/


























































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































Автор: Дейтел Х.М. Дейтел П.Дж.
Теги: языки программирования компьютерные технологии программирование язык программирования c++
ISBN: 978-5-9518-0224-8
Год: 2008




Текст
КАК ПРОГРАММИРОВАТЬ НА
пятое издание
C++
C++
How то Program
FIFTH EDITION
H.M. Deitel
Deitel & Associates, Inc.
RJ. Deitel
Deitel & Associates, Inc.
Upper Saddle River, New Jersey 07458
Х.М. Дейтел, П.Дж. Дейтел
КАК ПРОГРАММИРОВАТЬ НА
C++
пятое издание
Перевод
с английского
под редакцией
В.В. Тимофеева
Москва
Издательство БИНОМ
2008
УДК 004.43
ББК 32.973.26-018.1
Д27
Х.М. Дейтел, П.Дж. Дейтел
Как программировать на C++: Пятое издание. Пер. с англ. — М.: ООО
«Бином-Пресс», 2008 г. — 1456 с: ил.
Книга (оригинальное название «C++ How to Program, Fifth Edition») является одним из
самых популярных в мире учебников по C++. Характерной ее особенностью является
«раннее введение» в классы и объекты, т. е. начала объектно-ориентированного
программирования вводятся уже в 3-й главе, без предварительного изложения унаследованных от
языка С элементов процедурного и структурного программирования, как это делается в
большинстве курсов по C++. Большое внимание уделяется объектно-ориентированному
проектированию (OOD) программных систем с помощью графического языка UML 2,
чему посвящен ряд факультативных разделов, описывающих последовательную
разработку большого учебного проекта.
В текст книги включена масса примеров «живого кода» — подробно
комментированных работающих программ с образцами их запуска, а также несколько подробно
разбираемых интересных примеров. В конце каждой главы имеется обширный набор
контрольных вопросов и упражнений.
Книга может служить учебным пособием для начальных курсов по C++, а также будет
полезна широкому кругу как начинающих программистов, так и более опытных, не
работавших прежде с C++.
Все права защищены. Никакая часть этой книги не может быть воспроизведена в любой форме
или любыми средствами, электронными или механическими, включая фотографирование,
магнитную запись или иные средства копирования или сохранения информации без письменного
разрешения издательства.
Authorized translation from the English language edition, entitled C++ How to Program, 5th Edition by
Deitel & Associates, (Harvey & Paul), published by Pearson Education, Inc., publishing as Prentice Hall,
Copyright © 2006.
О Pearson Education Inc., 2006
ISBN 978-5-9518-0224-8 (рус.) © Издание на русском языке.
ISBN 0-13-185757-6 (англ.) Издательство Бином, 2008
Содержание
Предисловие . . 17
Глава 1. Введение в компьютеры, Internet и World Wide Web 53
1.1. Введение 54
1.2. Что такое компьютер? 56
1.3. Организация компьютера 57
1.4. Первые операционные системы 58
1.5. Модели обработки данных: персональная, распределенная
и клиент/сервер 59
1.6. Internet и World Wide Web 59
1.7. Машинные языки, языки ассемблера и языки высокого уровня. . 60
1.8. История С и C++ 61
1.9. Стандартная библиотека C++ 62
1.10. История языка Java 64
1.11. FORTRAN, COBOL, Pascal и Ada 64
1.12. BASIC, Visual Basic, Visual C++, C# и .NET 65
1.13. Ключевая тенденция в программировании: объектная
технология 66
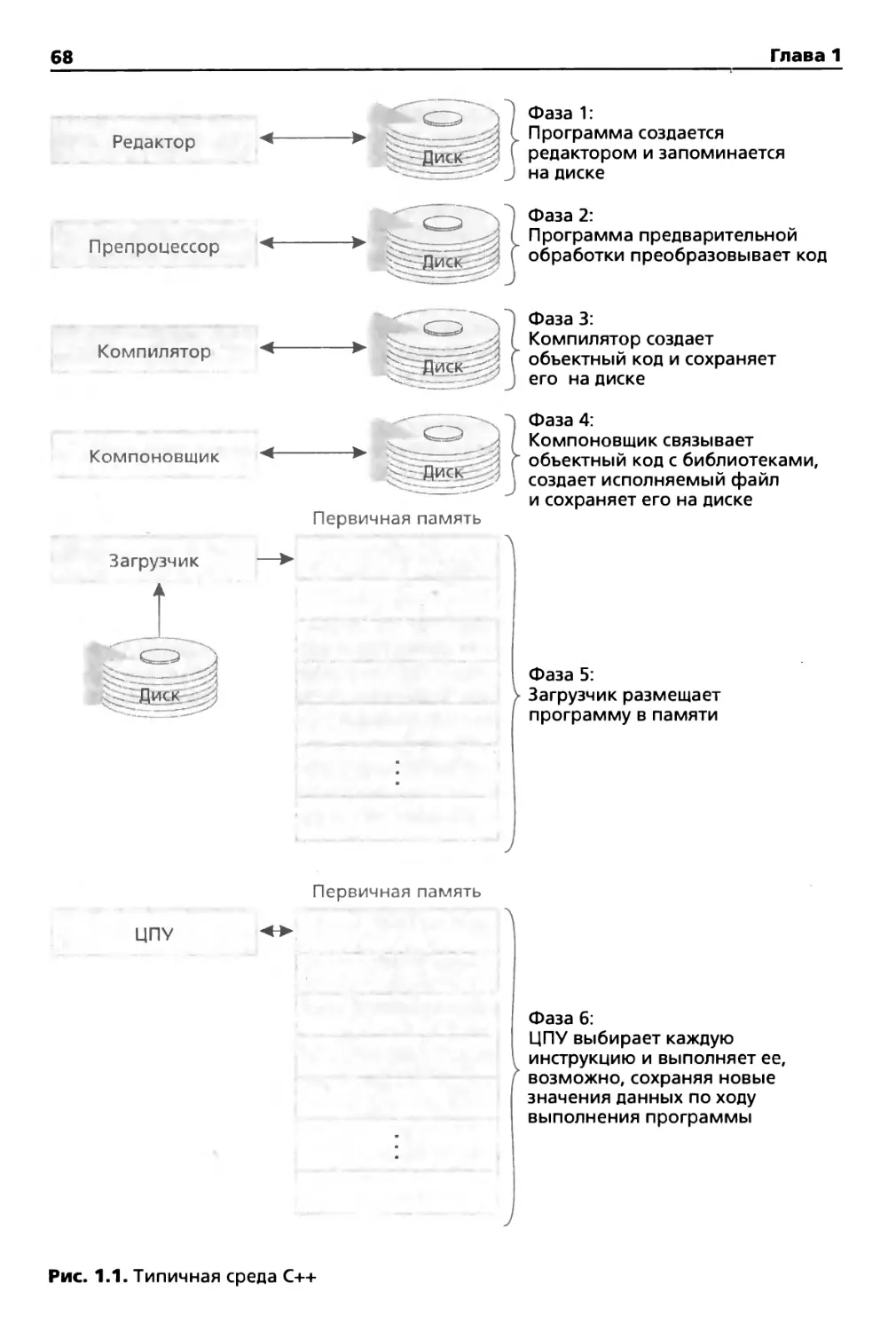
1.14. Типичная среда разработки C++ 67
1.15. Замечания о C++ и этой книге 70
1.16. Тестовый запуск приложения на C++ 72
1.17. Конструирование программного обеспечения. Введение
в объектную технологию и UML (обязательный раздел) 78
1.18. Заключение 85
1.19. Ресурсы Web 85
Глава 2. Введение в программирование на C++ 95
2.1. Введение 96
2.2. Первая программа на C++: печать строки текста 96
2.3. Модификация нашей первой программы 101
2.4. Другая программа на C++: сложение целых чисел 102
2.5. Организация памяти 107
2.6. Арифметика 109
2.7. Принятие решений: операции равенства и отношений 113
6
Как программировать на C++
2.8. Конструирование программного обеспечения.
Исследование требований к ATM (необязательный раздел). . . .118
2.9. Заключение 129
Глава 3. Введение в классы и объекты 139
3.1. Введение 140
3.2. Классы, объекты, элемент-функции и элементы данных . . . . 141
3.3. Обзор примеров главы 142
3.4. Определение класса с элемент-функцией 143
3.5. Определение элемент-функции с параметром 147
3.6. Элементы данных, set-функции и gef-функции 151
3.7. Инициализация объектов при помощи конструкторов 159
3.8. Размещение класса в отдельном файле 163
3.9. Отделение интерфейса от реализации 168
3.10. Подтверждение данных посредством set-функций 174
3.11. Конструирование программного обеспечения. Идентификация
классов в спецификации требований к ATM (необязательный
раздел) 180
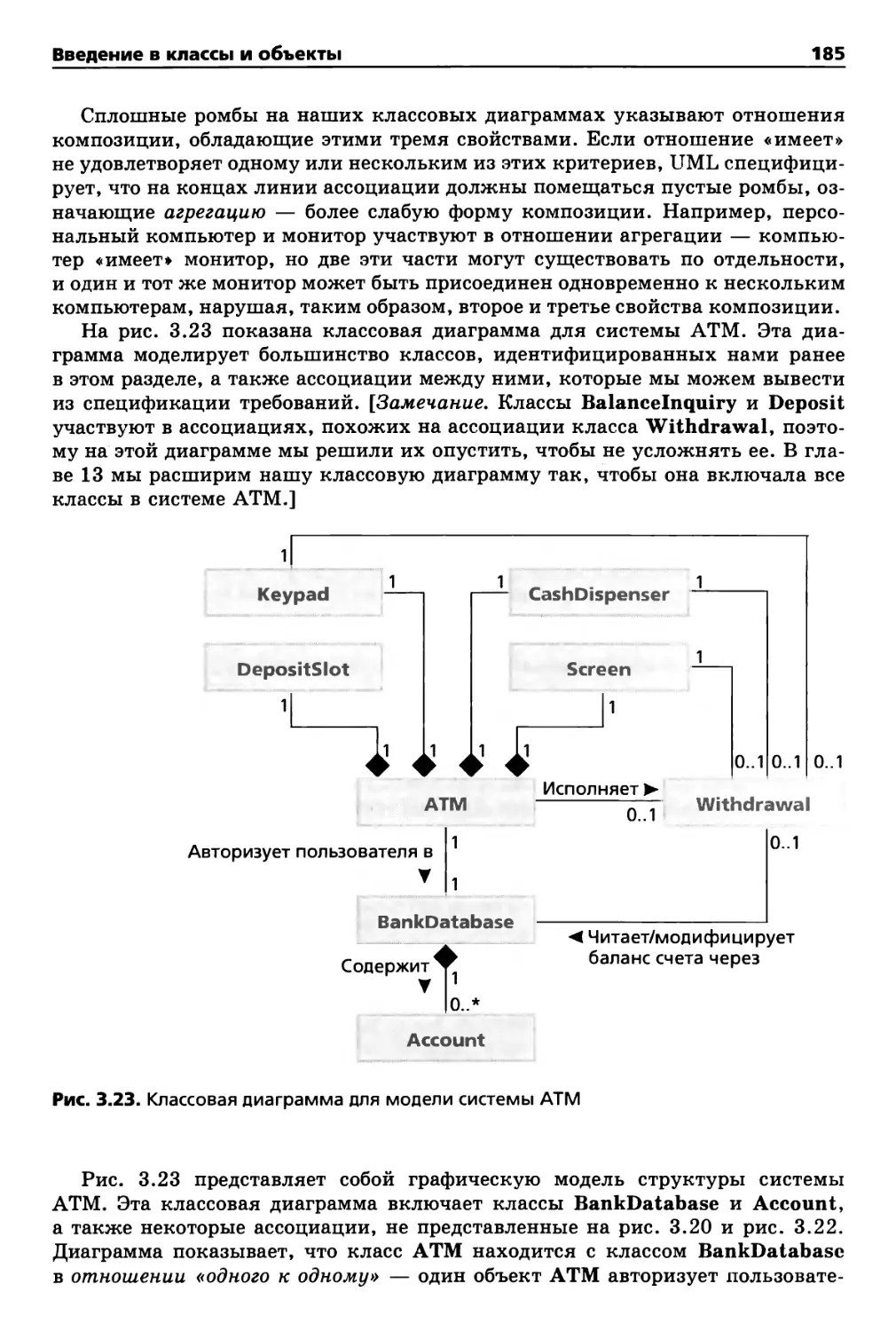
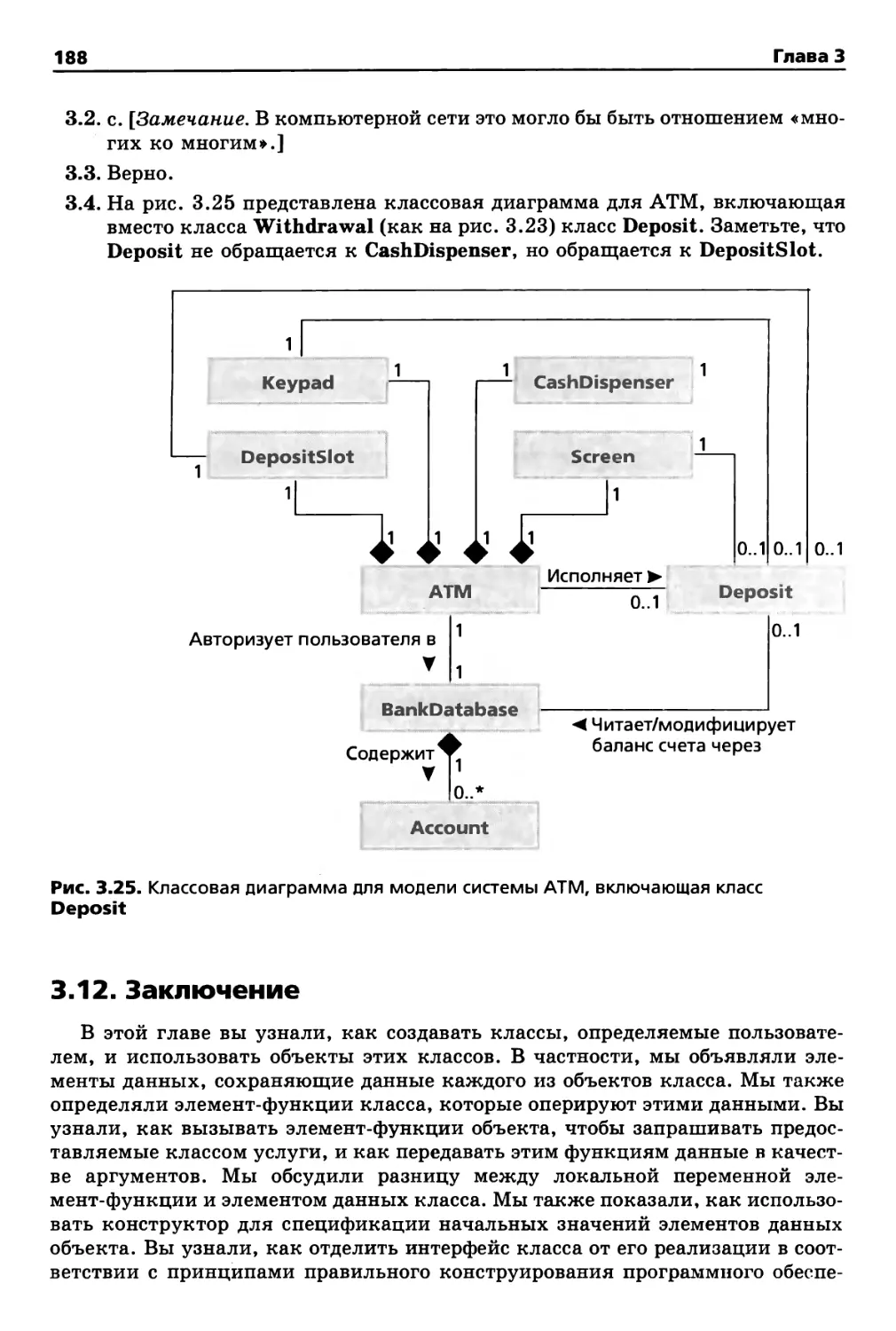
3.12. Заключение 188
Глава 4. Управляющие операторы: часть I 197
4.1. Введение 198
4.2. Алгоритмы 199
4.3. Псевдокод 199
4.4. Управляющие структуры 201
4.5. Оператор выбора if 205
4.6. Оператор выбора if...else 207
4.7. Оператор повторения while 212
4.8. Формулирование алгоритмов: повторение, управляемое
счетчиком 214
4.9. Формулирование алгоритмов: повторение, управляемое
контрольным значением 221
4.10. Формулирование алгоритмов: вложенные управляющие
операторы 233
4.11. Операции присваивания 238
4.12. Операции инкремента и декремента 239
4.13. Конструирование программного обеспечения. Идентификация
классовых атрибутов в системе ATM (необязательный раздел) . 242
4.14. Заключение 247
Глава 5. Управляющие операторы: часть II 265
5.1. Введение 266
5.2. Основы повторения, управляемого счетчиком 267
5.3. Оператор повторения for 269
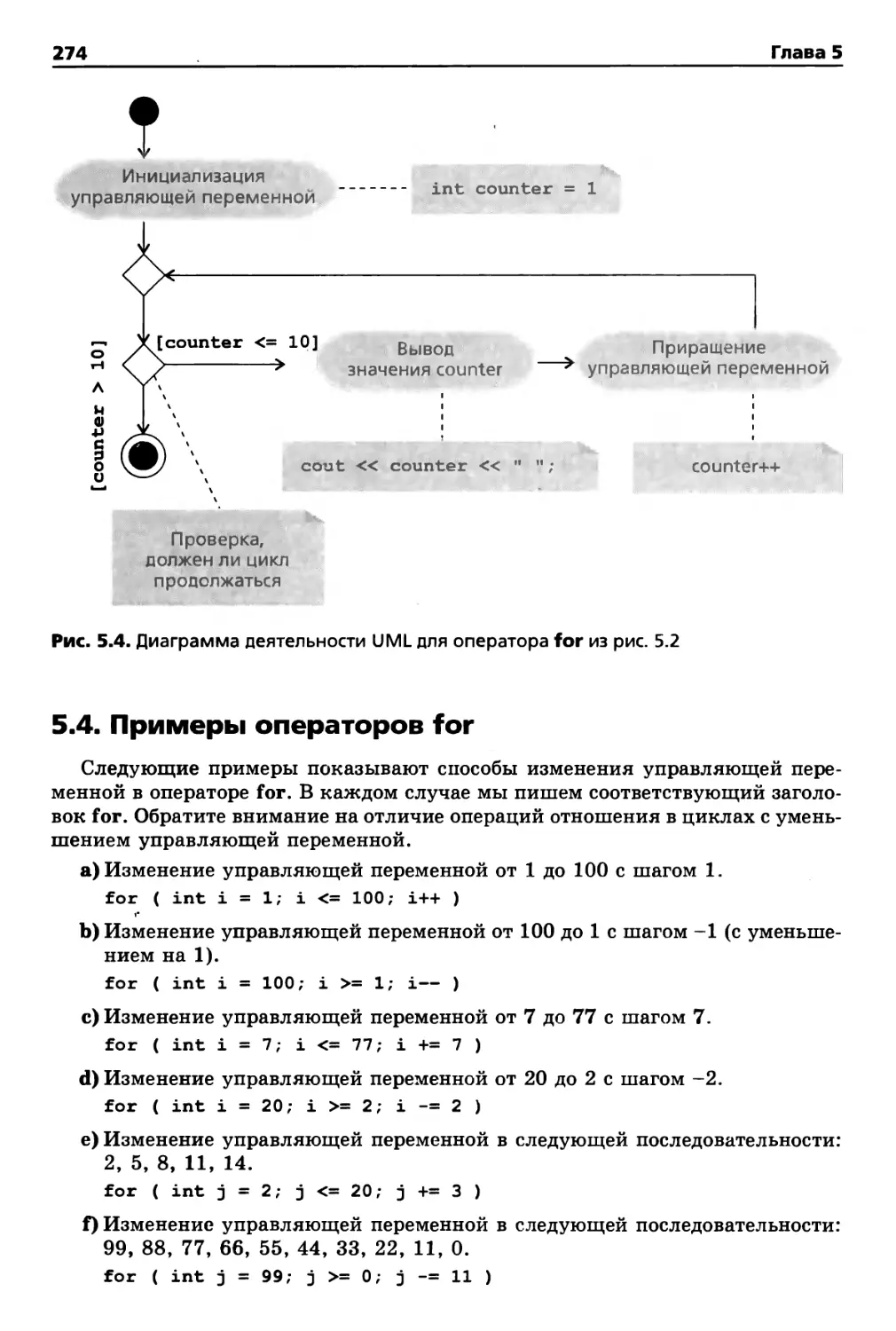
5.4. Примеры операторов for 274
5.5. Оператор повторения do...while 279
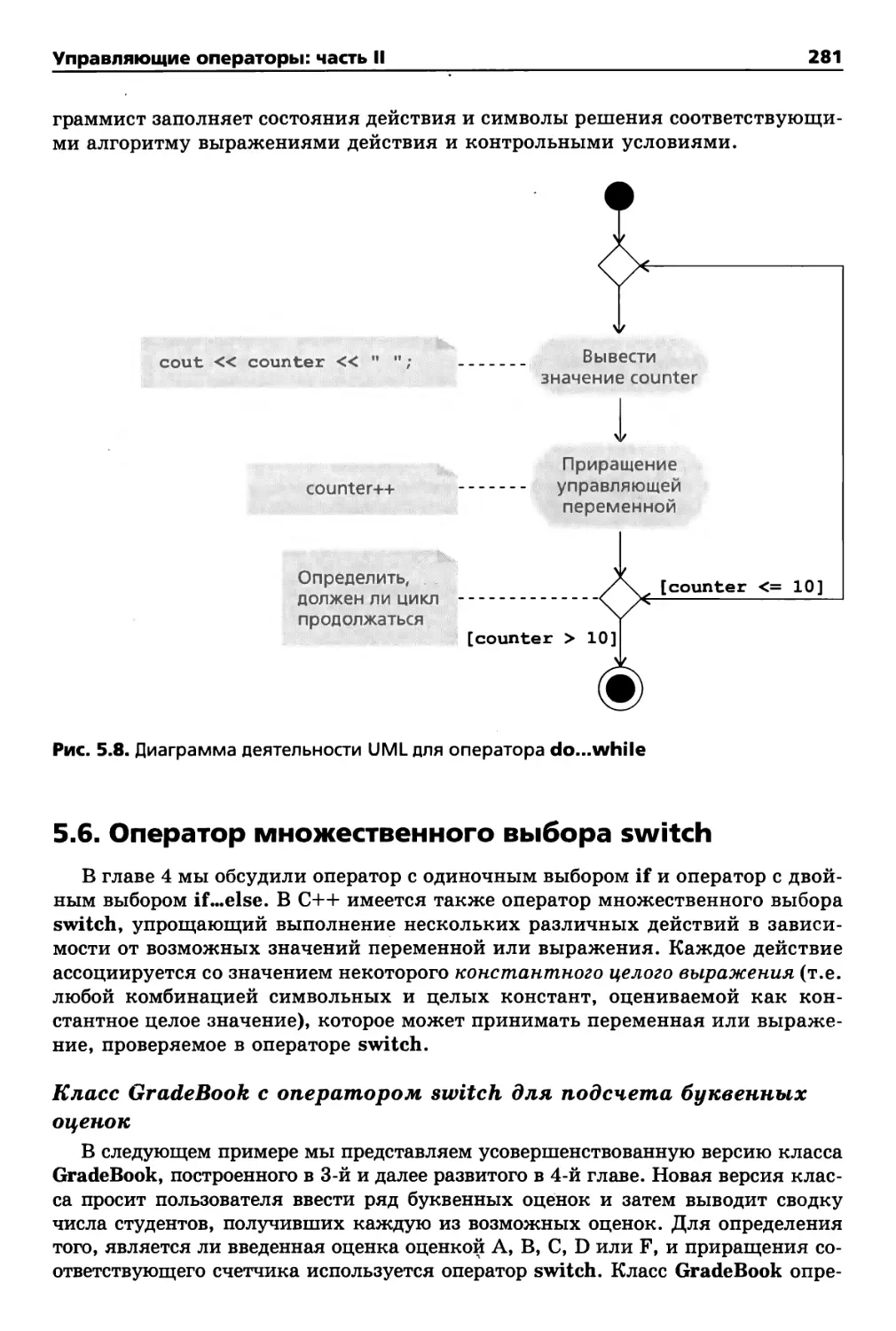
5.6. Оператор множественного выбора switch 281
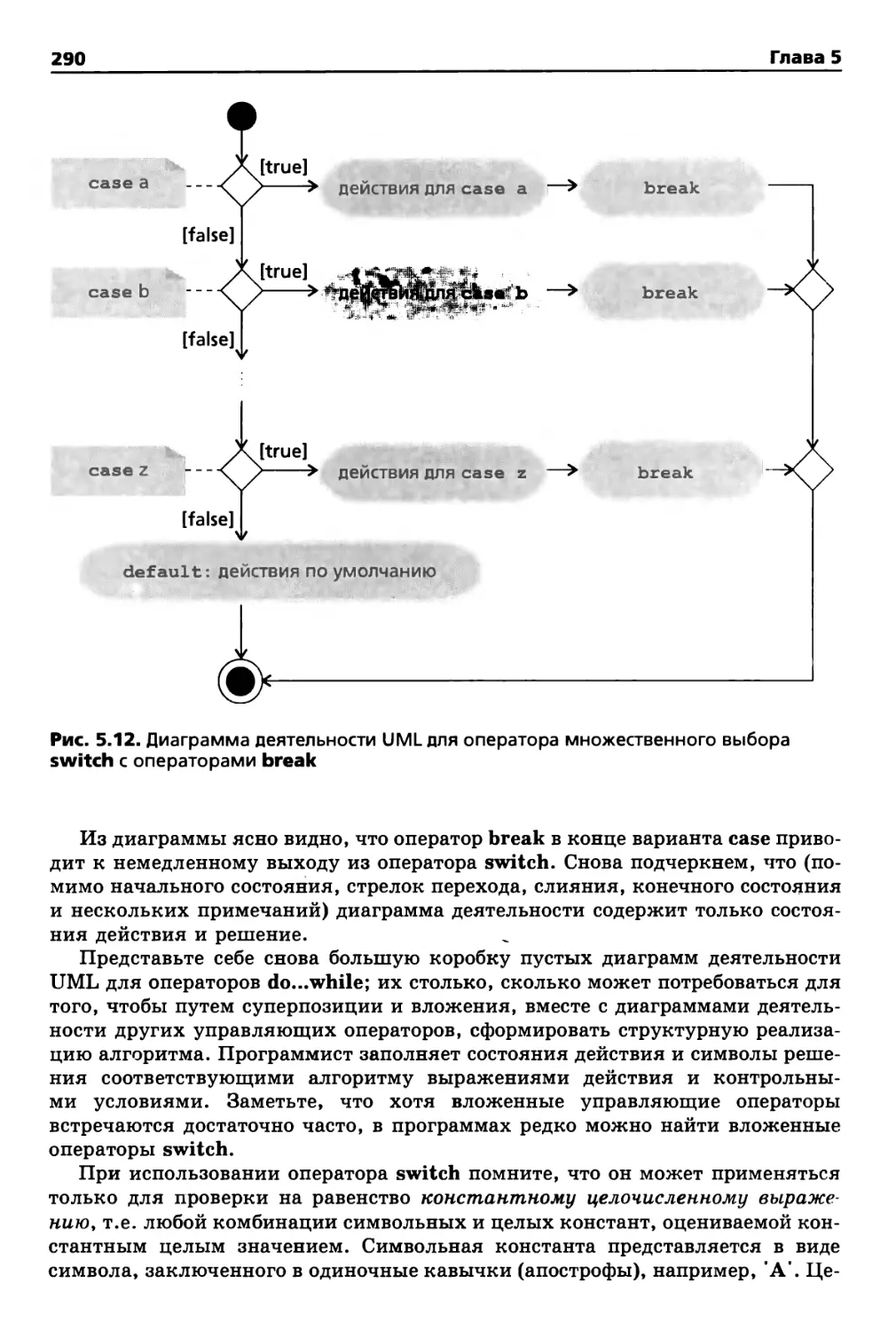
5.7. Операторы break и continue 292
Содержание 7
5.8. Логические операции 294
5.9. Случайная подмена операции равенства (==) присваиванием (=). 299
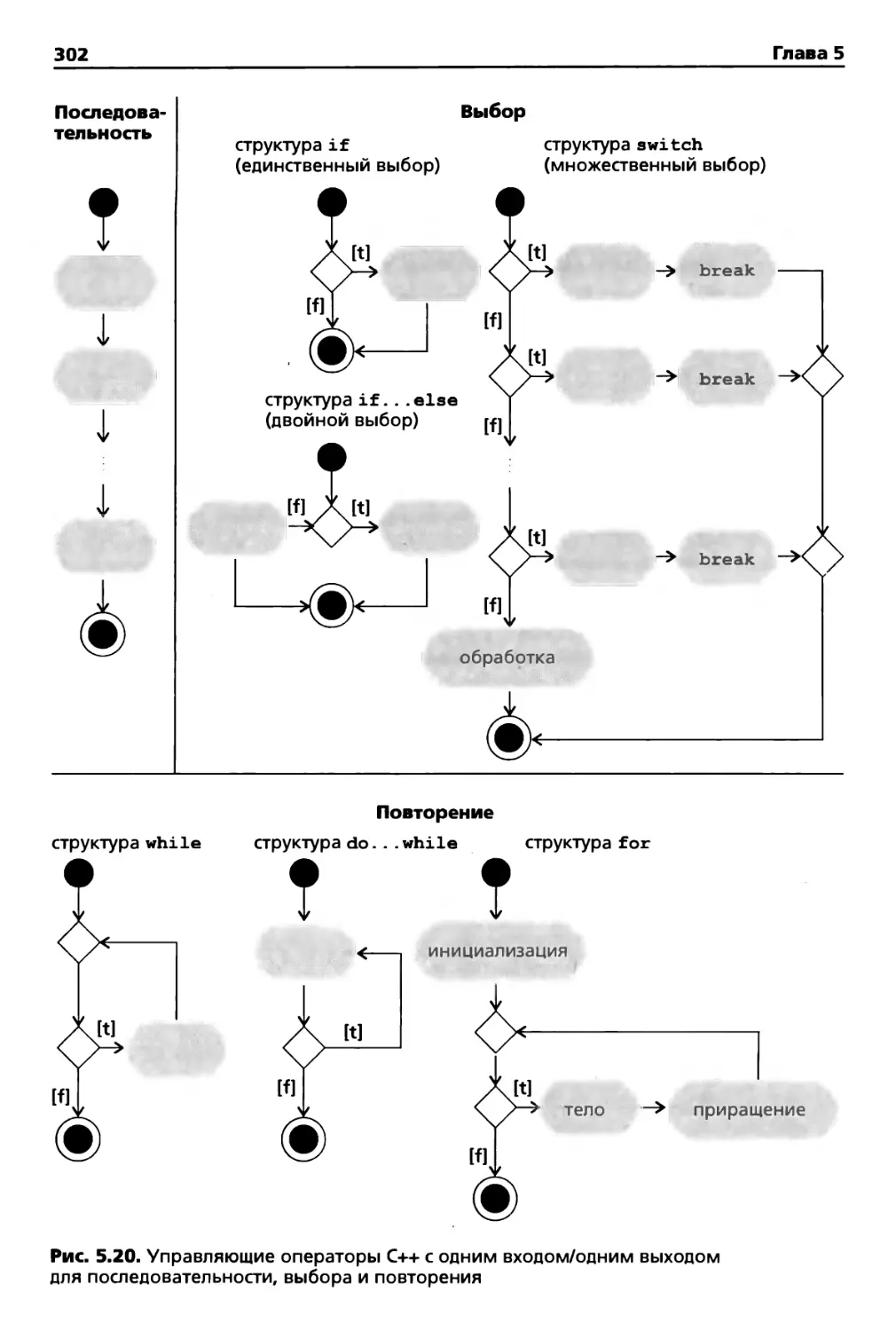
5.10. Структурное программирование: резюме 301
5.11. Конструирование программного обеспечения. Идентификация
состояний объектов и деятельности в системе ATM
(необязательный раздел) 307
5.12. Заключение 313
Глава 6. Функции и введение в рекурсию 325
6.1. Введение 326
6.2. Компоненты программ на C++ 327
6.3. Функции математической библиотеки 329
6.4. Определения функций с несколькими параметрами 331
6.5. Прототипы функций и принудительное приведение аргументов . 336
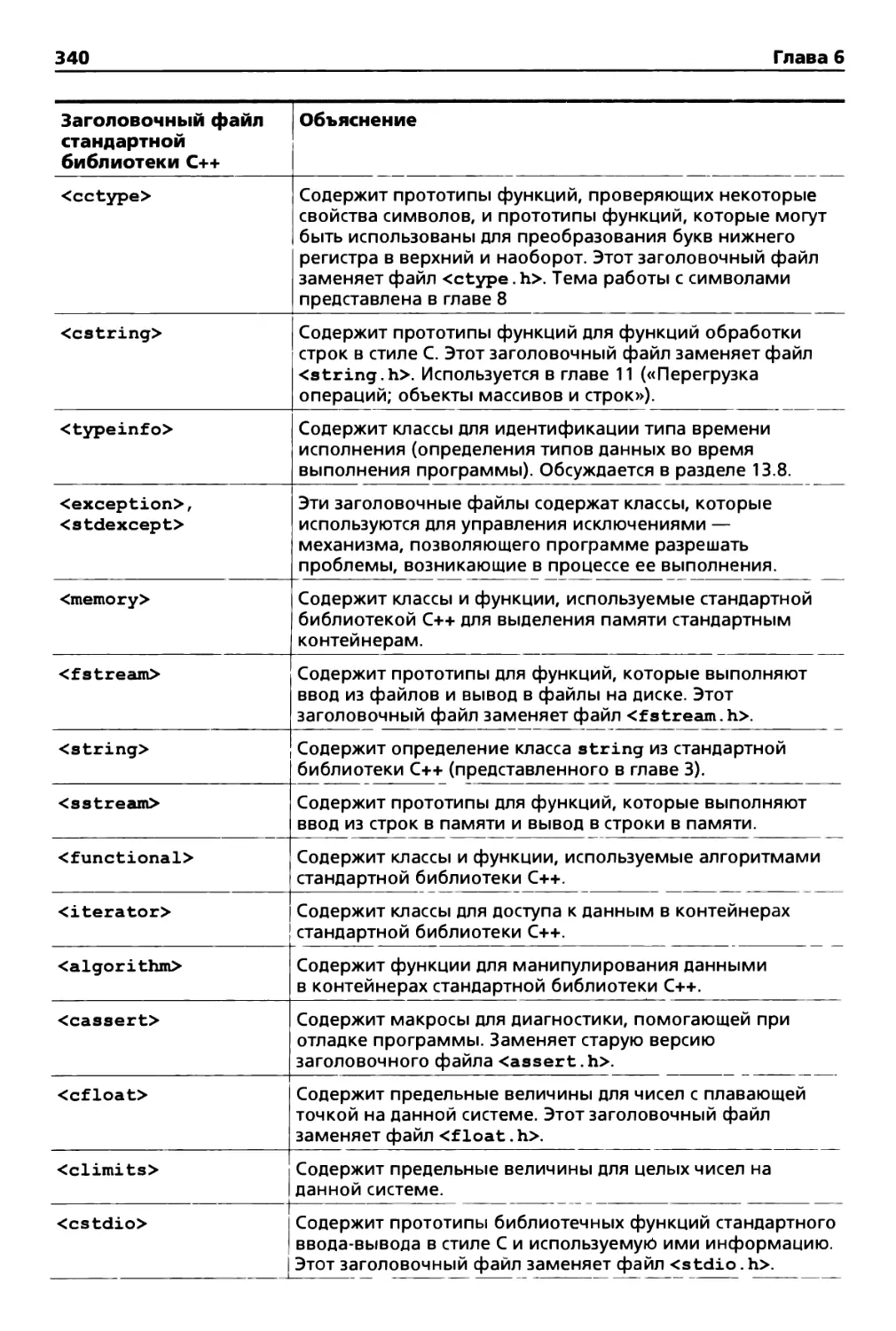
6.6. Заголовочные файлы стандартной библиотеки C++ 339
6.7. Пример: генерация случайных чисел 341
6.8. Пример: азартная игра с использованием перечисления (enum) . 347
6.9. Классы памяти 351
6.10. Правила для области действия 355
6.11. Стек вызовов и активационные записи 358
6.12. Функции с пустым списком параметров 363
6.13. Встроенные функции 365
6.14. Ссылки и ссылочные параметры 366
6.15. Аргументы по умолчанию 372
6.16. Унарная операция разрешения области действия 374
6.17. Перегрузка функций 375
6.18. Шаблоны функций 379
6.19. Рекурсия 381
6.20. Пример рекурсии: числа Фибоначчи 385
6.21. Рекурсия в сравнении с итерацией 388
6.22. Конструирование программного обеспечения. Идентификация
операций классов в системе ATM (необязательный раздел) . . . 392
6.23. Заключение 400
Глава 7. Массивы и векторы 423
7.1. Введение 424
7.2. Массивы 425
7.3. Объявление массивов 427
7.4. Примеры с массивами 428
7.5. Передача массивов функциям 446
7.6. Пример: класс GradeBook с массивом для хранения оценок . . . 450
7.7. Линейный поиск в массивах 457
7.8. Сортировка массивов вставкой 459
7.9. Многомерные массивы 461
7.10. Пример: класс GradeBook с двумерным массивом 465
7.11. Введение в шаблон класса vector стандартной библиотеки C++ . 472
8 Как программировать на C++
7.12. Конструирование программного обеспечения. Кооперация
объектов в системе ATM (необязательный раздел) 477
7.13. Заключение 486
Глава 8. Указатели и строки-указатели 505
8.1. Введение 506
8.2. Объявление и инициализация переменных-указателей 507
8.3. Операции указателей 508
8.4. Передача аргументов по ссылке с помощью указателей 512
8.5. Квалификатор const в применении к указателям 516
8.6. Сортировка выборкой с передачей по ссылке 524
8.7. Операции sizeof 527
8.8. Выражения с указателями и арифметика указателей 530
8.9. Взаимосвязь указателей и массивов 534
8.10. Массивы указателей 538
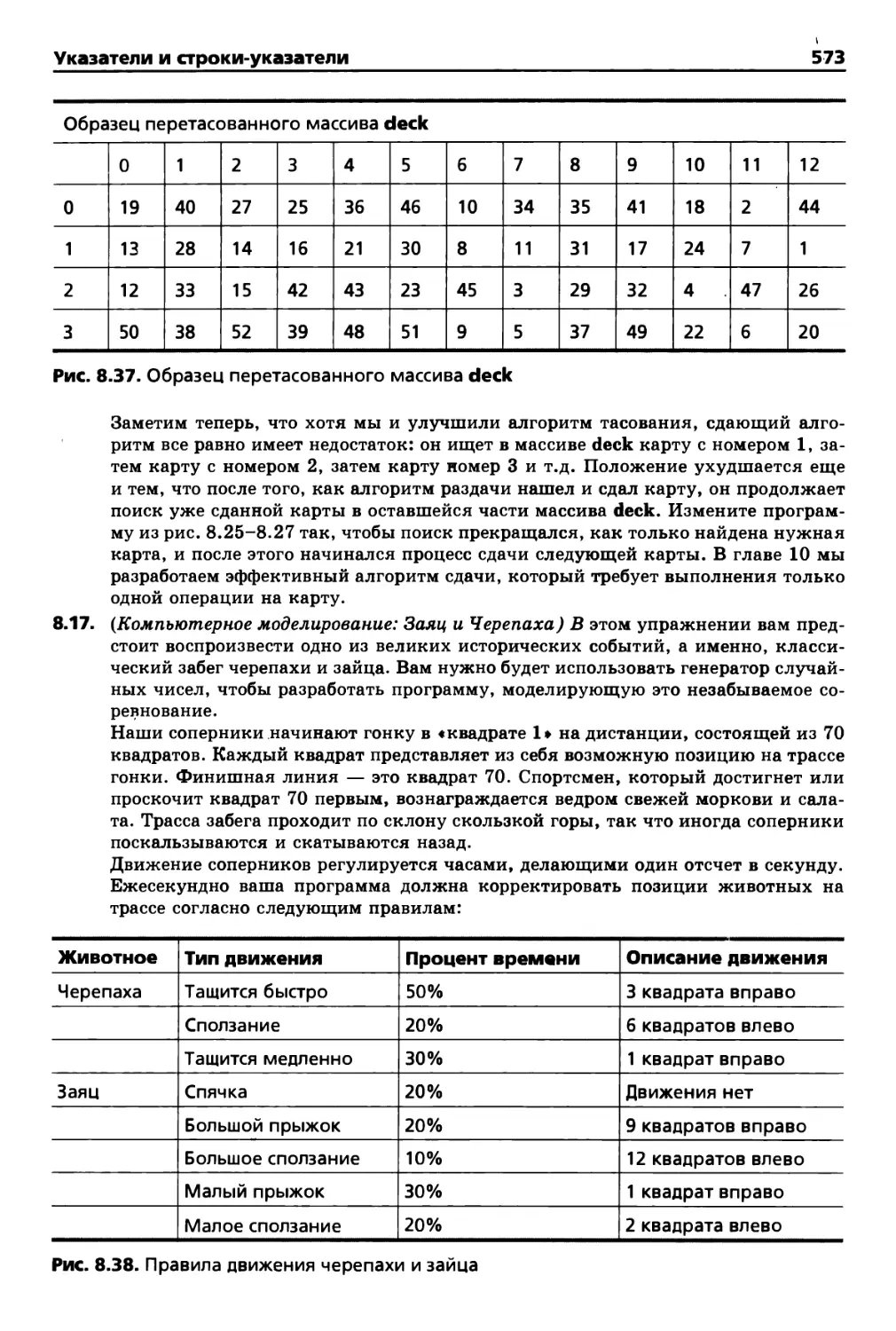
8.11. Пример: моделирование тасования и сдачи карт 540
8.12. Указатели на функцию 546
8.13. Введение в обработку строк-указателей 551
8.13.1. Элементарные сведения о символах и строках 551
8.13.2. Функции обработки строк из библиотеки <cstring> 554
8.14. Заключение 562
Глава 9. Классы: часть I 591
9.1. Введение 592
9.2. Пример: класс Time 593
9.3. Область действия класса и доступ к элементам класса 601
9.4. Отделение интерфейса от реализации 603
9.5. Функции доступа и сервисные функции 604
9.6. Пример: класс Time. Конструкторы с аргументами
по умолчанию 607
9.7. Деструкторы 613
9.8. Когда вызываются конструкторы и деструкторы 613
9.9. Пример: класс Time. Скрытая ошибка — возвращение ссылки
на закрытый элемент данных 617
9.10. Поэлементное присваивание по умолчанию 620
9.11. Утилизируемость программного обеспечения 622
9.12. Конструирование программного обеспечения. Начало
программирования классов системы ATM
(необязательный раздел) 623
9.13. Заключение 631
Глава 10. Классы: часть II 639
10.1. Введение 640
10.2. Константные объекты и константные элемент-функции .... 641
10.3. Композиция: объекты в качестве элементов класса 651
10.4. Дружественные функции и дружественные классы 658
10.5.-Указатель this 662
Содержание 9
10.6. Динамическое управление памятью с помощью операций
new и delete 668
10.7. Статические элементы класса 670
10.8. Абстракция данных и сокрытие информации 677
10.8.1. Пример: абстрактный тип данных — массив 678
10.8.2. Пример: абстрактный тип данных — строка 679
10.8.3. Пример: абстрактный тип данных — очередь 679
10.9. Классы-контейнеры и итераторы 680
10.10. Классы-посредники 681
10.11. Заключение 684
Глава 11. Перегрузка операций; объекты Array и String 691
11.1. Введение 692
11.2. Основы перегрузки операций 693
11.3. Ограничения на перегрузку операций 695
11.4. Функции-операции как элементы класса и как глобальные
функции 697
11.5. Перегрузка операций передачи в поток и извлечения
из потока 698
11.6. Перегрузка одноместных операций 702
11.7. Перегрузка двухместных операций 703
11.8. Пример: класс Array 703
11.9. Преобразование типов 716
11.10. Пример: класс String 717
11.11. Перегрузка++и-- 730
11.12. Пример: класс Date 732
11.13. Класс string стандартной библиотеки 737
11.14. explicit-конструкторы 741
11.15. Заключение 744
Глава 12. Объектно-ориентированное программирование:
наследование 759
12.1. Введение 760
12.2. Базовые и производные классы 762
12.3. Защищенные элементы 765
12.4. Отношения между базовыми и производными классами .... 766
12.4.1. Создание и тестирование класса CommissionEmployee 767
12.4.2. Создание класса BasePlusCommissionEmployee
без наследования 772
12.4.3. Создание иерархии наследования CommissionEmployee —
BasePlusCommissionEmployee 777
12.4.4. Иерархия наследования CommissionEmployee —
BasePlusCommissionEmployee с защищенными данными .... 783
12.4.5. Иерархия наследования CommissionEmployee —
BasePlusCommissionEmployee с закрытыми данными 790
12.5. Конструкторы и деструкторы в производных классах 798
12.6. Открытое, защищенное и закрытое наследование 806
10
Как программировать на C++
12.7. Наследование в конструировании программного обеспечения . . 807
12.8. Заключение 809
Глава 13. Объектно-ориентированное программирование:
полиморфизм 815
13.1. Введение 817
13.2. Примеры полиморфизма 818
13.3. Отношения между объектами в иерархии наследования .... 820
13.3.1. Вызов функций базового класса из объектов производного
класса 821
13 3.2. Установка указателей производного класса на объекты базового
класса 828
13.3.3. Вызов элемент-функций производного класса через указатели
базового класса 829
13.3.4. Виртуальные функции 831
13.3.5. Сводка допустимых присваиваний объектов указателям базового
и производного классов 837
13.4. Поля типа и операторы switch 838
13.5. Абстрактные классы и чисто виртуальные функции 839
13.6. Пример. Система начисления заработной платы, использующая
полиморфизм 842
13.6.1. Создание абстрактного базового класса Employee 843
13.6.2. Создание конкретного производного класса SalariedEmployee . 847
13.6.3. Создание конкретного производного класса HourlyEmployee . . 849
13.6.4. Создание конкретного производного класса
CommissionEmployee 851
13.6.5. Создание косвенного конкретного производного класса
BasePlusCommissionEmployee 853
13.6.6. Демонстрация полиморфной обработки 855
13.7. (Дополнительный раздел.) Техническая сторона полиморфизма,
виртуальных функций и динамического связывания 860
13.8. Пример. Система начисления заработной платы, использующая
полиморфизм и информацию о типе времени выполнения с
нисходящими приведениями типа, dynamic_cast, typeid
и type_info 864
13.9. Виртуальные деструкторы 868
13.10. Конструирование программного обеспечения. Введение
наследования в систему ATM (необязательный раздел) .... 869
13.11. Заключение 878
Глава 14. Шаблоны 885
14.1. Введение 886
14.2. Шаблоны функций 887
14.3. Перегрузка шаблонов функции 891
14.4. Шаблоны классов 891
14.5. Нетиповые параметры и типы по умолчанию для шаблонов
класса 898
14.6. Замечания о шаблонах и наследовании 899
14.7. Замечания о шаблонах и друзьях 900
Содержание 11
14.8. Замечания о шаблонах и статических элементах 901
14.9. Заключение 901
Глава 15. Потоковый ввод/вывод 907
15.1. Введение 909
15.2. Потоки 909
15.2.1. Классические и стандартные потоки 910
15.2.2. Заголовочные файлы библиотеки iostream 911
15.2.3. Классы и объекты потокового ввода/вывода 911
15.3. Потоковый вывод 914
15.3.1. Вывод переменных типа char * 914
15.3.2. Вывод символов с помощью элемент-функции put 915
15.4. Потоковый ввод 915
15.4.1. Элемент-функции get и getline 916
15.4.2. Элемент-функции peek, putback и ignore класса istream. . . . 919
15.4.3. Безопасный по типу ввод/вывод 920
15.5. Бесформатный ввод/вывод с помощью read, gcount и write. . . 920
15.6. Введение в манипуляторы потоков 921
15.6.1. Основание целых чисел: dec, oct, hex и setbase 921
15.6.2. Точность чисел с плавающей точкой (precision, setprecision). . 922
15.6.3. Ширина поля (setw, width) 924
15.6.4. Определяемые пользователем манипуляторы выходного
потока 925
15.7. Состояния формата потока и потоковые манипуляторы . . . . 927
15.7.1. Конечные нули и десятичные точки (showpoint) 928
15.7.2. Выравнивание (left, right, internal) 929
15.7.3. Заполнение (fill, setfill) 930
15.7.4. Основание целых чисел (dec, oct, hex, showbase) 932
15.7.5. Числа с плавающей точкой: научная и фиксированная нотация
(scientific, fixed) 933
15.7.6. Управление верхним/нижним регистрами (uppercase) 934
15.7.7. Спецификация булева формата (boolalpha) 935
15.7.8. Установка и сброс состояний формата с помощью
элемент-функции flags 936
15.8. Состояния ошибки потоков 937
15.9. Привязка потока вывода к потоку ввода 939
15.10. Заключение 940
Глава 16. Управление исключениями 951
16.1. Введение 952
16.2. Обзор управления исключениями 953
16.3. Пример: обработка попытки деления на ноль 954
16.4. Когда следует применять управление исключениями 961
16.5. Перебрасывание исключений 962
16.6. Спецификации исключений 964
16.7. Обработка непредусмотренных исключений 965
16.8. Разматывание стека 966
16.9. Конструкторы, деструкторы и управление исключениями ... 967
16.10. Исключения и наследование 968
12 Как программировать на C++
16.11. Обработка отказов операции new 969
16.12. Класс auto_ptr и динамическое выделение памяти 973
16.17. Иерархия исключений стандартной библиотеки 976
16.14. Другие методы обработки ошибок 978
16.15. Заключение 979
Глава 17. Обработка файлов 987
17.1. Введение 988
17.2. Иерархия данных 988
17.3. Файлы и потоки 991
17.4. Создание последовательного файла 992
17.5. Чтение данных из последовательного файла 996
17.6. Обновление последовательных файлов 1003
17.7. Файлы произвольного доступа 1003
17.8. Создание файла произвольного доступа 1004
17.9. Произвольная запись данных в файл произвольного доступа . 1010
17.10. Последовательное чтение из файла произвольного доступа . . 1012
17.11. Пример. Программа обработки транзакций 1015
17.12. Ввод/вывод объектов 1021
17.13. Заключение 1022
Глава 18. Класс string и обработка строковых потоков 1033
18.1. Введение 1034
18.2. Присваивание и конкатенация строк 1036
18.3. Сравнение строк 1038
18.4. Подстроки 1041
18.5. Обмен строк 1041
18.6. Характеристики строки 1042
18.7. Поиск в строке подстрок и символов 1045
18.8. Замена символов в строке 1047
18.9. Вставка символов в строку 1049
18.10. Преобразование в строки-указатели С типа char * 1050
18.11. Итераторы 1051
18.12. Обработка строковых потоков 1053
18.13. Заключение 1056
Глава 19. Поиск и сортировка 1063
19.1. Введение 1064
19.2. Алгоритмы поиска 1065
19.2.1. Эффективность линейного поиска 1065
19.2.2. Двоичный поиск 1067
19.3. Алгоритмы сортировки 1073
19.3.1. Эффективность сортировки выборкой 1073
19.3.2. Эффективность сортировки вставкой 1073
19.3.3. Сортировка слиянием (рекурсивная реализация) 1074
19.4. Заключение 1081
Содержание 13
Глава 20. Структуры данных 1089
20.1. Введение 1090
20.2. Автореферентные классы 1091
20.3. Динамическое распределение памяти и структуры данных . . 1092
20.4. Связанные списки 1093
20.5. Стеки 1109
20.6. Очереди 1113
20.7. Деревья 1117
20.8. Заключение 1127
Глава 21. Биты, символы, строки С и структуры 1153
21.1. Введение 1154
21.2. Определение структур 1155
21.3. Инициализация структур 1157
21.4. Использование структур с функциями 1158
21.5. typedef 1158
21.6. Пример. Высокоэффективное моделирование тасования
и сдачи карт 1159
21.7. Поразрядные операции 1162
21.8. Битовые поля 1171
21.9. Библиотека обработки символов 1175
21.10. Функции преобразования строк-указателей 1181
21.11. Функции поиска из библиотеки обработки строк-указателей . 1186
21.12. Функции управления памятью из библиотеки обработки
строк-указателей 1191
21.13. Заключение 1195
Глава 22. Библиотека стандартных шаблонов (STL) 1209
22.1. Введение в Библиотеку стандартных шаблонов (STL) 1211
22.1.1. Введение в контейнеры 1213
22.1.2. Введение в итераторы 1218
22.1.3. Введение в алгоритмы 1224
22.2. Контейнеры последовательностей 1226
22.2.1. Контейнер последовательности vector 1227
22.2.2. Контейнер последовательности list 1236
22.2.3. Контейнер последовательности deque 1240
22.3. Ассоциативные контейнеры 1242
22.3.1. Ассоциативный контейнер multiset 1242
22.3.2. Ассоциативный контейнер set 1245
22.3.3. Ассоциативный контейнер multimap 1247
22.3.4. Ассоциативный контейнер тар 1249
22.4. Адаптеры контейнеров 1250
22.4.1. Адаптер stack 1251
22.4.2. Адаптер queue 1253
22.4.3. Адаптер priority_queue 1254
22.5. Алгоритмы 1256
22.5.1. fill, filln, generate и generate_n 1257
22.5.2. equal, mismatch и lexicographical_compare 1258
14 Как программировать на C++
22.5.3. remove, remove_if, remove_copy и removecopyif 1261
22.5.4. replace, replace_if, replace_copy и replace_copy_if 1264
22.5.5. Математические алгоритмы 1266
22.5.6. Элементарные алгоритмы поиска и сортировки 1269
22.5.7. swap, iter_swap и swap_ranges 1272
22.5.8. copy_backward, merge, unique и reverse 1273
22.5.9. inplace_merge, unique_copy и reverse_copy 1276
22.5.10. Операции над множествами 1277
22.5.11. lower_bound, upper_bound и equal_range 1281
22.5.12. Кучевая сортировка 1283
22.5.13. min и max 1286
22.5.14. Алгоритмы STL, не представленные в этой главе 1287
22.6. Класс bitset 1289
22.7. Функциональные объекты 1292
22.8. Заключение 1296
22.9. Ресурсы по STL в Internet и Web 1296
Глава 23. Специальные вопросы 1307
23.1. Введение 1308
23.2. Операция const_cast 1308
23.3. Пространства имен 1310
23.4. Ключевые слова для операций 1315
23.5. Элементы класса со спецификатором mutable 1317
23.6. Указатели на элементы класса (.* и ->*) 1319
23.7. Сложное наследование 1321
23.8. Сложное наследование и виртуальные базовые классы .... 1326
23.9. Заключение 1331
23.10. Последние замечания 1331
Приложение А. Таблица старшинства и ассоциативности
операций 1337
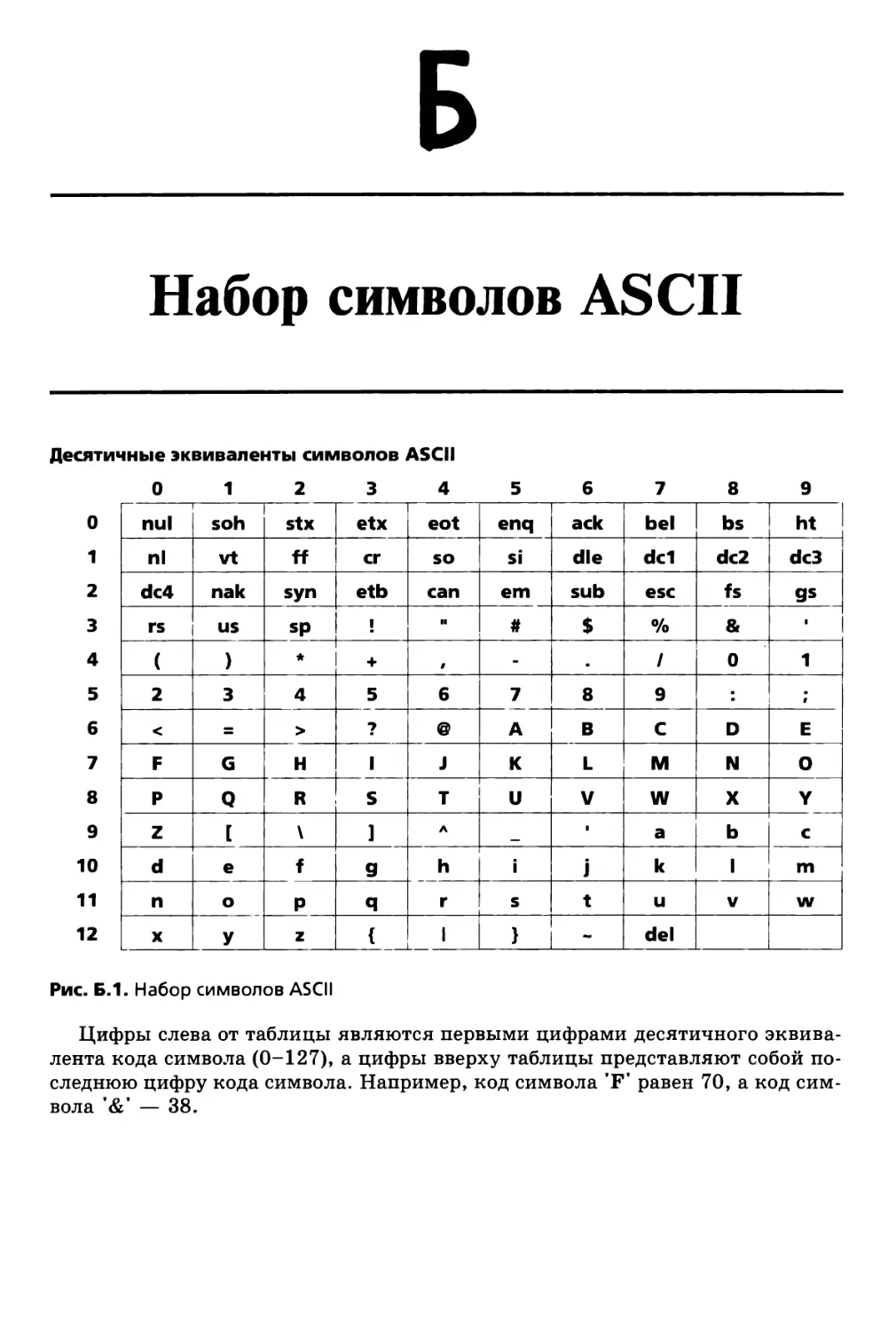
Приложение Б. Набор символов ASCII 1341
Приложение В. Основные типы 1343
Приложение Г. Код, унаследованный от С 1345
ГЛ. Введение 1346
Г.2. Иереадресация ввода/вывода в системах UNIX/LINUX/Mac OS X
и Windows 1346
Г.З. Списки аргументов переменной длины 1348
Г.4. Аргументы командной строки 1351
Г. 5. Замечания о компиляции программ из нескольких исходных
файлов 1352
Г.6. Выход из программы с помощью exit и atexit 1354
Г. 7. Квалификатор типа volatile 1356
Г.8. Суффиксы для целых констант и констант с плавающей
точкой 1356
Г.9. Обработка сигналов 1357
Г. 10. Динамическое распределение памяти с помощью calloc
и realloc 1359
Содержание 15
Г. 11. Безусловный переход: goto 1360
Г.12. Объединения 1362
Г. 13. Спецификации компоновки 1366
Г. 14. Заключение 1366
Приложение Д. Препроцессор 1373
Д.1. Введение 1374
Д.2. Директива препроцессора #include 1375
Д.З. Директива #define: символические константы 1375
Д.4. Директива #define: макросы 1376
Д. 5. Условная компиляция 1378
Д.6. Директивы #error и #pragma 1380
Д.7. Операции # и ## 1380
Д.8. Предопределенные символические константы 1381
Д.9. Макрос подтверждения 1381
Д.10. Заключение 1382
Приложение Е. Код учебного примера ATM 1387
ЕЛ. Реализация проекта ATM 1387
Е.2. Класс ATM 1388
Е.З. Класс Screen 1395
Е.4. Класс Keypad 1397
Е.5. Класс CashDispenser 1398
Е.6. Класс DepositSlot 1400
Е.7. Класс Account 1401
Е.8. Класс BankDatabase 1403
Е.9. Класс Transaction 1407
ЕЛО. Класс Balancelnquiry 1409
Е. 11. Класс Withdrawal 1411
Е.12. Класс Deposit 1416
Е.13. Тестовая программа ATMCaseStudy.cpp 1420
ЕЛ4. Заключение 1420
Приложение Ж. UML 2. Дополнительные типы диаграмм 1421
Ж.1. Введение 1421
Ж.2. Дополнительные типы диаграмм 1421
Приложение 3. Ресурсы в Internet и Web 1423
3.1. Ресурсы 1423
3.2. Учебные руководства 1425
3.3. FAQ (часто задаваемые вопросы) 1426
3.4. Visual C++ 1426
3.5. Группы новостей 1426
3.6. Компиляторы и инструменты разработки 1427
Литература 1429
Предметный указатель 1435
Предисловие
Главным достоинством языка
является ясность...
Гален
Добро пожаловать в мир программирования на C++! C++ является языком
программирования мирового класса для разработки профессиональных
высокоэффективных компьютерных приложений. Мы надеемся, что эта книга и
сопровождающие ее материалы предоставят преподавателям и студентам все
необходимое для эффективного, интересного, захватывающего и занимательного
процесса изучения C++. В этом предисловии мы делаем обзор того, что нового
появилось в пятом издании «Как программировать на C++». Раздел «Обзор
книги по главам» предисловия дает преподавателям, студентам и
специалистам представление о тематике C++ и объектно-ориентированного
программирования, охватываемой книгой. Мы также рассказываем о некоторых
используемых нами соглашениях. Мы приводим информацию о бесплатных
компиляторах, которые вы можете найти в Web, и описываем полный набор учебных
материалов, помогающих преподавателям максимально расширить опыт,
получаемый их студентами в процессе обучения. В этот набор входят Instructor's
Resource CD, слайды PowerPoint" к лекциям, системы организации курсов,
SafariX (публикации WebBook от Pearson Education) и многое другое.
Особенности данного издания
Мы, в Deitel & Associates, пишем учебники по компьютерным дисциплинам
и книги для специалистов. При подготовке этой книги мы, можно сказать, под
микроскопом исследовали предыдущее издание «Как программировать на
C++». Новое издание имеет многие привлекательные особенности:
• Существенный пересмотр содержания. Все главы подверглись
значительным изменениям и дополнениям. Мы стремились к ясности и
точности изложения. Мы также привели свою терминологию в соответствие со
стандартным документом ANSI/ISO по C++, который определяет этот
язык.
• Главы меньшего объема. Большие главы были разделены на меньшие,
более обозримые главы (например, глава 1 четвертого издания была
разбита на главы 1-2. Глава 2 теперь стала главами 4-5).
18
Как программировать на C++
• Подход «ранних классов и объектов». В плане педагогического подхода
мы перешли к раннему введению в классы и объекты. Студенты вводятся
в основные концепции и терминологию объектно-ориентированного
программирования в главе 1. В предыдущих изданиях студенты начинали
разрабатывать пользовательские утилизируемые классы в главе 6.
Теперь они делают это в совершенно новой 3-й главе. Главы 4-7 были
тщательно переписаны с позиции «ранних классов и объектов». Это новое
издание, от начала и до конца — объектно-ориентированное, насколько это
возможно. Перенос обсуждения классов и объектов в более ранние главы
заставляет студентов сразу «мыслить объектно-ориентированно»,
благодаря чему они более полно усваивают эти концепции.
Объектно-ориентированное программирование ни в коем случае не является тривиальным,
но писать объектно-ориентированные программы интересно, и студенты
могут сразу видеть получающиеся результаты.
• Интегрированные учебные примеры. Мы включили в текст несколько
развернутых учебных примеров, охватывающих те разделы и главы,
которые часто опираются на класс, представленный в книге ранее, чтобы
продемонстрировать новые концепции программирования позднее.
В число таких примеров входит разработка класса GradeBook в
главах 3-7, класса Time в нескольких разделах глав 9-10 и класса Employee
в главах 12-13.
• Интегрированный пример с классом GradeBook. Мы добавили в книгу
новый учебный пример с классом GradeBook, который представляет
«курсовой журнал» преподавателя и производит различные вычисления
с набором оценок студентов, например, вычисляет среднюю оценку,
находит минимальную и максимальную оценки и печатает диаграмму
распределения оценок.
• Unified Modeling Language™ 2.0 (UML 2.0). Унифицированный язык
моделирования (UML) стал наиболее популярным графическим языком
моделирования у проектировщиков объектно-ориентированных систем. Все
диаграммы UML в книге согласуются с новой спецификацией UML 2.O.
Мы пользуемся классовыми диаграммами UML для визуального
представления классов и диаграммы деятельности для демонстрации потока
управления в каждом из управляющих операторов C++.
• Процесс компиляции и компоновки программ из нескольких исходных
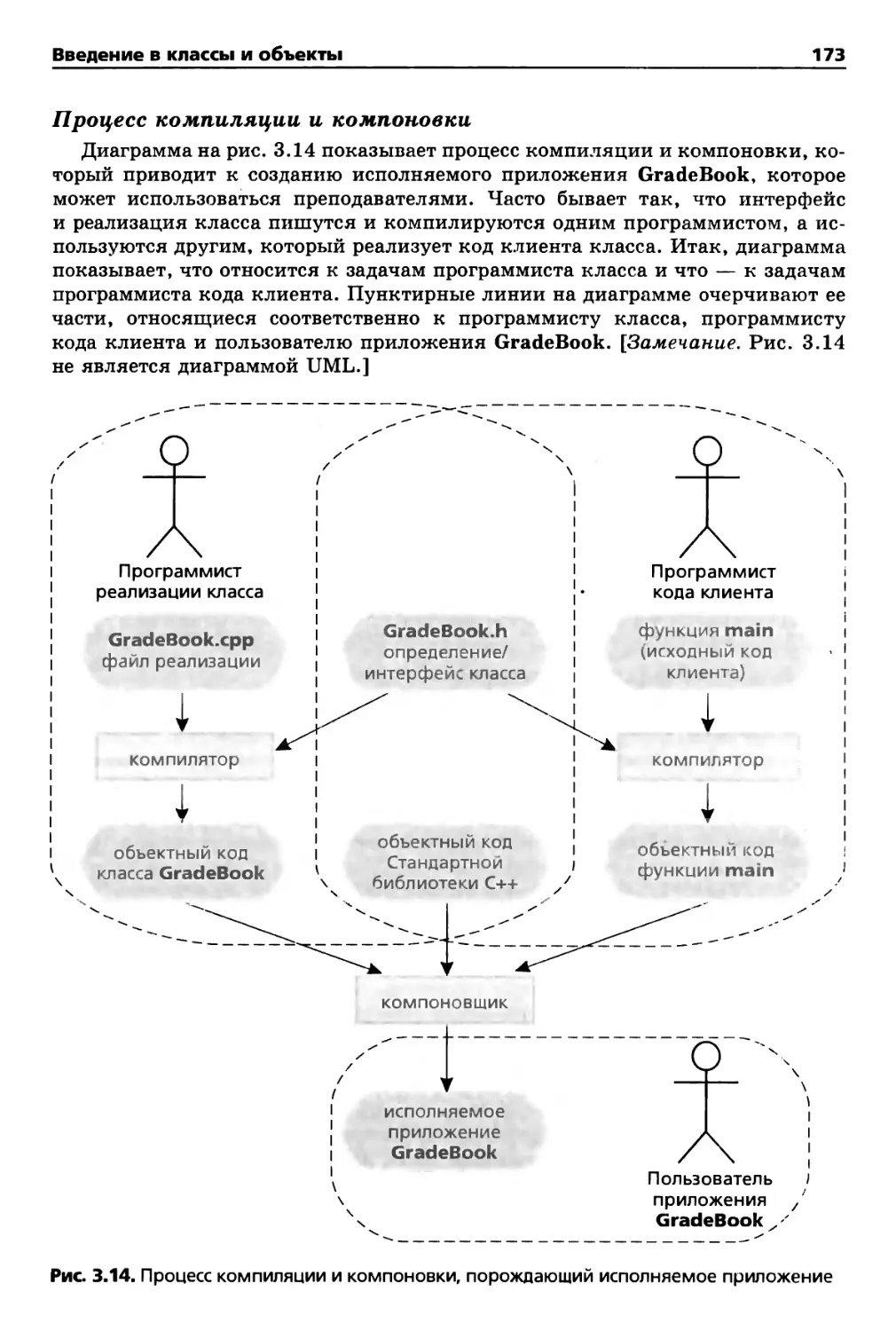
файлов. В главу 3 включены подробная диаграмма и обсуждение
процесса компиляции и компоновки, в результате которого генерируется
исполняемое приложение.
• Объяснение работы стека вызовов. В главе 6 мы проводим подробное
обсуждение (с иллюстрациями) стека вызова функций и активационных
записей, чтобы объяснить, каким образом C++ может следить за тем, какая
функция выполняется в данный момент, каким образом хранятся в
памяти автоматические переменные функций и каким образом функция
знает, куда она должна возвратить управление по своем завершении.
• Раннее введение в объекты string и vector стандартной библиотеки
C++. Чтобы сделать примеры в первых главах более
объектно-ориентированными, мы используем классы string и vector.
Предисловие
19
• Класс string. При обработке строк мы во всей книге пользуемся
преимущественно классом string вместо строк в стиле С типа char *. Мы
по-прежнему обсуждаем строки типа char * в главах 8, 10 и 11, чтобы
дать студентам попрактиковаться в обращении с указателями, для
иллюстрации динамического распределения памяти с помощью new и delete,
при построении своего собственного класса String и для того, чтобы
подготовить к студентов к работе в программной индустрии, где им придется
иметь дело со строками char * в коде, доставшемся в наследство от С
и первых версий C++.
• Шаблон класса vector. При обработке массивов мы во всей книге вместо
С-подобных массивов пользуемся шаблоном vector. Однако мы начинаем
главу 7 с обсуждения С-подобных массивов, чтобы подготовить студентов
к работе с унаследованном кодом на С и C++ в программной индустрии
и чтобы использовать С-подобные массивы как основу для построения
своего собственного специализированного класса Array в главе 11,
посвященной перегрузке операций.
• Уточненное изложение наследования и полиморфизма. Главы 12-13
были тщательно выверены, что сделало изложение наследования и
полиморфизма долее ясным и доступным для студентов, являющихся
новичками в OOP. Иерархию Point/Circle/Cylinder, использовавшуюся в
предыдущих изданиях для представления этой тематики, заменила
иерархия класса Employee. Эта новая иерархия более естественна.
• Обсуждение и иллюстрация «закулисной» работы полиморфизма.
Глава 13 содержит подробную схему и объяснение внутренней реализации
полиморфизма, виртуальных функций и динамического связывания
в C++. Это дает студентам ясное представление о том, как в
действительности работают эти механизмы. Что более важно, это помогает студентам
оценить издержки полиморфизма в плане дополнительных расходов
памяти и процессорного времени, благодаря чему они могут обоснованно
решить, когда следует использовать полиморфизм и когда лучше
избегать этого.
• Согласование со стандартом ANSI/ISO C++. Мы сверили свое
изложение, в плане полноты и точности, с самым последним стандартным
документом по ANSI/ISO C++. [Замечание. Если вам нужны дополнительные
технические детали по C++, вы, возможно, захотите прочитать
стандартный документ. Электронную версию документа, номер INCITS/ISO/IEC
14882-2003, можно получить в формате PDF за $18 на webstore.ansi.org/
ansidocstore/default.asp.]
• «Обогащенный код». Термином «обогащенный код» («code washing») мы
называем стиль написания кода с детальными комментариями,
использованием осмысленных идентификаторов, единообразными отступами,
вертикальным выравниванием фигурных скобок, завершением каждой
строки с закрывающей фигурной скобкой комментарием вида // конец...
и с вертикальной разрядкой, выделяющей смысловые единицы
программы, такие, как управляющие операторы и функции. Благодаря такому
подходу получаются гораздо более удобочитаемые и
самодокументированные программы. Мы «обогатили» таким образом весь код в книге и во
вспомогательных материалах к ней, затратив немалые усилия на то,
чтобы наш код стал образцовым.
20
Как программировать на C++
• Тестирование кода на различных платформах. Мы протестировали код
примеров на различных популярных платформах C++. По большей части
все примеры книги легко переносятся на все популярные компиляторы,
совместимые со стандартом ANSI/ISO. О всех возникающих проблемах
мы будем размещать сообщения на www.deitel.com/books/cpphtp5/in-
dex.html.
• Сообщения об ошибках и предупреждения на различных платформах.
Для программ, в которых имеются преднамеренные ошибки, мы
показываем сообщения, генерируемые различными компиляторами.
• Большая группа рецензентов. Книга тщательно изучалась группой из
более чем 30 известных специалистов, как из академического
сообщества, так и работающих в программной индустрии (поименно
перечисленных далее).
• Бесплатное Web-издание Cyber Classroom. Мы преобразовали нашу
популярную мультимедийную версию текста (которую мы называем Cyber
Classroom) из продукта, поставляемого на CD, в бесплатное доступное
в сети дополнение ко всем новым книгам, приобретаемым в Prentice Hall.
• Бесплатное руководство с решениями для студентов. Мы преобразовали
наше руководство «Student's Solution Manual», в котором содержатся
решения примерно для половины упражнений книги, из книжки в мягкой
обложке в бесплатное доступное в сети дополнение ко всем новым
книгам, приобретаемым в Prentice Hall.
• Бесплатное лабораторное руководство. Мы преобразовали наше
лабораторное руководство «C++ in the Lab» из книжки в мягкой обложке в
бесплатное доступное в сети дополнение, включенное в Cyber Classroom, ко
всем новым книгам, приобретаемым в Prentice Hall.
Если по ходу чтения книги у вас возникнут вопросы, пошлите сообщение на
deitel@deitel.com; мы незамедлительно ответим. Посетите наш Web-сайт, и не
забудьте подписаться на наш электронный бюллетень Deitel Buzz Online на
странице www.deitel.com/newsletter/subscribe.html, в котором сообщается о
дополнениях к этой книге и последняя информация по C++. Мы используем
также Web-сайт и бюллетень, чтобы держать наших читателей и клиентов в курсе
последних изданий Deitel и предлагаемых нами услуг. Вы можете получать
сведения о замеченных ошибках, обновлениях, относящихся к программному
обеспечению C++, бесплатных загрузках и других ресурсах на странице
www.deitel.com/books/cpphtp5/index.html
Подход к обучению
Данная книга содержит множество примеров, упражнений и проектов,
взятых из разнообразных областей, что дает студенту возможность решать
интересные задачи реального мира. Книга концентрирует внимание на принципах
правильного конструирования программного обеспечения. Мы старались
избегать хитроумных терминов и описаний синтаксиса, отдавая предпочтение
обучению на примерах. Мы — преподаватели, которым довелось обучать языкам
программирования на индустриальных курсах по всему миру. Д-р Харви Дей-
Предисловие
21
тел имеет двадцатилетний опыт преподавания в колледжах и был
председателем Отделения компьютерных наук в Бостонском колледже, и 15-летний опыт
обучения в программной индустрии. Пол Дейтел имеет 12-летний опыт
преподавания в программной индустрии. Дейтелы вели курсы по C++ на всех
уровнях для правительственных, промышленных, военных и академических
клиентов компании Deitel & Associates.
Обучение на примерах «живого кода» (Live-Code™)
В книге масса программ на C++ — каждое новое понятие представлено
в контексте законченной работающей программы на C++, за которой следует
один или несколько образцов запуска, показывающих ввод и вывод
программы. Мы называем такой стиль обучения и написания учебных пособий
методом Live-Code™. Для обучения языкам программирования мы используем языки
программирования. Чтение примеров в тексте во многом заменяет ввод и
выполнение его на компьютере. Мы предоставляем весь исходный код примеров
книги на www.deitel.com, благодаря чему студенты могут запускать каждый
пример по ходу его изучения.
Доступ через World Wide Web
Весь код, имеющийся в данной книге и других наших публикациях,
доступен для загрузки через Internet на
www.deitel.com
Зарегистрироваться на сайте просто, а загрузка бесплатна. Мы предлагаем
вам загрузить сразу все примеры и запускать каждую программу по ходу
чтения соответствующего текста. Возможность вносить в примеры изменения
и немедленно видеть их результат — поистине неоценимое преимущество
такого подхода к обучению.
Цели
Каждая глава начинается с объявления ее целей, что сразу сообщает
студентам о том, чего следует ожидать, и дает им возможность по прочтении
главы оценить, достигнуты ли эти цели. Это повышает доверие и способствует
позитивному восприятию материала.
План
План главы помогает студентам подойти к изучению по порядку и иметь
представление о том, что будет рассматриваться дальше, и установить для себя
удобный и эффективный темп обучения.
Программы-примеры с образцами ввода и вывода
Наши программы в «живом коде» меняются по размерам от нескольких
строк кода до достаточно объемных примеров. За каждой программой следует
окно, показывающее диалог ввода/вывода, полученный при запуске
программы, так что студенты могут убедиться в том, что программа работает, как
ожидалось. Соотнесение вывода программы с порождающими его операторами —
превосходный способ усвоения программных концепций.
22
Как программировать на C++
Иллюстрации и рисунки
В книге приводится большое количество диаграмм, рисунков и программ
с результатами их выполнения. Поток управления в управляющих операторах
мы моделируем UML-диаграммами деятельности. Элементы данных классов,
конструкторы и элемент-функции моделируются классовыми диаграммами.
Советы по программированию
Мы включаем в текст советы по программированию, чтобы помочь
читателям сосредоточиться на наиболее важных аспектах разработки программ. Мы
выделили эти советы в форме рубрик Хороший стиль программирования,
Типичная ошибка программирования, Вопросы производительности,
Переносимость программ, Общее методическое замечание и Предотвращение ошибок.
Эти советы и рекомендации представляют собой лучшее, что мы собрали за
несколько десятилетий активного программирования и преподавания. Одна из
наших студенток — математик — говорила нам, что этот подход подобен
выделению аксиом, теорем и следствий в книге по математике; это создает основу,
на которой строится хорошее программное обеспечение.
Хороший стиль программирования
Советы по хорошему стилю программирования обращают внимание
читателей на приемы и методы написания ясных программ. Такие
приемы помогают студентам создавать более удобочитаемые,
самодокументированные программы, которые проще сопровождать.
^ Типичные ошибки программирования
Студенты, изучающие язык (особенно, если для них это первый курс
программирования), обычно делают некоторые виды ошибок наиболее
часто. Обращение к рубрике «Типичные ошибки программирования»
помогает студентам избежать часто встречающихся ошибок. Эта
рубрика также поможет уменьшить длинные очереди за
консультацией к преподавателям.
Вопросы производительности
Исходя из нашего опыта, умение студентов писать ясные и
понятные программы — наиболее важная цель для учащихся первого курса,
изучающих программирование. Но студенты хотят писать
программы, которые работают быстрее, требуют меньше памяти, исходный
код которых короче. Студентам действительно небезразлична
эффективность кода, который они пишут. Они хотят знать, как им
«снабдить свои программы турбонаддувом». По этой причине мы включили
советы по повышению производительности — как заставить
программы работать быстрее и занимать меньше места в памяти.
Предисловие
23
Переносимость программ
Разработка программного обеспечения — сложная и дорогостоящая
деятельность. Организации, которые разрабатывают программное
обеспечение, часто должны создавать его версии, специально
приспособленные к различным компьютерам и операционным системам.
Поэтому в настоящее время большое внимание уделяется
переносимости, т.е. созданию программного обеспечения, которое будет
работать на различных компьютерных системах с незначительными,
если вообще они потребуются, изменениями. Некоторые
программисты полагают, что если они реализуют приложение на стандартном
C++, оно будет переносимым. Это просто не так. Достижение
переносимости требует внимательной и кропотливой разработки. Здесь
есть много ловушек и подводных камней. Мы приводим замечания по
переносимости программ, чтобы помочь читателям научиться
писать переносимый код.
Общие методические замечания
Методология объектно-ориентированного программирования требует
от программиста совершенно пересмотреть свой взгляд на
построение программных систем. C++ является эффективным языком для
правильного конструирования программного обеспечения. В этой
рубрике выделяются методики, проблемы архитектуры и
проектирования и т.д., которые влияют на архитектуру и конструирование
систем программного обеспечения, особенно крупномасштабных систем.
Многое из того, о чем узнают здесь студенты, будет полезно при
освоении курсов более высокого уровня и в программной индустрии, когда
студент начнет работать с большими, сложными реальными
системами.
Предотвращение ошибок
Когда мы впервые решили включить в книгу такой «тип советов», мы
думали, что они будут полезны для тестирования программ, чтобы
выявлять ошибки и устранять их. Фактически же большая часть из
этих советов представляет собой рекомендации по поводу написания
программ, предотвращающие возникновение ошибок и, таким
образом, упрощающие процессы тестирования и отладки.
Резюме
Каждая глава заканчивается дополнительным методическим материалом:
мы даем подробное, представленное в виде основных положений, резюме
главы. Это поможет читателям быстро просмотреть и закрепить ключевые
понятия.
Терминология
Для закрепления пройденного материала мы включили раздел
Терминология, содержащий перечень всех основных терминов, используемых в главе.
24
Как программировать на C++
Контрольные вопросы с ответами
Для самостоятельного изучения предусмотрены многочисленные
контрольные вопросы и ответы на них. Это дает читателю возможность научиться
уверенно ориентироваться в изученном материале и подготовиться к выполнению
основных упражнений. Читателям следует выполнять все упражнения для
самоконтроля и проверять свои ответы.
Упражнения
Каждая глава завершается солидным набором упражнений, которые
включают в себя: повторение основных терминов и понятий; написание отдельных
операторов; написание небольших фрагментов функций и классов C++;
написание законченных функций, классов C++ и даже целых программных
проектов. Большое количество упражнений позволит преподавателям приспособить
свои курсы к конкретным особенностям своей аудитории и каждый семестр
варьировать предлагаемые задания. Преподаватели могут использовать эти
упражнения для домашних заданий, контрольных работ и экзаменов.
Решения для большинства упражнений приводятся на компакт-диске
Instructor's Resource CD, который доступен только для преподавателей и
получить его можно только у представителей издательства Prentice Hall.
[Замечание. Пожалуйста, не обращайтесь к нам с просьбами предоставить вам
этот CD. Распространение их строго ограничено преподавателями высших
учебных заведений, которые осуществляют обучение на основе этой книги.
Преподаватели могут получить Instructor's Resource CD только от
официальных представителей издательства Prentice Hall. Мы сожалеем, что не
можем помочь профессионалам в решении этого вопроса.] Решения примерно
половины упражнений доступны для студентов в Web-пакете Cyber Classroom.
Для получения более подробной информации о Cyber Classroom посетите
www.deitel.com или подпишитесь на бесплатный электронный бюллетень
Deitel Buzz Online на странице www.deitel.com/newsletter/subscribe.html.
Предметный указатель
Мы включили в книгу предметный указатель, с помощью которого можно
быстро найти по ключевому слову нужный термин или понятие. Указатель
будет полезен тем, кто читает ее в первый раз, и особенно практическим
программистам, использующим книгу в качестве справочника.
Обзор книги по главам
В этом разделе мы проводим своего рода экскурсию по главам книги, чтобы
дать представление о тех богатых возможностях C++, которые вы будете
изучать по ходу чтения. Рис. 1 иллюстрирует зависимости между главами. Мы
рекомендуем изучать указанные темы, двигаясь по направлению стрелок, хотя
можно читать и в другом порядке. Эта книга широко используется в
преподавании C++ в курсах по программированию всех уровней. Вы можете поискать
в Web ключевые слова «syllabus», «C++» и «deitel», чтобы познакомиться
с конспектами таких курсов.
Предисловие
25
[названия глав]
1 Введение в компьютеры, Internet и World Wide Web
i
2 Введение
в программирование на C++
I
"► 15 Потоковый ввод/вывод
Рекомендуемый путь
изучения структур
данных
3 Введение в классы и объекты —► 18 Класс string и обработка
| строковых потоков
4 Управляющие операторы: часть 1
I
5 Управляющие операторы: часть 2
I
6 Функции и введение в рекурсию -
1
7 Массивы и векторы
I
21 Биты, символы, т
строки < 8 Указатели
и структуры и строки-указатели
9 Классы: часть 1
i
11 Перегрузка 10 Классы: часть 2
операций; объекты ч
Array и String
-► 6.19-6.21 Рекурсия
-> 19 Поиск
и сортировка
12 OOP: наследование
i
•14 Шаблоны
20 Структуры
данных
i
22 Библиотека
стандартных
шаблонов (STL)
13 OOP: полиморфизм
16 Управление 15 Потоковый 23 Специальные
исключениями ввод/вывод вопросы
I
17 Обработка файлов
1 Некоторые разделы главы 18 зависят
от главы 17
2 Рекурсию можно пропустить
Рис. 1. Схема, иллюстрирующая зависимости между главг-мг ■ чиги
26
Как программировать на C++
Глава 1 — «Введение в компьютеры, Internet и World Wide Web» —
рассказывает о том, что такое компьютеры, как они работают и как их
программируют. Глава вкратце знакомит с историей развития языков
программирования от машинных языков к языкам ассемблера и языкам высокого уровня.
Рассказывается об истоках языка C++. Наши бесплатные публикации о
других платформах серии Dive-Into™ можно найти на
www.deitel.com/books/downloads, html. В главу входит введение в типичную среду
программирования на C++. Мы также знакомим читателя с процессом «тестового запуска»
типичного приложения C++ на платформах Windows и Linux. Вводятся
основные понятия и терминология объектной технологии, а также UML
(Унифицированный язык моделирования).
Глава 2 — «Введение в программирование на C++» — содержит
упрощенное введение в программирование приложений на языке C++. Глава знакомит
непрограммистов с основными понятиями и конструкциями
программирования. Программы этой главы демонстрируют, как производить вывод данных на
экран и получать с клавиатуры данные от пользователя. Заканчивается глава
подробным рассмотрением принятия решений и арифметических операций.
Глава 3 — «Введение в классы и объекты» — является «изюминкой»
данного издания. В ней дается общепонятное раннее введение в классы и объекты.
Тщательно продуманная и совершенно новая, эта глава с самого начала
подводит студентов к естественной работе с объектной ориентацией. Она была
разработана при участии замечательной команды рецензентов — как из
академических кругов, так и работающих в программной индустрии. Мы представляем
классы, объекты, элемент-функции, конструкторы и элементы данных,
опираясь на ряд простых примеров из реального мира. Мы развиваем стройную
модель построения объектно-ориентированных программ на C++. Сначала мы
на простом примере обосновываем понятие класса. Затем представляем
логически выверенную последовательность из семи законченных работоспособных
программ, демонстрирующих создание и использование своих собственных
классов. Этими программами начинается наш интегрированный пример
разработки класса «курсового журнала», который может использоваться
преподавателями для хранения оценок, полученных студентами за контрольные
работы. Пример усовершенствуется в последующих главах, достигая своей
кульминации в главе 7, посвященной массивам и векторам. Пример класса
GradeBook описывает, как определить класс и использовать его для создания
объекта. Обсуждается объявление и определение элемент-функций,
реализующих поведение класса, объявление элементов данных и вызов
элемент-функций для выполнения предписанных им задач. Мы представляем класс string
из стандартной библиотеки C++ и создаем объекты string, которые служат для
хранения названия курса, представляемого объектом GradeBook. В главе
объясняется различие между элементами данных класса и локальными
переменными функции, и рассказывается об использовании конструкторов,
обеспечивающих инициализацию данных объекта при его создании. Мы показываем,
каким образом отделение класса от кода клиента (например, функции main),
использующего класс, способствует утилизации программного обеспечения.
Мы представляем также другой основной принцип правильного
конструирования программного обеспечения — отделение интерфейса от реализации. В
главу входит подробная схема и обсуждение процесса компиляции и компоновки,
в результате которого получается исполняемое приложение.
Предисловие
27
Глава 4 — «Управляющие операторы: часть 1» — сосредоточивает
внимание на процессе программной разработки, в результате которого получаются
полезные классы. В главе обсуждается, каким образом, исходя из постановки
задачи, через промежуточные этапы формулирования ее на псевдокоде,
разрабатывается работоспособная программа на C++. Глава вводит некоторые
простые управляющие операторы для принятия решений (if и if...else) и
повторения (while). Используя класс GradeBook из главы 3, мы исследуем
повторение, управляемое счетчиком, и управляемое контрольным значением. В главу
включены две усовершенствованные версии класса GradeBook, каждая из
которых разрабатывается на основе последней версии класса из'главы 3. В
каждой из этих версий имеется элемент-функция, использующая управляющие
операторы для вычисления среднего по набору оценок студентов. В первой
версии элемент-функция использует повторение, управляемое счетчиком, для
получения 10 оценок, вводимых пользователем, а затем определяет среднюю
оценку. Во второй версии в элемент-функции используется повторение,
управляемое контрольным значением, что позволяет вводить произвольное число
оценок, после чего также вычисляется среднее по введенным оценкам. Для
иллюстрации потока управления в каждом из управляющих операторов
приводятся простые диаграммы деятельности UML.
Глава 5 — «Управляющие операторы: часть 2» — продолжает обсуждение
управляющих операторов C++ на примерах оператора повторения for,
оператора повторения do...while, оператора выбора switch, операторов break
и continue. Мы снова создаем усовершенствованную версию класса
GradeBook, использующую оператор switch для подсчета буквенных оценок А, В, С, D
и F, которые вводит пользователь. Ввод оценок производится с
использованием повторения, управляемого контрольным значением. В процессе чтения
вводимых оценок элемент-функция модифицирует элементы данных,
отслеживающие количество оценок в каждой из категорий. Другая элемент-функция,
используя эти элементы данных, печатает отчет по введенным оценкам. В
главе также обсуждаются логические операции.
Глава 6 — «Функции и введение в рекурсию» — более внимательно
рассматривает объекты и их элемент-функции. Мы обсуждаем функции
Стандартной библиотеки C++ и более подробно рассказываем о том, каким образом
студенты могут создавать свои собственные функции. Методики,
представленные в главе 6, существенны для построения правильно организованных
программ, особенно больших программ и программного обеспечения, которое
и системным, и прикладным программистам придется, весьма вероятно,
разрабатывать в реальной жизни. Мы представляем стратегию «разделяй и
властвуй», как эффективное средство решения сложных задач путем подразделения
их на более простые взаимодействующие компоненты. Первый пример главы
продолжает развитие класса GradeBook, вводя в него функцию с несколькими
параметрами. Студентам понравится та часть главы, в которой идет речь о
случайных числах и моделировании игры в кости («крепе»), где изящно
применяются управляющие операторы. В главе обсуждаются так называемые
«улучшения, вносимые C++ в С», включая inline-функции, ссылочные параметры,
аргументы оп умолчанию, унарную операцию разрешения области действия,
перегрузку функций и шаблоны функций. Мы представляем также
возможности передачи аргументов по значению и по ссылке. В таблице заголовочных
файлов перечисляются многие из заголовков, которые читатель будет исполь-
28
Как программировать на C++
зовать на протяжении всей книги. В этом, новом издании мы даем детальное
(с иллюстрациями) обсуждение стека вызовов функций и активационных
записей, чтобы объяснить, каким образом C++ может следить за тем, какая
функция исполняется в данный момент, как хранятся в памяти
автоматические переменные функций и как функция знает о том, куда следует
возвратить управление после завершения своего выполнения. Затем предлагается
развернутое введение в рекурсию и перечисляются примеры и упражнения на
рекурсию, распределенные по различным главам книги. Некоторые учебники
рассматривают рекурсию в одной из последних глав; нам кажется, что эту
тему лучше всего охватывать постепенно на протяжении всей книги. Богатое
собрание упражнений в конце главы включает в себя несколько классических
рекурсивных задач, включая «Ханойскую башню».
Глава 7 — «Массивы и векторы» — объясняет, как обрабатываются
таблицы и списки значений. Вы обсуждаем структурирование данных в виде
массивов элементов одного и того же типа и демонстрируем, как массивы упрощают
выполняемые объектами задачи. Начальные разделы главы имеют дело с
массивами в стиле С, которые, как вы увидите в главе 8, являются по существу
указателями на содержимое массива в памяти. Затем, в последней части
главы, мы представляем массивы в виде полноценных объектов, реализуемых
шаблоном класса vector из стандартной библиотеки — надежной
структурой-массивом данных. В главе приводятся многочисленные примеры как
одномерных, так и двумерных массивов. В примерах исследуются различные
приемы работы с массивами, печать столбцовых диаграмм, сортировка
данных и передача массивов функциям. В главу входят два последних примера
с классом GradeBook, в которых мы используем массивы для хранения
оценок в течение выполнения программы. Предыдущие примеры обрабатывали
вводимые пользователем оценки, но не сохраняли отдельные значения оценок
в элементах данных класса. В этой главе объекты класса GradeBook
сохраняют оценки в памяти, что устраняет необходимость повторного ввода того же
набора оценок. Первая версия класса сохраняет оценки в одномерном массиве
и может создавать отчет, содержащий среднюю, минимальную и
максимальную оценки по группе, а также диаграмму, представляющую распределение
оценок. Вторая (т.е. последняя) версия класса использует двумерный массив,
в которых хранятся оценки нескольких студентов, полученных в течение
семестра за несколько контрольных работ. Эта версия может вычислять
среднюю оценку каждого студента за семестр, а также максимальную и
минимальную оценки из всех оценок, полученных всеми студентами в течение семестра.
Другим важным моментом главы является обсуждение элементарных методик
сортировки и поиска. Упражнения в конце главы включают разнообразные
интересные и нетривиальные задачи, такие, как улучшение методик
сортировки, разработка простой системы для заказа авиабилетов, введение в
концепцию «черепашьей графики» (которая легла в основу знаменитого языка
LOGO), а также задачи «Обход конем» и «Восемь ферзей», которые
представляют понятие эвристического программирования, широко применяемого в
области искусственного интеллекта. Заключает упражнения ряд задач на
рекурсию, в том числе сортировка выборкой, палиндромы, линейный поиск,
вариант «Восьми ферзей», печать массива, печать строки в обратном порядке
и нахождение минимального значения в массиве.
Предисловие
29
Глава 8 — «Указатели и строки-указатели» — представляет одно из
наиболее мощных средств языка C++ — указатели. В главе дается детальное
объяснение операций указателей, вызова по ссылке, выражений с указателями,
арифметики указателей, взаимоотношений между указателями и массивами,
массивов указателей и указателей на функцию. Мы демонстрируем
применение к указателям квалификатора const в интересах принципа наименьших
привилегий, что позволяет строить более надежное программное обеспечение.
Мы вводим также операцию sizeof для определения размера (в байтах) типа
данных или отдельных элементов данных во время компиляции. В C++
существует тесная взаимосвязь между указателями, массивами и строками в стиле
С, поэтому мы представляем элементарные принципы работы со строками С
и обсуждаем некоторые наиболее часто применяемые функции для обработки
таких строк, такие, как getline (ввод строки текста), strcpy и strncpy
(копирование строки), strcat и strncat (конкатенация двух строк), strcmp и strncmp
(сравнение двух строк), strtok (разбиение строки на составляющие ее
лексемы) и strlen (определение длины строки). В данном издании мы, где это
возможно, пользуемся вместо строк-указателей типа char * в стиле С объектами
string (которые вводятся в главе 3). Однако мы включили в главу 8 строки
char *, чтобы помочь читателю в освоении указателей и подготовке к
реальностям мира профессионального программирования, где он встретится с массой
кода, доставшегося в наследство от языка С, на котором программисты писали
в течение трех десятков лет. Таким образом, читатель познакомится с двумя
преобладающими методами создания и обработки строк в C++. Многие люди
находят, что тема указателей является пока наиболее трудной частью во
вводных курсах по программированию. В С и «сыром» C++ массивы и строки
являются указателями на содержимое массивов или строк в памяти (даже имена
функций являются указателями). Тщательная проработка этой главы
вознаградит вас глубоким пониманием указателей. Главу сопровождает множество
интересных упражнений. В их число входят моделирование классического
соревнования между черепахой и зайцем, алгоритмы тасования и сдачи карт,
рекурсивная быстрая сортировка и рекурсивные обходы лабиринта. В
упражнения включен и специальный раздел, озаглавленный «Как построить свой
собственный компьютер». В разделе рассказывается о программировании на
машинном языке, после чего развивается проект, включающий в себя
разработку и реализацию симулятора компьютера, что подводит студента к
написанию и запуску программ на машинном языке. Эта уникальная часть текста
будет особенно полезна читателю, который хочет понять, как на самом деле
работают компьютеры. Нашим студентам очень нравится этот проект, и они
часто вносят в него существенные усовершенствования, некоторые из которых
предлагаются читателю в качестве упражнений. Во второй специальный
раздел включены интересные упражнения по обработке строк, связанные с
анализом текста, редактированием, печатью дат в различных форматах, защитой
чеков, печатью словесного эквивалента денежных сумм, кодом Морзе и
преобразованием метрических и английских единиц измерения.
Глава 9 — «Классы: часть 1» — продолжает обсуждение
объектно-ориентированного программирования. В главе используется развернутый пример
развитого класса Time, который иллюстрирует элемент-функции доступа,
отделение интерфейса от реализации, использование функций доступа и
сервисных функций, инициализацию объектов конструкторами, уничтожение объ-
30
Как программировать на C++
ектов деструкторами, присваивание по умолчанию посредством поэлементного
копирования и утилизацию программного кода. Студенты узнают, в каком
порядке вызываются конструкторы и деструкторы на протяжении периода
жизни объектов. Модификация класса Time демонстрирует проблемы, которые
могут возникать, если элемент-функция возвращает ссылку на закрытый
элемент данных, нарушая тем самым инкапсуляцию класса. Упражнения главы
предлагают студенту разработать классы для времен, дат, прямоугольников
и игры в крестики-нолики. Студентом, как правило, приходятся по вкусу
игровые программы. Читателям со склонностью к математике понравятся
упражнения, предлагающие создать класс Complex (для комплексных чисел),
класс Rational (для рациональных чисел) и класс Hugelnteger (для
произвольно больших целых чисел).
Глава 10 — «Классы: часть 2» — продолжает изучение классов и
представляет дополнительные понятия объектно-ориентированного
программирования. В главе обсуждается объявление и использование константных объектов,
константных элемент-функций, композиция — процесс построения классов,
имеющих в качестве элементов объекты других классов, дружественные
функции и классы, имеющие особые права доступа к закрытым и защищенным
элементам классов, указатель this, который позволяет объекту знать свой
собственный адрес, динамическое распределение памяти, статические элементы
класса для хранения и обработки общеклассовых данных, примеры
распространенных абстрактных типов данных (массивов, строк и очередей),
контейнерные классы и итераторы. При обсуждении const-объектов мы упоминаем
ключевое слово mutable, которое позволяет в некоторых специальных
случаях модифицировать «невидимую» реализацию константных объектов. Мы
обсуждаем динамическое распределение памяти операциями new и delete. Когда
new не удается выделить память, программа по умолчанию завершается, так
как new в стандартном C++ «выбрасывает исключение». Мы обосновываем
применение статических элементов данных на примере видеоигры, Мы
подчеркиваем важность сокрытия деталей реализации от клиентов класса; после
этого мы обсуждаем классы-посредники, предоставляющие средства сокрытия
реализации (в том числе закрытых элементов данных в заголовках классов).
В число примеров главы входит разработка класса для сберегательного счета
и класса для хранения множества целых чисел.
Глава 11 — «Перегрузка операций; объекты Array и String» —
представляет один из наиболее популярных разделов в курсах по C++. Студентам этот
материал действительно нравится. Они находят его прекрасно согласующимся
с детальным обсуждением создания полезных классов в главах 9 и 10.
Перегрузка операций позволяет программисту указать компилятору, как
применять существующие операции к объектам новых типов. C++ уже знает, как
применять эти операции к объектам таких встроенных типов, как целые,
числа с плавающей точкой и символы. Но предположим, мы создали новый
класс — строки. Что означает применительно к строкам знак плюс (+)?
Многие программисты используют плюс применительно к строкам для
обозначения их конкатенации. Из главы 11 программист узнает, как «перегрузить»
этот знак таким образом, чтобы при его написании в выражении между двумя
строковыми объектами компилятор генерировал бы вызов
«функции-операции», которая соединит эти две строки. В главе рассматриваются основы
перегрузки операций, ограничения при перегрузке операций, различия в перегруз-
Предисловие
31
ке элемент-функций класса и функций, не являющихся элементами класса,
перегрузка унарных и бинарных операций и преобразование типов. Глава 11
содержит набор развернутых примеров, включая класс массивов (Array),
класс строк (String), класс дат, класс больших целых и класс совершенных
чисел (последние два приводятся с полным исходным кодом в упражнениях).
Студенты с математическими наклонностями найдут интересным создание
класса многочленов (polynomial). Этот материал сильно отличается от того,
что можно найти в других языках и курсах по программированию. Перегрузка
операций — сложная тема, но чрезвычайно плодотворная. Перегрузка
операций позволяет вам «отполировать» свои классы. Обсуждение классов Array
и String будет особенно полезным для студентов, уже работавших с классами
стандартной библиотеки C++ string и vector, которые обладают сходными
возможностями. В упражнениях студентам предлагается добавить перегрузку
операций в классы Complex, Rational и Hugelnteger для удобства
манипуляции объектами этих классов посредством символами операций (как в
математике), а не с помощью вызовов функций, как это делалось в упражнениях
главы 10.
Глава 12 — «Объектно-ориентированное программирование:
наследование* — представляет одну из наиболее фундаментальных особенностей
объектно-ориентированных программных языков — наследование: форму
утилизации программного кода, когда новые классы можно разрабатывать быстро
и легко, наделяя их возможностями существующих классов и добавляя новые
элементы. В контексте примера иерархии класса Employee эта (существенно
переработанная) глава представляет последовательность из пяти отдельных
примеров, демонстрирующих закрытые данные, защищенные данные и
правильную разработку программного обеспечения на основе наследования. Мы
начинаем с демонстрации класса, имеющего закрытые элементы данных и
открытые элемент-функции для манипуляции этими данными. Затем мы
реализуем второй класс с дополнительными возможностями, намеренно дублируя
большую часть кода из первого примера. Третьим примером начинается наше
обсуждение наследования и утилизации программного кода: используя класс
из первого примера в качестве базового класса, мы быстро и просто наследуем
его данные в новом, производном классе. Этот пример вводит механизм
наследования и демонстрирует, что производный класс не может непосредственно
обращаться к закрытым элементам данных базового класса. Тем самым
обосновывается наш четвертый пример, к котором мы вводим в базовом классе
защищенные данные и демонстрируем, что производный класс действительно
может обращаться к защищенным элементам, унаследованным от базового.
Последний пример в этом ряду демонстрирует правильное конструирование
программного обеспечения, определяя данные базового класса как закрытые
и используя для манипуляции этими данными в производном классе
открытые функции базового класса (которые наследуются производным классом).
В главе обсуждаются понятия базовых и производных классов, защищенные
элементы, открытое, защищенное и закрытое наследование, непосредственные
и косвенные базовые классы, конструкторы и деструкторы в базовых и
производных классах, а также конструирование программного обеспечения с
использованием наследования. В главе также сравнивается наследование
(отношение «является») с композицией (отношением «имеет») и вводятся
отношения «использует» и «знает».
32
Как программировать на C++
Глава 13 — «Объектно-ориентированное программирование:
полиморфизм» — рассматривает другой фундаментальный аспект
объектно-ориентированного программирования: полиморфное поведение. Полностью
переработанная, эта глава строится на концепциях наследования, представленных
в главе 12, и фокусирует внимание на отношениях классов в иерархии
наследования и тех возможностях, которые открываются благодаря этим
отношениям. Когда несколько классов являются, через наследование, родственными
одному базовому классу, объекты каждого из производных классов могут
рассматриваться как объекты базового класса. Это позволяет писать программы
в простом и обобщенном виде, не зависящем от конкретного типа объектов
производных классов. Новые виды объектов могут обрабатываться той же
самой программой, что делает систему расширяемой. Полиморфизм позволяет
устранить из программы сложную логику операторов switch, заменив ее
«прямолинейной» логикой. Менеджер экрана в видеоигре, например, может
послать сообщение draw каждому объекту в связанном списке объектов, которые
должны быть нарисованы. Каждый объект знает, как себя нарисовать. В
программу можно ввести объект нового класса, не модифицируя ее (если новый
объект также знает, как себя нарисовать). В главе обсуждается механика,
реализующая полиморфное поведение посредством виртуальных функций.
Проводится различение абстрактных классов (объекты-представители которого не
могут быть созданы) и конкретных классов (для которых возможно создание
представителей). Мы демонстрируем абстрактные классы и полиморфное
поведение, возвращаясь к иерархии класса Employee из главы 12. Мы вводим
абстрактный базовый класс Employee, от которого непосредственно
производятся классы CommissionEmoloyee, HourlyEmployee и SalariedEmployee,
а косвенно — класс BasePlusCommissiomEmployee. В прошлом наши
клиенты-профессионалы настаивали, чтобы мы подробнее рассказывали о том, как
в точности реализуется полиморфизм в C++ и, соответственно, какую «цену»
в плане памяти и времени выполнения приходится платить за удобства
программирования, предоставляемые этой мощной возможностью. В ответ на эти
требования мы приводим схему и подробное объяснение работы таблиц
виртуальных функций (vtable), которые автоматически строятся компилятором C++
для поддержки полиморфизма. В заключение мы рассказываем об
идентификации типа времени выполнения (RTTI) и динамическом приведении типов,
которые позволяют во время исполнения программы определить тип объекта
и затем обращаться с ним соответствующим образом. Используя RTTI и
динамическое приведение типа, мы даем 10-процентную надбавку служащим
определенного типа и затем вычисляем их зарплату. Зарплату служащих всех
других типов мы вычисляем полиморфно.
Глава 14 — «Шаблоны» — обсуждает одно из самых мощных средств C++
в плане утилизации программного обеспечения, а именно, шаблоны. Шаблоны
функций и шаблоны классов позволяют программистам специфицировать
в единственном сегменте кода весь диапазон родственных функций
(называемых специализациями шаблона функции) или родственных классов
(называемых специализациями шаблона класса). Эту методику называют обобщенным
программированием. Шаблоны функций вводятся в главе 6. В данной главе
проводится дополнительное обсуждение и приводятся примеры шаблонов
функций. Мы могли бы написать единственный шаблон для класса стека, а
потом C++ генерировал бы отдельные специализации шаблона класса, такие,
Предисловие
33
как класс «стек int», класс «стек float», класс «стек string» и т.д. В главе
обсуждаются параметры-типы, нетиповые параметры и типы по умолчанию для
шаблонов. Мы также обсуждаем взаимоотношения между шаблонами и
другими языковыми средствами C++, такими, как перегрузка, наследование,
дружественность и статические элементы. Упражнения предлагают студенту
написать разнообразные шаблоны функций и классов, а затем применить из в
законченных программах. Мы значительно усиливаем изложение шаблонов
обсуждением контейнеров, итераторов и алгоритмов Стандартной библиотеки
шаблонов C++ (STL) в главе 22.
Глава 15 — «Потоковый ввод /вывод * — содержит подробное изложение
стандартных возможностей ввода/вывода C++. В главе обсуждается диапазон
методик вода/вывода, достаточный для решения большинства задач, связанных
с вводом/выводом, и дается обзор остальных возможностей. Многие из
обсуждаемых средств ввода/вывода являются объектно-ориентированными. Такой
стиль ввода/вывода использует многие другие элементы языка, такие, как
ссылки, перегрузка функций и перегрузка операций. Рассматриваются самые
различные аспекты ввода/вывода в C++, включая вывод с помощью операции
передачи в поток, ввод с помощью операции извлечения из потока, безопасный
по типу ввод/вывод, форматированный ввод/вывод, неформатируемый
ввод/вывод (позволяющий повысить производительность). Пользователи могут
специфицировать, каким образом должен осуществляться ввод/вывод
определяемых пользователем типов, перегружая операцию передачи в поток («) и
извлечения из потока (»). Расширяемость является одной из наиболее ценных
особенностей C++. Для выполнения задач форматирования в C++
предусмотрены различные манипуляторы. В главе обсуждаются потоковые манипуляторы,
позволяющие выводить целые числа в различных системах счисления,
управлять точностью чисел с плавающей точкой, устанавливать ширину полей
вывода, отображать десятичную точку и конечные нули, выравнивать вывод,
устанавливать и сбрасывать состояния формата, задавать заполняющие символы
полей. Мы также представляем пример, в котором создается определяемый
пользователем манипулятор выходного потока.
Глава 16 — «Управление исключениями» — обсуждает, каким образом
исключения позволяют программистам писать программы более устойчивые,
толерантные к ошибкам и пригодные для окружения, критического в
отношении выживания (business-critical) или в отношении цели (mission-critical).
В главе рассматривается, в каких случаях управление исключениями
целесообразно; вводятся базовые элементы управления исключениями посредством
try-блоков, операторов throw и catch-обработчиков; рассказывается, как и
когда перебрасывать исключение; объясняется, как написать спецификацию
исключения; и наконец, обсуждаются важные взаимосвязи между
исключениями, конструкторами, деструкторами и наследованием. Упражнения главы
демонстрирую т студенту все разнообразие и мощь средств C++ для управления
исключениями. Мы обсуждаем перебрасывание исключения и демонстрируем,
каким образом операция new может отказать при нехватке памяти. Многие
более старые компиляторы C++ при отказе new по умолчанию возвращают 0.
Мы показываем новый стиль поведения new при отказе, когда операция
выбрасывает исключение bad_alloc (неудачное выделение памяти). Мы
демонстрируем, как с помощью функции set_new_handler специфицировать
специальную функцию, вызывающуюся для разрешения ситуаций исчерпания сво-
2 Заж. 1114
34
Как программировать на C++
бодной памяти. Мы обсуждаем, как использовать класс auto_ptr для неявного
удаления динамически выделенной памяти, чтобы избежать утечек. В
заключение мы представляем классовую иерархию исключений Стандартной
библиотеки.
Глава 17 — «Обработка файлов» — рассказывает о методиках создания
и обработки файлов как последовательного, так и произвольного доступа.
Глава начинается с иерархического представления данных — от битов к
байтам, полям, записям и файлам. Затем мы показываем файлы и потоки с
точки зрения C++. Мы обсуждаем последовательные файлы и строим
программы, показывающие, как открывать и закрывать файлы, как сохранять
данные в файле последовательно и последовательно их читать. Затем мы
обсуждаем файлы произвольного доступа и пишем программы,
показывающие, как создать файл для произвольного доступа, как читать и писать
данные, используя произвольный доступ к файлу, и как читать данные
последовательно из файла, обрабатывавшегося посредством произвольного доступа.
Учебный пример комбинирует методики последовательного и произвольного
доступа к файлам в законченной программе обработки транзакций.
Слушатели наших производственных семинаров отмечали, что после изучения
материала по обработке файлов они могли создавать большие программы для
обработки файлов, которые сразу становились весьма полезными в работе их
организаций. В упражнениях студенту предлагается реализовать
разнообразные программы, которые создают и обрабатывают файлы последовательного
и произвольного доступа.
Глава 18 — «Класс string и обработка строковых потоков» — обсуждает
возможности C++ в плане ввода данных из строк, находящихся в памяти,
и вывода данных в строки в памяти; это часто называют резидентным
форматированием или обработкой строковых потоков. Класс string является
необходимым компонентом Стандартной библиотеки. Мы сохранили изложение
строк-указателей в стиле С в главе 8 по нескольким причинам. Во-первых, оно
укрепляет у читателя понимание указателей. Во-вторых, в течение
следующего десятка лет программистам, работающим на C++, нужно будет уметь читать
и модифицировать огромное количество унаследованного от С кода,
накопившегося за четверть века, — этот код обрабатывает строки как указатели, что
в значительной мере относится и к большой части промышленного кода на
C++, написанного в последние несколько лет. В главе 18 мы обсуждаем
присваивание, конкатенацию и сравнение стандартных строк. Мы показываем,
как определить различные характеристики строки, такие, как длина и
вместимость, и то, является ли строка пустой. Мы рассказываем, как изменить
размер строки. Мы рассматриваем различные функции поиска, позволяющие
нам найти в строке подстроку (просматривая строку в прямом либо обратном
направлении), и показываем, как найти первое или последнее вхождение
в строку любого символа из указанной строки, и как найти первое или
последнее вхождение символа, не содержащегося в указанной строке. Мы
показываем, как заменять, вставлять и удалять символы в строке и как преобразовать
объект string в строку char * стиля С.
Глава 19 — «Поиск и сортировка» — обсуждает два из важнейших классов
алгоритмов. Для каждого из них мы рассматриваем специфические
алгоритмы и сравниваем их в плане требований к памяти и затрат процессорного
времени (попутно вводя нотацию «О большого», которая показывает, насколько
Предисловие
35
тяжело приходится алгоритму потрудиться, чтобы решить задачу). Поиск
в данных связан с выяснением того, присутствует ли некоторое значение
(ключ поиска) в наборе данных, и если присутствует, каково его
местонахождение. В примерах и упражнениях главы мы обсуждаем разнообразные
алгоритмы поиска, включая двоичный поиск и рекурсивные варианты линейного
и двоичного поиска. На примерах и упражнениях в главе объясняются
сортировка слиянием, пузырьковая сортировка, блочная сортировка и рекурсивная
быстрая сортировка.
Глава 20 — «Структуры данных» — рассматривает методики создания
и обработки динамических структур данных. Глава начинается обсуждением
автореферентных классов и динамического распределения памяти, после чего
переходит к созданию и поддержанию различных динамических структур
данных, включая связанные списки, очереди, стеки и деревья. Для каждого типа
структур данных мы представляем законченные работающие программы и
показываем образцы их вывода. Глава также поможет студентам овладеть
указателями, поскольку содержит множество примеров с косвенной и двойной
косвенной адресацией — концепция последней вызывает наибольшие
затруднения. Одной из проблем при изучении указателей является то, что студентам
трудно наглядно представить себе структуры данных и как их узлы связаны
между собой. Мы снабдили главу иллюстрациями, которые показывают связи
и последовательность их создания. Настоящим венцом изучения указателей
и динамических структур данных является пример двоичного дерева. Этот
пример создает двоичное дерево, подавляя дубликаты, и показывает
рекурсивный обход дерева с опережающей, порядковой и отложенной выборкой. После
изучения и реализации этого примера у студентов возникает чувство, что они
действительно чего-то достигли. Их особенно восхищает, когда они воочию
убеждаются, что обход с порядковой выборкой действительно печатает
значения узлов в сортированном виде. Мы включили в главу солидное собрание
упражнений. Среди них выделяется специальный раздел, предлагающий
построить «свой собственный компилятор». Упражнения раздела проводят студента
по разработке программы преобразования инфиксной нотации в постфиксную
и программы оценки постфиксных выражений. Затем мы модифицируем
алгоритм постфиксной оценки так, чтобы он генерировал код машинного языка.
Компилятор помещает этот код в файл (применяя приемы обработки файлов из
главы 17). После этого студенты запускают генерированный компилятором
машинный код на программных эмуляторах, которые они построили в
упражнениях главы 8! В число 35 упражнений главы входят рекурсивный поиск в
списке, рекурсивная печать списка в обратном порядке, удаление узла из
двоичного дерева, поуровневый обход двоичного дерева, распечатку деревьев,
написание фрагмента оптимизирующего компилятора, написание
интерпретатора, вставку/удаление произвольного узла связанного списка, реализацию
списков и очередей без хвостового указателя, анализ производительности
поиска и сортировки в двоичном дереве, реализация класса индексированного
списка и моделирование очереди в универсаме. После изучения главы 20 читатель
будет подготовлен к изложению контейнеров, итераторов и алгоритмов STL
в главе 22. Контейнеры STL представляют собой готовые шаблонные
реализации структур данных, которые большинство программистов найдет вполне
достаточными для подавляющего большинства тех приложений, что им придется
писать. STL явилась гигантским скачком вперед в плане утилизации кода.
36
Как программировать на C++
Глава 21 — «Биты, символы, строки и структуры» — представляет
разнообразные важные элементы языка. Глава начинается сравнением структур
C++ с классами, после чего обсуждается определение и использование С-по-
добных структур. Мы показываем, как объявлять структуры,
инициализировать структуры и передавать структуры функциям. Центральным примером
по структурам является высокоэффективный алгоритм тасования и сдачи
колоды карт. Он дает преподавателю прекрасную возможность показать, что
такое качество алгоритмов. Мощные средства манипуляции битами в C++
позволяют программистам писать программы, использующие низкоуровневые
возможности аппаратуры. Они помогают программам обрабатывать битовые
строки, устанавливать отдельные биты и более компактно хранить
информацию. Такие возможности, которые можно найти почти исключительно в
низкоуровневых языках ассемблера, очень ценятся программистами, пишущими
системное программное обеспечение, такое, как операционные системы и
сетевое обеспечение. Как вы помните, в главе 8 мы представили работу со
строками в стиле С типа char * и описали наиболее употребительные функции для
обработки строк. В главе 21 мы продолжаем тему о символах и строках в стиле
С. Мы представляем различные средства манипуляции символами библиотеки
<cctypc>, например, возможность проверки символа на предмет того,
является ли он цифрой, буквой, буквенно-цифровым символом, шестнадцатеричной
цифрой, буквой нижнего регистра или буквой верхнего регистра. Мы
представляем также другие функции для манипуляции строками из различных
библиотек, так или иначе связанных со строками; как всегда, каждая
функция обсуждается в контексте законченной работающей программы на C++. 32
упражнения побуждают студента самостоятельно испробовать большую часть
из описанного в главе. Центральное упражнение главы — разработка
программы проверки правописания. Эта глава более глубоко разбирает С-подобные
строки типа char * и будет полезна программистам, которым придется
работать с кодом, унаследованным от С.
Глава 22 — «Библиотека стандартных шаблонов (STL)» — На
протяжении всей книги мы подчеркиваем важность утилизации программного
обеспечения. Заметив, что многие структуры данных и алгоритмы постоянно
используются программирующими на C++, комитет по стандарту C++ включил
в стандартную библиотеку C++ Библиотеку стандартных шаблонов (STL). STL
определяет мощные утилизируемые компоненты, реализующие в форме
шаблонов многие типичные структуры данных и алгоритмы, применяемые для
обработки этих структур. STL является эталоном обобщенного
программирования, представленного в главе 14 и детально продемонстрированного в главе 20.
Данная глава представляет STL и обсуждает три основных ее компонента —
контейнеры (распространенные структуры данных в форме шаблонов),
итераторы и алгоритмы. Контейнеры STL являются структурами данных,
способными хранить объекты любого типа данных. Мы увидим, что существует три
категории контейнеров — настоящие контейнеры, адаптеры и потги-контей-
неры. Итераторы STL, сходные по своим свойствам с указателями,
используются программами для манипуляции элементами STL-контейнеров. На самом
деле с обычными массивами можно обращаться как с контейнерами,
используя в качестве итераторов указатели. Мы увидим, что манипуляция
контейнерами посредством итераторов удобна и в комбинации с алгоритмами является
мощнейшим выразительным средством, сводя в некоторых случаях многие
Предисловие
37
строки кода к единственному оператору. Алгоритмы STL являются
функциями, которые решают типичные задачи обработки данных, такие, как поиск,
сортировка и сравнение элементов (или контейнеров в целом). В STL
реализовано около 70 алгоритмов. Большинство из них использует для доступа к
элементам контейнеров итераторы. Мы увидим, что каждый настоящий
контейнер поддерживает специфические типы итераторов, из которых одни более,
а другие менее мощны. Поддерживаемый контейнером тип итератора
определяет то, может ли контейнер использоваться с конкретным алгоритмом.
Итератор инкапсулирует механизм доступа к элементам контейнера. Эта
инкапсуляция позволяет использовать многие алгоритмы STL с различными
контейнерами, безотносительно к внутренней организации контейнера конкретного
контейнера. Если итераторы контейнера соответствуют минимальным
требованиям алгоритма, то алгоритм может обрабатывать элементы этого
контейнера. Это также позволяет программистам писать алгоритмы, работающие с
элементами контейнеров нескольких различных типов. В главе 20 обсуждается,
как с помощью указателей, классов и динамической памяти реализуются
структуры данных. Код с указателями сложен, и малейшее упущение или
недосмотр может вести к серьезным ошибкам нарушения доступа и утечкам
памяти, не вызывая при этом нареканий со стороны компилятора. Реализация
дополнительных структур данных, таких, как двусторонние очереди,
приоритетные очереди, множества, карты и т.п. требует существенной
дополнительной работы. Кроме того, если многие программисты, работающие над
большим проектом, реализуют схожие алгоритмы для решения различных задач,
код становится трудным для модификации, сопровождения и отладки.
Преимущество STL состоит в том, что для реализации типичных представлений
и манипуляций с данными программисты могут утилизировать контейнеры,
итераторы и алгоритмы STL. Такая утилизация ведет к существенной
экономии времени и ресурсов. Это несложная, доступная глава, которая должна
убедить вас в ценности STL и побудить к дальнейшему ее изучению.
Глава 23 — «Специальные вопросы» — объединяет разделы, посвященные
разнообразной тематике. В главе обсуждается одна дополнительная операция
приведения — const_cast. Эта операция, вместе с операциями static_cast
(глава 5), dynamic_cast (глава 13) и reinterpret_cast (глава 17), предлагает более
надежный механизм для преобразования типов, чем первоначальные
операции приведения, которые C++ унаследовал от С (и которые теперь применять
не рекомендуется). Мы обсуждаем пространства имен — концепцию, которая
особо значима для разработчиков программного обеспечения, строящих
большие системы, особенно для тех, кто строит системы из компонентов классовых
библиотек. Пространства имен предотвращают конфликты именования,
которые могут сдерживать программную разработку, несмотря на затрачиваемые
усилия. В главе обсуждаются ключевые слова для операций, полезные
программистам, у которых клавиатура не поддерживает некоторых символов,
используемых для операций, таких, как &, Л, | и ~. Эти ключевые слова подойдут
также тем, кто не любит загадочных символов операций. Мы обсуждаем
ключевое слово mutable, которое позволяет изменять элемент константного
объекта. Прежде этого достигали «отведением константности», что считалось
опасным приемом. Мы обсуждаем также операции указателя на элемент .* и ->*,
сложное наследование (включая проблему «ромбовидного наследования»)
и виртуальные базовые классы.
38
Как программировать на C++
Приложение А — «Таблица старшинства и ассоциации операций» —
представляет полный набор символов операций C++, перечисляя по
отдельности знаки операций с их названиями и правилами ассоциации.
Приложение Б — «Набор символов ASCII» — в этом приложении
представлен набор символов ASCII, который используют все программы в этой
книге.
Приложение В — «Основные типы» — перечисляет все основные типы,
определяемые стандартом C++.
Приложение Г — «Код, унаследованный от С» — рассматривает
некоторые дополнительные вопросы, в том числе из углубленной тематики, которая
обычно не охватывается во вводных курсах. Мы показываем, как
переадресовать ввод программы на ввод из файла, а вывод на вывод в файл,
переадресовать вывод одной программы на ввод другой (конвейер) и присоединить вывод
программы к содержимому существующего файла. Мы разрабатываем
функции со списком аргументов переменной длины и показываем, как передать
функции main аргументы командной строки и использовать их в программе.
Мы обсуждаем, как компилировать программы из компонентов, находящихся
в нескольких файлах, как с помощью вызова atexit регистрировать функции,
которые должны вызываться при завершении программы, и как завершать
исполнение программы вызовом функции exit. Мы также обсуждаем квалифи-
каторы типа const и volatile, спецификацию типа числовых констант с
помощью суффиксов, использование библиотеки обработки сигналов для перехвата
непредвиденных событий, создание и перераспределение динамических
массивов с помощью calloc и realloc, использование объединений как средства
экономии памяти и спецификации внешних связей при компоновке программ
C++ с кодом, унаследованным от С. Как предполагает название, глава
адресована главным образом программистам на C++, которым придется работать
с унаследованным кодом, с чем, по-видимому, в некоторый момент своей
карьеры придется столкнуться почти каждому программисту.
Приложение Д — «Препроцессор» — подробно обсуждает директивы
препроцессора. Приложение содержит более подробную информацию по
директиве #include, которая перед компиляцией текущего файла заменяется на
копию указанного в файла, и директиве #define, которая создает символические
константы и макросы. В приложении объясняется условная компиляция,
позволяющая программисту управлять исполнением препроцессорных директив
и компиляцией кода программы. Обсуждаются операции #, преобразующая
свой операнд в строку, и ##, соединяющая вместе две лексемы. Описываются
предопределенные символические константы препроцессора ( LINE ,
_FILE_, _DATE_, _STDC_, _TIME_ и _TIMESTAMP_). Наконец,
обсуждается макрос assert из заголовочного файла <cassert>, полезный при
тестировании, отладке и верификации программы.
Приложение Е — «Код учебного примера ATM» — содержит реализацию
нашего учебного примера по объектно-ориентированному проектированию
с использованием UML. Это приложение обсуждается в обзоре учебного
примера (представленном следующем разделе).
Приложение Ж — «Диаграммы UML 2» — содержит обзор типов
диаграмм, не встречающихся в учебном примере по OOD/UML.
Приложение 3 — «Ресурсы Internet и World Wide Web» — содержит
список ценных ресурсов C++, таких, как демонстрационные программы, инфор-
Предисловие
39
мация о популярных компиляторах (включая бесплатные), книгах, статьях,
конференциях, предлагаемых вакансиях, журналы, справочники, учебные
руководства, FAQ (часто задаваемые вопросы), группы новостей, Web-курсы,
сведения о новых продуктах и инструментах разработки C++.
Библиография — перечислено более 100 книг и статей, чтобы поощрить
студента к дальнейшему чтению о C++ и объектно-ориентированном
программировании.
Предметный указатель — подробный указатель позволяет читателю найти
по ключевому слову объяснение любого термина или понятия,
встречающегося в книге.
Объектно-ориентированное проектирование системы
ATM с помощью UML. Обзор необязательного
учебного примера по конструированию
программного обеспечения
В этом разделе мы даем обзор включенного в книгу необязательного
учебного примера по объектно-ориентированному проектированию с использованием
языка UML. Обзор охватывает содержание девяти разделов «Конструирование
программного обеспечения» (в главах 1-7, 9 и 13). Завершив изучение
учебного примера, читатель получит ясное представление о продуманном процессе
объектно-ориентированном проектировании и реализации серьезного
приложения на C++.
Проект, представленный в учебном примере с ATM, был разработан
в Deitel & Associates, Inc. и тщательно изучался авторитетной группой
рецензентов, состоящей из преподавателей и промышленных специалистов. Мы
построили этот проект таким образом, чтобы он соответствовал
последовательности изучения C++ во вводных курсах. Реальные системы ATM, с которыми
имеют дело банки и их клиенты по всему миру, построены на основе более
сложных проектов, которые принимают во внимание гораздо более широкий
круг вопросов, чем мы рассматриваем здесь. Нашей главной целью было
создание простого проекта, понятного новичкам в OOD и UML, но который в то же
время демонстрировал бы ключевые концепции OOD и связанные с ними
методики моделирования UML. Нам пришлось потрудиться, чтобы проект и код
получились относительно небольшими и пример хорошо ложился на
последовательность вводного курса.
Раздел 1.17 — «Конструирование программного обеспечения. Введение
в объектную технологию и UML» — представляет учебный пример
объектно-ориентированного проектирования с помощью UML. Раздел вводит
основные концепции и терминологию объектной технологии, включая классы,
объекты, инкапсуляцию, наследование и полиморфизм. Мы рассказываем об
истории UML. Это единственный обязательный для изучения раздел учебного
примера.
Раздел 2.8 — «Конструирование программного обеспечения.
Исследование требований к ATM (необязательный раздел)» — обсуждает
спецификацию требований, документ, специфицирующий требования к системе,
которую мы будем проектировать и реализовывать, — программному обеспечению
для простого банкомата (ATM). Мы исследуем структуру и поведение объект-
40
Как программировать на C++
но-ориентированных систем вообще. Мы обсуждаем, какую помощь окажет
нам UML в процессе проектирования, развертываемого в последующих
разделах по конструированию программного обеспечения, предоставляя в наше
распоряжение различные типы диаграмм для моделирования системы. В разделе
приводится списки URL и ссылок на литературу по
объектно-ориентированному проектированию с помощью UML. Мы обсуждаем взаимодействие между
системой ATM, как ее описывает спецификация требований, и ее
пользователем. В частности, мы исследуем сценарии того, что может происходить между
пользователем и самой системой, — они называются вариантами
применения. Мы моделируем эти взаимодействия посредством диаграммы вариантов
применения.
Раздел 3.11 — «Конструирование программного обеспечения.
Идентификация классов в спецификации требований ATM (необязательный
раздел)» — начинает проектирование системы ATM. Мы идентифицируем ее
классы, или «строительные блоки», выделяя в спецификации требований
имена существительные и именные конструкции. Мы организуем эти классы
в классовую диаграмму UML, описывающую классовую структуру модели.
Классовая диаграмма описывает также взаимоотношения, или ассоциации,
между классами.
Раздел 4.13 — «Конструирование программного обеспечения.
Идентификация классовых атрибутов в системе ATM (необязательный раздел)» —
фокусирует внимание на атрибутах классов, обсуждавшихся в разделе 3.11.
Класс содержит как атрибуты (данные), так и операции (поведение). Как мы
увидим в последующих разделах, изменения в атрибутах объекта часто
влияют на его поведение. Чтобы определить атрибуты для классов в нашем
примере, мы выделяем в спецификации требований имена прилагательные,
относящиеся к существительным и именным конструкциям (уже определившим
наши классы), и затем размещаем атрибуты на классовой диаграмме,
созданной в разделе 3.11.
Раздел 5.11 — «Конструирование программного обеспечения.
Идентификация состояний объектов и деятельности в системе ATM (необязательный
раздел)» — говорит о том, что объект в каждый момент времени находится
в специфическом положении, называемом состоянием. Переход между
состояниями происходит, когда объект получает сообщение, требующее
изменения состояния. В UML определяется диаграмма машинных состояний,
идентифицирующая множество возможных состояний, в которых может
находиться объект, и моделирующая переходы состояний этого объекта. Объекту
присуща также деятельность — работа, которую он выполняет в течение
своего периода жизни. В UML предусмотрена диаграмма деятельности —
блок-схема, моделирующая деятельность объекта. В этом разделе мы
используем оба типа диаграмм для моделирования специфических аспектов
поведения нашей системы ATM, например, каким образом ATM производит
транзакцию снятия наличных и как ATM реагирует на авторизацию пользователя.
Раздел 6.22 — «Конструирование программного обеспечения.
Идентификация операций классов в системе ATM (необязательный раздел)» —
идентифицирует операции, или услуги наших классов. Мы выделяем в
спецификации требований глаголы и глагольные конструкции, специфицирующие
операции каждого класса. Затем мы модифицируем диаграмму из раздела 3.11,
чтобы она включала вместе с классом каждую его операцию. На данном этапе
Предисловие
41
учебного примера мы извлекли из спецификации требований всю возможную
информацию. Однако когда в следующих главах будут ведены такие понятия,
как наследование, мы модифицируем наши классы и диаграммы.
Раздел 7.12 — «Конструирование программного обеспечения.
Кооперация объектов в системе ATM (необязательный раздел)» — дает «грубый
набросок» нашей модели для системы ATM. Мы исследуем поведение модели,
обсуждая кооперации — сообщения, которые объекты посылают друг другу для
совместной деятельности. Операции классов, обнаруженные нами в
разделе 6.22, оказываются кооперациями объектов в нашей системе. Мы
определяем кооперации, а затем собираем их в диаграмме коммуникации — диаграмме
UML для моделирования коопераций. Диаграмма раскрывает, какие объекты
(и когда) кооперируют. Мы представляем диаграмму коммуникации для
коопераций объектов при выполнении ATM проверки баланса. Затем мы
представляем диаграмму последовательности UML для моделирования
взаимодействий в системе. Диаграмма выделяет хронологию сообщений. Диаграмма
последовательности моделирует, каким образом взаимодействуют объекты
для выполнения транзакций снятия и депонирования средств.
Раздел 9.12 — «Конструирование программного обеспечения. Начало
программирования классов системы ATM (необязательный раздел)» —
прерывает на время проектирование поведения нашей системы. Мы начинаем
процесс реализации, чтобы закрепить материал, обсуждавшийся в главе 9.
Используя классовую диаграмму в разделе 3.11, а также атрибуты и операции,
обсуждавшиеся в разделах 4.13 и 6.22, мы показываем, как реализовать класс
по его проекту. Мы не реализуем все классы — поскольку еще не завершили
процесс проектирования. Отправляясь от наших диаграмм UML, мы создаем
код для класса Withdrawal.
Раздел 13.10 — «Конструирование программного обеспечения. Введение
наследования в систему ATM (необязательный раздел)» — возобновляет
обсуждение объектно-ориентированного проектирования. Мы рассматриваем
наследование — классы, имеющие общие характеристики, могут наследовать
атрибуты и операции от одного «базового» класса. В этом разделе мы исследуем,
какие преимущества может получить наша система ATM от использования
наследования. Мы документируем результаты своих изысканий посредством
классовой диаграммы, моделирующей отношения наследования — в UML
такие отношения называются обобщениями. Мы модифицируем классовую
диаграмму из раздела 3.11, используя наследование для группировки классов со
сходными характеристиками. Этим разделом завершается частичное
проектирование нашей модели. В приложении Ж мы полностью реализуем модель
в 877 строках кода на C++.
Приложение Е — «Код учебного примера ATM» — Большая часть
учебного примера посвящена проектированию модели (т.е. данных и логики)
системы ATM. В этом приложении мы реализуем эту модель на C++. Опираясь на
все созданные нами диаграммы UML, мы представляем классы C++,
необходимые для реализации модели. Мы применяем здесь концепции
объектно-ориентированного моделирования с помощью UML и объектно-ориентированного
программирования на C++, которые вы изучали в главах книги. К концу
приложения студенты завершат проектирование и реализацию системы из
реального мира и будут чувствовать себя уверенно, принимаясь за более крупные
системы, какие строят профессиональные инженеры-программисты.
42
Как программировать на C++
Программное обеспечение для работы с книгой
Только на рынке академической системы образования данный учебник
доступен в пакете с интегрированной средой разработки Microsoft® Visual C++
.NET 2093 Standard Edition в качестве бесплатного дополнения. Лимита
времени на использование этого продукта нет.
Бесплатные компиляторы C++ и пробные версии компиляторов
C++ в Web
В Web имеется много компиляторов, доступных для загрузки. Мы
рассказываем здесь только о бесплатных или о предоставляемых для бесплатной
пробы. Следует помнить о том, что во многих случаях пробные выпуски
программного обеспечения не могут использоваться после истечения лимита
времени (часто весьма малого).
Одной из популярных организаций, разрабатывающих свободно
распространяемое программное обеспечение, является GNU Project (www.gnu.org),
первоначально созданная для разработки свободно распространяемой
операционной системы, подобной UNIX. GNU предлагает ресурсы разработчика,
включая редакторы, отладчики и компиляторы. Многие разработчики
используют компиляторы GCC (GNU Compiler Collection), доступные на сайте
gcc.gnu.org. Коллекция содержит компиляторы для С, C++, Java и других
языков. Компилятор GCC — это компилятор, работающий в режиме
командной строки (т.е. он не имеет графического пользовательского интерфейса).
Многие Linux- и Unix-системы поставляются с установленным компилятором
GCC. Red Hat разработала Cygwin (www.cygwin.com) — эмулятор, который
позволяет разработчикам использовать команды UNIX в Windows. Cygwin
включает в себя компиляторы GCC.
Borland предлагает инструмент разработки для Windows иод названием
C++Builder (www.borland.com/cbuilder/cppcom/index.html). Базовый
компилятор C++Builder (компилятор, работающий в режиме командной строки)
можно загрузить бесплатно. Borland предлагает также несколько версий
C++Builder, содержащих графический пользовательский интерфейс (GUI).
Эти GUI более формально называют интегрированными средами разработки
(IDE); в отличие от компиляторов, работающих в режиме командной строки,
они позволяют разработчику быстро редактировать, отлаживать и тестировать
программы. При использовании IDE многие задачи, которые были связаны
с утомительными командами, теперь могут выполняться посредством меню
и кнопок. Некоторые из этих продуктов доступны как бесплатные пробные
версии. Для получения более подробной информации о C++Builder посетите
www. borland. com/products/downloads/download_cbuilder. html
Для разработчиков Linux Borland предлагает среду разработки Borland Kylix.
Продукт Borland Kylix Open Edition, включающий IDE, можно загрузить с
www.borland.com/products/downloads/download_kylix.html
Borland предлагает также C++BuilderX — интегрированную среду для меж-
платформных разработок. Бесплатная версия Personal Edition доступна на
www.borland.com/products/downloads/download_cbuilderx.html
Предисловие
43
Компилятор с командной строкой (версия 5.6.4) из C++BuilderX — один
из тех, что мы использовали для тестирования программ в этой книге. Многие
загрузки, предлагаемые Borland, требуют регистрации пользователя.
Компилятор Digital Mars C++ Compiler (www.digitalmars.com) имеется для
Windows и DOS и включает учебные пособия и документацию. Читатели могут
загрузить версию компилятора с командной строкой или IDE-версию. Система
разработки DJGPP C/C++ доступна для компьютеров, работающих под DOS.
DJGPP — сокращение от DJ's GNU Programming Platform, где DJ (DJ
Delorie) — это имя создателя DJGPP. Информацию о DJGPP можно получить
на сайте www.delorie.com/djgpp. Адреса, откуда можно загрузить
компилятор, имеются на сайте www.delorie.com/djgpp/getting.html.
За перечнем других компиляторов, доступных для свободной загрузки,
обратитесь на
www.thefreecountry.com/developercity/ccompilers.shtml
www.compilers.net
Предупреждения и сообщения об ошибках в старых
компиляторах C++
Программы в этой книге разрабатывались для компиляторов,
поддерживающих стандартный C++. Однако у компиляторов встречаются те или иные
отклонения, которые могут иногда приводить к предупреждениям или
ошибкам. Кроме того, хотя стандарт и специфицирует различные ситуации,
которые требуют генерации сообщений об ошибках, он не специфицирует
содержание выдаваемых сообщений. Предупреждения и сообщения об ошибках от
компилятора"к компилятору изменяются — это нормально.
Некоторые более старые компиляторы, например, Microsoft Visual C++ 6,
Borland C++ 5.5 и различные старые версии GNU C++ генерируют ошибки или
предупреждения там, где новейшие компиляторы этого не делают. Хотя
большинство программ в этой книге будет работать и с этими компиляторами, есть
несколько примеров, требующих небольшой модификации. На Web-сайте
книги (www.deitel.com/books/cpphtp5/index.html) перечислены
предупреждения и сообщения об ошибках, выдаваемые некоторыми старыми
компиляторами и что можно (если можно) сделать, чтобы устранить эти сообщения.
Замечания относительно объявлений using и функций
стандартной библиотеки%С
В состав стандартной библиотеки C++ входят функции из стандартной
библиотеки С. В соответствии со стандартным документом C++, содержимое
заголовочных файлов из стандартной библиотеки С входит в именное пространство «std».
Некоторые компиляторы (и новые, и старые) генерируют сообщения об ошибках,
когда объявления using применяются к функциям С. Мы поместим список,
касающийся таких проблем, на www.deitel.com/books/cpphtp5/index.html.
Учебные пособия серии Dive-Into™ для популярных сред C++
Наши бесплатные публикации серии Dive-Into™, доступные вместе с другими
ресурсами для этой книги на www.deitel.com/books/cpphtp5/downloads.html,
помогают студентам и преподавателям освоить различные инструменты
разработки C++. В число этих публикаций входят:
44
Как программировать на C++
• Dive-Into Microsoft® Visual C++® 6
• Dive-Into Microsoft® Visual C++® .NET
• Dive-Into Borland™ C++Builder™ Compiler (версия с командной строкой)
• Dive-Into Borland™ C++Builder™ Personal (IDE-версия)
• Dive-Into GNU C++ on Linux и Dive-Into GNU C++ via Cygwin on Windows
(Cygwin— это эмулятор UNIX для Windows, в который входит
компилятор GNU C++).
Каждое из этих учебных пособий показывает, как компилировать,
выполнять и отлаживать приложения C++ на данном конкретном продукте. Многие
из этих документов предлагают также пошаговые инструкции и экранные
снимки, чтобы помочь читателям в установке программного обеспечения.
Каждый документ содержит обзор компилятора и его документации.
Учебные материалы к «C++ How to Program, 5/e»
Данная книга сопровождается разнообразными ресурсами для
преподавателей. Instructor's Resource CD (IRCD) содержит Solutions Manual с решениями
почти ко всем упражнениям книги, приведенным в конце глав, Test Item File
с вопросами и вариантами ответов (примерно по два на раздел) и слайды
PowerPoint, показывающие весь исходный код и рисунки в тексте, а также
резюме ключевых моментов текста. Преподаватель может настраивать слайды.
[Замечание. IRCD могут получить только преподаватели через
представителей Prentice Hall. Чтобы найти вашего местного представителя, посетите
vig.prenhall.com/replocator
Если вам требуется дополнительная помощь или у вас есть какие-то вопросы
о IRCD, пошлите нам e-mail на deitel@deitel.com. Мы ответим незамедлительно.]
Web-версия C++ Multimedia Cyber Classroom, 5/e
Как «C++ How to Program, 5/e», так и «Small C++ How to Program, 5/e»1
сопровождаются бесплатным сетевым мультимедийным пакетом — C++
Multimedia Cyber Classroom, 5/e. Наш содержит звуковое сопровождение
к примерам кода в тексте, решения примерно к половине упражнений,
бесплатное лабораторное руководство и многое другое. Чтобы подробнее узнать
о новом Cyber Classroom, посетите наш Web-сайт www.deitel.com или
подпишитесь на бесплатный электронный бюллетень Deitel® Buzz Online на странице
www.deitel.com/newsletter/subscribe.html
Студенты, использующие наши Cyber Classrooms, говорят, что им нравится
интерактивный характер работы и что Cyber Classroom является мощным
справочным инструментом. Профессора говорят, что их студенты получают удовольствие
от работы с Cyber Classroom и соответственно больше времени проводят на
курсах, осваивая больший объем материала, чем на курсах, где используются только
Есть русский перевод: Как программировать на C++. Пятое малое издание. М., БИНОМ
2006 — Прим. ред.
Предисловие
45
учебники. Чтобы получить полный список наших Cyber Classroom на CD посетите
www.deitel.com, www.prenhall.com/deitel или www.InformIT.com/deitel.
C++ in the Lab
C++ in the Lab: Lab Manual to Accompany C++ How to Program, 5/e — наше
бесплатное сетевое лабораторное руководство — дополняет «C++ How to Program,
5/е» и «Small C++ How to Program, 5/e» практическими лабораторными
заданиями, разработанными для закрепления понимания студентами лекционного
материала. Это лабораторное руководство предназначено для * закрытых
лабораторий» — регулярно проводимых занятий под наблюдением преподавателя.
Закрытые лаборатории обеспечивают превосходную учебную обстановку, так как
студенты могут применять концепции, с которыми познакомились на занятиях,
для решения тщательно подобранных лабораторных заданий. Преподаватели
могут лучше контролировать понимание материала студентами, следя за их
успехами в лаборатории. Это лабораторное руководство может также использоваться
для открытых лабораторий, домашних заданий и самостоятельной работы.
Главы лабораторного руководства делятся на Prelab Activities
(подготовительные задания), Lab Exercises (лабораторные работы) и Postlab Activities
(контрольные задания). Каждая глава начинается формулировками целей,
представляющих ключевые моменты лабораторной работы, и контрольным
списком, в котором студенты отмечают задания, назначенные им преподавателем.
Решения для подготовительных заданий, лабораторных работ и
контрольных заданий доступны в электронной форме. Преподаватели могут получить
эти материалы у своих постоянных представителей издательства Prentice Hall;
для студентов решения недоступны.
Подготовительные задания
Подготовительные задания должны выполняться студентами после
изучения каждой главы «C++ How to Program, 5/e». Они проверяют понимание
материала учебника и подготавливают студентов к программным упражнениям
на лабораторном занятии. Упражнения заостряют внимание на важнейших
терминах и программных концепциях, являясь эффективным средством
самоконтроля. В их число входят упражнения с вариантами ответов, «заполните
пропуски», вопросы «верно-неверно», «что выводится» (определить, что
делает короткий фрагмент кода, не запуская программы) и «исправьте код» (найти
и исправить все ошибки в коротком фрагменте кода).
Лабораторные работы
Наиболее важным разделом каждой главы является Lab Exercises. Они учат
студентов, как применять материал, изученный в книге, и готовят их к
написанию программ на C++. Каждая лабораторная работа состоит из одного или
нескольких упражнений и одной задачи на отладку. Лабораторные работы
содержат:
• Цели упражнений выделяют конкретные концепции, на которых
фокусирует внимание лабораторное упражнение.
• Описания задач формулируют детали упражнения и дают наводящие
указания, помогающие студентам решить задачу.
46
Как программировать на C++
• Образцы вывода иллюстрируют требуемое поведение программы, что
уточняет описания задач и помогает студентам писать программы.
• Шаблоны программ являются законченными программами, ключевые
строки которых заменены комментариями, описывающими
пропущенный код.
• Подсказки выделяют ключевые моменты, которые студенты должны
обдумать при решении задачи.
• Заключительные вопросы и упражнения предлагают модифицировать
решения упражнений, написать новые программы, похожие на эти
решения, или объяснить, почему был выбран тот или иной путь реализации
при решении задачи.
• Задачи на отладку состоят из блоков кода, который содержит
синтаксические и/или логические ошибки. Они предупреждают студентов о том,
с какого рода ошибками им придется встретиться при
программировании.
Контрольные задания
Преподаватели обычно назначают контрольные задания для того, чтобы
закрепить ключевые концепции или дать студентам возможность приобрести
дополнительный опыт вне лаборатории. Контрольные задания проверяют
понимание материала подготовительных заданий и лабораторных работ, и
предлагают студентам применить свои знания к написанию программ «с нуля».
Раздел содержит два типа программных заданий: упражнения на написание
кода и программные проекты. Упражнения на кодирование коротки и служат
своего рода опросом по выполнении подготовительных заданий и
лабораторных работ. В них требуется написать программы или программные
фрагменты, использующие ключевые концепции из учебника. Программные проекты
дают студенту возможность применить свои знания к серьезным
программным задачам.
Концепция PearsonChoices
Наше время предъявляет к студентам повышенные требования в плане их
времени и денег. Им приходится серьезно относиться к тому, как, где и чему
они учатся. Издательство Pearson/Prentice Hall, отделение Pearson Education,
ответило на эти созданием серий PearsonChoices, которые позволяют
факультетам и студентам выбирать учебники различного объема и по различным
ценам.
«Small C++ How to Program, 5/e» является нашим альтернативным
печатным изданием для «C++ How to Program, 5/e». «Small C++ How to Program,
5/e» — учебник меньшего объема, ориентированный на курсы 1-го уровня по
компьютерным дисциплинам (CS1) и существенно дешевле, чем наше издание
«C++ How to Program, 5/e» (из 23 глав) и другие учебники, конкурирующие на
рынке CS1.
Предисловие
47
Главы, входящие и в «Small C++ How to Program, 5/e» («Как
программировать на C++: 5-е малое издание»), и в «C++ How to
Program, 5/e»
Глава 1 — «Введение в компьютеры, Internet и World Wide Web»
Глава 2 — «Введение в программирование на C++»
Глава 3 — «Введение в классы и объекты»
Глава 4 — «Управляющие операторы: часть 1»
Глава 5 — «Управляющие операторы: часть 2»
Глава 6 — «Функции и введение в рекурсию»
Глава 7 — «Массивы и векторы»
Глава 8 — «Указатели и строки-указатели»
Глава 9 — «Классы: часть 1»
Глава 10 — «Классы: часть 2»
Глава 11 — «Перегрузка операций; объекты Array и String»
Глава 12 — «Объектно-ориентированное программирование: наследование»
Глава 13 — «Объектно-ориентированное программирование: полиморфизм»
Приложения, входящие и в «Small C++ How to Program, 5/e»
(«Как программировать на C++: 5-е малое издание»),
и в «C++ How to Program, 5/e»
«Таблица старшинства и ассоциативности операций»
«Набор символов ASCII»
«Основные типы»
«Ресурсы Internet и World Wide Web»
Главы, входящие только в «C++ How to Program, 5/e»
Глава 14 — «Шаблоны»
Глава 15 — «Потоковый ввод/вывод»
Глава 16 — «Управление исключениями»
Глава 17 — «Обработка файлов»
Глава 18 — «Класс string и обработка строковых потоков»
Глава 19 — «Поиск и сортировка»
Глава 20 — «Структуры данных»
Глава 21 — «Биты, символы, строки и структуры»
Глава 22 — «Библиотека стандартных шаблонов»
Глава 23 — «Специальные вопросы»
Приложения, входящие только в «C++ How to Program, 5/e»
«Код, унаследованный от С»
«Препроцессор»
«Код учебного проекта системы ATM»
«Диаграммы UML 2»
48
Как программировать на C++
SafariX WebBooks
Сетевые учебники SafariX является новой услугой для студентов
колледжей, которые стремятся сэкономить на учебниках, рекомендуемых в
академических курсах. Платформа WebBooks предлагает новую опцию на рынке
высшей школы — альтернатива обычным учебникам и сетевым образовательным
услугам. Pearson предлагает студентам издания WebBook за 50% цены их
печатного эквивалента.
SafariX WebBook просматривают в Web-браузере, подключенном к сети
Internet. He требуется никаких приставок и не нужно загружать никаких
приложений. Студенты просто регистрируются, покупают право доступа и
начинают учиться. Работая с SafariX Textbooks Online, можно производить поиск
в тексте, делать оперативные заметки, распечатывать заданные темы,
соответствующие конспекту прочитанной профессором лекции, и создавать закладки
в важных местах, к которым они хотят вернуться позднее. Они могут легко
переходить к конкретному номеру страницы, заданной теме или главе. Рядом
с текстом в левой колонке отображается содержание книги.
Мы рады, что можем предложить студентам SafariX WebBook «Small C++
How to Program, 5/e». За более подробной информацией обратитесь на
www.pcarsonchoices.com. В число других доступных в качестве SafariX
WebBook изданий входят «C++ How to Program, 5/e», «Java How to Program,
6/e», »Small Java How to Program, 6/e» и «Simply C++: An Application-Driven
Tutorial Approach». За более подробной информацией обратитесь на
www.safarix.com/tour.html.
Бесплатный электронный бюллетень Deitel® Buzz Online
Наш бесплатный электронный бюллетень Deitel® Buzz Online рассылается
примерно 38 тысячам зарегистрированных подписчиков и содержит
комментарии по тенденциям в компьютерной индустрии и по новым разработкам,
гиперссылки на бесплатные статьи и ресурсы из наших опубликованных книг
и готовящихся изданий, сроки выпуска новых продуктов, замеченные
ошибки, смелые проекты, анекдоты, информацию о наших корпоративных курсах
обучения и многое другое. Мы также будем быстро уведомлять своих
читателей обо всем, что касается «Small C++ How to Program, 5/e». Чтобы
подписаться, посетите
www.deitel.com/newsletter/subscribe.html
Благодарности
Один из самых приятных моментов при написании учебника состоит в
возможности выразить благодарность многим участникам проекта, чьи имена
могут и не стоять на обложке книги, но без чьей упорной работы, сотрудничества,
дружбы и понимания написание этого материала было бы невозможно. Многие
сотрудники в Deitel & Associates, Inc. упорно работали над этим проектом:
• Эндрю Б. Голдберг (Andrew В. Goldberg) — выпускник Amherst College,
где он получил степень бакалавра компьютерных наук. Эндрю
переработал главы 1-13 с учетом раннего введения классов и других изменений
содержания.
Предисловие
49
• Джефф Листфилд (Jeff Listfield) — выпускник факультета
компьютерных наук Harvard College. Он участвовал в работе над главами 18, 19
и 21, а также приложениями А-Е.
• Сю Жанг (Su Zhang) получила степени бакалавра и магистра
компьютерных наук в McGill University. Она участвовала в работе над
главами 14-23.
• Черил Ягер (Cheryl Yaeger) за три года окончила Бостонский университет
со степенью бакалавра компьютерных наук. Черил помогала в работе над
главами 4, 6, 8, 9 и 13.
• Барбара Дейте л (Barbara Deitel), финансовый директор Deitel &
Associates, Inc., отыскивала эпиграфы к главам и выправляла текст.
• Эбби Дейтел (Abbey Deitel), президент Deitel & Associates, Inc., является
выпускницей факультета промышленного менеджмента Университета
Карнеги-Меллон. Эбби внесла вклад в предисловие и 1-ю главу. Она
правила некоторые главы книги, руководила процессом рецензирования
и предложила тему и имена жучков для обложки книги.
• Кристи Келси (Christi Kelsey) окончила Purdue Univercity со степенью
бакалавра менеджмента и кандидата информационных систем. Кристи
внесла вклад в предисловие и 1-ю главу. Она редактировала предметный
указатель и координировала многие аспекты наших издательских
взаимоотношений с Prentice Hall.
В этом проекте нам посчастливилось работать с талантливой и увлеченной
профессиональной издательской группой из Prentice-Hall. Мы особенно ценим
необыкновенный труд нашего редактора по компьютерным наукам Кейт Хард-
жетт (Kate Hargett), и ее начальника, а нашего учителя в издательском деле —
Марсии Хортон (Marcia Horton), главного редактора отделения техники и
компьютерных наук в Prentice Hall. Дженнифер Капелло (Jennifer Cappello)
Проделала огромную работу по формированию группы рецензентов и руководила
процессом рецензирования со стороны Prentice Hall. Вине О'Брайен (Vince
O'Brian), Том Маншрек (Tom Manshreck) и Джон Ловелл (John Lovell)
замечательно справились со всеми производственными проблемами. Таланты Пола
Белфанти (Paul Belfanti), Кароула Энсона (Carole Anson), Ксиохонг Чжу
(Xiaohong Zhu) и Джеффри Кэссара (Geoffrey Cassar) ярко проявились в
переработанном оформлении текста и в новой обложке, а Сара Паркер (Sarah
Parker) занималась публикацией объемистого вспомогательного пакета.
Мы хотим поблагодарить за их труд рецензентов данного издания и
рецензентов, давших отзывы об опубликованном 4-м издании «C++ How to
Program»:
Академические рецензенты
Richard Albright, Goldey Beacon College
Karen Arlien, Bismarck State College
David Branigan, DeVry University, Illinois
Jimmy Chen, Salt Lake Community College
Martin Dulberg, North Carolina State University
Ric Heishman, Northern Virginia Community College
Richard Holladay, San Diego Mesa College
William Honig, Loyola University
50
Как программировать на C++
Earl LaBatt, OPNET Technologies, Inc.; University of New Hampshire
Brian Larson, Modesto Junior College
Robert Myers, Florida State University
Gavin Osborne, Saskatchewan Institute of Applied Science and Technology
Wolfgang Pelz, The Univercity of Akron
Donna Reese, Mississippi State University
Рецензенты, работающие в промышленности
Curtis Green, Boeing Integrated Defense Systems
Malesh Hariharan, Microsoft
James Huddleston, независимый консультант
Ed James-Beckham, Borland Software Corporation
Don Kostuch, независимый консультант
Meng Lee, Htwlett-Packard
Kriang Lerdsuwanakij, Siemens Limited
William Mike Miller, Edison Design Group, Inc.
Mark Schimmel, Borland International
Vicki Scott, Metrowerks
James Snell, Boeing Integrated Defense Systems
Raymond Stephenson, Microsoft
Рецензенты учебного примера по конструированию программного
обеспечения
Sinan Si Alhir, независимый консультант
Karen Arlien, Bismarck State College
David Branigan, DeVry University, Illinois
Martin Dulberg, North Carolina State University
Ric Heishman, Northern Virginia Community College
Richard Holladay, San Diego Mesa College
Earl LaBatt, OPNET Technologies, Inc.; University of New Hampshire
Brian Larson, Modesto Junior College
Gavin Osborne, Saskatchewan Institute of Applied Science and Technology
Praveen Sahdu, Infodat International, Inc.
Cameron Skinner, Embarcadero Technologies, Inc. / OMG
Steve Tockey, Construx Software
Рецензенты опубликованного 4-го издания «C++ How to Program»
Butch Anton, Wi-Tech Consulting
Karen Arlien, Bismarck State College
Jimmy Chen, Salt Lake Community College
Martin Dulberg, North Carolina State University
William Honig, Loyola University
Don Kostuch, Independent Consultant
Earl LaBatt, OPNET Technologies, Inc./ University of New Hampshire
Brian Larson, Modesto Junior College
Kriang Lerdsuwanakij, Siemens Limited
Robert Myers, Florida State University
Gavin Osborne, Saskatchewan Institute of Applied Science and Technology
Wolfgang Pelz, The University of Akron
David Papurt, независимый консультант
Предисловие
51
Donna Reese, Mississippi State University
Catherine Wyman, DeVry University, Phoenix
Salih Yurttas, Texas A&M University
В условиях жесткого лимита времени эти люди тщательно проверяли
каждый аспект текста и внесли бесчисленные предложения относительно точности
и полноты представления материала.
И вот книга перед вами. Добро пожаловать в захватывающий мир C++
и объектно-ориентированного программирования! Надеемся, вам интересно
будет это знакомство с современным компьютерным программированием. Мы
искренни в своем желании выслушать ваши комментарии, замечания,
поправки и предложения по совершенствованию книги. Пожалуйста, посылайте всю
корреспонденцию на наш электронный адрес:
deitel@deitel.com
Мы ответим незамедлительно, и будем размещать все исправления и
пояснения на
www.deitel.com.books/cpphtp5/index.html
Мы надеемся, вы получите от чтения этой книги такое же удовольствие,
какое получали мы, когда писали ее!
Д-р Харви М. Дейтел
Пол Дж. Дейтел
Об авторах
Д-р Харви М. Дейтел, председатель и директор по планированию Deitel &
Associates, Inc., обладает 43-летним опытом в области компьютерных
дисциплин, включая обширный опыт работы в высшей школе и промышленности.
Он — один из ведущих в мире преподавателей и руководителей семинаров по
компьютерным дисциплинам. Д-р Дейтел получил степень бакалавра и
магистра в Массачусетском технологическом институте и степень доктора
философии в Бостонском университете. Он имеет 20-летний стаж преподавания
в высших учебных заведениях. До создания совместно с Полом Дж. Дейтелом
компании Deitel & Associates, Inc. занимал пост председателя отделения
компьютерных дисциплин в Бостонском колледже. Д-р Дейтел провел сотни
семинаров по всему миру для сотрудников крупных корпораций,
правительственных и военных учреждений. Он и его сын, Пол Дейтел, являются соавторами
нескольких десятков книг и мультимедийных курсов, и продолжают писать
и сейчас. Опубликованные в переводах на японский, немецкий, русский,
испанский, итальянский, традиционный и упрощенный китайский, корейский,
французский, польский, итальянский, португальский, греческий, урду и
турецкий языки, книги Дейте лов получили международное признание.
Пол Дж. Дейтел, исполнительный директор и главный инженер Deitel &
Associates, Inc., закончил Школу менеджмента Слоун Массачусетского
технологического института, где он изучал информационные технологии.. Работая
52
Как программировать на C++
в компании Deitel & Associates, Inc., он вел курсы по C++, Java, С, Internet
и World Wide Web, а также обучал созданию приложений для Internet и World
Wide Web сотрудников промышленных фирм, в том числе Sun Microsystems,
IBM, Dell, Lucent Technologies, Fidelity, NASA в Космическом центре
Кеннеди, National Severe Storm Laboratory, White Sands Missile Range, PalmSource,
Rogue Wave Software, Boeing, Stratus, Cambridge Technology Partners, TJX,
One Wave, Hyperion Software, Adra Systems, Entergy, CableData Systems
и многих других организаций. Пол — один из самых опытных в мире
преподавателей языков Java и C++, который провел более 100 профессиональных
учебных курсов по этим языкам. Он также читал лекции по C++ и Java в
Бостонском отделении Ассоциации по вычислительной технике. Он и его отец, д-р
Харви М. Дейте л — авторы ставших мировыми бестселлерами учебников по
компьютерным наукам.
О Deitel & Associates, Inc.
Компания Deitel & Associates, Inc. является широко известной
организацией, осуществляющей обучение и создание информационного содержания,
специализирующейся на преподавании языков программирования, программных
технологий и объектных технологий. Компания предлагает проводимые
преподавателями курсы по важнейшим языкам программирования, таким, как
Java, Advanced Java, С, C++, языкам .NET, XML, Perl, Python; объектным
технологиям; программированию для Internet и World Wide Web.
Основателями Deitel & Associates, Inc. являются д-р Харви М. Дейтел и Пол Дж. Дейтел.
В числе клиентов компании — многие крупнейшие компьютерные компании,
правительственные агентства, отделения военных и коммерческих
организаций. В своем 29-летнем партнерстве с издательством Prentice Hall компания
Deitel & Associates, Inc. издает современные учебники по программированию,
книги для специалистов, интерактивные мультимедийные курсы серий Cyber
Classroom, Complete Training Course, учебные Web-курсы и электронное
содержание для таких популярных систем управления обучением, как WebCT,
Blackboard и Pearson's CourseCompass. С компанией Deitel & Associates, Inc.
и авторами можно связаться через e-mail по адресу
deitel@deitel.com
Чтобы больше узнать о компании Deitel & Associates, Inc., ее публикациях
и программах обучения, посетите
www.deitel.com
и подпишитесь на бесплатный электронный бюллетень Deitel® Buzz Online на
www.deitel.com/newsletter/subscribe.html
Желающие приобрести книги Х.М. Дейтела и П. Дж. Дейтела, пакеты
Cyber Classroom, Complete Training Course и учебные Web-курсы могут сделать
это через
www.deitel.com/books/index.html
Крупные заказы корпораций и академических организаций можно разместить
непосредственно в Prentice Hall.
1
Введение в компьютеры,
Internet и World Wide Web
ЦЕЛИ
В этой главе вы изучите:
• Основные понятия, касающиеся
аппаратуры и программного
обеспечения.
• Основные понятия объектной
технологии, такие, как классы,
объекты, атрибуты, поведение,
инкапсуляция и наследование.
• Различные типы языков
программирования.
• Какие языки программирования
применяются наиболее широко.
• Типичную среду разработки
программ на C++.
• Историю стандартного языка моделирования объектно-ориентированных
систем, UML.
• Историю Internet и World Wide Web.
• Как запустить для тестирования в двух популярных средах C++ —
GNU C++, работающей под Linux, и Visual C++® корпорации Microsoft
под Windows® XP.
54 Глава 1
1.1. Введение
1.2. Что такое компьютер?
1.3. Организация компьютера
1.4. Первые операционные системы
1.5. Модели обработки данных: персональная,
распределенная и клиент/сервер
1.6. Internet и World Wide Web
1.7. Машинные языки, языки ассемблера и языки
высокого уровня
1.8. История С и C++
1.9. Стандартная библиотека C++
1.10. История языка Java
1.11. FORTRAN, COBOL, Pascal и Ada
1.12. BASIC, Visual Basic, Visual C++, C# и .NET
1.13. Ключевая тенденция в программировании:
объектная технология
1.14. Типичная среда разработки C++
1.15. Замечания о C++и этой книге
1.16. Тестовый запуск приложения на C++
1.17. Конструирование программного обеспечения.
Введение в объектную технологию и UML
(обязательный раздел)
1.18. Заключение
1.19. Ресурсы Web
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
1.1. Введение
Итак, уважаемый читатель, добро пожаловать в мир программирования на
C++! Авторы потратили на эту книгу немало труда и надеются, что чтение ее
окажется для вас не только полезным, но и занимательным. C++ является
мощным языком программирования, который подойдет как техническим
специалистам, либо не имеющим вообще, либо имеющим небольшой опыт
программирования, так и опытным программистам, которые смогут использовать
его при создании больших информационных систем. «Как программировать
на C++» будет эффективным инструментом обучения для каждой из этих
читательских аудиторий.
Введение в компьютеры, Internet и World Wide Web
55
Эта книга делает акцент прежде всего на ясности программ, достигаемой
посредством апробированных методик объектно-ориентированного
программирования (это книга с «ранним введением в классы и объекты»), —
непрограммисты сразу будут учиться правильным навыкам программирования.
Материал излагается ясно, непосредственно и обильно иллюстрируется. Мы
обучаем различным элементам C++ в контексте законченных работающих
программ и показываем вывод этих программ при запуске их на компьютере;
мы называем это подходом «живого кода». Программы-примеры можно
загрузить с www.deitel.com или www.prenhall.com/deitel.
Первые главы книги вводят читателя в основы компьютеров,
компьютерного программирования и языка C++, закладывая твердую основу для более
глубокого изучения C++ в последующих главах. Опытные программисты обычно
быстро прочитывают первые главы и находят остальную часть книги строгой
и интересной.
Большинство людей хоть как-то, но знакомы с теми удивительными
делами, которые могут делать компьютеры. Читая этот учебник, вы узнаете, как
заставить компьютер их делать. Компьютеры (которые часто называют
аппаратными средствами, hardware) управляются программным обеспечением,
software (т.е. инструкциями, которые вы даете компьютеру о том, какие
действия он должен выполнить и какие решения принять). На сегодняшний день
C++ является одним из наиболее популярных языков разработки
программного обеспечения. Данный текст предлагает введение в программирование на
C++ в варианте, стандартизованном в США Американским институтом
национальных стандартов (ANSI), а во всем мире — Международной
организацией по стандартизации (ISO).
Почти во всех областях человеческой деятельности использование
компьютеров расширяется. Стоимость компьютерной обработки все падает благодаря
быстрому развитию как аппаратных, так и программных технологий.
Компьютеры, которые ранее занимали несколько комнат и стоили миллионы
долларов, сегодня помещаются в нескольких кремниевых кристаллах размером
с ноготь и ценой по несколько долларов каждый. (Те, огромные, компьютеры
назывались mainframes, «магистральными системами», и они широко
используются сегодня большим бизнесом, правительством и промышленностью.)
К счастью, кремний является наиболее распространенным материалом на
Земле — это ингредиент обычного песка. Технология кремниевых микросхем
сделала компьютеризацию настолько дешевой, что в настоящее время в мире
насчитывается около миллиарда компьютеров общего назначения, которые
помогают людям в бизнесе, промышленности, государственном управлении
и в частной жизни.
Годами многие программисты учились методологии, называемой
структурным программированием. Вы изучите как структурное программирование, так
и замечательную новую методологию, объектно-ориентированное
программирование. Почему мы учим в этой книге и тому, и другому? Объектная
ориентация — ключевая программная методология, которую используют сегодня
программисты. В этом тексте вы создадите массу программных объектов и будете
с ними работать. Тем не менее, вы обнаружите, что их внутренняя организация
часто строится с применением методик структурного программирования. Кроме
того, логика манипуляции объектами иногда выражается структурно.
56
Глава 1
Вы вступили на трудный, но благодарный путь. Если по ходу движения
у вас возникнут какие-то вопросы, пожалуйста, пишите нам по адресу
deitel@deitel.com
Мы немедленно ответим. Чтобы быть в курсе относительно развития тематики
C++ в Deitel & Associates, зарегистрируйтесь ля получения нашего
бесплатного электронного бюллетеня Deitel® Buzz Online на странице
www.deitel.com/newsletter/subscribe.html
Надеемся, вы получите удовольствие от работы с 5-м изданием «Как
программировать на C++».
1.2. Что такое компьютер?
Компьютер — это устройство, способное производить вычисления и
принимать логические решения в миллионы (и даже миллиарды) раз быстрее
человека. Например, многие из современных персональных компьютеров могут
выполнять в секунду миллиард сложений. Человек, работающий с
настольным калькулятором, мог бы провести бы всю жизнь, складывая числа,
и все-таки не сложить их столько, сколько мощный персональный компьютер
складывает за одну секунду. (Информация к размышлению: как можно было
бы узнать, правильно ли человек сложил числа? Как можно было бы узнать,
правильно ли сложил числа компьютер?) Сегодняшние самые быстрые
суперкомпьютеры могут выполнять триллионы сложений в секунду!
Компьютеры обрабатывают данные под управлением наборов инструкций,
называемых компьютерными программами. Эти компьютерные программы
проводят компьютер через упорядоченные наборы действий, описанных
людьми, которых называют компьютерными программистами.
Компьютер состоит из разнообразных устройств (таких, как клавиатура,
экран, мышь, диски, память, DVD и процессорные блоки), которые
называются аппаратными средствами (hardware). Программы, работающие на
компьютере, называют программным обеспечением (software). Стоимость аппаратных
средств в последние годы снизилась настолько, что персональные компьютеры
превратились в предмет массового потребления. По этой книге вы изучите
апробированную методологию, позволяющую снизить стоимость разработки
программного обеспечения — объектно-ориентированное программирование и (на
нашем необязательном учебном примере конструирования программного
обеспечения, представленном в главах 2-7, 9 и 13) объектно-ориентированное
проектирование.
Введение в компьютеры, Internet и World Wide Web
57
1.3. Организация компьютера
Независимо от различий в способах физической реализации, каждый
компьютер фактически можно разделить на шесть логических устройств или
«отделов »:
1. Входное устройство. Это «приемный» отдел компьютера. Устройство
получает информацию (данные и компьютерные программы) от
различных устройств ввода и предоставляет ее в распоряжение других
устройств для последующей обработки. Большая часть информации
поступает сегодня в компьютер через клавиатуру и мышь. Информации
может также вводиться в компьютер с голоса человека, путем
сканирования изображений и через сеть, такую, как Internet.
2. Выходное устройство. Этот отдел компьютера выполняет «отгрузку»
данных. Устройство забирает информацию, которая была обработана
компьютером, и размещает ее на различных физических устройствах
вывода, чтобы она стала пригодной для использования вне компьютера.
Большая часть выходной информации компьютера отображается
сегодня на экране, печатается на бумаге или используется для управления
другими устройствами. Компьютеры могут также выводить
информацию в сети, такие, как Internet.
3. Устройство памяти. Это — быстродействующий, но относительно
небольшого объема «склад» компьютера. Там хранится информация,
которая была введена через входное устройство, и эта информация может
стать доступной для обработки, как только это потребуется. Устройство
памяти хранит также информацию, которая уже обработана, до тех пор,
пока она не окажется размещенной на других устройствах (выходным
устройством). Информация в устройстве памяти обычно теряется при
выключении компьютера. Устройство памяти часто называют либо
просто памятью, либо первичной памятью.
4. Арифметико-логическое устройство (ALU). Это «производственный»
отдел компьютера. Устройство отвечает за выполнение вычислений,
таких, как сложение, вычитание, умножение и деление. Оно содержит
решающие механизмы, которые позволяют компьютеру, например,
сравнивать два элемента из памяти, чтобы определить, равны они или нет.
5. Центральное процессорное устройство (CPU). Это
«административный» отдел компьютера. Устройство координирует работу компьютера
и осуществляет надзор за работой всех других частей. CPU указывает
входному блоку, когда информация должна быть считана в блок памяти,
указывает ALU, когда информация из памяти должна быть
использована в вычислениях, и указывает выходному блоку, когда послать
информацию из блока памяти на определенное выходное устройство. Многие
современные компьютеры имеют несколько процессоров и,
следовательно, могут выполнять несколько одновременно операций — такие
компьютеры называют мультипроцессорами.
58
Глава 1
6. Устройство вторичного хранения. Этот отдел является «складом»
большой емкости для долгосрочного хранения информации. Программы или
данные, не используемые активно другими блоками, обычно
размещаются на вторичных запоминающих устройствах (таких, как диски), пока
они не потребуются снова, возможно, спустя дни, месяцы или даже годы.
Доступ к этой информации гораздо более медленный, чем к информации
в первичной памяти. В то же время стоимость единицы памяти
вторичных запоминающих устройств много меньше, чем в первичной памяти.
1.4. Первые операционные системы
Раньше компьютеры могли выполнять в каждый момент времени только
одно задание или задачу. Подобная форма работы называется
однопользовательской пакетной обработкой. Компьютер обрабатывает данные группами,
или пакетами, причем в каждый момент времени выполняется только одна
программа из группы. В то время пользователи представляли свои программы
в вычислительные центры в виде набора перфокарт и вынуждены были ждать
окончательной выдачи часами или даже в течение нескольких дней.
Для удобства работы с компьютерами были разработаны программные
средства, называемые операционными системами. Первые операционные системы
обеспечивали быстрое переключение между заданиями, ускоряя переходы от
одной задачи к другой, благодаря чему повышалась пропускная способность
компьютеров, т.е. общее количество выполняемой ими работы.
По мере совершенствования компьютеров становилось очевидным, что
однопользовательская пакетная обработка редко использует ресурсы компьютера
эффективно. Возникла идея, что несколько программ, или задач, могут
разделять между собой ресурсы компьютера, чтобы его загрузка была более
рациональной. Это называется мультипрограммированием.
Мультипрограммирование подразумевает «одновременное» выполнение на компьютере нескольких
задач; компьютер разделяет свои ресурсы между задачами, на них
претендующими. Но как и прежде, пользователи представляли свои программы
на перфокартах и ждали свои результаты по несколько часов.
И вот в шестидесятых годах в нескольких промышленных центрах и
университетах возникла новаторская концепция разделения времени. Разделение
времени — это специальный случай мультипрограммирования, когда
пользователи получают доступ к компьютеру через терминалы, обычно устройства
с экраном и клавиатурой. В компьютерной системе с разделением времени
могут одновременно работать десятки и сотни пользователей. На самом деле их
задания не выполняются компьютером одновременно. Процессор выполняет
небольшую часть одной задачи, затем переключается на другого пользователя,
в течение одной секунды возвращается, возможно, к каждому пользователю
несколько раз. Таким образом, программы пользователей работают как бы
одновременно. Преимущество систем разделения времени в том, что
пользователь получает почти немедленный отклик на свои запросы.
Введение в компьютеры, Internet и World Wide Web
59
1.5. Модели обработки данных: персональная,
распределенная и клиент/сервер
В 1977 году компания Apple Computer сделала общедоступной
персональную обработку данных. Компьютеры стали экономически доступными
настолько, что люди покупали их для решения своих личных или деловых
задач. В 1981 году компания IBM, мировой лидер в производстве компьютеров,
представила на рынке Персональный компьютер IBM. Очень быстро
персональная обработка данных приобрела законное право на применение в
бизнесе, промышленности и государственных учреждениях.
Эти компьютеры были «изолированными» единицами — для обмена
информацией люди носили диски туда и обратно. Несмотря на то, что ранние
персональные компьютеры были не настолько мощными, чтобы обеспечивать
разделение времени для нескольких пользователей, эти машины могли быть
объединены в компьютерные сети посредством телефонных линий или в локальные
сети (LANs) в пределах одной организации. Это привело к феномену
распределенной обработки данных, когда работа всей организации, вместо того, чтобы
быть выполненной непосредственно на центральном компьютере,
распределялась по сети на рабочие места, где и производилась в действительности.
Персональные компьютеры были достаточно мощными, чтобы удовлетворить
требования индивидуальных пользователей, а также справляться с задачами по
электронному обмену информацией.
Современные персональные компьютеры обладают такой же
вычислительной мощностью, как и машины стоимостью в миллион долларов пару
десятилетий назад. Наиболее мощные машины — рабочие станции — обеспечивают
индивидуальных пользователей невиданными возможностями. Информация
легко распределяется по компьютерным сетям, в которых отдельные
компьютеры, называемые файловыми серверами, хранят общий для всех набор
программ и данных, которые могут быть использованы компьютерами —
клиентами, входящими в состав сети. Отсюда происходит термин клиент/сервер.
Для написания программного обеспечения для операционных систем,
компьютерных сетей и для прикладных программ модели клиент/сервер стал
широко использоваться C++. Сегодняшние операционные системы, среди которых
можно назвать UNIX, Linux, Mac OS X и Microsoft Windows, поддерживают
все возможности, обсуждавшиеся в этом разделе.
1.6. Internet и World Wide Web
Основы Internet — глобальной компьютерной сети — были заложены
четыре десятилетия назад на средства Министерства обороны США.
Проектировавшаяся первоначально для соединения главных компьютерных систем
примерно десятка университетов и исследовательских организаций, Internet сегодня
стала доступна компьютерам во всем мире.
С появлением World Wide Web («Всемирной паутины») — которая
позволяет пользователям находить в Internet и просматривать
мультимедиа-документы практически по любому предмету — Internet поистине развернулась в один
из важнейших мировых механизмов коммуникации.
Internet и World Wide Web входят, безусловно, в число важнейших и
глубочайших творений человечества. В прошлом большинство компьютерных при-
60
Глава 1
ложений работали на компьютерах, не соединенных друг с другом.
Сегодняшние приложения можно писать так, что они будут осуществлять
коммуникацию между компьютерами всего мира. Internet объединяет технологии
компьютеров и коммуникаций. Она облегчает нашу работу. Она делает
мгновенно и удобно доступной мировую информацию. Она позволяет
индивидуумам и малым провинциальным предприятиям явить себя всему миру. Она
видоизменяет образ ведения дел. Люди могут находить наилучшие цены
практически на любые товары или услуги. Сообщества, имеющие особые интересы,
могут поддерживать контакт друг с другом. Исследователей можно
немедленно ставить в известность о самых последних достижениях.
1.7. Машинные языки, языки ассемблера и языки
высокого уровня
Программисты пишут программы на различных языках
программирования, некоторые из которых непосредственно понятны компьютеру, а другие
нуждаются в промежуточных стадиях трансляции. Сотни имеющихся
компьютерных языков могут быть разделены на три основных типа:
1. Машинные языки
2. Ассемблерные языки
3. Языки высокого уровня
Каждый компьютер может понимать только свой машинный язык,
который является естественным языком компьютера и, как такой, определяется
аппаратной частью последнего. [Замечание. Машинные языки часто называют
объектным кодом. Это термин более старый, чем «объектно-ориентированное
программирование». Два словоупотребления «объекта» друг с другом никак
не связаны.] Машинные языки в общем случае состоят из последовательностей
чисел (в пределе сводимых к нулям и единицам), которые задают исполнение,
по одной, самых элементарных операций компьютера. Машинные языки
являются машинно-зависимыми (т.е. конкретный машинный язык может быть
использован только на одном типе компьютеров). Машинные языки неудобны
для человека, что можно проиллюстрировать небольшой программой, в
которой к тарифной ставке прибавляются выплаты за сверхурочную работу, а
результат сохраняется в переменной общей выплаты:
+ 1300042774
+ 1400593419
+ 1200274027
Программирование на машинных языках было для большинства
программистов попросту слишком медленным, слишком уязвимым для ошибок и
утомительным. Вместо последовательностей чисел, непосредственно понятных
компьютеру, программисты для представления элементарных операций стали
применять англоязычные аббревиатуры, которые и сформировали основу язы
ков ассемблера. Для преобразования программ, написанных на таких языках,
в машинный язык были разработаны программы-трансляторы, называемые
ассемблерами. Преобразование происходило со скоростью, равной
быстродействию компьютера. Нижеприведенный фрагмент программы на языке ассемб-
Введение в компьютеры, Internet и World Wide Web
61
лера также вычисляет основную стоимость в виде суммы тарифной ставки
и сверхурочных:
LOAD BASEPAY
ADD OVERPAY
STORE GROSSPAY
С появлением языков ассемблера использование компьютеров значительно
расширилось, однако все еще требовалось написание большого количества
инструкций даже для реализации решения простейших задач. Для ускорения
процесса программирования были разработаны языки высокого уровня, в
которых для выполнения сложных действий достаточно написать один оператор.
Программы для преобразования последовательности операторов на языке
высокого уровня в машинный язык называются компиляторами. В языках
высокого уровня инструкции, написанные программистами, зачастую выглядят
как обычный текст на английском языке с применением общепринятых
математических знаков. Уже знакомое нам вычисление суммарной выплаты
выглядит так:
grossPay = basePay + overPay
Совершенно очевидно, что с точки зрения программистов языки высокого
уровня более предпочтительны, чем любые машинные или ассемблерные
языки. К числу наиболее мощных и широко используемых языков высокого
уровня относятся С, C++, языки .NET от Microsoft (напр., Visual Basic .NET,
Visual C++ .NET, C#) и Java.
Процесс компиляции программы на языке высокого уровня в машинный
код может занимать немалое время. Были разработаны программы-ы«тердгре-
таторы, которые могут непосредственно, хотя и более медленно, выполнять
программы на языках высокого уровня. Интерпретаторы популярны в средах
разработки программ, где код часто добавляется и исправляется. Как только
разработка завершена, можно компилировать более эффективную версию
программы.
1.8. История С и C++
C++ явился результатом эволюции С, который был продуктом двух более
ранних языков программирования, BCPL и В. BCPL был разработан в 1967
году Мартином Ричардсом в качестве языка для написания системного
программного обеспечения и компиляторов для операционных систем. Кен
Томпсон разработал многие элементы своего языка В по образцу BCPL и применил
В при создании в Bell Laboratories первых версий операционной системы
UNIX в 1970 году.
Язык С был создан Деннисом Ричи из Bell Laboratories на основе В. Он
использовал в С многие важные концепции BCPL и В. Сначала С приобрел
широкую известность как язык разработки операционной системы UNIX. Сегодня
большинство операционных систем написаны на С и/или C++. Теперь С
доступен для большинства систем и машинно-независим. При аккуратном
проектировании можно писать на С программы, которые будут переносимы на
большинство компьютеров.
62
Глава 1
Широкое использование С с разнообразными компьютерами (иногда
называемыми аппаратными платформами) привело, к сожалению, к появлению
многих вариаций языка. Это было серьезной проблемой для разработчиков
программ, которым требовалось писать переносимые программы, работающие
на нескольких платформах. Нужна была стандартная версия С. Для
всемирной стандартизации языка Американский институт национальных стандартов
работал совместно со Всемирной организации по стандартизации; совместный
документ стандарта был опубликован в 1990 году и получил наименование
ANSI/ISO 9899: 1990.
Ш"ъ Переносимость программ 1.1
Щ Поскольку С является стандартизованным, машинно-независимым,
широко доступным языком, написанные на С приложения, с
небольшими изменениями или вообще без таковых, часто можно запускать на
самых разнообразных компьютерных системах.
C++, расширение С, был разработан в Bell Laboratories Бьерном Страустру-
пом в начале 80-х годов. В C++ есть много элементов, которые
«приукрашивают» язык С, но что более важно, в нем предусмотрены возможности
объектно-ориентированного программирования.
В сообществе программистов назревает революция. Быстрое, без ошибок
и экономичное построение программного обеспечения все еще остается
ускользающей целью, и это в то время, когда потребность в новом и более мощном
программном обеспечении стремительно растет. Объекты являются по своему
существу утилизируемыми программными компонентами, моделирующими
предметы реального мира. Разработчикам программного обеспечения
становится ясно, что при модульном, объектно-ориентированном подходе к
проектированию и реализации их труд может стать гораздо производительнее, чем при
прежних популярных методиках программирования.
Объектно-ориентированные программы гораздо проще понимать, исправлять и модифицировать.
1.9. Стандартная библиотека C++
Программы на C++ составляются из фрагментов, называемых классами
и функциями. Вы можете сами программировать каждый фрагмент, который
может вам потребоваться для образования программы на C++. Однако
большинство программистов пользуются богатыми собраниями готовых классов
и функций, входящими в Стандартную библиотеку C++. Таким образом, на
самом деле есть два аспекта освоения «мира» C++. Первый — это изучение
самого языка; вторым является изучение того, как использовать классы и
функции из Стандартной библиотеки. На протяжении всей книги мы обсуждаем
многие из этих классов и функций. Каждый программист, которому
необходимо глубокое понимание библиотечных функций ANSI С, вошедших в C++,
и того, как их реализовать и использовать для написания переносимого кода,
должен прочитать книгу П. Дж. Плогера «Стандартная библиотека С» (P.J.
Plauger, The Standard С Library, Upper Saddle River, NJ: Prentice Hall PTR,
1992). Библиотеки стандартных классов обычно поставляются
производителями компиляторов. Многие библиотеки классов для специальных применений
поставляются независимыми производителями программного обеспечения.
Введение в компьютеры, Internet и World Wide Web
63
Общее методическое замечание 1.1
При создании программ следуйте идеологии «строительных блоков».
Избегайте изобретения колеса. Такой подход, называемый
утилизацией программного обеспечения, является одним из центральных
моментов объектно-ориентированного программирования.
Общее методическое замечание 1.2
Программируя на C++, вы, как правило, будете применять следующие
строительные блоки: классы и функции Стандартной библиотеки
C++, классы и функции, создаваемые вами и вашими коллегами, а
также классы и функции из различных популярных библиотек
независимых поставщиков.
Мы включили в текст много подобных Общих методических замечаний,
объясняющих концепции, которые могут улучшить общую архитектуру и
качество программных систем. Мы выделяем также советы других видов, в
число которых входят Хороший стиль программирования (чтобы помочь вам
писать более ясные, более понятные, проще сопровождаемые, тестируемые и
отлаживаемые — термин означает устранение ошибок — программы), Типичные
ошибки программирования (проблемы, о которых надо всегда помнить, чтобы
их избегать), Вопросы производительности (методики написания более
быстрых и компактных программ), Переносимость программ (методики,
помогающие писать программы, которые могут работать, с небольшими изменениями
или без них, на разнообразных компьютерах — сюда входят также общие
замечания о том, как в C++ достигается высокая степень переносимости) и
Предотвращение ошибок (методики устранения дефектов из ваших программ и,
что важнее, написания с самого начала кода, свободного от ошибок). Многие
из советов только дают вам наводящие указания. Вы, без сомнения, разовьете
свой собственный стиль программирования.
Преимущество написания своих собственных классов и функций
заключается в том, что вы будете знать в точности, как они работают. Издержки же
связаны с затратами времени и нелегкого труда, вложенного в
проектирование, разработку и сопровождение новых функций и классов, которые должны
работать корректно и эффективно.
шщ
Вопросы производительности 1.1
Использование функций и классов Стандартной библиотеки C++
вместо написания своих собственных может улучшить
производительность программы, поскольку они написаны очень тщательно, с
учетом требований эффективности. Такой подход, кроме того,
укорачивает время разработки программы.
Переносимость программ 1.1
Использование функций и классов Стандартной библиотеки C++
вместо написания своих собственных улучшает переносимость
программ, поскольку они имеются в любой реализации C++.
64
Глава 1
1.10. История языка Java
Микропроцессоры в настоящее время оказывают глубокое влияние на область
интеллектуальной бытовой электроники. Осознав это, Sun Microsystems в 1991
году финансировала корпоративный исследовательский проект под кодовым
названием «Green». В результате работ по проекту на основе С и C++ был создан
язык, который его создатель, Джеймс Гослинг. назвал «Oak» в честь дуба,
растущего за окном здания Sun. Позже оказалось, что язык программирования с
названием Oak уже существует. Когда группа разработчиков фирмы Sun зашла
в местную кофейню, было предложено имя Java, и оно закрепилось за языком.
Однако проект «Green» столкнулся с некоторыми трудностями. Рынок
интеллектуальных бытовых приборов в начале 90-х развивался не так быстро,
как ожидали в Sun. Проект был на грани закрытия. Только благодаря чистой
удаче именно в это время, в 1993 году, произошел взрыв популярности World
Wide Web, и в Sun тут же поняли, каким потенциалом в плане включения
в Web-страницы динамического содержания (напр., анимации,
интерактивных элементов и т.п.) обладает Java. Это вдохнуло в проект новую жизнь.
Формально Sun представила Java в 1995 году. Благодаря феноменальному
успеху World Wide Web язык немедленно возбудил интерес в деловом
сообществе. Сегодня Java используется для разработки крупномасштабных приложений
на предприятиях, для расширения возможностей Web-серверов (компьютеров,
создающих то, что мы видим в своих Web-обозревателях), создания
приложений для бытовых устройств (сотовых телефонов, пейджеров и персональных
цифровых секретарей) и многих других целей. Сходными возможностями
обладают современные версии C++, такие, как Microsoft® Visual C+H-^.NET и
Borland® C++Builder™.
1.11. FORTRAN, COBOL, Pascal и Ada
В свое время были разработаны сотни языков программирования высокого
уровня, но только немногие из них получили широкое распространение. В
середине 50-х корпорацией IBM был разработан FORTRAN (FORmula
TRANslation) в качестве языка для научных и технических приложений, в
которых требуется выполнять сложные математические вычисления. FORTRAN
все еще широко используется, особенно в технических приложениях.
COBOL (COmmon Business Oriented Language) разработан в 1959 году
группой, в которую входили производители и пользователи компьютеров. COBOL
главным образом используется в коммерческих прикладных программах,
когда необходима высокая точность при обработке большого количества данных.
Сегодня больше половины программного обеспечения, предназначенного для
использования в бизнесе, все еще написано на языке COBOL.
В 1960-е годы многие большие программные проекты столкнулись с
серьезными затруднениями. Как правило, сроки разработки затягивались, расходы
значительно превышали*бюджет, а законченные продукты были ненадежны.
Люди стали понимать, что разработка программного обеспечения — гораздо
более сложный процесс, чем им представлялось. Исследования 1960-х годов
привели к эволюции структурного программирования — упорядоченного
подхода к написанию программ, более ясных, чем неструктрированные, и
которые проще тестировать, отлаживать и модифицировать.
Введение в компьютеры, Internet и World Wide Web
65
Одним из знаменательных результатов этих исследований стала разработка
в 1971 году профессором Никласом Виртом языка Pascal. Этот язык,
названный в честь математика и философа семнадцатого века Блеза Паскаля,
проектировался как средство обучения структурному программированию и вскоре
стал основным языком, используемым для преподавания в большинстве
колледжей. К сожалению, в этом языке отсутствуют многие элементы,
необходимые для коммерческих, промышленных и административных приложений,
поэтому в этих областях он не получил широкого признания.
Язык программирования Ada был разработан в 1970-х и начале 80-х под
эгидой Министерства обороны США. Для создания огромной массы
программных систем управления и контроля МО использовались сотни различных
языков. Министерству же хотелось иметь единственный язык, который
удовлетворял бы большинству его нужд. Язык был назван в честь леди Ады Лавлейс,
дочери поэта лорда Байрона. Леди Лавлейс, как считается, написала в начале
XIX века первою компьютерную программу (для механической
Аналитической машины, спроектированной Чарльзом Бэббиджем). Одной из важных
особенностей языка Ada является т. н. многозадачноетъ> которая позволяет
программистам специфицировать параллельно выполняемые действия. Java,
благодаря встроенной в язык многопоточности, также позволяет писать
программы с параллельными действиями. Хотя в стандартном C++ многопоточ-
ность отсутствует, она может быть реализована при посредстве различных
дополнительных библиотек классов.
1.12. BASIC, Visual Basic, Visual C++, C# и .NET
Язык программирования BASIC (Beginner's АН-Purpose Symbolic Instruction
Code) был разработан в середине 1960-х профессорами Дартмуртского колледжа
Джоном Кеннеди и Томасом Курцем как средство для написания простых
программ. Основной целью BASIC было ознакомление новичков с приемами
программирования. Visual Basic, представленный корпорацией Microsoft в начале
90-х годов для упрощения разработки приложений Windows, стал одним из
самых популярных языков программирования в мире.
Самые последние инструменты разработки Microsoft являются частью
корпоративной стратегии интеграции в приложения возможностей Internet
и Web. Эта стратегия реализована в программной платформе .NET Microsoft,
которая предоставляет разработчикам средства для создания и запуска
приложений, которые могут работать на компьютерах, распределенных в сети.
Тремя главными языками Microsoft стали Visual Basic .NET (на основе
первоначального BASIC), Visual C++ .NET (на основе C++) и С# (новый язык на основе
C++ и Java, с самого начала приспособленный для платформы .NET).
Разработчики, использующие .NET, могут писать компоненты программного
обеспечения на языке, к которому они привыкли, а затем строить приложения,
комбинируя эти компоненты с компонентами, написанными на любом другом
.NET-языке.
3 Заг 1114
66
Глава 1
1.13. Ключевая тенденция в программировании:
объектная технология
Один из авторов, Харви Дейте л, помнит ту растерянность, которая
чувствовалась в 60-х годах в организациях, разрабатывавших программное
обеспечение, особенно в имевших дело с большими проектами. На старших курсах ему
посчастливилось работать в летнее время у ведущего производителя
программного обеспечения, в группах, разрабатывавших операционные системы с
разделением времени и виртуальной памятью. Для студента колледжа это
великолепная школа. Но летом 67-го года реальность внесла свои коррективы, когда
компания «отреклась» от создания этой системы, над которой работали в
течение многих лет сотни людей, в качестве коммерческого продукта. Трудно было
сделать все как следует. Программное обеспечение — «сложная штука».
Улучшение положения с программными технологиями стало ощущаться,
по-видимому, с приходом в 70-х годах того, что называют структурным про
граммированием (и родственных ему дисциплин структурного анализа и
проектирования). Но только с освоением объектно-ориентированной технологии
в 80-х и особенно широким ее применением в 90-х разработчики программного
обеспечения наконец почувствовали, что теперь у них есть инструменты,
позволяющие сделать решающие шаги в совершенствовании процесса разработки.
На самом деле история объектной технологии восходит к середине 60-х
годов. Язык программирования C++, созданный в начале 80-х в AT&T Бьерном
Страуструпом, базируется на двух языках — С, который первоначально
разрабатывался в AT&T для реализации системы UNIX, и Simula 67, языке
моделирования, созданном в Европе и выпущенном в 1967 году. C++ унаследовал все
возможности С, дополнив их средствами манипулирования объектами,
заимствованными у Simula. Ни С, ни C++ не предназначались для широкого
использования вне стен исследовательских лабораторий AT&T. Но очень быстро
оба языка стали доступны и для рядовых программистов.
Что такое объекты и чем они замечательны? Объектная технология — это
идея упаковки, которая позволяет нам создавать осмысленные модули
программного обеспечения большого размера, сфокусированные на отдельных
областях прикладного программирования. Есть объекты данных, объекты
времени, объекты-чеки, объекты-счета, звуковые объекты, видеообъекты,
файловые объекты, объекты записей и т.д. Фактически любое существительное
может быть представлено в виде объекта.
Мы живем в мире объектов. Только оглянитесь вокруг. Тут машины,
самолеты, люди, животные, здания, светофоры, лифты... До появления объект-
но-ориентрованных языков программные языки (такие, как FORTRAN,
Pascal, Basic и С) концентрировали внимание на действиях (глаголах), а не
вещах, или объектах (существительных). Живущие в мире объектов
программисты, общаясь с компьютером, были вынуждены программировать по
преимуществу с помощью глаголов. Это делало написание программ
довольно неудобным. Теперь, имея в своем распоряжении популярные
объектно-ориентированные языки, такие, как C++ и Java, программисты,
по-прежнему живя в объектном мире, могут и с компьютером работать в
объектно-ориентированном стиле. Этот более естественный, чем процедурное
программирование, процесс делает труд программиста гораздо
производительнее.
Введение в компьютеры, Internet и World Wide Web
67
Ключевой проблемой процедурного программирования является то, что
программные модули не вполне адекватно отражают сущности реального мира
и потому не особенно пригодны для многократного использования. Не так уж
редка ситуация, когда программисту приходится разрабатывать каждый новый
проект с самого начала и писать очень похожие программы «на пустом месте».
Это приводит к неоправданным затратам драгоценного времени и денег,
поскольку люди снова и снова «изобретают велосипед». В объектной технологии
программные сущности (называемые классами), если они грамотно
спроектированы, с большой долей вероятности могут быть утилизированы (использованы
повторно) в будущих проектах. Библиотеки утилизируемых компонентов,
например, MFC (Microsoft Foundation Classes), Microsoft .NET Framework Class
Library, библиотеки Rouge Wave и многих других производителей
программного обеспечения, могут значительно сократить усилия, затрачиваемые на
разработку некоторых видов систем (по сравнению с тем, что пришлось бы затратить
на повторное изобретение программных компонентов для новых проектов).
® Общая методическая рекомендация 1.1
Развитые классовые библиотеки многократно используемых
программных компонентов доступны в Internet и Word Wide Web. Многие
из них предоставляются бесплатно.
Некоторые организации сообщают, что на самом деле «утилизация»
программного обеспечения — не главное преимущество, которое дает им
объектно-ориентированное программирование. Они указывают, что
объектно-ориентированный подход порождает более понятные, лучше организованные
программы, которые проще сопровождать, модифицировать и отлаживать. Это
немаловажно, так как примерно 80% стоимости программного обеспечения
связана не с первоначальной разработкой, а с последующей его эволюцией
и сопровождением на протяжении всего времени жизни.
Каковы бы ни были выгоды, получаемые от ориентации на объекты, ясно,
что объектно-ориентированный подход будет ключевой методологией
программирования в будущие десятилетия.
1.14. Типичная среда разработки C++
Давайте разберем, поэтапно, создание и исполнение приложения C++ в
типичной среде разработки C++ (которую иллюстрирует рис. 1.1). Системы C++
обычно состоят из трех частей: среды разработки программ, языка и
Стандартной библиотеки C++. Программы на C++ обычно проходят через шесть
стадий: редактирования, препроцессорной обработки, компиляции, компоновки,
загрузки и исполнения. Нижеследующее обсуждение поясняет типичную
среду разработки программ C++. [Замечание. На нашем сайте www.deitel.com/
books/downloads/html предлагаются публикации Deitel™ Dive Into Series,
которые помогут вам освоить некоторые популярные инструменты разработки
C++, такие, как Borland® C++Builder™, Microsoft® Visual C++® 6, Microsoft®
Visual C++®.NET, GNU C++ в Linux и GNU C++ в среде Cygwin™ UNIX® для
Windows®. По мере того, как у преподавателей будет появляться потребность
в других средах, мы будем предлагать соответствующие публикации Deitel™
Dive Into Series.]
68
Глава 1
Редактор
ЖСК:
Фаза 1:
Программа создается
редактором и запоминается
на диске
Препроцессор
^
-^Диск-
Фаза 2:
Программа предварительной
обработки преобразовывает код
Компилятор
~ДЙСк:
Фаза 3:
Компилятор создает
объектный код и сохраняет
его на диске
Компоновщик
Загрузчик
<■ v диск;
Первичная память
Л Фаза 4:
\ I Компоновщик связывает
i г объектный код с библиотеками,
' \ создает исполняемый файл
и сохраняет его на диске
А
Фаза 5:
V Загрузчик размещает
программу в памяти
Первичная память
ЦПУ
Фаза 6:
ЦПУ выбирает каждую
инструкцию и выполняет ее,
возможно, сохраняя новые
значения данных по ходу
выполнения программы
, 1.1. Типичная среда C++
Введение в компьютеры, Internet и World Wide Web
69
Стадия 1: Создание программы
Первая стадия состоит в редактировании файла с помощью
программы-редактора (обычно называемой просто редактором). С помощью редактора вы
вводите программу на C++ (которую называют обычно исходным кодом),
вносите необходимые исправления и сохраняете программу на вторичном
запоминающем устройстве, например, своем жестком диске. Файлы исходного кода
C++ часто имеют расширения .срр, .схх, .ее или .С (обратите внимание, что
С — в верхнем регистре), показывающие, что файл содержит исходный код
C++. Посмотрите в своей документации по системе разработки, какая
дополнительная информация по расширениям имен файлов там имеется.
Два редактора, широко используемые в системе UNIX — это vi и emacs.
Программные пакеты для Microsoft Windows, такие, как Borland C++
(www.borland.com), Metrowerks Code Warrior (www.metrowerks.com) и
Microsoft Visual C++ (www.msdn.microsoft.com/visualc) имеют редакторы,
встроенные в среду программирования. Можно пользоваться для написания программ
на C++ и простым текстовым редактором, например, Notepad в Windows. Мы
предполагаем, что читатель знает, как отредактировать программу.
Стадии 2 и 3: Препроцессорная обработка и компиляция
программы
На второй стадии программист дает команду компилировать программу.
В системе C++ перед началом стадии компиляции автоматически исполняется
программа-препроцессор (поэтому мы называем препроцессорную обработку
стадией 2, а компиляцию — стадией 3). Препроцессор C++ распознает
команды, называемые препроцессорными директивами, которые указывают, что
над программой перед компиляцией должны быть произведены определенные
манипуляции. Эти манипуляции состоят обычно во включении в компиляцию
других текстовых файлов и в различных текстовых заменах. В этой книге
описываются наиболее распространенные директивы препроцессора. На третьей
стадии компилятор транслирует программу на C++ в код машинного языка
(называемый также объектным кодом).
Стадия 4: Компоновка
Четвертая стадия называется компоновкой (linking). Программы C++
обычно содержат ссылки на функции и данные, определяемые в другом месте,
например, в стандартных библиотеках или в частных библиотеках группы
программистов, работающих над конкретным проектом. Из-за отсутствия этих
частей в программах C++ имеются «дыры». Компоновщик (linker)
присоединяет к объектному коду код отсутствующих функций, чтобы создать
исполняемый образ (в котором нет отсутствующих частей). Если программа успешно
компилируется и компонуется, образуется исполняемый образ.
Стадия 5: Загрузка
Пятая стадия называется загрузкой. До того, как программа сможет
исполняться, ее нужно поместить в память. Это выполняется загрузчиком, который
берет с диска исполняемый образ и переносит его в память. Загружаются также
компоненты разделяемых библиотек, поддерживающие данную программу.
70
Глава 1
Стадия 6: Исполнение
Наконец, компьютер, под управлением CPU, исполняет программу
одиночными инструкциями.
Проблемы, которые могут встретиться во время исполнения
Программы не всегда начинают работать с первой попытки. Любая из
предыдущих стадий может окончиться неудачей из-за разнообразных ошибок,
которые мы обсуждаем на протяжении всей книги. Например, исполняющаяся
программа может попытаться произвести деление на ноль (незаконное
действие в арифметике целых чисел C++). Это приведет к тому, что будет выведено
сообщение об ошибке. В этом случае вам придется вернуться к стадии
редактирования, сделать соответствующие исправления и снова пройти через все
остальные стадии, чтобы определить, решают ли эти исправления данную
проблему (проблемы).
Большинство программ на C++ вводят и/или выводят данные.
Определенные функции C++ принимают ввод с tin (стандартного входного потока;
произносится «си-ин»), которым обычно является клавиатура, но cin может
быть переадресован и на другое устройство. Часто данные выводятся в cout
(стандартный выходной поток; произносится «си-аут»), которым обычно
является экран компьютера, но cout также может быть переадресован на другое
устройство. Когда мы говорим, что программа печатает результат, то обычно
имеем в виду, что результат отображается на экране. Данные могут выводить
ся на другие устройства, например, на диск или принтер. Имеется также
стандартный поток ошибок (называемый сегг). Поток сегг (обычно
подключенный к экрану) используется для отображения сообщений об ошибках.
Пользователи часто переадресуют cout на другое устройство, оставляя при
этом сегг подключенным к экрану, так что нормальный вывод отделяется от
сообщений об ошибках.
^ Типичная ошибка программирования 1.1
Ошибки вроде деления на ноль проявляются при работе программы,
поэтому их называют ошибками времени запуска или ошибками времени
выполнения. Деление на ноль — обычно фатальная ошибка, т.е. она
приводит к немедленному завершению программы; программе не
удается выполнить свою работу. He-фатальные ошибки допускают
продолжение программы, но последняя часто выдает неверные результаты.
(Замечание: На некоторых системах деление на ноль не является фа
тальной ошибкой. Справьтесь в документации по своей системе.)
1.15. Замечания о C++ и этой книге
Опытные программисты зачастую гордятся своим умением писать на C++
запутанные и загадочные тексты программ. Однако это плохой стиль
программирования. В результате программа становится неудобочитаемой,
увеличивается вероятность сбоев и затрудняется ее отладка и проверка. Данная книга
предназначена для начинающих программистов, поэтому мы делаем упор на
ясности. Вот наш первый совет по «хорошему стилю программирования».
Введение в компьютеры, Internet и World Wide Web
71
Хороший стиль программирования 1.1
Пишите свои программы на C++ в простой, четкой манере. Подобный
стиль иногда называют KIS («keep it simple» — пишите проще).
Вы слышали, что С и C++ — переносимые языки и что написанные на них
программы могут работать на разных компьютерах. Переносимость является
весьма труднодостижимым свойством. Документ ANSI по стандартному С
содержит длинный список пунктов, посвященных проблеме переносимости, и на
эту тему написаны целые книги.
Переносимость программ 1.3
Несмотря на принципиальную возможность написания переносимых
программ, существует много проблем с различными компиляторами С
и C++ и различными компьютерными системами, которые
затрудняют достижение переносимости. Само по себе написание программ на С
или C++ не гарантирует их переносимости. Программисту часто
приходится иметь дело с конкретными особенностями компиляторов
и компьютеров. В целом они называются особенностями платформ.
Мы очень тщательно сверили свое изложение со стандартным документом
ANSI/ISO C++. Однако C++ — богатый язык, и некоторые его тонкости в
книге не рассматриваются. Если читателю понадобятся дополнительные
технические детали C++, то он может сам прочитать стандартный документ по C++,
который можно заказать на сайте ANSI
webstore.ansi.org/ansidocstore/default.asp
Документ называется «Information technology — Programming Languages —
C++», а его номер — INCITS/ISO/IEC 14882-2003.
Мы включили в книгу обширную библиографию книг и статей по C++
и объектно-ориентированному программированию. Мы включили также
приложение «Ресурсы C++», в котором содержится много сайтов Internet и Web,
относящихся к объектно-ориентированному программированию и C++. В
разделе 1.19 мы перечисляем некоторые Web-сайты, включая ссылки к
бесплатным компиляторам C++, сайтам ресурсов и некоторым занимательным играм
на C++ и руководствам по программированию игр.
Хороший стиль программирования 1.2
Читайте руководства по версии C++, с которой вы работаете.
Частое обращение к ним позволит вам узнать много полезного об
особенностях языка C++ и поможет их корректно использовать.
Хороший стиль программирования 1.3
Компьютер и компилятор являются хорошими учителями. Если вы не
уверены в том, как работает та или иная конструкция C++,
поэкспериментируйте, написав маленькую «тестовую программу» и
посмотрите, что получится. Настройте компилятор на «максимум
предупреждений». Изучите каждое сообщение, выданное компилятором,
и исправьте программу, чтобы устранить эти сообщения.
72
Глава 1
1.16. Тестовый запуск приложения на C++
В этом разделе вы узнаете, как запустить ваше первое приложение C++
и как взаимодействовать с ним. Вы начнете с запуска забавной игры, которая
выбирает число от 1 до 1000 и предлагает вам его отгадать. Если ваша догадка
правильна, игра заканчивается. Если нет, приложение указывает, больше или
меньше ваша догадка правильного числа. На число попыток угадывания
ограничений нет. [Замечание. Только для данного раздела мы модифицировали это
приложение (из упражнения главы 6, «Функции и введение в рекурсию»).
Обычно это приложение выбирало бы для отгадывания различные числа при
каждом новом запуске, поскольку эти числа генерируются случайным
образом. Наше модифицированное приложение выбирает одни и те же
«правильные» отгадки всякий раз, когда вы ее запускаете. Это позволяет вам
использовать те же догадки и видеть те же отклики, что мы показываем здесь, по ходу
вашего взаимодействия с вашим первым приложением C++.]
Мы продемонстрируем два варианта запуска приложения C++ — из
командной строки Windows XP и в оболочке Linux (которая очень похожа на
командную строку Windows). Приложение на обеих платформах работает
одинаково. Существует много сред разработки, в которых читатели могут
компилировать, строить и запускать приложения C++, таких, как Borland C++Builder,
Metrowerks, GNU C++, Microsoft Visual C++.NET и т.д. Хотя мы не запускаем
приложение на всех этих платформах, в разделе 1.19 приводится информация
относительно компиляторов C++, доступных для бесплатной загрузки по
Internet. Обратитесь к своему преподавателю за информацией о своей
конкретной среде разработки. Кроме того, мы предлагаем несколько публикаций
Deitel™ Dive Into Series, которые помогут вам в освоении различных
компиляторов C++. Они доступны бесплатно на www.deitel.com/books/downloads/html.
В следующих пунктах вы запустите приложение и будете вводить
различные числа, чтобы отгадать правильное число. Элементы и функциональные
свойства приложения типичны для тех, что вы научитесь создавать по ходу
чтения книги. Для рисунков этого раздела мы изменили цвет фона окна
командной строки, чтобы текст был более отчетливым (это относится только
к запуску приложения в Windows). Чтобы модифицировать цвета окна на
своей системе, откройте командную строку, а затем щелкните правой кнопкой на
линейке заголовка и выберите Свойства. В диалоговой панели свойств
выберите закладку Цвета и выберите предпочтительные цвета текста и фона.
Запуск приложения C++ из командной строки Windows XP
1. Подготовительная проверка. Убедитесь, что вы правильно загрузили
и скопировали примеры этой книги на свой жесткий диск.
2. Локализация законченного приложения. Откройте окно командной
строки. Если вы работаете системой Windows 95, 98 или 2000, выберите
Пуск > Программы > Стандартные > Сеанс MS-DOS. В Windows XP
выберите Пуск > Все программы > Стандартные > Командная строка.
Чтобы перейти в каталог законченного приложения GuessNumber,
введите cd C:\examples\ch01\GuessNumber\Windows и нажмите Enter
(рис. 1.2). Команда cd служит для переключения каталогов.
Введение в компьютеры, Internet и World Wide Web 73
3. Запуск приложения GuessNumber. Теперь, когда вы находитесь в
каталоге, где содержится приложение GuessNumber, введите команду
GuessNumber (рис. 1.3) и нажмите Enter. [Замечание. В
действительности именем приложения является GuessNumber.exe, но Windows
предполагает расширение .ехе по умолчанию.]
4. Ввод вашей первой догадки. Приложение выводит «Please type your
first guess», затем, на следующей строке, вопросительный знак (?) в
качестве подсказки. В ответ введите 500 (рис. 1.4).
5. Ввод следующей догадки. Приложение выводит «Too high. Try again.»,
имея в виду, что введенное вами значение больше, чем выбранное
приложением «правильное» число. Следовательно, в качестве следующей
догадки вы должны ввести меньшее число. В ответ на подсказку введите
250 (рис. 1.5). Приложение снова выводит «Too high. Try again.»,
поскольку вы ввели значение, все еще большее правильной догадки.
Ш
Microsoft Uindows XP "[1е^йя~51Т'2б'о¥]
КС) Корпорация Майкрософт, 1985-2001.
C:\>cd C:\examples\ch01\GuessNumber\Uindows
|C:\examples\ch01\GuessNumber\Uindows >_
Рис. 1.2. Открытие окна командной строки и смена каталога
Ш
jC:\examples\ch01\GuessNumber\Uindows >GuessNumber
|I have a number between 1 and 1Q00.
Can you guess my number?
Please type your first guess.
Рис. 1.З. Запуск приложения GuessNumber
Ш
г
С :\examples\cli01\GuessNumber\Uindows>Guess Number
I have a number between 1 and 1000.
Can you guess my number?
Please type your first guess.
£ 500
[Too high. Try again.
Рис. 1.4. Ввод начальной догадки
П' X'
:Л|
-<-п: х
-!П| X,
74
Глава 1
faUJ
jC:\examples\ch01\GuessNumber\Uindous>GuessNumber
I have a number between 1 and 1000.
Can you guess my number?
Please type your first guess.
E 50°
[Too high. Try again.
j? 250
(Too high. Try again.
_]n] xi
d
▼ i
—
Рис. 1-5. Ввод второй догадки, получение отклика
6. Ввод дополнительных догадок. Продолжайте играть, вводя значения,
пока не угадаете правильное число. Когда вы угадаете ответ, приложение
выведет «Excellent! You guessed the answer!» (рис. 1.6).
7. Повторная игра или выход из приложения. После того как число
угадано, приложение спрашивает, хотели бы вы сыграть еще раз (рис. 1.6).
Если в ответ на подсказку «Would you like to play again (y or n)?» ввести
единственный символ у, приложение выберет новое число и выведет
сообщение «Please type your first guess» с последующим вопросительным
знаком (рис. 1.7), так что вы можете сделать свою первую догадку в
новой игре. Ввод символа п заканчивает приложение и возвращает вас в
каталог приложения в окне командной строки (рис. 1.8). Каждый раз,
когда вы исполняете приложение с начала (т.е. с шага 3), оно будет
выбирать для угадывания одни и те же числа.
8. Закройте окно командной строки.
ш
Too high, fry again.
{? 125
tToo low. Try again.
1? 187
Too high. Try again.
!? 159
Too high. Try again.
? 141
Too high. Try again.
Г? 133
Too high. Try again.
? 131
Excellent! Vou guessed
Would you like to play
the number!
again <y or
Рис. 1.6. Ввод дополнительных догадок и отгадывание правильного числа
Введение в компьютеры, Internet и World Wide Web 75
n&jf
г
{Excellent! You guessed the number?
jUould you like to play again <y or n>? у
I have a number between 1 and 100C.
Can you guess my number?
iPlease type your first guess.
Рис. 1.7. Повторная игра
ш
Excellent? You guessed the number?
Il/ould you like to play again <y or n)? n
I
)C: \examples\ch01\GuessNumber\Windows >_
Рис. 1.8. Выход из игры
Запуск приложения C++ с помощью GNU C++ в Linux
Мы предполагаем, что вы знаете, как скопировать примеры в свой
домашний каталог. Если у вас возникнут какие-то вопросы, касающиеся
копирования файлов на вашу систему Linux, обратитесь к своему преподавателю. В
рисунках этой главы мы выделяем жирным шрифтом ввод пользователя,
требуемый на каждом шаге. Подсказка на нашей системе использует символ тильды
(~) для представления домашнего каталога и оканчивается знаком доллара ($).
Подсказка может меняться от одной системы Linux к другой.
1. Локализация законченного приложения. В оболочке Linux перейдите
в каталог законченного приложения (рис. 1.9), набрав
cd examples\ch01\GuessNumber\GNU_Linux
и нажав Enter. Команда cd служит для переключения каталогов.
2. Компиляция приложения GuessNumber. Чтобы запустить приложение
в компиляторе GNU C++, его нужно сначала компилировать, для чего
следует ввести
g++ GuessNumber.срр -о GuessNumber
как на рис. 1.10. Эта команда компилирует приложение и создает
исполняемый файл с именем GuessNumber.
3. Запуск приложения GuessNumber. Чтобы запустить исполняемый файл
GuessNumber, введите в ответ на следующую подсказку ./GuessNumber
и нажмите Enter (рис. 1.11).
!п!х
-{□ х!
76
Глава 1
~$ cd examples\ch01\GuessNumber\GNU_Linux
~examples\ch01\GuessNumber\GNU__Linux$
Рис. 1.9. Переход в каталог приложения GuessNumber после регистрации в системе Linux
-examples\ch01\GuessNumber\GNU_JLinux$ g++ GuessNumber.cpp -o
GuessNumber
~examples\ch01\GuessNumber\GNU_Linux$
Рис. 1.10. Компиляция приложения GuessNumber командой g++
~examples\ch01\GuessNumber\GNU_Linux$ ./GuessNumber
I have a number between 1 and 1000.
Can you guess my number?
Please type your first guess.
о
Рис. 1.11. Запуск приложения GuessNumber
4. Ввод вашей первой догадки. Приложение выводит «Please type your
first guess.», затем, на следующей строке, вопросительный знак (?) в
качестве подсказки. В ответ введите 500 (рис. 1.12). [Замечание. Это то же
самое приложение, которое мы модифицировали и запускали в Windows,
но вывод его может отличаться в зависимости от используемого
компилятора.]
5. Ввод следующей догадки. Приложение выводит «Too high. Try again.»,
имея в виду, что введенное вами значение больше, чем выбранное
приложением «правильное» число (рис. 1.12). В ответ на подсказку введите
250 (рис. 1.13). Приложение снова выводит «Too high. Try again.»,
поскольку вы ввели значение, меньшее правильной догадки.
6. Ввод дополнительных догадок. Продолжайте играть (рис. 1.14), вводя
значения, пока не угадаете правильное число. Когда вы угадаете ответ,
приложение выведет «Excellent! You guessed the answer!» (рис. 1.14).
~examples\ch01\GuessNumber\GNU_Linux$ ./GuessNumber
I have a number between 1 and 1000.
Can you guess my number?
Please type your first guess.
? 500
Too high. Try again.
о
Рис. 1.12. Ввод начальной догадки
Введение в компьютеры, Internet и World Wide Web
77
~examples\ch01\GuessNumber\GNU_Linux$ ./GuessNumber
I have a number between 1 and 1000.
Can you guess my number?
Please type your first guess.
? 500
Too high. Try again.
? 250
Too low. Try again.
9
Рис. 1.13- Ввод второй догадки, получение отклика
Too low. Try again.
? 375
Too low. Try again.
? 437
Too high. Try again.
? 406
Too high. Try again.
? 391
Too high. Try again.
? 383
Too low. Try again.
? 387
Too high. Try again.
? 385
Too high. Try again.
? 384
Excellent! You guessed the answer!
Would you like to play again (y or n)?
Рис. 1.14. Ввод дополнительных догадок и отгадывание правильного числа
7. Повторная игра или выход из приложения. После того как число
угадано, приложение спрашивает, хотели бы вы сыграть еще раз. Если в
ответ на подсказку «Would you like to play again (y or n)?» ввести
единственный символ у, приложение выберет новое число и выводит сообщение
«Please type your first guess» с последующим вопросительным знаком
(рис. 1.15), так что вы можете сделать свою первую догадку в новой игре.
Ввод символа п заканчивает приложение и возвращает вас в каталог
приложения в окне командной строки (рис. 1.16). Каждый раз, когда вы
исполняете приложение с начала (т.е. с шага 3), оно будет выбирать для
угадывания одни и те же числа.
Excellent! You guessed the answer!
Would you like to play again (y or n)? у
I have a number between 1 and 1000.
Can you guess my number?
Please type your first guess.
9
Рис. 1.15. Повторная игра
78
Глава 1
Excellent! You guessed the answer!
Would you like to play again (y or n)? n
~examples\ch01\GuessNumber\GNU_Linux$
Рис. 1.16. Выход из игры
1.17. Конструирование программного обеспечения.
Введение в объектную технологию и UML
(обязательный раздел)
Теперь мы начинаем наше раннее введение в ориентацию на объекты, то
есть в естественный способ мышления о мире и написания компьютерных
программ. Каждая из глав 1-7, 9 и 13 заканчивается кратким разделом
«Конструирование программного обеспечения», где мы даем продуманное
последовательное введение в объектно-ориентированные реалии. Наша цель здесь —
помочь вам выработать объектно-ориентированный способ мышления и ввести
вас в Unified Modeling Language™, UML™ (Унифицированный язык
моделирования) — графический язык, позволяющий людям, разрабатывающим
системы программного обеспечения, пользоваться для их представления
стандартизованными обозначениями.
В этом, обязательном для чтения разделе мы представляем основные
объектно-ориентированные концепции и терминологию. Необязательные разделы
в главах 2-7, 9 и 13 показывают объектно-ориентированное проектирование
и реализацию программной системы для простого банкомата (ATM, Automated
Teller Machine). Разделы «Конструирование программного обеспечения» в
главах 2-7
• анализируют типичную спецификацию требований, описывающую
программную систему (т.е. ATM), которую нужно построить;
• определяют объекты, требуемые для реализации этой системы;
• определяют атрибуты, которыми должны обладать объекты;
• определяют поведение, которое должны проявлять эти объекты;
• специфицируют, каким образом объекты взаимодействуют друг с
другом, реализуя в этом процессе требования к системе в целом.
Разделы «Конструирование программного обеспечения» в главах 9 и 13
модифицируют и усовершенствуют проект, представленный в главах 2-7.
Приложение Е содержит полную работоспособную реализацию
объектно-ориентированной системы ATM.
Хотя наш учебный пример является «уменьшенным» вариантом настоящей
индустриальной задачи, он тем не менее охватывает многие типичные аспекты
программной индустрии. Вы приобретете солидный опыт
объектно-ориентированного проектирования с помощью UML. Кроме того, вы отточите свое
искусство чтения кода, проработав полную, тщательно написанную и хорошо
документированную реализацию ATM на C++.
Введение в компьютеры, Internet и World Wide Web
79
Основные понятия объектной технологии
Мы начнем представление объектной ориентации с ее ключевой
терминологии. Везде в реальном мире, куда бы вы ни взглянули, вы видите объекты —
людей, машины, самолеты, здания, компьютеры и так далее. Люди мыслят на
языке объектов. Телефоны, дома, светофоры, микроволновые печи и
холодильники — это просто некоторые объекты, которые мы видим вокруг нас
ежедневно.
Иногда мы делим объекты на две категории — одушевленные и
неодушевленные. Одушевленные объекты в некотором смысле «живые» — они
движутся и что-то делают. Неодушевленные объекты, с другой стороны, сами по себе
не движутся. Однако объекты обоих типов имеют нечто общее. Все они имеют
атрибуты (например, размер, форму, цвет и высоту), и они проявляют
поведение (например, мяч катится, скачет, надувается и сдувается; ребенок
плачет, спит, ползает, ходит и моргает; автомобиль разгоняется, тормозит и
поворачивает; полотенце впитывает воду). Мы будем изучать виды атрибутов и
поведения, свойственные программным объектам.
Люди познают существующие объекты, изучая их атрибуты и наблюдая их
поведение. Различные объекты могут иметь похожие свойства и проявлять
сходное поведение. Можно, например, провести сравнение между детьми
и взрослыми, между людьми и шимпанзе.
Объектно ориентированное проектирование (OOD, Object-Oriented Design)
моделирует программное обеспечение на языке, сходном с тем, которым
пользуются люди при описании объектов реального мира. OOD пользуется
средствами классификации, когда объекты определенного класса, например, класса
средств передвижения, имеют одинаковые характеристики — лимузины,
грузовики, маленькие красные фургончики и роликовые коньки имеют много
общего. OOD пользуется отношениями наследования, когда новые классы
объектов производятся путем поглощения характеристик существующих классов
и добавления к ним своих собственных уникальных характеристик. Объект
класса «кабриолет» обладает, безусловно, характеристиками более общего
класса «автомобиль», но, в частности, его крыша может подниматься и
опускаться.
Объектно-ориентированное проектирование предлагает естественный и
интуитивный подход к процессу проектирования программного обеспечения, —
а именно, моделирование объектов посредством их атрибутов, поведения и
взаимоотношений, точно так же, как мы поступаем при описании объектов
реального мира. OOD моделирует также коммуникацию между объектами. Точно так
же, как люди посылают друг другу сообщения (например, сержант дает солдату
команду стать по стойке «смирно»), обмениваются сообщениями и объекты.
Объект банковского счета может получить сообщение уменьшить свой баланс на
определенную сумму, поскольку клиент снял эту сумму со счета.
Атрибуты и действия (поведение) OOD инкапсулирует (т.е. упаковывает)
в объектах — атрибуты и действия объекта тесно связаны между собой.
Объекты обладают свойством сокрытия информации. Это означает, что объекты
могут знать, как взаимодействовать друг с другом при посредстве точно
определенных интерфейсов, но, как правило, им не дано знать, как реализованы
другие объекты; детали реализации скрыты внутри самих объектов. Мы
вполне, например, можем вести машину, не зная деталей того, как работают
двигатели, тормоза, трансмиссии и выхлопные системы — нам достаточно знать,
80
Глава 1
как обращаться с педалями акселератора и тормозов, рулевым колесом и так
далее. Сокрытие информации, как мы увидим, является ключом к
правильному проектированию программного обеспечения.
Языки, подобные C++, являются объектно-ориентированными.
Программирование на таком языке называют объектно-ориентированным
программированием (OOP), и оно позволяет программистам реализовать
объектно-ориентированный проект в качестве работающей программной системы. С другой
стороны, языки, подобные С, являются процедурными, соответственно
программирование тяготеет к ориентации на действия. В С программной
единицей является функция. В C++ программной единицей является класс, в
качестве представителей (синоним OOP для термина «экземпляр») которого
создаются объекты. Классы C++ содержат функции, которые реализуют
действия, и данные, которые реализуют атрибуты.
Программирующие на С концентрируют внимание на написании функций.
Они группируют действия, выполняющие определенную задачу, в функцию,
а функции группируются, образуя программу. Данные, конечно, важны в С,
но взгляд на них таков, что данные существуют прежде всего ради
выполняемых функцией действий. Определить набор совместно работающих функций,
которые реализуют систему, программистам помогают глаголы в
спецификации системы.
Классы, элементы данных и элемент-функции
Программирующие на C++ концентрируют внимание на создании своих
собственных определяемых пользователем типов, называемых классами.
Каждый класс содержит как данные, так и набор функций, манипулирующих
этими данными и предоставляющих услуги клиентам (т.е. другим классам
или функциям, использующим данный класс). Компоненты данных в классе
называются элементами данных. Например, класс банковского счета мог бы
включать номер счета и баланс. Функциональные компоненты класса
называются эле мент-функциями (в других объектно-ориентированных языка, таких,
как Java, их обычно называют методами). Например, класс банковского счета
мог бы включать элемент-функции для вклада (увеличения баланса), для
снятия денег (уменьшения баланса) и для справок о том, каков текущий баланс.
Для построения новых определяемых пользователем типов (классов)
программист использует в качестве «строительных блоков» встроенные типы (и другие
пользовательские типы). Определить набор классов, из которых создаются
совместно работающие и реализующие систему объекты, программистам
помогают существительные в спецификации системы.
Классы по отношению к объектам то же, что архитектурные планы по
отношению к домам — класс является «планом» для строительства объекта
класса. Точно так же, как по одному плану мы можем построить много домов, из
одного класса мы можем создать много объектов. Нельзя готовить пишу на
кухне архитектурного плана; пищу готовят на кухне в доме. Нельзя спать
в спальне плана; можно спать только в спальне, которая в доме.
Классы могут находиться в тех или иных отношениях с другими классами.
Например, в объектно-ориентированном проекте банка класс «кассира» должен
иметь отношения с другими классами, такими, как класс «клиента», класс
«кассы», класс «сейфа» и т.д. Эти отношения называются ассоциациями.
Введение в компьютеры, Internet и World Wide Web 81
Упаковка программного обеспечения в классах делает возможной
утилизацию классов в будущих программных системах. Группы взаимосвязанных
классов часто упаковываются в виде утилизируемых компонентов. Подобно
тому, как торговцы недвижимостью часто говорят, что тремя главными
факторами, влияющими на цену имения, являются «место, место и место», люди из
сообщества разработчиков программного обеспечения говорят, что тремя
главными факторами, влияющими на будущее индустрии программного
обеспечения, являются «утилизация, утилизация и утилизация».
Общее методическое замечание 1.4
Утилизация существующих классов при построении новых классов
экономит время, деньги и усилия. Утилизация, кроме того, помогает
программистам строить более надежные и эффективные системы,
поскольку существующие классы и компоненты часто уже прошли
тщательное тестирование, отладку и настройку для достижения
наилучшей эффективности.
На базе объектной технологии вы, действительно, можете строить большую
часть нового программного обеспечения, которое вам потребуется, путем
комбинирования существующих классов, точно так же, как производители
автомобилей комбинируют взаимозаменяемые агрегаты. Каждый создаваемый
вами класс имеет потенциальную возможность стать ценным программным
«активом», который вы it другие программисты будете утилизировать ради
ускорения и повышения качества будущих программных разработок.
Введение в объектно-ориентированный анализ и проектирование
(OOAD)
Скоро вы будете писать программы на С+-К Как вы будете создавать код
ваших программ? Возможно, еы, подобно многим начинающим программистам,
просто включите свой компьютер и начнете печатать. Такой подход может
работать для маленьких программ (подобных тем, что мы представляем в первых
главах этой книги), но что, если бы вас попросили создать программную
систему, управляющую тысячами банкоматов, принадлежащих большому банку?
Или если бы вас попросили руководить командой из 1000
программистов-разработчиков, которые трудятся над созданием системы нового поколения для
управления дорожным движением в США? В случае таких больших и
сложных проектов нельзя просто сесть и начать писать.
Чтобы реализовать наилучшие решения, вы должны следовать
детализированному процессу анализирования требований вашего задания (т.е.
определения того, что должна делать система) и разработки проекта, который им
удовлетворяет (т.е. принятия решения о том, как система будет это делать).
В идеале, до того, как будет написан какой-либо код, вы должны пройти весь
процесс и тщательно пересмотреть проект (либо дать проект па рассмотрение
другим специалистам по программному обеспечению). Если этот процесс
связан с анализом и проектированием вашей системы с
объектно-ориентированной точки зрения, он называется объектно ориентированным анализом и про
актированием (OOAD, Object-Oriented Analysis and Design). Опытные
программисты знают, что анализ и проектирование могут сэкономить мною часов
82
Глава 1
работы, помогая избежать плохо спланированного подхода к разработке,
когда, пройдя часть процесса ее реализации, от сделанного приходится
отказываться и, возможно, терять на этом время, деньги и затраченные усилия.
OOAD — обобщенный термин для процесса анализа задачи и выработки
подхода к ее решению. Небольшие задачи, подобные обсуждаемым в этих
первых главах, не требуют исчерпывающего OOAD. Может быть достаточным,
прежде чем программировать задачу на C++, написать псевдокод —
неформальное средство выражения программной логики в текстовой форме. Это не
язык программирования в собственном смысле, но его можно использовать
в качестве наброска, которым мы будем руководствоваться при написании
кода. Мы введем псевдокод в 4-й главе.
По мере увеличения размеров задач и групп людей, их решающих, методы
OOAD быстро становятся более адекватными, чем псевдокод. В идеале группа
должна договориться о четко определенном процессе решения своей задачи и
о единообразном способе передачи результатов этого процесса друг другу. Хотя
существует много вариантов процесса OOAD, широкое распространение
получил единственный графический язык для передачи результатов любого
процесса OOAD. Этот язык, получивший название (Unified Modeling Language UML),
был разработан в середине 90-х годов под первоначальным руководством трех
методологов программного обеспечения — Грейди Буча, Джеймса Рамбо и Ай-
вара Джекобсона (Grady Booch, James Rumbaugh and Ivar Jacobson).
История UML
В 80-х годах все большее число организаций стало применять для
разработки своих приложений OOP, и возникла потребность в стандартном процессе
OOAD. Многие методологи — в том числе Буч, Рамбо и Джекобсон —
независимо развивали собственные процессы, соответствующие их нуждам. Каждый
процесс для выражения результатов анализа и проектирования имел
собственные обозначения, или «язык» (в форме графических диаграмм).
В начале 90-х годов различные организации и даже отделы внутри одной
организации использовали свои уникальные процессы и обозначения. И этим
организациям хотелось иметь программные инструменты, которые
соответствовали бы их индивидуальным процессам. Производители программного
обеспечения сочли затруднительным предоставить инструменты для такого
количества различных процессов. Явно нужны были стандартные обозначения
и стандартные процессы.
В 1994 г. Джеймс Рамбо объединился с Грейди Бучем в Rational Software
Corporation (теперь отделение IBM), и они вдвоем начали работать над
унификацией своих популярных процессов. Вскоре к ним присоединился Айвар
Джекобсон. В 1996 г. группа представила сообществу конструкторов
программного обеспечения первые версии UML и попросила об отзывах.
Примерно в то же время организация под названием Object Management Group™
(OMG™) предложила подавать предложения об общем языке моделирования.
OMG (www.omg.com) — некоммерческая организация, поощряющая
стандартизацию объектно-ориентированных технологий путем распространения
руководящих принципов и спецификаций, подобных UML. К этому моменту
различные корпорации — в том числе HP, IBM, Microsoft, Oracle и Rational
Software — уже признали необходимость общего языка моделирования. В
ответ на просьбу OMG о предложениях эти компании образовали UML Part-
Введение в компьютеры, Internet и World Wide Web
83
ners — консорциум, который разработал UML версии 1.1 и представил его
OMG. OMG приняла предложение и в 1997 г. взяла на себя ответственность за
дальнейшее сопровождение и пересмотр UML. В марте 2003 г. OMG выпустила
UML версии 1.2. UML версии 2 — которая была принята и находилась в
процессе окончательного формулирования во время публикации этой книги —
отмечает собой первый существенный пересмотр стандарта 1997 г. версии 1.1.
Многие книги, инструменты моделирования и промышленные эксперты уже
используют UML версии 2, поэтому в этой книге мы представляем именно ее
терминологию и обозначения.
Что такое UML?
Унифицированный язык моделирования UML является сейчас наиболее
широко распространенной схемой графического представления для
моделирования объектно-ориентированных систем. Он действительно унифицировал
различные популярные схемы обозначений. Занимающиеся проектированием
систем пользуются этим языком (в форме диаграмм), как и мы в этой книге,
для их моделирования.
Привлекательной чертой UML является его гибкость. UML расширяем (т.е.
его можно усовершенствовать путем введения новых элементов) и независим
от любых конкретных вариантов процесса 00AD. Моделирующие с помощью
UML не связаны в использовании своего процесса проектирования системы, но
все разработчики могут теперь выразить свои проекты с помощью единого
стандартного набора графических обозначений.
UML — сложный графический язык с большим будущим. В наших
разделах «Конструирование программного обеспечения» по разработке
программной системы ATM (банкомата) мы представляем простое, сжатое
подмножество его элементов. Затем мы используем это подмножество для того, чтобы
провести вас через первый ваш опыт проектирования с помощью UML,
рассчитанный на начинающих «объектно-ориентированных» программистов
на их первом-втором году обучения программированию.
Этот учебный проект
Ресурсы Internet и World Wide Web
За дополнительной информацией по UML вы можете обратиться на
перечисленные ниже сайты. Информацию о других сайтах с материалами по UML
вы найдете в разделе 2.8.
www.uml.org
Страница ресурсов UML от Object Management Group (OMG) предлагает
документы по спецификациями UML и другим объектно-ориентированным
технологиям.
www. ibm. com/ software/rational /uml
Это страница ресурсов UML от IBM Rational — преемника Rational Software
Corporation (компании, создавшей UML).
84
Глава 1
Рекомендуемая литература
По UML опубликовано немало книг. Мы рекомендуем следующие книги,
рассказывающие об объектно-ориентированном проектировании с
использованием UML.
Arlow, J., and I. Neustadt. UML and the Unified Process: Practical Object-Oriented
Analysis and Design, London: Pearson Education Ltd., 2002.
Fowler, M. UML Distilled, Third Edition: A Brief Guide to the Standard Object
Modeling Language. Boston: Addison-Wesley, 2004.
Rumbaugh, J., I. Jacobson and G. Booch. The Unified Modeling Language User Guide.
Reading, MA: Addison-Wesley, 1999.
Информацию о других книгах по UML вы можете найти в списке
рекомендуемой литературы в конце раздела 2.8, либо вы можете посетить www.ama-
zon.corn или www.bn.com. IBM Rational, ранее Rational Software Corporation,
также предлагает список рекомендуемой литературы по UML на www.ibm.com/
software/rational/info/technical/books, jsp.
Контрольные вопросы к разделу 1.17
1.1. Приведите три примера объектов реального мира, которых мы не
упоминали. Для каждого объекта приведите несколько примеров атрибутов
и поведения.
1.2. Псевдокод является ...
a) другим названием для OOAD.
b) языком программирования, служащим для вывода диаграмм UML.
c) неформальным средством выражения программной логики.
d) схемой графического представления для моделирования
объектно-ориентированных систем.
1.3. UML используется главным образом для ...
a) тестирования объектно-ориентированных систем.
b) проектирования объектно-ориентированных систем.
c) реализации объектно-ориентированных систем.
d) целей а) и Ь).
Ответы на контрольные вопросы к разделу 1.17
1.1. [Замечание. Возможны различные ответы.] а) Атрибуты телевизора
включают в себя размер экрана, число цветов, которые он может
отображать, текущий канал и текущую громкость. Телевизор включается и
выключается, переключает каналы, отображает видеосигнал и
воспроизводит звук. Ь) Атрибуты кофеварки включают в себя максимальный объем
воды, который она вмещает, время, требуемое для приготовления кофе,
и температуру пластины подогрева, на которой стоит кофейник.
Кофеварка включается и выключается, варит кофе и разогревает кофе, с)
Атрибуты черепахи включают в себя возраст, размер панциря и вес.
Черепаха ползает, прячется в панцирь, высовывается из панциря и ест
растительную пищу.
Введение в компьютеры, Internet и World Wide Web
85
1.2. с).
1.3. b).
1.18. Заключение
В этой главе были представлены основные понятия аппаратной части и
программного обеспечения и исследована роль C++ в разработке распределенных
приложений клиент/сервер. Вы познакомились с историей Internet и World
Wide Web. Мы обсудили различные типы языков программирования, их
историю и то, какие из языков используются наиболее широко. Мы также
обсудили Стандартную библиотеку C++, которая содержит утилизируемые классы
и функции, помогающие программистам создавать переносимые программы.
Мы представили основные концепции объектной технологии, включая
классы, объекты, атрибуты, поведение, инкапсуляцию и наследование. Вы
познакомились также с историей и назначением UML — стандартного
графического языка для моделирования программных систем.
Вы изучили типичные стадии построения и исполнения приложения на
C++. Наконец, вы произвели «тестовый запуск» примера приложения на C++,
похожего на те приложения, которые вы будете учиться программировать
в этой книге.
В следующей главе вы будете создавать свои собственные приложения на
C++. Вы увидите несколько примеров, демонстрирующих, как программы
выводят на экран сообщения и получают от пользователя информацию с
клавиатуры для обработки. Мы анализируем и объясняем каждый пример, чтобы
помочь вам войти в мир программирования на С-М-.
1.19. Ресурсы Web
В этом разделе перечисляются ресурсы Web, которые могут быть вам
полезны при изучении C++. Сайты включают в себя ресурсы C++, инструменты
разработки C++ для учащихся и специалистов и ссылки на некоторые
занимательные игры, написанные на C++. В разделе перечисляются также наши
собственные Web-сайты, где вы сможете найти загружаемые файлы и ресурсы,
относящиеся к этой книге. Дополнительные ресурсы Web вы найдете в
приложении И.
Web-сайты Deitel & Associates
www.deitel.com/books/cpphtp5/index.html
Сайт Deitel & Associates C++ How to Program, Fifth Edition. Здесь вы
найдете ссылки на примеры книги и другие ресурсы, такие, как наши бесплатные
руководства Dive Into™, которые помогут вам освоить различные
интегрированные среды разработки (IDE) для C++.
www.deitel.com
Пожалуйста, проверьте сайт Deitel & Associates на предмет обновлений,
исправлений и дополнительных ресурсов для всех публикаций Deitel.
86
Глава 1
www.deitel.com/newsletter/subscribe.html
Пожалуйста, посетите этот сайт, чтобы подписаться на электронный
бюллетень Deitel® Buzz Online, который позволит вам следить за издательской
программой Deitel & Associates.
www.prenhall.com/deitel
Сайт Prentice Hall для изданий Deitel. Здесь вы найдете детальную
информацию об изданиях, отдельные главы и Web-сайты сопровождения,
содержащие специфические ресурсы для книг и глав — для студентов и
преподавателей.
Компиляторы и средства разработки
www.thefreecountry.com/developercity/ccompilers.shtmt
На сайте перечисляются бесплатные компиляторы С и C++ для различных
операционных систем.
msdn.microsoft.com/visualc
Сайт Microsoft Visual C++ предоставляет информацию о продукте, обзоры,
дополнительные материалы информацию о заказе компилятора Visual C++.
www.borland.com/bcppbuilder
Это ссылка на Borland C++Builder. Доступна для загрузки бесплатная
версия компилятора с командной строкой.
www.compilers.net
Сайт compilers.net разработан, чтобы помочь пользователям в поиске
компиляторов.
developer.intel.com/software/products/compilers/cwin/index.htm
На сайте доступна оценочная загрузка компилятора Intel C++.
www.kai.com/C_plus_plus
Сайт предлагает компилятор Kai C++ для 30-дневной бесплатной оценки.
www. symbian. com/developer/development/cppdev. html
Symbian предоставляет C++ Developer's Pack и ссылки на различные
ресурсы, включая код и инструменты разработки для программистов C++,
реализующих переносимые приложения для операционной системы Symbian»
популярной на таких устройствах, как мобильные телефоны.
Ресурсы
www.hal9k.com/cug
Сайт Группы пользователей C/C++ (CUG) содержит ресурсы C++,
журналы, разделяемое и бесплатное программное обеспечение.
www.devx.com
DevX является всесторонним ресурсом для программистов, предлагающим
последние известия, инструменты и методики для различных языков
программирования. C++ Zone предлагает советы, форумы для обсуждения,
техническую поддержку и online-бюллетени.
Введение в компьютеры, Internet и World Wide Web
87
www.acm.org/crossroads/xrds3-2/ovp32.html
Сайт Ассоциации вычислительной техники (АСМ) предлагает широкий
список ресурсов C++, включающий рекомендуемую литературу, журналы,
опубликованные стандарты, бюллетени, FAQs и группы новостей.
www.accu.informika.ru/resources/public/terse/cpp.htm
Сайт Ассоциации пользователей С & C++ (ACCU) содержит ссылки на
руководства по C++, статьи, информацию для разработчиков, обсуждения и
книжные обозрения.
www.cuj.com
C/C++ User's Journal — online-журнал, содержащий статьи, руководства
и загрузки. Сайт содержит также главные новости о C++, форумы и ссылки на
информацию об инструментах разработки.
www.research.att.com/~bs/homepage.html
Это сайт Бьерна Страуструпа, создателя языка программирования C++.
Сайт предлагает список ресурсов C++, FAQs и другую полезную информацию
по C++.
Игры
www.codearchive.com/list.php?go=0708
На сайте имеется несколько игр на C++, доступные для загрузки.
www.math-tools.net/C_C_/Games/
Сайт содержит многочисленные ссылки на игры, построенные с помощью
C++. Исходный код большинства игр доступен для загрузки.
www.gametutorials.com/Tutorials/GT/GT_Pgl.htm
На сайте имеются руководства по программированию игр на C++. Каждое
руководство включает описание игры и список методов и функций,
используемых в руководстве.
www. forum, nokia. com/main/0, 6566,050_20,00 . html
Посетите этот сайт Nokia, чтобы научиться использовать C++ для
программирования игр на некоторых беспроводных устройствах Nokia.
Резюме
• Различные устройства, из которых состоит компьютерная система, называются
аппаратной частью (hardware).
• Программы, работающие на компьютере, называют программным обеспечением
(software).
• Компьютер способен производить вычисления и принимать логические решения
в миллионы (и даже миллиарды) раз быстрее человека.
• Компьютеры обрабатывают данные под управлением наборов инструкций,
называемых компьютерными программами, которые проводят компьютер через
упорядоченные наборы действий, описанных компьютерными программистами.
• Входное устройство является «приемным» отделом компьютера. Оно получает
информацию от устройств ввода и предоставляет ее в распоряжение других устройств
для последующей обработки.
88
Глава 1
• Устройство памяти является быстродействующим, но небольшого объема «складом»
компьютера. Там хранится информация, которая была введена через входное
устройство, и эта информация может стать доступной для обработки, как только это
потребуется, а также хранится уже обработанная информация до тех пор, пока она не
будет размещена выходным устройством на устройствах вывода.
• Арифметико-логическое устройство (ALU) является «производственным» отделом
компьютера. Оно отвечает за выполнение вычислений и принятие решений.
• Центральное процессорное устройство (CPU) является «административным»
отделом компьютера. Оно координирует работу компьютера и осуществляет надзор за
работой всех других частей.
• Устройство вторичного хранения является «складом» большой емкости для
долгосрочного хранения информации. Программы или данные, не используемые другими
блоками, обычно размещаются на вторичных запоминающих устройствах (таких,
как диски), пока они не потребуются снова, возможно, спустя дни, месяцы или даже
годы.
• Операционные системы были разработаны для удобства работы с компьютерами.
• Мультипрограммирование разделяет ресурсы компьютера между различными
заданиями, на них претендующими, так что задания кажутся выполняющимися
одновременно.
• При распределенной обработке данных работа всей организации распределяется
по сети на рабочие места, где она в действительности и производится.
• Каждый компьютер может непосредственно понимать только свой собственный
машинный язык, который в общем случае состоит из последовательностей чисел,
задающих исполнение самых элементарных операций.
• Основу языков ассемблера составляют англоязычные аббревиатуры.
Программы-трансляторы, называемые ассемблерами, переводят программы на языках
ассемблера на машинный язык.
• Компиляторы переводят программы на языках высокого уровня на машинный
язык. Языки высокого уровня (подобные C++) содержат английские слова и
традиционные математические обозначения.
• Программы-интерпретаторы непосредственно исполняют программы на языках
высокого уровня, устраняя необходимость трансляции их в машинный язык.
• C++ явился результатом эволюции С, который был продуктом двух более ранних
языков программирования, BCPL и В.
• C++ является расширением С и был разработан в Bell Laboratories Бьерном Страуст-
рупом в начале 80-х годов. C++ обогащает язык С и предусматривает возможности
для объектно-ориентированного программирования.
• Объекты являются утилизируемыми программными компонентами,
моделирующими предметы реального мира. При модульном, объектно-ориентированном подходе
к проектированию и реализации производительность групп разработчиков может
стать гораздо выше, чем при прежних методиках программирования.
• Программы на C++ составляются из фрагментов, называемых классами и
функциями. Вы можете сами программировать каждый фрагмент, который нужен для
образования программы на C++. Однако большинство программистов пользуются
богатыми собраниями готовых классов и функций стандартной библиотеки C++.
• Java используется для создания динамического и интерактивного содержания
Web-страниц, разработки приложений на предприятиях, расширения возможностей
Web-серверов, создания приложений для бытовых устройств и многого другого.
• FORTRAN (FORmula TRANslation) был разработан корпорацией IBM в 50-х годах
для научных и технических приложений, в которых требуется выполнять сложные
математические вычисления.
Введение в компьютеры, Internet и World Wide Web
89
• COBOL (COmmon Business Oriented Language) разработан в конце 50-х группой
производителей и пользователей компьютеров. COBOL главным образом используется
в коммерческих приложениях, когда необходима высокая точность и эффективность
обработки данных.
• Язык Ada был разработан в 1970-х и начале 80-х под эгидой Министерства обороны
США. Ada предусматривает многозадачность, которая позволяет программистам
специфицировать параллельно выполняемые действия.
• BASIC (Beginners All-Purpose Symbolic Instruction Code) был разработан в середине
1960-х профессорами Дартмуртского колледжа Джоном Кеннеди и Томасом Курцем
как средство для написания простых программ. Основной целью BASIC было
ознакомление новичков с приемами программирования.
• Visual Basic был разработан корпорацией Microsoft в начале 90-х годов для
упрощения разработки приложений Windows.
• Последние инструменты Microsoft являются частью корпоративной стратегии
интеграции в приложения возможностей Internet и Web. Эта стратегия реализована
в программной платформе .NET.
• Тремя главными языками платформы .NET являются Visual Basic .NET (на основе
первоначального BASIC), Visual C++ .NET (на основе C++) и С# (новый язык на
основе C++ и Java, с самого начала приспособленный для платформы .NET).
• Разработчики, использующие .NET, могут писать программные компоненты на
своем привычном языке, а затем строить приложения, комбинируя эти компоненты
с компонентами, написанными на любом другом .NET-языке.
• Системы C++ обычно состоят из трех частей: среды разработки программ, языка
и Стандартной библиотеки C++.
• Программы на C++ обычно проходят через шесть стадий: редактирования, препро-
цессорной обработки, компиляции, компоновки, загрузки и исполнения.
• Файлы исходного кода C++ часто имеют расширения .срр, .схх, .ее или .С.
• Перед началом стадии компиляции автоматически исполняется
программа-препроцессор. Препроцессор C++ распознает команды, называемые препроцессорными
директивами, которые указывают, что над программой перед компиляцией должны
быть произведены определенные манипуляции.
• Объектный код, генерируемый компилятором C++, обычно содержит «дыры» из-за
ссылок на функции и данные, определяемые в другом месте. Компоновщик
присоединяет к объектному коду код отсутствующих функций, чтобы создать
исполняемый образ (в котором нет отсутствующих частей).
• Загрузчик берет с диска исполняемый образ и переносит его в память.
• Большинство программ на C++ вводят и/или выводят данные. Данные часто
вводятся из cin (стандартного входного потока), которым обычно является клавиатура, но
cin может быть переадресован и на другое устройство. Часто данные выводятся
в cout (стандартный выходной поток), которым обычно является экран компьютера,
но cout также может быть переадресован на другое устройство. Поток сегг
используется для отображения сообщений об ошибках.
• Унифицированный язык моделирования UML является графическим языком,
который позволяет людям, строящим системы, представлять свои
объектно-ориентированные проекты в единых обозначениях.
• Объектно-ориентированное проектирование (OOD) моделирует программное
обеспечение на языке объектов реального мира. OOD пользуется средствами
классификации, когда объекты определенного класса, например, класса средств передвижения,
имеют одинаковые характеристики. OOD также пользуется отношениями
наследования, когда новые классы объектов производятся путем поглощения характеристик
существующих классов и добавления к ним своих собственных уникальных характе-
90
Глава 1
ристик. Данные (атрибуты) и функции (поведение) OOD инкапсулирует в
объектах — данные и функции объекта тесно связаны между собой.
Объекты обладают свойством сокрытия информации, — как правило, объектам не
дано знать, как реализованы другие объекты.
Объектно-ориентированное программирование (OOP) позволяет программистам
реализовать объектно-ориентированные проекты в качестве работающих систем.
Программирующие на C++ создают свои собственные определяемые пользователем
типы, называемые классами. Каждый класс содержит данные (называемые
элементами данных) и набор функций (называемых элемент-функциями), которые
манипулируют этими данными и предоставляют услуги клиентам класса.
Классы могут находиться в тех или иных отношениях с другими классами. Эти
отношения называются ассоциациями.
Упаковка программного обеспечения в классах делает возможной утилизацию
классов в будущих программных системах. Группы взаимосвязанных классов часто
упаковываются в виде утилизируемых компонентов.
Представитель класса называется объектом.
На базе объектной технологии программисты могут строить большую часть
программного обеспечения, которое им потребуется, путем комбинирования
стандартизованных, взаимозаменяемых компонентов — классов.
Процесс анализа и проектирования системы с объектно-ориентированной точки
зрения называется объектно-ориентированным анализом и проектированием (OOAD).
Терминология
Ada
BASIC (Beginner's All-Purpose
Symbolic Instruction Code)
С
С стандарта ANSI/ISO
C#
C++
C++ стандарта ANSI/ISO
COBOL (COmmon Business Oriented
Language)
FORTRAN (FORmula TRANslation)
Internet
Java
MFC (Microsoft Foundation Classes)
Microsoft .NET Framework Class
Library
Object Management Group (OMG)
Rational Software Corporation
Unified Modeling Language (UML)
Visual Basic .NET
Visual C++ .NET
World Wide Web
Американский институт
национальных стандартов (ANSI)
анализ
анализ и проектирование
структурированных систем
аппаратная платформа
аппаратная часть
арифметико-логическое устройство
(ALU)
ассемблер
ассоциация
атрибут объекта
Буч, Грейди
выходное устройство
данные
действие
Джекобсон, Айвар
динамическое содержание
директивы препроцессора
загрузчик
задача
инкапсуляция
интерпретатор
интерфейс
исполняемый образ
исходный код
класс
компилятор
компонент
компоновщик
компьютер
компьютерная программа
компьютерный программист
логическое устройство
Введение в компьютеры, Internet и World Wide Web
91
машинно-зависимый
машинно-независимый
машинный язык
Международная организация
по стандартизации (ISO)
метод
многозадачность
многопоточность
мультипрограммирование
мультипроцессор
наследование
обработка в модели клиент/сервер
объект
объектно-ориентированное
программирование (OOP)
объектно-ориентированное
проектирование (OOD)
объектно-ориентированный анализ
и проектирование (OOAD)
объектный код
операционная система
отладка
ошибки времени запуска или ошибки
времени выполнения
пакетная обработка поведение объекта
память
первичная память
переносимость
персональная обработка
платформа
платформа .NET
подход «живого кода»
представитель
программа-транслятор
программное обеспечение
проект
пропускная способность
процедурное программирование
псевдокод
рабочая станция
разделение времени
Рамбо, Джеймс
распределенная обработка
расширяемость
редактор
решение
сокрытие информации
стадия загрузки
стадия исполнения
стадия компиляции
стадия компоновки
стадия препроцессорной обработки
стадия редактирования
Стандартная библиотека C++
структурное программирование
суперкомпьютер
тип, определяемый пользователем
трансляция
устройство вторичного хранения
устройство вывода
устройство памяти
утилизация программного
обеспечения
файловый сервер
функция
центральное процессорное устройство
(CPU)
элемент данных
элемент-функция
язык ассемблера
язык высокого уровня
Контрольные вопросы
1.1. Заполните пропуски в следующих предложениях:
а) Компанией, популяризовавшей персональные компьютеры, была
b) Компьютером, сделавшим персональную обработку данных в бизнесе и
промышленности узаконенной, был .
c) Компьютер обрабатывает данные под управлением наборов инструкций,
называемых компьютерными .
d) Шестью ключевыми логическими блоками компьютера являются ,
, , , и .
e) Тремя классами языков, обсуждавшихся в этой главе, являются ,
и .
Я Программы, которые переводят программы на языках высокого уровня на
машинный язык, называются .
92
Глава 1
g) Язык С широко известен как язык разработки операционной системы
h) Язык был разработан Виртом для обучения структурному
программированию.
i) Министерство обороны разработало язык Ada, снабдив его возможностями
, которая позволяет программистам специфицировать случаи, когда
много действий могут происходить параллельно.
1.2. Заполните пропуски в следующих предложениях о среде С ++:
а) Программы на C++ обычно вводятся в компьютер с помощью программы-
Ь) В системе C++ перед началом стадии компиляции выполняется программа-
c) Программа- комбинирует выход компилятора с различными
библиотечными функциями, чтобы получить исполняемый образ.
d) Программа- переносит исполняемый образ программы на C+i с
диска в память.
1.3. Заполните пропуски в следующих предложениях (по материалу раздела 1.17):
a) Объекты обладают свойством — хотя они могут знать, как
взаимодействовать друг с другом посредством точно определенных интерфейсов,
обычно им не позволено знать, как реализованы другие объекты.
b) Программисты C++ концентрируют внимание на создании , которые
содержат элементы данных и элемент-функции, которые манипулируют
этими данными и предоставляют услуги клиентам класса.
c) Классы могут иметь отношения с другими классами. Эти отношения
называются .
d) Процесс анализа и проектирования системы с объектно-ориентированной
точки зрения называется .
e) OOD также пользуется отношениями , когда новые классы объектов
производятся путем поглощения характеристик существующих классов и
добавления к ним собственных уникальных характеристик.
f) является графическим языком, который позволяет людям,
разрабатывающим системы, представлять свои объектно-ориентированные проекты
в стандартизованных обозначениях.
g) Размер, форма, цвет и вес объекта считаются объекта.
Ответы на контрольные вопросы
1.1. a) Apple, b) IBM PC. с) программами, d) входное устройство, выходное
устройство, устройство памяти, арифметико-логическое устройство, центральное
процессорное устройство, устройство вторичного хранения, е) машинные языки, языки
ассемблера, языки высокого уровня, f) компиляторами, g) UNIX, h) Pascal, i)
многозадачности.
1.2. а) редактора, b) препроцессор, с) компоновщик, d) загрузчик.
1.3. а) сокрытия информации. Ь) классов, с) ассоциациями, d) объектно-ириентьро-
ванным анализом и проектированием, е) наследования. 1) Унифицированный
язык моделирования (UML). g) атрибутами.
Упражнения
1.4. Укажите, к какой категории — к аппаратной части или программному
обеспечению — относится каждый из нижеперечисленных пунктов:
Введение в компьютеры, Internet и World Wide Web
93
a) CPU
b) компилятор C++
c) ALU
d) препроцессор C++
e) входное устройство
f) программа-редактор
1.5. Почему вы предпочли бы написать программу на машинно-независимом, а не
машинно-зависимом языке? Почему для написания некоторых типов программ
больше подошел бы машинно-зависимый язык?
1.6. Заполните пропуски в следующих предложениях:
a) Какое логическое устройство компьютера принимает информацию извне,
чтобы комьютер ее использовал? .
b) Процесс инструктирования компьютера для решения конкретных задач
называется .
c) Какой тип компьютерного языка использует для инструкций машинного
языка англоязычные аббревиатуры? .
d) Какое логическое устройство компьютера посылает уже обработанную
компьютером информацию на различные устройства, чтобы эта информация могла
использоваться вне компьютера? .
e) Какое логическое устройство компьютера сохраняет информацию? .
f) Какое логическое устройство компьютера производит вычисления? .
g) Какое логическое устройство компьютера принимает логические решения?
h) Уровень компьютерного языка, который наиболее подходит программисту для
быстрого и легкого написания программ, является .
i) Единственным языком, который компьютер понимает непосредственно,
является .
j) Какое логическое устройство компьютера координирует деятельность всех
остальных логических устройств? .
1.7. Почему объектно-ориентированное программирование вообще и C++ в частности
привлекают к себе сегодня такое большое внимание?
1.8. Проведите различие между терминами «фатальная ошибка» и «не-фатальная
ошибка». Почему фатальная ошибка может быть более желательной?
1.9. Дайте краткий ответ на каждый из следующих вопросов:
a) Почему в этом тексте в дополнение к объектно-ориентированному
программированию обсуждается структурное программирование?
b) Каковы типичные шаги (упомянутые в тексте) процесса
объектно-ориентированного проектирования?
c) Какого рода сообщения люди посылают друг другу?
d) Объекты посылают друг другу сообщения через точно определенные
интерфейсы. Какие интерфейсы предоставляет автомобильный радиоприемник
(объект) своему пользователю (объекту-человеку)?
1.10. Вы, вероятно, носите на запястье один из самых распространенных в мире
объектов — наручные часы. Рассмотрите, каким образом можно применить к
понятию наручных часов следующие термины и концепции: объект, атрибуты,
поведение, класс, наследование (возьмите, например, часы со звуковым сигналом),
абстракция, моделирование, сообщения, инкапсуляция, интерфейс, сокрытие
информации, элементы данных и элемент-функции.
2
Введение
в программирование на C++
ЦЕЛИ
В этой главе вы изучите:
• Как писать на C++ простые
компьютерные программы.
• Как писать простые операторы
ввода и вывода.
• Использование основных типов.
• Основные концепции организации
памяти компьютера
• Применение арифметических
операций.
• Старшинство арифметических
операций.
• Написание простых операторов
принятия решений.
96
Глава 2
Введение
Первая программа на C++: печать строки текста
Модификация нашей первой программы
Другая программа на C++: сложение целых чисел
Понятия, связанные с памятью
Арифметика
Принятие решений: операции равенства и отношения
Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
2.1. Введение
Мы представляем теперь программ ироваЕше на языке C++, который поощряет
организованный подход к проектированию программ. Большинство программ на
C++, с которыми вы встретитесь в этой книге, обрабатывает некоторую
информацию и выводит результаты. В этой главе мы покажем пять примеров,
демонстрирующих, каким образом ваши программы могут выводить сообщения и получать
от пользователя информацию для обработки. Первые три примера просто
выводят на экран сообщения. Следующим будет программа, которая получает от
пользователя два числа, вычисляет их сумму и выводит результат.
Сопровождающее этот пример обсуждение покажет, как выполнять различные
арифметические вычисления и сохранять их результаты для последующего
использования. Четвертый пример демонстрирует основы принятия решений, показывая,
как сравнивать два числа и затем выводить сообщения в зависимости от
результатов сравнения. Чтобы помочь вам в применении приобретенных здесь навыков,
в разделе «Упражнения» мы предлагаем ряд программных задач.
2.2. Первая программа на C++: печать строки текста
В C++ используются формы записи, которые непрограммисту могут
показаться странными. Мы начинаем с рассмотрения простой программы,
печатающей строку текста (рис. 2.1). Эта программа иллюстрирует несколько важных
особенностей языка C++. Рассмотрим детально каждую строку программы.
1 // Рис. 2.1: fig02_01.cpp
2 // Программа, печатающая текст.
3 #include <iostream> // позволяет программе выводить данные на экран
4
5 // функция main начинает исполнение программы
6 int main()
7 {
8 std::cout « "Welcome to C++!\n"; // вывести сообщение
Введение в программирование на C++
97
9
10 return 0; // показывает успешное завершение программы
11
12 } // конец функции main
Welcome to C++!
Рис- 2.1. Программа печати текста
Каждая из строк 1 и 2
// Рис. 2.1: fig02_01.cpp
// Программа, печатающая текст.
начинается с символов //, показывающих, что остальная часть строки — это
комментарий. Программисты пишут комментарии, чтобы документировать
программу и, кроме того, чтобы другим людям было легче читать и понимать
ее. Комментарии не вызывают при выполнении программы никаких действий
компьютера, — они игнорируются компилятором C++ и не вызывают
генерации какого-либо объектного кода на машинном языке. Комментарий
Программа, печатающая текст описывает цель программы. Комментарий,
который начинается с //, называется однострочным комментарием, потому что
комментарий заканчивается в конце текущей строки. [Замечание. В
программах на C++ могут также использоваться комментарии в стиле языка С, где
комментарий (возможно, содержащий много строк) начинается с /* и
заканчивается символами */.]
щ«га* Хороший стиль программирования 2.1
\^Х\ Каждая программа должна начинаться с комментария,
указывающего цель программы, автора, дату и время ее написания. (В программах
книги мы не показываем автора, дату и время, поскольку здесь такая
информация была бы излишней.)
Строка 3
#include <iostream> // позволяет программе выводить данные на экран
является директивой препроцессора, т.е. сообщением препроцессору C++
(о котором говорилось в разделе 1.14). Строки, начинающиеся с #,
обрабатываются препроцессором до компиляции программы. Данная строка дает
указание препроцессору включить в программу содержимое заголовочного файла
потоков ввода/вывода <iostream>. Этот файл должен быть включен во все
программы, которые выводят данные на экран или читают с клавиатуры,
используя принятый в C++ стиль потокового ввода-вывода. Как мы вскоре
увидим, программа на рис. 2.1 выводит данные на экран. Более подробно мы
обсуждаем заголовочные файлы в главе 6.
4 Зак. 1114
98
Глава 2
Типичная ошибка программирования 2.1
Если не включить заголовочный файл <iostream> в программу,
которая которая вводит данные с клавиатуры или производит вывод на
экран, компилятор выдаст сообщение об ошибке, так как не сможет
распознать обращения к потоковым компонентам (напр., cout).
Строка 4 — просто пустая. Программисты пользуются пустыми строками,
пробелами и символом TAB («табуляцией»), чтобы программы было легче
читать. Все эти символы в целом называются пробельными символами. Они
обычно игнорируются компилятором. В этой и нескольких следующих главах
мы обсудим соглашения относительно использования пробельных символов,
способствующие лучшей читаемости программ.
Хороший стиль программирования 2.2
Пользуйтесь пустыми строками и пробелами, чтобы сделать
программы более удобочитаемыми.
Строка 5
// функция main начинает исполнение программы
является еще одним однострочным комментарием, сообщающим, что
исполнение программы начинается со следующей строки.
Строка 6
int main()
имеется в любой программе на C++. Скобки после main показывают, что это
«строительный блок» программы, называемый функцией. Программы на C++
состоят обычно из одной или большего числа функций и классов (о которых вы
узнаете в 3-й главе). В точности одна функция в каждой программе должна
быть main. Программа на рис. 2.1 содержит всего одну функцию. Программы
на C++ всегда начинают выполняться с функции main, даже если она не
первая в программе. Ключевое слово int слева от main сообщает, что main
«возвращает» значение, являющееся целым числом. Ключевое слово является
словом в коде программы, имеющим в C++ специальное назначение. Полный
список ключевых слов языка C++ приведен на рис. 4.3. Мы объясним, что
означает выражение «функция возвращает значение», в разделе 3.5, когда
продемонстрируем, как создавать свои собственные функции, и в главе б, где
функции изучаются более глубоко. Пока же просто ставьте во всех своих
программах ключевое слово int слева от main.
Тело каждой функции должно начинаться с левой фигурной скобки {
(строка 7). Заканчивать тело функции должна соответствующая правая фигурная
скобка } (строка 12). Строка 8
std::cout « "Welcome to C++!\n"; // вывести сообщение
Введение в программирование на C++
99
инструктирует компьютер, что требуется выполнить действие, а именно,
напечатать строку символов, которые находятся между двойными
кавычками. Строки называют также символьными строками, сообщениями или
строковыми литералами. Мы называем символы между кавычками просто
строками. Пробельные символы, входящие в строку, компилятор не
игнорирует.
Вся строка 8, включая std::cout, операцию «, строку "Welcome to C++!"
и точку с запятой (;), называется оператором. Всякий оператор C++ должен
заканчиваться точкой с запятой (ее называют еще ограничителем оператора).
Директивы препроцессора (подобные #include) не оканчиваются точкой с
запятой. Вывод и ввод в C++ осуществляется посредством символьных потоков.
Когда выполняется вышеприведенный оператор, он посылает поток символов
Welcome to C++! на объект стандартного выходного потока, который
обычно «подсоединяется» к экрану.
Обратите внимание на то, что перед cout мы поместили std::. Это требуется
при использовании директивы препроцессора #include <iostream>. Запись
std::cout определяет, что мы используем имя, в данном случае — cout,
которое принадлежит «пространству имен» std. Имена cin (стандартный входной
поток) и сегг (стандартный поток ошибок) — они были представлены в 1-й
главе — также принадлежат пространству std. Пространство имен — это
новое средство C++. Мы обсуждаем подробно эту тему в главе 24 полного
издания «C++ How to Program, 5/е». Сейчас же вам следует просто помнить о
необходимости включать std:: перед каждым использованием cout, cin и сегг
в программе. Это может показаться утомительным, но в программе на
рис. 2.13 мы вводим объявление using, позволяющее избежать
необходимости помещения std:: перед каждым использованием имени из пространства
имен std.
Операция « называется операцией передачи в поток. Когда данная
программа выполняется, значение справа от операции, правый операнд,
помещается в выходной поток. Заметьте, что знаки операции направлены в
соответствии с направлением движения данных.Символы правого операнда
обычно выводятся точно так, как они записаны в строке внутри кавычек. Но
символы \п на экране не появляются. Знак обратной дроби (\) называется
escape-символом. Он указывает, что должен быть выведен некоторый
«специальный» символ. Когда в цепочке символов встречается обратная дробь,
с ним комбинируется следующий символ, образуя escape
последовательность. Esc-последовательность \п означает новую строку. Она заставляет
курсор (т.е. индикатор текущей позиции на экране) перейти к началу
следующей строки на экране. Некоторые другие часто употребляемые esc-последова-
тельности приведены на рис. 2.2.
100
Глава 2
Escape-последовательность
\n
\t
\r
\a
\\
\?
\"
Описание
Новая строка. Позиционирование курсора к началу
следующей строки.
Символ горизонтальной табуляции. Перемещение
курсора к следующей позиции табуляции.
Возврат каретки. Позиционирование курсора
к началу текущей строки; запрет перехода
к следующей строке.
Сигнал тревоги. Звук системного звонка.
Обратная дробная черта. Используется для печати
знака обратной дроби.
Апостроф (одиночная кавычка). Используют для
печати апострофа.
Двойные кавычки. Используют для печати символа
двойных кавычек.
Рис. 2.2,Некоторые часто используемые езсарепоследовательности
23 Типичная ошибка программирования 2.2
Пропуск точки с запятой в конце оператора C++ является
синтаксической ошибкой. (Повторим еще раз, что директивы препроцессора не
оканчиваются точкой с запятой.) Синтаксис языка
программирования задает правила создания правильных программ на этом языке.
Когда компилятор встречает код, нарушающий правила языка C++
(т.е. его синтаксис), происходит синтаксическая ошибка.
Компилятор обычно выдает при этом сообщение, помогающее программисту
найти и исправить неверный код. Синтаксические ошибки называют
еще ошибками компиляции или ошибками времени компиляции,
поскольку они обнаруживаюся компилятором на этапе компиляции
программы. Вы не сможете запустить свою программу, пока не
исправите в ней все синтаксические ошибки. Как вы увидите далее, не все
ошибки компиляции являются синтаксическими.
Строка 10
return 0; // показывает успешное завершение программы
демонстрирует один из нескольких способов, которые мы будем применять
для выхода из функции. Когда оператор return используется в конце main,
как показано здесь, значение 0 означает, что программа успешно
завершилась. В 6-й главе мы проведем детальное обсуждение функций, и станет ясна
цель включения такого оператора. Пока включайте этот оператор в каждую
программу, иначе на некоторых системах компилятор может выдавать
предупреждающие сообщения. Правая фигурная скобка, }, заканчивает функцию
main.
Введение в программирование на C++
101
Хороший стиль программирования 2.3
Многие программисты всегда в качестве последнего печатаемого
функцией символа выводят символ новой строки (\п). Тем самым
гарантируется, что функция оставит курсор в начале новой пустой
строки. Такого рода соглашения способствуют утилизации
программного кода, которая является ключевым моментом в разработке
программного обеспечения.
Хороший стиль программирования 2.4
Делайте отступ для всего тела каждой функции относительно
заключающих его фигурных скобок. Это выделяет функциональную
структуру программы и облегчает ее чтение.
Хороший стиль программирования 2.5
Установите для себя правило, определяющее подходящую величину
отступов, и всегда его придерживайтесь. Для создания отступов
можно воспользоваться клавишей табуляции, но шаг табуляции может
меняться. Мы рекомендуем табуляции с шагом в 1/4 дюйма, т.е. около
6 мм, или (что предпочтительнее) три пробела на каждый уровень
отступов.
2.3. Модификация нашей первой программы
В этом разделе мы продолжим наше введение в C++ и представим два
примера, показывающих, как напечатать текст в одну строку с помощью
нескольких операторов, и как напечатать несколько строк единственным оператором.
Печать одной строки текста несколькими операторами
Строку Welcome to C++! можно напечатать различными способами.
Например, программа на рис. 2.3 выполняет два оператора передачи в поток
(строки 8-9), однако выводит тот же самый результат, что и программа на
рис. 2.1. Каждая передача в поток возобновляет печать с того места, где
остановилась предыдущая. Первая передача в поток (строка 8) печатает Welcome,
за которым следует пробел, а вторая передача (строка 9) начинает печатать на
той же строке, сразу за пробелом. Вообще C++ позволяет программисту
записывать операторы самыми разными способами.
1 // Рис. 2.3: fig02_03.cpp
2 // Печать строки текста несколькими операторами.
3 #include <iostream> // позволяет программе выводить данные на экран
4
5 // функция main начинает исполнение программы
6 int main()
7 {
8 std::cout « "Welcome ";
9 std::cout « "to C++!\n";
10
11 return 0; // показывает успешное завершение программы
102
Глава 2
12
13 } // конец функции main
Welcome to C++!
Рис, 2.3. Печать строки текста с помощью нескольких операторов
Печать нескольких строк текста одним оператором
Одиночный оператор может напечатать несколько строчек, если
использовать символы новой строки, как в строке 8 на рис. 2.4. Каждый раз, когда
в выходном потоке встречается esc-последовательность \п (новая строка),
экранный курсор позиционируется на начало следующей строчки. Чтобы
вывести пустую строку, поставьте два символа новой строки сразу друг за другом,
как в строке 8.
1 // Рис. 2.4: fig02_04. срр
2 // Печать нескольких строк текста одним оператором.
3 #include <iostream> // позволяет программе выводить данные на экран
4
5 // функция main начинает исполнение программы
6 int main()
7 {
8 std::cout« "Welcome\nto\n\nC++!\n";
9
10 return 0; // показывает успешное завершение программы
11
12 } // конец функции main
Welcome
to
C++!
Рис. 2.4. Печать нескольких строк текста одним оператором
2.4. Другая программа на C++: сложение целых чисел
Наша следующая программа работает с объектом стандартного входного
потока std::cin, из которого с помощью операции извлечения из потока »
получает два целых числа, набранных пользователем на клавиатуре, вычисляет
сумму их значений и выводит результат в std::cout. Рис. 2.5 показывает
программу и образец входных и выходных данных.
1 // Рис. 2.5: fig02_05.cpp
2 // Программа сложения, показывающая сумму двух целых чисел.
3 #include <iostream> // позволяет программе производить ввод/вывод
4
5 // функция main начинает исполнение программы
6 int main()
Введение в программирование на C++
103
7 {
8 // объявления переменных
9 int number1; // первое из складываемых чисел
10 int number2; // второе из складываемых чисел
11 int sum; // сумма number1 и number2
12
13 std::cout « "Enter first integer: "; // запросить данные
14 std::cin » number1; // прочитать первое число в numberl
15
16 std::cout « "Enter second integer: "; // запросить данные
17 std::cin » number2; // прочитать второе число в number2
18
19 sum = numberl + number2; // сложить числа; записать сумму в sum
20
21 std::cout « "Sum is " « sum « std::endl; // вывести сумму
22
23 return 0; // показывает успешное завершение программы
24
25 } // конец функции main
Enter first integer: 45
Enter second integer: 72
Sum is 117
Рис. 2,5. Программа сложения, показывающая сумму двух целых чисел, введенных
с клавиатуры
Комментарии в строках 1 и 2
// Рис. 2.5: fig02_05.cpp
// Программа сложения, показывающая сумму двух целых чисел.
сообщают имя файла и назначение программы. Директива препроцессора C++
#include <iostream> // позволяет программе производить ввод/вывод
в строке 3 включает в программу содержимое заголовочного файла iostream.
Программа начинает исполняться с функции main (строка 6). Левая
фигурная скобка (строка 7) отмечает начало тела main, а соответствующая ей правая
скобка (строка 25) отмечает конец main.
Строки 9-11
int numberl; // первое из складываемых чисел
int number2; // второе из складываемых чисел
int sum; // сумма numberl и number2
являются объявлениями. Идентификаторы numberl, number2 и sum
являются именами переменных. Переменная — это место в памяти компьютера, где
может -сохраняться некоторое значение для использования его в программе.
Данное объявление определяет, что переменные integer 1, integer2 и sum
имеют тип данных int; это значит, что эти переменные всегда будут содержать
целые значения, т.е. целые числа, такие как 7, -11, 0, 31914. Все переменные
в программе должны объявляться с указанием имени и типа данных, прежде
чем с ними можно будет что-то делать. Несколько переменных одного типа мо-
104
Глава 2
гут быть объявлены в одном или в нескольких объявлениях. Мы могли бы
написать три объявления в одной строке:
int integer1, integer2, sum;
Но это делает программу менее ясной и, кроме того, не позволяет ввести
комментарии, описывающие назначение каждой из переменных. Если в
объявлении описывается более одной переменной (как в предыдущей строке), их имена
отделяются запятыми (,). Это называется списком, разделяемым запятыми.
Хороший стиль программирования 2.6
Ставьте пробел после каждой запятой (,), чтобы программу было
легче читать.
Хороший стиль программирования 2.7
Некоторые программисты предпочитают объявлять каждую
переменную на отдельной строке. Такой формат позволяет вставлять
описательный комментарий рядом с каждым объявлением.
Скоро мы обсудим тип данных double для спецификации вещественных
чисел и тип char для спецификации символьных данных. Вещественные
числа — это числа с десятичной точкой, например, 3.4, 0.0 и-11.19. Переменная
типа char может хранить только одну букву нижнего или верхнего регистра,
одну цифру или один специальный символ (например, $ или *). Такие типы,
как int, double и char, часто называют основными, примитивными или
встроенными типами. Имена основных типов являются ключевыми словами и,
следовательно, должны набираться только буквами нижнего регистра. Полный
список основных типов приведен в приложении В.
Именем переменной может служить любой корректный идентификатор
(такой, как number 1), не являющийся ключевым словом. Идентификатор —
это последовательность символов, состоящая из букв, цифр и символов
подчеркивания (_), не начинающаяся с цифры. C++ различает регистр — буквы
верхнего и нижнего регистра считаются различными символами, так что al
и А1 —различные идентификаторы.
Переносимость программ 2.1
C++ допускает идентификаторы любой длины, но ваша система
и/или реализация C++ может налагать некоторые ограничения на
длину идентификаторов. Для обеспечения переносимости
определяйте имена длиной не более 31 символа.
Хороший стиль программирования 2.8
Выбор осмысленных имен переменных делает программу
«самодокументированной», т.е. такую программу легче понимать при чтении,
даже не обращаясь к справочным пособиям или обширным
комментариям.
Введение в программирование на C++
105
Хороший стиль программирования 2.9
Избегайте сокращений в идентификаторах. Сокращения затрудняют
чтение программы.
Хороший стиль программирования 2.10
Избегайте идентификаторов, которые начинаются с подчеркивания,
потому что компилятор C++ может использовать похожие на них
внутренние имена для своих собственных целей. Это предотвратит
путаницу в именах, выбираемых вами и компилятором.
Предотвращение ошибок 2.1
Языки, подобные C++, находятся «в движении». По мере их эволюции
в язык могут вводиться новые ключевые слова. Избегайте выбора в
качестве идентификаторов «заряженных» слов (как, например, object).
Объявления могут размещаться в программе почти всюду, однако
объявления переменных должны предшествовать их использованию в программе.
Например, в программе на рис. 2.5 объявление в строке 9
int integer1; // первое из складываемых чисел
можно было бы поместить непосредственно перед строкой 14:
stdrrcin » integerl; // прочитать первое число в numberl
Объявление в строке 10
int integer2; // второе из складываемых чисел
можно было бы поместить перед строкой 17:
std::cin » integer2; прочитать второе число в number2
а объявление в строке 11
int sum; // сумма numberl и number2
перед строкой 19:
sum = integerl + integer2; // сложить числа; Записать сумму в sum
Хороший стиль программирования 2,11
Всегда помещайте пустую строку между объявлением и соседними
исполняемыми операторами. Это делает объявление заметным в
программе, а программу — более ясной.
Хороший стиль программирования 2.12
Если вы предпочитаете размещать объявления в начале функции,
отделяйте эти объявления от исполняемых операторов этой функции
пустой строкой, чтобы выделить конец объявлений и начало
исполняемых операторов.
106
Глава 2
Строка 13
std::cout « "Enter first integer: "; // запросить данные
выводит на экран "Enter first integer:" (такую строку называют строковым
литералом или просто литералом). Это сообщение называется подсказкой,
поскольку оно побуждает пользователя к определенному действию. Мы
предпочитаем произносить это как «std::cout получает символьную строку "Enter
first integer: "». Строка 14
std::cin » number1; // прочитать первое число в numberl
использует объект входного потока cin (из пространства имен std) и операцию
извлечения из потока », чтобы получить с клавиатуры значение. Операция
извлечения из потока с объектом std::cin принимает символьный ввод из
стандартного входного потока, который обычно связан с клавиатурой.
Предыдущий оператор читается как «stdrrcin выдает значение для numberl» или
просто «std::cin дает numberl».
jrt\ Предотвращение ошибок 2.2
\JjFy Программы должны проверять корректность всех входных значений,
чтобы предотвращать воздействие ошибочной информации на
работу программы.
Когда компьютер выполняет предыдущий оператор, он ждет от
пользователя ввода значения переменной integer 1. В ответ пользователь набирает на
клавиатуре целое число (в символьном представлении) и затем нажимает
клавишу возврата — Return (называемую иногда клавишей ввода — Enter), чтобы
послать символы в компьютер. Компьютер преобразует символьное
представление в целое число и присваивает (копирует) это число (или значение)
переменной integerl. Любое последующее обращение в программе к integerl будет
использовать это самое значение.
Объекты потоков std::cout и std::cin упрощают взаимодействие между
пользователем и компьютером. Поскольку это взаимодействие напоминает диалог,
часто говорят о диалоговой или интерактивной обработкой данных.
Строка 16
std::cout « "Enter second integer: "; // запросить данные
выводит на экран "Enter second integer: ", подсказывая пользователю, что от
него требуются дальнейшие действия. Строка 17
std::cin » number2; // прочитать второе число в number2
получает от пользователя значение для переменной number2.
Оператор присваивания в строке 19
sum = numberl + number2; // сложить числа; записать сумму в sum
вычисляет сумму переменных numberl и number2 и присваивает результат
переменной sum, применяя операцию присваивания =. Оператор читается как
«sum получает значение numberl + number2». Большинство вычислений
Введение в программирование на C++
107
производится в операторах присваивания. Операции + и = называются
бинарными (двухместными) операциями, так как каждая из них имеет по два
операнда. В случае + двумя операндами являются number 1 и number2. В случае
предыдущей операции = операндами являются sum и значение выражения
number 1 + number 2.
Хороший стиль программирования 2.13
Помещайте пробелы с обеих сторон от знака двухместной операции.
Это выделяет операцию и облегчает чтение программы, i
Строка 21
std::cout « "Sum is " « sum « std: :endl; // вывести сумму
выводит символьную строку Sum is, за которой следует численное значение
переменной sum и затем std::endl, — так называемый манипулятор потока.
Имя endl является сокращением от «end line», закончить строку, и
принадлежит к пространству имен std. Манипулятор std::endl выводит символ новой
строки и «сбрасывает буфер вывода». Последнее означает, что на некоторых
системах, накапливающих выводимые данные до тех пор, пока их не
накопится столько, что вывод их на экран будет «стоить затраченных усилий»,
std::endl принудительно выводит всю накопленную к данному моменту
информацию. Это может быть важным в тех случаях, когда вывод программы
должен своевременно побудить пользователя что-то сделать, например, ввести
данные.
Заметьте, что предыдущий оператор выводит несколько значений
различных типов. Операция передачи в поток «знает», как выводить каждый из
типов данных. Выполнение в одном операторе нескольких операций «
называют конкатенацией, сцеплением или каскадированием операций передачи в
поток. Нет необходимости писать несколько операторов, чтобы вывести
несколько единиц данных.
В операторах вывода можно также производить вычисления. Можно было
бы объединить операторы в строках 19 и 21, написав единственный оператор
std::cout « "Sum is " « numberl + number2 « std::endl;
устранив таким образом необходимость в переменной sum.
Чрезвычайно мощной стороной C++ является то, что пользователи могут
создавать свои собственные типы данных, называемые классами (мы введем
их в 3-й главе и детально исследуем в главах 9 и 10). Затем пользователи могут
«научить» C++, как вводить и выводить значения этих новых типов с
помощью операций » и « (это называется перегрузкой операций, — мы будем
изучать ее в 11-й главе).
2.5. Организация памяти
Имена переменных, такие как integer 1, integer2 и sum, в действительности
соответствуют ячейкам в памяти компьютера. Каждая переменная имеет имя,
тип, размер и значение.
108
Глава 2
В программе сложения на рис. 2.5 при выполнении оператора
std::cin » integer1/ // прочитать первое число в numberl
в строке 14 символы, введенные пользователем, преобразуются в целое. Это целое
помещается в ячейку памяти, которой компилятор C++ присвоил имя numberl.
Допустим, пользователь вводит в качестве значение numberl число 45.
Компилятор разместит 45 в ячейку памяти numberl, как показано на рис. 2.6.
Всякий раз, когда значение помещается в ячейку памяти, предыдущее
значение, хранившееся в этом месте, переписывается; таким образом, запись
нового значения в ячейку является разрушающим процессом.
Возвращаясь к нашей программе сложения, допустим, что при выполнении
оператора
std::cin » integer2; // прочитать второе число в number2
пользователь вводит значение 72. Это значение помещается в ячейку памяти
number2, и теперь распределение памяти выглядит так, как показано
на рис. 2.7. Заметьте, что эти ячейки не обязательно будут соседними в памяти.
Когда программа получила значения numberl и number2, она складывает
их и помещает сумму в переменную sum. Оператор
sum = integerl + integer2; // сложить числа; записать сумму в sum
выполняющий сложение, заменяет также любое значение, хранившееся
в sum. Это происходит, когда вычисленное значение суммы numberl и num-
ber2 помещается в ячейку памяти sum (вне зависимости от того, каково было
прежнее значение sum; это значение теряется). После вычисления sum память
выглядит так, как показано на рис. 2.8. Обратите внимание, что значения
numberl и number2 выглядят точно так же, как и до их участия в вычислении
sum. Эти значения использовались, но не были разрушены во время
выполняемых компьютером вычислений. Таким образом, считывание значений из
памяти является процессом неразрушающим.
number 1 45
Рис. 2.6. Имя и значение ячейки памяти для переменной numberl
number 1 45
number 2 72
Рис. 2.7. Ячейки памяти после сохранения значений для numberl и number2
Введение в программирование на C++
109
number 1
45
number 2
72
sum
117
Рис. 2.8. Ячейки памяти после вычисления и сохранения суммы numberl
2.6. Арифметика
Большинство программ выполняет арифметические вычисления.
Множество арифметических операций показано на рис. 1.10. Отметим использование
в них разнообразных специальных символов, не используемых в алгебре.
Звездочка (*) обозначает умножение, а знак процента (%) — это операция взятия
вычета по модулю (вычисление остатка от деления), которая вкратце будет
еще обсуждаться. Арифметические операции на рис. 1.10 являются
бинарными операциями. Например, выражение integerl + integer2 содержит
бинарную операцию + и два операнда integerl и integer2.
Целочисленное деление дает целый результат; например, выражение 7/4
равно 1, а выражение 17/5 равно 3. Заметим, что любая десятичная часть при
целочисленном делении просто отбрасывается (т.е. усекается) — округление
не производится. В C++ имеется операция взятия по модулю %, которая дает
в результате остаток от целочисленного деления. Выражение х % у дает
остаток от деления х на у. Таким образом, 7 % 4 равно 3, 17 % 5 равно 2. В
последующих главах мы обсудим много интересных применений операции
вычисления остатка, например, определение того, является ли одно число кратным
другому (специальный случай такой задачи — выяснение, является ли число
четным или нечетным).
Операция C++
Сложение
Вычитание
Умножение
Деление
Взятие по модулю
Арифметическая
операция C++
+
-
•
/
%
Алгебраическое
выражение
f+7
р-с
Ьт или b • т
X
-, х 1 у илих-гу
У
г mod s
Выражение на
f + 7
р-с
b * m
х / у
Г % S
C++
Рис. 2.9. Арифметические операции
Типичная ошибка программирования 1.4
Попытка использования операции взятия по модулю % с нецелочис
ленными операндами приводит к ошибке компиляции.
110
Глава 2
Арифметические выражения в линейной форме
Арифметические выражения C++ должны вводиться в компьютер в
линейной (т.е. однострочной) форме. Другими словами, «а деленное на Ь» должно
записываться в виде а / Ь, чтобы все константы, переменные и операции
находились на одной строке. Алгебраическая форма записи
а
Ь
для компиляторов, как правило, неприемлема, хотя существуют некоторые
программные продукты специального назначения, поддерживающие более
естественную нотацию сложных математических выражений.
Группировка подвыражений с помощью скобок
Круглые скобки в выражениях C++ используются таким же образом, как
в алгебраических выражениях. Например, чтобы умножить b + с на а, мы
пишем а * ( b + с ).
Правила старшинства операций
C++ применяет операции к операндам арифметических выражений в
совершенно однозначной последовательности, определяемой правилами
старшинства (или приоритета) операций, которые практически совпадают с теми, что
имеют место в алгебре:
1. Операции в выражениях, заключенных в круглые скобки, выполняются
в первую очередь. Таким образом, круглые скобки можно использовать
для формирования любой желательной для программиста
последовательности вычислений. О скобках говорят, что они имеют «наивысший
приоритет». В случае вложенных скобок, как в выражении
( ( а + Ь ) + с )
операции внутри самой внутренней пары скобок выполняются первыми.
2. Следующими выполняются операции умножения, деления и взятия по
модулю. Если выражение содержит несколько операций умножения,
деления и взятия по модулю, то операции выполняются слева направо.
Говорят, что операции умножения, деления и взятия по модулю имеют
одинаковый уровень приоритета.
3. Операции сложения и вычитания выполняются последними. Если
выражение содержит несколько операций сложения и вычитания, то
операции выполняются слева направо. Операции сложения и вычитания
также имеют одинаковый уровень приоритета.
Набор правил старшинства операций определяет в C++ порядок
применения операций. Когда мы говорим о выполнении операций слева направо, то мы
имеем в виду правило ассоциации операций. Например, в выражении
а + b + с
операции сложения (+) ассоциируются слева направо. Мы увидим в
дальнейшем, что некоторые из операций ассоциируются справа налево. Рис. 2.10 обоб-
Введение в программирование на C++
111
щает правила старшинства арифметических операций. Эта таблица будет
расширяться по мере знакомства с дополнительными операциями C++. Полная
таблица старшинства операций приведена в приложении А.
Операции
0
*
/
%
+
Действие
Круглые скобки
Умножение
Деление
Взятие по модулю
Сложение
Вычитание
Последовательность оценки
(старшинство)
Оцениваются в первую очередь. Если круглые
скобки — вложенные, выражение внутри самой
внутренней пары вычисляется первым. Если
имеется несколько пар круглых скобок
«одинакового уровня» (т.е. не вложенных), они
оцениваются слева направо.
Оцениваются во вторую очередь. Если их несколько,
они оцениваются слева направо.
Оцениваются последними. Если их несколько, они
оцениваются слева направо.
Рис. 2.10.Старшинство арифметических операций
Примеры алгебраических и их аналогов в C++
Теперь рассмотрим несколько выражений в свете правил, определяющих
последовательность выполнения операций. Каждый пример представляется
алгебраическим выражением и его эквивалентом на C++. Ниже приводится
пример среднего арифметического пяти членов:
a+b+c+d+e
Алгебра: т =
5
C++: m = (a + b + c + d + e) /5;
Круглые скобки необходимы, так как деление имеет более высокий
приоритет, чем сложение. Вся сумма (a + b + c + d + e) делится на 5. Если по ошибке
опустить круглые скобки, получим a + b + c + d + e/5, что будет оцениваться
неправильно как
a+b+c+d+-
5
Следующий пример — уравнение прямой линии:
Алгебра: у =тх + Ь
C++: у = m * х + Ь;
Никаких круглых скобок не требуется. Умножение выполняется первым,
потому что оно имеет более высокий приоритет, чем сложение.
Следующий пример содержит операции вычисления остатка (%),
умножения, деления, сложения и вычитания:
Алгебра: г = pr mod q + w/x - у
C++: z=p*r%q + w/x-y;
6 < 1 2.4 3 5
112
Глава 2
Цифры в кружках под операциями обозначают последовательность, в которой
C++ применяет операции. Умножение, взятие по модулю и деление
выполняются первыми в последовательности слева направо (т.е. они ассоциируются
слева направо), так как они имеют более высокий приоритет, чем сложение
и вычитание. Затем выполняются сложение и вычитание в той же
последовательности слева направо.
Оценка полинома второй степени
Чтобы лучше усвоить правила старшинства операций, рассмотрим
вычисление полинома второй степени (у = ах2 + Ьх + с):
у = а
6
Цифры в кружках под операциями обозначают последовательность, в которой
C++ применяет операции. В C++ нет арифметической операции возведения в
степень, поэтому мы представляем х2 как х * х. Скоро мы рассмотрим библиотечную
функцию pow («power»), которая выполняет возведение в степень. Поскольку
для понимания функции pow надо учитывать некоторые тонкие вопросы,
относящиеся к типам данных, мы отложим детальное рассмотрение pow до главы 6.
Типичная ошибка программирования 2.4
В некоторых языках программирования для возведения в степень
приняты обозначения ** или Л. C++ не поддерживает эти операции; их
использование приводит к ошибкам.
Допустим, что а, Ь, с и х имеют следующие начальные значения: а = 2. b = 3,
с = 7 и х = 5. Рис. 2.11 иллюстрирует последовательность, в которой
выполняются операции в предыдущем примере вычисления полинома второй степени.
Шаг 1. у = 2*5*5 + 3*5 + 7;
2*5 равно 10
f "'
Шаг 2. у = 10*5 + 3*5 + 7;
10 * 5 равно 50
Шаг 3. у = 50 + 3 * 5 + 7 ;
3*5 равно 15
Шаг 4. у = 50 + 15 + 7;
50 + 15 равно 65
Шаг 5. у = 65 + 7 ;
65+7 равно 72
Шаг 6. у = 72 ;
(Самое левое умножение)
(Самое левое умножение)
(Умножение перед сложением)
(Самое левое сложение)
(Последнее сложение)
(Последнее действие —
поместить 72 в у)
Рис. 2.11. Порядок оценки полинома второй степени
Введение в программирование на C++
113
Как и в алгебре, для того, чтобы сделать выражение яснее, в нем можно
расставлять дополнительные, не являющиеся необходимыми, скобки. Эти
дополнительные скобки называются избыточными скобками. Например, в
предыдущем операторе скобки могут быть расставлены следующим образом:
У = ( а
х ) + ( Ъ * х ) + с;
Хороший стиль программирования 2.14
Расстановка избыточных скобок в сложных арифметических
выражениях может сделать эти выражения более ясными.
2.7. Принятие решений: операции равенства
и отношений
Этот раздел познакомит вас с простой версией оператора if в C++, который
позволяет программе принимать решение, основываясь на истинности или
ложности некоторого условия. Если условие удовлетворено, т.е. равно true
(истинно), то оператор в теле if выполняется. Если условие не
удовлетворяется, т.е. равно false (ложно), то оператор в теле if не выполняется. Вскоре мы
покажем это на примере.
Условия в операторах if могут быть образованы с помощью операций
равенства и отношений, сводка которых приведена на рис. 2.12. Все операции
отношений имеют одинаковый приоритет и ассоциируются слева направо.
Операции равенства также имеют одинаковый приоритет, который, однако, ниже
приоритета операций отношений. Операции равенства также ассоциируются
слева направо.
Обычная
алгебраическая
операция проверки
на равенство
или отношения
Операции равенства
*
Операции отношения
>
<
>
<
1 Операция 1 Пример
1 равенства ' условия C++
или отношения C++
l i
!!= |х != у
> х > у
1 < 1х < у
>= х >= у
__' __ _|
<= |х <= у
1
_j :
Смысл
условия C++
х равен у
х не равен у
х больше у
х меньше у
х больше или
равен у
х меньше или
равен у
Рис. 2.12, Операции равенства и отношений
114
Глава 2
Типичная ошибка программирования 2.5
Если операции ==, /=, >= и <= содержат между своими символами
пробелы, возникнет синтаксическая ошибка.
Типичная ошибка программирования 2.6
Перестановка символов в обозначении операций: вместо !=, >= и <=
соответственно =/, => и =< обычно является синтаксической
ошибкой. В некоторых случаях запись =/ вместо != не будет
расцениваться как синтаксическая ошибка, но почти наверняка будет логической
ошибкой, которая проявит себя во время выполнения. Вы поймете,
почему, когда познакомитесь в главе 5 с логическими операциями C++.
Фатальная логическая ошибка приводит к краху и преждевременному
завершению программы. He-фатальная логическая ошибка позволяет
продолжать исполнение, но при этом программа выдает обычно невер
ные результаты.
Типичная ошибка программирования 2.7
Ошибочное употребление операции равенства == вместо операции
присваивания = и наоборот приводит к логическим ошибкам.
Операция равенства должна читаться как «равно», а операция присваива
ния должна читаться как «получает значение». Некоторые предпочи
тают читать операцию равенства как «двойное равно». Как мы
увидим в разделе 5.9, смешивание этих операций может вызывать не
легко локализуемую синтаксическую ошибку, а чрезвычайно трудно-
обнаружимые логические ошибки.
В приведенном ниже примере шесть операторов if сравнивают два
вводимых пользователем числа. Если в каком-либо из этих операторов условие
удовлетворяется, выполняется связанный с данным if оператор вывода.
Программа и три примера диалогов ввода/вывода показаны на рис. 2.13.
1 // Рис. 2.13: fig02_13.cpp
2 // Сравнение целых чисел с помощью операторов if,
3 // операций отношения и равенства.
4 #include <iostream> // позволяет программе производить ввод и вывод
5
6 using std::cout; // программа использует cout
7 using std::cin; // программа использует cin
8 using std::endl; // программа использует endl
9
10 // function main begins program execution
11 int main()
12 {
13 int number1; // первое из сравниваемых чисел
14 int number2; // второе из сравниваемых чисел
15
16 cout « "Enter two integers to compare: "; // запросить ввод
17 cin » numberl » number2; // прочитать два введенных числа
18
19 if { numberl = number2 )
Введение в программирование на C++
115
20 cout « number! « " == " « number2 < endl;
21
22 if ( number1 != number2 )
23 cout « numberl « " != " « number2 « endl;
24
25 if ( numberl < number2 )
26 cout « numberl « " « " « number2 « endl;
27
28 if ( numberl > number2 )
29 cout « numberl « " » " « number2 « endl;
30
31 if ( numberl <= number2 )
32 cout < numberl « " <= " « number2 < endl;
33
34 if ( numberl >= number2 )
35 cout < numberl « " >= " « number2 « endl;
36
37 return 0; // показывает успешное завершение программы
38
39 } // конец функции main
Enter two integers to compare: 3 7
3 != 7
3 < 7
3 <= 7
Enter two integers to compare: 22 12
22 != 12
22 > 12
22 >= 12
Enter two integers to compare: 7 7
7 = 7
7 <= 7
7 >= 7
Рис. 2.13. Операции равенства и отношений
Строки 6-8
using std::cout; // программа использует cout
using std::cin; // программа использует cin
using std::endl; // программа использует endl
являются объявлениями using, которые устраняют необходимость повторять
все время префикс std::, как мы это делали в предыдущих программах.
Разместив в начале программы такие объявления, мы можем везде далее писать
cout вместо std::cout, cin вместо std::cin и endl вместо std::endl. [Замечание.
Отсюда и далее в книге каждый пример будет содержать одно или несколько
объявлений using.]
116
Глава 2
Хороший стиль программирования 2.15
Размещайте объявления using непосредственно после директив
^include, к которым они относятся.
Строки 13-14
int numberl; // первое иэ сравниваемых чисел
int number2; // второе иэ сравниваемых чисел
объявляют переменные программы. Как вы помните, переменные можно
объявлять как в одном, так и в нескольких объявлениях.
Для ввода двух целых значений в программе используются каскадные
операции извлечения из потока (строка 17). Повторим, что мы имеем право
писать просто cin (вместо std::cin) благодаря объявлению в строке 7. Сначала
читается значение в переменную number 1, затем читается значение в number2.
Оператор if в строках 19-20
if ( numberl == number2 )
cout « numberl « " == " « number2 « endl;
сравнивает значения переменных numberl и number2 с целью проверки на
равенство. Если значения равны, оператор в строке 20 выводит строку текста,
указывающую, что данные числа равны. Если условие истинно (равно true)
в одном или нескольких операторах if, начинающихся в строках 22, 25, 28, 31
и 34, операторы в их теле выводят соответствующие сообщения.
Заметьте, что каждый из операторов if на рис. 2.13 имеет в своем теле по
одному оператору, и эти операторы записаны с отступом. В главе 4 мы
покажем, как пишутся операторы if с телом из нескольких операторов (это
делается путем охвата операторов тела фигурными скобками {}, в результате чего
получается то, что называют составным оператором или блоком.
Хороший стиль программирования 2.16
Записывайте оператор (операторы) в теле if с отступом, чтобы
программа была более удобочитаемой.
Хороший стиль программирования 2.17
Для большей ясности программы каждая ее строка должна содержать
не более одного оператора.
-] Типичная ошибка программирования 2.8
Помещение точки с запятой непосредственно за правой круглой
скобкой оператора if (после условия) часто будет логической (хотя и не
синтаксической) ошибкой. Такая точка с запятой делает тело if
пустым, так что оператор не будет выполнять никаких действий вне
зависимости от того, истинно или ложно его условие. Еще хуже, что
настоящее тело if станет оператором, следующим за оператором if
и буде выполняться всегда, из-за чего программа часто может
выдавать неверный результат.
Введение в программирование на C++
117
Обратите внимание на использование пробельных символов на рис. 2.13.
Как вы помните, пробельные символы, т.е. переводы строки, табуляции и
пробелы, обычно игнорируются компилятором. Поэтому операторы могут
распределяться по нескольким строкам и в них могут вставляться пробелы в
зависимости от предпочтений программиста. Однако расщепление на несколько
строк идентификаторов, строк (таких, как "hello") и констант (таких, как
число 1000) является синтаксической ошибкой.
q Типичная ошибка программирования 2.9
Разбиение идентификатора вставкой пробельных символов (то есть
написание main как та in) является синтаксической ошибкой.
Хороший стиль программирования 2,18
Длинный оператор может занимать несколько строк. Если нужно
распределить оператор по нескольким строкам, выбирайте
осмысленные точки переноса, например, после запятой в разделенном
запятыми списке или после знака операции в длинном выражении. Если
оператор разбит на две или более строк, сделайте отступы для всех строк
после первой и выровняйте их по левому краю.
Рис. 2.14 показывает старшинство и правила ассоциации для операций,
представленных в этой главе. Операции показаны сверху вниз в порядке
убывания приоритета. Заметьте, что все эти операции, за исключением
присваивания =, ассоциируются слева направо. Сложение ассоциативно слева,
поэтому, например, выражение х + у + z оценивается как (х + у) + z. Операция
присваивания = ассоциативна справа, поэтому выражение х = у = 0 оценивается
как х = (у = 0), где, как мы скоро увидим, сначала 0 присваивается
переменной у, а затем результат этого присваивания @) присваивается х.
Операции
0
/
+
< <=
! =
« »
=
%
>
>=
1
Ассоциативность
слева направо
слева направо
слева направо
слева направо
слева направо
, слева направо
:__
справа налево
1
Тип
круглые скобки
мультипликативные
аддитивные
отношения
равенства
передача/извлечение из потока
присваивание
Рис. 2.14. Старшинство и ассоциативность рассмотренных до сих пор операций
118
Глава 2
Хороший стиль программирования 2.19
При написании выражений, содержащих много операций,
справляйтесь с таблицей старшинства и ассоциативности. Убедитесь, что
операции в выражении выполняются в ожидаемой вами
последовательности. Если вы не уверены относительно порядка оценки в
сложном выражении, разбейте его на ряд более простых или используйте
для задания нужного порядка оценки круглые скобки, как вы это
делаете в алгебраических выражениях. Не забывайте, что некоторые
операции, например, присваивание (=), ассоциируются не слева
направо, а справа налево.
2.8. Конструирование программного обеспечения.
Исследование требований к ATM (необязательный
раздел)
Мы начинаем изучение необязательного примера проектирования и
реализации учебного приложения. Разделы «Конструирование программного
обеспечения» в конце этой и нескольких последующих глав помогут вам освоиться
в объектно-ориентированном мире. Мы разработаем программное обеспечение
для простого банкомата (ATM, Automated Teller Machine), что покажет вам
в сжатом и последовательном виде весь процесс проектирования и
реализации. В главах 3-7, 9 и 13 мы проработаем различные этапы
объектно-ориентированного проектирования (OOD) с использованием UML, одновременно
соотнося эти этапы с объектно-ориентированными концепциями, обсуждаемыми
в тексте глав. В приложении Е показана реализация ATM с применением
методик объектно-ориентированного программирования (OOP) на языке C++.
Мы приводим законченное решение учебного проекта. Это не упражнение;
скорее это исчерпывающая демонстрация, которая заканчивается детальным
разбором кода, реализующего наш проект. Она познакомит вас с тем, какого
рода существенные проблемы могут встретиться вам в программной
индустрии, и с возможными путями их решения.
Мы начнем процесс проектирования с представления спецификации
требований, документа, формулирующего, каково общее назначение системы ATM
и что она должна делать. На протяжении всего рассмотрения примера мы
ссылаемся на спецификацию требований для определения того, какими
функциональными свойствами должна обладать система.
Спецификация требований
Местный банк собирается установить новый банкомат (ATM), чтобы
пользователи (т.е. клиенты банка) могли с его помощью производить основные
финансовые операции, или транзакции (рис. 2.15). Каждый пользователь может
иметь в банке только один счет. Пользователи ATM должны иметь
возможность просматривать баланс своего счета, получать наличные (т.е. снимать
деньги со счета) и депонировать средства (т.е. вносить деньги на счет).
Введение в программирование на C++
119
Экран
Welcome!
Please enter your account number: 12345
Enter your PIN: 54321
Take cashe here
Лоток
выдачи
наличных
Кнопочная
панель
Insert deposit envelope here
Приемная
щель
Рис. 2.15. Пользовательский интерфейс ATM
Интерфейс банкомата содержит следующие аппаратные элементы:
• экран для вывода пользователю сообщений;
• кнопочная панель для получения от пользователя цифровых данных;
• выходной лоток для выдачи пользователю наличных и »
• приемная щель для получения от пользователя конвертов с вкладами.
Каждый день в лоток для выдачи наличных загружается 500
20-долларовых банкнот. [Замечание. Из-за ограниченного характера нашего учебного
примера некоторые элементы описываемого здесь ATM не в точности
имитируют элементы настоящего банкомата. Например, у настоящего банкомата
обычно имеется устройство, считывающее номер счета пользователя с
банковской карты, в то время как наш ATM просит пользователя набрать номер счета
на кнопочной панели. Настоящий ATM, кроме того, в конце сеанса печатает
квитанцию, а в нашем все выводится на экран.]
Банк хочет, чтобы вы разработали программное обеспечение, позволяющее
производить через ATM финансовые операции, проводимые клиентами банка.
Позднее банк встроит это программное обеспечение в аппаратную часть ATM.
Программное обеспечение должно инкапсулировать функции аппаратных
устройств (напр., лотка для выдачи наличных или приемной щели) внутри
программных компонентов, но не должно заботиться о том, каким образом эти
устройства выполняют свои функции. Аппаратная часть пока еще не
разработана, поэтому вместо написания программного обеспечения, которое
выполнялось бы на ATM, вы должны разработать первую его версию для исполнения
на персональном компьютере. Эта версия должна для эмуляции экрана ATM
использовать монитор, а для эмуляции кнопочной панели — клавиатуру
компьютера.
120
Глава 2
Сеанс ATM состоит в идентификации пользователя (т.е. удостоверении его
личности) по номеру его счета и личному идентификационном коду (PIN), за
которой следует оформление и выполнение финансовой операции. Для
идентификации пользователя и выполнения транзакций ATM должен
взаимодействовать с базой данных о счетах банка. [Замечание. База данных — это
организованный набор данных, хранящийся на компьютере.] Для каждого
банковского счета в базе данных хранится номер счета, PIN и баланс, показывающий
сумму денег на счете. [Замечание. Для простоты мы полагаем, что банк
планирует поставить только один банкомат, поэтому нам не нужно беспокоиться
о том, что несколько ATM могут обращаться к этой базе данных одновременно.
Более того, мы полагаем, что банк не будет производить каких-либо
изменений в информации базы данных в то время, когда клиент пользуется ATM.
Наконец, всякая коммерческая система вроде ATM сталкивается с достаточно
сложными проблемами безопасности, которые выходят далеко за рамки
курсов информатики первого-второго семестров. Однако мы полагаем для
простоты, что банк доверяет ATM в плане доступа и манипуляции с информацией его
базы данных без каких-либо специальных мер безопасности.]
После того как пользователь подойдет к ATM, должна происходить
следующая последовательность событий:
1. Экран показывает приветственное сообщение и предлагает пользователю
ввести номер счета.
2. Пользователь вводит пятизначный номер счета, набирая его на
кнопочной панели.
3. Экран предлагает пользователю ввести PIN (личный
идентификационный код), ассоциированный с данным номером счета.
4. Пользователь вводит пятизначный PIN-код, набирая его на кнопочной
панели (см. рис. 2.15).
