алгоритм устойчивый, т.е. он сохраняет относительный порядок
остающихся элементов последовательности.
Пример 5.15. Демонстрация использования обобщенного алгоритма remove
"ех05-15.срр" 110 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма remove." << endl;
const int N = 11;
int arrayl[N] = {l, 2, 0, 3, 4, 0, 5, 6, 7, 0, 8};
vector<int> vectorl;
int i ;
for (i = 0; i < N; ++i)
vectorl.push_back(arrayl[i]);
// Удаление всех нулей из vectorl:
vector<int>::iterator new_end;
new_end = remove(vectorl.begin(), vectorl.end(), 0);
// Размер vectorl остается неизменным:
assert (vectorl.size() == N);
// Ненулевые элементы остаются в диапазоне
// [vectorl.begin(), new_end). Удаление остальных
// элементов:
vectorl.erase(new_end, vectorl.end());
// Демонстрация того, что 3 элемента были удалены и
// что в контейнере остались ненулевые элементы в
// исходном порядке:
assert (vectorl.size() == N - 3);
for (i = 0; i < (int)vectorl.size(); ++i)
assert (vectorl [i] == i + 1);
cout << " Ok." << endl;
return 0;
}
Важно отметить, что алгоритм remove не изменяет размер контейнера, с которым работает.
Так, в приведенном примере vectorl содержит N элементов и после вызова remove, который
просто копирует элементы, не равные заданному значению, в меньший диапазон, и возвращает
конец этого меньшего диапазона. Элементы между новым маркером конца и концом вектора
находятся в неопределенном порядке. Используя новый маркер конца диапазона и функцию-
член erase класса vector, программа удаляет элементы от указанной точки до конца вектора.
Имеются копирующая и предикативная версии алгоритма remove. У всех версий
алгоритма временная сложность — линейная.
Глава 5. Обобщенные алгоритмы
111
5.3.7. replace
Обобщенный алгоритм replace заменяет элементы в диапазоне, равные некоторому
заданному значению, другим значением.
Пример 5.16. Демонстрация использования обобщенного алгоритма
replace
"ех05-16.срр" 111 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма replace." << endl;
string s("FERRARI");
vector<char> vectorl(s.begin(), s.end());
// Замена всех символов R символами S:
replace(vectorl.begin(), vectorl.end(), ' R', 'S');
assert (string(vectorl.begin(), vectorl.end()) ==
string("FESSASI"));
cout << " Ok." << endl;
return 0;
}
В этом примере все символы R заменяются символами S. Все прочие символы
последовательности остаются неизменными.
Имеются копирующая и предикативная версии replace. У всех версий алгоритма
временная сложность — линейная.
5.3.8. reverse
Обобщенный алгоритм reverse обращает порядок элементов диапазона. Итераторы,
определяющие диапазон, должны быть двунаправленными итераторами (см. примеры 2.1, 2.2
и 2.3). Временная сложность алгоритма reverse — линейная.
5.3.9. rotate
Обобщенный алгоритм rotate выполняет циклический сдвиг диапазона. Вызов
rotate(first, middle, last)
циклически сдвигает элементы в диапазоне [first; last) влево на middle - first
позиций. После вызова элементы, находившиеся в диапазоне [middle; last), появляются
в позициях [first /first + к), где к = last - middle, а элементы из диапазона
[first /middle) — в позициях [first + к; last). Аргументами алгоритма rotate
должны быть двунаправленные итераторы.
112
Часть I. Вводный курсе STL
Пример 5.17. Демонстрация использования обобщенного алгоритма rotate
"ех05-17.срр" 112а =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
int mainO
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма rotate." << endl;
string s("Software Engineering ");
vector<char> vectorl(s.begin(), s.end());
// Выполнение циклического сдвига вектора так, что
// слово "Engineering " оказывается первым:
rotate(vectorl.begin(), vectorl.begin() + 9,
vectorl.end());
assert (string(vectorl.begin() , vectorl.end()) ==
string("Engineering Software "));
cout << " Ok." << endl;
return 0;
}
Временная сложность алгоритма rotate — линейная.
5.3.10. swap
Обобщенный алгоритм swap обменивает два значения.
Пример 5.18. Демонстрация использования обобщенного алгоритма swap
"ех05-18.срр" 1126 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма swap." << endl;
int high = 250, low = 0;
swap(high, low);
assert (high == 0 && low == 250);
cout << " Ok." << endl;
vector<int> vectorl(100, 1), vector2(200, 2);
swap(vectorl, vector2);
assert (vectorl == vector<int>(200, 2) &&
Глава 5. Обобщенные алгоритмы
113
vector2 == vector<int>(100, 1));
return 0;
}
Временная сложность данной операции константная при применении ко встроенным
типам, и даже к парам контейнеров STL, как во втором вызове в примере. То есть обмен двух
векторов не выполняется через присваивания векторов, которые требовали бы O(N)
присваиваний типа int, где N— размер большего из двух векторов (200 в нашем случае).
Вместо этого, как рассказывается в разделе 6.1.7, vector имеет функцию-член swap, которая
может быть вызвана как vectorl. swap (vector2) и время работы которой —
константное, так как она выполняет обмен внутренних указателей представления vector. При вызове
swap (vectorl, vector2) библиотека на самом деле вызывает функцию-член swap
вектора, а не более обобщенную версию, выполняющую обмен через присваивания. Более
детально данный вопрос рассматривается в разделе 6.1.7.
5.3.11- swap_ranges
Обобщенный алгоритм swap_ranges обменивает два диапазона значений, которые
могут находиться в разных контейнерах. Вызов
swap_ranges(first1, lastl, first2)
обменивает содержимое [firstl; lastl) с содержимым [first2;first2 +N), где
N = lastl-firstl. Предполагается, что диапазоны не перекрываются.
Пример 5.19. Демонстрация использования обобщенного алгоритма
swapranges
мех05-19.сррм 113 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
#include <string>
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма swap_ranges." << endl;
vector<char> vectorl = make< vector<char> >("HELLO"),
vector2 = make< vector<char> >("THERE");
// Сохранение содержимого векторов vectorl и vector2
// для последующей проверки:
vector<char> tempi = vectorl, temp2 = vector2;
// Обмен содержимым векторов vectorl и vector2:
swap_ranges(vectorl.begin(), vectorl.end(),
vector2.begin());
assert (vectorl == temp2 && vector2 == tempi);
cout << " Ok." << endl;
return 0;
}
774
Часть I. Вводный курс в STL
Временная сложность алгоритма swapranges —линейная.
5.3.12. transform
Обобщенный алгоритм transform применяет функцию к каждому элементу диапазона
и сохраняет возвращаемые ею значения в другом диапазоне. Одна версия алгоритма
применяет к каждому элементу диапазона унарную функцию, в то время как другая применяет
бинарную функцию к соответствующим парам элементов из двух диапазонов. Бинарная версия
алгоритма transform демонстрируется в приведенном далее примере.
Пример 5.20. Демонстрация использования обобщенного алгоритма
transform
"ех05-20.срр" 114 =
#include <algorithm>
#include <iostream>
#include <iterator>
using namespace std;
int sum(int vail, int val2) { return val2 + vail; }
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма transform." << endl;
int arrayl[5] = {0, 1, 2, 3, 4};
int array2[5] = {6, 7, 8, 9, 10} ;
ostream_iterator<int> out(cout, " ");
// Помещает суммы соответствующих элементов массивов
// arrayl и array2 в выходной поток:
transform(&arrayl[0], &arrayl[5], &array2[0], out, sum);
cout << endl;
return 0;
}
Вывод примера 5.20
6 8 10 12 14
В этой программе алгоритм transform использован для получения сумм
соответствующих пар элементов из arrayl и аггау2. Получившаяся последовательность значений
помещается в стандартный поток вывода с применением итератора ostream.
Временная сложность алгоритма transform — линейная.
5.3.13. unique
Обобщенный алгоритм unique удаляет все последовательные дублирующиеся элементы
из входной последовательности. Элемент считается последовательным дублирующимся, если
он равен элементу, находящемуся непосредственно перед ним в последовательности, так что
удаляются все элементы групп одинаковых элементов, кроме первых. Как и в случае
алгоритма remove (см. раздел 5.3.6), алгоритм unique не изменяет размер контейнера, с кото-
Глава 5. Обобщенные алгоритмы
115
рым работает; он просто копирует элементы, не являющиеся последовательными
дублирующимися, в меньший диапазон и возвращает указатель на конец этого меньшего диапазона.
Пример 5.21. Демонстрация использования обобщенного алгоритма unique
»ех05-21.срр" 115 ш
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
#include <iostream>
#include <iterator>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма unique." << endl;
const int N = 11;
int arrayl[N] = {l, 2, 0, 3, 3, 0, 7, 1, 7, 0, 8};
vector<int> vectorl;
for (int i = 0; i < N; ++i)
vectorl.push_back(arrayl[i]);
// Удаление последовательных дублей из vectorl:
vector<int>::iterator new_end;
new_end = unique(vectorl.begin(), vectorl.end());
// Размер вектора vectorl остается неизменным
assert (vectorl.size() == N);
// Недублирующиеся элементы остаются в диапазоне
// [vectorl.begin(), new_end). Удаление остальных
// элементов до конца контейнера:
vectorl.erase(new_end, vectorl.end());
// Вывод содержимого вектора vectorl в стандартный
// выходной поток:
copy(vectorl.begin(), vectorl.end(),
ostream_iterator<int>(cout, " "));
cout << endl;
return 0;
Вывод примера 5.21
12030708
Ни один из нулей из контейнера не удален, поскольку последовательных нулей в контейнере
нет. Если вы хотите удалить все дубликаты, и вам не требуется сохранить порядок не
дублирующихся элементов, следует сначала отсортировать диапазон, после чего все дубликаты
окажутся в последовательных позициях, а затем применить алгоритм unique.
Временная сложность алгоритма unique — линейная.
116
Часть I. Вводный курс в STL
5.4. Алгоритмы, связанные с сортировкой
STL включает ряд алгоритмов, которые так или иначе связаны с сортировкой. Имеются
алгоритмы для сортировки и слияния последовательностей, а также для поиска и выполнения
теоретико-множественных операций с отсортированными последовательностями. В этом
разделе мы будем рассматривать все такие алгоритмы. Но перед этим нам нужна
определенная теоретическая подготовка.
5.4.1. Отношения сравнения
Существенной составной частью алгоритмов, связанных с сортировкой, является
сравнение элементов последовательностей. Каждый алгоритм имеет версию, которая использует
оператор <, а еще одна версия получает в качестве одного из параметров объект сравнения.
В этом разделе требования к объектам сравнения распространяются и на оператор <.
Объект сравнения должен представлять собой объект бинарного предиката, а бинарное
отношение, которое он определяет, должно подчиняться некоторым фундаментальным
законам, для того чтобы алгоритмы давали точно определенные результаты.
Начнем с рассмотрения множества требований, которое несколько строже, чем это в
действительности необходимо. Пусть 7Z — бинарное отношение на множестве S; тогда мы
говорим, что 1Z представляет собой строгое полное упорядочение на множестве S, если 11
подчиняется двум следующим правилам.
• Транзитивности: для всех х,у,х е S если xlZy и y1Zz, то xRz .
• Трихотомии: для всех x,yeS справедливо только одно из трех утверждений: xlZy,
уТЪс или х = у .
Отношения сравнения, являющиеся строгими полными упорядочениями, могут
использоваться в алгоритмах STL, связанных с сортировкой. Например, эти требования
удовлетворяются отношениями сравнения, определяемыми встроенными операторами C++ < или > над
встроенными числовыми типами. (Заметим, однако, что <= и >= не являются строгими
полными упорядочениями, поскольку нарушают правило трихотомии: одновременно могут
выполняться больше, чем одно из трех условий.) При определении объекта сравнения обычно
нетрудно получить строгое полное упорядочение, если просто определить его в терминах
некоторого ранее определенного оператора, подчиняющегося указанным правилам. STL
предоставляет два функциональных объекта less и greater (в заголовочном файле
functional) с шаблонным параметром типа Т, которые используют соответственно
операторы < и > для Т. Так, например,
sort(vectorl.begin(), vectorl.end(), less<int>());
выполняет сортировку vector< int > vectorl, как и
sort(vectorl.begin(), vectorl.end(), greater<int>());
Как вы увидите, при использовании less<int>() результатом является сортировка
в возрастающем порядке, а при использовании greater< int > () — в убывающем. В
качестве другого примера стандартный класс C++ string определяет оператор operator< для
строк как упорядочение по алфавиту, которое для строк является строгим полным
упорядочением. Таким образом,
sort(vector2.begin(), vector2.end(), less<string>());
выполняет сортировку vector<string> vector2 в возрастающем порядке (обычный
алфавитный порядок), а
sort(vector2.begin(), vector2.end(), greater<string>());
Глава 5. Обобщенные алгоритмы
117
сортирует этот вектор в убывающем порядке (обратный алфавитный порядок).
Строгое полное упорядочение полностью определяет порядок, в котором элементы могут
находиться в последовательности (отсюда и "полное" в названии), но иногда нас не
интересует порядок некоторых элементов. Например, если у нас имеется
struct Person {
string last_name;
string first_name;
};
то может потребоваться выполнить сортировку только в соответствии с фамилией (last name),
без учета порядка, в котором должны располагаться однофамильцы. Это можно сделать при
помощи определения
class LastNameLess {
public:
bool operator()(const Persons p, const Persons q) const
{
return p.last_name < q.last_name;
}
};
и сортировать, скажем, deque<Person> deque 1 при помощи
sort(dequel.begin(), deque1.end(), LastNameLess());
Тот факт, что такое определение работает, не следует из рассмотренного материала,
поскольку отношение 1Z, определяемое LastNameLess (), не является строгим полным
упорядочением. Оно не в состоянии указать порядок в некоторых парах (однофамильцев). То
есть, для некоторых различных объектов р и q типа Person оказываются неверными
и p7£q, и qRp . Фактически эти объекты рассматриваются как эквивалентные, хотя они не
идентичны. Необходимость такого рода сортировки достаточно распространена, так что
алгоритмы STL, связанные с сортировкой, спроектированы таким образом, чтобы они могли
работать с более слабыми отношениями, чем строгое полное упорядочение.
Действительные требования, предъявляемые библиотекой, являются требованиями к тому,
что именуется строгим неполным упорядочением ([18], с. 33), где "неполный" означает тот
факт, что требования недостаточно сильны для определения порядка всех элементов. Любые два
элемента, относительный порядок которых не определен, рассматриваются как эквивалентные.
Точный способ определения строгого неполного упорядочения дается в разделе 22.26.
Упорядочение, определенное объектом LastNameLess (), является строгим неполным упорядочением,
как и, например, любое упорядочение структур с несколькими членами, у которых одно поле
сравнивается с применением строгого полного упорядочения, а остальные поля игнорируются.
Еще одним распространенным примером является сравнение строк без учета регистра (когда
строки, отличающиеся только регистром букв, считаются одинаковыми).
Как уже упоминалось, объекты сравнения, определенные в терминах операторов
наподобие встроенных операторов <= и >=, не удовлетворяют требованиям строгого полного
упорядочения. Они не удовлетворяют и требованиям строгого неполного упорядочения, а значит,
не могут использоваться в алгоритмах STL, связанных с сортировкой. В действительности
при попытке сделать это, например, так:
sort(first, last, less_equal<int>()); // Неверно
вычисления могут даже зациклиться.
Еще одна важная вещь, о которой следует упомянуть, — это то, что алгоритмы, связанные
с сортировкой, не используют оператор ==. В описании результатов работы алгоритмов мы,
тем не менее, часто говорим об "эквивалентности" элементов, но здесь смысл
эквивалентности не связан со смыслом оператора ==. В данной ситуации, если сотр — оператор
сравнения, то эквивалентность equiv определяется следующим образом:
770
Часть I. Вводный курс в STL
equiv(jc,>>) тогда и только тогда, когда ложны и comp(jc,>>), и comp(>>,;t) .
Примером может служить способ описания устойчивости алгоритма сортировки. Обычно
алгоритм сортировки называется устойчивым, если он сохраняет относительный порядок
одинаковых элементов. Мы расширим это определение, подразумевая сохранение порядка
элементов, эквивалентных в только что определенном смысле.
5.4.2. Неубывающее и невозрастающее упорядочения
Алгоритмы сортировки и слияния STL размещают результаты работы в неубывающем
порядке в соответствии с заданным отношением сравнения 71. Это означает, что для каждого
итератора /, ссылающегося на элемент последовательности х, и любого неотрицательного
целого числа N, такого, что i + N ссылается на элемент последовательности у, отношение
уКх ложно.
Предположим, что нас интересует обратный порядок— невозрастающий порядок —
в соответствии с отношением 1Z. Для этого нам надо обратное к 1Z отношение. В общем
случае, если 1Z — бинарное отношение на S, его обращением является отношение С на S,
определенное как " хСу тогда и только тогда, когда ylZx ". Таким образом, обратное
отношение для оператора < для встроенных типов данных является отношением, вычисляемым
оператором >. Если для пользовательских типов данных определен оператор <, то определение
шаблона функции STL (в заголовочном файле utility) обеспечивает определение
оператора > как отношения, обратного к <:
template <typename T>
inline bool operator>(const T& x, const T& y) {
return у < x;
}
(Имеются аналогичные определения <= и >= через <; так что единственный оператор, который
достаточно определить,— это <. Как уже упоминалось, эти отношения не могут
использоваться в алгоритмах STL, связанных с сортировкой, но могут оказаться полезными для других
целей.)
Объект предиката STL greatег<Т> () инкапсулирует оператор > для типа Т в
функциональном объекте, который может быть передан алгоритму сортировки. Таким образом,
например, мы можем сортировать диапазон [first; last) целых чисел в невозрастающем
порядке при помощи вызова
sort(first, last, greater<int>());
Предположим, что вместо < в качестве отношения "меньше, чем" для некоторого
пользовательского типа данных U мы используем объект сравнения сотр. То есть, предположим, что
мы определили
class comp {
public:
bool operator()(const U& x, const U& y) const
{ // ...
b '
Тогда можно явно закодировать обратное отношение как
class comp_converse {
public:
bool operator()(const U& x, const U& y) const
return comp()(y, x);
Глава 5. Обобщенные алгоритмы
119
}
};
и выполнить сортировку в невозрастающем порядке при помощи
sort(first, last, comp_converse());
Мы будем периодически использовать термин возрастающий как синоним термина
"неубывающий", а убывающий — в качестве синонима термина "невозрастающий".
5.4.3. sort, stable_sort и partial_sort
STL предоставляет три обобщенных алгоритма сортировки,— sort, partial sort
и stable_sort. Каждый сортирует последовательность с произвольным доступом и
размещает результат в том же контейнере, с которым работает. Алгоритм partial_sort
требует константного количества дополнительной памяти, sort — логарифмического. Они оба
по сути являются алгоритмами, работающими "на месте", в то время как алгоритм
stable_sort может потребовать линейного количества дополнительной памяти. Все три
алгоритма демонстрируются в приведенном ниже примере 5.22.
Эти алгоритмы сортировки отличаются временем работы и устойчивостью. Алгоритм sort
сортирует последовательность длиной N при помощи 0(N\ogN) сравнений в среднем, но
в худшем случае время его работы — O^N2). Гарантированное поведение 0(N\ogN)
обеспечивает частный случай алгоритма partial_sort. Эти алгоритмы не являются
устойчивыми; т.е. относительные положения эквивалентных элементов не обязательно сохраняются.
Если требуется устойчивость сортировки, можно использовать алгоритм stable__sort,
время работы которого равно 0(N\ogN), если только имеется достаточно памяти (если ее
мало, время работы может немного увеличиться, о чем будет вскоре рассказано).
Читатели, знакомые с алгоритмами сортировки, вероятно, уже догадались, что алгоритм
sort планируется реализовать при помощи некоторой версии алгоритма быстрой
сортировки (quicksort), partial_sort— используя пирамидальную сортировку (heapsort),
a stable_sort — при помощи версии сортировки слиянием (mergesort). В простых
ситуациях, таких как сортировка векторов целых чисел или чисел с плавающей точкой, быстрая
сортировка обычно работает в два-три раза быстрее пирамидальной, но для некоторых видов
последовательностей ее время может вырасти до квадратичного и стать существенно
большим времени работы пирамидальной сортировки. Спецификация алгоритма sort была
написана именно таким образом, чтобы его можно было реализовать при помощи быстрой сортировки,
так что этот обычно очень быстрый алгоритм оказывается у программиста под рукой.
Поэтому стандарт специально оговаривает O^NlogN) как среднее время работы алгоритма sort,
добавляя затем предупреждение "если поведение в наихудшем случае оказывается
существенным, следует использовать алгоритм stable_sort или partial_sort".
Этот совет может оставить программиста в определенной растерянности при выборе
алгоритма сортировки, но, возможно, в будущих версиях стандарта эта дилемма будет
полностью устранена. Один из нас— Дэйв Мюссер— разработал новый алгоритм сортировки,
introsort [12], который для большинства последовательностей оказывается таким же
быстрым, как и алгоритм быстрой сортировки, и при этом имеет время работы в худшем случае
0(N\ogN). Этот алгоритм достигает данной цели путем применения обычной стратегии
разбиения, используемой быстрой сортировкой, но эта стратегия изменяется, если становится
неприемлемой (т.е. если встречается много "плохих разбиений" — источник ухудшения
времени работы быстрой сортировки до квадратичного). В таком случае происходит
переключение на алгоритм пирамидальной сортировки. Поскольку плохие разбиения редки, introsort
7ZC/
Часть I. Вводный курс в STL
почти всегда ведет себя как простой алгоритм быстрой сортировки, а в редких
исключениях — существенно лучше. Таким образом, алгоритм sort можно реализовать со временем
работы 0(NlogN) в наихудшем случае, поскольку при реализации библиотеки можно
применить алгоритм introsort, не теряя при этом преимущества скорости работы быстрой
сортировки. Фактически некоторые реализации STL уже используют (или планируют
использование) в алгоритме sort алгоритма интроспективной сортировки.
Наихудшее время работы алгоритма stable_sort равно o(N(\ogN)2). Эта граница
может быть достигнута при помощи алгоритма, основанного на принципе сортировки
слиянием, с применением еще одной важной технологии — адаптации к ограничениям памяти.
Если имеется память для как минимум N = 2 элементов, временная граница равна
0(N\ogN). В некоторых случаях stable_sort может быть даже быстрее, чем sort. Как
следует из его имени, главное достоинство данного алгоритма — его устойчивость, т.е.
сохранение относительного расположения одинаковых элементов. Это свойство зачастую
оказывается важным, когда элементы имеют несколько полей, по которым выполняется
сортировка. Пусть, например, у элемента имеются поле имени и поле города. При сортировке
сначала по городам, а затем по именам при помощи устойчивого алгоритма каждый набор
записей с одним и тем же именем будет отсортирован в соответствии с полем города. Как
уже говорилось, ни sort, ни partial_sort не обладают свойством устойчивости. В
примере 5.22 показано различие результатов работы устойчивой и неустойчивой сортировок.
Иногда требуется только частичная сортировка; например, может потребоваться знать
только 100 первых результатов из 20000. Вызов алгоритма partial_sort
partial_sort(first, middle, last)
помещает в диапазон [first/middle) k = middle - first наименьших элементов
диапазона [first/last) без полной сортировки всего диапазона. Элементы в диапазоне
[middle /last) остаются в неопределенном порядке. Так, если все результаты находятся
в векторе vector< float > scores, то вызов
partial_sort(scores.begin(), scores.begin() + 100,
scores.end(), greater<float>())
приводит к тому, что в диапазоне [scores . begin () / scores .begin () +100)
содержатся 100 наибольших результатов в убывающем порядке.
Время вычисления partial_sort составляет O^NXogk), где N = last-first,
ak = middle-first.
Как следует из спецификации алгоритма,
partial_sort(first, last, last)
сортирует весь диапазон [first /last). Этот частный случай представляет собой обычный
алгоритм пирамидальной сортировки со временем работы O(NlogN).
Приведенная далее программа иллюстрирует применение всех трех алгоритмов к вектору
целых чисел и применение объекта сравнения comp_last (), который сравнивает два целых числа
на основе их последних цифр в десятичном представлении. Так, например, comp_last () (13,6)
истинно, так как 3 < б, но и comp_last О (13,3),и comp_last () (3,13) ложны, так
что 3 и 13 рассматриваются как эквивалентные. При применении sort, 3 и 13 могут
оказаться не в том же относительном порядке в последовательности, в котором они были до
сортировки, но stablesort оставляет эту и прочие группы эквивалентных элементов в их
исходном относительном порядке.
Глава 5. Обобщенные алгоритмы
121
Пример 5.22. Демонстрация использования обобщенных алгоритмов sort,
stablesort и partialsort
"ех05-22.срр" 121 =
#include <vector>
#include <algorithm>
#include <iostream>
#include <iterator>
using namespace std;
class comp_last {
public:
bool operator()(int x, int y) const
// Сравнение х и у на основе их последних цифр в
// десятичном представлении:
{
return x%10<y%10;
}
};
int main()
{
cout << "Демонстрация использования обобщенных "
<< "алгоритмов sort, stable_sort и partial_sort."
<< endl;
const int N = 20;
vector<int> vectorO;
for (int i = 0; i < N; ++i)
vector0.push_back(i);
vector<int> vectorl = vectorO;
ostream_iterator<int> out(cout, " ");
cout << "До сортировки:\n";
copy(vectorl.begin(), vectorl.end(), out);
cout << endl;
sort(vectorl.begin(), vectorl.end(), comp_last() ) ;
cout << "После сортировки sort:\n";
copy(vectorl.begin(), vectorl.end(), out);
cout << endl << endl;
vectorl = vectorO;
cout << "До сортировки:\n";
copy(vectorl.begin(), vectorl.end(), out);
cout << endl;
stable_sort(vectorl.begin(), vectorl.end(),
comp_last());
cout << "После сортировки stable_sort:\n";
copy(vectorl.begin(), vectorl.end(), out);
cout << endl << endl;
vectorl = vectorO;
reverse(vectorl.begin(), vectorl.end());
cout << "До сортировки:\n";
copy(vectorl.begin(), vectorl.end(), out);
122
Часть I. Вводный курс в STL
cout << endl << endl;
partial_sort(vectorl.begin(), vectorl.begin() + 5,
vectorl.end(), comp_last());
cout << "После сортировки partial_sort — пять зна-\п"
<< "чений с минимальными последними цифрами:\п";
copy(vectorl.begin(), vectorl.end(), out);
cout << endl << endl;
return 0;
Вывод примера 5.22
До сортировки:
О 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
После сортировки sort:
10 0 11 1 12 2 13 3 4 14 5 15 6 16 7 17 8 18 9 19
До сортировки:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
После сортировки stable_sort:
0 10 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19
До сортировки:
19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
После сортировки partial_sort — пять
значений с минимальными последними цифрами:
10 0 11 1 12 19 18 17 16 15 9 8 7 6 5 4 14 13 3 2
5.4.4. nth_element
Обобщенный алгоритм nth_element помещает в N-ю позицию последовательности
элемент, который мог бы быть в этой позиции, если бы последовательность была
отсортирована. Алгоритм, кроме того, разбивает последовательность таким образом, что все элементы
слева от N~ro меньше или равны элементам справа от N-ro.
Пример 5.23. Демонстрация использования обобщенного алгоритма
nth_element
мех05-23.срр" 122 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма nth_element." << endl;
vector<int> v(7);
v[0] = 25; v[l] = 7; v[2] = 9;
v[3] = 2; v[4] = 0; v[5] = 5; v[6] = 21;
const int N = 4;
Глава 5. Обобщенные алгоритмы
123
// Используем nth_element для размещения N-ro по
// величине элемента v в N-ую позицию v.beginO + N:
nth_element (v. begin () , v.beginO + N, v.endO);
// Проверка того, что элемент в v.beginO + N, v[N],
// больше или равен каждому из предыдущих элементов:
int i ;
for (i = 0; i < N; ++i)
assert (v[N] >= v[i]);
// Проверка того, что элемент в v.beginO + N, v[N],
// меньше или равен каждому из последующих элементов:
for (i = N + 1; i < 7; + + i)
assert (v[N] <= v[i]);
cout << " Ok." << endl;
return 0;
}
В этом примере вызов nth_element помещает в позицию v.beginO + N элемент,
который находился бы там после полной сортировки вектора. Этот элемент, v [N], является
N-м по величине элементом, если считать элементы, начиная с нулевого, или (N + 1)-м,
если счет начинается с 1. То, что элемент v [N] является N-м по величине, проверяется при
помощи вызовов assert, которые демонстрируют, что элементы разбиты таким образом, что
все v [0],..., v [N] не превышают v [N + l],...,v[6].
Среднее время вычисления nth_element — линейное, но в наихудшем случае оно
может быть квадратичным. Однако и в наихудшем случае можно добиться линейного времени
работы, если реализовать nth_element с использованием алгоритма introselect, описанного
в [12]. Introselect, как и introsort, переключает используемый базовый алгоритм при наличии
большого количества плохих разбиений, обеспечивая в наихудшем случае линейное время
работы. Таким образом, следует ожидать, что в будущих версиях стандарта C++ время
работы алгоритма nth_element в наихудшем случае должно быть указано как линейное.
5.4.5. binary-search, lower_bound, upper_bound
и equal_range
Обобщенный алгоритм binary_search использует традиционный бинарный поиск для
нахождения элемента в отсортированной последовательности. Для данного отсортированного
диапазона [first; last) и элемента х обобщенный алгоритм binary_search
возвращает true, если в диапазоне имеется элемент, эквивалентный х, и false в противном случае.
Для тех же входных данных алгоритмы lower_bound и upper_bound возвращают
итератор i, указывающий соответственно на первую и последнюю позицию, в которую может
быть вставлено значение так, чтобы порядок сортировки сохранялся. (Заметим, что такая
спецификация определяет позицию в диапазоне независимо от того, имеется ли в нем
элемент, равный х, или нет.) Алгоритм equal_range возвращает пару итераторов, которая
вычисляется алгоритмами lower_bound и upper_bound.
В случае контейнеров с произвольным доступом функция binary_search выполняет не
более \ogN + 2 сравнений, 1 ower_bound и upper_bound—не более logN + 1 сравнений,
a equal_range — не более 21og7V + l сравнений. Заметим, что в контейнерах с
произвольным доступом можно выполнять поиск и при помощи обобщенного алгоритма find,
описанного в разделе 2.2. Этому алгоритму требуется линейное время для определения наличия
элемента в последовательности, независимо от того, отсортирована она или нет. Преимуще-
7Z4
Часть I. Вводный курс в STL
ство алгоритма find над алгоритмом бинарного поиска в том, что find может работать
с неотсортированными последовательностями. Кроме того, поскольку find требует всего
лишь входных итераторов, он может применяться для поиска элементов в таких структурах
данных, как входные потоки, одно- и двусвязные списки и т.д., с которыми алгоритм
бинарного поиска не в состоянии справиться.
Следует заметить, что хотя алгоритмы бинарного поиска достигают максимальной
эффективности (выполняют поиск за логарифмическое время) только для отсортированных
последовательностей с произвольным доступом, эти алгоритмы написаны таким образом, чтобы
работать и с другими контейнерами, такими как списки. Для всех структур данных, не
обладающих произвольным доступом, время работы бинарного поиска линейное, но количество
сравнений остается логарифмическим. В случаях, когда сравнение представляет собой
дорогостоящую операцию, может оказаться выгоднее (на некоторый постоянный множитель)
использовать бинарный поиск, а не алгоритм find.
Работа алгоритмов бинарного поиска проиллюстрирована в следующем примере.
Пример 5.24. Демонстрация использования обобщенных алгоритмов
бинарного поиска
"ех05-24.срр" 124 ■
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенных "
<< "алгоритмов бинарного поиска." << endl;
vector<int> v(5);
bool found;
// Инициализация:
int i ;
for (i = 0; i < 5; ++i) v[i] = i;
// Поиск каждого из целых чисел 0, 1, 2, 3, 4:
for (i = 0; i < 5; ++i) {
found = binary_search(v. begin () , v.endO, i) ;
assert (found == true);
}
// Попытка поиска отсутствующего значения:
found = binary_search (v.beginO, v.endO, 9) ;
assert (found == false);
v[l] = 7; v[2] = 7; v[3] = 7; v[4] = 8;
// Вектор v теперь содержит 0 7 7 7 8
// Применяем к вектору v алгоритмы upper_bound,
// lower_bound и equal_range:
vector<int>::iterator k;
k = lower_bound(v.begin() , v.endO, 7) ;
assert (k == v.begin() + 1 && *k == 7);
k = upper_bound(v. begin () , v.endO, 7);
Глава 5. Обобщенные алгоритмы
125
assert (к == v.end О - 1 && *к == 8);
pair<vector<int>::iterator, vector<int>::iterator> pi
= equal_range(v.begin(), v.end(), 7);
assert (pi.first == v.beginO + 1) ;
assert (pi.second == v.end() - 1);
cout << " Ok." << endl;
return 0;
5.4.6. merge
Обобщенный алгоритм merge выполняет слияние двух отсортированных диапазонов
и помещает результат в диапазон, не перекрывающийся с двумя входными. Алгоритм
inplace_merge выполняет слияние двух последовательных отсортированных диапазонов и
заменяет эти диапазоны получающейся в результате отсортированной последовательностью.
Временная сложность алгоритма merge — линейная. Временная же сложность
алгоритма inplace_merge зависит от количества доступной дополнительной памяти. Если
дополнительной доступной памяти нет, алгоритм может потребовать 0(NlogN) времени; в
противном случае время его работы линейное.
Пример 5.25. Демонстрация использования обобщенных алгоритмов
слияния
"ех05-25.срр" 125 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенных "
<< "алгоритмов слияния." << endl;
// Инициализация векторов целых чисел:
vector<int> vectorl(5);
vector<int> vector2(5);
vector<int> vector3(10);
int i ;
for (i = 0; i < 5; ++i)
vectorl [i] = 2 * i;
for (i = 0; i < 5; ++i)
vector2 [i] = 1 + 2 * i;
// Слияние содержимого vectorl и vector2,
// с помещением результата в vector3:
merge(vectorl.begin(), vectorl.end(),
vector2.begin(), vector2.end(),
vector3.begin());
for (i = 0; i < 10; ++i)
assert (vector3[i] == i);
for (i = 0; i < 5; ++i)
126
Часть I. Вводный курс в STL
vector3 [i] = vectorl [i] ;
for (i = 0; i < 5; ++i)
vector3 [i + 5] = vector2[i] ;
// Слияние двух отсортированных половин вектора
// vector3 на месте, для получения отсортированного
// вектора vector3:
inplace_merge(vector3.begin(), vector3.begin() + 5,
vector3.end());
for (i = 0; i < 10; ++i)
assert (vector3 [i] == i);
cout << " Ok." << endl;
return 0;
}
5.4.7. Теоретико-множественные операции над
отсортированными структурами
STL предоставляет пять алгоритмов, которые выполняют над отсортированными
последовательностями операции над множествами: includes, set_union, set_intersect ion,
set_dif f erence и set_symmetric_dif f erence.
Алгоритм includes проверяет, содержатся ли элементы диапазона [f irstl; lastl)
в другом диапазоне [f irst2 ; last2), и возвращает соответствующее значение типа bool.
Для двух данных диапазонов [firstl;lastl) и [first2;last2), представляющих
множества, алгоритм set_union генерирует объединение этих двух множеств в диапазоне
[result/last) и возвращает last— позицию за концом результирующей
последовательности.
Обобщенный алгоритм set_dif f erence создает множество элементов, которые есть
в первом диапазоне, но отсутствуют во втором; алгоритм set_intersection создает
множество из элементов, общих для обеих входных последовательностей; наконец, алгоритм
set_symmetric_dif f erence создает множество элементов, которые имеются в одном,
но не в обоих входных последовательностях. Подобно set_union, все эти функции
помещают результирующую последовательность в диапазон [result;last) и возвращают
last — позицию за концом результирующей последовательности.
У всех этих операций над множествами линейная временная сложность. Каждый
алгоритм выполняет не более 2(Nl+N2)-\ сравнений, где Nt =lastl-firstl, a
N2 =last2-first2.
Пример 5.26. Демонстрация использования обобщенных операций
над множествами
"ех05-26.срр" 126 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
Глава 5. Обобщенные алгоритмы
127
cout << "Демонстрация использования обобщенных "
<< "операций над множествами." << endl;
bool result;
vector<char> vectorl = make< vector<char> >("abcde")/
vector2 = make< vector<char> >("aeiou");
// Демонстрация includes:
result = includes(vectorl.begin(), vectorl.end(),
vector2.begin(), vector2.end());
assert (result == false);
result = includes(vectorl.begin(), vectorl.end(),
vector2.begin(), vector2.begin()+2);
// 'а' и 'е' содержатся в vectorl
assert (result == true);
// Демонстрация set_union:
vector<char> setUnion;
set_union(vectorl.begin(), vectorl.end(),
vector2.begin(), vector2.end(),
back_inserter(setUnion));
assert (setUnion == make< vector<char> >("abcdeiou"));
// Демонстрация set_intersection:
vector<char> setlntersection;
set_intersection(vectorl.begin(), vectorl.end(),
vector2.begin(), vector2.end(),
back_inserter(setlntersection));
assert (setlntersection ==
make< vector<char> >("ae"));
// Демонстрация set_symmetric_difference:
vector<char> setDifference;
set_symmetric_difference(vectorl.begin(),
vectorl.end(),
vector2.begin(), vector2.end(),
back_inserter(setDifference));
assert (setDifference ==
make< vector<char> >("bcdiou"));
cout << " Ok." << endl;
return 0;
5.4.8. Операции над пирамидами
Пирамида (heap) представляет определенную организацию структур данных с
произвольным доступом. Говорится, что заданный диапазон [first/last) представляет пирамиду,
если выполняются два ключевых свойства:
• значение, на которое указывает first, является наибольшим значением диапазона;
• значение, на которое указывает first, может быть удалено за логарифмическое
время; за то же время в пирамиду может быть добавлен новый элемент; обе операции
возвращают корректные пирамиды.
128
Часть I. Вводный курс в STL
STL предоставляет четыре алгоритма для создания и работы с пирамидами: make_heap,
pop_heap, push_heap и sort_heap.
Алгоритм push_heap полагает, что диапазон [first;last-l) содержит корректную
пирамиду и превращает [first; last) в пирамиду (тем самым внося значение в позиции
last-1 в пирамиду). Алгоритм pop_heap полагает, что диапазон [first/last)
представляет собой корректную пирамиду, обменивает значение в позиции first со значением в
позиции last-1 и преобразует диапазон [first; last-1) в пирамиду. Временная
сложность алгоритмов push_heap и pop_heap— O(logN), где N— размер диапазона
[first;last).
Алгоритм make_heap строит пирамиду в диапазоне [first;last) с использованием
элементов этого же диапазона, a sort_heap сортирует элементы, хранящиеся в пирамиде.
Временная сложность алгоритма make_heap — линейная, алгоритм требует выполнения не
более 3N сравнений; алгоритм sort_heap имеет время работы 0(NlogN) и выполняет не
более NiogN сравнений. Работа всех описанных алгоритмов проиллюстрирована в
следующем примере.
Пример 5.27. Демонстрация использования обобщенных операций над
пирамидами
"ех05-27.срр" 128 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенных "
<< "операций над пирамидами." << endl;
// Инициализация вектора целых чисел:
vector<int> vectorl(5);
int i ;
for (i = 0; i < 5; ++i)
vectorl[i] = i;
random_shuffle(vectorl.begin(), vectorl.end());
// Сортировка vectorl с помощью push_heap и pop_heap:
for (i = 2; i <= 5; ++i)
push_heap(vectorl.begin(), vectorl.begin() + i);
for (i = 5; i >= 2; --i)
pop_heap(vectorl.begin() , vectorl.begin() + i);
// Проверка отсортированности массива:
for (i = 0; i < 5; ++i)
assert (vectorl [i] == i);
// Еще раз перемешиваем элементы:
random_shuffie(vectorl.begin(), vectorl.end());
// Сортировка vectorl с помощью make_heap и sort_heap:
make_heap(vectorl.begin(), vectorl.end());
sort_heap(vectorl.begin(), vectorl.end());
/ лава о. иооощенные алгоритмы
7Zy
}
// Проверка отсортированности массива:
for (i = 0; i < 5; ++i)
assert (vectorl[i] == i);
cout << " Ok." << endl;
return 0;
Сортировка при помощи push_heap и pop_heap выполняется следующим образом.
Элемент v[0] рассматривается как корректная пирамида; затем четыре раза вызывается
push_heap, чтобы внести элементы вектора в пирамиду. После того как пирамида создана,
четыре раза вызывается pop_heap. При каждом вызове pop_heap берет первый элемент
пирамиды (который, как известно, является наибольшим в последовательности) и помещает
его в конец последовательности. После выполнения всех вызовов pop_heap
последовательность оказывается отсортированной.
5.4.9. Минимум и максимум
Обобщенные алгоритмы min и max получают по два элемента и возвращают
соответственно меньший или больший из них. Алгоритмы min_element и max_element
возвращают итератор, указывающий на соответственно минимальный или максимальный элемент
входной последовательности, как показано в приведенном далее примере.
Пример 5.28. Демонстрация использования обобщенных алгоритмов
min element И max element
"ех05-28.срр" 129 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенных "
<< "алгоритмов min_element и max_element."
<< endl;
// Инициализация вектора целых чисел:
vector<int> vectorl(5);
for(int i = 0; i < 5; ++i)
vectorl[i] = i;
random_shuffie(vectorl.begin(), vectorl.end());
// Поиск максимального элемента в vectorl:
vector<int>::iterator k =
max_element(vectorl.begin(), vectorl.end());
assert (*k == 4);
// Поиск минимального элемента в vectorl:
k = min_element(vectorl.begin(), vectorl.end());
assert (*k == 0);
cout << " Ok." << endl;
return 0;
часть I. ьвооный курс в Z> TL
5.4.10. Лексикографическое сравнение
Обобщенный алгоритм lexicographical_compare сравнивает две входные
последовательности следующим образом. Сравниваются соответствующие пары элементов el и е2
(из последовательностей 1 и 2). Если el < e2, то алгоритм немедленно возвращает true;
если е2 < el, алгоритм немедленно возвращает false. В противном случае сравнение
выполняется для следующей пары элементов. Если первая последовательность исчерпана,
а вторая нет— алгоритм возвращает true; в противном случае он возвращает false.
Оператор < должен быть определен для элементов последовательности как строгое неполное
упорядочение (можно также передавать функции lexicographical_compare объект
сравнения, который определяет строгое неполное упорядочение). Если < или объект
сравнения определяет строгое полное упорядочение, то упорядочение, определяемое алгоритмом
lexicographical_compare, также является строгим полным упорядочением; в
противном случае это строгое неполное упорядочение.
Пример 5.29. Демонстрация использования обобщенного алгоритма
lexicographical_compare
"ех05-29.срр" 130 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма lexicographical_compare." << endl;
vector<char> vectorl = make< vector<char> >("helio");
vector<char> vector2 = make< vector<char> >("hello");
// Демонстрация того, что vectorl лексикографически
// меньше, чем vector2:
bool result = lexicographical_compare(vectorl.begin(),
vectorl.end(), vector2.begin(), vector2.end());
assert (result == true);
cout << " Ok." << endl;
return 0;
}
5.4.11. Генераторы перестановок
STL предоставляет два алгоритма генерации перестановок: next_jpermutation
изменяет последовательность, превращая ее в очередную перестановку в лексикографическом
порядке, a prev_jDermutation изменяет последовательность, превращая ее в предыдущую
перестановку в лексикографическом порядке. Входная последовательность должна
поддерживать двунаправленные итераторы. В силу определения в терминах лексикографического
упорядочения для элементов последовательности должен быть определен оператор <,
представляющий строгое неполное упорядочение (алгоритмам можно также передать сравни-
Глава 5. Обобщенные алгоритмы
131
вающий объект, определяющий строгое неполное упорядочение). Эти алгоритмы
демонстрируются в следующем примере.
Пример 5.30. Демонстрация использования обобщенных алгоритмов
перестановок
•■ех05-30.срр" 131 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенных "
<< "алгоритмов перестановок." << endl;
// Инициализация вектора целых чисел:
vector<int> vectorl(3);
for (int i = 0; i < 3; + + i) vectorl[i] = i;
// В лексикографическом порядке перестановками 0 12
// являются перестановки 0 12, 02 1, 102, 12 0,
// 2 0 1, 2 1 0.
// Демонстрация того, что для 0 12 вызов
// next_permutation дает 0 2 1:
next_permutation(vectorl.begin(), vectorl.end());
assert (vectorl[0] == 0)
assert (vectorl[1] == 2)
assert (vectorl[2] == 1)
// Демонстрация того, что для 0 2 1 вызов
// prev_permutation() дает 0 12:
prev_permutation(vectorl.begin(), vectorl.end());
assert (vectorl[0] == 0)
assert (vectorl[1] == 1)
assert (vectorl[2] === 2)
}
cout << " Ok." << endl;
return 0;
5.5. Обобщенные числовые алгоритмы
В STL входят четыре обобщенных числовых алгоритма: accumulate, partial_sum,
adjacent_dif ference и inner_jproduct. В этом разделе мы рассмотрим примеры
использования каждого из этих алгоритмов.
5.5.1. accumulate
Обобщенный алгоритм accumulate суммирует значения из указанного диапазона.
делить i. овииныи курс в о / L
Пример 5.31. Демонстрация использования обобщенного алгоритма
accumulate
"ех05-31.срр" 132а &
#include <iostream>
#include <cassert>
#include <algorithm>
#include <functional>
#include <numeric>
using namespace std;
int mainO
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма accumulate." << endl;
int x[20] ;
for (int i = 0; i < 20; ++i)
x[i] = i;
// Демонстрация того, что
//5+0+1+2+ ... +19== 195:
int result = accumulate(&x[0], &x[20], 5);
assert (result == 195) ;
// Демонстрация того, что
// 10 * 1 * 2 * 3 * 4 == 240:
result = accumulate(&x[1], &x[5], 10,
multiplies<int>() ) ;
assert (result == 240) ;
cout << " Ok." << endl;
return 0;
Во втором вызове accumulate вместо суммирования использовано умножение, и
выполняется накопление значений с х [1] по х [4]. Кроме приведенного примера, применение
алгоритма accumulate имеется в примерах 2.12, 2.13 и 2.14.
5.5.2. partial_sum
Для данной последовательности x0,xlv..,jcn_, обобщенный алгоритм partial_sum
вычисляет последовательность сумм х0, х0 + хх, х0 + я, + х2,..., х0 + хх + • • • + *„_,. Алгоритм может
хранить эти частичные суммы либо на том же месте, где находилась исходная
последовательность, либо в другом диапазоне.
Пример 5.32. Демонстрация использования обобщенного алгоритма
partial_sum
"ех05-32.срр" 1326 =
#include <algorithm>
#include <numeric>
#include <iostream>
using namespace std;
int main()
{
Глава 5. Обобщенные алгоритмы 733
cout << "Демонстрация использования обобщенного "
<< "алгоритма partial_sum." << endl;
const int N = 20;
int xl [N] , x2 [N] ;
int i ;
for (i = 0; i < N; ++i)
xl[i] = i;
// Вычисление частичных сумм 0, 1, 2, 3, . .., N - 1,
I/ с размещением результата в х2:
partial_sum(&xl[0], &xl[N], &х2[0]);
for (i = 0; i < N; ++i)
cout << x2[i] << " ";
cout << endl;
return 0;
}
Вывод примера 5.32
0 1 3 6 10 15 21 28 36 45 55 66 78 91 105 120 136 153 171 190
5.5.3. adjacentdifference
Для данной последовательности jc0 , jc, ,...,xn_x обобщенный алгоритм adj acent_dif ference
вычисляет разности между соседними значениями в последовательности и размещает
результат хх -х0,х2 -х{,...,хп_х -хп_2 в ту же или иную последовательность. Первый элемент
выходного диапазона будет содержать значение х0.
Пример 5.33. Демонстрация использования обобщенного алгоритма
adj acentdi f ference
Mex05-33.cpp" 133 =
#include <iostream>
#include <cassert>
#include <algorithm>
#include <numeric>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма adjacent_difference." << endl;
const int N = 20;
int xl [N] , x2 [N] ;
int i ;
for (i = 0; i < N; ++i)
xl[i] = i;
// Вычисление частичных сумм ряда
// 0, 1, 2, 3, ..., N - 1, с размещением
// результата в х2:
partial_sum(&xl[0], &xl[N], &х2[0]);
// Вычисление последовательных разностей элементов х2,
// с размещением результатов в том же массиве х2:
adjacent_difference(&x2[0] , &х2[N] , &х2 [0]) ;
Часть I. Вводный курс в STL
}
// Результат представляет собой исходную
// последовательность 0, 1, 2, 3, . .., N - 1:
for (i = 0; i < N; ++i)
assert (x2 [i] == i) ;
cout << " Ok." << endl;
return 0;
В этой программе сначала выполняется вызов partial_sum для последовательности 0, 1,
..., N - 1. При применении adjacent_difference к последовательности частичных
сумм (см. вывод примера 5.32) получается исходная последовательность.
5.5.4. innerproduct
Обобщенный алгоритм inner_product вычисляет скалярное произведение двух входных
последовательностей. Приведенная ниже программа сначала вычисляет скалярное
произведений последовательностей 1, 2, 3, 4, 5 и 2, 3, 4, 5, 6 с использованием обычных определений
+ и *, которое равно
1x2 + 2x3 + 3x4 + 4x5 + 5x6 = 70
По умолчанию алгоритм использует операторы + и *, но можно использовать и иные
операторы, передавая алгоритму innerjproduct функциональные объекты. Приведенная программа
иллюстрирует этот факт вторым вызовом innerjproduct, в котором + и * меняются ролями:
(1 + 2)х(2 + 3)х(3 + 4)х(4 + 5)х(5 + б)==10395.
Пример 5.34. Демонстрация использования обобщенного алгоритма
innerproduc t
"ех05-34.срр" 134 =
#include <algorithm>
#include <iostream>
#include <functional>
#include <numeric>
using namespace std;
int main()
{
cout << "Демонстрация использования обобщенного "
<< "алгоритма inner_product." << endl;
const int N = 5;
int xl [N] , x2 [N] ;
for (int i = 0; i < N; ++i) {
xl[i] = i + 1;
x2[i] = i + 2;
}
// Вычисление скалярного произведения
// последовательностей 1, 2, . .., Ыи2, 3, ..., N+1:
int result = inner_product(&xl[0] , &xl[N] , &x2 [0] , 0);
cout << "Обычное скалярное произведение : "
<< result << endl;
// Вычисление "скалярного произведения" с измененными
// ролями операторов + и *:
Глава 5. Обобщенные алгоритмы
135
result = inner_product(&xl[0], &xl[N], &х2[0], 1,
multiplies<int>(), plus<int>() ) ;
cout << "Скалярное произведение с измененными + и *: "
<< result << endl;
return 0;
}
Вывод примера 5.34
Обычное скалярное произведение : 70
Скалярное произведение с измененными + и *: 10395
Четвертый аргумент inner_product представляет собой значение, инициализирующее
сумму произведений. Обычно это значение является единичным элементом для первого из
двух используемых операторов. Поэтому при вычислении суммы произведений в качестве
начального значения использовался 0, а для вычисления произведения сумм— 1.
Глава 6
Последовательные контейнеры
В этой и следующей главах будут подробно рассмотрены контейнеры STL, включая
описание и демонстрацию большинства их возможностей. И, что очень важно, будут
рассмотрены критерии выбора вида контейнера для решения конкретных задач.
Все классы контейнеров STL являются одной из наиболее важных концепций
программного обеспечения, абстракции данных, или абстрактные типы данных. Абстрактный тип
данных предоставляет множество объектов и множество операторов над этими объектами, и
оба они имеют общедоступно определенное абстрактное значение, отделенное от способа
представления объектов и реализации операций. Сохраняя их представление и реализацию
закрытыми (что достигается одной из возможностей классов C++), абстрактные типы данных
предохраняют программиста от написания кода, который зависит от конкретных внутренних
деталей, что в свою очередь повышает гибкость при внесении изменений и поддержке
программного обеспечения в течение всего жизненного цикла.
Многие программные библиотеки включают концепцию абстракции данных, но дизайн
классов контейнеров STL идет на шаг вперед и использует еще более высокоуровневую
концепцию семейства абстракций. STL предоставляет два семейства абстракций — контейнеры
последовательностей, или последовательные контейнеры, и отсортированные
ассоциативные контейнеры. К контейнерам последовательностей относятся vector, deque и list, а к
упорядоченным ассоциативным контейнерам— set, multiset, map и multimap. В
терминах предоставляемых функций различные члены семейства могут отличаться "на
границах"; например, деки и списки предоставляют функцию push_f ront, а векторы — нет.
Однако фундаментальное отличие в пределах семейства абстракций последовательностей
заключается в производительности, которая и диктует включение или исключение тех или
иных операций— причина отсутствия push_front у векторов в том, что такая операция
имела бы линейное время работы, в то время как в деках и списках она может быть
реализована как операция с константным временем работы.
Ни один из трех членов семейства не доминирует над всеми другими в смысле
производительности всех операций (если бы такой член семейства был, не было бы причин создавать
два остальных). Когда мы изучаем разницу между векторами, деками и списками, одна из
наиболее важных целей этого изучения — разобраться, в каких случаях тот или иной
контейнер превосходит другие. При программировании того или иного приложения, которое
включает создание и применение последовательностей, нам надо думать о том, какая
последовательность операций должна быть выполнена, и выбрать соответствующее представление
последовательности. Конечно, в начале проектирования мы имеем очень смутное
представление о наборе операций и можем начать работу до того, как будем знать точный ответ.
Одним из достоинств библиотеки STL является то, что она не только предоставляет различные
представления последовательностей, но и предоставляет их с практически одинаковым
интерфейсом — в этом и есть идея семейства абстракций. Это позволяет легко, путем внесения
малого количества изменений, переключаться между различными представлениями для вы-
13V
Часть I. Вводный курс в STL
полнения экспериментов по выяснению того, какое именно представление дает наивысшую
общую производительность. Там, где имеются различия между двумя интерфейсами — они
сделаны специально для того, чтобы дать лишний повод задуматься, какое именно
представление следует использовать.
Классы set, multiset, map и multimap являются членами семейства упорядоченных
ассоциативных абстракций и существенно отличаются не только производительностью, но и
самим смыслом операций. Основным различием между set и multiset является смысл
операции insert. Вставка в множество ничего не делает в случае, когда вставляемое
значение уже имеется в множестве, но при вставке в мультимножество в нем появляются дубликаты.
То же различие имеется и между тар и multimap, и эти два контейнера существенно
отличаются от setn multiset тем, что связывают значения с ключами другого типа; в случае set и
multiset хранятся только ключи. Требования, связанные с производительностью, у обоих
контейнеров по сути одинаковы — логарифмические вставка, удаление и поиск.12
STL предоставляет также несколько ограниченных по доступу контейнеров — стеки,
очереди и очереди с приоритетами. Однако они получаются посредством применения адаптеров
контейнеров и описаны в главе 9, "Адаптеры контейнеров".
Рассматривая последовательные контейнеры, мы очень полно и детально опишем
векторы, а затем рассмотрим деки и списки в терминах их отличия от векторов. Более подробное
описание всех классов контейнеров можно найти в главе 21, "Справочное руководство
по контейнерам".
6.1. Векторы
Векторы представляют собой последовательные контейнеры с быстрым произвольным
доступом к последовательностям переменной длины, а также с быстрой вставкой и
удалением в конце. Этот контейнер следует выбирать, когда требуется максимально быстрый
произвольный доступ и выполняется очень малое количество вставок и удалений не в конце
последовательности. Если же вставки и удаления необходимы и в начале последовательности, то
при использовании вектора они будут занимать линейное время. Если таких операций должно
быть много, лучшим выбором является дек, вставки и удаления в обоих концах которого
выполняются за константное время, при сохранении произвольного доступа к элементам.
(Компромисс в данном случае заключается в большем, чем для вектора, времени доступа к
элементам.) Наконец, если вставки и удаления должны выполняться во внутренних позициях,
то лучше использовать список, а не вектор или дек. (Кроме того, списки не поддерживают
произвольный доступ, но многие вычисления могут быть выполнены путем
последовательного обхода контейнеров, поддерживаемого списками.)
6.1.1. Типы
Параметры шаблона каждого класса последовательности задаются строкой
template <typename T, typename Allocator = allocator<T> >
Упорядоченные ассоциативные контейнеры, описанные здесь, — это контейнеры, которые были
приняты в качестве части стандартной библиотеки ANSI/ISO C++. Другое тесно связанное абстрактное
семейство — хешированные ассоциативные контейнеры, представляющие собой компромисс между
определенным снижением функциональности и повышением производительности. Требования к этим
контейнерам допускают представление хеш-таблиц с константным средним временем операций
сохранения и выборки. Хешированные ассоциативные контейнеры доступны в качестве расширения
стандартной библиотеки в некоторых реализациях C++, как описано в приложении Г, "Ресурсы".
Глава 6. Последовательные контейнеры
139
Первый параметр представляет собой тип хранимых данных, а второй — тип используемого
аллокатора, который по умолчанию представляет собой стандартный аллокатор.
Каждый класс контейнера STL определяет и делает общедоступными несколько типов.
• value_type. Тип элементов, хранящихся в контейнере (Т).
• pointer. Тип указателя на элементы контейнера (обычно Т*, но в общем случае этот
тип определяется типом аллокатора).
• reference. Тип размещения элементов контейнера (обычно Т&, но в общем случае
этот тип определяется типом аллокатора).
• iterator. Тип итератора, ссылающегося на значения типа reference; для
векторов этот тип находится в категории итераторов с произвольным доступом.
• dif ference_type. Знаковый целочисленный тип, который может представлять
разность между двумя итераторами.
• size_type. Беззнаковый целочисленный тип, который может представлять любое
неотрицательное значение типа dif f erence_type.
• reverse_iterator. Тип итератора, ссылающегося на значения типа reference и
определяющего инкремент и декремент как обратные к обычным определениям типа
iterator; для векторов этот тип находится в категории итераторов с произвольным
доступом.
Типы указателя, ссылки и итератора имеют соответствующие типы константного
указателя, константной ссылки и константного итератора— const_jpointer, const_ref erence
и const_iterator. Наконец, имеется также константный обратный итератор const_re-
verse_iterator.
В случае векторов все итераторы являются итераторами с произвольным доступом,
наиболее мощной категорией итераторов. Это означает, что с векторами могут работать все
обобщенные алгоритмы STL. Следовательно, единственными операциями, которые следует
определить классу вектора в качестве функций-членов, являются конструкторы, функции для
вставки, удаления элементов вектора и для доступа к базовой информации, такие как
итераторы, указывающие начало и конец вектора.
6.1.2. Конструирование последовательностей
Векторы имеют несколько разновидностей конструкторов. Конструктор по умолчанию,
использующийся в выражениях наподобие ve с tor <Т> () или в объявлениях наподобие
vector<T> vectorl;
создает изначально пустую последовательность. Выражение vector<T>(n, value) или
объявление
vector<T> vectorl(n, value);
создает последовательность, инициализированную N = п копиями значения value, которое
должно иметь тип Т или приводимый к нему. Второй параметр данного конструктора имеет
значение по умолчанию Т (); т.е. vector<T> (n) или
vector<T> vectorl(n);
140
Часть I. Вводный курс в STL
создает последовательность, инициализированную N = п копиями результата вызова
конструктора по умолчанию типа Т.13
Создание пустой последовательности конструктором по умолчанию требует константного
времени, а создание последовательности с N элементами — времени, пропорционального N.
Перед тем как обратиться к двум другим способам создания векторов, рассмотрим
простые примеры использования только что рассмотренных способов. Приведенная далее
программа демонстрирует первые два способа; она также использует функцию-член size,
которая возвращает количество элементов вектора, и возможность записи доступа к /-му элементу
вектора, как к элементу массива.
Пример 6.1. Демонстрация простейших конструкторов вектора STL
"ех06-01.срр" 140а =
#include <iostream>
#include <cassert>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация простейших "
<< "конструкторов вектора STL" << endl;
vector<char> vectorl, vector2(3, 'x1);
assert (vectorl.size() == 0) ;
assert (vector2.size() == 3);
assert (vector2 [0] == 'x1 && vector2[1] == 'x1 &&
vector2[2] == »x');
assert (vector2 == vector<char>(3, 'x') &&
vector2 != vector<char>(4, 'x'));
cout << " Ok." << endl;
return 0;
}
Вот пример построения вектора с элементами пользовательского типа, включающий
случай инициализации по умолчанию путем передачи в конструктор одного аргумента. Но
сначала мы определим тип U с членом-данными id, в котором хранится идентификационный
номер объекта U.
<Определение типа U 140б> =
class U {
public:
unsigned long id;
U() : id(0) { }
U(unsigned long x) : id(x) { }
) i
Используется в частях 141а, 145.
Мы также определим операторы == и ! = для типа U для сравнения идентификаторов
объектов.
Определение == и != для типа U 140в> =
bool operator==(const U& x, const U& y)
Этот способ работает, даже если Т представляет собой встроенный тип данных, такой как int,
поскольку int () и другие такие выражения должны быть определены (как 0, преобразуемый к типу Т
при инициализации по умолчанию). Если Т определен как класс, такой класс должен иметь конструктор
по умолчанию.
Глава 6. Последовательные контейнеры
141
return x.id == у.id;
}
bool operator!=(const U& x, const U& y)
(
return x.id != y.id;
}
Используется в частях 141а, 1416.
Пример 6.2. Демонстрация конструкторов вектора STL
с пользовательским типом
"ехОб-02.срр" 141а =
#include <iostream>
#include <cassert>
#include <vector>
using namespace std;
<Определение типа U 140б>
<Определение == и != для типа U 140в>
int main()
{
cout << "Демонстрация конструкторов вектора "
<< "STL с пользовательским типом." << endl;
vector<U> vector1, vector2(3);
assert (vectorl.size() == 0) ;
assert (vector2.size() == 3) ;
assert (vector2[0] == U() && vector2[1] == U() &&
vector2[2] == U());
assert (vector2 == vector<U>(3/ U()));
return 0;
При создании TV копий начального значения конструктор вектора вызывает копирующий
конструктор типа элемента. Для демонстрации этого давайте определим копирующий
конструктор для типа U для отслеживания "поколений" копий (изначально созданный объект имеет
значение поколения 0, его копия — значение 1, копия копии — 2, и т.д.). Кроме того, в
статической переменной мы будем отслеживать общее количество вызовов копирующего
конструктора U.
Пример 6.3. Демонстрация конструкторов вектора STL с использованием
пользовательского типа и явным копированием
"ехОб-ОЗ.срр" 1416 s
#include <iostream>
#include <cassert>
#include <vector>
using namespace std;
class U {
public:
unsigned long id;
unsigned long generation;
static unsigned long total__copies;
U() : id(0), generation(O) { }
U(unsigned long n) : id(n), generation(0) { }
U(const U& z) : id(z.id)/ generation(z.generation + 1)
742
Часть I. Вводный курс в STL
{ ++total_copies; }
};
<Определение == и != для типа U 140в>
unsigned long U::total_copies = 0;
int main()
cout << "Демонстрация конструкторов вектора\п"
<< "STL с использованием пользовательского\n"
<< "типа и явным копированием." << endl;
vector<U> vectorl, vector2(3);
assert (vectorl.size () == 0);
assert (vector2.size () == 3);
assert (vector2[0] == U() && vector2[1] == U() &&
vector2[2] == U());
for (int i = 0; i != 3; ++i)
cout << "vector2[" << i << "].generation: "
<< vector2 [i] .generation << endl;
cout << "Общее количество копирований: "
<< U::total_copies << endl;
return 0;
}
Вывод примера 6.3
Демонстрация конструкторов вектора
STL с использованием пользовательского
типа и явным копированием.
vector2 [0] .generation: l
vector2[1].generation: 1
vector2 [2] .generation: 1
Общее количество копирований: 3
Вывод этой программы показывает, что каждое значение U, хранящееся в векторе,
представляет собой копию поколения 1, а копирующий конструктор U вызывался по одному разу для
каждого из трех хранящихся значений.
Конечно же, у самого вектора также есть копирующий конструктор для копирования
другого вектора. В приведенной далее программе показано использование копирующего
конструктора и еще одного конструктора — для копирования диапазона элементов из другого вектора.
Пример 6.4. Демонстрация копирующих конструкторов вектора STL
"ех0б-04.срр" 142 =
#include <iostream>
#include <cassert>
#include <vector>
using namespace std;
int main()
{
cout << "Демонстрация копирующих конструкторов "
<< "вектора STL." << endl;
Глава 6. Последовательные контейнеры
143
char name[] = "George Foreman";
vector<char> George(name, name + 6);
vector<char> anotherGeorge(George.begin(),
George.end());
assert (anotherGeorge = = George);
vector<char> sonl(George); // Используется копирующий
// конструктор
assert (sonl == anotherGeorge);
vector<char> son2 = George; // Снова используется
// копирующий конструктор
assert (son2 == anotherGeorge);
return 0;
}
Конструктор для копирования диапазона значений при помощи итераторов более
обобщенный, чем показано в примере; как упоминалось в разделе 1.3.3, он может использоваться
с итераторами других контейнеров для копирования, например, диапазона списка, дека или
строки:
list<char> listl;
// ... код вставки символов в listl;
vector<char> vectorl(listl.begin(), listl.end());
Конструктор вектора, который позволяет использовать такой код, представляет собой
шаблонную функцию-член со следующим интерфейсом:
template <typename InputIterator>
vector(Inputlterator first, Inputlterator last);
6.1.3. Вставка
Наиболее полезной функцией-членом вектора для вставки элементов является функция
push__back, которая вставляет один элемент в конец последовательности. Эта функция уже
использовалась несколько раз в предыдущих главах. В приведенной далее программе эта
функция используется вместе с более общей функцией-членом insert.
Пример 6.5. Демонстрация функций вектора STLpushback и insert
"ех06-05.сррп 143 е
#include <iostream>
#include <cassert>
#include <vector>
#include <string>
#include <algorithm> // Алгоритм reverse
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
vector<char> vectorl =
make< vector<char> >("Bjarne Stroustrup"),
vector2;
vector<char>::iterator i;
cout << "Демонстрация функции push_back" << endl;
744
Часть I. Вводный курс в STL
for (i = vectorl.begin(); i != vectorl.end(); ++i)
vector2.push_back(*i);
assert (vectorl == vector2);
vectorl = make< vector<char> >("Bjarne Stroustrup");
vector2 = make< vector<char> >("");
cout << "Демонстрация вставки в начало вектора"
<< endl;
for (i = vectorl.begin(); i != vectorl.end(); ++i)
vector2.insert(vector2.begin(), *i);
assert (vector2 ==
make< vector<char> > ("purtsuortS enrajB"));
// Демонстрация того, что vector2 представляет собой
// обращение вектора vectorl при помощи обобщенной
// функции reverse, примененной к вектору vectorl:
reverse(vectorl.begin(), vectorl.end() ) ;
assert (vector2 == vectorl);
cout << " Ok." << endl;
return 0;
}
В первой части этой программы мы использовали push_back для создания вектора
путем вставки символов в его конец. Вторая часть реинициализирует векторы и вставляет те же
символы один за одним в начало вектора vector2, так что vector2 хранит строку,
обратную исходной. В этом можно убедиться при помощи вызова
assert(vector2 == make<vector<char> >("purtsuortS enrajB"));
но существует еще один способ — применяя обобщенный алгоритм reverse для обращения
исходной строки и сравнивая получившийся результат с вектором ve с tor 2.
Вставка элементов в вектор в позиции, отличной от конца вектора, вполне
работоспособна в небольшом примере, но при работе с большими векторами ее следует избегать, так как
она требует линейного времени (поскольку каждый элемент в позиции вставки и после нее
должен быть перемещен, чтобы освободить место для нового элемента). Если ваше
приложение требует выполнения таких вставок, вероятно, лучше воспользоваться деком или списком.
Кстати, выражение vectorl .push_back (x) функционально эквивалентно выражению
vectorl.insert(vectorl.end() , x); производительность их может немного
различаться, но оба они имеют константное (амортизированное) время работы.
Векторы предоставляют также функцию для вставки п - N копий элемента или
диапазона элементов из другой последовательности:
vectorl.insert(position, n, x);
Этот вызов функции insert функционально эквивалентен циклу
for (p = position, k = 0; к < п; ++к)
р = vectorl.insert(р, х) + 1;
однако выполняется гораздо быстрее, если position не находится в конце
последовательности. (Если в позиции position и после нее имеется Мэлементов, то версия с циклом для
каждого из N вызовов insert будет перемещать эти М элементов, т.е. всего будет
выполнено NM перемещений. Функция-член insert с параметром N будет выполнена за время
, так как она однократно переместит М элементов, освобождая место для N новых
элементов, т.е. в результате выполнит перемещение N + M элементов. Если, скажем,
М = N = 1000 , то всего будет выполнено только 2000 перемещений, а не миллион.)
Глава 6. Последовательные контейнеры
145
Имеется также функция-член вектора для вставки диапазона элементов из другой
последовательности: если first и last представляют собой итераторы некоторого типа
iterator_type и они определяют диапазон, то выражение
vectorl.insert(position, first, last)
функционально эквивалентно
for (p = position, i = first; i != last; ++i)
p = vectorl.insert(p, *i) + 1;
но выполняется гораздо быстрее, если position находится не в конце вектора. Тип
iterator_type должен принадлежать категории однонаправленных итераторов,
двунаправленных итераторов или итераторов с произвольным доступом. При работе с этими
итераторами возможно вычисление расстояния от first до last и резервирование
достаточного количества пространства для новых элементов, но в противном случае — например, для
итераторов istream — вставка будет выполняться элемент за элементом, как в случае цикла.
Эта функция-член на самом деле представляет собой шаблон функции:
template <typename InputIterator>
void insert(iterator position, Inputlterator first,
InputIterator last);
Применение insert может привести к перераспределению памяти, т.е. после вставки
элементы вектора могут оказаться в другой области памяти. Причина этого заключается в том,
что все элементы хранятся в непрерывном блоке памяти. Если в текущем блоке недостаточно
места для размещения нового элемента, то у аллокатора запрашивается новый блок памяти,
и все старые и новый элемент копируются в новый блок, а старый блок освобождается.
Размер нового блока вдвое превышает размер старого, что означает, что в случае вектора с N
элементами перераспределение памяти не потребуется до тех пор, пока не будет вставлено
еще N элементов. Таким образом, хотя перераспределение и может сделать конкретную
вставку дорогостоящей операцией, оно выполняется достаточно редко, чтобы
амортизированная стоимость вставки была константной.
Программист имеет возможность определенного контроля над тем, когда должно
выполняться перераспределение памяти, с помощью функций-членов capacity и reserve.
Функция capacity возвращает размер выделенного в настоящее время блока (количество
элементов, которое может в нем храниться). Вызов
vectorl.reserve(n);
гарантирует, что после вызова vectorl .capacity () вернет значение не менее N = п;
этот вызов приводит к перераспределению памяти тогда (и только тогда), когда текущая
емкость вектора меньше N. В любом случае текущий размер вектора (количество хранящихся в
нем элементов) не изменяется.
Если вы заранее знаете, что вам потребуется вставить около N элементов (при помощи
push_back или одного из вариантов insert), то можете ускорить работу программы при
помощи предварительного вызова reserve. Это гарантирует, что в процессе вставок не будут
выполняться никакие перераспределения памяти, пока размер вектора не достигнет значения N.
Пример 6.6. Демонстрация функций вектора STL capacity и reserve
"ех06-06.срр" 145 =
#include <iostream>
14 Если вектор пуст, то выделяется блок некоторого, зависящего от реализации, размера. Как
упоминалось в разделе 1.5.2, в некоторых реализациях может использоваться и другой множитель, не
равный 2, но любой постоянный множитель, больший 1, дает константное амортизированное время.
146
Часть I. Вводный курс в STL
#include <cassert>
#include <vector>
using namespace std;
<Определение типа U 140б>
int main()
{
cout << "Демонстрация функций вектора STL "
<< "capacity и reserve." << endl;
int N = 10000; // Размер векторов
vector<U> vectorl, vector2;
cout << "Выполнение " << N << " вставок в vectorl\n"
<< "без предварительного резервирования.\п";
int к;
for (к = 0; к != N; ++к) {
vector<U>::size_type cap = vectorl.capacity();
vectorl.push_back(U(k));
if (vectorl.capacity() != cap)
cout << "k: " << к << ", новая емкость: "
<< vectorl.capacity() << endl;
}
vector2.reserve(N);
cout << "\nTe же действия с vector2/\n"
<< "после reserve(" << N << ").\n";
for (k = 0; k != N; ++k) {
vector<U>::size_type cap = vector2.capacity();
vector2.push_back(U(k));
if (vector2.capacity() != cap)
cout << "k: " << k << ", новая емкость: "
<< vector2.capacity() << "\n";
}
return 0;
Вывод примера 6.6
Демонстрация функций вектора STL capacity и reserve.