5. Если пользователь вводит действительный номер счета и правильный
PIN для этого счета, экран показывает главное меню (рис. 2.16). Если
пользователь вводит недействительный номер счета или неправильный
PIN, экран показывает соответствующее сообщение, и ATM
возвращается к шагу 1У чтобы снова начать процесс идентификации.
После того как ATM идентифицирует пользователя, главное меню
(рис. 2.16) показывает перенумерованные опции для каждого из трех типов
транзакций: справки о балансе (опция 1), снятия (опция 2) и внесения денег
(опция 3). Главное меню показывает также опцию, позволяющую
пользователю выйти из системы (опция 4). Пользователь затем выбирает либо
выполнение транзакции (вводя 1, 2 или 3), либо выход из системы (вводя 4). Если
пользователь вводит недействительную опцию, экран показывает сообщение
об ошибке и затем снова выводит главное меню.
Если пользователь вводит 1, чтобы получить справку о балансе, экран
показывает баланс счета пользователя. Для этого ATM должен получить баланс
счета из базы данных банка.
Введение в программирование на C++
121
Когда пользователь вводит 2, чтобы получить наличные, выполняются
следующие действия:
6. Экран показывает меню (рис. 2.17), перечисляющее стандартные
снимаемые со счета суммы: $20 (опция 1), $40 (опция 2), $60 (опция 3),
$100 (опция 4) и $200 (опция 5). Меню содержит также опцию, которая
позволяет пользователю отменить операцию (опция 6).
7. С помощью кнопочной панели пользователь вводит выбранную опцию
A-6).
8. Если выбранная снимаемая сумма превышает баланс счета
пользователя, экран показывает сообщение, констатирующее это и предлагающее
пользователю выбрать меньшую сумму. Затем ATM возвращается
к шагу 6. Если выбранная снимаемая сумма меньше или равна балансу
счета пользователя (т.е. это приемлемая сумма), ATM переходит
к шагу 9. Если пользователь решает отменить операцию (опция 6), ATM
показывает главное меню (рис. 2.16) и ждет ввода пользователя.
9. Если лоток для выдачи содержит достаточно наличных для
удовлетворения запроса, ATM переходит к шагу 10. В противном случае экран
показывает сообщение, указывающее на возникшую проблему и
предлагающее пользователю выбрать меньшую сумму. Затем ATM возвращается
к шагу 6.
10. ATM дебетует (т.е. вычитает) снимаемую сумму с баланса счета
пользователя в базе данных банка.
11. Выходной лоток выдает пользователю желаемую сумму денег.
12. Экран показывает сообщение, напоминающее пользователю, чтобы он
забрал деньги.
1 Main
1 Ente
menu:
1
2
3
4
с а
- View my
balance 1
- Withdraw cash |
- Deposit
- Exit
choice:
funds 1
Take cashe here
Insert deposit envelope here
Рис. 2.16. Главное меню ATM
122
Глава 2
Withdrawal options:
1 - $20 4 - $100
2 - $40 5 - $200
3 - $60 б - Cancel transaction
Choose a withdrawal option A-6):
Take cashe here
Insert deposit envelope here
Рис. 2.17. Меню ATM для снятия наличных
Если пользователь вводит 3 (когда отображается главное меню),
выполняются следующие действия:
13. Экран предлагает пользователю ввести сумму депозита или нажать 0
(нуль), чтобы отменить операцию.
14. С помощью кнопочной панели пользователь вводит сумму депозита или
0. [Замечание. На кнопочной панели нет десятичной точки и знака
доллара, поэтому пользователь не может ввести реальную сумму в долларах
(напр., $1.25). Вместо этого он должен ввести сумму депозита как число
центов (напр., 125). Затем ATM, чтобы получить сумму в долларах, делит
это число на 100 (напр., 125 : 100 = 1.25).]
15. Если пользователь вводит сумму депозита, ATM переходит к шагу 16.
Если пользователь выбрал отмену операции (введя 0), ATM показывает
главное меню (рис. 2.16) и ждет ввода пользователя.
16. Экран показывает сообщение, предлагающее пользователю вставить
конверт с депозитом в приемную щель.
17. Если в течение двух минут приемная щель получает конверт с депозитом,
ATM кредитует (т.е. прибавляет) депонируемую сумму на баланс счета
пользователя в базе данных банка. [Замечание. Эти деньги не сразу
становятся доступными для снятия со счета. Сначала банк должен
физически проверить сумму наличных в конверте, а любые содержащиеся в нем
чеки должны пройти очистку (т.е. деньги должны быть переведены со
счета подписавшего чек на счет получателя). Когда будет произведена
любая из этих двух операций, банк соответствующим образом обновит
баланс пользователя, хранящийся в базе данных. Это происходит
независимо от системы ATM.] Если приемная щель не получает конверта в тече-
Введение в программирование на C++
123
ние указанного времени, экран показывает сообщение о том, что система
отменила операцию из-за бездеятельности пользователя. Затем ATM
показывает главное меню и ждет ввода пользователя.
После того как система успешно произведет транзакцию, она должна снова
показать главное меню (рис. 2.16), чтобы пользователь мог произвести
дополнительные операции. Если пользователь решает выйти из системы (опция 4),
экран должен поблагодарить его и показать приветственное сообщение для
следующего пользователя.
Анализ системы ATM
Предыдущий параграф является упрощенным примером спецификации
требований. Обычно такая спецификация является результатом процесса
подробного сбора требований, который может включать в себя опрос как
потенциальных пользователей системы, так и специалистов в областях, связанных
с ее функциями. Например, системный аналитик, которого пригласили, чтобы
подготовить спецификацию требований для банковского программного
обеспечения (напр., описанной здесь системы ATM), мог бы опросить экспертов по
финансам, чтобы получить более точное представление о том, что должна
делать программная система. Он использовал бы собранную информацию для
составления списка системных требований, которыми должны
руководствоваться разработчики системы.
Процесс сбора требований является ключевой задачей первого этапа
жизненного цикла программного обеспечения. Жизненный цикл программного
обеспечения характеризует этапы, которые программное обеспечение
проходит начиная с момента, когда его еще только задумали, и до момента, когда
оно уже перестает использоваться. Эти этапы обычно включают в себя: анализ,
проектирование, реализацию, тестирование и отладку, развертывание
(распространение), сопровождение и изъятие из обращения. Существуют
различные модели жизненного цикла, каждая со своими предпочтениями и
предписаниями относительно того, когда и как часто конструкторы программного
обеспечения должны выполнять каждый из этих этапов. Модели водопада
состоят из однократной их последовательности, в то время как итеративные
модели могут в течение жизненного цикла продукта несколько раз повторять
один или несколько этапов.
Этап анализа жизненного цикла программного обеспечения
сосредоточивает внимание на формулировке решаемой задачи. Разрабатывая любую
систему, нужно, конечно, правильно решить задачу, но не менее важно решить
правильную задачу. Системные аналитики собирают требования,
формулирующие конкретную задачу. Наша спецификация требований описывает
систему ATM с достаточными подробностями, в развернутый анализ которых вам
вдаваться нет нужды — это уже сделано за вас.
Чтобы понять, что должна делать будущая система, разработчики часто
применяют методику, называемую моделированием вариантов применения. Этот
процесс определяет варианты применения системы, каждый из которых
представляет одну из возможностей, которые система предоставляет своим
клиентам. Например, банкоматы обычно имеют несколько вариантов применения,
таких, как «Просмотреть баланс счета», «Снять наличные», «Депонировать
средства», «Перевести средства со счета на счет» и «Купить почтовые марки».
124
Глава 2
Упрощенная система ATM, которую мы создаем в данном случае, допускает
только первые три из перечисленных вариантов применения (рис. 2.18).
Каждый вариант применения описывает типичный сценарий
использования системы клиентом. Вы уже прочитали описания вариантов применения
системы ATM в спецификации требований; перечисление шагов, требуемых
для выполнения транзакций каждого типа (т.е. проверки баланса, снятия
и внесения денег) на самом деле описывают три варианта применения нашего
ATM — «Просмотреть баланс счета», «Снять наличные» и «Депонировать
средства».
Диаграммы вариантов применения
Теперь мы представим первую из нескольких диаграмм UML нашего
учебного примера. Мы создадим диаграмму вариантов применения, чтобы
смоделировать взаимодействия между клиентами системы (в нашем примере —
клиентами банка) и системой. Целью этого является представление видов
взаимодействий, в которые пользователи вступают с системой, без описания
их деталей — они даются в других диаграммах UML (которые мы
представляем по ходу дальнейшего изложения учебного примера). Диаграммы вариантов
применения часто сопровождаются неформальным текстом, более подробно
описывающим варианты применения — вроде текста, который содержится
в спецификации требований. В жизненном цикле программного обеспечения
диаграммы вариантов применения создаются на этапе анализа. В более
крупных системах диаграммы вариантов применения являются простым, но
необходимым инструментом, который помогает системным разработчикам
сосредоточиться на удовлетворении нужд пользователей.
На рис. 2.18 показана диаграмма вариантов применения для нашей
системы ATM. Человечек представляет актера, определяющего роли, которые
внешний объект — такой, как человек или другая система — может играть
в процессе взаимодействия с ATM. Заметьте, что в диаграмме вариантов
применения может быть несколько актеров. Например, диаграмма вариантов
применения для системы ATM реального банка могла бы также включать актера
с именем Администратор, который каждый день пополняет запас наличных
в выходном лотке.
Проверить баланс, счета
Снять наличные
Депонировать средства
Пользователь
Рис. 2.18. Диаграмма вариантов применения для системы ATM с точки зрения
пользователя
о
А
Введение в программирование на C++
125
В нашей системе мы находим актера, изучая спецификацию требований,
в которой говорится: «Пользователи ATM должны иметь возможность
просматривать баланс своего счета, получать наличные и депонировать средства».
Таким образом, актером в каждом из трех вариантов применения является
Пользователь, взаимодействующий с ATM. При финансовых операциях роль
Пользователя играет внешний объект — реальный человек. На диаграмме
рис. 2.18 показан один актер, под которым стоит его имя (Пользователь).
В UML каждый вариант использования представляется овалом, соединенным
с актером непрерывной линией.
Прежде чем программисты реализуют систему на конкретном языке
программирования, конструкторы программного обеспечения (точнее, системные
проектировщики) должны проанализировать ее спецификацию требований
или совокупность вариантов применения и спроектировать систему. На этапе
анализа проектировщики стараются вникнуть в требования к системе, чтобы
составить спецификацию высокого уровня, описывающую, что система
должна делать. Получающаяся в результате этапа проектирования спецификация
проекта должна ясно формулировать, как должна быть построена система,
удовлетворяющая данным требованиям. В нескольких следующих разделах
«Конструирование программного обеспечения» мы проделываем шаги
простого процесса объектно-ориентированного проектирования (OOD) для системы
ATM, чтобы получить спецификацию проекта, состоящую из набора диаграмм
UML и поясняющего текста. Как вы помните, UML разработан так, чтобы
быть применимым к любому процессу OOD. Существует много таких
процессов, из которых наиболее известен Rational Unified Process™ (RUP),
разработанный в Rational Software Corporation (ныне отделение IBM). RUP — это
мощный процесс, предназначенный для проектирования приложений
«промышленного качества». Для целей нашего учебного примера мы представляем
свой собственный упрощенный процесс проектирования.
Проектирование системы ATM
Мы приступаем к этапу проектирования нашей системы ATM. Система
является совокупностью компонентов, взаимодействующих между собой в целях
решения задачи. Например, в целях выполнения задач, для которых
предназначен банкомат, наша система ATM имеет пользовательский интерфейс
(рис. 2.15), включает программное обеспечение, производящее финансовые
операции, и взаимодействует с базой данных, содержащей информацию о
банковских счетах. Структура системы описывает объекты системы и их
взаимоотношения. Поведение системы описывает, как меняется система по ходу
взаимодействия ее объектов друг с другом. Каждая система имеет и структуру,
и поведение, — проектировщики должны специфицировать оба аспекта.
Существует несколько различных типов структур и поведений систем.
Например, взаимодействия между объектами в системе отличаются от
взаимодействий между пользователем и системой, но и те, и другие составляют часть ее
поведения.
UML 2 определяет 13 типов диаграмм для документирования системных
моделей. Каждая из них описывает отдельную характеристику структуры или
поведения системы; шесть диаграмм относятся к системной структуре,
остальные семь — к поведению. Мы перечисляем здесь только шесть типов
диаграмм, которые используются в нашем учебном примере; один тип диаграмм
126
Глава 2
(классовые диаграммы) описывает структуру системы, а остальные пять
описывают поведение. Мы даем обзор других диаграмм UML 2 в приложении Ж.
1. Диаграммы вариантов применения, примером которых является
диаграмма на рис. 2.18, моделируют взаимодействия между системой и ее
внешними объектами (актерами) в терминах вариантов применения
(возможностей системы, таких, как «Просмотреть баланс счета», «Снять
наличные» и «Депонировать средства».
2. Классовые диаграммы, которые вы изучите в разделе 3.11, моделируют
классы, или «строительные блоки», используемые в системе. Каждое
существительное, или «вещь», описанная в спецификации требований,
является кандидатом в классы системы (например, «счет», «кнопочная
панель»). Классовые диаграммы помогают описать структурные
взаимоотношения между частями системы. Например, классовая диаграмма
системы ATM покажет, что ATM физически состоит из экрана,
кнопочной панели, выходного лотка и приемной щели.
3. Диаграммы машинных состояний, которые вы изучите в разделе 5.11,
моделируют то, каким образом объект изменяет свое состояние.
Состояние объекта описывается значениями всех его атрибутов в данный
момент времени. Когда объект изменяет состояние, он может по-другому
вести себя в системе. Например, после подтверждения PIN-кода
пользователя ATM переходит из состояния «пользователь не идентифицирован»
в состояние «пользователь идентифицирован», и в этот момент ATM
разрешает пользователю производить финансовые операции (например,
проверить баланс счета, получить наличные, депонировать средства).
4. Диаграммы деятельности, которые вы также изучите в разделе 5.11,
моделируют деятельность объекта — его рабочий поток
(последовательность событий) в ходе исполнения программы. Диаграмма деятельности
моделирует производимые объектом действия и специфицирует порядок,
в котором он их производит. Например, диаграмма деятельности
показывает, что ATM должен получить баланс счета пользователя (из базы
данных банка с информацией о счетах), прежде чем экран сможет показать
пользователю баланс.
5. Диаграммы коммуникации (в первых версиях UML называвшиеся
диаграммами кооперации) моделируют взаимодействия между объектами
в системе, с акцентом на том, какие происходят взаимодействия. В
разделе 7.12 вы узнаете, что эти диаграммы показывают, какие объекты
должны взаимодействовать, чтобы произвести транзакцию ATM. Например,
чтобы получить баланс счета, ATM должен связаться с базой данных
банка.
6. Диаграммы последовательностей также моделируют взаимодействия
объектов в системе, но в отличие от диаграмм коммуникации они
акцентируют, когда происходят взаимодействия. В разделе 7.12 вы узнаете,
что эти диаграммы позволяют показать порядок, в котором происходят
взаимодействия при выполнении финансовой операции. Например,
перед выдачей пользователю наличных экран предлагает пользователю
ввести снимаемую сумму.
Введение в программирование на C++
127
В разделе 3.11 мы продолжим проектирование нашей системы ATM и,
исходя из спецификации требований, определим ее классы. Мы достигнем этого
путем извлечения из спецификации ключевых имен существительных и
именных словосочетаний. Используя эти классы, мы разработаем наш первый
набросок классовой диаграммы, моделирующей структуру нашей системы ATM.
Ресурсы Internet и Web
Нижеприведенные URL предлагают информацию по
объектно-ориентированному проектированию с помощью UML.
www-306.ibm.com/software/rational/uml/
Содержит список часто задаваемых вопросов о UML, предоставленный IBM
Rational.
www.softdocwiz.com/Dictionary.htm
Содержит Unified Modeling Language Dictionary — словарь, в котором
перечисляются и определяются все используемые в UML термины.
www-306.ibm.com/software/rational/offerings/design.html
Предлагает информацию по доступным программному обеспечению IBM
Rational для проектирования систем. Доступны для загрузки 30-дневные
пробные версии нескольких продуктов, таких, как IBM Rational Rose® XDE
Developer.
www.embarkadero.com/products/describe/index.html
Предлагает 15-дневную лицензию для UML-инструмеита моделирования
Describe™ от Embarcadero Technologies®.
www.borland.com/together/index.html
Предлагает бесплатную 30-дневную лицензию для загрузки пробной версии
Together® ControlCenter™ от Borland® — инструмента разработки,
поддерживающего UML.
www.ilogix.com/rhapsody/rhapsody.cfm
Предлагает бесплатную 30-дневную лицензию для загрузки пробной версии
I-Logix Rhapsody® — это управляемая моделью среда разработки,
базирующаяся на UML 2.
argouml.tigris.org
Содержит информацию и загрузки для ArgoUML, бесплатного инструмента
UML с открытым кодом.
www.objectsbydesign.com/books/booklist.html
Перечисляет книги по UML и объектно-ориентированному
проектированию.
www.objectsbydesign.corn/tools/umltools_byCompany.html
Перечисляет программные инструменты, использующие UML, такие, как
IBM Rational Rose, Embarcadero Describe, Sparx Systems Enterprise Architect,
I-Logix Rhapsody и Gentleware Poseidon for UML.
www.ootips.org/ood-principies.html
Отвечает на вопрос «Что отличает хороший объектно-ориентированный
проект?»
128
Глава 2
www.cetus-links.org/oo_uml.html
Представляет UML и предлагает ссылки на многочисленные ресурсы UML.
www.agilemodeling.com/essays/umlDiagrams.htm
Предлагает глубокие описания и учебные руководства по каждому из 13
типов диаграмм UML 2.
Рекомендуемая литература
Следующие книги содержат информацию по объектно-ориентированному
проектированию с помощью UML.
Booch, G. Object-Oriented Analysis and Design with Applications, Third Edition.
Boston: Addison-Wesley, 2004.
Eriksson, H., et al. UML 2 Toolkit, New York: John Wiley 2003.
Kruchten, P. The Rational Unified Process: An Introduction. Boston:
Addison-Wesley, 2004.
Larman, C. Applying UML and Patterns: An Introduction to Object-Oriented Analysis
and Design, Second Edition. Upper Saddle River, NJ: Prentice Hall, 2002.
Roques, P. UML in Practice: The Art of Modeling Software Systems Demonstrated
Through Worked Examples and Solutions. New York: John Wiley, 2004.
Rosenberg, D., and K. Scott. Applying Use Case Driven Object Modeling with UML: An
Annotated e-Commerce Example. Reading, MA: Addison-Wesley, 2001.
Rumbaugh, J., I. Jacobson and G. Booch. The Complete UML Training Course. Upper
Saddle River, NJ: Prentice Hall, 2000.
Rumbaugh, J., I. Jacobson and G. Booch. The Unified Modeling Language Reference
Manual. Reading, MA: Addison-Wesley, 1999.
Rumbaugh, J., I. Jacobson and G. Booch. The Unified Software Development Process.
Reading, MA: Addison-Wesley, 1999.
Контрольные вопросы по учебному примеру
2.1. Предположим, мы разрешили пользователю нашего ATM переводить
деньги с одного банковского счета на другой. Модифицируйте
соответствующим образом диаграмму вариантов применения на рис. 2.18.
2.2. моделируют взаимодействия между объектами в системе,
акцентируя то, когда эти взаимодействия происходят.
a) Классовые диаграммы
b) Диаграммы последовательностей
c) Диаграммы коммуникации
d) Диаграммы деятельности
2.3. Какой из нижеприведенных пунктов перечисляет этапы типичного
жизненного цикла программного обеспечения в правильном порядке?
a) проектирование, анализ, реализация, тестирование
b) проектирование, анализ, тестирование, реализация
c) анализ, проектирование, тестирование, реализация
d) анализ, проектирование, реализация, тестирование
Введение в программирование на C++ : 129
Ответы на контрольные вопросы по учебному примеру
2.1. Диаграмма вариантов применения для модифицированной версии
системы ATM, дополнительно позволяющей пользователям переводить
деньги с одного банковского счета на другой, показана на рис. 2.19.
Проверить баланс счета
Снять наличные
Депонировать средства
Перевести средства
с одного счета на другой
Рис. 2.19. Диаграмма вариантов применения для модифицированной системы ATM,
которая позволяет пользователям переводить деньги с одного счета на другой
2.2. Ь.
2.3. d.
2.9. Заключение
Вы познакомились со многими важными элементами C++, включая вывод
данных на экран, ввод данных с клавиатуры и объявление данных основных
типов. В частности, вы узнали, как пользоваться объектом выходного потока
cout и объектом входного потока cin при построении простых интерактивных
программ. Мы объяснили, каким образом переменные сохраняются и
извлекаются из памяти. Вы также узнали, как с помощью арифметических операций
производятся вычисления, и в каком порядке C++ применяет операции к
операндам выражения (т.е. о старшинстве и ассоциативности операций). Вы
узнали, каким образом оператор C++ if позволяет программе принимать решения.
Наконец, мы представили операции равенства и отношений, с помощью
которых образуются условия в операторе if.
Представленные здесь приложения, не являющиеся
объектно-ориентированными, ввели вас в элементарные принципы программирования. Как вы
увидите в главе 3, программы на C++ часто содержат в функции main всего
несколько строчек кода, которые создают объекты, выполняющие работу
приложения, — а затем эти объекты «берут все на себя». В главе 3 вы узнаете, как
реализовать свои собственные классы и использовать в приложениях объекты
этих классов.
О
5 Зак 1114
130
Глава 2
Резюме
• Однострочный комментарий начинается с символов //. Программисты пишут
комментарии, чтобы документировать программу и облегчить ее чтение.
• Комментарии не вызывают никаких действий компьютера при выполнении
программы, — они игнорируются компилятором C++ и не порождают никакого
объектного кода на машинном языке.
• Директива препроцессора начинается с # и является сообщением, адресованным
препроцессору C++. Препроцессор обрабатывает директивы до компиляции
программы. Директивы препроцессора не оканчиваются точкой с запятой.
• Строка #include <iostream> дает указание препроцессору C++ включить в
программу содержание заголовочного файла потоков ввода-вывода. Этот файл содержит
информацию, необходимую, чтобы компилировать программу, которая использует
std::cin и std::cout и операции « и ».
• Пробельные символы (т.е. пробелы, символы табуляции и пустые строки)
используются программистами для того, чтобы сделать программу более легкой для чтения.
Пробельные символы игнорируются компилятором.
• Программа на C++ начинает свое исполнение с функции main, даже если main не
идет в программе первой.
• Ключевое слово int слева от main означает, что main «возвращает» целое значение.
• Тело любой функции начинается с левой фигурной скобки, {. Соответствующая
правая фигурная скобка, }, заканчивает тело функции.
• Строку в двойных кавычках называют символьной строкой, сообщением или
строковым литералом. Пробельные символы, встречающиеся в строке, компилятор не
игнорирует.
• Каждый оператор должен оканчиваться точкой с запятой.
• Ввод и вывод в C++ осуществляется посредством символьных потоков.
• Объект потока вывода std::cout, обычно подключенный к экрану, используется для
вывода данных. Вывод нескольких единиц данных может быть выполнен путем
сцепления операций передачи в поток («).
• Объект потока ввода std::cin, обычно подключенный к клавиатуре, используется для
ввода данных. Ввод нескольких единиц данных может быть выполнен путем
сцепления операций извлечения из потока (»).
• Объекты потоков std::cin и std::cout облегчают взаимодействие пользователя с
компьютером. Поскольку это взаимодействие напоминает диалог, оно часто называется
диалоговыми или интерактивными вычислениями.
• Запись std::cout означает, что мы имеем в виду имя, в данном случае cout,
принадлежащее «пространству имен» std.
• Когда в символьной строке встречается обратная дробная черта (т.е. escape-символ),
с ней комбинируется следующий символ, образуя escape-последовательность.
• Escape-последовательность \п означает новую строку. Она заставляет курсор (т.е.
указатель текущей позиции экрана) переместиться к началу новой экранной строки.
• Сообщение, предлагающее пользователю предпринять некоторое действие,
называется подсказкой.
• Ключевое слово C++ return является одним из нескольких средств возврата из
функции.
• Все переменные в программе на C++ должны быть объявлены перед тем, как они
будут использоваться.
Введение в программирование на C++
131
• Имя переменной в C++ — это любой допустимый идентификатор, не являющийся
ключевым словом. Идентификатором называется последовательность символов,
состоящая из букв, цифр и символов подчеркивания (_). Идентификатор не может
начинаться с цифры. В C++ допускаются идентификаторы любой длины, но некоторые
системы и среды C++ могут налагать ограничения на длину идентификаторов.
• C++ различает регистр букв.
• Большинство вычислений выполняется в операторах присваивания.
• Переменная является ячейкой памяти компьютера, в которой программа может
хранить значение.
• В переменной типа int могут храниться целые значения, такие, как 7, -11, 0, 31914.
• Каждая переменная, хранящаяся в памяти компьютера, имеет имя, значение, тип
и размер.
• Всякий раз, когда новое значение помещается в ячейку памяти, оно замещает
предыдущее значение в этой ячейке. Предыдущее значение теряется.
• Когда значение считывается значения из памяти, это неразрушающий процесс, т.е.
считывается копия значения, а исходное значение остается в памяти нетронутым.
• Манипулятор потока std::endl выводит символ новой строки, а затем «сбрасывает
буфер вывода».
• C++ оценивает арифметические выражения в строго определенном порядке, в
соответствии с правилами старшинства и ассоциации операций.
• Для принудительного задания любого требуемого порядка оценки можно
использовать круглые скобки.
• Целое деление (т.е. когда и делимое, pi делитель являются целыми) дает целое
частное. Дробная часть при целом делении усекается — округления не происходит.
• Операция взятия по модулю (%) дает остаток от целого деления. Операцию можно
применять только к целым операндам.
• Оператор if позволяет программе принимать решения при выполнении
определенного условия. Оператор имеет следующий формат
if ( условие )
оператор ;
• Если условие истинно, оператор в теле if выполняется. Если условие не
выполняется, т.е. ложно, оператор тела пропускается.
• Условия в операторах if обычно образуются с помощью операций равенства и
отношения. Результат этих операций всегда равен true (истинному значению) или false
(ложному значению).
• Объявление
using std::cout;
является «объявлением using», которое устраняет необходимость повторения
префикса std::. Как только мы включили в программу такое объявление using, мы
можем в остальной части программы писать cout вместо std::cout.
Терминология
комментарий /* ... */ (в стиле С)
комментарий //
арифметическая операция
операция присваивания (=)
ассоциативность операций
бинарная (двухместная) операция
блок
тело функции
каскадирование операций передачи
в поток
различение регистра
сцепление операций передачи в поток
132
Глава 2
символьная строка
объект cin
список, разделенный запятыми
ошибка компиляции
ошибка времени компиляции
составной оператор
конкатенация операций передачи
в поток
условие
объект cout
курсор
тип данных
решение
объявление
разрушающая запись
операции равенства
== («равно»)
!= («не равно»)
escape-символ (\)
escape-последовательность
выход из функции
фатальная ошибка
функция
идентификатор
оператор if
заголовочный файл потоков ввода/
вывода <iostream>
тип данных int
целое (int)
целое деление
ассоциация слева направо
литерал
логическая ошибка
функция main
память
ячейка памяти
сообщение
операция взятия по модулю (%)
операция умножения (*)
вложенные скобки
символ новой строки (\п)
неразрушающее чтение
не-фатальная логическая ошибка
операнд
операция
круглые скобки ()
выполнение действия
старшинство (приоритет)
директива препроцессора
подсказка
избыточные скобки
операции отношений
< («меньше»)
<= («меньше или равно»)
> («больше»)
>= («больше или равно»)
оператор return
правила старшинства операций
самодокументированная программа
точка с запятой (;), ограничитель
оператора
ограничитель оператора (;)
объект стандартного входного потока
(cin)
объект стандартного выходного
потока (cout)
оператор
поток
операция передачи в поток («)
операция извлечения из потока (»)
манипулятор потока
строка
строковый литерал
синтаксическая ошибка
объявление using
переменная
пробельный символ
Контрольные вопросы
2.1.
2.2.
Заполните пропуски в следующих утверждениях:
а) Выполнение каждой программы на C++ начинается с функции .
Ь) начинает тело каждой функции, а заканчивает тело
каждой функции,
с) Каждый оператор заканчивается .
d) Управляющая последовательность \п представляет символ ,
который вызывает перемещение курсора к началу следующей строки на экране.
e) Оператор используется для принятия решений.
Укажите, что из нижеследующего верно или неверно. Если неверно, то
объясните, почему. Предположите, что используется оператор using std::cout;.
Введение в программирование на C++
133
a) Комментарии при выполнении программы вызывают печать компьютером на
экране текста после символов //.
b) Если вывод осуществляется в cout, то esc-последовательность \п вызывает
перемещение курсора к началу следующей строки на экране.
c) Все переменные должны быть объявлены до того, как они используются.
d) Всем переменным, когда они объявляются, должен быть присвоен тип.
e) C++ рассматривает переменные number и NuMbEr как одинаковые.
f) Объявления в теле функции C++ могут появляться почти везде.
g) Операция взятия по модулю (%) может применяться только к целым числам,
h) Все арифметические операции *,/,%,+ и — имеют одинаковый уровень
приоритета.
i) Программа на C++, которая выводит три строки, должна содержать три
оператора вывода, использующих cout.
2.3. Напишите по одному оператору C++, выполняющему следующие задачи:
a) Объявить переменные с, thisIsAVariable, q76354 и number типа int.
b) Предложить пользователю ввести целое число. Закончите
сообщение-подсказку двоеточием (:), за которым следует пробел, и установите курсор после
провела.
c) Прочитать целое число с клавиатуры и запомнить введенное значение в целой
переменной age.
d) Если переменная number не равна 7, напечатать "Значение переменной
number не равно 7.".
e) Напечатать сообщение "Это программа на C++" на одной строке.
f) Напечатать сообщение "Это программа на C++" на двух строках, где первая
строка заканчивается словом «программа».
g) Напечатать сообщение "Это программа на C++" так, чтобы на каждой строке
было только одно слово.
h) Напечатать сообщение "Это программа на C++" так, чтобы каждое слово
было отделено от следующего знаком табуляции.
2.4. Напишите операторы (или комментарии), выполняющие следующие задачи:
a) Указать, что программа будет вычислять произведение трех целых чисел.
b) Объявить переменные х, у, z и results типа int.
c) Предложить пользователю ввести три целых числа.
d) Считать три целых числа с клавиатуры и сохранить их в переменных х, у и z.
e) Вычислить произведение трех целых чисел, содержащихся в переменных х, у
и z, и присвоить результат переменной result.
f) Напечатать "Произведение равно " и потом значение переменной result.
g) Возвратить из функции main значение, свидетельствующее об успешном
завершении программы.
2.5. Используя написанные в упражнении 2.4 операторы, напишите полную
программу, которая вычисляет и печатает произведение трех чисел. Замечание: вам
понадобиться написать необходимый оператор using.
2.6. Укажите и исправьте ошибки в каждом из следующих операторов
(предположите, что используется оператор using std::cout;):
a) if ( с « 7 ) ;
cout « "с меньше 7\п";
b) if ( с => 7 ) ;
cout « "с равно или больше 7\п";
134
Глава 2
Ответы на контрольные вопросы
2.1. a) main, b) Левая фигурная скобка ({), правая фигурная скобка (}). с) точкой
с запятой, d) новая строка, е) if.
2.2. а) Неверно. Комментарии не вызывают каких-либо действий при выполнении
программы. Они используются для документирования программы и
улучшения ее читаемости.
b) Верно.
c) Верно.
d) Верно.
e) Неверно. C++ различает регистр, так что эти переменные различны.
f) Верно.
g) Верно.
h) Неверно. Операции *, / и % имеют одинаковый уровень приоритета, а + и -
имеют более низкий уровень,
i) Неверно. Один оператор вывода в cout с несколькими esc-символми \п может
напечатать несколько строк.
2.3. a) int с, thisIsAVariable, q76354, number;
b) std::cout « "Введите целое число: ";
c) std: :cin » age;
d) if ( number != 7 )
std::cout « "Значение переменной не равно 7.\п";
e) std: :cout « "Это программа на С++.\п";
f) std::cout « "Это программа\пна С++.\п";
g) std::cout « "Это\ппрограмма\пна\пС++.\n";
h)std::cout « "Это\Программа\tHa\tC++.\n";
2.4. a) // Вычисление произведения трех целых чисел
b) int x, у, z, result;
c) cout « "Введите три целых числа: ";
d) cin » х » у » z;
e) result = х * у * z;
f) cout « "Произведение равно " « result « endl;
g) return 0;
2.5. (См. следующий листинг.)
1 // Вычислить произведение трех целых чисел
2 #include <iostream> // позволяет программе выполнять ввод и вывод
3
4 using std::cout; // программа использует cout
5 using std::cin; // программа использует cin
6 using std::endl; // программа использует endl
7
8 // функция main начинает исполнение программы
9 int main()
Ю {
11 int x; // первое из перемножаемых чисел
12 int у; // второе из перемножаемых чисел
13 int z; // третье из перемножаемых чисел
14 int result; // произведение трех целых чисел
15
16 cout « "Enter three integers: "; // запросить данные
17 cin » х » у » z; // прочитать три целых числа пользователя
18 result = х * у * z; // перемножить числа; сохранить результат
Введение в программирование на C++
135
19 cout « "The product is " « result « endl; // напечатать
20
21 return 0; // показывает успешное завершение программы
22 } // конец функции main
2.6. а) Ошибка: точка с запятой после правой круглой скобки условия в операторе if.
Исправление: удалите точку с запятой после правой круглой скобки. [
Замечание. В результате этой ошибки оператор вывода будет выполняться
независимо от истинности условия в операторе if]. Точка с запятой после правой
круглой скобки считается пустым оператором — оператором, который ничего не
делает. Мы узнаем больше о пустом операторе в следующей главе.
Ь) Ошибка: операция сравнения =>. Исправление: измените => на >=.
Упражнения
2.7. Опишите смысл следующих объектов:
a) std::cin
b) std::cout
2.8. Заполните пропуски в следующих утверждениях:
а) используются для документирования программы и улучшения ее
читаемости.
b) Объект, используемый для вывода информации на экран, называется
c) Оператор C++, принимающий решение, называется .
d) Вычисления обычно выполняются с помощью оператора .
e) Объект вводит информацию с клавиатуры.
2.9. Напишите один или несколько операторов C++, выполняющих указанные ниже
задачи:
a) Напечатать сообщение «Введите два числа: *
b) Присвоить произведение переменных а и b переменной с.
c) Указать, что программа выполняет расчеты платежных ведомостей (т.е.
используйте текст, помогающий документировать программу).
d) Ввести три целых значения с клавиатуры и поместите эти значения в целые
переменные a, b и с.
2.10. Укажите, что из нижеследующего верно или неверно. Объясните ваши ответы.
a) Операции в C++ выполняются слева направо.
b) Все эти имена переменных допустимы: _under_bar_, m928134, t5, j7,
her_sales, his_account_njnfk, a, b, c, z, z2.
c) Оператор cout « "a = 5;" — типичный пример оператора присваивания.
d) Правильное арифметическое выражение на C++ без круглых скобок
выполняется слева направо.
e) Все эти имена переменных недопустимы: 3g, 87, 67h2, h22, 2h.
2.11. Заполните пропуски в следующих предложениях:
a) Какие арифметические операции имеют такой же уровень приоритета как
умножение? .
b) Какие из вложенных круглых скобок выполняются в арифметическом
выражении первыми? .
c) Области в памяти компьютера, которые могут содержать разные значения
в разное время в процессе выполнения программы, называются .
136
Глава 2
2.12. Что печатается, если это вообще возможно, при выполнении каждого из
следующих операторов. Если ничего не печатается, то ответьте «ничего».
Предполагайте, что х = 2, у = 3.
a) cout « х;
b) cout « х + х;
c) cout « мх=" ;
d) cout « "х =" < х;
e) cout « х + у « " = " « у + х;
f) z = х + у;
g) cin » x » у;
h) // cout « "х + у = " « х + у;
i) cout « "\n" ;
2.13. Какие из следующих операторов C++ содержат переменные, значения которых
замещаются?
a) cin » Ь » с » d » е » f ;
b)p = i + j+k = 7;
c) cout « "переменные, значения которых замещаются";
d) cout « "a = 5" ;
2.14. Какие из следующих операторов C++ верны для уравнения у = ах3 + 7:
а)у = а*х*х*х + 7;
Ь)у = а*х*х* (х + 7);
с)у= (а*х) *х* (х + 7);
d)y= (a*x) * х * х + 7 ;
е)у = а*(х*х*х)+7;
f) у = а * х * ( х * х + 7 ) ;
2.15. Укажите порядок выполнения действий в каждом из следующих операторов
C++ и назовите значения х после их выполнения:
а)х = 7 + 3*б/2-1;
Ь)х = 2%2 + 2*2-2/2;
с)х=C*9*C+(9*3/C))));
2.16. Напишите программу, которая просит пользователя ввести два числа, получает
числа от пользователя и затем печатает сумму, произведение, разность и частное
этих чисел.
2.17. Напишите программу, которая печатает числа от 1 до 4 на одной и той же
строке, так что соседние числа разделены одним пробелом:
a) Используя один оператор вывода с одним оператором поместить в поток.
b) Используя один оператор вывода с четырьмя операторами поместить в
поток.
c) Используя четыре оператора вывода.
2.18. Напишите программу, которая просит пользователя ввести два числа, получает
числа от пользователя и затем печатает большее число после слова "больше".
Если числа равны, напечатайте сообщение "Эти числа равны".
2.19. Напишите программу, которая вводит с клавиатуры три целых числа и печатает
сумму, среднее значение, произведение, меньшее и большее из этих чисел.
Диалог на экране должен выглядеть следующим образом:
Введение в программирование на C++
137
Введите три различных целых числа:
Сумма равна 54
Среднее значение равно 18
Произведение равно 4914
Наименьшее равно 13
Наибольшее равно 27
13 27 14
2.20. Напишите программу, которая считывает радиус круга и печатает диаметр
круга, длину окружности и площадь. Используйте значение константы 3.14159 для
числа ?. Выполните эти вычисления в операторе вывода. [Замечание. В этой
главе мы обсудили только целые константы и переменные. В главе 3 мы обсудим
числа с плавающей запятой, т.е. величины, которые могут иметь десятичную
запятую.]
2.21. Напишите программу, которая печатает прямоугольник, овал, стрелу и ромб
в следующем виде:
•••••••••
• *
• •
• •
• *
• •
• •
• •
*********
•
*
*
•
*
•
•
***
• *•
*
*
•
*
*
*
•
*
*•*
*****
*
*
*
*
*
•
*
*
*
*
*
*
*
•
*
*
•
*
*
*
*
*
2.22. Что печатает следующий оператор?
cout « "*\n**\n***\n****\n*****\n";
2.23. Напишите программу, которая считывает пять целых чисел, определяет и
печатает наибольшее и наименьшее из них. Используйте только те приемы
программирования, которые вы изучили в этой главе.
2.24. Напишите программу, которая считывает целое число, определяет и печатает,
четное оно или нечетное. [Подсказка. Используйте операцию вычисления
остатка. Четное число кратно двум. Любое число, кратное двум, при делении на 2 дает
в остатке нуль.]
2.25. Напишите программу, которая считывает два целых числа, определяет и
печатает, является ли первое число кратным второму. [Подсказка. Используйте
операцию вычисления остатка.]
2.26. Выведите следующий «шахматный» узор восемью операторами вывода, а затем
сделайте то же самое наименьшим возможным количеством операторов:
• **•••**
********
********
********
• •*•**••
********
**•*•*••
********
138
Глава 2
2.27. Заглянем немного вперед. В этой главе вы узнали о целых числах и типе int. C++
может также представлять прописные и строчные буквы и значительное
многообразие специальных символов. Для представления каждого отдельного символа
C++ использует небольшие целые числа. Компьютер использует множество
символов, и соответствующие целые представления для этих символов называются
набором символов компьютера. Вы можете напечатать символ, просто заключив
его в одиночные кавычки
cout « 'А';
Вы можете напечатать целочисленный эквивалент символа, используя static_cast
следующим образом:
cout « static_cast< int >( 'А' );
это называется приведением типа (формально о приведениях типа мы
поговорим в главе 4). Когда выполняется предшествующий оператор, он печатает
значение 65 (в системе, которая использует так называемый набор символов ASCII).
Напишите программу, которая печатает целочисленные эквиваленты ряда
прописных и строчных букв, цифр и специальных символов. Как минимум,
определите целочисленные эквиваленты следующих символов: ABCabc012$* + /
и пробела.
2.28. Напишите программу, которая вводит число из пяти цифр, разделяет число на
отдельные цифры и печатает их отдельно друг от друга с тремя пробелами между
ними. Например, если пользователь вводит в программу 42339, то должно быть
напечатано
4 2 3 3 9
2.29. Используя только технику программирования, изученную в этой главе,
напишите программу, которая вычисляет квадрат и куб чисел от 0 до 10 и использует
табуляцию для печати следующей таблицы значений:
число
0
1
2
3
4
5
6
7
8
9
10
квадрат
0
1
4
9
16
25
36
49
64
81
100
куб
0
1
8
27
64
125
216
343
512
729
1000
3
Введение в классы и объекты
ЦЕЛИ
В этой главе вы изучите:
• Что такое классы, объекты,
элемент-функции и элементы
данных.
• Как определить класс
и использовать его для создания
объектов.
• Как определить элемент-функции
класса, реализующие его
поведение.
• Как объявлять в классе элементы
данных, реализующие его атрибуты.
• Как вызвать элемент-функцию
объекта, выполняющую
определенную задачу.
• О различиях между элементами данных класса и локальными
переменными функции.
• Как определить конструктор, обеспечивающий инициализацию
данных объекта при его создании.
• Как разработать класс с интерфейсом, отделенным от реализации,
и с возможностями последующей утилизации.
140
Глава 3
3.1. Введение
3.2. Классы, объекты, элемент-функции и элементы
данных
3.3. Обзор примеров главы
3.4. Определение класса с элемент-функцией
3.5. Определение элемент-функции с параметром
3.6. Элементы данных, set-функции и get-функции
3.7. Инициализация объектов при помощи конструкторов
3.8. Размещение класса в отдельном файле
3.9. Отделение интерфейса от реализации
3.10. Подтверждение данных посредством set-функций
3.11. Конструирование программного обеспечения.
Идентификация классов в спецификации требований
к ATM (необязательный раздел)
3.12. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
3.1. Введение
В главе 2 вы создавали простые программы, которые выводили сообщения,
получали от пользователя данные, производили вычисления и принимали
решения. В этой главе вы начнете писать программы, основанные на
элементарных принципах объектно-ориентированного программирования,
представленных в разделе 1.17. Все программы 2-й главы имели ту общую особенность,
что все операторы, производящие какие-либо действия, размещались в
функции main. Как правило, программы, которые вы будете разрабатывать в этой
книге, будут состоять из функции main и одного или нескольких классов,
каждый из которых содержит элементы-данные и элементы-функции. Если вы
становитесь членом группы разработчиков в программной индустрии, то вам
приходится иногда работать над программными системами, состоящими из
сотен, если не тысяч, классов. В этой главе мы разрабатываем простую,
правильно сконструированную модель для организации объектно-ориентированных
программ на C++.
Прежде всего мы обосновываем понятие классов, рассматривая пример из
реального мира. Затем мы представляем продуманный ряд из семи
законченных программ, демонстрирующих создание и использование своих
собственных классов. Эти примеры начинают наш интегрированный учебный проект,
реализующий класс «журнала», в котором преподаватели могут сохранять
оценки студентов. В последующих главах мы будем развивать этот проект
и представим его наиболее полный вариант в главе 7, «Массивы и векторы».
Введение в классы и объекты
141
3.2. Классы, объекты, элемент-функции и элементы
данных
Чтобы помочь вам укрепить свое понимание классов и их содержимого,
о чем говорилось в разделе 1.17, мы начнем с простой аналогии.
Предположим, вы хотите поехать на машине; вы разгоняете ее, нажимая на
акселератор. Что должно произойти, прежде чем вы сможете это сделать? Вообще
говоря, чтобы вы могли ездить на машине, кто-то должен был спроектировать и
собрать ее. Автомобиль начинается с инженерных эскизов и чертежей, похожих
на планы дома. В эти чертежи входит конструкция педали акселератора, с
помощью которой водитель разгоняет машину. В некотором смысле эта педаль
«скрывает» за собой сложные механизмы, которые в действительности
заставляют машину ехать быстрее, точно так же, как педаль тормоза «скрывает»
механизмы, замедляющие машину, руль «скрывает» механизмы,
поворачивающие машину и т.д. Все это позволяет людям, мало или вообще ничего не
знающим о том, как устроен автомобиль, с легкостью водить его, просто нажимая
на акселератор и тормоз, поворачивая руль, переключая передачи и
манипулируя прочими простыми, привычными пользователю «интерфейсами»
сложных внутренних механизмов.
К сожалению, нельзя ездить на чертежах автомобиля; прежде чем вы
поедете, автомобиль должен быть собран согласно описывающим его чертежам.
В полностью собранном автомобиле будет настоящая педаль акселератора,
предназначенная для его ускорения. Но и этого недостаточно — автомобиль не
будет разгоняться сам собой; для этого нужно, чтобы водитель нажимал на эту
педаль, приказывая автомобилю ехать быстрее.
Теперь давайте воспользуемся примером с автомобилем, чтобы представить
ключевые концепции объектно-ориентированного программирования, которым
посвящен данный раздел. Чтобы выполнить в программе некоторую задачу,
требуется функция (такая, как функции main из 2-й главы). Функция
описывает механизмы, которые в действительности эту задачу выполняю!1. Функция
скрывает от пользователя выполняемые ею сложные задачи, точно так же как
акселератор скрывает от водителя сложные механизмы, заставляющие
автомобиль ускоряться. В C++ мы начинаем с создания программной единицы,
называемой классом, в которую входит функция — как в чертежи автомобиля
входит конструкция педали акселератора. Как вы помните, в разделе 1.17
функция, принадлежащая классу, называлась его элемент-функцией. В классе
предусматривают одну или более элемент-функций, предназначенных для
выполнения задач класса. Например, класс, представляющий банковский счет,
может содержать одну элемент-функцию для внесения денег на счет, другую
для снятия денег со счета и третью — для справок о текущем состоянии счета.
Точно так же, как нельзя ездить на чертежах автомобиля, нельзя «ездить»
на классе. Как кто-то должен был собрать автомобиль по чертежам, прежде
чем вы сможете на нем поехать, так и вы должны создать объект класса,
прежде чем программа сможет выполнять описываемые классом задачи. Заметьте,
что из одного класса можно точно так же породить много объектов, как по
одним и тем же чертежам — собрать много автомобилей.
Когда вы ведете машину, нажатие акселератора посылает машине
сообщение — ехать быстрее. Аналогичным образом вы посылаете объекту сообщения,
каждое из которых называется вызовом элемент-функции и приказывает эле-
142
Глава 3
мент-функции объекта выполнить ее задачу. Часто это называют запросом
услуг у объекта.
Выше мы пользовались аналогией с автомобилем, чтобы представить класс,
объекты и элементы-функции. Помимо предоставляемых автомобилем
возможностей, у него имеется также множество атрибутов, таких, как цвет,
число дверей, количество бензина в баке, текущая скорость и суммарный пробег
(т.е. показания счетчика-одометра). Как и возможности автомобиля, его
атрибуты представлены в проекте и чертежах. Когда вы ведете автомобиль, они все
время с ним ассоциируются. У каждого автомобиля имеются свои собственные
атрибуты. Например, каждый автомобиль знает о том, сколько бензина у него
в баке, но не о том, сколько бензина в баках других автомобилей.
Аналогичным образом объект имеет атрибуты, которые, в процессе использования его
в программе, всегда сопровождают объект. Спецификация этих атрибутов
является частью класса объекта. Например, объект банковского счета имеет
атрибут баланса, представляющий сумму денег на счете. Каждый объект
банковского счета знает баланс счета, им представляемого, но не балансы других
счетов банка. Атрибуты специфицируются элементами данных класса.
3.3. Обзор примеров главы
В оставшейся части главы мы приводим семь простых примеров,
демонстрирующих концепции, которые мы представили в контексте аналогии с
автомобилем. Данные примеры, сводка которых дана ниже, являются
последовательными этапами построения класса GradeBook:
1. Первый пример представляет класс GradeBook с одной
элемент-функцией, которая при вызове просто выводит приветственное сообщение. Затем
мы покажем, как создать объект этого класса и вызвать его функцию,
так что она выведет упомянутое сообщение.
2. Второй пример модифицирует первый, позволяя элемент-функции
принимать название курса в качестве т.н. аргумента. Затем функция
выводит полученное название как часть приветственного сообщения.
3. Третий пример показывает, как сохранить название курса в объекте
GradeBook. В данной версии класса мы покажем также, как
использовать элемент-функции для установки названия курса в объекте и
получения названия из объекта.
4. Четвертый пример демонстрирует, как данные в объекте GradeBook
могут быть инициализированы при его создании; эта инициализация
выполняется специальной элемент-функцией, называемой конструктором
класса. Пример также показывает, что каждый объект GradeBook
хранит в своем элементе данных собственное название курса.
5. Пятый пример модифицирует четвертый, демонстрируя, как, в целях
утилизации, разместить класс GradeBook в отдельном файле.
6. Шестой пример модифицирует пятый в соответствии с одним из принципов
правильного конструирования программ, а именно, принципом отделения
интерфейса класса от его реализации. Это облегчает модификацию класса,
которая в этом случае не влияет на клиентов класса, т.е. любых классов
или функций, извне вызывающих элемент-функции объектов класса.
Введение в классы и объекты
143
7. Последний пример усовершенствует класс Grade Boo к, вводя в него
подтверждение действительности данных, гарантирующее, что данные
в объекте соответствуют определенному формату или находятся в
допустимом диапазоне значений. Например, объект Date требовал бы, чтобы
значение месяца находилось в диапазоне 1-12. В этом примере класса
GradeBook элемент-функция, устанавливающая название курса,
подтверждает, что название курса состоит из 25 или меньшего числа
символов. Если то не так, функция берет только первые 25 символов названия
и выводит предупреждающее сообщение.
Заметьте, что примеры GradeBook в этой главе на самом деле не обрабатывают
и не хранят никаких оценок. Мы начнем обрабатывать оценки с помощью класса
GradeBook в 4-й главе, а сохранять их — в 7-й главе, «Массивы и векторы».
3.4. Определение класса с элемент-функцией
Начнем с примера (рис. 3.1), состоящего из класса GradeBook, который
представляет «классный журнал», позволяющий преподавателю сохранять
оценки студентов, и функции main (строки 20-25), которая создает объект
GradeBook. Это первый из ряда постепенно усложняющихся примеров, и этот
ряд в главе 7 приведет нас к полнофункциональному классу GradeBook.
Функция main использует этот объедет и его элемент-функцию для вывода на экран
сообщения с приветствием преподавателю.
1 // Рис. 3.1: fig03_01.cpp
2 // Определить класс GradeBook с элемент-функцией displayMessage;
3 // создать объект GradeBook и вызвать его функцию displayMessage.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 // определение класса GradeBook
9 class GradeBook
10 {
11 public:
12 // функция, выводящая приветствие пользователю GradeBook
13 void displayMessage()
14 {
15 cout « "Welcome to the Grade Book!" « endl;
16 } // конец функции displayMessage
17 }; // конец класса GradeBook
18
19 // функция main начинает исполнение программы
20 int main()
21 {
22 GradeBook myGradeBook; // создать GradeBook с именем myGradeBook
23 myGradeBook.displayMessage(); // вызвать displayMessage объекта
24 return 0; // показывает успешное завершение
25 } // конец main
Welcome to the Grade Book!
Рис. З.1. Определение класса GradeBook с элемент-функцией, создание объекта
GradeBook и вызов его функции
144
Глава 3
Сначала мы расскажем, как определить класс и элемент-функцию. Затем
мы объясним, как создается объект и как вызывается элемент-функция
объекта. Первые несколько примеров содержат функцию main и класс GradeBook
в одном файле. Потом мы представим более гибкие способы организации
программ, позволяющие улучшить их конструктивные качества.
Класс GradeBook
Прежде чем функция main (строки 20-25) сможет создать объект класса
GradeBook, мы должны сообщить компилятору, какие классу принадлежат
элементы — функции и данные. Это называют определением класса.
Определение класса GradeBook (строки 9-17) содержит элемент-функцию dis-
play Mess age, которая выводит на экран сообщение (строка 15). Вспомните,
что класс — это как бы чертеж, поэтому для того, чтобы строка 15 вывела
сообщение, нам нужно «сделать» объект класса GradeBook (строка 22) и вызвать
функцию displayMessage этого объекта. Мы скоро разберем строки 22-23
более подробно.
Определение класса начинается в строке 9 ключевым словом class, за
которым следует имя класса GradeBook. По общепринятому соглашению имена
классов, определяемых пользователем, начинаются с буквы верхнего
регистра, как и каждое из последующих слов в имени, — в целях удобочитаемости.
Такой стиль употребления прописных букв часто называют верблюжьим
регистром, так как чередование прописных и строчных букв напоминает силуэт
верблюда.
Тело каждого класса заключается в пару фигурных скобок ({ и }), как в
строках 10 и 17. Определение класса оканчивается точкой с запятой (строка 17).
Типичная ошибка программирования 3.1
Отсутствие точки с запятой в конце определения класса является
синтаксической ошибкой.
Как вы помните, всегда, когда программа начинает исполняться, функция
main вызывается автоматически. Как вы скоро увидите, чтобы функция dis-
playMessage выполнила свою задачу, ее нужно вызвать явным образом.
Стока 11 содержит метку спецификатора доступа public:. Ключевое слово
public называется спецификатором доступа. Строки 13-16 определяют
элемент-функцию display Mess age. Эта функция находится после спецификатора
доступа public:; это служит указанием на то, что она «открыта для публики»,
т.е. может вызываться другими функциями программы и элемент-функциями
других классов. За спецификаторами доступа всегда следует двоеточие (:).
Далее в тексте всюду, где встречается спецификатор public, мы будем опускать
двоеточие, как в этом предложении. В разделе 3.6 вводится второй
спецификатор доступа, private (мы также опускаем двоеточие — в тексте, но не в
программах).
Каждая функция в программе выполняет некоторую задачу и может
возвращать значение, когда ее выполнение завершается, — например, функция
может производить вычисления и возвращать их результат. При определении
вы должны специфицировать возвращаемый тип, т.е. тип значения,
возвращаемого функцией по завершении ее задачи. Ключевое слово void слева от
Введение в классы и объекты 145
имени функции displayMessagc в строке 13 является возвращаемым типом
функции. Возвращаемый тип void указывает, что функция displayMessage,
выполнив свою задачу, не возвратит своей вызывающей функции (в данном
случае это, как мы сейчас увидим, main) никакого значения. (На рис. 3.5 вы
познакомитесь с примером функции, возвращающей значение.)
За возвращаемым типом следует имя функции. По соглашению имена
функций начинаются с буквы нижнего регистра, а все последующие слова в имени —
с прописной буквы. Круглые скобки после имени элемент-функции
показывают, что это функция. Пустая пара скобок, как в строке 13, означает, что данной
функции для выполнения ее задачи не требуется дополнительных данных.
В разделе 3.5 вы увидите функцию, которой требуется дополнительные
данные. Строку 13 обычно называют заголовком функции. Тело всякой функции
ограничивается парой фигурных скобок ({ и }), как в строках 14 и 16.
Тело функции содержит операторы, выполняющие ее задачу. В данном
случае элемент-функция displayMessage содержит единственный оператор
(строка 15), который выводит сообщение "Welcome to the Grade Book!". После
исполнения этого оператора задача функции завершена.
<-—=- - Типичная ошибка программирования 3.2
Возврат значения из функции, возвращаемый тип которой объявлен
как void, приводит к ошибке компиляции.
Типичная ошибка программирования 3.3
Определение функции внутри другой функции является
синтаксической ошибкой.
Тестирование класса GradeBook
Далее нам хотелось бы протестировать класс GradeBook в программе. Как
вы узнали в главе 2, выполнение всякой программы начинается с функции
main. Строки 20-25 на рис. 3.1 содержат функцию main, которая будет
контролировать выполнение нашей программы.
В этой программе мы хотим вызвать элемент-функцию displayMessage
класса GradeBook, чтобы вывести на экран сообщение. Как правило, нельзя
вызвать элемент-функцию класса, пока не будет создан объект этого класса.
(Как вы узнаете разделе 10.2, это не относится к статическим функциям
класса.) строка 22 создает объект класса GradeBook с именем myGradeBook.
Обратите внимание, что типом переменной является GradeBook — класс,
определенный нами в строках 9-17. Когда мы объявляем переменные типа int,
компилятор знает, что такое int, — это основной тип. Но что касается строки 22,
компилятору не известно автоматически, что такое тип GradeBook, — это
тип, определяемый пользователем. Таким образом, мы должны сообщить
компилятору, что такое GradeBook, включив ч программу определение
класса, что мы и делаем в строках 9-17. Если бы мы опустили эти строки,
компилятор выдал бы сообщение об ошибке (например, Microsoft Visual C-l--b.NET —
«'GradeBook': undeclared identifier» или GNU C-f+ — «'GradeBook':
undeclared»). Каждый новый класс, который вы создаете, становится новым типом,
который можно использовать для создания объектов. Программисты могут
146
Глава 3
создавать новые типы по мере необходимости; это одна из причин того, почему
C++ называют расширяемым языком.
Строка 23 вызывает элемент-функцию displayMessage (определенную
в строках 13-16) через переменную myGradeBook, за которой следуют
операция-точка (.), имя функции displayMessage и пустая пара круглых скобок.
Этот вызов заставляет функцию displayMessage выполнить свою задачу.
«myGradeBook.» в начале строки 23 указывает, что main должна использовать
объект GradeBook, созданный в строке 22. Пустые круглые скобки означают,
что для выполнения задачи функции displayMessage не требуются
дополнительные данные. (В разделе 3.5 вы увидите, как передать функции данные.)
Когда displayMessage завершит свою работу, возобновится выполнение
функции main, со строки 24, которая показывает, что main успешно выполнила
свою задачу. Это конец функции main, так что программа завершается.
Классовая диаграмма UML для класса GradeBook
Как вы можете помнить из раздела 1.17, UML — это графический язык,
используемый программистами для представления объектно-ориентированных
систем стандартизированным образом. В UML каждый класс обозначается
прямоугольником с тремя отделениями. Рис. 3.2 показывает классовую
диаграмму UML для класса GradeBook из рис. 3.1. Верхнее отделение содержит
имя класса, центрированное по горизонтали и выделенное жирным шрифтом.
Среднее отделение перечисляет атрибуты класса, которым в C++
соответствуют элементы данных. На рис. 3.2 среднее отделение пусто, так как данная
версия класса GradeBook не имеет каких-либо атрибутов. (В разделе З.б
представлена версия GradeBook с атрибутом.) Нижнее отделение перечисляет действия
класса, которым соответствуют элемент-функции C++. UML обозначает
действие его именем, за которым следует пара круглых скобок. Класс GradeBook
имеет единственную элемент-функцию displayMessage, так что список в
нижнем отделении рис. 3.2 содержит только это имя. Для выполнения своей
задачи функции displayMessage не требуется дополнительной информации,
поэтому скобки, следующие за именем элемент-функции, остаются пустыми, как
и в ее заголовке в строке 13 на рис. 3.1. Знак + перед именем действия
показывает, что displayMessage является в UML открытым действием (т.е. открытой
элемент-функцией в C++). Мы часто будем пользоваться UML, чтобы
подытожить атрибуты и действия класса.
GradeBook
+ displayMessage(}
Рис. 3.2. Диаграмма UML, показывающая, что класс GradeBook имеет открытое
действие displayMessage
Введение в классы и объекты
147
3.5. Определение элемент-функции с параметром
В нашей автомобильной аналогии из раздела 3.2 мы упомянули, что
нажатие на педаль газа посылает автомобилю сообщение с приказом выполнить
определенное действие — ехать быстрее. Но насколько быстро должен поехать
автомобиль? Как вы знаете, чем дальше вы утапливаете педаль, тем быстрее
машина едет. Так что в сообщение автомобилю входит как действие, которое
нужно выполнить, так и дополнительная информация, помогающая
автомобилю в его задаче. Эта дополнительная информация называется параметром;
значение параметра позволяет автомобилю определить, как быстро он должен
ехать. Аналогичным образом элемент-функции может потребоваться один или
несколько параметров, представляющих необходимую дополнительную
информацию. Вызов функции передает значения — называемые аргументами —
для каждого из параметров функции. Предположим, например, что для
взносов на банковский счет в классе Account имеется элемент-функция deposit,
специфицирующая параметр, представляющий сумму взноса. Когда
вызывается функция deposit, значение аргумента, равное сумме взноса, копируется
в параметр функции. Функция затем прибавляет эту сумму к общему балансу
счета.
Определение и тестирование класса GradeBook
Наш следующий пример (рис. 3.3) определяет новый класс GradeBook
(строки 14-23) с элемент-функцией displayMessage (строки 28-22), которая
выводит в приветственном сообщении название курса. Новой функции
displayMessage требуется параметр (courseName в строке 18),
представляющий название курса, которое нужно вывести.
1 // Рис. 3.3: fig03_03.cpp
2 // Определить класс GradeBook с функцией, принимающей параметр;
3 // создать объект GradeBook и вызвать его функцию displayMessage.
4 #include <iostream>
5 using std::cout;
6 using std::cin;
7 using std::endl;
8
9 #include <string> // программа использует стандартный класс string
10 using std::string;
11 using std::getline;
12
13 // определение класса GradeBook
14 class GradeBook
15 {
16 public:
17 // функция, выводящая приветствие пользователю GradeBook
18 void displayMessage( string courseName )
19 {
20 cout « "Welcome to the grade book for\n « courseName « "!"
21 « endl;
22 } // конец функции displayMessage
23 }; // конец класса GradeBook
24
25 // функция, main начинает исполнение программы
148
Глава 3
26 int main ()
27 {
28 string nameOfCourse; // строка для хранения названия курса
29 GradeBook myGradeBook; // создать GradeBook с именем myGradeBook
30
31 // запросить и ввести название курса
32 cout « "Please enter the course name:" « endl;
33 getline( cin, nameOfCourse ); // прочитать название с пробелами
34 cout « endl; // вывести пустую строку
35
36 // вызвать функцию displayMessage объекта myGradeBook
37 // и передать ей nameOfCourse в качестве аргумента
38 myGradeBook.displayMessage( nameOfCourse );
39 return 0; // показывает успешное завершение
40 } // конец main
Please enter the course name:
CS101 Introduction to C++ Programming
Welcome to the grade book for
CS101 Introduction to C++ Programming!
Рис. 3.3. Определение класса GradeBook с элемент-функцией, принимающей
параметр
Перед тем, как обсудить несколько новых особенностей класса GradeBook,
давайте посмотрим, как этот класс используется в main (строки 26-40).
Строка 28 создает переменную типа string с именем nameOfCourse, в которой
будет храниться введенное пользователем название курса. Переменная типа
string представляет строку символов, например, "CS101 Introduction to C++
Programming". На самом деле она является объектом класса string из
Стандартной'библиотеки C++. Класс определяется в заголовочном файле <string>,
и имя string, подобно cout, принадлежит пространству имен std. Чтобы строка
28 могла быть компилирована, в строке 9 включается заголовок <string>.
Обратите внимание, что объявление using в строке 10 позволяет нам написать
в строке 28 просто string вместо std::string. Пока вы можете рассматривать
переменные типа string подобно переменным других типов, например, int. О
дополнительных возможностях класса string вы узнаете в разделе 3.10.
Строка 29 создает объект класса GradeBook с именем myGradeBook.
Строка 32 просит пользователя ввести название курса. Строка 33 читает название
и присваивает его переменной nameOfCourse, применяя для ввода
библиотечную функцию get line. Перед тем, как объяснить эту строку кода, давайте
рассмотрим, почему для получения названия курса мы не можем просто написать
cin » nameOfCourse;
При пробном запуске нашей программы мы вводим название «CS101
Introduction to C++ Programming», состоящее из нескольких слов. Операция
извлечения, применяемая к потоку cin, читает символы до тех пор, пока не
будет достигнут первый пробельный символ. Таким образом, предыдущий
оператор прочитал бы только «CS101». Оставшаяся часть названия курса должна
была бы читаться последующими операторами ввода.
Введение в классы и объекты
149
В этом примере нам хотелось бы, чтобы пользователь вводил полное
название курса, посылая его в программу нажатием Enter, и чтобы введенное
название целиком хранилось в строковой переменной nameOfCourse. Вызов
функции getline( cin, nameOfCourse ) в строке 33 читает символы (включая
символы пробела, разделяющие слова при вводе) из объекта стандартного ввода cin
(т.е. с клавиатуры) до тех пор, пока не встретится символ новой строки, и
записывает их в строковую переменную nameOfCourse, причем символ новой
строки отбрасывается. (Этот символ помещается во входной поток, когда вы
нажимаете клавишу Enter.) Заметьте также, что для вызова функции getline
нужно включить в программу заголовочных! файл <string> и что имя getline
принадлежит пространству имен std.
Строка 38 вызывает функцию display Message, элемент myGradeBook.
Переменная nameOfCourse в скобках является аргументом, передаваемым
функции display Message, чтобы последняя могла выполнить срою задачу. Значение
переменной nameOfCourse в main становится значением параметра courseNa-
me элемент-функции displayMessage (строка 18). Обратите внимание, что при
выполнении программы displayMessage выводит в качестве части
сообщения-приветствия напечатанное вами название курса (в нашем случае это
CS101 Introduction to C++ Programming).
Подробнее об аргументах и параметрах
Для указания того, что для выполнения своей задачи функции требуется
дополнительная информация, эта информация помещается в список
параметров функции, записываемый в круглых скобках после ее имени. Список
параметров может содержать любое их число, включая нулевое, если функции не
требуется никаких параметров (последний случай представлен пустыми
скобками в строке 13 на рис. 3.1). Список параметров элемент-функции
displayMessage (строка 18 на рис. 3.3) объявляет, что функции требуется один
параметр. Каждый параметр должен специфицировать тип и идентификатор.
В данном случае тип string и идентификатор courseName указывают, что
функции displayMessage для выполнения ее задачи требуется строка. Тело
функции использует параметр courseName для доступа к значению,
переданному функции в вызове (строка 38 в main). В строках 20-21 значение
параметра courseName выводится в качестве части приветственного сообщения.
Заметьте, что имя переменной-параметра (строка 18) может быть тем же самым,
а может отличаться от имени переменной-аргумента (строка 38); почему, вы
узнаете в главе 6.
При спецификации функцией нескольких параметров каждый
последующий параметр отделяется от предыдущего запятой (мы увидим пример этого
на рис. 6.4-6.5). Число и порядок аргументов в вызове функции должны
соответствовать числу и порядку параметров в заголовке вызываемой
элемент-функции. Кроме того, типы аргументов в вызове функции должны
соответствовать типам параметров в ее заголовке. (Как вы узнаете из последующих
глав, типы аргумента и соответствующего ему параметра не обязаны быть
идентичными, но они должны быть «согласованы».) В нашем примере один
аргумент типа string в вызове функции (т.е. nameOfCourse) точно
соответствует одному параметру типа string в определении элемент-функции (т.е.
courseName).
150
Глава 3
Типичная ошибка программирования 3.4
Точка с запятой после правой скобки, заключающей список
параметров в определении функции, является синтаксической ошибкой.
Типичная ошибка программирования 3.5
Повторное определение параметра функции в качестве ее локальной
переменной приводит к ошибке компиляции.
Хороший стиль программирования 3.1
Чтобы избежать двусмысленности, не используйте одинаковых имен
для передаваемых функции аргументов и соответствующих им
параметров в определении функции.
Хороший стиль программирования 3.2
Выбор осмысленных имен для функций и их параметров делает
программу более ясной и помогает избежать написания избыточных
комментариев.
Модифицированная классовая диаграмма UML для GradeBook
Классовая диаграмма UML на рис. 3.4 моделирует класс GradeBook из
рис. 3.3. Как и класс GradeBook, опредляемый на рис. 3.1, данный класс
GradeBook содержит открытую элемент-функцию displayMessage. Однако данная
версия displayMessage имеет параметр. В UML параметр моделируется
указанием (в скобках за именем действия) имени параметра, за которым следует
двоеточие и тип параметра. UML имеет свои собственные типы данных,
сходные с типами C++. Но UML независим от языка — он используется со многими
языками программирования, — поэтому его терминология не вполне
совпадает с терминологией C++. Например, типу C++ string соответствует UML-тип
String. Элемент-функция displayMessage класса GradeBook (рис. 3.3,
строки 18-22) имеет параметр типа string с именем eourseName, поэтому на
рис. 3.4 в скобках за именем действия displayMessage стоит eourseName :
String. Заметьте, что данная версия класса GradeBook все еще не имеет
никаких элементов данных.
GradeBook
+ displayMessage( eourseName : String )
Рис. 3.4. Диаграмма 11МЦ показывающая, что класс GradeBook имеет открытое
действие displayMessage с параметром eourseName UML-типа String
Введение в классы и объекты
151
3.6. Элементы данных, set-функции и get-функции
Во 2-й главе все переменные программы мы объявляли в ее функции main.
Переменные, объявленные в теле определения функции, называются
локальными переменными и могут использоваться в ней, начиная от строки с их
объявлением и до ближайшей закрывающей фигурной скобки (}) определения
функции. Локальная переменная должна быть объявлена до того, как ее
можно будет использовать. К локальной переменной нельзя обращаться извне
функции, которая ее объявляет. Когда функция завершается, значения всех ее
локальных переменных теряются. (Исключение из этого правила вы увидите
в главе 6, где мы обсуждаем статические локальные переменные.) Как вы
помните из раздела 3.2, у объекта имеются атрибуты, которые сопровождают
его везде, где этот объект используется в программе. Такие атрибуты
существуют на протяжении всей жизни объекта.
Обычно класс состоит из одной или нескольких элемент-функций, которые
манипулируют атрибутами, принадлежащими конкретному объекту данного
класса. Атрибуты представляются переменными в определении класса. Эти
переменные называются элементами данных и объявляются внутри определения
класса, но вне тела определений его элемент-функций. Каждый объект класса
сохраняет в памяти свой собственный экземпляр своих атрибутов. Пример этого
раздела демонстрирует класс GradeBook, который содержит элемент данных
courseName, представляющий название курса конкретного объекта GradeBook.
Класс GradeBook с элементом данных, set-функцией
и get-функцией
В нашем следующем примере класс GradeBook сохраняет название курса
в качестве элемента данных, так что оно может использоваться или
модифицироваться в любой момент в процессе исполнения программы. Класс
содержит элемент-функции setCourseName, getCourseName и display Message.
Элемент-функция setCourseName сохраняет название курса в элементе данных
класса GradeBook, a getCourseName получает название из этого элемента
данных. Элемент-функция displayMessage — которая теперь не специфицирует
никаких параметров — по-прежнему выводит приветственное сообщение,
включающее название курса. Однако как вы увидите, функция получает
название, вызывая другую функцию того же класса — getCourseName.
1 // Рис. 3.5: fig03_05.cpp
2 // Определить класс GradeBook, содержащий элемент данных courseName
3 //и элемент-функции для установки и извлечения его значений;
4 // создать и протестировать объект GradeBook.
5 #include <iostream>
6 using std::cout;
7 using std::cin;
8 using std::endl;
9
10 #include <string> // программа использует стандартный класс string
11 using std::string;
12 using std:igetline;
13
14 // определение класса GradeBook
15 class GradeBook
152
Глава 3
16 {.
17 public:
18 // функцияf устанавливающая название курса
19 void setCourseName( string name )
20 {
21 courseName = name; // сохранить название курса в объекте
22 } // конец функции setCourseName
23
24 // функция, получающая название курса
25 string getCourseName()
26 {
27 return courseName; // возвратить courseName объекта
28 } // конец функции getCourseName
29
30 // функция, выводящая сообщение-приветствие
31 void displayMessage()
32 {
33 // этот оператор вызывает getCourseName, чтобы получить
34 // название курса, представленного данным GradeBook
35 cout « "Welcome to the grade book for\n" « getCourseName ()
36 « " !" « endl;
37 } // конец функции displayMessage
38 private:
39 string courseName; // название курса для данного GradeBook
40 }; // конец класса GradeBook
41
42 // функция main начинает исполнение программы
43 int main()
44 {
45 string nameOfCourse; // строка для хранения названия курса
46 GradeBook myGradeBook; // создать GradeBook с именем myGradeBook
47
48 // вывести исходное значение courseName
49 cout « "Initial course name is: " « myGradeBook.getCourseName()
50 « endl;
51
52 // запросить, ввести и установить название курса
53 cout « "\nPlease enter the course name:" « endl;
54 getline( cin, nameOfCourse ); // прочитать название с пробелами
55 myGradeBook.setCourseName( nameOfCourse ); // установить название
56
57 cout « endl; // выводит пустую строку
58 myGradeBook.displayMessage(); // вывести новое название курса
59 return 0; // показывает успешное завершение
60 } // конец main
Initial course name is:
Please enter the course name:
CS 101 Introduction to C++ Programming
Welcome to the grade book for
CS 101 Introduction to C++ Programming!
Рис. З.5. Определение и тестирование класса GradeBook с элементом данных,
set-функцией и c/ef-функцией
Введение в классы и объекты
153
Хороший стиль программирования 3.3
Чтобы программу было легче читать, вставляйте между
определениями элемент-функций пустые строки.
Типичный преподаватель ведет, как правило, больше одного курса,
каждый из которых имеет свое собственное название. Строка 39 объявляет, что
courseName является переменной типа string. Поскольку эта переменная
объявляется внутри определения класса (строки 15-40), но вне тел определений
его элемент-функций (строки 19-22, 25-28 и 31-37), строка 39 является
объявлением элемента данных. Каждый представитель (т.е. объект) класса
GradeBook содержит по одному экземпляру каждого из элементов данных
класса. Например, если есть два объекта GradeBook, то, как мы увидим в
примере на рис. 3.7, каждый из них имеет свой собственный экземпляр
courseName (по одному на объект). Выгода от реализации courseName в виде
элемента данных состоит в том, что все элемент-функции класса (в данном
случае GradeBook) могут манипулировать любыми элементами данных,
входящими в определение класса (в данном случае элементом courseName).
Спецификаторы доступа public и private
Объявления элементов данных размещаются по большей части после метки
спецификатора доступа private: (строка 38). Переменные или функции,
объявленные после спецификатора private: (и до следующего спецификатора
доступа) доступны только для функций-элементов класса, в котором они
объявлены. Таким образом, элемент данных courseName может использоваться
только в элемент-функциях setCourseName, getCourseName и displayMessage
(каждого объекта) класса GradeBook. К закрытому (т.е. объявленному как
private) элементу данных courseName не могут обращаться никакие функции,
не принадлежащие классу (такие, как main), или элемент-функции других
классов в программе. Попытка обращения к courseName из этих мест
программы посредством выражения вида myGradeBook.courseName приведет
к ошибке компиляции с выдачей сообщения вроде
cannot access private member declared in class 'GradeBook'
Общее методическое замечание 3.1
В качестве общего правила, элементы данных следует объявлять как
private, а элемент-функции — как public. (В дальнейшем мы увидим,
что некоторые элемент-функции целесообразно объявлять private,
если к ним обращаются только функции того же класса.)
;н Типичная ошибка программирования 3.6
Попытка функции, не являющейся элементом некоторого класса (или
другом этого класса, как мы увидим в главе 10), обратиться к
закрытому элементу класса приводит к ошибке компиляции.
Доступ по умолчанию к элементам класса — закрытый (private), поэтому
все элементы между заголовком класса и первым спецификатором доступа
являются закрытыми. Спецификаторы public и private могут повторяться, хотя
в этом нет необходимости и может приводить к путанице.
154
Глава 3
Хороший стиль программирования 3.4
Несмотря на тот факт, что спецификаторы public и private могут
повторяться и перемежаться, перечисляйте сначала в одной группе
все открытые элементы класса, а затем в другой группе — все его
закрытые элементы. Это сразу привлекает внимание пользователя
к открытому интерфейсу класса, а не к его реализации.
Хороший стиль программирования 3.5
Если вы захотите расположить в начале определения класса
закрытые элементы, явно укажите для них спецификатор private, хотя он
и предполагается по умолчанию. Это улучшает ясность программы.
Объявление элементов данных со спецификатором доступа private известно
как сокрытие данных. Когда программа создает объект (представитель)
класса GradeBook, элемент данных courseName инкапсулируется (скрывается)
в объекте и оказывается доступным только для элемент-функций класса
объекта. В классе GradeBook элементом courseName непосредственно
манипулируют функции setCourseName и getCourseName (то же, при необходимости,
могла бы делать и display Message).
Общее методическое замечание 3.2
В главе 10 мы увидим, что к закрытым элементам класса могут
обращаться функции и классы, объявленные друзьями этого класса.
Предотвращение ошибок 3.1
Объявление элементов данных класса закрытыми, а
элемент-функций открытыми упрощает отладку, поскольку проблемы с
обработкой данных локализуются либо в элемент-функциях, либо в друзьях
класса.
Элемент-функции setCourseName и getCourseName
Элемент-функция setCourseName (определена в строках 19-22) не
возвращает по завершении своей работы никаких данных, поэтому ее возвращаемым
типом является void. Функция имеет один параметр (name), представляющий
название курса, которое будет передаваться функции в качестве аргумента
(как мы увидим, в строке 55 функции main). Строка 21 присваивает name
элементу данных courseName. В этом примере setCourseName не пытается
произвести подтверждение названия курса — т.е. функция не проверяет, что
название курса согласуется с каким-то определенным форматом или следует
каким-либо другим правилам, касающимся того, как выглядит «правильное»
название. Предположим, к примеру, что университет может распечатывать
копии зачетных ведомостей, содержащие в названиях курсов не более 25
символов. В этом случае нам захочется, чтобы класс GradeBook гарантировал, что
элемент данных courseName никогда не будет содержать более 25 символов.
Элементарные методики подтверждения будут обсуждаться в разделе 3.10.
Элемент-функция getCourseName (определенная в строках 25-28)
возвращает courseName конкретного объекта GradeBook. Функция имеет пустой
Введение в классы и объекты 155
список параметров, поэтому для выполнения своей задачи ей не требуется
никакой дополнительной информации. Функция специфицирует, что ее
возвращаемым типом является string. Когда вызывается функция,
специфицирующая отличный от void возвращаемый тип, то по завершении своей работы она
возвращает результат вызвавшей функции. Например, когда вы пользуетесь
банкоматом и справляетесь о балансе своего текущего счета, то ожидаете, что
банкомат возвратит вам значение, представляющее ваш баланс. Аналогичным
образом, когда оператор вызывает элемент-функцию getCourseName на
объекте Grade Во ok, он ожидает, что получит название курса этого объекта (в
данном случае в виде string, что специфицируется возвращаемым типом
функции). Если у вас есть функция square, возвращающая квадрат своего
аргумента, оператор
int result = square( 2 );
получает от функции square возвращаемое значение 4 и инициализирует
значением 4 переменную result. Если имеется функция maximum,
возвращающая наибольший из трех ее аргументов, оператор
int biggest = maximum ( 27, 114, 51 );
возвращает из функции maximum результат 114 и инициализирует
переменную biggest значением 114.
— - Типичная ошибка программирования 3.7
Если не возвратить значение из функции, которая предполагается
возвращающей значение, это приведет к ошибке компиляции.
Обратите внимание, что каждый из операторов в строках 21 и 27
используют переменную courseName (строка 39), хотя она не объявляется ни в одной
из элемент-функций. Мы можем обращаться к courseName в
элемент-функциях класса GradeBook, поскольку courseName является элементом данных
этого класса. Заметьте также, что порядок, в котором определяются
элемент-функции, не связан с тем, в каком порядке они вызываются во время
исполнения. Поэтому функция getCourseName могла бы определяться перед
setCourseName.
Элемент-функция display Message
Элемент-функция displayMessage (строки 31-37) не возвращает по
завершении работы никаких данных, поэтому ее возвращаемый тип — void. Функция
не принимает аргументов, поэтому ее список параметров пуст. Строки 35-36
выводят приветственное сообщение, в которое входит значение элемента
данных courseName. Для получения значения courseName строка 35 вызывает
элемент-функцию getCourseName. Заметьте, что элемент-функция
displayMessage могла бы обращаться к элементу данных courseName
непосредственно, точно так же, как setCourseName и getCourseName. Немного позже мы
объясним, почему для получения значения courseName мы предпочли
вызвать элемент-функцию getCourseName.
156
Глава 3
Тестирование класса GradeBook
Функция main (строки 43-60) создает один объект класса GradeBook и
вызывает каждую из его элемент-функций. Строка 46 создает объект GradeBook
с именем my GradeBook. Строки 49-50 выводят исходное название курса,
вызывая элемент-функцию getCourseName объекта. Заметьте, что в первой
строчке вывода программы отсутствует название курса, поскольку элемент
данных courseName объекта (т.е. string) исходно пуст — по умолчанию
начальное значение объекта string является т. н. пустой строкой, т.е. строкой,
не содержащей никаких символов. Когда выводится пустая строка, на экране
ничего не появляется.
Строка 53 просит пользователя ввести название курса. Локальная
переменная nameOfCourse типа string (объявленная в строке 45) устанавливается
введенным значением, которое получается посредством вызова функции getline
(строка 54). Строка 55 вызывает функцию setCourseName объекта myGra-
deBook, передавая последней в качестве аргумента nameOfCourse. При вызове
элемент-функции setCourseName (строки 19-22) значение аргумента
копируется в ее параметр name (строка 19). Затем значение параметра присваивается
элементу данных courseName (строка 21). Строка 57 пропускает одну строчку
вывода; строка 58 вызывает функцию displayMessage объекта my GradeBook,
чтобы вывести сообщение, содержащее название курса.
Set- и get-функции в конструировании программного обеспечения
Закрытые элементы данных класса могут обрабатываться только
элемент-функциями этого класса (и «друзьями» класса, как мы увидим в
главе 10). Поэтому клиент объекта — т.е. любой класс или любая функция, что
вызывает элемент-функции объекта извне — для запроса услуг конкретных
объектов класса вызывает открытые элемент-функции последнего. Вот почему
операторы в функции main (строки 43-60 на рис. 3.5) вызывают
элемент-функции setCourseName, gctCourseName и displayMessage на объекте
GradeBook В классах часто предусматриваются открытые элемент-функции,
позволяющие клиентам класса устанавливать (set) или получать (get)
закрытые элементы данных. Имена таких функций не обязательно должны
начинаться с set или get, но такое соглашение об именах является общепринятым.
В данном примере элемент-функция, устанавливающая значение элемента
данных courseName, называется setCourseName, а функция, получающая его
значение, называется getCourseName. Отметим, что set функции иногда
называют также mutators, (поскольку они вызывают «мутацию», изменение
значений), а get-функции — accessors (поскольку они осуществляют доступ, access,
к значениям).
Вспомните, что объявление элементов данных со спецификатором доступа
private осуществляет сокрытие данных. Предоставляя клиентам set и get -функции,
класс позволяет им обращаться к скрытым данным, но только косвенным
образом. Клиент знает, что пытается модифицировать или получить данные
объекта, но не знает, каким образом объект производит эти действия. В
некоторых случаях внутреннее представление единицы данных в классе отличается
от того, как класс представляет эти данные клиентам. Предположим,
например, класс Clock представляет время дня закрытым элементом данных time
типа int, в котором хранится число секунд, прошедшее с полуночи. Однако ко-
Введение в классы и объекты
157
гда клиент вызывает элемент-функцию getTime объекта Clock, объект мог бы
возвращать время в виде строки в формате "HH:MM:SS". Точно так же
предположим, что класс Clock предусматривает sef-функцию setTime,
принимающую строковый параметр в формате "HH:MM:SS". Используя широкие
возможности класса string, функция setTime могла бы преобразовывать эту
строку в число секунд, прошедшее с полуночи, которое сохранялось бы в закрытом
элементе данных. Set-функция могла бы также проверять, что получаемое ею
значение представляет допустимое время (например, 2:30:45" — допустимое
значение, а 2:85:70" — нет). Set- и gef-функции позволяют клиенту
взаимодействовать с объектом, но закрытые данные последнего остаются надежно
инкапсулированными (т.е. скрытыми) в самом объекте.
Целесообразно также использование set- и get-функций класса другими
элемент-функциями этого класса для обработки закрытых данных, хотя эти
функции могут обращаться к ним непосредственно. На рис. 3.5
setCourseName и getCourseName являются открытыми элемент-функциями,
поэтому они доступны как для клиентов, так и для самого класса.
Элемент-функция displayMessage для получения в целях вывода значения
элемента данных courseName вызывает getCourseName, хотя могла бы
непосредственно обращаться к courseName. Доступ к элементу данных через его get-
-функцию позволяет создать лучший, более устойчивый класс (т.е. класс,
который проще сопровождать и который с меньшей вероятностью откажется
работать). Если мы решим каким-то образом изменить элемент данных
courseName, определение displayMessage не потребуется модифицировать;
изменения затронут только тела set- и £е*-функций, которые непосредственно
манипулируют данными. Предположим, например, что мы решаем
представлять название курса двумя отдельными элементами данных — courseNumber
(напр., "CS101") и courseTitle (напр., "Introduction to C++ Programming").
Функция displayMessage по-прежнему могла бы получать полное название
курса (для вывода в качестве части приветствия) посредством единственного
вызова элемент-функции getCourseName. В этом случае getCourseName
должна была бы построить и возвратить строку, содержащую courseNumber,
за которым следует courseTitle. Функция displayMessage по-прежнему
выводила бы полное название курса «CS101 Introduction to C++ Programming»,
поскольку ее не затрагивают изменения элементов данных класса. Выгоды от
вызова sef-функции из другой элемент-функции класса станут ясны, когда мы
обсудим подтверждение данных в разделе 3.10.
Хороший стиль программирования 3.6
Всегда старайтесь локализовать эффекты изменения элементов
данных класса путем организации доступа к ним через их set- и
get-функции. Изменение имени элемента данных или типа, используемого для
его хранения повлияет в этом случае только на соответствующие
set- и get-функции, но не на функции, которые их вызывают.
Общее методическое замечание 3.3
Важно писать понятные и легко сопровождаемые программы.
Изменения программ являются скорее правилом, чем исключением.
Программисты должны предвидеть, что их код будет модифицироваться.
158
Глава 3
Ш Общее методическое замечание 3.4
Проектировщику класса не требуется предусматривать set-
и get-функции для каждого закрытого элемента данных; это нужно
делать только там, где это целесообразно. Если услуга полезна коду
клиента, открытый интерфейс класса должен, как правило, ее
предоставлять.
Классовая диаграмма UML для GradeBook с элементом данных,
set- и get-функциями
На рис. 3.6 приведена модифицированная классовая диаграмма UML для
версии класса GradeBook из рис. 3.5. В своем среднем отделении диаграмма
моделирует в качестве атрибута элемент данных courseName класса
GradeBook. UML представляет элементы данных как атрибуты, указывая имя
атрибута, за которым следует двоеточие и тип атрибута. UML-типом атрибута
courseName является String, которому в C++ соответствует string. В C++
элемент данных courseName является закрытым, поэтому на диаграмме UML
перед именем соответствующего атрибута указан знак минуса (-). Минус в UML
эквивалентен спецификатору доступа private в C++. Класс GradeBook
содержит три открытых элемент-функции, поэтому в третьем отделении диаграммы
UML перечислены три действия. Как вы помните, плюс (+) перед каждым из
действий показывает, что в C++ действие специфицируется как public.
Действие setCourseNstme имеет параметр типа String с именем пате.
Возвращаемый действием тип обозначается в UML двоеточием и возвращаемым типом
после скобок, следующих за именем действия. Элемент-функция getCour-
seName класса GradeBook (рис. 3.5) имеет в C++ возвращаемый тип string,
поэтому диаграмма на рис. 3.6 специфицирует возвращаемый UML-тип
String. Заметьте, что действия setCourseName и displayMessage не
возвращают значений (т.е. возвращают void), поэтому классовая диаграмма UML не
специфицирует для этих действий никакого типа после скобок. В UML не
используется тип void, как это делается в C++, когда функция не возвращает
значения.
GradeBook
- courseName : String
+ setCourseName( name : String )
+ setCourseName(): String
+ displayMessage()
Рис, 3.6, Классовая диаграмма UML для класса GradeBook с закрытым атрибутом
courseName и открытыми действиями setCourseName, getCourseName
и displayMessage
Введение в классы и объекты
159
3.7. Инициализация объектов при помощи
конструкторов
Как упоминалось в разделе 3.6, при создании объекта класса GradeBook
(рис. 3.5) его элемент данных courseName по умолчанию инициализируется
пустой строкой. Что, если вы хотите, создавая объект GradeBook, сразу задать
название курса? В каждом определяемом вами классе можно предусмотреть
конструктору который можно использовать для инициализации объекта
класса при его создании. Конструктор является специальной
элемент-функцией класса, которая должна определяться с тем же именем, что и класс, чтобы
компилятор мог отличить его от других функций класса. Важным отличием
конструкторов от других функций является то, что конструкторы не
возвращают значений, так что они не могут специфицировать возвращаемый тип
(даже void). Обычно конструкторы объявляются открытыми. В литературе
термин «constructor» часто сокращают до «ctor»; мы предпочитаем не
пользоваться этой аббревиатурой.
C++ требует вызова конструктора для каждого создаваемого объекта, что
позволяет гарантировать корректную инициализацию объекта перед тем, как
он будет использоваться в программе — когда объект создается, вызов
конструктора происходит автоматически. Любому классу, который не определяет
конструктор явным образом, компилятор предоставляет конструктор по
умолчанию, т.е. конструктор без параметров. Например, когда строка 46 на
рис. 3.5 создает объект GradeBook, вызывается конструктор по умолчанию,
так как объявление myGradeBook не специфицирует каких-либо аргументов
конструктора. Конструктор по умолчанию, предоставленный компилятором,
создает объект GradeBook, не давая его элементам данных каких-либо
начальных значений. [Замечание. Для элементов данных, являющихся объектами
каких-либо других классов, конструктор по умолчанию неявно вызывает их
конструкторы по умолчанию, чтобы гарантировать корректную
инициализацию элементов данных. На самом деле именно поэтому элемент courseName
(на рис. 3.5) типа string инициализировался пустой строкой — конструктор по
умолчанию класса string устанавливает в качестве значения объекта string
пустую строку. В разделе 10.3 вы больше узнаете об инициализации элементов
данных, являющихся объектами других классов.]
В примере на рис. 3.7 мы специфицируем название курса для объекта
GradeBook при его создании (строка 49). В данном случае конструктору
объекта GradeBook (строки 17-20) передается аргумент "CS101 Introduction to C++
Programming", используемый для инициализации courseName. Рис. 3.7
определяет модифицированный класс GradeBook, содержащий конструктор с
параметром типа string, принимающим начальное название курса.
1 // Рис. 3.7: fig03_07.cpp
2 // Создание нескольких объектов класса GradeBook и использование
3 // конструктора GradeBook для спецификации названия курса
4 // при создании каждого из объектов GradeBook.
5 #include <iostream>
6 using std::cout;
7 using std::endl;
8
9 #include <string> // программа использует стандартный класс string
160
Глава 3
10 using std::string;
11
12 // определение класса GradeBook
13 class GradeBook
14 {
15 public:
16 // конструктор инициализирует courseName переданной строкой
17 GradeBook( string name )
18 {
19 setCourseName( name ); // инициализировать вызовом set-функции
20 } // конец конструктора GradeBook
21
22 // функция для установки названия курса
23 void setCourseName( string name )
24 {
25 courseName = name; // сохранить название курса в объекте
26 } // конец функции setCourseName
27
28 // функция для получения названия курса
29 string getCourseName()
30 {
31 return courseName; // возвратить courseName объекта
32 } // конец функции getCourseName
33
34 // вывести сообщение-приветствие пользователю GradeBook
35 void displayMessage()
36 {
37 // вызвать getCourseName для получения courseName
38 cout « "Welcome to the grade book for\n" « getCourseName()
39 « M!" « endl;
40 } // конец функции displayMessage
41 private:
42 string courseName; // название курса для данного GradeBook
43 }; // конец класса GradeBook
44
45 // функция main начинает исполнение программы
46 int main()
47 {
48 // создать два объекта GradeBook
49 GradeBook gradeBookl( "CS101 Introduction to C++ Programming" );
50 GradeBook gradeBook2( "CS102 Data Structures in C++" );
51
52 // вывести исходное значение courseName для каждого GradeBook
53 cout « "gradeBookl created for: " « gradeBookl.getCourseName()
54 « "\ngradeBook2 created for: " « gradeBook2.getCourseName()
55 « endl;
56 return 0; // показывает успешное завершение
57 } // конец main
gradeBookl created for: CS101 Introduction to C++ Programming
gradeBook2 created for: CS102 Data Structures in C++
Рис. З.7. Создание нескольких представителей класса GradeBook и использование
конструктора GradeBook для спецификации названия курса при создании каждого
объекта класса
Введение в классы и объекты
161
Определение конструктора
Строки 17-20 на рис. 3.7 определяют конструктор для класса GradeBook.
Обратите внимание, что конструктор имеет то же имя, что и его класс,
GradeBook. В своем списке параметров конструктор специфицирует данные,
которые ему требуются для выполнения своей задачи. Когда вы создаете
новый объект, то помещаете эти данные в круглые скобки, следующие за именем
объекта (как это делаем мы в строках 49-50). Строка 17 указывает, что
конструктор класса GradeBook имеет строковый параметр с именем name.
Заметьте, что в строке 17 не специфицируется возвращаемый тип, так как
конструкторы не могут возвращать значений (или даже void).
Строка 19 в теле конструктора передает параметр конструктора name
элемент-функции setCourseName, которая присваивает значение элементу
данных courseName. Функция setCourseName (строки 23-26) просто присваивает
просто присваивает свой параметр name элементу данных courseName,
поэтому у вас может возникнуть вопрос, зачем мы вызываем ее в строке 19 —
конструктор, без сомнения, мог бы сам выполнить присваивание courseName =
name. В разделе 3.10 мы модифицируем setCourseName так, что она будет
производить подтверждение (гарантируя, в данном случае, что длина
courseName не превосходит 25 символов). Тогда преимущества вызова
setCourseName из конструктора станут ясны. Заметьте, что и конструктор
(строка 17), и функция setCourseName (строка 23) используют параметр
с именем name. Вы можете использовать в различных функциях параметры
с одинаковыми именами, потому что параметры являются в каждой функции
локальными; они не пересекаются друг с другом.
Тестирование класса GradeBook
Строки 46-57 на рис. 3.7 определяют функцию main, которая тестирует
класс GradeBook и демонстрирует инициализацию объектов GradeBook с
помощью конструктора. Строка 49 в функции main создает и инициализирует
объект GradeBook с именем gradeBookl. Когда эта строка исполняется, для
инициализации названия курса в gradeBookl вызывается (неявно)
конструктор GradeBook (строки 17-20) с аргументом "CS101 Introduction to C++
Programming". Строка 50 повторяет этот процесс для объекта GradeBook
с именем gradeBook2, передавая на этот раз для инициализации названия
курса в gradeBook2 аргумент "CS102 Data Structures in C++". Строки 53-54
используют функцию getCourseName каждого объекта для получения
названий курсов и демонстрации того, что они действительно были
инициализированы при создании объектов. Вывод программы подтверждает, что каждый
объект GradeBook сохраняет свой собственный экземпляр элемента данных
courseName.
6 Заг 1114
162
Глава 3
Два способа обеспечить класс конструктором, по умолчанию
Любой конструктор, не принимающий аргументов, называется
конструктором по умолчанию. Класс получает конструктор по умолчанию в двух случаях:
1. Для класса, который не определяет конструктора, конструктор по
умолчанию неявно создается компилятором. Такой конструктор не
инициализирует элементов данных класса, однако вызывает конструктор по
умолчанию для каждого элемента, являющегося объектом другого класса.
[Замечание. Неинициализированная переменная обычно содержит значе-
ние-«мусор» (например, неинициализированная целая переменная
может содержать -858993460, что в большинстве программ будет,
вероятно, недопустимым значением для этой переменной).]
2. Программист явным образом определяет конструктор, не принимающий
аргументов. Такой конструктор будет производить инициализацию,
специфицированную программистом, и вызовет конструктор по умолчанию
для каждого элемента данных, являющегося объектом другого класса.
Если программист определяет конструктор с аргументами, C++ не будет
неявно создавать для этого класса конструктор по умолчанию. Заметьте, что для
каждой версии класса GradeBook на рис. 3.1, 3.3 и 3.5 компилятор неявно
определял конструктор по умолчанию.
Предотвращение ошибок 3.2
Если только не окажется так, что элементы данных вашего класса
не требуют никакой инициализации (так не бывает почти никогда),
определяйте конструктор, гарантирующий, что элементы данных
каждого вновь созданного объекта класса будут инициализированы
осмысленными значениями.
Общее методическое замечание 3.5
Элементы данных могут инициализироваться конструктором
класса, либо их значения могут устанавливаться позднее, после создания
объекта. Однако согласно принципам правильного стиля
конструирования программного обеспечения, объект должен быть полностью
инициализирован до того, как код клиента станет вызывать его
элемент-функции. Вообще говоря, не следует полагаться на то, что код
клиента гарантирует корректную инициализацию объекта.
Добавление конструктора к классовой диаграмме UML для
GradeBook
Классовая диаграмма UML на рис. 3.8 моделирует класс GradeBook из
рис. 3.7, который имеет конструктор с параметром name типа string
(представляемого в UML типом String). Подобно действиям, конструкторы
моделируются в UML в третьем отделении класса на классовой диаграмме. Чтобы
отличить конструктор от действий класса, перед именем конструктора
помещается слово «constructor» в угловых кавычках (« и »). Обычно конструктор
класса записывают перед другими действиями в третьем отделении.
Введение в классы и объекты
163
GradeBook
- courseName : String
«constructor» + GradeBook( name : String )
+ setCourseName( name : String )
+ setCourseName(): String
+ displayMessage()
Рис. 3.8. Классовая диаграмма UML, показывающая, что класс GradeBook имеет
конструктор с параметром name UML-типа String
3.8. Размещение класса в отдельном файле
Мы уже развили класс GradeBook настолько, насколько это нам
необходимо с точки зрения программирования, поэтому давайте теперь займемся
некоторыми вопросами конструирования программного обеспечения. Одним из
преимуществ создания определений классов является то, что наши классы,
правильно «упакованные», могут утилизироваться всеми программистами,
в идеале — по всему миру. Например, мы можем утилизировать тип string из
Стандартной библиотеки C++ в любой программе на C++, включив в
последнюю заголовочный файл <string> (и, как мы увидим, имея также
возможность компоновки с объектным кодом библиотеки).
К сожалению, программисты, которые пожелают использовать наш класс
GradeBook, не смогут этого сделать, просто включив в другую программу файл
из рис. 3.7. Как вы узнали в главе 2, исполнение любой программы
начинается с функции main, и в каждой программе должна быть в точности одна main.
Если другой программист включит в свою программу код из рис. 3.7, он
получит в придачу кое-что лишнее — нашу main, — ив его программе окажутся
две функции main. Когда он попытается компилировать свою программу,
компилятор выдаст ошибку, так как, повторим, в программе должна быть только
одна main. Например, попытка компиляции программы с двумя функциями
main в Microsoft Visual C++ .NET вызовет ошибку
error C2084: function 'int main(void)' already has a body
когда компилятор встретит вторую функцию main. Точно так же компилятор
GNU C++ выдаст ошибку
redefinition of 'int main()'
Эти сообщения говорят о том, что в программе уже есть функция main. Итак,
размещение main в одном файле с определением класса делает невозможным
утилизацию класса в других программах. В этом разделе мы демонстрируем,
как сделать класс GradeBook утилизируемым, отделив его от функции main
и разместив в самостоятельном файле.
164
Глава 3
Заголовочные файлы
Каждый из предыдущих примеров этой главы состоял из единственного
.срр-файла, называемого еще файлом исходного кода, который содержал
определение класса GradeBook и функцию main. При построении
объектно-ориентированной программы на C++ утилизируемый исходный код (такой, как
класс) принято определять в файле, который, по соглашению, имеет
расширение .h и называется заголовочным файлом. Программы подключают
заголовочные файлы с помощью препроцессорной директивы #include и пользуются,
таким образом, преимуществами утилизируемых программных компонентов,
таких, как предлагаемый Стандартной библиотекой C++ тип string, или
типы, определяемые пользователем, подобные классу GradeBook.
В нашем следующем примере мы разделяем код из рис. 3.7 на два файла —
GradeBook.h (рис. 3.9) и fig03_10.cpp (рис. 3.10). Когда вы будете
просматривать заголовочный файл на рис. 3.9, обратите внимание, что он содержит
только определение класса GradeBook (строки 11-41) и строки 3-8, позволяющие
классу GradeBook использовать cout, endl и тип string. Функция main,
использующая класс GradeBook, определяется в строках 10-21 файла исходного
кода fig03_10.cpp (рис. 3.10). Чтобы помочь вам подготовиться к большим
программам, с которыми вы встретитесь в этой книге далее, мы часто будем
использовать для тестирования наших классов отдельный файл исходного
кода, содержащий функцию main (он называется программой-драйвером).
Скоро вы узнаете, как файл исходного кода с функцией main может
воспользоваться определением класса, находящимся заголовочном файле, для создания
объектов класса.
Включение заголовочного файла с классом, определяемым
пользователем
Заголовочный файл, такой, как GradeBook.h (рис. 3.9) не может быть
использован для запуска исполнения программы, поскольку в нем отсутствует
функция main. Если вы попытаетесь компилировать и компоновать
GradeBook.h сам по себе, чтобы получить исполняемое приложение, Microsoft Visual
C++ .NET выдаст следующее сообщение об ошибке:
error LNK2019: unresolved external symbol __main referenced in
function _mainCRTStartup
GNU C++ в Linux выдает сообщение об ошибке компоновщика:
undefined reference to 'main'
Эта ошибка показывает, что компоновщик не смог найти функцию main
программы. Чтобы протестировать класс GradeBook, требуется написать
отдельный файл исходного кода (подобный показанному на рис. 3.10), содержащий
функцию main, которая создает и использует объекты класса.
1 // Рис. 3.9: GradeBook.h
2 // Определение класса GradeBook в файле, отдельном от main.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
Введение в классы и объекты
165
6
7 #include <string> // класс GradeBook использует стандартные строки
8 using std::string;
9
10 // определение класса GradeBook
11 class GradeBook
12 {
13 public:
14 // конструктор инициализирует courseName переданной строкой
15 GradeBook( string паше )
16 {
17 setCourseName( name ); // инициализировать вызовом set-функции
18 } // конец конструктора GradeBook
19
20 // функция для установки названия курса
21 void setCourseName( string name )
22 {
23 courseName = name; // сохранить название курса в объекте
24 } // конец функции setCourseName
25
26 // функция для получения названия курса
27 string getCourseName()
28 {
29 return courseName; // возвратить courseName объекта
30 } // конец функции getCourseName
31
32 // вывести сообщение-приветствие пользователю GradeBook
33 void displayMessage()
34 {
35 // вызвать getCourseName для получения courseName
36 cout « "Welcome to the grade book for\n" « getCourseName ()
37 « "!" « endl;
38 } // конец функции displayMessage
39 private:
40 string courseName; // название курса для данного GradeBook
41 }; // конец класса GradeBook
Рис. 3.9. Определение класса GradeBook
1 // Рис. 3.10: fig03_10.cpp
2 // Включение класса GradeBook из GradeBook.h в главную программу.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "GradeBook.h" // включить определение класса GradeBook
8
9 // функция main начинает исполнение программы
10 int main()
11 {
12 // создать два объекта GradeBook
13 GradeBook gradeBookl( "CS101 Introduction to C++ Programming" ) ;
14 GradeBook gradeBook2( "CS102 Data Structures in C++" );
15
16 // вывести исходное значение courseName для каждого GradeBook
166
Глава 3
17 cout « "gradeBookl created for: " « gradeBookl.getCourseName()
18 « "\ngradeBook2 created for: " « gradeBook2.getCourseName()
19 « endl;
20 return 0; // показывает успешное завершение
21 } // конец main
gradeBookl created for: CS101 Introduction to C++ Programming
gradeBook2 created for: CS102 Data Structures in C++
Рис. 3.10. Включение класса GradeBook из файла GradeBook.h для использования
в main
Как говорилось в разделе 3.4, компилятор знает, что собой представляют
основные типы данных вроде int, но не знает, что такое GradeBook, поскольку
это тип, определяемый пользователем. На самом деле компилятору
неизвестны даже классы из Стандартной библиотеки C++. Чтобы помочь ему понять,
как использовать класс, мы должны предоставить компилятору определение
класса, — вот почему, например, для работы с типом string программа должна
включать заголовочный файл <string>. Это позволяет компилятору
определить объем памяти, которую он должен резервировать для объектов класса,
и убедиться, что программа корректно вызывает элемент-функции класса.
Чтобы создать объекты GradeBook gradeBookl и gradeBook2 (в строках
14-15 на рис. 3.10), компилятор должен знать размер объекта GradeBook.
Хотя логически объекты содержат элементы-данные и элементы-функции,
объекты C++ обычно содержат только данные. Компилятор создает только
один экземпляр элемент-функций класса, которую разделяют все объекты
данного класса. Разумеется, каждому объекту нужен свой собственный
экземпляр элементов данных класса, поскольку их содержимое может меняться от
объекта к объекту (например, два различных объекта Bank Account будут
иметь различные элементы данных для баланса счета). Однако код
элемент-функции не меняется, поэтому может разделяться всеми объектами
класса. Таким образом, размер объекта зависит от объема памяти,
необходимой для хранения элементов данных класса. Включив в строке 7 GradeBook.h,
мы даем компилятору доступ к информации (строка 40 на рис. 3.9),
необходимой ему для определения размера объекта GradeBook и того, корректно ли
используются объекты класса ( в строках 13-14 и 17-17 на рис. 3.10).
Строка 7 говорит препроцессору, что перед тем, как компилировать
программу, он должен заменить директиву копией содержимого GradeBook.h
(т.е. определением класса GradeBook). Так что, когда файл исходного кода
fig03_10.cpp компилируется, он уже содержит (благодаря #include)
определение класса GradeBook, и компилятор имеет возможность определить, как
создавать объекты GradeBook и как проверить, что их элемент-функции
вызываются правильно. Теперь, когда определение класса размещается в
заголовочном файле (без функции main), мы можем включить этот файл в любую
программу, которой требуется утилизировать наш класс GradeBook.
Как происходит поиск заголовочных файлов
Обратите внимание, что имя заголовочного файла GradeBook.h в строке 7
на рис. 3.10 заключено в кавычки (" "), а не в угловые скобки (< >). Обычно
файлы исходного кода программы и определяемые пользователем заголовоч-
Введение в классы и объекты
167
ные файлы располагают в одном и том же каталоге. Когда препроцессор
встречает имя заголовочного файла в кавычках (например, "GradeBook.h"), он
пытается найти этот файл в том же каталоге, что и тот, где находится файл с
директивой #include. Если препроцессор не может найти файл в этом каталоге,
он ищет его там же, где находятся заголовочные файлы Стандартной
библиотеки C++. Когда же препроцессор встречает имя заголовочного файла в
угловых скобках (например, <iostream>), он предполагает, что файл входит
в Стандартную библиотеку, и не просматривает каталог обрабатываемой
препроцессором программы.
<£gk Предотвращение ошибок 3.3
V^nFy Для гарантии того, что препроцессор сможет найти нужные вклю
чаемые файлы, директивы #include должны указывать имена
заголовочных файлов, определяемых пользователем, в кавычках (например,
"GradeBook.h"), а имена заголовочных файлов Стандартной
библиотеки С+-\ в угловых скобках (например, <iostream>).
Другие вопросы конструирования программного обеспечения
Теперь, когда класс GradeBook определен в заголовочном файле, класс стал
утилизируемым. К сожалению, размещение определения класса в
заголовочном файле, как на рис. 3.9, оставляет всю реализацию класса открытой для
его клиентов — GradeBook.h является просто текстовым файлом, который
может открыть и прочитать кто угодно. Традиционная
программно-конструкторская мудрость говорит, что для использования объекта класса коду клиента
необходимо знать только то, какие нужно вызывать элемент-функции, какие
аргументы нужно передавать каждой функции и возвращаемый результат
какого типа следует от нее ожидать. Коду клиента не требуется знать, как эти
функции реализованы.
Если код клиента знает, как реализован класс, программист, пишущий код
клиента, может использовать в нем знание деталей реализации. В идеале, если
эта реализация изменяется, не должно быть необходимости менять код
клиента класса. Сокрытие реализации класса упрощает изменение реализации
класса, сводя в то же время к минимуму и, если удастся, совершенно устраняя
необходимые изменения в коде клиента.
В разделе 3.9 мы покажем, как разбить класс GradeBook на два файла
таким образом, что
1. класс будет утилизируемым,
2. клиенты класса будут знать, какие элемент-функции в нем
предусмотрены, как их вызывать и какой возвращаемый тип ожидать,
3. клиенты не будут знать, как реализованы элемент-функции класса.
168
Глава 3
3.9. Отделение интерфейса от реализации
В предыдущем разделе мы показали, каким образом согласовать
написанный код с требованием утилизируемости, отделив определение класса от кода
клиента (например, от функции main), использующего класс. Теперь мы
введем еще один принцип правильного конструирования программного
обеспечения — отделение интерфейса от реализации.
Интерфейс класса
Интерфейсы определяют и стандартизируют то, каким образом различные
«вещи», такие, как люди и системы, взаимодействуют между собой.
Например, органы управления радиоприемника служат интерфейсом между
пользователями приемника и его внутренними компонентами. Органы управления
позволяют пользователям производить ограниченный набор действий (таких,
как перестройка на другую станцию, регулировка громкости и выбор
диапазонов AM/FM). Различные приемники могут реализовывать эти действия
по-разному — у некоторых есть кнопки, у других верньеры, а некоторые
поддерживают голосовые команды. Интерфейс специфицирует, какие действия
приемник позволяет производить пользователям, но не то, как эти действия
реализованы внутри приемника.
Аналогичным образом интерфейс класса описывает, какими услугами
могут пользоваться клиенты класса и как эти услуги запрашиваются, но не то,
как класс их осуществляет. Интерфейс класса состоит из открытых
элемент-функций класса (называемых также доступными услугами). Например,
интерфейс класса GradeBook (рис. 3.9) содержит конструктор и
элемент-функции setCourseName, getCourseName и displayMessage. Клиенты GradeBook
(например, main на рис. 3.10) вызывают эти функции для запроса услуг
класса. Как вы вскоре увидите, Можно специфицировать интерфейс класса,
написав определение класса, в котором будут перечислены только имена,
возвращаемые типы и типы параметров элемент-функций.
Отделение интерфейса от реализации
В наших предыдущих примерах каждое определение класса содержало
полные определения открытых элемент-функций класса и объявления его
закрытых элементов данных. Однако с точки зрения конструирования
программного обеспечения лучше определять элемент-функции вне определения
класса, так что детали их реализации можно будет скрыть от кода клиента.
Такая методика гарантирует, что программисты не будут писать код,
зависящий от деталей реализации класса. Если бы они могли это делать, то код
клиента с большей вероятностью мог бы «сломаться» при изменении реализации
класса.
Программа на рис. 3.11-3.3.13 отделяет интерфейс класса GradeBook от
его реализации, разбивая определение класса из рис. 3.9 на два файла —
заголовочный файл GradeBook.h (рис. 3.11), в котором класс определяется, и файл
исходного кода GradeBook.cpp (рис. 3.12), в котором определяются
элемент-функции класса. В соответствии с соглашением определения
элемент-функций размещаются в файле с тем же базовым именем (например,
GradeBook), что и имя класса, и с расширением .срр. Файл исходного кода
fig03_13.cpp (рис. 3.13) определяет функцию main (код клиента). Код и вывод
Введение в классы и объекты
169
программы на рис. 3.13 идентичны показанным на рис. 3.10. Рис. 3.15
показывает, каким образом компилируется эта трехфайловая программа с точки
зрения программиста класса GradeBook и программиста кода клиента; мы
в подробностях разберем этот рисунок.
GradeBook.h: определение интерфейса класса с прототипами
функций
Заголовочный файл GradeBook.h (рис. 3.11) содержит еще одну версию
определения класса (строки 9-18). Эта версия похожа на версию рис. 3.9, но
определения функций на рис. 3.9 заменены прототипами функций
(строки 12-15), которые описывают открытый интерфейс класса, не открывая
реализации элемент-функций. Прототип функции является объявлением
функции, которое сообщает компилятору имя функции, ее возвращаемый тип
и типы ее параметров. Заметьте, что заголовочный файл по-прежнему
специфицирует и закрытый элемент данных класса (строка 17). Повторим, что
компилятору необходимо знать элементы данных класса, чтобы определить,
сколько памяти нужно резервировать для каждого объекта класса. Включение
заголовочного файла GradeBook.h в код клиента (строка 8 на рис. 3.13)
предоставляет компилятору информацию, нужную ему для проверки того, что
код клиента корректно вызывает элемент-функции класса GradeBook.
1 // Рис. 3.11: GradeBook.h
2 // Определение класса GradeBook. Файл представляет собой открытый
3 // интерфейс GradeBook, не раскрывая реализации элемент-функций
4 // класса, которые определяются в GradeBook.срр.
5 #include <string> // класс GradeBook использует стандартные строки
6 using std::string;
7
8 // определение класса GradeBook
9 class GradeBook
Ю {
11 public:
12 GradeBook( string ); // конструктор, инициализирующий courseName
13 void setCourseName( string ); // устанавливает courseName
14 string getCourseName(); // получает название курса
15 void displayMessage(); // выводит сообщение-приветствие
16 private:
17 string courseName; // название курса для данного GradeBook
18 }; // конец класса GradeBook
Рис. 3.11. Определение класса GradeBook с прототипами функций,
специфицирующими интерфейс класса
Прототип функции в строке в строке 12 (рис. 3.11) указывает, что
конструктор требует одного параметра типа string. Как вы помните, у
конструкторов не возвращаемого типа, поэтому возвращаемый тип в прототипе
отсутствует. Прототип элемент-функции setCourseName (строка 13) указывает, что
функция требует параметра типа string и не возвращает значения (т.е. ее
возвращаемый тип — void). Прототип элемент-функции (строка 14) указывает,
что функция не требует параметров и возвращает string. Наконец, прототип
элемент-функции displayMessage (строка 15) специфицирует, что функция не
170
Глава 3
требует параметров и не возвращает значения. Эти прототипы функций
совпадают с соответствующими заголовками функций на рис. 3.9, за исключением
того, что в прототипы не включены имена параметров (они в прототипах не
обязательны) и прототип должен заканчиваться точкой с запятой.
Типичная ошибка программирования 3.8
Пропуск точки с запятой в конце прототипа функции является
синтаксической ошибкой.
Хороший стиль программирования 3.7
Хотя имена параметров в прототипах функций не обязательны (они
игнорируются компилятором), многие программисты их указывают
в целях документации.
Предотвращение ошибок 3.4
Имена параметров в прототипе функции (которые, повторим, не
обязательны) могут вводить в заблуждение, если они ошибочны или
неосмысленны. По этой причине многие программисты создают
прототипы, копируя первую строку определения соответствующей функции
(если исходный код функции доступен) и добавляя в конец прототипа
точку с запятой.
GradeBook.cpp: определение элемент-функций в отдельном файле
исходного кода
Файл исходного кода GradeBook.cpp (рис. 3.12) определяет
элемент-функции класса GradeBook, которые были объявлены в строках 12-15 на рис. 3.11.
Определения элемент-функций находятся в строках 11-34 и почти идентичны
определениям в строках 15-38 на рис. 3.9.
1 // Рис. 3.12: GradeBook.cpp
2 // Определения элемент-функций GradeBook. Файл содержит
3 // реализацию функций, прототипы которых объявлены в GradeBook.h.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "GradeBook.h" // включить определение класса GradeBook
9
10 // конструктор инициализирует courseName переданной строкой
11 GradeBook::GradeBook( string name )
12 {
13 setCourseName( name ); // инициализировать вызовом set-функции
14 } // конец конструктора GradeBook
15
16 // функция для установки названия курса
17 void GradeBook::setCourseName( string name )
18 {
19 courseName = name; // сохранить название курса в объекте
Введение в классы и объекты
171
20 } // конец функции setCourseName
21
22 // функция для получения названия курса
23 string GradeBook::getCourseName()
24 {
25 return courseName; // возвратить courseName объекта
26 } // конец функции getCourseName
27
28 // вывести сообщение-приветствие пользователю GradeBook
29 void GradeBook::displayMessage()
30 {
31 // вызвать getCourseName для получения courseName
32 cout « "Welcome to the grade book for\n" « getCourseName()
33 « "!" « endl;
34 } // конец функции displayMessage
Рис. 3.12. Определения элемент-функций GradeBook представляют реализацию
класса
Обратите внимание, что имя каждой элемент-функции в заголовках
функций (строки 11, 17, 23 и 29) предваряется именем класса и ::, бинарной
(двухместной) операцией разрешения области действия. Тем самым каждая
элемент-функция «привязывается» к (отделенному теперь) определению класса
GradeBook, где объявляются элемент-функции и элементы данных. Без
префикса «GradeBook::» перед каждым именем функции они не были бы
опознаны компилятором в качестве элемент-функций класса GradeBook —
компилятор посчитал бы их «свободными» или «автономными» функциями,
подобными main. Такие функции не могут обращаться к закрытым элементам данных
GradeBook или вызывать элемент-функции класса, не специфицируя объект.
Например, строки 19 и 25, обращающиеся к переменной courseName, вызвали
бы ошибки компиляции, так как courseName не определена в этих функциях
как локальная переменная — компилятор не знал бы, что courseName уже
определена в качестве элемента данных класса GradeBook.
Я Типичная ошибка программирования 3.8
Если при определении элемент-функций вне класса пропустить имя
класса и бинарную операцию разрешения области действия (::) перед
именами функций, возникнут ошибки компиляции.
Чтобы указать, что элемент-функции в GradeBook.epp являются частью
класса GradeBook, мы должны прежде всего включить заголовочный файл
GradeBook.h (строка 8 на рис. 3.12). Это дает нам доступ к имени класса
GradeBook в файле GradeBook.срр. При компилировании GradeBook.ерр
компилятор использует информацию из GradeBook.h, чтобы убедиться, что
1. первая строка каждой элемент-функции (строки 11, 17, 23 и 29)
соответствует ее прототипу в файле GradeBook.h — например, компилятор
проверяет, что getCourseName не принимает параметров и возвращает
string;
172
Глава 3
2. каждая элемент-функция знает об элементах данных класса и других
элемент-функциях — например, строки 19 и 25 могут обращаться к
переменной courseName, поскольку она объявлена в GradeBook.h как
элемент данных класса GradeBook, а строки 13 и 32 могут вызывать
соответственно функции setCourseName и get CourseName, поскольку каждая
из них объявлена в GradeBook.h как элемент-функция класса (и эти
вызовы согласуются с соответствующими прототипами).
Тестирование класса GradeBook
Рис. 3.13 производит с объектами GradeBook те же самые манипуляции,
что и рис. 3.10. Отделение интерфейса GradeBook от реализации его
элемент-функций не влияет на то, как код клиента использует этот класс.
Изменяется только процесс компиляции и компоновки программы, что мы вскоре
обсудим.
1 // Рис. 3.13: fig03_13.cpp
2 // Демонстрация класса GradeBook после отделения
3 // его интерфейса от реализации.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "GradeBook.h" // включить определение класса GradeBook
9
10 // функция main начинает исполнение программы
11 int main()
12 {
13 // создать два объекта GradeBook
14 GradeBook gradeBookl( "CS101 Introduction to C++ Programming" );
15 GradeBook gradeBook2( "CS102 Data Structures in C++" );
16
17 // вывести исходное значение courseName для каждого GradeBook
18 cout « "gradeBookl created for: " « gradeBookl.getCourseName()
19 « "\ngradeBook2 created for: " « gradeBook2.getCourseName()
20 « endl;
21 return 0; // показывает успешное завершение
22 } // конец main
gradeBookl created for: CS101 Introduction to C++ Programming
gradeBook2 created for: CS102 Data Structures in C++
Рис. 3.13, Демонстрация класса GradeBook после отделения его интерфейса
от реализации
Как и на рис. 3.10, строка 8 на рис. 3.13 включает заголовочный файл
GradeBook.h, что дает компилятору возможность убедиться в корректности
создания и использования объектов GradeBook. Перед исполнением этой
программы оба файла исходного кода на рис. 3.12 и 3.13 должны быть
компилированы, а затем скомпонованы друг с другом, т.е. вызовы элемент-функций
в коде клиента должны быть привязаны к реализациям элемент-функций
класса — эта работа выполняется компоновщиком.
Введение в классы и объекты
173
Процесс компиляции и компоновки
Диаграмма на рис. 3.14 показывает процесс компиляции и компоновки,
который приводит к созданию исполняемого приложения GradeBook, которое
может использоваться преподавателями. Часто бывает так, что интерфейс
и реализация класса пишутся и компилируются одним программистом, а
используются другим, который реализует код клиента класса. Итак, диаграмма
показывает, что относится к задачам программиста класса и что — к задачам
программиста кода клиента. Пунктирные линии на диаграмме очерчивают ее
части, относящиеся соответственно к программисту класса, программисту
кода клиента и пользователю приложения GradeBook. [Замечание. Рис. 3.14
не является диаграммой UML.]
о
А
Программист
реализации класса
GradeBook.срр
файл реализации
i
компилятор
I
объектный код
класса GradeBook
GradeBook.h
определение/
интерфейс класса
объектный код
Стандартной
библиотеки C++
о
Программист
кода клиента
функция main
(исходный код
клиента)
i
компилятор
I
объектный код
функции main
компоновщик
исполняемое
приложение
GradeBook
о
Пользователь
приложения /
GradeBook -'
Рис. 3.14. Процесс компиляции и компоновки, порождающий исполняемое приложение
174
Глава 3
Программист класса, отвечающий за создание утилизируемого класса
GradeBook, пишет заголовочный файл GradeBook.h и файл исходного кода
GradeBook.cpp, который включает директивой #include заголовочный файл,
а затем компилирует файл исходного кода, чтобы получить объектный код
класса GradeBook. Чтобы скрыть детали реализации элемент-функций
GradeBook, программист класса предоставит программисту кода клиента только
заголовочный файл GradeBook.h (который специфицирует интерфейс класса
и его элементы данных) и объектный код класса GradeBook, который
содержит инструкции машинного языка, представляющие элемент-функции
GradeBook. Программисту кода клиента не передается файл исходного кода
GradeBook, так что клиент остается в неведении относительно того, как
реализованы элемент-функции класса.
Коду клиента, чтобы использовать класс, необходимо знать только
интерфейс GradeBook и, кроме того, он должен иметь возможность компоноваться
с его объектным кодом. Поскольку интерфейс является частью определения
класса в заголовочном файле GradeBook.h, программист кода клиента должен
иметь доступ к этому файлу и включить его посредством #include в файл
исходного кода клиента. Когда код клиента компилируется, компилятор
использует определение класса в GradeBook.h для того, чтобы убедиться в
корректности создания объектов класса GradeBook и манипуляций ими в функции
main.
Последним шагом построения исполняемого приложения GradeBook,
которым смогут пользоваться преподаватели, является компоновка
1. объектного кода функции main (т.е. кода клиента),
2. объектного кода реализации элемент-функций класса GradeBook,
3. объектного кода Стандартной библиотеки C++ для классов C++
(например, string), применяемых программистом класса и программистом кода
клиента.
На выходе компоновщика получается исполняемое приложение GradeBook,
которым могут пользоваться преподаватели для отслеживания оценок своих
студентов.
Более подробную информацию о компиляции программ из нескольких
исходных файлов вы можете найти, обратившись к документации компилятора
или изучив публикации Dive-Into©, которые мы предлагаем для различных
компиляторов C++ на www.deitel.com/books/cpphtp5.
3.10. Подтверждение данных посредством
set-функций
В разделе 3.6 мы ввели set-функции, предоставляющие клиентам класса
возможность модификации закрытого элемента данных. Класс GradeBook на
рис. 3.5 определяет элемент-функцию setCourseName, которая просто
присваивает значение в своем параметре name элементу данных courseName.
Функция не проверяет, что название курса соответствует какому-либо
определенному формату или следует каким-то иным правилам относительно того,
как должно выглядеть «правильное» название. Как уже говорилось,
предположим, что университет может распечатывать зачетные ведомости,
содержащие названия курсов длиной не более 25 символов. Если для генерации ведо-
Введение в классы и объекты
175
мостей университет пользуется системой с объектами Grade Во ok, мы,
вероятно, захотим модифицировать класс GradeBook таким образом, чтобы
последний гарантировал, что элемент данных courseName никогда не будет
содержать более 25 символов. Программа на рис. 3.15-3.17 усовершенствует
функцию setCourseName, реализуя это подтверждение данных (его еще
называют проверкой действительности).
Определение класса GradeBook
Заметьте, что определение класса GradeBook на рис. 3.15 — и,
следовательно, его интерфейс — идентично определению на рис. 3.11. Поскольку
интерфейс не изменился, клиентам класса нет необходимости меняться, когда будет
модифицировано определение функции setCourseName. Это позволяет
клиентам воспользоваться преимуществами усовершенствованного класса
GradeBook, просто скомпоновав код клиента с новой версией объектного кода класса.
1 // Рис. 3.15: GradeBook.h
2 // Определение класса GradeBook представляет открытый интерфейс
3 // класса. Определения элемент-функций находятся в GradeBook.срр.
4 #include <string> // программа использует стандартный класс string
5 using std::string;
6
7 // определение класса GradeBook
8 class GradeBook
9 {
10 public:
11 GradeBook( string ); // инициализирует объект GradeBook
12 void setCourseName( string ); // устанавливает courseName
13 string getCourseName(); // функция, получающая название курса
14 void displayMessage(); // выводит сообщение-приветствие
15 private:
16 string courseName; // название курса для данного GradeBook
17 }; // конец класса GradeBook
Рис. 3.15. Определение класса GradeBook
1 // Рис. 3.16: GradeBook.срр
2 // Реализация элемент-функций GradeBook.
3 // Функция setCourseName производит подтверждение данных.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "GradeBook.h" // включить определение класса GradeBook
9
10 // конструктор инициализирует courseName переданной строкой
11 GradeBook::GradeBook( string name )
12 {
13 setCourseName ( name ); // проверить и сохранить courseName
14 } // конец конструктора GradeBook
15
16 // функция, устанавливающая название курса;
17 // гарантирует, что название курса содержит не более 25 символов
176
Глава 3
18 void GradeBook::setCourseName( string name )
19 {
20 if ( name.length() <= 25 ) // если не более 25 символов
21 courseName = name; // сохранить название курса в объекте
22
23 if ( name.length() > 25 ) // если в названии более 25 символов
24 {
25 // записать в courseName первые 25 символов параметра name
26 courseName = name.substr( 0, 25 ); // начать с 0, длина 25
27
28 cout « "Name \"" « name « "\" exceeds maximum length. \n"
29 « "Limiting courseName to first 25 characters.\n" « endl;
30 } // конец if
31 } // конец функции setCourseName
32
33 // функция для получения названия курса
34 string GradeBook::getCourseName()
35 {
36 return courseName; // возвратить courseName объекта
37 } // конец функции getCourseName
38
39 // вывести сообщение-приветствие пользователю GradeBook
40 void GradeBook:.displayMessage()
41 {
42 // вызвать getCourseName для получения courseName
43 cout « "Welcome to the grade book for\n" « getCourseName()
44 « "!" « endl;
45 } // конец функции displayMessage
Рис. 3.16. Определения элемент-функций класса GradeBook с set-функцией,
проверяющей длину элемента данных courseName
Подтверждение названия курса элемент-функцией
setCourseName
Усовершенствование класса GradeBook состоит в определении функции
setCourseName (строки 18-31 на рис. 3.16). Оператор if в строках 20-21
определяет, содержит ли параметр name действительное название курса (т.е.
строку из не более чем 25 символов). Если название курса действительно,
строка 21 сохраняет его в элементе данных courseName. Обратите внимание на
выражение name.length() в строке 20. Это вызов элемент-функции, подобный
myGradeBook.displayMessage(). Класс стандартной библиотеке C++ string
определяет элемент-функцию length, которая возвращает число символов в
объекте string. Параметр name является объектом string, поэтому вызов па-
me.length() возвращает число символов в name. Если это значение меньше или
равно 25, параметр действителен и исполняется строка 21.
Оператор if в строках 23-30 обрабатывает случай, когда setCourseName
получает недействительное название курса (т.е. имеющее длину более 25
символов). Даже если параметр name слишком длинный, мы хотим, тем не менее,
оставить объект GradeBook в согласованном состоянии, т.е. состоянии, в
котором элемент данных courseName содержит действительное значение (строку
длиной не более 25 символов). Итак, мы усекаем (т.е. укорачиваем)
специфицированное название курса и присваиваем элементу courseName первые 25
Введение в классы и объекты
177
символов параметра name (к сожалению, такое усечение может оказаться
довольно неуклюжим). В стандартном классе string предусмотрена
элемент-функция substr (сокращение от substring. 4подстрока»), возвращающая
новый объект string, образованный копированием части существующего
объекта string. Вызов в строке 26 (name.substr( О, 25 )) передает элемент-функции
substr объекта name два целых числа @ и 25). Эти аргументы указывают ту
часть строки name, которую требуется возвратить. Первый аргумент
специфицирует начальную позицию исходной строки, начиная с которой должны
копироваться символы; первый символ любой строки считается имеющим
позицию 0. Второй аргумент специфицирует число копируемых символов. Таким
образом, вызов в строке 26 возвращает 25-символьную подстроку name,
начинающуюся с позиции 0 (другими словами, первые 25 символов из name).
Например, если name содержит значение "CS101 Introduction to Programming
in C++ ", substr возвратит "CS101 Introduction to Pro". После вызова substr
строка 26 присваивает возвращенную substr подстроку элементу данных
course Name. Так организованная элемент-функция setCourseName
гарантирует, что courseName в любом случае присваивается строка, содержащая не
более 25 символов. Если функции приходится усекать название курса, чтобы
сделать его действительным, строки 28-29 выводят предупреждающее
сообщение.
Обратите внимание, что оператор if в строках 23-30 содержит в своем теле
два оператора: один для установки в courseName первых 25 символов
параметра name и один для вывода сопроводительного предупреждающего
сообщения. Мы хотим, чтобы в случае, когда name слишком длинно, исполнялись
оба этих оператора, поэтому мы заключаем их в фигурные скобки ({ }). Как вы
помните из главы 2, тем самым образуется блок. В главе 4 вы больше узнаете
о размещении в теле управляющего оператора нескольких операторов.
Оператор cout в строках 28-29 мог бы быть записан без операции передачи
в поток в начале второй строки:
cout « "Name \" " « name « "\" exceeds maximum length. \n"
"Limiting courseName to first 25 characters.\n" « endl ;
Компилятор C++ объединяет примыкающие друг у другу строковые
литералы, даже если они располагаются на разных строчках программы. Таким
образом, в вышеприведенном операторе компилятор объединит литералы "\"
exceeds maximum length.\n" и "Limiting courseName to first 25
characters.\n" в единственный строковый литерал, который продуцирует тот же
вывод, что и строки 28-29 на рис. 3.16. Такое поведение строковых литералов
позволяет вам печатать длинные строки, распределяя их по различным
строчкам программы без дополнительных операций передачи в поток.
1 // Рис. 3.17: fig03_17.cpp
2 // Создание объекта GradeBook; демонстрация подтверждения данных.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "GradeBook.h" // включить определение класса GradeBook
8
9 // функция main начинает исполнение программы
178
Глава 3
10 int main()
11 {
12 // создать два объекта GradeBook;
13 // исходное имя курса для gradeBookl слишком длинное
14 GradeBook gradeBookl( "CS101 Introduction to Programming in C++" );
15 GradeBook gradeBook2( "CS102 C++ Data Structures" );
16
17 // вывести courseName каждого GradeBook
18 cout « "gradeBooklf s initial course name is: "
19 « gradeBookl.getCourseName()
20 « "\ngradeBook2's initial course name is: "
21 « gradeBook2.getCourseName() « endl;
22
23 // модифицировать courseName для gradeBookl (корректной строкой)
24 gradeBookl.setCourseName( "CS101 C++ Programming" );
25
26 // вывести courseName каждого GradeBook
27 cout « "\ngradeBookl's course name is: "
28 « gradeBookl.getCourseName()
29 « "\ngradeBook2's course name is: "
30 « gradeBook2.getCourseName() « endl;
31 return 0; // показывает успешное завершение
32 } // конец main
Name "CS101 Introduction to Programming in C++" exceeds maximum
length.
Limiting courseName to first 25 characters.
gradeBookl's initial course name is: CS101 Introduction to Pro
gradeBook2's initial course name is: CS102 C++ Data Structures
gradeBookl's course name is: CS101 C++ Programming
gradeBook2's course name is: CS102 C++ Data Structures
Рис. 3.17. Демонстрация объекта GradeBook, в котором название курса ограничено
25 символами
Тестирование класса GradeBook
Рис. 3.17 демонстрирует класс GradeBook (рис. 3.15-3.16) с
подтверждением данных. Строка 14 создает объект GradeBook с именем gradeBookl.
Вспомните, что конструктор GradeBook вызывает для инициализации элемента
данных courseName элемент-функцию setCourseName. В предыдущих версиях
класса выгода от вызова setCourseName в конструкторе была не очевидной.
Теперь, однако, конструктор пользуется преимуществами подтверждения
данных, предусмотренного в setCourseName. Конструктор просто вызывает эту
функцию, а не дублирует код подтверждения. Когда строка 14 на рис. 3.17
передает конструктору GradeBook исходное название курса "CS101 Introduction
to Programming in C++", конструктор передает это название функции
setCourseName, где и происходит действительная инициализация. Поскольку
данное название содержит более 25 символов, исполняется тело второго из
операторов if, инициализирующее courseName усеченным до 25 символов
названием "CS101 Introduction to Pro". Обратите внимание, что вывод, показан-
Введение в классы и объекты
179
ный на рис. 3.17, содержит предупреждающее сообщение, выводимое
строками 28-29 на рис. 3.16 в функции. Строка 15 создает второй объект GradeBook
с именем gradeBook2, причем конструктору передается допустимое имя в
точности из 25 символов.
Строки 18-21 на рис. 3.17 выводят усеченное название курса для
gradeBookl и название курса для gradeBook2. Строка 24 непосредственно
вызывает элемент-функцию setCourseName для gradeBookl, чтобы изменить
название курса этого объекта GradeBook на более короткое, не требующее
усечения. Затем строки 27-30 снова выводят названия курсов для двух объектов
GradeBook.
Дополнительные замечания о set-функциях
Открытые set-функции, такие, как setCourseName должны тщательно
проверять каждую попытку модификации элемента данных (напр., courseName),
чтобы гарантировать, что новое значение является допустимым для этого
элемента. Например, попытка установить (set) день месяца равным 37 должна
быть отвергнута, как и попытки установить вес человека равным нулю или
отрицательному числу, оценку на экзамене равной 185 (в то время как
допустимый диапазон оценок — от 0 до 100) и т.д.
Общее методическое замечание 3,6
Определение элементов данных как private и контроль доступа
к ним, особенно доступа для записи, посредством открытых
элемент-функций помогает гарантировать целостность данных.
®
Ш
Предотвращение ошибок 3.5
Целостность данных не гарантируется автоматически объявлением
элементов данных закрытыми, — программист должен еще
обеспечить адекватную проверку действительности данных и средства
сообщения об ошибках.
Общее методическое замечание 3.7
Элемент-функции, устанавливающие значения закрытых данных,
должны удостовериться, что предлагаемые новые значения
допустимы; если нет, set-функции должны приводить закрытые элементы
данных в допустимое состояние.
Set-функции могут возвращать клиентам класса значения, сообщающие
о попытке присвоения объекту класса недействительных данных. Клиент
класса может проверить возвращаемое set-функцией значение и определить,
была ли попытка клиента модифицировать объект успешной, и предпринять
соответствующие действия. Чтобы программа на рис. 3.15-3.17 оставалась на
данном этапе изложения достаточно простой, функция setCourseName из
рис. 3.16 просто выводит на экран соответствующее сообщение.
180
Глава 3
3.11. Конструирование программного обеспечения.
Идентификация классов в спецификации требований
к ATM (необязательный раздел)
Мы приступаем к проектированию системы ATM, которую мы представили
во 2-й главе. В этом разделе мы определим необходимые для построения
системы классы, проанализировав имена существительные и именные
конструкции, которые входят в спецификацию требований. Мы представим классовые
диаграммы UML, моделирующие взаимоотношения между этими классами.
Это важный первый шаг в определении структуры нашей системы.
Идентификация классов в системе
Мы начнем наш процесс 00D с идентификации классов, необходимых для
построения системы ATM. В конечном итоге мы опишем эти классы с помощью
классовых диаграмм UML и реализуем их на C++. Сначала мы просмотрим нашу
спецификацию требований из раздела 2.8 и найдем ключевые существительные
и именные конструкции, которые помогут нам идентифицировать классы,
составляющие систему ATM. При этом мы можем решить, что некоторые из этих
существительных и именных конструкций являются атрибутами других классов
в системе. Мы также можем заключить, что некоторые из них не соответствуют
никаким частям системы и, таким образом, не должны моделироваться вообще.
По ходу этого процесса могут выявиться дополнительные классы.
На рис. 3.18 перечислены существительные и именные конструкции из
спецификации требований. Мы перечислили их слева направо в том порядке,
в котором они появляются в тексте спецификации. Мы указываем только
форму единственного числа существительного или именного словосочетания.
Мы будем создавать классы только для существительных и именных
конструкций, которые значимы для системы ATM. Нам не нужно моделировать
в качестве класса «банк», потому что банк не является частью системы
ATM — он только хочет, чтобы мы построили ATM. «Клиент» и
«пользователь» также представляют собой объекты за пределами системы — они
важны, поскольку взаимодействуют с нашей ATM, но нам не нужно моделировать
их в качестве классов в программном обеспечении ATM. Как вы помните, мы
моделировали пользователя (т.е. клиента банка) как актера в диаграмме
вариантов применения на рис. 2.18.
Существительные и именные конструкции в спецификации требований
банк
ATM
пользователь
клиент
транзакция
счет
баланс
деньги /средства
экран
кнопочная панель
выходной лоток
20-долларовая банкнота / наличные
приемная щель
конверт с депозитом
номер счета
PIN
база данных банка
проверка баланса
снятие денег
внесение денег
Рис. 3,18. Существительные и именные конструкции в спецификации требований
Введение в классы и объекты
181
Мы не моделируем в качестве классов «20-долларовую банкноту» или
«конверт с депозитом». Это физические объекты реального мира, но не часть того,
что здесь автоматизируется. Мы можем адекватно представить присутствие
в системе банкнот как атрибут класса, моделирующего выходной лоток. (Мы
будем приписывать классам атрибуты в разделе 4.13.) Например, выходной
лоток поддерживает счетчик числа банкнот, которые в нем содержатся.
Спецификация требований ничего не говорит о том, что система должна делать
с депозитными конвертами после того, как она их получит. Мы полагаем, что
для представления присутствия конверта в системе достаточно простого
уведомления о его получении — эта операция выполняется классом,
моделирующим приемную щель. (Мы приписываем классам операции в разделе 6.22.)
В нашей упрощенной системе ATM наиболее разумным кажется
представление «денег», включая «баланс» счета, в качестве атрибутов других классов.
Подобным же образом существительные «номер счета» и «PIN» представляют
важные элементы информации в системе ATM. Они являются важными
атрибутами банковского счета. Однако они не проявляют никакого поведения.
Таким образом, целесообразнее всего моделировать их в качестве атрибутов
класса счета.
Хотя «транзакция» в общем смысле часто употребляется в спецификации
требований, мы не моделируем в настоящий момент понятие финансовой
операции в широком смысле слова. Вместо этого мы моделируем в виде
самостоятельных классов три типа транзакций (т.е. «проверку баланса», «снятие
денег» и «внесение денег»). Эти классы обладают специфическими атрибутами,
необходимыми для осуществления представляемых ими транзакций.
Например, при снятии требуется знать сумму денег, которую хочет снять
пользователь. Однако для проверки баланса не требуется никаких дополнительных
данных. Более того, три класса транзакций проявляют уникальное поведение.
Снятие денег связано с выдачей пользователю наличных, в то время как
внесение денег включает получение от пользователя депозитных конвертов.
[Замечание. В разделе 13.10 мы «вынесем за скобки» общие черты всех транзакций
в обобщенный класс «транзакция», используя объектно-ориентированные
концепции абстрактного класса и наследования.]
Взяв оставшиеся существительные и именные конструкции из рис. 3.18,
мы определим классы для нашей системы. Каждое существительное из
рис. 3.18 связано с одним или несколькими пунктами следующего списка:
• ATM
• экран
• кнопочная панель
• выходной лоток
• приемная щель
• счет
• база данных банка
• проверка баланса
• снятие денег
• внесение денег
Элементы этого списка, вероятно, и являются классами, которые потребуются
для реализации нашей системы.
182
Глава 3
На основе созданного списка мы можем теперь моделировать классы нашей
системы. Мы пишем имена классов с прописной буквы (это соглашение UML),
как делали бы это при написании действительного кода на C++, реализующего
наш проект. Если имя класса содержит несколько слов, мы пишем их слитно,
начиная каждое с прописной буквы (например, MultipleWordName). В
соответствии с этим соглашением мы именуем наши классы ATM, Screen (экран),
Keypad (кнопочная панель), CashDispenser (выходной лоток), Deposit Slot
(приемная щель), Account (счет), BankDatabase (база данных банка), Balan-
celnquiry (проверка баланса), Withrawal (снятие денег) и Deposit (внесение
денег). Мы строим нашу систему, используя все эти классы в качестве
строительных блоков. Однако перед тем, как мы приступим к построению системы,
нам нужно глубже понять, как эти классы связаны друг с другом.
Моделирование классов
UML позволяет нам, посредством классовых диаграмм, моделировать
классы в нашей системе ATM и их взаимоотношения. Рис. 3.19 представляет класс
ATM. В UML каждый класс изображается прямоугольником с тремя
отделениями. Верхнее отделение содержит имя класса, написанное жирным
шрифтом с выравниванием по горизонтали. Среднее отделение содержит атрибуты
класса. (Атрибуты мы обсуждаем в разделах 4.13 и 5.11.) Нижнее отделение
содержит операции класса (обсуждаемые в разделе 6.22). На рис. 3.19 среднее
и нижнее отделения пусты, так как мы еще не определили атрибуты и
действия этого класса.
Классовые диаграммы показывают также отношения между классами
в системе. На рис. 3.20 показано, как соотносятся друг с другом классы ATM
и Withdrawal. Пока для простоты мы рассматриваем только это подмножество
классов. Далее в этом разделе мы приведем более подробную классовую
диаграмму. Обратите внимание, что на этой диаграмме прямоугольники,
представляющие классы, не имеют отделений. UML допускает такое опущение
атрибутов и операций, когда это уместно, чтобы диаграммы было легче читать.
Такую диаграмму называют неполной в том смысле, что некоторая
информация, такая, как содержимое второго и третьего отделений, на ней не
изображается. Мы поместим в эти отделения информацию в разделах 4.13 и 6.22.
ATM
Рис. 3.19, Представление класса на классовой диаграмме UML
ATM J Исполняет ► OJ, withdrawal
currentTransaction
Рис. 3.20. Классовая диаграмма, показывающая ассоциацию между классами
Введение в классы и объекты
183
Сплошная линия на рис. 3.20, соединяющая два класса, представляет
ассоциацию — отношение между классами. Числа, стоящие у концов линии,
являются значениями кратности, которые показывают, сколько объектов
каждого класса участвует в ассоциации. В данном случае, пройдя от одного конца
линии к другому, мы обнаружим, что в каждый конкретный момент один
объект ATM участвует в ассоциации с нулем или единицей объектов
Withdrawal — нулем, если текущий пользователь не производит в данный момент
никаких транзакций или запросил другой тип транзакции, и единицей, если
пользователь запросил снятие денег. UML может моделировать много типов
кратности. Они перечислены и поясняются на рис. 3.21.
Символ
0
1
/77
0..1
т, п
т.л
*
0..*
1..*
Смысл
Нет
Один
Целое значение
Ноль или один
т или п
По крайней мере т, но не более п
Любое неотрицательное целое (ноль или больше нуля)
Ноль или больше нуля (эквивалентно *)
Один или несколько
Рис. 3.21. Типы кратности
Ассоциация может быть именована. Например, слово Исполняет над
линией, соединяющей на рис. 3.20 классы ATM и Withdrawal, указывает имя этой
ассоциации. Эта часть диаграммы читается «один объект класса ATM
исполняет ноль или один объект класса Withdrawal». Обратите внимание, что
имена ассоциаций являются направленными, что обозначается закрашенным
«наконечником» стрелки, — поэтому неправильным было бы прочитать
предыдущую ассоциацию справа налево как «ноль или один объект класса Withdrawal
исполняет один объект класса ATM».
Слово currentTransaction (текущая транзакция) у конца линии ассоциации
со стороны Withdrawal на рис. 3.20 является ролевым именем,
идентифицирующим роль, играемую объектом Withdrawal в его отношении с ATM.
Указывая роль, которую играет класс в контексте ассоциации между классами,
ролевое имя придает дополнительное значение этой ассоциации. В одной и той
же системе класс может играть различные роли. Например, в системе
школьного персонала человек может играть роль «преподавателя» в отношении
учащихся. Тот же человек может брать на себя роль «коллеги» во
взаимоотношениях с другим преподавателем и «тренера», когда тренирует школьных
спортсменов. Ролевое имя currentTransaction на рис. 3.20 указывает, что объект
Withdrawal, участвующий в ассоциации Исполняет с объектом ATM,
представляет транзакцию, которую в данный момент обрабатывает ATM. В другом
контексте объект Withdrawal может играть другую роль (например,
предыдущей транзакции). Заметьте, что мы не специфицируем ролевое имя со стороны
184
Глава 3
ATM ассоциации Исполняет. Ролевые имена на классовых диаграммах часто
опускаются, когда смысл ассоциации ясен и без них.
Кроме указания простых отношений ассоциации могут специфицировать
и более сложные, например, то, что объекты одного класса составляются из
объектов других классов. Рассмотрим реальный банкомат. Из каких «кусков»
собрал его производитель, чтобы получилась работающая машина? Наша
спецификация требований говорит, что ATM состоит из экрана, кнопочной
панели, выходного лотка и приемной щели.
Сплошные ромбы на рис. 3.22 указывают, что класс ATM находится с
классами Screen, Keypad, CashDispenser и DepositSlot в отношениях композиции.
Композиция подразумевает отношение «целое/часть». Класс (в данном случае
ATM), имеющий на конце линии ассоциации символ композиции (сплошной
ромб), является «целым», а классы с другой стороны ассоциации (в данном
случае Screen, Keypad, CashDispenser и DepositSlot) — «частями». Композиции
на рис. 3.22 указывают, что объект класса ATM образован из одного объекта
класса Screen, одного объекта класса Keypad, одного объекта класса
CashDispenser и одного объекта класса DepositSlot. Композицию определяет
отношение «имеет». (В разделе «Конструирование программного обеспечения» главы
13 мы увидим, что наследование определяется отношением «является».)
Согласно спецификации UML, отношения композиции обладают
следующими свойствами:
1. Только один класс в отношении может представлять целое (т.е. ромб
может помещаться только на одном конце линии ассоциации). Например,
либо экран является частью ATM, либо ATM — частью экрана, но экран
и ATM не могут одновременно представлять в этом отношении целое.
2. Части в отношении композиции существуют только пока существует
целое, а целое отвечает за создание и уничтожение своих частей. Например,
акт построения ATM включает в себя изготовление его частей. Более
того, если ATM уничтожается, то его экран, кнопочная панель, выходной
лоток и приемная щель также уничтожаются.
3. Часть в каждый момент может принадлежать только одному целому,
хотя часть может быть удалена и прикреплена к некоторому другому
целому, которое в этом случае берет на себя ответственность за эту часть.
Screen
1 1 ж ^1 1
DepositSlot ^ ATM ^ CashDispenser
Т:
Keypad
Рис. 3.22. Классовая диаграмма, показывающая отношения композиции
Введение в классы и объекты
185
Сплошные ромбы на наших классовых диаграммах указывают отношения
композиции, обладающие этими тремя свойствами. Если отношение «имеет»
не удовлетворяет одному или нескольким из этих критериев, UML
специфицирует, что на концах линии ассоциации должны помещаться пустые ромбы,
означающие агрегацию — более слабую форму композиции. Например,
персональный компьютер и монитор участвуют в отношении агрегации —
компьютер «имеет» монитор, но две эти части могут существовать по отдельности,
и один и тот же монитор может быть присоединен одновременно к нескольким
компьютерам, нарушая, таким образом, второе и третье свойства композиции.
На рис. 3.23 показана классовая диаграмма для системы ATM. Эта
диаграмма моделирует большинство классов, идентифицированных нами ранее
в этом разделе, а также ассоциации между ними, которые мы можем вывести
из спецификации требований. [Замечание. Классы Balancelnquiry и Deposit
участвуют в ассоциациях, похожих на ассоциации класса Withdrawal,
поэтому на этой диаграмме мы решили их опустить, чтобы не усложнять ее. В
главе 13 мы расширим нашу классовую диаграмму так, чтобы она включала все
классы в системе ATM.]
1|
Keypad
DepositSlot
1|
v v ! v
1 ^ ..гч 1
— CashDispenser —
Авторизует пользователя в
ATM
'l
1
Screen
Исполняете
0..1
BankDatabase
Содержите
▼ I1
0..*
0..1 0..1
Withdrawal
I0..1
0..1
< Читает/модифицирует
баланс счета через
Account
Рис. 3.23. Классовая диаграмма для модели системы ATM
Рис. 3.23 представляет собой графическую модель структуры системы
ATM. Эта классовая диаграмма включает классы BankDatabase и Account,
а также некоторые ассоциации, не представленные на рис. 3.20 и рис. 3.22.
Диаграмма показывает, что класс ATM находится с классом BankDatabase
в отношении «одного к одному» — один объект ATM авторизует пользовате-
186
Глава 3
лей при помощи единственного объекта BankDatabase. На рис. 3.23 мы
моделируем также тот факт, что база данных банка содержит информацию о
многих счетах, — один объект класса BankDatabase участвует в отношении
композиции с нулем или большим числом объектов класса Account. Как вы
помните из рис. 3.21, значение кратности 0..* на стороне Account ассоциации
между классом BankDatabase и классом Account указывает, что в ассоциации
участвует ноль или большее нуля число объектов Account. Класс
BankDatabase находится с классом Account в отношении «одного ко
многим» — объект BankDatabase хранит много объектов Account. Точно так же
класс Account находится с классом BankDatabase в отношении «многих к
одному» — может существовать много объектов Account, хранящихся в одном
объекте BankDatabase. [Замечание. Как вы помните из рис. 3.21, значение
кратности * эквивалентно 0..*. Мы указываем на наших диаграммах 0..* для
большей наглядности.]
Рис. 3.23 указывает также, что если пользователь производит снятие
наличных, «один объект класса Withdrawal читает/модифицирует баланс счета
через один объект класса BankDatabase». Мы бы могли создать ассоциацию
непосредственно между классом Withdrawal и классом Account.
Спецификация требований, однако, говорит, что для выполнения транзакций «ATM
должен взаимодействовать с базой данных о счетах банка». Банковский счет
содержит критическую информацию, и системные инженеры при
проектировании системы всегда должны принимать в расчет безопасность личных данных.
Поэтому только BankDatabase может непосредственно обращаться к счету
и манипулировать им. Все остальные части системы для того, чтобы получать
и обновлять информацию счета (т.е. баланс счета), должны взаимодействовать
с базой данных.
Классовая диаграмма на рис. 3.23 моделирует также ассоциации между
классом Withdrawal и классами Screen, Keypad и CashDispenser. При
транзакции снятия наличных пользователю предлагается выбрать снимаемую
сумму и производится ввод числа. Эти действия требуют использования
соответственно экрана и кнопочной панели. Далее, для выдачи пользователю наличных
требуется обращение к выходному лотку.
Классы Balancelnquiry и Deposit, хотя и не показаны на рис. 3.23, также
участвуют в различных ассоциациях с другими классами системы ATM.
Подобно классу Withdrawal, каждый из этих классов ассоциируется с классами
ATM и BankDatabase. Объект класса Balancelnquiry ассоциируется также
с объектом класса Screen, чтобы показывать пользователю баланс счета. Класс
Deposit ассоциируется с классами Screen, Keypad и DepositSlot. Подобно
снятию наличных, транзакции внесения денег требуют использования экрана
и кнопочной панели соответственно для вывода приглашения и приема ввода.
Для получения конверта с депозитом объект Deposit обращается к приемной
щели.
Мы теперь идентифицировали классы нашей системы ATM (хотя по ходу
дальнейшего проектирования и реализации мы можем обнаружить и другие).
В разделе 4.13 мы определим атрибуты для каждого из этих классов, а в
разделе 5.11 используем эти атрибуты для изучения того, какие изменения
происходят с системой во времени. В разделе 6.22 мы определим действия классов
в нашей системе.
Введение в классы и объекты
187
Контрольные вопросы по конструированию программного
обеспечения
3.1. Предположим, у нас есть класс Саг, представляющий автомобиль.
Подумайте о том, какие детали должен был бы собрать производитель, чтобы
изготовить целый автомобиль. Создайте классовую диаграмму (сходную
с рис. 3.23), моделирующую некоторые из отношений композиции
класса Саг.
3.2. Предположим, у нас есть класс File, представляющий электронный
документ на автономном, не включенном в сеть компьютере,
представленном классом Computer. Какого рода ассоциация существует между
классом Computer и классом File?
a) Класс Computer находится с классом File в отношении «одного к
одному».
b) Класс Computer находится с классом File в отношении «многих к
одному».
c) Класс Computer находится с классом File в отношении «одного ко
многим ».
d) Класс Computer находится с классом File в отношении «многих ко
многим ».
3.3. Скажите, верно или неверно ли следующее утверждение, и если неверно,
объясните, почему: Диаграмма UML, в которой второе и третье
отделения не моделируются, называется неполной диаграммой.
3.4. Модифицируйте классовую диаграмму из рис. 3.23, чтобы она.
Ответы на контрольные вопросы по конструированию
программного обеспечения
3.1. [Замечание. Ответы студентов могут различаться.] На рис. 3.24
представлена классовая диаграмма, показывающая некоторые из отношений
композиции класса Саг.
Wheel
j;
SteeringWheel ^ Car ^ SeatBelt
♦,
2
Windshield
Рис. 3.24. Классовая диаграмма, показывающая отношения композиции класса Саг
188
Глава 3
3.2. с. [Замечание. В компьютерной сети это могло бы быть отношением
«многих ко многим».]
3.3. Верно.
3.4. На рис. 3.25 представлена классовая диаграмма для ATM, включающая
вместо класса Withdrawal (как на рис. 3.23) класс Deposit. Заметьте, что
Deposit не обращается к Cash Dispenser, но обращается к DepositSlot.
1
Keypad
DepositSlot
1|
w v v i
— CashDispenser
Screen
И
Авторизует пользователя в
ATM
'l
Исполняет ►
0..1
|0..1|0..1
Deposit
I0..1
0..1
1
BankDatabase
Содержит ▼
T
1
0..*
< Читает/модифицирует
баланс счета через
Account
Рис. 3.25. Классовая диаграмма для модели системы ATM, включающая класс
Deposit
3.12. Заключение
В этой главе вы узнали, как создавать классы, определяемые
пользователем, и использовать объекты этих классов. В частности, мы объявляли
элементы данных, сохраняющие данные каждого из объектов класса. Мы также
определяли элемент-функции класса, которые оперируют этими данными. Вы
узнали, как вызывать элемент-функции объекта, чтобы запрашивать
предоставляемые классом услуги, и как передавать этим функциям данные в
качестве аргументов. Мы обсудили разницу между локальной переменной
элемент-функции и элементом данных класса. Мы также показали, как
использовать конструктор для спецификации начальных значений элементов данных
объекта. Вы узнали, как отделить интерфейс класса от его реализации в
соответствии с принципами правильного конструирования программного обеспе-
Введение в классы и объекты
189
чения. Мы представили диаграмму, показывающую файлы, нужные
программистам реализации класса и программистам кода клиента для компиляции
написанного ими кода. Мы продемонстрировали, как можно использовать
set -функции для проверки действительности данных объекта и гарантировать,
что объекты поддерживаются в согласованном состоянии. В дополнение к
этому для моделирования классов и их конструкторов, элемент-функций и
элементов данных были использованы классовые диаграммы UML. В следующей
главе мы начнем наше введение в управляющие операторы, которые
специфицируют порядок выполнения действий в функциях.
Резюме
• Для выполнения в программе некоторой задачи требуется функция. Функция
скрывает от пользователя сложности выполняемой ею задачи.
• Функция в классе называется элемент-функцией и выполняет одну из задач класса.
• До того, как программа сможет выполнять описываемые классом задачи, нужно
создать объект класса. Это одна из причин того, что C++ называется
объектно-ориентированным языком.
• Каждое сообщение, посылаемое объекту, является вызовом элемент-функции,
который велит объекту выполнить некоторую задачу.
• У объекта есть атрибуты, сопровождающие его по ходу использования в программе.
Эти атрибуты специфицируются как элементы данных класса объекта.
• Определение класса содержит элементы данных и элемент-функции, которые
определяют соответственно атрибуты и поведение класса.
• Определение класса начинается ключевым словом class, за которым
непосредственно следует имя класса.
• По общепринятому соглашению имя определяемого пользователем класса
начинается с прописной буквы, и, в целях удобочитаемости, каждое из последующих слов
в имени также начинается с прописной буквы.
• Тело каждого класса заключается в пару фигурных скобок ({ и }) и оканчивается
точкой с запятой.
• Элемент-функции, следующие за спецификатором доступа public, могут вызываться
другими функциями программы и элемент-функциями других классов.
• За спецификаторами доступа всегда следует двоеточие (:).
• Ключевое слово void является специальным возвращаемым типом, указывающим,
что функция, выполняя некоторую задачу, не возвращает по завершении ее никаких
данных вызывающей функции.
• По соглашению имена функций начинаются со строчной буквы, а каждое из
последующих слов в имени начинается с прописной буквы.
• Пустая пара круглых скобок после имени функции указывает, что функции для
выполнения ее задачи не требуется никаких дополнительных данных.
• Тело каждой функции ограничивают фигурные скобки ({ и }).
• Обычно элемент-функция не может быть вызвана до того, как будет создан объект ее
класса.
• Каждый вновь создаваемый вами класс становится новым типом C++, который
может использоваться для объявления переменных и создания объектов. Это одна из
причин того, почему C++ называют расширяемым языком.
• Элемент-функции может потребоваться один или несколько параметров,
представляющих дополнительные данные, необходимые для выполнения ее задачи. Вызов
функции предоставляет аргументы для каждого из ее параметров.
190
Глава 3
• Элемент-функция вызывается посредством указания имени объекта, за которым
следуют операция-точка (.), имя функция и пара круглых скобок, заключающих
аргументы функции.
• Переменная класса Стандартной библиотеки C++ представляет строку символов. Это
класс определяется в заголовочном файле <string>, причем имя string принадлежит
пространству имен std.
• Функция getline (из заголовка <string>) читает символы из своего первого
аргумента, пока не встретится символ новой строки, а затем помещает эти символы
(исключая символ новой строки) в переменную типа string, специфицированную в качестве
второго аргумента. Символ новой строки отбрасывается.
• Список параметров может содержать любое их число, включая нулевое (что
представляется пустыми скобками), показывающее, что функция не требует никаких
параметров.
• Число аргументов в вызове функции должно соответствовать числу параметров
в списке параметров заголовка вызываемой функции. Кроме того, типы аргументов
в вызове должны быть совместимы с типами соответствующих параметров в
заголовке функции
• Переменные, объявленные в теле функции, являются локальными переменными
и могут использоваться только начиная с точки их объявления и до ближайшей
закрывающей фигурной скобки (}). Когда функция завершается, значения всех ее
локальных переменных теряются.
• Локальная переменная должна быть объявлена до того, как ее можно будет
использовать в функции. К локальной переменной нельзя обращаться их точки вне
функции, где она объявлена.
• Элементы данных класса обычно являются закрытыми. Переменные или функции,
объявляемые как private, доступны только для элемент-функций класса, в котором
они объявлены.
• Когда программа создает объект (представитель) класса, его закрытые элементы
данных инкапсулируются (скрываются) в объекте и доступны только для
элемент-функций класса объекта.
• Когда вызывается функция, которая специфицирует возвращаемый тип, отличный от
void, она по завершении своей работы возвращает результат вызывающей функции.
• По умолчанию начальным значением переменной типа string является пустая
строка, т.е. строка, не содержащая никаких символов. Когда выводится пустая строка,
на экране ничего не появляется.
• В классах часто предусматриваются открытые элемент-функции, позволяющие
клиентам класса устанавливать или получать значения закрытых элементов данных.
Имена этих функций обычно начинаются с set или get,
• Определение set- и £е*-функций позволяет клиентам класса косвенно обращаться
к скрытым данным. Клиент знает, что он пытается модифицировать или получить
данные объекта, но не знает, как объект производит эти операции.
• Set- и gW-функции класса должны также использоваться другими
элемент-функциями в классе для манипулирования его закрытыми данными, хотя эти функции
могут обращаться к закрытым данным непосредственно. Есле представление данных
в классе изменяется, элемент-функции, работающие с данными только через
посредство set- и get -функций, не потребуют модификации, — изменения необходимо будет
произвести только в теле set- и get -функций, которые непосредственно
манипулируют элементами данных.
• Открытая set-функция обычно должна тщательно проверять любую попытку
модификации элемента данных и убедиться, что новое значение допустимо для этого
элемента.
Введение в классы и объекты
191
• Каждый объявляемый вами класс должен предусматривать конструктор для
инициализации объекта класса при его создании. Конструктор является специальной
элемент-функцией, которая должна определяться с тем же именем, что и класс,
чтобы компилятор мог отличить ее от других элемент-функций класса.
• Отличи конструкторов от функций состоит в том, что конструкторы не могут
возвращать значений и потому не могут специфицировать возвращаемый тип (даже void).
Обычно конструкторы объявляются как public.
• C++ требует вызова конструктора при создании каждого объекта, что помогает
гарантировать инициализацию объекта до того, как он будет использоваться в
программе.
• Конструктор, не принимающий аргументов, является конструктором по умолчанию.
В любом классе, не имеющим конструктора, компилятор генерирует конструктор по
умолчанию. Программист класса может также явно определить конструктор по
умолчанию. Если программист определяет для класса какой-либо конструктор, C++
не создает конструктор по умолчанию.
• Правильно скомпонованные определения классов могут утилизироваться
программистами всего мира.
• Принято определять классы в заголовочных файлах с расширением имени .h.
• Если изменяется реализация класса, клиенты класса не должны требовать
изменений.
• Интерфейсы определяют и стандартизируют способы взаимодействия таких
«вещей», как люди и программные системы.
• Интерфейс класса описывает открытые элемент-функции класса (называемые также
доступными услугами), которые сделаны доступными для клиентов класса.
Интерфейс описывает, какими услугами могут пользоваться клиенты и как запрашивать
эти услуги, но не специфицирует, каким образом класс их осуществляет.
• Одним из основных принципов правильного конструирования программного
обеспечения является отделение интерфейса от реализации. Это облегчает модификацию
программ. Изменения в реализации класса не затрагивают клиента, пока не
меняется ранее предоставленный последнему интерфейс класса.
• Прототип функции содержит имя функции, ее возвращаемый тип и число, порядок
и типы ожидаемых функцией параметров.
• Как только класс определен и его элемент-функции объявлены (посредством
прототипов), элемент-функции должны быть определены в отдельном файле исходного
кода.
• В определении каждой элемент-функции, определяемой вне соответствующего
определения класса, имени функции должно предшествовать имя класса с бинарной
операцией разрешения области действия(::).
• Элемент-функция length класса string возвращает число символов в объекте string.
• Элемент-функция substr класса string возвращает новый объект string, созданный
путем копирования части существующего объекта string. Первый аргумент
функции специфицирует начальную позицию в исходной строке, откуда копируются
символы. Ее второй аргумент специфицирует число копируемых символов.
• Каждый класс в классовой диаграмме UML моделируется прямоугольником с тремя
отделениями. Верхнее отделение содержит имя класса в жирном шрифте,
центрированное по горизонтали. Среднее отделение содержит атрибуты класса (элементы
данных в C++). Нижнее отделение содержит действия класса (элемент-функции и
конструкторы в C++).
• Действия в UML моделируются записью имени действия, за которым следует пара
круглых скобок. Предшествующий действию знак плюса (+) показывает, что в UML
это открытое действие (т.е. открытая элемент-функция в C++).
192
Глава 3
Параметры действия моделируются в UML записью имени параметра, двоеточия
и типа параметра внутри пары скобок, следующих за именем действия.
UML имеет свои собственные типы данных. Не все UML-типы имеют имена,
совпадающие с именами соответствующих типов C++. UML-тип String соответствует типу
string в C++.
Элементы данных в UML представляются как атрибуты, посредством записи имени
атрибута, двоеточия и типа атрибута. Закрытые атрибуты обозначаются в UML
предшествующим атрибуту знаком минуса (-).
Возвращаемый тип действия указывается в UML записью двоеточия и
возвращаемого типа после скобок, следующих за именем действия.
Для действий, не возвращающих значения, возвращаемый тип в UML не
специфицируется.
Конструкторы в UML моделируются как действия в третьем отделении классовой
диаграммы. Чтобы отличить конструктор от действий класса, перед именем
конструктора помещается слово ♦constructor» (как здесь, в угловых типографских
кавычках).
Терминология
accessor
get -функция
mutator
sef-функция
активация элемент-функции
аргумент
атрибут (UML)
бинарная операция разрешения
области действия
верблюжий регистр
возвращаемый тип
возвращаемый тип void
вызов функции
вызов элемент-функции
вызывающая функция (вызывающий)
действие (UML)
доступные услуги класса
заголовок функции
заголовочный файл
заголовочный файл <string>
элемент-функция substr класса string
знак минуса (UML)
знак плюса (UML)
интерфейс класса
класс string
классовая диаграмма (UML)
классовая диаграмма UML
клиент объекта или класса
конструирование программного
обеспечения
конструктор
конструктор по умолчанию
локальная переменная
мутатор
объектный код
операция-точка (.)
определение класса
отделение интерфейса от реализации
отделение классовой диаграммы
(UML)
параметр
параметр действия (UML)
подтверждение данных
представитель класса
проверка действительности
программист кода клиента
программист реализации класса
прототип функции
пустая строка
расширяемый язык
реализация класса
согласованное состояние
сокрытие данных
сообщение (посылаемое объекту)
спецификатор доступа
спецификатор доступа private
спецификатор доступа public
список параметров
тело определения класса
типографские кавычки , « и * (UML)
точность
точность по умолчанию
файл исходного кода
функция getline библиотеки <string>
функция length библиотеки <string>
элемент данных
элемент-функция
Введение в классы и объекты
193
Контрольные вопросы
3.1. Заполните пропуски в каждом из следующих предложений:
a) Дом по отношению к чертежу — то же, что по отношению к классу.
b) Каждое определение класса начинается ключевым словом , за
которым непосредственно следует имя класса.
c) Определение класса обычно сохраняют в файле с расширением имени
d) Каждый параметр в заголовке функции должен специфицировать
и .
e) Каждый объект класса сохраняет свой собственный экземпляр атрибута;
переменную, представляющую атрибут, называют также .
f) Ключевое слово public является .
g) Возвращаемый тип указывает, что функция выполняет некоторую
задачу, но по завершении ее не возвращает никакой информации.
h) Функция из библиотеки <string> читает символы, пока не
встретится символ новой строки, а затем копирует их в специфицированную строку.
i) Когда элемент-функция определяется вне определения класса, ее заголовок
должен включать имя класса и , предшествующие имени функции,
чтобы * привязать» элемент-функцию к определению класса.
j) Файл исходного кода и любые другие файлы, использующие класс, могут
включить заголовочный файл класса посредством препроцессорной
директивы .
3.2. Установите, верно или неверно каждое из следующих утверждений. Если
утверждение неверно, объясните, почему.
a) В соответствии с соглашением, имена функций начинаются с прописной
буквы, и все последующие слова в имени также начинаются с прописной буквы.
b) Пустые скобки, следующие за именем функции в прототипе, указывают, что
функции для выполнения ее задачи не требуется никаких параметров.
c) Элементы данных или элемент-функции, объявленные со спецификатором
доступа private, доступны для элемент-функций класса, в котором они
объявлены.
d) Переменные, объявленные в теле некоторой элемент-функции, называются
элементами данных и могут использоваться во всех элемент-функциях класса.
e) Тело каждой функции ограничивается левой и правой фигурными скобками
( { и } ).
f) Для исполнения программы можно использовать любой файл исходного кода,
содержащий int main().
g) Типы аргументов в вызове функции должны быть согласованы с типами
соответствующих параметров в списке параметров прототипа функции.
3.3. Чем отличается локальная переменная от элемента данных?
3.4. Объясните назначение параметра функции. Чем отличается параметр от
аргумента?
7 Заг 1114
194
Глава 3
Ответы на контрольные вопросы
3.1. а) объект, b) class, с) .h. d) тип, имя. е) элементом данных, f) спецификатором
доступа, g) void, h) getline. i) бинарную операцию разрешения области действия
(::). j) #include.
3.2. а) Неверно. По соглашению имена функций начинаются со строчной буквы, а все
последующие слова в имени начинаются с прописной буквы. Ь) Верно, с) Верно,
d) Неверно. Такие переменные называются локальными переменными и могут
использоваться только в элемент-функции, где они объявлены, е) Верно, f)
Верно, g) Верно.
3.3. Локальная переменная объявляется в теле функции и может использоваться
только от точки объявления до ближайшей закрывающей фигурной скобки.
Элемент данных объявляется в определении класса, но не в теле какой-либо из
элемент-функций класса. Каждый объект (представитель) класса имеет
собственный экземпляр элементов данных класса. Кроме того, элементы данных
доступны для всех элемент-функций класса.
3.4. Параметр представляет дополнительную информацию, необходимую функции
для выполнения ее задачи. Каждый требуемый функцией параметр
специфицируется в заголовке функции. Аргумент является значением, указываемым в
вызове функции. При вызове функции значение аргумента передается в
соответствующий параметр функции, чтобы функция могла выполнить свою задачу.
Упражнения
3.5. Объясните разницу между прототипом и определением функции.
3.6. Что такое конструктор по умолчанию? Как инициализируются элементы
данных объекта, если класс имеет только неявно определенный конструктор по
умолчанию?
3.7. Объясните назначение элемента данных.
3.8. Что такое заголовочный файл? Что такое файл исходного кода? Рассмотрите
назначение каждого из них.
3.9. Объясните, каким образом программа могла бы использовать класс string, не
прибегая к объявлению using.
3.10. Объясните, зачем класс мог бы предусматривать для элемента данных set-функ-
цию и get-функцию.
3.11. (Модификация класса Grade Book )
Модифицируйте класс GradeBook (рис. 3.11-3.12) следующим образом:
a) Введите второй элемент данных string, представляющий имя преподавателя,
ведущего курс.
b) Предусмотрите в классе set-функцию для изменения имени преподавателя
и get-функцию для его извлечения.
c) Модифицируйте конструктор, чтобы он специфицировал два параметра: один
для названия курса и второй — для имени преподавателя.
d) Модифицируйте элемент-функцию displayMessage так, чтобы она сначала
выводила приветствие и название курса, а затем «This course is presented by: »
и имя преподавателя.
3.12. (Класс Account)
Создайте класс с именем Account, которым мог бы воспользоваться банк для
представления банковских счетов своих клиентов. Ваш класс должен иметь один
элемент данных типа int для представления банковского баланса. [Замечание.
В последующих главах для представления денежных сумм мы будем пользовать-
Введение в классы и объекты
195
ся числами с десятичной точкой — например, 2.75, — они называются числами
с плавающей точкой.] Класс должен предусматривать конструктор,
принимающий начальный баланс, используемый для инициализации элемента данных.
Конструктор должен подтверждать значение начального баланса и
гарантировать, что оно больше или равно 0. Если нет, баланс должен устанавливаться
равным 0, и конструктор должен выводить сообщение об ошибке, указывающее, что
начальный баланс был недействителен. В классе должны быть предусмотрены
три элемент-функции. Функция credit должна добавлять указанную сумму из
текущего баланса. Функция debit должна снимать деньги со счета,
предварительно убедившись, что указанная сумма не превосходит баланса счета. Если
превосходит, баланс нужно оставить без изменений и функция должна вывести
сообщение вроде «Запрошенная сумма превышает баланс счета». Функция
getBalance должна возвращать текущий баланс. Напишите программу, которая
создает два объекта класса Account и тестирует элемент-функции класса.
3.13. (Класс Invoice)
Создайте класс с именем Invoice, который мог бы использоваться на складе
хозяйственных товаров для представления накладных на товары, отпускаемые со
склада. Класс должен включать в качестве элементов данных четыре
информационных пункта в качестве элементов данных: артикул изделия (тип string),
описание изделия (тип string), число отпускаемых единиц изделия (тип int)
и цену за одно изделие (тип int). [Замечание. В последующих главах для
представления денежных сумм мы будем пользоваться числами с десятичной
точкой — например, 2.75, — они называются числами с плавающей точкой.] Класс
должен иметь конструктор, инициализирующий четыре элемента данных.
Предусмотрите для каждого элемента данных set- и £е£-функции. Кроме того,
предусмотрите элемент-функцию с именем get In voice Amount, которая вычисляет
общую сумму накладной (т.е. умножает цену одного изделия на число изделий)
и возвращает ее как целое число. Если число изделий не положительно, оно
должно устанавливаться равным 0. Напишите тестовую программу,
демонстрирующую возможности класса Invoice.
3.14. (Класс Employee)
Создайте класс с именем Employee («служащий»), включающий в качестве
элементов данных три информационных пункта: имя (тип string), фамилию (тип
string) и месячную зарплату (тип int). [Замечание. В последующих главах для
представления денежных сумм мы будем пользоваться числами с десятичной
точкой — например, 2.75, — они называются числами с плавающей точкой.] Ваш
класс должен иметь конструктор, инициализирующий три элемента данных.
Предусмотрите set- и get -функции для каждого элемента данных. Если зарплата не
положительна, устанавливайте ее равной 0. Напишите тестовую программу,
демонстрирующую возможности класса Employee. Создайте два объекта Employee и
выведите годовую зарплату для каждого объекта. Затем поднимите зарплату каждого
из «служащих» на 10% и снова выведите их годовую зарплату.
3.15. (Класс Date)
Создайте класс с именем Date, включающий в качестве элементов данных три
информационных пункта: месяц (тип int), день месяца (тип int) и год (тип int).
Ваш класс должен иметь конструктор с тремя параметрами для инициализации
этих элементов данных. Для целей этого упражнения предположите, что данные
для года и дня правильные, но проверьте, что значение месяца находится в
диапазоне 1-12; если нет, устанавливайте месяц равным 1. Предусмотрите set-
и £е£-функции для каждого элемента данных. Предусмотрите элемент-функцию
displayDate, которая выводит месяц, день и год, разделенные дробной чертой (/).
Напишите тестовую программу, демонстрирующую возможности класса Date.
4
Управляющие операторы:
часть I
ЦЕЛИ
В этой главе вы изучите:
• Основные методики решения задач.
• Методику разработки алгоритмов
путем нисходящего
последовательного уточнения.
• Использование операторов выбора
if и if...else для выбора
альтернативных действий.
• Использование оператора
повторения while для многократного
исполнения операторов в программе.
• Повторение, управляемое счетчиком,
и повторение, управляемое
контрольным значением.
• Операции инкремента, декремента и
присваивания.
198
Глава 4
4.1. Введение
4.2. Алгоритмы
4.3. Псевдокод
4.4. Управляиющие структуры
4.5. Оператор выбора if
4.6. Оператор двойного выбора if...else
4.7. Оператор повторения while
4.8. Формулирование алгоритмов: повторение,
управляемое счетчиком
4.9. Формулирование алгоритмов: повторение,
управляемое контрольным значением
4.10. Формулирование алгоритмов: вложенные
управляющие операторы
4.11. Операции присваивания
4.12. Операции инкремента и декремента
4.13. Конструирование программного обеспечения.
Идентификация классовых атрибутов в системе ATM
(необязательный раздел)
4.14. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
4.1. Введение
Прежде чем писать программу для решения конкретной задачи,
необходимо досконально понять эту задачу и тщательно спланировать пути ее решения.
Когда пишется программа, в равной степени важно понимать типы
имеющихся в распоряжении строительных блоков и следовать апробированным
методикам построения программ. В этой и следующих главах мы обсудим все эти
вопросы в процессе знакомства с теорией и принципами структурного
программирования. Представленные здесь концепции являются решающими для
построения эффективных классов и манипуляции объектами.
В этой главе мы представим операторы if, if...else и while, три
строительных блока, позволяющих программистам специфицировать логику,
требующуюся элемент-функциям для выполнения их задач. Часть этой главы (а
также части глав 5 и 7) мы посвятим дальнейшему развитию класса GradeBook,
представленного в главе 3. В частности, мы добавим к классу
элемент-функцию, которая применяет управляющие операторы для вычисления среднего по
набору оценок студентов. Другой пример демонстрирует альтернативные спо-
Управляющие операторы: часть I
199
собы соединения управляющих операторов для решения похожей задачи. Мы
введем операции присваивания C++ и исследуем операции инкремента и
декремента. Эти дополнительные операции сокращают и упрощают написание
многих программных операторов.
4.2. Алгоритмы
Любая вычислительная задача может быть решена путем выполнения в
определенной последовательности некоторой совокупности операций. Процедура
решения задачи, выраженная в категориях
1. операций, которые должны выполняться, и
2. последовательности, в которой эти операции должны выполняться,
называется алгоритмом. Приведенный ниже пример показывает,
насколько важно правильно определить последовательность выполнения
операций.
Рассмотрим «алгоритм утреннего пробуждения», который выполняет
младший клерк, вставая с постели и отправляясь на работу: A) встать с постели, B)
снять пижаму, C) принять душ, D) одеться, E) позавтракать, F) поехать на
работу.
Выполнение этой программы позволяет хорошо подготовиться к работе
и быть готовым к принятию важных решений. Предположим, однако, что те
же шаги выполняются в несколько другой последовательности: A) встать с
постели, B) снять пижаму, C) одеться, D) принять душ, E) позавтракать, F)
поехать на работу.
В этом случае наш клерк отправится на работу слегка мокрым.
Спецификация последовательности, в которой должны выполняться операторы
(действия) в компьютерной программе, называется программным управлением.
В этой главе мы изучаем программное управление в C++ посредством
управляющих операторов.
4.3. Псевдокод
Псевдокод — это искусственный и неформальный язык, который помогает
программистам разрабатывать алгоритмы. Псевдокод, который мы
рассматриваем, часто используется для разработки алгоритмов, которые потом должны
быть преобразованы в структурированные фрагменты программ на C++.
Псевдокод подобен разговорному языку; он удобный и ясный, но это не язык
программирования .
Программы на псевдокоде не могут выполняться на компьютере. Их
назначение — помочь программисту «продумать программу», прежде чем пытаться
написать ее на таком языке программирования, как C++. В этой главе мы
приводим несколько примеров того, как можно эффективно использовать
псевдокод при разработке программ на C++.
Тот псевдокод, который мы рассматриваем, состоит исключительно из
символов, так что программисты могут писать псевдокод в любом текстовом
редакторе. При необходимости программу на псевдокоде можно распечатать на
принтере. Тщательно подготовленная программа на псевдокоде может быть
легко преобразована в соответствующую программу на C++. Во многих с луча-
200
Глава 4
ях для этого достаточно просто заменить операторы псевдокода их
эквивалентами на C++.
Псевдокод обычно включает только исполняемые операторы — те,
вызывают конкретные действия, когда программа переведена из псевдокода на C++
и запущена на компьютере. Объявления (те, что не имеют инициализаторов
и не связаны с вызовами конструкторов) не являются исполняемыми
операторами. Например, объявление
int i ;
просто сообщает компилятору тип переменной i и дает указание
зарезервировать для нее место в памяти. Но это объявление не вызывает при выполнении
программы какого-то действия — ввода данных, их вывода или каких-нибудь
вычислений. Обычно мы не включаем в псевдокод объявления переменных.
Однако некоторые программисты предпочитают составлять список
переменных с кратким описанием их назначения и помещать его в начале программ на
псевдокоде.
Рассмотрим теперь пример псевдокода, который мог бы быть написан,
чтобы помочь программисту написать программу сложения на рис. 2.5.
Псевдокод (рис. 4.1) соответствует алгоритму, который вводит два целых числа
пользователя, складывает их и выводит сумму. Мы показываем здесь законченный
листинг псевдокода, но далее в этой главе мы продемонстрируем процесс
создания псевдокода по формулировке задачи.
Строки 1-2 соответствуют операторам в строках 13-14 на рис. 2.5.
Обратите внимание, что операторы псевдокода являются просто предложениями
обычного языка, передающими то, какая задача должна выполняться в C++.
Точно так же строки 4-5 соответствуют операторам в строках 16-17 на
рис. 2.5, а строки 7-8 — операторам в строках 19 и 21.
1 Попросить пользователя ввести первое число
2 Ввести первое число
3
4 Попросить пользователя ввести второе число
5 Ввести второе число
6
7 Сложить первое число и второе число, сохранить результат
8 Вывести результат
Рис. 4.1. Псевдокод для программы сложения на рис. 2.5
Псевдокод на рис. 4.1 имеет некоторые важные аспекты. Заметьте, что
псевдокод соответствует только коду внутри функции main. Это объясняется
тем, что псевдокод обычно используется не для законченных программ, а для
алгоритмов. В данном случае псевдокод представляет алгоритм. Функция,
в которой размещен этот код, не важна для самого алгоритма. По той же
причине в псевдокод не включена строка 25 из рис. 2.5 (оператор return) —
оператором return заканчивается любая функция main, и он не важен для
алгоритма. Наконец, в псевдокод не включены строки 9-11 на рис. 2.5, поскольку
объявления не являются исполняемыми операторами.
Управляющие операторы: часть I
201
4.4. Управляющие структуры
Обычно операторы программы выполняются друг за другом в той
последовательности, в которой они написаны. Это называется последовательным
исполнением. Однако некоторые операторы C++, которые мы будем здесь
обсуждать, позволяют программисту указать, что следующим должен выполняться
не очередной оператор в последовательности, а какой-то другой. Это
называется передачей управления.
В 60-е годы стало ясно, что неосторожное использование передач
управления является источником множества трудностей при групповой разработке
программного обеспечения. Вина была возложена на оператор goto, который
позволяет программисту передавать управление в очень широких пределах
(что приводит к коду, который иногда называют «лапшой»). Понятие так
называемого структурного программирования стало почти синонимом
«исключения goto».
Исследование Бема и Джакопини1 показало, что программы могут быть
написаны без использования оператора goto. В результате для программистов
настала эра перехода к стилю программирования «с минимальным
использованием goto». Но только в 70-х годах программисты принимать структурное
программирование всерьез. Результаты получились впечатляющие: группы
разработчиков программного обеспечения сообщали, что время разработок
сократилось, производительность труда выросла, и проекты стали чаще
укладываться в рамки бюджета. Ключом к успеху явилось то, что структурированные
программы стали более прозрачными, легче поддавались отладке и
модификации и, что самое главное, в них стало меньше ошибок.
Работа Бома и Джакопини показала, что все программы могут быть
написаны с использованием всего трех управляющих структур, а именно,
последовательной структуры, структуры выбора и структуры повторения. Термин
«управляющие структуры» взят из компьютерной теории. Когда мы будем
представлять реализацию управляющих структур в C++, мы, в соответствии
с терминологией стандартного документа по C++2, будем называть их
«управляющими операторами».
Последовательная структура в C++
Последовательная структура встроена в C++. Пока не указано иначе,
компьютер выполняет операторы C++ один за другим в той последовательности,
в которой они записаны. Диаграмма деятельности Унифицированного языка
моделирования (UML) на рис. 4.2 иллюстрирует типичную
последовательность операторов, в которой две вычислительные операции выполняются одна
за другой. C++ позволяет нам включать в последовательную структуру
сколько угодно действий. Как мы скоро увидим, везде, где может помещаться
одиночное действие, можно разместить несколько последовательных действий.
1 Bohm, С, and G. Jacopini, «Flow Diagrams, Turing Machines, and Languages with
Only Two Formation Rules,» Communications of the ACM, Vol. 9, May 1966,
pp. 366-371.
2 Говоря конкретнее, этот документ известен как NCITS/ISO/IEC 14882-2003
Programming Languages—C++ и доступен для загрузки (бесплатно) на webstore.an-
si.org/ansidocstore/ghjduct.asp?sku=INCITS%2FISO%2FIEC+14882%2D2003.
202
Глава 4
Соответствующий оператор C++:
total = total + grade;
Соответствующий оператор C++:
counter = counter + 1;
Рис- 4.2. Диаграмма деятельности для последовательной структуры
На этом рисунке два оператора выполняют прибавление оценки к
переменной total и прибавление к переменной counter значения 1. Такие операторы
могли бы появиться в программе, вычисляющей среднюю оценку для
нескольких студентов. Чтобы вычислить среднее, сумма всех усредняемых оценок
делится на их число. Переменная counter использовалась бы для отслеживания
числа усредняемых оценок. Вы увидите подобные операторе в программе
раздела 4.8.
Диаграммы деятельности являются частью UML. Диаграмма моделирует
рабочий поток (или деятельность) некоторой части программной системы.
Такие последовательности операций могут включать часть алгоритма, такую,
как показанная на рис. 4.2 последовательная структура. Диаграммы
деятельности составляются из специальных символов, таких как символы состояния
действия (прямоугольники, у которых левые и правые стороны заменяются
полуокружностями), ромбы и кружки; эти символы соединяются линиями со
стрелками, называемыми стрелками перехода, которые представляют поток
деятельности.
Подобно псевдокоду, диаграммы деятельности часто используются при
разработке и описании алгоритмов, хотя большинство программистов
предпочитает псевдокод. Диаграммы деятельности ясно показывают работу
управляющих структур.
Рассмотрим диаграмму деятельности для последовательной структуры
на рис. 4.2. Эта диаграмма деятельности содержит два состояния действия,
представляющих действия для выполнения. Каждое состояние действия
содержит выражение действия, например, «прибавить оценку к сумме» или
«прибавить 1 к счетчику», которое определяет конкретное действие для
выполнения. Другие действия могут включать вычисления или операции
ввода-вывода. Стрелки в диаграмме деятельности называются стрелками
перехода. Они представляют переходы, специфицирующие последовательность
выполнения действий, представленных состояниями действия — программа,
реализующая деятельность, описанную диаграммой на рис. 4.2, сначала
прибавляет grade к total, а затем к counter прибавляется 1.
т
прибавить grade к total
прибавить 1 к counter
Управляющие операторы: часть I
203
Закрашенный кружок в вершине диаграммы деятельности представляет
начальное состояние — начало рабочего потока перед тем, как программа станет
выполнять смоделированную деятельность. Закрашенный кружок внутри
окружности в нижней части диаграммы деятельности представляет конечное
состояние — окончание рабочего потока после того, как программа завершит
свою деятельность.
Рис. 4.2 содержит также прямоугольники с загнутым верхним правым
углом. Они называются в UML примечаниями. Примечания — это пояснения,
описывающие назначение символов в диаграмме. Примечания могут
использоваться в любой диаграмме UML — не только в диаграммах деятельности.
Примечания на рис. 4.2 показывают код C++, связанный с каждым
состоянием действия на диаграмме деятельности. Каждое примечание соединено
пунктирной линией с элементом, который оно описывает. Диаграммы
деятельности обычно не показывают код C++, который реализует деятельность. Мы
используем здесь примечания, чтобы продемонстрировать, как диаграмма
соотносится с кодом C++.
Операторы выбора в C++
C++ предусматривает три типа операторов выбора (обсуждаемых в этой
и следующей главах). Оператор выбора if либо выполняет (выбирает)
некоторое действие, если его условие (предикат) истинно, либо пропускает его, если
условие ложно. Оператор выбора if...else выполняет одно действие, если
условие истинно, или выполняет другое действие, если оно ложно. Оператор
выбора switch (глава 5) выполняет одно из набора различных действий в
зависимости от значения проверяемого выражения.
Оператор if называется оператором с одиночным выбором, поскольку он
выбирает или игнорирует единственное действие. Оператор if...else называется
оператором с двойным выбором, так как он выбирает одно из двух различных
действий. Оператор switch называется оператором с множественным
выбором, так как он выбирает одно из набора различных действий (или групп
действий).
Операторы повторения в C++
C++ предусматривает три типа операторов повторения (называемых также
операторами цикла или просто циклами), которые позволяют программам
многократно выполнять некоторые действия, пока условие (называемое
условием продолжения цикла) остается истинным. Этими операторами являются
операторы while, do...while и for (операторы do...while и for представлены в 5-й
главе). Операторы for и while выполняют действие (или группу действий)
в своем теле 0 или большее число раз. Оператор do...while по крайней мере
один раз выполняет действие (или группу действий) в своем теле.
Все эти слова (if, else, switch, while, do и for) являются ключевыми словами
C++. Ключевые слова зарезервированы в языке для реализации различных его
элементов, таких, как управляющие операторы C++. Ключевые слова нельзя
использовать как идентификаторы, например, для обозначения имен
переменных. Полный список ключевых слов C++ приведен на рис. 4.3.
204 Глава 4
Ключевые слова C++
Ключевые слова, общие для С и C++
auto
default
float
register
struct
volatile
break
do
for
return
switch
while
case
double
goto
short
typedef
char
else
if
signed
union
const
enum
int
sizeof
unsigned
continue
extern
long
static
void
Ключевые слова только C++
asm
dy nami c_ca s t
namespace
reintepret_cast
try
bool
explicit
new
static_cast
typeid
catch
false
operator
template
typename
class
friend
private
this
using
const_cast
inline
protected
throw
virtual
delete
mutable
public
true
wchar_t
Рис. 4.З. Ключевые слова C++
Типичная ошибка программирования 4.1
Использование ключевого слова в качестве идентификатора является
синтаксической ошибкой.
Типичная ошибка программирования 4.2
Запись ключевого слова с любой из букв в верхнем регистре является
синтаксической ошибкой. Все ключевые слова C++ содержат только
буквы в нижнем регистре.
Резюме управляющих операторов C++
В C++ всего три вида управляющих структур, которые мы далее будем
называть управляющими операторами: оператор последовательности, операторы
выбора (трех типов — if, if...else и switch) и операторы повторения (трех
типов — while, do...while и for). Любая программа на C++ формируется из такого
числа этих управляющих структур, какое необходимо для алгоритма,
реализуемого программой. Как и оператор последовательности на рис. 4.2, каждый
управляющий оператор может быть смоделирован диаграммой деятельности.
Каждая диаграмма содержит начальное и конечное состояния,
представляющие соответственно входную и выходную точки управляющего оператора.
Такие управляющие операторы с одним входом/одним выходом упрощают
построение программ — управляющие операторы прикрепляются друг к другу
соединением выходной точки одного с входной точкой другого. Это
напоминает то, как ребенок ставит кубики — один на другой, — и мы называем это
суперпозицией (надстраиванием) управляющих операторов. Вскоре мы узнаем,
что помимо рассмотренного есть еще только один способ соединения —
вложение управляющих операторов. Таким образом, алгоритмы в программах на
Управляющие операторы: часть I
205
C++ строятся всего из трех видов управляющих операторов, комбинируемых
всего двумя способами. В этом состоит сущность простоты.
Общее методическое замечание 4.1
Любая программа на C++ может быть построена только из семи
различных типов управляющих операторов (последовательность, if,
if,..else, switch, while, do...while и for), объединяемых всего двумя
способами (суперпозиция и вложение управляющих структур).
4.5. Оператор выбора if
Используя операторы выбора, программы избирают одно из
альтернативных направлений действия. Например, предположим, что проходной балл на
экзамене равен 60. Оператор псевдокода
Если оценка студента больше или равна 60
Напечатать "Сдано"
определяет, истинно или ложно условие «оценка студента больше или
равна 60». Если это условие истинно, то печатается «Сдано» и «выполняется»
следующее по порядку предложение псевдокода (напомним, что псевдокод — это
в действительности не язык программирования). Если же условие ложно, то
оператор печати игнорируется и сразу выполняется следующий по порядку
оператор псевдокода. Заметьте, что вторая строка оператора выбора записана
с отступом. Подобные отступы не обязательны, но рекомендуется их делать,
так как они подчеркивают логику структурированных программ. Когда вы
преобразуете псевдокод в код C++, компилятор C++ будет игнорировать
пробельные символы, такие, как пробелы, символы табуляции и перевода строки,
используемые для создания отступов и вертикальной разрядки.
Хороший стиль программирования 4.1
Придерживаясь во всех своих программах единообразных соглашений
об отступах, вы значительно улучшите их читаемость. Мы
советуем делать по три пробела на отступ. Некоторые предпочитают
использовать табуляции, но их размер может меняться от редактора
к редактору, из-за чего в одном редакторе строки программы будут
выровнены иначе, чем в другом.
Соответствующий приведенному псевдокоду оператор if может быть
записан на языке C++ как
if ( grade >= 60 )
cout « "Passed";
Обратите внимание, что код C++ очень близок к псевдокоду. Это одно из
свойств псевдокода, которое делает его столь полезным при разработке
программ.
Рис. 4.4 иллюстрирует оператор с одиночным выбором if. Эта диаграмма
деятельности содержит, может быть, самый важный символ диаграмм дея-
206
Глава 4
тельности —ромб или символ решения, который показывает, что должно быть
принято некоторое решение. Символ решения указывает, что рабочий поток
пойдет по пути, определенному ассоциированными с символом контрольными
условиями, которые могут быть истинными или ложными. Каждая стрелка
перехода, выходящая из символа решения, имеет контрольное условие
(специфицированное в квадратных скобках выше или рядом со стрелкой перехода).
Если контрольное условие истинно (true), рабочий поток входит в состояние
действия, на которое указывает стрелка перехода. На рис. 4.4, если оценка
больше или равна 60, программа выводит на экран «Passed» и переходит
затем в конечное состояние диаграммы. Если оценка меньше 60, программа
сразу переходит в конечное состояние, не выводя сообщения.
[qrade >= 60] > напечатать «Сдано»
[grade < 60] I I
#— '
Рис, 4.4. Диаграмма деятельности оператора одиночного выбора if
В главе 1 мы узнали, что решения могут основываться на условиях,
содержащих операции отношения или равенства. На самом деле решение в C++ может
основываться на любом выражении — если выражение оценивается как
нулевое, оно считается ложным; если как ненулевое, оно считается истинным. C++
предусматривает тип данных bool для переменных, которые могут хранить
только значения true и false; true и false являются ключевыми словами C++.
Ш Переносимость программ 4.1
Для совместимости с более ранними версиями С, в которых для
булевых значений использовались целые числа, значение true типа bool
может быть также представлено любым ненулевым значением
(компиляторы обычно используют 1), а значение false может быть
представлено нулем.
Заметьте, что оператор if является оператором с одним входом/одним
выходом. Скоро мы выясним, что диаграммы деятельности остальных
управляющих структур содержат также начальные состояния, стрелки перехода,
состояния действия, которые указывают действия для выполнения, символы
решения (с ассоциированными контрольными условиями), специфицирующие
решения, которые должны быть приняты, и конечные состояния. Это
согласуется с моделью программирования действие/решение, на которую мы хотим
обратить ваше внимание.
Мы можем представить себе семь коробок, каждая из которых содержит
пустые UML-диаграммы деятельности только для одного из семи типов управ-
S
Управляющие операторы: часть I
207
ляющих операторов. Задача программиста — собрать программу из диаграмм
деятельности таких типов и в таком количестве, как того требует алгоритм,
комбинируя диаграммы только двумя возможными способами (суперпозицией
или вложением) и затем заполнить состояния действия и символы решения
выражениями действия контрольными условиями таким образом, чтобы
получилась структурная реализация алгоритма. В дальнейшем мы обсудим
разнообразные способы записи действий и решений.
4.6. Оператор выбора if...else
Оператор if с одиночным выбором выполняет указанное действие только
тогда, когда условие истинно; в противном случае действие пропускается.
Оператор if...else с двойным выбором позволяет программисту определить как
действие, выполняемое, когда условие истинно, так и альтернативное
действие, выполняемое в том случае, когда условие ложно. Например, оператор
псевдокода
Если оценка студента больше или равна 60
Напечатать "Сдано"
Иначе
Напечатать "Не сдано"
печатает «Сдано», если оценка студента больше или равна 60, и печатает «Не
сдано», если оценка меньше 60. В обоих случаях после печати «выполняется»
следующий по порядку оператор псевдокода.
Вышеприведенный оператор псевдокода Если...Иначе может быть записан
на C++ как
if ( grade >= 60 )
cout « "Passed";
else
cout « "Failed";
Заметьте, что тело else также записано с отступом. Какой бы стиль
отступов вы ни приняли, нужно последовательно придерживаться его во всех
программах. Программы, текст которых не следует какому-либо единообразному
соглашению об отступах, трудно читать.
Хороший стиль программирования 4.2
Записывайте с отступом оба оператора в операторе if...else.
Хороший стиль программирования 4.3
Если есть несколько уровней отступов, каждый последующий уровень
должен иметь одно и то же число дополнительных пробелов.
Рис. 4.5 иллюстрирует поток управления в операторе if...else. Еще раз
отметим, что единственные символы на этой диаграмме деятельности (помимо
начального и конечного состояний и стрелок перехода) представляют
состояние действия и решение. Мы снова выделяем здесь модель действие-решение.
Представим себе снова большую коробку пустых диаграмм деятельности UML
208
Глава 4
для операторов с двойным выбором, — их столько, сколько может
потребоваться для того, чтобы путем суперпозиции и вложения, вместе с
диаграммами деятельности других управляющих операторов, сформировать
структурную реализацию алгоритма. Программирование сводится к соединению этих
операторов выбора (пакетированием или вложением) с другими
управляющими структурами, требуемыми алгоритмом. Программист заполняет состояния
действия и символы решения выражениями и контрольными условиями,
соответствующими алгоритму.
I
[grade < 60] /\ [grade >= 60]
напечатать «Не сдано» <—Е-— < >— — > напечатать «Сдано»
■Ф-
Рис. 4.5. Диаграмма деятельности оператора двойного выбора if...else
Условная операция (? :)
В C++ имеется условная операция (? :), которая тесно связана с оператором
if...else. Условная операция — единственная тернарная операция в C++, т.е.
имеющая три операнда. Эти операнды вместе с условной операцией образуют
условное выражение. Первый операнд является условием, второй содержит
значение условного выражения в случае, если условие истинно, а третий равен
значению условного выражения, если условие ложно. Например, оператор
вывода
cout « ( grade >= 60 ? "Passed" : "Failed" );
содержит условное выражение, которое оценивается как строка "Passed",
если условие grade >= 60 истинно, и как строка "Failed", если условие ложно.
Таким образом, этот оператор с условной операцией выполняет фактически те
же функции, что и приведенный ранее оператор if...else. Как мы увидим
далее, условная операция имеет низкое старшинство, и поэтому в приведенном
выражении потребовались скобки.
Хороший стиль программирования 4.4
Чтобы избежать неприятностей, связанных со старшинством
операций (и для большей ясности), помещайте условные выражения в
круглые скобки.
Значения условного выражения могут также быть исполняемыми
действиями. Например, следующее условное выражение также печатает «Passed»
или «Failed»:
grade >= 60 ? cout « "Passed\n" : cout « "Failed\n";
Управляющие операторы: часть I
209
Выражение читается так: «Если grade больше или равна 60, то cout «
"Passed\n"; в противном случае cout « "Failed\n"». Это также сопоставимо
с предыдущим оператором if...else. Условные выражения могут
использоваться в таких местах программы, где применение оператора if...else невозможно.
Вложенные операторы if...else
Для множественного выбора можно использовать вложенные операторы
if...else, помещая один оператор if...else внутрь другого. Например,
следующий оператор псевдокода Если...Иначе будет печатать А при экзаменационной
оценке, большей или равной 90, В — при оценке, лежащей в диапазоне от 80
до 89, С — при оценке в диапазоне 70-79, D — при оценке в диапазоне 60-69
и F — при других оценках.
Если оценка студента больше или равна 90
Напечатать "А"
Иначе
Если оценка студента больше или равна 80
Напечатать "В"
Иначе
Если оценка студента больше или равна 70
Напечатать "С"
Иначе
Если оценка студента больше или равна 60
Напечатать "D"
Иначе
Напечатать "F"
Этот псевдокод может быть записан на языке C++ в виде
if ( studentGrade >= 90 ) // 90 и более получает оценку "А"
cout « "А";
else
if ( studentGrade >= 80 ) // 80-89 получает "В"
cout « "В";
else
if ( studentGrade >= 70 ) // 70-79 получает "С"
cout « "С";
else
if ( studentGrade >= 60 ) // 60-69 получает MD"
cout « "D";
else // менее 60 получает MF"
cout « "F",
Если studentGrade (оценка студента) больше или равна 90, то четыре условия
истинны, но будет выполнен только оператор cout, расположенный после
проверки первого условия. После того как этот оператор cout выполнен, часть else
внешнего оператора if...else пропускается. Большинство программирующих
на C++ предпочтут записать предыдущий оператор if в виде
if ( studentGrade >= 90 ) // 90 и более получает оценку "А"
cout « "А";
else if ( studentGrade >= 80 ) // 80-89 получает "В"
cout « "В";
else if ( studentGrade >= 70 ) // 70-79 получает "С"
210
Глава 4
cout « "С";
else if ( studentGrade >= 60 ) // 60-6960-69 получает "D"
cout « "D";
else // менее 60 менее 60 получает "F"
cout « "F";
Обе формы эквивалентны, отличаясь только отступами и вертикальной
разрядкой, которые компилятором игнорируются. Последняя форма более
популярна, поскольку она позволяет избежать сдвига кода далеко вправо.
Подобный сдвиг часто оставляет мало места в строке, заставляя дробить и
переносить строки, что ухудшает читаемость программы.
Вопросы эффективности 4,1
Вложенные операторы if...else могут работать намного быстрее, чем
последовательность операторов if с одиночным выбором, так как
возможен ранний выход после удовлетворения одного из условий.
Вопросы эффективности 4.2
Во вложенных операторах if...else проверяйте сначала условия,
которые с большей вероятностью окажутся равными true. Это
способствует более быстрому выполнению вложенных операторов if...else и
более раннему выходу из них, чем при проверке в начале редких случаев.
Проблема «висящего else»
Компилятор C++ всегда ассоциирует else с ближайшим непосредственно
предшествующим if, если только не указано иначе (посредством фигурных
скобок { и }). Такое поведение компилятора может приводить к тому, что
называют «проблемой висящего else». Например*
if ( х > 5 )
if ( У > 5 )
cout « "x and у are > 5";
else
cout « "x is <= 5";
указывает, что если х больше 5, вложенный оператор if проверяет, является
ли у также большим 5. Если это так, печатается «х and у are > 5». В
противном случае, если х меньше или равен 5, часть else оператора if...else,
по-видимому, должна печатать «х is <= 5».
Но не торопитесь! Этот вложенный оператор if...else выполняется не так, как
кажется на первый взгляд. На самом деле компилятор интерпретирует его как
if ( х > 5 )
if ( У > 5 )
cout « "x and у are > 5";
else
cout « "x is <= 5";
где телом первого if является вложенный if...else. Внешний оператор if
проверяет, является ли х большим 5. Если да, то выполнение продолжается
проверкой, является ли у также большим 5. Если второе условие истинно, выводится
Управляющие операторы: часть I
211
правильная строка "х and у are > 5". Однако если второе условие ложно,
выводится строка "х is <= 5", хотя мы и знаем, что х больше 5.
Чтобы заставить вложенный оператор if...else выполняться так, как
предполагалось сначала, мы должны написать его следующим образом:
if ( х > 5 )
{
if ( У > 5 )
cout « "x and у are > 5й;
}
else
cout « "x is <= 5";
Фигурные скобки ({}) указывают компилятору, что телом первого if является
второй оператор if, и что else должно ассоциироваться с первым if. В
упражнениях 4.23 и 4.24 проводится дальнейшее исследование проблемы висящего
else.
Блоки
Оператор выбора if обычно предполагает наличие в своем теле только
одного оператора. Точно так же каждая из частей if и else оператора if...else
предполагает вхождение одиночного оператора. Чтобы включить в тело оператора
if или в любую из частей if...else несколько операторов, заключите их в
фигурные скобки: ({ и }). Группа операторов, заключенных в фигурные скобки,
называется составным оператором или блоком. Далее мы будем пользоваться
термином «блок».
® Общее методическое замечание 4.2
Блок может быть помещен в любом месте программы, где может
размещаться одиночный оператор.
Следующий пример включает блок в часть else оператора if...else.
if ( studentGrade >= 60 )
cout « "Passed.\n";
else {
cout « "Failed.\n" ;
cout « "You must take this course again.\n";
}
В этом случае при studentGrade, меньшей 60, программа выполнит оба
оператора в теле else и напечатает
Failed.
You must take this course again.
Обратите внимание, что два оператора в предложении else находятся внутри
фигурных скобок. Эти скобки важны. Без них оператор
cout « " You must take this course again.\n";
находился бы вне тела части else оператора if и выполнялся бы вне
зависимости от того, является ли studentGrade меньшей 60.
212
Глава 4
Типичная ошибка программирования 4.3
Пропуск одной или обеих фигурных скобок, ограничивающих блок,
может привести к синтаксическим или логическим ошибкам в программе.
Хороший стиль программирования 4.5
Использование фигурных скобок в операторе if...else (ив любом
управляющем операторе) помогает предотвратить возможные упущения,
особенно при последующем добавлении операторов в раздел if или else.
Некоторые программисты предпочитают сначала записать
открывающую и закрывающую скобки блока, а уже потом писать внутри
них требуемые операторы.
Точно так же, как в любом месте программы, где может находиться
одиночный оператор, можно разместить блок, можно вообще обойтись без оператора,
т.е. разместить нулевой, или пустой оператор. Для этого в то место, где
обычно должен находиться оператор, надо поместить символ точки с запятой (;).
Типичная ошибка программирования 4.4
Вставка точки с запятой после условия в операторе if приводит к
логической ошибке в операторе с одиночным и к синтаксической ошибке
в операторе с двойным выбором (если часть if в действительности
содержит оператор).
4.7. Оператор повторения while
Оператор повторения (называемый также оператором цикла или циклом)
позволяет программисту определить действие, которое должно повторяться,
пока некоторое условие остается истинным. Оператор псевдокода
Пока в моем списке покупок еще имеются невычеркнутые пункты
Сделать следующую покупку и вычеркнуть ее из списка
описывает повторение при походе по магазинам. Условие «в моем списке
покупок еще имеются невычеркнутые пункты» может быть истинным или
ложным. Если оно истинно, то осуществляется действие «Сделать следующую
покупку и вычеркнуть ее из списка». Это действие будет повторяться до тех пор,
пока условие остается истинным. Оператор, содержащийся в операторе
повторения Пока, образует тело Пока, которое может быть одиночным оператором
или блоком. В конце концов условие станет ложным (когда будет сделана
и вычеркнута из списка последняя покупка). В этой точке повторение
прерывается, и выполняется первый оператор псевдокода, следующий за оператором
повторения.
В качестве примера while в C++ рассмотрим фрагмент программы,
определяющий значение первой из степеней тройки, превышающее 100.
Предположим, что целая переменная product инициализирована значением 3. Когда
следующий оператор повторения while закончит свое выполнение, product
будет содержать искомый результат:
Управляющие операторы: часть I
213
IM
int product = 3;
while ( product <= 100 )
product = 3 * product;
Когда оператор while начинает выполняться, значение переменной product
равно 3. Каждое повторение цикла умножает product на 3, так что переменная
принимает последовательные значения 9, 27, 81 и 243. Когда product
становится равной 243, условие оператора while — product <= 100 — оказывается
ложным. Это завершает повторение, так что окончательным значением
product будет 243. Программа продолжает работу со следующего оператора
после while.
Типичная ошибка программирования 4.5
Если не предусмотреть в теле оператора while действия, которое
в конце концов делает условие в while ложным, возникает, как
правило, логическая оливка, называемая бесконечным циклом, в котором
повторение никогда не заканчивается. Если тело цикла не содержит
операторов, взаимодействиющих с пользователем, программа может
казаться «зависнувшей».
Диаграмма деятельности на рис. 4.6 иллюстрирует поток управления,
соответствующий вышеприведенному оператору while. Еще раз отметим, что
единственные символы на этой диаграмме (помимо начального и конечного
состояний, стрелок перехода и трех комментариев) представляют только состояние
действия и решение. На этой диаграмме вводится также символ слияния UML.
В UML и символ слияния, и символ решения представляются ромбами.
Символ слияния сводит два потока деятельности в один. На этой диаграмме
символ слияния объединяет переходы из начального состояния и из состояния
действия, так что оба переходят в решение, которое определяет, должен ли
цикл начать (или продолжить) свое выполнение. Хотя UML представляет
символы решения pi символы слияния одинаково, эти символы можно отличить по
числу «входящих» и «исходящих» стрелок перехода. Символ решения имеет
одну стрелку, направленную к ромбу, и две или большее число стрелок,
направленных от ромба, для указания возможных переходов из этой точки.
Кроме того, рядом с каждой стрелкой перехода, направленной от символа
решения, имеется контрольное условие. Символ слияния имеет две или большее
число стрелок перехода, направленных к ромбу, и только одну стрелку,
направленную от ромба; это указывает на то, что несколько потоков
деятельности сливаются и продолжаются как один поток. Заметим, что в отличие от
символа решения символ слияния ничему не соответствует в коде C++.
Никакие из стрелок перехода, ассоциированных с символом слияния, не имеют
контрольных условий.
214
Глава 4
слияние ^ Ь
утроить значение
произведения
Соответствующий оператор C++:
product - 3 * product;
Рис. 4.6. Диаграмма деятельности оператора повторения while
Диаграмма на рис. 4.6 ясно показывает повторение в операторе while,
обсуждавшемся выше. Стрелка перехода, исходящая из состояния действия,
указывает на слияние, которое переходит обратно к решению, проверяемому на
каждом проходе цикла, пока не станет истинным контрольное условие
product > 100. После этого происходит выход из оператора while (переход его
в конечное состояние) и управление переходит к следующему оператору в
последовательности .
Представьте себе снова большую коробку пустых диаграмм деятельности
UML для операторов while, — их столько, сколько может потребоваться для
того, чтобы путем суперпозиции и вложения, вместе с диаграммами
деятельности других управляющих операторов, сформировать структурную
реализацию алгоритма. Программист заполняет состояния действия и символы
решения соответствующими алгоритму выражениями действия и
контрольными условиями.
I—зц Вопросы эффективности 4.3
Г^Ф*| Многие из приводимых нами советов относительно эффективности
дают лишь небольшие улучшения, поэтому читатель может быть
склонен к тому, чтобы их игнорировать. Однако небольшие
улучшения в коде, исполняемогов цикле много раз, могут приводить к
значительному общему улучшению эффективности.
4.8. Формулирование алгоритмов: повторение,
управляемое счетчиком
Чтобы проиллюстрировать, как программисты разрабатывают алгоритмы,
в этом и следующем разделах мы решаем два варианта задачи усреднения.
Пусть задача сформулирована следующим образом:
Группа из десяти студентов выполняет контрольную работу. Вам известны
оценки за контрольную (целые числа в диапазоне 0-100). Определите и
выведите среднюю оценку по группе.
решение
[product <= 100]
[product > 100]
Управляющие операторы: часть I
215
Средняя по группе оценка равна сумме оценок, деленной на число студентов.
Алгоритм решения этой задачи на компьютере должен вводить каждую из
оценок, вычислить среднее и напечатать результат.
Давайте воспользуемся псевдокодом, чтобы перечислить действия, которые
должны быть выполнены, и определить порядок их выполнения. Мы применим
для ввода оценок повторение, управляемое счетчиком. Эта методика
использует для задания числа повторений группы исполняемых операторов (его
называют также числом итераций цикла) переменную, называемую счетчиком.
Повторение, управляемое счетчиком, часто называют определенным
повторением, поскольку число повторений известно до того, как цикл начнет
исполняться. В нашем примере повторение прерывается, когда значение счетчика
превысит 10. В этом разделе мы приводим полностью развитый алгоритм на
псевдокоде (рис. 4.7) и версию класса Grade Во ok (рис. 4.8-4.9), которая
реализует этот алгоритм в качестве элемент-функции. Затем мы представим
приложение (рис. 4.10), демонстрирующее алгоритм в действии. В разделе 4.9 мы
продемонстрируем, как, используя псевдокод, можно разработать такой
алгоритм «с нуля».
® Общее методическое замечание 4.3
Опыт показывает, что наиболее трудной частью решения задачи на
компьютере является разработка алгоритма решения. Как только
корректный алгоритм сформулирован, процесс произведения из
алгоритма работающей программы на C++ обычно вполне прямолинеен.
Обратите внимание на «сумму» и «счетчик» в алгоритме из рис. 4.7.
Сумма является переменной, в которой аккумулируется сумма ряда значений.
Счетчик является переменной, используемой для подсчета — в данном случае
счетчик оценок показывает, какая по счету оценка должна быть введена
пользователем. Переменные для хранения сумм перед их использованием в
программе обычно инициализируются нулем; в противном случае в сумму вошло
бы предыдущее значение, хранившееся в том месте памяти, которое отведено
под сумму.
1 Установить значение суммы в ноль
2 Установить счетчик оценок в единицу
3
4 Пока счетчик оценок меньше или равен 10
5 Попросить пользователя ввести следующую оценку
6 Ввести следующую оценку
7 Прибавить оценку к сумме
8 Прибавить к счетчику единицу
9
10 Определить среднюю оценку по группе как сумму, деленную на 10
11 Напечатать сумму оценок для всех студентов группы
12 Напечатать среднюю оценку по группе
Рис. 4.7. Алгоритм на псевдокоде, использующий повторение со счетчиком
для решения задачи о средней оценке
216
Глава 4
1 // Рис. 4.8: GradeBook.h
2 // Определение класса GradeBook, усредняющего оценки в группе.
3 // Элементы-функции определены в GradeBook.срр
4 #include <string> // программа использует стандартный класс string
5 using std::string;
6
7 // определение класса GradeBook
8 class GradeBook
9 {
10 public:
11 GradeBook( string ); // конструктор инициализирует название курса
12 void setCourseName( string ); // функция для установки названия
13 string getCourseName(); // функция для извлечения названия курса
14 void displayMessage(); // вывести приветственное сообщение
15 void determineClassAverage(); // усредняет введенные оценки
16 private:
17 string courseName; // название курса для данного GradeBook
18 }; // конец класса GradeBook
Рис. 4.8, Задача о среднем по группе с повторением, управляемым счетчиком:
заголовочный файл GradeBook
1 // Рис. 4.9: GradeBook.срр
2 // Определения элементов-функций класса GradeBook, реализующего
3 // программу вычисления среднего с повторением по счетчику.
4 #include <iostream>
5 using std::cout;
6 using std::cin;
7 using std::endl;
8
9 #include "GradeBook.h" // включить определение класса GradeBook
10
11 // конструктор инициализирует courseName переданной строкой
12 GradeBook::GradeBook( string name )
13 {
14 setCourseName( name ); // проверить и сохранить courseName
15 } // конец конструктора GradeBook
16
17 // функция для установки названия курса;
18 // гарантирует, что название курса содержит не более 25 символов
19 void GradeBook::setCourseName( string name )
20 {
21 if ( name.length() <= 25 ) // если в названии не более 25 симв.
22 courseName = name; // сохранить название курса в объекте
23 else // если название длиннее 25 символов
24 { // записать в courseName первые 25 символов параметра name
25 courseName = name.substr( 0, 25 ); // взять первые 25 символов
26 cout « "Name \""« name <<"\" exceeds maximum length B5).\n"
27 ' « "Limiting courseName to first 25 characters.\n" « endl;
28 } // конец if...else
29 } // конец функции setCourseName
30
31 // функция для получения названия курса
32 string GradeBook::getCourseName()
Управляющие операторы: часть I
217
33 {
34 return courseName;
35 } // конец функции getCourseName
36
37 // вывести сообщение-приветствие пользователю GradeBook
38 void GradeBook::displayMessage()
39 {
40 cout « "Welcome to the grade book for\n" « getCourseName ()
41 « "!\n" « endl;
42 } // конец функции displayMessage
43
44 // определить среднее по группе, исходя из 10 введенных оценок
45 void GradeBook::determineClassAverage()
46 {
47 int total; // сумма оценок, введенных пользователем
48 int gradeCounter; // номер следующей вводимой оценки
4 9 int grade; // значение введенной пользователем оценки
50 int average; // средняя оценка
51
52 // этап инициализации
53 total =0; // инициализировать сумму
54 gradeCounter =1; // инициализировать счетцик цикла
55
56 // этап обработки
57 while ( gradeCounter <= 10 ) // повторить 10 раз
58 {
59 cout « "Enter grade: "; // запросить ввод
60 cin » grade; // ввести следующую оценку
61 total = total + grade; // прибавить оценку к total
62 gradeCounter = gradeCounter + 1; // увеличить счетчик на 1
63 } // конец while
64
65 // этап завершения
66 average = total / 10; // целое деление дает целый результат
67
68 // вывести сумму и среднее значение оценок
69 cout « "\nTotal of all 10 grades is " « total « endl;
70 cout « "Class average is " « average « endl;
71 } // конец функции determineClassAverage
Рис, 4.9, Задача о среднем по группе с повторением, управляемым счетчиком: файл
исходного кода GradeBook
1 // Рис. 4.10: fig04_10.cpp
2 // Создать GradeBook и вызвать его функцию determineClassAverage.
3 #include "GradeBook.h" // включить определение класса GradeBook
4
5 int main()
6 {
7 // создать объект myGradeBook класса GradeBook
8 //и передать конструктору название курса
9 GradeBook myGradeBook( "CS101 C++ Programming" );
10
11 myGradeBook.displayMessage(); // вывести приветствие
12 myGradeBook.determineClassAverage(); // найти среднее 10 оценок
218
Глава 4
13 return 0; // показывает успешное завершение
14 } // конец main
Welcome to the grade book for
CS101
Enter
Enter
Enter
Enter
Enter
Enter
Enter
Enter
Enter
Enter
Total
Class
C++ Programming!
grade:
grade:
grade:
grade:
grade:
grade:
grade:
grade:
grade:
grade:
of all
67
78
89
67
87
98
93
85
82
100
10 grades
average is 84
Рис. 4.10. Задача о среднем по группе с повторением, управляемым счетчиком:
создание объекта класса GradeBook (рис. 4.8-4.9) и вызов его элемент-функции
determineClassAverage
Усовершенствование подтверждения данных в классе GradeBook
Прежде чем начать обсуждение алгоритма вычисления среднего, давайте
рассмотрим усовершенствование, сделанное нами в классе GradeBook. На
рис. 3.16 наша элемент-функция setCourseName подтверждала
действительность названия курса, проверяя с помощью оператора if, что длина названия
меньше или равна 25 символам. Если это подтверждалось, название курса
устанавливалось. Следом за этим другой оператор if проверял, не больше ли
длина названия 25 символов (в этом случае название укорачивалось). Заметьте,
что условие второго оператора if в точности противоположно условию первого
if. Если одно из условий оценивается как true, другое должно оцениваться как
false. Такая ситуация идеально подходит для оператора if...else, поэтому мы
модифицировали код, заменив два оператора if одним оператором if...else
(строки 21-28 на рис. 4.9).
Реализация в классе GradeBook повторения, управляемого
счетчиком
Класс GradeBook (рис. 4.8-4.9) содержит конструктор (объявленный
в строке 11 на рис. 4.8 и определенный в строках 12-15 на рис. 4.9), который
присваивает значения переменной представителя courseName (объявленной
в строке 17 на рис. 4.8). Строки 19-29, 32-35 и 38-42 на рис. 4.9 определяют
соответственно элемент-функции setCourseName, getCourseName и dis-
playMessage, которая реализует алгоритм среднего по группе, описываемый
псевдокодом на рис. 4.7.
Строки 47-50 определяют локальные переменные total, gradeCounter,
и average как принадлежащие к типу int. Переменная grade хранит введенное
пользователем значение. Обратите внимание, что эти объявления
размещаются в теле элемент-функции determineClassAverage.
Управляющие операторы: часть I
219
В версии класса GradeBook этой главы мы просто читаем и обрабатываем
набор оценок. Вычисление среднего производится в элемент-функции determi-
neClassAverage и использует локальные переменные, — мы не сохраняем
какой-либо информации об оценках студентов в переменных представителя
класса. В главе 7 («Массивы и векторы») мы модифицируем класс GradeBook
таким образом, чтобы он сохранял оценки в памяти, используя переменную
представителя, которая ссылается на структуру данных, называемую
массивом. Это позволяет объекту GradeBook производить с одним и тем же набором
оценок различные вычисления, не требуя от пользователя многократного
ввода оценок.
Хороший стиль программирования 4.5
Для улучшения читаемости отделяйте объявления от остальных
операторов функции пустой строкой.
Строки 53-54 инициализируют total значением 0 и gradeCounter —
значением 1. Заметьте, что эти переменные инициализируются до их
использования в вычислениях. Переменные-счетчики обычно инициализируются нулем
или единицей в зависимости от способа их использования (мы приведем
примеры обоих случаев). Неинициализированная переменная содержит «мусор»
(или неопределенное значение) — значение, хранившееся ранее в том месте
памяти, которое отводится под эту переменную. Переменные grade и average
(соответственно для ввода пользователя и вычисленного среднего) в данном
случае не требуют инициализации, — значения им присваиваются позже путем
ввода или вычислений.
Типичная ошибка программирования 4.6
Неинициализированные счетчики и суммы могут стать источником
логических ошибок.
Предотвращение ошибок 4,2
Инициализируйте все счетчики и суммы либо в объявлении, либо
в операторе присваивания. Суммы обычно инициализируются нулем.
Счетчики инициализируются нулем или единицей, в зависимости от
способа их использования (мы покажем примеры того, когда следует
использовать 0 и когда 1).
Хороший стиль программирования 4.6
Объявляйте каждую переменную в отдельной строке, со своим
собственным комментарием; это сделает программу более удобочитаемой.
Строка 47 указывает, что оператор while должен продолжать повторение
(итерацию), пока значение gradeCounter меньше или равно 10. Пока это
условие остается истинным, оператор while снова и снова выполняет операторы
внутри фигурных скобок, ограничивающих его тело (строки 58-63).
Строка 59 выводит подсказку "Enter grade: ". Эта строка соответствует
оператору псевдокода «Попросить пользователя ввести следующую оценку».
220
Глава 4
Строка 60 читает оценку, введенную пользователем, и присваивает ее
переменной grade. Строка соответствует оператору псевдокода «Ввести следующую
оценку». Как вы помните, переменная grade ранее в программе не
инициализировалась, поскольку программа на каждой итерации цикла получает
значение для grade от пользователя. Строка 61 суммирует total и новую введенную
оценку и сохраняет результат в total, заменяя ее прежнее значение.
Строка 62 прибавляет к gradeCounter единицу, указывая, что программа
обработала текущую оценку и готова получить от пользователя следующую.
Увеличение gradeCounter в конце концов приводит к тому, что значение
gradeCounter превысит 10. В этой точке выполнение цикла while
прерывается, так как его условие (строка 57) становится ложным.
Когда цикл завершается, строка 66 производит вычисление среднего и
присваивает результат переменной average. Строка 69 выводит текст "Total of all
10 grades is", за которым следует значение переменной total. Затем строка 70
выводит текст "Class average is " и значение переменной average. После этого
элемент-функция determineClassAverage возвращает управление
вызывающей функции (т.е. main из рис. 4.10).
Демонстрация класса GradeBook
Рис. 4.10 содержит функцию main данного приложения, которая создает
объект класса GradeBook и демонстрирует его возможности. Строка 9 на
рис. 4.10 создает объект новый объект GradeBook с именем myGradeBook.
В строке 9 конструктору GradeBook (строки 12-15 на рис. 4.9) передается
текстовая строка. Строка 11 вызывает элемент-функцию displayMessage объекта
myGradeBook, чтобы вывести приветственное сообщение пользователю. Затем
строка 12 вызывает элемент-функцию determineClassAverage объекта
myGradeBook, позволяя пользователю ввести 10 оценок, для которых
элемент-функция вычисляет и печатает среднее, — функция выполняет алгоритм,
описываемый псевдокодом на рис. 4.7.
Замечания о целом делении и усечении
Вычисление среднего, выполняемое элемент-функцией
determineClassAverage в ответ на ее вызов, дает целый результат. Вывод программы показывает,
что сумма значений оценок в данном пробном запуске равна 846, что дает
после деления на 10 значение 84.6, т.е. число с десятичной точкой. Однако
результат вычисления total / 10 (строка 66 на рис. 4.9) является целым числом
84, так как total и 10 — оба целые. Деление двух целых друг на друга
является целым делением — любая дробная часть результата теряется (т.е.
усекается). Как получить при вычислении среднего результат с десятичной точкой,
мы увидим в следующем разделе.
^ Типичная ошибка программирования 4.7
Предположение, что целое деление округляет (а не усекает) частное,
может приводить к неверным результатам.. Например, 7/4, что
в обычной арифметике дает 1.75, в целой арифметике усекается до 1,
а не округляется до 2.
Управляющие операторы: часть I
221
Если бы строка 66 на рис. 4.9 использовала для вычисления среднего не 10,
a gradeCounter, программа вывела бы неверное значение, 76. Это объясняется
тем, что в последней итерации оператора while значение gradeCounter
увеличивается в строке 62 до 11.
Р7?^ Типичная ошибка программирования 4.8
Использование управляющей переменной цикла со счетчиком в
вычислениях после завершения цикла приводит к распространенной ошибке
смещения на единицу. В случае цикла, управляемого счетчиком,
который на каждом проходе увеличивается на 1, прерывание цикла
происходит, когда значение счетчика становится на единицу больше, чем его
последнее допустимое значение (т.е. 11 в случае счета от 1 до 10).
4.9. Формулирование алгоритмов: повторение,
управляемое контрольным значением
Давайте обобщим задачу об усреднении по группе. Рассмотрим такую задачу:
Разработать программу усреднения по группе, которая при каждом запуске
обрабатывает оценки для произвольного числа студентов.
В предыдущем примере усреднения по группе в формулировке задачи
специфицировалось число студентов, так число оценок A0) было известно
заранее. В настоящем примере нет никаких указаний относительно числа оценок,
которые введет пользователь в процессе исполнения программы. Программа
должна обрабатывать произвольное число оценок. Как программа может
определить, когда остановить ввод оценок? Как она узнает, когда надо вычислить
и напечатать среднее по группе?
Одним из путей решения этой проблемы является использование
специального значения, называемого контрольным значением (иногда его называют
также сигнальным, фиктивным или флаговым значением), которое
указывает «конец ввода данных». Пользователь вводит оценки до тех пор, пока все
действительные оценки не будут исчерпаны. Затем он вводит контрольное
значение, показывая, что последняя оценка уже введена. Повторение,
управляемое контрольным значением, часто называют неопределенным повторением,
поскольку число повторений не известно до начала исполнения цикла.
Очевидно, что контрольное значение должно быть выбрано так, чтобы его
нельзя было спутать с допустимым входным значением. Поскольку оценки за
контрольную обычно являются неотрицательными целыми, в качестве
контрольного значения в данной задаче может быть выбрано -1. Тогда при
запуске программа среднего по группе могла бы обрабатывать входные данные,
подобные ряду 95, 96, 75, 74, 89 и -1. Затем программа вычисляла бы и печатала
среднее для оценок 95, 96, 75, 74 и 89. Поскольку -1 является контрольным
значением, оно не должно участвовать в вычислении среднего.
Типичная ошибка программирования 4.9
11 Выбор контрольного значения, которое является токже допустимым
значением данных, является логической ошибкой.
222
Глава 4
Разработка алгоритма на псевдокоде путем нисходящего
последовательного уточнения: верхний уровень и первое
уточнение
Мы подойдем к задаче среднего по группе с позиций методики так
называемого нисходящего последовательного уточнения, которая является
неотъемлемой частью создания правильного структурированных программ. Начнем
с записи псевдокода, представляющего верхний уровень — единственный
оператор, описывающий функцию программы в целом:
Определить среднюю по группе оценку за контрольную
Таким образом, верхний уровень является полным представлением
программы. К сожалению, верхний уровень (как в данном случае) редко отражает
достаточное количество деталей, на основании которых можно написать
программу. Поэтому мы начнем процесс уточнения. Разделим верхний уровень на ряд
более мелких задач и запишем их в том порядке, в котором они должны
выполняться. В результате получим следующее первое уточнение:
Инициализировать переменные
Ввести, просуммировать и подсчитать оценки за контрольную
Вычислить и напечатать общую сумму оценок студентов и среднее по группе
Это уточнение использует только последовательную структуру —
перечисленные шаги должны выполняться по порядку, один за другим.
® Общее методическое замечание 4.4
Каждое уточнение, как и сам верхний уровень, является полной
спецификацией алгоритма; меняется только уровень детализации.
S Общее методическое замечание 4.5
Многие программы можно логически разбить на три фазы: фазу
инициализации, которая инициализирует переменные программы; фазу
обработки данных, которая вводит данные и соответсвующим
образом корректирует значения переменных (таких, как счетчики и
суммы); фаза завершения, которая вычисляет и выводит окончательные
результаты.
Переход ко второму уточнению
Предыдущее «Общее методическое замечание» часто является
исчерпывающим описанием первого уточнения нисходящего процесса. Чтобы перейти
к следующему уровню уточнения, т.е. второму уточнению, мы должны
ввести специфические переменные. В этом примере нам потребуется текущая
сумма чисел, счетчик уже обработанных чисел, переменная для приема
каждой оценки при ее вводе пользователем и переменная для сохранения
вычисленного среднего. Оператор псевдокода
Инициализировать переменные
Управляющие операторы: часть I
223
может быть уточнен следующим образом:
Инициализировать нулем сумму
Инициализировать нулем счетчик
Инициализироваться перед использованием должны только переменные
суммы и счетчика. Переменные среднего и оценки не нуждаются в
инициализации, так как их значения будут замещаться по мере их вычисления или ввода.
Оператор псевдокода
Ввести, просуммировать и подсчитать оценки за контрольную
для последовательного ввода каждой оценки требует оператора повторения (т.е.
цикла). Поскольку мы не знаем заранее, сколько должно быть обработано
оценок, будем использовать повторение, управляемое контрольным значением.
Пользователь вводит действительные оценки по одной. После ввода последней
оценки он должен будет ввести контрольное значение. После ввода каждой
оценки программа проверяет, не является ли она контрольным значением,
и прерывает цикл, когда пользователь вводит контрольное значение. Таким
образом, вторым уточнением предыдущего оператора псевдокода является
Предложить пользователю ввести первую оценку
Ввести первую оценку (возможно, контрольное значение)
Пока пользователь не ввел контрольное значение
Прибавить данную оценку к текущей сумме
Прибавить единицу к счетчику оценок
Предложить пользователю ввести следующую оценку
Ввести следующую оценку (возможно, контрольное значение)
В псевдокоде мы не заключаем в фигурные скобки операторы, составляющих
тело структуры Пока. Мы просто записываем эти операторы с отступом под
Пока у чтобы показать, что все они принадлежат именно этому Пока.
Повторим еще раз, что псевдокод — всего лишь неформальное вспомогательное
средство разработки программ.
Оператор псевдокода
Вычислить и напечатать общую сумму оценок студентов и среднее по группе
можно уточнить следующим образом:
Если счетчик не равен нулю
Установить среднее равным сумме, поделенной на счетчик
Напечатать сумму оценок всех студентов в группе
Напечатать среднее по группе
Иначе
Напечатать "Оценки не были введены"
Здесь мы проявили осторожность, введя проверку возможности деления на
ноль — обычно это фатальная логическая ошибка, которая, если остается
необнаруженной, приводит к аварийному завершению («краху») программы.
Полностью второе уточнение псевдокода для задачи о среднем по группе
показано на рис. 4.11.
224
Глава 4
Типичная ошибка программирования 4.9
Попытка деления на ноль обычно приводит к фатальной логической
ошибке.
Предотвращение ошибок 4.3
Производя деление на выражение, значение которого может быть
нулем, явным образом проверяйте такую возможность и
обрабатывайте ее должным образом (например, печатая сообщение об ошибке), не
допуская возникновения фатальной ошибки
На рис. 4.7 и 4.11 мы включили в псевдокод пустые строки и отступы,
чтобы облегчить его чтение. Пустые строки разделяют псевдокод алгоритма на
различные фазы, а отступы выделяют тела управляющих операторов.
1 Инициализировать нулем сумму
2 Инициализировать нулем счетчик
3
4 Предложить пользователю ввести первую оценку
5 Ввести первую оценку (возможно, контрольное значение)
6
7 Пока пользователь не ввел контрольное значение
8 Прибавить данную оценку к текущей сумме
9 Прибавить единицу к счетчику оценок
10 Предложить пользователю ввести следующую оценку
11 Ввести следующую оценку (возможно, контрольное значение)
12
13 Если счетчик не равен нулю
14 Установить среднее равным сумме, поделенной на счетчик
15 Напечатать сумму оценок всех студентов в группе
16 Напечатать среднее по группе
17 Иначе
18 Напечатать "Оценки не были введены"
Рис. 4.11. Псевдокод алгоритма для задачи о среднем по группе, использующего
повторение, управляемое контрольным значением
Алгоритм рис. 4.11 решает более общую задачу о среднем по группе. Для
разработки этого алгоритма потребовалось всего два уровня уточнения.
Иногда необходимо большее число уровней.
Общее методическое замечание 4.6
Когда алгоритм на псевдокоде специфицирован со степенью
детализации, достаточной для того, чтобы вы могли преобразовать его в
программу на C++, завершите процесс нисходящего уточнения. Обычно
реализация программы на C++ на этом этапе не вызывает
затруднений.
Управляющие операторы: часть I
225
S Общее методическое замечание 4.7
Многие опытные программисты пишут программы, никогда не
используя таких инструментов разработки, как псевдокод. Они
считают, что раз конечной целью является решение задачи на компьютере,
написание псевдокода только задерживает достижение этой цели.
Хотя такой подход и работает в случае достаточно простых и
известных задач, в больших, сложных проектах он может привести
к серьезным затруднениям.
Реализация в классе GradeBook повторения, управляемого
контрольным значением
На рис. 4.12 и 4.13 показан класс C++ GradeBook с элемент-функцией
determineClassAverage, которая реализует алгоритм из рис. 4.11
(демонстрация класса показана на рис. 4.14). Хотя каждая вводимая оценка является
целым числом, вполне вероятно, что вычисление среднего даст число с
десятичной точкой — другими словами, вещественное число или число с плавающей
точкой (например, 7.33, 0.0975 или 1000.12345). Тип int не может
представлять такое число, поэтому для его представления класс должен использовать
другой тип. Для хранения в памяти значений с плавающей точкой в C++
предусмотрено несколько типов данных, в том числе float и double. Основным
различием между float и double является то, что переменные типа double
могут хранить числа большей величины и с большей точностью, т.е. большим
количеством цифр справа от десятичной точки. Чтобы вычисление среднего
дало результат в виде числа с плавающей точкой, в программе применяется
специальная операция, называемая операцией приведения типа. Эти детали
будут объясняться по ходу обсуждения программы.
1 // Рис. 4.12: GradeBook.h
2 // Определение класса GradeBook, усредняющего оценки в группе.
3 // Элемент-функции определены в GradeBook.срр
4 #include <string> // программа использует стандартный класс string
5 using std::string;
6
7 // определение класса GradeBook
8 class GradeBook
9 {
10 public:
11 GradeBook( string ); // конструктор инициализирует название курса
12 void setCourseName( string ); // функция для установки названия
13 string getCourseName(); // функция для извлечения названия курса
14 void displayMessage(); // вывести приветственное сообщение
15 void determineClassAverage(); // усредняет введенные оценки
16 private:
17 string courseName; // название курса для данного GradeBook
18 }; // конец класса GradeBook
Рис. 4.12, Задача о среднем по группе с повторением, управляемым контрольным
значением: заголовочный файл GradeBook
8 Заж И14
226
Глава
1 // Рис. 4.13: GradeBook.срр
2 // Определения элемент-функций класса GradeBook, реализующего
3 // вычисление среднего с повторением по контрольному значению.
4 #include <iostream>
5 using std::cout;
6 using std::cin;
7 using std::endl;
8 using std::fixed; // гарантирует вывод десятичной точки
9
10 #include <iomanip> // параметризованные манипуляторы потока
11 using std::setprecision; // устанавливает точность вывода чисел
12
13 // включить определение класса GradeBook из GradeBook.h
14 #include "GradeBook.h"
15
16 // конструктор инициализирует courseName переданной строкой
17 GradeBook::GradeBook( string name )
18 {
19 setCourseName( name ); // проверить и сохранить courseName
20 } // конец конструктора GradeBook
21
22 // функция для установки названия курса;
23 // гарантирует, что название курса содержит не более 25 символов
24 void GradeBook::setCourseName( string name )
25 {
26 if ( name.length() <= 25 ) // если в названии не более 25 симв.
27 courseName = name; // сохранить название курса в объекте
28 else // если название длиннее 25 символов
29 { // записать в courseName первые 25 символов параметра name
30 courseName = name.substr( 0, 25 ); // взять первые 25 символов
31 cout « "Name \""« name «"\" exceeds maximum length B5). \n"
32 « "Limiting courseName to first 25 characters.\n" « endl;
33 } // конец if...else
34 } // конец функции setCourseName
35
36 // функция для получения названия курса
37 string GradeBook::getCourseName()
38 {
39 return courseName;
40 } // конец функции getCourseName
41
42 // вывести сообщение-приветствие пользователю GradeBook
43 void GradeBook:idisplayMessage()
44 {
45 cout « "Welcome to the grade book for\n" « getCourseName ()
46 « "!\n" « endl;
47 } // конец функции displayMessage
48
49 // определить среднее по группе, исходя из 10 введенных оценок
50 void GradeBook::determineClassAverage()
51 {
52 int total; // сумма оценок, введенных пользователем
53 int gradeCounter; // число введенных оценок
54 int grade; // значение оценки
55 double average; // число с десятичной точкой для среднего
Управляющие операторы: часть I
227
57 // этап инициализации
58 total =0; // инициализировать сумму
59 gradeCounter =0; // инициализировать счетцик цикла
60
61 // этап обработки
62 // запросить ввод и прочитать введенную пользователем оценку
63 cout « "Enter grade or -1 to quit: ";
64 cin » grade; // ввести оценку или контрольное значение
65
66 // цикл, пока не будет прочитано контрольное значение
67 while ( grade != -1 ) // пока grade не равна -1
68 {
69 total = total + grade; // прибавить оценку к total
70 gradeCounter = gradeCounter + 1; // увеличить счетчик
71
72 // запросить ввод и прочитать следующую оценку пользователя
73 cout « "Enter grade or -1 to quit: ";
74 cin » grade; // ввести оценку или контрольное значение
75 } // конец while
76
77 // этап завершения
78 if ( gradeCounter != 0 ) // если введена хотя бы одна оценка
79 {
80 // вычислить среднее по всем введенным оценкам
81 average = static_cast< double >( total ) / gradeCounter;
82
83 // вывести сумму и среднее (с двумя цифрами точности)
84 cout « "\nTotal of all " « gradeCounter
85 « " grades entered is " « total < endl;
86 cout « "Class average is " « setprecision( 2 ) « fixed
87 « average « endl;
88 } // конец if
89 else // ничего не введено, вывести соответствующее сообщение
90 cout « "No grades were entered" « endl;
91 } // конец функции determinedassAverage
Рис, 4.13- Задача о среднем по группе с повторением, управляемым контрольным
значением: файл исходного кода GradeBook
1 // Рис. 4.14: fig04_14.cpp
2 // Создать GradeBook и вызвать его функцию determinedassAverage.
3
4 // включить определение класса GradeBook из GradeBook.h
5 #include "GradeBook.h"
6
7 int main()
8 {
9 // создать объект myGradeBook класса GradeBook
10 //и передать конструктору название курса
11 GradeBook myGradeBook( "CS101 C++ Programming" );
12
13 myGradeBook.displayMessage(); // вывести приветствие
14 myGradeBook.determineClassAverage(); // найти среднее оценок
15 return 0; // показывает успешное завершение
16 } // конец main
228
Глава 4
Welcome to the grade book for
CS101 C++ Programming!
Errter grade or -1 to quit: 97
Enter grade or -1 to quit: 88
Enter grade or -1 to quit: 72
Enter grade or -1 to quit: -1
Total of all 3 grades entered is 257
Class average is 85.67
Рис. 4.14. Задача о среднем по группе с повторением, управляемым контрольным
значением: создание объекта класса GradeBook (рис. 4.12-4.13) и вызов его
элемент-функции determineClassAverage
В этом примере мы видим, что управляющие операторы могут
надстраиваться один поверх другого (последовательно), точно так же, как ребенок
ставит один кубик на другой. Непосредственно за оператором while (строки 67-75
на рис. 4.13) следует оператор if...else (строки 78-90). Булыпая часть кода
в этой программе идентична коду на рис. 4.9, поэтому мы сосредоточим свое
на новых элементах и особенностях.
В строке 55 объявляется переменная average типа double. В предыдущем
примере для сохранения среднего по группе мы объявляли переменную типа
int. Использование типа double позволяет сохранить результат вычисления
среднего как число с плавающей точкой. Строка 59 инициализирует
переменную gradeCounter значением 0, так как еще не введено никаких оценок. Как
вы помните, в этой программе используется повторение, управляемое
контрольным значением. Чтобы точно знать число уже введенных оценок,
программа увеличивает переменную gradeCounter только тогда, когда
пользователь введет действительное значение оценки (не контрольное значение) и
программа завершит обработку этой оценки. Наконец, обратите внимание на то,
что обоим операторам ввода (строки 64 и 74) предшествуют операторы вывода,
которые предлагают пользователю ввести данные.
Хороший стиль программирования 4.7
Для каждого ввода с клавиатуры выводите пользователю подсказку.
Подсказка должна указывать форму ввода и специальные входные
значения.
Например, в цикле, управляемом контрольным значением, подсказки,
запрашивающие данные, должны явно напоминать пользователю,
чему это значение равно.
Программная логика для повторения, управляемого
контрольным значением, в сравнении с управлением
по счетчику
Давайте сравним программную логику для повторения, управляемого
контрольным значением, с логикой повторения, управляемого счетчиком на
рис. 4.9. В повторении со счетчиком каждая итерация оператора while
(строки 57-63 на рис. 4.9) читает значение, полученное от пользователя, причем
Управляющие операторы: часть I
229
производится заданное число итераций. В повторении с контрольным
значением программа, прежде чем дойдет до оператора while, читает первое значение
(строки 63-64 на рис. 4.13). Это значение определяет, должен ли поток
управления программы войти в тело оператора while. Если условие оператора while
ложно, значит, пользователь ввел контрольное значение, и тело оператора
while не исполняется (оценки не были введены). Если, с другой стороны,
условие истинно, начинается выполнение тела оператора, и цикл прибавляет
значение grade к total (строка 69). После этого строки 73-74 читают следующее
значение пользователя. Затем поток управления достигает закрывающей
скобки тела (}) в строке 75, и исполнение продолжается проверкой условия
оператора while (строка 67). В условии используется самое последнее введенное
пользователем значение grade, которое и определяет, должно ли тело while
выполняться снова. Заметьте, что значение переменной grade всегда вводится
непосредственно перед проверкой условия оператора while. Это позволяет
программе определить, является ли только что введенное значение контрольным,
до того, как она обработает это значение (то есть прибавит его к total и
увеличит gradeCounter на 1). Если введенное значение является контрольным,
цикл завершается и программа не прибавляет к total значение -1.
По завершении цикла исполняется оператор if...else в строках 78-90.
Условие в строке 78 определяет, были ли введены действительные оценки. Если
никаких оценок не введено, исполняется часть else оператора (строки 89-90),
выводя сообщение "No grades were entered", и элемент-функция возвращает
управление вызывающей функции.
Обратите внимание на блок в цикле while на рис. 4.13. Без фигурных
скобок последние три оператора тела выпали бы из цикла, и компилятор неверно
интерпретировал бы этот код следующим образом:
// цикл, пока не будет прочитано контрольное значение
while ( grade != -1 )
total = total + grade; // прибавить оценку к total
gradeCounter = gradeCounter + 1; // увеличить счетчик
// запросить ввод и прочитать следующую оценку пользователя
cout « "Enter grade or -1 to quit: ";
cin » grade;
Это привело бы к бесконечному циклу, если только пользователь не ввел сразу
—1 в качестве первой оценки (в строке 64).
q Типичная ошибка программирования 4.11
Пропуск ограничивающих блок фигурных скобок может приводить
к логическим ошибкам, например, бесконечным циклам. Чтобы
исключить возможность подобных проблем, некоторые программисты
заключают в фигурные скобки тела всех управляющих операторов,
даже если тело содержит единственный оператор.
230
Глава 4
Точность чисел с плавающей точкой и их требования к памяти
Переменные типа float служат для представления чисел с плавающей
точкой одинарной точности и на большинстве современных 32-битных систем
имеют семь значащих цифр. Переменные типа double представляют числа
с плавающей точкой двойной точности. Для их хранения требуется в два
раза больше памяти, чем для переменных типа float, и они обеспечивают на
32-битных системах представление 15 значащих цифр — приблизительно
вдвое больше, чем переменные float. Для диапазона значений, требуемого
в большинстве программ, достаточно типа float, но чтобы «обезопасить себя»,
вы можете использовать тип double. В некоторых программах даже тип double
оказывается недостаточным, но такие программы выходят за рамки этой
книги. Большинство программистов используют для представления чисел с
плавающей точкой тип double. На самом деле C++ по умолчанию рассматривает
все числа, которые вы печатаете в исходном коде программы (такие, как 7.33
и 0.0975), как значения типа double. Такие числа называют константами
с плавающей точкой. Диапазоны значений для float и double вы можете
найти в приложении В, «Основные типы».
Числа с плавающей точкой часто возникают в результате деления. Когда
в обычной арифметике мы делим 10 на 3, то получаем в результате 3.3333333...
с бесконечной последовательностью троек. Компьютер отводит под такое
значение ограниченное пространство в памяти, поэтому, очевидно, сохраняемое
значение с плавающей точкой может быть лишь приблизительным.
Типичная ошибка программирования 4.12
Использование чисел с плавающей точкой в предположении, что они
совершенно точны (например, в проверках на равенство), может
приводить к неверным результатам. Числа с плавающей точкой на
большинстве компьютеров представляются лишь приближенно.
Несмотря на то, что числа с плавающей точкой не всегда «стопроцентно
точны», они имеют множество практических приложений. Например, когда
мы говорим о «нормальной» температуре тела 98.6, нам не требуется большое
количество цифр. Когда мы видим, что термометр показывает температуру
98.6, в действительности она может быть равна 98.5999473210643. Однако
для большинства приложений, связанных с температурой тела, вполне
допустимо назвать ее просто 98.6. Вследствие неточной природы чисел с плавающей
запятой тип double предпочтительнее типа float, поскольку переменные типа
double могут представлять числа с плавающей точкой более точно. По этой
причине мы везде в книге используем тип double.
Явное и неявное преобразование основных типов
Переменная average объявлена как double (строка 55 на рис. 4.13), чтобы
учесть дробную часть результата вычислений. Однако и total, и gradeCounter
являются целыми переменными. Как вы помните, деление двух целых чисел
является целым делением, при котором любая дробная часть результата
теряется (т.е. усекается). В операторе
average = total / gradeCounter;
Управляющие операторы: часть I
231
сначала выполняется деление, поэтому дробная часть теряется прежде, чем
результат будет присвоен переменной average. Чтобы производить над целыми
числами вычисления с плавающей точкой, мы должны создать для этого
временные значения с плавающей точкой. В C++ для подобных целей
предусмотрена унарная операция приведения типа. В строке 81 используется операция
приведения static_cast<double>( total ), которая создает временную копию
с плавающей точкой своего операнда total (в круглых скобках). Подобное
применение операции приведения называется явным преобразованием. Значение,
сохраняемое в total, остается целым.
Вычисления теперь сводятся к делению значения с плавающей точкой
(временной копии total типа double) на целое gradeCounter. Компилятор C++
умеет оценивать только выражения с операндами, имеющими идентичные типы.
Чтобы обеспечить одинаковый тип операндов, компилятор производит над
некоторыми из них возведение типа (его называют также неявным преобразова
нием). Например, в выражении, содержащем значения типов int и double,
компилятор возводит операнды типа int до типа double. В нашем примере мы
обрабатываем переменную total как double (применив к ней унарную
операцию приведения), поэтому компилятор возводит gradeCounter до double,
обеспечивая тем самым возможность вычислений, и результат деления с
плавающей точкой присваивается переменной average. В главе 6 мы обсудим все
основные типы данных и порядок их возведения.
Типичная ошибка программирования 4.13
Операция приведения типа может применяться для преобразования
друг в друга основных численных типов данных, таких, как int
и double, и родственных классовых типов (это обсуждается в главе
13). Приведение к неверному типу может приводить к ошибкам как
времени компиляции, так и времени выполнения.
Операции приведения к типу возможны для любых типов данных и для
классовых типов. Операция static cast образуется из ключевого слова
static_cast, за которым следует имя типа данных, заключенное в угловые
скобки (< и >). Приведение типа является унарной (одноместной) операциейу
т.е. операцией, имеющей всего один операнд. В главе 1 мы изучили бинарные
арифметические операции. C++ поддерживает также унарные версии
операций «плюс» (+) и «минус» (—), благодаря которым программист может писать
выражения вроде —7 или +5. Операции приведения к типу имеют более
высокий приоритет, чем другие унарные операции, такие, как унарный плюс
и унарный минус. Их приоритет выше, чем у мультипликативных операций
*, / и %, и ниже, чем у круглых скобок. Мы указываем операцию приведения
с нотацией static_cast <7шгл>() в наших таблицах приоритетов (см., например,
рис. 4.22).
Форматирование чисел с плавающей точкой
Возможности форматирования, используемые на рис. 4.13, рассматриваются
здесь лишь вкратце; подробное обсуждение проводится в главе 15. Вызов
setprecision в строке 86 (с аргументом 2) указывает, что переменная двойной
точности average должна быть напечатана с точностью до двух знаков справа
232
Глава 4
от десятичной точки (например, 92.37). Этот вызов является
параметризованным манипулятором потока, поскольку он имеет параметр B в скобках).
Программы, в которых имеются подобные вызовы, должны содержать директиву
препроцессора (строка 10)
#include <iomanip>
Строка 11 специфицирует имена из заголовочного файла <iomanip>,
используемые в данной программе. Заметьте, что endl является непараметризован
ным манипулятором потока (поскольку за ним не следует значение или
выражение в скобках) и не требует включения <iomanip>. Если точность не
задана, то значения с плавающей точкой выводятся обычно с точностью в шесть
цифр (т.е. с точностью по умолчанию на современных 32-битных системах),
хотя мы вскоре увидим исключение из этого правила.
Манипулятор потока fixed (строка 86) указывает, что значения с
плавающей точкой должны выводиться в так называемом формате с фиксированной
точкой, в противоположность научной нотации. Научная нотация является
представлением числа в виде числа с плавающей точкой в диапазоне от 1
до 10, умноженного на степень 10. На пример, значение 3100 было бы
представлено в научной нотации как 3.1 х 103. Научная нотация полезна при
выводе либо очень больших, либо очень малых значений. Форматирование с
фиксированной точкой, с другой стороны, используется для вывода значений
с плавающей точкой с указанным числом цифр. Кроме того, форматирование
с фиксированной точкой задает принудительный вывод десятичной точки
и конечных нулей, даже если значение является в действительности целым
числом, например, 88.00. Без спецификации формата с фиксированной точкой
такое значение было бы напечатано как 88, без конечных нулей и без
десятичной точки. Когда в программе используются манипуляторы fixed и set
precision, печатаемое значение округляется до указанного числа десятичных
разрядов, хотя ее значение в памяти остается неизменным. Например, числа
87.945 и 67.543 будут напечатаны как 87.95 и 67.54. Заметим, что задавать
принудительный вывод десятичной точки можно также с помощью
манипулятора showpoint. При указании showpoint без fixed конечные нули печататься
не будут. Как и endl, манипуляторы потока showpoint и fixed являются
^параметризованными и не требуют заголовочного файла <iomanip>. Их можно
найти в заголовочном файле <iostream>.
Строки 86 и 87 на рис. 4.13 выводят среднее по группе. В этом примере мы
выводим среднее с округлением до сотых и печатаем его ровно с двумя
цифрами справа от десятичной точки. Параметризованной манипулятор потока set-
precision( 2 ) в строке 86 указывает, что значение переменной average должно
выводиться с точностью до двух цифр. Три оценки, введенные при пробном
запуске программы (рис. 4.14), составляют в сумме 257, что дает среднее
значение 85.666666.... Параметризованный манипулятор setprecision приводит
к округлению результата до указанного числа цифр дробной части. В данном
случае среднее округляется до сотых и выводится как 85.67.
Управляющие операторы: часть I
233
4.10. Формулирование алгоритмов: вложенные
управляющие операторы
Для нашего следующего примера мы снова сформулируем алгоритм,
используя псевдокод и нисходящее уточнение, после чего напишем
соответствующую программу на C++. Мы уже видели, что управляющие операторы
могут надстраиваться один поверх другого (последовательно), точно так же, как
ребенок ставит один кубик на другой. В этом примере мы исследуем
единственный альтернативный структурный способ соединения управляющих
операторов, а именно, вложение оного управляющего оператора в другой.
Рассмотрим следующую постановку задачи:
Колледж предлагает курс, который готовит студентов для государственного
экзамена на получение лицензии брокера. В прошедшем году сдавали экзамен
десять студентов, прослушавших этот курс. Естественно, колледж хочет знать,
насколько хорошо их студенты его сдали. Вас попросили написать программу
обработки результатов экзамена. Вам дали список 10 студентов. Против
каждой фамилии написано 1, если студент успешно сдал экзамен, и 2, если он его не
смог сдать.
Ваша программа должна проанализировать результаты экзамена следующим
образом:
1. Ввести экзаменационные результаты (т.е. 1 или 2). Всякий раз, когда
программа запрашивает результат экзамена для следующего студента, она
должна выводить подсказку «Введите результат».
2. Подсчитать число результатов каждого типа.
3. Вывести на экран сводку результатов экзамена, указав число студентов,
выдержавших и не выдержавших экзамен.
4. Если более 8 студентов экзамен выдержали, напечатать сообщение
«Повысить плату за обучение».
Прочитав внимательно формулировку задания на решение данной задачи,
вы можете отметить следующее:
1. Программа должна обработать результаты 10 студентов. Поскольку
число результатов экзамена известно заранее, можно использовать
повторение, управляемое счетчиком.
2. Каждый экзаменационный результат — число, равное 1 или 2. При
каждом чтении очередного результата программа должна определять, равно
ли введенное число 1 или 2. В своем алгоритме мы будем проверять,
равно ли число 1. Если число не 1, то мы предполагаем, что оно равно 2.
(Упражнение 4.20 рассматривает последствия такого предположения.)
3. Используются два счетчика — один для подсчета числа студентов,
сдавших экзамен, второй — для подсчета числа провалившихся студентов.
4. После того как программа обработает все результаты, она должна
решить, сдало ли экзамен более 8 студентов.
Давайте проведем нисходящую разработку с пошаговой детализацией. Мы
начнем с псевдокода, описывающего верхний уровень:
Проанализировать результаты экзамена и решить, должна ли быть повышена
плата за обучение
234
Глава 4
Снова подчеркнем, что верхний уровень описывает программу в целом, но
обычно необходимо пройти через ряд уточнений, прежде чем псевдокод
естественным образом разовьется в программу на C++. Наше первая детализация:
Инициализировать переменные
Ввести десять результатов экзамена и определить число сдавших и не сдавших
экзамен
Напечатать сводку результатов экзамена и решить, надо ли повышать плату
за обучение
Мы снова полностью описали программу в целом, но все равно требуется ее
дальнейшее уточнение. Введем конкретные переменные переменные.
Необходимы счетчики для записи числа сдавших и не сдавших экзамен, счетчик для
управления циклом и переменная для хранения введенной оценки. Последняя
не нуждается в инициализации, так как ее значение вводится пользователем
на каждой итерации цикла.
Оператор псевдокода
Инициализировать переменные
можно уточнить следующим образом:
Инициализировать нулем счетчик сдавших
Инициализировать нулем счетчик не сдавших
Инициализировать единицей счетчик студентов
Заметьте, что в начале алгоритма инициализируются только счетчики.
Оператор псевдокода
Ввести десять результатов экзамена и определить число сдавших и не сдавших
экзамен
требует цикла, который последовательно вводит результат каждого экзамена.
В данном случае заранее известно, что имеется ровно десять результатов, так
что для решения задачи подходит повторение, управляемое счетчиком.
Внутри цикла (т. у. вложенный в цикл) оператор if...else будет определять,
означает ли результат сданный или не сданный экзамен, и увеличивать на единицу
соответствующий счетчик. Таким образом, уточнение предыдущего оператора
псевдокода имеет вид
Пока счетчик студентов меньше или равен 10
Предложить пользователю ввести очередной результат экзамена
Ввести следующий результат экзамена
Если студент сдал экзамен
Прибавить единицу к счетчику сдавших
Иначе
Прибавить единицу к счетчику не сдавших
Прибавить единицу к счетчику студентов
Мы выделили управляющую структуру Если...Иначе пустыми строками,
которые облегчают чтение программы. Оператор псевдокода
Напечатать сводку результатов экзамена и решить, надо ли повышать плату
за обучение
Управляющие операторы: часть I
235
может быть уточнен следующим образом:
Напечатать число сдавших
Напечатать число не сдавших
Если экзамен сдало более восьми студентов
Напечатать "Повысить плату за обучение"
Полностью второе уточнение показано на рис. 4.15. Управляющая
структура Пока также выделена пустыми строками для улучшения читаемости.
Псевдокод теперь достаточно уточнен, чтобы можно было преобразовать его в
программу на C++.
1 Инициализировать нулем счетчик сдавших
2 Инициализировать нулем счетчик не сдавших
3 Инициализировать единицей счетчик студентов
4
5 Пока счетчик студентов меньше или равен десяти
6 Предложить пользователю ввести очередной результат экзамена
7 Ввести следующий результат экзамена
8
9 Если студент сдал экзамен
10 Прибавить единицу к счетчику сдавших
11 Иначе
12 Прибавить единицу к счетчику не сдавших
13
14 Прибавить единицу к счетчику студентов
15
16 Напечатать число сдавших
17 Напечатать число не сдавших
18
19 Если экзамен сдало более восьми студентов
20 Напечатать "Повысить плату за обучение"
Рис. 4.15. Псевдокод для задачи о результатах экзамена
Преобразование в класс Analysis
Класс C++, реализующий алгоритм на псевдокоде из рис. 4.15, показан на
рис. 4.16-4.17; два пробных запуска программы показаны на рис. 4.18.
1 // Рис. 4.16: Analysis.h
2 // Определение класса Analysis, анализирующего результаты экзамена.
3 // Элемент-функции определяются в Analysis.срр
4
5 // определение класса Analysis
6 class Analysis
7 {
8 public:
9 void processExamResuits(); // обработать результаты 10 студентов
10 }; // конец класса Analysis
Рис. 4.16. Задача о результатах экзамена: заголовочный файл Analysis
236
Глава 4
1 // Рис. 4.17: Analysis.cpp
2 // Определения элемент-функции класса Analysis,
3 // который анализирует результаты экзаменов.
4 #include <iostream>
5 using std::cout;
6 using std::cin;
7 using std::endl;
8
9 // включить определение класса Analysis из Analysis.h
10 #include "Analysis.h"
11
12 // обработать экзаменационные результаты 10 студентов
13 void Analysis::processExamResults()
14 {
15 // инициализация переменных при объявлении
16 int passes =0; // число сдавших
17 int failures =0; // число провалившихся
18 int studentCounter = 1; // счетчик студентов
19 int result; // один результат экзамена A = сдал, 2 = не сдал)
20
21 // обработать 10 студентов, используя цикл по счетчику
22 while ( studentCounter <= 10 )
23 {
24 // запросить у пользователя и ввести значение
25 cout « "Enter result A = pass, 2 = fail): ";
26 cin » result; // ввести результат
27
28 // if...else, вложенный в while
29 if ( result == 1 ) // если result равен 1,
30 passes = passes +1; // увеличить passes;
31 else // в противном случае result не 1,
32 failures = failures + 1; // поэтому увеличить failures
33
34 // увеличить studentCounter, чтобы цикл мог закончиться
35 studentCounter = studentCounter + 1;
36 } // конец while
37
38 // этап завершения; вывести число сдавших и не сдавших
39 cout « "Passed " « passes « "\nFailed " « failures « endl;
40
41 // определить, прошло ли более восьми студентов
42 if ( passes > 8 )
43 cout « "Raise tuition" « endl;
44 } // конец функции processExamResults
Рис. 4.17. Задача о результатах экзамена: вложенные управляющие операторы
в файле исходного кода Analysis
1 // Рис. 4.18: fig04_18.cpp
2 // Тестовая программа для класса Analysis.
3 #include "Analysis.h" // включить определение класса Analysis
4
5 int main()
6 {
7 Analysis application; // создать объект Analysis
Управляющие операторы: часть I
237
8 application.processExamResuits(); // вызвать функцию обработки
9 return 0; // показывает успешное завершение
10 } // конец main
Enter
Enter
Enter
Enter
Enter
Enter
Enter
Enter
Enter
Enter
result
result
result
result
result
result
result
result
result
result
Passed 9
Failed 1
Raise
tuition
A
A
A
A
A
A
A
A
A
A
i
=
=
=
=
=
=
=
=
=
=
pass,
pass,
pass,
pass,
pass,
pass,
pass,
pass,
pass,
pass,
2
2
2
2
2
2
2
2
2
2
Enter result
Enter result
Enter result
Enter result
Enter result
Enter result
Enter result
Enter result
Enter result
Enter result
Passed 6
Failed 4
A
A
A
A
A
A
A
A
A
A
=
=
=
=
=
=
=
=
=
=
pass,
pass,
pass,
pass,
pass,
pass,
pass,
pass,
pass,
pass,
2
2
2
2
2
2
2
2
2
2
=
=
=
=
=
=
=
=
=
=
fail)
fail)
fail)
fail)
fail)
fail)
fail)
fail)
fail)
fail)
1
2
2
1
1
1
2
1
1
2
Рис. 4.18. Тестовая программа для класса Analysis
Строки 16-19 на рис. 4.17 объявляют переменные, используемые
элемент-функцией processExamResults класса Analysis для обработки
результатов экзамена. Обратите внимание, что мы воспользовались здесь имеющейся
в C++ возможностью инициализации переменных при их объявленрш (passes
и failures инициализируются нулем, studentCounter — единицей). В
программах с циклами может потребоваться инициализация переменных в начале
каждого повторения цикла; такая реинициализация обычно выполняется не
в объявлениях, а с помощью операторов присваивания, либо посредством
перемещения объявлений внутрь тела цикла.
Оператор while (строки 22-36) выполняет 10 итераций. В каждой итерации
цикл вводит и обрабатывает один результат экзамена. Обратите внимание, что
оператор if...else (строки 29-32), обрабатывающий оценку, является
вложенным в оператор while. Если результат равен 1, оператор if...else увеличивает
на единицу passes; в противном случае он предполагает, что результат равен 2,
и увеличивает на единицу failures. Строка 35 увеличивает studentCounter
перед тем, как условие цикла снова будет тестироваться в строке 22. После ввода
всех 10 значений цикл завершается и строка 39 выводит число сдавших и
число не сдавших. Оператор if в строках 42-43 определяет, сдало ли экзамен
более 8 человек, и если это так, выводит сообщение "Raise tuition".
fail)
fail)
fail)
fail)
fail)
fail)
fail)
fail)
fail)
fail)
1
1
1
1
2
1
1
1
1
1
238
Глава 4
Демонстрация класса Analysis
Программа на рис. 4.18 создает объект класса Analysis (строка 7) и
активирует его элемент-функцию processExamResults (строка 8), чтобы обработать
введенный пользователем набор результатов. Рис. 4.18 показывает ввод и
вывод при двух пробных запусков программы. В конце первого исполнения
условие в строке 42 элемент-функции processExamResults на рис. 4.17 истинно —
экзамен сдали более восьми студентов, и программа выводит сообщение о том,
что плата за обучение должна быть повышена.
4.11. Операции присваивания
В C++ имеется несколько операций присваивания для сокращенной записи
выражений присваиваивания. Например, оператор
с = с + 3;
может быть сокращен применением операции присваивания суммы +=:
с += 3;
Операция += складывает значение выражения справа от операции со
значением переменной слева, и сохраняет результат в той же переменной. Любой
оператор вида
переменная = переменная операция выражение;
где в обе части присваивания входит одна и та же переменная, а операция —
одна из двухместных операций +, —, *, / или % (или других операций,
которые будут рассмотрены позднее), может быть записан в виде
переменная операция^ выражение;
Таким образом, присваивание с += 3 прибавляет 3 к с. Рис. 4.19
показывает арифметические операции присваивания, примеры выражений с этими
операциями и их объяснение.
1
Операция
присваивания
Пример
Пояснение
Результат
присваивания
Предположим: int с = 3, d=5, e = 4, f = 6, g=12;
+=
-=
•=
/=
%=
с += 7
d -= 4
е *= 5
f /= 3
g %= 9
с = с + 7
d = d - 4
е = е * 5
f = f / 3
g = g % 9
с = 10
d = 1
e = 20
f = 2
g = 3
Рис. 4.19. Арифметические операции присваивания
Управляющие операторы: часть I
239
4.12. Операции инкремента и декремента
Кроме арифметических операций присваивания, в C++ предусмотрены две
унарные операции для увеличения и уменьшения переменной на единицу. Это
операция инкремента ++ (увеличение на 1) и операция декремента —
(уменьшение на 1), сводка которых приведена на рис. 4.20. Если переменная с
должна быть увеличена на 1, лучше применить операцию ++, чем выражения
с = с + 1 или с += 1. Если операция инкремента или декремента помещается
перед переменной, говорят о префиксном инкременте или префиксном
декременте. Если операция инкремента или декремента помещается после
переменной, то говорят о постфиксом инкременте или постфиксном декременте.
Операция
++
++
Название
операции
преинкремент
постинкремент
предекремент
постдекремент
Пример
выражения
++а
а++
--Ь
Ь--
Пояснение
Значение а увеличивается на 1, затем
новое значение используется
в выражении, в которое входит а.
В выражении используется текущее
значение а, затем значение а
увеличивается на 1.
Значение b уменьшается на 1, затем
новое значение используется
в выражении, в которое входит Ь.
В выражении используется текущее
значение Ь, затем значение b
уменьшается на 1.
Рис. 4.20.Операции инкремента и декремента
Сокращенно префиксный инкремент (декремент) называют преинкремен-
том (предекрементом). Постфиксный инкремент (декремент) называется
постинкрементом (постдекрементом). При использовании операции преинкре-
мента (предекремента) переменная сначала увеличивается (уменьшается) на 1,
а затем ее новое значение используется в выражении, в которое она входит.
При операции постинкремента (постдекремента) в выражении используется
текущее значение переменной, а затем ее значение увеличивается
(уменьшается) на единицу.
Хороший стиль программирования 4.8
В отличие от бинарных операций, унарные операции инкремента
и декремента следует помещать рядом со своими операндами, без
разделяющего пробела.
Программа на рис. 4.21 демонстрирует различие между префиксной и
постфиксной формами операции инкремента ++. Операция декремента -- работает
точно так же. Заметьте, что в этом примере нет никакого класса, а только
файл исходного кода с функцией, которая выполняет всю работу приложения.
В этой и предыдущей главах вы имели дело с примерами, состоявшими из
класса (файлов заголовка и исходного кода для класса) и дополнительного
240
Глава 4
файла исходного кода, который тестировал этот класс. Этот файл содержал
функцию main, которая создавала объект класса и вызывала его
элемент-функцию. В этом примере мы просто хотим показать механику операции
инкремента, поэтому используем только файл исходного кода с функцией
main. Иногда, когда не имеет смысла пытаться создать утилизируемый класс
для демонстрации простой концепции, мы будем использовать механический
пример, полностью реализованный внутри функции main в единственном
файле исходного кода.
1 // Рис. 4.21: fig04_21.cpp
2 // Преинкремент и постинкремент.
3 #include <iostream>
4 using std::cout;
5 using std:rendl;
6
7 int main()
8 {
9 int c;
10
11 // продемонстрировать постинкремент
12 с = 5; // присвоить 5 переменной с
13 cout « с « endl; // печатает 5
14 cout « C++ « endl; // печатает 5, затем выполняет инкремент
15 cout « с « endl; // печатает б
16
17 cout « endl; // пропустить строку
18
19 // продемонстрировать преинкремент
20 с = 5; // присвоить 5 переменной с
21 cout « с « endl; // печатает 5
22 cout « ++с « endl; // выполняет инкремент и затем печатает 6
23 cout « с « endl; // печатает б
24 return 0; // показывает успешное завершение
25 } // конец main
5
5
6
5
6
б
Рис. 4.21. Операции преинкремента и постинкремента
Строка 12 инициализирует переменную с значением 5, и строка 13 выводит
ее исходное значение. Строка 14 выводит значение выражения C++ Это
выражение производит над с постинкремент, поэтому сначала выводится исходное
значение с, а затем ее значение инкрементируется. Таким образом, строка 14
снова выводит исходное значение с E). Строка 15 выводит новое значение
с F), показывая, что в строке 14 переменная действительно была инкременти-
рована.
Управляющие операторы: часть I
241
Строка 20 снова устанавливает с значением 5, и строка 21 выводит
значение переменной. Строка 22 выводит значение выражения ++с. Это выражение
производит над с преинкремент, поэтому сначала значение с инкрементирует-
ся, а затем выводится ее новое значение F). Строка 23 снова выводит значение
с, показывая, что оно не изменилось после исполнения оператора вывода
в строке 22.
Арифметические операции присваивания и операции
инкремента/декремента могут использоваться для упрощения операторов программы. Три
оператора присваивания на рис. 4.17
passes = passes + 1;
failures = failures + 1;
studentCounter = studentCounter + 1;
могут быть записаны с помощью операций присваивания более кратко, как
passes +=1;
failures += 1;
studentCounter += 1;
с префиксными операциями инкремента, как
++passes;
++failures;
++student;
или с постфиксными операциями инкремента, как
passes++;
failures++;
studentCounter++;
Важно отметить, что когда инкремент или декремент переменной
производится в отдельном операторе, то префиксная и постфиксная формы приводят
к одному и тому же результату. Только когда переменная появляется в
контексте более сложного выражения, префиксная и постфиксная формы
действуют по-разному.
Типичная ошибка программирования 4.14
Попытка использовать в операции инкремента или декремента
операнд, отличный от имени простой переменной, например, написание
++(х+1), является синтаксической ошибкой.
Рис. 4.22 показывает приоритет и ассоциативность операций,
представленных к настоящему моменту. Операции перечислены сверху вниз в порядке
убывания приоритета. Второй столбец показывает ассоциативность операций
на каждом уровне приоритета. Заметьте, что условная операция (?:), унарные
операции инкремента (++), декремента (--), плюс (+), минус (-) и приведения
типа, операции присваивания =, +=, -=, *=, /= и %= ассоциируются справа
налево. Все остальные операции на рис. 4.22 ассоциируются слева направо.
В третьем столбце приведены названия различных групп операций.
242
Глава 4
Операции
О
++ —
++ —
* /
+
static_cast<7>m> ()
+ + -
%
Ассоциативность
слева направо
слева направо
справа налево
слева направо
слева направо
I
Тип
круглые скобки
унарные (постфиксные)
унарные (префиксные)
мультипликативные
аддитивные
« »
<=
>=
I слева направо
| слева направо
слева направо
I передачи/извлечения
отношения
равенства
I
+= -= *= /= %=
| справа налево i условная
I справа налево i присваивания
Рис. 4.22. Приоритеты операций, встречавшихся в тексте к настоящему моменту
4.13. Конструирование программного обеспечения.
Идентификация классовых атрибутов в системе ATM
(необязательный раздел)
В разделе 3.11 мы проделали начальный этап объектно-ориентированного
проектирования (OOD) для нашей системы ATM — анализ спецификации
требований и идентификацию классов, необходимых для реализации системы.
Мы перечислили существительные и именные конструкции в спецификации
требований и идентифицировали отдельные классы для тех из них, что играют
существенную роль в системе ATM. Затем мы моделировали классы и их
взаимоотношения на классовой диаграмме UML (см. рис. 3.23). Классы имеют
атрибуты (данные) и операции (действия, поведение). Атрибуты класса
реализуются на языке C++ как элементы данных, а операции класса — как
элемент-функции. В этом разделе мы определим многие из атрибутов,
необходимых в системе ATM. В главе 5 мы исследуем, как эти атрибуты
представляют состояние объекта. В главе 6 мы определим операции классов.
Идентификация атрибутов
Рассмотрим атрибуты некоторых объектов реального мира. Атрибуты
человека включают в себя рост, вес и то, является ли он левшой, правшой или
двоеруким. Атрибуты радиоприемника включают установленную частоту
настройки, установленную громкость и установку AM/FM. Атрибуты
автомобиля включают показания спидометра и счетчика пробега, количество бензина
в баке и включенная передача. Атрибуты персонального компьютера
включают марку производителя (напр., Dell, Sun, Apple или IBM), тип экрана (напр.,
LCD или CRT), объем основной памяти и размер жесткого диска.
Мы можем идентифицировать многие атрибуты классов в нашей системе,
поискав описательные слова и словосочетания в спецификации требований. Для
каждого из найденных слов, если оно играет существенную роль в системе
ATM, мы создадим атрибут и припишем его к одному или нескольким классам,
Управляющие операторы: часть I
243
идентифицированным в разделе 3.11. Мы также будем создавать атрибуты для
представления любых дополнительных данных, которые могут понадобиться
классу, по ходу выявления этой надобности в процессе проектирования.
На рис. 4.23 перечислены слова и словосочетания из спецификации
требований, которые описывают каждый из классов. Мы образовали этот список, читая
спецификацию требований и идентифицируя любые слова или словосочетания,
относящиеся к характеристикам классов в системе. Например, спецификация
требований описывает шаги, необходимые для получения «снимаемой суммы»,
поэтому мы приписываем к классу Withdrawal слово «сумма».
Класс
ATM
Balancelnquiry
Withdrawal
Deposit
BankDatabase
Account
Screen
Keypad
CashOispenser
DepositSlot
Описательные слова и словосочетания
номер счета
номер счета
сумма
номер счета
сумма
[описательные слова или словосочетания отсутствуют]
номер счета
PIN
баланс
[описательные слова или словосочетания отсутствуют]
[описательные слова или словосочетания отсутствуют]
каждый день загружается 500 20-долларовых банкнот
[описательные слова или словосочетания отсутствуют]
Рис. 4.23. Описательные слова и словосочетания из требований к ATM
Руководствуясь списком на рис. 4.23, мы создаем один атрибут класса
ATM. Класс ATM хранит информацию о состоянии ATM. Словосочетание
«пользователь авторизован» описывает состояние ATM (мы вводим состояния
в разделе 5.11), поэтому мы присваиваем классу в качестве булева атрибута
user Authenticated (булев атрибут может иметь значение true или false). Тип
UML Boolean соответствует типу bool в C++. Атрибут указывает, удалось ли
ATM подтвердить личность текущего пользователя, — чтобы система
разрешила пользователю производить транзакции и обращаться к информации
счета, userAuthenticated должен быть равен true.
Классы Balancelnquiry, Withdrawal и Deposit разделяют один и тот же
атрибут. Каждая транзакция связана с некоторым «номером счета»,
соответствующим счету пользователя, производящего транзакцию. Каждому классу
транзакции мы присваиваем целый атрибут accountNumber, чтобы
идентифицировать счет, к которому относится объект класса.
Описательные слова и словосочетания в спецификации требований говорят
также о некоторых различиях в атрибутах, необходимых каждому из классов
транзакций. Спецификация показывает, что при снятии или внесении средств
пользователь должен ввести конкретную «сумму» денег, которая должна быть
244
Глава 4
соответственно снята или внесена. Таким образом, мы присваиваем классам
Withdrawal и Deposit атрибут amount, который сохраняет указанное
пользователем значение. Суммы денег, относящиеся к снятию и внесению, являются
определяющими характеристиками этих транзакций и необходимы системе
для исполнения последних. Однако класс Balancelnquiry не требует для
выполнения своей задачи никаких дополнительных данных — ему необходим
только номер счета, баланс которого нужно получить.
Класс Account имеет несколько атрибутов. Спецификация требований
гласит, что каждый банковский счет имеет «номер счета» и «PIN», которые
система использует для идентификации счетов и авторизации пользователей. Мы
присваиваем классу Account два целых атрибута: accountNumber и pin.
Спецификация требований также указывает, что счет хранит «баланс» суммы денег
на счете и что вносимые пользователем деньги не становятся доступными для
снятия до тех пор, пока банк не проверит сумму наличных в конверте с
депозитом и не очистит чеки, если они в нем имеются. Однако счет все равно должен
зарегистрировать сумму, внесенную пользователем. Поэтому мы решаем, что
должен представлять баланс двумя атрибутами UML-типа Double: availab-
leBalance и totalBalance. Атрибут availableBalance отслеживает сумму денег,
которую пользователь может снять со счета. Атрибут totalBalance относится
к общей сумме денег, которую пользователь имеет «на депозите» (т.е. сумме
доступных денег плюс сумма, которая ожидает окончания проверки или
очистки). Например, предположим, что пользователь ATM вносит $50.00 на пустой
счет. Атрибут totalBalance увеличился бы до $50.00, но availableBalance
остался бы нулевым. [Замечание. Предполагается, что банк обновляет атрибут
availableBalance объекта Account вскоре после того, как происходит
транзакция ATM, в ответ на подтверждение, что в конверте находятся $50 наличными
или чеком. Мы предполагаем, что это обновление выполняется посредством
транзакции, производимой банковским служащим при помощи какого-то
программного обеспечения, не относящегося к системе ATM. Поэтому в нашем
учебном примере мы не рассматриваем эту транзакцию.]
Класс CashDispenser имеет один атрибут. Спецификация требований
говорит, что в выходной лоток «каждый день загружается 500 20-долларовых
банкнот». Выходной лоток должен отслеживать число содержащихся в нем
банкнот, чтобы определять, достаточно ли имеется наличных для
удовлетворения запросов на снятие денег. Мы присваиваем классу CashDispenser целый
атрибут count, исходно устанавливаемый равным 500.
В реальных задачах программной индустрии нет гарантии, что
спецификация требований будет достаточно полной и точной для того, чтобы
проектировщик объектно-ориентированных систем мог определить все атрибуты или
даже классы. Необходимость введения дополнительных классов, атрибутов
и поведения может выясняться в ходе процесса проектирования. По ходу
изучения нашего учебного примера мы также будем добавлять, модифицировать
и отбрасывать информацию о классах в нашей системе.
Моделирование атрибутов
Классовая диаграмма на рис. 4.24 перечисляет некоторые из атрибутов для
классов в нашей системе — нам помогли их идентифицировать описательные
слова и словосочетания из рис. 4.23. Для простоты рис. 4.24 не показывает
ассоциации между классами; мы показали их на рис. 3.23. Так обычно и посту-
Управляющие операторы: часть I
245
пают проектировщики систем при разработке проектов. Как вы помните из
раздела 3.11, атрибуты класса размещаются в среднем отделении
изображающего класс прямоугольника. Мы записываем имя и тип каждого атрибута,
разделяя их двоеточием (:), после чего в некоторых случаях следует знак
равенства (=) и начальное значение.
ATM
userAuthentlcated : Boolean = false
Balancelnquiry
accountNumber: Integer
Account
accountNumber: Integer
pin : Integer
avallableBalance : Double
totalBalance: Double
Screen
Withdrawal
accountNumber: Integer
amount: Double
Keypad
Deposit
accountNumber: Integer
amount: Double
CashDispenser
count: Integer = 500
BankDatabase
Deposits lot
Рис. 4.24. Классы с их атрибутами
Рассмотрим атрибут user Authenticated класса ATM:
userAuthenticated : Boolean = false
Это объявление содержит три фрагмента информации об атрибуте. Именем
атрибута является userAuthenticated. Типом атрибута является Boolean.
246
Глава 4
На C++ атрибут может быть представлен основным типом, таким, как bool, int
или double, либо классовым типом, о чем говорилось в главе 3. Мы решили
моделировать рис. 4.24 только атрибуты примитивных типов; причины такого
решения мы вскоре обсудим. [Замечание. На рис. 4.24 указаны UML-типы
атрибутов. При реализации системы мы поставим в соответствие типам Boolean,
Integer и Double языка UML типы bool, int и double языка C++.]
Мы можем также указать для атрибута начальное значение. Атрибут
user Authenticated класса ATM имеет начальное значение false. Этим
указывается, что система сначала не считает пользователя авторизованным. Если
начальное значение для атрибута не специфицировано, указываются только его
имя и тип (разделенные двоеточием). Например, атрибут accountNumber
класса Balancelnquiry имеет тип Integer. Мы не показываем здесь никакого
начального значения, поскольку значением этого атрибута является число, которого
мы пока не знаем. Это число будет определяться во время исполнения в
зависимости от того, какой номер счета вводит текущий пользователь ATM.
Для классов Screen, Keypad и DepositSlot на рис. 4.24 не показано
никаких атрибутов. Это важные компоненты нашей системы, для которых наш
процесс проектирования еще просто не выявил каких-либо атрибутов. Однако
мы можем обнаружить некоторые их атрибуты на дальнейших стадиях
проектирования или при реализации этих классов на C++. Для итеративного
процесса конструирования программного обеспечения это совершенно нормально.
S Общее методическое замечание 4.8
На ранних стадиях проектирования у классов часто отсутствуют
атрибуты (и действия). Однако такие классы не следует исключать,
так как их атрибуты (и действия) могут выявиться на
последующих этапах проектирования и реализации.
Заметьте, что на рис. 4.24 не показаны также атрибуты для класса BankDa-
tabase. Как вы помните из главы 3, в C++ атрибуты могут быть представлены
либо основными, либо классовыми типами. Мы решили включить в классовую
диаграмму на рис. 4.24 (как и во все подобные классовые диаграммы нашего
учебного примера) только атрибуты основных типов. Атрибут классового типа
более наглядно моделируется посредством ассоциации (в частности,
композиции) между классом с таким атрибутом и классом объекта, экземпляром
которого является атрибут. Например, классовая диаграмма на рис. 3.23
указывает, что класс BankDatabase участвует в отношении композиции с нулем или
большим числом объектов Account. Из этой композиции мы можем
определить, что при реализации системы ATM на C++ нам потребуется создать
атрибут класса BankDatabase для хранения нуля или более объектов Account.
Аналогичным образом мы присвоим классу ATM атрибуты, которые будут
соответствовать его отношениям композиции с классами Screen, Keypad,
CashDispenser и DepositSlot. Эти композиционно-определяемые атрибуты
были бы избыточны, если моделировать их на рис. 4.24, поскольку
композиции, моделируемые на рис. 3.23, уже отражают тот факт, что база данных
содержит ноль или более счетов и что ATM состоит из экрана, кнопочной
панели, выходного лотка и приемной щели. Разработчики программного
обеспечения обычно моделируют эти отношения «целое/часть» как композиции, а не
как атрибуты, необходимые для реализации отношений.
Управляющие операторы: часть I
247
Классовая диаграмма на рис. 4.24 является надежным фундаментом для
построения нашей модели, но эта диаграмма еще не завершена. В разделе 5.11
мы идентифицируем состояния и деятельность объектов модели, а в
разделе 6.22 идентифицируем действия, которые производятся объектами. По мере
того, как мы будем представлять новые элементы UML и
объектно-ориентированного проектирования, мы будем упрочивать структуру нашей модели.
Контрольные вопросы по конструированию программного
обеспечения
4.1. Обычно мы идентифицируем атрибуты классов в системе, анализируя
в спецификации требований.
a) существительные и именные конструкции
b) описательные слова и словосочетания
c) глаголы и глагольные конструкции
d) Все вышеперечисленное.
4.2. Что из перечисленного ниже не является атрибутом самолета?
a) длина
b) размах крыльев
c) полет
d) число пассажирских мест
4.3. Объясните смысл следующего объявления атрибута класса в классовой
диаграмме на рис. 4.24:
count : Integer = 500
Ответы на контрольные вопросы по конструированию
программного обеспечения
4.1. Ь.
4.2. с. Полет является не атрибутом, а операцией или поведением самолета.
4.3. Оно указывает, что count есть Integer с начальным значением 500. Этот
атрибут отслеживает число банкнот, имеющихся в CashDispenser в
каждый момент времени.
4.14. Заключение
В этой главе были представлены основные методики решения задач,
используемые программистами при построении классов и разработки
элемент-функций для этих классов. Мы продемонстрировали, как строится
алгоритм (т.е. подход к решению задачи) на псевдокоде, как он уточняется,
проходя несколько стадий развития, и как в результате получается код C++,
который может исполняться в качестве части функции. Вы познакомились
с нисходящим последовательным уточнением, позволяющем спланировать
специфические действия, которые функция должна выполнять, и порядок,
в котором они будут выполняться.
Вы узнали, что для разработки любого алгоритма необходимы всего три
типа управляющих структур — последовательность, выбор и повторение. Мы
248
Глава 4
продемонстрировали два из операторов выбора языка C++ — оператор с
одиночным выбором if и оператор с двойным выбором if...else. Оператор if
используется для исполнения группы операторов в зависимости от условия — если
условие истинно, операторы исполняются; если оно ложно, операторы
пропускаются. Оператор с двойным выбором if...else используется для исполнения
одной группы операторов в случае, если условие истинно, и другой группы
операторов, если оно ложно. Затем мы обсудили оператор повторения while,
в котором группа операторов исполняется многократно, пока условие остается
истинным. Мы использовали суперпозицию управляющих операторов для
суммирования и вычисления среднего по набору оценок студентов с помощью
повторения, управляемого счетчиком и контрольным значением, и
использовали вложение управляющих операторов для анализа набора результатов
экзамена и принятия решений в зависимости от этих результатов. Мы
представили операции присваивания, с помощью которых можно записывать
операторы в сокращенной форме. Мы также представили операции инкремента
и декремента, используемые для увеличения или уменьшения переменной на
единицу. В следующей главе мы продолжим обсуждение управляющих
операторов и введем операторы for, do...while и switch.
Резюме
• Алгоритм — это процедура решения задачи, выраженная в категориях операций,
которые должны выполняться, и последовательности, в которой они должны
выполняться.
• Спецификация последовательности, в которой должны выполняться операторы
(действия) в компьютерной программе, называется программным управлением.
• Псевдокод помогает программисту продумать программу, прежде чем пытаться
написать ее на действительном языке программирования.
• Диаграммы деятельности являются частью Унифицированного языка
моделирования (UML) — промышленного стандарта для моделирования систем программного
обеспечения.
• Диаграмма деятельности моделирует рабочий поток (называемый также
деятельностью) программной системы.
• Диаграммы деятельности составляются из специальных символов, таких, как
символы состояния действия, ромбы и кружки. Эти символы соединяются стрелками
перехода, которые представляют поток деятельности.
• Как и псевдокод, диаграммы деятельности помогают программистам разрабатывать
и представлять алгоритмы.
• Состояние действия представляется прямоугольником, у которого левая и правая
стороны заменены полуокружностями. Внутри символа состояния действия
записывается выражение действия.
• Стрелки в диаграмме деятельности представляют переходы, специфицирующие
последовательность выполнения действий, представленных состояниями действия.
• Закрашенный кружок в вершине диаграммы деятельности представляет начальное
состояние — начало рабочего потока перед тем, как программа станет выполнять
смоделированные действия.
• Закрашенный кружок внутри окружности в нижней части диаграммы деятельности
представляет конечное состояние — окончание рабочего потока после того, как
программа выполнит свои действия.
Управляющие операторы: часть I
249
• Прямоугольники с загнутым правым верхним углом называются в UML
примечаниями. Примечания являются комментариями, описывающими назначение
символов диаграммы. Примечания соединяются с описываемыми символами
пунктирными линиями.
• Ромб, или символ решения, в диаграмме деятельности показывает, что должно быть
принято некоторое решение. Рабочий поток пойдет по пути, определенному
ассоциированными с символом контрольными условиями, которые могут быть истинными
или ложными. Каждая стрелка перехода, выходящая из символа решения, имеет
контрольное условие (специфицированное в квадратных скобках выше или рядом со
стрелкой перехода). Если контрольное условие истинно, рабочий поток входит в
состояние действия, на которое указывает стрелка перехода.
• Ромб на диаграмме деятельности представляет также символ слияния, который
сводит два потока деятельности в один. Символ слияния имеет две или большее число
стрелок перехода, направленных к ромбу, и только одну стрелку, направленную от
ромба; это указывает на то, что несколько потоков деятельности сливаются и
продолжаются как один поток.
• Нисходящее последовательное уточнение — это процесс уточнения псевдокода,
который на каждом уровне уточнения является полным представлением программы.
• Существует три типа управляющих структур — последовательность, выбор и
повторение.
• Последовательная структура встроена в C++ — по умолчанию операторы
выполняются в том порядке, в котором они написаны.
• Структура выбора избирает одно из нескольких альтернативных направлений
действия.
• Оператор if с одиночным выбором либо выполняет (выбирает) действие, если его
условие истинно, либо пропускает это действие, если условие ложно.
• Оператор if...else с двойным выбором выполняет (выбирает) действие, если его
условие истинно, и выполняет другое действие, если условие ложно.
• Чтобы включить в тело оператора if или в любую из частей if...else несколько
операторов, заключите их в фигурные скобки: ({ и }). Группа операторов, заключенных
в фигурные скобки, называется блоком. В любом месте программы, где может
находиться одиночный оператор, можно разместить блок.
• Нулевой оператор, указывающий, что не требуется выполнять никаких действий,
обозначается точкой с запятой (;).
• Оператор повторения специфицирует, что действие должно повторяться, пока
некоторое условие остается истинным.
• Значение, содержащее дробную часть, называется числом с плавающей точкой
и представляется (приближенно) такими типами данных, как float и double.
• Управление, управляемое счетчиком, подходит для случаев, когда число повторений
известно до того, как цикл начнет выполняться, т.е. когда имеет место определенное
повторение.
• Унарная операция приведения типа static_cast может использоваться для создания
временной копии своего операнда с плавающей точкой.
• Унарные операции имеют только один операнд; бинарные операции производятся
над двумя операндами.
• Параметризованный манипулятор потока задает число цифр точности, которые
должны выводиться справа от десятичной точки.
• Манипулятор потока fixed указывает, что значения с плавающей точкой должны
выводиться в т. н. формате с фиксированной точкой, альтернативном по отношению
к научной нотации.
250
Глава 4
Повторение, управляемое контрольным значением, используется в тех случаях,
когда число повторений не известно до начала выполнения цикла, т.е. когда имеет
место неопределенное повторение.
Вложенный управляющий оператор входит в тело другого управляющего оператора.
В C++ для сокращенной записи выражений присваивания предусмотрены
арифметические операции присваивания +=, -=, *=, /= и %=.
Операции инкремента ++ и декремента — соответственно увеличивают или
уменьшают переменную на 1. Если операция применяется в префиксной форме, переменная
сначала увеличивается или уменьшается на 1, и затем новое значение переменной
используется в выражении, в которое она входит. Если операция используется
в постфиксной форме, переменная сначала используется в выражении, а затем ее
значение увеличивается или уменьшается на 1.
Терминология
действие
состояние действия
символ состояния действия
программная модель действие/
решение
диаграмма деятельности
операция присваивания суммы
алгоритм
приближение чисел с плавающей
точкой
арифметические операции
присваивания
символ стрелки
операции присваивания
ассоциирование слева направо
ассоциирование справа налево
усреднение
бинарная (двухместная) операция
блок
крах программы
bool
операция приведения типа
составной оператор
условное выражение
вложение управляющих операторов
суперпозиция управляющих
операторов
счетчик
повторение, управляемое счетчиком
проблема «висящего else»
символ решения
операция декремента (—)
операция инкремента (++)
точность по умолчанию
определенное повторение
символ ромба
пунктирная линия
тип данных double
число с плавающей точкой двойной
точности
оператор с двойным выбором
фиктивное значение
пустой оператор
исполняемый оператор
явное преобразование
фатальная логическая ошибка
конечное состояние
первое уточнение
формат с фиксированной точкой
манипулятор потока fixed
флаговое значение
тип данных float
константа с плавающей точкой
число с плавающей точкой
«мусор»
исключение goto
оператор goto
оператор if...else с двойным выбором
неявное преобразование
неопределенное повторение
начальное состояние
целое деление
возведение целого значения
итерация
итерации цикла
ключевые слова
цикл
условие продолжения цикла
цикл, вложенный в цикл
оператор цикла
символ слияния
оператор с множественным выбором
вложенный управляющий оператор
^параметризованный манипулятор
потока
примечание
Управляющие операторы: часть I
251
нулевой оператор
объектно-ориентированное
проектирование (OOD)
ошибка смещения на единицу
операнд
приоритет операций
порядок, в котором должны
выполняться действия
параметризованный манипулятор
потока
постдекремент
точность
предекремент
префиксная операция декремента
префиксная операция инкремента
преинкремент
процедура
программное управление
возведение
псевдокод
оператор повторения
округление
научная нотация
второе уточнение
оператор выбора
повторение, управляемое
контрольным значением
контрольное значение
оператор последовательности
диаграмма деятельности
последовательных операторов
Контрольные вопросы
4.1. Ответьте на каждый из следующих вопросов:
a) Все программы могут быть написаны с использованием трех типов
управляющих структур: , и .
b) Оператор выбора используется для выполнения одного действия,
если его условие истинно, и другого действия, если условие ложно.
c) Повторение набора инструкций заданное число раз называется
повторением.
d) Когда заранее не известно, сколько раз должна исполняться группа
операторов, для прерывания повторения можно использовать значение.
4.2. Напишите четыре различных оператора C++, которые прибавляют 1 к целой
переменной х.
4.3. Напишите операторы C++, выполняющие следующие действия:
a) Присваивание суммы х и у переменной z и инкремент значения х после
вычисления.
b) Проверку, больше ли значение переменной count числа 10. Если больше, то
печать текста "Count is greater than 10".
c) Декремент переменной х и затем ее вычитание из переменной total.
последовательное выполнение
манипулятор потока setprecision
манипулятор потока showpoint
сигнальное значение
управляющий оператор с одним
входом/одним выходом
оператор if с одиночным выбором
число с плавающей точкой одинарной
точности
символ кружка
символ закрашенного кружка
манипулятор потока
структурное программирование
тернарная (трехместная) операция
верхний уровень
нисходящее последовательное
уточнение
сумма
передача управления
переход
символ стрелки перехода
усечение
унарная операция приведения
унарный минус (-)
унарный плюс (+)
унарная операция
неопределенное значение
оператор повторения while
рабочий поток части программной
системы
252
Глава 4
d) Вычисление остатка от деления q на divisor и присваивание результата
переменной q. Напишите два различных варианта такого оператора.
4.4. Напишите операторы C++, решающие следующие задачи:
a) Объявление переменных sum и х типа int.
b) Установка переменной х в 1.
c) Установка переменной sum в О.
d) Сложение переменных х и sum и присваивание результата переменной sum.
e) Печать "The sum is " и значения переменной sum.
4.5. Объедините операторы, которые вы написали в упражнении 4.4, в программу,
которая вычисляет и печатает сумму целых чисел от 1 до 10. Используйте
оператор while для организации цикла, включающего операторы вычислений и
инкремента. Цикл должен завершаться, когда значение х становится равным 11.
4.6. Определите значения каждой переменной после вычисления. Предположите, что
когда каждый оператор начинает выполняться, все переменные имеют целое
значение 5.
a) product *= х++ ;
b) quotient /= ++х;
4.7. Напишите одиночные операторы C++, выполняющие следующие действия:
a) Ввод целой переменной х с помощью cin и ».
b) Ввод целой переменной у с помощью cin и ».
c) Установка целой переменной i в 1.
d) Задание целой переменной power в 1.
e) Умножение переменной power на х и присваивание результата переменной
power.
f) Постинкремент переменной у на 1.
g) Проверка того, что переменная i меньше или равна у.
h) Вывод целой переменной power с помощью cout и «.
4.8. Используя операторы из упражнения 4.7, напишите программу на C++, которая
вычисляет х в степени у. В программе должен быть оператор повторения while.
4.9. Найдите и исправьте ошибки в следующих операторах:
a) while ( с <= 5 ) {
product *= с;
++с;
b) cin « value;
c) if ( gender = 1 )
cout « "Woman" « endl;
else;
cout « "Man" « endl;
4.10. Что не в порядке в следующем операторе повторения while?
while ( z >= 0 )
sum += z;
Управляющие операторы: часть I
253
Ответы на контрольные вопросы
4.1. а) последовательность, выбор, повторение, b) if...else. с) управляемым счетчиком
или определенным, d) контрольное, сигнальное, флаговое или фиктивное.
4.2. х = х + 1;
х += 1;
++х;
х++;
4.3. a) z = х++ + у;
b) if ( count > 10 )
count « "Count is greater than 10" « endl;
c) total -= -x;
d) q %= divisor;
q = q % divisor;
4.4. a) int sum, x;
b) x = 1 ;
c) sum = 0;
d) sum += x; Of sum = sum + x ;
e) cout « "The sum is " « sum « endl;
4.5. См. следующий код:
1 // Упражнение 4.5, решение: ех04_05.срр
2 // Вычислить сумму целых чисел от 1 до 10.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int ma±n()
8 {
9 int sum; // хранит сумму целых от 1 до 10
10 int x; // счетчик
11
12 х = 1; // считать от 1
13 sum =0; // инициализировать сумму
14
15 while ( х <= 10 ) // повторить 10 раз
16 {
17 sum += х; // прибавить х к сумме
18 х++; // приращение х
19 } // конец while
20
21 cout « "The sum is: " « sum « endl;
22 return 0; // показывает успешное завершение
23 } // конец main
The sum is: 55
254
Глава 4
4.6. a) product = 25, х = 6;
b) quotient = 0, x = 6;
1 // Упражнение 4.6, решение: ех04_06.срр
2 // вычислить значения произведения и частного.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int x = 5;
10 int product = 5;
11 int quotient = 5;
12
13 // часть а
14 product *= x++; // оператор части а
15 cout « "product after calculation: " « product « endl;
16 cout « "x after calculation: " « x « endl « endl;
17
18 // часть b
19 x = 5; // восстановить значение х
20 quotient /= ++x; // оператор части b
21 cout « "quotient after calculation: " « quotient « endl;
22 cout « "x after calculation: " « x « endl « endl;
23 return 0; // показывает успешное завершение
24 } // конец main
product after calculation: 25
x after calculation: 6
quotient after calculation: 0
x after calculation: 6
4.7. a) cin » x;
b) cin » y;
c) i = 1 ;
d) power = 1 ;
e) power *= x;
или
power = power * x;
f)y++;
g) if ( у <= x )
h) cout « power « endl;
4.8. См. следующий код:
1 // Упражнение 4.8, решение: ех04_08.срр
2 // Возвести х в степень у.
3 #include <iostream>
4 using std
5 using std
6 using std
:cout;
: cin ;
:endl;
Управляющие операторы: часть I
255
7
8 int main()
9 {
10 int x; // основание
11 int у; //' показатель степени
12 int i; // считает от 1 до у
13 int power; // используется для вычисления х в степени у
14
15 i = 1; // инициализировать i, чтобы счет шел от 1
16 power =1; // инициализировать показатель
17
18 cout « "Enter base as an integer: "; // запросить основание
19 cin » x, // ввести основание
20
21 cout « "Enter exponent as an integer: "; // запросить показатель
22 cin » у; // ввести показатель
23
24 // считать от 1 до у, умножая каждый раз power на х
25 while ( i <= у )
26 {
27 power *= х;
28 i++;
29 } // конец while
30
31 cout « power « endl; // вывести результат
32 return 0; // показывает успешное завершение
33 } // конец main
Enter base as an integer: 2
Enter exponent as an integer: 3
8
4.9. а) Ошибка: нет закрывающей фигурной скобки тела while.
Исправление: добавить закрывающую фигурную скобку после оператора
++с;.
b) Ошибка: использована операция передачи вместо извлечения из потока.
Исправление: заменить « на ».
c) Ошибка: точка с запятой после else ведет к логической ошибке. Второй
оператор вывода будет выполняться в любом случае.
Исправление: удалить точку с запятой после else.
4.10. Значение переменной z в операторе while не изменяется. Следовательно, если
условие продолжения цикла (z >= О) истинно, возникает бесконечный цикл.
Чтобы избежать бесконечного цикла, z должна декрементироваться, чтобы в
конечном итоге она стала меньше 0.
Упражнения
4.11. Найдите и исправьте ошибки в каждом из следующих фрагментов (в каждом
фрагменте может быть более чем одна ошибка):
a) if ( age >= 65 ) ;
cout « "Возраст больше или равен 65" « endl;
else
cout « "Возраст менее 65 « endl";
256
Гпщра
b) if ( age >= 65 )
cout « "Возраст больше или равен 65" « endl;
else
cout « "Возраст менее 65" « endl;
c) int x я 1, total;
while ( x <= 10 ) {
total += x;
++x;
>
d) while ( x <= 100 )
total +■ x;
++x;
e) while ( у > 0 ) {
cout « у « endl;
++y;
4.12. Что, напечатает следующая программа?
1 // Упражнение 4.12: ех04_12.срр
2 // Что печатает эта программа?
3 finclude <iostream>
4 using etd::cout;
5 using etd::endl;
6
7 int main()
8 {
9 int у; // обЧивить у
10 int x = 1; // инициализировать х
11 int total =0; // инициализировать total
12
13 while ( x <= 10 ) // повторить 10 раз
14 {
15 у » x * x; // произвести вычисление
16 cout « у « endl; // вывести результат
17 total += у; // прибавить у к total
18 х++; // увеличить счетчик х
19 } // конец while
20
21 cout « "Total is " « total « endl; // display result
22 return 0; // показывает успешное завершение
23 } // конец main
Для упражнений 4.13-4.16 выполните следующие шаги:
1. Прочтите постановку задачи.
2. Сформулируйте алгоритм, используя псевдокод и нисходящее последовательное
уточнение.
3. Напишите программу на C++.
4. Протестируйте, отладьте и выполните программу на C++.
Управляющие операторы: часть I
257
4.13. Водителям небезразличен пробег их автомобилей. Один водитель записал
данные о нескольких заправках своей машины, записывая пройденные мили и
число залитых в бак галлонов бензина. Разработайте программу на C++, которая,
используя оператор while, вводила бы пробег в милях и объем бензина в каждой
заправке. Программа должна вычислять и выводить на экран число миль на
галлон для каждой заправки, а также общее значение миль на галлон по всем
введенным к данному моменту заправкам.
Введите пройденный путь (-1, если ввод закончен): 287
Введите расход бензина: 13
Миль/галлон для этой заправки: 22.076923
Суммарное значение миль/галлон: 22.076923
Введите пройденный путь (-1, если ввод закончен): 200
Введите расход бензина: 10
Миль/галлон для этой заправки: 20.000000
Суммарное значение миль/галлон: 21.173913
Введите пройденный путь (-1, если ввод закончен): 120
Введите расход бензина: 5
Миль/галлон для этой заправки: 24.000000
Суммарное значение миль/галлон: 21.678571
Введите расход бензина (-1, если ввод закончен): -1
4.14. Разработайте программу на C++, которая будет определять, не превысили ли
расходы клиента, имеющего депозитный счет, предела кредита. Для каждого
клиента известны следующие данные:
a) Номер счета (целое).
b) Баланс с начала месяца.
c) Сумма всех расходов данного клиента в течение месяца.
d) Сумма всех приходов на счет данного клиента в течение месяца.
e) Допустимый размер кредита.
Программа должна ввести все эти данные, рассчитать новый баланс (равный
начальному балансу + расход - приход) и определить, не превысил ли новый
баланс предела кредита клиента. Для того клиента, чей кредит превышен,
программа должна вывести на экран номер счета клиента, предел кредита, новый
баланс и сообщение «Предел кредита превышен».
Введите номер счета (-1, если ввод закончен): 100
Введите начальный баланс: 5394.78
Введите сумму расходов: 1000.00
Введите сумму прихода: 500.00
Введите предел кредита: 5500.00
Новый баланс: 5894.78
Счет: 100
Предел кредита: 5500.00
Баланс: 5894.78
Предел кредита превышен
Введите номер счета (-1, если ввод закончен): 200
Введите начальный баланс: 1000.00
Введите сумму расходов: 123.45
Введите сумму прихода: 321.00
Введите предел кредита: 1500.00
Новый баланс: 802.45
9 Зак. 1114
258
Глава 4
Введите номер счета (-1, если ввод закончен): 300
Введите начальный баланс: 500.00
Введите сумму расходов: 274.73
Введите сумму прихода: 100.00
Введите предел кредита: 800.00
Новый баланс: 674.73
Введите номер счета (-1, если ввод закончен): -1
4.15. Одна большая химическая компания выплачивает своим продавцам
комиссионные. Продавец получает $200 в неделю плюс 9% от недельного объема продаж.
Например, продавец, который продал за неделю химикалий на $5000, получит
$200 плюс 9% от $5000, то есть всего $650. Разработайте программу на C++,
которая должна вводить для каждого продавца объем его продаж за последнюю
неделю, рассчитывать и выводить на экран его заработок. Данные вводятся
поочередно для каждого продавца.
Введите объем продаж в долларах (-1, если ввод закончен): 5000.00
Заработок: $650.00
Введите объем продаж в долларах (-1, если ввод закончен): 1234.56
Заработок: $311.11
Введите объем продаж в долларах (-1, если ввод закончен): 1088.89
Заработок: $298.00
Введите объем продаж в долларах (-1, если ввод закончен): -1
4.16. Разработайте программу на C++, которая должна определять заработную плату
для каждого из нескольких служащих. Компания выплачивает каждому
служащему повременную зарплату за первые 40 часов работы и выплачивает в
полуторном размере за сверхурочные свыше 40 часов. Вам дан список сотрудников
компании, число часов, отработанных каждым за последнюю неделю, и
почасовая ставка каждого сотрудника. Программа должна ввести эти данные для
каждого сотрудника, рассчитать и вывести на экран его суммарную зарплату.
Введите число раббчих часов (-1, если ввод закончен): 39
Введите почасовую ставку работника ($00.00): 10.00
Зарплата: $390.00
Введите число рабочих часов (-1, если ввод закончен): 40
Введите почасовую ставку работника ($00.00): 10.00
Зарплата: $400.00
Введите число рабочих часов (-1, если ввод закончен) : 41
Введите почасовую ставку работника ($00.00): 10.00
Зарплата: $415.00
Введите число рабочих часов (-1, если ввод закончен): -1
Управляющие операторы: часть I
259
4.17. Во многих компьютерных приложениях часто используется поиск наибольшего
числа (т.е. максимального из заданной группы чисел). Например, программа,
которая определяет победителя соревнования продавцов, должна вводить
объемы продаж каждого продавца. Тот, у кого объем продаж выше, является
победителем. Напишите псевдокод программы, а затем и саму программу на C++,
которая вводит последовательно 10 чисел, определяет наибольшее из них и печатает
его значение. Ваша программа должна использовать следующие переменные:
counter: счетчик для счета до 10 (для хранения количества введенных
чисел и определения момента, когда введены все 10 чисел).
number: текущее введенное число.
largest: максимальное найденное число.