Выполнение 10000 вставок в vectorl
без предварительного резервирования.
к: 0, новая емкость: 1024
к: 1024, новая емкость: 2048
к: 2048, новая емкость: 4096
к: 4096, новая емкость: 8192
к: 8192, новая емкость: 16384
Те же действия с vector2,
после reserve(10000) .
В цикле вставки в vectorl точка, когда происходит перераспределение памяти, может
отличаться в разных реализациях STL. В цикле вставки в vector2 вывод на экран не
выполняется, поскольку вызов reserve предотвращает перераспределения.
Помимо эффективности имеется и другая причина для использования reserve.
Перераспределение делает недействительными все итераторы и ссылки на позиции в векторе,
поскольку элементы могут оказаться перемещены в другое место памяти. Если же перераспре-
Глава 6. Последовательные контейнеры
147
деления не происходит, гарантируется, что вставка в конец вектора не портит никакие
итераторы или ссылки. Вставки в средину делают недействительными только те итераторы и
ссылки, которые указывают на точку вставки или после нее. Если имеется некоторая часть
программы, в которой требуется поддержка нескольких итераторов, указывающих в различные
места вектора, следует вызвать reserve с достаточно большим параметром во избежание
перераспределения памяти во время выполнения этой части.
6.1 А Удаление
Как push_back является наиболее полезной функцией-членом для вставки, наиболее
полезной функцией-членом для удаления является pop_back, которая удаляет один элемент из
конца последовательности за константное время. Эти две функции, вместе с еще одной
функцией-членом, back, позволяют использовать вектор в качестве стека — данные в нем могут
храниться и извлекаться в порядке "последний вошел — первый вышел". (Настоящая
абстракция стека более ограниченна, чем вектор — поскольку доступ к данным осуществляется
только через последний элемент. STL предоставляет эту более ограниченную абстракцию
посредством адаптера контейнера, как описано в главе 9, "Адаптеры контейнеров".)
Пример 6.7. Демонстрация операций back и popback над вектором STL
"ех06-07.срр" 147 =
#include <iostream>
#include <vector>
#include <string>
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация операций back и pop_back "
<< "над вектором STL." << endl;
vector<char> vectorl =
make< vector<char> >("abcdefghij");
cout << "Снятие символов с конца стека: ";
while (vectorl.size() > 0) {
cout << vectorl.back();
vectorl.pop_back();
}
cout << endl;
return 0;
}
Вывод примера 6.7
Демонстрация операций back и pop_back над вектором STL.
Снятие символов с конца стека: jihgfedcba
Эта программа многократно получает последний элемент вектора, выводит его и удаляет,
пока вектор не станет пустым.
Как и в случае вставки, вектор предоставляет более общую возможность удаления
элемента из произвольной позиции. Например, можно заменить цикл из предыдущей программы
циклом, который получает, выводит и удаляет первый, а не последний элемент:
148
Часть I. Вводный курс в STL
while (vectorl.size() > 0) {
cout << vectorl.front 0 ;
vectorl.erase(vectorl.begin());
}
Обратите внимание, что для удаления первого элемента мы используем erase, так как
функции-члена pop_f ront, соответствующей функции pop_back, у векторов нет. Причина
отсутствия такой функции у векторов (у деков и списков она есть) в неэффективности удаления
элементов в начале вектора. В случае деков и списков такое действие выполняется за
константное время, но в случае вектора необходимо перемещение всех элементов после точки
удаления для заполнения разрыва, на что требуется линейное время. Это означает, например,
что показанный выше цикл выполняется за квадратичное время.
Тем не менее возможность удаления произвольных элементов вектора программистам
предоставлена — для ситуаций, когда вектор в целом оказывается лучшим выбором, чем дек
или список, но при этом изредка приходится выполнять удаление не из конца
последовательности. Приведенная далее программа демонстрирует различные применения функции-члена
вектора erase, включая версию
iterator erase(iterator first, iterator last);
Эта функция удаляет все элементы диапазона [first; last) (элемент в позиции last,
если таковой имеется, не удаляется) и возвращает значение last.
Пример 6.8. Демонстрация функции erase вектора STL
"ех06-08.срр" 148 &
#include <iostream>
#include <cassert>
#include <vector>
#include <string>
#include <algorithm> // Алгоритм find
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация функции erase вектора STL."
< < endl;
vector<char> vectorl =
make< vector<char> >("remembering");
vector<char>::iterator j;
j = find(vectorl.begin(), vectorl.end(), 'm');
// Сейчас j указывает на первый символ 'm':
assert (*j == 'm1 && *(j+l) == 'e');
vectorl.erase(j-- ) ;
assert (vectorl == make<vector<char> >("reembering"));
// Сейчас j указывает на первый символ 'е1:
assert (*j == 'е' && Mj+D == 'е');
vectorl.erase (j--) ;
assert (vectorl == make< vector<char> >("rembering"));
assert (*j == 'r•);
// Удаление первых трех символов:
vectorl.erase(j, j + 3);
Глава 6. Последовательные контейнеры
149
assert (vectorl == make< vector<char> >("bering"));
vectorl.erase(vectorl.begin() + 1);
assert (vectorl == make< vector<char> >("bring"));
cout << " Ok." << endl;
return 0;
}
Приведенная программа иллюстрирует важную проблему взаимодействия erase и
итераторов. Функция erase делает недействительными все итераторы, указывающие на все
позиции после точки удаления, но итераторы, указывающие на позиции, предшествующие точке
удаления, остаются корректными. Вот почему строка
vectorl.erase (j - - ) ;
работает правильно, но похожий код
vectorl.erase(j ++);
не работает — поскольку j после удаления становится неверным.
Все контейнеры STL имеют функции-члены insert и erase, но способ их
взаимодействия с итераторами существенно различен. Мы еще вернемся к этому вопросу при
рассмотрении других контейнеров.
Функция-член erase для удаления диапазона (которая используется на предпоследнем этапе
программы) более эффективна, чем удаление элементов по одному. Для работы ей требуется время
О(р), где р — количество элементов после удаляемого, в то время как удаление элементов
по одному осуществляется за время 0{ер), где е — количество удаляемых элементов.
6.1.5. Функции доступа
Функции доступа (аксессоры) контейнера представляют собой функции-члены, которые
возвращают информацию о контейнере без его изменения. С большинством аксессоров вектора мы
уже встречались в предшествующих обсуждениях и примерах. Вот их полный список.
• iterator begin (). Возвращает итератор, указывающий на начало вектора.
• iterator end (). Возвращает итератор, указывающий на конец вектора.
• iterator rbegin (). Возвращает обратный итератор, указывающий на начало
вектора для обхода в обратном порядке.
• iterator rend (). Возвращает обратный итератор, указывающий на конец
вектора для обхода в обратном порядке.
• size_type size О const. Возвращает количество элементов в векторе.
• size_type max_size() const. Возвращает максимальное количество
элементов, которое может храниться в векторе.
• size_type capacity () const. Возвращает количество элементов, которые
могут быть сохранены в векторе без выполнения перераспределения памяти.
• bool empty () const. Возвращает true, если в векторе нет элементов, и false
в противном случае.
• reference front (). Возвращает ссылку на элемент в начале вектора.
• reference back (). Возвращает ссылку на элемент в конце вектора.
150
Часть I. Вводный курс в STL
• reference operator [] (size_type n). Возвращает ссылку на n-й от начала
элемент вектора.
• reference at(size_type n). Возвращает ссылку на n-й от начала элемент
вектора, если п находится в корректном диапазоне; в противном случае генерируется
исключение.
Функции-члены из списка, возвращающие итераторы, имеют также версии, которые при
применении к константным векторам возвращают константные итераторы; то же относится и
к функциям, возвращающим обратные итераторы и ссылки.
• const_iterator begin () const. Возвращает константный итератор,
указывающий на начало константного вектора.
• const_iterator end() const. Возвращает константный итератор,
указывающий на конец константного вектора.
• const_iterator rbegin () const. Возвращает константный обратный
итератор, указывающий на начало константного вектора для обхода в обратном порядке.
• const_iterator rend () const. Возвращает константный обратный итератор,
указывающий на конец константного вектора для обхода в обратном порядке.
• const_reference front () const. Возвращает константную ссылку на
элемент в начале константного вектора.
• const_reference operator [] (size_type n) const. Возвращает
константную ссылку на n-й от начала элемент константного вектора.
• const_reference at(size_type n) const. Возвращает константную
ссылку на n-й от начала элемент константного вектора, если п находится в корректном
диапазоне; в противном случае генерируется исключение out_of_range.
Все аксессоры выполняются за константное время.
6.1.6. Отношения равенства и "меньше, чем"
Мы уже встречались с многочисленными примерами сравнивания векторов в наших
программах. STL применяет обобщенное определение эквивалентности контейнеров, которое
позволяет сравнивать любые два контейнера одного типа (не только векторы):
• последовательности элементов должны быть одинакового размера;
• элементы в соответствующих позициях должны быть одинаковы, что определяется
оператором == типа элемента.
В действительности официальное отношение эквивалентности контейнеров выражается в
терминах функции-члена size и обобщенного алгоритма equal: для любых двух
контейнеров а и b одного типа а == b определяется выражением
a.size() == b.sizeO && equal (a. begin () , a.endO, b.beginO)
Количество операций ==, применяемых к парам элементов, не превышает а. size ().
Используется аналогичное определение отношения <: для любых двух контейнеров
одного типа а и Ь, если Т — тип содержащихся в нем элементов, и у этого типа имеется оператор
<, определяющий отношение строгого неполного упорядочения (см. раздел 5.4), то а < b
определяется выражением
lexicographical_compare(a.beginO, a.end(),
b.beginO , b.endO )
Глава 6. Последовательные контейнеры
151
Здесь используется обобщенная функция lexicographical_compare, получающая
последовательности из а и Ь. Количество операций <, применяемых к парам элементов, не
превышает 2min(a.size (),b.size ()) .
Как отношение равенства, так и отношение меньше применимы не только к
последовательным контейнерам, но и к ассоциативным контейнерам, поскольку последние включают
понятие содержащейся последовательности.
Другие отношения упорядочения (>,<=,>=) определяются через <, так что одного
данного определения достаточно для определения их всех.
6.1.7- Присваивания
Оператор присваивания = определен для всех контейнеров STL. Непосредственно после
присваивания х = у выполняется отношение х == у. Время выполнения присваивания
составляет O(N) , где N = max(x. size О,у. size ()) .
Для последовательных контейнеров имеется также шаблонная функция-член assign для
присваивания диапазона итераторов:
template <typename InputIterator>
void assign(Inputlterator first, Inputlterator last);
Она функционально эквивалентна записи
erase(begin(), end());
insert(begin(), first, last);
Наконец, имеется функция-член swap, такая, что выражение vectorl. swap (vector2)
обменивает значения vectorl и vector2. Она имеет константное время работы, которое
может быть достигнуто путем обмена внутренними указателями на представления векторов.
Библиотека также обеспечивает при вызове обобщенного алгоритма swap для векторов
swap (vectorl, vector2) вызов в действительности функции-члена swap класса
vector, так что этот алгоритм также выполняется за константное время. Чтобы понять, как
это делается, сначала рассмотрим, как может быть реализован обобщенный алгоритм swap
обычным образом, через три присваивания:
template <typename T>
void swap(T& х, T& у)
Т temp = х;
х = у;
у = temp;
}
При инстанцировании с vector<int> в качестве типа Т эта функция должна выполнить три
присваивания вектора. Но библиотека определяет также
template <typename U>
void swap(vector<U>& x, vector<U>& y)
{
x.swap(y);
}
Это определение является примером еще одной возможности шаблонов, поддерживаемой
C++ и называющейся частичной специализацией. Это определение специализирует исходный
шаблон функции swap для случая, когда Т представляет собой vector<U>, где U сам
является параметром типа. В таком случае результат остается шаблоном, который называется
15 В реально используемом определении аргумент vector содержит также шаблонный аргумент
аллокатора, но здесь для простоты мы его опустили.
152
Часть I. Вводный курс в STL
частичной специализацией в противоположность исходному шаблону функции (которая
полностью инстанцирует Т, после чего инстанцировать больше нечего). При наличии частичных
специализаций шаблона функции, соответствующих типам фактических параметров при
вызове, правила языка требуют использования наиболее специализированной из
соответствующих версий. Вот почему вызов swap (vectorl, vector2) в действительности вместо
трех присваиваний векторов вызывает vectorl. swap (vector).
В действительности все типы контейнеров STL имеют функцию-член swap, и библиотека
определяет соответствующие частичные специализации обобщенного алгоритма swap, так
что в каждом случае обмена контейнеров оно выполняется за константное время.
6.2. Деки
В плане функциональности деки мало отличаются от векторов. Основное отличие
заключается в производительности: вставки и удаления в начале дека выполняются гораздо
быстрее, чем в векторе, требуя не линейного, а константного времени; в то же время прочие
операции имеют то же время работы (или медленнее на константный множитель), что и
соответствующие операции векторов.16 Подобно векторам, деки предоставляют итераторы с
произвольным доступом; таким образом, все обобщенные алгоритмы STL могут быть
применены к декам. Поэтому деки следует выбирать тогда, когда вставки и удаления требуются с
обоих концов последовательности, и их достаточно много для того, чтобы общая
производительность приложения с деками оказалась выше, чем с векторами. Хотя деки поддерживают
вставку и удаление в средине последовательности, эти операции выполняются за линейное
время. Если в приложении должно выполняться много таких операций, лучшим выбором
могут оказаться списки.
Интерфейс класса деков настолько похож на интерфейс векторов, что многие программы,
использующие векторы, могут быть преобразованы в программы с применением деков
только с небольшими синтаксическими изменениями, в основном в объявлениях и других
применениях конструкторов. Этому описанию отвечают все программы для демонстрации
возможностей векторов. Здесь мы приведем один пример — отредактируем программу 6.5 и просто
заменим в ней все vector на deque. Получившийся исходный текст корректно
компилируется и выполняется; никаких других изменений не требуется. В приведенной далее версии мы
также изменили раздел
cout << "Демонстрация вставки в начало дека" << endl;
for (i = dequel.begin(); i != dequel.end(); ++i)
deque2.insert(deque2.begin(), *i) ;
с тем, чтобы в нем использовалась функция-член push_f ront, которая есть у дека, и
которой нет у вектора:
cout << "Демонстрация функции дека push_front" << endl;
for (i = dequel.begin(); i != dequel.end(); ++i)
deque2.push_front(*i);
Вот что у нас получилось.
Следует отметить одно существенное отличие векторов от деков (и всех прочих контейнеров) —
данные vector всегда хранятся последовательно, так что получение адреса первого элемента вектора
дает указатель на его содержимое. В этом смысле вектор совместим с массивом языка
программирования С, так что его можно использовать для работы с API на других языках программирования. —
Примеч. пер.
/ лава о. / юслеоовательные контейнеры
703
Пример 6.9. Демонстрация функций дека STL push back и pushf ront
"ех06-09.срр" 153 в
#include <iostream>
#include <cassert>
#include <string>
#include <deque>
#include <algorithm> // Алгоритм reverse
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
deque<char> dequel =
make< deque<char> >("Bjarne Stroustrup"),
deque2;
deque<char>::iterator i;
cout << "Демонстрация функции дека push_back"
<< endl;
for (i = dequel.begin(); i != dequel.end(); ++i)
deque2.push_back(*i);
assert (dequel == deque2);
dequel = make< deque<char> >("Bjarne Stroustrup");
deque2 = make< deque<char> >("");
cout << "Демонстрация функции дека push_front"
<< endl;
for (i = dequel.begin(); i != dequel.end(); ++i)
deque2.push_front(*i);
assert (deque2 ==
make< deque<char> >("purtsuortS enrajB"));
// Демонстрация того, что deque2 представляет собой
// обращение дека dequel при помощи обобщенной
// функции reverse, примененной к деку dequel:
reverse(dequel.begin(), dequel.end());
assert (deque2 == dequel);
cout << " Ok." << endl;
return 0;
Обратите внимание на то, что обобщенный алгоритм reverse работает с итераторами деков
точно так же, как и с итераторами векторов.
Единственное существенное изменение, необходимое при конвертации программы,
использующей векторы, в программу, работающую с деками, помимо объявления deque
вместо vector в объявлениях и конструкторах, заключается в удалении всех применений
функций-членов вектора capacity и reserve. Класс дека таких функций-членов не имеет,
потому что не испытывает необходимости в таком повышении производительности, как в
случае векторов. Однако мы должны еще раз вспомнить о применении reserve. Если
единственная его цель— повысить производительность, делая ненужными перераспределения
памяти, то не влияет на корректность работы векторов эта функция не влияет, и при переходе
к декам соответствующие вызовы могут быть просто удалены. Но, с другой стороны, если
основная цель предупреждения перераспределений памяти в том, чтобы сохранить коррект-
704
Часть I. Вводный курс в STL
ность итераторов, то надо основательно задуматься о способе применения итераторов,
поскольку вставки в деки и удаления из них не гарантируют сохранения корректности
итераторов так, как это (ограниченно) делается при вставках в векторы и удалениях из них. Более
детально этот вопрос рассматривается в разделах, посвященных вставкам (раздел 6.2.3) и
удалениям (раздел 6.2.4).
Реализация, отвечающая всем требованиям, предъявляемым к декам, использует
двухуровневую структуру, состоящую из блоков фиксированного размера и каталога с адресами
блоков. Каталог блоков инициализируется таким образом, что его активные записи занимают
средину каталога и расширяются по направлению к его границам. При вставке в начало дека,
если в первом блоке недостаточно места, выделяется новый блок, а в каталог в позицию
перед текущей первой записью добавляется указатель на этот блок. Вставка в конец дека
обрабатывается симметрично. Перераспределение памяти происходит только тогда, когда
нарушаются границы каталога, но и тогда перераспределение затрагивает только блок самого
каталога, но не блоки, содержащие данные. Поэтому перераспределение памяти выполняется
не часто и является недорогой операцией по сравнению с перераспределением памяти у
вектора. Тем не менее, когда оно происходит, все итераторы и ссылки внутрь дека могут стать
недействительны, так что мы должны быть осторожны и не писать кода, который зависит от
итераторов или ссылок, остающихся корректными при вставках.
6.2.1. Типы
Класс deque имеет те же шаблонные параметры Т и Allocator, что и класс vector, и
предоставляет определения тех же типов value_type, iterator, reverse_iterator,
pointer, reference, difference_type, size_type, const_iterator,
const_reverse_iterator, const _j?ointer и const_ref erence. Эти типы имеют то
же абстрактное значение, что и в классе вектора, хотя реализация может существенно
отличаться. Подобно итераторам вектора, итераторы деков являются итераторами с
произвольным доступом.
6.2.2. Конструкторы
Класс deque предоставляет в точности такой же набор конструкторов, как и класс
vector.
6.2.3. Вставка
Деки предоставляют такой же набор функций-членов insert, как и векторы, и
добавляют к нему функцию push_f ront для вставки в начало дека, как было показано в
примере 6.9. Однако, как уже говорилось, функции-члена reserve у деков нет. Различие между
деками и векторами заключается в производительности и в ситуациях, когда итераторы и
ссылки могут стать недействительными из-за вставок.
Вставка в начало либо конец дека выполняется за константное время. Вставка в средину
дека занимает время, пропорциональное расстоянию от точки вставки до ближайшего конца.
Так, например, операция
dequel.insert(dequel.begin() + 5, x)
17 r>
a такой двухуровневой реализации ссылки при перераспределении памяти не становятся
недействительными, однако такое может произойти в случае деков, реализованных в виде единого блока памяти
с данными посредине блока и возможностью роста в обоих направлениях.
Глава 6. Последовательные контейнеры
iw
будет выполнена за константное время, в то время как соответствующая операция над
вектором потребовала бы линейного времени.
Как и в случае векторов, вставка может вызвать перераспределение памяти, связанной с деком
(этот вопрос уже поднимался во введении к разделу 6.2). Вставки в средину дека могут привести к
недействительности всех итераторов и ссылок, независимо от перераспределения памяти. Эта
ситуация отличается от ситуации с векторами, где вставки, не вызывающие
перераспределения памяти, оставляют итераторы и ссылки на позиции до точки вставки корректными.
6.2.4. Удаление
Деки имеют тот же набор функций-членов erase, что и вектор, а также функцию
pop_f ront для удаления из начала дека. Все примечания о производительности вставок и
их влиянии на корректность итераторов и ссылок применимы и к удалениям.
6.2.5. Аксессоры
Класс дека предоставляет все аксессоры класса вектора, за исключением capacity, — а
именно begin, end, rbegin, rend, size, max_size, empty, operator [], at, front и
back. Как и в случае векторов, все они имеют константное время работы. Функция-член
capacity опущена за ненадобностью.
6.2.6. Отношения равенства и "меньше, чем"
Определения отношений равенства и "меньше, чем", приведенные в разделе 6.1.6,
применимы для всех контейнеров STL и таким образом применимы и для деков.
6.2.7. Присваивания
Определения функций-членов =, assign и swap, рассматривавшиеся в разделе 6.1.7,
имеют соответствующие определения и время вычисления и для деков.
6.3. Списки
Мы видели, что абстракции последовательностей вектор и дек почти идентичны в смысле
функциональности; единственное существенное их отличие— в производительности при
вставке в начало последовательности. Абстракция последовательности list, напротив,
существенно отличается от векторов и деков в смысле предоставляемых функций-членов.
Причина этого в том, что списки не поддерживают итераторов с произвольным доступом — это
цена за константное время вставки и удалений; при отсутствии произвольного доступа
некоторые обобщенные алгоритмы, такие как алгоритмы сортировки, не могут быть применены, а
потому соответствующие операции предоставляются в качестве функций-членов класса списка.
Кроме того, в виде функций-членов предоставляются и некоторые другие операции, такие
как обращение последовательности, которое хотя и может быть выполнено при помощи
обобщенного алгоритма reverse и двунаправленных итераторов, которые предоставляет
класс list, но при применении специальных алгоритмов, использующих связные структуры
списков, может быть выполнено существенно эффективнее.
Функции-члены для вставок и удалений предоставляют по сути тот же интерфейс, что
векторы и деки, но с существенной разницей в производительности. Вставки и удаления в
произвольной позиции списка (а не только в концах) выполняются за константное время.
Связное представление списков обеспечивает, кроме того, выполнение некоторых дополни-
часть /. овооныи курс в &IL
тельных операций, именуемых склейкой, для передачи элементов из одной
последовательности в другую за константное время — эти операции также реализованы как функции-члены.
Другим существенным отличием от векторов и деков является то, что вставка в список
никогда не делает недействительными никакие итераторы, а удаления — только итераторы,
указывающие на удаленный элемент.
К спискам следует прибегать, когда по ходу работы программы требуется большое
количество вставок и/или удалений во внутренних позициях и практически не требуется
переходить из одной позиции в другую, весьма удаленную. Такие связные структуры часто
используются вместо массивов просто потому, что они в состоянии динамически увеличиваться;
однако то же "умеют" и векторы с деками и именно их стоит использовать, если возможность
динамического роста — единственная причина для применения связных структур.
Давайте начнем наше рассмотрение класса list с программы, которую мы уже
рассматривали при изучении векторов и деков (примеры 6.5 и 6.9).
Пример 6.10. Демонстрация функций списков STLpushback и pushfront
"ехОб-Ю.срр" 156 s
#include <iostream>
#include <cassert>
#include <list>
#include <string>
#include <algorithm> // Алгоритм reverse
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
list<char> listl =
make< list<char> >("Bjarne Stroustrup"),
list2;
list<char>::iterator i;
cout << "Демонстрация функции push_back класса list"
<< endl;
for (i = listl.begin(); i != listl.end(); ++i)
list2.push_back(*i);
assert (listl == list2);
listl = make< list<char> >("Bjarne Stroustrup");
list2 = make< list<char> >("");
cout << "Демонстрация функции push_front класса list"
<< endl;
for (i = listl.begin(); i != listl.end(); ++i)
list2.push_front(*i);
assert (list2 ==
make< list<char> >("purtsuortS enrajB"));
// Демонстрация того, что список list2 является
// обращенным по отношению к списку listl, с
// применением обобщенной функции STL reverse для
// обращения списка listl:
reverse(listl.begin(), listl.end());
assert (list2 == listl);
cout << " Ok." << endl;
/ лава о. i юслеоовательные контейнеры
return 0;
}
Эта программа получилась из версии, использующей деки, в результате простой подстановки
list вместо каждого deque и 1st вместо каждого deq. Обратите внимание, что
обобщенный алгоритм reverse остался применим, поскольку список предоставляет требующиеся
для него двунаправленные итераторы. Он выполняет обращение последовательности путем
перемещения элементов последовательности из одной позиции в другую путем
присваиваний, но для некоторых видов данных может оказаться более эффективным обращение путем
перекомпоновки структуры списка. Если данные представляют собой символы, как в
рассматривающейся программе, присваивания оказываются не дорогостоящими операциями, но
для больших элементов данных более эффективной может оказаться перекомпоновка.
Алгоритм перекомпоновки предоставлен в виде функции-члена, так что вызов обобщенного
алгоритма reverse может быть заменен на
listl.reverse();
В других случаях такая замена обобщенных алгоритмов на функции-члены list может
быть обязательной. Подобные примеры мы рассмотрим при рассмотрении функций-членов,
имеющихся у класса списка.
6.3.1. Типы
Класс list имеет те же шаблонные параметры Т и Allocator, что и у векторов и
деков, и определяет те же типы: value_type, iterator, reverse_iterator,
pointer, reference, dif f erence_type, size_type, const__iterator,
const_reverse_iterator, const_pointer и const_ref erence. Итераторы списков
представляют собой двунаправленные итераторы, а не итераторы с произвольным доступом,
так что некоторые обобщенные алгоритмы, такие как алгоритмы сортировки, не могут быть
применены к спискам.
6.3.2. Конструкторы
Класс list предоставляет тот же набор конструкторов, что и классы векторов и деков.
6.3.3. Вставка
Функции-члены insert класса list обеспечивают ту же функциональность, что и у
вектора и дека, но они всегда требует для вставки одного элемента только константного времени.
Имеется еще одно существенное различие: вставки никогда не делают недействительными
никакие итераторы или ссылки. Функция-член reserve у списков отсутствует за ненадобностью.
Функции-члены splice (раздел 6.3.5) также выполняют операции, подобные вставке.
6.3.4. Удаление
Класс list содержит функции-члены erase, аналогичные функциям векторов и деков. В
случае списков удаление любого элемента занимает константное время, и при этом
становятся недействительны только итераторы и ссылки на удаленные элементы.
Вот пример, аналогичный рассматривавшемуся для векторов (см. пример 6.8).
ТОО
часть I. Вводный курс в blL
Пример 6.11. Демонстрация функции erase списков STL
"ехОб-И.срр" 158 в
#include <iostream>
#include <cassert>
#include <list>
#include <string>
#include <algorithm> // Алгоритм find
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация функции erase списков STL."
<< endl;
list<char> listl = make< list<char> >("remembering");
list<char>::iterator j;
j = find (listl.begin () , listl.endO, ' i');
listl.erase(j++);
assert (listl == make< list<char> >("rememberng"));
// Теперь j указывает на 'п':
listl.erase(j++);
assert (listl == make< list<char> >("rememberg"));
// Теперь j указывает на 'g':
listl.erase(j++);
assert (listl == make< list<char> >("remember"));
listl.erase(listl.begin());
assert (listl == make< list<char> >("emember"));
listl.erase(listl.begin());
assert (listl == make< list<char> >("member"));
}
cout << " Ok." << endl;
return 0;
В вызовах
listl.erase(j++);
выполняются действия, не поддерживаемые ни векторами, ни деками, поскольку они делают
недействительными итераторы, указывающие на позиции после удаленной. В случае списков
итератор, возвращаемый выражением j++, представляет собой итератор j перед
инкрементом. Этот итератор становится недействительным, но это не относится к увеличенному
значению, которое можно продолжать использовать в последующих инструкциях (в версии с
вектором мы использовали j—и выполняли несколько отличающиеся вычисления). Обратите
внимание, что следующий код
listl.erase(j); j++;
который может показаться эквивалентным предыдущему, на самом деле некорректен, так как
вызов erase делает недействительным j до того, как к нему будет применена операция
инкремента.
Функции-члены splice, описанные далее, также выполняют операции, похожие на
удаление.
Глава о. / юслеоовательные контейнеры
1ЭУ
6.3.5. Склейка
Одним из больших преимуществ связных структур по сравнению с хранением данных в
последовательных позициях в плане производительности является возможность
перегруппировки последовательности путем изменения связей, которое выполняется за константное
время независимо от количества элементов. Класс list предоставляет следующие функции-
члены splice, использующие это преимущество (пример 6.12):
• listl.splice(il, list2), где il представляет собой корректный итератор
listl, вставляет содержимое list2 перед il, оставляя list2 пустым, listl и
list2 должны быть разными списками;
• listl. splice (il, list2, i2), где il представляет собой корректный
итератор listl, a i2 — корректный разыменуемый итератор list2, удаляет элемент, на
который указывает i2, и вставляет его перед il в listl; listl и list2 могут быть
одним и тем же списком;
• listl .splice (il, list2, i2, j2), где il представляет собой корректный
итератор listl, a [i2; j2) — корректный диапазон list2, удаляет элементы
диапазона и вставляет их перед il в listl; listl и list2 могут быть одним и тем же
списком.
Первые два варианта имеют константное время работы. В третьем варианте время работы
константное, если listl и list2 являются одним и тем же списком; в противном случае
время работы — линейное.
Пример 6.12. Демонстрация функций splice списков STL18
"ех06-12.срр" 159 =
#include <iostream>
#include <cassert>
#include <list>
#include <string>
#include <algorithm> // Алгоритм find
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация функций splice списков STL."
<< endl;
list<char> listl, list2, list3;
list<char>::iterator i, j, k;
// Пример splice(iterator, list<char>&):
listl = make< list<char> >("There is something "
"about science.");
Iist2 = make< list<char> >("fascinating ");
i = find(listl.begin(), listl.end(), 'a');
listl.splice(i, list2) ;
assert (listl ==
make< list<char> >("There is something fascinating
"about science."));
18 В некоторых местах в этом примере (а позже — ив других примерах книги) мы разбиваем
строковые литералы на части, для того чтобы лучше разместить их на печатном листе. Компилятор собирает
такие соседние строковые литералы в один; например: " а" " b " эквивалентно " ab".
760
часть I. ьвооныи курс в о / l
assert (list2 == make< list<char> >(""));
// Пример splice(iterator, list<char>&, iterator):
listl =
make< list<char> >("One gets such wholesale "
"return of conjecture");
list2 =
make< list<char> >("out of such a trifling "
"investment of fact.");
list3 = make< list<char> >(" of");
i = searchdistl .begin() , listl.end(),
list3.begin(), list3.end());
// i указывает на пробел перед "of";
j = find(list2.begin(), list2.end(), ' s'Jz-
listl. splice (i , list2/ j);
assert (listl ==
make< list<char> >("One gets such wholesale "
"returns of conjecture"));
assert (list2 ==
make< list<char> >("out of such a trifling "
"investment of fact."));
// Пример splice(iterator, list<char>&,
// iterator, iterator):
listl = make< list<char> >("Mark Twain");
list2 = make< list<char> >(" ");
j = find(list2.begin(), list2.end(), ' •);
k = find(++j, list2.end()/ ' *); // Второй пробел
// Выполняем перенос
listl.splice(listl.begin(), list2, j, k);
assert (listl ==
make< list<char> >(" Mark Twain"));
assert (list2 == make< list<char> >(" "));
return 0;
6.3.6. Функции-члены, связанные с сортировкой
Как уже говорилось, обобщенный алгоритм sort требует итераторов с произвольным
доступом, а потому не может работать со списками, которые имеют всего лишь
двунаправленные итераторы. Так что для сортировки списков можно использовать функцию-член
sort. Приведенный далее пример показывает простое применение sort с другой функцией-
членом, unique, которая удаляет последовательные дубли.
Пример 6.13. Демонстрация функций sort и unique списков STL
мех06-13.срр" 160 s
#include <iostream>
#include <cassert>
#include <string>
#include <list>
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация функций sort и unique "
Глэва 6. Последовательные контейнеры
161
<< "списков STL." << endl;
list<char> listl = make< list<char> >("Stroustrup");
listl.sort();
assert (listl == make< list<char> >("Soprrsttuu"));
listl.unique();
assert (listl == make< list<char> >("Soprstu"));
cout << " Ok." << endl;
return 0;
}
Функция-член sort имеет другую версию, для сортировки с заданной функцией сравнения:
template <typename Compare>
void sort(Compare comp);
Аналогично, unique имеет версию с шаблонным параметром, позволяющим сравнивать
последовательные элементы при помощи заданного бинарного предиката. Эти функция-член
отличается от обобщенной функции unique тем, что работает путем перекомпоновки, а не
присваивания.
template <typename BinaryPredicate>
void unique(BinaryPredicate comp);
Еще одна связанная с сортировкой функция-член списка— merge, которая выполняет
слияние текущего списка с другим, при этом предполагается, что оба списка отсортированы.
Имеется и шаблонная версия этой функции-члена:
void merge(const list<T>& otherList);
template <typename Compare>
void merge(const list<T>& otherList, Compare comp);
Как и в случае reverse, обобщенный алгоритм merge может использоваться и со
списками (ему достаточно входных итераторов), но операция слияния, представленная в виде
функции-члена, использует алгоритм на основе перекомпоновки, а не перемещения
элементов путем присваивания.
6.3.7. Удаление
Очередная операция, имеющая вид функции-члена по тем же причинам, что и функции-
члены reverse и merge, — remove, которая удаляет все элементы списка, равные
некоторому значению или для которых выполняется данный предикат:
void remove(const T& value);
template <typename Predicate>
void remove_if(Predicate pred);
В отличие от применения обобщенного алгоритма remove к другим видам
последовательностей, эти функции-члены remove уменьшают размер списка на количество удаленных
элементов.
6.3.8. Аксессоры
Класс list предоставляет все те же аксессоры, что и класс вектора— за исключением
capacity, operator [] и at, — а именно begin, end, rbegin, rend, size, max_size,
empty, front и back. Как и в случае векторов, все это функции с константным временем
/о/
Часть I. Вводный курс в STL
работы. Функция-член capacity опущен за ненадобностью, a at и operator [] —
поскольку в случае списков они имеют линейное время работы.
6.3.9. Отношения равенства и "меньше, чем"
Определения равенства и отношений упорядочения, рассмотренные в раздела 6.1.6,
относятся ко всем контейнерам STL, а значит, применимы и к спискам.
6.3.10. Присваивания
Определения функций-членов =, assign и swap, рассматривавшихся в разделе 6.1.7,
имеют соответствующие определения и время работы и для списков.
Глава 7
Отсортированные ассоциативные
контейнеры
Теперь мы перейдем к отсортированным ассоциативным контейнерам, которые
представляют собой еще одно семейство абстракций, отличающееся от уже рассмотренного в главе 6,
"Последовательные контейнеры". В то время как последовательные контейнеры хранят свои
данные линейно, с сохранением относительных позиций, в которые были вставлены
элементы, отсортированные ассоциативные контейнеры обходятся без этого порядка, а вместо этого
сосредотачиваются на максимальной скорости выборки на основе ключей, которые хранятся
в элементе (или, в некоторых случаях, представляют собой сам элемент).
Один общий подход к ассоциативной выборке состоит в хранении ключей в
отсортированном состоянии в соответствии с некоторым глобальным упорядочением, таким как числовой
порядок или лексикографический, если ключи являются строками, и использовании бинарного
алгоритма поиска. Еще одним подходом является хеширование: разделение пространства
ключей на несколько подмножеств и вставка каждого ключа в предназначенное ему подмножество;
после этого поиск выполняется только в одном подмножестве. Каждый ключ связан со своим
подмножеством при помощи так называемой хеш-функции. Первый подход —
отсортированные ассоциативные контейнеры — можно реализовать в том числе с использованием
сбалансированных бинарных деревьев поиска, а последний — хешированные ассоциативные
контейнеры — при помощи любого из множества представлений хеш-таблиц.
Основным преимуществом хеширования является константное среднее время вставки и
выборки, а подхода с сортировкой — в гарантированности производительности.
(Производительность операций с хеш-таблицами в худшем случае может быть очень низкой —
линейно зависящей от размера N, но для сбалансированных бинарных деревьев она всегда
составляет O(logTV).)
В идеале в стандартной библиотеке C++ должны были бы быть и отсортированные, и
хешированные ассоциативные контейнеры, но в нее оказались включены только
отсортированные ассоциативные контейнеры (имеются неофициальные спецификации хеш-таблиц и их
реализации; см. первую сноску в главе 6, "Последовательные контейнеры", на с. 138).
Отсортированными ассоциативными контейнерами STL являются классы set,
multiset, map и multimap. В случае множеств и мультимножеств элементами данных
являются сами ключи, причем мультимножество допускает наличие одинаковых ключей, а
множество — нет. В отображениях и мультиотображениях элементы данных представляют
собой пары, состоящие из ключей и собственно данных некоторого другого типа, причем
мультиотображение допускает наличие одинаковых ключей, а отображение — нет. Мы рас-
164
Часть I. Вводный курс в STL
сматриваем множества и мультимножества в разделе 7.1, а отображения и мультиотображе-
ния — в разделе 7.2.
Хотя их фундаментальная природа и различна, отсортированные ассоциативные контейнеры
обладают многими свойствами, присущими последовательным контейнерам, поскольку они
поддерживают обход элементов данных в виде линейной последовательности, с применением
таких же аксессоров контейнеров, что и у последовательных контейнеров. Они предоставляют
двунаправленные итераторы, обход с использованием которых дает отсортированный порядок
элементов. Фактически в некоторых случаях (например, когда элементы данных представляют
собой большие структуры) сортировка последовательности элементов может быть выполнена
более эффективно путем вставки их в мультимножество и обхода мультимножества, чем
обобщенным алгоритмом сортировки или соответствующей функцией-членом списка.
7.1. Множества и мультимножества
7.1.1. Типы
Параметры шаблонов set и multiset задаются как
template <typename Key, typename Compare = less<Key>,
class Allocator = allocator<Key> >
Первый параметр представляет собой тип хранимых ключей, второй— тип функции
сравнения, используемой для определения порядка, а третий — тип используемого аллокатора.
Оба класса предоставляют определения тех же типов, что и в последовательных
контейнерах— value_type (определен как тип Key), size_type, difference_type,
reference, pointer, iterator, reverse_iterator, const_ref erence,
const_pointer, const_iterator и const_reverse_iterator, — а также:
• key_type — определен как тип Key;
• key_compare — определен как тип Compare;
• value_compare — определен как тип Compare.
Эти классы определяют как key_compare, так и value_compare для совместимости с
тар и multimap, где они представляют собой разные типы.
Функция сравнения должна определять отношение упорядочения для ключей, которое
используется для определения их порядка при линейном обходе контейнера при помощи
поддерживаемых итераторов. Требования к данному отношению те же, что и уже
рассматривались в разделе 5.4 для отношений, используемых алгоритмами STL, связанными с
сортировкой. Отношение упорядочения используется также при выяснении эквивалентности
двух ключей. Два ключа, kl и к2, рассматриваются как эквивалентные, если
key_compare(kl, k2) == false && key_compare(k2, kl) == false
В большинстве простых случаев такое определение эквивалентности соответствует
оператору ==. Например, если ключи представляют собой любые встроенные числовые типы и
key_compare (kl, k2) == (kl < k2), то определение эквивалентности сводится к
выражению
! (kl < k2) && ! (k2 < kl)
которое является тем же отношением, что и вычисляемое как kl == k2. Однако, конечно
же, возможны и несогласованности этих определений. В качестве тривиального примера
предположим, что ключи представляют собой контейнеры vector<int>, и мы определяем
Глава 1. Отсортированные ассоциативные контейнеры
165
key_compare как сравнение только их первых элементов. Тогда любые два вектора, у
которых первые элементы одинаковы, рассматриваются key_compare как эквивалентные, но с
точки зрения оператора = = эти векторы различны, если у них имеются несовпадения в
некоторой другой позиции.
Важно помнить об этом (потенциальном) отличии, поскольку, как будет показано позже,
понятие эквивалентности ключей в отсортированных ассоциативных контейнерах
используется по-разному, в частности, в зависимости от того, должен элемент быть вставлен в
множество, исходя из наличия в нем дубликатов (т.е. эквивалентных элементов), или выполняется
ли поиск в мультимножестве всех ключей, эквивалентных заданному. В любом случае, когда
мы говорим об эквивалентности ключей, мы имеем в виду приведенное здесь определение, а
не оператор ==.
Итераторы множества и мультимножества представляют собой двунаправленные
итераторы, а не итераторы с произвольным доступом, так что некоторые обобщенные алгоритмы,
такие как алгоритмы сортировки, к множествам и мультимножествам не применимы. Однако
алгоритмы сортировки к ним и не требуется применять, поскольку эти контейнеры постоянно
поддерживают свое содержимое отсортированным.
7.1.2. Конструкторы
Конструкторами множества являются
set(const Compare& comp = Compare());
template <typename InputIterator>
set(Inputlterator first, Inputlterator last,
const Compare& comp = Compare());
set(const set<Key, Compare, Allocator>& otherSet);
Первый из них создает пустое множество, второй — множество с копиями элементов из
диапазона [first; last) (с удаленными дублями), а третий (копирующий конструктор) —
множество с теми же элементами, что и у otherSet. Первый и второй конструкторы
получают необязательный второй параметр типа Compare, по умолчанию равный Compare ().
Конструкторы мультимножества имеют тот же вид и тот же смысл, за исключением того, что
они не отбрасывают дублирующиеся элементы.
7.1.3. Вставка
Простейшая функция-член insert классов set и multiset получает единственный
аргумент типа value_type, который представляет собой тип Key, и вставляет копию аргумента.
Пример 7.1. Демонстрация создания множества и вставки в него
"ех07-01.срр" 165 =
#include <iostream>
#include <cassert>
#include <list>
#include <string>
#include <set>
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация создания множества "
166
Часть I. Вводный курс в STL
}
<< "и вставки в него." << endl;
list<char> listl =
make< list<char> >("There is no distinctly native "
"American criminal class");
// Размещение символов из listl в setl:
set<char> setl;
list<char>::iterator i;
for (i = listl.begin(); i != listl.end(); ++i)
setl.insert(*i);
// Размещение символов из setl в list2 :
list<char> list2;
set<char>::iterator k;
for (k = setl .begin () ; k != setl.endO; ++k)
list2.push_back(*k);
assert (list2 ==
make< list<char> >(" ATacdehilmnorstvy"));
return 0;
После вставки символов listl в setl мы изучаем содержимое множества, копируя его
в list2 с помощью цикла с переменной итераторного типа set<char>: : iterator и
функциями-членами begin и end, которые отсортированные ассоциативные контейнеры
предоставляют точно так же, как и последовательные контейнеры. Вызов assert
показывает, что последовательность символов в list 2, а значит, ив setl, является отсортированной
и не содержит дублей.
Вот программа, которая выполняет те же действия с мультимножествами вместо множеств.
Пример 7.2. Демонстрация создания мультимножества и вставки в него
"ех07-02.срр" 166 =
#include <iostream>
#include <cassert>
#include <list>
#include <string>
#include <set>
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Демонстрация создания мультимножества "
<< "и вставки в него." << endl;
list<char> listl =
make<list<char> >("There is no distinctly native "
"American criminal class");
// Размещение символов из listl в multisetl:
multiset<char> multisetl;
list<char>::iterator i;
for (i = listl.begin(); i != listl.end(); ++i)
multisetl.insert(*i);
// Размещение символов из multisetl в list2 :
list<char> list2;
Глава 1. Отсортированные ассоциативные контейнеры
167
multiset<char>::iterator к;
for (к = multisetl.begin(); к != multisetl.end(); ++k)
list2.push_back(*k);
assert (list2 ==
make< list<char> >(" ATaaaaccccdeeeehiiiiiii"
"lllmmnnnnnorrrsssstttvy"));
cout << " Ok." << endl;
return 0;
}
В этом случае вызов assert показывает наличие дубликатов.
Функция-член insert, использовавшаяся в этих примерах, имеет разные возвращаемые
типы в классах setn multiset. В классе set ее интерфейс представляет собой
pair<iterator, bool> insert(const value_type& x);
в то время как в классе multiset он имеет вид
iterator insert(const value_type& x);
В версии set возвращаемый итератор указывает на позицию х во множестве, независимо от
того, был такой элемент во множестве или нет, а значение bool равно true, если элемент
был вставлен, и false, если он уже имелся во множестве. В версии multiset элемент
всегда вставляется, так что значение типа bool излишнее.
Время работы insert равно O(logTV), где N— количество элементов, хранящихся во
множестве или мультимножестве.
Функция-член insert отличается от функций-членов insert последовательных
контейнеров тем, что ей не передается итератор, указывающий, куда следует вставить новый
элемент. Здесь позиция нового элемента вычисляется так, чтобы поддерживалась
упорядоченность элементов. Имеется, однако, еще одна функция-член insert множества и
мультимножества, которая получает аргумент-итератор и таким образом имеет тот же интерфейс,
что и в последовательных контейнерах:
iterator insert(iterator position, const value_type& x);
Эта функция все равно помещает х в позицию, диктуемую требованием упорядоченности
содержимого, рассматривая position исключительно как "подсказку", где именно начинать
поиск. Она имеет константное амортизированное время работы, если х вставляется или уже
присутствует в позиции position. Простая ситуация, когда используется эта
возможность, — это копирование некоторого уже отсортированного контейнера во множество или
мультимножество, например:
vector<int>::iterator i;
for (i = vectorl.begin(); i != vectorl.end(); ++i)
setl.insert(setl.end(), *i);
Этот код работает независимо от того, отсортированы ли элементы vectorl, требуя
O(TVlogTV) времени (где N есть vectorl.size ()), если они не отсортированы, и только
0(7V) в противном случае.
Поскольку итератор вставки, получающийся в результате вызова inserter, работает
посредством функции insert, предыдущий код можно переписать в виде
copy(vectorl.begin(), vectorl.end(),
inserter(setl, setl.end()));
В общем случае версия с "подсказкой" функции-члена insert для множеств и
мультимножеств полезна при работе в связке с обобщенными алгоритмами для теоретико-
168
Часть I. Вводный курс в STL
множественных операций над отсортированными структурами (includes, set_union,
set_intersection, set_difference и set_symmetric_difference). Например,
код
set_union(setl.begin(), setl.endO,
set2.begin(), set2.end(),
inserter(set3, set3.end()));
помещает объединение setl и set2 в set3 за время 0(Nl+N2), где Nx и N2 — размеры
setl и set2.
У классов множеств и мультимножеств имеется еще одна функция-член insert,
предназначенная для вставки элементов из диапазона:
template <typename InputIterator>
void insert(Inputlterator first, Inputlterator last);
Время ее работы — о(мlog(iV + М)), где М— размер диапазона, а N— размер множества
или мультимножества.
7.1.4. Удаление
Элементы из множества или мультимножества могут быть удалены либо по ключу, либо
по позиции: для удаления всех элементов с ключом к из множества или мультимножества
setl используется выражение
setl.erase(к);
Если setl является множеством, то в нем может быть не более одного элемента с ключом к;
если такого элемента нет, этот вызов функции не выполняет никаких действий. Если i —
корректный разыменуемый итератор setl, то выражение
setl.erase (i) ;
удаляет элемент, на который указывает i. В случае, когда setl представляет собой
мультимножество и в нем имеются другие копии *i, будет удалена только та копия, на которую
указывает i. Для иллюстрации сказанного в приведенной далее программе определим новую
функцию make_string, преобразующую любой контейнер символов STL в строку.
<Функция make_string (создание строки из контейнера) 168а> =
#include <functional>
template <typename Container>
string make_string(const Container& c)
{
string s;
copy(с.begin(), с.end(), inserter(s, s.end()));
return s;
}
Используется в частях 1686, 170.
В данном примере для поиска элемента по ключу используется один из аксессоров
мультимножества, find.
Пример 7.3. Демонстрация функций erase мультимножества
"ех07-03.срр" 1686 =
#include <iostream>
#include <cassert>
#include <list>
#include <string>
Глава 1. Отсортированные ассоциативные контейнеры
169
#include <set>
using namespace std;
<Функция make (создание контейнера символов) 53б>
<Функция make_string (создание строки из контейнера) 1б8а>
int main()
{
cout << "Демонстрация функций erase мультимножества"
<< endl;
list<char> listl =
make< list<char> >("There is no distinctly native "
"American criminal class");
// Размещение символов listl в multisetl:
multiset<char> multisetl;
copy(listl.begin(), listl.end(),
inserter(multisetl, multisetl.end() ) ) ;
assert (make_string(multisetl) ==
" ATaaaaccccdeeeehiiiiiiilll"
"mmnnnnnorrrsssstttvy");
multisetl.erase('a');
assert (make_string(multisetl) ==
" ATccccdeeeehiiiiiiilll"
"mmnnnnnorrrsssstttvy");
multiset<char>::iterator i = multisetl.find('e');
multisetl.erase (i) ;
assert (make_string(multisetl) ==
" ATccccdeeehiiiiiiilll"
"mmnnnnnorrrsssstttvy");
cout << " Ok." << endl;
return 0;
}
Первый вызов erase получает ключ а и из multisetl удаляются все элементы с этим
ключом. Второй вызов erase получает итератор i, который возвращает вызов find и который
указывает на элемент, содержащий один из символов е, что приводит к тому, что удаляется
только один этот элемент. Кстати, можно объединить вызовы findneraseB одной строке:
multisetl.erase(multisetl.find(■e■));
Так можно избежать объявления переменной-итератора.
Классы set и multiset предоставляют еще одну функцию-член erase, которая
удаляет все элементы из диапазона. Например, к концу приведенной программы можно добавить
следующие строки:
i = multisetl.find( "Г1) ;
multiset<char>::iterator j = multisetl.find('v');
multisetl.erase (i, j);
assert (make_string(multisetl) == " Avy");
Все функции-члены erase имеют время работы О (log TV + E^, где N— размер множества
или мультимножества, &Е — количество удаляемых элементов.
170
Часть I. Вводный курс в STL
7.1.5. Аксессоры
Множества и мультимножества в основном имеют те же аксессоры, что и
последовательные контейнеры, использующиеся для получения информации об элементах линейной
отсортированной последовательности: begin, end, rbegin, rend, empty, size и max_size.
Как обычно, аксессоры, возвращающие итераторы, имеют версии, возвращающие
константные итераторы при применении их к константным множествам или мультимножествам.
Однако эти контейнеры имеют ряд функций-членов для получения информации по ключу:
find, lower_bound, upper_bound, equal_range и count.
Примеры использования find были приведены в разделе 7.1.4. Важно понимать отличие
между этой функцией-членом и обобщенным алгоритмом find. Как указывалось в
разделе 4.12, основное отличие заключается в эффективности: функция-член find множества или
мультимножества выполняется за время O(logTV), где N— размер контейнера, а
обобщенный алгоритм find— за время O(TV). Функция-член find гораздо эффективнее потому,
что использует тот факт, что ключи находятся в отсортированном порядке, так что можно
выполнить бинарный поиск, в то время как обобщенный алгоритм find выполняет
линейный поиск.
Еще одно отличие между функцией-членом find и обобщенным алгоритмом find в случае
мультимножеств заключается в элементе, на который указывает возвращаемый итератор.
Обобщенный алгоритм find возвращает позицию первого члена с данным ключом, но в случае
функции-члена find не указано, какой именно из имеющихся в мультимножестве одинаковых
ключей возвращается. Если важно получить первую позицию, то следует использовать
функцию-член lower_bound, а функция-член upper_bound возвращает итератор, указывающий
на позицию, следующую за концом диапазона позиций, содержащих интересующий нас ключ.
Пример 7.4. Демонстрация функций-членов мультимножества для поиска
"ех07-04.срр" 170 =
#include <iostream>
#include <cassert>
#include <list>
#include <string>
#include <set>
using namespace std;
<Функция make (создание контейнера символов) 53б>
<Функция make_string (создание строки из контейнера) 168а>
int main()
{
cout << "Демонстрация функций-членов "
<< "мультимножества для поиска." << endl;
list<char> listl =
make<list<char> >("There is no distinctly native "
"American criminal class"),
list2 =
make<list<char> >("except Congress. - Mark Twain");
// Размещение символов listl в multisetl:
multiset<char> multisetl;
copy(listl.begin(), listl.end(),
inserter(multisetl, multisetl.end()));
assert (make_string(multisetl) ==
Глава 1. Отсортированные ассоциативные контейнеры
171
" ATaaaaccccdeeeehiiiiiiilll"
"mmnnnnnorrrsssstttvy");
multiset<char>::iterator
i = multisetl.lower_bound('с'),
j = multisetl.upper_bound('r');
multisetl.erase(i, j);
assert (make_string(multisetl) ==
" ATaaaasssstttvy");
list<char> found, not_found;
list<char>::iterator k;
for (k = list2.begin(); к != Iist2.end(); ++k)
if (multisetl.find(*k) != multisetl.end())
found.push_back(*k);
else
not_found.push_back(*k);
assert (found == make< list<char> >("t ss а Та"));
assert (not_found ==
make< list<char> >("excepCongre.-Mrkwin"));
cout << " Ok." << endl;
return 0;
}
Можно рассматривать lower_bound как функцию, возвращающую первую позицию,
куда может быть вставлен ключ так, чтобы сохранилась отсортированность
последовательности, a upper_bound— как возвращающую последнюю такую позицию. Эти утверждения
истинны независимо от наличия ключа в контейнере. (Это тот же смысл, который имеют
обобщенные алгоритмы lower_bound и upper_bound при работе с отсортированными
последовательностями.)
Последняя часть программы выполняет поиск в multisetl каждого из символов list2
и помещает найденные символы в список found, а не найденные — в not_f ound.
Если нам нужны результаты lower_bound и upper_bound для одного и того же ключа,
их можно получить одновременно, вызвав функцию equal_range, которая возвращает пару
итераторов. Свое имя данная функция получила потому, что возвращаемые ею итераторы
определяют диапазон элементов, эквивалентных данному ключу. Этот диапазон пустой
(итераторы равны), если искомого элемента в контейнере нет.
Наконец, count возвращает расстояние от позиции lower_bound до позиции
upper_bound, которое равно количеству элементов, эквивалентных данному ключу. В
качестве примера использования equal_range и count можно добавить в конец предыдущей
программы следующие строки:
assert (make_string(multisetl) ==
" ATaaaasssstttvy");
i = multisetl.lower_bound('s');
j = multisetl.upper_bound('s');
pair<multiset<char>::iterator,
multiset<char>::iterator>
p = multisetl.equal_range('s');
assert (p.first == i && p.second == j);
assert (multisetl.count('s■) == 4);
multisetl.erase(p.first, p.second);
172
Часть I. Вводный курс в STL
assert (multisetl.count('s■) == 0);
assert (make_string(multisetl) ==
ATaaaatttvy");
Каждая функция поиска (за исключением count) имеет версию, возвращающую
константный итератор (или, в случае equal_range, пару константных итераторов) при применении
к константному контейнеру. Заметим, что хотя мы иллюстрировали применение функций
только к мультимножествам, каждая из них определена и для множеств. В случае множеств
функция-член count всегда возвращает либо 0, либо 1.
При работе с функциями поиска следует не забывать, что их смысл зависит от смысла
эквивалентности, которая определяется в терминах функции key_compare, а не оператором ==.
Все функции-члены для поиска выполняются за время O(logTV), где N— размер
множества или мультимножества, за исключением count, которой требуется время 0(\ogN + Е^,
где Е — количество элементов с заданным ключом.
7.1.6. Отношения эквивалентности и "меньше, чем"
Вспомним определение эквивалентности контейнеров, которое применимо ко всем
контейнерам STL (см. раздел 6.1.6):
• содержащиеся в них последовательности должны иметь одинаковую длину;
• элементы в соответствующих позициях должны быть эквивалентны, что определяется
оператором == типа элементов.
При применении ко множествам и мультимножествам STL с их свойством содержания
элементов в отсортированном порядке это определение отвечает нашим ожиданиям,
основанным на понятиях "множества" и "мультимножества" из математики. То есть, два
множества эквивалентны, если содержат одни и те же элементы — не важно, в каком именно
порядке. Два мультимножества эквивалентны, если содержат одинаковое количество каждого
элемента, опять же независимо от их порядка. Вместе с обобщенными алгоритмами STL для
выполнения теоретико-множественных операций над отсортированными структурами
(includes, set_union, set_intersection, set_difference и
set_symmetric_dif f erence) эти свойства обеспечивают возможность выполнения всех
основных и наиболее полезных вычислений со множествами и мультимножествами.
В действительности все не так просто, поскольку понятие "одинаковости" в данном
случае представляет собой не что иное, как отношение эквивалентности, определяемое функцией
key_compare: два ключа kl и к2 рассматриваются как эквивалентные, если
key_compare(kl, k2) == false && key_compare(k2, kl) == false
Как упоминалось в разделе 7.1.1, это определение не всегда идентично отношению,
вычисляемому оператором = = элементов. Если эти два отношения не согласованы, можно
получить несколько неожиданные результаты при проверке эквивалентности множеств и
мультимножеств.
Аналогичная проблема имеется и для оператора operator< для множеств и
мультимножеств, поскольку общее определение этого оператора для всех контейнеров использует
обобщенный алгоритм lexicographical_compare, который, в свою очередь, использует
оператор <, определенный для типа элементов. Если key_compare не сравнивает ключи так
же, как и оператор < для этого типа, сравнение множеств и мультимножеств может дать не
тот результат, который вы ожидаете.
Глава 1. Отсортированные ассоциативные контейнеры
173
7.1.7. Присваивание
Как уже упоминалось в разделе 6.1.7, operator^ определен для всех контейнеров STL,
так что х = у делает истинным х == у. Это операция с линейным временем работы. У
отсортированных ассоциативных контейнеров функции-члена assign не имеется, но есть
функция-член swap, обменивающая при помощи вызова х. swap (у) значения х и у за
константное время. Существует соответствующая специализация обобщенного алгоритма swap,
вызывающая использование соответствующей функции-члена swap.
7.2. Отображения и мультиотображения
Контейнеры отображений могут рассматриваться как массивы, индексированные
ключами некоторого произвольного типа Key, а не целыми числами 0,1,2,... . Они представляют
собой отсортированные ассоциативные контейнеры, обеспечивающие быструю выборку
информации некоторого типа Т на основе ключей другого типа Key, причем все сохраненные
ключи единственны. Мультиотображения обладают той же функциональностью, но
допускают дублирующиеся ключи. Отношения мультиотображений и отображений те же, что и
отношения мультимножеств и множеств.
Отображения и мультиотображения можно рассматривать как множества и
мультимножества, у которых с каждым ключом хранится дополнительная информация типа Т. Эти
дополнительные данные не влияют на способ поиска информации в контейнере или обхода его
элементов и играют роль только в некоторых дополнительных операциях, предназначенных
специально для их хранения и выборки. Наше рассмотрение отображений и
мультиотображений основывается на этом соображении, а потому будет достаточно коротким.
Конечно, можно было бы начать рассмотрение отсортированных ассоциативных
контейнеров с отображений и мультиотображений, а затем заявить, что множества и
мультимножества представляют собой отображения и мультиотображения, в которых не используются
дополнительные данные. Возможно, это лучший способ представления, поскольку отображения и
мультиотображения имеют более широкое применение, чем множества и мультимножества, но
мы решили начать именно с последних, так как они немного проще и их легче
проиллюстрировать маленькими программами-примерами. В этой главе мы представим только несколько
примеров отображений и мультиотображений, но вы еще встретитесь с ними в главах 14,
"Улучшенная программа поиска групп анаграмм", 15, "Ускорение программы поиска анаграмм:
использование мультиотображений", 18, "Программа вывода дерева ученых в области теории
вычислительных машин и систем", и 19, "Класс для хронометража обобщенных алгоритмов".
Возвращаясь к аналогии, с которой мы начали, массивы (а также векторы и деки)
предоставляют возможности отображений, ключи которых являются целыми числами из некоторого
диапазона 0,1,2,...,7V-1 для некоторого неотрицательного целого N. При высокой
эффективности они достаточно ограничены по сравнению с контейнерами отображений, во-первых
тем, что позволяют применять в качестве ключей только целые числа, а во-вторых, тем, что
требуют большого количества памяти, пропорционального N, даже если связанные с ними
данные имеет лишь небольшой процент ключей. Отображения и мультиотображения
преодолевают оба ограничения, допуская ключи почти любого типа и используя количество памяти,
пропорциональное количеству фактически сохраненных ключей.
Даже с целочисленными ключами "разреженное представление", обеспечиваемое
отображениями и мультиотображениями, может существенно сэкономить память и время
вычислений, как будет показано в разделе 7.2.3 в примере вычисления скалярного произведения двух
разреженных векторов (где под вектором мы подразумеваем кортеж из N чисел; он будет
представлен как тар, а не vector). К примерам отображений и мультиотображений с неце-
174
Часть I. Вводный курс в STL
лыми ключами мы перейдем в главах 14, "Улучшенная программа поиска групп анаграмм",
и 15, "Ускорение программы поиска анаграмм: использование мультиотображений".
7.2.1. Типы
Шаблонные параметры тар и multimap задаются следующим образом:
template <typename Key, typename T,
typename Compare = less<Key>,
class Allocator = allocator<pair<const Key, T> > >
Первый параметр представляет собой тип хранимых ключей, второй — тип объектов,
ассоциированных с ключами, третий — функцию сравнения, используемую для определения
порядка элементов, а четвертый — используемый аллокатор. Это те же параметры, что и у
множеств и мультимножеств, за исключением дополнительного параметра Т.
Оба класса предоставляют определения тех же типов, что и последовательные контейнеры:
value_type (который определен как тип pair<const Key, T>), pointer, reference,
iterator, reverse_iterator, difference_type, size_type, const_iterator,
const_reverse_iterator, const_pointer и const_ref erence, а также следующие:
• key_type — определен как тип Key;
• key_compare — определен как тип Compare;
• value_compare — функциональный тип, определенный для сравнения двух
объектов value_type на основе их ключей:
class value_compare
: public binary_function<value_type, value_type, bool>
{
protected:
Compare comp;
value_compare(Compare c) : comp(c) { }
public:
bool operator()(const value_type& x,
const value_type& y) const {
return comp(x.first, y.first);
}
};
Как и в случае множеств и мультимножеств, типы итераторов отображений и
мультиотображений двунаправленные и произвольный доступ не поддерживают.
7.2.2. Конструкторы
Конструкторы отображений и мультиотображений имеют тот же вид, что и конструкторы
множеств и мультимножеств, и то же отличие друг от друга: при создании отображения из
диапазона дублирующиеся ключи удаляются, а при создании мультиотображения — остаются
в нем. Временные границы те же, что и для конструкторов множеств и мультимножеств.
7.2.3. Вставка
Вставки в отображения и мультиотображения могут выполняться при помощи функций-
членов insert, которые имеют те же интерфейсы, что и соответствующие функции
множеств и мультимножеств. Заметим, однако, что здесь value_type представляет собой не
просто Key, a pair<const Key, T>; т.е., один аргумент типа value_type, переданный
функции-члену insert, содержит как значение типа Key, так и типа Т. Уже вставленные
пары можно изменять только присваиванием новых значений их членам Т; спецификатор
Глава 1. Отсортированные ассоциативные контейнеры
175
const перед Key предотвращает изменение ключа. Это ограничение критично для
целостности внутреннего представления отображения.
Еще один способ вставки в отображение использует operator [] :
mapl [k] = t;
Если в mapl нет пары с ключом к, то в него будет вставлена пара (к, t). Если же в нем уже
имеется пара (к, to) с некоторым значением to, то to заменяется на t. Еще один способ
выполнить такую замену (отклонимся на секунду от темы вставки) — воспользоваться
выражением
i->second = t;
где i представляет собой тар<Кеу, Т> : : iterator такой, что i->f irst == k. (Но мы
не можем записать i->first = kl, поскольку i->first является константным членом
value type.)
Возвращаясь к operator [], следует сказать, что он не определен для мультиотображе-
ний. Это может показаться сюрпризом, но если бы он был определен, то во многих случаях
сюрпризы были бы большими и существенно неприятнее. Связанное значение, например,
должно было бы обновляться для всех пар (ключ, значение) с одинаковыми ключами, чтобы
обеспечить выполнение требования, согласно которому присваивание multimapl [k] = v
гарантирует сразу же после его выполнения равенство multimapl [к] == v. Такой эффект
вряд ли желателен в большинстве случаев.
Но даже в случае отображений может возникнуть неожиданная ситуация: operator []
может привести к вставке в отображение просто потому, что он имеется в выражении,
причем необязательно в левой части присваивания. То есть, наличие
mapl[k]
в любом выражении возвращает значение Т, связанное с ключом к, если таковой имеется; но
если такого ключа в отображении не имеется, то в него будет вставлена пара (к, Т () ) и
указанное выражение вернет Т (). См. также вторую сноску в главе 6, "Последовательные
контейнеры", на стр. 140 о смысле Т () для встроенных типов наподобие int.
Рассмотрим некоторые примеры вставки с использованием operator []. В процессе
рассмотрения мы будем отмечать сходства и отличия между отображением и массивом, а
также векторами и деками. Рассмотрим проблему вычисления скалярного произведения двух
векторов действительных чисел. Здесь слово "вектор" мы используем в традиционном
математическом смысле, как означающее кортеж действительных чисел, а не как вектор STL.
Далее во избежание путаницы мы будем использовать термин кортеж. Если х = (х0,х1,...,хп_1) и
У - (У о j У\ j • • • j Уп-\)' то скалярное произведение х и у определяется как
п-\
/=0
Если х и у хранятся в массивах, векторах или деках, то скалярное произведение легко
вычислить следующим образом:
double sum = 0;
for (int i = 0; i < n; ++i)
sum += x[i] * у [i] ;
Имеется также обобщенный алгоритм STL inner_product, который можно
использовать для этой цели (см. раздел 5.5.4). Но предположим, что мы работаем с разреженными
кортежами, т.е. такими, у которых большинство элементов равны 0. Предположим,
например, что N равно миллиону, новхи^ имеется только несколько тысяч ненулевых элементов.
Ни показанный выше цикл for, ни обобщенный алгоритм STL inner_product не
используют преимущества разреженности; оба варианта будут "тупо" вычислять и суммировать
миллион произведений.
176
Часть I. Вводный курс в STL
Хранение х и у в отображениях, а не в векторах, причем хранение только ненулевых
элементов, позволяет существенно уменьшить затраты памяти. Далее, точно так же можно
сократить и время вычисления скалярного произведения — путем обхода ненулевых элементов
одного из кортежей.
Перед тем как рассмотреть версию с отображениями, обратимся к векторам.
Пример 7.5. Вычисление скалярного произведения кортежей,
представленных векторами
"ех07-05.срр" 176 =
#include <vector>
#include <iostream>
using namespace std;
int main()
{
cout << "Вычисление скалярного произведения\п"
<< "кортежей, представленных векторами."
<< endl;
const long N = 600000; // Длина кортежей х и у
const long S = 10; // Коэффициент разреженности
cout << "\пИнициализация..." << flush;
vector<double> x(N), y(N);
long k;
for (k = 0; 3 * k * S < N; ++k)
x[3 * k * S] = 1.0;
for (k = 0; 5 * k * S < N; ++k)
у[5 * k * S] = 1.0;
cout << "\п\пВычисление скалярного произведения "
<< "методом грубой силы: " << flush;
double sum = 0.0;
for (k = 0; k < N; ++k)
sum += x [k] * у [k] ;
cout << sum << endl;
return 0;
Вывод примера 7.5
Вычисление скалярного произведения
кортежей, представленных векторами.
Инициализация...
Вычисление скалярного произведения методом грубой силы: 4 000
Для инициализации х и у в этой программе использован конструктор вектора, принимающий
два аргумента, так что векторы после инициализации имеют по N элементов, равных 0.0. Это
важно, поскольку operator [] у вектора не приводит к увеличению последнего при запросе
индекса, превышающего текущий размер. Отображения не требуют такой инициализации,
поскольку никаких ограничений, кроме ограничений, накладываемых самим их типом, на размер
индексов (ключей) не накладывается. Можно начать работать с пустыми отображениями:
map<long, double> х, у;
Глава 1. Отсортированные ассоциативные контейнеры
177
Вычисление скалярного произведения теперь можно записать следующим образом:
map<long, double>::iterator ix, iy;
for (sum = 0.0, ix = x.beginO; ix != x. end () ; + + ix) {
long k = ix->first;
if (y.find(k) != y.end())
sum += x [k] * у [k] ;
}
где используется функция-член find отображения, которая имеет тот же смысл, что и для
множеств и мультимножеств: поиск заданного ключа и возврат итератора, указывающего на
запись с ключом, если таковой найден, или на позицию в контейнере, следующую за
последней, если не найден.
Вычисление у [к] включает, по сути, тот же поиск, но его повторения можно избежать,
сохраняя и разыменовывая итератор, возвращаемый вызовом у. find (к), для получения
значения у [к] . Аналогично, можно избежать неявного поиска и при получении х [к] путем
разыменования ix.
Пример 7.6. Вычисление скалярного произведения кортежей,
представленных отображениями
"ех07-0б.срр" 177 =
#include <map>
#include <iostream>
using namespace std;
int main()
{
cout << "Вычисление скалярного произведения кортежей,\п"
<< "представленных отображениями." << endl;
const long N = 600000; // Длины кортежей х и у
const long S = 10; // Коэффициент разреженности
cout << "\пИнициализация..." << flush;
map<long, double> x, у;
long k;
for (k = 0; 3 * k * S < N; ++k)
x[3 * k * S] = 1.0;
for (k = 0; 5 * k * S < N; ++k)
у[5 * k * S] = 1.0;
cout << "\п\пВычисление скалярного произведения\п"
<< "с учетом разреженности: " << flush;
double sum;
map<long, double>::iterator ix, iy;
for (sum =0.0, ix = x.beginO ; ix != x. end () ; + + ix) {
long i = ix->first;
iy = у.find(i);
if (iy != у.end())
sum += ix->second * iy->second;
}
cout << sum << endl;
return 0;
}
178
Часть I. Вводный курс в STL
Вывод примера 7.6
Вычисление скалярного произведения кортежей,
представленных отображениями.
Инициализация...
Вычисление скалярного произведения
с учетом разреженности: 4000
Эта программа выполняет только 4 000 сложений и 4 000 умножений вместо 600 000 в
исходной программе. Приведенная ниже таблица показывает также количество индексирований и
операций с итераторами, а также шагов, выполняемых операциями find. Вычисления
основаны на том факте, что в х хранятся 600 000/30 = 20 000 записей, а в у —
600 000/50 = 12 000 и в предположении, что в среднем каждая из 20000 операций find над
у требует log212 000 «13.5 шагов поиска.
Операции Использование векторов Использование отображений
Сложения 600000 4000
Умножения 600000 4000
Инкремент++к 600000
Итерирование + + ix 20000
Разыменование х [к] 600000
Разыменование *ix 20000
Разыменование у [к] 600000
Шаги поиска в у. f ind (i) 270 000
Разыменование *iy 12000
7.2.4. Удаление
Как и в случае множеств и мультимножеств, элементы из отображений и мультиотобра-
жений могут быть удалены по ключу или по позиции. Данные типа Т не играют никакой роли
в операциях удаления, так что эти операции ведут себя в точности так же, как и в случае
множеств и мультимножеств и имеют то же самое время работы 0(\ogN + Е^, где N—
размер отображения или мультиотображения, а Е — количество удаляемых элементов.
7.2.5. Аксессоры
И вновь все очень похоже на множества и мультимножества. Отображения и
мультиотображения имеют те же аксессоры, что и множества и мультимножества для обращения к
информации об элементах как о линейной, отсортированной последовательности: begin, end,
rbegin, rend, empty, size и max_size. Они имеют также одинаковые со множествами и
мультимножествами функции-члены для получения информации по ключу: find,
lower_bound, upper_bound и equal_range, а также count. Отображения имеют
новый аксессор operator [] . Этот аксессор неприменим к мультиотображениям, поскольку в
них с одним ключом могут быть связаны несколько элементов. Временные границы всех
операций поиска, включая operator [], одинаковы— O(logTV), где N— размер отображения
Глава 1. Отсортированные ассоциативные контейнеры
179
или мультиотображения. Единственным исключением является count со временем работы
(9(log7V + £), где Е — количество элементов с данным ключом.