4.18. Напишите программу на C++, использующую цикл и esc-последовательность
табуляции \t для печати следующей таблицы значений:
N
1
2
3
4
5
10*N
10
20
30
40
50
100*N
100
200
300
400
500
1000*N
1000
2000
3000
4000
5000
4.19. Используя подход упражнения 4.17, найдите два наибольших значения из 10
чисел. [Замечание. Каждое число вы должны вводить только один раз.]
4.20. Программа для результатов экзамена на рис. 4.16-4.18 предполагает, что любое
введенное пользователем значение, не равное 1, равно 2. Модифицируйте
приложение, чтобы подтверждало действительность ввода. При любом вводе, даже
если введено не 1 или 2, продолжайте цикл, пока пользователь не введет
корректное значение.
4.21. Что напечатает следующая программа?
1 // Упракжнение 4.21: ех04_21.срр
2 // Что печатает эта программа?
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main ()
8 {
9 int count = 1; // инициализировать count
10
11 while ( count <= 10 ) // повторить 10 pad
12 {
13 // вывести строку текста
14 cout « ( count % 2 ? "****" : »++++++++" ) « endl;
15 count++; // увеличить count
16 } // конец while
17
18 return 0; // показывает успешное завершение
19 } // конец main
260
Глава 4
4.22. Что напечатает следующая программа?
1 // Упражнение 4.22: ех04_22.срр
2 // Что печатает эта программа?
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int mainQ
8 {
9 int row =10; // инициализировать row
10 int column; // объявить column
11
12 while ( row >= 1 ) // цикл, пока row не станет меньше 1
13 {
14 column =1; // установить в начале итерации column равной 1
15
16 while ( column <= 10 ) // повторить 10 раз
17 {
18 cout « ( row % 2 ? "<" : ">" ); // вывод
19 column++; // увеличить column
20 } // конец внутреннего while
21
22 row--; // уменьшить row
23 cout « endl; // начать новую строку вывода
24 } // конец внешнего while
25
26 return 0; // показывает успешное завершение
27 } // конец main
4.23. (Проблема висящего else) Определите результат каждого из нижеприведенных
фрагментов кода при х = 9иу = 11,их=11иу = 9. Не забудьте, что компилятор
игнорирует отступы в программе на C++. Компилятор C++ всегда ассоциирует
else с предшествующим if, пока с помощью скобок { } не указано иначе.
Поскольку на первый взгляд программист может быть не уверен, какие if
соответствуют каким else, это известно как проблема «висящего else». Чтобы задача
была интереснее, мы удалили из кода отступы. [Подсказка. Примените
соглашения об отступах, которое вы изучили.]
a) if ( х < 10 )
if ( у > 10 )
cout « "*****" < endl;
else
cout « "#####" « endl;
cout « "$$$$$" « endl;
b) if ( x < 10 ) {
if ( у > 10 )
cout « "*****" « endl;
}
else {
cout « "#####" « endl;
cout « "$$$$$" « endl;
}
Управляющие операторы: часть I
261
4.24. (Другая проблема висящего else) Модифицируйте приведенный ниже код, чтобы
получить на экране показанный вывод. Используйте методику отступов. Вы не
должны делать никаких изменений помимо вставки фигурных скобок. Не
забудьте, что компилятор игнорирует отступы в программе на C++. Чтобы задача
была интереснее, мы удалили из кода отступы. [Замечание. Возможно, никакой
модификация не потребуется.]
if (
if (
cout
else
cout
cout
cout
у == 8 )
x == 5 )
« "@(a@@@"
« "#####"
« "$$$$$"
« "&&&&&"
«
«
«
«
endl ;
endl ;
endl ;
endl;
a) При x = 5 и у = 8 должен получиться следующий результат.
$$$$$
&&&&&
b) При х = 5 и у = 8 должен получиться следующий результат.
c) При х = 5 и у = 8 должен получиться следующий результат.
&&&&&
d) При х = 5 и у = 7 должен получиться следующий результат. [Замечание. Три
последних оператора вывода после else являются частью блока.]
#####
$$$$$
&&&&&
4.25. Напишите программу, которая читает размер стороны квадрата и затем печатает
звездочками и пробелами пустой квадрат заданного размера. Ваша программа
должна работать для любых размеров, заданных в интервале 1-20. Например,
если программа прочла размер 5, она должна напечатать:
••**•
* *
• *
••••*
4.26. Палиндром — число или текст, который одинаково читается слева направо
и справа налево. Например, каждое из следующих пятизначных целых чисел
является палиндромом: 12321, 55555, 45554 и 11611. Напишите программу,
которая читает пятизначные целые и определяет, являются ли они палиндромами.
[Подсказка, используйте операции деление и вычисления остатка, чтобы
выделить из числа отдельные разряды.]
262
Глава 4
4.27. Введите целые данные, содержащие только нули и единицы (т.е. «двоичные»
целые), и напечатайте их десятичный эквивалент. [Подсказка. Используйте
операции деления и вычисления остатка, чтобы «отрывать» разряды «двоичного»
числа по одному справа налево. В десятичной системе самая правая цифра имеет
позиционное значение 1, следующая цифра слева имеет позиционное значение 10,
затем 100, затем 1000 и т. д; в двоичной системе чисел самая правая цифра имеет
позиционное значение 1, следующая цифра слева имеет позиционное значение 2,
затем 4, затем 8 и т.д. Таким образом, десятичное число 234 может быть
представлено как 4*1 + 3*10 + 2*100. Десятичным эквивалентом двоичного 1101
является 1*1 + 0*2 + 1*4 + 1*8, или 1+0 + 4 + 8, что равняется 13.]
4.28. Напишите программу, которая выводит на экран звездочки в шахматном порядке:
*****••*
********
********
********
********
********
********
********
Программа должна использовать только три вида операторов вывода:
cout « "*
cout « ' ';
cout « endl;
4.29. Напишите программу, которая постоянно печатает степени целого числа 2,
соответственно 2, 4, 8, 16, 32, 64 и т.д. Число повторений вашего цикла не должно,
быть определено (т.е. вы должны создать бесконечный цикл). Что случилось,
когда вы выполнили эту программу?
4.30. Напишите программу, которая читает радиус (как значение типа double),
рассчитывает и печатает диаметр, длину окружности и площадь круга. Для ?
используйте значение 3.14159.
4.31. Чем ошибочен приведенный ниже оператор? Напишите правильный оператор,
который бы выполнял то, что пытался, вероятно, сделать программист.
cout « ++( х + у );
4.32. Напишите программу, которая читает три ненулевых значения типа double,
определяет и печатает, могут ли они представлять стороны треугольника.
4.33. Напишите программу, которая читает три ненулевых целых числа, определяет
и печатает, могут ли они представлять стороны прямоугольного треугольника.
4.34. Компания хочет передавать данные по телефону, но она обеспокоена
возможностью телефонного перехвата. Все передаваемые данные являются
четырехзначными целыми числами. Компания попросила вас написать программу, которая
должна шифровать эти данные так, чтобы они могли передаваться с большей
безопасностью. Ваша программа должна читать целые четырехзначные числа
и шифровать их следующим образом: заменять каждую цифру значением
(сумма этой цифры плюс 7) по модулю 10. Затем поменять местами первую цифру
с третьей и вторую с четвертой и напечатать полученное зашифрованное целое.
Напишите отдельную программу, которая вводила бы зашифрованные
четырехзначные целые и дешифрировала их, получая исходные числа.
Управляющие операторы: часть I
263
4.35. Факториал неотрицательного целого п записывается как п\ (произносится «эн
факториал») и определяется следующим образом:
л! = л • (л -1) * (л - 2) ... -1 (для значений л, больших 1)
и
л! = 1 (для л = 0 или л = 1).
Например, 5! = 5-4-3*2*1, что равняется 120. Воспользуйтесь оператором
while для решения следующих задач:
a) Напишите программу, которая читает неотрицательное целое, вычисляет его
факториал и печатает результат.
b) Напишите программу, которая приближенно вычисляет значение
математической константы еу используя формулу
111
Попросите пользователя ввести нужную точность (т.е. число суммируемых
членов ряда).
c) Напишите программу, которая вычисляет значение еху используя формулу
2 3
. „ х х х
e=1+Ti + Ii+si+-
Попросите пользователя ввести нужную точность (т.е. число суммируемых
членов ряда).
5
Управляющие операторы:
часть II
ЦЕЛИ
В этой главе вы изучите:
• Важнейшие моменты повторения,
управляемого счетчиком.
• Использование операторов for
и do...while для многократного
исполнения операторов программы.
• Множественный выбор с помощью
оператора switch.
• Использование управляющих
операторов break и continue для
изменения программного потока
управления.
• Применение логических операций
для образования сложных
условных выражений в управляющих операторах.
• Как избежать последствий ошибочного употребления операций равенства
и присваивания.
266
Глава 5
5.1. Введение
5.2. Основы повторения, управляемого счетчиком
5.3. Оператор повторения for
5.4. Примеры операторов for
5.5. Оператор повторения do...while
5.6. Оператор множественного выбора switch
5.7. Операторы break и continue
5.8. Логические операции
5.9. Ошибочная подмена операции равенства (==)
присваиванием (=)
5.10. Структурное программирование: резюме
5.11. Конструирование программного обеспечения.
Идентификация состояний объектов и деятельности
в системе ATM (необязательный раздел)
5.12. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
5.1. Введение
В главе 4 мы начали рассказывать о «строительных блоках», имеющихся
в нашем распоряжении для решения задач. Мы использовали их для
реализации апробированных методики конструирования программ. В этой главе мы
продолжаем рассказ о теории и принципах структурного программирования,
представляя остальные управляющие операторы C++. Изученные здесь и в 4-й
главе управляющие операторы помогут нам строить объекты и
манипулировать ими. Мы продолжаем наше раннее введение в объектно-ориентированное
программирование, начатое обсуждением в основных понятий 1-й главе и
продолженное развернутыми примерами кода и упражнениями в главах 3-4.
В этой главе мы демонстрируем операторы for, do...while и switch. На
нескольких коротких примерах с операторами while и for мы исследуем основы
повторения, управляемого счетчиком. Часть главы посвящается расширению
класса GradeBook, представленного в 3-4 главах. В частности, мы создаем
версию, класса, использующую для подсчета оценок А, В, С, D и F в наборе
буквенных оценок, введенных пользователем. Мы представляем управляющие
операторы break и continue. Мы обсудим логические операции, позволяющие
программистам использовать в управляющих операторах более сложные условные
выражения. Мы также рассматриваем распространенные ошибки неверного
употребления операций равенства (==) и присваивания (=) и то, как можно их
избежать. Наконец, мы даем сводку управляющих операторов C++ и
апробированных методик решения задач, представленных в этой и 4-й главах.
Управляющие операторы: часть II
267
5.2. Основы повторения, управляемого счетчиком
Чтобы формализовать элементы, необходимые для организации
повторения, управляемого счетчиком, мы используем оператор while. Для
управляемого счетчиком повторения требуется
1. Имя управляющей переменной (или счетчика цикла).
2. Начальное значение управляющей переменной.
3. Условие продолжения цикла, проверяющее, не достигла ли
управляющая переменная конечного значения.
4. Приращение (инкремент или декремент), на которое в каждом проходе
цикла изменяется управляющая переменная.
Рассмотрим простую программу, показанную на рис. 5.1, которая печатает
числа от 1 до 10. Объявление в строке 9 именует управляющую переменную
(counter), объявляет ее как целую, резервирует для нее место в памяти и
устанавливает ее начальное значение равным 1. Объявления, в которых
производится инициализация, являются по сути исполняемыми операторами. В C++
объявление, которое резервирует память, более точно следует называть
определением. Поскольку определения являются объявлениями, мы будем
использовать для них термин «объявление», за исключением тех случаев, когда это
различие является существенным.
1 // Рис. 5.1: fig05_01.cpp
2 // Повторение, управляемое счетчиком.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int counter =1; // объявить и инициализировать управляющую
10 // переменную
11 while ( counter <= 10 ) // условие продолжения цикла
12 {
13 cout « counter « " ";
14 counter++; // увеличить управляющую переменную на 1
15 } // end while
16
17 cout « endl; // вывести символ новой строки
18 return 0; // успешное завершение
19 } // конец main
123456789 10
Рис. 5-1. Повторение, управляемое счетчиком
Объявление и инициализацию счетчика можно было бы выполнить с
помощью операторов
int counter; // объявить управляющую переменную
counter = 1; // инициализировать управляющую переменную единицей
268
Глава 5
Для инициализации переменных мы пользуемся обоими методами.
Оператор в строке 14 производит приращение управляющей переменной
на 1 при каждом исполнении тела цикла. Условие продолжения цикла
(строка 11) в операторе while проверяет, что значение управляющей переменной
меньше или равно 10 (конечное значение, при котором условие истинно).
Заметьте, что тело этого while выполняется и тогда, когда управляющая
переменная равна 10. Выполнение цикла заканчивается, когда значение
управляющей переменной превысит 10 (т.е. counter становится равной 11).
Программа рис. 5.11 может быть записана более кратко, если
инициализировать counter нулем и заменить оператор while на
while ( ++counter <= 10 ) // условие продолжения цикла
cout « counter « " ";
Этот код экономит один оператор, поскольку приращение производится
непосредственно в условии оператора while перед проверкой условия.
Исключаются также скобки, охватывающие тело while, поскольку теперь while содержит
всего один оператор. Кодирование в подобной сжатой манере требует
некоторой практики и может приводить к программам, которые труднее читать,
отлаживать, модифицировать и сопровождать.
Типичная ошибка программирования 5.1
Поскольку числа с плавающей точкой являются приближенными,
использование в качестве счетчиков цикла переменных с плавающей
точкой может приводить к неточным значениям счетчика и
неправильным результатам проверки условия окончания.
Предотвращение ошибок 5.1
Используйте в качестве счетчиков цикла целые переменные.
Хороший стиль программирования 5.1
Оставляйте по одной пустой строке до и после каждого управляющего
оператора, чтобы выделить его в коде программы.
Хороший стиль программирования 5.2
Слишком много уровней вложенности может сделать программу
трудной для понимания. В качестве правила — старайтесь избегать
более трех уровней отступов.
Хороший стиль программирования 5.3
Вертикальная разрядка и отступы в теле управляющих операторов
относительно их заголовков придают программам двумерный вид
и значительно облегчают их чтение.
Управляющие операторы: часть II
269
5.3. Оператор повторения for
В предыдущем разделе были представлены основы повторения,
управляемого счетчиком. Для реализации любого повторения со счетчиком достаточно
оператора while. Однако в C++ предусмотрен также оператор повторения for,
специфицирующий все элементы повторения, управляемого счетчиком, в одной
строке кода. Чтобы проиллюстрировать широкие возможности этого оператора,
давайте перепишем программу из рис. 5.1. Результат показан на рис. 5.2.
1 // Рис. 5.2: fig05_02.cpp
2 // Повторение, управляемое счетчиком - оператор for.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 // Заголовок оператора for заключает в себе инициализацию,
10 // условие продолжение цикла и приращение.
11 for ( int counter = 1; counter <= 10; counter++ )
12 cout « counter « " ";
13
14 cout « endl; // вывести новую строку
15 return 0; // успешное завершение
16 } // конец main
123456789 10
Рис. 5.2. Повторение, управляемое счетчиком, с оператором for
Когда оператор for (строки 11-12) начинает выполняться, объявляется
и инициализируется (значением 1) управляющая переменная counter. Затем
проверяется условие продолжения цикла counter <= 10. Поскольку начальное
значение counter равно 1, условие удовлетворяется, и оператор тела
(строка 12) печатает значение counter, а именно 1. Затем выражение counter++
выполняет приращение управляющей переменной counter, и цикл снова
начинается с проверки условия продолжения. Поскольку значение counter теперь
равно 2, конечное значение не превышено, и программа снова исполняет тело
цикла. Этот процесс продолжается, пока тело цикла не будет исполнено 10 раз
и управляющая переменная counter не увеличится до 11, — это приведет
к тому, что проверка условия продолжения (строка 11, между двумя
символами точки с запятой) даст отрицательный результат и повторение будет
прервано. Выполнение программы продолжится с первого оператора,
расположенного после оператора for (в данном случае с оператора вывода в строке 14).
Компоненты заголовка оператора for
Рис. 5.3 в более подробно показывает заголовок оператора for (строка 11) из
рис. 5.2. Заметьте, что заголовок for «делает все сам» — он специфицирует
каждый из элементов, необходимых для повторения с управляющей
переменной-счетчиком. Если в теле for имеется более одного оператора, то тело
необходимо заключить в фигурные скобки.
270
Глава 5
Ключевое Имя Конечное значение
слово for управляющей Обязательный управляющей Обязательный
\ переменной разделитель переменной разделитель
for ( int counter = 1; counter <= 10; counter++)
\ I
it counter = 1;
Начальное значение I Приращение
управляющей Условие управляющей
переменной продолжения цикла переменой
Рис. 5.3. Компоненты заголовка оператора for
Обратите внимание, что условием продолжения цикла на рис. 5.2 является
counter <= 10. Если бы программист ошибочно написал counter < 10, то цикл
выполнялся бы всего 9 раз. Это типичная ошибка смещения на единицу.
Типичная ошибка программирования 5.2
Спецификация неправильной операции отношения или неправильного
конечного значения счетчика цикла в условии операторов while или
for может приводить к ошибкам смещения на единицу.
Хороший стиль программирования 5.4
Избежать ошибок смещения на единицу поможет использование в
условии операторов while или for конечного значения и операции
отношения <=. Например, в цикле для печати чисел от 1 до 10 условие
продолжения следует записать как counter <= 10, а не counter < 10 (что
приведет к ошибке смещения на единицу) или counter < 11 (хотя это
условие корректно). Многие программисты предпочитают т. н.
отсчет от нуля.
Общей формой оператора for является
for ( инициализация; условие_продолжения_цикла; приращение )
оператор
где выражение инициализации задает начальное значение управляющей
переменной цикла, условие_продолжения_цикла проверяет, должен ли цикл
продолжать свое выполнение, а выражение приращения модифицирует
управляющую переменную. В большинстве случаев оператор for можно представить
эквивалентным оператором while:
инициализация;
while ( условие_продолжения_цикла ) {
оператор
приращение ;
}
Управляющие операторы: часть II
271
Существует исключение из этого правила, которое мы обсудим в разделе 5.7.
Если выражение инициализации в заголовке оператора for объявляет
управляющую переменную (т.е. перед именем управляющей переменной
указан ее тип), то переменная может использоваться только в теле оператора
for — управляющая переменная вне оператора for будет неизвестна. Такое
ограничение на использование имени переменной называют областью действия
переменной. Область действия переменной определяет, где в программе она
может использоваться. Область действия подробно обсуждается в главе 6.
Типичная ошибка программирования 5.3
Когда управляющая переменная оператора for определяется его
разделе инициализации, использование этой переменной после выхода из
тела оператора приводит к ошибке компиляции.
Переносимость программ 5.2
В стандарте C++ область действия управляющей переменной,
объявленной в разделе инициализации оператора for, отличается от
области действия в более ранних компиляторах C++. В компиляторах,
существовавших до принятия стандарта, область действия
управляющей переменной не кончалась в конце блока, определяющего тело
оператора for; область действия продолжалась до конца блока,
включающего оператор for. Код C++, созданный для старых компиляторов
C++, может «сломаться» при трансляции компиляторами,
совместимыми со стандартом. Если вы работаете со старыми
компиляторами и хотите быть уверенным, что ваш код будет совместим и с
новыми компиляторами C++, согласующимися со стандартом, у вас есть
два пути. Либо определяйте в каждом операторе for управляющие
переменные с различными именами, либо, если вы предпочитаете
использовать для управляющей переменной в нескольких операторах for
одно и то же имя, объявляйте управляющую переменную перед первым
из этих операторов.
Как мы увидим далее, выражения инициализации и приращения могут
быть списками выражений, разделенных запятыми. В данном случае запятая
используется в качестве операции-запятой, которая гарантирует, что
выражения в списке будут оцениваться в порядке слева направо. Операция-запятая
имеет наинизший приоритет среди всех операций C++. Значение и тип списка
разделенных запятыми выражений совпадают со значением и типом самого
правого выражения в списке. Операция-запятая чаще всего применяется
в операторе for. Она предоставляет программисту возможность указать
несколько выражений для инициализации и/или приращения. Например, в
одном операторе for может быть несколько управляющих переменных, которые
нужно инициализировать и модифицировать.
272
Глава 5
Хороший стиль программирования 5.5
Помещайте в разделы инициализации и приращения переменных
оператора for только выражения, относящиеся к управляющей
переменной. Манипуляции с другими переменными должны размещаться или
до цикла (если они выполняются только один раз, подобно
операторам инициализации), или внутри тела цикла (если они должны
выполняться в каждом цикле, как, например, операторы инкремента
или декремента).
Все три выражения в операторе for являются необязательными. Если
опущено выражение для условия продолжения цикла, C++ предполагает, что
условие всегда истинно и, таким образом, получается бесконечный цикл. Можно
опустить выражение инициализации, если управляющая переменная
инициализируется в программе ранее. Можно опустить и выражение приращения,
если приращение переменной выполняется в теле оператора for или оно
вообще не требуется. Выражение приращения в заголовке for действует так же,
как автономный оператор в конце тела for. Следовательно, выражения
counter = counter + 1
counter += 1
++counter
counter++
в разделе приращения заголовка for эквивалентны (если там нет никакого
другого кода). Многие программисты предпочитают форму counter++,
поскольку приращение осуществляется после исполнения тела цикла. Поэтому
постфиксная форма представляется более естественной. Поскольку
модифицируемая переменная здесь не входит в какое-то выражение, обе формы
инкремента приводят к одному и тому же результату.
Типичная ошибка программирования 5.4
Использование запятых вместо двух обязательных точек с запятой
в заголовке оператора for является синтаксической ошибкой.
Типичная ошибка программирования 5,5
Точки с запятой, поставленная сразу после правой закрывающей
скобки заголовка for, делает тело for пустым оператором. Обычно это —
логическая ошибка.
Общее методическое замечание 5.1
Точка с запятой сразу после заголовка for используется иногда для
создания т. н. «цикла задержки». Такой цикл for с пустым телом
выполняется указанное число раз, не делая ничего, кроме подсчета
итераций. Цикл задержки можно использовать, например, для замедления
работы программы, которая выводит результаты на экран слишком
быстро, чтобы их можно было прочитать. Однако следует соблюдать
осторожность, поскольку такая задержка будет различной на
системах с различной скоростью процессоров.
Управляющие операторы: часть II
273
Разделы инициализации, условия и приращения цикла for могут содержать
арифметические выражения. Например, предположим, что х = 2 и у = 10. Если
х и у в теле цикла не модифицируются, то оператор
for ( int j=x; j<=4*x*y; j += у / x )
эквивалентен оператору
for ( int j = 2; j <= 80; j += 5 )
«Приращение» оператора for может быть отрицательным (в этом случае
имеет место не приращение, а уменьшение, и цикл на самом деле ведет отсчет
в нисходящей последовательности).
Если условие продолжения цикла с самого начала ложно, то операторы
тела for не исполняются и управление сразу передается оператору,
следующему за for.
Часто управляющая переменная печатается или используется в
вычислениях в теле оператора for, но это не обязательно. Вполне обычным является
использование ее исключительно для управления повторением, когда в теле
оператора она вообще не встречается.
j^pgk Предотвращение ошибок 5.2
^^у Хотя управляющая переменная может изменяться в теле оператора
for, избегайте этого, так как такая практика может приводить
к тонким логическим ошибкам.
Диаграмма деятельности UML для оператора for
Диаграмма деятельности UML для оператора for очень похожа на диаграмму
оператора while. На рис. 5.4 показана диаграмма деятельности для оператора
for из рис. 5.2. Диаграмма ясно показывает, что инициализация выполняется
только один раз, перед первой проверкой условия продолжения, и что
приращение производится на каждом проходе цикла, после исполнения оператора тела
цикла. Заметьте, что (помимо начального состояния, стрелок перехода,
слияния, конечного состояния и нескольких примечаний) диаграмма деятельности
содержит только состояния действия и решение. Представьте себе снова
большую коробку пустых диаграмм деятельности UML для операторов for, — их
столько, сколько может потребоваться для того, чтобы путем суперпозиции
и вложения, вместе с диаграммами деятельности других управляющих
операторов, сформировать структурную реализацию алгоритма. Программист
заполняет состояния действия и символы решения соответствующими алгоритму
выражениями действия и контрольными условиями.
274
Глава 5
?
Инициализация
управляющей переменной
int counter = 1
~ X [counter <= 10]
и
ф
4J
С
о
о
и
Вывод
значения counter
cout « counter «
Приращение
управляющей переменной
counter++
Проверка,
должен ли цикл
продолжаться
Рис. 5.4. Диаграмма деятельности UML для оператора for из рис. 5.2
5.4. Примеры операторов for
Следующие примеры показывают способы изменения управляющей
переменной в операторе for. В каждом случае мы пишем соответствующий
заголовок for. Обратите внимание на отличие операций отношения в циклах с
уменьшением управляющей переменной.
a) Изменение управляющей переменной от 1 до 100 с шагом 1.
for ( int i = 1; i <= 100; i++ )
b) Изменение управляющей переменной от 100 до 1 с шагом -1 (с
уменьшением на 1).
for ( int i = 100; i >= 1; i— )
c) Изменение управляющей переменной от 7 до 77 с шагом 7.
for ( int i = 7; i <= 77; i += 7 )
d) Изменение управляющей переменной от 20 до 2 с шагом -2.
for ( int i = 20; i >= 2; i -= 2 )
e) Изменение управляющей переменной в следующей последовательности:
2, 5, 8, 11, 14.
for ( int j = 2; j <= 20; j += 3 )
f) Изменение управляющей переменной в следующей последовательности:
99, 88, 77, 66, 55, 44, 33, 22, 11, 0.
for ( int j = 99; j >= 0; j -= 11 )
Управляющие операторы: часть II
275
Типичная ошибка программирования 5.6
Использование несоответствующей операции отношения в условии
продолжения цикла при счете сверху вниз (например, i <= 1 при счете
сверху до 1) обычно является логической ошибкой, которая приводит
к некорректным результатам при запуске программы.
Приложение: суммирование четных чисел от 2 до 20
Следующие два примера показывают простые приложения оператора for.
Программа на рис. 5.5 использует оператор for для суммирования всех четных
чисел от 2 до 20.
1 // Рис. 5.5: fig05_05.cpp
2 // Суммирование целых чисел в операторе for.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int total = 0; // инициализировать сумму
10
11 // суммировать четные числа от 2 до 20
12 for ( int number = 2; number <= 20; number += 2 )
13 total += number;
14
15 cout « "Sum is " « total « endl; // вывести результаты
16 return 0; // успешное завершение
17 } // конец main
Sum is 110
Рис. 5.5. Суммирование с помощью оператора for
Заметьте, что тело оператора for на рис. 5.20 на самом деле может быть
включено в правую часть заголовка for с помощью операции-запятой:
for ( int number = 2; // инициализация
number <= 20; // условие продолжения
total += number, number +=2 ) // сумма и инкремент
; // пустое тело
т
Хороший стиль программирования 5.6
Хотя операторы, предшествующие for, и операторы тела for часто
можно включить в заголовок for, это может затруднить чтение,
сопровождение, модификацию и отладку программы.
Хороший стиль программирования 5,7
Ограничивайте, если возможно, размер заголовка управляющих
операторов одной строкой.
276
Глава 5
Приложение: калькуляция сложных процентов
Следующий пример вычисляет с помощью оператора for сложные
проценты по вкладу. Рассмотрим следующую постановку задачи:
Некто внес $1000.00 на депозитный счет под 5% годовых. Предполагая, что
весь доход оставляется на депозите, рассчитать и напечатать суммы денег
на счете в конце каждого года в течение 10 лет. Использовать для расчета
следующую формулу:
а= рA + г)п
где
р — первоначальный (основной) вклад
г — годовая процентная ставка
п — число лет
а — сумма на депозите к концу п-го года.
Эта задача подразумевает цикл, в котором будет выполняться указанный
расчет для каждого из десяти лет, в течение которых деньги остаются на
депозите. Решение показано на рис. 5.6.
1 // Рис. 5.6: fig05_06.cpp
2 // Вычисление сложных процентов с помощью for.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::fixed;
7
8 #include <iomanip>
9 using std::setw; // позволяет программе устанавливать ширину поля
10 using std::setprecision;
11
12 #include <cmath> // стандартная матеметическая библиотека C++
13 using std::pow; // позволяет программе использовать функцию pow
14
15 int main()
16 {
17 double amount; // сумма на счете в конце каждого года
18 double principal = 1000.0; // исходная сумма
19 double rate = .05; // процентная ставка
20
21 // вывести заголовки
22 cout « "Year" « setw( 21 ) « "Amount on deposit" « endl;
23
24 // установить формат чисел с плавающей точкой
25 cout « fixed « setprecision( 2 );
26
27 // вычислить сумму на счете для каждого года
28 for ( int year = 1; year <= 10; year++ )
29 {
30 // вычислить новую сумму для указанного года
31 amount = principal * pow( 1.0 + rate, year );
32
33 // вывести год и сумму
Управляющие операторы: часть II
277
34 cout « setw( 4 ) « year « setw( 21 ) « amount « endl;
35 } // конец for
36
37 return 0; // успешное завершение
38 } // конец main
Year
1
2
3
4
5
6
7
8
9
10
Amount on deposit
1050.00
1102.50
1157.63
1215.51
1276.28
1340.10
1407.10
1477.46
1551.33
1628.89
Рис. 5.6. Вычисление сложных процентов с помощью for
Оператор for выполняет операторы своего тела 10 раз, причем
управляющая переменная изменяется от 1 до 10 с шагом 1. Так как в C++ нет операции
возведения в степень, мы воспользовались для этой цели функцией
стандартной библиотеки pow (строка 31). Функция pow(x, у) вычисляет значение х,
возведенное в степень у. В этом примере алгебраическое выражение A + г)п
записывается как powA.0 + rate, year), где переменная rate представляет г,
a year представляет п. Функция принимает два аргумента типа double и
возвращает результат типа double.
Эта программа не будет компилироваться без включения заголовочного
файла <cmath> (строка 12). Функция pow требует двух аргументов типа
double. Заметьте, что year имеет тип int. В файле <cmath> имеется
информация, которая дает указание компилятору преобразовать перед вызовом
функции значение year во временное представление типа double. Эта информация
содержится в прототипе функции pow. В главе 6 будет дана сводка по другим
функциям математической библиотеки.
Типичная ошибка программирования 5.7
Вообще говоря, если при использовании функций стандартной
библиотеки не включить в программу соответствующий заголовочный файл
(например, <cmath>, если вызываются математические функции),
это вызовет ошибку компиляции.
Использование типа double для представления денежных сумм
Обратите внимание, что мы объявили переменные amount, principal и rate
как double. Мы сделали это для простоты, поскольку имеем дело с дробной
частью долларов и нам нужен тип, позволяющий представлять значения с
десятичной точкой. К сожалению, это может привести к неприятностям. Вот
простой пример, поясняющий, что может произойти при использовании для
денежных сумм типов float или double (в предположении, что при печати
специфицируется setprecisionB), т.е. вывод двух цифр дробной части). Две
278
Глава 5
суммы, хранящиеся в памяти, могут иметь значения 14.234 (печатается
как 14.23) и 18.673 (печатается как 18.67). Когда эти значения складываются,
внутренним результатом будет 32.907, что печатается как 32.91. Таким
образом, вывод программы будет иметь вид
14.23
+18.67
32.91
в то время как пользователь, складывающий эти числа в том виде, в котором
они напечатаны, ожидает получить сумму 32.90! Будьте осторожны!
Хороший стиль программирования 5.8
Не используйте для денежных расчетов переменные типов float
и double. Неточность чисел с плавающей точкой может приводить
к ошибкам, которые проявятся в неверных значениях денежных сумм.
В упражнениях мы исследуем использование для денежных расчетов
целых чисел. [Замечание. Некоторые независимые поставщики
продают библиотеки классов C++, которые позволяют производить
точные денежные расчеты. В приложении 3 приведены несколько URL.]
Комбинация операторов вывода в строке 25 перед циклом for и в строке 34
внутри цикла приводит к печати значений переменных year и amount в
формате, заданном параметризованными манипуляторами потока setprecision
и setw и ^параметризованным манипулятором fixed. Вызов setwD)
указывает, что следующее выводимое значение будет напечатано с шириной поля 4,
т.е. под значение будет отведено по крайней мере 4 символьных позиции. Если
длина выводимого значения меньше 4 символов, оно по умолчанию будет
выровнено по правому краю поля. Если же его длина превосходит 4 позиции,
ширина поля будет увеличена, чтобы значение уместилось в нем целиком. Чтобы
задать выравнивание по левому краю, можно применить
^параметризованный манипулятор выходного потока left (находящийся в заголовочном файле
<iostream>). Правое выравнивание можно восстановить манипулятором
right.
Форматирование в этих операторах вывода указывает также, что
переменная amount должна печататься как значение с фиксированной точкой с
обязательным выводом точки (задается в строке 25 манипулятором fixed) с правым
выравниванием в поле размером в 21 позицию (задается в строке 34
манипулятором setwB1)) и с двумя цифрами после десятичной точки (задается в
строке 25 манипулятором setprecisionB)). Мы применяем манипуляторы fixed
и setprecision к выходному потоку (т.е. cout) перед циклом for, поскольку эти
установки остаются в силе до тех пор, пока не будут изменены; подобные
установки иногда называют залипающими. Таким образом, нет необходимости
применять их в каждой итерации цикла. Однако ширина поля,
специфицированная с помощью setw, применяется только к следующему выводимому
значению. Более подробно возможности форматирования ввода-вывода
языка C++ рассматриваются в главе 15.
Заметьте, что вычисление выражения 1.0 + rate, являющегося аргументом
функции pow, производится в теле оператора for. На самом деле вычисление
Управляющие операторы: часть II
279
этого выражения дает в каждом цикле один и тот же результат, так что его
повторные вычисления излишни; это вычисление должно производиться
единственный раз, перед началом цикла.
I—^ Вопросы производительности 5.1
"{^»»| Избегайте размещения внутри цикла выражений, значение которых
не изменяется. Однако если вы все же это сделаете, многие
современные оптимизирующие компиляторы во время генерации машинного
кода автоматически вынесут подобное выражение из цикла.
I—^ Вопросы производительности 5.2
~Г^у*| Многие компиляторы обладают возможностями оптимизации,
улучшающими код, который вы пишете, но лучше все же с самого начала
писать хороший код.
5.5. Оператор повторения do...while
Оператор повторения do...while похож на оператор while. В операторе while
условие продолжения цикла проверяется в начале цикла, перед выполнением
тела оператора. В операторе do...while проверка условия продолжения
производится после того, как тело цикла выполнено; следовательно, тело цикла
будет исполняться по крайней мере один раз. Когда do...while завершается,
выполнение программы продолжается с оператора, следующего за предложением
while. Заметьте, что в операторе do...while нет необходимости использовать
фигурные скобки, если его тело состоит из единственного оператора. Но
фигурные скобки обычно все же ставят, чтобы избежать путаницы между
операторами while и do...while. Например,
while ( условие )
обычно прочитывается как заголовок оператора while. Оператор do...while без
фигурных скобок и с единственным оператором в теле имеет вид
do
оператор
while ( условие ) ;
что может привести к путанице. Последняя строка — while (условие); —
может ошибочно интерпретироваться как заголовок оператора while,
содержащего пустой оператор. Поэтому, чтобы избежать путаницы, оператор
do...while с единственным оператором часто записывают в виде
do {
оператор
} while ( условие ) ;
280
Глава 5
Хороший стиль программирования 5.9
Некоторые программисты всегда включают фигурные скобки в
оператор do...while, даже если в них нет необходимости. Это помогает
устранить двусмысленность предложения while в операторах
do...while с единственным оператором в теле.
Программа на рис. 5.7 использует оператор do...while для печати чисел от 1
до 10. После входа в цикл строка 13 выводит значение counter, а строка 14
выполняет приращение counter. Затем, в конце цикла, программа оценивает
условие продолжения (строка 15). Если условие истинно, цикл продолжается
с первого оператора тела do...while (со строки 13). Если условие ложно, цикл
прекращается и программа продолжается со следующего оператора после
цикла (со строки 17).
1 // Рис. 5.11: fig05_ll.cpp
2 // Оператор повторения do...while.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int counter = 1; // инициализировать счетчик
10
11 do
12 {
13 cout « counter « " "; // вывести счетчик
14 counter++; // увеличить счетчик
15 } while ( counter <= 10 ); // конец do...while
16
17 cout « endl; // вывести новую строку
18 return 0; // успешное завершение
19 } // конец main
123456789 10
Рис. 5.7. Оператор повторения do...while
Диаграмма деятельности UML для оператора do...while
Диаграмма деятельности для оператора do...while показана на рис. 5.8. Она
наглядно демонстрирует, что условие продолжения цикла не оценивается,
пока цикл не выполнит состояния действия с своем теле хотя бы один раз.
Сравните эту диаграмму деятельности с диаграммой цикла while (рис. 4.6).
Снова подчеркнем, что (помимо начального состояния, стрелок перехода,
слияния, конечного состояния и нескольких примечаний) диаграмма
деятельности содержит только состояния действия и решение. Представьте себе снова
большую коробку пустых диаграмм деятельности UML для операторов
do...while; их столько, сколько может потребоваться для того, чтобы путем
суперпозиции и вложения, вместе с диаграммами деятельности других
управляющих операторов, сформировать структурную реализацию алгоритма. Про-
Управляющие операторы: часть II
281
граммист заполняет состояния действия и символы решения
соответствующими алгоритму выражениями действия и контрольными условиями.
cout « counter « " ";
counter++
Определить,
должен ли цикл
продолжаться
Вывести
значение counter
Приращение
управляющей
переменной
[counter > 10]
[counter <= 10]
Рис. 5.8. Диаграмма деятельности UML для оператора do...while
5.6. Оператор множественного выбора switch
В главе 4 мы обсудили оператор с одиночным выбором if и оператор с
двойным выбором if...else. В C++ имеется также оператор множественного выбора
switch, упрощающий выполнение нескольких различных действий в
зависимости от возможных значений переменной или выражения. Каждое действие
ассоциируется со значением некоторого константного целого выражения (т.е.
любой комбинацией символьных и целых констант, оцениваемой как
константное целое значение), которое может принимать переменная или
выражение, проверяемое в операторе switch.
Класс GradeBook с оператором switch для подсчета буквенных
оценок
В следующем примере мы представляем усовершенствованную версию класса
GradeBook, построенного в 3-й и далее развитого в 4-й главе. Новая версия
класса просит пользователя ввести ряд буквенных оценок и затем выводит сводку
числа студентов, получивших каждую из возможных оценок. Для определения
того, является ли введенная оценка оценкой А, В, С, D или F, и приращения
соответствующего счетчика используется оператор switch. Класс GradeBook опре-
282
Глава 5
деляется на рис. 5.9, а определения его элемент-функций показаны на
рис. 5.10. Рис. 5.11 демонстрирует образец ввода и вывода программы main,
использующей класс GradeBook для обработки набора оценок.
1 // Рис. 5.9: GradeBook.h
2 // Определение класса GradeBook, подсчитывающего оценки
3 //А, В, С, D и F. Элемент-функции определяются в GradeBook.срр
4
5 #include <string> // программа использует стандартный класс string
6 using std::string;
7
8 // определение класса GradeBook
9 class GradeBook
10 {
11 public:
12 GradeBook( string ); // конструктор инициализирует название курса
13 void setCourseName ( string ); // функция для установки названия
14 string getCourseName(); // функция для извлечения названия курса
15 void displayMessage(); // вывести приветственное сообщение
16 void inputGrades(); // ввести произвольное число оценок
17 void displayGradeReport(); // вывести отчет по введенным оценкам
18 private:
19 string courseName; // название курса для данного GradeBook
20 int aCount; // число оценок А
21 int bCount; // число оценок В
22 int cCount; // число оценок С
23 int dCount; // число оценок D
24 int fCount; // число оценок F
25 }; // конец класса GradeBook
Рис. 5.9. Определение класса GradeBook
1 // Рис. 5.10: GradeBook.срр
2 // Определения элемент-функций класса GradeBook, который
3 // использует оператор switch для подсчета оценок А, В, С, D и F.
4 #include <iostream>
5 using std::cout;
6 using std::cin;
7 using std::endl;
8
9 #include "GradeBook.h" // включить определение класса GradeBook
10
11 // конструктор инициализирует courseName переданной строкой;
12 // инициализирует элементы данных - счетчики оценок - нулями
13 GradeBook::GradeBook( string name )
14 {
15 setCourseName( name ); // проверить и сохранить courseName
16 aCount =0; // инициализировать нулем счетчик оценок А
17 bCount =0; // инициализировать нулем счетчик оценок В
18 cCount =0; // инициализировать нулем счетчик оценок С
19 dCount =0; // инициализировать нулем счетчик оценок D
20 fCount =0; // инициализировать нулем счетчик оценок F
21 } // конец конструктора GradeBook
22
Управляющие операторы: часть II
283
23 // функция для установки названия; ограничивает его 25 символами
24 void GradeBook::setCourseName( string name )
25 {
26 if ( name.length() <= 25 ) // если в названии не более 25 симв.
27 courseName = name; // сохранить название курса в объекте
28 else // если название длиннее 25 символов
29 { // записать в courseName первые 25 символов параметра name
30 courseName = name.substr( 0, 25 ); // взять первые 25 символов
31 cout « "Name \""« name «"\" exceeds maximum length B5).\n"
32 « "Limiting courseName to first 25 characters. \n" « endl;
33 } // конец if...else
34 } // конец функции setCourseName
35
36 // функция для получения названия курса
37 string GradeBook::getCourseName()
38 {
39 return courseName;
40 } // конец функции getCourseName
41
42 // вывести сообщение-приветствие пользователю GradeBook
43 void GradeBook::displayMessage()
44 {
45 // этот оператор вызывает getCourseName, чтобы получить
46 // название курса, представленного данным GradeBook
47 cout « "Welcome to the grade book for\n"
48 « getCourseName () « "!\n" « endl;
49 } // конец функции displayMessage
50
51 // ввести произвольное число оценок; обновить счетчик оценок
52 void GradeBook::inputGrades()
53 {
54 int grade; // оценка, введенная пользователем
55
56 cout « "Enter the letter grades." « endl
57 « "Enter the EOF character to end input." « endl;
58
59 // цикл, пока пользователь не введет комбинацию для конца файла
60 while ( ( grade = cin.get() ) != EOF )
61 {
62 // определить, какая введена оценка
63 switch ( grade ) // оператор switch, вложенный в while
64 {
65 case 'A': // оценка А в верхнем регистре
66 case 'a': // или а в нижнем регистре
67 aCount++; // увеличить aCount
68 break; // необходим для выхода из switenswitch
69
70 case 'В': // оценка В в верхнем регистре
71 case 'b': // или b в нижнем регистре
72 bCount++; // увеличить bCount
73 break; // выход из switch
74
75 case 'С: // оценка С в верхнем регистре
76 case 'с1: // или с в нижнем регистре
77 cCount++; // увеличить cCount
78 break; // выход из switch
79
284
Глава 5
80 case 'D': // оценка D в верхнем регистре
81 case '6V : // или d в нижнем регистре
82 dCount++; // увеличить dCount
83 break; // выход из switch
84
85 case 'F': // оценка F в верхнем регистре
86 case 'f: // или f в нижнем регистре
87 fCount++; // увеличить fCount
88 break; // выход из switch
89
90 case '\n': // игнорировать вводимые символы новой строки,
91 case ' \f: // табуляции
92 case ' ': // и пробела
93 break; // выход из switch
94
95 default: // перехватывает все остальные символы
96 cout « "Incorrect letter grade entered."
97 « " Enter a new grade." « endl;
98 break; // не обязателен; выход из switch в любом случае
99 } // конец switch
100 } // конец while
101 } // конец функции inputGrades
102
103 // вывести отчет по оценкам, введенным пользователем
104 void GradeBook::displayGradeReport()
105 {
106 // вывести сводку результатов
107 cout « "\n\nNumber of students who received each letter grade:
108 « "\nA
109 « "\nB
110 « "\nC
111 « "\nD
112 « "\nF
113 « endl
114 } // конец функции displayGradeReport
« aCount // вывести число оценок А
« bCount // вывести число оценок В
« cCount // вывести число оценок С
« dCount // вывести число оценок D
« fCount // вывести число оценок F
Рис. 5.10. Класс GradeBook использует оператор switch для подсчета буквенных
оценок А, В, С, D и F
Как и прежние версии определения класса, определение на рис. 5.9
содержит прототипы функций setCourseName (строка 13), getCourseName
(строка 14) и displayMessage (строка 15), а также конструктора класса (строка 12).
Определение класса объявляет также закрытый элемент данных courseName.
Новый класс GradeBook (рис. 5.9) содержит пять дополнительных
закрытых элементов данных (строки 20-24) — счетчики для оценок каждой
категории (т.е. А, В, С, D и F). В классе имеются и новые открытые элемент-функции
inputGrades и displayGradeReport. Функция inputGrades (объявленная
в строке 16) читает в цикле, управляемом контрольным значением,
произвольное число вводимых пользователем буквенных оценок и обновляет для каждой
введенной оценки соответствующий счетчик. Функция displayGradeReport
(объявленная в строке 17) выводит отчет, в котором сообщается число
студентов, получивших каждую буквенную оценку.
Управляющие операторы: часть II
285
Файл исходного кода GradeBook.cpp (рис. 5.10) содержит определения
элемент-функций класса GradeBook. Обратите внимание, что в строках 16-20
конструктор инициализирует пять счетчиков оценок нулями — когда
создается объект GradeBook, еще не введено никаких оценок. Как вы вскоре увидите,
эти счетчики инкрементируются в элемент-функции inputGrades по мере
ввода оценок пользователем. Определения элемент-функций setCourseName,
getCourseName и displayMessage идентичны тем, что имелись в прежних
версиях класса GradeBook. Давайте подробно рассмотрим новые
элемент-функции класса.
Чтение символьного ввода
Пользователь вводит буквенные оценки за курс в элемент-функции
inputGrades (строки 52-101). Внутри заголовка while, в строке 60, сначала
выполняется заключенное в скобки присваивание (grade = cin.get()). Функция
cin.get() читает один символ, введенный с клавиатуры, и сохраняет его в
целой переменной grade (объявленной в строке 54). Обычно символы хранятся
в переменных типа char; однако символы могут храниться в любом целом типе
данных, поскольку они представляются в компьютере как однобайтовые
целые. Таким образом, мы можем трактовать символ или как целое, или как
символ в зависимости от его использования. Например, оператор
cout « "The character (" « 'а' « ") has the value "
« static_cast< int > ( 'a' ) « endl;
напечатает символ а и его целое значение следующим образом:
The character (a) has the value 97
Целое число 97 является численным представлением символа в компьютере.
Многие компьютеры сегодня используют набор символов ASCII (American
Standard Code for Information Interchange), в котором букве 'а' в нижнем
регистре соответствует число 97. Список символов ASCII и их десятичных
значений представлен в приложении Б.
Оператор присваивания, как целое, имеет значение, которое равно
значению, присвоенному переменной слева от знака =. Таким образом, значение
присваивания grade = cin.get() равно значению, возвращенному функцией
cin.get() и присвоенному переменной grade.
Тот факт, что операторы присваивания имеют значение, можно
использовать для присвоения одного и того же значения сразу нескольким
переменным. Например, в операторе
а = Ь = с = 0;
сначала выполняется присваивание с = 0 (так как операция присваивания =
ассоциируется справа налево). Затем переменной b присваивается значение
присваивания с = 0 (которое равно 0). Затем переменной а присваивается
значение присваивания b = (с = О) (которое тоже равно 0). В нашей программе
значение присваивания grade = cin.get() сравнивается со значением EOF
(end-of-file) — символа «конца файла». Мы используем EOF (который обычно
имеет значение -1) в качестве контрольного значения. Однако для ввода
контрольного значения с клавиатуры набирается не число -1 и не буквы «EOF».
286
Глава 5
Вы набираете зависящую от системы комбинацию клавиш, означающую
«конец файла», показывая, что у вас нет больше данных для ввода. EOF —
символическая целая константа, определенная в заголовочном файле <iostream>.
Если значение, присвоенное переменной grade, равно EOF, цикл while
(строки 60-100) завершается. В данной программе мы выбрали для вводимых
символов тип int, так как EOF имеет целое значение.
В системе UNIX и многих других признак конца файла вводится
комбинацией
<ctrl> d
в отдельной строке. Эта нотация означает одновременное нажатие клавиши
ctrl и клавиши d. В других системах, например, Microsoft Windows, признак
конца файла вводится нажатием
<ctrl> г
[Замечание. В некоторых случаях после ввода приведенной выше комбинации
необходимо нажать Enter. Кроме того, иногда не экране появляются
символы "Z, представляющие конец файла, как показано на рис. 5.11.]
Ш Переносимость программ 5.2
Комбинация клавиш для ввода признака конца файла зависит от
системы.
Ш°п Переносимость программ 5.3
J Проверка на равенство символической константе EOF, а не минус
единице делает программу более мобильной. Стандарт ANSI
устанавливает, что EOF имеет целое отрицательное значение (но не
обязательно -1), поэтому EOF на разных системах может иметь
различные значения.
В этой программе пользователь вводит оценки с клавиатуры. Когда он
нажимает клавишу Enter (или Return), символы читаются функцией cin.get() по
одному. Если введенный символ не является признаком конца файла, поток
управления входит в оператор switch (строки 93-99), который в зависимости
от введенной оценки инкрементирует соответствующий счетчик.
Детали оператора switch
Оператор switch состоит из ряда вариантов с метками case и
необязательного варианта с меткой default. В этом примере они используются для
определения того, какой счетчик следует инкрементировать. Когда поток
управления достигает оператора switch (строка 63), программа оценивает следующее
за switch выражение в скобках (т.е. grade). Это так называемое управляющее
выражение. Оператор switch сравнивает значение управляющего выражения
с каждой из меток case. Предположим, пользователь ввел в качестве оценки
букву С. Программа сравнивает С с каждой меткой case в операторе switch.
Если встречается соответствие (case 'С: в строке 75), то исполняются
операторы, следующие за этой меткой. В случае буквы С строка 77 увеличивает
Управляющие операторы: часть И
287
cCount на 1. Оператор break (строка 78) заставляет программу перейти к
первому оператору после оператора switch — в данном случае управление
передается строке 100. Эта строка отмечает конец тела цикла while, который вводит
оценки (строки 60-100), поэтому управление переходит к условию while
(строка 60), которое определяет, должен ли цикл продолжать свое выполнение.
Варианты в нашем операторе switch явным образом проверяют
управляющее выражение на совпадение с оценками А, В, С, D и F и в верхнем, и в
нижнем регистре. Обратите внимание на строки 65-66, проверяющие значения 'А'
и 'а' (оба представляют оценку А). Если метки case записаны таким образом,
друг за другом без каких-либо операторов между ними, то оба варианта
приводят к одним и тем же действиям, — если управляющее выражение
оценивается либо как 'А', либо как 'а', будут исполняться операторы в строках 67-68.
Заметьте, что каждый из вариантов case может содержать несколько
операторов. В отличие от других управляющих операторов, switch не требует
заключать группу операторов для каждого варианта в фигурные скобки.
Без операторов break всякий раз, когда в операторе switch обнаруживается
соответствие, будут исполняться операторы и всех последующих меток case,
пока не встретится оператор break или не будет достигнут конец switch. Часто
говорят, что управление «проваливается» к операторам в последующих case.
(Такое поведение идеально подходит для написания компактной программы,
печатающей итеративную песенку «The Twelve Days of Christmas». [В качестве
аналога на русском языке можно привести стишок «Дом, который построил
Джек». — Прим. ред.])
Типичная ошибка программирования 5.8
Отсутствие оператора break там, где в операторе switch он
необходим, является логической ошибкой.
Типичная ошибка программирования 5.9
Отсутствие пробела между ключевым словом case и целым
значением, которое проверяется, в операторе switch, может привести к
логической ошибке. Например, запись сазеЗ: вместо case 3: просто создаст
неиспользуемую метку. В этом случае, когда управляющее выражение
будет иметь значение 3, оператор switch не произведет
соответствующих действий.
О варианте default
Если в операторе switch не найдется ни одной метки case, совпадающей со
значением управляющего выражения, исполняется вариант default
(строки 95-98). В нашем примере вариант default обрабатывает все значения
управляющего выражения, не являющиеся ни действительными оценками,
ни символами новой строки, табуляции или пробела (мы вскоре обсудим,
каким образом программа обрабатывает эти пробельные символы). Если
совпадение не обнаружено, исполняется вариант default, и строки 96-97 печатают
сообщение об ошибке, указывающее, что была введена некорректная оценка.
В операторе switch, не содержащем варианта default, программное
управление в этом случае просто перешло бы к первому оператору после switch.
288
Глава 5
Хороший стиль программирования 5.10
Во всех операторах switch предусматривайте вариант default.
Случаи, не проверяемые явно в операторе switch без default,
игнорируются. Включение в оператор варианта default фокусирует внимание
программиста на необходимости обрабатывать исключительные
ситуации. Бывают случаи, в которых не требуется никакой обработки по
умолчанию. Хотя предложения case и default могут следовать в
операторе switch в произвольном порядке, обычно предложение default
помещают последним.
Хороший стиль программирования 5.11
Если в операторе switch предложение default является последним,
оператор break в нем не требуется. Но некоторые программисты
включают break и здесь, для ясности и единообразия с другими вариантами.
Игнорирование символов новой строки, табуляций и пробелов
Строки 90-93 в операторе switch на рис. 5.10 позволяют программе
пропускать при вводе символы новой строки, табуляции и пробела. Чтение символов
по одному может создавать определенные проблемы. Чтобы программа
прочитала символы, они должны быть посланы в компьютер нажатием на
клавиатуре клавиши Enter. Тем самым после символа, который мы хотим ввести, во
входной поток помещается символ новой строки. Часто для того, чтобы
программа работала корректно, этот символ должен обрабатываться специальным
образом. Включив в наш оператор switch упомянутые выше строки 90-93, мы
предотвращаем сообщения об ошибках, которые печатал бы вариант default
всякий раз при вводе новой строки, табуляции или пробела.
Типичная ошибка программирования 5.10
Отсутствие обработки новой строки и других пробельных символов
при чтении символов по одному может приводить к логическим
ошибкам.
Тестирование класса GradeBook
Программа на рис. 5.11 создает объект GradeBook (строка 9). Строка 11
вызывает его элемент-функцию display Message, чтобы вывести приветственное
сообщение пользователю. В строке 12 вызывается элемент-функция enter Grades,
которая читает ряд вводимых пользователем оценок и отслеживает число
студентов, получивших каждую из оценок. Обратите внимание на сообщение об
ошибке в окне ввода/вывода на рис. 5.11, которое появляется в ответ на ввод
недействительной оценки (Е). Строка 13 вызывает элемент-функцию displayGra-
deReport (определяемую в строках 104-114 на рис. 5.10), которая печатает
отчет по введенным оценкам.
1 // Рис. 5.11: fig05_ll.cpp
2 // Создать объект GradeBook, ввести оценки и вывести отчет.
3
4 #include "GradeBook.h" // включить определение класса GradeBook
Управляющие операторы: часть II
289
5
6 int main()
7 {
8 // создать объект GradeBook
9 GradeBook myGradeBook( "CS101 C++ Programming" );
10
11 myGradeBook. display Me ss age () ; // вывести приветственное сообщение
12 myGradeBook.inputGrades(); // прочитать вводимые оценки
13 myGradeBook.displayGradeReport(); // вывести отчет по оценкам
14 return 0; // успешное завершение
15 } // конец main
Welcome to the grade book for
CS101 C++ Programming!
Enter the letter grades.
Enter the EOF character to end input.
a
В
с
С
Л
d
f
С
E
Incorrect letter grade entered. Enter a new grade.
D
A
b
AZ
Number of students who received each letter grade:
Рис. 5.11. Создание объекта GradeBook и вызов его элемент-функций
Диаграмма деятельности UML для оператора switch
На рис. 5.12 показана диаграмма деятельности UML для обобщенного
оператора множественного выбора switch. Большинство операторов switch содержат
в своих вариантах case операторы break, завершающие выполнение switch
после обработки варианта. Рис. 5.12 подчеркивает это включением в диаграмму
деятельности операторов break. Без оператора break управление после
обработки варианта не передавалось бы первому оператору после switch. Вместо этого
управление переходило бы к действиям следующего варианта case.
10 Зак 1114
290
Глава 5
case a
case b
Attrue]
действия для case a
[false]
[false]
[true] 4
break
break
case z
, [true]
-> действия для case z
break
[false]
default: действия по умолчанию
Рис. 5.12. Диаграмма деятельности UML для оператора множественного выбора
switch с операторами break
Из диаграммы ясно видно, что оператор break в конце варианта case
приводит к немедленному выходу из оператора switch. Снова подчеркнем, что
(помимо начального состояния, стрелок перехода, слияния, конечного состояния
и нескольких примечаний) диаграмма деятельности содержит только
состояния действия и решение.
Представьте себе снова большую коробку пустых диаграмм деятельности
UML для операторов do...while; их столько, сколько может потребоваться для
того, чтобы путем суперпозиции и вложения, вместе с диаграммами
деятельности других управляющих операторов, сформировать структурную
реализацию алгоритма. Программист заполняет состояния действия и символы
решения соответствующими алгоритму выражениями действия и
контрольными условиями. Заметьте, что хотя вложенные управляющие операторы
встречаются достаточно часто, в программах редко можно найти вложенные
операторы switch.
При использовании оператора switch помните, что он может применяться
только для проверки на равенство константному целочисленному
выражению, т.е. любой комбинации символьных и целых констант, оцениваемой
константным целым значением. Символьная константа представляется в виде
символа, заключенного в одиночные кавычки (апострофы), например, 'А'. Це-
Управляющие операторы: часть II
291
лая константа — это просто целое значение. Кроме того, каждая метка case
может специфицировать только одно константное целочисленное выражение.
Типичная ошибка программирования 5.11
Задание в метке case оператора switch выражения, в которое входят
переменные (например, а + Ъ) является синтаксической ошибкой.
Типичная ошибка программирования 5.12
Спецификация идентичных меток case в операторе switch вызывает
ошибку компиляции. Спецификация меток case с выражениями,
которые оцениваются одним и тем же значением, также приводит к
ошибке компиляции. Например, спецификация case 1 + 4: и case 3 + 2: в
одном операторе switch ошибочно, поскольку обе метки эквивалентны
case 5:.
В главе 13 мы представим более элегантный способ реализации логики
switch. Мы введем концепцию, называемую полиморфизмом, которая
позволяет создавать программы, оказывающиеся часто более ясными, более
сжатыми и более простыми для сопровождения и расширения, чем те, что
используют логику switch.
Замечания о типах данных
C++ имеет гибкие типы данных (см. приложение В по основным типам).
Различным программам, например, могут требоваться целочисленные данные
различного размера. В C++ есть несколько типов данных для представления целых
чисел. Диапазон целочисленных значений для каждого типа зависит от
аппаратной части конкретного компьютера. В дополнение к типам int и char в C++
имеются типы short (сокращение от short int) и long (сокращение от long int).
Минимальным диапазоном значений для целых типа short является диапазон
от -32768 до 32767. Для подавляющего большинства вычислений с целыми
числами достаточно типа long, минимальный диапазон значений которого
простирается от -2147483648 до 2147483647. На большинстве компьютеров int
эквивалентен или short, или long. Диапазон значений типа int по крайней мере
такой же, как у short, и не больше, чем у long. Тип данных char пригоден для
представления любых символов из набора символов компьютера. Тип char
можно также использовать для представления небольших целых чисел.
Переносимость программ 5.4
Поскольку размер типа int варьируется от системы к системе,
используйте тип long, если вы предполагаете обрабатывать числа,
значения которых могут лежать вне диапазона от -32768 до 32767, и
хотите запускать свою программу на нескольких различных
компьютерных системах.
Вопросы производительности 5.3
Когда память следует расходовать экономно, может оказаться
целесообразным использовать целые типы меньших размеров.
292
Глава 5
Вопросы производительности 5,4
Использование целых типов с меньшими размерами может привести
к замедлению программы, если машинные инструкции для
манипулирования ими не так эффективны, как инструкции для естественных
целых типов, т.е. тех, чей размер равен размеру машинного слова
(например, 32 битам на 32-битных машинах и 64 битам на 64-битных).
Всегда проверяйте эффективность предлагаемых «апгрейдов», чтобы
убедиться, что они действительно улучшают производительность.
5.7. Операторы break и continue
Помимо операторов выбора и повторения, для изменения потока
управления в C++ применяются операторы break и continue. В предыдущем разделе
было показано, каким образом можно использовать break для прерывания
исполнения оператора switch. В этом разделе мы покажем, как оператор break
используется в операторах повторения.
Оператор break
Когда оператор break исполняется в операторе while, for, do...while или
switch, происходит немедленный выход из этого оператора. Исполнение
программы продолжается со следующего оператора. Типичным применением
оператора break является досрочное прерывание цикла или пропуск оставшейся
части оператора switch (как на рис. 5.10). Рис. 5.13 демонстрирует исполнение
оператора break (строка 14) в операторе повторения.
1 // Рис. 5.13: fig05_13.cpp
2 // Выход из оператора for с помощью оператора break.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int count; // счетчик, используемый также после выхода из цикла
10
11 for ( count = 1; count <= 10; count++ ) // повторить 10 раз
12 {
13 if ( count ==5 ) // если count равен 5,
14 break; // завершить цикл
15
16 cout « count « "
17 } // конец for
18
19 cout « "\nBroke out of loop at count = " « count « endl;
20 return 0; // успешное завершение
21 } // конец main
12 3 4
Broke out of loop at count = 5
Рис. 5.13. Оператор break, осуществляющий выход из цикла for
Управляющие операторы: часть II
293
Когда оператор if определяет, что значение х равно 5, исполняется оператор
break. Это вызывает прерывание оператора for, и программа переходит к
строке 19 (следующей непосредственно за оператором for), которая выводит
сообщение, показывающее значение управляемой переменной при завершении
цикла. Оператор for выполняется полностью только четыре раза. Обратите
внимание, что управляющая переменная count определяется вне заголовка
оператора for, так что мы можем использовать ее как в теле цикла, так и после
того, как цикл завершит свое выполнение.
Оператор continue
Исполнение оператора continue в операторе while, for или do...while
вызывает пропуск оставшейся части тела оператора и переход к следующей итерации
цикла. В операторах while и do...while сразу после исполнения оператора
continue оценивается условие продолжения цикла. В операторе for сначала
исполняется выражение приращения, и затем оценивается условие продолжения.
В программе на рис. 5.27 оператор continue (строка 12) используется в
операторе for, чтобы пропустить оператор вывода (строка 14) в случае, когда
вложенный оператор if (строки 11-12) определяет, что значение count равно 5.
Когда исполняется оператор continue, программа продолжается с приращения
управляющей переменной в заголовке for (строка 9), и цикл выполняется еще
пять раз.
1 // Рис. 5.14: fig05_14.cpp
2 // Завершение итерации цикла for с помощью оператора continue.
3 #include <iostream>
4 using std::cout;
5 using std:rendl;
6
7 int main()
8 {
9 for ( int count = 1; count <= 10; count++ ) // повторить 10 раз
Ю {
11 if ( count == 5 ) // если count равен 5,
12 continue; // пропустить оставшийся код цикла
13
14 cout « count « " ";
15 } // конец for
16
17 cout « "\nUsed continue to skip printing 5" « endl;
18 return 0; // успешное завершение
19 } // конец main
12346789 10
Used continue to skip printing 5
Рис. 5.14. Использование оператора continue в операторе for
В разделе 5.3 мы утверждали, что оператор for в большинстве случаев
может быть представлен эквивалентным оператором while. Исключением
является случай, когда выражение приращения в операторе while расположено
после оператора continue. Тогда перед проверкой условия продолжения
приращение не производится, и оператор while работает не так, как for.
294
Глава 5
Хороший стиль программирования 5.12
Некоторым программистам кажется, что break и continue
нарушают принципы структурного программирования. Поскольку тех же
результатов можно достичь и с помощью приемов структурного
программирования, которые мы вскоре изучим, то эти программисты не
применяют break и continue. Большинство программистов все же
считают использование операторов break и continue приемлемым.
Вопросы производительности 5.5
При правильном использовании операторы break и continue
выполняются быстрее, чем соответствующий им код, применяющий приемы
структурного программирования.
Общее методическое замечание 5.2
Существует некоторое противоречие между стремлением к
качественному конструированию программ и стремлением к наилучшей
производительности. Часто одна из этих целей достигается за счет
другой. Во всех ситуациях кроме тех, что требуют максимально
возможной производительности, руководствуйтесь следующим основным
правилом: прежде всего пишите простой и корректный код; затем
делайте его быстрым и компактным, но только если это
действительно необходимо.
5.8. Логические операции
До сих пор мы рассматривали только простые условия, такие, как counter
<= 10, total > 1000 и number != sentinel Value. Мы выражали эти условия на
языке операций отношения >, <, >=, <= и операций равенства == и !=.
Каждое решение проверяло ровно одно условие. Если для принятия решения
нужно было проверить несколько условий, мы производили эти проверки в
отдельных операторах или во вложенных операторах if и if...else.
В C++ предусмотрены логические операции, которые используются для
образования более сложных условий путем комбинирования простых.
Логическими операциями являются && (логическое И), 11 (логическое ИЛИ) и !
(логическое НЕ, называемое также логическим отрицанием).
Операция логического И (&&)
Предположим, что прежде чем избрать определенный путь исполнения
программы, мы хотим убедиться в том, что из двух некоторых условий оба
истинны. Для этого мы можем воспользоваться операцией && (логического И):
if ( gender == 1 && age >= 65 )
sen±orFemales++;
Этот оператор if содержит два простых условия. Здесь оценивается условие
gender == 1, чтобы определить, является ли данное лицо женщиной. Условие
age >= 65 оценивается, чтобы определить, является ли лицо пожилым
гражданином. Простое условие слева от оператора && оценивается первым, по-
Управляющие операторы: часть II
295
скольку приоритет == выше, чем приоритет операции &&. Если необходимо,
следующим оценивается простое условие справа от операции &&, потому что
приоритет >= выше, чем приоритет &&. Как мы скоро увидим, правая часть
выражения с логическим И оценивается только тогда, когда его левая часть
равна true. Затем оператор if рассматривает комбинированное условие
gender ==*1 && age >= 65
Это условие равно true в том и только том случае, когда оба простых условия
равны true. Наконец, если эта комбинация условий действительно равна true,
то тело оператора if инкрементирует счетчик пожилых женщин seniorFema-
les. Если любое из двух простых условий равно (или оба равны) false,
программа пропускает оператор инкремента и переходит к оператору, следующему за
if. Данное комбинированное условие можно сделать более ясным, добавив
(избыточные) круглые скобки:
( gender == 1 ) && ( age >= 65 )
Типичная ошибка программирования 5,13
Хотя 3 < х < 7 является математически правильным условием, в C++
оно оценивается не так, как можно было бы предположить. В C++,
чтобы получить правильную оценку, нужно написать C < х && х <7).
Таблица на рис. 5.15 подытоживает свойства операции логического И (&&).
Эта таблица показывает все четыре возможных комбинации значений false
и true для выражения1 и выражения2. Подобные таблицы часто называют
таблицами истинности. Все выражения, содержащие операции отношения,
операции равенства и/или логические операции, оцениваются в C++
значениями false или true.
выражение!
false
false
true
true
выражение2
false
true
false
true
выражение! && выражение2
false
false
false
true
Рис. 5.15. Таблица истинности операции && (логического И)
Операция логического ИЛИ (\ \)
Теперь давайте рассмотрим операцию 11 (логического ИЛИ). Предположим,
в некоторой точке программы мы, прежде чем избрать определенный путь
исполнения, хотим убедиться в том, что из двух некоторых условий хотя бы
одно истинно. Для этого мы можем воспользоваться операцией | |:
if ( semesterAverage >= 90 || finalExam >= 90 )
cout « "Student grade is A" « endl;
Этот оператор также содержит два простых условия. Условие
semesterAverage >= 90 оценивается, чтобы определить, заслужил ли студент оценку «А»
296 Глава 5
благодаря добросовестной работе в течение всего семестра. Условие finalExam
>= 90 оценивается, чтобы определить, заслужил ли студент оценку «А»,
показав выдающийся результат на заключительном экзамене. Затем оператор if
рассматривает комбинированное условие
semesterAverage >= 90 || finalExam >= 90
и присуждает студенту «А», если одно или оба простых условия истинны.
Заметьте, что сообщение «Student grade is А» не печатается только в том случае,
если оба простых условия ложны. На рис. 5.16 приведена таблица истинности
для операции логического ИЛИ (| |).
выражение!
false
false
true
true
выражение2
false
true
false
true
выражение! 11 выражение2
false
true
true
true
Рис. 5.16. Таблица истинности операции 11 (логического ИЛИ)
Операция && имеет более высокий приоритет, чем | |. Обе эти операции
ассоциируются слева направо. Выражение, содержащее операции && и | |,
оценивается лишь до тех пор, пока его истинность или ложность не станет
очевидной. Таким образом, оценка выражения
gender == 1 && age >= 65
будет немедленно остановлена, если значение gender не равно 1 (т.е. условие
в целом заведомо ложно), и продолжится, если значение gender равно 1 (т.е.
условие в целом еще может быть истинным, если истинно условие age >= 65).
Эта особенность процесса оценки выражений с операциями логического И
и логического ИЛИ называется замкнутой, или укороченной оценкой.
Вопросы производительности 5.6
В выражениях, содержащих операцию &&, если отдельные условия
независимы друг от друга, записывайте комбинированное условие так,
чтобы самым левым было то простое условие, которое, вероятнее
всего, окажется ложным. В выражениях, использующих операцию \ \,
записывайте комбинированное условие так, чтобы самым левым было то
простое условие, которое, вероятнее всего, окажется истинным. Та
кое использование свойств замкнутой оценки может сократить
время выполнения программы.
Управляющие операторы: часть II
297
Операция логического отрицания (!)
В C++ предусмотрена также операция / (логического НЕ, или логического
отрицания), позволяющая программисту «перевернуть» смысл условия. В
отличие от операций && и 11, которые комбинируют два условия (и,
следовательно, являются бинарными операциями), операция отрицания имеет в качестве
операнда только одно условие (и, следовательно, является унарной
операцией). Перед условием помещается операция логического отрицания, когда мы
хотим выбрать некоторый путь исполнения в случае, если исходное (без
отрицания) условие ложно, как в следующем фрагменте программы:
if ( !( grade = sentinelValue ) )
cout « "The next grade is " « grade « endl;
Скобки, в которые заключено условие grade == sentinelValue, необходимы,
так как операция логического отрицания имеет более высокий приоритет, чем
операция равенства.
В большинстве случаев программист может избежать применения
логического отрицания, выразив условие с помощью подходящей операции
отношения и равенства. Например, предыдущий оператор может быть записан в виде
if ( grade != sentinelValue )
cout « " The next grade is " « grade « endl;
Такая гибкость часто помогает программисту выразить условие в наиболее
«естественном» или удобном виде. На рис. 5.17 приведена таблица истинности
для операции логического отрицания (!).
выражение
false
true
выражение
true
false
Рис. 5.17. Таблица истинности операции ! (логического отрицания)
Пример с логическими операциями
Программа на рис. 5.18 демонстрирует логические операции, печатая их
таблицы истинности. Вывод показывает каждое из оцениваемых выражений и его
булев результат. По умолчанию булевы значения true и false выводятся
операцией передачи в поток cout соответственно как 1 и О. Однако вызывая в
строке 11 манипулятор потока boolalpha, мы указываем, что значение любого
последующего логического выражения должно выводиться в виде слова «true»
или слова «false». Например, результат выражения false && false в строке 12
равен false, поэтому вторая строчка в окне вывода на рис. 5.18 оканчивается
словом «false». Строки 11-15 выводят таблицу истинности для операции &&,
строки 18-22 — для операции | | и строки 25-27 — для операции I.
298
Глава 5
1 // Рис. 5.18: fig05_18.cpp
2 // Логические операции.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std:iboolalpha; // печать булевых значений
7 //в виде "true" или "false"
8 int main()
9 {
10 // создать таблицу истинности для операции && (логическое И)
11 cout « boolalpha « "Logical AND (&&)"
12 « "\nfalse && false: " « ( false && false )
13 « "\nfalse && true: " « ( false && true )
14 « "\ntrue && false: " « ( true && false )
15 « "\ntrue && true: " « ( true && true ) « "\n\n";
16
17 // создать таблицу истинности для операции || (логическое ИЛИ)
18 cout « "Logical OR (||)"
19 « "\nfalse || false: " « ( false || false )
20 « "\nfalse || true: " « ( false || true )
21 « "\ntrue || false: " « ( true || false )
22 « "\ntrue || true: " « ( true || true ) « "\n\n";
23
24 // создать таблицу истинности для операции ! (логическое НЕ)
25 cout « "Logical NOT (!)"
26 « "\n!false: " « ( !false )
27 « "\n!true: " « ( !true ) « endl;
28 return 0; // успешное завершение
29 } // конец main
Logical AND (&&)
false && false: false
false && true: false
true && false: false
true && true: true
Logical OR (| |)
false || false: false
false || true: true
true || false: true
true || true: true
Logical NOT (!)
!false: true
!true: false
Рис. 5.18. Логические операции
Сводка приоритетов и ассоциативности операций
Таблица на рис. 5.19 показывает приоритет и правила ассоциации
операций C++, рассмотренных к настоящему моменту. Операции представлены
сверху вниз в порядке убывания приоритета.
Управляющие операторы: часть II
299
Операция
0
++ — static_cast<>(TMn)
++ — + -
* / %
++ —
« »
<<=>>=
== ! =
&&
II
?:
= += -= *= /= %=
г
Ассоциативность
слева направо
слева направо
справа налево
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
справа налево
справа налево
слева направо
Тип операций
круглые скобки
унарные (постфиксные)
унарные (префиксные)
мультипликативные
аддитивные
передать в/извлечь из
отношение
проверка на равенство
логическое И
логическое ИЛИ
условная
присваивание
запятая (последование)
Рис. 5.19. Приоритет и ассоциативность операций
5.9. Случайная подмена операции равенства (==)
присваиванием (=)
Есть одна ошибка, которую программирующие на C++, вне зависимости от
их квалификации, делают так часто, что мы решили отвести ей специальный
раздел. Речь идет о случайной подмене операции == (равенства )
операцией = (присваивания), и наоборот. Особую злокачественность этим подменам
придает то обстоятельство, что они, как правило, не приводят к
синтаксическим ошибкам. Операторы с такими ошибками обычно нормально
компилируются, и программа выполняется до конца, часто выдавая неверные результаты
из-за логических ошибок времени выполнения. [Замечание. Некоторые
компиляторы выдают предупреждение, когда операция = появляется в контексте,
обычно подразумевающем операцию ==.]
У языка C++ есть две особенности, которые ухудшают положение дел. Одна
из них состоит в том, что любое выражение, производящее некоторое
значение, может использоваться в части принятия решения любого управляющего
оператора. Если значение выражения равно нулю, оно трактуется как false,
а если не равно нулю — как true. Вторая особенность — то, что в C++
присваивание производит значение, а именно значение, которое присваивается
переменной слева от операции присваивания. Предположим, например, что мы
намерены написать
if ( payCode == 4 )
cout « "You get a bonus!" « endl;
но случайно написали
300
Глава 5
if ( payCode = 4 )
cout « "You get a bonus!" « endl;
Первый оператор if должным образом присуждает премию тому, чей payCode
равен 4. Второй (ошибочный) оператор if оценивает значение операции
присваивания в условии if константой 4. Поскольку любое ненулевое значение
интерпретируется как true, условие в данном операторе if всегда истинно, и
премию будут получать все, вне зависимости от действительного значения
payCode! Более того, переменная payCode будет изменена, хотя предполагается, что
она должна только проверяться!
Типичная ошибка программирования 5.14
Использование операции == для присваивания или операции = для
равенства является логической ошибкой.
Предотвращение ошибок 5.3
Обычно программисты записывают условия, подобные х == 7,
располагая имя переменной слева, а константу — справа. Если
переставить их так, чтобы константа была слева, а имя переменной справа,
т .е. написать 7 == х, то программист, по ошибке заменивший
операцию == операцией =, будет подстрахован компилятором. Компилятор
воспримет такую подмену как синтаксическую ошибку, поскольку
невозможно изменить значение константы. Тем самым будут
предотвращены потенциально разрушительные последствия логической
ошибки времени выполнения.
Говорят, что имена переменных являются lvalue («левыми значениями», от
«left value»), так как они могут использоваться с левой стороны от операции
присваивания. Константы же являются rvalue («правыми значениями», от
«right value»), и могут появляться только справа от операции присваивания.
Заметьте, что lvalue может использоваться в качестве rvalue, но не наоборот.
Возможна и другая, столь же неприятная, ситуация. Предположим,
программист хочет присвоить переменной значение простым оператором вроде
х = 1;
но случайно пишет
х == 1;
Это тоже не является синтаксической ошибкой. Компилятор просто оценивает
условное выражение. Если х равно 1, условие истинно и выражение
оценивается значением true. Если х не равно 1, условие ложно и выражение
оценивается как false. Каким бы ни было значения выражения, операция
присваивания отсутствует, так что это значение просто теряется. Значение х останется
неизменным, что, вероятно, вызовет логическую ошибку времени
выполнения. К сожалению, мы не знаем простого приема, который помог бы вам
справиться с этой проблемой!
Управляющие операторы: часть II
301
^f^ Предотвращение ошибок 5.4
К^^у Воспользуйтесь текстовым редактором для поиска всех вхождений
знака = в коде вашей программы и убедитесь, что везде
употребляется правильная операция — присваивания или равенства.
5.10. Структурное программирование: резюме
Архитекторы проектируют здания, опираясь на коллективную мудрость,
накопленную веками. Так же должны проектировать свои программы и
программисты. Наша область моложе, чем архитектура, и наш коллективный
опыт значительно беднее. Но мы знаем, что структурное программирование
позволяет создавать программы, корректные в математическом смысле и
более простые для понимания, тестирования, отладки и модификации, чем
неструктурированные программы.
Все управляющие операторы C++ представлены семью диаграммами
деятельности на рис. 5.20. Начальные и конечные состояния соответствуют точкам
одного входа/одного выхода каждого оператора. Произвольное соединение
отдельных символов в диаграмме деятельности может приводить к
неструктурированным программам. Поэтому в профессиональном программировании
применяется лишь ограниченный набор управляющих операторов, которые в целях
построения структурированных программ могут объединяться только двумя
простыми способами.
Для простоты используются только управляющие операторы с одним
входом/одним выходом; существует только один способ войти в каждый оператор
и один способ выйти из него. Последовательное соединение управляющих
операторов в структурном программировании очень просто: конечное состояние
одного оператора соединяется непосредственно с начальным состоянием
следующего, т.е. управляющие операторы размещаются в программе один за
другим. Мы уже называли такой способ соединения «суперпозицией
управляющих операторов». Правила построения структурированных программ
допускают также вложение управляющих операторов.
302
Глава 5
Последовательность
т
I
I
I
Выбор
структура if
(единственный выбор)
структура switch
(множественный выбор)
-> break
[fl
структура if. . .else
(ДВОЙНОЙ ВЫбор) [f]
[t]
-> break ->'
[t]
-> break ~>
обработка
структура while
it]
if]
Повторение
структура do. . .while структура for
T
?
[t]
инициализация
[f]
тело
приращение
[f]
Рис. 5.20. Управляющие операторы C++ с одним входом/одним выходом
для последовательности, выбора и повторения
Управляющие операторы: часть II
303
На рис. 5.21 приведены правила построения структурированных программ.
Эти правила предполагают, что состояния действия могут использоваться для
указания любых действий. Предполагается также, что мы начинаем с
простейшей диаграммы деятельности (рис. 5.22), состоящей только из начального
состояния, состояния действия, конечного состояния и стрелок перехода.
Правила построения структурированных программ
1) Начать с простейшей диаграммы деятельности (рис. 5.22).
2) Каждое состояние действия может быть замещено двумя
последовательными состояниями действия.
3) Каждое состояние действия может быть замещено любым
управляющим оператором (последовательности, if, if...else, switch,
while, do...while или for.
4) Правила 2 и З могут применяться любое число раз и в любой
последовательности.
Рис. 5.21. Правила построения структурированных программ
В результате применения правил из рис. 5.21 всегда получается диаграмма
деятельности, имеющая аккуратный, «модульный» вид. Например,
многократное применение правила 2 к простейшей диаграмме приводит к
диаграмме деятельности, содержащей ряд последовательных состояний действия
(рис. 5.23). Правило 2 генерирует «стопку» управляющих операторов; мы
назовем его правилом суперпозиции.
?
состояние действия
Рис. 5.22. Простейшая диаграмма деятельности
304
Глава 5
т
Правило 2
т
Правило 2
т
Правило 2
т
состояние
действия
состояние
действия
состояние
действия
состояние
действия
состояние
действия
\
t
•
V^/
состояние
действия
\1/
состояние
действия
•
V
состояние
действия
Рис. 5.23. Многократное применение правила 2 из рис. 5.21 к простейшей
диаграмме деятельности
Правило 3 называется правилом вложения. Многократное применение
правила 3 к простейшей диаграмме приводит к диаграмме деятельности с
вложенными управляющими операторами. Например, на рис. 5.24 состояние
действия простейшей диаграммы деятельности сначала замещается оператором
двойного выбора (if...else). Затем правило 3 применяется снова к состояниям
действия в операторе двойного выбора, заменяя каждое состояние действия
новым оператором двойного выбора. Пунктирные символы состояния
действия вокруг каждого из операторов двойного выбора представляют состояния
действия, замещенные в предыдущей диаграмме деятельности. [Замечание.
Пунктирные стрелки и пунктирные символы состояния действия на рис. 5.24
не имеют отношения к UML. Они используются здесь лишь для иллюстрации
того, что любое состояние действия может быть замещено управляющим
оператором.]
Управляющие операторы: часть II
305
Правило 2
/
/
состояние
действия
Правило 2 --
db
\/
состояние состояние _4__ Правило 2
действия действия
_>-
V
состояние
действия
состояние
действия
о
состояние
действия
состояние
действия
о
х>
Рис. 5.24. Двукратное применение правила 3 из рис. 5.21 к простейшей диаграмме
деятельности
Правило 4 позволяет генерировать большие, сложные операторы с
произвольной глубиной вложенности. Диаграммы, возникающие в результате
применения правил рис. 5.21, составляют множество всех возможных
структурированных диаграмм деятельности и, следовательно, множество всех возмож-
306
Глава 5
ных структурированных программ. Красота структурного подхода в том, что
мы используем всего семь простых управляющих операторов с одним
входом /одним выходом и соединяем их всего двумя простыми способами.
Если следовать правилам рис. 5.21, нельзя получить диаграмму
деятельности с недопустимым синтаксисом (подобную приведенной на рис. 5.25). Если
вы сомневаетесь, является ли некоторая диаграмма структурированной,
примените правила рис. 5.21 в обратном порядке, чтобы свести ее к простейшей
диаграмме деятельности. Если диаграмма может быть сведена к простейшей
диаграмме, то исходная диаграмма является структурированной; в противном
случае она таковой не является.
состояние
действия
v
состояние
действия
состояние состояние
действия * действия ~
Рис. 5.25. Диаграмма деятельности с некорректным синтаксисом
Структурное программирование поощряет простоту. Бом и Джакопини
показали, что необходимы всего три формы управления:
• последовательность,
• выбор,
• повторение.
Последовательная структура тривиальна. Операторы просто записываются
в том порядке, в котором они должны выполняться.
Выбор реализуется одним из трех способов:
• оператором if (одиночный выбор),
• оператором if...else (двойной выбор),
• оператором switch (множественный выбор).
На самом деле можно доказать, что для реализации любой формы выбора
достаточно простого оператора if, — все, что можно сделать операторами
if...else и switch, может быть реализовано (хотя, возможно, не так ясно и
эффективно) путем комбинации операторов if.
Повторение также реализуется одним из трех способов:
• оператором while,
• оператором do...while,
• оператором for.
«>
Управляющие операторы: часть II
307
Несложно показать, что для реализации любой формы повторения
достаточно оператора while. Все, что можно сделать операторами do...while и for,
может быть сделано (хотя, возможно, и не так аккуратно) оператором while.
Сводя вместе эти результаты, можно продемонстрировать, что любая форма
управления, которая может потребоваться в программе на C++, выразима
посредством
• последовательности,
• оператора if (выбора) и
• оператора while (повторения),
причем эти управляющие операторы могут комбинироваться только двумя
способами — суперпозицией и вложением. Воистину структурное
программирование поощряет простоту.
5.11. Конструирование программного обеспечения.
Идентификация состояний объектов и деятельности
в системе ATM (необязательный раздел)
В разделе 4.13 мы идентифицировали многие из классовых атрибутов,
необходимых для реализации системы ATM, и внесли их в классовую диаграмму
на рис. 4.24. В этом разделе мы покажем, каким образом эти атрибуты
представляют состояние объекта. Мы идентифицируем некоторые из ключевых
состояний, которые могут принимать наши объекты, и обсудим, как объекты
меняют свое состояние в ответ на различные события, происходящие в
системе. Мы обсудим также рабочий поток, или деятельность, производимую
объектами в системе ATM. В этом разделе мы рассмотрим деятельность объектов
транзакций Balancelnquiry и Withdrawal, поскольку они представляют собой
два ключевых вида деятельности в системе ATM.
Диаграммы машинных состояний
Каждый объект в системе проходит через ряд дискретных состояний.
Текущее состояние объекта указывается значениями его атрибутов в данный момент
времени. Диаграммы машинных состояний (называемые обычно просто
диаграммами состояний) моделируют ключевые состояния объекта и показывают,
при каких условиях он меняет свое состояние. В отличие от классовых
диаграмм, о которых говорилось в предыдущих разделах по программному
конструированию и которые были ориентированы главным образом на структуру,
диаграммы состояний моделируют некоторые аспекты поведения системы.
На рис. 5.26 приведена простая диаграмма состояний, моделирующая
некоторые из состояний объекта класса ATM. Каждое состояние на диаграмме
представляется в UML скругленным прямоугольником с именем состояния
внутри. Сплошной кружок с исходящей из него стрелкой обозначает
начальное состояние. Как вы помните, в классовой диаграмме на рис. 4.24 мы
моделировали информацию об этом состоянии булевым атрибутом userAuthentica-
ted. Атрибут инициализируется значением false, или, в соответствии с
диаграммой состояний, состоянием «Пользователь не авторизован».
308
Глава 5
база данных авторизует пользователя
ф > Пользователь не авторизован < * Пользователь авторизован
пользователь выходит из системы
Рис. 5.26. Диаграмма состояний для объекта ATM
Стрелки со штриховыми наконечниками показывают переходы между
состояниями. Объект может переходить из одного состояния в другое в ответ на
различные происходящие в системе события. Рядом со стрелкой,
соответствующей переходу, записывается имя или описание события, вызывающего
данный переход. Например, объект ATM меняет состояние с «Пользователь не
авторизован» на «Пользователь авторизован» после того, как банковская база
данных авторизует пользователя, сравнив введенные пользователем номер
счета и PIN с теми, что хранятся для соответствующего счета в базе данных.
Если база данных подтверждает, что пользователь ввел действительный номер
счета и правильный PIN, объект ATM переходит в состояние «Пользователь
авторизован» и меняет значение своего атрибута user Authenticated на true.
Когда пользователь выходит из системы, выбирая в главном меню опцию
выхода, объект ATM возвращается в состояние «Пользователь не авторизован»,
готовясь обслужить следующего пользователя.
S Общее методическое замечание 5.3
Проектировщики программного обеспечения обычно не создают
диаграмм, которые показывали бы все возможные состояния и переходы
между состояниями для всех атрибутов — их просто слишком много.
На диаграммах состояний, как правило, указываются только
важнейшие или наиболее сложные состояния и переходы между ними.
Диаграммы деятельности
Подобно диаграмме состояний, диаграмма деятельности моделирует
аспекты поведения системы. Но в отличие от первой, диаграмма деятельности
моделирует рабочий поток (последовательность событий) объекта во время
исполнения программы. Диаграмма моделирует, какие действия и в каком порядке
будет производить объект. Как вы помните, мы пользовались UML-диаграмма-
ми деятельности для иллюстрации программного потока в управляющих
операторах, представленных в главах 4 и 5.
Диаграмма деятельности на рис. 5.27 моделирует действия, связанные с
исполнением транзакции Balancelnquiry. Мы предполагаем, что объект
Balancelnquiry уже инициализирован и ему присвоен действительный номер
счета (соответствующий текущему пользователю), так что объект знает, какой
баланс ему нужно извлечь. В диаграмму входят действия, выполняющиеся
после того, как пользователь выберет в главном меню справку о балансе, и до
того, как ATM вернет пользователя в главное меню; объект Balancelnquiry не
производит и не инициирует эти действия, поэтому мы их здесь не
моделируем. Диаграмма начинается с извлечения из базы данных наличного баланса на
Управляющие операторы: часть II
309
счете пользователя. Затем Balancelnquiry извлекает общий баланс счета.
Наконец, транзакция выводит эти данные на экран. Этим действием исполнение
транзакции завершается.
получить из базы данных наличный баланс счета пользователя
I
получить из базы данных общий баланс счета пользователя
вывести балансы на экран
Рис. 5.27. Диаграмма деятельности для транзакции Balancelnquiry
Действие на диаграмме деятельности UML представляется как состояние
действия в виде прямоугольника, боковые стороны которого заменены дугами
выпуклостью наружу. Каждое состояние действия содержит выражение
действия — например, «получить из базы данных наличный баланс счета
пользователя», — формулирующее конкретное действие, которое должно быть
произведено. Стрелка со штриховым наконечником, соединяющая два состояния
действия, указывает порядок, в котором должны выполняться действия,
представленные состояниями действия. Сплошной кружок (сверху на рис. 5.27)
представляет начальное состояние деятельности — начало рабочего потока,
перед тем, как объект будет выполнять моделируемые действия. В данном
случае транзакция выполняет первым выражение действия «получить из базы
данных наличный баланс счета пользователя». Затем транзакция извлекает
общий баланс счета. Наконец, транзакция выводит оба баланса на экран.
Сплошной кружок, заключенный внутри пустого кружка (как на рис. 5.27
снизу ) представляет конечное состояние — конец рабочего потока после того,
как объект выполнит моделируемые действия.
310
Глава 5
?
вывести меню снимаемых сумм с опцией отмены
i
ввести выбор пользователя
[пользователь
отменил транзакцию] вывести сообщение
об отмене
[пользователь выбрал сумму]
установить атрибут суммы
i
получить из базы данных баланс пользователя
[сумма > наличного
баланса] вывести сообщение
об ошибке
[сумма <= наличному балансу]
установить атрибут суммы
наличных недостаточно вывести сообщение
об ошибке
наличных достаточно
взаимодействовать с базой данных
для дебетования суммы со счета пользователя
i
выдать наличные
i
предложить пользователю забрать деньги
[деньги не выданы \/
и пользователь
[деньги выданы или пользователь
не отменил транзакцию] Армения транзакцию]
Рис. 5.28. Диаграмма деятельности для транзакции Withdrawal
Управляющие операторы: часть II
311
На рис. 5.28 показана диаграмма деятельности для транзакции
Withdrawal. Мы предполагаем, что объекту Withdrawal был присвоен
действительный номер счета. Мы не моделируем то, что пользователь выбрал в главном
меню снятие наличных или что ATM возвращает пользователя в главное
меню, поскольку эти действия выполняются не объектом Withdrawal.
Транзакция сначала показывает меню стандартных снимаемых сумм (рис. 2.17)
с опцией для отмены транзакции. Затем транзакция вводит выбор
пользователя. Рабочий поток достигает теперь символа решения. В этой точке следующее
действие выбирается в зависимости от ассоциированных с ней контрольных
условий. Если пользователь отменяет транзакцию, система выводит
соответствующее сообщение. Затем поток отмены достигает символа слияния, где этот
поток соединяется с другими возможными в транзакции потоками
деятельности (которые мы вскоре обсудим). Заметьте, что слияние может иметь сколько
угодно входящих стрелок перехода, но только одну исходящую стрелку.
Решение в нижней части диаграммы определяет, должна ли транзакция
повториться с начала. Если пользователь отменил транзакцию, контрольное условие
«наличные выданы или пользователь отменил транзакцию» истинно, и
управление переходит к конечному состоянию деятельности.
Если пользователь выбрал в меню снимаемую сумму, выбранное
пользователем значение транзакция устанавливает в amount (атрибут класса
Withdrawal, исходно моделировавшийся на рис. 4.24). Затем транзакция получает из
базы данных наличный баланс счета пользователя (т.е. атрибут availableBa-
lance объекта Account пользователя). Поток деятельности приходит теперь
к еще одному решению. Если запрошенная снимаемая сумма превосходит
наличный баланс пользователя, система выводит соответствующее сообщение об
ошибке, информирующее пользователя о возникшей проблеме. Управление
затем сливается с другими потоками деятельности, перед тем как достигнуть
решения в нижней части диаграммы. Контрольное условие «наличные не
выданы и пользователь не отменил транзакцию» истинно, поэтому поток
деятельности возвращается в верхнюю часть диаграммы, и транзакция
предлагает пользователю ввести новую сумму.
Если запрошенная сумма меньше или равна наличному балансу
пользователя, транзакция проверяет, имеется ли в выходном лотке достаточное для
удовлетворения запроса количество наличных. Если нет, транзакция выводит
соответствующее сообщение об ошибке и проходит через слияние перед тем, как
достигнуть конечного решения. Наличные не выданы, так что поток
деятельности возвращается к началу диаграммы, и транзакция предлагает
пользователю выбрать новую сумму. Если наличных достаточно, транзакция
взаимодействует с базой данных, чтобы дебетовать со счета пользователя
запрошенную сумму (т.е. вычесть эту сумму из обоих атрибутов availableBalance
и totalBalance объекта Account пользователя). Транзакция затем выдает
требуемую сумму наличных и просит пользователя забрать выданные деньги.
Главный поток деятельности сливается после этого с двумя потоками ошибки
и потоком отмены. В данном случае наличные выданы, поэтому поток
деятельности достигает конечного состояния.
Мы предприняли первые шаги в моделировании поведения системы ATM
и показали, как атрибуты объекта участвуют в деятельности объекта. В
разделе 6.22 мы исследуем операции наших классов, чтобы создать более полную
модель поведения нашей системы.
312
Глава 5
Контрольные вопросы по конструированию программного
обеспечения
5.1. Укажите, является ли следующее утверждение верным или неверным,
и если оно неверно, объясните, почему:
Диаграммы состояний моделируют структурные аспекты системы.
5.2. Диаграмма деятельности моделирует , выполняемые
объектом, и порядок, в котором он их выполняет.
a) действия
b) атрибуты
c) состояния
d) переходы между состояниями
5.3. Руководствуясь спецификацией требований, создайте диаграмму
деятельности для транзакции внесения средств.
Ответы на контрольные вопросы по конструированию
программного обеспечения
5.1. Неверно. Диаграммы состояний моделируют некоторые аспекты
поведения системы.
5.2. а.
5.3. Диаграмма деятельности для транзакции внесения средств показана
на рис. 5.29. Диаграмма моделирует действия, происходящие после того,
как пользователь выберет в главном меню опцию внесения, и до того, как
ATM вернет пользователя в главное меню. Как вы помните, получение от
пользователя вносимой суммы включает перевод целого числа центов
в долларовую сумму. Вспомните также, кредитование на счет вносимой
суммы подразумевает увеличение только атрибута totalBalance объекта
Account пользователя. Банк обновит атрибут availableBalance объекта
Account, только проверив сумму наличных в депозитном конверте и
после того, как будут очищены содержащиеся там чеки; это происходит
независимо от системы ATM.
Управляющие операторы: часть II
313
?
предложить пользователю ввести сумму депозита или отменить
i
получить ввод пользователя
[пользователь отменил транзакцию]^
вывести сообщение
об отмене
I [пользователь ввел сумму]
установить атрибут суммы
I
попросить передать конверт с депозитом
г
попытаться получить конверт с депозитом
[конверт с депозитом не получен]
[конверт с депозитом получен]
вывести сообщение
об ошибке
взаимодействовать
с базой данных
для кредитования
суммы на счет
пользователя
Рис. 5.29. Диаграмма деятельности для транзакции Deposit
5.12. Заключение
Этой главой мы заканчиваем представление управляющих операторов C++,
позволяющих программисту управлять потоком исполнения в функциях.
В главе 4 мы обсуждали операторы if, if...else и while. В этой главе мы
продемонстрировали остальные управляющие операторы C++ — for, do...while
и switch. Мы показали, что любой алгоритм можно разработать, используя
комбинации последовательной структуры (т.е. операторов, перечисленных
314
Глава 5
в том порядке, в котором они должны выполняться), трех операторов выбора
(if, if...else и switch) и трех операторов повторения (while, do...while и for).
В этой и 4-й главах мы обсуждали, каким образом программисты могут
комбинировать эти строительные блоки, пользуясь апробированными методиками
решения задач и построения программ. В этой главе мы представили также
логические операции, которые позволяют программистам использовать
в управляющих операторах более сложные условные выражения. Наконец,
мы исследовали типичные ошибки случайной подмены операции равенства
присваиванием (и наоборот), и предложили способы, как их можно избежать.
В главе 3 мы представили программирование на C++ с применением
основных концепций объектов, классов и элемент-функций. В главе 4 и этой главе
мы дали подробное введение в типы управляющих операторов, используемых
для спецификации программной логики в функциях. В следующей главе мы
исследуем функции на более глубоком уровне.
Резюме
• В C++ объявление, которое резервирует память, более точно следует называть
определением.
• Оператор повторения for содержит все компоненты, необходимые для повторения,
управляемого счетчиком. Общей формой оператора for является
for ( инициализация; условие_продолжения_цикла; приращение )
оператор
где выражение инициализации задает начальное значение управляющей переменной
цикла, условие _продолжения_цикла проверяет, должен ли цикл продолжать свое
выполнение, а выражение приращения модифицирует управляющую переменную.
• Обычно операторы for используются для повторения, управляемого счетчиком,
а операторы while — для повторения, управляемого контрольным значением.
• Область действия переменной определяет, где в программе она может
использоваться. Например, управляемая переменная, объявленная в заголовке оператора for,
доступна только в пределах тела этого оператора — вне оператора она будет
неизвестна.
• Выражения инициализации и приращения в операторе for могут быть списками
выражений, разделенных запятыми. Запятые в этих выражениях выступают в
качестве операции-запятой, которая гарантирует, что выражения в списке будут
оцениваться в порядке слева направо. Операция-запятая имеет наинизший приоритет
среди всех операций C++. Значение и тип списка разделенных запятыми выражений
совпадают со значением и типом самого правого выражения в списке.
• Разделы инициализации, условия и приращения цикла for могут содержать
арифметические выражения. Кроме того, приращение оператора for может быть
отрицательным; в этом случае оно является по существу декрементом, и цикл ведет отсчет
в нисходящей последовательности.
• Если условие продолжения цикла с самого начала ложно, то операторы тела for не
исполняются и управление сразу передается оператору, следующему за for.
• Функция стандартной библиотеки pow(x, у) вычисляет значение х, возведенное
в степень у. Функция принимает два аргумента типа double и возвращает результат
типа double.
Управляющие операторы: часть II
315
• Параметризованный манипулятор потока setw специфицирует ширину поля, в
котором будет напечатано следующее выводимое значение. По умолчанию значение
выравнивается по правому краю поля. Если размер значения превосходит ширину
поля, последняя будет увеличена, чтобы значение уместилось в поле целиком.
Чтобы задать выравнивание по левому краю, можно применить ^параметризованный
манипулятор потока left (из заголовочного файла <iostream>). Правое
выравнивание можно восстановить манипулятором right.
• Оператор повторения do...while проверяет условие продолжения в конце цикла, так
что тело цикла будет выполнено, по крайней мере, один раз. Общей формой
оператора do...while является
do
оператор
while ( условие ) ;
• Оператор множественного выбора switch производит различные действия в
зависимости от возможных значений переменной или выражения. Каждое действие
ассоциируется со значением некоторого константного целого выражения (т.е. любой
комбинацией символьных и целых констант, оцениваемой как константное целое
значение), которое может принимать переменная или выражение, проверяемое
в операторе switch.
• Оператор switch состоит из ряда вариантов с метками case и необязательного
варианта default.
• Функция cin.get() читает один символ, введенный с клавиатуры. Обычно символы
хранятся в переменных типа char; однако символы могут храниться в любом целом
типе данных, поскольку они представляются в компьютере как однобайтовые целые.
Таким образом, мы можем трактовать символ или как целое, или как символ в
зависимости от его использования.
• Признак конца файла — это зависящая от системы комбинация клавиш,
сообщающая, что для ввода больше нет данных. EOF — символическая целая константа,
определенная в заголовочном файле <iostream>, указывающая на состояние «конца
файла».
• Следующее за switch выражение в скобках называется управляющим выражением
оператора switch. Оператор switch сравнивает значение управляющего выражения
с каждой из меток case.
• Если метки case записаны друг за другом без каких-либо операторов между ними, то
эти метки будут выполнять одну и ту же группу операторов.
• Каждый из вариантов case может содержать несколько операторов. В отличие от
других управляющих операторов, switch не требует заключать группу операторов
каждого варианта в фигурные скобки.
• Оператор switch может применяться только для проверки на равенство
константному целочисленному выражению. Символьная константа представляется в виде
символа, заключенного в одиночные кавычки (апострофы), например, 'А*. Целая
константа — это просто целое значение. Каждая метка case может специфицировать
только одно константное целочисленное выражение.
• В C++ есть несколько типов данных для представления целых чисел — int, char,
short и long. Диапазон целочисленных значений для каждого типа зависит от
аппаратной части конкретного компьютера.
• Когда оператор break исполняется в каком-либо из операторов повторения (while,
for и do...while), происходит немедленный выход из этого оператора.
316
Глава 5
• Исполнение оператора continue в операторе while, for или do...while вызывает
пропуск оставшейся части тела оператора и переход к следующей итерации цикла.
В операторах while и do...while сразу после исполнения оператора continue
оценивается условие продолжения цикла. В операторе for исполнение продолжается с
оценки выражения приращения.
• В C++ предусмотрены логические операции, которые используются для образования
более сложных условий путем комбинирования простых. Логическими операциями
являются && (логическое И), | | (логическое ИЛИ) и ! (логическое НЕ, называемое
также логическим отрицанием).
• Прежде чем избрать определенный путь исполнения, операция && (логического И)
проверяет, что из двух некоторых условий оба истинны.
• Прежде чем избрать определенный путь исполнения, операция 11 (логического ИЛИ)
проверяет, что из двух некоторых условий хотя бы одно истинно.
• Выражение, содержащее операции && и | |, оценивается лишь до тех пор, пока его
истинность или ложность не станет очевидной. Эта особенность процесса оценки
выражений с операциями логического И и логического ИЛИ называется замкнутой,
или укороченной оценкой.
• Операция/ (логического НЕ, или логического отрицания) позволяет программисту
«перевернуть» смысл условия. Унарная операция логического отрицания
помещается перед условием, чтобы выбрать некоторый путь исполнения в случае, если
исходное (без отрицания) условие ложно. В большинстве случаев программист может
избежать применения логического отрицания, выразив условие с помощью
подходящей операции отношения и равенства.
• При использовании в условии любое ненулевое выражение неявно преобразуется
в true; 0 (нуль) неявно преобразуется в false.
• По умолчанию булевы значения true и false выводятся в cout соответственно как 1
и О. Манипулятор потока boolalpha специфицирует, что значение любого
логического выражения должно выводиться в виде слова «true» или слова «false».
• Любая форма управления, которая может потребоваться в программе на C++,
выразима через последовательность, выбор и повторение, причем эти управляющие
операторы могут комбинироваться только двумя способами — суперпозицией и
вложением.
Терминология
!, операция логического НЕ
&&, операция логического И
||, операция логического ИЛИ
lvalue («левое значение»)
rvalue («правое значение»)
вариант default в switch
выравнивание по левому краю
выравнивание по правому краю
декремент управляющей переменной
заголовок for
залипающая установка
замкнутая (укороченная) оценка
имя управляющей переменной
инкремент управляющей переменной
конечное значение управляющей
переменной
константное целочисленное выражение
логическая операция
логическое И (&&)
логическое ИЛИ (| |)
логическое НЕ (!)
логическое отрицание (!)
манипулятор потока boolalpha
манипулятор потока left
манипулятор потока right
метка case
набор символов ASCII
начальное значение управляющей
переменной
область действия переменной
оператор break
оператор continue
оператор множественного выбора switch
оператор повторения for
Управляющие операторы: часть II
317
операция-запятая
определение
основной тип char
ошибка смещения на единицу
правило вложения
простое условие
счет от нуля
таблица истинности
управляющее выражение оператора
switch
условие продолжения цикла
функция стандартной библиотеки pow
цикл задержки
ширина поля
Контрольные вопросы
5.1. Определите, верно или неверно каждое из следующих утверждений. Если
утверждение неверно, объясните, почему.
a) В операторе выбора switch должна быть метка default.
b) В операторе выбора switch в разделе default требуется оператор break.
c) Выражение (х > у && а < Ь) истинно, если х > у или а < Ь.
d) Выражение, содержащее операцию | |, истинно, если истинны оба операнда
этой операции.
5.2. Напишите оператор C++ или несколько операторов, которые выполняли бы
каждое из следующих действий:
a) Суммирование нечетных целых чисел от 1 до 99 с помощью оператора for.
Предполагайте, что объявлены целые переменные sum и count.
b) Печать значения 333.546372 в поле шириной 15 символов с точностью 1, 2 и 3
разряда после десятичной точки. Печать всех чисел в одной строке с левым
выравниванием каждого числа в своем поле. Какие три значения будут напечатаны?
c) Вычисление 2.5 в степени 3 с использованием функции pow. Печать
результата с точностью 2 разряда после десятичной точки в поле шириной 10
символов. Что будет напечатано?
d) Печать целых чисел с 1 по 20 с использованием цикла while и счетчика х.
Предполагайте, что переменная х объявлена, но ее начальное значение не
задано. Печатайте по 5 чисел в строке. [Подсказка. Используйте х % 5. Если
результат равен О, выводите символ новой строки, в противном случае выведите
символ табуляции.}
e) Повторите упражнение 5.2 (d), используя оператор for.
5.3. Найдите ошибку в каждом из следующих программных фрагментов и
объясните, как ее исправить.
a) х = 1 ;
while ( х <= 10 );
х++;
)
b) for ( у = .1
cout «
c) switch (n)
у != 1.0; у += .1 )
/ « endl;
{
case 1:
cout «
case 2:
cout «
break/
default:
cout «
break;
"Число равно
"Число равно
1" « endl;
2" « endl;
"Число не равно ни 1, ни 2" « endl;
318
Глава 5
d) Следующие операторы должны печатать значения от 1 до 10.
п = 1;
while ( n < 10 )
cout « n++ « endl;
Ответы на контрольные вопросы
5.1. а) Неверно. Метка default необязательна. Если нет необходимости производить
какие-то действия по умолчанию, то метка default не нужна.
b) Неверно. Оператор break используется для выхода из оператора switch. Если
метка default последняя среди меток, то оператор break не требуется.
c) Неверно. При использовании операции && оба выражения отношения
должны быть истинными, чтобы было истинным все выражение в целом.
d) Верно.
5.2. a) sum = 0;
for ( count = 1; count <= 99; count += 2 )
sum += count;
b) cout « setiosflags(ios::fixed | ios::showpoint | ios::left)
« setprecision( 1 ) « setw( 15 ) « 333.546372
« setprecision( 2 ) « setw( 15 ) « 333.546372
« setprecision( 3 ) « setw( 15 ) « 333.546372
« endl;
Выводится:
333.5 333.55 333.546
c) cout « fixed « setprecision( 2 )
« setw( 10 ) « pow( 2.5, 3 )
« endl;
Выводится:
15.63
d) x = 1 ;
while ( x <= 20 )
cout « x;
{
if ( x % 5 = 0 )
cout « endl;
else
cout « ' \f ;
x++;
>
e) for ( x = 1; x <= 20; x++ )
{
cout « x;
if ( x % 5 = 0 )
cout « endl;
else
cout « '\f ;
)
или
for ( x = 1; x <= 20; x++ )
{
if ( x % 5 == 0 )
cout « x « endl;
else
cout « x « ' \t' ;
}
Управляющие операторы: часть И
319
5.3. а) Ошибка: точка с запятой после заголовка while приводит к бесконечному циклу.
Исправление: заменить точку с запятой скобкой { или удалить ; и }.
b) Ошибка: использование числа с плавающей запятой для управления
оператором повторения for.
Исправление: использовать целое и осуществить соответствующие
вычисления, чтобы получить желаемые значения:
for ( у = 1; у != 10; у++ )
cout « ( static_cast< double >( у ) / 10 ) « endl;
c) Ошибка: отсутствие оператора break после операторов для первой метки case.
Отметим, что это не обязательно является ошибкой, если программист хочет,
чтобы операторы после case 2: выполнялись каждый раз, когда выполняются
операторы после case 1:.
d) Ошибка: в условии продолжения повторения оператора while использована
неправильная операция отношения.
Исправление: использовать <= вместо < или изменить 10 на 11.
Упражнения
5.4. Найдите ошибки в следующих фрагментах (Замечание: ошибок может быть
более одной):
a) For ( х = 100, х >= 1, х++ )
cout « x « endl;
b) Следующий фрагмент должен печатать, является ли цеоле значение value
нечетным или четным:
switch ( value % 2 ) {
case 0:
cout « "Even integer" « endl;
case 1:
cout « "Odd integer" « endl;
>
c) Следующий код должен выводить нечетные числа от 19 до 1:
for ( х = 19; х >= 1; х += 2 )
cout « х « endl;
d) Следующий код должен выводить четные числа от 2 до 100:
counter = 2;
do {
cout « counter « endl;
counter += 2;
} While ( counter < 100 );
5.5. Напишите программу, которая суммирует последовательность целых чисел.
Считайте, что первое прочитанное целое число указывает количество целых
чисел, которые будут введены далее. Ваша программа должна читать в операторе
ввода только по одному значению. Типичная входная последовательность может
иметь вид
5 100 200 300 400 500
где 5 показывает, что будет введено последовательно 5 чисел, которые надо
суммировать.
320
Глава 5
5-6- Напишите программу, которая подсчитывает и печатает среднее значение
нескольких целых чисел. Считайте, что последняя вводимая величина является
контрольным значением 9999. Типичная входная последовательность может
иметь вид
10 8 11 7 9 9999
Должно быть посчитано среднее значение чисел, предшествующих 9999.
5.7. Что делает следующая программа?
1 // Упражнение 5.7: ех05_07.срр
2 // Что печатает эта программа?
3 #include <iostream>
4
5 using std:rcout;
6 using std::cin;
7 using std::endl;
8
9 int main()
10 {
11 int x; // объявить х
12 int у; // объявить у
13
14 // запросить ввод пользователя
15 cout « "Enter two integers in the range 1-20: ";
16 cin » x » у; // прочитать значения для х и у
17
18 for ( int i = 1; i <= y; i++ ) // считать от 1 до у
19 {
20 for ( int j = 1; j <= x; j++ ) // считать от 1 до х
21 cout « ' @'; // вывести @
22
23 cout « endl; // начать новую строку
24 } // конец внешнего for
25
26 return 0; // успешное завершение
27 } // конец main
5.8. Напишите программу, которая находит наименьшее из нескольких целых.
Полагайте, что первое прочитанное число задает количество последующих
вводимых чисел.
5.9. Напишите программу, которая считает и печатает произведение нечетных целых
от 1 до 15.
5.10. В задачах теории вероятностей часто используется функция факториала.
Воспользовавшись определением факториала из упражнения 4.35, напишите
программу вычисления факториалов целых чисел от 1 до 5. Напечатайте результаты
в табличном формате. Что могло бы помешать вам вычислить факториал 20?
5.11. Модифицируйте программу расчета сложных процентов из раздела 5.4,
повторив вычисления для ставок 5%, 6%, 7%, 8%, 9% и 10%. Для варьирования
ставки используйте цикл for.
5.12. Напишите программу, которая печатает по отдельности, один под другим,
показанные ниже треугольники. Используйте для генерации трафаретов цикл for.
Все звездочки (*) должны-печататься единственным оператором вида cout « '*';
(в результате звездочки будут печататься рядами). [Подсказка. Два последних
треугольника требуют, чтобы каждая строка начиналась с соответствующего
числа пробелов. Факультативная задача. Объедините код для решения
четырех отдельных задач в единую программу, которая печатала бы все четыре
треугольника рядом с помощью вложенных циклов for.]
Управляющие операторы: часть II
321
(а) (Ь) (с) (d)
• •**•*•*••• •••••*•••• *
*• ••••••••• ••••••••• *•
••• ******** ******** ***
•••• *•••••* ******* •***
***** ****** ****** *****
****** ***** ***** ******
••**••• ***• *•** ••••*•*
******** *** *** ********
********* ** ** *********
•••***•*•• * * **********
5.13. Одно из интересных приложений компьютеров — рисование диаграмм и
гистограмм. Напишите программу, которая читает пять чисел (каждое между 1 и 30).
Для каждого просчитанного числа ваша программа должна напечатать строку,
содержащую соответствующее число смежных звездочек. Например, если ваша
программа прочла число 7, она должна напечатать *******.
5.14. Торговый дом продает пять различных продуктов, розничная цена которых:
продукт 1 — $2.98, продукт 2 — $4.50, продукт 3 — $9.98, продукт 4 — $4.49
и продукт 5 — $6.87. Напишите программу, которая читает последовательность
пар чисел, означающих:
а) номер продукта;
б) количество, проданное за день.
Ваша программа должна использовать оператор switch, который помогает
определить розничную цену каждого продукта. Программа должна рассчитать и вывести
на экран общую розничную стоимость всех проданных за неделю продуктов.
5.15. Модифицируйте программу с классом GradeBook на рис. 5.9-5.11 так, чтобы она
рассчитывала среднюю оценку для класса. Считайте, что вес оценки 'А' — 4
пункта, оценки 'В' — 3 пункта и т.д.
5.16. Модифицируйте программу из рис. 5.6 так, чтобы для расчета сложных
процентов она использовала только целые чтсла. [Подсказка. Выразите все денежные
суммы как целое число центов. Затем «разбейте» результат на две
составляющие — доллары и центы, используя операции деления и вычисления остатка.
Вставьте точку между долларами и центами.]
5.17. Положим, что i = l,j = 2, к = 3ит = 2. Что напечатает каждый из приведенных
операторов? Необходимы ли скобки в каждом случае?
a) cout « ( i == 1 ) « endl ;
b) cout « ( j == 3 ) « endl ;
c) cout « ( i >= 1 && j < 4 ) « endl;
d) cout « ( m <= 99 && k < m ) « endl;
e) cout « ( j >= i | | k == m ) « endl ;
f) cout « (k + m<j || 3-j>=k)« endl ;
g) cout « ( !m ) « endl;
h) cout « ( ! ( j - m ) ) « endl ;
i) cout « ( ! ( r > m ) ) « endl;
5.18. Напишите программу, которая печатает таблицу двоичных, восьмеричных и шест-
надцатеричных эквивалентов десятичных чисел в диапазоне от 1 до 256. Если вы
плохо знакомы с этими системами счисления, прочтите сначала Приложение С.
5.19. Рассчитайте значение л как сумму бесконечного ряда
4 4 4 4 4
Я=4-3+5-7+9"П+-
Напечатайте таблицу, которая покажет, как значение я аппроксимируется
одним членом этого ряда, двумя членами, тремя и т.д. Сколько членов ряда
потребовалось для получения значения 3.14? 3.141? 3.1415? 3.14159?
11 Зак. 1114
322
Глава 5
5.20. (Пифагоровы тройки) Прямоугольный треугольник может иметь все стороны,
выраженные целыми числами. Множество троек целых значений сторон
прямоугольного треугольника называется тройками Пифагора. Эти три стороны
должны удовлетворять соотношению, по которому сумма квадратов двух сторон
(катетов) равна квадрату третьей стороны (гипотенузы). Найдите все тройки
Пифагора, в которых и катеты, и гипотенуза не больше 500. Используйте трижды
вложенные циклы for, которые перебирают все возможности. Это пример
вычисления «в лоб», сводящегося к перебору. Вы узнаете в более продвинутых курсах
компьютерных вычислений, что есть много интересных проблем, для которых
неизвестно других алгоритмов, кроме решения «в лоб».
5.21. Компания платит своим сотрудникам или как менеджерам (которые получают
фиксированный недельный оклад), или как почасовым работникам (которые
получают фиксированную почасовую оплату за первые 40 рабочих часов и
полуторную почасовую ставку за переработку сверх 40 часов), или как работникам на
комиссионных началах (которые получают $250 плюс 5.7% от суммы недельных
продаж), или как сдельщикам (которые получают фиксированную сумму с
каждой выработанной ими единицы продукции — каждый сдельщик в этой компании
выпускает только один вид продукции). Напишите программу расчета
еженедельной оплаты каждого сотрудника. Вы не знаете заранее числа сотрудников.
Каждый тип сотрудника имеет свой код оплаты: менеджеры имеют код 1, почасовые
работники — код 2, работающие на комиссионных началах имеют код 3,
сдельщики — код 4. Используйте switch, основанный на этих кодах оплаты, для расчета
выплат каждому сотруднику. В операторе switch предлагайте пользователю
(клерку, составляющему расчетную ведомость) ввести соответствующие данные,
необходимые для расчета выплаты сотруднику в соответствии с его кодом оплаты.
5.22. (Законы де Моргана) В этой главе мы обсуждали логические операции &&, 11 и !.
Законы де Моргана помогают иногда выразить с их помощью логические
выражения в более удобной форме. Эти законы гласят, что выражение \(условие1 &&
условие2) логически эквивалентно выражению (\условие1 \ \ \условие2).
Аналогично выражение \(условие1 \ \ условие2) эквивалентно выражению (\условие1
&& \условие2). Используйте законы де Моргана для записи выражений,
эквивалентных каждому из приведенных ниже, а затем напишите программу, которая
показала бы в каждом случае эквивалентность исходного и нового выражений:
a) ! ( х < 5 ) && ! ( у >= 7 )
b) ! ( а == Ь ) || ! ( g != 5 )
c) ! ( ( х <= 8 ) && ( у > 4 ) )
d) ! ( ( i > 4 ) | | ( j <=6 ) )
5.23. Напишите программу, которая напечатает показанный ниже ромб. Вы можете
использовать операторы вывода, которые печатают или одну звездочку (*), или
один пробел. Максимально используйте повторение (с вложенными операторами
for) и минимизируйте число операторов вывода.
*
• •*
*••**
*******
*********
*******
*****
***
•
Управляющие операторы: часть II
323
5.24. Модифицируйте программу, которую вы написали в упражнении 5.23, чтобы она
читала нечетное число в пределах от 1 до 19, определяющее число строк в ромбе.
Ваша программа должна выводить на экран ромб соответствующего размера.
5.25. В адрес операторов break и continue раздается критика по поводу того, что они
нарушают структурность. На самом деле эти операторы всегда могут быть
заменены структурированными операторами, хотя это может выглядеть некрасиво.
Опишите, как в общем случае вы могли бы удалить из цикла оператор break,
заменив его некоторым структурным эквивалентом. [Подсказка. Оператор break
осуществляет прерывание цикла в некотором месте внутри его тела. Другим
путем выхода из цикла является нарушение условия продолжения цикла.
Рассмотрите использование в условии продолжения цикла дополнительной проверки,
указывающей на «досрочный выход из цикла «по прерыванию»».] Используя
разработанный вами прием, удалите оператор break из программы на рис. 5.13.
5.26. Что делает следующий фрагмент программы?
for ( i = 1; i <= 5; i++ ) {
for ( j = 1; j <= 3; j++ ) {
for ( k = 1; k <= 4; k++ )
cout « '*';
cout « endl;
} // конец внутреннего for
cout « endl;
} // конец внешнего for
5.27. Опишите, как в общем случае вы могли бы удалить из цикла оператор continue,
заменив его некоторым структурным эквивалентом. Используя этот прием,
удалите оператор continue из программы на рис. 5.14.
5.28. (Песенка «The Twelve Days of Christmas») Напишите программу, использующую
повторение и оператора switch для печати текста песенки «The Twelve Da s of
Christ as»). Один оператор switch должен печатать день («First», «Second»
и т.д.). Отдельный от него оператор switch должен печатать остальной текст
каждого куплета. Посетите Web-сайт www.12days.com library carols 12daysofxmas,
где можно найти полный текст песенки.
5.29. (Проблема Питера Минъюта) Существует легенда, что в 1626 году Питер Минь-
ют купил Манхеттен за 24 доллара 00 центов. Было ли это удачным
капиталовложением? Чтобы ответить на этот вопрос, модифицируйте программу для сложных
процентов из рис. 5.6, чтобы она начинала с основного капитала $24.00 и
вычисляла сумму на депозите со сложными процентами в предположении, что деньги
пролежали на депозите вплоть до настоящего времени (к примеру, 379 лет вплоть
до 2005 года). Поместите цикл for, который производит вычисление сложных
процентов, во внешний цикл for, варьирующий процентную ставку от 5% до 10%,
и посмотрите на чудеса, происходящие со сложными процентами.
6
Функции и введение
в рекурсию
ЦЕЛИ
В этой главе вы изучите:
• Принципы модульного построения
программ из функций.
• Применение математических
функций общего назначения,
имеющихся в Стандартной
библиотеке C++.
• Создание функций с несколькими
параметрами.
• Механизмы передачи информации
между функциями и возврата
результатов.
• Каким образом стек вызовов
функций и активационные записи
реализуют механизм вызова/возврата.
• Как применять генерацию случайных чисел для реализации игровых
приложений.
• Ограничение видимости идентификаторов определенными областями
программы.
• Написание и использование рекурсивных функций, т.е. функций,
которые вызывают самих себя.
326
Глава 6
6.1. Введение
6.2. Компоненты программ на C++
6.3. Функции математической библиотеки
6.4. Определения функций с несколькими параметрами
6.5. Прототипы функций и принудительное приведение
аргументов
6.6. Заголовочные файлы Стандартной библиотеки C++
6.7. Пример: генерация случайных чисел
6.8. Пример: азартная игра с использованием
перечисления (enum)
6.9. Классы памяти
6.10. Правила для области действия
6.11. Стек вызова функций и активационные записи
6.12. Функции с пустым списком параметров
6.13. Встроенные функции
6.14. Ссылки и параметры-ссылки
6.15. Аргументы по умолчанию
6.16. Унарная операция разрешения области действия
6.17. Перегрузка функций
6.18. Шаблоны функций
6.19. Рекурсия
6.20. Пример рекурсии: числа Фибоначчи
6.21. Рекурсия в сравнении с итерацией
6.22. Конструирование программного обеспечения.
Идентификация операций классов в системе ATM
(необязательный раздел)
6.23. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
6.1. Введение
Большинство компьютерных программ, решающих реальные практические
задачи, намного превышают по размеру те, что были представлены в первых
главах книги. Опыт показывает, что наилучшим способом разработки и
сопровождения больших программ является построение их из маленьких простых
Функции и введение в рекурсию
327
фрагментов, или компонентов. Такую методику называют «разделяй и
властвуй». В 3-й главе мы ввели понятие функции (как составной части
программы). Теперь мы будем изучать функции на более глубоком уровне. Мы
стараемся подчеркнуть, каким образом объявление и использование функций
облегчает проектирование, реализацию и сопровождение больших программ.
Мы познакомимся с рядом математических функций стандартной
библиотеки C++, некоторым из которых требуется более одного параметра. Затем мы
покажем, как объявляются такие функции. Мы такэке более подробно
расскажем о прототипах функций и о том, как компилятор использует их, если это
необходимо, для преобразования типа аргумента в вызове функции в тип,
указанный в ее списке параметров.
После этого мы предпримем краткий экскурс в методики моделирования
с применением случайных чисел и разработаем версию игры в кости,
известной в казино под названием «крепе», в которой воспользуемся многими из тех
программных приемов, что вы узнали к настоящему моменту.
Затем мы расскажем о классах памяти C++ и о правилах области действия.
В совокупности они определяют период времени, в течение которого объект
существует в памяти, и то, где в программе можно обращаться к его
идентификатору. Мы также узнаем, каким образом C++ может следить за тем, какие
функции в данный момент выполняются, какие параметры и прочие
локальные переменные находятся в памяти и откуда функция знает, в какое место
следует возвратить управление после своего завершения. Мы обсудим два
вопроса, связанных с возможностью улучшения производительности
программ, — встроенные функции и параметры-ссылки, которые могут
применяться для эффективной передачи функциям больших блоков данных.
Многие из программ, которые вы будете разрабатывать, могут иметь по
нескольку функций с одним и тем же именем. Такая методика, называемая
перегрузкой функций, используется в программировании для реализации функций,
выполняющих сходные задачи для аргументов различных типов и, возможно,
различного их числа. Мы рассмотрим шаблоны функций — механизм для
определения семейства перегруженных функций. Заключается глава обсуждением
функций, которые вызывают самих себя либо непосредственно, либо косвенно
(через другие функции), — это называется рекурсией, которой уделяется много
внимания в углубленных курсах по компьютерным дисциплинам.
6.2. Компоненты программ на C++
Обычно программы на C++ пишутся путем объединения новых функций
и классов, которые пишет сам программист, с «готовыми» функциями и
классами, имеющимися в стандартной библиотеке C++. В этой главе мы
сосредоточим свое внимание на функциях.
Стандартная библиотека C++ предлагает широкий набор функций для
выполнения математических вычислений, операций со строками и символами,
ввода-вывода, обработки ошибок и многих других полезных операций. Это
облегчает работу программистов, поскольку эти функции реализуют многое из
того, что им обычно требуется. Функции стандартной библиотеки C++
являются одной из частей, составляющих среду программирования C++.
328
Глава 6
Общее методическое замечание 6.1
Для ознакомления с функциями и классами стандартной библиотеки
C++ почитайте документацию по вашему компилятору.
Функции (в других языках программирования их могут называть
методами или процедурами) позволяют программисту сделать программу
«модульной», разделив ее задачи на замкнутые в себе единицы. В любой программе,
которую вы написали, вы писали функции. Эти функции называют иногда
функциями, определенными пользователем или определенными
программистом. Операторы в теле функций пишутся лишь однажды, а используются,
возможно, во многих частях программы и скрыты от других функций.
В пользу разбиения программы на модули-функции можно привести
несколько соображений. Одно из них вытекает из подхода «разделяй и
властвуй», который делает разработку программы более контролируемой благодаря
построению ее из небольших, простых фрагментов. Другое связано со
стремлением к утилизации программного обеспечения — использованию
существующих функций в качестве строительных блоков вновь создаваемых программ.
Например, в рассмотренных ранее программах нам не нужно было
определять, как прочитать с клавиатуры строку текста, — в C++ такая возможность
обеспечивается функцией getline из заголовочного файла <string>. Третье
соображение — функции позволяют избежать повторений одного и того же кода.
Наконец, разбиение программы на осмысленные функции облегчают отладку
и сопровождение программы.
Общее методическое замечание 6.2
Из соображений будущей утилизации написанного кода каждая
функция должна ограничиваться выполнением единственной, четко
определенной задачи, причем последняя должна быть отражена в имени
функции. Такие функции облегчают написание, тестирование,
отладку и сопровождение программ.
Предотвращение ошибок 6.1
Небольшая функция, выполняющая единственную задачу, проще для
тестирования и отладки, чем большая функция, выполняющая много
задач.
Общее методическое замечание 6.3
Если вы затрудняетесь в выборе краткого имени, выражающего
назначение функции, это может означать, что ваша функция
пытается выполнить слишком много различных задач. Обычно такую
функцию лучше разбить не несколько меньших функций.
Как вы знаете, функция активируется путем вызова, а когда функция
завершает свою задачу, она либо возвращает результат, либо просто возвращает
управление вызывающему. В качестве аналогии такой программной
структуры можно взять иерархическую форму управления предприятием (рис. 6.1).
Начальник (соответствующий вызывающей функции) просит работника (вы-
Функции и введение в рекурсию
329
зываемую функцию) выполнить задание и доложить (т.е. возвратить
результат) о его выполнении. Функция-начальник не знает, каким образом
функция-работник выполнит порученное задание. Работник может вызвать другие
рабочие функции, о которых начальник даже не знает. Такое сокрытие
деталей реализации способствует правильной разработке программного
обеспечения. На рис. 6.1 показана функция-начальник (boss), иерархически
сообщающаяся с несколькими рабочими функциями (workera). Обратите внимание,
что по отношению к worker4 и worker5 функция workerl представляется в
качестве «функции-начальника».
boss
workerl worker2 worker3
/ \
worker4 worker5
Рис. 6.1- Иерархические отношения функций начальника/работника
6.3. Функции математической библиотеки
Как вы знаете, в классе могут быть предусмотрены элемент-функции,
реализующие услуги класса. Например, в главах 3-5 вы вызывали элемент-функции
объектов GradeBook разлхгчных версий, чтобы вывести приветственное
сообщение, установить название курса, получить набор оценок и вычислить их среднее.
Иногда функции не являются элементами класса. Такие функции
называются глобальными. Как и в случае элемент-функций класса, прототипы
глобальных функций размещаются в заголовочных файлах, так что они могут
утилизироваться любыми программами, включающими соответствующий
заголовочный файл и имеющими доступ к объектному коду функции.
Вспомните, например, что когда на рис. 5.6 мы возводили значение в степень, мы
воспользовались функцией pow из заголовочного файла <cmath>. Мы
представляем здесь различные функции из <cmath>, чтобы ввести понятие
глобальных функций, не принадлежащих какому-либо определенному классу.
В этой и последующих главах мы при реализации программных примеров
используем комбинацию глобальных функций (таких, как main) и классов с
элемент-функциями.
Заголовочный файл <cmath> прелагает собрание функций, позволяющих
производить элементарные математические вычисления. Например, вы
можете вычислить квадратный корень из 900.0 вызовом
sqrt( 900.0 )
Это выражение оценивается значением 30.0. Функция принимает аргумент
типа double и возвращает результат типа double. Обратите внимание, что пе-
330
Глава 6
ред вызовом sqrt нет необходимости создавать какие-либо объекты. Вообще,
все функции в заголовочном файле <cmath> являются глобальными и, таким
образом, любая из них вызывается просто путем указания имени функции, за
которым следуют заключенные в круглые скобки аргументы.
Аргументами функции могут быть константы, переменные или более
сложные выражения. Если с = 13.0, d = 3.0 и f = 4.0, то оператор
cout < sqrt( с + d * f ) < endl;
вычислит и напечатает квадратный корень из 13.0 + 3.0 * 4.0 = 25.0, а
именно 5.0. Некоторые функции математической библиотеки приведены на рис. 6.2.
Переменные х и у имеют тип double.
Функция
ceil( х )
cos( х )
ехр( х )
fabs( x )
floor( х )
fmod( x, у )
log( x )
logl0( x )
pow( x, у )
sin( x )
sqrt( x )
tan( x )
Описание
округление х до наименьшего целого,
не меньшего х
тригонометрический косинус х
(х в радианах)
экспоненциальная функция ех
абсолютное значение х
округление х до наибольшего целого,
не превосходящего х
остаток от х/у, как число с плавающей
точкой
натуральный логарифм х
(по основанию е)
десятичный логарифм х
(по основанию 10)
х в степени у
тригонометрический синус х
(х в радианах)
корень квадратный из
(где х — неотрицательное значение
тригонометрический тангенс х
(х в радианах)
Пример
ceil( 9.2 )= 10.0
ceil( -9.8 ) = -9.0
cos( 0.0 ) = 1.0
ехр( 1.0 ) = 2.718282
ехр( 2.0 ) = 7.389056
fabs( 5.1 )= 5.1
fabs( 0.0 )= 0.0
fabs( -8.76 ) = 8.76
floor( 9.2 )= 9.0
floor( -9.8 ) = -10.0
fmod( 2.6, 1.2 ) = 0.2
log( 2.718282 ) = 1.0
log( 7.389056 ) = 2.0
logl0( 10.0 ) = 1.0
logl0( 100.0 ) = 2.0
pow( 2, 7 ) = 128.0
pow( 9, 0.5 ) = 3.0
sin( 0.0 ) =0.0
sqrt( 9.0 )= 3.0
tan( 0.0 ) = 0.0
Рис. З.2. Функции математической библиотеки
Функции и введение в рекурсию
331
6.4. Определения функций с несколькими
параметрами
В главах 3-5 были представлены классы с простыми функциями, которые
имели не более одного параметра. Часто функциям для выполнения своей
задачи требуется более одной единицы информации. Рассмотрим теперь
функции с несколькими параметрами.
Программа на рис. 6.3-6.5 модифицирует наш класс, включая в него
определяемую пользователем функцию с именем maximum, которая находит и
возвращает наибольшее из трех целых значений. Когда приложение начинает
выполняться, функция main (строки 5-14 на рис. 6.5) создает один объект класса
GradeBook (строка 8) и вызывает его элемент-функцию inputGrades
(строка 11), чтобы предложить пользователю ввести три числа и прочитать их. Это
делают строки 54-55 в файле реализации класса GradeBook (рис. 6.4).
Строка 58 вызывает элемент-функцию maximum (определяемую в строках 62-75).
Функция maximum определяет наибольшее из значений, после чего оператор
return (строка 74) возвращает это значение в точку, где функция inputGrades
активировала maximum (строку 58). Затем элемент-функция inputGrades
сохраняет возвращаемое maximum значение в элементе данных maximumGrade.
Это значение выводится функцией displayGradeReport (строка 12 на рис. 6.5).
[Замечание. Мы назвали эту функцию displayGradeReport, так как
последующие версии класса GradeBook будут использовать ее для вывода полного
отчета по оценкам, включая минимальную и максимальную оценку.] В главе 7
(«Массивы и векторы») мы усовершенствуем класс GradeBook, чтобы он мог
обрабатывать произвольное число оценок.
1 // Рис. 6.3: GradeBook.h
2 // Класс GradeBook, находящий наибольшую из трех оценок.
3 // Элемент-функции определяются в GradeBook.срр
4 #include <string> // программа использует стандартный класс string
5 using std::string;
6
7 // определение класса GradeBook
8 class GradeBook
9 {
10 public:
11 GradeBook( string ); // конструктор инициализирует название курса
12 void setCourseNaxne( string ); // функция для установки названия
13 string getCourseName() ; // функция для извлечения названия курса
14 void displayMessage(); // вывести приветственное сообщение
15 void inputGrades(); // получить от пользователя три оценки
16 void displayGradeReport(); // вывести отчет по введенным оценкам
17 int maximum ( int, int, int ) ; // определить максимум из 3 целых
18 private:
19 string courseName; // название курса для данного GradeBook
20 int maximumGrade; // максимум из 3 значений
21 }; // конец класса GradeBook
Рис. 6.3. Заголовочный файл GradeBook
332
1 // Рис. 6.4: GradeBook.срр
2 // Определения элемент-функций класса GradeBook, который
3 // определяет максимум из трех значений.
4 #include <iostream>
5 using std::cout;
6 using std::cin;
7 using std::endl;
8
9 #include "GradeBook.h" // включить определение класса GradeBook
10
11 // конструктор инициализирует courseName переданной строкой;
12 // инициализирует нулем maximumGrade
13 GradeBook::GradeBook( string name )
14 {
15 setCourseName( name ); // проверить и сохранить courseName
16 maximumGrade = 0; // будет замещаться максимальной оценкой
17 } // конец конструктора GradeBook
18
19 // функция для установки названия курса - не более 25 символов
20 void GradeBook::setCourseName( string name )
21 {
22 if ( name.length() <= 25 ) // если не более 25 символов
23 courseName = name; // сохранить название курса в объекте
24 else // если название длиннее 25 символов
25 { // записать в courseName первые 25 символов параметра name
26 courseName = name.substr( 0, 25 ); // выделить первые 25 симв.
27 cout « "Name \""« name « "\" exceeds maximum length B5) . \n
28 « "Limiting courseName to first 25 characters.\n" « endl;
29 } // конец if...else
30 } // конец функции setCourseName
31
32 // функция для извлечения названия курса
33 string GradeBook::getСourseName()
34 {
35 return courseName;
36 } // конец функции getCourseName
37
38 // вывести сообщение-приветствие пользователю GradeBook
39 void GradeBook:rdisplayMessage()
40 {
41 // этот оператор вызывает getCourseName, чтобы получить
42 // название курса, представленного данным GradeBook
43 cout « "Welcome to the grade book for\n" « getCourseName()
44 « "!\n" « endl;
45 } // конец функции displayMessage
46
47 // получить от пользователя три оценки; определить максимум
48 void GradeBook::inputGrades()
49 {
50 int gradel; // первая оценка, введенная пользователем
51 int grade2; // вторая оценка, введенная пользователем
52 int grade3; // третья оценка, введенная пользователем
53
54 cout « "Enter three integer grades: ";
55 cin » gradel » grade2 » grade3;
56
57 // сохранить максимум в элементе studentMaximum
Функции и введение в рекурсию
333
58 maximumGrade = maximum( gradel, grade2, grade3 );
59 } // конец функции inputGrades
60
61 // возвращает наибольший из трех своих параметров
62 int GradeBook::maximum( int x, int y, int z )
63 {
64 int maximumValue = x; // предположить, что х - наибольший
65
66 // определить, не является ли у большим maximumValue
67 if ( у > maximumValue )
68 maximumValue = у; // сделать у новым maximumValue
69
70 // определить, не является ли z большим maximumValue
71 if ( z > maximumValue )
72 maximumValue = z; // сделать z новым maximumValue
73
74 return maximumValue;
75 } //' конец функции maximum
76
77 // вывести отчет по оценкам, введенным пользователем
78 void GradeBook::displayGradeReport()
79 {
80 // вывести максимум введенных оценок
81 cout « "Maximum of grades entered: " « maximumGrade « endl;
82 } // конец функции displayGradeReport
Рис. 6.4. Класс GradeBook определяет функцию maximum
1 // Рис. 6.5: fig06_05.cpp
2 // Создать объект GradeBook, ввести оценки и вывести отчет.
3 #include "GradeBook.h" // включить определение GradeBook
4
5 int main()
6 {
7 // создать объект GradeBook
8 GradeBook myGradeBook( "CS101 C++ Programming" );
9
10 myGradeBook.displayMessage(); // вывести приветствие
11 myGradeBook.inputGrades(); // прочитать вводимые оценки
12 myGradeBook.displayGradeReport(); // вывести отчет по оценкам
13 return 0; // успешное завершение
14 } // конец main
Welcome to the grade book for
CS101 C++ Programming!
Enter three integer grades: 86 67 75
Maximum of grades entered: 86
Welcome to the grade book for
CS101 C++ Programming!
Enter three integer grades: 67 86 75
Maximum of grades entered: 86
334
Глава 6
Welcome to the grade book for
CS101 C++ Programming!
Enter three integer grades: 67 75 86
Maximum of grades entered: 86
Рис. 6.5. Демонстрация функции maximum
Общее методическое замечание 6.4
Запятые в строке 58 на рис. 6.4, которые отделяют друг от друга
аргументы функции maximum, не являются операциями-запятыми,
обсуждавшимися в разделе 5.3. Операция-запятая гарантирует, что ее
операнды будут оцениваться слева направо. Однако порядок оценки
аргументов функции стандартом C++ не специфицируется. Таким образом,
различные компиляторы могут оценивать аргументы функции в
различном порядке. Стандарт C++ гарантирует лишь, что все аргументы
в вызове функции оцениваются до исполнения вызванной функции.
Переносимость программ 6.1
Иногда, когда аргументы функции являются более сложными
выражениями, например, производят вызов других функций, порядок, в
котором компилятор оценивает аргументы, может влиять на значения
одного или нескольких из них. Если порядок оценки от компилятора
к компилятору меняется, могут меняться и передаваемые функции
значения, приводя к тонким логическим ошибкам.
Предотвращение ошибок 6.2
Если у вас есть сомнения относительно порядка оценки аргументов
функции и того, повлияет этот порядок на передаваемые функции
значения, оцените аргументы перед вызовом функции в отдельных
операторах присваивания, присвойте результат каждого выражения
локальной переменной и затем передайте функции эти переменные
в качестве аргументов.
Прототип элемент-функции maximum (строка 17 на рис. 6.3) указывает,
что функция возвращает целое значение, ее именем является maximum и что
для выполнения своей задачи ей требуются три целых параметра. Заголовок
функции maximum (строка 12 на рис. 6.4) согласуется с ее прототипом и
указывает, что именами параметров являются х, у и z. Когда maximum
вызывается (в строке 58 на рис. 6.4), параметр х инициализируется значением
аргумента gradel, параметр у инициализируется значением аргумента grade2 и
параметр z — значением аргумента grade3. Каждому параметру (называемого
также формальным параметром) в определении функции должен
соответствовать один аргумент в вызове функции.
Обратите внимание, что несколько параметров и в прототипе, и в
определении функции специфицируются в виде разделенного запятыми списка.
Компилятор сверяется с прототипом функции, чтобы проверить, содержат ли вызовы
Функции и введение в рекурсию
335
maximum правильное число аргументов нужных типов и перечислены ли типы
аргументов в правильном порядке. Кроме того, прототип функции необходим
компилятору для того, чтобы убедиться, что возвращаемое функцией значение
корректно используется в вызвавшем функцию выражении (например, вызов
функции, возвращающий void, не может"входить в правую часть оператора
присваивания). Каждый аргумент должен быть совместим с типом
соответствующего параметра. Например, параметр типа double может принимать значения
7.35, 22 или -0.03456, но не строку вроде "hello". Если передаваемые функции
аргументы не совпадают по типу с параметрами, специфицированными в
прототипе функции, компилятор пытается преобразовать аргументы к
соответствующему типу. Это преобразование обсуждается в разделе 6.5.
Типичная ошибка программирования 6.1
Объявление параметров функции, относящихся к одному типу, в виде
double х, у вместо double, double у является синтаксической
ошибкой; для каждого параметра в списке параметров требуется явная
спецификация типа.
Типичная ошибка программирования 6.2
Если прототип функции, ее определение и ее вызовы не согласуются
все между собой по числу, типу и порядку аргументов и параметров,
происходят ошибки компиляции.
Общее методическое замечание 6.5
Функция, имеющая много параметров, выполняет, возможно,
слишком много задач. Рассмотрите возможность разбиения ее на более
мелкие функции, выполняющие
Чтобы определить максимальное значение (строки 62-75 на рис. 6.4), мы
начинаем с предположение, что наибольшее значение содержится в
параметре х, поэтому строка 64 функции maximum объявляет локальную переменную
maximum Value и инициализирует ее значением параметра х. Конечно, вполне
возможно, что действительное наибольшее значение содержится в параметре
или z, поэтому мы должны сравнить maximum Value с каждым из них.
Оператор if в строках 67-68 определяет, не превосходит ли у значения maximum
Value и, если это так, присваивает maximum Value значение у. Оператор if
в строках 71-72 определяет, не превосходит ли z значения maximum Value и,
если это так, присваивает maximum Value значение z. В этой точке в
maximum Value оказывается наибольшее из трех значений, и строка 74 возвращает
результат вызову в строке 58. Когда программное управление возвращается
в точку, где была вызвана maximum, ее параметры х, у и z более не доступны
для программы. Почему, мы увидим в следующем разделе.
Есть три способа возврата управления в точку, где была активирована
функция. Если функция не возвращает результата (т.е. она имеет
возвращаемый тип void), управление возвращается, когда программа достигает
оканчивающей функцию фигурной скобки или при исполнении оператора
return;
336
Глава 6
Если функция возвращает результат, оператор
return выражение;
оценивает выражение и возвращает его значение вызывающему.
6.5. Прототипы функций и принудительное
приведение аргументов
Прототип функции (называемый также объявлением функции) сообщает
компилятору имя функции, тип возвращаемых функцией данных, ожидаемое
число параметров, типы параметров и порядок, в котором функция ожидает
их получить.
Общее методическое замечание 6.6
В C++ прототипы функций являются обязательными. Чтобы
получить прототипы стандартных библиотечных функций, используйте
директивы препроцессора #include для включения заголовочных
файлов соответствующих библиотек (напр., прототип для
математической функции sqrt находится в заголовочном файле <cmath>;
выборочный перечень заголовочных файлов стандартной библиотеки C++
приведен в разделе 6.6). Используйте также #include для включения
заголовочных файлов с прототипами функций, написанных вами или
членами вашей рабочей группы.
Типичная ошибка программирования 6.3
Если функция определяется до того, как она вызывается, то
определение функции служит одновременно ее прототипом, так что
отдельный прототип в этом случае не является необходимым. Если
функция вызывается до ее определения и прототип для нее отсутствует,
происходит ошибка компиляции.
Общее методическое замечание 6.7
Всегда предусматривайте прототипы функций, даже если можно
опустить прототип в случае, когда функция определяется до ее
использования (и прототипом функции может служить ее заголовок).
Предусмотрев прототипы, вы избегаете привязки кода к порядку,
в котором определяются функции (этот порядок может измениться
в процессе развития программы).
Сигнатуры функций
Часть прототипа функции, включающая ее имя и типы аргументов,
называется сигнатурой функции. Сигнатура не специфицирует возвращаемый тип
функции. Функции в одной и той же области действия должны иметь
уникальные сигнатуры. Областью действия функции является та часть
программы, в которой функция известна и доступна. Подробнее об области действия
мы расскажем в разделе 6.10.
Функции и введение в рекурсию
337
Типичная ошибка программирования 6.4
Если две функции в одной и той же области действия имеют
одинаковые сигнатуры, происходит ошибка компиляции.
Если бы прототип функции в строке 17 на рис. 6.3 был бы написан как
void maximum( int, int, int );
то компилятор сообщил бы об ошибке, так как возвращаемый функцией тип
void отличался бы от возвращаемого типа int в заголовке функции.
Аналогичным образом такой прототип порождал бы ошибку при компиляции оператора
cout « maximum ( 6, 9, 0 ) ;
так как в данном операторе подразумевается, что maximum возвращает
результат, который нужно вывести.
Принудительное приведение аргументов
Другим важным аспектом прототипов функций является принудительное
приведение аргументов, т.е. автоматическое преобразование аргументов к
типам, специфицированным в объявлении параметров. Например, программа
может вызывать функцию с целым аргументом, даже если прототип функции
специфицирует параметр типа double, — функция все равно будет работать
правильно.
Правила возведения аргументов
Иногда значения аргументов, не соответствующие в точности типам
параметров в прототипе функции, могут быть перед вызовом преобразованы
компилятором в требуемый тип данных. Такие преобразования происходят в
соответствии с правилами возведения, специфицированными языком C++.
Правила возведения указывают, при каких преобразованиях типов не происходит
потери данных. Целое может быть преобразовано в double без изменения его
значения. Однако double, преобразованное в int, теряет свою дробную часть.
Не забывайте также, что переменные типа double могут хранить числа
намного большей величины, чем переменные типа int, поэтому потеря данных
может быть существенной. Данные могут также претерпевать искажения при
преобразовании больших целых типов в малые (например, long в short),
знаковых в беззнаковые или наоборот.
Правила возведения применяются к выражениям, содержащим значения
двух или более типов данных; такие выражения называют выражениями
смешанного типа. Тип каждого значения в выражении смешанного типа
возводится до «наивысшего» типа, имеющегося в выражении (на самом деле для
каждого значения создается и используется в выражении его временная
копия — исходные значения остаются неизменными). Возведение происходит
также, когда тип аргумента функции на совпадает типом параметра,
специфицированным в определении или прототипе функции. На рис. 6.6 перечислены
основные типы данных в порядке от «наивысшего» типа к «наинизшему».
Преобразование значений в более низкие основные типы может приводить
к неверным значениям. Поэтому значение может быть преобразовано в низ-
338
Глава 6
шии основной тип только путем его явного присваивания переменной низшего
типа (некоторые компиляторы выдают в этом случае предупреждение) либо
с помощью унарной операции приведения типа (см. раздел 4.9). Значения
аргументов функции преобразуются к типам параметров в прототипе функции
так, как если бы они были непосредственно присвоены переменным этих
типов. Если функция square, имеющая параметр целого типа, вызывается с
аргументом с плавающей точкой, последний преобразуется к типу int (низшему
типу) и square может возвратить неверное значение. Например, squareD.5)
возвращает 16, а не 20.25.
Типы данных
long double
double
float
unsigned long int
long int
unsigned int
int
unsigned short int
short int
unsigned char
char
bool
(синонимичен с unsigned long)
(синонимичен с long)
(синонимичен с unsigned)
(синонимичен с unsigned short)
(синонимичен с short)
Рис. 3.5. Иерархия возведения для основных типов данных
Типичная ошибка программирования 6.5
Преобразование от более высокого типа в иерархии возведения к более
низкому может исказить значение данных, что приведет к потере
информации.
Типичная ошибка программирования 6.5
Если аргументы в вызове функции не согласуются с числом и типом
параметров, объявленных в соответствующем прототипе,
происходит ошибка компиляции. Ошибкой является также случай, когда
число аргументов в вызове правильное, но они не могут быть неявно
преобразованы к ожидаемым типам.
Функции и введение в рекурсию
339
6.6. Заголовочные файлы стандартной библиотеки C++
Стандартная библиотека C++ разделяется на несколько частей, каждая из
которых имеет свой собственный заголовочный файл. Эти заголовочные файлы
содержат прототипы родственных функций, входящих в состав каждой из
частей библиотеки. Они содержат также определения различных классовых типов
и констант, которые необходимы этим функциям. Заголовочные файлы
«инструктируют» компилятор, каким образом следует взаимодействовать с
библиотечными компонентами и компонентами, которые пишет пользователь.
На рис. 6.7 перечислены некоторые общеупотребительные заголовочные
файлы стандартной библиотеки C++, большинство из которых обсуждаются
далее в книге. Заголовочные файлы, заканчивающиеся на .h, являются
файлами «старого стиля», которые были вытеснены заголовочными файлами
стандартной библиотеки C++. В этой книге мы пользуемся только стандартными
версиями заголовочных файлов для гарантии того, что наши примеры будут
работать на большинстве стандартных компиляторов C++.
Заголовочный файл
стандартной
библиотеки C++
<iostream>
<iomanip>
<cmath>
<cstdlib>
<ctime>
<vector>,
<list>,
<deque>,
<queue>,
<stack>,
<map>,
<set>,
<bitset>
Объяснение
Содержит прототипы для функций стандартного ввода
и стандартного вывода, представленных во 2-й главе. Этот
заголовочный файл заменяет файл <iostream.h>.
Содержит прототипы для потоковых манипуляторов,
форматировать потоки данных. Впервые используется
в разделе 45.9. Этот заголовочный файл заменяет файл
<iomanip.h>.
Содержит прототипы функций математической
библиотеки (обсуждавшихся в разделе б.З). Этот
заголовочный файл заменяет файл <math.h>.
Содержит прототипы функций для преобразований чисел
в текст, текста в числа, для выделения памяти, генерации
случайных чисел и других функций-утилит. Этот
заголовочный файл заменяет файл <stdlib.h>.
Содержит прототипы функций и типы для работы
с временем и датами. Этот заголовочный файл заменяет
файл <time.h>. Используется в разделе 6.7.
Эти заголовочные файлы содержат классы, реализующие
контейнеры стандартной библиотеки C++. Контейнеры
хранят данные во время исполнения программы.
Заголовок <vector> представлен в главе 7 («Массивы
и векторы»).
340
Глава 6
Заголовочный файл
стандартной
библиотеки C++
Объяснение
<cctype>
<cstring>
<typeinfo>
Содержит прототипы функций, проверяющих некоторые
свойства символов, и прототипы функций, которые могут
быть использованы для преобразования букв нижнего
регистра в верхний и наоборот. Этот заголовочный файл
заменяет файл <ctype.h>. Тема работы с символами
представлена в главе 8
Содержит прототипы функций для функций обработки
строк в стиле С. Этот заголовочный файл заменяет файл
<string.h>. Используется в главе 11 («Перегрузка
операций; объекты массивов и строк»).
Содержит классы для идентификации типа времени
исполнения (определения типов данных во время
выполнения программы). Обсуждается в разделе 13.8.
<exception>,
<stdexcept>
<memory>
<fstream>
<string>
<sstream>
<functional>
<iterator>
<algorithm>
<cassert>
<cfloat>
<climits>
<cstdio>
Эти заголовочные файлы содержат классы, которые
используются для управления исключениями —
механизма, позволяющего программе разрешать
проблемы, возникающие в процессе ее выполнения.
Содержит классы и функции, используемые стандартной
библиотекой C++ для выделения памяти стандартным
контейнерам.
Содержит прототипы для функций, которые выполняют
ввод из файлов и вывод в файлы на диске. Этот
заголовочный файл заменяет файл <f stream.h>.
Содержит определение класса string из стандартной
библиотеки C++ (представленного в главе 3).
Содержит прототипы для функций, которые выполняют
ввод из строк в памяти и вывод в строки в памяти.
Содержит классы и функции, используемые алгоритмами
стандартной библиотеки C++.
Содержит классы для доступа к данным в контейнерах
1 стандартной библиотеки C++.
Содержит функции для манипулирования данными
в контейнерах стандартной библиотеки C++.
Содержит макросы для диагностики, помогающей при
отладке программы. Заменяет старую версию
заголовочного файла <assert.h>.
Содержит предельные величины для чисел с плавающей
точкой на данной системе. Этот заголовочный файл
заменяет файл <float.h>.
Содержит предельные величины для целых чисел на
данной системе.
Содержит прототипы библиотечных функций стандартного
ввода-вывода в стиле С и используемую ими информацию.
Этот заголовочный файл заменяет файл <stdio. h>.
Функции и введение в рекурсию
341
Заголовочный файл
стандартной
библиотеки C++
<1оса1е>
<limits>
<utility>
Объяснение
Содержит классы и функции, обычно используемые при
потоковой обработке данных в форме, естественной для
различных языков (сюда относятся форматы денежных
сумм, сортировка строк, представление символов и т.д.).
Содержит классы для определения диапазонов значений
числовых типов на различных компьютерных платформах.
Содержит классы и функции, которые используются
многими заголовочными файлами стандартной
библиотеки C++.
Рис. 6.7. Заголовочные файлы стандартной библиотеки C++
6.7. Пример: генерация случайных чисел
Теперь мы предпримем краткую, но, надеемся, увлекательную экскурсию
в популярную область программирования, а именно в моделирование и игры.
В этом и следующем разделах мы разработаем игровую программу с
несколькими функциями. В ней мы применим большинство из рассмотренных к
настоящему моменту управляющих операторов.
Элемент случайности может быть введен в компьютерные приложения с
помощью функции rand из стандартной библиотеки C++.
Рассмотрим следующий оператор:
i = rand();
Функция rand генерирует целое число в диапазоне от О до RAND_MAX
(символическая константа, определенная в заголовочном файле <cstdlib>). Значение
RAND_MAX должно быть равно по меньшей мере 32767 — это максимальное
положительное значение двухбайтового (т.е. 16-битного) целого. Для GNU C++
значение RAND_MAX равно 214748647; для Visual Studio RAND_MAX
равно 32767. Если функция rand действительно вырабатывает случайные целые,
то при очередном вызове rand шансы быть выбранным (т.е. вероятность)
равны для всех чисел из диапазона от 0 до RAND_MAX.
Диапазон значений, которые непосредственно вырабатываются функцией
rand, часто отличается от того, который требуется конкретному приложению.
Например, программа, имитирующая бросание монеты, требует только двух
значений: 0 — для «орла» и 1 — для «решки». Программе, имитирующей
бросание игральной кости с шестью гранями, потребовались бы случайные числа
в диапазоне от 1 до 6. Программе, которая случайным образом определяет тип
следующего космического корабля (из четырех возможных), появляющегося
на горизонте в видеоигре, потребовались бы случайные числа от 1 до 4.
Бросание игральной кости
Чтобы продемонстрировать rand, давайте разработаем программу (рис. 6.8),
которая имитирует 20 бросков шестигранной игральной кости и печатает
результат каждого броска. Прототип функции rand находится в <cstdlib>. Для
342
Глава 6
того, чтобы выработать целые числа в диапазоне от 0 до 5, используем в
сочетании с rand операцию взятия по модулю %:
rand () % 6
Это называется масштабированием. Число 6 называется масштабирующим
коэффициентом. Затем мы смещаем диапазон чисел, прибавляя к
полученному результату единицу. Окно вывода на рис. 6.8 подтверждает, что результаты
лежат в диапазоне от 1 до 6.
1 // Рис. 6.8: fig06_08.cpp
2 // Смещенные и масштабированные случайные целые числа.
3 #include <iostream>
4 using std::cout;
5 using std:rendl;
6
7 #include <iomanip>
8 using std::setw;
9
10 #include <cstdlib> // содержит прототип для функции rand
11 using std:irand;
12
13 int main()
14 {
15 // повторить 20 pas
16 for ( int counter = 1; counter <= 20; counter++ )
17 {
18 // получить случайное число от 1 до 6 и вывести его
19 cout < setw( 10 ) < ( 1 + rand() % б );
20
21 // если counter делится на 5, начать новую строку вывода
22 if ( counter % 5 == 0 )
23 cout < endl;
24 } // конец for
25
26 return 0; // успешное завершение
27 } // конец main
5 3 5 5 2
4 2 5 5 5
3 2 2 15
1 4 6 4 6
Рис. 6.8. Смещенные масштабированные числа, генерируемые выражением
1 + rand() % 6
Бросание игральной кости 6 000 000 раз
Чтобы показать примерно равную вероятность появления чисел,
генерируемых функцией rand, программа на рис. 6.9 производит 6000000 бросаний
игральной кости. Каждое целое число от 1 до 6 должно появиться примерно
1000000 раз. Вывод программы на рис. 6.9 это подтверждает.
Функции и введение в рекурсию
343
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
// Рис. 6.9: fig06_09.cpp
// Бросание игральной кости 6 000 000 раз.
#include <iostream>
using std:rcout;
using std::endl;
#include <iomanip>
using std::setw;
#include <cstdlib>
using std::rand;
// содержит прототип для функции rand
int main()
{
int frequencyl
int frequency2
int frequency3
int frequency4
int frequency5
int frequency6
0; // счетчик выброшенных 1
0; // счетчик выброшенных 2
0; // счетчик выброшенных 3
0; // счетчик выброшенных 4
0; // счетчик выброшенных 5
0; // счетчик выброшенных 6
int face; // хранит последнее выброшенное значение
// подытожить результаты 6 000 000 бросаний кости
for ( int roll = 1; roll <= 6000000; roll++ )
{
face = 1 +■ rand() % 6; // случайное число от 1 до 6
face A-6) и увеличить нужный счетчик
// определить значение
switch ( face )
{
case 1:
++frequencyl; // увеличить счетчик 1
break;
case 2:
++frequency2; // увеличить счетчик 2
break;
case 3:
++frequency3; // увеличить счетчик З
break;
case 4:
++frequency4; // увеличить счетчик 4
break;
case 5:
++frequency5; // увеличить счетчик 5
break;
case 6:
++frequency6; // увеличить счетчик 6
break;
default: // недействительное значение
cout < "Program should never get here!";
} // конец switch
// конец for
cout « "Face" « setw( 13 )
cout « " 1" « setw( 13 )
« "Frequency" « endl;
« frequencyl
// заголовки
344
Глава 6
57
58
59
60
61
62
63
« "\n
« M\n
« "\n
« "\n
« "\n
return 0;
} // конец
2" « setw( 13 ) « frequency2
3" « setw( 13 ) « frequency3
4" « setw( 13 ) « frequency4
5" « setw( 13 ) « frequency5
6" « setw( 13 ) « frequency6 « endl;
// успешное завершение
main
Face Frequency
1 1001697
2 1000771
3 999082
4 997903
5 999165
6 1001382
Рис- 6.9. Бросание шестигранной игральной кости 6000000 раз
Как показывает вывод программы, с помощью масштабирования и
смещения чисел, генерируемых rand, мы действительно может моделировать
бросание игральной кости. Заметьте, что в этой программе управление никогда не
достигает варианта (строки 50-51) в операторе switch, так как значение
управляющего выражения (face) всегда лежит в диапазоне 1-6; тем не менее мы
предусмотрели вариант default в качестве примера полезных привычек. Когда
в главе 4 мы изучим массивы, то покажем, как можно изящно заменить весь
оператор switch единственным однострочным оператором.
j^rgk Предотвращение ошибок 6.3
\*$У Всегда предусматривайте в операторе switch вариант default для
перехвата ошибок, даже если вы абсолютно уверены в том, что никаких
ошибок у вас нет!
Рандомизация генератора случайных чисел
Повторный запуск программы на рис. 6.8 выводит
5 3 5 5 2
4 2 5 5 5
3 2 2 15
14 6 4 6
Как вы можете заметить, печатается точно та же последовательность чисел,
что показана на рис. 6.8. Какие же это случайные числа? Как ни странно, эта
повторяемость является важной характеристикой функции rand. При отладке
программы-симулятора такая повторяемость существенна для доказательства
того, что внесенные в программу коррекции работают должным образом.
На самом деле функция rand генерирует псевдослучайные числа.
Последовательные вызовы rand генерируют ряд чисел, которые кажутся случайными.
Однако этот ряд повторяется при каждом запуске программы. Когда
программа будет тщательно отлажена, ее можно будет модифицировать таким
образом, чтобы при каждом выполнении получались различные последовательно-
Функции и введение в рекурсию
345
сти случайных чисел. Это называется рандомизацией и достигается
применением функции srand стандартной библиотеки C++. Функция srand получает
целый аргумент типа unsigned и засевает функцию rand таким образом,
чтобы при каждом запуске программы она генерировала новую
последовательность случайных чисел.
Функция srand демонстрируется программой на рис. 6.10. В программе
использован тип unsigned, что является сокращением от unsigned int. Число
типа int занимает при хранении по меньшей мере два байта (четыре байта на
современных популярных 32-битных системах) и может принимать как
положительные, так и отрицательные значения. Переменная типа unsigned int
также хранится по крайней мере в двух байтах памяти. Двухбайтовое число
unsigned int может принимать только неотрицательные значения в диапазоне
0-65535. Четырехбайтовое unsigned int может принимать неотрицательные
значения в диапазоне 0-4294967295. Функция srand получает в качестве
аргумента unsigned int. Прототип функции srand находится в заголовочном
файле <cstdlib>.
1 // Рис. 6.10: fig06_10.cpp
2 // Рандомизация программы бросания кости.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 #include <iomanip>
9 using std::setw;
10
11 #include <cstdlib> // содержит прототипы для функций srand и rand
12 using std::rand;
13 using std::srand;
14
15 int main()
16 {
17 unsigned seed; // хранит введенное пользователем "семя"
18
19 cout « "Enter seed:
20 cin » seed;
21 srand( seed ); // засеять генератор случайных чисел
22
23 // повторить 10 раз
24 for ( int counter = 1; counter <= 10; counter++ )
25 {
26 // получить случайное число от 1 до 6 и вывести его
27 cout « setw( 10 ) « ( 1 + rand() % 6 );
28
29 // если counter делится на 5, начать новую строку вывода
30 if ( counter % 5 == 0 )
31 cout « endl;
32 } // конец for
33
34 return 0; // успешное завершение
35 } // конец main
346
Глава 6
Enter
Enter
Enter
seed:
6
6
seed:
2
5
seed:
6
6
67
432
67
5
3
6
1
5
3
1
1
4
4
1
1
4
2
3
4
4
2
5
1
2
5
5
1
1
Рис. 6.10. Программа рандомизации бросания игральной кости
Выполните программу несколько раз и рассмотрите полученные
результаты. Заметьте, что при вводи различных значений для семени получаются
различные последовательности случайных чисел. В первом и третьем образцах
мы ввели одинаковые значения, поэтому в обоих случаях был выведен один
и тот же ряд из 10 чисел.
Если производить рандомизацию, не вводя каждый раз значения семени,
можно написать оператор вроде
srand( time( 0 ) ) ;
Тогда для автоматического получения семени компьютер будет считывать
показания своих часов. Функция time (с аргументом 0, как написано в
приведенном операторе) текущее время как число секунд, прошедших с полуночи 1
января 1970 года по Гринвичу (GMT). Это значение преобразуется в целое типа
unsigned и используется в качестве семени генератора случайных чисел.
Прототип функции time находится в <ctime>.
Типичная ошибка программирования 6.7
Повторный вызов в программе функции srand перезапускает
последовательность псевдослучайных чисел и может повлиять на
«случайность» значений, генерируемых функцией rand.
Обобщенное масштабирование и смещение случайных чисел
Выше мы продемонстрировали, как написать одиночный оператор,
позволяющий моделировать бросание шестигранной игральной кости:
face = 1 + rand() % б;
Он всегда присваивает переменной face целое (случайное) значение в
диапазоне 1 < face < 6. Заметьте, что ширина этого диапазона (т.е. число попадающих
в него последовательных целых чисел) равна 6, а начальным числом
диапазона является 1. Обращаясь к предыдущему оператору, мы видим, что ширина
диапазона определяется числом, используемым для масштабирования rand
с помощью операции взятия по модулю (т.е. 6), а начальное число диапазона
равно числу (т.е. 1), которое прибавляется к rand % 6. Мы можем обобщить
этот результат в виде
Функции и введение в рекурсию
347
number = shiftingValue + rand() % scalingFactor;
где shift ingValue равняется первому числу из желаемого диапазона
последовательных целых чисел, a scalingF actor равняется ширине этого диапазона.
В упражнениях к этой главе мы увидим, что можно случайно выбирать целые
числа из набора значений, отличного от последовательного диапазона.
Типичная ошибка программирования 6.8
Использование srand вместо rand при попытке генерации случайных
чисел приводит к ошибке компиляции, поскольку функция srand не
возвращает значения.
6.8. Пример: азартная игра с использованием
перечисления (enum)
Одной из наиболее популярных азартных игр считается игра в кости,
известная как «крепе», в которую играют и в казино, и в глухих закоулках по
всему миру. Правила игры просты:
Игрок бросает две кости. Каждая кость имеет шесть граней. Эти грани содержат
1, 2, 3, 4, 5 и 6 точек. После того как кости остановятся, вычисляется сумма
точек на двух гранях, повернутых вверх. Если выпавшая сумма при первом броске
оказалась равной 7 или 11, то победил игрок. Если сумма при первом броске
составила 2, 3 или 12, то игрок проигрывает (выигрывает «банк»). Если сумма первого
броска равна 4, 5, 6, 8, 9 или 10, то эта сумма становится «очком» игрока. Чтобы
выиграть, вы должны продолжать бросать кости до тех пор, пока не «попадете
в очко». Игрок проигрывает, если при очередном броске выпадает 7.
Программа на рис. 6.11 моделирует игру * крепе».
Обратите внимание, что по правилам игры игрок как на первом броске, так
и на всех последующих должен бросать две кости. Мы определяем функцию
rollDice (строки 71-83), которая бросает кости, подсчитывает выпавшую
сумму и печатает ее. Функция rollDice определяется один раз, но вызывается из
двух мест программы (строки 27 и 51). Интересно, что rollDice не принимает
аргументов, поэтому в прототипе функции (строка 14) и в ее заголовке
(строка 71) мы указали пустой список параметров. Функция rollDice возвращает
сумму двух костей, поэтому в прототипе и в заголовке функции указан
возвращаемый тип int.
1 // Рис. 6.11: fig06_ll.cpp
2 // Моделирование игры "крепе".
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstdlib> // содержит прототипы функций для srand и rand
8 using std::rand;
9 using std::srand;
10
11 #include <ctime> // содержит прототип для функции time
12 using std::time;
348
13
14 int rollDice(); // бросает кости, вычисляет и выводит сумму
15
16 int main ()
17 {
18 // перечисление с константами, представляющими состояние игры
19 enum Status { CONTINUE, WON, LOST };
20
21 int myPoint; // "очко" (игра не выиграна и не проиграна сразу)
22 Status gameStatus; // может содержать CONTINUE, WON или LOST
23
24 // засеять генератор случайных чисел текущим временем
25 srand( time( 0 ) );
26
27 int sumOfDice = rollDice(); // первый бросок костей
28
29 // определить по первому броску состояние игры и "очко"
30 switch ( sumOfDice )
31 {
32 case 7: // выигрыш - 7 при первом броске
33 case 11: // выигрыш - 11 при первом броске
34 gameStatus = WON;
35 break;
36 case 2: // проигрыш - 2 при первом броске
37 case 3: // проигрыш - 3 при первом броске
38 case 12: // проигрыш - 12 при первом броске
39 gameStatus = LOST;
40 break;
41 default: // не выигрыш и не проигрыш, запомнить очко
42 gameStatus = CONTINUE; // игра не окончена
43 myPoint = sumOfDice; // запомнить пункт
44 cout « "Point is " « myPoint « endl;
45 break; // в конце switch не обязателен
46 } // конец switch
47
48 // пока игра не закончена
49 while ( gameStatus = CONTINUE ) // не WON или LOST
50 f
51 sumOfDice = rollDice(); // бросить кости снова
52
53 // determine game status
54 if ( sumOfDice == myPoint ) // выигрыш броском очка
55 gameStatus = WON;
56 else
57 if ( sumOfDice ==7 ) // проигрыш броском 7
58 gameStatus = LOST;
59 } // конец while
60
61 // вывести сообщение о выигрыше или проигрыше
62 if ( gameStatus == WON )
63 cout « "Player wins" « endl;
64 else
65 cout « "Player loses" « endl;
66
67 return 0; // успешное завершение
68 } // конец main
Функции и введение в рекурсию
349
70 // бросить кости, вычислить сумму и показать результаты
71 int rollDice()
72 {
73 // получить случайные значения для костей
74 int diel = 1 + rand() % б; // бросок первой кости
75 int die2 = 1 + rand() % 6; // бросок второй кости
76
77 int sum = diel + die2; // вычислить сумму костей
78
79 // показать результаты данного броска
80 cout « "Player rolled " « diel « " + " « die2
81 « " = " « sum « endl;
82 return sum; // возвратить сумму костей
83 } // конец функции rollDice
Player rolled 5+2=7
Player wins
Player rolled 1 + 1 =
Player loses
Player rolled 4+2=6
Point is 6
Player rolled 2+2=4
Player rolled 3+1=4
Player rolled 5+4=9
Player rolled 5+4=9
Player rolled 1+4=5
Player rolled 5+1=6
Player wins
Player rolled 4 + 6 = 10
Point is 10
Player rolled 6+2=8
Player rolled 1+1=2
Player rolled 2+2=4
Player rolled 4+1=5
Player rolled 2+3=5
Player rolled 1+1=2
Player rolled 3+6=9
Player rolled 3+1=4
Player rolled 2+6=8
Player rolled 5+1=6
Player rolled 3+4=7
Player loses
Рис. 6.11. Моделирование игры «крепе»
Игра довольно замысловата. Игрок может выиграть или проиграть после
первого же броска или после серии бросков. Переменная gameStatus
используется для запоминания состояния игры. Она объявлена как имеющая новый
тип Status. В строке 19 объявляется определяемый пользователем тип, назы-
350
Глава 6
ваемый перечислением. Перечисление, объявляемое ключевым словом епит>
за которым следует имя типа (в данном случае Status), является набором
целых констант, представленных идентификаторами. Значения этих
перечисляемых констант начинаются с 0, если не указано иначе, и увеличиваются
последовательно на единицу. В предыдущем перечислении константа
CONTINUE имеет значение О, WON — значение 1 и LOST — значение 2.
Идентификаторы в enum должны быть уникальны, но отдельные
перечисляемые константы могут иметь одно и то же целое значение.
Хороший стиль программирования 6.1
Делайте заглавной первую букву идентификатора, используемого как
имя типа, определяемого пользователем.
Хороший стиль программирования 6.2
Используйте в именах перечисляемых констант только буквы
верхнего регистра. Это выделяет константы в тексте программы и
напоминает программисту о том, что перечисляемые константы не
являются переменными.
Переменным определяемого пользователем типа Status может быть
присвоено только одно из трех значений, объявленных в перечислении. Если игра
выиграна, программа присваивает gameStatus значение WON (строки 34
и 55). Если игра проиграна, gameStatus устанавливается равной LOST
(строки 39 и 58). В ином случае программа присваивает gameStatus значение
CONTINUE (строка 42), указывая, что кости должны быть брошены снова.
Другим популярным перечислением является
enum Months { JAN = 1, FEB, MAR, APR, MAY, YUN, JUL, AUG,
SEP, OCT, NOV, DEC };
Это перечисление создает определяемый пользователем тип Months с
перечисляемыми константами, представляющими месяцы года. Поскольку первое
значение приведенного перечисления явно устанавливается равным 1, а
каждое последующее значение увеличивается на 1, в результате получается набор
значений от 1 до 12. В определении перечисления любой константе можно
присвоить целое значение, и каждая из последующих констант будет иметь
значение на единицу выше, чем предыдущая.
Если игра выиграна или проиграна после первого броска, программа
пропускает тело оператора while (строки 49-59), поскольку gameStatus не равна
CONTINUE. Программа переходит к оператору if...else в строках 62-65,
который печатает "Player wins", если gameStatus равна WON, и "Player loses",
если gameStatus равна LOST.
Если после первого броска игра не выиграна и не проиграна, программа
сохраняет сумму в myPoint (строка 43). Управление переходит к оператору
while, так как gameStatus равна CONTINUE. При каждой итерации while
программа вызывает rollDice для получения нового значения суммы. Если
совпадает с myPoint, программа устанавливает gameStatus равной WON
(строка 55), проверка условия while дает ложный результат, оператор if...else
печатает "Player wins" и вьшолнение программы завершается. Если sumOfDice
Функции и введение в рекурсию
351
равна 7, gameStatus устанавливается в LOST (строка 58), проверка while
также дает ложный результат, оператор if...else печатает "Player loses" и
программа завершается.
Обратите внимание на интересное применение различных управляющих
механизмов, которые мы обсуждали ранее. Программа использует две
функции — main и rollDice, операторы switch, while, вложенный if...else и
вложенный if. В упражнениях мы исследуем различные интересные моменты игры
«крепе».
Хороший стиль программирования 6.3
Использование перечислений вместо целых констант может сделать
программу яснее и проще для сопровождения. Значение перечисляемой
константы устанавливается только раз в объявлении перечисления.
Типичная ошибка программирования 6.9
Присваивание переменной, имеющей тип перечисления, целого
эквивалента перечисляемой константы приводит к ошибке компиляции.
Типичная ошибка программирования 6.10
После того как перечисляемая константа определена, попытка
присвоить ей другое значение приводит к ошибке компиляции.
6.9. Классы памяти
В программах, которые вы уже видели, использовались идентификаторы
для имен переменных. В число атрибутов переменной входят имя, тип, размер
и значение. В этой главе мы также используем идентификаторы в качестве
имен функций, определяемых пользователем. Но каждый идентификатор
в программе имеет и другие атрибуты, в том числе класс памяти, область
действия и компоновку.
В C++ имеется пять спецификаторов класса памяти: auto, register,
extern, mutable и static. В этом разделе обсуждаются спецификаторы класса
памяти auto, register, extern и static. Спецификатор mutable (обсуждается
подробно в главе 23) используется исключительно в классах.
Класс памяти, область действия и компоновка
Класс памяти идентификатора определяет период времени, в течение
которого этот идентификатор существует в памяти. Одни идентификаторы
существуют недолго, другие неоднократно создаются и уничтожаются, третьи
существуют на протяжении всего выполнения программы. В этом разделе
обсуждаются два класса памяти: статический и автоматический.
Областью действия идентификатора называется область программы, в
которой на данный идентификатор можно ссылаться. На некоторые
идентификаторы можно ссылаться в любом месте программы, тогда как на другие — только
в пределах ограниченной ее части. Область действия идентификаторов
обсуждается в разделе 6.10.
352
Глава 6
Компоновка идентификатора определяет, известен ли он только в том
исходном файле, где он определяется, или же в нескольких исходных файлах,
которые компилируются и затем компонуются в исполняемую программу.
Спецификатор класса памяти для идентификатора позволяет определить как
его класс памяти, так и компоновку.
Категории классов памяти
Спецификаторы класса памяти могут быть разбиты на два класса:
автоматический класс памяти и статический класс памяти. Для объявления
переменных автоматического класса памяти используются ключевые слова auto
и register. Такие переменные создаются при входе в блок, в котором они
объявлены, существуют, пока блок активен, и уничтожаются, когда программа
выходит из блока.
Локальные переменные
Автоматический класс памяти могут иметь только локальные переменные.
Локальные переменные и параметры функций обычно относятся к
автоматическому классу. Спецификатор auto явно объявляет переменные
автоматического класса памяти. Например, следующее объявление указывает, что
переменные х и у типа double являются локальными переменными
автоматического класса памяти — они существуют только в теле функции в пределах
ближайшей пары фигурных скобок, охватывающих данное объявление:
auto double x, у;
Локальные переменные имеют автоматический класс памяти по
умолчанию, так что ключевое слово auto используется редко. Далее в тексте мы
будем называть переменные автоматического класса памяти просто
автоматическими переменными.
Вопросы производительности 6.1
Автоматический класс памяти — это средство экономии памяти,
так как автоматические переменные существуют только в течение
исполнения блока, в котором они определяются.
Общее методическое замечание 6.8
Автоматическое хранение является примером принципа
наименьших привилегий, который является основой правильного
конструирования программного обеспечения. В контексте приложения принцип
гласит, что коду должны предоставляться только тот объем прав
и доступа к информации, которые необходимы для решения
назначенной ему задачи, но не более того. Зачем нам хранить переменные в
памяти и обеспечивать к ним доступ, когда они не нужны?
Функции и введение в рекурсию 353
Регистровые переменные
Обычно данные в программе, транслированной в машинный язык, для
вычислений и другой обработки загружаются в регистры.
•——i Вопросы производительности 6.2
~р^^1 Перед объявлением автоматической переменной может быть
помещен спецификатор класса памяти register, предлагающий
компилятору сохранять переменную не в памяти, а в одном из
высокоскоростных аппаратных регистров компьютера. Если интенсивно
используемые переменные, такие как счетчики или суммы, сохраняются
в аппаратных регистрах, исключаются накладные расходы на
многократную загрузку переменных из памяти в регистры и запись
результатов обратно в память.
Гу^Л Типичная ошибка программирования 6.11
14аГ I Указание для одного идентификатора нескольких спецификаторов
класса памяти является синтаксической ошибкой. К
идентификатору может быть применен только один спецификатор класса памяти.
Например, если вы указали register, нельзя указать также и auto.
Компилятор может игнорировать объявления register. Например, может не
оказаться достаточного количества доступных для использования регистров.
Приведенное ниже объявление предлагает разместить целую переменную
counter в одом из регистров компьютера; вне зависимости от того, сделает это
компилятор или нет, counter инициализируется единицей:
register int counter = 1;
Ключевое слово register может применяться только к локальным переменным
и параметрам функций.
•——i Вопросы производительности 6.3
f^$^| Часто объявления register оказываются не нужны. Современные
оптимизирующие компиляторы способны распознавать часто
используемые переменные и могут решить, что переменную следует
разместить в регистре, не нуждаясь в объявлении ее программистом как
register.
Статический класс памяти
Ключевые слова extern и static объявляют идентификаторы для
переменных статического класса памяти и для функций. Переменные статического
класса памяти существуют с момента, когда программа начинает
исполняться, и сохраняются в течение всего периода ее выполнения. Память для
переменной статического класса памяти выделяется в начале исполнения
программы. Такая переменная инициализируется единственный раз, когда программа
встречает ее объявление. Что касается объявленных таким образом функций,
то имя такой функции тоже существует с самого начала исполнения
программы, как и имена всех остальных функций. Однако даже если переменные
12 Заю 1114
354
Глава 6
и имена функций существуют с самого начала исполнения программы, это не
означает, что эти идентификаторы могут использоваться во всей программе.
Как мы увидим в разделе 6.10, класс памяти и область действия (где можно
использовать имя) — это разные понятия.
Идентификаторы со статическим классом памяти
Существует два типа идентификаторов со статическим классом памяти —
внешние идентификаторы (такие, как глобальные переменные и глобальные
имена функций) и локальные переменные, объявленные со спецификатором
класса памяти static. Глобальные переменные создаются путем размещения их
объявлений за пределами определений любых классов или функций.
Глобальные переменные сохраняют свои значения в течение всего выполнения
программы. На глобальные переменные и функции может ссылаться любая функция,
которая расположена в исходном файле после их объявления или описания.
Ш Общее методическое замечание 6,9
Объявление переменной глобальной, а не локальной может приводить
к неожиданным побочным эффектам, когда функция, не нуждающаяся
в доступе к этой переменной, случайно или умышленно ее изменяет.
Это еще одна иллюстрация принципа наименьших привилегий.
Вообще говоря, если не считать действительно глобальных ресурсов,
таких, как tin и cout, следует избегать использования глобальных
переменных, за исключением определенных ситуаций, когда к
производительности предъявляются уникальные требования.
Ш Общее методическое замечание 6,10
Переменные, используемые только в одной конкретной функции,
следует объявлять как локальные в этой функции, а не как глобальные.
Локальные переменные, объявленные с ключевым словом static, все равно
известны только в той функции, где они объявлены, но в отличие от
автоматических переменных сохраняют значения и после того, как функции возвратит
управление своему вызывающему. Когда функция вызывается снова, ее
статические локальные переменные содержат те значения, которые они имели при
завершении предыдущего исполнения функции. Следующий оператор
объявляет локальную переменную count как static и указывает, что она должна
инициализироваться значением 1:
static int count = 1;
Все числовые переменные статического класса памяти инициализируются
нулем, если программист их не инициализирует явным образом, но тем не менее
хороший стиль программирования предполагает явную инициализацию
любых переменных.
Спецификаторы класса памяти extern и static имеют специальное
значение, когда явным образом применяются к внешним идентификаторам, таким,
как глобальные переменные и глобальные имена функций. Такое
использование extern и static обсуждается в приложении Г.
Функции и введение в рекурсию
355
6.10. Правила для области действия
Та часть программы, в которой можно ссылаться на некоторый
идентификатор, называется его областью действия. Например, когда мы объявляем
локальную переменную в блоке, на нее можно ссылаться только в данном блоке
или во вложенном в него. В этом разделе обсуждаются четыре области
действия идентификатора: область действия функции, область действия файла,
область действия блока и область действия прототипа функции. Позднее
(в главе 9) мы обсудим также область действия класса. C++ определяет еще
одну область действия — пространства имен, — о которой рассказывается
в главе 23.
Идентификатор, объявленный вне любой функции или класса, имеет
область действия файла. Такой идентификатор известен всем функциям от
точки его объявления до конца файла. Все глобальные переменные, определения
функций и находящиеся вне функции прототипы функций имеют область
действия файла.
Метки (идентификаторы с последующим двоеточием, например, start:)
являются единственными идентификаторами, имеющими область действия
функции. Метки можно использовать всюду в функции, в которой они
появляются, но на них нельзя ссылаться вне тела функции. Метки используются
в операторах goto (приложение Г). Метки относятся к тем деталям
реализации, которые функции скрывают друг от друга.
Идентификаторы, объявленные внутри блока, имеют область действия
блока. Область действия блока начинается от объявления идентификатора и
заканчивается завершающей правой фигурной скобкой (}) блока, в котором
идентификатор объявляется. Локальные переменные функции имеют область
действия блока, как и параметры функции, которые также являются ее
локальными переменными. Любой блок может содержать объявления
переменных. Если блоки вложены и идентификатор во внешнем блоке имеет такое же
имя, как идентификатор во внутреннем блоке, идентификатор внешнего блока
«скрыт» до момента завершения работы внутреннего блока. Это означает, что
пока выполняется внутренний блок, он «видит» значение своего собственного
локального идентификатора, а не значение идентификатора с тем же именем
в охватывающем блоке. Локальные переменные, объявленные как static,
имеют область действия блока, несмотря на то, что они существуют с самого
начала исполнения программы. Период хранения не влияет на область действия
идентификатора.
Единственными идентификаторами с областью действия прототипа
являются те, что указываются в списке параметров прототипа функции. Как уже
говорилось, прототипы функций не требуют имен в списке параметров —
требуются только их типы. Если в списке параметров прототипа функции
указывается имя, компилятор его игнорирует. Идентификаторы, указанные в
прототипе функции, можно повторно использовать где угодно в программе, не
опасаясь неоднозначностей. В отдельном прототипе каждый идентификатор
должен встречаться только один раз.
356
Глава 6
Типичная ошибка программирования 6.12
Случайное использование во внутреннем блоке имени
идентификатора, которое уже принадлежит идентификатору во внешнем блоке,
когда на самом деле программист хочет, чтобы во время работы
внутреннего блока был активен идентификатор во внешнем блоке, обычно
является логической ошибкой.
Хороший стиль программирования 6.4
Избегайте давать переменным имена, которые скрывают имена во
внешних областях действия. Этого можно достичь, вообще избегая
использования в программе одинаковых идентификаторов.
Программа на рис. 6.12 демонстрирует области действия глобальных
переменных, автоматических локальных переменных и статических локальных
переменных.
1 // Рис. 6.12: fig06_12.cpp
2 // Пример на области действия.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 void useLocal ( void ); // прототип функции
8 void useStaticLocal( void ); // прототип функции
9 void useGlobal( void ); // прототип функции
10
11 int x = 1; // глобальная переменная
12
13 int main ()
14 {
15 int x = 5; // переменная, локальная в main
16
17 cout « "local x in main's outer scope is " « x « endl;
18
19 { // начинает новую область действия
20 int x = 7; // скрывает х во внешней области действия
21
22 cout « "local x in main's inner scope is " « x « endl;
23 } // конец новой области действия
24
25 cout « "local x in main's outer scope is " « x « endl;
26
27 useLocal(); // useLocal имеет локальную х
28 useStaticLocal(); // useStaticLocal имеет статическую локальную х
29 useGlobal(); // useGlobal использует глобальную х
30 useLocal (); // useLocal повторно инициализирует свою локальную х
31 useStaticLocal(); // статическая локальная х сохраняет значение
32 useGlobal(); // глобальная х также сохраняет свое значение
33
34 cout « "\nlocal х in main is " « х « endl;
35 return 0; // успешное завершение
36 } // конец main
37
Функции и введение в рекурсию
357
38 // useLocal реинициализирует локальную х при каждом вызове
39 void useLocal( void )
40 {
41 int x = 25; // инициализируется при каждом вызове useLocal
42
43 cout « "\nlocal х is " « х « " on entering useLocal" « endl;
44 x++;
45 cout « "local x is " « x « " on exiting useLocal" « endl;
46 } // конец функции useLocal
47
48 // useStaticLocal инициализирует статическую локальную переменную х
49 // только при первом вызове функции; между вызовами этой функции
50 // значение х сохраняется
51 void useStaticLocal( void )
52 {
53 static int x = 50; // инициализируется при первом вызове функции
54
55 cout « "\nlocal static x is " « х useStaticLocal"
56 « " on entering « endl;
57 x++;
58 cout « "local static x is " « x « " on exiting useStaticLocal"
59 « endl;
60 } // конец функции useStaticLocal
61
62 // useGlobal модифицирует глобальную переменную х при каждом вызове
63 void useGlobal( void )
64 {
65 cout « "\nglobal x is "« x « " on entering useGlobal" « endl;
66 x *= 10;
67 cout « "global x is " « x « " on exiting useGlobal" « endl;
68 } // конец функции useGlobal
local x in main's outer scope is 5
local x in main's inner scope is 7
local x in main's outer scope is 5
local x is 25 on entering useLocal
local x is 26 on exiting useLocal
local static x is 50 on entering useStaticLocal
local static x is 51 on exiting useStaticLocal
global x is 1 on entering useGlobal
global x is 10 on exiting useGlobal
local x is 25 on entering useLocal
local x is 26 on exiting useLocal
local static x is 51 on entering useStaticLocal
local static x is 52 on exiting useStaticLocal
global x is 10 on entering useGlobal
global x is 100 on exiting useGlobal
local x in main is 5
Рис. 6.12. Пример областей действия
358
Глава 6
Строка 11 объявляет и инициализирует значением 1 глобальную переменную х.
Эта глобальная переменная будет скрыта в любом блоке (или функции), где
объявляется переменная с именем х. В строке 11 функции main объявляется локальная
переменная х, инициализируемая значением 5. Строка 17 выводит эту
переменную, чтобы показать, что в main глобальная х скрыта. Далее строки 19-23
определяют новый блок в main с другой локальной переменной х, которая
инициализируется значением 7 (строка 20). Строка 22 выводит переменную, показывая, что
она скрывает х во внешнем блоке main. При выходе из блока переменная х со
значением 7 автоматически уничтожается. Затем строка 25 выводит локальную
переменную х внешнего блока main, показывая, что она больше не скрыта.
Для демонстрации других областей действия программа определяет три
функции, каждая из которых не принимает аргументов и ничего не
возвращает. Функция useLocal (строки 39-46) объявляет автоматическую
переменную х (строка 41) и инициализирует ее значением 25. При вызове useLocal
переменная печатается, получает приращение и снова печатается перед тем, как
функция возвращает управление вызывающему. Каждый раз, когда
программа вызывает данную функцию, автоматическая переменная х создается заново
и инициализируется значением 25.
Функция useStaticLocal (строки 51-60) объявляет статическую
переменную х и инициализирует ее значением 50. Локальные переменные,
объявленные как static, сохраняют свои значения, даже когда они находятся вне
области действия (т.е. когда функция, в которой они объявлены, не исполняется).
При вызове useStaticLocal переменная х печатается, получает приращение
и снова печатается перед тем, как функция возвращает управление. При
следующем вызове этой функции локальная статическая переменная х содержит
значение 51. Инициализация в строке 51 выолняется только однажды — при
первом вызове useStaticLocal.
Функция useGlobal (строки 63-68) не объявляет никаких переменных.
Таким образом, когда она ссылается на переменную х, используется глобальная х
(объявленная перед main). При вызове useGlobal глобальная переменная х
печатается, умножается на 10 и снова печатается перед тем, как функция
возвращает управление. Когда программа вызывает useGlobal в следующий раз,
глобальная переменная х содержит модифицированное значение A0). После
двукратного исполнения каждой из функций useLocal, useStaticLocal и useGlobal
программа снова печатает переменную х, локальную в main, чтобы показать,
что ни один из вызовов функций изменяет значения х, так как все функции
ссылаются на переменные в других областях действия.
6.11. Стек вызовов и активационные записи
Чтобы понять, каким образом C++ производит вызовы функций, нам
потребуется сначала рассмотреть структуру данных (т.е. собрание
взаимосвязанных единиц информации), называемую стеком. Вы можете представить себе
стек как нечто подобное горке тарелок. Когда тарелку помещают в горку, ее
обычно кладут сверху (это называется push — затолкнуть в стек). Точно так
же, когда тарелку извлекают из горки, ее обычно снимают сверху (это
называется pop — вытолкнуть из стека). Стек является структурой данных
«последним вошел, первым вышел» (LIFO, «last-in, first-out») — единица данных,
помещенная в стек последней, удаляется из него первой.
Функции и введение в рекурсию
359
Одним из важнейших механизмов, которые должны быть освоены
студентами компьютерных факультетов, является стек вызовов функций (иногда его
называют исполнительным стеком программы). Эта структура данных
(работающая «за кулисами») поддерживает механизм вызова/возврата функций.
Она также отвечает за создание, сохранение и уничтожение всех
автоматических переменных вызванной функции. Мы пояснили поведение стека
(последним вошел, первым вышел) аналогией с горкой тарелок. Как мы увидим из
рис. 6.14-6.16, это в точности то, что делает функция, возвращая управление
своей вызывающей функции.
Каждая вызванная функция может, в свою очередь, вызвать другую
функцию и т.д. — до тех пор, пока какая-либо из функций не возвратит
управление. Каждая функция в конце концов должна возвратить управление той
функции, которая ее вызвала. Следовательно, мы каким-то образом должны
отслеживать адреса возврата, которые требуются каждой из функций для
возвращения управления своей вызывающей функции. Стек вызовов является
идеальной структурой данных для управления этой информацией. Всякий
раз, когда функция вызывает другую функцию, в стек заталкивается блок
информации. Этот блок, называемый кадром стека или активационной
записью, содержит адрес возврата, который необходим вызванной функции для
возвращения в вызывающую функцию. Он содержит также некоторую
дополнительную информацию, которую мы вскоре обсудим. Если вызванная
функция не вызывает другую функцию, а выполняет возврат, кадр стека для ее
вызова выталкивается, и управление передается по адресу возврата,
содержащемуся в вытолкнутом кадре.
Красота стека вызовов в том, что любая вызванная функция всегда
находит информацию, необходимую ей для возвращения к своему вызывающему,
на вершине стека. А если функция производит вызов другой функции, в стек
просто заталкивается кадр для нового вызова. Таким образом, на вершине
стека оказывается теперь адрес возврата, который нужен вновь вызванной
функции.
Кадры стека выполняют еще одну важную обязанность. У большинства
функций имеются автоматические переменные — параметры и любые
объявляемые функцией локальные переменные. Автоматические переменные
должны существовать лишь в течение выполнения функции. Они должны
оставаться активными и тогда, когда функция производит вызовы других функций.
Но когда вызванная функция возвращает управление своему вызывающему,
ее автоматические переменные должны «исчезнуть». Для резервирования
памяти под автоматические переменные вызванной функции прекрасно
подходит ее кадр стека. Этот кадр стека существует все время, пока вызванная
функция остается активной. Когда она возвращает управление — и не
нуждается более в локальных автоматических переменных, — ее кадр стека
выталкивается, и эти переменные становятся неизвестными программе.
Конечно, память компьютера не безгранична, поэтому для хранения акти-
вационных записей на стеке вызовов может выделяться лишь ограниченный
ее объем. Если вызовов функций оказывается так много, что стек более не
может вместить их активационных записей, происходит ошибка, называемая
переполнением стека.
360
Глава 6
Стек вызовов в действии
Итак, как мы видели, механизм вызова/возврата функций, а также
создание и уничтожение автоматических переменных поддерживаются стеком
вызовов и активационными записями. Давайте разберем, каким образом
действует стек вызовов при исполнении функции square, вызываемой из main
(строки 11-17 на рис. 6.13). Сначала операционная система активирует
main — при этом в стек заталкивается активационная запись (показано на
рис. 16.14). Активационная запись сообщает main, как возвратиться в
операционную систему (т.е. передать управление по адресу R1), и резервирует
место для автоматической переменной main (т.е. а, которая инициализируется
значением 10).
1 // Рис. 6.13: fig06_13.cpp
2 // Функция square демонстрирует стек вызовов функций
3 //и записи активации.
4 #include <iostream>
5 using std::cin;
6 using std::cout;
7 using std::endl;
8
9 int square( int ); // прототип для функции square
10
11 int main()
12 {
13 int a = 10; // автоматическая локальная переменная в main
14
15 cout « a «" squared: "« square ( a )« endl; // вывести квадрат
16 return 0; // показывает успешное завершение
17 } // конец main
18
19 // возвращает квадрат целого числа
20 int square( int x ) // х - локальная переменная
21 {
22 return х * х; // вычислить квадрат и возвратить результат
23 } // конец функции square
10 squared: 100
Рис. 6.13. Функция square для демонстрации стека вызовов и активационных записей
Функции и введение в рекурсию
361
Шаг 1: операционная система активирует main для исполнения приложения
Операционная система
-► int main()
Адрес возврата R1
int a = 10;
cout « а « " squared: "
« square( a ) « end],
return 0;
Стек вызовов после Шага 1
Вершина стека
Активационная
запись для
функции main
Адрес возврата: R1
Автоматические
переменные:
а 10
Обозначения
Линии представляют
исполняемые инструкции
операционной системы
Рис. 6,14, Стек вызовов после того, как операционная система активирует main
для исполнения приложения
Функция main — до того, как возвратиться в операционную систему —
вызывает (в строке 15 на рис. 6.13) функцию square (строки 20-30). При этом
в стек вызовов заталкивается кадр стека для square (рис. 6.15). Этот кадр
стека содержит адрес возврата, необходимый square, чтобы возвратиться в main
(т.е. R2), и память для автоматической локальной переменной (т.е. х).
362
Глава 6
Шаг 2: main активирует функцию square для вычисления квадрата
int main()
Адрес возврата R2
{
int a = 10;
cout « а « " squared: "
« square( a ) « end];
return 0; I
-► int square( int x )
{
return x * x;
Стек вызовов после Шага 2
Вершина стека
Активационная
запись для
функции square
Адрес возврата: R2
Автоматические
переменные:
х 10
Активационная
запись для
функции main
Адрес возврата: R1
Автоматические
переменные:
а 10
Рис. 6.15. Стек вызовов после того, как main активирует функцию square
для вычисления квадрата
После того как функция square вычислит квадрат своего аргумента, ей
необходимо вернуться в main, и она больше не нуждается в памяти для
автоматической переменной х. Поэтому из стека выталкивается верхний кадр, что
дает square адрес для возврата в main (т.е. R2) и уничтожает ее
автоматическую переменную. На рис. 6.16 показан стек вызовов после того, как из него
выталкивается активационная запись для square.
Функции и введение в рекурсию
363
ШагЗ: square возвращает свой результат в main
int main()
Адрес возврата R2
{
int a = 10;
cout « а « " squared: "
« square( a ) « end]
return 0; I
->► int square( int x )
return x * x;
Стек вызовов после Шага 3
Вершина стека
Активационная
запись для
функции main
Адрес возврата: R1
Автоматические
переменные:
а 10
Рис. 6.16. Стек вызовов после того, как функция square возвращается в main
Теперь функция main выводит результат функции square (строка 15), а
затем исполняет оператор return (строка 16). Тем самым из стека выталкивается
активационная запись для main, что дает последней адрес для возврата в
операционную систему (т.е. R1 на рис. 6.14) и делает недоступной память для
автоматической локальной переменной main (т.е. а).
Вы видите теперь, насколько ценно понятие стековой структуры данных
для реализации ключевого механизма, поддерживающего исполнение
программы. Структуры данных играют важную роль во многих компьютерных
приложениях. Стеки, очереди, списки, деревья и другие структуры данных
обсуждаются в главах 20 и 22.
6.12. Функции с пустым списком параметров
В C++ пустой список параметров обозначается либо указанием в скобках
ключевого слова void, либо просто пустыми скобками. Прототип
364
Глава 6
void print();
указывает, что функция print не требует никаких аргументов и не возвращает
значений. Рис. 6.17 демонстрирует оба используемых способа объявления
функций с пустым списком параметров.
Переносимость программ 6.2
Смысл пустого списка параметров функции в C++ существенно
отличается от того, что имеет место в С. В С это означает, что
отключаются всякие проверки аргументов (т.е. вызов функции может
передавать любые аргументы). В C++ пустой список явным образом
указывает, что функция не принимает аргументов. Поэтому программы
на С, предполагающие старую семантику пустых списков
параметров, могут вызывать ошибки при компиляции их в C++.
1 // Рис. 6.17: fig06_17.cpp
2 // Функции, не принимающие никаких аргументов.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 void functionl(); // функция, не принимающая аргументов
8 void £unction2( void ); // функция, не принимающая аргументов
9
10 int main()
11 {
12 functionl(); // вызвать functionl без аргументов
13 function2(); // вызвать function2 без аргументов
14 return 0; // покаэьюает успешное завершение
15 } // конец main
16
17 // functionl использует пустой список параметров, чтобы
18 // показать, что функция не принимает никаких аргументов
19 void functionl()
20 {
21 cout « "functionl takes no arguments" « endl;
22 } // конец функции functionl
23
24 // function2 использует пустой список параметров, чтобы
25 // показать, что функция не принимает никаких аргументов
26 void function2( void )
27 {
28 cout « "function2 also takes no arguments" « endl;
29 } // конец функции function2
functionl takes no arguments
function2 also takes no arguments
Рис. 3.18. Два способа объявления и использования функций, не требующих
аргументов
Функции и введение в рекурсию 365
Типичная ошибка программирования 6.13
Программы на C++ не компилируются, если для каждой функции нет
соответствующего ей прототипа или каждая функция не
определяется до того, как она используется.
6.13. Встроенные функции
Реализация программы как набора функций хороша с точки зрения
конструирования программного обеспечения, но с вызовами функций связаны
определенные «накладные расходы» времени выполнения. Для снижения
дополнительных расходов на вызовы функций (особенно небольших) в C++
предусмотрены встроенные функции (inline-функции). Спецификация ключевого
слова inline перед возвращаемым типом в определении функции «советует»
компилятору генерировать вместо обычного вызова встроенную копию кода
функции. Недостатком такого метода является вставка в программу
множественных дубликатов кода функции (что может увеличить ее размер) вместо
единственного экземпляра кода, которому передается управление при каждом
вызове функции. Компилятор может игнорировать спецификацию inline
и обычно так и делает для большинства функций, кроме самых небольших.
Общее методическое замечание 6.11
Любые изменения inline-функции могут потребовать перекомпиляции
всех ее клиентов. Это может оказаться важным моментом в
некоторых ситуациях, возникающих в процессе разработки и сопровождения
программы.
Хороший стиль программирования 6,5
Спецификатор inline следует применять только к небольшим, часто
вызываемым функциям.
Г$Щ
Вопросы производительности 6.4
Использование inline-функции может уменьшить время выполнения
программы, но при этом увеличить ее размер.
Программа на рис. 6.18 использует встроенную функцию cube
(строки 11-14) для вычисления объема куба со стороной side. Ключевое слово const
в списке параметров cube (строка 11) сообщает компилятору о том, что
функция не модифицирует переменную side. Тем самым гарантируется, что
значение side не изменится при выполнении вычислений. (Ключевое слово const
подробно обсуждается в главах 7, 8 и 10.) Обратите внимание, что полное
определение функции cube появляется в программе до ее использования. Это
необходимо для того, чтобы компилятор знал, как расширять вызовы функции во
встроенный код. По этой причине утилизируемые встроенные функции
обычно помещают в заголовочные файлы, чтобы их определения могли включаться
в каждый исходный файл, который их использует.
366
Глава 6
Общее методическое замечание 6.12
Квалификатор const следует применять из соображений принципа
наименьших привилегий. Последовательно проводя принцип
наименьших привилегий в процессе разработки программы, можно
существенно сократить время отладки и нежелательные побочные эффекты,
а также облегчить ее модификацию и сопровождение.
1 // Рис. 6.18: fig06_18.cpp
2 // Использование встроенной функции для вычисления объема куба.
3 #include <iostream>
4 using stdr.cout;
5 using std::cin;
6 using std:rendl;
7
8 // Определение встроенной функции возведения в куб. Определение
9 // появляется до вызова функции, так что прототип для нее не нужен.
10 //В качестве прототипа служит первая строка определения функции.
11 inline double cube( const double side )
12 {
13 return side * side * side; // вычисляет куб
14 } // конец функции cube
15
16 int main ()
17 {
18 double sidevalue; // сохраняет значение, введенное пользователем
19 cout « "Enter the side length of your cube: ";
20 cin » sidevalue; // прочитать пользовательское значение
21
22 // вычислить куб sideValue и вывести результат
23 cout « "Volume of cube with side "
24 « sideValue « " is " « cube( sideValue ) « endl;
25 return 0; // успешное завершение
26 } // конец main
Enter the side length of your cube: 3.5
Volume of cube with side 3.5 is 42.875
Рис. 6.18- Встроенная функция, вычисляющая объем куба
6.14. Ссылки и ссылочные параметры
Во многих языках программирования имеются два способа передачи
аргументов функциям: передача по значению и передача по ссылке. Когда
аргумент передается по значению, создается копия аргумента, и последняя
передается (через стек вызовов) вызываемой функции. Изменения копии не влияют
на значение исходной переменной вызывающего. Это предотвращает
случайные побочные эффекты, препятствующие разработке корректных и надежных
программных систем. Все аргументы, которые передавались функциям в
программах этой главы, передавались по значению.
Функции и введение в рекурсию
367
Вопросы производительности 6.5
Один из недостатков передачи по значению состоит в том, что при
передаче большого объекта копирование может привести к
значительным затратам времени и памяти.
Ссылочные параметры
В этом разделе мы познакомимся со ссылочными параметрами — первым
из двух средств, предусмотренных в C++ для передачи по ссылке. В случае
передачи по ссылке вызывающий предоставляет вызываемой функции прямой
доступ к своим данным и возможность их модификации, если вызываемая
функция решит это сделать.
Вопросы производительности 6.6
Передача по ссылке выгодна по соображениям эффективности,
поскольку она устраняет непроизводительные расходы на копирование
больших объемов данных.
Общее методическое замечание 6.13
Передача по ссылке может ослабить защиту данных, так как
вызываемая функция может повредить данные вызывающего.
Позднее мы покажем, как можно воспользоваться преимуществами вызова
по ссылке в плане эффективности, одновременно обеспечив защиту данных
вызывающей функции.
Ссылочный параметр является псевдонимом соответствующего аргумента
в вызове функции. Для указания того, что параметр функции передается по
ссылке, просто поставьте символ амперсанда (&) после типа параметра в
прототипе функции; то же самое относится к типу в списке параметров заголовка
функции. Например, объявление в заголовке функции
int ficount
прочитанное справа налево, будет звучать как «count является ссылкой на
int». В вызове функции достаточно указать имя переменной, и она будет
передана по ссылке. Тогда обращение к переменной по имени параметра в теле
вызываемой функции будет в действительности относиться к исходной
переменной вызывающего, и исходная переменная может изменяться вызываемой
функцией непосредственно. Как обычно, прототип и заголовок функции
должны согласовываться друг с другом.
Передача аргументов по значению и по ссылке
Программа на рис. 6.19 сравнивает передачу по значению и передачу по
ссылке с помощью ссылочных параметров. Вид аргументов в вызовах
функций squareByValue и squareByReference один и тот же, т.е. обе переменных
просто указываются по имени. Без проверки прототипов или определений
функций по виду вызова невозможно выяснить, какая из этих двух функций
может изменять свой аргумент. Поскольку прототипы функций являются
обязательными, компилятор без труда разрешает эту неопределенность.
368
Глава
1 // Рис. 6.19: fig06_19.cpp
2 // Сравнение передачи по значению и передачи по ссылке.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int squareByValue( int ); // прототип (передача по значению)
8 void squareByReference( int & ); // прототип (передача по ссылке)
9
10 int main()
11 {
12 int x = 2; // воэведится в квадрат вызовом squareByValue
13 int z = 4; // воэведится в квадрат вызовом squareByReference
14
15 // демонстрация squareByValue
16 cout « "х = " « х « " before squareByValue\n";
17 cout « "Value returned by squareByValue: "
18 « squareByValue( x ) « endl;
19 cout « "x = " « x « " after squareByValue\n" « endl;
20
21 // демонстрация squareByReference
22 cout « "z = " « z « " before squareByReference" « endl;
23 squareByReference( z );
24 cout « "z = " « z « " after squareByReference" « endl;
25 return 0; // успешное завершение
26 } // конец main
27
28 // squareByValue умножает number на себя, сохраняет
29 // результат в number и возвращает новое значение number
30 int squareByValue( int number )
31 {
32 return number *= number; // аргумент вызывающего не изменяется
33 } // конец функции squareByValue
34
35 // squareByReference умножает на себя и сохраняет numberRef
36 // в переменной, на которую ссылается numberRef в функции main
37 void squareByReference( int &numberRef )
38 {
39 numberRef *= numberRef; // аргумент вызывающего модифицируется
40 } // конец функции squareByReference
х = 2 before squareByValue
Value returned by squareByValue: 4
x = 2 after squareByValue
z=4 before squareByReference
z = 16 after squareByReference
Рис. 6.19. Передача аргументов по значению и по ссылке
Функции и введение в рекурсию
369
Типичная ошибка программирования 6.14
Поскольку ссылочные параметры упоминаются в теле вызываемой
функции только по имени, программист может нечаянно принять их
за параметры, передаваемые по значению. Это может привести к
неожиданным побочным эффектам, если функция изменит исходные
экземпляры переменных.
В главе 8 мы будем рассматривать указатели; указатели позволяют
использовать альтернативную форму передачи аргументов, в которой способ вызова
ясно указывает на передачу по ссылке (и на возможное изменение аргументов
в операторе вызова).
Вопросы производительности 6.12
Для передачи больших объектов используйте константный
ссылочный параметр, имитирующий вид передачи по значению и в то же
время исключающий непроизводительные расходы на копирование.
Общее методическое замечание 6.14
Многие программисты не объявляют параметры, передаваемые
значением, как const, даже если вызываемая функция не должна
модифицировать переданный аргумент. Квалификатор const в данном
контексте защищает только копию передаваемого аргумента, а не сам
исходный аргумент, который при передаче значением не может быть
изменен вызываемой функцией.
Чтобы определить ссылку как константу, поместите перед спецификатором
типа в объявлении параметра квалификатор const.
Обратите внимание на расположение символа & в списке параметров
функции squareByReference (строка 37 на рис. 6.19). Некоторые программисты
предпочитают писать int& numberRef.
Общее методическое замечание 6.15
По одновременным соображениям ясности и эффективности многие
программисты предпочитают, чтобы модифицируемые аргументы
передавались функциям с помощью указателей (которые изучаются
в главе 8), небольшие аргументы, не подлежащие модификации —
вызовом по значению, а большие немодифицируемые аргументы — с
помощью ссылок на константы.
Ссылки как псевдонимы внутри функции
Ссылки можно также использовать как псевдонимы других переменных
внутри функции (хотя обычно они применяются с функциями так, как
показано на рис. 6.19). Например, код
int count =1; // объявление целой переменной count
int &cRef = count; // создание cRef как псевдонима для count
++cRef; // приращение count (используется ее псевдоним cRef)
370
Глава 6
выполняет инкремент переменной count через ее псевдоним cRef. Ссылочные
переменные должны инициализироваться при объявлении (см. рис. 6.20
и рис. 6.21) и не могут переприсваиваться. Как только ссылка объявляется
как псевдоним другой переменной, все операции, производимые над
псевдонимом (т.е. ссылкой), будут в действительности относиться к исходной
переменной. Ссылка в этом случае — просто другое имя для переменной. Взятие
адреса ссылки и сравнение ссылок не являются синтаксическими ошибками; на
самом деле, каждая операция выполняется над переменной, для которой ссылка
является псевдонимом. Аргумент-ссылка должен быть lvalue (например,
именем переменной), а не выражением, которое возвращает rvalue (например,
результат вычисления). См. определение терминов lvalue и rvalue в разделе 5.9.
1 // Рис. 6.20: fig06_20.cpp
2 // Ссылки должны инициализироваться.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int x = 3;
10 int &y = x; // у ссылается на (является псевдонимом для) х
11
12 cout « "х = " « х « endl « "у = " « у « endl;
13 у=7;//в действительности модифицирует х
14 cout « "х = " « х « endl « "у = " « у « endl;
15 return 0; // успешное завершение
16 } // конец main
х = 3
У = 3
х = 7
У = 7
Рис. 6.20. Инициализация ссылки
Типичная ошибка программирования 6.15
В объявлении ссылочной переменной ей не присваивается начальное
значение.
Типичная ошибка программирования 6.16
Попытка переприсвоить предварительно объявленную ссылку как
псевдоним другой переменной является логической ошибкой. Значение
другой переменной просто присваивается местоположению, для
которого эта ссылка уже является псевдонимом.
;п Типичная ошибка программирования 6.17
Возвращение ссылки на автоматическую переменную вызываемой
функции является логической ошибкой. Некоторые компиляторы
выдают в этом случае предупреждение.
Функции и введение в рекурсию
371
Возврат ссылки
Функции могут возвращать ссылки, но это может быть небезопасным.
Когда возвращается ссылка на переменную, объявленную в вызываемой
функции, эта переменная должна быть объявлена внутри функции как static.
В противном случае ссылка указывает на автоматическую переменную,
которая уничтожается по завершении функции; такая переменная считается
«неопределенной» и поведение программы непредсказуемо. Ссылки на
неопределенные переменные называют «висящими ссылками».
Сообщения об ошибках для неинициализированных ссылок
Стандарт C++ не специфицирует вид сообщений, которые должны
выдавать компиляторы C++ для указания на конкретные ошибки. Поэтому на
рис. 6.21 мы приводим сообщения об ошибке, генерируемые компилятором
командной строки Borland C++ 5.5, компилятором Microsoft Visual C++.NET
и компилятором GNU C++ в случае, когда ссылка не инициализируется.
1 // Рис. 6.21: fig06_21.cpp
2 // Ссылки должны инициализироваться.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int x = 3;
10 int &y; // Ошибка: у должна инициализироваться
11
12 cout « "х = " « х « endl « "у
13 у = 7;
14 cout « "х = " « х « endl « "у
15 return 0; // успешное завершение
16 } // конец main
Сообщение об ошибке компилятора Borland C++ с командной строкой:
Error E2304 C:\examples\ch06\Fig06_21\fig06__21.cpp 10:
Reference variable 'у' must be initialized in function main()
Сообщение об ошибке компилятора Microsoft Visual C++:
C:\examples\ch06\Fig06_21\fig06_21.cppA0) : error C2530: 'у'
references must be initialized
Сообщение об ошибке компилятора GNU C++:
fig06__21.cpp:10: error: 'у' : „
declared as a reference but not initialized
Рис. 6.21. Попытка использования неинициализированной ссылки
« у « endl;
« у « endl;
372
Глава 6
6.15. Аргументы по умолчанию
Нередко случается, что программа многократно вызывает функцию с
одним и тем же аргументом для некоторого параметра. В таких случаях
программист может указать, что для данного параметра имеется аргумент по
умолчанию, т.е. значение, которое по умолчанию должно передаваться
параметру. Когда программа не передает в вызове функции аргумент для такого
параметра, то компилятор генерирует вызов, подставляя в качестве аргумента
его значение по умолчанию.
Аргументы по умолчанию должны быть самыми правыми аргументами
в списке параметров функции. Если вызывается функция с двумя или более
аргументами по умолчанию и если пропущенный аргумент не является самым
правым в списке аргументов, то все аргументы справа от пропущенного тоже
пропускаются. Аргументы по умолчанию должны быть указаны при первом
появлении имени функции — обычно в прототипе функции. Если прототип
как таковой отсутствует и прототипом служит определение функции,
аргументы по умолчанию должны специфицироваться в заголовке функции. Значения
по умолчанию могут быть любыми выражениями, в том числе константами,
глобальными переменными или вызовами функций. Аргументы по
умолчанию можно указывать и для встроенных функций.
Рис. 6.22 демонстрирует использование аргументов по умолчанию при
вычислении объема прямоугольного ящика. Прототип функции boxVolume
(строка 8) специфицирует, что всем трем параметрам дается по умолчанию
значение 1. Заметьте, что для ясности мы указали в прототипе функции имена
переменных. Как всегда, имена переменных в прототипах не являются
обязательными.
Типичная ошибка программирования 6.18
Одновременная спецификация аргументов по умолчанию в прототипе
и заголовке функции приводит к ошибке компиляции.
1 // Рис. 6.22: fig06_22.cpp
2 // Аргументы по умолчанию.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 // прототип функции, специфицирующий аргументы по умолчанию
8 int boxVolume( int length = 1, int width = 1, int height = 1 ) ;
9
10 int main()
11 {
12 // нет аргументов - используются все значения по умолчанию
13 cout « "The default box volume is: " « boxVolume();
14
15 // специфицировать длину; ширина и высота по умолчанию
16 cout « "\n\nThe volume of a box with length 10,\n"
17 « "width 1 and height 1 is: " « boxVolume( 10 );
18
19 // специфицировать длину и ширину; высота по умолчанию
Функции и введение в рекурсию
373
20 cout « "\n\nThe volume of a box with length 10,\n"
21 « "width 5 and height 1 is: " « boxVolume( 10, 5 );
22
23 // специфицировать все аргументы
24 cout « "\n\nThe volume of a box with length 10,\n"
25 « "width 5 and height 2 is: " « boxVolume( 10, 5, 2 )
26 « endl;
27 return 0; // успешное завершение
28 } // конец main
29
30 // функция boxVolume вычисляет объем ящика
31 int boxVolume( int length, int width, int height )
32 {
33 return length * width * height;
34 } // конец функции boxVolume
The default box volume is: 1
The volume of a box with length 10,
width 1 and height 1 is: 10
The volume of a box with length 10,
width 5 and height 1 is: 50
The volume of a box with length 10,
width 5 and height 2 is: 100
Рис. 6.22. Аргументы функции по умолчанию
В первом вызове функции boxVolume (строка 13) не указано никаких
аргументов, поэтому используются все три значения по умолчанию (равные 1). Во
втором вызове (строка 17) передается аргумент length, поэтому значения по
умолчанию используются для аргументов width и height. В третьем вызове
(строка 21) передаются аргументы width и height, поэтому значение по
умолчанию используется только для аргумента height. В последнем вызове
(строка 25) передаются аргументы length, width и height, поэтому значения по
умолчанию не используются. Обратите внимание, что любые аргументы,
передаваемые функции явно, присваиваются ее параметрам слева направо. Таким
образом, когда boxVolume получает один аргумент, функция присваивает его
значение своему параметру length (т.е. самому левому в списке параметров).
Когда boxVolume получает два аргумента, их значения присваиваются
параметрам length и width (именно в такой последовательности). Наконец, когда
boxVolume получает все три аргумента, функция присваивает их значения
параметрам в последовательности length, width и height.
Хороший стиль программирования 6.6
Задание аргументов по умолчанию может упростить написание
вызовов функции. Однако некоторые программисты считают, что для
ясности лучше явно специфицировать все аргументы.
374
Глава 6
Общее методическое замечание 6.16
Если значения аргументов по умолчанию изменяются, код всех
клиентов функции должен компилироваться заново.
Типичная ошибка программирования 6.19
Спецификация и попытка использовать аргумент по умолчанию, не
являющийся самым правым (последним) аргументом (если
одновременно не используются умолчания и для всех аргументов справа от
него), является синтаксической ошибкой.
6.16. Унарная операция разрешения области действия
Вполне допустимым является объявление локальной и глобальной
переменных с одним и тем же именем. В C++ предусмотрена унарная операция
разрешения области действия (::) для доступа к глобальной переменной, когда в
области действия имеется локальная переменная с тем же именем. Унарная операция
разрешения области действия не позволяет обратиться к локальной переменной,
объявленной с тем же именем во внешнем блоке. Глобальная переменная может
быть доступна и непосредственно без операции разрешения области действия,
если в текущей области действия нет локальной переменной с тем же именем.
Рис. 6.23 демонстрирует применение унарной операции разрешения
области действия для случая локальной и глобальной переменных, имеющих одно
и то же имя (строки 7 и 11). Чтобы подчеркнуть различие локальной и
глобальной версий переменной number, программа объявляет одну из этих
переменных как int, а другую как double.
Применение унарной операции разрешения области действия к некоторому
имени переменной не обязательно, если единственной переменной с таким
именем является глобальная переменная.
1 // Рис. 6.23: fig06_23.cpp
2 // Унарная операция разрешения области действия.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int number = 7; // глобальная переменная с именем number
8
9 int main()
Ю {
11 double number = 10.5; // локальная переменная с именем number
12
13 // вывести значения локальной и глобальной переменных
14 cout « "Local double value of number = " « number
15 « "\nGlobal int value of number = " « ::number « endl;
16 return 0; // успешное завершение
17 } // конец main
Local double value of number =10.5
Global int value of number = 7
Рис. 6.23. Унарная операции разрешения области действия
Функции и введение в рекурсию
375
Типичная ошибка программирования 6.20
Попытка получить доступ к не глобальной переменной внешнего
блока, используя унарную операцию разрешения области действия,
является ошибкой. Если не существует глобальной переменной с таким
именем, происходит ошибка компиляции. Если глобальная переменная
с таким именем существует, то это —логическая ошибка, так как
программа будет обращаться к глобальной переменной, а не
переменной во внешнем блоке, которую вы имели в виду.
Хороший стиль программирования 6.7
Всегда используйте унарную операцию разрешения области действия
(::) для ссылки на глобальные переменные; это упрощает чтение и
понимание программ, поскольку ясно указывает, что вы хотите
обратиться к глобальной, а не к локальной переменной.
Общее методическое замечание 6.17
Использование унарной операции разрешения области действия (::)
для ссылки на глобальные переменные упрощает модификацию
программ за счет уменьшения риска возникновения коллизии имен с не
глобальными переменными.
Предотвращение ошибок 6.4
Всегда используйте унарную операцию разрешения области действия
(::) для ссылки на глобальную переменную; это устраняет
возможность логических ошибок, которые могут возникнуть, если не
глобальная переменная скрывает глобальную.
Предотвращение ошибок 6.5
Избегайте использования в программе переменных с одинаковыми
именами для разных целей. Это допускается в различных случаях, но
может приводить к путанице.
6.17. Перегрузка функций
C++ позволяет определить несколько функций с одним и тем же именем,
если эти функции имеют различные наборы параметров (различные в том, что
касается типа или числа параметров, либо порядка следования их типов). Эта
возможность называется перегрузкой функций. Когда вызывается
перегруженная функция, компилятор C++ выбирает нужную функцию путем анализа
числа, типов и порядка аргументов в вызове. Перегрузка функций
используется обычно для создания нескольких функций с одинаковыми именами,
выполняющих сходные задачи, но над различными типами данных. Например,
многие функции математической библиотеки перегружены для различных
числовых типов данных.1
Стандарт C++ требует перегрузки функций математической библиотеки,
обсуждавшихся в разделе 6.3, для типов float, double и long double.
376
Глава 6
Хороший стиль программирования 6.8
Перегруженные функции, которые выполняют тесно связанные
задачи, делают программы более удобочитаемыми и понятными.
Перегруженные функции square
На рис. 6.24 показаны перегруженные функции square для расчета
квадрата переменной типа int (строки 8-12) и типа double (строки 15-19). Строка 23
активирует версию square для типа int, поскольку в вызове передается
литеральное значение 7. В C++ целочисленные литералы по умолчанию
интерпретируются как значения типа int. Аналогичным образом строка 25 активирует
версию square для double путем передачи в вызове литерального значения 7.5,
которое C++ по умолчанию интерпретирует как double. В обоих случаях
компилятор выбирает нужную функцию, исходя из типа аргумента. Две строки
в окне вывода подтверждают, что в каждом случае была вызвана правильная
функция.
1 // Рис. 6.24: fig06_24.cpp
2 // Перегруженные функции.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
б
7 // функция square для значений типа int
8 int square( int x )
9 {
10 cout « "square of integer " « x « " is ";
11 return x * x;
12 } // конец функции square с аргументом int
13
14 // функция square для значений типа double
15 double square( double у )
16 {
17 cout « "square of double " « у « " is ";
18 return у * у;
19 } // конец функции square с аргументом double
20
21 int main()
22 {
23 cout « square( 7 ); // вызывает int-версию
24 cout « endl;
25 cout « square( 7.5 ); // вызывает double-версию
26 cout « endl;
27 return 0; // успешное завершение
28 } // конец main
square of integer 7 is 49
square of double 7.5 is 56.25
Рис. 6.24. Перегруженные функции square
Функции и введение в рекурсию
377
Как компилятор различает перегруженные функции
Перегруженные функции различаются по их сигнатурам. Сигнатура — это
комбинация имени функции и типов ее параметров (в определенном порядке).
Компилятор кодирует идентификатор каждой функции в зависимости от
числа и типа параметров (иногда это называется декорированием имени), чтобы
обеспечить безопасную по типу компоновку. Безопасная по типу компоновка
гарантирует, что будет вызвана нужная функция и что ее аргументы будут
согласованы по типу с параметрами.
Программа на рис. 6.25 транслировалась компилятором Borland C++ с
командной строкой. Вместо результатов работы программы (как мы обычно
делали раньше) мы показали декорированные имена функций, генерированные
Borland C++ на языке ассемблера. Каждое декорированное имя начинается
с символа @, за которым следует имя функции. Имя функции отделяется от
закодированного списка параметров символами $q. В списке параметров для
функции nothing2 (строка 25; см. четвертую строчку вывода) с представляет
тип char, i представляет int, rf представляет float& (т.е. ссылку на float) и rd
представляет doubled (т.е. ссылку на double). В списке параметров для
nothingl параметр i представляет тип int, f представляет float, с представляет
char и ri представляет int&. Две функции square различаются по спискам
параметров; одна специфицирует d для double, а другая — i для int.
Возвращаемые типы функций не отражаются в декорированных именах. Перегруженные
функции могут иметь различные возвращаемые типы, но в этом случае они
должны иметь и различные списки параметров. В программе не может быть
двух функций с одинаковыми сигнатурами и различными возвращаемыми
типами.
1 // Рис. 6.25: fig06_25.cpp
2 // Декорирование имен.
3
4 // функция square для значений типа int
5 int square( int x )
6 {
7 return x * x;
8 } // конец функции square
9
10 // функция square для значений типа double
11 double square( double у )
12 {
13 return у * у;
14 } // конец функции square
15
16 // функция, принимающая аргументы типов
17 // int, float, char и int &
18 void nothingl( int a, float b, char c, int &d )
19 {
20 // пустое тело функции
21 } // конец функции nothingl
22
23 // функция, принимающая аргументы типов
24 // char, int, float & и double &
25 int nothing2( char a, int b, float &c, double &d )
26 {
378
Глава 6
27 return 0;
28 } // конец функции nothing2
29
30 int main()
31 {
32 return 0; // успешное завершение
33 } // конец main
@square$qi
@square$qd
@nothing$qifcri
@nothing$qcirfrd
main
Рис. 6.25. Декорирование имен, обеспечивающее безопасную по типу компоновку
Типичная ошибка программирования 6.21
Определение перегруженных функций с идентичными списками
параметров и различными возвращаемыми типами приводит к ошибке
компиляции.
Для различения функций с одинаковыми именами компилятор использует
только списки параметров. Перегруженные функции не обязательно должны
иметь одинаковое число параметров. Программисту следует соблюдать
осторожность, перегружая функции с аргументами по умолчанию, поскольку это
может приводить к неоднозначности.
Типичная ошибка программирования 6.22
Вызов функции с пропущенными аргументами по умолчанию может
быть неотличим по виду от вызова другой перегруженной функции,
что приведет к ошибке компиляции. Например, если в программе
имеется как функция, явно не принимающая аргументов, так и функция
с тем же именем, все аргументы которой имеют значения по
умолчанию, то при попытке использовать это имя функции в вызове, не
передающем аргументов, произойдет ошибка компиляции.
Перегруженные операции
В главе 11 мы обсудим, каким образом осуществляется перегрузка
операций, которая позволяет определить их действия с объектами определенных
пользователем типов. (На самом деле мы уже давно пользовались
перегруженными операциями, в том числе операциями передачи в поток « и извлечения
из потока », каждая из которых перегружена для вывода или ввода данных
всех основных типов. О перегрузке операций « и » для объектов
пользовательских типов мы расскажем подробнее в главе 11.) В следующем разделе мы
представляем шаблоны функций, которые автоматически генерируют
перегруженные функции, выполняющие одни и те же задачи с различными
типами данных.
Функции и введение в рекурсию
379
6.18. Шаблоны функций
Перегруженные функции обычно используются для выполнения сходных
действий, связанных с различной программной логикой для различных типов
данных. Если программная логика и действия для всех типов идентичны, это
можно выполнить более компактно и удобно, используя шаблоны функций.
Программист пишет единственное определение шаблоне функции. Исходя на
типа аргументов, указанных в вызовах этой функции, C++ автоматически
генерирует разные специализации шаблона функции для соответствующей
обработки каждого типа вызовов. Таким образом, определение единственного
шаблона по существу определяет целое семейство перегруженных функций.
На рис. 6.24 показано определение шаблона для функции maximum,
которая находит наибольшее из трех значений. Все определения шаблонов
функций начинаются с ключевого слова template (строка 4), за которым следует
список параметров шаблона, заключенный в угловые скобки (< и >). Каждый
параметр в списке параметров шаблона (называемый часто формальным
параметром типа) предваряется либо ключевым словом typename, либо
ключевым словом class. Формальные параметры типа являются заместителями либо
основных типов, либо типов, определяемых пользователем. Они используются
для спецификации типов аргументов функции (строка 5), спецификации
возвращаемого типа (строка 5) и для объявления переменных внутри тела
определения функции (строка 7). Шаблон функции определяется так же, как и
любая другая функция, только вместо действительных типов данных шаблон
использует формальные типы в качестве их заместителей.
Шаблон функции на рис. 6.26 объявляет единственный формальный
параметр типа Т (строка 4) как заместитель типа данных, который должен
проверяться функцией maximum. Имя формального типа должно быть уникальным
в списке параметров данного определения шаблона. Когда компилятор
обнаруживает в исходном коде программы вызов maximum, тип данных,
передаваемых maximum, подставляется вместо Т всюду в определении шаблона, и C++
создает законченную функцию для определения максимального из трех
значений указанного типа данных. Затем вновь созданная функция компилируется.
Таким образом, шаблоны по сути являются средством генерации кода.
*п Типичная ошибка программирования 6.23
Отсутствие ключевого слова class или typename перед каким-либо
формальным параметром шаблона функции (т.е. написание < class S,
Т > вместо < class S, class T > является синтаксической ошибкой.
1 // Рис. 6.26: maximum.h
2 // Определение шаблона функции maximum.
3
4 template < class T > // или template< typename T >
5 Т maximum( T valuel, T value2, T value3 )
6 {
7 Т maximumValue = valuel; // предположим, valuel - максимум
8
9 // определить, не является ли value2 большим maximumValue
10 if ( value2 > maximumValue )
380
Глава 6
11 maximumValue = value2;
12
13 // определить, не является ли value3 большим maximumValue
14 if ( value3 > maximumValue )
15 maximumValue = value3;
16
17 return maximumValue;
18 } // конец шаблона функции maximum
Рис. 6.26. Заголовочный файл шаблона функции maximum
Программа на рис. 6.27 иллюстрирует использует шаблон функции
maximum (строки 20, 30 и 40) для нахождения наибольшего из трех значений
типа int, трех значений типа double и трех значений типа char.
1 // Рис. 6.27: fig06_27.cpp
2 // Тестовая программа для шаблона функции maximum.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 #include "maximum.h" // включить шаблон функции maximum
9
10 int main()
11 {
12 // демонстрация maximum со значениями типа int
13 int intl, int2, int3;
14
15 cout « "Input three integer values: ";
16 cin » intl » int2 » int3;
17
18 // вызвать int-версию maximum
19 cout « "The maximum integer value is: "
20 « maximum( intl, int2, int3 );
21
22 // демонстрация maximum со значениями типа double
23 double doublel, double2, double3;
24
25 cout « "\n\nlnput three double values: ";
26 cin » doublel » double2 » double3;
27
28 // вызвать double-версию maximum
29 cout « "The maximum double value is: "
30 « maximum( doublel, double2, double3 );
31
32 // демонстрация maximum со значениями типа char
33 char charl, char2, char3;
34
35 cout « "\n\nlnput three characters: ";
36 cin » charl » char2 » char3;
37
38 // вызвать char-версию maximum
39 cout « "The maximum character value is: "
40 « maximum( charl, char2, char3 ) « endl;
Функции и введение в рекурсию
381
41 return 0; // успешное завершение
42 } // конец main
Input three integer values: 12 3
The maximum integer value is: 3
Input three double values: 3.3 2.2 1.1
The maximum double value is: 3.3
Input three characters: А С В
The maximum character value is: С
Рис. 6.27. Демонстрация шаблона функции maximum
В результате вызовов в строках 20, 30 и 40 на рис. 6.27 создаются три
функции — ожидающих соответственно передачи трех значений типа int, трех
значений типа double трех значений типа char. Специализация шаблона функции
для типа int заменяет каждое вхождение Т на int:
int maximum( int valuel, int value2, int value3 )
{
int maximumValue = valuel;
// определить, не является ли value2 большим maximumValue
if ( value2 > maximumValue )
maximumValue = value2;
// определить, не является ли value3 большим maximumValue
if ( value3 > maximumValue )
maximumValue = value3;
return maximumValue;
} // конец шаблона функции maximum
6.19. Рекурсия
Программы, которые мы обсуждали до сих пор, были структурированы как
совокупности функций, вызывающих друг друга с соблюдением строгой
иерархии. В некоторых случаях полезно иметь функции, которые вызывают
самих себя. Рекурсивная функция — это функция, которая вызывает саму себя
либо непосредственно, либо косвенно (через другую функцию).1 Рекурсия
является важной темой, подробно разбираемой в специальных курсах
программирования. В этом и последующем разделах представлены простые примеры
рекурсии. В этой книге вопросы рекурсии рассматриваются достаточно
широко. На рис. 6.33 (в конце раздела 6.21) дается сводка примеров и упражнений
на рекурсию, представленных в книге.
Сначала мы рассмотрим концепцию рекурсии, а затем разберем несколько
программ, содержащих рекурсивные функции. Рекурсивные методы решения
Хотя многие компиляторы допускают, чтобы функция main вызывала саму себя,
параграф 3 раздела 6.3.1 стандартного документа C++ постулирует, что функция
main не должна вызываться внутри программы. Ее единственным назначением
является определение начальной точки для исполнения программы.
382
Глава 6
различных задач имеют некоторые общие элементы. Для решения задачи
вызывается рекурсивная функция. Эта функция в действительности знает
только, как решается простейший, так называемый основной случай задачи (или
несколько таких случаев). Если рекурсивная функция вызывается для
решения основного случая, она просто возвращает результат. Если рекурсивная
функция вызывается для решения более сложной задачи, она обычно делит
задачу на две концептуальные части: одну часть, которую функция умеет
решать, и другую, которую функция решать не умеет. Чтобы рекурсивное
решение было работоспособным, последняя часть должна быть похожа на исходную
задачу, но быть по сравнению с ней несколько проще или несколько меньше.
Поскольку эта новая задача подобна исходной, функция запускает (вызывает)
свой новый экземпляр, который будет работать над меньшей задачей; это
называется рекурсивным вызовом или шагом рекурсии. Шаг рекурсии тесно
связан с исполнением оператора return, так как возвращаемый рекурсивным
шагом результат будет комбинироваться с той частью задачи, которую функция
умеет решать, что даст конечный результат, передаваемый обратно
первоначальной вызывающей функции, возможно, функции main.
Шаг рекурсии выполняется при еще не закрытом исходном вызове
функции, т.е. когда исполнение функции еще не закончилось. Шаг рекурсии может
приводить к большому числу таких рекурсивных вызовов, поскольку
функция продолжает деление на две части каждой новой подзадачи. Чтобы
рекурсия могла завершиться, все новые и новые вызовы функцией самой себя, для
все более упрощающихся вариантов исходной задачи, должны образовывать
последовательность, сходящуюся в конце концов к основному случаю. В этот
момент функция распознает основной случай, возвращает результат своему
предыдущему экземпляру, и последовательность возвратов проходит весь путь
вызовов в обратном направлении, пока первоначальный вызов не возвратит
окончательный результат функции main. Все это звучит довольно экзотично
по сравнению с теми «традиционными» решениями, с которыми мы имели
дело до сих пор. В качестве примера того, как работает концепция рекурсии,
мы разберем рекурсивную программу для одного распространенного
математического вычисления.
Факториал неотрицательного целого числа /г, обозначаемый п\
(произносится эн-факториал), определяется как произведение
п • (п - 1) (л - 2) • ... • 1
причем 1! = 1 и 0! = 1. Например, 5! вычисляется как 5 • 4 • 3 • 2 • 1 и равен 120.
Факториал целого числа number, большего или равного 0, может быть
вычислен итеративно (нерекурсивно) с помощью оператора for следующим образом:
factorial = 1;
for ( int counter = number; counter >= 1; counter— )
factorial *= counter;
Рекурсивное определение функции factorial можно получить, заметив
следующую закономерность:
п\ = п • (п - 1)!
Функции и введение в рекурсию
383
Например, 5! равен, очевидно, 5 * 4!, поскольку
5! = 5 • 4 • 3 • 2 • 1
5! = 5 • D • 3 • 2 • 1)
5! = 5 • D!)
Оценка значения 5! происходила бы так, как показано на рис. 6.28.
Рис. 6.28 (а) показывает, как протекает процесс рекурсивных вызовов, пока 1!
не будет оценен значением 1, что приведет к завершению рекурсии. Рис. 6.28
(Ь) показывает значения, которые каждый из рекурсивных вызовов
возвращает своему вызывающему, пока не будет вычислено и возвращено
окончательное значение.
Итоговое значение 120
5! 5!
1 t
■ 41 с
1 '!
'3! 4
1 1
*2\ 3
1 I
г 1! 2
I t
возвращается 5! = 5 * 24 = 120
5*4! 5*4!
возвращается 4! = 4 * б = 24
4*3! 4*3!
возвращается 3! = 3 * 2 = б
3*2! 3*2!
возвращается 2! = 2 * 1 = 2
2*1! 2*1!
возвращается 1
1 1
а) Процесс рекурсивных вызовов б) Значения, возвращаемые после каждого
рекурсивного вызова
Рис. 6.28. Рекурсивная оценка значения 5!
Программа на рис. 6.29 рекурсию вычисляет и печатает факториалы целых
чисел от 0 до 10. (Выбор типа данных unsigned long мы сейчас объясним.)
Рекурсивная функция factorial (строки 23-29) сначала проверяет, выполнено ли
условие завершения рекурсии number <= 1 (строка 25). Если number
действительно меньше или равно 1, функция factorial возвращает 1 (строка 26),
дальнейшей рекурсии не требуется и функция завершается. Если number
больше 1, оператор в строке 28 представляет задачу как произведение переменной
384
Глава 6
number и рекурсивного вызова factorial для оценки факториала number — 1.
Заметьте, что factorial( number — 1 ) является чуть более простой задачей, чем
исходное вычисление factorial( number ).
1 // Рис. 6.29: fig06_29.cpp
2 // Тестирование рекурсивной функции факториала.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 unsigned long factorial( unsigned long ) ; // прототип функции
11
12 int main()
13 {
14 // вычислить факториал для эначенией от 0 до 10
15 for ( int counter = 0; counter <= 10; counter++ )
16 cout « setw( 2 ) « counter « "! = " « factorial( counter )
17 « endl;
18
19 return 0; // успешное завершение
20 } // конец main
21
22 // рекурсивное определение функции факториала
23 unsigned long factorial( unsigned long number )
24 {
25 if ( number <= 1 ) // проверить на основной случай
26 return 1; // основные случаи: 0! = 1 and 1! = 1
27 else // рекурсивный шаг
28 return number * factorial( number - 1 );
29 } // конец функции factorial
0!
1!
2!
3!
4!
5!
б!
7!
8!
9!
10!
=
=
=
=
=
=
=
=
=
=
=
1
1
2
6
24
120
720
5040
40320
362880
3628800
Рис. 6.29. Демонстрация функции factorial
В объявлении функции factorial указано, что она принимает параметр типа
unsigned long и возвращает результат типа unsigned long. Это сокращенная
запись для unsigned long int. Стандартный документ C++ требует, чтобы
переменная типа unsigned long int хранилась по крайней мере в 4-х байтах C2
битах); таким образом, она может содержать значения в диапазоне не уже, чем от
О до 4294967295. (Тип данных long int также хранится по крайней мере в 4-х
Функции и введение в рекурсию
385
байтах и может содержать значения в диапазоне не уже, чем от -2147483648 до
2147483647). Как можно видеть из рис. 29, значения факториала возрастают
очень быстро. Мы выбрали тип данных unsigned long, чтобы программа могла
вычислять факториалы, большие 7!, на компьютерах с малыми B-байтовыми)
целыми. К сожалению, функция factorial начинает вырабатывать большие
значения так быстро, что даже unsigned long не позволяет нам напечатать много
значений факториала, прежде чем они превысят предел для этого типа.
В упражнениях исследуется использование для вычисления факториалов
больших чисел переменных типа double. Это указывает на недостаток
большинства языков программирования, а именно на то, что языки общего назначения
не так просто расширить, чтобы они удовлетворяли уникальным требованиям
некоторых приложений. Как мы узнаем по ходу более глубокого изучения
объектно-ориентированного программирования, язык C++ является расширяемым
языком, позволяющим при желании создавать классы, которые способны
представлять произвольно большие целые числа. Такие классы имеются в
некоторых популярных классовых библиотеках,1 и мы будем работать над своими
собственными аналогичными классами в упражнениях 9.14 и 11.5.
Wi
Типичная ошибка программирования 3.20
Как пропуск обработки основного случая, так и неправильное
написание шага рекурсии, так что он не сходится к основному случаю,
приводят к «бесконечной» рекурсии, которая в конце концов исчерпывает
наличную память. Эта ситуация аналогична проблеме бесконечного
цикла в итеративных (нерекурсивных) решениях.
6.20. Пример рекурсии: числа Фибоначчи
Ряд Фибоначчи
0, 1, 1, 2, 3, 5, 8, 13, 21, ...
начинается с 0 и 1 и обладает тем свойством, что каждое последующее число
Фибоначчи представляет собой сумму двух предыдущих. Этот ряд часто
встречается в природе, в частности, он описывает форму спирали. Отношение
последовательных чисел Фибоначчи сходится к постоянной величине 1,618... Это
число также часто встречается в природе и называется золотым сечением или
золотым средним. Люди склонны рассматривать золотое сечение как
источник эстетического наслаждения. Архитекторы часто проектируют окна,
комнаты и здания так, что их длина и ширина находятся в отношении золотого
среднего. Часто можно встретить почтовые открытки с таким отношением
длины и ширине.
Ряд Фибоначчи можно рекурсивно определить следующим образом:
fibonacci( 0 ) = 0
fibonacci( 1 ) = 1
fibonacci( n ) = fibonacci( n - 1 ) + fibonacci( n - 2 )
l
Такие классы можно найти на shoup.net/ntl, cliodhna.cop.uop.edu/~hetrick/c-sources.html
и wwwinimphurst.coni/cpplibs/datapa^e.phtm^categorj^intro'.
13 Зак. 1114
386
Глава 6
В программе на рис. 6.30 n-е число Фибоначчи вычисляется рекурсивно
с помощью функции fibonacci. Заметьте, что числа Фибоначчи также имеют
тенденцию к быстрому росту, хотя и более медленному, чем факториалы.
Поэтому в функции fibonacci и для параметра, и для возвращаемого значения мы
выбрали тип unsigned long. На рис. 6.30 показано исполнение программы,
которая выводит числа Фибоначчи для некоторых порядковых номеров.
1 // Рис. б.30: fig06_30.cpp
2 // Тестирование рекурсивной функции вычисления чисел Фибоначчи.
3 #include <iostream>
4 using std::cout;
5 using std:rein;
6 using std::endl;
7
8 unsigned long fibonacci( unsigned long ); // прототип функции
9
10 int main()
11 {
12 // вычислить числа Фибоначчи с номерами от 0 до 10
13 for ( int counter = 0; counter <= 10; counter++ )
14 cout « "fibonacci( " « counter « " ) = "
15 « fibonacci( counter ) « endl;
16
17 // вывести числа Фибоначчи с более высокими номерами
18 cout « "fibonacci( 20 ) = " « fibonacci( 20 ) « endl;
19 cout « "fibonacci( 30 ) = " « fibonacci( 30 ) « endl;
20 cout « "fibonacci( 35 ) = " « fibonacci( 35 ) « endl;
21 return 0; // успешное завершение
22 } // конец main
23
24 // рекурсивный метод вычисления чисел Фибоначчи
25 unsigned long fibonacci( unsigned long number )
26 {
27 if ( ( number == 0 ) || ( number == 1 ) ) // основные случаи
28 return number;
29 else // рекурсивный шаг
30 return fibonacci( number - 1 ) + fibonacci( number - 2 ) ;
31 } // конец функции fibonacci
fibonacci( 0 ) = 0
fibonacci( 1 ) = 1
fibonacci( 2 ) = 1
fibonacci( 3 ) = 2
fibonacci( 4 ) = 3
fibonacci( 5 ) = 5
fibonacci( 6 ) = 8
fibonacci ( 7 ) = 13
fibonacci ( 8 ) = 21
fibonacci( 9 ) = 34
fibonacci( 10 ) =55
fibonacci( 20 ) = 6765
fibonacci( 30 ) = 832040
fibonacci( 35 ) = 9227465
Рис. 6.30. Демонстрация функции fibonacci
Функции и введение в рекурсию
387
Приложение начинается с оператора for, который вычисляет и выводит
числа Фибоначчи с номерами от 1 до 10. За ним следуют три вызова,
вычисляющих числа Фибоначчи с номерами 20, 30 и 35 (строки 18-20). Вызовы
функции fibonacci из main (в строках 15, 18, 19 и 20) не являются
рекурсивными, но вызовы в строке 30 внутри fibonacci — рекурсивные. При каждом
вызове fibonacci (строки 25-31) эта функция сразу проверяет, не относится ли
вызов к основным случаям, т.е. не равно ли number нулю или единице
(строка 27). Если это так, строка 28 возвращает number. Интересно, что при
number, большем 1, шаг рекурсии (строка 30) генерирует два рекурсивных вызова,
каждый из которых представляет собой несколько упрощенную задачу по
сравнению с исходным вызовом fibonacci. На рис. 6.31 показано, как функция
fibonacci оценивает fibonacci( 3 ).
return fibonacci( 2) + fibonacci( 1 )
1 1
return fibonacci( 1 ) + fibonacci(O) return 1
i 1
return 1 return 0
Рис.6.31. Рекурсивные вызовы функции fibonacci
Этот рисунок ставит некоторые интересные вопросы относительно порядка,
в котором компиляторы C++ будут оценивать операнды операций. Это не имеет
отношения к порядку применения операций к операндам, т.е. порядку,
диктуемому правилами старшинства и ассоциации. Из рис. 6.31 видно, что оценка
fibonacci( 3 ) порождает два рекурсивных вызова, а именно, fibonacci( 2 )
и fibonacci( 1 ). Но в каком порядке производятся эти вызовы?
Большинство программистов просто полагает, что операнды будут
оцениваться слева направо. Язык C++ не специфицирует порядок, в котором
должны оцениваться операнды большинства операций (включая +). Поэтому
программист не может делать каких-либо предположений насчет того, в каком
порядке будут производиться эти вызовы. Эти вызовы могли бы в
действительности выполнить сначала fibonacci( 2 ), потом fibonacci( 1 ), а могли бы
и в обратном порядке: сначала fibonacci( 1 ), потом fibonacci( 2 ). В этой
и большинстве других программ оказывается, что конечный результат будет
тем же самым. Однако в некоторых программах оценка операндов может да-
388 Глава 6
вать побочные эффекты (изменение значений данных), которые повлияют на
окончательный результат выражения.
Язык C++ определяет порядок оценки операндов только для четырех
операций, а именно &&, | |, операции-запятой (,) и условной операции (? :). Первые
три являются бинарными (двухместными) операциями, операнды которых
гарантированно вычисляются слева направо. Последняя операция —
единственная тернарная операция в C++. Первым всегда оценивается самый левый
операнд; если результат его оценки ненулевой (истинный), то следующим
оценивается средний операнд, а последний операнд игнорируется; если же результат
оценки самого левого операнда равен нулю (ложный), то следующим
оценивается третий операнд, а средний игнорируется.
Типичная ошибка программирования 6.25
Написание программ, которые предполагают определенный порядок
оценки операндов операций, отличных от &&, | \, операции-запятой (,)
и условной операции (? :), может приводить к логическим ошибкам.
Переносимость программ 6.3
Программы, предполагающие определенный порядок оценки операндов
операций, отличных от &&, | \, операции-запятой (,) и условной
операции (? :), могут работать по-разному на системах с различными
компиляторами.
Следует высказать одно предостережение относительно рекурсивных
программ, подобных той, которую мы использовали для генерации чисел
Фибоначчи. Каждый уровень рекурсии в функции fibonacci удваивает число ее
вызовов; другими словами, число рекурсивных вызовов, необходимых для
вычисления л-го числа Фибоначчи, оказывается порядка 2п. Объем работы
нарастает слишком быстро. Вычисление только 20-го числа Фибоначчи
требует порядка 220, или около миллиона вызовов, вычисление 30-го числа
Фибоначчи требует порядка 230, или около миллиарда вызовов и т.д. В теории
численных методов это называется экспоненциальной сложностью. Проблемы
такого рода не под силу даже самым мощным компьютерам в мире! Вопросы
сложности вообще, и экспоненциальной сложности в частности, детально
рассматриваются в специальных курсах, обычно называемых «Алгоритмы».
Вопросы производительности 6.8
Избегайте рекурсивных программ, подобных программе для чисел
Фибоначчи, которые приводят к «экспоненциальному взрыву» вызовов.
6.21. Рекурсия в сравнении с итерацией
В предыдущих разделах мы рассмотрели две функции, которые можно
легко реализовать как рекурсивно, так и итеративно. В этом разделе мы сравним
эти два подхода и обсудим соображения, исходя из которых программист
может предпочесть в конкретной ситуации тот или иной подход.
т
Функции и введение в рекурсию
389
Как итерация, так и рекурсия основаны на управляющих структурах:
в основе итерации лежит структура повторения, в основе рекурсии —
структура выбора. Как итерация, так и рекурсия связаны с повторениями:
итерация явным образом использует структуру повторения, рекурсия реализует
повторение посредством многократных вызовов функции. Как итерация, так
и рекурсия производят проверку условия окончания: итерация завершается
при нарушении условия продолжения цикла, рекурсия завершается при
распознавании основного случая. Как итерация с повторением, управляемым
счетчиком, так и рекурсия постепенно приближаются к своему
завершению: итерация модифицирует счетчик, пока он не достигнет значения, при
котором условие продолжения цикла становится ложным; рекурсия
порождает все более простые варианты исходной задачи, пока не будет достигнут
основной случай. Как итерация, так и рекурсия могут оказаться
бесконечными: при итерации возникает бесконечный цикл, если условие продолжения
цикла никогда не становится ложным; бесконечная рекурсия возникает,
когда шаг рекурсии не упрощает исходную задачу таким образом, чтобы она
сходилась к основному случаю.
Чтобы проиллюстрировать различия между итерацией и рекурсией,
рассмотрим итеративное решение задачи факториала (рис. 6.32). Обратите
внимание, что вместо оператора выбора, использованного в рекурсивном решении
(строки 28-29 на рис. 6.29), здесь используется оператор повторения
(строки 24-27 на рис. 6.32). Заметьте также, что оба решения производят проверку
завершения. В рекурсивном решении строка 24 производит проверку на
предмет основного случая. В итеративном решении строка 28 проверяет условие
продолжения цикла — если условие не удовлетворяется, цикл завершается.
Наконец, заметьте, что вместо порождения более простых вариантов исходной
задачи итеративное решение использует счетчик, модифицируемый до тех
пор, пока условие продолжения не станет ложным.
1 // Рис. 6.32: fig06_32.cpp
2 // Тестирование итеративного метода вычисления факториала.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 unsigned long factorial( unsigned long ); // прототип функции
11
12 int main()
13 {
14 // вычислить факториал для эначенией от 0 до 10
15 for ( int counter = 0; counter <= 10; counter++ )
16 cout « setw( 2 ) « counter « " ! = " « f actorial ( counter )
17 « endl;
18
19 return 0;
20 } // конец main
21
22 // итеративный метод вычисления факториала
23 unsigned long factorial( unsigned long number )
390
Глава 6
24 {
25 unsigned long result = 1;
26
27 // итеративное вычисление факториала
28 for ( unsigned long i = number; i >= 1; i— )
29 result *= i;
30
31 return result;
32 } // конец функции factorial
0! = 1
1! = 1
2! = 2
3! = 6
4! = 24
5» = 120
б! = 720
7! = 5040
8! = 40320
9! = 362880
10! = 3628800
Рис. 6.32. Итеративное решение для факториала
Рекурсия имеет много недостатков. Она многократно активирует механизм
вызовов — отсюда рост «накладных расходов». Они могут оказаться слишком
расточительными как в плане процессорного времени, так и в плане объема
памяти. Каждый рекурсивный вызов приводит к созданию нового экземпляра
функции (на самом деле создаются только новые экземпляры ее переменных);
на это может расходоваться значительная память. Итерация обычно
происходит внутри функции, так что накладные расходы на многократные вызовы
и выделение дополнительной памяти исключаются. Тогда для чего же
применять рекурсию?
Общее методическое замечание 6.18
Любую задачу, которая может быть решена рекурсивно, можно
решить и итеративно (нерекурсивно). Обычно рекурсивный подход
предпочитают итеративному, если он более естественно отражает
задачу и дает в результате программу, которую проще понять и
отладить. Другая причина выбора рекурсивного решения может состоять
в том, что итеративное решение оказывается неочевидным.
Вопросы производительности 6.9
Избегайте использования рекурсии в случаях, требующих высокой
эффективности. Рекурсивные вызовы требуют времени и
дополнительных затрат памяти.
Типичная ошибка программирования 6.26
Случайный вызов нерекурсивной функцией, прямо или косвенно (через
другую функцию), самой себя является логической ошибкой.
Функции и введение в рекурсию
391
Большинство учебников по программированию вводят рекурсию гораздо
позже, чем это сделано здесь. Мы считаем, что рекурсия — весьма обширная
и сложная тема, так что лучше познакомиться с ней пораньше и распределить
ее примеры по всему остальному тексту книги. На рис. 6.33 приведена сводка
имеющихся книге примеров и упражнений на рекурсию.
Глава
Глава 6
Раздел 6.19, рис. 6.29
Раздел 6.19, рис. 6.30
Упражнение 6.7
Упражнение 6.40
Упражнение 6.42
Упражнение 6.44
Упражнение 6.45
Упражнения 6.50 и 6.51
Глава 7
Упражнение 7.18
Упражнение 7.21
Упражнение 7.31
Упражнение 7.32
Упражнение 7.33
Упражнение 7.34
Упражнение 7.35
Упражнение 7.36
Упражнение 7.37
Упражнение 7.38
Глава 8
Упражнение 8.24
Упражнение 8.25
Упражнение 8.26
Упражнение 8.27
Глава 19
Раздел 19.3.3, рис. 19.5-19.7
Упражнение 19.8
Упражнение 19.9
Упражнение 19.10
Примеры и упражнения на рекурсию
Функция факториала
Функция Фибоначчи
Сумма двух чисел
Возведение целого числа в целую степень
Ханойская башня
Визуализация рекурсии
Наибольший общий делитель
«Что делает эта программа?»
«Что делает эта программа?»
«Что делает эта программа?»
Выборочная сортировка
Проверка того, является ли строка палиндромом
Линейный поиск
Двоичный поиск
Восемь ферзей
Печать массива
Печать строки в обратном порядке
Минимальное значение в массиве
Быстрая сортировка
Обход лабиринта
Генерация случайных лабиринтов
Лабиринты произвольного размера
Сортировка слиянием
Линейный поиск
Двоичный поиск
Быстрая сортировка
392
Глава 6
Глава
Глава 20
Раздел 20.7, рис. 20.20-20.22
Раздел 20.7, рис. 20.20-20.22
Раздел 20.7, рис. 20.20-20.22
Раздел 20.7, рис. 20.20-20.22
Упражнение 20.20
Упражнение 20.21
Упражнение 20.22
Упражнение 20.25
Примеры и упражнения на рекурсию
Вставка в двоичное дерево
Обход дерева с предварительной выборкой
Обход дерева с порядковой выборкой
Обход дерева с отложеной выборкой
Печать связанного списка в обратном порядке
Поиск в связанном списке
Удаление из двоичного дерева
Печать дерева
Рис. 6.33.Список примеров и упражнений на рекурсию в тексте книги
6.22. Конструирование программного обеспечения.
Идентификация операций классов в системе ATM
(необязательный раздел)
В разделах «Конструирование программного обеспечения» в конце глав 3, 4
и 5 мы предприняли первые шаги объектно-ориентированного
проектирования нашей системы ATM. В главе 3 мы идентифицировали классы, которые
необходимы для реализации, и создали нашу первую классовую диаграмму.
В главе 4 мы описали некоторые атрибуты наших классов. В главе 5 мы
исследовали состояния объектов и моделировали переходы состояний и
деятельность объектов. В этом разделе мы определим некоторые операции (действия,
или поведение) классов, необходимые для реализации системы ATM.
Идентификация операций
Операция является услугой, которую объекты класса предоставляют
клиентам класса. Рассмотрим операции некоторых объектов реального мира.
Операции радиоприемника включают в себя настройку на станцию и установку
громкости (обычно их активирует человек, манипулирующий органами
управления приемника). Операции автомобиля — это набор скорости
(активируемый водителем, который нажимает на педаль газа), сброс скорости
(активируемый водителем, который нажимает,на педаль тормоза или снимает ногу
с педали газа), поворот и переключение передач. Точно так же и программное
обеспечение может предлагать операции — например, программный
графический объект мог бы предлагать операции для рисования круга, рисования
прямой, рисования прямоугольника и т.п. Программный объект электронной
таблицы мог бы предлагать операции вроде печати таблицы, суммирования
элементов в строке или столбце и отображение своей информации в виде
столбиковой или секторной диаграммы.
Многие из операций каждого класса мы можем вывести посредством
исследования ключевых глаголов и глагольных конструкций в спецификации
требований. Затем мы соотнесем их с конкретными классами нашей системы
(рис. 6.34). Глагольные конструкции на рис. 6.34 помогут нам определить
операции каждого из классов.
Функции и введение в рекурсию
393
Класс
ATM
Balancelnquiry
Withdrawal
Deposit
BankDatabase
Account
Screen
Keypad
CashDispenser
DepositSlot
Глаголы и глагольные конструкции
исполняет финансовые транзакции
[в спецификации требований отсутствуют]
[в спецификации требований отсутствуют]
[в спецификации требований отсутствуют]
авторизует пользователя, извлекает баланс счета, кредитует
вносимую сумму на счет, дебетует снимаемую сумму со счета
извлекает баланс счета, кредитует вносимую сумму на счет,
дебетует снимаемую сумму со счета
показывает пользователю сообщение
принимает от пользователя численный ввод
выдает наличные, сообщает, достаточно ли наличных для
удовлетворения запроса о снятии денег
принимает конверт с депозитом
Рис. 6.34. Глаголы и глагольные конструкции для каждого из классов системы ATM
Моделирование операций
Для идентификации операций мы исследуем глагольные конструкции,
перечисленные для каждого класса на рис. 6.34. Конструкция «исполняет
финансовые транзакции», ассоциированная с классом ATM, подразумевает, что
класс ATM дает указания исполняться транзакциям. Таким образом, каждому
из классов Balancelnquiry, Withdrawal и Deposit требуется операция,
предоставляющая ATM такую услугу. Мы помещаем эту операцию (которую мы
назвали execute) в третий раздел этих трех классов транзакций в
модифицированной классовой диаграмме на рис. 6.35. Во время сеанса ATM объект ATM
будет активировать операцию execute каждого объекта транзакции, требуя,
чтобы он исполнился.
В UML операции (которые мы реализуем как элемент-функции C++)
представляются в виде перечисления имени операции, списка разделенных
запятыми параметров в скобках, двоеточия и возвращаемого типа:
имяОперации( параметре параметр2, .... параметре ) : возвращаемыиТип
Каждый параметр в разделенном запятыми списке состоит из имени
параметра, за которым следуют двоеточие и тип параметра:
имяПараметра : типПараметра
Пока мы не перечисляем параметры наших операций; вскоре мы
идентифицируем и смоделируем параметры некоторых из них. Для некоторых операций
мы еще не знаем возвращаемого типа, поэтому на диаграмме мы также
опускаем его. По ходу дальнейшего проектирования и реализации мы введем в
диаграмму остальные возвращаемые типы.
394
Глава 6
ATM
userAuthenticated : Boolean = false
Balancelnquiry
accountNumber: Integer
executeQ
Account
accountNumber: Integer
pin : Integer
availableBalance: Double
totalBalance : Double
validatePINO : Boolean
getAvailableBalance(): Double
getTotalBalance(): Double
creditO
debitQ
Withdrawal
accountNumber: Integer
amount: Double
executeQ
Deposit
accountNumber: Integer
amount: Double
executeQ
BankDatabase
authenticateUserO : Boolean
getAvailableBalance(): Double
getTotalBalance(): Double
creditO
debitQ
Screen
displayMessage()
Keypad
getlnputO : Integer
CashDispenser
count: Integer = 500
dispenseCashO
isSufficientCashAvaJlableO : Boolean
DepositSlot
isEnvelopeReceivedQ : Boolean
Рис. 6.35. Классы в системе ATM с атрибутами и операциями
Операции классов BankDatabase и Account
Первой в списке глагольных конструкций для класса BankDatabase на
рис. 6.34 идет «авторизует пользователя» — база данных является объектом,
который содержит информацию о счете, необходимую, чтобы определить,
соответствуют ли номер счета и PIN, введенные пользователем, действительному
счету банка. Таким образом, классу BankDatabase необходима операция,
предоставляющая ATM услугу авторизации. Мы помещаем в третий раздел к лас-
Функции и введение в рекурсию
395
са BankDatabase операцию authenticateUser (рис. 6.35).Однако номер счета
и PIN, к которым необходим доступ для авторизации пользователя, хранятся
в объекте класса Account, а не класса BankDatabase, поэтому класс Account
должен предоставлять услугу для сравнения PIN, полученного путем ввода от
пользователя, с PIN, хранящимся в объекте Account. Таким образом, мы
вводим в класс Account операцию validatePIN. Обратите внимание, что для
операций authenticateUser и validatePIN мы специфицируем возвращаемый тип
Boolean. Каждая из этих операций возвращает значение, указывающее,
закончилось ли выполнение ее задачи успехом (возвращается значение true) или
неудачей (возвращается значение false).
На рис. 6.34 для класса BankDatabase перечислены некоторые другие
глагольные конструкции: «извлекает баланс счета», «кредитует вносимую сумму
на счет» и «дебетует снимаемую сумму со счета». Как и конструкция
«авторизует пользователя», эти конструкции относятся к услугам, которые должна
предоставить ATM база данных, поскольку в последней хранятся все данные
о счете, используемые для авторизации пользователя и выполнения всех
транзакций ATM. Однако все операции, к которым относятся эти глагольные
конструкции, производит в действительности объект класса Account. Таким
образом, мы присваиваем операции, соответствующие этим конструкциям, как
классу BankDatabase, так и классу Account. Как вы помните, в разделе 3.11
говорилось о том, что поскольку банковский счет содержит критическую
информацию, мы не можем позволить ATM обращаться к счетам
непосредственно. База данных служит посредником между ATM и данными счета,
предотвращая незаконный доступ к последним. Как мы увидим в разделе 7.12, класс
ATM активирует операции класса BankDatabase, каждая из которых, в свою
очередь, активируеч одноименную операцию в классе Account.
Конструкция «извлекает баланс счета» предполагает, что каждому из
классов BankDatabase и Account требуется операция getBalance. Вспомните,
однако, что для представления баланса мы создали в классе Account два
атрибута — availableBalance и totalBalance. Для справки о балансе требуются
доступ к обоим атрибутам баланса, чтобы их можно было показать пользователю,
в то время как для снятия наличных необходимо проверить только значение
availableBalance. Чтобы объекты в системе могли получать значения
атрибутов баланса по отдельности, мы вводим в третий раздел классов BankDatabase
и Account операции getAvailableBalance и getTotalBalance (рис. 6.35). Для
каждой из этих операций мы специфицируем возвращаемый тип Double,
поскольку атрибуты баланса, которые они извлекают, имеют тип Double.
Конструкции «кредитует вносимую сумму на счет» и «дебетует снимаемую
сумму со счета» указывают, что классы BankDatabase и Account должны
производить операции для обновления счета соответственно во время внесения
и снятия денег. Таким образом, мы присваиваем классам BankDatabase
и Account операции credit и debit. Как вы помните, кредитование счета (как
при внесении денег) прибавляет денежную сумму только к атрибуту
totalBalance. С другой стороны, дебетование счета (как при снятии) вычитает
денежную сумму из обоих атрибутов баланса. Мы скрываем эти детали реализации
внутри класса Account. Это хороший пример инкапсуляции и сокрытия
информации.
Если бы это была настоящая система ATM, классы BankDatabase и
Account предусматривали бы также набор операций, предназначенных для того,
396
Глава 6
чтобы другая банковская система могла обновлять баланс счета пользователя
после подтверждения или опровержения всей или части суммы депозита.
Операция confirmDepositAmount, например, прибавляла бы сумму к атрибуту
availabluBalance, делая внесенные средства доступными для снятия.
Операция rejееtDepositAmount вычитала бы сумму из атрибута totalBalance для
указания того, что в депозитном конверте не оказалось той денежной суммы,
что недавно была внесена через ATM и прибавлена к totalBalance. Банк
активировал бы эту операцию, обнаружив, что пользователь не вложил в конверт
правильной суммы наличными или что чеки не были очищены (т.е. они
«вернулись обратно»). Хотя добавление этих операций сделало бы нашу систему
более полной, мы не включаем их в наши классовые диаграммы или
реализацию, так как они выходят за пределы тематики учебного примера.
Операции класса Screen
Несколько раз в течение сеанса ATM класс Screen «показывает
пользователю сообщение». Весь визуальный вывод происходит через экран ATM.
Спецификация требований описывает много типов сообщений (напр.,
приветственное сообщение, сообщение об ошибке, прощальное сообщение), которые экран
показывает пользователю. Спецификация требований указывает также, что
экран выводит пользователю приглашения и меню. Однако приглашение
является просто сообщением, описывающим, что пользователь должен сейчас
ввести, а меню по существу является подсказкой, состоящей из ряда
сообщений (т.е. опций меню), выводимых последовательно. Таким образом, вместо
того, чтобы присваивать классу Screen отдельные операции для вывода
каждого из типов сообщений, приглашений и меню, мы просто создаем одну
операцию, которая может показать любое сообщение, специфицированное ее
параметром. На нашей классовой диаграмме (рис. 6.35) мы помешаем эту
операцию (displayMessage) в третий раздел класса Screen. Заметьте, что в данный
момент нас не заботит параметр этой операции, — мы будем моделировать его
позднее в этом разделе.
Операции класса Keypad
Из фразы «принимает от пользователя численный ввод» для класса Keypad
на рис. 6.34 мы заключаем, что класс Keypad должен производить операцию
getlnput. Поскольку кнопочная панель ATM, в отличие от клавиатуры
компьютера, содержит только числа 0-9, мы специфицируем, что эта операция
возвращает целое значение. Как вы помните из спецификации требований, в
различных ситуациях от пользователя должны быть получены различные типы
чисел (напр., номер счета, PIN, номер опции меню, сумму депозита в центах).
Класс Keypad просто получает численное значение для своего клиента; он не
определяет, отвечает ли введенное значение специфическому критерию.
Любой класс, использующий эту операцию, должен сам проверять, вводит ли
пользователь подходящие числа, и если нет, выводить сообщения об ошибке
через класс Screen. [Замечание. Когда мы реализуем систему, мы будем
эмулировать кнопочную панель ATM при помощи клавиатуры компьютера, и для
простоты мы полагаем, что пользователь не вводит нечисловых данных,
нажимая клавиши, отсутствующие на кнопочной панели ATM. Позднее вы узнаете,
как исследовать ввод, чтобы определить, относится ли он к определенному
типу.]
Функции и введение в рекурсию
397
Операции классов CashDispenser и DepositSlot
Рис. 6.34 указывает для класса CashDispenser «выдает наличные». Таким
образом, мы создаем операцию dispenseCash и записываем ее на рис. 6.35 под
классом CashDispenser. Класс CashDispenser, кроме того, «сообщает,
достаточно ли наличных для удовлетворения запроса о снятии денег».
Соответственно мы включаем в класс isSufficientCashAvailable, операцию, которая
возвращает значение UML-типа Boolean. На рис. 6.34 указано также «принимает
конверт с депозитом» для класса DepositSlot. Приемная щель должна
сообщать, получила ли она конверт, поэтому мы записываем в третий раздел
класса DepositSlot операцию isEnvelopeReceived, которая возвращает значение
типа Boolean. [Замечание. Реальная аппаратная приемная щель, вероятнее
вего, посылала бы ATM сигнал, указывающий, что конверт получен. Мы,
однако, эмулируем такое поведение посредством операции класса DepositSlot.
которую класс ATM может вызвать, чтобы выяснить, получила ли приемная
щель конверт.]
Операции класса ATM
Пока мы не записываем для класса ATM никаких операций. Нам пока не
известны никакие услуги, которые класс ATM предоставлял бы другим
классам в системе. Однако когда мы реализуем систему в виде кода C++, могут
выявиться как операции этого класса, так и дополнительные операции других
классов.
Идентификация и моделирование параметров операций
До сих пор мы не занимались параметрами наших операций — мы
пытались достигнуть только элементарного понимания операций каждого класса.
Давайте теперь внимательнее посмотрим на некоторые параметры операций.
Мы идентифицируем параметры операции, изучая, какие данные требуются
ей для выполнения своей задачи.
Рассмотрим операцию authenticateUser класса BankDatabase. Чтобы
авторизовать пользователя, эта операция должна знать номер счета и PIN,
предоставленные пользователем. Таким образом, мы специфицируем, что операция
authenticateUser принимает целые параметры userAccountNumber и userPIN,
которые она должна сравнить с номером счета и PIN объекта Account в базе
данных. Мы даем именам этих параметров префикс «user», чтобы не путать
имена параметров операции с именами атрибутов, принадлежащий классу
Account. Мы записываем эти параметры в классовой диаграмме на рис. 6.36,
которая моделирует только класс BankDatabase. [Замечание. Ситуация, когда
на классовой диаграмме моделируется только один класс, совершенно
нормальна. В данном случае мы хотим прежде всего исследовать параметры этого
отдельного класса, поэтому опускаем остальные классы. Позже в учебном
примере, когда параметры операций уже не будут находиться в центре нашего
внимания, мы для экономии места будем опускать в классовых диаграммах эти
параметры. Помните, однако, что операции, перечисляемые на этих
диаграммах, все равно имеют параметры.]
Как вы помните, каждый параметр в разделенном запятыми списке
параметров операции моделируется в UML посредством указания имени
параметра, за которым следует двоеточие и тип параметра (в нотации UML). Таким об-
398
Глава 6
разом, рис. 6.36 специфицирует, что операция authenticateUser принимает
два параметра — user Account Number и user PIN, оба типа Integer. Когда мы
реализуем систему на C++, мы будем представлять эти параметры значениями
типа int.
Операциям getAvailableBalance, getTotalBalance, credit и debit класса
BankDatabase также требуется параметр userAccountNumber для
идентификации счета, к которому база данных будет применять эти операции, поэтому
мы включаем его в классовую диаграмму на рис. 6.36. Кроме того, операциям
credit и debit требуется параметр amount типа Double для спецификации
суммы денег, которая должна быть соответственно кредитована или дебетована.
BankDatabase
authenticateUser( userAccountNumber: Integer, userPIN : Integer): Boolean
getAvailableBalance( userAccountNumber: Integer): Double
getTotalBalance( userAccountNumber: Integer): Double
credit( userAccountNumber: Integer, amount: Double )
debit( userAccountNumber: Integer, amount: Double )
Рис. 6.36. Класс BankDatabase с параметрами операций
Account
accountNumber: Integer
pin : Integer
avallableBalance : Double
totalBalance : Double
valJdatePIN( userPIN : Integer): Boolean
getAvailableBalanceQ : Double
getTotalBalance(): Double
credit( amount: Double )
deblt( amount: Double )
Рис. 6.37. Класс Account с параметрами операций
Классовая диаграмма на рис. 6.37 моделирует параметры операций класса
Account. Операции validatePIN требуется только параметр userPIN, который
содержит указанный пользователем PIN для сравнения его с PIN, который
ассоциирован со счетом. Как и соответствующим операциям в классе
BankDatabase, операциям credit и debit требуется параметр amount типа Double,
который указывает участвующую в операции сумму денег. Операциям
getAvailableBalance и getTotalBalance класса Account для выполнения своих задач не
нужно никаких дополнительных данных. Обратите внимание, что операциям
класса Account не требуется параметр для номера счета — каждая из этих one-
Функции и введение в рекурсию
399
раций может быть вызвана только на конкретном объекте Account, так что
включать параметр для спецификации счета было бы излишне.
Рис. 6.38 моделирует класс Screen, специфицируя параметр для операции
display Message. Этой операции требуется только параметр message типа
String, специфицирующий текст, который должен выводиться. Как вы
помните, типы параметров, указанные в наших классовых диаграммах, записаны
в нотации UML, поэтому тип String на рис. 6.38 означает тип UML. Когда мы
реализуем систему на C++, мы будем для этого параметра использовать в
действительности объект C++ string.
Классовая диаграмма на рис. 6.39 специфицирует, что операция dispen-
seCash класса CashDispenser принимает параметр amount типа Double для
указания суммы наличных (в долларах), которая должна быть выдана.
Операция isSufficientCashAvailable также принимает параметр amount типа
Double для указания суммы наличных денег, о которой идет речь.
Screen
displayMessage( message : String )
Рис. 6.38. Класс Screen с параметрами операций
CashDispenser
count: Integer = 500
di5penseCash( amount: Double )
isSufficientCashAvailable( amount: Double ): Boolean
Рис. 6.39. Класс CashDispenser с параметрами операций
Заметьте, что мы не обсуждаем параметры для операции execute классов
Balancelnquiry, Withdrawal и Deposit, операции getlnput класса Keypad
и операции isEnvelopeReceived класса DepositSlot. В данной точке нашего
процесса проектирования мы не можем определить, требуются ли этим
операциям дополнительные данные для выполнения своих задач, поэтому мы
оставляем их списки параметров пустыми. По ходу развития нашего учебного
примера мы можем включить параметры для этих операций.
В этом разделе мы определили многие из операций, производимых
классами в системе ATM. Мы определили параметры и возвращаемые типы
некоторых операций. По ходу продолжения нашего учебного примера число
операций, принадлежащих каждому классу, может измениться — мы можем
обнаружить, что необходимы новые операции или что некоторые из имеющихся
операций не нужны, — или мы можем решить, что некоторым нашим
операциям требуются дополнительные параметры либо другие возвращаемые типы.
400
Глава 6
Контрольные вопросы по конструированию программного
обеспечения
6.1. Что из нижеперечисленного не является поведением?
a) чтение данных из файла
b) печать вывода
c) текстовый вывод
d) получение ввода от пользователя
6.2. Если бы вам потребовалось ввести в систему ATM операцию, которая
возвращает атрибут amount класса Withdrawal, как и где вы
специфицировали бы ее в классовой диаграмме на рис. 6.35?
6.3. Опишите смысл следующей операции, которая могла бы появиться
в классовой диаграмме для объектно-ориентированного проекта
калькулятора:
add( х : Integer, у : Integer ) : Integer
Ответы на контрольные вопросы по конструированию
программного обеспечения
6.1. с.
6.2. Чтобы специфицировать операцию, которая извлекает атрибут amount
класса Withdrawal, в операциональное (т.е. третье) отделение класса
Withdrawal нужно было бы поместить:
getAmount( ) : Double
6.3. Это операция с именем add, которая принимает в качестве параметров
целые х и у и возвращает целое значение.
6.23. Заключение
В этой главе вы ближе познакомились с деталями объявления функций.
В функциях можно выделить различные элементы, такие, как прототип,
сигнатура, заголовок и тело функции. Вы познакомились с принудительным
приведением аргументов, т.е. их преобразованием к типам, специфицированным
в объявлениях параметров функции. Мы показали, как с помощью функций
rand и srand генерируются последовательности случайных чисел, которые
можно использовать в задачах моделирования. Вы узнали также об области
действия переменных, т.е. тех частях программы, где можно использовать тот
или иной идентификатор. Были рассмотрены два способа передачи
аргументов — передача по значению и передача по ссылке. При передаче по ссылке
последняя используется в качестве псевдонима переменной. Вы узнали, что
несколько функций из одного класса с одинаковыми именами могут быть
перегружены, если они различаются своими сигнатурами. Такие функции могут
выполнять одинаковые или сходные задачи, используя различные типы или
различное число параметров. Затем мы продемонстрировали более простой
способ перегрузки функций с помощью шаблонов, когда функция
определяется единственный раз, но может вызываться для различных типов. Наконец,
Функции и введение в рекурсию
401
вы познакомились с концепцией рекурсии, при которой функция для решения
задачи вызывает саму себя.
В главе 7 вы познакомитесь с реализацией списков и таблиц данных в виде
массивов. Мы покажем более изящный способ решения задачи о бросании
игральной кости, а также две усовершенствованных версии класса GradeBook,
изучавшегося вами в главах 3-5, которые используют массивы для
сохранения введенпых оценок.
Резюме
• Опыт показывает, что наилучшим способом разработки и сопровождения больших
программ является построение их из маленьких простых фрагментов, или
компонентов. Такую методику называют ♦ разделяй и властвуй».
• Обычно программы на C++ пишутся путем объединения новых функций и классов,
которые пишет сам программист, с «готовыми* функциями и классами,
имеющимися в стандартной библиотеке C++.
• Функции позволяют программисту сделать программу «модульной», разделив ее
задачи на замкнутые в себе единицы.
• Операторы в теле функций пишутся лишь однажды, а используются, возможно, во
многих частях программы и скрыты от других функций.
• Компилятор сверяется с прототипом функции, чтобы проверить, содержат ли ее
вызовы правильное число аргументов нужных типов и перечислены ли типы
аргументов в правильном порядке, а также для того, чтобы убедиться, что возвращаемое
функцией значение корректно используется в вызвавшем функцию выражении.
• Есть три способа возврата управления в точку, где была активирована функция.
Если функция не возвращает результата (т.е. она имеет возвращаемый тип void),
управление возвращается, когда программа достигает оканчивающей функцию
фигурной скобки или при исполнении оператора
return;
Если функция возвращает результат, оператор
return выражение;
оценивает выражение и возвращает его значение вызывающему.
• Прототип функции сообщает компилятору имя функции, тип данных,
возвращаемый функцией, число ожидаемых функцией параметров, их типы и порядок, в
котором функция ожидает их получить.
• Часть прототипа функции, включающая ее имя и типы аргументов, называется
сигнатурой функции.
• Важным аспектом прототипов функций является принудительное приведение
аргументов, т.е. автоматическое преобразование аргументов к типам,
специфицированным в объявлении параметров.
• Значения аргументов, не соответствующие в точности типам параметров в прототипе
функции, могут быть перед вызовом преобразованы компилятором в требуемые
типы данных в соответствии с правилами возведения, специфицируемыми языком
C++. Правила возведения указывают, при каких преобразованиях типоа не
происходит потери данных.
• Элемент случайности может быть введен в компьютерные принижения с помощью
функции rand из стандартной библиотеки C++.
• Функция rand на самом деле генерирует псевдослучайные числа. Последовательные
вызовы rand генерируют ряд чисел, которые кажутся случайными. Однако этот ряд
повторяется при каждом запуске программы.
402
Глава 6
• Когда программа будет тщательно отлажена, ее можно будет модифицировать таким
образом, чтобы при каждом выполнении получались различные последовательности
случайных чисел. Это называется рандомизацией и достигается применением
функции srand стандартной библиотеки C++.
• Функция srand получает целый аргумент типа unsigned и засевает функцию rand
таким образом, чтобы при каждом запуске программы она генерировала новую
последовательность случайных чисел.
• Случайные числа, лежащие в заданном диапазоне, можно получить с помощью
оператора
number - shiftingValue + rand() % scaling!'actor;
где shiftingValue равняется первому числу из желаемого диапазона
последовательных целых чисел, a scalingFactor равняется ширине этого диапазона.
• Перечисление, объявляемое ключевым словом enum, за которым следует имя типа,
является набором целых констант, представленных идентификаторами. Значения
этих перечисляемых констант начинаются с 0, если не указано иначе, и
последовательно увеличиваются на единицу.
• Класс памяти идентификатора определяет период времени, в течение которого этот
идентификатор существует в памяти.
• Областью действия идентификатора называется область программы, в которой на
данный идентификатор можно ссылаться.
• Компоновка идентификатора определяет, известен ли он только в том исходном
файле, где он определяется, или же в нескольких исходных файлах, которые
компилируются и затем компонуются в исполняемую программу.
• Для объявления переменных автоматического класса памяти используются
ключевые слова auto и register. Такие переменные создаются при входе в блок, в котором
они объявлены, существуют, пока блок активен, и уничтожаются, когда программа
выходит из блока.
• Автоматический класс памяти могут иметь только локальные переменные.
• Спецификатор auto явно объявляет переменные автоматического класса памяти.
Локальные переменные имеют автоматический класс памяти по умолчанию, так что
ключевое слово auto используется редко.
• Ключевые слова extern и static объявляют идентификаторы для переменных
статического класса памяти и для функций. Переменные статического класса памяти
существуют с момента, когда программа начинает исполняться, и сохраняются в
течение всего периода ее выполнения.
• Память для переменной статического класса памяти выделяется в начале
исполнения программы. Такая переменная инициализируется единственный раз, когда
программа встречает ее объявление. Что касается объявленных таким образом
функций, то имя такой функции тоже существует с самого начала исполнения
программы, как и имена всех остальных функций.
• Существует два типа идентификаторов со статическим классом памяти — внешние
идентификаторы (такие, как глобальные переменные и глобальные имена функций)
и локальные переменные, объявленные со спецификатором класса памяти static.
• Глобальные переменные создаются путем размещения их объявлений за пределами
определений любых классов или функций. Глобальные переменные сохраняют свои
значения в течение всего выполнения программы. На глобальные переменные
и функции может ссылаться любая функция, которая расположена в исходном
файле после их объявления или описания.
Функции и введение в рекурсию
403
• Локальные переменные, объявленные с ключевым словом static, все равно известны
только в той функции, где они объявлены, но в отличие от автоматических
переменных сохраняют значения и после того, как функция возвратит управление своему
вызывающему. Когда функция вызывается снова, ее статические локальные
переменные содержат те значения, которые они имели при завершении предыдущего
исполнения функции.
• Идентификатор, объявленный вне любой функции или класса, имеет область
действия файла.
• Метки являются единственными идентификаторами, имеющими область действия
функции. Метки можно использовать всюду в функции, в которой они появляются,
но на них нельзя ссылаться вне тела функции.
• Идентификаторы, объявленные внутри блока, имеют область действия блока.
Область действия блока начинается от объявления идентификатора и заканчивается
завершающей правой фигурной скобкой (}) блока, в котором идентификатор
объявляется.
• Единственными идентификаторами областью действия прототипа являются те, что
указываются в списке параметров прототипа функции.
• Стек является структурой данных «последним вошел, первым вышел» (LIFO,
«last-in, first-out») — единица данных, помещенная в стек последней, удаляется из
него первой.
• Одним из важнейших механизмов, которые должны быть освоены студентами
компьютерных факультетов, является стек вызовов функций (иногда его называют
исполнительным стеком программы). Эта структура данных поддерживает механизм
вызова/возврата функций.
• Стек вызовов отвечает также за создание, сохранение и уничтожение всех
автоматических переменных вызванной функции.
• Всякий раз, когда функция вызывает другую функцию, в стек заталкивается блок
информации. Этот блок, называемый кадром стека или активационной записью,
содержит адрес возврата, который необходим вызванной функции для возвращения
в вызывающую функцию, а также автоматические переменные вызванной функции.
• Кадр стека существует все время, пока вызванная функция остается активной.
Когда она возвращает управление — и не нуждается более в локальных
автоматических переменных, — ее кадр стека выталкивается, и эти переменные становятся
неизвестными программе.
• В C++ пустой список параметров обозначается либо указанием в скобках ключевого
слова void, либо просто пустыми скобками.
• Для снижения дополнительных расходов на вызовы функций (особенно небольших)
в C++ предусмотрены встроенные функции. Спецификация ключевого слова inline
перед возвращаемым типом в определении функции «советует» компилятору
генерировать вместо обычного вызова встроенную копию кода функции.
• Во многих языках программирования имеются два способа передачи аргументов
функциям: передача по значению и передача по ссылке.
• Когда аргумент передается по значению, создается копия аргумента, и последняя
передается (через стек вызовов) вызываемой функции. Изменения копии не влияют на
значение исходной переменной вызывающего.
• В случае передачи по ссылке вызывающий предоставляет вызываемой функции
прямой доступ к своим данным и возможность их модификации, если вызываемая
функция решит это сделать.
• Ссылочный параметр является псевдонимом соответствующего аргумента в вызове
функции.
404
Глава 6
• Для указания того, что параметр функции передается по ссылке, просто поставьте
символ амперсанда (&) после типа параметра в прототипе функции; то же самое
относится к типу в списке параметров заголовка функции.
• Как только ссылка объявляется как псевдоним другой переменной, все операции,
производимые над псевдонимом (т.е. ссылкой), будут в действительности относиться
к исходной переменной. Ссылка в этом случае — просто другое имя для переменной.
• Нередко случается, что программа многократно вызывает функцию с одним и тем
же аргументом для некоторого параметра. В таких случаях программист может
указать, что для данного параметра имеется аргумент по умолчанию, т.е. значение,
которое по умолчанию должно передаваться параметру.
• Когда программа не передает в вызове функции аргумент для параметра с
аргументом по умолчанию, то компилятор генерирует вызов, подставляя в качестве
аргумента его значение по умолчанию.
• Аргументы по умолчанию должны быть самыми правыми аргументами в списке
параметров функции.
• Аргументы по умолчанию должны быть указаны при первом появлении имени
функции — обычно в прототипе функции.
• В C++ предусмотрена унарная операция разрешения области действия (::) для
доступа к глобальной переменной, когда в области действия имеется локальная
переменная с тем же именем.
• C++ позволяет определить несколько функций с одним и тем же именем, если эти
функции имеют различные наборы параметров (различные в том, что касается типа
или числа параметров, либо порядка следования их типов). Эта возможность
называется перегрузкой функций.
• Когда вызывается перегруженная функция, компилятор C++ выбирает нужную
функцию путем анализа числа, типов и порядка аргументов в вызове.
• Перегруженные функции различаются по их сигнатурам.
• Компилятор кодирует идентификатор каждой функции в зависимости от числа
и типа параметров, чтобы обеспечить безопасную по типу компоновку. Безопасная
по типу компоновка гарантирует, что будет вызвана нужная функция и что ее
аргументы будут согласованы по типу с параметрами.
• Перегруженные функции обычно используются для выполнения сходных действий,
связанных с различной программной логикой для различных типов данных. Если
программная логика и действия для всех типов идентичны, это можно выполнить
более компактно и удобно, используя шаблоны функций.
• Программист пишет единственное определение шаблона функции. Исходя на типа
аргументов, указанных в вызовах этой функции, C++ автоматически генерирует
разные специализации шаблона функции для соответствующей обработки каждого
типа вызовов. Таким образом, определение единственного шаблона по существу
определяет целое семейство перегруженных функций.
• Определения шаблонов функций начинаются с ключевого слова template, за
которым следует список параметров шаблона, заключенный в угловые скобки (< и >).
• Формальные параметры типа являются заместителями либо основных типов, либо
типов, определяемых пользователем. Они используются для спецификации типов
аргументов функции, спецификации возвращаемого типа и для объявления
переменных внутри тела определения функции.
• Рекурсивная функция — это функция, которая вызывает саму себя либо
непосредственно, либо косвенно (через другую функцию).
• Рекурсивная функция в действительности знает только, как решается простейший, так
называемый основной случай задачи (или несколько таких случаев). Если такая
функция вызывается для решения основного случая, она просто возвращает результат.
Функции и введение в рекурсию
405
Если рекурсивная функция вызывается для решения более сложной задачи, она
обычно делит задачу на две концептуальные части: одну часть, которую функция
умеет решать, и другую, которую функция решать не умеет. Чтобы рекурсивное
решение было работоспособным, последняя часть должна быть похожа на исходную
задачу, но быть по сравнению с ней несколько проще или несколько меньше.
Чтобы рекурсия могла завершиться, все новые и новые вызовы функцией самой
себя, для все более упрощающихся вариантов исходной задачи, должны
образовывать последовательность, сходящуюся в конце концов к основному случаю.
Отношение последовательных чисел Фибоначчи сходится к постоянной величине
1,618... Это число также часто встречается в природе и называется золотым
сечением или золотым средним.
Итерация и рекурсия во многом схожи: и та, и другая основываются на
управляющих структурах, связаны с повторениями, производят проверку завершения,
приближаются к завершению постепенно и могут происходить бесконечно.
Рекурсия имеет много недостатков. Она многократно активирует механизм
вызовов — отсюда рост ♦ накладных расходов». Они могут оказаться слишком
расточительными как в плане процессорного времени, так и в плане объема памяти.
Каждый рекурсивный вызов приводит к созданию нового экземпляра функции (на самом
деле создаются только новые экземпляры ее переменных); на это может
расходоваться значительная память.
Терминология
& в объявлении ссылки
автоматическая локальная
переменная
автоматический класс памяти
активационная запись
активация метода
аргумент по умолчанию
безопасная по типу компоновка
бесконечная рекурсия
бесконечный цикл
висящая ссылка
вложенные блоки
внешний блок
внутренний блок
возврат ссылки
возвращаемый тип void
встроенная функция
выражение смешанного типа
выталкивание из стека (pop)
выход из области действия
глобальная переменная
глобальная функция
♦ готовые» функции
декорирование имен
декорированное имя функции
завершающая фигурная скобка (})
блока
засевание функции rand
заталкивание в стек (push)
значение смещения
золотое сечение
золотое среднее
имя переменной
имя типа (перечисления)
имя функции
инициализация ссылки
исполнительный стек программы
итеративное решение
итерация
кадр стека
класс памяти
ключевое слово enum
ключевое слово inline
ключевое слово static
ключевое слово template
коэффициент масштабирования
масштабирование
метка
методы
модульное построение программы
из функций
♦ наивысший» тип
«наинизший» тип
накладные расходы при вызове
функции
накладные расходы при рекурсии
область действия блока
область действия идентификатора
область действия именного
пространства
406
Глава 6
область действия класса
область действия прототипа функции
область действия файла
область действия функции
объявление функции
обязательные прототипы функций
определение функции
определение шаблона
оптимизирующий компилятор
основной случай (случаи)
параметр
параметр типа
перегрузка
перегрузка функций
передача по значению
передача по ссылке
переполнение стека
перечисление
перечисляемая константа
побочный эффект выражения
повторяемость функции rand
подход «разделяй и властвуй»
последним вошел, первым вышел
(LIFO)
последовательность случайных чисел
правила возведения
пределы значений целых чисел
пределы значений числовых типов
принудительное приведение
аргументов
принцип наименьших привилегий
проверка завершения
проверка корректности вызова
прототип функции
процедура
псевдоним
псевдослучайные числа
рандомизация
рекурсивная оценка
рекурсивная функция
рекурсивное решение
рекурсивный вызов
рекурсия
ряд Фибоначчи
самые правые аргументы
семя
сигнатура
сигнатура функции
символическая константа
MAX_RAND
случайное число
смещение диапазона чисел
смещенные масштабированные целые
специализация шаблона функции
спецификатор класса памяти auto
спецификатор класса памяти extern
спецификатор класса памяти mutable
спецификатор класса памяти register
спецификатор класса памяти static
спецификаторы класса памяти
список параметров шаблона
ссылка на автоматическую
переменную
ссылка на константу
ссылочный параметр
статическая локальная переменная
статический класс памяти
стек
стек вызова функций
сходимость к основному случаю
тип компоновки
тип, определяемый пользователем
тип переменной
унарная операция разрешения
области действия (::)
усечение дробной части значения
типа double
условие завершения
утилизация программного
обеспечения
факториал
формальный параметр
формальный параметр типа
функция rand
функция srand
функция, определяемая
пользователем
функция, определяемая
программистом
шаблон функции
шаблонная функция
шаг рекурсии
ширина диапазона случайных чисел
экспоненциальная сложность
Функции и введение в рекурсию
407
Контрольные вопросы
6.1. Заполните пропуски в следующих предложениях:
a) Программные компоненты в C++ называются и .
b) Функция активируется с помощью .
c) Переменная, которая известна только внутри функции, где она определена,
называется .
d) Оператор в вызываемой функции используется, чтобы передать
значение выражения обратно в вызывающую функцию.
e) Ключевое слово используется в заголовке функции, чтобы
указать, что функция не возвращает значения, или что она не имеет параметров.
f) идентификатора — это часть программы, в которой
идентификатор может использоваться.
g) Существуют три способа возврата управления из вызванной функции в
оператор вызова: , и .
h) позволяет компилятору проверить число, тип и порядок
следования аргументов, передаваемых функции.
i) Функция используется для получения случайных чисел.
j) Функция используется для установки семени генератора
случайных чисел при рандомизации.
к) Спецификаторами класса памяти являются , ,
и .
I) Переменные, объявленные в блоке или в списке параметров функции, имеют
класс памяти , если не указано иное.
т) Спецификатор класса памяти является рекомендацией
компилятору хранить переменную в одном из регистров компьютера.
п) Переменная, объявленная вне любого блока или функции, является
переменной.
о) Чтобы локальная переменная функции сохраняла свое значение между
вызовами функции, она должна быть объявлена как имеющая класс памяти
р) Шестью возможными областями действия идентификатора являются
» » » >
и .
q) Функция, которая прямо или косвенно вызывает сама себя, называется
функцией.
г) Рекурсивная функция обычно имеет два компонента: один, который
обеспечивает завершение рекурсии, проверяя, не является ли задача ,
и другой, который представляет задачу как рекурсивный вызов для
упрощенной задачи.
s) В C++ можно иметь несколько функций с одним именем, каждая из которых
оперирует с различными типами и (или) количеством аргументов. Это
называется функций.
t) обеспечивает возможность доступа к глобальной переменной с тем
же именем, что и переменная в текущей области действия.
и) Квалификатор используется для объявления переменных только
для чтения.
v) функции позволяет определить единственную функцию для задач
со многими различными типами данных.
408
Глава 6
6.2. Для программы на рис. 6.34 установите области действия (область действия
функции, область действия файла, область действия блока или область действия
прототипа функции) каждого из следующих элементов:
a) Переменная х в main.
b) Переменная у в cube.
c) Функция cube.
d) Функция main.
e) Прототип функции cube.
f) Идентификатор у в прототипе функции cube.
1 // Упражнение 6.2: ех06_02.срр
2 #include <iostream>
3 using std::cout;
4 using std::endl;
5
6 int cube( int у ); // прототип функции
7
8 int main()
9 {
10 int x;
11
12 for ( x = 1; x <= 10; x++ ) // повторить 10 раз
13 cout « cube( x ) « endl; // вычислить и вывести куб х
14
15 return 0; // успешное завершение
16 } // конец main
17
18 // определение функции cube
19 int cube( int у )
20 {
21 return у * у * у;
22 } // конец функции cube
Рис. 6.40. Пример программы для упражнения 6.2
6.3. Напишите программу, которая проверяет, получают ли в действительности
показанные на рис. 6.2 примеры вызовов математических функций указанные
результаты.
6.4. Напишите заголовки для каждой из следующих функций:
a) Функция hypotenuse, которая принимает два аргумента с плавающей точкой
двойной точности si del и side2 и возвращает результат с плавающей точкой
двойной точности.
b) Функция smallest, которая принимает три целых значения х, у и z и
возвращает целое значение.
c) Функция instructions, которая не получает ни одного аргумента и не
возвращает значения. [Замечание. Такие функции обычно используются для выдачи
на экран указаний пользователю.]
d) Функция intToDouble, которая принимает целый аргумент number и
возвращает результат плавающей точкой одинарной точности.
6.5. Напишите прототипы для каждой из следующих функций:
a) Функции, описанной в упражнении 6.4 (а).
b) Функции, описанной в упражнении 6.4 (Ь).
c) Функции, описанной в упражнении 6.4 (с).
d) Функции, описанной в упражнении 6.4 (d).
Функции и введение в рекурсию 409
6.6. Напишите объявления для следующих переменных:
a) Целой переменной count, которая должна содержаться в регистре.
Инициализируйте count значением 0.
b) Переменной с плавающей точкой двойной точности lastVal, сохраняющей
свое значение между вызовами функции, в которой она определена.
6.7. Найдите ошибку в каждом из следующих программных фрагментов и
объясните, как можно исправить ошибку (см. также упражнение 6.53):
a) int g( void )
{
cout « "Inside function g" « endl;
int h( void )
{
cout « "Inside function h" « endl;
>
}
b) int sum( int x, int у )
{
int result;
result = x + y;
}
c) int sum( int n )
{
if ( n == 0 )
return 0;
else
n + sum( n - 1 ) ;
}
d) void f( double a );
{
float a;
cout « a « endl;
}
e) void product( void )
{
int a;
int b;
int c;
int result;
cout « "Enter three integers: "
cin » a » b » с »;
result = a * b * c;
cout « "Result is " « results-
return result;
>
6.8. В каком случае прототип функции мог бы объявлять тип параметра double &?
6.9. (Верно/неверно) Все аргументы функций в C++ передаются по значению.
6.10. Напишите законченную программу на C++ , которая предлагает пользователю
ввести радиус шара, после чего вычисляет и печатает его объем. Используйте
встроенную функцию sphere Volume, которая возвращает результат выражения
D.0 / 3.0) * 3.14159 * pow( radius, 3 ).
410
Глава 6
Ответы на контрольные вопросы
6.1. а) функциями, классами. Ь) вызова функции, с) локальной переменной, d) return.
е) void, f) Область действия, g) return;, return выражение; или достижение
закрывающей фигурной скобки функции, h) Прототип функции, i) rand, j) srand.
k) auto, register, extern, static. 1) auto, m) register, n) глобальной, о) static, p)
область действия функции, область действия файла, область действия блока,
область действия прототипа, область действия класса, область действия
именного пространства, q) рекурсивной, г) основным случаем, s) перегрузкой, t)
Унарная операция разрешения области действия (::). u) const, v) Шаблон.
6.2. а) Область действия блока. Ь) Область действия блока, с) Область действия
файла, d) Область действия файла, е) Область действия файла, f) Область действия
прототипа функции.
6.3. 1 // Упражнение 6.3: ех06_03.срр
2 // Тестирование функций математической библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::fixed/
7
8 #include <iomanip>
9 using std::setprecision;
10
11 #include <cmath>
12 using namespace std;
13
14 int main()
15 {
16 cout « fixed « setprecision( 1 );
17
18 cout « "sqrt(" « 900.0 « ") = " « sqrt( 900.0 )
19 « "\nsqrt(" « 9.0 « ") = " « sqrt( 9.0 );
20 cout « "\nexp(" « 1.0 « ") = " « setprecision( 6 )
21 « exp( 1.0 ) « "\nexp(" « setprecision( 1 ) «2.0
22 « ") = " « setprecision( 6 ) « exp( 2.0 );
23 cout « "\nlog(" « 2.718282 « ") = " « setprecision( 1 )
24 « log( 2.718282 )
25 « "\nlog(" « setprecision( 6 ) « 7.389056 « ") = "
26 « setprecision( 1 ) « log( 7.389056 );
27 cout « "\nlogl0(" « 1.0 « ") - " « logl0( 1.0 )
28 « "\nlogl0(" « 10.0 « ") - " « loglO( 10.0 )
29 « "\nlogl0(" « 100.0 « ") = " « loglO( 100.0 ) ;
30 cout « "\nfabs(" « 13.5 « ") = " « fabs( 13.5 )
31 « "\nfabs(" « 0.0 « ") = " « fabs( 0.0 )
32 « "\nfabs(" « -13.5 « ") = " « fabs( -13.5 );
33 cout « "\nceil(" « 9.2 « ") = " « ceil( 9.2 )
34 « "\nceil(" « -9.8 « ") - " « ceil( -9.8 );
35 cout « "\nfloor(" « 9.2 « ") = " « floor( 9.2 )
36 « "\nfloor(" « -9.8 « ") = " « floor( -9.8 );
37 cout « "\npow(" « 2.0 « ", " « 7.0 « ") = "
38 « pow( 2.0, 7.0 ) « "\npow(" « 9.0 « ", "
39 « 0.5 « ") = " « pow( 9.0, 0.5 );
40 cout « setprecisionC) « "\nfmod("
41 « 13.675 « ", " « 2.333 « ") = "
42 « fmod( 13.675, 2.333 ) « setprecision( 1 )
43 cout « "\nsin(" « 0.0 « ") ■ " « sin( 0.0 )
44 cout « "\ncos(" « 0.0 « ") - " « cos( 0.0 )
45 cout « "\ntan(" « 0.0 « ") - " « tan( 0.0 ) « endl;
46 return 0; // показывает успешное завершение
47 } // конец main
Функции и введение в рекурсию
411
sqrt(900.0) =30.0
sqrt(9.0) = 3.0
exp(l.O) = 2.718282
ехрB.0) s 7.389056
logB.718282) =1.0
logG.389056) = 2.0
loglO(l.O) =0.0
logl0A0.0) =1.0
loglOA00.0) =2.0
fabsA3.5) =13.5
fabs(O.O) =0.0
fabs(-13.5) = 13.5
ceil<9.2) = 10.0
ceil(-9.8) = -9.0
floor (9.2) =9.0
floor(-9.8) = -10.0
powB.0, 7.0) = 128.0
pow(9.0, 0.5) = 3.0
fmodA3.675, 2.333) = 2.010
sin(O.O) = 0.0
cos@.0) =1.0
tan@.0) = 0.0
6.4. a) double hypotenuse( double sidel, double side2 )
b) int smallest ( int x, int y, int z )
c) void instructions ( void ) // в C++ (void) можно записать как ()
d) double intToDouble ( int number )
6.5. a) double hipotenuse ( double, double ) ;
b) int smallest( int, int, int ) ;
c) void instructions ( void ) ; //в C++ (void) можно записать как ()
d) double intToDouble( int );
6.6. a) register int cout = 0;
b) static double lastVal;
6.7. а) Ошибка: функция h определяется в функции g.
Исправление: уберите определение h из определения g.
b) Ошибка: функция должна возвращать целое, но не делает этого.
Исправление: удалите переменную result и вставьте в функцию оператор
return х + у;
c) Ошибка: результат выражения n + sum( n — 1 ) не возвращается; sum
возвратит неверный результат.
Исправление: перепишите оператор предложения else в виде:
return n + sum( n - 1 );
d) Ошибки: точка с запятой после правой скобки, закрывающей список
параметров, и переопределение параметра а в теле функции.
Исправление: удалите точку с запятой после правой скобки списка
параметров и объявление float a;
e) Ошибка: функция возвращает значение, хотя не должна этого делать.
Исправление: удалите оператор return.
6.8. Если программист объявляет ссылочный параметр типа «ссылка на double»,
чтобы получить доступ по ссылке к исходной переменной вызывающей функции.
412
Глава 6
6.9. Неверно. C++ допускает вызов по ссылке посредством ссылочных параметров
(кроме того, можно использовать указатели, обсуждаемые в 8-й главе).
6.10. 1 // Упражнение 6.10: ех06_10.срр
2 // Встроенная функция, вычисляющая объем шара.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std:rendl;
7
8 #include <cmath>
9 using std::pow;
10
11 const double PI = 3.14159; // определить глобальную константу PI
12
13 // вычисляет объем шара
14 inline double sphereVolume( const double radius )
15 {
16 return 4.0/3.0* PI* pow( radius, 3 );
17 } // конец встроенной функции sphereVolume
18
19 int main()
20 {
21 double radiusValue;
22
23 // запросить у пользователя радиус
24 cout « "Enter the length of the radius of your sphere: "
25 cin » radiusValue; // ввести радиус
26
27 // вызвать radiusValue для вычисления объема и вывести результат
28 cout « "Volume of sphere with radius " « radiusValue
29 « " is " « sphereVolume ( radiusValue ) « endl;
30 return 0; // показывает успешное завершение
31 } // конец main
Упражнения
6.11. Укажите значение х после выполнения каждого из следующих операторов:
а)х = fabsG.5)
b) x = floorG.5)
c) х = f abs @.0)
d) x = ceil @.0)
e) x = f abs (-6.4)
f) x = ceil( -6.4 )
g) x = ceil( -fabs( -8 + floor ( -5.5 ) ) )
6.12. За стоянку длительностью до трех часов парковочный гараж запрашивает плату
минимум $2.00. В случае стоянки более трех часов гараж дополнительно
запрашивает $0.50 за каждый полный или неполный час сверх трех часов.
Максимальная плата за сутки составляет $10.00. Допустим, что никто не паркуется
более одного раза за сутки. Напишите программу расчета и печати оплаты за
парковку для каждого из трех клиентов, которые парковали свои автомобили вчера
в этом гараже. Вы должны вводить длительность парковки для каждого
клиента. Ваша программа должна печатать результаты в аккуратном табулированном
формате, вычислять и печатать общий вчерашний доход. Программа должна
использовать функцию calculateCharges, чтобы определять плату для каждого
клиента. Результаты работы должны представляться в следующем формате:
Функции и введение в рекурсию
413
Car Hours Charge
1 1.5 2.00
2 4.0 2.50
3 24.0 10.00
TOTAL 29.5 14.50
6.13. Одним из приложений функции floor является округление значения до
ближайшего целого. Оператор
у = floor( х + .5 );
округляет значение х до ближайшего целого и присваивает результат
переменной у. Напишите программу, которая читает несколько чисел и использует
указанный выше оператор для округления каждого из них. Для каждого
обрабатываемого числа напечатайте исходное число и его округленное значение.
6.14. Функция floor может использоваться для округления значения до
определенного числа знаков дробной части. Оператор
у = floor( х * 10 + .5 ) / 10;
округляет х с точностью до одной десятой (первая позиция справа от десятичной
точки). Оператор
у = floor( х * 100 + .5 )/ 100;
округляет х с точностью до одной сотой (вторая позиция справа от десятичной
точки). Напишите программу, которая определяет четыре функции для
округления х различными способами:
a) roundToInteger( number )
b) roundToTenths( number )
c) roundToHundredths( number )
d) roundToThousandths( number )
Для каждого прочитанного значения ваша программа должна печатать исходное
значение, число, округленное до ближайшего целого, число, округленное до
ближайшей десятой, число, округленное до ближайшей сотой и число, округленное
до ближайшей тысячной.
6.15. Ответьте на каждый из следующих вопросов:
a) Что означает выбрать «случайные» числа?
b) Почему функция rand полезна для моделирования азартных игр?
c) Каким образом рандомизируется программа при использовании функции
srand? При каких обстоятельствах рандомизация нежелательна?
d) Почему часто необходимо масштабировать и сдвигать числа, вырабатываемые
программой rand?
e) Чем полезно компьютерное моделирование реальных ситуаций?
6.16. Напишите операторы, которые присваивают случайные целые значения
переменной п в следующих диапазонах:
a) 1 < п < 2
b) 1 < п < 100
c) 0 < п < 9
d) 1000 < п ? 1112
e) -1 < п < 1
f) -3< п< 11
6.17. Для каждого из следующих наборов целых чисел напишите единственный
оператор, который будет печатать случайно выбранное число из набора:
414
Глава 6
a) 2, 4, 6, 8, 10
b) 3, 5, 7, 9, 11
c) 6, 10, 14, 18, 22
6.18. Напишите функцию integerPower( base, exponent ), которая возвращает
значение
basemxpon*nt
Например, integerPower( 3, 4) = 3*3*3*3. Считайте, что exponent —
положительное, не равное нулю, целое число, a base — целое. Функция integerPower
должна использовать для управления вычислением for или while. He
используйте никаких математических функций.
6.19. Определите функцию hypotenuse, которая вычисляет длину гипотенузы
прямоугольного треугольника, если две другие стороны известны. Используйте эту
функцию в программе для определения длины гипотенузы каждого из
следующих треугольников. Функции должны иметь два аргумента типа double и
возвращать значение гипотенузы как double.
Треугольник
1
2
3
Сторона 1
3.0
5.0
8.0
Сторона 2
4.0
12.0
15.0
6.20. Напишите функцию multiple, которая определяет для пары целых чисел,
кратно ли второе число первому. Функция должна принимать два целых аргумента
и возвращать true, если второе число кратно первому, и false, если нет.
Используйте эту функцию в программе, которая вводит последовательность пар целых
чисел.
6.21. Напишите программу, которая вводит последовательность целых чисел и
передает их по одному функции even, которая использует операцию вычисления
остатка для определения четности числа. Функция должна принимать целый
аргумент и возвращать true, если аргумент — четное число, и false в противном
случае.