7.2.6. Отношения равенства и "меньше, чем"
В основном отношения равенства и "меньше, чем" у отображений и мультиотображений
обладают теми же свойствами, что и у множеств и мультимножеств. Единственное отличие
заключается в наличии дополнительной информации типа Т, означающем менее частую
согласованность эквивалентности ключей с оператором value_type: :operator==, поскольку
последний, в отличие от key_compare, (обычно) учитывает член типа Т. То же самое
замечание относится и к различиям между key_compare и value_type : : operators.
7.2.7. Присваивания
Определениям оператора = и функции-члена swap, рассматривавшимся в разделе 6.1.7,
соответствуют аналогичные определения с тем же временем работы для отображений и
мультиотображений.
Глава 8
функциональные объекты
Теперь перейдем к четвертому типу компонентов STL, а именно — к функциональным
объектам. Большинство обобщенных алгоритмов STL (и некоторые классы контейнеров)
принимает в качестве параметра функциональный объект, что делает возможным влиять на
вычисления способом, отличным от управления итераторами. Функциональный объект
представляет собой любую сущность, которая может быть применена к нулю или большему
количеству элементов для получения значения и/или изменения состояния вычислений. В
программировании на C++ любая обычная функция отвечает этому определению, но ему же
отвечает и объект любого класса (или структуры), который перегружает оператор вызова
функции operator (). Как мы видели в разделе 2.4, как обычная функция типа
Определение multfun 181a> =
int multfun(int х, int у) { return x * у; }
Используется в части 182.
так и объект multf unobj типа multiply, определенного как
«^Определение multiply и multfunobj 181б> ■
class multiply {
public:
int operator()(int x, int y) const { return x * y; }
};
multiply multfunobj;
Используется в части 183.
могут быть применены к паре целочисленных аргументов, как показано ниже:
int productl = multfun(3, 7);
int product2 = multfunobj(3, 7);
В случае объекта типа multiply применяемая функция представляет собой функцию,
определенную в классе в качестве перегрузки оператора operator () для пары аргументов типа int.
Имеется несколько причин, по которым лучше определять функциональный объект, чем
использовать обычное хорошо знакомое определение функции. Поскольку эти причины связаны с идеей
функций, которые используют в качестве параметров для изменения поведения другие функции,
давайте сначала рассмотрим способы определения таких функциональных параметров.
8.1. Передача функций через указатели
Рассмотрим обобщенную функцию STL accumulate, которая, будучи вызвана с
итераторами first и last и значением init, прибавляет к init значения в позициях, начиная с
182
Часть I. Вводный курс в STL
first и заканчивая last (не включая последнюю), и возвращает получившуюся сумму. Ее
можно запрограммировать следующим образом:
template <typename InputIterator, typename T>
T accumulate(InputIterator first, Inputlterator last,
T init)
{
while (first != last) {
init = init + *first;
++first;
}
return init;
}
Но вместо сложения мы хотим разрешить использовать любую функцию, принимающую два
аргумента, причем чтобы ее можно было передать в качестве еще одного аргумента функции
accumulate. Традиционный метод достижения этой цели в С и C++ заключается в
объявлении дополнительного параметра, имеющего тип указателя на функцию; при вызове в качестве
фактического параметра передается адрес функции, такой как &mult, как показано в
следующем примере программы.19
•
Пример 8.1. Расширенное определение и вызов accumulate
"ех08-01.срр" 182 =
#include <iostream>
#include <cassert>
#include <vector>
using namespace std;
template <typename Inputlterator, typename T>
T accumulatel(Inputlterator first, Inputlterator last,
T init,
T (*binary_function)(T x, Ту)) // Новый параметр
while (first != last) {
init = (*binary_function)(init, *first);
++first;
}
return init;
}
<Определение multfun 181a>
int main()
{
cout << "Демонстрация передачи указателя на функцию."
<< endl;
int x[5] = {2, 3, 5, 7, 11};
// Инициализация vectorl значениями от х[0] до х[4]:
vector<int> vectorl(&x[0], &х[5]);
int product = accumulatel(vectorl.begin(),
vectorl.end(),
1, &multfun);
assert (product == 2310);
Читателям, не знакомым с передачей указателей на функции, нет необходимости пытаться
расшифровывать синтаксис нового формального параметра. Даже в ситуациях, которые будут рассмотрены
позже, и где желательно применение указателей на функции, при помощи адаптера "указатель на
функцию" обеспечивается простой синтаксис (см. раздел 11.3).
Глэва 8. Функциональные объекты
183
cout << " Ок." << endl;
return 0;
}
Одна фундаментальная проблема при таком традиционном подходе заключается в том, что он
не настолько обобщенный, насколько мог бы быть. Например, прототип указателя на
функцию записан как
Т (*binary_function)(Т х, Т у)
и он соответствует функции int mult fun (int, int), но если записать
Т (*binary_function)(const T& x, const T& у)
с тем, чтобы использовать более эффективную передачу параметров при больших размерах
типа Т, то наша функция mult fun не будет соответствовать этому типу, и ее придется
переписать с прототипом int multfun (const int&, const int&). Другая проблема
связана с эффективностью: в accumulate 1 мы должны выполнить разыменование указателя
для получения переданной функции, а затем вызвать ее (передав ей параметры, управление,
скопировав затем возвращаемое значение и передав управление в точку вызова). В случае
функций наподобие multfun эти шаги могут оказаться более дорогостоящими, чем
вычисления в самой функции, требующие одной-двух машинных команд.
8.2. Преимущества передачи функциональных
объектов как параметров шаблонов
К счастью, и проблема обобщенности, и проблема эффективности решаются путем
применения другого метода объявления параметра, являющегося функциональным объектом: он
объявляется как параметр шаблона, как показано в приведенном далее примере.
Пример 8.2. Расширенное определение и вызов accumulate
"ех08-02.срр" 183 в
#include <iostream>
#include <cassert>
#include <vector>
using namespace std;
template <typename InputIterator, typename T,
typename BinaryFunction>
T accumulate(Inputlterator first, Inputlterator last,
T init, Binary-Function binary_function)
{
while (first != last) {
init = binary_function(init, *first);
++first;
}
return init;
}
<Определение multiply и multfunobj 1816>
int main()
{
cout << "Демонстрация передачи функционального "
<< "объекта." << endl;
int x[5] = {2, 3, 5, 7, 11};
184
Часть I. Вводный курс в STL
// Инициализация vectorl значениями от х[0] до х[4]:
vector<int> vectorl(&х[0], &х[5]);
int product = accumulate(vectorl.begin(),
vectorl.end(),
1, multfunobj);
assert (product == 2310) ;
cout << " Ok." << endl;
return 0;
}
При таком определении accumulate (которое представляет собой вполне приемлемую
реализацию обобщенного алгоритма STL с этим именем) требования к типу передаваемого в
качестве последнего аргумента фактического параметра определяются его применением в
функции accumulate: он должен быть применим к двум аргументам типов Т1 и Т2, где Т
преобразуем в Т1, а значение типа Input Iterator преобразуем в Т2, а возвращаемый им
тип должен быть преобразуем Т. Таким образом оказываются приемлемыми многие
прототипы функций, — в противоположность строгому определению типа при передаче указателя на
функцию. Кроме того, теперь можно применять и функциональные объекты, определенные
как объекты класса, перегружающего оператор вызова функции, наподобие multfunobj,
которые в accumulatel использоваться не могли.
Что касается эффективности, то при передаче функционального объекта через параметр
шаблона и перегрузке оператора operator () компилятор может выполнить встраивание
вызова binary__function в теле accumulate, тем самым полностью устранив все
дополнительные шаги по разыменованию указателя и вызову функции по адресу.
В дополнение к обобщенности и эффективности, имеется еще одно преимущество
применения объектов класса в качестве функциональных объектов. Объекты класса могут
содержать дополнительную информацию, такую как определения типов, упрощающие
функциональным адаптерам задачу создания разновидностей функции помимо базового определения
перегрузки operator () (этот вопрос рассматривается в главе 11, "Функциональные
адаптеры"). Поскольку объекты класса могут иметь данные-члены, можно легко определять
функции, сохраняющие состояние между вызовами. В приведенных далее двух примерах эта
возможность используется для определения функционального объекта сравнения, который не
только сравнивает два значения, но и увеличивает значение счетчика. При его применении в
алгоритме сортировки он записывает количество выполненных в процессе сортировки
сравнений. В первой версии счетчик поддерживается как статический член класса
long_counter, определяющего функциональный объект подсчета для сравнений.
<Определение класса less со статическим счетчиком 184> =
template <typename T>
class less_with_count : public binary_function<T, T, bool> {
public:
less_with_count() { }
bool operator()(const T& x, const T& y) {
++counter;
return x < y;
long report() const {return counter;}
static long counter;
};
template <typename T>
long less_with_count<T>::counter = 0;
Используется в части 185.
Глава 8. Функциональные объекты
185
При использовании статических членов-данных имеется только одно место в памяти для всех
объектов класса; таким образом, не имеет значения, сколько объектов будет создано в
процессе работы алгоритма сортировки — все они будут увеличивать один и тот же счетчик, и
по окончании работы в нем будет храниться количество выполненных сравнений.
Пример 8.3. Использование функционального объекта для подсчета
операций, первая версия
»ех08-03.сррп 185 =
#include <iostream>
#include <iomanip>
#include <cassert>
#include <vector>
#include <algorithm>
#include <functional>
using namespace std;
Определение класса less со статическим счетчиком 184>
int main()
}
cout << "Использование функционального объекта для\п"
<< "подсчета операций, первая версия." << endl;
const long N1 = 1000, N2 = 128000;
for (long N = N1; N <= N2; N *= 2) {
vector<int> vectorl;
for (int k = 0; k < N; ++k)
vectorl.push_back(k);
random_shuffie(vectorl.begin(), vectorl.end());
less_with_count<int> comp_counter;
less_with_count<int>::counter = 0;
sort(vectorl.begin(), vectorl.end(),
comp_counter);
cout << "Размер задачи " << setw(9) << N
<< ", выполнено сравнений: "
<< setw(9) << comp_counter.report() << endl;
}
return 0;
Вывод программы может иметь следующий вид (точные значения зависят от конкретной
реализации STL).
Вывод примера 8.3
Использование функциональ
подсчета операций, первая
Размер задачи 1000,
Размер задачи 2 000,
Размер задачи 4 000,
Размер задачи 8000,
Размер задачи 16 000,
Размер задачи 32 00 0,
Размер задачи 64000,
Размер задачи 128000,
ного объекта для
версия.
выполнено сравнений: 10410
выполнено сравнений: 21889
выполнено сравнений: 49359
выполнено сравнений: 116360
выполнено сравнений: 259059
выполнено сравнений: 514470
выполнено сравнений: 1138309
выполнено сравнений: 2419759
При использовании статических переменных имеет место хорошо известная проблема,
заключающаяся в сложности их корректного применения при многопоточных вычислениях.
7tfO
Часть I. Вводный курс в STL
Поэтому далее мы покажем другой способ отслеживания количества сравнений с помощью
данных-членов объекта, а не класса. Это не так просто, как может показаться, поскольку
исходный функциональный объект, создаваемый в основной программе и передаваемый
функции sort, может копироваться, например, если он передается по значению другим
внутренним функциям в теле sort. В действительности может оказаться даже несколько
"поколений" копий. И каждая копия имеет собственный счетчик-член counter, и мы
должны изменять все их, чтобы получить общее количество сравнений. Предложенное здесь
решение состоит в записи в каждой копии функционального объекта адреса его прародителя,
т.е. объекта, из которого получаются все копии.
<Определение класса less без статического члена 186а> =
template <typename T>
class less_with_count : public binary_function<T/ T, bool> {
public:
less_with_count() : counter(0), progenitor(0) { }
// Копирующий конструктор:
less_with_count(less_with_count<T>& x) : counter(0),
progenitor(x.progenitor ? x.progenitor : &x) { }
bool operator()(const T& x, const T& y) {
++counter;
return x < y;
}
long report() const { return counter; }
~less_with_count() { // Деструктор
if (progenitor) {
progenitor->counter += counter;
}
}
private:
long counter;
less with count<T>* progenitor;
};
Используется в части 1866.
У объекта, создаваемого конструктором по умолчанию, член progenitor содержит
нулевой указатель. Копирующий конструктор выполняет следующее: если член progenitor
не нулевой, он копируется; в противном случае в него записывается адрес копируемого
объекта. При уничтожении объекта его последним действием становится добавление
собственного счетчика к счетчику прародителя.20
Пример 8.4. Использование функционального объекта для подсчета
операций, вторая версия
"ех08-04.срр" 1866 =
#include <iostream>
#include <iomanip>
#include <cassert>
#include <vector>
#include <algorithm>
#include <functional>
using namespace std;
Это не совсем обобщенное решение, поскольку прародитель объекта может быть уничтожен до
того, как будет уничтожен объект. Однако при способе работы алгоритма сортировки STL этого не
происходит — исходный функциональный объект переживает своих потомков.
Глава 8. Функциональные объекты
187
<Определение класса less без статического члена 18ба>
int main()
{
cout << "Использование функционального объекта "
<< "для подсчета операций, первая версия."
<< endl;
const long N1 = 1000, N2 = 128000;
for (long N = N1; N <= N2; N *= 2) {
vector<int> vectorl;
for (int k = 0; k < N; ++k)
vectorl.push_back(k);
random_shuffie(vectorl.begin(), vectorl.end());
less_with_count<int> comp_counter;
sort(vectorl.begin(), vectorl.end(),
comp_counter);
cout << "Размер задачи " << setw(9) << N
<< ", выполнено сравнений: "
<< setw(9) << comp_counter.report() << endl;
}
return 0;
}
Вывод этой программы в точности такой же, как и у предыдущего примера (конечно, если
оба примера компилируются с одной и той же библиотекой).
8.3. Функциональные объекты,
предоставляемые STL
STL предоставляет с десяток или около того функциональных объектов для наиболее
распространенных случаев. Их детальное описание можно найти в главе 23, "Справочное
руководство по функциональным объектам и адаптерам".
Глава 9
Адаптеры контейнеров
Адаптеры представляют собой компоненты STL, которые могут использоваться для
изменения интерфейса другого компонента. Они определены как шаблоны классов, получающие
тип компонента в качестве параметра. В STL имеются адаптеры контейнеров, адаптеры
итераторов и функциональные адаптеры. Мы по очереди рассмотрим их в этой и двух
последующих главах.
Чтобы увидеть преимущества механизма адаптации интерфейсов, давайте начнем с
рассмотрения проблемы предоставления таких фундаментальных структур данных, как стеки и
очереди.
Стек представляет собой более простой вид контейнера, чем vector, list или deque;
любой из этих контейнеров может использоваться в качестве стека в том смысле, что каждый
из них поддерживает операции, которые поддерживает стек:
• вставка с одного конца (push_back);
• удаление с того же конца (pop_back);
• получение значения в том же конце (back);
• проверка, пуст ли стек (empty или size).
Еще одним важным свойством стека является тот факт, что он предоставляет только
очень ограниченный интерфейс. Стек не выполняет никаких операций с данными, кроме
перечисленных.
Этот момент следует особо отметить, поскольку хотя мы можем выбрать для текущей
реализации стека, скажем, list, мы можем впоследствии захотеть перейти к другой
реализации операций со стеком. Так что если только мы специально не ограничим интерфейс,
будет трудно гарантировать непреднамеренное использование текущей реализации и иными,
"не стековыми способами".
Обычным решением, используемым в библиотеках классов контейнеров C++, является
определение стекового типа в виде класса, StackAsList, с закрытым членом для хранения
объекта списка, и определение открытых функций-членов push, pop, top и empty через
операции списка. При таком решении ни одна другая операция списка не доступна через
стековые объекты, которые предоставляют программистам только ту функциональность,
которая от них требуется.
Однако поскольку в некоторых ситуациях лучше вместо списка для представления стека
использовать вектор, такие библиотеки вынуждены предоставлять и другой класс —
StackAsVector. Тот же подход используется и с другими контейнерами, что проводит к по-
часть I. Вводный курс в STL
явлению массы классов, таких как QueueAsVector, QueueAsList, QueueAsDoubleList,
PriorityQueueAsVector, PriorityQueueAsList и т.д.
В STL такого разрастания классов легко избежать путем применения адаптеров
контейнеров. STL предоставляет адаптеры контейнеров для получения из последовательных
контейнеров классов stack, queue и priority_queue.
9.1. Адаптер стека
Адаптер контейнера stack может быть применен к vector, list или deque.
• stack<T> — представляет собой стек элементов типа Т с реализацией по умолчанию,
использующей deque.
• stack<T, vector<T> > — представляет собой стек элементов типа Т с
реализацией, использующей vector.
• stack<T, list<T> > — представляет собой стек элементов типа Т с реализацией,
использующей list.
• stack<T, deque<T> > — представляет собой стек элементов типа Т с
реализацией, использующей deque (идентичен stack<T>).
Класс stack предоставляет операции empty, size, top, push и pop. Возвращаемый
функцией pop тип — void, поскольку если бы она возвращала элемент, удаляемый с
вершины стека, то возврат следовало бы делать по значению. Возврат ссылки приводил бы к
висящему указателю на значение, уже удаленное из контейнера stack. Возврат же значения
требовал бы вызова конструктора, который приводил бы только к снижению
производительности, если бы возвращаемое значение не использовалось вызывающей
функцией.21 Так что если требуется значение на вершине стека, его можно получить при помощи
функции top, вызываемой перед функцией pop.
Адаптер стека можно применить к любому контейнеру, который поддерживает операции
empty, size, push_back, pop_back и back. Каждый из контейнеров vector<T>,
list<T> и deque<T> отвечает этому требованию, так что каждый из них может быть
переделан в стек. Если определить новый класс контейнера С<Т>, который поддерживает
указанные операции, то его также можно адаптировать для использования в качестве стека как
stack<T, C<T> >.
Вот простой пример, иллюстрирующий создание стека при помощи адаптера и работу с ним.
Пример 9.1. Иллюстрация адаптера стека
"ех09-01.срр" 190 =
#include <iostream>
#include <stack>
using namespace std;
int main()
{
cout << "Иллюстрация адаптера стека." << endl;
int thedata[] = {45, 34, 56, 27, 71, 50, 62};
Следует заметить, что помимо соображений производительности к такому решению приводит и
учет вопросов безопасности в смысле исключений. Подробно эта тема рассматривается в [24], задача
2.3. —Примеч. пер.
Глава 9. Адаптеры контейнеров
7Л7
stack<int> s;
cout << "Размер стека равен " << s.sizeO << endl;
int i ;
cout << "Внесение в стек 4 элементов " << endl;
for (i = 0; i < 4; ++i)
s.push(thedata[i]);
cout << "Размер стека равен " << s.sizeO << endl;
cout << "Снятие со стека 3 элементов " << endl;
for (i = 0; i < 3; ++i) {
cout << s.topO << endl;
s.pop();
}
cout << "Размер стека равен " << s.sizeO << endl;
cout << "Внесение в стек 3 элементов " << endl;
for(i = 4; i < 7; + + i)
s.push(thedata [i]);
cout << "Размер стека равен " << s.sizeO << endl;
cout << "Снятие со стека всех элементов" << endl;
while (!s. empty О) {
cout << s.topO << endl;
s.pop();
}
cout << "Размер стека равен " << s.sizeO << endl;
return 0;
Вывод примера 9.1
Иллюстрация адаптера стека.
Размер стека равен 0
Внесение в стек 4 элементов
Размер стека равен 4
Снятие со стека 3 элементов
27
56
34
Размер стека равен 1
Внесение в стек 3 элементов
Размер стека равен 4
Снятие со стека всех элементов
62
50
71
45
Размер стека равен 0
9.2. Адаптер очереди
j
Очередь отличается от стека тем, что элементы в нее вставляются с одного конца, а
извлекаются с другого. О ней часто говорят как о буфере "первый вошел, первый вышел" (first-
in, first-out (FIFO)), в отличие от "последний вошел, первый вышел" (last-in, first-out (LIFO))
для стека.
STL предоставляет адаптер контейнера queue, который может быть применен к любому
контейнеру, поддерживающему операции empty, size, front, back, push_back и
19^
часть I. ьвооный курс в biL
pop_f ront. Эти операции поддерживаются классами STL list и deque, так что очередь
может создаваться адаптацией этих контейнеров.
• queue<Т> — представляет собой очередь элементов типа Т с реализацией по
умолчанию, использующей контейнер deque.
• queue<T, list<T> >— представляет собой очередь элементов типа Т с
реализацией, использующей контейнер list.
• queue<T, deque<T> > — представляет собой очередь элементов типа Т с
реализацией, использующей контейнер deque (идентична queue<Т>).
Класс queue предоставляет в распоряжение программиста операции empty, size,
front, back, push и pop. Функция pop, как и в случае адаптера stack, не возвращает
значения. Для получения значения в начале очереди используется функция-член front.
Заметим, что адаптер queue не может быть применен к контейнеру vector, потому что
vector не поддерживает операцию pop_f ront. Почему эта операция отсутствует у
векторов? Ее легко запрограммировать как v. erase (v. begin () ), но такого рода операций
следует избегать, поскольку они очень неэффективны у длинных векторов — все элементы после
первой позиции при такой операции должны быть перемещены для заполнения
образовавшегося промежутка, что требует линейного времени работы.
Предоставляя функцию pop_f ront в list и deque (где эта операция выполняется за
константное время) и не включая ее в класс vector (где она требует линейного времени),
STL облегчает создание эффективных реализаций очередей и затрудняет создание очередей
неэффективных.
В приведенном далее примере мы (произвольно) используем для создания очереди list
вместо deque (по умолчанию). Далее в очередь помещаются те же значения данных, что и в
предыдущем примере, но теперь при удалении данных из очереди мы получаем иную
последовательность значений — поскольку в очереди удаление производится с другого конца,
противоположного тому, где выполняется вставка.
Пример 9.2. Иллюстрация адаптера очереди
"ех09-02.срр" 192 =
#include <iostream>
#include <queue>
#include <list>
using namespace std;
int mainO
{
cout << "Иллюстрация адаптера очереди." << endl;
int thedata[] = {45, 34, 56, 27, 71, 50, 62};
queue<int, list<int> > q;
cout << "Размер очереди " << q.size О << endl;
int i ;
cout << "Вставка 4 элементов " << endl;
for (i = 0; i < 4; ++i)
q.push(thedata[i] ) ;
cout << "Размер очереди " << q.size О << endl;
cout << "Извлечение 3 элементов " << endl;
for (i = 0; i < 3; ++i) {
cout << q.front() << endl;
q.pop();
}
cout << "Размер очереди " << q.sizeO << endl;
ffiaeB У. моаптеры кинтеинерио
cout << "Вставка 3 элементов " << endl;
for(i = 4; i < 7; ++i)
q.push(thedata[i]);
cout << "Размер очереди " << q.size О << endl;
cout << "Извлечение всех элементов" << endl;
while (Iq.emptyO) {
cout << q.front () << endl;
q.pop();
}
cout << "Размер очереди " << q.sizeO << endl;
return 0;
}
Вывод примера 9.2
Иллюстрация адаптера очереди.
Размер очереди О
Вставка 4 элементов
Размер очереди 4
Извлечение 3 элементов
45
34
56
Размер очереди 1
Вставка 3 элементов
Размер очереди 4
Извлечение всех элементов
27
71
50
62
Размер очереди 0
9.3. Адаптер очереди с приоритетами
Очередь с приоритетами представляет собой тип последовательности, в которой
элемент, доступный для выборки, является наибольшим в последовательности при некотором
способе упорядочения. Адаптер STL priority_queue преобразует в очередь с
приоритетами любой контейнер, который предоставляет итераторы с произвольным доступом и
операции empty, size, push_back, pop_back и front вместе с функциональным объектом
сравнения сотр (очередь с приоритетами использует сотр для сравнения при выяснении,
какой из элементов наибольший).
Как vector<T>, так и deque<T> предоставляют итераторы с произвольным доступом и
все необходимые операции.
• priority_queue<int>— хранит значения типа int в реализации контейнера по
умолчанию (vector) и использует функциональный объект сравнения по умолчанию
(less<int>).
• priority_queue<int/ vector<int>, greater<int> >— хранит значения
типа int в контейнере типа vector и использует встроенный оператор >,
определенный для int.
nawiiD /. оаиимыи кури е о IL
• priority_queue<float, deque<float>, greater<float> >— хранит
значения типа float в контейнере deque и использует встроенный оператор >,
определенный для float.
Поскольку во втором и третьем примерах вместо оператора < используется оператор >9
элемент, доступный для выборки, в этих случаях представляет собой наименьший, а не
наибольший элемент.
Операции, предоставляемые priority_queue— empty, size, top, push и pop.
Функция pop, подобно соответствующей функции в адаптерах stack и queue, не
возвращает значения. Для получения доступного значения перед применением pop следует
использовать функцию-член top.
В приведенном далее примере мы помещаем в очередь с приоритетами те же значения,
что и ранее в стек и очередь, но получаемые из нее значения оказываются в ином порядке,
чем в примерах со стеком и очередью.
Пример 9.3. Иллюстрация адаптера очереди с приоритетами
"ех09-03.срр" 194 =
#include <iostream>
#include <queue> // Определение queue и priority_queue
using namespace std;
int main()
{
cout << "Иллюстрация адаптера очереди с приоритетами."
<< endl;
int thedata[] = {45, 34, 56, 27, 71, 50, 62};
priority_queue<int> pq;
cout << "Размер priority_queue равен " << pq.sizeO
<< endl;
int i ;
cout << "Вставка 4 элементов " << endl;
for (i = 0; i < 4; ++i)
pq.push(thedata[i] );
cout << "Размер priority_queue равен " << pq.sizeO
< < endl;
cout << "Извлечение 3 элементов " << endl;
for (i = 0; i < 3; + + i) {
cout << pq.topO << endl;
pq.popO ;
}
cout << "Размер priority_queue равен " << pq.sizeO
< < endl;
cout << "Вставка 3 элементов " << endl;
for(i = 4; i < 7; ++i)
pq.push(thedata[i]);
cout << "Размер priority_queue равен " << pq.sizeO
< < endl;
cout << "Извлечение всех элементов" << endl;
while (!pq.empty()) {
cout << pq.topO << endl;
pq.popO ;
}
cout << "Размер priority_queue равен " << pq.sizeO
<< endl;
return 0;
}
Глава и. /лоаптеры Kutimvuncfjuo
Вывод примера 9.3
Иллюстрация адаптера очереди с приоритетами.
размер priority_queue равен О
Зставка 4 элементов
Размер priority_queue равен 4
Извлечение 3 элементов
56
45
Размер priority_queue равен 1
Вставка 3 элементов
размер priority_queue равен 4
Извлечение всех элементов
71
62
50
27
Размер priority_queue равен О
Глава 10
Адаптеры итераторов
Адаптеры итераторов представляют собой компоненты STL, которые могут
использоваться для изменения интерфейса итератора. В STL предопределен адаптер итераторов
только одного вида — адаптер обратного итератора, который преобразует данный
двунаправленный итератор или итератор с произвольным доступом в итератор с обратным
направлением обхода. Преобразованный итератор имеет тот же интерфейс, что и исходный.
Этот адаптер определен как шаблон класса, который получает тип итератора в качестве
параметра. Пример непосредственного применения адаптера обратного итератора был приведен
в разделе 2.5. В большинстве же случаев необходимости в непосредственном применении
этого адаптера нет, поскольку каждый тип контейнера STL предоставляет два типа обратных
итераторов (которые предопределены с помощью адаптера), изменяемый итератор
reverse_iterator и константный const_reverse_iterator. Каждый контейнер,
кроме того, предоставляет функции-члены rbegin и rend, которые могут использоваться в
циклах или передаваться алгоритмам для определения начала и конца последовательности
при обходе в обратном направлении, как показано в приведенном далее примере.
Пример 10.1. Демонстрация прямого и обратного обхода
"ех10-01.срр" 197 =
#include <iostream>
#include <vector>
#include <list>
using namespace std;
template <typename Container>
void display (const ContainerSt c)
{
cout << "Элементы в прямом порядке : ";
typename Container::const_iterator i;
for (i = c.beginO; i 1= c.endO; ++i)
cout << *i << " ";
cout << endl;
cout << "Элементы в обратном порядке : ";
typename Container::const_reverse_iterator r;
for (r = c.rbeginO; r != c.rendO; ++r)
cout << *r << " ";
cout << endl;
}
int main()
cout << "Прямой и обратный обход вектора:\n";
~шигпь i. ввооныи курс в SIL
vector<int> vectorl;
vectorl.push_back(2)
vectorl.push_back(3)
vectorl.push_back(5)
vectorl.push_back(7)
vectorl.push_back(11);
display(vectorl) ;
cout << "Прямой и обратный обход списка :\п" ;
list<int> listl(vectorl.begin(), vectorl.end() ]
display(listl);
return 0;
Вывод примера 10.1
Прямой и обратный обход вектора
Элементы в прямом порядке
Элементы в обратном порядке
Прямой и обратный обход списка
Элементы в прямом порядке
Элементы в обратном порядке
2 3 5 7 11
11 7 5 3 2
2 3 5 7 11
11 7 5 3 2
Когда обратные итераторы передаются обобщенному алгоритму, они заставляют
алгоритм "смотреть в обратном направлении" вдоль содержащейся в контейнере
последовательности. В противном случае все вычисления выполняются в прямом направлении. Например,
обобщенный алгоритм find обычно возвращает итератор, указывающий на первое
местоположение с данным значением. Если же требуется последнее местоположение, то его можно
получить, вызывая find с обратными итераторами.
Пример 10.2. Использование find с обычными и обратными итераторами
"ех10-02.срр" 198 =
#include <iostream>
#include <vector>
#include <algorithm> // Алгоритм find
#include <iterator>
using namespace std;
<Функция make (создание контейнера символов) 53б>
int main()
{
cout << "Использование find с обычными и "
<< "обратными итераторами:\п";
vector<char> vectorl =
make< vector<char> >("now is the time")
ostream iterator<char> out(cout, " ");
vector<char>::iterator i =
find(vectorl.begin(), vectorl.end(), •
cout << "символы от первого t до конца
copy(i, vectorl .end () , out); cout << endl;
f );
cout << "символы от последнего t до начала:
vector<char>::reverse iterator r =
Глава 7 и. Аоаптеры итьршпи^ио
}
find(vectorl.rbegin(), vectorl.rend(), 't');
copy(r, vectorl.rend(), out); cout << endl;
cout << "символы от последнего t до конца : ";
copy(r.base() - 1, vectorl.end(), out); cout << endl;
return 0;
На последнем этапе данной программы использована функция-член base, определяемая
классом reverse_iterator, возвращающая итератор, адаптированный в обратный.
Фундаментальное отношение между обратным итератором г и итератором, из которого он
получается (г. base ()) имеет вид &* г == &*(г.base () - 1). То есть, если г представляет
собой обратный итератор, который логически рассматривается как указывающий на
некоторую позицию р, то г внутренне хранит итератор i, который на самом деле указывает на
позицию р+1.22 Таким образом, чтобы включить значение, на которое указывает г в последней
строке вывода, в качестве первого нормального итератора, передаваемого сору вместе с
vectorl. end (), используется г. base () - 1.
Вывод примера 10.2
Использование find с обычными и обратными итераторами:
символы от первого t до конца
символы от последнего t до начала
символы от последнего t до конца
the time
t e h t si
time
Обратите внимание, что символы от последнего ' t' до начала последовательности
перечислены в обратном порядке, поскольку они выводятся с применением обратных итераторов.
Если их требуется вывести в прямом порядке, можно использовать уже рассмотренный выше
метод вычитания 1 из итератора, лежащего в основе обратного итератора. Если вывести эти
символы при помощи выражения
copy(vectorl.begin(), г.base О - 1, out);
то вывод примет вид
символы от первого до последнего t:now is the t
Хотя обратные итераторы и являются единственными адаптерами итераторов,
предопределенными в STL, концепция адаптеров итераторов имеет много иных приложений. Простой
пример пользовательского адаптера итератора рассматривается в главе 16, "Определение
класса итератора".
22 Это смещение на 1 требуется исходя из необходимости использовать итератор, указывающий на
первую позицию последовательности, как внутреннее значение итератора, указывающего на позицию за
концом последовательности при обратном обходе: в частности, в случае массивов нет гарантии
доступности позиции, предшествующей первой позиции массива, которая имеется для последней позиции.
' 1
Глава 11
функциональные адаптеры
Мы уже видели, что множество обобщенных алгоритмов STL могут принимать в качестве
аргумента функциональный объект и работать по-разному в зависимости от этого аргумента.
Как функциональные объекты, так и итераторы могут рассматриваться как адаптеры
алгоритмов.
Так же как адаптеры итераторов помогают строить более широкий набор итераторов для
работы с алгоритмами, так и функциональные адаптеры помогают создавать более широкий
набор функциональных объектов. Использование функциональных адаптеров часто
оказывается более простым, чем непосредственное создание нового типа функционального объекта
при помощи определения структуры или класса. STL предоставляет три категории
функциональных адаптеров: связыватели (binders), инверторы (negators) и адаптеры для указателей
на функции (adaptors for pointers to functions). Эти адаптеры определены как шаблоны
классов, но сопровождаются шаблонами функций, которые делают применение классов более
удобным. Кроме того, удобно при описании адаптеров сконцентрироваться на
сопровождающих функциях и также говорить о них, как о функциональных адаптерах.
11.1. Связыватели
Связыватель представляет собой разновидность функционального адаптера,
используемого для преобразования бинарных функциональных объектов в унарные путем связывания
аргумента с некоторым конкретным значением. Например,
int* where = find_if(&arrayl[0], fcarrayl[1000],
bind2nd(greater<int>(), 200));
находит первое целое число в arrayl, большее 200. Алгоритм f ind_if подобен алгоритму
find, но вместо значения для поиска он получает функциональный объект унарного
предиката р (т.е. функциональный объект, который инкапсулирует функцию с одним аргументом,
возвращающую значение типа bool):
where = find_if(first, last, p) ;
присваивает переменной where итератор, указывающий на первую позицию диапазона от
first до last, для которой р вернет true, или last, если такой позиции не существует. В
приведенном примере предикат для поиска создается при помощи greater< int > (),
функционального объекта, определяющего бинарную функцию
bool operator()(int х, int у) const { return x > у; }
Применение bind2nd к этому функциональному объекту и значению 200 дает
функциональный объект, определяющий унарную функцию
Часть I. Вводный курс в STL
bool operator()(int x) const { return x > 200; }
так же, как если бы мы запрограммировали функциональный объект другого типа
struct Greater200 : unary_function<int, bool> {
bool operator()(int x) const { return x > 200; }
};
непосредственно. Функциональный адаптер bindlst может использоваться аналогично для
связывания первого аргумента бинарного функционального объекта. Большое количество
примеров использования связывателей и инверторов имеется в следующем разделе и в
части II, "Примеры программ".
11.2. Инверторы
Инвертор представляет собой разновидность функционального адаптера, используемую
для обращения смысла функционального объекта предиката. В STL имеется два инвертора,
not 1 и not2. Например,
where = find_if(fcarrayl[0], fcarrayl[1000],
notl(bind2nd(greater<int>(), 200)));
выполняет поиск первого целого числа в arrayl, которое не превышает 2 00 (<= 2 00). В
общем случае для данного объекта унарного предиката р инвертор notl возвращает объект
унарного предиката, определяющий функцию
bool operator()(const T& х) const { return !(p(x)); }
где Т представляет собой тип аргумента р. В данном конкретном случае можно получить тот
же функциональный объект более просто, воспользовавшись другим функциональным
объектом STL, less_equal<T>():
where = find_if(&arrayl[0],&arrayl[1000],
bind2nd(less_equal<int>(),200));
Второй инвертор обращает бинарный предикат. В качестве примера использования not2
предположим, что у нас есть тип U с функцией-членом, являющимся бинарным предикатом,
сравнивающим объекты на основе их членов id.
class U : public binary_function<U, U, bool> {
public:
int id;
bool operator()(const U& x, const U& y) const {
return x.id >= y.id;
}
friend ostream& operator<<(ostream& o, const U& x) {
о << x.id;
return o;
>- ' I
Заметим, что, поскольку класс перегружает оператор вызова функции, а сам класс является
производным от public binary_function<U/ U, bool>, объекты типа и могут
использоваться в качестве функциональных объектов, как объекты бинарных предикатов.
Предположим теперь, что у нас есть vectorl, определенный следующим образом:
vector<U> vectorl(1000);
for (int i = 0; i != 1000; ++i)
vectorl[i].id = 1000 - i - 1;
Если мы хотим отсортировать vectorl в возрастающем порядке по членам id, то мы не
можем воспользоваться упорядочением по умолчанию, потому что для него требуется определение
Глава 11. Функциональные адаптеры
оператора < для объектов типа U. Мы не можем воспользоваться и перегруженным оператором,
определенным типом, так как он использует для сравнения членов id оператор >=, а не <. Но
мы можем легко решить поставленную задачу, воспользовавшись инвертором not 2:
sort(vectorl.begin(), vectorl.end(), not2(U()));
Вот как выглядит пример полностью.
Пример 11.1. Сортировка вектора в возрастающем порядке членов id
"exll-Ol.cpp" 203 ж
#include <iostream>
#include <cassert>
#include <vector>
#include <algorithm>
#include <functional>
using namespace std;
class U : public binary_function<U, U, bool> {
public:
int id;
bool operator()(const U& x, const U& y) const {
return x.id >= y.id;
}
friend ostream& operator<<(ostream& o, const U& x) {
о << x.id;
return o;
}
};
int main()
{
vector<U> vectorl(1000) ;
for (int i = 0; i != 1000; ++i)
vectorl [i] .id = 1000 - i - 1;
sort(vectorl.begin(), vectorl.end(), not2(U()));
for (int k = 0; k 1= 1000; ++k)
assert (vectorl[k].id == k);
cout << " Ok." << endl;
return 0;
}
11.3. Адаптеры для указателей на функции
Адаптеры для указателей на функции предоставляются для того, чтобы позволить
указателям на унарные и бинарные функции работать вместе с другими функциональными
адаптерами библиотеки. Эти адаптеры могут также оказаться полезными, чтобы избежать одного из
видов "разбухания кода" (см. раздел 1.4), как будет показано в примере в этом разделе.
Хотя функциональные объекты всегда могут использоваться вместо старого менее
эффективного метода передачи указателей на функции, бывают случаи, когда требуется применять
именно указатели на функции. Предположим, например, что в одной и той же программе нам
надо использовать два разных множества, которые отличаются только переданными им
функциями сравнения:
set<string, less<string> > setl;
set<string/ greater<string> > set2;
Часть I. Вводный курс в STL
Проблема в этом случае заключается в том, что компилятор будет дублировать большую
часть или даже весь код, реализующий множества, несмотря на то, что в основном у обоих
экземпляров он идентичен.
Чтобы избежать дублирования, можно работать с одним экземпляром set, используя
адаптер для указателей на функции в качестве типа функции сравнения для множества:
set<string/
pointer_to_binary_function<const strings,
const strings, bool> >
При создании множеств этого типа мы передаем экземпляр типа данного адаптера,
созданного на основе указателя на бинарную функцию с помощью ptr_f un, как это сделано в
приведенной далее программе.
Пример 11.2. Демонстрация применения адаптера для указателей
на функции
"exll-02.cpp" 204 ж
#include <iostream>
#include <string>
#include <set>
using namespace std;
bool lessl(const strings x, const strings y)
return x < y;
bool greaterl(const strings x, const strings y)
return x > y;
int main()
cout << "Демонстрация применения адаптера для "
<< "указателей на функции." << endl;
typedef
set<string/
pointer_to_binary_function<const strings,
const string^
bool> >
set_typel;
set_typel setl(ptr_fun(lessl));
set1.insert("the");
setl.insert("quick");
setl.insert("brown");
setl.insert("fox");
set_typel::iterator i;
for (i = setl.begin() ; i != setl.endO; ++i)
cout << *i << " ";
cout << endl;
set_typel set2(ptr_fun(greaterl));
set2.insert("the");
set2.insert("quick");
set2.insert("brown");
Глава 11. Функциональные адаптеры
гио
set2.insert("fox");
for (i = set2 .beginO ; i != set2.end(); ++i)
cout << *i << " ";
cout << endl;
return 0;
}
Вывод примера 11.2
Демонстрация применения адаптера для указателей на функции.
brown fox quick the
the quick fox brown
В этом примере имеется только один экземпляр типа set, а именно set_typel.
Создаются два объекта: set_typel: setl, который использует ptr_fun(lessl) в качестве
объекта сравнения, и set2, который использует ptr_fun(greaterl). Наличие
дополнительного уровня косвенности при использовании указателей на функции приводит к тому, что
программа работает немного медленнее, чем соответствующая программа с отдельными
экземплярами set, но при этом имеет заметно меньший размер выполняемого файла.
Дополнительные примеры использования функциональных адаптеров имеются в
главах 13, "Программа поиска всех групп анаграмм", и 15, "Ускорение программы поиска
анаграмм: использование мультиотображений".
Часть II
Примеры программ
В этой части мы решим несколько простых, но нетривиальных
программных задач с использованием компонентов STL. В главах
с 12, "Программа для поиска в словаре", по 15, "Ускорение
программы поиска анаграмм: использование мультиотображений",
мы будем выполнять поиск в словаре анаграмм (слов, которые
созданы путем перестановки букв данного слова). В этих главах мы
постоянно будем решать задачи этого вида, применяя разные
подходы, включая (в главе 13, "Программа поиска всех групп
анаграмм") комбинацию компонентов STL с пользовательскими
типами. В главе 16, "Определение класса итератора", приведен
небольшой пример определения нового типа итератора и
использование его с существующими компонентами STL. Пример
программы в главе 17, "STL и объектно-ориентированное
программирование", иллюстрирует комбинацию STL с объектно-
ориентированным программированием. В главе 18, "Программа
вывода дерева ученых в области теории вычислительных машин
и систем", STL используется для реализации более сложных
структур данных, чем рассмотренные в предыдущих примерах.
Наконец, в главе 19, "Класс для хронометража обобщенных
алгоритмов", мы рассмотрим подход к хронометрированию
алгоритмов, позволяющий обоснованно принимать те или иные
проектные решения при использовании STL.
Глава 12
Программа для поиска в словаре
В части I, "Вводный курс в STL", примеры иллюстрировали отдельные компоненты STL и
были малы по размеру. Теперь, в части II, "Примеры программ", мы рассмотрим несколько
большие примеры, в которых одновременно демонстрируются несколько компонентов STL.
12.1. Поиск анаграмм данного слова
Начнем с задачи поиска в заданном словаре всех анаграмм данного слова. Мы
разработаем программу, которая читает словарь из файла, затем многократно повторяет следующие
действия — принимает слово (или произвольную строку букв) из стандартного потока ввода
и ищет все перестановки его букв в словаре, выводя найденные слова. Далее приведен пример
того, как может выглядеть сеанс работы с программой (пользовательский ввод выделен
полужирным шрифтом).
Вывод примера 12.1
Программа поиска анаграмм:
поиск в словаре всех слов, которые могут
быть образованы из букв данного слова.
Введите имя файла со словарем: diction
Чтение словаря...
Словарь содержит 20159 слов.
Введите слово (или строку букв): rseuce
cereus
recuse
rescue
secure
Введите другое слово
(или символ конца файла для останова): nadeirga
drainage
gardenia
Введите другое слово
(или символ конца файла для останова): grinch
Ничего не найдено.
Введите другое слово
210
Часть II. Примеры программ
(или символ конца файла для останова): gonar
argon
groan
organ
Введите другое слово
(или символ конца файла для останова):
Точный результат, конечно же, зависит от конкретного словаря. В данном примере
использован словарь, указанный в приложении Г, "Ресурсы".
Далее мы подробно рассмотрим саму программу, ее код и принципы работы.
Пример 12.1. Программа поиска анаграмм в словаре, считываемом
из файла
"ех12-01.срр" 210 =
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
int main()
{
cout << "Программа поиска анаграмм:\п"
<< "поиск в словаре всех слов, которые могут\п"
<< "быть образованы из букв данного слова.\п"
< < endl;
<Получение имени словаря и подготовка к чтению 211а>
<Копирование словаря в вектор 211б>
<Запрос слов и поиск анаграмм 212а>
return 0;
Грамотное программирование
В примерах программ в части II, "Примеры программ", используется стиль
"грамотного программирования" (literate programming) [10], в котором код и его
документация объединены. При таком стиле нет отдельной версии поддерживаемого кода;
вместо этого специальная программа используется для того, чтобы получить из одного
исходного файла с кодом файл(ы) для подготовки печатного документа (в случае
оригинального издания данной книги это гЛ^Х) и файл(ы) с исходным текстом для
компиляции (в нашем случае это исходные файлы C++), Основная идея, лежащая в основе
грамотного программирования, заключается в том, что многие программы гораздо чаще
читаются, чем выполняются, так что жизненно необходимо сделать их удобочитаемыми
и гарантировать согласованность документации с кодом. При представлении программы
в стиле грамотного программирования мы разбиваем ее на небольшие части, определяем
и описываем роль каждой части и соединяем части в единую программу. Другая идея
состоит в том, что части могут располагаться в любом порядке (а не в том, который
требуют правила языка программирования).
Глава 12. Программа для поиска в словаре
211
Мы использовали для поддержки утилиту Briggs's Nuweb [3], в которой программные
части именуются фразами и автоматически нумеруются в соответствии с номерами стра-
ниц, на которых они находятся; части на одной странице различаются путем добавления
букв. Ссылки из другого кода осуществляются по имени части и ее номеру.
В примере 12.1 использовано нисходящее представление— сначала показана
структура всей программы со ссылками на части, которые буду! определены позже. Например, I
часть
копирование словаря в вектор 211б>
■ I
определена на стр. 211. В главе 14, "Улучшенная программа поиска групп анаграмм", на-
против, в основном используется восходящее представление, когда сначала определяют-
ся части, а уже затем — общая программа.
Несколько других замечаний о грамотном программировании имеются в других врез- !
ках главы.
12.2. Работа со строками и потоками
Мы считываем имя файла в виде строки, используя стандартный класс string, а затем
подготавливаемся к чтению словаря из указанного файла с применением if stream.
<Получение имени словаря и подготовка к чтению 211а> =
cout << "Введите имя файла со словарем: " << flush;
string dictionary_name;
cin >> dictionary_name;
ifstream ifs(dictionary_name.c_str());
if (!ifs.is_open()) {
cout << "He могу открыть файл словаря "
<< dictionary__name << endl ;
exit(1);
}
Используется в частях 210, 220а, 2276, 232.
Части программ часто используются в разных программах
Одно из преимуществ стиля грамотного программирования в том, что каждая часть
может, будучи один раз определенной, многократно использоваться в разных программах.
Приведенная часть применяется не только в рассматриваемой программе, но и в других, на j
; страницах, указанных в списке "Используется в частях..." под определением части.
Для использования в программе определим тип string_input как тип итератора
istream. Затем мы можем копировать файл словаря в контейнер vector при помощи
обобщенного алгоритма сору и итератора вставки back_inserter, который обеспечивает вставку
слов из словаря в конец вектора по одному. Значения из словаря считываются до тех пор, пока
итератор stream_input не станет равным string_input (), значению конца потока.
<Копирование словаря в вектор 211б> =
cout << "\пЧтение словаря..." << flush;
typedef istream_iterator<string> string_input;
vector<string> dictionary;
copy(string_input(ifs), string_input(),
212
Часть II. Примеры программ
back_inserter(dictionary));
cout << "\пСловарь содержит "
<< dictionary.size() << " слов.\п\п";
Используется в части 210.
После того как словарь считан, сообщается о его размере. Теперь программа готова к
приему строки от пользователя и поиску анаграмм. Поиск выполняется при помощи
обобщенного алгоритма binary_search, требующего, чтобы словарь находился в алфавитном
порядке. Здесь предполагается, что файл словаря упорядочен по алфавиту; если это не так —
то сразу после его чтения можно прибегнуть к сортировке:
sort(dictionary.begin(), dictionary.end());
Ввод слов пользователем управляется итератором istream j, настроенным для работы со
стандартным потоком ввода с in до считывания индикатора конца потока:
<Запрос слов и поиск анаграмм 212а> =
cout << "Введите слово (или строку букв): " << flush;
for (string_input j(cin); j != string_input(); ++j) {
string word = * j ;
<Поиск анаграмм в словаре 212б>
cout << "\пВведите другое слово\п"
<< "(или символ конца файла для останова): "
<< flush;
}
Используется в части 210.
В теле показанного выше цикла генерируются все перестановки букв данного слова и
выполняется поиск каждой из них в словаре.
<Поиск анаграмм в словаре 212б> =
<Перестановка букв слова в алфавитном порядке 212в>
<Многократная генерация перестановок и их поиск 213>
Используется в части 212а.
Части могут ссылаться на другие части
Как показано в приведенных частях, в них могут содержаться ссылки на другие части
(произвольной глубины вложенности), однако циклические ссылки запрещены.
Для генерации всех перестановок мы воспользуемся обобщенным алгоритмом
next_permutation. Начальная строка, передаваемая next _j?er mutation, должна
содержать буквы в алфавитном порядке, так что нам надо воспользоваться обобщенным
алгоритмом sort для их сортировки. Как рассказывается в приложении Б, "Справочное
руководство по строкам", класс string предоставляет итераторы с произвольным доступом и
функции-члены begin и end. (Класс string очень похож на vector<char>.)
<Перестановка букв слова в алфавитном порядке 212в> =
sort(word.begin(), word.end О);
Используется в части 2126.
Отсортированное слово представляет собой первую перестановку букв, которую программа
ищет в словаре. Так, например, если буквы в word представляют собой gonar, то после
сортировки word будет содержать agnor.
Глава 12. Программа для поиска в словаре
213
12.3. Генерация перестановок и поиск
в словаре
Внутренний цикл выполняет проверку наличия каждой перестановки в словаре:
<Многократная генерация перестановок и их поиск 213> =
bool found_one = false;
do {
if (binary_search(dictionary.begin(),
dictionary.end(),
word)) {
cout << " " << word << endl;
found_one = true;
}
} while (next_permutation(word.begin(), word.end()));
if (!found_one)
cout << "Ничего не найдено.\n";
Используется в части 2126.
Обобщенный алгоритм binary_search возвращает true, если находит запрошенное
слово в словаре, и false в противном случае.23 Время поиска пропорционально логарифму
размера словаря.
Если word найдено в словаре, то эта перестановка исходной последовательности
символов выводится в стандартный поток вывода.
Затем обобщенный алгоритм next_j?ermutation выполняется заново для получения
очередной перестановки символов word в лексикографическом порядке. (Изначально символы в
word были отсортированы, чтобы начать работу с первой перестановки в данном порядке.)
Например, исходя из букв agnor, мы получим следующие перестановки в
лексикографическом порядке: agnor, agnro, agonr, agorn, angor, angro, ..., argon, ..., groan, ...,
organ,..., ronga (общее количество таких перестановок составляет 5! = 120).
Если последняя перестановка в лексикографическом порядке не достигнута,
next_j?ermutation помещает в word очередную перестановку и возвращает true; в
противном случае word преобразуется в первую перестановку в лексикографическом порядке, а
функция возвращает false, завершая тем самым работу внутреннего цикла.
12.4. Полная программа
Полная программа, составленная из всех частей, имеет следующий вид.
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
int main()
Как говорилось в главе 5, "Обобщенные алгоритмы*', STL предоставляет еще три алгоритма,
основанных на бинарном поиске: lower_bound, upper_bound и equal_range. Эти алгоритмы
возвращают итераторы, указывающие позицию или диапазон, содержащие значения, равные заданному.
Все они имеют логарифмическое время работы.
214
Часть II. Примеры программ
{
cout << "Программа поиска анаграмм:\п"
<< "поиск в словаре всех слов, которые могут\п"
<< "быть образованы из букв данного слова.\п"
<< endl;
cout << "Введите имя файла со словарем: " << flush;
string dictionary_name;
cin >> dictionary_name;
ifstream ifs(dictionary_name.c_str());
if (!ifs.is_open()) {
cout << "He могу открыть файл словаря "
<< dictionary_name << endl;
exit(l);
}
cout << "\пЧтение словаря..." << flush;
typedef istream_iterator<string> string_input;
vector<string> dictionary;
copy(string_input(ifs), string_input(),
back_inserter(dictionary));
cout << "\пСловарь содержит "
<< dictionary.size() << " слов.\п\п";
cout << "Введите слово (или строку букв): " << flush;
for (string_input j(cin); j != string_input(); ++j) {
string word = * j ;
sort (word.begin () , word.endO);
bool found_one = false;
do {
if (binary_search(dictionary.begin(),
dictionary.end(),
word)) {
cout << " " << word << endl;
found_one = true;
}
} while (next_permutation(word.begin(), word.endO));
if (!found_one)
cout << "Ничего не найдено.\п";
cout << "\пВведите другое слово\п"
<< "(или символ конца файла для останова): "
<< flush;
}
return 0;
}
В последующих главах мы не будем приводить полный код программы, собранный Nuweb
из отдельных частей, поскольку при наличии небольшой практики читать и понимать
исходный текст программы легче по частям.
12.5. Насколько быстр разработанный код
Приведенная программа для небольших строк работает достаточно быстро, но заметим,
что количество перестановок строки длиной N равно N\, так что она требует заметного
времени работы при 7V более 8 или около того. Хотя мы не будем возвращаться к этой программе
Глава 12. Программа для поиска в словаре
215
в последующих главах, ее можно перепрограммировать с использованием подходов,
рассматриваемых в этих главах, так что она заметно ускорится. (Считайте это домашним заданием!)
г Происхождение грамотного программирования
Как концепция грамотного программирования, так и первый инструментарий для нее I
[ были разработаны Д.Э. Кнутом (D.E. Knuth), который изобрел этот метод при разработке
! и документировании исходных текстов своей типографской системы igX (над которой
| позже Л. Лампортом (L. Lamport) был надстроен rTTgX ). Исходная система Кнута, Web,
| имела отдельные утилиты для извлечения кода и документации, которые носили названия
\ соответственно tangle и weave. Языком программирования, поддерживавшимся Web,
был Pascal. Позже С. Леви (S. Levy) разработал С Web, поддерживающий сначала про- !
\ граммирование на С, а позже — и на C++. Nuweb независим от языка программирования, !
\ поскольку, в отличие от Web или CWeb, не подсвечивает ключевые слова и не использует !
\ никаких иных специальных соглашений по форматированию программного кода. Это уп- :
' решает его использование по сравнению с CWeb.
Глава 13
Программа поиска всех групп
анаграмм
Программа, разработанная в этой главе, подобно программе из главы 12, "Программа для
поиска в словаре", использует словарь, но в этот раз операции со словарем более сложные.
Программа выполняет поиск в словаре всех групп анаграмм, т.е. групп слов, являющихся
перестановками друг друга, наподобие caret, carte, cater, crate и trace.
В большинстве предыдущих примеров все типы данных либо были встроенными типами
C++, либо типами, предоставляемыми STL. В данном примере мы используем компоненты
библиотеки с определенным нами типом.
13.1. Поиск групп анаграмм
Основная идея программы заключается в создании внутреннего словаря в виде вектора,
содержащего пары строк (шаблон класса pair рассматривается в разделах 1.3.1 и 25.3). Эти
пары строк обладают следующими свойствами:
• второй член пары хранит слово w из файла словаря;
• первый член хранит строку, которая представляет собой результат сортировки букв w
в алфавитном порядке.
После сортировки этих пар с использованием первых членов в качестве ключей все слова,
представляющие собой анаграммы, оказываются в последовательных позициях вектора.
Например, если файл словаря содержит слова
argon cater cereus groan maker organ secure trace
то вектор пар после вставки слов будет иметь следующий вид:
first
agnor
acert
ceersu
agnor
aekmr
agnor
ceersu
acert
second
argon
cater
cereus
groan
maker
organ
secure
trace
218
Часть II. 11римеры программ
После сортировки по первым членам пар вектор будет содержать следующие слова:
first
acert
acert
aekmr
agnor
agnor
agnor
ceersu
ceersu
second
cater
trace
maker
argon
groan
organ
cereus
secure
Таким образом, группы анаграмм наподобие argon, groan и organ объединяются.
Затем программе достаточно выполнить единственный проход по словарю, чтобы найти все
группы пар с одинаковыми первыми членами и вывести список вторых членов. Слова, не
имеющие анаграмм, наподобие
first second
aekmr maker
просто игнорируются.
13.2. Определение структуры данных
для работы с STL
Для реализации этого подхода определим сначала следующую структуру данных:
<Определение структуры PS для хранения пары строк 218> =
struct PS : pair<string, string> {
PS () : pair<string, string>(string(), stringO) { }
PS(const string& s) : pair<string, string>(s, s) {
sort(first.begin(), first.end());
}
operator string() const { return second; }
};
Используется в части 219в.
Эта структура определяет тип PS как структуру, производную от pair<string, string>,
с использованием шаблона класса STL pair (рассматриваемого в разделе 1.3.1 и 25.3). В
общем случае, если р представляет собой объект типа pair<Tl, Т2 >, то р. first означает
первый член пары типа Т1, а р. second — второй член, типа Т2. Второй конструктор
получает строковый аргумент, сохраняет его копии в членах first и second пары, а затем
сортирует символы члена first. Этот конструктор служит для преобразования типа string в
PS, a operator string () предоставляет возможность приведения типа PS обратно в
string. Наличие таких преобразований позволяет использовать обобщенный алгоритм
сору для копирования строк из входной строки в вектор объектов PS и из вектора в
выходной поток.
1
/ лава i j. / /рограмма поиска всех групп анаграмм
£1У
Вместо определения структуры PS можно было бы использовать тип
pair<string, string>. Но тогда у нас не было бы возможности определения
преобразований типов, необходимых для использования обобщенного алгоритма сору, и нам
пришлось бы кодировать цикл ввода-вывода явно.
13.3. Создание функциональных объектов
для сравнений
Для того чтобы использовать компоненты STL для выполнения операций наподобие
сортировки и поиска объектов PS, требуется создать два функционального объекта —
first Less и fir st Equal — для того, чтобы объяснить компонентам, как следует
сравнивать два объекта PS.
<Определение функционального объекта для сравнения PS 219а> =
struct FirstLess : binary_function<PS/ PS, bool> {
bool operator()(const PS& p, const PS& q) const
{
return p.first < q.first;
}
} firstLess;
Используется в части 219в.
Таким образом, когда объект firstLess передается алгоритмам наподобие
binary_search или sort, происходит сравнение объектов PS по их членам first.
Поскольку тип члена first в объектах PS представляет собой string, алгоритм использует
оператор <, определенный для строк. Это — лексикографическое упорядочение, т.е. именно
то упорядочение по алфавиту, которое нам и надо.
Точно так же определим функциональный объект first Equal, который проверяет
равенство объектов PS.
<Определение проверки равенства объектов PS 219б> =
struct FirstEqual : binary_function<PS/ PS, bool> {
bool operator()(const PS& p, const PS& q) const
return p.first == q.first;
} firstEqual;
Используется в части 219в.
Соберем все эти определения вместе в небольшой заголовочный файл (который будет
использован и в главе 14, "Улучшенная программа поиска групп анаграмм").
"ps.h" 219в &
#include <functional>
using namespace std;
<Определение структуры PS для хранения пары строк 218>
<Определение функционального объекта для сравнения PS 219а>
<Определение проверки равенства объектов PS 219б>
zzu
Часть II. I фимеры программ
13.4. Полная программа поиска групп анаграмм
Здесь мы представим общую структуру программы, а в оставшейся части главы
рассмотрим ее работу детальнее.
Пример 13.1. Поиск всех групп анаграмм в словаре и вывод их
в стандартный поток вывода
"ех13-01.срр" 220а =
#include <algorithm>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <iterator>
using namespace std;
#include "ps.h" // Определения PS, firstLess, firstEqual
int main() {
cout << "Программа поиска групп анаграмм:\п"
<< "находит все группы анаграмм в словаре.\п\п"
<< flush;
<Получение имени словаря и подготовка к чтению 211а>
<Копирование словаря в вектор объектов PS 22 0б>
<Сбор всех групп анаграмм 221а>
<Подготовка к выводу групп анаграмм 221б>
<Вывод всех групп анаграмм 221в>
return 0;
}
13.5. Чтение словаря в вектор объектов ps
Первая часть программы очень похожа на первую часть программы из главы 12,
"Программа для поиска в словаре": мы считываем словарь из файла и сохраняем его в
векторе. Однако вместо того, чтобы хранить только каждую считанную строку, мы храним
объекты PS, созданные из строк. Преобразование string в PS выполняется неявно в процессе
операции сору.
<Копирование словаря в вектор объектов PS 22 0б> ■
cout << "\пЧтение словаря..." << flush;
typedef istream_iterator<string> string_input;
vector<PS> word_pairs;
copy(string_input(ifs), string_input(),
back_inserter(word_pairs));
cout << "\пПоиск среди " << word_pairs.size()
<< " слов групп анаграмм..." << flush;
Используется в частях 220а,
2276.
/ ji&aci ю. i ifJuefjciMMcl nuuuna oi/сд cfjyiui апасрамм
В качестве части определения конструктора PS (const string&) выполняется
сортировка первого члена пары. Поэтому вектор word_jpairs вначале имеет вид, показанный
в первой таблице раздела 13.1.
13.6. Использование объекта сравнения
для сортировки
Следующим шагом алгоритма является использование функционального объекта
f irstLess для того, чтобы указать обобщенному алгоритму sort, как следует
упорядочивать объекты PS на основании их первых членов.
<Сбор всех групп анаграмм 221а> =
sort(word_pairs.begin(), word_pairs.end(), firstLess);
Используется в частях 220а, 2276.
Операция сортировки переставляет элементы вектора пар так, чтобы все пары, содержащие
слова, являющиеся анаграммами, находились в последовательных позициях вектора. В этот
момент вектор word_pairs имеет структуру, показанную во второй таблице раздела 13.1.
13.7. Использование предиката
эквивалентности для поиска равных
элементов
Наконец, мы готовы к выводу групп анаграмм при помощи константных итераторов,
указывающих на начало и конец вектора:
<Подготовка к выводу групп анаграмм 221б> ■
vector<PS>::const_iterator j = word_pairs.begin(),
finis = word_pairs.end(), k;
Используется в части 220а.
В цикле приведенного ниже вывода итератор j используется для сканирования вектора в
поисках начала группы анаграмм.
<Вывод всех групп анаграмм 221в> ■
cout << "\п\пГруппы анаграмм:" << endl;
while (true) {
<Перемещение j к началу следующей группы 222а>
<Проверка завершения 222б>
<Поиск конца к группы, начинающейся в j 222в>
<Вывод группы в позициях от j до к 222г>
j = к;
}
Используется в части 220а.
Сначала мы используем обобщенный алгоритм поиска adjacent_f ind. Итератор j
представляет собой vector<PS>: :const_iterator; вспомним, что это означает, что j
указывает на константу, а не что j является константой. Поэтому совершенно корректно
присвоить j новое значение.
222
Часть II. Примеры программ
<Перемещение j к началу следующей группы 222а> ■
j = adjacent_find(j, finis, firstEqual);
Используется в частях 221в, 228.
Это перемещение j к первой позиции в word_pairs, где f irstEqual (*j , *(j+l))
равно true; если таких последовательных значений в диапазоне нет, будет возвращено
значение finis.
Если достигнут конец словаря, цикл и вся программа завершаются:
<Проверка завершения 222б> =
if (j == finis) break;
Используется в частях 221b, 228, 232.
В противном случае следует повторить далее, с позиции j +1, поиск пары, у которой первый
элемент не равен первому элементу пары, на которую указывает j. Детали того, как это
делается, будут рассмотрены в следующем разделе.
13.8. Использование функционального
адаптера для получения объекта
предиката
Нам надо выполнить необходимый поиск при помощи обобщенного алгоритма find,
отличающийся тем, что мы считаем его успешным, когда находим значение, не равное
заданному. Поэтому мы используем f ind_if — версию find, которая принимает объект
предиката. Поскольку у нас нет готового объекта предиката для передачи алгоритму f ind_if,
воспользуемся парой функциональных адаптеров, для того чтобы получить его из
firstEqual.
Сначала мы применим к f irstEqual адаптер bindlst и значение * j, чтобы получить
функциональный объект, который получает единственный аргумент х и возвращает true;
если * j == х, nfalseB противном случае.
Получающийся функциональный объект предиката имеет смысл, противоположный тому,
который нам требуется, так что мы используем другой функциональный адаптер — notl. В
результате получается функциональный объект предиката, который возвращает true, если
* j ! = х, nfalseB противном случае, что именно то, что нам и требовалось:
<Поиск конца к группы, начинающейся в j 222в> =
к = find_if(j + 1, finis, notl(bindlst(firstEqual, *j)));
Используется в частях 221в, 228.
13.9. Копирование группы анаграмм
в выходной поток
Итак, итератор j, возвращаемый алгоритмом adjacent_find, и итератор к,
возвращаемый алгоритмом f ind_if, определяют диапазон пар слов, содержащих во вторых своих
компонентах анаграммы, и теперь пришло время следующей части программы,
<Вывод группы в позициях от j до к 222г> =
COUt << " »;
coPy(J/ к, ostream_iterator<string>(cout, " "));
ГЛЭва 7v*. / /рограмма поиика ьи&л групп амаерамм
cout << endl;
Используется в части 221в.
которая помещает слова в стандартный поток вывода. Заметим, что в процессе операции
сору выполняется неявное преобразование пары слов PS в string: когда объект PS
преобразуется в string, возвращается его второй член.
Наконец, мы перемещаем j в к для продолжения поиска следующей группы анаграмм.
13.10. Вывод программы
Вот какой вид имеет вывод программы (ввод пользователя выделен полужирным
шрифтом) при использовании указанного в приложении Г, "Ресурсы", файла словаря.
Вывод примера 13.1
Программа поиска групп анаграмм:
находит все группы анаграмм в словаре.
Введите имя файла со словарем: diction
Чтение словаря...
Поиск среди 20159 слов групп анаграмм...
Группы анаграмм:
hasn't shan•t
drawback backward
bacterial calibrate
cabaret abreact
bandpass passband
abroad aboard
banal nabla
balsa basal
saccade cascade
coagulate catalogue
ascertain sectarian
activate cavitate
vacuolate autoclave
caveat vacate
charisma archaism
maniac caiman
caviar variac
scalar lascar rascal sacral
causal casual
drainage gardenia
emanate manatee
и т.д. Программа находит 865 групп анаграмм в этом словаре, содержащем 20159 слов.
Глава 14
Улучшенная программа поиска групп
анаграмм
Одна из проблем программы поиска анаграмм из главы 13, "Программа поиска всех групп
анаграмм", заключается в неорганизованности вывода; хотелось бы видеть группы анаграмм
упорядоченные таким образом, чтобы первыми шли группы максимального размера. В этой
главе мы усовершенствуем программу, организовав ее вывод так, как сказано выше, и в
процессе работы проиллюстрируем применение как еще одного последовательного контейнера,
list, так и отсортированного ассоциативного контейнера тар.
14.1. Структура данных для хранения пар
итераторов
В этой программе мы создадим другую структуру данных, использующую шаблон класса
pair. Эта пара называется PPS, и ее объекты хранят итераторы, которые указывают на
векторы структур PS (разработанные нами в предыдущей главе).
<Определение структуры данных пар итераторов 225> =
typedef vector<PS>::const_iterator PSi;
typedef pair<PSi, PSi> PPS;
Используется в части 2276.
Пара итераторов PPS будет использоваться для определения диапазона записей словаря, у
которых вторые члены образуют группу анаграмм, как показано на рис. 14.1. Обратите
внимание, что на диаграмме второй итератор PPS указывает на позицию за концом анаграмм,
что соответствует стандартному соглашению диапазонов итераторов STL.
first
acert
acert
aekmr
agnor
agnor
agnor
ceersu
ceersu
second
cater
trace
maker
argon
groan
organ
cereus
secure
Рис. 14.1. Пара PPS определяет группу анаграмм
PS
PPS
first second
zzo
Часть II. Примеры программ
14.2. Хранение информации в отображении
списков
Теперь после сортировки вектора словаря для сбора групп анаграмм мы сканируем его
как и ранее, но вместо вывода каждой группы анаграмм после ее нахождения мы сохраняем
ее диапазон в паре PPS. Для простоты вывода групп в соответствии с их размером мы
сохраняем все диапазоны данного размера s в списке (list) пар PPS и сохраняем список как
значение, связанное с s, в отображении (тар):
<Отображение размеров групп на их списки 22 6а> =
typedef map<int/ list<PPS>, greater<int> > map_l;
map_l groups;
Используется в части 2276.
To есть, для данного целочисленного размера группы s выражение groups [s] хранит
список объектов PPS, причем отображение организовано так, чтобы его проход от
groups, begin () до groups, end О выдавал записи в порядке от наибольшей до
наименьшей. (Для обратного порядка следует передать классу тар в качестве передаваемого
функционального типа значение по умолчанию less<int>.)
Эта структура данных показана на рис. 14.2. Вспомните, что каждая пара PPS указывает
группу анаграмм в векторе записей PS, как показано на рис. 14.1.
key
4
3
2
data
1 pps | _f*| pps | ц*| pps | -4*| pps | -4-
1 pps | ^j pps | -4-
1 pps | -4*| pps | -4*| pps | -4*| pps | -4*| pps
-4*
Рис. 14.2. Отображение groups, связывающее целые числа со списками PPS
Итак, при генерации объекта PPS (j , k) его надо вставить в список groups [k- j ],
поскольку k-j представляет собой размер диапазона (а следовательно, и группы анаграмм):
<Хранение пар j, к в отображении groups 22 6б> =
if (k-j > 1)
// Сохранение позиций j и к, ограничивающих группу
// анаграмм, в списке групп размером k-j:
groups[k-j].push_back(PPS(j, k));
Используется в части 228.
14.3. Упорядоченный по размерам вывод
групп анаграмм
После сканирования всего вектора пар мы проходим по отображению групп следующим
образом.
Глава 14. Улучшенная программа поиска групп анаграмм
<Вывод групп анаграмм в порядке убывания размеров 227а> ■
п\ар_1: :const_iterator m;
for (m = groups.begin(); m != groups.end(); ++m) {
cout << "\пГруппы анаграмм размером "
<< m->first << ":\n";
list<PPS>::Const_iterator 1;
for (1 = m->second.begin();
1 != m->second.end(); ++1) {
cout << " ";
j = l->first; // Начало группы анаграмм
k - l->second; // Конец группы анаграмм
copy(j/ k, ostream_iterator<string>(cout, " "));
cout << endl;
}
}
Используется в части 2276.
Размер группы m равен m->first, a m-> second представляет собой соответствующую
запись, объект list<PPS>. Во внутреннем цикле for выполняется обход всех элементов
списка. Каждая запись списка *1 представляет собой пару, первый и второй члены которой
являются итераторами vector<PS>, указывающими диапазон вектора записей word_pairs,
в котором содержится группа анаграмм, так что нам надо просто скопировать их в выходной
поток. И вновь в процессе копирования выполняется неявное преобразование пар в строки.
14.4. Улучшенная программа поиска анаграмм
Соединяя все вместе, мы получаем следующую программу.
Пример 14.1. Вывод всех групп анаграмм в порядке уменьшения размера
"ех14-01.срр" 2276 =
#include <algorithm>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <list>
#include <map>
#include <iterator>
using namespace std;
#include "ps.h" // Определение PS, firstLess, firstEqual
<Определение структуры данных пар итераторов 225>
int main() {
cout << "Программа поиска групп анаграмм:\п"
<< "находит все группы анаграмм в словаре.\п\п"
<< flush;
<Получение имени словаря и подготовка к чтению 211а>
<Копирование словаря в вектор объектов PS 220б>
<Сбор всех групп анаграмм 221а>
<Отображение размеров групп на их списки 22ба>
<Поиск групп и сохранение их позиций в отображении 228>
<Вывод групп анаграмм в порядке убывания размеров 227а>
ZZ0
Часть II. I фимеры программ
return 0;
}
Вспомним, что заголовочный файл ps . h был определен в главе 13, "Программа поиска всех
групп анаграмм". Осталась не определенной только одна часть, которую очень легко записать
с помощью частей, определенных ранее в данной и предыдущей главе.
<Поиск групп и сохранение их позиций в отображении 228> =
cout << "\п\пГруппы анаграмм:" << endl;
PSi j = word_pairs.begin(), finis = word_pairs.end(), k;
while (true) {
«^Перемещение j к началу следующей группы 222а>
<Проверка завершения 222б>
<Поиск конца к группы, начинающейся в j 222в>
<Хранение пар j, к в отображении groups 22бб>
j = к;
}
Используется в части 2276.
14.5. Вывод программы
При применении программы к словарю из 20159 слов (см. приложение Г, "Ресурсы")
начало вывода программы имеет следующий вид (пользовательский ввод выделен полужирным
шрифтом).
Вывод примера 14.1
Программа поиска групп анаграмм:
находит все группы анаграмм в словаре.
Введите имя файла со словарем: diction
Чтение словаря...
Словарь содержит 20159 слов.
Группы анаграмм:
Группы анаграмм размером 5:
crate carte cater caret trace
Группы анаграмм размером 4:
scalar lascar rascal sacral
bate beat beta abet
glare lager large regal
mantle mantel mental lament
peal pale leap plea
leapt plate pleat petal
slate steal stale least
mane name mean amen
mate team tame meat
pare pear reap rape
tea ate eat eta
cereus recuse rescue secure
edit tide tied diet
vile live evil veil
item mite emit time
Глава 14. Улучшенная программа поиска групп анаграмм
229
rinse siren resin risen
stripe sprite esprit priest
Группы анаграмм размером 3:
abed bead bade
bread debar beard
brad bard drab
brae bare bear
garb grab brag
tuba tabu abut
came mace acme
cavern carven craven
secant stance ascent
avocet octave vocate
care acre race
infarct frantic infract
gander danger garden
и т.д. В данном словаре имеется 79 групп анаграмм размером 3 и 768 групп размером 2.
14.6. Причины использования отображения
Вернемся еще раз к данному примеру и подумаем, в чем заключается преимущество
использования тар для связи списков групп слов с целочисленными размерами? Похоже на то,
что мы могли бы использовать небольшой массив или вектор, поскольку у нас не должно
быть очень больших групп анаграмм даже при очень большом словаре (в случае файла
diction максимальный размер равен 5). Ключевое преимущество применения отображений
заключается в следующем.
• Независимость от размера. В случае массива мы бы должны были побеспокоиться о
его размере (достаточно ли массива из 20 элементов?), а в случае отображения нас
этот вопрос совершенно не волнует— даже если мы столкнемся с некоторым
аномальным словарем с большими группами анаграмм (например, словарь, в котором
слово просто повторяется много раз).
• Автоматическое расширение. При применении контейнера vector мы получаем
возможность расширения, но она не является автоматической. Если мы обнаруживаем
группу с размером большим, чем текущий, то должны самостоятельно увеличить
вектор до необходимого размера и инициализировать новые записи пустыми списками.
При использовании контейнера тар мы полностью избавляемся от указанных проблем.
■'■ш
•<* 'щ
Глава 15
Ускорение программы поиска
анаграмм: использование
мультиот
Зачастую, когда мы начинаем размышлять о реализации приложения, мы не уверены в
том, какой из нескольких возможных подходов окажется наиболее эффективным. Как
говорилось в главе 6, "Последовательные контейнеры", одним из важнейших преимуществ при
создании программ с применением STL является то, что можно без внесения особых
изменений в программу испытать различные структуры данных и алгоритмы. В этой главе мы
проиллюстрируем данное утверждение путем еще одной модификации программы для поиска
групп анаграмм. В этот раз наша цель состоит не в усовершенствовании вывода программы,
как это делалось в главе 14, "Улучшенная программа поиска групп анаграмм", а в
рассмотрении иного способа хранения словаря, который делает программу немного быстрее.
15.1. Поиск групп анаграмм, версия 3
Структура данных для хранения пары строк PS, использовавшаяся в программах поиска
анаграмм в двух предыдущих главах, обеспечивала возможность ассоциации строки s с
другой строкой, которая представляет собой результат сортировки букв, составляющих строку s.
Давайте рассмотрим еще один способ получения такой ассоциации с использованием
multimap— одного из отсортированных ассоциативных контейнеров STL. Поскольку эти
контейнеры спроектированы для эффективной обработки ассоциаций, представляется
логичным проверить, не окажется ли приложение для поиска анаграмм с применением мультио-
тображений более эффективным, чем при хранении объектов PS в векторе.
Мультиотображение позволяет хранить несколько ключей данного типа Key и
эффективно получать значения другого типа Т на основе значений Key. В программе, разрабатываемой
в данной главе, как Key, так и Т представляют собой тип string. Мы создаем для каждого
найденного в словаре слова запись в мультиотображении с использованием версии слова с
отсортированными буквами в качестве ключа и исходного слова в качестве связанного значения.
По сути это тот же подход, что и при использовании вектора объектов типа PS в
главах 13, "Программа поиска всех групп анаграмм", и 14, "Улучшенная программа поиска
групп анаграмм". В самом деле, как показано на рис. 15.1, структура данных почти идентична
структуре данных из предыдущей главы, но в случае мультиотображения записи
автоматически упорядочиваются, так что нет необходимости в их явной сортировке, как при
использовании вектора. Тип итератора, предоставляемый мультиотображением, проводит нас по запи-
ображений
Часть II. Примеры программ
сям в соответствии с их порядком сортировки, так что поиск групп анаграмм оказывается
очень похожим на способ, применявшийся в предыдущих главах при работе с вектором.
key
acert
acert
aekmr
agnor
agnor
agnor
ceersu
ceersu
data
cater
trace
maker
argon
groan
organ
cereus
secure
Рис. 15.1. Пара PPS, указывающая группу анаграмм
Сортировка словаря в соответствии с первыми членами объектов PS является основной
частью вычислений, которая может быть сделана более быстрой. Почему мы считаем, что
при использовании мультиотображения ее можно выполнить быстрее, чем в случае вектора?
Помещение объектов в вектор с их последующей сортировкой может быть одним из наиболее
эффективных методов сортировки, но только если объекты достаточно малы, чтобы их
можно было легко перемещать по вектору. В случае больших объектов оказывается более
эффективной сортировка с использованием указателей, которые меньше, чем сами объекты. Хотя
объекты PS не такие уж и большие, они могут быть достаточно велики, чтобы сортировка
посредством указателей оказалась быстрее сортировки на основе перемещения самих объектов.
Поскольку мультиотображения (и другие отсортированные ассоциативные контейнеры STL)
выполняют сортировку с применением указателей, стоит выяснить, не приведет ли их
применение к ускорению сортировки в программе.
Сейчас мы представим программу, после чего детально рассмотрим ключевые моменты
ее реализации.
Пример 15.1. Поиск всех групп анаграмм в заданном словаре
"ех15-01.срр" 232 =
#include <algorithm>
#include <iostream>
#include <fstream>
#include <string>
#include <list>
#include <map>
#include <iterator>
#include <functional>
using namespace std;
typedef multimap<string/ string> multimap_l;
<Определение PS как multimap_l::value_type 234a>
typedef multimap_l::const_iterator PSi;
typedef pair<PSi, PSi> PPS;
int main() {
cout << "Программа поиска групп анаграмм:\п"
<< "находит все группы анаграмм в словаре.\п\п";
multimap_l
PPS
first second
fnaea 15. Ускорение программы поиска анаграмм: использование мультиотображений 233
<Получение имени словаря и подготовка к чтению 211а>
cout << "\пЧтение словаря..." << flush;
// Копирование слов из файла словаря в
// мультиотображение:
typedef istream__iterator<string> string_input;
multimap_l word_pairs;
<Копирование словаря в мультиотображение 234б>
cout << " \пПоиск среди " << word_jpairs . size ()
<< " слов групп анаграмм..." << flush;
// Создание отображения размеров групп анаграмм на
// списки групп этого размера:
typedef map<int, list<PPS>/ greater<int> > map_l;
map_l groups;
// Поиск всех групп анаграмм и сохранение их позиций в
// отображении groups:
cout << "\п\пГруппы анаграмм: " << endl;
<Подготовка к проходу по мультиотображению 234в>
while (true) {
// Итератор j должен указывать на следующую группу
// анаграмм, или на конец мультиотображения:
<Поиск смежных равных записей отображения 235а>
<Проверка завершения 222б>
<Поиск конца ряда смежных равных записей 235б>
<Получение размера диапазона и сохранение 235в>
// Подготовка к продолжению поиска с позиции к:
j = к;
}
// Проход по отображению groups для вывода групп
// анаграмм в убывающем порядке:
map_l::const_iterator т;
for (т = groups.begin(); т != groups.end(); ++т) {
cout << "\пГруппы анаграмм размером "
<< m->first << ":\п";
list<PPS>::const_iterator l;
for (1 = m->second.begin();
1 != m->second.end(); + + 1) {
cout << " ";
<Вывод групп анаграмм 23б>
cout << endl;
}
}
return 0;
}
234
Часть II. Примеры программ
15.2. Объявление мультиотображения
В объявлении
typedef multimap<string, string> multimap_l;
мы определяем multimap__l как сокращенное имя для типа мультиотображения, типы Key и
Т которого являются строками и записи которого упорядочены в соответствии с обычным
упорядочением ключей "меньше, чем". Типом записей контейнера multimap_l является
pair<const string, string>
и этот тип задается как multimap_l: : value_type. В следующем объявлении мы
используем указанный тип для определения другого сокращенного имени типа, PS, которое будет
использоваться далее в программе:
<Определение PS как multimap_l::value_type 234a> =
typedef multimap_l::value_type PS;
Используется в части 232.
Тип PS подобен типу PS, определенному в предыдущей главе, но в этот раз мы не должны
определять преобразования типов между объектами PS и string или функциональные
объекты для сравнивания объектов PS. Вместо этого можно воспользоваться возможностями,
автоматически предоставляемыми типом multimap.
кЩ
15.3. Чтение словаря в мультиотображение
На первом этапе программы, после создания пустого мультиотображения word_pairs,
мы читаем каждую строку входного потока и создаем ее отсортированную версию в другой
строке word. Затем мы вставляем запись в мультиотображение word_pairs с word в
качестве ключа и исходной строкой в качестве связанного значения. Код, который все это
выполняет, приведен ниже.
<Копирование словаря в мультиотображение 234б> =
for (string_input in(ifs); in != string_input(); ++in) {
string word = *in;
sort (word.begin () , word.endO);
word_pairs.insert(PS(word, *in));
Используется в части 232.
15.4. Поиск групп анаграмм
в мультиотображении
Затем мы настраиваем отображение groups, как и в предыдущей версии программы, и
подготавливаемся к обходу мультиотображения word_jpairs для поиска всех групп
смежных записей с равными ключами.
<Подготовка к проходу по мультиотображению 234в> =
PSi j = word_jpairs. begin () , finis = word_pairs. end () , k;
Используется в части 232.
Глава 15. Ускорение программы поиска анаграмм: использование мулыпиотображений Z35
Это объявление готовит программу к проходу по всем записям мультиотображения в
порядке, соответствующем функции сравнения в определении multimap__l, которая в нашем
случае совпадает с функцией сравнения по умолчанию— less<string>.
В цикле, который следует за инициализацией, используется та же стратегия, что и в
предыдущих версиях программы; фактически цикл можно сделать практически идентичным
предыдущим, если определить функциональный объект, аналогичный firstEqual для
сравнения объектов PS.
Однако в случае мультиотображений можно воспользоваться наличием функции-члена
value_comp, которая предоставляет функциональный объект для сравнения записей на основе
сравнения их ключей, который в случае multimap_l представляет собой сравнение по
умолчанию — less<string>. Эта функция используется при создании предиката, который, будучи
передан функции STL adj acent_f ind, позволяет определить очередную группу анаграмм.
Цель заключается в определении предиката, который позволил бы найти очередную
запись мультиотображения, большую предыдущей. Это делается с учетом того факта, что в
мультиотображений для любых двух последовательных записей и и v, и либо меньше v, либо
равно v. Следовательно, выполняя поиск двух последовательных записей и и v, таких, что и
не меньше v, можно найти первые равные записи.
Поскольку объект предиката word_j?airs . value_comp () возвращает true для
операндов и и v таких, что и меньше v, все, что нам надо — это обратить его при помощи
бинарного функционального адаптера not 2 и получить объект, который затем передать
adj acent_find:
<Поиск смежных равных записей отображения 2 35а> =
j = adjacent_find(j, finis,
not2(word_pairs.value_comp()));
Используется в части 232.
Этот вызов adjacent_f ind находит начало последовательности записей с равными
ключами. Как и в предыдущих версиях, f ind_if может использоваться для обнаружения
конца последовательности, в этом случае объект предиката строится с использованием
word_jpairs .value_comp () nbindlst:
<Поиск конца ряда смежных равных записей 23 5б> =
k = find_if(j, finis,
bindlst(word pairs.value comp(), *j));
_
Используется в части 232.
Как и в версии в главе 14, "Улучшенная программа поиска групп анаграмм", затем мы
должны вычислить расстояние от начальной позиции j до конечной к и сохранить эту пару
итераторов для последующего вывода. В главе 14 это расстояние вычислялось как к - j, но
это было возможно только потому, что j и к представляли собой итераторы с произвольным
доступом, для которых определен оператор "-". В нашем же случае j и к представляют
собой двунаправленные итераторы, так что оператор "-" недоступен. Вместо него следует
применить обобщенную функцию distance:
<Получение размера диапазона и сохранение 235в> =
multimap_l::size_type n = distance(j, k) ;
if (n > 1)
// Сохранение позиций j и к, ограничивающих группу
// анаграмм, в списке групп размером п:
groups[n].push_back(PPS(j, k) ) ;
Используется в части 232.
ZJO
Часть II. Примеры программ
Функция distance выполняется за линейное время, и обычно ее применения избегают*
однако она используется в особых ситуациях, как данная, когда, как ожидается, поиск должен
быть коротким. Эта функция более подробно рассматривается в разделе 20.7.
■
15.5. Упорядоченный по размерам вывод
групп анаграмм
Этот этап программы очень похож на соответствующий этап программы в главе 14,
"Улучшенная программа поиска групп анаграмм". Единственное отличие заключается в том
что теперь мы не можем использовать сору для помещения объектов PS в выходной поток
поскольку не имеем преобразования объектов типа PS в строки. Вместо этого применяется
цикл:
<Вывод групп анаграмм 23б> з
j = l->first; // Начало группы анаграмм
k = l->second; // Конец группы анаграмм
for (; j != к; ++j)
cout << j->second << " ";
Используется в части 232.
15.6. Вывод программы
Вывод этой версии программы поиска групп анаграмм тот же, что и вывод программы из
главы 14, "Улучшенная программа поиска групп анаграмм".
15.7. Скорость работы программы
Как показывают замеры времени работы, эта версия программы примерно на 30%
быстрее версии из главы 14, "Улучшенная программа поиска групп анаграмм". Второй и третий
этапы программы в новой версии могут оказаться немного медленнее (потому что обход с
применением итераторов мультиотображений медленнее, чем с итераторами векторов), так
что основной выигрыш наблюдается на первом этапе, при сохранении словаря в
мультиотображений, когда используется неявная сортировка — в отличие от вектора, который следует
сортировать явно.
Глава 16
Определение класса итератора
Мы надеемся, что примеры из предыдущих глав показали, что одна из наиболее
привлекательных возможностей STL — это проектирование интерфейсов компонентов так, что оно
позволяет компоновать алгоритмы и структуры данных несметным количеством способов.
Эта особенность не только обеспечивает высокое отношение функциональность/размер у
STL, но и поясняет, почему STL лучше любых других библиотек приспособлена для
применения в качестве основы для разработки и более обширных, и более специализированных
библиотек. Конечно, большинство пользователей STL не будут заниматься ее расширением,
но многие в какой-то момент получат возможность создать простой новый компонент. В этой
главе мы рассмотрим небольшой пример создания такого компонента — адаптера итератора,
который будет полезен при отладке или оптимизации программ, использующих итераторы.
16.1. Новый вид итератора:
подсчитывающий итератор
Определим новый тип итератора под названием подсчитывающий итератор, который
работает как обычный итератор, но при этом отслеживает количество выполненных операций
типа ++. По запросу этот итератор выводит накопленные значения, таким образом
обеспечивая программиста статистикой работы итератора. Рассмотрим следующий код.
Пример 16.1. Демонстрация класса подсчитывающего итератора
"ех16-01.срр" 237 =
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
<Определение класса подсчитывающего итератора 238>
int main()
{
cout << "Демонстрация класса подсчитывающего "
<< "итератора." << endl;
int x[] = {12, 4, 3, 7, 17, 9, 11, б};
counting_iterator<int*> i(&x[0], "Curly"),
j(&x[0], "Мое"),
end(&x[8], "Larry");
cout << "Обход массива х\п"
238
Часть II. Примеры программ
<< " от i (Curly) до end (Larry)\n";
while (i != end) {
cout << *i << endl;
. "1"
cout << "После обхода:\n";
i.report(cout);
end.report(cout);
cout << "Присваивание i (Curly) значения j (Мое)."
<< endl;
i - j;
cout << "Поиск в массиве\п"
<< " от i (Мое) до end (Larry)\n"
<< " с помощью find\n";
counting_iterator<int*> k = find(i, end, 9);
cout << "После поиска:\n";
k.report(cout);
i.report(cout);
end.report(cout);
return 0;
}
В этой программе предполагается, что вызов функции-члена report выводит
информацию об итераторе — имя, данное при вызове конструктора, номер версии (изначально равный
1 и возрастающий всякий раз при копировании итератора), и количество операций ++,
выполненных итератором. Например, первый вызов i . report (cout), должен вывести
Итератор Curly, версия 1, 8 операций ++
поскольку цикл while выполняет действие + + i восемь раз. Чтобы программа корректно
работала, надо определить counting_iterator как класс, объекты которого ведут себя как
итераторы, но при этом отслеживают количество выполненных операций ++.
Для краткости мы ограничимся только однонаправленными итераторами, т.е. создадим
адаптер итератора, который преобразует любой однонаправленный итератор (итератор,
который предоставляет как минимум все операции однонаправленного итератора, но может
предоставлять и другие) в однонаправленный итератор, выполняющий обход
последовательности в точности так же, как и исходный итератор, и при этом отслеживающий количество
примененных к нему операций ++. Новый итератор, кроме того, имеет функцию-член
report, обеспечивающую вывод накопленной информации.
16.2. Класс подсчитывающего итератора
Вот как выглядит определение класса:
<Определение класса подсчитывающего итератора 238> =
template <typename ForwardIterator>
class counting_iterator {
private:
<Определение закрытых членов-данных 23 9а>
public:
typedef counting_iterator<ForwardIterator> self;
<Определение типов для других адаптеров 23 9б>
<Определение конструктора 240а>
<Определение конструктора по умолчанию 24 0в>
Глава 16. Определение класса итератора
ZJV
<Определение копирующего конструктора 24 0б>
<Определение *, = =, 1= и ++ 240г>
<Определение функции-члена вывода статистики 241>
};
Используется в части 237.
Это определение класса начинается с объявления закрытых членов-данных, необходимых для
отслеживания состояния итератора (current), количества выполнений операции ++
(plus_count), а также имени и версии для идентификации итератора в копирующем
конструкторе и функции вывода информации.
«^Определение закрытых членов-данных 23 9а> s
Forwardlterator current;
int plus_count;
string name;
int version;
Используется в части 238.
Чтобы корректно определить некоторые члены count ing_it era tor, нам надо знать
некоторые из типов, связанных с параметром шаблона Forwardlterator, такие как его
value__type и ref erence_type. Эту информацию можно получить, воспользовавшись
классом iterator_traits. В свою очередь мы можем определить эти и другие полезные
типы для counting_iterator, тем самым предоставляя эту информацию для
последующего использования адаптерами, которые могут быть применены к итератору данного вида.
(В общем случае предоставление этих typedef в компоненте STL необходимо (но не
достаточно), чтобы сделать компонент "адаптируемым".)
Определение типов для других адаптеров 23 9б> =
typedef typename
iterator_traits<ForwardIterator>::value_type
value_type;
typedef typename
iterator_traits<ForwardIterator>::reference
reference;
typedef typename
iterator_traits<ForwardIterator>::pointer
pointer;
typedef typename
iterator_traits<ForwardIterator>::difference_type
difference_type;
typedef forward_iterator_tag iterator_category;
Используется в части 238.
Для любого типа итераторов, включая указатели, класс iterator_traits<Iterator>
определяет различные вложенные типы, указывающие свойства итератора. Более полно
iterator_traits рассматривается в главе 20, "Справочное руководство по итераторам".
Заметим, что, поскольку мы ограничились в нашей реализации однонаправленными
итераторами, то явно используем для категории итератора дескриптор f orward_iterator_tag.
Даже если исходный итератор представляет собой итератор с произвольным доступом,
подсчитывающий итератор будет просто однонаправленным итератором. Если бы мы создавали более
обобщенный адаптер итератора, то могли бы захотеть, чтобы наш новый итератор был той же
категории, что и исходный адаптируемый итератор. В этом случае можно было бы записать
typedef typename
iterator_traits<Iterator>::iterator_category
iterator_category;
240
Часть II. Примеры программ
При этом, конечно же, было бы необходимо реализовать все операции итератора с
произвольным доступом.
Основной конструктор получает итератор, который будет адаптирован, и имя для
создаваемого подсчитывающего итератора. Счетчик инициализируется значением 0, а номер
версии устанавливается равным 1.
<Определение конструктора 24 0а> =
counting_iterator(Forwardlterator first, const stringfc n)
: current(first), plus_count(0), name(n), version(l) {}
Используется в части 238.
Копирующий конструктор выполняет копирование этих членов-данных, за исключением
version, значение которого увеличивается на 1, и выводит имя и новый номер версии в
стандартный поток вывода.
<Определение копирующего конструктора 24 0б> =
counting_iterator(const self& other)
: current(other.current),
plus_count(other.plus_count), name(other.name),
version(other.version + 1)
{
cout << "Копирование " << name
<< ", новая версия "
<< version << endl;
}
Используется в части 238.
Такой "говорящий копирующий конструктор" может существенно помочь в понимании того,
где и сколько раз копируется объект итератора.
Мы определим конструктор по умолчанию, который необходим согласно требованиям к
однонаправленным итераторам (хотя для нашей программы он и не требуется).
<Определение конструктора по умолчанию 24 0в> =
counting_iterator() : current(0)/ plus_count(0),
name("null"), version(1) {}
Операторы ==, ! = и обе (префиксная и постфиксная) версии ++ должны быть
предоставлены в соответствии с требованиями STL к однонаправленным итераторам (см. раздел 20.3).
Мы просто применяем те же операции к базовому итератору current. В функции
operator++ мы, кроме того, увеличиваем счетчик количества операций plus_count.
<Определение *, ==, != и ++ 240г> =
reference operator*()
// Разыменование
{
return *current;
}
bool operator==(const self& other) const
// Проверка на равенство
{
return current == other.current;
}
bool operator!=(const self& other) const
// Проверка на неравенство
return current != other.current;
}
self& operator++()
// Префиксный ++
Глава 16. Определение класса итератора
{
++current;
++plus_count;
return *this;
}
self operator++(int)
// Постфиксный ++
{
self tmp ш *this;
++(*this);
return tmp;
}
Используется в части 238.
Обратите внимание, что постфиксная версия ++ определяется через префиксную.
Функция вывода информации принимает аргумент ostream и выводит статистику в этот
поток.
Определение функции-члена вывода статистики 241> з
void report(ostreamfc o) const
// Вывод статистической информации в поток о
{
о << "Итератор " << name << ", версия " << version
<< ", " << plus_count << " операций ++" << endl;
}
Используется в части 238.
При таком определении counting_iterator полный вывод программы-примера,
приведенной в начале главы, имеет следующий вид.
Вывод примера 16.1
Демонстрация класса подсчитывающего итератора.
Обход массива х
от i (Curly) до end (Larry)
12
4
3
7
17
9
11
6
После обхода:
Итератор Curly, версия 1, 8 операций ++
Итератор Larry, версия 1, 0 операций ++
Присваивание i (Curly) значения j (Мое).
Поиск в массиве
от i (Мое) до end (Larry)
с помощью find
Копирование Мое, новая версия 2
Копирование Larry, новая версия 2
Копирование Мое, новая версия 3
После поиска:
Итератор Мое, версия 3, 5 операций ++
Итератор Мое, версия 1, 0 операций ++
Итератор Larry, версия 1, 0 операций ++
£.**£.
Часть И. Примеры программ
Обратите внимание, что вызов функции find приводит к копированию i и end (потому что
параметры в функцию find передаются по значению), а окончательное значение копии i
(Мое, версия 2) копируется при возврате результата в к (Мое, версия 3).
Поскольку мы определили counting_iterator как адаптер итератора (он получает
класс итератора в качестве параметра шаблона), его можно использовать для преобразования
типа итератора, связанного с любым классом контейнера STL, в подсчитывающий итератор.
Например, чтобы объявить подсчитывающий итератор i, работающий с list<char>,
можно записать
list<char> 1;
counting_iterator<list<char>::iterator>
i(l.begin(), "Shemp");
В том виде, в котором мы его определили, count ing_iterator производит итераторы из
категории однонаправленных (было бы корректнее дать ему имя f orward_counting_iterator).
Поэтому данные итераторы не могут применяться в алгоритмах STL, которые требуют
двунаправленные итераторы или итераторы с произвольным доступом, но определение
подсчитывающих итераторов для этих категорий — достаточно простое упражнение (если вы
захотите выполнить его самостоятельно, обратитесь к разделам 20.4 и 20.5, в которых
рассматриваются требования к итераторам указанных категорий).
Резюмируя, можно сказать, что адаптер итератора, такой как counting_iterator,
может подтвердить или раскрыть информацию о том, как обобщенный алгоритм STL или
пользовательский код используют итераторы, что может оказаться весьма полезным при отладке
или оптимизации программ. Мы надеемся, что этот пример проиллюстрировал также
некоторые из основных вопросов определения других типов адаптеров итераторов или иных новых
программных компонентов, совместимых с STL.
Глава 17
STL и объектно-ориентированное
программирование
У многих программистов первая реакция на STL: "Тут же нет ничего объектно-
ориентированного!". Да, STL очень слабо использует наследование, а второй главный
признак объектно-ориентированного программирования — виртуальные функции — не
применяет совсем.24 Однако STL мало что теряет от этого. Использование шаблонов и хорошо
спроектированных небольших взаимозаменяемых компонентов обеспечивает STL при
сохранении высокой производительности такой гибкостью, которую обычно не найти в
программах, активно применяющих наследование и виртуальные функции.
Тем не менее, причины для применения производных классов и виртуальных функций в
некоторых ситуациях остаются, так что эти методы программирования вполне могут
комбинироваться с STL и давать отличные результаты. Вот две причины поступать таким образом.
• Потребность в контейнерах для хранения объектов разных типов. Нам может
потребоваться хранить в одном контейнере объекты разных типов; такой контейнер
представляет собой гетерогенное хранилище, в отличие от гомогенных хранилищ,
непосредственно предоставляемых шаблонами классов контейнеров STL.
• Устранение "разбухания кода ". Даже если во всех контейнерах нам требуется только
гомогенное хранение, могут потребоваться различные экземпляры одного и того же
типа контейнера, что приведет к проблеме "разбухания кода" — например, к наличию
list<int>, list<string>, list<vector<int> > и т.д. в одной и той же
программе, что приведет к появлению мало отличающихся копий кода класса list в
выполняемом файле.5
В этой главе мы на простом примере покажем, как компоненты STL и методы
обобщенного программирования могут комбинироваться с наследованием классов и виртуальными
функциями для достижения одной или двух упомянутых целей за счет небольшой потери
эффективности и проверок времени компиляции.
24 Зато две другие возможности языка программирования, которые обычно рассматриваются как
неотъемлемая часть объектно-ориентированного программирования— абстракция данных
(инкапсуляция) и полиморфизм — в STL представлены очень широко.
25 Теоретически компиляторы способны во многих случаях прибегать к "совместному
использованию кода". Например, если sizeof (Tl) == sizeof (T2), то большая часть кода list<Tl> и
list<T2> может использоваться совместно, так как не зависит от типа хранимых элементов. Однако
имеющиеся в настоящее время компиляторы C++, похоже, на такой подвиг не способны.
244
Часть II. Примеры программ
17.1. Использование наследования
и виртуальных функций
Пример основан на ранее рассматривавшихся в разделе 6.4 книги Б. Страуструпа [20]
"фигурах". Эта простая программа для черчения геометрических фигур на экране
используется для иллюстрации методов объектно-ориентированного программирования. Она включает
следующее.
• Диспетчер экрана: низкоуровневые подпрограммы и структуры данных для работы с
экраном. Они знают только о том, как выводить точки и прямые линии.
• Библиотека фигур: набор определений фигур, таких как прямоугольники и
окружности, и стандартных программ для работы с ними.
• Прикладная программа: набор определений и использующего их кода, специфичных
для данной программы.
Библиотека фигур организует поддерживаемые ею различные фигуры в простую иерархию
классов, состоящую из базового класса shape и производных классов line и rectangle.
Операции вывода и перемещения фигур определены как виртуальные функции в классе shape
и получают конкретный смысл в каждом производном классе. Такая организация позволяет
выводить или перемещать все фигуры посредством интерфейса, предоставляемого классом shape.
Она также обеспечивает возможность хранения объектов разных типов (rectangle и line) в
одном контейнере, поскольку они могут храниться с помощью указателей shape*.
Детальное описание диспетчера экрана и библиотеки фигур можно найти в уже
упоминавшейся книге [20]. Заголовочные файлы screen. h и shape. h, а также соответствующие
файлы реализации screen.срр и shape, срр приведены в приложении В, "Заголовочные
файлы, используемые в примерах программ". Для нашего рассмотрения точные детали не
имеют значения, главное — что draw и move определены как виртуальные функции в классе
shape, так что функции уровня приложения (такие, как размещение фигур одна поверх
другой), написанные в терминах draw и move, будут работать со всеми фигурами. Например,
поскольку draw представляет собой виртуальную функцию, при ее применении к объекту
shape, являющемуся прямоугольником, используется функция draw, определенная в
производном классе rectangle; то же самое относится к классу line или другим производным
классам, которые могут быть добавлены впоследствии.
Прикладная программа в [20] очень проста — она выводит стилизованную фигуру и
перемещает ее. В нашем адаптированном примере мы определим vector<shape*> и
покажем, как работать с конкретными фигурами в векторе этого типа с помощью комбинации
(невиртуальных) функций-членов вектора STL, обобщенных алгоритмов STL и виртуальных
функций shape.
Пример 17.1. Комбинация компонентов STL с наследованием
и виртуальными функциями
"ех17-01.срр" 244 =
#include "shape.h"
#include <vector>
#include <algorithm>
#include <iostream>
#include <functional>
using namespace std;
class myshape : public rectangle {
Глава 17. STL и объектно-ориентированное программирование
/* Определение новой фигуры, простого "лица",
производной от rectangle.
*/
line* l_eye;
line* r_eye;
line* mouth;
public:
myshape(point, point);
void draw();
void move(int, int);
};
myshape::myshape(point a, point b) : rectangle(a,b)
{
int 11 = neastO.x - swest().x+l;
int hh = neastO .y - swestO .y+1;
l_eye =
new line(point(swest().x+2,swest().y+hh*3/4),2);
r_eye =
new line(point(swest().x+11-4,
swest().y+hh*3/4),2);
mouth =
new line(point(swest().x+2,
swest().y+hh/4),11-4);
}
void myshape::draw()
// Черчение фигуры путем вывода прямоугольника и точки
// "носа"; объекты глаз и рта обновляются отдельно
// функцией shape_refresh.
{
rectangle::draw();
int a = (swestO.x + neast().x)/2;
int b ■ (swestO.y + neast () .y)/2;
put_point(point(a,b));
}
void myshape:-.move (int a, int b)
// Перемещение объекта путем перемещения базового
// прямоугольника и вторичных объектов.
{
rectangle::move(a,b);
l_eye->move(a,b);
r_eye->move(a,b);
mouth->move(a,b);
}
// Начало определений, необходимых для использования STL с
// классами фигур.
struct CompWestX : binary_function<shape*, shape*, bool> {
bool operator()(shape* p, shape* q) const
// Сравнение фигур по х-координате западной точки.
// Функция west — виртуальная, так что сравнение
// выполняется с учетом того, как она определена
// для конкретной фигуры.
{
return p->west().x < q->west().x;
}
} compWestX;
void outputWestX (const vector<shape*>& vs)
Часть II. Примеры программ
// Вывод х-координаты западной точки каждой фигуры в
// векторе vs.
{
vector<shape*>::const_iterator i;
for (i = vs.begin(); i != vs.end(); ++i)
cout << "х-координата западной точки фигуры "
<< i - vs.begin() << " равна "
<< (*i)->west().x << endl;
}
// Конец определений, добавленных для обеспечения
// использования STL.
int main()
{
// Первая часть та же, что и в книге Страуструпа:
screen_init();
shape* pi = new rectangle(point(0,0),point(10,10));
shape* p2 = new line(point(0,15),17);
shape* p3 = new myshape(point(15,10),point(27,18));
shape_refresh();
p3->move(-10,-10);
stack(p2,p3);
stack(pl,p2);
shape_refresh();
// Эта часть добавлена как маленький пример
// использования STL с кодом, использующим иерархию
// классов и виртуальные функции. Сначала вносим
// фигуры в вектор STL:
vector<shape*> vs;
vs.push_back(pi)
vs.push_back(p2)
vs.push_back(p3)
// Используем итератор STL для перемещения всех точек
//по горизонтали на 2 0 единиц:
vector<shape*>::iterator i;
for (i = vs.beginO; i != vs.endO; ++i)
(*i)->move(20, 0) ;
shape_refresh();
// Демонстрируем применение обобщенного алгоритма
// сортировки STL к объектам в иерархии классов:
outputWestX(vs);
cout << "Сортировка фигур в соответствии с\п"
<< "х-координатой западной точки." << endl;
sort(vs.begin(), vs.end(), compWestX);
cout << "После сортировки:" << endl;
outputWestX(vs);
screen_destroy();
return 0;
}
Сначала разные фигуры выводятся в их исходных позициях.
Глава 17. STL и объектнснэриентированное программирование
Вывод примера 17.1
*******••***•
* **
*****************
* ****••**• *
*********** *************
***********
Затем фигуры перемещаются, образуя следующий рисунок.
***********
• *
***********
*****************
**•******••**
• ********* *
*************
Все фигуры перемещаются на 20 знакомест вправо путем размещения их в векторе и
обхода этого вектора с перемещением каждой содержащейся в нем фигуры.
***********
***********
*****************
*************
* ********* *
*************
£.tO
Часть II. Примеры программ
В последней части выводятся х-координаты западных точек фигур в векторе до
сортировки и после применения обобщенного алгоритма сортировки STL sort.
х-координата западной точки фигуры 0 равна 26
х-координата западной точки фигуры 1 равна 23
х-координата западной точки фигуры 2 равна 25
Сортировка фигур в соответствии с
х-координатой западной точки.
После сортировки:
х-координата западной точки фигуры 0 равна 23
х-координата западной точки фигуры 1 равна 25
х-координата западной точки фигуры 2 равна 26
17.2. Устранение "разбухания кода"
Тип vector< shape*>, введенный в примере 17.1, позволяет хранить в одном
контейнере различные фигуры (прямоугольники, отрезки и т.д.). В ряде случаев нам может не
требоваться гетерогенное хранение; вместо него может возникнуть необходимость в различных
экземплярах векторов для хранения фигур определенного вида, например:
vector<rectangle> vr,-
vector<line> vl, vl2;
vector<circle> vc;
vector<myshape> msl, ms2, ms3;
// ... и т.д.
При этом возникает проблема, связанная с тем, что компилятор может вставить копию
кода класса вектора для каждого экземпляра vector, что приведет к неприемлемому
увеличению выполняемого файла. Один из способов избежать такого разрастания заключается в
применении vector< shape* > в качестве типа для всех векторов фигур:
vector<shape*> vr;
vector<shape*> vl, vl2;
vector<shape*> vc;
vector<shape*> msl, ms2, ms3;
// ... и т.д.
В этом случае в выполняемый файл будет включена только одна копия кода vector. Наши
потери при этом заключаются в определенной потере проверки типов компилятором во
время компиляции (которая была строже при первом наборе объявлений), и небольшом
снижении эффективности, связанном с дополнительным уровнем косвенности при вызове
виртуальных функций.
Конечно, этот метод работает только когда типы объектов, которые мы намерены хранить
в контейнерах, являются производными от некоторого базового класса. Если же это не так,
можно попытаться реорганизовать их в такую иерархию.
В качестве последнего замечания отметим, что такие методы могут применяться для
устранения разбухания кода, получающегося вследствие инстанцирования любого шаблона
класса, не только классов контейнеров STL. Степень уменьшения размера выполняемого файла
зависит от того, насколько реализация класса независима от точного типа своих параметров
шаблонов. В случае шаблонов классов, определяющих контейнеры, обычно наблюдается
большая независимость, чем для других шаблонов классов. В разделе 11.3 имеются описания
других методов устранения разбухания кода за счет шаблонов классов и функций.
Глава 18
Программа вывода дерева ученых
в области теории вычислительных
машин и систем
На веб-странице SIGACT Theoretical Computer Science Genealogy26 приведена информация
о докторских степенях (руководитель, университет и год) в области теории вычислительных
машин и систем. Веб-сайт предоставляет удобные средства для быстрого поиска информации
о конкретных людях. Но чтобы получить общую картину, стоит вывести весь лес деревьев
академических предшественников, представленный в базе данных на сайте.
Это делает программа, представленная в данной главе, которая работает с текстовой
версией данных27 (76 Кбайт) и создает листинг (102 Кбайт), содержащий древовидную структуру
с использованием отступов. У каждого руководителя защитившиеся аспиранты приводятся в
порядке их защиты.
Весьма поучительно рассмотреть не только вывод программы, но и ее исходный текст, и
изучить, каким образом для эффективного и лаконичного решения поставленной задачи в нем
комбинируются различные компоненты STL (векторы, отображения, мультимножества,
обобщенный алгоритм find, а также библиотечные и пользовательские функциональные объекты).
18.1. Сортировка аспирантов по датам
Поскольку мы хотим выводить список аспирантов в порядке их защиты, нам надо
определить функцию, которая может сравнивать аспирантов по датам получения степени. Для
простоты считаем, что все годы состоят из четырех цифр (годы между 1000 и 9999, чего явно
должно быть достаточно). Такое упрощение позволяет нам рассматривать годы как строки,
избегая преобразования строк в целые числа и обратно, и позволяет использовать одну и ту
же структуру данных и для места, и для времени защиты.
Поскольку функция должна обращаться к датам, мы храним даты и места защиты как
части класса сравнения. Определим тип data_map как отображение, связывающее две строки.
Мы будем использовать его с именами аспирантов в качестве ключей и датами и местами в
качестве связанных значений.
http://sigact.acm.org/genealogy
27 Получена с адреса http://sigact.acm.org/genealogy/textfile.html и немного
модифицирована.
Часть II. Примеры программ
<Определение типа отображения строк на строки 250а> ■
typedef map<string, string> data_map;
Используется в части 256д.
Теперь можно определить отношение сравнения с использованием типа данных data_map
для хранения дат и мест.
Определение функционального объекта для сравнения 250б> =
struct earlier: binary_function<string/ string, bool> {
bool operator()(const strings namel,
const strings name2) const {
return dates[namel] < dates[name2];
)
static data_map dates;
// dates[name] хранит год получения степени аспирантом
// name
static data_map places;
// places[name] хранит институт, в котором проходила
// защита диссертации
};
data_map earlier::dates;
data_map earlier::places;
Используется в части 277.
В качестве примера— Брайан Керниган защитился в Принстоне в 1969 году, так что
dates ["Brian Kernighan"] = "1969" и
places["Brian Kernighan"] = "Princeton".
18.2. Связь аспирантов с руководителями
В конечном итоге мы хотим получить дерево, корнями которого будут аспиранты с
неизвестными руководителями. Для каждого аспиранта мы выводим имя, университет и год
защиты, после чего с отступом следует список аспирантов, у которых он был руководителем.
Фрагмент такого дерева приведен ниже.
Вывод примера 18.1
SIGACT Theoretical Computer Science Genealogy
Peter Weiner ( )
Brian Kernighan (Princeton 1969)
D.H. Younger ( )
С L. Lucchesi (Waterloo 1976)
Dean Arden ( )
C.L. Liu (MIT 1962)
Andy Yao (Harvard 1972)
Scot Drysdale (Stanford 1979)
David Levine (Dartmouth 1986)
Barry Schaudt (Dartmouth 1991)
Ken Clarkson (Stanford 1984)
Joan Feigenbaum (Stanford 1986)
Weizhen Mao (Princeton 1990)
Don Friesen (UIUC 1978)
Mike Langston (Texas A&M 1981)
Shmuel Zaks (UIUC 1979)
Hon Wai Leong (UIUC 1986)
Глава 18. Программа вывооа оерева ученых а аилами iи ui^Kj^uL,
-l*J\*J 1ЩЛ1 I l\sj
Pravin Vaidya (UIUC 1986)
Ran Libeskind-Hadas (UIUC 1993)
Здесь показано, например, что Брайан Керниган защитился в 1969 году в Принстоне, и его
руководителем был Питер Вайнер (информации о защите которого в базе данных нет, так что
скобки после его имени остались пустыми).
Чтобы получить такой вывод, используется отображение, которое связывает имя
руководителя с множеством его аспирантов. Это множество упорядочено по дате защиты с
помощью ранее определенного отношения earlier. Мы используем multiset, поскольку в
один и тот же год у одного руководителя могло защититься несколько аспирантов. Такие
аспиранты, несмотря на разницу в именах, с точки зрения отношения earlier являются
эквивалентными.
Определение мультимножества, упорядоченного по датам 251а> =
typedef multiset<string/ earlier> date_ordered_mset;
Используется в части 256д.
Определение отображения строк на мультимножества 251б> ■
typedef map<string/ date_ordered_mset> relation_map;
Используется в части 256д.
Ключом отображения является имя руководителя, а множество содержит его аспирантов. В
качестве примера на рис. 18.1 показаны записи отображения для аспирантов из примера
вывода программы. Обратите внимание, что ключи отсортированы в алфавитном порядке по
имени. Множества аспирантов отсортированы по датам с использованием отношения
earlier. Конечно, реальное отображение содержит гораздо большее количество записей.
Ключ Данные
Andy Yao Scot Drysdale, Ken Clarkson, Joan Feigenbaum, Weizhen Mao
C.L. Liu Andy Yao, Don Friesen, Shmuel Zaks, Hon Wai Leong, Pravin
Vaidya Ran Libeskind-Hadas
D.H. Younger С L. Lucchesi
Dean Arden C.L. Liu
Don Friesen Mike Langston
Peter Weiner Brian Kernighan
Scot Drysdale David Levine, Barry Schaudt
Рис. 18.1. Пример relation_map с именами из вывода примера 18.1,
связывающего руководителей с их аспирантами
18.3. Поиск корней дерева
Корнями дерева являются аспиранты, руководители которых неизвестны. В базу данных
внесено множество таких аспирантов, руководителями которых указаны (или ?, что мы
конвертируем при чтении файла в ). Таким образом, чтобы найти корни дерева, мы ищем
аспирантов с руководителем .
Однако в этом множестве будут не все корни. Когда ничего не известно о защите — даже
университет или год — аспирант полностью удаляется из базы данных. Например,
руководителем Брайана Кернигана был Питер Вайнер. Но в базе данных нет явной записи о том, что
Часть II. Примеры программ
руководителем Питера Вайнера был . Следовательно, чтобы найти все корни дерева, не*
обходимо просканировать базу данных в поисках людей, которые указаны, как руководители,
но для которых в базе данных нет записей.
Для этого мы используем еще одно отображение relation_map, которое обратно
рассмотренному нами ранее. В этом отображении ключами являются имена аспирантов, а
связанными данными — множество, содержащее руководителя(ей) аспиранта. Обычно в таком
множестве будет только один элемент, поскольку у большинства аспирантов только один
руководитель, но в некоторых случаях их может быть и несколько.
В разделе 18.2 в отображении была запись, перечислявшая аспирантов Энди Яо — Скотта
Дрисдейла, Кена Кларксона, Джоан Файгенбаум и Вижен Мао. В новом отображении эта
запись соответствует четырем записям, показанным на рис. 18.2. Записи вновь отсортированы в
алфавитном порядке по имени, и понятно, что здесь показано только малое их количество.
Ключ
Joan Feigenbaum
Ken Clarkson
Scot Drysdale
Weizhen Mao
Данные
Andy Yao
Andy Yao
Andy Yao
Andy Yao
Рис. 18.2. Пример relation_map,
связывающего аспирантов с их руководителями
Имея эти два отображения relation_map, которые мы назовем students (см.
рис. 18.1) и advisors (см. рис. 18.2), можно найти все корни дерева. После инициализации
множества корней дерева выполняется проход по списку аспирантов, и для каждого из них
выясняется, можно ли достичь его из одного из уже определенных корней дерева. Если нет —
первый руководитель вносится в список корней.
<Поиск аспирантов с неизвестными руководителями 252а> =
инициализация множества корней 252б>
relation_map::iterator i;
date_ordered_mset::iterator j;
bool any_advisor;
for (i = advisors.begin(); i != advisors.end(); ++i) {
<Проверка наличия руководителя в базе 253а>
<Если нет, добавление в множество корней 253б>
}
используется в части 256д.
Множество корней инициализируем аспирантами, руководители которых указаны в базе дан-
шх как .
^Инициализация множества корней 252б> ш
date_ordered_mset& roots = students[" "];
1спользуется в части 252а.
Дель заключается в том, чтобы гарантировать, что все аспиранты в базе данных будут
выведены при обходе иерархии, начиная с корней дерева. Если аспирант достижим из
существующего корня, мы не делаем ничего. В противном случае необходимо добавить одного из
>уководителей в качестве корня.
Имеется два способа, которыми аспирант может быть достигнут из существующего корня.
1сли руководитель аспиранта (неизвестен), то этот аспирант уже находится в списке
Глдвэ lb. программа вывооа оерева ученых в иилаити iuvu/juu оычиолишслопшл машип...
корней в соответствии с правилом инициализации. Если любой из руководителей аспиранта
имеется в базе данных, то этого аспиранта можно достичь данным путем. Следовательно, при
проходе по списку руководителей сначала проверяется равенство , а затем — имеется ли
это имя в списке аспирантов (ключей отображения advisors).
<Проверка наличия руководителя в базе 253а> =
any_advisor = false;
for (j = i->second.begin(); j != i->second.end(); + +j ) {
if (*j == stringC'---") | |
advisors.find(*j) != advisors.end())
any_advisor = true;
}
Используется в части 252а.
Пожалуй, это лучше пояснить на примере. Как мы упоминали ранее, руководитель
Брайана Кернигана, Питер Вайнер, в базе данных отсутствует. Следовательно, в некоторый момент
в процессе прохода по отображению advisors итератор i указывает на пару, показанную
на рис. 18.3. Во втором цикле мы проходим по множеству руководителей Брайана Кернигана
(в данном случае он состоит из одного элемента). При первой итерации j указывает на
"Peter Weiner". Поскольку он в базе данных отсутствует, его руководителем не является
, а значит, он не внесен в список корней дерева. Кроме того, поиск
advisors . find ("Peter Weiner") будет неуспешен, так что значением any_advisor
останется false.
Ключ Данные
Brian Kemlghan Peter Weiner
Рис. 18.3. Запись Брайана Кернигана в
отображении advisors
В этот момент мы выяснили, что руководителей текущего аспиранта в базе данных нет,
так что надо добавить новую запись в множество корней дерева. Добавляя только первого
руководителя, мы избегаем дублирования частей дерева при выводе. Если будут добавлены
все руководители, то этот аспирант (а также все его аспиранты, аспиранты его аспирантов и
т.д.) будут перечислены отдельно для каждого руководителя.
<Если нет, добавление в множество корней 253б> =
if (!any_advisor) {
string first_advisor = *(i->second.begin());
// Проверка, нет ли его в списке в данный момент. Для
// проверки требуется выполнить линейный поиск с
// использованием обобщенного алгоритма find, так как
// мультимножество упорядочено по датам, а не по
// именам (к счастью, размер мультимножества невелик,
// так что особой проблемы такой поиск не
// представляет) .
if (find(roots.begin(), roots.end(), first_advisor)
== roots.end())
roots.insert(first_advisor);
}
Используется в части 252а.
часть п. i /римеры программ
18.4. Чтение файла
Данные хранятся в текстовом файле ASCII, по одному аспиранту в строке. Строка,
начинающаяся с символа #, рассматривается как комментарий и игнорируется. Все прочие строки
содержат четыре поля, разделенные символами табуляции: имя аспиранта, имя руководителя
название университета и год получения степени. В некоторых случаях, если информация
неполная, одно или несколько полей (но не имя аспиранта) может содержать ? или .
Напишем вспомогательную функцию, которая читает очередное поле из файла либо
считывая информацию до очередного символа табуляции, либо до достижения конца файла.28
Сначала удаляется все содержимое из результирующей переменной типа string (что
упрощает применение функции в цикле, когда одна и та же переменная будет использована
многократно). Затем зарезервируем некоторый объем памяти, чтобы избежать частого ее
перераспределения. Наконец, приступаем к считыванию символов в цикле.
<Получение всех символов строки до терминатора 2 54а> =
void get_chunk(istreams in, stringfc s,
char terminator = '\t')
{
s.erase(s.begin(), s.endO);
s.reserve(2 0);
string: :value__type ch;
while (in.get(ch) && ch != terminator)
s.insert(s.end(), ch);
}
Используется в части 25бд.
Теперь можно построить цикл для чтения данных. Определим переменные для хранения
двух отображений relation_map, которые были рассмотрены ранее: одно, students,
связывает руководителей с их аспирантами, а другое, advisors, хранит обратное отношение,
связывая аспирантов с их руководителями.
Мы определим переменные для хранения при чтении строки каждого из четырех полей.
Цикл сначала проверяет, не является ли очередная строка комментарием, и игнорирует такие
строки. Если же строка — не комментарий, то считываемые значения записываются в
структуры данных. Цикл завершается по достижении конца файла.
<Считывание файла базы данных и создание отображений 254б> =
<Получение имени файла и подготовка к чтению 255а>
relation_map advisors, students;
string name, advisor, place, date;
while (true) {
// Игнорирование комментариев
if (ifs.peekO == ■#•) {
get_chunk(ifs, name, '\n");
continue;
}
<Чтение строки данных, завершение в конце файла 255б>
Используется в части 25бд.
По сути, эта функция эквивалентна стандартной функции get line, которая, впрочем, в данной
книге не рассматривалась. Однако эта функция требует шаблонных потоков, которые пока что
поддерживаются не всеми компиляторами.
Глэва 78. программа вывооа оерева ученых в иилаиши mvu/juu ошчиилишслопом машип...
Открытие файла практически идентично коду, использовавшемуся при открытии файла
словаря в главах с 12, "Программа для поиска в словаре", по 15, "Ускорение программы
поиска анаграмм: использование мультиотображений".
<Получение имени файла и подготовка к чтению 255а> =
cout << "Введите имя файла с данными: " << flush;
string file_name;
сin >> file_name,-
ifstream ifs(file_name.c_str());
if (!ifs.is_open()) {
cout << "He могу открыть файл " << file_name
<< endl;
exit(l);
}
Используется в части 2546.
При обработке одной строки входного файла мы считываем значения четырех полей и
убеждаемся, что конец файла при этом не достигнут. Затем дату и место защиты мы
вставляем в data_maps класса earlier и добавляем отношения "руководитель-аспирант" в
отображения relation_map. Кроме того, заменяем ? в поле руководителя на , так что
имеется только один ключ отображения, указывающий неизвестного руководителя.
<Чтение строки данных, завершение в конце файла 255б> =
ge t_chunk(i f s, name);
if ( !ifs) break;
get_chunk(ifs, advisor);
get_chunk(ifs, place);
get_chunk(ifs, date, '\n');
earlier::places[name] = place;
earlier::dates[name] = date;
if (advisor == "?")
advisor = " ";
students[advisor].insert(name);
advisors[name].insert(advisor);
Используется в части 2546.
18.5. Вывод результатов
Последнее, что нам надо — это функция для вывода результатов. Мы делаем это рекурсивно
при помощи функции, которая выводит информацию об одном аспиранте. После
соответствующего отступа мы выводим имя аспиранта, а также место и дату его защиты. Наконец, мы
рекурсивно используем эту же функцию для вывода его аспирантов, если таковые имеются.
<Функция вывода ветви дерева с корнем name 2 55в> =
void output_tree(const strings name,
relation_map& students,
data_map& places,
data_map& dates,
int indentation_leve1 = 0)
{
<Вывод отступа в соответствии с уровнем 256а>
<Вывод информации об аспиранте 2 56б>
<Вывод информации о его аспирантах 25бв>
}
Используется в части 256д.
Часть и. I фимеры программ
Каждая из этих частей относительно проста. Отступ создается простым выводом нужного
количества пробелов (мы используем отступ в четыре пробела).
<Вывод отступа в соответствии с уровнем 25ба> =
for (int k = 0; k != indentation_level; ++k)
cout << " ";
Используется в части 255в.
Вывод информации об аспиранте включает имя и университет и дату в скобках.
<Вывод информации об аспиранте 256б> ■
cout << name << " (" << places[name] << " "
<< dates[name] << ")" << endl;
Используется в части 255в.
Для вывода информации об аспирантах мы проходим по множеству, упорядоченному по дате,
с увеличенным на единицу уровнем отступа.
<Вывод информации о его аспирантах 25бв> =
date_ordered_mset& L = students[name];
date_ordered_mset::const_iterator j;
for (j = L.beginO ; j != L.endO; ++j)
output_tree(*j, students, places, dates,
indentation_level + 1);
Используется в части 255в.
Для вывода всего множества результатов надо вывести все деревья, найденные ранее при
поисках аспирантов без руководителей. Таким образом, мы проходим по множеству roots,
выводя каждое из деревьев с уровнем отступа по умолчанию.
<Вывод всех деревьев с корнем 256г> з
for (j = roots.begin(); j != roots.end(); ++j)
output_tree(*j, students, earlier::places,
earlier::dates);
Используется в части 256д.
18.6. Полный исходный текст программы
Теперь, наконец, мы можем собрать все части программы воедино.
Пример 18.1. Вывод дерева ученых в области теории вычислительных
машин и систем
"ех18-01.срр" 25бд ■
#include <algorithm>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <iomanip>
#include <map>
#include <set>
using namespace std;
<Определение типа отображения строк на строки 250а>
<Определение функционального объекта для сравнения 250б>
Глава 18. Программа вывода дерева ученых в области теории вычислительных машин... 257
<Определение мультимножества, упорядоченного по датам 251а>
<Определение отображения строк на мультимножества 251б>
<Функция вывода ветви дерева с корнем name 255в>
<Получение всех символов строки до терминатора 254а>
int main()
cout << "SIGACT Theoretical Computer Science Genealogy"
< < endl;
<Считывание файла базы данных и создание отображений 254б>
<Поиск аспирантов с неизвестными руководителями 252а>
<Вывод всех деревьев с корнем 256г>
return 0;
Глава 19
Класс для хронометража
обобщенных алгоритмов
Очень полезно иметь возможность измерить реальное время работы того или иного
алгоритма, либо для сравнения двух и более алгоритмов для решения одной и той же задачи, либо
для лучшего понимания того, как растет время работы алгоритма в зависимости от входных
данных. Например, как растет время работы алгоритма сортировки с ростом длины N
входной последовательности: как O(N) (линейно), #(#2) (квадратично) или как O(NlogN)?
Помимо О-формул (которые могут уже быть выведены аналитически), может возникнуть
вопрос о сравнении эффективности двух алгоритмов, у которых одно и то же время работы
0(N log N) .В этой главе мы представим класс, который может использоваться для
автоматизации хронометража. Затем мы воспользуемся им для того, чтобы продемонстрировать
некоторые интересные свойства производительности разных алгоритмов сортировки STL.
19.1. Препятствия точному хронометражу
алгоритмов
Хотя создается впечатление, что написать программу для хронометража алгоритмов
достаточно просто, такие программы часто не дают точные или повторяющиеся результаты.
Например, в стандартной библиотеке C/C++ имеется функция clock (в заголовочном файле
с time), которая может иногда использоваться для определения времени вычислений:
clock_t start, finish;
start = clock();
sort (x.begin () , x.endO); // Вызов обобщенного алгоритма
finish = clock(); // сортировки
cout << "Время сортировки в секундах: "
<< ((double)(finish - start))/CLOCKS_PER_SEC << endl;
Тип clock_t и константа CLOCKS_PER_SEC определены в заголовочном файле ctime.
В типичных Unix-системах CLOCKS_PER_SEC равно 1 миллиону, что может привести к
мысли о минимальном интервале времени в 1 микросекунду. Однако обычно этот интервал
между "тиками" часов гораздо больше, например, 1/100 секунды (просто число,
возвращаемое вызовом clock, в 10000 больше предыдущего, что и создает впечатление измерения
времени в микросекундах). Хотя 1/100 секунды может оказаться достаточно для точного
измерения времени действий человека, для компьютера это невыносимо долгий промежуток
времени. Современные процессоры в состоянии выполнить миллионы команд за такой срок.
260
Часть II. Примеры программ
В приведенном примере, если алгоритм сортировки достаточно хорош, для того, чтобы время
его работы было диагностировано как ненулевое, требуется последовательность из 10000 и
более элементов. При измерении более коротких отрезков времени вызов алгоритма можно
поместить в цикл для накопления измеримого таким образом времени, а затем поделить
полученное значение на количество выполненных итераций цикла.
Даже если входная последовательность достаточно велика (или сортировка повторяется
достаточное количество раз), чтобы время работы алгоритма стало измеримым, это время
может быть не очень точным. Например, может оказаться, что время, затраченное на
сортировку последовательности из 20000 элементов, больше времени сортировки
последовательности из 30000 элементов. У такой неточности есть две основные причины.
Во-первых, хотя функция clock, как предполагается, возвращает только время,
использованное процессом пользователя, а не системное время, при загрузке процессора другими
процессами неминуемы флуктуации измеряемого времени. Даже в однопользовательской
рабочей станции или персональном компьютере современные операционной системы часто
запускают десяток-другой различных процессов, например, для работы с сетью или
выполнения иных невидимых пользователю действий. Во-вторых, функция clock часто плохо
реализована, что приводит к "потере тиков", так что накопленная ошибка может привести к
неточности измерений до 50%.
19.2. Преодоление препятствий
Если не принять специальные меры, временные флуктуации могут привести к
бессмысленности хронометража алгоритмов. К счастью, есть способ преодоления основных проблем.
Хотя он и сложнее, чем приведенный в примере выше, его для простоты использования
можно вынести в определение класса.
Ключевая идея заключается в помещении алгоритма в цикл и подсчет количества итераций
между двумя сигналами часов. Затем это измерение повторяется, скажем, десять раз, так что
даже если промежутки между отметками времени и варьируются, усредненное значение должно
быть более точным. Давайте рассмотрим пример. Мы хотим провести эксперимент по изучению
обобщенного алгоритма sort. Мы повторяем выполнение алгоритма г раз для случайно
сгенерированного массива размером N, где N и г берутся из пользовательского ввода. Чтобы
гарантировать идентичность итераций, мы копируем исходный массив перед его сортировкой. Так мы
всегда имеем одни и те же начальные условия, а не сортируем уже отсортированный массив.
Пример 19.1. Первая попытка хронометража алгоритма sort
"ех19-01.срр" 260 =
#include <cmath>
#include <cstdlib>
#include <ctime>
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
cout << "Первая попытка хронометража алгоритма sort."
<< endl;
double* A, *B;
unsigned long N;
unsigned int reps;
Глава 19. Класс для хронометража обобщенных алгоритмов
261
cout << "Размер массива и количество повторений: ";
cin >> N >> reps;
А = new double[N];
В = new double[N];
srand(time(0) ) ;
for (unsigned int i = 0; i < N; ++i)
A[i] ш (double) randO ;
vector<long> iterations;
iterations.reserve(reps);
time_t start, finish;
start = time(0) ;
while (iterations.size() < reps) {
int count = 0;
do {
++count;
copy (A, A + N, B) ;
sort(В, В + N) ;
finish = time(0);
}
// Продолжение до очередного тика:
while (finish ■■ start);
// Запись количества итераций:
iterations.push_back(count);
start = finish;
}
cout << "Количество итераций: " << endl;
unsigned int k;
for (k = 0; k < iterations.size(); ++k)
cout << iterations[k] << " ";
cout << endl;
cout << "Отсортированное количество итераций: "
<< endl;
sort(iterations.begin(), iterations.end());
for (k = 0; k < iterations.size(); ++k)
cout << iterations[k] << " ";
cout << endl;
cout << "Выбранное значение: "
<< iterations[reps/2] << endl;
cout << "Время: " << 1000.0/iterations[reps/2]
<< " мс " << endl;
return 0;
}
Вот пример вывода программы (пользовательский ввод выделен полужирным шрифтом).
Вывод примера 19.1
Первая попытка хронометража алгоритма sort.
Размер массива и количество повторений: 10000 10
Количество итераций:
53 103 128 134 127 126 126 128 135 128
Отсортированное количество итераций:
53 103 126 126 127 128 128 128 134 135
Выбранное значение: 128
Время: 7.8125 мс
262
Часть II. Примеры программ
В этой программе вместо стандартной функции clock использована другая стандартная
функция, time, которая выполняет отсчет времени каждую секунду. Программа записывает
количества итераций в вектор STL. Обратите внимание на количества итераций — их разброс
иллюстрирует обсуждавшуюся ранее проблему неточности. Однако после сортировки видно,
что значения в средине последовательности достаточно тесно сгруппированы. Значения на
концах сильно варьируются, так что мы полностью игнорируем их и выбираем центральное
значение последовательности (128, которое представляет собой медиану исходной
последовательности) в качестве представительного значения средней группы. Время одной итерации
цикла в таком случае равно
1/128 = 0.0078125 с = 7.8125 мс .
Конечно, реальное время зависит от платформы, на которой выполнялась и
компилировалась программа. Приведенный результат получен на лэптопе с процессором Pentium 400 МГц
и 128 мегабайтами памяти, под управлением Windows 98; использовался компилятор д++ с
включенной оптимизацией. Если выполнить этот тест несколько раз на одной и той же
платформе, то полученные результаты будут отличаться только на несколько процентов. В общем
случае этот метод дает более повторяемые результаты, чем простой хронометраж (даже при
использовании медианы или усреднения результатов нескольких экспериментов).
19.3. Уточнение метода
В данную базовую стратегию следует внести определенные усовершенствования. Время,
затрачиваемое на итерацию цикла, не совпадает со временем вызова алгоритма, поскольку
оно включает накладные расходы на сам цикл — время вызова функции time, увеличение и
проверка счетчика цикла и т.п., а главное — копирование массива в каждой итерации. Таким
образом, следует измерить время работы цикла без копирования, чтобы вычесть его из
времени работы цикла с копированием и получить "чистое" время работы цикла. Если
закомментировать вызов алгоритма в приведенной программе
// sort(В, В + N);
перекомпилировать и выполнить ее, то получатся результаты наподобие следующих.
Вывод примера 19.1а
Первая попытка хронометража алгоритма sort.
Размер массива и количество повторений: 10000 10
Количество итераций:
128 656 1036 1048 1044 1050 1102 1045 1045 1033
Отсортированное количество итераций:
128 656 1033 1036 1044 1045 1045 1048 1050 1102
Выбранное значение: 1045
Время: 0.956938 мс
Таким образом, базовое время работы цикла составляет 0.956938 мс, а время выполнения
самого алгоритма равно
7.8125 мс - 0.956938 мс = 6.855562 мс
Понятно, что нет никакого смысла указывать все цифры полученного результата —
значащими являются только первые пару цифр.
Глава 19. Класс для хронометража обобщенных алгоритмов
263
19.4. Автоматизация анализа при помощи
класса
Далее представлен класс timer, который автоматизирует большую часть работы,
выполняемой таким анализом. Поскольку каждый эксперимент выполняется в цикле в течение 1 с,
наиболее точные результаты будут получаться для вычислений, требующих не более 100 мс.
Применение класса выглядит следующим образом.
timer tim; // Declare a timer, tim
// ...
// Базовый хронометраж, 10 попыток
tim.start_baseline(10);
do {
// Код настройки для вызова алгоритма
// (может отсутствовать)
} while (tim.checkO);
// Запись базового времени и вывод информации в поток cout;
// для получения детального вывода следует заменить false на
// true:
tim.report(false);
tim.start(10, 1000); // Начало реального хронометража; 10
// попыток, размер задачи 1000
do {
// Код настройки для вызова алгоритма
// (может отсутствовать)
// ВЫЗОВ АЛГОРИТМА:
} while (tim.checkO);
// Запись времени работы алгоритма и вывод информации в
// поток cout; для получения детального вывода следует
// заменить false на true:
tim.report(false) ;
Это использование соответствует приведенному далее интерфейсу. Имеется также метод
results для непосредственного доступа к результатам хронометража, которые
представлены в виде отображения тар времен выполнения (в миллисекундах), индексированных
размером задач.
<Интерфейс класса timer 263> s
#include <iostream>
#include <iomanip>
#include <vector>
#include <map>
#include <algorithm>
using namespace std;
class timer {
public:
timer(); // Конструктор по умолчанию
// Запуск серии из г попыток задачи размером N:
void start(unsigned int r, unsigned long N);
// Запуск серии из г попыток для определения базового
// времени:
void start_baseline(unsigned int г);
// Возвращает true, если попытки завершены, false в
// противном случае
bool check();
// Вывод информации о результатах попыток в поток cout
// с дополнительной информацией, если значение verbose
// равно true:
264
Часть II. Примеры программ
void report(bool verbose);
// Возвращает результаты для внешнего применения
const map<unsigned int, double>& results() const;
private:
unsigned int reps; // Количество попыток
// Для хранения итераций цикла попыток
vector<long> iterations;
// Для хранения начального и конечного времени попыток
time_t initial, final;
// Для подсчета количества итераций циклов попыток
unsigned long count;
// Для хранения размера задачи (N) для текущих попыток
unsigned int problem_size;
// Для хранения пар (размер задачи, время)
map<unsigned int, double> result_map;
// true, если это базовое выполнение (без вызова
// алгоритма), false в противном случае
bool baseline;
// Для записи базового времени
double baseline_time;
};
Используется в части 267а.
Конструктор достаточно тривиален и просто устанавливает значение переменной baseline
равным false (которое сохраняется до тех пор, пока не будет вызван метод start_baseline).
<Конструктор timer по умолчанию 264а> =
timer::timer() { baseline = false; }
Используется в части 267а.
Метод start устанавливает количество повторений и размер задачи. Он также
инициализирует вектор iterations, переменную count, а также сохраняет начальное время. Этот
метод должен быть вызван для того чтобы можно было приступить к хронометражу.
<Реализация метода start класса timer 264б> =
void timer::start(unsigned int r, unsigned long N)
{
reps = r;
problem_size = N;
count = 0;
iterations.clear();
iterations.reserve(reps);
initial = time(O);
}
Используется в части 267а.
Метод start_baseline просто устанавливает переменную baseline равной true и
вызывает метод start для инициализации других членов класса. Этот метод должен быть вызван
для того, чтобы приступить к определению базового времени, затрачиваемого на работу цикла.
<Метод start_baseline класса timer 264в> =
void timer::start_baseline(unsigned int r)
baseline = true;
start(r, 0) ;
}
Используется в части 267а.
I Лава I if. ГЛаСС ОЛИ XfJUMUMtflll/Jcimcl иииищеппыл алсириштио
Метод check используется для определения, завершено ли испытание. Он возвращает
true до тех пор, пока испытание продолжается. Когда испытание завершено (с очередным
сигналом таймера), количество выполненных итераций сохраняется, а состояние таймера
сбрасывается для очередного испытания.
<Метод check класса timer 265a> =
bool timer::check()
{
++count;
final = time(0) ;
if (initial < final) {
iterations.push_back(count);
initial = final;
count = 0;
}
return (iterations.size() < reps);
}
Используется в части 267а.
Метод results просто возвращает отображение, содержащее результаты хронометража. Он
может оказаться полезен при необходимости вывода более сложного отчета, чем
генерируемый функцией report.
<Метод results класса timer 265б> =
const map<unsigned int, double>& timer::results() const
{
return result_map;
}
Используется в части 267а.
19.4.1. Вывод результатов
Основная работа класса timer выполняется методом report. Именно здесь происходит
вычисление времени работы и вывод для каждого размера задачи. Кроме того, мы добавили
возможность, отсутствующую в ранних примерах. Хотя может быть использована любая
последовательность размеров задач, но если мы на каждом шаге будем удваивать размер задачи,
функция report покажет степень роста времени решения задачи размером N по сравнению с
решением задачи размером N/2. Это отношение представляет собой способ выяснить
производительность алгоритма независимо от используемой платформы. Мы еще поговорим об
этом в следующем разделе.
Функция report сортирует количества итераций и выбирает медиану для вычисления
времени работы. В режиме подробного вывода в поток выводятся все количества итераций
как до их сортировки, так и после. Если испытание является базовым, то найденное время
сохраняется для последующего использования. В противном случае время добавляется в
результирующее отображение и выводится в поток.
<Реализация метода report класса timer 265в> =
void timer::report(bool verbose)
if (verbose) {
<Вывод количества итераций 266в>
}
sort(iterations.begin(), iterations.end());
if (verbose) {
cout << "Отсортированные количества:" << endl;
<Вывод количества итераций 266в>
}
-lamina и. 1 if^uivicfjni ii/juc/JcIMM
<Выбор медианы как самого точного значения 2 66а>
if (baseline) {
baseline_time = 1000.0/selected_count;
cout << "Базовое время: "
<< baseline_time << endl;
baseline = false;
} else {
double calculated_time/ growth_factor;
result_map[problem_size] = calculated_time =
1000.0/selected_count - baseline_time;
cout << setiosflags(ios::fixed) << setprecision(4)
<< setw(35) << problem_size << setw(12)
<< calculated_time << " мс ";
<Вычисление степени роста времени 266б>
cout << endl;
}
}
Используется в части 267а.
Медиана находится как срединное значение после сортировки. В режиме подробного
вывода это число выводится в поток.
<Выбор медианы как самого точного значения 266а> =
int selected_count = iterations[reps/2];
if (verbose)
cout << "Выбранное количество: "
<< selected_count << endl;
Используется в части 265в.
Степень роста вычисляется как отношение времени решения задачи размером N ко
времени решения задачи размером N/2 . Поэтому первый шаг для вычисления степени роста
состоит в определении, имеются ли результаты для требуемого размера задачи. Если да, то
ищется отношение соответствующих времен вычислений.
<Вычисление степени роста времени 266б> з
if (result_map.find(problem_size/2) != result_map.end()) {
growth_factor =
calculated_time / result_map[problem_size/2];
cout << setiosflags(ios::fixed) << setprecision(4)
<< setw(8) << growth factor;
}
Используется в части 265в.
Количество итераций выводится в простом цикле. Мы можем использовать алгоритм STL
сору с итератором ostream_iterator, но написание собственного цикла позволяет нам
разбивать вывод на строки каждые десять значений, что делает вывод более удобочитаемым.
Этот код используется как для вывода исходных, не отсортированных значений, так и для
значений после сортировки.
<Вывод количества итераций 2ббв> =
for (unsigned int k = 0; k < iterations.size(); ++k) {
cout << iterations[k] << " ";
if ( (k+1) % 10 == 0)
cout << endl;
}
cout << endl;
используется в части 265в.
/ лаа& iif. ISJIUCC ОЛЯ хримим&т/ллжа иииищенныл си icv/sui имио
Этот класс мы помещаем в заголовочный файл timer.h, который будет использоваться в
оставшейся части главы для анализа алгоритмов сортировки STL.
"timer.h" 267а =
<Интерфейс класса timer 263>
<Конструктор timer по умолчанию 264а>
<Реализация метода start класса timer 264б>
<Метод start_baseline класса timer 286c>
<Метод check класса timer 265a>
<Реализация метода report класса timer 265в>
<Метод results класса timer 265б>
19.5. Хронометраж алгоритмов
сортировки STL
Теперь мы можем воспользоваться нашим классом timer для сравнения различных
алгоритмов сортировки STL. Приведенная далее программа хронометрирует работу алгоритма
sort со случайными векторами, размеры которых удваиваются на каждой итерации.
Пример 19.2. Хронометраж алгоритма sort со случайными векторами
"ех19-02.срр" 2676 в
#include <cmath>
#include <cstdlib>
#include <ctime>
#include <iostream>
#include <vector>
#include <algorithm>
#include "timer.h"
using namespace std;
int main()
{
cout << "Хронометраж алгоритма sort со "
<< "случайными векторами." << endl;
srand(time(0));
vector<double> v, v0;
unsigned long N, N1, N2;
unsigned int reps;
cout << "Повторения, начальный размер, "
<< "конечный размер: ";
cin >> reps >> N1 >> N2;
timer tim;
for (N = N1; N <= N2; N *= 2) {
v.clear();
v.reserve(N);
for (unsigned int i = 0; i < N; ++i)
v.push_back((double)rand());
vO = v; // Сохранение входного вектора в v0
// Вычисление базового времени для N
tim.start_baseline(reps);
do {
// Присваивание вектора входит в базовое время
~няиию ii. i ijjuMVfJbi i ifJuafJtiMM
V = VO;
} while (tim.check());
tim.report(false) ;
tim.start(reps, N);
do {
v = vO; // Восстанавливаем сохраненный вектор
// vO в v
sort (v.begin() , v.endO);
} while (tim.checkO ) ;
tim.report(false) ;
}
return 0;
}
Пример вывода приведен далее.