6.22. Напишите программу, которая отображает у левого края экрана сплошной
квадрат из звездочек, сторона которого указана целым параметром side. Например,
если side равна 4, функция должна отображать следующую картинку:
# * * *
# • * *
# • • •
# * * *
6.23. Модифицируйте функцию, созданную в упражнении 6.22, так, чтобы
формировать квадрат из любых символов, указанных в символьном параметре
fillCharacter. Таким образом, если side равна 5 и fillCharacter есть #, то эта
функция должна напечатать:
# # # # #
# # # # #
# # # # #
# # # # #
# # # # #
Функции и введение в рекурсию
415
6.24. Используйте подход, развитый в упражнениях 6.22 и 6.23, для создания
программы, которая вычерчивает разнообразные формы.
6.25. Напишите фрагменты программ, которые выполняли бы следующее:
a) Вычислить целую часть частного от деления целого числа а на целое число Ь.
b) Вычислить целый остаток от деления целого числа а на целое число Ь.
c) Использовать фрагменты программ, созданные в пунктах (а) и (Ь), для
написания функции, которая вводит целое число из диапазона от 1 до 32767 и
печатает его как последовательность цифр, каждая из которых отделена от
соседней двумя пробелами. Например, целое число 4562 должно быть напечатано
в виде
4 5 6 2
6.26. Напишите функцию, которая принимает время как три целых аргумента (часы,
минуты и секунды) и возвращает число секунд, прошедших со времени, когда
часы в последний раз «пробили 12». Используйте эту функцию для вычисления
интервала времени в секундах между двумя моментами, находящимися внутри
двенадцатичасового цикла.
6.27. (Температура по Цельсию и по Фаренгейту) Разработайте следующие целые
функции:
a) Функцию celsius, которая возвращает температуру по Цельсию,
эквивалентную температуре по Фаренгейту.
b) Функцию fahrenheit, которая возвращает температуру по Фаренгейту,
эквивалентную температуре по Цельсию.
c) Используйте эти функции для написания программы, которая печатает
таблицу, показывающую эквивалент по Фаренгейту всех температур по Цельсию от
О до 100 градусов и эквивалент по Цельсию всех температур по Фаренгейту от
32 до 212 градусов. Напечатайте вывод в аккуратном табулированном
формате с минимальным количеством строк при сохранении хорошей читаемости.
6.28. Напишите программу, которая вводит три числа с плавающей точкой двойной
точности и передает их функции, возвращающей наименьшее из них.
6.29. (Совершенные числа) Говорят, что целое число является совершенным, если его
делители, включая 1 (но не само число) в сумме дают это число. Например, 6 —
совершенное число, так как 6 = 1 + 2 + 3. Напишите функцию perfect, которая
определяет, является ли ее параметр number совершенным числом. Используйте
эту функцию в программе, которая определяет и печатает все совершенные
числа в диапазоне от 1 до 1000. Напечатайте сомножители каждого совершенного
числа, чтобы убедиться, что число, действительно, совершенное. Исследуйте
мощность вашего компьютера проверкой чисел, много больших 1000.
6.30. (Простые числа) Говорят, что целое число является простым, если оно делится
только на 1 и на самое себя. Например, 2,3,5 — простые числа, а 4, 6, 8 — нет.
a) Напишите функцию, определяющую, является ли число простым.
b) Используйте эту функцию в программе, которая определяет и печатает все
простые числа, лежащие в диапазоне от 1 до 10000. Сколько из этих 10000
чисел вы должны действительно проверить, чтобы убедиться в том, что найдены
все простые числа?
c) Сначала вы могли бы подумать, что верхней границей, до которой вы должны
проводить проверку, чтобы увидеть, является ли число п простым, будет п/2,
но на самом деле вам не нужно идти далее корня квадратного из п. Почему?
Перепишите программу и запустите ее для обоих способов. Оцените
улучшение производительности.
416
Глава 6
6.31- (Обращение порядка цифр) Напишите функцию, которая принимает целое
значение и возвращает число с обратным порядком цифр. Например, принимается
число 7631, а возвращается число 1367.
6.32. Наибольший общий делитель (ИОД) двух целых чисел — это наибольшее
число, на которое без остатка делится каждое из двух чисел. Напишите функцию
gcd, которая возвращает наибольший общий делитель двух чисел.
6.33. Напишите функцию quality Points, которая вводит среднюю оценку студентов
и возвращает 4, если средняя оценка 90-100, 3, если средняя оценка 80-89, 2,
если средняя оценка 70-79, 1, если средняя оценка 60-69, и 0, если средняя
оценка меньше 60.
6.34. Напишите программу, моделирующую бросание монеты. Для каждого броска
монеты программа должна печатать «Орел» или ♦Решка». Промоделируйте с
помощью этой программы бросание 100 раз и подсчитайте, сколько раз появилась
каждая сторона монеты. Напечатайте результаты. Программа должна вызывать
отдельную функцию flip, которая не принимает никаких аргументов и
возвращает 0 для «Орла» и 1 для «Решки». Замечание: если программа действительно
моделирует бросание монеты, каждая сторона монеты должна появляться
примерно в половине случаев.
6.35. (Компьютеры в школе) Компьютеры играют все возрастающую роль в
образовании. Напишите программу, которая поможет ученикам младших классов
выучить таблицу умножения. Используйте rand для выработки двух
положительных одноразрядных целых чисел. Программа должна печатать вопросы типа
Сколько будет 6*7?
Затем учащийся печатает ответ. Ваша программа проверяет этот ответ. Если он
правильный, напечатайте «Очень хорошо!» и затем задайте следующий вопрос
на умножение. Если ответ неправильный, напечатайте «Нет. Повторите,
пожалуйста, снова» и затем задавайте тот же самый вопрос повторно до получения
правильного ответа.
6.36. (Компьютерная обучающая система) Использование компьютеров в
образовании относится к области компьютерных обучающих систем. Одной из проблем
обучающих систем является утомляемость учеников. Этого можно избежать,
разнообразив компьютерные диалоги, чтобы они удерживали внимание ученика.
Модифицируйте программу из упражнения 6.35 так, чтобы для каждого
правильного или неправильного ответов печатались разнообразные комментарии
типа:
Отклики на правильные ответы
Очень хорошо?
Отлично!
Чудесная работа!
Продолжайте работать в том же духе?
Отклики на неправильные ответы
Нет. Попытайтесь, пожалуйста, снова.
Неверно. Попытайтесь еще раз.
Не опускайте руки!
Нет. Продолжайте ваши попытки.
Используя генератор случайных чисел для выбора чисел от 1 до 4, выбирайте
подходящую реплику для каждого ответа. Используйте структуру switch для
представления отклика.
Функции и введение в рекурсию
417
6.37. Более развитые компьютерные обучающие системы следят за работой ученика
в течение некоторого периода времени. Решение о начале новой темы часто
принимается исходя из успехов учащегося в изучении предыдущей темы.
Модифицируйте программу в упражнении 6.35 так, чтобы считать количество
правильных и неправильных ответов, введенных учащимся. После того как учащийся
напечатал 10 ответов, ваша программа должна подсчитать процент правильных
ответов. Если он ниже 75%, ваша программа должна напечатать «Пожалуйста,
попросите вашего преподавателя помочь вам» и закончить свою работу.
6.38. (Игра «Угадай число») Напишите программу, которая играет в игру «Угадай
число» следующим образом: ваша программа выбирает случайное число, которое
должно быть отгадано, в диапазоне от 1 до 1000. Затем программа печатает:
Мое число между 1 и 1000.
Вы можете его отгадать?
Пожалуйста, напечатайте вашу первую догадку.
Затем игрок печатает свою первую догадку. Программа отвечает одним из
следующих вариантов:
1. Отлично! Вы отгадали число!
Хотите сыграть еще (Да или Нет)?
2. Слишком мало. Попытайтесь снова.
3. Слишком много. Попытайтесь снова.
Если догадка игрока неверна, ваша программа должна работать циклически до
получения верного ответа. Программа должна говорить игроку «Слишком мало*
или «Слишком много», чтобы помочь ему угадать правильный ответ.
6.39. Модифицируйте программу упражнения 6.38 так, чтобы она вычисляла
количество попыток игрока отгадать число. Если это число 10 или меньше, напечатайте
«Или вы знаете секрет, или вы счастливчик!». Если игрок отгадал число за 10
попыток, напечатайте «О! Вы знаете секрет!». Если игрок отгадывает больше чем
за 10 попыток, то напечатайте «Вы должны развивать свои способности!».
Почему отгадка не должна требовать более 10 попыток? Да потому, что каждая
«хорошая догадка» должна исключать половину чисел. Теперь покажите, почему
любое число от 1 до 1000 может быть отгадано не более чем за 10 попыток.
6.40. Напишите рекурсивную функцию power (base, exponent), которая возвращала
бы значение
baseexpon#nt
Например, power C, 4) = 3 * 3 * 3 * 3. Пусть exponent — целое число, большее
или равное 1. Подсказка: шаг рекурсии может использовать соотношение
base#xponent = base . baseexponent " l
а завершение может иметь место, когда exponent равна 1, потому что
base1 = base
6.41. (Ряд Фибоначчи) Ряд Фибоначчи
0, 1, 1, 2, 3, 5, 8, 13, 21, . ..
начинается с 0 и 1 и имеет то свойство, что каждый последующий его член является
суммой двух предыдущих, (а) Напишите нерекурсивную функцию, которая
вычисляет л-ое число Фибоначчи. (Ь) Определите наибольшее число Фибоначчи, которое
может быть напечатано в вашей системе. Модифицируйте программу части (а) так,
чтобы для вычислении и возврата чисел Фибоначчи использовался тип double
вместо int; и выполните модифицированную программу для задания части (Ь).
418
Глава 6
6.42. (Ханойская башня). В этой главе вы изучали функции, которые могут быть
легко реализованы как рекурсивно, так и итеративно. В данном упражнении мы
представляем задачу, решение которой демонстрирует изящество рекурсии,
причем ее итеративное решение далеко не очевидно.
Каждый подающий надежды программист рано или поздно должен столкнуться
с некоторыми классическими задачами. Ханойская башня (см. рис. 6.3) — одна
из самых известных среди них. Легенда гласит, что в одном из монастырей
Дальнего Востока монахи пытались переместить стопку дисков с одного колышка на
другой. Начальная стопка имела 64 диска, нанизанных на один колышек так,
что их размеры последовательно уменьшались к вершине. Монахи пытались
переместить эту стопку с этого колышка на второй при условии, что при каждом
перемещении можно брать только один диск и больший диск никогда не должен
находиться над меньшим диском. Третий колышек предоставляет возможность
временного размещения дисков. Считают, что когда монахи решат свою задачу,
наступит конец света, так что у нас мало поводов им помогать.
Предположим, что монахи пытаются переместить диски с колышка 1 на
колышек 3. Мы хотим построить алгоритм, который будет печатать четкую
последовательность перемещений дисков с колышка на колышек.
Если бы мы пытались найти решение этой задачи обычными методами, мы
быстро бы обнаружили безнадежность попыток манипуляций дисками. Но если мы
решим действовать рекурсивно, проблема сразу становится легко разрешимой.
Перемещение п дисков может быть легко представлено в терминах перемещения
только п - 1 диска (и, следовательно, рекурсивно):
a) Переместить п — 1 дисков с колышка 1 на колышек 2, используя колышек 3
как место временного размещения.
b) Переместить последний диск (наибольший) с колышка 1 на колышек 3.
c) Переместить п - 1 дисков с колышка 2 на колышек 3, используя колышек 1
как место временного размещения.
Этот процесс завершается, когда последняя задача будет состоять из
перемещения п = 1 дисков, т.е. окажется базовой задачей. Она соответствует
тривиальному перемещению диска без использования места временного размещения.
Напишите программу решения задачи о Ханойских башнях. Используйте
рекурсивную функцию с четырьмя параметрами:
a) Количество дисков, которое должно быть перемещено.
b) Колышек, на который эти диски нанизаны первоначально.
c) Колышек, на который эта группа дисков должна быть перемещена.
d) Колышек, используемый как место временного размещения.
Ваша программа должна печатать четкие инструкции, что нужно делать для
перемещения дисков с начального колышка на конечный. Например, чтобы
передвинуть группу из трех дисков с колышка 1 на колышек 3, ваша программа
должна напечатать следующую последовательность перемещений:
1 -> 3 (Это означает перемещение одного диска с колышка 1 на колышек 3)
1 -> 2
3 -> 2
-1 -> 3
2 -> 1
2 -> 3
1 -> 3
Функции и введение в рекурсию
419
peg 1 peg 2 peg 3
Рис. 6.41. Ханойская башня для случая с четырьмя дисками
6.43. Любая программа, которая может быть реализована как рекурсивная, может
быть реализована также итеративно, хотя иногда с большими трудностями
и меньшей ясностью. Попытайтесь написать итеративную версию задачи о
Ханойских башнях. Если вам это удастся, сравните вашу итеративную версию с
рекурсивной, разработанной в упражнении 6.42. Исследуйте вопросы
производительности, ясности и возможности обосновать корректность программ.
6.44. (Визуализация рекурсии) Интересно наблюдать рекурсию «в действии».
Модифицируйте функцию факториала на рис. 6.29 так, чтобы печатать ее локальную
переменную и параметр рекурсивного вызова. Для каждого рекурсивного вызова
отобразите выходные данные в отдельной строке и добавьте отступ. Сделайте все
возможное для того, чтобы выходные данные были ясными, интересными и
значимыми. Ваша цель — разработать и реализовать такой формат выходных
данных, который поможет лучше понять рекурсию. Вы можете добавлять такие
изобразительные возможности во многие другие примеры и упражнения по
рекурсии в этой книге.
6.45. (Рекурсивное нахождение НОД) Наибольший общий делитель (НОД) двух
целых чисел х и у — это наибольшее целое, на которое без остатка делится каждое
из двух чисел. Напишите рекурсивную функцию gcd, которая возвращает
наибольший общий делитель чисел х и у. НОД для х и у определяется рекурсивно
следующим образом: если у равно 0, то nod( x, у ) возвращает х; в противном
случае gcd( х, у ) равняется gcd( у, х % у ), где % — это операция взятия по модулю.
6.46. Можно ли рекурсивно вызывать функцию main на вашей системе? Напишите
программу, содержащую функцию main. Включите в нее локальную
статическую переменную count, инициализировав ее значением 1. Инкрементируйте
и печатайте значение count при каждом вызове main. Запустите вашу
программу. Что произойдет?
6.47. Упражнения с 6.35 по 6.37 были посвящены разработке компьютерных
программ для обучения учеников младших классов умножению. В данном
упражнении попытайтесь их усовершенствовать.
а) Модифицируйте программу так, чтобы дать возможность пользователю ввести
уровень своих возможностей. Первый уровень означает, что в задачах
используются только одноразрядные числа, второй уровень означает использование
двухразрядных чисел и т.д.
420
Глава 6
b) Модифицируйте программу так, чтобы позволить пользователю выбрать тип
арифметических операций для изучения. Опция 1 пусть означает только
операцию сложения, 2 — операцию вычитания, 3 — операцию умножения, 4 —
операцию деления, 5 — случайную смесь операций этих типов.
6.48. Напишите функцию distance, которая вычисляет расстояние между двумя
точками (xl, yl) и (х2, у2). Все числа и возвращаемые значения должны быть типа
double.
6.49. Что не так в следующей программе?
1 // Упражнение 6.49: ехО 6_49.срр
2 // Что неверно в этой программе?
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6
7 int main()
8 {
9 int c;
10
11 if ( ( с = cin.get() ) != EOF )
12 {
13 main () ;
14 cout « c;
15 } // end if
16
17 return 0; // показывает успешное завершение
18 } // конец main
6.50. Что делает следующая программа?
1 // Упражнение 6.50: ех06_50.срр
2 // Что делает эта программа?
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 int mystery( int, int ); // прототип функции
9
10 int main()
11 {
12 int x, y;
13
14 cout « "Enter two integers: ";
15 cin » x » y;
16 cout « "The result is " « mystery( x, у ) « endl;
17
18 return 0; // показывает успешное завершение
19 } // конец main
20
21 // b должен быть » 0, чтобы не получилось бесконечной рекурсии
22 int mystery( int a, int b )
23 {
24 if ( b == 1 ) // основной случай
25 return a;
26 else // рекурсивный шаг
27 return a + mystery( a, b - 1 );
28 } // конец функции mystery
6.51. После того как вы определили, что делает программа в упражнении 6.50,
модифицируйте программу так, чтобы она работала без ограничения, требующего,
чтобы второй аргумент был неотрицательным.
Функции и введение в рекурсию
421
6.52. Напишите программу, которая проверяет как можно больше математических
функций из рис. 6.2. Поупражняйтесь с каждой из этих функций, выводя в
вашей программе на печать таблицы возвращаемых значений для различных
значений аргументов.
6.53. Найдите ошибку в каждом из приведенных ниже программных фрагментов
и объясните, как ее исправить:
a) float cube( float ); // прототип функции
double cube( float number ) // определение функции
{
return number * number * number;
}
b) register auto int x = 7;
c) int randomNumber = srand();
d) float у = 123.45678;
int x;
x = y;
cout « static__cast< f loat> ( x )« endl;
e) double square( double number )
{
double number
return number * number;
}
f) int sum( int n )
{
if ( n == 0 )
return 0; . »
else
return n + sum( n ) ;
}
6.54. Модифицируйте программу для игры «крепе» из рис. 6.11 так, чтобы можно
было заключать пари. Оформите в виде функции часть программы, которая
моделирует одну игру в «крепе». Присвойте переменной bankBalance начальное
значение 1000 долларов. Предложите игроку ввести ставку (в переменную
wager). Используя цикл while, проверьте, что wager не больше, чем
bankBalance, и, если больше — предложите пользователю повторно вводить
wager до тех пор, пока не будет введено правильное значение ставки. После
введения правильного значения wager запустите моделирование одной игры
в «крепе». Если игрок выиграл, увеличьте bankBalance на wager и напечатайте
ноьое значение bankBalance. Если игрок проиграл, уменьшите bankBalance на
wager, напечатайте новое значение bankBalance, проверьте, не стало ли
значение bankBalance равным нулю, и если стало, напечатайте сообщение «Извините.
Вы обанкротились!» Пока игра продолжается, печатайте различные сообщения,
чтобы создать некоторый «разговорный фон» типа: «О! Вы собираетесь
разориться, ха!», или «Испытайте судьбу!», или «Вам везет! Теперь самое время
обменять фишки на деньги!».
6.55. Напишите программу на C++, которая запрашивает у пользователя радиус
круга, а затем вызывает встроенную функцию circleArea для вычисления его
площади.
422
Глава 6
6.56. Напишите законченную программу на C++ с двумя указанными ниже
альтернативными функциями, каждая из которых просто утраивает переменную count,
определенную в main. Затем сравните и противопоставьте эти два подхода. Вот
эти две функции:
a) Функция tripleCallByValue, в которую передается копия count по значению,
в функции эта копия утраивается и возвращается соответствующее значение.
b) Функция tripleByReference, в которую передается count по ссылке
посредством ссылочного параметра, а функция утраивает исходную копию count через
ее псевдоним (т.е. ссылочный параметр).
6.57. Каково назначение унарной операции разрешения области действия?
6.58. Напишите программу, которая использует шаблон функции с именем min для
определения наименьшего из двух аргументов. Проверьте программу, используя
пары целых чисел, символов и чисел с плавающей запятой.
6.59. Напишите программу, которая использует шаблон функции с именем max для
определения наибольшего из двух аргументов. Проверьте программу, используя
пары целых чисел, символов и чисел с плавающей запятой.
6.60. Определите, имеются ли ошибки в следующих программных фрагментах. Для
каждой ошибки укажите, как она может быть исправлена. [Замечание. В
некоторых фрагментах ошибки могут отсутствовать.]
a) template < class A >
int sum( int numl, int num2, int num3 )
{
return numl + num2 + num3;
}
b) void printResults( int x, int у )
{
cout « "The sum is " « x + у « ' \nf;
return x + y;
>
c) template < A >
A product ( A numl, A num2, A num3 )
{
return numl * num2 * num3;
}
d) double cube( int );
int cube( int ) ;
7
Массивы и векторы
ЦЕЛИ
В этой главе вы изучите:
• Использование структуры данных,
называемой массивом, для
представления родственных
элементов данных.
• Использование массивов для
хранения, сортировки и поиска
в списках и таблицах значений.
• Объявление массивов,
их инициализацию и обращение
к их отдельным элементам.
• Передачу массивов функциям.
• Элементарные методики поиска
и сортировки.
• Объявление и операции с многомерными массивами.
• Использование шаблона класса vector стандартной библиотеки C++.
424
Глава 7
7.1. Введение
7.2. Массивы
7.3. Объявление массивов
7.4. Примеры с массивами
7.5. Передача массивов функциям
7.6. Пример: класс GradeBook с массивом для хранения
оценок
7.7. Линейный поиск в массивах
7.8. Сортировка массивов вставкой
7.9. Многомерные массивы
7.10. Пример: класс GradeBook с двумерным массивом
7.11. Введение в шаблон класса vector стандартной
библиотеки C++
7.12. Конструирование программного обеспечения.
Кооперация объектов в системе ATM (необязательный
раздел)
7.13. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
7.1. Введение
В этой главе мы представляем важную тему о структурах данных —
коллекциях взаимосвязанных единиц информации. Массивы являются
структурами данных, состоящими из элементов одного и того же типа. В главе 3 вы
познакомились с классами. В главе 9 мы будем обсуждать понятие структур.
Как структуры, так и классы могут хранить взаимосвязанные элементы
данных, возможно, различных типов. Массивы, структуры и классы являются
«статическими» сущностями в том отношении, что они не изменяют своего
размера в течение всего времени исполнения программы. (Они, конечно, могут
иметь автоматический класс памяти и, таким образом, создаваться и
уничтожаться при каждом входе и выходе из блока, в котором они определены.)
После обсуждения того, как объявляются, создаются и инициализируются
массивы, мы приводим ряд практических примеров, демонстрирующих
распространенные операции с массивами. Затем мы объясняем, как с помощью
массивов можно реализовать символьные строки (до сих пор
представлявшиеся объектами класса string). Мы приведем пример поиска в массивах для
нахождения определенных элементов. В главе рассматривается также одно из
важнейших компьютерных приложений — сортировка данных (т.е.
расположение их в некотором заданном порядке). Два раздела главы развивают при-
Массивы и векторы
425
мер класса GradeBook, созданного в главах 3-6. В частности, мы применим
массивы, чтобы класс мог сохранять в памяти набор оценок и анализировать
оценки студентов за несколько контрольных работ в течение семестра — эти
возможности отсутствовали в предыдущих версиях класса GradeBook. Эти
примеры и примеры из последующих глав демонстрируют способы
организации и обработки данных, возможные благодаря использованию массивов.
Массивы, которыми мы пользуемся на протяжении большей части данной
главы, — это массивы «в стиле С», реализованные на основе указателей. (Мы
будем изучать указатели в главе 8.) В последнем разделе главы мы
познакомимся с массивами, которые реализуются как полноценные объекты,
называемые векторами. Мы увидим, что эти «объектные» массивы более безопасны и
более гибки, чем рассматриваемые в начале главы массивы в стиле С,
опирающиеся на указатели.
7.2. Массивы
Массив — это группа последовательных ячеек памяти, имеющих один и тот
же тип. Чтобы обратиться к определенной ячейке, или элементу массива, мы
специфицируем имя массива и номер позиции элемента в массиве.
На рис. 7.1 показан целый массив с именем с. Он содержит 12 элементов.
Программа ссылается на любой из этих элементов, указывая имя массива, за
которым следует номер позиции нужного элемента в квадратных скобках ([]).
На более формальном языке номер позиции называют индексом элемента (но-
Номер позиции элемента
в массиве с
Имя отдельного элемента
массива
1
с[0]
с[1]
с[2]
с[3]
w. г\ л 1
W- С[ 4 J
с[5]
с[6]
с[7]
с[8]
с[9]
с[ 10]
с[11]
Именем массива является с
-45
6
0
72
1543 < Значение
-89
0
62
-3
1
6453
78
Рис. 7.1. Массив из 12 элементов
426
Глава 7
мер позиции равен числу элементов, предшествующих в массиве данному
элементу). Первый элемент любого массива имеет индекс 0 и называется иногда
нулевым элементом. Таким образом, элементы массива с именуются с[ 0 ],
с[ 1 ], с[ 2 ] и т. д. Наибольший индекс в массиве с равен 11, что на единицу
меньше 12 — числа элементов в массиве. Имена массивов следуют тем же
соглашениям, что и другие имена переменных, т. е. они должны быть
идентификаторами.
Индекс должен быть целым числом или целым выражением
(принадлежащим к любому целочисленному типу). Если программа использует в качестве
индекса выражение, то для определения индекса она оценивает это
выражение. Например, в предположении, что переменная а равна 5, а переменная b
равна 6, то оператор
с[ а + Ь ] += 2;
прибавляет 2 к элементу с[ 11 ]. Обратите внимание, что индексированное имя
переменной является lvalue, — оно может стоять в левой части присваивания,
как и имена обычных переменных.
Давайте рассмотрим массив на рис. 7.1 более внимательно. Именем всего
массива является с. На 12 его элементов мы ссылаемся как на с[ 0 ], с[ 1 ],
с[ 3 ], ..., с[ 11 ], значение элемента с[ 0 ] равно -45, значение с[ 1 ] — 6,
значение с[ 2 ] — 0, значение с[ 7 ] — 62, а значение с[ 1 ] —78. Чтобы напечатать
сумму значений, содержащихся в первых трех элементах массива, мы
написали бы
cout «c[0]+c[l]+c[2]« endl;
Чтобы поделить значение с[ 6 ] на 2 и присвоить результат переменной х, мы
могли бы написать
х = с[ б ] / 2;
Типичная ошибка программирования 7.1
Важно отметить различие между «седьмым элементом массива»
и «элементом массива 7». Поскольку индексы массива начинаются
с 0, «седьмой элемент массива» имеет индекс 6, тогда как «элемент
массива 7» имеет индекс 7 и на самом деле является восьмым
элементом. К сожалению, это различие часто служит источником ошибок
смещения на единицу. Чтобы избежать подобных ошибок, мы явно
называем конкретные элементы по имени массива с указанием индекса
(например, с[ 6 ] или с[ 7 ].
Квадратные скобки, в которые заключается индекс массива, являются в
действительности операцией языка C++. Квадратные скобку имеют тот же
уровень приоритета, что и круглые скобки. На рис. 7.2 показаны приоритеты
и правила ассоциации всех операций, представленных к настоящему моменту.
Обратите внимание, что квадратные скобки ([]) стоят в первой строке таблицы
на рис. 7.2. Операции расположены сверху вниз в порядке убывания
приоритета с указанием их ассоциативности и типа.
Массивы и векторы
427
Операции
0 []
++ — static
++ — + -
* / %
+ -
« »
<<=>>=
== ! =
&&
II
?:
= += _= *=
г
cast<type>()
i
/= %=
Ассоциативность
слева направо
слева направо
справа налево
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
справа налево
справа налево
слева направо
Тип
наивысший приоритет
унарные (постфиксные)
унарные (префиксные)
мультипликативные
аддитивные
передачи/извлечения
из потока
отношения
равенства
логическое И
логическое ИЛИ
условная
присваивания
запятая
Рис. 7.2. Приоритеты и ассоциативность операций
7.3. Объявление массивов
Массивы занимают в памяти некоторое пространство. Программист
специфицирует имя массива и требуемое число его элементов следующим образом:
тип имя_массива [ размер_массива ] ;
и компилятор резервирует под массив соответствующий объем памяти.
Указанный размер_массива должен целой константой, большей нуля. Например,
чтобы компилятор зарезервировал 12 элементов для массива с, следует
написать
int с[ 12 ]; // с - массив из 12 целых
В одном объявлении можно зарезервировать память для нескольких массивов.
Следующее объявление резервирует 100 элементов для целого массива b и 27
элементов для целого массива х:
int b[ 100 ], // b - массив из 100 целых
х[ 27 ]; // х - массив из 27 целых
Хороший стиль программирования 7.1
Для удобства чтения, модификации и комментирования мы
предпочитаем объявлять каждый массив по отдельности (в отдельном
объявлении).
Можно объявлять массивы, содержащие значения любого не ссылочного
типа данных. Например, для хранения символьной строки можно использо-
428
Глава 7
вать массив типа char. До сих пор для хранения символьных строк мы
пользовались объектами string. В разделе 7.4 рассматривается использование для
этой цели символьных массивов. Символьные строки и их сходство с
массивами (их взаимосвязь C++ унаследовал от С), а также взаимосвязь массивов и
указателей мы обсуждаем в главе 8.
7.4. Примеры с массивами
В этом разделе представлено много примеров, демонстрирующих, как
объявлять массивы, инициализировать их и производить над ними некоторые
распространенные действия.
Объявление массива и его инициализация с применением цикла
Программа на рис. 7.3 объявляет 10-элементный целый массив п
(строка 12). Оператор for в строках 15-16 инициализирует элементы массива
нулями. Первый оператор вывода (строка 18) выводит заголовки колонок, которые
печатаются в табличном формате последующим оператором for
(строки 21-22). Не забудьте, что манипулятор setw специфицирует ширину поля
для вывода только следующего значения.
1 // Рис. 7.3: fig07_03.cpp
2 // Инициализация массива.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 int main()
11 {
12 int n[ 10 ]; // n - массив из 10 целых
13
14 // инициализировать элементы массива п нулями
15 for ( int i = 0; i < 10; i++ )
16 n[ i ] = 0; // установить элемент в позиции i в 0
17
18 cout « "Element" « setw( 13 ) « "Value" « endl;
19
20 // вывести значение каждого элемента массива
21 for ( int j = 0; j < 10; j++ )
22 cout « setw( 7 ) « j « setw( 13 ) « n[ j ] « endl;
23
24 return 0; // показывает успешное завершение
25 } // конец main
Element Value
0 0
1 0
2 0
3 0
4 0
Массивы и векторы
429
5 О
6 О
7 О
8 О
9 О
Рис. 7.3. Инициализация элементов массива нулями и печать массива
Инициализация массива в объявлении с применением списка
инициализаторов
Элементы массива могут быть инициализированы в его объявлении. Для
этого после имени массива через знак равенства записывается разделенный
запятыми список инициализаторов (заключенный в фигурные скобки).
Программа на рис. 7.4 использует список инициализаторов для инициализации
целого массива десятью значениями (строка 13) и печатает массив в
табличном формате (строки 15-19).
1 // Рис. 7.4: fig07_04.cpp
2 // Инициализация массива в объявлении.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 int main()
11 {
12 // использовать для массива п список инициализаторов
13 int n[ 10 ] = { 32, 27, 64, 18, 95, 14, 90, 70, 60, 37 };
14
15 cout « "Element" « setw( 13 ) « "Value" « endl;
16
17 // вывести значение каждого элемента массива
18 for ( int i = 0; i < 10; i++ )
19 cout « setw( 7 ) « i « setw( 13 ) « n[ i ] « endl;
20
21 return 0; // успешное завершение
22 } // конец main
Element
0
1
2
3
4
5
6
7
8
9
Value
32
27
64
18
95
14
90
70
60
37
Рис. 7.4. Инициализация элементов массива в его объявлении
430
Глава 7
Если число инициализаторов меньше, чем число элементов в массиве,
оставшиеся элементы инициализируются нулями. Например, элементы
массива п на рис. 7.3 могли бы инициализироваться объявлением
int n[ 10 ] = { 0 }/ // инициализировать элементы массива п нулями
Это объявление явным образом инициализирует нулем только первый
элемент; оставшиеся элементы инициализируются нулями неявно, поскольку
инициализаторов меньше, чем элементов в массиве. Автоматические массивы
не инициализируются нулями по умолчанию, хотя статические —
инициализируются. Чтобы инициализировать нулями автоматический массив,
программист должен явно инициализировать хотя бы его первый элемент. Метод
инициализации, продемонстрированный на рис. 7.3, может применяться к
массиву неоднократно в ходе исполнения программы.
Если в объявлении со списком инициализаторов размер массива опущен,
компилятор определяет число элементов в массиве путем подсчета числа
инициализаторов. Например, объявление
int n[] = { 1, 2, 3, 4, 5 };
создает пятиэлементный массив.
Если в объявлении массива специфицируется и размер, и список
инициализаторов, то число инициализаторов должно быть не больше размера массива.
Объявление
int n[ 5 ] = { 32, 27, 64, 18, 95, 14 };
приводит к ошибке компиляции, так как инициализаторов здесь шесть, а
элементов массива всего пять.
\-p\tl Типичная ошибка программирования 7.2
Указание в списке инициализации массива большего числа
инициализаторов, чем число элементов в массиве, вызывает ошибку
компиляции.
r-p^f\ Типичная ошибка программирования 7.3
Пропуск по недосмотру инициализации массива, элементы которого
должны быть инициализированы, является логической ошибкой
Спецификация размера массива с помощью константной
переменной и установка его элементов вычисляемыми
значениями
Программа на рис. 7.5 устанавливает элементы 10-элементного массива
четными числами 2, 4, 6, ..., 20 (строки 17-18) и печатает его в табличном
формате (строки 20-24). Четные числа генерируются в строке 18 посредством
умножения счетчика цикла на 2 с последующим прибавлением двойки
(строка 18).
Массивы и векторы
431
1 // Рис. 7.5: fig07_05.cpp
2 // Записать в массив s четные числа от 2 до 20.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 int main()
11 {
12 // для задания размера массива допускается константная переменная
13 const int arraySize = 10;
14
15 int s[ arraySize ]; // массив s имеет 10 элементов
16
17 for ( int i = 0; i < arraySize; i++ ) // установить значения
18 s[i]=2 + 2*i;
19
20 cout « "Element" « setw( 13 ) « "Value" « endl;
21
22 // вывести содержимое массива s в табличном формате
23 for ( int j = 0; j < arraySize; j++ )
24 cout « setw( 7 ) « j « setw( 13 ) « s [ j ] « endl;
25
26 return 0; // успешное завершение
27 } // конец main
Element Value
0 2
1 4
2 6
3 8
4 10
5 12
6 14
7 16
8 18
9 20
Рис. 7.5. Генерирование значений для размещения в элементах массива
В строке 13 для объявления константной переменной arraySize
используется ква лификатор const. Константные переменные должны
инициализироваться константным выражением при объявлении и не могут впоследствии
модифицироваться (как показывают рис. 7.6 и рис. 7.7). Константные
переменные называют также именованными константами или read-only variables —
«переменными только для чтения».
1 // Рис. 7.6: fig07_06.cpp
2 // Правильно инициализированная константная переменная.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
432
Глава 7
6
7 int main()
8 {
9 const int x = 7; // инициализированная константная переменная
10
11 cout « "The value of constant variable x is: " « x « endl;
12
13 return 0; // успешное завершение
14 } // конец main
The value of constant variable x is: 7
Рис- 7.6. Инициализация и использование константной переменной
1 // Рис. 7.7: fig07_07.cpp
2 // Константная переменная должна инициализироваться.
3
4 int main()
5 {
6 const int x; // Ошибка: х должна быть инициализирована
7
8 х = 7; // Ошибка: нельзя модифицировать константную переменную
9
10 return 0; // успешное завершение
11 } // конец main
Сообщения об ошибках компилятора Borland C++ с командной строкой:
fig07_07.cpp:
Error E2304 fig07_07.cpp 6: Constant variable 'x' must be
initialized in function main()
Error E2024 fig07_07.cpp 8: Cannot modify a const object
in function main()
Сообщения об ошибках компилятора Visual C++.NET:
C:\cpphtp5_examples\ch07\fig07__07.срр(б) : error C2734:
'х' : const object must be initialized if not extern
C:\cpphtp5__examples\cho7\fig07_07.cpp(8) : error C2166:
1-value specifies const object
Сообщения об ошибках компилятора GNU C++:
fig07_07.cpp:б: error: uninitialized const 'x'
fig07_07.cpp:8: error: assignment of read-only variable 'x'
Рис. 7.7. Переменные-константы должны инициализироваться
Массивы и векторы
433
Типичная ошибка программирования 7.4
Отсутствие инициализирующего значения в объявлении
константной переменной приводит к ошибке компиляции.
Типичная ошибка программирования 7.5
Присваивание значения константной переменной в исполняемом
операторе приводит к ошибке компиляции.
Константные переменные могут помещаться везде, где ожидается
константное выражение. На рис. 7.5 константная переменная arraySize
специфицирует в строке 15 размер массива s.
Типичная ошибка программирования 7.6
Для объявления размера автоматических и статических массивов
могут использоваться только константы. Нарушение этого правила
приводит к ошибке компиляции.
Использование для спецификации размера массивов константных
переменных делает программы масштабируемыми. На рис. 7.5 первый оператор for
мог бы заполнять четными числами 1000-элементный массив, если просто
изменить значение в объявлении arraySize с 10 на 1000. Если не использовать
константную переменную arraySize, то нам пришлось бы изменить
строки 15, 17 и 23 этой программы, чтобы масштабировать ее для обработки 1000
элементов массива, по мере того, как размеры программ возрастают, такой
прием становится все более существенным для написания ясных, более
пригодных для модификации программ.
Общее методическое замечание 7.1
Определение размера каждого массива с помощью константной
переменной, а не литеральной константы может делать программы более
масштабируемыми.
Хороший стиль программирования 7.2
Определение размера массива с помощью константной переменной, а
не литеральной константы делает программу яснее. Такая методика
устраняет так называемые магические числа. Например,
многократное употребление размера 10 в коде, обрабатывающем 10-эле-
ментный массив, придает числу 10 нарочитую значимость и может
вводить читающего в заблуждение в случае, когда в программе
имеются другие вхождения числа 10, не имеющие ничего общего с размером
массива.
Суммирование элементов массива
Часто элементы массива содержат ряд значений, которые должны
использоваться в некотором вычислении. Например, если элементы массива
представляют экзаменационные оценки, преподавателю может потребоваться вы-
434
Глава 7
числить их сумму и использовать полученный результат для вычисления
средней оценки за экзамен. Такой подход реализуется позднее в этой главе
классом GradeBook, показанном на рис. 7.16-7.12.
Программа на рис. 7.8 суммирует значения, содержащиеся в 10-элемент-
ном массиве а. Программа объявляет, создает и инициализирует массив в
строке 10. Вычисление производится оператором for в строках 14-15.
Значения, предоставляемые в качестве инициализаторов массива, могли бы
печататься пользователем и вводиться в программу с клавиатуры, либо читаться
из дискового файла. Например, оператор
for ( int j = 0; j < arraySize; j++ )
cin » a[ j ];
читает значения с клавиатуры по одному и сохраняет очередное значение в
элементе а[ j ].
1 // Рис. 7.8: fig07_08.cpp
2 // Вычислить сумму элементов массива.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 const int arraySize = 10; // указывает размер массива
10 int a[ arraySize ] = { 87, 68, 94, 100, 83, 78, 85, 91, 76, 87 };
11 int total = 0;
12
13 // суммировать содержимое массива а
14 for ( int i = 0; i < arraySize; i++ )
15 total += a[ i ];
16
17 cout « "Total of array elements: " « total « endl;
18
19 return 0; // успешное завершение
20 } // конец main
Total of array elements: 849
Рис. 7.8. Вычисление суммы элементов массива
Создание столбцовых диаграмм для графического представления
данных
Многие программы показывают пользователю свои данные в графической
форме. Например, численные значения часто выводятся в виде столбиков на
столбцовой диаграмме. На такой диаграмме более длинные столбики
представляют большие значения с соблюдением пропорции. Одним из простейших
способов графического отображения численных данных на диаграмме является
представление каждого значения в виде столбика из звездочек (*).
Преподавателям часто нравится исследовать распределение оценок,
выставленных на экзамене. Преподаватель мог бы построить график числа
оценок в каждой из нескольких категорий и таким образом визуализировать рас-
Массивы и векторы
435
пределение оценок. Предположим, были выставлены оценки 87, 68, 94, 100,
83, 78, 85, 91, 76 и 87. Заметьте, что здесь имеется одна оценка 100, две
оценки между 90 и 100, четыре оценки между 80 и 90, две оценки между 70 и 80 и
одна между 60 и 70; оценок ниже 60 нет. Наша следующая программа
(рис.7.9) сохраняет данное распределение оценок в массиве из 11 элементов,
каждый из которых соответствует некоторой категории оценок. Например,
п[ 0 ] указывает число оценок в диапазоне 0-9, п[ 7 ] — число оценок в
диапазоне 70-79, а п[ 10 ] — число оценок, равных 100. Две представленных далее
версии класса GradeBook (на рис. 7.16-7.17 и рис. 7.23-7.24) содержат код,
вычисляющий частоты оценок, исходя из заданного их набора. Пока мы
создаем массив вручную согласно набору оценок, приведенному выше.
1 // Рис. 7.9: fig07_09.cpp
2 // Программа печати столбцовой диаграммы.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 int main()
11 {
12 const int arraySize = 11;
13 int n[ arraySize ] = { 0, 0, 0, 0, 0, 0, 1, 2, 4, 2, 1 };
14
15 cout « "Grade distribution:" « endl;
16
17 // для каждого элемента массива п вывести столбик диаграммы
18 for ( int i = 0; i < arraySize; i++ )
19 {
20 // вывести метку столбика (-9:", ..., "90-99:", 00:" )
21 if ( i == 0 )
22 cout « " 0-9: ";
23 else if ( i == 10 )
24 cout « " 100:
25 else
26 cout « i * 10 « "-" « ( i * 10 ) + 9 « ": ";
27
28 // напечатать столбик звездочек
29 for ( int stars = 0; stars < n[ i ]; stars++ )
30 cout « '*';
31
32 cout « endl; // начать новую строку вывода
33 } // конец внешнего for
34
35 return 0; // успешное завершение
36 } // конец main
0-9
10-19
20-29
30-39
40-49
436
Глава 7
50-59
60-69
70-79
80-89
90-99
100
•
*•
• ***
*•
•
Рис. 7,9. Программа, печатающая столбцовую диаграмму
Программа читает числа из массива и отображает их на столбцовой
диаграмме. Для каждого из диапазонов оценок выводится метка, за которой
следует столбик звездочек, указывающий число оценок в данном диапазоне.
Чтобы пометить диапазон, строки 21-26 выводят его границы (например,
0-79:") в зависимости от значения переменной-счетчика i. Вложенный
оператор for (строки 29-30) выводит столбики звездочек. Обратите внимание на
условие продолжения цикла в строке 29 (stars < n[ i ]). Всякий раз, когда
программа доходит до внутреннего for, цикл считает от 0 до n[ i ], используя,
таким образом, для определения числа выводимых звездочек значение из
массива п. В этом примере п[ 0 ]- п[ 5 ] содержат нули, поскольку никто из
студентов не получил оценки ниже 60. Поэтому для первых пяти диапазонов оценок
программа не выводит звездочек.
Типичная ошибка программирования 7.7
Хотя возможно использование одной и той же управляющей
переменной во внешнем операторе for и втором, вложенном в него операторе,
это создает путаницу и может вести к логическим ошибкам.
Элементы массива в качестве счетчиков
Иногда программы применяют переменные-счетчики, чтобы получить
сводку некоторых данных, например, результатов статистического исследования. В
программе на рис. 6.9 мы использовали отдельные счетчики, отслеживавшие
число выпадений каждой грани в процессе 6 000 000 бросаний игральной кости.
На рис. 7.10 приведена версия этой программы с массивом счетчиков.
1 // Рис. 7.10: fig07_10.cpp
2 // Бросание игральной кости 6 000 000 раз.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 #include <cstdlib>
11 using std::rand;
12 using std::srand;
13
14 #include <ctime>
15 using std::time;
16
17 int main()
Массивы и векторы
437
18 {
19 const int arraySize =7; // игнорировать нулевой элемент
20 int frequency[ arraySize ] = { 0 };
21
22 srand( time( 0 ) ); // засеять генератор случайных чисел
23
24 // бросить кость 6000000 раз; использовать значение как индекс
25 for ( int roll = 1; roll <= 6000000; roll++ )
26 frequency[ 1 + rand() % 6 ]++;
27
28 cout « "Face" « setw( 13 ) « "Frequency" « endl;
29
30 // вывести значение каждого элемента массива
31 for ( int face = 1; face < arraySize; face++ )
32 cout « setw( 4 ) « face « setw( 13 ) « frequency[ face ]
33 « endl;
34
35 return 0; // успешное завершение
36 } // конец main
Face Frequency
1 1001341
2 1000531
3 999584
4 999471
5 999046
6 1000027
Рис, 7.10- Программа для бросания кости с использованием массива вместо
оператора switch
Подсчет выпадений каждой грани кости производится в массиве frequency
(строка 20). Единственный оператор в строке 26 заменяет весь оператор
switch в строках 30-52 на рис. 6.9. В строке 26 очередное случайное число
определяет, какой элемент frequency следует инкрементировать на каждом
проходе цикла. Выражение в строке 26 генерирует случайный индекс в диапазоне
от 1 до 6, поэтому массив frequency должен быть достаточно велик, чтобы
вместить шесть счетчиков. Однако мы определяем семиэлементный массив, в
котором frequency[ О ] игнорируется, поскольку при выпадении грани со
значением 1 естественнее инкрементировать frequency[ 1 ], чем frequency[ О ].
Таким образом, значение каждой грани используется для индексации массива
frequency. Мы также заменили строки 56-61 на рис. 6.9 циклом,
перебирающим массив frequency для вывода результатов (строки 31-33).
Применение массивов для анализа результатов опроса
В нашем следующем примере (рис. 7.11) массивы используются для
анализа данных, полученных в результате общественного опроса. Рассмотрим
следующую постановку задачи:
Сорока студентам было предложено оценить качество пищи в студенческом
кафетерии по шкале от 1 до 10 (подразумевалось, что 1 — ужасное, а 10 —
превосходное качество). Поместите 40 ответов в целый массив и суммируйте
результаты опроса.
438
Глава 7
Это типичное приложение обработки массивов. Мы хотим подсчитать число
ответов каждого типа (т. е. значений от 1 до 10). Массив responses (строки
17-19) является 40-элементным целым массивом ответов, дававшихся
студентами в ходе опроса. Обратите внимание, что этот массив объявлен как const,
поскольку его значения не изменяются (и не должны изменяться). Для
подсчета ответов каждого типа мы используем 11-элементный массив frequency
(строка 22). Каждый из его элементов является счетчиком для одного из
возможных ответов и инициализируется нулем. Как и на рис. 7.10, мы
игнорируем frequency[ 0 ].
1 // Рис. 7.11: fig07_ll.cpp
2 // Программа опроса студентов.
3 #include <iostream>
4 using std::cout;
5 using std::endl/
6
7 #include <iomanip>
8 using std::setw;
9
10 int main()
11 {
12 // определить размеры массивов
13 const int responseSize = 40; // размер массива ответов
14 const int frequencySize = 11; // размер массива частот
15
16 // поместить ответы опроса в массив responses
17 const int responses[ responseSize ] = { 1, 2, 6, 4, 8, 5, 9, 7,
18 8, 10, 1, 6, 3, 8, 6, 10, 3, 8, 2, 7, 6, 5, 7, 6, 8, 6, 7,
19 5, 6, 6, 5, 6, 7, 5, 6, 4, 8, 6, 8, 10 };
20
21 // инициализировать счетчики частот нулями
22 int frequency[ frequencySize ] = { 0 };
23
24 // для каждого ответа выбрать элемент responses и использовать
25 // его как индекс инкрементируемого элемента массива frequency
26 for ( int answer = 0; answer < responseSize; answer++ )
27 frequency[ responses[ answer ] ]++;
28
29 cout « "Rating" « setw( 17 ) « "Frequency" « endl;
30
31 // вывести значение каждого элемента массива
32 for ( int rating = 1; rating < frequencySize; rating++ )
33 cout « setw( 6 ) « rating « setw( 17 )
34 « frequency[ rating ] « endl;
35
36 return 0; // успешное завершение
37 } // конец main
Rating Frequency
1 2
2 2
3 2
4 2
Массивы и векторы
439
5 5
6 11
7 5
8 7
9 1
10 3
Рис. 7-11- Анализ результатов опроса
Общее методическое замечание 7.2
Квалификатор const должен использоваться в интересах принципа
наименьших привилегий. Последовательное проведение этого
принципа при правильном подходе к проектированию программы может
существенно сократить затраты времени на отладку и свести к
минимуму нежелательные побочные эффекты, а также облегчить
модификацию и сопровождение программы.
Хороший стиль программирования 7.3
Стремитесь к ясности программ. Иногда ради написания ясного кода
стоит пожертвовать наиболее эффективным использованием
памяти.
Вопросы производительности 7.1
Иногда соображения эффективности значительно перевешивают
соображения ясности.
Первый оператор for (строки 26-27) по одному берет ответы из массива
responses и инкрементирует один из 10 счетчиков в массиве (от frequency[ 1 ]
до frequency[ 10 ]). Ключевой оператор цикла, расположенный в строке 27,
инкрементирует тот или иной счетчик frequency в зависимости от значения
responses! answer ].
Давайте рассмотрим несколько итераций цикла for. Когда управляющая
переменная answer равна 0, значением является responses[ 0 ] (т. е. 1 в строке 17),
поэтому программа интерпретирует выражение frequency[ responses[
answer ] ]++ как
frequency[ 1 ]++
что приводит к инкременту значения в элементе массива с индексом 1. Для
оценки выражения следует начать со значения в самой внутренней паре
квадратных скобок (т. е. answer). Когда вам известно значение answer (значение
управляющей переменной цикла в строке 26), подставьте его в выражение и
оцените следующую пару скобок (т. е. responses! answer ], что является
значением, выбранным из массива ответов в строках 17-19). Затем используйте
полученное значение в качестве индекса массива frequency, определяющего,
который из счетчиков должен получить приращение.
Когда номер ответа (answer) равен 1, responses! answer ] представляет
значение responses! 1 ], равняющееся 2, поэтому программа интерпретирует
выражение frequency! responses! answer ] ]++ как
440
Глава 7
frequency[ 2 ]++
что приводит к инкременту значения в элементе массива с индексом 2.
Когда answer равен 2, responses[ answer ] представляет значение respon-
ses[ 2 ], равняющееся 6, поэтому программа интерпретирует выражение
frequence responses[ answer ] ]++ как
frequency[ б ]++
что приводит к инкременту значения в элементе массива с индексом 6 и т. д.
Вне зависимости от числа обрабатываемых в опросе ответов, программе
требуется для подсчета результатов лишь 11-элементный массив (нулевой элемент
игнорируется), поскольку все ответы имеют значения от 1 до 10, а
индексы 11-элементном массиве пробегают значения от 0 до 10.
Если бы данные в массиве responses содержали неверное значение,
например, 13, программа попыталась бы прибавить единицу к frequency[ 13 ], что
находится за пределами массива. В C++ отсутствует проверка границ,
которая предотвращала бы ссылки на несуществующий элемент массива.
Следовательно, исполняющаяся программа может без всякого предупреждения
«уйти» за любой из его концов. Программист должен убедиться, что все
ссылки на массив остаются в пределах его границ.
~т^] Типичная ошибка программирования 7.8
Ссылка на элемент за пределами массива является логической
ошибкой времени выполнения. Это не синтаксическая ошибка.
При переборе элементов массива в цикле индекс никогда не должен
опускаться ниже 0 и всегда должен быть меньше общего числа его элементов (не
превышать значения размера минус 1). Убедитесь, что условие завершения цикла
предотвращает обращение к элементам вне указанного диапазона.
Переносимость программ 7.1
Последствия (как правило, серьезные) обращения к элементам вне
границ массива зависят от системы. Часто это приводит к
изменениям значения некоторой совершенно посторонней переменной или к
фатальной ошибке, прерывающей исполнение программы.
C++ является расширяемым языком. В разделе 7.11 представлен шаблон
класса из стандартной библиотеки vector, который позволяет программистам
производить многие операции, невозможные со встроенными массивами C++.
Например, мы сможем непосредственно сравнивать два вектора или
присваивать один вектор другому. В главе 11 мы еще далее расширим C++, реализовав
массив как свой собственный пользовательский класс. Новое определение
массива даст нам возможность вводить и выводить массивы целиком, используя
cin и cout, инициализировать массивы при создании, предотвращать
обращения к элементам за границами массива и изменять диапазон индексов (и даже
изменять тип индексов), так что первый элемент массива не обязан будет
иметь индекс 0. Мы сможем даже использовать нецелые индексы.
Массивы м векторы
441
^» Предотвращение ошибок 7.2
\£^у В главе 11 мы увидим, каким образом можно разработать класс,
реализующий «сообразительный массив», который сам проверяет, что
индексы всех обращений к нему во время выполнения находятся в
допустимых границах. Такие «сообразительные» типы данных
помогают устранять программные дефекты.
Использование массивов для храпения и обработки строк
До сих пор мы говорили только о целых массивах. Однако массивы могут
быть любого типа. Теперь мы представим хранение символьных строк в
символьных массивах. Как вы помните, начиная с 3-й главы мы для хранения
символьных строк, например, для названия курса в нашем классе GradeBook,
использовали объекты типа string. Строка, такая, как "hello", является на
самом деле массивом символов. Хотя объекты string удобны и сводят к
минимуму потенциальные ошибки, массивы в качестве представления символьных
строк обладают некоторыми уникальными особенностями, которые мы и
обсудим в этом разделе. По ходу изучения C++ вы встретитесь с такими
возможностями языка, которые потребуют применения символьных массивов, а не
объектов string. He исключено также, что вам придется обновлять существующий
код, использующий символьные массивы.
Символьный массив может быть инициализирован строковым литералом.
Например, объявление
char stringl[] = "first";
инициализирует элементы массива stringl отдельными символами,
составляющими строковый литерал "first". Размер массива stringl в показанном
объявлении определяется компилятором, исходя из длины строки. Важно
отметить, что строка "first" содержит пять символов, плюс специальный символ
ограничения строки, называемый нуль-символом. Таким образом, массив
stringl в действительности содержит шесть элементов. Нуль-символ
представляется символьной константой \0' (обратная дробная черта, за которой
следует 0). Любые строки, представляемые символьными массивами, оканчиваются
этим символом. Символьный массив, представляющий строку, должен
объявляться достаточно большим, чтобы вместить символы строки и
ограничивающий ее нуль-символ.
Символьные массивы могут инициализироваться также списком отдельных
символьных констант. Предыдущее объявление эквивалентно более
неуклюжей форме
char stringl [] = { 'г"', 'i', 'r', 's', 't', ' \0' };
Обратите внимание на употребление одиночных кавычек (апострофов),
выделяющих каждую из символьных констант, а также на то, что в качестве
последнего инициализатора мы явно указываем нуль-символ. Без него этот массив был
бы просто символьным массивом, а не строкой. Как мы увидим в главе 8,
опущение ограничивающего нуль-символа может приводить к логическим
ошибкам.
Поскольку строка является массивом символов, мы можем обращаться к
отдельным ее символам непосредственно, применяя нотацию индексации. На-
442 Глава 7
пример, stringl[ 0 ] представляет собой символ Т, stringl[ 3 ] — символ V, а
stringl[ 5 ] является нуль-символом.
Мы можем также вводить строку с клавиатуры прямо в символьный
массив, используя cin и ». Например, объявление
char string2[ 20 ];
создает символьный массив, который может строку длиной 19 символов с
ограничивающим нуль-символом. Оператор
cin » string2;
читает в string2 строку с клавиатуры, присоединяя к концу введенной
пользователем строки нуль-символ. Обратите внимание, что в вышеприведенном
операторе указано только имя массива, а какая-либо информация о его размере
отсутствует. Ответственность за то, что массив будет способен вместить любую
строку, которую введет пользователь, возлагается на программиста. По
умолчанию cin читает символы с клавиатуры до тех пор, пока не встретится первый
пробельный символ — вне зависимости от размера массива. Таким образом,
ввод данных с помощью cin и » может записать данные за концом массива
(см. раздел 8.13, рассматривающий вопрос о том, как предотвратить запись за
границей символьного массива).
Типичная ошибка программирования 7.9
Использование с cin » массива, размер которого недостаточен для
размещения введенной с клавиатуры строки, может привести к
потере данных и другим серьезным ошибкам времени выполнения.
Символьный массив, представляющий строку с завершающим
нуль-символом, можно вывести с помощью cout и «. Оператор
cout « string2;
печатает массив string2. Обратите внимание, что cout «, как и cin », не
обращает внимания на то, насколько велик символьный массив. Символы
строки выводятся до тех пор, пока не встретится завершающий нуль-символ.
[Замечание, cin и cout предполагают, что символьные массивы должны
обрабатываться как ограниченные нулем строки; такая особенность обработки не
относится к массивам других типов.]
Рис. 7.12 демонстрирует инициализацию символьного массива строковым
литералом, чтение строки в символьный массив, печать символьного массива
как строки и доступ к отдельным символом строки.
1 // Рис. 7.12: fig07_12.cpp
2 // Символьные массивы в качестве строк.
3 #include <iostream>
4 using std:icout;
5 using std::cin;
6 using std::endl;
7
8 int main()
Массивы и векторы
443
9 {
10 char stringl[ 20 ]; // резервирует 20 символов
11 char string2[] = "string literal"; // резервирует 15 символов
12
13 // прочитать строку пользователя в stringl
14 cout « "Enter the string V'hello there\": ";
15 cin » stringl; // читает "hello" [пробел прекращает ввод]
16
17 // вывести строки
18 cout « "stringl is: " « stringl « "\nstring2 is: " « string2;
19
20 cout « "\nstringl with spaces between characters is:\n";
21
22 // выводить символы, пока не встретится нуль-символ
23 for ( int i = 0; stringl[ i ] != '\0'; i++ )
24 cout « stringl[ i ] « '
25
26 cin » stringl; // reads "there"
27 cout « "\nstringl is: " « stringl « endl;
28
29 return 0; // успешное завершение
30 } // конец main
Enter the string "hello there": hello there
stringl is: hello
string2 is: string literal
stringl with spaces between characters is:
hello
stringl is: there
Рис.7.12. Символьные массивы в качестве строк
Оператор for в строках 23-24 на рис. 7.12 перебирает массив stringl и
печатает отдельные символы, отделенные друг от друга пробелами. Условие
stringl[ i ] != '\0' в операторе for истинно до тех пор, пока цикл не встретит
завершающий нуль-символ строки.
Статические и автоматические локальные массивы
В главе 6 обсуждался спецификатор класса памяти static. Статическая
локальная переменная в определении функции существует в течение всего
периода выполнения программы, но видима только в теле функции.
I—^-п Вопросы производительности 7.2
Г^Ф*! Мы можем применить static к объявлению локального массива, чтобы
массив не создавался и не инициализировался всякий раз заново при
каждом вызове функции программой, и не уничтожался бы всякий раз
при ее завершении. Это может улучшить общую производительность,
особенно при наличии больших массивов.
Программа инициализирует статические локальные массивы, когда их
объявление встречается в первый раз. Если статический массив не
инициализируется программистом явно, компилятор при создании инициализирует каждый
444
Глава 7
его элемент нулем. Как вы помните, для автоматических переменных такая
инициализация по умолчанию в C++ не выполняется.
На рис. 7.13 демонстрируется функция staticArraylnit (строки 25-41) со
статическим локальным массивом (строка 28) и функция automaticArraylnit
(строки 44-60) с автоматическим локальным массивом (строка 47).
1 // Рис. 7.13: fig07_13.cpp
2 // Статические массивы инициализируются нулями.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 void staticArraylnit( void ); // прототип функции
8 void automaticArraylnit( void ) ; // прототип функции
9
10 int main()
11 {
12 cout « "First call to each function:\n";
13 staticArraylnit() ;
14 automaticArraylnit() ;
15
16 cout « "\n\nSecond call to each function:\n";
17 staticArraylnit();
18 automaticArraylnit();
19 cout « endl;
20
21 return 0; // успешное завершение
22 } // конец main
23
24 // функция для демонстрации статического локального массива
25 void staticArraylnit( void )
26 {
27 // initializes elements to 0 first time function is called
28 static int arrayl[ 3 ]; // статический локальный массив
29
30 cout « "\nValues on entering staticArraylnit:\n";
31
32 // вывести содержимое arrayl
33 for ( int i = 0; i < 3; i++ )
34 cout « "arrayl[" « i « "] = " « arrayl[ i ] « "
35
36 cout « "\nValues on exiting staticArraylnit:\n";
37
38 // модифицировать и вывести содержимое arrayl
39 for ( int j = 0; j < 3; j++ )
40 cout « "arrayl[" « j « "] = " « (arrayl[ j ] += 5) « " ";
41 } // конец функции staticArraylnit
42
43 // функция для демонстрации автоматического локального массива
44 void automaticArraylnit( void )
45 {
46 // инициализирует элементы при каждом вызове функции
47 int array2[ 3]={1, 2, 3};// автоматический локальный массив
48
49 cout « "\n\nValues on entering automaticArraylnit:\n";
Массивы и векторы
445
50
51 // вывести содержимое агray2
52 for ( int i = 0; i < 3; i++ )
53 cout « "array2[" « i « "] = " « array2[ i ] « "
54
55 cout « "\nValues on exiting automaticArraylnit:\n";
56
57 // модифицировать и вывести содержимое array2
58 for ( int j = 0; j < 3; j++ )
59 cout « "аггаугг « j « "] = " « (array2 [ j ] += 5) «
60 } // конец функции automaticArraylnit
First call to each function:
Values on entering staticArraylnit:
arrayl[0] = 0 arrayl[l] = 0 arrayl[2] = 0
Values on exiting staticArraylnit:
arrayl[0] = 5 arrayl[l] = 5 arrayl[2] = 5
Values on entering automaticArraylnit:
array2[0J = 1 array2[l] = 2 array2[2] = 3
Values on exiting automaticArraylnit:
array2[0] = 6 array2[l] = 7 array2[2] = 8
Second call to each function:
Values on entering staticArraylnit:
arrayl[0] = 5 arrayl[l] = 5 arrayl[2] = 5
Values on exiting staticArraylnit:
arrayl[0] = 10 arrayl[l] = 10 arrayl[2] = 10
Values on entering automaticArraylnit:
array2[0] = 1 array2[l] = 2 array2[2] = 3
Values on exiting automaticArraylnit:
array2[0] = 6 array2[l] = 7 array2[2] = 8
Рис. 7.13. Инициализация статического и автоматического массивов
Функция staticArraylnit вызывается дважды (строки 13 и 17).
Статический локальный массив компилятор инициализирует нулями, когда функция
вызывается в первый раз. Функция печатает массив, прибавляет к каждому
элементу 5 и печатает массив снова. При втором вызове функции статический
массив содержит модифицированные значения, сохранившиеся от
предыдущего вызова. Функция automaticArraylnit также вызывается дважды
(строки 14 и 18). Элементы автоматического локального массива
инициализируются (строка 47) значениями 1, 2 и 3. Функция печатает массив, прибавляет к
каждому элементу 5 и печатает массив снова. При втором вызове функции
элементы повторно инициализируются значениями 1, 2 и 3. Массив имеет
автоматический класс памяти, поэтому он создается заново при каждом вызове
automaticArraylnit.
446
Глава 7
п Типичная ошибка программирования 7.10
Предположение, что элементы статического массива,
принадлежащего функции, инициализируются при каждом ее вызове, может
стать причиной логических ошибок в программе.
7.5. Передача массивов функциям
Чтобы передать массив в качестве аргумента функции, укажите имя
массива без каких-либо квадратных скобок. Например, если массив hourlyTempera-
tures объявлен как
int hourlyTemperatures[ 24 ];
то вызов
modifyArray( hourlyTemperatures, 24 );
передаст функции modify Array массив hourlyTemperatures и его размер. При
передаче массива функции обычно передается и его размер, чтобы функция
смогла обработать конкретное число элементов массива. (В противном случае
нам пришлось бы встроить знание о размере в саму вызываемую функцию
или, что еще хуже, поместить размер массива в глобальную переменную.)
Когда в разделе 7.11 мы представим шаблон класса vector из стандартной
библиотеки C++, реализующий более надежный тип массива, вы увидите, что
размер вектора является встроенным, — каждый объект vector «знает» свой
собственный размер, который можно получить, вызвав его элемент-функцию
size. Таким образом, когда мы передаем функции объект-вектор, нам не
приходится передавать в качестве аргумента также и его размер.
C++ передает функциям массивы по ссылке, — вызываемые функции могут
модифицировать значения элементов в исходных массивах вызывающих.
Значением имени массива является адрес первого элемента массива в памяти
компьютера. Поскольку передается адрес начала массива, вызвтваемая функция
точно знает, где в памяти хранится массив. Таким образом, когда вызываемая
функция модифицирует в своем теле элементы переданного массива, она
модифицирует действительные элементы массива в их исходных ячейках памяти.
Вопросы производительности 7.3
Передача массивов по ссылке оправданна по соображениям
эффективности. Если бы массивы передавались по значению, передавалась бы
копия каждого элемента. В случае больших, часто передаваемых
массивов это занимало бы значительное время и требовало больших
объемов памяти для копий.
Хотя массивы как целое передаются по ссылке, отдельные их элементы
передаются по значению, точно так же, как и переменные. Такие простые
единицы данных называют скалярами или скалярными величинами. Чтобы
передать функции элемент массива, укажите в качестве аргумента вызова имя
массива с соответствующим индексом элемента. В главе 6 мы показали, как
передавать скаляры (т. е. отдельные переменные или элементы массивов)
Массивы и векторы
447
по ссылке с помощью ссылок. В главе 8 мы покажем, как передавать скаляры
по ссылке с помощью указателей.
Чтобы в результате вызова функции последняя получила массив, ее список
параметров должен специфицировать, что ожидается получение массива.
Например, заголовок функции modify Array мог бы иметь вид
void modifyArray( int b[], int arraySize )
указывающий, что modifyArray ожидает получить адрес массива в
параметре b и число элементов массива в параметре arraySize. Размер массива внутри
квадратных скобок не требуется. Если он указан, компилятор игнорирует его.
Так как C++ передает массивы по ссылке, то когда вызываемая функция
использует имя массива Ь, она в действительности обращается к массиву в
вызывающей функции (т. е. массиву hourlyTemperatures, приведенному в качестве
примера в начале раздела).
Обратите внимание на странный вид прототипа функции modifyArray:
void modifyArray( int [] , int );
Прототип можно было бы записать как
void modifyArray ( int anyArrayName[], int anyVariableName );
но, как мы узнали в главе 3, компиляторы C++ игнорируют имена
переменных в прототипах. Вспомните, что прототип сообщает компилятору о числе
аргументов и типе каждого из них (в том порядке, в котором аргументы должны
следовать в вызове).
Программа на рис. 7.14 демонстрирует различие между передачей массива
целиком и передачей элемента массива. Строки 22-23 печатают пять
исходных элементов целого массива а. Строка 28 передает а и его размер функции
(строки 45-50), которая умножает каждый элемент а (через параметр Ь) на 2.
Затем строки 32-33 снова печатают а в main. Как показывает вывод
программы, modifyArray действительно модифицирует элементы массива. После этого
строка 36 печатает значение скаляра а[ 3 ], и строка 38 передает элемент а[ 3 ]
функции modifyElement (строки 54-58), которая умножает свой параметр
на 2 и печатает новое значение. Обратите внимание, что при повторной печати
а[ 3 ] в main (строка 39) значение оказывается не модифицированным, так как
отдельные элементы массива передаются по значению.
1 // Рис. 7.14: fig07_14.cpp
2 // Передача функциям массивов и отдельных элементов массива.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 void modifyArray( int [], int ); // выглядит странно
11 void modifyElement( int );
12
13 int main()
14 {
15 const int arraySize =5; // размер массива а
16 int a[ arraySize ] = { 0, 1, 2, 3, 4 }; // инициализация массива
448
Глава 7
17
18 cout « "Effects of passing entire array by reference:"
19 « "\n\nThe values of the original array are:\n";
20
21 // вывести элементы исходного массива
22 for ( int i = 0; i < arraySize; i++ )
23 cout « setw( 3 ) « a[ i ];
24
25 cout « endl;
26
27 // передать массив а в modifyArray по ссылке
28 modifyArray( a, arraySize );
29 cout « "The values of the modified array are:\n";
30
31 // вывести элементы модифицированного массива
32 for ( int j = 0; j < arraySize; j++ )
33 cout « setw( 3 ) « a[ j ];
34
35 cout « "\n\n\nEffects of passing array element by value:"
36 « "\n\na[3] before modifyElement: " « a[ 3 ] « endl;
37
38 modifyElement( a[ 3 ] ); // передать элемент а[ 3 ] по значению
39 cout « "a[3] after modifyElement: " « a[ 3 ] « endl;
40
41 return 0; // успешное завершение
42 } // конец main
43
44 //в modifyArray "b" указывает в памяти на исходный массив "а"
45 void modifyArray( int b[J, int sizeOfArray )
46 {
47 // умножить каждый элемент массива на 2
48 for ( int k = 0; k < sizeOf Array; k++ )
49 b[ k ] *= 2;
50 } // конец функции modifyArray
51
52 //в функции modifyElement "e" является локальной копией
53 // элемента массива а[ 3 ], переданного из main
54 void modifyElement( int e )
55 {
56 // умножить параметр на 2
57 cout « "Value of element in modifyElement: "« (e *= 2) « endl;
58 } // конец функции modifyElement
Effects of passing entire array by reference:
The values of the original array are:
0 12 3 4
The values of the modified array are:
0 2 4 6 8
Effects of passing array element by value:
a[3] before modifyElement: 6
Value of element in modifyElement: 12
a[3] after modifyElement: 6
Рис. 7,14. Передача функциям массивов и их отдельных элементов
Массивы и векторы
449
В своих программах вы можете встретиться с ситуацией, когда функции
нельзя позволить изменять элементы переданного массива. Для
предотвращения модификации значений массива вызываемой функцией в C++
предусмотрен квалификатор типа const. Когда функция специфицирует свой
параметр-массив как const, элементы его становятся в теле функции константами,
и любая попытка модифицировать элемент в теле функции приводит к ошибке
компиляции. Это позволяет программисту предотвратить случайную
модификацию элементов массива в теле функции.
Рис. 7.15 демонстрирует действие квалификатора const. Функция tryToMo-
difyArray (строки 21-26) определяется с параметром const int b[], который
специфицирует, что массив b является константным и не может быть
модифицирован. Каждая из трех попыток функции модифицировать элементы массива b (в
строках 23-25) приводит к ошибке компиляции. Компилятор Microsoft
Visual C++.NET генерирует, например, ошибку «1-value specifies const object». [За
мечание. Стандарт C++ определяет «объект» как «любую область памяти»,
включая сюда, таким образом, как представители классов (которые мы называли
объектами), так и переменные или элементы массива основных типов данных.]
1 // Рис. 7.15: fig07_15.cpp
2 // Демонстрация квалификатора типа const.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 void tryToModifyArray( const int [] ); // прототип функции
8
9 int main()
10 {
11 int a[] = { 10, 20, 30 };
12
13 tryToModifyArray( a );
14 cout « a[ 0 ] « ' ' « a[ 1 ] « ' ' « a[ 2 ] « '\n';
15
16 return 0; // успешное завершение
17 } // конец main
18
19 //В функции tryToModifyArray "b" не может использоваться
20 // для модификации исходного массива "а" в main.
21 void tryToModifyArray( const int b[] )
22 {
23 b[ 0 ] /= 2; // ошибка
24 b[ 1 ] /= 2; // ошибка
25 b[ 2 ] /= 2; // ошибка
26 } // конец функции tryToModifyArray
Сообщения об ошибках компилятора Borland C++ с командной строкой:
Error E2024 fig07_15.cpp 23: Cannot modify a const object
in function tryToModifyArray(const int * const)
Error E2024 fig07_15.cpp 24: Cannot modify a const object
in function tryToModifyArray(const int * const)
Error E2024 fig07_15.cpp 25: Cannot modify a const object
in function tryToModifyArray(const int * const)
15 Зак. 1114
450
Глава 7
Сообщения об ошибках компилятора Microsoft Visual C++.NET:
C:\scpphtp5_examples\ch07\fig07_15.cppB3) : error C2166:
1-value specifies const object
C:\scpphtp5_examples\ch07\fig07_15.cppB4) : error C2166:
1-value specifies const object
C:\scpphtp5_examples\ch07\fig07_15.cppB5) : error C2166:
1-value specifies const object
Сообщения об ошибках компилятора GNU C++:
fig07_15.cpp:23
fig07_15.cpp:24
fig07_15.cpp:25
error: assignment of read-only location
error: assignment of read-only location
error: assignment of read-only location
Рис. 7,15. Квалификатор типа const, примененный к параметру-массиву
-п Типичная ошибка программирования 7.11
Упущение из виду того факта, что массивы вызывающей функции
передаются по ссылке и, следовательно, могут быть модифицированы в
вызываемых функциях, может приводить к логическим ошибкам.
Общее методическое замечание 7.3
Применение к параметру-массиву в определении функции квалифика-
тора const с целью предотвратить его модификацию в теле функции
является еще одним примером принципа наименьших привилегий.
Функциям не следует предоставлять возможность модифицировать
массивы, если это не является совершенно необходимым.
7.6. Пример: класс GradeBook с массивом для
хранения оценок
Этот раздел посвящен дальнейшему развитию класса GradeBook,
введенного в главе 3 и расширенному в главах 4-6. Как вы помните, этот класс
представляет журнал оценок, используемый преподавателем для хранения и
анализа набора оценок студентов. Предыдущие версии класса обрабатывают
набор оценок, введенных пользователем, но не сохраняют отдельные значения
оценок в качестве элементов данных класса. Следовательно, для повторных
вычислений пользователю потребовалось бы заново ввести те же оценки.
Одним из путей решения этой проблемы является сохранение каждой введенной
оценки в отдельном элементе данных класса. Например, для сохранения
оценок десяти студентов мы могли бы создать в классе GradeBook элементы
данных grade 1, grade2, ... gradelO. Однако код для подсчета их суммы и
определения средней оценки был бы весьма неуклюжим. В этом разделе мы решаем
эту проблему, сохраняя оценки в массиве.
Массивы и векторы
451
Класс GradeBook, сохраняющий оценки студентов в массиве
Представленная здесь версия класса GradeBook (рис. 7.16-7.17) использует
массив целых для сохранения оценок, полученных несколькими студентами
за одну контрольную работу. Это устраняет необходимость повторного ввода
тех же самых оценок. Массив grades объявляется в строке 29 на рис. 7.16 как
элемент данных; таким образом, каждый объект класса GradeBook содержит
свой собственный набор оценок.
1 // Рис. 7.16: GradeBook.h
2 // Определение класса GradeBook, использующего массив для хранения
3 // оценок. Элемент-функции определяются в GradeBook.срр
4
5 #include <string> // программа использует стандартный класс string
6 using std::string;
7
8 // определение класса GradeBook
9 class GradeBook
Ю {
11 public:
12 // константа - число студентов, сдававших экзамен
13 const static int students = 10; // заметьте: public-данные
14
15 // конструктор инициализирует название курса и массив оценок
16 GradeBook( string, const int [] );
17
18 void setCourseName( string ); // устанавливает название курса
19 string getCourseName(); // извлекает название курса
20 void displayMessage(); // вывести приветственное сообщение
21 void processGrades(); // различные действия над оценками
22 int getMinimum() ; // найти минимальную оценку за контрольную
23 int getMaximum() ; // найти максимальную оценку за контрольную
24 double getAverage(); // определить среднюю оценку за контрольную
25 void outputBarChart(); // вывести диаграмму распределения оценок
26 void outputGrades(); // вывести содержимое массива оценок
27 private:
28 string courseName; // название курса для данного GradeBook
29 int grades[ students ]; // массив оценок студентов
30 }; // конец класса GradeBook
Рис. 7.16. Определение класса GradeBook с массивом для хранения оценок
за контрольную
1 // Рис. 7.17: GradeBook.срр
2 // Определения элемент-функций класса GradeBook,
3 // использующего массив для хранения оценок студентов.
4 #include <iostream>
5 using std::cout;
6 using std::cin;
7 using std::endl;
8 using std::fixed;
9
10 #include <iomanip>
11 using std::setprecision;
452
12 using std::setw;
13
14 #include "GradeBook.h" // определение класса GradeBook
15
16 // конструктор инициализирует название курса и массив оценок
17 GradeBook::GradeBook( string name, const int gradesArray[] )
18 {
19 setCourseName( name ); // инициализировать courseName
20
21 // копировать оценки из gradeArray в элемент данных grades
22 for ( int grade = 0; grade < students; grade++ )
23 grades[ grade ] = gradesArray[ grade ];
24 } // конец конструктора GradeBook
25
26 // функция для установки названия курса
27 void GradeBook::setCourseName( string name )
28 {
29 courseName = name; // store the course name
30 } // конец функции setCourseName
31
32 // функция для извлечения названия курса
33 string GradeBook::getCourseName()
34 {
35 return courseName;
36 } // конец функции getCourseName
37
38 // вывести сообщение-приветствие пользователю GradeBook
39 void GradeBook::displayMessage()
40 {
41 // этот оператор вызывает getCourseName, чтобы получить
42 // название курса, представленного данным GradeBook
43 cout « "Welcome to the grade book for\n" « getCourseName ()
44 « " !" « endl;
45 } // конец функции displayMessage
46
47 // произвести над данными различные операции
48 void GradeBook::processGrades()
49 {
50 // вывести массив оценок
51 outputGrades();
52
53 // вызвать функцию getAverage для вычисления средней оценки
54 cout « "\nClass average is " « setprecision( 2 ) « fixed «
55 getAverage() « endl;
56
57 // вызвать функции getMinimum и getMaximum
58 cout « "Lowest grade is " « getMinimum()
59 « "\nHighest grade is " « getMaximum() « endl;
60
61 // вызвать outputBarChart для печати диаграммы распределения
62 outputBarChart();
63 } // конец функции processGrades
64
65 // найти минимальную оценку
66 int GradeBook::getMinimum()
67 {
68 int lowGrade = 100; // принять низшую оценку равной 100
Массивы и векторы
453
69
70 // цикл по массиву grades
71 for ( int grade = 0; grade < students; grade++ )
72 {
73 // если текущая оценка меньше lowGrade, присвоить ее lowGrade
74 if ( grades[ grade ] < lowGrade )
75 lowGrade = grades[ grade ]; // новая низшая оценка
76 } // конец for
77
78 return lowGrade; // возвратить низшую оценку
79 } // конец функции getMinimum
80
81 // найти максимальную оценку
82 int GradeBook::getMaximum()
83 {
84 int highGrade =0; // принять высшую оценку равной 0
85
86 // цикл по массиву grades
87 for ( int grade = 0; grade < students; grade++ )
88 {
89 // если текущая оценка выше highGrade, присвоить ее highGrade
90 if ( grades[ grade ] > highGrade )
91 highGrade = grades[ grade ]; // новая высшая оценка
92 } // конец for
93
94 return highGrade; // возвратить высшую оценку
95 } // конец функции getMaximum
96
97 // определить среднюю оценку за экзамен
98 double GradeBook::getAverage()
99 {
100 int total =0; // инициализировать сумму
101
102 // суммировать оценки в массиве
103 for ( int grade = 0; grade < students; grade++ )
104 total += grades[ grade ];
105
106 // возвратить среднее для оценок
107 return static_cast< double >( total ) / students;
108 } // конец функции getAverage
109
110 // вывести столбцовую диаграмму, показывающую распределение оценок
111 void GradeBook::outputBarChart()
112 {
113 cout « M\nGrade distribution:" « endl;
114
115 // хранит частоты для каждого из диапазонов по 10 оценок
116 const int frequencySize = 11;
117 int frequency[ frequencySize ] = { 0 };
118
119 // для каждой оценки увеличить соответствующую частоту
120 for ( int grade = 0; grade < students; grade++ )
121 frequency[ grades[ grade ] / 10 ]++;
122
123 // для каждой частоты вывести столбец диаграммы
124 for ( int count = 0; count < frequencySize; count++ )
125 {
454
Глава 7
126 // вывести метки столбцов (-9:", ..., "90-99:", 00:" )
127 if ( count == 0 )
128 cout « " 0-9: " ;
129 else if ( count == 10 )
130 cout « " 100: ";
131 else
132 cout « count * 10 « "-" « ( count * 10 ) + 9 « ":
133
134 // напечатать столбец звездочек
135 for ( int stars = 0; stars < frequency[ count ]; stars++ )
136 cout « ■*■ ;
137
138 cout « endl; // начать новую строку вывода
139 } // конец внешнего for
140 } // конец функции outputBarChart
141
142 // вывести содержимое массива оценок
143 void GradeBook::outputGrades()
144 {
145 cout « "\nThe grades are:\n\n";
146
147 // вывести оценку каждого студента
148 for ( int student = 0; student < students; student++ )
149 cout « "Student " « setw( 2 ) « student + 1 « ": "
150 « setw( 3 ) « grades[ student ] « endl;
151 } // конец функции outputGrades
Рис. 7.17. Элемент-функции класса GradeBook, обрабатывающие массив оценок
Обратите внимание, что размер массива специфицируется открытым
статическим константным элементом данных students (объявленным в строке 13).
Этот элемент данных объявлен как public, что делает его доступным для
клиентов класса. Скоро мы увидим пример того, как программа-клиент
использует эту константу. Объявление students с квалификатором const указывает, что
этот элемент данных является константным — его значение не может быть
изменено после инициализации. Ключевое слово static в данном объявлении
переменной означает, что элемент данных разделяется всеми объектами
класса — все объекты GradeBook хранят оценки для одного и того же числа
студентов. Вспомните, в разделе 3.6 говорилось о том, что когда каждый объект
содержит свой собственный экземпляр атрибута, переменная,
представляющая атрибут, называется элементом данных — каждый объект
(представитель) класса имеет отдельный экземпляр этой переменной в памяти.
Существуют переменные, для которых нет отдельных экземпляров у каждого объекта
класса. Так обстоит дело со статическими элементами данных, которые
называют также переменными класса. Когда создаются объекты класса,
содержащего статические элементы данных, все объекты разделяют единственный
экземпляр этих элементов данных. Статический элемент данных доступен в
пределах определения класса и в определениях элемент-функций, как и любой
другой элемент данных. Как вы вскоре увидите, к открытому статическому
элементу данных можно обращаться вне класса, даже если не существует его
объектов, посредством указания имени класса с последующей операцией
разрешения области действия (::) и именем элемента данных. Подробнее о
статических элементах данных вы узнаете в главе 10.
Массивы и векторы
455
Конструктор класса (объявленный в строке 16 на рис. 7.16 и определяемый
в строках 17-24 на рис. 7.17) имеет два параметра — название курса и массив
оценок. Когда программа создает объект GradeBook (т.е. в строке 13 на
рис. 7.18), она передает конструктору существующий целый массив, значения
которого копируются конструктором в элемент данных grades (строки 22-23
на рис. 7.17). Значения оценок в переданном массиве могли бы быть введены
пользователем или прочитаны из дискового файла. В нашей тестовой
программе мы просто инициализируем массив набором значений оценок (рис. 7.18,
строки 10-11). Как только оценки записаны в элемент данных grades класса
GradeBook, все элемент-функции класса могут, если нужно, в своих
вычислениях обращаться к массиву grades.
Элемент-функция proceedGrades (объявленная в строке 21 на рис. 7.16 и
определенная в строках 48-63 на рис. 7.17) содержит ряд вызовов
элемент-функций, которые выводят отчет по оценкам. Строка 51 вызывает
элемент-функцию outputGrades для печати содержимого массива grades.
Строки 148-150 в функции outputGrades выводят оценку каждого студента с
помощью оператора for. Хотя индексы массива начинаются с 0, преподаватель
обычно нумеровал бы своих студентов начиная с 1. Поэтому строки 149-150
выводят в качестве номера студента student + 1, чтобы получить метки для
оценок "Student 1: ", "Student 2: " и т.д.
Затем proceedGrades вызывает элемент-функцию getAverage
(строки 54-55) для получения среднего по оценкам в массиве. Функция getAverage
(объявленная в строке 24 на рис. 7.16 и определяемая в строках 98-108) с
помощью оператора for сначала подсчитывает сумму значений в массиве grades
и вычисляет их среднее. Обратите внимание, что вычисление среднего в
строке 107 для определения числа усредняемых оценок использует константный
статический элемент данных students.
Строки 58-59 в функции proceedGrades вызывают элемент-функции
getMinimum и getMaximum для определения соответственно наинизшей и
наивысшей из всех оценок, полученных студентами на экзамене. Давайте
исследуем, каким образом функция getMinimum находит наинизшую оценку.
Поскольку наивысшая допустимая оценка равна 100, мы начинаем с
предположения, что наинизшей оценкой является 100 (строка 68). Затем мы
сравниваем каждый из элементов массива с наинизшей оценкой, чтобы найти оценки
более низкие. Строки 71-76 в функции getMinimum проходят в цикле по
массиву, сравнивая каждую оценку с lowGrade (строки 74-75). Если оценка
меньше, последней присваивается значение этой оценки. Когда исполняется
строка 78, lowGrade содержит наинизшую из оценок в массиве. Функция
getMaximum (строки 82-95) аналогичным образом определяет наивысшую оценку.
Наконец, строка 62 в функции proceedGrades вызывает элемент-функцию
outputBarChart для печати диаграммы распределения данных по оценкам с
применением методики, которая аналогична показанной на рис. 7.9. Там мы
вручную подсчитали число оценок в каждой из категорий (т.е. 0-9, 10-19, ...
90-99 и 100), просто посмотрев на имеющийся набор оценок. В настоящем
примере строки 120-121 реализуют методику для подсчета частот, сходную с
представленной на рис. 7.10 и рис. 7.11. Строка 117 объявляет и создает
массив frequency из 11 целых для хранения оценок в каждой из категорий. Для
каждой оценки в массиве grades строки 120-121 инкрементируют
соответствующий элемент массива frequency. Для определения того, какой элемент еле-
456 l Глава 7
дует инкрементировать, в строке 121 текущее значение grade делится на 10
(целое деление). Например, если значение grade равно 85, строка 121 инкре-
ментирует frequency[ 8 ], обновляя счетчик оценок в диапазоне 80-89. Затем
строки 124-139 печатают диаграмму (см. рис. 7.18), отражающую содержимое
массива frequency. Как и строки 29-30 на рис. 7.9, строки 135-136
на рис. 7.17 используют значение из массива frequency для определения числа
звездочек, выводимых в каждом столбце.
Тестирование класса GradeBook
Программа на рис. 7.18 создает объект класса GradeBook (рис. 7.16-7.17),
используя целый массив grades Array (объявляемый и инициализируемый
в строках 10-11). Заметьте, что для доступа к статической константе students
класса GradeBook мы используем бинарную операцию разрешения области
действия (::) в выражении «GradeBook::students» (строка 10). Эта константа
нужна здесь для создания массива того же размера, что и массив grades,
хранящийся в качестве элемента данных класса GradeBook. Строки 13-14
передают конструктору название курса и gradesArray. Строка 15 выводит
приветственное сообщение, а строка 16 вызывает элемент-функцию peocessGrades
объекта GradeBook. Вывод программы показывает сводную информацию
по 10 оценкам в my Grade Book.
1 // Рис. 7.18: fig07_18.cpp
2 // Codдает объект GradeBook, используя массив оценок.
3
4 #include "GradeBook.h" // определение класса GradeBook
5
6 // функция main начинает исполнение программы
7 int main()
8 {
9 // массив оценок студентов
10 int gradesArray[ GradeBook::students ] =
11 { 87, 68, 94, 100, 83, 78, 85, 91, 76, 87 };
12
13 GradeBook myGradeBook(
14 "CS101 Introduction to C++ Programming", gradesArray );
15 myGradeBook.displayMessage();
16 myGradeBook.processGrades();
17 return 0;
18 } // конец main
Welcome to the grade book for
CS101 Introduction to C++ Programming!
The grades are:
Student
Student
Student
Student
Student
Student
Student
1
2
3
4
5
6
7
87
68
94
100
83
78
85
Массивы и векторы
457
Student 8: 91
Student 9: 76
Student 10: 87
Class average is 84.90
Lowest grade is 68
Highest grade is 100
Grade distribution:
o-s
10-
20-
30-
40-
50-
60-
70-
80-
90-
-19
-29
-39
•49
-59
-69
-79
-89
-99
100
Рис. 7.18. Создает объект GradeBook с помощью массива оценок, затем вызывает
processGrades для их анализа
7.7. Линейный поиск в массивах
Программисту часто приходится работать с большими объемами данных,
сохраняемых в массивах. Нередко требуется определить, содержит ли массив
значение, совпадающее с некоторым ключевым значением. Процесс
нахождения в массиве конкретного элемента называется поиском. В этом разделе мы
обсудим простой линейный поиск. В упражнении 7.33 в конце главы вам
нужно будет реализовать рекурсивный вариант линейного поиска. Если вы
захотите познакомиться с более сложным, но более эффективным двоичным
поиском, посетите en.wikipedia.org/wiki/Binary_search.
Линейный поиск
При линейном поиске (рис. 7 Л 9, строки 37-44) каждый элемент массива
сравнивается с ключом поиска (строка 40). Поскольку массив не
предполагается упорядоченным каким-либо определенным образом, вероятность
встретить искомое значение в первом элементе такая же, как в последнем. В
среднем, следовательно, программа должна будет сравнить ключ поиска с
половиной элементов массива. Чтобы определить, что значение в массиве
отсутствует, программе потребуется сравнить ключ поиска со всеми
элементами массива.
Линейный метод поиска хорошо работает с небольшими или
несортированными массивами (т. е. не упорядоченными каким-либо определенным
образом). Однако для больших массивов линейный поиск неэффективен. Если
массив сортирован (например, в восходящем порядке), вы можете
воспользоваться высокоскоростной методикой двоичного поиска (en.wikipedia.org/wiki/
Binary_search).
458
Глава 7
1 // Рис. 7.19: fig07_19.cpp
2 // Линейный поиск в массиве.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 int linearSearch( const int [], int, int ); // прототип
9
10 int main()
11 {
12 const int arraySize = 100; // размер массива а
13 int a[ arraySize ]; // создать массив а
14 int searchKey; // значение для поиска в массиве а
15
16 for ( int i = 0; i < arraySize; i++ )
17 a[i]=2*i;// создать некоторые данные
18
19 cout « "Enter integer search key: ";
20 cin » searchKey;
21
22 // попытка поиска searchKey в массиве а
23 int element = linearSearch( a, searchKey, arraySize );
24
25 // вывести результаты
26 if ( element != -1 )
27 cout « "Found value in element " « element « endl;
28 else
29 cout « "Value not found" « endl;
30
31 return 0; // успешное завершение
32 } // конец main
33
34 // сравнивать ключ с каждым элементом массива, пока не будет
35 // найдена его позиция или не встретится конец массива; возвратить
36 // индекс элемента, если ключ найден, или -1, если не найден
37 int linearSearch( const int array[], int key, int sizeOfArray )
38 {
39 for ( int j = 0; j < sizeOfArray; j++ )
40 if ( array[ j ] == key ) // если найден,
41 return j; // возвратить позицию ключа
42
43 return -1; // ключ не найден
44 } // конец функции linearSearch
Enter
Found
Enter
Value
integer search key:
value in element 18
integer search
not found
key:
36
37
Рис. 7.19. Линейный поиск в массиве
Массивы и векторы
459
7.8. Сортировка массивов вставкой
Сортировка данных (т. е. расположение их в некотором определенном
порядке, например, восходящем или нисходящем) является одним из
важнейших приложений компьютеров. Банк сортирует все чеки по номерам счетов,
чтобы в конце каждого месяца подготовить индивидуальные выписки.
Телефонные компании сортируют свои телефонные справочники по фамилиям и
затем по именам, чтобы было проще отыскать нужный телефонный номер.
Практически каждой организации приходится сортировать какие-либо
данные, а во многих случаях огромные объемы данных. Сортировка данных —
захватывающая задача, на которую затрачивалась масса исследовательских
усилий в области компьютерной науки. В этой главе мы обсуждаем простую схему
сортировки. В упражнениях мы исследуем более сложные схемы, работающие
намного эффективнее.
г—-=ц Вопросы производительности 7.4
рФ$*| Иногда простые алгоритмы работают плохо. Достоинство их в том,
что их легко писать, тестировать и отлаживать. Для реализации
наилучшей производительности могут потребоваться более сложные
алгоритмы.
Сортировка вставкой
Программа на рис. 7.20 сортирует значения 10-элементного массива data в
восходящем порядке. Используемая нами методика известна под названием
сортировки вставкой — это простой, но эффективный алгоритм сортировки.
Первая итерация алгоритма берет второй элемент и, если он меньше первого
элемента, обменивает его с первым элементом (т. е. программа вставляет
второй элемент перед первым). Вторая итерация рассматривает третий элемент и
вставляет его в нужное место по отношению к двум первым, так что все три
элемента оказываются в правильном порядке. На /-ой итерации окажутся
сортированными первые / элементов исходного массива.
1 // Рис. 7.20: fig07_20.cpp
2 // Эта программа сортирует значения массива в восходящем порядке.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 int main()
11 {
12 const int arraySize = 10; // размер массива а
13 int data[ arraySize ] = { 34, 56, 4, 10, 77, 51, 93, 30, 5, 52 };
14 int insert; // временная переменная для вставляемого элемента
15
16 cout « "Unsorted array:\n";
17
18 // вывести исходный массив
460
Глава 7
19 for ( int i = 0; i < arraySize; i++ )
20 cout « setw( 4 ) « data[ i ];
21
22 // сортировка вставкой
23 // цикл по элементам массива
24 for ( int next = 1; next < arraySize; next++ )
25 {
26 insert = data[ next ]; // сохранить значение текущего элемента
27
28 int moveltem = next; // инициализировать позицию для вставки
29
30 // найти позицию для размещения текущего элемента
31 while ( ( moveltem > 0 ) && ( data[ moveltem - 1 ] > insert ) )
32 {
33 // сдвинуть элемент на одну ячейку вправо
34 data[ moveltem ] = data[ moveltem - 1 ] ;
3 5 move I tern- - ;
36 } // конец while
37
38 data[ moveltem ] = insert; // вставить текущий элемент в массив
39 } // конец for
40
41 cout « "\nSorted array:\n";
42
43 // вывести сортированный массив
44 for ( int i = 0; i < arraySize; i++ )
45 cout « setw( 4 ) « data[ i ];
46
47 cout « endl;
48 return 0; // успешное завершение
49 } // конец main
Unsorted array:
34 56 4 10 77 51 93 30 5 52
Sorted array:
4 5 10 30 34 51 52 56 77 93
Рис. 7.20. Применение к массиву сортировки вставкой
Строка 13 на рис. 7.20 объявляет и инициализирует массив data со
следующими значениями:
34 56 4 10 77 51 93 30 5 52
Программа рассматривает сначала data[ О ] и data[ 1 ], чьи значения равны
соответственно 34 и 56. Эти два элемента уже расположены по порядку,
поэтому программа продолжается; если бы они шли не по порядку, программа
поменяла их местами.
На второй итерации программа рассматривает значение data[ 2 ], равное 4.
Это значение меньше 56, поэтому программа сохраняет 4 во временной
переменной и перемещает 56 на один элемент вправо. Затем программа проверяет
и обнаруживает, что 4 меньше 34, поэтому она перемещает 34 на один элемент
вправо. Программа достигла начала массива, поэтому она помещает 4
в data[ О ]. Теперь массив имеет вид
Массивы и векторы
461
4 34 56 10 77 51 93 30 5 52
На третьей итерации программа сохраняет во временной переменой значение
data[ 3 ], равное 10. Затем она сравнивает 10 с 56 и перемещает 56 на один
элемент вправо, поскольку 56 больше 10. Затем 10 сравнивается с 34 и 34
перемещается на один элемент вправо. Когда программа сравнивает 10 с 4,
оказывается, что 10 больше 4, и она помещает 10 в data[ 1 ]. Теперь массив имеет вид
4 10 34 56 77 51 93 30 5 52
При работе этого алгоритма на i-ой итерации окажутся сортированными
первые / элементов исходного массива. Однако они могут находиться не на
своих окончательных местах, так как далее в массиве могут встретиться меньшие
значения.
Сортировка производится оператором for в строках 24-39, который
организует цикл по элементам массива. На каждой итерации строка 26 временно
сохраняет значение элемента, который будет вставляться в нужное место
массива, в переменной insert (объявленной в строке 14). Строка 28 объявляет и
инициализирует переменную moveltem, которая отслеживает, куда будет
вставлен элемент. Цикл в строках 31-36 находит правильную позицию для
вставки. Цикл завершается либо при достижении программой начала массива,
либо при нахождении элемента, меньшего, чем вставляемый. Строка 34
перемещает элемент вправо, а строка 35 декрементирует позицию, в которую будет
вставлен элемент. По завершении цикла while строка 38 ставит элемент на
место. Когда завершается оператор for в строках 24-39, элементы массива
сортированы.
Главным достоинством сортировки вставкой является простота ее
программирования; однако выполняется она медленно. При сортировке больших
массивов это становится очевидным. В упражнениях мы исследуем некоторые
альтернативные алгоритмы для сортировки массива.
7.9. Многомерные массивы
Многомерные массивы с двумя измерениями часто используются для
представления таблиц значений^ состоящих из информации, организованной по
строкам и столбцам. Для идентификации определенного элемента таблицы
мы должны специфицировать два индекса. По общепринятому соглашению
первый индекс идентифицирует строку, второй — столбец элемента. Массивы,
требующие двух индексов для идентификации элемента, называются
двумерными массивами. Заметьте, что многомерные массивы могут иметь и более
двух измерений (т.е. индексов). Рис. 7.21 иллюстрирует двумерный массив а.
Массив содержит три строки и четыре столбца, поэтому говорят, что это
массив 3 на 4. Вообще массив с т строками и п столбцами называется массивом т
на п.
462
Глава 7
Строка О
Строка 1
Строка 2
Столбец 1
а[ 0 ][ 0 ]
а[ 1 ][ 0 ]
а[ 2 ] [ 0 ■]
Столбец 2
а[ 0 ] [ 1 ]
а[ 1 ][ 1 ]
а[ 2 ][ 1 ]
А А А
Столбец 3
а[ 0 ][ 2 ]
а[ 1 ][ 2 ]
а[ 2 ][ 2 ]
Индекс столбца
Индекс строки
Имя массива
Столбец 4
а[ 0 ][ 3 ]
а[ 1 ][ 3 ]
а[ 2 ][ 3 ]
Рис, 7.21. Двумерный массив с тремя строками и двумя столбцами
Типичная ошибка программирования 7.12
Обращение к элементу двумерного массива в виде а[ х, у ] вместо
°>[ х ][ У ] является ошибкой. На самом деле а[ х, у ] будет
трактоваться как а[ у ], поскольку C++ оценивает выражение х, у
(содержащее операцию-запятую) просто как у (последнее из разделенных
запятыми выражений).
Многомерный массив может быть инициализирован при объявлении, во
многом подобно одномерному массиву. Например, двумерный массив b со
значениями 1 и 2 в строке 0 и значениями 3 и 4 в строке 1 можно
инициализировать объявлением
int Ь[ 2 ] [ 2 ] = { { 1, 2 >, { 3, 4 } };
Значения группируются в фигурных скобках построчно. Таким образом, 1 и 2
инициализируют соответственно Ь[ 0 ][ 0 ] и Ь[ 0 ][ 1 ], а 3 и 4 — соответственно
Ь[ 1 ][ О ] и Ь[ 1 ][ 1 ]. Если для некоторой строки инициализаторов
недостаточно, оставшиеся элементы строки инициализируются нулями. Следовательно,
объявление
int Ь[ 2 ][ 2 ] = { { 1 >, { 3, 4 } >;
инициализирует Ь[ О ][ 0 ] значением 1, Ь[ 0 ][ 1 ] значением О, Ь[ 1 ][ 0 ]
значением 3 и Ь[ 1 ][ 1 ] значением 4.
Рис. 7.22 демонстрирует инициализацию двумерных массивов в их
объявлениях. В строках 11-13 объявляются три массива, каждый с двумя строками
и тремя столбцами.
1
2
3
4
5
6
7
// Рис. 7.22: fig07_22.cpp
// Инициализация многомерных массивов.
#include <iostream>
using std::cout;
using std::endl;
void printArray( const int [][ 3 ] ); // прототип
Массивы и векторы
463
8
9 int main()
Ю {
11 int arrayl[ 2 ][ 3 ] = { { 1, 2, 3 }, { 4, 5, б } };
12 int array2[2][3]={1,2,3,4,5};
13 int array3[ 2 ][ 3 ] = { { 1, 2 }, { 4 } };
14
15 cout « "Values in arrayl by row are:" « endl;
16 printArray( arrayl );
17
18 cout « "\nValues in array2 by row are:" « endl;
19 printArray( array2 );
20
21 cout « "\nValues in array3 by row are:" « endl;
22 printArray( аггауЗ );
23 return 0; // успешное завершение
24 } // конец main
25
26 // вывести массив с двумя строками и тремя столбцами
27 void printArray( const int a[][ 3 ] )
28 {
29 // цикл по строкам массива
30 for ( int i = 0; i < 2; i++ )
31 {
32 // цикл по столбцам текущей строки
33 for ( int j = 0; j < 3; j++ )
34 cout « a[ i ] [ j ] « '
35
36 cout « endl; // начать новую строку вывода
37 } // конец внешнего for
38 } // конец функции printArray
Values in arrayl by row are:
12 3
4 5 6
Values in array2 by row are:
12 3
4 5 0
Values in аггауЗ by row are:
12 0
4 0 0
Рис. 7.22. Инициализация многомерных массивов
Объявление arrayl (строка 11) специфицирует шесть инициализаторов
в двух подсписках. Первый подсписок инициализирует строку 0 массива
значениями 1, 2 и 3; второй подсписок инициализирует строку 1 значениями 4, 5
и 6. Если из списка инициализации arrayl удалить фигурные скобки, в
которые заключены подсписки, компилятор инициализирует сначала элементы
строки 0, а затем элементы строки 1, и результат будет тем же самым.
Объявление аггау2 (строка 12) специфицирует всего пять
инициализаторов. Инициализаторы присваиваются сначала строке 0, затем строке 1. Любой
464
Глава 7
элемент, не имеющий явного инициализатора, неявно инициализируется
нулем, поэтому аггау2[ 1 ][ 2 ] инициализируется нулем.
Объявление аггауЗ (строка 13) специфицирует три инициализатора в двух
подсписках. Подсписок для строки 0 явно инициализирует первые два
элемента строки значениями 1 и 2; третий элемент неявно инициализируется нулем.
Подсписок для строки 1 явно инициализирует первый элемент значением 4
и неявно инициализирует два оставшиеся элемента строки нулями.
Для вывода элементов каждого из массивов программа вызывает функцию
print Array. Обратите внимание, что определение функции (строки 27-38)
специфицирует параметр const int a[][ 3 ]. Когда функция принимает в качестве
аргумента одномерный массив, квадратные скобки в списке параметров
функции оставляют пустыми. Для двумерного массива размер первого измерения
(т. е. число строк) также указывать не требуется, но размеры всех
последующих измерений обязательны. Компилятор использует эти размеры, чтобы
определить положение в памяти элементов многомерного массива. Все элементы
массива, вне зависимости от числа его измерений, расположены в памяти
последовательно. В случае двумерного массива сначала располагается строка О,
затем строка 1. В двумерном массиве каждая строка является одномерным
массивом. Чтобы найти элемент в определенной строке, функция должна
точно знать, сколько элементов содержится в каждой строке, чтобы она могла
пропустить нужное число ячеек памяти при обращении к массиву. Например,
при обращении к а[ 1 ][ 2 ] функция знает, что для получения доступа к
строке 1 она должна пропустить в памяти три элемента строки 0. Затем функция
обращается к элементу 2 найденной строки 1.
Во многих распространенных операциях с массивами применяются
операторы повторения for. Например, следующий оператор for устанавливает
в нуль все элементы строки 2 массива на рис. 7.21:
for ( column = 0; column < 4; column++ )
а[ 2 ][ column ] = 0;
Оператор варьирует только второй индекс (т. е. индекс столбца). Этот оператор
for эквивалентен следующим операторам присваивания:
а[ 2 ][ 0 ] = 0;
а[ 2 ][ 1 ] = 0; .
а[ 2 ] [ 2 ] = 0;
а[ 2 ][ 3 ] = 0;
Следующий вложенный оператор for определяет сумму всех элементов
массива а:
total = 0;
for ( row = 0; row < 3; row++ )
for ( column = 0; column < 4; column++ )
total += a[ row ][ column ];
Этот оператор суммирует элементы массива построчно. Внешний оператор for
начинает с установки row (т. е. индекса строки) значением 0, чтобы
внутренний for мог просуммировать элементы строки 0. Затем внешний for инкремен-
тирует row до 1, чтобы можно было просуммировать элементы строки 1. Затем
Массивы и векторы
465
внешний for инкрементирует row до 2, чтобы можно было просуммировать
элементы строки 2. Когда весь вложенный оператор for завершается, total
содержит сумму всех элементов массива.
7.10. Пример: класс GradeBook с двумерным
массивом
В разделе 7.6 мы представили класс GradeBook (рис. 7.16-7.17), в котором
использовался одномерный массив для хранения оценок, полученных
студентами за единственную контрольную работу. Обычно за семестр студенты
пишут несколько контрольных. Преподавателям, возможно, захочется
проанализировать оценки за весь семестр, как для каждого студента по отдельности,
так и для группы в целом.
Класс GradeBook, сохраняющий оценки в двумерном массиве
Рис. 7.23-7.24 содержат вариант класса GradeBook с двумерным массивом
grades, который используется для хранения оценок, полученных студентами
за несколько контрольных. Каждая строка массива представляет оценки
студента за весь курс, каждый из столбцов представляет все оценки, полученные
студентами за какую-то одну контрольную. Программа-клиент, например,
fig07__25.cpp, передает конструктору GradeBook в качестве аргумента массив.
В этом примере мы используем массив десять на три, содержащий оценки
десяти студентов за три контрольных.
Пять элемент-функций (объявленных в строках 23-27 на рис. 7.23) для
обработки оценок производят операции над массивом. Каждая из них походит
на одноименную функцию в прежней версии класса GradeBook с одномерным
массивом (рис. 7.16-7.17). Функция get Minimum (определенная в
строках 65-82 на рис. 7.24) определяет наинизшую оценку в группе за весь
семестр. Функция getMaximum (определенная в строках 85-102 на рис. 7.24)
определяет наивысшую оценку в группе за весь семестр. Функция getAverage
(строки 105-115 на рис. 7.24) определяет среднюю оценку конкретного
студента за семестр. Функция outputBarChart (строки 118-149 на рис. 7.24)
выводит диаграмму распределения оценок всех студентов за семестр. Функция
outputGrades (строки 152-17 на рис. 7.24) выводит в табличной форме
двумерный массив оценок вместе со средними оценками студентов.
1 // Рис. 7.23: GradeBook.h
2 // Определение класса GradeBook, использующего для хранения
3 // экзаменационных оценок двумерный массив.
4 // Элемент-функции определяются в GradeBook.срр
5 #include <string> // программа использует стандартный класс string
6 using std::string;
7
8 // определение класса GradeBook
9 class GradeBook
10 {
11 public:
12 // константы
13 const static int students = 10; // число студентов
14 const static int tests =3; // число контрольных
466
Глава 7
15
16 // конструктор инициализирует название курса и массив оценок
17 GradeBook( string, const int [][ tests ] );
18
19 void setCourseName( string ); // устанавливает название курса
20 string getCourseName(); // извлекает название курса
21 void displayMessage(); // вывести приветственное сообщение
22 void processGrades(); // различные действия над оценками
23 int getMinimum(); // найти минимальную оценку в GradeBook
24 int getMaximum(); // найти максимальную оценку в GradeBook
25 double getAverage( const int [], const int ); // найти среднее
26 void outputBarChart(); // вывести диаграмму распределения оценок
27 void outputGrades(); // вывести содержимое массива оценок
28 private:
29 string courseName; // название курса для данного GradeBook
30 int grades[ students ][ tests ]; // двумерный массив оценок
31 }; // конец класса GradeBook
Рис. 7.23. Определение класса GrdeBook с двумерным массивом для хранения оценок
1 // Рис. 7.24: GradeBook.срр
2 // Определения элемент-функций класса GradeBook,
3 // использующего двумерный массив для хранения оценок.
4 #include <iostream>
5 using std::cout;
6 using std::cin;
7 using std::endl;
8 using std::fixed;
9
10 #include <iomanip> // параметризованные манипуляторы потока
11 using std::setprecision; // устанавливает точность вывода чисел
12 using std::setw; // устанавливает ширину поля
13
14 // включить определение класса GradeBook из GradeBook.h
15 #include "GradeBook, h"
16
17 // конструктор с двумя аргументами инициализирует название и оценки
18 GradeBook::GradeBook( string name, const int gradesArray[][tests] )
19 {
20 setCourseName ( name ); // инициализировать courseName
21
22 // копировать оценки из gradeArray в grades
23 for ( int student = 0; student < students; student++ )
24
25 for ( int test = 0; test < tests; test++ )
26 grades[ student ][ test ] = gradesArray[ student ][ test ];
27 } // конец конструктора GradeBook с двумя аргументами
28
29 // функция для установки названия курса
30 void GradeBook::setCourseName( string name )
31 {
32 courseName = name; // сохранить название курса
33 } // конец функции setCourseName
34
35 // функция для извлечения названия курса
Массивы и векторы
467
36 string GradeBook:.getCourseName()
37 {
38 return courseName;
39 } // конец функции getCourseName
40
41 // вывести сообщение-приветствие пользователю GradeBook
42 void GradeBook::displayMessage()
43 {
44 // этот оператор вызывает getCourseName, чтобы получить
45 // название курса, представленного данным GradeBook
46 cout « "Welcome to the grade book for\n" « getCourseName()
47 « "!" « endl;
48 } // конец функции displayMessage
49
50 // произвести над данными различные операции
51 void GradeBook::processGrades()
52 {
53 // вывести массив оценок
54 outputGrades();
55
56 // вызвать функции getMinimum и getMaximum
57 cout « "\nLowest grade in the grade book is " « getMinimum ()
58 «"\nHighest grade in the grade book is "« getMaximum()« endl;
59
60 // вывести диаграмму распределения оценок по всем экзаменам
61 outputBarChart();
62 } // конец функции processGrades
63
64 // найти минимальную оценку
65 int GradeBook::getMinimum()
66 {
67 int lowGrade = 100; // принять низшую оценку равной 100
68
69 // цикл по строкам массива grades
70 for ( int student = 0; student < students; student++ )
71 {
72 // цикл по столбцам текущей строки
73 for ( int test = 0; test < tests; test++ )
74 {
75 // если текущая оценка меньше lowGrade, присвоить ее lowGrade
76 if ( grades [ student ][ test ] < lowGrade )
77 lowGrade = grades[ student ][ test ]; // новая низшая
78 } // конец внутреннего for
79 } // конец внешнего for
80
81 return lowGrade; // возвратить низшую оценку
82 } // конец функции getMinimum
83
84 // найти максимальную оценку
85 int GradeBook::getMaximum()
86 {
87 int highGrade =0; // принять высшую оценку равной 0
88
89 // цикл по строкам массива grades
90 for ( int student = 0; student < students; student++ )
91 {
92 // цикл по столбцам текущей строки
468
Глава
93 for ( int test = 0; test < tests; test++ )
94 {
95 // если текущая оценка выше highGrade, присвоить ее highGrade
96 if ( grades[ student ][ test ] > highGrade )
97 highGrade = grades[ student ][ test ]; // новая высшая
98 } // конец внутреннего for
99 } // конец внешнего for
100
101 return highGrade; // возвратить высшую оценку
102 } // конец функции getMaximum
103
104 // определить среднее для конкретного набора оценок
105 double GradeBook::getAverage(
const int setOfGrades[], const int grades )
106 {
107 int total =0; // инициализировать сумму
108
109 // суммировать оценки в массиве
110 for ( int grade = 0; grade < grades; grade++ )
111 total += setOfGrades[ grade ];
112
113 // возвратить среднее для оценок
114 return static_cast< double >( total ) / grades;
115 } // конец функции getAverage
116
117 // вывести столбцовую диаграмму, показывающую распределение оценок
118 void GradeBook::outputBarChart()
119 {
120 cout « "\nOverall grade distribution:" « endl;
121
122 // хранит частоты для каждого из диапазонов по 10 оценок
123 const int frequencySize = 11;
124 int frequency[ frequencySize ] = { 0 };
125
126 // для каждой оценки увеличить соответствующую частоту
127 for ( int student = 0; student < students; student++ )
128
129 for ( int test = 0; test < tests; test++ )
130 ++frequency[ grades[ student ][ test ] / 10 ];
131
132 // для каждой частоты вывести столбец диаграммы
133 for ( int count = 0; count < frequencySize; count++ )
134 {
135 // вывести метки столбцов (-9:", ..., "90-99:", 00:" )
136 if ( count = 0 )
137 cout « " 0-9: ";
138 else if ( count == 10 )
139 cout « " 100: ";
140 else
141 cout « count * 10 « "-" « ( count * 10 ) + 9 « "j ";
142
143 // напечатать столбец звездочек
144 for ( int stars = 0; stars < frequency[ count ]; stars++ )
145 cout « '*';
146
147 cout « endl; // начать новую строку вывода
148 } // конец внешнего for
Массивы и векторы
469
149 } // конец функции outputBarChart
150
151 // вывести содержимое массива оценок
152 void GradeBook::outputGrades()
153 {
154 cout « "\nThe grades are:\n\n";
155 cout « " "; // выровнять заголовки колонок
156
157 // создать заголовки колонок для каждой из контрольных
158 for ( int test = 0; test < tests; test++ )
159 cout « "Test " « test + 1 « "
160
161 cout « "Average" « endl; // заголовок для средних оценок
162
163 // создать строки/столбцы текста, представляющие массив grades
164 for ( int student = 0; student < students; student++ )
165 {
166 cout « "Student " « setw( 2 ) « student + 1;
167
168 // вывести оценки студента
169 for ( int test = 0; test < tests; test++ )
170 cout « setw( 8 ) « grades[ student ][ test ];
171
172 // вызвать getAverage для получения средней оценки студента;
173 // передать в аргументах строку оценок и число контрольных
174 double average = getAverage( grades[ student ], tests );
175 cout « setw(9) « setprecisionB) « fixed « average « endl;
176 } // конец внешнего for
177 } // конец функции outputGrades
Рис. 7.24. Определения элемент-функций класса GradeBook с двумерным
массивом оценок
Каждая из элемент-функций get Minimum, getMaximum, outputBarChart
и outputGrades обрабатывает в цикле массив grades, применяя вложенные
операторы for. Например, рассмотрим вложенный оператор for в функции
getMinimum (строки 70-79). Внешний оператор for начинается с установки
student (т. е. индекса строки) в 0, чтобы в теле внутреннего оператора for
можно было сравнить lowGrade с элементами строки 0. Внутренний оператор for
проходит по оценкам в определенной строке и сравнивает каждую оценку
с lowGrade. Если оценка меньше lowGrade, ее значение присваивается
lowGrade. Затем внешний оператор for инкрементирует индекс строки до 1,
и с переменной lowGrade сравниваются элементы строки 1. Затем внешний
оператор for инкрементирует индекс строки до 2, и с переменной lowGrade
сравниваются элементы строки 2. Это повторяется до тех пор, пока не будут
пройдены все строки массива grades. Когда исполнение вложенного оператора
for завершается, lowGrade содержит наименьшую из оценок в двумерном
массиве. Функция getMaximum работает аналогичным образом.
Функция outputBarChart почти идентична показанной на рис. 7.17.
Однако, чтобы вывести общее распределение оценок за весь семестр, функция
использует вложенный оператор for, создающий одномерный массив frequency,
отражающий оценки в двумерном массиве. Остальной код в двух версиях
функции outputBarChart, выводящий диаграмму, совершенно одинаков.
470
Глава 7
Функция outputGrades (строки 152-177) также использует вложенные
операторы for для вывода оценок в массиве grades, а также средней оценки за
семестр для каждого из студентов. Вывод программы на рис. 7.25 показывает
результат, напоминающий по форме настоящую таблицу в журнале
преподавателя. Строки 158-159 печатают заголовки колонок для каждого экзамена. Мы
применяем оператор повторения for, управляемый счетчиком, чтобы пометить
каждую из колонок соответствующим номером. Аналогичным образом
оператор for в строках 164-176 сначала выводит метку строки, используя
переменную-счетчик для идентификации каждого студента (строка 166). Хотя
индексы массива начинаются с 0, заметьте, что строки 159 и 166 выводят
соответственно test + 1 и student + 1, чтобы получить номера контрольных и студентов,
начинающиеся с 1 (см. рис. 7.25). Внутренний оператор for в строках 169-170
использует переменную-счетчик student внешнего for для прохода по
конкретной строке массива grades и вывода оценки каждого студента. Наконец,
строка 174 получает среднюю оценку каждого студента, передавая
элемент-функции getAverage текущую строку оценок (т. е. grades[ student ]).
Функция getAverage (строки 105-115) принимает два аргумента —
одномерный массив оценок определенного студента и число оценок в массиве.
Когда строка 174 вызывает getAverage, первым аргумент grades[ student ]
означает, что функции getAverage должна быть передана определенная строка
двумерного массива grades. Например, аргумент grades[ 1 ] представляет три
значения (одномерный массив оценок), хранящиеся в строке 1 двумерного
массива grades. Двумерный массив можно рассматривать как массив,
элементами которого являются одномерные массивы. Функция getAverage
вычисляет сумму элементов массива, делит ее на число контрольных и возвращает
результат как значение типа double (строка 114).
1 // Рис. 7.25: fig07_25.cpp
2 // Создает объект GradeBook, используя двумерный массив оценок.
3
4 #include "GradeBook.h" // определение класса GradeBook
5
6 // функция main начинает исполнение программы
7 int main()
8 { *
9 // двумерный массив оценок студентов
10 int gradesArray[ GradeBook::students ][ GradeBook::tests ] =
11 { { 87, 96, 70 },
12 { 68, 87, 90 },
13 { 94, 100, 90 },
14 { 100, 81, 82 },
15 { 83, 65, 85 },
16 { 78, 87, 65 },
17 { 85, 75, 83 },
18 { 91, 94, 100 },
19 { 76, 72, 84 },
20 { 87, 93, 73 } };
21
22 GradeBook myGradeBook(
23 "CS101 Introduction to C++ Programming", gradesArray );
24 myGradeBook.displayMessage();
25 myGradeBook.processGrades();
Массивы и векторы
471
26 return 0; // показывает успешное завершение
27 } // конец main
Welcome to the grade book for
CS101 Introduction to C++ Programming!
The grades are:
Student
Student
Student
Student
Student
Student
Student
Student
Student
Student
1
2
3
4
5
6
7
8
9
10
Test 1
87
68
94
100
83
78
85
91
76
87
Test 2
96
87
100
81
65
87
75
94
72
93
Test 3
70
90
90
82
85
65
83
100
84
73
Average
84.33
81.67
94.67
87.67
77.67
76.67
81.00
95.00
77.33
84.33
Lowest grade in the grade book is 65
Highest grade in the grade book is 100
Overall grade distribution
0-9
10-19
20-29
30-39
40-49
50-59
60-69
70-79
80-89
90-99
100
• *•
******
***********
*******
• **
Рис. 7.25. Создает объект GradeBook с помощью двумерного массива оценок, затем
вызывает элемент-функцию processGrades для их обработки
Тестирование класса GradeBook
Программа на рис. 7.25 создает объект класса GradeBook (рис. 7.23-7.24),
используя двумерный массив целых с именем gradesArray (объявляемый
и инициализируемый в строках 10-20). Обратите внимание, что строка 10
обращается к статическим константам students и tests класса GradeBook, чтобы
указать размер каждого из измерений массива gradesArray. Строки 22-23
передают конструктору GradeBook название курса и gradesArray. Затем
строки 24-25 вызывают функции displayMessage и processGrades класса
GradeBook, чтобы вывести приветственное сообщение и получить отчет по оценкам
студентов в течение семестра.
472
Глава 7
7.11. Введение в шаблон класса vector стандартной
библиотеки C++
В этом разделе мы представляем шаблон класса vector стандартной
библиотеки C++, который является более надежным типом массива, обладающим
многими дополнительными возможностями. Как вы увидите в последних
главах и в более глубоких курсах по C++, массивы-указатели в стиле С (т. е. те
массивы, о которых мы говорили до сих пор) открывают перед программистом
широчайшее поле для потенциальных ошибок. Например, как уже
упоминалось, программа легко может «перешагнуть» через любую из границ массива,
поскольку в C++ не предусмотрена проверка на выход индекса из допустимого
диапазона. Два массива нельзя осмысленно сравнивать друг с другом
операциями равенства или отношения. Как вы узнаете в главе 8,
переменные-указатели (называемые обычно просто указателями) в качестве своих значений
содержат адреса памяти. Имена массивов являются по сути указателями на
место в памяти, где начинаются массивы, и, конечно, два массива всегда будут
располагаться в разных местах. Когда массив передается функции общего
назначения, разработанной для операций с массивами любого размера,
необходимо передавать функции размер массива в качестве дополнительного
аргумента. Более того, один массив нельзя присвоить другому операцией
присваивания, — имена массивов являются константными указателями, а
константный указатель, как вы увидите в главе 8, не может использоваться в
левой части присваивания. Эти и другие возможности кажутся вполне
«естественными» по отношению к массивам, но в C++ они не предусмотрены.
Однако в стандартной библиотеке C++ имеется шаблон класса vector,
позволяющий программистам создавать более мощные и менее уязвимые для
ошибок альтернативные массивы. В главе 11 мы представим средства для
реализации массивов с теми возможностями, что предоставляются шаблоном vector.
Мы узнаем, как приспособить операции для использования с вашими
собственными классами (эта методика называется перегрузкой операций).
Шаблон класса vector доступен любому, кто разрабатывает приложения
на C++. Код в нашем следующем примере может быть для вас непривычным,
так как векторы используют нотацию шаблонов. Вспомните, в разделе 6.18 мы
обсуждали шаблоны функций. Шаблоны классов C++ обсуждаются в главе 14
этой книги. Однако вы, возможно, найдете вполне приемлемым применение
шаблона vector путем подражания синтаксису в примере, который мы
показываем в этом разделе.
Программа на рис. 7.26 демонстрирует возможности, которыми обладает
шаблон класса vector из стандартной библиотеки C++ и которые недоступны
для массивов-указателей в стиле С. Стандартный шаблон класса vector по
своим свойствам сходен с классом Array, который мы построим в главе 8. Шаблон
класса vector определен в заголовке <vector> (строка 11) pi принадлежит
к именному пространству std (строка 12).
1 // Рис. 7.26: fig07_26.cpp
2 // Демонстрация шаблона класса vector стандартной библиотеки C++.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
Массивы и векторы
473
7
8 #include <iomanip>
9 using std::setw;
10
11 #include <vector>
12 using std::vector;
13
14 void outputVector( const vector< int >&);// вывести вектор
15 void inputVector( vector< int > & ) ; // ввести значения в вектор
16
17 int main ()
18 {
19 vector< int > integers1( 7 ); // 7-элементный vector< int >
20 vector< int > integers2( 10 ); // 10-элементный vector< int >
21
22 // напечатать размер и содержимое integers1
23 cout « "Size of vector integersl is " « integersl.size ()
24 « "\nvector after initialization:" « endl;
25 outputVector( integersl );
26
27 // напечатать размер и содержимое integers2
28 cout « "\nSize of vector integers2 is " « integers2.size ()
29 « "\nvector after initialization:" « endl;
30 outputVector( integers2 );
31
32 // ввести и напечатать integersl и integers2
33 cout « "\nEnter 17 integers:" « endl;
34 inputVector( integersl );
35 inputVector( integers2 );
36
37 cout « "\nAfter input, the vectors contain:\n"
38 « "integersl." « endl;
39 outputVector( integersl );
40 cout « "integers2:" « endl;
41 outputVector( integers2 );
42
43 // применить к объектам vector операцию неравенства (!=)
44 cout « "\nEvaluating: integersl != integers2" « endl;
45
46 if ( integersl != integers2 )
47 cout « "integersl and integers2 are not equal" « endl;
48
49 // создать вектор integers3, используя в качестве инициализатора
50 // integersl; напечатать размер и содержимое integers3
51 vector< int > integers3( integersl ); // конструктор копии
52
53 cout « "\nSize of vector integers3 is " « integers3.size ()
54 « "\nvector after initialization:" « endl;
55 outputVector( integers3 );
56
57 // применить к объектам vector операцию присваивания (=)
58 cout « "\nAssigning integers2 to integersl:" « endl;
59 integersl = integers2; // integersl больше, чем integers2
60
61 cout « "integersl:" « endl;
62 outputVector( integersl );
63 cout « "integers2:" « endl;
474
Глава 7
64 outputVector( integers2 );
65
66 // применить к объектам vector опер&ц*зо равенства (==)
67 cout « "\nEvaluating: integersl = integers2" « endl;
68
69 if ( integers1 == integers2 )
70 cout « "integersl and integers2 are equal" « endl;
71
72 // использовать квадратныа скобки для образования rvalue
73 cout « "\nintegersl[5] is " « integersl[ 5 ];
74
75 // использовать квадратные скобки для образования lvalue
76 cout « "\n\nAssigning 1000 to integersl[5]" « endl;
77 integersl[ 5 ] = 1000;
78 cout « "integersl:" « endl;
79 outputVector( integersl );
80
81 // попытка указания индекса вне диапазона
82 cout « "\nAttempt to assign 1000 to integersl.at( 15 )" « endl;
83 integersl.at( 15 ) = 1000; // ОШИБКА: выход из диапазона
84 return 0;
85 } // конец main
86
87 // вывести содержимое вектора
88 void outputVector( const vector< int > fiarray )
89 {
90 size_t i; // объявить управляющую переменную
91
92 for ( i = 0; i < array.size(); i++ )
93 {
94 cout « setw( 12 ) « array[ i ];
95
96 if ( ( i + 1 ) % '. — 0 ) // no 4 числа в строке вывода
97 cout « endl;
98 } // конец for
99
100 if ( i % 4 != 0 )
101 cout « endl;
102 } // конец функции outputVector
103
104 // ввести содержимое вектора
105 void inputVector{ vector< int > fcarray )
106 {
107 for ( size_t 1-0; i < array. size () ; i+-! )
108 cin » array[ i ];
109 } // конец функции InputVector
Size ->f vector integersl ic 7
vector after initialisation:
0 0
0 0
Size of vector integ*-js2 ir. 10
vector after initialisation:
0 0 0 0
0 0
0
Массивы и векторы
475
0 0 0 0
о о
Enter 17 integers:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
After input, the vectors contain:
integersl:
12 3 4
5 6 7
integers2:
8 9 10 11
12 13 14 15
16 17
Evaluating: integersl != integers2
integarsl and integers2 are not equal
Size of vector integers3 is 7
vector after initialization:
12 3 4
5 6 7
Assigning integers2 to integersl:
integersl:
8 9 10 11
12 13 14 15
16 17
integers2:
8 9 10 11
12 13 14 15
16 17
Evaluating: == integers2
integersl and integers2 are equal
integersl[5] is 13
Assigning 1000 to integersl[5]
integersl:
8 9
12 1000
16 17
10
14
11
15
Attempt to assign 1000 to integersl.at( 15 )
Abnormal program termination
Рис. 7.26. Шаблон класса vector стандартной библиотеки C++
Строки 19-20 создают два объекта vector для хранения значений типа
int — integersl содержит 7 значений, a integers2 10 значений. По умолчанию
все элементы объектов vector устанавливаются равными 0. Заметьте, что
можно определять векторы для хранения любого типа данных, заменив int
в vector< int > на соответствующий тип. Такая нотация, специфицирующая
476
Глава 7
сохраняемый в векторе тип, сходна с нотацией, введенной в разделе 6.18 для
шаблонов функций.
Строка 23 использует элемент-функцию вектора size для получения
размера (т. е. числа элементов) integers!.. Строка 25 передает integersl функции
output Vector (строки 88-102), которая применяет к вектору квадратные
скобки ([]), чтобы получить значение каждого из элементов вектора, используемое
в целях вывода. Обратите внимание на сходство этой нотации с нотацией для
доступа к элементу массива. Строки 28 и 30 выполняют те же действия для
integers2.
Элемент-функция size шаблона класса vector возвращает число элементов
вектора как значение типа size_t (который на многих системах эквивалентен
unsigned int). Вследствие этого строка 90 объявляет управляющую
переменную i также как имеющую тип size_t. На некоторых компиляторах
объявление i как int заставило бы компилятор выдать предупреждающее сообщение,
поскольку в условии продолжения цикла (строка 92) значение со знаком (т. е.
int i) сравнивалось бы с беззнаковым (т. е. со значением типа size_t,
возвращаемым функцией size).
Строки 34-35 передают integersl и integers2 функции input Vector
(строки 105-109) для чтения значений элементов каждого из векторов, которые
вводятся пользователем. Функция inputVector применяет квадратные
скобки, чтобы получить lvalue, посредством которых можно сохранять значения в
каждом из элементов вектора.
Строка 46 демонстрирует, что объекты vector можно непосредственно
сравнивать операцией !=. Если содержимое двух векторов различно, операция
возвращает true, в противном случае возвращается false.
Шаблон класса vector позволяет программисту создать новый объект
vector, инициализированный содержимым существующего вектора. Строка 51
создает объект-вектор (integers3) и инициализирует его посредством
копирования integersl. Тем самым вызывается т. н. конструктор копии,
выполняющий операцию копирования. Подробнее с конструкторами копии вы
познакомитесь в главе 11. Строки 53 и 55 выводят размер и содержимое integers3,
показывая, что он был инициализирован корректно.
Строка 59 присваивает вектор integers2 вектору integersl, демонстрируя,
что к объектам-векторам можно применять операцию присваивания (=).
Строки 62 и 64 выводят содержимое обоих векторов, чтобы показать, что теперь
они содержат одни и те же значения. Затем строка 69 сравнивает integersl с
integers2 операцией равенства (==), чтобы определить, является ли
идентичным содержимое двух объектов после присваивания в строке 59 (является).
Строки 73 и 74 демонстрирует, что программа может применять
квадратные скобки ([]) для получения элемента вектора в качестве соответственно не-
модифицируемого lvalue и модифицируемого lvalue. Немодифицируемое lvalue
является выражением, которое идентифицирует объект в памяти (например,
элемент вектора), но не может быть использовано для модификации этого
объекта. Модифицируемое lvalue также идентифицирует объект в памяти, но
может быть использовано для его модификации. Как и в случае
массивов-указателей в стиле С, C++ не производит какой-либо проверки диапазона при
доступе к элементам вектора с помощью квадратных скобок. Следовательно,
программист должен убедиться, что операции с использованием [] не
попытаются случайно воздействовать на элементы за пределами вектора. Стандарт-
Массивы и векторы
477
ный шаблон класса vector предусматривает, тем не менее, средство проверки
диапазона в виде своей элемент-функции at, которая «выбрасывает
исключение», если ее аргумент является недопустимым индексом. По умолчанию это
приводит к завершению программы. Если индекс действителен, функция at
возвращает элемент в указанной позиции как модифицируемое или немоди-
фицируемое lvalue в зависимости от контекста (неконстантного или
константного), в котором произошел вызов. Строка 83 демонстрирует вызов функции
at с недействительным индексом.
В этом разделе мы продемонстрировали шаблон класса vector из
стандартной библиотеки C++, надежный утилизируемый класс, который может
заменить массивы-указатели в стиле С. В главе 11 вы увидите, что многие из своих
возможностей vector реализует за счет «перегрузки» встроенных операций
C++, и вы узнаете, как можно сходным образом приспосабливать операции
для использования с вашими собственными классами. Например, мы
создадим класс Array, который, подобно шаблону класса vector, расширяет
элементарные возможности массивов. Наш класс Array обладает и дополнительными
свойствами, например, возможностью ввода и вывода массивов целиком с
помощью операций » и «.
7.12. Конструирование программного обеспечения.
Кооперация объектов в системе ATM
(необязательный раздел)
В этом разделе мы будем говорить о кооперациях (взаимодействиях)
объектов в нашей системе ATM. Когда два объекта вступают друг с другом в
коммуникацию, говорят, что они кооперируются; они делают это, активируя
операции друг друга. Кооперация состоит в том, что объект одного класса посылает
сообщение объекту другого класса. В C++ сообщения посылаются посредством
вызова элемент-функций.
В разделе 6.18 мы определили многие из операций классов в нашей
системе. В этом разделе мы сосредоточим внимание на сообщениях, которыми эти
операции активируются. Чтобы идентифицировать в системе кооперации, мы
вернемся к спецификации требований в разделе 2.8. Как вы помните, эта
спецификация описывает разнообразную деятельность, которая происходит во
время сеанса ATM (например, идентификация пользователя, выполнение
транзакций). Пошаговые описания того, как система должна выполнять
каждую из этих задач, будут для нас первым указанием на кооперации в нашей
системе. По ходу изучения этого и остальных разделов «Конструирование
программного обеспечения» мы можем вскрыть дополнительные кооперации.
Идентификация коопераций в системе
Мы идентифицируем кооперации в системе, внимательно читая те разделы
спецификации требований, в которых описывается, что должен делать ATM,
чтобы авторизовать пользователя и производить транзакции каждого типа.
Для каждого действия или шага, описанного в спецификации, мы решаем,
какие объекты системы должны взаимодействовать, чтобы достигнуть
желаемого результата. Мы идентифицируем один объект как объект-отправитель (т.е.
объект, отправляющий сообщение), а другой — как объект-получатель (т.е.
478
Глава 7
объект, предлагающий клиентам класса данную операцию). Затем мы
выбираем одну из операций объекта-получателя (идентифицированных в
разделе 6.18), которая должна быть активирована объектом-отправителем для
осуществления нужного поведения. Например, в состоянии ожидания ATM
показывает приветственное сообщение. Мы знаем, что объект класса Screen
выводит пользователю сообщение посредством своей операции displayMessa-
ge. Следовательно, мы решаем, что система может показать приветственное
сообщение, осуществляя кооперацию между ATM и Screen, в которой ATM
посылает Screen сообщение displayMessage путем активации операции
displayMessage класса Screen. [Замечание. Чтобы избежать повторений слов
«объект класса...», мы называем каждый объект просто по имени его
класса, — например, «ATM» относится к объекту класса ATM.]
На рис. 7.27 перечислены кооперации, которые можно вывести из
спецификации требований. Для каждого объекта-отправителя мы перечисляем
кооперации в том порядке, в каком они обсуждаются в спецификации требований.
Мы записываем каждую кооперацию, включающую уникальных отправителя,
сообщение и получателя, только один раз, хотя кооперация может
происходить неоднократно в течение сеанса ATM. Например, первая строка на
рис. 7.27 означает, что ATM кооперируется со Screen во всех случаях, когда
ATM должен показать пользователю сообщение.
Объект класса...
ATM
Balancelnquiry
Withdrawal
Deposit
отправляет сообщение...
displayMessage
getlnput
authenticateUser
execute
execute
execute
getAvailableBalance
getTotalBalance
displayMessage
displayMessage
getlnput
getAvailableBalance
isSufficientCashAvailable
debit
dispenseCash
displayMessage
getlnput
isEnvelopeReceived
credit
объекту класса...
Screen
Keypad
BankDatabase %
Balancelnquiry
Withdrawal
Deposit
BankDatabase
BankDatabase
Screen
Screen
Keypad
BankDatabase
CashDispenser
BankDatabase
CashDispenser
Screen
Keypad
DepositSlot
BankDatabase
Массивы и векторы
479
Объект класса...
BankDatabase
отправляет сообщение...
validatePIN
getAvailableBalance
getTotalBalance
debit
credit
объекту класса...
Account
Account
Account
Account
Account
Рис. 7.27. Кооперации в системе ATM
Давайте разберем кооперации на рис. 7.27. Перед тем, как разрешить
пользователю производить какие-либо транзакции, ATM должен предложить
пользователю ввести номер своего счета, затем ввести PIN. ATM решает каждую из
этих задач, посылая Screen сообщение display Message. Оба этих действия
относятся к одной и той же кооперации между ATM и Screen, которая уже
учтена на рис. 7.27. ATM получает от пользователя ввод в ответ на приглашение,
посылая Keypad сообщение get Input. Далее ATM должен определить,
соответствуют ли номер счета и PIN, указанные пользователем, номеру и PIN счета,
хранящегося в базе данных. Он делает это, посылая BankDatabase сообщение
authenticateUser. Как вы помните, BankDatabase не может авторизовать
пользователя непосредственно — только Account пользователя (т. е. тот
Account, который содержит указанный пользователем номер счета) имеет
доступ к PIN пользователя и может его авторизовать. Соответственно на рис. 7.27
учтена кооперация, в которой BankDatabase посылает Account сообщение
validatePIN.
Как только пользователь авторизован, ATM показывает главное меню,
посылая Screen ряд сообщений displayMessage, и получает ввод — выбор в
меню, — посылая Keypad сообщение get Input. Мы уже учли эти кооперации.
После того, как пользователь выберет нужный тип транзакции, ATM
исполняет эту транзакцию, посылая сообщение execute объекту соответствующего
класса транзакции (т. е. Balancelnquiry, Withdrawal или Deposit). Например,
если пользователь выбрал проверку баланса, ATM посылает сообщение
execute объекту Balancelnquiry.
Дальнейшее изучение спецификации требований раскрывает кооперации,
участвующие в исполнении транзакций каждого типа. Balancelnquiry
получает наличную сумму денег на счете пользователя, посылая сообщение
getAvailableBalance объекту BankDatabase, который в ответ на это посылает
сообщение getAvailableBalance объекту Account пользователя. Аналогичным
образом Balancelnquiry получает сумму денег на депозите, посылая
BankDatabase сообщение getTotalBalance, a BankDatabase посылает то же сообщение
объекту Account. Для одновременного вывода обеих сумм баланса
Balancelnquiry посылает Screen сообщение displayMessage.
Withdrawal посылает Screen ряд сообщений displayMessage, чтобы вывести
меню стандартных снимаемых сумм (т. е. $20, $40, $60, $100 и $200). Чтобы
получить выбор пользователя в меню, Withdrawal посылает Keypad сообщение
get Input. Затем Withdrawal проверяет, что запрошенная сумма меньше или
равна балансу счета пользователя. Withdrawal может получить сумму,
наличную на счете пользователя, послав BankDatabase сообщение
getAvailableBalance. Withdrawal затем проверяет, достаточно ли наличных в выходном лотке,
480
Глава 7
посылая CashDispenser сообщение isSufficientCashAvailable. Withdrawal
посылает BankDatabase сообщение debit, чтобы снять сумму с баланса
пользователя. BankDatabase в свою очередь посылает то же сообщение
соответствующему Account. Как вы помните, дебетование средств со счета уменьшает как to-
talBalance, так и availableBalance. Для выдачи запрошенной суммы наличных
BankDatabase посылает CashDispenser сообщение dispenseCash. Наконец,
Withdrawal посылает Screen сообщение display Message, предлагая
пользователю забрать деньги.
Deposit откликается на сообщение execute, посылая сначала Screen
сообщение displayMessage, чтобы предложить пользователю ввести депонируемую
сумму. Чтобы получить ввод пользователя, Deposit посылает Keypad
сообщение get Input. Затем Deposit посылает Screen сообщение displayMessage,
чтобы предложить пользователю вставить конверт с депозитом в приемную щель.
Чтобы определить, получила ли приемная щель конверт, Deposit посылает
DepositSlot сообщение isEnvelopeReceived. Deposit обновляет счет
пользователя, посылая сообщение credit объекту BankDatabase, который в свою
очередь посылает credit пользовательскому Account. Как вы помните,
кредитование средств на счет увеличивает только totalBalance, но не availableBalance.
Диаграммы взаимодействия
Теперь, когда мы идентифицировали набор возможных коопераций между
объектами в нашей системе, давайте графически смоделируем эти
взаимодействия с помощью UML. В UML предусмотрено несколько типов диаграмм
взаимодействия, моделирующих поведение системы путем моделирования того,
как объекты взаимодействуют друг с другом. Диаграмма коммуникации
подчеркивает то, какие объекты участвуют в кооперациях. [Замечание. В ранних
версиях UML диаграммы коммуникации назывались диаграммами
кооперации.] Как и диаграмма коммуникации, диаграмма последовательности
показывает кооперации между объектами, но акцент в ней делается на том, как
посылаемые объектами сообщения соотносятся во времени.
Диаграммы коммуникации
Рис. 7.28 показывает диаграмму коммуникации, которая моделирует ATM,
исполняющий Balancelnquiry. Объекты моделируются в UML
прямоугольниками с именами объектов в форме имяОбъекта : имяКласса. В данном
примере, где участвует только по одному объекту каждого класса, мы опускаем имя
объекта и указываем только имя класса, которому предшествует двоеточие.
[Замечание. Когда на диаграмме коммуникации моделируется несколько
объектов одного класса, рекомендуется специфицировать имя каждого объекта.]
Объекты, участвующие в коммуникации, соединяются сплошными линиями,
а сообщения между ними передаются вдоль этих линий в направлении,
указанном стрелками. Имя сообщения, указываемое рядом со стрелкой, является
именем операции (т. е. элемент-функции), принадлежащей
объекту-получателю; другими словами, имя — это услуга, которую объект-получатель
предлагает объектам-отправителям (своим «клиентам»).
Массивы и векторы
481
execute()
►
:АТМ : Balancelnquiry
Рис. 7.28. Диаграмма коммуникации для ATM, исполняющего проверку баланса
Сплошная стрелка с закрашенным наконечником на рис. 7.27 представляет
сообщение — или синхронный вызов — в UML и вызов функции в C++.
Это стрелка показывает, что поток управления идет от объекта-отправителя
(ATM) к объекту-получателю (Balancelnquiry). Поскольку это синхронный
вызов, объект-отправитель не может посылать другие сообщения или делать
что-нибудь еще, пока объект-получатель не обработает сообщение и не
возвратит управление отправителю. Отправитель просто ждет. Например, на рис. 7.28
ATM вызывает элемент-функцию execute объекта Balancelnquiry и не может
послать другое сообщение, пока execute не закончится и не возвратит
управление ATM. [Замечание. Если бы это был асинхронный вызов, представляемый
штриховым наконечником, объекту-отправителю не нужно было ждать, пока
объект-получатель не вернет управление, — он мог бы сразу после
асинхронного вызова продолжить отправку дополнительных сообщений. В C++
асинхронные вызовы часто можно реализовать, используя зависимые от платформы
библиотеки, поставляемые с компилятором. Такие методики лежат за пределами
тематики данной книги.]
Последовательность сообщений на диаграмме коммуникации
Рис. 7.29 показывает диаграмму коммуникации, которая моделирует
взаимодействия между объектами в системе при исполнении объекта класса
Balancelnquiry. Предполагается, что атрибут accountNumber объекта
содержит номер счета текущего пользователя. Кооперации на рис. 7.29 начинаются
после того, как ATM посылает Balancelnquiry сообщение execute (т. е. после
взаимодействия, моделируемого на рис. 7.28). Число слева от сообщения
показывает порядковый номер передаваемого сообщения. Последовательность
сообщений на диаграмме коммуникации идет в порядке их номеров от
наименьшего к наибольшему. На этой диаграмме нумерация начинается с сообщения 1
и заканчивается сообщением 3. Сначала Balancelnquiry посылает BankData-
base сообщение getAvailableBalance (сообщение 1), затем посылает BankDa-
tabase сообщение getTotalBalance (сообщение 2). В скобках, следующих за
именем сообщения, мы можем специфицировать разделенный запятыми
список имен параметров, посылаемых с сообщением (т. е. аргументов в
функциональном вызове C++) — Balancelnquiry посылает со своими сообщениями
к BankDatabase атрибут accountNumber для указания того, о балансе какого
счета требуется получить информацию. Вспомните (см. рис. 6.36), что каждой
из операций getAvailableBalance и getTotalBalance класса BankDatabase
требуется параметр для идентификации счета. Затем Balancelnquiry показывает
пользователю availableBalance и totalBalance, посылая Screen сообщение
displayMessage (сообщение 3), включающее текст (message), который нужно
вывести.
16 Зак. 1114
482
Глава 7
:Screen
3: displayMessage( message)
: Balancelnquiry
I 1: getAvallableBalance( accountNumber)
I 2: getTotalBalance( accountNumber)
: BankDatabase w : Account
1.1: getAvailableBalance()
2.1: getTotalBalance()
Рис. 7.29. Диаграмма коммуникаций для исполнения проверки баланса
Заметьте, однако, что рис. 7.29 моделирует два дополнительных
сообщения, передаваемых от BankDatabase к Account (сообщение 1.1 и
сообщение 2.1). Чтобы предоставить ATM два баланса пользовательского счета
(запрошенных сообщениями 1 и 2), BankDatabase должен передать сообщения
getAvailableBalance и getTotalBalance пользовательскому Account. Такие
сообщения, передаваемые внутри обработки другого сообщения, называются
вложенными сообщениями. UML рекомендует использовать для нумерации
вложенных сообщений нотацию с точкой. Например, сообщение 1.1 есть
первое сообщение, вложенное в сообщение 1, — BankDatabase посылает
сообщение getAvailableBalance в то время, когда он обрабатывает сообщение с тем
же именем. [Замечание. Если бы BankDatabase в процессе обработки
сообщения 1 потребовалось послать второе вложенное сообщение, второе сообщение
нумеровалось бы как 1.2.] Сообщение может быть передано только после того,
как будут переданы все сообщения, вложенные в предыдущее сообщение.
Например, Balancelnquiry передает сообщение 3 только после передачи
сообщений 2 и 2.1, в указанном порядке.
Схема вложенной нумерации, используемая на диаграммах
коммуникации, помогает прояснить, когда в точности и в каком контексте передается
каждое сообщение. Например, если бы мы нумеровали сообщения на рис. 7.29,
используя линейную схему (т. е. 1, 2, 3, 4, 5), то, взглянув на диаграмму,
нельзя было бы определить, что BankDatabase передает Account сообщение
getAvailableBalance (сообщение 1.1) во время обработки сообщения 1, а не
после того, как завершит обработку сообщения 1. Вложенная нумерация с
точкой делает ясным, что второе сообщение getAvailableBalance (сообщение 1.1)
передается Account в процессе обработки объектом BankDatabase первого
сообщения getAvailableBalance (сообщения 1).
Массивы и векторы
483
Диаграммы последовательности
Диаграммы коммуникации акцентируют участников коопераций, но
несколько неуклюже моделируют их временной аспект. Диаграммы
последовательности помогают моделировать временные отношения коопераций более
ясно. Рис. 7.30 показывает диаграмму последовательности, моделирующую
последовательность взаимодействий при исполнении Withdrawal.
Пунктирная линия, идущая от прямоугольника-объекта вниз — это мировая линия
данного объекта, представляющая течение времени. Действия обычно
происходят вдоль мировой линии объекта в хронологическом порядке — действие,
расположенное ближе к верхнему концу линии, обычно происходит раньше
того, что расположено ближе к ее нижнему концу.
Передача сообщений на диаграмме последовательности изображается
аналогично передаче сообщений на диаграмме коммуникации. Сообщение
представляется сплошной стрелкой с закрашенным наконечником, идущей от
объекта-отправителя к объекту-получателю. Наконечник указывает на
активацию на мировой линии объекта-получателя. Активация, показанная как
узкий вертикальный прямоугольник, показывает, что объект исполняется.
Когда объект возвращает управление, то от его активации к активации
объекта, пославшего исходное сообщение, проходит обратное сообщение,
показанное в виде пунктирной линии со штриховым наконечником. Чтобы не
загромождать диаграмму, мы опускаем стрелки обратных сообщений — в UML, в
целях большей ясности диаграмм, это допускается. Как и диаграммы
коммуникации, диаграммы последовательности могут указывать имена
параметров сообщения в скобках после имени сообщения.
Последовательность сообщений на рис. 7.30 начинается, когда Withdrawal
предлагает пользователю выбрать снимаемую сумму, посылая сообщение dis-
playMessage объекту Screen. Затем Withdrawal посылает сообщение getlnput
объекту Keypad, который получает ввод пользователя. Мы уже моделировали
логику управления при исполнении Withdrawal в диаграмме деятельности
на рис. 5.28, так что не показываем ее в диаграмме последовательности
на рис. 7.30. Вместо этого мы моделируем здесь сценарий наилучшего случая,
когда баланс пользовательского счета больше или равен снимаемой сумме, а в
выходном лотке достаточно наличных для удовлетворения запроса. За
информацией о том, как моделировать на диаграмме последовательности логику
управления, обратитесь к ресурсам Web и рекомендованной литературе в
разделе 2.8.
После получения снимаемой суммы Withdrawal посылает сообщение
объекту BankDatabase, который в свою очередь посылает сообщение getAvailab-
leBalance объекту Account. В предположении, что на счете пользователя
достаточно денег для разрешения транзакции, Withdrawal затем посылает
сообщение isSufficientCashAvailable объекту CashDispenser. В предположении,
что в выходном лотке достаточно наличных, Withdrawal уменьшает баланс
счета пользователя (т. е. и totalBalance, и availableBalance), посылая
сообщение debit объекту BankDatabase. Последний реагирует на это, посылая
сообщение debit объекту Account пользователя. Наконец, Withdrawal посылает
сообщение dispenseCash объекту CashDispenser и сообщение displayMessage
объекту Screen, информируя пользователя, что он может забрать из
банкомата деньги.
484
Глава 7
Мы идентифицировали кооперации между объектами в системе ATM и
моделировали некоторые из этих коопераций с помощью диаграмм
взаимодействия UML — как диаграмм коммуникации, так и диаграмм
последовательности. В следующем разделе «Конструирование программного обеспечения»
(раздел 9.12) мы усовершенствуем структуру нашей модели, завершив тем
самым предварительное объектно-ориентированное проектирование, а затем
начнем реализацию системы ATM.
Withdrawal
:Keypad
:Accont
:Screen
displayMessalge( message )
► r
getlrjputO
:BankDatabase
getAvailable,Balance( accourptNumber)
.CashDispenser
getAvailableiBalanceQ
1 isSufficienTCashAvailable('amount)
debit( accountNumber, amount)
1 s ►
debit( amount)
► '
dispenseCash( amqunt)
displayMessajge( message )
Рис. 7.30. Диаграмма последовательности, моделирующая исполнение Withdrawal
Массивы и векторы
485
Контрольные вопросы по конструированию программного
обеспечения
7.1. состоит в том, что объект одного класса посылает сообщение
объекту другого класса.
a) ассоциация
b) агрегация
c) кооперация
d) композиция
7.2. Какая форма диаграмм взаимодействия акцентирует, какие кооперации
происходят? Какая форма акцентирует, когда происходят кооперации?
7.3. Создайте диаграмму последовательности, которая моделирует
взаимодействия объектов в системе ATM, происходящие в случае, когда
Deposit завершается успешно, и объясните последовательность
сообщений, моделируемую диаграммой.
Ответы на контрольные вопросы по конструированию
программного обеспечения
7.1. с.
7.2. То, какие происходят кооперации, акцентируют диаграммы
коммуникации. То, когда происходят кооперации, акцентируют диаграммы
последовательности.
7.3. На рис. 7.31 представлена диаграмма последовательности,
моделирующая взаимодействия объектов в системе ATM, происходящие в случае,
когда Deposit завершается успешно. Диаграмма показывает, что сначала
Deposit посылает сообщение displayMessage объекту Screen, чтобы
попросить пользователя ввести сумму депозита. Затем Deposit посылает
сообщение getlnput объекту Keypad, чтобы получить введенную
пользователем сумму. После этого Deposit просит пользователя вставить
конверт с депозитом в щель, посылая сообщение displayMessage объекту
Screen. Deposit затем посылает сообщение isEnvelopeReceived объекту
DepositSlot, чтобы подтвердить, что конверт получен. Наконец, Deposit
увеличивает атрибут totalBalance (но не availableBalance) объекта
Account пользователя, посылая сообщение credit объекту BankDatabase.
Последний реагирует на это, посылая то же сообщение объекту Account
пользователя.
486
Глава 7
:Deposit
:Keypad
:BankDatabase
:Screen
displayMessabe( message )
► Г
getlnput()
displayMessa£je( message )
► '
isEnvelopeReceive|d()
:DepositSlot
credit( accourVtNumber, amoUnt)
I I
:Account
credit( amount)
Рис. 7.31. Диаграмма последовательности, моделирующая исполнение Deposit
7.13. Заключение
В этой главе началось наше введение в структуры данных, — изучение
использования массивов и векторов для хранения и извлечения данных в
списках и таблицах значений. Примеры главы продемонстрировали, как
объявить и инициализировать массив, как обращаться к отдельным его элементам.
Мы также показали, как передавать массивы функциям и как использовать
квалификатор const для осуществления принципа наименьших привилегий.
Примеры главы представили также элементарные методики поиска и
сортировки. Бы узнали, как объявлять многомерные массивы и как производить
над ними типичные действия. Наконец, мы продемонстрировали возможности
шаблона класса vector стандартной библиотеки C++.
К настоящему моменту мы ввели основные концепции классов, объектов,
управляющих операторов, функций и массивов. В главе 8 мы представим один
из самых мощных элементов C++ — указатель. Указатели отслеживают, где в
памяти находятся данные и функции, что позволяет нам манипулировать ими
Массивы и векторы
487
очень интересными способами. После введения в основные понятия
указателей мы подробнее изучим взаимоотношения между массивами, указателями и
строками.
Резюме
• Структуры данных являются коллекциями взаимосвязанных единиц информации.
Массивы являются структурами данных, состоящими из элементов одного и того же
типа. Массивы являются «статическими» сущностями в том отношении, что они не
изменяют своего размера в течение всего времени исполнения программы. (Они,
конечно, могут иметь автоматический класс памяти и, таким образом, создаваться и
уничтожаться при каждом входе и выходе из блока, в котором они определены.)
• Массив — это группа последовательных ячеек памяти, имеющих один и тот же тип.
• Чтобы обратиться к определенной ячейке, или элементу массива, мы
специфицируем имя массива и номер позиции элемента в массиве.
• Программа ссылается на любой из элементов массива, указывая имя массива, за
которым следует номер позиции нужного элемента в квадратных скобках ([]). На более
формальном языке номер позиции называют индексом элемента (номер позиции
равен числу элементов, предшествующих в массиве данному элементу).
• Первый элемент любого массива имеет индекс 0 и называется иногда нулевым
элементом.
• Индекс должен быть целым числом или целым выражением (принадлежащим к
любому целочисленному типу).
• Важно отметить различие между «седьмым элементом массива» и «элементом
массива 7». Поскольку индексы массива начинаются с 0, «седьмой элемент массива»
имеет индекс 6, тогда как «элемент массива 7» имеет индекс 7 и на самом деле
является восьмым элементом. Это различие часто служит источником ошибок смещения
на единицу.
• Квадратные скобки, в которые заключается индекс массива, являются в
действительности операцией языка C++. Квадратные скобку имеют тот же уровень
приоритета, что и круглые скобки.
• Массивы занимают в памяти некоторое пространство. Программист специфицирует
имя массива и требуемое число его элементов следующим образом:
тип имя_массива [ размер_массива ] ;
и компилятор резервирует под массив соответствующий объем памяти.
• Можно объявлять массивы, содержащие значения любого типа данных. Например,
для хранения символьной строки можно использовать массив типа char.
• Элементы массива могут быть инициализированы в его объявлении. Для этого после
имени массива через знак равенства записывается разделенный запятыми список
константных инициализаторов (заключенный в фигурные скобки). Если число
инициализаторов меньше, чем число элементов в массиве, оставшиеся элементы
инициализируются нулями.
• Если в объявлении со списком инициализации размер массива опущен, компилятор
определяет число элементов в массиве путем подсчета числа инициализаторов.
• Если в объявлении массива специфицируется и размер, и список инициализаторов,
то число инициализаторов должно быть не больше размера массива. Указание в
списке инициализации массива большего числа инициализаторов, чем число элементов
в массиве, вызывает ошибку компиляции.
488
Глава 7
• Константы должны инициализироваться константным выражением при объявлении
и не могут впоследствии модифицироваться. Константы могут помещаться везде, где
ожидается константное выражение.
• В C++ отсутствует проверка границ, которая предотвращала бы ссылки на
несуществующий элемент массива. Следовательно, исполняющаяся программа может без
всякого предупреждения «уйти» за любую из его границ. Программист должен
убедиться, что все ссылки на массив остаются в его пределах.
• Символьный массив может быть инициализирован строковым литералом. Размер
массива определяется компилятором, исходя из длины строки плюс специальный
символ ограничения строки, называемый нуль-символом (он представляется
символьной константой '\0').
• Любые строки, представляемые символьными массивами, оканчиваются
нуль-символом. Символьный массив, представляющий строку, должен объявляться
достаточно большим, чтобы вместить символы строки и ограничивающий ее нуль-символ.
• Символьные массивы могут инициализироваться списком отдельных символьных
констант.
• К отдельным символам строки можно обращаться непосредственно, применяя
нотацию индексации.
• Можно вводить строку с клавиатуры прямо в символьный массив, используя cin и ».
• Символьный массив, содержащий строку с завершающим нуль-символом, можно
вывести с помощью cout и <<.
• Статическая локальная переменная в определении функции существует в течение
всего периода выполнения программы, но видима только в теле функции.
• Программа инициализирует статические локальные массивы, когда их объявление
встречается в первый раз. Если статический массив не инициализируется
программистом явно, компилятор при создании инициализирует каждый его элемент нулем.
• Чтобы передать массив в качестве аргумента функции, укажите имя массива без
каких-либо квадратных скобок. Чтобы передать функции элемент массива, укажите в
качестве аргумента вызова имя массива с соответствующим индексом элемента.
• C++ передает функциям массивы по ссылке, — вызываемые функции могут
модифицировать значения элементов в исходных массивах вызывающих. Значением имени
массива является адрес первого элемента массива в памяти компьютера. Поскольку
передается адрес начала массива, вызываемая функция точно знает, где в памяти
хранится массив.
• Отдельные элементы массивов передаются по значению, точно так же, как простые
переменные. Такие простые единицы данных называют скалярами или скалярными
величинами.
• Чтобы в результате вызова функции последняя получила массив, ее список
параметров должен специфицировать, что ожидается получение массива. Размер массива
внутри квадратных скобок не требуется.
• Для предотвращения модификации значений массива вызываемой функцией в C++
предусмотрен квалификатор типа const. Когда функция специфицирует свой
параметр-массив как const, элементы его становятся в теле функции константами, и любая
попытка модифицировать элемент в теле функции приводит к ошибке компиляции.
• При линейном поиске каждый элемент массива сравнивается с ключом поиска.
Поскольку массив не предполагается упорядоченным каким-либо определенным
образом, вероятность встретить искомое значение в первом элементе такая же, как в
последнем. В среднем, следовательно, программа должна будет сравнить ключ поиска с
половиной элементов массива. Чтобы определить, что значение в массиве
отсутствует, программе потребуется сравнить ключ поиска со всеми элементами массива.
Линейный метод поиска хорошо работает с небольшими массивами и приемлем для
несортированных массивов.
Массивы и векторы
489
Массив можно сортировать с помощью сортировки вставкой. Первая итерация этого
алгоритма берет второй элемент и, если он меньше первого элемента, обменивает его
с первым элементом (т. е. программа вставляет второй элемент перед первым).
Вторая итерация рассматривает третий элемент и вставляет его в нужное место по
отношению к двум первым, так что все три элемента оказываются в правильном порядке.
На i-ой итерации окажутся сортированными первые / элементов исходного массива.
Сортировка вставкой пригодна для небольших массивов, но неэффективна для
больших массивов в сравнении с более совершенными алгоритмами.
Многомерные массивы с двумя измерениями часто используются для представления
таблиц значений, состоящих из информации, организованной по строкам и столбцам.
Массивы, требующие двух индексов для идентификации элемента, называются
двумерными массивами. Массив с т строками и п столбцами называется массивом т на п.
Шаблон класса vector стандартной библиотеки C++ представляет собой более
надежный тип массива, обладающий многими возможностями, не предусмотренными для
массивов-указателей в стиле С.
По умолчанию все элементы целого вектора устанавливаются равными 0.
Можно определить вектор для хранения любого типа данных, объявив его в форме
vector< тип > имя( размер )
Элемент-функция size шаблона класса vector возвращает число элементов вектора,
для которого она вызвана.
Можно получить или модифицировать элемент вектора, применив квадратные скоб-
ки ([]).
Объекты класса vector можно непосредственно сравнивать операциями равенства
(==) и неравенства (!=). К объектам-векторам можно применять также операцию
присваивания (=).
Немодифицируемое lvalue является выражением, которое идентифицирует объект в
памяти (например, элемент вектора), но не может быть использовано для
модификации этого объекта. Модифицируемое lvalue также идентифицирует объект в памяти,
но может быть использовано для его модификации.
Стандартный шаблон класса vector предусматривает средство проверки диапазона в
форме элемент-функции at, которая «выбрасывает исключение», если ее аргумент
является недопустимым индексом. По умолчанию это приводит к завершению
программы.
Терминология
a[i]
а[ i ][ j ]
vector (шаблон класса из стандартной
библиотеки C++)
двумерный массив
двумерный массив
значение элемента
именованная константа
имя массива
индекс
индекс
индекс столбца
индекс строки
инициализатор
инициализация массива
квадратные скобки []
квалификатор типа const
ключ поиска
ключевое значение
константная переменная
линейный поиск в массиве
магическое число
массив
массив т на п
масштабируемость
многомерный массив
модифицируемое lvalue
немодифицируемое lvalue
номер позиции
нулевой индекс
490
Глава 7
нулевой элемент
нуль-символ ('\0')
объявление массива
одномерный массив
ошибка смещения на единицу
передача массивов функциям
передача по ссылке
поиск в массиве
проверка границ
скаляр
скалярная величина
сортировка вставкой
сортировка массива
список инициализаторов
список инициализаторов массива
статический элемент данных
столбец двумерного массива
строка двумерного массива
строка, представленная символьным
массивом
структура данных
таблица значений
табличный формат
«уход» за пределы массива
элемент массива
элемент-функция at вектора
элемент-функция size вектора
Контрольные вопросы
7.1. Заполните пропуски в следующих предложениях:
а) Списки и таблицы значений хранятся в или
7.2.
7.3.
b) Элементы массива связаны тем, что они имеют одни и те же
и .
c) Число, используемое для обращения к отдельному элементу массива,
называется .
d) Для объявления размера массива должна использоваться , потому
что она делает программу более масштабируемой.
e) Процесс упорядоченного размещения элементов в массиве называется
f) Процесс определения значения ключа, содержащегося в массиве, называется
g) Массив, использующий два индекса, называется .
Определите, верны или не верны следующие утверждения. Если утверждение
неверно, объясните, почему.
a) Массив может хранить много различный типов данных.
b) Индексы массива обычно должны иметь тип float.
c) Если количество начальных значений в списке инициализации меньше, чем
количество элементов массива, оставшиеся элементы автоматически
получают в качестве начальных значений последние значения из списка
инициализации.
d) Если список инициализации содержит начальных значений больше, чем
элементов массива, то это — ошибка.
e) Отдельный элемент массива, который передается функции и модифицируется
в этой функции, будет содержать модифицированное значение после
завершения выполнения вызываемой функции.
Напишите операторы, реализующие следующие операции с массивом fractions.
a) Определите именованную константу arraySize с начальным значением 10.
b) Объявите массив с числом элементов arraySize типа double, имеющими
нулевые начальные значения.
c) Назовите четвертый элемент от начала массива.
d) Обратитесь к элементу массива 4.
e) Присвойте значение 1.667 элементу массива 9.
Массивы и векторы
491
f) Присвойте значение 3.333 седьмому элементу массива.
g) Напечатайте элементы массива 6 и 9 с двумя цифрами справа от десятичной
точки и покажите, как будут выглядеть выходные данные, отображаемые на
экране.
h) Напечатайте все элементы массива, используя структуру повторения for.
Определите целую переменную х в качестве переменной, управляющей циклом.
Покажите, как будут выглядеть выходные данные.
7.4. Напишите операторы, реализующие следующие операции с массивом table.
a) Объявите массив, который должен быть массивом целых чисел и иметь три
строки и три столбца. Полагайте, что определена именованная константа
arraySize, равная 3.
b) Сколько элементов содержит массив?
c) Используйте структуру повторения for для задания начальных значений
каждому элементу массива, равных сумме его индексов. Полагайте, что
объявлены целые переменные х и у, являющиеся управляющими переменными.
d) Напишите фрагмент программы для печати каждого элемента массива table
в табличном формате с тремя строками и тремя столбцами. Предположите,
что массив получил начальные значения в объявлении
int table [ arraySize ][ arraySize ]={{1,8},{2,4,6},{5}};
и объявлены целые переменные х и у, являющиеся управляющими
переменными. Покажите, как будут выглядеть выходные данные.
7.5. Найдите и исправьте ошибку в каждом из следующих фрагментов программ.
a) #include <iostream.h>;
b) arraySize = 10;// переменная arraySize была объявлена как const
c) Допустим, что int Ь[ 10 ] = { 0 } ;
for ( int i = 0; i <= 10; i++ )
b[ i ] = 1;
d) Допустим, что а[ 2 ][ 2 ] = { { 1, 2 }, { 3, 4 } };
a[ 1, 1 ] = 5;
Ответы на контрольные вопросы
7.1. а) массивах, векторах. Ь) имя, тип. с) индекс, d) именованная константа, е)
сортировка, f) поиск, g) двумерный.
7.2. а) Неверно. Массив может хранить значения только одинакового типа.
b) Неверно. Индексы массива обязательно должны быть целыми числами или
целыми выражениями.
c) Неверно. Оставшиеся элементы автоматически получают нулевые начальные
значения.
d) Верно.
e) Неверно. Отдельные элементы массива передаются по значению. Только если
функции передается массив целиком, любые его модификации будут
отражаться на оригинале.
7.3. a) const int arraySize = 10;
b) float fractions[ arraySize ] = { 0 };
c) fractions [ 3 ]
d) fractions[ 4 ]
e) fractions [ 9 ] = 1.667;
492
Глава 7
f) fractions [ 6 ] = 3.333;
g) cout « setiosflags( ios::fixed I ios::shiwpoint )
« setprecision( 2 ) « fractions[ 6 ] « ' '
« fractions [ 9 ] « endl;
Выводит: 3.33 1.67.
h) for ( int x = 0; x < arraySize; x++ )
cout « " fractions [" « x « "] = " « fractions! x ] « endl;
Выводит:
fractions[ 0 ] = 0
fractions[ 1 ] = 0
fractions[ 2 ] = 0
fractions[ 3 ] = 0
fractions[ 4 ] = 0
fractions[ 5 ] = 0
fractions[ 6 ] = 3.333
fractions[ 7 ] = 0
fractions[ 8 ] = 0
fractions[ 9 ]= 1.667
7.4. a) int table [ arraySize ] [ arraySize ] ;
b) Девять.
c) for ( x = 0; x < arraySize; x++ )
for ( у = 0; у < arraySize; y++ )
table[ x ] [ у ] = x + у;
d) cout « " [0] [1] [2] " « endl;
for ( int x = 0; x < arraySize; x++ ) {
cout « ' [' « x « " ] " ;
for ( int у = 0; у < arraySize; y++ )
cout « setw( 3 ) « table[ x ][ у ] « "
cout « endl;
Вывс
[0]
[1]
[2]
>дит:
[0]
1
2
5
[1]
8
4
0
[2]
0
6
0
7.5. а) Ошибка: точка с запятой в конце директивы препроцессора #include.
Исправление: удалить точку с запятой,
о) Ошибка: присваивание значения именованной константе оператором
присваивания.
Исправление: присвоить значение именованной константе в объявлении const
int arraySize.
c) Ошибка: ссылка на элемент массива, находящийся за границами массива
(Ъ[ Ю ]).
Исправление: сделать конечное значение управляющей переменной равным 9.
d) Ошибка: индексирование массива сделано неверно.
Исправление: изменить оператор на а[ 1 ][ 1 ] = 5;
Массивы и векторы
493
Упражнения
7.6. Заполните пропуски в следующих предложениях:
a) Именами четырех первых элемента массива р (int p[ 4 ];) являются ,
, и .
b) Именование массива, задание его типа и указание числа элементов массива
называется массива.
c) В двумерном массиве первый индекс (по соглашению) определяет
элемента, а второй определяет элемента.
d) Массив т на п содержит строк, столбцов
и элементов.
e) Именем элемента в строке 3 и столбце 5 массива является .
7.7. Определите, верны или не верны следующие утверждения. Если утверждение
неверно, объясните, почему.
a) Чтобы сослаться на конкретную ячейку или элемент внутри массива, мы
указываем имя массива и значение данного элемента.
b) Объявление массива резервирует для него память.
c) Чтобы указать, что для массива целых чисел р должно быть зарезервировано
100 ячеек памяти, программист пишет объявление
р[ ЮО ];
d) Программа на C++, присваивающая начальные нулевые значения массиву из
15 элементов, должна содержать, по меньшей мере, один оператор for.
e) Программа на C++, которая суммирует элементы двумерного массива, должна
содержать вложенные циклы for.
7.8. Напишите операторы C++, соответствующие следующим задачам:
a) Выведите на экран значение седьмого элемента символьного массива f.
b) Введите значение элемента 4 одномерного массива b с плавающей запятой.
c) Присвойте начальное значение 8 каждому из 5 элементов одномерного массива
целых чисел g.
d) Просуммируйте и напечатайте сумму 100 элементов массива g с плавающей
точкой.
e) Скопируйте массив а в первую часть массива Ь. Считайте, что массивы
объявлены как double а[ 11 ], Ь[ 34 ];
f) Определите и напечатайте наименьшее и наибольшее значения, содержащиеся
в массиве w с 99 элементами с плавающей запятой.
7.9. Рассматривается массив целых чисел t размером 3 на 4.
a) Напишите объявление для t.
b) Сколько строк в массиве t?
c) Сколько столбцов в массиве t?
d) Сколько элементов в массиве t?
e) Напишите имена всех элементов второй строки массива t.
f) Напишите имена всех элементов третьего столбца массива t.
g) Напишите один оператор, который устанавливает в нуль элемент первой
строки и второго столбца массива t.
h) Напишите последовательность операторов, которые присваивают нулевые
начальные значения всем элементам массива t. He используйте структуру
повторения.
494
Глава 7
i) Напишите вложенную структуру for, которая присваивает нулевые начальные
значения всем элементам массива t.
j) Напишите оператор ввода элементов массива t с клавиатуры.
к) Напишите последовательность операторов, которая определяет и печатает
наименьшее значение в массиве t.
1) Напишите оператор, который выводит на экран элементы первой строки массива t.
m) Напишите оператор, который суммирует элементы четвертого столбца массива t.
п) Напишите последовательность операторов, которая печатает массив t в
табулированном формате. Перечислите индексы столбцов как заголовки вверху
и индексы строк слева в каждой строке.
7.10. Используйте одномерный массив для решения следующей задачи. Компания
платит своим продавцам на комиссионной основе. Продавцы получают 200 долларов
в неделю плюс 9 процентов от валовой продажи за эту неделю. Например,
продавец, валовая продажа которого за неделю составила 5000 долларов, получает 200
долларов плюс 9 процентов от 5000 долларов, или всего 650 долларов. Напишите
программу (используя массив счетчиков), которая определяет, сколько продавцов
получили заработную плату в каждом из следующих диапазонов (примем
допущение, что зарплата каждого продавца округляется до целого значения):
1. $200-$299
2. $300-$399
3. $400-$499
4. $500-$599
5. $600-$699
6. $700-$799
7. $800-$899
8. $900-$999
9. $1000 и более
7.11. (Пузырьковая сортировка) В алгоритме пузырьковой сортировки меньшие
значения постепенно «всплывают» к началу массива подобно пузырькам в воде, в то
время как большие значения опускаются «на дно». Пузырьковая сортировка
выполняет несколько проходов по массиву. На каждом проходе сравниваются пары
смежных элементов. Если порядок элементов в паре восходящий (или элементы
идентичны), мы оставляем их так, как есть. Если порядок элементов
нисходящий, их значения в массиве обмениваются. Напишите программу,
сортирующую массив из 10 целых чисел посредством пузырьковой сортировки.
7.12. Пузырьковая сортировка, представленная в упражнении 7.11, неэффективна
для больших массивов. Выполните следующие простые модификации для
улучшения эффективности пузырьковой сортировки.
a) После первого прохода наибольшее число гарантированно окажется в
элементе массива с наивысшим номером; после второго прохода «на месте» окажутся
два наибольших числа и так далее. Модифицируйте пузырьковую сортировку
так, чтобы вместо выполнения девяти сравнений на каждом проходе на
втором проходе было восемь сравнений, на третьем проходе — семь и так далее.
b) Данные в массиве могут уже находиться в необходимом порядке, либо
близком к нему, так зачем же делать девять проходов, если достаточно сделать
меньше? Модифицируйте сортировку так, чтобы в конце каждого прохода
проверялось, были ли сделаны какие-либо перестановки. Если не было ни
одной, значит, данные уже находятся в соответствующем порядке, так что
программа должна завершиться. Если перестановки были сделаны, нужно
сделать, по меньшей мере, еще один проход.
Массивы и векторы
495
7.13. Напишите по одному оператору для выполнения следующих операций с
одномерным массивом:
a) Присвойте нулевые начальные значения 10 элементам массива целых чисел
counts.
b) Прибавьте 1 к каждому из 15 элементов массива целых чисел bonus.
c) Прочитайте 12 значений массива monthlyTemperatures типа double с
клавиатуры.
d) Напечатайте в виде столбца 5 значений массива целых чисел best Scores.
7.14. Найдите ошибку (или ошибки) в каждом из следующих операторов:
a) Допустим: char str[ 5 ] ;
cin » str; // Пользователь печатает "hello"
b) Допустим: int a[ 3 ];
cout « a[ 1 ] « " " « a[ 2 ] « " " « a [ 3 ] « endl ;
c) double f[ 3 ] = { 1.1, 10.01, 100.001, 1000.0001 };
d) Допустим: double d[ 2 ] [ 10 ] ;
d[ 1, 9 ] = 2.345;
7.15. Используйте одномерный массив для решения следующей задачи. Прочитайте
20 чисел, каждое из которых находится в диапазоне от 10 до 100 включительно.
После того, как прочли очередное число, напечатайте его, но только в том
случае, если оно не дублирует ранее прочитанные числа. Предусмотрите
«наихудший случай», когда все 20 чисел различны. Используйте наименьший
возможный массив для решения этой задачи.
7.16. Укажите, в каком порядке будут обнуляться элементы двумерного массива sales
размером 3 на 5 следующим фрагментом программы:
for ( row = 0; row < 3; row++ )
;for ( column = 0; column < 5; column++ )
sales[ row ][ column ] = 0;
7.17. Напишите программу, моделирующую бросание двух костей. Программа
должна использовать rand для бросания первой кости и затем — снова rand для
метания второй кости. Затем должна подсчитываться сумма двух значений.
Замечание: поскольку каждая кость может показать целое значение от 1 до 6, то сумма
двух чисел может варьироваться от 2 до 12 с наиболее частым значением суммы
7 и наименее частыми значениями 2 и 12. Рис. 7.32 показывает 36 возможных
комбинаций двух костей. Ваша программа должна выбрасывать две кости 36000
раз. Используйте одномерный массив, чтобы подсчитывать, сколько раз выпада-
12 3 4 5 6
1
2
3
4
5
6
2
3
4
5
6
7
3
4
5
6
7
8
4
5
6
7
8
9
5
6
7
8
9
10
6
7
8
9
10
11
7
8
9
10
11
12
Рис. 7.32. 36 возможных исходов бросания двух костей
496
Глава 7
ет каждая возможная сумма. Напечатайте результат в табулированном формате.
Определите приемлемость полученных результатов: поскольку существует
шесть возможных способов выпадения 7, приблизительно в одной шестой части
всех случаев бросания должно выпадать 7.
7.18. Что делает следующая программа?
1 // Упражнение 7.18: ех07_18.срр
2 // Что делает эта программа?
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int whatlsThis( int [] , int ); // прототип функции
8
9 int main()
10 {
11 const int arraySize = 10;
12 int a[ arraySize ]={1,2,3,4,5,6,7,8,9, 10};
13
14 int result = whatlsThis( a, arraySize );
15
16 cout « "Result is " « result « endl;
17
18 return 0; // показывает успешное завершение
19 } // конец main
20
21 // Что делает эта функция?
22 int whatlsThis( int b[], int size )
23 {
24 if ( size == 1 ) // основной случай
25 return b[ 0 ];
26 else // рекурсивный шаг
27 return b[ size - 1 ] + whatlsThis( b, size - 1 );
28 } // конец функции whatlsThis
7.19. Модифицируйте программу на рис. 6.11, чтобы она проводила 1000 игр в крепе.
Программа должна запоминать статистические данные и отвечать на следующие
вопросы:
a) Сколько игр выиграно при первом бросании, при втором бросании, ..., при
двадцатом бросании, после двадцатого бросания?
b) Сколько игр проиграно при первом бросании, при втором бросании, ..., при
двадцатом бросании, после двадцатого бросания?
c) Каковы шансы на выигрыш в крепе? [Замечание. Вы должны учесть, что
крепе — одна из наиболее популярных игр в казино. Как вы думаете, что бы
это значило?]
d) Какова средняя продолжительность игры в крепе?
e) Растут ли шансы выигрыша с увеличением продолжительности игры?
7.20. (Система резервирования авиабилетов) Небольшая авиакомпания купила
компьютеры для своей новой автоматизированной системы резервирования. Вас
попросили запрограммировать новую систему. Вы должны написать программу
выделения мест на каждый полет единственного самолета (вместимость: 10
мест).
Ваша программа должна отображать следующее меню альтернатив:
Введите, пожалуйста, 1 для "курящих"
Введите, пожалуйста, 2 для "некурящих"
Если клиент ввел 1, ваша программа должна выделять место в салоне для
курящих (места 1-5). Если клиент ввел 2, ваша программа должна выделять место
Массивы и векторы
497
в салоне для некурящих (места 6-10). Ваша программа должна также
напечатать посадочный талон, указывающий номер места клиента и тип салона в
самолете — для курящих или некурящих.
Используйте одномерный массив для представления схемы расположения мест
в самолете. Присвойте всем элементам массива нулевые начальные значения,
чтобы показать, что все места свободны. Как только место выделено пассажиру,
устанавливайте соответствующий элемент массива в состояние 1, чтобы
показать, что место уже занято.
Ваша программа, конечно, никогда не должна выделять уже занятые места.
Если салон для курящих заполнен, ваша программа должна спросить у клиента,
приемлем ли для него салон для некурящих. Если да, то сделайте выделение
соответствующего места. Если нет, то напечатайте сообщение «Следующий полет
состоится через три часа».
7.21. Что делает следующая программа?
1 // Упражнение 7.21: ех07_21.срр
2 // Что делает эта программа?
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 void someFunction( int [], int, int ); // прототип функции
8
9 int main ()
10 {
11 const int arraySize - 10;
12 int a[ arraySize ]={1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
13
14 cout « "The values in the array are:" « endl;
15 someFunction( a, 0, arraySize );
16 cout « endl;
17
18 return 0; // показывает успешное завершение
19 ) // конец main
20
21 // Что делает эта функция?
22 void someFunction( int b[], int current, int size )
23 {
24 if ( current < size )
25 {
26 someFunction( b, current + 1, size );
27 cout « b[ current ] « "
28 } // конец if
29 } // конец функции someFunction
7.22. Используйте двумерный массив для решения следующей задачи. Компания
имеет четырех продавцов (их номера с 1 по 4), которые продают 5 разных продуктов
(их номера с 1 по 5). Раз в день каждый продавец заносит в регистрационную
карточку (отдельную для каждого типа проданных продуктов) следующие
сведения:
1. Номер продавца.
2. Номер продукта.
3. Общую выручку в долларах за проданный в этот день продукт.
Таким образом, каждый продавец заполняет от 0 до 5 карточек продажи в день.
Допустим, что в наличии имеется информация обо всех регистрационных
карточках за последний месяц. Напишите программу, которая считывает всю эту
информацию о продажах за последний месяц и суммирует общую продажу по
продуктам и по продавцам. Все итоги должны храниться в двумерном массиве
498
Глава 7
sales. После обработки всей информации за последний месяц, напечатайте
результат в табулированном формате, представляя в каждом столбце отдельного
продавца и в каждой строке отдельный продукт. Общий итог каждой строки
должен давать сумму продаж каждого продукта за последний месяц; общий итог
каждого столбца должен давать сумму продаж каждого продавца за последний
месяц. Ваши табулированные выходные данные должны включать эти итоги
справа от суммируемых строк и внизу суммируемых столбцов.
7.23. (Черепашья графика) Язык Лого, особенно популярный среди пользователей
персональных компьютеров, сделал знаменитой черепашью графику.
Представьте себе механическую черепаху, которая ползает по комнате под управлением
программы на C++. Черепаха несет пишущее перо, которое может находиться
в одной из двух позиций — нижней или верхней. Если перо в нижней позиции,
черепаха вычерчивает траекторию движения, если в верхней, то черепаха
передвигается свободно и ничего не вычерчивает. В этой задаче вы будете
моделировать действия черепахи и создавать компьютеризованный эскиз пути.
Используйте массив floor размером 20 на 20 с нулевыми начальными
условиями. Считывайте команды из содержащего их массива. Все время отмечайте
текущую позицию черепахи и положение пера — нижнее или верхнее.
Предполагайте, что черепаха всегда стартует из позиции 0, 0 на полу с верхним положением
пера. Ваша программа должна подавать команды черепахе в соответствии со
следующими обозначениями:
Команда
1
2
3
4
5, 10
6
9
Значение
Поднять перо
Опустить перо
Поворот направо
Поворот налево
Движение вперед на 10 шагов (или на иное число шагов)
Печать массива 20 на 20
Конец данных (контрольное значение)
Рис. 7.33. Команды черепашьей графики
Предположим, что черепаха находится где-то возле центра комнаты. Следующая
«программа управления черепахой» начертила бы квадрат 12 на 12 и оставила
бы перо в верхней позиции:
2
5,12
3
5,12
3
5,12
3
5,12
1
6
9
Если черепаха передвигается с пером, находящимся в нижней позиции,
устанавливайте соответствующие элементы массива floor равными 1. При подаче
команды 6 (печать) отображайте звездочкой или каким-либо другим символом все
значения 1 в массиве, где бы они ни были. Все нули, где бы они ни были, отобразите
Массивы и векторы
499
пробелами. Напишите программу, реализующую рассмотренные возможности
отображения траектории передвижения черепахи. Добавьте другие команды для
повышения мощности вашего языка управления траекторией черепахи.
7.24. (Путешествие коня) Одной из наиболее интересных шахматных головоломок
является задача о путешествии коня, впервые предложенная математиком
Эйлером. Вопрос заключается в следующем: может ли шахматная фигура,
называемая конем, обойти все 64 клетки шахматной доски, побывав на каждой из них
только один раз? Рассмотрим эту интересную задачу более подробно.
Конь ходит «буквой Г» (на две клетки в каком-либо направлении и затем на одну
клетку в перпендикулярном ему). Таким образом, из клетки в середине пустой
доски конь может сделать восемь разных ходов (пронумерованных от 0 до 7), как
показано на рис. 7.34.
0 12 3 4 5 6 7
0
1 2 1
2 3 0
3 К
4 4 7
5 5 6
6
7
Рис. 7.34. Восемь возможных ходов коня
a) Нарисуйте на листе бумаги шахматную доску 8 на 8 и попытайтесь выполнить
путешествие коня вручную. Пометьте цифрой 1 первую клетку, куда вы ходите
конем, цифрой 2 вторую, цифрой 3 третью и т.д. Перед началом путешествия
определите, на сколько ходов вперед вы будете думать, памятуя о том, что полное
путешествие состоит из 64 ходов. Как далеко вы уйдете? Что препятствует
вашим планам?
b) Теперь разработайте программу передвижения коня по шахматной доске.
Доску представим двумерным массивом board 8 на 8. Каждой клетке дадим
нулевое начальное значение. Опишем каждый из восьми возможных ходов в
терминах их горизонтальной и вертикальной компонент. Например, ход типа 0,
как показано на рис. 7.25, содержит перемещение на две клетки
горизонтально направо и на одну клетку вертикально вверх. Ход 2 состоит из
перемещения на одну клетку горизонтально налево и на две клетки вертикально вверх.
Горизонтальные перемещения налево и вертикальные перемещения вверх
будем отмечать отрицательными числами. Восемь ходов, которые могли бы быть
описаны двумя одномерными массивами, horizontal и vertical, выглядят
следующим образом:
horizontal[ 0 ] = 2
horizontal[ 1 ] = 1
horizontal[ 2 ] = -1
horizontal[ 3 ] = -2
500
Глава 7
horizontal[ 4 ] = -2
horizontal[ 5 ] = -1
horizontal[ 6 ] = 1
horizontal[ 7 ] = 2
vertical[ 0 ]
vertical[ 1 ]
vertical[ 2 ]
vertical[ 3 ]
vertical[ 4 ]
vertical[ 5 ]
vertical[ 6 ]
vertical[ 7 ]
=
=
=
=
=
=
=
=
-1
-2
-2
-1
1
2
2
1
Пусть переменные currentRow и currentColumn указывают строку и столбец
текущей позиции коня. Чтобы сделать ход типа moveNumber, где
moveNumber — число от 0 до 7, ваша программа использует операторы
currentRow += vertical[ moveNumber ];
currentColumn += horizontal[ moveNumber ];
Введите счетчик, который изменяется от 1 до 64. Записывайте последний
номер каждой клетки, на которую передвинулся конь. Помните, что для
контроля каждого возможного хода конем нужно видеть, был ли уже конь на этой
клетке. И, конечно, проверяйте каждый возможный ход, чтобы быть
уверенным в том, что конь не вышел за пределы доски. Теперь напишите программу
передвижения коня по доске. Запустите программу. Сколько ходов сделал
конь?
с) После попытки написать и запустить программу путешествия коня вы,
вероятно, получили более глубокие представления о задаче. Вы будете
использовать их для создания эвристики (или стратегии) передвижения коня.
Эвристика не гарантирует успеха, но при тщательной разработке обычно существенно
повышает шансы на успех. Вы можете заметить, что клетки на краях доски
более трудны для обхода, чем клетки в центре доски. Наиболее трудны для
обхода или даже недоступны четыре угловые клетки.
Интуиция может подсказать вам, что в первую очередь нужно попытаться
обойти конем наиболее трудные клетки и оставить «на потом» те, доступ к
которым проще, чтобы, когда доска окажется к концу путешествия заполненной
сделанными ходами, было больше шансов на успех.
Мы можем разработать «эвристику доступности» путем классификации
каждой клетки в соответствии с ее доступностью (в терминах хода конем,
конечно) и перемещать коня на наиболее недоступную клетку. Мы пометим
двумерный массив accessibility числами, указывающими, со скольких клеток
доступна каждая клетка. На пустой доске каждая центральная клетка
оценивается как 8, а каждая угловая клетка как 2, остальные клетки имеют
числа доступности 3, 4 или 6 в соответствии с таблицей:
2
3
4
4
4
4
3
2
3
4
6
6
6
6
4
3
4
6
8
8
8
8
6
4
4
6
8
8
8
8
6
4
4
6
8
8
8
8
6
4
4
6
8
8
8
8
6
4
3
4
6
6
6
6
4
3
2
3
4
4
4
4
3
2
Теперь напишите вариант программы «Путешествие коня», используя
эвристику доступности. В любом случае конь должен ходить на клетку с
наименьшим числом доступности. В случае равенства чисел доступности для разных
клеток конь может ходить на любую из них. Таким образом, путешествие
Массивы и векторы
501
можно начать в любом из четырех углов. [Замечание. По мере перемещения
коня по доске ваша программа должна уменьшать числа доступности по мере
того, как больше клеток оказываются занятыми. Таким образом, в каждый
данный момент путешествия число доступности каждой имеющейся в
распоряжении клетки будет делаться равным количеству клеток, из которых
можно пойти на данную клетку.]
Выполните эту версию вашей программы. Смогли ли вы совершить полное
путешествие? Теперь модифицируйте программу для выполнения 64
путешествий, каждое из которых начинается со своей клетки шахматной доски.
Сколько полных путешествий удалось сделать?
d) Напишите версию программы «Путешествие коня», которая при встрече
с двумя или более альтернативными клетками с равными числами
доступности решала бы, какую клетку выбрать, просматривая вперед достижимость
клеток из числа альтернативных. Ваша программа должна ходить на клетку,
для которой следующий ход достигал бы клетки с наименьшим числом
доступности.
7.25. (Путешествие коня: методы решения «в лоб») В упражнении 7.24 вы
разрабатывали решение задачи о путешествии коня. Использованный подход,
названный «эвристикой доступности», генерирует множество решений и работает
эффективно.
С возрастанием мощности компьютеров мы получаем возможность решать
больше проблем за счет только мощности компьютера, не прибегая к изощренным
алгоритмам. Назовем такой подход методом решения проблемы «в лоб» или
жестким силовым вариантом.
a) Используйте генерацию случайного числа для предоставления коню
возможности ходить по шахматной доске случайным образом (конечно, только
допустимыми для коня ходами). Ваша программа должна запускать путешествие
и печатать окончательный вид шахматной доски. Насколько далеко смог
пойти конь?
b) Наиболее вероятно, что предыдущая программа совершит относительно
короткое путешествие. Теперь модифицируйте вашу программу так, чтобы она
сделала 1000 попыток путешествия. Используйте одномерный массив для
регистрации количества путешествий каждой длины. По окончании 1000 попыток
путешествия программа должна напечатать эту информацию в строгом
табулированном формате. Каков наилучший результат?
c) Наиболее вероятно, что предыдущая программа даст вам несколько
«приличных», но не полных путешествий. Теперь «проигнорируйте все остановы»
и просто позвольте вашей программе выполняться до получения полного
путешествия. [Предупреждение. Эта версия программы может выполняться
часами даже на мощном компьютере.] Снова заведите таблицу для регистрации
количества путешествий каждой длины и напечатайте эту таблицу, как
только будет выполнено первое полное путешествие. Сколько путешествий
попыталась совершить программа перед выполнением полного путешествия?
Сколько времени это заняло?
d) Сравните жесткий силовой вариант путешествия коня с вариантом эвристики
доступности. Какой из них требует более тщательного изучения проблемы?
Разработка какого алгоритма более трудна? Какой из них требует более
высокой мощности компьютера? Могли бы вы заранее быть уверенным в
выполнении полного путешествия на основе эвристики: доступности? Могли бы вы
заранее быть уверенным в выполнении полного путешествия на основе жесткого
силового подхода? Аргументируйте доводы «за» и «против» методов решения
проблемы «в лоб» вообще.
502
Глава 7
7.26. (Восемь ферзей) Другой шахматной головоломкой является задача о восьми
ферзях: можно ли поставить на пустой шахматной доске восемь ферзей так, чтобы
ни один из них не «атаковал» другого, т.е. никакие два ферзя не стояли бы на
одном и том же столбце, или на одной и той же строке, или на одной и той же
диагонали? Используйте размышления, приведенные в упражнении 7.24, чтобы
сформулировать эвристику для решения задачи о восьми ферзях. Запустите
вашу программу. [Подсказка. Можно присвоить значение каждой клетке
шахматной доски, указывающее, сколько клеток пустой шахматной доски
«исключается*, если ферзя поместить на эту клетку. Каждому углу должно быть
присвоено значение 22, как на рис. 7.35.] Как только эти «числа исключения» будут
присвоены всем 64 клеткам, можно предложить эвристику: ставить каждого
следующего ферзя на клетку с наименьшим числом исключения. Почему эта
стратегия интуитивно привлекательна?
********
* *
* *
* *
* *
* *
* *
* *
Рис. 7.35. 22 клетки, исключаемые при помещении ферзя в левый верхний угол
7.27. (Восемь ферзей: методы решения «в лоб») В этом упражнении вы будете
развивать методы решения «в лоб» задачи о восьми ферзях, с которой вы
познакомились в упражнении 7.26.
a) Решите задачу о восьми ферзях, используя технику случайного «лобового»
подхода, развитую в упражнении 7.25.
b) Используйте исчерпывающий «лобовой» подход, т.е. попробуйте все
возможные комбинации восьми ферзей на шахматной доске.
c) Почему вы полагаете, что исчерпывающий «лобовой» вариант может не
подойти для решения задачи о Восьми Ферзях?
d) Сравните и сопоставьте случайный «лобовой» подход и исчерпывающий
«лобовой» подход в целом.
7.28. (Путешествие коня: проверка замкнутости маршрута) В путешествии коня
полное путешествие означает, что конь сделал 64 хода, проходя каждую клетку
шахматной доски один и только один раз. Незамкнутое путешествие имеет место
тогда, когда 64-й ход — это ход вдали от места, в котором конь начал
путешествие. Модифицируйте программу путешествия коня, которую вы написали в
упражнении 7.24, чтобы проверить, является ли выполненное полное путешествие
замкнутым.
7.29. (Решето Эратосфена) Простое число — это любое целое число, которое точно
делится без остатка только само на себя и на 1. Решето Эратосфена — это способ
нахождения простых чисел. Он работает следующим образом:
Массивы и векторы
503
a) Создайте массив, все элементы которого имеют начальные значения 1
(истина). Элементы массива с простыми индексами останутся равными 1. Все
другие элементы массива, в конечном счете, установятся равными нулю.
b) Начиная с индекса массива 2 (индекс 1 должен быть простым), каждый раз
отыскивается элемент массива с единичным значением, циклически
обрабатывается оставшаяся часть массива и устанавливается в нуль каждый элемент
массива, чей индекс кратен индексу элемента с единичным значением. Для
индекса 2 все элементы в массиве с большим чем 2 индексом и кратные 2
установятся равными нулю (индексы 4, 6, 8 и тому подобные); для индекса 3 все
элементы с индексом свыше 3 и кратные 3, установятся равными нулю
(индексы 6, 9, 12 и тому подобные) и т.д.
Когда процесс закончится, элементы массива с единичным значением
указывают, что их индексы — простые числа. Эти индексы могут быть напечатаны.
Напишите программу, которая использует массив с 1000 элементами для
определения и печати простых чисел между 1 и 999. Элемент 0 массива во внимание не
принимайте.
7.30. (Блочная сортировка) Блочная сортировка требует наличия одномерного
массива положительных целых чисел, который нужно сортировать, и двумерного
массива целых чисел со строками, проиндексированными от 0 до 9, и столбцами,
проиндексированными от 0 до п - 1, где п — количество значений в массиве,
который должен сортироваться. Каждая строка двумерного массива
рассматривается как блок. Напишите функцию bucketSort, которая принимает массив
целых чисел и его размер как аргументы и выполняет следующее:
a) Поместите каждое значение одномерного массива в строку массива блоков,
основываясь на значении его первого разряда. Например, 97 помещается в
строку 7, 3 помещается в строку 3, а 100 помещается в строку 0. Это называется
«распределяющий проход».
b) Циклически обработайте массив блоков строка за строкой и скопируйте
значения обратно в исходный массив. Это называется «собирающий Проход».
Новый порядок предыдущих значений в одномерном массиве будет 100, 3 и 97.
c) Повторите этот процесс для каждого последовательного разряда (десятки,
сотни, тысячи и тому подобное).
На втором проходе 100 разместится в строке 0, 3 разместится в строке 0 (потому
что 3 не имеет разряда десятков), а 97 разместится в строке 9. На третьем
проходе 100 поместится в строке 1, 3 поместится в нулевой строке и 97 поместится
в нулевой строке (после цифры 3). После последнего собирающего прохода
исходный массив будет отсортирован.
Заметьте, что двумерный массив блоков в десять раз больше размера массива,
который сортируется. Этот метод сортировки обеспечивает более высокую
производительность по сравнению с пузырьковой, но требует много больше памяти.
Для пузырьковой сортировки требуется всего один дополнительный элемент
данных. Это пример дилеммы память-время: блочная сортировка использует
больше памяти, чем пузырьковая, но работает лучше. Другая возможность
заключается в создании двумерного массива блоков и повторного обмена данными
между двумя массивами блоков.
504
Глава 7
Упражнения на рекурсию
7.31. (Сортировка выборкой). Сортировка выборкой анализирует массив, отыскивая
наименьший элемент массива. Затем этот наименьший элемент обменивается
местами с первым элементом массива. Процесс повторяется для подмассива,
начинающегося со второго элемента массива. В результате каждого прохода один из
элементов занимает соответствующее место. Эта сортировка по производительности
сравнима с пузырьковой — для массива из п элементов нужно выполнить п — 1
проход, а для каждого подмассива нужно выполнить п - 1 сравнение для
определения наименьшего значения. Когда обрабатываемый подмассив будет
содержать только один элемент, значит массив отсортирован. Напишите рекурсивную
функцию selectionSort, выполняющую этот алгоритм.
7.32. (Палиндромы) Палиндром — это строка, которая читается одинаково от начала
и от конца. Вот некоторые примеры палиндромов: «радар», «потоп», «а роза
упала на лапу азора» (если игнорировать пробелы) и т. д. Напишите рекурсивную
функцию testPalindrome, которая возвращает 1, если хранящаяся в массиве
строка — палиндром, и 0 в противном случае.
7.33. (Линейный поиск) Модифицируйте программу на рис. 7.19, написав
рекурсивную функцию linearSeach для линейного поиска в массиве. Функция должна
принимать массив целых чисел и размер массива как аргументы. Если ключ
поиска найден, верните индекс массива, в противном случае верните -1.
7.34. (Восемь ферзей) Модифицируйте программу Восемь ферзей, которую вы создали
в упражнении 7.26, для рекурсивного решения задачи.
7.35. (Печать массива) Напишите рекурсивную функцию printArray, которая
принимает массив и размер массива как аргументы и ничего не возвращает. Функция
должна прекращать свою работу и возвращаться, если принимаемый массив
имеет нулевой размер.
7.36. (Печать строки в обратном порядке) Напишите рекурсивную функцию string-
Reverse, которая принимает символьный массив, содержащий строку, как
аргумент, печатает строку в обратном порядке и ничего не возвращает. Функция
должна прекращать свою работу и возвращаться, если обнаружен завершающий
нулевой символ.
7.37. (Поиск наименьшего значения в массиве) Напишите рекурсивную функцию
recur si veMinimum, которая принимает массив и размер массива как аргументы
и возвращает наименьший элемент массива. Функция должна прекращать свою
работу и возвращаться, если принимаемый массив имеет один элемент.
Упражнения с векторами
7.38. Используйте целый вектор для решения задачи, описанной в упражнении 7.10.
7.39. Модифицируйте программу бросания костей, которую вы написали в
упражнении 7.17, используя вектор для сохранения числа выпадений возможных сумм
двух костей.
7.40. (Поиск наименьшего значения в векторе) Модифицируйте свое решение
упражнения 7.37 для поиска наименьшего значения не в массиве, а в векторе.
8
Указатели и строки-указатели
ЦЕЛИ
В этой главе вы изучите:
• Что такое указатели.
• Сходство и различия указателей
и ссылок и то, когда следует
применять те или другие.
• Передачу аргументов по ссылке
с помощью указателей.
• Использование строк в стиле С.
• Тесную взаимосвязь между
указателями, массивами
и строками в стиле С.
• Применение указателей
на функцию.
• Объявление и использование массивов строк в стиле С.
506
Глава 8
8.1. Введение
8.2. Объявление и инициализация переменных-указателей
8.3. Операции указателей
8.4. Передача аргументов по ссылке с помощью
указателей
8.5. Квалификатор const в применении к указателям
8.6. Сортировка выборкой с передачей по ссылке
8.7. Операции sizeof
8.8. Выражения с указателями и арифметика указателей
8.9. Взаимосвязь указателей и массивов
8.10. Массивы указателей
8.11. Пример: моделирование тасования и сдачи карт
8.12. Указатели на функцию
8.13. Введение в обработку строк-указателей
8.13.1. Элементарные сведения о символах и строках
8.13.2. Функции обработки строк из библиотеки
<cstring>
8.14. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
• Специальный раздел: как самому построить компьютер
• Упражнения с указателями • Упражнения по обработке строк
• Специальный раздел: сложные упражнения со строками
• Специальный проект с обработкой строк
8.1. Введение
В этой главе мы обсудим один из наиболее мощных элементов языка C++ —
указатель. В главе 3 мы увидели, что для передачи по ссылке можно
воспользоваться ссылками C++. Указатели также позволяют осуществить передачу по
ссылке и, кроме того, могут использоваться для реализации динамических
структур данных (т.е. таких, которые могут расти и сокращаться в объеме),
среди которых можно назвать связанные списки, очереди, стеки и деревья.
В этой главе мы вводим основные понятия, связанные с указателями, и
подчеркиваем тесную взаимосвязь между указателями и массивами. Взгляд на
массив как указатель унаследован от языка С. Как мы видели в главе 7, класс
стандартной библиотеки C++ vector предлагает реализацию массивов как
полноценных объектов.
Указатели и строки-указатели
507
Сходным образом C++ предлагает два типа строк — объекты класса string
(которыми мы пользовались начиная с 3-й главы) и строки в стиле С,
представляемые указателями char *. Мы обсуждаем в этой главе строки типа
char *, чтобы вы более глубоко усвоили понятие указателя. На самом деле
ограниченные нулем строки, введенные в разделе 7.4 и используемые на
рис. 7.12, являются строками типа char *. Строки в стиле С широко
используются в системах, которые C++ унаследовал от С. Поэтому, если вы работаете со
старыми программными системами, создававшимися на С, вам может
потребоваться обрабатывать эти строки типа char *.
В главе 13, где мы будем говорить о полиморфизме, мы исследуем
использование указателей с классами и увидим, что так называемая «полиморфная
обработка» в объектно-ориентированном программировании производится с
помощью указателей и ссылок.
8.2. Объявление и инициализация
переменных-указателей
Переменные-указатели содержат в качестве своих значений адреса памяти.
Обычно переменная непосредственно содержит некоторое значение. Указатель
же содержит адрес переменной, которая, в свою очередь, содержит значение.
В этом смысле имя переменной ссылается на значение прямо, а указатель
ссылается на значение косвенно (рис. 8.1). Обращение к значению через
указатель называют часто называют косвенной адресацией.
count
У count непосредственно ссылается
на переменную, содержащую значение 7
countPtr count
# ^ 7 Указатель countPtr косвенно ссылается
на переменную, содержащую значение 7
Рис. 8.1. Прямая и косвенная ссылки на значение
Указатели, как и любые другие переменные, перед использованием
должны быть объявлены. Например, для указателя на рис. 8.1 объявление
int *countPtr, count;
специфицирует, что переменная countPtr имеет тип int * (т.е. указатель на
int) и читается или "countPtr" указывает на объект типа "int". Кроме того,
переменная count объявляется как int, а не указатель на int. Каждой
переменной, объявляемой как указатель, должна предшествовать звездочка (*).
Например, объявление
double *xPtr, *yPtr;
508
Глава 8
специфицирует, что и xPtr, и yPtr являются указателями на значения типа
double. Когда звездочка появляется в объявлении, она не является операцией;
она только сообщает, что переменная объявляется как указатель. Можно
объявлять указатели, ссылающиеся на объекты любого типа.
Типичная ошибка программирования 8.1
Предположение, что звездочка в объявлении указателя относится ко
всем именам переменных в списке, разделяемом запятыми, может
приводить к ошибкам. Каждый из указателей в списке должен
объявляться с предшествующей имени звездочкой (или с пробелом, или без
него — компилятор игнорирует этот пробел). Объявление
переменных по отдельности помогает избежать подобных ошибок и облегча
ет чтение программы.
Хороший стиль программирования 8.1
Включайте в имена переменных- указателей буквы Ptr, чтобы сразу
было ясно, что эти переменные являются указателями и с ними
следует обращаться соответственным образом.
Указатели должны инициализироваться либо при объявлении, либо путем
присваивания. Указатель можно инициализировать значением либо адресом.
Указатель со значением 0 или NULL ни на что не указывает и называется
нулевым указателем. Символическая константа NULL определяется в
заголовочном файле <iostream> (и некоторых других заголовочных файлах
стандартной библиотеки) и представляет значение 0. Инициализация указателя
константой NULL эквивалентна инициализации значением 0, но в C++
принято инициализировать указатели нулем. Когда присваивается значение 0, оно
преобразуется в указатель соответствующего типа. Нуль — единственное
целое значение, которое можно непосредственно присвоить
переменной-указателю, не приводя предварительно целое к типу указателя. Присваивание
указателю численного значения адреса переменной обсуждается в разделе 8.3.
Предотвращение ошибок 8,1
Инициализируйте указатели, чтобы предотвратить ссылки на
неизвестную или неинициализированную область памяти.
8.3. Операции указателей
Операция взятия адреса (&) является унарной операцией, возвращающей
адрес в памяти своего операнда. Например, если имеются объявления
int у = 5; // объявить переменную у
int *yPtr; // объявить переменную-указатель yPtr
то оператор
yPtr = &у; // присвоить адрес у указателю уPtr
присваивает адрес переменной у указателю yPtr. В этом случае говорят, что
yPtr «указывает» на у. Теперь yPtr косвенно ссылается на значение перемен-
Указатели и строки-указатели
509
ной у. Заметьте, что использование & в предыдущем присваивании отличается
от использования & в объявлении переменной-ссылки, которому всегда
предшествует имя типа данных.
Рис. 8.2 схематически показывает состояние памяти после данного
присваивания. «Отношение указывания» представлено изображением стрелки,
идущей от квадрата, обозначающего указатель, к квадрату, обозначающему
переменную.
На рис. 8.3 показано еще одно представление указателя в памяти,
предполагающее, что целая переменная у расположена в памяти по адресу 600000,
а переменная-указатель yPtr — по адресу 500000. Операнд операции взятия
адреса должен являться lvalue (т.е. чем-то, чему может быть присвоено
значение, например, именем переменной или ссылкой); операция не может
применяться к константам или выражениям, которые не дают в результате ссылку.
yPtr у
• ► 5
Рис. 8.2. Графическое представление указателя, ссылающегося на переменную в памяти
yPtr у
ячейка ячейка
500000 600000 600000 5
Рис. 8.3. Представление у и yPtr в памяти
Операция *, обычно называемая операцией разыменования или операцией
косвенной адресации, возвращает синоним (т.е. псевдоним) для объекта, на
который указывает ее операнд-указатель. Например (возвращаясь к рис. 8.2),
оператор
cout « *yPtr « endl;
печатает значение переменной у, а именно 5, точно так же, как напечатал бы
оператор
cout « у « endl;
Такое использование * называют разыменованием указателя. Обратите
внимание, что разыменованный указатель может стоять в левой части оператора
присваивания, например
*yPtr = 9;
в результате чего у на рис. 8.3 будет присвоено значение 9. Разыменованный
указатель может также использоваться для получения вводимого значения,
как в операторе
cin » *yPtr;
510
Глава 8
который помещает введенное значение в у. Разыменованный указатель
является lvalue.
Типичная ошибка программирования 8.2
Разыменование указателя, который не был корректно
инициализирован или которому не был присвоен адрес конкретного места в
памяти, может привести к фатальной ошибке времени выполнения или
к случайной модификации важных данных, в результате которой
программа все же может выполниться до конца, но дать при этом,
возможно, неверный результат.
Типичная ошибка программирования 8.3
Попытка разыменовать переменную, не являющуюся указателем,
приводит к ошибке компиляции.
Типичная ошибка программирования 8.4
Разыменование нулевого указателя обычно приводит к фатальной
ошибке времени выполнения.
Программа на рис. 8.4 демонстрирует операции указателей & и *. Адреса
памяти выводятся здесь с помощью « в виде шестнадцатеричиых (т.е. по
основанию 16) целых чисел. Следует заметить, что шестнадцатеричные
значения адресов, выводимые этой программой, зависят как от компилятора, так
и от используемой операционной системы, поэтому при запуске программы вы
можете получить иные результаты.
Переносимость программ 8.1
Формат, в котором выводятся указатели, зависит от компилятора.
Некоторые компиляторы выводят указатели в виде
шестнадцатеричиых целых, другие — в виде десятичных.
1 // Рис. 8.4: fig08_04.срр
2 // Использование операций & и *.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int a; //a - целое
10 int *aPtr; // aPtr является int * - указателем на целое
11
12 a = 7; // присвоить 7 переменной а
13 aPtr = &a; // присвоить адрес а указателю aPtr
14
15 cout « "The address of a is " « &a
16 « "\nThe value of aPtr is " « aPtr;
17 cout « "\n\nThe value of a is " « a
18 « "\nThe value of *aPtr is " « *aPtr;
Указатели и строки-указатели
511
19 cout « "\n\nShowing that * and & are inverses of "
20 « "each other.\n&*aPtr = " « &*aPtr
21 « "\n*&aPtr = " « *&aPtr « endl;
22 return 0; // показывает успешное завершение
23 } // конец main
The address of a is 0012FF88
The value of aPtr is 0012FF88
The value of a is 7
The value of *aPtr is 7
Showing that * and & are inverses of each other.
&*aPtr = 0012FF88
*&aPtr = 0012FF88
Рис. 8.4. Операции указателей & и *
Заметьте, что адрес а (строка 15) и значение aPtr (строка 16) на выходе
программы одинаковы, и подтверждают, что переменной-указателю aPtr
действительно присваивается адрес а. Операции & и * являются обратными друг
другу — последовательно применяемые к aPtr в любом порядке, эти операции
«взаимно сокращаются» и в обоих случаях печатается одно и то же значение
(значение в aPtr).
В таблице на рис. 8.5 показаны приоритеты и правила ассоциации
операций, рассмотренных к настоящему моменту. Обратите внимание, что
операции адреса (&) и разыменования (*) являются унарными операциями,
принадлежащими к третьему уровню приоритета на рис. 8.5.
Операции
0 []
++ — static_cast< тип > (операнд)
++ — + - ! & *
* / %
+ -
« »
<<=>>=
== ! =
&&
II
?:
= += -= *= /= %=
г
Ассоциативность
слева направо
слева направо
справа налево
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
справа налево
справа налево
слева направо
Тип
наивысший приоритет
унарные (постфиксные)
унарные (префиксные)
мультипликативные
аддитивные
передачи/извлечения
отношения
равенства
логическое И
логическое ИЛИ
условная
присваивания
запятая
Рис. 8.5. Приоритет и ассоциативность операций
512
Глава 8
8.4. Передача аргументов по ссылке с помощью
указателей
В C++ имеется три способа передачи аргументов функциям: передача по
значению, передача по ссылке посредством аргументов-ссылок и передача по
ссылке посредством аргументов-указателей. В главе 6 мы сравнивали и
противопоставляли передачу по значению с передачей по ссылке посредством
аргументов-ссылок. Здесь мы рассмотрим передачу по ссылке посредством
аргументов-указателей .
Как мы видели в главе 6, для возврата вызывающему одного значения из
вызываемой функции можно воспользоваться оператором return (с помощью
которого можно также возвращать управление, не передавая вызывающему
никакого значения). Мы видели также, что аргументы могут передаваться
функции посредством ссылок. Такие аргументы позволяют вызываемой
функции модифицировать исходные значения аргументов в вызывающей функции.
Они позволяют также программам передавать функциям большие объекты,
избегая расходов, присущих передаче по значению (которая, естественно,
требует создания копии объекта). Указатели, подобно ссылкам, также могут быть
использованы для модификации одной или нескольких переменных в
вызывающей функции или для передачи больших объектов без расходов на их
копирование.
Для реализации передачи по ссылке программисты могут применять в C++
указатели и операцию разыменования (*); именно так осуществляется
передача по ссылке в С, поскольку в С отсутствуют ссылки. При вызове функции,
аргумент которой должен быть модифицирован, ей передается адрес аргумента.
Обычно это достигается применением операции взятия адреса (&) к имени
переменной, которая должна модифицироваться.
Как мы видели в главе 7, при передаче массивов не применяется операция
&, поскольку имя массива является адресом начала массива в памяти (т.е. имя
массива уже является указателем). Имя массива arrayName эквивалентно
&arrayName[ 0 ]. Когда функции передан адрес переменной, в функции
можно применить операцию разыменования для образования псевдонима имени
этой переменной, который, в свою очередь, можно использовать для
модификации значения переменной по данному адресу в памяти вызывающего.
Рис. 8.6 и 8.7 демонстрируют две версии функции, возводящей в куб целое
число — cubeByValue и cubeByReference. На рис. 8.6 переменная number
передается функции cubeByValue по значению (строка 15). Функция
cubeByValue (строки 21-24) возводит свой аргумент в куб и передает полученное
значение обратно в main с помощью оператора return (строка 23). В main это
значение снова присваивается number (строка 15). Заметьте, что вызывающая
функция имеет возможность исследовать результат вызова функции перед
тем, как модифицировать значение переменной number. Например, в этой
программе мы могли бы сохранить результат cubeByValue в другой
переменной, исследовать ее значение и присвоить его number только после того, как
будет установлено, что полученное значение имеет смысл.
Указатели и строки-указатели
513
1 // Рис. 8.6: fig08_06.cpp
2 // Возвести в куб переменную с передачей по значению.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int cubeByValue( int ); // прототип
8
9 int main()
10 {
11 int number = 5;
12
13 cout « "The original value of number is " « number;
14
15 number = cubeByValue( number ); // передача number по значению
16 cout « "\nThe new value of number is " « number « endl;
17 return 0; // показывает успешное завершение
18 } // конец main
19
20 // вычислить и возвратить куб целого аргумента
21 int cubeByValue( int n )
22 {
23 return n * n * n; // возвратить куб локальной п
24 } // конец функции cubeByValue
The original value of number is 5
The new value of number is 125
Рис. 8.6. Возведение переменной в куб с передачей по значению
На рис. 8.7 переменная number передается функции cubeByReference по
ссылке посредством аргумента-указателя (строка 15) — функции передается
адрес number. Функция cubeByReference (строки 22-25) специфицирует для
приема аргумента параметр nPtr (указатель на int). Функция разыменовывает
указатель и возводит в куб значение, на которое указывает nPtr (строка 24).
Тем самым непосредственно изменяется значение number в main.
r-pyf] Типичная ошибка программирования 8.5
Невыполнение разыменования в случае, когда оно необходимо для
доступа к значению, на которое ссылается указатель, является ошибкой.
1 // Рис. 8.7: fig08_07.cpp
2 // Возвести в куб переменную с передачей по ссылке указателем.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 void cubeByReference( int * ); // прототип
8
9 int main()
10 {
11 int number = 5;
17 Зак. 1114
514
Глава 8
12
13 cout « "The original value of number is " « number;
14
15 cubeByReference( finumber ); // передать адрес number
16
17 cout « "\nThe new value of number is " « number « endl;
18 return 0; // показывает успешное завершение
19 } // конец main
20
21 // вычислить куб *nPtr; модифицирует переменную number в main
22 void cubeByReference( int *nPtr )
23 {
24 *nPtr = *nPtr * *nPtr * *nPtr; // возвести в куб *nPtr
25 } // конец функции cubeByReference
The original value of number is 5
The new value of number is 125
Рис. 8.7. Возведение переменной в куб с передачей по ссылке с помощью указателя
Функция, принимающая в качестве аргумента адрес, для получения его
должна определять параметр-указатель. Например, заголовок функции
cubeByReference (строка 22) специфицирует, что cubeByReference принимает
в качестве аргумента адрес переменной типа int (т.е. указатель на int),
сохраняет его локально в nPtr и не возвращает значения.
Прототип для функции cubeByReference (строка 7) содержит в скобках
int *. Как и в случае переменных других типов, имена параметров-указателей
в прототипах не обязательны. Имена, указываемые в целях документации,
компилятор игнорирует.
Рис. 8.8-8.9 графически представляют исполнение программ на рис. 8.6 и 8.7.
Общее методическое замечание 8.1
Передавайте аргументы по значению, если только вызывающая
функция явно не требует, чтобы значения ее переменных, передаваемых
вызываемой функции, модифицировались последней. Это опять же
пример принципа наименьших привилегий.
В заголовке и в прототипе функции, которая ожидает в качестве аргумента
одномерный массив, можно использовать в списке параметров нотацию
указателя. Компилятор не делает различий между функцией, которая принимает
указатель, и функцией, которая принимает одномерный массив. Это означает,
конечно, что функция должна «знать», принимает ли она массив или просто
одну переменную, для которой выполняется передача вызовом по ссылке.
Когда компилятор сталкивается с параметром функции в виде одномерного
массива, например, int b[ ], он преобразует параметр в нотацию указателя int *b
(читается как «Ь является указателем на int»). Обе формы объявления
параметра функции как одномерного массива взыимозаменяемы.
Указатели и строки-указатели
515
Шаг 1. Перед тем, как main вызывает cubeByValue:
int. main ()
{
number
int number = 5; 5
number = cubeByValue( number );
int
{
}
cubeByValue(
return n * n
int
* n
n
не
)
n
определена
Шаг 2. После получения вызова функцией cubeByValue:
int main ()
{
number
int number = 5; *
number = cubeByValue( number );
int cubeByValue( int n )
{
return n * n * n;
}
Шаг З. После возведения в куб параметра п и перед возвратом из cubeByValue в main:
int main()
{
}
int number = 5;
number =
cubeByValue(
number
number
1#l
) ;
int cubeByValue( int n )
{ 125
return n * n * n;
}
§&f
Шаг 4. После возврата из cubeByValue в main и до присвоения результата number:
int main()
{
}
int number = 5/
number =
125
cubeByValue(
numbe
number
ЯР»-!
r );
int cubeByValue( int n )
{
return n * n * n;
не определена
Шаг 5. После присвоения результата переменной number:
int main()
{
int number = 5;
125 125
number
125
number = cubeByValue( number ),
int cubeByValue( int n )
{
return n * n * n;
^рцредеявна
Рис. 8.8. Анализ передачи по значению в программе на рис. 8.6
516
Глава 8
Шаг 1. Перед тем, как main вызывает cubeByReference:
int main () number
{
int number =5; 5
cubeByReference( &number );
void cubeByRefertnct( int *nPtr )
{
*nPtr = *nPtr * *nPtr * *nPtr
nPtr
не определена
Шаг 2. После получения вызова функцией cubeByValue и до возведения *nPtr в куб:
int main () number
int number = 5; Г 5
cubeByReference( &number )
N
N
void cubeByReference( int *nPtr )
{
*nPtr
*nPtr * *nPtr * *nPtr
вызов устанавливает
указатель
nPtr
—•
Шаг 3. После возведения *nPtr в куб и перед возвратом управления в main:
int main ()
{
number
int number = 5; 125
cubeByReference( &number ); ^\J
void cubeByReference( int *nPtr )
{ 125
*nPtr = *nPtr * *nPtr * *nPtr;
)
вызванная функция изменяет nPtr
переменную вызывающего
Рис. 8.9. Анализ передачи по ссылке (посредством указателя) в программе на рис. 8.7
8.5. Квалификатор const в применении к указателям
Как вы помните, квалификатор const дает возможность программисту
информировать компилятор о том, что значение данной переменной не должно
изменяться.
Переносимость программ 8.2
Хотя квалификатор const определен в ANSI С и C++, в некоторых
компиляторах она не реализована должным образом. Хорошим
правилом является «знайте свой компилятор».
За прошедшие годы накопилось много кода, написанного на ранних
версиях С, в котором спецификатор const не использовался, потому что его просто
не было в наличии. По этой причине существуют огромные возможности для
улучшения разработок программного обеспечения старого
(«унаследованного») кода на С. Кроме того, многие программисты, в настоящее время
работающие с ANSI С и C++, не применяют в своих программах const, потому что они
Указатели и строки-указатели
517
начинали программировать на ранних версиях С. Эти программисты упускают
много возможностей для правильной разработки программного обеспечения.
Существует много вариантов использования (или не использования) const
с параметрами функции — две с передачей параметров по значению и четыре
с передачей параметров по ссылке. Как выбрать один из этих вариантов?
Руководствуйтесь принципом наименьших привилегий. Всегда обеспечивайте
функцию в ее параметрах достаточным доступом к данным, чтобы она могла
выполнять свои задачи, но не более того. В этом разделе мы обсудим, каким
образом комбинировать const с указателями, чтобы удовлетворялся принцип
наименьших привилегий.
В главе 6 объяснялось, что когда функция вызывается с передачей
аргумента по значению, при вызове создается копия аргумента (или аргументов),
которая и передается функции. Если копия в функции модифицируется, исходное
значение в вызывающем остается без изменений. Во многих случаях значение,
передаваемое функции, модифицируется, чтобы функция могла выполнить
свою задачу. Однако иногда значение в вызываемой функции не должно
изменяться, даже несмотря на то, что она манипулирует копией исходного
значения. '
Рассмотрим, например, функцию, которая получает в качестве аргументов
одномерный массив и его размер и печатает этот массив. Такая функция
должна циклически обрабатывать массив и выводить значения каждого его
элемента. Размер массива используется в теле функции для определения верхнего
индекса массива, при котором цикл должен завершаться, так как печать
окончена. Размер массива не изменяется в теле функции, поэтому он должен
объявляться как const. Конечно, поскольку массив только печатается, он тоже
должен объявляться как const. Это особенно важно потому, что массив в
целом всегда передается по ссылке и мог бы легко быть изменен в вызываемой
функции.
S Общее методическое замечание 8.2
Если значение не изменяется (или не должно изменяться) в теле
функции, которой оно передается, параметр должен быть объявлен
как const, чтобы иметь гарантию от неожиданных его изменений.
В случае попытки изменить значение константного параметра выдается
либо предупреждение, либо сообщение об ошибке в зависимости от
конкретного компилятора.
.£«* Предотвращение ошибок 8.2
\£чРЧг Прежде чем использовать функцию, проверьте ее прототип, чтобы
определить, какие параметры она может модифицировать.
Имеется четыре способа передать функции указатель: неконстантный
указатель на неконстантные данные (рис. 8.10), неконстантный указатель на
константные данные (рис. 8.11 и 8.12), константный указатель на неконстантные
данные (рис. 8.13) и константный указатель на константные данные (рис. 8.14).
518
Глава 8
Неконстантный указатель на неконстантные данные
Наивысший уровень доступа предоставляется неконстантным
указателем на неконстантные данные — данные можно модифицировать через
разыменованный указатель, а сам указатель может быть модифицирован для
ссылки на другие данные. Объявление неконстантного указателя на неконстантные
данные не содержит const. Такой указатель можно применить для получения
ограниченной нулем строки в функции, которая меняет значение указателя
для обработки (и, возможно, модификации) каждого символа в строке.
Вспомните, в разделе 7.4 говорилось о том, что ограниченная нулем строка может
размещаться в символьном массиве, содержащем символы строки и
нуль-символ, указывающий, в каком месте строка кончается.
На рис. 8.10 функция convertToUppercase (строки 25-34) объявляет
параметр sPtr (строка 25) как неконстантный указатель на неконстантные данные.
Функция посимвольно обрабатывает ограниченную нулем строку в символьном
массиве (строки 27-33). Не забывайте, что имя символьного массива
эквивалентно указателю на первый символ массива, поэтому возможна передача
phrase в качестве аргумента convertToUppercase. Функция islower (строка 29)
принимает символьный аргумент и возвращает true, если символ находится
в нижнем регистре, и false в противном случае. Символы в диапазоне от 'а' до
V преобразуются в соответствующие прописные буквы с помощью функции
toupper (строка 30), а остальные символы остаются неизменными. Функция
toupper получает в качестве аргумента символ. Если символ — строчная буква,
возвращается соответствующая прописная буква; в противном случае
возвращается исходный символ. Функция toupper и функция islower входят в состав
библиотеки обработки символов <cctype>. После обработки символа строка 32
увеличивает на 1 (это было бы невозможно, если бы sPtr был объявлен как
const). Когда операция ++ применяется к указателю, ссылающемуся на массив,
хранящийся в указателе адрес памяти модифицируется так, чтобы
соответствовать следующему элементу массива (в данном случае следующему символу
строки). Прибавление к указателю единицы является допустимой операцией
в арифметике указателей, о которой подробнее говорится в разделах 8.8 и 8.9.
1 // Рис. 8.10: fig08_10.cpp
2 // Преобразование букв нижнего регистра в верхний регистр,
3 // используя неконстантный указатель на неконстантные данные.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <cctype> // прототипы для islower и toupper
9 using std::islower;
10 using std::toupper;
11
12 void convertToUppercase( char * );
13
14 int main()
15 {
16 char phrase[] = "characters and $32.98";
17
18 cout « "The phrase before conversion is: " « phrase;
19 convertToUppercase( phrase );
Указатели и строки-указатели
519
20 cout « "\nThe phrase after conversion is: " « phrase « endl;
21 return 0; // показывает успешное завершение
22 } // конец main
23
24 // преобразовать строку в верхний регистр
25 void convertToUppercase( char *sPtr )
26 {
27 while ( *sPtr != '\0' ) // цикл, пока текущий символ не '\0'
28 {
29 if ( islower( *sPtr ) ) // если символ - нижнего регистра,
30 *sPtr = toupper( *sPtr ); // преобразовать в верхний регистр
31
32 sPtr++; // передвинуть sPtr на следующий символ строки
33 } // конец while
34 } // конец функции convertToUppercase
The phrase before conversion is: characters and $32.98
The phrase after conversion is: CHARACTERS AND $32.98
Рис. 8.10. Преобразование строки в верхний регистр
Неконстантный указатель на константные данные
Неконстантный указатель на константные данные — это указатель,
который можно модифицировать, чтобы он ссылался на любые элементы данных
подходящего типа, но данные, на которые он ссылается, не могут быть
модифицированы. Такой указатель можно было бы использовать для получения
аргумента-массива в функции, которая будет обрабатывать каждый элемент
массива без модификации данных. Например, функция printCharacters
(строки 22-26 на рис. 8.11) объявляет параметр sPtr (строка 22) типа const char *,
так что он может принимать ограниченную нулем строку. Объявление
читается: «sPtr является указателем на символьную константу». Тело функции
использует оператор for (строки 24-25) для вывода каждого символа в строке до
тех пор, пока не встретится нулевой символ. После того как символ будет
напечатан, указатель sPtr инкрементируется, чтобы указать на следующий символ
в строке (это возможно, поскольку указатель не является const). Функция main
создает символьный массив phrase, который передается функции
printCharacters. Здесь мы снова можем передать функции массив phrase, так как имя
массива является на самом деле указателем на первый символ массива.
1 // Рис. 8.11: fig08_ll.cpp
2 // Посимвольная печать строки с использованием
3 // неконстантного указателя на константные данные.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 void printCharacters( const char * ); // печать константных данных
9
10 int main()
11 {
12 const char phrase[] = "print characters of a string";
520
Глава 8
13
14 cout « "The string is:\n";
15 printCharacters( phrase ); // печатать символы фразы
16 cout « endl;
17 return 0; // показывает успешное завершение
18 } // конец main
19
20 // sPtr можно модифицировать, но через него нельзя модифицировать
21 // символ, на который он указывает, т.е. sPtr - read-only-указатель
22 void printCharacters( const char *sPtr )
23 {
24 for ( ; *sPtr != '\0'; sPtr++ ) // инициализация отсутствует
25 cout « *sPtr; // вывести символ
26 } // конец функции printCharacters
The string is:
print characters of a string
Рис. 8.11. Посимвольная печать строки с использованием неконстантного указателя
на константные данные
Рис. 8.12 демонстрирует сообщения об ошибке, выдаваемые при попытке
компилировать функцию, которая принимает неконстантный указатель на
константные данные и затем пытается использовать этот указатель для
модификации данных. [Замечание. Помните, что сообщения об ошибках меняются
от компилятора к компилятору.]
1 // Рис. 8.12: fig08_12.cpp
2 // Попытка модификации данных через
3 // неконстантный указатель на константные данные.
4
5 void f( const int * ); // прототип
6
7 int main()
8 {
9 int у;
10
11 f( &y ); // f пытается произвести недопустимую модификацию
12 return 0; // показывает успешное завершение
13 } // конец main
14
15 // через xPtr нельзя модифицировать константную переменную
16 void f( const int *xPtr )
17 {
18 *xPtr = 100; // ошибка: нельзя модифицировать const-ob'beKT
19 } // конец функции £
Сообщение об ошибке компилятора Borland C++ с командной строкой
Error E2024 fig08_12.cpp 18:
Cannot modify a const object in function f(const int *)
Указатели и строки-указатели
521
Сообщение об ошибке компилятора Microsoft Visual C++
c:\scpphtp5_examples\ch08\Fig08_12\fig08_12.cpp A8) :
error C2166: 1-value specifies const object
Сообщение об ошибке компилятора GNU C++
fig08_12.cpp: In function 'void f(const int*)*:
fig08__12.cpp:18: error: assignment of read-only location
Рис. 8.12. Попытка модификации данных через неконстантный указатель
на константные данные .
Как мы знаем, массивы — это агрегатные типы данных, которые хранят
связанные элементы данных одинакового типа с одинаковым именем. При
вызове функции с массивом в качестве аргумента массив передается функции по
ссылке. Однако объекты всегда передаются по значению — передается копия
всего объекта. Это требует во время выполнения накладных расходов на
создание копии каждого элемента данных в объекте и сохранения ее в стеке
вызовов функции. Когда функции должен быть передан огбъект, мы можем
использовать указатель на константные данные (или ссылка на константные
данные), чтобы достичь эффективности передачи по ссылке и защиты
передачи по значению. При передаче указателя на объект должна быть сделана
копия только адреса объекта; сам объект не копируется. На машине с
4-байтовыми адресами делается копия 4 байтов памяти, а не копия, возможно, большого
объекта.
I—зд Вопросы производительности 8.1
1#Ф*| Если не требуется модификация объектов вызываемой функцией,
передавайте большие объекты с помощью указателя или ссылки на
константные данные, чтобы воспользоваться выгодами, в плане
производительности, передачи по ссылке.
S Общее методическое замечание 8.3
Передавайте большие объекты с помощью указателей на
константные данные, чтобы достичь защиты, характерной для передачи по
значению.
Константный указатель на неконстантные данные
Константный указатель на неконстантные данные — это указатель,
который всегда ссылается на одно и то же место в памяти; данные в этом месте
можно модифицировать через указатель. Так обстоит дело по умолчанию для
имени массива. Имя массива — это константный указатель на начало массива.
Получить доступ к данным массива можно через индексацию имени массива.
Указатели, объявленные как const, должны инициализироваться при
объявлении (если указатель является параметром функции, он инициализируется
указателем, который передается функции). Программа на рис. 8.13 пытается
модифицировать константный указатель. В строке 11 указатель ptr объявлен
как int * const. Это объявление читается: «ptr является константным указате-
522
Глава 8
лем на целое». Указатель инициализируется адресом целой переменной х.
Строка 14 пытается присвоить указателю ptr адрес у, но это приводит к
сообщению об ошибке. Заметьте, что когда строка 13 присваивает *ptr значение 7,
ошибки не происходит — значение, на которое указывает ptr, можно
модифицировать через разыменованный указатель, хотя сам ptr объявлен как const.
Типичная ошибка программирования 8.6
Отсутствие инициализации указателя, объявленного как const,
приводит к ошибке компиляции.
1 // Рис. 8.13: fig08_13.cpp
2 // Попытка модификации константного указателя на не-const данные.
3
4 int main()
5 {
6 int x, у;
7
8 // ptr - константный указатель на целое, которое может быть
9 // модифицировано через ptr, но ptr всегда указывает на
10 // одну и ту же ячейку памяти.
11 int * const ptr = fix;
12
13 *ptr =7; // допустимо: *ptr не является const
14 ptr = &y; // ошибка: ptr есть const; нельзя присвоить новый адрес
15 return 0; // показывает успешное завершение
16 } // конец main
Сообщение об ошибке компилятора Borland C++ с командной строкой
Error E2024 fig08_13.cpp 14:
Cannot modify a const object in function main()
Сообщение об ошибке компилятора Microsoft Visual C++
c:\scpphtp5_examples\ch08\Fig08_13\fig08_13.cppA4) :
error C2166: 1-value specifies const object
Сообщение об ошибке компилятора GNU C++
fig08_13.срр: In function 'int main()':
fig08_13.cpp:14: error: assignment of read-only variable 'ptr'
Рис. 8.13. Попытка модификации константного указателя на неконстантные данные
Константный указатель на константные данные
Наименьшие привилегии доступа допускает константный указатель на
константные данные. Такой указатель всегда указывает на одно и то же
место в памяти и находящиеся в этом месте данные нельзя модифицировать. Так
должен передаваться массив функции, которая только читает массив
посредством нотации индексов, но не модифицирует его. Программа на рис. 8.14
объявляет переменную-указатель ptr типа const int * const (строка 14). Это объяв-
Указатели и строки-указатели
523
ление читается: «ptr является константным указателем на константное
целое». На рисунке показаны сообщения об ошибке, генерируемые при попытке
модифицировать данные, на которые указывает ptr (строка 18), и при попытке
модифицировать адрес, хранящийся в переменной-указателе (строка 19).
Заметьте, что не происходит никакой ошибки при попытке разыменования ptr
или при попытке вывести значение, на которое он указывает (строка 16), так
как в этом операторе ни указатель, ни данные, на которые он указывает, не
модифицируются.
1 // Рис. 8.14: fig08_14.cpp
2 // Попытка модификации константного указателя на const-данные.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int x = 5, y;
10
11 // ptr - константный указатель на целую константу.
12 // ptr всегда указывает на одну и ту же ячейку; целое
13 //в этой ячейке не может быть модифицировано.
14 const int *const ptr = &x;
15
16 cout « *ptr « endl;
17
18 *ptr =7; // ошибка: *ptr есть const; нельзя присвоить значение
19 ptr = &y; // ошибка: ptr есть const; нельзя присвоить новый адрес
20 return 0; // показывает успешное завершение
21 } // конец main
Сообщение об ошибках компилятора Borland C++ с командной строкой
Error E2024 fig08_14.cpp 18:
Cannot modify a const object in function main()
Error E2024 fig08_14.cpp 19:
Cannot modify a const object in function main()
Сообщение об ошибках компилятора Microsoft Visual C++
c:\scpphtp5_examples\ch08\Fig08_14\fig08_14.cpp A8)
error C2166: 1-value specifies const object
c:\scpphtp5_examples\ch08\Fig08_14\fig08_14.cppA9)
error C2166: 1-value specifies const object
Сообщение об ошибках компилятора GNU C++
fig08_14.cpp: In function 'int main()':
fig08_14.cpp:18: error: assignment of read-only location
fig08_14.cpp:19: error: assignment of read-only variable 'ptr'
Рис. 8.14. Попытка модификации константного указателя на константные данные
524
Глава 8
8.6. Сортировка выборкой с передачей по ссылке
В этом разделе мы напишем программу сортировки для иллюстрации
передачи массивов и их отдельных элементов по ссылке. Мы воспользуемся
алгоритмом сортировки выборкой, который легко программируется, но, к
сожалению, неэффективен. Первая итерация алгоритма выбирает наименьший
элемент в массиве и обменивает его с первым элементом. Вторая итерация
выбирает следующий по величине элемент (который является наименьшим
среди оставшихся) и обменивает его со вторым элементом. Так продолжается
до тех пор, пока последняя итерация не выберет предпоследний в ряду
возрастания элемент и не обменяет его с элементом, имеющим предпоследний
индекс, оставив наибольшему элементу последний индекс. После /-ой итерации i
наименьших значений массива будут сортированы в порядке возрастания
в первых / элементах массива.
Рассмотрим, например, массив
34 56 4 10 77 51 93 30 5 52
Программа, реализующая сортировку выборкой, сначала определяет
наименьшее значение D) в данном массиве, которой содержится в элементе 2.
Программа затем обменивает 4 с элементом 0 C4), что дает в результате
4 56 34 10 77 51 93 30 5 52
[Замечание. Элементы, которые были обменены, мы выделяем курсивом.]
После этого программа определяет наименьшее значение среди оставшихся
элементов (всех элементов, исключая 4), которое равно 5 и содержится в
элементе 8. Это значение обменивается с элементом 1 E6), что дает
4 5 34 10 77 51 93 30 56 52
На третьей итерации программа определяет следующее наименьшее значение
A0) и обменивает его с элементом 2 C4).
4 5 10 34 11 51 93 30 56 52
Этот процесс продолжается до тех пор, пока массив не будет полностью
сортирован.
4 5 10 30 34 51 52 56 77 93
Заметьте, что после первой итерации наименьший элемент занимает первую
позицию. После второй итерации два наименьших элемента находятся в
правильном порядке в первых двух позициях. После третьей итерации три
наименьших элемента занимают в правильном порядке первые три позиции.
Рис. 8.15 показывает реализацию сортировки выборкой, состоящую из
двух функций — selectionSort и swap. Функция selectionSort (строки 36-53)
сортирует массив. Строка 38 объявляет переменную smallest, в которой будет
сохраняться индекс наименьшего элемента из оставшихся в массиве. Цикл
в строках 41-52 выполняется size — 1 раз. Строка 43 устанавливает индекс
наименьшего элемента равным текущему индексу. Цикл в строках 46-49
перебирает оставшиеся элементы. Каждый из этих элементов сравнивается
в строке 48 со значением наименьшего элемента. Если текущий элемент мень-
Указатели и строки-указатели
525
ше наименьшего значения, строка 49 присваивает smallest индекс текущего
элемента. По завершении этого цикла smallest будет содержать индекс
наименьшего элемента из числа оставшихся в массиве. Строка 51 вызывает
функцию swap (строки 57-62), чтобы поместить наименьший из оставшихся
элемент в следующую позицию массива (т.е. обменять элементы аггау[ i ]
и аггау[ smallest ]).
1 // Рис. 8.15: fig08_15.cpp
2 // Программа помещает в массив значения, сортирует массив
3 //в восходящем порядке и печатает полученный массив.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <iomanip>
9 using std::setw;
10
11 void selectionSort( int * const, const int ); // прототип
12 void swap( int * const, int * const ); // прототип
13
14 int main()
15 {
16 const int arraySize = 10;
17 int a[ arraySize ] = { 2, 6, 4, 8, 10, 12, 89, 68, 45, 37 };
18
19 cout « "Data items in original order\n";
20
21 for ( int i = 0; i < arraySize; i++ )
22 cout « setw( 4 ) « a[ i ];
23
24 selectionSort( a, arraySize ); // сортировать массив
25
26 cout « "\nData items in ascending order\n";
27
28 for ( int j = 0; j < arraySize; j++ )
29 cout « setw( 4 ) « a[ j ];
30
31 cout « endl;
32 return 0; // показывает успешное завершение
33 } // конец main
34
35 // функция для сортировки массива
36 void selectionSort( int * const array, const int size )
37 {
38 int smallest; // индекс наименьшего элемента
39
40 // loop over size - 1 elements
41 for ( int i = 0; i < size - 1; i++ )
42 {
43 smallest = i; // первый индекс оставшегося массива
44
45 // цикл для определения индекса наименьшего элемента
46 for ( int index = i + 1; index < size; index++ )
47
48 if ( array[ index ] < array[ smallest ] )
526
Глава 8
49 smallest = index;
50
51 swap( &array[ i ], &array[ smallest ] );
52 } // конец if
53 } // конец функции selectionSort
54
55 // обменять значения в ячейках, на которые указывают
56 // elementlPtr и element2Ptr
57 void swap( int * const elementlPtr, int * const element2Ptr )
58 {
59 int hold = *elementlPtr;
60 *elementlPtr = *element2Ptr;
61 *element2Ptr = hold;
62 } // конец функции swap
Data items in original order
2 6 4 8 10 12 89 68 45 37
Data items in ascending order
2 4 6 8 10 12 37 45 68 89
Рис. 8,15, Сортировка выборкой с передачей по ссылке
Давайте более внимательно посмотрим на функцию swap. Вспомните, что
C++ скрывает от функции информацию других функций, поэтому swap не
имеет доступа к отдельным элементам массива в selectionSort. Поскольку
selectionSort хочет, чтобы swap имела доступ к обмениваемым элементам,
она передает swap каждый из этих элементов по ссылке, — явным образом
передавая их адреса. Хотя массивы в целом всегда передаются по ссылке,
отдельные элементы массивов являются скалярами и в обычных случаях
передаются по значению. Поэтому к каждому из элементов в вызове swap (строка 51)
selectionSort применяет операцию адреса (&), осуществляя таким образом
передачу по ссылке. Функция swap (строки 57-62) получает указатель &аг-
ray[ i ] в переменной-указателе elementlPtr. Сокрытие информации не
позволяет swap «знать» имя array[ i ], но она может использовать ^elementlPtr
в качестве синонима array[ i ]. Таким образом, когда swap ссылается на
''elementlPtr, она в действительности обращается к array[ i ] в selectionSort.
Аналогичным образом, ссылаясь Ha*element2Ptr, функция swap в
действительности обращается к array[ smallest ] в selectionSort.
Хотя swap не позволяется использовать операторы
hold = array[ i ] ;
array[ i ] = array[ smallest ];
array[ smallest ] = hold;
в точности того же эффекта достигают операторы
int hold = *elementlPtr;
♦elementlPtr = *element2Ptr;
*element2Ptr = hold;
в функции swap на рис. 8.15.
Следует отметить несколько моментов в функции selectionSort. Заголовок
функции (строка 36) объявляет array как int * const array, а не int array[],
Указатели и строки-указатели
527
чтобы указать, что selectionSort получает в качестве аргумента одномерный
массив. Как параметр-указатель array, так и параметр size объявляются const
согласно принципу наименьших привилегий. Хотя параметр size принимает
копию значения в main, и модификация копии не может изменить это
исходное значение, selectionSort для выполнения своей задачи не требуется
изменять size — размер массива остается неизменным во время выполнения
selectionSort. Поэтому size объявляется как const, чтобы гарантировать, что эта
переменная не будет модифицирована. Если бы в процессе сортировки размер
массива был модифицирован, алгоритм работал бы неправильно.
Обратите внимание, что функция selectionSort получает в качестве
параметра размер массива, так как для выполнения сортировки ей необходима эта
информация. Когда функции передается массив-указатель, последняя
получает только адрес в памяти первого элемента массива; размер его должен
передаваться функции отдельно.
Определяя, что функция selectionSort получает размер массива как
параметр, мы делаем возможным использование этой функции в любой программе,
сортирующей одномерные целые массивы произвольного размера. Размер
массива мог бы быть непосредственно запрограммирован в функции, но это
ограничило бы ее применение сортировкой массивов конкретного размера и сузило
возможности ее утилизации, — такую функцию могли бы использовать только
программы, обрабатывающие одномерные целые массивы определенного,
«зашитого» в функции, размера.
Общая методическая рекомендация 8.4
Передавая функции массив, передавайте та же и его размер (а не
встраивайте в функцию знание о размере массива). Это делает
функцию более пригодной для утилизации.
8.7. Операции sizeof
В C++ предусмотрена унарная операция sizeof для определения во время
компиляции размера массива (а также любого типа данных, переменной или
константы) в байтах. Применяемая к имени массива (как в строке 14 на
рис. 8.16), операция sizeof возвращает общее число байт в массиве как
значение типа size_t (в большинстве компиляторов это псевдоним для unsigned int).
Заметьте, что это не то же самое, что размер size, например, у vector< int >,
который равен числу целых элементов вектора. Компьютер, на котором мы
компилировали данную программу, сохраняет переменные типа double в 8
байтах, и массив array, объявленный как имеющий 20 элементов (строка 12),
занимает поэтому в памяти 160 байт. Применяемая к указателю-параметру
функции, принимающей в качестве аргумента массив (строка 24), операция
возвращает размер (в байтах) указателя, а не размер массива.
Типичная ошибка программирования 8.7
Применение операции sizeof в функции для определения размера
параметра-массива дает размер в байтах указателя, а не массива.
528
Глава 8
1 // Рис. 8.16: fig08_16.cpp
2 // Операция sizeof, применяемая к имени массива,
3 // возвращает размер массива в байтах.
4 #include <iostream>
5 using std:icout;
6 using std::endl;
7
8 size_t getSize( double * ); // прототип
9
10 int main()
11 {
12 double array[ 20 ]; // 20 чисел double; занимает 160 байт
13
14 cout « "The number of bytes in the array is "« sizeof ( array ) ;
15
16 cout « "\nThe number of bytes returned by getSize is "
17 « getSize( array ) « endl;
18 return 0; // показывает успешное завершение
19 } // конец main
20
21 // возвратить размер ptr
22 size_t getSize( double *ptr )
23 {
24 return sizeof( ptr );
25 } // конец функции getSize
The number of bytes in the array is 160
The number of bytes returned by getSize is 4
Рис. 8,16. Операция sizeof, применяемая к имени массива, возвращает число байт
в массиве
[Замечание, Когда программа на рис. 8.16 компилируется на Borland C++,
компилятор выдает предупреждающее сообщение "Parameter 'ptr' is never
used in function getSize(double *)". Это связано с тем, что операция sizeof
является на самом деле операцией времени компиляции, поэтому переменная
ptr действительно не используется в теле функции во время исполнения.
Многие компиляторы выдают подобные сообщения, давая вам знать, что та или
иная переменная не используется, чтобы вы могли либо исключить эту
переменную из кода, либо модифицировать код так, чтобы он корректно
использовал переменную. Различные компиляторы выдают похожие сообщения и при
компиляции программы на рис. 8.17.]
Применив две операции sizeof, можно определить и число элементов
массива. Рассмотрим, например, такое объявление:
double realArray[ 22 ];
Если переменные типа double хранятся в восьми байтах памяти, массив
realArray содержит всего 176 байт. Чтобы определить число его элементов,
можно использовать следующее выражение:
sizeof realArray / sizeof( double ) // вычислить число элементов
Указатели и строки-указатели
529
Это выражение определяет размер в байтах массива realArray A76) и делит
его на число байтов, используемых для хранения значения типа double (8).
В результате получится число элементов в массиве B2).
Определение размеров основных типов, массива и указателя
Программа на рис. 8.17 применяет операцию sizeof для вычисления числа
байтов, используемых для хранения большинства стандартных типов данных.
Обратите внимание, что вывод на рис. 8.17 указывает одинаковый размер для
типов double и long double. Типы могут иметь различный размер в
зависимости от системы, на которой запускается программа. На другой системе,
например, типы double и long double могли бы отличаться по размеру.
1 // Рис. 8.17: fig08_17.cpp
2 // Демонстрация операции sizeof.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 char с; // переменная типа char
10 short s; // переменная типа short
11 int i; // переменная типа int
12 long 1; // переменная типа long
13 float f; // переменная типа float
14 double d; // переменная типа double
15 long double Id; // переменная типа long double
16 int array[ 20 ]; // массив типа int
17 int *ptr = array; // переменная типа int*, т.е. указатель на int
18
19 cout « "sizeof с = " « sizeof с
20 « "\tsizeof(char) = " « sizeof( char )
21 « "\nsizeof s = " « sizeof s
22 « "\tsizeof(short) = " « sizeof( short )
23 « "\nsizeof i = " « sizeof i
24 « "\tsizeof(int) = " « sizeof( int )
25 « "\nsizeof 1 = " « sizeof 1
26 « "\tsizeof(long) = " « sizeof( long )
27 « "\nsizeof f = " « sizeof f
28 « "\tsizeof(float) = " « sizeof( float )
29 « "\nsizeof d = " « sizeof d
30 « "\tsizeof(double) = " « sizeof( double )
31 « "\nsizeof Id = " « sizeof Id
32 « "\tsizeof(long double) = " « sizeof( long double )
33 « "\nsizeof array = " « sizeof array
34 « "\nsizeof ptr = " « sizeof ptr « endl;
35 return 0; // показывает успешное завершение
36 } // конец main
sizeof с = 1 sizeof(char) = 1
sizeof s = 2 sizeof(short) = 2
sizeof i = 4 sizeof(int) = 4
sizeof 1=4 sizeof(long) = 4
sizeof f = 4 sizeof(float) = 4
530
Глава 8
sizeof d = 8 sizeof(double) = 8
sizeof Id = 8 sizeof(long double) = 8
sizeof array = 80
sizeof ptr = 4
Рис. 8.17. Применение операции sizeof для определения размеров стандартных
типов данных
Переносимость программ 8.3
Число байтов, используемых для хранения конкретного типа данных,
может меняться от системы к системе. При написании программ,
которые зависят от размера типов данных и которые должны будут
работать на различных системах, используйте sizeof для выяснения
действительных размеров типов.
Операция sizeof может применяться к любому имени переменной, имени
типа или константному значению. Когда sizeof применяется к имени
переменной (не являющемуся именем массива) или константному значению, она
возвращает число байтов, использующихся для хранения конкретного типа, к
которому принадлежит переменная или константа. Заметьте, что скобки,
использующиеся с операцией sizeof, обязательны только в случае, когда ее
операндом является имя типа (напр., int). Скобки не требуются, когда
операндом sizeof является имя переменной или константа. Помните, что sizeof
является операцией, а не функцией, и производится она во время компиляции, а не
выполнения программы.
Типичная ошибка программирования 8.8
Отсутствие скобок в операции sizeof, когда ее операндом является
имя типа, приводит к ошибке компиляции.
Вопросы производительности 8.2
Поскольку sizeof является операцией времени компиляции, а не
времени выполнения, ее использование не может иметь негативных
последствий в плане эффективности работы программы.
Предотвращение ошибок 8.3
Чтобы избежать шибок, связанных с пропуском скобок вокруг
операнда операции sizeof, многие программисты используют эти скобки
с любыми операндами.
8.8. Выражения с указателями и арифметика
указателей
Указатели являются допустимыми операндами в арифметических
выражениях, выражениях присваивания и сравнения. Однако не все операции,
обычно встречающиеся в таких выражениях, дают верный результат для
переменных-указателей. Этот раздел описывает операции, которые могут применяться
к указателям, и как эти операции должны использоваться.
Указатели и строки-указатели
531
К указателям может применяться ограниченный набор арифметических
операций. Указатель может быть инкрементирован (++) или декрементирован
(—), к указателю может быть прибавлено целое число (+ или +=), из
указателя можно вычесть целое число (— или —=) и можно вычислить разность двух
указателей.
Предположим, объявлен массив int v[ 10 ], первый элемент которого имеет
адрес в памяти, равный 3000. Инициализируем указатель vPtr значением
адреса v[ 0 ], т.е. значение vPtr равно 3000. На рис. 8.18 этот пример изображен
графически для машины с 4-байтовыми целыми. Заметим, что для того, чтобы
vPtr указывал на массив v, его можно инициализировать любым из
следующих операторов (поскольку имя массива эквивалентно указателю на его
первый элемент):
int *vPtr = v;
int *vPtr = &v[ 0 ];
ячейка
3000 3004 3008 3012 3016
, ► v[0] v[1] v[2] v[3] v[4]
переменная-указатель vPtr
Рис. 8.18i Массив v и переменная-указатель vPtr, указывающая на v
rjjrfti Переносимость программ 8.4
fgyW Большинство компьютеров сегодня поддерживают 2-байтовые или
4-байтовые целые. Некоторые из новейших машин имеют еще и
8-байтовые целые. Поскольку результат арифметики указателей зависит
от размера объектов, на которые ссылается указатель, то
арифметика указателей является машинно-зависимой.
В обычной арифметике результатом сложения 3000 + 2 будет
значение 3002. В арифметике указателей результат чаще всего будет другим. При
прибавлении или вычитании из указателя целого числа значение его
увеличивается или уменьшается не на это число, а на произведение числа на размер
объекта, на который указатель ссылается.
Размер объекта в байтах зависит от типа объекта. Например, оператор
vPtr += 2;
даст результат 3008 C000 + 2*4), если для целого числа отводится в памяти 4
байта. Теперь vPtr будет ссылаться на элемент v[ 2 ] (рис. 8.19). Если бы целое
число занимало 2 байта, то предыдущий расчет дал бы адрес в
памяти 3004 C000 + 2*2). Если бы массив состоял из данных другого типа, преды-
532
Глава 8
дущий оператор увеличил бы указатель на удвоенный размер объекта данного
типа. При выполнении арифметических операций с указателем на
символьный массив результаты будут совпадать с арифметическими, потому что под
каждый символ отводится в памяти один байт.
ячейка
3000 3004 3008 3012 3016
I I I I I
v[0] v[1] v[2] ' v[3] v[4]
переменная-указатель vPtr
Рис. 8.19. Указатель vPtr после сложения
Если бы vPtr был увеличен до значения 3016, которое соответствует адресу
элемента массива v[4], то оператор
vPtr -= 4;
вернул бы vPtr к значению 3000, соответствующему началу массива. При
увеличении или уменьшении указателя на единицу можно использовать
операции инкремента (++) и декремента (--). Каждый из следующих операторов
++vPtr;
vPtr++;
увеличивает значение указателя, который будет ссылаться на следующий
элемент массива. Любой из следующих операторов
--vPtr;
vPtr--;
уменьшает значение указателя, который получает при этом доступ к
предыдущему элементу массива.
Переменные-указатели могут вычитаться друг из друга. Например, если
значение vPtr равно 3000, a v2Ptr содержит адрес 3008, то в результате
выполнения оператора
х = v2Ptr - vPtr;
переменной х будет присвоено число элементов массива, расположенных
начиная с адреса vPtr и до v2Ptr; в нашем случае это будет значение 2. Обычно
арифметические операции с указателями имеют смысл только при работе с
массивами. Элементы массива хранятся последовательно, друг за другом, а две
переменные одного и того же типа не обязательно находятся в памяти рядом.
Указатели и строки-указатели
533
Типичная ошибка программирования 8.9
Применение арифметических операций к указателю, ссылающемуся
не на элементы массива.
Типичная ошибка программирования 8.10
Вычитание или сравнение двух указателей, ссылающихся не на один
и тот же массив.
гъ=±я Типичная ошибка программирования 8.11
Выход за начало или конец массива при арифметических операциях
с указателем.
Указатель может быть присвоен другому указателю, если оба указателя
имеют один и тот же тип. В противном случае нужно использовать операцию
приведения типа указателя в правой части оператора присваивания к типу
указателя в левой части. Исключением из этого правила является указатель
на void (т.е. типа void *), обобщенный указатель, который может представлять
любой тип указателя. Указателю на void может быть присвоен указатель
любого типа без приведения типа указателя. Указатель на void может быть
присвоен указателю другого типа только с явным приведением типа.
Общее методическое замечание 8.5
Неконстантные аргументы-указатели могут передаваться
константным параметрам-указателям. Это полезно, когда в теле
программы для доступа к данным используется неконстантный
указатель, но нежелательно, чтобы данные модифицировались вызываемой
из программы функцией.
Указатель на void не может быть разыменован. Например, при
разыменовании указателя на целое компилятор знает, что тот ссылается на четыре байта
памяти (на машине с целыми числами размером в 4 байта), но void-указатель
содержит адрес памяти для неизвестного типа данных, размер которого не известен
компилятору. Компилятор должен знать тип данных и, тем самым, размер
элемента данных в байтах, чтобы правильно разыменовать указатель. В случае
указателя на void размер элемента в байтах не может быть определен компилятором.
Типичная ошибка программирования 8.12
Присвоение значения указателя одного типа указателю другого типа,
когда ни один из них не является указателем типа void *, приводит
к ошибке компиляции.
-, Типичная ошибка программирования 8.13
Все операции над void-указателями приводят к ошибкам компиляции,
если только это не сравнение с другими указателями, приведение
указателей void к действительным типам указателей и присваивание
адресов указателям void.
534
Глава 8
Указатели могут сравниваться друг с другом при помощи операций
равенства и отношения, но сравнение указателей операциями отношения обычно не
имеет смысла, если они не ссылаются на элементы одного и того же массива.
При сравнении указателей сравниваются адреса, являющиеся значениями
указателей. Сравнение двух указателей, ссылающихся на элементы одного
и того же массива, могло бы показать, например, что один указатель
ссылается на элемент с большим значением индекса, чем другой указатель. Другая
часто используемая операция сравнения указателя — это проверка, не равно
ли его значение NULL.
8.9. Взаимосвязь указателей и массивов
Массивы и указатели в C++ тесно связаны друг с другом и практически
являются взаимозаменяемыми. Имя массива можно рассматривать как
указатель-константу. А над указателями можно выполнять различные операции,
в том числе использовать с указателем индексные выражения.
Предположим, сделаны следующие объявления:
int Ь[ 5 ]; // создать 5-элементный целый массив b
int *bPtr; // создать указатель на целое bPtr
Так как имя массива (без индекса) является указателем (константным) на его
первый элемент, мы можем присвоить указателю bPtr адрес первого элемента
массива b при помощи оператора присваивания
bPtr = Ь;
Этот оператор эквивалентен следующему, в котором используется операция
взятия адреса первого элемента массива:
bPtr = &Ь[ 0 ];
Альтернативный способ ссылки на элемент массива Ь[ 3 ], использующий
выражение с указателем, представлен в следующем операторе:
*( bPtr + 3 )
Константа 3 в приведенном выражении называется смещением. Когда
указатель ссылается на начало массива, величина смещения указывает, к какому
элементу массива производится обращение; значение смещения равно
значению индекса массива. Приведенный способ записи носит название нотации
указатель/смещение. В этом выражении использованы круглые скобки,
потому что операция * имеет больший приоритет, чем операция +. Без круглых
скобок в вышеупомянутом выражении значение 3 было бы прибавлено к
значению выражения *bPtr (т.е. число 3 будет прибавлено к элементу Ь[ О ], так
как bPtr указывает на начало массива). Поскольку на значение элемента
массива можно сослаться при помощи выражения с указателем, адрес элемента
&Ь[ 3 ] представляется выражением
bPtr + 3
Указатели и строки-указатели
535
Имя массива может рассматриваться как указатель, так что его можно
использовать в выражениях арифметики указателей. Например, выражение
*( Ь + 3 )
будет ссылаться на элемент массива Ь[ 3 ]. Вообще говоря, все выражения с
индексами могут быть преобразованы в выражения с указателем и смещением.
В этом случае в качестве указателя можно использовать имя массива.
Обратите внимание на то, что в предыдущем выражении значение указателя b не
изменяется, он по-прежнему указывает на первый элемент в массиве.
Указатели, в свою очередь, могут быть использованы вместо имен массивов
в индексных выражениях. Например, выражение
bPtr[ 1 ]
ссылается на элемент массива Ь[ 1 ]. Такой способ записи можно назвать
нотацией указатель/индекс.
Не забудьте, что имя массива — это указатель-константа и он всегда
указывает на начало массива. Поэтому выражение
Ь += 3
является недопустимым, так как в нем делается попытка изменить значение
начального адреса массива.
Типичная ошибка программирования 8.14
Хотя имена массивов являются указателями на начало массива
и указатели могут модифицироваться в арифметических
выражениях, имена массивов нельзя модифицировать арифметическими
выражениями, поскольку они являются константными указателями.
Хороший стиль программирования 8.2
Для ясности при обработке массивов пользуйтесь нотацией массивов,
а не нотацией указателей.
В программе на рис. 8.20 используются четыре метода ссылки на элементы
массива, которые мы обсудили — индексацию массива, указатель/смещение
с именем массива в качестве указателя, индексацию указателя и
указатель/смещение с указателем, — для вывода четырех элементов
целочисленного массива Ь.
1 // Рис. 8.20: fig08_20.cpp
2 // Использование с массивами нотаций указателей и индексации.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 int b[] = { 10, 20, 30, 40 }; // создать 4-элементный массив b
10 int *bPtr = b; // установить bPtr на массив b
536
Глава 8
11
12 // вывести массив Ь, используя нотацию индексации массива
13 cout « "Array b printed with :\n\nArray subscript notation\n";
14
15 for ( int i = 0; i < 4; i++ )
16 cout « "b[" « i « "] = " « b[ i ] « '\n';
17
18 // вывести b, используя имя массива и нотацию указатель/смещение
19 cout « "\nPointer/offset notation where "
20 « "the pointer is the array name\n";
21
22 for ( int offsetl = 0; offsetl < 4; offsetl++ )
23 cout « "*(b + " « offsetl « ") = "« * (b + offsetl) « '\n';
24
25 // вывести массив b, используя bPtr и нотацию индексации массива
26 cout « "\nPointer subscript notation\n";
27
28 for ( int j = 0; j < 4; j++ )
29 cout « "bPtr[" « j « "] = " « bPtr[ j ] « '\n';
30
31 cout « "\nPointer/offset notation\n";
32
33 // вывести массив b, используя bPtr и нотацию указатель/смещение
34 for ( int offset2 = 0; offset2 < 4; offset2++ )
35 cout « "*(bPtr + " « offset2 « ") = "
36 « *( bPtr + offset2 ) « '\nf;
37
38 return 0; // показывает успешное завершение
39 } // конец main
Array b printed with:
Array subscript notation
b[0] = 10
b[l] = 20
b[2] = 30
b[3] = 40
Pointer/offset notation where the pointer is the array name
*(b + 0) =10
*(b + 1) =20
*(b + 2) =30
*(b + 3) =40
Pointer subscript notation
bPtr[0] = 10
bPtr[l] = 20
bPtr[2] = 30
bPtr[3] = 40
Pointer/offset notation
*(bPtr + 0) = 10
*(bPtr + 1) = 20
MbPtr + 2) = 30
MbPtr + 3) = 40
Рис. 8.20. Обращение к элементам массива через имя массива и через указатели
Указатели и строки-указатели
537
В качестве еще одного примера взаимозаменяемости массивов и указателей
рассмотрим две функции копирования строк — copyl и сору2 — в программе
на рис. 8.21. Обе функции копируют строку символов (возможно, символьный
массив) в массив символов. Прототипы функций copyl и сору2 абсолютно
идентичны. И действительно, они выполняют одну и ту же задачу, но делают
это по-разному.
1 // Рис. 8.21: fig08_21.cpp
2 // Копирование строки с применением нотации массивов и указателей.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 void copyl( char *, const char * ); // прототип
8 void copy2( char *, const char * ); // прототип
9
10 int main()
11 {
12 char stringl[ 10 ];
13 char *string2 = "Hello";
14 char string3[ 10 ];
15 char string4[] = "Good Bye";
16
17 copyl( stringl, string2 ); // копировать string2 в stringl
18 cout « "stringl = " « stringl « endl;
19
20 copy2( string3, string4 ); // копировать string4 в string3
21 cout « "string3 = " « string3 « endl;
22 return 0; // показывает успешное завершение
23 } // конец main
24
25 // копировать s2 в si, используя нотацию массивов
26 void copyl( char * si, const char * s2 )
21 {
28 // копирование происходит в заголовке for
29 for ( int i = 0; ( sl[ i ] = s2[ i ] ) != '\0'; i++ )
30 ; // в теле ничего не делается
31 } // конец функции copyl
32
33 // копировать s2 в si, используя нотацию указателей
34 void copy2( char *sl, const char *s2 )
35 {
36 // copying occurs in the for header
37 for ( ; ( *sl = *s2 ) != '\0'; sl++, s2++ )
38 ; // в теле ничего не делается
39 } // конец функции сору2
stringl = Hello
string3 = Good Bye
Рис. 8.21. Копирование строки с применением нотации массивов и нотации
указателей
538
Глава 8
Функция copyl (строки 26-31) применяет для копирования строки s2
в массив si индексную нотацию. Функция определяет целую
переменную-счетчик i, используемую как индекс массива. Вся работа по созданию
копии выполняется в заголовке оператора for (строка 29), при этом тело его
пусто. В заголовке i инициализируется нулем и увеличивается на единицу на
каждом шаге цикла. Условие цикла for, sl[ i ] = s2[ i ], выполняет посимвольное
копирование строки s2 в si. Когда в s2 встречается нуль-символ, он
присваивается si, и цикл завершается, потому что целочисленное значение
нуль-символа равно нулю (false). Напомним, что значением оператора присваивания
является значение, получаемое левым операндом.
Функция сору2 (строки 34-39) при копировании строки s2 в символьный
массив si использует указатели и арифметику указателей. Здесь также все
операции копирования производятся в заголовке оператора for (строка 37).
В цикле не используется управляющая переменная. Как и в функции copyl,
копирование символов строки выполняется в выражении условия цикла
(*sl = *s2) != '\0*. Указатель s2 разыменовывается и полученный символ
присваивается разыменованному указателю si. После выполнения присваивания
в выражении условия цикла указатели увеличиваются для перехода
соответственно к следующему элементу массива si и следующему символу строки s2.
Когда в строке s2 встречается нуль-символ, он присваивается
разыменованному указателю si и цикл завершается. Обратите внимание, что в «разделе
инкремента» этого оператора два выражения инкремента разделяются
операцией-запятой.
Первый аргумент функций copyl и сору2 должен быть массивом
достаточно большого размера, чтобы вместить строку, передаваемую вторым
параметром. В противном случае произойдет ошибка при записи в область памяти,
которая не является частью массива. Заметьте также, что второй параметр
каждой функции объявлен как const char * (указатель на символьную константу,
т.е. строка-константа). В обеих функциях второй аргумент копируется в
первый аргумент, при этом символы из второго аргумента читаются по одному
и не изменяются. Поэтому, в соответствии с принципом наименьших
привилегий, второй параметр объявляется указателем на значение-константу. Ни
одной из функций не нужно изменять второй аргумент, поэтому ни одной из них
и не предоставляется такое право.
8.10. Массивы указателей
Массивы могут содержать указатели. Обычный случай такого массива —
это массив строк. Элементом такого массива является строка, а строки в C++
являются, по существу, указателями на первый символ строки. Значит,
элементами строкового массива являются указатели на начала строк. В качестве
примера рассмотрим массив suit, который может пригодиться для описания
игральных карт.
const char *suit[ 4 ] =
{ "Hearts", "Diamonds", "Clubs", "Spades" };
Выражение suit[ 4 ] в объявлении означает массив из четырех элементов.
Спецификацией char * элементы этого массива объявляются имеющими тип
«указатель на константные символьные данные». В массив помещаются четыре зна-
Указатели и строки-указатели
539
чения "Hearts", "Diamonds", "Clubs" и "Spades" ("Червы", "Бубны", "Трефы"
и "Пики"). Каждое из этих значений хранится в памяти как символьная строка
с ограничивающим нулем, длиной на один символ больше, чем количество
символов, заключенных в кавычки. Строки эти занимают в памяти
соответственно 7, 9, 6 и 7 байт. И хотя кажется, что в массив помещаются сами строки,
элементами массива являются указатели, как показано на рис. 8.22. Каждый
указатель ссылается на первый символ соответствующей строки. Таким образом,
хотя массив suit имеет фиксированный размер, он предоставляет доступ к
символьным строкам произвольной длины. Это еще один пример мощных
возможностей структурирования данных в C++.
suit[1] • ► 'D' V 'а' 'т' 'о' 'гГ 'd' Y '\0'
suit[2] • ► -с Т 'u' 'b' У '\0'
suit[3] • ► .s. .р. .а. .d. .е. v .ю.
Рис. 8.22. Графическое представление массива мастей
Карточные масти можно было бы сделать двумерным массивом: имя
каждой масти занимало бы одну строку, а в каждом столбце помещалось бы по
одному символу имени масти. Такая структура данных должна была бы иметь
одинаковое число столбцов в каждой строке, равное размеру самой длинной
строки символов. Это привело бы к неоправданному расходу памяти в случае,
когда большинство сохраняемых строк короче, чем самая длинная строка.
В следующем разделе мы будем использовать массивы строк для
представления колоды карт.
Строковые массивы обыкновенно используются для представления
аргументов командной строки, передаваемых функции main, когда программа
начинает свое исполнение. Такие аргументы указываются после имени
программы, когда последняя запускается из командной строки. Типичным
использованием аргументов командной строки является передача опций.
Например, в командной строке системы Windows пользователь может ввести
dir /P
чтобы получить листинг содержания текущего каталога с паузами после
каждого выведенного экрана с информацией. Когда команда dir исполняется,
опция /Р передается ей в качестве аргумента командной строки. Такие
аргументы помещаются в строковый массив, получаемый main как параметр.
540
Глава 8
8.11. Пример: моделирование тасования и сдачи карт
В этом разделе, используя генератор случайных чисел, мы составим
программу, моделирующую тасование и сдачу карт. Эту программу можно будет
потом использовать при написании игровых карточных программ. Мы
намеренно использовали неоптимальные алгоритмы тасования и сдачи, чтобы таким
образом познакомить вас с некоторыми тонкими проблемами эффективности.
В упражнениях и в главе 10 мы разработаем более эффективные алгоритмы.
Действуя методом нисходящего последовательного уточнения, мы
разработаем программу, которая перетасует колоду из 52 игральных карт и затем все
их раздаст. Нисходящий метод особенно полезен при решении больших
и сложных проблем, а не таких простых, как те, с которыми мы имели дело
в предыдущих главах.
Для представления колоды мы используем двумерный массив deck
размером 4 на 13 (рис. 8.23). Строки массива соответствуют мастям; строка 0 —
червы, строка 1 — бубны, строка 2 — трефы, и строка 3 представляет пики. По
столбцам записаны номиналы карт, столбцы с индексом от 0 до 9
соответствуют картам соответственно от туза до десятки, а столбцы с 10-го по 12-й
соответствуют валету, даме и королю. Мы заполним строковый массив suit
именами четырех мастей, а массив face — строками, соответствующими тринадцати
карточным номиналам.
Червы
Бубны
Трефы
Пики
0
1
2
3
Туз
Двойка
Тройка
Четверка
Пятерка
0 12 3 4
Шестерка
Семерка
Восьмерка
5 6 7
Девятка
8
Десятка
9
deck [2] [12] представляет короля треф
Трефы Король
Валет
10
.,/'
Дама
11
/
Король
12
.Г
Рис, 8.23. Представление колоды карт двумерным массивом
Эта воображаемая колода может быть перетасована следующим образом.
Сначала массив deck заполняется нулями. Затем случайным образом
выбирается номер строки row (число от 0 до 3) и номер столбца column (число в
диапазоне 0-12). В выбранный таким образом элемент массива deck[ row ][ column ]
помещается число 1, которое означает, что эта карта из «перетасованной» колоды
будет сдана первой. Этот процесс продолжается далее для чисел 2, 3, ..., 52,
вставляемых случайным образом в массив deck и обозначающих карты, кото
Указатели и строки-указатели
541
рые должны быть сданы второй, третьей и т.д. до пятьдесят второй. Как только
массив deck начинает заполняться числами, возникает вероятность, что
некоторые карты будут выбраны дважды, т.е. при выборе некоторого элемента
deck[ row ][ column ] его значение будет отлично от нуля. В этом случае
случайный выбор row и column повторяется до тех пор, пока не будет найдена карта,
которая еще не выбиралась. В конечном счете числа от 1 до 52 займут все 52
элемента массива deck. Тем самым колода будет полностью перетасована.
Такой алгоритм тасования может выполняться неопределенно долго, если
карты, которые уже были сданы, продолжают выпадать в случайном выборе.
Это явление известно и носит название бесконечной, или неопределенной
отсрочки. В упражнениях мы обсудим улучшенный алгоритм тасования колоды,
в котором устранена возможность бесконечной отсрочки.
I—з Вопросы производительности 8.3
|^Ф*| Часто «естественный» алгоритм может столкнуться с
неожиданными препятствиями при своем выполнении, как, например,
неопределенная отсрочка. Ищите алгоритмы, которые не содержат в себе
таких «неопределенностей».
Чтобы сдать первую карту, мы должны найти элемент массива
deck[ row ][ column ], значение которого равно 1. Эту задачу выполняют
вложенные циклы for, в которых row изменяется от 0 до 3, a column — от 0 до 12.
Как узнать, какая карта соответствует данному элементу массива? Так как
массив мастей suit был уже нами определен, для того, чтобы получить
название масти, нужно вывести строку suit[ row ]. Аналогично, чтобы получить
название номинала карты, нам нужно вывести строку face[ column ]. Кроме
того, мы выводим строку " of ". Информация относительно всех сданных карт
выводится в форме "King of Clubs", "Асе of Diamonds" и т.д.
Давайте приступим к процессу нисходящего последовательного уточнения.
Сначала запишем нашу задачу в общем виде
Тасование и раздача 52 карт
На первом шаге уточнения алгоритма его можно представить так:
Инициализация массива suit
Инициализация массива face
Инициализация массива deck
Тасование колоды
Раздача 52 карт
Пункт "Тасование колоды" может быть расширен следующим образом:
Для каждой из 52 карт
Записать номер карты в выбранный случайным образом свободный
элемент массива deck
Пункт "Раздача 52 карт" может быть расширен следующим образом:
Для каждой из 52 карт
Найти номер карты в массиве deck и вывести название номинала
и масти карты
542
Глава 8
С учетом сделанных расширений мы получаем второе уточнение:
Инициализация массива suit
Инициализация массива face
Инициализация массива deck
Для каждой из 52 карт
Записать номер карты в выбранный случайным образом свободный
элемент массива deck
Для каждой из 52 карт
Найти номер карты в массиве deck и вывести название номинала
и масти карты
Пункт "Записать номер карты в выбранный случайным образом свободный
элемент массива deck" может быть расширен следующим образом:
Выбрать случайным образом элемент массива deck
Пока выбранный элемент уже выбирался ранее
Выбрать случайным образом элемент массива deck
Записать номер карты в выбранный элемент массива deck
Пункт "Найти номер карты в массиве deck и вывести название номинала
и масти карты" можно расширить так:
Для каждого элемента массива
Если элемент содержит искомый номер карты
Вывести название номинала карты и ее масть
Объединение этих расширений дает нам третье уточнение (рис. 8.24).
На этом процесс детализации алгоритма можно завершить. Рис. 8.25-8.27
показывают программу тасования и сдачи, а также образец ее исполнения.
Строки 61-67 функции deal (рис. 8.26) реализуют строки 1-2 алгоритма на
рис. 8.24. Конструктор (строки 22-35 на рис. 8.26) реализует строку 3 на
рис. 8.24. Функция shuffle (строки 38-55 на рис. 8.26) реализует строки 5-11
на рис. 8.24. Функция deal (строки 58-88 на рис. 8.26) реализует
строки 13-16 на рис. 8.24. Обратите внимание на форматирование в функции deal
(строки 81-83). Оператор вывода печатает номинал с выравниванием по
правому краю поля из пяти символов, а масть — с выравниванием по левому краю
поля из восьми символов (рис. 8.27). Печать производится в две колонки —
если карта печатается в первой колонке, после нее выводится табуляция,
чтобы перейти ко второй колонке; в противном случае выводится новая строка.
У нашего алгоритма сдачи карт есть один недостаток. Когда найдена
нужная карта, иногда с первой попытки, два внутренних цикла for продолжают
поиск в оставшейся части массива deck. В упражнениях мы исправим этот
дефект.
1 Инициализация массива suit
2 Инициализация массива face
3 Инициализация массива deck
4
5 Для каждой из 52 карт
6 Выбрать случайным образом элемент массива deck
7
Указатели и строки-указатели
543
8 Пока выбранный элемент уже выбирался ранее
9 Выбрать случайным образом элемент массива deck
10
11 Записать номер карты в выбранный элемент массива deck
12
13 Для каждой из 52 карт
14 Для каждого элемента массива
15 Если элемент содержит искомый номер карты
16 Вывести название номинала карты и ее масть
Рис. 8-24. Алгоритм на псевдокоде для программы тасования и сдачи карт
1 // Рис. 8.25: DeckOfCards.h
2 // Определение класса DeckOfCards, представляющего
3 // колоду игральных карт.
4
5 // определение класса DeckOfCards
6 class DeckOfCards
7 {
8 public:
9 DeckOfCards(); // конструктор инициализирует колоду
10 void shuffle(); // тасует карты в колоде
11 void deal(); // сдает карты
12
13 private:
14 int deck[ 4 ][ 13 ]; // представляет колоду карт
15 }; // конец класса DeckOfCards
Рис. 8.25. Заголовочный файл DeckOfCards
1 // Рис. 8.26: DeckOfCards.срр
2 // Определения элемент-функций класса DeckOfCards,
3 // моделирующего тасование и сдачу колоды игральных карт.
4 #include <iostream>
5 using std::cout;
6 using std::left;
7 using std::right;
8
9 #include <iomanip>
10 using std::setw;
11
12 #include <cstdlib> // прототипы для rand и srand
13 using std::rand;
14 using std::srand;
15
16 #include <ctime> // прототип для time
17 using std::time;
18
19 #include "DeckOfCards.h" // определение класса DeckOfCards
20
21 // конструктор по умолчанию DeckOfCards инициализирует колоду
22 DeckOfCards::DeckOfCards()
23 {
544
24 // цикл по строкам deck
25 for ( int row = 0; row <= 3; row++ )
26 {
27 // цикл по столбцам в текущей строке deck
28 for ( int column = 0; column <= 12; column++ )
29 {
30 deck[ row ][ column ] =0; // установить ячейку в 0
31 } // конец внутреннего for
32 } // конец внешнего for
33
34 srand( time( 0 ) ); // засеять генератор случайных чисел
35 } // конец конструктора по умолчанию DeckOfCards
36
37 // перетасовать карты в колоде
38 void DeckOfCards::shuffle()
39 {
40 int row; // представляет масть карты
41 int column; // представляет численный номинал карты
42
43 // для каждой иэ 52 карт случайно выбрать ячейку deck
44 for ( int card = 1; card <= 52; card++ )
45 {
46 do // выбрать новую позицию, пока не найдется свободная
47 {
48 row = rand() % 4; // случайно выбрать строку
4 9 column = rand() % 13; // случайно выбрать столбец
50 } while( deck[ row ][ column ] != 0 ); // конец do/while
51
52 // поместить номер карты в выбранную ячейку deck
53 deck[ row ][ column ] = card;
54 } // конец for
55 } // конец функции shuffle
56
57 // сдать карты
58 void DeckOfCards::deal()
59 {
60 // инициализировать массив мастей
61 static const char *suit[ 4 ] =
62 { "Hearts", "Diamonds", "Clubs", "Spades" };
63
64 // инициализировать массив номиналов
65 static const char *face[ 13 ] =
66 { "Ace", "Deuce", "Three", "Four", "Five", "Six", "Seven
67 "Eight", "Nine", "Ten", "Jack", "Queen", "King" };
68
69 // для каждой иэ 52 карт
70 for ( int card = 1; card <= 52; card++ )
71 {
72 // цикл по строкам deck
73 for ( int row = 0; row <= 3; row++ )
74 {
75 // цикл про столбцам в текущей строке deck
76 for ( int column = 0; column <= 12; column++ )
77 {
78 // если ячейка содержит текущую карту, вывести карту
79 if ( deck[ row ][ column ] == card )
80 {
Указатели и строки-указатели
545
В1 cout « setw( 5 ) « right « fасе[ column ]
B2 « " of " « setw( 8 ) « left « suit[ row ]
83 « ( card % 2 == 0 ? '\n' : '\t' );
84 } // конец if
85 } // конец самого внутреннего for
86 } // конец внутреннего for
87 } // конец внешнего for
88 } // конец функции deal
Рис. 8.26- Определения элемент-функций для тасования и сдачи карт
1 // Рис. 8.27: fig08_27.cpp
2 // Программа тасования и сдачи карт.
3 #include "DeckOfCards.h" // определение класса DeckOfCards
4
5 int main()
6 {
7 DeckOfCards deckOfCards; // создать объект DeckOfCards
8
9 deckOfCards.shuffle(); // перетасовать карты колоды
10 deckOfCards.deal(); // сдать карты колоды
11 return 0; // успешное завершение
12 } // конец main
Six
Ten
Six
Seven
Five
Four
Three
Six
Eight
Queen
Seven
Three
Ace
Eight
Nine
Queen
Deuce
Five
Four
Queen
King
Deuce
Eight
Ten
Deuce
Nine
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
Spades
Diamonds
Clubs
Hearts
Clubs
Spades
Hearts
Hearts
Spades
Diamonds
Clubs
Diamonds
Clubs
Hearts
Clubs
Spades
Clubs
Diamonds
Hearts
Clubs
Diamonds
Hearts
Diamonds
Clubs
Spades
Hearts
Three
King
Ace
Five
Nine
Nine
Six
Three
Eight
Four
Deuce
Five
Ace
Jack
King
Ten
Jack
Ace
Jack
Ten
Jack
Seven
Four
King
Seven
Queen
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
Spades
Hearts
Hearts
Hearts
Diamonds
Spades
Diamonds
Clubs
Clubs
Diamonds
Diamonds
Spades
Diamonds
Clubs
Clubs
Spades
Hearts
Spades
Spades
Hearts
Diamonds
Spades
Clubs
Spades
Diamonds
Hearts
Рис. 8.27. Программа тасования и сдачи карт
18 Зак. 1114
546
Глава 8
8.12. Указатели на функцию
Указатель на функцию — это переменная, содержащая адрес в памяти, по
которому расположена функция. Из главы 6 мы знаем, что имя массива
является адресом первого элемента массива. Аналогичным образом имя
функции — это адрес начала программного кода функции. Указатели на функции
могут передаваться в качестве аргументов функциям, могут возвращаться
функциями, сохраняться в массивах и присваиваться другим указателям на
функции.
Многоцелевая сортировка выборкой с указателями на функцию
Чтобы проиллюстрировать использование указателей на функции, мы
модифицируем программу сортировки выборкой, приведенную на рис. 8.15;
модифицированный вариант показан на рис. 8.28. Наша новая программа
состоит из main (строки 17-55) и функций selectionSort (строки 59-76), swap
(строки 80-85), ascending (строки 89-92) и descending (строки 96-99).
Функция selectionSort в дополнение к двум прежним параметрам, целому массиву
и его размеру, получает указатель на функцию — это может быть функция
ascending или descending. Во время исполнения программа запрашивает
у пользователя способ сортировки — в восходящем или нисходящем порядке.
Если пользователь вводит 1, функции selectionSort передается указатель на
функцию ascending и производится сортировка переданного массива в
восходящем порядке. Если пользователь вводит 2, то selectionSort передается
указатель на функцию descending и производится сортировка массива в
нисходящем порядке.
1 // Рис. 8.28: fig08_28.cpp
2 // Многоцелевая программа сортировки с указателями на функцию.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 #include <iomanip>
9 using std::setw;
10
11 // прототипы
12 void selectionSort( int [], const int, bool (*)( int, int ) );
13 void swap( int * const, int * const );
14 bool ascending( int, int ); // реализует восходящий порядок
15 bool descending( int, int ); // реализует нисходящий порядок
16
17 int main()
18 {
19 const int arraySize = 10;
20 int order; // 1 = восходящий, 2 = нисходящий
21 int counter; // индекс массива
22 int a[ arraySize ] = { 2, 6, 4, 8, 10, 12, 89, 68, 45, 37 };
23
24 cout « "Enter 1 to sort in ascending order,\n"
25 « "Enter 2 to sort in descending order: ";
26 cin » order;
Указатели и строки-указатели
547
27 cout « M\nData items in original order\n";
28
29 // вывести исходный массив
30 for ( counter = 0; counter «£ arraySize; counter++ )
31 cout « setw( 4 ) « a[ counter ];
32
33 // сортировать массив в восходящем порядке; передать в качестве
34 // аргумента функцию ascending для задания восходящего порядка
35 if ( order = 1 )
36 {
37 selectionSort( a, arraySize, ascending );
38 cout « "\nData items in ascending order\n";
39 } // конец if
40
41 // сортировать массив в нисходящем порядке; передать в качестве
42 // аргумента функцию descending для задания нисходящего порядка
43 else
44 {
45 selectionSort( a, arraySize, descending );
4 6 cout « "\nData items in descending order\n";
47 } // конец части else из if...else
48
49 // вывести сортированный массив
50 for ( counter = 0; counter < arraySize; counter++ )
51 cout « setw( 4 ) « a[ counter ];
52
53 cout « endl;
54 return 0; // показывает успешное завершение
55 } // конец main
56
57 // многоцелевая выборочная сортировка; параметр compare - указатель
58 //на функцию сравнения, определяющую порядок сортироки
59 void selectionSort( int work[], const int size,
60 bool (*compare)( int, int ) )
61 {
62 int smallestOrLargest; // индекс наименьшего (наибольшего) эл-та
63
64 // цикл по size - 1 элементам
65 for ( int i = 0; i < size - 1; i++ )
66 {
67 smallestOrLargest = i; // первый индекс оставшегося вектора
68
69 // цикл для нахождения наименьшего (наибольшего) элемента
70 for ( int index = i + 1; index < size; index++ )
71 if ( (*compare)( work[ index ], work[ smallestOrLargest ] ) )
72 smallestOrLargest = index;
73
74 swap( &work[ i ], &work[ smallestOrLargest ] );
75 } // конец if
76 } // конец функции selectionSort
77
78 // обменять значения в ячейках, на которые указывают
79 // elementlPtr и element2Ptr
80 void swap( int * const elementlPtr, int * const element2Ptr )
81 {
82 int hold = *elementlPtr;
83 *elementlPtr = *element2Ptr;
548
Глава 8
84 *element2Ptr = hold;
85 } // конец функции swap
86
87 // определить, нарушен ли порядок элементов
88 // при сортировке в восходящем порядке
89 bool ascending( int a, int b )
90 {
91 return a < b; // определить наименьший индекс, если а меньше b
92 } // конец функции ascending
93
94 // определить, нарушен ли порядок элементов
95 // при сортировке в нисходящем порядке
96 bool descending( int a, int b )
97 {
98 return a > b; // определить наибольший индекс, если а больше Ь
99 } // конец функции descending
Enter l to sort in ascending order,
Enter 2 to sort in descending order: 1
Data items in original order
2 6 4 8 10 12 89 68 45 37
Data items in ascending order
2 4 6 8 10 12 37 4 68 89
Enter 1 to sort in ascending order,
Enter 2 to sort in descending order: 2
Data items in original order
2 6 4 8 10 12 89 68 45 37
Data items in descending order
89 68 45 37 12 10 8 6 4 2
Рис. 8.28. Многоцелевая программа сортировки с указателями на функцию
В заголовке функции selectionSort (строка 60) имеется следующий параметр:
bool ( *compare )( int, int )
Это значит, что функция selectionSort получает аргумент, являющийся
указателем на функцию. Ключевое слово bool специфицирует, что
указываемая функция возвращает результат булева типа. Текст ( *сотраге )
специфицирует имя указателя на функцию (* показывает, что параметр compare —
указатель). Текст ( int, int ) сообщает, что указываемая функция принимает
два целых аргумента. Вокруг *compare необходимы круглые скобки,
показывающие, что compare является указателем на функцию. Если мы уберем
круглые скобки, то объявление будет иметь вид
bool *compare( int, int )
и будет обозначать функцию, которая получает два целых параметра и
возвращает указатель на bool.
Указатели и строки-указатели
549
Соответствующим параметром в прототипе функции selectionSort является
bool (*)( int, int )
Обратите внимание, что в прототипе специфицируются только типы. Как
обычно, в целях документирования программист может включить в прототип
имена. Компилятор будет их игнорировать.
Функция, переданная функции selectionSort, вызывается в строке 71
следующим образом:
( *compare )( work[ index ], work[ smallestOrLargest ] ) )
Подобно тому, как разыменовывают указатель на переменную, чтобы
получить ее значение, указатель на функцию разыменовывают, чтобы произвести
вызов этой функции.
Функцию можно вызвать и без разыменования указателя, как в
compare( work[ index ], work[ smallestOrLargest ] )
где указатель используется непосредственно как имя функции. Мы
предпочитаем первый метод вызова — с разыменованием указателя, потому что в этом
варианте явно видно, что compare является указателем на функцию. При
втором методе вызова может создаться впечатление, что compare — это имя
функции. В результате пользователь программы может запутаться, если
попытается найти определение функции compare и обнаружит, что она нигде
в файле не определена.
Массивы указателей на функцию
Одним из применений указателей на функцию являются так называемые
системы, управляемые меню. Пользователь выбирает команду меню
(например, одну из пяти). Каждая команда обслуживается своей функцией.
Указатели на каждую функцию находятся в массиве указателей. Выбор пользователя
служит индексом, по которому из массива выбирается указатель на нужную
функцию.
Рис. 8.29 показывает «механический» пример определения и
использования массива указателей на функцию. Определяются три функции — func-
tionl, function2 и function3, — каждая из которых принимает целый
аргумент и не возвращает значения. В строке 17 указатели на эти три функции
сохраняются в массиве f. В этом случае все три функции, на которые указывает
массив, должны иметь один и тот же возвращаемый тип и одинаковые типы
параметров. Объявление в строке 17 читается, начиная с самой левой пары
скобок и звучит как: «f — массив из трех указателей на функцию, каждая из
которых принимает целый аргумент и не возвращает значения». Массив
инициализируется именами трех функций (которые, повторим, являются
указателями). Когда пользователь вводит значение от 0 до 2, это значение
используется в качестве индекса массива указателей на функцию. Строка 29 вызывает
одну из функций в массиве f. В этом вызове f[ choice ] выбирает указатель по
индексу choice. Для вызова функции указатель разыменовывается, а
переменная choice передается функции в качестве аргумента. Каждая функция
выводит значение полученного аргумента и свое имя, что позволяет убедиться
в правильности вызова. В упражнениях вы разработаете программу, управляв-
550
Глава 8
мую меню. В главе 13 мы увидим, что массивы указателей на функцию
используются компилятором для реализации механизма виртуальных
функций — ключевой технологии, стоящей за полиморфизмом.
1 // Рис. 8.29: fig08_29.cpp
2 // Демонстрация массива указателей на функцию.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 // прототипы функций - функции производят схожие действия
9 void functionO( int )
10 void functionl( int )
11 void function2( int )
12
13 int main()
14 {
15 // инициализировать массив из 3 указателей на функции, каждая
16 //из которых принимает аргумент типа int и возвращает void
17 void (*f[ 3 ])( int ) = { functionO, functionl, function2 };
18
19 int choice;
20
21 cout « "Enter a number between 0 and 2, 3 to end: ";
22 cin » choice;
23
24 // обработать выбор пользователя
25 while ( ( choice >= 0 ) && ( choice < 3 ) )
26 {'
27 // вызвать функцию в позиции choice массива f
28 //и передать choice в качестве аргумента
29 (*f[ choice ])( choice );
30
31 cout « "Enter a number between 0 and 2, 3 to end: ";
32 cin » choice;
33 } // конец while
34
35 cout « "Program execution completed." « endl;
36 return 0; // показывает успешное завершение
37 } // конец main
38
39 void functionO( int a )
40 {
41 cout « "You entered " « a « " so functionO was called\n\n";
42 } // конец функции functionO
43
44 void functionl( int b )
45 {
46 cout « "You entered " « b « " so functionl was called\n\n";
47 } // конец функции functionl
48
49 void function2( int с )
50 {
51 cout « "You entered " « с « " so function2 was called\n\n";
52 } // конец функции function2
Указатели и строки-указатели
551
Enter a number between 0 and 2, 3 to end: 0
You entered 0 so functionO was called
Enter a number between 0 and 2, 3 to end: 1
You entered 1 so functionl was called
Enter a number between 0 and 2, 3 to end: 2
You entered 2 so function2 was called
Enter a number between 0 and 2, 3 to end: 3
Program execution completed.
Рис. 8.29. Массив указателей на функцию
8.13. Введение в обработку строк-указателей
В этом разделе мы познакомимся с некоторыми типичными функциями
стандартной библиотеки C++, упрощающими обработку строк. Обсуждаемые
здесь методики подходят для разработки текстовых редакторов,
лингвистических процессоров, программ верстки, систем компьютеризированного набора
и других программных систем обработки текстов. В нескольких примерах мы
уже пользовались классам стандартной библиотеки string, позволяющих
представлять символьные строке в форме полноценных объектов. Например,
в примерах класса GradeBook в главах 3-7 название курса представлялось
объектом string. Хотя использовать объекты string обычно проще, в данном
разделе мы рассматриваем ограниченные нулем строки-указатели. Многие
функции стандартной библиотеки C++ оперируют только такими строками,
работать с которыми сложнее, чем со объектами string. Кроме того, если вы
работаете с кодом, «доставшимся в наследство» от С и первых версий C++, вам
скорее всего придется иметь дело с этими строками-указателями.
8.13.1. Элементарные сведения о символах и строках
Символы — это «строительный материал» исходного кода программы
на C++. Любая программа составляется из последовательности символов,
которые (если они сгруппированы осмысленно) воспринимаются компьютером
как ряд инструкций, описывающих решение задачи. Программа может
содержать символьные константы. Символьная константа — это значение типа
int, представляемое в виде символа, заключенного в одинарные кавычки
(апострофы). Значением символьной константы является целое значение из набора
символов, используемых машиной. Например, V представляет целое
значение символа z A22 в наборе символов ASCII; см. приложение Б), а '\п
представляет целое значение символа новой строки A0 в наборе ASCII).
Строка является последовательностью символов, с которой обращаются как
с единым объектом. Строка может содержать буквы, цифры и различные
специальные символы, такие как +, —, *, /, $ и другие. В C++ строковые
литералы, или строковые константы заключаются в двойные кавычки:
552
Глава 8
"John Q. Doe" (имя)
"9999 Main Street" (дом и улица)
"Waltham, Massachusetts" (город и штат)
"B01) 555-1212" (номер телефона)
Строка-указатель в C++ является массивом символов, который
заканчивается нуль-символом (ЛО'). Доступ к строке осуществляется через указатель,
ссылающийся на ее первый символ. Значением строки является адрес ее
первого символа. Таким образом, в C++ правомерно сказать, что строка является
константным указателем, — на самом деле, указателем на первый символ
строки. В этом смысле строки подобны массивам, поскольку имя массива
также является указателем на его первый элемент.
Строковый литерал может быть использован в качестве инициализатора
либо символьного массива, либо переменной типа char *. Каждое из
объявлений
char color[] = "blue";
const char *colorPtr =;
инициализирует переменную строкой "blue". Первое объявление создает пя-
тиэлементный массив color, содержащий символы Ъ\ Т, 'и , V и '\0\ Второе
объявление создает переменную-указатель colorPtr, который указывает на
строку "blue" (оканчивающуюся нуль-символом), расположенную где-то в
памяти. Строковые литералы имеют статический класс памяти (они существуют
на протяжении всего периода выполнения программы) и могут быть либо
разделяемыми, либо нет, когда имеются ссылки на одинаковые литералы в
различных местах программы. Кроме того, строковые литералы в C++ являются
константами — их символы нельзя модифицировать.
Приведенное выше объявление char color[] = "blue"; можно также записать
как
char color[] = { 'b', '1', 'и', 'е', '\0' };
При объявлении массива символов для хранения строки он должен иметь
достаточный размер, чтобы вместить собственно строку и ограничивающий
нуль-символ. В приведенном объявлении размер массива определяется
автоматически, исходя из числа инициализаторов в списке.
Типичная ошибка программирования 8.15
Недостаточный размер символьного массива, выделенного для строки,
чтобы сохранить ограничивающий нуль-символ, является ошибкой.
Типичная ошибка программирования 8.16
Создание или использование строки в стиле С, которая не содержит
ограничивающего нуль-символа, может приводить к логическим
ошибкам.
Указатели и строки-указатели
553
^г* Предотвращение ошибок 8,4
ул^у Когда вы сохраняете строку в символьном массиве, убедитесь, что
размер его достаточен для хранения самой большой строки, с которой
предполагается работать. Язык C++ позволяет сохранять строку
любой длины. Если строка оказалась длиннее массива, в котором она
должна сохраняться, то символы, выходящие за размер массива,
перепишут данные в области памяти, следующей сразу за массивом.
Можно прочитать в массив строку, используя операцию извлечения с
потоком cin. Например, следующий оператор читает строку в символьный массив
word[ 20 ]:
cin » word;
Строка, введенная пользователем, сохраняется в word. Этот оператор будет
читать-символы до тех пор, пока не встретится пробельный символ или конец
файла. Обратите внимание, что длина строки не должна превышать 19
символов, чтобы оставалось место для ограничивающего нуль-символа. Чтобы
гарантировать, что читаемая в word строка не превысит размер массива, можно
применить манипулятор setw. Например, оператор
cin » setw( 20 ) » word;
специфицирует, что cin должен прочитать в массив word не более 19 символов
и резервировать 20-й элемент массива для ограничивающего нуль-символа
строки. Манипулятор потока setw применяется только к следующему
вводимому значению. Если вводится более 19 символов, оставшиеся символы не
сохраняются в массиве word, но могут быть прочитаны впоследствии и
сохранены в другой переменной.
В некоторых случаях желательно ввести в массив строку текста целиком.
Для этой цели в C++ предусмотрена функция cin.getline (заголовочный файл
<iostream>). В главе 3 была представлена похожая функция getline из
заголовочного файла <string>, которая читает символы, пока не будет прочитан
символ новой строки, и сохраняет ввод (без символа новой строки) в объекте
string, переданном функции в качестве аргумента. Функция cin.getline
принимает три аргумента — символьный массив, в котором будет сохраняться
строка текста, длина и символ-ограничитель. Например, фрагмент программы
char sentence[ 80 ];
cin.getline( sentence, 80, '\n' );
объявляет массив sentence из 80 символов и читает строку текста с клавиатуры
в этот массив. Функция прекращает ввод, когда либо встретит символ '\п', либо
будет введен признак конца файла, либо число уже прочитанных символов
будет на единицу меньше длины, специфицированной вторым аргументом.
(Последний символ массива резервируется для ограничивающего нуль-символа.)
Если встречается символ-ограничитель, он прочитывается и отбрасывается.
Третий аргумент cin.getline имеет значение по умолчанию, равное '\п> так что
предыдущий вызов функции можно было бы записать в виде
cin.getline( sentence, 80 );
554
Глава 8
В главе 15 проводится подробное рассмотрение cin.getline и других
функций ввода/вывода.
Типичная ошибка программирования 8.17
Обработка одиночного символа как символьной строки может
привести к фатальной ошибке времени выполнения. Строка — это
указатель, который, возможно, представляется весьма большим числом.
Символ же является небольшим целым (значения ASCII лежат в
диапазоне 0-255). На многих системах разыменование символа вызовет
ошибку, поскольку младшие адреса памяти резервируются для
специального использования — например, под вектора прерываний
операционной системы, — что приведет к «нарушению доступа».
Типичная ошибка программирования 8.18
Передача строки в качестве аргумента функции, которая ожидает
символ, приведет к ошибке компиляции.
8.13.2. Функции обработки строк из библиотеки <cstring>
Библиотека обработки строк предлагает много полезных функций для
работы со строковыми данными, сравнения строк, поиска в строках символов
и других строк, разбиения строк на лексемы (разделения строк на логические
единицы, такие, как слова в предложении) и определения длины строк. В этом
разделе представлены некоторые общеупотребительные функции для работы
со строками библиотеки обработки строк (из стандартной библиотеки). Сводка
этих функций представлена в таблице на рис. 8.30. Прототипы их находятся
в заголовочном файле <cstring>.
Прототип функции
Описание функции
char *strcpy( char *sl, const char *s2 );
Копирует строку s2 в массив символов si. Возвращает
значение si.
char *strncpy( char *sl, const char *s2, size__t n );
Копирует не более п символов из строки s2 в массив
символов si. Возвращает значение s1.
char *strcat( char *sl, const char *s2 );
Присоединяет строку s2 к строке si. Первый символ строки
s2 записывается поверх завершающего нулевого символа
строки si. Возвращает значение si.
char *strncat( char *sl, const char *s2, size_t n );
Присоединяет не более п символов строки s2 к строке si.
Первый символ из s2 записывается поверх завершающего
нулевого символа в si. Возвращает значение si.
Указатели и строки-указатели
555
Прототип функции Описание функции
int strcmp( const char *sl, const char *s2 )
Сравнивает строки si и s2. Функция возвращает значение О,
меньшее, чем 0 или большее, чем 0, если si соответственно
равна, меньше или больше, чем s2.
int strcmp( const char *sl, const char *s2, size_t n );
Сравнивает до п символов строки si со строкой s2. Функция
возвращает значение 0, меньшее, чем 0 или большее, чем О,
если si соответственно равна, меньше или больше, чем s2.
char *strtok( char *sl, const char *s2 );
Последовательность вызовов strtok разбивает строку si на
«лексемы» -логические единицы, такие, как слова в строке
текста - разделенные символами, содержащимися в строке s2.
Первый вызов содержит в качестве первого аргумента si,
а последующие вызовы для продолжения обработки той же
строки, содержат в качестве первого аргумента null. При
каждом вызове возвращается указатель на текущую лексему.
Если при вызове функции лексем больше нет, возвращается
NULL.
size t strlen( const char *s );
Определяет длину строки s. Возвращает число символов,
предшествующих завершающему нулевому символу.
Рис. 8.30. Функции работы со строками из библиотеки обработки строк
Заметьте, что некоторые функции на рис. 8.30 имеют параметры типа
size_t. Этот тип определяется в заголовочном файле <cstring> как
беззнаковый целый тип, такой, как unsigned int или unsigned long.
^ Типичная ошибка программирования 8.19
Если не включить заголовочный файл <cstring> при использовании
функций из библиотеки обработки строк, произойдет ошибка
компиляции.
Копирование строк с помощью strcpy и strncpy
Функция strcpy копирует свой второй аргумент (строку) в свой первый
аргумент — символьный массив, который должен быть достаточно большим,
чтобы хранить строку и ее завершающий нуль-символ, который также
копируется. Функция strncpy эквивалентна strcpy за исключением того, что
strncpy специфицирует число символов, которое должно быть скопировано из
строки в массив. Заметьте, что функция strncpy не обязательно должна
копировать завершающий нуль-символ своего второго аргумента; завершающий
нуль-символ записывается только в том случае, если число символов, которое
должно быть скопировано, по крайней мере на единицу больше длины строки.
Например, если второй аргумент — "test", завершающий нулевой символ
записывается только в случае, если третий аргумент strncpy равен, по меньшей
мере, 5 (четыре символа в "test" плюс один завершающий нулевой символ).
556
Глава 8
Если третий аргумент больше пяти, завершающий нулевой символ
добавляется к массиву до тех пор, пока не будет записано общее количество символов,
указанное третьим аргументом.
Типичная ошибка программирования 8.20
При использовании strncpy завершающий нуль-символ ее второго
аргумента не будет копироваться в первый аргумент, если третий
аргумент меньше или равен длине строки во втором аргументе. Это
может привести к фатальной ошибке, если только программист не
ограничит получившуюся строку нулем вручную.
В программе на рис. 8.31 strcpy (строка 17) используется для копирования
полной строки массива х в массив у, a strncpy (строка 23) — для копирования
первых 14 символов массива х в массив z. Строка 24 присоединяет к массиву z
нуль-символ С\0), так как вызов strncpy в этой программе не записывает
в массив завершающий нуль-символ (третий аргумент меньше, чем длина
строки второго аргумента плюс один).
1 // Рис. 8.31: fig08_31.cpp
2 // Использование strcpy и strncpy.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототипы для strcpy и strncpy
8 using std::strcpy;
9 using std::strncpy;
10
11 int main()
12 {
13 char x[] = "Happy Birthday to You"; // длина строки 21
14 char y[ 25 ];
15 char z[ 15 ];
16
17 strcpy( y, x ); // копировать содержимое х в у
18
19 cout « "The string in array x is: " « x
20 « "\nThe string in array у is: " « у « ' \n';
21
22 // копировать первые 14 символов х в z
23 strncpy( z, x, 14 ); //не копирует нуль-символ
24 z[ 14 ] = '\0'; // присоединить к содержимому z символ '\0'
25
26 cout « "The string in array z is: " « z « endl;
27 return 0; // показывает успешное завершение
28 } // конец main
The string in array x is: Happy Birthday to You
The string in array у is: Happy Birthday to You
The string in array z is: Happy Birthday
Рис. 8.31. Функции strcpy и strncpy
Указатели и строки-указатели
557
Конкатенация строк с помощью strcat и strncat
Функция strcat присоединяет свой второй аргумент (строку) к первому
аргументу — массиву символов, содержащему строку. Первый символ второго
аргумента замещает нулевой символ ('\0'), который завершал строку в первом
аргументе. Программист должен быть уверен, что массив, используемый для
хранения первой строки, достаточно велик для того, чтобы хранить
комбинацию первой строки, второй строки и завершающего нулевого символа
(скопированного из второй строки). Функция strncat присоединяет указанное
количество символов из второй строки к первой строке. К результату добавляется
завершающий нулевой символ. Программа на рис. 8.32 демонстрирует
функцию strcat (строки 19 и 29) и функцию strncat (строка 24).
1 // Рис. 8.32: fig08_32.cpp
2 // Использование strcat и strncat.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототипы для strcat и strncat
8 using std::strcat;
9 using std::strncat;
10
11 int main()
12 {
13 char sl[ 20 ] = "Happy "; // длина б
14 char s2[] = "New Year "; // длина 9
15 char s3[ 40 ] = "";
16
17 cout « "si = " « si « "\ns2 = " « s2;
18
19 strcat( si, s2 ); // присоединить s2 к si (длина 15)
20
21 cout « "\n\nAfter strcat(sl, s2):\nsl = "« si <<"\ns2 = "« s2 ;
22
23 // присоединить первые 6 символов si к s3
24 strncat( s3, si, 6 ); // помещает '\0' за последним символом
25
26 cout « "\n\nAfter strncat(s3, si, 6):\nsl = " « si
27 « "\ns3 = " « s3;
28
29 strcat( s3, si ); // присоединить si к s3
30 cout « "\n\nAfter strcat(s3, sl):\nsl = " « si
31 « "\ns3 = " « s3 « endl;
32 return 0; // показывает успешное завершение
33 } // конец main
si = Happy
s2 = New Year
After strcat(sl, s2):
si = Happy New Year
s2 = New Year
After strncat(s3, si, 6):
558
Глава 8
si = Happy New Year
s3 = Happy
After strcat(s3, si):
si = Happy New Year
s3 = Happy Happy New Year
Рис. 8.32. Функции strcat и strncat
Сравнение строк с помощью strcmp и strncmp
Программа на рис. 8.33 сравнивает три сроки, используя функции strcmp
(строки 21, 22 и 23) и strncmp (строки 26, 27 и 28). Функция strcmp
посимвольно сравнивает строку в своем первом аргументе со строкой в своем втором
аргументе. Функция возвращает 0, если строки равны, отрицательное
значение, если первая строка меньше, чем вторая, и положительное значение, если
первая строка больше, чем вторая. Функция strncmp эквивалентна strcmp, за
исключением того, что strncmp проводит сравнение только до указанного
количества символов. Функция strncmp завершает сравнение, если встречает
нуль-символ в одном из своих аргументов. Программа печатает целое
значение, возвращаемое при каждом вызове функции.
Типичная ошибка программирования 5.22
Предположение, что strcmp и strncmp возвращают 1 (истинное
значение), если их аргументы равны, является логической ошибкой. При
равенстве аргументов обе функции возвращают 0 (ложное значение
в C++). Поэтому при проверке двух строк на равенство результат
функции strcmp или strncmp должен для констатации равенства
строк сравниваться с 0.
1 // Рис. 8.33: fig08_33.cpp
2 // Использование strcmp и strncmp.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::setw;
9
10 #include <cstring> // прототипы для strcmp и strncmp
11 using std::strcmp;
12 using std::strncmp;
13
14 int main()
15 {
16 char *sl = "Happy New Year";
17 char *s2 = "Happy New Year";
18 char *s3 = "Happy Holidays";
19
20 cout « "si = " « si « "\ns2 = " « s2 « "\ns3 = " « s3
21 « "\n\nstrcmp(sl, s2) = " « setw( 2 ) « strcmp( si, s2 )
22 « "\nstrcmp(sl, s3) = " « setw( 2 ) « strcmp( si, s3 )
Указатели и строки-указатели
559
23 « "\nstrcmp(s3, si) = " « setw( 2 ) « strcmp( s3, si );
24
25 cout « "\n\nstrncmp(sl, s3, 6) = " « setw ( 2 )
26 « strncmp( si, s3, 6 ) «"\nstrncmp(si, s3, 7) = "« setw( 2 )
27 « strncmp( si, s3, 7 ) «"\nstrncmp (s3, si, 7) = "« setw( 2 )
28 « strncmp( s3, si, 7 ) « endl;
29 return 0; // показывает успешное завершение
30 } // конец main
si = Happy New Year
s2 = Happy New Year
s3 = Happy Holidays
strcmp(sl, s2) = 0
strcmp(sl, s3) = 6
strcmp(s3, si) = -6
strncmp(sl, s3, 6) = 0
strncmp(sl, s3, 7) = 1
strncmp(s3, si, 7) = -1
Рис. 8.33. Функции strcmp и strncmp
Чтобы понять, что означает «больше» или «меньше», когда речь идет
о строках, рассмотрим процесс расстановки имен по алфавиту. Читатель, без
сомнения, поставил бы "Jones" перед "Smith", потому что в алфавите первая
буква имени "Jones" стоит раньше первой буквы имени "Smith". Но
алфавит — это больше, чем просто список из 26 букв, — он упорядочивает список
символов. Каждая буква занимает внутри списка определенную позицию.
"Z" — это больше, чем просто буква алфавита; "Z" — это двадцать шестая
буква алфавита.
Откуда компьютер знает о порядке следования букв? Все символы
представляются внутри компьютера как численные коды; когда компьютер
сравнивает две строки, он на самом деле сравнивает численные коды символов
в строке.
Швд Переносимость программ 8.5
Ш Внутренний численный код, используемый для представления
символов, может быть различным для разных компьютеров, так как онц
могут работать с различными наборами символов.
Ш"=г| Переносимость программ 8.6
J] Не тестируйте явно ASCII-код, как, например, if( ch ==65 ); вместо
этого используйте соответствующую символьную константу,
например, if( ch == A' ).
В стремлении стандартизировать представление символов большинство
производителей компьютеров спроектировало свои машины так, чтобы
использовать одну из двух популярных схем кодировки — ASCII или EBCDIC.
ASCII означает «Американский стандартный код для обмена информацией»
(«American Standard Code for Information Interchange»), a EBCDIC означает
560
Глава 8
«Расширенный двоично-десятичный код обмена» («Extended Binary Coded
Decimal Interchange Code»), Существуют и другие схемы кодирования, но эти
две наиболее популярны.
ASCII и EBCDIC называют символьными кодами или наборами символов.
Большинство читателей этой книги будут работать с настольными и
переносными компьютерами, которые используют набор символов ASCII.
Магистральные системы IBM используют символьный набор EBCDIC. С распространением
Internet и World Wide Web растет популярность символьного набора Unicode.
За более подробной информацией о Unicode обратитесь на www.unicode.org.
Манипуляции со строками и символами на самом деле подразумевают
манипуляцию с соответствующими численными кодами, а не с самими символами.
Это объясняет взаимозаменяемость символов и небольших целых чисел в C++.
Так как имеет смысл говорить, что один численный код больше, меньше или
равен другому численному коду, стало возможным сопоставлять различные
строки и символы друг с другом путем ссылки на коды символов.
Приложение Б содержит список кодов символов ASCII.
Разбиение строки на лексемы с помощью strtok
Функция strtok используется для разбиения строки на ряд лексем.
Лексема (token) — это последовательность символов, отделенная от других лексем
символами-разделителями (обычно пробелами или знаками пунктуации).
Например, в строке текста каждое слово может рассматриваться как лексема,
а пробелы, отделяющие слова друг от друга, можно рассматривать как
разделители.
Для разбиения строки на лексемы требуется несколько вызовов функции
strtok (при условии, что строка содержит больше одной лексемы). Первый
вызов strtok содержит два аргумента: строку, которую нужно разбить на
лексемы, и строку, которая содержит символы, разделяющие лексемы (т.е.
разделители). Строка 19 на рис. 8.34 присваивает tokenPtr указатель на первую
лексему в sentence. Второй аргумент strtok, " " указывает, что лексемы в
sentence разделяются пробелами. Функция strtok находит первый символ в
sentence, не являющийся разделителем (пробелом). Это начало первой лексемы.
Затем функция находит следующий разделительный символ в строке и
заменяет его нуль-символом ('\0')- Этим заканчивается текущая лексема.
Функция strtok сохраняет указатель на следующий символ, находящийся в
sentence за данной лексемой, и возвращает указатель на текущую лексему.
1 // Рис. 8.34: fig08_34.cpp
2 // Использование strtok.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип для strtok
8 using std::strtok;
9
10 int main()
11 {
12 char sentence[] = "This is a sentence with 7 tokens";
13 char *tokenPtr;
Указатели и строки-указатели
561
14
15 cout « "The string to be tokenized is:\n" « sentence
16 « "\n\nThe tokens are:\n\n";
17
18 // начать разбиение предложения на лексемы
19 tokenPtr = strtok( sentence, " " );
20
21 // продолжать разбиение строки, пока tokenPtr не станет NULL
22 while ( tokenPtr != NULL )
23 {
24 cout « tokenPtr « ' \n';
25 tokenPtr = strtok( NULL, " " ); // получить следующую лексему
26 } // конец while
27
28 cout « "\nAfter strtok, sentence = " « sentence « endl;
29 return 0; // показывает успешное завершение
30 } // конец main
The string to be tokenized is:
This is a sentence with 7 tokens
The tokens are:
This
is
a
sentence
with
7
tokens
After strtok, sentence = This
Рис. 8.34. Функция strtok
Последующие вызовы strtok для продолжения разбиения sentence на
лексемы содержат в качестве первого аргумента NULL. Аргумент NULL
указывает, что вызов strtok должен продолжать разбиение на лексемы, начиная с
позиции в, сохраненной последним вызовом strtok. Если лексем при вызове
strtok больше не оказалось, strtok возвращает NULL. Программа на рис. 8.34
использует strtok для разбиения на лексемы строки "This is a sentence with 7
tokens". Каждая лексема печатается отдельно. Строка 28 выводит sentence
после завершения разбиения. Заметьте, что strtok модифицирует входную
строку; поэтому следует сделать копию строки, если программе после вызовов
strtok потребуется оригинал. Когда sentence выводится после разбиения на
лексемы, печатается только слово "This", так как strtok в процессе разбиения
заменила каждый пробел в sentence нуль-символом ('\0').
Типичная ошибка программирования 5.22
Непонимание того, что strtok изменяет разбиваемую на лексемы
строку, и последующая попытка использовать эту строку, как если
бы она была исходной не модифицированной строкой, является
логической ошибкой.
562
Глава 8
Определение длины строки
Функция strlen получает в качестве аргумента строку и возвращает число
символов в строке — завершающий нуль-символ в длину строки не
включается. Программа на рис. 8.35 демонстрирует функцию strlen.
1 // Рис. 8.35: fig08_35.cpp
2 // Использование strlen.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип для strlen
8 using std::strlen;
9
10 int main()
11 {
12 char *stringl = "abcdefghijklmnopqrstuvwxyz";
13 char *string2 = "four";
14 char *string3 = "Boston";
15
16 cout « "The length of \"" « stringl « "\" is "
17 « strlen( stringl )«"\nThe length of \""« string2« "\" is
18 « strlen( string2 )«"\nThe length of \""« string3« "\" is
19 « strlen( string3 ) « endl;
20 return 0; // показывает успешное завершение
21 } // конец main
The length of "abcdefghijklmnopqrstuvwxyz" is 26
The length of "four" is 4
The length of "Boston" is 6
Рис. 8.35. Функция strlen возвращает длину строки типа char *
8.14. Заключение
В этой главе мы представили подробное введение в указатели, или
переменные, которые содержат в качестве значений адреса памяти. Мы начали с
демонстрации того, как объявлять и инициализировать указатели. Вы увидели,
как используется операция взятия адреса (&) для присваивания указателю
адреса переменной и операция разыменования (*) для доступа к данным
переменной, косвенно адресуемой указателем. Мы обсудили передачу аргументов
по ссылке с помощью как аргументов-указателей, так и аргументов-ссылок.
Вы узнали, как использовать квалификатор const с указателями в
интересах принципа наименьших привилегий. Мы продемонстрировали
использование неконстантных указателей на неконстантные данные, неконстантных
указателей на константные данные, константных указателей на неконстантные
данные и константных указателей на константные данные. Затем на примере
выборочной сортировки мы продемонстрировали передачу массивов и их
отдельных элементов по ссылке. Мы обсудили операцию sizeof, с помощью
которой можно определять размеры типов данных в байтах во время компиляции
программы.
Указатели и строки-указатели
563
Мы продолжили демонстрацией того, как используются указатели в
арифметических выражениях и сравнениях. Вы увидели, как с помощью
арифметики указателей можно переходить от одного элемента массива к другому. Вы
узнали, как использовать массивы указателей и, в частности, строковые
массивы (массивы строк). Затем мы обсудили указатели на функцию,
позволяющие программистам передавать функции в качестве параметров. Заключили
мы главу обсуждением ряда функций C++, манипулирующих
строками-указателями. Вы узнали о таких возможностях обработки строк, как копирование,
разбиение на лексемы и определение длины строк.
В следующей главе мы начнем углубленное рассмотрение классов. Вы
узнаете об области действия элементов класса и о том, как поддерживать
объекты в согласованном состоянии. Вы также узнаете об использовании
специальных элемент-функций, называемых конструкторами и деструкторами,
которые исполняются соответственно при создании и уничтожении объектов.
Резюме
• Указатели являются переменными, которые содержат в качестве значений адреса
в памяти других переменных.
• Объявление
int *ptr;
объявляет ptr указателем на переменную типа int и читается «ptr есть указатель на
int». Знак *, используемый таким образом в объявлении, показывает, что
переменная является указателем.
• Указатель можно инициализировать тремя значениями: О, NULL либо адресом
соответствующего типа. Инициализация константой NULL эквивалентна
инициализации значением 0; в C++ по соглашению принято последнее.
• Нуль — единственное целое, которое можно непосредственно присвоить указателю
без приведения типа.
• Операция & (взятия адреса) возвращает адрес в памяти своего операнда.
• Операнд операции взятия адреса должен являться именем переменной (или другим
lvalue); операция не может применяться к константам или выражениям, которые не
дают в результате ссылку.
• Операция *, называемая операцией разыменования или операцией косвенной
адресации, возвращает синоним (т.е. псевдоним) для объекта, на который указывает ее
операнд-указатель. Это называется разыменованием указателя.
• При вызове функции с аргументом, который должен модифицироваться вызываемой
функцией, можно передать адрес этого аргумента. Вызываемая функция затем
использует операцию * для разыменования указателя и модификации значения
аргумента в вызывающей функции.
• Функция, принимающая в качестве аргумента адрес, для получения его должна
определять параметр-указатель.
• Квалификатор const дает возможность программисту информировать компилятор
о том, что значение некоторой переменной не должно изменяться через
специфицированный идентификатор. В случае попытки изменить значение константного
значения выдается либо предупреждение, либо сообщение об ошибке в зависимости от
конкретного компилятора.
564 , Глава 8
• Имеется четыре способа передать функции указатель — неконстантный указатель на
неконстантные данные, неконстантный указатель на константные данные,
константный указатель на неконстантные данные и константный указатель на
константные данные.
• Значением имени массива является адрес (указатель) первого элемента массива.
• Чтобы передать отдельный элемент массива по ссылке с помощью указателя,
передайте адрес требуемого элемента.
• В C++ предусмотрена унарная операция sizeof для определения во время
компиляции размера массива (а также любого типа данных, переменной или константы)
в байтах.
• Применяемая к имени массива, операция sizeof возвращает общее число байт в
массиве как значение типа size_t.
• К указателям могут применяться следующие арифметические операции: указатель
может быть инкрементирован (++) или декрементирован (—), к указателю может
быть прибавлено целое число (+ или +=), из указателя можно вычесть целое число
(— или —=) и можно вычислить разность двух указателей.
• При прибавлении или вычитании из указателя целого числа значение его
увеличивается или уменьшается на произведение числа на размер объекта, на который
указатель ссылается.
• Указатель может быть присвоен другому указателю, если оба указателя имеют один
и тот же тип. В противном случае нужно использовать операцию приведения типа.
Исключением из этого правила является указатель на void, обобщенный указатель,
который может представлять любой тип указателя. Указателю на void может быть
присвоен указатель любого типа. Указатель на может быть присвоен указателю
другого типа только с явным приведением типа.
• Допустимыми операциями над указателями типа void * являются сравнение с
другими указателями, приведение указателей void к действительным типам указателей
и присваивание адресов указателям void.
• Указатели могут сравниваться друг с другом при помощи операций равенства и
отношения. Сравнение указателей операциями отношения обычно не имеет смысла,
если они не ссылаются на элементы одного и того же массива. •
• Указатель, ссылающийся на массив, можно индексировать точно так же, как имя
массива.
• В нотации указатель/смещение, если указатель ссылается на начало массива,
смещение эквивалентно индексу массива.
• Все выражения с индексацией массивов могут быть преобразованы в выражения
с указателем и смещением, если использовать либо имя массива в качестве
указателя, либо отдельный указатель на массив.
• Массивы могут содержать указатели.
• Указатель на функцию является адресом начала программного кода функции.
• Указатели на функции могут передаваться в качестве аргументов функциям, могут
возвращаться функциями, сохраняться в массивах и присваиваться другим
указателям на функции.
• Одним из применений указателей на функцию являются так называемые системы,
управляемые меню. Указатели на функцию в них используются для выбора
функции, которую следует вызвать для конкретного пункта меню.
• Функция strcpy копирует свой второй аргумент (строку) в свой первый аргумент —
символьный массив. Программист должен предоставить для копирования массив
достаточно большой, чтобы в нем разместилась строка и ограничивающий ее
нуль-символ.
Указатели и строки-указатели
565
Функция strncpy эквивалентна strcpy за исключением того, что strncpy
специфицирует число символов, которое должно быть скопировано из строки в массив.
Завершающий нуль-символ записывается только в том случае, если число символов,
которое должно быть скопировано, по крайней мере на единицу больше длины строки.
Функция strcat присоединяет свой второй аргумент (строку) к первому аргументу —
массиву символов, содержащему строку. Первый символ второго аргумента замещает
нулевой символ ('\0'), который завершал строку в первом аргументе. Программист
должен быть уверен, что массив, используемый для хранения первой строки,
достаточно велик для того, чтобы хранить комбинацию первой строки и второй строки.
Функция strncat эквивалентна strcat за исключением того, что она присоединяет
указанное количество символов из второй строки к первой строке. К результату
добавляется завершающий нуль-символ.
Функция strcmp посимвольно сравнивает строку в своем первом аргументе со
строкой в своем втором аргументе. Функция возвращает 0, если строки равны,
отрицательное значение, если первая строка меньше, чем вторая, и положительное
значение, если первая строка больше, чем вторая.
Функция strncmp эквивалентна strcmp за исключением того, что strncmp проводит
сравнение только до указанного количества символов. Функция strncmp завершает
сравнение, если встречает нуль-символ в одном из своих аргументов.
Последовательность вызовов strtok разбивает строку на лексемы, отделенные друг
от друга символами, содержащимися в ее втором строковом аргументе. Первый
вызов специфицирует в качестве первого аргумента строку, которую требуется разбить
на лексемы. Последующие вызовы для продолжения разбиения специфицируют
в первом аргументе NULL. При каждом вызове функция возвращает указатель на
текущую лексему. Если при очередном вызове больше не оказывается лексем,
возвращается NULL.
Функция strlen получает в качестве аргумента строку и возвращает число символов
в строке — завершающий нуль-символ в длину строки не включается.
Терминология
& (операция взятия адреса)
* (косвенная адресация или операция
разыменования)
'\п (нуль-символ)
ASCII (Американский стандартный
код обмена информацией)
const с параметрами функции
EBCDIC (Расширенный двоично-
десятичный код обмена)
алгоритм сортировки выборкой
аргументы командной строки
арифметика указателей
бесконечная отсрочка
взаимозаменяемость массивов
и указателей
вызов функций по ссылке
вычитание указателей
декрементирование указателя
завершающий нуль-символ
инкрементирование указателя
конкатенация строк
константный указатель
константный указатель
на константные данные
константный указатель
на неконстантные данные
копирование строк
копирование строк
косвенная адресация
косвенная ссылка на значение
лексема
массив указателей на функцию
модификация адреса
в переменной-указателе
модификация константного указателя
неконстантный указатель
на константные данные
неконстантный указатель
на неконстантные данные
нулевой указатель
нуль-символ С\п)
ограниченная нулем строка
566
Глава 8
операция sizeof
операция взятия адреса (&)
операция косвенной адресации (*)
операция разыменования (*)
операция разыменования указателя (*)
передача по ссылке
с аргументом-ссылкой
передача по ссылке
с аргументом-указателем
прямая ссылка на значение
разбиваемая на лексемы строка
разбиение на лексемы
разыменование нулевого указателя
разыменование указателя
символ-ограничитель
символьная константа
символьный код
смещение указателя
специальные символы
сравнение строк
ссылка на константные данные
ссылка на элемент массива
строки-указатели
строковая константа
Контрольные вопросы
8.1. Заполните пропуски в следующих предложениях:
a) Указатель — это переменная, которая содержит в качестве своего значения
другой переменной.
b) Для инициализации указателя можно использовать три значения:
, или .
c) Единственным целым, которое может быть присвоено указателю, является
8.2. Укажите, верны или неверны следующие утверждения. Если утверждение
неверно, объясните, почему.
a) Операция взятия адреса может быть применима только к константам, к
выражениям, не дающим в качестве результата ссылки, и к переменным,
объявленным с классом памяти register.
b) Указатель, объявленный как void, может быть разыменован.
c) Указатели разных типов нельзя присваивать друг другу без операции
приведения типа.
8.3. Для каждого из следующих пунктов напишите операторы C++, выполняющие
указанную задачу. Предположите, что числа с плавающей запятой двойной
точности хранятся в 8 байтах и что начальный адрес массива в памяти равен
1002500. Каждая часть упражнения использует соответствующие результаты
предыдущих частей.
a) Объявите массив типа double с именем numbers с 10 элементами и
инициализируйте элементы значениями 0.0, 1.1, 2.2, ..., 9.9. Предположите, что
определена символическая константа SIZE, равная 10.
b) Объявите указатель nPtr, который указывает на объект типа double.
строковый массив
тип size_t
указатель на функцию
указатель функции
функция getline потока cin
функция islower (<cctype>)
функция strcat заголовочного файла
<cstring>
функция strcmp заголовочного файла
<cstring>
функция strcpy заголовочного файла
<cstring>
функция strlen заголовочного файла
<cstring>
функция strncat заголовочного файла
<cstring>
функция strncmp заголовочного
файла <cstring>
функция strncpy заголовочного файла
<cstring>
функция strtok заголовочного файла
<cstring>
функция toupper (<cctype>)
Указатели и строки-указатели
567
c) Напечатайте элементы массива numbers, используя оператор for и нотацию
индексов массива. Напечатайте каждое число с одной значащей цифрой
справа от десятичной точки.
d) Напишите два одиночных оператора, каждый из которых присваивает
начальный адрес массива numbers переменной-указателю nPtr.
e) Напечатайте элементы массива numbers, используя указатель nPtr.
f) Напечатайте элементы массива numbers, используя нотацию
указатель-смещение с именем массива как указателем.
g) Напечатайте элементы массива numbers, используя индексацию указателя
nPtr.
h) Сошлитесь на элемент 4 массива number, используя нотацию индекса
массива, нотацию указатель-смещение с именем массива как указателем, запись
индекса указателя nPtr и запись указатель-смещение с nPtr.
i) Предполагая, что nPtr указывает на начало массива numbers, определите, на
какой адрес ссылается выражение nPtr + 8? Какое значение хранится по
этому адресу?
j) Предполагая, что nPtr указывает на numbers[5], определите, на какой адрес
будет ссылаться nPtr после выполнения оператора nPtr —= 4. Какое значение
хранится по этому адресу?
8.4. Для каждого из следующих пунктов напишите один оператор, который
выполняет указанное задание. Предположите, что переменные с плавающей запятой
number 1 и number2 уже объявлены и что numberl инициализирована
значением 7.3. Кроме того, предположите, что переменная ptr имеет тип char*,
а 100-элементные массивы sin s2 — тип char.
a) Объявите переменную fPtr как указатель на объект типа double.
b) Присвойте адрес переменной numberl переменной-указателю fPtr.
c) Напечатайте значение объекта, на который указывает fPtr.
d) Присвойте значение объекта, на который указывает fPtr, переменной num-
ber2.
e) Напечатайте значение number2.
f) Напечатайте адрес numberl.
g) Напечатайте адрес, хранимый в fPtr. Совпадает ли напечатанное значение
с адресом numberl?
h) Скопируйте строку, хранящуюся в массиве s2, в массив si.
i) Сравните строку si со строкой s2.
j) присоедините 10 символов из строки s2 к строке si.
к) Определите длину строки si. Напечатайте результат.
1) Присвойте ptr позицию первой лексемы в s2. Лексемы в s2 разделены запятыми (,).
8.5. Проделайте указанное в каждом пункте:
a) Напишите заголовок функции exchange, которая получает в качестве
параметров два указателя на числа с плавающей точкой х и у и не возвращает
никакого значения.
b) Напишите прототип функции из пункта а).
c) Напишите заголовок функции evaluate, которая возвращает целое и которая
получает в качестве параметров целое и указатель на функцию poly. Функция
poly получает целый параметр и возвращает целое.
d) Напишите прототип функции из пункта с).
e) Напишите два различных оператора, инициализирующих массив символов
vowel строкой гласных "AEIOU".
568
Глава 8
8.6. Найдите ошибку в каждом из следующих фрагментов программ. Полагайте, что
int *zPtr; // zPtr будет указывать на массив z
int *aPtr = NULL;
void *sPtr = NULL;
int number, i;
int z[5]={l,2,3,4,5};
sPtr = z;
a) ++zptr;
b) // использование указателя для получения первого значения массива
number = zPtr;
c) // присваивание number значения элемента 2 массива (значения 3)
number = *zPtr[ 2 ] ;
d) // печать всего массива z
for ( i = 0; i <= 5; i++ )
cout « zPtr[ i ] « endl;
e) // присваивание значения, указываемого sPtr, переменной number
number = *sPtr;
f) ++z;
g) char s[ 10 ] ;
cout « strncpy( s, "hello", 5 ) « endl;
h) char s[ 12 ];
strcpy( s, "Welcome Home" );
i) if ( strcmp( stringl, string2 ) )
cout « "Строки равны" « endl;
8.7. Что печатается (если что-либо печатается) при выполнении каждого из
следующих операторов? Если оператор содержит ошибку, опишите ее и укажите, как ее
исправить. Предполагайте следующие объявления переменных:
char sl[ 50 ] = "jack";
s2[ 50 ] = "jill";
s3{ 50 ], *sptr;
a) cout « strcpy( s3, s2 ) « endl;
b) cout « strcat( strcat( strcpy( s3, si ), " and " ), s2 )
« endl;
c) cout « strlen( si ) + strlen( s2 ) « endl;
d) cout « strlen( s3 ) « endl;
Ответы на контрольные вопросы
8.1. а) адрес. Ь) О, NULL, адрес, с) О.
8.2. а) Ошибка. Операция адресации может быть применена только к переменным
и не может быть применена к константам, выражениям или переменным,
объявленным с классом хранения register.
b) Ошибка. Указатель на void не может быть разыменован, потому что не
существует способа узнать точно, сколько байтов памяти должно быть разыменовано.
c) Ошибка. Указателю на void можно присваивать все типы указателей без
приведения типа. Однако указатель на void может быть присвоен указателю
другого типа только явным приведением к типу соответствующего указателя.
8.3. a) double numbers [ SIZE ] =
{ 0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8, 9.9 };
b) double *nPtr;
Указатели и строки-указатели
569
c) cout « setiosflags( ios::fixed | ios::showpoint )
« setprecision( 1 );
for ( i = 0; i < SIZE; i++ )
cout « numbers [ 1 ] « '
d) nPtr = numbers;
nPtr =&numbers[ 0 ];
e) cout « setiosflags( ios::fixed | ios::showpoint )
« setprecision( 1 );
for ( i = 0; i < SIZE; i++ )
cout « * ( nPtr + i ) « ' ' ;
f) cout « setiosflags( ios::fixed | ios::showpoint )
« setprecision( 1 );
for ( i = 0; i < SIZE; i++ )
cout « * ( numbers + i ) « ' ' ;
g)cout « setiosflags( ios::fixed | ios::showpoint « setprecision ( 1 ) ;
for ( i = 0; i < SIZE; i++ )
cout « nPtr [ i ] « '
h) numbers[ 3 ]
*( numbers + 3 )
nPtr[ 3 ]
*( nPtr + 3 )
i) Адрес равен 1002500 + 8*8 = 1002564. Значение равно 8.8.
j) Адрес numbers [5] равен 1002500 + 5*8 = 1002540.
Адрес nPtr -= 4 равен 1002540 -4*8 = 1002508.
Значение равно 1.1.
8.4. a) double *fPtr;
b) fPtr = finumberl;
c) cout « "The value of *fPtr is " « *fPtr « endl;
d) number2 = *fPtr;
e) cout « "The value of number2 is " « number2 « endl;
f) cout « "The address of numberl is " « finumberl « endl;
g) cout « "The address stored in fPtr is " « fPtr « endl;
Да, значение то же самое.
h) strcpy( si, s2 );
i) cout « "strcmp(sl, s2) = " « strcmp( si, s2 ) « endl;
j) strncat( si, s2, 10 );
k) cout « "strlen(sl) = " « strlen( si ) « endl;
1) ptr = strtok( s2, "," ) ;
8.5. a) void exchange ( double *x, double *y )
b) void exchange ( double *, double * );
c) int evaluate ( int x, int ( *poly ) ( int ) )
d) int evaluate ( int, int (*) ( int ) ) ;
e) char vowel[] = "AEIOU";
char vowel [] = { 'A', 'E', 'I', 'O', 'U', '\0' };
8.6. а) Ошибка: zPtr не был инициализирован.
Исправление: присвоить zPtr начальное значение zPtr = z;
b) Ошибка: указатель не разыменован.
Исправление: изменить оператор на number = *zPtr;
570
Глава 8
c) Ошибка: zPtr[2] — не указатель и не может быть разыменован.
Исправление: изменить *zPtr[2] на zPtr[2].
d) Ошибка: ссылка с помощью индексации указателя на элемент массива,
находящийся вне его границ.
Исправление: изменить операцию отношения в структуре for на <, чтобы
избежать выхода за конец массива.
e) Ошибка: разыменование указателя void.
Исправление: чтобы разыменовать указатель, он сначала должен быть
приведен к целому указателю. Измените оператор на number = *( int * )sPtr;
f) Ошибка: попытка изменить имя массива с помощью арифметической
операции над указателем.
Исправление: или для выполнения арифметических действий с указателями
используйте вместо имени массива переменную-указатель, или индексируйте
имя массива, чтобы сослаться на отдельный элемент.
g) Ошибка: функция strncpy не записывает завершающий нулевой символ в
массив s, потому что ее третий аргумент равен длине строки "hello".
Исправление: сделайте третий аргумент strncpy равным 6 или присвойте s[ 5 ]
значение '\0', чтобы быть уверенным, что завершающий нулевой символ
добавляется к строке.
h) Ошибка: массив символов s недостаточно велик для хранения завершающего
нуль-символа.
Исправление: Объявите массив с большим числом элементов,
i) Ошибка: функция strcmp возвратит О, если строки равны, поэтому условие
в структуре if будет ложным и оператор вывода данных не будет выполнен.
Исправление: явно сравнить результат strcmp с 0 в условии структуры if.
8.7. a) jill
b) jack and jill
c) 8
d) 13
Упражнения
8.8. Укажите, являются ли следующие утверждения верными или неверными. Если
утверждение неверно, объясните, почему.
a) Не имеет смысла сравнивать два указателя, которые указывают на различные
массивы.
b) Поскольку имя массива является указателем на первый элемент массива,
имена массивов могут использоваться совершенно аналогично указателям.
8.9. Выполните следующие задания. Считайте, что целые числа без знака занимают
в памяти 2 байта, и что начальный адрес массива равен 1002500.
a) Объявите массив типа целое без знака с именем values, состоящий из 5
элементов, и инициализируйте элементы массива четными целыми числами от 2
до 10. Используйте символическую константу SIZE, равную 5.
b) Объявите указатель vPtr на объект типа unsigned int.
c) Выведите элементы массива values с использованием обращения к элементам
массива по методу имя массива/индекс. Используйте для этой цели цикл for
с управляющей переменной i, которую считайте определенной.
d) Запишите два оператора, при помощи которых можно присвоить начальный
адрес массива values указателю vPtr.
e) Выведите элементы массива values, используя нотацию указатель/смещение.
Указатели и строки-указатели
571
f) Выведите элементы массива values, используя нотацию указатель/смещение,
где в качестве указателя используется имя массива.
g) Выведите элементы массива values, используя индекс с указателем на массив.
h) Сошлитесь на 5-й элемент массива values, используя индексацию массива,
нотацию указатель/смещение с именем массива в качестве указателя,
индексацию указателя и нотацию указатель/смещение.
i) На какой адрес ссылается выражение vPtr + 3? Чему равно находящееся по
этому адресу значение?
j) Если предположить, что vPtr ссылается на values[4], чему будет равно
значение адреса, находящегося в vPtr, после выполнения оператора vPtr —= 4?
Какое значение находится по данному адресу?
8.10. Выполните следующие задания, написав для каждого по одному оператору.
Считайте, что переменные valuel и value2 типа long определены и переменной
valuel присвоено значение 200000.
a) Объявите указатель lPtr на объект данных типа long.
b) Присвойте значение адреса переменной valuel указателю lPtr.
c) Выведите значение объекта, на который ссылается указатель lPtr.
d) Присвойте значение объекта, на который ссылается lPtr, переменной value2.
e) Выведите значение value2.
f) Выведите адрес valuel.
g) Выведите значение адреса, находящееся в lPtr. Совпадает ли выведенное
значение с адресом valuel?
8.11. Выполните следующие задания.
a) Напишите заголовок функции zero, которая имеет параметром
целочисленный массив biglntegers типа long и не возвращает значение.
b) Напишите прототип для функции из предыдущего задания.
c) Напишите заголовок функции addAndSum, имеющей целочисленный массив
oneTooSmall в качестве параметра и возвращающей целое число.
d) Напишите прототип функции из предыдущего задания.
Замечание: Упражнения с 8.12 по 8.15 являются довольно сложными.
Но если вы с ними справитесь, то сможете легко программировать
популярные карточные игры.
8.12. Измените программу на рис. 8.27 так, чтобы функция раздачи сдавала по пять
карт для игры в покер. Затем напишите следующие дополнительные функции,
которые могут:
a) Определить, имеется ли на руках у игрока пара.
b) Определить, имеется ли на руках у игрока две пары.
c) Определить, имеется ли на руках тройка (например, три валета).
d) Определить, имеет ли игрок каре (например, четыре туза).
e) Определить, имеется ли на руках флеш (т.е. пять карт одной масти).
f) Определить, имеется ли на руках стрит (т.е. пять карт последовательных
номиналов).
8.13. Используя функции, разработанные в упражнении 8.12, напишите программу,
которая сдает двум игрокам в покер на руки по пять карт и оценивает, чья карта
лучше.
572
Глава 8
8.14. Измените программу, разработанную в упражнении 8.13, таким образом, чтобы
она исполняла роль сдающего. Карты сдающего кладутся «лицом вниз», так что
играющий с программой их не видит. Программа должна затем оценить карту
сдающего и, основываясь на качестве карт, сдающий должен взять себе одну, две
или три карты взамен не устраивающих его карт из первоначально розданных.
После этого программа должна оценить карты сдающего еще раз.
[Предостережение, Это трудная задача!]
8.15. Измените программу из упражнения 8.14 так, чтобы она манипулировала
картами сдающего, а играющий с программой решал бы сам, какие карты ему нужно
менять. Программа должна затем оценивать карты играющих и определять
победителя. Теперь сыграйте с этой программой 20 игр. Кто выиграет большее
количество игр, вы или компьютер? После этого пусть один из ваших друзей сыграет
еще 20 игр с компьютером. Кто выиграет большее количество игр? Основываясь
на результатах этих игр, сделайте соответствующие изменения, которые
позволили бы усовершенствовать вашу программу игры в покер (это также будет трудной
задачей). Сыграйте еще 20 игр. Не стала ли ваша программа играть лучше?
8.16. В программе тасования и сдачи карт, приведенной на рис. 8.25-8.27, мы
преднамеренно использовали неэффективный алгоритм тасования, который может
приводить к бесконечным отсрочкам. В связи с этой проблемой вам предстоит
создать быстродействующий алгоритм тасования, в котором этой опасности просто
не существует.
Модифицируйте программу на рис. 8.25-8.27следующим образом. Начните
с инициализации массива deck так, как показано на рис. 8.36. Измените
функцию shuffle таким образом, чтобы она в цикле по строкам и столбцам массива
перебирала элементы массива по разу и меняла местами значения текущего
элемента и случайно выбранного элемента массива.
Неперетасованный массив deck
0
1
2
3
0
1
14
27
40
1
2
15
28
41
2
3
16
29
42
3
4
17
30
43
4
5
18
31
44
5
6
19
32
45
6
7
20
33
46
7
8
21
34
47
8
9
22
35
48
9
10
23
36
49
10
11
24
37
50
11
12
25
38
51
12
13
26
39
52
Рис. 8.36. Неперетасованный массив deck
Выведите полученный в результате массив, чтобы определить, достаточно ли
хорошо перетасована колода (как, например, на рис. 8.37). Вы можете вызывать
в вашей программе функцию shuffle несколько раз, чтобы гарантировать
качество тасования.
Указатели и строки-указатели 573
Образец перетасованного массива deck
0
1
2
3
0
19
13
12
50
1
40
28
33
38
2
27
14
15
52
3
25
16
42
39
4
36
21
43
48
5
46
30
23
51
6
10
8
45
9
7
34
11
3
5
8
35
31
29
37
9
41
17
32
49
10
18
24
4
22
11
2
7
47
6
12
44
1
26
20
Рис. 8.37. Образец перетасованного массива deck
Заметим теперь, что хотя мы и улучшили алгоритм тасования, сдающий
алгоритм все равно имеет недостаток: он ищет в массиве deck карту с номером 1,
затем карту с номером 2, затем карту номер 3 и т.д. Положение ухудшается еще
и тем, что после того, как алгоритм раздачи нашел и сдал карту, он продолжает
поиск уже сданной карты в оставшейся части массива deck. Измените
программу из рис. 8.25-8.27 так, чтобы поиск прекращался, как только найдена нужная
карта, и после этого начинался процесс сдачи следующей карты. В главе 10 мы
разработаем эффективный алгоритм сдачи, который требует выполнения только
одной операции на карту.
8.17. (Компьютерное моделирование: Заяц и Черепаха) В этом упражнении вам
предстоит воспроизвести одно из великих исторических событий, а именно,
классический забег черепахи и зайца. Вам нужно будет использовать генератор
случайных чисел, чтобы разработать программу, моделирующую это незабываемое
соревнование.
Наши соперники начинают гонку в «квадрате 1» на дистанции, состоящей из 70
квадратов. Каждый квадрат представляет из себя возможную позицию на трассе
гонки. Финишная линия — это квадрат 70. Спортсмен, который достигнет или
проскочит квадрат 70 первым, вознаграждается ведром свежей моркови и
салата. Трасса забега проходит по склону скользкой горы, так что иногда соперники
поскальзываются и скатываются назад.
Движение соперников регулируется часами, делающими один отсчет в секунду.
Ежесекундно ваша программа должна корректировать позиции животных на
трассе согласно следующим правилам:
Животное
Черепаха
Заяц
Тип движения
Тащится быстро
Сползание
Тащится медленно
Спячка
Большой прыжок
Большое сползание
Малый прыжок
Малое сползание
Процент времени
50%
20%
30%
20%
20%
10%
30%
20%
Описание движения
3 квадрата вправо
6 квадратов влево
1 квадрат вправо
Движения нет
9 квадратов вправо
12 квадратов влево
1 квадрат вправо
2 квадрата влево
Рис. 8.38. Правила движения черепахи и зайца
574
Глава 8
Используйте переменные для хранения позиции животного на трассе (т.е. числа
величиной от 1 до 70). Каждое животное начинает свое движение с позиции 1.
Если животное соскальзывает за позицию 1, передвигайте его в начальную
позицию — квадрат 1.
Выбирайте тип движения в соответствии с частотными процентами,
приведенными в таблице, разыгрывая случайное целое число, i, в диапазоне 1 < i < 10.
Для черепахи «тащится быстро» выпадает в случае, когда 1 < i < 5,
«сползание» — когда 6 < i < 7 и «тащится медленно» — когда 8 < i < 10. Используйте
этот же метод для выбора движения зайца.
Начинайте забег с вывода сообщения
BANG !!!!!
AND THE'RE OFF MM!
Затем с каждым шагом часов (т.е. с каждым шагом цикла) выводите строку из
70 позиций, показывая символ Т (Tortoise) в позиции черепахи и символ Н
(Hare) — в позиции зайца. Часто соперники будут попадать в один и тот же
квадрат. В этом случае черепаха будет кусать зайца, а ваша программа должна
выводить сообщение "OUCH!!!", начиная с этого квадрата. Все остальные позиции,
кроме тех, где выведено Т, Н или OUCH!!!, должны быть пустыми.
После вывода очередной строки проверяйте, не удалось ли кому-либо из
животных достичь или перепрыгнуть квадрат с номером 70. Если это так, то выводите
имя победителя и заканчивайте процесс моделирования. Если победила
черепаха, выводите строку "TORTOISE WINS!!! YAY!!!" Если выиграл заяц, то строка
должна быть такой: "Hare wins. Yuch". Если оба животных приходят к финишу
одновременно, вы можете отдать предпочтение черепахе («аутсайдеру») или
вывести сообщение о том, что забег закончился вничью. Если на данном шаге никто
не достиг финиша, начинайте новый шаг цикла, соответствующий следующему
временному отсчету. Когда вы готовы будете выполнить вашу программу,
пригласите группу болельщиков, чтобы наблюдать за соревнованиями. Вы
удивитесь тому, как ваша аудитория будет увлечена происходящим!
Специальный раздел: как самому построить
компьютер
В следующих задачах мы временно отойдем далеко от программирования на
языке высокого уровня. Мы «снимем кожух» компьютера и рассмотрим его
внутреннее устройство. Мы познакомим вас с программированием на машинном
языке и напишем на нем несколько программ. И, чтобы сделать этот опыт
особенно ценным, мы затем «построим» компьютер (методом программного
моделирования), на котором вы сможете выполнять ваши программы на машинном
языке!
8.18. (Программирование на машинном языке) Мы создадим компьютер и назовем его
Симплетрон. Как следует из самого имени компьютера, это — простая машина,
но, как мы скоро в этом убедимся, машина мощная. Симплетрон выполняет
программы, написанные на единственном языке, который он способен понимать и
который мы назовем Машинным языком Симплетрона (Simpletron Mashine
Language), или сокращенно SML.
Симплетрон имеет аккумулятор — «специальный регистр», в который
помещается информация для выполнения вычислений или различных операций сравнения.
Вся информация в Симплетроне хранится в виде слов. Словом будем здесь
называть десятичное число из четырех цифр со знаком, например, +3364, -1293,
+0007, -0001 и т.д. Симплетрон имеет память размером в 100 слов, ссылка на
которые производится посредством чисел 00, 01, ..., 99.
Указатели и строки-указатели
575
Перед тем как запустить программу на SML, мы должны загрузить эту
программу в память. Первая команда любой программы на SML всегда помещается по
адресу 00.
Каждая команда SML занимает одно слово памяти Симплетрона (и,
следовательно, команды являются десятичными числами из четырех цифр со знаком). Мы
договоримся о том, что команды SML всегда имеют знак плюс, тогда как знак слова
данных может быть либо плюсом, либо минусом. Каждое слово в памяти
Симплетрона может содержать либо команду, либо данные, обрабатываемые программой,
или может быть неиспользуемым (в этом случае значение его не определено).
Первые две цифры каждой SML-команды — это код операции, которую нужно
выполнить. Допустимые коды операций SML представлены на рис. 8.39.
Код операции
Смысл
Операции ввода/вывода
const int READ = 10;
const int WRITE = 11;
Вводит слово с терминала в указанное место
памяти.
Выводит на терминал слово из указанного адреса
памяти.
Операции загрузки!выгрузки
const int LOAD = 20;
const int STORE = 21;
Помещает в аккумулятор слово из указанного
адреса памяти.
Выгружает слово из аккумулятора по указанному
адресу памяти.
Арифметические операции
const int ADD = 30;
const int SUBTRACT = 31;
const int DIVIDE = 32;
const int MULTIPLY = 33;
Выполняет сложение слова в аккумуляторе и слова
из указанного места в памяти (результат операции
остается в аккумуляторе).
Вычитает из слова в аккумуляторе слово из
указанного места в памяти (результат операции
остается в аккумуляторе).
Выполняет деление слова в аккумуляторе на слово
из указанного места в памяти (результат операции
остается в аккумуляторе).
Вычисляет произведение слова в аккумуляторе
и слова из указанного места в памяти (результат
операции остается в аккумуляторе).
Операции передачи управления
const int BRANCH = 40;
const int BRANCHNEG = 41;
const int BRANCHZERO = 42;
const int HALT = 43;
Переход к указанному адресу памяти.
Переход к указанному адресу памяти, если
в аккумуляторе находится отрицательное число.
Переход к указанному адресу памяти, если
в аккумуляторе находится ноль.
Останов, выполняется при завершении
программой своей работы.
Рис. 8.39. Коды операций SML- Машинного языка Симплетрона
576
Глава 8
Последние две цифры SML-команды — операнду являющийся адресом слова, над
которым выполняется операция. А теперь давайте разберем две простых
программы на SML.
SML-программа на рис. 8.40 считывает два числа, введенных с клавиатуры,
вычисляет их сумму и выводит ее. Команда +1007 вводит первое число и помещает
его в слово с адресом 07 (которое было инициализировано нулем). Затем команда
+1008 вводит следующее число и записывает его по адресу 08. Команда
загрузки, +2007, помещает первое число в аккумулятор, а команда сложения, +3008,
прибавляет второе число к числу, записанному в аккумуляторе. Все
арифметические команды SML оставляют результат вычислений в аккумуляторе. Команда
выгрузки, +2109, помещает результат, находящийся в аккумуляторе, обратно
в память по адресу 09, из которого команда вывода, +1109, выводит это число
(в виде десятичного целого числа из четырех цифр со знаком). Команда останова,
+4300, завершает выполнение программы.
Адрес
00
01
02
03
04
05
06
07
08
09
Число
+1007
+1008
+2007
+3008
+2109
+1109
+4300
+0000
+0000
+0000
Описание
(Ввод А)
(Ввод В)
(Загрузка А в аккумулятор)
(Прибавить В)
(Выгрузить в С)
(Вывод С)
(Останов)
(Переменная А)
(Переменная В)
(Результат С)
Рис. 8.40. Первый пример на SML
Следующая SML-программа (рис. 8.41) вводит с клавиатуры два числа,
определяет большее из них и выводит это значение. Обратите внимание на команду
+4107 — условную передачу управления, напоминающую оператор if в языке С.
Адрес
00
01
02
03
04
05
06
07
08
09
10
Число
+1009
+1010
+2009
+3110
+4107
+1109
+4300
+1110
+4300
+0000
+0000
Описание
(Ввод А)
(Ввод В)
(Загрузка А в аккумулятор)
(Вычесть В)
(Переход по минусу к 07)
(Вывод А)
(Останов)
(Вывод В)
(Останов)
(Переменная А)
(Переменная В)
Рис. 8.41. Второй пример на SML
Указатели и строки-указатели
577
Теперь сами напишите программы на SML, выполняющие следующие задачи.
a) Напишите цикл (прерываемый вводом контрольного значения) для ввода 10
положительных чисел, вычисления суммы этих чисел и ее вывода.
b) Используя управляемый счетчиком цикл, введите семь чисел,
положительных и отрицательных, а затем вычислите и выведите их среднее значение.
c) Введите ряд чисел, определите большее среди них и выведите найденное
значение. В первом вводимом числе указывается количество чисел, которые
должны быть обработаны.
8.19. (Симулятор компьютера) Вам это может показаться диким, но для решения
этой задачи вам нужно собрать свой собственный компьютер. Нет, вам не
придется брать в руки паяльник и отвертку. Вместо этого вы воспользуетесь
мощным методом компьютерного моделирования и создадите симулятор (т.е.
программную модель) Симплетрона. Вы не будете разочарованы. Программа-симу-
лятор Симплетрона превратит ваш компьютер в «настоящий» Симплетрон и вы
сможете исполнять, тестировать и отлаживать программы SML, которые вы
написали в упражнении 8.18.
При запуске вашего Симплетрона на экран должен выводиться примерно такой
текст:
*** Симплетрон приветствует вас! ***
*** Пожалуйста, введите вашу программу, по одной команде ***
*** (или слову данных) за раз. Я буду выводить в качестве ***
*** подсказки текущий адрес и знак вопроса (?). Введенное ***
*** вами слово будет размещено по указанному адресу. Для ***
*** прекращения ввода программы введите число -99999. ***
В качестве модели памяти Симплетрона объявите одномерный массив memory
из 100 элементов. Теперь представим, что наша симулятор запущен, и разберем
процесс ввода программы примера 2 из упражнения 8.18:
00?
01?
02?
03?
04?
05?
Об?
07?
08?
09?
10?
11?
• ••
• •*
+1009
+1010
+2009
+3110
+4107
+1109
+4300
+1110
+4300
+0000
+0000
-99999
Загрузка
Начинаю
программы
выполнение
завершена ***
программы ***
Программа SML теперь помещена (т.е. загружена) в массив memory. Теперь
Симплетрон должен выполнить вашу программу. Выполнение программы
начинается с команды, расположенной по адресу 00 и, подобно С, продолжается
последовательно, если не встретится команда передачи управления в другую часть
программы.
Для представления аккумулятора используйте переменную accumulator.
В переменной instructionCounter храните адрес следующей исполняемой
команды. Для хранения кода операции текущей исполняемой команды, т.е. левых
двух цифр слова команды, используйте переменную operationCode. В
переменной operand можно хранить адрес операнда текущей исполняемой команды.
Напомним, что адрес операнда — это две правые цифры командного слова. Не
выполняйте команды непосредственно из памяти. Используйте промежуточную
переменную instructionRegister для хранения исполняемой команды. И уже из
19 Зак. 1114
578
Глава 8
нее выделите две левые цифры кода операции, поместите их в переменную
operationCode, затем выделите правые две цифры адреса операнда команды
и поместите их в переменную operand. Перед тем, как Симплетрон начнет
выполнение программы, все специальные регистры должны быть
инициализированы нулями.
Теперь давайте «пройдем» выполнение первой SML-команды, +1009,
расположенной по адресу 00. Процесс выполнения команды называется циклом
исполнения команды.
В регистре команд instructionCounter расположен адрес следующей исполняемой
команды. Мы выбираем слово этой команды из массива memory с помощью
следующего оператора:
instructionRegister = memory[ instructionCounter ];
Извлечем из регистра команд код операции и адрес операнда, используя операторы
operationCode = instructionRegister / 100;
operand = instructionRegister % 100;
Теперь Симплетрон должен определить, что данному коду операции
соответствует команда ввода (а не вывода, загрузки и т.д.). Нужный выбор из двенадцати
возможных команд SML можно сделать в операторе switch.
В операторе switch различные SML-команды моделируются согласно описаниям
на рис. 8.42 (с остальными вы должны разобраться самостоятельно).
ввод: cin » memory [ operand ] ;
загрузка: accumulator = memory [ operand ] ;
сложение: accumulator += memory [ operand ] ;
команды передачи управления: мы обсудим их чуть позже
останов: эта команда выводит сообщение
*** Симплетрон закончил свои вычисления ***
Рис. 8.42, Поведение инструкций SML
По окончании работы Симплетрон выводит имя и содержимое каждого регистра
и своей памяти. Такая распечатка часто называется компьютерным дампом,
или дампом памяти. Формат дампа показан на рис. 8.43. Он поможет вам в
программировании функции, выводящей дамп памяти. Не забудьте, что после
выполнения Симплетроном программы дамп памяти должен отражать
фактические значения команд и данных на момент завершения программы.
Продолжим процесс разбора выполнения первой команды нашей программы,
а именно +1009, расположенной по адресу 00. Мы моделируем команду ввода
в структуре switch при помощи оператора C++
cin » memory[ operand ];
Перед исполнением этого оператора на экран должен быть выведен знак вопроса
(?) в качестве запроса ввода данных. Симплетрон ждет до тех пор, пока
пользователь не введет число и не нажмет клавишу Enter. Введенное значение будет
помещено в ячейку памяти с адресом 09.
На этом выполнение первой команды завершается. Остается только подготовить
Симплетрон к выполнению следующей команды. Так как команда, которую мы
только что выполнили, не является командой передачи управления, нам нужно
просто увеличить регистр счетчика команд:
++instructionCounter;
Указатели и строки-указатели
579
РЕГИСТРЫ
accumulator
instructionCounter
instructionRegister
operationCode
operand
ПАМЯТЬ:
0
0 +0000
10 +0000
20 +0000
30 +0000
40 +0000
50 +0000
60 +0000
70 +0000
80 +0000
90 +0000
1
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
2
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
00
+0000
00
00
3 4
+0000 +0000
+0000 +0000
+0000 +0000
+0000 +0000
+0000 +0000
+0000 +0000
+0000 +0000
+0000 +0000
+0000 +0000
+0000 +0000
5
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
6
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
7
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
8
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
9
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
+0000
Рис. 8.43. Пример дампа памяти
На этом выполнение первой команды завершается полностью. После этого весь
процесс (т.е. цикл исполнения команды) начинается снова с выборки из памяти
следующей исполняемой команды.
Теперь давайте рассмотрим моделирование команд перехода (передачи
управления). Все, что мы должны сделать — это правильно скорректировать значение
регистра счетчика команд. Безусловная команда перехода D0) моделируется
в операторе switch как
instructionCounter = operand;
Условная команда перехода «переход, если аккумулятор — ноль» может быть
реализована следующими операторами:
if ( accumulator == 0 )
instructionCounter = operand;
Теперь можете приступать к написанию программы — модели Симплетрона,
через которую вы должны пропустить все программы, разработанные в
упражнении 8.18. Вы можете добавить в SML какие-либо усовершенствования, но не
забудьте включить их и в модель Симплетрона.
Ваш симулятор должен уметь обрабатывать различные ошибки. Например, при
вводе программы входные данные должны находится в интервале от —9999 до
+9999. Поэтому ввод данных должен происходить внутри цикла while, в
котором производится проверка введенной величины и, если введено неверное
значение, процесс ввода должен продолжаться до тех пор, пока пользователь не введет
верное значение.
Во время выполнения программы симулятор должен обрабатывать различные
серьезные ошибки, например, попытку деления на ноль, попытку выполнить
команду с неправильным кодом операции, переполнение аккумулятора (т.е.
получение в процессе вычислений величины большей +9999 или меньшей —9999)
и другие. Такие серьезные ошибки называются фатальными ошибками. В
случае возникновения такой ошибки симулятор должен выдать сообщение вроде
580
Глава 8
*** Попытка деления на ноль ***
*** Симплетрон аварийно завершил выполнение программы ***
и выдать полный дамп памяти в формате, предложенном выше. Этот дамп может
помочь пользователю обнаружить ошибку в программе.
Упражнения с указателями
8.20. Модифицируйте программу тасования и сдачи карт из рис. 8.25-8.27 так, чтобы
процесс тасования и сдачи выполняла бы одна функция (shuffleAndDeal).
Подобно функции shuffle из рис. 8.26 эта функция должна содержать один
вложенный цикл.
8.21. Что делает эта программа?
1 // Упр. 8.21: ех08_21.срр
2 // Что делает эта программа?
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 void mysteryl( char *, const char * ); // прототип
9
10 int main()
11 {
12 char stringl[ 80 ];
13 char string2[ 80 ];
14
15 cout « "Enter two strings:
16 cin » stringl » string2;
17 mysteryl( stringl, string2 );
18 cout « stringl « endl;
19 return 0; // показывает успешное завершение
20' } // конец main
21
22 // Что делает эта функция?
23 void mysteryl( char *sl, const char *s2 )
24 {
25 while ( *sl != '\0' )
26 ++sl;
27
28 for ( ; *sl = *s2; sl++, s2++ )
29 ; // пустой оператор
30 } // конец функции mysteryl
8.22. Что делает эта программа?
1 // Упр. 8.22: ех08_22.срр
2 // Что делает эта программа?
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 int mystery2( const char * ); // прототип
9
10 int main()
11 {
12 char stringl[ 80 ];
13
14 cout « "Enter a string: ";
15 cin » stringl;
16 cout « mystery2( stringl ) « endl;
17 return 0; // показывает успешное завершение
Указатели и строки-указатели
581
18 } // конец main
19
20 // Что делает эта функция?
21 int mystery2( const char *s )
22 {
23 int x;
24
25 for ( x = 0; *s != '\0'; s++ )
26 ++x;
27
28 return x;
29 } // конец функции mystery2
8.23. Найдите ошибку в каждом из следующих программных фрагментов. Если
ошибку можно исправить, объясните, как это сделать.
a) int *number;
cout « number « endl;
b) double *realPtr;
long *integerPtr;
integerPtr = realPtr;
c) int *x, y;
x = y;
d) char s[] = "this is a character array";
for ( ; *s != '\0'; s++ )
cout « *s « ' ';
e) short *numPtr, result;
void *genericPtr = numPtr;
result = *genericPtr + 7;
f) double x = 19.34;
double xPtr = fix;
cout « xPtr « endl;
g) char *s;
cout « s « endl;
8.24. (Быстрая сортировка) В примерах и упражнениях главы 6 мы обсуждали
алгоритмы сортировки, такие, как пузырьковая или блочная сортировка. Мы
представим вам теперь рекурсивный алгоритм сортировки, называемый быстрой
сортировкой. Алгоритм для одномерного массива выглядит следующим образом:
a) Шаг разбиения: Возьмите первый элемент несортированного массива и
определите его расположение в сортированном массиве. Это положение будет
найдено, если все значения слева от данного элемента будут меньше, а все значения
направо от элемента — больше значения данного элемента. Мы теперь имеем
один элемент, расположенный на своем месте в сортированном массиве, и два
несортированных подмассива.
b) Шаг рекурсии: Выполните шаг 1 на каждом из несортированных под массивов.
Каждый раз после выполнения шага 1 на подмассиве следующий элемент
массива помещается на свое место в сортированном массиве, и создаются два
несортированных подмассива. Когда мы дойдем до подмассива, состоящего из одного
элемента, этот элемент будет находится на своем окончательном месте в
упорядоченном массиве.
Это описание алгоритма в целом кажется достаточно ясным, но как нам
определить окончательную позицию первого элемента каждого подмассива? В качестве
примера рассмотрим следующий набор значений:
37 2 6 4 89 8 10 12 68 45
582
Глава 8
a) Начиная с правого элемента массива, будем сравнивать каждый элемент с
числом 37 до тех пор, пока не будет найден элемент, меньший 37, после чего
найденный элемент и 37 должны поменяться своими местами. Первым
элементом, который меньше 37, является число 12, поэтому они меняются местами.
Теперь массив выглядит так:
12 2 6 4 89 8 10 37 68 45
b) Элемент 12 выделен курсивом, чтобы указать на то, что он поменялся местами
с числом 37. 2) Теперь начинаем движение с левой части массива, но начинаем
со следующего элемента после 12, и сравниваем каждый элемент с 37, пока не
обнаружим элемент, больший 37, после чего меняем местами 37 и этот
найденный элемент. В нашем случае первый элемент, больший 37 — это 89, так
что 37 и 89 меняются местами. Новый массив имеет вид:
12 2 6 4 37 8 10 89 68 45
c) Теперь начинаем справа, но начинаем с элемента, предшествующего 89, и
сравниваем каждый элемент с 37 до тех пор, пока не найдем элемент, меньший 37,
и опять поменяем местами 37 и этот элемент. Первый элемент, который
меньше 37 — это 10, — меняем местами с 37. Теперь наш массив имеет вид:
12 2 6 4 10 8 37 89 68 45
d) Теперь начинаем движение с левой части массива, но начинаем с элемента,
следующего за 10, и сравниваем каждый элемент с 37, пока не обнаружим
элемент, больший 37, после чего меняем местами 37 и этот найденный
элемент. В нашем случае элементов, больших 37, не осталось, и когда мы
сравним 37 с самим собой, это будет означать, что процесс закончен и элемент 37
нашел свое окончательное место.
После завершения этой операции мы имеем два неупорядоченных подмассива.
Подмассив со значениями меньше 37 содержит элементы 12, 2, 6, 4, 10 и 8. Под-
массив со значениями большими 37 содержит 89, 68 и 45. Сортировка
продолжается путем применения алгоритма разбиения к полученным подмассивам, как
это делалось с первоначальным массивом.
На основе описанного выше алгоритма напишите рекурсивную функцию
quicksort, сортирующую одномерный целочисленный массив. Функция должна
иметь параметрами целочисленный массив, начальное значение индекса и
конечное значение индекса. Функция quicksort должна вызывать функцию
partition, выполняющую разбиение массива.
8-25. (Обход лабиринта) Приведенная ниже сетка символов — двумерный массив,
представляющий лабиринт.
#...# #
# #.#
# #...#
############
Рис. 8.44. Представление лабиринта в виде двумерного массива
Указатели и строки-указатели
583
Символами # обозначены стенки, а точками — дорожки в лабиринте.
Существует простой алгоритм прохода через лабиринт, который гарантирует,
что вы найдете выход (если он, конечно, существует). Если лабиринт не имеет
выхода, то вы вернетесь к тому месту, из которого вышли. Касайтесь правой
рукой стены (которая находится справа от вас) и начинайте движение вперед. Все
время касайтесь рукой стены. Если лабиринт поворачивает направо, вы должны
следовать за поворотом стены направо. И если вы не будете отпускать руку, то
в конечном счете вы доберетесь до выхода из лабиринта. Возможно, существует
и более короткий путь, чем тот, которым вы прошли, но указанный метод в
любом случае гарантирует вам выход из лабиринта.
Напишите рекурсивную функцию mazeTraverse прохода через лабиринт.
Функция должна получать в качестве аргументов массив символов 12 на 12,
представляющий лабиринт, и отправную точку. В процессе поиска выхода из лабиринта
mazeTraverse помещает символ X в каждый пройденный квадрат пути.
Функция должна перерисовывать лабиринт после каждого перемещения, чтобы
пользователь мог наблюдать процесс решения задачи.
8.26. (Генератор случайных лабиринтов) Напишите функцию mazeGenerator,
имеющую параметром двумерный символьный массив 12 на 12, которая
генерирует лабиринт при помощи случайных чисел. Функция должна производить
лабиринты, имеющие вход и выход. Испытайте вашу функцию mazeTraverse из
упражнения 8.25 на нескольких лабиринтах.
8.27. (Лабиринты произвольного размера) Обобщите функции mazeTraverse и maze-
Generator из упражнений 8.25 и 8.26 для работы с лабиринтами произвольной
ширины и высоты.
8.28. (Усовершенствование симулятора Симплетрона) В упражнении 8.19 вы
написали программную модель компьютера, которая может исполнять программы
на Машинном языке Симплетрона (SML). В этом упражнении мы предлагаем
вам ввести в модель Симплетрона несколько усовершенствований и расширений.
В упражнениях 12.26 и 12.27 мы предложим вам написать компилятор,
транслирующий программы на языке высокого уровня (разновидности BASIC) в
программы на Машинном языке Симплетрона. Некоторые из следующих
усовершенствований и расширений могут потребоваться для выполнения программ,
порожденных этим компилятором.
a) Увеличьте память Симплетрона до 1000 единиц, чтобы он мог выполнять
программы большего размера.
b) Добавьте в Симплетрон возможность взятия значений по модулю. Для этого
потребуется ввести в Машинный язык Симплетрона новый код операции.
c) Добавьте в Симплетрон возможность вычисления степени числа. Для этого
также потребуется ввести новый код операции в SML.
d) Замените десятичные числа шестнадцатеричными при кодировании операций
bSML.
e) Добавьте в Симплетрон возможность вывода новой строки, для чего введите
новый код операции в SML.
f) Внесите необходимые изменения в программу-симулятор, чтобы Симплетрон,
кроме целых, мог обрабатывать числа с плавающей точкой.
g) Добавьте в Симплетрон возможность ввода строк. [Подсказка. Каждое слово
Симплетрона может быть разделено на две части, каждая из которых
является числом из двух цифр. Используйте эти числа для представления
десятичного эквивалента ASCII-кода символа. Введите в машинный язык новую
операцию, которая осуществляет ввод строки и ее запись по определенному адресу
в памяти Симплетрона. При этом в первую половину первого машинного
слова, из числа отведенных для хранения строки, записывается количество сим-
584
Глава 8
волов в строке, т.е. длина строки. Каждое из последующих полуслов
используется для хранения десятичного ASCII-кода символа. Эта новая машинная
операция должна преобразовывать каждый вводимый символ в
соответствующий ASCII-код и записывать его в половину слова.]
h) Добавьте в Симплетрон возможность вывода строк, хранящихся в памяти по
формату из задания (g). Совет: введите в машинный язык новую инструкцию
вывода строки, расположенной по указанному адресу памяти. В первой
половине первого слова записано количество символов в строке (т.е. длина строки).
Каждое из последующих полуслов содержит десятичные ASCII-коды
символов строки. Машинная инструкция проверяет длину строки, преобразует
десятичное число в соответствующий символ и выводит его.
8.29. Что делает эта программа?
1 // Упр. 8.29: ех08_29.срр
2 // Что делает эта программа?
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 bool mystery3( const char *, const char * ); // прототип
9
10 int mainQ
11 {
12 char stringl[ 80 ], string2[ 80 ];
13
14 cout « "Enter two strings: ";
15 cin » stringl » string2;
16 cout « "The result is " « mystery3 ( stringl, string2 ) « endl;
17 return 0; // показывает успешное завершение
18 } // конец main
19
20 // Что делает эта функция?
21 bool mystery3( const char *sl, const char *s2 )
22 {
23 for ( ; *sl != '\0' && *s2 != '\0■; sl++, s2++ )
24
25 if ( *sl != *s2 )
26 return false;
27
28 return true;
29 } // конец функции mystery3
Упражнения по обработке строк
[Замечание. Следующие задачи должны решаться с применением
строк-указателей в стиле С]
8.30. Напишите программу, которая использует функцию strcmp для сравнения двух
строк, введенных пользователем. Программа должна определить, является ли
первая строка меньшей, равной или большей второй строки.
8.31. Напишите программу, которая использует функцию strcnmp для сравнения
двух строк, введенных пользователем. Программа должна вводить число
сравниваемых символов. Программа должна определить, является ли первая строка
меньшей, равной или большей второй строки.
Указатели и строки-указатели
585
8.32. Напишите программу, которая использует генератор случайных чисел для
создания предложений. Программа должна использовать четыре массива
указателей на char с именами article (артикль), noun (существительное), verb (глагол)
и preposition (предлог). Программа должна создавать предложения, выбирая
случайным образом слова из массивов в следующем порядке: article, noun, verb,
preposition, article и noun. После выбора очередного слова выполняется
конкатенация с предыдущим словом в массиве, который должен быть достаточно
большим, чтобы уместить полное предложение. Слова должны отделяться
пробелами. Заключительное предложение при выводе должно начинаться с заглавной
буквы и оканчиваться точкой. Программа должна образовать 20 таких
предложений.
В массивах должны содержаться следующие слова: article должен содержать
артикли "the", "a", "one" (один), "some" (некоторые), и "any" (любой); noun
должен содержать существительные "boy" (юноша), "girl" (девушка), "dog"
(собака), "town" (город) и "саг" (автомобиль); verb должен содержать глаголы
"drove" (ехал), "jumped" (подпрыгнул), "ran" (побежал), "walked" (шел)
и "skipped" (скакал); preposition должен содержать предлоги "to" (к), "from"
(от), "over" (через) и "on" (на).
Когда программа будет написана и отлажена, измените ее так, чтобы она создала
короткий рассказ, состоящий из нескольких таких предложений.
8.33. (Лимерики) Лимерик — юмористическое стихотворение из пяти строк, в
котором первая и вторая строки рифмуются с пятой, а третья рифмуется с четвертой.
Используя методику, рассмотренную в упражнении 8.32, напишите программу,
которая производит случайные стихотворения. Отладка программы до уровня,
на котором она создавала бы хорошие стихотворения, является серьезной и
увлекательной проблемой, но результат будет стоить усилий!
8.34. Напишите программу, которая переводит английские фразы во фразы
«свинячьей латыни». Свинячья латынь — это форма кодированного языка, который часто
используется в развлекательных целях. Существует много вариаций методов
формирования фраз. Для простоты используйте следующий алгоритм.
Для формирования фразы свинячьей латыни из фразы английского языка
разбейте последнюю на слова (лексемы), используя функцию strtok. Чтобы
перевести каждое английское слово в слово свинячьей латыни, поместите первый
символ слова в конец и добавьте буквы "ау". Таким образом, слово "jump"
становится "umpjay", слово "the" становится словом "hetay" и слово "computer"
становится "omputercay". Пробелы между словами остаются пробелами.
Предположим следующее: английская фраза состоит из слов, разделенных
пробелами, отсутствуют любые знаки препинания и все слова имеют два или большее
число символов. Функция printLatinWord должна выводить каждое слово.
Подсказка: каждый раз, когда при обращении к функции strtok найдена очередная
лексема, передайте указатель лексемы функции printLatinWord и выведите
получившееся слово.
8.35. Напишите программу, которая вводит телефонный номер как строку в формате
E55) 555-5555. Программа должна использовать функцию strtok, чтобы
извлекать в качестве лексем код региона, первые три цифры номера телефона и
последние четыре цифры номера телефона. Семь цифр номера телефона должны
объединяться в одну строку операцией конкатенации. Программа должна
преобразовать строку кода региона в тип int, а строку номера телефона в тип long.
И код региона и номер должны быть выведены на печать.
8.36. Напишите программу, которая вводит строку текста, разбивает ее на лексемы
с помощью функции strtok и выводит лексемы в обратном порядке.
586
Глава 8
8.37. Используйте функции сравнения строк, рассмотренные в разделе 8.13.2, и
методы сортировки массивов, развитые в главе 7, чтобы написать программу
алфавитной сортировки списка строк. В качестве данных используйте названия 10 -
15 городов вашей области.
8.38. Напишите по две версии функций копирования и конкатенации строк,
приведенных на рис. 8.30. Первая версия должна использовать индексацию массива,
а вторая версия должна использовать указатели и арифметические операции над
указателями.
8.39. Напишите две версии для каждой из функций сравнения строк, приведенных на
рис. 8.30. Первая версия должна использовать индексацию массива, а вторая
версия должна использовать указатели и арифметические операции над
указателями.
8.40. Напишите две версии функции strlen, приведенной на рис. 8.30. Первая версия
должна использовать индексацию массива, а вторая — указатели и
арифметические операции над указателями.
Специальный раздел: сложные упражнения
со строками
Предыдущие упражнения важны для понимания текста главы и разработаны,
чтобы проверить понимание читателем основных принципов, применяемых при
обработке строк. Данный раздел включает рад задач средней и повышенной
сложности. Читатель может найти некоторые из них чересчур сложными,
однако их решение должно принести определенное удовлетворение. Задачи
существенно различаются по сложности. Некоторые требуют всего одного или двух
часов для написания и отладки программы. Другие полезны для лабораторных
занятий; для их решения могут потребоваться две или три недели. Некоторые
задачи могут послужить основой курсового проекта.
8.41. (Анализ текста) Доступность компьютеров с возможностями обработки строк
сделала реальными довольно интересные идеи относительно анализа текстов
великих авторов. Много внимания было сосредоточено на том, существовал ли
вообще Вильям Шекспир. Некоторые ученые полагают, что имеются достоверные
указания на то, что автором шедевров, приписываемых Шекспиру, является
Кристофер Марло. Исследователи применяли компьютеры, чтобы найти
совпадения в текстах эти двух авторов. Данное упражнение исследует три метода
компьютерного анализа текстов.
a) Напишите программу, которая читает несколько строк текста и выводит
таблицу, показывающую число вхождений каждого символа алфавита в текст.
Например, фраза
То be, or not to be: that is the question:
содержит один символ "а", два "b", ни одного "с" и т.д.
b) Напишите программу, которая читает несколько строк текста и выводит
таблицу, показывающую число слов в тексте, содержащих один символ, два
символа, три символа и т.д. Например, фраза
Whether 'tis nobler in the mind to suffer
содержит
Указатели и строки-указатели
587
Длина слова
1
2
3
4
5
6
7
Число слов
0
2
2
2 (включая 'tis)
0
2
1
с) Напишите программу, которая читает несколько строк текста и выводит
таблицу, показывающую число вхождений в текст каждого слова. Первый
вариант вашей программы должен включать слова в таблицу в том же самом
порядке, в котором они появляются в тексте. Более интересной (и полезной)
является таблица, в которой слова сортируются в алфавитном порядке.
Например, строки
То be, or not to be: that is the guestion:
Whether 'tis nobler in the mind to suffer
содержат три слова "to", два слова "be", одно слово "or" и т.д.
8.42. (Обработка текстов) Детальное рассмотрение обработки строк в этой главе
в значительной степени обязано захватывающему росту в последнее время числа
приложений обработки текстов. ОДной из важных функций в системах
обработки слов является функция выравнивания — выравнивание слов по левому и
правому полям страницы. Она генерирует профессионально выглядящий документ,
который производит впечатление, что его скорее напечатали в типографии, чем
подготовили на пишущей машинке. Выравнивание может быть выполнено на
компьютерной системе, если вставить один или большее количество символов
пробела между словами в строке таким образом, чтобы самое правое слово
выравнивалось по правому полю.
Напишите программу, которая читает несколько строк текста и печатает этот
текст в выровненном формате. Предположим, что текст должен быть напечатан
на бумаге шириной 8 1/2 дюймов, а с левой и правой стороны напечатанной
страницы должны оставаться поля шириной в один дюйм. Предположим также, что
компьютер печатает 10 символов на дюйм по горизонтали. Следовательно, ваша
программа должна выводить текст шириной 6 1/2 дюймов, что соответствует 65
символам в строке.
8.43. (Печать дат в различных форматах) Даты в деловой корреспонденции
печатаются, как правило, в нескольких различных форматах. Двумя из наиболее
распространенных форматов являются:
07/21/55 и July 21, 1955
Напишите программу, которая читает дату в первом формате и выводит во
втором.
8.44. (Защита чеков) Компьютеры часто используются в системах печати чеков,
например, при расчете зарплат и оплате счетов. Циркулирует много странных
историй, относящихся к ошибочной выдаче чеков еженедельных зарплат на суммы
более одного миллиона долларов. Сверхъестественные суммы напечатаны
автоматизированными системами из-за ошибки человека и/или из-за отказа
машины. Проектировщики, конечно, прилагают все усилия, чтобы встроить в свои
системы средства контроля, предотвращающие ошибочную выдачу чеков.
588
Глава 8
Другая серьезная проблема — намеренное дописывание суммы чека
мошенником, который предполагает получить наличные деньги по подложному чеку.
Чтобы предотвратить дописывание суммы, большинство автоматизированных
денежных систем используют методику, которая называется защитой чеков.
Чеки, разработанные для компьютерного вывода, содержат фиксированное
число пробелов, в которых компьютер может печатать сумму. Предположим, что
платежный чек содержит восемь пустых полей, в которых компьютер печатает
еженедельную сумму выплаты. Если сумма большая, то будут заполнены все
восемь полей, например:
1,230.60 (сумма чека)
12345678 (позиции цифр)
С другой стороны, если сумма меньше $1000, то несколько полей должны были
бы остаться незаполненными. Например, запись
99.87
12345678
содержит три пустых поля. Если чек будет напечатан с пустыми полями, то
мошенник достаточно просто может дописать сумму чека. Для предотвращения
этого большая часть систем выдачи чеков печатает в пустых полях символы
звездочек:
•••99.87
12345678
Напишите программу, которая вводит долларовую сумму и печатает ее на чеке,
вставляя, при необходимости, символы звездочек.
8.45. (Словесный эквивалент суммы чека) Продолжая обсуждение предыдущего
примера, мы еще раз подчеркнем важность проектирования систем выдачи чеков,
защищенных от подделок посредством дописывания суммы. В одном из
распространенных методов защиты используется запись суммы в двух представлениях:
в виде обычной цифровой записи и в виде ее словесного эквивалента. Если
кто-нибудь и способен изменить числовую часть чека, то изменить величину
суммы, записанную словами, чрезвычайно трудно.
Многие автоматизированные системы выдачи чека не печатают словесный
эквивалент суммы. Возможно, основная причина этого упущения состоит в том, что
большинство языков высокого уровня, используемых в коммерческих
прикладных программах, не имеют адекватных средств обработки строк. Другой
причиной является то, что логика записи словесных эквивалентов сумм чеков
вызывает определенные трудности.
Напишите программу на С, которая вводит числовую сумму чека и выводит ее
словесный эквивалент. Например, сумма 112.43 должна быть записана как
ONE HUNDRED TWELVE and 43/100
8.46. (Код Морзе) Возможно, самой знаменитой схемой кодирования является код
(азбука) Морзе, разработанный Самуэлем Морзе в 1832 году для телеграфа. Код
Морзе присваивает последовательность точек и тире каждому символу алфавита,
каждой цифре и нескольким специальным символам (точке, запятой, двоеточию
и точке с запятой). В звуковых системах точка представляется в виде короткого,
а тире в виде долгого звука. Другие представления точек и тире используются со
световыми системами и в системах с сигнальными флажками.
Разделяющий слова символ обозначается пробелом или, попросту говоря,
отсутствием точки или тире. В звуковых системах пробел обозначается коротким вре-
Указатели и строки-указатели
589
менным отрезком, в течение которого звук не передается. Международная
версия кода Морзе приведена на рис. 8.45.
Напишите программу, которая читает фразу на английском языке и кодирует ее,
используя азбуку Морзе. Также напишите программу, которая читает фразу,
закодированную азбукой Морзе, и преобразует ее в английский языковый
эквивалент. Используйте один пробел между символами азбуки Морзе и три пробела
между словами, записанными в этом коде.
Символ
А
В
С
D
Е
F
G
Н
1
J
К
L
М
Код
.-
-...
-.-.
-..
..-.
-.
.—
-.-
.-..
-
Символ
N
О
Р
Q
R
S
Т
и
V
W
X
Y
Z
Код
-.
—
.-.
--.-
.-.
-
..-
...-
.--
-..-
-.--
--..
Цифры
1
2
3
4
5
.—-
..—
...--
....-
6
7
8
9
0
-....
--...
--...
—..
Рис. 8.45. Буквы алфавита, записанные в международном коде Морзе
8.47. (Программа преобразования систем измерений) Напишите программу, которая
поможет пользователю с преобразованиями систем измерений. Ваша программа
должна позволять пользователю определять в виде строк название единиц
(сантиметров, литров, грамм и т.д. для метрической системы единиц и дюймов,
кварт, фунтов и т.д. для английской системы измерений) и должна отвечать на
простые вопросы типа:
"How many inches are in 2 meters?"
(Сколько дюймов в 2 метрах?)
"How many liters are in 10 quarts?"
(Сколько литров в 10 квартах?)
590
Глава 8
Ваша программа должна распознавать недопустимые преобразования.
Например, вопрос
"How many feet in 5 kilograms?"
(Сколько футов в 5 килограммах?)
не имеет смысла, поскольку «футы» — единицы длины, а «килограмм» —
единица веса.
Специальный проект с обработкой строк
8.48. (Генератор кроссвордов) Большинство людей наверняка сталкивались с
решением кроссвордов, но немногие пытались сами составить хотя бы один.
Производство кроссвордов является сложной задачей. Она предлагается здесь как
проект по теме обработки строк, требующий больших усилий. В этом проекте
имеется множество частных задач, которые должен решить программист, чтобы
запустить в работу даже простейшую программу генерирования кроссвордов.
Например, как представить сетку кроссворда внутри компьютера? Нужно ли
использовать ряд строк или двумерные массивы? Программисту нужен источник
слов (т.е. компьютерный словарь), к которому должна обращаться программа.
В какой форме нужно хранить слова, чтобы упростить сложную обработку,
требующуюся программе? По-настоящему честолюбивый читатель захочет
генерировать и ту часть головоломки, в которой приводятся вопросы кроссворда. Но
даже генерация пустого кроссворда является непростой задачей.
9
Классы: часть I
ЦЕЛИ
В этой главе вы изучите:
• Как использовать «препроцессорную
обертку», чтобы предотвратить
ошибки многократного определения
из-за включения в исходный файл
более одного экземпляра
заголовочного файла.
• Область действия класса и доступ
к элементам класса через имя
объекта, ссылку на объект
или указатель на объект.
• Как определять конструкторы
с аргументами по умолчанию.
• Как используются деструкторы для
«заключительной приборки» объекта перед тем, как он будет уничтожен.
• Когда вызываются конструкторы и деструкторы и в каком порядке они
вызываются.
• Логические ошибки, которые могут происходить, когда открытая
элемент-функция класса возвращает ссылку на закрытые данные.
• Как присвоить элементы данных одного объекта элементам другого
объекта посредством поэлементного присваивания по умолчанию.
592
Глава 9
9.1. Введение
9.2. Пример: класс Time
9.3. Область действия класса и доступ к элементам класса
9.4. Отделение интерфейса от реализации
9.5. Функции доступа и сервисные функции
9.6. Пример: класс Time. Конструкторы с аргументами
по умолчанию
9.7. Деструкторы
9.8. Когда вызываются конструкторы и деструкторы
9.9. Пример: класс Time. Скрытая ошибка — возвращение
ссылки на закрытый элемент данных
9.10. Поэлементное присваивание по умолчанию
9.11. Утилизируемость программного обеспечения
9.12. Конструирование программного обеспечения. Начало
программирования классов системы ATM
(необязательный раздел)
9.13. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
9.1. Введение
В предыдущих главах мы ввели многие основные понятия и концепции
объектно-ориентированного программирования на C++. Мы также обсуждали
нашу методологию программных разработок: для каждого класса мы
выбирали подходящие атрибуты и поведение и специфицировали, каким образом
объекты наших классов действуют совместно с объектами классов стандартной
библиотеки C++, достигая в результате конечных целей программы.
В этой главе мы рассмотрим классы более внимательно. Мы будем
рассматривать интегрированный учебный пример класса Time — три отдельных
примера в этой главе и два в главе 10, чтобы показать различные аспекты
построения класса. Мы начнем с класса Time, повторяющего некоторые моменты,
представленные в предыдущих главах. Пример продемонстрирует также
важную концепцию конструирования программ на C++ — использование «пре-
процессорной обертки» в заголовочных файлах, чтобы предотвратить
повторное включение кода из заголовочного файла в тот же самый исходный файл.
Так как класс может определяться только однажды, применение таких пре-
процессорных директив предотвращает ошибки многократного определения.
Затем мы обсудим область действия класса и взаимоотношения между
элементами класса. Мы также продемонстрируем, как код клиента может обра-
Классы: часть I
593
щаться к открытым элементам класса через три типа * рычагов»
(дескрипторов) — имя объекта, ссылку на объект и указатель на объект. Как вы увидите,
для доступа к открытому элементу имена объектов и ссылки могут
использоваться с операцией-точкой (.) выбора элемента, а указатели — с
операцией-стрелкой (->) выбора элемента.
Мы обсудим функции доступа, которые могут читать или выводить данные
в объекте. Типичным применением таких функций является проверка
истинности или ложности некоторого условия — такие функции называются
предикатными функциями. Мы также продемонстрируем понятие сервисной (или
вспомогательной) функции — закрытой элемент-функции, поддерживающей
действия открытых элемент-функций, но не предназначенной для вызова
клиентами класса.
Во втором примере с классом Time мы демонстрируем, как конструкторам
передаются аргументы и как можно использовать в конструкторе аргументы
по умолчанию, тем самым позволяя клиентам класса инициализировать
объекты класса разнообразными наборами аргументов. Затем мы обсудим особую
элемент-функцию, называемую деструктором, которая имеется в любом
классе и используется для выполнения «заключительной приборки» объекта перед
тем, как он будет уничтожен. Мы продемонстрируем, в каком порядке
вызываются конструкторы и деструкторы, потому что корректность работы вашей
программы будет зависеть от того, использует ли она правильно
инициализированные объекты, которые еще не были уничтожены.
Последний пример с классом Time в этой главе показывает опасный
момент, когда элемент-функция класса возвращает ссылку на закрытые данные.
Мы обсудим, каким образом это нарушает инкапсуляцию класса и позволяет
его клиентам непосредственно обращаться к данным объекта. Этот пример
показывает также, что объекты одного и того же класса могут присваиваться
друг другу посредством поэлементного присваивания по умолчанию, которое
копирует элементы данных объекта в правой части присваивания
соответствующим элементам объекта в левой части. Глава завершается обсуждением
утилизируемости программного обеспечения.
9.2. Пример: класс Time
Наш первый пример (рис. 9.1-9.3) создает класс Time и
программу-драйвер, тестирующую класс. Вы уже создавали в этой книге несколько классов.
В этой главе мы повторим многое из того, о чем говорилось в главе 3 и
продемонстрируем важный прием конструирования программного обеспечения на
C++ — использование в заголовочных файлах «препроцессорной обертки»,
которая предотвращает повторное включение кода заголовочного файла в тот же
самый файл исходного кода.
1 // Рис. 9.1: Time.h
2 // Объявление класса Time.
3 // Элемент-функции определяются в Time.cpp
4
5 // предотвратить многократное включение заголовочного файла
6 #ifndef TIME_H
7 #define TIME_H
8
594
Глава 9
9 // определение класса Time
10 class Time
11 {
12 public:
13 Time(); // конструктор
14 void setTime( int, int, int ); // установить час, минуту, секунду
15 void printUniversal(); // напечатать в формате всемирного времени
16 void printStandard(); // напечатать в стандартном формате времени
17 private:
18 int hour; // 0 - 23 B4-часовой формат времени)
19 int minute; //0-59
20 int second; //0-59
21 }; // конец класса Time
22
23 #endif
Рис. 9-1- Определение класса Time
Определение класса Time
Определение класса (рис. 9.1) содержит прототипы (строки 13-16) для
элемент-функций Time, setTime, printUniversal и printStandard. Класс
содержит закрытые целые элементы данных hour, minute и second (строки 18-20).
Обращаться к закрытым элементам данных могут только четыре
элемент-функции. В главе 12 в ходе изучения наследования и той роли, которую
оно играет в объектно-ориентированном программировании, будет введен
третий спецификатор доступа — protected.
Хороший стиль программирования 9,1
Для ясности используйте в определении класса каждый
спецификатор доступа только один раз. Разместите в начале определения
элементы со спецификатором public, чтобы их легче было найти.
Общее методическое замечание 9.1
Каждый элемент класса должен иметь видимость private, если
нельзя достоверно обосновать, что ему необходима видимость public. Это
еще один пример принципа наименьших привилегий.
Обратите внимание, что на рис. 9.1 определение класса заключено в
следующую препроцессорую обертку (строки 5-7 и 23):
// предотвратить многократное включение заголовочного файла
#ifndef TIME_H
#define TIME_H
#endi£
Когда мы строим программы большого объема, другие определения и
объявления также размещаются в заголовочных файлах. Приведенная выше препро-
цессорная * обертка предотвращает включение кода, находящегося между
#ifndef (что означает «если не определено») и #endify если имя Т1МЕ_Н было
Классы: часть I
595
ранее определено. Если заголовок ранее не включался в исходный файл,
директива #define определяет имя Т1МЕ_Н и включаются операторы
заголовочного файла. Если заголовок включался ранее, Т1МЕ_Н уже определено и
содержимое заголовочного файла повторно не включается. Попытки
(ненамеренные) многократного включения заголовочного файла случаются обычно
в больших программах с большим числом заголовочных файлов, которые
в свою очередь включают другие заголовочные файлы. [Замечание. В
соответствии с общепринятым соглашением, имя символической константы в этих
препроцессорных директивах является просто именем заголовочного файла
в верхнем регистре с заменой точки на символ подчеркивания.]
Предотвращение ошибок 9.1
Используйте директивы препроцессора #ifndef, #define и #endif для
образования препроцессорной обертки, предотвращающей
многократное включение заголовочного файла в программу.
Хороший стиль программирования 9,2
В препроцессорных директивах #ifndef и #define заголовочного файла
используйте имя заголовочного файла в верхнем регистре с
подчеркиванием вместо точки.
Элемент-функции класса Time
Конструктор (строки 14-17 на рис. 9.2) инициализирует элементы данных
нулями (т.е. всемирным временем, эквивалентным 12 AM). Тем самым объект
начинает свое существование в согласованном состоянии. В элементах данных
объекта Time не могут оказаться недействительные данные, так как при
создании объекта вызывается конструктор, а последующие попытки клиента
модифицировать элементы данных проверяются функцией setTime (которую мы
вскоре обсудим). Наконец, что важно отметить, программист может
определять для класса несколько перегруженных конструкторов.
1 // Рис. 9.2: Time.cpp
2 // Определение элемент-функций класса Time.
3 #include <iostream>
4 using std:icout;
5
6 #include <iomanip>
7 using std::setfill;
8 using std::setw;
9
10 #include "Time.h" // включить определение класса Time из Time.h
11
12 // Конструктор Time инициализирует каждый элемент данных нулем.
13 // Гарантирует, что объекты создаются в согласованном состоянии.
14 Time::Time()
15 {
16 hour = minute = second = 0;
17 } // конец конструктора Time
18
19 // установить значение времени (во всемирном формате); убедиться,
596
Глава 9
20 // что данные согласованы: недействительные элементы обнуляются
21 void Time::setTime( int h, int m, int s )
22 {
23 hour = ( h >= 0 && h < 24 ) ? h : 0; // проверить часы
24 minute = ( m >= 0 && m < 60 ) ? m : 0; // проверить минуты
25 second = ( s >= 0 && s < 60 ) ? s : 0; // проверить секунды
26 } // конец функции setTime
27
28 // Напечатать в формате всемирного времени (HH:MM:SS)
29 void Time::printUniversal()
30 {
31 cout « setfill( '0' ) « setw( 2 ) « hour « ":"
32 « setw( 2 ) « minute « " :" « setw( 2 ) « second;
33 } // конец функции printUniversal
34
35 // Напечатать в стандартном формате времени (HH:MM:SS AM или РМ)
36 void Time::printStandard()
37 {
38 cout « ( ( hour == 0 | | hour == 12 ) ? 12 : hour % 12 ) « ":
39 « setfill( '0' ) « setw( 2 ) « minute « ":" « setw( 2 )
40 « second « ( hour < 12 ? " AM" : " PM" );
41 } // конец функции printstandard
Рис. 9.2. Определения элемент-функций класса Time
Элементы данных класса не могут инициализироваться там, где они
объявляются в теле класса. Настоятельно рекомендуется инициализировать их в
конструкторе класса (так как инициализация по умолчанию для элементов данных
основных типов не производится). Значения элементам данных могут также
присваиваться set-функциями класса Time. [Замечание. Глава 10
демонстрирует, что в теле класса могут инициализироваться только статические
константные элементы данных класса целочисленных или перечислимых типов.]
Kgfa Типичная ошибка программирования 9.1
I jar I Попытка явным образом инициализировать не-статический элемент
данных класса в определении класса является синтаксической ошибкой.
Функция setTime (строки 21-26) является открытой функцией, которая
объявляет три целых параметра и использует их для установки времени.
Каждый аргумент проверяется условным выражением, определяющим, находится
ли его значение в специфицированном диапазоне. Например, значение hour
(строка 23) должно быть больше или равно 0 и меньше 24, так как всемирный
формат времени представляет часы как целые числа от 0 до 23 (например,
1 РМ — это 13 часов, а 11 РМ — 23 часа; полночь — 0 часов, полдень — 12
часов). Точно так же значения minute и second должны быть больше или
равны 0 и меньше 60. Любые значения вне этих диапазонов устанавливаются
равными 0, чтобы гарантировать согласованное состояние данных объекта Time,
т.е. значения данных объекта всегда остаются в допустимом диапазоне, даже
если значения, переданные функции setTime в качестве аргументов, были
некорректны. В данном примере нуль — согласованное значение для hour,
minute и second.
Классы: часть I
597
Значение, передаваемое set Time, является корректным значением, если
оно находится в допустимом диапазоне для элемента, который оно
инициализирует. Таким образом, любое значение в диапазоне 0-23 будет корректным
значением для hour. Корректное значение всегда является согласованным.
Однако согласованное значение не обязательно корректно. Если setTime
устанавливает hour в 0 из-за того, что полученный аргумент не находился в
допустимом диапазоне, то значение hour будет корректным только в том случае, если
в данный момент наступила полночь.
Функция printUniversal (строки 29-33 на рис. 9.2) не принимает
аргументов и выводит данные в формате всемирного времени, т.е. в виде трех пар
цифр, разделенных двоеточиями — соответственно для часов, минут и секунд.
Например, если бы время было 1:30:07 РМ, printUniversal напечатала бы
13:30:07. Обратите внимание, что в строке 31 использован параметризованный
манипулятор потока set fill, специфицирующий символ заполнения, который
отображается, когда целое число выводится в поле более широкое, чем число
цифр в значении. По умолчанию символы заполнения выводятся слева от
цифр числа. Если бы в нашем примере minute имела значение 2, то оно
выводилось бы как 02, поскольку в качестве символа заполнения установлен ноль
('О'). Если выводимое число заполняет все поле, символы заполнения не
выводятся. Заметьте, что как только символ заполнения специфицирован (с
помощью setfill), он будет относиться ко всем последующим значениям,
выводимым в поля более широкие, чем значение (т.е. setfill является «залипающей»
установкой). Совсем по-другому ведет себя установка setw, которая
применяется только к следующему выводимому значению (setw является «незалипаю-
щей» установкой).
j£g\ Предотвращение ошибок 9.2
V^y Для каждой залипающей установки (такой, как символ заполнения
или точность значений с плавающей точкой) следует
восстанавливать ее предыдущее значение, когда она более не нужна. Если этого не
сделать, последующий вывод программы может оказаться
форматированным неверно.
Функция printstandard (строки 36-41) не принимает аргументов и
выводит данные в стандартном формате времени, т.е. в виде разделенных
двоеточиями значений hour, minute и second, за которыми следует индикатор AM
или РМ (например, 1:27:06 РМ). Как и printUniversal, функция printStan-
dard использует манипулятор setfill( '0' ) для форматирования минут и секунд
в виде двузначных значений с ведущими нулями, если они необходимы.
Строка 38 использует условную операцию (? :), определяющую, как должно
выводиться значение hour. Если значение hour равно 0 или 12 (AM или РМ),
выводится 12; в противном случае выводится число от 1 до 11. Условная операция
в строке 40 определяет, должно ли выводиться AM или РМ.
Определение элемент-функций вне определения класса; область
действия класса
Хотя элемент-функция, объявленная в определении класса, может
определяться вне определения класса (и «привязываться» к классу бинарной
операцией разрешения области действия), она все равно остается в области дейст-
598
Глава 9
вия класса; другими словами, ее имя известно только другим элементам
класса, если только на него не ссылаются через объект класса, ссылку на объект
класса, указатель на объект класса или операцию разрешения области
действия. Чуть позже мы еще поговорим об области действия класса.
Если элемент-функция определяется в теле определения класса,
компилятор C++ пытается расширять ее вызовы как встроенные. Элемент-функции,
определяемые вне определения класса, можно сделать встроенными явным
указанием ключевого слова inline. Помните, что компилятор оставляет за
собой право не делать функцию встроенной.
Вопросы производительности 9.1
Определение элемент-функции внутри определения класса делает
функцию встроенной (если компилятор не решит иначе). Это может
улучшить производительность программы.
Общее методическое замечание 9.2
Определение небольшой элемент-функции внутри определения
класса — не лучшее решение с точки зрения конструирования
программного обеспечение, поскольку клиенты класса смогут видеть реализацию
функции, и в случае изменения определения функции придется
перекомпилировать код клиента.
Общее методическое замечание 9.3
Определять в определении класса следует только простейшие и
наиболее стабильные функции (т.е. те, реализация которых вряд ли
будет изменяться).
Элемент-функции и глобальные функции
Интересно отметить, что элемент-функции printUniversal и printStandard
не принимают никаких аргументов. Это потому, что эти элемент-функции
неявным образом знают, что они должны печатать элементы данных того
конкретного объекта Time, для которого они вызываются. Тем самым вызовы
элемент-функций могут быть сделаны более краткими, чем обычные вызовы
функций в процедурном программировании.
Общее методическое замечание 9.4
Объектно-ориентированный подход часто может упростить вызовы
функций благодаря сокращению числа передаваемых аргументов. Это
преимущество объектно-ориентированного программирования
вытекает из того факта, что инкапсуляция элементов данных и
элемент-функций в объекте дает элемент-функциям право доступа
к элементам данных.
Классы: часть I
599
Общее методическое замечание 9.5
Элемент-функции обычно короче, чем функции в процедурном
программировании, так как данные, хранящиеся в виде элементов класса, по
идее должны быть уже проверены конструктором или
элемент-функциями, сохраняющими новые данные. Поскольку данные уже
находятся в объекте, вызовы элемент-функций часто не принимают
аргументов или, по крайней мере, требуют меньшего их числа, чем типичные
вызовы в процедурном программировании. Таким образом, и вызовы,
и определения, и прототипы функций становятся короче. Это
упрощает многие аспекты разработки программ.
Предотвращение ошибок 9.3
Тот факт, что вызовы элемент-функций, как правило, либо не имеют
аргументов, либо требуют значительно меньшего их числа, чем
вызовы обычных функций в языках, не являющихся
объектно-ориентированными, сокращает вероятность передачи неправильных
аргументов, неправильных типов или неправильного числа аргументов.
Использование класса Time
Как только класс Time определен, его можно использовать как тип в
объявлении объекта, массива, указателя и ссылки, например:
Time sunset; // объект типа Time
Time arrayOfTimes[ 5 ]; // массив из 5 объектов Time
Time &dinnerTime = sunset; // ссылка на объект Time
Time *timePtr = &dinnerTime; // указатель на объект Time
Программа на рис. 9.3 тестирует класс Time. Строка 12 создает одиночный
объект класса Time с именем t. При создании объекта класса вызывается
конструктор Time, инициализирующий нулем каждый из закрытых элементов
данных. Затем строки 16 и 18 печатают время во всемирном и стандартном
форматах, чтобы показать корректность инициализации элементов. Строка 20
устанавливает новое время, вызывая элемент-функцию setTime, а строки 24
и 26 снова печатают время в обоих форматах. Строка 28 пытается установить
для элементов данных недействительные значения; функция setTime
распознает это и заменяет недействительные значения нулями, чтобы объект
оставался в согласованном состоянии. Наконец, строки 33 и 35 снова печатают
время в обоих форматах.
1 // Рис. 9.3: fig09_03.cpp
2 // Программа для тестирования класса Time.
3 // ЗАМЕЧАНИЕ: Файл должен компилироваться совместно с Time.cpp.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "Time.h" // включить определение класса Time из Time.h
9
10 int main()
11 {
600
Глава 9
12 Time t; // создать объект t класса Time
13
14 // вывести исходные значения объекта t класса Time
15 cout « "The initial universal time is ";
16 t.printUniversal(); // 00:00:00
17 cout « "\nThe initial standard time is ";
18 t.printStandard(); // 12:00:00 AM
19
20 t.setTime( 13, 27, 6 ); // изменить время
21
22 // вывести новые значения объекта t
23 cout « "\n\nUniversal time after setTime is ";
24 t.printUniversal(); // 13:27:06
25 cout « "\nStandard time after setTime is ";
26 t.printStandard(); // 1:27:06 PM
27
28 t.setTime( 99, 99, 99 ); // попытка некорректной установки
29
30 // вывести значения t после задания недействительных установок
31 cout « "\n\nAfter attempting invalid settings:"
32 « "\nUniversal time: ";
33 t.printUniversal(); // 00:00:00
34 cout « "\nStandard time:
35 t.printstandard(); // 12:00:00 AM
36 cout « endl;
37 return 0;
38 } // конец main
The initial universal time is 00:00:00
The initial standard time is 12:00:00 AM
Universal time after setTime is 13:27:06
Standard time after setTime is 1:27:06 PM
After attempting invalid settings:
Universal time: 00:00:00
Standard time: 12:00:00 AM
Рис. 9.З. Программа для тестирования класса Time
О композиции и наследовании
Часто не требуется создавать класс «на пустом месте». Иногда в него могут
входить в качестве элементов другие классы, или он может производиться от
другого класса, имеющего атрибуты и поведение, которые новый класс может
использовать. Такая утилизация программного обеспечения намного
увеличивает производительность труда программиста и упрощает сопровождение
кода. Включение объектов класса в качестве элементов других классов
называется композицией (или агрегацией) и обсуждается в главе 10. Порождение
новых классов от существующих называется наследованием и обсуждается
у главе 12.
Классы: часть I
601
Размер объекта
Новички в объектно-ориентированном программировании часто полагают,
что объекты должны быть довольно велики, так как они содержат элементы
данных и элемент-функции. Логически это так — программист может
представлять себе объект как содержащий данные и функции (и наше изложение,
действительно, способствовало такому взгляду на вещи); физически, однако,
дело обстоит по-другому.
I—^ Вопросы производительности 9.2
py^l Объекты содержат только данные, поэтому они существенно
меньше, чем были бы, если содержали еще и элемент-функции. Применение
к имени класса или объекту класса операции sizeof покажет только
размер элементов данных этого класса. Компилятор создает всего
один экземпляр элемент-функций, отдельный от всех объектов
класса. Все объекты класса разделяют этот единственный экземпляр.
Каждому объекту, конечно, требуется свой собственный экземпляр
данных класса, так как данные от объекта к объекту могу различаться.
Код функций является немодифицируемым (его называют также по-
вторно-входимым или чисто процедурным кодом) и,
следовательно, может разделяться всеми объектами одного класса.
9.3. Область действия класса и доступ к элементам
класса
Элементы данных класса (переменные, объявленные в определении класса)
и его элемент-функции (функции, объявленные в определении класса)
принадлежат к области действия этого класса. Обычные функции (не элементы)
определяются в области действия файла.
В пределах области действия класса элементы класса непосредственно
доступны для всех элемент-функций этого класса, и к ним можно обращаться
просто по имени. Вне области действия класса к его открытым элементам
можно обращаться через один из дескрипторов объекта — имя объекта,
ссылку на объект или указатель на объект. Тип объекта, ссылки или указателя
специфицирует интерфейс (т.е. элемент-функции), доступный для клиента.
[Замечание. В главе 10 мы увидим, что каждое обращение к элементу данных или
элемент-функции, которое происходит в пределах объекта, компилятор
снабжает неявным дескриптором.]
Элемент-функции класса могут быть перегружены, но только другими
элемент-функциями того же класса. Чтобы перегрузить элемент-функцию,
нужно просто предусмотреть в определении класса прототипы для всех версий
перегружаемой функции, а также отдельные определения для каждой версии
функции.
Переменные, объявленные в элемент-функции, имеют область действия
блока и известны только этой функции. Если элемент-функция определяет
переменную с тем же именем, что и у переменной в области действия класса,
переменная в области действия блока скрывает переменную в области действия
класса. Обратиться к такой скрытой переменной можно, поместив перед ее
именем имя класса с операцией разрешения области действия (::). Доступ
602
Глава 9
к скрытым глобальным переменным возможен с помощью унарной операции
разрешения области действия (см. главу 6).
Для доступа к элементам объекта операция-точка выбора элемента (.)
предваряется именем объекта или ссылкой на объект. Операция-стрелка выбора
элемента (->) предваряется указателем на объект.
На рис. 9.4 простой класс Count (строки 8-25) с закрытым элементом
данных х типа int (строка 24), открытой элемент-функцией setX (строки 12-15)
и открытой элемент-функцией print (строки 18-21) используется для
иллюстрации доступа к элементам класса с помощью операций выбора элемента. Для
простоты мы разместили определение этого небольшого класса в одном файле
с использующей его функцией main. Строки 29-31 создают три переменные,
относящиеся к типу Count, — counter (объект Count), counterPtr (указатель
на объект Count) и counterRef (ссылку на объект Count). Переменная coun-
terRef ссылается на counter, а переменная counterPtr указывает на counter.
Обратите внимание (строки 34-35 и 38-39), что программа может
активировать элемент-функции setX и print, используя операцию-точку (.) либо с
предшествующим ей именем объекта (counter), либо с предшествующей ссылкой
на объект (counterRef, которая является псевдонимом для counter). Точно так
же строки 42-43 демонстрируют, что программа может активировать
элемент-функции setX и print, используя указатель (counterPtr) и
операцию-стрелку (->).
1 // Рис. 9.4: fig09_04.cpp
2 // Демонстрация операций доступа к элементам . и ->.
3 #include <iostream>
4 using std::cout;
5 using std::endl/
6
7 // определение класса Count
8 class Count
9 {
10 public: // открытые данные опасны
11 // устанавливает значение закрытого элемента данных х
12 void setX( int value )
13 {
14 x = value;
15 } // конец функции setX
16
17 // печатает значение закрытого элемента данных х
18 void print()
19 {
20 cout « x « endl;
21 } // конец функции print
22
23 private:
24 int x;
25 }; // конец класса Count
26
27 int main()
28 {
29 Count counter; // создать объект counter
30 Count *counterPtr = ficounter; // создать указатель на counter
31 Count &counterRef = counter; // создать ссылку на counter
Классы: часть I
603
32
33 cout « "Set x to 1 and print using the object's name: ";
34 counter.setX( 1 ); // установить элемент данных х в 1
35 counter.print(); // вызвать элемент-функцию print
36
37 cout « "Set x to 2 and print using a reference to an object: ";
38 counterRef.setX( 2 ); // установить элемент данных х в 2
39 counterRef.print(); // вызвать элемент-функцию print
40
41 cout « "Set x to 3 and print using a pointer to an object: ";
42 counterPtr->setX( 3 ); // установить элемент данных х в 3
43 counterPtr->print(); // вызвать элемент-функцию print
44 return 0;
45 } // конец main
Set x to 1 and print using the object's name: 1
Set x to 2 and print using a reference to an object: 2
Set x to 3 and print using a pointer to an object: 3
Рис. 9-4. Доступ к элемент-функциям объекта через дескрипторы всех типов —
имя объекта, ссылку на объект и указатель на объект
9.4. Отделение интерфейса от реализации
Приступая в главе 3 к изучению классов, мы сначала размещали
определение класса и определения его элемент-функций в одном файле. Затем мы
продемонстрировали разделение этого кода на две части — заголовочный файл
с определением класса (т.е. интерфейсом класса) и файл исходного кода с
определениями элемент-функций (т.е. реализацией класса). Как вы помните, это
облегчает модификацию программ, — если говорить о клиентах класса, то
изменения в реализации класса не влияют на клиента, пока изначально
предоставленный ему интерфейс класса остается неизменным.
Общее методическое замечание 9.6
Чтобы использовать класс, его клиентам не требуется доступ к
исходному коду класса. Клиенты, однако, должны иметь возможность
компоноваться с его объектным кодом (т.е. компилированной версией
класса). Это побуждает независимых производителей программного
обеспечения (Independent Software Vendors, ISV) к созданию
классовых библиотек, продаваемых или лицензируемых. ISV поставляют
в составе своих продуктов только заголовочные файлы и объектные
модули. При этом не раскрывается никакая информация, являющаяся
собственностью производителя, — как это было бы с случае
поставки исходного кода. От этого выигрывает сообщество пользователей
C++, так как появляется больше доступных классовых библиотек,
создаваемых ISV.
На самом деле все не так благополучно. Заголовочные файлы все-таки
содержат некоторые части реализации и намеки на другие ее части. Встроенные
элемент-функции, например, должны находиться в заголовочном файле,
чтобы при компиляции клиента компилятор мог включать в код определения
604
Глава 9
inline-функций. Закрытые элементы класса перечисляются в определении
класса в заголовочном файле, так что они видимы для клиентов, хотя
последние и не могут обращаться к закрытым элементам. В главе 10 мы покажем,
каким образом, используя «класс-посредник», можно скрыть от клиентов даже
сами закрытые данные класса.
® Общее методическое замечание 9.7
Информация, важная для клиента в плане использования интерфейса
класса, должна включаться в заголовочный файл. Информация,
которая будет использоваться только внутри класса и не потребуется
клиентам, должна включаться в не публикуемый исходный файл. Это
опять пример принципа минимальных привилегий.
9.5. Функции доступа и сервисные функции
Функции доступа могут читать или выводить данные. Другим
распространенным применением функций доступа является проверка истинности или
ложности некоторого условия, — такие функции часто называют предикат
ными функциями. Примером предикатной функции могла бы быть функция
isEmpty любого класса-контейнера — класса, в который может хранить много
объектов, как, например, связанный список, стек или очередь. Программа
могла бы проверять isEmpty перед попыткой прочитать следующую единицу
данных из объекта-контейнера. Предикатная функция isFull могла бы
проверять объект класса-контейнера на предмет наличия свободного места.
Полезными предикатными функциями для нашего класса Time могли бы быть isAM
и isPM.
Программа на рис. 9.5-9.7 демонстрирует понятие сервисной (или
вспомогательной) функции. Сервисная функция не входит в состав открытого
интерфейса класса; она чаще всего бывает закрытой элемент-функцией,
поддерживающей операции открытых элемент-функций класса. Сервисные функции не
предназначены для использования клиентами класса (но могут вызываться
друзьями класса, как мы увидим в главе 10).
1 // Рис. 9.5: Salesperson.h
2 // Определение класса Salesperson.
3 // Элемент-функции определяются в Salesperson.срр.
4 #ifndef SALESP_H
5 #define SALESP_H
6
7 class Salesperson
8 {
9 public:
10 Salesperson(); // конструктор
11 void getSalesFromUser(); // ввести с клавиатуры суммы продаж
12 void setSales( int, double ); // установить сумму для # месяца
13 void printAnnualSales(); // подытожить и напечатать суммы продаж
14 private:
15 double totalAnnualSales(); // прототип вспомогательной функции
16 double sales[ 12 ]; // 12 сумм месячных продаж
Классы: часть I
605
17 }; // конец класса Salesperson
18
19 #endi£
Рис. 9.5. Определение класса Salesperson
Класс Salesperson (рис. 9.5) объявляет массив для 12-ти сумм месячных
продаж (строка 16) и прототипы для конструктора и элемент-функций,
манипулирующих этим массивом.
Конструктор Salesperson (рис. 9.6, строки 15-19) инициализирует массив
sales нулями. Открытая элемент-функция setSales (строки 36-43)
устанавливает в массиве sales сумму продаж для одного месяца. Открытая
элемент-функция printAnnualSales (строки 46-51) печатает общую сумму
продаж за последние 12 месяцев. Закрытая сервисная функция totalAnnualSales
(строки 54-62) суммирует все 12 месячных показателей продаж в интересах
функции printAnnualSales. Последняя преобразует полученную сумму в
денежный формат.
1 // Рис. 9.6: Salesperson.срр
2 // Элемент-функции класса Salesperson.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7 using std::fixed;
8
9 #include <iomanip>
10 using std::setprecision;
11
12 #include "Salesperson.h" // включить определение класса Salesperson
13
14 // инициализировать элементы массива sales значениями 0.0
15 Salesperson::Salesperson()
16 {
17 for ( int i = 0; i < 12; i++ )
18 sales[ i ] = 0.0;
19 } // конец конструктора Salesperson
20
21 // получить от пользователя (с клавиатуры) 12 сумм месячных продаж
22 void Salesperson::getSalesFromUser()
23 {
24 double salesFigure;
25
26 for ( int i = 1; i <= 12; i++ )
27 {
28 cout « "Enter sales amount for month " « i « ":
29 cin » salesFigure;
30 setSales( i, salesFigure );
31 } // конец for
32 } // конец функции getSalesFromUser
33
34 // установить одну из 12 месячных сумм; функция вычитает из
35 // значения месяца 1, чтобы получить правильный индекс массива
36 void Salesperson::setSales( int month, double amount )
606
Глава 9
37 {
38 // проверить действительность значений месяца и суммы продаж
39 if ( month >= 1 && month <= 12 && amount > 0 )
40 sales[ month - 1 ] = amount; // adjust for subscripts 0-11
41 else // недействительное значение месяца или суммы
42 cout « "Invalid month or sales figure" « endl;
43 } // конец функции setSales
44
45 // напечатать родовую сумму (с помощью вспомогательной функции)
46 void Salesperson::printAnnualSales()
47 {
48 cout « setprecision( 2 ) « fixed
49 « "\nThe total annual sales are: $"
50 « totalAnnualSales() « endl; // вызов вспомогательной функции
51 } // конец функции printAnnualSales
52
53 // закрытая вспомогательная функция для суммирования продаж за год
54 double Salesperson::totalAnnualSales()
55 {
56 double total = 0.0; // инициализировать годовую сумму
57
58 for ( int i = 0; i < 12; i++ ) // подытожить продажи за год
59 total += sales[ i ]; // прибавить продажи месяца i к total
60
61 return total;
62 } // конец функции totalAnnualSales
Рис, 9.6. Определения элемент-функций класса Salesperson
Обратите внимание, что функция main на рис. 8.7 содержит только
простую последовательность вызовов элемент-функций — в ней нет никаких
управляющих операторов. Логика манипуляций с массивом sales полностью
инкапсулирована в элемент-функциях класса Salesperson.
Общее методическое замечание 9.8
Феномен объектно-ориентированного программирования состоит
в том, что как только класс определен, создание объектов класса
и манипуляция ими часто сводятся всего лишь к выдаче простой
последовательности вызовов элемент-функций; не требуется никаких,
или почти никаких, управляющих операторов. Напротив, в
реализации элемент-функций класса применение управляющих операторов —
обычное явление.
1 // Рис. 9.7: fig09_07.cpp
2 // Демонстрация вспомогательной функции.
3 // Компилируйте эту программу с Salesperson.срр
4
5 // включить определение класса Salesperson из Salesperson.h
6 #include "Salesperson.h"
7
8 int main()
9 {
Классы: часть I
607
10 Salesperson s; // создать объект s класса Salesperson
11
12 s.getSalesFromUser(); // обратите внимание на простую структуру;
13 s.printAnnualSales(); // в main нет управляющих операторов
14 return 0;
15 } // конец main
Enter sales amount for month 1: 5314.76
Enter sales amount for month 2: 4292.38
Enter sales amount for month 3: 4589.83
Enter sales amount for month 4: 5534.03
Enter sales amount for month 5: 4376.34
Enter sales amount for month 6: 5698.45
Enter sales amount for month 7: 4439.22
Enter sales amount for month 8: 5893.57
Enter sales amount for month 9: 4909.67
Enter sales amount for month 10: 5123.45
Enter sales amount for month 11: 4024.97
Enter sales amount for month 12: 5923.92
The total annual sales are: $60120.59
Рис. 9.7. Демонстрация сервисной функции
9.6. Пример: класс Time. Конструкторы с аргументами
по умолчанию
Программа на рис. 9.8-9.10 усовершенствует класс Time и демонстрирует,
как конструктору передаются неявные аргументы. Конструктор,
определенный на рис. 9.2, инициализировал hour, minute и second значением 0 (т.е.
устанавливал полночь по всемирному времени). Как и другие функции,
конструкторы могут специфицировать аргументы по умолчанию. Строка 13 на
рис. 9.8 объявляет конструктор Time с аргументами по умолчанию,
специфицируя нулевое значение по умолчанию для каждого из аргументов. На рис. 9.9
строки 14-17 определяют новую версию конструктора Time, которая
принимает значения для параметров hr, min и sec, которые будут использоваться
для инициализации закрытых элементов данных hour, minute и second.
Обратите внимание, что в классе Time предусмотрены set- и £е£-функции для
каждого из элементов данных. Конструктор Time теперь вызывает setTime,
вызывающую функции setHour, setMinute и setSecond для проверки и
присваивания значений элементам данных. Аргументы по умолчанию для конструктора
гарантируют, что даже если в вызове конструктора не будет передано никаких
значений, конструктор все равно инициализирует элементы данных так, что
объект будет в согласованном состоянии. Конструктор, предусматривающий
значения по умолчанию для всех своих аргументов, является одновременно
конструктором по умолчанию, т.е. конструктором, который может
активироваться без аргументов. В классе может быть не более одного конструктора по
умолчанию.
1 // Рис. 9.8: Time.h
2 // Объявление класса Time.
3 // Элемент-функции определяются в Time.cpp.
4
5 // предотвратить многократное включение заголовочного файла
6 #ifndef TIME_H
7 #define TIME_H
8
9 // определение абстрактного типа данных Time
10 class Time
11 {
12 public:
13 Time( int = 0, int = 0, int =0 ); // конструктор по умолчанию
14
15 // set-функции
16 void setTime ( int, int, int ); // установить время
17 void setHour( int ); // установить часы (после проверки)
18 void setMinute( int ); // установить минуты (после проверки)
19 void setSecond( int ); // установить секунды (после проверки)
20
21 // get-функции
22 int getHour(); // возвратить часы
23 int getMinute(); // возвратить минуты
24 int getSecond(); // возвратить секунды
25
26 void printUniversal(); // вывести в формате всемирного времени
27 void printstandard(); // вывести в стандартном формате времени
28 private:*
29 int hour; //0-23 B4-часовой формат времени)
30 int minute; //0-59
31 int second; //0-59
32 }; // конец класса Time
33
34 #endif
Рис. 9.8. Класс Time, имеющий конструктор с аргументами по умолчанию
г
1 // Рис. 9.9: Time.cpp
2 // Определение элемент-функций класса Time.
3 #include <iostream>
4 using std::cout;
5
6 #include <iomanip>
7 using std::setfill;
8 using std::setw;
9
10 #include "Time.h" // включить определение класса Time из Time.h
11
12 // конструктор Time инициализирует каждый элемент данных нулем;
13 // Гарантирует, что объекты создаются в согласованном состоянии
14 Time::Time( int hr, int min, int sec )
15 {
16 setTime ( hr, min, sec ); // проверить и установить время
17 } // конец конструктора Time
.Классы: часть I
609
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
// установить новое времг (во всемирном формате); убедиться,
// что данные согласованы: недействительные элементы обнуляются
void Time::setTime( int h, int m, int s )
(
setHour( h ); // установить закрытое поле часов
setMinute( m ); // установить закрытое поле минут
setSecond( s ); // установить закрытое поле секунд
} // конец функции setTime
// установить значение часов
void Time::setHour( int h )
{
hour = ( h >= 0 && h < 24
} // конец функции setHour
) ? h : 0; // проверить часы
0; // проверить минуты
) ? s : 0; // проверить секунды
// установить значение минут
void Time::setMinute( int m )
{
minute =(m>=0&&m<60
} // конец функции setMinute
// установить значение секунд
void Time::setSecond( int s )
{
second = ( s >= 0 && s < 60
} // конец функции setSecond
// возвратить значение часов
int Time::getHour()
{
return hour;
} // конец функции getHour
// возвратить значение минут
int Time::getMinute()
{
return minute;
} // конец функции getMinute
// возвратить значение секунд
int Time::getSecond()
{
return second;
} // конец функции getSecond
// Напечатать в формате всемирного времени (HH:MM:SS)
void Time::printUniversal()
{
cout « setfill( '0' ) « setw( 2 ) « getHour() « ":"
« setw( 2 ) « getMinute () « ": " « setw( 2 ) « getSecond () ;
} // конец функции printUniversal i
// Напечатать в стандартном формате времени (HH:MM:SS AM или РМ)
void Time::printstandard()
{
cout « ((getHour() == 0 || getHour() == 12) ? 12 : getHour()%12)
20 iaic 1114
610
Глава 9
75 « " :" « setfill( '0' ) « setw( 2 ) « getMinute() « " :"
7 6 « setw( 2 ) « getSecond() « ( hour < 12 ? " AM" : " PM" );
77 } // конец функции printstandard
Рис. 9.9. Элемент-функции класса Time, в том числе конструктор, принимающий
аргументы
На рис. 9.9 строка 16 конструктора вызывает элемент-функцию setTime со
значениями, переданными конструктору (или значениями по умолчанию).
Функция setTime вызывает setHpur, чтобы убедиться, что значение,
переданное для hour, находится в диапазоне 0-23, затем вызывает setMinute
и set Second, чтобы убедиться, что значения для minute и second находятся
в диапазоне 0-59. Если значение лежит вне диапазона, оно устанавливается
равным нулю (гарантируя тем самым, что все элементы данных будут в
согласованном состоянии). В главе 16 мы выбрасываем исключения, чтобы
информировать пользователя о том, что значение находится вне допустимого диапазона;
здесь же мы просто заменяем его согласованным значением по умолчанию.
Заметьте, что конструктор Time мог бы быть написан так, чтобы содержать
те же операторы, что и элемент-функция setTime, или даже отдельные
операторы из функций setHour, setMinute и setSecond. Вызов setHour, setMinute
и setSecond непосредственно из конструктора мог бы быть чуть более
эффективным, поскольку исключался бы промежуточный вызов setTime. Точно так
же копирование в конструктор кода из строк 31, 37 и 43 исключило бы
накладные расходы вызовов setTime, setHour, setMinute и setSecond.
Написание конструктора Time или элемент-функции setTime в виде копии кода
строк 31, 37 и 43 затруднило бы сопровождение данного класса. Если бы
реализация setHour, setMinute и setSecond изменилась, соответственно
потребовалось бы изменить реализацию любой элемент-функции, дублирующей
строки 31, 37 и 43. Реализация конструктора Time, который вызывает setTime,
а последняя в свою очередь вызывает setHour, setMinute и setSecond,
позволяет нам инкапсулировать код, подтверждающий действительность hour,
minute или second, в соответствующей set-функции. Это уменьшает
вероятность ошибок при изменении реализации класса. Кроме того, эффективность
конструктора Time и setTime можно улучшить, явно объявив их как inline
или определив внутри определения класса (что также делает определение
функции встроенным).
S Общее методическое замечание 9.9
Если элемент-функция класса уже реализует полностью или
частично поведение, необходимое конструктору (или другой
элемент-функции класса), вызовите эту функцию из конструктора (или из другой
элемент-функции). Это упростит сопровождение кода и уменьшит
вероятность ошибок, если реализация кода будет изменяться. Общее
правило: избегайте повторений кода.
® Общее методическое замечание 9.10
Любое изменение значений аргументов функции по умолчанию
требует перекомпиляции кода клиента (чтобы гарантировать, что
программа после изменений будет работать корректно).
Классы: часть I
611
1 // Рис. 9.10: fig09_10.cpp
2 // Демонстрация конструктора по умолчанию для класса Time.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Time.h" // включить определение класса Time из Time.h
8
9 int main()
10 {
11 Time tl; // все аргументы по умолчанию
12 Time t2 ( 2 ) ; // указаны часы; минуты и секунды по умолчанию
13 Time t3 ( 21, 34 ) ; // указаны часы и минуты; секунды по умолчанию
14 Time t4 ( 12, 25, 42 ); // указаны часы, минуты и секунды
15 Time t5( 27, 74, 99 ); // все значения недействительны
16
17 cout « "Constructed with:\n\ntl: all arguments defaulted\n ";
18 tl.printUniversal(); // 00:00:00
19 cout « "\n ";
20 tl.printstandard(); // 12:00:00 AM
21
22 cout «"\n\nt2: hour specified; minute and second defaulted\n ";
23 t2.printUniversal(); // 02:00:00
24 cout « "\n ";
25 t2.printstandard(); // 2:00:00 AM
26
27 cout «"\n\nt3: hour and minute specified; second defaulted\n ";
28 t3.printUniversal(); // 21:34:00
29 cout « "\n
30 t3.printstandard(); // 9:34:00 PM
31
32 cout « "\n\nt4: hour, minute and second specified\n ";
33 t4.printUniversal(); // 12:25:42
34 cout « "\n
35 t4.printStandard(); // 12:25:42 PM
36
37 cout « "\n\nt5: all invalid values specified\n ";
38 t5.printUniversal(); // 00:00:00
39 cout « "\n
40 t5.printstandard(); // 12:00:00 AM
41 cout « endl;
42 return 0;
43 } // конец main
Constructed with:
tl: all arguments defaulted
00:00:00
12:00:00 AM
t2: hour specified; minute and second defaulted
02:00:00
2:00:00 AM
t3: hour and minute specified; second defaulted
21:34:00
612
Глава 9
9:34:00 РМ
t4: hour, minute and second specified
12:25:42
12:25:42 PM
t5: all invalid values specified
00:00:00
12:00:00 AM
Рис. 9.10. Конструктор с аргументами по умолчанию
Функция main на рис. 9.10 инициализирует пять объектов Time — один со
всеми опущенными аргументами в неявном вызове конструктора (строка 11),
второй с одним специфицированным аргументом (строка 12), третий с двумя
аргументами (строка 13), четвертый с тремя аргументами (строка 14) и пятый
с тремя недействительными аргументами (строка 15). Затем программа
выводит каждый объект во всемирном и стандартном форматах времени.
Замечания относительно set- и get-функций и конструктора
класса Time
Set- и £е£-функции класса Time вызываются в теле класса повсюду. В
частности, функция setTime (строки 21-26 на рис. 9.9) вызывает функции
setHour, setMinute и setSecond, а функции printUniversal и prntStandard
вызывают getHour, get Minute и getSecond соответственно в строках 67-68
и 74-76. В каждом случае эти функции могли бы обращаться к закрытым
данным класса непосредственно, не вызывая set- и get-функции. Однако
рассмотрите случай, когда представление времени в классе изменяется: вместо трех
целых значений (занимающих 12 байт) используется одно (требующее всего
четыре байта), в котором хранится число секунд, истекшее с полуночи. При
таком изменении потребовалось бы модифицировать только тела функций,
непосредственно обращающихся к закрытым данным, а именно set- и get-функ-
ций для hour, min и second. Тела функций setSecond, printUniversal или
prntStandard модифицировать не потребуется, так как они не обращаются
к данным непосредственно. Разрабатывая класс таким образом, мы
уменьшаем вероятность ошибок при изменении его реализации.
Аналогично, конструктор Time можно было бы написать так, чтобы он
содержал копию соответствующих операторов из функции setTime. Это сделало
бы конструктор чуть более эффективным, поскольку исключался бы вызов
setTime. Однако дублирование операторов в нескольких функциях или
конструкторах затрудняет изменение внутреннего представления данных класса.
Когда конструктор вызывает функцию setTime, любые изменения в
реализации setTime требуется выполнить только один раз.
_ п Типичная ошибка программирования 9.2
Конструктор может вызывать другие элемент-функции класса,
такие, как set- и get-функции, но поскольку конструктор инициализирует
объект, элементы данных могут еде не быть в согласованном
состоянии. Использование элементов данных до того, как они будут
правильно инициализированы, может приводить к логическим ошибкам.
Классы: часть I
613
9.7. Деструкторы
Еще одним типом специальной элемент-функции является деструктор.
Имя деструктора для класса образуется из имени класса, которому
предшествует символ тильды (~). Такое соглашение интуитивно привлекательно, так
как операция-тильда, как мы увидим далее, является операцией поразрядного
дополнения, а деструктор, в некотором смысле, дополнителен к конструктору.
В литературе для деструктора часто используют сокращение «dtor». Мы
предпочитаем не пользоваться этой аббревиатурой.
Деструктор вызывается неявным образом при уничтожении объекта. Это
происходит, например, когда автоматический объект уничтожается
вследствие того, что исполнение программы выходит из области действия, в которой
объект был создан. Сам деструктор в действительности не освобождает
память объекта, — он производит его заключительную приборку перед тем,
как система освободит память, чтобы ее можно было использовать для новых
объектов.
Деструктор не принимает параметров и не возвращает значения.
Деструктор не может специфицировать возвращаемый тип — даже void. В классе
может быть только один деструктор — перегрузка деструкторов не допускается.
Типичная ошибка программирования 9.3
Попытка передать деструктору аргументы, специфицировать воз
вращаемый деструктором тип (нельзя специфицировать даже void),
возвратить значение из деструктора является синтаксической
ошибкой.
Хотя мы не предусматривали деструкторов в рассмотренных до сих пор
классах, деструктор имеется в каждом классе. Если программист не
определяет деструктор явным образом, компилятор создает «пустой» деструктор. [За
мечание. Мы увидим, что такой деструктор производит в действительности
важные действия над объектами, создаваемыми путем композиции (глава 10)
и наследования (глава 12).] В главе 11 мы будем строить деструкторы,
необходимые для классов, объекты которых содержат динамически выделенную
память (например, для массивов и строк) или используют другие системные
ресурсы (например, файлы на диске). Каким образом динамически выделяется
и освобождается память, мы обсудим в главе 11.
Общее методическое замечание 9.11
Как мы увидим в оставшейся части книги, конструкторы и
деструкторы играют в C++ и объектно-ориентированном программировании
значительно более важную роль, чем можно понять из нашего
краткого введения.
9.8. Когда вызываются конструкторы и деструкторы
Конструкторы и деструкторы вызываются компилятором неявно. Порядок,
в котором происходят эти вызовы, зависит от порядка входа исполнения в
области действия, где создаются объекты, и выхода из них. Как правило, вызо-
614
Глава 9
вы деструкторов происходят в обратном порядке по отношению к вызовам
конструкторов, но, как мы увидим из рис. 9.11-9.13, порядок вызова
деструкторов может меняться в зависимости от класса памяти объектов.
Для объектов, объявленных в глобальной области действия, конструкторы
вызываются до того, как станут исполняться какие-либо другие функции
(включая main) в этом файле (хотя порядок вызова конструкторов глобальных
объектов в различных файлах не гарантируется). Соответствующие
деструкторы вызываются при завершении main. Функция exit заставляет программу
завершиться немедленно и не исполняет деструкторы автоматических объектов.
Эта функция часто используется для завершения программы в случае
обнаружения ошибки ввода или если файл, подлежащий обработке, не может быть
открыт. Функция abort действует подобно функции exit, но заставляет
программу завершиться, не позволяя вызвать деструкторы каких-либо объектов
вообще. Функция abort применяется обычно для индикации аварийного
завершения программы.
Конструктор автоматического объекта вызывается, когда исполнение
достигает точки, где объект определяется; соответствующий деструктор
вызывается, когда исполнение покидает область действия объекта (т.е. блок, в
котором определен объект, завершает свое исполнение). Конструкторы и
деструкторы автоматических объектов вызываются всякий раз, как исполнение
входит и выходит из области действия объекта. Деструкторы для
автоматических объектов не вызывается, если программа завершается вызовом функции
exit или функции abort.
Конструктор статического локального объекта вызывается лишь однажды,
когда исполнение в первый раз достигнет точки, где объект определяется;
соответствующий деструктор вызывается, когда завершается функция main или
вызывается функция exit. Деструкторы для локальных статических объектов
не вызываются, если программа завершается вызовом функции abort.
Программа на рис. 9.11-9.13 демонстрирует порядок вызова конструкторов
и деструкторов для объектов класса CreateAndDestroy (рис. 9.11-9.12) с
различными классами памяти в нескольких областях действия. Каждый объект
класса CreateAndDestroy содержит целое objectID и строку message
(строки 16-17), которые используются в выводе программы для идентификации
объекта. Мы приводим этот механический пример в чисто педагогических
целях. По этой причине строка 23 деструктора на рис. 9.12 определяет, имеет ли
уничтожаемый объект objectID, равный 1 или 6, и если это так, выводит
символ новой строки. Это делает вывод программы более удобочитаемым.
1 // Рис. 9.11: CreateAndDestroy.h
2 // Определение класса CreateAndDestroy.
3 // Элемент-функции определяются в CreateAndDestroy.срр.
4 #include <string>
5 using std::string;
6
7 #ifndef CREATE_H
8 #define CREATE_H
9
10 class CreateAndDestroy
11 {
12 public:
13 CreateAndDestroy( int, string ); // конструктор
Классы: часть I
615
14 ^CreateAndDestroy(); // деструктор
15 private:
16 int objectID; // ID-значение для объекта
17 string message; // сообщение, описывающее объект
18 }; // конец класса CreateAndDestroy
19
20 #endif
Рис. 9.11. Определение класса CreateAndDestroy
1 // Рис. 9.12: CreateAndDestroy.срр
2 // Определение элемент-функций класса CreateAndDestroy.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "CreateAndDestroy.h" // включить класс CreateAndDestroy
8
9 // конструктор
10 CreateAndDestroy::CreateAndDestroy( int ID, string messageString )
11 {
12 objectID = ID; // установить идентификационный номер объекта
13 message = messageString; // установить описательное сообщение
14
15 cout « "Object " « objectID « " constructor runs "
16 « message « endl;
17 } // конец конструктора CreateAndDestroy
18
19 // деструктор
20 CreateAndDestroy::-CreateAndDestroy()
21 {
22 // для некоторых объектов выводить \п; улучшает читаемость
23 cout « ( objectID == 1 || objectID == 6 ? "\n" : "" );
24
25 cout « "Object " « objectID « " destructor runs
26 « message « endl;
27 } // конец деструктора -CreateAndDestroy
Рис. 9.12. Определения элемент-функций класса CreateAndDestroy
1 // Рис. 9.13: fig09_13.cpp
2 // Демонстрация порядка, в котором вызываются
3 // конструкторы и деструкторы.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "CreateAndDestroy.h" // включить класс CreateAndDestroy
9
10 void create( void ); // прототип
11
12 CreateAndDestroy first( 1, "(global before main)" ); // глобальный
13
616
Глава 9
14 int main()
15 {
16 cout « "\nMAIN FUNCTION: EXECUTION BEGINS" « endl;
17 CreateAndDestroy second( 2, "(local automatic in main)" );
18 static CreateAndDestroy third( 3, "(local static in main)" );
19
20 create(); // вызвать функцию для создания объектов
21
22 cout « "\nMAIN FUNCTION: EXECUTION RESUMES" « endl;
23 CreateAndDestroy fourth( 4, "(local automatic in main)" );
24 cout « "\nMAIN FUNCTION: EXECUTION ENDS" « endl;
25 return 0;
26 } // конец main
27
28 // функция для создания объектов
29 void create( void )
30 {
31 cout « "\nCREATE FUNCTION: EXECUTION BEGINS" « endl;
32 CreateAndDestroy fifth( 5, "(local automatic in create)" );
33 static CreateAndDestroy sixth( 6, "(local static in create)" )
34 CreateAndDestroy seventh( 7, "(local automatic in create)" );
35 cout « "\nCREATE FUNCTION: EXECUTION ENDS" « endl;
36 } // конец функции create
Object 1 constructor runs (global before main)
MAIN FUNCTION: EXECUTION BEGINS
Object 2 constructor runs (local automatic in main)
Object 3 constructor runs (local static in main)
CREATE FUNCTION: EXECUTION BEGINS
Object 5 constructor runs (local automatic in create)
Object 6 constructor runs (local static in create)
Object 7 constructor runs (local automatic in create)
CREATE FUNCTION: EXECUTION ENDS
Object 7 destructor runs (local automatic in create)
Object 5 destructor runs (local automatic in create)
MAIN FUNCTION: EXECUTION RESUMES
Object 4 constructor runs (local automatic in main)
MAIN FUNCTION: EXECUTION ENDS
Object 4 destructor runs (local automatic in main)
Object 2 destructor runs (local automatic in main)
Object 6 destructor runs (local static in create)
Object 3 destructor runs (local static in main)
Object 1 destructor runs (global before main)
Рис.9.13. Порядок, в котором вызываются конструкторы и деструкторы
Классы: часть I
617
Рис. 9.13 определяет объект first (строка 12) в глобальной области
действия. Его конструктор в действительности вызывается до исполнения любых
операторов в main, а деструктор вызывается при завершении программы
после того, как выполнятся деструкторы всех остальных объектов.
Функция main (строки 14-26) объявляет три объекта. Объекты second
(строка 17) и fourth (строка 23) являются локальными автоматическими
объектами, а объект third (строка 18) является статическим локальным объектом.
Конструктор для каждого из этих объектов вызывается, когда исполнение
достигает точки, где определяется данный объект. Деструкторы для объектов
fourth и затем second (т.е. в порядке, обратном вызову конструкторов)
вызываются, когда исполнение достигает конца main. Поскольку объект third
является статическим, он существует, пока программа не завершится.
Деструктор для объекта third вызывается перед деструктором глобального объекта
first, но после уничтожения всех остальных объектов.
Функция create (строки 29-36) объявляет три объекта — fifth (строка 32)
и seventh (строка 34) являются локальными автоматическими объектами,
a sixth — статическим локальным объектом. Деструкторы для объектов
seventh и затем fifth (т.е. в порядке, обратном вызову конструкторов)
вызываются, когда завершается функция create. Поскольку объект sixth является
статическим, он существует, пока программа не завершится. Деструктор для
sixth вызывается перед деструкторами third и first, но после уничтожения
всех остальных объектов.
9.9. Пример: класс Time. Скрытая ошибка —
возвращение ссылки на закрытый элемент данных
Ссылка на объект является псевдонимом для имени объекта и,
следовательно, может появляться в левой части оператора присваивания. В таком
контексте ссылка оказывается совершенно законным lvalue, которое может получать
значение. Одним из путей эксплуатации такой возможности (к сожалению!)
является определение открытой элемент-функции класса, которая возвращает
ссылку на закрытый элемент данных этого класса. Заметьте, что если
функция возвращает константную ссылку, последняя не может использоваться
в качестве модифицируемого lvalue.
В программе на рис. 9.14-9.16 определяется упрощенный класс Time
(рис. 9.14 и рис. 9.15), позволяющий продемонстрировать возврат
элемент-функцией badSetHour (объявленной в строке 15 на рис. 9.14 и определенной в
строках 29-33 на рис. 9.15) ссылки на закрытый элемент данных.Такой возврат
ссылки по существу делает вызов элемент-функции badSetHour псевдонимом
закрытого элемента данных hour! Этот вызов функции может использоваться
любым способом, который возможен для элемента данных, в том числе в
качестве lvalue в операторе присваивания, что позволяет клиентам класса делать
с его закрытыми данными все что угодно! Заметьте, что та же проблема
возникает в случае возврата функцией указателя на закрытый элемент данных.
618
Глава 9
1 // Рис. 9.14: Time.h
2 // Объявление класса Time.
3 // Элемент-функции определяются в Time.cpp
4
5 // предотвратить многократное включение заголовочного файла
6 #ifndef TIME_H
7 #define TIME_H
8
9 class Time
Ю {
11 public:
12 Time( int = 0, int = 0, int = 0 );
13 void setTime( int, int, int );
14 int getHour();
15 int &badSetHour( int ); // ОПАСНЫЙ возврат ссылки
16 private:
17 int hour;
18 int minute;
19 int second;
20 }; // конец класса Time
21
22 #endif
Рис. 9.14. Возврат ссылки на закрытый элемент данных
1 // Рис. 9.15: Time.cpp
2 // Определение элемент-функций класса.
3 #include "Time.h" // включить определение класса Time
4
5 // функция конструктора инициализирует закрытые данные;
6 // для установки переменных вызывает элемент-функцию setTime;
7 // значения по умолчанию равны 0 (см. определение класса)
8 Time::Time ( int hr, int min, int sec )
9 {
10 setTime( hr, min, sec );
11 } // конец конструктора Time
12
13 // установить значения часов, минут и секунд
14 void Time::setTime( int h, int m, int s )
15 {
16 hour = ( h >= 0 && h < 24 ) ? h : 0; // проверить часы
17 minute = ( m >= 0 && m < 60 ) ? m : 0; // проверить минуты
18 second = ( s >= 0 && s < 60 ) ? s : 0; // проверить секунды
19 } // конец функции setTime
20
21 // возвратить значение часов
22 int Time::getHour()
23 {
24 return hour;
25 } // конец функции getHour
26
27 // ПЛОХОЙ СТИЛЬ ПРОГРАММИРОВАНИЯ:
28 // Возврат ссылки на закрытый элемент данных.
29 int &Time:ibadSetHour( int hh )
Классы: часть I
619
30 {
31 hour = ( hh >= 0 && hh < 24 ) ? hh : 0;
32 return hour; // ОПАСНЫЙ возврат ссылки
33 } // конец функции badSetHour
Рис. 9.15. Возврат ссылки на закрытый элемент данных
1 // Рис. 9.16: fig09_16.cpp
2 // Демонстрация открытой элемент-функции, которая
3 // возвращает ссылку на закрытый элемент данных.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "Time.h" // включить определение класса Time
9
10 int main()
11 {
12 Time t; // создать объект Time
13
14 // инициализировать hourRef ссылкой, возвращаемой badSetHour
15 int &hourRe£ = t.badSetHour( 20 ); // 20 - корректный час
16
17 cout « "Valid hour before modification: " « hourRef;
18 hourRef = 30; // установка через hourRef плохого значения в t
19 cout « "\nlnvalid hour after modification: " « t.getHour();
20
21 // Опасно: Вызов, возвращающий ссылку,
22 // который можно использовать в качестве lvalue!
23 t. badSetHour ( 12 ) = 74; // еще одно присваивание плохого часа
24
25 cout « "\n\n*************************************************\nM
26 « "POOR PROGRAMMING PRACTICE!!!!!!!!\n"
27 « "t.badSetHour( 12 ) as an lvalue, invalid hour: "
28 « t.getHour()
29 «"\n************************************************ *"« endl;
30 return 0;
31 } // конец main
Valid hour before modification: 20
Invalid hour after modification: 30
••••••••••*••••••••••••••••••*•••••••••••**••••••
POOR PROGRAMMING PRACTICE!!!!!!!!
t.badSetHour( 12 ) as an lvalue, invalid hour: 74
••••••••••••••••••••••••••••••••••••••••••л******
Рис. 9.16. Возврат ссылки на закрытый элемент данных
Рис. 9.16 объявляет объект Time с именем t (строка 12) и ссылку hourRef
(строка 15), которая инициализируется ссылкой, возвращаемой вызовом
t.badSetHourB0). Строка 17 выводит значение псевдонима hourRef. Этим
демонстрируется, как hourRef нарушает инкапсуляцию класса, — операторы
в main не должны иметь доступа к закрытым данным класса. Затем строка 18
620
Глава 9
использует псевдоним для установки значения hour равным 30
(недействительному значению), а строка 19 выводит значение, возвращаемое функцией
getHour, показывая, что присваивание значения ссылке hourRcf
действительно модифицирует закрытые данные в объекте t класса Time. Наконец,
строка 23 использует сам вызов функции badSctHour в качестве lvalue и
присваивает ссылке, которую возвращает функция, значение 74 (также
недействительное значение). Строка 28 снова выводит значение, возвращаемое
функцией getHour, показывая, что присваивание значения результату вызова
функции в строке 23 модифицирует закрытые данные в объекте t класса Time.
jT&l Предотвращение ошибок 9.4
\№у Возврат ссылки или указателя на закрытый элемент данных
нарушает инкапсуляцию класса и делает код клиента зависимым от
представления данных класса. Таким образом, возврат ссылок или
указателей на закрытые данные является опасным и его следует
избегать.
9.10. Поэлементное присваивание по умолчанию
Операция присваивания (=) может применяться для присваивания одного
объекта другому объекту того же типа. По умолчанию такое присваивание
производится посредством поэлементного присваивания — каждый элемент
данных объекта справа от операции присваивания по отдельности
присваивается соответствующему элементу объекта слева от операции присваивания.
Рис. 9.17-9.18 определяют класс Date для данной демонстрации. Строка 20 на
рис. 9.19 выполняет поэлементное присваивание по умолчанию для
присваивания элементов данных объекта datel соответствующим элементам данных
объекта date2. При этом элемент month объекта datel присваивается
элементу month объекта date2, элемент day объекта datel присваивается элементу
day объекта date2, а элемент year объекта datel присваивается элементу year
объекта date2. [Предостережение. Поэлементное присваивание может вызвать
серьезные проблемы, если используется с классом, чьи элементы данных
содержат указатели на динамически выделенную память; мы обсудим эти
проблемы в главе 11 и покажем, как они решаются.] Как можно заметить,
конструктор Date не содержит никакого кода проверки на ошибку; мы оставляем
это для упражнений.
1 // Рис. 9.17: Date.h
2 // Объявление класса Date.
3 // Элемент-функции определяются в Date.cpp
4
5 // предотвратить многократное включение заголовочного файла
6 #ifndef DATE_H
7 #define DATE_H
8
9 // определение класса Date
10 class Date
11 {
12 public:
13 Date ( int = 1, int = 1, int = 2000 ); // конструктор по умолчанию
Классы: часть I
621
14 void print();
15 private:
16 int month;
17 int day;
18 int year;
19 }; // конец класса Date
20
21 #endif
Рис. 9.17. Заголовочный файл класса Date
1 // Рис. 9.18: Date.cpp
2 // Определение элемент-функций класса Date.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Date.h" // включить определение класса Date из Date.h
8
9 // конструктор Date constructor (должен проверять диапазон)
10 Date::Date( int m, int d, int у )
11 {
12 month = m;
13 day = d;
14 year = y;
15 } // конец конструктора Date
16
17 // напечатать дату в формате mm/dd/yyyy
18 void Date::print()
19 {
20 cout « month « '/* « day « '/' « year;
21 } // конец функции print
Рис. 9.18. Определения элемент-функций класса Date
1 // Рис. 9.19: fig09_19.cpp
2 // Демонстрация того, что объекты классов можно присваивать
3 // друг другу посредством поэлементного копирования по умолчанию.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "Date.h" // включить определение класса Date из Date.h
9
10 int main()
11 {
12 Date datel( 7, 4, 2004 ); \
13 Date date2; // date2.no умолчанию 1/1/2000
14
15 cout « "datel = ";
16 datel.print();
17 cout « "\ndate2 = ";
18 date2.print();
622
Глава 9
19
20 date2 = datel; // поэлементное копирование по умолчанию
21
22 cout « M\n\nAfter default memberwise assignment, date2 =
23 date2.print();
24 cout « endl;
25 return 0;
26 } // конец main
datel = 7/4/2004
date2 = 1/1/2000
After default memberwise assignment, date2 = 7/4/2004
Рис. 9.19. Поэлементное присваивание по умолчанию
Объекты могут передаваться функциям в качестве аргументов, и могут
возвращаться функциями. По умолчанию это осуществляется посредством
передачи по значению — передается или возвращается копия объекта. В таких
случаях C++ создает новый объект и применяет конструктор копии для
копирования значений исходного объекта в новый объект. Для каждого класса
компилятор генерирует конструктор копии по умолчанию, копирующий
каждый элемент исходного объекта в соответствующий элемент нового объекта.
Как и поэлементное присваивание, конструкторы копии могут вызвать
серьезные проблемы, когда используются с классом, чьи элементы данных содержат
указатели на динамически выделенную память. В главе 11 обсуждается,
каким образом программист может определить специальный конструктор
копии, который корректно копирует объекты, содержащие указатели на
динамически выделенную память.
I—^ Вопросы производительности 9.3
р^Ф^| Передача объекта по значению хороша с точки зрения безопасности,
так как вызываемая функция не имеет доступа к исходному объекту
вызывающего, но передача по значению может ухудшить
эффективность, когда приходится делать копию большого объекта. Объект
можно передать по ссылке, передавая либо указатель, либо ссылку на
него. Передача по ссылке обеспечивает хорошую эффективность, но
слабее с точки зрения безопасности, поскольку вызывающей функции
разрешается доступ к исходному объекту. Безопасной и эффективной
альтернативой является передача по константной ссылке (это
можно осуществить посредством параметра — константной ссылки или
параметра — указателя на константные данные).
9.11. Утилизируемость программного обеспечения
Люди, пишущие объектно-ориентированные программы, сосредоточивают
свое внимание на реализации полезных классов. Существуют сильнейшие
побудительные причины для сбора и каталогизации классов, чтобы их могли
использовать значительные части сообщества программистов. Существует много
больших библиотек классов, и по всему миру разрабатываются новые. Про-
Классы: часть I
623
граммное обеспечение все в большей степени строится из существующих,
точно определенных, тщательно протестированных, хорошо документированных,
переносимых, высокоэффективных, общедоступных компонентов. Такого
рода утилизируемость ускоряет разработку мощного высококачественного
программного обеспечения. Важной областью программной индустрии стала
ускоренная разработка приложений (RAD) на основе механизмов утилизации
компонентов.
Однако должны быть решены важные проблемы, прежде чем потенциал
утилизации программного обеспечения будет полностью реализован. Нам
нужны схемы каталогизации, лицензирования, механизмы защиты,
гарантирующие, что эталонные копии классов не будут повреждены, схемы описания,
позволяющие проектировщикам новых систем легко определить,
удовлетворяют ли существующие объекты их требованиям, механизмы просмотра для
выяснения того, какие классы имеются в наличии и насколько близко они
соответствуют потребностям разработчика, и т.п. Имеются сильнейшие
побудительные причины для решения этих проблем, так как потенциальная
ценность их решения огромна.
9.12. Конструирование программного обеспечения.
Начало программирования классов системы ATM
(необязательный раздел)
В разделах «Конструирование программного обеспечения» в главах 1-7 мы
представили основы ориентации на объекты и разработали
объектно-ориентированный проект для нашей системы ATM. Ранее в этой главе мы многие
детали программирования с классами C++. Теперь мы начинаем реализацию
нашего объектно-ориентированного проекта на C++. В конце этого раздела мы
покажем, как преобразовать наши классовые диаграммы в заголовочные
файлы C++. В финальном разделе «Конструирование программного обеспечения»
(раздел 13.10) мы модифицируем эти заголовочные файлы в соответствии
с объектно-ориентированной концепцией наследования. Полный код
реализации на C++ приводится в приложении Е.
Видимость
Сейчас мы применим к элементам наших классов спецификаторы доступа.
В главе 3 мы ввели спецификаторы доступа public и private. Спецификаторы
доступа определяют видимость, или доступность, атрибутов и операций
объекта для других объектов. Прежде чем мы начнем реализацию нашего
проекта, мы должны рассмотреть, какие атрибуты и операции наших классов
должны быть открытыми (public), а какие закрытыми (private).
В главе 3 мы отмечали, что элементы данных обычно должны быть
закрытыми, а элемент-функции, вызываемые клиентами класса — открытыми.
Однако элемент-функции, вызываемые только другими элемент-функциями
класса в качестве «сервисных функций», обычно должны быть
закрытыми.Для моделирования видимости атрибутов и операций в UML используются
маркеры видимости. Открытая видимость обозначается знаком плюс (+) перед
операцией или атрибутом; знак минус (—) обозначает закрытую видимость.
Рис. 9.20 показывает нашу модифицированную классовую диаграмму, допол-
624
Глава 9
ненную маркерами видимости. [Замечание. Мы не включили в диаграмму на
рис. 9.20 никаких параметров операций. Это совершенно нормально.
Добавление маркеров видимости никак не влияет на параметры, уже
смоделированные на классовых диаграммах из рис. 6.36-6.39).]
ATM
userAuthenticated : Boolean = false
Balancelnquiry
-- accountNumber: Integer
+ executeQ
Account
- accountNumber: Integer
- pin : Integer
- availableBalance : Double
- totalBalance Double
+ validatePINO : Boolean
+ getAvailableBalance() : Double
4 getTotalBalanreQ : Double
+ credit()
+ debitO
Withdrawal
- accountNumber: Integer
- amount: Double
+ executeQ
Deposit
accountNumber: Integer
amount: Double
+ executeQ
BankDatabase
+ authenticateUserQ : Boolean
+ getAvailableBalanceQ : Double
+ getTotalBalanceQ : Double
+ creditQ
+ debitQ
Screen
+ displayMessageQ
Keypad
+ getlnputO : Integer
CashDispenser
- count: Integer = 500
+ dispenseCashO
+ isSufficientCashAvailableQ : Boolean
DepositSlot
+ isEnvelopeReceivedQ : Boolean
Рис. 9.20. Классовая диаграмма с маркерами видимости
Классы: часть I
625
Проходимость
Прежде чем начать реализацию нашего проекта на C++, мы введем еще
одно условное обозначение UML. Классовая диаграмма на рис. 9.21 еще далее
уточняет взаимоотношения между классами в системе ATM, добавляя к
линиям ассоциаций стрелки проходимости. Стрелки проходимости
(изображаемые на классовой диаграмме в виде стрелок со штриховыми наконечниками)
показывают, в каком направлении может проходиться ассоциация, и
основываются на кооперациях, моделируемых в диаграммах коммуникации и
последовательности (см. раздел 7.12). Реализуя систему, спроектированную с
помощью UML, программисты используют стрелки проходимости, чтобы быстро
определить, каким объектам требуются ссылки или указатели на другие
объекты. Например, стрелка проходимости, направленная от класса ATM к
классу BankDatabase, показывает, что мы можем пройти от первого ко второму,
что позволяет ATM активировать операции BankDatabase. Однако поскольку
на рис. 9.21 нет стрелки проходимости, которая была бы направлена от класса
BankDatabase к классу ATM, BankDatabase не может обращаться к
операциям ATM. Заметьте, что ассоциации на классовой диаграмме, которые имеют
стрелки проходимости на обоих концах либо не имеют их вообще, показывают
двунаправленную проходимость — по ассоциации можно пройти в обоих
направлениях.
Как и на классовой диаграмме из рис. 3.23, на рис. 9.21 опущены классы
Balancelnquiry и Deposit, чтобы не усложнять диаграмму. Проходимость
ассоциаций, в которых участвуют эти классы, весьма схожа с проходимостью
ассоциаций класса Withdrawal. Как вы должны помнить из раздела 3.11,
класс Balancelnquiry имеет ассоциацию с классом Screen. Мы можем пройти
по этой ассоциации от класса Balancelnquiry к классу Screen, но не можем
пройти от класса Screen к классу Balancelnquiry. Таким образом, если бы на
рис. 9.21 мы моделировали класс Balancelnquiry, то поставили бы стрелку
проходимости на этой ассоциации со стороны Screen. Вспомните также, что
класс Deposit ассоциируется с классами Screen, Keypad и DepositSlot. Мы
можем пройти от класса Deposit к каждому из этих классов, но не наоборот.
Мы следовательно, должны поместить стрелки проходимости со стороны
классов Screen, Keypad и DepositSlot этих ассоциаций. [Замечание. Мы
смоделируем эти дополнительные классы и ассоциации на нашей окончательной
классовой диаграмме в разделе 13.10, после того, как упростим структуру
нашей системы, воспользовавшись объектно-ориентированной концепцией
наследования.]
626
Глава 9
i
Keypad
DepositSlot
't
4-, r-4-
1 * 1' *
CashDispenser
Screen
•г-,
j,
Исполняет ►
0..1
Авторизует пользователя в
0..1 0..1
Withdrawal
I0..1
0..1
BankDatabase <-
Содержит
T
1
< Читает/модифицирует
баланс счета через
Account
Рис. 9.21. Классовая диаграмма со стрелками проходимости
Реализация системы ATM no ее UML-проекту
Теперь мы готовы приступить к реализации системы ATM. Сначала мы
преобразуем классы на диаграммах из рис. 9.20 и 9.21 в заголовочные файлы
C++. Этот код будет представлять собой «скелет» системы. В главе 13 мы
модифицируем заголовочные файлы в соответствии с концепцией наследования.
В приложении Е мы приводим полностью работоспособный код C++ для
нашей модели.
В качестве примера мы начнем разрабатывать по нашему проекту на
рис. 9.20 заголовочный файл для класса Withdrawal. Мы воспользуемся
этим рисунком для определения атрибутов и операций класса. Модель UML
на рис. 9.21 мы используем для определения ассоциаций между классами.
Для каждого класса мы будем руководствоваться следующими пятью
указаниями:
1. Используйте имя, находящееся в первом разделе класса на классовой
диаграмме, для определения имени класса в заголовочном файле
(рис. 9.22). Посредством директив #ifndef, #define и #endif
предотвратите повторное включение заголовочного файла в программу.
2. Используйте находящиеся во втором разделе класса атрибуты для
объявления элементов данных. Например, закрытые атрибуты account Number
и amount класса Account дают код, показанный на рис. 9.23.
Классы: часть I
627
3. Используйте описанные в классовой диаграмме ассоциации для,
объявления ссылок (или указателей, где это целесообразно) на другие объекты.
Например, согласно рис. 9.21, Withdrawal может обращаться к одному
объекту класса Screen, одному объекту класса Keypad, одному объекту
класса CashDispenser и одному объекту класса BankDatabase. Класс
Withdrawal должен хранить дескрипторы этих объектов, чтобы
посылать им сообщения, поэтому строки 19-22 на рис. 9.24 объявляют
четыре ссылки в качестве закрытых элементов данных. В реализации класса
в приложении Е конструктор инициализирует эти ссылки ссылками на
действительные объекты. Обратите внимание, строки 6-9 включают
заголовочные файлы с определениями классов Screen, Keypad,
CashDispenser и BankDatabase, так что мы имеем право объявлять в
строках 19-22 ссылки на объекты этих классов.
1 // Рис. 9.22: Withdrawal.h
2 // Определение класса Withdrawal. Представляет транзакцию снятия.
3 #ifndef WITHDRAWAL_H
4 #define WITHDRAWAL_H
5
6 class Withdrawal
7 {
8 }; // конец класса Withdrawal
9
10 #endif // WITHDRAWAL H
Рис. 9.22. Определение класса Withdrawal, заключенное в препроцессорную
обертку
1 // Рис. 9.23: Withdrawal.h
2 // Определение класса Withdrawal. Представляет транзакцию снятия.
3 #ifndef WITHDRAWAL_H
4 #define WITHDRAWAL_H
5
6 class Withdrawal
7 {
8 private:
9 // атрибуты
10 int accountNumber; // счет, с которого снимаются средства
11 double amount; // снимаемая сумма
12 }; // конец класса Withdrawal
13
14 #endif // WITHDRAWAL H
Рис. 9.23. Добавление атрибутов в заголовочный файл класса Withdrawal
1 // Рис. 9.24: Withdrawal.h
2 // Определение класса Withdrawal. Представляет транзакцию снятия.
3 #ifndef WITHDRAWAL_H
4 #define WITHDRAWAL_H
5
6 #include "Screen.h" // включить определение класса Screen
628
Глава 9
7 #include "Keypad.h" // определение класса Keypad
8 #include "CashDispenser.h" // определение класса CashDispenser
9 #include "BankDatabase.h" // определение класса BankDatabase
10
11 class Withdrawal
12 {
13 private:
14 // атрибуты
15 int accountNumber; // счет, с которого снимаются средства
16 double amount; // снимаемая сумма
17
18 // ссылки на ассоциированные объекты
19 Screen fiscreen; // ссылка на экран ATM
20 Keypad &keypad; // ссылка на кнопочную панель ATM
21 CashDispenser ficashDispenser; // ссылка на выходной лоток ATM
22 BankDatabase &bankDatabase // ссылка на базу данных со счетами
23 }; // конец класса Withdrawal
24
25 #endif // WITHDRAWAL^
Рис. 9.24. Объявление ссылок на объекты, ассоциированные с классом Withdrawal
4. Оказывается, однако, что включение заголовочных файлов для классов
Screen, Keypad, CashDispenser и BankDatabase на рис. 9.24 — это
слишком много. Класс Withdrawal содержит ссылки на объекты этих
классов — он не содержит действительных объектов, — а количество
информации, необходимой компилятору для создания ссылки, отличается от того,
что требуется для создания объекта. Вспомните, что создание объекта
требует, чтобы вы снабдили компилятор определением класса, которое вводит
имя класса в качестве нового определенного пользователем типа и
указывает элементы данных, определяющие объем памяти, требуемой для
хранения объекта. Объявление ссылки (или указателя) на объект требует
только, чтобы компилятор знал, что класс объекта существует, — ему не
нужно знать размер объекта. Любая ссылка (или указатель) вне
зависимости от класса объекта, на который она ссылается, содержит только адрес
памяти действительного объекта. Количество памяти, необходимой для
хранения адреса, есть физическая характеристика аппаратной части
компьютера. Компилятору, таким образом, известен размер любой ссылки
(или указателя). В результате при объявлении только ссылки включение
полного заголовочного файла класса оказывается излишним, — нам
нужно ввести имя класса, но не требуется предоставлять расположение
данных в объекте, поскольку компилятору заранее известен размер всех
ссылок. В C++ предусмотрен оператор, называемый опережающим
объявлением, который предупреждает, что заголовочный файл содержит ссылки или
указатели на класс, но определение класса остается вне заголовочного
файла. Мы можем заменить директивы #include в определении класса
Withdrawal на рис. 9.24 опережающими объявлениями классов Screen,
Keypad, CashDispenser и BankDatabase (строки 6-9 на рис. 9.25). Вместо
того, чтобы включать для каждого из этих классов весь заголовочный
файл, мы помещаем в заголовочный файл класса Withdrawal только
опережающее объявление для каждого класса. Заметьте, что если бы класс
Классы: часть I
629
Withdrawal содержал действительные объекты вместо ссылок (т.е. ампер-
санды в строках 6-9 были опущены), то мы действительно должны были
включить полные заголовочные файлы.
Обратите внимание, что использование опережающих объявлений (где
это возможно) вместо включения полных заголовочных файлов
устраняет препроцессорную проблему, называемую круговым включением. Эта
проблема возникает, когда заголовочный файл для класса А включает
заголовочный файл для класса В, и наоборот. Некоторые препроцессоры
не могут разрешать такие директивы #include, что приводит к ошибке
компиляции. Если класс А, например, использует только ссылку на
объект класса В, то директиву #include в заголовочном файле класса А
можно заменить опережающим объявлением, чтобы предотвратить
круговое включение.
1 // Рис. 9.25: Withdrawal.h
2 // Определение класса Withdrawal. Представляет транзакцию снятия.
3 #ifndef WITHDRAWAL_H
4 #define WITHDRAWAL_H
5 ,
6 class Screen; // опережающее объявление класса Screen
7 class Keypad; // опережающее объявление класса Keypad
8 class CashDispenser; // опережающее объявление класса CashDispenser
9 class BankDatabase; // опережающее объявление класса BankDatabase
10
11 class Withdrawal
12 {
13 private:
14 // атрибуты
15 int accountNumber; // счет, с которого снимаются средства
16 double amount; // снимаемая сумма
17
18 // ссылки на ассоциированные объекты
19 Screen &screen; // ссылка на экран ATM
20 Keypad fikeypad; // ссылка на кнопочную панель ATM
21 CashDispenser ficashDispenser; // ссылка на выходной лоток ATM
22 BankDatabase &bankDatabase // ссылка на базу данных со счетами
23 }; // конец класса Withdrawal
24
25 #endif // WITHDRAWAL^
Рис. 9.25, Использование опережающих объявлений вместо директив #include
5. Используйте операции, находящиеся в третьем разделе диаграммы на
рис. 9.20, для написания прототипов элемент-функций класса. Если мы
еще не специфицировали для операции возвращаемый тип, то
объявляем ее с возвращаемым типом void. Обратитесь к классовым диаграммам
на рис. 6.36-6.39 и объявите любые необходимые параметры.
Например, добавление в класс Withdrawal открытой операции execute,
имеющей пустой список параметров, дает прототип в строке 15 на рис. 9.26.
[Замечание. Мы кодируем определения элемент-функций в .срр-файлах,
когда реализуем законченную систему ATM в приложении Ж.]
630
Глава 9
1 // Рис. 9.26: Withdrawal.h
2 // Определение класса Withdrawal. Представляет транзакцию снятия.
3 #ifndef WITHDRAWAL_H
4 #define WITHDRAWAL_H
5
6 class Screen; // опережающее объявление класса Screen
7 class Keypad; // опережающее объявление класса Keypad
8 class CashOispenser; // опережающее объявление класса CashDispenser
9 class BankDatabase; // опережающее объявление класса BankDatabase
10
11 class Withdrawal
12 {
13 public:
14 // операции
15 void execute(); // произвести транзакцию
16 private:
17 // атрибуты
18 int accountNumber; // счет, с которого снимаются средства
19 double amount; // снимаемая сумма
20
21 // ссылки на ассоциированные объекты
22 Screen fiscreen; // ссылка на экран ATM
23 Keypad fikeypad; // ссылка на кнопочную панель ATM
24 CashDispenser 6cashDispenser; // ссылка на выходной лоток ATM
25 BankDatabase SbankDatabase // ссылка на базу данных со счетами
26 }; // конец класса Withdrawal
27
28 #endif // WITHDRAWAL_H
Рис. 9.26. Добавление операций в заголовочный файл класса Withdrawal
Общее методическое замечание 9.12
Различные инструменты моделирования с UML могут
преобразовывать базирующиеся на UML проекты в код C++, значительно ускоряя
процесс реализации. За более подробной информацией об этих
«автоматических» генераторах кода обратитесь к ресурсам Internet и Web,
перечисленным в конце раздела .8.
На этом завершается наше обсуждение элементарных основ порождения
заголовочных файлов для классов по диаграммам UML. В финальном
разделе «Конструирование программного обеспечения» (раздел 13.10) мы
продемонстрируем, как модифицировать заголовочные файлы в свете
объектно-ориентированной концепции наследования.
Контрольные вопросы по конструированию программного
обеспечения
9.1. Укажите, является ли следующее утверждение верным или неверным,
и если оно неверно, объясните, почему:
Если атрибут класса помечен на классовой диаграмме знаком минус (—),
атрибут не является непосредственно доступным вне класса.
Классы: часть I
631
9.2. Ассоциация между ATM и Screen означает, что:
a) мы можем пройти от Screen к ATM
b) мы можем пройти от ATM к Screen
c) и а, и b; ассоциация является двунаправленной
d) ничего из вышеперечисленного
9.3. Напишите код C++, чтобы начать реализацию проекта для класса
Account.
Ответы на контрольные вопросы по конструированию
программного обеспечения
9.1. Верно. Знак минус (-) означает закрытую видимость. Мы уже
упоминали о «дружественности», являющейся исключением для закрытой
видимости. Дружественность обсуждается в главе 10.
9.2. Ь.
9.3. Проект для класса Account дает заголовочный файл на рис. 9.27.
1 // Рис. 9.27: Account.h
2 // Определение класса Account. Представляет банковский счет.
3 #ifndef ACCOUNT_H
4 #define ACCOUNT_H
5
6 class Account
7 {
8 public:
9 bool validatePIN( int ) const; // введенный PIN правилен?
10 double getAvailableBalance () const; // возвращает наличный баланс
11 double getTotalBalance() const; // возвращает общий баланс
12 void credit ( double ) ; // прибавляет сумму к балансу счета
13 void debit( double ); // вычитает сумму из баланса счета
14 private:
15 int accountNumber; // номер счета
16 int pin; // PIN для авторизации
17 double availableBalance; // средства, доступные для снятия
18 double totalBalance; // доступные средства + ожидающие очистки
19 }; // конец класса Account
20
21 #endif // ACCOUNT H
Рис. 9.27. Заголовочный файл класса Account по рис. 9.20 и 9.21
9.13. Заключение
Эта глава углубила наше знакомство с классами, продемонстрировав
развернутый учебный пример класса Time, в процессе развития которого было
представлено несколько новых аспектов классов. Вы увидели, что
элемент-функции обычно короче, чем глобальные функции, поскольку они могут
непосредственно обращаться к элементам данных объекта и, следовательно,
они могут принимать меньшее число аргументов, чем функции в процедурных
языках программирования. Вы узнали, как применять операцию-стрелку для
доступа к элементам объекта через указатель классового типа объекта.
632
Глава 9
Вы узнали, что элемент-функции имеют область действия класса, т.е. имя
элемент-функции известно только другим элементам того же класса, если
только на него не ссылаться через объект класса, ссылку на объект класса,
указатель на объект класса или бинарную операцию разрешения области
действия. Мы такл\.е обсудили функции доступа (используемые обычно для
извлечения значений элементов данных или для проверки истинности либо
ложности условий) и сервисные функции (закрытые элемент-функции,
поддерживающие работу открытых элемент-функций класса).
Вы узнали, что конструктор может специфицировать аргументы по
умолчанию, позволяющие вызывать его различными способами. Вы также узнали,
что любой конструктор, который можно вызывать без аргументов, является
конструктором по умолчанию и что в классе может быть не более одного
такого конструктора. Мы обсудили деструкторы и их назначение, состоящее в
заключительной приборке в объекте перед уничтожением последнего. Мы также
продемонстрировали порядок, в котором вызываются конструкторы и
деструкторы объектов.
Мы продемонстрировали проблемы, возникающие в случае, когда
элемент-функция возвращает ссылку на закрытый элемент данных, что нарушает
инкапсуляцию класса. Мы также показали, что объекты одного и того же
класса можно присваивать друг другу посредством поэлементного
присваивания по умолчанию. Наконец, мы обсудили преимущества использования
классовых библиотек в плане ускорения процесса создания кода и улучшения
качества программного обеспечения.
Глава 10 продолжает представление концепций программирования с
классами. Мы увидим, каким образом можно использовать const для индикации
того, что элемент-функция не модифицирует объект класса. Вы увидите, как
строить классы с композицией, — т.е. классы, содержащие в качестве
элементов объекты других классов. Мы покажем, как класс может разрешить так
называемым «дружественным» функциям обращаться к своим неоткрытым
элементам. Мы также покажем, как не-статическая элемент-функция класса
может использовать специальный указатель с именем this для доступа
к элементам объекта. Затем вы узнаете, как применяются операции C++ new
и delete, позволяющие программисту по мере необходимости получать и
освобождать память в процессе выполнения программы.
Резюме
• Препроцессорные директивы #ifndef (что означает «если не определено») и #endif
используются для предотвращения многократного включения заголовочного файла.
Если код между этими директивами ранее не включался в приложение, директива
#define определяет имя, которое может использоваться для предотвращения
последующих включений, и код включается в исходный файл.
• Элементы данных класса не могут инициализироваться там, где они объявляются
в теле класса (за исключением статических константных элементов данных
целочисленных или перечислимых типов, как вы увидите в главе 10). Настоятельно
рекомендуется инициализировать их в конструкторе класса (так как инициализация по
умолчанию для элементов данных основных типов не производится).
• Манипулятор потока setfill специфицирует символ заполнения, который отобража-
, ется, когда целое число выводится в поле более широкое, чем число цифр в значе-
Классы: часть I
633
• По умолчанию символы заполнения выводятся слева от цифр числа.
• Манипулятор потока setfill является «залипающей» установкой, т.е. как только
символ заполнения специфицирован, он будет относиться ко всем последующим
выводимым полям.
• Хотя элемент-функция, объявленная в определении класса, может определяться вне
определения класса (и «привязываться» к классу бинарной операцией разрешения
области действия), она все равно остается в области действия класса; другими
словами, ее имя известно только другим элементам класса, если только на него не
ссылаются через объект класса, ссылку на объект класса или указатель на объект класса.
• Если элемент-функция определяется в теле определения класса, компилятор C++
пытается расширять ее вызовы как встроенные.
• Классы не обязаны создаваться «на пустом месте». Иногда в них могут входить в
качестве элементов другие классы, или они могут производиться от других Включение
объектов класса в качестве элементов других классов называется композицией.
• Элементы данных и элемент-функции класса принадлежат к области действия этого
класса.
• Обычные функции определяются в области действия файла.
• В пределах области действия класса элементы класса непосредственно доступны для
всех элемент-функций этого класса, и к ним можно обращаться просто по имени.
• Вне области действия класса к открытым элементам класса можно обращаться через
один из дескрипторов объекта — имя объекта, ссылку на объект или указатель на
объект.
• Элемент-функции класса могут быть перегружены, но только другими
элемент-функциями того же класса.
• Чтобы перегрузить элемент-функцию, нужно просто предусмотреть в определении
класса прототипы для всех версий перегружаемой функции, а также отдельные
определения для каждой версии функции.
• Переменные, объявленные в элемент-функции, имеют область действия блока и
известны только этой функции.
• Если элемент-функция определяет переменную с тем же именем, что и у переменной
в области действия класса, переменная в области действия блока скрывает
переменную в области действия класса.
• Для доступа к открытым элементам объекта операция-точка выбора элемента (.)
предваряется именем объекта или ссылкой на объект.
• Для доступа к открытым элементам объекта операция-стрелка выбора элемента (->)
предваряется указателем на объект.
• Заголовочные файлы все-таки содержат некоторые части реализации и намеки на
другие ее части. Встроенные элемент-функции, например, должны находиться в
заголовочном файле, чтобы при компиляции клиента компилятор мог включать в код
определения inline-функций.
• Закрытые элементы класса перечисляются в определении класса в заголовочном
файле, так что они видимы для клиентов, хотя последние и не могут обращаться
к закрытым элементам.
• Сервисная (или вспомогательная) функция является закрытой элемент-функцией,
поддерживающей операции открытых элемент-функций класса. Сервисные
функции не предназначены для использования клиентами класса (но могут вызываться
друзьями класса).
• Как и другие функции, конструкторы могут специфицировать аргументы по
умолчанию.
• Деструктор вызывается неявным образом при уничтожении объекта.
634
Глава 9
• Имя деструктора для класса образуется из имени класса, которому предшествует
символ тильды (-).
• Сам деструктор в действительности не освобождает память объекта, — он
производит его заключительную приборку перед тем, как система освободит память, чтобы
ее можно было использовать для новых объектов.
• Деструктор не принимает параметров и не возвращает значения. В классе может
быть только один деструктор.
• Если программист не определяет деструктор явным образом, компилятор создает
«пустой» деструктор, так что каждый класс имеет в точности один деструктор.
• Порядок, в котором вызываются конструкторы и деструкторы, зависит от порядка
входа исполнения в области действия, где создаются объекты, и выхода из них.
• Как правило, вызовы деструкторов происходят в обратном порядке по отношению
к вызовам конструкторов, однако порядок вызова деструкторов может меняться
в зависимости от класса памяти объектов.
• Ссылка на объект является псевдонимом для имени объекта и, следовательно, может
появляться в левой части оператора присваивания. В таком контексте ссылка
оказывается совершенно законным lvalue, которое может получать значение. Одним из
путей использования такой возможности (к сожалению!) является определение
открытой элемент-функции класса, которая возвращает ссылку на закрытый элемент
данных этого класса. Если функция возвращает константную ссылку, последняя не
может использоваться в качестве модифицируемого lvalue.
• Операция присваивания (=) может применяться для присваивания одного объекта
другому объекту того же типа. По умолчанию такое присваивание производится
посредством поэлементного присваивания — каждый элемент данных объекта справа
от операции присваивания по отдельности присваивается соответствующему
элементу объекта слева от операции присваивания.
• Объекты могут передаваться функциям в качестве аргументов, и могут
возвращаться функциями. По умолчанию это осуществляется посредством передачи по
значению — передается или возвращается копия объекта. В таких случаях C++ создает
новый объект и применяет конструктор копии для копирования значений исходного
объекта в новый объект. В деталях мы объясним это в главе 11.
• Для каждого класса компилятор генерирует конструктор копии по умолчанию,
копирующий каждый элемент исходного объекта в соответствующий элемент нового
объекта.
• Существует много больших библиотек классов, и по всему миру разрабатываются
новые.
• Утилизируемость ускоряет разработку мощного высококачественного программного
обеспечения. Важной областью программной индустрии стала ускоренная
разработка приложений (RAD) на основе механизмов утилизации компонентов.
Терминология
агрегация деструктор
аргументы по умолчанию директива препроцессора #define
в конструкторах директива препроцессора #endif
вспомогательная функция директива препроцессора #ifndef
выход объекта из области действия заключительная приборка
дескриптор объекта инициализатор
дескриптор-имя объекта классовые библиотеки
дескриптор-ссылка объекта композиция
дескриптор-указатель объекта конструктор копии
Классы: часть I 635
наследование
неявный дескриптор объекта
область действия класса
область действия файла
операция-стрелка выбора
элемента (->)
параметризованный манипулятор
потока setfill
перегруженная элемент-функция
перегруженный конструктор
передача объекта по значению
повторно-входимый код
порождение одного класса от другого
порядок вызова конструкторов
и деструкторов
поэлементное присваивание
Контрольные вопросы
9.1. Заполните пропуски в следующих предложениях:
a) Элементы класса доступны через операцию- в сочетании с именем
объекта (или ссылкой на объект) этого класса или через операцию-
в сочетании с указателем на объект класса.
b) Элементы класса, специфицированные как , доступны только для
элемент-функций класса и для друзей класса.
c) Элементы класса, специфицированные как , доступны везде, где
в области действия имеется объект класса.
d) может использоваться для присваивания объекта класса другому
объекту того же класса.
9.2. Найдите ошибку (ошибки) в каждом из нижеприведенных пунктов и объясните,
как ее (их) исправить:
a) Предположим, в классе Time объявлен следующий прототип:
void ~Time( int );
b) Рассмотрите следующее частичное определение класса Time:
class Time
{
public:
// прототипы функций
private:
int hour = 0;
int minute = 0;
int second = 0;
} // конец класса Time
c) Предположим, в классе Employee объявлен следующий прототип:
int Employee( const char *, const char * );
поэлементное присваивание
по умолчанию
предикатная функция
препроцессорная обертка
присваивание объектов класса
символ заполнения
символ тильды (~) в имени
деструктора
ускоренная разработка приложений
(RAD)
утилизируемые компоненты
функция abort
функция exit
функция доступа
чистая процедура
636
Глава 9
Ответы на контрольные вопросы
9.1. а) точку (.), стрелку (->). b) private, с) public, d) Поэлементное присваивание по
умолчанию (выполняемое операцией присваивания).
9.2. а) Ошибка: для деструкторов не допускается возврат значений (и даже
спецификация возвращаемого типа void) или получение аргументов.
Исправление: удалить из объявления возвращаемый тип void и тип параметра
int.
b) Ошибка: элементы данных не могут явно инициализироваться в определении
класса.
Исправление: удалить из определения класса явную инициализацию
элементов и инициализировать элементы данных в конструкторе.
c) Ошибка: Для конструкторов не допускается возврат значений.
Исправление: удалить из объявления возвращаемый тип int.
Упражнения
9.3. Каково назначение операции разрешения области действия?
9.4. (Усовершенствование класса Time) Напишите конструктор, который может
использовать текущее время, возвращаемое функцией time() — объявленной в
заголовке <ctime> стандартной библиотеки C++, — для инициализации объекта
класса Time.
9.5. (Класс Complex) Создайте класс с именем Complex для выполнения
арифметических операций с комплексными числами. Напишите программу для
тестирования вашего класса.
Комплексные числа имеют вид
realPart + imaginaryPart * I,
где i равно V-l.
Используйте для представления закрытых данных класса переменные типа
double. Определите конструктор, который дает возможность инициализировать
объект класса при его объявлении. Конструктор должен содержать значения по
умолчанию на случай отсутствия инициализаторов. Предусмотрите
элемент-функции для каждого из следующих действий:
a) Сложение двух чисел типа Complex: складываются вместе их вещественные
части и их мнимые части.
b) Вычитание двух чисел типа Complex: вещественная часть правого операнда
вычитается из вещественной части левого операнда и мнимая часть правого
операнда вычитается из мнимой части левого.
c) Вывод чисел типа Complex в виде (а, Ь), где а — вещественная часть и b —
мнимая.
9.6. (Класс Rational) Создайте класс с именем Rational для выполнения
арифметических действий с дробями. Напишите программу для тестирования вашего класса.
Используйте целочисленные переменные для представления закрытых данных
класса — числителя и знаменателя. Предусмотрите конструктор, который дает
возможность инициализировать объект класса при его объявлении. Конструктор
должен содержать значения по умолчанию на случай отсутствия
инициализаторов и должен хранить дробь в несокращаемом виде. Например, для дроби
2^
4
в объекте хранится 1 в числителе и 2 в знаменателе. Предусмотрите открытые
элементы-функции для каждого из следующих действий:
Классы: часть I
637
а) Сложение двух рациональных чисел. Результат должен быть сохранен в
несокращаемом виде.
о) Вычитание двух рациональных чисел. Результат должен быть сохранен в
несокращаемом виде.
c) Умножение двух рациональных чисел. Результат должен быть сохранен в
несокращаемом виде.
d) Деление двух рациональных чисел. Результат должен быть сохранен в
несокращаемом виде.
e) Печать рациональных чисел в виде а/b, где а является числителем и b —
знаменателем.
f) Печать рациональных чисел в формате с плавающей точкой.
9.7. (Усовершенствование класса Time) Модифицируйте класс Time из рис. 9.8-9.9,
включив в него элемент-функцию tick, которая инкрементирует хранящееся
в объекте время на одну секунду. Объект Time всегда должен находиться в
согласованном состоянии. Напишите программу, тестирующую элемент-функцию
tick в цикле, который на каждой итерации печатает время в стандартном
формате, чтобы показать правильность работы функции tick. Обязательно проверьте
следующие случаи:
a) Переход к следующей минуте.
b) Переход к следующему часу.
c) Переход к следующему дню (т.е. от 11:59:59 РМ к 12:00:00 AM).
9.8. (Усовершенствование класса Date) Модифицируйте класс Date из рис. 9.17-9.18,
чтобы он производил проверку инициализирующих значений для элементов
данных month, day и year. Кроме того, предусмотрите элемент-функцию nextDay,
инкрементирующую дату на единицу. Объект Date всегда должен находиться
в согласованном состоянии. Напишите программу, тестирующую
элемент-функцию nextDay в цикле, который на каждой итерации печатает дату, чтобы
показать правильность работы функции nextDay. Обязательно проверьте следующие
случаи:
a) Переход к следующему месяцу.
b) Переход к следующему году.
9.9. (Комбинация классов Time и Date) Объедините модифицированный класс Time
из упражнения 9.7 и модифицированный класс Date из упражнения 9.8 в один
класс с именем DateAndTime. (В главе 12 мы обсудим наследование, которое
позволит нам быстро осуществить это, не модифицируя существующие
определения классов.) Модифицируйте функцию tick, чтобы она вызывала nextDay, если
инкремент времени переходит к следующему дню. Модифицируйте функции
printstandard и printUniversal, чтобы они выводили дату и время. Напишите
программу для тестирования класса DateAndTime. В частности, протестируйте
переход времени к следующему дню.
9.10. (Возврат индикаторов ошибки из set-функций класса Time) Модифицируйте
spf-функции класса Time из рис. 9.8-9.9, чтобы они возвращали специальное
значение ошибки, если делается попытка установить в элементе данных объекта
класса Time недействительное значение. Напишите программу, тестирующую
вашу новую версию класса. Выводите сообщения об ошибках, когда sef-функции
возвращают значение ошибки.
9.11. (Класс Rectangle) Создайте класс Rectangle. Класс имеет атрибуты length
и width, каждый из которых по умолчанию равен 1. У него имеются
элементы-функции perimeter и area для вычисления соответственно периметра и
площади прямоугольника. S^-функции должны гарантировать, что length и width
являются значениями с плавающей точкой, большими 0.0 и меньшими 20.0.
638
Глава 9
9.12. (Усовершенствование класса Rectangle) Создайте более сложный класс
Rectangle, чем в предыдущем упражнении. Этот класс хранит только декартовы
координаты четырех углов прямоугольника. Конструктор вызывает я^-функцию,
принимающую четыре пары координат и проверяет, что каждая из них лежит в
первом квадранте и никакое из значений х- и у-координат не превышает 20.0.
Функция также проверяет, что переданные координаты действительно задают
прямоугольник. Функции-элементы вычисляют длину, ширину, периметр и
площадь. Длиной является большее из двух измерений. Предусмотрите предикатную
функцию square, определяющую, является ли прямоугольник квадратом.
9.13. (Усовершенствование класса Rectangle) Модифицируйте класс Rectangle из
упражнения 9.12, включив в него функцию draw, которая выводит
прямоугольник внутри рамки 25 на 25, охватывающей часть первого квадранта,
содержащую прямоугольник. Предусмотрите функцию setFillCharacter для задания
символа, которым будет заполняться внутренность прямоугольника, и функцию
setPerimeterCharacter для задания символа, которым будет нарисован его
периметр. Если вы честолюбивы, то можете написать функции для масштабирования
прямоугольника, вращения и перемещения его в пределах определенной области
первого квадранта.
9.14. (Класс Hugelnteger) Создайте класс Hugelnteger, который хранит в 40-элемент-
ном массиве цифр целые числа разрядностью до 40 знаков. Напишите
функции-элементы input, output, add и subtract. Для сравнения объектов Hugelnteger
предусмотрите функции isEqualTo, isNotEqualTo, isGreaterThan, isLcssThan,
isGreaterThanOrEqualTo и isLessThanOrEqualTo, каждая из которых является
«предикатной» функцией, просто возвращающей true, если данное соотношение
двух больших целых имеет место, и false, если соотношение не выполняется.
Предусмотрите предикатную функцию isZero. Если вы честолюбивы, напишите
также функции multiply, divide и modulus.
9.15. (Класс TicTacToe) Создайте класс TicTacToe, который позволит вам написать
законченную программу для игры в «крестики-нолики». Класс содержит
закрытые данные в массиве целых размером 3 на 3. Конструктор должен
инициализировать все пустое поле нулями. Играют два человека. Когда ходит первый игрок,
поместите в соответствующую клетку 1, когда ходит второй — 2. Каждый ход
должен делаться на пустую клетку. После каждого хода проверяйте, не выиграл
ли один из игроков и не закончилась ли игра ничьей. Если вы честолюбивы,
модифицируйте программу, чтобы за одного из игроков автоматически ходил
компьютер. Пусть игрок имеет возможность указать, хочет ли он ходить первым или
вторым. А если вы крайне честолюбивы, разработайте программу для игры
в трехмерные крестики-нолики на доске размером 4 на 4 на 4.
[Предостережение. Это чрезвычайно сложный проект, на который может потребоваться много
недель напряженного труда!]
10
Классы: часть II
ЦЕЛИ jp
В этой главе вы изучите: I
• Спецификацию константных J
объектов и константных I <
элемент-функций.
• Создание объектов, составленных
из других объектов.
• Использование дружественных
функций и дружественных
классов.
• Использование указателя this.
• Динамическое создание
и уничтожение объектов
операциями new и delete.
• Использование статических
элементов данных и элемент-функций.
• Концепцию контейнерных классов.
• Понятие классов-итераторов, перебирающих элементы контейнеров
• Создание классов-посредников для сокрытия деталей реализации от
клиентов класса.
640
Глава 10
10.1. Введение
10.2. Константные объекты и константные элемент-функции
10.3. Композиция: объекты в качестве элементов класса
10.4. Дружественные функции и дружественные классы
10.5. Указатель this
10.6. Динамическое управление памятью с помощью
операций new и delete
10.7. Статические элементы класса
10.8. Абстракция данных и сокрытие информации
10.8.1. Пример: абстрактный тип данных — массив
10.8.2. Пример: абстрактный тип данных — строка
10.8.3. Пример: абстрактный тип данных — очередь
10.9. Классы-контейнеры и итераторы
10.10. Классы-посредники
10.11. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
10.1. Введение
В этой главе мы продолжим изучение классов и абстракции данных,
рассмотрев ряд более сложных вопросов. Мы будем использовать константные
объекты и константные элемент-функции, чтобы предотвратить модификацию
объектов и удовлетворить принципу минимума привилегий. Мы обсудим
композицию — форму утилизации, когда класс может иметь в качестве элементов
объекты других классов. Затем мы введем понятие дружественности, которое
позволяет разработчику класса специфицировать не принадлежащие классу
функции, которые имеют право доступа к неоткрытым элементам класса;
друзья часто используются при перегрузке операций (глава 11) по соображениям
эффективности. Мы обсудим специальный указатель (с именем this),
передаваемый в качестве неявного аргумента каждой не статической
элемент-функции класса, что позволяет этим функциям обращаться к элементам данных
и другим не статическим элемент-функциям нужного объекта. Затем мы
обсудим динамическое управление памятью и покажем, как создавать и
уничтожать объекты динамически с помощью операций new и delete. Затем мы
обоснуем необходимость статических элементов класса и покажем, как
использовать статические элементы данных и элемент-функции в своих собственных
классах. Наконец, мы покажем, как создать класс-посредник, скрывающий
детали реализации класса (включая его закрытые элементы данных) от
клиентов класса.
Классы: часть II
641
Как вы помните, в главе 3 мы представили класс string из стандартной
библиотеки C++, реализующий строки в форме полноценных объектов класса.
В этой главе, однако, мы используем строки-указатели, показанные в главе 8,
чтобы помочь читателю в освоении указателей и подготовить его к миру
профессионального программирования, в котором он встретится с большими
объемами унаследованного от С кода, накопленного за последние два десятилетия.
Таким образом, читатель познакомится с двумя преобладающими методами
реализации строк в C++.
10.2. Константные объекты и константные
элемент-функции
Мы неоднократно акцентировали внимание на принципе минимума
привилегий как на одном из наиболее фундаментальных принципов правильного
конструирования программного обеспечения. Давайте рассмотрим этот
принцип в применении к объектам.
Некоторые объекты должны быть модифицируемыми, а другие нет.
Программист может использовать ключевое слово const, чтобы указать, что
объект не является модифицируемым и что любая попытка изменения этого
объекта является ошибкой. Оператор
const Time noon( 12, 0, 0 );
объявляет константный объект noon класса Time и инициализирует его 12
часами дня.
S Общее методическое замечание 10.1
Объявление объекта с модификатором const способствует
реализации принципа минимума привилегий. Попытки изменить объект
выявляются во время компиляции, а не приводят к ошибкам времени
выполнения. Правильное применение const является критическим для
правильного проектирования классов, проектирования программ и
написания кода.
I—^г| Вопросы производительности 10.1
Г^$^;| Объявление переменных и объектов как const может улучшить
эффективность, поскольку современные изощренные компиляторы
могут производить для констант некоторые оптимизации,
невозможные для переменных.
Компиляторы C++ отвергают любые вызовы элемент-функций для
константных объектов, если только сама функция не объявлена константной. Это
верно даже для gef-функций, которые не модифицируют объект. Кроме того,
компилятор не позволяет элемент функциям, объявленным как const,
модифицировать объект.
Функция специфицируется в качестве константной как в ее прототипе
(рис. 10.1, строки 19-24), так и в определении (рис. 10.2, строки 47, 53, 59
и 65) путем вставки ключевого слова const после списка параметров и, в слу-
21 Зак. 1114
642
Глава 10
чае определения функции, перед левой фигурной скобкой, которой начинается
тело функции.
Типичная ошибка программирования 10.1
Определение как const элемент-функции, которая изменяет элемент
данных объекта, приводит к ошибке компиляции.
jg Типичная ошибка программирования 10.2
Определение как const элемент-функции, которая вызывает не-кон-
стантную функцию для того же представителя класса, приводит
к ошибке компиляции.
~~г^ Типичная ошибка программирования 10.3
Вызов неконстантной элемент-функции для константного объекта
приводит к ошибке компиляции.
Общее методическое замечание 10.2
Константная элемент-функция может быть перегружена
неконстантной версией. Компилятор делает выбор нужной
элемент-функции в зависимости от объекта, для которого вызывается функция.
Если объект является константным, компилятор использует
const-версию. В противном случае компилятор вызывает не-кон-
стантную версию.
Здесь возникает интересная проблема в отношении конструкторов и
деструкторов; и те и другие, как правило, модифицируют свои объекты.
Конструкторы и деструкторы не могут объявляться как const. Конструктор должен
иметь возможность модифицировать объект, чтобы последний был правильно
инициализирован. Деструктор должен иметь возможность произвести
заключительную приборку перед тем, как система освободит память объекта.
Типичная ошибка программирования 10.4
Попытка объявить конструктор или деструктор как const является
синтаксической ошибкой.
Определение и использование константных элемент-функций
Программа на рис. 10.1-10.3 модифицирует класс Time из рис. 9.9-9.10,
делая его gef-функции и функцию printUniversal константными. В
заголовочном файле Time.h (рис. 10.1) строки 19-21 и 24 специфицируют теперь
ключевое слово const после списка параметров каждой из функций.
Соответствующие определения функций на рис. 10.2 (строки 47, 53, 59 и 65) также
специфицируют const после списка параметров каждой из функций.
На рис. 10.3 создается два объекта Time — не-константный wakeUp
(строка 7) и константный noon (строка 8). Программа пытается активировать для
константного объекта noon не-константные элемент-функции setHour
(строка 13) и print Standard (строка 20). В каждом случае компилятор генерирует
Классы: часть II
643
сообщение об ошибке. Программа также демонстрирует три других
комбинации вызовов элемент-функций с объектами — не-константной функции для
не-константного объекта (строка 11), константной функции для не-констант-
ного объекта (строка 15) и константной функции для константного объекта
(строки 17-18). Сообщения об ошибках, генерируемые для вызовов не-кон-
стантных функций с константными объектами, показаны в окне вывода.
Заметьте, что хотя некоторые современные компиляторы выдают только
предупреждения для строк 13 и 20 (позволяя, таким образом, запустить
программу), мы считаем эти предупреждения ошибками, поскольку стандарт
ANSI/ISO C++ не допускает активацию не-константной элемент-функции для
константного объекта.
1 // Рис. 10.1: Time.h
2 // Определение класса Time.
3 // Элемент-функции определяются в Time.cpp.
4 #ifndef TIME_H
5 #define TIME_H
6
7 class Time
8 {
9 public:
10 Time( int = 0, int = 0, int =0 ); // конструктор по умолчанию
11
12 // set-функции
13 void setTime( int, int, int ); // установить время
14 void setHour( int ); // установить часы
15 void setMinute( int ); // установить минуты
16 void setSecond( int ); // установить секунды
17
18 // get-функции (обычно объявляются как const)
19 int getHour() const; // возвратить часы
20 int getMinute() const; // возвратить минуты
21 int getSecond() const; // возвратить секунды
22
23 // функции печати (обычно объявляются как const)
24 void printUniversal() const; // вывести всемирное время
25 void printStandard(); // должна быть const
26 private:
27 int hour; // 0 - 23 B4-часовой формат времени)
28 int minute; //0-59
29 int second; //0-59
30 }; // конец класса Time
31
32 #endif
Рис, 10.1. Определение класса Time с константными элемент-функциями
1 // Рис. 10.2: Time.cpp
2 // Определение элемент-функций класса Time.
3 #include <iostream>
4 using std::cout;
5
6 #include <iomanip>
644
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
using std::setfill;
using std::setw;
#include "Time.h" // включить определение класса Time
// функция конструктора инициализирует закрытые данные;
// для установки переменных вызывает элемент-функцию setTime;
// значения по умолчанию равны 0 (см. определение класса)
Time::Time( int hour, int minute, int second )
{
setTime( hour, minute, second );
} // конец конструктора Time
// установить значения часов,
void Time::setTime( int hour,
{
setHour( hour );
setMinute( minute );
setSecond( second );
} // конец функции setTime
// установить значение часов
void Time::setHour( int h )
{
hour = ( h >= 0 && h < 24
} // конец функции setHour
минут и секунд
int minute, int second )
) ? h : 0; // подтвердить часы
// установить значение минут
void Time::setMinute( int m )
{
minute = ( m >= 0 && m < 60
} // конец функции setMinute
// установить значение секунд
void Time::setSecond( int s )
0; // подтвердить минуты
}
second = ( s >= 0 && s < 60
// конец функции setSecond
) ? s : 0; // подтвердить секунды
// возвратить значение часов
int Time::getHour() const // get-функции должны быть const
{
return hour;
} // конец функции getHour
// возвратить значение секунд
int Time:igetMinute() const
{
return minute;
} // конец функции getMinute
// возвратить значение секунд
int Time::getSecond() const
{
return second;
} // конец функции getSecond
Классы: часть II
645
63
64 // напечатать в формате всемирного времени (HH:MM:SS)
65 void Time::printUniversal() const
66 {
67 cout « setfill( '0' ) « setw( 2 ) « hour « " :"
68 « setw( 2 ) « minute « " : " «setw( 2 ) « second;
69 } // конец функции printUniversal
70
71 // напечатать в стандартном формате времени (HH:MM:SS AM или РМ)
72 void Time::printStandard() // обратите внимание на.отсутствие const
73 {
74 cout « ( ( hour == 0 || hour == 12 ) ? 12 : hour % 12 )
75 « ":." « setfill( '0' ) « setw( 2 ) « minute
76 « " :" « setw( 2 ) « second « ( hour < 12 ? " AM" : " PM" );
77 } // конец функции printstandard
Рис. 10.2. Определения элемент-функций класса Time, включая константные
элемент-функции
1 // Рис. 10.3: figl0_03.cpp
2 // Попытка обращения к const-объекту не-const элемент-функциями.
3 #include "Time.h" // включить определение класса Time
4
5 int main()
6 {
7 Time wakeUp( 6, 45, 0 ); // неконстантный объект
8 const Time noon ( 12, 0, 0 ); // константный объект
9
10 // ОБЪЕКТ ЭЛЕМЕНТ-ФУНКЦИЯ
11 wakeUp.setHour( 18 ); // неконстантный неконстантная
12
13 noon.setHour( 12 ); // константный неконстантная
14
15 wakeUp.getHour(); // неконстантный константная
16
17 noon.getMinute(); // константный константная
18 noon.printUniversal(); // константный константная
19
20 noon.printstandard(); // константный неконстантная
21 return 0;
22 } // конец main
Сообщения об ошибках компилятора с командной строкой Borland C++:
Warning W8037 figl0_03.cpp 13: Non-const function Time::setHour (int)
called for const object in function main()
Warning W8037 figl0_03.cpp 20: Non-const function
Time::printstandard() called for const object in function main()
Сообщения об ошибках компилятора Microsoft Visual C++ .NET:
С:\cpphtp5_examples\chl0\Figl0_01_03\figl0_03.cppA3) : error C2662:
1 Time: :setHour' : cannot convert 'this' pointer from
'const Time' to 'Time &'
646
Глава 10
Conversion loses qualifiers
C:\cpphtp5_examples\chlO\FiglO__01__03\figlO_03.cpp B0) : error C2662:
'Time::printstandard' : cannot convert 'this' pointer from
'const Time' to 'Time &'
Conversion loses qualifiers
Сообщения об ошибках компилятора GNU C++:
figl0_03.cpp:13: error: passing 'const Time' as 'this' argument of
'void Time::setHour(int)' discards qualifiers
figl0_03.cpp:20: error: passing 'const Time' as 'this' argument of
'void Time::printStandard()' discards qualifiers
Рис. 10.3. Константные объекты и константные элемент-функции
Обратите внимание, что хотя конструктор должен быть не-константной
элемент-функцией (рис. 10.2, строки 15-18), он все равно может
использоваться для инициализации константного объекта (рис. 10.3, строка 8).
Определение конструктора Time (рис. 10.2, строки 15-18) показывает, что
конструктор вызывает не-константную элемент-функцию setTime (строки 21-26),
чтобы выполнить инициализацию объекта Time. Вызов не-константной
функции из конструктора в процессе инициализации константного объекта
допускается. «Константность» объекта вступает в силу с момента, когда
конструктор завершит его инициализацию, и действует вплоть до вызова
деструктора объекта.
Заметьте также, что строка 20 на рис. 10.3 вызывает ошибку компиляции,
хотя функция printStandard класса Time не модифицирует объект, для
которого вызывается. Тот факт, что элемент-функция не модифицирует объект,
еще не достаточен для того, чтобы функция была константной, — функция
явным образом должна быть объявлена как const.
Инициализация константного элемента данных с помощью
инициализатора элемента
Программа на рис. 10.4-10.6 представляет синтаксис инициализатора
элемента. Все элементы данных могут инициализироваться таким образом, но
константные элементы данных и элементы данных, являющиеся ссылками, должны
инициализироваться с помощью инициализаторов. Далее в этой главе мы
увидим, что так же должны инициализироваться элементы-объекты. В главе 12, где
мы будем изучать наследование, мы увидим, что базовые части производных
классов должны инициализироваться таким же образом.
1 // Рис. 10.4: Increment.h
2 // Определение класса Increment.
3 #ifndef INCREMENT_H
4 #define INCREMENT_H
5
6 class Increment
7 {
8 public:
9 Increment( int с = 0, int i = 1 ); // конструктор по умолчанию
10
Классы: часть II
647
11 // определение функции addlncrement
12 void addlncrement()
13 {
14 count += increment;
15 } // конец функции addlncrement
16
17 void print() const; // печатает count и increment
18 private:
19 int count;
20 const int increment; // константный элемент данных
21 }; // конец класса Increment
22
23 #endif
Рис. 10.4. Определение класса Increment с неконстантным элементом данных
count и константным элементом данных increment
1 // Рис. 10.5: Increment.срр
2 // Определения элемент-функций класса Increment демонстрируют
3 // инициализатор элемента для установки константы встроенного типа.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "Increment.h" // включить определение класса Increment
9
10 // конструктор
11 Increment::Increment( int c, int i )
12 : count( с ), // инициализатор неконстантного элемента
13 increment( i ) // требуемый инициализатор константного элемента
14 {
15 // пустое тело
16 } // конец конструктора Increment
17
18 // напечатать значения count и increment
19 void Increment::print() const
20 {
21 cout «"count = "« count «", increment = "« increment « endl;
22 } // конец функции print
Рис. 10.5. Инициализатор элемента для установки константы встроенного типа
1 // Рис. 10.6: figl0_06.cpp
2 // Программа для тестирования класса Increment.
3 #include <iostream>
4 using std::cout;
5
6 #include "Increment.h" // включить определение класса Increment
7
8 int main()
9 {
10 Increment value( 10, 5 );
11
648
Глава 10
12 cout « "Before incrementing: ";
13 value.print();
14
15 for ( int j = 1; j <= 3; j++ )
16 {
17 value.addlncrement();
18 cout « "After increment " « j «
19 value.print();
20 } // конец for
21
22 return 0;
23 } // конец main
Before incrementing: count = 10, increment = 5
After increment 1: count = 15, increment = 5
After increment 2: count = 20, increment = 5
After increment 3: count = 25, increment = 5
Рис. 10.6. Вызов элемент-функций print и addlncrement объекта Increment
Определение конструктора (рис. 10.5, строки 11-16) содержит список
инициализаторов элементов, инициализирующий элементы данных класса
Increment — не-константное целое count и константное целое increment
(объявленные в строках 19-20 на рис. 10.4). Инициализаторы элементов
размещаются между списком параметров и левой фигурной скобкой, начинающей тело
конструктора. Список инициализаторов (рис. 10.5, строки 12-13) отделяется
от списка параметров двоеточием (:). Каждый инициализатор элемента
состоит из имени элемента данных, за которым следуют скобки, содержащие
начальное значение элемента. В данном примере count инициализируется
значением параметра конструктора с, a increment — значением параметра
конструктора i. Если инициализаторов несколько, они разделяются запятыми.
Обратите внимание, что список инициализаторов исполняется до того, как
начнет выполняться тело конструктора.
® Общее методическое замечание 10.3
Константный объект нельзя модифицировать присваиванием,
поэтому он должен быть инициализирован. Когда элемент данных класса
объявлен как const, требуется инициализатор элемента, чтобы
снабдить конструктор начальным значением элемента для объекта
класса. То же относится и к ссылкам.
Попытка инициализировать константный элемент данных
присваиванием
Программа на рис. 10.7-10.9 иллюстрирует ошибки компиляции,
вызванные попыткой инициализации константный элемент данных increment
оператором присваивания (строка 14 на рис. 10.8) в теле конструктора Increment,
а не с помощью инициализатора элемента. Заметьте, что строка 13 на рис. 10.8
не генерирует ошибки компиляции, так как count не объявлен как const.
Заметьте также, что в сообщениях об ошибках, выдаваемых компилятором
Microsoft Visual C++ .NET, целый элемент данных increment называется
Классы: часть II
649
«const object». Стандарт ANSI/ISO C++ определяет «объект» как любую
«область хранения». Переменные основных типов, как и представители классов,
также занимают пространство в памяти, поэтому о них часто говорят как об
«объектах».
Типичная ошибка программирования 10,5
Отсутствие инициализатора элемента для константного элемента
данных является ошибкой компиляции.
Общее методическое замечание 10.4
Константные элементы класса (const-объекты и const-переменные),
а также те, что объявлены как ссылки, необходимо
инициализировать, используя синтаксис инициализатора элемента; присваивания
в теле конструктора для этих данных не допускаются.
1 // Рис. 10.7: Increment.h
2 // Определение класса Increment.
3 #ifndef INCREMENT_H
4 #define INCREMENT_H
5
6 class Increment
7 {
8 public:
9 Increment( int с = 0, int i = 1 ); // конструктор по умолчанию
10
11 // определение функции addlncrement
12 void addlncrement()
13 {
14 count += increment;
15 } // конец функции addlncrement
16
17 void print() const; // печатает count и increment
18 private:
19 int count;
20 const int increment; // константный элемент данных
21 }; // конец класса Increment
22
23 #endif
Рис. 10.7. Определение класса Increment с неконстантным элементом данных
count и константным элементом данных increment
1 // Рис. 10.8: Increment.срр
2 // Попытка инициализации константы встроенного типа
3 // посредством присваивания.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include "Increment.h" // включить определение класса Increment
9
650
Глава 10
10 // конструктор; константный элемент 'increment' не инициализируется
11 Increment::Increment( int с, int i ) .
12 {
13 count = с; // допустимо, поскольку count не константа
14 increment = i; // ОШИБКА: Нельзя изменить константный объект
15 } // конец конструктора Increment
16
17 // напечатать значения count и increment
18 void Increment::print() const
19 {
20 cout «"count = "« count «", increment = "« increment « endl;
21 } // конец функции print
Рис. 10.8. Ошибочная попытка инициализировать константу встроенного типа
путем присваивания
1 // Рис. 10.9: figl0_09.cpp
2 // Программа для тестирования класса Increment.
3 #include <iostream>
4 using std::cout;
5
6 #include "Increment.hM // включить определение класса Increment
7
8 int main()
9 {
10 Increment value( 10, 5 );
11
12 cout « "Before incrementing: ";
13 value.print();
14
15 for ( int j = 10; j <= 3; j++ )
16 {
17 value.addlncrement();
18 cout « "After increment " « j « ": ";
19 value.print() ;
20 } // конец for
21
22 return 0;
23 } // конец main
Сообщение об ошибке компилятора с командной строкой Borland C++:
Error E2024 Increment.срр 14: Cannot modify a const object in function
Increment::Increment(int,int)
Сообщения об ошибках компилятора Microsoft Visual C++ .NET:
C:\cpphtp5_examples\chlO\FiglO_07_09\Increment. срр A2) : error C2758:
'Increment::increment' : must be initialized in constructor
base/member initializer list
C:\cpphtp5_examples\chlO\FiglO__07_09\Increment.h B0) :
see declaration of 'Increment::increment'
C:\cpphtp5_examples\chl0\Figl0__07_09\Increment.cppA4) : error C2166:
1-value specifies const object
Классы: часть II
651
Сообщения об ошибках компилятора GNU C++:
Increment.cpp:12: error: uninitialized member 'Increment::increment'
with 'const' type 'const int'
Increment.cpp:14: error: assignment of read-only data member
'Increment::increment'
Рис. 10.9. Программа, тестирующая класс Increment, генерирует ошибки
компиляции
Заметьте, что функция print (строки 18-21 на рис. 10.8) объявлена как
const. Это может показаться странным, потому что в программе, вероятно,
никогда не будет константного объекта Increment. Однако может случиться, что
в программе будет константная ссылка или указатель на константу,
указывающий на объект Increment. Обычно это случается, если объект класса
Increment передается функции или возвращается функцией. В таких случаях
через ссылку или указатель могут вызываться только константные
элемент-функции класса Increment. Поэтому целесообразно объявить функцию
print как const; это предотвратит возможные ошибки в ситуациях, когда
объект Increment рассматривается в качестве константного.
Предотвращение ошибок 10.1
Объявляйте как const все элемент-функции, не модифицирующие
объект, на котором они действуют. Иногда это может выглядеть
бессмысленным, потому что вы не собираетесь создавать константные
объекты данного класса или обращаться к объектам класса через
константные ссылки или указатели на константу. И все же объявление
таких функций константными приносит определенную выгоду. Если
вы по невнимательности модифицируете объект в такой функции,
компилятор выдаст сообщение об ошибке.
10.3. Композиция: объекты в качестве элементов
класса
Объекту класса AlarmClock (будильник) необходимо знать о времени, когда
он должен зазвонить, так почему бы не включить объект Time в качестве
элемента класса AlarmClock? Такое включение называется композицией; иногда
его называют отношением «имеет». Класс может иметь в качестве элементов
объекты других классов.
S Общее методическое замечание 10.5
Распространенной формой утилизации программного обеспечения
является композиция, когда класс содержит в качестве элементов
объекты других классов.
При создании объекта его конструктор вызывается автоматически. Ранее
мы видели, как передавать аргументы конструктору объекта, который мы
создаем в main. Данный раздел показывает, каким образом конструктор объекта
®
652
Глава 10
может передавать аргументы конструкторам объектов-элементов, что
достигается посредством инициализаторов элементов. Объекты-элементы
конструируются в том порядке, в каком они объявляются в определении класса (а не
в том, в каком они перечислены в списке инициализации), и до
конструирования объектов, которые их содержат (последние иногда называют
объектами-хозяевами).
Программа на рис. 10.10-10.14 использует классы Date
(рис. 10.10-10.11) и Employee (рис. 10.12-10.13) для демонстрации объектов
как элементов других объектов. Определение класса Employee (рис. 10.12)
содержит закрытые элементы данных lastName, firstName, birthDate
и hireDate. Элементы birthDate и hireDate являются константными
объектами класса Date, который содержит закрытые элементы данных month, day
и year. Заголовок конструктора Employee (рис. 10.13, строки 18-21)
специфицирует, что конструктор принимает четыре параметра (first, second,
dateOfBirth и dateOfHire). Первые два используются в теле конструктора
для инициализации символьных массивов firstName и lastName. Последние
два параметра передаются через инициализаторы элементов конструктору
класса Date. Двоеточие (:) в заголовке отделяет инициализаторы от списка
параметров. Инициализаторы элементов специфицируют параметры
конструктора, передаваемые конструкторам элементов — объектов Date.
Параметр dateOfBirth передается конструктору объекта birthDate (рис. 10.13,
строка 20), а параметр dateOfHire — конструктору объекта hireDate
(рис. 10.13, строка 21). Инициализаторы элементов разделены запятой. При
изучении класса Date (рис. 10.10) обратите внимание на то, что в классе не
предусмотрен конструктор, принимающий параметр типа Date. Тогда как же
список инициализации элементов в конструкторе Employee может
инициализировать объекты birthDate и hireDate, передавая их конструкторам
объекты Date? Как упоминалось в главе 9, компилятор снабжает каждый класс
конструктором копии по умолчанию, который копирует каждый элемент
своего аргумента-объекта в соответствующий элемент инициализируемого
объекта. В главе 11 обсуждается, каким образом программист может
определять специализированные конструкторы копии.
1 // Рис. 10.10: Date.h
2 // Объявление класса Date; элемент-функции определяются в Date.cpp
3 #ifndef DATE_H
4 #define DATE__H
5
6 class Date
7 {
8 public:
9 Date( int = 1, int = 1, int = 1900 ); // конструктор по умолчанию
10 void print() const; // напечатать дату в формате месяц/день/год
11 -Date(); // предусмотрен для подтверждения порядка деструкции
12 private:
13 int month; // 1-12 (январь-декабрь)
14 int day; // 1-31 в зависимости от месяца
15 int year; // любой год
16
17 // вспомогательная функция для проверки допустимости дня месяца
18 int checkDay( int ) const;
Классы: часть II
653
19 }; // конец класса Date
20
21 #endif
Рис. 10.10. Определение класса Date
1 // Рис. 10.11: Date.cpp
2 // Определение элемент-функций класса Date.
3 #include <iostream>
4 using std:icout;
5 using std::endl;
6
7 #include "Date.h" // включить определение класса Date
8
9 // конструктор подтверждает действительность месяца; вызывает
10 // вспомогательную функцию checkDay для подтверждения значения дня
11 Date::Date( int mn, int dy, int yr )
12 {
13 if ( mn > 0 && mn <= 12 ) // проверить значение месяца
14 month = mn;
15 else
16 {
17 month =1; // недействительный месяц заменяется на 1
18 cout « "Invalid month (" « mn « ") set to l.\n";
19 } // конец else
20
21 year = yr; // можно было бы проверить год
22 day = checkDay( dy ); // проверить день
23
24 // вывести объект Date, чтобы обозначить вызов конструктора
25 cout « "Date object constructor for date ";
26 print();
27 cout « endl;
28 } // конец конструктора Date
29
30 // напечатать объект Date в формате mm/dd/yyyy
31 void Date::print() const
32 {
33 cout « month « '/' « day « '/' « year;
34 } // конец функции print
35
36 // вывести объект Date, чтобы обозначить вызов деструктора
37 Date::-Date()
38 {
39 cout « "Date object destructor for date ";
40 print();
41 cout « endl;
42 } // конец деструктора ~Date
43
44 // вспомогательная функция для подтверждения действительности
45 // дня для данных месяца и года (обрабатывает високосные годы)
46 int Date::checkDay( int testDay ) const
47 {
48 static const int daysPerMonth[ 13 ] =
49 { 0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
654
Глава 10
50
51 // определить действительность testDay для указанного месяца
52 if ( testDay > 0 && testDay <= daysPerMonth[ month ] )
53 return testDay;
54
55 // проверить 29 февраля для високосного года
56 if ( month == 2 && testDay == 29 && ( year % 400 == 0 ||
57 ( year % 4 == 0 && year % 100 != 0 ) ) )
58 return testDay;
59
60 cout « "Invalid day (" « testDay « ") set to l.\n";
61 return 1; // оставить объект в корректном состоянии
62 } // конец функции checkDay
Рис. 10.11. Определения элемент-функций класса Date
1 // Рис. 10.12: Employee.h
2 // Определение класса Employee.
3 // Элемент-функции определяются в Employee.срр.
4 #ifndef EMPLOYEE_H
5 #define EMPLOYEE_H
6
7 #include "Date.h" // включить определение класса Date
8
9 class Employee
10 {
11 public:
12 Employee( const char * const, const char * const,
13 const Date 6, const Date & );
14 void print() const;
15 ~Employee(); // предусмотрен для подтверждения порядка деструкции
16 private:
17 char firstName[ 25 ];
18 char lastName[ 25 ];
19 const Date birthDate; // композиция: элемент-объект
20 const Date hireDate; // композиция: элемент-объект
21 }; // конец класса Employee
22
23 #endif
Рис. 10.12. Определение класса Employee, показывающее композицию
1 // Рис. 10.13: Employee.срр
2 // Определение элемент-функций класса Employee.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототипы strlen и strncpy
8 using std::strlen;
9 using std::strncpy;
10
11 #include "Employee.h" // определение класса Employee
Классы: часть II
655
12 #include "Date.h" // определение класса Date
13
14 // Конструктор использует список инициализаторов, чтобы передать
15 // значения конструкторам элементов-объектов birthDate и hireDate
16 // [Замечание: здесь вызывается "конструктор копии по умолчанию",
17 // неявно генерируемый компилятором C++].
18 Employee::Employee(const char* const first, const char* const last,
19 const Date fidateOfBirth, const Date SdateOfHire )
20 : birthDate( dateOfBirth ), // инициализировать birthDate
21 hireDate( dateOfHire ) // инициализировать hireDate
22 {
23 // копировать first в firstName; убедиться, что строка поместится
24 int length = strlen( first );
25 length = ( length < 25 ? length : 24 );
26 strncpy( firstName, first, length );
27 firstName[ length ] = ' \0';
28
29 // копировать last в lastName и убедиться, что строка поместится
30 length = strlen( last );
31 length = ( length < 25 ? length : 24 );
32 strncpy( lastName, last, length );
33 lastName[ length ] = '\0';
34
35 // вывести объект Employee, чтобы обозначить вызов конструктора
36 cout « "Employee object constructor: "
37 « firstName « ' ' « lastName « endl;
38 } // конец конструктора Employee
39
40 // напечатать объект Employee
41 void Employee::print() const
42 {
43 cout « lastName « ", " « firstName « " Hired:
44 hireDate.print();
45 cout « " Birthday: ";
46 birthDate.print();
47 cout « endl;
48 } // конец функции print
49
50 // вывести объект Employee, чтобы обозначить вызов деструктора
51 Employee::-Employee()
52 {
53 cout « "Employee object destructor: "
54 « lastName « ", " « firstName « endl;
55 } // конец деструктора -Employee
Рис. 10.13. Определения элемент-функций класса Employee, включая конструктор
со списком инициализации элементов
На рис. 10.14 создается два объекта Date (строки 11-12), которые
передаются конструктору объекта Employee, создаваемого в строке 13. Строка 16
выводит данные объекта Employee. При создании объектов Date в строках 11-12
конструктор Date, определенный в строках 11-28 на рис. 10.11, выводит
сообщение, показывающее, что конструктор был вызван (см. первые две строчки
образца вывода). [Замечание. Строка 13 на рис. 10.14 генерирует еще два
вызова конструктора Date, которые не отражены в выводе программы. Когда ини-
656
Глава 10
циализируются два объекта-элемента в конструкторе Employee, вызывается
конструктор копии по умолчанию для класса Date. Этот конструктор
определяется компилятором неявно и не содержит каких-либо операторов вывода,
показывающих, что конструктор вызывается. Мы обсуждаем конструкторы
копии и конструкторы копии по умолчанию в главе 11.]
1 // Рис. 10.14: figl0_14.cpp
2 // Демонстрация композиции - объекта с элементами-объектами.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Employee.h" // определение класса Employee
8
9 int main()
10 {
11 Date birth( 7, 24, 1949 );
12 Date hire( 3, 12, 1988 );
13 Employee manager( "Bob", "Blue", birth, hire );
14
15 cout « endl;
16 manager.print();
17
18 cout « "\nTest Date constructor with invalid values:\n";
19 Date lastDayOff( 14, 35, 1994 ); // недействильные день и месяц
20 cout « endl;
21 return 0;
22 } // конец main
Date object constructor for date 7/24/1949
Date object constructor for date 3/12/1988
Employee object constructor: Bob Blue
Blue, Bob Hired: 3/12/1988 Birthday: 7/24/1949
Test Date constructor with invalid values:
Invalid month A4) set to 1.
Invalid day C5) set to 1.
Date object constructor for date 1/1/1994
Date object destructor for date 1/1/1994
Employee object destructor: Blue, Bob
Date object destructor for date 3/12/1988
Date object destructor for date 7/24/194 9
Date object destructor for date 3/12/1988
Date object destructor for date 7/24/1949
Рис. 10.14. Инициализаторы элементов-объектов
Каждый из классов Date и Employee содержит деструктор (строки 37-42 на
рис. 10.11 и 51-55 на рис. 10.13), который при уничтожении объекта печатает
сообщение. Это позволяет нам подтвердить в выводе программы, что объекты
конструируются, начиная «изнутри», а уничтожаются, начиная снаружи (т.е.
элементы — объекты Date уничтожаются после содержащего их объекта
Классы: часть II
657
Employee). Обратите внимание на последние четыре строчки вывода на
рис. 10.14. Последние две из них выводятся деструктором Date, исполняемым
соответственно на объектах hire (строка 12) и birth (строка 11). Вывод
подтверждает, что три создаваемых в main объекта уничтожаются в порядке, обратном
их конструированию. (Деструктор объекта Employee выводит пятую строчку
снизу.) Четвертая и третья строчки снизу показывают деструкторы,
исполняемые для объектов — элементов Employee hireDate (рис. 10.12, строка 20)
и birthDate (строка 19). Вывод подтверждает, что объект Employee
уничтожается, начиная снаружи, т.е. сначала активируется деструктор Employee (который
выводит пятую строчку снизу), а затем уничтожаются объекты-элементы в
порядке, обратном их конструированию. Как уже говорилось, вывод программы
на рис. 10.14 не показывает выполнение конструкторов этих объектов, так как
это конструкторы копии по умолчанию, генерируемые компилятором C++.
Объект-элемент не обязательно должен инициализироваться явным
образом через инициализатор элемента. Если инициализатор элемента
отсутствует, для объекта-элемента будет неявно вызван конструктор по умолчанию.
Значения, устанавливаемые конструктором по умолчанию (если такие
имеются), можно заменить с помощью set-функций. Однако при сложной
инициализации такой подход может потребовать значительных дополнительных затрат
труда и времени.
Типичная ошибка программирования 10.6
Если объект-элемент не инициализируется посредством
инициализатора элемента, и в классе объекта-элемента отсутствует
конструктор по умолчанию (т.е. класс определяет один или несколько
конструкторов, но ни один из них не является конструктором по
умолчанию), происходит ошибка компиляции.
ф&\
Вопросы производительности 10.2
Явно инициализируйте объекты-элементы с помощью
инициализаторов элементов. Это устраняет накладные расходы, связанные с
«двойной инициализацией» объектов, — первый раз при вызове
конструктора по умолчанию для объекта элемента и снова при инициализации
элемента с помощью set-функций, вызываемых в теле конструктора
(или позднее).
Общее методическое замечание 10.6
Если элемент класса является объектом другого класса, объявление
его как public не нарушает инкапсуляции и сокрытия закрытых
элементов объекта-элемента. Однако это нарушает инкапсуляцию и
сокрытие информации содержащего класса, поэтому
элементы-объекты, как и другие элементы данных, должны объявляться как private.
Обратите внимание на вызов элемент-функции print класса Date в строке 26
на рис. 10.11. Многие элемент-функции классов в C++ не требуют аргументов,
так как каждая элемент-функция содержит неявный дескриптор (в форме
указателя) для объекта, на котором она исполняется. Мы обсуждаем этот неявный
указатель, представляемый ключевым словом this, в разделе 10.5.
658
Глава 10
Для представления имени и фамилии служащего класс Employee
использует два 25-символьных массива (рис. 10.12, строки 17-18). Эти массивы будут
занимать лишнее место в случае, когда имя и фамилия короче 24 символов.
(Как вы помните, один символ каждого из массивов предназначен для
завершающего нуль-символа строки.) Кроме того, имена и фамилии длиннее 24
символов должны усекаться, чтобы они уместились в этих массивах
фиксированного размера. В разделе 10.7 представлена другая версия класса Employee,
которая динамически выделяет в точности такое пространство в памяти, какое
необходимо для хранения имени и фамилии.
Простейшим способом представления имени и фамилии служащего в
минимальном пространстве памяти было бы использование двух объектов string
(класс string стандартной библиотеки C++ был представлен в главе 3). В этом
случае конструктор Employee имел бы вид
Employee::Employee(const string fifirst, const string filast,
const Date fidateOfBirth, const Date fidateOfHire )
: firstName( first ), // инициализировать firstName
lastName( last ), // инициализировать lastName
birthDate( dateOfBirth ), // инициализировать birthDate
hireDate( dateOfHire ) // инициализировать hireDate
{
// вывести объект Employee, чтобы обозначить вызов конструктора
cout « "Employee object constructor: "
« firstName « ? ? « lastName « endl;
} конец конструктора Employee
Обратите внимание, что элементы данных firstName и lastName (теперь
это объекты string) инициализируются с помощью инициализаторов
элементов. Класс Employee, представленный в главах 12-13, использует объекты
string именно таким образом. В этой главе мы пользуемся
строками-указателями, чтобы предоставить читателю дополнительный материал для освоения
работы с указателями.
10.4. Дружественные функции и дружественные
классы
Дружественная функция класса определяется вне области действия этого
класса, однако имеет право доступа к его неоткрытым (и открытым)
элементам. В качестве «друзей» класса могут быть объявлены автономные функции
или целые классы.
Использование дружественных функций может повысить эффективность.
Здесь мы приводим механический пример того, как работает дружественная
функция. Далее в этой книге дружественные функции перегружают операции,
применяемые к объектам класса (глава 11). Обычным является также
использование дружественных функций для создания классов итераторов. Объекты
класса-итератора служат для последовательного перебора элементов или
других действий над содержимым объекта класса-контейнера (см. раздел 10.9).
Объекты контейнерных классов могут хранить некоторые единицы
информации. Определение дружественной функции часто оказывается
целесообразным, когда для некоторых операций не может быть использована
элемент-функция, что мы увидим в главе 11.
Классы: часть II
659
Чтобы объявить функцию в качестве друга некоторого класса, поместите
перед прототипом этой функции в определении класса ключевое слово friend.
Чтобы объявить класс ClassTwo в качестве друга класса ClassOne, поместите
в определение класса ClassOne объявление вида
friend class ClassTwo;
Общее методическое замечание 10.7
Хотя прототипы дружественных функций входят в определение
класса, они не являются его элемент-функциями.
Общее методическое замечание 10.8
Понятия прав доступа — private, protected и public — не имеют
смысла для объявлений друзей, поэтому эти объявления могут
размещаться в любом месте определения класса.
Хороший стиль программирования 10.1
Помещайте все объявления дружественности в начале тела
определения класса, не предваряя их никаким спецификатором доступа.
Дружба даруется, а не берется силой, т.е. для того, чтобы класс В был
другом класса А, в классе А должно быть объявлено, что класс В является его
другом. Кроме того, понятие дружественности не является ни симметричным, ни
транзитивным, т.е. из того, что класс А является другом класса В, а класс В
является другом класса С, вы не можете заключить ни того, что класс В
является другом класса А (дружественность не симметрична), ни того, что класс С
является другом класса В (опять же потому, что дружественность не
симметрична), или что класс А является другом класса С (дружественность не транзи-
тивна).
Общее методическое замечание 10.9
Некоторые программисты считают, что «дружественность»
нарушает сокрытие информации и снижает ценность
объектно-ориентированного подхода к проектированию. В этой книге мы приводим ряд
примеров ответственного использования дружественности.
Модификация закрытых данных класса с помощью
дружественной функции
На рис. 10.15 показан механический пример определения дружественной
функции setX для установки закрытого элемента данных х класса Count.
Обратите внимание, что объявление friend (строка 10) появляется первым (по
соглашению) в объявлении класса, даже до объявления открытых
функций-элементов. Повторим, что объявление дружественности может размещаться в
любом месте класса.
660
Глава 10
1 // Рис. 10.15: figl0_15.cpp
2 // Друзья могут обращаться к закрытым элементам класса.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 // определение класса Count
8 class Count
9 {
10 friend void setX( Count &, int ) ; // объявление друга
11 public:
12 // конструктор
13 Count()
14 : x( 0 ) // инициализировать х нулем
15 {
16 // пустое тело
17 } // конец конструктора Count
18
19 // вывести х
20 void print() const
21 {
22 cout « х « endl;
23 } // конец функции print
24 private:
25 int x; // элемент данных
26 }; // конец класса Count
27
28 // функция setX может модифицировать закрытые данные Count,
29 // так как setX объявлена в качестве друга Count (строка 10)
30 void setX( Count &c, int val )
31 {
32 c.x = val; // допустимо, так как setX - друг Count
33 } // конец функции setX
34
35 int main ()
36 {
37 Count counter; // create Count object
38
39 cout « "counter.x after instantiation: ";
40 counter.print();
41
42 setX( counter, 8 ); // установить х с помощью функции-друга
43 cout « "counter.x after call to setX friend function: ";
44 counter.print();
45 return 0;
46 } // конец main
counter.x after instantiation: 0
counter.x after call to setX friend function: 8
Рис. 10.15. Друзья могут обращаться к закрытым элементам класса
Классы: часть II
661
Функция cstX (строки 30-33) — С-подобная автономная функция и не
является элементом класса Count. По этой причине при активации setX для
объекта counter строка 42 передает counter в качестве аргумента setX, а не
использует дескриптор в форме
counter.setX( 8 );
Как мы говорили, рис. 17.5 является «механическим» примером
дружественной функции. Обычно функции) setX было бы целесообразнее определить как
элемент класса Count. Кроме того, программу на рис. 10.15 следовало бы
разместить в трех файлах:
1. Заголовочный файл (напр., Count.h), содержащий определение класса
Count, которое, в свою очередь, содержит объявление дружественной
функции setX.
2. Файл реализации (напр.. Count.срр), содержащий определения
элемент-функций класса Count и определение дружественной функции
setX.
3. Файл, содержащий тестовую программу (напр., figl0_15.cpp) с
функцией main.
Попытка модификации закрытого элемента не-дружественной
функцией
Программа на рис. 10.16 демонстрирует сообщения об ошибках,
выдаваемые компилятором при попытке модификации закрытого элемента данных х
вызовом не-дружественной функции cannotSetX.
Можно определять в качестве друзей класса перегруженные функции.
Каждая перегруженная функция, которую собираются сделать дружественной,
должна быть явно объявлена в определении класса в качестве друга.
1 // Рис. 10.16: figl0_16.cpp
2 //Не друзья/не элементы не имеют доступа к закрытым данным класса.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 // определение класса Count (объявление friend отсутствует)
8 class Count
9 {
10 public:
11 // конструктор
12 Count()
13 : x( 0 ) // инициализировать х нулем
14 {
15 // пустое тело
16 } // конец конструктора Count
17
18 // вывести х
19 void print() const
20 {
21 cout « x « endl;
22 } // конец функции print
662
Глава 10
23 private:
24 int x; // элемент данных
25 }; // конец класса Count
26
27 // функция cannotSetX пытается модифицировать закрытые
28 // данные Count, но не может, поскольку не является другом Count
29 void cannotSetX( Count &c, int val )
30 {
31 c.x = val; // ОШИБКА: не может обращаться к закрытым денным Count
32 } // конец функции cannotSetX
33
34 int main ()
35 {
36 Count counter; // создать объект Count
37
38 cannotSetX( counter, 3 ); // cannotSetX не является другом
39 return 0;
40 } // конец main
Сообщение об ошибке компилятора с командной строкой Borland C++:
Error E2247 figl0_16.cpp 31: 'Count::x' is not accessible in
function cannotSetX(Count &,int)
Сообщения об ошибках компилятора Microsoft Visual C++ .NET:
C:\cpphtp5_examples\chlO\FiglO_16\figlO_16.cpp C1) : error C2248:
'Count::x' : cannot access private member declared in class 'Count'
С: \cpphtp5_examples\chlO\FiglO_16\f igl0__16 . cpp B4) :
see declaration of 'Count::x'
С : \cpphtp5___exarnples\chlO\FiglO_16\f igl0_16 . cpp (9) :
see declaration of 'Count'
Сообщения об ошибках компилятора GNU C++:
figl0_16.cpp:24: error: 'int Count::x' is private
figl0_16.cpp:31: error: within this context
Рис. 10.16. He друзья и не элементы не могут обращаться к закрытым элементам
10.5. Указатель this
Вы видели, что элемент-функции объекта могут обращаться к данным
объекта. Откуда элемент-функции знают, данными какого объекта они должны
манипулировать? Каждый объект имеет доступ к своему собственному адресу
через указатель с именем this (ключевое слово C++). Указатель this объекта не
является частью собственно объекта, т.е. этот указатель не отражается на
результате примененной к объекту операции sizeof. Точнее будет сказать, что
указатель this передается (компилятором) в объект в качестве неявного
аргумента вызова каждой не статической его функции. Раздел 10.7 представляет
статические элементы класса и объясняет, почему статическим
элемент-функциям не передается неявный указатель this.
Объекты используют указатель this для доступа к своим элементам данных
и элемент-функциям как неявно (что мы и видели до сих пор), так и явным обра-
Классы: часть II
663
зом. Тип указателя this зависит от типа объекта, а также от того, объявлена ли
константной элемент-функция, в которой используется указатель this.
Например, в не-константной элемент-функции класса Employee указатель this имеет
тип Employee * const (константный указатель на объект Employee). В
константной элемент-функции класса Employee указатель this имеет тип Employee
const * const (константный указатель на константный объект Employee).
Наш первый пример в этом разделе демонстрирует явное и неявное
использование указателя this; позже в этой главе и главе 11 мы продемонстрируем
некоторые важные и тонкие примеры применения этого указателя.
Явное и неявное использование указателя this для доступа
к элементам данных объекта
Рис. 10.17 показыдает явное и неявное использование указателя this в
элемент-функции для печати закрытого элемента данных х объекта Test.
1 // Рис. 10.17: figl0_17.cpp
2 // Использование указателя this для доступа к элементам объекта.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 class Test
8 {
9 public:
10 Test( int =0 ); // конструктор по умолчанию
11 void print() const;
12 private:
13 int x;
14 \; // конец класса Test
15
16 // конструктор
17 Test::Test( int value )
18 : x( value ) // инициализировать х значением value
19 {
20 // пустое тело
21 } // конец конструктора Test
22
23 // напечатать х, используя явный и неявный указатели this;
24 // скобки вокруг *this необходимы
25 void Test::print() const
26 {
27 // неявное использование указателя this для доступа к элементу х
28 cout « " х = " « х;
29
30 // явное использование указателя this и операции-стрелки
31 // для доступа к элементу х
32 cout « "\n this->x = " « this->x;
33
34 // явное использование указателя this и операции-точки
35 // для доступа к элементу х
36 cout « "\n(*this).x = " « ( *this ).х « endl;
37 } // конец функции print
38
39 int main()
664
Глава 10
40 {
41 Test testObject( 12 ); // создать и инициализировать testObject
42
43 testObject.print() ;
44 return 0;
45 } // конец main
x = 12
this->x = 12
(*this).x = 12
Рис. 10.17, Указатель this, неявно и явно используемый для доступа к элементам
объекта
В иллюстративных целях элемент-функция print (строки 25-37) сначала
печатает х, используя this неявно (строка 28), указывая только имя элемента.
Затем print использует две различные нотации для доступа к х через
указатель this — операцию-стрелку (->) с указателем (строка 32) и операцию-точку
(.) с разыменованным указателем (строка 36).
Обратите внимание на скобки вокруг *this при использовании указателя
this с операцией выбора элемента (.). Скобки необходимы, поскольку
операция-точка имеет более высокий приоритет, чем операция *. Без круглых
скобок выражение *this.x оценивалось бы как *(this.x), что является ошибкой
компиляции, поскольку операция-точка к указателю применяться не может.
Интересным применением указателя this является недопущение
присваивания объекта самому себе. Как мы увидим в главе 11, присваивание объекта
себе самому может вызвать серьезные ошибки, если объекты содержат
указатели на динамически выделенную память.
ртуоЗ Типичная ошибка программирования 10.7
I уГг [ Попытка применить операцию выбора элемента (.) к указателю на
объект является ошибкой компиляции — операция-точка может
применяться только к lvalue, такому, как имя объекта, ссылка на
объект или разыменованный указатель на объект.
Применение указателя this для реализации каскадных вызовов
функций
Другим применением указателя this является реализация каскадных
вызовов элемент-функций, когда несколько функций вызываются в одном и том
же операторе (как в строке 24 на рис. 10.20). Программа на рис. 10.18-10.20
модифицирует sef-функции setTime, setHour, setMinute и setSecond класса
Time таким образом, что каждая из них возвращает теперь ссылку на объект
Time, позволяя осуществлять каскадные вызовы элемент-функций. Заметьте,
что последний оператор тела каждой из этих функций на рис. 10.19
возвращает *this при возвращаемом типе Time &.
1 // Рис. 10.18: Time.h
2 // Каскадные вызовы элемент-функций.
3
4 // Определение класса Time .
Классы: часть II
665
5 // Элемент-функции определяются в Time.cpp.
6 #ifndef TIME_H
7 #define TIME_H
8
9 class Time
10 {
11 public:
12 Time( int = 0, int = 0, int =0 ); // конструктор по умолчанию
13
14 // set-функции(Time и возвращаемые типы допускают каскадирование)
15 Time fisetTime( int, int, int ); // установить время
16 Time &setHour( int ); // установить часы
17 Time SsetMinute( int ); // установить минуты
18 Time &setSecond( int ); // установить секунды
19
20 // get-функции (обычно объявляются как const)
21 int getHour() const; // возвратить часы
22 int getMinute() const; // возвратить минуты
23 int getSecond() const; // возвратить секунды
24
25 // функции печати (обычно объявляются как const)
26 void printUniversal() const; // вывести всемирное время
27 void printStandard() const; // вывести стандартное время
28 private:
29 int hour; // 0 - 23 B4-часовой формат времени)
30 int minute; //0-59
31 int second; //0-59
32 }; // конец класса Time
33
34 #endi£
Рис. 10.18. Определение класса Time, модифицированное для каскадирования
вызовов элемент-функций
1 // Рис. 10.19: Time.cpp
2 // Определение элемент-функций класса Time.
3 #include <iostream>
4 using std::cout;
5
6 #include <iomanip>
7 using std::setfill;
8 using std::setw;
9
10 #include "Time.h" // определение класса Time
11
12 // функция конструктора инициализирует закрытые данные;
13 // для установки переменных вызывает элемент-функцию setTime;
14 // значения по умолчанию равны 0 (см. определение класса)
15 Time::Time( int hr, int rain, int sec )
16 {
17 setTime( hr, min, sec );
18 } // конец конструктора Time
19
20 // установить значения часов, минут и секунд
21 Time &Time::setTime( int h, int m, int s ) // NB: возврат Times
666
22 {
23 setHour( h );
24 setMinute( m ) ;
25 setSecond( s ) ;
26 return *this; // обеспечивает каскадирование
27 } // конец функции setTime
28
29 // установить значение часов
30 Time &Time::setHour( int h ) // NB: возврат Time&
31 {
32 hour = ( h >= 0 && h < 24 ) ? h : 0; // проверить часы
33 return *this; // обеспечивает каскадирование
34 } // конец функции setHour
35
36 // установить значение минут
37 Time &Time: : setMinute ( int m ) // NB: возврат Time&
38 {
39 minute = ( m >= 0 && m < 60 ) ? m : 0; // проверить минуты
40 return *this; // обеспечивает каскадирование
41 } // конец функции setMinute
42
43 // установить значение секунд
44 Time &Time::setSecond( int s ) // NB: возврат Time&
45 {
46 second = ( s >= 0 && s < 60 ) ? s : 0; // проверить секунды
47 return *this; // обеспечивает каскадирование
48 } // конец функции setSecond
49
50 // возвратить значение часов
51 int Time:igetHour() const
52 {
53 return hour;
54 } // конец функции getHour
55
56 // возвратить значение секунд
57 int Time::getMinute() const
58 {
59 return minute;
60 } // конец функции getMinute
61
62 // возвратить значение секунд
63 int Time::getSecond() const
64 {
65 return second;
66 } // конец функции getSecond
67
68 // напечатать в формате всемирного времени (HH:MM:SS)
69 void Time:rprintUniversal() const
70 {
71 cout « setfill( '0' ) « setw( 2 ) « hour « ":"
72 « setw( 2 ) « minute « ": " « setw( 2 ) « second;
73 } // конец функции printUniversal
74
75 // напечатать в стандартном формате времени (HH:MM:SS AM или
76 void Time::printStandard() const
77 {
78 cout « ( ( hour == 0 || hour == 12 ) ? 12 : hour % 12 )
Классы: часть II
667
79 « ":" « setfill( '0' ) « setw( 2 ) « minute
80 « ":" « setw( 2 ) « second « ( hour < 12 ? " AM" : " PM" ) ;
81 } // конец функции printstandard
Рис. 10.19. Определения элемент-функций класса Time, модифицированные для
каскадирования вызовов
1 // Рис. 10.20: figl0_20.cpp
2 // Каскадирование вызовов с помощью указателя this.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Time.h" // определение класса Time
8
9 int main()
10 {
11 Time t; // создать объект Time
12
13 // каскадные вызовы функций
14 t.setHour( 18 ).setMinute( 30 ).setSecond( 22 );
15
16 // вывести время во всемирном и стандартном форматах
17 cout « "Universal time: ";
18 t.printUniversal();
19
20 cout « "\nStandard time:
21 t.printstandard();
22
23 cout « "\n\nNew standard time: ";
24
25 // каскадные вызовы функций
26 t.setTime( 20, 20, 20 ).printStandard();
27 cout « endl;
28 return 0;
29 } // конец main
Universal time: 18:30:22
Standard time: 6:30:22 PM
New standard time: 8:20:20 PM
Рис. 10.20. Каскадирование вызовов элемент-функций
Программа на рис. 10.20 создает объект t класса Time (строка 11) и затем
использует его для каскадных вызовов элемент-функций (строки 14 и 26).
Почему работает прием, основанный на возврате *this в качестве ссылки?
Операция-точка (.) ассоциируется слева направо, поэтому строка 14 оценивает
сначала t.setHour( 18 ), а затем возвращает ссылку на t как значение этого вызова
функции. Оставшееся выражение затем интерпретируется как
t.setMinute( 30 ).setSecond( 22 );
668
Глава 10
Выполняется вызов t.setMinute( 30 ) и возвращается ссылка на t. Оставшееся
выражение интерпретируется как
t.setSecond( 22 );
В строке 26 также осуществляется каскадирование. Вызовы должны
выполняться именно в указанном порядке, поскольку определенная в классе
функция print Standard не возвращает ссылку на t. Если поместить в в
строке 26 вызов printStandard перед вызовом setTime, это приведет к ошибке
компиляции. В главе 11 приводится ряд практических примеров использования
каскадных вызовов функций. В одном из них показано применение
операций « с потоком cout для вывода нескольких значений в одном операторе.
10.6. Динамическое управление памятью с помощью
операций new и delete
C++ позволяет программистам управлять выделением и освобождением
памяти в программе для любого встроенного или определяемого пользователем
типа. Это называется динамическим распределением памяти и
осуществляется с помощью операций new и delete. Вспомните, что в классе Employee
(рис. 10.12-10.14) для представления имени и фамилии служащего
использовались два 25-символьных массива. Определение класса Employee (рис. 10.12)
Должно специфицировать число элементов в каждом из этих массивов, когда
последние объявляются в качестве элементов данных, поскольку размер этих
массивов определяет размер памяти, требуемой для хранения объекта
Employee. Как уже говорилось, эти массивы занимают лишнюю память, если
имя (фамилия) короче 24 символов. Кроме того, имена (фамилии) длиннее 24
символов должны усекаться, чтобы они могли поместиться в массивах
фиксированного размера.
Разве не заманчиво было бы использовать массивы, содержащие ровно
столько элементов, сколько требуется для хранения имени и фамилии в
объекте Employee? Динамическое распределение памяти позволяет нам сделать
именно это. Как вы увидите в примере раздела 10.7, если мы заменим
массивы — элементы данных lastName и firstName — указателями на char, то
сможем с помощью операции new динамически выделять (т.е. резервировать)
точный объем памяти, необходимый для хранения имени и фамилии во время
исполнения. Такое динамическое выделение памяти создает массив (или
любой встроенный или определяемый пользователем тип) в свободной памяти
(ее иногда называют «кучей») — области памяти, которая придается каждой
программе для хранения объектов, создаваемых во время исполнения. Как
только память под массив выделена, мы можем получить к нему доступ,
установив указатель на первый элемент массива. Когда массив будет больше не
нужен, мы сможем возвратить память в область свободной памяти с помощью
операции delete, которая освобождает (т.е. возвращает программе) память
и делает ее доступной для использования последующими операциями new.
Пример в разделе 10.7 снова представляет модифицированный класс
Employee. Здесь мы обсудим сначала детали применения операций new
и delete для выделения памяти под объекты, основные типы и массивы.
Классы: часть II
669
Рассмотрим следующие объявление и оператор:
Time *timePtr;
timePtr = new Time;
Операция new выделяет память нужного размера для объекта типа Time,
вызывает для инициализации объекта конструктор по умолчанию и возвращает
указатель типа, специфицированного справа от операции new (т.е. Time *).
Заметьте, что new может использоваться для динамического размещения в
памяти любого основного (такого, как int или double) или классового типа. Если
new не может найти в памяти достаточного места для объекта, она
сигнализирует об ошибке, «выбрасывая исключение». Управление исключениями
подробно рассматривается в 16-й главе с учетом нововведений ANSI/ISO C++.
В частности, мы покажем, как «перехватывать» исключения. Если программа
не «перехватывает» исключение, она немедленно завершается. [Замечание.
В версиях C++, существовавших до стандарта ANSI/ISO, операция new
возвращала при ошибке нулевой указатель. В этой книге мы везде используем
стандартную версию операции new.]
Чтобы уничтожить динамически выделенный объект и освободить
занимаемую им память, используйте операцию delete:
delete timePtr;
Этот оператор сначала вызывает деструктор для объекта, на который указывает
timePtr, а затем освобождает ассоциированную с объектом память. После этого
память может утилизироваться системой для размещения других объектов.
Типичная ошибка программирования 10,8
Если не освобождать динамически выделяемую память, когда она
становится более не нужна, в системе может возникнуть нехватка
свободной памяти. Иногда это называют «утечкой памяти».
C++ позволяет указать инициализатор для вновь создаваемой переменной
основного типа, как в операторе
double *ptr = new double( 3.14159 );
который инициализирует созданное число двойной точности
значением 3.14159 и присваивает полученный указатель переменной ptr. Тот же
синтаксис может быть использован для указания разделенного запятыми списка
аргументов конструктора объекта. Например, оператор
Time *timePtr = new Time( 12, 45, 0 );
инициализирует вновь созданный объект Time временем 12:45 РМ и
присваивает полученный указатель переменной timePtr.
Как уже говорилось, с помощью операции new можно динамически
выделять массивы. Например, 10-элементный целый массив можно выделить
и присвоить указателю gradesArray оператором
int *gradesArray = new int[ 10 ];
который объявляет указатель gradesArray и присваивает ему указатель на
первый элемент динамически выделенного 10-элементного массива целых.
670
Глава 10
Как вы помните, размер массива, создаваемого во время компиляции, должен
быть специфицирован константным целочисленным выражение. Однако
размер динамически выделенного массива может специфицироваться любым
целочисленным выражением, которое может оцениваться во время выполнения.
Заметьте также, что при динамическом выделении массива объектов
программист не может передать аргументы конструктору каждого объекта. Вместо
этого каждый объект в массиве инициализируется конструктором по
умолчанию. Чтобы удалить динамически выделенный массив, на который указывает
gradesArray, используйте оператор
delete [] gradesArray;
Этот оператор освобождает массив, на который указывает gradesArray. Если
указатель в этом операторе ссылается на массив объектов, сначала для
каждого объекта в массиве вызывается деструктор, после чего память массива
освобождается. Если бы в предыдущем операторе отсутствовали квадратные
скобки ([]), a gradesArray указывал на массив объектов, деструктор был бы вызван
только для первого объекта в массиве.
Типичная ошибка программирования 10.9
Применение к массивам delete вместо delete[] может приводить к
логическим ошибкам времени выполнения. Чтобы избежать
неприятностей, нужно удалять массивы операцией delete[], в то время как
память, выделенная как индивидуальный элемент, должна удаляться
операцией delete.
10.7. Статические элементы класса
Существует одно важное исключения из правила, что каждый объект
класса имеет свой собственный экземпляр всех элементов данных класса. В
некоторых случаях все элементы класса должны разделять один и тот же экземпляр
конкретного элемента данных. По этой и другим причинам используются
статические элементы данных. Статический элемент данных представляет
«общеклассовую» информацию (т.е. являющуюся общей собственностью всех
представителей класса, а не конкретного его объекта). Объявление
статического элемента начинается с ключевого слова static. Вспомните, что версии
класса GradeBook из главы 7 использовали статические элементы данных для
хранения констант, представляющих общее число оценок, которое могли
храниться в объектах GradeBook.
Давайте обоснуем полезность статических общеклассовых данных на
примере видеоигры. Допустим, у нас есть игра с марсианами и другими
космическими тварями. Каждый Martian агрессивен и склонен атаковать другие
существа, если знает, что в данный момент имеется по крайней мере пять живых
марсиан. Если их меньше пяти, марсианин становится труслив. Поэтому
каждый марсианин должен знать счетчик martianCount. Мы могли бы придать
martianCount в качестве элемента данных каждому представителю класса
Martian. Если мы это сделаем, каждый марсианин будет иметь отдельный
экземпляр элемента данных. Всякий раз при создании нового марсианина нам
нужно будет обновить martianCount каждого объекта Martian. Для этого нуж-
Классы: часть II
671
но, чтобы каждый объект Martian имел доступ к дескрипторам всех других
объектов Martian в памяти. Это излишний расход памяти, поскольку
создаются избыточные копии, и времени, которое тратится на обновление этих копий.
Вместо этого мы объявляем martianCount как static. Это делает его
общеклассовыми данными. Каждый Martian может видеть martianCount так же, как
собственные элементы данных, но C++ сохраняет только один экземпляр
статического martianCount. Это экономит память. Мы экономим и время, так
как конструктор Martian производит инкремент, а деструктор Martian —
декремент единственной статической переменной martianCount.
■——i Вопросы производительности 10.3
f^^l С целью экономии памяти определяйте статические элементы
данных, если для всех объектов достаточно единственного экземпляра
данных.
Хотя может показаться, что статические элементы данных подобны
глобальным переменным, они имеют область действия класса. Статические
элементы могут быть открытыми, закрытыми или защищенными. Статические
элементы данных основных типов по умолчанию инициализируются
значением 0. Если вам требуется другое значение, статический элемент данных может
быть инициализирован один (и только один) раз. Константный статический
элемент данных целочисленного или перечислимого типа может
инициализироваться при его объявлении в определении класса. Однако любые другие
статические элементы данных должны определяться в области действия файла
(т.е. вне тела определения класса) и могут инициализироваться только в этих
определениях. Заметьте, что статические элементы данных классовых типов
(т.е. статические элементы-объекты), имеющие конструкторы по умолчанию,
не требуют инициализации, поскольку для них будут вызываться
конструкторы по умолчанию.
Обращение к закрытым или защищенным статическим элементам класса
обычно производится через открытые элемент-функкции класса или через
друзей класса. (В главе 12 мы увидим, что к закрытым или защищенным
статическим элементам класса можно обращаться также через защищенные
функции класса.) Статические элементы класса существуют, даже если не
существует ни одного объекта этого класса. Для обращения к открытому
статическому элементу класса в случае, когда не существует ни одного объекта
этого класса, просто поместите перед именем элемента имя класса с бинарной
операцией разрешения области действия (::). Например,' если наша
переменная martianCount является открытой, к ней можно обращаться посредством
выражения Martian::martianCount, даже если объектов Martian не
существует. (Разумеется, использование открытых данных не поощряется.)
К открытым статическим элементам данных класса можно также
обращаться через любой объект этого класса, используя имя объекта,
операцию-точку и имя элемента (например, myMartian.martianCount). Для
обращения к закрытому или защищенному статическому элементу класса в
случае, когда не существует ни одного объекта этого класса, должна быть
предусмотрена открытая статическая элемент-функция, при вызове которой
ее имени должны предшествовать имя класса и бинарная операция
разрешения области действия. (Как мы увидим в главе 12, для этой цели может слу-
672
Глава 10
жить также защищенная статическая элемент-функция класса.) Статическая
элемент-функция относится к услугам, которые предоставляет класс, а не
конкретный его объект.
Общее методическое замечание 10.10
Статические элементы данных и статические элемент-функции
существуют и к ним можно обращаться, даже если не создано ни одного
представителя класса.
Программа на рис. 10.21-10.23 демонстрирует закрытый статический
элемент данных с именем count (строка 21 на рис. 10.21) и открытую
статическую элемент-функцию с именем getCount (строка 15 на рис. 10.21). На
рис. 10.22 строка 14 определяет в области действия файла и инициализирует
нулем элемент данных count, а строки 18-21 определяют статическую
элемент-функцию getCount. Обратите внимание, что ни строка 14, ни строка 18
не содержат ключевого слова static, хотя обе относятся к статическим
элементам класса. Когда static применяется к некоторому имени в области действия
файла, это значит, что имя будет известно только в этом файле. Статические
элементы класса должны быть доступны из любого кода клиента, имеющего
доступ к файлу, поэтому мы не можем объявлять их как static в .срр-файле, —
мы объявляем их как static только в .h-файле. Элемент данных count хранит
счетчик числа созданных представителей класса Employee. Когда объекты
класса Employee существуют, на элемент count можно ссылаться через любую
элемент-функцию объекта Employee, — на рис. 10.22 на count ссылается
строка 33 в конструкторе и строка 48 в деструкторе. Кроме того, заметьте, что
поскольку элемент count относится к типу int, его можно было бы
инициализировать в строке 21 заголовочного файла на рис. 10.21.
гт^т Типичная ошибка программирования 10-10
\ЩГ I Включение ключевого слова static в определение статических элементов
данных в области действия файла приводит к ошибке компиляции.
1 // Рис. 10.21: Employee.h
2 // Определение класса Employee.
3 #ifndef EMPLOYEE_H
4 #define EMPLOYEE_H
5
6 class Employee
7 {
8 public:
9 Employee( const char* const, const char* const ); // конструктор
10 ^Employee(); // destructor
11 const char *getFirstName() const; // возвратить имя
12 const char *getLastName() const; // возвратить фамилию
13
14 // статическая элемент-функция
15 static int getCount(); // возвратить число созданных объектов
16 private:
17 char *firstName;
Классы: часть II
673
18 char *lastName;
19
20 // static data
21 static int count; // число созданных объектов
22 }; // конец класса Employee
23
24 #endif
Рис. 10.21. Определение класса Employee со статическим элементом данных для
отслеживания числа объектов Employee в памяти
1 // Рис. 10.22: Employee.срр
2 // Определение элемент-функций класса Employee.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототипы strlen и strncpy
8 using std::strlen;
9 using std::strcpy;
10
11 #include "Employee.h" // определение класса Employee
12
13 // определить и инициализировать статический элемент данных
14 int Employee::count = 0;
15
16 // определить статическую элемент-функцию, возвращающую число
17 // созданных объектов Employee (объявлена static в Employee.h)
18 int Employee::getCount()
19 {
20 return count;
21 } // конец статической функции getCount
22
23 // конструктор динамически выделяет память для имени и фамилии
24 //и вызывает strcpy для копирования имени и фамилии в объект
25 Employee::Employee(const char* const first, const char* const last)
26 {
27 firstName = new char[ strlen( first ) + 1 ];
28 strcpy( firstName, first );
29
30 lastName = new char[ strlen( last ) +1 ];
31 strcpy( lastName, last );
32
33 count++; // увеличить статический счетчик служащих
34
35 cout « "Employee constructor for " « firstName
36 « ' ' « lastName « " called." « endl;
37 } // конец конструктора Employee
38
39 // деструктор освобождает динамически выделенную память
40 Employee::-Employee()
41 {
42 cout « "-Employee() called for " « firstName
43 « ' ' « lastName « endl;
44
22 Зак. 1114
674
Глава 10
45 delete [] firstName; // освободить память
46 delete [] lastName; // освободить память
47
48 count—; // уменьшить статический счетчик служащих
49 } // конец деструктора ~Employee
50
51 // возвратить имя служащего
52 const char *Employee::getFirstName() const
53 {
54 // const перед возвращаемым типом не дает клиенту модифицировать
55 // закрытые данные; клиент должен скопировать строку, прежде чем
56 // деструктор освободит память и указатель станет неопределенным
57 return firstName;
58 } // конец функции getFirstName
59
60 // возвратить фамилию служащего
61 const char *Employee::getLastName0 const
62 {
63 // const перед возвращаемым типом не дает клиенту модифицировать
64 // закрытые данные; клиент должен скопировать строку, прежде чем
65 // деструктор освободит память и указатель станет неопределенным
66 return lastName;
67 } // конец функции getLastName
Рис. 10.22. Определение элемент-функций класса Employee
Обратите внимание, как в конструкторе класса Employee на рис. 10.22
используется операция new (строки 27 и 30) для выделения нужного объема
памяти под элементы firstName и lastName. Если операция new не сможет
удовлетворить запрос о выделении памяти для любого из этих символьных
массивов, программа немедленно завершится.
Заметьте также, что реализации функций getFirstName (строки 52-58)
и getLastName (строки 61-67) возвращают указатели на константные
символьные данные. При такой реализации, если клиент хочет иметь у себя копию
имени или фамилии, то после получения из объекта указателя на константные
символьные данные он отвечает за копирование динамически выделенной памяти
в объекте Employee. Возможна также такая реализация getFirstName
и getLastName, когда клиент должен передавать каждой из этих функций
символьный массив и его размер. Тогда функции могли бы копировать
соответствующие данные в предоставленный клиентом массив. Опять же заметьте, что
мы могли бы использовать здесь класс string и возвращать вызывающему
копию объекта string, а не указатель на закрытые данные.
Программа на рис. 10.23 использует статическую элемент-функцию getCount
для определения числа созданных представителей класса Employee. Обратите
внимание, что когда в программе не создано ни одного представителя,
производится вызов в форме Employee::getCount() (строки 14 и 38). Однако когда
имеются объекты, функция getCount может вызываться через любой из них, как
показано в операторе в строках 22-23, где для вызова getCount использован
указатель elPtr. Использование e2Ptr->getCount() или Employee::getCount() дало бы
тот же самый результат, так как getCount всегда обращается к одному и тому же
статическому элементу count.
Классы: часть II
675
1 // Рис. 10.23: figl0_23.cpp
2 // Тестер для класса Employee.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Employee.h" // определение класса Employee
8
9 int main()
10 {
11 // использовать имя класса и операцию разрешения области
12 // действия, чтобы обратиться к статическому элементу getCount
13 cout « "Number of employees before creation of any objects is "
14 « Employee::getCount() « endl; // использовать имя класса
15
16 // использовать new для динамического создания двух Employee
17 // операция new вызывает также конструктор объекта
18 Employee *elPtr = new Employee( "Susan", "Baker" );
19 Employee *e2Ptr = new Employee( "Robert", "Jones" );
20
21 // вызвать getCount для первого объекта Employee
22 cout « "Number of employees after objects are instantiated is "
23 « elPtr->getCount();
24
25 cout « "\n\nEmployee 1: "
26 « elPtr->getFirstName() « " " « elPtr->getLastName()
27 « "\nEmployee 2: " « e2Ptr->getFirstName()
28 « " " « e2Ptr->getLastName() « "\n\n";
29
30 delete elPtr; // освободить память
31 elPtr =0; // отсоединить указатель от области свободной памяти
32 delete e2Ptr; // освободить память
33 e2Ptr =0; // отсоединить указатель от области свободной памяти
34
35 // объектов нет, поэтому для вызова статической функции getCount
36 // используется имя класса и операция разрешения области действия
37 cout « "Number of employees after objects are deleted is "
38 « Employee::getCount() « endl;
39 return 0;
40 } // конец main
Number of employees before creation of any objects is 0
Employee constructor for Susan Baker called.
Employee constructor for Robert Jones called.
Number of employees after objects are instantiated is 2
Employee 1: Susan Baker
Employee 2: Robert Jones
-Employee() called for Susan Baker
-Employee() called for Robert Jones
Number of employees after objects are deleted is 0
Рис. 10.23. Статический элемент данных, отслеживающий число объектов класса
676
Глава 10
Общее методическое замечание 10.11
Некоторые организации указывают в своих стандартах по
разработке программного обеспечения, что любые вызовы статических
элемент-функций должны производиться через имя класса, а не через
дескриптор объекта.
Элемент-функция должна объявляться как static, если она не обращается
к не-статическим элементам данных или не-статическим элемент-функциям
класса. В отличие от не-статических элемен-функций, статическая
элемент-функция не имеет указателя this, так как статические элементы данных
и статические элемент-функции существуют независимо от каких-либо
объектов класса. Указатель this должен ссылаться на конкретный объект, но когда
вызывается статическая элемент-функция, в памяти может не быть никаких
объектов класса.
Типичная ошибка программирования 10.11
Использование указателя this внутри статической
элемент-функции является ошибкой компиляции.
Д1 Типичная ошибка программирования 10.12
Объявление статической элемент-функции как const является
ошибкой компиляции. Квалификатор const указывает, что функция не
может модифицировать содержимое объекта, на котором она
действует, но статические элемент-функции существуют и действуют
независимо от каких-либо объектов класса.
Строки 18-19 на рис. 10.23 используют операцию new для динамического
выделения двух объектов Employee. Помните, что при невозможности
выделения памяти для любого из этих объектов программа немедленно завершится.
Когда выделяется каждый из объектов Employee, вызывается его
конструктор. Когда в строках 30 и 32 используется операция delete, для каждого
объекта вызывается деструктор.
Предотвращение ошибок 10.2
После удаления динамически выделенной памяти установите в 0
указатель, который ссылался на эту память. Это отсоединит
указатель от ранее выделенного ему пространства свободной памяти. Это
пространство еще может содержать какую-то информацию,
несмотря на его удаление. При установке указателя в 0 программа лишается
какого-либо доступа к этому пространству, которое на самом деле
могло бы уже быть выделено для другой цели. Если вы не установите
указатель в 0, ваш код может случайно получить доступ к этой
новой информации, что приведет к чрезвычайно тонким и
невоспроизводимым логическим ошибкам.
Классы: часть II
677
10.8. Абстракция данных и сокрытие информации
Класс обычно скрывает подробности своей реализации от клиентов. Это
называется сокрытием информации. В качестве примера сокрытия информации
рассмотрим структуру данных стека, представленную в разделе 6.11.
Стеки могут быть реализованы с помощью массивов или других структур
данных, например, связанных списков. Клиенту класса стека не нужно знать
о его внутреннем устройстве. Клиент знает только, что когда единицы данных
помещаются в стек, они будут выбираться из него в порядке «последним
вошел, первым вышел». Что действительно заботит пользователя — это то,
какие функциональные возможности предлагает стек, а не то, как они
реализуются. Эта концепция носит название абстракции данных. Хотя
программисты и могут знать детали реализации класса, они не должны писать код,
зависящий от этих деталей. Это означает, что некоторый класс (например,
реализующий стек и его операции push ирор) можно заменить другой его версией,
не затрагивая при этом остальной системы. Пока открытые услуги класса не
изменяются (т.е. каждая открытая элемент-функция имеет в новом
определении класса тот же самый прототип, что и прежняя функция), остальные части
системы не будут затронуты.
Многие языки программирования акцентируют действия. В этих языках
данные существуют для поддержки действий, которые должны
предпринимать программы. Во всяком случае, данные «менее интересны», чем действия.
Данные «примитивны». Существует всего несколько встроенных типов
данных, и программистам нелегко создавать свои собственные новые типы. C++
и объектно-ориентированный стиль программирования повышают значимость
данных. Основное поле деятельности в C++ — это создание новых типов (т.е.
классов) и выражение взаимодействий между объектами этих типов. Чтобы
продвигаться в этом направлении, специалистам в области языков
программирования нужно было формализовать некоторые понятия, касающиеся данных.
Рассматриваемая здесь нами формализация — это понятие абстрактного
типа данных (ADT), которое позволяет улучшить процесс разработки
программ.
Что такое абстрактный тип данных? Рассмотрим встроенный тип int,
который у многих людей ассоциируется с целым числом в математике. Однако тип
int — это не целое число, а его абстрактное представление. В отличие от
математических, компьютерные целые имеют фиксированный размер. Например,
тип int на 32-разрядных машинах ограничен обычно диапазоном
от -2147483648 до +2147483647. Если результат вычисления выпадает из
этого диапазона, происходит переполнение, и компьютер реагирует некоторым
машинно-зависимым образом. Он может, например, «молча» выдать
неправильный результат, например, значение слишком большое для того, чтобы
поместиться в переменной типа int (это называется обычно арифметическим
переполнением). С математическими целыми этой проблемы не возникает.
Таким образом, понятие компьютерного типа int на самом деле является только
приближением понятия настоящего целого числа. Тот же самое верно и для
типа double.
Даже тип char является таким приближением; значения типа char обычно
являются 8-битовыми комбинациями нолей и единиц, которые совсем не
похожи на символы, которые они представляют, такие, как прописная буква Z,
678
Глава 10
символ нижнего регистра z, знак доллара ($), цифра (например, 5) и т.д.
Значения типа char на большинстве компьютеров довольно ограниченны в
сравнении с множеством реально существующих символов. Семиразрядный набор
символов ASCII (см. приложение Б) допускает 128 различных значений
символов. Это совершенно недостаточно для представления таких языков, как
японский и китайский, для которых требуются тысячи символов. По мере того,
как использование Internet и World Wide Web становится всепроникающим,
быстро растет популярность более нового набора символов Unicode, благодаря
его способности представлять алфавиты большинства существующих языков.
Более подробную информацию вы можете найти на www.unicode.org.
Суть в том, что даже встроенные типы данных, предоставляемые языками
программирования, подобными C++, в действительности являются только
приближениями, или несовершенными моделями, понятий и поведения в
реальном мире. До настоящего времени мы воспринимали тип int как нечто само
собой разумеющееся, однако теперь вы можете взглянуть на него в иной
перспективе. Типы, такие как int, float, char и другие, — все они являются
примерами абстрактных типов данных. Они являются, по существу, способами
представления понятий реального мира внутри компьютерной системы на
некотором приемлемом уровне точности.
Абстрактный тип данных на самом деле охватывает два понятия, а именно
представление данных и действия, которые могут производиться над этими
данными. Например, int в языке C++ содержит целое значение (данные)
и предусматривает (в числе прочих) операции сложения, вычитания,
умножения, деления и взятия по модулю, однако деление на ноль не определено. Для
выполнения этих разрешенных действий небезразличны характеристики
компьютера, такие, как фиксированный размер слова базовой компьютерной
системы. Другой пример — понятие отрицательных целых чисел, действия над
которыми и представление данных достаточно ясны, но извлечение
квадратного корня из отрицательного числа не определено. В C++ для реализации
абстрактных типов данных и их поведения программист использует классы.
10.8.1. Пример: абстрактный тип данных — массив
Мы обсуждали массивы в главе 7. Массив не более чем указатель и
некоторое пространство памяти. Примитивные возможности такого представления
приемлемы для выполнения действий над массивами, если программист
осторожен и нетребователен. Существует много действий, которые хотелось бы
выполнять с массивами, но которые не встроены в C++. На основе механизма
классов C++ программист может разработать ADT массива, более
совершенного, чем «сырые» массивы. Класс массива может реализовать множество новых
полезных возможностей, например:
• проверку диапазона индексов;
• произвольный диапазон индексов вместо диапазона, всегда
начинающегося с 0;
• присваивание массивов;
• сравнение массивов;
• ввод/вывод массивов;
• массивы, знающие свой размер;
Классы: часть II
679
• динамическое расширение массивов для размещения большего числа
элементов;
• массивы, которые могут распечатывать себя в аккуратном табличном
формате.
Мы создадим свой собственный класс массивов в главе 11, когда будем
изучать перегрузку операций в C++. Как вы помните, шаблон класса vector из
стандартной библиотеки C++ (представленный в главе 7) реализует и многие
из упомянутых возможностей. Набор встроенных типов C++ невелик. Классы
расширяют базовый язык программирования, вводя в него новые типы.
S Общее методическое замечание 10.12
Механизм классов позволяет программисту создавать новые типы.
Эти новые типы могут быть спроектированы так, что их будет
столь же удобно использовать, как и встроенные типы. Другими
словами, C++ — это расширяемый язык. Хотя язык C++ несложно
расширять с помощью новых типов, сам базовый язык изменений не
допускает.
Новые классы, созданные в программных средах C++, могут быть
собственностью отдельных программистов, небольших групп или компаний. Классы
могут также помещаться в стандартные классовые библиотеки, предназначенные
для широкого распространения. ANSI (Американский институт национальных
стандартов) и ISO (Международная организация по стандартам) разработали
стандартную версию C++, которая включает в себя стандартную библиотеку
классов. Читатель, изучающий C++ и объектно-ориентированное
программирование, будет готов воспользоваться преимуществами новых видов ускоренной,
ориентированной на компоненты разработки программного обеспечения,
которая становится возможной с появлением все более богатых библиотек.
10.8.2. Пример: абстрактный тип данных — строка
C++ намеренно сделан «бедным» языком и предоставляет программистам
только сырые средства для создания широкого диапазона систем (рассматривайте
его как инструмент для изготовления инструментов). Язык спроектирован так,
чтобы минимизировать издержки в плане производительности. C++ подходит
как для прикладного, так и для системного программирования, которое требует
эффективного выполнения программ. Конечно, можно было бы включить в число
встроенных типов языка C++ строковый тип. Однако проектировщики
предпочли вместо этого снабдить язык механизмом для создания и реализации
строковых абстрактных типов данных на основе классов. В главе 3 мы представили
класс string Стандартной библиотеки, а в главе 11 мы разработаем свой
собственный ADT String. Подробно класс string рассматривается в главе 18.
10.8.3. Пример: абстрактный тип данных — очередь
Всем нам время от времени приходится стоять в очереди. Очередью мы
называем ожидание в ряд, один за другим. Мы стоим в очереди в кассу в
универмаге, мы стоим в очереди на бензоколонке, мы стоим в очереди, чтобы сесть
в автрбус, мы стоим в очереди, чтобы оплатить пошлинный сбор на скоростной
680
Глава 10
магистрали, а все студенты слишком хорошо знают об очередях при записи на
курсы, которые они хотели бы прослушать. Компьютерные системы внутри
себя используют много разновидностей очередей, поэтому нам необходимо
уметь писать программы, которые моделируют очереди и то, что в них
происходит.
Очередь является хорошим примером абстрактного типа данных. Очереди
предоставляют своим клиентам понятную схему поведения. Клиенты по
одному помещают объекты в очередь — используя для этого операцию постановки
в очередь, enqueue, — и по одному получают эти объекты обратно по мере
необходимости, используя для этого операцию исключения из очереди, dequeue.
Чисто умозрительно очередь может стать бесконечно длинной. Реальная
очередь, разумеется, имеет конечную длину. Элементы возвращаются из очереди
в порядке first-in, first-out (FIFO, «первым пришел, первым вышел»), —
элемент, поставленный в очередь первым, будет первым элементом, извлеченным
из очереди.
Очередь скрывает внутреннее представление данных, в котором каким-то
образом предусмотрено отслеживание элементов, ожидающих в очереди в
настоящее время, и предлагает своим клиентам набор действий, а именно
постановку в очередь и исключение из очереди. Клиентов не интересует реализация
очереди. Клиенты просто хотят, чтобы очередь функционировала «как было
обещано». Когда клиент ставит в очередь новый элемент, очередь должна
принять этот элемент и как-то поместить его в некоторую структуру данных FIFO.
Когда клиенту нужен следующий элемент из начала очереди, очередь должна
удалить этот элемент из своего внутреннего представления и передать во
внешний мир (т.е. клиенту очереди) в порядке FIFO, т.е. при исключении из
очереди следующим должен быть возвращен элемент, находившийся в очереди
наибольшее время.
ADT очереди гарантирует целостность своей внутренней структуры
данных. Клиенты не могут непосредственно манипулировать этой структурой.
Только сам абстрактный тип очереди имеет доступ к своим внутренним
данным. Клиенты могут инициировать выполнение только допустимых действий
над представлением данных: операции, не предусмотренные открытым
интерфейсом ADT, отвергаются некоторым адекватным образом. Это может
означать выдачу сообщения об ошибке, завершение выполнения программы или
просто игнорирование запроса этой операции.
10.9. Классы-контейнеры и итераторы
К наиболее популярным типам классов принадлежат классы-контейнеры
(также называемые классами-коллекциями), т.е. классы, предназначенные
для хранения совокупностей объектов. Классы-контейнеры обычно
предоставляют услуги типа вставки, удаления, поиска, сортировки, проверки того,
имеется ли в контейнере некоторый элемент и т.п. Массивы, стеки, деревья,
очереди и связанные списки являются примерами контейнеров; мы изучали
массивы в главе 7. Другие упомянутые структуры данных рассматриваются в 20-й
главе.
Обычно с классами-контейнерами ассоциируют объекты-итераторы, или
просто итераторы. Итератор — это объект, который «проходит» по коллекции,
возвращая ее следующий элемент (или производя некоторые действия над еле-
Классы: часть II
681
дующим элементом). После реализации итератора для класса несложно написать
выражение для получения следующего элемента контейнера. Подобно тому, как
в книге, которой пользуются несколько людей, может быть сразу несколько
закладок, на классе-контейнере могут одновременно действовать несколько
итераторов. Каждый итератор хранит информацию о своем собственном
«местоположении». Контейнеры и итераторы рассматриваются в 22-й главе.
10.10. Классы-посредники
Как вы помните, двумя основными принципами правильного
конструирования программного обеспечения являются отделение интерфейса от
реализации и сокрытие подробностей реализации. Мы пытаемся достичь этих целей,
определяя класс в заголовочном файле и реализуя его элемент-функции в
отдельном файле реализации. Однако, как мы отметили в главе 9, заголовочные
файлы все-таки содержат некоторые части реализации и позволяют делать
догадки относительно других ее частей. Закрытые элементы класса, например,
перечисляются в определении класса в заголовочном файле, так что они
видимы для клиентов, хотя последние и не могут обращаться к закрытым
элементам. Подобное раскрытие private-данных класса в принципе является
раскрытием информации, являющейся собственностью производителя. Мы
представим здесь понятие класса-посредника, который позволяет скрыть от клиентов
даже сами private-данные класса.
Для реализации класса-посредника требуется несколько шагов, которые
мы демонстрируем на рис. 10.24-10.27. Прежде всего мы создаем определение
для класса, содержащее частную реализацию, которую нам хотелось бы
скрыть. Наш примерный класс с именем Implementation показан
на рис. 10.24. Класс-посредник Interface показан на рис. 10.25-10.26.
Тестовая программа с образцом вывода показана на рис. 10.27.
Класс Implementation (рис. 10.24) содержит единственный закрытый
элемент данных с именем value (данные, которые мы хотим скрыть от клиента),
конструктор для инициализации value и функции setValue и getValue.
1 // Рис. 10.24: Implementation.h
2 // Заголовочный файл для класса Implementation
3
4 class Implementation
5 {
6 public:
7 // конструктор
8 Implementation( int v )
9 : value( v ) // инициализировать value значением v
10 {
11 // пустое тело
12 } // конец конструктора Implementation
13
14 // установить value равным v
15 void setValue( int v )
16 {
17 value = v; // v должно проверяться
18 } // конец функции setValue
19
682
Глава 10
20 // возвратить value
21 int getValue() const
22 {
23 return value;
24 } // конец функции getValue
25 private:
26 int value; // данные, которые мы хотим скрыть от клиента
27 }; // конец класса Implementation
Рис. 10.24. Определение класса Implementation
1 // Рис. 10.25: Interfaced
2 // Заголовочный файл для класса Interface
3 // Клиент видит данный исходный код, но этот код не раскрывает
4 // структуру данных класса Implementation.
5
6 class Implementation; // опережающее объявление для строки 17
7
8 class Interface
9 {
10 public:
11 Interface( int ); // конструктор
12 void setValue( int ); // тот же открытый интерфейс,
13 int getValue() const; // что и в классе Implementation
14 ^Interface(); // деструктор
15 private:
16 // требует опережающего объявления (строка 6)
17 Implementation *ptr;
18 }; // конец класса Interface
Рис. 10.25. Определение класса Interface
1 // Рис. 10.26: Interface.срр
2 // Реализация класса Interface - клиент получает этот файл
3 // только в форме объектного кода; реализация остается скрытой.
4 #include "Interface.h" // определение класса Interface
5 #include "Implementation.h" // определение класса Implementation
6
7 // конструктор
8 Interface::Interface( int v )
9 : ptr ( new Implementation( v ) ) // инициализировать ptr Новым
10 { // объектом Implementation
11 // пустое тело
12 } // конец конструктора Interface
13
14 // вызвать функцию setValue класса Implementation
15 void Interface::setValue( int v )
16 {
17 ptr->setValue( v );
18 } // конец функции setValue
19
20 // вызвать функцию getValue класса Implementation
21 int Interface::getValue() const
Классы: часть II
683
22 {
23 return ptr->getValue();
24 } // конец функции getValue
25
26 // деструктор
27 Interface: ^Interface ()
28 {
29 delete ptr;
30 } // конец деструктора --Interface
Рис. 10.26. Определения элемент-функций класса Interface
Далее мы определяем класс-посредник Interface (рис. 10.25) с открытым
интерфейсом, идентичным интерфейсу класса Implementation (за исключением
имен конструктора и деструктора). Единственным закрытым элементом данных
класса-посредника является указатель на объект класса Implementation.
Использование такого указателя позволяет нам скрыть от клиента подробности
реализации класса Implementation. Заметьте, что единственными
упоминаниями в классе Interface о классе Implementation являются объявление указателя
(строка 17) и опережающее объявление класса в строке 6. Когда определение
класса (такого, как класс Interface) использует только указатель или ссылку на
объект другого класса (такого, как класс Implementation), в определение не
требуется включать директивой #inhclude заголовочный файл для этого
другого класса (который в обычном случае раскрывал бы его private-данные). Вы
можете просто объявить этот класс как тип данных в опережающем объявлении
класса (строка 6) перед тем, как использовать его в файле.
Файл с реализациями элемент-функций для класса-посредника Interface
(рис. 10.26) — единственный файл, который включает заголовочный файл
Implementation.h (строка 5), содержащий класс Implementation. Клиенту
предоставляется файл с уже компилированным объектным кодом файла
Interface.срр (рис. 10.26) и заголовочный файл Interface.h, который включает
прототипы функций-услуг, предоставляемых классом-посредником. Поскольку
Interface.срр доступен для клиента только в форме объектного кода, клиент не
может видеть, как взаимодействуют класс-посредник и частный класс
(строки 9, 17, 23 и 29). Заметьте, что класс-посредник вводит дополнительный
«слой» функциональных вызовов в качестве «цены», которую приходится
заплатить за сокрытие private-данных класса Implementation. Учитывая
быстродействие современных компьютеров и тот факт, что многие компиляторы
способны автоматически генерировать встроенные расширения простых
функциональных вызовов, потери из-за этих дополнительных вызовов часто
оказываются пренебрежимо малы.
Программа на рис. 10.27 тестирует класс Interface. Обратите внимание, что
в код клиента включается только заголовочный файл для класса Interface —
нигде нет упоминания о существовании отдельного класса с именем
Implementation. Таким образом, клиент никогда не увидит закрытых данных
класса Implementation, и код клиента никогда не станет зависимым от кода
Implementation.
684
Глава 10
1 // Рис. 10.27: figl0_27.cpp
2 // Сокрытие закрытых данных класса с помощью класса-посредника.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Interface.h" // определение класса Interface
8
9 int main()
10 {
11 Interface i( 5 ); // создать объект класса Interface
12
13 cout « "Interface contains: " « i.getValue()
14 « " before setValue" « endl;
15
16 i.setValue( 10 ) ;
17
18 cout « "Interface contains: " « i.getValue()
19 « " after setValue" « endl;
20 return 0;
21 } // конец main
Interface contains: 5 before setValue
Interface contains: 10 after setValue
Рис. 10.27. Реализация класса-посредника
10.11. Заключение
В этой главе мы представили несколько более сложных вопросов,
относящихся к классам и абстракции данных. Вы узнали, как специфицировать
константные элементы данных и константные элемент-функции, чтобы
предотвратить модификацию объектов, проводя, таким образом, принцип минимума
привилегий. Вы также узнали, что класс, посредством композиции, может
содержать в качестве элементов объекты других классов. Мы ввели понятие
дружественности и привели примеры, демонстрирующие использование
дружественных функций.
Вы узнали, что каждой не-статической элемент-функции класса передается
в качестве неявного аргумента указатель this, позволяющий функции
обращаться к элементам данных и другим элемент-функциям нужного объекта.
Вы увидели также явное использование указателя this для доступа к
элементам объекта и для реализации каскадных вызовов элемент-функций.
В главе была представлена концепция динамического распределения
памяти. Вы узнали, что C++ позволяет создавать и уничтожать объекты
динамически с помощью операций new и delete. Мы обосновали необходимость
статических элементов данных и показали, как объявлять и использовать
статические элементы данных и элемент-функции в своих собственных классах.
Вы узнали об абстракции данных и о сокрытии информации — двух
фундаментальных принципах объектно-ориентированного программирования. Мы
обсудили абстрактные типы данных, являющиеся способом представления
в компьютерной системе реальных или концептуальных понятий на некото-
Классы: часть II
685
ром приемлемом уровне точности. Затем вы увидели три примера абстрактных
типов данных — массивы, строки и очереди. Мы ввели понятие
класса-контейнера, в котором хранится коллекция объектов, и понятие класса итератора,
который проходит по элементам контейнера. Наконец, вы узнали, как
создается класс-посредник, скрывающий подробности реализации класса (включая
закрытые элементы данных последнего) от клиентов класса.
В главе 11 мы продолжим изучение классов и объектов, показав, каким
образом можно заставить операции C++ работать с объектами; это называется
перегрузкой операций. Например, вы увидите, как «перегрузить»
операцию «, чтобы ее можно было использовать для вывода всего массива без
применения оператора повторения.
Резюме
• Ключевое слово const может использоваться для того, чтобы указать, что объект не
является модифицируемым и что любая попытка изменения этого объекта является
ошибкой.
• Компиляторы C++ отвергают вызовы не-константных элемент-функций для
константных объектов.
• Попытка константной элемент-функции модифицировать объект своего класса
(*this) приводит к ошибке компиляции.
• Функция специфицируется в качестве константной как в ее прототипе, так и в
определении.
• Значение константного объекта должно инициализироваться, а не присваиваться.
• Конструкторы и деструкторы не могут объявляться как const.
• Константные элементы данных и элементы данных, являющиеся ссылками, должны
инициализироваться с помощью инициализаторов элемента.
• Класс может иметь в качестве элементов объекты других классов; это называется
композицией.
• Объекты-элементы конструируются в том порядке, в каком они объявляются в
определении, и до конструирования объектов, которые их содержат.
• «Если инициализатор элемента отсутствует, для объекта-элемента будет неявно
вызван конструктор по умолчанию.
• Дружественная функция класса определяется вне области действия этого класса,
однако имеет право доступа к его неоткрытым (и открытым) элементам. В качестве
друзей класса могут быть объявлены автономные функции или целые классы.
• Объявления дружественности могут размещаться в любом месте определения
класса. «Друг» по существу является частью открытого интерфейса класса.
• Отношение дружественности не является ни симметричным, ни транзитивным.
• Каждый объект имеет доступ к своему собственному адресу через указатель с именем
this.
• Указатель this объекта не является частью собственно объекта, т.е. этот указатель не
отражается на результате примененной к объекту операции sizeof.
• Указатель this передается (компилятором) в качестве неявного аргумента вызова
каждой не-статической функции объекта.
• Объекты используют указатель this для доступа к своим элементам данных и
элемент-функциям как неявно, так и явным образом.
• Указатель this позволяет осуществлять каскадные вызовы элемент-функций, когда
несколько функций вызываются в одном и том же операторе.
686
Глава 10
• Динамическое распределение памяти позволяет программистам управлять
выделением и освобождением памяти в программе для любого встроенного или
определяемого пользователем типа.
• Свободная память (ее иногда называют «кучей») является областью памяти, которая
придается каждой программе для хранения объектов, создаваемых во время
исполнения.
• Операция new выделяет память для объекта нужного объема, вызывает для
инициализации объекта конструктор и возвращает указатель соответствующего типа.
Операция new может использоваться для динамического размещения в памяти любого
основного (такого, как int или double) или классового типа. Если new не может
найти в памяти достаточного места для объекта, она сигнализирует об ошибке,
«выбрасывая исключение». В этом случае программа обычно немедленно завершается.
• Чтобы уничтожить динамически выделенный объект и освободить занимаемую им
память, используется операция delete.
• Операцией new может динамически выделяться массив объектов, как в операторе
int *ptr = new int[ 100 ];
который выделяет массив из 100 целых и присваивает его начальный адрес
указателю ptr. Предыдущий массив удаляется оператором
delete[] ptr;
• Статический элемент данных представляет «общеклассовую» информацию (т.е.
являющуюся общей собственностью всех представителей класса, а не конкретного его
объекта).
• Статические элементы имеют область действия класса и могут объявляться
открытыми, закрытыми или защищенными.
• Статические элементы класса существуют, даже если не существует ни одного
объекта этого класса.
• Для обращения к открытому статическому элементу класса в случае, когда не
существует ни одного объекта этого класса, просто поместите перед именем элемента имя
класса с бинарной операцией разрешения области действия (::).
• К открытым статическим элементам данных класса можно обращаться через любой
объект этого класса.
• Элемент-функция должна объявляться как static, если она не обращается к не-ста-
тическим элементам данных или не-статическим элемент-функциям класса. В
отличие от не-статических элемен-функций, статическая элемент-функция не имеет
указателя this, так как статические элементы данных и статические элемент-функции
существуют независимо от каких-либо объектов класса.
• Абстрактные типы данных являются способами представления понятий, реального
мира внутри компьютерной системы на некотором приемлемом уровне точности.
• Абстрактный тип данных охватывает два понятия, а именно представление данных
и действия, которые могут производиться над этими данными.
• C++ намеренно сделан «бедным» языком и предоставляет программистам только
сырые средства для создания широкого диапазона систем. Язык спроектирован так,
чтобы минимизировать издержки в плане производительности.
• Элементы возвращаются из очереди в порядке «первым пришел, первым вышел»
(FIFO), — элемент, поставленный в очередь первым, будет первым элементом,
извлеченным из очереди.
• Классы-контейнеры (также называемые классами-коллекциями) предназначены
для хранения совокупностей объектов. Классы-контейнеры обычно предоставляют
услуги типа вставки, удаления, поиска, сортировки и проверки того, имеется ли
в контейнере некоторый элемент.
Классы: часть II
687
• Обычно с классами-контейнерами ассоциируют итераторы. Итератор — это объект,
который «проходит» по коллекции, возвращая ее следующий элемент (или
производя некоторые действия над следующим элементом).
• Предоставление клиентам вашего класса класс-посредник, которому известен
только открытый интерфейс вашего класса, позволяет клиентам пользоваться услугами
класса, не давая им возможности видеть детали его реализации, такие, как
закрытые данные.
• Когда определение класса использует только указатель или ссылку на объект
другого класса, в определение не требуется включать директивой #inhclude заголовочный
файл для этого другого класса (который в обычном случае раскрывал бы его
private-данные). Вы можете просто объявить этот класс как тип данных в
опережающем объявлении класса перед использованием этого типа в файле.
• Файл с реализациями элемент-функций для класса-посредника — единственный
файл, который включает заголовочный файл класса, чьи закрытые данные нам
хотелось бы скрыть.
• Клиенту предоставляется файл с уже компилированным объектным кодом
элемент-функций класса-посредника и заголовочный файл, который включает
прототипы функций-услуг, предоставляемых классом-посредником.
Терминология
dequeue (операция очереди)
enqueue (операция очереди)
абстрактный тип данных (ADT)
абстрактный тип данных очереди
абстракция данных
арифметическое переполнение
выделение памяти
действия в ADT
динамические объекты
динамическое распределение памяти
дружественная функция
дружественный класс
инициализатор элемента
итератор
каскадные вызовы элемент-функций
класс-коллекция
класс-контейнер
класс-посредник
композиция
константная элемент-функция
константный объект
конструктор объекта-элемента
Контрольные вопросы
10.1. Заполните пропуски в каждом из следующих утверждений:
а) Для инициализации константных элементов класса используется синтаксис
Ь) Функция — не элемент класса должна быть объявлена в классе как
, чтобы иметь доступ к закрытым элементам данных этого класса.
куча
объект-хозяин
объект-элемент
операция delete
операция delete[]
операция new
операция new[]
опережающее объявление класса
освобождение памяти
отношение «имеет»
«первым пришел, первым вышел»
(FIFO)
«последним пришел, первым вышел»
(LIFO)
представление данных
свободная память
сокрытие информации
список инициализации элементов
статическая элемент-функция
статический элемент данных
указатель this
утечка памяти
688
Глава 10
c) Операция динамически выделяет память для объекта указанного
типа и возвращает на этот тип.
d) Константный объект должен быть ; после создания он не может
быть изменен.
е) элемент данных хранит «общеклассовую» информацию.
f) Функции-элементы класса имеют доступ к «указателю объекта на себя»,
называемому указателем .
g) Ключевое слово указывает, что объект или переменная после
инициализации не может модифицироваться.
h) Если не предусмотрен инициализатор для элемента-объекта класса, то для
него вызывается .
i) Элемент-функция должна быть объявлена статической, если она не
обращается к элементам класса.
с
j) Элементы-объекты конструируются объекта включающего их
класса,
к) Операция возвращает системе память, предварительно
выделенную операцией new.
10.2. Найдите ошибки в следующем классе и объясните, как их можно исправить.
class Example {
public:
Example( int у = 10 )
: data( у )
{
// пустое тело
} // конец конструктора Example
int getlncrementedData() const
{
return data++;
} // конец функции getlncrementedData
static int getCount()
{
cout « "Data is " « data « endl;
return count;
} // конец функции getCount
private:
int data;
static int count;
}; // конец класса Example
Ответы на контрольные вопросы
10.1. а) инициализатора элемента, b) friend, с) new, указатель, d) инициализирован.
е) Статический, f) this, g) const, h) конструктор по умолчанию, i) не-статиче-
ским. j) до. k) delete.
10.2. Ошибка: в определении класса Example две ошибки. Первая — в функции
getlncrementedData. Эта функция объявлена как const, однако изменяет объект.
Исправление: чтобы исправить первую ошибку, уберите ключевое слово const из
определения функции getlncrementedData.
Вторая ошибка — в функции getCount. Эта функция объявлена статической,
поэтому ей не разрешен доступ к не-статическим элементам класса.
Исправление: уберите из определения функции getCount строку, в которой
выводятся данные.
Классы: часть II
689
Упражнения
10.3. Сравните и противопоставьте операции динамического распределения памяти
new, new[], delete и delete[].
10.4. Объясните понятие дружественности в C++. Объясните отрицательные аспекты
дружественности, как это описано в тексте.
10.5. Может ли корректное определение класса Time включать оба нижеследующих
конструктора? Если нет, объясните, почему.
Time( int h = 0, int m = 0, int s = 0 );
Time() ;
10.6. Что происходит, если для конструктора или деструктора определяется тип
возвращаемого значения (даже void)?
10.7. Модифицируйте класс Date из рис. 10.10, введя в него следующие возможности:
a) Выведите дату в нескольких форматах, например:
DDD YYYY
MM/DD/YY
June 14, 1992
b) Используйте перегруженные конструкторы для создания объектов Date,
инициализированных датами в форматах из пункта (а).
c) Создайте конструктор класса Date, который считывает системную дату,
используя стандартные библиотечные функции из заголовка, и устанавливает
элементы Date. (Подробную информацию о функциях в <ctime> см. в
справочной документации вашего компилятора или на www.cplusplus.com/ref/
ctime/index.htmi.)
В главе 11 мы сможем создать операции для проверки двух дат на равенство
и для сравнения дат с целью определения того, раньше ли одна дата другой или
позже.
10.8. Создайте класс Savings Account. Определите статический элемент данных ап-
nuallnterestRate для хранения общей для всех вкладчиков годовой процентной
ставки. Каждый объект класса содержит закрытый элемент данных savingsBa-
lance, показывающий текущую сумму на депозите вкладчика. Определите
функцию-элемент calculateMonthlylnterest, которая вычисляет месячный прирост,
умножая баланс на annuallnterestRate, поделенную на 12; это значение должно
прибавляться к savingsBalance. Предусмотрите статическую функцию modify-
InterestRate, которая устанавливает статический элемент annuallnterestRate
новым значением. Напишите программу-драйвер для тестирования класса.
Создайте два различных объекта SavingsAccount, saver 1 и saver2, с балансами
соответственно $2000.00 и $3000.00. Установите annuallnterestRate равной 3%,
рассчитайте затем месячный прирост и распечатайте новые значения баланса
обоих вкладчиков. Установите затем annuallnterestRate равной 4% и
вычислите прирост для следующего месяца; распечатайте новые значения баланса
вкладчиков.
10.9. Создайте класс IntegerSet, каждый объект которого может содержать
множество целых чисел в диапазоне от 0 до 100. Внутренним представлением множества
является массив из единиц и нулей. Элемент массива а[ i ] содержит 1, если i
входит в множество, в противном случае а[ i ] ссодержит 0. Конструктор по
умолчанию инициализирует множество т. н. «пустым множеством», т.е.
множеством, представление-массив которого содержит одни нули.
Предусмотрите элемент-функции для обычных действий с множествами.
Например, определите элемент-функцию unionOfSets, которая создает новое
множество, являющееся теоретико-множественным объединением двух существующих
690
Глава 10
множеств (т.е. элемент массива нового множества устанавливается в 1, если этот
элемент равен 1 в любом или в обоих исходных множествах, и элемент массива
нового множества устанавливается в 0, если этот элемент равен 0 в обоих
исходных множествах).
Определите элемент-функцию intersectionOfSets, которая создает новое
множество, являющееся теоретико-множественным пересечением двух существующих
множеств (т.е. элемент массива нового множества устанавливается в 0, если этот
элемент равен 0 в любом или в обоих исходных множествах, и элемент массива
нового множества устанавливается в 1, если этот элемент равен 1 в обоих
исходных множествах).
Предусмотрите элемент-функцию insertElement, которая помещает в множество
целое число k (устанавливая а[ к ] в 1). Предусмотрите элемент-функцию
deleteElement, которая удаляет из множества целое число т (устанавливая
а[ m ] в 0).
Предусмотрите элемент-функцию printSet, печатающую множество в виде
списка чисел, разделенных пробелами. Печатайте только числа, присутствующие
в множестве (т.е. позиции которых в массиве содержат 1). Для пустого
множества печатайте
Предусмотрите элемент-функцию isEqualTo, определяющую, равны ли два
множества.
Предусмотрите дополнительный конструктор, принимающий целый массив
и размер этого массива, и использует полученный маассив для инициализации
объекта-множества.
Напишите программу-драйвер для тестирования вашего класса IntegerSet.
Создайте несколько объектов IntegerSet. Проверьте, что все ваши элемент-функции
работают правильно.
10.10. Для класса Time из рис. 10.18-10.19 было бы вполне разумным внутреннее
представление времени в виде числа секунд, прошедших с полуночи, а не трех
целых значений hour, minute и second. Клиенты могли бы вызывать те же
самые открытые методы, получая те же результаты. Модифицируйте класс Time
из рис. 10.18 так, чтобы он представлял время числом секунд от полуночи, и
покажите, что для клиентов класса его функциональные свойства не претерпели
видимых изменений. [Замечание. Этот пример прекрасно демонстрирует
достоинства сокрытия реализации.]
11
Перегрузка операций;
объекты Array и String
ЦЕЛИ
В этой главе вы изучите: ! I
• Что такое перегрузка операций !
и каким образом она делает | \
программы более ясными,
а программирование более удобным.
• Переопределение (перегрузку)
операций для работы с объектами
определяемых пользователем
классов.
• Отличия в перегрузке одноместных
и двухместных операций.
• Как преобразуются объекты одного
класса в объекты другого класса.
• Когда следует и когда не следует
перегружать операции.
• Создание классов PhoneNumber, Array, String и Date, демонстрирующих
перегрузку операций.
• Использование перегруженных операций и других элемент-функций
класса string стандартной библиотеки.
• Применение ключевого слова explicit, запрещающего использование
конструкторов с одним аргументом для неявных преобразований.
692
Глава 11
11.1. Введение
11.2. Основы перегрузки операций
11.3. Ограничения на перегрузку операций
11.4. Функции-операции как элементы класса и как
глобальные функции
11.5. Перегрузка операций передачи в поток и извлечения
из потока
11.6. Перегрузка одноместных операций
11.7. Перегрузка двухместных операций
11.8. Пример: класс Array
11.9. Преобразование типов
11.10. Пример: класс String
11.11. Перегрузка ++ и --
11.12. Пример: класс Date
11.13. Класс string стандартной библиотеки
11.14. explicit-конструкторы
11.15. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
11.1. Введение
В главах 9-10 были представлены основы классов C++. Получение услуг
класса осуществлялись посредством посылки объектам сообщений (в форме
вызова элемент-функций). Для определенных категорий классов (например,
математических) нотация вызова функций неудобна. Кроме того, многие
распространенные действия (например, ввод и вывод) выполняются с помощью
операций. Чтобы манипулировать объектами, мы можем использовать
широкий набор встроенных операций C++. В этом разделе мы покажем, как
разрешить операциям C++ работать с объектами класса, — эта методика
называется перегрузкой операций и является прямым и естественным путем
расширения C++, но ее следует применять с осторожностью.
Примером перегруженной операции, встроенной в C++, является «,
которая используется и как операция передачи в поток, и как операция сдвига
влево. Операция » также перегружена; она используется и как операция
извлечения из потока, и как операция правого сдвига. [Замечание. Операции
поразрядного левого сдвига и поразрядного правого сдвига подробно
обсуждаются в 21-й главе.] Обе эти операции перегружаются в стандартной
библиотеке C++.
Перегрузка операций; объекты Array и String
693
Хотя перегрузка операций может на первый взгляд показаться чем-то
экзотическим, многие программисты все время неявно пользуются
перегруженными операциями. Например, сам язык C++ перегружает операции сложения (+)
и вычитания (-). Эти операции работают по-разному в зависимости от
контекста — в целой арифметике, арифметике с плавающей точкой и арифметике
указателей.
C++ позволяет программисту перегружать большинство операций, делая
их зависимыми от контекста, в котором они применяются, — компилятор
генерирует соответствующий код, исходя из способа применения (например,
типа операндов). Некоторые операции перегружаются достаточно часто,
особенно операции присваивания и различные арифметические операции, такие,
как + и —. Действия, выполняемые перегруженными операциями, могут
выполняться и посредством явных вызовов функций, но нотация операций, как
правило, яснее и привычнее для программистов.
Мы обсудим случаи, когда целесообразно перегружать операции и когда
этого делать не следует. Мы реализуем определяемые пользователем классы
PhoneNumber, Array, String и Date, чтобы продемонстрировать, как
перегружаются операции, в том числе операции передачи в поток, извлечения из
потока, присваивания, равенства, отношений, индексации, логического
отрицания, круглых скобок и инкремента. Глава заканчивается примером,
демонстрирующим библиотечный класс string, в котором много перегруженных
операций, сходных с операциями нашего класса String, рассматриваемого
в главе ранее. В упражнениях от вас потребуется реализовать несколько клас
сов с перегруженными операциями. В упражнениях используются также
классы Complex (для комплексных чисел) и Hugelnt (для целых чисел
больших, чем могут быть представлены типом long), чтобы продемонстрировать
перегрузку арифметических операций + и —. Мы попросим вас
усовершенствовать эти классы, перегрузив другие арифметические операции.
11.2. Основы перегрузки операций
Программирование на C++ является процессом, чувствительным к типу
и ориентированным на типы. Программист может использовать встроенные
типы и может определять новые. Встроенные типы могут использоваться
с широким набором операций C++. Операции дают программистам сжатую
нотацию манипуляций с объектами встроенных типов.
Программист также может использовать операции с типами,
определенными пользователем. Хотя C++ не позволяет создавать новые операции, он
позволяет перегружать уже существующие, так что когда операции
применяются к объектам класса, они приобретают смысл, соответствующий новым
типам. Это одна из самых сильных сторон C++.
S Общее методическое замечание 11.1
Перегрузка операций является одним из аспектов расширяемости
C++ и одной из наиболее привлекательных особенностей языка.
694
Глава 11
Хороший стиль программирования 11.1
Перегружайте операции, когда это помогает сделать программу
яснее, чем при выполнении тех же действий посредством явного вызова
функций.
Хороший стиль программирования 11,2
Перегруженные операции по своей семантике должны как-то
соответствовать своим встроенным эквивалентам, — например,
операция + должна перегружаться для выполнения сложения, а не
вычитания. Избегайте избыточной или непоследовательной перегрузки
операций, так как это может сделать программу загадочной и трудной
для чтения.
Операции перегружаются посредством написания обычного определения
не-статической элемент-функции или глобальной функции, за исключением
того, что именем функции должно быть ключевое слово operator с
последующим символом перегружаемой операции. Например, имя функции operatorH-
служило бы для перегрузки операции сложения. Когда операции
перегружаются как элемент-функции, они должны быть не-статическими, поскольку
должны вызываться для объекта класса и действовать на этом объекте.
Чтобы применять операцию к объектам класса, она должна быть
перегружена, но здесь есть три исключения. Операция присваивания (=) может
использоваться с любым классом для выполнения поэлементного присваивания
элементов данных класса, — каждый элемент данных «объекта-источника»
присваивается соответствующему элементу «объекта-приемника» операции.
Далее мы увидим, что такое поэлементное присваивание, генерируемое по
умолчанию, представляет опасность для классов с элементами-указателями;
для таких классов мы будем явным образом перегружать операцию
присваивания. Операция адреса (&) и операция-запятая (,) также могут использоваться
с объектами любого класса без перегрузки. Операция & возвращает адрес
объекта в памяти. Операция-запятая оценивает сначала выражение слева от себя,
затем выражение справа. Обе эти операции могут быть перегружены.
Перегрузка особенно подходит для математических классов. Они часто
требуют перегрузки большого перечня операций, чтобы сохранялась
согласованность со способом обработки математических объектов, которые существуют
в реальной жизни. Например, было бы странно перегружать для класса
комплексных чисел только операцию сложения, поскольку другие
арифметические операции над комплексными числами производятся не менее часто.
Перегрузка операций позволяет достигнуть той же лаконичной и
привычной формы выражений, которую C++ обеспечивает для встроенных типов за
счет богатого набора операций. Перегрузка операций не является
автоматическим процессом, и для выполнения нужной процедуры программист должен
написать перегружающую операцию функцию. Иногда эту роль лучше
выполняют элемент-функции, иногда дружественные функции; в отдельных
случаях эту роль могут выполнять глобальные функции, не являющиеся друзьями.
Далее в главе мы обсуждаем все эти вопросы.
Перегрузка операций; объекты Array и String
695
11.3. Ограничения на перегрузку операций
Большая часть операций C++ может быть перегружена. Эти операции
приведены на рис. 11.1. На рис. 11.2 приведены операции, которые
перегружаться не могут.
Типичная ошибка программирования 11,1
Попытка перегрузить неперегружаемую операцию является
синтаксической ошибкой.
Операции, которые могут быть перегружены
+
~
/=
<=
--
new[]
-
!
%=
==
->*
•
=
Л_
1 =
1
delete[]
/
<
& =
<=
~>
%
>
1 =
>=
[]
А
+=
<
&&
0
&
-=
>
11
new
1
*=
>=
++
delete
Рис. 11.1. Операции, которые могут быть перегружены
Операции, которые не могут быть перегружены
sizeof
Рис. 11.2. Операции, которые не могут быть перегружены
Приоритет, ассоциативность и число операндов
Приоритет (старшинство) операций не может быть изменен посредством
перегрузки. Это может приводить к неудобным ситуациям, когда операция
перегружается так, что ее фиксированный приоритет плохо соответствует смыслу
выполняемых действий. Однако всегда имеется возможность использовать
скобки для определения порядка оценки перегруженных операций в
выражении.
Ассоциативность операций (т.е. то, выполняются ли последовательные
операции слева направо или справа налево) также не может быть изменена
посредством перегрузки.
Нельзя изменить и «мощность» операции, т.е. число операндов, которое
подразумевает операция. Одноместная (унарная) операция остается
одноместной и при перегрузке, а двухместная (бинарная) остается двухместной.
Единственная трехместная операция C++, условная (?:), не может быть
перегружена. Каждая из операций &, *, + и — имеет одноместную и двухместную формы,
которые могут перегружаться раздельно.
696
Глава 11
Типичная ошибка программирования 11.2
Попытка изменить посредством перегрузки число операндов операции
приводит к ошибке компиляции.
Создание новых операций
Новую операцию создать нельзя; перегружаться могут только
существующие операции. К сожалению, это не дает возможности программисту
использовать распространенные нотации, такие, как операция **, означающая в
некоторых языках возведение в степень. [Замечание. Для возведения в степень
вы можете перегрузить операцию ", которая также используется для этой цели
в некоторых языках.]
Типичная ошибка программирования 11.3
Попытка создать новую операцию путем перегрузки является
синтаксической ошибкой.
Операции для основных типов
Нельзя изменить способ воздействия операции на объекты основных типов.
Например, программист не может изменить способ сложения операцией +
двух целых. Перегрузка операций работает только с объектами, тип которых
определен пользователем, или в смешанных ситуациях, когда объект
пользовательского типа участвует в операции вместе с объектом основного типа.
Общее методическое замечание 11.2
Хотя бы один аргумент функции-операции должен быть объектом
или ссылкой определенного пользователем типа. Это делает
невозможной попытку изменения способа воздействия операции на объек
ты основных типов.
ъг?%£\ Типичная ошибка программирования 11.4
Попытка модифицировать способ работы операции с объектами
встроенных типов является ошибкой компиляции.
Родственные операции
Перегрузка для класса операций присваивания и сложения с целью
разрешить операторы вроде
object2 = object2 + objectl;
не означает, что автоматически будет перегружена операция +=, чтобы
выполнялся такой оператор, как
object2 += objectl;
Такое поведение может быть достигнуто только посредством явной перегрузки
операции += для этого класса.
Перегрузка операций; объекты Array и String
697
Типичная ошибка программирования 11.5
Предположение, что перегрузка операций вроде + автоматически
перегружает операции присваивания, такие как +=, или что перегрузка
== перегружает родственную операцию, такую как /=. Операции
могут быть перегружены только явным образом; неявной перегрузки не
происходит.
11.4. Функции-операции как элементы класса
и как глобальные функции
Функции-операции могут быть элементами класса или глобальными
функциями; функции — не элементы обычно делают друзьями из соображений
эффективности. Элемент-функции используют неявный указатель this, чтобы
получить один из аргументов-объектов своего класса (левый операнд у
двухместных операций). При вызове глобальной функции должны быть явным
образом указаны оба операнда двухместной операции.
Операции, которые должны перегружаться элемент-функциями
При перегрузке операций (), [], —> или любой операции присваивания
функция, перегружающая операцию, должна быть объявлена элементом
класса. Для других операций перегружающая функция может быть как элементом
класса, так и глобальной функцией.
Операции как элемент-функции и как глобальные функции
Независимо от того, объявляется ли функция-операция как
элемент-функция или как глобальная функция, в выражении операция используется
одинаковым образом. Так какой же вариант лучше?
Когда функция-операция реализуется как элемент, левый (или
единственный) операнд должен быть объектом (или ссылкой на объект),
принадлежащим классу этой операции. Если необходимо, чтобы левый операнд был
объектом другого класса или объектом основного типа, эта функция-операция
должна объявляться как функция, не являющаяся элементом класса (как мы
сделаем в разделе 11.5, где перегружаются « и » в качестве операций
передачи и извлечения из потока). Глобальная функция-операция может быть
сделана другом, если она должна иметь непосредственный доступ к закрытым
или защищенным элементам класса.
Функции-операции, являющиеся элементами некоторого класса,
вызываются (неявно компилятором) только когда левый операнд двухместной
операции является объектом данного конкретного класса, либо когда единственный
операнд одноместной операции является объектом этого класса.
Почему операции передачи в поток и извлечения из потока
перегружаются как глобальные функции
Перегруженная операция передачи в поток («) используется в
выражениях, где левый операнд имеет тип ostream &, как выражении cout «
classObject. Чтобы можно было записывать операцию таким образом, когда
правый операнд является объектом определенного пользователем класса, она
698
Глава 11
должна перегружаться как глобальная функция. Элемент-функция для
операции « должна была бы быть элементом класса ostream. Это невозможно, так
как нам не позволяется модифицировать классы стандартной библиотеки
C++. Аналогично операция извлечения из потока (») имеет в качестве левого
операнда тип istream &, как в выражении cin » classObject, и если правый
операнд является объектом определенного пользователем класса, она также
должна быть глобальной функцией. Кроме того, каждая из этих
перегружающих операции функций может потребовать доступа к закрытым элементам
данных объектов, которые должны выводиться или вводиться, так что эти
функции делаются обычно дружественными функциями класса по
соображениям эффективности.
■——| Вопросы производительности 11.1
р^Ф*| Операцию можно перегрузить как функцию, не являющуюся
элементом или дружественной функцией, но, если такой функции
требуется доступ к закрытым или защищенным данным класса, то ей
придется обращаться к get- или set-функциям его открытого интерфейса.
Издержки вызовов этих функций могут привести к потере
эффективности, так что их целесообразно реализовать как встроенные.
Коммутативные операции
Другая причина, по которой для перегрузки операции можно выбрать
функцию, не являющуюся элементом, — требование коммутативности
операции. Например, у нас есть объект number типа long int и объект biglntegerl,
принадлежащий к классу Hugelnteger (класс, в котором целые могут быть
произвольно большими вне зависимости от ограничений разрядности
аппаратной части; класс Hugelnteger разрабатывается в разделе упражнений).
Операция сложения (+) генерирует временный объект Hugelnteger как сумму
Hugelnteger и long int (как в выражении biglntegerl + number), или как
сумму long int и Hugelnteger (как в number + biglntegerl). Таким образом, мы
требуем, чтобы операция сложения была коммутативна (в точности как
обычно). Проблема состоит в том, что объект класса должен стоять в левой части
суммы, если операция перегружена как элемент-функция. Таким образом,
чтобы разрешить Hugelnteger находиться в правой части суммы, мы
перегружаем операцию как друга. Функция operator+, которая обрабатывает
Hugelnteger с левой стороны, может оставаться элемент-функцией.
11.5. Перегрузка операций передачи в поток
и извлечения из потока
В C++ можно вводить и выводить стандартные типы данных с помощью
операций извлечения из потока » и передачи в поток «. Эти операции
перегружаются библиотеками классов, поставляемых с компиляторами C++, для
обработки всех основных типов данных, включая указатели и строки char *
в стиле С. Кроме того, операции передачи и извлечения из потока могут быть
перегружены, чтобы выполнять ввод и вывод типов, определяемых
пользователем. На рис. 11.3-11.5 показана перегрузка операций передачи и
извлечения из потока, позволяющая им обрабатывать данные определенного пользо-
Перегрузка операций; объекты Array и String
699
вателем класса телефонного номера PhoneNumber. Предполагается, что
телефонные номера вводятся корректно.
1 // Рис. 11.3: PhoneNumber.h
2 // Определение класса PhoneNumber
3 #ifndef PHONENUMBER_H
4 #define PHONENUMBERJi
5
6 #include <iostream>
7 using std::ostream;
8 using std::istream;
9
10 #include <string>
11 using std::string;
12
13 class PhoneNumber
14 {
15 friend ostream &operator«( оstream &, const PhoneNumber & );
16 friend istream &operator»( istream &, PhoneNumber & ) ;
17 private:
18 string areaCode; // 3 цифры регионального кода
19 string exchange; // 3 цифры кода АТС
20 string line; // 4 цифры номера линии
21 }; // конец класса PhoneNumber
22
23 #endif
Рис. 11.3. Класс PhoneNumber с перегруженными операциями передачи/
извлечения из потока
1 // Рис. 11.4: PhoneNumber.срр
2 // Перегруженные операции извлечения и передачи в поток
3 // для класса PhoneNumber.
4 #include <iomanip>
5 using std::setw;
6
7 #include "PhoneNumber.h"
8
9 // перегруженная операция передачи в поток; не может быть
10 // элементом класса, если мы хотим применять ее в форме
11 // cout « somePhoneNumber;
12 ostream &operatoг«( ostream &output, const PhoneNumber &number )
13 {
14 output « "(" « number.areaCode « ") "
15 « number.exchange « "-" « number.line;
16 return output; // допускает форму cout « a « b « c;
17 } // конец функции operator«
18
19 // перегруженная операция извлечения из потока; не может быть
20 // элементом класса, если мы хотим применять ее в форме
21 // cin » somePhoneNumber;
22 istream &operator»( istream & input, PhoneNumber & number )
23 {
24 input.ignore(); // пропустить (
700
Глава 11
25 input » setw( 3 ) » number.areaCode; // ввести код региона
26 input.ignore( 2 ); // пропустить ) и пробел
27 input » setw( 3 ) » number.exchange; // ввести код АТС
28 input.ignore(); // пропустить дефис (-)
29 input » setw( 4 ) » number.line; // ввести номер линии
30 return input; // допускает форму cin » a » b » c;
31 } // конец функции operator»
Рис. 11.4. Перегруженные операции извлечения и передачи в поток для класса
PhoneNumber
1 // Рис. 11.5: figll_05.cpp
2 // Демонстрация перегруженных операций извлечения и передачи
3 //в поток для класса PhoneNumber.
4 #include <iostream>
5 using std:icout;
6 using std::cin;
7 using std::endl;
8
9 #include "PhoneNumber.h"
10
11 int main()
12 {
13 PhoneNumber phone; // создать объект phone
14
15 cout « "Enter phone number in the form A23) 456-7890:" « endl;
16
17 // cin » phone вызывает operator», неявно генерируя
18 // вызов глобальной функции operator»( cin, phone )
19 cin » phone;
20
21 cout « "The phone number entered was: ";
22
23 // cout « phone вызывает operator«, неявно генерируя
24 // вызов глобальной функции opera to r«( cout, phone )
25 cout « phone « endl;
26 return 0;
27 } // конец main
Enter phone number in the form A23) 456-7890:
(800) 555-1212
The phone number entered was: (800) 555-1212
Рис. 11.5. Перегруженные операции извлечения и передачи в поток
Функция-операция извлечения из потока operator» (рис. 11.4,
строки 22-31) принимает в качестве аргументов ссылку на istream с именем input
и ссылку на PhoneNumber с именем num, возвращая ссылку на istream.