Вывод примера 19.2
Хронометраж алгоритма sort со случайными векторами.
Повторения, начальный размер, конечный размер: 11 1000 64000
Базовое время: 0.148522
1000
2000
4000
8000
16000
32000
64000
0
1
2
5
11
27,
58.
.5115
.0885
.3337
.1642
.0252
.0833
.3333
мс
мс
мс
мс
мс
мс
мс
2
2,
2,
2,
2.
2.
.1279
.1439
.2128
.1349
.4565
.1538
Базовое время: 0.2119
Базовое время: 0.3472
Базовое время: 0.6498
Базовое время: 1.7953
Базовое время: 4.1667
Базовое время: 8.3333
Как и ожидалось, поскольку время работы алгоритма sort составляет 0(N log N), степень
роста немного превышает 2. Если мы изменим программу и используем алгоритм
stable_sort, то получим приведенные далее результаты. Вспомним, что алгоритм
stable_sort также имеет время работы 0(N log N), и как мы видим, степень роста та же;
однако реальное время работы примерно в 1.5 раза больше в случае алгоритма stable_sort.
Вывод примера 19.2а
Хронометраж алгоритма sort со случайными векторами.
Повторения, начальный размер, конечный размер: 11 1000 64000
Базовое время: 0.148017
Базовое время: 0.2418
Базовое время: 0.3427
Базовое время: 0.6618
Базовое время: 1.7606
Базовое время: 4.1494
Базовое время: 8.4034
1000
2000
4000
8000
16000
32000
64000
0
1
3
7 ,
17,
41.
134,
.7901
.5034
.6734
.2747
.4702
.3052
.4538
мс
мс
мс
мс
мс
мс
мс
1
2
1
2
2
3,
.9028
.4434
.9804
.4015
.3643
.2551
Глава 19. Класс для хронометража обобщенных алгоритмов
Аналогично, если мы применим в разработанной программе алгоритм partial sort
(сортируя весь вектор при помощи вызова part ial_sort (v. begin () , v. end () ,
v.endO )ty, то получим результаты, приведенные ниже. Так же, как алгоритмы sort и
stable_sprt, алгоритм partial_sort имеет время работы O(NlogN), и степень роста
более или менее соответствует таковой у алгоритма sort. Реальное же время работы вновь
оказывается примерно в 1.5 раза больше.
Вывод примера 19.26
Хронометраж алгоритма sort со случайными векторами.
Повторения, начальный размер, конечный размер: 11 1000 64000
Базовое время: 0.152416
Базовое время: 0.2437
Базовое время: 0.3525
Базовое время: 0.6423
Базовое время: 1.8519
Базовое время: 4.2194
Базовое время: 8.3333
Это упражнение демонстрирует важность понимания истинной производительности
алгоритма, основанного на результатах реального хронометража. Ообозначения являются удобной
мерой эффективности алгоритма, но неявный постоянный множитель зачастую может скрывать
важную информацию о заложенных в реализации алгоритмов компромиссных решениях.
1000
2000
4000
8000
16000
32000
64000
0.
1.
3,
8
17
41
116
.8251
.7444
.7459
.2073
.3789
.2351
.6667
мс
мс
мс
мс
мс
мс
мс
2,
2
2
2
2
2
.1142
.1474
.1910
.1175
.3727
.8293
Часть
Справочное
руководство по STL
Эта часть представляет собой полное описание всех
компонентов STL, включая некоторые детали, не упомянутые в
предыдущих частях. Данное руководство не содержит примеров
(примеры и учебные описания почти всех компонентов можно
найти в предыдущих частях).
Глава 20\
Справочное руководство
по ищераторам
Эта глава представляет собой справочное руководство по итераторам STL. В ней
рассматриваются следующие темы.
• Требования, которым должны удовлетворять классы или встроенные типы, чтобы
использоваться в качестве итераторов определенной категории (входные итераторы,
выходные итераторы, однонаправленные итераторы, двунаправленные итераторы или
итераторы с произвольным доступом).
• Классы потоковых итераторов для работы обобщенных алгоритмов со входными или
выходными потоками.
• Адаптеры итераторов (обратные итераторы и итераторы вставки).
При рассмотрении требований к итераторам используется следующая терминология.
• Тип значения (value type). Тип (класс или встроенный тип данных) значения,
возвращаемого при применении оператора operator* к итератору.
• Тип разности (difference type). Знаковый целочисленный тип данных,
представляющий расстояние между двумя итераторами, для которых определено отношение
эквивалентности.
• Значения за концом (past-the-end values). Значение итератора, указывающего на
позицию после последнего элемента соответствующего контейнера. Так же как обычный
указатель на массив гарантирует существование корректного значения указателя,
который указывает за последний элемент массива, так и итераторы STL гарантируют
существование значения за концом.
• Разыменуемые значения (dereferenceable values). Значения итераторов, для которых
определен оператор operator*. Компоненты STL никогда не полагаются на разыме-
нуемость значений за концом.
• Сингулярные значения (singular values). Значения, не связанные ни с каким контейнером.
Например, после объявления неинициализированного указателя х (как в случае int* x)
х должен рассматриваться как сингулярное значение указателя. Для сингулярных
значений результаты большинства выражений не определены. Единственным исключением
является присваивание несингулярного значения итератору, который хранил сингулярное
значение. В этом случае сингулярное значение перезаписывается так же, как и любое
другое значение. Разыменуемые значения и значения за концом всегда несингулярны.
Часть III. Справочное руководство по STL
• Достижимость (reachability). Итератор j называется достижимым из итератора i
тогда и только тогда, когда существует конечная последовательность применений
оператора operator++ к i, которая обеспечивает i == j. Если итератор j достижим из
другого итератора i, то эти итераторы относятся к одному и тому же контейнеру.
• Диапазон (range). Пара итераторов, которая служит в качестве начального/и конечного
маркеров для вычислений. Диапазон [ i; i) представляет собой пустой диапазон;
диапазон [ i; j ) состоит из итераторов, начинающихся с i и получающихся путем
применения оператора operator++ до достижения j, не включая сам итератор j.
Диапазон [i;j) корректен тогда и только тогда, когда j достижшк из i. Все
алгоритмические шаблоны библиотеки, работающие с контейнерами,/имеют
интерфейсы, использующие диапазоны. Результат применения библиотечный алгоритмов к
некорректным диапазонам не определен.
• Изменяемые (mutable) и константные (constant). Зависит от поведения результата
применения оператора operator* — ссылки (изменяемый) или ссылки на константу
(константный). Константные итераторы не удовлетворяют требованиям к выходным
итераторам.
Все операции с итераторами, наличие которых требуется каждой категорией итераторов,
должны иметь (амортизированное) константное время работы. По этой причине нигде далее
отдельно требования ко времени работы не упоминаются.
20.1. Требования ко входным итераторам
Как подчеркивали Степанов и Ли [19], важно указывать максимально обобщенные
требования к компонентам. Например, вместо того, чтобы сказать "класс X должен определять
функцию-член operator++ ()", мы говорим "для любого объекта х типа X определено
выражение ++х". (Мы оставляем открытым вопрос о возможности X быть встроенным типом
данных и о том, что указанный оператор может быть определен глобально, а не являться
функцией-членом класса.)
В этом и четырех последующих разделах требований данной главы для каждого типа
итератора X предполагается следующее:
• а и b представляют собой значения типа X;
• п представляет собой значение типа разности для X;
• г и s представляют собой значения типа Х&;
• t представляет собой значение типа Т, т.е. типа value_type итератора;
• u, tmp и m являются идентификаторами.
Класс или встроенный тип данных X удовлетворяет требованиям ко входным итераторам
с типом значения Т тогда и только тогда, когда определены и соответствуют указанным для
них требованиям следующие выражения.
х(а) Копирующий конструктор, обеспечивающий х (а) == а. Предполагается
наличие деструктора.
х и(а); В результате и == а.
х u = а; Тоже, что их и (а).
и = а,- В результате и == а.
Глава 20. Справочное руководство по итераторам
275
а == Ь\ Возвращаемый тип должен преобразовываться Bbool, а оператор == дол-
\ жен быть отношением эквивалентности.
а != b \ Возвращаемый тип должен преобразовываться Bbool, а результат должен
быть тем же, что и ! (а == Ь).
*а Возвращаемый тип — т. Предполагается, что а является разыменуемым.
\ Если а == Ь, то и *а == *Ь.
а->т Эквивалентно (*а) .т, в предположении, что это выражение определено.
++г Возвращаемый тип — х&. Предполагается, что г является разыменуемым. В
результате г либо остается разыменуемым, либо значением за концом
контейнера, а кроме того, &г == &++г.
(void) r++ Эквивалентно (void) ++r.
*г++ Результат должен быть тем же, что и
{ Т tmp = *r; ++r; return tmp; }.
Для входных итераторов из а == b не следует ++а == + +Ь. Главное следствие из этого
факта заключается в том, что алгоритмы, работающие с входными итераторами, должны
быть однопроходными; т.е. они никогда не должны пытаться скопировать значение итератора
и использовать его для повторного прохода по одной и той же позиции. Кроме того, тип
значения Т не обязан быть ссылочным, так что алгоритмы, работающие со входными
итераторами, не должны пытаться посредством них выполнять присваивания. (У однонаправленных
итераторов это ограничение отсутствует.)
20.2. Требования к выходным итераторам
Класс или встроенный тип данных X удовлетворяет требованиям к выходным итераторам
с типом значения Т тогда и только тогда, когда определены и соответствуют указанным для
них требованиям следующие выражения.
х(а) *а = t эквивалентно *х(а) = t. Предполагается наличие деструктора.
х и (а) ; В результате и становится копией а. Заметим, однако, что равенство и
неравенство определены не обязательно, и алгоритмы не должны пытаться
использовать выходные итераторы для повторного прохода по позиции (они
должны быть однопроходными).
X и = а; Тоже, что их и (а).
*а = t Посредством итератора t присваивается позиции, на которую он указывает.
Возвращаемое значение операции не используется.
++г Возвращаемый тип — х&. Предполагается, что г является разыменуемым в
левой части присваивания. В результате г либо остается разыменуемым в
левой части присваивания, либо значением за концом контейнера, а кроме
того, &г == &++г.
г++ Возвращаемый тип должен быть преобразуем в const x&. Результат
должен быть тем же, что и { X tmp = r; ++r; return tmp; }-
*r++ = t Результат должен быть тем же, что и { *r = t; ++r; }. Возвращаемое
значение операции не используется.
Единственное корректное применение оператора operator* ко входным итераторам
в левой части инструкции присваивания. Как и в случае входных итераторов, алгоритмы, ис-
z/o
Часть III. Справочное руководство по STL
пользующие выходные итераторы, должны быть однопроходными. Операторы равенства и
неравенства не могут быть определены. Алгоритмы, использующие выходные итераторы,
могут работать с выходными потоками для размещения данных посредством класса
ostream_iterator, а также с итераторами и указателями вставки.
20.3. Требования к однонаправленным
итераторам
Класс или встроенный тип данных X удовлетворяет требованиям к однонаправленным
итераторам с типом значения Т тогда и только тогда, когда определены и соответствуют
указанным для них требованиям следующие выражения.
х и; Результирующее значение и может быть сингулярным. Предполагается
наличие деструктора.
х () х () может быть сингулярным значением.
х (а) Результат должен удовлетворять условию а = = х (а).
х и(а); Результат должен удовлетворять условию и == а.
X и = а; Тоже, что их и(а).
а == b Тип результата должен быть приводим Kbool, а оператор == должен быть
отношением эквивалентности.
а ! = b Тип результата должен быть приводим Kbool, а результат должен быть тем
же, что и ! (а == Ь).
г = а Возвращаемый тип — х&, а результат должен удовлетворять условию
г == а.
*а Возвращаемый тип — т&. Предполагается, что а разыменуемо. Если
а == Ь, то должно выполняться условие * а == *Ь. Если х — изменяемый
тип, то выражение *а = t корректно.
а->т Эквивалентно (*а) .га, в предположении, что это выражение определено.
++г Возвращаемый тип — х&. Предполагается, что г — разыменуемо. В
результате г либо остается разыменуемым, либо значением за концом
контейнера, а кроме того, &г == &++г. Также, если г == s и г разыменуемо, то
отсюда следует, что ++r == ++s.
г++ Возвращаемый тип должен быть преобразуем в const x&. Результат
должен быть тем же, что и { X tmp = r; ++r; return tmp; }.
*г++ Возвращаемый тип — т&.
Два свойства однонаправленных итераторов позволяют применять их в многопроходных
однонаправленных алгоритмах: во-первых, то, что из условия а == b следует ++а == ++Ь
(что неверно для входных и выходных итераторов), а во-вторых, то, что удалено ограничение
на количество присваиваний посредством итераторов (накладываемое на выходные итераторы).
/ лава *и. справочное руковооство по итераторам
20.4. Требования к двунаправленным
итераторам
Класс или встроенный тип данных X удовлетворяет требованиям к двунаправленным
итераторам с типом значения Т тогда и только тогда, когда в дополнение к требованиям к
однонаправленным итераторам определены и соответствуют указанным для них требованиям
следующие выражения.
- -г Возвращаемый тип — х&. Предполагается, что существует s такое, что
г == ++s; тогда - -г указывает на ту же позицию, что и s. Кроме того, - -г
разыменуемо, и &г == &--г. Должны выполняться следующие свойства:
--(++г) == г, и если --г == --s, тог == s.
г- - Возвращаемый тип должен быть преобразуем в const x&. Результат
должен быть тем же, что и { X tmp = г; --г; return tmp; }.
*r- - Возвращаемый тип должен быть преобразуем в т.
20.5. Требования к итераторам
с произвольным доступом
Класс или встроенный тип данных X удовлетворяет требованиям к итераторам с
произвольным доступом с типом значения Т тогда и только тогда, когда в дополнение к
требованиям к двунаправленным итераторам определены и соответствуют указанным для них
требованиям следующие выражения.
г += п Возвращаемый тип — х&. Результат должен быть таким же, как если бы он
был получен путем вычислений
{
Distance m = n;
if (m >= 0)
while (m--) ++r;
else
while (m++) --r;
return r;
}
Время вычисления должно быть константным.
а + п Возвращаемый тип — х. Результат должен быть таким же, как если бы он
был получен путем вычислений { х tmp = a; return tmp += n; }.
n + а То же, что и а + п.
г -= п Возвращаемый тип — х&. Результат должен быть таким же, как если бы он
был получен путем вычислений г += -п.
а - п Возвращаемый тип — х. Результат должен быть таким же, как если бы он
был получен путем вычислений { X tmp = a; return tmp -= n; }.
b - а Возвращаемый тип — тип разности итераторов. Предполагается, что
существует значение п типа разности такое, что а + n == b; возвращаемый
результат равен п.
а [п] Возвращаемый тип должен быть приводим к типу т. Результат равен * (а + п).
а < b Возвращаемый тип должен быть приводим к типу bool, а оператор < дол-
-шить т. справочное рукоьоосгпьо по oil
жен представляет собой отношение полного упорядочения (отношения
упорядочения рассматриваются в разделе 5.4).
а > b Возвращаемый тип должен быть приводим к типу bool, а оператор >
должен представляет собой отношение полного упорядочения, обратное <.
а >= Ь Возвращаемый тип должен быть приводим к типу bool, а результат должен
быть тем же, что и ! (а < Ь).
а <= b Возвращаемый тип должен быть приводим к типу bool, а результат должен
быть тем же, что и ! (Ь < а).
20.6. Свойства итераторов
В алгоритмах, определенных в терминах итераторов, часто необходимо определить
свойства итератора: его тип значения, тип разности, категорию и т.д. В результате для типа
Iterator должны быть определены пять типов:
• iterator_traits<Iterator> : :dif ference_type— тип, который может
использоваться для представления расстояния между двумя итераторами;
• iterator_traits<Iterator> : :value_type— тип результата разыменования
итератора;
• iterator_traits<Iterator> : : pointer — указатель на value_type;
• iterator_traits<Iterator>::reference — ссылка на value_type;
• iterator_traits<Iterator>: : iterator_category определяет категорию
итератора (входной, выходной, однонаправленный и т.д.); возможные определения
iterator_category представлены в разделе 20.6.2.
Шаблон класса iterator_traits определен следующим образом.
template <typename Iterators struct iterator_traits {
typedef typename Iterator::difference_type
difference_type;
typedef typename Iterator::value_type value_type;
typedef typename Iterator::pointer pointer;
typedef typename Iterator::reference reference;
typedef typename Iterator::iterator_category
iterator category;
};
Таким образом, класс итератора должен определять типы dif f erence_type, value_type,
reference, pointer и iterator_category. Для определения этих типов может
использоваться базовый класс iterator (детальнее рассматривается в разделе 20.6.1).
Чтобы данный механизм работал корректно для указателей (которые представляют собой
итераторы с произвольным доступом), определены две специализации iterator_traits.
template <typename T> struct iterator_traits<T*> {
typedef ptrdiff_t difference_type;
typedef T value_type;
typedef T* pointer;
typedef T& reference;
typedef random_access_iterator_tag iterator_category;
template <typename T> struct iterator_traits<const T*> {
typedef ptrdiff_t difference_type;
typedef T value_type;
/ лава ли. справочное руковооство по итераторам
*iv
typedef const T* pointer;
typedef const T& reference;
typedef randora_access_iterator_tag iterator_category;
};
Применение iterator_traits демонстрируется в примере 16.1.
20.6.1. Базовый класс iterator
Для упрощения определения типов, требуемых iterator_traits, библиотека
предоставляет шаблон класса с необходимыми определениями. Класс итератора может
использовать iterator в качестве базового класса для автоматической генерации
необходимых определений.
template <typename Category, typename T,
typename Difference = ptrdiff_t,
typename Pointer = T*, typename Reference = T&>
struct iterator {
typedef T value_type;
typedef Difference difference_type;
typedef Pointer pointer,-
typedef Reference reference;
typedef Category iterator_category;
};
20.6.2. Стандартные дескрипторы итераторов
Тип iterator_category, определенный в iterator_traits, можно использовать
для выбора различных алгоритмов на основе типа итератора, предоставляемого в качестве
аргумента функции. Библиотека предоставляет для использования в качестве категорий
итераторов пять типов. Итератор должен использовать в качестве категории наиболее точный
дескриптор.
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator__tag:
public input_iterator_tag {};
struct bidirectional_iterator_tag :
public forward_iterator_tag {};
struct random_access_iterator_tag :
public bidirectional_iterator_tag {};
Ниже приведен пример использования категории итератора для выбора одной из
альтернативных реализаций.
template <typename InputIterator>
void my_algorithm(InputIterator start, Inputlterator finish)
{
typedef iterator_traits<InputIterator> traits;
my_algorithm_impl(start, finish,
typename traits::iterator_category());
}
template <typename RandomAccessIterator>
void my_algorithm_impl(RandomAccessIterator start,
RandomAccessIterator finish,
random_access_iterator_tag) {
// Специализированная реализация для итераторов с
// произвольным доступом
}
*1аить ш. справочное руковооство по сэ/ (.
template <typename InputIterator>
void my_algorithm_impl(Inputlterator start,
Inputlterator finish,
input_iterator_tag) {
// Реализация по умолчанию, работающая с входными
// итераторами
}
Функция my_algorithm определена для входных итераторов, но имеется
специализированная, более эффективная ее реализация для итераторов с произвольным доступом. Когда
my_algorithm вызывается для определенного диапазона, она вызывает
my_algorithm_impl, передавая ей в качестве дополнительного аргумента категорию
итератора. Если это итератор с произвольным доступом, то используется первая версия
my_algorithm_impl. Для всех прочих категорий используется вторая версия.
20.7. Операции с итераторами
Поскольку операции + и - имеются только у итераторов с произвольным доступом,
библиотека предоставляет шаблоны функций для выполнения тех же действий для входных,
однонаправленных и двунаправленных итераторов (а также для итераторов с произвольным
доступом). При применении к итераторам с произвольным доступом эти функции используют
существующие операторы + и - для выполнения вычислений, так что они требуют
константного времени. Для прочих категорий итераторов они выполняются за линейное время с
применением операции ++.
template <typename Inputlterator, typename Difference>
void advance(Inputlterator^ i, Difference n);
Увеличивает (или уменьшает при п < 0) i на величину п. Значение п может быть
отрицательно только для итераторов с произвольным доступом и двунаправленных итераторов.
template <typename InputIterator>
typename iterator_traits<InputIterator>::difference_type
distance(Inputlterator first, Inputlterator last);
Возвращает количество увеличений, необходимых для достижения last из first; last
должен быть достижим из first.
20.8. istream_iterator
STL предоставляет потоковые итераторы, определенные как шаблоны классов, чтобы
алгоритмы могли работать непосредственно с потоками ввода-вывода. Класс istream__
iterator определяет входной итератор, a ostream_iterator— выходной. Например,
следующий фрагмент исходного текста
istream_iterator<int> end_of_stream,-
partial_sum(istream_iterator<int>(cin),
end_of_stream,
ostream_iterator<int>(cout, "\n"));
считывает файл, содержащий целые числа, из входного потока cin, и отправляет частичные
суммы в поток cout, разделяя их символами новой строки.
Этот раздел представляет собой справочное руководство по итераторам istream_iterator,
которые используются для чтения значений из входных потоков, для которых они
сконструированы. В разделе 20.9 рассматриваются итераторы ostream_iterator, которые
используются для записи значений в выходные потоки, для которых они сконструированы.
Глава 20. Справочное руководство по итераторам
281
20.8.1. Файлы
^include <iterator>
20.8.2. Объявление класса
template <typename Т, typename charT = char,
typename traits = char_traits<charT>/
typename Difference = ptrdiff_t>
class istream_iterator :
public iterator<input_iterator_tag/ T,
Difference, const T*, const T&>
20.8.3. Примеры
См. примеры 4.1, 12.1, 13.1, 14.1 и 15.1.
20.8.4. Описание
Итератор istream_iterator<T> читает (при помощи оператора operator>>)
последовательные элементы типа Т из входного потока, для которого он сконструирован. Всякий
раз при применении оператора ++ к построенному объекту istream_iterator<T>,
итератор считывает и сохраняет значение типа Т. Значение конца потока достигается, когда
operator void* () потока возвращает значение false. В этом случае итератор
становится равным значению итератора конца потока. Это значение может быть создано только при
помощи конструктора без аргументов: istream_iterator<T> (). Два итератора конца
потока всегда эквивалентны. Итератор конца потока не равен итератору, не являющемуся
итератором конца потока. Два итератора, не являющихся концами потока, эквивалентны, если
они построены из одного и того же потока.
Использовать istream_iterator можно только для чтения значений; невозможно что-
либо сохранить в позиции, на которую указывает istream_iterator.
Главной особенностью итераторов istream_iterator является тот факт, что
операторы + + не сохраняют эквивалентность; т.е. выполнение условия i == j не гарантирует
выполнения + + i == ++j. При каждом выполнении оператора ++ из связанного с итератором
потока считывается новое значение. Практическое следствие из этого факта в том, что
istream_iterator может использоваться только в однопроходных алгоритмах.
20.8.5. Определения типов
char_type
Тип символов (обычно char или wchar_t), содержащихся в потоке
(charT).
traits_type
Свойства символьного типа, содержащегося в потоке (traits).
Дополнительная информация о свойствах символов имеется в разделе Б.2.
istream_type
Тип потока, лежащего в основе итератора
(basic_istream<charT/ traits>).
20.8.6. Конструкторы
istream__iterator () ;
Создает итератор конца потока. Обратите внимание, что два итератора
конца потока всегда равны.
282
Часть III. Справочное руководство по STL
istream_iterator(istream_type& s);
Создает объект istream_iterator<T>, который выполняет чтение
значений из входного потока s. Первое значение может быть считано из потока как
в этот же момент времени (в конструкторе), так и при первом обращении.
istream_iterator(const istream_iterator<T, charT,
traits, Differences x) ;
Копирующий конструктор.
~istream_iterator();
Деструктор.
20.8.7. Открытые функции-члены
const T& operator*() const;
Оператор разыменования. Возвращая ссылку на const T, он гарантирует
невозможность записи значений во входной поток, для которого итератор
был создан.
const T* operator->() const;
Оператор разыменования. Возвращая указатель на const T, он
гарантирует невозможность записи значений во входной поток, для которого итератор
был создан.
istream_iterator<T, charT, traits, Differences operator++();
Считывает и сохраняет значение типа Т при каждом вызове.
istream_iterator<T/ charT, traits, Difference> operator++(int);
Считывает и сохраняет значение типа Т при каждом вызове.
,т
20.8.8. Операции сравнения
template <typename Т, typename charT,
typename traits, typename Difference>
bool operator==(
const istream_iterator<T/ charT,
traits, Differences x,
const istream_iterator<T, charT,
traits, Difference>& у
);
Оператор сравнения. Два итератора конца потока всегда эквивалентны.
Итератор конца потока не равен итератору, не являющемуся итератором
конца потока. Два итератора, не являющихся итераторами конца потока,
равны тогда, когда они созданы из одного и того же потока.
20.9. ostream_iterator
20.9.1. Файлы
#include <iterator>
Глава 20. Справочное руководство по итераторам
283
20.9.2. Объявление класса
template <typename Т, typename charT = char,
typename traits = char_traits<charT> >
class ostream_iterator :
public iterator<output_iterator_tag, void,
void, void, void>
20.9.3. Примеры
См. примеры 10.2, 13.1 и 14.1.
20.9.4. Описание
Объект ostream_iterator<T> записывает (с помощью оператора operator<<)
последовательные элементы в выходной поток, для которого он был построен. Если итератор
создан с charT* в качестве аргумента конструктора, то эта строка-разделитель записывается
в поток после каждого записанного значения Т.
Невозможно читать значения при помощи выходного итератора. Он может
использоваться только для записи значений в выходной поток, для которого он был создан.
20.9.5. Определения типов
char_type
Тип символов (обычно char или wchar_t), содержащихся в потоке
(charT).
traits_type
Свойства символьного типа, содержащегося в потоке (traits).
Дополнительная информация о свойствах символов имеется в разделе Б.2.
ostream_type
Тип потока, лежащего в основе итератора
(basic_ostream<charT, traits>).
20.9.6. Конструкторы
ostream_iterator(ostream_type& s);
Создает итератор, который может использоваться для записи в выходной
поток s.
ostream_iterator(ostream_type& s, const charT* delimiter);
Создает итератор, который может применяться для записи в выходной
поток s. Символьная строка delimiter выводится в поток после is каждого
значения (типа Т), записанного в s.
ostream_iterator(const ostream_iterator<T, charT, traits>& x);
Копирующий конструктор.
~ostream_iterator();
Деструктор.
284
Часть III. Справочное руководство по STL
20.9.7. Открытые функции-члены
ostream_iterator<T/ charT, traits>& operator*();
Оператор разыменования. Присваивание *о = t посредством выходного
итератора о приводит к записи t в выходной поток и подготовке указателя
потока к очередной записи.
ostream_iterator<T, charT, traits>& operator=(const T& x);
Приводит к записи значения х в выходной поток и подготовке указателя
потока к очередной записи.
ostream_iterator<T/ charT, traits>& operator++();
ostream_iterator<T/ charT, traits> operator++(int x);
Позволяет использовать итераторы с алгоритмами, которые выполняют как
присваивание посредством итератора, так и перемещение итератора; в
действительности эти операторы ничего не делают, поскольку присваивания
посредством итераторов автоматически перемещают указатель потока.
20.10. reverse_iterator
20.10.1. Файлы
#include <iterator>
20.10.2. Объявление класса
template <typename Iterator>
class reverse_iterator :
public iterator<
typename iterator_traits<Iterator>::iterator_category,
typename iterator_traits<Iterator>::value_type,
typename iterator_traits<Iterator>::difference_type,
typename iterator_traits<Iterator>::pointer,
typename iterator_traits<Iterator>::reference>
В последующих разделах для краткости предполагается наличие следующего определения типа:
typedef reverse_iterator<Iterator> self;
Класс предоставляет следующее определение для типа адаптированного итератора.
typedef Iterator iterator_type;
20.10.3. Примеры
См. примеры 2.15, 10.1 и 10.2.
^0.10.4. Описание
Адаптер reverse_iterator получает итератор с произвольным доступом или
двунаправленный итератор и создает новый итератор для обхода в направлении, противоположном
обычному. Для обхода элементов некоторого корректного диапазона [ i; j ) в обратном
порядке надо начать с обратного итератора, инициализированного j, и увеличивать его
j - i - 1 раз при помощи оператора ++. Обходимые элементы в этом случае — те,
которые получались бы при инициализации обычного итератора значением j - 1 с
последующим уменьшением его j - i - 1 раз при помощи оператора --, т.е. находящиеся в пози-
Глава 20. Справочное руководство по итераторам
285
циях j-1, j-2, ..., i+1, i. Заметим, что итератор i - 1 может не быть определен
(фактически это так и есть, если i указывает начало некоторого контейнера) и, таким
образом, не может служить значением за концом для обратного обхода. Эта проблема решается
путем определения итератора разыменования * для обратного итератора так, что
&*(reverse_iterator(i)) == &*(i - 1)
Такое отображение позволяет обратному итератору использовать итераторы j, j-1,
i+1 как если бы это были j-1, j-2, ..., i+1, i,H итератор i в этом случае можно
использовать в качестве значения за концом диапазона.
Адаптер reverse_iterator может использоваться как с итераторами с произвольным
доступом, так и с двунаправленными итераторами. Получающийся reverse_iterator
принадлежит той же категории, что и исходный. Таким образом, если имеется обращение к
любой из функций-членов operator+, operator-, operator+=, operator-= и
operator [] или глобальных операций operator<, operator>, operator<=,
operator>=, operator- и operator+ так, что требуется инстанцирование (т.е.
reverse_iterator рассматривается как итератор с произвольным доступом), то типом
адаптируемого итератора так же должен быть итератор с произвольным доступом.
20.10.5. Конструктор
reverse_iterator();
Конструктор по умолчанию; дает сингулярное значение.
explicit reverse_iterator(iterator_type x);
Создает обратный итератор с текущей позицией, определяемой значением
х, в соответствии с соотношением из раздела 20.10.4
(&* (reverse_iterator (x) ) == &*(х-1)).
template <typename U>
reverse_iterator(const reverse_iterator<U>& u);
Создает обратный итератор с текущей позицией, определяемой значением
u.base(). Это предполагает существование преобразования из U в
Iterator.
20.10.6. Открытые функции-члены
iterator_type base О const;
Возвращает итератор, указывающий на текущую позицию (для которого
операторы ++ и - имеют смысл, противоположный смыслу для обратного
итератора).
reference operator*() const;
Оператор разыменования; результат должен быть тем же, что и при
вычислении { iterator_type tmp = base(); return *--tmp; }.
pointer operator->() const;
Оператор разыменования; возвращает & (operator* () ).
self& operator++();
Изменяет текущую позицию на base () - 1 и возвращает получившийся
итератор.
self operator++(int);
286
Часть III. Справочное руководство по STL
Изменяет текущую позицию на base() - 1и возвращает итератор на
старую позицию.
self& operator--О;
Изменяет текущую позицию на base () + 1 и возвращает получившийся
итератор.
self operator--(int);
Изменяет текущую позицию на base () + 1 и возвращает итератор на
старую позицию.
self operator*(difference_type n) const;
Возвращает обратный итератор с произвольным доступом, указывающий на
позицию base () - п.
self& operator+=(difference type n);
—
Изменяет текущую позицию на base () - пи возвращает получившийся
итератор.
self operator-(difference_type n) const;
Возвращает обратный итератор с произвольным доступом, указывающий на
позицию base () + п.
self& operator-=(difference_type n);
Изменяет текущую позицию на base () + пи возвращает получившийся
итератор.
reference operator [] (difference_type n) const;
Возвращает * (*this + n).
20.10.7. Глобальные операции
template <typename Iterator>
typename reverse_iterator<Iterator>::difference_type
operator-(const reverse_iterator<Iterator>& x,
const reverse_iterator<Iterator>& y);
Возвращает у. base () - x. base ().
template <typename Iterator>
reverse_iterator<Iterator>
operator*(
typename reverse_iterator<Iterator>::difference_type n,
const reverse_iterator<Iterator>& y);
Возвращает у + п.
20.10.8. Предикаты равенства и упорядочения
template <typename Iterator>
bool operator==(const reverse_iterator<Iterator>& x,
const reverse_iterator<Iterator>& y);
Возвращает (x.base () == y.baseO).
template <typename Iterator>
bool operator<(const reverse_iterator<Iterator>& x,
const reverse_iterator<Iterator>& y);
Возвращает (у. base () < x.baseO).
Глава 20. Справочное руководство по итераторам
287
20.11. back_insert_iterator
20.11.1- Файлы
#include <iterator>
20.11.2. Объявление класса
template <typename Containers
class back_insert_iterator :
public iterator<output_iterator_tag,
void, void, void, void>
Container должен быть типом, для которого имеется тип
Container: : const_ref erence и который имеет функцию-член
push_back, принимающую единственный аргумент типа
Container::const_reference.
20.11.3. Примеры
См. примеры 12.1, 13.1 и 14.1.
20.11.4. Описание
Адаптеры итераторов вставки получают контейнер (а в некоторых случаях — итератор,
указывающий в контейнер) и генерируют выходные итераторы, преобразующие присваивания
посредством итератора во вставки. Имеется три типа адаптеров итераторов вставки. Одним из них
является back_insert_iterator<Container>, объекты которого используют функцию-
член push_back класса Container для выполнения вставок в конец контейнера. Этот класс
описывается в данном разделе, вместе с шаблоном функции back_inserter, работать с
которой обычно более удобно, чем непосредственно с классом. В следующем разделе описываются
соответствующие компоненты STL, использующие для вставки функцию-член push_f ront, a
именно класс front_insert_iterator<Container> и шаблон функции front_
inserter; в разделе 20.13 описываются компоненты для использования insert, а именно —
класс insert_iterator<Container> и шаблон функции inserter.
20.11.5. Конструкторы
explicit back_insert_iterator(Container&c x);
Создает итератор вставки i для преобразования присваиваний
*i = value в вызовы х.push_back (value).
20.11.6. Открытые функции-члены
back_insert_iterator<Container>&
operator=(typename Container::const_reference& value);
Выполняет x.push_back (value), где x— контейнер, связанный с
итератором. Возвращает итератор.
back_insert__iterator<Container>& operator*();
288
Часть III. Справочное руководство по STL.
Возвращает сам итератор (*this), так что присваивание *i = value
использует описанный выше оператор = класса back__insert
iterator<Container>, а не соответствующий оператор Container :Т
value_type.
back_insert_iterator<Container>& operator++();
back_insert_iterator<Container> operator++(int);
He делает ничего, не считая возврата самого итератора (*this).
20.11.7. Сопутствующие шаблоны функций
template <typename Container>
back_insert_iterator<Container> back_inserter(Container& x);
Возвращает back_insert_iterator<Container> (x). Функция
предоставляется библиотекой исключительно для удобства.
20.12. front_insert_iterator
20.12.1. Файлы
#include <iterator>
20.12.2. Объявление класса
template <typename Container>
class front_insert_iterator
: public iterator<output_iterator_tag/
void, void, void, void>
Container должен быть типом, для которого имеется тип
Container: : const_ref erence и который имеет функцию-член
push_f ront, принимающую единственный аргумент типа
Container::const_reference.
20.12.3. Конструкторы
explicit front_insert_iterator(Container& x) ;
Создает итератор вставки i для преобразования присваиваний
*i = value в вызовы х. push_f ront (value).
20.12.4. Открытые функции-члены
front_insert_iterator<Container>&
operator=(typename Container::const_reference& value);
Выполняет x.push_f ront (value), где x — контейнер, связанный с
итератором. Возвращает итератор.
front_insert_iterator<Container>& operator*();
Возвращает сам итератор (*this), так что присваивание *i = value
использует описанный выше оператор = класса
/ flUOCt £.KJ. О/ /уУС1виЧПKJ4S IJyi\\JW\JVslllV3KJ ll\J UMIt7Jb/u>iiWr/w.F.
f ront_insert_iterator<Container>, а не соответствующий
оператор Container::value_type.
front_insert_iterator<Container>& operator++();
front_insert_iterator<Container> operator++(int);
He делает ничего, не считая возврата самого итератора (*this).
20.12.5. Сопутствующие шаблоны функций
template <typename Containers
front_insert__iterator<Container> front_inserter(Containers x);
Возвращает f ront_insert_iterator<Container> (x). Функция
предоставляется библиотекой исключительно для удобства.
20.13. insert_iterator
20.13.1. Файлы
#include <iterator>
20.13.2. Объявление класса
template <typename Containers
class insert_iterator :
public iterator<output_iterator_tag, void, void, void, void>
Container должен быть типом, для которого имеются типы
Container::iterator и Container::const_reference и который
имеет функцию-член insert с интерфейсом
typename Container::iterator
insert(typename Container::iterator,
typename Container::const_referenceS);
20.13.3. Примеры
См. примеры 7.3 и 7.4.
20.13.4. Конструкторы
insert_iterator (Containers: x,
typename Container::iterator i) ;
Создает итератор вставки i для преобразования присваиваний
*i = value в вызовы х. insert (i, value).
20.13.5. Открытые функции-члены
insert_iterator<Container>&
operator=(typename Container::const_reference& value);
Выполняет i = x. insert (i, value) ; ++i;, где x — контейнер,
связанный с итератором, a i — текущее значение итератора, передаваемого
-fdwiio ш. 01 ifjciau^nuv fjyKuauuumeo ПО £> IL
конструктору и обновляемого при вставке так, как показано выше.
Возвращает итератор вставки.
insert_iterator<Container>& operator*О;
Возвращает сам итератор (*this), так что присваивание *i = value
использует описанный выше оператор = класса
insert_iterator<Container>, а не соответствующий оператор
Container::const_reference.
insert_iterator<Container>& operator++();
insert_iterator<Container> operator++(int);
He делает ничего, не считая возврата самого итератора (*this).
20.13.6. Сопутствующие шаблоны функций
template <typename Container, typename Iterator>
insert_iterator<Container> inserter(Containers: x, Iterator i);
Возвращает insert_iterator<Container>(x,i) (см. примеры 7.3
и 7.4). Функция предоставляется библиотекой исключительно для удобства.
Глава 21
Справочное руководство
по контейнерам
21.1. Требования
21.1.1. Дизайн и организация контейнеров STL
Контейнеры STL делятся на два больших семейства— контейнеры последовательностей
(или просто последовательные контейнеры) и отсортированные ассоциативные контейнеры.
Контейнеры последовательностей включают векторы, списки и деки, которые содержат
элементы одного типа в строгом линейном порядке. Хотя в библиотеке представлены только
три базовых контейнера последовательностей, можно эффективно создавать другие
контейнеры последовательностей на основе базовых благодаря применению адаптеров
контейнеров, которые представляют собой классы STL, обеспечивающие отображение интерфейсов.
STL предоставляет адаптеры для стеков, очередей и очередей с приоритетами.
Отсортированные ассоциативные контейнеры включают множества, мультимножества,
отображения и мультиотображения. Ассоциативные контейнеры обеспечивают быструю
выборку данных на основе ключей. Например, отображение позволяет пользователю получить
объект типа Т на основе ключа некоторого другого типа; множества позволяют быстро
получать сами ключи.
Все контейнеры STL обладают тремя важными характеристиками.
1. Каждый контейнер сам управляет выделением для себя памяти.
2. Каждый контейнер предоставляет минимальный набор операций в виде функций-
членов для доступа и обслуживания хранимых элементов.
• Конструкторы и деструкторы позволяют пользователям создавать и уничтожать
экземпляры контейнеров. Большинство контейнеров имеет конструкторы
нескольких видов.
• Функции-члены для доступа к элементам позволяют пользователям обращаться к
элементам, хранящимся в контейнере. В большинстве экземпляров функции-члены
для доступа к элементам не изменяют контейнер.
• Функции-члены вставки используются для вставки элементов в контейнер.
• Функции-члены удаления используются для удаления элементов из контейнера.
1ы\,то т. \sii/jaou*inu& fjynuauuuiiitsu Iiu 0/£.
3. Каждый контейнер имеет объект аллокатора, связанный с ним. Аллокатор
инкапсулирует информацию об используемой модели памяти и позволяет переносить классы
между различными платформами.
Для функций всех контейнеров используется одно и то же соглашение об именовании
что в результате дает унифицированный интерфейс у всех классов. Между интерфейсами
контейнеров последовательностей и отсортированных ассоциативных контейнеров
имеются определенные различия, которые мы рассмотрим после того, как ознакомимся с общими
компонентами.
21.1.2. Общие члены всех контейнеров
Открытые члены контейнеров STL подразделяются в соответствии с двухуровневой
иерархией. Первый уровень определяет члены, общие для всех контейнеров, в то время как
второй уровень содержит две категории:
• члены, общие для контейнеров последовательностей (векторов, списков, деков);
• члены, общие для ассоциативных контейнеров (множеств, мультимножеств,
отображений, мультиотображений).
Общие члены всех контейнеров STL делятся на две категории: определения типов и
функции-члены. Мы по очереди рассмотрим и те, и другие.
Общие определения типов для всех контейнеров. Далее приведены общие определения
типов, имеющиеся во всех контейнерах STL. В определениях предполагается, что:
• X представляет собой класс контейнера, содержащего объекты типа Т;
• а и b представляют собой значения X;
• и представляет собой идентификатор;
• г представляет собой значение Х&.
X::value_type
Тип значений, хранящихся в контейнере.
X::reference
Тип, который может использоваться для записи в объекты
X: : value_type. Обычно это тип X: : value_type&.
X::const_reference
Тип, который может использоваться для записи в константные объекты
X: : value_type. обычно это тип const X: : value_type&.
X::iterator
Тип итератора для обхода элементов в контейнере X. Он может
принадлежать любой категории итераторов, кроме выходных. Все контейнеры STL
используют либо итераторы с произвольным доступом (векторы и деки),
либо двунаправленные итераторы (все прочие контейнеры).
X::const_iterator
Тип итератора для обхода элементов в константном контейнере X. Он
может принадлежать любой категории константных итераторов, кроме
выходных. Все контейнеры STL используют либо константные итераторы с
произвольным доступом (векторы и деки), либо константные двунаправленные
итераторы (все прочие контейнеры).
Глава 21. Справочное руководство по контейнерам
дез
X::difference_type
Тип, который может представлять расстояние между двумя объектами
итераторов X (зависит от конкретной модели памяти).
X::size_type
Тип, который может представлять размер X (зависит от конкретной модели
памяти).
Общие функции-члены для всех контейнеров. Здесь перечислены общие функции-члены,
которые должны быть в каждом STL-контейнере. При их описании предполагается, что:
• X представляет собой класс контейнера, содержащего объекты типа Т;
• а и b представляют собой значения X;
• и представляет собой идентификатор;
• г представляет собой значение Х&.
Все операции, если не указано иное, имеют константное время выполнения.
Х() ;
Конструктор по умолчанию.
Х(а) ;
X и(а) ;
(&а)->~Х();
a.begin();
а.end();
а == b
а != b
a.size();
a.max_size()
а.empty();
Копирующий конструктор. Требует линейного времени.
Деструктор. При его выполнении вызываются деструкторы всех элементов
а и освобождается вся память. Требует линейного времени.
Возвращает iterator (const_iterator для константного а), который
может использоваться для начала обхода всех позиций контейнера.
Возвращает iterator (const_iterator для константного а), который
может использоваться в сравнении для завершения обхода контейнера.
Проверка равенства контейнеру того же типа. Возвращает true, когда
последовательности элементов в а и b поэлементно равны (используется
оператор X: : value_type: : operator==). Требует линейного времени.
Противоположно проверке равенства. Требует линейного времени.
Возвращает количество элементов в контейнере.29
Количество элементов (size О) в контейнере максимально допустимого
размера.
29 Хотя size в общем случае операция с константным временем выполнения, стандарт C++ оставляет
возможность линейного времени работы этой функции. Одним из примеров могут служить списки, где для
определения количества элементов требуется их обход. Обычно вполне безопасно можно считать, что
size выполняется за константное время. То же предупреждение относится и к max_size, и к swap.
Часть HI. Справочное руководство по STL
Возвращает true, если контейнер пуст (т.е. если a. size () == 0).
а < b
Лексикографически сравнивает два контейнера. Требует линейного времени.
а > b
Возвращает true, если b < а. Требует линейного времени.
а <= b
Возвращает true, если ! (а > Ь). Требует линейного времени.
а >= b
Возвращает true, если ! (а < b). Требует линейного времени.
г = а
Оператор присваивания для контейнеров. Требует линейного времени.
a.swap(b);
Обменивает два контейнера одного и того же типа.
21.1.3. Требования к обратимым контейнерам
Если итераторы контейнера являются итераторами с произвольным доступом или
двунаправленными итераторами, то контейнер обратим (reversible). Все контейнеры STL
обратимы. Обратимые контейнеры должны предоставлять два дополнительных типа и два
дополнительных метода обращения к элементам. Эти дополнительные члены определены ниже. В
определениях предполагается, что:
• X представляет собой класс обратимого контейнера (например, вектор, список или дек);
• а представляет собой значение X.
X::reverse_iterator
Тип итератора для обхода контейнера X в обратном направлении.
X::const_reverse_iterator
Тип константного итератора для обхода контейнера X в обратном направлении.
а.rbegin();
Возвращает reverse_iterator (const_reverse_iterator для
константного а), который может использоваться для начала обхода всех
позиций контейнера в порядке, обратном нормальному.
а.rend();
Возвращает reverse_iterator (const_reverse_iterator для
константного а), который может использоваться в сравнении для завершения
обхода всех позиций контейнера в порядке, обратном нормальному.
21.1.4. Требования к контейнерам последовательностей
Все контейнеры последовательностей STL определяют два конструктора, три функции-
члена вставки и две функции-члена для удаления в дополнение к обычным типам и
функциям-членам, упоминавшимся в предыдущем разделе. Упомянутые дополнительные члены
приведены ниже. В их определениях предполагается, что:
• X представляет собой класс последовательности (например, вектор, список или дек);
• а представляет собой значение X;
Глава 21. Справочное руководство по контейнерам
гэь
• i и j удовлетворяют требованиям к входным итераторам, а [ i ; j ) представляет
собой корректный диапазон;
• п представляет собой значение X: : s i ze__type;
• р представляет собой корректный итератор, указывающий на а;
• q, ql и q2 представляют собой корректные разыменуемые итераторы, указывающие
на a, a [ql; q2) представляет собой корректный диапазон;
• t представляет собой значение X: : value_type.
X(n, t);
X a(n, t);
Конструкторы последовательности из п копий t.
X(i, j);
X a(i, j) ;
Конструкторы последовательности, эквивалентной содержимому диапазона
[i;j).
a.insert(р, t);
Вставляет копию t перед р. Возвращает итератор, указывающий на
вставленную копию.
a.insert(р, n, t) ;
Вставляет п копий t перед р.
a.insert(р, i, j);
Вставляет копии элементов из диапазона [i; j ) перед р. Итераторы i и j
не должны быть итераторами, указывающими в контейнер а.
a.erase(q);
Удаляет элемент, на который указывает q. Возвращает итератор,
указывающий на элемент, следовавший за q до его удаления, или на а. end (),
если q был последним элементом последовательности.
a.erase(ql, q2);
Удаляет элементы из диапазона [ql;q2). Возвращает итератор,
указывающий на элемент, на который указывал q2 до удаления, или на а. end (),
если такового элемента нет.
a. clear();
Удаляет все элементы контейнера. Эквивалентно выражению
а. erase (a.begin () , а. end () ), с тем отличием, что clear не имеет
возвращаемого значения.
21.1.5. Требования к отсортированным ассоциативным
контейнерам
STL предоставляет четыре основных разновидности отсортированных ассоциативных
контейнеров: set, multiset, map и multimap. Перед тем как перейти к детальному
рассмотрению определений типов и функций-членов, предоставляемых ассоциативными
контейнерами, мы должны определить несколько терминов и пояснить некоторые идеи, лежащие
в основе дизайна этих контейнеров.
Все ассоциативные контейнеры параметризованы типом Key и отношением упорядочения
Compare, которое приводит к строгому неполному упорядочению элементов типа Key. Kpo-
4VO
Часть III. Справочное руководство по STL.
ме того, тар и multimap связывают с элементами Key элементы произвольного типа Т.
Объект типа Compare называется объектом сравнения контейнера.
Для отсортированных ассоциативных контейнеров эквивалентность ключей означает
эквивалентность в смысле отношения сравнения, а не в смысле оператора operator== для ключей. Так,
два ключа kl и к2 рассматриваются как эквивалентные при применении объекта сравнения сотр
тогда и только тогда, когда comp (kl,k2) == false && comp(k2,kl) == false.
Контейнеры set и map поддерживают единственность ключей, т.е. они могут содержать
не более одного элемента каждого класса эквивалентности ключей. Контейнеры multiset и
multimap поддерживают эквивалентные ключи: в них может содержаться несколько
элементов с ключами из одного и того же класса эквивалентности.
В случае контейнеров set и multiset тип значения совпадает с типом ключа, т.е.
значениями, хранящимися во множествах и мультимножествах, являются сами ключи. У
контейнеров тар и multimap типом значения является pair<const Key, T>: элементы,
хранящиеся в отображениях и мультиотображениях, представляют собой пары, первыми
элементами которых являются значениями const Key, а вторыми элементами — значения типа Т.
Наконец, iterator у отсортированного ассоциативного контейнера представляет собой
двунаправленный итератор. Операции insert не влияют на корректность итераторов и
ссылок в контейнер, а операции erase делают недействительными только те итераторы и
ссылки, которые указывали на удаляемые элементы.
Далее приведен список определений типов и функций-членов, определенных для
отсортированных ассоциативных контейнеров в дополнение к общим членам контейнеров,
описанным ранее. Во всех приведенных определениях предполагается, что:
• X представляет собой класс отсортированного ассоциативного контейнера;
• а представляет собой значение X;
• a_uniq представляет собой значение X, когда X поддерживает единственные ключи,
a a_eq — значение X, когда X поддерживает эквивалентные ключи;
• i и j удовлетворяют требованиям ко входным итераторам и указывают на элементы
типа value_type, a [i; j ) представляет собой корректный диапазон;
• р представляет собой корректный итератор а;
• q, ql и q2 представляют собой корректные разыменуемые итераторы a, a [ql; q2) —
корректный диапазон;
• t представляет собой значение типа X: : value_type;
• к представляет собой значение типа X: : key_type.
X: :key__type
Тип ключей Key, с которым инстанцируется контейнер X.
X::key_compare
Тип объекта сравнения Compare, с которым инстанцируется контейнер X.
По умолчанию это less<key_type>.
X::value_compare
Тип объектов сравнения X: :value_type. Для контейнеров set и
multiset это тот же тип, что и key_compare, в то время как для тар
и multimap это тип, сравнивающий пары значений Key и Т путем
сравнения ключей с использованием X: : key_compare.
Следующие операции имеют константное время работы, если явно не указано иное.
Глава 21. Справочное руководство по контейнерам
297
Х() ;
X а;
Конструирует пустой контейнер с использованием Compare () в качестве
объекта сравнения.
Х(с) ;
X а(с) ;
Конструирует пустой контейнер с использованием с в качестве объекта
сравнения.
X(i, j/ с) ;
X a(i, j, с) ;
Создает пустой контейнер с использованием с в качестве объекта сравнения
и вставляет в него элементы из диапазона [ i; j ). В общем случае имеет
время работы O(NlogN) , где N— расстояние от i до j; время работы
линейное, если диапазон [i; j ) отсортирован с помощью value_comp ().
X(i, j);
X a(i, j) ;
To же, что и X (i, j , с) иХ a (i, j , с), но в качестве объекта сравнения
использует Compare ().
а.key_comp();
Возвращает объект сравнения типа X: : key_compare, с которым был
построен контейнер а.
а.value_comp();
Возвращает объект типа X: :value_compare, созданный из объекта
сравнения.
a_uniq.insert(t);
Вставляет t тогда и только тогда, когда в контейнере нет элемента с ключом,
эквивалентным ключу t. Возвращает пару pair<iterator, bool>,
значение компонента bool которой указывает, была ли выполнена вставка, а
компонент iterator указывает на элемент с ключом, эквивалентным ключу t.
Выполняется за время, логарифмически зависящее от размера контейнера.
a_eq.insert(р, t);
Вставляет в контейнер t и возвращает итератор, указывающий на вновь
вставленный элемент.
a.insert(p, t);
Вставляет t тогда и только тогда, когда в контейнере нет элемента с
ключом, эквивалентным ключу t, в случае контейнера, поддерживающего
единственность ключей (множества и отображения). Всегда вставляет t в
контейнеры, поддерживающие эквивалентные ключи (мультимножества и
мультиотображения). Итератор р представляет собой подсказку,
указывающую, где операция должна начать поиск места для вставки. В общем случае
требует логарифмического времени работы, но если t вставляется сразу
после р, то операция имеет амортизированное константное время работы.
Возвращает итератор, указывающий на элемент с ключом, эквивалентным t.
a.insert(i, j) ;
Вставляет элементы из диапазона [ i; j ) в контейнер тогда и только тогда,
когда отсутствуют элементы с эквивалентными ключами при вставке в
контейнер, поддерживающий единственность ключей. В общем случае время
£УО
Часть III. Справочное руководство по STL
работы составляет o(N\og(size () + N)} , где N представляет собой
расстояние от i до j. Если диапазон [ i; j) отсортирован согласно
value_comp (), то время работы становится линейным.
a.erase(к);
Удаляет из контейнера все элементы с ключами, равными к. Возвращает
количество удаленных элементов. Время работы составляет
tf(log(size()) + count (k)) .
a.erase(q);
Удаляет элемент, на который указывает q.
a.erase(ql, q2);
Удаляет все элементы из диапазона [ql;q2). Время работы составляет
(9(log(size ()) + N), где N представляет собой расстояние от ql до q2.
a.clear();
Удаляет все элементы контейнера. Эквивалентно выражению
а. erase (a.begin () , а. end () ), с тем отличием, что clear не имеет
возвращаемого значения.
a.find(к);
Возвращает итератор, указывающий на элемент с ключом, эквивалентным
к, или а. end (), если такой элемент не найден. Время работы —
логарифмическое.
a.count(k);
Возвращает количество элементов с ключами, эквивалентными к. Время
работы составляет 0(log(size ()) +count (к)) .
а.lower_bound(к) ;
Возвращает итератор, указывающий на первый элемент с ключом, не
меньшим, чем к. Время работы — логарифмическое.
a.upper_bound(k);
Возвращает итератор, указывающий на первый элемент с ключом, большим,
чем к. Время работы — логарифмическое.
а. equal_range (k) ;
Возвращает пару итераторов (константных, если контейнер а константный),
где первый итератор равен a. lower_bound(k), а второй —
а. upper_bound (k). Время работы — логарифмическое.
21.2. Описания организации классов
контейнеров
В остальных разделах этой главы описываются специфические требования к трем
контейнерам последовательностей (vector, list, deque) и отсортированным ассоциативным
контейнерам (set, multiset, map, multimap). Каждое из этих описаний классов
контейнеров содержит следующие подразделы.
21.2.1. Файлы
В этом разделе указаны заголовочные файлы, которые должны быть включены в
программу, использующую данный класс.
Глава 21. Справочное руководство по контейнерам ^уу
21.2.2. Объявление класса
Указывает имя класса и параметры шаблона.
21.2.3. Примеры
Ссылки на программы из частей I, "Вводный курс в STL", и II, "Примеры программ", в
которых имеется нетривиальное применение данного контейнера. Описания функций-членов
также могут включать ссылки на примеры.
21.2.4. Описание
В этом разделе описывается базовая функциональность класса. Раздел служит кратким
введением к детальному описанию рассматриваемого контейнера.
21.2.5. Определения типов
Описываются определения типов в открытом интерфейсе класса.
21.2.6. Конструкторы, деструкторы и связанные функции
Содержит описания конструкторов и деструкторов класса. У некоторых классов имеются
другие функции, имеющие отношение к выделению и освобождению памяти, которые при
необходимости рассматриваются в этом же разделе.
21.2.7. Операции сравнения
Содержит описание всех операторов, использующихся для сравнения двух контейнеров.
21.2.8. Функции-члены для обращения к элементам
Описывается функциональность всех функций-членов, использующихся для обращения к
элементам контейнера.
21.2.9. Функции-члены для вставки
Описываются все функции-члены, использующиеся для вставки элементов в контейнеры.
21.2.10. Функции-члены для удаления
Описываются все функции-члены, использующиеся для удаления элементов из контейнеров.
21.2.11. Раздел(ы) дополнительных примечаний
В этом разделе (или разделах) содержатся дополнительные сведения, такие как
зависимости реализации, рассмотрение временной сложности функций-членов для вставки и удаления,
модель памяти и т.п. Сюда включена вся важная информация, не вошедшая в другие разделы.
о и i/
Часть III. Справочное руководство по STL
21.3. vector
21.3.1. Файлы
#include <vector>
21.3.2. Объявление класса
template <typename Т, typename Allocator = allocator<T> >
class vector
Мы не будем детально описывать параметр Allocator. Информацию об аллокаторах вы
можете почерпнуть из главы 24, "Справочное руководство по аллокаторам", и врезки
"Аллокаторы".
Аллокаторы
Каждый контейнер STL параметризован типом аллокатора, значение которого по
умолчанию— allocator<T>. Этот параметр типа определяет стратегию
распределения памяти, используемую контейнером. Каждый конструктор контейнера, не
являющийся копирующим конструктором, получает необязательный аргумент типа Allocator^.
Копирующий конструктор копирует аллокатор копируемого объекта.
Кроме того, каждый контейнер определяет тип allocator_type как псевдоним для
Allocator и определяет функцию-член get_allocator, который возвращает копию
аллокатора, использованную конструктором.
Детальное описание аллокаторов, включая аргумент конструктора, отложено да
главы 24, "Справочное руководство по аллокаторам". Для полноты изложения в этой главе мы
приводим allocator_type, get_allocator и аргументы конструктора по умолчанию.
21.3.3. Примеры
См. примеры 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 12.1, 13.1, 14.1 и 17.1.
21.3.4. Описание
Векторы представляют собой контейнеры, которые располагают элементы данного типа в
строгом линейном порядке и обеспечивают быстрый произвольный доступ к любому
элементу (обращение к любому элементу выполняется за константное время).
Векторы обеспечивают вставку в конец последовательности и удаление из него за
константное время. Вставка и/или удаление элементов в средине вектора имеет линейное время
выполнения. Другую информацию о временной сложности вставки в вектор можно найти в
разделе примечаний.
Класс vector специализирован для векторов значений bool, обеспечивая хранение
каждого значения как отдельного бита.30 С точки зрения функциональности эта специализация
идентична другим векторам с дополнением метода flip, который обращает все значения вектора.
Некоторые нетривиальные замечания о специализации vector<bool> можно найти в
соответствующем подразделе задачи 1.13 книги [24]. —Примеч. пер.
Глава 21. Справочное руководство по контейнерам
301
Кроме того, тип reference специализации поддерживает аналогичный метод flip,
который обращает конкретный элемент (например, v[0] .flip() изменяет первый элемент
вектора). В настоящее время все еще ведутся дебаты о несколько противоречивых
требованиях к типу вектора reference. С одной стороны, общее требование к вектору требует, чтобы
типом vector <bool> : : reference был bool&. С другой стороны, для поддержки метода
flip это должен быть тип некоторого класса. До окончательного решения этого вопроса,
пожалуй, лучше воздержаться от применения flip.
21.3.5. Определения типов
iterator
const_iterator
Тип итератора с произвольным доступом iterator указывает на Т;
cons t_it era tor представляет собой тип константного итератора с
произвольным доступом, указывающего на const Т. Гарантируется
существование конструктора const_iterator на основе iterator.
reference
const_reference
reference представляет собой тип позиций элементов в контейнере. Это
просто Т& (или const T& для const_ref erence).
pointer
const_pointer
pointer представляет собой тип указателя на элементы контейнера
(обычно Т*, но в общем случае это определяется типом аллокатора);
const ^pointer представляет собой соответствующий тип константного
указателя.
size_type
Беззнаковый целочисленный тип, который может представлять размер
любого экземпляра вектора.
difference_type
Знаковый целочисленный тип, который может представлять расстояние
между любыми двумя объектами vector: : iterator.
value_type
Тип хранимых в векторе значений. Это просто Т.
reverse_iterator
const__reverse_iterator
Неконстантный и константный обратные итераторы с произвольным доступом.
allocator_type
Тип аллокатора, используемого вектором. Эквивалентен Allocator.
21.3.6. Конструкторы, деструкторы и связанные функции
вектора
vector(const Allocator& = Allocator());
Конструктор по умолчанию, создающий вектор нулевого размера (см.
примеры 6.1, 6.2 и 6.3).
302
Часть III. Справочное руководство по STL
explicit vector(size_type n, const T& value = T(),
const Allocators^ = Allocator());
Создает вектор размера п и инициализирует все его элементы значением
value (см. примеры 6.1, 6.2 и 6.3). Если второй аргумент не передается,
value получается путем применения конструктора по умолчанию Т () типа
значения Т.
vector(const vector<T, Allocator>& x); /
Копирующий конструктор вектора, который создает вектор и
инициализирует его копиями элементов вектора х (см. пример 6.4).
template <typename InputIterator>
vector(Inputlterator first, Inputlterator last,
const Allocator& = Allocator());
Создает вектор размера last-first и инициализирует его копиями
элементов из диапазона [f irst; last), который должен представляет собой
корректный диапазон элементов типа Т (см. пример 6.4).
vector<T\ Allocator>&
operator=(const vector<T, Allocator>& x);
Оператор присваивания вектора. Замещает содержимое текущего вектора
копией вектора х, переданного в качестве параметра.
template <typename InputIterator>
void assign(Inputlterator first, Inputlterator last);
Эквивалентно { clear (); insert (begin () , first, last); }.
Делает содержимое вектора копией элементов в диапазоне [first; last),
который должен быть корректным диапазоном элементов типа Т.
void assign(size_type n, const T& u);
Эквивалентно { clear (); insert (begin () , n, u) ; }. Делает
вектор содержащим п элементов со значением и.
void reserve(size_type n) ;
Директива, информирующая вектор о планируемом изменении размера, с тем
чтобы можно было выполнить соответствующий запрос памяти (см. пример
6.6). Этот вызов не изменяет размер вектора, а время его работы не более чем
линейно зависит от размера вектора. Перераспределение памяти при вызове
выполняется тогда и только тогда, когда текущая емкость (capacity)
вектора меньше переданного аргумента (capacity— функция-член вектора,
возвращающая размер выделенной для вектора памяти). После вызова reserve
емкость становится не менее переданного функции-члену аргумента, если
перераспределение состоялось, и остается неизменной в противном случае.
Перераспределение делает недействительными все ссылки, указатели и
итераторы, указывающие на элементы вектора. Гарантируется, что после
вызова reserve в процессе вставок в вектор перераспределения памяти не
будут выполняться до тех пор, пока размер вектора не достигнет размера,
указанного в аргументе reserve.
-vector() ;
Деструктор вектора.
/oid swap(vector<T, Allocator>& x) ;
Обменивает содержимое текущего вектора с содержимым вектора х.
Текущий вектор замещает х и наоборот.
Глава 21. Справочное руководство по контейнерам
303
21.3.7. Операции сравнения
template <typename Т, typename Allocator>
bool operator==(const vector<T, Allocator>& x,
const vector<T, Allocator>& y);
Операция проверки эквивалентности векторов. Возвращает true, если
последовательности элементов х и у поэлементно равны (проверка
выполняется с применением Т: : operator==). Требует линейного времени.
template <typename Т, typename Allocator>
bool operator<(const vector<T/ Allocator>& x,
const vector<T, Allocator>& y);
Возвращает true, если х лексикографически меньше у, в противном
случае— false. Требует линейного времени. Определение
лексикографического сравнения можно найти в разделе 22.34.
21.3.8. Функции-члены вектора для обращения к элементам
iterator begin();
const_iterator begin() const;
Возвращает iterator (const_iterator в случае константного
вектора), который может использоваться для начала обхода вектора.
iterator end О;
const_iterator end() const;
Возвращает iterator (const_iterator в случае константного
вектора), который может использоваться в сравнении для завершения обхода
вектора.
reverse_iterator rbeginO;
const_reverse_iterator rbeginO;
Возвращает reverse_iterator (const_reverse_iterator в случае
константного вектора), который может использоваться для начала обхода
вектора в направлении, обратном нормальному (см. примеры 10.1 и 10.2).
reverse_iterator rend О;
const_reverse_iterator rend ();
Возвращает reverse_iterator (const_reverse_iterator в случае
константного вектора), который может использоваться в сравнении для
завершения обхода вектора в направлении, обратном нормальному (см.
примеры 10.1 и 10.2).
size_type size() const;
Возвращает количество элементов, хранящихся в векторе в данный момент.
size_type max_size() const;
Возвращает максимально возможный размер вектора.
void resize(size_type sz, T с = Т());
Изменяет размер вектора до sz элементов, либо вставляя копии с, либо
удаляя элементы с конца последовательности.
size_type capacity() const;
Возвращает максимальное количество элементов, которые вектор может
хранить без перераспределения памяти (см. пример 6.6). См. также
описание функции-члена reserve.
304 Часть III. Справочное руководство по STL
bool empty() const; /
Возвращает true, если вектор не содержит элементов (если
begin () == end ()), в противном случае — false. /
reference operator [] (size_type n) ; /
const_reference operator [] (size_type n) const; /
Возвращает п-й с начала вектора элемент за константное время]
reference at(size_type n);
const_reference at(size_type n) const;
Возвращает п-й с начала вектора элемент за константное
верки границ вектора. Генерирует исключение out_
п >= size().
reference front О;
const_reference front() const;
Возвращает первый элемент вектора (элемент, на который указывает
итератор begin ()). Не определен, если вектор пуст.
reference back О;
const_reference back() const;
Возвращает последний элемент вектора (элемент, на который указывает
итератор end О -1; см. пример 6.7). Не определен, если вектор пуст.
allocator_type get_allocator() const;
Возвращает копию аллокатора, использованного при создании объекта.
21.3.9. Функции-члены вектора для вставки
Временная сложность всех функций для вставки описывается в разделе21.3.11.
void push_back(const T& х);
Добавляет элемент х в конец вектора (см. пример 6.5).
iterator insert(iterator position, const T& x);
Вставляет элемент х в вектор в позиции, на которую указывает position
(см. пример 6.5). Элементы, находящиеся в векторе, при необходимости
перемещаются. Возвращаемый итератор указывает на позицию, в которую
был вставлен элемент.
void insert(iterator position, size_type n, const T& x);
Вставляет п копий элемента х, начиная с позиции, на которую указывает
position.
template <typename InputIterator>
void insert(iterator position,
Inputlterator first,
InputIterator last);
Вставляет копии элементов из диапазона [first;last) в вектор в
позиции, на которую указывает position. Диапазон [first;last) должен
быть корректным диапазоном элементов типа Т.
21.3.10. Функции-члены вектора для удаления
void pop_back();
Удаляет последний элемент вектора (см. пример 6.7). Результат не
определен, если вектор пуст.
после про-
range, если
Глава 21. Справочное руководство по контейнерам
305
iterator, erase(iterator position);
Удаляет элемент в позиции, на которую указывает position (см. пример
6.8). Результат не определен, если вектор пуст. Возвращает итератор,
указывающий на элемент, следующий за удаленным, или end (), если удален
последний элемент.
iterator ejrase (iterator first, iterator last) ;
\ Предполагается, что итераторы first и last указывают в вектор; при
этом все элементы из диапазона [first; last) удаляются из вектора (см.
пример 6.8). Возвращает итератор, указывающий на элемент, следующий за
удаленными значениями, или end (), если удален последний элемент.
Требует линейного времени.
void clear();
Удаляет все элементы вектора. Эквивалентно
а. erase (a.begin () , а. end () ), с тем отличием, что clear не имеет
возвращаемого значения.
21.3.11. Замечания о функциях-членах вставки и удаления
Вставка одного элемента в вектор требует времени, линейно зависящего от расстояния от
точки вставки до конца вектора. Амортизированное время вставки одного элемента в конец
вектора— константное (см. материал, посвященный амортизированному времени, в разделе 1.5.2).
Вставка нескольких элементов в вектор посредством одного вызова функции-члена insert
выполняется за время, линейно зависящее от суммы количества элементов и расстояния до
конца вектора, если только итераторы не являются входными итераторами. В случае входных
итераторов сложность пропорциональна длине диапазона, умноженной на расстояние до конца
вектора. Таким образом, вставка нескольких элементов в средину вектора выполняется гораздо
быстрее одним вызовом соответствующей функции-члена, чем по одной вставке за раз.
Все функции-члены для вставки вызывают перераспределение памяти, если новый размер
вектора оказывается больше, чем его старая емкость. Если перераспределение не выполняется,
все итераторы и ссылки, указывающие на элементы до точки вставки, остаются корректными.
Функция erase делает недействительными все итераторы и ссылки после точки
удаления. Деструктор Т вызывается для каждого удаляемого элемента, а оператор присваивания Т
вызывается столько раз, сколько имеется элементов в векторе после удаленных элементов.
21.4. deque
21.4.1. Файлы
#include <deque>
21.4.2. Объявление класса
template <typename Т, typename Allocator = allocator<T> >
class deque
Мы опускаем все детали, связанные с параметром Allocator. Информацию об аллока-
торах можно найти во врезке "Аллокаторы" на стр.300 в разделе 21.3.2, и в главе 24,
"Справочное руководство по аллокаторам".
306
Часть III. Справочное руководство по STL
21.4.3. Примеры
См. пример 6.9.
21.4.4. Описание
Этот класс предоставляет последовательности, которые могут эффективно расширяться в
обе стороны: вставка и удаление объектов с любого конца последовательности/выполняется
за константное время. Подобно векторам, деки обеспечивают быстрый произвольный доступ
к любому элементу (за константное время).
21.4.5. Определения типов
Те же, что и у вектора (см. раздел 21.3.5).
21.4.6. Конструкторы, деструкторы и связанные функции дека
deque(const Allocator^ = Allocator());
Конструктор по умолчанию. Создает дек нулевого размера.
explicit deque(size_type n, const T& value = T(),
const Allocator& = Allocator());
Создает дек размера п и инициализирует все его элементы значением
value. По умолчанию значение value устанавливается равным Т (), где
Т () — конструктор по умолчанию типа, для которого инстанцируется дек.
deque(const deque<T, Allocator>& x);
Копирующий конструктор дека. Создает дек и инициализирует его копиями
элементов дека х.
template <typename InputIterator>
deque(Inputlterator first,
Inputlterator last,
const Allocatork = Allocator());
Создает дек размером last-first и инициализирует его копиями
элементов из диапазона [first; last), который должен быть корректным
диапазоном элементов типа Т.
deque<T, Allocator>& operator=(const deque<T\ Allocators x);
Оператор присваивания дека. Заменяет содержимое текущего дека копией
дека х, переданного в качестве параметра.
template <typ#natne InputIterator>
void assign(Inputlterator first, Inputlterator last);
Эквивалентно {clear () ; insert (begin () , first, last) ;}. Делает
дек содержащим копии элементов из диапазона [first; last), который
должен быть корректным диапазоном элементов типа Т.
void assign(size_type n, const T& u) ;
Эквивалентно {clear (); insert (begin () ,n,u) ;}. Делает дек
содержащим n элементов со значением и.
-deque();
Деструктор дека.
void swap (deque<T, Allocators x) ;
Обменивает содержимое текущего дека с содержимым дека х. Текущий дек
замещает х и наоборот.
Глава 21. Справочное руководство по контейнерам
307
21.4.7. Операции сравнения
template <typename Т, typename Allocator>
bool operator==(const deque<T, Allocator>& x,
const deque<T, Allocator>& y);
Операция проверю! эквивалентности деков. Возвращает true, если
последовательности элементов х и у поэлементно равны (проверка выполняется с
применением Т: : operator==). Требует линейного времени.
template <typename T, typename Allocator>
bool operator<(const deque<T, Allocator>& x,
const deque<T, Allocator>& y);
Возвращает true, если х лексикографически меньше у, в противном
случае — false. Требует линейного времени.