Функция-операция operator» используется для ввода телефонного номера
в формате
(800) 555-1212
в объект класса PhoneNumber. Когда компилятор встречает в main выражение
Перегрузка операций; объекты Array и String
701
cin » phone
он генерирует вызов функции
operator»( cin, phone ) ;
Когда выполняется этот вызов, параметр input (рис. 11.4, строка 22)
становится псевдонимом для cin, а параметр num становится псевдонимом для phone.
Функция-операция читает три части телефонного номера в качестве строк
в элементы areaCode (строка 25), exchange (строка 27) и line (строка 29)
объекта PhoneNumber, на который ссылается параметр num. Манипулятор
потока setw ограничивает число символов, читаемых в каждый из массивов.
В применении к cin и типу string этот манипулятор ограничивает число
прочитанных символов значением своего аргумента (т.е. setw( 3 ) позволяет
прочитать три символа). Символы скобок, пробела и дефиса пропускаются
вызовом элемент-функции ignore класса istream (рис. 11.4, строки 24, 26 и 28),
которая отбрасывает заданное число символов во входном потоке (по умолчанию
один символ). Функция operator» возвращает input (т.е. cin) как ссылку на
istream. Это разрешает каскадирование операций ввода объектов
PhoneNumber с вводом других объектов PhoneNumber или объектов других типов.
Например, два объекта PhoneNumber могут вводиться следующим образом:
cin » phonel » phone2
Сначала выполняется выражение cin » phonel посредством вызова функции
operator»( cin, phonel ) ;
Этот вызов возвращает cin как значение выражения cin » phonel, так что
оставшаяся часть выражения интерпретировалась бы просто как cin » phone2.
Это выражение исполнялось бы как вызов
operator»( cin, phone2 ) ;
Операция передачи в поток (рис. 11.4, строки 12-17) принимает в качестве
аргументов ссылку (output) на osrteam и константную ссылку (num) на
PhoneNumber, возвращая ссылку на ostream. Функция operator« выводит
объекты типа PhoneNumber. Когда компилятор встречает в строке 25 на рис. 11.5
выражение
cout « phone
он генерирует вызов функции
opera tor« (cout, phone);
Функция operator« выводит части телефонного номера как стандартные
строки, поскольку они хранятся в объектах string.
Обратите внимание, что функции operator» и operator« объявляются
в классе PhoneNumber в качестве глобальных дружественных функций
(рис. 11.3, строки 15-16). Это глобальные функции, так как объекты класса
PhoneNumber всегда появляются в операции в качестве правого операнда. Как
вы помните, перегружать операцию как элемент-функцию можно только то-
702
Глава 11
гда, когда операнд в левой части операции является объектом класса, в
который входит функция. Перегруженные операции ввода и вывода, если им
необходимо иметь прямой доступ к элементам класса, не объявленным как public
(по соображениям эффективности или потому, что в классе не предусмотрены
соответствующие get -функции), должны объявляться как друзья. Также
заметьте, что ссылка на PhoneNumber в списке параметров operator«
(рис. 11.3, строка 12) является const, поскольку объект PhoneNumber просто
выводится, а ссылка на PhoneNumber в списке параметров operator»
(строка 22) константной не является, так как объект PhoneNumber при записи
в него телефонного номера должен быть модифицирован.
Ш Общее методическое замечание 11.3
Новые возможности ввода/вывода типов, определяемых
пользователем, могут быть введены в C++ без модификации классов
стандартной библиотеки. Это еще один пример расширяемости языка C++.
11.6. Перегрузка одноместных операций
Одноместная (унарная) операция для класса может быть перегружена как
не-статическая элемент-функция без аргументов или как глобальная функция
с одним аргументом. Этот аргумент должен быть либо объектом класса, либо
ссылкой на него. Элемент-функции, реализующие перегруженные операции,
не могут быть статическими, так как им требуется обращаться к не-статиче-
ским данным класса. Как вы помните, статические элемент-функции могут
обращаться только к статическим элементам класса.
Позднее в этой главе мы перегрузим одноместную операцию !, которая
будет проверять, является ли пустым объект определяемого нами класса String
(раздел 11.10), и возвращать результат типа bool. Рассмотрим выражение !s,
где s — объект типа String. Когда одноместная операция, такая, как !,
перегружается элемент-функцией без аргументов, и компилятор встречает
выражение !s, он генерирует вызов s.operator!(). Операнд s является объектом
класса, для которого вызывается функция-элемент operator! класса String.
Функция объявляется в определении класса следующим образом:
class String {
public:
bool operator!() const;
}; // конец класса String
Одноместная операция, такая, как !, может быть перегружена как
глобальная функция с одним аргументом двумя различными способами: либо с
аргументом, являющимся объектом (это требует копии объекта, чтобы побочные
эффекты функции не отражались на исходном объекте), либо с аргументом,
который ссылается на объект (копии объекта не делается, так что все
побочные эффекты функции воздействуют на исходный объект). Если s является
объектом класса String (или ссылкой на объект класса String), то !s
воспринимается точно так же, как выражение operator!( s ), вызывающее глобальную
элемент-функцию, объявленную как
bool operator!( const String & );
Перегрузка операций; объекты Array и String
703
11.7. Перегрузка двухместных операций
Двухместная операция может быть перегружена как не-статическая
элемент-функция с одним аргументом или как глобальная функция с двумя
аргументами (один из которых должен быть либо объектом класса, либо ссылкой
на объект класса).
Позднее в этой главе мы перегрузим операцию < для сравнения двух
объектов класса String. При перегрузке двухместной операции < элемент-функцией
класса String с одним аргументом, если у и z являются объектами класса, то
выражение у < z воспринимается точно так же, как выражение y.operator<( z ),
вызывающее элемент-функцию operator<, объявленную как
class String {
public:
bool operator<( const String & ) const;
}; // конец класса String
Если двухместная операция < перегружается как глобальная функция, она
должна принимать два аргумента, один из которых должен быть объект
класса или ссылкой на объект. Если у и z являются объектами класса String, то у <
z воспринимается точно так же, как выражение operator<( у, z ), вызывающее
элемент-функцию operator<, объявленную как
bool operator<( const String &, const String & );
11.8. Пример: класс Array
С массивами-указателями возникает немало проблем.. Например,
программа может просто «проскочить» границу массива, поскольку C++ не проверяет,
не вышел ли индекс за допустимые пределы (программист, тем не менее,
может делать это явным образом). В массиве размера п элементы должны
нумероваться следующим образом: 0, ..., п—1; альтернативные пределы
индексации не разрешены. За один раз нельзя ввести или вывести массив в целом,
если он не символьный; каждый элемент должен считываться и записываться
индивидуально. Два массива нельзя осмысленно сравнивать операциями
равенства или отношения (так как имена массивов являются просто
указателями на начало массива в памяти). Когда массив передается функции общего
назначения, предназначенной для обработки массивов любого размера, размер
массива должен быть передан в качестве дополнительного аргумента. Один
массив не может быть присвоен другому массиву операцией присваивания
(так как имена массивов являются константными указателями, а такой
указатель не может стоять в левой части присваивания). Подобные свойства и
действия выглядели бы «естественно» при работе с массивами, но в C++ они не
предусмотрены. Однако в C++ имеется возможность реализовать подобные
свойства массивов посредством механизма перегрузки операций.
В этом примере мы разработаем мощный класс Array, который выполняет
проверку индексации, чтобы убедиться, что индекс остается в заданных
границах. Этот класс позволяет использовать операцию присваивания для
присваивания одного объекта-массива другому. Объекты класса Array
автоматически знают свой размер, поэтому нет необходимости передавать его в качест-
704
Глава 11
ве аргумента при передаче массива функции. Весь массив в целом может быть
введен или выведен при помощи операций извлечения из потока и операции
передачи в поток. Сравнение массивов может осуществляться при помощи
операций == или !=.
Этот пример позволит вам лучше почувствовать значение абстракции данных.
Вероятно, вы сможете предложить много усовершенствований этого класса
массивов. Разработка класса — интересная, творческая и апеллирующая к
интеллекту деятельность, имеющая своей целью «изготовление ценных классов».
Программа на рис. 11.6-11.8 демонстрирует класс Array и его
перегруженные операции. Сначала мы пройдем по программе-тестеру main (рис. 11.8).
Затем мы рассмотрим определение класса (рис. 11.6) и определения каждой его
элемент-функций и дружественных функций (рис. 11.7).
1 // Рис. 11.6: Array.h
2 // Класс массива для хранения целых чисел.
3 #ifndef ARRAY_H
4 #define ARRAY_H
5
6 #include <iostream>
7 using std::ostream;
8 using std::istream;
9
10 class Array
11 {
12 friend о stream &operator«( ostream &, const Array & );
13 friend istream &operator»( istream &, Array & ) ;
14 public:
15 Array( int = 10 ); // конструктор по умолчанию
16 Array( const Array & ); // конструктор копии
17 ~Array(); // деструктор
18 int getSize() const; // возвратить размер
19
20 const Array &operator=( const Array & ); // операция присваивания
21 bool operator=( const Array & ) const; // операция равенства
22
23 // операция неравенства; результат противоположен операции ==
24 bool operator!=( const Array firight ) const
25 {
26 return ! ( *this = right ); // вызывает Array::operator==
27 } // конец функции operator!=
28
29 // индексация для неконстантных объектов возвращает lvalue
30 int &operator[]( int );
31
32 // индексация для константных объектов возвращает rvalue
33 int operator[]( int ) const;
34 private:
35 int size; // размер массива, заданного указателем
36 int *ptr; // указатель на первый элемент массива
37 }; // конец класса Array
38
39 #endif
Рис, 11,6. Класс Array с перегруженными операциями
Перегрузка операций; объекты Array и String
705
1 // Рис 11.7: Array.срр
2 // Определения элемент-функций для класса Array
3 #include <iostream>
4 using std::cerr;
5 using std::cout;
6 using std::cin;
7 using std::endl;
8
9 #include <iomanip>
10 using std::setw;
11
12 #include <cstdlib> // прототип функции exit
13 using std::exit;
14
15 #include "Array.h" // определение класса Array
16
17 // конструктор Array по умолчанию (размер по умолчанию 10)
18 Array::Array( int arraySize )
19 {
20 size = ( arraySize > 0 ? arraySize : 10 ) ; // проверить arraySize
21 ptr = new int[ size ]; // выделить пространство для массива
22
23 for ( int i = 0; i < size; i++ )
24 ptr[ i ] =0; // установить элемент массива-указателя
25 } // конец конструктора Array по умолчанию
26
27 // конструктор копии для класса Array;
28 // для предотвращения бесконечной рекурсии должен возвращать ссылку
29 Array::Array( const Array fiarrayToCopy )
30 : size( arrayToCopy.size )
31 {
32 ptr = new int[ size ] ; // выделить пространство для массива
33
34 for ( int i = 0; i < size; i++ )
35 ptr[ i ] = arrayToCopy.ptr[ i ]; // копировать в объект
36 } // конец конструктора копии Array
37
38 // деструктор для класса Array
3 9 Array::-Array()
40 {
41 delete [] ptr; // освободить пространство массива
42 } // конец деструктора
43
44 // возвратить число элементов Array
45 int Array::getSize() const
46 {
47 return size; // число элементов в Array
48 } // конец функции getSize
49
50 // перегруженная операция присваивания;
51 // возвращаемая константа предотвращает: ( al = а2 ) = аЗ
52 const Array & Array::operator=( const Array &right )
53 {
54 if ( firight != this ) // избегать самоприсваивания
55 {
56 // для массивов разного размера освободить исходный массив
23 Зак. 1114
706
Глава 11
57 //в левой части, затем выделить новый массив для левой части
58 if ( size != right.size )
59 {
60 delete [] ptr; // освободить пространство
61 size = right.size; // переустановить размер этого объекта
62 ptr = new int[ size ]; // создать пространство для копии
63 } // конец внутреннего if
64
65 for ( int i = 0; i < size; i++ )
66 ptr[ i ] = right.ptr[ i ]; // копировать массив в объект
67 } // конец внешнего if
68
69 return *this; // позволяет писать, например, х = у = z
70 } // конец функции operator=
71
72 // определить, равны ли два массива, если равны,
73 // возвратить true, в противном случае возвратить false
74 bool Array::operator==( const Array bright ) const
75 {
76 if ( size != right.size )
77 return false; // массивы с различным числом элементов
78
79 for ( int i = 0; i < size; i++ )
80 if ( ptr[ i ] != right.ptr[ i ] )
81 return false; // содержимое массивов различно
82
83 return true; // массивы равны
84 } // конец функции operator=
85
86 // перегруженная операция индексации для неконстантных массивов;
87 // возврат ссылки создает модифицируемое lvalue
88 int &Array::operator[]( int subscript )
89 {
90 // проверить индекс на выход за пределы массива
91 if ( subscript < 0 || subscript >= size )
92 {
93 cerr « M\nError: Subscript " « subscript
94 « " out of range" « endl;
95 exit( 1 ); // завершить программу; индекс вне диапазона
96 } // конец if
97
98 return ptr[ subscript ]; // возврат ссылки
99 } // конец функции operator[]
100
101 // перегруженная операция индексации для константных массивов;
102 // возврат константной ссылки создает rvalue
103 int Array::operator[]( int subscript ) const
104 {
105 // проверить индекс на выход за пределы массива
106 if ( subscript < 0 || subscript >= size )
107 {
108 cerr « "\nError: Subscript " « subscript
109 « " out of range" « endl;
110 exit( 1 ); // завершить программу; индекс вне диапазона
111 } // конец if
112
113 return ptr[ subscript ]; // возвращает копию элемента
Перегрузка операций; объекты Array и String
707
114 } // конец функции operator[]
115
116 // перегруженная операция ввода для класса Array;
117 // вводит значения для всего массива
118 istream &operator»( istream fiinput, Array &a )
119 {
120 for ( int i = 0; i < a.size; i++ )
121 input » a.ptr[ i ];
122
123 return input; // enables cin » x » y;
124 } // конец функции operator»
125
126 // перегруженная операция вывода для класса Array
127 ostream &operator«( ostream fioutput, const Array &a )
128 {
129 int i;
130
131 // вывести закрытый массив, адресуемый указателем
132 for ( i = 0; i < a.size; i++ )
133 {
134 output « setw( 12 ) « a.ptr[ i ];
135
136 if ( ( i + 1 ) % 4 = 0 ) // no 4 числа в строке вывода
137 output « endl;
138 } // конец for
139
140 if ( i % 4 != 0 ) // закончить последнюю строку вывода
141 output « endl;
142
143 return output; // позволяет писать cout « x « y;
144 } // конец функции operator«
Рис. 11.7. Определения элемент-функций и друзей класса Array
1 // Рис. 11.8: figll_08.cpp
2 // Тестовая программа для класса Array.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 #include "Array.h"
9
10 int main()
11 {
12 Array integers1( 7 ); // 7-элементный Array
13 Array integers2; // 10-элементный Array по умолчанию
14
15 // напечатать размер и содержимое integers1
16 cout « "Size of Array integersl is "
17 « integersl.getSize()
18 « "\nArray after initialization:\n" « integersl;
19
20 // напечатать размер и содержимое integers2
21 cout « "\nSize of Array integers2 is "
708
Глава 11
22 « integers2.getSize()
23 « M\nArray after initialization:\n" « integers2;
24
25 // ввести и напечатать integersl и integers2
26 cout « "\nEnter 17 integers:" « endl;
27 cin » integersl » integers2;
28
29 cout « "\nAfter input, the Arrays contain:\n"
30 « "integersl:\n" « integersl
31 « "integers2:\n" « integers2;
32
33 // применить перегруженную операцию неравенства (!=)
34 cout « "\nEvaluating: integersl != integers2" « endl;
35
36 if ( integersl != integers2 )
37 cout « "integersl and integers2 are not equal" « endl;
38
39 // создать массив integers3, используя как инициализатор
40 // integersl; напечатать размер и содержимое
41 Array integers3( integersl ); // вызывает конструктор копии
42
43 cout « "\nSize of Array integers3 is "
44 « integers3.getSize()
45 « "\nArray after initialization:\n" « integers3;
46
47 // применить перегруженную операцию присваивания (=)
48 cout « "\nAssigning integers2 to integersl:" « endl;
49 integersl = integers2; // заметьте, что целевой массив меньше
50
51 cout « "integersl:\n" « integersl
52 « "integers2:\n" « integers2;
53
54 // применить перегруженную операцию равенства (==)
55 cout « v'\nEvaluating: integersl == integers2" « endl;
56
57 if ( integersl == integers2 )
58 cout « "integersl and integers2 are equal" « endl;
59
60 // применить перегруженную операцию индексации, дающую rvalue
61 cout « "\nintegersl[5] is " « integersl[ 5 ];
62
63 // применить перегруженную операцию индексации, дающую lvalue
64 cout « M\n\nAssigning 1000 to integersl[5]" « endl;
65 integersl[ 5 ] = 1000;
66 cout « "integersl:\n" « integersl;
67
68 // попытка использования индекса вне диапазона
69 cout « "\nAttempt to assign 1000 to integersl[15]" « endl;
70 integersl[ 15 ] = 1000; // ОШИБКА: выход за диапазон
71 return 0;
72 } // конец main
Size of Array integersl is 7
Array after initialization:
0 0 0 0
0 0 0
Перегрузка операций; объекты Array и String 709
Size of Array integers2 is 10
Array after initialization:
0 0 0 0
0 0 0 0
0 0
Enter 17 integers:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
After input, the Arrays contain
mtegersl:
1 2
5 6
inteqers2:
8 9
12 13
16 17
Evaluating: integersl != integers2
integersl and integers2 are not equal
Size of Array integers3 is 7
Array after initialization:
12 3 4
5 6 7
Assigning integers2 to integersl
integersl:
8 9
12 13
16 17
integers2:
8 9
12 13
16 17
Evaluating: integersl == integers2
integersl and integers2 are equal
integersl[5] is 13
Assigning 1000 to integersl[5]
integersl:
8 9 10 11
12 1000 14 15
16 17
Attempt to assign 1000 to integersl[15]
Error: Subscript 15 out of range
3 4
7
10 11
14 15
10
14
10
14
11
15
11
15
Рис. 11.8. Тестовая программа для класса Array
710
Глава 11
Создание массивов, вывод их размеров и содержимого
Программа начинает с того, что создает два объекта класса Array —
integersl (рис. 11.8, строка 12) с семью элементами и integers2 (строка 13),
имеющий размер 10 элементов по умолчанию (специфицированный
конструктором Array в строке 15 на рис. 11.6). В строках 16-18 элемент-функция
getSize определяет размер массива integersl и выводится сам массив
посредством перегруженной операции передачи в поток класса Array. Образец
вывода подтверждает, что элементы массива были корректно инициализированы
конструктором нулями. Затем строках 21-23 выводится размер массива
integers2 и перегруженной операцией передачи в поток выводится сам массив.
Применение перегруженной операции извлечения из потока для
заполнения массива
Строка 26 предлагает пользователю ввести 17 целых чисел. Для чтения
этих значений в оба массива в строке 27 используется перегруженная
операция извлечения из потока класса Array. Первые семь значений сохраняются
в integersl, а остальные значения в integers2. Чтобы подтвердить
корректность ввода, два массива выводятся в строках 29-31 перегруженной операцией
передачи в поток класса Array.
Использование перегруженной операции неравенства
Строка 36 тестирует перегруженную операцию неравенства оценкой условия
integersl != integers2
Вывод программы показывает, что два массива действительно не равны.
Инициализация нового массива копией содержимого
существующего массива
Строка 41 создает третий массив с именем integers3 и инициализирует его
массивом integersl. Тем самым вызывается конструктор копии класса Array,
копирующий элементы integersl в integers3. Конструктор копии мы обсудим
чуть позже. Заметьте, что конструктор копии можно было бы вызвать,
написав в строке 41
Array integers3 = integersl;
Знак равенства не является здесь операцией присваивания. Когда знак
равенства появляется в объявлении объекта, он вызывает конструктор для этого
объекта. Такая форма может передавать конструктору только один аргумент.
В строках 43-45 выводится размер массива integers3 и затем
перегруженной операцией передачи в поток выводится сам массив, чтобы подтвердить
корректную инициализацию конструктором элементов массива.
Использование перегруженной операции присваивания
Строка 49 тестирует перегруженную операцию присваивания (=),
присваивая массив integers2 массиву integersl. Строки 51-52 печатают оба массива
для подтверждения успешности присваивания. Заметьте, что integersl
содержит изначально 7 чисел, и требуется изменение размера этого мяг^т^я. хтТобы
Перегрузка операций; объекты Array и String
711
он вместил копию 10 элементов из массива integers2. Как мы увидим,
перегруженная операция присваивания выполняет изменение размера массива
скрытым от вызвавшей операцию программы образом.
Использование перегруженной операции равенства
Затем строка 57 применяет перегруженную операцию равенства (==),
чтобы подтвердить, что объекты integers 1 и integers2 после присваивания
действительно идентичны.
Использование перегруженной операции индексации
Строка 61 использует перегруженную операцию индексации для ссылки на
элемент integersl[ 5 ], находящийся в допустимых пределах индекса integers 1.
Это индексированное имя используется как rvalue для печати значения inte-
gersl[ 5 ]. Строка 65 использует integersl[ 5 ] как модифицируемое lvalue с
левой стороны операции присваивания, чтобы присвоить элементу integerslf 5 ]
новое значение 1000. Обратите внимание, что operator[] возвращает ссылку
для использования ее как lvalue после того, как проверит, что индекс 5
принадлежит допустимому диапазону индексов integers 1.
Строка 70 пытается присвоить значение 1000 элементу integersl[ 15 ],
который находится за пределами массива. В этом примере operator[] определяет,
что индекс выходит из допустимого диапазона, печатает сообщение и
завершает программу. Это логическая ошибка времени выполнения, а не ошибка
компиляции.
Интересно, что операцию индексации [] не запрещено перегружать и для
других целей: она может использоваться для выбора элементов из других
видов контейнерных классов, таких, как связанные списки, строки и словари.
Индексам также не обязательно быть целыми, например, они могут быть
символами, строками, числами с плавающей точкой или даже объектами
определенного пользователем класса. Класс тар стандартной библиотеки C++
допускает не-целые индексы.
Определение класса Array
Теперь, когда мы познакомились с тем, как работает программа, давайте
пройдем по заголовку класса (рис. 11.6). По ходу рассмотрения каждой из
элемент-функций в заголовке мы будем обсуждать реализацию этой функции на
рис. 11.7. Строки 35-36 на рис. 11.16 представляют закрытые элементы
данных класса Array. Каждый объект Array состоит из элемента size,
показывающего число элементов в массиве, указателя на int — ptr, — который ссылается
на динамически выделенный массив целых, поддерживаемый объектом Array.
Перегрузка операций передачи в поток и извлечения из потока
в качестве друзей класса
Строки 12-13 на рис. 11.6 объявляют перегруженные операции передачи
в поток и извлечения из потока как друзей класса Array. Когда компилятор
встречает выражение вроде cout « arrayObject, он вызывает глобальную
функцию operator«, генерируя вызов
operator«( cout, arrayObject )
712
Глава 11
Когда компилятор встречает выражение вроде cin >> arrayObject, он
вызывает глобальную функцию operator», генерируя вызов
operator» ( cin, arrayObject )
Еще раз отметим, что эти функции-операции не могут быть элементами класса
Array, так как объект Array всегда находится с правой стороны операций
передачи и извлечения из потока. Если бы эти функции-операции были
элементами класса Array, для ввода и вывода массива пришлось бы писать
следующие неуклюжие операторы:
arrayObject « cout;
arrayObject » cin;
Такие операторы вводили бы в заблуждение многих программистов, которые
привыкли, что cout и cin стоят слева от операций « и ».
Функция operator« (определяемая в строках 127-144 на рис. 11.7)
выводит определяемое size число элементов из массива, на который указывает ptr.
Функция operator» (определяемая в строках 118-124 на рис. 11.7)
производит ввод непосредственно в массив, на который указывает ptr. Каждая их этих
функций-операций возвращает соответствующую ссылку, чтобы сделать
возможным каскадирование операций ввода и вывода. Заметьте, что каждая из
этих функций имеет доступ к закрытым данным класса Array, так как эти
функции объявлены в классе Array как друзья. Заметьте также, что
operator« и operator» могли бы использовать функции getSize и operator[]
класса Array, и в этом случае их не нужно было бы объявлять друзьями.
Однако дополнительные вызовы функций могли бы привести к издержкам времени
выполнения.
Конструктор Array no умолчанию
Строка 15 на рис. 11.6 объявляет конструктор класса по умолчанию и
специфицирует размер массива по умолчанию A0 элементов). Когда компилятор
встречает такое объявление, как в строке 13 на рис. 11.8, он вызывает
конструктор по умолчанию (не забывайте, что конструктор по умолчанию в этом
примере на самом деле принимает аргумент типа int со значением по
умолчанию, равным 10). Конструктор по умолчанию (определяемый в строках 18-25
на рис. 11.7) проверяет и присваивает аргумент элементу данных size,
использует new для выделения памяти под внутреннее представление массива и
присваивает элементу ptr указатель, возвращаемый new. Затем конструктор
использует цикл for для инициализации всех элементов массива нулями. Можно
было бы определить такой класс Array, который не производит
инициализацию своих элементов, если, например, требуется, чтобы эти элементы считы-
вались позднее. Но это считается плохим стилем программирования.
Массивы, и вообще объекты, должны все время поддерживаться в правильно
инициализированном и согласованном состоянии.
Конструктор копии Array
Строка 16 на рис. 11.6 объявляет конструктор копии (определяемый
в строках 29-36 на рис. 11.7), который инициализирует объект Array
копированием существующего объекта Array. Такое копирование должно выпол-
Перегрузка операций; объекты Array и String
713
няться осторожно, чтобы избежать ситуации с двумя объектами Array,
указывающими на одну и ту же динамически выделенную память. Именно это
произойдет, если разрешить компилятору генерировать конструктор копии по
умолчанию для этого класса. Конструктор копии вызывается всякий раз,
когда понадобится копия объекта, например, при вызове по значению, при
возврате объекта из вызванной функции или при инициализации объекта копией
другого объекта того же класса. Конструктор копии вызывается при
объявлении, когда объект класса Array создается и инициализируется другим
объектом класса Array, как в объявлении в строке 41 на рис. 11.8.
Общее методическое замечание 11.4
Аргумент конструктора копии должен быть константной ссылкой,
чтобы допускать копирование константного объекта.
Типичная ошибка программирования 11.6
Заметьте, что конструктор копии должен получать свой аргумент
по ссылке, а не по значению. В противном случае вызов конструктора
копии приводил бы к бесконечной рекурсии (фатальной логической
ошибке), потому что при передаче по значению должна быть сделана
копия аргумента-объекта, для чего необходим конструктор копии.
Вспомните, что всякий раз, когда необходима копия объекта,
вызывается конструктор копии класса. Если бы конструктор копии получал
аргумент по значению, он рекурсивно вызывал бы самого себя, чтобы
сделать копию своего аргумента!
Конструктор копии для Array использует инициализатор элемента (рис. 11.7,
строка 30) для копирования размера инициализирующего массива в элемент
данных size, выделяет операцией new память для внутреннего представления
этого массива и присваивает элементу ptr указатель, возвращаемый new.1
Затем конструктор копии использует цикл for для копирования всех элементов
массива-инициализатора в новый объект Array. Заметьте, что объект класса
может видеть закрытые данные любого другого объекта этого класса (используя
дескриптор, указывающий, к какому объекту производится доступ).
prT^si Типичная ошибка программирования 11.7
Если бы конструктор копии просто копировал указатель
объекта-источника в указатель целевого объекта, то оба объекта указывали бы
на одну и ту же динамически выделенную память. Первый вызов
деструктора удалил бы динамически выделенную память, и указатель
другого объекта стал бы неопределенным. Такая ситуация
называется «висящим указателем» и при попытке использования указателя
чаще всего вызывает серьезную ошибку времени выполнения,
например, преждевременное завершение программы.
Заметьте, что операция new при выделении требуемой памяти может потерпеть неудачу.
Отказы операции new обсуждаются в главе 16.
714
Глава 11
Деструктор Array
Строка 17 на рис. 11.6 объявляет деструктор класса (определяемый в
строках 39-42 на рис. 11.7). Деструктор вызывается, когда объект класса Array
выходит из области действия. Деструктор использует delete[], чтобы
освободить динамическую память, выделенную в конструкторе операцией new.
Элемент-функция get Size
Строка 18 на рис. 11.6 объявляет функцию getSize (определяемую в
строках 45-48 на рис. 11.7), которая возвращает число элементов в объекте Array.
Перегруженная операция присваивания
Строка 20 на рис. 11.6 объявляет перегруженную функцию-операцию
присваивания класса. Когда компилятор встречает в строке 49 на рис. 11.8
выражение integers 1 = integers2, он выполняет функцию operator=, генерируя вызов
integersl.operator=( integers2 )
Реализация элемент-функции operator= (рис. 11.7, строки 52-70) производит
проверку на самоприсваивание (строка 54), когда объект класса Array
присваивается самому себе. Если делается попытка самоприсваивания,
присваивание пропускается (т.е. объект уже является самим собой; вскоре мы увидим,
почему самоприсваивание опасно). Если это не самоприсваивание,
элемент-функция определяет, совпадают ли размеры массивов (строка 58); в этом
случае первоначальный массив объекта в левой части не перераспределяется.
Если размеры не равны, operator= освобождает операцией delete (строка 60)
память, первоначально отведенную под массив-приемник, копирует из
массива-источника значение size в size целевого массива (строка 61), выделяет
операцией new пространство под целевой массив и присваивает указатель,
возвращаемый new, элементу ptr приемника.1 Затем цикл for в строках 65-66
копирует элементы массива-источника в целевой массив. Вне зависимости от того,
самоприсваивание это или нет, элемент-функция возвращает после вызова
свой объект (т.е. *this) как константную ссылку; это разрешает каскадные
присваивания Array, такие как х = у = z. Если бы проверка на
самоприсваивание не производилась, то при самоприсваивании функция operator= перед
своим завершением удаляла бы динамическую память, ассоциированную
с объектом Array. В результате ptr указывал бы на память, которая была
удалена, что могло бы привести к фатальным ошибкам времени выполнения.
Общее методическое замечание 11.5
Деструктор, операция присваивания и конструктор копии класса
обычно составляют единую группу, которая входит в любой класс,
использующий динамически распределяемую память.
Типичная ошибка программирования 11,8
Отсутствие перегруженной операции присваивания и конструктора
копии для класса, объекты которого содержат указатели на
динамически распределяемую память, является логической ошибкой.
Здесь также операция new может потерпеть неудачу.
Перегрузка операций; объекты Array и String
715
Общее методическое замечание 11.6
Можно предотвратить присваивание одного объекта класса другому;
для этого нужно объявить операцию присваивания класса как private.
Общее методическое замечание 11.7
Можно предотвратить копирование объектов класса; для этого
нужно объявить перегруженную операцию присваивания и конструктор
копии класса как private.
Перегруженные операции равенства и неравенства
Строка 21 на рис. 11.6 объявляет перегруженную операцию равенства (==)
класса. Когда компилятор встречает выражение integersl == integers2 в
строке 57 на рис. 11.8, он выполняет элемент-функцию operator==, генерируя вызов
integersl.operator==( integers2 )
Элемент-функция operator== (определяемая на рис. 11.7 в строках 74-84)
сразу возвращает false, если элементы size объектов различны. В противном
случае функция сравнивает каждую пару элементов массивов. Если все они
одинаковы, возвращается true. Первая пара отличающихся элементов сразу
приводит к возврату false.
Строки 24-27 заголовочного файла определяют перегруженную операцию
неравенства (!=) класса. Элемент-функция operator!= использует
перегруженную функцию operator==, чтобы определить, равны ли массивы, и
возвращает противоположный результат. Такая реализация operator!= позволяет
утилизировать operator== и сократить общий объем кода, который нужно писать
для класса. Заметьте также, что в заголовочном файле класса Array находится
полное определение operator!=. Это позволяет компилятору генерировать
встроенные расширения operator!=, устраняя тем самым издержки на
дополнительные вызовы функции.
Перегруженные операции индексации
Строки 30 и 33 на рис. 11.6 объявляют две перегруженных операции
индексации класса (определяемые на рис. 11.7 соответственно в строках 88-99
и 103-114). Когда компилятор встречает выражение integersl[ 5 ] (строка 61
на рис. 11.8), он выполняет соответствующую перегруженную
элемент-функцию operator^], генерируя вызов
integersi.operator[]( 5 )
Когда операция индексации применяется к const-объекту, компилятор
генерирует вызов const-версии operator[] (строки 103-114 на рис. 11.7).
Например, если оператором
const Array z ( 5 ) ;
создан константный объект z, то для исполнения оператора
cout « z[ 3 ] « endl;
потребуется вызвать константную версию operator[]. Помните, что для
const-объекта могут вызываться только его const-функции.
716
Глава 11
Каждое из определений operator[] проверяет, находится ли индекс в
допустимых пределах. Если нет, каждая из функций печатает сообщение об ошибке
и завершает программу вызовом функции exit (заголовок <cstdlib>).1 Если
индекс имеет допустимое значение, не-константная версия operator[]
возвращает соответствующий элемент массива в форме ссылки, которая может
использоваться как модифицируемое lvalue (например, в левой части операции
присваивания). Константная версия операции в случае допустимого индекса
возвращает значение соответствующего элемента массива. Возвращаемое
значение является rvalue.
11.9. Преобразование типов
Большинство программ обрабатывают информацию разнообразных типов.
Иногда все операции «остаются в пределах одного типа». Например,
суммирование int с int дает int (до тех пор, пока результат не становится слишком
большим, когда он уже не может быть представлен значением типа int). Однако
часто возникает необходимость преобразования данных одного типа в данные
другого типа. Это может происходить при присваивании, в вычислениях, при
передаче аргументов функциям и при возврате функциями значений.
Компилятор знает, как выполнять определенные преобразования для основных типов
(что обсуждалось в главе 6). Программист может принудительно выполнять
преобразования основных типов посредством операций приведения.
Но как насчет типов, определяемых пользователем? Компилятор не может
заранее знать, как производить преобразования между типами,
определяемыми пользователем, и преобразования между пользовательскими и основными
типами. Программист должен специфицировать, как должны производиться
такие преобразования. Они могут выполняться конструкторами
преобразований — конструкторами с одним аргументом, которые превращают объекты
различных типов (включая основные) в объекты конкретного класса. В
разделе 11.10 мы используем конструктор преобразования для преобразования
обычных строк типа char * в объекты класса String.
Операция преобразования (также называемая операцией приведения) может
применяться к объекту класса, преобразуя его в объект другого класса или
в объект основного типа. Такого рода операция преобразования должна быть
не-статической элемент-функцией класса. Прототип функции
А::operator char *() const;
объявляет перегруженную функцию-операцию приведения для
преобразования объекта определяемого пользователем типа А во временный объект типа
char *. Функция объявлена const, так как она не модифицирует исходный
объект. Перегруженная функция-операция приведения не специфицирует
возвращаемый тип — она возвращает тип, к которому преобразуется данный
объект. Если s — объект класса, то, когда компилятор встречает выражение
static_cast<char *>( s ), он генерирует вызов
s.operator char *()
При выходе индекса за пределы массива более целесообразным было бы ♦выбросить
исключение», указывающее на ошибку индексации. Затем программа могла бы
«перехватить» исключение, обработать его и, возможно, продолжить выполнение.
Перегрузка операций; объекты Array и String
717
Операнд s является объектом s, для которого вызывается элемент-функция
operator char *.
Перегруженная функция-операция приведения может определяться для
преобразования объекта определяемого пользователем типа А в объекты
встроенных типов или в объекты других пользовательских типов. Прототипы функций
А: :operator int() const;
А::operator OtherClass() const;
объявляют перегруженные функции-операции приведения для
преобразования объекта пользовательского типа А в целый тип и для преобразования
объекта типа А в объект пользовательского типа OtherClass.
Одной их замечательных особенностей операций приведения и
конструкторов преобразования является то, что при необходимости компилятор может
автоматически вызывать эти функции для создания временных объектов.
Например, если объект s определенного пользователем класса String появляется
в программе там, где ожидается обычная строка char *, например
cout « s;
то компилятор вызывает перегруженную функцию-операцию приведения
operator char *, чтобы преобразовать объект в char * и использовать в
выражении полученную строку. Если в классе String предусмотрена такая операция
приведения, то для вывода объектов String в cout не нужно перегружать
операцию передачи в поток.
11.10. Пример: класс String
В качестве «краеугольного камня» изучения перегрузки операций мы
построим класс String (рис. 11.9-11.11), который управляет созданием и
обработкой строк. Стандартная библиотека C++ предоставляет похожий, более
надежный.класс string. Как вы помните, мы ввели стандартный класс string
в главе 3. Дополнительный пример с классом string рассматривается в
разделе 11.13. Сейчас мы воспользуемся перегрузкой операций для создания своего
собственного класса String.
Сначала мы рассмотрим заголовок класса String и обсудим закрытые
данные, используемые для представления объектов String. Затем мы
проанализируем открытый интерфейс класса, обсуждая каждую из услуг, которые
предоставляет наш класс. Мы обсудим определения элемент-функций класса
String. Для каждой перегруженной операции мы рассмотрим код в
программе-драйвере, который активирует данную функцию-операцию, и объясним,
как работает эта перегруженная функция-операция.
Определение класса
Рассмотрим заголовочный файл класса String на рис. 11.9. Мы начнем
с внутреннего представления String. В строках 55-56 объявляются закрытые
элементы данных класса. Наша реализация класса String имеет поле длины
length, представляющее число символов в строке, не считая завершающего
нуль-символа, и указатель ptr на динамически выделенную память для
внутреннего представления строки символов.
718
Глава 11
1 // Рис. 11.9: String.h
2 // Определение класса String.
3 #ifndef STRING_H
4 #define STRING_H
5
6 #include <iostream>
7 using std::ostream;
8 using std::istream;
9
10 class String
11 {
12 friend о stream &operator«( ostream &, const String & ) ;
13 friend istream &operator»( istream &, String & ) ;
14 public:
15 String( const char * = "" ); // к-тор преобразования/по умолчанию
16 String( const String & ); // конструктор копии
17 ^String(); // деструктор
18
19 const String &operator=( const String & ); // on. присваивания
20 const String &operator+=( const String & ); // on. конкатенации
21
22 bool operator!() const; // пуста ли строка?
23 bool operator=( const String & ) const; // проверить si == s2
24 bool operator<( const String & ) const; // проверить si < s2
25
26 // проверить si != s2
27 bool operator!=( const String firight ) const
28 {
29 return !( *this == right );
30 } // конец функции operator!=
31
32 // проверить si > s2
33 bool operator>( const String bright ) const
34 {
35 return right < *this;
36 } // конец функции operator>
37
38 // проверить si <= s2
39 bool operator<=( const String firight ) const
40 {
41 return !( right < *this );
42 } // конец функции operator <=
43
44 // проверить si >= s2
45 bool operator>=( const String bright ) const
46 {
47 return !( *this < right );
48 } // конец функции operator>=
49
50 char &operator[]( int ); // операция индексации (lvalue)
51 char operator[]( int ) const; // операция индексации (rvalue)
52 String operator()( int, int = 0 ) const; // возвратить подстроку
53 int getLength() const; // возвратить длину строки
54 private:
55 int length; // длина строки (не считая завершающий нуль)
56 char *sPtr; // указатель на начало представления строки
Перегрузка операций; объекты Array и String
719
57
58 void setString( const char * ); // вспомогательная функция
59 }; // конец класса String
60
61 #endi£
Рис. 11.9. Определение класса String с перегрузкой операций
1 // Рис. 11.10: String.срр
2 // Определение элемент-функций для класса String.
3 #include <iostream>
4 using std::cerr;
5 using std::cout;
6 using std::endl;
7
8 #include <iomanip>
9 using std::setw;
10
11 #include <cstring> // прототипы strcpy и streat
12 using std:rstremp;
13 using std::strcpy;
14 using std::strcat;
15
16 #include <cstdlib> // прототип exit
17 using std::exit;
18
19 #include "String.h" // определение класса String
20
21 // конструктор преобразования (и по умолчанию) char* в String
22 String::String( const char *s )
23 : length( ( s != 0 ) ? strlen( s ) : 0 )
24 {
25 cout « "Conversion (and default) constructor: " « s « endl;
26 setString( s ); // call utility function
27 } // конец конструктора преобразования String
28
29 // конструктор копии
30 String::String( const String © )
31 : length( copy.length )
32 {
33 cout « "Copy constructor: " « copy.sPtr « endl;
34 setString( copy.sPtr ); // call utility function
35 } // конец конструктора копии String
36
37 // деструктор
38 String::-String()
39 {
40 cout « "Destructor: " « sPtr « endl;
41 delete [] sPtr; // освободить строку, представленную указателем
42 } // конец деструктора -String
43
44 // перегруженная операция =; предотвращает самоприсваивание
45 const String fiString::operator=( const String bright )
46 {
47 cout « "operator= called" « endl;
720
Глава 11
48
49 if ( firight != this ) // предотвратить самоприсваивание
50 {
51 delete [] sPtr; // предотвращает утечку памяти
52 length = right.length; // новая длина строки
53 setString( right.sPtr ); // вызвать вспомогательную функцию
54 } // конец if
55 else
56 cout « "Attempted assignment of a String to itself" « endl;
57
58 return *this; // разрешает каскадное присваивание
59 } // конец функции operator=
60
61 // присоединить правый операнд к объекту и сохранить в объекте
62 const String fiString::operator+=( const String firight )
63 {
64 size_t newLength = length + right.length; // новая длина
65 char *tempPtr = new char[ newLength + 1 ]; // выделить память
66
67 strcpy( tempPtr, sPtr ); // копировать sPtr
68 strcpy( tempPtr + length, right.sPtr ); // копировать right.sPtr
69
70 delete [] sPtr; // освободить старый массив
71 sPtr = tempPtr; // присвоить sPtr новый массив
72 length = newLength; // присвоить length новую длину
73 return *this; // разрешает каскадные вызовы
74 } // конец функции operator+=
75
76 // Пуста ли строка?
77 bool String::operator!() const
78 {
79 return length == 0;
80 } // конец функции operator!
81
82 // Равна ли данная строка правой строке?
83 bool String::operator==( const String &right ) const
84 {
85 return strcmp( sPtr, right.sPtr ) == 0;
86 } // конец функции operator==
87
88 // Меньше ли данная строка правой строке?
89 bool String::operator<( const String &right ) const
90 {
91 return strcmp( sPtr, right.sPtr ) < 0;
92 } // конец функции operator<
93
94 // возвратить ссылку на символ строки как модифицируемое lvalue
95 char fiString::operator[] f int subscript )
96 {
97 // проверить на выход индекса из диапазона
98 if ( subscript < 0 || subscript >= length )
99 {
100 cerr « "Error: Subscript " « subscript
101 « " out of range" « endl;
102 exit( 1 ); // завершить программу
103 } // конец if
104
Перегрузка операций; объекты Array и String
721
105 return sPtr[ subscript ]; // модифицируемое lvalue
106 } // конец функции operator[]
107
108 // возвратить ссылку на символ строки как rvalue
109 char String: .-operator[] ( int subscript ) const
110 {
111 // проверить на выход индекса из диапазона
112 if ( subscript < 0 || subscript >= length )
113 {
114 cerr « "Error: Subscript " « subscript
115 « " out of range" « endl;
116 exit( 1 ); // завершить программу
117 } // конец if
118
119 return sPtr[ subscript ]; // возвращает копию элемента
120 } // конец функции operator[]
121
122 // возвратить подстроку, начинающуюся с index и длиной subLength
123 String String::operator()( int index, int subLength ) const
124 {
125 // если индекс вне диапазона или длина строки < 0,
126 // возвратить пустоцй объект String
127 if ( index < 0 || index >= length || subLength < 0 )
128 return ""; // автоматически преобразуется в объект String
129
130 // определить длину подстроки
131 int len;
132
133 if ( ( subLength == 0 ) || ( index + subLength > length ) )
134 len = length - index;
135 else
136 len = subLength;
137
138 // выделить временный массив для подстроки
139 //и завершающего нулевого символа
140 char *tempPtr = new char[ len + 1 ];
141
142 // копировать строку в массив и завершить строку
143 strncpy( tempPtr, &sPtr[ index ], len );
144 tempPtr[ len ] = '\0■;
145
146 // создать временный объект String, содержащий подстроку
147 String tempString( tempPtr );
148 delete [] tempPtr; // удалить временный массив
14 9 return tempString; // возвратить копию временного объекта String
150 } // конец функции operator()
151
152 // возвратить длину строки
153 int String::getLength() const
154 {
155 return length;
156 } // конец функции getLength
157
158 // вспомогательная функция, вызываемая конструкторами и operator=
159 void String::setstring( const char *string2 )
160 {
161 sPtr = new char[ length +1 ]; // выделить память
722
Глава 11
162
163 if ( string2 != О ) // если string2 - не NULL, копировать
164 strcpy( sPtr, string2 ); // копировать литерал в объект
165 else // если string2 - NULL, сделать this пустой строкой
166 sPtr[ 0 ] = '\0'; // пустая строка
167 } // конец функции setString
168
169 // перегруженная операция вывода
170 ostream &operator«( оstream Soutput, const String &s )
171 {
172 output « s.sPtr;
173 return output; // разрешает каскадирование
174 } // конец функции operator«
175
176 // перегруженная операция ввода
177 istream &operator»( istream fiinput, String &s )
178 {
179 char temp[ 100 ]; // буфер для хранения ввода
180 input » setw( 100 ) » temp;
181 s = temp; // использовать операцию присваивания класса String
182 return input; // разрешает каскадирование
183 } // конец функции operator»
Рис. 11.10. Определения элемент-функций и друзей класса String
1 // Рис. 11.11: figll_ll.cpp
2 // Тестовая программа для класса String.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::boolalpha;
7
8 #include "String.h"
9
10 int main()
11 {
12 String si( "happy" );
13 String s2( " birthday" );
14 String s3;
15
16 // тестировать перегруженные операции равенства и отношений
17 cout « "si is \"" « si « "\"; s2 is \"" « s2
18 « "\"; s3 is \"" « s3 « 'V '
19 « boolalpha « "\n\nThe results of comparing s2 and si:"
20 « "\ns2 == si yields " « ( s2 = si )
21 « "\ns2 != si yields " « ( s2 != si )
22 « "\ns2 > si yields " « ( s2 > si )
23 « "\ns2 < si yields " « ( s2 < si )
24 « "\ns2 >= si yields " « ( s2 >= si )
25 « "\ns2 <= si yields " « ( s2 <= si );
26
27
28 // тестировать перегруженную операцию "пусто" (!) класса String
29 cout « "\n\nTesting !s3:" « endl;
Перегрузка операций; объекты Array и String
723
31 if ( !s3 )
32 {
33 cout « "s3 is empty; assigning si to s3;" « endl;
34 s3 = si; // протестировать перегруженное присваивание
35 cout « Ms3 is \"" « s3 « "\"";
36 } // конец if
37
38 // тестировать перегруженную операцию конкатенации строк
39 cout « "\n\nsl += s2 yields si = ";
40 si += s2; // протестировать перегруженную конкатенацию
41 cout « si;
42
43 // тестировать конструктор преобразования
44 cout « "\n\nsl += \" to you\" yields" « endl;
45 si += " to you"; // test conversion constructor
46 cout « "si = " « si « "\n\n";
47
48 // тестировать операцию вызова () для подстроки
49 cout « "The substring of si starting at\n"
50 « "location 0 for 14 characters, sl@, 14), is:\n"
51 « sl( 0, 14 ) « "\n\n";
52
53 // тестировать случай подстроки "до конца строки"
54 cout « "The substring of si starting at\n"
55 « "location 15, si A5), is: "
56 « sl( 15 ) « "\n\n";
57
58 // тестировать конструктор копии
59 String *s4Ptr = new String( si );
60 cout « "\n*s4Ptr = " « *s4Ptr « "\n\n";
61
62 // тестировать операцию присваивания (=) с самоприсваиванием
63 cout « "assigning *s4Ptr to *s4Ptr" « endl;
64 *s4Ptr = *s4Ptr; // протестировать перегруженное присваивание
65 cout « "*s4Ptr = " « *s4Ptr « endl;
66
67 // тестировать деструктор
68 delete s4Ptr;
69
70 // тестировать использование индексации для получения lvalue
71 sl[ 0 ] = 'Н';
72 sl[ 6 ] = 'В';
73 cout « "\nsl after sl[0] = 'H' and sl[6] = 'B' is: "
74 « si « "\n\n";
75
76 // тестировать выход индекса из диапазона
77 ccut « "Attempt to assign 'd' to sl[30] yields:" « endl;
78 sl[ 30 ] = 'd'; // ОШИБКА: индекс вне диапазона
79 return 0;
80 } // конец main
Conversion (and default) constructor: happy
Conversion (and default) constructor: birthday
Conversion (and default) constructor:
si is "happy"; s2 is " birthday"; s3 is ""
724
Глава 1
The results of comparing s2 and si:
s2 == si yields false
s2 != si yields true
s2 > si yields false
s2 < si yields true
s2 >= si yields false
s2 <= si yields true
Testing !s3:
s3 is empty; assigning si to s3;
operator= called
s3 is "happy"
si += s2 yields si = happy birthday
si += " to you" yields
Conversion (and default) constructor: to you
Destructor: to you
si = happy birthday to you
Conversion (and default) constructor: happy birthday
Copy constructor: happy birthday
Destructor: happy birthday
The substring of si starting at
location 0 for 14 characters, sl@, 14), is:
happy birthday
Destructor: happy birthday
Conversion (and default) constructor: to you
Copy constructor: to you
Destructor: to you
The substring of si starting at
location 15, si A5) , is: to you
Destructor: to you
Copy constructor: happy birthday to you
*s4Ptr = happy birthday to you
assigning *s4Ptr to *s4Ptr
operator= called
Attempted assignment of a String to itself
*s4Ptr = happy birthday to you
Destructor: happy birthday to you
si after sl[0] = 'H' and sl [6] = 'B' is: Happy Birthday to you
Attempt to assign 'd1 to sl[30] yields:
Error: Subscript 30 out of range
Рис. 11.11. Тестовая программа для класса String
Перегрузка операций; объекты Array и String
725
Перегрузка операций передачи в поток и извлечения из потока
в качестве друзей класса
В строках 12-13 (рис. 11.9) в качестве друзей класса объявляются
перегруженные функции-операции передачи в поток operator« и извлечения из
потока operator» (определяемые на рис. 11.10 в строках 170-174 и 177-183).
Реализация operator« очевидна. Заметьте, что ограничивает общее число
символов, которые могут быть считаны в массив temp, 99 символами с
помощью setw (строка 180); 100-я позиция резервируется для завершающего
нуль-символа. [Замечание. У нас не было такого ограничения для operator»
в классе Array (рис. 11.6-1.7), так как функция operator» этого класса
читала элементы массива по одному и завершала чтение, когда достигала конца
массива. Объект cin по умолчанию не знает, как это сделать при вводе
символьных массивов.] Обратите также внимание на использование operator=
(строка 181) для присваивания строки temp в стиле С объекту String, на
который ссылается s. Этот оператор активирует конструктор преобразования для
создания временного объекта String, содержащего строку С; временный
объект String присваивается затем s. Мы могли бы здесь исключить издержки
создания временного объекта String, предусмотрев еще одну перегруженную
операцию присваивания, которая принимает параметр типа const char *.
Конструктор преобразования
В строке 15 объявляется конструктор преобразования. Этот конструктор
(определяемый на рис. 11.10 в строках 22-27) принимает аргумент const char*
(по умолчанию пустую строку; см. строку 15 на рис. 11.9) и инициализирует
объект String, содержащий эту строку символов. Любой конструктор с
единственным аргументом может рассматриваться как конструктор
преобразования. Как мы увидим, такие конструкторы полезны, когда мы выполняем
любую операцию для String, используя аргументы типа char*. Конструктор
преобразования преобразует соответствующую строку в объект String, который
затем присваивается целевому объекту String. Наличие этого конструктора
преобразования означает, что нет необходимости применять перегруженную
операцию присваивания специально для присваивания объектам String
символьных строк. Компилятор автоматически активирует конструктор
преобразования для создания временного объекта String, содержащего строку
символов. Затем вызывается перегруженная операция присваивания, чтобы
присвоить временный объект String другому объекту String.
S Общее методическое замечание 11-8
При применении конструктора преобразования для выполнения
неявного преобразования типов C++ может использовать неявный вызов
только одного конструктора (т.е. одно определенное пользователем
преобразование)t чтобы попытаться удовлетворить требование
другой перегруженной операции. Компилятор не может удовлетворить
требования перегруженных операций путем выполнения
последовательности неявных определенных пользователем преобразований.
Конструктор преобразования String может быть активирован, например,
таким объявлением: String sl( "happy" ). Конструктор преобразования вычис-
726
Глава 11
ляет длину строки символов и присваивает эту длину закрытому элементу
данных length в списке инициализаторов элементов. Затем строка 26 вызывает
сервисную функцию setString (определенную на рис. 8.8 в строках 159-167),
которая использует new для выделения необходимого объема памяти
закрытому элементу данных sPtr, и применяет strcpy для копирования строки
символов в область памяти, на которую указывает sPtr.1
Конструктор копии
В строке 16 на рис. 11.9 объявляется конструктор копии (определенный на
рис. 11.10 в строках 30-35). Он инициализирует новый объект String,
копируя существующий объект String. Как и в случае нашего класса Array, такое
копирование должно быть выполнено аккуратно, чтобы избежать
неприятностей, когда оба объекта String указывают на одну и ту же динамически
выделенную область памяти. Конструктор копирования работает аналогично
конструктору преобразования, за исключением того, что он просто копирует
элемент length из исходного объекта String в целевой объект String. Заметьте,
что конструктор копии вызывает setString для создания новой области
памяти для внутреннего представления строки символов целевого объекта. Если бы
он просто копировал sPtr в исходном объекте в sPtr целевого объекта, то оба
объекта указывали бы на одну и ту же динамически выделенную область
памяти. Первое выполнение деструктора уничтожило бы тогда динамически
выделенную область памяти, и указатель ptr второго объекта оказался бы
неопределенным (т.е. стал висящим указателем), что привело бы к ситуации,
способной вызвать серьезную ошибку времени выполнения.
Деструктор
В строке 17 на рис. 11.9 объявляется деструктор класса String
(определенный на рис. 11.10 в строках 38-42). Деструктор использует delete[] для
освобождения динамически выделенной памяти, на которую указывает sPtr.
Перегруженная операция присваивания
В строке 19 (рис. 11.9) объявляется перегруженная операция присваивания
(определенная на рис. 11.10 в строках 45-59). Когда компилятор встречает
выражение вида stringl = string2, он генерирует вызов функции
stringl.operator=( string2 );
Перегруженная функция-операция присваивания operator= сначала
проверяет, не осуществляется ли самоприсваивание. Если это самоприсваивание,
функции нет необходимости изменять объект. Если бы эта проверка была
пропущена, функция сразу же освобождала область памяти в целевом объекте
и поэтому теряла бы строку символов, так что указатель больше не указывал
1 В реализации этого конструктора преобразования есть один тонкий момент. В данной
реализации, если конструктору передать нулевой указатель (т. е. 0), программа аварийно
завершится. Правильная реализация этого конструктора распознавала бы случай, когда
конструктору передается нулевой указатель, и «выбрасывала исключение». Таким
образом мы можем делать классы более надежными. Кроме того, не забывайте, что нулевой
указатель @) не то же самое, что пустая строка (""). Нулевой указатель — это указатель,
ни на что не указывающий. Пустая строка — это действительная строка, содержащая
только нуль-символ ('\0').
Перегрузка операций; объекты Array и String
727
бы на действительные данные, — типичный пример висящего указателя. Если
самоприсваивания не происходит, функция освобождает область памяти и
копирует поле длины исходного объекта в целевой объект. Затем operator=
вызывает setString для создания новой области памяти для целевого объекта
и копирует в него строку символов из исходного объекта. Вне зависимости от
того, было или не было самоприсваивания, возвращается *this, что
обеспечивает возможность каскадных присваиваний.
Перегруженная операция присваивания суммы
В строке 20 на рис. 11.9 объявляется перегруженная операция
конкатенации строк += (определяется.на рис. 11.10 в строках 62-74). Когда компилятор
встречает выражение si += s2 (строка 40 на рис. 11.11), генерируется вызов
элемент-функции
si.operator+=( s2 )
Функция operator+= вычисляет общую длину объединяемых строк и сохраняет
ее в локальной переменной newLength, создает временный указатель (tempPtr)
и распределяет новый символьный массив, в котором будет храниться
конкатенированная строка. Затем operator+= использует strcpy для копирования
исходных символьных строк из sPtr и right.sPtr в область памяти, на которую
указывает tempPtr. Обратите внимание на то, что позиция, в которую strcpy будет
копировать первый символ right.sPtr, определяется вычислением tempPtr + length
в арифметике указателей. Это вычисление указывает, что первый символ
right.sPtr должен быть помещен в позицию length в массиве, на который
указывает tempPtr. Далее operator+= использует delete[], чтобы освободить область
памяти, занятую исходной символьной строкой этого объекта, присваивает
tempPtr полю length и возвращает *this как const String &, чтобы обеспечить
возможность сцепленных вызовов операции +=.
Нужна ли нам вторая перегруженная операция конкатенации объекта типа
String со строкой типа char*? Нет. Конструктор преобразования const char*
преобразует строку во временный объект класса String, с которым затем и
выполняется описанная перегруженная операция сцепления. Это именно то, что
делает компилятор, встретив строку 44 на рис. 11.11. Повторим, что C++
может выполнять такие преобразования только на глубину одного уровня. C++
может также выполнять неявное, зависящее от компилятора преобразование
между встроенными типами перед выполнением преобразования между
основным типом и классом. Заметьте, что при создании временного объекта класса
String вызываются конструктор преобразования и деструктор (см.
на рис. 11.11 вывод в результате выполнения строки 45, sl+="to you"). Это
пример скрытых от клиента класса непроизводительных потерь от вызовов
функций при создании и уничтожении временных объектов класса во время
неявных преобразований. Аналогичные непроизводительные потери вносятся
конструкторами копии при передаче им параметров по значению и при
возвращении значений — объектов класса.
728
Глава 11
.—_, Вопросы производительности 11.2
рЗК^Ч Перегрузка операции конкатенации += дополнительной функцией,
которая получает один аргумент типа const char*, более эффективна,
чем определение единственной версии операции сцепления,
принимающей аргумент типа String. Без версии операции += для типа const
char* аргумент const char* сначала преобразовывался бы в объект
String конструктором преобразования класса String, а затем
вызывалась операция += для выполнения конкатенации.
® Общее методическое замечание 11.9
Использование неявных преобразований с перегруженными
операциями вместо перегрузки операторов для различных типов операндов
часто требует меньшего объема кода, что упрощает модификацию,
сопровождение и отладку класса.
Перегруженная операция отрицания
В строке 22 на рис. 11.9 объявляется перегруженная операция отрицания
(определяется на рис. 11.10 в строках 89-92). Эта операция определяет, не
является ли объект нашего класса String пустым. Например, когда компилятор
встречает выражение Istringl, он генерирует вызов функции
stringl.operator!()
Эта функция просто возвращает результат проверки, не равняется ли length
нулю.
Перегруженные операции равенства и отношений
В строках 23-24 на рис. 11.9 объявляются перегруженная операция
равенства (определяется на рис. 11.10 в строках 83-86) и перегруженная операция
«меньше» (определяется на рис. 11.10 в строках 89-92) для класса String.
Схожесть этих операций позволяет нам ограничиться рассмотрением только
одной из них, а именно перегрузкой операции ==. Когда компилятор
встречает выражение вида stringl == string2, он генерирует вызов функции
stringl.operator==( string2 )
которая возвращает true, если stringl равна string2. Каждая из
рассматриваемых операций использует strcmp (из <cstring>) для сравнения символьных
строк в объектах типа String. Многие программисты отстаивают
использование одних перегруженных функций-операций для реализации других. Таким
образом, операции !=, >, <= и >= реализуются (рис. 11.9, строки 27-48) через
operator== и operator<. Например, перегруженная функция operator>=
(реализуется в строках 45-48 заголовочного файла) использует перегруженную
операцию <, чтобы определить, больше или равен один объект типа String
другому. Заметьте, что функции-операции для !=, >, <= и >= определяются
в заголовочном файле. Компилятор встраивает эти определения для
устранения лишних вызовов функций.
Перегрузка операций; объекты Array и String
729
Ш Общее методическое замечание 11.10
Реализуя элемент-функции с использованием ранее определенных
элемент-функций, программист утилизирует код, уменьшая объем кода,
который необходимо написать и сопровождать.
Перегруженные операции индексации
В строках 50-51 в заголовочном файле объявляются две перегруженные
операции индексации (определенные на рис. 11.10 в строках 95-106
и 109-120): одна — для не-константных объектов String и вторая — для
константных объектов String. Когда компилятор встречает выражение вида
stringl[ 0 ], он генерирует вызов элемент-функции
stringl.operator[]( 0 )
(используя соответствующую версию operator[], исходя из того, является ли
объект String константным). Каждая реализация operator[] сначала
проверяет, находится ли индекс внутри допустимого диапазона; если индекс вне
диапазона, каждая из функций печатает сообщение об ошибке и завершает
программу вызовом exit.1 Если индекс находится в допустимом диапазоне,
неконстантная версия operator[]" возвращает соответствующий символ строки
объекта класса String как char &; ссылку char & можно использовать как
lvalue для модификации указанного символа строки объекта String.
Константная версия функции operator[] возвращает const char & для соответствующего
символа объекта String; эту ссылку char & можно использовать как rvalue для
считывания значения символа.
jgrjL Предотвращение ошибок 11.2
\£ftj/ Опасно возвращать ссылку char из перегруженной операции
индексирования в классе String. Например, клиент мог бы использовать эту
ссылку для вставки нуля (\0') в любом месте строки.
Перегруженная операция вызова
В строке 52 программы на рис. 11.9 объявляется перегруженная операция
вызова функции (определяемая на рис. 11.10 в строках 123-150). Мы
перегружаем эту операцию для выделения подстроки объекта класса String. Два
целых параметра указывают индекс начала и длину подстроки, выделяемой
в строке объекта класса String. Если индекс начала находится вне
допустимого диапазона или длина подстроки отрицательна, операция просто возвращает
пустую строку. Если длина подстроки равна 0, то подстрока выделяется до
конца строки в объекте класса String. Например, предположим, что stringl
является объектом класса String, содержащим строку символов "AEIOU".
Когда компилятор встречает выражение stringl( 2, 2 ), он генерирует
stringl.operator () ( 2, 2 )
При выполнении этого вызова создается временный объект String,
содержащий строку 0", и возвращается копия этого объекта.
Как уже говорилось, целесообразнее было бы при выходе индекса за допустимые
пределы «выбросить исключение*, указывающее на ошибку индексации.
730
Глава 11
Перегрузка операций вызова функций () является мощным средством,
потому что функции могут получать списки параметров произвольной длины
и сложности. Мы можем использовать эти возможности для многих
интересных задач. Одним из таких применений операции вызова функции является
альтернативная запись индексированного массива: вместо неудобной
принятой в С записи двойных квадратных скобок для двумерного массива, имеющей
вид а[Ь][с], некоторые программисты предпочитают перегрузить операцию
вызова функции, чтобы иметь возможность записывать а(Ь, с). Перегруженная
операция вызова функции может быть только не статической
элемент-функцией. Эта операция используется только когда «имя функции» является
объектом класса String.
Элемент-функция getLength
В строке 53 на рис. 11.9 объявляется функция getLength (определяемая
на рис. 11.10 в строках 153-166), которая возвращает длину объекта String.
Замечания о нашем классе строк
Теперь читатель может сам просмотреть программу main, изучить ее вывод
и исследовать результаты каждого использования перегруженной операции.
По ходу изучения вывода обратите особое внимание на неявные вызовы
конструкторов, генерируемые на всем протяжении программы для создания
временных объектов String. Многие из них вносят в программу дополнительные
издержки, которых можно было бы избежать, предусмотрев перегруженные
операции, принимающие аргументы типа char *. Однако дополнительные
операции могли бы сделать класс более трудным для сопровождения,
модификации и отладки.
11.11. Перегрузка ++ и --
Все операции инкремента и декремента — преинкремент, постинкремент,
предекремент и постдекремент — могут быть перегружены. Мы увидим,
каким образом компилятор различает префиксную и постфиксную версии
операций инкремента и декремента.
Чтобы перегрузить операцию инкремента и в преинкрементной, и в
постинкрементной формах, перегруженные функции-операции должны иметь
различные сигнатуры, позволяющие компилятору определить, какая из
операций ++ подразумевается. Префиксные версии перегружаются точно так же,
как перегружалась бы любая другая префиксная одноместная операция.
Перегрузка префиксной операции инкремента
Предположим, что мы хотим прибавить 1 к значению дня в объекте dl
пользовательского класса Date. Когда компилятор встречает выражение пре-
инкремента
++dl
он генерирует вызов функции
dl.operator++()
Перегрузка операций; объекты Array и String
731
Прототип этой функции-операции объявлялся бы как
Date &operator++();
Если преинкремент реализуется как глобальная функция, то при появлении
выражения
++dl
компилятор генерирует вызов функции
operator++( dl )
Прототип этой функции-операции объявлялся бы в классе Date как
Date &operator++( Date & );
Перегрузка постфиксной операции инкремента
Перегрузка операции постинкремента представляет некоторую сложность,
поскольку компилятор должен видеть разницу между сигнатурами
перегруженных функций-операций преинкремента и постинкремента. Соглашение,
принятое в C++, состоит в том, что когда компилятор встречает выражение
постинкремента
dl++
он генерирует вызов функции
dl.operator++( 0 )
чей прототип объявляется как
Date operator++( int )
Здесь 0 является просто «значением-пустышкой», чтобы список аргументов
operator++ для постинкремента был отличим от списка аргументов функции
для преинкремента.
Если постинкремент реализуется как глобальная функция, то при появле-
нии выражения
dl++
компилятор генерирует вызов функции
operator++( dl, 0 )
чей прототип объявлялся бы как
Date operator++( Date &, int );
Здесь также аргумент О используется компилятором для того, чтобы список
аргументов operator++ для операции постинкремента отличался бы от списка
аргументов для операции преинкремента. Обратите внимание, что
постфиксная операция инкремента возвращает объекты Date по значению, в то время
как префиксная операция возвращает объекты по ссылке, поскольку пост-
732
Глава 11
фиксная операция, как правило, возвращает временный объект, содержащий
копию первоначального значения объекта до инкремента. C++ расценивает
такие объекты как rvalue, которые не могут появляться в левой части
присваивания. Префиксная операция инкремента возвращает действительный инкре-
ментированный объект с новым значением. Такие объекты могут
использоваться в качестве lvalue в процессе дальнейшей оценки выражения.
•——j Вопросы производительности 11.3
р^у*| Дополнительный объект, создаваемый операцией посфиксного
инкремента (или декремента) может привести к серьезным проблемам
в плане производительности, особенно когда операция исполняется
в цикле. По этой причине следует использовать операцию посфиксного
инкремента (или декремента) только в случаях, когда этого
настоятельно требует логика программы.
Все, что мы сказали в этом разделе по поводу перегрузки операций преин-
кремента и постинкремента, равным образом относится и к перегрузке
операций предекремента и постдекремента. Далее мы исследуем класс Date с
операциями префиксного и посфиксного инкремента.
11.12. Пример: класс Date
Программа на рис. 11.12-11.14 демонстрирует класс Date. Класс
определяет перегруженные операции инкремента в префиксной и постфиксной формах
для прибавления 1 к дню в объекте Date, что может вызвать в ряде случаев
увеличение на 1 и месяца, и года. Заголовочный файл Date (рис. 11.12)
специфицирует, что открытый интерфейс Date включает в себя перегруженную
операцию передачи в поток (строка 11), конструктор по умолчанию (строка 13),
функцию setDate (строка 14), перегруженные функции-операции инкремента
в префиксной и постфиксной формах (строки 15 и 16), перегруженную
операцию сложения с присваиванием (+=) (строка 17), функцию проверки
високосного года (строка 18) и функцию, определяющую, является ли указанный день
последним днем месяца (строка 19).
1 // Рис. 11.12: Date.h
2 // Определение класса Date.
3 #ifndef DATE_H
4 #define DATE_H
5
6 #include <iostream>
7 using std:rostream;
8
9 class Date
10 {
11 friend ostrearn &operator«( ostream &, const Date & );
12 public:
13 Date( int m = 1, int d = 1, int у = 1900 ); // к-тор по умолчанию
14 void setDate( int, int, int ); // установить месяц, день, год
15 Date fioperator++(); // операция префиксного инкремента
16 Date operator++( int ); // операция постфиксного инкремента
Перегрузка операций; объекты Array и String
733
17 const Date &operator+=( int ); // прибавить дни к дате
18 bool leapYear( int ) const; // високосный год?
19 bool endOfMonth( int ) const; // последний день месяца?
20 private:
21 int month;
22 int day;
23 int year;
24
25 static const int days[]; // массив дней в месяцах
26 void helplncrement(); // сервисная функция для инкремента даты
27 }; // конец класса Date
28
29 #endif
Рис. 11.12. Определение класса Date с перегруженными операциями инкремента
1 // Рис. 11.13: Date.cpp
2 // Определения элемент-функций класса Date.
3 #include <iostream>
4 #include "Date.h"
5
6 // инициализировать статический элемент в области действия файла
7 const int Date::days[] =
8 { 0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
9
10 // конструктор Date
11 Date::Date( int m, int d, int у )
12 {
13 setDate( m, d, у ) ;
14 } // конец конструктора Date
15
16 // установить месяц, день и год
17 void Date::setDate( int mm, int dd,
18 {
19 month = ( mm >= 1 && mm <= 12 ) ?
20 year = ( yy >= 1900 && yy <= 2100
21
22 // проверить, високосный ли год
23 if ( month = 2 && leapYear( year ) )
24 day = ( dd >= 1 && dd <= 29 ) ? dd : 1;
25 else
26 day = ( dd >= 1 && dd <= days[ month ] ) ? dd : 1;
27 } // конец функции setDate
28
29 // перегруженная операция префиксного инкремента
30 Date &Date::operator++()
31 {
32 helplncrement(); // инкрементировать дату
33 return *this; // возврат ссылки для получения lvalue
34 } // конец функции operator++
35
36 // перегруженная операция постфиксного инкремента; заметьте, что
37 // для целого параметра-пустышки нет имени параметра
38 Date Date::operator++( int )
39 {
int yy )
mm : 1;
) ? yy : 1900;
734
Глава 11
40 Date temp = *this; // запомнить текущее состояние объекта
41 helpIncrement();
42
43 // вернуть неинкрементированный сохраненный объект
44 return temp; // возврат значения, не ссылки
45 } // конец функции operator++
46
47 // прибавить к дате указанное число дней
48 const Date fiDate::operator+=( int additionalDays )
49 {
50 for ( int i = 0; i < additionalDays; i++ )
51 helplncrement();
52
53 return *this; // разрешает каскадирование
54 } // конец функции operator+=
55
56 // если год високосный, возвратить true; иначе возвратить false
57 bool Date::leapYear( int testYear ) const
58 {
59 if ( testYear % 400 = 0 ||
60 ( testYear % 100 != 0 && testYear % 4 = 0 ) )
61 return true; // високосный год
62 else
63 return false; // невисокосный год
64 } // конец функции leapYear
65
66 // определить, является ли день последним днем месяца
67 bool Date::endOfMonth( int testDay ) const
68 {
69 if ( month = 2 && leapYear( year ) )
70 return testDay = 29; // последний день февраля високосн. года
71 else
72 return testDay == days[ month ];
73 } // конец функции endOfMonth
74
75 // вспомогатильная функция для инкремента даты
76 void Date::helplncrement()
77 {
78 //не последний день месяца
79 if ( !endOfMonth( day ) )
80 day++; // инкрементировать день
81 else
82 if ( month < 12 ) // последний день месяца и месяц < 12
83 {
84 month++; // инкрементировать месяц
85 day =1; // первый день нового месяца
86 } // конец if
87 else // последний день года
88 {
89 уеаг++; // инкрементировать год
90 month =1; // первый месяц нового года
91 day = 1; // первый день нового месяца
92 } // конец else
93 } // конец функции helplncrement
94
95 // перегруженная операция вывода
96 ostream &operator«( оstream fioutput, const Date &d )
Перегрузка операций; объекты Array и String
735
97 {
98 static char *monthName[ 13 ] = { "", "January", "February",
99 "March", "April", "May", "June", "July", "August",
100 "September", "October", "November", "December" };
101 output « monthName[ d.month ] « ' ' « d.day « ", " « d.year;
102 return output; // разрешает каскадирование
103 } // конец функции operator«
Рис. 11,13. Определения элемент-функций и друзей класса Date
1 // Рис. 11.14: figll_14.cpp
2 // Тестовая программа для класса Date.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Date.h" // определение класса Date
8
9 int main()
10 {
11 Date dl; // по умолчанию 1 января 1900 г.
12 Date d2( 12, 27, 1992 ); // 27 декабря 1992 г.
13 Date d3( 0, 99, 8045 ); // недействительная дата
14
15 cout « "dl is " « dl « "\nd2 is " « d2 « "\nd3 is " « d3;
16 c6ut « "\n\nd2 += 7 is " « ( d2 += 7 );
17
18 d3.setDate( 2, 28, 1992 );
19 cout « "\n\n d3 is " « d3;
20 cout « "\n++d3 is " « ++d3 « " (leap year allows 29th)";
21
22 Date d4( 7, 13, 2002 );
23
24 cout « "\n\nTesting the prefix increment operator:\n"
25 « " d4 is " « d4 « endl;
26 cout « "++d4 is " « ++d4 « endl;
27 cout « " d4 is " « d4;
28
29 cout « "\n\nTesting the postfix increment operator:\n"
30 « " d4 is " « d4 « endl;
31 cout « "d4++ is " « d4++ « endl;
32 cout « " d4 is " « d4 « endl;
33 return 0;
34 } // конец main
dl is January 1, 1900
d2 is December 27, 1992
d3 is January 1, 1900
d2 += 7 is January 3, 1993
d3 is February 28, 1992
++d3 is February 29, 1992 (leap year allows 29th)
736
Глава 11
Testing the prefix increment operator:
d4 is July 13, 2002
++d4 is July 14, 2002
d4 is July 14, 2002
Testing the postfix increment operator:
d4 is July 14, 2002
d4++ is July 14, 2002
d4 is July 15, 2002
Рис. 11.14. Тестовая программа для класса Date
Функция main (рис. 11.14) создает три объекта Date (строки 11-13): dl по
умолчанию инициализируется первым января 1900 года, d2
инициализируется датой 27 декабря 1992 года, a d3 программа пытается инициализировать
недействительной датой. Конструктор Date (определяемый на рис. 11.13 в
строках 11-14) вызывает setDate для проверки и установки заданных значений
месяца, дня и года. Если месяц неправильный, он устанавливается равным 1,
неправильный год устанавливается равным 1900 и неправильный день
устанавливается равным 1.
Строки 15-16 в main выводят каждый из сконструированных объектов
Date, используя перегруженную операцию передачи в поток (определяется на
рис. 11.13 в строках 96-103). Строка 16 использует перегруженную
операцию += для прибавления к d2 семи дней. В строке 18 используется функция
setDate для установки в d3 даты 28 февраля 1992 года (високосный год).
Строка 20 выполняет преинкремент даты, показывая, что в результате получается
правильная дата B9 февраля). Далее, в строке 22 создается Date-объект d4,
который инициализируется датой 13 июля 2002 года. Затем строка 26
увеличивает d4 на 1 с помощью перегруженной операции префиксного инкремента.
Строки 24-27 печатают дату до и после инкремента, чтобы убедиться, что
преинкремент работает правильно. Наконец, строка 31 инкрементирует d4
перегруженной операцией постфиксного инкремента. Строки 29-32 печатают d4
до и после инкремента, показывая, что он работает правильно.
Перегрузка операции префиксного инкремента проста. Операция преин-
кремента (определяемая на рис. 11.13 в строках 30-34) вызывает закрытую
сервисную функцию helplncrement (определяемую на рис. 11.13 в
строках 76-93), чтобы выполнить собственно инкремент. Эта функция
обеспечивает переходы от конца месяца к началу следующего, когда мы инкрементируем
последний день месяца. Если месяц уже равен 12, то тогда нужно увеличить
год, а месяц установить равным 1. Функция helplncrement использует
функцию endOfMonth для правильного инкрементирования дня.
Перегруженная операция префиксного инкремента возвращает ссылку на
текущий объект Date (т.е. с уже измененной датой). Это происходит потому,
что текущий объект, *this, возвращается как Date &. Это позволяет
использовать преинкрементированный объект Date как lvalue — так встроенная
операция преинкремента работает при применении к основным типам.
Перегрузка операции постфиксного инкремента (определяется на рис. 11.13
в строках 30-34) немного сложнее. Чтобы эмулировать действие постфиксного
инкремента, мы должны вернуть немодифицированную копию объекта Date.
Например, если целая переменная х имеет значение 7, оператор
Перегрузка операций; объекты Array и String
737
cout « x++ « endl;
выводит первоначальное значение х. Нам хотелось бы, чтобы наша операция
постинкремента с объектом Date работала так же. Поэтому при входе
в operator++ мы сохраняем текущий объект (*this) в temp (строка 40). Затем
мы вызываем helplncrement, чтобы инкрементировать текущий объект Date.
Затем строка 44 возвращает копию исходного объекта, сохраненного раннее
в temp. Заметьте, что эта функция не может вернуть ссылку на локальный
объект Date (temp), так как локальная переменная уничтожается, когда
функция, в которой она объявлена, завершается. Таким образом, объявление
возвращаемого этой функцией типа как Date & привело бы к ссылке на объект,
который больше не существует. Возвращение ссылки (или указателя) на
локальную переменную является распространенной ошибкой, для которой
большинство компиляторов выдадут предупреждение.
11.13. Класс string стандартной библиотеки
В этой главе вы узнали, что можно построить класс String (рис. 11.9-11.11),
который лучше, чем строки char* в стиле С, перенесенные в C++ из С. Кроме
того, вы узнали, что можно создать класс Array (рис. 11.6-11.8), который
лучше массивов-указателей в стиле С, также перенесенных в C++ из С.
Создание полезных утилизируемых классов, подобных String и Array,
требует немалой работы. Однако после того, как такие классы созданы,
протестированы и отлажены, они могут использоваться вами, вашими коллегами,
вашей компанией, многими компаниями, целой отраслью или многими
отраслями (если они размещаются в общедоступных или коммерческих библиотеках).
Именно к этому стремились разработчики C++, встраивая в стандарт C++
классы string (которым мы пользуемся начиная с главы 3) и vector (который
мы ввели в главе 7). Эти классы доступны любому человеку,
разрабатывающему приложения на C++. В стандартной библиотеке C++ предусмотрено
несколько предопределенных шаблонов классов, которые вы можете
использовать в своих программах.
В заключение мы переработаем наш пример с классом String
(рис. 11.9-11.11), используя стандартный класс C++ string. Мы
переработали этот пример, чтобы продемонстрировать аналогичные функциональные
возможности, предоставляемые стандартным классом string. Мы также
демонстрируем три элемент-функции стандартного класса string — empty,
substr и at, — которых не было в нашем примере класса String. Функция
empty определяет, не пуста ли строка, функция substr возвращает строку,
представляющую часть исходной строки, а функция at возвращает символ
с указанным индексом (предварительно проверяя, находится ли индекс в
допустимом диапазоне).
Класс string стандартной библиотеки
На рис. 11.15 заново реализуется программа из рис. 11.11, с
использованием стандартного класса string. Как вы увидите из этого примера, класс string
обеспечивает все функциональные возможности нашего класса String,
представленного в программе на рис. 11.9-11.10. Класс string определяется в
заголовке <string> (строка 7) и принадлежит к пространству имен std (строка 8).
24 Зак. 1114
738
Глава 11
1 // Рис. 11.15: figll_15.cpp
2 // Тестовая программа для класса string стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 int main()
11 {
12 string si( "happy" );
13 string s2( " birthday" );
14 string s3;
15
16 // тест перегруженных операций равенства и отношений
17 cout « "si is \"" « si « "\"; s2 is \"" « s2
18 « "\"; s3 is \"" « s3 « '\"'
19 « "\n\nThe results of comparing s2 and si:"
20 « "\ns2 == si yields " « ( s2 == si ? "true" : "false" )
21 « "\ns2 != si yields " « ( s2 != si ? "true" : "false" )
22 « "\ns2 > si yields " « ( s2 > si ? "true" : "false" )
23 « "\ns2 < si yields " « ( s2 < si ? "true" : "false" )
24 « "\ns2 >= si yields " « ( s2 >= si ? "true" : "false" )
25 « "\ns2 <= si yields " « ( s2 <= si ? "true" : "false" );
26
27 // тест элемент-функции empty класса string
28 cout « "\n\nTesting s3.empty():" « endl;
29
30 if ( s3. empty () )
31 {
32 cout « "s3 is empty; assigning si to s3;" « endl;
33 s3 = si; // assign si to s3
34 cout « "s3 is \"" « s3 « "\"";
35 } // end if
36
37 // тест перегруженной операции конкатенации строк
38 cout « "\n\nsl += s2 yields si = ";
39 si += s2; // тестировать перегруженную конкатенацию
40 cout « si;
41
42 // тест перегруженной операции конкатенации со строкой в стиле С
43 cout « "\n\nsl += \" to you\" yields" « endl;
44 si += " to you";
45 cout « "si = " « si « "\n\n";
46
47 // тест элемент-функции substr
48 cout « "The substring of si starting at location 0 for\n"
49 « 4 characters, sl.substr@, 14), is:\n"
50 « sl.substr( 0, 14 ) « "\n\n";
51
52 // тест опции "до конца строки" функции substr
53 cout « "The substring of si starting at\n"
54 « "location 15, si.substrA5), is:\n"
55 « si.substr( 15 ) « endl;
56
Перегрузка операций; объекты Array и String
739
57 // тест конструктора копии
58 string *s4Ptr = new string( si );
59 cout « "\n*s4Ptr = » « *s4Ptr « "\n\n";
60
61 // тест присваивания операции (=) operator с самоприсваиванием
62 cout « "assigning *s4Ptr to *s4Ptr" « endl;
63 *s4Ptr = *s4Ptr;
64 cout « "*s4Ptr = " « *s4Ptr «
endives
66 // тест деструктора
67 delete s4Ptr;
68
69 // тест операции индексации для создания lvalue
70 sl[ 0 ] = 'Н';
71 sl[ 6 ] = 'В';
72 cout « "\nsl after sl[0] = 'H' and sl[6] = 'B' is: "
73 « sl « "\n\n";
74
75 // тест проверки диапазона индекса функцией "at" класса string
76 cout « "Attempt to assign 'd' to sl.at( 30 ) yields:" « endl;
77 sl.at( 30 ) = ' d1; // ОШИБКА: индекс вне диапазона
78 return 0;
79 } // конец main
sl is "happy"; s2 is " birthday"; s3 is ""
The results of comparing s2 and sl:
s2 == sl yields false
s2 != sl yields true
s2 > sl yields false
s2 < sl yields true
s2 >= sl yields false
s2 <= sl yields true
Testing s3.empty():
s3 is empty; assigning sl to s3;
s3 is "happy"
sl += s2 yields sl = happy birthday
sl += " to you" yields
sl = happy birthday to you
The substring of sl starting at location 0 for
14 characters, sl.substr@, 14), is:
happy birthday
The substring of sl starting at
location 15, sl.substrA5), is:
to ycu
*s4Ptr = happy birthday to you
assigning *s4Ptr to *s4Ptr
*s4Ptr = happy birthday to you
740
Глава 11
si after sl[0] = 'H' and sl[6] = 'B' is: Happy Birthday to you
Attempt to assign 'd' to sl.at( 30 ) yields:
Abnormal program termination
Рис. 11.15. Класс string стандартной библиотеки
В строках 12-14 создаются три объекта класса string: sl инициализируется
литералом "happy", s2 инициализируется литералом "birthday" и
s3"использует конструктор string по умолчанию для создания пустой строки. Код
в строках 17-18 выводит эти три объекта, используя cout и операцию «,
которую разработчики класса string перегрузилит для обработки
string-объектов. После этого в строках 19-25 выводятся результаты сравнения s2 с sl с
использованием перегруженных операций равенства и отношений класса string.
Наш класс String (рис. 11.9-11.10) предусматривал перегруженную
операцию operator!, которая проверяла объект String на предмет того, является ли
он пустым. Стандартный класс string не предоставляет такой возможности
в качестве перегруженной операции; вместо этого он предусматривает
элемент-функцию empty у которая демонстрируется в строке 30. Функция empty
возвращает true, если строка пуста; в противном случае она возвращает false.
Строка 33 демонстрирует перегруженную операцию присваивания класса
string, присваивая объект sl объекту s3. Строка 41 выводит s3 для
демонстрации того, что присваивание выполнено корректно.
В строке 39 демонстрируется перегруженная операция += класса string для
конкатенации строк. В данном случае содержимое s2 присоединяется к sl.
Затем в строке 40 выводится полученная строка, которая сохраняется в sl.
Строка 44 демонстрирует, что к объекту string с помощью операции += может
быть присоединен строковый литерал в стиле С. Строка 45 выводит результат.
Наш класс String (рис. 11.9-11.10) предусматривал перегруженную
операцию operator() для получения подстрок. Стандартный класс string не
предоставляет такой возможности в качестве перегруженной операции; вместо этого
он предусматривает элемент-функцию substr (строки 50 и 55). Вызов substr
в строке 50 возвращает подстроку длиной 14 символов (задается вторым
аргументом) объекта sl, начиная с позиции 0 (задается первым аргументом).
Вызов substr в строке 55 возвращает подстроку объекта sl, начиная с
позиции 15. Когда второй аргумент не указан, substr возвращает оставшуюся часть
объекта string, для которого она вызывается.
Строка 58 динамически выделяет объект string и инициализирует его
копией sl. Это приводит к вызову конструктора копии класса string. В строке 63
используется перегруженная операция = класса string для демонстрации того,
что самоприсваивание обрабатывается правильно.
В строках 70-71 используется перегруженная операция [] класса string для
создания lvalue9 которые позволяют заместить имеющиеся в sl символы
новыми символами. Строка 73 выводит новое значение sl. В нашем классе String
(рис. 11.9-11.10) перегруженная операция [] выполняла проверку границ для
определения того, является ли индекс, полученный ею как аргумент,
допустимым индексом в строке. Если индекс был недействительным, операция
печатала сообщение об ошибке и завершала программу. Перегруженная операция
[] стандартного класса string не выполняет проверку границ. Поэтому про-
Перегрузка операций; объекты Array и String
741
граммист должен убедиться, что операции, использующие перегруженную
операцию [] стандартного класса string, не будут случайно манипулировать
элементами вне границ строки. Стандартный класс string предусматривает
проверку границ в форме элемент-функции at, которая «выбрасывает
исключение», если ее аргумент является недопустимым индексом. По умолчанию
в таких случаях программа C++ завершается. Если индекс является
допустимым, функция at возвращает символ в указанной позиции как
модифицируемое lvalue или немодифицируемое rvalue, в зависимости от контекста, в
котором появляется вызов. Строка 77 демонстрирует вызов функции at с
недопустимым индексом.
11.14. explicit-конструкторы
В разделах 11.8 и 11.9 мы говорили о том, что конструктор с одним
аргументом может вызываться компилятором для выполнения неявного
преобразования, — тип, принимаемый конструктором, преобразуется в объект класса,
в котором определен конструктор. Преобразование производится
автоматически, и программисту не нужно использовать операцию приведения. В
некоторых ситуациях неявные преобразования нежелательны или уязвимы для
ошибок. Например, наш класс Array на рис. 11.6 определяет конструктор,
принимающий аргумент типа int. Этот конструктор предназначен для создания
объекта Array, содержащего специфицированное аргументом число
элементов. Однако компилятор может ошибочно использовать этот конструктор для
неявного преобразования.
Случайное использование конструктора с одним аргументом
в качестве конструктора преобразования
Программа на рис. 11.16 использует класс Array из рис. 11.6-11.7, чтобы
продемонстрировать ошибочное неявное преобразование.
Строка 13 в main создает объект Array с именем integers 1 и вызывает
конструктор с одним аргументом с целым значением 7, специфицирующим число
элементов в массиве. Вспомните, что конструктор Array на рис. 11.7,
принимающий целый аргумент, инициализирует все элементы массива нулями.
Строка 14 вызывает функцию outputArray (определенную в строках 20-24),
принимающую в качестве аргумента константную ссылку на Array. Функция
выводит число элементов в массиве и его содержимое. В данном случае размер
массива равен 7, поэтому выводится семь нулей.
Строка 15 вызывает функцию outputArray с целым значением аргумента 3.
Однако в программе нет функции outputArray, которая принимала бы
аргумент типа int. Поэтому компилятор выясняет, нет ли в классе Array
конструктора преобразования, который может преобразовать int в Array. Поскольку
любой конструктор, принимающий единственный аргумент, рассматривается как
конструктор преобразования, компилятор полагает, что конструктор Array,
принимающий аргумент типа int, является конструктором преобразования,
и использует его для преобразования аргумента 3 во временный объект Array,
содержащий три элемента. Затем компилятор передает это временный объект
функции outputArray для вывода содержимого массива. Таким образом, хотя
мы и не предусмотрели в классе явно функции outputArray, принимающей ар-
742
Глава 11
гумент типа int, компилятор все же может компилировать строку 15. Вывод
показывает содержимое трехэлементного массива с тремя нулями.
1 // Рис. 11.16: Figll_16.cpp
2 // Драйвер для простого класса Array.
3 #include <iostream>
4 using std:rcout;
5 using std::endl;
6
7 #include "Array.h"
8
9 void outputArray( const Array & ); // прототип
10
11 int main()
12 {
13 Array integers1( 7 ); // 7-элементный массив
14 outputArray( integersl ); // вывести массив integersl
15 outputArray( 3 ); // преобразовать З в Array и вывести содержимое
16 return 0;
17 } // конец main
18
19 // печать содержимого массива
20 void outputArray( const Array fiarrayToOutput )
21 {
22 cout « "The Array received has " « arrayToOutput.getSize ()
23 « " elements. The contents are:\n" « arrayToOutput « endl;
24 } // конец функции outputArray
The Array received has 7 elements. The contents are:
0 0 0 0
0 0 0
The Array received has 3 elements. The contents are:
0 0 0
Рис. 11.16, Конструкторы с одним аргументом и неявные преобразования
Предотвращение случайного использования конструктора
с одним аргументом в качестве конструктора преобразования
В C++ имеется ключевое слово explicit, которое позволяет подавить
неявные преобразования посредством конструкторов с одним аргументом, когда
такие преобразования не должны допускаться. Рис. 11.17 объявляет в классе
Array explicit-конструктор. Единственной модификацией в классе Array
является добавление ключевого слова explicit к объявлению конструктора с
одним аргументом в строке 15. Файл исходного кода с определениями
элемент-функций класса Array не требует никаких изменений.
1 // Рис. 11.17: Array.h
2 // Класс Array для хранения массива целых чисел.
3 #ifndef ARRAY_H
4 #define ARRAY_H
5
6 #include <iostream>
Перегрузка операций; объекты Array и String
743
7 using std::ostream;
8 using std::istrearn;
9
10 class Array
11 {
12 friend о stream &operator«( ostream &, const Array & );
13 friend istream &operator»( istream &, Array & ) ;
14 public:
15 explicit Array( int =10 ); // конструктор по умолчанию
16 Array( const Array & ); // конструктор копии
17 ~Array(); // деструктор
18 int getSize() const; // возвратить размер
19
20 const Array &operator=( const Array & ); // операция присваивания
21 bool operator==( const Array & ) const; // операция равенства
22
23 // операция неравенства; возвращает обратное операции ==
24 bool operator!=( const Array bright ) const
25 {
26 return ! ( *this == right ); // invokes Array::operator=
27 } // конец функции operator!=
28
29 // операция индексации для не-const-объектов возвращает lvalue
30 int &operator[]( int );
31
32 // операция индексации для const-объектов возвращает rvalue
33 const int &operator[]( int ) const;
34 private:
35 int size; // размер массива-указателя
36 int *ptr; // указатель на первый элемент массива
37 }; // конец класса Array
38
39 #endif
Рис. 11.17. Определение класса Array с explicit-конструктором
На рис. 11.18 представлена слегка модифицированная версия программы
из рис. 11.16. Когда данная программа компилируется, компилятор выдает
сообщение об ошибке, указывающее, что целое значение, передаваемое
функции output Array в строке 15, не может быть преобразовано в const Array &.
Сообщение компилятора об ошибке показано в окне вывода. Строка 16
показывает, как можно использовать explicit-конструктор для создания
временного массива из 3-х элементов и передать его функции outputArray.
Типичная ошибка программирования 11.10
Попытка вызвать explicit-конструктор для неявного преобразования
является ошибкой компиляции.
Типичная ошибка программирования 11,11
Применение ключевого слова explicit к элементам данных или
элемент-функциям, не являющимся конструкторами с одним
аргументом, является ошибкой компиляции.
744
Глава 11
Предотвращение ошибок 11.3
Применяйте ключевое слово explicit к конструкторам с одним
аргументом, которые не должны использоваться компилятором для
неявных преобразований типа.
1 // Рис. 11.18: Figll_18.cpp
2 // Драйвер для простого класса Array.
3 #include <iostreazn>
4 using std::cout;
5 using std::endl;
6
7 #include "Array.h"
8
9 void outputArray( const Array & ); // прототип
10
11 int main()
12 {
13 Array integers1( 7 ); // 7-элементный массив
14 outputArray( integersl ); // вывести массив integersl
15 outputArray( 3 ); // преобразовать З в Array и вывести содержимое
16 outputArray ( Array ( 3 ) ) ; // явный вызов к-pa преобразования
17 return 0;
18 } // конец main
19
20 // print array contents
21 void outputArray( const Array &arrayToOutput )
22 {
23 cout « "The Array received has " « arrayToOutput.getSize ()
24 « " elements. The contents are:\n" « arrayToOutput « endl;
25 } // конец функции outputArray
c:\cpphtp5_examples\chll\Figll_17__18\Figll__18.cpp A5) : error C2664 :
'outputArray' : cannot convert parameter 1 from 'int' to 'const
Arrays'
Reason: cannot convert from 'int' to 'const Array'
Constructor for class 'Array' is declared 'explicit'
Рис, 11.18. Демонстрация explicit-конструктора
11.15. Заключение
В этой главе вы узнали, как строить более совершенные классы, определяя
перегруженные операции, которые позволяют работать с объектами ваших
классов так, как если бы они являлись основными типами C++. Мы
представили основные концепции перегрузки операций, а также рассказали об
ограничениях, накладываемых на перегруженные операции. Вы изучили
основания для реализации перегруженных операций в виде элемент-функций или
глобальных функций. Мы обсудили различия в перегрузке одноместных
и двухместных операций как элемент-функций и глобальных функций.
Говоря о глобальных функциях, мы показали, как реализовать ввод и вывод
объектов наших классов перегруженными функциями извлечения из потока и пере-
Перегрузка операций; объекты Array и String
745
дачи в поток. Мы показали специальную синтаксическую форму,
необходимую для различения префиксной и постфиксной версий операции инкремента
(++). Мы продемонстрировали также стандартный класс C++ string, широко
использующий перегруженные операции и являющийся надежным
утилизируемым классом, который может заменить строки-указатели в стиле С.
Наконец, вы узнали, как с помощью ключевого слова explicit предотвратить вызов
компилятором конструктора с одним аргументом для неявного
преобразования типов. В следующей главе мы продолжим обсуждение классов, представив
форму утилизации программного обеспечения, называемую наследованием.
Мы увидим, что классы часто имеют общие атрибуты и поведение. В таких
случаях можно определить эти атрибуты и поведение в общем «базовом»
классе и «наследовать» их в определениях новых классов.
Резюме
• C++ позволяет программисту перегружать большинство операций, делая их
зависимыми от контекста, в котором они применяются, — компилятор генерирует
соответствующий код, исходя из способа применения (например, типа операндов).
• Большинство операций C++ могут быть перегружены для работы с типами, оперде-
ляемыми пользователем.
• Примером перегруженной операции, встроенной в C++, является «, которая
используется и как операция передачи в поток, и как операция сдвига влево.
Операция >> также перегружена; она используется и как операция извлечения из потока,
и как операция правого сдвига.
• C++ перегружает операции сложения (+) и вычитания (—). Эти операции работают
по-разному в зависимости от контекста — в целой арифметике, арифметике с
плавающей точкой и арифметике указателей.
• Действия, выполняемые перегруженными операциями, могут выполняться и
посредством явных вызовов функций, но нотация операций, как правило, яснее и
привычнее для программистов.
• Операции перегружаются посредством написания обычного определения не-статиче-
ской элемент-функции или глобальной функции, за исключением того, что именем
функции должно быть ключевое слово operator с последующим символом
перегружаемой операции.
• Когда операции перегружаются как элемент-функции, они должны быть не-статиче-
скими, поскольку должны вызываться для объекта класса и действовать на этом
объекте.
• Чтобы использовать операцию с объектами класса, эта операция должна быть
перегружена, но здесь есть два исключения: операция присваивания (=), операция
взятия адреса (&) и операция-запятая (,).
• Приоритет и ассоциативность операции не могут быть изменены посредством
перегрузки.
• Нельзя изменить «мощность» операции, т.е. число операндов, которое
подразумевает операция.
• Нельзя создавать новые операции; могут быть перегружены только существующие
операции.
• Нельзя изменить способ воздействия операции на объекты основных типов.
• Перегрузка для класса операций присваивания и сложения не означает, что
автоматически будет перегружена операция +=. Такое поведение может быть достигнуто
только посредством явной перегрузки операции += для этого класса.
746
Глава 11
• Функции-операции могут быть элементами класса или глобальными функциями;
функции — не элементы обычно делают друзьями из соображений эффективности.
Элемент-функции используют неявный указатель this, чтобы получить один из
аргументов-объектов своего класса (левый операнд у двухместных операций). При
вызове глобальной функции должны быть явным образом указаны оба операнда
двухместной операции.
• При перегрузке операций (), [], —> или любой операции присваивания функция,
перегружающая операцию, должна быть объявлена элементом класса. Для других
операций перегружающая функция может быть как элементом класса, так и
глобальной функцией.
• Когда функция-операция реализуется как элемент, левый (или единственный)
операнд должен быть объектом (или ссылкой на объект), принадлежащим классу этой
операции.
• Если необходимо, чтобы левый операнд был объектом другого класса или объектом
основного типа, эта функция-операция должна объявляться как глобальная функция.
• Глобальная функция-операция может быть сделана другом, если она должна иметь
непосредственный доступ к закрытым или защищенным элементам класса.
• Перегруженная операция передачи в поток («) используется в выражениях, где
левый операнд имеет тип ostream &. Чтобы можно было записывать операцию таким
образом, когда правый операнд является объектом определенного пользователем класса,
она должна перегружаться как глобальная функция. Элемент-функция для операции
« должна была быть элементом класса ostream. Это невозможно, так как нам не
позволяется модифицировать классы стандартной библиотеки C++. Аналогично
операция извлечения из потока (») также должна быть глобальной функцией.
• Операции-элементы класса вызываются только тогда, когда левый операнд
двухместной операции является некоторым объектом этого класса или когда единственный
операнд одноместной операции является объектом этого класса.
• Другая причина, по которой для перегрузки операции можно выбрать функцию, не
являющуюся элементом, — требование коммутативности операции.
• В применении к cin и типу string манипулятор потока setw ограничивает число
прочитанных символов значением своего аргумента.
• Элемент-функция ignore класса istream отбрасывает заданное число символов во
входном потоке (по умолчанию один символ).
• Перегруженные операции ввода и вывода, если им необходимо иметь прямой доступ
к элементам класса, не объявленным как public, по соображениям эффективности
должны объявляться как друзья.
• Одноместная (унарная) операция для класса может быть перегружена как не-стати-
ческая элемент-функция без аргументов или как глобальная функция с одним
аргументом. Этот аргумент должен быть либо объектом класса, либо ссылкой на него.
• Элемент-функции, реализующие перегруженные операции, не могут быть
статическими, так как им требуется обращаться к не-статическим данным класса.
• Двухместная операция может быть перегружена как не-статическая
элемент-функция с одним аргументом или как глобальная функция с двумя аргументами (один из
которых должен быть либо объектом класса, либо ссылкой на объект класса).
• Конструктор копии инициализирует объект, используя другой объект того же класса.
Когда объекты класса содержат динамически выделенную память, в класса должен
определяться конструктор копии, гарантирующий, что каждый объект будет иметь
свою собственную копию динамически выделенной памяти. Обычно в таком классе
предусматривают также деструктор и перегруженную операцию присваивания.
• Реализация элемент-функции operator= должна производить проверку на
самоприсваивание (случай, когда объект присваивают самому себе).
Перегрузка операций; объекты Array и String
747
• Когда операция индексации применяется к const-объекту, компилятор генерирует
вызов const-версии operator[]. В случае применения операции к неконстантному
объекту вызывается неконстантная версия операции.
• Перегруженная операция индексации [] не обязательно должна применяться только
с массивами: она может использоваться для выбора элементов из других видов
контейнерных классов. Индексам также не обязательно быть целыми, например, они
могут быть символами или строками.
• Компилятор не может заранее знать, как производить преобразования между
типами, определяемыми пользователем, и преобразования между пользовательскими
и основными типами. Программист должен специфицировать, как должны
производиться такие преобразования. Они могут выполняться конструкторами
преобразований — конструкторами с одним аргументом, которые превращают объекты
различных типов (включая основные) в объекты конкретного класса.
• Операция преобразования (также называемая операцией приведения) может
применяться к объекту класса, преобразуя его в объект другого класса или в объект
основного типа. Такого рода операция преобразования должна быть не-статической
элемент-функцией класса. Перегруженная функция-операция приведения может
определяться для преобразования объекта определяемого пользователем тика в объекты
встроенных типов или в объекты других пользовательских типов.
• Перегруженная функция-операция приведения не специфицирует возвращаемый
тип — она возвращает тип, к которому преобразуется данный объект.
• Одной их замечательных особенностей операций приведения и конструкторов
преобразования является то, что при необходимости компилятор может автоматически
вызывать эти функции для создания временных объектов.
• Любой конструктор с единственным аргументом может рассматириваться в качестве
конструктора преобразования.
• Перегрузка операций вызова функций () является мощным средством, потому что
функции могут получать списки параметров произвольной длины и сложности.
• Все операции инкремента и декремента могут быть перегружены.
• Чтобы перегрузить операцию инкремента и в преинкрементной, и в
постинкрементной формах, перегруженные функции-операции должны иметь различные
сигнатуры, позволяющие компилятору определить, какая из операций ++ подразумевается.
Префиксные версии перегружаются точно так же, как перегружалась бы любая
другая префиксная одноместная операция. Чтобы обеспечить уникальность сигнатуры
для операции постинкремента, для нее объявляют второй аргумент, который должен
иметь тип int. В коде клиента этот рагумент не специфицируется. Он неявно
используется компилятором для различения префиксной и постфикской версий операции
инкремента.
• Стандартный класс string определяется в заголовке <string> и принадлежит к
пространству имен std.
• В классе string предусмотрено много перегруженных операций, в том числе
операции равенства, отношений, присваивания, присваивания суммы (для конкатенации)
и индексации.
• Класс string предусматривает элемент-функцию empty, которая возвращает true,
если строка пуста; в противном случае она возвращает false.
• Класс string предусматривает элемент-функцию substr, которая возвращает
подстроку (длина которой специфицируется вторым аргументом), начинающуюся
с позиции, специфицированной первым аргументом. Когда второй аргумент не
указан, substr возвращает оставшуюся часть объекта string, для которого она
вызывается.
748
Глава 11
Перегруженная операция [] стандартного класса string не выполняет проверку
границ. Поэтому программист должен убедиться, что операции, использующие
перегруженную операцию [] стандартного класса string, не будут случайно
манипулировать элементами вне границ строки.
Стандартный класс string предусматривает проверку границ в форме
элемент-функции at, которая «выбрасывает исключение», если ее аргумент является
недопустимым индексом. По умолчанию в таких случаях программа C++
завершается. Если индекс является допустимым, функция at возвращает символ в
указанной позиции как lvalue или rvalue, в зависимости от контекста, в котором
появляется вызов.
В C++ имеется ключевое слово explicit, которое позволяет подавить неявные
преобразования посредством конструкторов с одним аргументом, когда такие
преобразования не должны допускаться. Конструктор, объяленный как explicit, не может быть
использован в невном преобразовании.
Терминология
explicit-конструкторы
lvalue («левое значение»)
operator!
operator!=
operator()
operator!]
operator+
operator++
operator++( int )
operator+=
operator—
operator<
operator«
operator<=
operator=
operator==
operator>
operator>=
operator»
string (стандартный класс C++)
класс Array
ключевое слово operator
коммутативная операция
конкатенация строк
конструктор копии
конструктор преобразования
конструктор с одним аргументом
неявные преобразования,
определяемые пользователем
операция вызова функции ()
операция преобразования
перегруженная операция
перегруженная операция —
перегруженная операция !=
перегруженная операция []
перегруженная операция +
перегруженная операция ++
перегруженная операция +=
перегруженная операция <
перегруженная операция «
перегруженная операция <=
перегруженная операция ==
перегруженная операция >
перегруженная операция >=
перегруженная операция »
перегруженная операция
присваивания (=)
перегруженная операция-элемент
класса
перегрузка двухместной операции
перегрузка одноместной операции
перегрузка операции глобальной
функцией
перегрузка операций
подстрока
преобразование, определяемое
пользователем
преобразования между встроенными
типами и классами
преобразования между классовыми
типами
самоприсваивание
«мощность» операции
тип, определяемый пользователем
функция преобразования
функция-операция
функция-операция приведения
функция-операция присваивания
элемент-функция empty класса string
элемент-функция ignore класса
istream
элемент-функция substr класса string
Перегрузка операций; объекты Array и String
749
Контрольные вопросы
11-1- Заполните пропуски в следующих предложениях:
a) Предположим, что а и b — переменные целого типа, и мы формируем сумму
а + Ь. Теперь предположим, что с и d — переменные с плавающей точкой,
и мы формируем сумму с + d. Очевидно, что в данном случае две операции +
используются для различных целей. Это является примером .
b) Ключевое слово начинает определение перегруженной
функции-операции.
c) Чтобы использовать операции на объектах класса, они должны быть
перегружены, за исключением операций , и .
d) , и операций не могут быть изменены
перегрузкой.
11.2. Поясните многозначность операций « и » в C++.
11.3- В каком контексте может использоваться имя operator/ в C++?
11.4. (Верно/неверно) В C++ могут быть перегружены только уже существующие
операции.
11.5. Как соотносится приоритет перегруженной операции в C++ с приоритетом
первоначальной операции?
Ответы на контрольные вопросы
11-1. а) перегрузки операций b) operator с) присваивания (=), адреса (&),
операции-запятой (,) d) Приоритет, ассоциативность, «мощность».
11.2. Операция » является как операцией сдвига вправо, так и операцией
извлечения из потока в зависимости от контекста. Операция « является как операцией
сдвига влево, так и операцией передачи в поток.
11.3. Для перегрузки операции: это было бы именем функции, которая дала бы
версию операции / для некоторого класса.
11А Верно.
11.5. Идентичны.
Упражнения
11.6. Приведите, сколько сможете, примеров неявной перегрузки операций в C++.
Дайте мотивированный пример ситуации, в которой вам могло бы понадобиться
перегрузить операцию в C++ явным образом.
11.7. Операциями C++, которые не могут быть перегружены, являются ,
11.8. Конкатенация строк требует двух операндов — две строки, которые должны
быть соединены. В тексте мы показали, как реализовать операцию
конкатенации, которая присоединяет второй объект String, стоящий справа от операции,
к первому объекту String, модифицируя таким образом первый объект. В
некоторых приложениях желательно получать конкатенированный объект String, не
модифицируя аргументы операции. Модифицируйте operator+, чтобы
разрешить операции вида
stringl = string2 + string3;
750
Глава 11
11.9. (Упражнение на «элементарную» перегрузку операций) Чтобы в полной мере
оценить осторожность, которая требуется при выборе операций для перегрузки,
перечислите все перегружаемые операции C++, и для каждой из них укажите
возможный смысл (или несколько, если это целесообразно) для нескольких
классов, которые вы изучали в тексте. Мы предлагаем попытаться сделать это для
классов
a) Array
b) Stack
c) String
После того как вы это сделаете, выскажите свои замечания о том, какие
операции могут иметь смысл для широкого разнообразия классов. Какие операции
предсталяются малоценными в плане перегрузки? Какие представляются
сомнительными?
11.10. Теперь проделайте работу, обратную описанной в упражнении 11.9. Перечислите
все перегружаемые операции C++. Для каждой укажите, для какого, по вашему
мнению, возможного «элементаного действия» должна использоваться данная
операция. Если таких подходящих действий есть несколько отличных
кандидатов, перечислите их все.
11.11. Хорошим примером перегрузки операции вызова функции () является
реализация альтернативной формы индексации двумерных массивов, популярной в
некоторых языках программирования. Вместо того, чтобы писать для массива
обектов
chessBoard[ row ][ column ]
перегрузите операцию вызова, чтобы разрешить альтернативную запись
chessBoard( row, column )
Создайте класс DoubleSubscriptedArray с возможностями, похожими на
возможности класса Array из рис. 11.6-11.7. Во время конструирования класс
должен создавать массив с произвольным числом строк и столбцов. В классе должна
быть предусмотрена операция operator(), позволяющая производить действия
с двумерными массивами. Например, для DoubleSubscriptedArray размером 3
на 5 с именем а пользователь для доступа к элементу в строке 1 и столбце 3 мог
бы написать а( 1, 3 ). Как вы помните, operator() может принимать произвольное
число аргументов (см. пример operator() в классе String на рис. 11.9-11.10).
Внутренним представлением двумерного массива должен быть одномерный
массив с числом элементов, равным произведению числа строк на число столбцов
двумерного массива. Для доступа к каждому из элементов массива функция
operator() должна выполнять соответствующую арифметику указателей.
Должно быть две версии функции, одна из которых возвращает & int (чтобы элемент
DoubleSubscriptedArray можно было использовать в качестве lvalue), а другая
const & int (чтобы элемент const DoubleSubscriptedArray можно было
использовать в качестве rvalue). Класс должен также предусматривать следующие
операции: ==, !=, =, « (для вывода массива в формате таблицы со строками и
столбцами) и » (для вывода всего содержимого массива).
11.12. Перегрузите операцию индексации, чтобы она возвращала наибольший элемент
коллекции, второй по величине элемент, третий и т.д.
11.13. Рассмотрите класс Complex, показанный на рис. 11.19-11.21. Этот класс
позволяет производить действия над комплексными числами, которые записываются
в форме realPart + imaginaryPart * i, где i имеет значение корня из минус
единицы.
Перегрузка операций; объекты Array и String
751
a) Модифицируйте класс, чтобы разрешить ввод и вывод комплексных чисел
посредством перегруженных операций » и « (вы должны удалить из класса
функцию print).
b) Перегрузите операцию умножения, чтобы стало возможным умножение двух
комплексных чисел по стандартным правилам алгебры.
c) Перегрузите операции == и != для сравнения комплексных чисел.
1 // Рис. 11.19: Complex.h
2 // Определение класса Complex.
3 #ifndef COMPLEX_H
4 #define COMPLEX_H
5
6 class Complex
7 {
8 public:
9 Complex( double = 0.0, double = 0.0 ); // конструктор
10 Complex operator*( const Complex & ) const; // сложение
11 Complex operator-( const Complex & ) const; // вычитение
12 void print() const; // вывод
13 private:
14 double real; // действительная часть
15 double imaginary; // мнимая часть
16 }; // конец класса Complex
17
18 #endif
Рис. 11.19. Определение класса Complex
1 // Рис. 11.20: Complex.cpp
2 // Определения элемент-функций класса Complex.
3 #include <iostream>
4 using std::cout;
5
6 #include "Complex.h" // определение класса Complex
7
8 // конструктор
9 Complex::Complex( double realPart, double imaginaryPart )
10 : real( realPart ),
11 imaginary( imaginaryPart )
12 {
13 // пустое тело
14 } // конец конструктора Complex
15
16 // операция сложения
17 Complex Complex::operator+( const Complex &operand2 ) const
18 {
19 return Complex( real + operand2.real,
20 imaginary + operand2.imaginary );
21 } // конец функции operator+
22
23 // операция вычитания
24 Complex Complex::operator-( const Complex &operand2 ) const
25 {
752
Глава 11
26 return Complex( real - operand2.real,
27 imaginary - operand2.imaginary );
28 } // конец функции operator-
29
30 // вывести объект Complex в форме (a, b)
31 void Complex::print() const
32 {
33 cout « ' (' « real « ", " « imaginary « ') '
34 } // конец функции print
Рис. 11.20. Определения элемент-функций класса Complex
1 // Рис. 11.21: figll_21.cpp
2 // Тестовая программа для класса Complex.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Complex.h"
8
9 int mainQ
10 {
11 Complex x;
12 Complex у( 4.3, 8.2 );
13 Complex z( 3.3, 1.1 ) ;
14
15 cout « "x: ";
16 x.print();
17 cout « "\ny: ";
18 y.print();
19 cout « "\nz: ";
20 z.print();
21
22 x = у + z;
23 cout « "\n\nx = у + z:" « endl;
24 x.print();
25 cout « " =
26 y.print();
27 cout « " +
28 z. print () ;
29
30 x = у - z;
31 cout « "\n\nx = у - z:" « endl;
32 x.print();
33 cout « " = ";
34 y.print();
35 cout « " - ";
36 z.print();
37 cout « endl;
38 return 0;
39 } // конец main
Перегрузка операций; объекты Array и String
753
х: @, 0)
у: D.3, 8.2)
z: C.3, 1.1)
х = у + z:
G.6, 9.3) = D.3, 8.2) + C.3, 1.1)
х = у - z:
A, 7.1) = D.3, 8.2) - C.3, 1.1)
Рис. 11.21. Комплексные числа
11.14. Машина с 32-битовыми целыми может представлять целые числа в диапазоне
примерно от -2 миллиардов до +2 миллиардов. Ограничение этого
фиксированного диапазона редко дает о себе знать. Но существует много приложений, в
которых вы хотели бы иметь возможность представления целых в гораздо более
широком диапазоне. Вот для этого и был создан C++ — для создания мощных
новых типов данных. Рассмотрите класс Hugelnt на рис. 11.22-11.24.
Тщательно изучите класс, а затем:
a) Точно опишите, как он работает.
b) Какие ограничения имеет класс?
c) Перегрузите операцию умножения *.
d) Перегрузите операцию деления /.
e) Перегрузите операции отношения и проверки на равенство.
[Замечание. Мы не показываем для класса Hugelnt операцию присваивания
и конструктор копии, поскольку операция присваивания и конструктор копии,
генерируемые компилятором, могут правильно копировать весь массив данных.]
1 // Рис. 11.22: Hugeint.h
2 // Определение класса Hugelnt.
3 #ifndef HUGEINT_H
4 #define HUGEINT_H
5
6 #include <iostream>
7 using std::ostream;
8
9 class Hugelnt
10 {
11 friend оstream &operator« ( ostream &, const Hugelnt & );
12 public:
13 Hugelnt( long = 0 ) ; // конструктор преобразования/по умолчанию
14 Hugelnt( const char * ); // конструктор преобразования
,15
16 // операция сложения; Hugelnt + Hugelnt
17 Hugelnt operator+( const Hugelnt & ) const;
18
19 // операция сложения; Hugelnt + int
20 Hugelnt operator+( int ) const;
21
22 // операция сложения;
23 // Hugelnt + строка, представляющая большое целое значение
24 Hugelnt operator+( const char * ) const;
754
Глава 11
25 private:
26 short integer[ 30 ];
27 }; // конец класса Hugelnt
28
29 #endif
Рис. 11.22. Определение класса Hugelnt
1 // Рис. 11.23: Hugeint.cpp
2 // Определения элемент-функций и друзей класса Hugelnt.
3 #include <cctype> // прототип функции isdigit
4 using std::isdigit;
5
6 #include <cstring> // прототип функции strlen
7 using std::strlen;
8
9 #include "Hugeint.h" // определение класса Hugelnt
10
11 // конструктор по умолчанию; конструктор преобразования
12 // длинного целого в объект Hugelnt
13 Hugelnt::Hugelnt( long value )
14 {
15 // инициализировать массив нулем
16 for ( int i = 0; i <= 29; i++ )
17 integer[ i ] = 0;
18
19 // поместить в массив цифры аргумента
20 for ( int j = 29; value != 0 && j >= 0; j— )
21 {
22 integer[ j ] = value % 10;
23 value /= 10;
24 } // end for
25 } // конец конструктора преобразования/по умолчанию Hugelnt
26
27 // конструктор преобразования символьной строки,
28 // представляюще большое целое, в объект Hugelnt
29 Hugelnt::Hugelnt( const char *string )
30 {
31 // инициализировать массив нулем
32 for ( int i = 0; i <= 29; i++ )
33 integer[ i ] = 0;
34
35 // поместить в массив цифры аргумента
36 int length = strlen( string );
37
38 for ( int j = 30 - length, k = 0; j <= 29; j++, k++ )
39
40 if ( isdigit( string[ k ] ) )
41 integer[ j ] = string[ k ] - '0';
42 } // конец конструктора преобразования Hugelnt
43
44 // операция сложения; Hugelnt + Hugelnt
45 Hugelnt Hugelnt::operator+( const Hugelnt &op2 ) const
46 {
47 Hugelnt temp; // временный результат
Перегрузка операций; объекты Array и String
755
48 int carry = 0;
49
50 for ( int i - 29; i >= Q; i-- )
51 {,
52 temp.integer[ i ] =
53 integer[ i ] + op2.integer[ i ] + carry;
54
55 // определить, нужен ли перенос
56 if ( temp.integer[ i ] > 9 )
57 {
58 temp.integer[ i ] %= 10; // редуцировать к 0-9
59 carry = 1;
60 } // конец if
61 else // переноса нет
62 carry = 0;
63 } // конец for
64
65 return temp; // возвратить копию временного объекта
66 } // конец функции operator+
67
68 // операция сложения; HugeInt + int
69 HugeInt Hugelnt::operator+( int op2 ) const
70 {
71 // преобразовать ор2 в Hugelnt, затем вызвать
72 // operator+ для двух объектов Hugelnt
73 return *this + Hugelnt( op2 );
74 } // конец функции operator+
75
76 // операция сложения;
77 // Hugelnt + строка, представляющая большое целое значение
78 Hugelnt Hugelnt::operator*( const char *op2 ) const
79 {
80 // преобразовать op2 в Hugelnt, затем вызвать
81 // operatoг+ для двух объектов Hugelnt
82 return *this + Hugelnt( op2 );
83 } // конец функции operator*
84
85 // перегруженная операция вывода
86 ostreamS operator«( ostream fioutput, const Hugelnt &num )
87 {
88 int i;
89
90 for ( i = 0; ( num.integer[ i ] == 0 ) && ( i <= 29 ); i++ )
91 ; // пропустить начальные нули
92
93 if ( i == 30 )
94 ^ output « 0;
95 else
96
97 for ( ; i <= 29;* i++ )
98 output « num.integer[ i ];
99
100 return output;
101 } // конец функции operator«
Рис. 11,23. Определения элемент-функций и друзей класса Hugelnt
756
Глава 11
1 // Рис. 11.24: figll_24.cpp
2 // Тестовая программа для Hugelnt.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Hugeint.h"
8
9 int main()
10 {
11 Hugelnt nl( 7654321 );
12 Hugelnt n2( 7891234 );
13 Hugelnt n3( "99999999999999999999999999999" );
14 Hugelnt n4( " );
15 Hugelnt n5;
16
17 cout « "nl is " « nl « "\nn2 is " « n2
18 « "\nn3 is " « n3 « "\nn4 is " « n4
19 « "\nn5 is " « n5 « "\n\n";
20
21 n5 = nl + n2;
22 cout « nl « " + " « n2 « " = " « n5 « "\n\n";
23
24 cout « n3 « " + " « n4 « "\n= " « ( n3 + n4 ) « "\n\n";
25
26 n5 = nl + 9;
27 cout « nl « " + " « 9 « " = " « n5 « "\n\n";
28
29 n5 = n2 + 0000";
30 cout « n2 « " + " « 0000" « " = " « n5 « endl;
31 return 0;
32 } // конец main
nl is 7654321
n2 is 7891234
n3 is 99999999999999999999999999999
n4 is 1
n5 is 0
7654321 + 7891234 = 15545555
999999999999999999999999Э9999 + 1
= 100000000000000000000000000000
7654321 + 9 = 7654330
7891234 + 10000 = 7901234
Рис. 11.24. Очень большие целые числа
Перегрузка операций; объекты Array и String
757
11.15. Создайте класс RationalNumber (дроби) со следующими возможностями:
a) Создайте конструктор, который предотвращает равенство нулю знаменателя
дроби, сокращает или упрощает дроби, если они не в сокращенной форме,
и исключает отрицательные знаменатели.
b) Перегрузите для класса операции сложения, вычитания, умножения и
деления.
c) Перегрузите операции отношения и проверки на равенство.
11.16. Изучите функции библиотеки обработки строк С и реализуйте каждую из этих
функций как часть класса String (рис. 11.9-11.19). Используйте затем эти
функции для выполнения операций с текстами.
11.17. Разработайте класс Polinomial (полином). Внутренним представлением класса
Polinomial является массив членов полинома. Каждый член содержит
коэффициент и показатель степени. Член
2х4
имеет коэффициент 2 и показатель степени 4. Разработайте полный класс,
содержащий соответствующие функции конструктора, деструктора, а также функции
set и get. Класс должен обеспечивать путем использования перегруженных
операций следующие возможности:
a) Перегрузить операцию сложения (+), чтобы складывать два объекта класса
Polinomial.
b) Перегрузить операцию вычитания (-), чтобы вычитать два объекта класса
Polinomial.
c) Перегрузить операцию присваивания (=), чтобы присваивать один объект
класса Polinomial другому.
d) Перегрузить операцию умножения (*), чтобы перемножать два объекта класса
Polinomial.
e) Перегрузить операцию сложения с присваиванием (+=), операцию вычитания
с присваиванием (-=), операцию умножения с присваиванием (*=).
11.18. Программа на рис. 11.3-11.5 содержит комментарий «перегруженная операция
передачи в поток; не может быть элементом класса, если мы хотим применять
ее в форме cout « somePhoneNumber;». На самом деле она может быть
элементом класса PhoneNumber, если бы мы согласились применять ее одним из
следующих способов: somePhoneNumber.operator«( cout ); или
somePhoneNumber « cout;. Перепишите программу из рис. 11.3 с перегруженной операцией
передачи в поток operator« в форме элемент-функции, и проверьте два
предыдущих оператора, чтобы показать, что они работают.
12
Объектно-ориентированное
программирование:
наследование
ЦЕЛИ
В этой главе вы изучите:
• Создание новых классов на основе
существующих путем наследования.
• Каким образом наследование
способствует утилизации
программного обеспечения.
• Понятия базовых и производных
классов и взаимоотношения между
ними.
• Спецификатор доступа protected.
• Использование конструкторов
и деструкторов в иерархиях
наследования.
• Различия между открытым,
защищенным и закрытым наследованием.
• Использование наследования для настройки существующего
программного обеспечения.
760
Глава 12
12.1. Введение
12.2. Базовые и производные классы
12.3. Защищенные элементы
12.4. Отношения между базовыми и производными
классами
12.4.1. Создание и тестирование класса
CommissionEmployee
12.4.2. Создание класса BasePlusCommissionEmployee
без наследования
12.4.3. Создание иерархии наследования
CommissionEmployee —
BasePlusCommissionEmployee
12.4.4. Иерархия наследования
CommissionEmployee —
BasePlusCommissionEmployee с защищенными
данными
12.4.5. Иерархия наследования
CommissionEmployee —
BasePlusCommissionEmployee с закрытыми
данными
12.5. Конструкторы и деструкторы в производных классах
12.6. Открытое, защищенное и закрытое наследование
12.7. Наследование в конструировании программного
обеспечения
12.8. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
12.1. Введение
В этой главе мы продолжаем наше обсуждение объектно-ориентированного
программирования (OOP) и представляем еще один из его ключевых
моментов — наследование. Наследование является формой утилизации
программного обеспечения, когда программист создает класс, ассимилирующий данные
и поведение существующего класса и обогащающий их добавлением новых
свойств. Утилизация программного обеспечения экономит время,
затрачиваемое на программную разработку. Оно также поощряет использование
проверенного, отлаженного, высококачественного программного кода, позволяя
надеяться на то, что система будет реализована эффективно.
Объектно-ориентированное программирование: наследование
761
Создавая класс, программист вместо того, чтобы писать совершенно новые
элементы данных и элемент-функции, может указать, что новый класс должен
наследовать элементы существующего класса. Этот существующий класс
называется базовым классом, а новый класс — производным классом. (В других
языках программирования, например, в Java, базовый класс называют
суперклассом, а производный класс субклассом.) Производный класс служит
представлением более специализированной группы объектов. Как правило,
производный класс обладает поведением базового и какими-то дополнительными
элементами поведения. Как мы увидим, производный класс может также
настраивать поведение базового класса. Непосредственный базовый класс
является классом, который явно наследуется производным классом. Косвенный
базовый класс расположен на два или более уровней выше в иерархии
наследования. В случае простого наследования класс является производным
единственного (непосредственного) базового класса. C++ поддерживает также
сложное наследование, когда производный класс наследует нескольким
(возможно, не родственным между собой) базовым классам. Простое наследование
достаточно очевидно, — мы покажем несколько примеров, благодаря которым
читатель быстро усвоит это понятие. Сложное наследование может
образовывать нетривиальные структуры и быть небезопасным. Мы рассматриваем
сложное наследование в главе 23.
C++ предлагает три вида наследования: открытое (public), защищенное
(protected) и закрытое (private). В этой главе мы сосредоточим внимание на
открытом наследовании, а о других двух видах расскажем вкратце. В
некоторых случаях закрытое наследование может служить альтернативой
композиции. Третья форма, защищенное наследование, используется редко. В случае
открытого наследования любой объект производного класса является также
объектом базового (для данного производного) класса. Однако объекты
базового класса не являются при этом объектами производного класса. Например,
если взять в качестве базового класса «средство передвижения», а в качестве
производного — «автомобиль», то все автомобили являются средствами
передвижения, но не все средства передвижения — автомобили. По мере того, как
мы будем продолжать свое изучение объектно-ориентированного
программирования в этой и следующей главах, мы будем пользоваться этими
отношениями для выполнения некоторых интересных манипуляций.
Опыт построения систем программного обеспечения показывает, что
значительные объемы кода имеют дело с обработкой близкородственных
специальных случаев. Когда программисты погружаются в эти специальные случаи,
детали последних могут затемнить общую картину. В
объектно-ориентированном программировании программисты могут сосредоточиться на выявлении
общего в объектах системы, а не на отдельных случаях.
Мы различаем отношение «является» и отношение «имеет». Отношение
«является» представляет наследование. При таком отношении объекты
производного класса могут также рассматриваться в качестве объектов базового
класса, — например, автомобиль является средством передвижения, поэтому
все свойства и поведение средства передвижения являются также свойствами
автомобиля. Напротив, отношение «имеет» представляет композицию.
(Композиция обсуждалась в главе 10.) При таком отношении объект содержит в
качестве элементов один или несколько объектов других классов. Например, ав-
762
Глава 12
томобиль содержит многие компоненты, — он имеет рулевое колесо, имеет
педаль тормоза, имеет коробку передач и имеет много других частей.
Элемент-функциям производного класса может требоваться доступ к
элементам данных и элемент-функциям базового класса. Производный класс
может обращаться к элементам базового класса, не являющимся закрытыми.
Элементы базового класса, которые не должны быть доступны
элемент-функциям производного, должны объявляться в базовом классе как private.
Производный класс может производить изменения в состоянии закрытых элементов
базового, но только через не закрытые элемент-функции, предусмотренные
в базовом классе и наследуемые производным классом.
® Общее методическое замечание 12.1
Элемент-функции производного класса не могут непосредственно
обращаться к закрытым элемента базового класса.
® Общее методическое замечание 12.2
Если бы производный класс мог обращаться к закрытым элементам
базового, классы, наследующие производному классу, тоже могли бы
к ним обращаться. Таким образом, доступность того, что должно
было быть «закрытыми данными», распространялась бы далее, и все
преимущества сокрытия информации были потеряны.
Одной из проблем наследования является то, что производный класс может
унаследовать элементы данных и функции, которые ему не нужны или
которых он.не должен иметь. Проектировщик класса отвечает за то, что
возможности, предоставляемые классом, являются адекватными в свете будущих
производных классов. Даже если элемент-функция базового класса подходит для
производного класса, последнему часто требуется, чтобы она вела себя в
соответствии с его специфическими требованиями. В таких случаях
элемент-функция базового класса может быть переопределена в производном классе с
соответствующей ее реализацией.
12.2. Базовые и производные классы
Очень часто объект некоторого класса является также и объектом другого
класса. Прямоугольник — Rectangle, конечно же, является
четырехугольником — Quadrilateral (как и квадрат, и параллелограмм, и трапеция). Таким
образом, о классе Rectangle можно сказать, что он наследует классу
Quadrilateral. В этом контексте класс Quadrilateral называется базовым, а класс
Rectangle производным. Прямоугольник является специальным типом
четырехугольника, но нельзя исходя из этого утверждать, что четырехугольник
является прямоугольником, — он может быть, например, параллелограммом или
другой фигурой. Рис. 12.1 показывает несколько простых примеров
отношений наследования.
Объектно-ориентированное программирование: наследование 763
Базовый класс
Student (учащийся)
Shape (фигура)
Loan (ссуда)
Employee (сотрудник)
Account (счет)
Производные классы
GraduateStudent (аспирант)
UndegraduateStudent (студент)
Circle (круг)
Triangle (треугольник)
Rectangle (прямоугольник)
Sphere (сфера)
Cube (куб)
CarLoan (ссуда при покупке машины)
HomelmprovementLoan (ссуда на улучшение жилья)
MortgageLoan (ссуда по закладной)
Faculty (профессорско-преподавательский состав)
Staff (вспомогательный персонал)
CheckingAccount (текущий счет)
SavingsAccount (сберегательный счет)
Рис. 12.1- Некоторые простые примеры наследования
Поскольку каждый объект производного класса является объектом его
базового класса, и один базовый класс может иметь много производных,
множество объектов, представляемых базовым классом, обычно больше множества
объектов, представляемых любым из его производных классов. Так, класс
Vehicle представляет все средства передвижения, включая автомобили,
автобусы, лодки, самолеты, велосипеды и т.д. Напротив, производный класс Саг
представляет меньшее, более специфическое подмножество средств
передвижения.
Отношения наследования образуют древовидные иерархические
структуры. Базовый класс находится в иерархическом отношении со своими
производными классами. Хотя классы могут существовать независимо друг от
друга, они, оказываясь в иерархических отношениях, становятся родственными
друг другу. Класс становится либо базовым — предоставляя свои элементы
другим классам, — либо производным — наследуя элементы других
классов, — либо и тем, и другим.
Давайте разработаем простую иерархию наследования с пятью уровнями
(представленную классовой диаграммой UML на рис. 12.2). Университетское
сообщество насчитывает тысячи членов. Эти люди — сотрудники, учащиеся
и бывшие питомцы университета (alumni). Сотрудники относятся либо к
профессорско-преподавательскому составу, либо к вспомогательному персоналу.
Первые являются либо администраторами (такими, как деканы и члены
ученых советов), либо преподавателями. Заметьте, что некоторые
администраторы могут преподавать, поэтому посредством сложного наследования мы
образовали класс AdministratorTeacher. Заметьте также, что данная иерархия
могла бы содержать много других классов. Например, учащиеся могут
делиться на студентов и аспирантов. Студенты могут быть первокурсниками,
второкурсниками, студентами младших курсов и старшекурсниками.
764
Глава 12
CommunityMember
/ t *
\
Простое
Employee Student Alumnus наследование
/ \
r
/\
ЭГ
\ /
Простое
Faculty Staff наследование
Простое
Administrator Teacher наследование
Сложное
AdministratorTeacher наследование
Рис. 12.2. Иерархия наследования для членов университетского сообщества
(CommunityMember)
Каждая стрелка в иерархии (рис. 12.2) представляет отношение
«является». Следуя по стрелкам этой иерархии, мы можем, например,
констатировать, что «Employee (сотрудник) является CommunityMember (членом
сообщества), a Teacher (преподаватель) является членом Faculty
(профессорско-преподавательского состава факультета). CommunityMember является
непосредственным базовым классом для Employee, Student и Alumnus. Кроме
того, CommunityMember — косвенный базовый класс для всех остальных
классов на диаграмме. Начиная снизу, читатель может пройти по стрелкам
диаграммы и проследить отношение «является» до наивысшего базового
класса. Так, AdministratorTeacher является Administrator, является членом
Faculty, является Employee и является CommunityMember.
Рассмотрим теперь иерархию наследования Shape на рис. 12.3. Иерархия
начинается с базового класса Shape (фигура). От него производятся классы
TwoDimensionalShape и ThreeDimensionalShape, — фигуры бывают либо
двумерными, либо трехмерными. Третий уровень иерархии содержит
некоторые более специфические типа двумерных и трехмерных фигур. Как и на
рис. 12.2, мы, начиная снизу, можем пройти по стрелкам до наивысшего
базового класса этой иерархии, идентифицируя отношения «является».
Например, Triangle является TwoDimensionalShape и является Shape. Заметьте,
что эта иерархия могла бы содержать многие другие классы, такие, как
прямоугольники, эллипсы и трапеции, которые все являются двумерными
фигурами.
Объектно-ориентированное программирование: наследование
765
Shape
-'' \.
TwoDimensionalShape ThreeDimensionalShape
* ' к \ * к >
/ Т \ / I
Circle Square Triangle Sphere Cube Tetrahedron
Рис, 12,3. Иерархия наследования для «фигур»
Спецификация того, что класс TwoDimensionalShape производится от (или
наследует от) класса Shape, записывается в C++ следующим образом:
class TwoDimensionalShape : public Shape
Это пример открытого наследования^ наиболее распространенной формы
последнего. Мы будем также рассматривать закрытое наследование и
защищенное наследование (раздел 12.6). При любой форме наследования закрытые
элементы базового класса непосредственно не доступны из его производных
классов, но эти закрытые элементы базового класса все равно наследуются (т.е. они
все же входят в состав производных классов). В случае открытого
наследования все другие элементы базового класса, становясь элементами производного
класса, сохраняют свои спецификации доступа (открытые элементы базового
класса становятся открытыми элементами производного класса, и, как мы
вскоре увидим, защищенные элементы базового класса становятся
защищенными элементами производного).
Наследование не обязательно подходит для выражения любых отношений
классов. В главе 10 мы обсуждали отношение «имеет», когда классы имеют
элементы, являющиеся объектами других классов. Такие отношения
образуют классы путем композиции существующих классов. Например, если взять
классы Employee, BirthDate и TelephoneNumber, то нельзя сказать, что
Employee является BirthDate (датой своего рождения) или что Employee
является TelephoneNumber (своим телефонным номером). Однако вполне можно
сказать, что Employee имеет BirthDate и что Employee имеет TelephoneNumber.
С объектами базового класса и производного класса можно обращаться
одинаковым образом; их общность выражается в элементах базового класса.
Объекты всех классов, производных от общего базового класса, могут
трактоваться как объекты базового класса (т.е. такие объекты находятся с базовым
классом в отношении «является»). В главе 13 мы рассмотрим много примеров,
в которых воспользуемся наличием таких отношений.
12.3. Защищенные элементы
В главе 3 были представлены спецификаторы открытого и закрытого
доступа — public и private. Открытые элементы базового класса доступны в
пределах тела класса и везде в программе, где имеется дескриптор (т.е. имя, указа-
766
Глава 12
те ль или ссылка) объекта этого класса или его производного класса. Закрытые
элементы базового класса доступны только в пределах тела этого класса
и друзьям класса. В этом разделе мы вводим еще один спецификатор доступа:
protected (защищенного доступа).
Защищенный доступ предлагает уровень защиты, промежуточный между
открытым и закрытым доступом. Защищенные элементы базового класса
доступны в пределах тела данного класса, для его друзей и для элементов и
друзей классов, производных от данного.
Элемент-функции производного класса могут обращаться к открытым и
защищенным элементам базового класса просто по именам элементов. Когда
элемент-функция производного класса переопределяет элемент-функцию
базового, к последней можно обращаться в производном классе, предваряя имя
функции именем базового класса с бинарной операцией разрешения области
действия (::). Мы будем обсуждать доступ к переопределенным элементам
базового класса в разделе 12.4 и использование защищенных данных — в
разделе 12.4.4.
12.4. Отношения между базовыми и производными
классами
В этой главе мы используем иерархию наследования в приложении для
начисления заработной платы служащим компании, состоящую из различных
категорий служащих, чтобы обсудить отношения между базовым классом
и производным классом. Служащим, получающим только комиссионные (их
будет представлять базовый класс), выплачивается процент от суммы
совершенных ими сделок (продаж), в то время как служащие-комиссионеры с
минимальной зарплатой (которых будет представлять производный класс)
получают минимально гарантированную зарплату плюс процент от их сделок. Мы
разобьем наше обсуждение отношений между этими классами служащих на
продуманную последовательность из пяти примеров:
1. В нашем первом примере мы создаем класс CommissionEmployee,
который содержит в качестве закрытых элементов данных имя, фамилию,
номер социальной страховки, комиссионную ставку (процент) и объем (т.е.
общую сумму) продаж.
2. Второй пример определяет класс BasePlusCommissionEmployee, который
содержит в качестве закрытых элементов данных имя, фамилию, номер
социальной страховки, комиссионную ставку, объем продаж и
минимальную зарплату. Мы создадим этот класс, вручную написав каждую
необходимую строчку кода, — вскоре мы увидим, что гораздо более
эффективным будет создание этого класса просто путем наследования от
класса CommissionEmployee.
3. Третий пример определяет новую версию класса
BasePlusCommissionEmployee, которая непосредственно производится от класса
CommissionEmployee (т.е. BasePlusCommissionEmployee является CommissionEmployee,
который получает еще гарантированную плату) и пытается обратиться к
закрытым элементам данных класса CommissionEmployee, что приводит
к ошибкам компиляции, поскольку производный класс не имеет доступа
к закрытым данным базового класса.
Объектно-ориентированное программирование: наследование
767
4. Четвертый пример показывает, что если объявить данные класса Сот-
missionEmployee как protected, to новая версия класса BasePlusCom-
missionEmployee, производная от класса CommissionEmployee, может
непосредственно обращаться к этим данным. Для этой демонстрации мы
определяем новую версию класса CommissionEmployee с защищенными
данными. Как версия BasePlusCommissionEmployee с наследованием, так
и его версия без наследования обладают одинаковыми функциональными
свойствами, но мы показываем, что версию с наследованием от класса
CommissionEmployee создать и сопровождать значительно проще.
5. Обсудив удобства использования защищенных данных, мы создаем
пятый пример, который снова делает элементы данных класса
CommissionEmployee закрытыми в соответствии с принципами правильного
конструирования программного обеспечения. Этот пример
демонстрирует, что производный класс BasePlusCommissionEmployee может
использовать открытые элемент-функции базового класса CommissionEmployee
для манипуляции его закрытыми данными.
12.4.1. Создание и тестирование класса
CommissionEmployee
Давайте сначала разберем определение класса CommissionEmployee
(рис. 12.4-12.5). Заголовочный файл CommissionEmployee (рис. 12.4)
специфицирует открытые услуги класса, в число которых входят конструктор
(строки 12-13) и элемент-функции earnings (строка 30) и print (строка 31).
Строки 15-28 объявляют открытые set- и £е£-функции для манипуляций
элементами данных класса (объявляются в строках 33-37) — first Name, lastName,
socialSecurityNumber, grossSales и commissionRate. Заголовочный файл
CommissionEmployee специфицирует все эти элементы как private, поэтому
объекты других классов не могут обращаться к ним непосредственно.
Объявление элементов данных как private и определение не-закрытых set-
и gef-функций для подтверждения данных и манипуляций с ними
соответствует принципам правильного конструирования программного обеспечения.
Элемент-функции setGrossSales (определяется в строках 57-60 на рис. 12.5)
и setCommissionRate (определяется в строках 69-72 на рис. 12.5), например,
подтверждают действительность своих аргументов, прежде чем присвоить их
значения элементам данных grossSales и commissionRate.
1 // Рис. 12.4: CommissionEmployee.h
2 // Класс CommissionEmployee - служащий, получающий комиссионные.
3 #ifndef COMMISSION^
4 #de£ine COMMISSION_H
5
6 #include <string> // стандартный класс C++ string
7 using std::string;
8
9 class CommissionEmployee
10 {
11 public:
12 CommissionEmployee( const string &, const string &,
13 const string &, double = 0.0, double = 0.0 );
768
Глава 12
14
15 void setFirstName( const string & ); // установить имя
16 string getFirstName() const; // возвратить имя
17
18 void setLastName( const string & ); // установить фамилию
19 string getLastName() const; // возвратить фамилию
20
21 void setSocialSecurityNuznber( const string & ); // установить SSN
22 string getSocialSecurityNumber() const; // возвратить SSN
23
24 void setGrossSales( double ); // установить общую сумму продаж
25 double getGrossSales() const; // возвратить общую сумму продаж
26
27 void setCommissionRate ( double ); // установить процент
28 double getCommissionRate() const; // возвратить процент
29
30 double earnings() const; // вычислить заработок
31 void print() const; // напечатать объект CommissionEmployee
32 private:
33 string firstName;
34 string lastName;
35 string socialSecurityNumber;
36 double grossSales; // продажи за неделю
37 double commissionRate; .// комиссионный процент
38 }; // конец класса CommissionEmployee
39
40 #endif
Рис. 12.4. Заголовочный файл класса CommissionEmployee
1 // Рис. 12.5: CommissionEmployee.срр
2 // Определения элемент-функции класса CommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 #include "CommissionEmployee.h" // определение CommissionEmployee
7
8 // конструктор
9 CommissionEmployee::CommissionEmployee(
10 const string &first, const string &last, const string &ssn,
11 double sales, double rate )
12 {
13 firstName = first; // должно проверяться
14 lastName = last; // должно проверяться
15 socialSecurityNumber = ssn; // должно проверяться
16 setGrossSales( sales ); // проверить и сохранить объем продаж
17 setCommissionRate( rate ); // проверить и сохранить процент
18 } // конец конструктора CommissionEmployee
19
20 // установить имя
21 void CommissionEmployee::setFirstName( const string &first )
22 {
23 firstName = first; // должно проверяться
24 } // end function setFirstName
25
Объектно-ориентированное программирование: наследование 769
26 // возвратить имя
27 string CommissionEmployee:rgetFirstName() const
28 {
29 return firstName;
30 } // конец функции getFirstName
31
32 // установить фамилию
33 void CommissionEmployee::setLastName( const string &last )
34 {
35 lastName = last; // должно проверяться
36 } // конец функции setLastName
37
38 // возвратить фамилию
39 string CommissionEmployee:rgetLastName() const
40 {
41 return lastName;
42 } // конец функции getLastName
43
44 // установить номер страховки
45 void CommissionEmployee::setSocialSecurityNumber(const string &ssn)
46 {
47 socialSecurityNumber = ssn; // должно проверяться
48 } // конец функции setSocialSecurityNumber
49
50 // возвратить номер страховки
51 string CommissionEmployee:.getSocialSecurityNumber() const
52 {
53 return socialSecurityNumber;
54 } // конец функции getSocialSecurityNumber
55
56 // установить общую сумму продаж
57 void CommissionEmployee::setGrossSales( double sales )
58 {
59 grossSales = ( sales < 0.0 ) ? 0.0 : sales;
60 } // конец функции setGrossSales
61
62 // возвратить общую сумму продаж
63 double CommissionEmployee:igetGrossSales() const
64 {
65 return grossSales;
66 } // конец функции getGrossSales
67
68 // установить комиссионный процент
69 void CommissionEmployee::setCommissionRate( double rate )
70 {
71 commissionRate = ( rate > 0.0 6& rate < 1.0 ) ? rate : 0.0;
72 } // конец функции setCommissionRate
73
74 // возвратить комиссионный процент
75 double CommissionEmployee::getCommissionRate() const
76 {
77 return commissionRate;
78 } // конец функции getCommissionRate
79
80 // вычислить заработок
81 double CommissionEmployee::earnings() const
82 {
25 Зак 1114
770
Глава 12
83 return commissionRate * grossSales;
84 } // конец функции earnings
85
86 // напечатать объект CommissionEmployee
87 void CommissionEmployee::print() const
88 {
89 cout « "commission employee: " « firstName « ' • « lastName
90 « "\nsocial security number: " « socialSecurityNumber
91 « "\ngross sales: " « grossSales
92 « "\ncommission rate: " « commissionRate;
93 } // конец функции print
Рис. 12.5. Файл реализации для класса CommissionEmployee, представляющего
служащего, которому платят процент от объема продаж
Определение конструктора CommissionEmployee в первых нескольких
примерах этого раздела намеренно не использует синтаксис инициализаторов
элементов, чтобы мы могли продемонстрировать, как спецификаторы private
и protected влияют на доступ к элементам в производных классах. Как
показано на рис. 12.5 в строках 13-15, мы присваиваем значения элементам данных
firstName, lastName и socialSecurityNumber в теле конструктора. Позже
в этом разделе мы вернемся к использованию в конструкторах списков
инициализации элементов.
Обратите внимание, что мы не подтверждаем действительности значений
аргументов конструктора first, last и ssn перед присвоением их соответствующим
элементам данных. Мы, безусловно, могли бы проверять имя и фамилию, —
возможно, убедившись, что они имеют разумную длину. Аналогично можно
было бы проверять номер социальной страховки, — он должен содержать
девять цифр, с дефисами или без них (например, 123-45-6789 или 123456789).
Элемент-функция earnings (строки 81-84) вычисляет заработок для
служащего. Строка 83 умножает commissionRate на grossSales и возвращает
результат. Элемент-функция print (строки 87-93) выводит значения элементов
данных объекта CommissionEmployee.
Программа на рис. 12.6 тестирует класс CommissionEmployee.
Строки 16-17 создают объект employee класса CommissionEmployee и вызывают
конструктор класса для инициализации объекта со значениями "Sue"
и "Jones" для имени и фамилии, 22-22-2222" для номера социальной
страховки, 10000 для объема продаж и .06 для комиссионной ставки.
Строки 23-29 вызывают #е£-функции объекта employee для вывода значений его
элементов данных. Строки 31-32 вызывают элемент-функции setGrossSales
и setCommissionRate объекта для изменения значений элементов данных
grossSales и commissionRate. Строка 36 вызывает затем элемент-функцию
print объекта employee, чтобы вывести обновленную информацию о
служащем. Наконец, строка 39 выводит заработок служащего, вычисленный
элемент-функцией earnings объекта на основании обновленных значений его
элементов данных grossSales и commissionRate.
1 // Рис. 12.6: figl2_06.cpp
2 // Тестирование класса CommissionEmployee.
3 #include <iostream>
4 using std::cout;
Объектно-ориентированное программирование: наследование 771
5 using std::endl;
6 using std::fixed;
7
8 #include <iomanip>
9 using std::setprecision;
10
11 #include "CommissionEmployee.h" // определение CommissionEmployee
12
13 int main()
14 {
15 // создать объект CommissionEmployee
16 CommissionEmployee employee(
17 "Sue", "Jones", 22-22-2222", 10000, .06 );
18
19 // установить формат вывода чисел с плавающей точкой
20 cout « fixed « setprecision( 2 );
21
22 // получить данные служащего
23 cout « "Employee information obtained by get functions: \n"
24 « "\nFirst name is " « employee .getFirstName ()
25 « "\nLast name is " « employee.getLastName()
26 « "\nSocial security number is "
27 « employee.getSocialSecurityNumber()
28 « "\nGross sales is " « employee.getGrossSales ()
29 « "\nCommission rate is "«employee.getCommissionRate()«endl;
30
31 employee.setGrossSales( 8000 ); // установить объем продаж
32 employee.setCommissionRate( .1 ); // установить процент
33
34 cout « "\nUpdated employee information "
35 « "output by print function: \n"« endl;
36 employee.print(); // вывести новую информацию о служащем
37
38 // вывести заработок служащего
39 cout «"\n\nEmployee's earnings: $"« employee.earnings ()« endl;
40
41 return 0;
42 } // конец main
Employee information obtained by get functions:
First name is Sue
Last name is Jones
Social security number is 222-22-2222
Gross sales is 10000.00
Commission rate is 0.06
Updated employee information output by print function:
commission employee: Sue Jones
social security number: 222-22-2222
gross sales: 8000.00
commission rate: 0.10
Employee's earnings: $800.00
Рис. 12.6. Тестовая программа для класса CommissionEmployee
772
Глава 12
12.4.2. Создание класса BasePlusCommissionEmployee
без наследования
Теперь мы перейдем ко второй части нашего введения в наследование и
создадим класс (совершенно новый и независимый)
BasePlusCommissionEmployee (рис. 12.7-12.8), который содержит имя, фамилию, номер социальной
страховки, объем продаж, комиссионную ставку и основную зарплату.
Определение класса BasePlusCommissionEmployee
Заголовочный файл BasePlusCommissionEmployee (рис. 12.7)
специфицирует открытые услуги класса, в число которых входят конструктор (строки 13-14)
и элемент-функции earnings (строка 34) и print (строка 35). Строки 16-32
объявляют открытые set- и ^г-функции для манипуляций элементами данных
класса (объявляются в строках 37-42) — first Name, lastName, socialSe-
curityNumber, gTossSales, commissionRate и baseSalary. Эти переменные
и элемент-функции инкапсулируют все необходимое для представления
служащего на зарплате, получающего комиссионные. Обратите внимание на сходство
между этим классом и классом CommissionEmployee (рис. 12.4-12.5); в этом
примере мы пока не воспользуемся этим сходством.
Элемент-функция earnings класса BasePlusCommissionEmployee
(определенная в строках 96-99 на рис. 12.8) вычисляет заработок служащего на
зарплате, получающего комиссионные. Строка 98 возвращает результат
суммирования зарплаты с произведением комиссионной ставки и объема продаж.
1 // Рис. 12.7: BasePlusCommissionEmployee.h
2 // Определение класса BasePlusCommissionEmployee представляет
3 // служащего, получающего основную зарплату и комиссионные.
4 #ifndef BASEPLUS_H
5 #define BASEPLUS_H
6
7 #include <string> // стандартный класс C++ string
8 using std::string;
9
10 class BasePlusCommissionEmployee
11 {
12 public:
13 BasePlusCommissionEmployee( const string &, const string &,
14 const string &, double = 0.0, double =0.0, double = 0.0 );
15
16 void setFirstName( const string & ); // установить имя
17 string getFirstName() const; // возвратить имя
18
19 void setLastName( const string & ); // установить фамилию
20 string getLastName() const; // возвратить фамилию
21
22 void setSocialSecurityNumber( const string & ); // установить SSN
23 string getSocialSecurityNumber() const; // возвратить SSN
24
25 void setGrossSales( double ); // установить общую сумму продаж
26 double getGrossSales() const; // возвратить общую сумму продаж
27
28 void setCommissionRate( double ); // установить процент
Объектно-ориентированное программирование: наследование
773
29 double getCommissionRate() const; // возвратить процент
30
31 void setBaseSalary( double ); // установить основную зарплату
32 double getBaseSalary() const; // возвратить основную зарплату
33
34 double earnings() const; // вычислить заработок
35 void print() const; // напечатать объект CommissionEmployee
36 private:
37 string firstName;
38 string lastName;
39 string socialSecurityNumber;
40 double grossSales; // продажи за неделю
41 double commissionRate; // комиссионный процент
42 double baseSalary; // основная зарплата
43 }; // конец класса BasePlusCommissionEmployee
44
45 #endi£
Рис. 12.7. Заголовочный файл класса BasePlusCommissionEmployee
1 // Рис. 12.8: BasePlusCommissionEmployee.срр
2 // Определения элемент-функции класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 // определение класса BasePlusCommissionEmployee
7 #include "BasePlusCommissionEmployee.h"
8
9 // конструктор
10 BasePlusCommissionEmployee: :BasePlusCommissionEmployee (
11 const string &first, const string &last, const string &ssn,
12 double sales, double rate, double salary )
13 {
14 firstName = first; // должно проверяться
15 lastName = last; // должно проверяться
16 socialSecurityNumber = ssn; // должно проверяться
17 setGrossSales( sales ); // проверить и сохранить объем продаж
18 setCommissionRate( rate ); // проверить и сохранить процент
19 setBaseSalary( salary ); // проверить и сохранить зарплату
20 } // конец конструктора BasePlusCommissionEmployee
21
22 // установить имя
23 void BasePlusCommissionEmployee::setFirstName(const string &first)
24 {
25 firstName = first; // должно проверяться
26 } // конец функции setFirstName
27
28 // возвратить имя
29 string BasePlusCommissionEmployee::getFirstName() const
30 {
31 return firstName;
32 } // конец функции getFirstName
33
34 // установить фамилию
35 void BasePlusCommissionEmployee::setLastName( const string &last )
774
Глава
36 {
37 lastName = last; // should validate
38 } // конец функции setLastName
39
40 // возвратить фамилию
41 string BasePlusCommissionEmployee::getLastName() const
42 {
43 return lastName;
44 } // конец функции getLastName
45
46 // установить номер страховки
47 void BasePlusCommissionEmployee::setSocialSecurityNumber(
48 const string &ssn )
49 {
50 socialSecurityNumber = ssn; // should validate
51 } // конец функции setSocialSecurityNumber
52
53 // возвратить номер страховки
54 string BasePlusCommissionEmployee::getSocialSecurityNumber() const
55 {
56 return socialSecurityNumber;
57 } // конец функции getSocialSecurityNumber
58
59 // установить общую сумму продаж
60 void BasePlusCommissionEmployee::setGrossSales( double sales )
61 {
62 grossSales = ( sales < 0.0 ) ? 0.0 : sales;
63 } // конец функции setGrossSales
64
65 // возвратить общую сумму продаж
66 double BasePlusCommissionEmployee::getGrossSales() const
67 {
68 return grossSales;
69 } // конец функции getGrossSales
70
71 // установить комиссионный процент
72 void BasePlusCommissionEmployee::setCommissionRate( double rate )
73 {
74 commissionRate = ( rate > 0.0 && rate < 1.0 ) ? rate : 0.0;
75 } // конец функции setCommissionRate
76
77 // возвратить комиссионный процент
78 double BasePlusCommissionEmployee::getCommissionRate() const
79 {
80 return commissionRate;
81 } // конец функции getCommissionRate
82
83 // установить зарплату
84 void BasePlusCommissionEmployee::setBaseSalary( double salary )
85 {
86 baseSalary = ( salary < 0.0 ) ? 0.0 : salary;
87 } // конец функции setBaseSalary
88
89 // возвратить зарплату
90 double BasePlusCommissionEmployee::getBaseSalary() const
91 {
92 return baseSalary;
Объектно-ориентированное программирование: наследование
775
93 } // конец функции getBaseSalary
94
95 // вычислить заработок
96 double BasePlusCommissionEmployee:learnings() const
97 {
98 return baseSalary + ( commassionRate * grossSales );
99 } // конец функции earnings
100
101 // напечатать объект BasePlusCommissionEmployee
102 void BasePlusCommissionEmployee::print() const
103 {
104 cout « "base-salaried commission employee: " « firstName « '
105 « lastName « "\nsocial security number: "
106 « socialSecurityNumber « "\ngross sales: " « grossSales
107 « "\ncommission rate: " « commissionRate
108 « "\nbase salary: " « baseSalary;
109 } // конец функции print
Рис. 12.8. Класс BasePlusCommissionEmployee представляет служащего,
получающего, кроме комиссионных, еще зарплату
Тестирование класса BasePlusCommissionEmployee
Программа на рис. 12.9 тестирует класс BasePlusCommissionEmployee.
Строки 17-18 создают объект employee класса BasePlusCommissionEmployee,
передавая конструктору значения "Bob", "Lewis", 33-33-3333", 5000, .04
и 300 соответственно для имени, фамилии, номера социальной страховки,
объема продаж, комиссионной ставки и зарплаты. Строки 24-31 вызывают
£е£-функции объекта employee для извлечения и вывода значений его элементов
данных. Строка 33 вызывает элемент-функцию объекта setBaseSalary, чтобы
изменить зарплату. Элемент-функция setBaseSalary (рис. 12.8, строки 84-87)
гарантирует, что элементу данных baseSalary не будет присвоено
отрицательное значение. Строка 37 вызывает элемент-функцию print объекта, чтобы
вывести обновленную информацию о служащем, а строка 40 вызывает
элемент-функцию earnings для вывода заработка BasePlusCommissionEmployee.
1 // Рис. 12.9: figl2_09.cpp
2 // Тестирование класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::fixed;
7
8 #include <iomanip>
9 using std::setprecision;
10
11 // определение класса BasePlusCommissionEmployee
12 #include "BasePlusCommissionEmployee.h"
13
14 int main()
15 {
16 // создать объект BasePlusCommissionEmployee
17 BasePlusCommissionEmployee
776
Глава 12
18 employee( "Bob", "Lewis", 33-33-3333", 5000, .04, 300 );
19
20 // установить формат вывода чисел с плавающей точкой
21 cout « fixed « setprecision( 2 );
22
23 // получить данные служащего
24 cout « "Employee information obtained by get functions: \n"
25 « "\nFirst name is " « employee.getFirstName()
26 « "\nLast name is " « employee.getLastName()
27 « "\nSocial security number is "
28 « employee.getSocialSecurityNumber()
29 « "\nGross sales is " « employee.getGrossSales()
30 « "\nCommission rate is " « employee.getCommissionRate ()
31 « "\nBase salary is " « employee.getBaseSalary() « endl;
32
33 employee.setBaseSalary( 1000 ); // установить зарплату
34
35 cout « "\nUpdated employee information "
36 « "output by print function: \n" « endl;
37 employee.print(); // вывести информацию о служащем
38
39 // вывести заработок служащего
40 cout «"\n\nEmployee1 s earnings: $"« employee.earnings ()« endl;
41
42 return 0;
43 } // конец main
Employee information obtained by get functions:
First name is Bob
Last name is Lewis
Social security number is 333-33-3333
Gross sales is 5000.00
Commission rate is 0.04
Base salary is 300.00
Updated employee information output by print function:
base-salaried commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
base salary: 1000.00
Employee's earnings: $1200.00
Рис. 12.9. Тестовая программа для класса BasePlusCommissionEmployee
Исследование сходства классов BasePlusCommissionEmployee
и CommissionEmployee
Обратите внимание, как много в классе BasePlusCommissionEmployee
(рис. 12.7-12.8) кода, схожего, если не полностью совпадающего, с кодом класса
CommissionEmployee (рис. 12.4-12.5). Например, в классе
BasePlusCommissionEmployee закрытые элементы данных firstName и lastName и эле-
Объектно-ориентированное программирование: наследование 777
мент-функции setFirstName, getFirstName, setLastName и getLastName
идентичны имеющимся в классе CommissionEmployee. Как класс
BasePlusCommissionEmployee, так и класс CommissionEmployee содержат также закрытые
элементы данных socialSecurityNumber, comissionRate и gross Sales вместе с set-
и ^-функциями для манипуляции этими элементами. Кроме того, конструктор
BasePlusCommissionEmployee почти идентичен конструктору
CommissionEmployee за исключением того, что конструктор BasePlusCommissionEmployee
устанавливает еще baseSalary. Другими дополнениями в классе
BasePlusCommissionEmployee являются закрытый элемент данных baseSalary и
элемент-функции setBaseSalary и getBaseSalary. Элемент-функция print класса
BasePlusCommissionEmployee идентична определенной в классе CommissionEmployee за
исключением того, что print из BasePlusCommissionEmployee выводит еще
значение элемента данных baseSalary.
Мы буквально скопировали код из класса CommissionEmployee и вставили
его в класс BasePlusCommissionEmployee, а затем модифицировали
последний, включив в него зарплату и функции, манипулирующие этой зарплатой.
Этот подход «копировать/вставить» часто поглощает много времени и не
гарантирован от ошибок. Что еще хуже, он может размножать в системе копии
одного и того же кода, превращая его сопровождение в кошмар. Существует
ли способ, не дублируя код, «ассимилировать» элементы данных и
элемент-функции класса таким образом, чтобы они становились составляющими
других классов? В нескольких следующих разделах мы, воспользовавшись
наследованием, сделаем именно это.
® Общее методическое замечание 12.3
Копирование и вставка кода из одного класса в другой может
приводить к распространению ошибок по многим файлам исходного кода.
Чтобы избежать дублирования кода (и, возможно, ошибок),
используйте наследование вместо подхода «копировать/вставить» в
ситуациях, где вы хотите «ассимилировать» элементы данных и функции
другого класса.
S Общее методическое замечание 12.4
При наследовании общие элементы данных и элемент-функции всех
классов в иерархии объявляются в базовом классе. Когда эти общие
элементы потребуют изменений, разработчикам программного
обеспечения нужно будет сделать эти изменения только в базовом
классе; производные классы тогда их унаследовать. Без наследования
нужно было бы сделать во всех исходных файлах, которые содержат про
дублированный код.
12.4.3. Создание иерархии наследования
CommissionEmployee — BasePlusCommissionEmployee
Теперь мы создадим и протестируем новую версию класса (рис. 12.10-12.11),
как производного от класса CommissionEmployee (рис. 12.4-12.5). В этом
примере объект BasePlusCommissionEmployee является объектом
CommissionEmployee (поскольку наследование передает ему свойства класса CommissionEm-
778
Глава 12
ployee), но класс BasePlusCommissionEmployee имеет дополнительный элемент
данных baseSalary (рис. 12.10, строка 24). Двоеточие (:) в строке 12
определения класса указывает на наследование. Ключевое слово public указывает тип
наследования. Как производный класс (порожденный открытым
наследованием), BasePlusCommissionEmployee наследует все элементы класса Commis-
sionEmployee, за исключением конструктора; каждый класс определяет свои
собственные, специфические для него конструкторы. [Заметьте, что
деструкторы также не наследуются.] Таким образом, в число открытых услуг класса
BasePlusCommissionEmployee входят его конструктор (строки 15-16) и
открытые элемент-функции, наследуемые от класса CommissionEmployee, — хотя мы
и не можем видеть эти унаследованные функции в исходном коде
BasePlusCommissionEmployee, они, тем не менее, являются частью этого производного
класса. К открытым услугам класса принадлежат также элемент-функции setBa-
seSalary, getBaseSalary, earnings и print.
1 // Рис. 12.10: BasePlusCommissionEmployee.h
2 // Класс BasePlusCommissionEmployee, производный от класса
3 // CommissionEmployee.
4 #ifndef BASEPLUS_H
5 #define BASEPLUS_H
6
7 #include <string> // стандартный класс C++ string
8 using std::string;
9
10 #include "CommissionEmployee.h" // объявление CommissionEmployee
11
12 class BasePlusCommissionEmployee : public CommissionEmployee
13 {
14 public:
15 BasePlusCommissionEmployee( const string &, const string &,
16 const string &, double = 0.0, double = 0.0, double = 0.0 );
17
18 void setBaseSalary( double ); // установить зарплату
19 double getBaseSalary() const; // возвратить зарплату
20
21 double earnings() const; // вычислить заработок
22 void print() const; // печать объекта BasePlusCommissionEmployee
23 private:
24 double baseSalary; // зарплата
25 }; // конец класса BasePlusCommissionEmployee
26
27 #endif
Рис. 12.10. Определение класса BasePlusCommissionEmployee,
специфицирующее наследование от класса CommissionEmployee
Рис. 12.11 показывает реализацию элемент-функций
BasePlusCommissionEmployee. Конструктор (строки 10-17) демонстрирует синтаксис
инициализатора базового класса (строка 14), который в инициализаторе элемента
передает аргументы конструктору базового класса (CommissionEmployee). C++
требует, чтобы конструктор производного класса вызывал конструктор своего
базового класса для инициализации унаследованных элементов данных. Стро-
Объектно-ориентированное программирование: наследование 779
ка 14 выполняет эту задачу, активируя конструктор CommissionEmployee по
имени, передавая в качестве аргументов свои параметры first, last, ssn, sales
и rate, чтобы инициализировать элементы базового класса first Name, last
Name, socialSecurityNumber, grossSales и commissionRate. Если бы
конструктор BasePlusCommissionEmployee не вызывал конструктор
CommissionEmployee явным образом, C++ попытался бы вызвать конструктор по умолчанию
класса CommissionEmployee, — но у последнего нет такого конструктора,
поэтому компилятор выдал бы ошибку. Вспомните, в главе 3 говорилось, что
компилятор создает в классе конструктор по умолчанию без параметров
только в том случае, когда этот класс не определяет явно никаких конструкторов.
Но CommissionEmployee определяет явный конструктор, поэтому
конструктор по умолчанию не создается и любая попытка неявного вызова
конструктора CommissionEmployee по умолчанию приводит к ошибке компиляции.
1 // Рис. 12.11: BasePlusCommissionEmployee.ерр
2 // Определения элемент-функций класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 // определение класса BasePlusCommissionEmployee
7 #include "BasePlusCommissionEmployee.h"
8
9 // конструктор
10 BasePlusCommissionEmployee::BasePlusCommissionEmployee(
11 const string &first, const string filast, const string fissn,
12 double sales, double rate, double salary )
13 // явно вызвать конструктор базового класса
14 : CommissionEmployee( first, last, ssn, sales, rate )
15 {
16 setBaseSalary( salary ); // проверить и сохранить зарплату
17 } // конец конструктора BasePlusCommissionEmployee
18
19 // установить зарплату
20 void BasePlusCommissionEmployee::setBaseSalary( double salary )
21 {
22 baseSalary = ( salary < 0.0 ) ? 0.0 : salary;
23 } // конец функции setBaseSalary
24
25 // возвратить зарплату
26 double BasePlusCommissionEmployee::getBaseSalary() const
27 {
28 return baseSalary;
29 } // конец функции getBaseSalary
30
31 // вычислить заработок
32 double BasePlusCommissionEmployee::earnings() const
33 {
34 // производному классу недоступны закрытые данные базового класса
35 return baseSalary + ( commissionRate * grossSales );
36 } // конец функции earnings
37
38 // напечатать объект BasePlusCommissionEmployee
39 void BasePlusCommissionEmployee::print() const
40 {
780
Глава 12
41 // производному классу недоступны закрытые данные базового класса
42 cout « "base-salaried commission employee: " « firstName « ' '
43 « lastName « "\nsocial security number: "
44 « socialSecurityNumber « "\ngross sales: " « grossSales
45 « "\ncommission rate: " « commissionRate
4 6 « "\nbase salary: " « baseSalary;
47 } // конец функции print
С:\cpphtp5_examples\chl2\Figl2_10_ll\BasePlusCommissionEmployee.cpp
C5) : error C2248: 'CommissionEmployee::commissionRate'
cannot access private member declared in class 'CommissionEmployee'
C:\cpphtp5_examples\chl2\Figl2_10_ll\CoinraissionEmployee.h C7) :
see declaration of 'CommissionEmployee: '.commissionRate'
C: \cpphtp5__examples\chl2\Figl2__10_ll\CommissionEmployee.h A0)
see declaration of 'CommissionEmployee'
С : \cpphtp5_examples\chl2\Figl2_10_ll\BasePlusCommissionEmployee . cpp
C5) : error C2248: 'CommissionEmployee::grossSales'
cannot access private member declared in class 'CommissionEmployeer
C: \cpphtp5_examples\chl2\Figl2__10__ll\CommissionEmployee .hC6)
see declaration of 'CommissionEmployee::grossSales'
C:\cpphtp5__examples\chl2\Figl2_10_ll\CommissionEmployee.hA0)
see declaration of 'CommissionEmployee'
С: \cpphtp5__examples\chl2\Figl2_10_ll\BasePlusCommissionEmployee.cpp
D2) : error C2248: 'CommissionEmployee::firstName'
cannot access private member declared in class 'CommissionEmployee'
С:\cpphtp5_examples\chl2\Figl2_10_ll\CommissionEmployee.hC3)
see declaration of 'CommissionEmployee::firstName'
C:\cpphtp5_examples\chl2\Figl2_10_ll\CommissionEmployee.hA0)
see declaration of 'CommissionEmployee'
С:\cpphtp5_examples\chl2\Figl2_10_ll\BasePlusCommissionEmployee.cpp
D3) : error C2248: 'CommissionEmployee::lastName'
cannot access private member declared in class 'CommissionEmployee'
C: \cpphtp5_examples\chl2\Figl2_JL0__ll\CommissionEmployee .h C4)
see declaration of 'CommissionEmployee::lastName'
C:\cpphtp5_examples\chl2\Figl2_10_ll\CommissionEmployee.hA0)
see declaration of 'CommissionEmployee'
С:\cpphtp5_examples\chl2\Figl2_10_ll\BasePlusCommissionEmployee.cpp
D3) : error C2248: 'CommissionEmployee::socialSecurityNumber'
cannot access private member declared in class 'CommissionEmployee'
C:\cpphtp5_examples\chl2\Figl2_10_ll\CommissionEmployee.hC5)
see declaration of 'CommissionEmployee::socialSecurityNumber'
C:\cpphtp5_examples\chl2\Figl2_10_ll\CommissionEmployee.hA0)
see declaration of 'CommissionEmployee'
С:\cpphtp5_examples\chl2\Figl2_10_ll\BasePlusCommissionEmployee.cpp
D4) : error C2248: 'CommissionEmployee::grossSales':
cannot access private member declared in class 'CommissionEmployee'
С:\cpphtp5_examples\chl2\Figl2_10_ll\CommissionEmployee.hC6)
see declaration of 'CommissionEmployee::grossSales'
C:\cpphtp5_examples\chl2\Figl2_10_ll\CommissionEmployee.hA0) :
see declaration of 'CommissionEmployee'
Объектно-ориентированное программирование: наследование
781
С: \cpphtp5_examples\chl2\Figl2_10__ll\BasePlusCommissionEmployee . срр
D5) : error C2248: 'CommissionEmployee::commissionRate '
cannot access private member declared in class
' CommissionEmployee'
C: \cpphtp5_examples\chl2\Figl2_10_ll\CommissionEmployee . h C7)
see declaration of 'CommissionEmployee::commissionRate'
С : \cpphtp5__examples\chl2\Figl2_10__ll\CommissionEmployee . h A0)
see declaration of 'CommissionEmployee'
Рис. 12.11. Файл реализации BasePlusCommissionEmployee: закрытые данные
базового класса недоступны для производного класса
—_^ Типичная ошибка программирования 12.1
Если конструктор производного класса вызывает один из
конструкторов своего базового класса с аргументами, не соответствующими
по числу и типам параметрам в определении конструктора базового
класса, происходит ошибка компиляции.
Вопросы производительности 12.1
$й
Инициализация элементов-объектов и вызов базового конструктора
в списке инициализаторов конструктора производного класса
предотвращает дублирование инициализации, когда вызывается
конструктор по умолчанию, а затем элементы данных модифицируются
в теле конструктора производного класса.
Компилятор генерирует ошибку для строки 35 на рис. 12.11, так как
элементы данных commissionRate и grossSales класса CommissionEmployee
являются закрытыми, — функциям производного класса
BasePlusCommissionEmployee не разрешен доступ к закрытым данным базового класса
CommissionEmployee. По той же причине компилятор выдает дополнительные
сообщения для строк 42-45 функции print класса
BasePlusCommissionEmployee. Как видите, C++ строго относится к ограничениям на доступ к
закрытым данным, так что даже производный класс (близко родственный базовому)
не может обращаться к закрытым данным базового класса. [Замечание. Ради
экономии места мы показали в этом примере только сообщения компилятора
Visual C++ .NET. Сообщения вашего компилятора могут отличаться от
показанных. Обратите также внимание, что мы выделили курсивом ключевые
строчки длинных сообщений.]
Мы намеренно написали в рис. 12.11 ошибочный код, чтобы
продемонстрировать недоступность закрытых данных базового класса для элемент-функций
производного класса. Ошибок в BasePlusCommissionEmployee можно было бы
избежать, если воспользоваться get -функциями, унаследованными от класса
CommissionEmployee. Например, строка 35 для доступа к закрытым
элементам данных commissionRate и grossSales класса могла бы вызывать
getCommissionRate и getGrossSales. Точно так же в строках 42-45 можно
было бы воспользоваться соответствующими get-функциями для извлечения
значений элементов данных базового класса. В следующем примере мы
покажем, что использование защищенных данных также позволяет предотвратить
ошибки, с которыми мы столкнулись в этом примере.
782
Глава 12
Включение директивой #include заголовочного файла базового
класса в заголовок производного класса
Обратите внимание, что мы включили в заголовочный файл производного
класса заголовочный файл базового класса (директива #include встроке 10
на рис. 12.10). Это необходимо по трем причинам. Прежде всего, чтобы
производный класс мог использовать в строке 12 имя базового класса, мы должны
сообщить компилятору, что такой класс существует; определение класса
в CommissionEmployee.h делает именно это.
Вторая причина состоит в том, что компилятор использует определение
класса для выяснения размера объекта этого класса (как говорилось в разделе 3.8).
Программа клиента, создающая объект класса, должна включать его
определение, чтобы компилятор мог резервировать под объект соответствующее
пространство в памяти. При наследовании размер объекта производного класса
зависит от элементов данных, объявленных в определении класса явным образом,
и от элементов данных, унаследованных от непосредственных и косвенных
базовых классов. Включение определения базового класса в строке 10 позволяет
компилятору определить, какая память требуется для элементов данных
базового класса, которые становятся частью объекта производного класса и, таким
образом, вносят свой вклад в общий размер объекта производного класса.
Наконец, строка 10 необходима для того, чтобы компилятор мог
определить, правильно ли производный класс использует унаследованные элементы
базового класса. Например, в программе на рис. 12.10-12.11 компилятор,
используя заголовочный файл базового класса, определяет, что элементы
данных, к которым обращается производный класс, объявлены в базовом классе
как private. Поскольку таковые недоступны для производного класса,
компилятор генерирует ошибки. Компилятор использует также прототипы функций
базового класса для проверки вызовов, посылаемых в производном классе
унаследованным функциям базового класса. Пример такого вызова вы
увидите на рис. 12.16.
Процесс компоновки в иерархии наследования
В разделе 3.9 мы обсуждали процесс компоновки при создании
исполняемого приложения GradeBook. В том примере вы видели, что объектный код
клиента компоновался с объектным кодом класса GradeBook, а также с
объектным кодом всех классов стандартной библиотеки C++, используемых либо
в коде клиента, либо в классе GradeBook.
Похожим образом происходит компоновка программы, использующей
классы в иерархии наследования. Для нее требуется объектный код всех классов,
используемых в программе, и объектный код непосредственных и косвенных
базовых классов любого из производных классов, используемых в программе.
Предположим, клиент хочет создать приложение, использующее класс Ва-
sePlusCommissionEmployee, который является производным от Commis-
sionEmployee (мы увидим подобный пример в разделе 12.4.4). При компиляции
приложения клиента объектный код клиента должен компоноваться с
объектным кодом классов BasePlusCommissionEmployee и CommissionEmployee, так
как BasePlusCommissionEmployee наследует элемент-функции своего базового
класса CommissionEmployee. Код компонуется также с объектом кодом любых
классов стандартной библиотеки, используемых в классе CommissionEmployee,
Объектно-ориентированное программирование: наследование
783
классе BasePlusCommissionEmployee или коде клиента. Это обеспечивает
программе доступ к реализации всех используемых в ней функций.
12.4.4. Иерархия наследования CommissionEmployee —
BasePlusCommissionEmployee с защищенными данными
Чтобы разрешить классу BasePlusCommissionEmployee непосредственно
обращаться к элементам данных first Name, lastName, socialSecurityNumber,
grossSales и commissionRate класса CommissionEmployee, мы можем
объявить эти элементы в базовом классе как protected. Как говорилось в
разделе 12.3, к защищенным элементам базового класса могут обращаться
элементы и друзья базового класса и элементы и друзья любых классов, производных
от данного базового класса.
Хороший стиль программирования 12.1
Объявляйте сначала открытые элементы класса, затем
защищенные и после всех прочих — закрытые.
Определение базового класса CommissionEmployee с защищенными
данными
Класс CommissionEmployee (рис. 12.12-12.13) объявляет теперь элементы
данных firstName, lastName, socialSecurityNumber, grossSales и
commissionRate (строки 33-37 на рис. 12.12) не как закрытые, а как защищенные.
Реализация элемент-функций на рис. 12.13 идентична показанной на рис. 12.5.
1 // Рис. 12.12: CommissionEmployee.h
2 // Класс CommissionEmployee - служащий, получающий комиссионные.
3 #ifndef COMMISSION_H
4 #define COMMISSION^
5
6 #include <string> // стандартный класс C++ string
7 using std::string;
8
9 class CommissionEmployee
10 {
11 public:
12 CommissionEmployee( const string &, const string &, const string &,
13 double =0.0, double = 0.0 );
14
15 void setFirstName( const string & ); // установить имя
16 string getFirstName() const; // возвратить имя
17
18 void setLastName( const string & ); // установить фамилию
19 string getLastName() const; // возвратить фамилию
20
21 void setSocialSecurityNumber( const string & ); // установить SSN
22 string getSocialSecurityNumber() const; // возвратить SSN
23
24 void setGrossSales( double ); // установить общую сумму продаж
25 double getGrossSales() const; // возвратить общую сумму продаж
26
27 void setCommissionRate( double ); // установить процент
784
Глава 12
28 double getCommissionRate() const; // возвратить процент
29
30 double earnings() const; // вычислить заработок
31 void print() const; // напечатать объект CommissionEmployee
32 protected:
33 string firstName;
34 string lastName;
35 string socialSecurityNumber;
36 double grossSales; // продажи за неделю
37 double commissionRate; // комиссионный процент
38 }; // конец класса CommissionEmployee
39
40 #endif
Рис. 12.12. Определение класса CommissionEmployee, объявляющего
защищенные данные, чтобы разрешить доступ к ним производным классам
1 // Рис. 12.13: CommissionEmployee.срр
2 // Определения элемент-функций класса CommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 #include "CommissionEmployee.h" // определение CommissionEmployee
7
8 // 'конструктор
9 CommissionEmployee::CommissionEmployee(
10 const string fifirst, const string filast, const string &ssn,
11 double sales, double rate )
12 {
13 firstName = first; // должно проверяться
14 lastName = last; // должно проверяться
15 socialSecurityNumber = ssn; // должно проверяться
16 setGrossSales ( sales ); // проверить и сохранить объем продаж
17 setCommissionRate( rate ); // проверить и сохранить процент
18 } // конец конструктора CommissionEmployee
19
20 // установить имя
21 void CommissionEmployee::setFirstName( const string fifirst )
22 {
23 firstName = first; // должно проверяться
24 } // end function setFirstName
25
26 // возвратить имя
27 string CommissionEmployee:rgetFirstName() const
28 {
29 return firstName;
30 } // конец функции getFirstName
31
32 // установить фамилию
33 void CommissionEmployee::setLastName( const string filast )
34 {
35 lastName = last; // должно проверяться
36 } // конец функции setLastName
37
38 // возвратить фамилию
Объектно-ориентированное программирование: наследование
785
39 string CommissionEmployee::getLastName() const
40 {
41 return lastName;
42 } // конец функции getLastName
43
44 // установить номер страховки
45 void CommissionEmployee::setSocialSecurityNumber(const string &ssn)
46 {
47 socialSecurityNumber = ssn; // должно проверяться
48 } // конец функции setSocialSecurityNumber
49
50 // возвратить номер страховки
51 string CommissionEmployee::getSocialSecurityNumber() const
52 {
53 return socialSecurityNumber;
54 } // конец функции getSocialSecurityNumber
55
56 // установить общую сумму продаж
57 void CommissionEmployee::setGrossSales( double sales )
58 {
59 grossSales = ( sales < 0.0 ) ? 0.0 : sales;
60 } // конец функции setGrossSales
61
62 // возвратить общую сумму продаж
63 double CommissionEmployee::getGrossSales() const
64 {
65 return grossSales;
66 } // конец функции getGrossSales
67
68 // установить комиссионный процент
69 void CommissionEmployee::setCommissionRate( double rate )
70 {
71 commissionRate = ( rate > 0.0 && rate < 1.0 ) ? rate : 0.0;
72 } // конец функции setCommissionRate
73
74 // возвратить комиссионный процент
75 double CommissionEmployee::getCommissionRate() const
76 {
77 return commissionRate;
78 } // конец функции getCommissionRate
79
80 // вычислить заработок
81 double CommissionEmployee:.earnings() const
82 {
83 return commissionRate * grossSales;
84 } // конец функции earnings
85
86 // напечатать объект CommissionEmployee
87 void CommissionEmployee::print() const
88 {
89 cout « "commission employee: " « firstName « ' ' « lastName
90 « "\nsocial security number: " « socialSecurityNumber
91 « "\ngross sales: " « grossSales
92 « "\ncommission rate: " « commissionRate;
93 } // конец функции print
Рис. 12.13. Класс CommissionEmployee с защищенными данными
786
Глава 12
Модификация производного класса BasePlusCommissionEmployee
Теперь мы можем модифицировать класс BasePlusCommissionEmployee
(рис. 12.14-12-15), чтобы он производился от версии класса CommissionEm-
ployee на рис. 12.12-12.13. Поскольку класс BasePlusCommissionEmployee —
производный от данной версии Commission Employee, его объекты могут
теперь обращаться к унаследованным элементам данных, объявленных в классе
CommissionEmployee как protected (т.е. к элементам first Name, lastName,
socialSecurityNumber, grossSales и commissionRate). В результате
компилятор теперь не генерирует ошибок при компиляции определений
элемент-функций earnings и print класса BasePlusCommissionEmployee на рис. 12.14
(строки 32-36 и 39-47). Это подтверждает особые привилегии, предоставляемые
производному классу в плане доступа к защищенным элементам базового
класса. Объекты производного класса могут также обращаться к защищенным
элементам любого из его косвенных базовых классов.
1 // Рис. 12.14: BasePlusCommissionEmployee.h
2 // Класс BasePlusCommissionEmployee, производный от класса
3 // CommissionEmployee.
4 #ifndef BASEPLUS_H
5 #define BASEPLUS_H
6
7 #include <string> // стандартный класс C++ string
8 using std::string;
9
10 #include "CommissionEmployee.h" // объявление CommissionEmployee
11
12 class BasePlusCommissionEmployee : public CommissionEmployee
13 {
14 public:
15 BasePlusCommissionEmployee( const string &, const string &,
16 const string &, double = 0.0, double = 0.0, double = 0.0 );
17
18 void setBaseSalary( double ); // установить зарплату
19 double getBaseSalary() const; // возвратить зарплату
20
21 double earnings() const; // вычислить заработок
22 void print() const; // печать объекта BasePlusCommissionEmployee
23 private:
24 double baseSalary; // зарплата
25 }; // конец класса BasePlusCommissionEmployee
26
27 #endif
Рис. 12.14. Заголовочный файл класса BasePlusCommissionEmployee
1 // Рис. 12.15: BasePlusCommissionEmployee.срр
2 // Определения элемент-функций класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 // определение класса BasePlusCommissionEmployee
7 #include "BasePlusCommissionEmployee.h"
Объектно-ориентированное программирование: наследование 787
8
9 // конструктор
10 BasePlusCommissionEmployee::BasePlusConrniissionEmployee(
11 const string &first, const string &last, const string &ssn,
12 double sales, double rate, double salary )
13 // явно вызвать конструктор базового класса
14 : CommissionEmployee( first, last, ssn, sales, rate )
15 {
16 setBaseSalary( salary ); // проверить и сохранить зарплату
17 } // конец конструктора BasePlusCommissionEmployee
18
19 // установить зарплату
20 void BasePlusCommissionEmployee::setBaseSalary( double salary )
21 {
22 baseSalary = ( salary < 0.0 ) ? 0.0 : salary;
23 } // конец функции setBaseSalary
24
25 // возвратить зарплату
26 double BasePlusCommissionEmployee::getBaseSalary() const
27 {
28 return baseSalary;
29 } // конец функции getBaseSalary
30
31 // вычислить заработок
32 double BasePlusCommissionEmployee::earnings() const
33 {
34 // может обращаться к защищенным данным базового класса
35 return baseSalary + ( commissionRate * grossSales );
36 } // конец функции earnings
37
38 // напечатать объект BasePlusCommissionEmployee
39 void BasePlusCommissionEmployee::print() const
40 {
41 // может обращаться к защищенным данным базового класса
42 cout « "base-salaried commission employee: " « firstName « ' '
43 « lastName « "\nsocial security number: "
44 « socialSecurityNumber « "\ngross sales: " « grossSales
45 « "\ncommission rate: " « commissionRate
46 « "\nbase salary: " « baseSalary;
47 } // конец функции print
Рис. 12.15. Файл реализации класса BasePlusCommissionEmployee, наследующего
защищенные данные класса CommissionEmployee
Класс BasePlusCommissionEmployee не наследует конструктор класса
CommissionEmployee. Однако конструктор BasePlusCommissionEmployee
(строки 10-17 на рис. 12.15) явно вызывает конструктор CommissionEmployee
(строка 14). Как вы помните, конструктор BasePlusCommissionEmployee
должен вызывать конструктор CommissionEmployee явным образом, поскольку
последний не содержит конструктора по умолчанию, который мог бы
вызываться неявно.
788
Глава 12
Тестирование класса BasePlusCommissionEmployee
На рис. 12.16 объект BasePlusCommissionEmployee используется для
выполнения тех же задач, что выполнялись на рис. 12.9 с объектом первой
версии класса BasePlusCommissionEmployee (рис. 12.7-12.8). Обратите
внимание, что вывод программ в обоих случаях один и тот жет. Мы создали первый
класс BasePlusCommissionEmployee без наследования; однако оба класса
обладают одними и теми же функциональными свойствами. Заметьте, что код
класса BasePlusCommissionEmployee (т.е. файлы заголовка и реализации)
составляет в данном случае 74 строки, что значительно короче кода для версии
класса без наследования, который содержал 154 строки, благодаря тому, что
версия с наследованием ассимилирует часть свойств класса CommissionEm-
ployee, в то время как версия без наследования ничего не ассимилирует.
Кроме того, теперь существует единственный экземпляр функционального кода
CommissionEmployee, который объявлен и определен в классе
Commissi onEmploy ее. Это делает исходный код проще для сопровождения,
модификации и отладки, так как исходный код, связанный со свойствами
CommissionEmployee, присутствует только в файлах на рис. 12.12-12.13.
1 // Рис. 12.16: figl2_16.cpp
2 // Тестирование класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::fixed;
7
8 #include <iomanip>
9 using std::setprecision;
10
11 // определение класса BasePlusCommissionEmployee
12 #include "BasePlusCommissionEmployee.h"
13
14 int main()
15 {
16 // создать объект BasePlusCommissionEmployee
17 BasePlusCommissionEmployee
18 employee( "Bob", "Lewis", 33-33-3333", 5000, .04, 300 );
19
20 // установить формат вывода чисел с плавающей точкой
21 cout « fixed « setprecision( 2 );
22
23 // получить данные служащего
24 cout « "Employee information obtained by get functions: \n"
25 « "\nFirst name is " « employee.getFirstName()
26 « "\nLast name is " « employee.getLastName()
27 « "\nSocial security number is "
28 « employee.getSocialSecurityNumber()
29 « "\nGross sales is " « employee.getGrossSales()
30 « "\nCommission rate is " « employee.getCommissionRate()
31 « "\nBase salary is " « employee.getBaseSalary() « endl;
32
33 employee.setBaseSalary( 1000 ); // установить зарплату
34
35 cout « "\nUpdated employee information "
Объектно-ориентированное программирование: наследование
789
36 « "output by print function: \n" « endl;
37 employee.print(); // вывести информацию о служащем
38
39 // вывести заработок служащего
40 cout «"XnXnEmployee's earnings: $"« employee.earnings ()« endl;
41
42 return 0;
43 } // конец main
Employee information obtained by get functions:
First name is Bob
Last name is Lewis
Social * security number is 333-33-3333
Gross sales is 5000.00
Commission rate is 0.04
Base salary is 300.00
Updated employee information output by print function:
base-salaried commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
base salary: 1000.00
Employee's earnings: $1200.00
Рис. 12.16. Защищенные данные базового класса теперь доступны для производного
класса
Замечания о защищенных данных
В этом примере мы объявили элементы данных базового класса как
protected, так что производные классы могут модифицировать их непосредственно.
Наследование защищенных данных несколько улучшает производительность,
поскольку мы можем непосредственно обращаться к элементам, не привнося
расходов на вызовы set- или get-функций. В большинстве случаев, однако,
лучше использовать закрытые элементы данных, что соответствует правильному
конструированию программного обеспечения, и оставить оптимизацию кода
на усмотрение компилятора. Ваш код будет проще сопровождать,
модифицировать и отлаживать.
Защищенные элементы данных порождают две главных проблемы. Первая
связана с тем, что объекту производного класса не требуется вызывать
элемент-функцию, чтобы установить значение защищенного элемента данных
базового класса. Следовательно, объект производного класса легко присвоить
защищенному элементу недействительное значение, оставив объект в несогласованном
состоянии. Например, если элемент gross Sales класса CommissionEmployee
защищенный, объект производного класса (например, BasePlusCommissionEm-
ployee) может присвоить ему отрицательное значение. Вторая проблема с
защищенными элементами состоит в том, что элемент-функции производного класса
с большей вероятностью окажутся зависимыми от реализации базового класса.
Производные классы должны фактически зависеть только от услуг базового
790
Глава 12
класса (т.е. его открытых элемент-функций), но не от его реализации. В случае
защищенных элементов данных в базовом классе при изменении его реализации
может потребоваться модифицировать все классы, производные от этого базового
класса. Например, если по какой-то причине мы поменяем имена элементов
данных first Name и lastName на first и last, то мы должны будем сделать это везде,
где производный класс непосредственно ссылается на эти элементы базового
класса. В таких случаях говорят, что программный код является хрупким, так
как небольшое изменение в базовом классе «сломает» реализацию производного
класса. Программист должен иметь возможность менять реализацию базового
класса, предоставляя в то же время производным классам те же услуги.
(Конечно, если изменяются услуги базового класса, нам придется заново реализовать
наши производные классы; правильное объектно-ориентированное
проектирование пытается предотвратить именно это.)
S Общее методическое замечание 12.5
Целесообразно использовать спецификатор доступа protected в тех
случаях, когда базовый класс должен предоставлять услугу (т.е.
элемент-функцию) только своим производным классам (и друзьям), но не
другим клиентам.
Ш Общее методическое замечание 12.6
Объявление элементов данных базового класса как private (в
противоположность объявлению их как protected) позволяет программистам
менять реализацию базового класса без необходимости изменений
в реализации производных классов.
j^sk Предотвращение ошибок 12.1
^Рчг По возможности избегайте включения в базовый класс защищенных
данных. Вместо этого предусмотрите незакрытые
элемент-функции, обеспечивающие доступ к закрытым элементам данных,
гарантирующие, что объект будет поддерживаться в согласованном
состоянии.
12.4.5. Иерархия наследования CommissionEmployee —
BasePlusCommissionEmployee с закрытыми данными
Теперь мы еще раз пересмотрим нашу иерархию, подойдя к ней с позиций
наилучшего стиля конструирования программного обеспечения. Класс
CommissionEmployee (рис. 12.17-12.18) теперь снова определяет элементы
данных first Name, lastName, socialSecurityNumber, grossSales и commissionRa-
te как private (рис. 12.17, строки 33-37), предусматривая для манипуляции
их значениями открытые элемент-функции setFirstName, getFirstName,
setLastName, getLastName, setSocialSecurityNumber, getSocialSecuri-
tyNumber, setGrossSales, getGrossSales, setCommissionRate, getCommis-
sionRate, earnings и print, если мы решим поменять имена элементов данных,
определения earnings и print не потребуют модификации; модифицировать
придется только определения set- и £е£-функций, непосредственно манипули-
Объектно-ориентированное программирование: наследование 791
рующих элементами данных. Заметьте, что эти изменения происходят
исключительно в базовом классе — производные классы модифицировать не
требуется. Подобная локализация эффектов изменений является правильным стилем
конструирования программного обеспечения. Производный класс Ва-
sePlusCommissionEmployee (рис. 12.19-12.20) наследует не-закрытые
элемент-функции CommissionEmployee и может получать через них доступ к
закрытым элементам базового класса.
1 // Рис. 12.17: CommissionEmployee.h
2 // Правильно сконструированный класс CommissionEmployee.
3 #ifndef COMMISSION^
4 #define COMMISSION_H
5
6 #include <string> // стандартный класс C++ string
7 using std::string;
8
9 class CommissionEmployee
10 {
11 public:
12 CommissionEmployee( const string &, const string &,
13 const string &, double =0.0, double = 0.0 );
14
15 void setFirstName( const string & )/ // установить имя
16 string getFirstName() const; // возвратить имя
17
18 void setLastName( const string & ); // установить фамилию
19 string getLastName() const; // возвратить фамилию
20
21 void setSocialSecurityNumber( const string & ); // установить SSN
22 string getSocialSecurityNumber() const; // возвратить SSN
23
24 void setGrossSales( double ); // установить общую сумму продаж
25 double getGrossSales() const; // возвратить общую сумму продаж
26
27 void setCommissionRate( double ); // установить процент
28 double getCommissionRate() const; // возвратить процент
29
30 double earnings() const; // вычислить заработок
31 void print() const; // напечатать объект CommissionEmployee
32 private:
33 string firstName;
34 string lastName;
35 string socialSecurityNumber;
36 double grossSales; // продажи за неделю
37 double commissionRate; // комиссионный процент
38 }; // конец класса CommissionEmployee
39
40 #endif
Рис. 12.17. Класс CommissionEmployee, определенный в соответствии
с правильным стилем конструирования программного обеспечения
792
Глава
1 // Рис. 12.18: CommissionEmployee.срр
2 // Определения элемент-функций класса CommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 #include "CommissionEmployee.h" // определение CommissionEmployee
7
8 // конструктор
9 CommissionEmployee::CommissionEmployee(
10 const string fifirst, const string filast, const string &ssn,
11 double sales, double rate )
12 : firstName(first), lastName(last), socialSecurityNumber(ssn)
13 {
14 setGrossSales( sales ); // проверить и сохранить объем продаж
15 setCommissionRate( rate ); // проверить и сохранить процент
16 } // конец конструктора CommissionEmployee
17
18 // установить имя
19 void CommissionEmployee::setFirstName( const string &£irst )
20 {
21 firstName = first; // должно проверяться
22 } // конец функции setFirstName
23
24 // возвратить имя
25 string CommissionEmployee:rgetFirstName() const
26 {
27 return firstName;
28 } // конец функции getFirstName
29
30 // установить фамилию
31 void CommissionEmployee::setLastName( const string &last )
32 {
33 lastName = last; // должно проверяться
34 } // конец функции setLastName
35
36 // возвратить фамилию
37 string CommissionEmployee::getLastName() const
38 {
39 return lastName;
40 } // конец функции getLastName
41
42 // установить номер страховки
43 void CommissionEmployee::setSocialSecurityNumber(const string &ssn)
44 {
45 socialSecurityNumber = ssn; // должно проверяться
4 6 } // конец функции setSocialSecurityNumber
47
48 // возвратить номер страховки
4 9 string CommissionEmployee::getSocialSecurityNumber() const
50 {
51 return socialSecurityNumber;
52 } // конец функции getSocialSecurityNumber
53
54 // установить общую сумму продаж
55 void CommissionEmployee::setGrossSales( double sales )
56 {
Объектно-ориентированное программирование: наследование
793
57 grossSales = ( sales < 0.0 ) ? 0.0 : sales;
58 } // конец функции setGrossSales
59
60 // возвратить общую сумму продаж
61 double CommissionEniployee: : getGrossSales () const
62 {
63 return grossSales;
64 } // конец функции getGrossSales
65
66 // установить комиссионный процент
67 void CommissionEmployee::setCommissionRate( double rate )
68 {
69 commissionRate = ( rate > 0.0 && rate < 1.0 ) ? rate : 0.0;
70 } // конец функции setCommissionRate
71
72 // возвратить комиссионный процент
73 double CommissionEmployee::getCommissionRate() const
74 {
75 return commissionRate;
76 } // конец функции getCommissionRate
77
78 // вычислить заработок
79 double CommissionEmployee::earnings() const
80 {
81 return getCommissionRate() * getGrossSales();
82 } // конец функции earnings
83
84 // напечатать объект CommissionEmployee
85 void CommissionEmployee::print() const
86 {
87 cout « "commission employee: "
88 « getFirstName() « ' ' « getLastName ()
89 « "\nsocial security number: " « getSocialSecurityNumber()
90 « "\ngross sales: " « getGrossSales()
91 « "\ncommission rate: " « getCommissionRate ();
92 } // конец функции print
Рис. 12.18. Файл реализации для класса CommissionEmployee: класс использует
элемент-функции для манипуляции своими закрытыми данными
Обратите внимание, что в реализации конструктора класса
CommissionEmployee (рис. 12.18, строки 9-16) мы используем инициализаторы
элементов для установки значений элементов firstName, lastName и socialSecu-
rityNumber. Мы показываем, что производный класс BasePlusCommissionEm-
ployee (рис. 12.19-12.20) может вызывать не-закрытые элемент-функции
(setFirstName, get First Name, setLastName, getLastName, setSocialSecuri-
tyNumber и getSocialSecurityNumber) для манипуляции этими элементами
данных.
794
Глава 12
Вопросы производительности 12.2
Использование элемент-функции для доступа к значению элемента
данных может работать чуть медленнее, чем непосредственный
доступ к данным. Однако сегодняшние оптимизирующие компиляторы
могут производить разнообразные неявные оптимизации (такие, как
встроенное расширение вызовов set- и get-функций). Поэтому
программистам следует придерживаться правильных принципов
конструирования программного кода, и оставить вопросы оптимизации в ведении
компилятора. Хорошее правило — «не быть хитрее компилятора».
В классе BasePlusCommissionEmployee (рис. 12.19-12.20) есть несколько
изменений в реализации его элемент-функций (рис. 12.20), отличающих его от
предыдущей версии класса (рис. 12.14-12.15). Каждая из элемент-функций
earnings (рис. 12.20, строки 32-35) и print (строки C8-46) для получения
значения зарплаты вызывает элемент-функцию, а не обращается к baseSalary
непосредственно. Это изолирует earnings и print от возможных изменений
реализации элемента baseSalary. Например, елей мы решим переименовать этот
элемент данных или изменить его тип, изменений потребуют только функции
setBaseSalary и getBaseSalary.
1 // Рис. 12.19: BasePlusCommissionEmployee.h
2 // Класс BasePlusCommissionEmployee, производный от класса
3 // CommissionEmployee.
4 #ifndef BASEPLUS_H
5 #define BASEPLUS_H
6
7 #include <string> // стандартный класс C++ string
8 using std::string;
9
10 #include "CommissionEmployee.h" // объявление CommissionEmployee
11
12 class BasePlusCommissionEmployee : public CommissionEmployee
13 {
14 public:
15 BasePlusCommissionEmployee( const string &, const string &,
16 const string &, double =0.0, double =0.0, double = 0.0 );
17
18 void setBaseSalary( double ); // установить основную зарплату
19 double getBaseSalary() const; // возвратить основную зарплату
20
21 double earnings() const; // вычислить заработок
22 void print() const; // напечатать BasePlusCommissionEmployee
23 private:
24 double baseSalary; // основная зарплата
25 }; // конец класса BasePlusCommissionEmployee
26
27 #endif
Рис. 12.19. Заголовочный файл класса BasePlusCommissionEmployee
Объектно-ориентированное программирование: наследование
795
1 // Рис. 12.20: BasePlusCommissionEmployee.cpp
2 // Определения элемент-функций, класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 // определение класса BasePlusCommissionEmployee
7 #include "BasePlusCommissionEmployee.h"
8
9 // конструктор
10 BasePlusCommissionEmployee::BasePlusCommissionEmployee(
11 const string fifirst, const string &last, const string &ssn,
12 double sales, double rate, double salary )
13 // explicitly call base-class constructor
14 : CommissionEmployee( first, last, ssn, sales, rate )
15 {
16 setBaseSalary( salary ); // проверить и сохранить зарплату
17 } // конец конструктора BasePlusCommissionEmployee
18
19 // установить основную зарплату
20 void BasePlusCommissionEmployee::setBaseSalary( double salary )
21 {
22 baseSalary = ( salary < 0.0 ) ? 0.0 : salary;
23 } // конец функции setBaseSalary
24
25 // возвратить основную зарплату
26 double BasePlusCommissionEmployee::getBaseSalary() const
27 {
28 return baseSalary;
29 } // конец функции getBaseSalary
30
31 // вычислить заработок
32 double BasePlusCommissionEmployee::earnings() const
33 {
34 return getBaseSalary () + CommissionEmployee: .-earnings () ;
35 } // конец функции earnings
36
37 // напечатать объект BasePlusCommissionEmployee
38 void BasePlusCommissionEmployee::print() const
39 {
40 cout « "base-salaried ";
41
42 // вызвать функцию print класса CommissionEmployee
43 CommissionEmployee::print();
44
45 cout « "\nbase salary: " « getBaseSalary();
46 } // конец функции print
Рис. 12.20. Класс BasePlusCommissionEmployee, который наследует от
CommissionEmployee, но не может непосредственно обращаться к его закрытым данным
Функция earnings (рис. 12.20, строки 32-35) класса
BasePlusCommissionEmployee переопределяет функцию earnings класса
CommissionEmployee (рис. 12.18, строки 79-82) для вычисления заработка служащего с
основной зарплатой и выплатой комиссионных. Версия earnings из класса
BasePlusCommissionEmployee получает часть заработка служащего, относя-
796
Глава 12
щуюся к комиссионным, вызывая функцию earnings базового класса с
помощью выражения CommissionEmployee: :earnings() (строка 34 на рис. 12.20).
Затем функция earnings класса BasePlusCommissionEmployee прибавляет
к полученному значению основную зарплату, получая общую сумму заработка
служащего. Обратите внимание на синтаксис вызова переопределенной
элемент-функции базового класса из производного класса — перед именем
элемент-функции помещается имя базового класса с операцией разрешения
области действия (::). Такой вызов соответствует правильному стилю
конструирования программ: вспомните «Общее методическое замечание 9.9», где
говорилось, что если элемент-функция объекта производит действия,
необходимые другой его функции, то следует вызвать эту элемент-функцию, а не
дублировать код ее тела. Вызывая в функции earnings класса
BasePlusCommissionEmployee функцию earnings базового класса для расчета части заработка
служащего, мы избегаем дублирования кода и проблем с его сопровождением.
—р\^\ Типичная ошибка программирования 12.2
Когда элемент-функция базового класса переопределяется в
производном классе, функция производного класса часто вызывает функцию
базового класса для выполнения части работы. Если при этом не
поместить перед именем функции имя базового класса с операцией ::,
возникнет бесконечная рекурсия, поскольку в этом случае функция
производного класса будет вызывать себя.
Типичная ошибка программирования 12.3
Включение в производный класс функции базового класса с другой
сигнатурой скрывает версию функции базового класса. Попытка
вызвать функцию базового класса через открытый интерфейс объекта
производного класса приведет к ошибке компиляции.
Аналогичным образом функция print класса BasePlusCommissionEmployee
(рис. 12.20, строки 38-46) переопределяет функцию print класса Commis-
sionEmployee (рис. 12.18, строки 85-92) для вывода информации,
соответствующей служащему с основной зарплатой и комиссионными. Версия класса
BasePlusCommissionEmployee выводит ту информацию объекта
BasePlusCommissionEmployee, что относится к комиссионным (т.е. строку "commission
employee" и значения закрытых данных класса CommissionEmployee), вызывая
функцию print класса CommissionEmployee по квалифицированному имени
CommissionEmployee::print() (рис. 12.20, строка 43). Затем print класса
BasePlusCommissionEmployee выводит оставшуюся информацию объекта
BasePlusCommissionEmployee (т.е. значение зарплаты).
Программа на рис. 12.21 производит те же действия с объектом
BasePlusCommissionEmployee, что и программы на рис. 12.9 и рис. 12.16. Хотя
все три версии класса ведут себя одинаково, версия на рис. 12.19-12.20
сконструирована наилучшим образом. Используя наследование и вызовы
элемент-функций, скрывающих данные и гарантирующих согласованность
объекта, мы быстро получаем эффективный, правильно сконструированный
класс.
Объектно-ориентированное программирование: наследование
797
1 // Рис. 12.21: figl2_21.cpp
2 // Тестирование класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std:-.fixed;
7
8 #include <iomanip>
9 using std::setprecision;
10
11 // определение класса BasePlusCommissionEmployee
12 #include "BasePlusCommissionEmployee.h"
13
14 int main()
15 {
16 // создать объект BasePlusCommissionEmployee
17 BasePlusCommissionEmployee
18 employee( "Bob", "Lewis", 33-33-3333", 5000, .04, 300 );
19
20 // установить формат вывода чисел с плавающей точкой
21 cout « fixed « setprecision( 2 );
22
23 // получить данные служащего
24 cout « "Employee information obtained by get functions: \n"
25 « "\nFirst name is " « employee.getFirstName()
26 « "\nLast name is " « employee.getLastName()
27 « "\nSocial security number is "
28 « employee.getSocialSecurityNumber()
29 « "\nGross sales is " « employee.getGrossSales()
30 « "\nCommission rate is " « employee.getCommissionRate ()
31 « "\nBase salary is " « employee.getBaseSalary() « endl;
32
33 employee.setBaseSalary( 1000 ); // установить зарплату
34
35 cout « "\nUpdated employee information "
36 « "output by print function: \n" « endl;
37 employee.print(); // вывести информацию о служащем
38
39 // вывести заработок служащего
40 cout <<"\n\nEmployee's earnings: $"« employee.earnings()« endl;
41
42 return 0;
43 } // конец main
Employee information obtained by get functions:
First name is Bob
Last name is Lewis
Social security number is 333-33-3333
Gross sales is 5000.00
Commission rate is 0.04
Base salary is 300.00
Updated employee information output by print function:
base-salaried commission employee: Bob Lewis
798
Глава 12
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
base salary: 1000.00
Employee's earnings: $1200.00
Рис. 12.21. Закрытые данные базового класса доступны для производного класса через
открытую или защищенную элемент-функцию, наследуемую производным классом
В этом разделе вы увидели ряд эволюционирующих примеров, специально
разработанных для того, чтобы показать ключевые моменты правильного
конструирования программного обеспечения на основе наследования. Вы узнали,
как, опираясь на наследование, создать производный класс, как использовать
защищенные элементы базового класса, чтобы предоставить производному
классу доступ к унаследованным элементам данных, и как переопределить
элемент-функции базового класса, чтобы создать их версии, более
соответствующие объектам производного класса. Кроме того, вы увидели, как
применяются методики правильного конструирования программного обеспечения
из глав 9-10 для создания классов, простых в сопровождении, модификации
и отладке.
12.5. Конструкторы и деструкторы в производных
классах
Как мы объяснили в предыдущем разделе, создание объекта производного
класса начинает цепочку вызовов конструкторов, в которой конструктор
производного класса, перед выполнением своих собственных задач, вызывает
конструктор своего непосредственного базового класса — либо явным образом (через
инициализатор базового класса), либо неявно (вызывая конструктор по
умолчанию базового класса). Аналогично, когда базовый класс сам является
производным от другого класса, он должен вызвать конструктор следующего класса
вверх по иерархии и т.д. Последний конструктор в этой цепочке вызовов
является конструктором класса, лежащего в основании иерархии, чье тело
фактически заканчивает выполнение первым. Тело конструктора первоначального
производного класса заканчивает свое выполнение последним. Конструктор
каждого базового класса инициализирует элементы базового класса, наследуемые
производным классом. Рассмотрим, например, иерархию CommissionEm-
ployee / BasePlusCommissionEmployee из рис. 12.17-12.20. Когда программа
создает объект BasePlusCommissionEmployee, вызывается конструктор Сот-
missionEmployee. Так как CommissionEmployee является основой иерархии,
его конструктор исполняется, инициализируя закрытые элементы данных
CommissionEmployee, которые являются частью объекта
BasePlusCommissionEmployee. Когда конструктор CommissionEmployee завершает выполнение,
он возвращает управление конструктору BasePlusCommissionEmployee,
который инициализирует элемент baseSalary объекта
BasePlusCommissionEmployee.
Объектно-ориентированное программирование: наследование
799
® Общее методическое замечание 12.7
Когда программа создает объект производного класса, его
конструктор немедленно вызывает конструктор базового класса, исполняется
тело базового конструктора, затем исполняются инициализаторы
элементов и, наконец, исполняется тело конструктора производного
класса. Если иерархия содержит более двух уровней, этот процесс
«надстраивается» вверх по иерархии.
Когда объект производного класса уничтожается, программа вызывает его
деструктор. Это начинает цепочку вызовов деструкторов, в которой
деструктор производного класса, деструкторы прямых и косвенных базовых классов
и деструкторы элементов классов исполняются в последовательности,
обратной последовательности исполнения конструкторов. Когда вызывается
деструктор производного класса, он выполняет свою задачу, затем вызывает
деструктор следующего базового класса вверх по иерархии. Этот процесс
продолжается, пока не будет вызван деструктор конечного базового класса на
вершине иерархии. После этого объект удаляется из памяти.
S Общее методическое замечание 12.8
Предположим, мы создаем объект производного класса, причем и
базовый, и производный класс содержат объекты других классов. Когда
создается объект этого производного класса, сначала исполняются
конструкторы объектов-элементов базового класса, затем
конструктор базового класса, затем конструкторы объектов-элементов
производного класса и, наконец, конструктор производного класса.
Деструкторы для объектов производного класса вызываются в
последовательности, обратной последовательности вызова
конструкторов.
Конструкторы, деструкторы и перегруженные операции присваивания (см.
главу 11) базовых классов не наследуются производными классами. Однако
конструкторы производных классов, деструкторы и перегруженные операции
присваивания могут вызывать конструкторы, деструкторы и перегруженные
операции присваивания базовых классов.
Наш следующий пример пересматривает иерархию
служащих-комиссионеров, определяя класс CommissionEmployee (рис. 12.22-12.23) и класс Ва-
sePlusCommissionEmployee (рис. 12.24-12.25), которые содержат
конструкторы и деструкторы, печатающие сообщения при их активации. Как вы
увидите в выводе программы не рис. 12.26, эти сообщения демонстрируют
порядок вызова конструкторов и деструкторов для объектов в иерархии
наследования.
В этом примере мы модифицировали конструктор CommissionEmployee
(строки 10-21 на рис. 12.23) и включили в класс CommissionEmployee
деструктор (строки 24-29); оба они при вызове выводят строчку текста. Мы
модифицировали также конструктор BasePlusCommissionEmployee (строки 11-22
на рис. 12.25) и включили в класс деструктор (строки 25-30). При вызове они
выводят строчку текста.
800
Глава 12
1 // Рис. 12.22: CommissionEmployee.h
2 // Класс CommissionEmployee - служащий, получающий комиссионные.
3 #ifndef COMMISSION^
4 #define COMMISSION_H
5
6 #include <string> // стандартный класс C++ string
7 using std::string;
8
9 class CommissionEmployee
10 {
11 public:
12 CommissionEmployee( const string &, const string &,
13 const string &, double = 0.0, double = 0.0 );
14 -CommissionEmployee(); // деструктор
15
16 void setFirstName ( const string & ); // установить имя
17 string getFirstName() const; // возвратить имя
18
19 void setLastName( const string & ); // установить фамилию
20 string getLastName() const; // возвратить фамилию
21
22 void setSocialSecurityNumber( const string & ); // установить SSN
23 string getSocialSecurityNumber() const; // возвратить SSN
24
25 void setGrossSales( double ); // установить общую сумму продаж
26 double getGrossSales() const; // возвратить общую сумму продаж
27
28 void setCommissionRate( double ); // установить процент
29 double getCommissionRate() const; // возвратить процент
30
31 double earnings() const; // вычислить заработок
32 void print() const; // напечатать объект CommissionEmployee
33 private:
34 string firstName;
35 string lastName;
36 string socialSecurityNumber;
37 double grossSales; // продажи за неделю
38 double commissionRate; // комиссионный процент
39 }; // конец класса CommissionEmployee
40
41 #endi£
Рис. 12.22. Заголовочный файл класса CommissionEmployee
1 // Рис. 12.23: CommissionEmployee.cpp
2 // Определения элемент-функций класса CommissionEmployee.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "CommissionEmployee.h" // определение CommissionEmployee
8
9 // конструктор
Объектно-ориентированное программирование: наследование 801
10 CommissionEmployee::CommissionEmployee(
11 const string &f±rst, const string filast, const string &ssn,
12 double sales, double rate )
13 : firstName(first), lastName(last), socialSecurityNumber(ssn)
14 {
15 setGrossSales( sales ); // проверить и сохранить объем продаж
16 setCommissionRate( rate ); // проверить и сохранить процент
17
18 cout « "Commission employee constructor:" « endl;
19 print();
20 cout « "\n\n";
21 } // конец конструктора CommissionEmployee
22
23 // деструктор
24 CommissionEmployee::-CommissionEmployee()
25 {
26 cout « "Commission employee destructor:" « endl;
27 print ();
28 cout « "\n\n";
29 } // конец деструктора CommissionEmployee
30
31 // установить имя
32 void CommissionEmployee::setFirstName( const string &first )
33 {
34 firstName = first; // должно проверяться
35 } // конец функции setFirstName
36
37 // возвратить имя
38 string CommissionEmployee::getFirstName() const
39 {
40 return firstName;
41 } // конец функции getFirstName
42
43 // установить фамилию
44 void CommissionEmployee::setLastName( const string filast )
45 {
46 lastName = last; // должно проверяться
47 } // конец функции setLastName
48
49 // возвратить фамилию
50 string CommissionEmployee::getLastName() const
51 {
52 return lastName;
53 } // конец функции getLastName
54
55 // установить номер страховки
56 void CommissionEmployee::setSocialSecurityNumber(const string &ssn)
57 {
58 socialSecurityNumber = ssn; // должно проверяться
59 } // конец функции setSocialSecurityNumber
60
61 // возвратить номер страховки
62 string CommissionEmployee::getSocialSecurityNumber() const
63 {
64 return socialSecurityNumber;
26 Зак 1114
802
Глава 12
65 } // конец функции getSocialSecurityNumber
66
67 // установить общую сумму продаж
68 void CommissionEmployee::setGrossSales( double sales )
69 {
70 grossSales = ( sales < 0.0 ) ? 0.0 : sales;
71 } // конец функции setGrossSales
72
73 // возвратить общую сумму продаж
74 double CommissionEmployee::getGrossSales() const
75 {
76 return grossSales;
77 } // конец функции getGrossSales
78
79 // установить комиссионный процент
80 void CommissionEmployee::setCommissionRate( double rate )
81 {
82 commissionRate = ( rate > 0.0 && rate < 1.0 ) ? rate : 0.0;
83 } // конец функции setCommissionRate
84
85 // возвратить комиссионный процент
86 double CommissionEmployee::getCommissionRate() const
87 {
88 return commissionRate;
89 } // конец функции getCommissionRate
90
91 // вычислить заработок
92 double CommissionEmployee::earnings() const
93 {
94 return getCommissionRate() * getGrossSales();
95 } // конец функции earnings
96
97 // напечатать объект CommissionEmployee
98 void CommissionEmployee::print() const
99 {
100 cout « "commission employee: "
101 « getFirstNameO « ' ' « getLastName()
102 « "\nsocial security number: " « getSocialSecurityNumber()
103 « "\ngross sales: " « getGrossSales()
104 « "\ncommission rate: " « getCommissionRate () ;
105 } // конец функции print
Рис. 12.23. Конструктор CommissionEmployee выводит текст
1 // Рис. 12.24: BasePlusCommissionEmployee.h
2 // Класс BasePlusCommissionEmployee, производный от класса
3 // CommissionEmployee.
4 #ifndef BASEPLUS_H
5 #define BASEPLUS_H
6
7 #include <string> // стандартный класс C++ string
8 using std::string;
9
10 #include "CommissionEmployee.h" // объявление CommissionEmployee
Объектно-ориентированное программирование: наследование
803
11
12 class BasePlusCommissionEmployee : public CommissionEmployee
13 {
14 public:
15 BasePlusCommissionEmployee( const string &, const string &,
16 const string &, double =0.0, double =0.0, double = 0.0 );
17 ^BasePlusCommissionEmployee(); // деструктор
18
19 void setBaseSalary( double ); // установить зарплату
20 double getBaseSalary() const; // возвратить зарплату
21
22 double earnings() const; // вычислить заработок
23 void print() const; // напечатать BasePlusCommissionEmployee
24 private:
25 double baseSalary; // зарплата
26 }; // конец класса BasePlusCommissionEmployee
27
28 #endif
Рис. 12.24. Заголовочный файл класса BasePlusCommissionEmployee
1 // Рис. 12.25: BasePlusCommissionEmployee.срр
2 // Определения элемент-функций класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 // определение класса BasePlusCommissionEmployee
8 #include "BasePlusCommissionEmployee.h"
9
10 // конструктор
11 BasePlusCommissionEmployee::BasePlusCommissionEmployee (
12 const string &first, const string filast, const string &ssn,
13 double sales, double rate, double salary )
14 // явно вызвать конструктор базового класса
15 : CommissionEmployee( first, last, ssn, sales, rate )
16 {
17 setBaseSalary( salary ); // проверить и сохранить зарплату
18
19 cout « "BasePlusCommissionEmployee constructor:11 « endl;
20 print ();
21 cout « "\n\n";
22 } // конец конструктора BasePlusCommissionEmployee
23
24 // деструктор
25 BasePlusCommissionEmployee::-BasePlusCommissionEmployee()
26 {
27 cout « "BasePlusCommissionEmployee destructor:" « endl;
28 print();
29 cout « "\n\n";
30 } // конец деструктора BasePlusCommissionEmployee
31
32 // установить зарплату
33 void BasePlusCommissionEmployee::setBaseSalary( double salary )
804
Глава 12
34 {
35 baseSalary = ( salary < 0.0 ) ? 0.0 : salary;
36 } // конец функции setBaseSalary
37
38 // возвратить зарплату
39 double BasePlusCommissionEmployee::getBaseSalary() const
40 {
41 return baseSalary;
42 } // конец функции getBaseSalary
43
44 // вычислить заработок
45 double BasePlusCommissionEmployee:learnings() const
46 {
47 return getBaseSalary() + CommissionEmployee::earnings() ;
48 } // конец функции earnings
49
50 // напечатать объект BasePlusCommissionEmployee
51 void BasePlusCommissionEmployee::print() const
52 {
53 cout « "base-salaried ";
54
55 // вызвать функцию print класса CommissionEmployee
56 CommissionEmployee::print();
57
58 cout « "\nbase salary: " « getBaseSalary();
59 } // конец функции print
Рис. 12.25. Конструктор BasePlusCommissionEmployee выводит текст
1 // Рис. 12.26: figl2_26.cpp
2 // Показать порядок, в котором вызываются
3 // конструкторы и деструкторы базового и производного классов.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7 using std::fixed;
8
9 #include <iomanip>
10 using std::setprecision;
11
12 // определение класса BasePlusCommissionEmployee
13 #include "BasePlusCommissionEmployee.h"
14
15 int main()
16 {
17 // установить форматирование чисел с плавающей точкой
18 cout « fixed « setprecision( 2 );
19
20 { // начало новой области действия
21 CommissionEmployee employeel(
22 "Bob", "Lewis", 33-33-3333", 5000, .04 );
23 } // конец области действия
24
25 cout « endl;
Объектно-ориентированное программирование: наследование
805
26 BasePlusCommissionEmployee
27 employee2( "Lisa", "Jones",
28
29 cout « endl;
30 BasePlusCommissionEmployee
31 employee3( "Mark", "Sands",
32 cout « endl^-
SS return 0;
34 } // конец main
Commission employee constructor:
commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
Commission employee destructor:
commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
Commission employee constructor:
commission employee: Lisa Jones
social security number: 555-55-5555
gross sales: 2000.00
commission rate: 0.06
BasePlusCommissionEmployee constructor:
base-salaried commission employee: Lisa Jones
social security number: 555-55-5555
gross sales: 2000.00
commission rate: 0.06
base salary: 800.00
Commission employee constructor:
commission employee: Mark Sands
social security number: 888-88-8888
gross sales: 8000.00
commission rate: 0.15
BasePlusCommissionEmployee constructor:
base-salaried commission employee: Mark Sands
social security number: 888-88-8888
gross sales: 8000.00
commission rate: 0.15
base salary: 2000.00
BasePlusCommissionEmployee destructor:
base-salaried commission employee: Mark Sands
social security number: 888-88-8888
gross sales: 8000.00
55-55-5555", 2000, .06, 800 );
"888-88-8888", 8000, .15, 2000 );
806
Глава 12
commission rate: 0.15
base salary: 2000.00
Commission employee destructor:
commission employee: Mark Sands
social security number: 888-88-8888
gross sales: 8000.00
commission rate: 0.15
BasePlusCommissionEmployee destructor:
base-salaried commission employee: Lisa Jones
social security number: 555-55-5555
gross sales: 2000.00
commission rate: 0.06
base salary: 800.00
Commission employee destructor:
commission employee: Lisa Jones
social security number: 555-55-5555
gross sales: 2000.00
commission rate: 0.06
Рис. 12.26. Порядок вызова конструкторов и деструкторов
12.6. Открытое, защищенное и закрытое наследование
Когда мы производим класс от базового класса, наследование может быть
открытым, защищенным или закрытым. Защищенное и закрытое
наследование встречается редко, и каждое из них должно применяться с большой
осторожностью; в этой книге мы используем только открытое наследование.
На рис. 12.27 показана сводка доступности элементов базового класса в
производном классе для всех типов наследования. В первой колонке указаны
спецификаторы доступа в базовом классе.
При наследовании открытого базового класса открытые элементы
базового класса становятся открытыми, а защищенные — защищенными
элементами базового класса. Закрытые элементы базового класса никогда не
доступны из производного класса непосредственно, но к ним можно
обращаться посредством вызовов открытых или защищенных элементов базового
класса.
При наследовании защищенного базового класса открытые и
защищенные элементы базового класса становятся защищенными элементами
производного класса. При наследовании закрытого базового класса открытые
и защищенные элементы базовый класс становятся закрытыми элементами
производного класса (т.е. функции становятся сервисными функциями).
Закрытое и защищенное наследование нельзя считать отношениями
«является».
Объектно-ориентированное программирование: наследование
807
Спецификатор
доступа элемента
базового класса
0
•Н
0*
тз
>rotec
№
4J
>
•и
Он
public
public
в производном
классе.
Непосредственно
доступен для
элемент-функций,
дружественных и
обычных функций
protected
в производном
классе.
Непосредственно
доступен для
элемент-функций и
дружественных
функций
Скрыт
в производном
классе.
Может быть
доступен для
элемент-функций и
дружественных
функций через
открытые или
защищенные
элемент-функции
базового класса
Тип наследования
protected
protected
в производном
классе.
Непосредственно
доступен для
элемент-функций и
дружественных
функций
protected
в производном
классе.
Непосредственно
доступен для
элемент-функций и
дружественных
функций
Скрыт
в производном
классе.
Может быть
доступен для
элемент-функций и
дружественных
функций через
открытые или
защищенные
элемент-функции
базового класса
private
private
в производном
классе.
Непосредственно
доступен для
элемент-функций и
дружественных
функций
private
в производном
классе.
Непосредственно
доступен для
элемент-функций и
дружественных
функций
Скрыт
в производном
классе.
Может быть
доступен для
элемент-функций и
дружественных
функций через
открытые или
защищенные
элемент-функции
базового класса
Рис. 12.27. Сводка доступности элементов базового класса в производном классе
12.7. Наследование в конструировании программного
обеспечения
В этом разделе мы обсудим использование наследования в целях настройки
существующего программного обеспечения. Когда мы применяем
наследование для создания нового класса из уже существующего, новый класс наследует
элементы — данные и функции — существующего класса, как показывает
рис. 12.27. Мы можем настроить новый класс, включая в него
дополнительные элементы и переопределяя элементы базового класса. Программист
производного класса делает это, не обращаясь к самому исходному коду базового
класса. Производный класс должен иметь возможность компоноваться с
объектным кодом базового класса. Эта черта C++ весьма привлекательна для
независимых производителей программного обеспечения (ISV). Они могут
разрабатывать, для продажи или лицензирования, являющиеся их собственностью
классы и поставлять их пользователям в форме объектного кода. Пользовате-
808
Глава 12
ли могут затем быстро и не обращаясь к исходному коду производить от этих
библиотечных классов новые классы. Все, что ISV должны поставлять в
дополнение к объектному коду — это заголовочные файлы.
Иногда студентам бывает трудно оценить диапазон проблем, которые
встают перед проектировщиками, работающими над масштабными проектами
в программной индустрии. Люди, знакомые с подобными проектами, скажут,
что эффективная утилизация программного обеспечения улучшает процесс
программных разработок. Объектно-ориентированное программирование
упрощает утилизацию программного обеспечения, сокращая, таким образом,
сроки разработок и улучшая качество программного обеспечения.
Доступность больших и полезных библиотек классов приносит
максимальные выгоды в плане утилизации программного обеспечения посредством
наследования. Как производство «завернутых в целлофан» программ с
появлением персональных компьютеров испытало взрывной рост и стало
индустрией, точно так же растет по экспоненте интерес к созданию и продаже
классовых библиотек. Разработчики приложений строят на основе этих
библиотек свои приложения, а разработчики библиотек выигрывают от того, что
их библиотеки поставляются вместе с этими приложениями. Стандартные
библиотеки C++, поставляемые с компиляторами, являются по преимуществу
библиотеками общего назначения и ограничены по своему применению.
Однако во всем мире растет тенденция к созданию классовых библиотек для
огромного разнообразия областей прикладных разработок.
Общее методическое замечание 12.9
На стадии проектирования объектно-ориентированной системы
разработчик часто обнаруживает, что некоторые классы являются
близкородственными. Разработчик должен «вынести за скобки»
общие атрибуты и поведение, разместив из в базовом классе, а затем
образовать посредством наследования производные классы, наделяя
их необходимыми свойствами, выходящими за рамки унаследованных
от базового класса.
Общее методическое замечание 12.10
Создание производного класса не воздействует на исходный код
базового класса. Наследование не нарушает целостности базового класса.
Общее методическое замечание 12.11
Точно так же, как разработчики систем не
объектно-ориентированных должны избегать «размножения» функций, разработчики
объектно-ориентированных систем должны избегать «размножения»
классов. Размножение классов создает проблемы управления ими и
может затруднять их утилизацию, так как клиенту оказывается
непросто найти в огромной библиотеке наиболее подходящий класс.
Альтернативой является создание классов с более широкими
функциональными возможностями, но в этом случае таких возможностей
может оказаться слишком много.
Объектно-ориентированное программирование: наследование
809
Вопросы производительности 12.3
Если порожденные путем наследования классы оказываются
большими, чем нужно (т.е. обладают слишком широкими функциональными
возможностями), память и ресурсы процессора могут расходоваться
впустую. Наследуйте от классов, функциональные свойства которых
ближе всего к тому, что требуется.
Чтение определений производных классов может озадачивать, поскольку
их унаследованные элементы не видны физически, хотя и присутствуют.
Похожая проблема возникает и при документировании элементов производных
классов.
12.8. Заключение
В этой главе было представлено наследование — возможность создания
класса путем ассимиляции элементов данных и элемент-функций
существующего класса и расширения их новыми возможностями. На ряде примеров,
в которых использовалась иерархия классов служащих, вы изучили понятия
базовых и производных классов и посредством открытого наследования
создали производный класс, наследующий элементы базового класса. В главе был
введен спецификатор доступа protected; элемент-функции производного
класса могут обращаться к защищенным элементам базового класса. Вы узнали,
как обращаться к переопределенным элементам базового класса,
квалифицируя их имена именем базового класса с операцией разрешения области
действия (::). Вы также увидели, в каком порядке вызываются конструкторы и
деструкторы для объектов классов, входящих в классовую иерархию. Наконец,
мы рассказали о трех типах наследования — открытом, защищенном и
закрытом — и о доступности элементов базового класса в производном классе при
наследовании каждого типа.
В главе 13 мы разовьем наше обсуждение наследования, представив
полиморфизм — объектно-ориентированную концепцию, позволяющую нам писать
программы, которые некоторым общим образом обрабатывают объекты
разнообразных классов, связанных отношениями наследования. После прочтения
13-й главы вы освоите уже все существенные аспекты
объектно-ориентированного программирования, — классы, объекты, инкапсуляцию, наследование
и полиморфизм.
Резюме
• Утилизация программного обеспечения сокращает время и стоимость програмных
разработок.
• Наследование является формой утилизации программного обеспечения, когда
программист создает класс, ассимилирующий данные и поведение существующего
класса и обогащающий их добавлением новых свойств. Существующий класс называется
базовым классом, а новый класс — производным классом.
• Непосредственный базовый класс (его имя специфицируется справа от : в первой
строке определения класса) является классом, который явно наследуется
производным классом. Косвенный базовый класс расположен в иерархии классов на два или
более уровней выше.
810
Глава 12
• В случае простого наследования класс является производным единственного
базового класса. При сложном наследовании производный класс наследует нескольким
(возможно, не родственным между собой) базовым классам.
• Производный класс представляет более специализированную группу объектов.
Обычно производный класс расширяет поведение, унаследованное от базового
класса. Производный класс может также настраивать поведение базового класса.
• Любой объект производного класса является также объектом класса, базового для
данного класса. Однако объект базового класса не является при этом объектом
производного класса.
• Отношение «является» представляет наследование. При таком отношении объекты
производного класса могут также рассматриваться в качестве объектов базового
класса.
• Отношение «имеет» представляет композицию. При таком отношении объект
содержит в качестве элементов один или несколько объектов других классов.
• Производный класс не может непосредственно обращаться к закрытым элементам
базового класса; это нарушало бы инкапсуляцию класса. Однако он может
непосредственно обращаться к защищенным элементам базового класса.
• Производный класс может производить изменения в состоянии закрытых элементов
базового, но только через не закрытые элемент-функции, предусмотренные в
базовом классе и наследуемые производным классом.
• Отношения простого наследования образуют древовидные иерархические
структуры. Базовый класс находится в иерархическом отношении со своими производными
классами.
• С объектами базового класса и производного класса можно обращаться одинаковым
образом; их общность выражается в элементах данных и элемент-функциях базового
класса.
• Открытые элементы базового класса доступны в пределах тела класса и везде в
программе, где имеется дескриптор объекта этого класса или одного из его производных
классов, — или, при использовании операции разрешения области действия, везде,
где имя класса находится в области действия.
• Закрытые элементы базового класса доступны только в пределах тела этого класса
и друзьям класса.
• Защищенный доступ предлагает уровень защиты, промежуточный между открытым
и закрытым доступом. Защищенные элементы базового класса доступны в пределах
тела данного класса, для его друзей и для элементов и друзей классов, производных
от данного.
• Защищенные элементы данных порождают две главных проблемы. Первая связана
с тем, что объекту производного класса не требуется вызывать элемент-функцию,
чтобы установить значение защищенного элемента данных базового класса. Вторая
состоит в том, что элемент-функции производного класса с большей вероятностью
окажутся зависимыми от реализации базового класса.
• Когда производный класс переопределяет элемент-функцию базового класса, к
последней можно обратиться, квалифицировав имя элемент-функции именем базового
класса с операцией разрешения области действия (::).
• Когда создается объект производного класса, немедленно вызывается (явно или
неявно) конструктор его базового класса для инициализации элементов данных
базового класса в объекте производного класса (до того, как будут создаваться элементы
данных производного класса).
• Объявление элементов данных как private с предоставлением не-закрытых
элемент-функций для манипуляции ими и проверки действительности помогает
правильно конструировать программное обеспечение.
Объектно-ориентированное программирование: наследование
811
• Когда объект производного класса уничтожается, деструкторы исполняются в
последовательности, обратной последовательности исполнения конструкторов, — сначала
вызывается деструктор производного, затем деструктор базового класса.
• При порождении производного класса от базового наследование может быть
открытым, защищенным или закрытым.
• При наследовании открытого базового класса открытые элементы базового класса
становятся открытыми, а защищенные — защищенными элементами базового класса.
• При наследовании защищенного базового класса открытые и защищенные элементы
базового класса становятся защищенными элементами производного класса.
• При наследовании закрытого базового класса открытые и защищенные элементы
базового класса становятся закрытыми элементами производного класса.
Терминология
базовый класс
деструктор базового класса
деструктор производного класса
друзья базового класса
друзья производного класса
закрытое наследование
закрытый базовый класс
защищенное наследование
защищенный базовый класс
защищенный элемент класса
иерархическое отношение
иерархия классов
инициализатор базового класса
квалифицированное имя
ключевое слово protected
композиция
конструктор базового класса
конструктор базового класса
по умолчанию
Контрольные вопросы
12.1. Заполните пропуски в каждом из следующих предложений:
а) — это форма утилизации программного обеспечения, в которой
новые классы ассимилируют данные и поведение существующих классов
и обогащают эти классы новыми возможностями.
Ь) элементы базового класса доступны только в определении
базового класса или в определениях производных классов.
c) При отношении объект производного класса может также
рассматриваться как объект своего базового класса.
d) При отношении объект класса содержит один или несколько
объектов других классов в качестве элементов.
e) При простом наследовании класс находится в отношении со
своими производными классами.
f) элементы базового класса доступны везде, где программа имеет
дескриптор объекта этого класса или объекта одного из его производных классов.
g) Защищенные элементы базового класса предоставляют промежуточный
уровень защиты между открытым и доступом.
конструктор производного класса
косвенный базовый класс
наследование
наследование элементов
существующего класса
настройка программного обеспечения
непосредственный базовый класс
открытое наследование
открытый базовый класс
отношение «имеет»
отношение «является»
переопределение элемент-функции
базового класса
производный класс
простое наследование
сложное наследование
субкласс
суперкласс
«хрупкое» программное обеспечение
812
Глава 12
h) C++ предусматривает , которое позволяет производному классу
наследовать от нескольких базовых классов, возможно, не из родственных
друг другу.
i) Когда создается объект производного класса, явно или неявно
вызывается базового класса для выполнения всей необходимой инициализации
элементов данных базового класса в объекте производного класса,
j) При произведении класса от базового класса посредством открытого
наследования открытые элементы базового класса становятся элементами
производного класса и защищенные элементы базового класса
становятся элементами производного класса.
к) При произведении класса от базового класса посредством защищенного
наследования открытые элементы базового класса становятся
элементами производного класса и защищенные элементы базового класса
становятся элементами производного класса.
12.2. Определите, верно или неверно каждое из следующих утверждений. Если
утверждение неверно, объясните, почему.
a) Можно рассматривать объекты базового класса и объекты производного
класса аналогичным образом.
b) Отношение «имеет» реализуется наследованием.
c) Класс Саг (автомобиль) находится в отношении «является» с его классами
SteeringWheel (руль) и Brakes (тормоза).
d) Наследование способствует утилизации проверенного высококачественного кода.
e) Когда объект производного класса уничтожается, деструкторы исполняются в
последовательности, обратной последовательности исполнения конструкторов.
Ответы на контрольные вопросы
12.1. а) Наследование. Ь) Защищенные, с) «является», или наследовании, d) «имеет»,
или композиции, е) иерархическом, f) открытые, g) закрытым, h) сложное
наследование, i) конструктор, j) открытыми, защищенными, к) защищенными,
защищенными.
12.2. а) Верно. Ь) Неверно. Отношение «имеет* реализуется композицией. Отношение
«является» реализуется наследованием, с) Неверно. Это пример отношения
«имеет». Класс Саг находится с классом Vehicle в отношении «является»,
d) Верно, е) Верно.
Упражнения
12.3. Многие программы, написанные с использованием наследования, могли бы быть
вместо этого написаны с композицией и наоборот. Перепишите класс Ва-
sePlusCommissionEmployee из иерархии CommissionEmployee / BasePlusCommi-
ssionEmployee, используя вместо наследования композицию. После того как вы
это сделайте, разберите сравнительные достоинства двух подходов к
проектированию данной иерархии и к объектно-ориентированному программированию
вообще. Какой из подходов более естественен? Почему?
12.4. Обсудите аспекты того, каким образом наследование способствует утилизации
программного обеспечения, экономит время при программных разработках и
помогает в предотвращении ошибок.
12.5. Некоторые программисты предпочитают не использовать защищенный доступ,
считая, что он нарушает инкапсуляцию базового класса. Обсудите
сравнительные достоинства использования защищенного доступа, противопоставив его
закрытому.
Объектно-ориентированное программирование: наследование
813
12.6. Нарисуйте иерархию наследования для обучающихся в университете,
аналогичную иерархии, показанной на рис. 12.2. В качестве базового класса иерархии
возьмите Student, затем включите в нее классы UndegraduateStudent и Gradua-
teStudent, производные от Student. Продолжите расширение иерархии глубоко
(т.е. на возможно большее число уровней). Например, от UndegraduateStudent
могут происходить Freshman, Sophomore, Junior и Senior, а от
GraduateStudent — DoctoralStudent и MastersStudent. После того как вы
нарисуете иерархию, обсудите существующие между классами отношения.
[Замечание. Для этого упражнения не требуется писать никакого кода.]
12.7. Мир фигур (форм) гораздо богаче, чем та совокупность, что входит в иерархию на
рис. 12.3. Запишите все формы, которые сможете придумать — как двумерные,
так и трехмерные, — и образуйте из них более полную иерархию класса Shape
с возможно большим числом уровней. Базовым классом вашей иерархии должен
быть Shape, от которого производятся классы TwoDimensionalShape и ThreeDi-
mensionalShape. [Замечание. Для этого упражнения не требуется писать
никакого кода.] Мы воспользуемся этой иерархией в главе 13 для обработки
конкретных форм как объектов базового класса Shape. (Эта методика, называемая
полиморфизмом, и является предметом обсуждения в главе 13.)
12.8. Нарисуйте иерархию наследования для классов Quadrilateral, Trapezoid,
Parallelogram, Rectangle и Square. Сделайте базовым классом иерархии
Quadrilateral. Сделайте иерархию возможно более глубокой.
12.9. (Иерархия наследования Package) Службы доставки посылок, такие, как
FedEx51, DHL® и UPS("\ предлагают ряд услуг по доставке, каждую по своей
цене. Создайте иерархию наследования для представления различных типов
посылок. В качестве базового класса иерархии используйте класс Package, затем
включите в нее классы TwoDayPackage и OvernightPackage, производные от
Package. Базовый класс Package должен содержать элементы данных для
представления имени, адреса, города, штата и ZIP-кода как отправителя, так и
получателя посылки, в дополнение к элементам, в которых хранится вес (в унциях)
и цена доставки за унцию. Конструктор Package должен инициализировать эти
элементы данных. Убедитесь, что вес и цена за унцию имеют положительные
значения. Класс Package должен предусматривать открытую элемент-функцию
calculateCost, возвращающую значение типа double, которое будет означать
стоимость доставки. Функция calculateCost из Package должна определять
стоимость, умножая цену за унцию на вес. Производный класс TwoDayPackage
должен наследовать функциональные возможности класса Package, но иметь также
элемент данных, представляющий постоянную наценку, взимаемую компанией
за двухдневную доставку. Конструктор TwoDayPackage должен принимать
значение для инициализации этого элемента. Класс TwoDayPackage должен
переопределять элемент-функцию calculateCost, чтобы она вычисляла стоимость
доставки, прибавляя наценку к цене за вес, вычисляемой функцией
calculateCost базового класса Package. Класс OvernightPackage должен быть
непосредственным производным Package и иметь дополнительный элемент данных,
представляющий дополнительную наценку за унцию при доставке на следующий
день. OvernightPackage должен переопределять элемент-функцию
calculateCost, чтобы она вычисляла цену доставки, прибавляя эту наценку к
стандартной цене за унцию перед вычислением стоимости доставки. Напишите тестовую
программу, которая создает объекты посылок каждого типа и проверяет
функцию calculateCost.
814
Глава 12
12.10. (Иерархия наследования Account) Создайте иерархию наследования, которую
мог бы использовать банк для представления счетов своих клиентов. Все
клиенты могут вносить (кредит) деньги на свои чета и снимать (дебет) деньги со счетов.
Существуют и более специфические типы счетов. Например, сберегательный
счет приносит вкладчику проценты с денег, лежащих на счете. С другой
стороны, за транзакции (т.е. кредиты или дебеты), производимые через расчетные
счета, взимается определенная плата.
Создайте иерархию с базовым классом Account и производными от него
классами SavingsAccount и CheckingAccount. Класс Account должен иметь элемент
данных типа double для представления баланса счета. В классе должен быть
предусмотрен конструктор, принимающий начальную сумму баланса и использует
ее для инициализации элемента данных. Конструктор должен проверять
начальный баланс, гарантируя, что он больше или равен 0.0. В противном случае
баланс должен устанавливаться равным 0.0 и конструктор должен выводить
сообщение об ошибке, указывающее, что был специфицирован недействительный
начальный баланс. В классе нужно предусмотреть три элемент-функции. Функция
credit должна прибавлять сумму к текущему балансу, а функция debit снимать
сумму с текущего баланса, гарантируя при этом, что сумма дебета не
превосходит баланса счета. В противном случае следует оставить баланс без изменений
и напечатать сообщение "Debit amount exceeds account balance".
Элемент-функция getBalance должна возвращать текущий баланс.
Производный класс SavingsAccount должен наследовать функциональные
свойства Account, но включать также элемент данных типа double,
специфицирующий процентную ставку, присвоенную данному счету. Конструктор
SavingsAccount должен принимать начальное значение баланса и значение процентной
ставки для SavingsAccount. В классе должна быть предусмотрена открытая
элемент-функция calculatelnterest, которая возвращает число двойной точности,
указывающее сумму начисленных процентов по счету. Функция
calculatelnterest должна вычислять эту суму, умножая текущий баланс на процентную
ставку. [Замечание. SavingsAccount должен наследовать функции credit и debit, не
переопределяя их.]
Производный класс CheckingAccount должен наследовать от класса Account
и иметь дополнительный элемент данных типа double, представляющий плату,
взимаемую за транзакцию. Конструктор CheckingAccount должен принимать
начальный баланс и параметр, указывающий плату за транзакцию. Класс
CheckingAccount должен переопределять функции credit и debit, чтобы они
вычитали из текущего баланса эту плату при любой успешной транзакции. Версии этих
функций из CheckingAccount для обновления баланса должны вызывать свои
базовые версии. Функция debit должна взимать плату только в случае, когда
деньги действительно снимаются со счета (т.е. сумма дебета не превосходит
баланса счета). [Подсказка. Определите функцию debit для CheckingAccount
таким образом, чтобы она возвращала булево значение, указывающее, были ли
сняты деньги. Затем используйте возвращаемое значение, чтобы определить,
следует ли взимать плату.]
После определения классов иерархии напишите программу, которая создает
объекты каждого класса и тестирует их элемент-функции. Прибавьте начисленные
проценты к объекту SavingsAccount, вызвав сначала его функцию
calculatelnterest, а затем передав возвращенное значение функции credit объекта.
13
Объектно-ориентированное
программирование:
полиморфизм
ЦЕЛИ
В этой главе вы изучите:
• Что такое полиморфизм, каким
образом он делает программирование
более удобным и способствует
расширяемости программных
систем.
• Как объявляются и используются
виртуальные функции с целью
реализации полиморфизма.
• Различие между абстрактными
и конкретными классами.
• Как объявляются чисто виртуальные
функции с целью создания
абстрактных классов.
• Как использовать информацию о типе времени выполнения (RTTI)
с нисходящими приведениями типа, dynamic_cast, typeid и type_info.
• Какова «закулисная» реализация виртуальных функций
и динамического связывания в C++.
• Использование виртуальных деструкторов для гарантии того,
что на объекте будут выполнены все необходимые деструкторы.
816
Глава 13
13.1. Введение
13.2. Примеры полиморфизма
13.3. Отношения между объектами в иерархии
наследования
13.3.1. Вызов функций базового класса из объектов
производного класса
13.3.2. Установка указателей производного класса на
объекты базового класса
13.3.3. Вызов элемент-функций производного класса
через указатели базового класса
13.3.4. Виртуальные функции
13.3.5. Сводка допустимых присваиваний объектов
указателям базового и производного классов
13.4. Поля типа и операторы switch
13.5. Абстрактные классы и чисто виртуальные функции
13.6. Пример. Система начисления заработной платы,
использующая полиморфизм
13.6.1. Создание абстрактного базового класса
Employee
13.6.2. Создание конкретного производного класса
SalariedEmployee
13.6.3. Создание конкретного производного класса
HourlyEmployee
13.6.4. Создание конкретного производного класса
CommissionEmployee
13.6.5. Создание косвенного конкретного
производного класса
BasePlusCommissionEmployee
13.6.6. Демонстрация полиморфной обработки
13.7. (Дополнительный раздел.) Техническая сторона
полиморфизма, виртуальных функций
и динамического связывания
13.8. Пример. Система начисления заработной платы,
использующая полиморфизм и информацию о типе
времени выполнения с нисходящими приведениями
типа, dynamiccast, typeid и typeinfo
Объектно-ориентированное программирование: полиморфизм
817
Виртуальные деструкторы
Конструирование программного обеспечения.
Введение наследования в систему ATM
(необязательный раздел)
Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
13.1. Введение
В главах 9-12 мы обсуждали ключевые технологии
объектно-ориентированного программирования, включая классы, объекты, инкапсуляцию,
перегрузку операций и наследование. Теперь мы продолжим наше изучение OOP,
объяснив и продемонстрировав полиморфизм в иерархиях наследования.
Полиморфизм позволяет нам программировать «в общем», а не «в частности».
Говоря конкретнее, полиморфизм позволяет писать программы, работающие
с объектами различных классов, входящих в одну иерархию наследования,
так, как если бы все они являлись объектами базового класса этой иерархии.
Как мы скоро увидим, полиморфное программирование оперирует
дескрипторами-указателями и дескрипторами-ссылками на объекты, но не
дескрипторами-именами.
Рассмотрим следующий пример полиморфизма. Предположим, мы создаем
программу для биологического исследования, которая моделирует поведение
различных типов животных. Классы Fish, Frog и Bird представляют три
исследуемых типа животных (рыба, лягушка, птица). Пусть каждый их этих
классов производится от класса Animal, имеющего функцию move (движение)
и хранящего текущее местоположение животного. Каждый из производных
классов реализует функцию move. Наша программа поддерживает вектор
указателей на объекты классов, производных от Animal. Чтобы моделировать
перемещения животных, программа раз в секунду посылает каждому объекту
одно и то же сообщение — а именно, move. Однако каждый конкретный тип
животного откликается на это сообщение по-своему, — рыба может проплыть
два фута, лягушка прыгнуть на три фута, а птица пролететь десять футов.
Знание каждым объектом того, «как себя вести» (т.е. какое поведение присуще
объектам данного типа) в ответ на один и тот же вызов функции, является
ключевым моментом полиморфизма. Одно и то же сообщение (в данном случае
move), посылаемое разнообразным объектам, приводит к «многим формам»
поведения — отсюда и термин «полиморфизм».
Используя возможности полиморфизма, достаточно просто создавать
расширяемые системы: к системе можно добавлять новые классы без каких-либо
или с малыми модификациями имеющегося «обобщенного» кода, если новые
классы входят в обобщенную иерархию, обрабатываемую программой.
Изменений потребуют только те части программы, котором необходимо
непосредственное знание новых классов, добавляемых к иерархии. Например, если мы
создадим класс Tortoise (черепаха), производный от Animal (черепаха может
818
Глава 13
реагировать на сообщение move, передвигаясь на один дюйм), нам потребуется
написать только класс Tortoise и ту часть симулятора, которая создает объект
Tortoise. Те части программы, что обрабатывают поведение животных
обобщенным образом, могут не требовать изменений.
Мы начнем с ряда небольших, узконаправленных примеров, которые
приведут нас к пониманию виртуальных функций и динамического связывания —
двух технологий, лежащих в основе полиморфизма. Затем мы представим
учебный пример, который пересматривает иерархию Employee из главы 12.
В этом примере мы определим «интерфейс» (т.е. набор функций), общий для
всех классов иерархии. Общие функциональные свойства всех классов
служащих определяются в т. н. абстрактном базовом классе Employee, от которого
непосредственно производятся классы SalariedEmployee, HourlyEmployee
и CommissionEmployee и косвенно — класс BasePlusCommissionEmployee.
Мы скоро увидим, что именно делает класс «абстрактным» или, в
противоположность абстрактному, «конкретным».
В этой иерархии каждый служащий имеет функцию earnings для расчета
его недельного заработка. Эти функции различны в зависимости от типа
служащих. Например, SalariedEmployee получают фиксированный недельный
оклад вне зависимости от числа отработанных часов, в то время как
HourlyEmployee получают почасовую оплату и сверхурочные. Мы покажем,
каким образом обработать служащих «в общем», т.е. вызывая функции
earnings объектов нескольких производных классов через указатели на
базовый класс. При этом программист имеет дело с функциональными вызовами
только одного вида, которые могут выполнять различные задачи в
зависимости от типа объекта, на который ссылается указатель базового класса.
Важным в этой главе является дополнительный раздел, детально
разбирающий внутренние механизмы полиморфизма, виртуальных функций и
динамического связывания, в котором приводится подробная диаграмма возможной
реализации полиморфизма в C++.
Иногда при полиморфной обработке нам приходится программировать
нечто «в частности», т.е. некоторые операции, которые должны производиться
над объектами специфического типа в иерархии и которые, вообще говоря, не-
приложимы к объектам других типов. Мы снова воспользуемся нашей
иерархией Employee, чтобы продемонстрировать мощные возможности информации
о типе времени выполнения и динамического приведения типа, которые
позволяют программе определять тип объекта во время исполнения и
обращаться с ним соответствующим образом. Мы используем эти возможности, чтобы
определить, не относится ли служащий к типу BasePlusCommissionEmployee,
и если это так, мы начисляем ему 10-процентную премию.
13.2. Примеры полиморфизма
В этом разделе мы приведем несколько примеров полиморфизма. При
полиморфном программировании одна и та же функция может производить
различные действия в зависимости от типа объекта, для которого она
активируется. Это дает программисту огромные выразительные возможности. Если класс
Rectangle является производным от Quadrilateral, то объект Rectangle
представляет собой более конкретный случай объекта Quadrilateral. Таким
образом, любая операция (такая, как вычисление периметра или площади), кото-
Объектно-ориентированное программирование: полиморфизм
819
рую можно произвести над объектом класса Quadrilateral, может быть
произведена и над объектом класса Rectangle. Эти же операции могут
производиться и над другими видами четырехугольников, такими, как
Square, Parallelogram и Trapezoid. Полиморфизм имеет место, когда
программа вызывает виртуальную функцию через указатель или ссылку базового
класса (т.е. Quadrilateral); в этом случае C++ динамически (т.е. во время
исполнения) выбирает нужную функцию из того класса, в качестве
представителя которого бы создан объект. Вы увидите пример кода, иллюстрирующего
этот процесс, в разделе 13.3.
Другой пример. Предположим, мы разрабатываем видеоигру, которая
манипулирует объектами многих типов, включая объекты классов Martian,
Venutian, Plutonian, Spaceship и Laser Beam. Пусть все эти классы являются
производными от общего базового класса SpaceObject, в котором имеется
элемент-функция draw. Каждый производный класс реализует эту функцию так,
как требуется для объектов данного вида. Программа экранного менеджера
имеет контейнер (т.е. vector), в котором хранятся указатели типа SpaceObject
на объекты различных классов. Для обновления изображения экранный
менеджер периодически посылает всем объектам одно и то же сообщение —
draw. Объект каждого из типов реагирует на это сообщение по-своему.
Например, объект Martian может изобразить себя в вида красного существа с
антеннами. Объект Spaceship нарисует себя в виде серебристой летающей тарелки.
Объект LaserBeam нарисует себя как ярко-красный луч, пересекающий
экран. Итак, одно и то же сообщение (т.е. draw), посылаемое различным
объектам, приводит к «полиморфным» результатам.
Полиморфный экранный менеджер позволяет вводить в систему новые
классы с минимальными модификациями ее кода. Предположим, что мы
хотим дополнить нашу игру объектами класса Mercurian. Для этого нам нужно
построить класс Mercurian, производный от SpaceObject, но имеющий свою
собственную элемент-функцию draw. Теперь, когда в контейнере появятся
объекты класса Mercurian, программисту не нужно будет модифицировать
код экранного менеджера. Экранный менеджер активирует функцию draw для
каждого объекта в контейнере, вне зависимости от типа объекта, так что
новые объекты Mercurian попросту «втыкаются» в программу. Таким образом,
не производя в системе модификаций (помимо написания и включения самих
классов), программисты, используя полиморфизм, могут вводить в нее
дополнительные классы, наличие которых не предусматривалось при
проектировании системы.
Общее методическое замечание 13.1
Используя виртуальные функции и полиморфизм, вы можете
сосредоточиться на обобщенных аспектах и предоставить заботу о
специфике объектов среде времени исполнения. Вы можете заставить
разнообразные объекты вести себя в соответствии со своей спецификой,
даже не зная их конкретного типа (при условии, что эти объекты
принадлежат к одной иерархии наследования и обращения к ним про
изводятся через указатели общего базового класса).
820
Глава 13
Ш Общее методическое замечание 13,2
Полиморфизм помогает обеспечить расширяемость: код,
активирующий полиморфное поведение, пишется независимо от типов объектов,
которым посылаются сообщения. Таким образом, без изменения
базовой системы в нее могут быть инкорпорированы новые типы
объектов, которые способны откликаться на существующие сообщения.
Для включения новых типов должен быть модифицирован только код
клиента, отвечающий за создание новых объектов.
13.3. Отношения между объектами в иерархии
наследования
В разделе 12.4 мы создали иерархию классов служащих, в которой класс
BasePlusCommissionEmployee являлся производным от Commission Employee.
В главе 12 для вызова элемент-функций объектов CommissionEmployee и
BasePlusCommissionEmployee мы использовали имена объектов. Теперь мы
исследуем отношения классов в этой иерархии более внимательно. Следующие
несколько параграфов покажут ряд примеров, которые продемонстрируют,
каким образом указатели базового и производного классов могут
устанавливаться на объекты базового и производного классов, и как эти указатели могут
использоваться для активации элемент-функций этих объектов. К концу
раздела 13.3 мы покажем, как реализовать полиморфное поведение указателей
базового класса, установленных на объекты производного класса.
В разделе 13.3.1 мы присвоим адрес объекта производного класса указателю
базового класса и покажем, что вызов функции через базовый указатель
активирует функцию базового класса, т.е. что класс вызванной функции
определяется типом дескриптора. В разделе 13.3.2 мы присвоим адрес объекта базового
класса указателю производного класса, что приведет к ошибке компиляции.
Мы рассмотрим выдаваемое сообщение об ошибке и разберем, почему
компилятор не допускает таких присваиваний. В разделе 13.3.3 мы присвоим адрес
объекта производного класса указателю базового класса и покажем, что через этот
указатель можно активировать только «базовую» часть функциональных
свойств объекта, — когда мы пытаемся вызвать через указатель базового класса
элемент-функции производного класса, происходят ошибки компиляции.
Наконец, в разделе 13.3.4 мы введем в иерархию виртуальные функции и
полиморфизм, объявив элемент-функцию базового класса как virtual. После этого
мы присвоим объект производного класса указателю базового класса и
используем этот указатель для активации функции производного класса — это именно
то, что требуется для реализации полиморфного поведения.
Основной целью этих примеров является демонстрация того, что с объектом
производного класса можно обращаться, как с объектом его базового класса.
Здесь открывается много интересных возможностей. Например, программа
может создать массив указателей базового класса, указывающих на объекты
производных классов различного типа. Несмотря на то, что объекты
производных классов принадлежат к различным типам, компилятор это допускает, так
как каждый объект производного класса является объектом его базового
класса. Однако мы не можем обращаться с объектом базового класса как с
объектом какого-либо из его производных классов. Например, в иерархии из гла-
Объектно-ориентированное программирование: полиморфизм 821
вы 12 объект CommissionEmployee не является BasePlusCommissionEm-
ployee — класс CommissionEmployee не имеет элемента данных baseSalary
и элемент-функций setBaseSalary и getBaseSalary. Отношение является
направлено только от производного класса к его непосредственным и косвенным
базовым классам.
13.3.1. Вызов функций базового класса из объектов
производного класса
Пример на рис. 13.1-13.5 демонстрирует три возможности установки
указателей базового и производного классов на объекты базового класса и
производного класса. Первые две очевидны — мы устанавливаем указатель базового
класса на объект базового класса (и активируем функцию базового класса),
а указатель производного класса устанавливаем на объект производного
класса (и активируем функцию производного класса). Затем мы демонстрируем
отношение между производными классами и базовыми классами (т.е. отношение
является)у устанавливая указатель базового класса на объект производного
класса (и показывая, что функция базового класса действительно доступна
в объекте производного класса).
Класс CommissionEmployee (рис. 13.1-13.2), обсуждавшийся в главе 12,
представляет служащего, получающего комиссионный процент с суммы
заключенных им сделок (продаж). Класс BasePlusCommissionEmployce
(рис. 13.3-13.4), также обсуждавшийся в главе 12, представляет служащего,
получающего базовую зарплату плюс комиссионный процент. Каждый объект
BasePlusCommissionEmployee является объектом CommissionEmployee,
который получает дополнительно фиксированную базовую плату.
Элемент-функция earnings класса BasePlusCommissionEmployee (строки 32-35 на рис. 13.4)
переопределяет функцию earnings класса CommissionEmployee (строки 79-82
на рис. 13.2), включая в расчет базовую плату из объекта
BasePlusCommissionEmployee. Элемент-функция print класса
BasePlusCommissionEmployee (строки 38-46 на рис. 13.4) переопределяет функцию print класса
CommissionEmployee (строки 85-92 на рис. 13.2), выводя ту же информацию,
что и функция из CommissionEmployee, а также значение базовой платы.
1 // Рис. 13.1: CommissionEmployee.h
2 // Класс CommissionEmployee - служащий, получающий комиссионные.
3 #ifndef COMMISSION_H
4 #define COMMISSION_H
5
6 #include <string> // стандартный класс C++ string
7 using std::string;
8
9 class CommissionEmployee
10 {
11 public:
12 CommissionEmployee( const string &, const string &,
13 const string &, double = 0.0, double = 0.0 );
14
15 void setFirstName( const string & ); // установить имя
16 string getFirstName() const; // возвратить имя
17
822
Глава 13
18 void setLastName( const string & ); // установить фамилию
19 string getLastName() const; // возвратить фамилию
20
21 void setSocialSecurityNumber( const string & ); // установить SSN
22 string getSocialSecurityNumber() const; // возвратить SSN
23
24 void setGrossSales( double ); // установить общую сумму продаж
25 double getGrossSales() const; // возвратить общую сумму продаж
26
27 void setCommissionRate ( double ); // установить процент
28 double getCommissionRate() const; // возвратить процент
29
30 double earnings() const; // вычислить заработок
31 void print() const; // напечатать объект CommissionEmployee
32 private:
33 string firstName;
34 string 1astName;
35 string socialSecurityNumber;
36 double grossSales; // продажи за неделю
37 double commissionRate; // комиссионный процент
38 }; // конец класса CommissionEmployee
39
40 #endif
Рис. 13.1. Заголовочный файл класса CommissionEmployee
1 // Рис. 13.2: CommissionEmployee.срр
2 // Определения элемент-функций класса CommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 #include "CommissionEmployee.h" // определение CommissionEmployee
7
8 // конструктор
9 CommissionEmployee::CommissionEmployee(
10 const string &first, const string &last, const string &ssn,
11 double sales, double rate )
12 : firstName(first), lastName(last), socialSecurityNumber(ssn)
13 {
14 setGrossSales( sales ); // проверить и сохранить объем продаж
15 setCommissionRate( rate ); // проверить и сохранить процент
16 } // конец конструктора CommissionEmployee
17
18 // установить имя
19 void CommissionEmployee::setFirstName( const string &first )
20 {
21 firstName = first; // should validate
22 } // конец функции setFirstName
23
24 // возвратить имя
25 string CommissionEmployee:rgetFirstName() const
26 {
27 return firstName;
28 } // конец функции getFirstName
29
Объектно-ориентированное программирование: полиморфизм
823
30 // установить фамилию
31 void CommissionEmployee::setLastName( const string filast )
32 {
33 lastName = last; // should validate
34 } // конец функции setLastName
35
36 // возвратить фамилию
37 string CommissionEmployee::getLastName() const
38 {
39 return lastName;
40 } // конец функции getLastName
41
42 // установить номер страховки
43 void CommissionEmployee::setSocialSecurityNumber(const string &ssn)
44 {
45 socialSecurityNumber = ssn; // should validate
46 } // конец функции setSocialSecurityNumber
47
48 // возвратить номер страховки
49 string CommissionEmployee::getSocialSecurityNumber() const
50 {
51 return socialSecurityNumber;
52 } // конец функции getSocialSecurityNumber
53
54 // установить общую сумму продаж
55 void CommissionEmployee::setGrossSales( double sales )
56 {
57 grossSales = ( sales < 0.0 ) ? 0.0 : sales;
58 ) // конец функции setGrossSales
59
60 // возвратить общую сумму продаж
61 double CommissionEmployee:igetGrossSales() const
62 {
63 return grossSales;
64 } // конец функции getGrossSales
65
66 // установить комиссионный процент
67 void CommissionEmployee::setCommissionRate( double rate )
68 {
69 commissionRate = ( rate > 0.0 && rate < 1.0 ) ? rate : 0.0;
70 } // конец функции setCommissionRate
71
72 // возвратить комиссионный процент
73 double CommissionEmployee::getCommissionRate() const
74 {
75 return commissionRate;
76 } // конец функции getCommissionRate
77
78 // вычислить заработок
79 double CommissionEmployee::earnings() const
80 {
81 return getCommissionRate() * getGrossSales();
82 } // конец функции earnings
83
84 // напечатать объект CommissionEmployee
85 void CommissionEmployee::print() const
86 {
824
Глава 13
87 cout « "commission employee: "
88 « getFirstName() « ' ' « getLastName ()
89 « "\nsocial security number: " « getSocialSecurityNumber()
90 « "\ngross sales: " « getGrossSales()
91 « "\ncommission rate: " « getCommissionRate();
92 } // конец функции print
Рис. 13.2. Файл реализации класса CommissionEmployee
1 // Рис. 13.3: BasePlusCommissionEmployee.h
2 // Класс BasePlusCommissionEmployee, производный от класса
3 // CommissionEmployee.
4 #ifndef BASEPLUS_H
5 #define BASEPLUS_H
6
7 #include <string> // стандартный класс C++ string
8 using std::string;
9
10 #include "CommissionEmployee.h" // объявление CommissionEmployee
11
12 class BasePlusCommissionEmployee : public CommissionEmployee
13 {
14 public:
15 BasePlusCommissionEmployee( const string &, const string &,
16 const string &, double = 0.0, double = 0.0, double = 0.0 );
17
18 void setBaseSalary( double ); // установить основную зарплату
19 double getBaseSalary() const; // возвратить основную зарплату
20
21 double earnings() const; // вычислить заработок
22 void print() const; // напечатать BasePlusCommissionEmployee
23 private:
24 double baseSalary; // основная зарплата
25 }; // конец класса BasePlusCommissionEmployee
26
27 #endif
Рис. 13.3. Заголовочный файл класса BasePlusCommissionEmployee
1 // Рис. 13.4: BasePlusCommissionEmployee.срр
2 // Определения элемент-функций класса BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 // определение класса BasePlusCommissionEmployee
7 #include "BasePlusCommissionEmployee.h"
8
9 // конструктор
10 BasePlusCommissionEmployee::BasePlusCommissionEmployee(
11 const string fifirst, const string filast, const string &ssn,
12 double sales, double rate, double salary )
13 // explicitly call base-class constructor
14 : CommissionEmployee( first, last, ssn, sales, rate )
Объектно-ориентированное программирование: полиморфизм
825
15 {
16 setBaseSalary( salary ); // проверить и сохранить зарплату
17 } // конец конструктора BasePlusCommissionEmployee
18
19 // установить основную зарплату
20 void BasePlusCommissionEmployee::setBaseSalary( double salary )
21 {
22 baseSalary = ( salary < 0.0 ) ? 0.0 : salary;
23 } // конец функции setBaseSalary
24
25 // возвратить основную зарплату
26 double BasePlusCommissionEmployee: :getBaseSalary () const
27 {
28 return baseSalary;
29 } // конец функции getBaseSalary
30
31 // вычислить заработок
32 double BasePlusCommissionEmployee::earnings() const
33 {
34 return getBaseSalary() + CommissionEmployee:learnings () ;
35 } // конец функции earnings
36
37 // напечатать объект BasePlusCommissionEmployee
38 void BasePlusCommissionEmployee::print() const
39 {
40 cout « "base-salaried ";
41
42 // вызвать функцию print класса CommissionEmployee
43 CommissionEmployee::print();
44
45 cout « "\nbase salary: " « getBaseSalary();
46 } // конец функции print
Рис. 13.4. Файл реализации класса BasePlusCommissionEmployee
Строки 19-20 на рис. 13.5 создают объект CommissionEmployee, а
строка 23 — указатель на CommissionEmployee; строки 26-27 создают объект
BasePlusCommissionEmployee, а строка 30 — указатель на
BasePlusCommissionEmployee. Строки 37 и 39 используют имена объектов (соответственно
CommissionEmployee и basePlusCommissionEmployee) для вызова
элемент-функции print каждого объекта. Строка 42 присваивает адрес объекта
базового класса CommissionEmployee указателю базового класса commis-
sionEmployeePtr, который используется в строке 45 для активации
элемент-функции print на этом объекте. Тем самым вызывается версия print,
определенная в базовом классе CommissionEmployee. Аналогично строка 48
присваивает адрес объекта производного класса basePlusCommissionEmployee
указателю производного класса basePlusCommissionEmployeePtr который
используется в строке 52 для активации элемент-функции print на этом объекте.
Тем самым вызывается версия print, определенная в производном классе
BasePlusCommissionEmployee. Строка 55 присваивает затем адрес объекта
производного класса basePlusCommissionEmployee указателю базового класса
commissionEmployeePtr, который строка 59 использует для активации
элемент-функции print. Компилятор C++ допускает такое «скрещивание», по-
826
Глава 13
скольку объект производного класса является объектом базового класса.
Обратите внимание, что хотя указатель базового класса CommissionEmployee
ссылается на объект производного класса BasePlusCommissionEmployee,
вызывается функция print базового класса CommissionEmployee (а не функция
производного класса BasePlusCommissionEmployee). Вывод при каждом из
вызовов функции print показывает, что класс, функция которого
активируется, определяется типом дескриптора (т.е. типом указателя или ссылки),
используемого при вызове, а не типом объекта, на который дескриптор
ссылается. В разделе 13.3.4, где мы введем виртуальные функции, мы
продемонстрируем, как можно вызвать функцию класса объекта, а не класса
дескриптора. Мы увидим, что это является критическим моментом реализации
полиморфного поведения — центральной темы этой главы.
1 // Рис. 13.5: figl3_05.cpp
2 // Установка указателей базового и производного класса
3 //на объекты соответственно базового класса и производного класса.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7 using std::fixed;
8
9 #include <iomanip>
10 using std::setprecision;
11
12 // включить определения классов
13 #include "CommissionEmployee.h"
14 #include "BasePlusCommissionEmployee.h"
15
16 int main()
17 {
18 // создать объект базового класса
19 CommissionEmployee CommissionEmployee(
20 "Sue", "Jones", 22-22-2222", 10000, .06 );
21
22 // создать указатель базового класса
23 CommissionEmployee *commissionEmployeePtr = 0;
24
25 // создать объект производного класса
26 BasePlusCommissionEmployee basePlusCommissionEmployee(
27 "Bob", "Lewis", 33-33-3333", 5000, .04, 300 );
28
29 // создать указатель производного класса
30 BasePlusCommissionEmployee *basePlusCommissionEmployeePtr = 0;
31
32 // задать формат вывода чисел с плавающей точкой
33 cout « fixed « setprecision( 2 );
34
35 // вывести CommissionEmployee и basePlusCommissionEmployee
36 cout « "Print base-class and derived-class objects:\n\n";
37 commissionEmployee.print(); // вызов print базового класса
38 cout « "\n\n";
39 basePlusCommissionEmployee.print(); // вызов производной print
40
41 // установить базовый указатель на базовый объект; напечатать
Объектно-ориентированное программирование: полиморфизм 827
42 commissionEmployeePtr = ficommissionEmployee; // естественно
43 cout « "\n\n\nCalling print with base-class pointer to\n"
44 « "base-class object invokes base-class print function:\n\n";
45 commissionEmployeePtr->print(); // вызывает базовую print
46
47 // установить производный указатель на производный объект
48 basePlusCommissionEmployeePtr = fibasePlusCommissionEmployee;
49 cout « "\n\n\nCalling print with derived-class pointer to "
50 « "\nderived-class object invokes derived-class "
51 « "print function:\n\n";
52 basePlusCommissionEmployeePtr->print(); // производная print
53
54 // установить базовый указатель на производный объект; напечатать
55 commissionEmployeePtr = fibasePlusCommissionEmployee;
56 cout « "\n\n\nCalling print with base-class pointer to "
57 « "derived-class object\ninvokes base-class print "
58 « "function on that derived-class object:\n\n";
59 commissionEmployeePtr->print(); // вызывает базовую print
60 cout « endl;
61 return 0;
62 } // конец main
Print base-class and derived-class objects:
commission employee: Sue Jones
social security number: 222-22-2222
gross sales: 10000.00
commission rate: 0.06
base-salaried commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
base salary: 300.00
Calling print with base-class pointer to
base-class object invokes base-class print function:
commission employee: Sue Jones
social security number: 222-22-2222
gross sales: 10000.00
commission rate: 0.06
Calling print with derived-class pointer to
derived-class object invokes derived-class print function:
base-salaried commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
base salary: 300.00
Calling print with base-class pointer to derived-class object
828
Глава 13
invokes base-class print function on that derived-class object:
commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
Рис. 13.5. Присваивание адресов объектов базового и производного классов
указателям базового и производного класса
13.3.2. Установка указателей производного класса
на объекты базового класса
В разделе 13.3.1 мы присвоили адрес объекта производного класса
указателю базового класса и показали, что компилятор C++ допускает такое
присваивание, так как объект производного класса является объектом базового
класса. На рис. 13.6 мы пробуем подойти к этому с другой стороны, устанавливая
указатель производного класса на объект базового класса. [Замечание.
Программа использует классы CommissionEmployee и BasePlusCommissionEm-
ployee из рис. 13.1-13.4.] Строки 8-9 на рис. 13.6 создают объект
CommissionEmployee, а строка 10 создает указатель BasePlusCommissionEmployee.
Строка 14 пытается присвоить адрес объекта CommissionEmployee базового
класса указателю basePlusCommissionEmployeePtr производного класса, но
компилятор C++ генерирует сообщение об ошибке. Компилятор не допускает
такого присваивания, поскольку CommissionEmployee не является
BasePlusCommissionEmployee. Рассмотрим последствия в случае, если бы
компилятор допускал подобное присваивание. Через указатель
BasePlusCommissionEmployee мы можем вызвать любую элемент-функцию класса
BasePlusCommissionEmployee, включая setBaseSalary, для объекта, на
который ссылается указатель (т.е. объекта базового класса CommissionEmployee).
Но объект CommissionEmployee не имеет элемент-функции setBaseSalary, как
не имеет и элемента данных baseSalary, который она должна устанавливать.
Это могло бы создать серьезные проблемы, поскольку setBaseSalary
предполагает, что элемент baseSalary находится «на своем обычном месте» в объекте
BasePlusCommissionEmployee. Это место в памяти не принадлежит объекту
CommissionEmployee, так что элемент-функция setBaseSalary могла бы
переписать какие-то другие важные данные, находящиеся в памяти, возможно,
принадлежащие другому объекту.
1 // Рис. 13.6: figl3_06.cpp
2 // Установка указателя производного класса на базовый объект.
3 #include "CommissionEmployee.h"
4 #include "BasePlusCommissionEmployee.h"
5
6 int main()
7 {
8 CommissionEmployee CommissionEmployee(
9 "Sue", "Jones", 22-22-2222", 10000, .06 );
10 BasePlusCommissionEmployee ^basePlusCommissionEmployeePtr = 0;
11
12 // установить указатель производного класса на базовый объект
Объектно-ориентированное программирование: полиморфизм 829
13 // Ошибка: CommissionEmployee не есть BasePlusCommissionEmployee
14 basePlusCommissionEmployeePtr = ficommissionEmployee;
15 return 0;
16 } // конец main
Сообщение об ошибке компилятора Borland C++ с командной строкой:
Error E2034 figl3_06.cpp 14: Cannot convert 'CommissionEmployee *'
to 'BasePlusCommissionEmployee *' in function main()
Сообщение об ошибке компилятора GNU C++;
figl3_06.cpp:14: error, invalid conversion from
■CommissionEmployee*' to 'BasePlusCommissionEmployee*'
Сообщение об ошибке компилятора Visual C++.NET:
с:\cpphtp_examples\chl3\figl3__06\figl3_06.cppA4) : error C2440:
'=' : cannot convert from 'CommissionEmployee * w64 ' to
'BasePlusCommissionEmployee *'
Cast from base to derived require3 dynamic_cast or static_cast
Рис. 13.6. Установка указателя производного класса на объект базового класса
13.3.3. Вызов элемент-функций производного класса
через указатели базового класса
Через указатель базового класса компилятор позволяет нам вызывать
только элемент-функции базового класса. Таким образом, если указатель базового
класса ссылается на объект производного класса, попытка обращения через
него к функции, имеющейся только в производном классе вызовет ошибку
компиляции.
Рис. 13.7 показывает последствия попытки вызова функции производного
класса через указатель базового класса. [Замечание. Мы снова используем
классы CommissionEmployee и BasePlusCommissionEmployee из рис. 13.1-13.4.]
Строка 9 создает commissionEmployeePtr — указатель на объект
CommissionEmployee, — а строки 10-11 создают объект класса
BasePlusCommissionEmployee. Строка 14 устанавливает commissionEmployeePtr на объект
производного класса basePlusCommissionEmployee. Как вы помните из раздела
13.3.1, компилятор позволяет это сделать, так как
BasePlusCommissionEmployee является CommissionEmployee (в том смысле, что объект
BasePlusCommissionEmployee обладает всеми функциональными свойствами объекта
CommissionEmployee). Строки 18-22 вызывают через указатель базового класса
элемент-функции базового класса getFirstName, get Last Name, getSocialSe-
curityNumber, getGrossSales и getCommissionRate. Все эти вызовы законны,
так как класс BasePlusCommissionEmployee наследует эти функции от
CommissionEmployee. Мы знаем, что commissionEmployeePtr ссылается на объект
BasePlusCommissionEmployee, поэтому в строках 26-27 мы пытаемся вызвать
элемент-функции getBaseSalary и setBaseSalary. Компилятор генерирует
ошибку для обеих этих строк, так как вызываемые функции не являются
элементами базового класса CommissionEmployee. Дескриптор может активиро-
830
Глава 13
вать только те функции, что являются элементами класса, ассоциированного
с данным дескриптором. (В данном случае через CommissionEmployee * мы
можем вызывать только элемент-функции CommissionEmployee — set First Name,
getFirstName, setLastName, getLastName, setSocialSecurityNumber, getSo-
cialSecurityNumber, setGrossSales, getGrossSales, setCommissionRate, getCom-
missionRate и print.)
1 // Рис. 13.7: figl3_07.cpp
2 // Попытка активировать функцию, наличную лишь
3 //в производном классе, через указатель базового класса.
4 #include "CommissionEmployee.h"
5 #include "BasePlusCommissionEmployee.h"
6
7 int main()
8 {
9 CommissionEmployee *commissionEmployeePtr =0; // базовьз! класс
10 BasePlusCommissionEmployee basePlusCommissionEmployee(
11 "Bob", "Lewis", 33-33-3333", 5000, .04, 300 ); // производный
12
13 // установить указатель базового класса на производный объект
14 commissionEmployeePtr = &basePlusCommissionEmployee;
15
16 // вызов функций базового класса для объекта производного
17 // класса через указатель базового класса
18 string firstName = commissionEmployeePtr->getFirstName() ;
19 string lastName = commissionEmployeePtr->getLastName();
20 string ssn = commissionEmployeePtr->getSocialSecurityNumber();
21 double grossSales = commissionEmployeePtr->getGrossSales();
22 double commissionRate=commissionEmployeePtr->getCommissionRate();
23
24 // попытка вызове функций только производного класса для
25 // объекта производного класса через базовый указатель
26 double baseSalary = commissionEmployeePtr->getBaseSalary();
27 commissionEmployeePtr->setBaseSalary( 500 );
28 return 0;
29 } // конец main
Сообщения об ошибках компилятора Borland C++ с командной строкой:
Error E2316 figl3_07.cpp 26: 'getBaseSalary' is not a member of
'CommissionEmployee' in function main()
Error E2316 figl3_07.cpp 27: 'setBaseSalary' is not a member of
'CommissionEmployee' in function main()
Сообщения об ошибках компилятора Visual C++.NET:
c:\cpphtp_examples\chl3\figl3_07\figl3__07.cppB6) : error C2039:
'getBaseSalary' : is not a member of 'CommissionEmployee'
c:\scpphtp_examples\chl3\figl3_07\commissionemployee.hA0)
see declaration of 'CommissionEmployee'
c:\cpphtp_examples\chl3\figl3_07\figl3_07.cppB7) : error C2039:
'setBaseSalary' : is not a member of 'CommissionEmployee'
c:\scpphtp_examples\chl3\figl3_07\commissionemployee.hA0)
see declaration of 'CommissionEmployee'
Объектно-ориентированное программирование: полиморфизм
831
Сообщения об ошибках компилятора GNU C++:
figl3_07.срр:26: error: 'getBaseSalary' undeclared
(first use this function)
figl3__07.cpp:26: error: (each undeclared identifier is reported
only once for each function it appears in)
figl3__07.cpp:27: error: 'setBaseSalary' undeclared
(first use this function)
Рис. 13.7, Попытка вызвать функцию только производного класса через указатель
базового класса
Оказывается, что компилятор C++ позволяет обращаться к элементам,
входящим только в производный класс, из указателя базового класса,
ссылающегося на производный класс, лишь при условии явного приведения указателя
базового класса к типу производного класса; это называют нисходящим
приведением. Как вы узнали в разделе 13.3.1, можно установить указатель базового
класса на объект производного класса. Однако как показывает рис. 13.7,
указатель базового класса может использоваться лишь для вызова функций,
объявленных в базовом классе. Нисходящее приведение позволяет программе
производить специфические для производного класса операции над объектом
производного класса, на который ссылается указатель базового класса. После
нисходящего приведения программа может вызывать функции производного
класса, которые не входят в базовый класс. В разделе 13.8 мы покажем
конкретный пример нисходящего приведения.
S Общее методическое замечание 13.3
Если адрес объекта производного класса был присвоен указателю
одного из его непосредственных или косвенных базовых классов,
возможно обратное приведение этого указателя к типу указателя
производного класса. На самом деле это необходимо сделать, чтобы можно
было посылать объекту производного класса сообщения, не
определенные в базовом классе.
13.3.4. Виртуальные функции
В разделе 13.3.1 мы устанавливали указатель базового класса Commis-
sionEmployee на объект производного класса BasePlusCommissionEmployec,
а затем вызывали через этот указатель элемент-функцию print. Вспомните,
что тип дескриптора определяет, функция какого класса будет вызвана. В
данном случае указатель CommissionEmployee вызывал функцию print класса
CommissionEmployee на объекте производного класса BasePlusCommis-
sionEmployee, хотя указатель ссылался на объект BasePlusCommissionEm-
ployee, имеющий свою собственную версию print. В случае виртуальных
функций не тип дескриптора, а тип указываемого объекта определяет,
функция какого класса будет вызвана.
Рассмотрим сначала, почему виртуальные функции полезны.
Предположим, что от одного класса Shape производится ряд классов геометрических
фигур, например, Circle, Triangle, Rectangle и Square. В
объектно-ориентированном программировании каждый из этих классов может быть наделен спо-
832
Глава 13
собностью нарисовать самого себя. Хотя каждый класс имеет собственную
функцию draw, эти функции существенно различаются. При рисовании
фигуры, чем бы она ни являлась, было бы удобно рассматривать ее обобщенно, как
объект базового класса Shape. Тогда, чтобы нарисовать любую фигуру, мы
могли бы просто вызвать функцию draw класса Shape, предоставив программе
динамически (т.е. во время выполнения) определить, которую из функций
draw производных классов использовать, в зависимости от типа объекта, на
который в тот или иной момент ссылается указатель базового класса Shape.
Чтобы реализовать такого рода поведение, мы объявляем функцию draw
в базовом классе как виртуальную функцию и затем заменяем ее в каждом из
производных классов функцией, которая может нарисовать соответствующую
фигуру. Функция объявляется виртуальной указанием ключевого слова
virtual перед прототипом функции в базовом классе. Например, класс Shape
может содержать такое объявление:
virtual void draw() const;
Этот прототип объявляет draw виртуальной константной функцией, не
принимающей аргументов и ничего не возвращающей. Функция объявляется как
const, так как типичная функция draw не изменяла бы объект Shape, для
которого вызывается. Виртуальные функции не обязательно должны быть
константными.
Общее методическое замечание 13.4
Если функция объявляется, как virtual, она остается виртуальной во
всей иерархии наследования ниже данной точки, даже если она не
объявляется явно виртуальной в классах, которые ее переопределяют.
Хороший стиль программирования 13.1
Хотя некоторые функции являются неявно виртуальными благодаря
объявлению в некотором базовом классе, ради ясности программы
явно объявляйте эти функции как virtual на всех уровнях иерархии.
Общее методическое замечание 13.5
Если в производном классе виртуальная функция не заменяется, то
он просто наследует реализацию виртуальной функции своего
базового класса.
Если функция draw объявлена в базовом классе как виртуальная, и мы
вызываем ее через указатель или ссылку базового класса на объект производного
класса (например, shapePtr—>draw()),To программа динамически (т.е. во
время исполнения) выберет функцию draw нужного производного класса — в
зависимости от типа объекта, а не типа указателя или ссылки. Выбор нужной
функции во время исполнения (а не во время компиляции) называется
динамическим или поздним связыванием.
Если виртуальная функция вызывается через имя объекта с
операцией-точкой выбора элемента (например, squareObject.drawQ), то ссылка разрешается
во время компиляции (это называется статическим связыванием) и вызыва-
Объектно-ориентированное программирование: полиморфизм 833
ется виртуальная функция, определенная (или унаследованная) классом,
которому принадлежит данный объект; это не является полиморфным
поведением. Таким образом, динамическое связывание виртуальных функций имеет
место только в случае использования дескрипторов-указателей (или ссылок,
как мы скоро увидим).
Теперь давайте посмотрим, каким образом виртуальные функции могут
реализовать полиморфное поведение в нашей иерархии служащих.
Рис. 13.8-13.9 показывают заголовочные файлы соответственно для классов
CommissionEmployee и BasePlusCommissionEmployee. Заметьте, что
единственным отличием этих файлов от приведенных на рис. 13.1 и рис. 13.3
является спецификация элемент-функций earnings и print как virtual (строки 30-31
на рис. 13.8 и 21-22 на рис. 13.9). Так как функции earnings и print в классе
CommissionEmployee — виртуальные, функции earnings и print класса
BasePlusCommissionEmployee заменяют соответствующие функции
CommissionEmployee. Теперь, если мы установим указатель базового класса
CommissionEmployee на объект производного класса BasePlusCommissionEmployee
и используем этот указатель для вызова любой из функций earnings и print,
будет активирована функция объекта BasePlusCommissionEmployee.
Реализации элемент-функций классов CommissionEmployee и
BasePlusCommissionEmployee изменений не требуют, так что мы используем их версии из
рис. 13.2 и рис. 13.4.
1 // Рис. 13.8: CommissionEmployee.h
2 // Класс CommissionEmployee - служащий, получающий комиссионные.
3 #ifndef COMMISSION_H
4 #define COMMISSIONJH
5
6 #include <string> // стандартный класс C++ string
7 using std::string;
8
9 class CommissionEmployee
10 {
11 public:
12 CommissionEmployee( const string &, const string &,
13 const string &, double = 0.0, double = 0.0 );
14
15 void setFirstName( const string & ); // установить имя
16 string getFirstName() const; // возвратить имя
17
18 void setLastName( const string & ); // установить фамилию
19 string getLastName() const; // возвратить фамилию
20
21 void setSocialSecurityNumber( const string & ); // установить SSN
22 string getSocialSecurityNumber() const; // возвратить SSN
23
24 void setGrossSales( double ); // установить общую сумму продаж
25 double getGrossSales() const; // возвратить общую сумму продаж
26
27 void setCommissionRate( double ); // установить процент
28 double getCommissionRate() const; // возвратить процент
29
30 virtual double earnings() const; // вычислить заработок
31 virtual void print() const; // напечатать объект
27 Зак. 1114
834
Глава 13
32 private:
33 string firstName;
34 string lastName;
35 string socialSecurityNumber;
36 double grossSales; // продажи за неделю
37 double commissionRate; // комиссионный процент
38 }; // конец класса CommissionEmployee
39
40 #endif
Рис. 13.8. Заголовочный файл класса CommissionEmployee объявляет функции
earnings и print как virtual
1 // Рис. 13.9: BasePlusCommissionEmployee.h
2 // Класс BasePlusCommissionEmployee, производный от класса
3 // CommissionEmployee.
4 #ifndef BASEPLUS_H
5 #define BASEPLUS_H
6
7 #include <string> // стандартный класс C++ string
8 using std::string;
9
10 #include "CommissionEmployee.h" // объявление CommissionEmployee
11
12 class BasePlusCommissionEmployee : public CommissionEmployee
13 {
14 public:
15 BasePlusCommissionEmployee( const string &, const string &,
16 const string &, double =0.0, double =0.0, double = 0.0 );
17
18 void setBaseSalary( double ); // установить основную зарплату
19 double getBaseSalary() const; // возвратить основную зарплату
20
21 virtual double earnings() const; // вычислить заработок
22 virtual void print() const; // напечатать объект
23 private:
24 double baseSalary; // основная зарплата
25 }; // конец класса BasePlusCommissionEmployee
26
27 #endif
Рис. 13.9. Заголовочный файл класса BasePlusCommissionEmployee объявляет
функции earnings и print как virtual
1 // Рис. 13.10: figl3_10.cpp
2 // Полиморфизм, виртуальные функции и динамическое связывание.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::fixed;
7
8 #include <iomanip>
9 using std::setprecision;
Объектно-ориентированное программирование: полиморфизм
835
10
11 // включить определения классов
12 #include "CoiranissionEmployee.h"
13 #include "BasePlusCommissionEmployee.h"
14
15 int main()
16 {
17 // создать объект базового класса
18 CommissionEmployee commissionEmployee(
19 "Sue", "Jones", 22-22-2222", 10000, .06 );
20
21 // создать указатель базового класса
22 CommissionEmployee *commissionEmployeePtr = 0;
23
24 // создать объект производного класса
25 BasePlusCommissionEmployee basePlusCommissionEmployee(
26 "Bob", "Lewis", 33-33-3333", 5000, .04, 300 );
27
28 // создать указатель базового класса
29 BasePlusCommissionEmployee *basePlusCommissionEmployeePtr = 0;
30
31 // задать форматирование чисел с плавающей точкой
32 cout « fixed « setprecision( 2 );
33
34 // вывести объекты, используя статическое связывание
35 cout « "Invoking print function on base-class and derived-class"
36 « "\nobjects with static binding\n\n";
37 commissionEmployee.print(); // статическое связывание
38 cout « "\n\n";
39 basePlusCommissionEmployee.print(); // статическое связывание
40
41 // вывести объекты, используя динамическое связывание
42 cout « "\n\n\nInvoking print function on base-class and "
43 « "derived-class \nobjects with dynamic binding";
44
45 // установить базовый указатель на базовый объект
46 commissionEmployeePtr = ficommissionEmployee;
47 cout « "\n\nCalling virtual function print with base-class "
48 « "pointer\nto base-class object invokes base-class "
4 9 « "print function:\n\n";
50 commissionEmployeePtr->print(); // print базового класса
51
52 // установить производный указатель на производный объект
53 basePlusCommissionEmployeePtr = &basePlusCommissionEmployee;
54 cout « "\n\nCalling virtual function print with derived-class "
55 « "pointer\nto derived-class object invokes derived-class "
56 « "print function:\n\n";
57 basePlusCommissionEmployeePtr->print(); // производная print
58
59 // установить базовый указатель на производный объект
60 commissionEmployeePtr = fibasePlusCommissionEmployee;
61 cout « "\n\nCalling virtual function print with base-class "
62 « "pointer\nto derived-class object invokes derived-class "
63 « "print function:\n\n";
64
65 // полиморфизм; вызывает print из BasePlusCommissionEmployee;
66 // указатель базового класса на объект производного класса
836
Глава 13
67 commissionEinployeePtr->print () ;
68 cout « endl;
69 return 0;
70 } // конец main
Invoking print function on base-class and derived-class
objects with static binding
commission employee: Sue Jones
social security number: 222-22-2222
gross sales: 10000.00
commission rate: 0.06
base-salaried commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
base salary: 300.00
Invoking print function on base-class and derived-class
objects with dynamic binding
Calling virtual function print with base-class pointer
to base-class object invokes base-class print function:
commission employee: Sue Jones
social security number: 222-22-2222
gross sales: 10000.00
commission rate: 0.06
Calling virtual function print with derived-class pointer
to derived-class object invokes derived-class print function:
base-salaried commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
base salary: 300.00
Calling virtual function print with base-class pointer
to derived-class object invokes derived-class print function:
base-salaried commission employee: Bob Lewis
social security number: 333-33-3333
gross sales: 5000.00
commission rate: 0.04
base salary: 300.00
Рис. 13.10. Демонстрация полиморфизма: вызов виртуальной функции
производного класса через указатель базового класса на объект производного класса
Программа на рис. 13.10 является модификацией программы на рис. 13.5.
Строки 46-57 снова демонстрируют, что указатель CommissionEmployee,
установленный на объект CommissionEmployee, может быть использован для
активации функций CommissionEmployee, а указатель BasePlusCommissionEm-
Объектно-ориентированное программирование: полиморфизм 837
ployee, установленный на объект BasePlusCommissionEmployee, может быть
использован для активации функций BasePlusCommissionEmployee.
Строка 60 устанавливает указатель базового класса commissionEmployeePtr на
объект производного класса basePlusCommissionEmployee. Обратите
внимание, что когда строка 67 вызывает функцию print через указатель базового
класса, активируется функция print класса BasePlusCommissionEmployee,
и строка 67 выводит текст, отличный от выводимого строкой 59 на рис. 13.5
(когда элемент-функция print не была объявлена виртуальной).
Мы видим, что объявление элемент-функции как virtual заставляет
программу динамически определять по типу объекта, а не типу дескриптора,
какая из функций должна быть вызвана. Такое решение относительно
вызываемой функции является примером полиморфизма. Еще раз заметьте, что когда
указатель commissionEmployeePtr ссылается на объект CommissionEmployee
(строка 46), вызывается функция print из CommissionEmployee, а когда тот
же указатель ссылается на объект BasePlusCommissionEmployee, вызывается
функция из BasePlusCommissionEmployee. Таким образом, одно и то же
сообщение — в данном случае print, — посылаемое (через указатель базового
класса) различным объектам, связанным с этим базовым классом отношениями
наследования, принимает различные формы; это — полиморфное поведение.
13.3.5. Сводка допустимых присваиваний объектов
указателям базового и производного классов
Теперь, когда вы увидели законченное приложение, полиморфно
обрабатывающее различные объекты, мы подытожим, что можно и чего нельзя делать
с объектами и указателями базовых и производных классов. Хотя объект
производного класса является также объектом базового класса, эти объекты, тем
не менее, различны. Как уже говорилось, с объектами производного класса
можно обращаться так, как если бы они были объектами базового класса. Это
логично, так как производный класс содержит все элементы базового класса.
Однако с объектами базового класса нельзя обращаться так, как если бы они
были объектами производного класса, — производный класс имеет
дополнительные, принадлежащие только ему элементы. По этой причине установка
указателя производного класса на объект базового класса не допускается без
явного приведения типа — такое присваивание оставило бы неопределенными
элементы, принадлежащие только производному классу. Приведение типа
снимает с компилятора обязанность выдавать сообщение об ошибке.
Выполняя приведение, вы, по сути, говорите: «Я знаю, что то, что я делаю, опасно,
и беру на себя ответственность за последствия своих действий».
В этом разделе и главе 12 мы обсудили четыре возможности присваивания
объектов базового и производного классов указателям базового и производного
классов:
1. Установка указателя базового класса на объект базового класса является
естественной — вызовы, производимые через указатель базового класса,
просто активируют функции базового класса.
2. Установка указателя производного класса на объект производного
класса является естественной — вызовы, производимые через указатель
производного класса, просто активируют функции производного класса.
838
Глава 13
3. Установка указателя базового класса на объект производного класса
безопасна, поскольку объект производного класса является также объектом
базового класса. Однако этот указатель может использоваться только для
активации элемент-функций базового класса. Если программист
попытается сослаться через указатель базового класса на элемент, имеющийся
только в производном классе, компилятор сообщит об ошибке. Чтобы
избежать этой ошибки, программист должен привести указатель базового
класса к типу производного класса. После приведения указатель может
использоваться для активации любых функций объекта производного
класса. Однако такой прием, называемый нисходящим приведением,
потенциально опасен. В разделе 13.8 показано, каким образом можно
безопасно выполнять нисходящее приведение типов.
4. Установка указателя производного класса на объект базового класса
генерирует ошибку компиляции. Отношение является имеет место в
направлении от производного класса к непосредственным и косвенным
базовым классам, но не наоборот. Объект базового класса не содержит
элементов, имеющихся только в производном классе и которые можно было
бы вызвать через указатель базового класса.
Типичная ошибка программирования 13.1
После установки указателя базового класса на объект производного
класса попытка сослаться через этот указатель на элементы,
имеющиеся только в производном классе, приводит к ошибке компиляции.
—/3 Типичная ошибка программирования 13.2
Манипулирование объектом базового производного класса так, как
если бы он являлся объектом производного класса, может приводить
к ошибкам.
13.4. Поля типа и операторы switch
Один из способов определения типа объекта, инкорпорированного в более
крупную программу, является использование оператора switch. Он позволяет
различать типы объектов и затем активировать соответствующее конкретному
объекту действие. Например, в иерархии фигур, где каждая фигура имеет
атрибут (поле) shapeType, оператор switch может проверять shapeType,
определяя, какую из функций print следует вызвать.
Однако при этом возникает масса потенциальных проблем. Программист
может забыть сделать проверку типа там, где она необходима, или упустить из
виду какие-то варианты в switch. При добавлении нового типа программист
может забыть вставить новые case-метки во все операторы switch, имеющие
отношение к модификации. При любом добавлении или удалении класса
необходимо внести изменения во все операторы switch, имеющиеся в/
модифицируемой системе; этот процесс может отнять много времени и породить новые
ошибки.
Объектно-ориентированное программирование: полиморфизм
839
® Общее методическое замечание 13,6
Полиморфное программирование позволяет отказаться от логики
оператора switch. Реализуя эквивалентную логику на основе
полиморфного механизма, программист может предотвратить появление
ошибок, характерных для систем с логикой switch.
S Общее методическое замечание 13.7
Интересным следствием использования полиморфизма является то,
что программы приобретают более простой вид. Они содержат
меньше логики ветвления и больше обычного линейного кода. Такое
упрощение облегчает тестирование, отладку и сопровождение программ.
13.5. Абстрактные классы и чисто виртуальные
функции
Когда мы говорим о классе как о типе, мы подразумеваем, что будут
создаваться объекты этого типа. Однако во многих случаях бывает полезно
определять классы, объекты которых программист и не собирается никогда создавать.
Такие классы называются абстрактными классами. Поскольку в
наследовании они играют роль базовых, мы будем называть их абстрактными базовыми
классами. Никаких представителей абстрактного базового класса создать
нельзя, поскольку, как мы скоро увидим, абстрактные классы являются
неполными; «недостающие части» должны определяться производными классами. Мы
будем строить программы с абстрактными классами в разделе 13.6.
Цель определения абстрактного класса состоит в том, чтобы предусмотреть
обобщенный базовый класс, от которого будут производиться другие классы.
Классы, которые могут использоваться для создания представителей,
называются конкретными классами. Такие классы должны предусматривать
реализации для всех определяемых ими элемент-функций. Мы могли бы определить
абстрактный базовый класс TwoDimensionalShape и произвести от него такие
конкретные классы, как Square, Circle и Triangle. Мы могли бы также
создать абстрактный базовый класс ThreeDimensionalShape и произвести от него
конкретные классы Cube, Sphere и Cylinder. Абстрактные базовые классы
слишком общи, чтобы определять реальные объекты; нужно внести в них
какую-то специфику, прежде чем мы сможем говорить о создании объектов.
Например, если кто-то скажет вам «нарисуй двумерную фигуру», какую фигуру
вы нарисуете? Конкретные классы делают именно это; они вносят в
абстрактный класс специфику, благодаря которой имеет смысл создавать
представители таких классов.
Иерархия наследования не должна в обязательном порядке содержать
абстрактные классы, но, как мы увидим, многие хорошо продуманные
объектно-ориентированные системы имеют иерархии, возглавляемые абстрактным
базовым классом. В некоторых случаях абстрактные классы занимают
несколько верхних уровней иерархии. Хороший пример такой иерархии дает
иерархия геометрических фигур на рис. 12.3, которая начинается с абстрактного
базового класса Shape. На следующем уровне находятся еще два абстрактных
базовых класса, а именно TwoDimensionalShape и ThreeDimensionalShape.
Следующий уровень иерархии определяет конкретные классы двумерных фи-
840
Глава 13
гур (Square, Circle и Triangle) и конкретные классы трехмерных форм
(Sphere, Cube и Tetrahedron).
Класс будет абстрактным, если одна или несколько его виртуальных
функций объявлены «чистыми». Чисто виртуальная функция — это функция,
объявление которой завершается инициализатором = 0:
virtual float earnings() const =0; // чисто виртуальная функция
Инициализатор «= 0» называется чистым спецификатором. Для чисто
виртуальных функций реализаций не предусматривается. Каждый
конкретный производный класс должен заменять все чисто виртуальные функции
базового класса их конкретными реализациями. Разница между виртуальными
и чисто виртуальными функциями та, что виртуальная функция имеет
реализацию и предоставляет производному классу возможность ее замены; в
противоположность этому чистая виртуальная функции не предусматривает
реализации и требует замены в производном классе (если производный класс
должен быть конкретным; иначе производный класс также будет абстрактным).
Чисто виртуальные функции используются, когда нет смысла
предусматривать в базовом классе реализацию функции, но программист хочет, чтобы ее
реализовывали все конкретные производные классы. Возвращаясь к нашему
примеру игры с космическими объектами, заметим, что в базовом классе
SpaceObject нет смысла иметь реализацию функции draw (так как
невозможно нарисовать обобщенный объект без более точной информации о нем). В
качестве примера функции, которая определялась бы виртуальной (но не чисто
виртуальной), можно привести функцию, возвращающую название объекта.
Мы можем назвать обобщенный SpaceObject (например, "space object"), так
что для этой функции можно предусмотреть реализацию по умолчанию, и ей
нет необходимости быть чисто виртуальной. Но функция все лее объявляется
как виртуальная, так как ожидается, что производные классы будут ее
заменять, давая своим объектам более специфические названия.
Общее методическое замечание 13.8
Абстрактный базовый класс определяет общий открытый
интерфейс для различных классов в иерархии наследования. Абстрактный
класс содержит одну или несколько чисто виртуальных функций,
которые должны заменяться в конкретных производных классах.
Типичная ошибка программирования 13.3
Попытка создать представитель абстрактного класса вызывает
ошибку компиляции.
Типичная ошибка программирования 13.4
Если не предусмотреть в производном классе замену чистой
виртуальной функции, попытка создать объект этого класса приведет
к ошибке компиляции.
Объектно-ориентированное программирование: полиморфизм
841
S Общее методическое замечание 13.9
Абстрактный класс имеет хотя бы одну чисто виртуальную
функцию. Абстрактный класс может также иметь элементы данных
и конкретные функции (включая конструкторы и деструкторы),
которые подчиняются обычным правилам наследования производными
классами.
Хотя создавать объекты абстрактных базовых классов нельзя, мы можем
использовать абстрактный базовый класс для объявления указателей и
ссылок, которые могут ссылаться на объекты любых конкретных классов,
производных от него. Программы обычно используют такие указатели и ссылки для
полиморфных манипуляций объектами производных классов.
Давайте рассмотрим еще одно приложение полиморфизма. Экранный
менеджер должен выводить на экран разнообразные объекты, включая объекты
новых типов, которые будут введены в систему уже после написания
менеджера. Системе может потребоваться выводить на экран различные
геометрические фигуры, например, классов Circle, Triangle или Rectangle, производных
от абстрактного базового класса Shape. Менеджер экрана использует
указатели на Shape для управления выводимыми на экран объектами. Чтобы
нарисовать любой объект (вне зависимости от уровня иерархии, на котором
находится класс этого объекта), менеджер использует ссылающийся на объект
указатель на базовый класс, чтобы активировать функцию draw объекта, которая
является чисто виртуальной в базовом классе Shape; следовательно, эта
функция должна быть реализована в каждом из производных классов. Каждый
объект Shape в иерархии знает, как нарисовать самого себя. Экранному
менеджеру не нужно беспокоиться о типе каждого объекта или а том, встретится ли
ему когда-нибудь объект некоторого типа.
Полиморфизм особенно эффективен при создании многослойных систем
программного обеспечения. В операционных системах, например, каждый тип
физического устройства может функционировать совершенно отлично от
устройств других типов. Тем не менее, команды read или write, читающие данные
с устройств или записывающие их на устройства, могут быть представлены
единообразно. Команда write, посланная объекту драйвера устройства, должна
интерпретироваться в контексте данного драйвера и в соответствии с тем, каким
образом он управляет устройствами конкретного типа. Но сам по себе вызов
write не отличается от вызова write для любого другого устройства системы, —
это просто команда передать указанному устройству некоторое число байт
данных из памяти. Объектно-ориентированная операционная система может
использовать абстрактный базовый класс, чтобы обеспечить интерфейс,
подходящий для всех драйверов устройств. Затем образуются производные классы,
которые, благодаря наследованию от этого абстрактного класса, будут вести себя
схожим образом. Возможности драйверов устройств (т.е. их открытый
интерфейс) определяются чисто виртуальными функциями абстрактного базового
класса. Реализация этих виртуальных функций осуществляется в производных
классах, соответствующих конкретным типам драйверов. Такая архитектура
позволяет также легко добавлять к системе новые устройства, даже после того,
как операционная система будет написана. Пользователь может просто
вставить устройство в компьютер и установить для него новый драйвер.
Операционная система «говорит» с устройством через его драйвер, имеющий те же самые
842
Глава 13
открытые элемент-функции (определяемые в абстрактном базовом классе
драйвера устройства), что и любые другие драйверы устройств.
Обычным в объектно-ориентированном программировании является
определение класса итератора, который может перебирать все элементы
контейнера (такого, как массив). Например, программа могла бы напечатать список
объектов, содержащихся в векторе, создав объект-итератор и использовав его
для получения следующего элемента всякий раз, когда вызывается итератор.
Итераторы часто используются в полиморфном программировании для
перебора массива или связанного списка указателей на объекты из различных
уровней иерархии. Все указатели в таком списке являются указателями базового
класса. Список указателей базового класса TwoDimensionalShape мог бы
содержать указатели на объекты классов Square, Circle, Triangle и т.п. При
использовании полиморфизма посылка сообщения draw (через указатель
TwoDimensionalShape *) всем объектам в списке обеспечила бы правильное
отображение на экране каждого из объектов.
13.6. Пример. Система начисления заработной платы,
использующая полиморфизм
В этом разделе мы пересматриваем иерархию CommissionEmployee—Ва-
sePlusCommissionEmployee, которую мы исследовали начиная с раздела 12.4.
В этом примере мы используем абстрактный класс и полиморфизм для
выполнения вычислений, связанных с начислением зарплаты, в соответствии с
категорией, к которой принадлежит служащий. Мы создадим расширенную
иерархию для решения следующей задачи:
Компания выплачивает служащим жалованье каждую неделю. Служащие
делятся на четыре категории. Служащие с постоянной зарплатой получают
фиксированную недельную плату вне зависимости от числа отработанных
часов; служащие с почасовой оплатой получают почасовую ставку и
сверхурочные за время, отработанное сверх 40 часов в неделю; служащие-комиссионеры
получают процент от заключенных ими сделок; наконец, некоторые получают
фиксированную недельную плату плюс процент со сделок. В данный момент
компания решила премировать последнюю категорию служащих, выплатив
им дополнительно 10% от базовой недельной платы. Компания хочет
реализовать на C++ программу, которая вычисляет заработок служащих полиморфно.
Для представления обобщенного понятия «служащий» мы используем
абстрактный класс Employee. Непосредственными производными от него
являются SalariedEmployee, CommissionEmployee и HourlyEmployee. Класс Ва-
sePlusCommissionEmployee — производный от CommissionEmployee —
представляет последнюю категорию служащих. Классовая диаграмма UML
на рис. 13.11 показывает иерархию наследования для нашего полиморфного
приложения, начисляющего жалованье. По принятому в UML соглашению
абстрактный класс Employee выделен курсивом.
Абстрактный базовый класс Employee объявляет «интерфейс» иерархии,
т.е. набор элемент-функций, которые могут вызываться для всех объектов
Employee. Каждый служащий, вне зависимости от способа вычисления
заработка, имеет имя, фамилию и номер социального страхования, так что
абстрактный базовый класс Employee имеет закрытые элементы данных firstNa-
me, lastName и socialSecurityNumber.
Объектно-ориентированное программирование: полиморфизм
843
. Класс Employee
тр оуее является абстрактным;
t
^^ выделен курсивом
SalariedEmployee CommissionEmployee HourlyEmployee
t
BasePlusCommissionEmployee
Рис. 13.11. Классовая диаграмма UML для иерархии Employee
Общее методическое замечание 13.10
Класс может наследовать от базового класса интерфейс или
реализацию. Иерархии, ориентированные на наследование реализации, имеют
тенденцию ассоциировать свое поведение с верхними уровнями
иерархии, — каждый новый производный класс наследует одну или
несколько функций, определенных в базовом классе, и использует их
реализации из базового класса. Поведение иерархий, ориентированных на
наследование интерфейса, ассоциировано с более низкими уровнями, —
базовый класс специфицирует одну или несколько функций, которые
должны быть определены в каждом из классов иерархии (т.е. во всех
классах они имеют одну и ту же сигнатуру), но производные классы
предусматривают для этих функций свои собственные реализации.
В следующих разделах мы реализуем иерархию Employee. Каждый из
первых пяти реализует один из классов иерархии. Последний раздел реализует
тестовую программу, которая конструирует объекты этих классов и
полиморфно обрабатывает их.
13.6.1. Создание абстрактного базового класса Employee
Класс Employee (рис. 13.13-13.14), подробно обсуждаемый чуть ниже, в
дополнение к нескольким set- и get-фуякциям для манипуляции элементами
данных предусматривает функции earnings и print. Функция earnings,
естественно, применима в общем смысле ко всем служащим, но конкретные
вычисления зависят от класса, к которому принадлежит служащий. Поэтому мы
объявляем earnings в классе Employee как чисто виртуальную, так как для
этой функции реализация по умолчанию не имеет смысла — без
дополнительных сведений невозможно определить, какое значение функция должна
возвращать. Каждый производный класс заменяет earnings соответствующей
реализацией. Чтобы вычислить заработок служащего, программа присваивает
адрес его объекта указателю базового класса Employee и активирует на
объекте функцию earnings. У нас имеется вектор указателей типа Employee,
каждый из которых указывает на объект Employee (разумеется, объектов класса
Employee не существует, поскольку это абстрактный класс, однако благодаря
наследованию мы можем рассматривать все объекты любых производных от
844
Глава 13
Employee классов в качестве объектов Employee). Программа проходит по
вектору и вызывает earnings для каждого объекта Employee. C++ обрабатывает
эти вызовы полиморфно. Включив earnings в Employee в качестве чисто
виртуальной функции, мы заставляем каждый непосредственный производный от
Employee класс, если он должен быть конкретным, заменять earnings. Это
позволяет проектировщику классовой иерархии потребовать, чтобы каждый
конкретный производный класс иерархии определял свой собственный способ
расчета заработка.
Функция print в классе Employee выводит имя, фамилию и номер карточки
социального страхования служащего. Как мы увидим, каждый производный
класс заменяет функцию print, чтобы вывести категорию служащего (например,
"salaried employee:"), за которой следует остальная информация о служащем.
Таблица на рис. 13.12 показывает слева каждый из пяти классов иерархии,
а сверху — функции earnings и print. Для каждого класса показаны
желаемые результаты вызова этих функций. Обратите внимание, что класс
Employee специфицирует «= О» для функции earnings, показывая, что это чисто
виртуальная функция. Каждый производный класс заменяет эту функцию,
предусматривая соответствующую реализацию. Мы не перечисляем в таблице
set- и get-функции класса Employee, так как они не заменяются ни в одном из
производных классов — эти функции наследуются каждым производным
классом и используются «как они есть».
Employee
Salaried-
Employee
Hourly-
Employee
Commission-
Employee
BasePlus-
Commission-
Employee
earnings
= 0
i weeklySalary
If hours <= 40
wage * hours
I // hours > 40
I ( 40* wage)+
((hours-40)
* wage * 1.5 )
commissionRate *
grossSales
baseSalary +
(commissionRate
GrossSales)
print
1 firstName lastName
, social security number: SSN
I salaried employee: firstNarne lastName
I social security number: SSN
; weekly salary: weekly salary
\ hourly employee: firstNarne lastName
1 social security number: SSN
I hourly wage : wage; hours worked: hours
j commission employee: firstNarne lastName
i social security number: SSN
I grossSales: grossSales;
! commission rate: commissionRate
i base salaried commission employee:
firstNarne lastName
I social security number: SSN
grossSales: grossSales;
; commission rate: commissionRate;
I base salary: baseSalary
Рис. 13.12. Полиморфный интерфейс для классов иерархии Employee
Объектно-ориентированное программирование: полиморфизм 845
Давайте рассмотрим заголовочный файл класса Employee (рис. 13.13).
В число его открытых элемент-функций входят конструктор, принимающий
в качестве аргументов имя, фамилию и номер социальной страховки
(строка 12); set-функции, устанавливающие имя, фамилию и номер страховки
(соответственно строки 14, 17 и 20); get -функции, возвращающие имя, фамилию
и номер страховки (строки 15, 18 и 21); чисто виртуальная функция earnings
(строка 24) и виртуальная функция print (строка 25).
Как вы помните, мы объявили earnings чисто виртуальной функцией, так
как, чтобы определить способ расчета заработка, мы должны знать конкретный
тип служащего. Объявление этой функции как чисто виртуальной указывает,
что каждый конкретный класс должен предусматривать соответствующую
реализацию earnings и что программа может использовать указатели базового
класса Employee, чтобы полиморфно вызывать функцию для служащих любого типа.
Рис. 13.14 показывает реализации элемент-функций для класса Employee.
Для виртуальной функции earnings реализации не предусмотрено. Заметьте,
что конструктор Employee (строки 10-15) не проверяет корректность номера
социальной страховки. Обычно такая проверка должна производиться. В
качестве упражнения в главе 12 предлагается проверить номер страховки,
убедившись, что она представлен в форме ###-##-####, где # обозначает цифру.
1 // Рис. 13.13: Employee.h
2 // Абстрактный базовый класс Employee.
3 #ifndef EMPLOYEE_H
4 #define EMPLOYEE_H
5
6 #include <string> // стандартный класс C++ string
7 using std::string;
8
9 class Employee
10 {
11 public:
12 Employee( const string &, const string &, const string & );
13
14 void setFirstName( const string & ); // установить имя
15 string getFirstName() const; // возвратить имя
16
17 void setLastName( const string & ); // установить фамилию
18 string getLastName() const; // возвратить фамилию
19
20 void setSocialSecurityNumber( const string & ); // установить SSN
21 string getSocialSecurityNumber() const; // возвратить SSN
22
23 // чисто виртуальная функция делает Employee абстрактным классом
24 virtual double earnings() const =0; // чисто виртуальная
25 virtual void print() const; // виртуальная
26 private:
27 string firstName;
28 string lastName;
29 string socialSecurityNumber;
30 }; // конец класса Employee
31
32 #endif // EMPLOYEE H
Рис. 13.13. Заголовочный файл класса Employee
846
Глава
1 // Рис. 13.14: Employee.cpp
2 // Определения элемент-функций базового класса Employee.
3 // Замечание. Для чисто виртуальных функций определений не дается.
4 #include <iostream>
5 using std::cout;
6
7 #include "Employee.h" // определение класса Employee
8
9 // конструктор
10 Employee::Employee( const string fifirst, const string blast,
11 const string &ssn )
12 : firstName(first), lastName(last), socialSecurityNumber(ssn)
13 {
14 // пустое тело
15 } // конец конструктора Employee
16
17 // установить имя
18 void Employee::setFirstName( const string fifirst )
19 {
20 firstName = first;
21 } // конец функции setFirstName
22
23 // возвратить имя
24 string Employee::getFirstName() const
25 {
26 return firstName;
27 } // конец функции getFirstName
28
29 // установить фамилию
30 void Employee::setLastName( const string &last )
31 {
32 lastName = last;
33 } // конец функции setLastName
34
35 // возвратить фамилию
36 string Employee::getLastName() const
37 {
38 return lastName;
39 } // конец функции getLastName
40
41 // установить номер социального страхования
42 void Employee::setSocialSecurityNumber( const string &ssn )
43 {
44 socialSecurityNumber = ssn; // should validate
45 } // конец функции setSocialSecurityNumber
46
47 // возвратить номер социального страхования
48 string Employee::getSocialSecurityNumber() const
49 {
50 return socialSecurityNumber;
51 } // конец функции getSocialSecurityNumber
52
53 // напечатать информацию о служащем (виртуальная, но не чистая)
54 void Employee::print() const
55 {
Объектно-ориентированное программирование: полиморфизм 847
56 cout « getFirstName() « ' ' « getLastName()
57 « "\nsocial security number: " « getSocialSecurityNumber();
58 } // конец функции print
Рис. 13.14. Файл реализации класса Employee
Обратите внимание, что для виртуальной функции print (строки 54-58 на
рис. 13.14) предусмотрена реализация, которая будет заменяться в каждом из
производных классов. Однако каждая из этих реализаций будет вызывать
версию print абстрактного класса для вывода информации, общей для всех
классов иерархии Employee.
13.6.2. Создание конкретного производного класса
SalariedEmployee
Класс SalariedEmployee (рис. 13.15-13.16) является производным от
Employee (строка 8 на рис. 13.15). В число его открытых элемент-функций
входят конструктор, принимающий в качестве аргументов имя, фамилию,
номер социальной страховки и недельную ставку зарплаты (строки 11-12);
set-функция для присваивания нового неотрицательного значения элементу
данных weeklySalary (строка 14); get-функция, возвращающая значение
weeklySalary (строка 15); виртуальная функция earnings, вычисляющая
заработок служащего SalariedEmployee (строка 18); виртуальная функция print,
выводящая тип служащего (а именно, "salaried employee: "), за которым
следует информация о служащем, выдаваемая функцией print класса Employee
и функцией getWeeklySalary (строка 19).
Рис. 13.16 показывает реализации элемент-функций для
SalariedEmployee. Конструктор класса передает имя, фамилию и номер страховки
конструктору Employee (строка 11) для инициализации закрытых элементов
данных, унаследованных от базового класса, но недоступных в производном
классе. Функция earnings (строки 30-33) заменяет чисто виртуальную функцию
earnings в Employee конкретной реализацией, возвращающей недельную
зарплату служащего SalariedEmployee. Если не реализовать earnings, класс
SalariedEmployee был бы абстрактным и любая попытка создать объект этого
класса приводила бы к ошибке компиляции (а мы, естественно, хотим здесь,
чтобы SalariedEmployee был конкретным классом). Заметьте, что в
заголовочном файле класса SalariedEmployee мы объявили элемент-функции earnings
и print как virtual (строки 18-19 на рис. 13.15), хотя на самом деле указание
ключевого слова virtual перед этими функциями является излишним. Мы
объявили их виртуальными в базовом классе Employee, поэтому они останутся
виртуальными во всей классовой иерархии. Вспомните, в замечании
«Хороший стиль программирования» 13.1 говорилось о том, что явное объявление
таких функций виртуальными на всех уровнях иерархии способствует ясности
программы.
1 // Рис. 13.15: SalariedEmployee.h
2 // Класс SalariedEmployee, производный от Employee.
3 #ifndef SALARIED_H
4 #define SALARIED_H
5
848
Глава 13
6 #include "Employee.h" // определение класса Employee
7
8 class SalariedEmployee : public Employee
9 {
10 public:
11 SalariedEmployee( const string &, const string &,
12 const string &, double = 0.0 );
13
14 void setWeeklySalary( double ); // установить недельную зарплату
15 double getWeeklySalary() const; // возвратить недельную зарплату
16
17 // ключевое слово virtual указывает на замену реализации
18 virtual double earnings() const; // вычислить заработок
19 virtual void print() const; // напечатать объект SalariedEmployee
20 private:
21 double weeklySalary; // недельная зарплата
22 }; // конец класса SalariedEmployee
23
24 #endif // SALARIED H
Рис. 13.15. Заголовочный файл класса SalariedEmployee
1 // Рис. 13.16: SalariedEmployee.срр
2 // Определения элемент-функций класса SalariedEmployee.
3 #include <iostream>
4 using std::cout;
5
6 #include "SalariedEmployee.h" // определение SalariedEmployee
7
8 // constructor
9 SalariedEmployee::SalariedEmployee( const string &first,
10 const string filast, const string &ssn, double salary )
11 : Employee( first, last, ssn )
12 {
13 setWeeklySalary( salary );
14 } // конец конструктора SalariedEmployee
15
16 // установить недельную зарплату
17 void SalariedEmployee::setWeeklySalary( double salary )
18 {
19 weeklySalary = ( salary < 0.0 ) ? 0.0 : salary;
20 } // конец функции setWeeklySalary
21
22 // возвратить недельную зарплату
23 double SalariedEmployee::getWeeklySalary() const
24 {
25 return weeklySalary;
26 } // конец функции getWeeklySalary
27
28 // вычислить заработок;
29 // заменяет чисто виртуальную функцию earnings в Employee
30 double SalariedEmployee:'.earnings () const
31 {
32 return getWeeklySalary();
33 } // конец функции earnings
Объектно-ориентированное программирование: полиморфизм
849
34
35 // напечатать информацию о SalariedEmployee
36 void SalariedEmployee::print() const
37 {
38 cout « "salaried employee: ";
39 Employee::print(); // утилизировать функцию print базового класса
40 cout « "\nweekly salary: " « getWeeklySalary();
41 } // конец функции print
Рис. 13.16. Файл реализации класса SalariedEmployee
Функция print класса SalariedEmployee (строки 36-41 на рис. 13.16)
заменяет функцию print в Employee. Если бы класс не заменял print, он
унаследовал бы версию print из Employee. В этом случае функция print выдавала бы
для SalariedEmployee только полное имя и номер страховки, что не является
вполне адекватным для служащего SalariedEmployee. Чтобы напечатать
полную информацию о служащем, функция print производного класса выводит
"salaried employee:", после чего следует информация базового класса
Employee (т.е. имя, фамилия и номер страховки), печатаемая посредством
вызова базовой функции print при помощи операции разрешения области
действия (строка 39) — это хороший пример утилизации кода. Вывод функции
print класса SalariedEmployee содержит также недельную зарплату
служащего, получаемую вызовом функции getWeeklySalary класса.
13.6.3. Создание конкретного производного класса
HourlyEmployee
Класс HourlyEmployee (рис. 13.17-13.18) также является производным от
Employee (строка 8 на рис. 13.17). В число его открытых элемент-функций
входят конструктор (строки 11-12), принимающий в качестве аргументов
имя, фамилию, номер социальной страховки, ставку почасовой зарплаты
и число отработанных за неделю часов; sef-функции, присваивающие новые
значения элементам данных wage и hours (строки 14 и 17); get-функции,
возвращающие значения wage и hours (строки 15 и 18); виртуальная функция
earnings, вычисляющая заработок служащего HourlyEmployee (строка 21)
и виртуальная функция print, выводящая тип служащего (а именно, "salaried
employee:"), за которым следует информация о служащем (строка 22).
1 // Рис. 13.17: HourlyEmployee.h
2 // Определение класса HourlyEmployee.
3 #ifndef HOURLY_H
4 #define HOURLY_H
5
6 #include "Employee.h" // определение класса Employee
7
8 class HourlyEmployee : public Employee
9 {
10 public:
11 HourlyEmployee( const string &, const string &,
12 const string &, double = 0.0, double = 0.0 );
13
14 void setWage( double ); // установить почасовую ставку
850
Глава 13
15 double getWage() const; // возвратить почасовую ставку
16
17 void setHours( double ); // установить число отработанных часов
18 double getHours() const; // возвратить число отработанных часов
19
20 // ключевое слово virtual указывает на замену реализации
21 virtual double earnings() const; // вычислить заработок
22 virtual void print() const; // напечатать объект HourlyEmployee
23 private:
24 double wage; // почасовая ставка
25 double hours; // число отработанных часов за неделю
26 }; // конец класса HourlyEmployee
27
28 #endif // HOURLY H
Рис. 13.17, Заголовочный файл класса HourlyEmployee
1 // Рис. 13.18: HourlyEmployee.срр
2 // Определения элемент-функций класса HourlyEmployee.
3 #include <iostream>
4 using std::cout;
5
6 #include "HourlyEmployee.h" // определение класса HourlyEmployee
7
8 // конструктор
9 HourlyEmployee::HourlyEmployee( const string fifirst,
10 const string &last, const string &ssn, double hourlyWage,
11 double hoursWorked ) : Employee( first, last, ssn )
12 {
13 setWage( hourlyWage ); // проверить почасовую ставку
14 setHours( hoursWorked ); // проверить рабочие часы
15 } // конец конструктора HourlyEmployee
16
17 // установить почасовую ставку
18 void HourlyEmployee::setWage( double hourlyWage )
19 <
20 wage = ( hourlyWage < 0.0 ? 0.0 : hourlyWage );
21 } // конец функции setWage
22
23 // возвратить почасовую ставку
24 double HourlyEmployee::getWage() const
25 {
26 return wage;
27 } // конец функции getWage
28
29 // установить число рабочих часов
30 void HourlyEmployee::setHours( double hoursWorked )
31 {
32 hours = ( ( (hoursWorked >= 0.0) && (hoursWorked <= 168.0) ) ?
33 hoursWorked : 0.0 );
34 } // конец функции setHours
35
36 // возвратить число рабочих часов
37 double HourlyEmployee::getHours() const
38 {
Объектно-ориентированное программирование: полиморфизм
851
39 return hours;
40 } // конец функции getHours
41
42 // вычислить заработок;
43 // заменяет чисто виртуальную функцию earnings в Employee
44 double HourlyEmployee::earnings() const
45 {
46 if ( getHours() <= 40 ) // сверхурочных нет
47 return getWage() * getHours();
48 else
49 return 40 * getWage() + ((getHours() - 40) * getWage() * 1.5);
50 } // конец функции earnings
51
52 // напечатать информацию о HourlyEmployee
53 void HourlyEmployee::print() const
54 {
55 cout « "hourly employee: ";
56 Employee::print(); // утилизация кода
57 cout « "\nhourly wage: " « getWage() «
58 "; hours worked: " « getHours();
59 } // конец функции print
Рис. 13.18. Файл реализации класса HourlyEmployee
Рис. 13.18 показывает реализации элемент-функций для HourlyEmployee.
Строки 18-21 и 30-34 определяют set-функции, присваивающие новые
значения элементам данных wage и hours. Функция setWage (строки 18-21)
убеждается, что значение wage неотрицательно, a setHours (строки 30-34)
гарантирует, что значение hours лежит в пределах от 0 до 168 (общее число часов в
неделе). Get-функции класса HourlyEmployee реализуются в строках 24-27
и 37-40. Мы не объявляем их виртуальными, поэтому классы, производные от
HourlyEmployee, не могут их заменять (хотя, разумеется, производные
классы могут переопределять их). Заметьте, что конструктор HourlyEmployee,
подобно конструктору SalariedEmployee, передает имя, фамилию и номер
страховки конструктору базового класса Employee (строка 11) для инициализации
унаследованных закрытых элементов данных, объявленных в базовом классе.
Отметим также, что функция print класса HourlyEmployee вызывает
функцию print базового класса (строка 56), чтобы вывести информацию,
специфицируемую классом Employee (т.е. имя, фамилию и номер страховки).
13.6.4. Создание конкретного производного класса
CommissionEmployee
Класс CommissionEmployee (рис. 13.19-13.20) является производным от
Employee (строка 8 на рис. 13.19). Реализации его элемент-функций
(рис. 13.20) включают конструктор (строки 9-15), принимающий имя,
фамилию, номер социальной страховки, объем продаж и комиссионный процент;
set -функции (строки 18-21 и 30-33) для присвоения новых значений
элементам данных commissionRate и grossSales; £е£-функции (строки 24-27
и 36-39), извлекающие значения этих элементов данных; функцию earnings
(строки 43-46), вычисляющую заработок служащего CommissionEmployee,
и функцию print (строки 49-55), выводящую тип служащего (а именно,
852
Глава 13
"commission employee:"), за которым следует информация о служащем.
Конструктор CommissionEmployee также передает имя, фамилию и номер
страховки конструктору Employee (строка 11) для инициализации закрытых
элементов данных класса Employee. Функция print вызывает функцию print
базового класса (строка 52) для вывода информации, специфицируемой классом
Employee (т.е. имени, фамилии и номера страховки).
1 // Рис. 13.19: CommissionEmployee.h
2 // Класс CommissionEmployee, производный от Employee.
3 #ifndef COMMISSION^
4 #define COMMISSION_H
5
6 #include "Employee.h" // определение класса Employee
7
8 class CommissionEmployee : public Employee
9 {
10 public:
11 CommissionEmployee( const string &, const string &,
12 const string &, double =0.0, double = 0.0 );
13
14 void setCommissionRate( double ); // установить процент
15 double getCommissionRate() const; // возвратить процент
16
17 void setGrossSales( double ); // установить объем продаж
18 double getGrossSales() const; // возвратить объем продаж
19
20 // ключевое слово virtual указывает на замену реализации
21 virtual double earnings() const; // вычислить заработок
22 virtual void print() const; // напечатать объект
23 private:
24 double grossSales; // недельный объем продаж
25 double commissionRate; // комиссионный процент
26 }; // конец класса CommissionEmployee
27
28 #endif // COMMISSION H
Рис. 13.19. Заголовочный файл класса CommissionEmployee
1 // Рис. 13.20: CommissionEmployee.срр
2 // Определения элемент-функций класса CommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 #include "CommissionEmployee.h" // определение CommissionEmployee
7
8 // конструктор
9 CommissionEmployee::CommissionEmployee(const string &first,
10 const string filast, const string &ssn, double sales, double rate)
11 : Employee( first, last, ssn )
12 {
13 setGrossSales( sales );
14 setCommissionRate( rate );
15 } // конец конструктора CommissionEmployee
Объектно-ориентированное программирование: полиморфизм 853
16
17 // установить комиссионный процент
18 void CommissionEmployee::setCommissionRate( double rate )
19 {
20 commissionRate = ( ( rate > 0.0 && rate < 1.0 ) ? rate : 0.0 );
21 } // конец функции setCommissionRate
22
23 // возвратить комиссионный процент
24 double CommissionEmployee::getCommissionRate() const
25 {
26 return commissionRate;
27 } // конец функции getCommissionRate
28
29 // установить объем продаж
30 void CommissionEmployee::setGrossSales( double sales )
31 {
32 grossSales = ( ( sales < 0.0 ) ? 0.0 : sales );
33 } // конец функции setGrossSales
34
35 // возвратить объем продаж
36 double CommissionEmployee::getGrossSales() const
37 {
38 return grossSales;
39 } // конец функции getGrossSales
40
41 // вычислить заработок;
42 // заменяет чисто виртуальную функцию earnings в Employee
43 double CommissionEmployee::earnings() const
44 {
45 return getCommissionRate() * getGrossSales();
46 } // конец функции earnings
47
48 // напечатать информацию о CommissionEmployee
49 void CommissionEmployee::print() const
50 {
51 cout « "commission employee: ";
52 Employee::print(); // утилизация кода
53 cout « "\ngross sales: " « getGrossSales()
54 « "; commission rate: " « getCommissionRate();
55 } // конец функции print
Рис. 13.20. Файл реализации класса CommissionEmployee
13.6.5. Создание косвенного конкретного производного
класса BasePlusCommissionEmployee
Класс BasePlusCommissionEmployee (рис. 13.21-22) непосредственно
наследует классу CommissionEmployee (строка 8 на рис. 13.21) и, следовательно,
является косвенным производным от класса Employee. Реализации его
элемент-функций включают конструктор (строки 10-16 на рис. 13.22),
принимающий имя, фамилию, номер страховки, объем продаж, комиссионный
процент и базовую зарплату. Он передает имя, фамилию, номер страховки, объем
продаж и комиссионный процент конструктору CommissionEmployee (стро-
854
Глава 13
ка 13) для инициализации унаследованных элементов данных. BasePlusCom-
missionEmployee содержит также sef-функцию (строки 19-22) для присвоения
нового значения элементу данных baseSalary и gef-функцию (строки 25-28)
для извлечения значения этого элемента. Функция earnings (строки 32-35)
вычисляет заработок BasePlusCommissionEmployee. Обратите внимание, что
строка 34 функции earnings вызывает функцию базового класса Commis-
sionEmployee для вычисления «комиссионной» составляющей заработка
служащего. Это хороший пример утилизации кода. Функция print класса
BasePlusCommissionEmployee (строки 38-43) выводит "base-salaried", после
чего следует вывод функции print базового класса CommissionEmployee (еще
один пример утилизации кода) и базовая зарплата. Результирующий вывод
начинается со слов "base-salaried commission employee: ", за которыми
следует остальная информация о служащем BasePlusCommissionEmployee. Как вы
помните, функция print класса CommissionEmployee выводит имя, фамилию
и номер страховки, вызывая функцию print своего базового класса (т.е.
Employee) — также пример утилизации кода. Заметьте, что вызов print класса
BasePlusCommissionEmployee начинает цепочку вызовов, вовлекающую три
уровня иерархии Employee.
1 // Рис. 13.21: BasePlusCommissionEmployee.h
2 // Класс BasePlusCommissionEmployee, производный от Employee.
3 #ifndef BASEPLUS_H
4 #define BASEPLUS_H
5
6 #include "CommissionEmployee.h" // определение CommissionEmployee
7
8 class BasePlusCommissionEmployee : public CommissionEmployee
9 {
10 public:
11 BasePlusCommissionEmployee( const string &, const string &,
12 const string &, double = 0.0, double = 0.0, double = 0.0 );
13
14 void setBaseSalary( double ); // установить базовую зарплату
15 double getBaseSalary() const; // возвратить базовую зарплату
16
17 // ключевое слово virtual указывает на замену реализации
18 virtual double earnings() const; // вычислить заработок
19 virtual void print() const; // напечатать объект
20 private:
21 double baseSalary; // базовая недельная зарплата
22 }; // конец класса BasePlusCommissionEmployee
23
24 #endif // BASEPLUS H
Рис. 13.21. Заголовочный файл класса BasePlusCommissionEmployee
1 // Рис. 13.22: BasePlusCommissionEmployee.cpp
2 // Определения элемент-функций BasePlusCommissionEmployee.
3 #include <iostream>
4 using std::cout;
5
6 // определение класса BasePlusCommissionEmployee
Объектно-ориентированное программирование: полиморфизм 855
7 #include "BasePlusCommissionEmployee.h"
8
9 // конструктор
10 BasePlusCommissionEmployee::BasePlusCommissionEmployee(
11 const string fifirst, const string filast, const string &ssn,
12 double sales, double rate, double salary )
13 : CommissionEmployee( first, last, ssn, sales, rate )
14 {
15 setBaseSalary( salary ); // проверить и сохранить зарплату
16 } // конец конструктора BasePlusCommissionEmployee
17
18 // установить базовую зарплату
19 void BasePlusCommissionEmployee::setBaseSalary( double salary )
20 {
21 baseSalary = ( ( salary < 0.0 ) ? 0.0 : salary );
22 } // конец функции setBaseSalary
23
24 // возвратить базовую зарплату
25 double BasePlusCommissionEmployee::getBaseSalary() const
26 {
27 return baseSalary;
28 } // конец функции getBaseSalary
29
30 // вычислить заработок;
31 // заменяет чисто виртуальную функцию earnings в Employee
32 double BasePlusCommissionEmployee::earnings() const
33 {
34 return getBaseSalary() + CommissionEmployee::earnings();
35 } // конец функции earnings
36
37 // напечатать информацию о BasePlusCommissionEmployee
38 void BasePlusCommissionEmployee: .-print () const
39 {
40 cout « "base-salaried ";
41 CommissionEmployee::print(); // утилизация кода
42 cout « "; base salary: " « getBaseSalary();
43 } // конец функции print
Рис. 13.22. Файл реализации класса BasePlusCommissionEmployee
13.6.6. Демонстрация полиморфной обработки
Для тестирования нашей иерархии Employee программа на рис. 13.23
создает по объекту каждого из четырех конкретных классов SalariedEmployee,
HourlyEmployee, CommissionEmployee и BasePlusCommissionEmployee.
Программа производит манипуляции с этими объектами, сначала используя
статическое связывание, а затем полиморфно, используя вектор указателей
Employee. Строки 31-38 создают объекты четырех производных от Employee
конкретных классов. Строки 43-51 выводят информацию о служащем и
заработок для каждого из объектов. Каждый из вызовов элемент-функций в
строках 43-51 является примером статического связывания — во время
компиляции, поскольку в них используются дескрипторы-имена (а не ссылки или
указатели, которые могли бы устанавливаться во время исполнения), по которым
856
Глава 13
компилятор может идентифицировать тип каждого объекта и определить,
какие из функций earnings и print вызываются.
1 // Рис. 13.23: figl3_23.cpp
2 // Индивидуальная и полиморфная обработка объектов,
3 // производных от Employee.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7 using std::fixed;
8
9 #include <iomanip>
10 using std::setprecision;
11
12 #include <vector>
13 using std: -.vector;
14
15 // включить определения классов иерархии Employee
16 #include "Employee.h"
17 #include "SalariedEmployee.h"
18 #include "HourlyEmployee.h"
19 #include "CommissionEmployee.h"
20 #include "BasePlusCommissionEmployee.h"
21
22 void virtualViaPointer( const Employee * const ); // прототип
23 void virtualViaReference( const Employee & ); // прототип
24
25 int main()
26 {
27 // задать форматирование чисел с плавающей точкой
28 cout « fixed « setprecision( 2 );
29
30 // создать объекты производных классов
31 SalariedEmployee salariedEmployee(
32 "John", "Smith", 11-11-1111", 800 );
33 HourlyEmployee hourlyEmployee(
34 "Karen", "Price", 22-22-2222", 16.75, 40 );
35 CommissionEmployee commissionEmployee(
36 "Sue", "Jones", 33-33-3333", 10000, .06 );
37 BasePlusCommissionEmployee basePlusCommissionEmployee(
38 "Bob", "Lewis", 44-44-4444", 5000, .04, 300 ) ;
39
40 cout « "Employees processed individually using static
binding:\n\n";
41
42 // вывести информацию и заработок (статическое связывание)
43 salariedEmployee.print();
44 cout « "\nearned $" « salariedEmployee.earnings() « "\n\n";
45 hourlyEmployee.print();
4 6 cout « "\nearned $" « hourlyEmployee.earnings() « "\n\n";
47 commissionEmployee.print();
48 cout « "\nearned $" « commissionEmployee.earnings() « "\n\n";
4 9 basePlusCommissionEmployee.print();
50 cout « "\nearned $" « basePlusCommissionEmployee.earnings()
51 « "\n\n";
52
53 // создать вектор из четырех указателей базового класса
Объектно-ориентированное программирование: полиморфизм
857
54 vector < Employee * > employees( 4 ) ;
55
56 // инициализировать вектор имеющимися объектами
57 employees[ 0 ] = SsalariedEmployee;
58 employees[ 1 ] = &hourlyEmployее;
59 employees[ 2 ] = &commissionEmployee;
60 employees! 3 ] = fibasePlusCommissionEmployee;
61
62 cout « "Employees processed polymorphically via dynamic
binding:\n\n";
63
64 // вызвать virtualViaPointer для печати информации объектов
65 //и заработка, используя динамическое связывание
66 cout « "Virtual function calls made off base-class
pointers:\n\n";
67
68 for ( size_t i = 0; i < employees.size(); i++ )
69 virtualViaPointer( employees[ i ] );
70
71 // вызвать virtualViaReference для печати информации объектов
72 //и заработка, используя динамическое связывание
73 cout « "Virtual function calls made off base-class
references:\n\n";
74
75 for ( size_t i = 0; i < employees.size(); i++ )
76 virtualViaRef erence ( * employee s [ i ] ); // NB: разыменование
77
78 return 0;
79 } // конец main
80
81 // вызвать виртуальные функции print и earnings через
82 // указатель на базовый класс (динамическое связывание)
83 void virtualViaPointer( const Employee * const baseClassPtr )
84 {
85 baseClassPtr->print();
86 cout « "\nearned $" « baseClassPtr->earnings() « "\n\n";
87 } // конец функции virtualViaPointer
88
89 // вызвать виртуальные функции print и earnings через
90 // ссылку на базовый класс (динамическое связывание)
91 void virtualViaReference( const Employee &baseClassRef )
92 {
93 baseClassRef.print();
94 cout « "\nearned $" « baseClassRef.earnings() « "\n\n";
95 } // конец функции virtualViaReference
Employees processed individually using static binding:
salaried employee: John Smith
social security number: 111-11-1111
weekly salary: 800.00
earned $800.00
hourly employee: Karen Price
social security number: 222-22-2222
hourly wage: 16.75; hours worked: 40.00
earned $670.00
858
commission employee: Sue Jones
social security number: 333-33-3333
gross sales: 10000.00; commission rate: 0.06
earned $600.00
base-salaried commission employee: Bob Lewis
social security number: 444-44-4444
gross sales: 5000.00; commission rate: 0.04; base salary: 300
earned $500.00
Employees processed polymorphically via dynamic binding:
Virtual function calls made off base-class pointers:
salaried employee: John Smith
social security number: 111-11-1111
weekly salary: 800.00
earned $800.00
hourly employee: Karen Price
social security number: 222-22-2222
hourly wage: 16.75; hours worked: 40.00
earned $670.00
commission employee: Sue Jones
social security number: 333-33-3333
gross sales: 10000.00; commission rate: 0.06
earned $600.00
base-salaried commission employee: Bob Lewis
social security number: 444-44-4444
gross sales: 5000.00; commission rate: 0.04; base salary: 300
earned $500.00
Virtual function calls made off base-class references:
salaried employee: John Smith
social security number: 111-11-1111
weekly salary: 800.00
earned $800.00
hourly employee: Karen Price
social security number: 222-22-2222
hourly wage: 16.75; hours worked: 40.00
earned $670.00
commission employee: Sue Jones
social security number: 333-33-3333
gross sales: 10000.00; commission rate: 0.06
earned $600.00
base-salaried commission employee: Bob Lewis
social security number: 444-44-4444
gross sales: 5000.00; commission rate: 0.04; base salary: 300
earned $500.00
Рис. 13.23. Программа-драйвер для иерархии Employee
Объектно-ориентированное программирование: полиморфизм 859
Строка 54 выделяет вектор employees, который содержит четыре указателя
Employee. Строка 57 устанавливает employees[ 0 ] на объект salariedEm-
ployee. Строка 58 устанавливает employees[ 1 ] на объект hourlyEmployee.
Строка 59 устанавливает employees[ 2 ] на объект commissionEmployee.
Строка 60 устанавливает employees! 3 ] на объект basePlusCommissionEmployee.
Компилятор разрешает эти присваивания, поскольку SalariedEmployee
является Employee, HourlyEmployee является Employee, CommissionEmployee
является Employee и BasePlusCommissionEmployee является Employee.
Следовательно, мы можем присваивать адреса объектов SalariedEmployee,
HourlyEmployee, CommissionEmployee и BasePlusCommissionEmployee
указателям базового класса Employee (несмотря на то, что Employee — абстрактный
класс).
Оператор for в строках 68-69 проходит по вектору employees и активирует
для каждого элемента вектора функцию virtualViaPointer (строки 83-87).
Функция virtualViaPointer в параметре baseClassPtr (типа const Employee *
const) принимает адрес, хранящийся в элементе employees. Каждый вызов
virtualViaPointer использует baseClassPtr для активации виртуальных
функций print (строка 85) и earnings (строка 86). Заметьте, что функция
virtualViaPointer не содержит никакой информации о типах
SalariedEmployee, HourlyEmployee, CommissionEmployee или
BasePlusCommissionEmployee. Функции известен только тип базового класса Employee.
Следовательно, во время компиляции компилятор не может знать, функции каких
конкретных классов должны вызываться через baseClassPtr. И все же во время
исполнения каждый вызов виртуальной функции активирует функцию
объекта, на который в данный момент указывает baseClassPtr. Вывод программы
подтверждает, что действительно для каждого класса вызываются
соответствующие функции и выводится информация, соответствующая типу объекта.
Например, для SalariedEmployee выводится недельный оклад, а для
CommissionEmployee и BasePlusCommissionEmployee выводится объем продаж.
Заметьте также, что полиморфное определение заработка каждого служащего
в строке 86 дает те же результаты, что определение заработка посредством
статического связывания в строках 44, 46, 48 и 50. Все виртуальные вызовы
функций print и earnings разрешаются во время исполнения посредством
динамического связывания.
Наконец, другой оператор for (строки 75-76) проходит вектор employees
и активирует для каждого элемента вектора функцию virtualViaReference
(строки 91-95). Функция virtualViaReference в параметре baseClassRef (типа
const Employee &) принимает ссылку, образованную разыменованием
указателя в элементе employees (строка 76). Каждый вызов virtualViaReference
активирует через ссылку baseClassRef виртуальные функции print (строка 93)
и earnings (строка 94), демонстрируя, что виртуальная обработка реализуется
и при использовании ссылок базового класса. Каждый вызов виртуальной
функции активирует функцию объекта, на который во время исполнения
ссылается baseClassRef. Это еще один пример динамического связывания. Вывод,
получаемый при использовании ссылок базового класса, совпадает с тем, что
получается при использовании указателей.
860
Глава 13
13.7. (Дополнительный раздел.) Техническая сторона
полиморфизма, виртуальных функций
и динамического связывания
C++ делает программирование полиморфизма несложным. Конечно, вполне
возможно программирование полиморфизма и в языках, не
объектно-ориентированных, таких, как С, но это связано со сложными и потенциально опасными
манипуляциями с указателями. В этом разделе мы обсудим возможную
внутреннюю реализацию полиморфизма, виртуальных функций и позднего
связывания в C++. Это даст вам твердое понимание того, как в действительности
работают эти механизмы. И что более важно, вы сможете оценить издержки
полиморфизма в плане дополнительного расхода памяти и процессорного времени.
Это поможет вам в принятии решений относительно того, когда целесообразно
использовать полиморфизм и когда следует этого избегать. Заметьте, что
компоненты библиотеки стандартных шаблонов C++ (STL) реализованы без
полиморфизма и виртуальных функций; это было сделано ради исключения связанных
с ними расходов времени исполнения и для достижения максимальной
эффективности, к которой в STL предъявляются исключительные требования.
Сначала мы расскажем о структурах данных, которые C++ строит во время
компиляции и которые служат для поддержки полиморфизма во время
исполнения. Вы увидите, что полиморфизм достигается благодаря трем уровням
указателей (т.е. путем «тройной косвенной адресации»). Затем мы покажем,
как исполняемая программа пользуется этими структурами для активации
виртуальных функций, реализуя лежащее в основе полиморфизма
динамическое связывание. Следует иметь в виду, что мы обсуждаем здесь одну из
возможных реализаций полиморфизма в C++; она не диктуется спецификациями
языка.
Когда C++ компилирует класс с одной или несколькими виртуальными
функциями, он строит для него таблицу виртуальных функций, или vtable.
При посредстве vtable выполняющаяся программа выбирает нужную
реализацию функции всякий раз, когда вызывается виртуальная функция данного
класса. Крайний левый столбец на рис. 13.24 иллюстрирует vtable для классов
Employee, SalariedEmployee, Hourly Employee, CommissionEmployee и Ba-
sePlusCommissionEmployee.
В vtable для класса Employee первый указатель на функцию
устанавливается равным 0 (т.е. нулевому указателю). Это делается потому, что earnings —
чисто виртуальная функция и, следовательно, реализация ее отсутствует.
Второй указатель ссылается на функцию print, которая выводит полное имя и
номер социальной страховки служащего. [Замечание. Для экономии места мы
показываем вывод каждой из функций print в сокращенном виде.] Любой
класс, имеющий в своей vtable один или несколько нулевых указателей,
является абстрактным. Классы без нулевых указателей в vtable (такие, как
SalariedEmployee, Hourly Employee, CommissionEmployee и BasePlusCommis-
sionEmployee) являются конкретными.
Объектно-ориентированное программирование: полиморфизм
861
(абстрактный класс)
vtable класса Employe*
first last
ssn: ...
earnings 0
print
@ - указывает, что функция чисто виртуальная)
vtable класса
SalariedEmployee
salariedEmployee
weeklySalary-
salaried
employee:
print
wage *
hours
hourly
vtable класса
HourlyEmployee
^-
earnings
print
->
employee ...
vtable класса
CommissionEmployее
^ earnings
grossSales ^ •
* commissionRate
commxssion -^-
employee:
print
John Smith
111-11-1111
$800.00
commissionEmployee
vtable класса
BasePlusCommissionEmployee
Sue Jones
333-33-333
$10,000.00
.06
basePlusCommissionEmployee
baseSalary + eaj
(grossSales «i
* commissionRate)
base- -*-
salaried
commission
employee: .
print
Bob Lewis
444-44-4444
$5,000.00
.04
$300.00
vector < Employee * >
employees ( 4 ) ;
baseClassPtr
Поток управления виртуального вызова baseClassPtr->print(),
когда baseClassPtr указывает на объект hourlyEmployee
- передача &hourlyEmployee
параметру baseClassPtr
переход к vtable класса
HourlyEmployee
исполнение print для
HourlyEmployee
переход к объекту
hourlyEmployee
переход к указателю на print
в vtable
Рис. 13.24. Как работают виртуальные вызовы функций
862
Глава 13
Класс SalariedEmployee заменяет функцию earnings, чтобы она
возвращала недельный оклад, поэтому соответствующий указатель ссылается на
функцию earnings класса SalariedEmployee. Этот класс заменяет и функцию print,
поэтому соответствующий указатель ссылается на элемент-функцию класса
SalariedEmployee, которая печатает "salaried employee: " и затем полное имя,
номер страховки и недельный оклад.
Указатель функции earnings в vtable для класса HourlyEmployee ссылается
на функцию earnings из HourlyEmployee, возвращающую почасовую ставку
служащего, умноженную на число отработанных часов. Здесь также для
экономии места мы упоминаем, что служащие с почасовой оплатой получают
полуторную плату за сверхурочную работу. Указатель функции print ссылается
на версию функции из класса HourlyEmployee, которая печатает "hourly
employee:", полное имя, номер страховки, почасовую ставку и отработанные
часы. Обе функции заменяют соответствующие функции в классе Employee.
Указатель функции earnings в vtable для класса CommissionEmployee
ссылается на функцию earnings из CommissionEmployee, возвращающую общую
сумму продаж, умноженную на комиссионный процент. Указатель функции
print ссылается на версию функции из класса CommissionEmployee, которая
печатает тип служащего, имя, номер страховки, комиссионный процент
и сумму продаж. Как и в классе HourlyEmployee, обе функции заменяют
соответствующие функции в классе Employee.
Указатель функции earnings в vtable для класса BasePlusCommissionEm-
ployee ссылается на функцию earnings из CommissionEmployee,
возвращающую базовый оклад плюс объем продаж, умноженный на комиссионный
процент. Указатель функции print ссылается на версию функции из класса
BasePlusCommissionEmployee, которая печатает базовый оклад в дополнение
к типу, имени, номеру страховки, комиссионному проценту и сумме продаж.
Обе функции заменяют соответствующие функции в классе Employee.
Заметьте, что в нашем примере каждый конкретный класс
предусматривает свои собственные реализации для виртуальных функций earnings и print.
Вы уже знаете, что каждый класс, непосредственно наследующий
абстрактному базовому классу Employee, должен, чтобы быть конкретным классом, реа-
лизовывать функцию earnings, поскольку это — чисто виртуальная функция.
Однако этим классам, чтобы быть конкретными, не обязательно реализовы-
вать функцию print — это не чисто виртуальная функция и производные
классы могут наследовать ее реализацию в классе Employee. Более того, классу
BasePlusCommissionEmployee не обязательно реализовывать ни print, ни
earnings — обе реализации могут наследоваться от класса
CommissionEmployee. Если бы класс в нашей иерархии подобным образом наследовал
реализации функций, их указатели в vtable просто ссылались бы на наследуемую
реализацию функции. Например, если бы класс
BasePlusCommissionEmployee не заменял earnings, указатель функции earnings в vtable для класса
BasePlusCommissionEmployee ссылался бы на ту же самую функцию, на
которую указывает vtable для класса BasePlusCommissionEmployee.
Полиморфизм реализуется посредством изящной структуры данных с
тремя уровнями указателей. Пока мы обсудили только один уровень — указатели
на функции в vtable. Они указывают на действительные функции,
исполняемые при активации виртуальной функции.
Объектно-ориентированное программирование: полиморфизм 863
Рассмотрим теперь второй уровень указателей. Всякий раз, когда создается
объект класса с одной или несколькими виртуальными функциями,
компилятор прикрепляет к объекту указатель на utable для данного класса. Этот
указатель располагается обычно в начале объекта, но он не обязательно должен быть
реализован именно таким образом. На рис. 13.24 эти указатели ассоциированы
с объектами, создаваемыми программой на рис. 13.23 (по одному объекту для
каждого из классов SalariedEmployec, Hourly Employee, CommissionEmployee
и BasePlusCommissionEmployee). На диаграмме показаны также значения
элементов данных этих объектов. Например, объект salariedEmployee содержит
указатель на utable класса SalariedEmployee; объект содержит также значения
John Smith, 111-11-1111 и $800.0.
Третий уровень указателей представлен просто дескрипторами объектов,
получающих вызовы виртуальных функций. Дескрипторы на этом уровне
могут быть и ссылками. Обратите внимание, что на рис. 13.24 справа показан
вектор employees, содержащий указатели на Employee.
Давайте теперь проследим, как исполняется типичный вызов виртуальной
функции. Рассмотрим вызов baseClassPtr->print() в функции virtualViaPointer
(строка 85 на рис. 13.23). Предположим, baseClassPtr содержит employees[ 1 ]
(т.е. адрес объекта hourlyEmployee в employees). Когда компилятор
обрабатывает этот вызов, он определяет, что вызов действительно производится через
указатель базового класса и что print является виртуальной функцией.
Компилятор определяет, что print идет вторым пунктом в каждой из
виртуальных таблиц. Чтобы найти эту функцию, компилятор замечает, что ему
нужно пропустить первый пункт. Таким образом, компилятор вычисляет
смещение в машинном представлении таблицы указателей, равное четырем
байтам (на современных 32-битных машинах указатель занимает четыре байта,
и нужно пропустить всего один указатель), позволяющее найти код
исполняемой виртуальной функции.
Компилятор генерирует код, выполняющий следующие операции. [Замечание.
Нумерация в списке соответствует обведенным кружком цифрам на рис. 13.24.]
1. Выбрать i-й элемент employees (в данном случае адрес объекта
hourlyEmployee) и передать его в качестве аргумента функции virtualViaPoin-
ter. Теперь baseClassPtr указывает на hourlyEmployee.
2. Разыменовать этот указатель, чтобы перейти к самому объекту
hourlyEmployee, который, как вы помните, начинается с указателя на utable
класса HourlyEmployee.
3. Разыменовать указатель на utable в объекте hourlyEmployee, чтобы
перейти к utable класса HourlyEmployee.
4. Пропустить смещение, равное четырем байтам, чтобы выбрать указатель
на функцию print.
5. Разыменовать указатель на функцию print, чтобы получить «имя»
действительной функции, которая должна исполняться, и применить
операцию вызова () для исполнения соответствующей функции print, которая
в данном случае печатает тип служащего, имя, номер страховки,
почасовую ставку и отработанные часы.
864
Глава 13
Структуры данных на рис. 13.24 могут показаться сложными, но
компилятор скрывает от вас эту сложность, делая полиморфное программирование
довольно прямолинейным. Операции разыменования указателей и обращения
к памяти, происходящие при каждом вызове виртуальной функции, требуют
некоторых дополнительных затрат времени. Виртуальные таблицы и
прикрепляемые к объектам указатели на них требуют некоторой дополнительной
памяти. Вы теперь располагаете достаточной информацией, чтобы решить,
подходят ли для ваших программ виртуальные функции.
Вопросы производительности 13,1
$Щ
Полиморфизм в том виде, как он реализуется в C++ посредством
виртуальных функций и динамического связывания, весьма эффективен.
Использование его возможностей наносит эффективности лишь
номинальный ущерб.
Вопросы производительности 13.2
Виртуальные функции и динамическое связывание делают
полиморфное программирование реальной альтернативой программированию
логики switch. Оптимизирующие компиляторы обычно генерируют
полиморфный код, работающий столь же эффективно, как и
закодированная вручную логика с операторами switch. Издержки
полиморфизма приемлемы для большинства приложений. Но в
некоторых ситуациях — например, в приложениях реального времени с их
жесткими требованиями к производительности — «накладные
расходы» полиморфизма могут оказаться слишком велики.
Общее методическое замечание 13.11
Динамическое связывание позволяет независимым производителям
программного обеспечения (ISV) распространять программное
обеспечение, не раскрывая своих секретов. Дистрибутивы могут состоять
только из заголовочных и объектных файлов — исходный код раскры
вать не требуется. Разработчики программ могут затем
использовать наследование для создания новых классов из тех, что
поставляют ISV. Программное обеспечение, работавшее с поставляемыми ISV
классами, будет работать и с производными классами, вызывая
(посредством динамического связывания) замещенные виртуальные
функции, предусмотренные в этих классах.
13.8. Пример. Система начисления заработной платы,
использующая полиморфизм и информацию о типе
времени выполнения с нисходящими приведениями
типа, dynamic_cast, typeid и type_info
Вспомните постановку задачи в начале раздела 13.6, где говорилось, что
в текущий расчетный период наша воображаемая компания решила
премировать служащих BasePlusCommissionEmployee, увеличив на 10% их базовый
оклад. Обрабатывая в разделе 13.6.6 объекты Employee полиморфно, мы не
Объектно-ориентированное программирование: полиморфизм 865
беспокоились об их «частностях». Теперь, однако, чтобы модифицировать
базовые оклады для BasePlusCommissionEmployee, мы должны
идентифицировать тип каждого служащего во время исполнения и затем действовать
соответственно. Этот раздел демонстрирует мощные возможности,
предоставляемые информацией о типе времени выполнения (RTTI) и нисходящими
приведениями типа, которые позволяют программе определять тип объекта во
время исполнения и обращаться с объектом соответствующим образом.
Некоторые компиляторы, в том числе Visual C++ .NET, требуют перед
использованием RTTI в программе разрешить эту опцию. Справьтесь в
документации по вашему компилятору, не требует ли он чего-то подобного. Чтобы
разрешить RTTI в Visual C++ .NET, откройте меню Project и выберите пункт
Properties. В появившемся диалоге Property Pages выберите Configuration
Properties > C/C++ > Language. Затем выберите Yes (/GR) рядом с Enable
Run-Time Type Info. Наконец, нажмите ОК для сохранения установок.
Программа на рис. 13.25 использует разработанную в разделе 13.6
иерархию Employee и увеличивает на 10% базовый оклад каждого из служащих
BasePlusCommissionEmployee. Строка 41 объявляет четырехэлементный
вектор employees, в котором хранятся указатели на объекты Employee.
Строки 34-41 заполняют вектор адресами динамически выделенных объектов
классов SalariedEmployee (рис. 13.15-13.16), HourlyEmployee (рис. 13.17-13.18),
CommissionEmployee (рис. 13.9-13.20) и BasePlusCommissionEmployee
(рис. 13.21-13.22).
Оператор for в строках 44-66 проходит по вектору employees и выводит
информацию о каждом служащем, вызывая элемент-функцию print (строка 46).
Поскольку, как вы помните, print объявлена в базовом классе Employee
виртуальной, система активирует соответствующую функцию ргп^объекта
производного класса.
1 // Рис. 13.25: figl3_25.cpp
2 // Демонстрация нисходящего приведения и информации о типе
3 // времени выполнения. ЗАМЕЧАНИЕ. Чтобы пример работал
4 //в Visual C++ .NET, нужно разрешить в проекте опцию RTTI.
5 #include <iostream>
6 using std::cout;
7 using std::endl;
8 using std:.fixed;
9
10 #include <iomanip>
11 using std::setprecision;
12
13 #include <vector>
14 using std::vector;
15
16 #include <typeinfo>
17
18 // включить определения классов иерархии Employee
19 #include "Employee.h"
20 #include "SalariedEmployee.h"
21 #include "HourlyEmployee.h"
22 #include "CommissionEmployee.h"
23 #include "BasePlusCommissionEmployee.h"
24
28 Зак. 1114
866
Глава
25 int main ()
26 {
27 // задать формат вывода чисел с плавающей точкой
28 cout « fixed « setprecision( 2 );
29
30 // создать вектор из четырех указателей базового класса
31 vector < Employee * > employees( 4 ) ;
32
33 // инициализировать вектор различными объектами Employee
34 employees[ 0 ] = new SalariedEmployee(
35 "John", "Smith", 11-11-1111", 800 );
36 employees[ 1 ] = new HourlyEmployее(
37 "Karen", "Price", 22-22-2222", 16.75, 40 );
38 employees[ 2 ] = new CommissionEmployee(
39 "Sue", "Jones", 33-33-3333", 10000, .06 );
40 employees[ 3 ] = new BasePlusCommissionEmployee(
41 "Bob", "Lewis", 44-44-4444", 5000, .04, 300 );
42
43 // полиморфно обработать каждый элемент вектора employees
44 for ( size__t i = 0; i < employees. size () ; i++ )
45 {
46 employees [ i ]->print(); // вывести информацию о служащем
47 cout « endl;
48
49 // нисходящее приведение указателя
50 BasePlusCommissionEmployee *derivedPtr =
51 dynamic__cast < BasePlusCommissionEmployee * >
52 ( employees[ i ] );
53
54 // определить, ссылается ли указатель на служащего
55 // типа BasePlusCommissionEmployee
56 if ( derivedPtr != 0 ) //0, если не BasePlusCommissionEmployee
57 {
58 double oldBaseSalary = derivedPtr->getBaseSalary();
59 cout « "old base salary: $" « oldBaseSalary « endl;
60 derivedPtr->setBaseSalary( 1.10 * oldBaseSalary );
61 cout « "new base salary with 10% increase is: $"
62 « derivedPtr->getBaseSalary() « endl;
63 } // конец if
64
65 cout « "earned $" « employees[ i ]->earnings() « "\n\n";
66 } // конец for
67
68 // освободить объекты, на которые указывают элементы вектора
69 for ( size_t j = 0; j < employees.size(); j++ )
70 {
71 // вывести имя класса
72 cout « "deleting object of "
73 « typeid( *employees[ j ] ).name() « endl;
74
75 delete employees[ j ];
76 } // конец for
77
78 return 0;
79 } // конец main
Объектно-ориентированное программирование: полиморфизм 867
salaried employee: John Smith
social security number: 111-11-1111
weekly salary: 800.00
earned $800.00
hourly employee: Karen Price
social security number: 222-22-2222
hourly wage: 16.75; hours worked: 40.00
earned $670.00
commission employee: Sue Jones
social security number: 333-33-3333
gross sales: 10000.00; commission rate: 0.06
earned $600.00
base-salaried commission employee: Bob Lewis
social security number: 444-44-4444
gross sales: 5000.00; commission rate: 0.04; base salary: 300.00
old base salary: $300.00
new base salary with 10% increase is: $330.00
earned $530.00
deleting object of SalariedEmployee
deleting object of HourlyEmployee
deleting object of CommissionEmployee
deleting object of BasePlusCommissionEmployee
Рис. 13.25. Демонстрация нисходящего приведения и информации о типе времени
выполнения
В этом примере мы хотим, встречая объекты
BasePlusCommissionEmployee, увеличивать их базовый оклад на 10 процентов. Так как мы
обрабатываем служащих обобщенным образом (т.е. полиморфно), мы не можем
(используя то, чему научились) иметь уверенность относительно типа объекта
Employee, с которым работаем в каждый момент времени. Это создает
проблему, поскольку мы должны идентифицировать объекты
BasePlusCommissionEmployee, если они нам встречаются, чтобы они могли получить
10-процентную прибавку к окладу. Чтобы это осуществить, мы используем операцию
dynamic_cast (строка 51), которая позволяет нам определить, относится ли
объект к типу BasePlusCommissionEmployee. Это операция нисходящего
приведения, о которой мы упоминали в разделе 13.3.3. Строки 50-52
динамически приводят employees[ i ] от типа Employee * к типу
BasePlusCommissionEmployee *. Если элемент вектора указывает на объект, который является
объектом BasePlusCommissionEmployee, то адрес этого объекта присваивается
указателю derivedPtr. В противном случае derivedPtr присваивается О.
Если значение, возвращаемое операцией dynamic_cast в строках 50-52,
не 0, то это объект нужного типа и оператор if в строках 56-63 производит
специальную обработку, требуемую объектом BasePlusCommissionEmployee.
Строки 58, 60 и 62 вызывают функции getBaseSalary и setBaseSalary для
извлечения и обновления оклада служащего.
Строка 65 вызывает функцию earnings для объекта, на который указывает
employees! i ]. Так как функция earnings объявлена в базовом классе вирту-
868
Глава 13
альной, программа вызывает функцию earnings объекта производного
класса — еще один пример динамического связывания.
Цикл for в строках 69-76 выводит тип каждого объекта Employee и
использует операцию delete для освобождения динамической памяти, на которую
указывает каждый из элементов вектора. Операция typeid (строка 73)
возвращает ссылку на объект класса typejinfo, который содержит информацию
о типе операнда операции, включая имя этого типа. Вызов элемент-функции
пате класса type_info (строка 73) возвращает строку-указатель с именем типа
(например, "class BasePlusCominissionEmployee") аргумента, переданного
typeid. [Замечание. Точное содержимое возвращаемой элемент-функцией
name строки может меняться от компилятора к компилятору.] Чтобы
использовать typeid, программа должна включать заголовочный файл <typeinfo>
(строка 16).
Заметьте, что в этом примере мы, приводя указатель Employee к типу
BasePlusCominissionEmployee (строки 50-52), избегаем нескольких ошибок
компиляции. Если мы удалим из строки 51 dynamic_east и попытаемся
присвоить текущий указатель Employee непосредственно указателю derivedPtr,
то получим сообщение об ошибке компиляции. C++ не позволяет программе
присваивать указатель базового класса указателю производного класса,
поскольку здесь не имеет места отношение является — Employee не является
BasePlusCominissionEmployee. Отношение является приложимо только в
направлении от производного класса к базовому, но не наоборот.
Аналогично, если бы мы в строках 58, 60 и 62 использовали для вызова
функций производного класса getBaseSalary и setBaseSalary не указатель
производного класса derivedPtr, а текущий указатель базового класса из
employees, то получили бы сообщения об ошибках компиляции в каждой из
этих строк. Как вы знаете из раздела 13.3.3, недопустима попытка вызова
функции, имеющейся только в производном классе, через указатель базового
класса. Хотя строки 58, 60 и 62 исполняются только в случае, когда
derivedPtr не 0 (т.е. приведение может быть произведено), мы не можем пытаться
вызывать функции getBaseSalary и setBaseSalary класса
BasePlusCominissionEmployee через указатель базового класса Employee. Через указатель
базового класса Employee можно вызывать только функции, имеющиеся в
базовом классе, т.е. earnings, print, get- и sef-функции класса Employee.
13.9. Виртуальные деструкторы
При полиморфной обработке динамически распределенных объектов
классовой иерархии может возникать одна проблема. Пока вы встречались только
с невиртуальными деструкторами, т.е. теми, что объявлялись без ключевого
слова virtual. Если объект производного класса с не-виртуальным деструктором
уничтожается явным применением операции delete к указателю базового
класса, стандарт C++ специфицирует, что в этом случае поведение не определено.
Простым решением этой проблемы является создание в базовом классе
виртуального деструктора (т.е. деструктора, объявленного с ключевым словом
virtual). Это делает виртуальными деструкторы всех производных классов,
несмотря на то, что их имена отличаются от имени деструктора базового
класса. Теперь, если объект иерархии уничтожается явным образом
применением операции delete к указателю базового класса, будет вызван деструктор
Объектно-ориентированное программирование: полиморфизм
869
соответствующего класса в зависимости от объекта, на который этот указатель
ссылается. Как вы помните, при уничтожении объекта производного класса
уничтожается и базовая часть объекта производного класса, поэтому важно,
чтобы исполнялись деструкторы и производного, и базового классов.
Деструктор базового класса исполняется автоматически после исполнения деструктора
производного класса.
Хороший стиль программирования 13.2
Если в классе имеются виртуальные функции, предусмотрите для
него виртуальный деструктор, даже если он и не требуется классу.
Классы, производные от него, могут содержать деструкторы,
которые должны вызываться должным образом.
Типичная ошибка программирования 13,5
Конструкторы не могут быть виртуальными. Объявление
конструктора виртуальным приводит к ошибке компиляции.
13.10. Конструирование программного обеспечения.
Введение наследования в систему ATM
(необязательный раздел)
Теперь мы возвратимся к нашей системе ATM и посмотрим, какие выгоды
мы можем получить здесь от наследования. Чтобы применить наследование,
мы прежде всего поищем общность между классами в системе. Мы создадим
иерархию наследования, чтобы моделировать схожие (и все же не идентичные)
классы более эффективным и элегантным образом, что позволит нам
обрабатывать объекты этих классов полиморфно. Затем мы модифицируем нашу
классовую диаграмму, отразив в ней новые отношения наследования.
Наконец, мы продемонстрируем, как наша модифицированная диаграмма
переводится в заголовочные классы C++.
В разделе 3.11 мы столкнулись с проблемой представления финансовых
транзакций в системе. Вместо того, чтобы создать один класс,
представляющий все типы транзакций, мы решили создать три отдельных класса —
Balancelnquiry, Withdrawal и Deposit — для представления транзакций,
которые может производить система ATM. Рис. 13.26 показывает атрибуты
и операции этих классов. Обратите внимание, что они имеют один общий
атрибут (accountNumber) и одну общую операцию (execute). Каждому классу
требуется атрибут accountNumber для указания счета, к которому
применяется транзакция. Каждый класс содержит операцию execute, которую ATM
активирует, чтобы произвести транзакцию. Очевидно, что Balancelnquiry,
Withdrawal и Deposit представляют типы транзакций. Рис. 13.26 раскрывает
общность в классах транзакций, поэтому представляется целесообразным
использовать в проектировании этих классов наследование, чтобы вынести эту
общность «за скобки». Мы поместим то общее, что имеется у этих классов,
в базовый класс Transaction и произведем классы Balancelnquiry,
Withdrawal и Deposit от Transaction (рис. 13.27).
870
Глава 13
Balancelnquiry
- accountNumber: Integer
+ execute()
Withdrawal Deposit
- accountNumber: Integer - accountNumber: Integer
-amount: Double - amount: Double
+ executeO + execute()
Рис. 13.23. Атрибуты и операции классов Balancelnquiry, Withdrawal и Deposit
Transaction
- accountNumber: Integer
+ getAccountNumber()
+ executeQ
Balancelnquiry Withdrawal Deposit
- account: Double - account: Double
+ executeQ + executeO + executeO
Рис. 13.27. Классовая диаграмма, моделирующая отношение обобщения между
базовым классом Transaction и производными классами Balancelnquiry,
Withdrawal и Deposit
Для моделирования наследования UML специфицирует отношение,
называемое обобщением. Рис. 13.27 является классовой диаграммой,
моделирующей отношения наследования между базовым классом Transaction и тремя
производными классами. Стрелки с пустыми треугольными наконечниками
показывают, что классы Balancelnquiry, Withdrawal и Deposit являются
производными от класса Transaction. Говорят, что класс Transaction является
обобщением своих производных классов. Производные классы называют
в этом случае специализациями класса Transaction.
Классы Balancelnquiry, Withdrawal и Deposit разделяют целый атрибут
accountNumber, поэтому мы выносим этот атрибут за скобки и помещаем его
в базовый класс Transaction. Мы больше не упоминаем accountNumber во вто-
Объектно-ориентированное программирование: полиморфизм 871
ром разделе каждого из производных классов, поскольку три производных
класса наследуют этот атрибут от Transaction. Вспомните, однако, что
производные классы не могут обращаться к закрытым атрибутам базового класса.
Поэтому мы включаем в класс Transaction открытую элемент-функцию
getAccountNumber. Эту функцию наследует каждый производный класс, что
позволяет производному классу обращаться к своему номеру счета, если по
ходу исполнения транзакции в этом возникает необходимость.
В соответствии с рис. 13.26 классы Balancelnquiry, Withdrawal и Deposit
разделяют также операцию execute, поэтому базовый класс Transaction
должен содержать открытую элемент-функцию execute. Однако бессмысленно
реализовывать execute в классе Transaction, так как действия, которые
должна выполнять эта функция, зависят от конкретного типа действительной
транзакции. Поэтому в базовом классе Transaction мы объявляем
элемент-функцию execute как чисто виртуальную. Это делает Transaction абстрактным
классом и требует, чтобы каждый производный от Transaction класс, если он
должен быть конкретным классом (т.е. Balancelnquiry, Withdrawal
и Deposit), реализовывал виртуальную элемент-функцию execute. UML
требует, чтобы имена всех абстрактных классов (и чисто виртуальных функций —
в UML абстрактных операций) выделялись курсивом, поэтому на рис. 13.27
класс Transaction и его элемент-функция execute записаны курсивом.
Заметьте, что в производных классах Balancelnquiry, Withdrawal и Deposit
операция execute записана обычным шрифтом. Каждый производный класс заменяет
элемент-функцию базового класса Transaction соответствующей реализацией.
Заметьте, что на рис. 13.27 операция execute включена в третий раздел классов
Balancelnquiry, Withdrawal и Deposit, поскольку каждый из них имеет свою
собственную конкретную реализации заменяемой элемент-функции.
Как вы узнали в этой главе, производный класс может наследовать от
базового интерфейс или реализацию. В сравнении с иерархией, спроектированной
для наследования реализации, в иерархии, спроектированной для
наследования интерфейса, функциональные свойства реализуются ниже — базовый
класс обозначает одну или несколько функций, которые должны определяться
каждым классом иерархии, но отдельные производные классы
предусматривают свои собственные реализации функций. Иерархия наследования,
спроектированная для ATM, использует преимущества такого типа наследования,
которое позволяет ATM изящно исполнять «вообще» транзакции. Каждый
производный от Transaction класс наследует некоторые элементы реализации
(напр., элемент данных accountNumber), но главная выгода от введения
в нашу систему наследования состоит в том, что производные классы
разделяют единый интерфейс (т.е. виртуальную элемент-функцию execute). ATM
может установить указатель типа Transaction на любую транзакцию, и когда
ATM активирует execute через этот указатель, будет автоматически запущена
версия execute, соответствующая данной транзакции (т.е. реализованная
в .срр-файле данного производного класса). Например, предположим, что
пользователь выбрал справку о балансе. ATM устанавливает указатель типа
Transaction на новый объект класса Balancelnquiry, что компилятор C++
допускает, поскольку Balancelnquiry является Transaction. Когда ATM
использует этот указатель для активации execute, будет вызвана версия execute из
Balancelnquiry.
872
Глава 13
Такой полиморфный подход, кроме того, делает систему легко
расширяемой. Если бы мы захотели создать новый тип транзакции (напр., перевод
средств или оплату счета), мы просто создали бы новый производный от
Transaction класс, заменяющий элемент-функцию execute версией,
соответствующей новому типу транзакции. Нам потребовалось бы сделать в коде
системы лишь минимальные изменения, чтобы пользователи могли выбирать
в главном меню новый тип транзакции, a ATM — создавать и исполнять
объекты нового производного класса. Для исполнения транзакций нового типа
ATM достаточно было бы существующего кода, поскольку он исполняет все
транзакции автоматически.
Как вы узнали в этой главе ранее, абстрактный класс, подобный
Transaction — это класс, для которого программист никогда не собирается
создавать объектов. Абстрактный класс просто объявляет атрибуты и
поведение, общие для его производных классов в иерархии наследования. Класс
Transaction определяет понятие о том, что такое транзакция, которая имеет
номер счета и исполняется. Вас может удивить, зачем нам понадобилось
включать в класс Transaction чисто виртуальную элемент-функцию execute, если
у нее нет конкретной реализации. Говоря абстрактно, мы включили эту
функцию, поскольку она является определяющим поведением всех транзакций —
их исполнением. Технически же мы обязаны включить элемент-функцию
execute в базовый класс Transaction, чтобы ATM (или любой другой класс)
мог полиморфно активировать версию этой функции в каждом производном
классе через указатель или ссылку на Transaction.
Производные классы Balancelnquiry, Withdrawal и Deposit наследуют от
Transaction атрибут accountNumber, но классы Withdrawal и Deposit имеют
дополнительный атрибут amount, что отличает их от класса Balancelnquiry.
Этот атрибут требуется классам Withdrawal и Deposit для хранения суммы,
которую пользователь хочет снять или положить на счет. Классу
Balancelnquiry такой атрибут не нужен, для исполнения ему достаточно
номера счета. Несмотря на то, что этот атрибут разделяют два из трех классов,
производных от Transaction, мы не помещаем его в базовый класс Transaction, —
мы помещаем в базовый класс только то, что является общим для всех
производных классов, чтобы последние не наследовали ненужных атрибутов (и
операций).
На рис. 13.28 представлена обновленная классовая диаграмма нашей
модели, которая включает наследование и вводит класс Transaction. Мы
моделируем ассоциацию между классом ATM и классом Transaction, показывая, что
ATM в каждый момент времени либо исполняет, либо не исполняет
транзакцию (т.е. одновременно существует ноль или один объектов типа Transaction).
Поскольку Withdrawal является типом транзакции, мы больше не проводим
линию ассоциации непосредственно между классом ATM и классом
Withdrawal, — производный класс Withdrawal наследует ассоциацию с ATM
базового класса Transaction. Производные классы Balancelnquiry и Deposit
также наследуют эту ассоциацию, которая замещает опущенные ранее
ассоциации между классами Balancelnquiry и Deposit и классом ATM. Обратите
опять внимание на пустые треугольные наконечники стрелок, указывающие
на специализации класса Transaction, как на рис. 13.27.
Объектно-ориентированное программирование: полиморфизм
873
*
Л
Keypad < |
I
DepositSlot ! |
1 1
> CashDispenser <-
it
Screen
Ь
1-,
0.1
0..1
-i ! l П
♦ ♦ ♦ ♦
Withdrawal
0.1
0..1
ATM
Исполняет ►
"r Transaction <-
0..1
0..1
Авторизует пользователя в
0..1
BankDatabase <—
Содержит
;1
bo..
Account
< Читает/
модифицирует
баланс: счета
через
Deposit
Balancelnquiry
Рис. 13.28. Классовая диаграмма системы ATM (с наследованием). Обратите
внимание, что имя абстрактного класса Transaction показано курсивом
Мы вводим также ассоциацию между классами Transaction и
BankDatabase (рис. 13.28). Всем транзакциям требуется ссылка на BankDatabase, чтобы
они могли обращаться к информации счета и модифицировать ее. Каждый
класс, производный от Transaction, наследует эту ссылку, так что нам больше
не нужно моделировать ассоциацию между классами Withdrawal и
BankDatabase. Заметьте, что ассоциация между классом Transaction и BankDatabase
замещает опущенные ранее ассоциации между классами Balancelnquiry и
Deposit и классом BankDatabase.
Мы включили ассоциацию между классом Transaction и, так как все
транзакции выводят через Screen сообщения пользователю. Каждый производный
класс наследует эту ассоциацию. Таким образом, мы больше не включаем
моделировавшуюся прежде ассоциацию между Withdrawal и Screen. Однако
класс Withdrawal все еще участвует в ассоциациях с CashDispenser и
Keypad — эти ассоциации относятся к производному классу Withdrawal, но не
к классам Balancelnquiry и Deposit, поэтому мы не перемещаем их в базовый
класс Transaction.
Наша классовая диаграмма, включающая наследование (рис. 13.28),
моделирует также Deposit и Balancelnquiry. Мы показываем ассоциации между
классом Deposit и классами Deposit и Keypad. Обратите внимание, что класс
Balancelnquiry не участвует в каких-либо ассоциациях помимо унаследован-
874
Глава 13
ных от класса Transaction — Balancelnquiry взаимодействует только с BankDa-
tabase и Screen.
ATM
- userAuthenticated : Boolean = false
Transaction
- accountNumber: Integer
+ getAccountNumberO
+ execute ()
Balancelnquiry
+ execute()
Withdrawal
- amount: Double
+ executeO
Deposit
- amount: Double
+ executeO
BankDatabase
Account
- accountNumber: Integer
- pin : Integer
- availableBalance : Double
- totalBalance : Double
+ validatePINO : Boolean
+ getAvailableBalanceQ : Double
+ getTotalBalance() : Double
+ credit()
+ debitQ
Screen
+ displayMessage()
Keypad
+ getlnput(): Integer
CashDispenser
-count: Integer = 500
+ dispenseCashO
+ isSufficientCashAvailableO : Boolean
DepositSlot
+ authenticateUser() : Boolean
+ getAvailableBalance(): Double
+ getTotalBalance() : Double
+ creditO
+ debitQ
+ isEnvelopeReceivedQ : Boolean
Рис. 13.29. Классовая диаграмма после введения в систему наследования
Объектно-ориентированное программирование: полиморфизм
875
Классовая диаграмма на рис. 9.20 показывала атрибуты и операции с
маркерами видимости. Теперь мы представляем модифицированную диаграмму
(рис. 13.29), которая включает абстрактный базовый класс Transaction. Эта
сокращенная диаграмма не показывает отношений наследования (они видны
из рис. 13.28), но зато показывает атрибуты и операции после того, как мы
ввели в нашу систему наследование. Обатите внимание, что имя
абстрактного класса Transaction и имя абстрактной операции execute в классе
Transaction выделены курсивом. Для экономии места мы, как и на рис. 4.24,
не включаем те атрибуты, которые показаны ассоциациями на рис. 13.28;
тем не менее, мы включаем их в реализацию на C++ в приложении Ж.
Мы также опускаем все параметры операций, как мы делали на рис. 9.20 —
введении наследования никак не влияет на параметры, уже
моделировавшиеся на рис. 6.36-6.39.
S Общее методическое замечание 13.12
Полная классовая диаграмма показывает все ассоциации между
классам и все атрибуты и операции для каждого класса. Когда число
атрибутов класса, операций и ассоциаций значительно (как на рис. 13.28
и 13.29), хорошим правилом, способствующим удобочитаемости,
является разделение всей информации между двумя классовыми
диаграммами — одна сосредоточивает внимание на ассоциациях, а другая
на атрибутах и операциях. Однако при изучении моделируемых
подобным образом классов важно рассматривать обе классовых диаграммы,
чтобы получить о классах полное представление. Например, чтобы
принять во внимание отношения наследования между Transaction
и его производными классами, опущенные на рис. 13.29, нужно
обратиться к рис. 13.28.
Реализация проекта системы ATM с наследованием
В разделе 9.12 мы начали реализацию проекта системы ATM в коде C++.
Теперь мы модифицируем нашу реализацию и введем в нее наследование, взяв
в качестве примера класс Withdrawal.
1. Если класс А является обобщением класса В, то класс В является
производным от (и специализацией) класса А. Например, абстрактный класс
Transaction является обобщением класса Withdrawal. Следовательно,
класс Withdrawal является производным от (и специализацией) класса
Transaction. Рис. 13.30 показывает часть заголовочного файла класса
Withdrawal, где определение класса специфицирует отношение
наследования между Withdrawal и Transaction (строка 9).
1 // Рис. 13.30: Withdrawal.h
2 // Определение класса Withdrawal. Представляет транзакцию снятия.
3 #ifndef WITHDRAWAL_H
4 #define WITHDRAWAL_H
5
6 #include "Transaction.h" // определение класса Transaction
7
8 // класс Withdrawal является производным от класса Transaction
9 class Withdrawal : public Transaction
876
Глава 13
Ю {
11 }; // конец класса Withdrawal
12
13 #endif // WITHDRAWAL H
Рис. 13.30. Определение класса Withdrawal как производного от Transaction
2. Если класс А является абстрактным классом, а класс В производным от
него, то класс В, чтобы быть конкретным классом, должен реализовы-
вать чисто виртуальные функции класса А. Например, класс Transaction
содержит чисто виртуальную функцию execute, поэтому, если мы хотим
создать объект Withdrawal, класс Withdrawal должен реализовывать эту
элемент-функцию. На рис. 13.31 показан заголовочный файл C++ для
класса Withdrawal из рис. 13.28 и 13.29. Класс Withdrawal наследует
элемент данных accountNumber от своего базового класса Transaction,
поэтому Withdrawal не объявляет этот элемент данных. Класс
Withdrawal наследует также от своего базового класса Transaction ссылки
на Screen и BankDatabase, поэтому мы не включаем в наш код эти
ссылки. Рис. 13.29 специфицирует для класса Withdrawal атрибут amount
и операцию execute. Строка 19 на рис. 13.31 объявляет элемент данных
amount. Строка 16 содержит прототип функции для операции execute.
Как вы помните, чтобы быть конкретным классом, производный класс
Withdrawal должен предусматривать реализацию чисто виртуальной
функции execute базового класса Transaction. Прототип в строке 16
сообщает о вашем намерении заменить чисто виртуальную функцию
базового класса. Вы должны указать этот прототип, если предоставите
реализацию в .срр-файле. Мы представим эту реализацию в приложении Ж.
Ссылки keypad и cashDispenser (строки 20-21) являются элементами
данных, соответствующие ассоциациям класса Withdrawal на рис. 13.28.
В реализации класса в приложении Ж конструктор инициализирует эти
ссылки действительными объектами. Повторим, что для компиляции
ссылок в строках 20-21 мы включаем опережающие объявления в
строках 8-9.
1 // Рис. 13.31: Withdrawal.h
2 // Определение класса Withdrawal. Представляет транзакцию снятия.
3 #ifndef WITHDRAWAL_H
4 #define WITHDRAWAL_H
5
6 #include "Transaction.h" // определение класса Transaction
7
8 class Keypad; // опережающее объявление класса Keypad
9 class CashDispenser; // опережающее объявление класса CashDispenser
10
11 // класс Withdrawal является производным от класса Transaction
12 class Withdrawal : public Transaction
13 {
14 pubJic:
15 // элемент-функция заменяет execute в базовом классе Transaction
16 virtual void execute(); // произвести транзакцию
17 private:
Объектно-ориентированное программирование: полиморфизм 877
18 // атрибуты
19 int amount; // снимаемая сумма
20 Keypad &keypad; // ссылка на кнопочную панель ATM
21 CashDispenser ficashDispenser, // ссылка на выходной лоток ATM
22 }; // конец класса Withdrawal
23
24 #endif // WITHDRAWAL H
Рис. 13.31. Заголовочный файл класса Withdrawal из рис. 13.28 и 13.29
Заключение по учебному примеру с ATM
Этим заканчивается наше объектно-ориентированное проектирование
системы ATM. Полная реализация системы, содержащая 877 строк кода,
приведена в приложении Е. Эта работающая реализация демонстрирует ключевые
понятия программирования, в том числе классы, объекты, инкапсуляцию,
видимость, композицию, наследование и полиморфизм. Код содержит
подробные комментарии и согласуется с правилами написания кода, которые вы
изучали. Разбор этого кода даст вам неоценимый опыт после изучения всего того,
о чем рассказывалось в главах 1-13.
Контрольные вопросы по конструированию программного
обеспечения
13.1. Для указания отношения обобщения в UML используется стрелка
a) со сплошным закрашенным наконечником
b) с треугольным пустым наконечником
c) с ромбовидным пустым наконечником
d) со штриховым наконечником
Укажите, является ли следующее утверждение верным или неверным,
и если оно неверно, объясните, почему:
UML требует, чтобы имена абстрактных классом и абстрактных
операций выделялись подчеркиванием.
Напишите заголовочный файл С+-Ь, чтобы начать реализацию проекта
для класса Transaction, специфицируемого рис. 13.28 и 13.29. Не
забудьте включить в него закрытые ссылки, соответствующие
ассоциациям класса Transaction. He забудьте также предусмотреть get -функции
для любых закрытых элементов данных, к которым должны обращаться
производные классы для выполнения своих задач.
Ответы на контрольные вопросы по конструированию
программного обеспечения
13.1. Ь.
13.2. Неверно. UML требует, чтобы имена абстрактных классом и
абстрактных операций выделялись курсивом.
878
Глава 13
13.3. Проект для класса Transaction дает заголовочный файл на рис. 13.32.
В реализации в приложении Ж конструктор инициализирует закрытые
ссылочные атрибуты screen и bankDatabase действительными объектами,
а элемент-функции getScreen и getBankDatabase осуществляют доступ
к этим атрибутам. Эти элемент-функции позволяют производным от
Transaction классам получать доступ к экрану ATM и базе данных банка.
1 // Рис. 13.32: Transaction.h
2 // Определение абстрактного базового класса Transaction
3 #ifndef TRANSACTION^
4 #define TRANSACTION_H
5
6 class Screen; // опережающее объявление класса Screen
7 class BankDatabase; // опережающее объявление класса BankDatabase
8
9 class Transaction
10 {
11 public:
12 int getAccountNumber() const; // возвратить номер счета
13 Screen &getScreen() const; // возвратить ссылку на экран
14 BankDatabase figetBankDatabase() const; // ссылку на базу данных
15
16 // чисто виртуальная функция для исполнения транзакции
17 virtual void execute() =0; // заменяется в производных классах
18 private:
19 int accountNumber; // указывает обрабатываемый счет
20 Screen &screen; // ссылка на экран ATM
21 BankDatabase (bankDatabase; // ссылка на банковскую базу данных
22 }; // конец класса Transaction
23
24 #endif // TRANSACTION H
Рис. 13.32. Заголовочный файл класса Transaction по рис. 13.28 и 13.29
13.11. Заключение
В этой главе обсуждался полиморфизм, который позволяет нам
программировать «в общем», а не «в частности», и мы показали, каким образом это
делает программы более просто расширяемыми. Мы начали с примера того, как
полиморфизм позволял бы экранному менеджеру отображать различные
«космические» объекты. Затем мы продемонстрировали установку указателей
базового и производного классов на объекты базового класса и производного
класса. Мы сказали, что установка указателя базового класса на объект
базового класса естественна, как и установка указателя производного класса на
объект производного класса. Установка указателей базового класса на
объекты производного класса также естественна, поскольку объект производного
класса является объектом базового класса. Вы узнали, почему установка
указателя производного класса на объект базового класса опасна и почему
компилятор не допускает таких присваиваний. Мы представили виртуальные
функции, которые обеспечивают вызов нужных функций, когда объекты на разных
уровнях иерархии наследования адресуются (во время исполнения) указателя-
Объектно-ориентированное программирование: полиморфизм 879
ми базового класса. Это называется динамическим или поздним связыванием.
Затем мы обсудили чисто виртуальные функции (виртуальные функции, для
которых не предусмотрена реализация) и абстрактные классы (классы с одной
или несколькими чисто виртуальными функциями). Вы узнали, что
абстрактные классы не могут использоваться для создания объектов, а конкретные
классы могут. Затем мы продемонстрировали использование абстрактных
классов в иерархии наследования. Вы познакомились с работой внутренних
механизмов полиморфизма, поддерживаемых виртуальными таблицами,
которые создает компилятор. Мы обсудили нисходящее приведение указателей
базового класса к производному классу, которое позволяет программе
вызывать элемент-функции, имеющиеся только в производном классе. Главу
завершило обсуждение виртуальных деструкторов и того, как они гарантируют
исполнение всех необходимых деструкторов для объекта производного класса
иерархии, когда он удаляется через указатель базового класса.
Теперь вы познакомились с классами, объектами, инкапсуляцией,
наследованием и полиморфизмом — самыми существенными аспектами
объектно-ориентированного программирования. Пока на этом и закончим. Примите
поздравления по поводу окончания этого вводного курса по
программированию на C++. Мы желаем вам всего наилучшего и надеемся, что вы продолжите
изучение этого языка. Если у вас возникли какие-то вопросы, не стесняйтесь,
пишите нам по адресу deitel@deitel.com, и мы постараемся ответить
незамедлительно.
Резюме
• При использовании виртуальных функций и полиморфизма оказывается
возможным проектирование и реализация систем, допускающих более простое расширение.
Программы могут писаться так, что они будут работать даже с объектами типов,
которых могло не существовать, когда программа разрабатывалась.
• Полиморфное программирование позволяет отказаться от логики оператора switch.
Реализуя эквивалентную логику на основе полиморфного механизма, программист
может предотвратить появление ошибок, характерных для систем с логикой switch.
• Производные классы могут предусматривать, если необходимо, свои собственные
реализации виртуальной функции базового класса, но если таких реализаций не
предусмотрено, используется реализация базового класса.
• Если виртуальная функция вызывается через имя объекта с операцией-точкой
выбора элемента (например, squareObject.draw()), то ссылка разрешается во время
компиляции (это называется статическим связыванием) и вызывается виртуальная
функция, определенная (или унаследованная) классом, которому принадлежит
данный объект.
• Во многих случаях бывает полезно определять классы, объекты которых
программист не собирается никогда создавать. Такие классы называются абстрактными
классами. Поскольку в наследовании они играют роль базовых, мы называем их
абстрактными базовыми классами. Никаких представителей абстрактного базового
класса создать нельзя.
• Классы, которые могут использоваться для создания представителей, называются
конкретными классами.
• Класс будет абстрактным, если одна или несколько его виртуальных функций
объявлены чистыми. Чисто виртуальная функция — это функция, объявление которой
завершается инициализатором = О.
880
Глава 13
• Если класс является производным от класса с чисто виртуальной функцией и не
предусматривает реализации этой функции, то последняя остается чисто виртуальной
и в производном классе. Соответственно производный класс является также
абстрактным.
• В C++ возможен полиморфизм — способность объектов различных классов,
связанных наследованием, по-разному откликаться на один и тот же вызов
элемент-функции.
• Полиморфизм реализуется посредством виртуальных функций и динамического
связывания.
• Когда производится вызов виртуальной функции объекта через указатель или
ссылку базового класса, C++ выбирает правильную замещающую функцию в
соответствующем производном классе, ассоциированном с объектом.
• При использовании виртуальных функций и полиморфизма вызов элемент-функции
может приводить к различным действиям в зависимости от типа объекта, которому
направлен вызов.
• Хотя создавать объекты абстрактных базовых классов нельзя, мы можем объявлять
указатели и ссылки на абстрактный базовый класс. Такие указатели и ссылки
обычно используются для полиморфных манипуляций объектами, создаваемыми из
конкретных производных классов.
• Динамическое связывание требует, чтобы вызов виртуальной элемент-функции во
время исполнения направлялся версии виртуальной функции, соответствующей
классу объекта. Таблица виртуальных функций, или vtable, реализуется как массив,
содержащий указатели на функции. Каждый класс с. виртуальными функциями
имеет vtable. Для каждой виртуальной функции класса в vtable имеется элемент,
содержащий указатель на версию виртуальной функции, которая должна
использоваться с объектами этого класса. Виртуальная функция, которая должна
использоваться с некоторым классом, может быть функцией, определенной в этом классе,
или функцией, наследуемой от непосредственного или косвенного базового класса,
расположенного выше в иерархии.
• Когда базовый класс объявляет виртуальную элемент-функцию, производные
классы могут эту функцию заменять, но не обязаны этого делать. Таким образом,
производный класс может использовать версию виртуальной функции базового класса.
• Каждый объект класса с виртуальными функциями содержит указатель на vtable
для этого класса. Когда вызов функции направляется от указателя базового класса
к объекту производного класса, из vtable извлекается соответствующий указатель на
функцию, который разыменовывается, чтобы разрешить вызов во время
исполнения. Поиск в vtable и разыменование указателя требуют незначительных
дополнительных расходов времени выполнения.
• Класс, имеющий в vtable один или один или несколько нулевых указателей,
является абстрактным. Классы без нулевых указателей в vtable являются конкретными.
• В системы время от времени вводятся новые виды классов. Новые классы
инкорпорируются в систему посредством динамического, или позднего связывания. Чтобы
компилировать вызов виртуальной функции, нет необходимости знать при
компиляции тип объекта. Во время исполнения для объекта, на который ссылается
указатель, будет вызвана соответствующая элемент-функция.
• Операция dynamiccast проверяет тип объекта, на который ссылается указатель,
и определяет, находится ли этот тип в отношении является с типом, к которому
преобразуется указатель. Если имеет место отношение является, dynamic_cast
возвращает адрес объекта. В противном случае возвращается 0.
Объектно-ориентированное программирование: полиморфизм 881
• Операция typeid возвращает ссылку на объект класса type_info, который содержит
информацию о типе операнда операции, включая имя этого типа. Чтобы
использовать typeid, программа должна включать заголовочный файл <typeinfo>.
• Вызов элемент-функции name класса type_info возвращает строку-указатель с
именем типа аргумента, представляемого объектом type_info.
• Операции dynamic_cast и typeid являются частью системы идентификации типа
времени выполнения (RTTI) C++, которая позволяет программе определять тип
объекта во время исполнения.
• Если в базовом классе имеются виртуальные функции, определите его деструктор
как virtual. Это сделает виртуальными деструкторы всех производных классов,
несмотря на то, что их имена отличаются от имени деструктора базового класса. Если
объект иерархии уничтожается явным образом применением операции delete к
указателю базового класса, будет вызван деструктор соответствующего класса в
зависимости от объекта, на который этот указатель ссылается. После исполнения
деструктора производного класса исполняются деструкторы для всех его базовых классов
вплоть до вершины иерархии; последним исполняется деструктор корневого класса
иерархии.
Терминология
dynamic_cast
RTTI (информация о типе времени
выполнения)
v tabic
абстрактный базовый класс
абстрактный класс
виртуальная функция
виртуальный деструктор
динамическое определение функции
для исполнения
динамическое связывание
заголовочный файл <typeini'o>
замена функции
класс type__info
класс итератора
ключевое слово virtual
конкретный класс
логика switch
наследование интерфейса
наследование реализации
не-виртуальный деструктор
опасная манипуляция с указателем
операция typeid
позднее связывание
полиморфизм
полиморфизм как альтернатива
логике switch
полиморфное программирование
поток управления при вызове
виртуальной функции
программирование «в общем»
программирование «в частности»
смещение в viable
смещение нисходящее приведение
типа
статическое связывание
таблица виртуальных функций
(vtable)
указатель базового класса на объект
базового класса
указатель базового класса на объект
производного класса
указатель на vtable
указатель объекта на vtable
указатель производного класса
на объект базового класса
указатель производного класса
на объект производного класса
функция name класса type_info
чисто виртуальная функция
чистый спецификатор
882
Глава 13
Контрольные вопросы
13.1. Заполните пропуски в следующих предложениях:
a) Интерпретация объекта базового класса как может привести
к ошибкам.
b) Полиморфизм помогает исключить логику .
c) Если класс содержит хотя бы одну чисто виртуальную функцию, он
является классом.
d) Классы, объекты которых можно создавать, называются
классами.
e) Операция может использоваться для безопасного нисходящего
приведения указателей.
f) Операция typeid возвращает ссылку на объект .
g) состоит в использовании указателя или ссылки базового класса
для вызова виртуальных функций объектов базового и производного классов,
h) Функции, доступные для замены, объявляются с помощью ключевого слова
i) Приведение указателя базового класса к типу производного класса называется
13.2. Укажите, являются ли следующие утверждения верными или неверными. Если
утверждение неверно, объясните, почему.
a) Все виртуальные функции в абстрактном базовом классе должны объявляться
как чисто виртуальные функции.
b) Обращение к объекту производного класса через дескриптор базового класса
опасно.
c) Класс будет абстрактным, если его объявить как virtual.
d) Если базовый класс объявляет чисто виртуальную функцию, производный
класс, чтобы стать конкретным классом, должен реализовать эту функцию.
e) Полиморфное программирование может исключить необходимость
применения логики switch.
Ответы на контрольные вопросы
13.1. а) объекта производного класса. Ь) оператора switch, с) абстрактным, d)
конкретными, е) dynamic_cast. f) type_info. g) Полиморфизм, h) virtual, i)
нисходящим приведением типа.
13.2. а) Неверно. Абстрактный базовый класс может содержать виртуальные функции
с реализациями.
b) Неверно. Опасным является обращение к объекту базового класса через
дескриптор производного.
c) Неверно. Классы никогда не объявляются как virtual. Чтобы быть
абстрактным, класс должен объявлять хотя бы одну чисто виртуальную функцию.
d) Верно.
e) Верно.
Объектно-ориентированное программирование: полиморфизм
883
Упражнения
13.3. Каким образом полиморфизм позволяет нам программировать «в общем», а не
«в частности»? Обсудите главные преимущества программирования «в общем».
13.4. Обсудите проблемы, возникающие при программировании логики switch.
Объясните, почему полиморфизм является эффективной альтернативой
использованию логики switch.
13.5. Сформулируйте различие между наследованием интерфейса и наследованием
реализации. Чем отличаются иерархии наследования, ориентированные на
наследование интерфейса, от иерархий, ориентированных на наследование
реализации?
13.6. Что такое виртуальные функции? Опишите, в каких обстоятельствах было бы
уместным применение виртуальных функций.
13.7. Сформулируйте различие между статическим и динамическим связыванием.
Объясните, как работают виртуальные функции и vtable при динамическом
связывании.
13.8. Сформулируйте различие между виртуальными и чисто виртуальными
функциями.
13.9. Предложите один или несколько дополнительных уровней абстрактных базовых
классов для иерархии Shape, обсуждавшейся в этой главе и показанной на
рис. 12.3. (Первый уровень образует класс Shape, на втором уровне
располагаются классы TwoDimensionalShape и ThreeDimensionalShape.)
13.10. Каким образом полиморфизм способствует расширяемости?
13.11. Допустим, вас попросили разработать летный симулятор, который должен
отображать сложную детализированную графику. Объясните, почему для задач
такого рода полиморфное программирование было бы особенно эффективным.
13.12. (Модификация системы начисления зарплаты) Модифицируйте систему
начисления зарплаты из рис. 13.13-13.23, включив в класс Employee закрытый
элемент данных birthDate для дня рождения служащего. Для представления
даты воспользуйтесь классом Date из рис. 11.12-11.13. Предположите, что
платежная ведомость обрабатывается раз в месяц. Создайте вектор ссылок на
Employee для хранения различных объектов производных классов. Вычислите
в цикле заработок каждого служащего (полиморфно), и добавьте к нему премию
в $100.00, если день рождения служащего приходится на текущий месяц.
13.13. (Иерархия Shape) Реализуйте иерархию Shape, спроектированную в
упражнении 12.7 (основанную на иерархии из рис. 12.3). Каждый класс
TwoDimensionalShape должен иметь функцию getArea для расчета площади
двумерной фигуры. Каждый класс TreeDimensionalShape должен иметь
элемент-функции getArea и getVolume для расчета соответственно площади
поверхности и объема трехмерного тела. Создайте программу, использующую
вектор указателей Shape на объекты каждого из конкретных классов иерархии.
Программа должна распечатывать объекты, на которые указывают элементы
вектора. Кроме того, в цикле, обрабатывающем все объекты вектора,
определяйте, является ли каждый из объектов объектом TwoDimensionalShape или
TreeDimensionalShape. Если это TwoDimensionalShape, выводите площадь.
Если TreeDimensionalShape, выводите площадь и объем.
13.14. (Полиморфный экранный менеджер, использующий иерархию Shape)
Разработайте элементарный графический пакет. Воспользуйтесь иерархией класса
Shape, реализованной в упражнении 13.13. Ограничьтесь двумерными
геометрическими фигурами, такими, как квадраты, прямоугольники, треугольники
и круги. Предусмотрите интерактивное взаимодействие с пользователем. Он
может указывать положение, размер, форму и заполняющие символы, которые бу-
884
Глава 13
дут использоваться при рисовании каждой фигуры. Он может нарисовать много
объектов одной формы. При создании каждой фигуры помещайте указатель
Shape на вновь созданный объект в массив. Каждый класс имеет собственную
функцию draw. Напишите полиморфный экранный менеджер, который
формирует изображение, проходя по массиву и посылая сообщение draw каждому его
объекту. Выполняйте перерисовку изображения всякий раз, когда пользователь
специфицирует новую фигуру.
13.15. (Иерархия наследования Package) Используйте иерархию наследования
Package, созданную в упражнении 12.9, для создания программы, которая
распечатывает адресную информацию и вычисляет стоимость доставки для
нескольких посылок. Программа должна содержать вектор указателей Package на
объекты классов TwoDayPackage и Overnight Package. Пройдите в цикле по
вектору, чтобы обработать посылки полиморфно. Для каждой посылки вызывайте
£е£-функции для получения адресной информации об отправителе и получателе,
и распечатывайте два адреса так, как они выглядели бы на почтовой наклейке.
Кроме того, вызывайте элемент-функцию calculateCost каждого объекта и
печатайте результат. Отслеживайте суммарную стоимость всех отправлений в
векторе и выведите ее, когда цикл завершится.
13.16. (Полиморфная банковская программа с иерархией Account) Разработайте
полиморфную банковскую программу на основе иерархии Account, созданной в
упражнении 12.10. Создайте вектор указателей Account на объекты SavingsAc-
count и CheckingAccount. Для каждого счета в векторе разрешите
специфицировать сумму, снимаемую со счета элемент-функцией debit, или вносимую на счет
элемент-функцией credit. По ходу обработки счетов определяйте тип каждого
счета. Если счет является Savings Account, определите начисленные проценты
с помощью элемент-функции calculatelnterest и прибавьте результат к
текущему балансу с помощью функции credit. После обработки счета распечатайте
обновленный баланс, получаемый вызовом элемент-функции базового класса
getBalance.
14
Шаблоны
ЦЕЛИ
В этой главе вы изучите:
• Использование шаблона функции
для создания группы родственных
(перегруженных) функций.
• Отличие между шаблонами
функций и их специализациями.
• Использование шаблонов класса
для создания группы родственных
типов.
• Отличие между шаблонами классов
и их специализациями.
• Перегрузку шаблонов функции.
• Взаимосвязь между шаблонами,
друзьями, наследованием
и статическими элементами.
886
Глава 14
14.1. Введение
14.2. Шаблоны функций
14.3. Перегрузка шаблонов функций
14.4. Шаблоны классов
14.5. Нетиповые параметры и типы по умолчанию
для шаблонов класса
14.6. Замечания о шаблонах и наследовании
14.7. Замечания о шаблонах и друзьях
14.8. Замечания о шаблонах и статических элементах
14.9. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
14.1. Введение
В этой главе мы обсудим один из наиболее мощных инструментов
утилизации программного обеспечения в C++, а именно шаблоны. Шаблоны дают нам
возможность определять при помощи одного фрагмента кода целый набор
родственных (перегруженных) функций, называемых специализациями шаблона
функции, или набор родственных классов, называемых специализациями
шаблона класса. Такая методика называется обобщенным программированием.
Мы могли бы написать один шаблон функции для сортировки массива, на
основе которого C++ автоматически генерировал бы отдельные специализации
этого шаблона, сортирующие массивы типа int, массивы типа float, массивы
типа string и т.д. Мы ввели шаблоны функций в главе 6. В этой главе мы
проводим дополнительное обсуждение и даем пример их использования.
Мы могли бы написать один шаблон класса стека, на основе которого C++
автоматически генерировал бы отдельные специализации этого шаблона,
такие, как класс стека для int, стека для float, стека для string и т.д.
Обратите внимание на различие между шаблонами и специализациями
шаблонов: шаблоны функций и шаблоны классов являются как бы
трафаретами, по которым мы вычерчиваем фигуры; специализации шаблонов функций
и классов подобны отдельным вычерченным фигурам одинаковой формы,
которые, однако, могут иметь, например, различный цвет.
В этой главе мы представим шаблоны функций и шаблоны классов. Мы
также рассмотрим взаимосвязь между шаблонами и другими элементами C++,
такими, как перегрузка, наследование, друзья и статические элементы.
Устройство и детали механизма шаблонов, обсуждаемые здесь, основаны на
работах Бьерна Страуструпа, представленных в его статье «Параметризованные
типы в C++» (Bjarne Stroustrup, Parameterized Types for C++), изданной в
трудах конференции USENIX C++, которая проходила в Денвере, штат Колорадо,
в октябре 1988 г.
Шаблоны
887
Эта глава является только введением в шаблоны. В главе 22 представлено
углубленное изложение шаблонных контейнерных классов, итераторов и
алгоритмов библиотеки стандартных шаблонов C++ (STL). В главе 22 содержатся
десятки примеров живого кода с использованием шаблонов, иллюстрирующих более
развитые приемы программирования с шаблонами, чем представленные здесь.
Ш Общее методическое замечание 14.1
Большинство компиляторов C++ требуют, чтобы в файле кода
клиента, использующего шаблон, присутствовало полное его определение.
По этой причине и по соображениям утилизируемости шаблоны
часто определяют в заголовочных файлах, которые затем включаются
с соответствующие файлы кода клиента. Для шаблонов классов это
означает, что элемент-функции также должны определяться в
заголовочном файле.
14.2. Шаблоны функций
Перегруженные функции обычно выполняют схожие или идентичные
операции над различными типами данных. Если операции для каждого типа
идентичны, они могут быть выражены проще и компактнее с помощью
шаблона функции. Программист пишет единственное определение шаблона
функции. Исходя из типов аргументов, указанных явно или подразумеваемых в
вызове этой функции, компилятор автоматически генерирует объектный код
функций (т.е. специализаций шаблона функции), соответствующим образом
обрабатывающих каждый тип данных. В языке С эта задача могла
выполняться при помощи макросов, определяемых директивой препроцессора #define
(см. приложение Д, «Препроцессор»). Однако макросы часто имеют серьезные
побочные эффекты и не позволяют компилятору производить проверку типов
параметров. Шаблоны функций, являясь таким же компактным решением,
как и макросы, позволяют компилятору полностью контролировать
согласование типов.
1*ЪК Предотвращение ошибок 14.1
WaN/ Шаблоны функций, подобно макросам, допускают утилизацию
программного кода, однако в отличие от них позволяют устранить
многие ошибки благодаря возможностям полной проверки соответствия
типов в C++.
Все определения шаблонов функций начинаются с ключевого слова
template, за которым следует список параметров шаблона, заключенный в
угловые скобки (< и >); каждому параметру, представляющему тип, должно
предшествовать одно из взаимозаменяемых ключевых слов class или
typename, например,
template< class T >
или
template< typename ElementType >
888
Глава 14
или
template< typenaxne BorderType, typename FillType >
Типовые параметры шаблона в определении шаблона функции
используются для спецификации типов аргументов функции, спецификации ее
возвращаемого типа и для объявления переменных внутри функции. Далее следует
определение функции, которое выглядит аналогично любому другому
определению функции. Заметьте, что ключевые слова class и typename на самом деле
означают здесь «любой встроенный или определяемый пользователем тип».
-t^s] Типичная ошибка программирования 14.1
Отсутствие ключевого слова class или typename перед любым из
типовых параметров шаблона функции является синтаксической ошибкой.
Пример: шаблон функции print Array
Давайте рассмотрим в качестве примера шаблон функции printArray на
рис. 14.1, строки 8-15. В шаблоне функции printArray объявляется один
типовой параметр Т (Т может быть любым допустимым идентификатором) для
типа массива, который будет выводиться функцией printArray; T называется
типовым параметром шаблона, или просто типовым параметром. Нетиповые
параметры шаблона вы увидите в разделе 14.5.
1 // Рис. 14.1: figl4_01.cpp
2 // Использование шаблонных функций.
3 #±nclude <iostream>
4 using std::cout;
5 using std::endl;
6
7 // определение шаблона функции printArray
8 template< typename T >
9 void printArray( const T *array, int count )
10 {
11 for ( int i = 0; i < count; i++ )
12 cout « array[ i ] « "
13
14 cout « endl;
15 } // конец шаблона функции printArray
16
17 int main()
18 {
19 const int aCount =5; // размер массива а
20 const int bCount =7; // размер массива Ь
21 const int cCount =6; // размер массива с
22
23 int a[ aCount ]={1,2,3,4,5};
24 double b[ bCount ] = { 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7 };
25 char c[ cCount ] = "HELLO"; // 6-я позиция для нуля
26
27 cout « "Array a contains:" « endl;
28
29 // вызвать int-специализацию шаблона функции
30 printArray( a, aCount );
Шаблоны
889
31
32 cout « "Array b contains:" « endl;
33
34 // вызвать double-специализацию шаблона функции
35 printArray( b, bCount );
36
37 cout « "Array с contains:" « endl;
38
39 // вызвать char-специализацию шаблона функции
40 printArray( с, cCount );
41 return 0;
42 } // конец main
Array a contains:
12 3 4 5
Array b contains:
1.1 2.2 3.3 4.4 5.5 6.6 7.7
Array с contains:
HELLO
Рис. 14.1. Специализации шаблона функции print Array
Когда компилятор встречает в программе клиента вызов функции print
Array (например, в строках 30, 35 и 40), он использует свой механизм
разрешения перегрузки, чтобы найти определение функции print Array, которое
наилучшим образом согласуется с вызовом. В данном случае единственной
функцией printArray с соответствующим числом параметров является шаблон
printArray (строки 8-15). Рассмотрим вызов функции в строке 30.
Компилятор сравнивает тип первого аргумента printArray (int * в строке 30) с первым
параметром шаблона функции printArray (const T * в строке 9) и делает
вывод, что подстановка int вместо типового параметра Т согласует параметр с
аргументом. После этого компилятор подставляет int вместо Т по всему
определению шаблона и компилирует специализацию printArray, которая может
выводить массив целых значений. На рис. 14.1 компилятор создает три
специализации printArray: одна принимает массив типа int, вторая — массив
типа double и третья — массив типа char. Например, специализация для типа
int имеет вид
void printArray( const int *array, int count )
{
for ( int i = 0; i < count; i++ )
cout « array[ i ] «
cout « endl;
} // конец функции printArray
Имя параметра шаблона может объявляться в списке шаблонных
параметров в заголовке шаблона только один раз, но может неоднократно
использоваться в заголовке и теле функции. Имена шаблонных параметров не обязаны
быть уникальными среди всех шаблонов функций.
Рис. 14.1 демонстрирует шаблон функции printArray (строки 8-15).
Программа начинается с объявления пятиэлементного массива а типа int, семи-
элементного массива b типа double и шестиэлементного массива с типа char
890
Глава 14
(строки 23-25). Затем программа выводит каждый массив, вызывая
printArray — сначала с первым аргументом типа int * (строка 30), второй раз
с аргументом типа double * (строка 35) и третий раз с аргументом типа char *
(строка 40). Вызов в строке 30, например, заставляет компилятор заключить,
что Т — это int, и создать специализированный представитель шаблона print-
Array, в котором типовой параметр Т есть int. Вызов в строке 35 заставляет
компилятор заключить, что Т — это double, и создать специализированный
представитель шаблона printArray, в котором типовой параметр Т есть
double. Соответственно вызов в строке 40 заставляет компилятор заключить,
что Т — это char, и создать специализированный представитель шаблона
printArray, в котором типовой параметр Т есть char. Важно отметить, что
если Т (строка 8) представляет тип, определяемый пользователем (на рис. 14.1
такой случай не представлен), то для этого типа должна существовать
перегруженная операция передачи в поток; в противном случае первая операция
передачи в поток (строка 12) компилироваться не будет.
;-7^-] Типичная ошибка программирования 14.2
Если шаблон вызывается для типа, определенного пользователем,
и если этот шаблон использует функции или операции (напр., ==, +,
<=) с объектами этого классового типа, то эти функции и операции
должны быть перегружены для определенного пользователем типа.
Отсутствие перегрузки таких операций приводит к ошибкам
компиляции.
В этом примере механизм шаблонов избавляет программиста от
необходимости писать три отдельных перегруженных функции с прототипами
void printArray( const int *, int );
void printArray( const double *, int );
void printArray( const char *, int );
с одинаковым кодом, отличающиеся только типом Т (используемым, как
в строке 9).
Вопросы производительности 14.1
Хотя шаблоны позволяют реализовать выгоды утилизируемости
кода, помните, что в программе создаются множественные
специализации шаблонов функций и классов (во время компиляции), несмотря
на то, что шаблоны пишутся только один раз. Эти экземпляры
шаблонов могут занимать значительные объемы памяти. Однако обычно
это не имеет значения, поскольку код, генерируемый шаблоном, имеет
тот же размер, что и код, который написал бы программист для
реализации отдельных перегруженных функций.
Шаблоны
891
14.3. Перегрузка шаблонов функции
Шаблоны функций и перегрузка тесно связаны друг с другом.
Специализации, генерируемые из шаблона функции, имеют одно и то же имя, поэтому
компилятор вызывает нужную функцию, пользуясь механизмом разрешения
перегрузки.
Шаблон функции может быть перегружен по-разному. Можно определить
другие шаблоны функций, специфицирующие одно и то же имя, но другие
параметры функции. Например, шаблон функции printArray на рис. 14.1 можно
было бы перегрузить другим шаблоном функции printArray с
дополнительными параметрами lowSubscript и high Subscript, специфицирующими часть
массива, которую следует напечатать (см. упражнение 14.4).
Шаблон функции может быть также перегружен обычными (не-шаблонны-
ми) функциями с тем же самым именем функции, но другими параметрами.
Например, шаблон функции printArray на рис. 14.1 можно было бы
перегрузить не-шаблонной версией функции, которая печатала бы специально
строковые массивы в аккуратном табличном формате (см. упражнение 14.5).
Чтобы определить, какая функция должна быть вызвана, компилятор
производит следующую процедуру сопоставления параметров. Сначала
компилятор находит все шаблоны функции, которые соответствуют функции,
именованной в вызове, и создает специализации в зависимости от аргументов в
вызове функции. Затем компилятор находит все обычные функции, которые
соответствуют функции, именованной в вызове. Если одна из обычных
функций или специализаций шаблона наилучшим образом сопоставляется с
вызовом, используется эта обычная функция или специализация шаблона. Если
и обычная функция, и одна из специализаций шаблона одинаково хорошо
подходят к вызову, выбирается обычная функция. В противном случает, если
имеется несколько возможных сопоставлений, компилятор считает вызов
неоднозначным и генерирует сообщение об ошибке.
гр*Ш Типичная ошибка программирования 14.3
Ira?I Если соответствующее некоторому вызову определение функции не
может быть найдено или если имеется несколько соответствий, то
компилятор генерирует ошибку.
14.4. Шаблоны классов
Концепцию «стека» (структуры данных, в которую мы помещаем элементы
сверху и извлекаем их в порядке «последним вошел, первым вышел») можно
понять независимо от того, какого типа элементы размещаются в стеке.
Однако чтобы создать экземпляр стека, нужно специфицировать тип данных. Здесь
возникает прекрасная возможность для утилизации программного
обеспечения. Нам нужны средства обобщенного описания понятия стека и создания
классов, являющихся представителями обобщенного стекового класса для
специфических типов. C++ предусматривает такие возможности в форме
шаблонов классов.
892
Глава 14
Общее методическое замечание 14.2
Шаблоны классов поощряют утилизацию программного обеспечения,
позволяя создавать представители обобщенных классов для
специфических типов.
Шаблоны классов называют параметризованными типами, поскольку они
требуют одного или нескольких типовых параметров, специфицирующих,
каким образом нужно настроить «обобщенный класс», чтобы образовать нужную
специализацию шаблона класса.
Программист, который хочет создавать разнообразные специализации,
пишет только одно определение шаблона класса. Всякий раз, когда требуется
дополнительная специализация шаблона, он использует лаконичную, простую
нотацию, а компилятор «пишет» исходный код требуемой специализации.
Единственный шаблон класса Stack, например, мог бы, таким образом, стать
основой для создания многих классов Stack (таких, как «стек значений
double», «стек значений int», «стек значений char», «стек объектов Employee»
и т.д.) для использования их в программе.
Создание шаблона класса Stack< T >
Обратите внимание на определение шаблона класса на рис. 14.2. Оно
выглядит как обыкновенное определение класса, за исключением того, что ему
предшествует заголовок (строка 6)
template< typename T >
специфицирующий определение шаблона класса с типовым параметром Т,
который служит заместителем для типа создаваемого класса стека.
Программисту не нужно использовать именно идентификатор Т; годится любой
допустимый идентификатор. Тип элементов, размещаемых в этом стеке, во всем
заголовке класса и определениях элемент-функций обозначается обобщенно как Т.
Мы вскоре покажем, каким образом Т ассоциируется с конкретным типом,
таким, как int или double. Из-за характера конструкции данного шаблона есть
два ограничения на использование шаблона с нетривиальными типами — они
должны иметь конструктор по умолчанию (применяемый в строке 44 для
создания массива, хранящего элементы стека) и поддерживать операцию
присваивания (строки 55 и 69).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Рис. 14.2: Stack.h
// Шаблон класса Stack
#ifndef STACK H
#define STACK_H
template< typename T >
class Stack
{
public:
Stack( int = 10 ) ; /
// деструктор
-Stack()
{
// конструктор по умолчанию (размер стека 10)
Шаблоны
893
15 delete [] stackPtr; // удалить внутреннее представление стека
16 } // конец деструктора -Stack
17
18 bool push( const T& ); // затолкнуть элемент в стек
19 bool pop( T& ); // вытолкнуть элемент из стека
20
21 // определить, пуст ли стек
22 bool isEmpty() const
23 {
24 return top == -1;
25 } // конец функции isEmpty
26
27 // определить, полон ли стек
28 bool isFull() const
29 {
30 return top == size - 1;
31 } // конец функции isFull
32
33 private:
34 int size; // # элементов в стеке
35 int top; // позиция верхнего элемента (-1 означает - стек пуст)
36 Т *stackPtr; // указатель на внутреннее представление стека
37 }; // конец шаблона класса Stack
38
39 // шаблон конструктора
40 template< typename T >
41 Stack< T >::Stack( int s )
42 : size( s > 0 ? s : 10 ), // проверить размер
43 top( -1 ), // стек изначально пуст
44 stackPtr( new T[ size ] ) // выделить память для элементов
45 {
4 6 // пустое тело
47 } // конец шаблона конструктора Stack
48
49 // затолкнуть элемент в стек;
50 // если успешна, возвратить true; в противном случае false
51 template< typename T >
52 bool Stack< T >::push( const T fipushValue )
53 {
54 if ( !isFull() )
55 {
56 stackPtr[ ++top ] = pushValue; // поместить элемент в стек
57 return true; // операция удачна
58 } // конец if
59
60 return false; // операция неудачна
61 } // конец шаблона функции push
62
63 // вытолкнуть элемент из стека;
64 // если успешна, возвратить true; в противном случае false
65 template< typename T >
66 bool Stack< T >::pop( T fipopValue )
67 {
68 if ( !isEmpty() )
69 {
70 popValue = stackPtr[ top-- ]; // удалить элемент из стека
71 return true; // операция удачна
894
Глава 14
72 } // конец if
73
74 return false; // операция неудачна
75 } // конец шаблона функции pop
76
77 #endif
Рис. 14.2. Шаблон класса Stack
Определения элемент-функций шаблона класса являются шаблонами
функций. Определения элемент-функций, расположенные вне определения
шаблона класса, начинаются с заголовка
template< typename T >
(строки 40, 51 и 65). Таким образом, каждое определение напоминает обычное
определение функции, за исключением того, что тип элементов стека везде
указывается обобщенно как типовой параметр Т. Чтобы привязать каждую
элемент-функцию к области действия шаблона класса, используется бинарная
операция разрешения области действия с именем шаблона класса Stack< T >
(строки 41, 52 и 66). В данном случае обобщенным именем класса является
Stack< T >. Когда создается представитель стека double Stack как
Stack< double >, специализация шаблона функции конструктора применяет
new для создания массива элементов типа double, представляющего стек
(строка 44). Инициализатор
stackPtr( new T[ size ] )
в определении шаблона класса преобразуется компилятором в
stackPtr( new double[ size ] )
Создание драйвера для тестирования шаблона класса Stack< T >
Давайте теперь рассмотрим драйвер (рис. 14.3), испытывающий шаблон
класса Stack< T >. Драйвер начинается с создания объекта doubleStack с
размером 5 (строка 11). Объект объявляется как принадлежащий классу
Stack< double >. Компилятор ассоциирует тип double с типовым параметром
Т в определении шаблона и образует исходный код класса стека для типа
double. Хотя шаблоны позволяют реализовать выгоды утилизируемости кода,
помните, что в программе создаются множественные специализации шаблона,
несмотря на то, что шаблон пишется только один раз.
1 // Рис. 14.3: figl4_03.cpp
2 // Тестовая программа для шаблона класса стека.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Stack.h" // определение шаблона класса Stack
8
9 int main()
10 {
11 Stack< double > doubleStack( 5 ); // размер 5
Шаблоны
895
12 double doubleValue = 1.1;
13
14 cout « "Pushing elements onto doublestack\n";
15
16 // затолкнуть в doublestack 5 значений типа double
17 while ( doublestack.push( doubleValue ) )
18 {
19 cout « doubleValue « '
20 doubleValue += 1.1;
21 } // конец while
22
23 cout « "\nStack is full. Cannot push " « doubleValue
24 « "\n\nPopping elements from doubleStack\n";
25
26 // вытолкнуть элементы из doublestack
27 while ( doubleStack.pop( doubleValue ) )
28 cout « doubleValue « '
29
30 cout « "\nStack is empty. Cannot pop\n";
31
32 Stack< int > intStack; // размер по умолчанию 10
33 int intValue = 1;
34 cout « "\nPushing elements onto intStack\n";
35
36 // затолкнуть в intStack 10 значений типа int
37 while ( intStack.push( intValue ) )
38 {
39 cout « intValue « '
40 intValue++;
41 } // конец while
42
43 cout « "\nStack is full. Cannot push " « intValue
44 « "\n\nPopping elements from intStack\n";
45
46 // вытолкнуть элементы из intStack
47 while ( intStack.pop( intValue ) )
48 cout « intValue « '
49
50 cout « "\nStack is empty. Cannot pop" « endl;
51 return 0;
52 } // конец main
Pushing elements onto doubleStack
1.1 2.2 3.3 4.4 5.5
Stack is full. Cannot push 6.6
Popping elements from doubleStack
5.5 4.4 3.3 2.2 1.1
Stack is empty. Cannot pop
Pushing elements onto intStack
123456789 10
Stack is full. Cannot push 11
Popping elements from intStack
10 987654321
Stack is empty. Cannot pop
Рис. 14.3. Тестовая программа для шаблона класса Stack
896
Глава 14
Строки 17-21 вызывают push, чтобы поместить в doubleStack значения
1.1, 2.2, 3.3, 4.4 и 5.5. Цикл while завершается, когда драйвер пытается
затолкнуть в doubleStack шестое значение (стек уже полон, поскольку он может
содержать не более пяти элементов). Обратите внимание, что push возвращает
false, если не может затолкнуть значение в стек.1
Строки 27-28 вызывают pop в цикле while, чтобы удалить пять элементов
из стека (заметьте, что на рис. 14.3 значения выталкиваются в порядке
«последним вошел, первым вышел»). Когда драйвер пытается вытолкнуть шестое
значение, doubleStack пуст, и цикл завершается.
Строка 32 создает целый стек intStack посредством объявления
Stack< int > intStack;
Поскольку размер стека не указан, он по умолчанию принимается равным 10,
как указано в конструкторе по умолчанию (рис. 14.2, строка 10). Цикл в
строках 37-41 вызывает push, помещая в intStack значения до тех пор, пока он не
будет заполнен, а затем строки 47-48 в цикле вызывают pop до тех пор, пока
intStack не станет пустым. Заметьте снова, что в окне вывода вытолкнутые
значения следуют в порядке «последним вошел, первым вышел».
Создание шаблонов функций для тестирования шаблона класса
Stack< T >
Заметьте, что код в функции main на рис. 14.3, относящийся к
тестированию doubleStack (строки 11-30) и к тестированию intStack (строки 32-50)
практически идентичен. Здесь открывается еще одна возможность
применения шаблона функции. На рис. 14.4 определяется шаблон функции testStack
(строки 14-38), которая производит те же действия, что и main на рис. 14.3 —
заталкивает значения в Stack< T > и выталкивает их из него. В шаблоне
функции testStack используется параметр шаблона Т (специфицируемый
в строке 14) для представления типа, хранящегося в Stack< T >. Шаблон
функции принимает четыре аргумента (строки16-19) —ссылку на объект типа
Stack< Т >, значение типа Т, которое будет первым из заталкиваемых в стек
значений, значение типа Т, используемое в качестве приращения
заталкиваемых значений, и строка, представляющее имя объекта Stack< T > в целях
вывода. Функция main (строки 40-49) создает объект Stack< double > с именем
doubleStack (строка 42) и объект типа Stack< int > с именем intStack (строка
43), после чего использует эти объекты в строках 45 и 46. Каждый из вызовов
функции testStack создает специализацию шаблона функции testStack.
Компилятор определяет тип Т исходя из типа, использованного при создании
первого аргумента функции (т.е. типа, использованного при создании
doubleStack или intStack). Вывод на рис. 14.4 в точности соответствует выводу на
рис. 14.3.
В классе Stack (рис. 14.2) предусмотрена функция isFull, которой программист может
воспользоваться для проверки заполнения стека перед тем, как попытаться произвести
заталкивание в стек. Это предотвратит потенциальную ошибку заталкивания в полный стек.
В главе 16 функция push при невозможности выполнить операцию * выбрасывает
исключение». Программист может написать код, чтобы «перехватить» это исключение и
решить, как следует обработать его в контексте данного приложения. Та же методика может
быть использована с функцией pop при попытке вытолкнуть элемент из пустого стека.
Шаблоны
897
1 // Рис. 14.4: figl4_04.cpp
2 // Тестовая программа для шаблона класса Stack. Использует
3 // для тестирования объектов типа Stack< T > шаблон функции.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <string>
9 using std:istring;
10
11 #include "Stack.h" // определение шаблона класса Stack
12
13 // шаблон функции, тестирующей Stack< T >
14 template< typename T >
15 void testStack(
16 Stack< T > fitheStack, // ссылка на Stack< T >
17 T value, // начальное заталкиваемое значение
18 T increment, // инкремент для последующих значений
19 const string stackName ) // имя объекта Stack< T >
20 {
21 cout « "\nPushing elements onto " « stackName « ' \n';
22
23 // затолкнуть элемент в стек
24 while ( theStack.push( value ) )
25 {
26 cout « value « ' •;
27 value += increment;
28 } // конец while
29
30 cout « "\nStack is full. Cannot push " « value
31 « "\n\nPopping elements from " « stackName « '\n!;
32
33 // вытолкнуть элементы из стека
34 while ( theStack.pop( value ) )
35 cout « value « ' ';
36
37 cout « "\nStack is empty. Cannot pop" « endl;
38 } // end function template testStack
39
40 int main()
41 {
42 Stack< double > doubleStack( 5 ); // размер 5
43 Stack< int > intStack; // размер по умолчанию 10
44
45 testStack( doubleStack, 1.1, 1.1, "doublestack" );
46 testStack( intStack, 1, 1, "intStack" );
47
48 return 0;
49 } // конец main
Pushing elements onto doubleStack
1.1 2.2 3.3 4.4 5.5
Stack is full. Cannot push 6.6
Popping elements from doubleStack
5.5 4.4 3.3 2.2 1.1
29 Зак 1114
898
Глава 14
Stack is empty. Cannot pop
Pushing elements onto intStack
123456789 10
Stack is full. Cannot push 11
Popping elements from intStack
10 987654321
Stack is empty. Cannot pop
Рис. 14.4. Передача шаблону функции шаблонного объекта Stack
14.5. Нетиповые параметры и типы по умолчанию
для шаблонов класса
Шаблон класса Stack из раздела 14.4 имел в заголовке шаблона только
типовой параметр. Но возможны также нетиповые параметры шаблона, или
просто нетиповые параметры, которые могут иметь аргументы по умолчанию
и трактуются как константы. Например, заголовок шаблона можно было бы
модифицировать так, чтобы он принимал параметр целого типа elements:
template< typename Т, int elements > // нетиповой параметр elements
Тогда объявление вида
Stack< double, 100 > mostRecentSalesFigures;
могло бы использоваться для создания (на этапе компиляции) специализации
шаблона для 100-элементного стека значений типа double с именем
mostRecentSalesFigures; такая специализация шаблона класса имела бы тип
Stack< double, 100 >. Заголовок класса мог бы содержать закрытый элемент
данных, объявленный как массив, например
Т stackHolder[ elements ]; // массив для хранения данных стека
Кроме того, для типового параметра можно специфицировать тип по
умолчанию. Например, заголовок
Template< typename T = string > // по умолчанию тип string
указывал бы, что стек по умолчанию содержит объекты типа string. Тогда для
создания специализации шаблона Stack строкового типа с именем jobDescrip-
tions можно было бы написать объявление
Stack jobDescriptions;
Эта специализация шаблона класса имела бы тип Stack< string >. Типовые
параметры по умолчанию должны быть самыми правыми (последними) в
списке типовых параметров шаблона. Когда создается класс-специализация с
одним или несколькими типами по умолчанию, то в случае, если опущенный тип
не является последним в списке типовых параметров, должны опускаться
и все другие типовые параметры справа от него.
Шаблоны
899
I——j Вопросы производительности 14.2
рррч Когда это возможно, указывайте размер контейнерного класса
(такого, как класс массива или класс стека) во время компиляции
(возможно, с помощью нетипового параметра шаблона). Это устраняет
издержки вызовов new для динамического выделения пространства во
время исполнения.
S Общее методическое замечание 14.3
Спецификация размера контейнера во время компиляции позволяет
избежать потенциально фатальных ошибок времени исполнения,
когда new не может получить требуемую память.
В упражнениях вам будет предложено использовать нетиповой параметр
при создании шаблона для нашего класса Array, разработанного в главе 11.
Этот шаблон позволит создавать объекты с заданным числом элементов
заданного типа на этапе компиляции, а не выделять пространство для объектов
Array во время выполнения.
В некоторых случаях использование с шаблоном класса некоторого
специфического типа может оказаться невозможным. Например, шаблон Stack из
рис. 14.2 требует, чтобы определяемые пользователем типы, которые будут
сохраняться в стеке, имели конструктор по умолчанию и операцию
присваивания. Если некоторый конкретный тип не будет работать с нашим шаблоном
Stack или потребует некоторой дополнительной обработки, вы можете
определить для этого типа явную специализацию шаблона класса. Предположим, мы
хотим создать явную специализацию стека для объектов Employee. Для этого
мы образуем новый класс с именем Stack< Employee > следующим образом:
Template
class Stack< Employee >
{
// тело определения класса
};
Заметьте, что явная специализация Stack< Employee > полностью
замещает шаблон класса Stack — она ничего не использует из исходного шаблона
и даже может иметь отличные от него элементы.
14.6. Замечания о шаблонах и наследовании
Шаблоны и наследование связаны друг с другом следующим образом:
• Шаблон класса может быть производным от специализации шаблона класса.
• Шаблон класса может быть производным от нешаблонного класса.
• Специализация шаблона класса может быть производной от специализа,-
ции шаблона класса.
• Нешаблонный класс может быть производным от специализации
шаблона класса.
900
Глава 14
14.7. Замечания о шаблонах и друзьях
Мы уже знаем, что функции и целые классы могут быть объявлены
друзьями нешаблонных классов. Для шаблонов классов также могут быть
установлены отношения дружественности. Дружественность может быть иметь место
между шаблоном класса и глобальной функцией, элемент-функцией другого
класса (возможно, специализацией шаблона класса) или даже целым классом
(возможно, специализацией шаблона класса).
Далее в этом разделе мы предполагаем, что у нас уже определен шаблон для
класса с именем X, имеющий единственный типовой параметр Т:
template< typename T > class X
При таком предположении мы можем сделать функцию f 1 другом каждой
специализации шаблона класса, образованной из шаблона для класса X. Для
этого требуется следующее объявление дружественности:
friend void fl() ;
Функция fl будет другом, например, Х< double >, X< string >, X< Employee >
и т.д.
Можно также сделать функцию f2 другом специализации шаблона с тем же
самым типовым аргументом. Для этого требуется следующее объявление
дружественности:
friend void f2( Х< Т > & );
Например, если Т — float, то функция f2(X< float > &) будет другом
специализации шаблона Х< double >, но не другом специализации Х< string >.
Вы можете объявить, что элемент-функция другого класса является другом
любой специализации, генерированной из шаблона класса. Для этого
объявление дружественности должно квалифицировать имя элемент-функции другого
класса именем класса с операцией разрешения области действия:
friend void A::f3();
Такое объявление делает элемент-функцию f3 класса А другом каждой
специализации, образованной из вышеупомянутого шаблона класса. Например,
функция f3 класса А будет другом Х< double >, X< string >, X< Employee >
и т.д.
Как и в случае с глобальной функцией, элемент-функция другого класса
может быть сделана другом только специализации шаблона с тем же типовым
аргументом. Объявление дружественности в форме
friend void C< T >::f4 ( Х< Т > & );
для некоторого типа Т, например, float, делает элемент-функцию
С< float >::f4( X< float > & )
делает элемент-функцию f4 другом только специализации Х< float >.
Шаблоны
901
В некоторых случаях желательно сделать друзьями шаблона весь набор
элемент-функций некоторого класса. В этом случае объявление
дружественности в форме
friend class Y;
делает каждую элемент-функцию класса Y другом каждой специализации,
образованной из шаблона класса X.
Наконец, можно сделать все элемент-функции специализации шаблона
одного класса друзьями специализации шаблона другого класса с тем же
типовым аргументом. Например, объявление дружественности в форме
friend class Z< T >;
указывает, что когда образуется специализация шаблона класса для
определенного типа Т (например, float), все элемент-функции специализации
Z< float > становятся друзьями специализации Х< float >. Такое отношение
дружественности встречается в нескольких примерах главы 20.
14.8. Замечания о шаблонах и статических элементах
А как обстоит дело со статическими элементами данных? Как вы помните,
в случае нешаблонного класса все объекты класса разделяют единственный
экземпляр каждого статического элемента данных, и этот элемент данных
должен инициализироваться в области действия файла.
Каждая специализация, образованная из шаблона класса, имеет свой
экземпляр каждого статического элемента данных шаблона класса; все объекты
этой специализации разделяют этот единственный статический элемент.
Кроме того, как и в случае статических элементов данных нешаблонных классов,
статические элементы специализаций шаблона должны определяться и, если
необходимо, инициализироваться в области действия файла. Каждая
специализация шаблона класса имеет свой собственный экземпляр статических
элемент-функций шаблона класса.
14.9. Заключение
В этой главе было представлено одно из самых мощных средств языка C++ —
шаблоны. Вы узнали, как пользоваться шаблонами функций, которые
позволяют компилятору порождать набор специализаций шаблона, которые
представляют собой группу родственных перегруженных функций. Мы также обсудили, как
перегрузить шаблон функции, чтобы создать специальную версию функции,
обрабатывающую некоторый специфический тип данных особым, отличным от
других специализаций образом. Затем вы узнали о шаблонах классов и о
специализациях шаблона класса. Вы видели примеры использования шаблона класса
для создания группы родственных классов, выполняющих идентичную
обработку различных типов данных. Наконец, вы узнали о некоторых взаимосвязях
между шаблонами, друзьями, наследованием и статическими элементами.
В следующей главе мы обсудим многие возможности C++ в плане
ввода/вывода и продемонстрируем несколько потоковых манипуляторов, которые
выполняют различные задачи форматирования.
902
Глава 14
Резюме
• Шаблоны дают нам возможность определять набор родственных (перегруженных)
функций — называемых специализациями шаблона функции — или набор
родственных классов, называемых специализациями шаблона класса.
• Программист пишет единственное определение шаблона функции. Исходя из типов
аргументов, указанных в вызовах этой функции, C++ генерирует отдельные
специализации шаблона, соответствующим образом обрабатывающих каждый тип данных.
Они компилируются наряду с остальным исходным кодом программы.
• Все определения шаблонов функций начинаются с ключевого слова template, за
которым следует список параметров шаблона, заключенный в угловые скобки (< и >);
каждому параметру, представляющему тип, должно предшествовать одно из
взаимозаменяемых ключевых слов class или typename. Ключевые слова class и typename
на самом деле означают здесь «любой встроенный или определяемый пользователем
тип».
• Типовые параметры шаблона в определении шаблона функции используются для
спецификации типов аргументов функции, спецификации ее возвращаемого типа
и для объявления переменных внутри функции.
• Имя параметра шаблона может объявляться в списке шаблонных параметров в
заголовке шаблона только один раз, но может неоднократно использоваться в заголовке
и теле функции. Имена шаблонных параметров не обязаны быть уникальными среди
всех шаблонов функций.
• Шаблон функции может быть перегружен по-разному. Можно определить другие
шаблоны функций, специфицирующие одно и то же имя, но другие параметры
функции. Шаблон функции может быть также перегружен обычными (не-шаблон-
ными) функциями с тем же самым именем функции, но другими параметрами.
• Шаблоны классов являются средством обобщенного описания класса и порождения
классов, являющихся специализациями*этого обобщенного класса.
• Шаблоны классов называют параметризованными типами; они требуют указания
типовых параметров, специфицирующих, каким образом нужно настроить
обобщенный шаблон класса, чтобы образовать конкретную специализацию шаблона.
• Программист, который хочет создавать разнообразные специализации, пишет
только одно определение шаблона класса. Всякий раз, когда требуется дополнительная
специализация шаблона, он использует лаконичную нотацию, а компилятор
«пишет» исходный код требуемой специализации.
• Определение шаблона класса выглядит как обыкновенное определение класса, за
исключением того, что ему предшествует заголовок template< typename T > (или
template< class T >), специфицирующий определение шаблона класса с типовым
параметром Т, который служит заместителем типа, для которого создается класс. Тип
Т используется по всему заголовку класса и в определениях его элемент-функций
как обобщенное имя типа.
• Определения элемент-функций, расположенные вне определения шаблона класса,
начинаются с заголовка template< typename T > (или template< class T >). Таким
образом, каждое определение напоминает обычное определение функции, за
исключением того, что обобщенные данные класса везде специфицируются обобщенно, как
типовой параметр Т. Чтобы привязать каждую элемент-функцию к области действия
шаблона класса, используется бинарная операция разрешения области действия
с именем шаблона класса.
• В заголовке шаблона класса или функции возможно использование нетиповых
параметров.
• Чтобы заменить определение шаблона класса для некоторого специфического типа,
может быть предусмотрена явная специализация шаблона.
Шаблоны
903
• Шаблон класса может быть производным от специализации шаблона класса.
Шаблон класса может быть производным от нешаблонного класса. Специализация
шаблона класса может быть производной от специализации шаблона класса.
Нешаблонный класс может быть производным от специализации шаблона класса.
• Функции и целые классы могут быть объявлены друзьями нешаблонных классов.
Для шаблонов классов также могут быть установлены отношения дружественности.
Дружественность может быть иметь место между шаблоном класса и' глобальной
функцией, элемент-функцией другого класса (возможно, специализацией шаблона
класса) или даже целым классом (возможно, специализацией шаблона класса).
• Каждая специализация, образованная из шаблона класса, имеет свой экземпляр
каждого статического элемента данных шаблона класса; все объекты этой
специализации разделяют этот единственный статический элемент. Как и в случае статических
элементов данных нешаблонных классов, статические элементы специализаций
шаблона должны определяться и, если необходимо, инициализироваться в области
действия файла.
• Каждая специализация шаблона класса имеет свой собственный экземпляр
статических элемент-функций шаблона класса.
Терминология
template< class T >
template< typename T >
typename
друг шаблона
ключевое слово class в типовом
параметре шаблона
ключевое слово template
ключевое слово typename
макрос
нетиповой параметр
нетиповой параметр шаблона
обобщенное программирование
определение шаблона класса
определение шаблона функции
параметр шаблона
параметризованный тип
перегрузка шаблона функции
специализация шаблона класса
Контрольные вопросы
14-1- Определите, являются ли следующие утверждения верными или неверными.
Если утверждение неверно, объясните, почему.
a) Параметры шаблона в определении шаблона функции используются для
спецификации типов аргументов функции, типа возвращаемого значения и для
объявления переменных внутри функции.
b) Ключевые слова class и typename, используемые для типовых параметров
шаблона, означают: «любой определяемый пользователем классовый тип».
c) Шаблон функции может быть перегружен другим шаблоном функции с тем же
самым именем функции.
d) Имена параметров шаблона должны быть уникальны среди всех определений
шаблонов.
специализация шаблона функции
статическая элемент-функция
специализации шаблона класса
статическая элемент-функция
шаблона класса
статический элемент данных
специализации шаблона класса
статический элемент данных шаблона
класса
типовой параметр
типовой параметр шаблона
угловые скобки (< и >)
шаблон класса
шаблон функции
элемент-функция специализации
шаблона класса
явная специализация
904
Глава 14
e) Каждое определение элемент-функции вне шаблона класса должно
начинаться с заголовка шаблона.
f) Дружественная функция шаблона класса должна быть специализацией
шаблона функции.
g) Если несколько шаблонных классов произведены от одного и того же шаблона
класса с единственным статическим членом данных, то каждый из
шаблонных классов совместно использует одну копию этого статического члена
данных.
14.2. Заполните пропуски в каждом из следующих предложений:
a) Шаблоны дают нам возможность определить при помощи одного фрагмента
кода группу родственных функций, называемых , или группу
родственных классов, называемых .
b) Все описания шаблонов функций начинаются с ключевого слова ,
за которым следует список параметров шаблона функции, заключаемый
в .
c) Все функции, образованные из одного шаблона функции, имеют одно и то же
имя, поэтому компилятор использует механизм для того, чтобы
обеспечить вызов соответствующей функции.
d) Шаблоны классов также называются типами.
e) операция используется с именем шаблона класса,
чтобы связать описание элемент-функции с областью действия шаблона
класса.
f) Как и статические элементы данных нешаблонных классов, статические
элементы данных шаблонов классов должны быть инициализированы в области
действия .
Ответы на контрольные вопросы
14.1. а) Верно. Ь. Неверно. Ключевые слова class и typename в этом контексте могут
также допускать типовой параметр любого встроенного типа, с) Верно, d)
Неверно. Имена параметров шаблона не обязательно должны быть уникальны
среди всех шаблонов, е) Верно, f) Неверно. Это может быть и не шаблонная
функция, g) Неверно. Каждая специализация шаблона класса будет иметь
свой собственный экземпляр статического элемента данных.
14.2. а) специализациями шаблона функции, специализациями шаблона класса. Ь)
template, угловые скобки (< и >). с) перегрузки, d) параметризованными, е)
бинарная, разрешения области действия, f) файла.
Упражнения
14.3. Напишите шаблон функции bubbleSort для программы сортировки из рис. 8.15.
Напишите программу-драйвер для ввода, сортировки и вывода массивов типа int
и float.
14.4. Перегрузите шаблон функции print Array из рис. 14.1, добавив два
дополнительных параметра, а именно, int lowSubscript и int highSubscript. В результате
вызова этой функции должна выводиться только часть массива с индексами,
ограниченными этими параметрами. Введите проверки допустимых значений
highSubscript и lowSubscript. Если какой-то из них лежит вне допустимых
пределов или если highSubscript имеет значение, не большее, чем значение
lowSubscript, то перегруженная функция printArray должна возвращать
нулевое значение; в противном случае printArray должна возвращать число выведен-,
ных элементов. После этого измените функцию main, чтобы проверить обе вер-
Шаблоны
905
сии функций printArray на массивах a, b и с. Постарайтесь протестировать все
возможности обеих версий printArray.
14.5. Перегрузите шаблон функции printArray (см. рис. 14.2) версией нешаблонной
функции, выводящей массивы символьных строк в аккуратном табличном
формате, по столбцам.
14.6. Напишите простой шаблон предикатной функции isEqualTo, которая
сравнивает два своих параметра при помощи операции равенства (==) и возвращает true,
если они равны, и false, если не равны. Используйте этот шаблон функции в
программе, которая вызывает isEqualTo с различными встроенными типами
аргументов. Затем напишите отдельную версию программы, которая вызывает
isEqualTo с определяемым пользователем типом и неперегруженной операцией
равенства. Что случится, когда вы попытаетесь выполнить эту программу?
Теперь перегрузите операцию равенства (посредством функции-операции). Что
получится, если вы теперь попытаетесь выполнить эту программу?
14.7. Используя целый нетиповой параметр numberOfElements и типовой параметр
elementType, создайте шаблон класса Array (рис. 11.6-11.7), который мы
разработали в главе 11. Этот шаблон позволит создавать экземпляры класса Array
с заданным числом элементов указанного типа, определенным во время
компиляции.
14.8. Напишите программу, в которой используется шаблон класса Array. Из этого
шаблона может быть получен представитель класса Array для любого типа
элементов. Переопределите шаблон явным определением класса Array для типа
float (class Array< float >). В программе-драйвере создайте представитель
класса Array типа int при помощи шаблона и покажите, что при создании
представителя класса Array типа float используется явное определение класса class
Array< float >.
14.9. Объясните различие между терминами «шаблон функции» и «специализация
шаблона функции».
14.10. Что можно сравнить с трафаретом, шаблон класса или специализацию шаблона
класса? Аргументируйте ваш ответ.
14.11. Как связаны между собой шаблоны функций и перегрузка?
14.12. Почему предпочтительнее использовать шаблоны функций, а не макросы?
14.13. Как может отразиться на эффективности программы использование шаблонов
функций и шаблонов классов?
14.14. При вызове функции компилятор выполняет процедуру сопоставления, чтобы
определить, какую специализацию шаблона функции следует вызвать. При
каких обстоятельствах эта процедура приводит к ошибке компиляции?
14.15. Почему шаблон класса уместно назвать параметризованным типом?
14.16. Объясните, для чего в программе на C++ мог бы быть использован оператор
Array< Employee > workerList( 100 );
14.17. Пересмотрите ваш ответ на упражнение 14.16. Почему программа на C++ могла
бы использовать оператор
Array< Employee > workerList;
14.18. Объясните использование следующей нотации в программе C++:
template< class T > Array< T >::Array( int s )
14.19. Почему вы могли бы использовать в шаблоне класса для контейнера (вроде
массива или стека) нетиповой параметр?
14.20. Опишите, как реализовать явную специализацию шаблона класса.
14.21. Опишите взаимосвязь между шаблонами классов и наследованием.
906
Глава 14
14.22. Предположим, что шаблон класса имеет заголовок
template< class Tl > class CI
Опишите отношения дружественности, возникающие, если внутри шаблона класса
поместить приведенные ниже объявления дружественности. Идентификаторы,
начинающиеся с символа «f», являются функциями, идентификаторы,
начинающиеся с символа «С» — классы, а идентификаторы с начальным символом «Т»
обозначают любой тип (т.е. встроенный или классовый тип).
a) friend void f 1 () ;
b) friend void f2 ( Cl< Tl > & ) ;
c) friend void C2 : : f4 () ;
d) friend void C3< Tl >::f5 ( Cl< Tl > & ) ;
e) friend class C5;
f) friend class C6< Tl >;
14.23. Предположим, что шаблон класса Employee имеет статический элемент данных
count. Предположим далее, что из этого шаблона класса образованы три
специализации. Сколько будет существовать экземпляров статического элемента
данных? Каковы будут (если будут вообще) ограничения на использование каждого
из них?
15
Потоковый ввод/вывод
ЦЕЛИ
В этой главе вы изучите:
• Принципы объектно-
ориентированного потокового
ввода/вывода C++.
• Форматирование ввода и вывода.
• Иерархию классов потокового
ввода/вывода.
• Использование потоковых
манипуляторов.
• Управление выравниванием
и заполнением поля.
• Определение успеха или неудачи
операций ввода/вывода.
• Привязку выходного потока к входному
908
Глава 15
15.1. Введение
15.2. Потоки
15.2.1. Классические и стандартные потоки
15.2.2. Заголовочные файлы библиотеки iostream
15.2.3. Классы и объекты потокового ввода/вывода
15.3. Потоковый вывод
15.3.1. Вывод переменных типа char *
15.3.2. Вывод символов с помощью элемент-функции put
15.4. Потоковый ввод
15.4.1. Элемент-функции get и getline
15.4.2. Элемент-функции peek, putback и ignore
класса istream
15.4.3. Безопасный по типу ввод/вывод
15.5. Бесформатный ввод/вывод спомощью read, gcount и write
15.6. Введение в манипуляторы потоков
15.6.1. Основание целых чисел: dec, oct, hex и setbase
15.6.2. Точность чисел с плавающей точкой (precision,
setprecision)
15.6.3. Ширина поля (setw, width)
15.6.4. Определяемые пользователем манипуляторы
выходногопотока
15.7. Состояние формата потока и потоковые
манипуляторы
15.7.1. Конечные нули и десятичные точки (showpoint)
15.7.2. Выравнивание (left, right и internal)
15.7.3. Заполнение (fill, setfill)
15.7.4. Основание целых чисел (dec, oct, hex, showbase)
15.7.5. Числа с плавающей точкой: научная
и фиксированная нотация (scientific, fixed)
15.7.6. Управление верхним/нижним регистрами
(uppercase)
15.7.7. Спецификация булева формата (boolalpha)
15.7.8. Установка и сброс состояний формата
с помощью элемент-функции flags
15.8. Состояния ошибки потоков
15.9. Привязка потока вывода к потоку ввода
15.10. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
Потоковый ввод/вывод
909
15.1. Введение
Стандартные библиотеки C++ предлагают широкий выбор возможностей
ввода/вывода. В этой главе обсуждается ряд методов, достаточных для
выполнения основных операций ввода/вывода, а остальные даются в виде краткого
обзора. Некоторые из них уже обсуждались в тексте ранее, но в этой главе
проводится более полное изложение ввода/вывода в C++. Многие из
представленных здесь методик ввода/вывода являются объектно-ориентированными.
Такой стиль операций ввода/вывода интенсивно использует другие элементы
C++, например, ссылки и перегрузку функций и операций.
C++ обеспечивает безопасный по типу ввод/вывод. Каждая операция
ввода/вывода выполняется по-разному в зависимости от типа обрабатываемых
данных. Если для специфического типа данных определена функция
ввода/вывода, то она автоматически вызывается для обработки этого типа. Если
имеется несоответствие между типом действительных данных и функцией,
предназначенной для обработки этого типа, компилятор генерирует
сообщение об ошибке. Такая защита не пропускает через систему недопустимые
данные (как это случалось в С, из-за чего в С происходили трудноуловимые и
часто причудливые ошибки).
В C++ пользователи могут определять, как должен производиться
ввод/вывод объектов создаваемых ими типов, перегружая операции передачи в поток
(«) и извлечения из потока (»). Эта расширяемость — одна из наиболее
ценных особенностей C++.
Ш Общая методическая рекомендация 15.1
В программах на C++ используйте только ввод/вывод в стиле C++,
хотя в C++ доступны функции ввода/вывода С.
j^rjpsy Предотвращение ошибок 15.1
\Лу Ввод/вывод в стиле C++ безопасен в отношении типов.
Ш Общая методическая рекомендация 15,2
С ++ предлагает единообразный подход к вводу/выводу для
предопределенных типов и типов, определяемых пользователем. Благодаря
такой общности облегчается процесс разработки программ и
утилизация программного кода.
15.2. Потоки
В C++ ввод/вывод данных производится потоками, т.е.
последовательностями байтов. При операциях ввода байты направляются от устройства
(например, клавиатуры, дисковода, сетевой платы) в основную память. В
операциях вывода поток байтов направляется из основной памяти на устройство
(например, экран монитора, принтер, дисковод, сетевую плату).
Специфический смысл этим байтам придают прикладные программы.
Байты могут представлять ASCII-символы, сырые данные внутреннего формата,
910
Глава 15
графические изображения, оцифрованную речь, цифровое видео или любой
другой вид информации, с которой работает приложение.
Системные механизмы ввода/вывода должны обеспечивать целостное и
надежное перемещение байтов данных от устройств в память (и наоборот).
Передача данных нередко связана с механическим движением, например,
вращением магнитного диска, протяжкой ленты или нажатием клавиш на
клавиатуре. Время, которое уходит на обмен данными с такими устройствами, обычно
значительно превышает то, что требуется процессору на обработку этих
данных. Поэтому операции ввода/вывода требуют тщательного планирования
и настройки для того, чтобы обеспечивалась максимальная
производительность системы.
В C++ имеются возможности ввода/вывода «низкого уровня» и «высокого
уровня». Низкоуровневый, т.е. бесформатный ввод/вывод обычно состоит
в передаче заданного числа байт от устройства в память или из памяти
устройству. В таких операциях единицей информации является байт. Операции
низкого уровня способны быстро передавать большие объемы информации, но
в не слишком удобной для человека форме.
Люди предпочитают пользоваться операциями ввода/вывода высокого
уровня, т.е. форматируемым вводом/выводом, в котором байты группируются
в осмысленные единицы данных вроде целых чисел, чисел с плавающей
точкой, символов, строк и определяемых пользователем типов. Такой,
ориентированный на тип, подход пригоден для большинства задач ввода/вывода, кроме
обработки файлов большого объема.
Вопросы производиельности 15.1
При обработке файлов большого объема применяйте бесформатный
ввод/вывод.
Переносимость программ 15.1
Применение бесформатного ввода/вывода может создавать проблемы
в плане переносимости, так как различные платформы не всегда
совместимы между собой по неформатированным данным.
15.2.1. Классические и стандартные потоки
В прошлом библиотеки классических потоков C++ позволяли вводить
и выводить данные типа char. Поскольку тип char занимает один байт, он
способен представлять лишь ограниченный набор символов (например, входящих
в набор символов ASCII). Однако многие языки имеют алфавиты, содержащие
гораздо больше символов, чем может быть представлено однобайтовым char.
Набор ASCII этих символов не предусматривает; их представление допускает
набор символов Unicode. Unicode — это широкий интернациональный набор
символов, представляющий большинство мировых «коммерчески пригодных»
языков, математические символы и многое другое. Более подробно о Unicode
можно узнать на www.unicode.org.
C++ включает также библиотеки стандартных потоков, которые
позволяют разработчикам строить системы, способные производить операции
ввода/вывода с символами Unicode. Для этой цели в C++ имеется дополнитель-
Потоковый ввод/вывод
911
ный символьный тип wcharjtj который может хранить символы Unicode.
Кроме того, классические классы потоков C++, которые обрабатывали только тип
char, в стандартном C++ переработаны в шаблоны классов с отдельными
специализациями для обработки типов char и wchar_t. На протяжении всей
книги мы пользуемся специализациями этих шаблонов для типа char.
15.2.2. Заголовочные файлы библиотеки iostream
Библиотека C++ iostream предоставляет программисту сотни
разнообразных возможностей ввода/вывода. Части библиотечного интерфейса
содержатся в нескольких файлах заголовков.
Большинство программ на C++ включают заголовочный файл <iostream>,
который содержит основную информацию, необходимую для всех операций
потокового ввода/вывода. В файле <iostream> определяются объекты cin,
cout, cerr и clog, которые ассоциируются соответственно со стандартным
потоком ввода, стандартным потоком вывода и стандартными небуферизованным
и буферизованным потоками ошибок. Поддерживается как форматируемый,
так и бесформатный ввод/вывод.
Заголовок <iomanip> определяет средства, полезные для управления
форматируемым вводом/выводом с помощью так называемых
параметризованных манипуляторов потока.
Заголовок <fstream> объявляет средства для управляемой пользователем
обработки файлов. Мы используем этот заголовок в программах главы 17.
Реализации C++ обычно имеют дополнительные библиотеки, связанные
с вводом/выводом, которые поддерживают системно-специфические
возможности, например, управление специальными устройствами для ввода/вывода
аудио- и видеоинформации.
15.2.3. Классы и объекты потокового ввода/вывода
Библиотека iostream содержит много классов, поддерживающих
разнообразные операции ввода/вывода. Например, шаблон класса basic_istream
отвечает за операции потокового ввода, шаблон basic_ostream обеспечивает
операции потокового вывода, а шаблон basic_iostream поддерживает операции
как потокового ввода, так и вывода. Каждый шаблон имеет предопределенную
специализацию, обеспечивающую операции с типом char. Кроме того, в
библиотеке iostream предусмотрен набор объявлений typedef, которые
специфицируют псевдонимы для этих специализаций шаблонов. Спецификатор
typedef служит для объявления синонимов (псевдонимов) для ранее
определенных типов данных. Программисты иногда используют typedef, чтобы
ввести более короткие или удобочитаемые имена типов. Например, оператор
typedef Card *CardPtr;
вводит дополнительное имя CardPtr в качестве синонима для Card *.
Заметьте, что создание имени с помощью typedef не создает типа данных; typedef
создает только имя, которое можно использовать в программе. Раздел 22.5
подробно обсуждает typedef. Псевдоним istream представляет специализацию
basic_istream, которая обеспечивает ввод для типа char. Точно так же
псевдоним ostream представляет специализацию basicostream, обеспечивающую
912
Глава 15
вывод для типа char. Наконец, iostream представляет специализацию Ьа-
sic_iostream, обеспечивающую для типа char как ввод, так и вывод. Мы
используем эти псевдонимы на протяжении всей главы.
Иерархия шаблонов потокового ввода/вывода и перегрузка
операций *
Оба шаблона basic_istream и basic_ostream производятся простым
наследованием от базового шаблона basic^os.1 Шаблон basic_iostream производится
путем сложного наследования от шаблонов basic_istream и basic_ostream.2
Классовая диаграмма UML на рис. 15.1 изображает эти отношения
наследования.
basicjos
basic istream basic ostream
basicjostream
Рис. 15.1. Часть иерархии шаблонов потокового ввода/вывода
Для операций ввода/вывода используется удобная нотация с применением
знаков перегруженных операций. Для обозначения операции потокового
вывода используется перегруженная операция левого сдвига («), которая
называется операцией передачи в поток. Для операции потокового ввода
используется перегруженная операция правого сдвига (»), которая называется
операцией извлечения из потока. Эти операции могут применяться с объектами
стандартных потоков cin, cout, cerr, clog и, как правило, с объектами потоков,
определяемыми пользователем.
Объекты стандартных потоков cin, cout, cerr и clog
Предопределенный объект cin является представителем класса istream,
«подключенным», как говорят, или прикрепленным к стандартному входному
устройству, обычно клавиатуре. Операция извлечения из потока (»),
показанная в следующем операторе, вводит в память целое значение, полученное
из cin (предполагается, что переменная grade объявлена как int):
cin » grade; // данные "текут" в направлении стрелок
Технически шаблоны не наследуют от других шаблонов. Однако в этой главе мы
обсуждаем шаблоны только в контексте их специализаций, обеспечивающих вывод для типа
char. Эти специализации являются классами и могут наследовать друг другу.
Сложное наследование обсуждается в главе 24.
Потоковый ввод/вывод 913
Обратите внимание, что компилятор определяет тип данных grade и
выбирает соответствующую перегруженную операцию извлечения из потока. Если
переменная grade была должным образом объявлена, операции извлечения из
потока не требуется никакой дополнительной информации о типе (как этого
требует, например, ввод/вывод в стиле С). Операция » перегружена для
ввода единиц данных встроенных типов, строк и значений типов указателей.
Предопределенный объект cout является представителем класса ostream,
«подключенным» к стандартному выходному устройству, обычно экрану
монитора. Операция передачи в поток, показанная в следующем операторе,
выводит значение целой переменной grade из памяти на стандартное устройство
вывода:
cout « grade; // данные "текут" в направлении стрелок
Обратите внимание, что компилятор также определяет тип данных grade
и выбирает соответствующую перегруженную операцию передачи в поток.
Если переменная grade была должным образом объявлена, операции передачи
в поток не требуется никакой дополнительной информации о типе.
Операция « перегружена для ввода единиц данных встроенных типов, строк и
значений типа указателей.
Предопределенный объект сегг класса ostream «подключен» к
стандартному устройству ошибок. Вывод в объект сегг небуферизован, т.е. результат
каждой операции передачи в сегг выводится немедленно, а не помещается в буфер;
это подходит для оперативного оповещения пользователя об ошибках.
Предопределенный объект clog класса ostream «подключен» к
стандартному устройству ошибок. Вывод на clog буферизован. Это означает, что каждая
передача в clog может помещать свой результат в буфер, пока буфер не
заполнится или не будет сброшен. Буферизация является методикой оптимизации
ввода/вывода и обсуждается в курсах по операционным системам.
Шаблоны для обработки файлов
Обработка файлов в C++ использует шаблоны basicifstream (для
файлового ввода), basic_ofstream (для файлового вывода) и basic_fstream (для ввода
и вывода). Каждый шаблон имеет предопределенную специализацию,
обеспечивающую операции с типом char. В C++ предусмотрен набор объявлений
typedef, которые специфицируют псевдонимы для этих специализаций
шаблонов. Псевдоним ifstream представляет специализацию basic_ifstream,
которая обеспечивает ввод char из файла. Псевдоним ofstream представляет
специализацию basic_ofstream, обеспечивающую вывод char в файл. Наконец,
fstream представляет специализацию basic_fstream, обеспечивающую как
файловый ввод, так и вывод char. Шаблон basic_ifstream является
производным от basic_istream, шаблон basicof stream — производным от basic_ost-
ream и шаблон basic_fstream является производным от basic_iostream.
Классовая диаграмма UML на рис. 15.12 изображает различные отношения
наследования классов, связанных с вводом/выводом. Полная иерархия классов
потокового ввода/вывода реализует большую часть возможностей,
необходимых программистам. За подробной информацией по работе с файлами
обращайтесь к описанию библиотеки классов вашей системы C++.
914
Глава 15
basic_ios
/ Ч
basic_istream basic_ostream
У Ч / \
basic_if stream basic_iostream basic_of stream
A
basic_fstream
Рис. 15.2. Часть иерархии шаблонов потокового ввода/вывода с основными
шаблонами обработки файлов
15.3. Потоковый вывод
Форматируемый и бесформатный вывод в C++ обеспечивается классом
ostream. Его возможности включают в себя: вывод стандартных типов данных
операцией передачи в поток («); вывод символов посредством
элемент-функции put; бесформатный вывод посредством элемент-функции write
(раздел 15.5); вывод целых чисел в десятичном, восьмеричном и шестнадцатерич-
ном форматах (раздел 15.6.1); вывод значений с плавающей точкой с различной
точностью (раздел 15.6.2), с принудительной десятичной точкой (раздел 15.7.1),
в научной нотации и с фиксированной точкой (раздел 15.7.5); вывод данных
с выравниванием в полях заданной ширины (раздел 15.7.2); вывод данных
с символами-заполнителями (раздел 15.7.3) и вывод букв верхнего регистра
в научной и шестнадцатеричной нотации (раздел 15.7.6).
15.3.1. Вывод переменных типа char *
Определение типов данных в C++ осуществляется автоматически, что
является улучшением по сравнению с С. К сожалению, это улучшение порой
«мешает» программистам. Предположим, например, что мы хотим напечатать
значение указателя не символьную строку (типа char *), т.е. адрес в памяти
первого символа этой строки. Однако операция « перегружена таким
образом, что выводит данные типа char * как ограниченную нулем строку,
решение состоит в том, чтобы привести указатель char * к типу void * (на самом
деле так нужно поступать с любой переменной-указателем, которую мы хотим
напечатать как адрес). Рис. 15.3 демонстрирует печать переменной типа char *
как в формате строки, так и в формате адреса. Заметьте, что адрес печатается
как шестнадцатеричное (по основанию 16) число. Мы еще будем говорить об
управлении основаниями чисел в разделах 15.6.1, 15.7.4, 15.7.5 и 15.7.7. [За
мечание. Адрес памяти, показанный в окне вывода на рис. 15.3, может
различаться от компилятора к компилятору.]
Потоковый ввод/вывод
915
1 // Рис. 15.3: Figl5_03.cpp
2 // Печать адреса, хранящегося в переменной типа char *.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 char *word = "again";
10
11 // Вывести значение char *, затем вывести char *,
12 // приведенный к void * с помощью static_cast
13 cout « "Value of word is: " « word « endl
14 « "Value of static_cast< void * >( word ) is: "
15 « static_cast< void * >( word ) « endl;
16 return 0;
17 } // конец main
Value of word is: again
Value of static_cast< void * >( word ) is: 4419748
Рис. 15.3. Печать адреса, хранящегося в переменной типа char *
15.3.2. Вывод символов с помощью элемент-функции put
Символы можно выводить с помощью элемент-функции put. Например,
оператор
cout.put( 'A' );
выводит одиночный символ А. Вызовы put могут каскадироваться:
cout.put( 'A' ).put( '\n' );
Оператор выводит символ А с последующим символом новой строки. Как
и в случае «, этот оператор исполняется именно таким образом потому, что
операция-точка (.) оценивается слева направо, а функция put возвращает
ссылку на объект ostream (cout), который принимает вызов put. Функции put
можно передавать в качестве аргумента выражение, которое представляет
значение ASCII, например, оператор
cout.put( 65 ) ;
также выводит символ А.
15.4. Потоковый ввод
Теперь давайте рассмотрим потоковый ввод. Форматируемый и
бесформатный ввод обеспечивается классом istream. Операция извлечения из потока
(т.е. перегруженная операция правого сдвига ») обычно пропускает
встреченные во входном потоке пробельные символы (такие, как пробелы,
табуляции и символы новой строки); позже мы увидим, как можно изменить такое
поведение. После каждого ввода операция возвращает ссылку на объект пото-
916
Глава 15
ка, принявший вызов операции извлечения (напр., cin в выражении cin »
grade). Если эта ссылка используется в условии (напр., в условии
продолжения цикла while), неявно вызывается перегруженная операция приведения
void * потока, преобразующая ссылку в ненулевое значение указателя или
нулевой указатель, в зависимости от успеха или неудачи последней операции
ввода. Ненулевой указатель преобразуется в булево значение true,
указывающее на успех операции, а нулевой указатель преобразуется в false,
указывающее на неудачу. Когда делается попытка чтения за концом потока,
перегруженная операция приведения void * возвращает нулевой указатель,
сигнализирующий о конце файла.
Каждый поток имеет набор битов состояния, служащих для управления
состоянием потока (т.е. форматированием, состояниями ошибок и т.д.). Эти
биты используются перегруженной операцией приведения void * потока для
определения того, следует ли возвратить ненулевой или нулевой указатель.
При вводе неправильного типа операция извлечения из потока приводит к
установке бита failbit; в случае ошибки потока устанавливается также badbit.
Разделы 15.7 и 15.8 подробно обсуждают биты состояния потока и
демонстрируют, как проверить эти биты после операции ввода/вывода.
15.4.1. Элемент-функции get и getline
Элемент-функция get без аргументов вводит один символ из указанного
потока ввода (включая пробельные и другие не-графические символы, такие,
как последовательность клавиш, представляющая конец файла) и возвращает
его в качестве своего значения. Когда в потоке встречается конец файла, эта
версия функции get возвращает EOF.
Элемент-функции eof, get и put
На рис. 15.4 показан пример использования элемент-функций eof и get
входного потока cin и элемент-функции put выходного потока cout.
Программа сначала выводит значение вызова cin.eof(), т.е. false (О в выводе
программы), чтобы показать, что конец файла в cin еще не встретился. Затем
пользователь вводит строку текста, завершая ее концом файла (<ctrl>-z для
совместимых с PC систем, <ctrl>-d для UNIX и Macintosh). Строка 17 читает каждый
символ, который затем строка 18 выводит в поток cout, вызывая
элемент-функцию put. Когда встречается конец файла, цикл while завершается
и строка 22 выводит возвращаемое значение cin.eof(), равное теперь true (О
в выводе), показывая, что на cin установлен признак конца файла. Обратите
внимание, что в программе используется версия функции get класса istream,
которая не принимает аргументов и возвращает введенный символ (стока 17).
Функция eof возвращает true только после того, как программа попытается
прочитать символ после последнего символа в потоке.
Потоковый ввод/вывод
917
1 // Рис. 15.4: Figl5_04.cpp
2 // Демонстрация элемент-функций get, put и eof.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std:rendl;
7
8 int main()
9 {
10 int character; // int, так как char не может представлять EOF
11
12 // попросить пользователя ввести строку текста
13 cout « "Before input, cin.eof() is " « cin.eof() « endl
14 « "Enter a sentence followed by end-of-file:" « endl;
15
16 // вызвать get для чтения символа; вызывать put для вывода
17 while ( ( character = cin.get() ) != EOF )
18 cout.put( character );
19
20 // вывести символ конца файла
21 cout « "\nEOF in this system is: " « character « endl;
22 cout « "After input of EOF, cin.eof () is " « cin.eof () « endl;
23 return 0;
24 } // конец main
Before input, cin.eof() is 0
Enter a sentence followed by end-of-file:
Testing the get and put member functions
Testing the get and put member functions
*Z
EOF in this system is: -1
After input of EOF, cin.eof() is 1
Рис. 15.4. Элемент-функции get, put и eof
Элемент-функция get с символьным аргументом-ссылкой извлекает из
потока ввода следующий символ (даже если это пробельный символ) и сохраняет
его в символьном аргументе. Эта версия get возвращает ссылку на объект
istream, для которого она вызывалась.
Третья версия элемент-функции get имеет три аргумента — символьный
массив, предельный*размер и символ-ограничитель (по умолчанию это '\п').
Эта функция читает символы из входного потока и завершается, когда либо
будет введено на один символ меньше указанного предельного числа, либо
встретится символ-ограничитель. В конец строки, считанной в символьный
массив, дописывается нуль-символ. Символ-ограничитель не записывается
в символьный массив, но остается во входном потоке (он будет следующим
читаемым символом). Таким образом, результатом последующего вызова get
будет пустая строка, если только не удалить символ-ограничитель из потока
(например, вызовом cin.ignore()).
918
Глава 15
Сравнение cin и cin.get
На рис. 15.5 сравнивается ввод из потока путем извлечения из cin (при этом
символы читаются до тех пор, пока не встретится пробельный символ) и ввод
с помощью cin.get. Обратите внимание, что в вызове cin.get (строка 24) не
специфицируется символ-ограничитель, поэтому по умолчанию принимается
символ '\п-
1 // Рис. 15.5: Figl5_05.cpp
2 // Сравнение ввода строки через cin и с помощью cin.get.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::endl;
7
8 int main()
9 {
10 // создать 2 символьных массива, каждый с 80 элементами
11 const int SIZE = 80;
12 char bufferl[ SIZE ];
13 char buffer2[ SIZE ];
14
15 // cin для ввода символов в bufferl
16 cout « "Enter a sentence:" « endl;
17 cin » bufferl;
18
19 // вывести содержимое bufferl
20 cout « "\nThe string read with cin was:" « endl
21 « buffer1 « endl « endl;
22
23 // использовать cin.get для ввода символов в buffer2
24 cin.get( buffer2, SIZE );
25
26 // вывести содержимое buffer2
27 cout « "The string read with cin.get was:" « endl
28 « buffer2 « endl;
29 return 0;
30 } // конец main
Enter a sentence:
Contrasting string input with cin and cin.get
The string read with cin was:
Contrasting
The string read with cin.get was:
string input with cin and cin.get
Рис. 15.5. Сравнение ввода из cin путем извлечения и с помощью cin.get
Элемент-функция getline
Элемент-функция getline работает подобно третьей версии функции get
и добавляет нуль-символ в конец считанной в символьный массив строки.
Функция getline удаляет из потока символ-ограничитель (т.е. читает и отбра-
Потоковый ввод/вывод
919
сывает его), но не сохраняет его в символьном массиве. Программа на рис. 15.6
демонстрирует работу функции getline при вводе строки текста (строка 15).
1 // Рис. 15.6: Figl5_06.cpp
2 // Ввод символов с помощью элемент-функции getline.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::endl;
7
8 int main()
9 {
10 const int SIZE = 80;
11 char buffer[ SIZE ]; // создать массив из 80 символов
12
13 // ввод символов в buffer функцией getline из cin
14 cout « "Enter a sentence:" « endl;
15 cin.getline( buffer, SIZE );
16
17 // вывести содержимое buffer
18 cout « "\nThe sentence entered is:" « endl « buffer « endl;
19 return 0;
20 } // конец main
Enter a sentence:
Using the getline member function
The sentence entered is:
Using the getline member function
Рис. 15.6. Ввод символьных данных с помощью элемент-функции getline
15.4.2. Элемент-функции peek, putback и ignore
класса istream
Элемент-функция ignore отбрасывает указанное число символов входного
потока (по умолчанию один) или завершается, если встретит указанный
символ-ограничитель (по умолчанию им является EOF, который заставляет
ignore пропустить все вплоть до конца файла, если чтение производится из
файла).
Элемент-функция putback возвращает обратно в поток последний символ,
полученный из входного потока функцией get. Эта функция удобна для
использования в прикладных программах, которые просматривают входной
поток в поисках фрагмента, начинающегося со специфического символа. Когда
такой символ обнаруживается, приложение возвращает его обратно в поток,
чтобы нужный фрагмент данных был считан затем целиком.
Элемент-функция peek возвращает следующий символ из входного потока,
но не удаляет его из потока.
920
Глава 15
15.4.3. Безопасный по типу ввод/вывод
C++ реализует безопасный по типу ввод/вывод. Операции « и »
перегружены для работы со специфическими типами данных. При обработке
недопустимого типа устанавливаются различные биты ошибок, которые
пользователь может проверить и определить, завершилась ли операция ввода/вывода
успешно или неудачно. Если операция « не была перегружена для
определенного пользователем типа и делается попытка ввести или вывести
содержимое объекта такого типа, компилятор сообщает об ошибке. Таким образом
программа может «держать все под контролем». Мы обсудим состояния ошибок
в разделе 15.8.
15.5. Бесформатный ввод/вывод с помощью read,
gcount и write
Бесформатный ввод/вывод выполняется соответственно
элемент-функциями read и write. Функция read вводит некоторое число байт в массив в
памяти; функция write выводит байты из массива. Эти байты никак не
форматируются. Они просто вводятся или выводятся в сыром виде. Например, в
результате вызова
char buffer[] = "HAPPY BIRTHDAY";
cout.write( buffer, 10 );
на экран будут выведены первые 10 байт массива buffer (включая
нуль-символы, которые, если бы встретились, вызвали завершение вывода в cout с
помощью «). В результате вызова
cout.write( "ABCDEFGHIJKLMNOPQRSTUVWXYZ", 10 );
будут выведены первые 10 букв алфавита.
Элемент-функция read вводит в символьный массив указанное число
символов. Если прочитано меньшее количество символов, чем требовалось,
устанавливается бит failbit. В разделе 15.8 показано, как определить состояние
этого бита. Функция gcount возвращает число символов, прочитанное
последней операцией ввода.
В программе на рис. 15.7 показан пример применения элемент-функций
read и gcount класса istream и элемент-функции write класса ostream.
Программа, используя функцию read, вводит 20 символов (из более длинной
входной строки) в символьный массив buffer (строка 15), определяет с помощью
gcount количество реально введенных символов (строка 19) и выводит
символы из buffer функцией write (строка 19).
1 // Рис. 15.7: Figl5_07.cpp
2 // Бесформатный I/O с использованием read, gcount и write.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::endl;
7
8 int main()
Потоковый ввод/вывод
921
9 {
10 const int SIZE = 80;
11 char buffer[ SIZE ]; // создать массив из 80 символов
12
13 // вызвать read для ввода символов в buffer
14 cout « "Enter a sentence:" « endl;
15 cin.read( buffer, 20 );
16
17 // использовать write и gcount для вывода символов из buffer
18 cout « endl « "The sentence entered was:" « endl;
19 cout.write( buffer, cin.gcount() );
20 cout « endl;
21 return 0;
22 } // конец main
Enter a sentence:
Using the read, write, and gcount member functions
The sentence entered was:
Using the read, writ
Рис. 15.7. Бесформатный ввод/вывод с использованием элемент-функций read,
gcount и write
15.6. Введение в манипуляторы потоков
В C++ имеются различные манипуляторы потоков, которые служат
задачам форматирования. Манипуляторы могут производить установку ширины
поля, задание точности, установку и сброс флагов форматирования, задание
символа-заполнителя, очистку потоков, передачу в выходной поток символа
новой строки (со сбросом потока), передачу в выходной поток нуль-символа,
пропуск пробельных символов во входном потоке. Эти манипуляторы
описываются в следующих разделах.
15.6.1. Основание целых чисел: dec, oct, hex и setbase
Целые числа обычно интерпретируются как десятичные (по основанию 10)
значения. Чтобы изменить основание системы счисления, в которой поток
будет интерпретировать целые числа, используют манипулятор hex для шестна-
дцатеричной системы (по основанию 16) и манипулятор oct для восьмеричной
(по основанию 8). Манипулятор потока dec возвращает поток к десятичной
системе счисления.
Основание системы счисления в потоке также можно изменить
манипулятором потока setbase у который имеет один целый аргумент, принимающий
значения 10, 8 или 16 для основания системы счисления. Поскольку
манипулятор setbase принимает аргумент, он называется параметризованным
манипулятором потока. При использовании setbase или любого другого
параметризованного манипулятора необходимо включить в программу заголовочный
файл <iomanip>. Установленное для потока основание остается в силе, пока
не будет изменено явным образом (это «залипающая» установка). На рис. 15.8
показано применение манипуляторов hex, oct, dec и ?(tbase.
922
Глава 15
1 // Рис. 15.8: Figl5_08.cpp
2 // Демонстрация потоковых манипуляторов hex, oct, dec и setbase.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::dec;
7 using std::endl;
8 using std::hex;
9 using std::oct;
10
11 #include <iomanip>
12 using std::setbase;
13
14 int main()
15 {
16 int number;
17
18 cout « "Enter a decimal number: ";
19 cin » number; // ввести число
20
21 // использование hex для вывода шестнадцатеричного числа
22 cout « number « " in hexadecimal is: " « hex
23 « number « endl;
24
25 // использование oct для вывода восьмеричного числа
26 cout « dec « number « " in octal is: "
27 « oct « number « endl;
28
29 // использование setbase для вывода десятичного числа
30 cout « setbase( 10 ) « number « " in decimal is: "
31 « number « endl;
32 return 0;
33 } // конец main
Enter a decimal number: 20
20 in hexadecimal is: 14
20 in octal is: 24
20 in decimal is: 20
Рис. 15.8. Манипуляторы потока hex, oct, dec и setbase
15.6.2. Точность чисел с плавающей точкой (precision,
setprecision)
Мы можем управлять точностью представления чисел с плавающей
точкой (т.е. числом цифр справа от десятичной точки), используя манипулятор
потока setprecision или элемент-функцию precision из класса iosjbase. И
манипулятор, и функция устанавливают точность для всех последующих
операций вывода, пока не будет задана другая точность. Элемент-функция precision
без аргумента возвращает текущую установку точности (это позволяет вам
восстановить исходную точность, когда «залипающая» установка будет более не
нужна). Программа на рис. 15.9 применяет оба способа — и функцию
precision (строка 28), и манипулятор setprecision (строка 37) — для вывода
таблицы квадратного корня из двойки с точностью, изменяющейся от О до 9.
Потоковый ввод/вывод
923
1 // Рис. 15.9: Figl5_09.cpp
2 // Управление точностью значений с плавающей точкой.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::fixed;
7
8 #include <iomanip>
9 using std::setprecision;
10
11 #include <cmath>
12 using std::sqrt; // прототип sqrt
13
14 int main()
15 {
16 double root2 = sqrt ( 2.0 ); // вычислить квадратный корень из 2
17 int places; // точность, изменяется в диапазоне 0-9
18
19 cout « "Square root of 2 with precisions 0-9." « endl
20 « "Precision set by iosjbase member function "
21 « "precision:" « endl;
22
23 cout « fixed; // применить формат с фиксированной точкой
24
25 // вывести квадратный корень, используя функцию precision
26 for ( places = 0; places <= 9; places++ )
27 {
28 cout.precision( places );
29 cout « root2 « endl;
30 } // конец for
31
32 cout « "\nPrecision set by stream manipulator "
33 « "setprecision:" « endl;
34
35 // установить очередное значение точности, затем вывести корень
36 for ( places = 0; places <= 9; places++ )
37 cout « setprecision( places ) « root2 « endl;
38
39 return 0;
40 ,} // конец main
Square root of 2 with precisions 0-9.
Precision set by ios_base member function precision:
1
1.4
1.41
1.414
1.4142
1.41421
1.414214
1.4142136
1.41421356
1.414213562
924
Глава 15
Precision set by stream manipulator setprecision:
1
1.4
1.41
1.414
1.4142
1.41421
1.414214
1.4142136
1.41421356
1.414213562
Рис. 15.9. Точность значений с плавающей точкой
15.6.3. Ширина поля (setw, width)
Элемент-функция width (из класса ios_base) устанавливает ширину поля
(т.е. число символьных позиций, в которых должно размещаться выводимое
значение, или число символов, которые нужно ввести) и возвращает
предыдущее значение ширины. В случае, если выводимые значения занимают места
меньше, чем ширина поля, в оставшихся позициях выводится
символ-заполнитель. Если вывод значения требует больше места, чем отведенная ширина
поля, усечение не производится и значение выводится полностью.
Установленное значение ширины применяется только для следующей операции передачи
или извлечения, после чего ширина поля устанавливается равной 0, т.е.
выводимые значения будут занимать поля ширины, необходимой для вывода
данного значения. Функция width без аргумента возвращает текущее значение
ширины поля.
ргт^з Типичная ошибка программирования 15.1
Установка ширины поля воздействует только на следующую
операцию передачи или извлечения (т.е. установка ширины не является
«залипающей» ); после нее ширина неявно устанавливается в О (т.е.
выводимые значения будут занимать места ровно столько, сколько
им нужно). Предположение, что установка ширины будет
относиться ко всем последующим операциям вывода, является логической
ошибкой.
ргчт^з Типичная ошибка программирования 15.2
Если поле недостаточно широко для вывода, вывод будет размещен
в поле необходимой ширины, но при этом результат вывода может
быть неудобочитаем.
На рис. 15.10 показано действие элемент-функции width при вводе и
выводе. Обратите внимание, что при вводе максимально считывается на один
символ меньше, чем ширина поля, что оставляет место для нуль-символа,
добавляемого в конец введенной строки. Помните, что операция извлечения из
потока завершается при появлении в потоке пробельного символа. Для задания
ширины поля можно также использовать манипулятор setw.
Потоковый ввод/вывод
925
1 // Рис. 15.10: Figl5_10.cpp
2 // Демонстрация элемент-функции width.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::endl;
7
8 int main()
9 {
10 int widthValue = 4;
11 char sentence[ 10 ];
12
13 cout « "Enter a sentence:" « endl;
14 cin.width( 5 ); // ввести только 5 символов предложения
15
16 // установить ширину поля, в зависимости от нее вывести символы
17 while ( cin » sentence )
18 {
19 cout.width( widthValue++ );
20 cout « sentence « endl;
21 cin.width( 5 ); // ввести еще 5 символов предложения
22 } // конец while
23
24 return 0;
25 } // конец main
Enter a sentence:
This is a test of the width member function
This
is
a
test
of
the
widt
h
memb
er
func
tion
Рис. 15.10. Элемент-функция width класса ios_base
[Замечание. Когда программа на рис. 15.10 запрашивает ввод строчки
текста, пользователь должен ввести текст и нажать Enter, после чего ввести
комбинацию «конец файла» (<ctrl>-z в системе Windows, <ctrl>-d в UNIX и
Macintosh).]
15.6.4. Определяемые пользователем манипуляторы
выходного потока
Пользователи могут создавать свои собственные манипуляторы потока. На
рис. 15.11 показано создание и проверка новых манипуляторов потока bell
(строки 10-13), carriageReturn (строки 16-18), tab (строки 22-25) и endLine
926
Глава 15
(строки 29-32). Возвращаемым типом манипуляторов выходного потока
должен быть ostream &. Когда строка 37 передает в выходной поток манипулятор
endLine, вызывается функция endLine и строка 31 передает в стандартный
выходной поток cout esc-последовательность \п и манипулятор flush.
Аналогичным образом, когда строки 37-46 передают в выходной поток
манипуляторы tab, bell и carriageReturn, вызываются их соответствующие функции —
tab (строка 22), bell (строка 10) и carriageReturn (строка 16), которые, в свою
очередь, выводят различные esc-последовательности.
1 // Рис. 15.11: Figl5_ll.cpp
2 // Создание и тестирование пользовательских
3 // непараметризованных потоковых манипуляторов.
4 #include <iostream>
5 using std::ostream;
6 using std::cout;
7 using std::flush;
8
9 // манипулятор bell (использующий escape-последовательность \a)
10 ostream& bell ( ostreamfi output )
11 {
12 return output « '\a'; // выдать системный звонок
13 } // конец манипулятора bell
14
15 // манипулятор carriageReturn (использующий последовательность \г)
16 ostream& carriageReturn( ostream& output )
17 {
18 return output « '\r'; // выдать возврат каретки
19 } // конец манипулятора carriageReturn
20
21 // tab (использующий последовательность \t)
22 оstreams tab( оstreams output )
23 {
24 return output « '\t'; // выдать табуляцию
25 } // конец манипулятора tab
26
27 // манипулятор endLine (использующий последовательность \п
28 //и элемент-функцию flush)
29 ostream& endLine( оstreams output )
30 {
31 return output « '\n' « flush; // выдать конец строки
32 } // конец манипулятора endLine
33
34 int main()
35 {
36 // использовать манипуляторы tab и endLine
37 cout « "Testing the tab manipulator:" « endLine
38 « 'a' « tab « 'b' « tab « 'с' « endLine;
39
40 cout « "Testing the carriageReturn and bell manipulators:"
41 « endLine « "
42
43 cout « bell; // use bell manipulator
44
45 // использовать манипуляторы ret и endLine
4 6 cout « carriageReturn « " " « endLine;
Потоковый ввод/вывод
927
47 return 0;
48 } // конец main
Testing the tab manipulator:
a b с
Testing the carriageReturn and bell manipulators:
Рис. 15.11. Определяемые пользователем ^параметризованные манипуляторы
15.7. Состояния формата потока и потоковые
манипуляторы
Для спецификации форматирования, которое должно выполняться при
операциях ввода/вывода, могут использоваться разнообразные манипуляторы
потоков. Манипуляторы управляют установками формата вывода. На
рис. 15.12 перечислены манипуляторы, каждый из которых управляет тем
или иным состоянием формата потока. Все они принадлежат классу ios_base.
В нескольких следующих разделах мы покажем примеры большинства из
этих манипуляторов.
Манипулятор потока
Описание
skipws
Пропускать пробельные символы во входном потоке.
Установка сбрасывается манипулятором noskipws
left
Выравнивать вывод по левому краю поля. Если необходимо,
справа выводятся заполняющие символы.
right
Выравнивать вывод по правому краю поля. Если
необходимо, слева выводятся заполняющие символы.
internal
dec
oct
hex
showbase
Указывает, что знак числа должен выравниваться по
левому, а его величина — по правому краю поля (т.е.
заполняющие символы выводятся между знаком и числом).
Указывает, что целые числа должны трактоваться как
десятичные (по основанию 10) значения.
Указывает, что целые числа должны трактоваться как
восьмеричные (по основанию 8) значения.
Указывает, что целые числа должны трактоваться как
шестнадцатеричные (по основанию 16) значения.
Выводить перед числом индикатор основания (О для
восьмеричных и Ох или ОХ для шестнадцатеричных чисел).
Установка сбрасывается манипулятором noshowbase.
showpoint
Выводить значения с плавающей точкой с обязательной
десятичной точкой. Флаг обычно используется совместно
с fixed, чтобы гарантировать вывод заданного числа цифр
справа от десятичной точки. Установка сбрасывается
манипулятором noshowpoint.
928
Глава 15
Манипулятор потока
uppercase
Описание
Указывает, что в шестнадцатеричных числах должны
выводиться буквы верхнего регистра (т.е. X и A-F )
и в научной нотации чисел с плавающей точкой должна
использоваься буква Е верхнего регистра. Установка
сбрасывается манипулятором nouppercase.
showpos
Выводить перед положительными числами знак плюс (+).
Установка сбрасывается манипулятором noshowpos.
scientific
fixed
Выводить значения с плавающей точкой в научной нотации.
Выводить значения с плавающей точкой в фиксированном
формате с заданным числом цифр справа от десятичной
точки.
Рис. 15.12. Манипуляторы состояния формата потока из <iostream>
15.7.1. Конечные нули и десятичные точки (showpoint)
Манипулятор потока showpoint используется для принудительного вывода
числа с плавающей точкой с десятичной точкой и конечными нулями.
Например, значение с плавающей точкой 79.0 без установки showpoint будет
напечатано как 79, а с установкой showpoint — как 79.000000 (количество нулей
определяется текущей точностью). Программа на рис. 15.13 демонстрирует
использование манипулятора showpoint для управления печатью конечных
нулей и десятичной точки для значений с плавающей точкой. Как вы
помните, по умолчанию точность числа с плавающей точкой равна 6. Когда не
используется ни манипулятор fixed, ни манипулятор scientific, точность задает
число выводимых значащих цифр (т.е. общее число выводимых цифр), а не
число цифр, выводимых после десятичной точки.
1 // Рис. 15.13: Figl5_13.cpp
2 // Использование showpoint для управления печатью конечных нулей
3 //и десятичной точки для типа double.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7 using std::showpoint;
8
9 int main()
10 {
11 // вывести значения типа double в формате по умолчанию
12 cout « "Before using showpoint" « endl
13 « "9.9900 prints as: " « 9.9900 « endl
14 « "9.9000 prints as: " « 9.9000 « endl
15 « "9.0000 prints as: " « 9.0000 « endl « endl;
16
17 // вывести значения типа double после showpoint
18 cout « showpoint
19 « "After using showpoint" « endl
20 « "9.9900 prints as: " « 9.9900 « endl
21 « "9.9000 prints as: " « 9.9000 « endl
Потоковый ввод/вывод
929
22 « "9.0000 prints as: " « 9.0000 « endl;
23 return 0;
24 } // конец main
Before using showpoint
9.9900 prints as: 9.99
9.9000 prints as: 9.9
9.0000 prints as: 9
After using showpoint
9.9900 prints as: 9.99000
9.9000 prints as: 9.90000
9.0000 prints as: 9.00000
Рис. 15.13. Управление печатью конечных нулей и десятичной точки в значениях
с плавающей точкой
15.7.2. Выравнивание (left, right, internal)
Манипуляторы потока left и right позволяют выводить данные в поле
соответственно или с левым выравниванием и заполняющими символами в правой
части поля, или с правым выравниванием и заполняющими символами слева.
Заполняющий символ специфицируется элемент-функцией fill или
параметризованным манипулятором setfill (который мы обсуждаем в разделе 15.7.3).
На рис. 15.14 показано использование манипуляторов setw, left и right для
управления левым и правым выравниванием целых данных.
1 // Рис. 15.14: Figl5_14.cpp
2 // Демонстрация выравнивания по правому и левому краю.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::left;
7 using std::right;
8
9 #include <iomanip>
10 using std::setw;
11
12 int main()
13 {
14 int x = 12345;
15
16 // вывести x с выравниванием вправо (по умолчанию)
17 cout « "Default is right justified:" « endl
18 « setw( 10 ) « x;
19
20 // применить манипулятор left для вывода х с выравниванием влево
21 ccut « "\n\nUse std::left to left justify x:\n"
22 « left « setw( 10 ) « x;
23
24 // применить манипулятор right для вывода с выравниванием вправо
25 cout « "\n\nUse std::right to right justify x:\n"
26 « right « setw( 10 ) « x « endl;
30 Зак 1114
930
Глава 15
27 return 0;
28 } // конец main
Default is right justified:
12345
Use std::left to left justify x:
12345
Use std:-.right to right justify x:
12345
Рис, 15.14. Выравнивание по левому и правому краю с помощью манипуляторов
left и right
Манипулятор потока internal указывает, что знак числа (или основание
системы счисления, если используется манипулятор showbase) должен
выравниваться по левому краю поля, значение числа должно быть выровнено по
правому краю, а в оставшееся пустое место должны выводиться
символы-заполнители. На рис. 15.15 показано использование потоковых манипулятора
internal для установки внутреннего выравнивания (строка 15). Обратите
внимание, что showpos принудительно выводит знак «плюс» (строка 15). Для
сброса установки showpos следует вывести манипулятор noshowpos.
1 // Рис. 15.15: Figl5_15.cpp
2 // Печать целого с внутренним выравниванием и знаком плюс.
3 #include <iostream>
4 using std::соиt;
5 using std::endl;
6 using std::internal;
7 using std::showpos;
8
9 #include <iomanip>
10 using std::setw;
11
12 int main()
13 {
14 // вывести значение с внутренним выравниванием и знаком плюс
15 cout « internal « showpos « setw( 10 ) « 123 « endl;
16 return 0;
17 } // конец main
+ 123
Рис. 15.15. Печать целого с внутренним выравниванием и знаком плюс
15.7.3. Заполнение (fill, setfill)
Элемент-функция fill определяет символ-заполнитель, используемый при
выравнивании данных в поле; если не определено иначе, для заполнения
выводятся пробелы. Функция fill возвращает значение предыдущего
заполняющего символа. Задать символ-заполнитель можно также при помощи манипу-
Потоковый ввод/вывод
931
лятора потока setfill. Пример задания символа-заполнителя приведен на
рис. 15.16, где для этой цели применяется элемент-функция fill (строка 40)
и манипулятор setfill (строки 44 и 47).
1 // Рис. 15.16: Figl5_16.cpp
2 // Использование элемент-функции fill и манипулятора setfill для
3 // замены символа заполнения в полях шире выводимых значений.
4 #include <iostream>
5 using std::cout;
6 using std::dec;
7 using std::endl;
8 using std::hex;
9 using std::internal;
10 using std::left;
11 using std::right;
12 using std::showbase;
13
14 #include <iomanip>
15 using std::setfill;
16 using std::setw;
17
18 int main()
19 {
20 int x = 10000;
21
22 // вывести х
23 cout « x « " printed as int right and left justified\n"
24 « "and as hex with internal justification.\n"
25 « "Using the default pad character (space):" « endl;
26
27 // вывести х с основанием
28 cout « showbase « setw( 10 ) « x « endl;
29
30 // вывести x с выравниванием влево
31 cout « left « setw( 10 ) « x « endl;
32
33 // вывести x как шестнадцатеричное с внутренним выравниванием
34 cout « internal « setw( 10 ) « hex « x « endl « endl;
35
36 cout « "Using various padding characters:" « endl;
37
38 // вывести х с символами заполнения (выравнивание вправо)
39 cout « right;
40 cout.fill( '*' );
41 cout « setw( 10 ) « dec « x « endl;
42
43 // вывести х с символами заполнения (выравнивание влево)
44 cout « left « setw( 10 ) « setfill( '%' ) « x « endl;
45
46 // вывести x с символами заполнения (внутреннее выравнивание)
47 cout « internal « setw( 10 ) « setfill( 'Af ) « hex
48 « x « endl;
49 return 0;
50 } // конец main
932
Глава 15
10000 printed as int right and left justified
and as hex with internal justification.
Using the default pad character (space):
10000
10000
Ox 2710
Using various padding characters:
•••••10000
10000%%%%%
0xAAAA2710
Рис. 15.16. Использование элемент-функции fill и манипулятора setfill для замены
символа заполнения в полях более широких, чем печатаемые значения
15.7.4. Основание целых чисел (dec, oct, hex, showbase)
В C++ предусмотрены манипуляторы потока dec, hex и oct для указания
того, что целые числа должны отображаться соответственно как десятичные,
шестнадцатеричные или восьмеричные значения. Если ни один из этих
манипуляторов не использован, то по умолчанию целые числа выводятся как
десятичные. При операции извлечения из потока целые числа, начинающиеся с О,
интерпретируются как восьмеричные значения, целые числа, начинающиеся
с Ох или ОХ, интерпретируются как шестнадцатеричные значения, а все
другие целые числа интерпретируются как десятичные. Если же для потока
указывается определенное основание, то все целые значения данных в этом
потоке обрабатываются с использованием этого основания до тех пор, пока не
задано новое основание или пока программа не завершится.
Манипулятор потока showbase задает принудительный вывод основания
целочисленных значений. Десятичные числа выводятся обычным способом,
восьмеричные числа выводятся с ведущим нулем, а шестнадцатеричные числа
выводятся с префиксом Ох или ОХ (как мы увидим в разделе 15.7.6, выбор
одного из этих двух вариантов определяется манипулятором потока uppercase).
На рис. 15.17 показано использование манипулятора потока showbase для
печати целых чисел в десятичном, восьмеричном и шестнадцатеричном
форматах. Для сброса установки showbase выводится манипулятор noshowbase.
1 // Рис. 15.17: Figl5_17.cpp
2 // Демонстрация манипулятора потока showbase.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::hex;
7 using std::oct;
8 using std::showbase;
9
10 int main()
11 {
12 int x = 100;
13
14 // применение showbase для отображения основания числа
15 cout « "Printing integers preceded by their base:" « endl
16 « showbase;
Потоковый ввод/вывод
933
17
18 cout « x « endl; // напечатать десятичное значение
19 cout « oct « x « endl; // восьмеричное значение
20 cout « hex « х « endl; // шестнадцатеричное значение
21 return 0;
22 } // конец main
Printing integers preceded by their base:
100
0144
0x64
Рис. 15.17. Манипулятор потока showbase
15.7.5. Числа с плавающей точкой: научная
и фиксированная нотация (scientific, fixed)
Манипуляторы потока scientific и fixed управляют форматом вывода чисел
с плавающей точкой. Манипулятор scientific задает принудительный вывод
чисел с плавающей точкой в научном формате. Манипулятор fixed задает
вывод определенного числа цифр (которое специфицируется элемент-функцией
precision или манипулятором setprecision) справа от десятичной точки. Без
использования того или иного манипулятора формат вывода определяется
значением числа с плавающей точкой.
Рис. 15.18 демонстрирует вывод чисел с плавающей точкой в
фиксированном и научном форматах с использованием манипуляторов scientific
(строка 21) и fixed (строка 25). Формат экспоненты в научной нотации может
меняться от компилятора к компилятору.
1 // Рис. 15.18: Figl5_18.cpp-
2 // Вывод значений с плавающей точкой в форматах по умолчанию,
3 // научном и фиксированном.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7 using std::fixed;
8 using std::scientific;
9
10 int mainQ
11 {
12 double x = 0.001234567;
13 double у = 1.946e9;
14
15 // вывести x и у в формате по умолчанию
16 cout « "Displayed in default format:" « endl
17 « x « '\t' « у « endl;
18
19 // вывести x и у в научном формате
20 cout « "\nDisplayed in scientific format:" « endl
21 « scientific « x « ' \t' « у « endl;
22
23 // вывести х и у в фиксированном формате
24 cout « "\nDisplayed in fixed format." « endl
25 « fixed « x « '\t' « у « endl;
934
Глава 15
26 return 0;
27 } // конец main
Displayed in default format:
0.00123457 1.946e+09
Displayed in scientific format:
1.234567e-03 1.946000e+09
Displayed in fixed format:
0.001235 1946000000.000000
Рис. 15.18. Значения с плавающей точкой, выводимые в формате по умолчанию,
научном и фиксированном
15.7.6. Управление верхним/нижним регистрами (uppercase)
Манипулятор потока uppercase выводит в верхнем регистре буквы X и Е,
используемые в шестнадцатеричном и научном форматах (рис. 15.19). Кроме
того, при использовании манипулятора uppercase в верхнем регистре
выводятся все буквы, используемые в шестнадцатеричной нотации. По умолчанию
буквы в шестнадцатеричных значениях и экспонента научной нотации
выводятся в нижнем регистре. Для сброса установки uppercase выводится
манипулятор nouppercase.
1 // Рис. 15.19: Figl5_19.cpp
2 // Манипулятор потока uppercase.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::hex;
7 using std::showbase;
8 using std::uppercase;
9
10 int main()
11 {
12 cout « "Printing uppercase letters in scientific" « endl
13 « "notation exponents and hexadecimal values:" « endl;
14
15 // std:uppercase выводит буквы в верхнем регистре; std::hex и
16 // std::showbase выводит шестнадцатеричное с его основанием
17 cout « uppercase « 4.345е10 « endl
18 « hex « showbase « 123456789 « endl;
19 return 0;
20 } // конец main
Printing uppercase letters in scientific
notation exponents and hexadecimal values:
4.345E+10
0X75BCD15
Рис. 15.19. Манипулятор потока uppercase
Потоковый ввод/вывод
935
15.7.7. Спецификация булева формата (boolalpha)
В качестве альтернативы старому стилю, где для ложных значений
использовался О, а для истинных любое ненулевое значение, в C++ предусмотрен тип
bool, который может принимать значения false или true. Переменная типа
bool по умолчанию выводится как 0 или 1. Однако мы можем применить
манипулятор потока boolalpha, чтобы выходной поток выводил булевы значения
как строки "true" и "false". Для вывода булевых значений как целых (т.е.
установки состояния потока по умолчанию) используется манипулятор потока
noboolalpha. Программа на рис. 15.20 демонстрирует эти манипуляторы.
Строка 14 выводит булево значение, установленное в строке 11 в true, в виде
целого числа. Строка 18 использует манипулятор boolalpha для вывода булева
значения в виде строки. Затем строки 21-22 изменяют булево значение и
используют манипулятор noboolalpha, так что строка 25 выводит это значение как
целое число. Строка 29 снова использует манипулятор boolalpha для вывода
булева значения в виде строки. Как boolalpha, так и noboolalpha являются
«залипающими» установками.
1 // Рис. 15.20: Figl5_20.cpp
2 // Демонстрация манипуляторов потока boolalpha и noboolalpha.
3 #include <iostream>
4 using std::boolalpha;
5 using std::cout;
6 using std::endl;
7 using std::noboolalpha;
8
9 int main()
10 {
11 bool booleanValue = true;
12
13 // вывести истинное booleanValue по умолчанию
14 cout « "booleanValue is " « booleanValue « endl;
15
16 // вывести booleanValue после применения boolalpha
17 cout « "booleanValue (after using boolalpha) is "
18 « boolalpha « booleanValue « endl « endl;
19
20 cout « "switch booleanValue and use noboolalpha" « endl;
21 booleanValue = false; // изменить booleanValue
22 cout « noboolalpha « endl; // применить noboolalpha
23
24 // вывести ложное booleanValue по умолчанию после noboolalpha
25 cout « "booleanValue is " « booleanValue « endl;
26
27 // вывести booleanValue после повторного применения boolalpha
28 cout « "booleanValue (after using boolalpha) is "
29 « boolalpha « booleanValue « endl;
30 return 0;
31 } // конец main
936
Глава 15
booleanValue is 1
booleanValue (after using boolalpha) is true
switch booleanValue and use noboolalpha
booleanValue is 0
booleanValue (after using boolalpha) is false
Рис. 15.20. Манипуляторы потока boolalpha и noboolalpha
15.7.8. Установка и сброс состояний формата с помощью
элемент-функции flags
На протяжении всего раздела 15.7 мы применяли манипуляторы для
изменения характеристик формата вывода. Теперь мы обсудим, как вернуть
формат потока к его исходному состоянию после того, как над ним были
произведены различные манипуляции. Элемент-функция flags без аргумента
возвращает текущее состояние установок формата как значение типа fmtflags (из
класса ios_base). Элемент-функция flags, вызванная с аргументом типа
fmtflags, устанавливает состояние формата в соответствии со значением
аргумента и возвращает предыдущие установки состояния. Начальные установки,
возвращаемые функцией flags, на разных системах могут быть различными.
Программа на рис. 15.21 демонстрирует применение элемент-функции flags
для сохранения исходного состояния формата (строка 22) и восстановления
исходных установок формата (строка 30).
1 // Рис. 15.21: Figl5_21.cpp
2 // Демонстрация элемент-функции flags.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::ios_base;
7 using std::oct;
8 using std::scientific;
9 using std::showbase;
10
11 int main() ■
12 {
13 int integerValue = 1000;
14 double doubleValue = 0.0947628;
15
16 // вывести flags, значения int и double (исходный формат)
17 cout « "The value of the flags variable is: " « cout.flags()
18 « "\nPrint int and double in original format:\n"
19 « integerValue « '\t' « doubleValue « endl « endl;
20
21 // использовать функцию flags для сохранения исходного формата
22 ios_base::fmtflags originalFormat = cout.flags();
23 cout « showbase « oct « scientific; // change format
24
25 // вывести flags, значения int и double (новый формат)
26 cout « "The value of the flags variable is: " « cout.flags()
27 « "\nPrint int and double in a new format:\n"
Потоковый ввод/вывод
937
28 « integerValue « ' \t' « doubleValue « endl « endl;
29
30 cout.flags( originalFormat ); // восстановить format
31
32 // вывести flags, значения int и double (исходный формат)
33 cout « "The restored value of the flags variable is: "
34 « cout.flags()
35 « "\nPrint values in original format again:\n"
36 « integerValue « '\t' « doubleValue « endl;
37 return 0;
38 } // конец main
The value of the flags variable is: 4104
Print int and double in original format:
1000 0.0947628
The value of the flags variable is: 011240
Print int and double in a new format:
01750 9.476280e-02
The restored value of the flags variable is: 4104
Print values in original format again:
1000 0.0947628
Рис. 15.21. Элемент-функция flags
15.8. Состояния ошибки потоков
Состояние потока может быть проверено при помощи битов, определенных
в классе ios_base. Чуть позже мы на примере рис. 15.22 покажем, как
проверять эти биты.
Бит eofbit входного потока устанавливается, когда в потоке встречается
конец файла. Программа может использовать элемент-функцию eof, чтобы
определить, встретился ли конец файла при попытке извлечь данные из
исчерпанного потока. Вызов
cin.eof()
возвращает true, если в cin встретился конец файла, и false в противном случае.
Бит failbit устанавливается, когда в потоке происходит ошибка
форматирования, но символы при этом не теряются. Об ошибке потоковой операции
сообщает элемент-функция fail; обычно такую ошибку можно исправить.
Установленный badbit свидетельствует о том, что произошла ошибка,
связанная с потерей данных. Об ошибке такого рода сообщает элемент-функция
bad. Вообще говоря, такая серьезная ошибка обычно неисправима.
Бит goodbit устанавливается, если для потока не установлен ни один из
битов eofbit, failbit или badbit.
Элемент-функция good возвращает true, если все функции bad, fail и eof
возвращают false. Операции ввода/вывода должны выполняться только на
«хороших» потоках.
Элемент-функция гdstate возвращает состояние потока. Например, вызов
cout.rdstatc() возвратит состояние потока cout, которое можно затем исследо-
938
Глава 15
вать при помощи оператора switch и проверить флаги eofbit, badbit, failbit
и goodbit. Но предпочтение в тестировании состояния потока следует отдать
элемент-функциям eof, bad, fail и good; при использовании этих функций
программисту не нужно хорошо знать отдельные биты состояния.
Элемент-функция clear обычно используется для восстановления
«хорошего» состояния потока, после чего на нем можно продолжать операции
ввода/вывода. Аргументом по умолчанию для clear является goodbit, так что
в результате вызова
cin.clear();
будут очищены биты ошибки потока cin и установлен goodbit. Оператор
cin.clear( ios::failbit )
устанавливает failbit. Такая операция может понадобиться для обработки
ошибок при вводе типов, определяемых пользователем. Имя clear (очистить)
может показаться в этом контексте неподходящим, но оно таково.
Программа на рис. 15.22 иллюстрирует вызовы элемент-функций rdstate,
eof, fail, bad, good и clear. [Замечание. Действительные выводимые значения
могут меняться от компилятора к компилятору.]
1 // Рис. 15.22: Figl5_22.cpp
2 // Тестирование состояний ошибки.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::endl;
7
8 int main()
9 {
10 int integerValue;
11
12 // показать результат функций cin
13 cout « "Before a bad input operation:"
14 « "\ncin.rdstate()
15 « "\n cin.eof()
16 « "\n cin.fail()
17 « "\n cin.bad()
18 « "\n cin.good()
« cin.rdstate()
« cin.eof()
« cin.fail()
« cin.bad()
« cin.good()
19 « "\n\nExpects an integer, but enter a character: ";
20
21 cin » integerValue; // ввести символьное значение
22 cout « endl;
23
24 // показать результат функций cin после ошибочного ввода
25 cout « "After a bad input operation:"
26 « "\ncin.rdstate()
27 « "\n cin.eof()
28 « "\n cin.fail()
29 « "\n cin.bad()
30 « "\n cin.good()
31
32 cin.clear(); // очистить поток
« cin.rds tate()
« cin.eof()
« cin.fail()
« cin.bad()
« cin.good() « endl « endl;
Потоковый ввод/вывод
939
33
34 // показать результат функций cin после очистки cin
35 cout « "After cin.clear()" « "\ncin.faiA () : " « cin.fail ()
36 « n\ncin.good(): " « cin.good() « endl;
37 return 0;
38 } // конец main
Before a bad input operation:
cin.rdstate(): 0
cin.eof(): 0
cin.fail () : 0
cin.bad(): 0
cin.good(): 1
Expects an integer, but enter a character: f
After a bad input operation:
cin.rdstate(): 4
cin.eof(): 0
cin.fail(): 1
cin.bad() : 0
cin.good() : 0
After cin.clear()
cin.fail() : 0
cin.good() : 1
Рис. 15.22. Тестирование состояний ошибки
Элемент-функция operator! из basic_ios возвращает true, если установлен
или badbit, или failbit, или оба бита. Элемент-функция operator void *
возвращает false (О), если установлены badbit и/или failbit. Эти функции удобны
при обработке файлов, когда в операторе выбора или повторения проверяется
условие true/false.
15.9. Привязка потока вывода к потоку ввода
Интерактивные прикладные программы обычно используют класс istream
для ввода данных и класс ostream для вывода. Часто пользователь вводит
требуемые данные в ответ на подсказку программы. Очевидно, что текст
подсказки должен появляться на экране перед операцией ввода данных, но так как
операции вывода буферизованы, то вывод появляется только тогда, когда
буфер заполнен, или очищается программой явно, или сбрасывается
автоматически по окончании ее работы. В C++ имеется элемент-функция tie для
синхронизации, т.е. «привязки» друг к другу, работы потоков istream и ostream, что
гарантирует появление вывода на экране до того, как станет выполняться
следующий за ним ввод. В вызове
cin.tie( cout );
поток cout (типа ostream) привязывается к потоку cin (типа istream). На
самом деле такой вызов избыточен, потому что C++ выполняет эту операцию
автоматически, создавая стандартную пользовательскую среду ввода/вывода.
940
Глава 15
Однако пользователю может потребоваться связывание других пар
istream/ostream. Чтобы «отвязать» входной поток input Stream от выходного
потока, используется вызов
inputstream.tie( 0 );
15.10. Заключение
Резюме
• Специфика операций ввода/вывода чувствительна к типу данных.
• В C++ ввод/вывод производится посредством потоков. Поток является
последовательностью байтов.
• Системные механизмы эффективно и надежно перемещают байты от устройств в
память и наоборот.
• В C++ имеются возможности ввода/вывода «низкого уровня» и «высокого уровня».
Низкоуровневый ввод/вывод состоит в передаче заданного числа байт от устройства
в память или из памяти устройству. Ввод/вывод высокого уровня производится
с байтами, сгруппированными в осмысленные единицы данных вроде целых чисел,
чисел с плавающей точкой, символов, строк и определяемых пользователем типов.
• В C++ возможны как бесформатные, так и форматируемые операции ввода/вывода.
Бесформатная передача данных быстра, но производится с сырыми данными,
неудобными для восприятия людьми. Форматируемый ввод-вывод производится с
осмысленными единицами данных, но требует дополнительного времени на их
обработку, что может ухудшить производительность при передаче больших объемов
данных.
• Заголовочный файл <iostream> объявляет все операции потокового ввода/вывода.
• Заголовок <iomanip> объявляет параметризованные манипуляторы потоков.
• Заголовок <fstream> объявляет операции обработки файлов.
• Шаблон basic_istream поддерживает операции потокового ввода.
• Шаблон basic_ostream поддерживает операции потокового вывода.
• Шаблон basiciostream поддерживает операции как потокового ввода, так и
потокового вывода.
• Оба шаблона basic_istream и basic_ostream являются производятся простым
наследованием от шаблона basic_ios.
• Шаблон basic_iostream производится путем сложного наследования от шаблонов
basicistream и basic_ostream.
• Для обозначения операции потокового вывода используется перегруженная
операция левого сдвига («), которая называется операцией передачи в поток.
• Для операции потокового ввода используется перегруженная операция правого
сдвига (»),'которая называется операцией извлечения из потока.
• Объект cin класса istream прикрепляется к стандартному входному устройству,
обычно клавиатуре.
• Объект cout класса ostream прикрепляется к стандартному выходному устройству,
обычно экрану монитора.
• Объект сегг класса ostream прикремляется к стандартному устройству ошибок.
Вывод в сегг небуферизован; результат каждой передачи в сегг появляется немедленно.
• Компилятор C++ автоматически определяет тип данных при вводе и выводе.
• Адреса памяти по умолчанию выводятся в шестнадцатеричном формате.
Потоковый ввод/вывод
941
• Чтобы напечатать адрес, который содержится в указателе, приведите указатель
к типу void *.
• Элемент-функция put выводит один символ. Вызовы put могут каскадироваться.
• Потоковый ввод производится перегруженной операцией извлечения из потока ».
Эта операция автоматически пропускает пробельные символы во входном потоке.
• Извлечение из потока устанавливает failbit при ошибочном вводе и badbit при
отказе операции.
• Ряд значений можно ввести, если использовать операцию извлечения из потока в
заголовке цикла while. Когда встречается конец файла, операция возвращает О.
• Элемент-функция get без аргументов вводит один символ и возвращает его. Когда
в потоке встречается конец файла, возвращается EOF.
• Элемент-функция get с символьным аргументом-ссылкой извлекает из потока ввода
следующий символ и сохраняет его в символьном аргументе. Эта версия get
возвращает ссылку на объект istream, для которого она вызывалась.
• Элемент-функция get с тремя аргументами — символьным массивом, предельным
размером и символом-ограничителем (по умолчанию это новая строка) — читает
символы из входного потока и завершается, когда либо будет введено на один символ
меньше указанного предела, либо встретится символ-ограничитель. Прочитанная
строка ограничивается нуль-символом. Символ-ограничитель не записывается
в символьный массив, но остается во входном потоке.
• Элемент-функция getline работает подобно элемент-функции get с тремя
аргументами. Функция getline удаляет ограничитель из потока ввода, но не сохраняет его
в строке.
• Элемент-функция ignore отбрасывает указанное число символов входного потока (по
умолчанию один) или завершается, если встретит указанный символ-ограничитель
(по умолчанию им является EOF).
• Элемент-функция putback возвращает обратно в поток последний символ,
полученный из входного потока функцией get.
• Элемент-функция peek возвращает следующий символ из входного потока, но не
удаляет его из потока.
• C++ реализует безопасный по типу ввод/вывод. Если операции « и » встречают
непредусмотренный тип данных, устанавливаются различные биты ошибок,
которые пользователь может проверить и определить, завершилась ли операция
ввода/вывода успешно или неудачно. Если операция « не была перегружена для
определенного пользователем типа, компилятор сообщает об ошибке.
• Бесформатный ввод/вывод выполняется элемент-функциями read и write. Эти
функции вводят в память или выводят из памяти некоторое число байт, начиная
с указанного адреса. Они вводят или выводят сырые байты без форматирования.
• Элемент-функция gcount возвращает число символов, прочитанное последней
операцией ввода.
• Элемент-функция read вводит в символьный массив указанное число символов. Если
прочитано меньшее количество символов, чем специфицировано, устанавливается
failbit.
• Чтобы изменить основание системы счисления, в которой выводятся целые числа,
используют манипулятор hex для шестнадцатеричной системы (по основанию 16)
и манипулятор oct для восьмеричной (по основанию 8). Манипулятор dec
возвращает поток к десятичной системе счисления. Основание остается тем же самым, пока не
будет явно изменено.
• Основание системы счисления при целочисленном выводе изменяет также
параметризованный манипулятор потока setbase, который принимает один целый аргумент,
принимающий значения 10, 8 или 16 для основания системы счисления.
942
Глава 15
• Управлять точностью чисел с плавающей точкой можно, используя манипулятор
потока setprecision или элемент-функцию precision. Они устанавливают точность для
всех последующих операций вывода, пока не будет сделан следующий вызов
установки точности. Вызов функции precision без аргумента возвращает текущую
установку точности.
• Параметризованные манипуляторы требуют включения заголовочного файла
<iomanip>.
• Элемент-функция width устанавливает ширину поля и возвращает предыдущее
значение ширины. Установленное значение ширины применяется только для
следующей операции передачи или извлечения; ширина поля неявно устанавливается
равной О (выводимые значения будут занимать поля ширины, необходимой для вывода
данного значения). Значения более широкие, чем отведенная ширина поля,
выводятся полностью. Ширину поля устанавливает также манипулятор setw.
• Для ввода манипулятор setw устанавливает максимальный размер строки; если
вводится более длинная строка, она разбивается на отрезки, не превышающие
установленного размера.
• Программисты могут создавать свои собственные манипуляторы.
• Манипулятор потока showpoint принудительно выводит числа с плавающей точкой
с десятичной точкой и с числом значащих цифр, определяемым точностью.
• Манипуляторы потока left и right выводят данные в поле или с левым
выравниванием и заполняющими символами в правой части поля, или с правым выравниванием
и заполняющими символами слева.
• Манипулятор потока internal указывает, что знак числа (или основание, если
используется манипулятор showbase) должен выравниваться по левому краю поля,
значение числа должно быть выровнено по правому краю, а в оставшееся пустое
место должны выводиться символы-заполнители.
• Элемент-функция fill определяет символ-заполнитель, используемый при
выравнивании данных в поле (по умолчанию принимается пробел); возвращается
предыдущий заполняющий символ. Символ-заполнитель устанавливается также
манипулятором потока setfill.
• Манипуляторы потока dec, hex и oct специфицируют, что целые числа должны
отображаться соответственно как; десятичные, шестнадцатеричные или восьмеричные
значения. Если ни один из этих манипуляторов не использован, то по умолчанию
целые числа выводятся как десятичные; извлечение из потока производится в
соответствии с формой, в которой данные вводятся.
• Манипулятор потока showbase задает принудительный вывод основания
целочисленных значений.
• Манипулятор scientific задает принудительный вывод чисел с плавающей точкой
в научном формате. Манипулятор fixed задает вывод числа с плавающей точкой
с точностью, которая специфицирована элемент-функцией precision.
• Манипулятор потока uppercase выводит в верхнем регистре буквы X и Е,
используемые соответственно в шестнадцатеричном и научном форматах. При установке
uppercase в верхнем регистре выводятся все буквы, используемые в шестнадцате-
ричной нотации.
• Элемент-функция flags без аргумента возвращает текущее состояние формата как
значение типа fmtflags. Функция flags, вызванная с аргументом типа fmtflags,
устанавливает состояние формата в соответствии со значением аргумента.
• Состояние потока можно проверить с помощью битов, определенных в классе
iosjbase.
• Бит eofbit входного потока устанавливается после того, как в потоке встречается
конец файла. Элемент-функция eof сообщает, был ли установлен eofbit.
Потоковый ввод/вывод
943
Бит failbit потока устанавливается, когда в потоке происходит ошибка
форматирования. Элемент-функция fail сообщает, был ли установлен failbit; после таких
ошибок обычно возможно восстановление.
Бит badbit потока устанавливается, если произошла ошибка, приведшая к потере
данных. Элемент-функция bad сообщает, был ли установлен badbit. Такие
серьезные ошибки обычно неисправимы.
Элемент-функция good возвращает true, если все функции bad, fail и eof возвращают
false. Операции ввода/вывода должны выполняться только на «хороших» потоках.
Элемент-функция rdstate возвращает состояние ошибок потока.
Элемент-функция clear используется для восстановления «хорошего» состояния
потока, после чего на нем можно продолжать ввод/вывод.
C++ имеется элемент-функция tie для синхронизации работы потоков istream
и ostream, что гарантирует появление вывода до выполнения последующего ввода.
Терминология
badbit
eofbit
failbit
fmtflags
f stream
ifstream
iostream
istream
ofstream
ostream
typedef
безопасный по типу ввод/вывод
бесформатный ввод/вывод
буферизация вывода
ведущий 0 (восьмеричный)
заголовочный файл <iomanip>
заполнение
класс ios_base
конец файла
манипулятор потока
манипулятор потока boolalpha
манипулятор потока dec
манипулятор потока fixed
манипулятор потока hex
манипулятор потока internal
манипулятор потока left
манипулятор потока noboolalpha
манипулятор потока noshowbase
манипулятор потока noshowpoint
манипулятор потока noshowpos
манипулятор потока noskipws
манипулятор потока nouppercase
манипулятор потока oct
манипулятор потока right
манипулятор потока scientific
манипулятор потока setbase
манипулятор потока setfill
манипулятор потока setprecision
манипулятор потока setw
манипулятор потока showbase
манипулятор потока showpoint
манипулятор потока showpos
манипулятор потока skipws
манипулятор потока uppercase
манипулятор потока width
небуферизованный вывод
операция извлечения из потока (»)
операция передачи в поток («)
параметризованный манипулятор
потока
потоковый ввод
потоковый вывод
предопределенные потоки
префикс Ох или ОХ
символ-заполнитель
символ-заполнитель по умолчанию
(пробел)
состояния формата
точность по умолчанию
форматируемый ввод/вывод
шаблон класса basic_fstream
шаблон класса basic_ifstream
шаблон класса basic_ios
шаблон класса basic_iostream
шаблон класса basic_istream
шаблон класса basic_ofstream
шаблон класса basic_ostream
ширина поля
элемент-функция bad из basic_ios
элемент-функция clear из basic_ios
элемент-функция eof из basic_ios
элемент-функция fail из basic_ios
944
Глава 15
элемент-функция fill из basic_ios
элемент-функция flags из ios_base
элемент-функция gcount из
basic_istream
элемент-функция get из basic_istream
элемент-функция getline из
basic_istream
элемент-функция good из basic_ios
элемент-функция ignore из
basic_istream
элемент-функция operator void * из
basic_ios
элемент-функция operator! из
basic ios
элемент-функция peek из
basic_istreara
элемент-функция precision из
ios_base
элемент-функция put из
basic_ostream
элемент-функция putback из
basic_istream
элемент-функция rdstate из basic_ios
элемент-функция read из
basic_istream
элемент-функция tie из basic_ios
элемент-функция write из
basic ostream
Контрольные вопросы
15.1.
15.2.
байтов.
выравнивание, являются
Заполните пропуски в следующих предложениях:
a) Ввод-вывод в C++ представляет собой обработку
b) Манипуляторами потока, форматирующими
, и .
c) Для установки и сброса состояния формата может использоваться
элемент-функция .
d) Большая часть программ на C++, производящих ввод/вывод, должна
включать заголовочный файл , содержащий объявления, необходимые
для всех операций ввода-вывода.
e) При использовании параметризованных манипуляторов должен быть включен
заголовочный файл .
f) Заголовочный файл содержит информацию для управления
обработкой файлов.
g) Элемент-функция класса ostream используется для выполнения
неформатированного вывода.
h) Операции ввода поддерживаются классом .
i) Вывод в стандартный поток ошибок направляется в объекты потоков
или .
j) Операции вывода поддерживаются классом .
к) Для операции передачи в поток используется символ .
1) Четырьмя объектами, которые соответствуют стандартным устройствам
системы, являются , , и .
т) Для операции извлечения из потока используется символ .
п) Манипуляторы потока , и используются,
чтобы задать соответственно восьмеричный, шестнадцатеричный и
десятичный форматы представления целых чисел.
о) Использование манипулятора потока . вызывает печать знака
«плюс» для положительных чисел.
Укажите, являются ли следующие утверждения верными или неверными. Если
утверждение неверно, объясните, почему.
а) Элемент-функция потока flags с аргументом типа long присваивает
переменной состояния flags значение своего аргумента и возвращает ее прежнее
значение.
Потоковый ввод/вывод
945
b) Операция передачи в поток « и операция извлечения из потока »
перегружены для обработки всех стандартных типов данных, включая строки, адреса
памяти (только для операции передачи в поток) и всех типов данных,
определенных пользователем.
c) Элемент-функция потока flags без аргументов производит сброс всех битов
флагов в переменной состояния flags.
d) Операция операция извлечения из потока » может быть перегружена с
помощью функции-операции, которая принимает ссылку на istream, ссылку на
определенный пользователем тип и возвращает ссылку на istream.
e) Операция передачи в поток « может быть перегружена с помощью
функции-операции, которая принимает ссылку на istream, ссылку на
определенный пользователем тип и возвращает ссылку на istream.
f) При вводе с помощью операции извлечения из потока » всегда происходит
пропуск ведущих пробельных символов во входном потоке.
g) Элемент-функция потока rdstate возвращает текущее состояние потока,
h) Поток cout обычно связан с экраном дисплея.
i) Элемент-функция потока good возвращает true, если все элемент-функции
bad, fail и eof возвращают false.
j) Поток класса cin обычно связан с экраном дисплея.
к) Если при операциях с потоком возникают неисправимые ошибки,
элемент-функция bad возвращает true.
1) Вывод в сегг является небуферизованным, а вывод в clog — буферизованным.
т) Манипулятор потока showpoint вызывает печать чисел с плавающей точкой
по умолчанию с точностью в шесть цифр, если только точность не была
изменена; тогда значения печатаются со специфицированной точностью.
п) Элемент-функция put из ostream выводит заданное число символов.
о) Манипуляторы потока dec, oct и hex воздействуют только на следующую
операцию вывода целого числа.
р) Адреса памяти при выводе выводятся по умолчанию как целые типа long.
15.3. Напишите по одному оператору, решающему следующие задачи:
a) Выведите строку "Enter your name: ".
b) Используйте манипулятор потока для вывода в верхнем регистре экспонент
в научной нотации и букв в шестнадцатеричных значениях.
c) Выведите адрес переменной myString типа char *.
d) Используйте манипулятор потока, гарантирующий вывод чисел с плавающей
точкой в научной нотации.
e) Выведите адрес переменной integerPrt типа int *.
f) Используйте манипулятор потока такой, чтобы при выводе целых значений
в случае восьмеричных и шестнадцатеричных значений отображалось их
основание.
g) Выведите значение типа float *, на которое указывает floatPtr.
h) Используйте элемент-функцию потока, чтобы установить '*' в качестве
заполняющего символа для печати с шириной поля, превышающей требуемую для
печатаемого значения. Напишите отдельный оператор, чтобы сделать то же
самое с помощью манипулятора потока.
i) Выведите символы 'О' и 'К' в одном операторе с помощью функции put класса
ostream.
j) Получите следующий символ из входного потока, не удаляя его из потока.
946
Глава 15
к) Введите один символ в переменную charValue типа char с помощью функции
get класса istream двумя различными способами.
1) Введите и отбросьте очередные шесть символов из входного потока.
т) Используйте элемент-функцию read класса istream для ввода 50 символов
в массив line типа char.
п) Прочитайте 10 символов в массив name. Остановите чтение, если в потоке
встретится ограничитель '.'. Не удаляйте ограничитель из входного потока.
Напишите другой оператор, который выполняет ту же задачу, но удаляет
ограничитель из входного потока.
о) Используйте элемент-функцию gcount класса istream для определения числа
символов, введенных в символьный массив line последним вызовом
элемент-функции read из istream, и выведите это число символов с помощью
элемент-функции write класса ostream.
р) Выведите следующие значения: 124, 18.376, 'Z', 1000000 и "String".
q) Напечатайте текущую установку точности с помощью элемент-функции
объекта cout.
г) Введите целое число в переменную months типа int и число с плавающей
точкой в переменную percentageRate типа float.
s) Напечатайте 1.92, 1.925 и 1.9258 с точностью в три цифры, используя
манипулятор потока.
t) Напечатайте целое число 100 в восьмеричном, шестнадцатеричном и
десятичном форматах с помощью манипуляторов потока.
и) Напечатайте целое число 100 в десятичном, восьмеричном и
шестнадцатеричном форматах, используя манипулятор потока для изменения основания.
v) Напечатайте 1234 с правым выравниванием в поле шириной 10 цифр.
w) Прочитайте символы в массив line до появления символа V, но не более 20
символов (включая ограничивающий нуль-символ). Не удаляйте
символ-ограничитель из потока.
х) Используйте целые переменные х и у, чтобы задать ширину поля и точность,
используемые для вывода значения 87.4573 типа double, и выведите это
значение.
15.4. Найдите ошибку в каждом их следующих операторов и объясните, как ее
исправить.
a) cout « "Value of x <= у is : " « х <= у;
b) Следующий оператор должен печатать целое значение 'с',
cout « •с';
c) cout « ""A string in quotes"";
15.5. Для каждого из следующих операторов покажите, что будет выведено.
a) cout « 2345" « endl; .
cout.width( 5 ) ;
cout.fill( '*' );
cout « 123 « endl « 123;
b) cout « setw( 10 ) « setfill( '$■ ) « 10000;
c) cout « setw( 8 ) « setprecision( 3 ) « 1024.987654;
d) cout « showbase « oct « 99 « endl « hex « 99;
e) cout « 100000 « endl « showpos « 100000;
f) cout « setw( 10 ) « setprecision ( 2 ) « scientific « 444.93738;
Потоковый ввод/вывод
947
Ответы на контрольные вопросы
15.1. а) потоков, b) left, right, internal, с) flags, d) <iostream>. e) <iomanip>. f)
<fstream>. g) write, h) istream. I) cerr или clog, j) ostream. k) «. 1) cin,
cout, cerr и clog, m) » . n) oct, hex, dec o) showpos.
15.2. а) Неверно. Элемент-функция потока flags с аргументом типа f rat flags
присваивает переменной состояния flags значение своего аргумента и возвращает
предыдущие установки состояния.
b) Неверно. Операции передачи в поток и извлечения из потока не перегружены
для типов, определенных пользователем. Программист при создании
собственного класса должен специально создать перегруженные
функции-операторы, чтобы перегрузить операции с потоками для определенных им типов.
c) Неверно. Элемент-функция потока flag() без аргумента возвращает текущие
установки состояния как значение типа fmtflags, представляющего
состояние формата.
d) Верно.
e) Неверно. Чтобы перегрузить операцию передачи в поток «, перегруженная
функция-операция должна принимать ссылку на ostream, ссылку на тип,
определенный пользователем, и вернуть ссылку на ostream.
f) Верно.
g) Верно,
h) Верно,
i) Верно.
j) Неверно. Поток cin связан со стандартным устройством ввода компьютера,
обычно с клавиатурой.
к) Верно.
1) Верно.
т) Верно.
п) Неверно. Элемент-функция put класса ostream выводит свой аргумент,
представляющий одиночный символ.
о) Неверно. Манипуляторы потока dec, oct и hex устанавливают основание для
вывода целых чисел, которое действует до тех пор, пока основание не будет
изменено или программа не завершится.
р) Неверно. Адреса памяти отображаются по умолчанию в шестнадцатеричном
формате. Чтобы отображать адреса как целые типа long, необходимо
привести адреса к типу long.
15.3. a) cout « "Enter your name: ";
b) cout « uppercase;
c) cout « static_cast< void * > ( my String ) ;
d) cout « scientific;
e) cout « integerPtr;
f) cout « showcase;
g) cout « *floatPtr;
h) cout.fill( •*• );
cout « setfill ( •*' ) ;
i)cout.put( 'O' ).put( 'K' );
j) cin.peek () ;
k) с = cin.get () ;
cin.get( с ) ;
948
Глава 15
l) cin . ignore ( 6 ) ;
m)cin.read( line, 50 );
n) cin.get( name, 10, '.' );
cin.getline( name, 10, '.' );
o) cout.write( line, cin.gcount() );
p) cout « 124 « 18.376 « 'Z' « 1000000 « "String";
q) cout « cout.precision();
r) cin » months » percentageRate;
s) cout « setprecisionC) « 1.92 « '\t' « 1.925 « '\t' « 1.9258;
t) cout « oct « 100 « hex « 100 « dec « 100;
u) cout « 100 « setbase( 8 ) « 100 « setbase ( 16 ) « 100;
v) cout « setw( 10 ) « 1234;
w) cin. get ( line, 20, ' z' );
x) cout « setw( x ) « sertprecision ( у ) « 87.4573;
15.4. а) Ошибка: приоритет операции « выше приоритета <=, поэтому оператор
оценивается неправильно и это приводит к ошибке компиляции.
Исправление: для исправления этого оператора заключите выражение х <= у
в скобки. Подобные ошибки будут возникать с любыми выражениями, в
которых используются операции с более низким приоритетом, чем приоритет «,
и которые не заключены в скобки.
b) Ошибка: в отличие от языка С символы в языке C++ не рассматриваются как
небольшие целые.
Исправление: чтобы напечатать численное значение символа из набора
символов компьютера, символ нужно привести к целому значению, например,
следующим образом:
cout « int( 'с' );
c) Ошибка: символы кавычек не могут быть напечатаны в строке, если не
использовать esc-последовательность.
Исправление: напечатайте строку одним из следующих способов:
cout « *"' « "A string in quotes" « '"';
cout « "\" A string in quotes \"";
15.5. a) 12345
**123
123
b) $$$$$100000
c) 1024.988
d) 0143
0x63
e) 100000
+100000
f) 4.45e+02
Упражнения
15.6. Напишите по одному оператору, выполняющему следующее:
a) Напечатайте целое число 40000 с выравниванием по левой границе поля
шириной 15 цифр.
b) Прочитайте строку в переменную символьного массива state.
c) Напечатайте число 200 со знаком и без него.
Потоковый ввод/вывод
949
d) Напечатайте десятичное значение 100 в шестнадцатеричном формате с
предшествующими символами Ох.
e) Считывайте символы в массив s, пока не встретится символ 'р', но не более 10
символов (включая завершающий нуль-символ). Извлеките указанный
ограничитель из входного потока и отбросьте его.
f) Напечатайте число 1.234 в поле шириной 9 цифр с ведущими нулями.
g) Прочитайте строку в форме "characters" из стандартного входного потока.
Сохраните строку в символьном массиве s. Удалите из входного потока кавычки.
Прочитайте максимум 50 символов (включая завершающий нуль-символ).
15.7. Напишите программу для тестирования ввода целых значений в десятичном,
восьмеричном и шестнадцатеричном форматах. Выводите каждое прочитанное
целое число во всех трех форматах. Протестируйте программу со следующими
входными данными: 10, 010, 0x10.
15.8. Напишите программу, которая печатает значения указателей, используя
приведение ко всем целым типам данных. Почему печатаются странные значения? По
чему получаются ошибки?
15.9. Напишите программу для тестирования результатов вывода на печать целого
значения 12345 и значения с плавающей точкой 1.2345 в поля разной ширины.
Что происходит, когда значения печатаются в полях, ширина которых меньше,
чем требуется для значений?
15.10. Напишите программу, которая печатает значение 100.453627, округленное до
ближайшего целого, до одной десятой, сотой, тысячной и десятитысячной.
15.11. Напишите программу, которая вводит строку с клавиатуры и определяет длину
строки. Напечатайте строку длины, вдвое превышающей ширину поля.
15.12. Напишите программу, которая преобразует температуру в целых числах по
Фаренгейту от 0 до 212 градусов к значениям с плавающей точкой температуры по
Цельсию с точностью до 3 знаков. Используйте для вычислений формулу
Celsius =5.0/9.0* ( fahrenheit - 32 ) ;
Выходные данные должны быть напечатаны в две колонки с выравниванием
вправо, причем значения температуры по Цельсию должны содержать знак и
перед положительными, и перед отрицательными температурами.
15.13. В некоторых языках программирования вводимые строки заключаются либо
в одиночные кавычки (апострофы), либо з двойные кавычки. Напишите
программу, которая читает три следующие строки: suzy, "suzy" и 'suzy'.
Игнорируются ли одиночные и двойные кавычки, или они читаются как часть строки?
15.14. На рис. 11.5 операции извлечения и передачи в поток были перегружены для
ввода и вывода объектов класса PhoneNumber. Перепишите операцию
извлечения и потока, чтобы она производила при вводе следующую проверку на
ошибку. Функцию operator» должна быть реализована заново.
a) Введите весь телефонный номер в массив. Проверьте, что введено
соответствующее число символов. Всего для телефонного номера в форме (800) 555-1212
должно быть прочитано 14 символов. Используйте элемент-функцию clear из
ios_base для установки бита failbit в случае неправильного ввода.
b) Код региона и подстанции не должны начинаться с 0 или 1. Проверьте первую
цифру в коде региона и подстанции, чтобы убедиться, что они не начинаются
ни с 0, ни с 1. Используйте элемент-функцию clear для установки флага
failbit в случае неправильного ввода.
950
Глава 15
с) Средняя цифра кода региона всегда О или 1 (хотя недавно это положение
изменилось). Проверьте среднюю цифру на 0 и 1. Используйте элемент-функцию
clear для установки флага failbit в случае неправильного ввода. Если ни одна
из приведенных выше операций не привела к установке флага failbit,
скопируйте три части телефонного номера в элементы areaCode, exchange и line
объекта класса PhoneNumber. В главной программе, если failbit установлен,
программа должна не печатать номер, а вывести сообщение об ошибке.
15.15. Напишите программу, которая реализует следующее:
a) Создайте пользовательский класс Point, который содержит закрытые
элементы данных xCoordinate и yCoordinate и объявляет перегруженные
функции-операции извлечения из потока и передачи в поток как дружественные
функции класса.
b) Определите функции-операции извлечения из потока и передачи в поток.
Функция-операция извлечения из потока должна определять, являются ли
вводимые данные корректными, и если нет, устанавливать failbit для
индикации неправильного ввода. Если произошла ошибка ввода, операция передачи
в поток не должна иметь возможности вывести объект Point.
c) Напишите функцию main, которая тестирует ввод и вывод определенного
пользователем класса Point с использованием перегруженных операций
извлечения из потока и передачи в поток.
15.16. Напишите программу, которая реализует следующее:
a) Создайте пользовательский класс Complex, который содержит закрытые
целые элементы данных real и imaginary, и объявляет перегруженные
функции-операции извлечения из потока и передачи в поток как дружественные
функции класса.
b) Определите функции-операции извлечения из потока и передачи в поток.
Функция-операция извлечения из потока должна определять, являются ли
вводимые данные корректными, и если нет, устанавливать failbit для
индикации неправильного ввода. Входные данные должны иметь форму
3 + 8i
c) Значения могут быть как положительными, так и отрицательными, и одно из
двух значений (действительная или мнимая часть) может отсутствовать. Если
значение отсутствует, то соответствующий элемент данных должен
устанавливаться равным 0. Операция передачи в поток не должна производить вывод,
если произошла ошибка ввода. Формат вывода должен быть идентичен
показанному выше формату ввода. Для отрицательных значений мнимой части
должен быть напечатан минус вместо плюса.
d) Напишите функцию main, которая тестирует ввод и вывод определенного
пользователем класса Complex с использованием перегруженных операций
извлечения из потока и передачи в поток.
15.17. Напишите программу, которая использует оператор for для печати таблицы
значений ASCII для символов из набора ASCII в диапазоне от 33 до 126. Программа
должна печатать десятичное, восьмеричное, шестнадцатеричное и символьное
значения каждого символа. Для печати целых значений используйте
манипуляторы потока dec, oct и hex.
15.18. Напишите программу, которая показывает, что каждая из элемент-функций класса
istream getline и get с тремя аргументами заканчивает ввод строки завершающим
нуль-символом. Покажите также, что get оставляет символ-ограничитель во
входном потоке, a getline извлекает символ-ограничитель и отбрасывает его. Что
происходит с непрочитанными символами в потоке?
16
Управление исключениями
ЦЕЛИ
В этой главе вы изучите:
• Что такое исключения и когда они
используются.
• Как применять try, catch и throw
соответственно для обнаружения,
обработки и сообщения
об исключениях.
• Обработку неперехваченных
и непредусмотренных исключений.
• Объявление новых классов
исключений.
• Каким образом разматывание
стека позволяет перехватывать
исключения, не перехваченные
в текущей области действия.
• Обработку отказов операции new.
• Использование auto_ptr для предотвращения утечек памяти.
• Иерархию стандартных исключений.
952
Глава 16
16.1. Введение
16.2. Обзор управления исключениями
16.3. Пример: обработка попытки деления на ноль
16.4. Когда следует применять управление исключениями
16.5. Перебрасывание исключений
16.6. Спецификации исключений
16.7. Обработка непредусмотренных искл
16.8. Разматывание стека
16.9. Конструкторы, деструкторы и управление
исключениями
16.10. Исключения и наследовани
16.11. Обработка отказов операции new
16.12. Класс autoptr и динамическое выделение памяти
16.13. Иерархия исключений стандартной библиотеки
16.14. Другие методы обработки ошибок
16.15. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
16.1. Введение
В этой главе мы представляем управление исключениями
(исключительными ситуациями). Термин «исключение» подразумевает, что проблемная
ситуация возникает нечасто — если «как правило» оператор исполняется корректно,
то «исключением из правила» является возникновение ошибки. Управление
исключениями дает программистам возможность создавать приложения,
способные разрешать (или обрабатывать) исключительные ситуации. Во многих
случаях обработка исключения позволяет программе продолжать выполнение, как
будто никакой проблемы не возникало. Более серьезная проблема может не дать
программе продолжаться нормально; в этом случае программа должна
уведомить пользователя о проблеме и затем завершиться контролируемым образом.
Средства языка, описываемые ниже, позволяют программистам писать
программы более ясные, более устойчивые, более толерантные но отношению
к ошибкам, которые способны либо решать свои проблемы и продолжаться
далее, либо аккуратно завершаться. Стиль и детали управления исключениями,
Управление исключениями
953
представленные в этой главе, основаны на работе Эндрю Кенига и Бьерна Страу-
струпа, изложенной в их статье «Exception Handling for C++ (revised)».1
Предотвращение ошибок 16.1
Управление исключениями помогает улучшить толерантность
программы по отношению к ошибкам.
Общее методическое замечание 16.1
Управление исключениями предлагает стандартный механизм для
обработки ошибок. Это особенно важно, когда над проектом
работает большая группа программистов.
Глава начинается с обзора концепций управления исключениями, затем
демонстрирует основные приемы обработки исключений. Мы показываем эти
приемы на примере обработки ситуации, когда функция пытается произвести
деление на ноль. Затем мы обсуждает дополнительные аспекты управления
исключениями, например, как обрабатывать исключения, которые
происходят в конструкторе или деструкторе, и как обрабатывать исключения,
возникающие, когда операции new не удается выделить память для объекта. Мы
завершаем главу представлением некоторых классов, предусмотренных в
стандартной библиотеке C++ для управления исключениями.
16.2. Обзор управления исключениями
В программах часто используется проверка некоторых условий для
определения дальнейших действий. Например, рассмотрим следующий псевдокод:
Выполнить задачу
Если предыдущая задача выполнилась некорректно
Выполнить обработку ошибок
Выполнить следующую задачу
Если предыдущая задача выполнилась некорректно
Выполнить обработку ошибок
В этом псевдокоде мы начинаем с выполнения некоторой задачи. Затем
проверяем корректность этого выполнения. Если задача выполнена некорректно,
мы обрабатываем ошибку. В противном случае мы переходим к следующей
задаче. Хотя такая форма обработки ошибок работает, смешивание логики
программы с логикой обработки ошибок делает программу трудной для чтения,
модификации, сопровождения и отладки, особенно в случае больших
приложений.
Koenig, A., and В. Stroustrup, «Exception Handling for C++ (revised),» Proceedings of the
Usenix C++ Conference, pp. 149 176, San Francisco, April 1990.
954
Глава 16
:<$Щ
Вопросы производительности 16.1
Если потенциальные проблемы встречаются нечасто, смешивание
программной логики с логикой обработки ошибок могут ухудшить
производительность программы, так как программа должна
(потенциально) часто производить проверки того, выполнена ли задача
корректно и следует ли перейти к следующей задаче.
Обработка исключений позволяет программисту вынести код обработки
ошибок из «генеральной линии» выполнения программы. Это улучшает
ясность программы и упрощает внесение в нее изменений. Программист может
выбрать, какие исключения нужно обрабатывать — все виды исключений,
исключения определенного типа или группу исключений родственных типов
(например, типы исключений, входящих в иерархию наследования). Такая
гибкость уменьшает вероятность того, что обработка каких-то ошибок не будет
предусмотрена, и, таким образом, делает программу более устойчивой.
В языках программирования, не поддерживающих обработку исключений,
программисты часто откладывают написание процедур обработки ошибок или
вообще забывают их написать. Получающиеся в результате программы менее
устойчивы. C++ позволяет программисту задуматься над обработкой
исключений уже при формировании концепции проекта.
16.3. Пример: обработка попытки деления на ноль
Давайте разберем простой пример управления исключениями (рис. 16.1-16.2).
Целью примера является предотвращение распространенной арифметической
ошибки — деления на ноль. В C++ деление на ноль в целой арифметике обычно
приводит к преждевременному завершению программы. В арифметике с
плавающей точкой деление на ноль допускается; его результатом является
положительная или отрицательная бесконечность, отображаемая как INF или —INF.
В данном примере мы определяем функцию с именем quotient, которая
принимает два введенных пользователем целых числа и делит свой первый
целый параметр на второй. Перед выполнением деления функция приводит
значение первого параметра к типу double. После этого значение второго целого
параметра для вычисления возводится до double. Так что функция quotient по
существу производит деление двух значений типа double и возвращает double.
Хотя в арифметике с плавающей точкой деление на ноль допускается, в целях
данного примера мы рассматриваем любую попытку деления на ноль как
ошибку. Функция quotient перед тем, как перейти к делению, проверяет второй
параметр, чтобы убедиться, что он ненулевой. Если второй параметр — ноль,
функция посредством исключения уведомляет вызывающего о возникшей проблеме.
Вызывающий (в данном случае main) может затем обработать это исключения
и дает пользователю возможность ввести два новых значения, после чего снова
вызывает quotient. Таким образом программа может продолжить исполнение,
даже если вводится неправильное значение, т.е. она делается более устойчивой.
Пример состоит из двух файлов — DivideByZeroException.h (рис. 16.1)
определяет класс исключения, представляющий тип проблемы, которая может
возникнуть в примере, a figl6_02.cpp (рис. 16.2) определяет функцию
quotient и функцию main, которая ее вызывает. Код, демонстрирующий
управление исключениями, содержится в main.
Управление исключениями
955
1 // Рис. 16.1: DivideByZeroException.h
2 // Определение класса DivideByZeroException.
3 #include <stdexcept> // заголовок stdexcept содержит runtime_error
4 using std::runtime_error; // стандартный класс runtime_error
5
6 // функции должны выбрасывать объекты DivideByZeroException
7 // при обнаружении исключений деления на ноль
8 class DivideByZeroException : public runtime_error
9 {
10 public:
11 // конструктор определяет сообщение по умолчанию
12 DivideByZeroException::DivideByZeroException()
13 : runtime_error( "attempted to divide by zero" ) {}
14 }; // конец класса DivideByZeroException
Рис. 16.1. Определение класса DivideByZeroException
1 // Рис. 16.2: Figl6_02.cpp
2 // Простой пример обработки исключений, проверяющий
3 // ошибки деления на ноль.
4 #include <iostream>
5 using std::cin;
6 using std::cout;
7 using std::endl;
8
9 #include "DivideByZeroException.h" // класс DivideByZeroException
10
11 // произвести деление и выбросить объект DivideByZeroException,
12 // если происходит деление на ноль
13 double quotient( int numerator, int denominator )
14 {
15 // выбросить DivideByZeroException при попытке деления на ноль
16 if ( denominator == 0 )
17 throw DivideByZeroException(); // завершить функцию
18
19 // возвратить результат деления
20 return static_cast< double >( numerator ) / denominator;
21 } // конец функции quotient
22
23 int main()
24 {
25 int number1; // заданный пользователем числитель
26 int number2; // заданный пользователем знаменатель
27 double result; // результат деления
28
29 cout « "Enter two integers (end-of-file to end): ";
30
31 // прочитать два целых числа, введенные пользователем
32 while ( cin » numberl » number2 )
33 {
34 // try-блок содержит код, который может выбросить исключение,
35 //и код, который не должен исполняться при исключении
36 try
37 {
956
Глава 16
38 result = quotient( number1, number2 );
39 cout « "The quotient is: " « result « endl;
40 } // конец try
41
42 // обработчик исключения обслуживает деление на ноль
43 catch ( DivideByZeroException ÷ByZeroException )
44 {
45 cout « "Exception occurred: "
4 6 « divideByZeroException.what() « endl;
47 } // конец catch
48
4 9 cout « "\nEnter two integers (end-of-file to end): ";
50 } // конец while
51
52 cout « endl;
53 return 0; // нормальное завершение
54 } // конец main
Enter two integers (end-of-file to end): 100 7
The quotient is: 14.2857
Enter two integers (end-of-file to end): 100 0
Exception occurred: attempted to divide by zero
Enter two integers (end-of-file to end): AZ
Рис, 16.2. Пример обработки исключений, выбрасывающий исключения при
попытках деления на ноль
Определение класса исключения, представляющего тип
возможной проблемы
Рис. 16.1 определяет класс DivideByZeroException как производный от
класса стандартной библиотеки runtimejerror (определенного в заголовочном
файле <stdexcept>). Класс runtime_error — производный от класса
стандартной библиотеки exception (также определенного в заголовочном файле
<stdexcept>) — является стандартным базовым классом C++ для
представления ошибок времени выполнения. Класс exception является стандартным
базовым классом C++ для всех исключений. (В разделе 16.13 обсуждаются
детали класса exception и его производных классов.) Типичный класс
исключения, производный от runtime_error, определяет только конструктор
(например, как в строках 12-13), который передает конструктору базового
класса runtime_error строку с сообщением об ошибке. Любой класс
исключения, прямо или косвенно наследующий от exception, содержит виртуальную
функцию what, которая возвращает сообщение об ошибке объекта
исключения. Заметьте, что вам не требуется определять специальный класс
исключения, подобный DivideByZeroException, как производный от стандартных
классов, предусмотренных в C++. Однако это позволяет программистам
воспользоваться виртуальной функцией what для получения соответствующего
сообщения об ошибке. Мы используем объект класса DivideByZeroException
на рис. 16.2, чтобы сигнализировать о попытке деления на ноль.
Управление исключениями
957
Демонстрация управления исключениями
Программа на рис. 16.2 использует управление исключениями,
охватывающее код, который может выбросить исключение «деление на ноль», и
выполняющее обработку этого исключения в случае, если таковое происходит.
Приложение позволяет пользователю ввести два числа, которые передаются в
качестве аргументов функции quotient (строки 13-21). Эта функция делит
первое число (numerator) на второе (denominator). В предположении, что
пользователь не указывает в качестве делителя 0, функция quotient
возвращает результат деления. Однако если пользователь вводит для делителя О,
функция выбрасывает исключение. В выводе примера первые две строчки
показывают успешное вычисление, а две следующие — неудавшееся вследствие
попытки деления на ноль. Когда возникает исключение, программа
информирует пользователя об ошибке и предлагает ему ввести два других
целых числа. После обсуждения кода мы рассмотрим ввод пользователя и
программный поток управления, приводящие к показанным результатам.
Заключение кода в try-блок
Программа начинается предложением пользователю ввести два целых
числа. Числа вводятся в условии цикла while (строка 32). После того как
пользователь введет значения, представляющие делимое и делитель, управление
переходит в тело цикла (строки 33-50). Строка 38 передает эти значения
функции quotient (строки 13-21), которая либо делит их и возвращает результат,
либо выбрасывает исключение (т.е. указывает, что произошла ошибка) при
попытке деления на ноль. Управление исключениями приспособлено к
ситуациям, когда функция, обнаружившая ошибку, не может обработать
последнюю.
Для управления исключениями в C++ предусмотрены try-блоки. Такой
блок состоит из ключевого слова try, за которым следуют фигурные скобки ({
и }), определяющие блок кода, где могут возникать исключения. В try-блок
заключаются операторы, которые могли бы вызывать исключения, а также
операторы, которые должны быть пропущены в случае, если исключение
возникает.
Обратите внимание, что в try-блоке (строки 36-40) заключены вызов
функции quotient и оператор, который выводит результат деления. В этом
примере, поскольку вызов функции quotient (строка 38) может выбросить
исключение, мы заключаем этот вызов в try-блок. Включение в try-блок оператора
вывода (строка 39) гарантирует, что вывод будет производиться только в случае,
когда quotient возвращает результат.
® Общее методическое замечание 16.2
Исключения могут возникать в коде, явно присутствующем в
try-блока, в результате вызовов других функций и более глубоко вложенных
функциональных вызовов, инициированных кодом в try-блоке.
958
Глава 16
Определение catch-обработчика для исключения
DivideByZeroException
Исключения обслуживаются catch-обработчиками (или обработчиками
исключений)у которые перехватывают и обрабатывают исключения. За
каждым try-блоком должен непосредственно следовать хотя бы один
catch-обработчик (строки 43-47). Каждый обработчик начинается ключевым словом
catch и специфицирует (в круглых скобках) параметр исключения,
представляющий тип исключений, которые могут обслуживаться данным
обработчиком (в данном случае это DivideByZeroException). Когда в try-блоке возникает
исключение, исполняется тот catch-обработчик, тип которого согласуется
с типом данного исключения (т.е. тип в catch-блоке либо совпадает с типом
выброшенного исключения, либо является его базовым классом). Если
параметр исключения содержит необязательное имя параметра, catch-обработчик
может использовать это имя в своем теле (которое заключено в фигурные
скобки) для взаимодействия с перехваченным объектом исключения. Обычно
catch-обработчик сообщает пользователю об ошибке, регистрирует ее в файле,
аккуратно завершает программу или избирает альтернативную стратегию
выполнения неудавшейся операции. В данном примере catch-обработчик просто
сообщает о том, что пользователь попытался делить на ноль. Затем программа
предлагает пользователю ввести два новых целых числа.
Типичная ошибка программирования 16.1
Размещение любого кода между try-блоком и соответствующими ему
catch-обработчиками является синтаксической ошибкой.
—*^ Типичная ошибка программирования 16,2
Каждый catch-обработчик может иметь лишь один параметр —
спецификация списка разделенных запятыми параметров исключения
является синтаксической ошибкой.
Типичная ошибка программирования 16,3
Перехват одного и того же типа в двух различных
catch-обработчиках одного try-блока является логической ошибкой.
Завершающая модель управления исключениями
Если в результате исполнения оператора в try-блоке возникает
исключение, исполнение try-блока прекращается (т.е. он немедленно завершается).
Затем программа ищет первый catch-обработчик, который может обработать тип
возникшего исключения. Программа находит подходящий обработчик,
сравнивая тип выброшенного исключения с типом параметра исключения каждого
из catch-обработчиков, пока не обнаружит согласование. Согласование имеет
место, если типы либо идентичны, либо тип выброшенного прерывания
является производным классом от типа параметра исключения. При согласовании
исполняется код, содержащийся внутри catch-обработчика. Когда обработчик
завершается достижением его закрывающей фигурной скобки (}), исключение
считается обработанным и локальные переменные, определенные внутри
Управление исключениями
959
catch-обработчика (включая параметр исключения) выходят из области
действия. Программное управление не возвращается в точку, где исключение
возникло (т. н. точку выброса), поскольку try-блок прекращен. Вместо этого
управление переходит к первому оператору (строка 49) после последнего из
catch-обработчиков, следующих за try-блоком. Это называют завершающей
моделью управления исключениями. [Замечание. В некоторых языках
используется возобновляющая модель управления исключениями, в которой после
обработки исполнение возобновляется сразу за точкой выброса.] Как и в случае
любого другого блока, при завершении try-блока определенные в нем
локальные переменные выходят из области действия.
Типичная ошибка программирования 16.4
Если вы предполагаете, что после обработки исключения управление
вернется к первому оператору за точкой выброса, могут возникнуть
логические ошибки.
Предотвращение ошибок 14.2
При наличии обработки исключений программа, после разрешения
проблемы, может продолжить исполнение (вместо того, чтобы сразу
завершиться). Это помогает в реализации устойчивых приложений,
осуществляющих то, что называют обработкой, критической в
отношении цели или критической в отношении выживания
(mission-critical or business-critical computing).
Если try-блок завершает свое исполнение успешно (т.е. никаких
исключений в нем не происходит), программа пропускает catch-обработчики и
управление переходит к первому оператору после последнего из catch-обработчиков,
следующих за try-блоком. Другими словами, если исключений в try-блоке не
происходит, программа игнорирует все его catch-обработчики.
Если для возникшего в try-блоке исключения не находится подходящего
обработчика, или если исключение возникает в операторе, не заключенном
в try-блок, функция, содержащая этот оператор, немедленно завершается,
и программа пытается найти охватывающий try-блок в вызывающей функции.
Этот процесс, обсуждаемый в разделе 16.8, называется разматыванием стека.
Поток управления в случае, когда пользователь вводит
ненулевой делитель
Рассмотрим поток управления в случае, когда пользователь вводит делимое
100 и делитель 7 (что соответствует первым двум строчкам вывода на
рис. 16.2). В строке 16 функция quotient определяет, что denominator не
равен нулю, так что строка 20 производит деление и возвращает результат
A4.2587) строке 38 как значение типа double (static_cast< double > в строке
20 гарантирует правильный тип возвращаемого значения). После строки 38
исполнение продолжается последовательно, и строка 39 выводит результат
деления, а строка 40 заканчивает try-блок. Поскольку try-блок завершился
успешно, программа не исполняет операторы внутри catch-обработчика,
и управление переходит к строке 49 (первой строке кода после
catch-обработчика), которая предлагает пользователю ввести еще два числа.
960
Глава 16
Поток управления в случае, когда пользователь вводит нулевой
делитель
Давайте теперь рассмотрим более интересный случай, когда пользователь
вводит делимое 100 и делитель 0 (что соответствует третьей и четвертой
строчкам в окне вывода на рис. 16.2). В строке 16 quotient определяет, что
denominator равен нулю, т.е. имеет место попытка деления на ноль. Строка 17
выбрасывает исключение, которое мы представляем как объект класса
DivideByZeroException (рис. 16.1).
Обратите внимание, что в строке 17 используется ключевое слово throw, за
которым следует операнд, представляющий тип исключения, которое мы
хотим выбросить. Обычно оператор throw специфицирует единственный
операнд. (В разделе 16.5 мы обсудим, каким образом используется throw без
операнда.) Операнд в операторе throw может быть любого типа. Если он является
объектом, мы называем его объектом исключения; в данном примере объект
исключения является объектом класса DivideByZeroException. Однако
операнд мог бы принимать и другие значения, например, значение выражения
(скажем, throw x > 5) или значение целого типа (throw 5). В примерах этой
главы мы имеем дело только с исключениями-объектами.
Типичная ошибка программирования 16.5
Выбрасывая в качестве исключения результат условной операции
(? :), будьте осторожны, так как правила возведения типов могут
дать тип значения, отличный от ожидаемого. Например, если в одном
и том же условном выражении выбрасывается тип int либо тип
double, значение int будет преобразовано к типу double. Таким
образом, результат всегда будет перехватываться обработчиком как
double, а не так, что при выброшенном int перехватывается int, а при
выброшенном double перехватывается double.
В процессе выбрасывания исключения создается операнд throw, которым
инициализируется параметр catch-обработчика, который мы обсудим через
минуту. В нашем примере оператор throw в строке 17 создает объект класса
DivideByZeroException. Когда строка 17 выбрасывает исключение,
происходит немедленный выход из функции quotient. Таким образом, исключение
выбрасывается до того, как функция сможет произвести деление в строке 20.
Функция должна выбрасывать исключение до того, как ошибка получит
возможность произойти.
Поскольку мы заключили вызов функции quotient (строка 38) в try-блок,
программное управление входит в catch-обработчик (строки 43-47),
непосредственно следующий за try-блоком. Этот catch-обработчик служит в качестве
обработчика для исключений типа «деление на ноль». Вообще, когда
исключение выбрасывается внутри try-блока, оно перехватывается
catch-обработчиком, который специфицирует тип, согласованный с выброшенным
исключением. В данной программе catch-обработчик специфицирует, что он
перехватывает объекты DivideByZeroException; этот тип согласуется с типом объекта,
выбрасываемого в функции quotient. На самом деле этот обработчик
перехватывает ссылку на объект DivideByZeroException, созданный оператором
throw в функции quotient (строка 17).
Управление исключениями
961
Вопросы производительности 16.2
Перехват объекта исключения по ссылке исключает накладные
расходы, на копирование объекта, представляющего выброшенное
исключение.
Хороший стиль программирования 16.1
Сопоставление каждой ошибке времени выполнения осмысленно
названного объекта улучшает ясность программы.
Тело catch-обработчика (строки 45-46) печатает ассоциированное с
исключением сообщение об ошибке, возвращаемое вызовом функции what базового
класса runtime_error. Функция возвращает строку, которую конструктор
DivideByZeroException (строки 12-13 на рис. 16.1) передает конструктору
базового класса runtime_error.
16.4. Когда следует применять управление
исключениями
Управление исключениями предназначено для обработки синхронных
ошибок, которые происходят при исполнении некоторого оператора. Типичными
примерами таких ошибок являются выход индекса за границы массива,
арифметическое переполнение (т.е. выход значения за диапазон представимых
чисел), деление на ноль, недействительные параметры функции и отказ
выделения памяти (из-за нехватки памяти). Управление исключениями не
предназначается для обработки ошибок, связанных с асинхронными событиями
(напр., завершением дискового обмена, поступлением сетевых сообщений,
щелчками мыши и нажатием клавиш на клавиатуре), которые происходят
параллельно и независимо от потока управления программы.
Общее методическое замечание 16.3
Предусмотрите в вашей системе стратегию управления
исключениями с самого начала процесса проектирования. Включение управления
исключениями в систему после того, как она реализована, может
быть затруднительном.
Общее методическое замечание 16.4
Управление исключениями предлагает единообразную методику
обработки возникающих проблем. Это помогает программистам,
работающим над большими проектами, понимать код обработки ошибок,
написанный каждым из них.
Общее методическое замечание 16.5
Избегайте использования исключений в качестве альтернативной
формы программного управления. Такие «добавочные» исключения
могут «вставать на пути» настоящих исключений, связанных с
ошибками.
31 Зак. 1114
962
Глава 16
Общее методическое замечание 16.6
Управление исключениями упрощает комбинирование компонентов
программного обеспечения и позволяет им эффективно работать
вместе, так как допускает передачу проблем от готовых компонентов
компонентам, специфическим для приложения, которые затем могут
обрабатывать проблемы некоторым специальным образом.
Механизм управления исключениями полезен также для обработки
проблем, возникающих при взаимодействии программы с такими элементами
программного обеспечения, как элемент-функции, конструкторы,
деструкторы и классы. Вместо внутренней обработки проблем такие элементы часто
используют исключения, чтобы уведомлять о них программу. Это позволяет
программистам реализовать для каждого приложения специализированную
обработку ошибок.
ЩЩ
Вопросы производительности 16.3
Когда никаких исключений не происходит, код обработки исключений
дает малые потери производительности (или вообще никаких).
Таким образом, программы, реализующие управление исключениями,
работают более эффективно, чем программы, которые совмещают код
обработки ошибок с программной логикой.
Общее методическое замечание 16.7
Функции, в которых возникают типичные состояния ошибки,
должны не выбрасывать исключения, а возвращать 0 или NULL (или
другие подходящие значения). Программа, вызывающая такую функцию,
может проверить возвращаемое значение и определить, был ли вызов
успешен или неуспешен.
Сложные приложения обычно состоят из готовых программных
компонентов и компонентов, специфических для приложения, которые их используют.
Когда готовый компонент сталкивается с проблемой, ему нужен механизм,
чтобы передать информацию о проблеме специальному компоненту; готовый
компонент не может знать заранее, каким образом каждое приложение
должно эту проблему обрабатывать.
16.5. Перебрасывание исключений
Возможны случаи, когда обработчик, перехватив возникшее исключение,
может решить, что он либо не может обработать это исключение, либо может
обработать его только частично. В таких случаях обработчик исключения может
передать обработку исключения (возможно, частично) другому обработчику.
Это достигается путем перебрасывания исключения исполнением оператора
throw;
Вне зависимости от того, способен ли обработчик обслужить исключение
(хотя бы частично), он может перебросить его для дальнейшей обработки во
Управление исключениями
963
внешнем коде. Следующий охватывающий try-блок детектирует
переброшенное исключение, которое попытается обслужить обработчик,
ассоциированный с этим try-блоком.
Типичная ошибка программирования 16.6
Исполнение пустого оператора throw, который находится вне
catch-обработчика, приводит к вызову функции terminate, которая
прерывает обработку исключения и немедленно завершает программу.
Программа на рис. 16.3 демонстрирует перебрасывание исключения.
В try-блоке функции main (строки 32-37) строка 35 вызывает функцию
throwException (строки 11-27). Эта функция также содержит try-блок
(строки 14-18), из которого оператор throw в строке 17 выбрасывает объект класса
стандартной библиотеки exception. Обработчик catch в функции
throwException (строки 19-24) перехватывает исключение, печатает сообщение об
ошибке (строки 21-22) и перебрасывает исключение (строка 23). При этом функция
throwException завершается и управление возвращается к строке 35 блока
try ...catch в main. Блок try завершается (т.е. строка 36 не исполняется) и
исключение перехватывается catch-обработчиком в main (строки 38-41),
который печатает сообщение об ошибке (строка 40). [Замечание. Поскольку мы
здесь не используем в catch-обработчиках параметры-исключения, то не
указываем имена параметров, а только тип исключения, который нужно
перехватить (строки 19 и 38).]
1 // Рис. 16.3: Figl6_03.cpp
2 // Демонстрация переброса исключения.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <exception>
8 using std::exception;
9
10 // выбросить, перехватить и перебросить исключение
11 void throwException()
12 {
13 // выбросить исключение и немедленно перехватить его
14 try
15 {
16 cout « " Function throwException throws an exception\n";
17 throw exception(); // генерировать исключение
18 } // конец try
19 catch ( exception & ) // обработать исключение
20 {
21 cout « " Exception handled in function throwException"
22 « "\n Function throwException rethrows exception";
23 throw; // перебросить исключение для дальнейшей обработки
24 } // конец catch
25
26 cout « "This also should not print\n";
27 } // конец функции throwException
28
964
Глава 16
29 int main ()
30 {
31 // выбросить исключение
32 try
33 {
34 cout « "\nmain invokes function throwException\n";
35 throwException();
36 cout « "This should not print\n";
37 } // конец try
38 catch ( exception & ) // обработать исключение
39 {
40 cout « "\n\nException handled in main\n";
41 } // конец catch
42
43 cout « "Program control continues after catch in main\n";
44 return 0;
45 } // конец main
main invokes function throwException
Function throwException throws an exception
Exception handled in function throwException
Function throwException rethrows exception
Exception handled in main
Program control continues after catch in main
Рис. 16.3. Перебрасывание исключения
16.6. Спецификации исключений
Необязательная спецификация исключений (или список throw)
перечисляет исключения, которые могут выбрасываться функцией. Рассмотрим,
например, следующее объявление функции:
int someFunction( double value )
throw ( ExceptionA, ExceptionB, ExceptionC )
{
// тело функции
}
В этом определении спецификация исключений, которая начинается
ключевым словом throw непосредственно вслед за закрывающей скобкой списка
параметров функции, указывает, что someFunction может выбрасывать
исключения типов ExceptionA, ExceptionB и ExceptionC. Функции разрешается
выбрасывать только исключения типов, перечисленных в спецификации, или
любых производных от них. Если функция выбрасывает исключение, не
принадлежащее к специфицированному типу, вызывается функция unexpected,
которая обычно завершает программу.
Функция, не определяющая спецификацию исключений, может
выбрасывать любые исключения. Размещение после списка параметров throw() —
пустой спецификации исключений — указывает, что функция не выбрасывает
исключений. Если такая функция пытается выбросить исключение, вызывается
Управление исключениями 965
unexpected. В разделе 16.7 показано, каким образом можно изменить
поведение функции unexpected посредством вызова set__unexpected.
Типичная ошибка программирования 16.7
Выбрасывание исключения, не объявленного в спецификации
исключений функции, приводит к вызову функции unexpected.
Предотвращение ошибок 16.3
Компилятор не будет генерировать сообщение об ошибке, если функция
содержит выражение throw для исключения, не перечисленного в ее
спецификации исключений. Ошибка возникает только в том случае, если
функция попытается выбросить это исключение во время исполнения.
Чтобы избежать неприятностей во время исполнения, внимательно
просмотрите ваш код и убедитесь, что функции не выбрасывают
исключений, не перечисленных в их спецификациях исключений.
16.7. Обработка непредусмотренных исключений
Функция unexpected активирует функцию, зарегистрированную вызовом
set_unexpected (определяется в заголовочном файле exception). Если никакой
функции не было зарегистрировано таким образом, по умолчанию вызывается
terminate. Функция terminate может вызываться в следующих случаях:
1. Механизм исключений не может найти для выброшенного исключения
подходящий catch.
2. Деструктор пытается выбросить исключение в процессе разматывания
стека.
3. При попытке перебросить исключение, когда в данный момент никакое
исключение не обрабатывается.
4. Вызов функции unexpected по умолчанию вызывает terminate.
(В разделе 15.5.1 Стандартного документа по C++ перечислены некоторые
дополнительные случаи.) Посредством вызова setjberminate можно
специфицировать функцию, активируемую при вызове terminate. В противном случае
terminate будет активировать функцию abort, которая завершает программу,
не вызывая никаких деструкторов еще остающихся объектов с
автоматическим или статическим классом памяти. При преждевременном завершении
программы это может приводить к утечкам ресурсов.
Обе функции set_unexpected и set_terminate возвращают указатель на
последнюю функцию, вызывавшуюся соответственно функциями unexpected
и terminate (или 0, если функция вызывается впервые). Это позволяет
программисту сохранить указатель на функцию, чтобы впоследствии ее можно
было восстановить. Функции set_unexpected и set_terminate принимают в
качестве аргумента указатель на функцию без параметров с возвращаемым
типом void.
Если последним действием определенной программистом функции
завершения не является выход из программы, будет вызвана функция abort для
завершения ее выполнения после того, как исполнятся все остальные операторы
завершающей функции.
966
Глава 16
16.8. Разматывание стека
Когда в некоторой области действия исключение выброшено, но не
перехвачено, стек функциональных вызовов начинает разматываться и делается
попытка перехватить исключение в следующем, внешнем блоке try ...catch.
Разматывание стека вызовов означает, что функция, в которой исключение не
перехвачено, завершается, все ее локальные переменные уничтожаются
и управление возвращается оператору, ранее вызвавшему эту функцию. Если
этот оператор охвачен try-блоком, делается попытка перехватить исключение.
Если оператор не охвачен try-блоком, снова происходит разматывание стека.
Если никакой catch-обработчик так и не перехватывает исключение,
вызывается функция terminate для завершения программы. Программа на рис. 16.4
демонстрирует разматывание стека.
1 // Рис. 16.4: Figl6_04.cpp
2 // Демонстрация разматывания стека.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <stdexcept>
8 using std::runtime_error;
9
10 // function3 выбрасывает ошибку времени выполнения
11 void function3() throw ( runtime_error )
12 {
13 cout « "In function 3" « endl;
14
15 // нет try-блока, стек разматывается, возврат в function2
16 throw runtime_error( "runtime_error in function3" );
17 } // конец function3
18
19 // function2 вызывает function3
20 void function2() throw ( runtime_error )
21 {
22 cout « "function3 is called inside function2" « endl;
23 function3(); // стек разматывается, возврат в functionl
24 } // конец function2
25
26 // functionl вызывает function2
27 void functionl() throw ( runtime_error )
28 {
29 cout « Mfunction2 is called inside functionl" « endl;
30 function2(); // стек разматывается, возврат в main
31 } // конец functionl
32
33 // демонстрация разматывания стека
34 int main()
35 {
36 // вызвать functionl
37 try
38 {
39 cout « "functionl is called inside main" « endl;
40 functionl(); // вызвать functionl, выбрасывающую runtime_error
Управление исключениями
967
41 } // конец try
42 catch ( runtime_error &error ) // обработать runtime_error
43 {
44 cout « "Exception occurred: " « error.what() « endl;
45 cout « "Exception handled in main" « endl;
46 } // конец catch
47
48 return 0;
49 } // конец main
functionl is called inside main
function2 is called inside functionl
function3 is called inside function2
In function 3
Exception occurred: runtime_error in function3
Exception handled in main
Рис. 16.4. Разматывание стека
Блок try в main (строки 37-41) вызывает functionl (строки 27-31). Затем
functionl вызывает function2 (строки 20-24), которая в свою очередь
вызывает function3 (строки 11-17). Строка 16 функции function3 выбрасывает
объект runtime__error. Однако поскольку оператор throw в строке 16 не охвачен
никаким try-блоком, происходит разматывание стека: выполнение function3
завершается в строке 16, и управление возвращается оператору в function2,
который вызвал function3 (т.е. строке 23). Поскольку строка 23 не охвачена
никаким try-блоком, снова происходит разматывание стека — function2
завершается в строке 23 и возвращает управление оператору в functionl,
который вызвал function2 (т.е. строке 30). Строка 30 также не охвачена
try-блоком, и стек разматывается еще раз — functionl завершается в строке 30 и
возвращает управление оператору в main, вызвавшему functionl (т.е. строке 40).
Этот оператор охвачен try-блоком в строках 37-41, поэтому первый
подходящий catch-обработчик после этого try-блока (строки 42-46) перехватывает
и обрабатывает данное исключение. В строке 44 используется функция what,
чтобы вывести сообщение об ошибке. Как вы помните, это виртуальная
функция класса exception, которую можно переопределить в производном классе,
чтобы выводилось соответствующее сообщение.
16.9. Конструкторы, деструкторы и управление
исключениями
Сначала давайте обсудим вопрос, о котором мы уже упоминали, но на
который пока не дали удовлетворительного ответа: что происходит, когда ошибка
обнаруживается в конструкторе? Например, как будет реагировать
конструктор объекта, когда операция new терпит неудачу из-за того, что не может
выделить требуемой памяти для хранения внутреннего представления объекта?
Поскольку для индикации ошибки конструктор не может возвратить
значение, мы должны найти альтернативное средство для сообщения о том, что
объект не был конструирован должным образом. Одним из возможных путей
может быть возврат неправильно конструированного объекта в надежде на то,
968
Глава 16
что тот, кто собирается с ним работать, произведет соответствующие проверки
и обнаружит, что объект находится в несогласованном состоянии. Другое
решение — установить некоторую переменную вне конструктора. Возможно,
наилучшее решение — потребовать, чтобы конструктор выбрасывал
исключение, содержащее информацию об ошибке, давая программе, таким образом,
возможность справиться с проблемой.
Исключения, выбрасываемые в конструкторе, приводят к тому, что
вызываются деструкторы для всех объектов, созданных в качестве частей
конструируемого объекта до того, как было выброшено исключение. Вызываются
деструкторы для всех автоматических объектов, конструированных в try-блоке до
исключения. Гарантируется, что к моменту начала исполнения обработчика
исключения разматывание стека будет завершено. Если деструктор,
вызванный в процессе разматывания стека, выбрасывает исключение, вызывается
terminate.
Если объект имеет элементы-объекты, и исключение выбрасывается до
того, как будет завершено конструирование внешнего объекта, то будут
исполняться деструкторы элементов-объектов, уже конструированных к моменту
возникновения исключения. Если к моменту возникновения исключения был
частично конструирован массив объектов, то будут вызваны деструкторы
только для уже конструированных объектов в массиве.
Исключение может воспрепятствовать исполнению кода, который в
нормальной ситуации освобождал бы некоторый ресурс, приводя тем самым
к утечке ресурса. Одним из методов решения этой проблемы является
инициализация локального объекта для доступа к ресурсу. Если возникнет
исключение, для этого объекта будет вызван деструктор, который сможет этот ресурс
освободить.
j£-gk Предотвращение ошибок 16.4
\jftjy Когда исключение возникает в конструкторе объекта, создаваемого
в выражении операции new, динамически выделенная для объекта
память освобождается.
16.10. Исключения и наследование
От одного общего класса исключений может производиться несколько
различных классов, о чем говорилось в разделе 16.3, где мы создали класс
DivideByZeroException в качестве производного от класса exception. Если
catch-обработчик перехватывает указатель или ссылку на объект исключения
базового класса, он может также перехватывать указатели или ссылки на все
объекты классов, являющихся открытыми производными этого базового
класса, что позволяет полиморфно обрабатывать родственные ошибки.
Управление исключениями
969
^«* Предотвращение ошибок 16.5
yf^y Совместное использование исключений и наследования позволяет
catch-обработчику обслуживать родственные ошибки с применением
весьма лаконичной нотации. Одной из методик является перехват
указателей или ссылок на объекты исключений производных классов
по отдельности, но более экономный подход — перехватывать
указатели или ссылки на объекты исключений базового класса. Кроме того,
перехват указателей или ссылок на объекты исключений
производных классов уязвим для ошибок, особенно если программист забудет
явно проверить один или несколько типов указателей или ссылок
производных классов.
16.11. Обработка отказов операции new
Стандарт C++ специфицирует, что когда операция new терпит неудачу, она
выбрасывает исключение bad_alloc (определенное в заголовочном файле
<new>). Однако некоторые компиляторы не совместимы в этом отношении со
стандартным C++ и реализуют версию new, которая при отказе возвращает О.
Например, Microsoft Visual Studio .NET при отказе new выбрасывает
исключение bad_alloc, в то время как Microsoft Visual C++ 6.0 возвращает О.
Компиляторы по-разному поддерживают обработку отказов new. Многие
старые компиляторы по умолчанию возвращают 0. Некоторые поддерживают
исключения, если включить заголовочный файл <new> (или <new.h>).
Другие по умолчанию выбрасывают bad_alloc вне зависимости от того, включен
или нет файл <new>. Справьтесь в документации по вашему компилятору,
каким образом в нем осуществляется поддержка обработки ошибок new.
В этом разделе мы представим три примера отказов операции new. В
первом из них операция при отказе возвращает 0. Во втором примере
используется версия new, при отказе выбрасывающая исключение bad_alloc. Третий
пример использует для обработки отказов функцию set__new_handler.
[Замечание. Примеры на рис. 16.5-16.7 выделяют очень большие объемы памяти,
поэтому ваш компьютер может стать довольно медлительным.]
Операция new, при отказе возвращающая 0
Рис. 16.5 демонстрирует версию new, которая при неудавшемся выделении
требуемого объема памяти возвращает 0. Оператор for в строках 13-24 должен
выполнить 50 проходов, выделяя на каждом проходе массив из 50 000 000
значений типа double (т.е. 400 000 000 байт, поскольку double обычно занимает 8
байт). Оператор if в строке 17 проверяет результат каждой из операций new,
определяя, была ли память успешно выделена. Если new терпит неудачу и
возвращает 0, строка 19 печатает сообщение об ошибке и цикл завершается. [За
мечание. Для запуска этого примера мы воспользовались компилятором
Microsoft Visual C++ 6.0, поскольку Microsoft Visual Studio .NET при отказе
new не возвращает 0, а выбрасывает исключение bad_alloc]
970
Глава 16
1 // Рис. 16.5: Figl6_05.cpp
2 // Демонстрация до-стандартной new, возвращающей 0, если память
3 //не выделена.
4 #include <iostream>
5 using std:rcerr;
6 using std::cout;
7
8 int main()
9 {
10 double *ptr[ 50 ] ;
11
12 // выделить память для ptr
13 for ( int i = 0; i < 50; i++ )
14 {
15 ptr[ i ] = new doublet 50000000 ];
16
17 if ( ptr[ i ] = 0 ) // если new не удается выделить память
18 {
19 cerr « "Memory allocation failed for ptr[ " « i « " ]\n";
20 break;
21 } // конец if
22 else// успешное выделение памяти
23 cout « "Allocated 50000000 doubles in ptr[ " « i « " ]\n";
24 } // конец for
25
26 return 0;
27 } // конец main
Allocated 50000000 doubles in ptr[ 0 ]
Allocated 50000000 doubles in ptr[ 1 ]
Memory allocation failed for ptr[ 2 ]
Рис. 16.5- Операция new, при неудаче возвращающая 0
Вывод программы показывает, что она выполнила всего две итерации,
после чего new потерпела неудачу и цикл завершился. У вас вывод программы
может отличаться от нашего в зависимости от объема физической памяти,
дискового пространства, доступного для виртуальной памяти на вашей системе,
и используемого компилятора.
Операция new, при отказе возвращающая badjalloc
Рис. 16.6 демонстрирует операцию new, которая при неудавшемся
выделении требуемого объема памяти выбрасывает исключение bad_alloc. Оператор
for (строки 20-24) внутри try-блока должен выполнить 50 проходов, выделяя
на каждом проходе массив из 50 000 000 значений типа double. Если new
терпит неудачу и выбрасывает bad_alloc, цикл завершается и программа
продолжается со строки 28, где catch-обработчик перехватывает и обрабатывает
исключение. Строки 30-31 печатают сообщение "Exception occurred:", за
которым следует сообщение об ошибке, возвращаемое функцией what базового
класса exception (т.е. определяемое реализацией и специфическое для
исключения сообщение, например, в Microsoft Visual Studio .NET 2003 это
"Allocation Failure"). Вывод показывает, что программа выполнила всего две
Управление исключениями
971
итерации цикла, после чего new потерпела неудачу и выбросила исключение
bad_alloc. У вас вывод программы может отличаться от нашего в зависимости
от объема физической памяти, дискового пространства, доступного для
виртуальной памяти на вашей системе, и используемого компилятора.
1 // Рис. 16.6: Figl6_06.cpp
2 // Демонстрация стандартной new, выбрасывающей bad_alloc,
3 // если память не может быть выделена.
4 #include <iostream>
5 using std::cerr;
6 using std::cout;
7 using std::endl;
8
9 #include <new> // стандартная операция new
10 using std::bad_alloc;
11
12 int main()
13 {
14 double *ptr[ 50 ];
15
16 // выделить память для ptr
17 try
18 {
19 // выделить память для ptr[ i ] ; new выбрасывает bad_alloc
20 for ( int i = 0; i < 50; i++ )
21 {
22 ptr[ i ] = new double[ 50000000 ]; // возможно исключение
23 cout « "Allocated 50000000 doubles in ptr[ " « i « " ] \n" ;
24 } // конец for
25 } // конец try
26
27 // обработать исключение bad_alloc
28 catch ( bad_alloc fimemoryAllocationException )
29 {
30 cerr « "Exception occurred: "
31 « memoryAllocationException.what() « endl;
32 } // конец catch
33
34 return 0;
35 } // конец main
Allocated 50000000 doubles in ptr[ 0 ]
Allocated 50000000 doubles in ptr[ 1 ]
Exception occurred: bad alloc exception thrown
Рис. 16.6. Операция new, выбрасывающая при неудаче bad.alloc
Стандарт C++ специфицирует, что совместимые с ним компиляторы могут
допускать использование версии new, при отказе возвращающей О. Для этой
цели заголовочный файл <new> определяет объект nothrow (типа nothrow_t),
используемый следующим образом:
double *ptr = new( nothrow ) doublet 50000000 ];
972
Глава 16
Этот оператор для выделения массива из 50 000 000 значений типа double
использует версию new, не выбрасывающую исключений bad_alloc.
Общее методическое замечание 16.8
Чтобы программы были более устойчивыми, применяйте версию new,
которая при отказе выбрасывает исключение badjalloc.
Обработка отказов new с использованием функции
set_new_handler
Существует дополнительное средство, которое можно применить для
реализации обработки отказов new. Функция set_new_handler (с прототипом в
заголовочном файле <new>) принимает в качестве аргумента указатель на
функцию, которая не принимает аргументов и возвращает void. Этот указатель
регистрируется как функция, которая должна вызываться при отказах new. Тем
самым программисту предоставляется стандартный метод обработки всех
отказов new вне зависимости от того, в каком месте программы возникла
ошибка. После того как обработчик new зарегистрирован в программе вызовом
set_new_handler, операция new при отказах не будет выбрасывать
исключений bad_alloc; вместо этого она будет пересылать ошибку
зарегистрированному обработчику.
Если new удалось выделить память, она возвращает указатель на нее. Если
память выделить не удается и никакой функции обработчика new с помощью
set__new_handler зарегистрировано не было, операция new выбрасывает
исключение bad_alloc. Если память выделить не удается и была
зарегистрирована функция обработчика new, то вызывается эта функция. Стандарт C++
определяет, что функция обработчика new должна выполнить одно из следующих
действий:
1. Увеличить объем доступной памяти путем освобождения других областей
динамической памяти (либо попросить пользователя закрыть другие
приложения) и возвратиться к операции new, чтобы возобновить
попытки выделения памяти.
2. Выбросить исключение типа bad_alloc.
3. Вызвать функцию abort или exit (обе из заголовочного файла <cstdlib>)
для завершения программы.
Программа на рис. 16.7 демонстрирует set_new_handler. Функция
customNewHandler (строки 14-18) печатает сообщение об ошибке (строка 16),
а затем завершает программу вызовом abort (строка 17). Вывод показывает,
что программа выполнила всего две итерации цикла, после чего new потерпела
неудачу и активировала функцию customNewHandler. У вас вывод
программы может отличаться от нашего в зависимости от объема физической памяти,
дискового пространства, доступного для виртуальной памяти на вашей
системе, и используемого компилятора.
Управление исключениями
973
1 // Рис. 16.7: Figl6_07.cpp
2 // Демонстрация set_new__handler.
3 #include <iostream>
4 using std::cerr;
5 using std::cout;
6
7 #include <new> // стандартная операция new и set__new_handler
8 using std::set_new_handler;
9
10 #include <cstdlib> // прототип функции abort
11 using std::abort;
12
13 // обработать неудачу выделения памяти
14 void customNewHandler()
15 {
16 cerr « "customNewHandler was called";
17 abort();
18 } // конец функции customNewHandler
19
20 // применение set_new__handler для обработки исключения new
21 int main()
22 {
23 double *ptr[ 50 ];
24
25 // указать, что при неудачном выделении памяти
26 // должна вызываться функция customNewHandler
27 set__new_handler ( customNewHandler );
28
29 // выделить память для ptr[ i ] ; при неудаче выделения памяти
30 // будет вызвана функция customNewHandler
31 for ( int i = 0; i < 50; i++ )
32 {
33 ptr[ i ] = new doublet 50000000 ]; // возможно исключение
34 cout « "Allocated 50000000 doubles in ptr[ " « i « " ]\n" ;
35 } // конец for
36
37 return 0;
38 } // конец main
Allocated 50000000 doubles in ptr[ 0 ]
Allocated 50000000 doubles in ptr[ 1 ]
customNewHandler was called
Abnormal program termination
Рис. 16.7. Спецификация функции, вызываемой при отказе new
16.12. Класс auto_ptr и динамическое выделение
памяти
Обычной программной практикой программирования является выделение
динамической памяти, присваивание адреса этой памяти указателю,
использование этого указателя для манипулирования памятью и освобождение
памяти с помощью delete, когда она больше не нужна. Если после того, как память
была выделена, но до того, как будет выполнен оператор delete, возникает ис-
974
Глава 16
ключение, может иметь место утечка памяти. Для разрешения такой
ситуации в стандартной библиотеке C++ (в заголовочном файле <тетогу>) имеется
шаблон класса auto_ptr.
Объект класса auto_ptr хранит указатель на динамически выделенную
память. Когда объект auto_ptr выходит из области действия, он выполняет над
своим элементом-указателем операцию delete. Шаблон класса auto_ptr
предусматривает перегруженные операции * и —>, чтобы с объектом auto_ptr
можно было обращаться как с обычной переменной-указателем. Рис. 16.10
демонстрирует объект auto_ptr, который указывает на динамически выделенный
объект класса Integer (рис. 16.8-16.9).
1 // Рис. 16.8: Integer.h
2 // Определение класса Integer.
3
4 class Integer
5 {
6 public:
7 Integer( int i = 0 ); // конструктор Integer по умолчанию
8 -'Integer () ; // деструктор Integer
9 void setlnteger( int i ); // установить значение Integer
10 int getlnteger() const; // возвратить значение Integer
11 private:
12 int value;
13 }; // конец класса Integer
Рис. 16.8. Определение класса Integer
1 // Рис. 16.9: Integer.cpp
2 // Определение элемент-функций класса Integer.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Integer.h"
8
9 // конструктор Integer по умолчанию
10 Integer::Integer( int i )
11 : value( i )
12 {
13 cout « "Constructor for Integer " « value « endl;
14 } // конец конструктора Integer
15
16 // деструктор Integer
17 Integer::^Integer()
18 {
19 cout « "Destructor for Integer " « value « endl;
20 } // конец деструктора Integer
21
22 // установить значение Integer
23 void Integer::setlnteger( int i )
24 {
25 value = i;
26 } // конец функции setlnteger
Управление исключениями
975
27
28 // возвратить значение Integer
29 int Integer::getlnteger() const
30 {
31 return value;
32 } // конец функции getlnteger
Рис. 16.9. Определение элемент-функций класса Integer
1 // Рис. 16.10: Figl6_10.cpp
2 // Демонстрация auto_ptr.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <memory>
8 using std::auto_ptr; // определение класса auto_ptr
9
10 #include "Integer.h"
11
12 // применение auto_ptr для управления объектом Integer
13 int main ()
14 {
15 cout «"Creating an auto_ptr object that points to an Integer\n";
16
17 // "нацелить" auto_ptr на объект Integer
18 auto_ptr< Integer > ptrToInteger( new Integer( 7 ) );
19
20 cout « "\nUsing the auto__ptr to manipulate the Integer\n";
21 ptrToInteger->setInteger( 99 ); // установить значение Integer
22
23 // получить значение Integer через auto_ptr
24 cout «"Integer after setlnteger: M«(*ptrToInteger) .getlnteger ()
25 « "\n\nTerminating program" « endl;
26 return 0;
27 } // конец main
Creating an auto_ptr object that points to an Integer
Constructor for Integer 7
Using the auto_ptr to manipulate the Integer
Integer after setlnteger: 99
Terminating program
Destructor for Integer 99
Рис. 16.10. Объект auto_ptr управляет динамически выделяемой памятью
Строка 18 на рис. 16.10 создает объект ptrToInteger класса auto_ptr и
инициализирует его указателем на динамически выделенный объект Integer,
содержащий значение 7. Строка 21 применяет перегруженную операцию —>
класса auto__ptr для вызова функции setlnteger объекта Integer, на который
указывает ptrToInteger. Строка 24 применяет перегруженную операцию *
976
Глава 16
класса auto_ptr для разыменования ptrToInteger, а после этого использует
операцию-точку (.) для вызова функции getlnteger объекта Integer, на
который указывает ptrToInteger. Как и с обычным указателем, для доступа к
объекту, на который указывает auto_ptr, могут применяться операции -> и *.
Поскольку ptrToInteger является локальной автоматической переменной
в main, при завершении main ptrToInteger уничтожается. Деструктор
autojtr принудительно применяет delete к объекту Integer, на который
указывает ptrToInteger, что в свою очередь приводит к вызову деструктора класса
Integer. Память, занимаемая объектом Integer, освобождается вне
зависимости от того, каким образом управление покидает блок (напр., по оператору
return или из-за исключения). Самое важное здесь то, что такая методика
может предотвратить утечки памяти. Предположим, например, что функция
возвращает указатель, нацеленный на некоторый объект. Если вызывающая
функция, получающая этот указатель, не удаляет объект, возникает утечка
памяти. Однако если функция возвращает указывающий на объект auto_ptr,
объект будет автоматически удален при вызове деструктора объекта auto_ptr.
Объект auto_ptr может передавать «права» на контролируемую им
динамическую память посредством своей перегруженной операции присваивания или
конструктора копии. Последний объект auto_ptr, контролирующий указатель
на динамическую память, удалит ее. Это делает auto_ptr идеальным
инструментом для возврата коду клиента динамически выделенной памяти. Когда
auto_ptr в коде клиента выходит из области действия, его деструктор удаляет
динамическую память.
I ^ | Общее методическое замечание16.9
JHMjt. Имеются ограничения на некоторые операции с auto_ptr. Например,
auto_ptr не может указывать на массив или стандартный
контейнерный класс.
16.17. Иерархия исключений стандартной библиотеки
Опыт показывает, что исключения можно четко разделить на ряд
категорий. Стандартная библиотека C++ реализует иерархию классов исключений.
Вершиной иерархии является базовый класс exception (определенный в
заголовочном файле <exception>), который содержит функцию what(),
переопределяемую в каждом производном классе для выдачи соответствующего
сообщения об ошибке.
Непосредственными производными классами базового класса exception
являются runtime_error и logic_error (оба определены в заголовочном файле
<stdexcept>), каждый из которых имеет несколько производных классов.
Кроме того, производными от exception являются исключения, генерируемые
операциями C++, например, bad_alloc, которое выбрасывается операцией new
(раздел 16.11), bad_cast, выбрасываемое операцией dynamiccast (глава 13)
и badjtypeidy выбрасываемое typeid (глава 13). Если включить в список throw
функции спецификацию bad_exception, то при появлении
непредусмотренного исключения unexpected сможет выбрасывать bad_exception — вместо
завершения программы (по умолчанию) или вызова другой функции,
зарегистрированной в set_unexpected.
Управление исключениями
977
Класс logic_error является базовым классом нескольких стандартных
классов исключений, указывающих на ошибки в программной логике. Класс
invalid_argument указывает, что функции был передан недопустимый
аргумент. (Правильное написание кода может, конечно, предотвратить передачу
функции недопустимых аргументов). Класс length_error указывает, что для
объекта была использована длина, большая максимально допустимой для
объекта, над которым выполняются манипуляции. Класс outjof_range
указывает, что значение, например, индекса массива находится вне допустимого
диапазона.
Класс runtime_error является базовым классом нескольких других
стандартных классов исключений, указывающих на ошибки времени выполнения.
Класс overflow_error указывает на ошибку арифметического переполнения
(т.е. результат арифметической операции превосходит максимальное число,
которое может хранить компьютер). Класс underflow_error указывает на ошибку
исчезновения арифметического порядка (т.е. результат арифметической
операции меньше минимального числа, которое может хранить компьютер).
Типичная ошибка программирования 16.9
Определяемые пользователем классы исключений не обязательно
должны производиться от exception. Так что написание catch(
exception anyException ) не гарантирует перехвата всех исключений,
которые могут встретиться в программе.
Предотвращение ошибок 16.6
Для перехвата всех исключений, которые могут быть выброшены
в try-блоке, используйте catch(...). Одним из слабых мест такого
перехвата исключений является то, что тип перехваченного
исключения неизвестен во время компиляции. Другая слабость состоит в том,
что без именованного параметра невозможно сослаться на объект
исключения внутри обработчика исключения.
Общее методическое замечание 16.10
Иерархия стандартных исключений exception хороша в качестве
некоторой «отправной точки». Программисты могут строить
программы, которые выбрасывают стандартные исключения, производные
от стандартных исключений или свои собственные исключения, не
являющиеся производными от стандартных.
Общее методическое замечание 16.11
Для процедуры восстановления после ошибок, не зависящей от типа
исключения (напр., для освобождения общих ресурсов), используйте
catchf...). Для активации более специфических catch-обработчиков
исключение может быть переброшено.
978 Глава 16
16.14. Другие методы обработки ошибок
Выше мы обсудили несколько способов разрешения исключительных
ситуаций. Подытожим уже сказанное, а также некоторые другие методики
обработки ошибок:
• Игнорирование исключения. Если возникает исключение, программа
вполне может аварийно завершиться благодаря неперехваченному
исключению. Это губительно для коммерческого продукта или программ
специального назначения, разработанных для критических в отношении
цели ситуаций, но в программах, разрабатываемых для ваших
собственных нужд, игнорирование многих видов ошибок является обычным
делом.
Типичная ошибка программирования 16.10
Аварийное завершение программы из-за неперехваченного исключения
может оставить ресурс — например, файловый поток или
устройство ввода/вывода — в таком состоянии, что другие программы не
смогут получить к нему доступ. Это называют «утечкой ресурса».
• Завершение программы. Это, разумеется, не даст программе
выполниться до конца с выдачей неправильных результатов. Для многих видов
ошибок это приемлемо, особенно в случае нефатальных ошибок, которые
позволяют программе выполняться до завершения (возможно, вводя
программиста в заблуждение относительно правильности своего
функционирования). Подобная стратегия недопустима в случае приложений,
критических в отношении цели. Важны здесь и вопросы ресурсов. Если
программа получает ресурс, она должна освободить его до своего
завершения.
• Установка индикаторов ошибки. Проблема при таком подходе состоит
в том, что программа может не проверять эти индикаторы во всех тех
местах, где ошибки могут причинить неприятности.
• Проверить состояние ошибки, вывести сообщение об ошибке и вызвать
exit (из <cstdlib>) с соответственным кодом для передачи программной
среде.
• Использование функций set jump и longjump. Эти библиотечные
функции из <csetjmp> позволяют программисту специфицировать
непосредственный переход из глубоко вложенного вызова функции к обработчику
ошибки. Без setjump и longjump программе потребовалось бы выполнить
несколько возвратов, чтобы выйти из вложенных функциональных
вызовов. Функции setjump и longjump небезопасны, так как они
разматывают стек без вызова деструкторов для автоматических объектов. Это
может порождать серьезные проблемы.
• Для некоторых специфических типов ошибок существуют специальные
методики обработки. Например, когда операции new не удается
выделить память, для обработки отказа может быть исполнена функция
new_handler. Эта функция может быть специализирована путем
передачи имени в качестве аргумента set_new_handler, как обсуждалось в
разделе 16.11.
Управление исключениями
979
16.15. Заключение
В этой главе вы узнали, как использовать управление исключениями для
обработки ошибок в программе. Вы узнали, что управление исключениями
позволяет программисту убрать код обработки ошибок из «основной линии»
потока исполнения программы. Мы продемонстрировали управление
исключениями в контексте примера с делением на ноль. Мы также показали, как
заключать в try-блоки код, который может выбрасывать исключения, и как
использовать catch-обработчики для обслуживания исключений, которые
могут возникать. Вы узнали, как выбрасывать и перебрасывать исключения,
и как обрабатываются исключения, которые могут происходить в
конструкторах. В главе были далее рассмотрены вопросы обработки отказов new,
динамического распределения памяти с помощью класса auto_ptr и иерархия
исключений стандартной библиотеки. В следующей главе вы узнаете об обработке
файлов, включая то, каким образом сохраняются устойчивые данные и как
с ними обращаться.
Резюме
• Исключение является индикацией проблемы, возникшей во время исполнения
программы.
• Управление исключениями позволяет программистам создавать программы,
способные разрешать возникающие во время исполнения проблемы, — иногда разрешая
программе продолжать выполняться, как если бы никаких проблем не было. Более
серьезные проблемы могут потребовать, чтобы программа уведомила пользователя
о проблеме и завершиться контролируемым образом.
• Управление исключениями позволяет программисту убрать код обработки ошибок
из «основной линии» потока исполнения программы, что улучшает ясность
программного кода и облегчает его модификацию.
• В C++ используется завершающая модель управления исключениями.
• Блок try состоит из ключевого слова try, за которым следуют фигурные скобки ({}),
определяющие блок кода, в котором могут происходить исключения. Блок try
содержит операторы, способные приводить к исключениям, и операторы, которые н
должны исполняться, если исключения происходят.
• Непосредственно за try-блоком должен следовать хотя бы один catch-обработчик.
Каждый catch-обработчик специфицирует параметр исключения, определяющий
тип исключения, который может обслуживаться обработчиком.
• Если параметр исключения содержит необязательное имя параметра,
catch-обработчик может использовать это имя для взаимодействия с объектом перехваченного
исключения.
• Точка программы, где происходит исключение, называется точкой выброса.
• Если в try-блоке происходит исключение, исполнение блока заканчивается и
управление переходит к первому catch-обработчику, тип параметра которого согласуется
с типом выброшенного исключения.
• Когда try-блок завершается, определенные в нем локальные переменные выходят из
области действия.
• Если исполнение try-блока завершается в результате возникающего исключения,
программа ищет первый catch-обработчик, который может обработать тип
возникшего исключения. Программа находит подходящий обработчик, сравнивая тип
выброшенного исключения с типом параметра исключения каждого из
catch-обработчиков, пока не обнаружит согласование. Согласование имеет место, если типы либо
980
Глава 16
идентичны, либо тип выброшенного прерывания является производным классом от
типа параметра исключения. При согласовании исполняется код, содержащийся
внутри catch-обработчика.
• Когда catch-обработчик заканчивает свою работу, его параметр и определенные
внутри него локальные переменные выходят из области действия, оставшиеся
catch-обработчики данного try-блока игнорируются и исполнение продолжается
с первой строки кода после структуры try ...catch.
• Если никаких исключений в try-блоке не происходит, программа пропускает
catch-обработчики данного блока. Исполнение программы продолжается со
следующего оператора после структуры try ...catch.
• Если для возникшего в try-блоке исключения не находится подходящего
обработчика, или если исключение возникает в операторе, не заключенном в try-блок,
функция, содержащая этот оператор, немедленно завершается, и программа пытается
найти охватывающий try-блок в вызывающей функции. Этот процесс называется
разматыванием стека.
• Управление исключениями предназначено для обработки синхронных ошибок,
которые происходят при исполнении некоторого оператора.
• Управление исключениями не предназначается для обработки ошибок, связанных
с асинхронными событиями, которые происходят параллельно и независимо от
потока управления программы.
• Чтобы выбросить исключение, используйте ключевое слово throw с последующим
операндом, представляющим тип выбрасываемого исключения. Обычно оператор
throw специфицирует единственный операнд.
• Операнд throw может быть любого типа.
• Обработчик исключения может передать обработку исключения (или, возможно,
часть ее) другому обработчику. В обоих случаях это достигается путем
перебрасывания исключения.
• Типичными примерами исключений являются выход индекса за границы массива,
арифметическое переполнение, деление на ноль, недействительные параметры
функции и отказ выделения памяти.
• Стандартным базовым классом C++ для исключений является класс exception.
В классе предусмотрена виртуальная функция what, которая возвращает
соответствующее сообщение об ошибке и может быть переопределена в производных классах.
• Необязательная спецификация исключений перечисляет исключения, которые
могут выбрасываться функцией. Функции разрешается выбрасывать только
исключения типов, перечисленных в спецификации, или любых производных от них. Если
функция выбрасывает исключение, не принадлежащее к специфицированному
типу, вызывается функция unexpected, которая обычно завершает программу.
• Функция, не определяющая спецификацию исключений, может выбрасывать любые
исключения. Пустая спецификация исключений throw() указывает, что функция не
выбрасывает исключений. Если такая функция пытается выбросить исключение,
вызывается unexpected.
• Функция unexpected активирует функцию, зарегистрированную вызовом
set_unexpected. Если никакой функции не было зарегистрировано таким образом,
по умолчанию вызывается terminate.
• Посредством вызова set_terminate можно специфицировать функцию,
активируемую при вызове terminate. В противном случае terminate будет активировать
функцию abort, которая завершает программу, не вызывая никаких деструкторов еще
остающихся объектов, объявленных как static или auto.
Управление исключениями
981
• Обе функции set_unexpected и set_terminate возвращают указатель на последнюю
функцию, вызывавшуюся соответственно функциями unexpected и terminate (или
О, если функция вызывается впервые). Это позволяет программисту сохранить
указатель на функцию, чтобы впоследствии ее можно было восстановить.
• Функции set_unexpected и set_terminate принимают в качестве аргумента
указатель на функцию без параметров с возвращаемым типом void.
• Если последним действием определенной программистом функции завершения не
является выход из программы, будет вызвана функция abort для завершения ее
выполнения после того, как исполнятся все остальные операторы завершающей
функции.
• Разматывание стека вызовов означает, что функция, в которой исключение не
перехвачено, завершается, все ее локальные переменные уничтожаются и управление
возвращается оператору, ранее вызвавшему эту функцию.
• Класс runtime_error (определенный в заголовке <stdexcept>) является стандартным
базовым классом C++ для представления ошибок времени выполнения.
• Исключения, выбрасываемые в конструкторе, приводят X тому, что вызываются
деструкторы для всех объектов, созданных в качестве частей конструируемого объекта
до того, как было выброшено исключение.
• Вызываются деструкторы для всех автоматических объектов, конструированных
в try-блоке до исключения.
• К моменту начала исполнения обработчика исключения разматывание стека
завершается.
• Если деструктор, вызванный в процессе разматывания стека, выбрасывает
исключение, вызывается terminate.
• Если объект имеет элементы-объекты, и исключение выбрасывается до того, как
будет завершено конструирование внешнего объекта, то будут исполняться
деструкторы элементов-объектов, уже конструированных к моменту возникновения
исключения.
• Если к моменту возникновения исключения был частично конструирован массив
объектов, то будут вызваны деструкторы только для уже конструированных
объектов в массиве.
• Когда исключение возникает в конструкторе объекта, создаваемого в выражении
операции new, динамически выделенная для объекта память освобождается.
• Если catch-обработчик перехватывает указатель или ссылку на объект исключения
базового класса, он может также перехватывать указатели или ссылки на все
объекты классов, являющихся открытыми производными этого базового класса, что
позволяет полиморфно обрабатывать родственные ошибки.
• Стандарт C++ специфицирует, что когда операция new терпит неудачу, она
выбрасывает исключение bad_alloc (определенное в заголовочном файле <new>).
• Функция set_new_handler принимает в качестве аргумента указатель на функцию,
которая не принимает аргументов и возвращает void. Этот указатель ссылается на
функцию, которая должна вызываться при отказах new.
• Если new удалось выделить память, она возвращает указатель на нее.
• Если после того, как память была выделена, но до того, как будет выполнен оператор
delete, возникает исключение, может иметь место утечка памяти.
• Для преддотвращения утечек памяти в стандартной библиотеке C++ имеется шаблон
класса auto_ptr.
• Объект класса auto_ptr хранит указатель на динамически выделенную память.
Деструктор объекта auto_ptr выполняет над этим элементом-указателем операцию
delete.
982
Глава 16
Шаблон класса auto_ptr предусматривает перегруженные операции * и —>, чтобы
с объектом auto_ptr можно было обращаться как с обычной переменной-указателем.
Объект auto_ptr может также передавать права собственности на контролируемую
им динамическую память посредством своей перегруженной операции присваивания
или конструктора копии.
Стандартная библиотека C++ реализует иерархию классов исключений. Вершиной
иерархии является базовый класс exception.
Непосредственными производными классами базового класса exception являются
runtime_error и logic_error (оба определены в заголовочном файле <stdexcept>),
каждый из которых имеет несколько производных классов.
Некоторые операции выбрасывают стандартные исключения — операция new
выбрасывает bad_alloc, операция dynamic_cast выбрасывает bad_cast и typeid
выбрасывает bad_typeid.
Если включить в список throw функции спецификацию bad_exception, то при
появлении непредусмотренного исключения unexpected сможет выбрасывать
bad_exception, вместо завершения программы или вызова другой функции,
зарегистрированной в set_unexpected.
Терминология
catch( ... )
catch-обработчик
throw без аргументов
try-блок
асинхронное событие
возобновляющая модель управления
исключениями
выбрасывание исключения
выбрасывание непредусмотренного
исключения
завершающая модель управления
исключениями
заголовочный файл <exception>
заголовочный файл <memory>
заголовочный файл <new>
заголовочный файл <stdexcept>
исключение
исключение bad_alloc
исключение bad_cast
исключение bad_exception
исключение bad_typeid
исключение invalid_argument
исключение length_error
исключение logic_error
исключение out_of_range
исключение overflow_error
исключение runtime_error
исключение underflow_error
исключительная ситуация
ключевое слово catch
ключевое слово throw
ключевое слово try
обработчик исключения
обработчик отказов new
объект nothrow
объект исключения
ошибка арифметического переполнения
ошибка исчезновения порядка
параметр исключения
перебрасывание исключения
перехват всех исключений
перехват исключения
пустая спецификация исключений
разматывание стека
синхронная ошибка
спецификация исключений
список throw
толерантность к ошибкам
точка выброса
устойчивость программы
функция abort
функция exit
функция set_new_handler
функция set_terminate
функция set_unexpected
функция terminate
функция unexpected
шаблон класса auto_ptr
Управление исключениями
983
Контрольные вопросы
16.1. Перечислите пять типичных примеров исключений.
16.2. Приведите несколько причин, по которым методы обработки исключений не
должны использоваться для обычного программного управления.
16.3. Почему целесообразно использовать исключения для обработки ошибок,
вызванных библиотечными функциями?
16.4. Что такое «утечка ресурса»?
16.5. Если в блоке try не выбрасываются никакие исключения, куда передается
управление после того, как блок try завершит работу?
16.6. Что произойдет, если исключение выбрасывается вне блока try?
16.7. Укажите основное достоинство и основной недостаток использования catch(...).
16.8. Что произойдет, если ни один из catch-обработчиков не подходит к типу
выброшенного объекта?
16.9. Что случится, если несколько catch-обработчиков подходят к типу
выброшенного объекта?
16.10. Почему программисту может быть желательно специфицировать в качестве типа
обработчика catch базовый класс и затем выбрасывать объекты производных
классов?
16.11. Предположим, что доступен обработчик catch с точным соответствием типу
объекта исключения. При каких обстоятельствах может выполняться не этот, а
другой обработчик для объектов исключения этого типа?
16.12. Должно ли выбрасывание исключения вызывать завершение программы?
16.17. Что происходит, когда обработчик catch выбрасывает исключение?
16.14. Что делает оператор throw;?
16.15. Как программист ограничивает типы исключений, которые могут
выбрасываться функцией?
16.16. Что происходит, если функция выбрасывает исключение типа, не допускаемого
спецификацией исключений этой функции?
16.17. Что происходит с автоматическими объектами, которые были конструированы
в блоке try, когда этот блок выбрасывает исключение?
Ответы на контрольные вопросы
16.1. Нехватка памяти для удовлетворения запроса new, выход индекса за пределы
массива, арифметическое переполнение, деление на ноль, недопустимые
параметры функций.
16.2. (а) Обработка исключений предназначена для того, чтобы обрабатывать нечасто
встречающиеся ситуации, но которые часто приводят к завершению программы,
так что от авторов компиляторов не требуется, чтобы управление исключений
работало оптимально. (Ь) Поток управления со стандартными управляющими
структурами, как правило, более ясен и более эффективен, чем применение
исключений, (с) Могут возникать проблемы, связанные с тем, что при появлении
исключения стек не размотан и ресурсы, выделенные до исключения, могут не
освобождаться, (d) «Дополнительные» исключения могут вставать на пути
подлинных исключений, связанных с ошибками. Поэтому программисту становится
труднее следить за большим числом исключений.
16.3. Маловероятно, чтобы библиотечная функция выполняла такую обработку
ошибок, которая удовлетворяла бы специфическим требованиям всех пользователей.
984
Глава 16
16.4. Внезапное завершение программы может оставить ресурс в состоянии, в котором
другие программы не будут способны его использовать, либо сама программа не
может вновь получить доступ к ресурсу.
16.5. Обработчики исключений (в блоках catch) для этого блока try пропускаются,
и программа продолжает выполнение, начиная с оператора после последнего
catch-обработчика.
16.6. Исключение, выброшенное вне блока try, приводит к вызову функции
terminate.
16.7. Обработчик вида catch( ... ) перехватывает ошибки любого типа, выброшенные
в try-блоке. Преимущество состоит в том, что никакая ошибка не может
ускользнуть от обработки. Недостаток заключается в том, что такой обработчик catch не
имеет параметра и, значит, не может ссылаться на информацию в выброшенном
объекте и не может знать причину ошибки.
16.8. Это вызовет продолжение поиска соответствия в следующем охватывающем
блоке try, если таковой имеется. При продолжении этого процесса может оказаться,
что в программе не имеется ни одного обработчика, соответствующего типу
выброшенного объекта; в этом случае вызывается функция terminate, которая по
умолчанию вызывает abort. Альтернативная функция terminate может быть
задана как аргумент set_terminate.
16.9. Выполняется первый из согласующихся обработчиков исключения после блока
try.
16.10. Это прекрасный способ перехватывать родственные типы исключений.
16.11. Если объект исключения производного класса будет перехвачен обработчиком
базового класса.
16.12. Нет, но завершается выполнение блока, в котором выброшено исключение.
16.13. Исключение будет обработано обработчиком catch (если таковой существует),
связанным с блоком try (если он есть), охватывающим тот обработчик catch,
который выбросил исключение.
16.14. Он перебрасывает исключение, если исполняется в catch-обработчике; в
противном случае вызывается функция unexpected.
16.15. Предусматривает спецификацию исключений, перечисляющую типы
исключений, которые могут выбрасываться функцией.
16.16. Вызывается функция unexpected.
16.17. Исполнение try-блока прекращается, что приводит к вызову деструкторов всех
этих объектов.
Упражнения
16.18. Перечислите различные исключительные ситуации, которые встречались в этой
книге. Перечислите столько дополнительных исключительных ситуаций,
сколько сможете. Для каждой из них кратко опишите, как программа могла бы
обработать данное исключение, используя методы управления исключениями,
рассмотренные в этой главе. Некоторые типичные исключения: деление на ноль,
арифметическое переполнение, выход индекса массива за допустимые пределы,
нехватка свободной памяти и т.д.
16.19. При каких обстоятельствах программист мог бы не указывать имя параметра
при описании типа объекта, который будет перехватываться обработчиком?
16.20. Программа содержит оператор
throw;
Где обычно встречается этот оператор? Что будет, если этот оператор появляется
в другой части программы?
Управление исключениями
985
16.21. Сравните обработку исключений с другими способами обработки ошибок,
рассмотренными в этой главе.
16.22. Почему исключения не должны использоваться как альтернативная форма про-»
граммного управления?
16.23. Опишите методику обработки родственных исключений.
16.24. До этой главы мы выяснили, что обработка ошибок, обнаруженных
конструкторами, несколько затруднительна. Исключения дают нам намного более удобные
средства работы с такими ошибками. Рассмотрите конструктор для класса
String. Конструктор использует операцию new, чтобы выделить область памяти.
Предположим, происходит отказ операции new. Покажите, как бы вы поступали
в этом случае без управления исключениями. Рассмотрите ключевые моменты.
Покажите, как бы вы обрабатывали подобную нехватку памяти с помощью
управления исключениями. Объясните, почему подход с управлением
исключениями предпочтительнее.
16.25. Предположим, программа выбрасывает исключение и начинает выполняться
соответствующий обработчик исключения. Предположим далее, что обработчик
исключения сам выбрасывает такое же исключение. Создает ли это бесконечную
рекурсию? Напишите программу на C++, чтобы проверить ваш анализ этой ситуации.