21.4.8. Функции-члены дека для обращения к элементам
iterator begin() ;
const_iterator begin() const;
Возвращает iterator (const_iterator в случае константного дека),
который может использоваться для начала обхода дека.
iterator end();
const_iterator end() const;
Возвращает iterator (const_iterator в случае константного дека),
который может использоваться в сравнении для завершения обхода дека.
reverse_iterator rbeginO;
const_reverse_iterator rbegin() const;
Возвращает reverse_iterator (const_reverse_iterator в случае
константного дека), который может использоваться для начала обхода дека
в направлении, обратном нормальному.
reverse_iterator rend();
const_reverse_iterator rend () ;
Возвращает reverse_iterator (const_reverse_iterator в случае
константного дека), который может использоваться в сравнении для
завершения обхода дека в направлении, обратном нормальному.
size_type size() const;
Возвращает количество элементов дека.
size_type max_size() const;
Возвращает максимально возможный размер дека.
void resize(size_type sz, T с = Т());
Изменяет размер дека до sz элементов, либо вставляя копии с, либо удаляя
элементы с конца последовательности.
bool empty О const;
Возвращает true, если дек не содержит элементов (если
begin () == end О), в противном случае—false.
reference operator [] (size_type n) ;
const_reference operator [] (size_type n) const;
Обеспечивает обращение к n-му элементу дека за константное время.
Результат операции не определен, если дек пуст.
308
Часть III. Справочное руководство по STL.
reference at(size_type n); /
const_reference at(size_type n) const; /
Возвращает п-й с начала дека элемент за константное время, после проверки
границ дека. Генерирует исключение out_of _range, если n >= size().
reference front(); /
const_reference front() const; У
Возвращает первый элемент дека (элемент, на который указывает итератор
begin ()). Не определен, если дек пуст.
reference back();
const_reference back() const;
Возвращает последний элемент дека (элемент, на который указывает
итератор end () -1). Не определен, если дек пуст.
allocator type get allocator() const;
Возвращает копию аллокатора, использованного при создании объекта.
21.4.9. Функции-члены дека для вставки
void push_front(const T& х);
Добавляет элемент х в начало дека (см. пример 6.9).
void push_back(const T& х);
Добавляет элемент х в конец дека (см. пример 6.9).
iterator insert(iterator position, const T& x);
Вставляет элемент х в дек в позицию, на которую указывает position.
Возвращаемый итератор указывает на позицию, содержащую вставленный
элемент.
void insert(iterator position, size_type n, const T& x);
Вставляет п копий элемента х, начиная с позиции, на которую указывает
position.
template <typename InputIterator>
void insert(iterator position,
Inputlterator first,
Inputlterator last);
Вставляет копии элементов из диапазона [first /last) в дек в позиции,
на которую указывает position. Диапазон [first;last) должен быть
корректным диапазоном элементов типа Т.
21.4.10. Функции-члены дека для удаления
void pop_front();
Удаляет первый элемент дека. Результат не определен, если дек пуст.
void pop_back();
Удаляет последний элемент дека. Результат не определен, если дек пуст.
iterator erase(iterator position);
Удаляет элемент в позиции, на которую указывает position. Возвращает
итератор, указывающий на элемент, следующий за удаленным, или end (),
если удален последний элемент.
Глава 21. Справочное руководство по контейнерам
309
iterator erase(iterator first, iterator last);
Предполагается, что итераторы first и last указывают в дек; при этом
все элементы из диапазона [first; last) удаляются из дека. Возвращает
итератор, указывающий на элемент, следующий за удаленными значениями,
или end (), если удален последний элемент. Требует линейного времени.
void clear();
Удаляет все элементы дека. Эквивалентно a.erase (a.begin () ,
а. end () ), с тем отличием, что clear не имеет возвращаемого значения.
21.4.11. Сложность вставки в дек
Деки оптимизированы для вставки одного элемента либо в начало, либо в конец
структуры данных. Такие вставки выполняются за константное время и вызывают копирующий
конструктор Т один раз (Т — тип вставляемого объекта).
Если элемент вставляется в средину дека, то в наихудшем случае для выполнения этой
операции требуется время, линейно зависящее от меньшего значения среди расстояний от
точки вставки до начала и до конца дека.
Функции-члены insert, push_f ront и push_back делают недействительными все
итераторы, указывающие в дек. Ссылки также делаются недействительными при вставке в
средину дека.
21.4.12. Замечания о функциях-членах удаления
Функции-члены erase, pop_f ront и pop_back делают недействительными все
итераторы, указывающие в дек. Ссылки также делаются недействительными при удалении из
средины дека. Количество вызовов деструктора удаляемого типа Т равно количеству удаляемых
элементов, но количество оператора присваивания типа Т равно наименьшему значению
среди количества элементов до удаляемых и количества элементов после удаляемых.
21.5. list
21.5.1. Файлы
#include <list>
21.5.2. Объявление класса
template <typename Т, typename Allocator = allocator<T> >
class list
Мы опускаем все детали, связанные с параметром Allocator. Информацию об аллока-
торах можно найти во врезке "Аллокаторы" на стр.300 в разделе 21.3.2, и в главе 24,
"Справочное руководство по аллокаторам".
21.5.3. Примеры
См. примеры 6.10, 6.11, 6.12, 6.13 и 14.1.
w 310
Часть III. Справочное руководство по STL
21.5.4. Описание
Данный класс реализует абстракцию последовательности в виде связанного списка. Все
списки — двусвязные, и могут обходиться в любом направлении.
Списки должны предпочитаться другим абстракциям последовательностей в тех случаях,
когда имеется много вставок и удалений в средине списка. Как и во всех прочих контейнерах
STL, управление памятью выполняется автоматически.
В отличие от векторов и деков, списки не являются структурами данных с произвольным
доступом. По этой причине некоторые обобщенные алгоритмы STL, такие как sort и
random_shuf f le, не могут работать со списками. Класс list предоставляет собственную
функцию-член sort.
Помимо sort списки включают специальные функции-члены для склейки двух списков,
обращения списков, удаления дублей и слияния списков. Специальные функции-члены
рассматриваются в разделе 21.5.11.
21.5.5. Определения типов
iterator
const_iterator
Тип двунаправленного итератора iterator указывает на Т.
cons t_it era tor представляет собой тип двунаправленного итератора,
указывающего на const Т. Гарантируется существование конструктора
const_iterator на основе iterator.
reference
const_reference
reference представляет собой тип позиций элементов в контейнере. Это
просто Т& (или const T& для const_ref erence).
pointer
const_pointer
pointer представляет собой тип указателя на элементы контейнера
(обычно Т*, но в общем случае это определяется типом аллокатора);
const_pointer представляет собой соответствующий тип константного
указателя.
size_type
Беззнаковый целочисленный тип, который может представлять размер
любого экземпляра списка.
difference_type
Знаковый целочисленный тип, который может представлять расстояние
между любыми двумя объектами list: : iterator.
value_type
Тип Т хранимых в списке значений.
reverse_iterator
const_reverse_iterator
Неконстантный и константный обратные двунаправленные итераторы.
allocator_type
Тип аллокатора, используемого списком. Эквивалентен Allocator.
Глава 21. Справочное руководство по контейнерам
311
21.5.6. Конструкторы, деструкторы и связанные
функции списка
list(const Allocatorfc = Allocator());
Конструктор по умолчанию. Создает пустой список.
explicit list(size_type n, const T& value = T(),
const Allocator^ = Allocator());
Создает список размера п и инициализирует все его элементы значением
value,
list(const list<T, Allocator>& x);
Копирующий конструктор списка. Создает список и инициализирует его
копиями элементов списка х.
template <typename InputIterator>
list(Inputlterator first,
Inputlterator last,
const Allocators^ = Allocator());
Создает список размера last-first и инициализирует его копиями
элементов из диапазона [first; last), который должен представляет собой
корректный диапазон элементов типа Т.
list<T, Allocators operator=(const list<T, Allocators x);
Оператор присваивания списка. Замещает содержимое текущего списка
копией списка х, переданного в качестве параметра.
template <typename InputIterator>
void assign(Inputlterator first, Inputlterator last);
Эквивалентно { clear(); insert (begin() , first, last); }.
Делает содержимое списка копией элементов в диапазоне [first/last),
который должен быть корректным диапазоном элементов типа Т.
void assign(size_type n, const T& u);
Эквивалентно { clear (); insert (begin () , n, u) ; }. Делает
список содержащим п элементов со значением и.
-list () ;
Деструктор списка.
void swap(list<T, Allocators х) ;
Обменивает содержимое текущего списка с содержимым списка х. Текущий
список замещает х и наоборот.
21.5.7. Операции сравнения
template <typename T, typename Allocator>
bool operator==(const list<T, Allocators x,
const list<T, Allocators y);
Операция проверки эквивалентности списков. Возвращает true, если
последовательности элементов х и у поэлементно равны (проверка
выполняется с применением Т: : operator==). Требует линейного времени.
template <typename Т, typename Allocator>
bool operator<(const list<T, Allocators x,
const list<T, Allocators y) ;
312
Часть III. Справочное руководство по STL
Возвращает true, если х лексикографически меньше у, в противном
случае— false. Требует линейного времени. Определение
лексикографического сравнения можно найти в разделе 22.34.
■
21.5.8. Функции-члены списка для обращения к элементам
iterator begin();
const_iterator begin() const;
Возвращает iterator (const_iterator в случае константного списка),
который может использоваться для начала обхода списка.
iterator end();
const_iterator end() const;
Возвращает iterator (const_iterator в случае константного списка),
который может использоваться в сравнении для завершения обхода списка.
reverse_iterator rbegin();
const_reverse_iterator rbegin() const;
Возвращает reverse_iterator (const_reverse_iterator в случае
константного списка), который может использоваться для начала обхода
списка в направлении, обратном нормальному (см. примеры 10.1 и 10.2).
reverse_iterator rend О ;
const_reverse_iterator rend() const;
Возвращает reverse_iterator (const_reverse_iterator в случае
константного списка), который может использоваться в сравнении для
завершения обхода списка в направлении, обратном нормальному (см.
примеры 10.1 и 10.2).
size_type size() const;
Возвращает количество элементов, хранящихся в списке в данный момент.
size_type max_size() const;
Возвращает максимально возможный размер списка.
void resize (size_type sz, T с = ТО);
Изменяет размер списка до sz элементов, либо вставляя копии с, либо
удаляя элементы с конца последовательности.
bool empty() const;
Возвращает true, если список не содержит элементов (если
begin () == end ()), в противном случае—false.
reference front();
const_reference front() const;
Возвращает первый элемент списка (элемент, на который указывает
итератор begin ()). Результат не определен, если список пуст.
reference back();
const_reference back() const;
Возвращает последний элемент списка (элемент, на который указывает
итератор end О -1). Результат не определен, если список пуст.
allocator_type get_allocator() const;
Возвращает копию аллокатора, использованного при создании объекта.
Глава 21. Справочное руководство по контейнерам
313
21.5.9. Функции-члены списка для вставки
void push_front(const T& х);
Вставляет элемент х в начало списка (см. пример 6.10).
void push_back(const T& х);
Вставляет элемент х в конец списка (см. примеры 6.10 и 15.1).
iterator insert(iterator position, const T& x) ;
Вставляет элемент х в список в позицию, на которую указывает position.
Возвращаемый итератор указывает на позицию, содержащую вставленный
элемент.
void insert(iterator position, size_type n, const T& x);
Вставляет п копий элемента х, начиная с позиции, на которую указывает
position.
template <typename InputIterator>
void insert(iterator position,
Inputlterator first,
Inputlterator last);
Вставляет копии элементов из диапазона [first; last) в список в
позиции, на которую указывает position. Диапазон [first/last) должен
быть корректным диапазоном элементов типа Т.
21.5.10. Функции-члены списка для удаления
void pop_front();
Удаляет первый элемент списка. Результат не определен, если список пуст.
void pop_back();
Удаляет последний элемент списка. Результат не определен, если список
пуст.
iterator erase(iterator position);
Удаляет элемент в позиции, на которую указывает position (см. пример
6.11). Результат не определен, если список пуст. Возвращает итератор,
указывающий на элемент, следующий за удаленным, или end (), если удален
последний элемент.
iterator erase(iterator first, iterator last);
Предполагается, что итераторы first и last указывают в список; при
этом все элементы из диапазона [first; last) удаляются из списка.
Возвращает итератор, указывающий на элемент, следующий за удаленными
значениями, или end (), если удален последний элемент.
void clear();
Удаляет все элементы списка. Эквивалентно a.erase (a.beginO ,
а. end ()), с тем отличием, что clear не имеет возвращаемого значения.
21.5.11. Специальные операции со списками
void splice(iterator position, list<T, Allocator>& x);
Вставляет содержимое списка х перед позицией position и удаляет все
элементы из х (см. пример 6.12). Выполняется за константное время. По
314
Часть III. Справочное руководство по STL
существу, содержимое х переносится в текущий список. Делает
недействительными все итераторы, указывающие в список х.
void splice(iterator position,
list<T, Allocator>& x,
iterator i);
Вставляет элемент, на который указывает итератор i, из списка х перед
position, и удаляет элемент из х (см. пример 6.12). Выполняется за
константное время. Предполагается, что i представляет собой корректный
итератор списка х. Делает недействительными итераторы и ссылки на
переносимый элемент.
void splice(iterator position,
list<T\ Allocators x,
iterator first, iterator last);
Вставляет элементы из диапазона [first; last) списка х перед
position и удаляет эти элементы из списка х (см. пример 6.12). Операция
выполняется за время, пропорциональное last-first, если только не
выполняется условие &х == this; в таком случае операция выполняется за
константное время. Предполагается, что диапазон [first; last) является
корректным диапазоном списка х, а итератор position не должен
находиться в [first/last). Делает недействительными итераторы и ссылки
на переносимые элементы.
void remove(const T& value);
Удаляет все элементы списка, равные value (равенство проверяется при
помощи оператора Т: : operator==). Влияния на относительный порядок
других элементов не оказывает. Весь список обходится ровно один раз.
template <typename Predicate>
void remove_if(Predicate pred);
Удаляет все элементы списка, удовлетворяющие предикату pred (все х, для
которых pred(x) возвращает true). Влияния на относительный порядок
других элементов не оказывает. Весь список обходится ровно один раз.
void unique();
Удаляет все, кроме первого, элементы каждой последовательной группы
равных элементов списка (см. пример 6.13). Выполняется ровно size () -1
сравнений Т: : operator==. Наиболее полезна эта функция в ситуации, когда
список отсортирован, так что все эквивалентные элементы находятся в соседних
позициях. В этом случае получается список, все элементы которого различны.
template <typename BinaryPredicate>
void unique(BinaryPredicate binary_pred);
Удаляет все, кроме первого, элементы каждой последовательной группы
элементов списка таких, что binary_pred возвращает true при
применении к паре элементов. Предикат binary_pred выполняется ровно
size () -1 раз.
void merge (list<T, Allocators x) ;
Выполняет слияние списка х с текущим списком. Предполагается, что оба
списка отсортированы в соответствии с оператором operator< типа Т.
Слияние устойчиво; в случае эквивалентных элементов в обоих списках
элементы из текущего списка всегда предшествуют элементам из списка х,
Глава 21. Справочное руководство по контейнерам
315
передаваемого в качестве аргумента. После слияния список х становится
пустым. Выполняется не более size()+x.size()-l сравнений.
template <typename Compare>
void merge(list<T, Allocator>& x, Compare comp);
Выполняет слияние списка х с текущим списком. Предполагается, что оба
списка отсортированы в соответствии с объектом сравнения сотр. Слияние
устойчиво; в случае эквивалентных элементов в обоих списках элементы из
текущего списка всегда предшествуют элементам из списка х,
передаваемого в качестве аргумента. После слияния список х становится пустым.
Выполняется не более size()+x.size()-l сравнений.
void reverse();
Обращает порядок элементов в списке. Выполняется за линейное время.
void sort();
Сортирует список в соответствии с оператором operator< типа Т (см.
пример 6.13). Сортировка устойчива — сохраняется относительный порядок
эквивалентных элементов. Выполняется 0(N\ogN) сравнений, где N —
размер списка.
template <typename Compare>
void sort(Compare comp);
Сортирует список в соответствии с упорядочением, определяемым
функциональным объектом сотр. Сортировка устойчива — сохраняется
относительный порядок эквивалентных элементов. Выполняется O(NlogN)
сравнений, где N— размер списка.
21.5.12. Замечания о функциях-членах вставки
Операции вставки в список не влияют на корректность итераторов и ссылок на другие
элементы списка. Вставка единственного элемента типа Т в список выполняется за
константное время и осуществляет только один вызов копирующего конструктора Т. Вставка
нескольких элементов в список требует времени, линейно зависящего от количества вставляемых
элементов, а количество вызовов копирующих конструкторов Т в точности совпадает с
количеством вставляемых элементов.
21.5.13. Замечания о функциях-членах удаления
Функция erase делает недействительными только итераторы и ссылки на удаляемые
элементы. Удаление одного элемента типа Т выполняется за константное время с
единственным вызовом деструктора Т. Удаление диапазона из списка выполняется за время, линейно
зависящее от размера диапазона, а количество вызовов деструкторов типа Т в точности равно
размеру диапазона.
21.6. set
21.6.1. Файлы
#include <set>
316
Часть III. Справочное руководство по STL
21.6.2. Объявление кЛасса
template <typename Key, typename Compare = less<Key>,
typename Allocator = allocator<Key> >
class set
Мы опускаем все детали, связанные с параметром Allocator. Информацию об аллока-
торах можно найти во врезке "Аллокаторы" на стр.300 в разделе 21.3.2, и в главе 24,
"Справочное руководство по аллокаторам".
См. примеры 7.1 и 11.2.
21.6.3. Примеры
См. примеры 7.1 и 1
21.6.4. Описание
Множество set<Key, Compare, Allocators хранит уникальные элементы типа
Key и обеспечивает их выборку. Все элементы в множестве упорядочены с использованием
отношения упорядочения Compare, которое должно обеспечивать строгое неполное
упорядочение элементов (см. раздел 22.26).
Как и все остальные контейнеры STL, множество только выделяет память и обеспечивает
минимальный набор операций (таких как insert, erase, find, count и т.д.). Класс set сам
по себе не предоставляет операций для объединения, пересечения, разности и т.п. действий со
множествами. Эти операции выполняются обобщенными алгоритмами STL (см. раздел 22.31).
21.6.5. Определения типов
key_type
Тип ключей, Key, с которым инстанцируется множество.
value_type
То же, что и key_type.
reference
const_reference
Тип reference представляет собой константный ссылочный тип позиций в
контейнере. Это просто Кеу& (или const Key& в случае const_ref erence).
pointer
const_pointer
Тип pointer представляет собой тип указателей на элементы контейнера
(обычно Key*, но в общем случае определяется типом аллокатора);
const ^pointer представляет собой соответствующий тип константного
указателя.
key_compare
Тип объекта сравнения, Compare, с которым инстанцируется множество.
Этот тип используется для упорядочения ключей во множестве.
value_compare
Тип отношения упорядочения, который используется для упорядочения
значений, хранящихся во множестве. Совпадает с key_compare, поскольку
типом хранимых во множестве значений является тип ключа.
/ лава Z7. справочное руковооство по контейнерам
л/
iterator
const_iterator
Тип iterator представляет собой константный двунаправленный
итератор, указывающий на const_Key; const_iterator представляет собой
тот же тип, что и iterator.
size_type
Беззнаковый целочисленный тип, который может представить размер
любого экземпляра множества.
difference_type
Знаковый целочисленный тип, который может представить расстояние
между любыми двумя объектами set: : iterator.
reverse_iterator
const_reverse_iterator
Один и тот же тип константного обратного двунаправленного итератора,
allocator_type
Тип аллокатора, используемого множеством. Эквивалентен Allocator.
21.6.6. Конструкторы, деструкторы и связанные функции
множества
explicit set(const Comparefc comp = Compare(),
const Allocatorfc = Allocator());
Конструктор по умолчанию (см. пример 7.1). Создает пустое множество и
сохраняет объект сравнения comp, использующийся для упорядочения
элементов,
set(const set<Key, Compare, Allocators x) ;
Копирующий конструктор множества. Создает множество и
инициализирует его копиями элементов из множества х.
template <typename InputIterator>
set(Inputlterator first, Inputlterator last,
const Compared comp = Compare(),
const Allocatorfc = Allocator());
Создает пустое множество и вставляет в него копии элементов из диапазона
[first; last), который должен быть корректным диапазоном элементов
типа value_type (Key). Объект сравнения comp используется для
упорядочения элементов множества.
set<Key, Compare, Allocator>&
operator=(const set<Key, Compare, Allocator>& x);
Оператор присваивания множества. Замещает содержимое текущего
множества копией множества х.
void swap(set<Key, Compare, Allocator>& x);
Обменивает содержимое текущего множества с содержимым множества х.
-set О ;
Деструктор множества.
21.6.7. Операции сравнения
template <typename Key, typename Compare, typename Allocator>
bool operator—(const set<Key, Compare, Allocator>& x,
const set<Key, Compare, Allocator>& y);
318
Часть III. Справочное руковооство по STL
Операция проверки эквивалентности множеств. Возвращает true, если
последовательности элементов х и у поэлементно равны (проверка
выполняется с применением Т: : operator==). Требует линейного времени.
template <typename Key, typename Compare, typename Allocator>
bool operator<(const set<Key, Compare, Allocator>& x,
const set<Key, Compare, Allocator>& y);
Возвращает true, если х лексикографически меньше у, в противном
случае— false. Требует линейного времени. Определение
лексикографического сравнения можно найти в разделе 22.34.
- % щ
21.6.8. Функции-члены множества для обращения
к элементам
key_compare key_comp() const;
Возвращает объект сравнения множества.
value_compare value_comp() const;
Возвращает объект типа value_compare, построенный на базе объекта
сравнения. Для множеств этот объект совпадает с объектом сравнения
множества.
iterator begin() const;
Возвращает константный итератор, который может использоваться для
начала обхода множества.
iterator end О const;
Возвращает константный итератор, который может использоваться в
сравнении для завершения обхода множества.
reverse_iterator rbegin() const;
Возвращает константный итератор, который может использоваться для
начала обхода множества в направлении, противоположном нормальному.
reverse_iterator rend() const;
Возвращает константный итератор, который может использоваться в
сравнении для завершения обхода множества в направлении, противоположном
нормальному.
bool empty() const;
Возвращает true, если множество пустое, false — в противном случае.
size_type size О const;
Возвращает количество элементов, хранящихся во множестве в данный
момент.
size_type max_size() const;
Возвращает максимально возможный размер множества. Максимальный
размер представляет собой просто общее количество элементов типа Key,
которые могут быть представлены в используемой модели памяти.
allocator_type get_allocator() const;
Возвращает копию аллокатора, использованного при создании объекта.
/ лава л. справочное руковооство по контейнерам
OI&
21.6.9. Функции-члены множества для вставки
iterator insert(iterator position, const value_type& x);
Вставляет элемент х в множество, если х в нем отсутствует. Итератор
position представляет собой подсказку, указывающую, где функция
insert должна начинать поиск места для вставки. Такой поиск необходим,
поскольку множества представляют собой упорядоченные контейнеры.
Время выполнения вставки составляет O(logN), где N— количество
элементов в множестве, но если вставка выполняется сразу после позиции
position, то амортизированное время ее выполнения константное.
pair<iterator, bool> insert(const value_type& x);
Вставляет элемент х в множество, если х в нем отсутствует (см. примеры
7.1 и 11.2). Возвращаемое значение представляет собой пару pair, в
которой элемент типа bool указывает, была ли выполнена вставка, а элемент
типа iterator указывает на только что вставленный во множество
элемент, если вставка имела место; в противном случае он указывает на уже
имеющийся в множестве элемент х. Время выполнения вставки —
0{\ogN), где N— количество элементов в множестве.
template <typename InputIterator>
void insert(Inputlterator first, Inputlterator last);
Вставляет в множество копии элементов из диапазона [first; last).
Диапазон [first; last) должен быть корректным диапазоном элементов
типа value_type (Key). В общем случае время выполнения вставки
составляет o(d\og(N + d)), где N— размер множества, a d— расстояние от
first до last. Время вставки линейное, если диапазон [first; last)
отсортирован в соответствии с отношением упорядочения value_comp ().
21.6.10. Функции-члены множества для удаления
void erase(iterator position);
Удаляет из множества элемент, на который указывает position.
Выполняется за амортизированное константное время.
size_type erase(const key_type& x) ;
Удаляет из множества элемент, эквивалентный х, если таковой
присутствует в множестве. Возвращает количество удаленных элементов, которое
равно 1, если х имеется в множестве, и 0 в противном случае. Время
выполнения удаления — (9(logN), где TV — размер множества.
void erase(iterator first, iterator last);
В предположении, что итераторы first и last указывают в множество,
удаляет из последнего все элементы из диапазона [first;last). Время
выполнения удаления— 0(d + logN), где TV— размер множества, a d —
расстояние от first до last.
void clear();
Удаляет все элементы множества. Эквивалентно a.erase (a.begin () ,
а.end()).
JZI/
часть ш. справочное руковооство по а / l
21.6.11. Специализированные операции множества
iterator find(const key_type& x) const;
Выполняет поиск элемента х в множестве. Если х найден, функция
возвращает итератор, указывающий на этот элемент, в противном случае возвращает
end (). Время выполнения поиска — 0(\ogN), где N— размер множества.
size_type count(const key_type& x) const;
Возвращает количество элементов множества, равных х. Если х имеется в
множестве, это значение равно 1, в противном случае это 0. Выполняется за
время 0(\ogN), где N— размер множества.
iterator lower_bound(const key_type& x) const;
Возвращает итератор, указывающий на первый элемент множества, не
меньший х. Если все элементы множества меньше х, возвращает значение
end (). Поскольку элементы множества не повторяются, при наличии х в
множестве возвращаемый итератор указывает на х. Выполняется за время
O(logN), где N— размер множества.
iterator upper_bound(const key_type& x) const;
Функция upperbound возвращает итератор, указывающий на первый
элемент множества, больший х. Если в множестве нет элемента, большего
х, возвращается значение end (). Выполняется за время O(logAf), где N—
размер множества.
pair<iterator,iterator> equal_range(const key_type& x) const;
Возвращает пару (lower_bound (x) , upper_bound (x)). Выполняется за
время О (log TV), где N— размер множества.
21.7. multiset
21.7.1. Файлы
#include <set>
21.7.2. Объявление класса
template <typename Key, typename Compare = less<Key>/
typename Allocator = allocator<Key> >
class multiset
Мы опускаем все детали, связанные с параметром Allocator. Информацию об аллока-
торах можно найти во врезке "Аллокаторы" на стр.300 в разделе 21.3.2, и в главе 24,
"Справочное руководство по аллокаторам".
21.7.3. Примеры
См. примеры 7.2, 7.3, 7.4 и 18.1.
Глава 21. Справочное руководство по контейнерам
21.7.4. Описание
Мультимножество представляет собой отсортированный ассоциативный контейнер,
который может хранить несколько копий одного и того же ключа. Как и в случае множеств, все
элементы мультимножества упорядочены при помощи отношения упорядочения Compare,
которое обеспечивает строгое неполное упорядочение элементов.
Мультимножества необходимы, поскольку иногда требуется хранить элементы,
одинаковые во множестве аспектов, но отличающиеся некоторыми отдельными характеристиками.
Например, множество автомобилей, отсортированных по производителю, может быть
мультимножеством: все автомобили могут быть от одного производителя, но отличаться другими
характеристиками, такими, как мощность двигателя, цена и т.д.
Интерфейс класса мультимножества в точности такой же, как и у класса множества.
Единственное отличие заключается в том, что мультимножество может содержать несколько
значений одного и того же ключа. В результате некоторые из функций-членов имеют немного
отличающуюся семантику.
21.7.5. Определения типов
Те же, что и у класса set (см. раздел 21.6.5).
21.7.6. Конструкторы, деструкторы и связанные функции
мул ьти м ножества
explicit multiset(const Comparefc comp = Compare(),
const Allocator& = Allocator());
Конструктор по умолчанию (см. пример 7.2). Создает пустое
мультимножество и сохраняет объект сравнения comp, использующийся для
упорядочения элементов.
multiset(const multiset<Key, Compare, Allocators x);
Копирующий конструктор мультимножества. Создает мультимножество и
инициализирует его копиями элементов из мультимножествах.
template <typename InputIterator>
multiset(Inputlterator first, Inputlterator last,
const Compared comp = Compare(),
const Allocators: = Allocator () ) ;
Создает пустое мультимножество и вставляет в него копии элементов из
диапазона [first;last), который должен быть корректным диапазоном
элементов типа value_type (Key). Объект сравнения comp используется
для упорядочения элементов мультимножества.
multiset<Key, Compare, Allocator>&
operator=(const multiset<Key, Compare, Allocator>& x);
Оператор присваивания мультимножества. Замещает содержимое текущего
мультимножества копией мультимножествах.
void swap(multiset<Key, Compare, Allocator>& x);
Обменивает содержимое текущего мультимножества с содержимым
мультимножества х.
-multiset();
Деструктор мультимножества.
JZZ
Часть III. Справочное руководство по STL
21.7.7. Операции сравнения
template <typename Key, typename Compare, typename Allocators
bool operator==(const multiset<Key/ Compare, Allocator>& x,
const multiset<Key, Compare, Allocator>& y);
Операция проверки эквивалентности мультимножеств. Возвращает true,
если последовательности элементов х и у поэлементно равны (проверка
выполняется с применением Т: : operator==). Требует линейного времени.
template <typename Key, typename Compare, typename Allocator>
bool operator<(const multiset<Key, Compare, Allocator>& x,
const multiset<Key, Compare, Allocators y);
Возвращает true, если х лексикографически меньше у, в противном
случае— false. Требует линейного времени. Определение
лексикографического сравнения можно найти в разделе 22.34.
21.7.8. Функции-члены мультимножества для обращения
к элементам
key_compare key_comp() const;
Возвращает объект сравнения мультимножества.
value_compare value_comp() const;
Возвращает объект типа value_compare, построенный на базе объекта
сравнения. Для мультимножеств этот объект совпадает с объектом
сравнения мультимножества — то же, что и key_comp.
iterator begin() const;
Возвращает константный итератор, который может использоваться для
начала обхода мультимножества.
iterator end() const;
Возвращает константный итератор, который может использоваться в
сравнении для завершения обхода мультимножества.
reverse_iterator rbegin();
Возвращает константный итератор, который может использоваться для начала
обхода мультимножества в направлении, противоположном нормальному.
reverse_iterator rend();
Возвращает константный итератор, который может использоваться в
сравнении для завершения обхода мультимножества в направлении,
противоположном нормальному.
bool empty() const;
Возвращает true, если мультимножество пустое, false— в противном
случае.
size_type size() const;
Возвращает количество элементов, хранящихся в мультимножестве в
данный момент.
size_type max_size() const;
Возвращает максимально возможный размер мультимножества.
Глава 21. Справочное руководство по контейнерам
JZJ
allocator_type get_allocator() const;
Возвращает копию аллокатора, использованного при создании объекта.
21.7.9. Функции-члены мультимножества для вставки
iterator insert(iterator position, const value_type& x);
Вставляет элемент х в мультимножество. Итератор position представляет
собой подсказку, указывающую, где функция insert должна начинать
поиск места для вставки. Возвращает итератор, указывающий на вновь
вставленный элемент. Время выполнения вставки в общем случае составляет
O(logN), где N— количество элементов в мультимножестве, но если
вставка выполняется сразу после позиции position, то амортизированное
время ее выполнения константное.
iterator insert(const value_type& x);
Вставляет элемент х в мультимножество (см. пример 7.2) и возвращает
итератор, указывающий на вновь вставленный элемент. Время выполнения
вставки — O(logN), где N— количество элементов в мультимножестве.
template <typename InputIterator>
void insert(Inputlterator first, Inputlterator last);
Вставляет в мультимножество копии элементов из диапазона
[first /last). Диапазон [first; last) должен быть корректным
диапазоном элементов типа value_type (Key). В общем случае время
выполнения вставки составляет o(c/log(N+ с/)), где N— размер
мультимножества, a d— расстояние от first до last. Время вставки линейное, если
диапазон [first; last) отсортирован в соответствии с отношением
упорядочения value_comp().
21.7.10. Функции-члены мультимножества для удаления
void erase(iterator position);
Удаляет из мультимножества элемент, на который указывает position
(см. пример 7.3). Выполняется за амортизированное константное время.
Обратите внимание, что эта функция удаляет только один элемент, оставляя в
мультимножестве другие элементы с ключами, эквивалентными
*position.
size_type erase(const key_type& x);
Удаляет из мультимножества все элементы, эквивалентные х (см. пример
7.3). Возвращает количество удаленных элементов. Время выполнения
удаления в обще случае — 0(d\o%(N + d)) , где N— размер мультимножества,
ас/ — количество элементов с ключом, эквивалентнымх.
void erase(iterator first, iterator last);
В предположении, что итераторы first и last указывают в
мультимножество, удаляет из последнего все элементы из диапазона [first/last)
(см. пример 7.4). Время выполнения удаления— 0(d + \ogN), где N
размер мультимножества, ас/— расстояние от first до last.
JZ*
Часть III. Справочное руководство по STL
void clear();
Удаляет все элементы мультимножества. Эквивалентно a. erase
(a.begin(), a.endO).
21.7.11. Специализированные операции мультимножества
iterator find(const key_type& x) const;
Выполняет поиск элемента х в мультимножестве (см. пример 7.3). Если х
найден, функция возвращает итератор, указывающий на этот элемент,
в противном случае возвращает end (). Время выполнения поиска —
0{\ogN), где N— размер мультимножества.
size_type count(const key_type& x) const;
Возвращает количество элементов мультимножества, эквивалентных х.
Выполняется за время 0(\ogN + count (x)) , где N— размер мультимножества.
iterator 1ower_bound(const key_type& x) const;
Возвращает итератор, указывающий на первый элемент мультимножества,
не меньший х (см. пример 7.4). Если все элементы мультимножества
меньше х, возвращает значение end(). Выполняется за время O(logAf), где
N— размер мультимножества.
iterator upper_bound(const key_type& x) const;
Возвращает итератор, указывающий на первый элемент мультимножества,
больший х (см. пример 7.4). Если в мультимножестве нет элемента,
большего х, возвращается значение end(). Выполняется за время O(logiV), где
N— размер мультимножества.
pair<iterator,iterator> equal_range(const key_type& x) const;
Возвращает пару (lower_bound (x) , upper_bound (x)). Выполняется за
время 0(logN), где TV— размер мультимножества.
21.8. map
21.8.1. Файлы
#include <map>
21.8.2. Объявление класса
template <typename Key, typename T,
typename Compare = less<Key>,
class Allocator = allocator<pair<const Key, T> > >
class map
Мы опускаем все детали, связанные с параметром Allocator. Информацию об аллока-
горах можно найти во врезке "Аллокаторы" на стр.300 в разделе 21.3.2, и в главе 24,
"Справочное руководство по аллокаторам".
Глава 21. Справочное руководство по контейнерам о^о
21.8.3. Примеры
См. примеры 2.4, 7.6, 14.1, 15.1, 18.1 и 19.1.
21.8.4. Описание
Отображение представляет собой отсортированный ассоциативный контейнер, который
поддерживает уникальные ключи данного типа Key и обеспечивает быструю выборку
значений другого типа Т на основе сохраненных ключей. Как и во всех других отсортированных
ассоциативных контейнерах STL, для упорядочения элементов отображения используется
отношение упорядочения Compare.
Элементы хранятся в отображениях в виде пар, в которых каждый ключ типа Key имеет
связанное значение типа Т. Поскольку отображения хранят только уникальные ключи, для
каждого значения Key в отображении может храниться только одна пара значений Key, Т.
Невозможно связать с одним ключом более одного значения.
21.8.5. Определения типов
key_type
Тип ключей отображения Key.
mapped_type
Тип связанных значений Т.
value_type
Тип хранящихся в отображении значений, pair<const Key, T>. Первый
член пары объявлен как const, так что ключ невозможно изменить с
использованием неконстантного итератора или ссылки (но можно изменить
второй член — связанное значение типа Т).
key_compare
Тип объекта сравнения, Compare, с которым инстанцировано отображение.
Используется для упорядочения ключей в отображении.
value_compare
Тип объекта сравнения для выяснения отношений объектов
map: :value_type (объектов типа pair<const Кеу,Т>) путем
сравнения их ключей с использованием тар: : key_compare.
iterator
const__iterator
Тип iterator представляет собой константный двунаправленный
итератор, указывающий на value_type; константный двунаправленный
итератор, указывающий на const value_type. Гарантируется наличие
конструктора const__iterator из iterator.
reference
const_reference
Тип reference представляет собой тип позиций значений, хранящихся в
отображении. Это просто pair<const Кеу&, Т>& (или const
pair<const Кеу&, T>& в случае const_ref erence).
pointer
const_pointer
Тип pointer представляет собой тип указателей на элементы контейнере
(обычно pair<const Кеу&, Т>*, но в общем случае определяются ти-
326
Часть III. Справочное руководство по STL
пом аллокатора); const_pointer представляет собой соответствующий
константный тип.
size__type
Беззнаковый целочисленный тип, который может представить размер
любого экземпляра отображения.
difference_type
Знаковый целочисленный тип, который может представить расстояние
между любыми двумя объектами тар: : iterator.
reverse_iterator
const_reverse_iterator
Типы неконстантного и константного обратных двунаправленных итераторов.
allocator_type
Тип аллокатора, используемого отображением. Эквивалентен Allocator.
21.8.6. Конструкторы, деструкторы и связанные функции
отображения
explicit map(const Compared comp = Compare(),
const Allocators: = Allocator () ) ;
Конструктор по умолчанию. Создает пустое отображение и сохраняет
объект сравнения comp для упорядочения элементов.
map(const тар<Кеу, T\ Compare, Allocator>& x);
Копирующий конструктор отображения. Создает отображение и
инициализирует его копиями элементов из отображения х.
template <typename InputIterator>
map(Inputlterator first, Inputlterator last,
const Compared comp = Compare(),
const Allocator& = Allocator());
Создает пустое отображение и вставляет в него копии элементов из
диапазона [first/last). Объект сравнения comp используется для
упорядочения элементов отображения.
map<Key, T, Compare, Allocator>&
operator=(const map<Key, T, Compare, Allocator>& x);
Оператор присваивания отображения. Замещает содержимое текущего
отображения копией отображения х.
void swap(map<Key, T, Compare, Allocator>& x);
Обменивает содержимое текущего отображения с содержимым
отображения х. Текущее отображение заменяет х и наоборот.
-тар () ;
Деструктор отображения.
21.8.7. Операции сравнения
template <typename Key, typename T,
typename Compare, typename Allocator>
bool operator==(const map<Key, T, Compare, Allocator>& x,
const map<Key, T, Compare, Allocator>& y)
Глава 21. Справочное руководство по контейнерам
3Z/
Операция проверки эквивалентности отображений. Возвращает true, если
последовательности элементов х и у поэлементно равны (проверка
выполняется с применением Т: : operator==). Требует линейного времени.
template <typename Key, typename T,
typename Compare, typename Allocator>
bool operator<(const map<Key, T, Compare, Allocator>& x,
const map<Key, T, Compare, Allocator>& y);
Возвращает true, если х лексикографически меньше у, в противном
случае— false. Требует линейного времени. Определение
лексикографического сравнения можно найти в разделе 22.34.
21.8.8. Функции-члены отображения для обращения
к элементам
key_compare key_comp() const;
Возвращает объект сравнения отображения.
value_compare value_comp() const;
Возвращает объект типа value_compare, построенный на базе объекта
сравнения. Возвращаемый объект сравнивает пары отображения путем
сравнения их ключей при помощи key_comp ().
iterator beginO;
const_iterator begin() const;
Возвращает iterator (const_iterator для константного
отображения), который может использоваться для начала обхода отображения.
iterator end();
const_iterator end() const;
Возвращает iterator (const_iterator для константного
отображения), который может использоваться в сравнении для завершения обхода
отображения.
reverse_iterator rbeginO;
const_reverse_iterator rbeginO const;
Возвращает reverse_iterator (const_reverse_iterator для
константных отображений), который может использоваться для начала обхода
отображения в направлении, противоположном нормальному.
reverse_iterator rend();
const_reverse_iterator rend() const;
Возвращает reverse_iterator (const_reverse_iterator для
константных отображений), который может использоваться в сравнении для
завершения обхода отображения в направлении, противоположном нормальному.
bool empty() const;
Возвращает true, если отображение пустое, false в противном случае.
size_type size О const;
Возвращает количество элементов в отображении.
size_type max_size() const;
Возвращает максимально возможный размер отображения.
Т& operator [] (const key_type& х) ;
const T& operator [] (const key_type& x) const;
JZO
Часть III. Справочное руководство по STL
Возвращает ссылку на значение типа Т, связанное с ключом х. В случае
константного отображения возвращается константная ссылка. Оператор индекса
отличается от соответствующего оператора векторов и деков тем, что если
отображение не содержит элемента типа Т, связанного с ключом х, то в
отображение вставляется пара (х# Т ()). Время выполнения составляет 0(\ogN).
allocator_type get_allocator() const;
Возвращает копию аллокатора, использованного при создании объекта.
21.8.9. Функции-члены отображения для вставки
iterator insert(iterator position, const value_type& x);
Вставляет значение х в отображение, если в нем нет элемента с
эквивалентным ключом. Итератор position представляет собой подсказку,
указывающую, где функция insert должна начинать поиск места для вставки. Время
выполнения вставки в общем случае составляет 0(\ogN), где N—
количество элементов в отображении, но если вставка выполняется сразу после
позиции position, то амортизированное время ее выполнения константное.
pair<iterator, bool> insert(const value_type& x);
Вставляет значение х в отображение, если в нем нет элемента с
эквивалентным ключом. Возвращаемое значение представляет собой пару pair, в
которой элемент типа bool указывает, была ли выполнена вставка, а элемент
типа iterator указывает на только что вставленный в отображение
элемент, если вставка имела место; в противном случае он указывает на уже
имеющийся в отображении элемент х. Обратите внимание, что типом х
является pair<const Key, T>, а не Key. Время выполнения вставки —
O(logTV), где N— количество элементов в отображении.
template <typename InputIterator>
void insert(Inputlterator first, Inputlterator last);
Вставляет в отображение копии элементов из диапазона [first; last).
Диапазон [first; last) должен быть корректным диапазоном элементов
типа value_type (pair<Key, T>). В общем случае время выполнения
вставки составляет 0(d\og(N + d)), где N— размер отображения, a d —
расстояние от first до last. Время вставки линейное, если диапазон
[first; last) отсортирован в соответствии с отношением упорядочения
value_comp().
21.8.10. Функции-члены отображения для удаления
void erase(iterator position);
Удаляет из отображения элемент, на который указывает position.
Выполняется за амортизированное константное время.
^ize_type erase(const key_type& x) ;
Удаляет из отображения элемент с ключом, эквивалентным х, если таковой
присутствует в отображении. Возвращает количество удаленных элементов,
которое равно 1, если элемент с ключом, эквивалентным х, имеется в ото-
Глава 21. Справочное руководство по контейнерам
бражении, и 0 в противном случае. Время выполнения удаления —
O(logN), где N— размер отображения.
void erase(iterator first, iterator last);
В предположении, что итераторы first и last указывают в отображение,
удаляет из последнего все элементы из диапазона [first; last). Время
выполнения удаления — 0(d + log TV) , где N— размер отображения, a d
расстояние от first до last.
void clear();
Удаляет все элементы отображения. Эквивалентно
a.erase (a.begin() , a.endO).
21.8.11. Специализированные операции отображения
iterator find(const key_type& x);
const_iterator find(const key_type& x) const;
Выполняет поиск в отображении элемента с ключом, эквивалентным х (см.
пример 7.6). Если такой элемент найден, функция возвращает iterator
(const_iterator в случае константного отображения), указывающий на
него. В противном случае возвращается значение end (). Время
выполнения составляет O(logN), где N— количество элементов в отображении.
size_type count(const key_type& x) const;
Возвращает количество элементов отображения с ключом, эквивалентным
х. Это— число 1 или 0. Время выполнения составляет O(logN), где N —
количество элементов в отображении.
iterator lower_bound(const key_type& x);
const_iterator lower_bound(const key_type& x) const;
Возвращает iterator (const_iterator в случае константного
отображения), указывающий на первый элемент отображения, ключ которого не
меньше х. Если в отображении содержится элемент с ключом, не меньшим
х, возвращаемый итератор указывает на него; если же ключи всех
элементов отображения меньше х, возвращается значение end (). Время
выполнения составляет O(logTV), где N— количество элементов в отображении.
iterator upper_bound(const key_type& x);
const_iterator upper_bound(const key_type& x) const;
Возвращает iterator (const__iterator в случае константного
отображения), указывающий на первый элемент отображения, ключ которого
больше х. Если в отображении содержится элемент с ключом, большим х,
возвращаемый итератор указывает на него; если же ключи всех элементов
отображения не больше х, возвращается значение end (). Время
выполнения составляет 0(\ogN), где N— количество элементов в отображении.
pair<iterator# iterator>
equal_range(const key_type& x);
pair<const_iterator, const_iterator>
equal__range (const key_type& x) const;
330
Часть III. Справочное руководство по STL
Возвращает пару (lower_bound (x) , upper_bound (x) ). Выполняется за
время O(logiV), где N— размер отображения.
21.9. multimap
21.9.1. Файлы
({include <map>
21.9.2. Объявление класса
:emplate <typename Key, typename T,
typename Compare = less<Key>,
class Allocator = allocator<pair<const Key, T> > >
:lass multimap
Мы опускаем все детали, связанные с параметром Allocator. Информацию об аллока-
горах можно найти во врезке "Аллокаторы" на стр.300 в разделе 21.3.2, и в главе 24,
'Справочное руководство по аллокаторам".
21.9.3. Примеры
См. пример 15.1.
21.9.4. Описание
Мультиотображение представляет собой отсортированный ассоциативный контейнер, ко-
орый позволяет хранить несколько эквивалентных ключей данного типа Key и обеспечивает
>ыструю выборку значений другого типа Т на основе сохраненных ключей. Как и во всех других
^сортированных ассоциативных контейнерах STL, для упорядочения элементов мультиотоб-
>ажения используется отношение упорядочения Compare. Элементы хранятся в мультиотоб-
>ажениях в виде пар, в которых каждый ключ типа Key имеет связанное значение типа Т.
М.9.5. Определения типов
Те же, что и для класса тар (см. раздел 21.8.5).
М.9.6. Конструкторы, деструкторы и связанные функции
мультиотображения
ixplicit multimap(const Compares, comp = Compare(),
const Allocators: = Allocator () ) ;
Конструктор по умолчанию. Создает пустое мультиотображение и
сохраняет объект сравнения comp для упорядочения элементов.
lultimap(const multimap<Key/ Т, Compare, Allocator>& x) ;
Копирующий конструктор мультиотображения. Создает
мультиотображение и инициализирует его копиями элементов из мультиотображения х.
Глава 21. Справочное руковооство по контейнерам
template <typename InputIterator>
multimap(Inputlterator first, Inputlterator last,
const Compare& comp = Compare(),
const Allocator& = Allocator());
Создает пустое мультиотображение и вставляет в него копии элементов из
диапазона [first/last). Объект сравнения comp используется для
упорядочения элементов мультиотображения.
multimap<Key, Т, Compare, Allocator>&
operator=(const multimap<Key, T, Compare, Allocators x);
Оператор присваивания мультиотображения. Замещает содержимое
текущего мультиотображения копией мультиотображения х.
void swap(multimap<Key, T, Compare, Allocators x);
Обменивает содержимое текущего мультиотображения с содержимым
мультиотображения х. Текущее мультиотображение заменяет х и наоборот.
-multimap () ;
Деструктор мультиотображения.
21.9.7. Операции сравнения
template <typename Key, typename T,
typename Compare, typename Allocator>
bool operator==(const multimap<Key, T, Compare, Allocator>& x,
const multimap<Key, T, Compare, Allocator>& y);
Операция проверки эквивалентности мультиотображений. Возвращает true,
если последовательности элементов х и у поэлементно равны (проверка
выполняется с применением Т: : operator==). Требует линейного времени.
template <typename Key, typename T,
typename Compare, typename Allocator>
bool operator<(const multimap<Key, T, Compare, Allocator>& x,
const multimap<Key, T, Compare, Allocator>& y);
Возвращает true, если х лексикографически меньше у, в противном
случае— false. Требует линейного времени. Определение
лексикографического сравнения можно найти в разделе 22.34.
21.9.8. Функции-члены мультиотображения для
обращения к элементам
key_compare key_comp() const;
Возвращает объект сравнения мультиотображения.
value_compare value_comp() const;
Возвращает объект типа value_compare, построенный на базе объекта
сравнения. Возвращаемый объект сравнивает пары мультиотображения
путем сравнения их ключей при помощи key_comp ().
iterator begin();
const_iterator begin() const;
Возвращает iterator (const_iterator для константного
мультиотображения), который может использоваться для начала обхода
мультиотображения.
33Z
Часть III. Справочное руководство по STL
iterator end();
const_iterator end() const;
Возвращает iterator (const_iterator для константного
мультиотображения), который может использоваться в сравнении для завершения
обхода мультиотображения.
reverse_iterator rbeginO;
const_reverse_iterator rbeginO const;
Возвращает reverse_iterator (const_reverse_iterator для
константных мультиотображений), который может использоваться для начала
обхода мультиотображения в направлении, противоположном нормальному.
reverse_iterator rend О;
const_reverse_iterator rend() const;
Возвращает reverse_iterator (const_reverse_iterator для
константных мультиотображений), который может использоваться в сравнении
для завершения обхода мультиотображения в направлении,
противоположном нормальному.
bool empty() const;
Возвращает true, если мультиотображение пустое, false в противном
случае.
size_type size() const;
Возвращает количество элементов в мультиотображений.
size_type max_size() const;
Возвращает максимально возможный размер мультиотображения.
allocator_type get_allocator() const;
Возвращает копию аллокатора, использованного при создании объекта.
21.9.9. Функции-члены мультиотображения для вставки
iterator insert(iterator position, const value_type& x);
Вставляет значение х в мультиотображение. Обратите внимание, что типом
х является pair<const Key, T>. Итератор position представляет
собой подсказку, указывающую, где функция insert должна начинать поиск
места для вставки. Время выполнения вставки в общем случае составляет
O(logN), где N— количество элементов в мультиотображений, но если
вставка выполняется сразу после позиции position, то амортизированное
время ее выполнения константное.
iterator insert(const value_type& x);
Вставляет значение х в мультиотображение и возвращает итератор,
указывающий на вновь вставленное значение (см. пример 15.1). Обратите
внимание, что типом х является pair<const Key, T>. Время выполнения
вставки — 0(\ogN), где N— количество элементов в мультиотображений.
template <typename InputIterator>
/oid insert(InputIterator first, Inputlterator last);
Вставляет в мультиотображение копии элементов из диапазона
[f irst; last). Диапазон [ first; last) должен быть корректным
диапазоном элементов типа value_type (pair<Key, T>). В общем случае
Глава 21. Справочное руководство по контейнерам
jjj
время выполнения вставки составляет o(d\og(N + d)\, где TV— размер
мультиотображения, ad— расстояние от first до last. Время вставки
линейное, если диапазон [first; last) отсортирован в соответствии с
отношением упорядочения value_comp ().
21.9.10. Функции-члены мультиотображения для удаления
void erase(iterator position);
Удаляет из мультиотображения элемент, на который указывает position.
Выполняется за амортизированное константное время.
size_type erase(const key_type& x) ;
Удаляет из мультиотображения все элементы с ключами, эквивалентными
х. Возвращает количество удаленных элементов. В общем случае время
выполнения удаления— 0(d\og(N + d)), где N— размер
мультиотображения, a d— количество элементов с ключами, эквивалентными х.
void erase(iterator first, iterator last);
В предположении, что итераторы first и last указывают в мультиотоб-
ражение, удаляет из последнего все элементы из диапазона
[first; last). Время выполнения удаления— 0(d + \ogN), где N —
размер мультиотображения, a d — расстояние от first до last,
void clear();
Удаляет все элементы мультиотображения. Эквивалентно
a.erase (a.begin () , a.end О).
21.9.11. Специализированные операции мультиотображения
iterator find(const key_type& x);
const_iterator find(const key_type& x) const;
Выполняет поиск в мультиотображении элемента с ключом, эквивалентным х.
Если такой элемент найден, функция возвращает iterator (cons t_it era -
tor в случае константного мультиотображения), указывающий на него.
В противном случае возвращается значение end (). Время выполнения
составляет O(logTV), где TV— количество элементов в мультиотображении.
size_type count(const key_type& x) const;
Возвращает количество элементов мультиотображения с ключом,
эквивалентным х. Время выполнения составляет 0(\ogN + count (х)), где N —
количество элементов в мультиотображении.
iterator lower_bound(const key_type& x);
const_iterator lower_bound(const key__type& x) const;
Возвращает iterator (const_iterator в случае константного
мультиотображения), указывающий на первый элемент мультиотображения,
ключ которого не меньше х. Если в мультиотображении содержится
элемент с ключом, не меньшим х, возвращаемый итератор указывает на него;
если же ключи всех элементов мультиотображения меньше х, возвращается
значение end (). Время выполнения составляет O(logN), где N—
количество элементов в мультиотображении.
334
Часть III. Справочное руководство по STL
я
iterator upper_bound(const key_type& x);
const_iterator upper_bound(const key_type& x) const;
Возвращает iterator (cons t_it era tor в случае константного муль-
тиотображения), указывающий на первый элемент мультиотображения,
ключ которого больше х. Если в мультиотображении содержится элемент с
ключом, большим х, возвращаемый итератор указывает на него; если же
ключи всех элементов мультиотображения не больше х, возвращается
значение end (). Время выполнения составляет 0(\ogN), где N— количество
элементов в мультиотображении.
pair<iterator, iterator>
equal_range(const key_type& x);
pair<const_iterator, const_iterator>
equal_range(const key_type& x) const;
Возвращает пару (lower_bound (x) , upper_bound (x)). Выполняется за
время 0(\ogN), где N— размер мультиотображения.
21.10. Адаптер контейнера stack
21.10.1. Файлы
#include <stack>
21.10.2. Объявление класса
template <typename Т, typename Container = deque<T> >
class stack
21.10.3. Примеры
См. пример 9.1.
21.10.4. Описание
Стек представляет собой структуру данных, которая допускает следующие операции:
вставку с одного конца, удаление с того же конца, выборка значения на том же конце и проверка на
пустоту контейнера. Таким образом, стек предоставляет службу "последним вошел, первым
вышел". Удаляемый или запрашиваемый элемент всегда тот, который был вставлен последним.
STL предоставляет адаптер контейнера stack, который может использоваться для
реализации стека с любым контейнером, поддерживающим над последовательностями следующие
операции: back, push_back и pop_back (по умолчанию используется deque). В
дополнение к перечисленным операциям адаптер должен поддерживать операции empty и size,
однако поскольку они поддерживаются всеми контейнерами STL, это требование не
накладывает никаких практических ограничений на тип используемого контейнера. В частности, для
реализации стека могут использоваться векторы, списки и деки.
• stack<char, vector<char> > Стек символов на основе вектора.
• stack<int, list<int> > Стек целых чисел на основе списка.
• stack<float> Стек чисел с плавающей точкой на основе дека.
Глава 21. Справочное руководство по контейнерам
Отличие между stack и указанными абстракциями последовательностей заключается в том,
что stack имеет гораздо более ограниченный интерфейс, который не допускает выполнения
никаких операций над объектами, кроме обычных операций над стеком.
21.10.5. Определения типов
value_type
Тип значений, хранящихся в стеке. Обычно это Т, но в общем случае это
тип value_type класса Container.
size_type
Определяется как size_type класса Container.
container_type
Тип Container, представляющий контейнер, лежащий в основе стека.
21.10.6. Конструкторы
explicit stack(const Containers: cont = Container());
Конструктор по умолчанию. Создает пустой стек и использует контейнер
cont для хранения элементов.
21.10.7. Открытые функции-члены
bool empty() const;
Возвращает true, если стек пуст, в противном случае— false.
size_type size () const;
Возвращает количество элементов в стеке.
void push(const value_type& x) ;
Вносит значение х на вершину стека,
void pop();
Удаляет элемент с вершины стека. Результат не определен, если стек пуст.
value_type& top О;
const value_type& top() const;
Возвращает элемент, последним внесенный в стек. Стек остается неизменным.
21.10.8. Операции сравнения
template <typename T, typename Container>
bool operator==(const stack<T, Container>& x,
const stack<T\ Container>& y);
Операция проверки равенства стеков. Возвращает true, если
последовательности элементов в х и у поэлементно равны (для проверки равенства
элементов применяется Т: : operator==). Выполняется за линейное время.
template <typename T, typename Container>
bool operator<(const stack<T, Container>& x,
const stack<T, Container>& y);
Возвращает true, если х лексикографически меньше у, в противном
случае — false. Выполняется за линейное время.
JJO
Часть HI. Справочное руководство по STL
21.11. Адаптер контейнера queue
21.11.1. Файлы
#include <queue>
21.11.2. Объявление класса
template <typename T, typename Container = deque<T> >
class queue
21.11.3. Примеры
См. пример 9.2.
21.11.4. Описание
Очередь представляет собой структуру данных, в которой элементы вставляются с одного
конца, а удаляются с другого. Порядок удаления тот же, что и порядок вставки (первым
вошел, первым вышел).
STL предоставляет адаптер контейнера queue, который может использоваться для
реализации очереди на основе любого контейнера последовательности, который поддерживает
следующие операции: empty, size, front, back, push_back и pop_front (по умолчанию
используется deque). В частности, для реализации очередей могут использоваться списки и деки:
• queue< in t, list<int> > — очередь целых чисел на основе списка;
• queue< float > — очередь чисел с плавающей точкой на основе дека.
Обратите внимание, что векторы не могут использоваться с адаптером queue, поскольку они
не имеют функции-члена pop_f ront. Этой функции у векторов нет, поскольку ее
реализация для длинных векторов неэффективна.
21.11.5. Определения типов
value_type
Тип значений, хранящихся в очереди. Обычно это Т, но в общем случае это
тип value_type класса Container.
size_type
Определяется как size_type класса Container.
container_type
Тип Container, представляющий контейнер, лежащий в основе очереди.
21.11.6. Конструкторы
explicit queue(const Container& cont = Container());
Конструктор по умолчанию. Создает пустую очередь и использует
контейнер cont для хранения элементов.
Глава 21. Справочное руководство по контейнерам
oot
21.11.7. Открытые функции-члены
bool empty() const;
Возвращает true, если очередь пуста, в противном случае— false.
size_type size () const;
Возвращает количество элементов в очереди.
void push(const value_type& x);
Вносит элемент х в конец очереди.
void pop();
Удаляет элемент из начала очереди.
value_type& front();
const value_type& front() const;
Возвращает элемент в начале очереди. Очередь остается неизменной.
value_type& back();
const value__type& back() const;
Возвращает элемент в конце очереди. Это тот элемент, который был внесен
в очередь последним. Очередь остается неизменной.
21.11.8. Операции сравнения
template <typename Т, typename Container>
bool operator==(const queue<T, Container>& x,
const queue<T, Container>& y);
Операция проверки равенства очередей. Возвращает true, если
последовательности элементов в х и у поэлементно равны (для проверки равенства
элементов применяется Т: : operator==). Выполняется за линейное время.
template <typename Т, typename Container>
bool operator<(const queue<T, Container>& x,
const queue<T, Container>& y);
Возвращает true, если х лексикографически меньше у, в противном
случае — false. Выполняется за линейное время.
21.12. Адаптер контейнера prior ityqueue
21.12.1. Файлы
#include <queue>
21.12.2. Объявление класса
template <typename T, typename Container = vector<T>/
typename Compare =
less<typename Container::value_type> >
class priority_queue
21.12.3. Примеры
См. пример 9.3.
338
Часть III. Справочное руководство по STL
21.12.4. Описание
Очередь с приоритетами представляет собой контейнер, в котором элемент, доступный
для выборки, является наибольшим среди элементов контейнера при некотором виде их
упорядочения.
STL предоставляет адаптер контейнера priority_queue, который может
использоваться для реализации очереди с приоритетами на основе любого контейнера, который
поддерживает итераторы с произвольным доступом и следующие операции: empty, size, front,
push_back и pop_back (по умолчанию используется vector). В частности, с адаптером
контейнера priority_queue могут использоваться векторы и деки.
Обратите внимание, что поскольку адаптер priority_queue подразумевает
упорядочение элементов, ему необходимо передать функциональный объект для сравнения элементов:
• priority_queue<int, vector<int>, less<int> > — очередь целых чисел с
приоритетами на основе вектора, использующая для упорядочения объектов
встроенный оператор < для целых чисел;
• priority_queue<char/ deque<char>, greater<char> > — очередь
символов на основе дека, использующая для упорядочения объектов встроенный оператор >
для символов; обратите внимание, что поскольку в этой очереди используется
оператор >, а не <, доступный для выборки элемент оказывается наименьшим, а не
наибольшим в очереди.
21.12.5. Определения типов
value_type
Тип значений, хранящихся в очереди с приоритетами. Обычно это Т, но в
общем случае это тип value_type класса Container.
size_type
Определяется как size_type класса Container.
container_type
Тип Container, представляющий контейнер, лежащий в основе очереди с
приоритетами.
21.12.6. Конструкторы
explicit priority_queue(const Compare& comp = Compare(),
const Containers: cont = Container());
Создает пустую очередь с приоритетами и сохраняет функциональный объект
сравнения comp для упорядочения элементов. Инициализирует лежащий в
основе контейнер с копией cont и вызывает make_heap (с.begin() ,
с.end(), comp).
template <typename InputIterator>
priority_queue(Inputlterator first, Inputlterator last,
const Compare& comp = Compare(),
const Container& cont = Container());
Создает очередь с приоритетами и вставляет в нее копии элементов из
диапазона [first;last). Объект сравнения comp используется для
упорядочения элементов очереди с приоритетами. После вставки элементов
вызывает make_heap(с.begin() , с.end(), comp) для лежащего в
основе контейнера.
Глава 21. Справочное руководство по контейнерам
**до
21.12.7. Открытые функции-члены
bool empty О const;
Возвращает true, если очередь с приоритетами пуста, в противном
случае— false.
size_type size() const;
Возвращает количество элементов в очереди с приоритетами.
const value_type& top() const;
Возвращает элемент очереди с приоритетами, который имеет наивысший
приоритет. Очередь с приоритетами остается неизменной.
void push(const value_type& x);
Вносит элемент х в очередь с приоритетами.
void pop();
Удаляет из очереди с приоритетами элемент с наивысшим приоритетом.
21.12.8. Операторы сравнения
Операции сравнения (равенства и меньше, чем) для очередей с приоритетами не
предоставляются.
Глава 22
Справочное руководство
по обобщенным алгоритмам
Обобщенные алгоритмы STL можно разделить на четыре основные категории:
• неизменяющие алгоритмы над последовательностями;
• изменяющие алгоритмы над последовательностями;
• алгоритмы, связанные с сортировкой;
• обобщенные числовые алгоритмы.
Все библиотечные алгоритмы являются обобщенными, в том смысле, что они могут
работать с разными контейнерами. Алгоритмы не параметризуются контейнерами
непосредственно — вместо этого используются типы итераторов. Это позволяет работать алгоритмам с
пользовательскими структурами данных, лишь бы эти контейнеры имели итераторы, которые
удовлетворяют требованиям алгоритмов. Таким образом, семантическое описание
алгоритмов осуществляется в терминах типов итераторов и объектов итераторов.
Заголовочный файл для всех обобщенных алгоритмов STL— <algorithms
22.1. Организация описаний алгоритмов
В пределах основных категорий мы разбиваем описания алгоритмов на разделы,
группируя в каждом разделе все алгоритмы со схожим назначением и семантикой. Каждый из
разделов алгоритмов, в свою очередь, состоит из трех частей: прототипы, описание и временная
сложность.
22.1.1. Прототипы
В этой части приводятся прототипы функций для всех описываемых в разделе
алгоритмов. В большинстве разделов имеются несколько одноименных алгоритмов, различающихся
по типам их параметров (перегрузка функций). Наиболее частый случай перегрузки
функций — с использованием предикатов. Такие функции принимают в качестве параметра
функциональный объект, возвращающий значение типа bool, который используется вместо
оператора, такого как == или <.
В некоторых случаях имеются две функции, предназначенные для решения одной и той
же основной задачи (такие, как find и ее версия с предикатом f ind_if в разделе 22.4 или
fill и f ill_n в разделе 22.18), и потому они могли бы иметь одно и то же имя. Однако это
342
Часть III. Справочное руководство по STL
невозможно, так как различить эти функции по типам параметров не удается. Имена
алгоритмов обсуждаются в главе 5, "Обобщенные алгоритмы", в частности, в разделе 5.1.
Одной из ключевых частей спецификации обобщенных алгоритмов STL являются
требования к итераторным параметрам шаблонов. Эта информация неявно указывается в прототипах, и
обычно в разделе описания не фигурирует, поскольку соглашения об именовании параметров
шаблонов точно указывают, какие именно итераторы требуются. Использующиеся имена
(InputIterator, OutputIterator, Forwardlterator, BidirectionalIterator и
RandomAccessIterator) соответствуют пяти категориям итераторов. См. также главу4,
"Итераторы", в частности, раздел 4.6.
22.1.2. Примеры
В этом разделе приводятся ссылки на программы (если таковые имеются) из частей I,
"Вводный курс в STL", и II, "Примеры программ", использующие данные алгоритмы. В
случаях, когда пример применим только к конкретному перегруженному варианту функции, это
различие указывается явно. Однако в большинстве случаев различные формы алгоритма
достаточно одинаковы, чтобы примеры могли работать со всеми ними.
22.1.3. Описание
Здесь описывается семантика каждого алгоритма группы, всегда с использованием имен и
типов параметров из раздела прототипов. Описание включает воздействие алгоритма на его
параметры (если таковое имеется) и возвращаемое значение (если оно возвращается).
Почти все обобщенные алгоритмы STL получают как минимум два параметра-итератора,
определяющие диапазон элементов в некотором контейнере (некоторые алгоритмы получают
еще два параметра, определяющих другой диапазон, или один, указывающий начало такого
диапазона). За дополнительной информацией о концепции диапазонов обратитесь к
введениям в главы 4, "Итераторы", и 20, "Справочное руководство по итераторам".
Некоторые из предикативных версий алгоритмов требуют, чтобы передаваемый в
качестве параметра функциональный объект предиката обладал определенными семантическими
свойствами. В частности, все алгоритмы, связанные с сортировкой, предполагают, что
переданные им функциональные объекты определяют строгое неполное упорядочение. Этот
термин определен в обзорной части раздела 22.26; см. также раздел 5.4.
В этой главе нет никаких примеров, но множество их имеется в главе 5, "Обобщенные
алгоритмы".
22.1.4. Временная сложность
В этом разделе приводятся границы времени вычисления для каждого алгоритма.
Терминология и обозначения (О-обозначения), используемые здесь, рассматривались в разделе 1.5.
Во многих случаях указываются более точные границы — как количество применений
операторов или функциональных объектов, использующихся в алгоритме.
22.2. Неизменяющие алгоритмы над
последовательностями
Неизменяющие алгоритмы над последовательностями непосредственно не модифицируют
контейнеры, с которыми работают. В этой категории имеется десять подкатегорий:
• f or_each применяет данную функцию к каждому элементу;
Глава 22. Справочное руководство по оОойщенным алгоритмам
• f ind выполняет линейный поиск;
• f i nd_f i r s t_o f выполняет линейный поиск любого из множества значений;
• adj acent_f ind выполняет линейный поиск смежных равных элементов;
• count подсчитывает количество элементов с данным значением;
• mismatch сканирует две последовательности в поисках первой позиции, где они
различны;
• equal сканирует две последовательности для проверки их поэлементной
эквивалентности;
• search сканирует последовательность в поисках другой подпоследовательности;
• search_n сканирует последовательность в поисках ряда идентичных элементов с
данным значением;
• f ind_end сканирует последовательность в поисках последнего совпадения с другой
последовательностью.
Каждый из этих алгоритмов, за исключением f or_each, имеет две версии: одна
использует для сравнения ==, а вторая — функциональный объект предиката. Семантических
требований к объектам предикатов нет, хотя если они не определяют отношение эквивалентности,
применение слова "эквивалентно" в описаниях результатов работы алгоритма следует
интерпретировать соответствующим образом. Например, описание алгоритма adjacent_f ind в
разделе 22.6 использует термин последовательные дубликаты, который описан как элемент,
эквивалентный элементу, следующему непосредственно за ним в диапазоне. В версии с
предикатом последовательные дубликаты должны интерпретироваться как последовательные
элементы х и у такие, что binary_jpred (х,у) ==true. Такая формулировка корректна,
даже если binary_jpred не определяет отношение эквивалентности.
22.3. f or_each
#%** ~ Л Г-.
22.3.1. Прототип
template <typename InputIterator, typename Function>
Function for_each(InputIterator first,
Inputlterator last,
Function f) ,-
22.3.2. Примеры
См. пример 5.7.
22.3.3. Описание
Алгоритм for_each применяет функцию f к каждому элементу диапазона
[f irst;last). Возвращаемое значение for_each представляет собой функциональный
аргумент f.
Функция f применяется к результату разыменования каждого итератора в диапазоне
[first; last). Предполагается, что f не использует никакую неконстантную функцию
посредством разыменованного итератора. Функция f применяется ровно last - first раз.
Если f возвращает некоторый результат, он игнорируется.
344
Часть III. Справочное руководство по STL
22.3.4. Временная сложность
Линейная. Если N— размер диапазона [first; last), то выполняется ровно N
применений f.
22.4. find
22.4.1. Прототипы
template <typename Inputlterator, typename T>
Inputlterator find(Inputlterator first,
Inputlterator last,
const T& value);
template <typename Inputlterator, typename Predicate>
Inputlterator find_if(Inputlterator first,
Inputlterator last,
Predicate pred);
22.4.2. Примеры
См. примеры 2.5, 2.6, 2.7, 2.8, 4.1 и 10.2 для алгоритма find и примеры 5.4, 13.1 и 14.1
для f ind_if.
22.4.3. Описание
Первая версия алгоритма обходит диапазон [first; last) и возвращает первый
итератор i такой, что *i == value. Вторая версия возвращает первый итератор i такой,
что pred (*i) == true. В обоих случаях, если такой итератор не найден, возвращается
итератор last.
22.4.4. Временная сложность
Линейная. Максимальное количество применений оператора ! = (или pred в случае
f ind__if) равно размеру диапазона [first; last). Если соответствие найдено, количество
сравнений (или применений pred) на одно больше размера диапазона [f irst; i).
22.5. find_f irst_of
22.5.1. Прототипы
template <typename Forwardlteratorl,
typename ForwardIterator2>
Forwardlteratorl find_first_of(Forwardlteratorl firstl,
Forwardlteratorl lastl,
ForwardIterator2 first2,
ForwardIterator2 last2);
template <typename Forwardlteratorl,
typename ForwardIterator2,
typename BinaryPredicate>
Глава 22. Справочное руководство по обобщенным алгоритмам
345
Forwardlteratorl find_first_of(Forwardlteratorl firstl,
Forwardlteratorl lastl,
ForwardIterator2 first2,
ForwardIterator2 last2,
Binary-Predicate pred) ;
22.5.2. Описание
Алгоритм аналогичен алгоритму find с тем отличием, что вместо поиска единственного
значения он выполняет поиск любого из значений диапазона [first 2; last 2). Первая версия
алгоритма обходит диапазон [firstl; lastl) и возвращает первый итератор i такой, что для
некоторого итератора j из диапазона [first2;last2) выполняется равенство *i == * j. Во
второй версии искомым условием является не *i == *j,a pred(*i, *j ) == true. В
любом случае, если такой итератор не найден, возвращается итератор lastl.
22.5.3. Временная сложность
Квадратичная. Если N— размер диапазона [firstl; lastl), aM— размер диапазона
[first2;last2),TO количество применений == (или pred в случае версии с предикатом)
не превышает NM.
22.6. adjacent_f ind
22.6.1. Прототипы
template <typename ForwardIterator>
Forwardlterator adjacent_find(Forwardlterator first,
Forwardlterator last);
template <typename Forwardlterator, typename BinaryPredicate>
Forwardlterator adjacent_find(Forwardlterator first,
Forwardlterator last,
BinaryPredicate binary_pred);
22.6.2. Примеры
См. примеры 5.5, 13.1, 14.1 и 15.1.
22.6.3. Описание
Алгоритм adjacent_f ind возвращает итератор i, указывающий на первый из
последовательных дубликатов в диапазоне [first; last), или last, если такого элемента нет.
Последовательный дубликат — это элемент, эквивалентный элементу, следующему
непосредственно за ним в диапазоне.
Сравнение выполняется с применением оператора == в первой версии алгоритма и
функционального объекта binary_pred во второй версии.
22.6.4. Временная сложность
Линейная. Количество сравнений равно размеру диапазона [first; i).
346
Часть III. Справочное руководство по STL
22.7. count
22.7.1. Прототипы
template <typename InputIterator, typename T>
typename iterator_t.raits<Inputiterator>::difference_type
count(Inputlterator first, Inputlterator last,
const T& value);
template <typename Inputlterator, typename Predicate>
typename iterator_traits<InputIterator>::difference_type
count_if(Inputlterator first, Inputlterator last,
Predicate pred);
22.7.2. Примеры
См. пример 5.6.
22.7.3. Описание
Алгоритм count возвращает количество элементов диапазона [first/last), равных
value.
Алгоритм count_if возвращает количество итераторов диапазона [first; last), для
которых выполняется равенство pred (* i) == true.
22.7.4. Временная сложность
Линейная. Количество выполняемых сравнений равно размеру диапазона [ first; last).
22.8. mismatch
22.8.1. Прототипы
template <typename Inputlteratorl, typename InputIterator2>
pair<InputIteratorl, InputIterator2>
mismatch(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2);
template <typename Inputlteratorl, typename InputIterator2,
typename BinaryPredicate>
pair<InputIteratorl, InputIterator2>
mismatch(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2,
BinaryPredicate binary_pred);
22.8.2. Примеры
См. пример 5.8.
Глава 22. Справочное руководство по обобщенным алгоритмам
347
22.8.3. Описание
Алгоритм mismatch сравнивает соответствующие пары элементов из двух диапазонов и
возвращает первую несовпадающую пару. Алгоритм находит первую позицию, в которой
значение в диапазоне [firstl;lastl) не совпадает со значением в диапазоне,
начинающемся с f irst2. Алгоритм возвращает пару итераторов i и j, удовлетворяющую
следующим условиям:
• i указывает в диапазон [f irstl; lastl);
• j указывает в диапазон, начинающийся с f i r s 12;
• i и j находятся на равных расстояниях от начал соответствующих диапазонов;
• ! (*i == *j) или binary pred(i, j) == false, в зависимости от версии
алгоритма mismatch; в первой версии сравнение выполняется с применением
оператора ==, а во второй — при помощи функционального объекта binary_pred.
22.8.4. Временная сложность
Линейная. Количество выполняемых сравнений не превышает размера диапазона
[f irstl; lastl), если результат true; в противном случае это размер диапазона
[firstl/i), где i— итератор, указывающий на первый элемент диапазона
[f irstl; lastl), который не эквивалентен соответствующему элементу диапазона,
начинающегося с first2.
22.9. equal
22.9.1. Прототипы
template <typename Inputlteratorl, typename InputIterator2>
bool equal(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2);
template <typename Inputlteratorl, typename InputIterator2,
typename BinaryPredicate>
bool equal(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2,
BinaryPredicate binary_pred);
22.9.2. Примеры
См. пример 5.8.
22.9.3. Описание
Алгоритм equal возвращает true, если диапазон [f irstl;lastl) и диапазон
размером lastl-firstl, начинающийся с first2, содержат одни и те же элементы в одном и
том же порядке; в противном случае возвращает false. В первой версии сравнение
выполняется с помощью оператора ==, а во второй— с помощью функционального объекта
binary_jpred.
348
Часть III. Справочное руководство по STL
22.9.4. Временная сложность
Линейная. Количество выполняемых сравнений равно размеру диапазона [f irstl; lastl),
если результат true; в противном случае это размер диапазона [f irstl; i), где i —
итератор, указывающий на первый элемент диапазона [firstl; lastl), который не
эквивалентен соответствующему элементу диапазона, начинающегося с f irst2.
22.10. search
22.10.1. Прототипы
template <typename Forwardlteratorl,
typename ForwardIterator2>
Forwardlteratorl search(Forwardlteratorl firstl,
Forwardlteratorl lastl,
ForwardIterator2 first2,
ForwardIterator2 last2);
template <typename Forwardlteratorl,
typename ForwardIterator2,
typename BinaryPredicate>
Forwardlteratorl search(Forwardlteratorl firstl,
Forwardlteratorl lastl,
ForwardIterator2 first2,
ForwardIterator2 last2,
BinaryPredicate binary_j?red);
22.10.2. Примеры
См. пример 5.9.
22.10.3. Описание
Алгоритм search проверяет наличие последовательности из второго диапазона
[f irst2; last2) в качестве подпоследовательности в первом диапазоне [firstl; lastl).
Если она имеется, возвращается итератор i из диапазона [firstl; lastl), который
представляет начало подпоследовательности. В противном случае возвращается lastl.
В первой версии алгоритма сравнение выполняется с помощью оператора ==, во
второй — с помощью функционального объекта binary_pred.
22.10.4. Временная сложность
Временная сложность квадратичная. Если N— размер диапазона [firstl;lastl), a
М— размер диапазона [first2;last2), то количество применений == или
А nary_pred самое большее (N-M)M, что не превышает N2/a . Реализация не
использует алгоритм Кнута-Морриса-Пратта, который, гарантируя линейное время работы, тем не
менее в большинстве практических случаев оказывается более медленным, чем "наивный"
алгоритм с квадратичным поведением в наихудшем случае. Наихудший же случай на практике
встречается исключительно редко.
Глава 22. Справочное руководство по обобщенным алгоритмам
349
22.11. search_n
22.11.1- Прототипы
template <typename Forwardlterator, typename Size,
typename T>
Forwardlterator search_n(Forwardlterator first,
Forwardlterator last,
Size count, const T& value);
template <typename Forwardlterator, typename Size,
typename T, typename BinaryPredicate>
Forwardlterator search_n(Forwardlterator first,
Forwardlterator last,
Size count, const T& value,
BinaryPredicate binary_jpred);
22.11.2. Описание
Алгоритм search_n обходит диапазон [first; last-count) в поисках ряда из
count элементов, эквивалентных value. Если такой ряд имеется, возвращается итератор i,
представляющий начало найденной подпоследовательности (при этом для всех целых
n < count значение * (i + n) эквивалентно value). В противном случае возвращается last.
В первой версии алгоритма сравнение выполняется с помощью оператора ==, во
второй — с помощью функционального объекта binary_pred.
22.11.3. Временная сложность
Временная сложность квадратичная. Если N— размер диапазона [first; last), то
количество применений == или binary_jpred не превышает Account.
22.12. find end
22.12.1. Прототипы
template <typename Forwardlteratorl,
typename ForwardIterator2>
Forwardlterator1
find_end(ForwardIteratorl firstl, Forwardlteratorl lastl,
ForwardIterator2 first2, ForwardIterator2 last2);
template <typename Forwardlteratorl,
typename ForwardIterator2,
typename BinaryPredicate>
Forwardlteratorl
find_end(Forwardlteratorl firstl, Forwardlteratorl lastl,
ForwardIterator2 first2/ ForwardIterator2 last2,
BinaryPredicate binary_pred);
350
Часть III. Справочное руководство по STL
22.12.2. Описание
Подобно search, f ind_end проверяет, является ли последовательность из второго
диапазона [first2;last2) подпоследовательностью первого диапазона [firstl;lastl).
Отличие заключается в том, что в то время как search возвращает первую такую
подпоследовательность, find_end возвращает последнюю. Если соответствующей
подпоследовательности нет, возвращается lastl.
В первой версии алгоритма сравнение выполняется с помощью оператора ==, во
второй — с помощью функционального объекта binaryjpred.
22.12.3. Временная сложность
Временная сложность квадратичная. Если N— размер диапазона [firstl; lastl), а
М— размер диапазона [first2;last2), то количество применений == или
binary_pred не превышает [N - М + \)М .
22.13. Обзор изменяющих алгоритмов
над последовательностями
Изменяющие алгоритмы над последовательностями обычно модифицируют контейнеры, с
которыми работают. В этой категории алгоритмов имеется двенадцать подкатегорий.
сору копирует элементы в другую (возможно, перекрывающуюся) последовательность.
swap обменивает элементы одной последовательности с элементами другой.
transform замещает каждый элемент значением, возвращаемым после применения
переданной в качестве параметра функции к элементу.
replace замещает каждый элемент, равный некоторому значению, копией другого
заданного значения.
fill замещает каждый элемент копией другого заданного значения.
generate замещает каждый элемент значением, возвращаемым вызовом функции.
remove удаляет элементы, равные заданному значению.
unique удаляет последовательные равные элементы.
reverse обращает относительный порядок элементов.
rotate выполняет циклический сдвиг элементов.
random_shuf f le псевдослучайно переупорядочивает элементы.
partition переупорядочивает элементы таким образом, что элементы,
удовлетворяющие указанному предикату, предшествуют элементам, не удовлетворяющим ему.
Алгоритмы replace, remove и unique имеют как версии, использующие для
сравнения оператор ==, так и версии с применением объекта предиката. Семантические требования
к объекту предиката рассматриваются в разделе 22.2. Алгоритм partition имеет вторую
версию, отличающуюся устойчивостью (она сохраняет относительный порядок элементов в
каждой группе).
Глава 22. Справочное руководство по обобщенным алгоритмам
351
22.14. сору
22.14.1. Прототипы
template<typename InputIterator, typename OutputIterator>
Outputlterator copy(Inputlterator firstl,
Inputlterator lastl,
Outputlterator first2);
template <typename Bidirectionallteratorl,
typename BidirectionalIterator2>
BidirectionalIterator2
copy_backward(Bidirectionallteratorl firstl,
Bidirectionallteratorl lastl,
BidirectionalIterator2 last2);
22.14.2. Примеры
См. примеры 5.10, 12.1, 12.1, 13.1 и 14.1.
22.14.3. Описание
Эти алгоритмы копируют элементы из одного диапазона в другой. Алгоритм сору
копирует [firstl;lastl) в [first2;last2), где last2==first2+(lastl-firstl) и
возвращает last2. Алгоритм работает в прямом направлении, копируя исходные элементы в
порядке firstl, firstl + 1, ..., lastl-1, откуда следует, что целевой диапазон может
перекрываться с исходным, если последний не содержит first2. Таким образом, например,
сору может использоваться для сдвига диапазона на одну позицию по направлению к началу,
но не к концу.
Для алгоритма copy_backward справедливо обратное, так как он выполняет
копирование [firstl;lastl) в [first2;last2) (где first2==last2-(lastl-firstl))и
возвращает first2, работая в обратном направлении, т.е. копируя исходные элементы в
порядке lastl-1, lastl-2, ..., firstl. Таким образом, копирование выполняется
корректно, если исходный диапазон не содержит last2.
22.14.4. Временная сложность
Линейная для обоих алгоритмов. Выполняется ровно N присваиваний, где N— размер
диапазона [f irstl ;lastl).
22.15. swap
22.15.1. Прототипы
template <typename T>
void swap(T& x, T& y);
template <typename Forwardlteratorl,
typename ForwardIterator2>
ForwardIterator2 swap_ranges(Forwardlteratorl firstl,
Forwardlteratorl lastl,
ForwardIterator2 first2);
352
Часть III. Справочное руководство по STL
template <typename Forwardlteratorl,
typename ForwardIterator2>
void iter_swap(Forwardlteratorl a, ForwardIterator2 b);
22.15.2. Примеры ш
См. пример 5.18 для алгоритма swap и пример 5.19 для алгоритма swap_ranges.
22.15.3. Описание
Алгоритм swap обменивает значения, хранящиеся в позициях х и у. Алгоритм
swap_ranges обменивает элементы из диапазона [f irstl;lastl) с элементами из
диапазона размером N = lastl-f irstl, начинающимся с f irst2. Алгоритм swap_ranges
возвращает итератор за концом диапазона, f irst2+7V.
Алгоритм iter_swap (а, b) идентичен swap (*а,*b) и существует только по
техническим причинам, потому что некоторые компиляторы неспособны корректно выполнить
вывод типа, для того чтобы верно интерпретировать swap (*а,*b).
22.15.4. Временная сложность
Амортизированное константное время для алгоритмов swap и iter_swap; линейное для
алгоритма swap_ranges, который выполняет N обменов элементов.
22.16. transform
22.16.1. Прототипы
template <typename InputIterator,
typename OutputIterator,
typename UnaryOperation>
Outputlterator transform(Inputlterator first,
Inputlterator last,
Outputlterator result,
UnaryOperation unary_op);
template <typename Inputlteratorl,
typename InputIterator2,
typename Outputlterator,
typename BinaryOperation>
Outputlterator transform(Inputlteratorl firstl,
Inputlteratorl lastl,
InputIterator2 first2,
Outputlterator result,
BinaryOperation binary_op);
22.16.2. Примеры
См. пример 5.20.
Глава 22. Справочное руковооство по оооощенным шти^итмам
22.16.3. Описание
Первая версия transform генерирует последовательность элементов путем применения
унарной функции unary_op к каждому элементу диапазона [first; last). Вторая версия
transform получает диапазон [f irstl; lastl) и диапазон длиной
N = lastl-firstl, начинающийся с first2, и генерирует диапазон путем применения
бинарной функции binary_op для каждой пары соответствующих элементов из обоих
диапазонов.
Для обеих версий transform получающаяся в результате последовательность
размещается начиная с позиции result; алгоритмы возвращают итератор за концом
последовательности, result+N. Итератор result может быть равен first в случае унарного
преобразования, или f irstl, или first 2 в случае бинарного.
Объекты unary_op и binary_op не должны иметь побочных действий.
22.16.4. Временная сложность
Линейная. Количество применений unary_op равно размеру диапазона [first; last),
а количество применений binary_op равно размеру диапазона [firstl; lastl).
22.17. replace
22.17.1. Прототипы
template <typename Forwardlterator, typename T>
void replace(Forwardlterator first, Forwardlterator last,
const T& old_value, const T& new_value) ;
template <typename Forwardlterator, typename Predicate,
typename T>
void replace_if(Forwardlterator first, Forwardlterator last,
Predicate pred, const T& new_value);
template <typename Inputlterator, typename Outputlterator,
typename T>
Outputlterator replace_copy(Inputlterator first,
Inputlterator last,
Outputlterator result,
const T& old_value,
const T& new_value);
template <typename Inputlterator, typename Outputlterator,
typename Predicate, typename T>
Outputlterator replace_copy_if(Inputlterator first,
Inputlterator last,
Outputlterator result,
Predicate pred,
const T& new_value);
22.17.2. Примеры
См. пример 5.16.
»*%/-г Часть III. Справочное руководство по STL
22.17.3. Описание
Алгоритм replace модифицирует диапазон [first; last) таким образом, что все
элементы, равные old_value, замещаются на new_value, в то время как другие элементы
остаются неизменными.
Алгоритм replace__if модифицирует диапазон [first/last) так, что все элементы,
удовлетворяющие предикату pred, Заменяются на new_value, в то время как другие
элементы остаются неизменными.
Алгоритмы replace_copy и replace_copy_if аналогичны replace и
replace_if, за исключением того, что исходная последовательность не модифицируется.
Вместо этого измененная последовательность помещается в диапазон размера
N = last-first, начинающийся с result. Алгоритмы возвращают итератор после конца
последовательности, result +N
Итератор result не должен быть в диапазоне [first /last).
22.17.4. Временная сложность
Линейная. Количество выполненных операций == или применений предиката pred равно N.
22.18. fill
22.18.1. Прототипы
template «ctypename Forwardlterator, typename T>
void fill(Forwardlterator first, Forwardlterator last,
const T& value);
template <typename Forwardlterator, typename Size,
typename T>
void fill_n(OutputIterator first, Size n, const T& value);
22.18.2. Примеры
См. пример 5.11.
22.18.3. Описание
Алгоритм fill помещает значение value во все позиции диапазона [first; last).
Алгоритм f ill_n помещает value во все позиции диапазона [first; f irst+n).
22.18.4. Временная сложность
Линейная. Количество присваиваний в обоих версиях алгоритма равно размеру диапазона
[first;last).
22.19. generate
22.19.1. Прототипы
:emplate <typename Forwardlterator, typename Generator>
roid generate(Forwardlterator first, Forwardlterator last,
Generator gen);
Глава 22. Справочное руководство по обобщенным алгоритмам
template <typename Forwardlterator, typename Size,
typename Generator>
void generate_n(OutputIterator first, Size n,
Generator gen);
22.19.2. Примеры
См. пример 5.12.
22.19.3. Описание
Алгоритм generate заполняет диапазон [first; last) последовательностью,
генерируемой путем last-first последовательных вызовов функционального объекта gen.
Алгоритм generate_n заполняет диапазон размером п, начинающийся в позиции first
последовательностью, генерируемой п последовательными вызовами gen.
22.19.4. Временная сложность
Линейная. Количество присваиваний и вызовов gen в случае generate равно размеру
диапазона [first; last); для generate_n это количество равно п.
22.20. remove
22.20.1. Прототипы
template <typename Forwardlterator, typename T>
Forwardlterator remove(Forwardlterator first,
Forwardlterator last,
const T& value);
template <typename Forwardlterator, typename Predicate>
Forwardlterator remove_if(Forwardlterator first,
Forwardlterator last,
Predicate pred);
template <typename Inputlterator,
typename OutputIterator, typename T>
Outputlterator remove_copy(Inputlterator first,
Inputlterator last,
Outputlterator result,
const T& value);
template <typename Inputlterator,
typename Outputlterator, typename Predicate>
Outputlterator remove_copy_if(Inputlterator first,
Inputlterator last,
Outputlterator result,
Predicate pred);
22.20.2. Примеры
См. пример 5.15.
часть III. Справочное руководство по STL
22.20.3. Описание
Функция remove удаляет из диапазона [first /last) элементы, эквивалентные
value, и возвращает позицию i, которая представляет собой итератор за концом
результирующего диапазона со значениями, не равными value.
Функция remove_if удаляет из диапазона [first;last) те элементы, которые
удовлетворяют предикату pred, и возвращав позицию i, которая представляет собой итератор за
концом результирующего диапазона со значениями, не удовлетворяющими предикату pred.
Важно отметить, что ни remove, ни remove_if не изменяют размер исходного
контейнера: алгоритм работает при помощи копирований (с присваиваниями) в диапазон
[first;i). He делается никаких вызовов функций-членов insert или erase
контейнеров, с которыми работают алгоритмы.
Алгоритмы remove_copy и remove_copy_if аналогичны алгоритмам remove и
remove_if, за исключением того, что результирующие последовательности копируются в
диапазон, начинающийся с позиции result.
Все версии алгоритма устойчивы, т.е. относительный порядок элементов, которые не
были удалены, остается тем же, что и в исходном диапазоне.
22.20.4. Временная сложность
Линейная. Количество присваиваний равно количеству не удаленных элементов, которое
не превышает размера диапазона [first/last), а количество применений оператора ==
или функционального объекта pred в точности равно размеру диапазона [first /last).
22.21. unique
22.21.1. Прототипы
template <typename ForwardIterator>
Forwardlterator unique(Forwardlterator first,
Forwardlterator last);
template <typename Forwardlterator,
typename BinaryPredicate>
Forwardlterator unique(Forwardlterator first,
Forwardlterator last,
BinaryPredicate binary_pred);
template <typename Inputlterator, typename Outputlterator>
Outputlterator unique_copy(Inputlterator first,
Inputlterator last,
Outputlterator result);
template <typename Inputlterator, typename Outputlterator,
typename BinaryPredicate>
Outputlterator unique_copy(Inputlterator first,
Inputlterator last,
Outputlterator result,
BinaryPredicate binary_pred);
22.21.2. Примеры
См. пример 5.21.
Глава 22. Справочное руководство по обобщенным алгоритмам
ои/
22.21.3. Описание
Алгоритм unique удаляет последовательные дубликаты из диапазона [first;last).
Элемент рассматривается как последовательный дубликат, если он эквивалентен элементу в
позиции, следующей в диапазоне непосредственно за ним.
В первой версии unique эквивалентность проверяется с помощью operator==, а во
второй — с помощью функционального объекта binary_jpred.
Алгоритм unique_copy аналогичен алгоритму unique, за исключением того, что
результирующая последовательность копируется в диапазон, начинающийся с позиции
result, оставляя исходную последовательность неизменной.
Все версии unique возвращают конец результирующего диапазона.
Алгоритмы unique обычно применяются к отсортированным диапазонам, поскольку в
этом случае все дубликаты становятся последовательными.
22.21.4. Временная сложность
Линейная. Выполняется ровно last-f irst-1 (или 0, если диапазон пуст) применений
соответствующих предикатов обоими версиями unique. Алгоритм unique_copy
применяет предикат last-f irst раз.
22.22. reverse
22.22.1. Прототипы
template <typename BidirectionalIterator>
void reverse(Bidirectionallterator first,
Bidirectionallterator last);
template <typename Bidirectionallterator,
typename Outputlterator>
Outputlterator reverse_copy(Bidirectionallterator first,
Bidirectionallterator last,
Outputlterator result);
22.22.2. Примеры
См. примеры 2.1, 2.2, 2.3, 5.22 и 6.5 для reverse, и пример 5.2 для reverse_copy.
22.22.3. Описание
Алгоритм reverse обращает относительный порядок элементов диапазона
[first;last).
Алгоритм reverse_copy помещает обращенный диапазон [first; last) в диапазон,
начинающийся с позиции result, оставляя диапазон [first; last) неизменным.
Алгоритм возвращает итератор за концом диапазона result+last- first.
JJO
Часть III. Справочное руководство по STL
22.22.4. Временная сложность
Линейная. В случае алгоритма reverse выполняется ровно N/2 обменов элементов, где
N— размер диапазона [first; last). В случае алгоритма reverse_copy выполняется
ровно N присваиваний.
22.23. rotate
22.23.1. Прототипы
template <typename ForwardIterator>
void rotate(Forwardlterator first,
Forwardlterator middle,
Forwardlterator last);
template <typename Forwardlterator,
typename Outputlterator>
OutputIterator
rotate_copy(Forwardlterator first,
Forwardlterator middle,
Forwardlterator last,
OutputIterator result);
22.23.2. Примеры
См. пример 5.17.
22.23.3. Описание
Алгоритм rotate смещает элементы последовательности следующим образом: для
N = last-first, M = middle-first, и каждого неотрицательного целого числа i<N
алгоритм rotate перемещает элемент из позиции first+i в позицию f irst + (/ + M)%7V .
Алгоритм rotate_copy аналогичен алгоритму rotate за исключением того, что он
помещает элементы результирующей последовательности в диапазон [result, result+ЛО ,
оставляя диапазон [first;last) неизменным. Возвращает выходной итератор, значение кото-
юго представляет собой конец результирующего диапазона, result + (last - first).
22.23.4. Временная сложность
Линейная. Алгоритм rotate выполняет не более N обменов (а следовательно, 3N
присваиваний); алгоритм rotate_copy выполняет ровно N присваиваний.
22.24. random_shuf f le
12.24.1. Прототипы
emplate <typename RandomAccessIterator>
roid random_shuffle(RandomAccessIterator first,
RandomAccessIterator last);
Глава 22. Справочное руководство по обобщенным алгоритмам
template <typename RandomAccessIterator,
typename RandomNumberGenerator>
void random_shuffle(RandomAccessIterator first,
RandomAccessIterator last,
RandomNumberGenerator& rand);
22.24.2. Примеры
См. примеры 5.14, 8.3 и 8.4.
22.24.3. Описание
Алгоритм random_shuf f le случайным образом переупорядочивает элементы
диапазона [first/last), используя функцию генерации псевдослучайных чисел. Перестановки,
генерируемые алгоритмом random_shuf f le, имеют примерно равномерное распределение
вероятностей; вероятность каждой из N\ перестановок диапазона размера N приближенно
равна \/N\. Вторая версия получает в качестве параметра функциональный объект для
генерации случайных чисел rand такой, что каждый вызов rand (N) возвращает
псевдослучайное целое число из интервала [0,ЛГ).
22.24.4. Временная сложность
Линейная. Выполняется ровно (last-first) -1 обменов (а следовательно, в три раза
больше присваиваний).
22.25. partition
22.25.1. Прототипы
template <typename Bidirectionallterator,
typename Predicate>
Bidirectionallterator
partition(Bidirectionallterator first,
Bidirectionallterator last,
Predicate pred);
template <typename Bidirectionallterator,
typename Predicate>
Bidirectionallterator
stable_partition(Bidirectionallterator first,
Bidirectionallterator last,
Predicate pred);
22.25.2. Примеры
См. пример 5.13.
22.25.3. Описание
Алгоритм partition помещает все элементы диапазона [first; last), которые
удовлетворяют предикату pred, перед всеми элементами, ему не удовлетворяющими.
Часть III. Справочное руководство по STL
Оба алгоритма возвращают итератор i такой, что для любого итератора j в диапазоне
[first;i) выполняется pred(*j) == true, а для любого итератора к из диапазона
[i; last) справедливо pred (*k) == false.
В случае алгоритма stable_partition относительные положения элементов в обоих
группах сохраняются. Алгоритм partition свойство устойчивости не гарантирует.
22.25.4. Временная сложность
Линейная для partition; линейная или O(NlogN) для stable_partition— в
зависимости от наличия дополнительной памяти.
Алгоритм partition выполняет примерно N/2 обменов элементов, где N представляет
собой размер диапазона [first; last), и ровно N применений предиката pred. При
наличии доступной дополнительной памяти для N элементов алгоритм stable_partition
выполняет 2N присваиваний; при отсутствии такого количества памяти выполняется не более
NlogN обменов. В любом случае предикат pred выполняется ровно N раз.
22.26. Обзор алгоритмов, связанных
с сортировкой
Имеется девять подкатегорий алгоритмов, тем или иным способом связанных с сортировкой.
• Алгоритмы sort, stable_sort и partial_sort переставляют элементы
последовательности в порядке возрастания.
• Алгоритм nth_element находит N-й наименьший элемент последовательности.
• Алгоритмы binary_search, lower_bound, upper_bound и equal_range
выполняют поиск в отсортированной последовательности методом деления пополам.
• Алгоритм merge сливает две отсортированные последовательности в одну.
• Алгоритмы includes, set_union, set_intersection, set_difference и
set_symmetric_dif f erence выполняют теоретико-множественные операции над
отсортированными структурами.
• Алгоритм push_heap, pop_heap, make_heap и sort_heap выполняют операции
по упорядочению последовательности, организованной в виде пирамиды (помимо
всего прочего, эти алгоритмы используются в очередях с приоритетами).
• Алгоритмы min, max, min_element и max_element находят минимальный или
максимальный элемент пары или последовательности.
• Алгоритм lexicographical_compare лексикографически сравнивает две
последовательности.
• Алгоритмы next_permutation и prev_permutation генерируют перестановки
последовательности, основываясь на лексикографическом упорядочении множества
всех перестановок.
Все девять алгоритмов имеют две версии: одна для сравнений использует оператор <, а
торая — функциональный объект сотр типа Compare.
Compare comp должен быть функциональным объектом, который принимает два аргу-
ента и возвращает true, если первый аргумент меньше второго, и false в противном слу-
ае. Compare comp используется во всех алгоритмах, подразумевающих отношение упоря-
Глава 22. Справочное руковооство по оооощенным алгоритмам
дочения. Предполагается, что сотр не выполняет никаких неконстантных функций над
разыменованным итератором.
Для всех алгоритмов, принимающих в качестве аргумента Compare, имеется версия,
использующая вместо него оператор <. Т.е., comp (*i, * j ) == true по умолчанию
эквивалентно *i < * j == true.
Функциональный объект comp может использовать любое строгое неполное
упорядочение (strict weak ordering). "Строгое" означает нерефлексивное отношение, так, например,
можно использовать операторы < или > типа int (или любого другого встроенного типа), но
не <= или >=. "Неполное" означает более слабые требования, чем при полном упорядочении
(но более сильные, чем при частичном). Точные требования ([18], с. 33) к отношению 1Z,
являющемуся строгим неполным упорядочением, выглядят следующим образом.
1. 1Z должно быть частичным упорядочением:
• транзитивным: для всех x9y9z если xRy и yIZz , то xRz ;
• нерефлексивным: для всех jc отношение xRx ложно.
2. Отношение £ , определяемое как " х£у тогда и только тогда, когда хЯу и уКх
ложны" должно быть транзитивным. При соответствии указанным требованиям £
представляет собой отношение эквивалентности:
• транзитивно: для всех x,y9z если х£у и y£z 9to x£z\
• симметрично: для всех х,у если х£у , то у£х;
• рефлексивно: для всех х выполняется х£х .
Можно показать, что 1Z порождает вполне определенное отношение сравнения 1Z/£ над
классами эквивалентности, порожденными отношением £ , такое, что lZ/£ представляет
собой полное упорядочение. Таким образом, само по себе 1Z не обязательно является полным
упорядочением, но таковым является TZ/£ .
В терминах comp определение отношения эквивалентности £ имеет вид
х£у тогда и только тогда, когда ! (comp (х, у) && ! (comp (у, х).
Отношение эквивалентности £ используется не только в описании требований к comp,
но и в описании других требований к алгоритмам, связанным с сортировкой. Например,
устойчивость алгоритма сортировки определяется как свойство, заключающееся в том, что
сохраняется относительный порядок эквивалентных элементов. Под эквивалентностью
понимается отношение £ .
Последовательность является отсортированной по отношению к функции сравнения comp,
если для любого итератора i, указывающего в последовательность, и любого неотрицательного
целого N, такого, что i+N представляет собой корректный итератор, указывающий на элемент
последовательности, выполняется соотношение с omp (*(i+n),*i) == false.
22.27. sort
22.27.1. Прототипы
template <typename RandomAccessIterator>
void sort(RandomAccessIterator first,
RandomAccessIterator last);
часть III. Справочное руководство по STL
template <typename RandomAccessIterator, typename Compare>
void sort(RandomAccessIterator first,
RandomAccessIterator last, Compare comp);
template <typename RandomAccessIterator>
void stable_sort(RandomAccessIterator first,
RandomAccessIterator last);
template <typename RandomAccessIterator, typename Compare>
void stable_sort(RandomAccessIterator first,
RandomAccessIterator last, Compare comp);
template <typename RandomAccessIterator>
void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last);
template <typename RandomAccessIterator, typename Compare>
void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last, Compare comp);
template <typename Inputlterator,
typename RandomAccessIterator>
RandomAccessIterator
partial_sort_copy(Inputlterator first, Inputlterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last);
template <typename Inputlterator,
typename RandomAccessIterator,
typename Compare>
RandomAccessIterator
partial_sort_copy(Inputlterator first, Inputlterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last,
Compare comp);
22.27.2. Примеры
См. примеры 5.1, 5.3, 8.3, 8.4, 11.1, 13.1, 14.1, 17.1 и 19.1 для алгоритма sort и примеры
5.22 и 19.2 для всех трех алгоритмов сортировки.
22.27.3. Описание
Для сортировки используются три основных алгоритма: sort, stable_sort и
partial_sort. Имеется также копирующая версия алгоритма part ial_sort.
Алгоритм sort сортирует элементы в диапазоне [f irst; last).
Алгоритм stable_sort сортирует элементы в диапазоне [first; last), гарантируя
при этом сохранение относительного порядка эквивалентных элементов.
В случае part ial_sort, итератор middle должен указывать в диапазон [first; last).
Если М - middle-first, то алгоритм помещает в [first/middle) Mэлементов,
которые находились бы там, если бы весь диапазон [first; last) был отсортирован. Порядок
остальных элементов (находящихся в диапазоне [middle; last) ) не определен.
В случае алгоритма partial_sort_copy обозначим N = last-first и
R = result_last-result_f irst. Есть два варианта.
Глава 22. Справочное руковооство по оииищенным алси^иттат
1. Если R<N, алгоритм partial_sort_copy помещает в диапазон
[result_f irst; result_last) R элементов, которые находились бы в диапазоне
[f irst, first +R), если бы был отсортирован весь диапазон [first; last).
Диапазон [first; last) при этом не изменяется. Возвращается result_last.
2. В противном случае в диапазон [result_f irst, result_f irst + N)
помещаются элементы диапазона [first/last) в отсортированном порядке. Диапазоны
[first; last) и [result_f irst+N, result_last) остаются неизменными.
Возвращается result_f irst+iV.
22.27.4. Временная сложность
Алгоритм sort сортирует последовательность длиной N при помощи O(iVlogN)
сравнений и присваиваний в среднем. Однако имеется небольшое количество входных
последовательностей, которые требуют квадратичного времени работы алгоритма.
Для гарантированного поведения 0(N\ogN) можно использовать алгоритм
partial_sort с middle == last. В общем случае, если М = middle-first,
алгоритм partial_sort выполняется за время 0[N\ogM).
Время работы алгоритма partial_sort_copy составляет 0(N\ogK), где
K = min(N,R). Время работы stable_sort равно 0(N\ogN) или o(N(\ogN)2], в
зависимости от доступности дополнительной памяти для работы алгоритма. Если имеется дополни
тельная память для как минимум N/2 элементов, время работы равно O(NlogN) .
■
22.28. nthelement
22.28.1. Прототипы
template <typename RandomAccessIterator>
void nth_element(RandomAccessIterator first,
RandomAccessIterator position,
RandomAccessIterator last);
template <typename RandomAccessIterator, typename Compare>
void nth_element(RandomAccessIterator first,
RandomAccessIterator position,
RandomAccessIterator last, Compare comp);
22.28.2. Примеры
См. пример 5.23.
22.28.3. Описание
Алгоритм nth_element помещает элемент последовательности в позицию, в которой с
находился бы, если бы последовательность была отсортирована.
В первой версии алгоритма сравнение выполняется при помощи оператора <, а во вт<
рой — при помощи функционального объекта сотр.
часть III. Справочное руководство по STL
После вызова nth_element элемент, помещаемый в позицию position, представляет
собой N-ый в порядке возрастания элемент диапазона, где N = position-first. Кроме
того, для любого итератора i из диапазона [first /position) и любого итератора j из
диапазона [position;last) выполняется соотношение ! (*j<*i) (в первой версии; во второй
версии это соотношение — ! сотр (* j , *i)). Таким образом, алгоритм разбивает элементы
последовательности в соответствии с размером: все элементы слева от position не превосходят
элементы справа. Порядок, в котором находятся элементы каждой части, не определен.
22.28.4. Временная сложность
Линейная в среднем, квадратичная в наихудшем случае.
22.29. Бинарный поиск
Все описанные в этом разделе алгоритмы представляют собой версии бинарного поиска.
Хотя бинарный поиск обычно весьма эффективен (имеет логарифмическое время работы)
только для последовательностей с произвольным доступом (таких как векторы, деки или массивы),
алгоритмы написаны так, чтобы могли работать и для последовательностей других видов (таких
как списки). В последнем случае время работы алгоритма становится линейно зависящим от
размера контейнера, но количество сравнений все равно остается логарифмическим.
22.29.1. Прототипы
template <typename Forwardlterator, typename T>
bool binary_search(ForwardIterator first,
Forwardlterator last, const T& value);
template <typename Forwardlterator, typename T,
typename Compare>
bool binary_search(Forwardlterator first,
Forwardlterator last, const T& value,
Compare comp);
template <typename Forwardlterator, typename T>
Forwardlterator
lower_bound(Forwardlterator first, Forwardlterator last,
const T& value);
template <typename Forwardlterator, typename T,
typename Compare>
Forwardlterator
lower_bound(Forwardlterator first, Forwardlterator last,
const T& value, Compare comp);
template <typename Forwardlterator, typename T>
Forwardlterator
apper_bound(Forwardlterator first, Forwardlterator last,
const T& value);
template <typename Forwardlterator, typename T,
typename Compare>
forwardlterator
apper_bound(Forwardlterator first, Forwardlterator last,
const T& value, Compare comp);
Глава 22. Справочное руководство по обобщенным алгоритмам
template <typename Forwardlterator, typename T>
pair<ForwardIterator, Forwardlterator>
equal_range(Forwardlterator first, Forwardlterator last,
const T& value);
template <typename Forwardlterator, typename T,
typename Compare>
pair<ForwardIterator, ForwardIterator>
equal_range(Forwardlterator first, Forwardlterator last,
const T& value, Compare comp);
22.29.2. Примеры
См. примеры 5.24 и 12.1.
22.29.3. Описание
Для всех трех алгоритмов предусловием является отсортированность диапазона
[first ,-last) с использованием оператора < или функционального объекта comp в случае,
когда алгоритм принимает аргумент типа Compare.
Алгоритмы binary_search возвращают true, если значение value имеется в
диапазоне [first; last), и false в противном случае.
Алгоритмы lower_bound возвращают итератор, указывающий на первую позицию в
диапазоне [first /last), в которую значение value могло бы быть вставлено без
нарушения порядка сортировки.
Алгоритмы upper_bound возвращают итератор, указывающий на последнюю позицию в
диапазоне [first/last), в которую значение value могло бы быть вставлено без
нарушения порядка сортировки.
Функции equal_range возвращают пару итераторов, которые были бы возвращены
алгоритмами lower_bound и upper__bound.
22.29.4. Временная сложность
Логарифмическая для последовательностей с произвольным доступом, линейная в
противном случае. Количество операций сравнения в любом случае логарифмическое. Для
последовательностей, не являющихся последовательностями с произвольным доступом,
количество операций ++ линейно, что и делает общее время работы алгоритма линейным.
В случае lower_bound и upper_bound количество сравнений не превышает logAT + 1,
у binary_search оно не превышает logN + 2, а в случае equal_range оно не выше
21ogN+ 1, где N—размер диапазона [first; last).
22.30. merge
22.30.1. Прототипы
template <typename Inputlteratorl, typename InputIterator2,
typename Outputlterator>
OutputIterator
merge(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result);
Часть III. Справочное руководство по STL
template <typename Inputlteratorl, typename InputIterator2,
typename OutputIterator, typename Compare>
OutputIterator
merge(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2,
Outputlterator result, Compare comp);
template <typename BidirectionalIterator>
void inplace_merge(Bidirectionallterator first,
Bidirectionallterator middle,
Bidirectionallterator last);
template <typename Bidirectionallterator, typename Compare>
void inplace_merge(Bidirectionallterator first,
Bidirectionallterator middle,
Bidirectionallterator last,
Compare comp);
22.30.2. Примеры
См. примеры 2.9, 2.10 и 5.25.
22.30.3. Описание
Алгоритм merge сливает два отсортированных диапазона [firstl;lastl) и
[f irst2;last2) в диапазон [result, result+ЛО , где # = #,+ЛГ2, Nx =lastl-firstl,
a N2 = last2 - f irst2 . Алгоритм устойчив, т.е. эквивалентные элементы из первого
диапазона всегда предшествуют элементам из второго диапазона. Алгоритм merge возвращает
result +N. Результат алгоритма merge не определен, если результирующий диапазон
перекрывается с любым из исходных диапазонов.
Алгоритм inplace_merge сливает два отсортированных последовательных диапазона
[first /middle) и [middle; last), размещая результат в диапазоне [first; last).
Слияние устойчиво.
22.30.4. Временная сложность
Линейная в случае merge. В случае in_place__merge, временная сложность зависит от
доступной дополнительной памяти. Если имеется дополнительная память для
N = last-first элементов, время работы составляет O(N); в противном случае оно
равно O(NlogN).
В обоих алгоритмах выполняется не более N сравнений.
22.31. Теоретико-множественные операции
над отсортированными структурами
В библиотеке имеется пять алгоритмов для выполнения теоретико-множественных
операций: includes, set_union, set_intersection, set_difference и
set_symmetric_difference.
Эти операции работают с любыми отсортированными структурами, включая
отсортированные ассоциативные контейнеры.
Глава 22. Справочное руковооство по ооиищенным
Эти алгоритмы работают даже с мультимножествами, содержащими множественные
эквивалентные элементы. Семантика данных алгоритмов обобщается на случай
мультимножеств стандартным образом— объединение содержит максимальное число эквивалентных
элементов в мультимножестве, пересечение — минимальное, и т.д.
22.31.1. Прототипы
template <typename Inputlteratorl, typename InputIterator2>
bool includes(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2);
template <typename Inputlteratorl, typename InputIterator2,
typename Compare>
bool includes(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2,
Compare comp);
template <typename Inputlteratorl, typename InputIterator2,
typename Outputlterator>
OutputIterator
set_union(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result);
template <typename Inputlteratorl, typename InputIterator2,
typename Outputlterator, typename Compare>
OutputIterator
set_union(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2,
Outputlterator result, Compare comp);
template <typename Inputlteratorl, typename InputIterator2,
typename Outputlterator>
Outputlterator
set_intersection(Inputlteratorl firstl,
Inputlteratorl lastl,
InputIterator2 first2,
InputIterator2 last2,
Outputlterator result);
template <typename Inputlteratorl, typename InputIterator2,
typename Outputlterator, typename Compare>
Outputlterator
set_intersection(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2,
Outputlterator result, Compare comp);
template <typename Inputlteratorl, typename InputIterator2,
typename Outputlterator>
Outputlterator
set_difference(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2,
Outputlterator result);
template <typename Inputlteratorl, typename InputIterator2,
typename Outputlterator, typename Compare>
Outputlterator
set_difference(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, InputIterator2 last2,
Outputlterator result, Compare comp);
JUO
Часть III. Справочное руководство по STL
template <typename Inputlteratorl, typename InputIterator2,
typename Outputlterator>
OutputIterator
set_symmetric_difference(InputIteratorl firstl,
Inputlteratorl lastl,
InputIterator2 first2/
InputIterator2 last2,
OutputIterator result);
template <typename Inputlteratorl, typename InputIterator2,
typename OutputIterator, typename Compare>
OutputIterator
set_symmetric_difference(Inputlteratorl firstl,
Inputlteratorl lastl,
InputIterator2 first2,
InputIterator2 last2,
Outputlterator result,
Compare comp);
22.31.2. Примеры
См. пример 5.26.
22.31.3. Описание
Алгоритм includes возвращает true, если каждый элемент диапазона
[f irst2 ; last2) содержится в [f irstl; lastl), и false в противном случае. Каждый
из остальных алгоритмов помещает результат в диапазон, начинающийся с result, и
возвращает итератор за концом диапазона.
Алгоритм set_union строит отсортированное объединение элементов из двух
диапазонов. Алгоритм set_union устойчивый, т.е. если элемент первого диапазона эквивалентен
элементу второго диапазона, то будет скопирован элемент первого диапазона.
Алгоритм set_inter sect ion строит отсортированное пересечение элементов из двух
диапазонов. Алгоритм set_intersection устойчив.
Алгоритм set_dif ference строит отсортированную разность элементов из двух
диапазонов. Эта разность содержит элементы, содержащиеся в первом множестве, и не
содержащиеся во втором.
Алгоритм set_symmetric_difference строит отсортированную симметричную
разность элементов из двух диапазонов, в которую входят все элементы первого диапазона, не
содержащиеся во втором, и все элементы второго диапазона, отсутствующие в первом.
Результат каждого алгоритма не определен, если результирующий диапазон
перекрывается с любым из исходных диапазонов.
22.31.4. Временная сложность
Линейная. Во всех случаях выполняется не более 2(Nl+N2)-l сравнений, где
N} =lastl-firstl,a N2=last2-first2.
Глава 22. Справочное руководство по обобщенным алгоритмам
оо»
22.32. Операции с пирамидами
В контексте сортировки пирамида (heap)31 представляет собой определенную
организацию последовательности, которая позволяет выполнять некоторые операции выбора и
сортировки за логарифмическое время. Мы говорим, что данный диапазон [first/last), где
first и last представляют собой итераторы с произвольным доступом, является
пирамидой, если выполняются два ключевых свойства:
• значение, на которое указывает итератор first, является наибольшим значением
диапазона;
• значение, на которое указывает итератор first, можно удалить при помощи
вызова pop_heap, а также добавить новое значение вызовом push_heap (время
выполнения обоих операций логарифмическое); при этом результирующий диапазон
остается пирамидой.
Эти свойства позволяют использовать пирамиду в качестве очереди с приоритетами.
В дополнение к pop_heap и push_heap имеются еще два алгоритма для работы с
пирамидами: make_heap для создания пирамиды из произвольного диапазона, а также
sort_heap для сортировки пирамиды.
22.32.1. Прототипы
template <typename RandomAccessIterator>
void push_heap(RandomAccessIterator first,
RandomAccessIterator last);
template <typename RandomAccessIterator, typename Compare>
void push_heap(RandomAccessIterator first,
RandomAccessIterator last, Compare comp);
template «ctypename RandomAccessIterator>
void pop_heap(RandomAccessIterator first,
RandomAccessIterator last);
template «ctypename RandomAccessIterator, typename Compare>
void pop_heap(RandomAccessIterator first,
RandomAccessIterator last, Compare comp);
template <typename RandomAccessIterator>
void make_heap(RandomAccessIterator first,
RandomAccessIterator last);
template <typename RandomAccessIterator, typename Compare>
void make_heap(RandomAccessIterator first,
RandomAccessIterator last, Compare comp);
template <typename RandomAccessIterator>
void sort_heap(RandomAccessIterator first,
RandomAccessIterator last);
template <typename RandomAccessIterator, typename Compare>
31 В русскоязычной литературе встречается также перевод heap как куча, однако этот термин
относится к памяти со сборкой мусора; здесь же используется перевод, принятый в [23], который тесно
связан с пирамидальной сортировкой. — Примеч. пер.
370
Часть III. Справочное руководство по STL
void sort_heap(RandomAccessIterator first,
RandomAccessIterator last, Compare comp);
22.32.2. Примеры
См. пример 5.27.
22.32.3. Описание
Если диапазон [firstl;last-l) представляет собой пирамиду, push_heap
переставляет элементы диапазона [first /last), делая из него пирамиду. Мы говорим, что элемент
в позиции last-1 "внесен в пирамиду".
Если диапазон [first;last) представляет собой пирамиду, pop_heap обменивает
значение в позиции first со значением в позиции last-1 и выполняет перестановку
элементов в диапазоне [first; last-1), превращая его в пирамиду.
Алгоритм make__heap переставляет элементы в диапазоне [ first; last), организуя их
в пирамиду.
Алгоритм sort_heap сортирует элементы пирамиды в диапазоне [first; last).
22.32.4. Временная сложность
Обозначим через N размер диапазона [first; last).
Алгоритмы push_heap и pop_heap выполняются за логарифмическое время. Алгоритм
push_heap выполняет не более \ogN сравнений, pop_heap — не более 2\ogN сравнений.
Время работы алгоритма make_heap — линейное, с выполнением не более 3N сравнений.
Время работы алгоритма sort_heap— O(NlogN), с выполнением не более NlogN
сравнений.
22.33. min и max
22.33.1. Прототипы
template <typename T>
const T& min(const T& a, const T& b);
template <typename T, typename Compare>
const T& min(const T& a, const T& b, Compare comp);
template <typename T>
const T& max(const T& a, const T& b) ;
template <typename T, typename Compare>
const T& max(const T& a, const T& b, Compare comp);
template <typename ForwardIterator>
Forwardlterator
min_element(Forwardlterator first, Forwardlterator last);
template <typename Forwardlterator, typename Compare>
Forwardlterator
min_element(Forwardlterator first, Forwardlterator last,
Compare comp);
Глава 22. Справочное руководство по обобщенным алгоритмам
зп
template <typename ForwardIterator>
Forwardlterator
max_element(Forwardlterator first, Forwardlterator last);
template <typename Forwardlterator, typename Compare>
Forwardlterator
max_element(Forwardlterator first, Forwardlterator last,
Compare comp);
22.33.2. Примеры
См. пример 5.28.
22.33.3. Описание
Алгоритм min возвращает меньший из двух аргументов, алгоритм max — больший. Если
аргументы равны, возвращается первый из них.
Алгоритм min_element возвращает первый итератор, указывающий на минимальный
элемент диапазона [first; last).
Алгоритм max_element возвращает первый итератор, указывающий на максимальный
элемент диапазона [first /last).
22.33.4. Временная сложность
Константная для min и max, линейная для min_element или max_element.
Количество сравнений элементов у алгоритмов min_element и max_element равно
тах(лг-1,0),где# = last-first.
22.34. Лексикографическое сравнение
22.34.1. Прототипы
template <typename Inputlteratorl, typename InputIterator2>
bool lexicographical_compare(Inputlteratorl firstl,
Inputlteratorl lastl,
InputIterator2 first2,
InputIterator2 last2);
template <typename Inputlteratorl, typename InputIterator2/
typename Compare>
bool lexicographical_compare(Inputlteratorl firstl,
Inputlteratorl lastl,
InputIterator2 first2,
InputIterator2 last2,
Compare comp);
22.34.2. Примеры
См. пример 5.29.
372
Часть III. Справочное руководство по STL
22.34.3. Описание
Лексикографическое сравнение двух последовательностей [firstl;lastl) и
[first2;last2) определяется следующим образом: при обходе последовательностей
сравниваются пары соответствующих элементов el и е2; если el < e2, обход завершается
и возвращается значение true; если е2 < el, обход завершается и возвращается значение
false; в противном случае выполняется переход к следующей паре элементов. Если первая
последовательность заканчивается, а вторая еще нет, возвращается true; в противном случае
возвращается false.
22.34.4. Временная сложность
Линейная. Количество выполняемых сравнений— не более /, где f irst+/— первая
позиция, в которой встречается несовпадение элементов.
22.35. Генераторы перестановок
В STL имеются два алгоритма генерации перестановок: next_permutation и
prev_permutation. Каждый из них получает последовательность и генерирует новую ее
перестановку таким образом, что N! последовательных применений дает все перестановки N
элементов. При этом требуется строгое неполное упорядочение элементов, обеспечиваемое
оператором < или функциональным объектом сотр. При использовании такого
упорядочения все перестановки последовательностей находятся в лексикографическом порядке. При
этом первой (наименьшей) перестановкой является та, элементы которой находятся в
возрастающем порядке, а последней (наибольшей) — та, в которой элементы находятся в
убывающем порядке. Алгоритм next_permutation переставляет элементы последовательности
так, что образуется перестановка, следующая за текущей в лексикографическом порядке, а
алгоритм prev_jpermutation создает предыдущую перестановку.
22.35.1. Прототипы
template <typename BidirectionalIterator>
bool next_permutation(Bidirectionallterator first,
Bidirectionallterator last);
template <typename Bidirectionallterator, typename Compare>
bool next_permutation(Bidirectionallterator first,
Bidirectionallterator last,
Compare comp);
template <typename BidirectionalIterator>
bool prev_permutation(Bidirectionallterator first,
Bidirectionallterator last);
template <typename Bidirectionallterator, typename Compare>
bool prev_permutation(Bidirectionallterator first,
Bidirectionallterator last,
Compare comp);
22.35.2. Примеры
См. примеры 5.30 и 12.1.
Глава 22. Справочное руководство по оооощенным алгоритмам ^#о
22.35.3. Описание
Алгоритм next_j?ermutation выполняет перестановку последовательности
[first; last), получая ее преемника в лексикографическом упорядочении всех
перестановок. Если такая перестановка существует, алгоритм возвращает true. В противном случае
последовательность преобразуется в наименьшую (в возрастающем порядке элементов)
перестановку, и возвращается значение false.
Алгоритм prev_permutation выполняет перестановку последовательности
[first;last), получая ее предшественника в лексикографическом упорядочении всех
перестановок. Если такая перестановка существует, алгоритм возвращает true. В противном
случае последовательность преобразуется в наибольшую (в убывающем порядке элементов)
перестановку, и возвращается значение false.
22.35.4. Временная сложность
Линейная. Выполняется не более N/2 обменов и N/2 сравнений, где N = last-first.
22.36. Обзор обобщенных численных
алгоритмов
Библиотека предоставляет четыре подкатегории численных алгоритмов.
• Алгоритм accumulate вычисляет сумму элементов последовательности.
• Алгоритм inner__product вычисляет сумму произведений соответствующих
элементов двух последовательностей.
• Алгоритм partial_sum вычисляет частичные суммы элементов последовательности
и сохраняет их в другой (или той же) последовательности.
• Алгоритм adj acent_dif f erence вычисляет разности смежных элементов и
сохраняет их в другой (или той же) последовательности.
У каждого алгоритма вторая версия позволяет использовать другие, не стандартные
бинарные операторы. Например, можно вычислить произведение целых чисел
последовательности при помощи алгоритма accumulate, передав алгоритму функциональный объект
multiplies<int>, так что вместо операции + будет использоваться операция *.
Из названия "обобщенные численные алгоритмы" понятно, что используемые элементы и
операторы не обязательно числовые. Например, алгоритм accumulate можно использовать
для слияния списков, передавая функциональный объект, инкапсулирующий функцию-член
merge списков.
22.37. accumulate
22.37.1. Прототипы
template <typename InputIterator, typename T>
T accumulate(Inputlterator first, Inputlterator last,
T initial_value);
template <typename Inputlterator, typename T,
typename BinaryOperation>
J/4
Часть III. Справочное руководство по STL
Т accumulate(InputIterator first, Inputlterator last,
T initial_value/ Binary-Operation binary_op) ;
22.37.2. Примеры
См. примеры 2.11, 2.12, 2.13, 2.14, 2.15 и 5.31.
22.37.3. Описание
Первая версия алгоритма accumulate инициализирует переменную (именуемую
accumulator) значением initial_value, а затем модифицирует ее при помощи
выполнения
accumulator = accumulator + *i
по очереди для каждого итератора i из диапазона [first;_last),a затем возвращает
значение accumulator.
Вторая версия выполняет те же действия, с тем отличием, что вместо оператора +
используется функциональный объект bi na гу_ор:
accumulator = binary_op(accumulator, *i)
Предполагается, что binary_op не вызывает никаких побочных действий.
22.37.4. Временная сложность
Линейная. Количество применений оператора + или функционального объекта
binary_op равно размеру диапазона [first; last).
22.38. inner_product
22.38.1. Прототипы
template <typename Inputlteratorl, typename InputIterator2,
typename T>
T inner_product(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, T initial_value);
template <typename Inputlteratorl, typename InputIterator2,
typename T,
typename BinaryOperationl,
typename BinaryOperation2>
T inner_product(Inputlteratorl firstl, Inputlteratorl lastl,
InputIterator2 first2, T initial_value,
BinaryOperationl binary_opl,
Binary0peration2 binary_op2);
22.38.2. Примеры
См. пример 5.34.
22.38.3. Описание
Первый вид алгоритма inner_jproduct инициализирует переменную (именуемую
accumulator) значением initial_value, а затем модифицирует ее при помощи выполнения
Глава 22. Справочное руководство по обобщенным алгоритмам
Of О
accumulator = accumulator + (*il) * (*i2)
по очереди для каждого итератора il из диапазона [firstl;last2) и каждого итератора ±2
из диапазона [f irst2; f irst2+ (lastl-f irst2) ) и возвращает значение accumulator.
Вторая версия работает аналогично, с тем отличием, что вместо оператора + используется
функциональный объект binary_opl, а вместо оператора * — функциональный объект
binary_op2:
accumulator = binary_opl(accumulator, binary_op2(*il, *i2))
Предполагается, что ни binary_opl, ни binary_op2 не вызывают побочных действий.
22.38.4. Временная сложность
Линейная. Количество применений + или binary_opl и * или binary_op2 равно
размеру диапазона [first; last).
22.39. partial_sum
22.39.1. Прототипы
template <typename InputIterator, typename Outputlterator>
OutputIterator
partial_sum(InputIterator first, Inputlterator last,
OutputIterator result);
template <typename Inputlterator, typename OutputIterator,
typename BinaryOperation>
OutputIterator
partial_sum(Inputlterator first, Inputlterator last,
Outputlterator result,
BinaryOperation binary_op);
22.39.2. Примеры
См. пример 5.32.
22.39.3. Описание
Пусть xk =* (first+fc) для fc = 0,l,...,N-l, где N = last-first. Тогда k-ая
частичная сумма элементов диапазона [first; last) определяется как
Первый вид алгоритма partial_sum помещает sk в позиции result +k при
Л: = 0,1, , А^ — 1. Вторая версия выполняет те же действия, но &-ая частичная "сумма"
вычисляется с применением функционального объекта binary op:
sk = binary_op(... binary_op(binary_op(x0,x,),x2),...,xk) .
Предполагается, что binary_op не вызывает побочных действий.
В обоих версиях partial_sum возвращает result +N.
376
Часть III. Справочное руководство по STL
Обратите внимание, что result может быть равен first: это возможно, если алгоритм
работает "на месте", т.е. генерирует частичные суммы и заменяет ими исходную
последовательность.
22.39.4. Временная сложность
Линейная. Количество применений + или binary_op равно N-\.
22.40. adjacent_dif ference
22.40.1. Прототипы
template <typename InputIterator, typename Outputlterator>
OutputIterator
adjacent_difference(InputIterator first,
Inputlterator last,
Outputlterator result);
template <typename Inputlterator, typename Outputlterator,
typename BinaryOperation>
Outputlterator
adjacent_difference(Inputlterator first,
Inputlterator last,
Outputlterator result,
BinaryOperation binary_op);
22.40.2. Примеры
См. пример 5.33.
22.40.3. Описание
Пусть xk =* (first+ £) для £ = 0,1,...,N-1, где N = last-first. Тогда для
к = 1,2,..., N -1 А>ая разность соседних элементов в диапазоне [first; last) определяется
как
4 =**-**-! •
Первая версия adjacent_difference помещает dk в позиции result+A: при
fc = l,2,...,N-l. Вторая версия выполняет те же действия, за исключением того, что к-ая
"разность" вычисляется с применением функционального объекта biпагу_ор:
dk - binary_op(^,^_,) .
В обоих случаях adj acent_dif ference помещает * first в *result, и возвращает
result+JV.
Итератор result может быть равен first, т.е. алгоритм может работать "на месте".
22.40.4. Временная сложность
Линейная. Количество применений - или binary_op равно N-\.
Глава 23
Справочное руководство
по функциональным объектам
и адаптерам
23.1. Требования
Все рассматриваемые в данной главе функции и классы находятся в заголовочном файле
<functional>.
23.1.1. Функциональные объекты
Определенные в виде классов функциональные объекты инкапсулируют в объектах
функции, используемые другими компонентами. Это делается при помощи перегрузки оператора
вызова функции operator () соответствующего класса (см. примеры 2.13, 8.2, 8.3, 8.4,11.1 и 17.1).
Передача алгоритму определенного в виде класса функционального объекта аналогична
передаче указателя на функцию, но с одним важным отличием. Определенные в виде класса
функциональные объекты являются классами с перегруженным оператором operator (),
что делает возможным следующее:
• передачу функционального объекта алгоритму во время компиляции;
• повышение эффективности путем встраивания соответствующего вызова;
• локальную инкапсуляцию информации, используемой функциональным объектом; в
случае указателя на функцию такая возможность достигается путем применения
статических или глобальных данных (см. пример 18.1).
Первые два фактора существенны в случае очень простых функций, таких как
суммирование или сравнение целых чисел. Последний фактор может оказаться важен в гораздо
большем множестве случаев.
23.1.2. Функциональные адаптеры
Функциональные адаптеры представляют собой классы STL, которые позволяют
пользователям создавать широкий круг функциональных объектов. Использование функциональных
адаптеров зачастую оказывается проще непосредственного создания нового функционально-
378
Часть III. Справочное руководство по STL
го объекта при помощи определения структуры или класса. Имеется четыре подкатегории
функциональных адаптеров.
1. Связыватели представляют собой функциональные адаптеры, которые преобразуют
бинарные функциональные объекты в унарные путем назначения аргументу
некоторого конкретного значения.
2. Инверторы представляют собой функциональные адаптеры, которые обращают смысл
функциональных объектов предикатов.
3. Адаптеры для указателей на функции позволяют указателям на (бинарные или унарные)
функции работать с предоставляемыми библиотекой функциональными адаптерами.
4. Адаптеры для указателей на функции-члены позволяют указателям на (унарные и
бинарные, включая неявный указатель this) функции-члены работать с
предоставляемыми библиотекой функциональными адаптерами.
23.2. Базовые классы
Унарный функциональный объект, передаваемый адаптеру в качестве аргумента, должен
определять типы argument_type и result_type, естественным образом
соответствующие типу аргумента функции и ее возвращаемого значения. Аналогично, бинарные
функциональные объекты должны определять f irst_argument_type, second_argument_type
и result_type. Для упрощения решения этой задачи библиотека предоставляет два
базового класса, которым могут наследовать функциональные объекты.
template <typename Arg, typename Result>
struct unary_function {
typedef Arg argument_type;
typedef Result result type;
};
template <typename Argl, typename Arg2, typename Result>
struct binary_function {
typedef Argl first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type;
)!
Класс binary_function используется в примерах 8.3, 8.4, 11.1, 17.1 и 18.1 и файле
ps . h из примеров 13.1 и 14.1.
23.3. Арифметические операции
STL предоставляет базовые классы функциональных объектов для всех арифметических
операторов языка. Функциональность операторов описывается далее.
template <typename T> struct plus;
Принимает два операнда типа Т и возвращает их сумму.
template <typename T> struct minus;
Принимает два операнда типа Т и возвращает результат вычитания второго
операнда из первого.
template <typename T> struct multiplies;
Принимает два операнда типа Т и возвращает их произведение (см. пример 2.14).
template <typename T> struct divides;
Глава 23. Справочное руководство по функциональным объектам и адаптерам
3/У
Принимает два операнда типа Т и возвращает результат деления первого
операнда на второй.
template <typename T> struct modulus;
Принимает два операнда, х и у, типа Т и возвращает результат вычисления х%у.
template <typename T> struct negate;
Унарный функциональный объект, который принимает единственный
операнд типа Т и возвращают значение с обратным знаком.
23.4. Операции сравнения
STL предоставляет базовые классы функциональных объектов для всех операторов
сравнения языка. Базовая функциональность объектов сравнения описывается далее.
template <typename T> struct equal_to;
Принимает два параметра, х и у, типа Т и возвращает true, если х == у;
в противном случае возвращает false,
template <typename T> struct not_equal_to;
Принимает два параметра, х и у, типа Т и возвращает true, если х ! = у;
в противном случае возвращает false,
template «ctypename T> struct greater;
Принимает два параметра, х и у, типа Т и возвращает true, если х > у; в
противном случае возвращает false (см. пример 5.3).
template <typename T> struct less;
Принимает два параметра, х и у, типа Т и возвращает true, если х < у; в
противном случае возвращает false,
template <typename T> struct greater_equal;
Принимает два параметра, х и у, типа Т и возвращает true, если х >= у;
в противном случае возвращает false,
template <typename T> struct less_equal;
Принимает два параметра, х и у, типа Т и возвращает true, если х <= у;
в противном случае возвращает false.
23.5. Логические операции
STL предоставляет базовые классы функциональных объектов для следующих логических
операторов языка: н, или, не. Базовая функциональность логических операторов описывается далее.
template <typename T> struct logical_and;
Принимает два параметра, х и у, типа Т и возвращает результат типа bool
логической операции и: х && у.
template <typename T> struct logical_or;
Принимает два параметра, х и у, типа Т и возвращает результат типа bool
логической операции или: х | | у.
template <typename T> struct logical_not;
Принимает один параметр х типа Т и возвращает результат типа bool
логической операции не: ! х.
380
Часть III. Справочное руководство по STL
23.6. Инверторы
Инверторы представляют собой функциональные адаптеры, которые получают предикат и
возвращают обратный ему. STL предоставляет инверторы notl и not2, которые получают
унарный и бинарный предикаты соответственно, и возвращают обратные им.
template <typename Predicate> class unary_negate;
template <typename Predicate>
unary_negate<Predicate> notl(const Predicates x);
Функция notl принимает унарный предикат х и возвращает предикат !х в
виде экземпляра unary_negate (см. пример 13.1). Объект типа
unary_negate может также инстанцироваться непосредственно. Его
конструктор получает унарный предикат рred.
template <typename Predicate> class binary_negate;
template <typename Predicate>
binary_negate<Predicate> not2(const Predicates x);
Эта функция принимает бинарный предикат х и возвращает предикат !х
(см. примеры 11.1 и 15.1). Объект типа binary_negate также может быть
инстанцирован непосредственно с передачей конструктору бинарного
предиката pred.
23.7. Связыватели
Связыватели представляют собой функциональные адаптеры, которые преобразуют
бинарные функциональные объекты в унарные путем назначения аргументу некоторого
конкретного значения. STL предоставляет два связывателя, bindlst и bind2nd.
template <typename Operation> class binderlst;
template <typename Operation, typename T>
binderlst<Operation>
bindlst(const Operation^ op, const T& x);
Принимает функциональный объект op от двух аргументов и значение х
типа Т. Возвращает функциональный объект от одного аргумента,
созданный из ор, первый аргумент которого равен х (см. примеры 13.1 и 15.1).
Тип binderlst имеет конструктор с аргументами, аналогичными
аргументам bindlst, а именно const Operation& и const T&.
template <typename 0peration> class binder2nd;
template <typename Operation, typename T>
binder2nd<0peration>
bind2nd(const Operation& op, const T& x);
Принимает функциональный объект ор от двух аргументов и значение х
типа Т. Возвращает функциональный объект от одного аргумента,
созданный из ор, второй аргумент которого равен х. Тип binder2nd имеет
конструктор с аргументами const Operation^ и const T&.
Глава 23. Справочное руководство по функциональным объектам и адаптерам
381
23.8. Адаптеры для указателей на функции
Адаптеры для указателей на функции предоставляются для того, чтобы позволить
указателям на бинарные и унарные функции работать с функциональными адаптерами,
предоставляемыми библиотекой. Они также могут помочь избежать разбухания кода из-за
множественных экземпляров шаблонов в одной программе (см. раздел 11.3 и пример 11.2).
template <typename Arg, typename Result>
class pointer_to_unary_function;
template <typename Arg, typename Result>
pointer_to_unary_function<Arg, Result>
ptr_fun(Result (*x) (Arg));
Получает указатель на унарную функцию, которая принимает аргумент
типа Arg, и возвращает результат типа Result. На основе данного
указателя создается и возвращается функциональный объект типа
pointer_to_unary_function<Arg, Result>. Конструктор класса
pointer_to_unary_function получает в качестве аргумента
указатель на функцию соответствующего типа.
template <typename Argl, typename Arg2, typename Result>
class pointer_to_binary_function;
template <typename Argl, typename Arg2, typename Result>
pointer_to_binary_function<Argl/ Arg2, Result>
ptr_fun(Result (*x) (Argl, Arg2));
Получает указатель на бинарную функцию, которая принимает аргументы
типа Argl и Arg2, и возвращает результат типа Result. На основе
данного указателя создается и возвращается функциональный объект типа
pointer_to_binary_function<Argl,Arg2,Result>. Конструктор
pointer_to_binary_function получает в качестве аргумента
указатель на функцию соответствующего типа. См. пример 11.2.
23.9. Адаптеры для указателей на
функции-члены
Адаптеры для указателей на функции-члены предоставляются для того, чтобы позволить
указателям на функции-члены работать с функциональными адаптерами, предоставляемыми
библиотекой. Когда функция-член превращается в обычный функциональный объект,
указатель this становится аргументом новой функции. Таким образом, функция-член класса X,
которая не получает аргументов, превращается в функцию, которая имеет один аргумент типа
X* (или Х&, если используется адаптер mem_fun_ref). Адаптеры предоставляются для
функций-членов без аргументов или с одним аргументом.
template <typename Result, typename T>
class mem_fun_t;
template <typename Result, typename T>
mem_fun_t<Result, T> mem_fun(Result (T::*x) ());
Принимает указатель на функцию-член класса Т, которая не получает
аргументов и возвращает результат типа Result. На основе данного указателя
создается и возвращается функциональный объект типа mem_f un_t<Result, Т>.
382
Часть III. Справочное руководство по STL
Если функциональный объект вызывается как f (р), где р представляет собой
указатель на Т, то он возвращает результат выполнения (р- >*х) ().
template <typename Result, typename T, typename Arg>
class mem_funl_t;
template <typename Result, typename T, typename Arg>
mem_funl_t<Result/ T\ Arg> mem_fun(Result (T::*x) (Arg));
Принимает указатель на унарную функцию-член класса Т, которая получает
аргумент типа Arg, и возвращает результат типа Result. На основе
данного указателя создается и возвращается функциональный объект типа
mem_f unl_t<Result, T, Arg>. Если функциональный объект вызывается
как f (p, arg), где р представляет собой указатель на Т, a arg имеет тип
Arg, то он возвращает результат выполнения (р->*х) (arg).
template <typename Result, typename T>
class mem_fun_ref_t;
template <typename Result, typename T>
mem_fun_ref_t<Result, T> mem_fun_ref(Result (T::*x) ());
Принимает указатель на функцию-член класса Т, которая не получает
аргументов и возвращает результат типа Result. На основе данного указателя
создается и возвращается функциональный объект типа mem_fun_
ref_t<Result,T>. Если функциональный объект вызывается как f (r), где
г имеет тип Т&, то он возвращает результат выполнения (г.*х) ().
template <typename Result, typename T, typename Arg>
class mem_funl_ref_t;
template <typename Result, typename T, typename Arg>
mem_funl_ref_t<Result, T, Arg>
mem_fun_ref(Result (T::*x) (Arg));
Принимает указатель на унарную функцию-член класса Т, которая получает
аргумент типа Arg, и возвращает результат типа Result. На основе
данного указателя создается и возвращается функциональный объект типа
mem_funl_ref_t<Result/T/Arg>. Если функциональный объект
вызывается как f (r# arg), где г имеет тип Т&, a arg имеет тип Arg, то он
возвращает результат выполнения (г. *х) (arg).
template <typename Result, typename T>
class const_mem_fun_t;
template <typename Result, typename T>
const_mem_fun_t<Result, T> mem_fun(Result (T::*x) 0 const);
Принимает указатель на константную функцию-член класса Т, которая не
получает аргументы, и возвращает результат типа Result. На основе
данного указателя создается и возвращается функциональный объект типа
const_mem_fun_t<Result,T>. Если функциональный объект
вызывается как f (р), где р имеет тип const T*, то он возвращает результат
выполнения (р->*х) ().
template <typename Result, typename T, typename Arg>
class const_mem_funl_t;
template <typename Result, typename T, typename Arg>
const_mem_funl_t<Resuit, T, Arg>
mem_fun(Result (T::*x) (Arg) const);
Глава 23. Справочное руководство по функциональным объектам и абаптерам jbj
Принимает указатель на константную функцию-член класса Т, которая
получает аргумент типа Arg и возвращает результат типа Result. На основе
данного указателя создается и возвращается функциональный объект типа
const_mem_funl_t<Result/T/Arg>. Если функциональный объект
вызывается как f (р, arg), где р имеет тип const T*, a arg имеет тип
Arg, то он возвращает результат выполнения (р- >*х) (arg).
template <typename Result, typename T>
class const_mem_fun_ref_t;
template <typename Result, typename T>
const_mem_fun_ref_t<Resuit, T>
mem_fun_ref(Result (T::*x) () const);
Принимает указатель на константную функцию-член класса Т, которая не
получает аргументы, и возвращает результат типа Result. На основе
данного указателя создается и возвращается функциональный объект типа
const_mem_fun_ref_t<Result/T>. Если функциональный объект
вызывается как f (г), где г имеет тип const T&, то он возвращает результат
выполнения (г. *х) ().
template <typename Result, typename T, typename Arg>
class const_mem_funl_ref_t;
template <typename Result, typename T, typename Arg>
const_mem_funl_ref_t<Result, T, Arg>
mem_fun_ref(Result (T::*x) (Arg) const);
Принимает указатель на константную функцию-член класса Т, которая
получает аргумент типа Arg и возвращает результат типа Result. На основе
данного указателя создается и возвращается функциональный объект типа
cons t_mem_f unl_ref _t< Re suit, T, Arg>. Если функциональный объект
вызывается как f (г, arg), где г имеет тип const T&, a arg имеет тип Arg,
то он возвращает результат выполнения (г. *х) (arg).
Глава 24
Справочное руководство
по аллокаторам
24.1. Введение
Каждый класс контейнера STL использует класс Allocator для инкапсуляции
информации о модели распределения памяти, используемой программой. Например, отладочный ал-
локатор может выполнять проверки границ областей памяти или выявлять утечки памяти.
Аллокатор представляет собой шаблон класса, параметризованный типом объекта, для
которого он может выделять память. Класс Allocator инкапсулирует информацию об
указателях, константных указателях, ссылках, константных ссылках, размерах объектов, типе
разности между указателями, функции выделения и освобождения памяти, а также некоторые
другие функции. Точный набор типов и функций, определенных в аллокаторе,
рассматривается в разделе 24.3.
Поскольку информация о модели распределения памяти может быть инкапсулирована в
аллокаторе, контейнеры STL могут работать с разными моделями, просто используя
различные аллокаторы. Ожидается, что все операции с аллокаторами имеют константное
амортизированное время выполнения.
24.1.1. Передача аллокаторов контейнерам STL
После того как класс аллокатора для некоторой модели распределения памяти создан, его
следует передать контейнеру STL, для того чтобы тот корректно работал с рассматриваемой
моделью. Это выполняется путем передачи аллокатора контейнеру STL в виде параметра
шаблона. Например, контейнер vector имеет следующий интерфейс:
template <typename T\ typename Allocator = allocator<T> >
class vector
По умолчанию значение параметра Allocator— allocator<T>. Этот тип является
типом аллокатора по умолчанию, предоставляемым библиотекой.
24.2. Требования к аллокаторам
Определения типов, общие для всех аллокаторов. Далее приведены общие
определения типов, которые должны быть во всех классах аллокаторов. Предполагается, что X —
класс аллокатора для объектов типа Т, a Y — класс аллокатора для объектов типа U.
value_type
Тип объектов, создаваемых аллокатором. Этот тип идентичен Т.
reference
Тип, который может использоваться для сохранения информации в
объектах типа value_type. Этот тип идентичен Т&.
const_reference
Тип, который может использоваться для сохранения информации в
константных объектах типа value_type. Этот тип идентичен const T&.
pointer
Тип, который может использоваться для адресации объектов типа
value_type.
const_pointer
Тип, который может использоваться для адресации константных объектов
типа value_type.
difference_type
Тип, который может представлять разность между двумя указателями в
модели распределения памяти (обычно ptrdif f _t).
size_type
Тип, который может представлять размер наибольшего объекта в модели
распределения памяти (обычно size_t).
template rebind<U>::other
Предоставляет механизм для получения типа аллокатора, Y, для объектов
типа U, которые используют ту же модель памяти, что и X. По сути, это
шаблонное определение типа такое, что если X представляет собой
SomeAllocator<T>, то rebind<U> : : other является тем же типом, что
и SomeAllocator<U>. Отношение транзитивно, т.е. Y: .-template
rebind<T>: : other представляет собой X.
В реализациях контейнеров разрешается считать, что pointer представляет собой Т*,
const_jpointer— const T*, size_type— size_t, a dif ference_type
представляет собой ptrdif f_t.
Функции-члены, общие для всех аллокаторов. Далее приведен список функций-
членов, которые должны присутствовать в любом аллокаторе. В приведенных далее
описаниях предполагается следующее.
• Т и U — могут быть любыми типами.
• X — представляет собой класс аллокатора для объектов типа Т.
• Y — представляет собой класс аллокатора для объектов типа U.
• t — представляет собой значение типа const T&.
• a, al и а2 — являются значениями типа Х&.
• b — является значением типа Y.
• р — является значением типа X: :pointer, полученным вызовом al. allocate, где
al == a.
• q — является значением типа X: : const_pointer, полученным путем
преобразования из значения р.
• г — является значением типа X: : reference, полученным при помощи выражения *р.
• s — является значением типа X: : const_ref erence, полученным при помощи
выражения *q или путем преобразования значения г.
• и— является значением типа Y: :const^pointer, полученным посредством
Y: :allocate,B противном случае значением 0.
• п — является значением типа X: : s i z e_type.
Все приведенные далее операции выполняются за константное амортизированное время.
Х();
Конструктор по умолчанию.
X а(Ь)
Создает аллокатор типа Т из аллокатора для типа U. Заметим, что, как
частный случай, типы Т и U могут быть одинаковы, и в этом случае X а (Ь)
представляет собой копирующий конструктор. Постусловием является
выполнение соотношения Y (а) = = Ь.
a.address(r)
a.address(s)
a.allocate(n)
a.allocate(n.
Возвращает адрес объекта г (или константной ссылки s) в виде значения
типа X: : pointer (X: : const_pointer для s).
г
Возвращает указатель типа X: : pointer на начальный элемент массива из
п объектов типа Т. Сами объекты не конструируются.
Как и в случае а. allocate (n), возвращает указатель типа X: : pointer на
начальный элемент массива из п объектов типа Т. Сами объекты не
конструируются. Второй аргумент, и, представляет собой подсказку, которая может
использоваться для повышения локальности ссылки. В случае контейнеров
хорошим выбором является this или указатель на соседний элемент.
a.deallocate(р, п);
Освобождает память для п объектов типа Т по адресу р. До вызова
deallocate должны быть вызваны деструкторы объектов. Значение п
должно соответствовать значению, переданному вызову allocate, a p не
может быть нулевым.
a.max size О
al == a2
al != a2
Возвращает значение типа X: :size_type, представляющее наибольшую
величину, которая может быть осмысленно передана вызову
X::allocate.
Возвращает true тогда и только тогда, когда память, выделенная одним
аллокатором, может быть освобождена другим. В реализациях контейнеров
разрешается считать, что это соотношение всегда истинно для экземпляров
одного и того же типа аллокатора.
Тоже, что и ! (al == a2).
a.construct(p, t);
Создает копию t в памяти по адресу р. Это то же выражение, что и
new ((void*)p) T(t).
a.destroy(p);
Уничтожает объект в памяти по адресу р. Это то же выражение, что и
((Т*)р)->~Т().
24.3. Аллокатор по умолчанию
24.3.1. Файлы
#include <memory>
24.3.2. Объявление класса
template <typename T> class allocator
24.3.3. Описание
Библиотека предоставляет реализацию аллокатора по умолчанию, которая имеет имя
класса allocator и используется классами контейнеров, когда тип аллокатора явно не
указан. Этот аллокатор использует операторы :: operator new (size t) и
: : operator delete (void *) для выделения и освобождения памяти соответственно.
24.3.4. Определения типов
size_type
Тип, который может представить размер наибольшего объекта в
используемой модели распределения памяти, size_t.
difference_type
Тип, который может представлять разность между двумя указателями в
используемой модели распределения памяти, ptrdif f_t.
pointer
const_pointer
pointer представляет собой тип адресов памяти выделенных объектов, Т*.
const_pointer — соответствующий константный тип указателя, const T*.
reference
const_reference
reference представляет собой тип местоположений выделенных
объектов, Т&, a const_reference— соответствующий константный
ссылочный тип, const Т&.
value_type
Тип объектов, создаваемых аллокатором — Т.
template rebind<U>::other
Указывает аллокатор по умолчанию для типа U. Эквивалентно allocator<U>.
24.3.5. Конструкторы, деструкторы и связанные функции
allocator();
Конструктор по умолчанию.
Глава 24. Справочное руководство по аллокаторам
389
allocator (const allocators:) ;
Копирующий конструктор,
template <typename U> allocator(const allocator<U>&);
Конструирует аллокатор объектов типа Т из аллокатора объектов типа U.
-allocator();
Деструктор.
24.3.6. Другие функции-члены
pointer address(reference x) const;
const_pointer address(const_reference x) const;
Возвращает указатель на ссылочный объект х. Конкретно, она возвращает &х.
pointer allocate(size_type n,
typename allocator<void>::const_pointer hint = 0);
Выделяет память для п объектов типа value_type, но сами объекты не
создаются. Использует глобальный оператор new. Обратите внимание, что
различные модели распределения памяти требуют различных функций
allocate (вот почему эта функция инкапсулирована в класс аллокатора).
Функция-член allocate может генерировать соответствующее
исключение. Указатель hint может использоваться для повышения степени
локализации. В функции-члене контейнера в качестве параметра hint обычно
передается указатель this. Когда и как часто должен вызываться оператор
: : operator new, не указывается.
void deallocate(pointer р, size_type n) ;
Освобождает память, на которую указывает указатель р, при помощи
глобального оператора delete. Все объекты в области, на которую указывает
р, должны быть уничтожены до вызова deallocate. Когда и как часто
должен вызываться оператор : : operator delete, не указывается.
size_type max_size();
Возвращает наибольшее положительное значение N, для которого вызов
allocate (N) может быть успешен.
void construct(pointer р, const T& val);
Создает копию val в памяти, на которую указывает р, при помощи вызова
new ((void*)p) T(val).
void destroy(pointer p);
Уничтожает объект, на который указывает р, при помощи вызова
( (Т*)р)->~Т().
24.3.7. Операции сравнения
template «ctypename Tl, typename T2>
bool operator==(const allocator<Tl>&,
const allocator<T2>&);
Всегда возвращает true.
template <typename Tl, typename T2>
bool operator!=(const allocator<Tl>&,
const allocator<T2>&);
Всегда возвращает false.
390
Часть III. Справочное руководство по STL
24.3.8. Специализация для void
Для типа void имеется отдельная специализация, поскольку ссылка на void и выделение
памяти для объекта типа void невозможно.
template о class allocator<void> { // Специализация
public:
typedef void* pointer;
typedef const void* const_pointer;
typedef void value__type;
template <typename U> struct rebind {
typedef allocator<U> other;
};
};
24.4. Пользовательские аллокаторы
В качестве примера пользовательского аллокатора мы рассмотрим аллокатор,
записывающий все выделения и освобождения памяти в поток сегг. Он может также
использоваться вместе с отладчиком для установки точек останова в функциях allocate и deallocate.
Наш записывающий аллокатор будет использовать некоторый другой аллокатор в
качестве базы для выполнения реальных операций распределения памяти. Записывающий
аллокатор, таким образом, в действительности представляет собой адаптер, который добавляет к
любому существующему классу аллокатора функциональность записи.
Мы поместим код в приведенный ниже заголовочный файл 1 ода 11 ос.h. Детали его
реализации будут рассмотрены ниже.
"logalloc.h" 390 =
#include <memory>
#include <iostream>
using namespace std;
template <typename T, typename Allocator = allocator<T> >
class logging allocator
{
private:
Allocator alloc;
public:
typedef typename Allocator::size_type size_type;
typedef typename Allocator::difference_type
difference_type;
typedef typename Allocator::pointer pointer;
typedef typename Allocator::const_pointer
const_pointer;
typedef typename Allocator::reference reference;
typedef typename Allocator::const_reference
const_reference;
typedef typename Allocator::value_type value_type;
template <typename U> struct rebind {
typedef
logging_allocator<U,
typename Allocator::template
rebind<U>::other> other;
};
logging_allocator() {}
logging_allocator(const logging_allocator& x)
: alloc(x.alloc) {}
Глава 24. Справочное руководство по аллокаторам
391
};
template <typename U>
logging_allocator(const logging_allocator<U,
typename Allocator::template
rebind<U>::other>& x)
: alloc(x.alloc) {}
~logging_allocator() {}
pointer address(reference x) const {
return alloc.address(x);
}
const_pointer address(const_reference x) const {
return alloc.address(x);
}
size_type max_size() const {
return alloc.max_size();
}
void construct(pointer p, const value_type& val) {
alloc.construct(p, val);
}
void destroy(pointer p) { alloc.destroy(p); }
pointer allocate(size_type n, const void* hint = 0) {
ios::fmtflags flags = cerr.flags();
cerr << "allocate(" << n << ", "
<< hex << hint << dec << ") = ";
pointer result = alloc.allocate(n, hint);
cerr << hex << result << dec << endl;
cerr.setf(flags);
return result;
}
void deallocate(pointer p, size_type n) {
ios::fmtflags flags = cerr.flags();
cerr << "deallocate(" << hex << p << dec << ", "
<< n << ")" << endl;
alloc.deallocate(p, n);
cerr.setf(flags);
}
template <typename T, typename Allocatorl,
typename U, typename Allocator2>
bool operator==(const logging_allocator<T, Allocatorl>& x,
const logging_allocator<U, Allocator2>& y)
{
return x.alloc == y.alloc;
}
template <typename T\ typename Allocatorl,
typename U, typename Allocator2>
bool operator!=(const logging_allocator<T/ Allocatorl>& x,
const logging_allocator<U, Allocator2>& y)
{
return x.alloc != y.alloc;
}
Мы определили наш новый аллокатор logging_allocator как шаблон класса с типом
значения и типом адаптируемого аллокатора в качестве параметров. Это позволяет использо-
392
Часть III. Справочное руководство по STL
вать наш класс с аллокатором по умолчанию, не препятствуя при этом применению других
пользовательских аллокаторов.
Чтобы использовать наш аллокатор для выделения памяти для целых чисел при помощи алло-
катора по умолчанию, мы пишем просто logging_allocator<int>. Чтобы воспользоваться
другим аллокатором, например, MyAllocator, мы пишем logging allocator<int,
MyAllocator<int> >, передавая в качестве параметров шаблона тип значения и тип алло-
катора.
Типы, требуемые аллокаторами, определены в терминах параметра шаблона Allocator.
Шаблон rebind несколько необычен, поскольку нам надо переопределить оба параметра
шаблона через новый тип значения.
Конструкторы, деструктор и все функции-члены за исключением allocate
и deallocate просто передают управление базовому аллокатору. То же делается и в случае
операций сравнения с базовым аллокатором для определения эквивалентности.
Функция allocate выводит свои аргументы и возвращаемое значение в поток сегг,
а вся реальная работа выполняется методом allocate базового аллокатора. Мы сохраняем
и восстанавливаем флаги форматирования сегг, поскольку они изменяются при выводе
указателя в шестнадцатеричной системе счисления.
pointer allocate(size_type n, const void* hint = 0) {
ios::fmtflags flags = cerr.flags();
cerr << "allocate(" << n << ", "
<< hex << hint << dec << ") = ";
pointer result = alloc.allocate(n, hint);
cerr << hex << result << dec << endl;
cerr.setf(flags);
return result;
}
Функция deallocate подобна функции allocate. Она выводит свои аргументы и
вызывает метод deallocate базового аллокатора для освобождения памяти. Здесь также
сохраняются и восстанавливаются флаги форматирования для потока сегг.
void deallocate(pointer р, size_type n) {
ios::fmtflags flags = cerr.flags();
cerr << "deallocate(" << hex << p << dec << ", "
<< n << ")" << endl;
alloc.deallocate(p, n);
cerr.setf(flags);
}
В следующем примере демонстрируется использование нашего аллокатора. Мы создаем
три вектора, один из которых использует аллокатор по умолчанию, а два — записывающий
аллокатор. Затем мы вставляем десять элементов в каждый вектор. В третьем случае мы
сначала вызываем v3 . reserve (10) для резервирования памяти для элементов до вставки.
Заметим, что в каждом случае отличаются только типы векторов. Код вставки элементов в
векторы идентичен для всех случаев.
Пример 24.1. Демонстрация применения пользовательского аллокатора
мех24-01.срр" 392 г
#include <iostream>
#include <vector>
using namespace std;
Глава 24. Справочное руководство по аллокаторам
393
#include "logalloc.h"
int main()
{
cout << "Демонстрация использования "
<< "пользовательского аллокатора."
< < endl;
cout << "-- Аллокатор по умолчанию --" << endl;
vector<int> vl;
for (int i = 0; i < 10; ++i) {
cout << " Вставка " << i << endl;
vl.push_back(i);
}
cout << "-- Выполнено. --" << endl;
cout << "\n-- Пользовательский аллокатор --"
<< endl;
vector<int/ logging_allocator<int> > v2;
for (int i = 0; i < 10; ++i) {
cout << " Вставка " << i << endl;
v2.push back(i);
}
cout << "-- Выполнено. --" << endl;
cout << "\n-- Пользовательский аллокатор "
<< "с вызовом reserve --"
<< endl;
vector<int/ logging_allocator<int> > v3;
v3.reserve(10);
for (int i = 0; i < 10; ++i) {
cout << " Вставка " << i << endl;
v3.push_back(i);
}
cout << "-- Выполнено. --" << endl;
return 0;
}
В следующем примере вывода программы обратите внимание на то, что точная последе
вательность выделений памяти может варьироваться в зависимости от конкретной реализа
ции STL (как могут варьироваться и конкретные адреса выделяемой памяти).
Вывод примера 24.1
Демонстрация использования пользовательского аллокатора.
-- Аллокатор по умолчанию --
Вставка 0
Вставка 1
Вставка 2
Вставка 3
Вставка 4
Вставка 5
Вставка 6
Вставка 7
Вставка 8
Вставка 9
-- Выполнено. --
-- Пользовательский аллокатор --
Вставка 0
allocated, 0x0) = 0х46213е8
394 Часть III. Справочное руководство по STL
Вставка 1
allocate(2, 0x0) = 0х46213е0
deallocate(0x4621368, 1)
Вставка 2
allocate(4, 0x0) = 0x4621480
deallocate(0x4621360, 2)
Вставка 3
Вставка 4
allocate(8, 0x0) = 0x4621528
deallocate(0x4621480, 4)
Вставка 5
Вставка 6
Вставка 7
Вставка 8
allocate(16, 0x0) = 0х46217е8
deallocate(0x4621528, 8)
Вставка 9
-- Выполнено. --
-- Пользовательский аллокатор с вызовом reserve --
allocate(10, 0x0) = 0х4621а48
Вставка 0
Вставка 1
Вставка 2
Вставка 3
Вставка 4
Вставка 5
Вставка 6
Вставка 7
Вставка 8
Вставка 9
-- Выполнено. --
deallocate(0х4621а48, 10)
deallocate(0х46217е8, 16)
В первом случае, само собой разумеется, нет никакого вывода, связанного с распределением
памяти, поскольку в нем используется аллокатор по умолчанию. Однако во втором и третьем
случаях всякий раз при выделении или освобождении памяти вектором выводится
соответствующее сообщение. Во второй части видно, как по мере добавления элементов размер вектора
увеличивается в геометрической прогрессии. Всякий раз при вставке элемента, заполняющего
доступную память, вектору выделяется память в два раза превышающая имевшуюся ранее.
Например, при вставке четвертого элемента, после вывода сообщения Вставка 4, у
вектора больше нет памяти для размещения других элементов. Поэтому вектором выделяется
память для удвоенного количества элементов по сравнению с имеющимся
(allocate (8, 0x0) = 0x4 6214с8), старые значения копируются во вновь выделенную память,
а ранее использовавшийся блок памяти освобождается (deal locate (0x4 621420, 4)).
Третий случай демонстрирует, как вызов reserve выполняет выделение памяти сразу
для десяти элементов. После этого элементы вставляются в вектор без дополнительных
вызовов allocate или deallocate.
Последние два вызова deallocate выполняются деструкторами v2 и v3.
Глава 25
Справочное руководство
по утилитам
25.1. Введение
Заголовочный файл <utility> определяет ряд шаблонов функций и классов общего
применения, не относящихся ни к одной из рассмотренных в предыдущих главах категорий.
Эти шаблоны можно разделить на две подкатегории — шаблоны функций сравнения и
шаблоны класса pair.
25.2. Функции сравнения
Для упрощения определения полного набора функций сравнения для новых типов
предоставлены шаблоны функций для operator !=, operators operator>= и operator<=.
Эти функции реализованы через операторы == и <. Таким образом, для любого типа
необходимо явно определить сравнения "равно" и "меньше", чтобы получить полный набор
операций сравнения.
Эти функции находятся в пространстве имен std: : rel_ops. Для доступа к ним следует
включить в вашу программу строку using namespace std: : rel_ops.
template <typename T>
bool operator!=(const T&x, const T& y);
Возвращает ! (x == y).
template <typename T> bool
operator>(const T&x, const T& y);
Возвращает у < x.
template <typename T>
bool operator<=(const T&x, const T& y);
Возвращает ! (у < х).
template <typename T>
bool operator>=(const T&x, const T& y);
Возвращает ! (x < y).
396
Часть III. Справочное руководство по STL
25.3. pair
25.3.1. Файлы
#include <utility>
25.3.2. Объявление класса
template <typename Tl, typename T2> struct pair
25.3.3. Примеры
См. примеры 13.1 и 14.1.
25.3.4. Описание
Класс pair предоставляет структуру данных для хранения упорядоченных пар
произвольных типов. Элементы пары хранятся в двух членах-данных, first и second.
25.3.5. Определения типов
first_type
Тип значений в элементе first пары — Т1.
second_type
Тип значений в элементе second пары — Т2.
25.3.6. Члены-данные
first
Первый элемент пары.
second
Второй элемент пары.
25.3.7. Конструкторы
pair () ;
Конструктор по умолчанию, создающий пару, в которой каждый элемент
инициализируется собственным конструктором по умолчанию.
pair(const T1& х, const T2& у);
Создает пару, в которой элемент first инициализируется значением х, а
second — значением у.
template <typename U, typename V> pair(const pair<U, V> &p);
Создает пару, инициализируя first и second соответствующими
элементами пары р, выполняя при необходимости неявные преобразования типов.
template <typename Tl, typename T2>
pair<Tl, T2> make_pair(const T1& x, const T2& y);
Эта функция определена для удобства. Поскольку параметры шаблона
выводятся из аргументов функции, данная функция может в ряде ситуаций быть
синтаксически проще вызова конструктора. Сравните выражения pair<int, \
double>(5/ 3.1415926) Hmake_j?air (5, 3.1415926).
25.3.8. Функции сравнения
template <typename Tl, typename T2>
bool operator==(const pair<Tl, T2>& x,
const pair<Tl, T2>& y);
Возвращает true, если оба элемента пар равны:
х. first == у. first ScSc x. second == у. second.
template <typename Tl, typename T2>
bool operator<(const pair<Tl, T2>& x,
const pair<Tl, T2>& y);
Реализует лексикографическое сравнение элементов пар. Если элемент
first пары х меньше такового в паре у, функция возвращает true. В
противном случае, если элементы first пар равны, возвращается результат
сравнениях, second < у. second.
Приложение А
Заголовочные файлы STL
Чтобы использовать в своих программах компоненты STL, вы должны воспользоваться
директивой #include препроцессора для того, чтобы включить в программу один или
несколько заголовочных файлов. Во всех примерах данной книги предполагается, что
заголовочные файлы STL организованы и именованы согласно стандарту C++. Заголовочные файлы
библиотеки C++ в стандарте не используют суффикс .п. Те заголовочные файлы, которые
одновременно являются заголовочными файлами библиотеки С, имеют префикс с (например,
stdlib. h становится cstdlib). Прочие компоненты описаны далее.
1. Классы контейнеров vector, list и deque находятся в заголовочных файлах
<vector>, <list> и <deque> соответственно.
2. Классы set и multiset располагаются в заголовочном файле <set>, а классы тар
и multimap — в <тар>.
3. Адаптер stack находится в заголовочном файле <stack>, а адаптеры queue и
priority_queue — в <queue>.
4. Все обобщенные алгоритмы STL располагаются в заголовочном файле
<algorithm>, за исключением обобщенных числовых алгоритмов, которые
располагаются в заголовочном файле <numeric>.
5. Классы итераторов STL (кроме тех, что определены в классах контейнеров) и
адаптеры итераторов находятся в заголовочном файле <iterator>.
6. Классы функциональных объектов и функциональных адаптеров располагаются в
заголовочном файле <functional>.
Приложение Б
Справочное руководство
по строкам
Строки в стандартной библиотеке C++ реализованы как контейнер последовательности
"символов" (см. детальное определение контейнеров последовательностей в разделе 21.1.4).
Это означает, что, подобно всем контейнерам STL, строки поддерживают выражения,
определенные для контейнеров, включая итераторы (которые представляют собой аналог char* в
обычных нуль-завершенных строках С) и могут использоваться со всеми алгоритмами STL.
В этом приложении классы строк C++ представлены в их связи с STL, а потому это
приложение не может рассматриваться как полное руководство по строкам. Например, класс
basic_string предоставляет члены для добавления к строке, поиска в строке символов
или подстрок и замены диапазона символов другим диапазоном. Поскольку в общем случае
эти операции не поддерживаются контейнерами последовательностей, здесь они не
рассматриваются. Наша цель — рассмотреть те аспекты строк, которые связаны с использованием
строк с алгоритмами STL.
Б.1. Классы строк
Б.1.1. Файлы
#include <string>
Б.1.2. Объявление класса
template <typename charT,
typename traits = char_traits<charT>/
typename Allocator ■ allocator<charT> >
class basic_string
Мы не рассматриваем здесь параметр Allocator. Материал, посвященный аллокаторам,
вы можете найти в главе 24, "Справочное руководство по аллокаторам", и врезке
"Аллокаторы" в разделе 21.3.2.
В.1.3. Описание
Строки реализованы шаблоном класса basic_string. Для удобства при помощи typedef
класс basic_string<char> получает имя string, a basic_string<wchar__t>—
402
Приложение Б. Справочное руководство по строкам
wstring. Параметры шаблона charT и traits позволяют использовать различные типы
символов и даже различную семантику, как, например, сравнение, нечувствительное к регистру символов
или упорядочение в соответствии с национальным алфавитом.
Символы, которые могут содержаться в строке, не ограничены типом char. В
действительности символы могут быть практически любым типом без конструктора, для которого
можно определить свойства символов. Свойства символов определяют различные
характеристики символов, включая их порядок для сравнения, метод завершения последовательностей,
а также как копировать и перемещать диапазоны символов. Это обеспечивает высокую
гибкость представления символов, включая типы многобайтных символов, использующиеся в
международных наборах символов (но не ограничиваясь ими). Более подробно свойства
символов рассматриваются в разделе Б.2.
Класс basic_string выделяет и освобождает память посредством аллокатора. Класс
basic_string представляет собой контейнер последовательности (определенный в
разделе 21.1.4) и предоставляет итераторы произвольного доступа. Поэтому временные сложности
строковых операций также отвечают соответствующим требованиям к контейнерам
последовательностей (если явно не оговорено иное). В разделе Б. 1.10 описывается, когда итераторы
строк могут становиться недействительными.
Б.1.4. Определения типов
traits_type
Параметр шаблона traits.
char_type
Тип символов в строке. То же, что и charT и char_type параметра traits.
value_type
То же, что и char_type.
size_type
Беззнаковый целочисленный тип, который может представлять размер
любого экземпляра basic_string.
difference_type
Знаковый целочисленный тип, который может представлять разность между
двумя объектами basic_string: : iterator.
reference
const_reference
reference представляет собой тип местоположений символов в строке,
charTSc (или const charT& в случае const_ref erence).
pointer
const_pointer
pointer представляет собой тип указателей на символы строки (обычно
charT*, но в общем случае определяется типом аллокатора).
const_pointer — соответствующий константный тип указателя.
iterator
const_iterator
iterator представляет собой тип итератора с произвольным доступом для
обращения к charT, a const_iterator— константный итератор с
произвольным доступом для обращения к const charT. Гарантируется
наличие конструктора, создающего const_iterator из iterator.
Приложение Б. Справочное руководство по строкам
403
reverse_iterator
const_reverse_iterator
Неконстантный и константный обратные итераторы с произвольным
доступом.
allocator_type
Тип аллокатора, используемого строкой. Эквивалентно Allocator.
Б.1.5. Конструкторы, деструкторы и связанные функции
basic_string(const Allocators: = Allocator());
Конструктор по умолчанию для basic_string. Создает пустую строку
без символов (эквивалент ""). Время работы — константное.
basic_string(const basic_string& str, size_type pos = 0,
size_type n = npos,
const Allocators = Allocator());
Создает объект basic_string, содержимое которого представляет собой
подстроку str. Подстрока начинается с позиции, задаваемой pos, и
содержит не более п символов (меньше, если строка слишком короткая). В
частности, новая строка имеет размер, равный минимуму из значений п и
str.sizeO -pos. Обратите внимание, что в случае значений pos и п по
умолчанию мы получаем копирующий конструктор. Время работы —
O(N), где N— длина создаваемой строки.
basic_string(const charT* s, size_type n,
const Allocators: = Allocator () ) ;
Создает basic_string, содержимое которого представляет собой п
символов, на которые указывает s. Время работы линейно зависит от п.
basic_string(const charT* s,
const Allocators: = Allocator () ) ;
Создает объект basic_string, содержимое которого эквивалентно
массиву символов длиной traits: : length (s). Время работы составляет
O(n) , где N— длина создаваемой строки.
basic_string(size_type n, charT с,
const Allocators: = Allocator ()) ;
Создает объект basic_string с п копиями с. Время работы линейно
зависит от п.
template <typename InputIterator>
basic_string(InputIterator begin, Inputlterator end,
const Allocators = Allocator());
Создает объект basic_string из значений в диапазоне [begin;end), за
исключением случая, когда Inputlterator представляет собой
целочисленный тип — в этом случае результат таков, как если бы был выполнен вызов
basic_string(static_cast<size_type>(begin),
static_cast<value_type>(end))
Другими словами, в этом случае результат представляет собой begin
копий символа end. Время работы составляет O(N) , где N— длина
создаваемой строки.
404
Приложение Б. Справочное руководство по строкам
~basic_string();
Деструктор basicstring. Освобождает всю выделенную для строки память.
basic_string& operator=(const basic_string& str);
Оператор присваивания basic_string. Замещает содержимое текущей
последовательности копией строки str. Время работы пропорционально
длине строки str.
basic_string& operator=(const charT* s) ;
Оператор присваивания basic_string. Результат эквивалентен
присваиванию * this = basic_string(s).
basic_string& operator=(charT c);
Оператор присваивания basic_string. Результат эквивалентен
присваиванию *this = basic_string(l,с).
basic_string& assign(const basic_string& str);
Эквивалентно operator= (str).
basic_string& assign(const basic_string& str,
size_type pos, size_type n);
Эквивалентно assign(basic_string(str,pos,n)). В результате
строка содержит подстроку str, начинающуюся с позиции pos и
содержащую минимум H3nHstr.size() -pos символов.
basic_string& assign(const charT* s, size_type n) ;
Эквивалентно assign (basic_string (s#n) ). В результате строка
содержит п символов, на которые указывает s.
basic_string& assign(const charT* s);
Эквивалентно operator= (s).
basic_string& assign(size_type n, charT c);
Эквивалентно { clear (); insert (begin () ,n, c) ; }. В результате
строка содержит п символов со значением с.
template «ctypename InputIterator>
basic_string& assign(Inputlterator first,
Inputlterator last);
В результате строка содержит копии символов из диапазона [first; last),
который должен быть корректным диапазоном символов типа charT.
Эквивалентно { clear(); insert(begin(),first,last); }.
void reserve(size_type res_arg = 0);
Директива, которая информирует строку о планируемом изменении размера,
чтобы она могла соответствующим образом работать с памятью. Размер
строки при этом не изменяется, а время работы функции не более чем линейно
зависит от размера строки. Перераспределение памяти имеет место тогда и
только тогда, когда текущая емкость меньше аргумента функции (размер
выделенной для строки памяти возвращает функция-член capacity). После
вызова reserve в случае выполнения перераспределения памяти емкость
строки становится не меньше значения аргумента функции.
Перераспределение делает недействительными все ссылки, указатели и
итераторы, ссылающиеся на символы строки. Гарантируется, что после вызова
reserve не будут выполняться никакие перераспределения памяти, пока
Приложение Б. Справочное руководство по строкам
405
размер строки не достигнет размера, переданного в качестве аргумента
функции reserve,
void swap(basic_string<charT/ traits, Allocators str);
Обменивает содержимое текущей строки с содержимым строки str.
Текущая строка заменяет str и наоборот.
Б.1.6. Операции сравнения
template <typename charT, typename traits, typename Allocator>
bool operator==(
const basic_string<charT, traits, Allocators lhs,
const basic_string<charT, traits, Allocators rhs);
template <typename charT, typename traits, typename Allocator>
bool operator==(
const charT* lhs,
const basic_string<charT, traits, Allocators rhs);
template <typename charT, typename traits, typename Allocator>
bool operator==(
const basic_string<charT, traits, Allocators lhs,
const charT* rhs);
Операция эквивалентности для строк. Возвращает true, если
последовательности символов lhs и rhs посимвольно равны (с использованием
оператора charT: : operator==). Выполняется за линейное время. Во втором
варианте, где lhs имеет тип const charT*, результат эквивалентен
basic__string (lhs) == rhs. Третья функция аналогична второй.
template <typename charT, typename traits, typename Allocator>
bool operator!=(
const basic_string<charT, traits, Allocators lhs,
const basic_string<charT, traits, Allocators rhs);
template <typename charT, typename traits, typename Allocator>
bool operator!=(
const charT* lhs,
const basic_string<charT, traits, Allocators rhs);
template <typename charT, typename traits, typename Allocator>
bool operator!=(
const basic_string<charT, traits, Allocators lhs,
const charT* rhs);
Операция неэквивалентности для строк. Значения типа const charT*
преобразуются в строки basic_string(lhs) (или rhs). Возвращает
true, если последовательности символов в lhs и rhs посимвольно не
эквивалентны (с использованием оператора charT: : operator! =).
Выполняется за линейное время.
template <typename charT, typename traits, typename Allocator>
bool operator<(
const basic_string<charT, traits, Allocators lhs,
const basic_string<charT, traits, Allocators rhs);
template <typename charT, typename traits, typename Allocator>
bool operator<(
const charT* lhs,
const basic_string<charT, traits, Allocators rhs);
406
Приложение Б. Справочное руководство по строкам
template <typename charT, typename traits, typename Allocator>
bool operators (
const basic_string<charT, traits, Allocator>& lhs,
const charT* rhs);
Возвращает true, если lhs лексикографически меньше rhs, и false в
противном случае. Значения типа const charT* преобразуются в строки
basic_string (lhs) (или rhs). Выполняется за линейное время.
template <typename charT, typename traits, typename Allocator>
bool operator>(
const basic_string<charT, traits, Allocator>& lhs,
const basic_string<charT, traits, Allocator>& rhs);
template <typename charT, typename traits, typename Allocator>
bool operator>(
const charT* lhs,
const basic_string<charT, traits, Allocator>& rhs);
template <typename charT, typename traits, typename Allocator>
bool operator>(
const basic_string<charT, traits, Allocator>& lhs,
const charT* rhs);
Возвращает true, если lhs лексикографически больше rhs, и false в
противном случае. Значения типа const charT* преобразуются в строки
basic_string (lhs) (или rhs). Выполняется за линейное время.
template <typename charT, typename traits, typename Allocator>
bool operator<=(
const basic_string<charT, traits, Allocator>& lhs,
const basic_string<charT, traits, Allocator>& rhs);
template <typename charT, typename traits, typename Allocator>
bool operator<=(
const charT* lhs,
const basic_string<charT, traits, Allocator>& rhs);
template <typename charT, typename traits, typename Allocator>
bool operator<=(
const basic_string<charT, traits, Allocator>& lhs,
const charT* rhs);
Возвращает true, если lhs лексикографически меньше или равно rhs, и
false в противном случае. Значения типа const charT* преобразуются
в строки basic_string (lhs) (или rhs). Выполняется за линейное время.
template <typename charT, typename traits, typename Allocator>
bool operator>=(
const basic_string<charT, traits, Allocator>& lhs,
const basic_string<charT, traits, Allocator>& rhs);
template <typename charT, typename traits, typename Allocator>
bool operator>=(
const charT* lhs,
const basic_string<charT, traits, Allocator>& rhs);
template <typename charT, typename traits, typename Allocator>
bool operator>=(
const basic_string<charT, traits, Allocator>& lhs,
const charT* rhs);
Приложение Б. Справочное руководство по строкам
40
Возвращает true, если lhs лексикографически больше или равно rhs, i
false в противном случае. Значения типа const charT* преобразуются
в строки basic_string (lhs) (или rhs). Выполняется за линейное время.
Б.1.7. Функции-члены для доступа к элементам
iterator begin();
const_iterator begin() const;
Возвращает iterator (const_iterator в случае константной строки)
который может использоваться для начала обхода строки.
iterator end О;
const_iterator end() const;
Возвращает iterator (const_iterator в случае константной строки)
который может использоваться в сравнении для окончания обхода строки.
reverse_iterator rbeginO;
const_reverse_iterator rbeginO const;
Возвращает reverse_iterator (const_reverse_iterator в случа<
константной строки), который может использоваться для начала обход;
строки в обратном направлении.
reverse_iterator rend();
const_reverse_iterator rend() const;
Возвращает reverse_iterator (const_reverse_iterator в случае
константной строки), который может использоваться в сравнении для за
вершения обхода строки в обратном направлении.
size_type size О const;
Возвращает количество символов, хранящихся в настоящее время в строке.
size_type max_size() const;
Возвращает максимально возможный размер строки.
size_type capacity О const;
Возвращает наибольшее количество символов, которое строка может хра
нить без перераспределения памяти. См. также функцию-член reserve,
bool empty() const;
Возвращает true, если строка пустая (т.е. если begin () == end ()), i
false в противном случае.
reference operator[](size_type pos);
const_reference operator [] (size_type pos) const;
За константное время возвращает N-и символ от начала строки.
reference at(size_type n);
const_reference at(size_type n) const;
За константное время возвращает n-й символ от начала строки (после про
верки на выход за границы строки). Генерирует исключение
out_of_range, если n >= size ().
allocator_type get_allocator() const;
Возвращает копию аллокатора, использованного при создании объекта.
408
Приложение Б. Справочное руководство по строкам
Б. 1.8. Функции-члены для вставки
void push_back(const charT с);
Добавляет символ с в конец строки.
basic_string& insert(size_type posl, const basic_string& str);
Вставляет символы из строки str в текущую строку в позицию,
определяемую значением posl.
basic_string& insert(size_type posl, const basic_string& str,
size_type pos2, size_type n) ;
Вставляет в текущую строку в позицию, определяемую значением posl,
подстроку строки str. Подстрока начинается с позиции pos2 и содержит
количество символов, равное минимуму из значений п и
str.size()-pos2.
basic_string& insert(size_type pos, const charT* s,
size_type n);
Вставляет п символов, на которые указывает s, в позицию текущей строки,
определяемую значением posl.
basic_string& insert(size_type pos, const charT* s);
Вставляет traits : : length (s) символов, на которые указывает s, в
позицию текущей строки, определяемую значением posl.
basic_string& insert(size_type pos, size_type n, charT c);
Вставляет п копий символа с, начиная с позиции, определяемой значением pos.
iterator insert(iterator p, charT c);
Вставляет символ с в позицию строки, определяемую значением р.
Находящиеся в строке символы при необходимости сдвигаются. Возвращаемый
итератор указывает на позицию, куда был вставлен символ.
void insert(iterator p, size_type n, charT с);
Вставляет п копий символа с начиная с позиции, на которую указывает
итератор position.
template <typename InputIterator>
void insert(iterator p,
Inputlterator first, Inputlterator last);
Эквивалентно insert (p,basic_string (first, last) ). Обратите
внимание на работу конструктора в частном случае, когда Inputlterator
является целочисленным типом.
Б.1.9. Функции-члены для удаления
basic_string& erase(size_type pos = 0, size_type n = npos);
Удаляет xlen символов в позиции pos, где xlen представляет собой
минимум из значений п и size () -pos. В случае аргументов по умолчанию
эквивалентно clear ().
iterator erase(iterator position);
Удаляет символ строки, на который указывает position. Результат не
определен, если строка пуста. Возвращает итератор, указывающий на символ,
следующий за удаленным, или end (), если удален последний символ.
Приложение Б. Справочное руководство по строкам
409
iterator erase(iterator first, iterator last);
Предполагается, что итераторы first и last указывают в строку. Все
символы в диапазоне [first/last) удаляются из строки. Возвращает
итератор, указывающий на символ, следующий за удаленными, или end (),
если удален последний символ.
void clear();
Удаляет все символы в строке. Эквивалентно вызову а. erase (а.begin () ,
а. end () ) за исключением того, что clear не возвращает значения.
Б. 1.10. Дополнительные примечания
Все ссылки, указатели и итераторы на basic_string становятся недействительны после
следующих операций.
• Использование строки в качестве аргумента функций swap, operator >> и get line,
не являющихся членами.
• Использование строки в качестве аргумента basic_string: : swap.
• Вызов c_str или data.
• Вызов любой неконстантной функции-члена, отличной от operator [], at, begin,
rbegin, end и rend.
Б.2. Свойства символов
Б.2.1. Файлы
#include <string>
Б.2.2. Описание
Свойства символов используются для определения характеристик конкретного типа
символов. Класс свойств символов определяет упорядочение значений символов и типы и
функции для управления символами.
Имеется два предопределенных класса свойств символов: char_traits<char> и
char_traits<wchar_t>. В общем случае они используются в качестве параметров
шаблонов других классов, таких как basic_string (см. раздел Б.1). Нет никаких причин (а в общем
случае это и невозможно) для создания объекта типа char_traits, поскольку классы
char_traits содержат только определения синонимов типов и функции-члены, но не данные.
Б.2.3. Определения типов
char_type
Тип символов, свойства которого описываются.
int_type
Тип, достаточно большой для представления всех корректных значений
с ha r_ type вместе со значением конца файла.
47(/
Приложение Б. Справочное руководство по строкам
pos_type
Тип, который может использоваться для представления позиции символа в
файле. Обычно это streampos.
off_type
Тип, который может использоваться для представления разности между
двумя значениями роs_type. Обычно это streamof f.
state_type
Тип, который может использоваться для записи информации о состоянии в
процессе кодирования и декодирования многобайтных символов. Обычно
это mbstate__t.
Б.2.4 Функции для работы с символами
Все функции, определяемые типом свойств символов, — статические. Если явно не
указано иное, время работы таких функций — константное.
void assign(char_type& с, const char_type& d);
Присваивает значение d символу с.
bool eq(const char_type& с, const char_type& d);
Возвращает true, если с эквивалентно d, в противном случае— false,
bool It(const char_type& c, const char_type& d) ;
Возвращает true, если с меньше d, в противном случае— false.
int compare(const char_type* p, const char_type* q, size_t n);
Обобщение С-функции strcmp. Сравнивает массивы длины п, задаваемые
указателями р и q. Если для всех i из диапазона [0;п) вызов
eq(p[i] , q[i] ) возвращает true, функция возвращает 0. В противном
случае, если существует некоторое/ из диапазона [0 ;п), такое, что вызов
It (p [j] ,q [j] ) возвращает true, и для всех i из [0;j) вызов
eq(p[i] ,q[i] ) также возвращает true, функция возвращает
отрицательное значение. Если не выполняется ни первое, ни второе условие, функция
возвращает положительное значение. Время работы функции — линейное.
size_t length(const char_type* p) ;
Обобщение С-функции strlen. Возвращает наименьшее целое i такое, что
eq (p [i] , char_type () ) равно true. Время работы функции — линейное.
const char_type* find(const char_type* p,
size_t n, const char_type& c);
Обобщение С-функции strchr. Возвращает наименьший указатель q из
диапазона [р;р+п), такой, что eq(*q,c) равно true. В отличие от
обобщенного алгоритма find (но аналогично strchr), эта функция
возвращает нулевой указатель, если символ с не найден. Время работы
функции — линейное.
char_type* move(char_type* s, const char_type* p, size_t n);
Обобщение С-функции memmove. Перемещает символы из диапазона
[р;р+п) в диапазон [s; s+n), работая корректно даже в случае
перекрытия диапазонов. Возвращает s и имеет линейное время работы.
Приложение Б. Справочное руководство по строкам
411
char_type* copy(char_type* s, const char_type* p, size_t n);
Обобщение С-функции memcpy. Подобно move, копирует символы из
диапазона [р;р+п) в диапазон [s;s+n), но в данном случае диапазоны не
могут перекрываться. Возвращает s и имеет линейное время работы.
char_type* assign(char_type* s, size_t n, const char_type& c);
Обобщение С-функции memset. Вносит символ с во все позиции диапазона
[s; s+n). Возвращает s и имеет линейное время работы.
int_type not_eof(const int_type& e);
Возвращает е, если ecj__int_type (e, eof () ) равно false. В противном
случае возвращает некоторое значение типа int_type, отличное от eof ().
char_type to_char_type(const int_type& e);
Если е соответствует некоторому корректному значению char_type,
возвращает последнее. Если е представляет собой eof (), возвращаемое
значение не определено.
int_type to_int_type(const char_type& с);
Преобразует с в тип int_type.
bool eq_int_type(const int_type& e, const int_type& f);
Если е и f соответствуют корректным значениям char_type (т.е. если
существуют некоторые значения end, такие, что е представляет собой
to_int_type (с), a f— to_int_type (d)), то результат равен
eq(c,d). В противном случае функция возвращает true, если и е, и f
равны eof (), и false, если только одно из значений равно eof ().
int_type eof();
Возвращает значение, представляющее конец файла. Это значение должно
отличаться от всех корректных значений char_type. Таким образом,
eq_int_type (to_int_type (с) , eof () ) должно быть равно false
для всех значений с.
Приложение В
Заголовочные файлы, используемые
в примерах программ
В.1. Файлы, используемые в примере 17.1
Эти файлы взяты непосредственно из книги Страуструпа ([20], раздел 6.4).
"screen.h" 413a =
const int XMAX=4 0;
const int YMAX=24;
struct point {
int x,y;
point() {}
point(int a, int b) { x=a; y=b; }
};
extern void put_point(int a, int b);
inline void put_point(point p)
{ put_point(p.x, p.y); }
extern void put_line(int, int, int, int);
inline void put_line(point a, point b)
{ put_line(a.x, a.y, b.x, b.y); }
extern void screen_init();
extern void screen_destroy();
extern void screen_refresh();
extern void screen_clear();
"screen.cpp" 4136 =
#include "screen.h"
#include <iostream>
using namespace std;
enum color { black=■*', white=' ' } ;
char screen[XMAX][YMAX];
void screen_init()
{
for (int y=0; y<YMAX; y++)
for (int x=0; x<XMAX; x++)
screen[x][y] = white;
}
414 Приложение В. Заголовочные файлы, используемые в примерах программ
void screen_destroy() {}
inline int on_screen (int a., int b) // обрезка
{
return 0<=a && a<XMAX && 0<=b && b<YMAX;
}
void put_point(int a, int b)
{
if (on_screen(a, b)) screen[a][b] = black;
}
void put_line(int xO, int yO, int xl, int yl)
/*
Выводит отрезок от (xO, yO) до (xl, yl).
Выводимый отрезок - b(x-xO) +a(y-yO) = 0.
Минимизирует abs(eps)/ где eps = 2*(b(x-x0) + a(y-yO).
См. книгу Newman and Sproull
"Principles of Interactive Computer Graphics"
McGraw-Hill, New York, 1979. pp. 33-44.
*/
{
register int dx = 1;
int a = xl - xO;
if (a < 0) dx= -1, a = -a,-
register int dy = 1;
int b = yl - yO;
if (b < 0) dy = -1, b = -b;
int two_a = 2*a;
int two_b = 2*b;
int xcrit = -b + two_a;
register int eps = 0;
for(;;) {
put_point(xO,yO);
if (x0 = =xl ScSc yO == yl) break;
if (eps <= xcrit) xO += dx, eps += two_b;
if (eps>=a || a<=b) yO += dy, eps -= two_a;
void screen_clear() { screen_init(); }
void screen refresh()
{
for (int y=YMAX-l; 0<=y; y--) { // Сверху вниз
for (int x=0; x<XMAX; x++) // Слева направо
cout << screen[x][y];
cout << '\n';
"shape.h" 414 =
#include "screen.h"
inline int max(int a, int b) { return a<b ? b : a; }
inline int min(int a, int b) { return a<b ? a : b; }
Приложение В. Заголовочные файлы, используемые в примерах программ
415
struct shape {
static shape* list;
shape* next;
shape() { next = list; list = this; }
virtual point north() const = 0;
virtual point south() const = 0;
virtual point east() const = 0;
virtual point west() const = 0;
virtual point neast() const = 0;
virtual point seastO const = 0;
virtual point nwestO const = 0;
virtual point swestO const = 0;
virtual void draw() = 0;
virtual void move(int, int) = 0;
};
class line : public shape {
/*
Отрезок от "w" до "е".
north() определяется как
"самая удаленная точка над центром"
*/
point w, e;
public:
point north() const
{ return point((w.x+e.x)/2, max(e.y,w.y)); }
point south() const
{ return point((w.x+e.x)/2, min(e.y,w.y)); }
point east() const
{ return point(max(e.x, w.x), (w.y+e.y)/2); }
point west() const
{ return point(min(e.x, w.x), (w.y+e.y)/2); }
point neast() const
{ return point(max(e.x, w.x), max(e.y, w.y)); }
point seastO const
{ return point(max(e.x, w.x), min(e.y, w.y)); }
point nwestO const
{ return point(min(e.x, w.x), max(e.y, w.y)); }
point swestO const
{ return point(min(e.x, w.x), min(e.y, w.y)); }
void move(int a, int b)
{ w.x += a; w.y += b; e.x += a; e.y += b; }
void draw() { put_line(w,e); }
line(point a, point b) { w = a; e = b; }
line(point a, int len)
{ w = point(a.x + len - 1, a.y); e = a; }
ь
class rectangle : public shape {
/*
nw n ne
wee
1 I
1 1
sw s se
*/
point sw, ne;
public:
point north() const
{ return point((sw.x+ne.x)/2,
ne.y);
}
416
Приложение В. Заголовочные файлы, используемые в примерах программ
};
point south() const
{ return point((sw.x+ne.x)/2, sw.y); }
point eastO const
{ return point(ne.x, (ne.y+sw.y)/2); }
point west() const
{ return point(sw.x, (ne.y+sw.y)/2); }
point neastO const { return ne; }
point seastO const { return point(ne.x, sw.y); }
point nwestO const { return point(sw.x/ ne.y); }
point swestO const { return sw; }
void move(int a, int b)
{ sw.x += a; sw.y += b; ne.x += a; ne.y += b; }
void draw();
rectangle(point, point);
void shape_refresh(); // Вывод всех фигур
void stack(shape* p, const shape* q); // Помещает р над q
11 shape, cpp" 416 =
#include "shape.h"
rectangle: .-rectangle (point a, point b)
{
if (a.x <= b.x) {
if (а.у <= b.y) {
sw = a;
ne = b;
}
else {
sw = point(a.x, b.y);
ne = point(b.x, a.y);
}
}
else {
if (a.y <= b.y) {
sw ■ point(b.x, a.y);
ne = point(a.x, b.y);
}
else {
sw = b;
ne = a;
}
}
void rectangle::draw()
{
point nw(sw.x, ne.y);
point se(ne.x, sw.y);
put_line(nw,ne);
put_line(ne,se);
put_line(se,sw);
put_line(sw,nw);
void shape_refresh()
screen_clear();
for (shape* p = shape::list; p; p=p->next) p->draw();
Приложение В. Заголовочные файлы, используемые в примерах программ 417
screen refreshO;
}
void stack(shape* p, const shape* q) // put p on top of q
{
point n = q->north();
point s = p->south();
p->move(n.x-s.x; n.y-s.y+1);
}
shape* shape::list = 0;
Приложение Г
Ресурсы
Г.1. Адрес реализации SGI STL
На момент написания книги SGI Reference Implementation of STL была доступна по адресу
http://www.sgi.com/tech/stl/download.html.
Г.2. Адрес для получения исходных текстов
данной книги
Все файлы и информация, связанная с данной книгой, доступны на сайте издательства по
адресу http://www.awl.com/cseng/titles/0-201-37923-6/.
На сайте доступны:
• исходные тексты всех примеров данной книги;
• файл словаря, использованный в примерах программ в части II, "Примеры программ";
• текстовый файл, использовавшийся в качестве входного в примерах программ в
части II, "Примеры программ".
Г.З. Использованные компиляторы
В примерах данной книги успешно использовались следующие компиляторы:
• Borland C++, version 5.5 (DOS/Windows);
• Borland C++ Builder 6 с использованием STLport или старой реализации Rogue Wave
STL;
• SGI C++, version 7.3.1.1m.
Кроме того, примеры были протестированы с помощью компилятора от Free Software
Foundation:
• GNU C++, version 2.95.2.
Все примеры программ успешно компилировались и корректно работали при
использовании данного компилятора.
Список литературы
1. Accredited Standards Committee X3 (American National Standards Institute). Working
paper for draft proposed international standard for information systems—programming
language C++. Technical Report X3J16/95-0185, WG21/N0785, Information Processing
Systems, 1995.
2. Matthew H. Austern. Generic Programming and the STL: Using and Extending the C++
Standard Template Library. Addison-Wesley, Reading, MA, 1999.
3. Preston Briggs. Nuweb, a simple literate programming tool. Version 0.87, 1989.
4. Margaret A. Ellis and Bjarne Stroustrup. The Annotated C++ Reference Manual.
Addison-Wesley, Reading, MA, 1990.
5. ISO/IEC. International standard, programming languages—C++. Technical Report
ISO/IEC 14882:1998(E), American National Standards Institute, 1998.
6. M. Jazayeri. Component programming—a fresh look at software components. In Proc.
5th European Software Engineering Conference, Sitges, Spain, September 25-28, 1995.
7. Nicolai M. Josuttis. The C++ Standard Template Library: A Tutorial and Reference.
Addison-Wesley, Boston, MA, 1999.
8. D. Kapur, D. R. Musser, and A. A. Stepanov. Operators and algebraic structures. In Proc.
of Conference on Functional Programming Languages and Computer Architecture,
Portsmouth, NH, October 1981.
9. D. Kapur, D. R. Musser, and A. A. Stepanov. Tecton, a language for manipulating generic
objects. In Proc. of Workshop on Program Specification, Aarhus, Denmark, August 1981.
Also published in Lecture Notes in Computer Science, Springer-Verlag, New York, Vol.
134, 1982.
10. Donald E. Knuth. Literate programming. Computer Journal, 27:97-111, 1984.
11. D. Mcllroy. Mass-produced software components. Technical report, Petrocelli/Charter,
1976.
12. D. R. Musser. Introspective sorting and selection algorithms. Software—Practice and
Experience, 8:983-993, 1997.
13. D. R. Musser and G. V. Nishanov. A fast generic sequence matching algorithm.
http: //www.es .rpi .edu/-musser/gp, 1998.
14. D. R. Musser and A. A. Stepanov. The Ada Generic Library: Linear List Processing
Packages. Springer-Verlag, New York, 1989.
15. D. R. Musser and A. A. Stepanov. Algorithm-oriented generic libraries. Software
Practice and Experience, 24(7):623-642, July 1994.
16. D. R. Musser and A. A. Stepanov. Generic programming. In P. Gianni, editor, ISSAC '88
Symbolic and Algebraic Computation Proceedings, 1988. Also published in Lecture
Notes in Computer Science, Springer-Verlag, New York, Vol. 358.
17. P. J. Plauger, Alexander A. Stepanov, Meng Lee, and David R. Musser. The C++
Standard Template Library. Prentice-Hall, Upper Saddle River, NJ, 2001.
18. F. S. Roberts. Measurement theory. In Gian-Carlo Rota, editor, Encyclopedia of
Mathematics and Its Applications, Vol. 7. Addison-Wesley, Reading, MA, 1979.
19. A. A. Stepanov and M. Lee. The standard template library. Technical Report HP-94-34,
Hewlett-Packard, April 1994. Revised July 7, 1995.
20. Bjarne Stroustrup. The C++ Programming Language. Addison-Wesley, Reading, MA,
third edition, 1997.
21. Bjame Stroustrup. The Design and Evolution of C++. Addison-Wesley, Reading, MA,
1994.
22. Bjarne Stroustrup. Making a vector fit for a standard. The C++ Report, October 1994.
23. Т. Кормен, Ч. Лейзерсон, Р. Ривест, К. Штайн. Алгоритмы: построение и анализ,
2-е издание. — М.: Издательский дом "Вильяме", 2005.
24. Герб Саттер. Решение сложных задач на C++. — М.: Издательский дом "Вильяме",
2002.
А
accumulate, 131; 373
adjacentdifference, 133; 376
adjacentfind, 97; 345
assert, 53
в
backinsertiterator, 83; 287
Конструктор, 287
Объявление, 287
Функции-члены, 287
backinserter, 83; 288
basicstring, 401
assign, 404
at, 407
begin, 407
capacity, 404; 407
clear, 409
empty, 407
end, 407
erase, 408
getallocator, 407
insert, 408
maxsize, 407
operatorf], 407
pushback, 408
rbegin, 407
rend, 407
reserve, 404
size, 407
swap, 405
Конструктор, 403
Типы, 402
>inaryJunction, 378
anarynegate, 380
»inary_search, 123; 364
bindlst,202;380
bind2nd,201;380
С
chartraits, 409
assign, 410; 411
compare, 410
copy, 411
eof,411
eq,410
eq_int type, 411
find, 410
length, 410
It, 410
move, 410
noteof, 411
tochartype, 411
tointtype, 411
Типы, 409
clock, 259
copy, 104; 351
copybackward, 104; 351
count, 98; 346
countif, 99; 346
D
deque, 152-55; 305
assign, 306
at, 155
back, 155; 308
begin, 155; 307
clear, 309
empty, 155; 307
end, 155; 307
erase, 155; 308
front, 155; 308
getallocator, 308
insert, 308
maxsize, 155; 307
operator[], 155; 307
popback, 308
pop_front, 155; 308
pushback, 308
pushjront, 154; 308
rbegin, 155; 307
rend, 155; 307
resize, 307
size, 155; 307
Конструктор, 306
Объявление, 305
Типы, 306
distance, 236
divides, 378
E
equal, 100; 347
equalrange, 123; 364
equaljo, 379
F
fill, 105; 354
fill_n, 105; 354
find, 96; 344
find_end, 349
findfirstof, 344
find_if, 96; 344
for_each, 99; 343
frontinsertiterator, 83; 288
Конструктор, 288
Объявление, 288
Функции-члены, 288
frontjnserter, 84; 289
G
generate, 106; 354
generaten, 354
greater, 379
greaterequal, 379
I
includes, 126; 366
inner_product, 134; 374
inplacemerge, 125; 365
insertiterator, 83; 289
Конструктор, 289
Объявление, 289
Функции-члены, 289
inserter, 84; 290
istreamiterator, 280
Конструктор, 281
Объявление, 281
Функции-члены, 282
iterswap, 351
iterator, 279
iteratorcategory, 279
iteratortraits, 278
L
less, 379
lessequal, 379
lexicographicalcompare, 130; 371
list, 155-62; 309
assign, 311
back, 161; 312
begin, 161; 312
clear, 313
empty, 161; 312
end, 161; 312
erase, 157; 313
front, 161; 312
getallocator, 312
insert, 157; 313
maxsize, 161; 312
merge, 161; 314; 315
popback, 313
pop front, 313
pushback, 313
pushfront, 313
rbegin, 161; 312
remove, 314
removeif, 314
rend, 161; 312
resize, 312
reverse, 157; 315
size, 161; 312
sort, 160; 315
splice, 159; 313
swap, 306; 311
unique, 160; 314
Конструктор, 311
Объявление, 309
Типы, 310
logicaland, 379
logicalnot, 379
logical_or, 379
lowerbound, 123; 364
M
makeheap, 128; 369
map, 173-80; 324
begin, 178; 327
clear, 329
count, 178; 329
empty, 178; 327
end, 178; 327
equalrange, 178; 329
erase, 328
find, 178; 329
getallocator, 328
insert, 174; 328
keycomp, 327
lowerbound, 178; 329
max_size, 178; 327
operator[], 175; 178; 328
rbegin, 178; 327
rend, 178; 327
size, 178; 327
swap, 326
upperbound, 178; 329
valuecomp, 327
Конструктор, 326
Объявление, 324
Типы, 325
max, 129; 370
maxelement, 129; 370
mem fun, 381; 382
mem funref, 382; 383
merge, 125; 365
min, 129; 370
minelement, 129; 370
minus, 378
mismatch, 100; 346
modulus, 379
multimap, 173-80; 330
begin, 178; 331
clear, 333
count, 178; 333
empty, 178; 332
end, 178; 331
equalrange, 178; 334
erase, 333
find, 178; 333
getallocator, 332
insert, 174; 332
keycomp, 331
lowerbound, 178; 333
max_size, 178; 332
rbegin, 178; 332
rend, 178; 332
size, 178; 332
swap, 331
upperbound, 178; 333
valuecomp, 331
Конструктор, 330
Объявление, 330
Типы, 330
multiplies, 378
multiset, 164-73; 320
begin, 170; 322
clear, 323
count, 171; 324
empty, 170; 322
end, 170; 322
equalrange, 171; 324
erase, 168; 323
find, 170; 324
getallocator, 322
insert, 167; 323
keycomp, 322
lowerbound, 170; 324
maxsize, 170; 322
rbegin, 170; 322
rend, 170; 322
size, 170; 322
swap, 173; 321
upperbound, 170; 324
valuecomp, 322
Конструктор, 321
Объявление, 320
Типы, 321
N
negate, 379
nextjpermutation, 130; 372
notequalto, 379
notl,202;380
not2, 202; 380
nthelement, 122; 363
о
operator(), 181
ostreamiterator, 282
Конструктор, 283
Объявление, 283
Функции-члены, 284
О-обозначения, 48
р
pair, 396
partialsort, 120; 361
partialsortcopy, 361
partial_sum, 132; 375
partition, 107; 359
plus, 378
pointertobinary function, 381
pointertounaryfunction, 381
popheap, 128; 369
prev_permutation, 130; 372
priorityqueue, 193; 337
empty, 339
pop, 339
push, 339
size, 339
top, 339
Конструктор, 338
Объявление, 337
Типы, 338
ptrfun, 381
pushheap, 128; 369
Q
queue, 191; 336
back, 337
empty, 337
front, 337
pop, 337
push, 337
size, 337
Конструктор, 336
Объявление, 336
Типы, 336
R
randomshuffle, 109; 358
remove, 110; 355
removecopy, 355
removecopyif, 355
removeif, 355
replace, 111; 353
replacecopy, 353
replacecopyif, 353
replaceif, 353
reverse, 111; 357
reverse_copy, 357
reverseiterator, 284
Конструктор, 285
Объявление, 284
Функции-члены, 285
rotate, 111; 358
rotatecopy, 358
s
search, 102; 348
search_n, 349
set, 164-73; 315
begin, 170; 318
clear, 319
count, 171; 320
empty, 170; 318
end, 170; 318
equalrange, 171; 320
erase, 168; 319
find, 170; 320
getallocator, 318
insert, 167; 319
keycomp, 318
lowerbound, 170; 320
maxsize, 170; 318
rbegin, 170; 318
rend, 170; 318
size, 170; 318
swap, 173; 317
upperbound, 170; 320
valuecomp, 318
Конструктор, 317
Объявление, 316
Типы, 316
setdifference, 126; 366
setintersection, 126; 366
setsymmetricdifference, 126; 366
setunion, 126; 366
sort, 119; 361
sortheap, 128; 369
stable_partition, 107; 359
stablesort, 120; 361
stack, 190; 334
empty, 335
pop, 335
push, 335
size, 335
top, 335
Конструктор, 335
Объявление, 334
Типы, 335
string, 401
swap, 112; 351
swapranges, 113; 351
T
transform, 114; 352
и
unary function, 378
unarynegate, 380
unique, 114; 356
uniquecopy, 356
upperbound, 123; 364
V
vector, 138-52; 300
assign, 151; 302
at, 150; 304
back, 149; 304
begin, 149; 303
capacity, 145; 149; 302; 303
clear, 305
empty, 149; 303
end, 149; 303
erase, 148; 304
front, 149; 304
getallocator, 304
insert, 144; 304
maxsize, 149; 303
operator[], 150; 304
popback, 147; 304
pushback, 143; 304
rbegin, 149; 303
rend, 149; 303
reserve, 145; 302
resize, 303
size, 149; 303
swap, 151; 302
Конструктор, 301
Объявление, 300
Присваивание, 302
Типы, 301
vector<bool>, 300
w
wstring, 402
A
Абстрактный тип данных, 137
Адаптер, 67
backinsertiterator, 287
frontinsertiterator, 288
insertiterator, 289
reverseiterator, 67; 284
Для указателя на функцию, 69;
203; 378
Для указателя на функцию-член, 378
Инвертор, 69
Итератора, 197
Контейнера, 189
Обратного итератора, 197
Очереди, 69; 191; 336
Очереди с приоритетами, 69;
193;337
Связыватель, 69
Стека, 69; 190; 334
Функциональный, 201; 377
Адаптивность, 40
Аксессор, 149
Алгоритм
accumulate, 62; 64; 131; 373
adjacentdifference, 133; 376
adjacent_find, 97; 345
binarysearch, 123; 364
copy, 78; 104; 351
copybackward, 104; 351
count, 98; 346
count_if, 99; 346
equal, 100; 347
equalrange, 123; 364
fill, 105; 354
fill_n, 105; 354
find, 56; 96; 344
find_end, 349
findfirstof, 344
find_if, 96; 344
for_each, 99; 343
generate, 106; 354
generaten, 354
includes, 126; 366
inner_product, 134; 374
inplacemerge, 125; 365
iterswap, 351
lexicographicalcompare, 130; 371
lowerbound, 123; 364
makeheap, 128; 369
max, 129; 370
maxelement, 129; 370
merge, 59; 125; 365
min, 129; 370
minelement, 129; 370
mismatch, 100; 346
next_permutation, 130; 372
nthelement, 122; 363
partialsort, 120; 361
partialsortcopy, 361
partial_sum, 132; 375
partition, 107; 359
popheap, 128; 369
prev_permutation, 130; 372
pushheap, 128; 369
random_shuffle, 109; 358
remove, 110; 355
removecopy, 355
remove_copy_if, 355
removeif, 355
replace, 111; 353
replacecopy, 353
replacecopyif, 353
replaceif, 353
reverse, 111; 357
reverse_copy, 357
rotate, 111; 358
rotatecopy, 358
search, 102; 348
searchn, 349
setdifference, 126; 366
setintersection, 126; 366
setsymmetricdifference, 126; 366
setunion, 126; 366
sort, 119; 361
sortjieap, 128; 369
stable_partition, 107; 359
stable_sort, 120; 361
swap, 112; 351
swapranges, 113; 351
transform, 114; 352
unique, 114; 356
uniquecopy, 356
upperbound, 123; 364
Амортизированное время работы, 49
Быстрой сортировки, 119
Время работы, 49
Выбор, 89
Генерации перестановок, 130
Евклида, 27
Интроспективной сортировки, 120
Обобщенный, 56
Пирамидальной сортировки,
119;120
Хронометраж, 259
Аллокатор, 70; 300; 385
Общие функции-члены, 386
Определения типов, 385
По умолчанию, 388
Специализация для void, 390
В
Вектор, 138-52
Вставка, 143; 304
Доступ к элементам, 149
Конструктор, 139
Перераспределение памяти, 145
Присваивание, 302
Типы, 138
Удаление, 147; 304
Виртуальная функция, 244
Входной итератор, 76
Зыходной итератор, 77
г
Грамотное программирование, 34; 54;
210
д
Двунаправленный итератор, 79
Дек, 152-55
Вставка, 154; 308
Конструктор, 154
Объявление, 305
Удаление, 155; 308
Диапазон, 75; 274
Достижимость, 274
Доступ
Произвольный, 51
И
инвертор, 202; 378; 380
тнстанцирование, 43
итератор, 58; 61; 75; 273-90
istream, 76; 85
ostream, 78
Вставки, 83
Входной, 75; 274
Выходной, 77; 275
Двунаправленный, 79; 277
Диапазон, 75
Изменяемый, 89
Недействительность, 146; 149; 153;
158; 302; 309; 315; 409
Однонаправленный, 78; 276
С произвольным доступом, 81
Стандартные дескрипторы, 279
К
Ключ, 163
Константный, 89
Контейнер, 51
deque, 152-55; 305
list, 155-62; 309
map, 173-80; 324
multimap, 173-80; 330
multiset, 164—73; 320
priorityqueue, 337
queue, 336
set, 164-73; 315
stack, 334
vector, 138-52; 300
Ассоциативный, 55; 163; 295
Обратимый, 294
Общие функции-члены, 293
Объект сравнения, 296
Определения типов, 292
Последовательности, 51; 294
Эквивалентность, 150
л
Лексикографическое сравнение,
130; 371
м
Множество, 164-73
Вставка, 165; 319
Конструктор, 165
Отношение упорядочения, 164
Присваивание, 173
Удаление, 168; 319
Мультимножество, 164-73
Вставка, 165; 323
Конструктор, 165
Отношение упорядочения, 164
Присваивание, 173
Удаление, 168; 323
Мультиотображение, 173-80
Вставка, 174; 332
Конструктор, 174
Присваивание, 179
Удаление, 178; 333
н
Наследование, 244
Недействительность итератора, 146;
149; 153; 158; 302; 309; 315; 409
О
Обобщенное программирование, 27; 40
Обобщенный алгоритм, 56
Однонаправленный итератор, 78
Отношение сравнения, 116
эквивалентности, 361
Отображение, 173-80
Вставка, 174; 328
Конструктор, 174
Присваивание, 179
С приоритетами, 193
Удаление, 178; 328
Очередь, 191; 336
Очередь с приоритетами, 337
п
Параметр типа, 43
Параметры шаблона по умолчанию, 47
Передача аргументов по значению, 43
Перестановка, 130
Пирамида, 127; 369
Последовательный дубликат, 345
Предикат, 95
Программирование
Обобщенное, 40
Произвольный доступ, 51
Пустой диапазон, 75
Р
Разбухание кода, 48; 203; 243; 248
Разыменуемое значение, 273
С
Связыватель, 201; 378; 380
Семантика значений, 30
Семейство абстракций, 137
Сингулярное значение, 273
Сортировка, 119
Устойчивая, 118
Специализация, 47
Список, 155-62
Вставка, 157; 313
Конструктор, 157
Склейка, 159
Сортировка, 160
Удаление, 157; 161; 313
Сравнение
Лексикографическое, 130; 371
Отношение, 116
Стек, 147; 190; 334
Строгое неполное упорядочение, 361
Строгое полное упорядочение, 116
у
Указатель на функцию, 182
Устойчивая сортировка, 118
ф
Функциональный адаптер, 377
bindlst, 380
bind2nd, 380
divides, 378
equal_to, 379
greater, 379
greaterequal, 379
less, 379
less_equal, 379
logicaland, 379
logicalnot, 379
logicalor, 379
mem fun, 381; 382
memfunref, 382; 383
minus, 378
modulus, 379
multiplies, 378
negate, 379
notequalto, 379
notl,380
not2, 380
plus, 378
pointertobinary function, 381
pointertounaryfunction, 381
Инвертор, 202
Связыватель, 201
Функциональный объект, 65; 181; 377
X
Хешированные ассоциативные
контейнеры, 138
Хронометраж алгоритма, 259
ч
Частичная специализация, 47; 151
Частичное упорядочение, 361
ш
Шаблон
Класса, 42
Функции, 44
Функции-члена, 45
э
Эквивалентность, 117; 296
Контейнеров, 150
Эффективность, 88; 184
С++/Языки программирования
"Во втором издании материал изложен более понятно, и здесь больше примеров
практического использования STL. Кроме того, сделан акцент на вопросах
производительности и инструментарии для ее измерения. Это очень важные
изменения".
Лоуренс Раухвергер (Lawrence Rauchwerger), Texas А&М University
"Так много алгоритмов и так мало времени на их изучение! Глава, посвященная
обобщенным алгоритмам, содержит еще больше примеров, чем в первом издании!
Примеры в этой книге охватывают практически все аспекты использования
алгоритмов, контейнеров и итераторов".
Макс А. Лебоу (Max A. Lebow), Unisys Corporation
Первое издание было с воодушевлением принято программистами как наиболее
понятное, полное и практичное введение в стандартную библиотеку шаблонов
(STL). Включая большое множество обобщенных структур данных C++ и
алгоритмов, STL предоставляет повторно используемые, взаимозаменяемые компоненты,
применимые для решения множества различных задач без потери эффективности.
Написанная авторами, принимавшими участие в разработке и практическом
применении STL, эта книга представляет собой полное справочное руководство по
данной теме. Она включает небольшой учебный курс, подробное описание каждого
элемента библиотеки и большое количество примеров.
В книге вы найдете подробное описание итераторов, обобщенных алгоритмов,
контейнеров, функциональных объектов и т.д. Ряд нетривиальных приложений
демонстрирует использование мощи и гибкости STL в повседневной работе программиста.
Книга также разъясняет, как интегрировать STL с другими
объектно-ориентированными методами программирования. Она будет вашим постоянным спутником и
советчиком при работе над проектами любой степени сложности.
Во втором издании отражены все самые последние изменения в STL на момент
написания книги; в нем появились новые главы и приложения. Множество новых
примеров иллюстрируют отдельные концепции и технологии; большие
демонстрационные программы показывают, как использовать STL в реальной разработке
приложений на языке программирования C++. Все упомянутые исходные тексты можно
найти по адресу http://www.aw.com/cseng/titles/0-20l-37923-6/.
Дэвид Р. Мюссер преподает в политехническом институте. Он работает с STL начиная
с момента ее зарождения: первая реализация библиотеки была разработана Александром
Степановым в сотрудничестве с Дэвидом. Кроме того, он немало потрудился для того,
чтобы STL была включена в стандарт ANSI/ISO C++.
Жилмер Дж. Дердж является президентом и исполнительным директором
консалтинговой фирмы Toltec Software Services, Inc. Он имеет более чем десятилетний опыт
разработки приложений на C++, в- том числе семь лет в General Electric Corporate R&D.
Атул Сейни является президентом и исполнительным директором фирмы Fiorano
Software Inc., производителя программного обеспечения для высокоскоростного обмена
сообщениями, разрабатываемого на C++. Атул Сейни был первым, кто разглядел
коммерческий потенциал STL и предложил свою компанию для продажи библиотеки еще
в 1994 году, до того как она вошла в стандарт C++.