16.26. Используйте наследование, чтобы создать различные производные классы от
runtime_error. Затем покажите, что catch-обработчик, специфицирующий
базовый класс, может перехватывать исключения производных классов.
16.27. Напишите условное выражение, которое возвращает или тип double, или int.
Напишите catch-обработчики для перехвата типа int и типа double. Покажите,
что выполняется только catch-обработчик для типа double вне зависимости от
того, возвращается ли тип int или тип double.
16.28. Напишите программу, предназначенную для генерации и обработки ошибки,
связанной с нехваткой памяти. Ваша программа должна в цикле давать запрос
на динамическое выделение памяти с помощью операции new.
16.29. Напишите программу, которая демонстрирует, что все деструкторы объектов,
конструированных в блоке, вызываются прежде, чем в этом блоке
выбрасывается исключение.
16.30. Напишите программу, которая демонстрирует, что при возникновении
исключения вызываются деструкторы только тех элементов-объектов, которые были
конструированы до того, как было выброшено исключение.
16.31. Напишите программу, которая демонстрирует перехват нескольких типов
исключений с помощью catch( ... ).
16.32. Напишите программу, которая демонстрирует важность порядка обработчиков
исключений. Выполняется первый согласующийся по типу обработчик.
Попробуйте компилировать и запустить вашу программу с двумя различными
последовательностями обработчиков, чтобы показать, что при этом наблюдаются
различные результаты.
16.33. Напишите программу, которая демонстрирует конструктор, передающий
информацию о своем отказе обработчику исключения после блока try.
16.34. Напишите программу, которая иллюстрирует перебрасывание исключения.
16.35. Напишите программу, которая демонстрирует, что функция со своим
собственным try-блоком не обязана перехватывать каждую возможную ошибку,
генерированную внутри try. Некоторые исключения могут быть выпущены во внешние
области действия и обрабатываться в них.
16.36. Напишите программу, которая выбрасывает исключение в глубоко вложенной
функции, и все-таки перехватывает исключение обработчиком catch,
следующим за try-блоком, охватывающим цепочку вызовов.
17
Обработка файлов
ЦЕЛИ
В этой главе вы изучите:
• Создание, чтение, запись
и обновление файлов.
• Обработку последовательных
файлов.
• Обработку файлов произвольного
доступа.
• Высокопроизводительные
бесформатные операции
ввода/вывода.
• Различия в обработке файлов
с форматированными и сырыми
данными.
• Построение программы обработки
транзакций с применением файла произвольного доступа.
988
Глава 17
17.1. Введение
17.2. Иерархия данных
17.3. Файлы и потоки
17.4. Создание последовательного файла
17.5. Чтение данных из последовательного файла
17.6. Обновление последовательных файлов
17.7. Файлы произвольного доступа
17.8. Создание файла произвольного доступа
17.9. Произвольная запись данных в файл произвольного
доступа
17.10. Последовательное чтение из файла произвольного
доступа
17.11. Пример. Программа обработки транзакций
17.12. Ввод/вывод объектов
17.13. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
17.1. Введение
Хранение данных в переменных и массивах является временным. Для
долговременных, или устойчивых данных, т.е. для данных большого объема,
сохраняемых постоянно, используются файлы. Компьютеры хранят файлы на
устройствах вторичной памяти, таких, как жесткие диски, оптические
диски и магнитные ленты. В этой главе мы расскажем, как писать программы на
C++, которые создают, обновляют и обрабатывают файлы данных. Мы
рассмотрим как последовательные файлы, так и файлы произвольного доступа.
В главе 18 мы рассмотрим чтение и запись данных с использованием
строковых потоков вместо файлов.
17.2. Иерархия данных
В конечном счете все данные, обрабатываемые цифровыми машинами,
сводятся к комбинациям нулей и единиц. Дело в том, что проще и экономичнее
изготовлять электронные схемы, которые могут находиться в двух
устойчивых состояниях — одно из таких состояний представляет 0, а другое 1.
Удивительно, но все сложнейшие задачи, которые способен выполнять компьютер,
основываются на самых элементарных манипуляциях с нулями и единицами.
Наименьшая единица данных, к которой может обращаться компьютер,
называется битом (по-английски bit сокращение от «6/nary digit» — двоичная
Обработка файлов
989
цифра). Каждая такая единица данных, или бит, может принимать либо
значение 0, либо значение 1. Совокупность операций, выполняемых компьютером,
сводится к различным простым действиям над битами, таким, как определение
значения бита, установка значения бита, инверсия бита A вместо О и наоборот).
Для программистов очень обременительно работать с данными низкого
уровня, какими являются биты. Вместо этого программисты предпочитают
работать с данными в виде десятичных цифр (то есть 0, 1, 2, 3, 4, 5, 6, 7, 8 и 9),
букв (от А до Z и от а до z), и специальных знаков ($, @, %, *, (,), -, +, ", :, ?, /
и многих других). Цифры, буквы и специальные знаки называются
символами. Множество символов, которыми можно пользоваться при написании
программ и представлении элементов данных на конкретном компьютере,
называется его набором символов. Так как компьютеры могут обрабатывать только
нули и единицы, каждый символ из набора символов компьютера
представляется комбинацией из О и 1 (называемой байтом). Байты состоят из восьми
битов. Программисты записывают программы и элементы данных, пользуясь
символами; компьютеры в дальнейшем обрабатывают эти символы как
битовые наборы. Например, в C++ имеется тип char. Каждый char занимает один
байт памяти. В C++ предусмотрен также тип wchar_t, который может
занимать более одного байта (и поддерживать более широкие символьные наборы,
например, набор символов Unicode®). За подробной информацией о Unicode®
обратитесь на www.unicode.org.
Sally Black
Tom Blue
Judy Green Файл
Iris Orange
Randy Red
Judy Green Запись
t
Judy Field
t
01001010 Байт (ASCII-символ J)
t
1 Бит
Рис. 17.1. Иерархия данных
990
Глава 17
Подобно тому, как символы состоят из битов, поля состоят из символов.
Поле представляет собой группу символов, которая передает некоторое
значение. Например, поле, состоящее исключительно из букв верхнего и нижнего
регистра, может использоваться для представления имени человека.
Обрабатываемые компьютерами элементы образуют иерархию данных
(рис. 17.1), в которой элементы данных становятся больше по размеру и сложнее
по структуре по мере продвижения от битов к символам (байтам), полям и т.д.
Запись (которая в C++ может представляться классом) состоит из
нескольких полей (т.е. элементов данных класса C++). Например, в программе для
начисления заработной платы запись для конкретного работника может состоять
из следующих полей:
1. Идентификационный номер служащего
2. Имя
3. Адрес
4. Почасовая ставка оплаты
5. Количество налоговых льгот
6. Заработок с начала года
7. Сумма удержанных налогов
Таким образом, запись — это группа родственных полей. В предыдущем
примере каждое поле принадлежало одному и тому же работнику. Файлом
называется группа родственных записей.1 Файл начисления заработной платы
содержит по одной записи на каждого работника. Таким образом, файл
начисления заработной платы маленькой компании может содержать 22 записи,
в то время как такой же файл большой компании может содержать 100000
записей. Вполне обычна ситуация, когда организация имеет сотни и даже
тысячи файлов, которые могут содержать миллионы или даже миллиарды и
триллионы символов информации.
Чтобы облегчить поиск необходимых данных, по крайней мере одно поле
в каждой записи файла выбирается в качестве ключа записи. Ключ
идентифицирует запись как принадлежащую конкретному лицу или объекту, и
отличает данную запись от всех остальных. В записи платежной ведомости, подобной
описанной выше, в качестве ключа удобно выбрать идентификационный
номер работника.
Существует множество способов организации записей в файле. Наиболее
популярный из них называется последовательным файлом, в котором записи,
как правило, хранятся в порядке, определяемом ключом. В файле платежной
ведомости, например, записи хранились бы упорядоченными по
идентификационным номерам. Запись для первого работника в файле имела бы
наименьший идентификационный номер, а последующие записи содержали
возрастающие номера.
Большинство организаций используют для хранения данных много
различных файлов. Например, компания может иметь файлы платежных
ведомостей, файлы приходных счетов (списки сумм, причитающихся с клиентов),
Вообще говоря, файл может содержать произвольные данные в произвольных форматах.
В некоторых операционных системах файл — это не более чем собрание байтов. В
подобной операционной системе любая организация байтов в файле (например, в виде записей)
есть представление данных, создаваемое прикладным программистом.
Обработка файлов
991
расходных счетов (по которым следует уплатить поставщикам), файлы
инвентаризации (учитывающие все те товары, с которыми имеет дело компания),
а также многочисленные файлы других типов. Группа связанных файлов
иногда называется базой данных. Набор программ, предназначенный для
создания и поддержки баз данных, называется системой управления базами
данных (DBMS — Database Management System).
17.3. Файлы и потоки
В C++ каждый файл рассматривается как последовательность байтов
(рис. 17.2). Каждый файл завершается маркером конца файла (end-of-file
marker) или байтом с номером, записанным в некоторой служебной структуре
данных, поддерживаемой системой. Когда файл открывается, то создается
объект и с этим объектом связывается поток. В главе 15 мы видели, что когда
в программу включается <iostream>, автоматически создаются четыре
объекта — cin, cout, сегг и clog. Потоки, связанные с этими объектами,
обеспечивают каналы связи между программой и отдельными файлами или
устройствами. Например, объект cin (объект стандартного потока ввода) дает
возможность программе вводить данные с клавиатуры, объект cout (объект
стандартного потока вывода) позволяет программе выводить данные на экран,
объекты сегг и clog (объекты стандартного потока ошибок) позволяют
программе выводить на экран или другое устройство сообщения об ошибках.
0123456789. ..п-1
маркер конца файла
Рис. 17.2. Вид файла из п байт с точки зрения C++
Для организации работы с файлами в программы на C++ должны
включаться заголовочные файлы <iostream> и <fstream>. В заголовке <fstream>
определены шаблоны классов потоков basic_ifstream (для файлового ввода),
basic_ofstream (для файлового вывода) и basic_fstream (для ввода и вывода).
Для каждого шаблона существуют предопределенные специализации для
ввода/вывода данных типа char. Кроме того, библиотека fstream содержит набор
определений typedef, представляющих псевдонимы для этих специализаций.
Например, typedef if stream представляет специализацию basic_if stream,
позволяющую считывать данные типа char из файлов. Аналогично, typedef
of stream представляет специализацию basic_ofstream, позволяющую
записывать данные типа char в файлы. Кроме того, typedef fstream представляет
специализацию basic_fstream, позволяющую считывать данные типа char из
файла и записывать их в файл.
Файлы открываются посредством создания объектов специализаций
потоковых шаблонов. Эти шаблоны «производятся» соответственно от шаблонов
basic_istream, basic_ostream и basic_iostream. Таким образом, все
элемент-функции, операции и манипуляторы, принадлежащие последним
(которые мы описывали в главе 15), применимы также к файловым потокам. На
992
Глава 17
рис. 17.3 показаны отношения наследования классов ввода/вывода, которые
мы обсудили к настоящему моменту.
basicjos
Ч
basic.istream basic_ostream
/ \ / \
basicjf stream basic_iostream basic.of stream
A
basicfstream
Рис. 17.3. Часть иерархии шаблонов потокового ввода/вывода
17.4. Создание последовательного файла
C++ не «навязывает» файлу никакой структуры. Иными словами, C++ не
определяет для файлов таких понятий, как «запись». Таким образом,
ответственность за структурирование файлов в соответствии с требованиями
конкретного приложения лежит на программисте. Следующий пример показывает
создание простой структуры записей в файле.
Программа на рис. 17.4 создает простой последовательный файл, который
можно использовать в программе учета оплаты счетов, помогающей следить за
суммами задолженности клиентов компании. Для каждого клиента
программа просит ввести номер счета, имя клиента и баланс (то есть сумму, которую
клиент должен компании за товары и услуги, полученные в прошлом).
Данные на каждого из клиентов образуют «запись» для этого клиента. В этом
приложении в качестве ключа записи используется номер счета. Другими
словами, файл будет создаваться и поддерживаться упорядоченным по номерам
счетов. Эта программа подразумевает, что пользователи вводят записи в порядке
возрастания номеров. В более удобной для работы системе регистрации счетов
должна обеспечиваться возможность сортировки, чтобы пользователь мог
вводить записи в произвольном порядке. В этом случае записи должны сначала
упорядочиваться, а затем уже записываться в файл.
1 // Рис. 17.4: Figl7_04.cpp
2 // Создание последовательного файла.
3 #include <iostream>
4 using std
5 using std
6 using std
:cerr;
: cin ;
:cout;
Обработка файлов
993
7 using std::endl;
8 using std::ios;
9
10 #include <fstream> // файловый поток
11 using std::ofstream; // выходной файловый поток
12
13 #include <cstdlib>
14 using std::exit; // прототип функции exit
15
16 int main()
17 {
18 // конструктор ofstream открывает файл
19 ofstream outClientFile( "clients.dat", ios::out );
20
21 // если невозможно создать файл, выйти из программы
22 if ( !outClientFile ) // перегруженная операция !
23 {
24 cerr « "File could not be opened" « endl;
25 exit( 1 );
26 } // конец if
27
28 cout « "Enter the account, name, and balance." « endl
29 « "Enter end-of-file to end input.\n? ";
30
31 int account;
32 char name[ 30 ];
33 double balance;
34
35 // прочитать из cin счет, имя и баланс, затем записать в файл
36 while ( cin » account » name » balance )
37 {
38 outClientFile « account« ' '« name« ' '« balance « endl;
39 cout « "?
40 } // конец while
41
42 return 0; // деструктор ofstream закрывает файл
43 } // конец main
Enter the account, name, and balance.
Enter end-of-file to end input.
? 100 Jones 24.98
? 200 Doe 345.67
? 300 White 0.00
? 400 Stone -42.16
? 500 Rich 224.62
? AZ
Рис. 17.4. Создание последовательного файла
Давайте посмотрим, как устроена эта программа. Как уже говорилось,
файлы открываются путем создания объектов if stream, of stream или f stream. Ha
рис. 17.4 файл должен быть открыт для вывода, так что создается объект of-
stream. Конструктору объекта передаются два аргумента — имя файла и
режим открытия файла (строка 19). Для объекта of stream режим открытия
файла может быть или ios::out для вывода данных в файл, или ios::app для до-
32 Зак. 1114
994
Глава 17
писывания данных в конец файла (без модификации каких-либо данных, уже
имеющихся в файле). Существующие файлы, открываемые режимом ios::out,
усекаются — все данные в файле отбрасываются. Если специфицированный
файл еще не существует, создается новый файл с указанным именем.
Строка 19 создает объект of stream с именем outClientFile, ассоциируемый
с файлом client.dat, который открывается для вывода. Аргументы client.dat
и ios::out передаются конструктору ofstream, который открывает файл. При
этом образуется «линия связи» с файлом. Объекты ofstream по умолчанию
открываются для вывода, так что в строке 19 можно было бы написать оператор
ofstream outClientFile( "clients.dat" );
На рис. 17.5 перечислены режимы открытия файлов.
q Типичная ошибка программирования 1.1
Открывая для вывода существующий файл (ios::out), будьте
осторожны, особенно если вы хотите сохранить содержимое файла, так
как оно удаляется без предупреждения.
Режим
ios::app
ios::ate
ios::in
ios::out
ios::trunc
ios::binary
Описание
Дописать весь вывод в конец файла.
Открыть файл для вывода и переместиться в конец файла
(обычно применяется для дописывания данных в конец файла).
Данные могут быть записаны в любое место файла.
Открыть файл для ввода.
Открыть файл для вывода.
Отбросить содержимое файла, если он существует
(это также по умолчанию делается для ios::out).
Открыть файл для двоичного (то есть нетекстового) ввода или вывода.
Рис. 17.5. Режимы открытия файла
Создать объект ofstream можно и не открывая конкретного файла; файл
можно будет прикрепить к объекту позднее. Например, оператор
ofstream outClientFile;
создает объект ofstream с именем outClientFile. Элемент-функция open класса
ofstream открывает файл и прикрепляет его к существующему объекту
ofstream:
outClientFile.open( "clients.dat", ios::out );
Типичная ошибка программирования 1.2
Попытка обратиться к файлу в программе до того, как он будет
открыт, приводит к ошибке.
Обработка файлов
995
После создания объекта ofstream и попытки открыть его программа
проверяет, была ли операция открытия файла успешной. Оператор if в
строках 22-26 использует перегруженную функцию-операцию operator! класса
ios, чтобы определить, успешно ли открылся файл. Условие возвращает
значение true, если при операции open для потока устанавливается failbit или
badbit. Некоторые возможные ошибки являются следствием попытки открыть
для чтения несуществующий файл, попытки открыть файл для чтения или
записи без надлежащих привилегий или открытия файла для записи, когда на
диске нет свободного места.
Если условие указывает на неудачу попытки открыть файл, строка 24
выводит сообщение "File could not be opened", и строка 25 вызывает функцию exit
для завершения программы. Аргумент exit возвращается окружению, откуда
была запущена программа. Нулевой аргумент означает, что программа
завершилась нормально; любое другое значение указывает на завершение из-за
ошибки. Вызывающее окружение (чаще всего операционная система)
использует возвращаемое exit значение, чтобы должным образом отреагировать на
ошибку.
Другая перегруженная функция-операция из ios — operator void * —
преобразует поток в указатель, чтобы его можно было проверить на равенство О
(т.е. нулевому указателю) или ненулевому значению (т.е. любому другому
значению указателя). Когда в качестве условия используется значение-указатель,
C++ преобразует нулевой указатель в булево значение false, а ненулевой —
в true. Если установлен failbit или badbit (см. главу 15), возвращается О
(false). Условие оператора while в строках 36-40 неявно вызывает
элемент-функцию operator void * объекта cin. Условие остается истинным, пока
для cin не установлен ни failbit, ни badbit. Ввод признака конца файла
устанавливает failbit для cin. Функция operator void * может использоваться для
проверки входного потока на «конец файла» без явного вызова его
элемент-функции eof.
Если строка 19 успешно открывает файл, программа начинает обработку
данных. Строки 28-29 предлагают пользователю ввести различные поля
следующей записи или признак конца файла, если ввод данных закончен. На
рис. 17.6 показаны комбинации клавиш для ввода конца файла на различных
системах.
Система
UNIX/Linux/Mac OS X
Microsoft Windows
VAX (VMS)
Комбинация клавиш
<ctrl-d> (в отдельной строке)
<ctrl-z> (иногда с последующим Enter)
<ctrl-z>
Рис, 17.6. Комбинации клавиш «конец файла» для различных популярных
компьютерных систем
Строка 36 читает набор данных и определяет, не был ли введен конец
файла. Когда встречается конец файла или когда вводятся «плохие» данные,
operator void * возвращает нулевой указатель (который преобразуется в false)
и оператор while завершается. Чтобы сообщить программе, что далее
обрабатывать данные не требуется, пользователь вводит конец файла. При этом уста-
996
Глава 17
навливается признак конца файла. Цикл while выполняется до тех пор, пока
признак конца файла не будет установлен.
Строка 38 записывает набор данных в файл clients.dat, используя
операцию передачи в поток « и объект outClientFile, ассоциированный с файлом
в начал программы. Данные могут восстанавливаться программой,
предназначенной для чтения файла (см. раздел 17.5). Заметьте, что поскольку файл,
создаваемый на рис. 17.4, является просто текстовым файлом, его можно
просмотреть любым текстовым редактором.
Как только пользователь вводит признак конца файла, main завершается.
При этом неявно вызывается функция деструктора объекта outClientFile,
в результате чего файл clients.dat закрывается. Программист может и явным
образом закрыть объект ofstream с помощью его элемент-функции close,
выполнив оператор
outClientFile.close();
Вопросы производительности 17.1
'^Щ
Явное закрытие файлов, когда программе более не нужно к ним
обращаться, может сократить расход ресурсов (особенно если исполнение
программы продолжается после того, как она закроет файлы).
В образце исполнения программы на рис. 17.4 пользователь вводит
информацию для пяти счетов, затем вводом конца файла (в Microsoft Windows
отображается ~Z) сигнализирует, что ввод данных завершен. Окно этого диалога
не показывает, в каком виде данные записываются в файл. Чтобы проверить,
успешно ли создан файл, мы в следующем разделе покажем, как написать
программу, читающую этот файл и распечатывающую его содержимое.
•
17.5. Чтение данных из последовательного файла
Данные сохраняют в файлах для того, чтобы их можно было восстановить
и обработать. В предыдущем разделе было показано, как создать файл с
последовательным доступом. Сейчас мы обсудим, как последовательно читать
данные из файла.
Программа на рис. 17.7 читает данные из файла clients.dat, созданного
нами с помощью программы из рис. 17.4, и выводит содержание записей.
Создание объекта ifstream открывает файл для ввода. Конструктор ifstream
может принимать в качестве аргументов имя файла и режим открытия файла.
Строка 31 создает объект ifstream с именем inClientFale и ассоциирует его
с файлом clients.dat. Аргументы в скобках передаются функции
конструктора, которая открывает файл и организует «канал связи» с ним.
Хороший стиль программирования 17.1
Если содержимое файла не должно модифицироваться, открывайте
файл только для чтения (с помощью iosr.in). Это предотвратит не
намеренное изменение содержимого файла и является примером
принципа наименьших привилегий.
Обработка файлов
997
1 // Рис. 17.7: Figl7_07.cpp
2 // Чтение и распечатка последовательного файла.
3 #include <iostream>
4 using std::cerr;
5 using std::cout;
6 using std::endl;
7 using std::fixed;
8 using std::ios;
9 using std::left;
10 using std::right;
11 using std::showpoint;
12
13 #include <fstream> // файловый поток
14 using std::ifstream; // входной файловый поток
15
16 #include <iomanip>
17 using std::setw;
18 using std::setprecision;
19
20 #include <string>
21 using std::string;
22
23 #include <cstdlib>
24 using std::exit; // прототип функции exit
25
26 void outputLine( int, const string, double ); // прототип
27
28 int main()
29 {
30 // конструктор ifstream открывает файл
31 ifstream inClientFile( "clients.dat", ios::in );
32
33 // если ifstream не смог открыть файл, выйти из программы
34 if ( !inClientFile )
35 {
36 cerr « "File could not be opened" « endl;
37 exit( 1 );
38 } // конец if
39
40 int account;
41 char name[ 30 ];
42 double balance;
43
44 cout « left « setw( 10 ) « "Account" « setw( 13 )
45 « "Name" « "Balance" « endl « fixed « showpoint;
46
47 // вывести каждую запись файла
48 while ( inClientFile » account » name » balance )
49 outputLine( account, name, balance );
50
51 return 0; // деструктор ifstream закрывает файл
52 } // конец main
53
54 // вывести одиночную запись файла
55 void outputLine( int account, const string name, double balance )
998
Глава 17
56 {
57 cout « left « setw( 10 ) « account « setw( 13 ) « name
58 « setw( 7 ) « setprecision( 2 ) « right « balance « endl;
59 } // конец функции outputLine
Account Name Balance
100 Jones 24.98
200 Doe 345.67
300 White 0.00
400 Stone -42.16
500 Rich 224.62
Рис. 17.7. Чтение и распечатка последовательного файла
Объекты класса if stream по умолчанию открываются для ввода. Чтобы
открыть для ввода clients.dat, можно было бы написать оператор
ifstream inClientFile( "clients.dat" );
Как и в случае с объектом of stream, объект if stream может быть создан без
открытия конкретного файла, поскольку файл можно присоединить к нему
позднее.
Перед попыткой извлечения данных из файла программа проверяет
условие JinClientFile, чтобы определить, был ли файл успешно открыт. Строка 48
читает из файла набор данных (т.е. запись). После первого исполнения этой
строки account имеет значение 100, name — «Jones«, a balance — 24.98.
Каждый раз, когда исполняется строка 48, из файла в переменные account, name
и balance читается новая запись. Строка 49 выводит записи с помощью
функции outhutLine (строки 55-58), которая использует параметризованные
манипуляторы потока для форматирования выводимых данных. Когда достигается
конец файла, неявный вызов operator void * в условии оператора while
возвращает нулевой указатель (преобразуемый в булево значение false), деструктор
if stream закрывает файл и программа завершается.
Для последовательного извлечения данных из файла программы обычно
начинают чтение с начала файла и продолжают читать, пока не будут найдены
нужные данные. В процессе исполнения программы может потребоваться
многократная последовательная обработка файла (начиная каждый раз с его
начала). Как if stream, так л of stream предусматривают элемент-функции для
переустановки указателя позиции файла (номера байта в файле, который будет
читаться или записываться следующим). Этими функциями являются seekg
(«seek get») для if stream и seekp («seek put») для of stream. Каждый объект
if stream имеет «get-указатель», указывающий номер байта в файле, с
которого будет происходить следующий ввод, а каждый объект of stream имеет
«put-указатель», указывающий номер байта в файле, начиная с которого будет
помещаться следующий вывод. Оператор
inClientFile.seekg( 0 );
переустанавливает указатель позиции на начало (позицию 0) файла,
прикрепленного к inClientFile. Аргументом seekg обычно является длинное целое.
Может указываться второй аргумент, задающий направление поиска.
Направление поиска может иметь значения ios::begin (по умолчанию) для почи-
Обработка файлов
999
ционирования относительно начала потока, ios::cur для позиционирования
относительно текущей позиции или ios::end для позиционирования
относительно конца потока. Указатель позиции файла является целым значением,
задающим положение в файле как число байтов от начала файла (его
называют также смещением относительно начала файла). Вот несколько примеров
позиционирования «get-указателя» файла:
// позиционирует на n-й байт fileObject (подразумевается ios::begin)
fileObject.seekg( n );
// позиционирует fileObject на п байтов вперед
fileObject.seekg( n, ios::cur );
// позиционирует на п байтов назад от конца fileObject
fileObject.seekg( n, ios::end );
// позиционирует на конец fileObject
fileObject.seekg( 0, ios::end );
Те же самые операции можно производить с помощью функции seekp
класса of stream. Для определения текущего положения «get»- и «put»-указателей
предусмотрены соответственно элемент-функции tellg и tellp. Следующий
оператор присваивает значение «get»-указателя позиции файла переменной
location типа long:
location = fileObject.tellg();
Программа на рис. 17.8 позволяет администратору по кредитам выводить
информацию о счетах заказчиков с нулевым балансом (т.е. тех заказчиков,
которые ничего не должны компании), с кредитовыми (отрицательными)
балансами (заказчики, которым должна компания) и с дебетовыми
(положительными) балансами (заказчики, задолжавшие компании за полученные
в прошлом товары и услуги). Программа выводит меню и позволяет
администратору указать одну из трех опций получения информации. Опция 1
распечатывает список счетов с нулевым балансом. Опция 2 распечатывает список
счетов с кредитовыми балансами. Опция 3 распечатывает список счетов с
дебетовыми балансами. Опция 4 завершает выполнение программы. Ввод
недействительной опции вызывает повторный вывод подсказки для выбора
другой опции.
1 // Рис. 17.8: Figl7_08.cpp
2 // Программа для справок о кредите.
3 #include <iostream>
4 using std::cerr;
5 using std::cin;
6 using std::cout;
7 using std::endl;
8 using std::fixed;
9 using std::ios;
10 using std::left;
11 using std::right;
12 using std::showpoint;
13
1000
Глава
14 #include <fstream>
15 using std::ifstream;
16
17 #include <iomanip>
18 using std::setw;
19 using std::setprecision;
20
21 #include <string>
22 using std::string;
23
24 #include <cstdlib>
25 using std::exit; // прототип функции exit
26
27 enum RequestType {ZERO_BALANCE=l/CREDIT_BALANCE,DEBIT_BALANCE,END} ;
28 int getRequest() ;
29 bool shouldDisplay( int, double );
30 void outputLine( int, const string, double );
31
32 int main()
33 {
34 // конструктор ifstream открывает файл
35 ifstream inClientFile( "clients.dat", ios::in );
36
37 // если ifstream не смог открыть файл, выйти иэ программы
38 if ( !inClientFile )
39 {
40 cerr « "File could not be opened" « endl;
41 exit( 1 );
42 } // конец if
43
44 int request;
45 int account;
46 char name[ 30 ];
47 double balance;
48
49 // получить запрос пользователя (напр., о кредитовых балансах)
50 request = getRequest();
51
52 // обработать запрос пользователя
53 while ( request != END )
54 " {
55 switch ( request )
56 {
57 case ZERO_BALANCE:
58 cout « "\nAccounts with zero balances:\n";
59 break;
60 case CREDIT_BALANCE:
61 cout « "\nAccounts with credit balances:\n";
62 break;
63 case DEBIT_BALANCE:
64 cout « "\nAccounts with debit balances:\n";
65 break;
66 } // конец switch
67
68 // прочитать из файла счет, имя и баланс
69 inClientFile » account » name » balance;
Обработка файлов
1001
71 // вывести содержимое файла (пока не eof)
72 while ( !inClientFile.eof() )
73 {
74 // вывести запись
75 if ( shouldDisplay( request, balance ) )
76 outputLine( account, name, balance );
77
78 // прочитать из файла счет, имя и баланс
79 inClientFile » account » name » balance;
80 } // конец внутреннего while
81
82 inClientFile.clear () ; // сбросить eof для следующего ввода
83 inClientFile.seekg( 0 ); // переустановить на начало файла
84 request = getRequest(); // получить следующий запрос
85 } // конец внешнего while
86
87 cout « "End of run." « endl;
88 return 0; // деструктор ifstream закрывает файл
89 } // конец main
90
91 // получить запрос пользователя
92 int getRequest()
93 {
94 int request; // запрос
95
96 // показать опции запроса
97 cout « "\nEnter request" « endl
98 « " 1 - List accounts with zero balances" « endl
99 « " 2 - List accounts with credit balances" « endl
100 « " 3 - List accounts with debit balances" « endl
101 « " 4 - End of run" « fixed « showpoint;
102
103 do // ввести запрос пользователя
104 {
105 cout « "\n? ";
106 cin » request;
107 } while ( request « ZERO_BALANCE && request » END );
108
109 return request;
110 } // конец функции getRequest
111
112 // определить, следует ли выводить данную запись
113 bool shouldDisplay( int type, double balance )
114 {
115 // выводить ли нулевые балансы
116 if ( type = ZERO_BALANCE && balance = 0 )
117 return true;
118
119 // выводить ли кредитовые балансы
120 if ( type == CREDIT_BALANCE && balance < 0 )
121 return true;
122
123 // выводить ли дебетовые балансы
124 if ( type == DEBIT__BALANCE && balance > 0 )
125 return true;
126
127 return false;
1002
Глава 17
128 } // конец функции shouldDisplay
129
130 // вывести одиночную запись файла
131 void outputLine( int account, const string name, double balance )
132 {
133 cout « left « setw( 10 ) « account « setw( 13 ) « name
134 « setw( 7 ) « setprecision( 2 ) « right « balance « endl;
135 } // конец функции outputLine
Enter request
1 - List accounts with zero balances
2 - List accounts with credit balances
3 - List accounts with debit balances
4 - End of run
? 1
Accounts with zero balances:
300 White 0.00
Enter request
1 - List accounts with zero balances
2 - List accounts with credit balances
3 - List accounts with debit balances
4 - End of run
? 2
Accounts with credit balances:
400 Stone -42.16
Enter request
1 - List accounts with zero balances
2 - List accounts with credit balances
3 - List accounts with debit balances
4 - End of run
? 3
Accounts with debit balances:
100 Jones 24.98
200 Doe 345.67
500 Rich 224.62
Enter request
1 - List accounts with zero balances
2 - List accounts with credit balances
3 - List accounts with debit balances
4 - End of run
? 4
End of run.
Рис. 17.8, Программа для справок о кредите
Обработка файлов
1003
17.6. Обновление последовательных файлов
Данные, форматированные и записанные в файл так, как показано в разделе
17.4, не могут быть модифицированы без риска уничтожения других данных
в файле. Например, если имя «White» нужно заменить на «Worthington»,
старое имя нельзя переписать, не испортив файла. Данные для White были
записаны в файл как
300 White 0.00
Если переписать запись, начиная с той же самой позиции в файле, но с более
длинным именем, запись будет иметь вид
300 Worthington 0.00
Новая запись содержит на шесть символов больше, чем первоначальная.
Таким образом, символы после второго «о» в «Worthington» перепишут начало
следующей по порядку записи файла. Проблема состоит в том, что при
форматируемом вводе/выводе с помощью операций передачи в поток « и
извлечения из потока >> поля — и, следовательно, записи — могут иметь различный
размер. Например, значения 7, 14, -117, 2074 и 27383 относятся все к типу
int, который хранит их внутреннее представление в одном и том же числе
«сырых байтов» (на современных распространенных 32-битных машинах это
обычно четыре байта). Однако эти целые числа будут занимать поля
различной длины, если выводить их как форматированный текст (как
последовательности символов). Как следствие, форматируемая модель ввода/вывода при
обновлении записей «по месту» обычно не используется.
Такое обновление выполняется очень неудобно. Например, для
упомянутого выше изменения имени записи последовательного файла, расположенные
перед 300 White 0.00, нужно скопировать в новый файл, записать в новый
файл обновленную запись, после чего скопировать в него записи,
расположенные после 300 White 0.00. При этом для обновления одной записи придется
обработать все записи файла. Однако такая методика может быть приемлема,
если за один проход по файлу обновляется много записей.
17.7. Файлы произвольного доступа
К настоящему моменту мы увидели, как создавать последовательные
файлы и находить в них нужную информацию. Последовательные файлы не
годятся для приложении мгновенного доступа, в которых требуемая запись
должна быть найдена немедленно. Типичными приложениями мгновенного
доступа являются системы резервирования авиабилетов, банковские системы,
банкоматы, сетевые магазины и другие системы обработки транзакций,
требующие быстрого доступа к конкретным данным. У банка могут быть сотни
тысяч (и даже миллионы) других клиентов, и тем не менее, когда клиент
пользуется банкоматом, пярограмма проверяет состояние его счета за считанные
секунды. Такого рода мгновенный доступ становится возможен при
использовании файлов произвольного доступа. Доступ к отдельным записям в файле
произвольного доступа является непосредственным (и быстрым) и не требует
просмотра других записей.
1004
Глава 17
Как мы уже сказали, C++ не накладывает на структуру файла никаких
ограничений. Поэтому программа, собирающаяся работать с файлами
произвольного доступа, должна сама их создавать. Здесь могут использоваться
различные методики. Возможно, простейший метод — потребовать, чтобы все
записи в файле имели одну и ту же фиксированную длину. При использовании
записей фиксированной длины программе несложно вычислить (как функцию
размера записи и ключа записи) точное положение любой записи относительно
начала файла. Скоро мы увидим, насколько это упрощает доступ к
конкретным записям, даже для больших файлов.
Рис. 17.9 иллюстрирует файл произвольного доступа (с точки зрения C++),
составленный из записей фиксированной длины (каждая запись в данном
случае имеет длину 100 байт). Файл произвольного доступа похож на поезд с
множеством вагонов одного и того же размера — некоторые из которых пусты,
а некоторые загружены.
0 100 200 300 400 500 *\
1 I I | I |\. байтовое
1 1 1 1 1 т / смещение
Judy Judy Judy Judy Judy Judy
100 байт 100 байт 100 байт 100 байт 100 байт 100 байт
Рис. 17.9. Файл произвольного доступа с точки зрения C++
Данные в файл произвольного доступа можно помещать, не разрушая
других данных файла. Ранее сохраненные данные можно также обновлять или
удалять, не переписывая всего файла. В следующих разделах мы расскажем,
как создать файл произвольного доступа, вводить в файл данные, читать
данные — как последовательно, так и произвольно, — обновлять данные и
удалять более не нужные данные.
17.8. Создание файла произвольного доступа
Элемент-функция write из ostream выводит в специфицированный поток
фиксированное число байт, начиная с некоторого места в памяти. Когда
поток ассоциирован с файлом, функция write записывает данные в место
файла, определяемое его «put»-указателем позиции. Элемент-функция read из
istream вводит фиксированное число байт из специфицированного потока
в память, начиная с некоторого адреса. Если поток ассоциирован с файлом,
функция read читает байты из места, определяемого «get»-указателем
позиции файла.
Обработка файлов
1005
Запись байтов элемент-функцией write класса ostream
При записи в файл четырехбайтового целого number вместо оператора
outFile « number;
который для единственного числа может напечатать как одну цифру, так и все
11 A0 цифр плюс знак; каждый символ требует для хранения один байт), мы
можем воспользоваться оператором
outFile.write( reinterpret_cast< const char * >( &number ),
sizeof( number ) );
который всегда записывает двоичное представление четырехбайтового целого
числа (на машине с четырехбайтовыми целыми). Функция write трактует свой
первый аргумент как группу байтов, рассматривая объект в памяти как const
char *, т.е. как указатель на байт (как вы помните, тип char занимает один
байт). Начиная с этого места функция выводит байты, число которых
специфицировано вторым аргументом — целым типа size_t. Как мы увидим,
впоследствии можно использовать функцию read из istream, чтобы прочитать эти
четыре байта обратно в переменную number.
Преобразование типа указателей с помощью операции
reinterpret __cast
К сожалению, большинство указателей, которые мы передаем функции
write в качестве первого аргумента, не относятся к типу const char *. Чтобы
выводить объекты других типов, мы должны преобразовать указатели на эти
объекты к типу const char *; в противном случае компилятор не будет
транслировать вызовы функции write. Для подобных случаев в C++ предусмотрена
операция reinterpret_cast, с помощью которой указатель одного типа может
быть приведен к другому, не связанному с первым, типу. Эту операцию можно
также применять для преобразований типов указателей в целые типы и
наоборот. Без reinterpret_cast оператор, выводящий целое number,
компилироваться не будет, так как компилятор не допускает передачи указателя типа int *
(возвращаемого выражением &number) функции, которая ожидает аргумент
типа const char * — насколько это касается компилятора, эти типы
несовместимы.
Операция reinterpret_cast производится во время компиляции и не
изменяет значение объекта, на который указывает ее операнд. Вместо этого она
просит компилятор интерпретировать операнд как целевой тип (указанный
в угловых скобках после ключевого слова reinterpret_cast). В программе на
рис. 17.12 мы применяем reinterpret_cast, чтобы преобразовать указатель на
ClientData в const char *, в результате чего объект ClientData
интерпретируется как массив байтов, который выводится в файл. Программы,
обрабатывающие файлы произвольного доступа, редко записывают в файл одиночное поле.
Обычно они записывают за один раз объект класса, что мы покажем в
последующих примерах.
1006
Глава 17
Предотвращение ошибок 17.1
С помощью reinterpretjcast можно легко производить опасные
преобразования, которые могут приводить к серьезным ошибкам времени
выполнения.
Переносимость программ 17.1
Выполнение reinterpret jcast зависит от компилятора, из-за чего
программы могут вести себя на различных платформах по-разному.
Использовать reinterpret jcast следует только в тех случаях, когда это
совершенно необходимо.
Переносимость программ 17.2
Программа, читающая неформатированные данные (записанные
функцией write), должна компилироваться и выполняться на
системе, совместимой с программой, записавшей эти данные, поскольку
внутреннее представление данных может изменяться от системы
к системе.
Программа для обработки кредита
Рассмотрим следующую формулировку задачи:
Создать для компании, которая может иметь до 100 клиентов,
программу для обработки кредита, которая способна хранить до 100 записей
фиксированной длины. Каждая запись должна состоять из полей номера
счета (служащего ключом записи), фамилии, имени и баланса счета.
Программа должна обеспечивать обновление счета, вставку нового счета,
удаление счета и вывод записей для всех счетов в форматированный
текстовый файл для распечатки.
В нескольких следующих разделах мы представим методики, необходимые
для создания такой программы. Рис. 17.12 иллюстрирует открытие файла
произвольного доступа, формат записи которого определяется объектом
класса ClientData (рис. 17.10-17.11), и запись данных на диск в двоичном
формате. Программа инициализирует все 100 записей файла credit.dat пустыми
объектами, используя функцию write. Каждый пустой объект содержит 0 для
номера счета, нулевые строки для фамилии и имени (представленные пустыми
кавычками) и 0.0 для баланса. Под каждую запись отводится пустое
пространство, в котором будут храниться данные счета.
1 // Рис. 17.10: ClientData.h
2 // Определение класса ClientData для программ на рис. 17.12-17.15.
3 #ifndef CLIENTDATA_H
4 #define CLIENTDATA_H
5
6 #include <string>
7 using std::string;
8
9 class ClientData
10 {
Обработка файлов
1007
11 public:
12 // конструктор ClientData по умолчанию
13 ClientData( int = 0, string = "", string = "", double = 0.0 );
14
15 // функции доступа для accountNumber
16 void setAccountNumber( int );
17 int getAccountNumber() const;
18
19 // функции доступа для lastName
20 void setLastName( string );
21 string getLastName() const;
22
23 // функции доступа для firstName
24 void setFirstName( string );
25 string getFirstName() const;
26
27 // функции доступа для balance
28 void setBalance( double );
29 double getBalance() const;
30 private:
31 int accountNumber;
32 char lastName[ 15 ];
33 char firstName[ 10 ];
34 double balance;
35 }; // конец класса ClientData
36
37 #endif
Рис. 17.10. Заголовочный файл класса ClientData
1 // Рис. 17.11: ClientData.cpp
2 // Класс ClientData хранит информацию о кредите клиента.
3 #include <string>
4 using std::string;
5
6 #include "ClientData.h"
7
8 // конструктор ClientData по умолчанию
9 ClientData::ClientData(int accountNumberValue,
10 string lastNameValue, string firstNameValue, double balanceValue)
11 {
12 setAccountNumber( accountNumberValue );
13 setLastName( lastNameValue );
14 setFirstName( firstNameValue );
15 setBalance( balanceValue );
16 } // конец конструктора ClientData
17
18 // получить значение номера счета
19 int ClientData::getAccountNumber() const
20 {
21 return accountNumber;
22 } // конец функции getAccountNumber
23
24 // установить значение номера счета
1008
Глава 17
25 void ClientData::setAccountNumber( int accountNuinberValue )
26 {
27 accountNumber = accountNuinberValue; // должно проверяться
28 } // конец функции setAccountNumber
29
30 // получить значение фамилии
31 string ClientData::getLastName() const
32 {
33 return lastName;
34 } // конец функции getLastName
35
36 // установить значение фамилии
37 void ClientData::setLastName( string lastNameString )
38 {
39 // скопировать из строки в lastName не более 15 символов
40 const char *lastNameValue = lastNameString.data();
41 int length = lastNameString.size();
42 length = ( length < 15 ? length : 14 ) ;
43 strncpy( lastName, lastNameValue, length );
44 lastName[ length ] = '\0'; // дополнить lastName нуль-символом
45 } // конец функции setLastName
46
47 // получить значение имени
48 string ClientData::getFirstName() const
49 {
50 return firstName;
51 } // конец функции getFirstName
52
53 // установить значение имени
54 void ClientData::setFirstName( string firstNameString )
55 {
56 // скопировать из строки в firstName не более 10 символов
57 const char *firstNameValue = firstNameString.data() ;
58 int length = firstNameString.size();
59 length = ( length < 10 ? length : 9 ) ;
60 strncpy( firstName, firstNameValue, length );
61 firstName [ length ] = '\0' ; // дополнить firstName нуль-символом
62 } // конец функции setFirstName
63
64 // получить значение баланса
65 double ClientData::getBalance() const
66 {
67 return balance;
68 } // конец функции getBalance
69
70 // установить значение баланса
71 void ClientData::setBalance( double balanceValue )
72 {
73 balance = balanceValue;
74 } // конец функции setBalance
Рис. 17.11. Класс ClientData представляет информацию о кредите клиента
Обработка файлов
1009
Объекты класса string не имеют единообразного размера, поскольку они
используют динамически распределяемую память, чтобы хранить строки
различной длины. Эта программа должна работать с записями постоянной длины,
поэтому класс ClientData сохраняет имя и фамилию клиента в символьных
массивах фиксированного размера. Элемент-функции setLastName (рис. 17.11,
строки 37-45) и setFirstName (рис. 17.11, строки 54-62) копируют символы
из объекта string в соответствующие символьные массивы. Рассмотрим
функцию setLastName. Строка 40 инициализирует const char *lastNameValue
результатом вызова функции data класса string, которая возвращает массив,
содержащий символы строки. [Замечание. Этот массив не обязательно ограничен
нулем.] Строка 41 вызывает функцию size класса string, чтобы получить
длину lastNameString. Строка 42 гарантирует, что длина строки (length) будет не
более 15 символов, после чего строка 43 копирует length символов из lastNa-
meValue в символьный массив lastName. Элемент-функция setFirstName
производит те же действия для имени клиента.
1 // Рис. 17.12: Figl7_12.cpp
2 // Создание файла произвольного доступа.
3 #include <iostream>
4 using std::cerr;
5 using std::endl;
6 using std::ios;
7
8 #include <fstream>
9 using std::ofstream
10
11 #include <cstdlib>
12 using std::exit; // прототип функции exit
13
14 #include "ClientCata.h" // определение класса ClientData
15
16 int main()
17 {
18 ofstream outCredit( "credit.dat", ios::binary );
19
20 // если ofstream не смог открыть файл, выйти из программы
21 if ( loutCredit )
22 {
23 cerr « "File could not be opened." « endl;
24 exit( 1 );
25 } // конец if
26
27 ClientData blankClient; // конструктор обнуляет все элементы
28
29 // вывести в файл 100 пустых записей
30 for ( int i = 0; i < 100; i++ )
31 outCredit.write( reinterpret_cast<const char *>(&blankClient),
32 sizeof( ClientData ) );
33
34 return 0;
35 } // конец main
Рис, 17.12. Последовательное создание файла произвольного доступа
1010
Глава 17
Строка 18 на рис. 17.12 создает объект ofstream для файла credit.dat.
Второй аргумент конструктора — ios::binary — указывает, что мы открываем
файл для вывода в двоичном режиме, который необходим, если нам нужно
записывать записи фиксированной длины. Строки 31-32 записывают пустые
объекты blankClient в файл credit.dat, ассоциированный с объектом потока
о lit Credit. Как вы помните, операция sizeof возвращает размер в байтах
объекта, заключенного в скобки (см. главу 8). Первый аргумент функции write
в строке 31 должен быть типа const char *. Но &blankClient имеет тип
ClientData *. Чтобы преобразовать &blankClient в const char *, в строке 31
используется операция приведения reinterpret_cast, иначе компиляция вызова
функции write приводила бы к ошибке.
17.9. Произвольная запись данных в файл
произвольного доступа
Программа на рис. 17.13 записывает данные в файл credit.dat, используя
комбинацию функций seekp и write класса fstream для сохранения данных
в точно указанном месте файла. Функция seekp устанавливает
«put-указатель» позиции файла в указанное положение, после чего write выводит
данные. Обратите внимание, что строка 19 специфицирует заголовочный файл
ClientData.h, приведенный на рис. 17.10, чтобы программа могла работать
с объектами fstream.
1 // Рис. 17.13: Figl7_13.cpp
2 // Запись в файл произвольного доступа.
3 #include <iostream>
4 using std::cerr;
5 using std::cin;
6 using std::cout;
7 using std::endl;
8 using std::ios;
9
10 #include <iomanip>
11 using std::setw;
12
13 #include <fstream>
14 using std::fstream;
15
16 #include <cstdlib>
17 using std::exit; // прототип функции exit
18
19 #include "ClientData.h" // определение класса ClientData
20
21 int main()
22 {
23 int accountNumber;
24 char lastName[ 15 ];
25 char firstName[ 10 ];
26 double balance;
27
28 fstream outCredit( "credit.dat", ios::in|ios::out|ios::binary );
29
Обработка файлов
1011
30 // если fstream не смог открыть файл, выйти из программы
31 if ( loutCredit )
32 {
33 cerr « "File could not be opened." « endl;
34 exit( 1 );
35 } // конец if
36
37 cout « "Enter account number A to 100, 0 to end input)\n? ";
38
39 // попросить пользователя указать номер счета
40 ClientData client;
41 cin » accountNumber;
42
43 // пользователь вводит информацию, которая копируется в файл
44 while ( accountNumber > 0 && accountNumber <= 100 )
45 {
46 // прользователь вводит фамилию, имя и баланс
47 cout « "Enter lastname, firstname, balance\n? ";
48 cin » setw( 15 ) » lastName;
49 cin » setw( 10 ) » firstName;
50 cin » balance;
51
52 // установить accountNumber, lastName, firstName и balance
53 client.setAccountNumber( accountNumber );
54 client.setLastName( lastName );
55 client.setFirstName( firstName );
56 client.setBalance( balance );
57
58 // найти позицию записи
59 outCredit.seekp( ( client.getAccountNumber() - 1 ) *
60 sizeof( ClientData ) );
61
62 // записать специфицированную пользователем информацию в файл
63 outCredit.write( reinterpret_cast< const char * >( (client ),
64 sizeof( ClientData ) );
65
66 // предложить пользователю ввести следующий счет
67 cout « "Enter account number\n? ";
68 cin » accountNumber;
69 } // конец while
70
71 return 0;
72 } // конец main
Enter account number A to 100, 0 to end input)
? 37
Enter lastname, firstname, balance
? Barker Doug 0.00
Enter account number
? 29
Enter lastname, firstname, balance
? Brown Nansy -24.54
Enter account number
? 96
Enter lastname, firstname, balance
? Stone Sam 34.98
1012
Глава 17
Enter account number
? 88
Enter lastname, firstname, balance
? Smith Dave 258.34
Enter account number
? 33
Enter lastname, firstname, balance
? Dunn Stacey 314.33
Enter account number
? 0
Рис. 17.13. Запись в файл произвольного доступа
Строки 59-60 устанавливают put-указатель файла для объекта outCredit
в позицию, вычисляемую выражением
( client.getAccountNumber() - 1 ) * sizeof( ClientData )
Так как номер счета лежит в пределах от 1 до 100, при вычислении позиции
записи из него вычитается единица. Таким образом, для записи 1 указатель
позиции файла устанавливается на байт 0. Заметьте, что строка 20 использует
объект outCredit типа fstream для открытия существующего файла credit.dat.
Файл открывается для чтения и записи в двоичном режиме, для чего
комбинируются режимы открытия ios::in, ios::out и ios::binary. Несколько режимов
открытия комбинируются посредством операции поразрядного включающего
ИЛИ (|). Открывая файл credit.dat таким образом, мы гарантируем, что
программа сможет манипулировать записями, сохраненными в файле
программой на рис. 17.12, а не создаст файл заново. Поразрядная операция
включающего ИЛИ детально обсуждается в главе 21.
17.10. Последовательное чтение из файла
произвольного доступа
В предыдущих разделах мы создали файл произвольного доступа и
записали в него данные. Теперь мы разработаем программу, которая последовательно
читает этот файл и распечатывает только те его записи, что содержат данные.
Все эти программы дают некоторую дополнительную выгоду. Посмотрим,
сможете ли вы сказать сами, в чем эта выгода состоит.
Функция read из istream вводит в объект специфицированное число байт,
начиная с текущей позиции указанного потока. Например, строки 57-58 на
рис. 17.14 читают число байт, специфицируемое выражением sizeof(
ClientData ), из файла, ассоциированного с объектом inCredit класса if stream, и
сохраняют данные в записи client. Обратите внимание, что функции read требуется
первый аргумент типа char *. Поскольку &client имеет тип ClientData *, &cli-
ent необходимо привести к char * с помощью операции reinterpret_cast.
Заметьте, что строка 24 включает заголовочный файл ClientData.h, показанный
на рис. 17.10, поэтому программа может работать с объектами ClientData.
Программа на рис. 17.14 последовательно читает все записи в файле
credit.dat, проверяет каждую запись на предмет того, содержит ли она
данные, и выводит для содержащих данные записей форматированные строки.
Условие в строке 50 использует функцию eof класса ios, чтобы определить мо-
Обработка файлов
1013
мент, когда достигается конец файла, что заставляет оператор while
завершиться. Кроме того, цикл завершается, если при чтении файла происходит
ошибка, так как в этом случае inCredit оценивается как false. Данные,
введенные из файла, выводятся функцией outputLine (строки 65-72), принимающей
два аргумента — объект ostream и структуру ClientData, которая должна
выводиться. Здесь интересен тип параметра ostream, так как в качестве аргумента
можно передать любой объект ostream (такой, как cout) или объект класса,
производного от ostream (например, класса of stream). Это означает, что функцию
можно использовать, например, для вывода в стандартный выходной поток
и в файловый поток, не предусматривая для этого отдельных функций.
1 // Рис. 17.14: Figl7__14.cpp
2 // Последовательное чтение файла произвольного доступа.
3 #include <iostream>
4 using std::cerr;
5 using std:rcout;
6 using std::endl;
7 using std::fixed;
8 using std::ios;
9 using std::left;
10 using std::right;
11 using std::showpoint;
12
13 #include <iomanip>
14 using std:rsetprecision;
15 using std::setw;
16
17 #include <fstream>
18 using std::ifstream;
19 using std::ostream;
20
21 #include <cstdlib>
22 using std::exit; // прототип функции exit
23
24 #include "ClientData.h" // определение класса ClientData
25
26 void outputLine( ostream&, const ClientData & ); // прототип
27
28 int main()
29 {
30 ifstream inCredit( "credit.dat", ios::in );
31
32 // если ifstream не смог открыть файл, выйти из программы
33 if ( !inCredit )
34 {
35 cerr « "File could not be opened." « endl;
36 exit( 1 );
37 } // конец if
38
39 cout « left « setw( 10 ) « "Account" « setw( 16 )
40 « "Last Name" « setw( 11 ) « "First Name" « left
41 « setw( 10 ) « right « "Balance" « endl;
42
43 ClientData client; // создать запись
44
1014
Глава 17
45 // прочитать из файла первую запись
46 inCredit.read( reinterpret_cast< char * >( ficlient ),
47 sizeof( ClientData ) );
48
49 // прочитать все записи файла
50 while ( inCredit && !inCredit.eof') )
51 {
52 // вывести запись
53 if ( client.getAccountNumber<) != 0 )
54 outputLine( cout, client );
55
56 // прочитать из файла следующую запись
57 inCredit.read( reinterpret_cast< char * >( ficlient ),
58 sizeof( ClientData ) );
59 } // конец while
60
61 return 0;
62 } // конец main
63
64 // вывести одиночную запись
65 void outputLine( ostream fioutput, const ClientData &record )
66 {
67 output « left « setw( 10 ) « record. getAccountNumber ()
68 « setw( 16 ) « record.getLastName()
69 « setw( 11 ) « record.getFirstName()
70 « setw( 10 ) « setprecision( 2 ) « right « fixed
71 « showpoint « record.getBalance() « endl;
72 } // конец функции outputLine
Account Last Name
29 Brown
33 Dunn
37 Barker
88 Smith
96 Stone
First Name
Nans у
Stacey
Doug
Dave
Sam
Balance
-24.54
314.33
0.00
258.34
34.98
Рис. 17,14. Последовательное чтение файла произвольного доступа
А как же насчет дополнительной выгоды, которую мы обещали? Если вы
изучите окно вывода, то заметите, что записи выводятся в сортированном (по
номерам счетов) виде. Это следствие того, что мы сохраняли записи в файле,
используя методики прямого доступа. В сравнении с сортировкой посредством
вставки, использованной в главе 7, сортировка с помощью прямого доступа
относительно быстра. Быстрота достигается за счет создания файла, достаточно
большого, чтобы вместить любую возможную запись, которая могла бы быть
создана. Это, конечно, означает, что по большей части файл будет заполнен
довольно скудно и будет зря занимать дисковое пространство. Это еще один
пример компромисса между пространством и временем: расходуя большие объемы
пространства, мы можем разработать гораздо более быстрый алгоритм
сортировки. К счастью, непрерывное сокращение цен на устройства памяти делает
этот вопрос менее существенным.
Обработка файлов
1015
17.11. Пример. Программа обработки транзакций
Теперь мы представим развитую программу обработки транзакций
(рис. 17.15), использующую файл произвольного доступа, который
обеспечивает «мгновенную» обработку. Программа служит для сопровождения
информации о счетах банка. Она обновляет существующие счета, добавляет новые,
удаляет счета и сохраняет в текстовом файле форматированный листинг всех
имеющихся на текущий момент счетов. Предполагается, что файл credit.dat
был создан программой на рис. 17.12, а программа на рис. 17.13 внесла в него
первоначальные данные.
1 // Рис. 17.15: Figl7_15.cpp
2 // Программа последовательно читает файл произвольного доступа,
3 // обновляет ранее записанные данные, создает данные для записи
4 //в файл и удаляет имеющиеся в файле данные.
5 #include <iostream>
6 using std::cerr;
7 using std::cin;
8 using std::cout;
9 using std::endl;
10 using std::fixed;
11 using std::ios;
12 using std::left;
13 using std::right;
14 using std::showpoint;
15
16 #include <fstream>
17 using std::ofstream;
18 using std::ostream;
19 using std::fstream;
20
21 #include <iomanip>
22 using std::setw;
23 using std::setprecision;
24
25 #include <cstdlib>
26 using std::exit; // прототип функции exit
27
28 #include "ClientData.h" // определение класса ClientData
29
30 int enterChoice();
31 void createTextFile( fstreams );
32 void updateRecord( fstreams );
33 void newRecord( fstreams );
34 void deleteRecord( fstreams );
35 void outputLine( ostreamS, const ClientData S );
36 int getAccount( const char * const );
37
38 enum Choices { PRINT = 1, UPDATE, NEW, DELETE, END };
39
40 int main()
41 {
42 // открыть файл для чтения и записи
43 fstream inOutCredit( "credit.dat", ios::in | ios::out );
44
1016
Глава 17
45 // если fstream не смог открыть файл, выйти иэ программы
46 if ( !inOutCredit )
47 {
48 cerr « "File could not be opened." « endl;
49 exit ( 1 ) ;
50 } // конец if
51
52 int choice; // хранит выбор пользователя
53
54 // предложить пользователю задать действие
55 while ( ( choice = enterChoice() ) != END )
56 {
57 switch ( choice )
58 {
59 case PRINT: // создать из файла записей текстовый файл
60 createTextFile( inOutCredit );
61 break;
62 case UPDATE: // обновить запись
63 updateRecord( inOutCredit );
64 break;
65 case NEW: // создать запись
66 newRecord( inOutCredit );
67 break;
68 case DELETE: // удалить существующую запись
69 deleteRecord( inOutCredit );
70 break;
71 default: // ошибка - пользователь указал недопустимый выбор
72 cerr « "Incorrect choice" « endl;
73 break;
74 } // конец switch
75
76 inOutCredit.clear(); // сбросить индикатор конца файла
77 } // конец while
78
79 return 0;
80 } // конец main
81
82 // предложить пользователю сделать выбор в меню
83 int enterChoice()
84 {
85 // вывести доступные опции
86 cout « "\nEnter your choice" « endl
87 « - store a formatted text file of accounts" « endl
88 « " called V'print.txt\" for printing" « endl
89 « - update an account" « endl
90 « - add a new account" « endl
91 « - delete an account" « endl
92 « - end program\n? ";
93
94 int menuChoice;
95 cin » menuChoice; // ввести выбор пользователя
96 return menuChoice;
97 } // конец функции enterChoice
98
99 // создать форматированный текстовый файл для печати
100 void createTextFile( fstream fcreadFromFile )
101 {
Обработка файлов
1017
102 // create text file
103 ofstream outPrintFile( "print.txt", ios::out );
104
105 // если of stream не смог создать файл, выйти иэ программы
106 if ( !outPrintFile )
107 {
108 cerr « "File could not be created." « endl;
109 exit( 1 ) ;
110 } // конец if
111
112 outPrintFile « left « setw( 10 ) « "Account" « setw( 16 )
113 « "Last Name" « setw( 11 ) « "First Name" « right
114 « setw( 10 ) « "Balance" « endl;
115
116 // установить указатель позиции файла на начало readFromFile
117 readFromFile.seekg( 0 );
118
119 // прочитать первую запись из файла записей
120 ClientData client;
121 readFromFile.read( reinterpret_cast< char * >( &client ),
122 sizeof( ClientData ) );
123
124 // скопировать все записи из файла записей в текстовый файл
125 while ( IreadFromFile.eof() )
126 {
127 // записать в текстовый файл одиночную запись
128 if ( client.getAccountNumber() != 0 ) // пропускать пустые
129 outputLine( outPrintFile, client );
130
131 // прочитать из файла записей следующую запись
132 readFromFile.read( reinterpret_cast< char * >( &client ),
133 sizeof( ClientData ) );
134 } // конец while
135 } // конец функции createTextFile
136
137 // обновить баланс в записи
138 void updateRecord( fstream &updateFile )
139 {
140 // получить номер обновляемого счета
141 int accountNumber = getAccount( "Enter account to update" );
142
143 // переместить указатель позиции файла к нужной записи
144 updateFile.seekg( ( accountNumber - 1 ) * sizeof( ClientData ) );
145
146 // прочитать запись иэ файла
147 ClientData client;
148 updateFile.read( reinterpret_cast< char * >( ficlient ),
149 sizeof( ClientData ) ),
150
151 // обновить запись
152 if ( client.getAccountNumber() != 0 )
153 {
154 outputLine( cout, client ); // вывести запись
155
156 // запросить у пользователя вид транзакции
157 cout « "\nEnter charge (+) or payment (-): ";
158 double transaction; // начисление или платеж
1018
Глава
159 cin » transaction;
160
161 // обновить баланс записи
162 double oldBalance = client.getBalance();
163 client.setBalance( oldBalance + transaction );
164 outputLine( cout, client ); // display the record
165
166 // переместить указатель позиции файла к нужной записи
167 updateFile.seekp( ( accountNumber-1 ) * sizeof( ClientData ) )
168
169 // записать обновленную запись в файл поверх старой записи
170 updateFile.write( reinterpret_cast< const char * >( ficlient ),
171 sizeof( ClientData ) );
172 } // конец if
173 else // если счет не существует, сообщить об ошибке
174 cerr « "Account #" « accountNumber
175 « " has no information." « endl;
176 } // конец функции updateRecord
177
178 // создать и вставить запись
179 void newRecord( fstream fiinsertlnFile )
180 {
181 // получить номер создаваемого счета
182 int accountNumber = getAccount( "Enter new account number" );
183
184 // переместить указатель позиции файла к нужной записи
185 insertlnFile.seekg( ( accountNumber-1 ) * sizeof( ClientData ) )
186
187 // прочитать запись из файла
188 ClientData client;
189 insertlnFile.read( reinterpret_cast< char * >( ficlient ),
190 sizeof( ClientData ) );
191
192 // если записи еще не существует, создать запись
193 if ( client.getAccountNumber() == 0 )
194 {
195 l char lastName[ 15 ];
196 char firstName[ 10 ];
197 double balance;
198
199 // пользователь вводит фамилию, имя и баланс
200 cout « "Enter lastname, firstname, balance\n? ";
201 cin » setw( 15 ) » lastName;
202 cin » setw( 10 ) » firstName;
203 cin » balance;
204
205 // использовать значения для заполнения полей записи
206 client.setLastName( lastName );
207 client.setFirstName( firstName );
208 client.setBalance( balance );
209 client.setAccountNumber( accountNumber );
210
211 // переместить указатель позиции файла к нужной записи
212 insertlnFile.seekp( ( accountNumber-1 ) * sizeof(ClientData) );
213
214 // вставить запись в файл
215 insertlnFile.write( reinterpret_cast<const char *>( ficlient ),
Обработка файлов
1019
216 sizeof( ClientData ) );
217 } // конец if
218 else // если счет уже существует, сообщить об ошибке
219 cerr « "Account #" « accountNumber
220 « " already contains information." « endl;
221 } // конец функции newRecord
222
223 // удалить существующую запись
224 void deleteRecord( fstream fideleteFromFile )
225 {
226 // получить номер удаляемого счета
227 int accountNumber = getAccount( "Enter account to delete" );
228
229 // переместить указатель позиции файла к нужной записи
230 deleteFromFile.seekg( ( accountNumber-1 ) * sizeof(ClientData) );
231
232 // прочитать запись из файла
233 ClientData client;
234 deleteFromFile.read( reinterpret_cast< char * >( ficlient ),
235 sizeof( ClientData ) );
236
237 // если запись существует, удалить запись из файла
238 if ( client.getAccountNumber() != 0 )
239 {
240 ClientData blankClient; // создать пустую запись
241
242 // переместить указатель позиции файла к нужной записи
243 deleteFromFile.seekp( ( accountNumber - 1 ) *
244 sizeof( ClientData ) );
245
246 // заменить существующую запись пустой записью
247 deleteFromFile.write(
248 reinterpret_cast< const char * >( &blankClient ),
249 sizeof( ClientData ) );
250
251 cout « "Account #" « accountNumber « " deleted. \n" ;
252 } // конец if
253 else // если запись не существует, сообщить об ошибке
254 cerr « "Account #" « accountNumber « " is empty. \n";
255 } // конец функции deleteRecord
256
257 // вывести одиночную запись
258 void outputLine( оstream &output, const ClientData &record )
259 {
260 output « left « setw( 10 ) « record. getAccountNumber ()
261 « setw( 16 ) « record.getLastName ()
262 « setw( 11 ) « record.getFirstNameO
263 « setw( 10 ) « setprecision ( 2 ) « right « fixed
264 « showpoint « record.getBalance() « endl;
265 } // конец функции outputLine
266
267 // получить от пользователя Номер счета
268 int getAccount( const char * const prompt )
269 {
270 int accountNumber;
271
272 // получить значение номера счета
1020
Глава 17
273 do
274 {
275 cout « prompt « " A - 100) :
276 cin » accountNumber;
277 } while ( accountNumber < 1 || accountNumber > 100 );
278
279 return accountNumber;
280 } // конец функции getAccount
Рис. 17.15. Программа для работы с банковскими счетами
У программы есть пять опций (опция 5 завершает ее выполнение). Опция 1
вызывает функцию createTextFile для сохранения информации о всех счетах
в текстовом файле с именем print.txt, который может быть распечатан.
Функция createTextFile (строки 100-135) принимает в качестве аргумента объект
fstream, который должен использоваться для ввода данных из файла
credit.dat. Функция вызывает элемент-функцию read из istream
(строки 132-133) и применяет методики последовательного доступа, показанные на
рис. 17.14, для ввода данных из credit.dat. Для вывода данных в файл
print.txt используется функция output Line, обсуждавшаяся в разделе 17.10.
Обратите внимание, что createTextFile вызывает элемент-функцию seekg из
istream, чтобы гарантировать установку указателя позиции файла на его
начало. После выбора опции 1 файл print.txt содержит:
Account
29
33
37
88
96
Last Name
Brown
Dunn
Barker
Smith
Stone
First Name
Nansy
Stacey
Doug
Dave
Sam
Balance
-24.54
314.33
0.00
258.34
34.98
Опция 2 вызывает updateRecord (строки 138-176), чтобы обновить счет.
Эта функция обновляет только существующие счета, поэтому она сначала
проверяет, не пуста ли соответствующая запись. Строки 148-149 читают данные
в объект client с помощью элемент-функции read из istream. Затем строка 152
сравнивает с нулем значение, возвращаемое функцией get Account Number
структуры client, чтобы определить, содержит ли запись информацию. Если
значение нулевое, строки 174-175 печатают сообщение об ошибке,
показывающее, что запись пуста. Если запись содержит информацию, строка 154
выводит ее с помощью функции outputLine, строка 159 вводит сумму
транзакции, а строки 162-171 вычисляют новый баланс и переписывают содержимое
записи в файле. Типичный вывод для опции 2:
Обработка файлов
1021
Enter account to update A - 100): 37
37 Barker Doug 0.00
Enter charge ( + ) or payment {-): +87.99
37 Barker Doug 87.99
Опция З вызывает функцию newRecord, чтобы добавить в файл новый счет.
Если пользователь вводит номер для существующего счета, newRecord
выводит сообщение об ошибке, показывающее, что счет уже имеется
(строки 219-220). Эта функция добавляет новый счет так же, как это делается
в программе на рис. 17.12. Типичный вывод для опции 3:
Enter new account number A - 100): 22
Enter lastname, firstname, balance
? Johnston Sarah 247.45
Опция 4 функцию deleteRecord (строки 224-255), чтобы удалить запись из
файла. Строка 227 предлагает пользователю ввести номер счета. Удалить
можно только существующую запись, поэтому, если указанный счет пуст,
строка 254 выводит сообщение об ошибке. Если счет существует, строки 247-249
реинициализируют его, копируя в файл пустую запись (blankClient).
Строка 251 выводит сообщение, информирующее пользователя, что запись
удалена. Типичный вывод для опции 4:
Enter account to delete A -- 100) : 29
Account #29 deleted.
Заметьте, что строка 43 открывает файл credit.dat, создавая объект fstream
как для чтения, так и для записи, комбинируя по ИЛИ режимы ios::in
и ios::out.
17.12. Ввод/вывод объектов
В этой главе и в главе 15 мы представили объектно-ориентированный стиль
ввода/вывода в C++. Однако наши примеры сосредоточивали внимание на
вводе/выводе традиционных типов данных, а не объектов пользовательских
типов. В главе 11 мы показывали, как вводить и выводить объекты, используя
перегрузку операций. Мы реализовывали ввод объектов, перегружая
операцию извлечения из потока » для соответствующего класса istream. Вывод
объектов осуществлялся перегрузкой операции передачи в поток « для
соответствующего класса ostream. В обоих случаях вводились или выводились
только элементы данных объекта, и с каждом случае в формате, имеющем
смысл только для данного конкретного абстрактного типа данных.
Элемент-функции объекта не вводятся и не выводятся вместе с его элементами
данных; во внутреннем представлении остается доступным только один
экземпляр элемент-функций класса, разделяемый всеми объектами этого класса.
Когда элементы данных объекта выводятся в дисковый файл, мы теряем
информацию о типе объекта. Мы сохраняем в файле только байты данных, но
1022
Глава 17
не информацию о типе. Если программа, читающая данные, знает тип
объекта, которому они соответствуют, она будет читать их в объекты этого типа.
Интересная проблема возникает, когда мы сохраняем в одном файле
объекты различных типов. Каким образом мы можем при чтении различить их (или
наборы их элементов данных)? Проблема в том, что объекты обычно не имеют
полей типа (мы внимательно изучили этот вопрос в главе 13).
Один из возможных подходов — потребовать, чтобы каждая из
перегруженных операций вывода записывала код типа перед каждым набором элементов
данных, представляющих один объект. Тогда ввод объекта всегда будет
начинаться с чтения поля типа, после чего оператор switch будет вызывать
соответствующую перегруженную функцию. Хотя такому решению недостает
изящества полиморфного программирования, оно дает вполне работоспособный
механизм для сохранения объектов в файлах и извлечения их оттуда по мере
необходимости.
17.13. Заключение
В этой главе мы представили различные методики обработки файлов для
манипулирования долговременными данными. Вы узнали, что данные в
компьютерах сохраняются в форме нолей и единиц, и что комбинации этих
значений образуют байты, поля, записи и, наконец, файлы. Вы получили
представление о символьно-ориентированных и байтово-ориентированных потоках и
о различных шаблонах классов для обработки файлов в заголовочном файле
<fstream>. Затем вы узнали, как осуществляется последовательная обработка
файлов для манипуляции записями, хранящимися по порядку полей ключа
записи. Вы также узнали, как использовать файлы произвольного доступа,
чтобы осуществить «мгновенное» извлечение и обработку записей
фиксированной длины. Наконец, мы представили пример развитой программы
обработки транзакций, использующей файл произвольного доступа для
реализации обработки с «мгновенным» доступом к данным. В следующей главе мы
обсуждаем типичные операции со строками, предлагаемые шаблоном класса
basic_string. Мы также представим возможности обработки строковых
потоков, позволяющие вводить строки из памяти и выводить их в память.
Резюме
• Файлы обеспечивают долговременность, или устойчивость, данных — постоянное
хранение больших объемов информации.
• Наименьшая единица данных, к которой может обращаться компьютер, называется
битом (сокращение от «binary digit» — двоичная цифра, которая может принимать
одно из двух значений, 0 или 1).
• Цифры, буквы и специальные знаки называются символами.
• Множество символов, которыми можно пользоваться при написании программ
и представлении элементов данных на конкретном компьютере, называется его
набором символов.
• Байты состоят из восьми битов.
• Подобно тому, как символы состоят из битов, поля состоят из символов. Поле
представляет собой группу символов, которая передает некоторое значение.
• Обычно запись (т.е. класс в C++ ) состоит из нескольких полей (т.е. элементов
данных класса C++).
Обработка файлов
1023
• По крайней мере одно поле в каждой записи файла выбирается в качестве ключа
записи, который идентифицирует запись как принадлежащую конкретному лицу или
объекту и отличает данную запись от всех остальных.
• В последовательном файле записи, как правило, хранятся в порядке, определяемом
полем ключа.
• Группа связанных файлов часто сохраняется в базе данных.
• Набор программ, предназначенный для создания и поддержки баз данных,
называется системой управления базами данных (DBMS).
• В C++ каждый файл рассматривается как последовательность байтов.
• Каждый файл завершается маркером конца файла или байтом с номером,
записанным в некоторой служебной структуре данных, поддерживаемой системой.
• В заголовке <fstream> определены шаблоны классов потоков basic_ifstream (для
файлового ввода), basic_ofstream (для файлового вывода) и basic_fstream (для ввода
и вывода).
• Для объекта ofstream режим открытия файла может быть или ios::out для вывода
данных в файл, или ios::app для дописывания данных в конец файла (без модифика-'
ции каких-либо данных, уже имеющихся в файле).
• Режим ios::ate открывает файл для вывода и перемещает указатель в конец файла.
Обычно этот режим открытия применяется для дописывания данных в конец файла,
но данные могут быть записаны в любое место файла.
• Существующие файлы, открываемые режимом ios::out, усекаются (т.е. все данные
в файле отбрасываются).
• Объекты ofstream по умолчанию открываются для вывода.
• Элемент-функция open класса ofstream открывает файл и прикрепляет его к
существующему объекту ofstream.
• Перегруженная функция-операция operator void * из ios преобразует поток в
указатель, чтобы его можно было проверить на равенство 0 (т.е. нулевому указателю) или
ненулевому значению (т.е. любому другому значению указателя).
• Программист может явным образом закрыть объект ofstream с помощью его
элемент-функции close.
• Как if stream, так и ofstream предусматривают элемент-функции для переустановки
указателя позиции файла (номера байта в файле, который будет читаться или
записываться следующим). Этими функциями являются seekg («seek get*) для if stream
и seekp («seek put») для ofstream.
• Направление поиска может иметь значения ios::begin (по умолчанию) для
позиционирования относительно начала потока, ios::cur для позиционирования
относительно текущей позиции или ios::end для позиционирования относительно конца потока.
• Для определения текущего положения «get»- и «put»-указателей предусмотрены
соответственно элемент-функции tellg и tellp.
• Доступ к отдельным записям в файле произвольного доступа является
непосредственным (и быстрым) и не требует просмотра других записей.
• Элемент-функция write из ostream выводит в специфицированный поток
фиксированное число байт, начиная с некоторого места в памяти. Когда поток ассоциирован
с файлом, функция write записывает данные в место файла, определяемое его
«put»-указателем позиции.
• Элемент-функция read из istream вводит фиксированное число байт из
специфицированного потока в память, начиная с некоторого адреса. Если поток ассоциирован с файлом,
функция read читает байты из места, определяемого «get»-указателем позиции файла.
• Элемент-функция data класса string преобразует строку в символьный массив в
стиле С, не ограниченный нулем.
1024 Глава 17
Терминология
cin (стандартный ввод)
clog (стандартный буферизованный
поток ошибок)
cout (стандартный вывод)
f stream
база данных
байт
бит
двоичная цифра
десятичная цифра
заголовочный файл <fstream>
запись
иерархия данных
имя файла
ключ записи
конец файла
набор символов
направление поиска
направление поиска ios::beg
направление поиска ios::cur
направление поиска ios::end
открытие файла
поле
последовательный файл
приложение мгновенного доступа
режим открытия файла ios::app
Контрольные вопросы
17.1. Заполните пропуски в следующих предложениях:
a) Все элементы данных, обрабатываемые компьютером, в конечном итоге
сводятся к комбинациям .
b) Наименьший элемент данных, который может обрабатываться компьютером,
называется .
с) — это группа связанных записей.
d) Цифры, буквы и специальные знаки называются .
e) Группа связанных файлов называется .
f) Элемент-функция классов файловых потоков fstream, if stream
и ostream закрывает файл.
g) Элемент-функция класса istream читает символ из заданного потока.
h) Элемент-функция классов потоков fstream, ifstream и ofstream
открывает файл.
i) Элемент-функция класса istream обычно используется в
приложениях для чтения данных из файла произвольного доступа.
j) Элемент-функции и классов istream ь ostream
устанавливают соответствующий указатель позиции в заданную позицию
соответственно во входном и выходном потоках.
17.2. Укажите, верны или неверны следующие утверждения. Если утверждение
неверно, объясните, почему.
режим открытия файла ios::ate
режим открытия файла ios::binary
режим открытия файла ios::in
режим открытия файла ios::out
режим открытия файла ios::trunc
символьное поле
система обработки транзакций
система управления базами данных
(DBMS)
смещение от начала файла
специальный знак
указатель позиции файла
усечение существующего файла
устойчивость данных
устройство вторичной памяти
файл
файл произвольного доступа
функция data из string
функция size из string
элемент-функция close из ofstream
элемент-функция open из ofstream
элемент-функция seekg из ifstream
элемент-функция seekp из ofstream
элемент-функция tellg из ifstream
элемент-функция tellp из ofstream
Обработка файлов
1025
a) Элемент-функция read не может быть использована для чтения данных из
объекта ввода cin.
b) Программист обязан явным образом создавать объекты cin, cout, сегг и clog.
c) Программа должна явным образом вызывать функцию close, чтобы закрыть
файл, связанный с объектами if stream, of stream или f stream.
d) Если указатель позиции файла показывает на позицию в последовательном
файле, отличную от начала, то для считывания с начала файла он должен
быть закрыт и заново открыт.
e) Элемент-функция write класса ostream может записывать в стандартный
поток вывода cout.
f) Данные в файле последовательного доступа всегда обновляются без перезаписи
соседних данных.
g) Чтобы найти требуемую запись, необходимо просмотреть все записи в файле
произвольного доступа.
h) Записи в файлах произвольного доступа должны быть одной длины.
i) Элемент-функции seekg и seekp проводят поиск относительно начала файла.
17.3. Предполагается, что каждый из перечисленных ниже операторов относится к
одной и той же программе.
a) Напишите оператор, который открывает файл oldmast.dat для ввода;
используйте объект inOldMaster класса if stream.
b) Напишите оператор, который открывает файл trans.dat для ввода;
используйте объект inTransaction класса ifstream.
c) Напишите оператор, который открывает (или создает) файл newmast.dat для
вывода; используйте объект outNewMaster класса of stream.
d) Напишите оператор, который считывает запись из файла oldmast.dat. Запись
состоит из целого accountNum, строки name и числа с плавающей запятой
currentBalane; используйте объект inOldMaster класса ifstream.
e) Напишите оператор, который считывает запись из файла trans.dat. Запись
состоит из целого accountNum и числа с плавающей запятой dollar Amount;
используйте объект inTransaction класса ifstream.
f) Напишите оператор, который заносит запись в файл newmast.dat. Запись
состоит из целого accountNum, строки name и числа с плавающей запятой
currentBalance; используйте объект outNewMaster класса of stream.
17.4. Найдите ошибку и покажите, каким образом исправить ее в перечисленных
ниже высказываниях:
a) Файл payables.dat, на который ссылаются с помощью объекта outPayable
класса of stream, не был открыт.
outPayable « account « company « amount « endl;
b) Следующий оператор должен читать запись из файла payables.dat. Объект in-
Payable класса ifstream ссылается на этот файл, а объект inReceivable класса
istream ссылается на файл receivables.dat.
inReceivable » account » company » amount;
c) Файл tools.dat должен быть открыт для добавления данных в файл без
уничтожения текущих данных.
ofstream outTools( "tools.dat", ios::out );
33 Зак. II14
1026
Глава 17
Ответы на контрольные вопросы
17.1. а) единиц и нулей. Ь) бит. с) Файл, d) символами, е) базой данных, f) close, g) get.
h) open, i) read, j) seekg, seekp.
17.2. а) Неверно. Функция read может быть использована для чтения данных из
любого объекта потока, производного от istream.
b) Неверно. Эти четыре потока создаются автоматически. Для использования
потоков в файл должен быть включен заголовочный файл <iostream>. Он
содержит объявления всех этих объектов потоков.
c) Неверно. Файлы закрываются, когда выполняются деструкторы объектов
классов if stream, ofstream или fstream, а это происходит, когда объекты
потоков выходят из области действия или перед завершением выполнения
программы; но, все же, хорошим стилем программирования является закрытие
всех файлов явным образом с помощью функции close, когда уже нет
потребности в этих файлах.
d) Неверно. Для установки указателей позиции «put» и «get» на начало файла
могут быть использованы элемент-функции seekg и seekp.
e) Верно.
f) Неверно. В большинстве случаев записи последовательного файла не имеют
одинаковой длины. Следовательно, вполне возможно, что обновление записи
приведет к необходимости перезаписать остальные данные.
g) Верно.
h) Неверно, но обычно записи в файле произвольного доступа имеют одинаковую
длину.
i) Неверно. Возможен поиск от начала файла, от его конца или от текущей записи
файла.
17.3. a) ifstream inOldMaster( "oldmast.dat", ios::in );
b) ifstream Transaction( "trans.dat", ios::in );
c) ofstrem outNewMaster( "newmast.dat", ios::out );
d) inOldMaster » accountNum » name » currentBalance ;
e) inTransaction » accountNum » dollarAmount;
f) outNewMaster « accountNum « name « currentBalance;
17.4. а) Ошибка: файл payables.dat не был открыт до попытки вывода данных в поток.
Исправление: используйте для открытия payables.dat на вывод функцию open
класса ostream.
b) Ошибка: используется неверный объект класса istream для чтения записи из
файла payables.dat.
Исправление: используйте для обращения к файлу payables.dat объект
inPayable класса istream.
c) Ошибка: содержимое файла отбрасывается, потому что файл открыт для
вывода (ios::out).
Исправление: для добавления данных в файл или откройте его для
обновления (ios::ate), или откройте для добавления в конец (ios::app).
Обработка файлов
1027
Упражнения
17.5. Заполните пропуски в следующих предложениях:
а) Компьютеры хранят большие объемы данных на устройствах вторичной
памяти, таких, как .
Ь) состоит из нескольких полей.
c) Для обеспечения поиска заданных записей в файле одно поле в каждой записи
выбирается в качестве .
d) Подавляющее большинство сведений в компьютерной системе хранится
в .
e) Группа связных символов, имеющая некоторый смысл, называется
f) Объектами стандартных потоков, объявляемыми в заголовке <iostream>,
являются , и .
g) Элемент-функция класса ostream выводит символ в заданный поток.
h) Элемент-функция класса ostream обычно используется для
записи данных в файл произвольного доступа.
i) Элемент-функция класса istream изменяет позицию указателя
позиции файла.
17.6. Укажите, верны или неверны следующие утверждения. Если утверждение
неверно, объясните, почему.
a) Впечатляющие функциональные возможности компьютера по существу
сводятся к манипуляциям с нулями и единицами.
b) Люди предпочитают манипулировать с битами вместо символов и полей,
поскольку биты более компактны.
c) Люди формулируют программы и единицы данных посредством символов;
компьютеры затем манипулируют этими символами и обрабатывают их как
группы из нулей и единиц.
d) Почтовый пятизначный код является примером численного поля.
e) Адрес человека обычно рассматривается в приложениях для компьютера как
буквенное поле.
f) Единицы данных образуют в компьютерах иерархию данных, в которой
единицы данных становятся все больше и сложнее по мере продвижения от полей
к символам, затем к битам и т.д.
g) Ключ записи идентифицирует запись как принадлежащую конкретному полю,
h) Большинство организаций хранит всю свою информацию в единственном
файле для облегчения процесса компьютерной обработки.
i) Когда программа создает файл, он автоматически сохраняется для
последующих ссылок.
17.7. В упражнении 17.3 мы просили читателя написать ряд отдельных операторов.
В действительности эти операторы образует ядро важного типа программ,
а именно программ сопоставления файлов. В программах обработки данных для
коммерческой сферы обычным является использование нескольких файлов.
Например, в программе, предназначенной для работы со счетами клиентов,
имеется так называемый главный файл, содержащий подробную информацию о
каждом заказчике, такую как имя заказчика, его адрес, номер телефона,
задолженность, лимит кредита, условия скидки, условия договора, и, кроме того, краткая
сводка последних заказов и поступления платежей.
Если произошла транзакция (то есть совершена покупка и получен денежный
перевод), она вносится в файл. В конце каждого делового цикла (то есть месяца
1028
Глава 17
для одних компаний, недели для других, а в некоторых случаях дня) файл
транзакций (в упражнении 17.3 он назван trans.dat) вводится в главный файл (в
упражнении 17.3 oldmasl.dat) и, таким образом, производится обновление записей
заказов и платежей. После того как все обновления сделаны, главный файл
переписывается как новый файл (newmast.dat), который затем используется в конце
следующего делового цикла, чтобы опять произвести процесс обновления.
Программа сопоставления файлов неизбежно сталкивается с некоторыми
проблемами, которых не возникает в программах, работающих с одним файлом. Например,
сопоставление записей возможно не всегда. В главном файле содержится запись
о заказчике, но за текущий деловой период он не делал никаких покупок или
платежей и, следовательно, записи в файле транзакций для этого заказчика
отсутствуют. А возможна и обратная ситуация, когда заказчик совершил несколько покупок
или денежных платежей, но сделал это впервые и вполне возможно, что в
компании на данный момент запись в главном файле для этого заказчика отсутствует.
Используя в качестве основы операторы, написанные в упражнении 17.3,
напишите полную программу обработки транзакций с сопоставлением файлов. Для
целей сопоставления используйте номер счета в каждом файле как ключ.
Исходите из того, что каждый файл является файлом последовательного доступа с
записями, хранящимися в порядке возрастания номера счета.
Когда имеется пара записей, которые можно сопоставить (т.е. имеются записи
с одним и тем же номером счета в главном файле и файле транзакций),
прибавьте сумму в долларах из файла транзакций к текущему балансу главного файла
и поместите соответствующую запись в файл newmast.dat. (Предположим, что
в файле транзакций заказам соответствуют положительные денежные суммы,
а полученным платежам — отрицательные.) Когда для конкретного счета
имеется главная запись, но не существует соответствующей записи в файле транзакций,
то главная запись просто переносится в файл newmast.dat. Когда есть запись
в файле транзакций, но нет соответствующей главной записи, программа должна
выдавать сообщение «Unmatched transaction record for account number ...» (на
месте многоточия должен стоять номер счета из записи файла транзакций).
17.8. После написания программы упражнения 17.7 напишите простую программу
создания контрольных данных для ее тестирования. Используйте следующий
пример данных:
Основной файл
Номер счета
100
300
500
700
Имя
Alan Jones
Mary Smith
Sam Sharp
Suzy Green
Баланс
348.17
27.19
0.00
-14.22
Файл текущих записей
Номер счета
100
300
400
900
Сумма в долларах
27.14
62.11
100.56
82.17
Обработка файлов
1029
17.9. Выполните программу упражнения 17.7, используя файлы тестовых данных,
созданные в упражнении 17.8. Отпечатайте новый основной файл. Проверьте,
правильно ли обновлены счета.
17.10. Возможно (и даже часто), имеется несколько текущих записей с одинаковым
ключом записи. Это происходит из-за того, что клиент мог совершить за
расчетный период несколько операций. Перепишите вашу программу сопоставления
файлов из упражнения 17.7, чтобы обеспечить возможность обработки
нескольких текущих записей с одним ключом. Модифицируйте тестовые данные
упражнения 17.8, включив в них следующие дополнительные текущие записи:
Номер счета
300
700
700
Сумма в долларах
83.89
80.78
1.53
17.11. Напишите ряд операторов для выполнения каждой из приведенных ниже
операций. Предположите, что определена структура, содержащая закрытые элементы
данных:
char lastName[ 15 ];
char £irstName[ 15 ];
char age[ 4 ];
и открытые элемент-функции:
// функции доступа к фамилии (lastName)
void setLastName( string );
string getLastName() const;
// функции доступа к имени (firstName)
void setFirstName( string );
string getFirstName() const;
// функции доступа к возрасту (age)
void setAge( string );
string getAge() const;
Также предположите, что открыты все требуемые файлы произвольного доступа.
a) Инициализируйте файл nameage.dat со 100 записями, содержащими
lastName = "unassigned", firstName = "" и age= ".
b) Введите 10 фамилий, имен и соответствующие возрасты, запишите эти данные
в файл.
c) Обновите записи, которые имеют указанные сведения, а если таких сведений
нет, то сообщите пользователю «Нет сведений».
d) Удалите запись, которая содержит информацию, путем ее повторной
инициализации.
17.12. Вы являетесь владельцем склада металлических изделий и нуждаетесь в
инвентаризации, которая сказала бы вам, сколько всего различных изделий вы
имеете, какое количество каждого из них у вас на руках и стоимость каждого из них.
Напишите программу, которая бы создала файл произвольного доступа
hardware.dat на сотню пустых записей, позволяла бы вводить данные по
каждому изделию, давала бы вам возможность получать список всех изделий, удалять
записи по изделиям, которых у вас уже нет, и позволяла бы обновлять любую
информацию в файле. Ключом должен быть идентификационный номер
изделия. Используйте следующую информацию для начала работы с вашим файлом:
1030
Глава 17
Номер записи
3
17
24
39
56
68
77
83
Название инструмента
Шлифовальный станок
Молоток
Лобзик
Газонокосилка
Электропила
Отвертка
Кувалда
Гаечный ключ
Количество
7
76
21
3
18
106
11
34
Стоимость
57.98
11.99
11.00
79.50
99.99
6.99
21.50
7.50
17.13. (Генератор слов для телефонного номера) Стандартный набор кнопок телефона
содержит цифры от 0 до 9. Каждая цифра от 2 до 9 имеет связанные с ней три
буквы, что отражено в следующей таблице:
Цифра
2
3
4
5
6
7
8
9
Буква
ABC
DEF
GHI
JKL
MNO
PRS
TUV
XYZ
Многие люди с трудом запоминают номера телефонов, поэтому они используют
соответствие между цифрами и буквами, чтобы подобрать слово из семи букв,
которое соответствовало бы телефонному номеру. Например, человек,
телефонный номер которого 686-2377, может воспользоваться подобной таблицей и
подобрать семибуквенное слово «NUMBERS».
Предприниматели часто пытаются получить номер телефона, который было бы
легко запомнить их клиентам. Если предприниматель сможет поместить в
рекламе простое слово, по которому клиенты могли бы звонить в его контору, тогда,
вне всяких сомнений, звонков будет несколько больше.
Каждое слово из семи букв соответствует ровно одному телефонному номеру.
Ресторан, желающий увеличить количество заказов на дом, безусловно сможет
сделать это, если его номер 825-3688 (т.е. «TAKEOUT»).
Каждому из семизначных номеров соответствует множество слов из семи букв.
К сожалению, большинство из них представляет собой бессмысленные
комбинации букв. Возможно, однако, что владелец парикмахерской был бы приятно
удивлен, узнав, что его телефон 424-7288 соответствует «HAIRCUT». Владелец
магазина, торгующего алкоголем, обрадуется, обнаружив, что телефон магазина
233-7226 соответствует «BEERCAN». Ветеринар, телефонный номер которого
738-2273, будет рад узнать, что этот номер соответствует слову «PETCARE».
Обработка файлов
1031
Напишите программу на С, которая для данного семизначного числа записывает
в файл все возможные слова из семи букв, соответствующие этому номеру.
Существует 2187 (три в седьмой степени) таких слов. Избегайте телефонных номеров
с цифрами 0 и 1.
17.14, Напишите программу, которая использует операцию sizeof для определения
числа байт в различных типах данных на используемой вами компьютерной
системе. Запишите результаты в файл datasize.dat, чтобы позднее его можно было
распечатать. Результаты должны выводиться в две колонки, в левой — имя
типа, в правой — размер, как показано ниже:
Data type
char
unsigned char
short int
unsigned short int
int
unsigned int
long int
unsigned long int
float
double
long double
Size
1
1
2
2
4
4
4
4
4
8
10
[Замечание. Размеры встроенных типов данных на вашем компьютере могут от
личаться от приведенных выше.]
I
\
/
18
Класс string и обработка
строковых потоков
ЦЕЛИ
В этой главе вы изучите:
• Класс string из Стандартной
библиотеки C++, позволяющий
обращаться со строками как
полноценными объектами.
• Присваивание, конкатенацию,
сравнение, поиск и обмен строк.
• Определение характеристик
строки.
• Поиск, замену и вставку символов
в строках.
• Преобразование стандартных строк
в строки стиля С и наоборот.
• Использование итераторов для
строк.
• Ввод из строки и вывод в строку в памяти.
1034
Глава 18
18.1. Введение
18.2. Присваивание и конкатенация строк
18.3. Сравнение строк
18.4. Подстроки
18.5. Обмен строк
18.6. Характеристики строки
18.7. Поиск в строке подстрок и символов
18.8. Замена символов в строке
18.9. Вставка символов в строку
18.10. Преобразование в строки-указатели С типа char
18.11. Итераторы
18.12. Обработка строковых потоков
18.13. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
18.1. Введение
Шаблон класса C++ basicjstring реализует типичные операции со
строками, такие, как копирование, поиск и т.д. Определение шаблона и все его
средства поддержки определяются в именном пространстве std; в их число входит
оператор typedef
typedef basic_string< char > string;
создающий тип-псевдоним для basic_string< char >. Предусмотрен также
typedef для типа wchar_t. Тип wchai^t1 хранит символы (напр., двухбайтовые
или четырехбайтовые символы) для поддержки иных символьных наборов.
В этой главе мы пользуемся исключительно типом string. Чтобы использовать
строки, нужно включить заголовочный файл <string>.
Объект string может быть инициализирован аргументом конструктора,
например,
string text( "Hello" ); // создает строку из const char *
что создает строку из символов, входящих в "Hello", или двумя аргументами
конструктора, например,
Тип wchar_t обычно используется для представления Unicode'*, имеющего 16-битные
символы, но размер wchar_t стандартом не фиксируется. Стандарт Unicode
предусматривает спецификацию для единообразной кодировки букв и символов мировых систем
письменности. Чтобы более подробно познакомиться со стандартом Unicode, посетите
www.unicode.org.
Класс string и обработка строковых потоков
1035
string name( 8, *х' ); // строка из 8 символов 'х'
что создает строку, содержащую 8 символов 'х'. В классе string
предусмотрены также конструктор по умолчанию (создающий пустую строку) и
конструктор копии. Пустой строкой называется строка, не содержащая никаких
символов.
Строка также может быть инициализирована посредством альтернативной
формы определения
string month = "March"; // то же, что и string month( "March" );
Помните, что операция = в этом объявлении не является присваиванием; она
обозначает здесь неявный вызов конструктора класса string, который
производит преобразование.
Заметьте, что в классе string не предусмотрено преобразований из int или
char в string в определении строки. Например, определения
string errorl = 'с';
string error2( 'и' );
string еггогЗ = 22;
string error4 ( 8 ) ;
приводят к синтаксическим ошибкам. Однако в операторе присваивания
допускается присвоение объекту string одиночного символа, например,
stringl = 'n';
77Y/3 Типичная ошибка программирования 18,1
Попытка преобразования int или char в string через инициализацию
в объявлении или через аргумент конструктора является
синтаксической ошибкой.
В отличие от строк char * в стиле С стандартные строки не обязательно
ограничены нулем. [Замечание. Стандартный документ C++ дает только
описание интерфейса для класса string — реализация зависит от платформы.]
Длину строки можно получить применением элемент-функции length и
элемент-функции size. Co строками может применяться операция индексации, [],
для чтения и модификации отдельных символов. Как и строки стиля С,
стандартные строки имеют начальный индекс 0 и конечный length() — 1.
Большинство элемент-функций string принимают в качестве аргументов
индекс начальной позиции и число символов, над которыми требуется
произвести операцию.
Операция извлечения из потока (») перегружена для строк. Оператор
string stringObject;
cin » stringObject;
читает строку со стандартного устройства ввода. Ввод ограничивается
пробельными символами. Когда встречается ограничитель, операция ввода
завершается. Функция getline также перегружена для строк. Оператор
string stringl;
getline( cin, stringl );
1036
Глава 18
читает в stringl строку с клавиатуры. Ввод ограничивается символом новой
строки (Ли'), поэтому gctline может читать в объект string строку текста.
18.2. Присваивание и конкатенация строк
На рис. 18.1 демонстрируется присваивание и конкатенация строк.
Строка 7 включает заголовок <string> для класса string. В строках 12-14
создаются строки stringl, string2 и snring3. Строка 16 присваивает string2 значение
stringl. После присваивания string2 является копией stringl. Строка 17
применяет элемент-функцию assign для копирования stringl в snring3. Создается
отдельная копия (т.е. stringl и snring3 — независимые объекты). В классе
string предусмотрена также перегруженная версия assign для копирования
указанного числа символов, например,
targetString.assign( sourceString, start, numberOfCharacters );
где sourceString — копируемая строка, start — начальный индекс и
numberOf Characters — число копируемых символов.
1 // Рис. 18.1: Figl8_01.cpp
2 // Демонстрация присваивания и конкатенации строк.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 int main()
11 {
12 string stringl( "cat" );
13 string string2;
14 string string3;
15
16 string2 = stringl; // присвоить stringl -> string2
17 string3.assign( stringl ); // присвоить stringl -> string3
18 cout « "stringl: " « stringl « "\nstring2: " « string2
19 « "\nstring3: " « string3 « "\n\n";
20
21 // модифицировать string2 и string3
22 string2[ 0 ] = string3[ 2 ] = 'r';
23
24 cout«"After modification of string2 and string3 :\n"«Mstringl:
25 « stringl « "\nstring2: " « string2 « "\nstring3: ";
26
27 // демонстрация элемент-функции at
28 for ( int i = 0; i < string3.length(); i++ )
29 cout « string3.at( i );
30
31 // объявить string4 и string5
32 string string4( stringl + "apult" ); // конкатенация
33 string string5;
34
35 // перегрузка +=
Класс string и обработка строковых потоков
1037
36 string3 += "pet"; // создать "carpet"
37 stringl.append( "acomb" ); // создать "catacomb"
38
39 // присоединить начиная с индекса 4 до конца stringl, чтобы
40 // получилась строка "comb" (string5 была исходно пуста)
41 strings.append( stringl, 4, stringl.length() - 4 );
42
43 cout « "\n\nAfter concatenation:\nstringl: " « stringl
44 « "\nstring2: " « string2 « "\nstring3: "« string3
45 « "\nstring4: " « string4 « "\nstring5: "« string5 « endl;
46 return 0;
47 } // конец main
stringl: cat
string2: cat
string3: cat
After modification of string2 and string3:
stringl: cat
string2: rat
string3: car
After concatenation:
stringl: catacomb
string2: rat
string3: carpet
string4: catapult
string5: comb
Рис. 18.1. Демонстрация присваивания и конкатенации строк
Строка 22 использует операцию индексации, чтобы присвоить 'г' string3[ 2 ]
(получается "саг") и string2[ 0 ] (получается "rat"). Затем строки выводятся.
Строки 28-29 выводят содержимое string3 по одному символу, используя
элемент-функцию at. Элемент-функция at обеспечивает проверяемый доступ
(или проверку диапазона); другими словами, при выходе за пределы строки
выбрасывается исключение out_of_range. (См. главу 16 с подробным
обсуждением управления исключениями.) Заметьте, что операция индексации [] не
обеспечивает проверяемого доступа, что соответствует поведению этой
операции с массивами.
Типичная ошибка программирования 18.2
Обращение к индексу за пределами строки посредством функции at
является логической ошибкой, которая приводит к исключению
out__ofjrange.
-1 Типичная ошибка программирования 18.3
Обращение к индексу за пределами строки посредством операции
индексации является непроверяемой логической ошибкой.
В строке 32 объявляется string4, которая инициализируется результатом
конкатенации stringl и "apult" с помощью перегруженной операции сложения +,
1038
Глава 18
которая для класса string обозначает конкатенацию. Строка 36 применяет для
конкатенации string3 и "pet" операцию присвоения суммы, +=. Строка 37
вызывает для конкатенации stringl и "acomb" элемент-функцию append.
Строка 41 присоединяет "comb" к пустой строке string5. Функции append
передается строка (stringl), из которой будут извлекаться символы,
начальный индекс в строке D) и число присоединяемых символов (значение,
возвращаемое stringl. length() — 4).
18.3. Сравнение строк
Класс string предусматривает элемент-функции для сравнения строк.
Рис. 18.2 демонстрирует возможности сравнения.
1 // Рис. 18.2: Figl8_02.cpp
2 // Демонстрация возможностей сравнения строк.
3 #include <iostream>
4 using std:icout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 int main()
11 {
12 string stringl( "Testing the comparison functions." );
13 string string2( "Hello" );
14 string string3( "stinger" );
15 string string4( string2 );
16
17 cout « "stringl: " « stringl « "\nstring2: " « string2
18 « "\nstring3: " « string3 «"\nstring4: "« string4 <<"\n\n";
19
20 // сравнение stringl и string4
21 if ( stringl = string4 )
22 cout « "stringl = string4\n";
23 else // stringl != string4
24 {
25 if ( stringl > string4 )
26 cout « "stringl > string4\n";
27 else // stringl < string4
28 cout « "stringl < string4\n";
29 } // конец else
30
31 // сравнение stringl и string2
32 int result = stringl.compare( string2 );
33
34 if ( result = 0 )
35 cout « "stringl.compare( string2 ) == 0\n";
36 else // result != 0
37 {
38 if ( result > 0 )
39 cout « "stringl.compare( string2 ) > 0\n";
40 else // result < 0
41 cout « "stringl.compare( string2 ) < 0\n";
42 } // конец else
Класс string и обработка строковых потоков
1039
43
44 // сравнение stringl (элементы 2-5) и string3 (элементы 0-5)
45 result = stringl.compare( 2, 5, string3, 0, 5 );
46
47 if ( result == 0 )
48 cout « "stringl.compare( 2, 5, string3, 0, 5 ) == 0\n";
49 else // result != 0
50 {
51 if ( result > 0 )
52 cout « "stringl.compare( 2, 5, string3, 0, 5 ) > 0\n";
53 else // result < 0
54 cout « "stringl.compare( 2, 5, string3, 0, 5 ) < 0\n";
55 } // конец else
56
57 // сравнение string2 и string4
58 result = string4.compare( 0, string2.length(), string2 );
59
60 if ( result == 0 )
61 cout « "string4.compare( 0, string2.length(), "
62 « "string2 ) == 0" « endl;
63 else // result != 0
64 {
65 if ( result > 0 )
66 cout « "string4.compare( 0, string2.length(), "
67 « "string2 ) > 0" « endl;
68 else // result < 0
69 cout « "string4.compare( 0, string2.length(), "
70 « Mstring2 ) < 0" « endl;
71 } // конец else
72
73 // сравнение string2 и string4
74 result = string2.compare( 0, 3, string4 );
75
76 if ( result == 0 )
77 cout « "string2.compare( 0, 3, string4 ) = 0" « endl;
78 else // result != 0
79 {
80 if ( result > 0 )
81 cout « Mstring2.compare( 0, 3, string4 ) > 0" « endl;
82 else // result < 0
83 cout « "string2.compare( 0, 3, string4 ) < 0" « endl;
84 } // конец else
85
86 return 0;
87 } // конец main
stringl: Testing the comparison functions.
string2: Hello
string3: stinger
string4: Hello
stringl > string4
stringl.compare( string2 ) > 0
stringl.compare( 2, 5, string3, 0, 5 ) =0
string4.compare( 0, string2.length(), string2 ) == 0
string2.compare( 0, 3, string4 ) < 0
Рис. 18.2. Сравнение строк
1040
Глава 18
Программа объявляет четыре строки (строки 12-15) и выводит каждую из
них (строки 17-18). Условие в строке 21 проверяет на равенство stringl
и string4 с помощью перегруженной операции равенства. Если условие
истинно, выводится "stringl == string4" Если условие ложно, проверяется условие
в строке 25. Все перегруженные функции-операции, как
продемонстрированные, так и те, что здесь не демонстрируются (!=, <, >= и <=), возвращают
булевы значения.
Строка 32 применяет элемент-функцию compare для сравнения stringl
и string2. Переменной result присваивается 0, если строки идентичны,
положительное число, если stringl лексикографически больше string2, и
отрицательное число, если stringl лексикографически меньше string2. Поскольку
строка, начинающаяся с Т', считается лексикографически больше строки,
начинающейся с 'Н', переменной result присваивается значение, большее 0, что
и подтверждается выводом программы. Лексикон — это словарь. Когда мы
говорим, что одна строка лексикографически меньше другой, мы имеем в виду,
что первая строка идет по алфавиту раньше. Компьютер применяет тот же
критерий, что применили бы вы, расставляя по алфавиту имена в списке.
Строка 45 вызывает перегруженную версию элемент-функции compare,
чтобы сравнить части stringl и string3. Первые два аргумента B и 5)
специфицируют начальный индекс и длину части stringl ("sting"), которая должна
сравниваться со string3. Третий аргумент является строкой для сравнения.
Последние два аргумента (О и 5) являются начальным индексом и длиной
сравниваемой части строки сравнения (тоже "sting"). Значение,
присваиваемое result, равно 0 в случае равенства, положительному числу, если stringl
лексикографически больше string3, и отрицательному числу, если stringl
лексикографически меньше string3. Поскольку сравниваемые части двух
строк идентичны, результату присваивается 0.
Строка 58 использует другую перегруженную версию функции compare для
сравнения string4 и string2. Первые два аргументы те же — начальный
индекс и длина. Последний аргумент является строкой сравнения.
Возвращаемые значения те же самые — 0 в случае равенства, положительное число, если
string4 лексикографически больше string2, и отрицательное число, если
string4 лексикографически меньше string2. Поскольку сравниваемые части
двух строк идентичны, результату присваивается О.
Строка 74 вызывает элемент-функцию compare для сравнения первых 3
символов string2 со string4. Поскольку "Hel" меньше, чем "Hello",
возвращается значение, меньшее 0.
Класс string и обработка строковых потоков
1041
18.4. Подстроки
В классе string имеется элемент-функция substr для выделения подстроки.
Результатом является новый объект string, скопированный из исходной
строки. Рис. 18.3 демонстрирует substr.
1 // Рис. 18.3: Figl8_03.cpp
2 // Демонстрация элемент-функции substr класса string.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 int main()
11 {
12 string stringl( "The airplane landed on time," );
13
14 // извлечь подстроку "plane", которая
15 // начинается с индекса 7 и состоит из 5 элементов
16 cout « stringl.substr( 7, 5 ) « endl;
17 return 0;
18 } // конец main
plane
Рис. 18.3. Демонстрация элемент-функции substr класса string
Программа объявляет и инициализирует объект string в строке 12.
Строка 16 вызывает элемент-функцию substr, чтобы извлечь из stringl подстроку.
Первый аргумент специфицирует начальный индекс нужной подстроки;
второй аргумент специфицирует длину подстроки.
18.5. Обмен строк
В классе string имеется элемент-функция swap для обмена содержимого
строк. Программа на рис. 18.4. обменивает две строки.
Строки 12-13 объявляют и инициализируют строки first и second.
Строка 18 вызывает элемент-функцию swap для обмена значений first и second.
Чтобы подтвердить обмен, строки печатаются снова. Элемент-функция swap
полезна при реализации программ, которые сортируют строки.
1 // Рис. 18.4: Figl8_04.cpp
2 // Использование функции swap для обмена двух строк.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
1042
Глава 18
10 int main ()
11 {
12 string first( "one" );
13 string second( "two" );
14
15 // вывести строки
16 cout « "Before swap:\n first: "« first «"\nsecond: "« second;
17
18 first.swap( second ); // обменять строки
19
20 cout « "\n\nAfter swap:\n first: " « first
21 « "\nsecond: " « second « endl;
22 return 0;
23 } // конец main
Before swap:
first: one
second: two
After swap:
first: two
second: one
Рис. 18.4. Использование функции swap для обмена двух строк
18.6. Характеристики строки
Класс string предусматривает элемент-функции для получения
информации о размере, длине, вместимости, максимальной длине и других
характеристиках строки. Размер или длина строки — это число символов, хранящихся
в строке в текущий момент. Вместимость равна числу символов, которые
могут сохраняться в строке без дополнительного выделения динамической
памяти. Вместимость строки должна быть по крайней мере равна ее текущему
размеру, однако может превышать его. Точное значение вместимости зависит от
реализации. Максимальный размер является наибольшим возможным
размером, который может иметь строка. Если это значение превышается,
выбрасывается исключение length_error. Рис. 18.5 демонстрирует элемент-функции
класса string для определения различных характеристик строк.
1 // Рис. 18.5: Figl8_05.cpp
2 // Демонстрация элямент-функций, относящихся к размеру и объему.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::cin;
7 using std::boolalpha;
8
9 #include <string>
10 using std::string;
11
12 void printStatistics( const string & );
13
Класс string и обработка строковых потоков
1043
14 int main()
15 {
16 string stringl;
17
18 cout « "Statistics before input:\n" « boolalpha;
19 printStatistics( stringl );
20
21 // прочитать только "tomato" ид "tomato soup"
22 cout « "\n\nEnter a string: ";
23 cin » stringl; // ограничивается пробелом
24 cout « "The string entered was: " « stringl;
25
26 cout « "\nStatistics after input:\n";
27 printStatistics( stringl );
28
29 // прочитать "soup"
30 cin » stringl; // ограничивается пробелом
31 cout « "\n\nThe remaining string is: " « stringl « endl;
32 printStatistics( stringl );
33
34 // присоединить к stringl 46 символов
35 stringl += 234567890abcdefghijklmnopqrstuvwxyzl234567890";
36 cout « "\n\nstringl is now: " « stringl « endl;
37 printStatistics( stringl );
38
39 // прибавить к stringl 10 элементов
40 stringl.resize( stringl.length() +10 );
41 cout « "\n\nStats after resizing by (length + 10):\n";
42 printStatistics( stringl );
43
44 cout « endl;
45 return 0;
46 } // конец main
47
48 // вывести статистику для строки
49 void printStatistics( const string &stringRef )
50 {
51 cout « "capacity: " « stringRef .capacity() « "\nmax size:
52 « stringRef .max_size () « "\nsize: " « stringRef. size ()
53 « "\nlength: " « stringRef.length()
54 « "\nempty: " « stringRef.empty();
55 } // конец printStatistics
Statistics before input:
capacity: 0
max size: 4294967294
size: 0
length: 0
empty: true
Enter a string: tomato soup
The string entered was: tomato
Statistics after input:
capacity: 15
max size: 4294967293
size: 6
1044
Глава 18
length: 6
empty: false
The remaining string is: soup
capacity: 15
max size: 4294967294
size: 4
length: 4
empty: false
stringl is now: soupl234567890abcdefghijklmnopqrstuvwxyzl234567890
capacity: 63
max size: 4294967293
size: 50
length: 50
empty: false
Stats after resizing by (length + 10):
capacity: 63
max size: 4294967293
size: 60
length: 60
empty: false
Рис. 18.5. Печать характеристик строки
Программа объявляет пустую строку stringl (строка 16) и передает ее
функции printstatistics (строка 19). Функция printStatistics (строки 49-55)
принимает в качестве аргумента ссылку на константную строку и выводит ее
вместимость (вызывая элемент-функцию capacity), максимальный размер (вызывая
элемент-функцию maxjsize), размер (вызывая элемент-функцию size), длину
(вызывая элемент-функцию length) и сообщает, является ли строка пустой
(вызывая элемент-функцию empty). Первоначальный вызов printStatistics
показывает, что начальные значения для вместимости, размера и длины равны 0.
Равные 0 размер и длина показывают, что в строке не хранится никаких
символов. Поскольку начальная вместимость равна О, то при помещении
в stringl символов выделяется память для их размещения. Как вы помните,
размер и длина всегда равны. В данной реализации максимальный размер
равен 4294967293. Объект stringl является пустой строкой, поэтому функция
empty возвращает true.
Строка 23 читает строку со стандартного ввода. В данном примере вводится
"tomato soup". Поскольку символ пробела является ограничителем, в stringl
сохраняется только "tomato"; однако "soup" сохраняется в буфере ввода.
Строка 21 вызывает функцию printStatistics для вывода характеристик
stringl. Обратите внимание, что длина теперь равна 6, а вместимость 15.
•——i Вопросы производительности 18.1
Р^^Ч Чтобы уменьшить число распределений и освобождений памяти,
некоторые реализации класса string предусматривают вместимость по
умолчанию, превышающую длину строки.
Класс string и обработка строковых потоков
1045
Строка 30 читает из буфера ввода слово "soup" и сохраняет его в stringl,
переписывая, таким образом, "tomato". Строка 32 передает stringl функции
printStatistics.
Строка 35 использует перегруженную операцию += для присоединения
к stringl 46-символьной строки. Строка 37 передает stringl функции
printStatistics. Обратите внимание, что вместимость увеличилась до 63
элементов, а длина равняется теперь 50.
Строка 40 вызывает элемент-функцию resize для увеличения длины stringl
на 10 символов. Дополнительные элементы заполняются нулевыми
символами. Заметьте, что вместимость не изменилась, в то время как длина равняется
теперь 60.
18.7. Поиск в строке подстрок и символов
Класс string предусматривает константные элемент-функции для поиска
в строке подстрок и символов. Рис. 18.6 демонстрирует функции поиска.
1 // Рис. 18.6: Figl8_06.cpp
2 // Демонстрация элемент-функций string для поиска.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 int mainQ
11 {
12 string stringl( "noon is 12 pm; midnight is not." );
13 int location;
14
15 // найти "is" в позициях 5 и 24
16 cout « "Original string:\n" « stringl
17 « "\n\n(find) \"is\" was found at: " « stringl.find( "is" )
18 « "\n(rfind) \"is\" was found at: " « stringl.rfind( "is" );
19
20 // найти 'о' в позиции 1
21 location = stringl.find_first_of( "misop" );
22 cout « "\n\n(find_first_of) found '" « stringl[ location ]
23 « "' from the group \"misop\" at: " « location;
24
25 // найти 'о' в позиции 28
26 location = stringl.find_last_of( "misop" );
27 cout « "\n\n(find_last_of) found ' " « stringl[ location ]
28 « "' from the group \"misop\" at: " « location;
29
30 // найти '1' в позиции 8
31 location = stringl.find_first_not_of( "noi spm" );
32 cout « "\n\n(find_first_not_of) '" « stringl[ location ]
33 « "' is not contained in \"noi spm\" and was found at:"
34 « location;
35
36 // найти ';' в позиции 13
1046
Глава 18
37 location = stringl. f ind__f irst_not_of ( 2noi spm" );
38 cout « "\n\n(find_first__not_of) '" « stringl[ location ]
39 « "' is not contained in \2noi spm\M and was "
40 « "found at:" « location « endl;
41
42 // найти символы, отсутствующие в stringl
43 location = stringl. find_f irst_not__of (
44 "noon is 12 pm; midnight is not." );
45 cout «"\nfind_first__not_of (\"noon is 12 pm; midnight is not.\")"
46 « " returned: " « location « endl;
47 return 0;
48 } // конец main
Original string:
noon is 12 pm; midnight is not.
(find) "is" was found at: 5
(rfind) "is" was found at: 24
(find_first__of) found 'o' from the group "misop" at: 1
(find_last__of) found 'o' from the group "misop" at: 28
(find_first_not_of) 'Г is not contained in "noi spm" and was
found at:8
(find_first_not_of) ';' is not contained in 2noi spm" and was
found at:13
find_first_not__of("noon is 12 pm; midnight is not.") returned: -1
Рис. 18.6. Демонстрация функций string для поиска
В строке 12 объявляется и инициализируется строка stringl. Строка 17
пытается найти в stringl "is" с помощью функции find. Если "is" найдено,
возвращается индекс начальной позиции этой строки. Если строка не
найдена, возвращается значение string::npos (открытая статическая константа,
определенная в классе string). Это значение возвращают функции string,
связанные с поиском, для указания того, что подстрока или символ в строке не
найдены.
Строка 18 вызывает элемент-функцию rfind, которая производит в строке
обратный поиск (т.е. справа налево). Если "is" найдено, возвращается индекс
позиции. Если строка не найдена, возвращается значение string::npos.
[Замечание. Остальные функции поиска, представленные в этом разделе,
возвращают такие же значения, если не оговорено иначе.]
Строка 21 вызывает элемент-функцию find_first_of, чтобы найти первое
вхождение в stringl любого символа из "misop". Поиск производится с начала
строки. В элементе 1 обнаруживается символ 'о'.
Строка 26 вызывает элемент-функцию find_last_of, чтобы найти последнее
вхождение в stringl любого символа из "misop". Поиск производится с конца
строки. В элементе 28 обнаруживается символ V.
Класс string и обработка строковых потоков
1047
Строка 31 вызывает элемент-функцию find_fir8t_not_of9 чтобы найти
в stringl первый символ не из "noi spm". Поиск производится с начала
строки. В элементе 8 обнаруживается символ '1\
Строка 37 вызывает элемент-функцию find__first_not_of, чтобы найти
в stringl первый символ не из 2noi spm". Поиск производится с начала
строки. В элементе 13 обнаруживается символ ';'.
Строки 43-44 используют элемент-функцию find_first_not_of, чтобы
найти в stringl первый символ не из "noon is 12 pm; midnight is not.". В данном
случае строка содержит все символы, специфицированные в аргументе.
Поскольку никакого символа не найдено, возвращается string::npos (имеющая
в данном случае значение —1).
18.8. Замена символов в строке
Рис. 18.7 демонстрирует элемент-функции string для замены и удаления
символов. В строках 13-17 объявляется и инициализируется строка stringl.
Строка 23 вызывает элемент-функцию erase, чтобы удалить все, начиная
с символа в позиции 62 (включительно) до конца stringl. [Замечание. Каждый
символ новой строки занимает в строке один элемент.]
1 // Рис. 18.7: Figl8_07.cpp
2 // Демонстрация элемент-функций erase и replace класса string.
3 #include <iostream>
4 using std::cout;
5 using std:rendl;
6
7 #include <string>
8 using std::string/
9
10 int main()
11 {
12 // компилятор сцепляет все части в одну строку
13 string stringl( "The values in any left subtree"
14 "\nare less than the value in the"
15 "\nparent node and the values in"
16 "\nany right subtree are greater"
17 "\nthan the value in the parent node" );
18
19 cout « "Original string: \n" « stringl « endl « endl;
20
21 // удалить все символы начиная с позиции 62(включительно)
22 //до конца stringl
23 stringl.erase( 62 );
24
25 // вывести новую строку
26 cout « "Original string after erase:\n" « stringl
27 « "\n\nAfter first replacement:\n";
28
29 int position = stringl.find( " " ); // найти первый пробел
30
31 // заменить все пробелы точками
32 while ( position != string::npos )
33 {
1048
Глава 18
34 stringl.replace( position, 1, "." );
35 position = stringl.find( " ", position + 1 );
36 } // конец while
37
38 cout « stringl « "\n\nAfter second replacement:\n";
39
40 position = stringl.find( "." ); // найти первую точку
41
42 // заменить все точки на две точки с запятой
43 // ЗАМЕЧАНИЕ: будут переписаны символы
44 while ( position != string::npos )
45 {
46 stringl.replace( position, 2, "xxxxx;;yyy", 5, 2 );
47 position = stringl.find( ".", position + 1 );
48 } // конец while
49
50 cout « stringl « endl;
51 return 0;
52 } // конец main
Original string:
The values in any left subtree
are less than the value in the
parent node and the values in
any right subtree are greater
than the value in the parent node
Original string after erase:
The values in any left subtree
are less than the value in the
After first replacement:
The.values.in.any.left.subtree
are.less.than.the.value.in.the
After second replacement:
The;;alues;;n;;ny,;eft;;ubtree
are;;es s;;han;;he;;alue;;n;;he
Рис. 18.7. Демонстрация функций erase и replace
Строки 29-36 используют функцию find, чтобы найти каждое вхождение
символа пробела. Каждый пробел заменяется точкой посредством вызова
элемент-функции replace. Функция replace принимает три аргумента: индекс
символа в строке, с которого начинается замена, число заменяемых символов
и строка замены. Когда символ не найден, функция find возвращает
string::npos. В строке 35 к position прибавляется 1, чтобы продолжить поиск
с позиции следующего символа.
Строки 40-48 используют функцию find, чтобы найти каждую точку,
и другую перегруженную функцию replace, чтобы заменить каждую точку
и следующий за ней символ двумя точками с запятой. Аргументами,
передаваемыми этой версии replace, являются индекс элемента, с которого начинает-
Класс string и обработка строковых потоков
1049
ся операция замены, число заменяемых символов, символьная строка замены,
из которой выделяется подстрока, чьи символы будут использоваться для
замены, элемент символьной строки, с которого начинается заменяющая
подстрока, и число символов, используемых в заменяющей подстроке.
18.9. Вставка символов в строку
Класс string предусматривает элемент-функции для вставки символов
в строку. Рис. 18.8 демонстрирует возможности вставки.
1 // Рис. 18.8: Figl8_08.cpp
2 // Демонстрация элемент-функций string для вставки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 int main()
11 {
12 string stringl( "beginning end" );
13 string string2( "middle " );
14 string string3( 2345678" );
15 string string4( "xx" );
16
17 cout « "Initial strings:\nstringl: " « stringl
18 « "\nstring2: " « string2 « "\nstring3: " « string3
19 « "\nstring4: " « string4 « "\n\n";
20
21 // вставить "middle" в строку stringl в позиции 10
22 stringl.insert( 10, string2 );
23
24 // вставить "xx" в string3 в позиции З
25 string3.insert( 3, string4, 0, string::npos );
26
27 cout « "Strings after insert:\nstringl: " « stringl
28 « "\nstring2: " « string2 « "\nstring3: " « string3
29 « "\nstring4: " « string4 « endl;
30 return 0;
31 } // конец main
Initial strings:
stringl: beginning end
string2: middle
string3: 12345678
string4: xx
Strings after insert:
stringl: beginning middle end
string2: middle
string3: 123xx45678
string4: xx
Рис. 18.8. Демонстрация элемент-функций string для вставки
1050
Глава 18
Программа объявляет, инициализирует и затем выводит строки stringl,
string2, string3 и string4. Строка 22 вызывает элемент-функцию insert, чтобы
вставить содержимое string2 в stringl перед элементом 10.
Строка 25 вызывает insert, чтобы вставить символы из string4 в string3
перед элементом 3. Последние два аргумента специфицируют начальный и
конечный элементы string4 из тех, что должны быть вставлены. Указание
string::npos приводит к вставке всей строки.
18.10. Преобразование в строки-указатели С типа char *
Класс string предусматривает элемент-функции для преобразования
объектов класса string в строки-указатели стиля С. Как упоминалось ранее,
стандартные строки, с отличие от строк-указателей, не обязательно ограничены
нулем. Описываемые функции преобразования полезны, когда некоторая
функция принимает в качестве аргумента строку-указатель. Рис. 18.9
демонстрирует преобразование стандартных строк в строки-указатели.
1 // Рис. 18.9: Figl8_09.cpp
2 // Преобразование в строки стиля С.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 int main()
11 {
12 string stringl( "STRINGS" ); //конструктор string с арг. char*
13 const char *ptrl =0; // инициализация *ptrl
14 int length = stringl.length();
15 char *ptr2 = new char[ length + 1 ]; // включая нуль
16
17 // копировать символы из stringl в выделенную память
18 stringl.copy( ptr2, length, 0 ); // копировать stringl в ptr2
19 ptr2[ length ] = '\0'; // добавить нуль-ограничитель
20
21 cout « "string stringl is " « stringl
22 « "\nstringl converted to a C-Style string is "
23 « stringl.c_str() « "\nptrl is ";
24
25 // Присвоить указателю ptrl константный char *, возвращаемый
26 // функцией data(). ЗАМЕЧАНИЕ: это потенциально опасное
27 // присваивание. Если stringl модифицируется, указатель ptrl
28 // может стать недействительным.
29 ptrl = stringl.data();
30
31 // вывести каждый символ, используя указатель
32 for ( int i = 0; i < length; i++ )
33 cout « *( ptrl + i ); // применить арифметику указателей
34
35 cout « "\nptr2 is " « ptr2 « endl;
Класс string и обработка строковых потоков
1051
36 delete [] ptr2; // возвратить динамически выделенную память
37 return 0;
38 } // конец main
string stringl is STRINGS
stringl converted to a C-Style string is STRINGS
ptrl is STRINGS
ptr2 is STRINGS
Рис. 18.9. Преобразование строк в строки стиля С и символьные массивы
Программа объявляет строку, целое и два указателя на char
(строки 12-15). Строка stringl инициализируется символами "STRINGS", ptrl
инициализируется нулем и length инициализируется длиной stringl.
Указателю ptr2 присваивается динамически выделенная память размера,
достаточного для хранения С-эквивалента строки stringl.
Строка 18 вызывает элемент-функцию сору класса string, чтобы
копировать объект stringl в символьный массив, на который указывает ptr2.
Строка 19 вручную помещает в конец символьного массива ограничивающий
нуль-символ.
Строка 23 вызывает функцию c_str, которая копирует объект stringl и
автоматически присоединяет ограничивающий нуль-символ. Эта функция
возвращает const char *, который выводится операцией передачи в поток.
Строка 29 присваивает указателю ptrl (типа const char *) указатель,
возвращаемый элемент-функцией data класса string. Эта функция возвращает не
ограниченный нулем символьный массив в стиле С. Заметьте, что в этом
примере мы не модифицируем stringl. Если бы stringl была модифицирована
(напр., изменился адрес динамической памяти строки из-за вызова
элемент-функции вроде stringl.insert( 0, "abed" );), ptrl мог бы оказаться
недействительным, что могло бы привести к непредсказуемым результатам.
Строки 32-33 используют арифметику указателей для вывода символьного
массива, на который указывает ptrl. В строках 35-36 строка стиля С, на
которую указывает ptr2, выводится, а динамически выделенная указателю память
освобождается операцией delete, чтобы предотвратить утечку памяти.
П^/з Типичная ошибка программирования 18.4
Если не ограничить нулем символьный массив, возвращаемый
функцией data, могут возникнуть ошибки времени выполнения.
Хороший стиль программирования 18,1
Когда возможно, используйте более надежные объекты класса string,
а не строки-указатели в стиле С.
18.11. Итераторы
Класс string предусматривает итераторы для перемещения по строке в
прямом и обратном направлении. Итераторы обеспечивают доступ к отдельным
символам посредством нотации, похожей на нотацию операций с указателями.
1052
Глава 18
Итераторы не обеспечивают проверку диапазона. Заметьте, что в этом разделе
мы даем для демонстрации итераторов «механические примеры». Более
осмысленные примеры применения итераторов мы обсудим в главе 22.
Рис. 18.10 демонстрирует итераторы.
1 // Рис. 18.10: Figl8_10.cpp
2 // Использование итератора для вывода строки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 int main()
11 {
12 string stringl( "Testing iterators" );
13 string:iconst_iterator iteratorl = stringl.begin();
14
15 cout « "stringl = " « stringl
16 « "\n(Using iterator iteratorl) stringl is: ";
17
18 // итерация по строке
19 while ( iteratorl != stringl.end() )
20 {
21 cout « *iteratorl; // разыменовать итератор и получить символ
22 iteratorl++; // передвинуть итератор на следующий скдевол
23 } // конец while
24
25 cout « endl;
26 return 0/
27 } // конец main
stringl = Testing iterators
(Using iterator iteratorl) stringl is: Testing iterators
Рис. 18.10. Вывод строки при помощи итератора
Строки 12-13 объявляют строку stringl и string: :const_iterator iteratorl.
Итератор типа const_iterator не может модифицировать объект — в данном
случае string, — по которому он перемещается. Итератор iteratorl
инициализируется установкой на начало строки с помощью элемент-функции begin
класса string. Существует две версии begin — одна, возвращающая итератор
для перемещения по не-константной строке, и константная версия,
возвращающая const_iterator для константных строк. Строка 15 выводит stringl.
Строки 19-23 используют итератор iteratorl для «прохода» по stringl.
Элемент-функция end класса string возвращает iterator (либо const_iterator)
для позиции, следующей за последним элементом строки. Каждый элемент
печатается посредством разыменования итератора, во многом аналогично тому,
как вы разыменовывали бы указатель, и итератор продвигается на одну
позицию вперед применением к нему операции ++.
Класс string предусматривает элемент-функции rbegin и rend для
обращения к отдельным символам строки при проходе в обратном порядке, от конца
Класс string и обработка строковых потоков
1053
строки к ее началу. Функции rbegin и rend могут возвращать итераторы типа
reverse__iterator и const_reverse_iterator (в зависимости от того, является ли
строка не-константной или константной). В упражнениях мы просим читателя
написать программу, демонстрирующую эти возможности. Мы будем более
широко использовать итераторы в главе 23.
Предотвращение ошибок 18.1
Если вы хотите воспользоваться преимуществами проверки
диапазона, применяйте элемент-функцию at.
Хороший стиль программирования 18.2
Когда операции, в которых участвует итератор, не должны
изменять обрабатываемые данные, используйте const_iterator. Это еще
один пример принципа наименьших привилегий.
18.12. Обработка строковых потоков
В дополнение к вводу/выводу стандартных и файловых потоков потоковый
ввод/вывод C++ включает возможности ввода из строк и вывода в строки,
которые расположены в памяти. Эти возможности часто называют
вводом/выводом в памяти или обработкой строковых потоков.
Ввод из строки поддерживается классом istringstream y вывод в строку —
классом ostringstream. Имена классов istringstream и ostringstream
являются в действительности псевдонимами, которые определяются как
typedef basic_istringstream< char > istringstream;
typedef basic_ostringstream< char > ostringstream;
Шаблоны класса basicistringstream и basic_ostringstream предлагают те же
функциональные возможности, что и классы istrean и ostream, плюс
дополнительные элемент-функции, специфические для форматирования в памяти.
Программы, использующие форматирование в памяти, должны включать
заголовочные файлы <sstream> и <iostream>.
Одним из приложений ввода/вывода в памяти является подтверждение
действительности данных. Программа может читать за один раз целую строку из
входного потока в объект string. Затем процедура подтверждения
действительности может изучать содержимое полученной строки и, если необходимо,
корректировать (или исправлять) данные. Затем программа может перейти к
чтению данных из строки, зная, что вводимые данные имеют правильный формат.
Вывод в строку дает возможность воспользоваться преимуществами
мощных средств форматирования потоков C++. В строке можно подготовить
данные, имитирующие отредактированный экранный формат. Такая строка
может быть записана в дисковый файл, в котором будет храниться образ экрана.
Для сохранения выводимых данных объект ostringstream использует объект
string. Элемент-функция str класса ostringstream возвращает копию этой строки.
Рис. 18.11 демонстрирует объект ostringstream. Программа создает объект
outputstring класса ostringstream (строка 15) и использует операцию
передачи в поток для вывода в него ряда строк и числовых значений.
1054
Глава 18
1 // Рис. 18.11: Figl8_ll.cpp
2 // Использование динамически выделенного объекта ostringstream.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 #include <sstream> // заголовок для обработки строковых потоков
11 using std::ostringstream; // операции передачи в строковый поток
12
13 int main()
14 {
15 ostringstream outputString; // создать ostringstream
16
17 string stringl( "Output of several data types " );
18 string string2( "to an ostringstream object:" );
19 string string3( "\n double: " );
20 string string4( "\n int: " );
21 string string5( "\naddress of int: " );
22
23 double doublel = 123.4567;
24 int integer = 22;
25
26 // вывести строки, double и int в ostringstream outputString
27 outputString « stringl « string2 « string3 « doublel
28 « string4 « integer « string5 « &integer;
29
30 // вызвать str для получения содержимого ostringstream
31 cout « "outputString contains:\n" « outputString.str();
32
33 // добавить символы и вызвать str для вывода строки
34 outputString « "\nmore characters added";
35 cout « "\n\nafter additional stream insertions,\n"
36 « "outputString contains:\n" « outputString.str() « endl;
37 return 0;
38 } // конец main
outputString contains:
Output of several data types to an ostringstream object:
double: 123.457
int: 22
address of int: 1244580
after additional stream insertions,
outputString contains:
Output of several data types to an ostringstream object:
double: 123.457
int: 22
address of int: 1244580
more characters added
Рис. 18.11. Использование динамически выделенного объекта ostringstream
Класс string и обработка строковых потоков
1055
Строки 27-28 выводят строки stringl, string2, string3, double double 1,
строку string4, int integer, строку string5 и адрес int integer — все в объект
outputstring. Строка 31 использует операцию передачи в поток и вызов
outputString.str() для отображения на экране копии получившейся в
результате строки. Строка 34 демонстрирует, что к строке в памяти можно
присоединить дополнительные данные, просто применив к outputString еще одну
операцию передачи в поток. Строки 35-36 выводят на экран строку объекта
outputString после присоединения дополнительных символов.
Объект istringstream вводит данные из строки в памяти в переменные
программы. Данные хранятся в объекте istringstream в виде символов. Ввод из
istringstream работает идентично вводу из любого файла. Конец строки
интерпретируется объектом istringstream как конец файла.
Рис. 18.12 демонстрирует ввод из объекта istringstream. Строки 15-16
создают строку input, содержащую данные, и объект istringstream inputString,
конструируемый из данных в строке input. Строка содержит данные
Input test 123 4.7 А
которые, при чтении в качестве вводимых в программу, состоят из двух строк
("Input" и "test") и значений int A23), double D.7) и char ('А'). Эти данные
извлекаются в строке 23 в переменные stringl, string2, integer, double 1
и character.
1 // Рис. 18.12: Figl8_12.cpp
2 // Демонстрация ввода из объекта istringstream.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <string>
8 using std::string;
9
10 #include <sstream>
11 using std::istringstream;
12
13 int main()
14 {
15 string input( "Input test 123 4.7 A" );
16 istringstream inputString( input );
17 string stringl;
18 string string2;
19 int integer;
20 double doublel;
21 char character;
22
23 inputString » stringl »string2 »integer »doublel »character;
24
25 cout « "The following items were extracted\n"
26 « "from the istringstream object:" « "\nstring: " « stringl
27 « "\nstring: " « string2 « "\n int: " « integer
28 « "\ndouble: " « doublel « "\n char: " « character;
29
30 // попытка чтения из пустого потока
31 long value;
1056
Глава 18
32 inputString » value;
33
34 // проверить результат потока
35 if ( inputString.good() )
36 cout « "\n\nlong value is: " « value « endl;
37 else
38 cout « "\n\ninputString is empty" « endl;
39
40 return 0;
41 } // конец main
The following items were extracted
from the istringstream object:
string: Input
string: test
int: 123
double: 4.7
char: A
inputString is empty
Рис. 18.12. Демонстрация ввода из объекта istringstream
Затем в строках 25-28 данные выводятся. В строке 32 программа снова
пытается читать из inputString. Условие if в строке 35 использует функцию good
(раздел 15.8) для проверки того, остались ли еще данные. Поскольку данных не
осталось, функция возвращает false и исполняется часть else оператора if...else.
18.13. Заключение
В этой главе был представлен класс string из Стандартной библиотеки C++,
который позволяет программам обращаться со строками как с полноценными
объектами. Мы обсудили присваивание, конкатенацию, сравнение, поиск и обмен строк.
Мы также представили ряд методов для определения характеристик строк, поиска,
замены и вставки символов в строках, а также преобразование стандартных строк
в строки стиля С и наоборот. Вы также узнали об итераторах строк и о вводе/выводе
строк в памяти. В следующей главе мы обсудили алгоритм двоичного поиска и
алгоритм сортировки слиянием. Мы введем также нотацию "О большого" для анализа и
сравнения эффективности различных алгоритмов поиска и сортировки.
Резюме
• Шаблон класса C++ basic_string реализует типичные операции со строками, такие,
как копирование, поиск и т.д.
• Оператор typedef
typed©f basic_string< char > string;
создает тип-псевдоним для basic_string< char >. Предусмотрен также typedef для
типа wchar_t. Тип wchar_t обычно хранит двухбайтовые A6-битные) символы для
поддержки иных символьных наборов. Размер wchar_t стандартом не фиксируется.
• Чтобы использовать строки, нужно включить заголовочный файл <string>
Стандартной библиотеки C++.
Класс string и обработка строковых потоков
1057
• В классе siring не предусмотрено конструкторов для преобразования из int или char
в string.
• В операторе присваивания допускается присваивание объекту string одиночного
символа.
• Стандартные строки не обязательно ограничены нулем.
• Большинство элемент-функций класса string принимают в качестве аргументов
индекс начальной позиции и число символов, над которыми производится операция.
• Для присваивания строк в классе string предусмотрены перегруженная операция
operator= и элемент-функция assign.
• Операция индексации, [], обеспечивает доступ для чтения/записи к произвольному
элементу строки.
• Элемент-функция at класса string обеспечивает проверяемый доступ — при выходе
за любой из концов строки выбрасывается исключение out__of__range. Операция
индексации, [], не обеспечивает проверяемого доступа.
• Для конкатенации строк в классе string предусмотрены перегруженные операции +
и += и элемент-функция append.
• Для сравнения строк в классе string предусмотрены перегруженные операции ==,
!=, <, >, <= и >=.
• Элемент-функция compare сравнивает две строки (или подстроки), возвращая 0,
если строки идентичны, положительное число, если первая строка
лексикографически больше второй, и отрицательное число, если первая строка лексикографически
меньше второй.
• Элемент-функция substr класса string извлекает из строки подстроку.
• Элемент-функции size и length класса string возвращают размер или длину строки
(т.е. число символов, хранящихся в строке в текущий момент).
• Элемент-функция capacity класса string возвращает число символов, которые могут
сохраняться в строке без дополнительного выделения динамической памяти.
• Элемент-функция max_size класса string возвращает наибольший возможный
размер, который может иметь строка.
• Функции поиска find, rfind, find_first_of, find_last_of и find_first_not_of класса
string производят в строке поиск подстрок либо символов.
• Элемент-функция erase класса string удаляет элементы строки.
• Элемент-функция replace класса string производит замену символов строки.
• Элемент-функция insert класса string производит вставку символов в строку.
• Элемент-функция c_str класса string возвращает const char *, указывающий на
ограниченную нулем символьную строку в стиле С, которая содержит все символы
исходной строки.
• Элемент-функция data класса string возвращает const char *, указывающий на не
ограниченный нулем символьный массив в стиле С, который содержит все символы
исходной строки.
• Класс string предусматривает элемент-функции begin и end для прохода по
отдельным символам строки.
• Класс string предусматривает элемент-функции rbegin и rend для обращения к
отдельным символам строки в обратном порядке, от конца строки к ее началу.
• Ввод из строки поддерживается классом istringstream, вывод в строку — классом
ostringstream.
• Элемент-функция str класса ostringstream возвращает копию строки объекта
ostringstream.
Я4 Зак. 1114
1058 Глава 18
Терминология
const_iterator
const_reverse_iterator
iterator
reverse__iterator
ввод/вывод в памяти
вместимость строки
длина строки
заголовочный файл <sstream>
класс istringstream
класс ostringstream
константа string::npos
лексикографическое сравнение
максимальный размер строки
обработка строковых потоков
проверка диапазона
проверяемый доступ
пустая строка
тип wchar_t
шаблон класса basic_string
элемент-функция append класса
string
элемент-функция assign класса string
элемент-функция at класса string
элемент-функция begin класса string
элемент-функция c_str класса string
элемент-функция capacity класса string
элемент-функция compare класса string
Контрольные вопросы
18.1. Заполните пропуски в следующих утверждениях:
a) Для класса string должен включаться заголовок .
b) Класс string принадлежит к пространству имен .
c) Функция удаляет символы из строки.
d) Функция находит первое вхождение любого символа из указанной
строки.
18.2. Укажите, какие из следующих утверждений верны, а какие — нет. Если
утверждение неверно, объясните, почему.
a) Конкатенация объектов string может выполняться с помощью операции
присвоения суммы, +=.
b) Индексы символов в строке начинаются с 0.
c) Операция присваивания, =, копирует строку.
d) Строка в стиле С является объектом string.
18.3. Найдите ошибки в следующих фрагментах и объясните, как их исправить:
a) string stringl( 28 ); // конструирование строки stringl
string string2( 'z" ); // конструирование строки string2
b) // предполагается, что пространство имен std известно
const char *ptr = name.data(); // name содержит "joe bob"
ptr[ 3 ] = '-•;
cout « ptr « endl;
элемент-функция copy класса string
элемент-функция data класса string
элемент-функция end класса string
элемент-функция erase класса string
элемент-функция find класса string
элемент-функция find_first_not_of
класса string
элемент-функция find_first_of класса
string
элемент-функция find_last_of класса
string
элемент-функция getline класса
string
элемент-функция insert класса string
элемент-функция length класса string
элемент-функция max_size класса
string
элемент-функция rbegin класса string
элемент-функция rend класса string
элемент-функция replace класса string
элемент-функция resize класса string
элемент-функция rfind класса string
элемент-функция size класса string
элемент-функция substr класса string
элемент-функция swap класса string
элемент-функция str класса
ostringstream
Класс string и обработка строковых потоков
1059
Ответы на контрольные вопросы
18.1. a) <string>. b) std. с) erase, d) find_first_of.
18.2. а) Верно.
b) Верно.
c) Верно.
d) Неверно. Объект string (стандартная строка) предоставляет много различных
услуг. Строка в стиле С никаких услуг не предлагает. Строки в стиле С
ограничиваются нулем; стандартные строки не обязательно ограничены нулем.
Строки в стиле С являются указателями; стандартные строки — нет.
18.3. а) В классе string не существует конструкторов, принимающих целый или
символьный аргумент. Следует использовать другие, допустимые конструкторы,
при необходимости с преобразованием аргумента в строку.
Ь) Функция data не присоединяет ограничивающий нуль. Кроме того, код
пытается модифицировать const char. Все три строки следует заменить следующим
кодом:
cout « name.substr( 0, 3 ) + "-" + name.substr( 4 ) « endl;
Упражнения
18.4. Заполните пропуски в следующих утверждениях:
a) Элемент-функции и класса string преобразуют
стандартные строки в строки стиля С.
b) Элемент-функция класса string используется для присваивания.
c) Возвращаемым типом элемент-функции rbegin класса string является
d) Элемент-функция класса string используется для извлечения
подстроки.
18.5. Укажите, какие из следующих утверждений верны, а какие — нет. Если
утверждение неверно, объясните, почему.
a) Стандартные строки всегда ограничиваются нулем.
b) Элемент-функция max_size класса string возвращает максимальный размер
строки.
c) Элемент-функция at класса string может выбрасывать исключение out_of_range.
d) Элемент-функция begin класса string возвращает iterator.
18.6. Найдите ошибки в следующих фрагментах и объясните, как их исправить:
a)std::cout « s.data() « std::endl; // s содержит "hello"
b) erase ( s.rfind( "x" ), 1 ); // s содержит "xenon"
c) strings foo( void )
{
string s( "Hello" );
... // другие операторы
return;
)
18.7. (Простое шифрование) Некоторая информация в Internet может быть
зашифрована с помощью простого алгоритма, известного как «rot 13», который
циклически перемещает каждый символ на 13 позиций в алфавите. При этом 'а'
соответствует 'п', а 'х' соответствует 'k'. Rotl3 — пример шифрования по
симметричному ключу. При шифровании по симметричному ключу как в схеме шифрования,
так и в схеме дешифрования используется один и тот же ключ.
1060
Глава 18
a) Напишите программу, которая шифрует сообщение с помощью rotl3.
b) Напишите программу, которая расшифровывает зашифрованное сообщение
с использованием 13 в качестве ключа.
c) После написания программ пунктов (а) и (Ь) кратко ответьте на следующий
вопрос. Если бы вы не знали ключа для программы пункта (Ь), насколько трудно,
по вашему мнению, было бы расшифровать код? А если бы вы имели доступ
к большим вычислительным мощностям (напр., суперкомпьютерам)? В
упражнении 18.26 мы попросим вас написать программу для выполнения этой задачи.
18.8. Напишите программу, использующую итераторы, которая демонстрирует
применение функций rbegin и rend.
18.9. Напишите программу, которая считывает несколько строк и печатает только
строки, заканчивающиеся на "г" или "ау". Должны приниматься во внимание
только строчные буквы.
18.10. Напишите программу, которая демонстрирует передачу строки по ссылке и по
значению.
18.11. Напишите программу, которая вводит имя и фамилию, а затем объединяет их
в новую строку.
18.12. Напишите программу, которая играет в «виселицу». Программа должна выбрать
слово (которое либо закодировано непосредственно в программу, либо считыва-
ется из текстового файла) и вывести следующее:
Угадай слово: ХХХХХХ
Каждая X представляет букву. Если пользователь угадывает слово правильно,
программа должна вывести:
Поздравляю! Вы угадали мое слово. Играем снова? да/нет
Должен быть введен соответствующий ответ (да или нет) . Если пользователь
угадывает слово неправильно, на экране отображается соответствующая часть тела.
После семи неудачных попыток пользователь должен быть «повешен». Вывод
должен выглядеть так:
0
/l\
I
/ \
После каждой попытки выводятся все предложенные варианты слова.
18.13. Напишите программу, которая вводит строку и печатает ее в обратном
направлении. Преобразуйте все прописные буквы в строчные и все строчные — в прописные.
18.14. Напишите программу, которая использует возможности сравнения, описанные
в этой главе, для расстановки по алфавиту ряда названий животных. Для
сравнений должны использоваться только прописные буквы.
18.15. Напишите программу, которая создает из строки криптограмму.
Криптограмма — это сообщение или слово, в котором каждая буква заменена другой буквой.
Например, строка
The birds name was squawk
может быть зашифрована как
xms kbypo zhqs fbo obrhfu
Обратите внимание на то, что пробелы не шифруются. В данном конкретном
случае 'Т' была заменена на 'х', каждая 'а' была заменена на 'h' и т.д. Буквы
верхнего регистра в криптограмме заменяются на буквы нижнего регистра.
Используйте приемы, аналогичные применявшимся в упражнении 18.7.
Класс string и обработка строковых потоков
1061
18.16. Модифицируйте упражнение 18.22, чтобы дать пользователю возможность
решить криптограмму. Пользователь должен вводить по два символа: первый
символ указывает букву в криптограмме, а второй специфицирует заменяющую
букву. Если догадка пользователя верна, замените букву в криптограмме на
заменяющую букву.
18.17. Напишите программу, которая вводит предложение и подсчитывает в нем число
палиндромов. Палиндром — это слово, которое читается одинаково при чтении
его в прямом и обратном направлении. Например, слово "tree" не является
палиндромом, а слово "noon" — это палиндром.
18.18. Напишите программу, которая подсчитывает общее число гласных в
предложении. Выведите частоту каждой гласной.
18.19. Напишите программу, которая вставляет символы "******" точно в середину
строки.
18.20. Напишите программу, которая удаляет из строки сочетания "by" и "BY".
18.21. Напишите программу, которая вводит строку текста, заменяет все знаки
пунктуации пробелами, а затем использует функцию strtok библиотеки строк С для
разбивки строки на отдельные слова.
18.22. Напишите программу, которая вводит строку текста и печатает этот текст в
обратном направлении. Используйте в вашем решении итераторы.
18.23. Напишите рекурсивную версию упражнения 18.22.
18.24. Напишите программу, демонстрирующую использование функций erase,
которые принимают аргументы типа iterator.
18.25. Напишите программу, которая генерирует из строки
"abcdefghijklnmopqrstuvwxyz { " следующее:
а
ЬсЬ
cdedc
defgfed
efghihgfe
fghijkjihgf
ghijklmlkjihg
hijklmnonmlkjih
ijklmnopqponmlkji
jklmnopqrsrqponmlkj
klmnopqrstuts rqpomnlk
lmnopqrs tuvwvutsrqponml
mnopqrstuvwxyxwvutsrqponm
nopqrstuvwxyz{zyxwvutsrqpon
18.26. В упражнении 18.7 мы просили вас написать простой алгоритм шифрования.
Напишите программу, которая попытается расшифровать «rot 13»-сообщение,
используя простую частотную подстановку (предположим, что вы не знаете
ключ). Наиболее часто повторяющиеся буквы в зашифрованной фразе должны
заменяться наиболее часто используемыми буквами английского алфавита (а, е,
i, о, u, s, t, r и т.д.). Запишите возможные варианты в файл. Что позволяет легко
«взломать» код? Как можно улучшить механизм шифрования?
18.27. Напишите версию программы сортировки выборкой (рис. 8.28) для стандартных
строк. Используйте в вашем решении функцию swap.
18.28. Модифицируйте класс Employee из рис. 13.6-13.7, добавив закрытую сервисную
функцию с именем isValidSocialSecurityNumber. Эта элемент-функция должна
подтверждать формат номера социального страхования (напр., ###-##-####,
где # — цифра). Если формат действителен, возвратите true, в противном случае
возвратите false.
19
Поиск и сортировка
ЦЕЛИ
В этой главе вы изучите:
• Отыскание в векторе заданного
значения посредством двоичного
поиска.
• Сортировку вектора посредством
рекурсивного алгоритма сортировки
слиянием.
• Эффективность алгоритмов
сортировки и поиска.
Г
~.ъ>-
1064
Глава 19
19.1. Введение
19.2. Алгоритмы поиска
19.2.1. Эффективность линейного поиска
19.2.2. Двоичный поиск
19.3. Алгоритмы сортировки
19.3.1. Эффективность сортировки выборкой
19.3.2. Эффективность сортировки вставкой
19.3.3. Сортировка слиянием (рекурсивная
реализация)
19.4. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
19.1. Введение
Поиск в данных подразумевает определение того, содержится ли в наборе
данных некоторое значение (называемое ключом поиска) и, если содержится,
каково его местоположение. Популярными алгоритмами поиска являются
простой линейный поиск (представленный в разделе 7.7) и более быстрый, но
и более сложный двоичный поиск, который мы представляем в этой главе.
Сортировка размещает данные в определенном порядке, обычно
восходящем или нисходящем, по одному или нескольким ключам сортировки.
Список фамилий можно сортировать в алфавитном порядке, банковские счета
можно сортировать по их номерам, записи платежной ведомости можно
сортировать по номерам социальной страховки и т.д. Вы уже видели сортировку
вставкой (раздел 7.8) и сортировку выборкой (раздел 8.6). В этой главе будет
представлена более быстрая, но более сложная сортировка слиянием. На
рис. 19.1 приведена сводка всех алгоритмов поиска и сортировки,
обсуждаемых в примерах и упражнениях книги. В этой главе мы введем также
нотацию «О большого», применяемую для выражения оценки наихудшего времени
выполнения алгоритма, — т.е. того, насколько большую работу алгоритм
должен проделать, чтобы решить свою задачу.
Глава
Алгоритм
I Где описан
Алгоритмы поиска
19
Линейный поиск
Двоичный поиск
Рекурсивный линейный поиск
Рекурсивный двоичный поиск
раздел 7.7
раздел 19.2.2
упражнение 19.8
упражнение 19.9
Поиск и сортировка
1065
Глава
20
Алгоритм
Поиск в двоичном дереве
Линейный поиск в связанном списке
22 [ Функция стандартной библиотеки binary ^search
Алгоритмы сортировки
7
8
19
20
22
I
Сортировка вставкой
Сортировка выборкой
Рекурсивная сортировка слиянием
Пузырьковая сортировка
Блочная сортировка
Рекурсивная быстрая сортировка
Сортировка в двоичном дереве
Функция стандартной библиотеки sort
Кучевая сортировка
Где описан
раздел 20.7
упражнение 20.21
раздел 22.5.6
раздел 7.8
раздел 8.6
раздел 19.3.3
упражнения 19.5 и 19.6
упражнение 19.7
упражнение 19.10
раздел 20.7
раздел 22.5.6
раздел 22.5.12
Рис. 19.1- Алгоритмы поиска и сортировки в книге
19.2. Алгоритмы поиска
Отыскание номера телефона, доступ к Web-сайту и проверка значения
слова в словаре связаны с поиском в больших объемах данных. Все алгоритмы
поиска служат одной и той же цели — нахождению элемента, соответствующего
заданному ключу поиска, если такой элемент действительно существует.
Однако здесь имеется ряд факторов, отличающих алгоритмы поиска друг от
друга. Основным различием является мера работы, которую алгоритм должен
затратить на выполнение поиска. Одним из способов описания этой работы
является нотация «О большого». В случае алгоритмов поиска и сортировки она
особенно сильно зависит от числа элементов данных.
В главе 7 мы обсуждали алгоритм линейного поиска, который прост и
несложен для реализации. Теперь мы обсудим эффективность алгоритма
линейного поиска, выразив ее в нотации «О большого». Затем мы опишем
относительно более эффективный алгоритм поиска, который, однако, более сложен
и более труден для реализации.
19.2.1. Эффективность линейного поиска
Предположим, некоторый алгоритм просто проверяет, равен ли первый
элемент вектора второму элементу. Если вектор содержит 10 элементов,
алгоритму требуется одно сравнение. Если вектор содержит 1000 элементов,
алгоритму все равно требуется одно сравнение. На самом деле алгоритм
совершенно не зависит от числа элементов в векторе. Говорят, что такой алгоритм имеет
постоянное время выполнения, что в нотации «О большого» выражается как
0A). Алгоритм 0A) не обязательно требует единственного сравнения. O(l)
означает просто, что число сравнений постоянно — оно не растет с увеличени-
1066
Глава 19
ем размера вектора. Алгоритм, проверяющий, равен ли первый элемент
вектора любому из последующих трех элементов всегда потребует трех сравнений,
но в нотации «О большого» он описывается как 0A). Обозначение 0A) часто
читают как «равно по порядку величины единице» или, проще, «порядка
единицы».
Алгоритм, проверяющий, равен ли первый элемент вектора любому из
остальных его элементов, требует не более л - 1 сравнений, где л является
числом элементов вектора. Если в векторе имеется 10 элементов, алгоритм
потребует до девяти сравнений. Если в векторе содержится 1000 элементов,
потребуется до 999 сравнений. С ростом л «преобладает» часть выражения,
представленная л, а вычитание единицы становится несущественным.
«О большое» предназначено для того, чтобы выделить преобладающие члены
и отбросить те, что с ростом л становятся несущественными. По этой причине
алгоритм, требующий в сумме п - 1 сравнений (подобный тому, что описан
выше), определяют как О(п). Алгоритм О(п), как говорят, имеет линейное
время выполнения. Обозначение О(п) часто читают как «равно по порядку
величины л» или просто «порядка л».
Предположим теперь, что у нас есть алгоритм, проверяющий, повторяется
ли где-нибудь в векторе любой из его элементов. Первый элемент должен
сравниваться со всеми остальными элементами вектора. Второй элемент должен
сравниваться со всеми остальными элементами за исключением первого (он
уже с ним сравнивался). Третий элемент должен сравниваться со всеми
остальными элементами за исключением первых двух. В конечном счете
алгоритму потребуется (л - 1) + (л - 2) + ... + 2 + 1, или л2/2 - л/2 сравнений.
С ростом л преобладает член с л2, а член с л становится несущественным. Как
обычно, нотация «О большого» выделяет член с л2, оставляя только л2/2. Как
мы увидим ниже, в нотации «О большого» постоянные коэффициенты
опускаются.
Нотация «О большого» выражает то, как растет время выполнения
алгоритма по отношению к росту числа обрабатываемых единиц данных.
Предположим, алгоритм требует л2 сравнений. При четырех элементах
потребуется 16 сравнений, при восьми элементах — 64 сравнения. При удвоении числа
элементов число сравнений учетверяется. Допустим, другой алгоритм требует
л2/2 сравнений. При четырех элементах этот алгоритм потребует 8 сравнений,
при восьми — 32 сравнения. Здесь также удвоение числа элементов учетверяет
число сравнений. Оба этих алгоритма характеризуются квадратичным ростом,
поэтому «О большое» игнорирует константу и рассматривает оба алгоритма
как 0(п2), что называется квадратичным временем выполнения и читается
«равно по порядку величины л квадрат» или просто «порядка л квадрат».
Когда л мало, алгоритмы 0(п2) (при работе на современных персональных
компьютерах с миллиардами операций в секунду) не дают заметного влияния
на производительность. Но с ростом л ухудшение производительности
становится заметным. Алгоритм 0(п2), выполняющийся над вектором с
миллионом элементов, потребует триллиона «операций» (каждая из которых может
на самом деле требовать исполнения нескольких машинных инструкций). Это
может вылиться в несколько часов работы машины. Вектор с миллиардом
элементов потребовал бы квинтиллиона операций, числа настолько большого, что
алгоритм выполнялся бы несколько десятилетий! Как вы видели в
предыдущих главах, алгоритмы 0(п2) писать легко. В этой главе вы увидите алгорит-
Поиск и сортировка
1067
мы с более благоприятными мерами «О большого». Для создания таких
эффективных алгоритмов часто нужно больше изобретательности и затраченных
усилий, но их превосходная эффективность оправдывает эти дополнительные
затраты, особенно когда п становится большим и когда алгоритмы
инкорпорируются в большие программы.
Алгоритм линейного поиска имеет время выполнения О(п). Наихудшим
случаем является, когда для определения того, существует ли в векторе ключ
поиска, приходится проверить все элементы вектора. Если размер вектора
удваивается, то удваивается и число операций, которые должен выполнить
алгоритм. Заметьте, что линейный поиск может показать отличную
эффективность, если элемент, соответствующий ключу поиска, оказывается близко
к началу вектора. Но мы ищем алгоритмы, которые в среднем хорошо
работают при всех возможных поисках, включая те случаи, когда искомый элемент
находится где-то в конце вектора.
Линейный поиск является простейшим для реализации алгоритмом, но по
сравнению с другими алгоритмами поиска он может работать медленно. Если
программе нужно выполнять много операций поиска на больших векторах,
может быть, предпочтительнее реализовать другой, более эффективный алгоритм,
такой, как двоичный поиск, который мы представляем в следующем разделе.
I——, Вопросы производительности 19.1
р^^| Иногда простейшие алгоритмы работают плохо. Их достоинство
в том, что их легко программировать, тестировать и отлаживать.
Для достижения максимальной производительности иногда
требуются более сложные алгоритмы.
19.2.2. Двоичный поиск
Алгоритм двоичного поиска более эффективен, чем алгоритм линейного
поиска, но требует, чтобы вектор был сортированным. Применение его оправдано
только в случае, когда в векторе, сортированном единственный раз, поиск будет
производиться многократно, или когда к приложению предъявляются жесткие
требования по скорости. Первая итерация проверяет средний элемент вектора.
Если он совпадает с ключом поиска, алгоритм заканчивается. Предположим,
вектор сортирован в восходящем порядке, тогда, если ключ поиска меньше, чем
средний элемент, ключ не может совпадать ни с каким элементом во второй
половине вектора, и алгоритм продолжает выполняться только на первой
половине вектора (т.е. от первого элемента до, но не включая, среднего элемента
вектора). Если ключ поиска больше среднего элемента, ключ не может совпадать ни
с каким элементом в первой половине вектора, и алгоритм продолжает свое
выполнение только на второй половине вектора (т.е. от элемента, следующего за
средним, и до последнего элемента вектора). Каждая итерация проверяет
средний элемент в остающейся части вектора. Если он не совпадает с ключом
поиска, алгоритм исключает половину остающихся элементов. Алгоритм
заканчивается либо при нахождении элемента, соответствующего ключу поиска, либо
при сокращении подвектора до нулевого размера.
В качестве примера возьмем 15-элементный сортированный вектор
2 3 5 10 27 30 34 51 56 65 77 81 82 93 99
1068
Глава 19
и ключ поиска 65. Программа, реализующая алгоритм двоичного поиска,
сначала проверила бы, не равно ли 51 ключу поиска (так как 51 является средним
элементом вектора). Ключ поиска F5) больше, чем 51, поэтому 51, вместе
с первой половиной вектора (элементами, меньшими 51), отбрасывается.
Затем алгоритм проверяет, не совпадает ли с ключом поиска 81 (средним
элементом остатка вектора). Ключ поиска F5) меньше, чем 81, поэтому 81 и все
элементы, большие его, отбрасываются. После всего двух сравнений алгоритм
сузил число подлежащих проверке элементов до трех E6, 65 и 77). Затем
алгоритм проверяет число 65 (которое и в самом деле совпадает с ключом),
и возвращает индекс (9) элемента вектора, содержащего 65. В данном случае
для определения того, совпадает ли какой-либо элемент вектора с ключом
поиска, алгоритм потребовал только трех сравнений. Алгоритму линейного
поиска потребовалось бы 10 сравнений. [Замечание. Мы выбрали в данном
примере вектор с 15 элементами, чтобы в векторе всегда существовал очевидный
средний элемент. В случае четного числа элементов середина вектора
находится между двумя элементами. Мы реализуем алгоритм так, что в этом случае
выбирается больший из этих двух элементов.]
Рис. 19.2-19.3 определяют соответственно класс BinarySearch и его
элемент-функции. Класс BinarySearch похож на LinearSearch (раздел 7.7) —
в нем имеется конструктор, функция поиска (binarySearch), функция dis-
playElements, два закрытых элемента данных и закрытая сервисная функция
(displaySubElements). Строки 18-28 на рис. 19.3 определяют конструктор.
После инициализации вектора случайными числами из диапазона 10-99
(строки 24-25) строка 27 вызывает для вектора data функцию стандартной
библиотеки sort. Функция sort принимает два итератора произвольного
доступа и сортирует элементы вектора data в восходящем порядке. Итератор
произвольного доступа позволяет в любой момент обратиться к любому
элементу данных. В данном случае мы применяем data.begin() и data.end(),
заключающие между собой весь вектор. Как вы помните, алгоритм двоичного
поиска будет работать только с сортированным вектором.
1 // Рис. 19.2: BinarySearch.h
2 // Класс, содержащий вектор случайных целых значений и функцию,
3 // использующую двоичный поиск для отыскания целого ключа.
4 #include <vector>
5 using std::vector;
6
7 class BinarySearch
8 {
9 public:
10 BinarySearch( int ); // конструктор инициализирует вектор
11 int binarySearch( int ) const; // двоичный поиск в векторе
12 void displayElements() const; // вывести элементы вектора
13 private:
14 int size; // размер вектора
15 vector< int > data; // вектор значений int
16 void displaySubElements( int, int ) const; // вывести диапазон
17 }; // конец класса BinarySearch
Рис. 19.2. Определение класса BinarySearch
Поиск и сортировка
1069
1 // Рис. 19.3: BinarySearch.срр
2 // Определения элемент-функций класса BinarySearch
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstdlib> // прототипы для функций srand и rand
8 using std::rand;
9 using std::srand;
10
11 #include <ctime> // прототип для функции time
12 using std::time;
13
14 #include <algorithm> // прототип для функции sort
15 #include "BinarySearch.h" // определение класса BinarySearch
16
17 // конструктор инициализирует случайными целыми и сортирует вектор
18 BinarySearch::BinarySearch( int vectorSize )
19 {
20 size = ( vectorSize > 0 ? vectorSize : 10 ); // проверить размер
21 srand( time( 0 ) ); // засеять текущим временем
22
23 // заполнить вектор случайными целыми в диапазоне 10-99
24 for ( int i = 0; i < size; i++ )
25 data.pushjback( 10 + rand() % 90 ); // 10-99
26
27 std::sort( data.begin(), data.end() ); // сортировать данные
28 } // конец конструктора BinarySearch
29
30 // произвести двоичный поиск в данных
31 int BinarySearch::binarySearch( int searchElement ) const
32 {
33 int low =0; // нижний предел области поиска
34 int high = size - 1; // верхний предел области поиска
35 int middle = ( low + high + 1 ) / 2; // средний элемент
36 int location = -1; // возвращаемое значение; -1, если не найдено
37 do // цикл поиска элемента
38 {
39 // распечатать элементы вектора, оставшиеся для поиска
40 displaySubElements( low, high );
41
42 // вывести пробелы для выравнивания
43 for ( int i = 0; i < middle; i++ )
44 cout « " ";
45
4 6 cout « " * " « endl; // показать текущую середину
47
48 // если элемент найден в середине
49 if ( searchElement == data[ middle ] )
50 location = middle; // location равно текущей середине
51 else if ( searchElement < data[ middle ] ) // слишком велик
52 high = middle - 1; // отбросить верхнюю половину
53 else // средний элемент слишком мал
54 low = middle +1; // отбросить нижнюю половину
55
56 middle = ( low + high +1 ) /2; // пересчитать середину
1070
Глава 19
57 } while ( ( low <= high ) && ( location == -1 ) ) ;
58
59 . return location; // возвратить позицию ключа поиска
60 } // конец фунции binarySearch
61
62 // показать значения в векторе
63 void BinarySearch:idisplayElements() const
64 {
65 displaySubElements( 0, size - 1 );
66 } // конец фунции displayElements
67
68 // показать некоторые значения в векторе
69 void BinarySearch::displaySubElements( int low, int high ) const
70 {
71 for ( int i = 0; i < low; i++ ) // пробелы для выравнивания
72 cout « "
73
74 for ( int i = low; i <= high; i++ ) // вывести оставшиеся
75 cout « data[ i ] « "
76
77 cout « endl;
78 } // конец фунции displaySubElements
Рис. 19.3. Определения элемент-функций класса BinarySearch
Строки 31-61 определяют функцию binarySearch. Ключ поиска передается
в параметре searchElement (строка 31). Строки 33-35 вычисляют конечный
индекс low, конечный индекс high и средний индекс middle для той части
вектора, на которой в данный момент производится поиск. В начале функции low
равен О, high равен размеру вектора минус единица и middle равен среднему
от этих двух значений. Строка 36 инициализирует положение (location)
найденного элемента значением -1, которое будет возвращено в случае, если ключ
поиска не найден. Цикл в строках 38-58 повторяется, пока low не станет
больше high (это происходит, когда элемент не найден) или location не станет
отличным от -1 (показывая, что ключ поиска найден). Строка 50 проверяет,
равен ли средний элемент значению searchElement. Если равен, строка 51
присваивает location значение middle. Тогда цикл завершается и location
возвращается вызывающей функции. Каждая итерация цикла производит
единственное сравнение (строка 50) и исключает половину из остающихся
элементов вектора (строка 53 или 55).
1 // Рис. 19.4: Fig20_04.cpp
2 // Тестовая программа для BinarySearch.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::endl;
7
8 #include "BinarySearch.h" // определение класса BinarySearch
9
10 int main()
11 {
12 int searchint; // ключ поиска
13 int position; // позиция ключа поиска в векторе
Поиск и сортировка
1071
14
15 // создать вектор и вывести его
16 BinarySearch searchVector ( 15 );
17 searchVector.displayElements();
18
19 // получить от пользователя ключ поиска
20 cout « M\nPlease enter an integer value (-1 to quit): ";
21 cin » searchlnt; // прочитать введенное пользователем целое
22 cout « endl;
23
24 // повторно ввести число; -1 завершает программу
25 while ( searchlnt != -1 )
26 {
27 // попытаться найти число, применив двоичную сортировку
28 position = searchVector.binarySearch( searchlnt );
29
30 // возвращаемое значение -1 указывает, что число не найдено
31 if ( position == -1 )
32 cout « "The integer " « searchlnt « " was not found.\n";
33 else
34 cout « "The integer " « searchlnt
35 « " was found in position " « position « ".\n";
36
37 // получить ввод пользователя
38 cout « "\n\nPlease enter an integer value (-1 to quit): ";
39 cin » searchlnt; // прочитать число пользователя
40 cout « endl;
41 } // конец while
42
43 return 0;
44 } // конец main
12 14 15 16 18 30 41 59 63 67 71 88 92 94 96
Please enter an integer value (-1 to quit): 16
12 14 15 16 18 30 41 59 63 67 71 88 92 94 96
12 14 15 16 18 30 41
The integer 16 was found in position 3.
Please enter an integer value (-1 to quit): 94
12 14 15 16 18 30 41 59 63 67 71 88 92 94 96
63 67 71 88 92 94 96
92 94 96
*
The integer 94 was found in position 13.
Please enter an integer value (-1 to quit): 11
1072
Глава 19
12 14 15 16 18 30 41 59 63 67 71 88 92 94 96
12 14 15 16 18 30 41
12 14 15
12
The integer 11 was not found.
Please enter an integer value (-1 to quit): -1
Рис. 19.4. Тестовая программа для BinarySearch
Строки 25-41 на рис. 19.4 повторяются, пока пользователь не введет
значение —1. Для любого другого введенного числа программа производит
двоичный поиск, чтобы определить, совпадает ли оно с некоторым элементом
вектора. Первая строка вывода программы показывает вектор целых значений
в восходящем порядке. Когда пользователь предлагает программе
отыскать 16, программа сначала проверяет средний элемент, который равен 59
(указан звездочкой). Ключ поиска меньше 59, поэтому программа исключает
вторую половину вектора и проверяет средний элемент его первой половины.
Ключ поиска равен 16, поэтому программа возвращает индекс 3.
Эффективность двоичного поиска
В наиболее неблагоприятном случае двоичный поиск в векторе с 1023
элементами потребует всего 10 сравнений. Последовательное деление 1023 на два
(так как после каждого сравнения мы можем исключить половину вектора)
с округлением в сторону меньшего значения (поскольку мы удаляем также
и средний элемент) дает значения 511, 255, 127, 63, 31, 15, 7, 3, 1 и 0. Чтобы
получить 0, Число 1023 B10 - 1) нужно поделить на два всего 10 раз, чтобы
получился 0, показывающий, что требующих проверки элементов больше нет.
Деление на 2 эквивалентно одному сравнению в алгоритме двоичного поиска.
Таким образом, для поиска ключа в векторе с 1 048 575 B20 - 1) элементами
потребуется максимум 20 сравнений, а для поиска в векторе с миллиардом
элементов — максимум 30 сравнений. Это громадное повышение
эффективности по сравнению с линейным поиском. Для вектора с миллиардом
элементов — это разница между 500 миллионами (в среднем) сравнений для
линейного поиска и максимум 30 сравнениями для двоичного поиска! Максимальное
число сравнений, необходимых для двоичного поиска в произвольном векторе,
равно первому показателю степени, в которую нужно возвести 2, чтобы
получить значение, превосходящее число элементов в векторе, что представляется
как log2 n- Все логарифмы растут примерно с одной скоростью, поэтому в
нотации «О большого» основание можно опустить. Это дает для двоичного поиска
оценку 0(\og n)y что называется также логарифмическим временем
выполнения и читается как «равно по порядку величины логарифму п» или просто
«порядка логарифма /г».
Поиск и сортировка
1073
19.3. Алгоритмы сортировки
Сортировка данных (т.е. распололсение их в некотором определенном
порядке, например, восходящем или нисходящем) является одним из
важнейших компьютерных приложений. Банк сортирует все чеки по номерам счетов,
чтобы в конце каждого месяца подготовить индивидуальные банковские
бюллетени. Телефонные компании сортируют свои списки клиентов по фамилиям
и затем по именам, чтобы упростить поиск телефонных номеров. Практически
каждая организация должна сортировать какие-то данные, а часто большие
их объемы. Сортировка данных — захватывающая компьютерная проблема,
привлекавшая большие исследовательские силы.
Важно понимать, что конечный результат сортировки — сортированный
вектор — будет одним и тем же вне зависимости от того, какой алгоритм
сортировки вы применяете. Выбор алгоритма влияет только на время
выполнения программы и ее требования к памяти. В предыдущих главах мы
представили сортировку выборкой и сортировку вставкой — алгоритмы, простые для
реализации, но неэффективные. В следующем разделе мы исследуем
эффективность этих двух алгоритмов, выразив ее в нотации «О большого».
Последний алгоритм — сортировка слиянием, — который мы опишем в этой главе,
гораздо быстрее, но более труден для реализации.
19.3.1. Эффективность сортировки выборкой
Сортировка выборкой является простым для реализации, но
неэффективным алгоритмом. Первая итерация алгоритма выбирает наименьший элемент
вектора и обменивает его с первым элементом. Вторая итерация выбирает
элемент, второй по малости (являющийся наименьшим среди оставшихся), и
обменивает его со вторым элементом. Алгоритм продолжает выполняться, пока
последняя итерация не выберет второй по величине элемент, обменяв его
с предпоследним элементом вектора, в результате чего наибольший элемент
будет иметь последний индекс. После i-ой итерации i наименьших элементов
будут сортированы по возрастанию в первых i элементах вектора.
Алгоритм сортировки выборкой выполняет п - 1 итерацию, каждый раз
помещая наименьший остающийся элемент его окончательную позицию.
Нахождение наименьшего остающегося элемента требует п - 1 сравнения на первой
итерации, п - 2 сравнений на второй, затем п - 3, ..., 3, 2, 1. Это дает в
результате п(п - 1) / 2, или (я2 - п) I 2 сравнений. В нотации «О большого» меньшие
члены выпадают, а константы игнорируются, что дает в конечном счете
оценку 0(п2).
19.3.2. Эффективность сортировки вставкой
Сортировка вставкой — еще один простой в реализации, но неэффективный
алгоритм. Первая итерация этого алгоритма берет второй элемент вектора и,
если он меньше первого элемента, обменивает его с этим первым элементом.
Вторая итерация рассматривает третий элемент и вставляет его в правильную
позицию по отношению к первым двум элементам, так что все три этих
элемента оказываются в правильном порядке. На i-ой итерации этого алгоритма
будут сортированы первые / элементов исходного вектора.
1074
Глава 19
Сортировка вставкой выполняет п - 1 итерацию, вставляя элемент в
соответствующую позицию среди уже сортированных элементов. На каждой
итерации для определения того, куда должен быть вставлен элемент, может
оказаться необходимым сравнить его с каждым из предшествующих элементов
в векторе. В худшем случае для этого потребуется п - 1 сравнение. Каждый
отдельный оператор повторения выполняется за время О(п). При нахождении
оценки «О большого» вложенные операторы повторения означают, что вам
нужно перемножить число сравнений. Для каждой итерации внешнего цикла
будет выполнено некоторое число итераций внутреннего цикла. В данном
алгоритме на каждую из О(п) итераций внешнего цикла придется О(п)
итераций внутреннего, что даст оценку 0(п * п), или 0(п2).
19.3.3. Сортировка слиянием (рекурсивная реализация)
Сортировка слиянием является эффективным алгоритмом сортировки, но
концептуально она сложнее, чем сортировка выборкой и сортировка вставкой.
Алгоритм сортировки слиянием упорядочивает вектор, разбивая его на два
подвектора равного размера, после чего сортирует каждый из подвекторов
и затем производит их слияние в один большой вектор. В случае нечетного
числа элементов алгоритм создает два подвектора, один из которых содержит
на один элемент больше, чем другой.
Реализация сортировки слиянием в этом примере является рекурсивной.
Основным случаем является вектор с одним элементом. Такой вектор,
разумеется, уже сортирован, так что сортировка слиянием немедленно возвращает
управление, если вызывается для вектора с единственным элементом. Шаг
рекурсии разбивает вектор из двух или большего числа элементов на два
подвектора равного размера, рекурсивно сортирует каждый подвектор и затем
производит их слияние в один сортированный вектор большего размера. [Повторим,
что если число элементов нечетно, один из подвекторов будет содержать на
один элемент больше, чем другой.]
Предположим, алгоритм уже произвел слияние меньших подвекторов и
образовал сортированные векторы А:
4 10 34 56 77
и В:
5 30 51 52 93
Сортировка слиянием объединяет эти два вектора в один большой
сортированный вектор. Наименьшим элементом из А является 4 (находится в позиции
нулевого индекса А). Наименьшим элементом из В является 5 (находится в
позиции нулевого индекса В). Чтобы определить наименьший элемент в большом
векторе, алгоритм сравнивает 4 и 5. Значение из А меньше, поэтому первым
элементом объединенного вектора становится 4. Далее алгоритм сравнивает 10
(второй элемент из А) и 5 (первый элемент из В). Значение из В меньше, так что
вторым элементом в большом векторе становится 5. Далее алгоритм
сравнивает 10 и 30, третьим элементом в векторе становится 10 и т.д.
Рис. 19.5 определяет класс MergeSort; строки 31-34 на рис. 30.6
определяют функцию sort. Строка 33 вызывает функцию sort Sub Vector с
аргументами О и size —1. Аргументы соответствуют начальному и конечному индексам
Поиск и сортировка
1075
вектора, который должен сортироваться, так что sortSubVector будет
действовать на всем векторе. Функция sortSub Vector определяется в строках 37-61.
Строка 40 производит проверку на основной случай. Если размер вектора
равен 1, вектор уже сортирован, и функция просто возвращает управление. Если
размер вектора больше 1, функция разбивает вектор пополам, рекурсивно
вызывает sortSub Vector для двух подвекторов, а затем производит их слияние.
Строка 55 рекурсивно вызывает sortSub Vector для первой половины вектора,
а строка 56 рекурсивно вызывает sortSub Vector для его второй половины.
Когда произойдет возврат из обоих этих рекурсивных вызовов, каждая половина
вектора окажется сортированной. Строка 59 вызывает функцию merge
(строки 64-108) для двух половин вектора, чтобы объединить два сортированных
вектора в один большой сортированный вектор.
1 // Рис. 19.05: MergeSort.h
2 // Класс создает вектор, содержащий случайные целые числа.
3 // Предусматривает функцию для сортировки слиянием.
4 #include <vector>
5 using std::vector;
6
7 // определение класса MergeSort
8 class MergeSort
9 {
10 public:
11 MergeSort( int ); // конструктор инициализирует вектор
12 void sort(); // сортировать вектор сортировкой слиянием
13 void displayElements() const; // вывести элементы вектора
14 private:
15 int size; // размер вектора
16 vector< int > data; // вектор значений int
17 void sortSubVector( int, int ); // сортировать подвектор
18 void merge( int, int, int, int ); // слить два подвектора
19 void displaySubVector( int, int ) const; // вывести подвектор
20 }; // конец класса SelectionSort
Рис. 19.5. Определение класса MergeSort
1 // Рис. 19.06: MergeSort.срр
2 // Определения элемент-функций класса MergeSort.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <vector>
8 using std::vector;
9
10 #include <cstdlib> // прототипы ля функций srand и rand
11 using std::rand/
12 using std::srand;
13
14 #include <ctime> // прототип для функции time
15 using std::time;
16
1076
Глава 19
17 #include "MergeSort.h" // определение класса MergeSort
18
19 // конструктор заполняет вектор случайными целыми
20 MergeSort::MergeSort( int vectorSize )
21 {
22 size = ( vectorSize > 0 ? vectorSize : 10 ); // проверить размер
23 srand( time( 0 ) ); // засеять генератор текущим временем
24
25 // заполнить вектор случайными целыми в диапазоне 10-99
26 for ( int i = 0; i < size; i++ )
27 data.push_back( 10 + rand() % 90 );
28 } // конец конструктора MergeSort
29
30 // разделить вектор, сортировать подвекторы и слить в один вектор
31 void MergeSort::sort()
32 {
33 sortSubVector( 0, size - 1 ); // рекурсивная сортировка вектора
34 } // конец функции sort
35
36 // рекурсивная функция для сортировки подвектора
37 void MergeSort::sortSub Vector( int low, int high )
38 {
39 // проверить базовый случай; размер вектора равен 1
40 if ( ( high - low ) >= 1 У // если не базовый случай
41 {
42 int middlel = ( low + high ) /2; // определить середину
43 int middle2 = middlel + 1; // следующий элемент после среднего
44
45 // вывести шаг разбивки
46 cout « "split:
47 displaySub Vector( low, high );
48 cout « endl « "
4 9 displaySubVector( low, middlel );
50 cout « endl « "
51 displaySubVector( middle2, high ) ;
52 cout « endl « endl;
53
54 // разбить вектор пополам; сортировать каждую половину (рекурсия)
55 sortSubVector( low, middlel ); // первая половина вектора
56 sortSubVector( middle2, high ); // вторая половина вектора
57
58 // слить два сортированных вектора после возврата вызовов
59 merge ( low, middlel, middle2, high );
60 } // конец if
61 } // конец функции sortSubVector
62
63 // слить два сортированных подвектора в один сортированный вектор
64 void MergeSort::merge( int left,int middlel,int middle2,int right )
65 {
66 int leftlndex = left; // индекс в левом подвекторе
67 int rightlndex = middle2; // индекс в правом подвекторе
68 int combinedlndex = left; // индекс во временном рабочем векторе
69 vector< int > combined( size ); // рабочий вектор
70
71 // вывести два подвектора перед слиянием
72 cout « "merge:
73 displaySubVector( left, middlel );
Поиск и сортировка
1077
74 cout « endl « "
75 displaySubVector( middle2, right );
76 cout « endl;
77
78 // сливать векторы, пока не будет достигнут конец каждого
79 while ( leftlndex <= middlel && rightlndex <= right )
80 {
81 // поместить в результат меньшее из двух текущих значений
82 //и переместиться к следующему за ним элементу
83 if ( data[ leftlndex ] <= data[ rightlndex ] )
84 combined[ combinedIndex++ ] = data[ leftlndex++ ];
85 else
86 combined[ combinedIndex++ ] = data[ rightlndex++ ];
87 } // конец while
88
89 if ( leftlndex = middle2 ) // если конец левого вектора
90 {
91 while ( rightlndex <= right ) // копировать остаток правого
92 combined[ combinedIndex++ ] = data[ rightlndex++ ];
93 } // конец if
94 else // если конец правого вектора
95 {
96 while ( leftlndex <= middlel ) // копировать остаток левого
97 combined[ combinedIndex++ ] = data[ leftlndex++ ];
98 } // конец else
99
100 // копировать значения обратно в исходный вектор
101 for ( int i = left; i <= right; i++ )
102 data[ i ] = combined[ i ];
103
104 // вывести слитый вектор
105 cout « "
106 displaySubVector( left, right );
107 cout « endl « endl;
108 } // конец функции merge
109
110 // вывести элеметы вектора
111 void MergeSort::displayElements() const
112 {
113 displaySubVector( 0, size - 1 );
114 } // конец функции displayElements
115
116 // вывести некоторые значения вектора
117 void MergeSort::displaySubVector( int low, int high ) const
118 {
119 // вывести пробелы для выравнивания
120 for ( int i = 0; i < low; i++ )
121 cout « "
122
123 // вывести оставшиеся элементы вектора
124 for ( int i = low; i <= high; i++ )
125 cout « " " « data[ i ];
126 } // конец функции displaySubVector
Рис. 19.6. Определение элемент-функций класса MergeSort
1078
Глава 19
Цикл в строках 79-87 в функции merge выполняется, пока программа не
достигнет конца любого из подвекторов. Строка 83 выясняет, который из
элементов в начале векторов меньше. Если меньше элемент левого вектора,
строка 84 помещает его в позицию объединенного вектора. Если меньше элемент
правого вектора, строка 86 помещает в позицию объединенного вектора этот
элемент. Когда цикл while завершается (строка 87), один из подвекторов уже
целиком размещен в объединенном векторе, но другой подвектор еще
содержит данные. Строка 89 проверяет, достигнут ли конец левого вектора. Если
да, строки 91-92 заполняют объединенный вектор элементами правого
вектора. Если конец левого вектора еще не достигнут, значит, должен быть
достигнут конец правого вектора, и строки 96-97 заполняют объединенный
вектор элементами левого вектора. Наконец, строки 101-102 копируют
объединенный вектор в исходный вектор. Рис. 19.7 создает и тестирует объект
MergeSort. Вывод этой программы отображает разбиения и слияния,
производимые при сортировке, показывая ее прохождение на каждом шаге
алгоритма.
1 // Fhc. 19.07: Fig20_07.cpp
2 // Тестовая программа для MergeSort.
3 #include <iostream>
4 using std:rcout/
5 using std::endl;
6
7 #include "MergeSort.h" // определение класса MergeSort
8
9 int main()
10 {
11 // создать объект для выполнения сортировки слиянием
12 MergeSort sortVector( 10 );
13
14 cout « "Unsorted vector:" « endl;
15 sortVector.displayElements(); // распечатать исходный вектор
16 cout « endl « endl;
17
18 sortVector.sort(); // сортировать вектор
19
20 cout « "Sorted vector:" « endl;
21 sortVector.displayElements(); // распечатать сортированный вектор
22 cout « endl;
23 return 0;
24 } // конец main
Unsorted vector:
69 40 14 45 68 60 70 44 21 58
split: 69 40 14 45 68 60 70 44 21 58
69 40 14 45 68
60 70 44 21 58
split: 69 40 14 45 68
69 40 14
45 68
Поиск и сортировка
1079
split: 69 40 14
69 40
14
split: 69 40
69
40
merge: 69
40
40 69
merge: 40 69
14
14 40 69
split: 45 68
45
68
merge: 45
68
45 68
merge: 14 40 69
45 68
14 40 45 68 69
split: 60 70 44 21 58
60 70 44
21 58
split: 60 70 44
60 70
44
split: 60 70
60
70
merge: 60
70
60 70
merge: 60 70
44
44 60 70
split: 21 58
21
58
merge: 21
58
21 58
1080
Глава 19
merge: 44 60 70
21 58
21 44 58 60 70
merge: 14 40 45 68 69
21 44 58 60 70
14 21 40 44 45 58 60 68 69 70
Sorted vector:
14 21 40 44 45 58 60 68 69 70
Рис. 19.7. Тестовая программа для MergeSort
Эффективность сортировки слиянием
Сортировка слиянием — гораздо более эффективный алгоритм, чем и
сортировка выборкой, и сортировка вставкой (хотя, глядя на оживленную
деятельность на рис. 19.7, в это может быть трудно поверить). Рассмотрим
первый (нерекурсивный) вызов функции sortSubVector. Он приводит к двум
рекурсивным вызовам sortSubVector с подвекторами, каждый из которых
имеет размер примерно вдвое меньше размера исходного вектора, и одному
вызову функции merge. Этот вызов функции merge требует в худшем случае
п - 1 сравнение для заполнения исходного вектора, т.е. О(п) сравнений.
(Вспомните, что каждый элемент вектора выбирается путем сравнения
элементов, взятых из разных подвекторов.) Два вызова функции sortSubVector
приводят еще к четырем рекурсивным вызовам sortSubVector, а также двум
вызовам функции merge. Эти два вызова merge потребуют в худшем случае
п/2 - 1 сравнение каждый, что дает суммарное число сравнений О(п). Этот
процесс, в котором каждый вызов sortSubVector порождает по два
дополнительных вызова sortSubVector и одному вызову merge, продолжается, пока
алгоритм не разобьет вектор на одноэлементные подвекторы. На каждом
уровне для слияния подвекторов требуется О(п) сравнений. Каждый уровень
уменьшает размер подвекторов вдвое, так что при удвоении размера исходного
вектора потребуется еще один уровень алгоритма. Увеличение размера
вектора вчетверо потребует двух дополнительных уровней. Это логарифмическая
зависимость, которая дает в результате log2 n уровней. Общая эффективность
получается равной 0(п log n). На рис. 19.8 приведена сводка многих из
описанных в этой книге алгоритмов поиска и сортировки с указанием оценки
«О большого» для каждого. На рис. 19.9 перечислены выражения для «О
большого», рассмотренные в этой главе, с указанием примерных чисел для
некоторых значений л, чтобы подчеркнуть различия в темпах роста.
Поиск и сортировка
1081
Алгоритм
Где описан
«О большое»
Алгоритмы поиска
Линейный поиск
Двоичный поиск
Рекурсивный линейный поиск
Рекурсивный двоичный поиск
раздел 7.7
раздел 19.2.2
упражнение 19.8
упражнение 19.9
О(п)
Oflog п)
О(п)
Oflog n)
Алгоритмы сортировки
Сортировка вставкой
Сортировка выборкой
Сортировка слиянием
Пузырьковая сортировка
Быстрая сортировка
раздел 7.8
раздел 8.6
раздел 19.3.3
упражнения 16.3 и 16.4
упражнение 19.10
0(п2)
0(п2)
0(n log n)
0(п2)
Худший случай: 0(п2)
Средний случай: 0(n log n)
Рис. 19.8. Алгоритмы поиска и сортировки с оценками «О большого»
л
2-о
2"
2зо
Приблизительное десятичное значение
1000
1 000 000
1 000 000 000
Oflog n)
10
20
30
О(п)
2-.
220
2»
0(n log n)
10-2'°
20 • 220
30 • 2Э0
0(п2)
2м
•у АО
-у60
Рис. 19.9. Примерное число сравнений для распространенных выражений «О большого»
19.4. Заключение
В этой главе обсуждались поиск и сортировка данных. Мы рассмотрели
алгоритм двоичного поиска — более быстрый, но и более сложный алгоритм по
сравнению с линейным поиском (раздел 7.7). Алгоритм двоичного поиска
будет работать только на сортированном массиве, но каждая итерация двоичного
поиска исключает половину элементов массива. Вы изучили также алгоритм
сортировки слиянием, который эффективнее и сортировки вставкой (раздел
7.8), и сортировки выборкой (раздел 8.6). Мы также ввели нотацию «О
большого», которая помогает выразить эффективность алгоритма. *0 большое»
оценивает наихудший случай времени выполнения алгоритма. Значение «О
большого» для алгоритма полезно при сравнении алгоритмов, когда нужно
выбрать наиболее эффективный. В следующей главе вы будете изучать
динамические структуры данных, которые могут расти или сокращаться во время
выполнения.
1082
Глава 19
Резюме
• Поиск в данных подразумевает определение того, содержится ли в наборе данных
некоторый ключ поиска и, если содержится, каково его местоположение.
• Сортировка размещает данные в определенном порядке.
• Алгоритм линейного поиска последовательно ищет нужный элемент, пока не найдет
его. Если элемента нет в векторе, алгоритм проверяет все элементы, и при
достижении конца вектора информирует пользователя, что требуемый элемент отсутствует.
Если элемент в векторе, алгоритм проверяет каждый элемент, пока не найдет
нужный.
• Основным отличием алгоритмов поиска друг от друга является мера «усилий»,
которые требуются от алгоритма на выполнение поиска.
• Одним из способов описания эффективности алгоритмов является нотация «О
большого» (О), которая показывает, какой объем работы должен выполнить алгоритм
для решения задачи.
• В случае алгоритмов поиска и сортировки «О большое» описывает, каким образом
для данного алгоритма необходимый объем работы возрастает с ростом числа
элементов в данных.
• Говорят, что алгоритм с оценкой 0A) имеет постоянное время выполнения. 0A) не
означает, что алгоритм требует единственного сравнения. Это просто значит, что
число сравнений не растет с увеличением размера вектора.
• Алгоритм О(п), как говорят, имеет линейное время выполнения.
• «О большое» предназначено для того, чтобы выделить преобладающие члены и
отбросить те, что с ростом п становятся несущественными.
• Алгоритм линейного поиска имеет время выполнения О(п).
• Наихудшим случаем для линейного поиска является, когда для определения того,
присутствует ли элемент в векторе, приходится проверить каждый элемент. Это
происходит, когда ключ поиска является последним элементом в векторе или же
отсутствует.
• Алгоритм двоичного поиска более эффективен, чем алгоритм линейного поиска, но
требует, чтобы вектор был сортированным. Применение его оправдано только в
случае, когда в векторе, сортированном единственный раз, поиск будет производиться
многократно, или когда к приложению предъявляются жесткие требования по
скорости.
• Первая итерация проверяет средний элемент вектора. Если он совпадает с ключом
поиска, алгоритм возвращает его позицию. Если ключ поиска меньше, чем средний
элемент, алгоритм продолжает выполняться только на первой половине вектора.
Если ключ поиска больше среднего элемента, алгоритм продолжает свое выполнение
только на второй половине вектора. Каждая итерация проверяет средний элемент
в остающейся части вектора. Если он не совпадает с ключом поиска, алгоритм
исключает половину остающихся элементов.
• Алгоритм двоичного поиска эффективнее линейного поиска, поскольку с каждым
сравнением он исключает из рассмотрения половину элементов вектора.
• Двоичный поиск имеет время выполнения 0(\og n)> поскольку каждый шаг
исключает половину остающихся элементов.
• Если размер вектора удваивается, двоичному поиску требуется для успешного
завершения всего одно дополнительное сравнение.
• Сортировка выборкой является простым, но неэффективным алгоритмом
сортировки.
Поиск и сортировка
1083
• Первая итерация сортировки выборкой выбирает наименьший элемент вектора и
обменивает его с первым элементом. Вторая итерация выбирает элемент, второй по
малости (являющийся наименьшим среди оставшихся), и обменивает его со вторым
элементом. Алгоритм продолжает выполняться, пока последняя итерация не
выберет второй по величине элемент, обменяв его с предпоследним элементом вектора,
в результате чего наибольший элемент будет иметь последний индекс. После i-ой
итерации i наименьших элементов будут сортированы по возрастанию в первых i
элементах вектора.
• Алгоритм сортировки выборкой выполняется за время 0(п2).
• Первая итерация сортировки вставкой берет второй элемент вектора и, если он
меньше первого элемента, обменивает его с этим первым элементом. Вторая итерация
рассматривает третий элемент и вставляет его в правильную позицию по отношению
к первым двум элементам. На i-ой итерации этого алгоритма будут сортированы
первые i элементов исходного вектора. Всего требуется п - 1 итерация.
• Алгоритм сортировки вставкой выполняется за время 0(п2).
• Сортировка слиянием является алгоритмом сортировки, более эффективным, но
более сложным для реализации, чем сортировка выборкой и сортировка вставкой.
• Алгоритм сортировки слиянием упорядочивает вектор, разбивая его на два подвек-
тора равного размера, после чего сортирует каждый из подвекторов и затем
производит их слияние в один большой вектор.
• Основным случаем сортировки слиянием является вектор с одним элементом. Такой
вектор уже сортирован, так что сортировка слиянием немедленно возвращает
управление, если вызывается для вектора с единственным элементом. В части слияния
алгоритм берет два сортированных вектора (которые могут быть одноэлементными
векторами) и объединяет из в один сортированный вектор большего размера.
• При слиянии алгоритм сортировки слиянием рассматривает первый элемент
каждого из двух векторов, который является также наименьшим его элементом. Алгоритм
берет меньший из них и помещает его в первый элемент большого сортированного
вектора. Если в подвекторе имеются еще элементы, рассматривается второй его
элемент (являющийся теперь наименьшим из оставшихся), который сравнивается
с первым элементом другого подвектора. Процесс продолжается, пока большой
вектор не будет заполнен.
• В наихудшем случае первый вызов сортировки слиянием должен сделать О(п)
сравнений, чтобы заполнить п позиций в конечном векторе.
• Часть слияния в алгоритме сортировки слиянием выполняется на двух подвекторах
размером приблизительно л/2 каждый. Для создания каждого подвектора требуется
п/2 - 1 сравнение, или всего О(п) сравнений. То же самое имеет место на всех
уровнях алгоритма — каждый последующий работает на вдвое большем числе векторов,
которые, однако, имеют вдвое меньший размер по сравнению с предыдущим
вектором.
• Как и в алгоритме двоичного поиска, при таком «делении пополам» получается log n
уровней, каждый из которых требует О(п) сравнений, что дает общую
эффективность 0(п log n).
1084 Глава 19
Терминология
O(l)
0(\og n)
0(п log n)
О(п)
0(п2)
двоичный поиск
итератор произвольного доступа
квадратичное время выполнения
ключ поиска
ключ сортировки
линейное время выполнения
логарифмическое время выполнения
наихудший случай времени
выполнения алгоритма
Контрольные вопросы
19.1. Заполните пропуски в следующих предложениях:
a) Приложению сортировки выборкой потребуется для сортировки 128-элемент-
ного вектора приблизительно в раз больше времени, чем для
сортировки 32-элементного.
b) Эффективность сортировки слиянием равна .
19.2. Какой аспект двоичного поиска и сортировки слиянием приводит к появлению
логарифмического фактора в их оценках «О большого»?
19.3. В каком смысле сортировка вставкой «лучше» сортировки слиянием? В каком
смысле сортировка слиянием «лучше» сортировки вставкой?
19.4. В тексте главы говорилось, что после того, как сортировка слиянием разобьет
вектор на два подвектора, она сортирует эти подвекторы и затем сливает их.
Почему кому-то может показаться странной в этой фразе часть «она сортирует эти
подвекторы»?
Ответы на контрольные вопросы
19.1. а) 16, поскольку алгоритму с эффективностью 0(п2) для обработки вчетверо
большего объема данных требуется в 16 раз больше времени, b) 0(n log n).
19.2. Оба эти алгоритма связаны с «делением пополам», т.е. они каким-то образом
что-то сокращают вдвое. Двоичный поиск после каждого сравнения исключает
из рассмотрения одну половину вектора. Сортировка слиянием при каждом
вызове разбивает вектор пополам.
19.3. Сортировку вставкой проще понять и реализовать, чем сортировку слиянием.
Сортировка слиянием гораздо более эффективна @(n log n) против 0(п2) для
сортировки вставкой).
19.4. В некотором смысле сортировка слиянием вовсе не сортирует эти два
подвектора. Она просто снова и снова производит разбиение исходного вектора пополам,
пока не получится одноэлементный подвектор, который, разумеется, является
сортированным. Затем она восстанавливает исходный вектор, сливая эти
одноэлементные векторы в более крупные подвекторы, затем в еще более крупные
и т.д.
нотация «О большого»
поиск в данных
порядка 1
порядка log n
порядка п
порядка л-квадрат
постоянное время выполнения
разбиение вектора в сортировке
слиянием
слияние двух векторов
сортировка данных
сортировка слиянием
функция стандартной библиотеки sort
Поиск и сортировка
1085
Упражнения
[Замечание. Большинство предлагаемых в этом разделе упражнений повторяют
упражнения из глав 7-8. Мы включаем их здесь для удобства читателей,
изучающих поиск и сортировку в этой главе.]
19.5. (Пузырьковая сортировка) Реализуйте пузырьковую сортировку — еще одну
простую, но неэффективную методику сортировки. Она называется пузырьковой
сортировкой, поскольку в ней меньшие значения постепенно «всплывают» вверх
(к началу вектора), подобно пузырькам воздуха в воде, в то время как большие
значения опускаются на дно (в конец вектора). Эта методика использует
вложенные циклы для выполнения нескольких проходов по вектору. На каждом
проходе сравниваются последовательные пары соседних элементов. Если элементы
пары следуют в восходящем порядке (или их значения равны), мы оставляем их
как есть. Если элементы следуют в нисходящем порядке, мы обмениваем в
векторе их значения.
На первом проходе сравниваются и переставляются, если необходимо, два
первых элемента вектора. Затем сравниваются второй и третий элементы вектора.
В конце этого прохода сравниваются и при необходимости переставляются два
последних элемента. После одного прохода наибольший элемент окажется в
позиции с последним индексом. После двух проходов в позициях двух последних
индексов окажутся два наибольших элемента. Объясните, почему пузырьковая
сортировка является алгоритмом с эффективностью 0(п2).
19.6. Сделайте следующие простые модификации для улучшения эффективности
пузырьковой сортировки, разработанной в упражнении 19.5:
a) После первого прохода наибольшее число гарантированно окажется в
элементе вектора с наивысшим номером; после второго прохода «на месте» окажутся
два наибольших числа и так далее. Вместо выполнения девяти сравнений на
каждом проходе (для 10-элементного вектора), модифицируйте пузырьковую
сортировку так, чтобы на втором проходе было восемь сравнений, на третьем
проходе — семь и т.д.
b) Данные в векторе могут уже находиться в необходимом порядке, либо
близком к нему, так зачем же делать девять проходов (для 10-элементного
вектора), если достаточно сделать меньше? Модифицируйте сортировку так, чтобы
в конце каждого прохода проверялось, были ли сделаны какие-либо
перестановки. Если не было ни одной, значит, данные уже находятся в
соответствующем порядке, так что программа должна завершиться. Если перестановки
были сделаны, нужно сделать, по меньшей мере, еще один проход.
19.7. (Блочная сортировка) Блочная сортировка требует наличия одномерного
вектора положительных целых чисел, который нужно сортировать, и двумерного
вектора целых чисел со строками, индексированными от 0 до 9, и столбцами,
индексированными от 0 до п - 1, где п — число значений в векторе, который должен
сортироваться. Каждая строка двумерного вектора рассматривается как блок.
Напишите класс с именем BucketSort, содержащий функцию sort, которая
выполняет следующее:
a) Поместите каждое значение одномерного вектора в строку вектора блоков,
исходя из значения его первого разряда. Например, 97 помещается в строку 7, 3
помещается в строку 3, а 100 помещается в строку 0. Это называется
распределяющим проходом.
b) Циклически обработайте вектор блоков строка за строкой и скопируйте
значения обратно в исходный вектор. Это называется собирающим проходом.
Новый порядок предыдущих значений в одномерном векторе будет 100, 3
и 97.
1086
Глава 19
с) Повторите этот процесс для каждого последовательного разряда (десятки,
сотни, тысячи и т.п.).
На втором проходе 100 разместится в строке 0, 3 разместится в строке 0
(потому что 3 не имеет разряда десятков), а 97 разместится в строке 9. На третьем
проходе 100 поместится в строке 1, 3 поместится в нулевой строке и 97
поместится в нулевой строке (после цифры 3). После последнего собирающего
прохода исходный вектор будет сортирован.
Заметьте, что двумерный вектор блоков в десять раз больше размера вектора,
который сортируется. Эта методика сортировки обеспечивает более высокую
производительность по сравнению с пузырьковой, но требует намного больше
памяти. Для пузырьковой сортировки требуется всего один дополнительный
элемент данных. Это пример компромисса память-время: блочная сортировка
использует больше памяти, чем пузырьковая, но работает лучше. Данная
версия блочной сортировки требует копирования на каждом проходе всех данных
обратно в исходный вектор. Другая возможность заключается в создании
второго двумерного вектора блоков и последовательного обмена данными между
двумя векторами блоков.
19.8. (Рекурсивный линейный поиск) Модифицируйте программу из упражнения
7.33, написав рекурсивную функцию recursiveLinearSeach для линейного
поиска в векторе. Функция должна принимать в качестве аргументов ключ поиска
и начальный индекс. Если ключ поиска найден, возвратите его индекс в векторе,
в противном случае возвратите -1. Каждый вызов рекурсивной функции должен
проверять один индекс вектора.
19.9. (Рекурсивный двоичный поиск) Модифицируйте рис. 19.3 так, чтобы
программа выполняла рекурсивный двоичный поиск в векторе с помощью
рекурсивной функции recursiveBinarySearch. Функция должна принимать в
качестве аргументов ключ поиска, начальный индекс и конечный индекс. Если
ключ поиска найден, возвратите его индекс в векторе, в противном случае
возвратите -1.
19.10. (Быстрая сортировка) Базовый алгоритм рекурсивной методики сортировки,
называемой быстрой сортировкой, для одномерного вектора значений выглядит
следующим образом:
a) Шаг разбиения: Возьмите первый элемент несортированного вектора и
определите его окончательное положение в сортированном векторе, т.е. все значения
слева от данного элемента будут меньше, а все значения справа — больше
значения данного элемента (как это обеспечить, мы покажем ниже). Мы теперь
имеем один элемент, расположенный на своем месте в сортированном векторе,
и два несортированных подвектора.
b) Шаг рекурсии: Выполните шаг 1 на каждом из несортированных подвекторов.
Каждый раз после выполнения шага 1 на подвекторе следующий элемент
вектора помещается на свое место в отсортированном векторе, и создаются два
несортированных подвектора. Когда мы дойдем до подвектора, состоящего из
одного элемента, этот элемент будет находиться на своем окончательном месте
в упорядоченном векторе.
Это описание алгоритма в целом кажется достаточно ясным, но как нам
определить окончательную позицию первого элемента каждого подвектора? В
качестве примера рассмотрим следующий набор значений (элемент, выделенный
жирным — элемент разбиения, — должен быть помещен на свое
окончательное место в сортированном векторе):
37 2 6 4 89 8 10 12 68 45
Поиск и сортировка
1087
Начиная с правого элемента вектора будем сравнивать каждый элемент с
числом 37 до тех пор, пока не будет найден элемент, меньший 37, после чего
найденный элемент и 37 должны поменяться местами. Первым элементом,
который меньше 37, является число 12, поэтому они меняются местами. Теперь
вектор выглядит так:
12 2 б 4 89 8 10 37 68 45
Элемент 12 выделен курсивом, чтобы указать на то, что он поменялся местами
с числом 37.
Теперь начинаем движение от левого конца вектора, но со следующего
элемента после 12, и сравниваем каждый элемент с 37, пока не обнаружим элемент,
больший 37, после чего меняем местами 37 и этот найденный элемент. В
нашем случае первый элемент больший 37 — это 89, так что 37 и 89 меняются
местами. Новый вектор имеет вид:
12 2 б 4 37 8 10 89 68 45
c) Теперь начинаем справа, но с элемента, предшествующего 89, и сравниваем
каждый элемент с 37 до тех пор, пока не найдем меньший чем 37, и опять
поменяем местами 37 и этот элемент. Первый элемент, который меньше 37 —
это 10, — меняем местами с 37. Теперь наш вектор имеет вид:
12 2 б 4 10 8 37 89 68 45
d) Теперь начинаем движение слева, но с элемента, следующего за 10, и
сравниваем каждый элемент с 37, пока не обнаружим элемент, больший 37, после
чего меняем местами 37 и этот найденный элемент. В нашем случае
элементов, больших 37, не осталось, и когда мы сравним 37 с самим собой, это будет
означать, что процесс закончен и элемент 37 нашел свое окончательное
место.
После завершения этой операции мы имеем два неупорядоченных подвекто-
ра. Подвектор со значениями меньше 37 содержит элементы 12, 2, 6, 4, 10
и 8. Подвектор со значениями больше 37 содержит 89, 68 и 45. Сортировка
продолжается путем применения алгоритма разбиения к полученным под-
векторам, как это делалось с первоначальным вектором.
На основе описанного выше алгоритма напишите рекурсивную функцию
quickSortHelper для сортировки одномерного целого вектора. Функция
должна принимать в качестве аргументов начальный и конечный индексы
в исходном сортируемом векторе.
I
20
Структуры данных
ЦЕЛИ
В этой главе вы изучите:
• Формирование связанных структур
данных с использованием
указателей, автореферентных
классов и рекурсии.
• Создание и операции
с динамическими структурами
данных, такими, как связанные
списки, очереди, стеки и двоичные
деревья.
• Использование деревьев двоичного
поиска для высокоскоростного
поиска и сортировки.
• Различные важные приложения
связанных структур данных.
• Создание утилизируемых структур данных на основе шаблонов классов,
наследования и композиции.
35 Зак. 1114
1090
Глава 20
20.1. Введение
20.2. Автореферентные классы
20.3. Динамическое распределение памяти и структуры
данных
20.4. Связанные списки
20.5. Стеки
20.6. Очереди
20.7. Деревья
20.8. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
• Специальный раздел: как написать свой собственный компилятор
20.1. Введение
К настоящему моменту мы изучили структуры данных фиксированного
размера, такие, как одномерные и двумерные массивы, а также структуры
struct. В этой главе мы представляем динамические структуры данных,
которые растут и сокращаются в процессе исполнения. Связанные списки
являются наборами единиц данных, «выстроенных в цепочку», — вставка и удаление
может производиться в любом месте связанного списка. Стеки играют
важную роль в компиляторах и операционных системах; вставка и удаление
производятся только с одного конца стека — в его вершине. Очереди связаны
с ожиданием; вставка производится в конце (который называют также
хвостом) очереди, а удаление — в ее начале (которое называют головой).
Двоичные деревья помогают реализовать высокоскоростной поиск и сортировку
данных, эффективное устранение дубликатов, представление каталогов файловых
систем и компиляцию выражений в машинный язык. Эти структуры данных
имеют и много других интересных приложений.
Мы обсудим некоторые распространенные и важные структуры данных
и реализуем программы, которые создают и обрабатывают их. Мы используем
классы, шаблоны классов, наследование и композицию, что позволит создать
и упаковать эти структуры данных в виде, пригодном для утилизации и
сопровождения.
Изучение этой главы важно в качестве подготовки к главе 22,
обсуждающей Библиотеку стандартных шаблонов (STL). STL составляет основную часть
Стандартной библиотеки C++. В STL предусмотрены контейнеры, итераторы
для обхода этих контейнеров и алгоритмы для обработки их элементов. Вы
увидите, что STL упаковывает все обсуждаемые здесь структуры данных
в классы, оформленные в виде шаблонов. STL написана так, чтобы ее код был
переносимым, эффективным и расширяемым. Поняв принципы и устройство
структур данных, представленных в этой главе, вы сможете использовать
готовые контейнеры, итераторы и алгоритмы STL наилучшим образом.
Структуры данных
1091
Примеры главы являются практическими программами, которые можно
использовать в углубленных курсах и промышленных приложениях.
Программы широко оперируют указателями. В упражнениях вы найдете богатое
собрание полезных приложений.
Мы предлагаем вам попытаться реализовать большой проект, описанный
в специальном разделе («Как построить свой собственный компилятор»). С
помощью компилятора C++ вы транслировали свои программы в машинный
язык, чтобы их можно было исполнять на вашем компьютере. В данном
проекте вы фактически построите свой собственный компилятор. Он будет читать
файл с операторами, написанными на простом, но мощном языке высокого
уровня, похожем на ранние версии популярного языка BASIC. Ваш
компилятор будет транслировать эти операторы в файл инструкций Машинного языка
Симплетрона (SML) — языка, который вы изучили в специальном разделе
главы 8 («Как построить свой собственный компьютер»). Затем ваша
программа-эмулятор Симплетрона будет исполнять SML-программу, генерированную
вашим компилятором! Реализация данного проекта на основе
объектно-ориентированного подхода даст вам превосходную возможность на практике
применить большую часть из того, что вы изучили в этой книге. Специальный
раздел последовательно проводит вас по спецификации языка высокого уровня
и описывает алгоритмы, которые потребуются вам для преобразования
каждого типа операторов языка высокого уровня в инструкции машинного языка.
Если вам нравятся трудные задачи, вы можете попробовать внести как в
компилятор, так и в эмулятор Симплетрона усовершенствования, предлагаемые
в упражнениях главы.
20.2. Автореферентные классы
Автореферентный класс содержит элемент-указатель, ссылающийся на
объект того же классового типа. Например, определение
class Node
{
public:
Node( int ); // конструктор
void setData( int ); // установить элемент data
int getData() const; // получить элемент data
void setNextPtr( Node * ); // установить указатель на след. узел
Node *getNextPtr(); // получить указатель на следующий узел
private:
int data; // данные, хранящиеся в этом узле
Node *nextPtr; // указатель на другой объект того же типа
}; // конец класса Node
специфицирует тип Node. Класс Node имеет два закрытых элемента
данных — целый элемент data и элемент-указатель nextPtr. Элемент nextPtr
указывает на объект типа Node — другой объект того же типа, что объявляется
здесь, отсюда и термин «автореферентный класс». Элемент nextPtr называют
связкой — nextPtr может «связывать» объект типа Node с другим объектом
того же типа. Класс Node имеет также пять элемент-функций — конструктор,
принимающий целое значение для инициализации элемента data, функцию
setData для установки значения элемента data, функцию getData, возвра-
1092
Глава 20
щающую значение элемента data, функцию setNextPtr для установки
значения элемента nextPtr и функцию getNextPtr, возвращающую значение
элемента nextPtr.
Объекты автореферентного класса могут связываться между собой, образуя
полезные структуры данных, такие, как списки, очереди, стеки и деревья. Так,
рис. 20.1 иллюстрирует связь двух объектов автореферентного класса в
связанном списке. Обратите внимание, что в элементе-связке второго объекта стоит
косая черта (изображающая нулевой указатель), показывающая, что связка не
указывает ни на какой другой объект. Косая черта служит здесь только целям
иллюстрации; она не имеет отношения к символу обратной дроби в C++.
Нулевой указатель обычно служит индикатором конца структуры данных, подобно
тому, как нуль-символ С\0') служит индикатором конца строки.
• ► 15 •" ► 10
Рис. 20.1. Два объекта автореферентного класса, связанные между собой
Типичная ошибка программирования 20.1
Неравенство нулю связки в последнем элементе связанной
структуры данных является (возможно, фатальной) логической ошибкой.
20.3. Динамическое распределение памяти
и структуры данных
Создание динамических структур данных и операции над ними требуют
динамического управления памятью, которое позволяет программе выделять во
время исполнения дополнительную память под новые узлы. Когда память
программе больше не нужна, она может освобождаться и утилизироваться
впоследствии для выделения под другие объекты. Предельный объем
динамически выделяемой памяти может определяться доступной физической памятью
компьютера или объемом доступной виртуальной памяти в системе с
виртуальной памятью. Но часто этот предел оказывается гораздо меньше, поскольку
доступная память должна делиться между многими программами.
Операция new принимает в качестве аргумента тип объекта, под который
выделяется память, и возвращает указатель на объект этого типа. Например,
оператор
Node *newPtr = new Node( 10 ); // создать узел с data =10
выделяет sizeof( Node ) байтов, запускает конструктор Node и присваивает
адрес нового объекта Node указателю newPtr. Если доступной памяти нет, new
выбрасывает исключение bad_alloc. Конструктору Node передается
значение 10, которым инициализируется элемент data объекта Node.
Операция delete запускает деструктор Node и освобождает память,
выделенную операцией new; память возвращается системе, чтобы ее можно было
впоследствии перераспределить. Чтобы освободить память, динамически
выделенную предыдущей операцией new, используйте оператор
Структуры данных
1093
delete newPtr;
Заметьте, здесь удаляется не сам указатель newPtr; удаляется пространство
памяти, на которое newPtr указывает. Если newPtr имеет значение нулевого
указателя, данный оператор не производит никаких действий. Удаление
нулевого указателя не является ошибкой.
В следующих разделах обсуждаются списки, стеки, очереди и деревья.
Представленные в этой главе структуры данных создаются и поддерживаются
с использованием динамического распределения памяти, автореферентных
классов, шаблонов классов и шаблонов функций.
20.4. Связанные списки
Связанный список является линейным набором объектов автореферентного
класса, называемых узлами, соединенных указателями-связками — отсюда
название «связанный» список. Доступ к связанному списку осуществляется
через указатель на первый узел списка. Обращение к каждому последующему
узлу осуществляется через указатель, хранящийся в предыдущем узле. По
соглашению указатель-связка в последнем узле списка устанавливается
в нуль @), который отмечает конец списка. Данные сохраняются в связанном
списке динамически — узлы создаются по мере необходимости. Узел может
содержать данные любого типа, включая объекты других классов. Если узлы
содержат указатели базового класса на объекты базового или производного
классов, связанных отношением наследования, мы можем образовать из таких
узлов связанный список и полиморфно обрабатывать эти объекты посредством
вызовов виртуальных функций. Стеки и очереди также являются линейными
структурами данных и, как мы увидим, могут рассматриваться как
ограниченные разновидности связанных списков. Деревья являются нелинейными
структурами данных.
Списки данных могут храниться в массивах, однако связанные списки
имеют несколько преимуществ. Связанный список более подходит для случаев,
когда число одновременно представленных элементов данных нельзя
предсказать заранее. Связанные списки являются динамическими, поэтому длина
списка может возрастать или сокращаться по мере необходимости. Размер же
«обыкновенного» массива C++ изменить нельзя, поскольку его размер
фиксируется во время компиляции. «Обыкновенные» массивы могут заполняться до
отказа. Связанные списки заполняются до отказа только в том случае, когда
памяти в системе оказывается недостаточно для удовлетворения запросов
динамического выделения памяти.
■——i Вопросы производительности 20.1
Г^$^| Можно объявить массив с числом элементов, большим ожидаемого
числа единиц данных, но это может приводить к неоправданному рас
ходу памяти. В таких ситуациях связанные списки обеспечивают
лучшее использование памяти. Связанные списки позволяют
программе адаптироваться к требованиям времени выполнения. Заметьте,
что шаблон класса vector (представленный в разделе 7.11) реализует
массивоподобную структуру данных с динамически изменяемым
размером.
1094
Глава 20
Связанные списки могут поддерживаться в сортированном состоянии, если
вставлять каждый новый элемент в нужное место списка. Существующие
элементы при этом перемещать не требуется.
Вопросы производительности 20.2
Вставка и удаление в сортированном массиве могут требовать
существенных временных затрат — все элементы, следующие за
вставляемым или удаляемым, должны соответствующим образом
сдвигаться. Связанный список позволяет производить эффективные
операции вставки/удаления в любом месте списка.
Вопросы производительности 20.3
Элементы массива располагаются в памяти непрерывно. Это обеспе
чивает немедленный доступ к любому его элементу, поскольку адрес
любого элемента можно вычислить непосредственно по его
положению относительно начала массива. Связанные списки не допускают
подобного «прямого доступа» к своим элементам. Поэтому доступ
к отдельным элементам в связанном списке может требовать
значительно больших затрат, чем доступ к отдельным элементам в
массиве. Выбор конкретной структуры данных делается обычно исходя из
эффективности специфических операций, производимых в программе,
и характера организации единиц данных в структуре. Например,
вставка элемента в сортированный связанный список обычно
эффективнее, чем вставка в сортированный массив.
Узлы связанного списка, вообще говоря, не расположены в памяти
непрерывно. Однако логически они представляются непрерывной
последовательностью. Рис. 20.2 иллюстрирует связанный список с несколькими узлами.
firstPtr lastPtr
t
-► D • ► •■• ► Q
Рис. 20.2. Графическое представление списка
Вопросы производительности 20.4
Динамическое распределение памяти (вместо определения массивов
фиксированного размера) для структур данных, которые растут
и сокращаются во время выполнения, может экономить память. Но
помните, что указатели также занимают пространство в памяти
и что при динамическом распределении памяти неизбежны
накладные расходы на вызовы функций.
Структуры данных
1095
Реализация связанного списка
Программа на рис. 20.3-20.5 использует шаблон класса List (о шаблонах
классов см. главу 14) для операций над списком целых значений и списком
значений с плавающей точкой. Программа-драйвер (рис. 20.5)
предусматривает пять опций: 1) вставка значения в начало списка, 2) вставка значения в
конец списка, 3) удаление значения из начала списка, 4) удаление значения из
конца списка и 5) завершение обработки списка. Подробное обсуждение
программы следует ниже. В упражнении 20.20 вам предлагается реализовать
рекурсивную функцию, которая распечатывает список в обратном порядке, а
в упражнении 20.21 — рекурсивную функцию, которая ищет в списке
требуемую единицу данных.
1 // Рис. 20.3: Listnode.h
2 // Определение шаблона класса ListNode.
3 #ifndef LISTNODE_H
4 #define LISTNODE_H
5
6 // Опережающее объявление класса List необходимо, чтобы List
7 // можно было использовать в объявлении дружественности в строке 13
8 template< typename NODETYPE > class List;
9
10 template< typename NODETYPE >
11 class ListNode
12 {
13 friend class List< NODETYPE >; // сделать List другом
14
15 public:
16 ListNode( const NODETYPE & ); // конструктор
17 NODETYPE getData() const; // возвратить данные в узле
18 private:
19 NODETYPE data; // данные
20 ListNode< NODETYPE > *nextPtr; // следующий узел в списке
21 }; // конец класса ListNode
22
23 // конструктор
24 template< typename NODETYPE >
25 ListNode< NODETYPE >::ListNode( const NODETYPE fiinfo )
26 : data( info ), nextPtr( 0 )
27 {
28 // пустое тело
29 } // конец конструктора ListNode
30
31 // возвратить копию данных в узле
32 template< typename NODETYPE >
33 NODETYPE ListNode< NODETYPE >::getData() const
34 {
35 return data;
36 } // конец функции getData
37
38 #endif
Рис. 20.3. Определение шаблона класса ListNode
1096
Глава 20
Программа использует шаблоны классов ListNode (рис. 31.3) и List
(рис. 20.4). В каждом объекте List инкапсулируется связанный список объектов
ListNode. Шаблон класса ListNode (рис. 20.3) содержит закрытые элементы
data и nextPtr (строки 19-20), конструктор для инициализации этих элементов
и функцию get Data, возвращающую данные узла. Элемент data хранит
значение типа NODETYPE, являющегося типовым параметром, передаваемым
шаблону класса. Элемент nextPtr хранит указатель на следующий объект ListNode
в связанном списке. Обратите внимание, что строка 13 определения шаблона
класса ListNode объявляет класс List< NODETYPE > как дружественный. Это
делает все элемент-функции конкретной специализации шаблона List друзьями
соответствующей специализации шаблона ListNode, так что они могут
обращаться к закрытым элементам объектов ListNode этой специализации.
Поскольку в объявлении friend в качестве аргумента для List используется
параметр NODETYPE шаблона ListNode, узлы ListNode, специализированные для
конкретного типа, могут обрабатываться только списком List,
специализированным для того же самого типа (напр., список значений типа int управляет
объектами ListNode, в которых хранятся значения типа int).
1 // Рис. 20.4: List.h
2 // Определение шаблона класса List.
3 #ifndef LIST_H
4 #define LIST_H
5
6 #include <iostream>
7 using std::cout;
8
9 #include "Listnode.h" // определение класса ListNode
10
11 template< typename NODETYPE >
12 class List
13 {
14 public:
15 List(); // конструктор
16 ~List(); // деструктор
17 void insertAtFront( const NODETYPE & );
18 void insertAtBack( const NODETYPE & );
19 bool removeFromFront( NODETYPE & );
20 bool removeFromBack( NODETYPE & );
21 bool isEmptyO const;
22 void print() const;
23 private:
24 ListNode< NODETYPE > *firstPtr; // указатель на первый узел
25 ListNode< NODETYPE > *lastPtr; // указатель на последний узел
26
27 // сервисная функция для выделения памяти нового узла
28 ListNode< NODETYPE > *getNewNode( const NODETYPE & );
29 }; // конец класса List
30
31 // конструктор по умолчанию
32 template< typename NODETYPE >
33 List< NODETYPE >::List()
34 : firstPtr( 0 ), lastPtr( 0 )
35 {
36 // пустое тело
Структуры данных
1097
37 } // конец конструктора List
38
39 // деструктор
40 template< typename NODETYPE >
41 List< NODETYPE >::~List()
42 {
43 if ( ! isEmptyO ) // список не пуст
44 {
45 cout « "Destroying nodes ...\n";
46
47 ListNode< NODETYPE > *currentPtr = firstPtr;
48 ListNode< NODETYPE > *tempPtr;
49
50 while ( currentPtr != 0 ) // удалить оставшиеся узлы
51 {
52 tempPtr = currentPtr;
53 cout « tempPtr->data « ' \n';
54 currentPtr = currentPtr->nextPtr;
55 delete tempPtr;
56 } // конец while
57 } // конец if
58
59 cout « "All nodes destroyed\n\n";
60 } // конец деструкора List
61
62 // вставить узел в начало списка
63 template< typename NODETYPE >
64 void List< NODETYPE >::insertAtFront( const NODETYPE fivalue )
65 {
66 ListNode< NODETYPE > *newPtr = getNewNode( value ); // новый узел
67
68 if ( isEmptyO ) // список пуст
69 firstPtr = lastPtr = newPtr; // список имеет всего один узел
70 else // List is not empty
71 {
72 newPtr->nextPtr = firstPtr; // новый указывает на предыдущий
73 firstPtr = newPtr; // направить firstPtr на новый узел
74 } // конец else
75 } // конец функции insertAtFront
76
77 // вставить узел в начало списка
78 template< typename NODETYPE >
79 void List< NODETYPE >::insertAtBack( const NODETYPE &value )
80 {
81 ListNode< NODETYPE > *newPtr = getNewNode( value ); // новый узел
82
83 if ( isEmptyO ) // список пуст
84 firstPtr = lastPtr = newPtr; // список имеет всего один узел
85 else // список не пуст
86 {
87 lastPtr->nextPtr = newPtr; // обновить бывший последний узел
88 lastPtr = newPtr; // новый последний узел
89 } // конец else
90 } // конец функции insertAtBack
91
92 // удалить узел из начала списка
93 template< typename NODETYPE >
1098
Глава 20
94 bool List< NODETYPE >::removeFromFront( NODETYPE fivalue )
95 {
96 if ( isEmptyO ) // список пуст
97 return false; // неудачное удаление
98 else
99 {
100 ListNode< NODETYPE > *tempPtr = firstPtr; // для удаления
101
102 if ( firstPtr = lastPtr )
103 firstPtr = lastPtr =0; // после удаления узлов нет
104 else
105 firstPtr = firstPtr->nextPtr; // направить на бывший 2-й узел
106
107 value = tempPtr->data; // возвратить удаляемые данные
108 delete tempPtr; // освободить удаленный первый узел
109 return true; // удачное удаление
110 } // конец else
111 } // конец функции removeFromFront
112
113 // удалить узел из конца списка
114 template< typename NODETYPE >
115 bool List< NODETYPE >::removeFromBack( NODETYPE fivalue )
116 {
117 if ( isEmptyO ) // список пуст
118 return false; // неудачное удаление
119 else
120 {
121 ListNode< NODETYPE > *tempPtr = lastPtr; // для удаления
122
123 if ( firstPtr == lastPtr ) //в списке один элемент
124 firstPtr = lastPtr =0; // после удаления узлов нет
125 else
126 {
127 ListNode< NODETYPE > *currentPtr = firstPtr;
128
129 // locate second-to-last element
130 while ( currentPtr->nextPtr != lastPtr )
131 currentPtr = currentPtr->nextPtr; // перейти к следующему
132
133 lastPtr = currentPtr; // удалить последний узел
134 currentPtr->nextPtr =0; // теперь это последний узел
135 } // конец else
136
137 value = tempPtr->data; // возвратить данные бывшего последнего
138 delete tempPtr; // освободить бывший последний узел
139 return true; // удачное удаление
140 } // конец else
141 } // конец функции removeFromBack
142
143 // список пуст?
144 template< typename NODETYPE >
145 bool List< NODETYPE >::isEmptyO const
146 {
147 return firstPtr = 0;
148 } // конец функции isEmpty
149
150 // возвратить указатель на вновь выделенный узел
Структуры данных
1099
151 template< typename NODETYPE >
152 ListNode< NODETYPE > *List< NODETYPE >::getNewNode(
153 const NODETYPE fivalue )
154 {
155 return new ListNode< NODETYPE >( value );
156 } // конец функции getNewNode
157
158 // вывести содержимое списка
159 template< typename NODETYPE >
160 void List< NODETYPE >::print() const
161 {
162 if ( isEmptyO ) // список пуст
163 {
164 cout « "The list is empty\n\n";
165 return;
166 } // конец if
167
168 ListNode< NODETYPE > *currentPtr = firstPtr;
169
170 cout « "The list is: ";
171
172 while ( currentPtr != 0 ) // получить данные элемента
173 {
174 cout « currentPtr->data « ' ' ;
175 currentPtr = currentPtr->nextPtr;
176 } // конец while
177
178 cout « "\n\n";
179 } // конец функции print
180
181 #endif
Рис. 20.4. Определение шаблона класса List
Строки 24-25 шаблона класса List (рис. 20.4) объявляют закрытые
элементы данных firstPtr (указатель на первый объект ListNode в списке) и lastPtr
(указатель на последний ListNode в списке). Конструктор по умолчанию
(строки 32-37) инициализирует оба указателя значением О (нулем). Деструктор
(строки 40-60) гарантирует, что при уничтожении объекта List будут
уничтожены все содержащиеся в нем объекты ListNode. Важнейшими функциями
класса List являются insertAtFront (строки 63-75), insertAtBack
(строки 78-90), removeFromFront (строки 93-111) и removeFromBack
(строки 114-141).
Функция isEmpty (строки 144-148) называется предикатной функцией;
она не изменяет списка, а только определяет, пуст ли он (т.е. равен ли нулю
указатель на первый узел списка). Если список пуст, возвращается true; в
противном случае возвращается false. Функция print (строки 159-179) выводит
содержимое списка. Сервисная функция getNewNode (строки 151-156)
возвращает динамически выделенный объект ListNode. Эта функция вызывается
из функций insertAtFront и insertAtBack.
1100
Глава 20
Предотвращение ошибок 20.1
Присваивайте элементу-связке нового узла значение 0 (нуль). Перед
использованием указатели должны инициализироваться.
1 // Рис. 20.5: Fig21_05.cpp
2 // Тестовая программа для класса List.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::endl;
7
8 #include <string>
9 using std::string;
10
11 #include "List.h" // определение класса List
12
13 // функция для тестирования списка
14 template< typename T >
15 void testList( List< T > filistObject, const string &typeName )
16 {
17 cout « "Testing a List of " « typeName « " values\n";
18 instructions(); // вывести инструкции
19
20 int choice; // хранит выбор пользователя
21 T value; // хранит введенное значение
22
23 do // произвести действия, выбранные пользователем
24 {
25 cout « "?
26 cin » choice;
27
28 switch ( choice )
29 {
30 case 1: // вставить в начало
31 cout « "Ehter " « typeName « ": ";
32 cin » value;
33 listObject.insertAtFront( value );
34 listObject.print();
35 break;
36 case 2: // вставить в конец
37 cout « "Enter " « typeName « ": ";
38 cin » value;
39 listObject.insertAtBack( value );
40 listObject.print();
41 break;
42 case 3: // удалить из начала
43 if ( listObject.removeFromFront( value ) )
44 cout « value « " removed from list\n";
45
46 listObject.print();
47 break;
48 case 4: // удалить из конца
49 if ( listObject.removeFromBack( value ) )
50 cout « value « " removed from list\n";
Структуры данных
1101
52 listObject.print();
53 break;
54 } // конец switch
55 } while ( choice != 5 ); // конец do...while
56
57 cout « "End list test\n\n";
58 } // конец функции testList
59
60 // вывести инструкции для пользователя программы
61 void instructions()
62 {
63 cout « "Enter one of the following:\n"
1 to insert at beginning of list\n"
2 to insert at end of list\n"
3 to delete from beginning of list\n"
4 to delete from end of list\n"
5 to end list processing\n";
69 } // конец функции instructions
70
71 int main()
72 {
73 // протестировать список значений int
74 List< int > integerList;
75 testList( integerList, "integer" );
76
77 // протестировать список значений double
78 List< double > doubleList;
79 testList( doubleList, "double" );
80 return 0;
81 } // конец main
64 «
65 «
66 «
67 «
68 «
Testing a List of integer values
Enter one of the following:
1 to insert at beginning of list
2 to insert at end of list
3 to delete from beginning of list
4 to delete from end of list
5 to end list processing
? 1
Enter integer: 1
The list is: 1
? 1
Enter integer: 2
The list is: 2 1
? 2
Enter integer: 3
The list is: 2 13
? 2
Enter integer: 4
The list is: 2 1 3 4
? 3
2 removed from list
The list is: 13 4
? 3
1 removed from list
The list is: 3 4
? 4
4 removed from list
The list is: 3
? 4
3 removed from list
The list is empty
? 5
End list test
Testing a List of double values
Enter one of the following:
1 to insert at beginning of list
2 to insert at end of list
3 to delete from beginning of lis
4 to delete from end of list
5 to end list processing
? 1
Enter double: 1.1
The list is: 1.1
? 1
Enter double: 2.2
The list is: 2.2 1.1
? 2
Enter double: 3.3
The list is: 2.2 1.1 3.3
? 2
Enter double: 4.4
The list is: 2.2 1.1 3.3 4.4
? 3
2.2 removed from list
The list is: 1.1 3.3 4.4
? 3
1.1 removed from list
The list is: 3.3 4.4
? 4
4.4 removed from list
The list is: 3.3
? 4
3.3 removed from list
The list is empty
? 5
End list test
Структуры данных
1103
All nodes destroyed
All nodes destroyed
Рис. 20.5. Операции со связанным списком
Программа-драйвер (рис. 20.5) использует шаблон функции test List,
позволяющий пользователю производить операции над объектами класса List.
Строки 74 и 78 создают объекты List соответственно для типов int и double.
Строки 75 и 79 вызывают шаблон функции testList с этими объектами.
Элемент-функция insertAtFront
Следующие несколько страниц посвящены подробному обсуждению
элемент-функций класса List. Функция insertAtFront (рис. 20.4, строки 63-75)
помещает новый узел в начало списка. Функция состоит из нескольких шагов:
1. Вызывается функция getNewNode (строка 66), которой передается
константная ссылка на значение нового узла.
2. Функция getNewNode (строки 151-156) создает новый узел с помощью
операции new и возвращает указатель на этот узел, который
в insertAtFront присваивается указателю newPtr (строка 66).
3. Если список пуст (строка 68), обоим указателям firstPtr и lastPtr
присваивается newPtr (строка 69).
4. Если список не пуст (строка 70), то узел, на который указывает newPtr,
включается в список посредством копирования firstPtr в newPtr->nextPtr
(строка 72), так что новый узел указывает теперь на тот, что был прежде
первым узлом списка, и копирования newPtr в firstPtr (строка 73), так что
firstPtr указывает теперь на новый первый узел списка.
Рис. 20.6 иллюстрирует функцию insertAtFront. Часть (а) рисунка
показывает список и новый узел перед операцией вставки. Пунктирные стрелки
в части (Ь) иллюстрируют шаг 4 операции insertAtFront, в результате
которого узел, содержащий значение 12, становится новым началом списка.
(a) firstPtr
• ► 7 • ► 11
newPtr
• ► 12
(b) firstPtr
7 • ► 11
V A
newPtr v \J 1
I
• ► 12 i
Рис. 20.6. Графическое представление операции insertAtFront
1104
Глава 20
Элемент-функция insertAtBack
Функция insertAtBack (рис. 20.4, строки 78-90) помещает новый узел в
конец списка. Функция состоит из нескольких шагов:
1. Вызывается функция getNewNode (строка 81), которой передается
константная ссылка на значение нового узла.
2. Функция getNewNode (строки 151-156) создает новый узел с помощью
операции new и возвращает указатель на этот узел, который
в insertAtFront присваивается указателю newPtr (строка 81).
3. Если список пуст (строка 83), обоим указателям firstPtr и lastPtr
присваивается newPtr (строка 84).
4. Если список не пуст (строка 85), то узел, на который указывает newPtr,
включается в список посредством копирования newPtr в lastPtr->nextPtr
(строка 87), так что узел, являвшийся последним узлом списка, указывает
теперь на новый узел, и копирования newPtr в lastPtr, так что lastPtr
указывает теперь на новый последний узел списка.
Рис. 20.7 иллюстрирует операцию insertAtBack. Часть (а) рисунка
показывает список и новый узел перед операцией. Пунктирные стрелки в части (Ь)
иллюстрируют шаг 4 операции insertAtBack, в результате которого новый
узел добавляется в конец непустого списка.
(a) firstPtr
lastPtr
newPtr
12
t
-> 11
(b) firstPtr
lastPtr
newPtr
1
12
t
-> 11
Рис. 20.7. Графическое представление операции insertAtBack
Элемент-функция removeFromFront
Функция removeFromFront (рис. 20.4, строки 93-111) исключает из
списка первый узел и копирует его значение в параметр-ссылку. Функция
возвращает false, если делается попытка удалить узел из пустого списка
(строки 96-97), и true в случае успешного удаления. Функция состоит из
нескольких шагов:
Структуры данных
1105
1. Указателю tempPtr присваивается адрес, на который указывает firstPtr
(строка 100). Этот указатель будет использован впоследствии для
удаления исключаемого узла.
2. Если firstPtr равен lastPtr (строка102), т.е. если в списке перед
попыткой удаления имеется всего один элемент, то для исключения его из
списка firstPtr и lastPtr устанавливаются в нуль (строка 103), и список
становится пустым.
3. Если перед операцией исключения список содержит более одного узла,
то lastPtr остается без изменений, a firstPtr устанавливается равным
firstPtr->nextPtr (строка 105); другими словами, firstPtr указывает
теперь на узел, являвшийся прежде вторым узлом списка.
4. После завершения всех этих манипуляций с указателями элемент data
удаляемого узла копируется в ссылочный параметр value (строка 107).
5. Узел, на который указывает tempPtr, удаляется операцией delete
(строка 108).
6. Функция возвращает true, показывая успешное удаление (строка 109).
Рис. 20.8 иллюстрирует операцию removeFromFront. Часть (а) рисунка
показывает список перед операцией. Часть (Ь) иллюстрирует фактические
манипуляции с указателями при удалении узла из непустого списка.
(a) firstPtr
lastPtr
12
-> 11
t
-> 5
(b) firstPtr
lastPtr
12 • ► 7
-> 11
tempPtr
Рис. 20.8. Графическое представление операции removeFromFront
1106
Глава 20
Элемент-функция removeFromBack
Функция removeFromBack (рис. 20.4, строки 114-141) исключает из
списка последний узел и копирует его значение в параметр-ссылку. Функция
возвращает false, если делается попытка удалить узел из пустого списка
(строки 117-118), и true в случае успешного удаления. Функция состоит из
нескольких шагов:
1. Указателю tempPtr присваивается адрес, на который указывает lastPtr
(строка 1210). Этот указатель будет использован впоследствии для
удаления исключаемого узла.
2. Если firstPtr равен lastPtr (строка123), т.е. если в списке перед
попыткой удаления имеется всего один элемент, то для исключения его из
списка firstPtr и lastPtr устанавливаются в нуль (строка 124), и список
становится пустым.
3. Если перед операцией исключения список содержит более одного узла, то
указателю currentPtr присваивается адрес, на который указывает firstPtr
(строка 127), чтобы подготовить «проход по списку».
4. Далее производится «проход по списку» указателя currentPtr, пока
currentPtr не укажет на предпоследний узел списка. После завершения
операции удаления этот узел станет последним узлом. Проход
производится оператором while (строки 130-131), который все время заменяет
значение currentPtr на currentPtr->nextPtr, пока currentPtr->nextPtr
не окажется равен lastPtr.
5. Указателю lastPtr присваивается адрес, на который указывает
currentPtr (строка 133), чтобы исключить из списка последний узел.
6. Указатель-связка currentPtr->nextPtr в новом последнем узле списка
устанавливается в 0 (строка 134).
7. После завершения всех манипуляций с указателями элемент data
удаляемого узла копируется в ссылочный параметр value (строка 137).
8. Узел, на который указывает tempPtr, удаляется операцией delete
(строка 138).
9. Функция возвращает true, показывая успешное удаление (строка 139).
Рис. 20.9 иллюстрирует removeFromBack. Часть (а) рисунка показывает
список перед операцией удаления. Часть (Ь) иллюстрирует фактические
манипуляции с указателями.
Структуры данных
1107
(a)firstPtr currentPtr
lastPtr
12
11
t
-► 5
(b) firstPtr
currentPtr
12
-> 7
4 I
-► 11
lastPtr
tempPtr
Рис. 20.9. Графическое представление операции removeFromBack
Элемент-функция print
Прежде всего функция print (строки 159-179) определяет, не пуст ли список
(строка 162). Если список пуст, функция печатает "The list is empty" и
возвращает управление (строки 164-165). В противном случае она проходит по списку
и выводит значение в каждом узле. Функция инициализирует currentPtr
копией firstPtr (строка 168), после чего печатает строку "The list is: " (строка 170).
Пока currentPtr не нуль (строка 172), печатается currentPtr->data (строка 174)
и currentPtr присваивается значение currentPtr->nextPtr (строка 175).
Заметьте, что если связка в последнем узле списка ненулевая, алгоритм печати
ошибочно выйдет за пределы списка. Алгоритм печати один и тот же для связанных
списков, стеков и очередей (так как все эти структуры данных реализованы
у нас на основе одной и той же инфраструктуры связанного списка).
Линейные и циклические, односвязные и двусвязные списки
Та разновидность связанных списков, которую мы обсуждали, называется
односвязным списком — список начинается с указателя на первый узел, и
каждый узел содержит указатель на следующий «по порядку» узел. Этот список
оканчивается узлом, чей элемент-указатель имеет значение 0. Односвязный
список можно проходить только в одном направлении.
Циклический односвязный список (рис. 20.10) начинается с указателя на
первый узел, и каждый узел содержит указатель на следующий узел. Но
«последний узел» не содержит нулевого указателя; указатель в последнем узле
ссылается на первый узел, замыкая таким образом «кольцо».
1108
Глава 20
firstPtr
12
-> 7 • ► 11
-> 5
t
Рис. 20.10. Циклический односвязный список
Двусвязный список (рис. 20.11) допускает прохождение как в прямом, так
и в обратном направлении. Такой список часто реализуют с двумя
«начальными указателями» — один указывает на первый элемент списка и позволяет
пройти список от начала к концу, а второй указывает на последний элемент
и позволяет пройти список от конца к началу. Каждый узел имеет как прямой
указатель на следующий узел списка в прямом направлении, так и обратный
указатель на следующий узел в обратном направлении. Если, например, ваш
список содержит алфавитный телефонный справочник, то поиск лица, чья
фамилия начинается с какой-то буквы из начала алфавита, можно начать от
начала списка. Если же требуется найти кого-то, чья фамилия начинается с
буквы в конце алфавита, то поиск следовало бы начать с конца списка.
В циклическом двусвязном списке (рис. 20.12) прямой указатель
последнего узла ссылается на первый узел, а обратный указатель первого узла — на
последний узел, замыкая таким образом «кольцо».
firstPtr
lastPtr
12
—►
< •
11
-—►
< •
Рис. 20.11. Двусвязный список
firstPtr
lastPtr
^
•
У ■
12
т ^
Щ. ■
7
л W
^ •
11
<
>
1
►
Г
\
5
Рис. 20.12. Циклический двусвязный список
Структуры данных
1109
20.5. Стеки
В главе 14 мы описали шаблон класса стека, реализованный на основе
массива. В этом разделе мы используем в качестве основы реализации связанный
список, организованный с помощью указателей. Мы также будем обсуждать
стеки в главе 23, посвященной библиотеке стандартных шаблонов (STL).
Структура данных стека допускает добавление и удаление узлов только
в вершине стека. По этой причине стек называют структурой данных типа
♦последним вошел, первым вышел» (LIFO). Одним из способов реализации
стека является организация его в виде ограниченного варианта связанного
списка. В такой реализации элемент-связка в последнем узле стека
устанавливается в нуль и служит признаком конца (основания) стека.
Основными элемент-функциями для манипуляций со стеком являются push
(втолкнуть) и pop (вытолкнуть). Функция push помещает новый узел на
вершину стека. Функция pop удаляет узел с вершины стека, сохраняет вытолкнутое
значение в ссылочной переменной, которая передана вызывающей функцией,
и возвращает true в случае успешной операции pop (в противном случае
возвращается false).
У стеков много интересных приложений. Например, если производится
вызов функции, последняя должна знать, как возвратить управление своей
вызывающей функции, поэтом адрес возврата заталкивается в стек. Если
происходит ряд последовательных вызовов, последовательные адреса возврата
организуются в стеке в порядке «последним вошел, первым вышел», так что
каждая функция может возвратить управление своему вызывающему.
Рекурсивные вызовы функций поддерживаются стеком точно таким же образом,
как и обычные нерекурсивные. Стек вызовов подробно описывается в
разделе 6.11.
При каждом вызове функции в стеке отводится память под автоматические
переменные, где сохраняются их значения. Когда функция возвращает
управление или выбрасывает исключение, вызывается деструктор (если таковой
имеется) для каждого из локальных объектов, пространство, отведенное под
автоматические переменные функции, выталкивается из стека, и переменные
становятся неизвестными программе.
В компиляторах стеки используются в процессе оценки выражений и
генерации кода машинного языка. В упражнениях главы исследуются несколько
приложений стеков, в том числе те, что потребуются вам для разработки
своего собственного законченного компилятора.
Для реализации класса стека мы воспользуемся близким родством между
списками и стеками, которое позволит нам утилизировать класс списка.
Сначала мы реализуем класс стека посредством закрытого наследования класса
списка. Затем посредством композиции мы реализуем класс стека,
работающий идентично первому, включив в класс объект списка в качестве закрытого
элемента. Разумеется, все структуры данных в этой главе, в том числе эти два
класса стека, реализуются в качестве шаблонов, чтобы обеспечить
возможность их дальнейшую утилизацию.
Программа на рис. 20.13-20.14 создает шаблон класса Stack (рис. 20.13)
путем закрытого наследования (строка 9) шаблона класса List из рис. 20.4.
Мы хотим, чтобы класс Stack имел элемент-функции push (строки 13-16),
pop (строки 19-22), isStackEmpty (строки 25-28) и printStack (строки 31-34).
1110
Глава 20
Заметьте, что это по существу функции insert At Front, removeFromFront,
isEmpty и print шаблона класса List. Конечно, в шаблоне класса List имеются
и другие элемент-функции (т.е. insertAtBack и removeFromBack), которые
нам не хотелось бы делать доступными через открытый интерфейс класса
Stack. Поэтому, когда мы указываем, что шаблон класса Stack должен
наследовать шаблону класса List, мы специфицируем закрытое (private)
наследование. Это делает все открытые элемент-функции шаблона класса List
закрытыми элементами в шаблоне класса Stack. Когда мы реализуем
элемент-функции класса Stack, то вызываем из них соответствующие функции класса
List — push вызывает insertAtFront (строка 15), pop вызывает
removeFromFront (строка 21), isStackEmpty вызывает isEmpty (строка 27)
и printStack вызывает print (строка 33); это называют делегированием.
1 // Рис. 20.13: Stack.h
2 // Определение шаблона класса Stack, производного от List.
3 #ifndef STACK_H
4 #define STACK_H
5
6 #include "List.h" // определение класса List
7
8 template< typename STACKTYPE >
9 class Stack : private List< STACKTYPE >
10 {
11 public:
12 // push вызывает функцию insertAtFront класса List
13 void push( const STACKTYPE fidata )
14 {
15 insertAtFront( data );
16 } // конец функции push
17
18 // pop вызывает функцию removeFromFront класса List
19 bool pop( STACKTYPE &data )
20 {
21 return removeFromFront( data );
22 } // конец функции pop
23
24 // isStackEmpty вызывает функцию isEmpty класса List
25 bool isStackEmpty() const
26 {
27 return isEmpty();
28 } // конец функции isStackEmpty
29
30 // printStack вызывает функцию print класса List
31 void printStack() const
32 {
33 print ();
34 } // конец функции print
35 }; // конец класса Stack
36
37 #endif
Рис. 20.13. Определение шаблона класса Stack
Структуры данных
1111
Шаблон класса стека используется в main на рис. 20.14 для создания
представителя целого стека intStack типа Stack< int > (строка 11). В intStack
заталкиваются целые от 0 до 2 (строки 16-29), которые затем выталкиваются из
него (строки 25-30). После этого программа использует шаблон класса Stack
для создания стека doubleStack типа Stack< double > (строка 32). В doub-
leStack заталкиваются значения 1.1, 2.2 и 3.3 (строки 38-43), которые затем
выталкиваются (строки 48-53).
1 // Рис. 20.14: Fig21_14.cpp
2 // Тестовая программа для шаблона класса Stack.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Stack.h" // определение класса Stack
8
9 int main()
10 {
11 Stack< int > intStack; // создать стек для значений int
12
13 cout « "processing an integer Stack" « endl;
14
15 // затолкнуть в intStack целые значения
16 for ( int i = 0; i < 3; i++ )
17 {
18 intStack.push( i );
19 intStack.printStack();
20 } // конец for
21
22 int poplnteger; // сохраняет int, вытолкнутое из стека
23
24 // вытолкнуть целые из intStack
25 while ( !intStack.isStackEmpty() )
26 {
27 intStack.pop( poplnteger );
28 cout « poplnteger « " popped from stack" « endl;
29 intStack.printStack();
30 } // конец while
31
32 Stack< double > doubleStack; // создать стек для значений double
33 double value = 1.1;
34
35 cout « "processing a double Stack" « endl;
36
37 // затолкнуть в doubleStack значения с плавающей точкой
38 for ( int j = 0; j < 3; j++ )
39 {
40 doubleStack.push( value );
41 doubleStack.printStack();
42 value += 1.1;
43 } // конец for
44
45 double popDouble; // сохраняет double, вытолкнутое из стека
46
47 // вытолкнуть значения с плавающей точкой из doubleStack
1112
Глава 20
48 while ( !doublestack.isStackEmpty() )
49 {
50 doublestack.pop( popDouble );
51 cout « popDouble « " popped from stack" « endl;
52 doubleStack.printStack();
53 } // конец while
54
55 return 0;
56 } // конец main
processing an integer Stack
The list is: 0
The list is: 1 0
The list is: 2 10
2 popped from stack
The list is: 10
1 popped from stack
The list is: 0
0 popped from stack
The list is empty
processing a double Stack
The list is: 1.1
The list is: 2.2 1.1
The list is: 3.3 2.2 1.1
3.3 popped from stack
The list is: 2.2 1.1
2.2 popped from stack
The list is: 1.1
1.1 popped from stack
The list is empty
All nodes destroyed
All nodes destroyed
Рис. 20.14. Простая программа со стеком
Другим способом реализации шаблона класса Stack является утилизация
шаблона класса List посредством композиции. На рис. 20.15 заново
реализуется шаблон класса Stack, который содержит объект типа List< STACKTYPE >
с именем stackList (строка 38). Эта версия стека также использует шаблон
класса List из рис. 20.4. Чтобы протестировать этот стек, используйте
программу-драйвер из рис. 20.14, но в строке 6 включите в нее новый заголовоч-
Структуры данных
1113
ный файл — Stackcomposition.h. Вывод программы для обеих версий класса
Stack идентичен.
1 // Рис. 20.15: Stackcomposition.h
2 // Определение шаблона класса Stack с композитным обектом List.
3 #ifndef STACKCOMPOSITION_H
4 #define STACKCOMPOSITION_H
5
6 #include "List.h" // определение класса List
7
8 template< typename STACKTYPE >
9 class Stack
10 {
11 public:
12 // конструктора нет; инициализацию производит конструктор List
13
14 // push вызывает функцию insertAtFront объекта stackList
15 void push( const STACKTYPE fidata )
16 {
17 stackList.insertAtFront( data );
18 } // конец функции push
19
20 // pop вызывает функцию removeFromFront объекта stackList
21 bool pop( STACKTYPE fidata )
22 {
23 return stackList.removeFromFront( data );
24 } // конец функции pop
25
26 // isStackEmpty вызывает функцию isEmpty объекта stackList
27 bool isStackEmpty() const
28 {
29 return stackList.isEmptyO ;
30 } // конец функции isStackEmpty
31
32 // printStack вызывает функцию print объекта stackList
33 void printStack() const
34 {
35 stackList.print();
36 } // конец функции printStack
37 private:
38 List< STACKTYPE > stackList; // композиция с объектом List
39 }; // конец класса Stack
40
41 #endif
Рис. 20.15. Шаблон класса Stack с композитным объектом List
20.6. Очереди
Очередь похожа на то, что мы видим у кассы универсама — человек,
подошедший к кассе первым, обслуживается первым, а другие покупатели
становятся в хвост очереди и ждут, когда их обслужат. Узлы удаляются только из
начала (головы) очереди, а вставляются только в ее конец (хвост). Поэтому
очередь называют структурой данных «первым вошел, первым вышел» (FIFO).
1114
Глава 20
Операции вставки и удаления называются enqueue (постановка в очередь)
и dequeue (изъятие из очереди).
Очереди находят много применений в компьютерных системах.
Компьютеры, имеющие единственный процессор, могут обслуживать в каждый момент
только одного пользователя. Запросы для других пользователей ставятся
в очередь. Каждый запрос по мере обслуживания пользователей постепенно
продвигается к началу очереди. Запрос, находящийся в начале очереди, будет
обслужен следующим.
Очереди используются также для поддержки пакетной печати (print
spooling). Например, все пользователи сети могут разделять доступ к
единственному принтеру. Задания печати могут посылать на принтер многие
пользователи, даже если принтер уже занят. Эти задания ожидают в очереди до тех
пор, пока принтер не освободится. Очередью управляет программа,
называемая менеджером печати (spooler), которая гарантирует, что по завершении
текущего задания печати на принтер будет послано следующее задание.
Информационные пакеты в компьютерных сетях также ожидают в
очередях. Всякий раз, когда на сетевой узел приходит пакет, он должен быть
переправлен следующему узлу сети, лежащему на пути к конечному пункту
назначения пакета. Узел-маршрутизатор обрабатывает в каждый момент только
один пакет, поэтому другие пакеты ставятся в очередь до тех пор, пока
маршрутизатор не получит возможность переправить их дальше.
Файловый сервер в компьютерной сети обслуживает запросы на доступ
к файлам от многих клиентов сети. Северы обладают ограниченными
возможностями обслуживания клиентских запросов. Когда эти возможности
оказываются исчерпанными, запросы клиентов ожидают в очередях.
Программа на рис. 20.16-20.17 создает шаблон класса Queue (рис. 20.16)
путем закрытого наследования (строка 9) шаблона класса List из рис. 20.4.
Мы хотим, чтобы класс Queue имел элемент-функции enqueue (строки 13-16),
dequeue (строки 19-22), isQueueEmpty (строки 25-28) и printQueue
(строки 31-34). Заметьте, что это по существу функции insert At Back, remo-
veFromFront, isEmpty и print шаблона класса List. Конечно, в шаблоне класса
List имеются и другие элемент-функции (т.е. insertAtFront и removeFromBack),
которые нам не хотелось бы делать доступными через открытый интерфейс
класса Queue. Поэтому, когда мы указываем, что шаблон класса Queue
должен наследовать шаблону класса List, мы специфицируем закрытое
наследование. Это делает все открытые элемент-функции шаблона класса List
закрытыми элементами в шаблоне класса Queue. Когда мы реализуем
элемент-функции класса Queue, то вызываем из них соответствующие функции класса
List — enqueue вызывает insertAtBack (строка 15), dequeue вызывает
removeFromFront (строка 21), isQueueEmpty вызывает isEmpty (строка 27)
и printQueue вызывает print (строка 33); это, как уже говорилось, называется
делегированием.
1 // Рис. 20.16: Queue.h
2 // Определение шаблона класса Queue, производного от List.
3 #ifndef QUEUE_H
4 #define QUEUEJH
5
6 #include "List.h" // определение класса List
7
Структуры данных
1115
8 template< typename QUEUETYPE >
9 class Queue: private List< QUEUETYPE >
10 {
11 public:
12 // enqueue вызывает функцию insertAtBack класса List
13 void enqueue( const QUEUETYPE fidata )
14 {
15 insertAtBack( data );
16 } // конец функции enqueue
17
18 // dequeue вызывает функцию removeFromFront класса List
19
20 bool dequeue( QUEUETYPE fidata )
21 {
22 return removeFromFront( data );
23 } // конец функции dequeue
24
25 // isQueueEmpty вызывает функцию isEmpty класса List
26
27 bool isQueueEmpty() const
28 {
29 return isEmptyO ;
30 } // конец функции isQueueEmpty
31
32 // printQueue вызывает функцию print класса List
33
34 void printQueue() const
35 {
36 print ();
37 } // конец функции printQueue
38 }; // конец класса Queue
39
40 #endif
Рис. 20.16. Определение шаблона класса Queue
Шаблон класса очереди используется на рис. 20.14 для создания
представителя целой очереди intQueue типа Queue< int > (строка 11). В очередь
intQueue ставятся целые от О до 2 (строки 16-29), которые затем изымаются
из очереди в порядке «первым вошел, первым вышел» (строки 25-30). После
этого программа использует шаблон класса Queue для создания очереди
doubleQueue типа Queue< double > (строка 32). В doubleQueue ставятся
значения 1.1, 2.2 и 3.3 (строки 38-43), которые затем изымаются в порядке
«первым вошел, первым вышел» (строки 48-53).
1 // Рис. 20.17: Fig21_17.cpp
2 // Тестовая программа для шаблона класса Queue.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Queue.h" // определение класса Queue
8
9 int main()
1116
Глава 20
ю {
11 Queue< int > intQueue; // создать очередь целых
12
13 cout « "processing an integer Queue" « endl;
14
15 // поместить в intQueue целые значения
16 for ( int i = 0; i < 3; i++ )
17 {
18 intQueue.enqueue( i );
19 intQueue.printQueue();
20 } // конец for
21
22 int dequeueInteger; // хранит извлеченное из очереди целое
23
24 // удалить целые из intQueue
25 while ( !intQueue.isQueueEmpty() )
26 {
27 intQueue.dequeue( dequeueInteger );
28 cout « dequeuelnteger « " dequeued" « endl;
2 9 intQueue.printQueue();
30 } // конец while
31
32 Queue< double > doubleQueue; // создать очередь для double
33 double value = 1.1;
34
35 cout « "processing a double Queue" « endl;
36
37 // поместить в doubleQueue значения с плавающей точкой
38 for ( int j = 0; j < 3; j++ )
39 {
40 doubleQueue.enqueue( value );
41 doubleQueue.printQueue();
42 value += 1.1;
43 } // конец for
44
45 double dequeueDouble; // хранит извлеченное из очереди значение
46
47 // извлечь значения из doubleQueue
48 while ( !doubleQueue.isQueueEmpty() )
49 {
50 doubleQueue. dequeue ( dequeueDouble );
51 cout « dequeueDouble « " dequeued" « endl;
52 doubleQueue.printQueue();
53 } // конец while
54
55 return 0;
56 } // конец main
processing an integer Queue
The list is: 0
The list is: 0 1
The list is: 0 12
0 dequeued
Структуры данных
1117
The list is: 1 2
1 dequeued
The list is: 2
2 dequeued
The list is empty
processing a double Queue
The list is: 1.1
The list is: 1.1 2.2
The list is: 1.1 2.2 3.3
1.1 dequeued
The list is: 2.2 3.3
2.2 dequeued
The list is: 3.3
3.3 dequeued
The list is empty
All nodes destroyed
All nodes destroyed
Рис. 20.17. Программа обработки очереди
20.7. Деревья
Связанные списки, стеки и очереди являются линейными структурами
данных. Дерево — это нелинейная, двумерная структура. Узлы дерева содержат
две или большее число связок. В этом разделе обсуждаются двоичные деревья
(рис. 20.18), узлы которых содержат две связки (одна из которых или обе
могут быть нулевыми).
Базовая терминология
В целях данного обсуждения мы будем говорить об узлах А, В, С и D на
рис. 20.18. Корневой узел (узел В) является начальным узлом дерева. Каждая
связка в корневом узле ссылается на потомка (узлы А и D). Левый потомок
является корневым узлом левого поддерева (которое содержит только узел А),
а правый потомок (узел D) является корневым узлом правого поддерева
(которое содержит узлы D и С). Потомки одного узла называются сиблингами
(напр., сиблингами являются узлы А и D). Узел без потомков называется
листом (напр., листами являются узлы А и С). Программисты обычно рисуют
деревья от корневого узла вниз — в точности наоборот по отношению к тому, как
растут деревья в природе.
1118
Глава 20
Двоичные деревья поиска
Мы обсуждаем здесь двоичные деревья специального вида, называемые
двоичными деревьями поиска. Двоичное дерево поиска (без дублирования
значений в узлах) имеет то свойство, что значения в любом левом поддереве меньше
значения в его родительском узле, а значения в любом правом поддереве
больше значения в родительском узле. Рис. 20.19 иллюстрирует двоичное дерево
поиска с 9 значениями. Заметьте, что форма дерева, соответствующего
некоторому набору данных, может меняться в зависимости от того, в каком порядке
данные вводятся в дерево.
указатель на корневой узел
левое
поддерево узла,
содержащего В
правое
поддерево узла,
содержащего В
Рис. 20.18. Графическое представление двоичного дерева
Рис. 20.19. Двоичное дерево поиска
Структуры данных
1119
Реализация программы для двоичного дерева поиска
Программа на рис. 20.20-20.22 создает двоичное дерево поиска и обходит его
(т.е. проходит по всем его узлам) тремя способами — с порядковой, предварительной
и отложенной выборкой. Об этих алгоритмах обхода мы расскажем чуть позже.
Мы начнем обсуждение с программы-драйвера (рис. 20.22), а затем перейдем
к реализации классов TreeNode (рис. 20.20) и Tree (рис. 20.21). Функция main
на рис. 20.22 начинается с создания представителя целого дерева intTree типа
Тгее< int > (строка 15). Программа запрашивает 10 целых значений, каждое из
которых помещается в двоичное дерево вызовом insertNode (строка 24). Затем
программа выполняет обходы intTree с предварительной, порядковой и
отложенной выборкой (соответственно строки 28, 31 и 34). После этого программа создает
представитель дерева для значений с плавающей точкой doubleTree типа
Тгее< double > (строка 36). Программа запрашивает 10 значений с плавающей
точкой, каждое из которых помещается в двоичное дерево вызовом insertNode
(строка 46). Затем программа выполняет обходы doubleTree с предварительной,
порядковой и отложенной выборкой (соответственно строки 50, 53 и 56).
1 // Рис. 20.20: Treenode.h
2 // Определение шаблона класса TreeNode.
3 #ifndef TREENODE_H
4 #define TREENODE_H
5
6 // операжающее объявление класса Tree
7 template< typename NODETYPE > class Tree;
8
9 // определение шаблона класса TreeNode
10 template< typename NODETYPE >
11 class TreeNode
12 {
13 friend class Tree< NODETYPE >;
14 public:
15 // конструктор
16 TreeNode( const NODETYPE &d )
17 : le£tPtr( 0 ), // указатель на левое поддерево
18 data( d ), // данные узла
19 rightPtr( 0 ) // указатель на правое поддерево
20 {
21 // пустое тело
22 } // конец конструктора TreeNode
23
24 // воэратить копию данных узла
25 NODETYPE getData() const
26 {
27 return data;
28 } // конец функции getData
29 private:
30 TreeNode< NODETYPE > *leftPtr; // указатель на левое поддерево
31 NODETYPE data;
32 TreeNode< NODETYPE > *rightPtr; // указатель на правое поддерево
33 }; // конец класса TreeNode
34
35 #endif
Рис. 20.20. Определение шаблона класса TreeNode
1120
Глава 20
1 // Рис. 20.21: Tree.h
2 // Определение шаблона класса Tree.
3 #ifndef TREE_H
4 #define TREE_H
5
6 #include <iostream>
7 using std::cout;
8 using std:rendl/
9
10 #include <new>
11 #include "Treenode.h"
12
13 // определение шаблона класса Tree
14 template< typename NODETYPE > class Tree
15 {
16 public:
17 Tree(); // конструктор
18 void insertNode( const NODETYPE & );
19 void preOrderTraversal() const;
20 void inOrderTraversal() const;
21 void postOrderTraversal() const;
22 private:
23 TreeNode< NODETYPE > *rootPtr;
24
25 // сервисные функции
26 void insertNodeHelper( TreeNode< NODETYPE >**, const NODETYPE& );
27 void preOrderHelper( TreeNode< NODETYPE > * ) const;
28 void inOrderHelper( TreeNode< NODETYPE > * ) const;
29 void postOrderHelper( TreeNode< NODETYPE > * ) const;
30 }; // конец класса Tree
31
32 // конструктор
33 template< typename NODETYPE >
34 Tree< NODETYPE >::Tree()
35 {
36 rootPtr = 0; // указывает, что дерево изначально пусто
37 } // конец конструктора Tree
38
39 // вставить узел в дерево
40 template< typename NODETYPE.>
41 void Tree< NODETYPE >::insertNode( const NODETYPE fivalue )
42 {
43 insertNodeHelper( firootPtr, value );
44 } // конец функции insertNode
45
46 // сервисная функция, вызываемая insertNode; принимает указатель
47 //на указатель, чтобы функция могла изменять значение указателя
48 template< typename NODETYPE >
49 void Tree< NODETYPE >::insertNodeHelper(
50 TreeNode< NODETYPE > **ptr, const NODETYPE &value )
51 {
52 // поддерево пусто; создать новый TreeNode, содержащий value
53 if ( *ptr == 0 )
54 *ptr = new TreeNode< NODETYPE >( value );
55 else // поддерево не пусто
56 {
Структуры данных
1121
57 // вставляемые данные меньше, чем данные в текущем узле
58 if ( value < ( *ptr )->data )
59 insertNodeHelper( &( ( *ptr )->leftPtr ), value );
60 else
61 {
62 // вставляемые данные больше, чем данные в текущем узле
63 if ( value > ( *ptr )->data )
64 insertNodeHelper( &( ( *ptr )->rightPtr ), value );
65 else// дубликаты значений данных игнорируются
66 cout « value « " dup" « endl;
67 } // конец else
68 } // конец else
69 } // конец функции insertNodeHelper
70
71 // начать обход дерева с опережающей выборкой
72 template< typename NODETYPE >
73 void Tree< NODETYPE >::preOrderTraversal() const
74 {
75 preOrderHelper( rootPtr );
76 } // конец функции preOrderTraversal
77
78 // сервисная функция для обхода дерева с опережающей выборкой
79 template< typename NODETYPE >
80 void Tree<NODETYPE>: :preOrderHelper (TreeNode<NODETYPE> *ptr) const
81 {
82 if ( ptr != 0 )
83 {
84 cout « ptr->data « ' '; // обработать узел
85 preOrderHelper( ptr->leftPtr ); // обойти левое поддерево
86 preOrderHelper( ptr->rightPtr ); // обойти правое поддерево
87 } // конец if
88 } // конец функции preOrderHelper
89
90 // начать обход дерева с порядковой выборкой
91 template< typename NODETYPE >
92 void Tree< NODETYPE >::inOrderTraversal() const
93 {
94 inOrderHelper( rootPtr );
95 } // конец функции inOrderTraversal
96
97 // сервисная функция для обхода дерева с порядковой выборкой
98 template< typename NODETYPE >
99 void Tree<NODETYPE>: : inOrderHelper ( TreeNode<NODETYPE> *ptr ) const
100 {
101 if ( ptr != 0 )
102 {
103 inOrderHelper( ptr->leftPtr ); // обойти левое поддерево
104 cout « ptr->data « ' '; // обработать узел
105 inOrderHelper( ptr->rightPtr ); // обойти правое поддерево
106 } // конец if
107 } // конец функции inOrderHelper
108
109 // начать обход дерева с отложенной выборкой
110 template< typename NODETYPE >
111 void Tree< NODETYPE >:rpostOrderTraversal() const
112 {
113 postOrderHelper( rootPtr );
36 Зак. 1114
1122
Глава 20
114 } // конец функции postOrderTraversal
115
116 // сервисная функция для обхода дерева с отложенной выборкой
117 template< typename NODETYPE >
118 void Tree< NODETYPE >:ipostOrderHelper(
119 TreeNode< NODETYPE > *ptr ) const
120 {
121 if ( ptr != 0 )
122 {
123 postOrderHelper( ptr->leftPtr ); // обойти левое поддерево
124 postOrderHelper( ptr->rightPtr ); // обойти правое поддерево
125 cout « ptr->data « ' '; // обработать узел
126 } // конец if
127 } // конец функции postOrderHelper
128
129 #endif
Рис. 20.21. Определение шаблона класса Tree
Теперь обсудим шаблоны классов. Начнем с определения шаблона класса
TreeNode (рис. 20.20), которое объявляет Тгее< NODETYPE > как
дружественный класс (строка 13). Это делает все элемент-функции конкретной
специализации шаблона класса Tree (рис. 20.21) друзьями соответствующей
специализации шаблона TreeNode, так что они могут обращаться к закрытым
элементам объектов TreeNode данного типа. Поскольку параметр NODETYPE
шаблона Tree используется как параметр шаблона для Tree в определении
дружественности, объекты TreeNode, специализированные для конкретного
типа, могут обрабатываться только в деревьях Tree, специализированных тем
же самым типом (напр., дерево целых значений управляет объектами
TreeNode, которые хранят целые значения).
1 // Рис. 20.22: Fig21_22.cpp
2 // Тестовая программа для класса Tree.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::fixed;
7
8 #include <iomanip>
9 using std::setprecision;
10
11 #include "Tree.h" // определение класса Tree
12
13 int main()
14 {
15 Tree< int > intTree; // создать дерево целых значений
16 int intValue;
17
18 cout « "Enter 10 integer values:\n";
19
20 // вставить в intTree 10 целых значений
21 for ( int i = 0; i < 10; i++ )
22 {
23 cin » intValue;
Структуры данных
1123
24 intTree.insertNode( intValue );
25 } // конец for
26
27 cout « "\nPreorder traversal\n";
2 8 intTree.preOrderTraversal();
29
30 cout « "\nInorder traversal\n";
31 intTree.inOrderTraversal();
32
33 cout « "\nPostorder traversal\n";
34 intTree.postOrderTraversal();
35
36 Tree< double > doubleTree; // создать дерево значений double
37 double doubleValue;
38
39 cout « fixed « setprecision( 1 )
40 « M\n\n\nEnter 10 double values:\n";
41
42 // вставить в doubleTree 10 значений double
43 for ( int j = 0; j < 10; j++ )
44 {
45 cin » doubleValue;
46 doubleTree.insertNode( doubleValue );
47 } // конец for
48
49 cout « "\nPreorder traversal\n";
50 doubleTree.preOrderTraversal();
51
52 cout « "\nInorder traversal\n";
53 doubleTree.inOrderTraversal();
54
55 cout « "\nPostorder traversal\n";
56 doubleTree.postOrderTraversal();
57
58 cout « endl;
59 return 0;
60 } // конец main
Enter 10 integer values:
50 25 75 12 33 67 88 6 13 68
Preorder traversal
50 25 12 6 13 33 75 67 68 88
Inorder traversal
6 12 13 25 33 50 67 68 75 88
Postorder traversal
6 13 12 33 25 68 67 88 75 50
Enter 10 double values:
39.2 16.5 82.7 3.3 65.2 90.8 1.1 4.4 89.5 92.5
Preorder traversal
39.2 16.5 3.3 1.1 4.4 82.7 65.2 90.8 89.5 92.5
Inorder traversal
1124
Глава 20
1.1 3.3 4.4 16.5 39.2 65.2 82.7 89.5 90.8 92.5
Postorder traversal
1.1 4.4 3.3 16.5 65.2 89.5 92.5 90.8 82.7 39.2
Рис. 20.22. Создание и обход двоичного дерева
Строки 30-32 объявляют закрытые данные TreeNode — значение в узле
data и указатели leftPtr (на левое поддерево узла) и rightPtr (на правое
поддерево). Конструктор (строки 16-22) устанавливает в data значение, переданное
как аргумент конструктора, и устанавливает указатели leftPtr и rightPtr
в нуль (инициализируя тем самым узел в качестве листа). Элемент-функция
getData возвращает значение data.
Шаблон класса Tree (рис. 20.21) объявляет как закрытый элемент данных
rootPtr (строка 22), указатель на корневой узел дерева. Строки 17-20 шаблона
класса объявляют открытые элемент-функции insertNode (вставляет в дерево
новый узел), а также preOrderTraversal, inOrderTraversal и postOrderTraver-
sal, каждая из которых выполняет обход дерева согласно соответствующему
алгоритму. Каждая из трех последних функций вызывает свою собственную
рекурсивную сервисную функцию, выполняющую соответствующие операции
над внутренним представлением дерева, так что для выполнения этих
действий программе не требуется обращаться к закрытым данным. Как вы помните,
рекурсия требует, чтобы мы передавали указатель на поддерево, которое
должно обрабатываться следующим. Конструктор Tree инициализирует
rootPtr нулем, показывая, что дерево изначально пусто.
Сервисная функция insertNodeHelper (строки 47-68) класса Tree
вызывается из insertNode для рекурсивной вставки зла в дерево. Узел может быть
вставлен в двоичное дерево поиска только в качестве листа. Если дерево
пусто, создается, инициализируется и вставляется в дерево новый TreeNode
(строки 53-54).
Если дерево не пусто, программа сравнивает вставляемое значение со
значением data в корневом узле. Если вставляемое значение меньше (строка 57),
программа рекурсивно вызывает insertNodeHelper (строка 58) для вставки
значения в левое поддерево. Если вставляемое значение больше (строка 62),
программа рекурсивно вызывает insertNodeHelper (строка 64) для вставки
значения в правое поддерево. Если вставляемое значение совпадает со
значением в корневом узле, программа печатает сообщение "dup" (строка 65) и
возвращается, не вставляя в дерево дубликата значения. Обратите внимание, что
insertNode передает insertNodeHelper адрес указателя rootPtr (строка 42),
чтобы insertNodeHelper могла модифицировать значение, хранящееся
в rootPtr (т.е. адрес корневого узла). Для получения указателя на rootPtr
первый параметр insertNodeHelper объявляется как указатель на указатель на
TreeNode.
Каждая из элемент-функций inOrderTraversal (строки 90-94),
preOrderTraversal (строки 71-75) и postOrderTraversal (строки 109-113) обходит
дерево и распечатывает значения в узлах. Для целей последующего
обсуждения мы возьмем двоичное дерево поиска на рис. 20.23.
Структуры данных
1125
27
13 42
б 17 33 48
Рис. 20.23. Двоичное дерево поиска
Алгоритм обхода с порядковой выборкой
Функция inOrderTraversal для выполнения обхода двоичного дерева с
порядковой выборкой вызывает сервисную функцию in Order Helper. Шаги
обхода с порядковой выборкой таковы:
1. Обойти с порядковой выборкой левое поддерево. (Это выполняется
вызовом inOrderHelper в строке 102).
2. Обработать значение в узле — т.е. распечатать значение узла
(строка 103).
3. Обойти с порядковой выборкой правое поддерево. (Это выполняется
вызовом inOrderHelper в строке 104).
Значение в узле не обрабатывается, пока не будут обработаны значения в
левом поддереве, так как каждый вызов inOrderHelper немедленно снова
вызывает inOrderHelper с указателем на левое поддерево. Обход с порядковой
выборкой дерева на рис. 20.23 дает
6 13 17 27 33 42 48
Обратите внимание, что обход двоичного дерева поиска с порядковой
выборкой печатает значения в восходящем порядке. Процесс создания двоичного
дерева поиска по существу сортирует данные — поэтому этот процесс
называют сортировкой в двоичном дереве.
Алгоритм обхода с предварительной выборкой
Функция preOrderTraversal для выполнения обхода двоичного дерева
с предварительной выборкой вызывает сервисную функцию preOrderHelper.
Шаги обхода с предварительной выборкой таковы:
1. Обработать значение в узле (строка 83).
2. Обойти с предварительной выборкой левое поддерево. (Это выполняется
вызовом preOrderHelper в строке 84).
3. Обойти с предварительной выборкой правое поддерево. (Это
выполняется вызовом preOrderHelper в строке 85).
Значение в каждом узле обрабатывается при посещении узла. После обработки
значения в данном узле обрабатываются значения в его левом поддереве.
Затем обрабатываются значения в правом поддереве. Обход с предварительной
выборкой дерева на рис. 20.23 дает
27 13 б 17 42 33 48
1126
Глава 20
Алгоритм обхода с отложенной выборкой
Функция postOrderTraversal для выполнения обхода двоичного дерева
с отложенной выборкой вызывает сервисную функцию postOrderHelper. Шаги
обхода с отложенной выборкой таковы:
1. Обойти с отложенной выборкой левое поддерево. (Это выполняется
вызовом postOrderHelper в строке 122).
2. Обойти с отложенной выборкой правое поддерево. (Это выполняется
вызовом postOrderHelper в строке 123).
3. Обработать значение в узле (строка 124).
Значение в узле не печатается, пока не будут напечатаны значения его
потомков. Обход с отложенной выборкой дерева на рис. 20.23 дает
б 17 13 33 48 42 27
Исключение дубликатов
Двоичное дерево поиска упрощает исключение дубликатов. Попытка
включения дубликата будет обнаружена в ходе создания дерева, поскольку
дубликат при каждом сравнении будет следовать тем же решениям «пойти налево»
или «пойти направо», что и первоначальное значение при его вставке в дерево.
Таким образом, в конце концов дубликат будет сравниваться с узлом,
содержащим то же самое значение. В этой точки дублирующее значение можно
отбросить.
Поиск в двоичном дереве значения, совпадающего с ключом, также
выполняется быстро. Если дерево сбалансировано, то каждая ветвь содержит
приблизительно половину всех его узлов. Каждое сравнение узла с ключом поиска
исключает половину узлов. Это называется алгоритмом 0(log ri). (Нотация
«О больщо»го обсуждается в главе 20). Поэтому двоичное дерево с п
элементами потребует не более log2 n сравнений для того, чтобы либо найти совпадение,
либо установить, что совпадения отсутствуют. Это означает, например, что для
поиска в (сбалансированном) 1000-элементном двоичном дереве потребуется
выполнить не более 10 сравнений, поскольку 210 > 1000. Для поиска в
(сбалансированном) 1000000-элементном двоичном дереве потребуется выполнить не
более 20 сравнений, поскольку 220 > 1000000.
Обзор упражнений по двоичным деревьям
В упражнениях представлены алгоритмы для некоторых других операций
двоичных деревьев, например, удаления элемента из двоичного дерева,
распечатки двоичного дерева в двумерном формате и обхода двоичного дерева по
уровням. Обход двоичного дерева по уровням посещает узлы дерева ряд за
рядом, начиная с уровня корневого узла. На каждом уровне узлы посещаются
слева направо. В число упражнений по двоичным деревьям входят также
разрешение дублирования значений в дереве, вставка в двоичное дерево
строковых значений и определение числа уровней в дереве.
Структуры данных
1127
20.8. Заключение
В этой главе вы узнали, что связанные списки представляют собой наборы
элементов данных, «связанных в цепочку». Вы узнали также, что программа
может производить вставки и удаления в любом месте связанного списка (хотя
наша реализация выполняла вставку и удаление только в начале и конце
списка). Мы продемонстрировали, что структуры данных стека и очереди
являются ограниченными версиями связанных списков. В случае стека вы видели,
что вставки и удаления производятся только в его вершине. В очередях
вставки производятся только в конце, а удаления — в голове очереди. Мы
представили также структуру данных двоичного дерева. Вы увидели двоичное дерево
поиска, которое упрощает высокоскоростной поиск, сортировку данных и
исключение дубликатов. На протяжении вей главы вы учились реализации
структур данных в виде шаблонов для упрощения их утилизации и
сопровождения. В следующей главе мы введем структуры struct, похожие на классы,
и обсудим операции с битами, символами и строками в стиле С.
Резюме
• Динамические структуры данных растут и сокращаются в процессе исполнения.
• Связанные списки представляют собой наборы элементов данных, «выстроенных
в цепь»; вставки и удаления производятся в любом месте связанного списка.
• Стеки играют важную роль в компиляторах и операционных системах; вставки
и удаления производятся только в одном конце стека — в его вершине.
• Очереди связаны с ожиданием; вставки производятся только в конце (называемым
хвостом), а удаления в начале (голове) очереди.
• Двоичные деревья упрощают высокоскоростной поиск и сортировку данных,
исключение дубликатов, представление структуры каталогов файловой системы и
компиляцию выражений в машинный язык.
• Автореферентный класс содержит элемент-указатель, ссылающийся на объект того
же классового типа.
• Объекты автореферентного класса могут связываться между собой, образуя
полезные структуры данных, такие, как списки, очереди, стеки и деревья.
• Предельный объем динамически выделяемой памяти может определяться доступной
физической памятью компьютера или объемом доступной виртуальной памяти в
системе с виртуальной памятью.
• Связанный список является линейным набором объектов автореферентного класса,
называемых узлами, соединенных указателями-связками — отсюда название
«связанный» список.
• Доступ к связанному списку осуществляется через указатель на первый узел списка.
Обращение к каждому последующему узлу осуществляется через указатель,
хранящийся в предыдущем узле.
• Связанные списки, стеки и очереди являются линейными структурами данных.
Деревья являются нелинейными структурами данных.
• Связанный список подходит для случаев, когда число одновременно представленных
элементов данных нельзя предсказать заранее.
• Связанные списки являются динамическими, поэтому длина списка может
возрастать или сокращаться по мере необходимости.
• Связанный список начинается с указателя на первый узел, и каждый узел содержит
указатель на следующий «по порядку» узел.
1128
Глава 20
• Циклический односвязный список начинается с указателя на первый узел, и
каждый узел содержит указатель на следующий узел. «Последний узел» не содержит
нулевого указателя; указатель в последнем узле ссылается на первый узел, замыкая
таким образом «кольцо».
• Двусвязный список допускает прохождение как в прямом, так и в обратном
направлении.
• Двусвязный список часто реализуют с двумя «начальными указателями» — один
указывает на первый элемент списка и позволяет пройти список от начала к концу,
а второй указывает на последний элемент и позволяет пройти список от конца к
началу. Каждый узел имеет как прямой указатель на следующий узел списка в прямом
направлении, так и обратный указатель на следующий узел в обратном
направлении.
• В циклическом двусвязном списке прямой указатель последнего узла ссылается на
первый узел, а обратный указатель первого узла — на последний узел, замыкая
таким образом «кольцо».
• Структура данных стека допускает добавление и удаление узлов только в вершине
стека.
• Стек называют структурой данных типа «последним вошел, первым вышел» (LIFO).
• Основными элемент-функциями для манипуляций со стеком являются push
(затолкнуть) и pop (вытолкнуть). Функция push помещает новый узел на вершину стека.
Функция pop удаляет узел с вершины стека.
• Очередь похожа на то, что мы видим у кассы универсама — человек, подошедший
к кассе первым, обслуживается первым, а другие покупатели становятся в хвост
очереди и ждут, когда их обслужат.
• Узлы удаляются только из начала (головы) очереди, а вставляются только в ее конец
(хвост).
• Очередь называют структурой данных «первым вошел, первым вышел» (FIFO).
Операции вставки и удаления называются enqueue (постановка в очередь) и dequeue
(изъятие из очереди).
• Двоичные деревья являются деревьями, узлы которых содержат две связки (одна из
которых или обе могут быть нулевыми).
• Корневой узел является начальным узлом дерева.
• Каждая связка в корневом узле ссылается на потомка. Левый потомок является
корневым узлом левого поддерева, а правый потомок является корневым узлом правого
поддерева.
• Потомки одного узла называются сиблингами. Узел без потомков называется
листом.
• Двоичное дерево поиска (без дублирования значений в узлах) имеет то свойство, что
значения в любом левом поддереве меньше значения в его родительском узле, а
значения в любом правом поддереве больше значения в родительском узле.
• Узел может быть вставлен в двоичное дерево поиска только в качестве листа.
• При обходе двоичного дерева с порядковой выборкой выполняется обход с
порядковой выборкой левого поддерева, обработка значения в корневом узле, а затем обход
с порядковой выборкой правого поддерева. Значение в узле не обрабатывается, пока
не будут обработаны значения в его левом поддереве.
• При обходе с предварительной выборкой выполняется обработка значения в
корневом узле, обход с предварительной выборкой левого поддерева, и обход с
предварительной выборкой правого поддерева. Значение в каждом узле обрабатывается при
посещении узла.
Структуры данных
1129
• При обходе двоичного дерева с отложенной выборкой выполняется обход с
отложенной выборкой левого поддерева, обход с отложенной выборкой правого поддерева,
а затем обработка значения в корневом узле. Значение в узле не обрабатывается,
пока не будут обработаны значения в обоих его поддеревьях.
• Двоичное дерево поиска упрощает исключение дубликатов. Попытка включения
дубликата будет обнаружена в ходе создания дерева, и дублирующее значение
можно будет отбросить.
• Обход двоичного дерева по уровням посещает узлы дерева ряд за рядом, начиная
с уровня корневого узла. На каждом уровне узлы посещаются слева направо.
Терминология
dequeue
enqueue
pop
push
автореферентная структура
вершина стека
вставка узла
голова очереди
двоичное дерево
двоичное дерево поиска
двусвязный список
делегирование
динамические структуры данных
исключение дубликатов
левое поддерево
левый потомок
линейная структура данных
лист
менеджер печати
нелинейная структура данных
обход двоичного дерева с отложенной
выборкой
обход двоичного дерева с порядковой
выборкой
Контрольные вопросы
20.1. Заполните пропуски в следующих утверждениях:
а) класс используется для создания динамических структур данных,
которые могут расти и сокращаться во время выполнения.
Ь) Операция используется для динамического выделения памяти
и конструирования объекта. Эта операция возвращает указатель на
выделенную память.
с) является ограниченным вариантом связанного списка, в котором
узлы могут вставляться и удаляться только в его вершине. Эта структура
данных возвращает значения в узлах в порядке * последним вошел, первым
вышел*.
d) Функция, которая не меняет связанный список, а просто его просматривает
и определяет, не является ли он пустым, является примером
функции.
обход двоичного дерева
с предварительной выборкой
обход по уровням
односвязный список
очередь
пакетная печать
первым вошел, первым вышел (FIFO)
последним вошел, первым вышел
(LIFO)
правое поддерево
правый потомок
родительский узел
связанный список
связка
сиблинги
сортировка в двоичном дереве
стек
структура данных
узел
узел-потомок
указатель-связка
хвост очереди
циклический двусвязный список
циклический односвязный список
1130
Глава 20
е) Очередь называется структурой данных типа
поскольку узлы,
вставляемые в очередь первыми, удаляются из нее первыми.
f) Указатель на следующий узел в связанном списке называется .
g) Для освобождения динамически выделенной памяти используется операция
h).
является ограниченным вариантом связанного списка, в котором
узлы могут быть помещаться только в конец списка, а удаляться только из его
начала,
i) является нелинейной двумерной структурой данных, содержащей
узлы с двумя или большим числом связок,
j) Стек относится к структурам данных типа
поскольку последний
помещенный в него узел удаляется первым.
к) Узлы дерева содержат по два элемента-связки.
1) Первый узел дерева называется узлом.
т) Каждая связка в узле дерева указывает на или
ного узла,
п) Узел дерева, который не имеет потомков, называется
. дан-
о) Четыре алгоритма обхода дерева двоичного поиска, которые были упомянуты
в главе, называются обходами , ,
и .
20.2. Каковы различия между связанным списком и стеком?
20.3. Каковы различия между стеком и очередью?
20.4. Возможно, более подходящим названием для этой главы было бы
«Утилизируемые структуры данных». Поясните, каким образом каждый из перечисленных
ниже объектов и понятий способствует утилизации структур данных:
a) классы
b) шаблоны классов
c) наследование
d) закрытое наследование
e) композиция.
20.5. Проделайте вручную обход с порядковой, предварительной и отложенной
выборкой дерева двоичного поиска на рис. 20.24.
11 19 32 44 69 72 92 99
Рис. 20.24. Двоичное дерево поиска с 15 узлами
Структуры данных
1131
Ответы на контрольные вопросы
20.1. а) Автореферентный, b) new. с) Стек, d) предикатной, е) «первым вошел, первым
вышел» (FIFO), f) связкой, g) delete, h) Очередь, i) Дерево, j) «последним
вошел, первым вышел» (LIFO). к) двоичного. 1) корневым, т) узел-потомок,
поддерево, п) листом, о) с порядковой, предварительной, отложенной выборкой
и обходом по уровням.
20.2. В связанном списке можно вставлять узел в любое место списка и удалять узел
из любого места списка. Узлы в стеке могут помещаться только на вершину,
а удаляться только с вершины стека.
20.3. Очередь позволяет удалять узлы только из головы очереди, а вставлять только
в хвост очереди. Очередь называют структурой данных типа «первым вошел,
первым вышел» (FIFO). Стек позволяет помещать узлы только на вершину,
а удалять только с вершины.
20.4. а) Классы позволяют нам создавать столько объектов структур данных
определенного типа (т.е. класса), сколько необходимо.
b) Шаблоны классов позволяют нам создавать родственные классы, каждый из
которых построен исходя из параметров различных типов, и мы можем
создавать столько объектов каждого шаблонного класса, сколько необходимо.
c) Наследование позволяет нам утилизировать в производном классе код
базового класса, так что структуры данных производного класса также являются
структурами данных базового класса (при открытом наследовании).
d) Закрытое наследование позволяет нам утилизировать часть кода базового
класса для создания структуры данных производного класса; поскольку
наследование является закрытым, то открытые элемент-функции базового
класса становятся закрытыми в производном классе. Это позволяет нам
предотвратить обращение клиентов производного класса к тем функциям базового
класса, которые не применимы к производному классу.
e) Композиция позволяет нам утилизировать код, сделав структуру данных
объекта класса элементом композитного класса; если мы сделаем объект класса
закрытым элементом композитного класса, то открытые элемент-функции
объекта класса не будут доступны через интерфейс композитного объекта.
20.5. Обход с порядковой выборкой:
11 18 19 28 32 40 44 49 69 71 72 83 92 97 99
Обход с предварительной выборкой:
49 28 18 11 19 40 32 44 83 71 69 72 97 92 99
Обход с отложенной выборкой:
11 19 18 32 44 40 28 69 72 71 92 99 97 83 49
Упражнения
20.6. Напишите программу, выполняющую конкатенацию двух объектов связанного
списка символов. Программа должна включать функцию concatenate, которая
принимает в качестве аргументов ссылки на оба списка и присоединяет второй
список к первому.
20.7. Напишите программу, которая объединяет два объекта упорядоченного списка
целых чисел в один объект упорядоченного списка. Функция merge должна
получать ссылки на каждый из объектов списка, которые необходимо объединить,
и ссылку на объект списка, в котором должны размещаться объединенные
элементы.
1132
Глава 20
20.8. Напишите программу, которая вставляет 25 случайных целых значений от 0 до
100 в объект упорядоченного связанного списка. Программа должна вычислять
сумму элементов и среднее значение, которое должно быть числом с плавающей
точкой.
20.9. Напишите программу, которая создает объект связанного списка из 10
символов, после чего создает копию списка с элементами, размещенными в обратном
порядке.
20.10. Напишите программу, которая считывает строку текста и использует объект
стека, чтобы распечатать эту строку в обратном порядке.
20.11. Напишите программу, которая использует объект стека, чтобы определить,
является ли строка палиндромом (т.е. пишется по букам одинаково в прямом
и в обратном направлении). Программа должна игнорировать пробелы и знаки
пунктуации.
20.12. Стеки используются компиляторами как вспомогательное средство в процессе
оценки выражений и генерирования машинного кода. В этом и следующем
упражнении мы выясним, как компиляторы оценивают арифметические
выражения, состоящие только из констант, знаков операций и скобок.
Люди обычно записывают выражения в виде 3 + 4 и 7 / 9, т.е. знак операции
(в данном случае это + или /) записывается между операндами; такая запись
называется инфиксной нотацией. Компьютеры «предпочитают» постфиксную но
тацию, в которой знак операции записывается справа от двух операндов.
Предыдущие инфиксные выражения в постфиксной нотации будут выглядеть
соответственно как 3 4 + и 7 9 /.
Для оценки сложного инфиксного выражения компилятор должен сначала
перевести его в постфиксную форму, а затем оценить постфиксный вариант
выражения. Каждый из этих алгоритмов требует всего одного прохода выражения
слева направо. Обоим алгоритмам требуется стек для выполнения операций, но
стек в этих алгоритмах используется для разных целей.
В этом упражнении вы напишете реализацию на C++ алгоритма преобразования
инфиксной записи в постфиксную. В следующем упражнении вы напишете
реализацию алгоритма оценки постфиксных выражений. Далее вы увидите, что
написанный в этом упражнении код поможет вам реализовать законченный
работающий компилятор.
Напишите программу, которая преобразует обычное инфиксное арифметическое
выражение (подразумевается, что вводится допустимое выражение) с
однозначными целыми, такое, как
F + 2) * 5 - 8 / 4
в постфиксное выражение. Постфиксный вариант предыдущего инфиксного
выражения выглядит следующим образом:
62 + 5*84/-
Программа должна считывать выражение в массив символов infix и
использовать видоизмененные варианты функций работы со стеком, представленных
в этой главе, чтобы с их помощью сохранить постфиксное выражение в
символьном массиве postfix. Алгоритм создания постфиксного выражения следующий:
1) Затолкнуть в стек левую скобку '('•
2) Добавить правую скобку ')' в конец infix.
3) Пока стек не пуст, считывать infix слева направо и выполнять следующие
действия:
Структуры данных
1133
Если текущий символ в infix — цифра, копировать его в следующий
элемент postfix.
Если текущий символ в infix — левая скобка, затолкнуть ее в стек.
Если текущий символ в infix — знак операции,
выталкивать знаки операций из стека (если они там есть),
пока соответствующие им операции имеют равный или более
высокий приоритет по сравнению с текущей операцией,
и помещать извлеченные знаки операций в postfix.
Затолкнуть текущий символ из infix в стек.
Если текущий символ в infix — правая скобка,
выталкивать знаки операций из стека и помещать их в postfix,
пока на вершине стека не появится левая скобка.
Вытолкнуть из стека левую скобку и отбросить ее.
В выражении допускается использование следующих арифметических операций:
+ сложение
— вычитание
* умножение
/ деление
возведение в степень
% взятие по модулю
[Замечание. В целях данного упражнения мы полагаем, что все операции
ассоциируются слева направо.] Стек должен поддерживать узлы, состоящие из
элемента данных и указателя на следующий узел стека.
Возможно, вы захотите предусмотреть в программе следующие функции:
a) функцию convertToPostfix, которая преобразует инфиксное выражение
в постфиксную нотацию;
b) функцию isOperator, которая определяет, является ли с знаком операции;
c) функцию precedence, которая определяет, что старшинство операции opera-
tori меньше, равно или выше по сравнению с operator2 (функция возвращает
соответственно -1, 0 или 1);
d) функцию push, которая заталкивает значение в стек;
e) функцию pop, которая выталкивает значение из стека;
f) функцию stackTop, которая возвращает значение в верхнем узле стека, не
выталкивая его из стека;
g) функцию isEmpty, которая определяет, является ли стек пустым;
h) функцию prints tack, которая распечатывает стек.
20.13. Напишите программу, оценивающую постфиксное выражение (предполагается,
что вводится допустимое выражение), такое, как
62 + 5*84/-
Программа должна вводить постфиксное выражение, состоящее из цифр и
знаков операций, в символьный массив. Используя модифицированные варианты
функций работы со стеком, рассмотренных ранее в этой главе, программа
должна сканировать выражение и оценивать его. Используйте следующий алгоритм:
1) Добавить символ NULL ('\0') в конец постфиксного выражения. Как только
встречается символ NULL, дальнейшую обработку можно прекратить.
2) Пока не встретился '\0\ считывать выражение слева направо.
1134
Глава 20
Если текущий символ — цифра,
затолкнуть ее значение в стек (значение цифры равно значению
ее символа в таблице символов компьютера минус значение
символа 'О').
В противном случае, если текущий символ — знак операции,
вытолкнуть два верхних элемента из стека в переменные х и у.
Вычислить у операция х.
Затолкнуть результат вычисления в стек.
3) Когда в выражении встретится символ NULL, вытолкнуть из стека верхнее
значение. Оно и будет результатом постфиксного выражения.
[Замечание. В пункте 2), если знак операции — '/', на вершине стека
находится 2, и следующий элемент в стеке 8, то 2 выталкивается в х, 8 выталкивается
в у, вычисляется 8 / 2, и результат 4 заталкивается обратно в стек. Все
вышесказанное относится и к операции '—'.] В выражении допустимы следующие
арифметические операции:
+ сложение
— вычитание
* умножение
/ деление
возведение в степень
% взятие по модулю
[Замечание. В целях данного упражнения мы полагаем, что все операции
ассоциируются слева направо.] Стек должен поддерживать узлы, состоящие из
элемента данных и указателя на следующий узел стека. Возможно, вы захотите
предусмотреть в программе следующие функции:
a) функцию evaluatePostfixExpression, которая которая оценивает постфиксное
выражение;
b) функцию calculate, которая оценивает выражение opl operator op2;
c) функцию push, которая заталкивает значение в стек;
d) функцию pop, которая выталкивает значение из стека;
e) функцию isEmpty, которая определяет, является ли стек пустым;
f) функцию prints tack, которая распечатыывает стек.
20.14. Усовершенствуйте программу упражнения 20.13, оценивающую постфиксное
выражение, чтобы она могла работать с целыми операндами, большими девяти.
20.15. (Моделирование супермаркета) Напишите программу, которая моделирует
очередь в кассу супермаркета. Очередь является объектом. Покупатели (также
объекты) подходят к кассе через случайно выбранные целые интервалы времени,
заключенные в диапазоне от одной до четырех минут. На обслуживание каждого
покупателя тратится тоже случайно выбранное целое число минут от одной до
четырех. Очевидно, что эти интервалы должны быть сбалансированы. Если
средний темп появления покупателей у кассы выше, чем средний темп
обслуживания, очередь будет бесконечно расти. Даже при * сбалансированных» темпах
из-за их вероятностного характера все равно могут образовываться длинные
очереди. Создайте программу моделирования для 12-часового дня G20 минут),
используя следующий алгоритм:
1) Выбрать случайное целое число от одного до четырех для определения
минуты, в которую появляется первый покупатель.
2) После появления первого покупателя:
Определитть время обслуживания покупателя (случайно выбранное целое от 1
до 4).
Структуры данных
1135
Начать обслуживание покупателя.
Найти время появления следующего покупателя (к текущему времени
прибавляется случайно выбранное целое от 1 до 4).
3) Для каждой минуты рабочего дня супермаркета:
Если появился следующий покупатель,
поставить его в очередь.
Определить время появления следующего покупателя.
Если обслуживание очередного покупателя завершено,
извлечь из очереди следующего покупателя, который должен
обслуживаться.
Определить время обслуживания покупателя (случайно выбранное
целое число от 1 до 4).
Теперь запустите ваше моделирование для 720 минут и ответьте на следующие
вопросы:
a) Какое максимальное количество покупателей оказалось в очереди за это время?
b) Чему равно максимальное время, которое покупателю пришлось ждать
обслуживания?
c) Что произойдет, если интервал появления покупателей поменять с 1-4 минут
на 1-3 минуты?
20.16. Модифицируйте программу на рис. 20.20-20.22 так, чтобы двоичное дерево
могло содержать дубликаты.
20.17. На основе программы, представленной на рис. 20.20-20.22, напишите
программу, которая вводит строку текста, разделяет предложение на отдельные слова
(вы можете воспользоваться библиотечной функцией strtok), вставляет слова
в двоичное дерево поиска и распечатывает результаты его обхода с порядковой,
предварительной и отложенной выборкой. Используйте
объектно-ориентированный подход.
20.18. В этой главе мы увидели, что при создании двоичного дерева поиска дубликаты
исключаются очень просто. Опишите, как бы вы выполнили исключение
дубликатов, если бы использовали просто одномерный массив. Сравните исключение
дубликатов в массиве и ту же самую операцию в двоичном дереве поиска.
20.19. Напишите элемент-функцию depth, принимающую в качестве аргумента
двоичное дерево и определяющую, сколько уровней оно содержит.
20.20. (Рекурсивная печать списка в обратном порядке) Напишите элемент-функцию
printListBackward, которая рекурсивно печатает элементы связанного списка
в обратном порядке. Используйте вашу функцию в тестовой программе, которая
создает упорядоченный список целых чисел и распечатывает его в обратном
порядке.
20.21. (Рекурсивный поиск в списке) Напишите элемент-функцию searchList, которая
выполняет рекурсивный поиск заданного значения в связанном списке. В том
случае, если оно обнаружено, функция должна возвращать указатель на
значение; в противном случае должно возвращаться значение NULL. Используйте
вашу функцию в тестовой программе, которая создает список целых чисел.
Программа должна предлагать пользователю ввести значение, которое необходимо
обнаружить в списке.
20.22. (Удаление из двоичного дерева) В этом упражнении мы обсудим удаление
элементов из двоичных деревьев поиска. Алгоритм удаления не так прост, как
алгоритм вставки. При удалении элемента данных возможен один из трех случаев:
элемент содержится в листе (т.е. узле, не имеющем потомков), в узле, имеющем
одного потомка, или в узле, имеющем двух потомков.
1136
Глава 20
Если удаляемый элемент содержится в листе, лист удаляется, а указателю в его
родительском узле присваивается NULL.
Если удаляемый элемент принадлежит узлу с одним потомком, то указатель
в его родительском узле устанавливается на потомка, а узел, содержащий
элемент данных, удаляется. В этом случае потомок занимает в дереве место
удаленного узла.
Третий случай наиболее сложен. Если удаляется узел, имеющий двух потомков,
его место должен занять другой узел дерева. Однако нельзя просто присвоить
указателю в родительском узле указатель на одного из потомков узла, который
должен быть удален. В большинстве случаев получающееся в результате дерево
не будет удовлетворять следующему критерию двоичного дерева поиска:
значения в любом левом поддереве должны быть меньше, чем значение в его
родительском узле, а значения в любом правом поддереве должны быть больше, чем
значение в родительском узле.
Какой же узел должен быть использован в качестве замещающего узла, чтобы
удовлетворить этому условию? Ответ такой: или узел, содержащий наибольшее
из всех значений в дереве, меньшее, чем значение в удаляемом узле, или узел,
содержащий наименьшее из всех значений в дереве, большее, чем значение
в удаляемом узле. Давайте рассмотрим узел с меньшим значением. В двоичном
дереве поиска наибольшее значение, меньшее, чем родительское значение,
расположено в левом поддереве родительского узла и гарантированно будет
содержаться в самом правом узле поддерева. Этот узел можно найти, спускаясь вниз
по левому поддереву вправо до тех пор, пока указатель на правого потомка в
текущем узле не будет равен NULL. Это и есть интересующий нас узел, который
будет или листом, или узлом, имеющим только одного потомка, причем слева.
Если замещающий узел — лист, то для удаления необходимо выполнить
следующие шаги:
1) Сохранить указатель на узел, который необходимо удалить, во временном
указателе (этот указатель будет использован для освобождения динамически
выделенной памяти).
2) Установить указатель в родительском, по отношению к удаляемому, узле, на
замещающий узел.
3) Установить указатель в родительском, по отношению к замещающему, узле на
NULL.
4) Установить указатель на правое поддерево в замещающем узле на правое
поддерево удаляемого узла.
5) Удалить узел, на который указывает временный указатель.
Шаги, которые необходимо выполнить при удалении в случае, если заменяющий
узел имеет левого потомка, такие же, как и при замене узла, не имеющего
потомков, но алгоритм, кроме этого, должен переместить потомка в позицию
замещающего узла. Если замещающий узел — узел с левым потомком, то для
удаления необходимо выполнить следующие шаги:
1) Сохранить указатель на узел, который должен быть удален, во временной
переменной.
2) Установить указатель в родительском, по отношению удаляемому, узле на
замещающий узел.
3) Установить указатель в родительском, по отношению к замещающему, узле на
левого потомка замещающего узла.
4) Установить указатель на правое поддерево в замещающем узле на правое
поддерево удаляемого узла.
5) Удалить узел, на который указывает временный указатель.
Структуры данных
1137
Напишите элемент-функцию deleteNode, которая принимает в качестве
аргументов указатель на корневой узел объекта дерева и значение, которое
необходимо удалить. Функция должна находить в дереве узел, содержащий указанное
значение, и применить обсуждавшийся выше алгоритм для удаления узла. Если
требуемое значение в дереве не обнаружено, функция должна напечатать
соответствующее сообщение. Модифицируйте программу на рис. 20.20-20.22 так,
чтобы она использовала эту функцию. После удаления элемента вызовите
функции обхода inOrder, preOrder и postOrder для проверки корректности удаления.
20.23. (Поиск в двоичном дереве) Напишите элемент-функцию binaryTreeSearch,
которая будет искать заданное значение в объекте двоичного дерева. Функция
должна принимать в качестве аргумента ключевое значение, которое
необходимо найти. Если узел, содержащий ключевое значение, обнаружен, функция
должна вернуть указатель на этот узел; в противном случае функция должна
возвратить NULL.
20.24. (Обход двоичного дерева по уровням) Программа на рис. 20.20-20.22
иллюстрирует три рекурсивных метода обхода двоичных деревьев: с порядковой,
предварительной и отложенной выборкой. В этом упражнении обход двоичного дерева
производится по уровням, т.е. значения узлов выводятся на печать ряд за рядом,
начиная от корневого узла. Узлы каждого уровня печатаются слева направо.
Обход по уровням не является рекурсивным алгоритмом. Для управления выводом
значений узлов он использует объект очереди. Алгоритм заключается в
следующем:
1) Поместить корневой узел в очередь.
2) Пока в очереди остаются узлы,
прочитать следующий узел в очереди
распечатать значение в узле
если указатель на левого потомка узла не NULL
поместить левого потомка в очередь
если указатель на правого потомка не NULL
поместить правого потомка в очередь.
Напишите элемент-функцию levelOrder, выполняющую обход объекта
двоичного дерева по уровням. Модифицируйте программу на рис. 20.20-20.22, чтобы
можно было протестировать эту функцию. [Замечание. Вам также придется
модифицировать и включить в эту программу функцию, обрабатывающую очередь,
представленную на рис. 20.16.]
20.25. (Вывод деревьев на печать) Напишите рекурсивную элемент-функцию
outputTree для изображения на экране двоичного дерева. Функция должна
выводить дерево ряд за рядом, вершина дерева должна располагаться в левой части
экрана, а его низ справа. Каждый ряд выводится вертикально. Например,
изображение двоичного дерева на рис. 20.24 должно выглядеть на экране так:
99
97
92
83
72
71
69
49
44
40
32
28
19
18
11
1138
Глава 20
Обратите внимание, что крайний справа листовой узел появляется вверху в самой
правой колонке, а корневой узел появляется в левой части экрана. Каждый
столбец выводится через пять пробелов от предыдущего. Функция outputTree должна
получать в качестве аргументов указатель на корневой узел дерева и целое число
totalSpaces, задающее число пробелов перед очередным столбцом (эта переменная
должна иметь начальное значение равное нулю, чтобы корневой узел выводился
с левого края экрана). Функция использует модифицированный обход дерева с
порядковой выборкой. Он начинается в крайнем правом узле дерева, от которого
перемещается влево. Алгоритм выполняется следующим образом:
Пока указатель на текущий узел не нулевой
рекурсивно вызвать outputTree с правым поддеревом текущего
узла и totalSpaces+5
воспользоваться оператором for для подсчета от 1 до totalSpaces
и вывода пробелов
вывести значение в текущем узле
установить указатель текущего узла на левое поддерево текущего узла
увеличить значение totalSpaces на 5.
Специальный раздел: как написать свой собственный
компилятор
В упражнениях 8.18 и 8.19 мы представили Машинный язык Симплетрона (SML),
и вы создали симулятор компьютера, выполняющий программы, написанные на
SML. В этом разделе мы создадим компилятор, который будет транслировать
программы, написанные на языке программирования высокого уровня, в SML. В этом
разделе «связываются» воедино отдельные моменты процесса программирования.
Мы будем писать программы на языке высокого уровня, компилировать их с
помощью компилятора, который мы здесь создадим, и запускать компилированные
программы на симуляторе, созданном в упражнении 8.19.
20.26. (Язык Simple) Прежде чем мы начнем разрабатывать компилятор, мы обсудим
простой, но в тоже время достаточно мощный язык высокого уровня, похожий на
первые версии популярного языка BASIC. Назовем его язык Simple. Каждый
оператор состоит из номера строки и инструкции Simple. Номера строк должны
следовать в порядке возрастания. Каждая инструкция начинается с одной из
следующих команд Simple: rem, input, let, print, goto, if...goto и end (см. рис. 20.25). Все
команды, за исключением end, могут встречаться в программе многократно.
Simple оперирует только с целыми выражениями, включающими операции +, —, *
и /. Эти операции имеют такое же старшинство, как и в C++. Для изменения
порядка оценки выражения можно использовать скобки.
Наш компилятор Simple распознает только буквы нижнего регистра. Все
символы в файле Simple должны быть набраны в нижнем регистре (буквы, набранные
в верхнем регистре, приведут к синтаксической ошибке, если только они не
входят в оператор rem, для которого регистр игнорируется). Имя переменной
состоит из одной буквы. Simple не позволяет использовать осмысленные имена
переменных, поэтому их желательно описывать в комментариях. Simple оперирует
только с целыми переменными. В нем отсутствует объявление переменных —
простое упоминание имени переменной в программе автоматически вызывает ее
объявление и присвоение нулевого значения. Синтаксис языка Simple не
позволяет выполнять операций со строками (чтение строки, запись строки, сравнение
двух строк и т.д.). Если в программе на Simple встречается строка (после
команды, отличной от rem), компилятор генерирует сообщение о синтаксической
ошибке. В нашем компиляторе предполагается, что программа на Simple введена
правильно. В упражнении 20.29 читателю будет предложено усовершенствовать
Структуры данных
1139
компилятор, чтобы он мог выполнять проверку программы на синтаксические
ошибки.
Simple имеет операторы условного (if...goto) и безусловного (goto) переходов для
изменения порядка выполнения операций в процессе выполнения программы.
Если условие в операторе if...goto истинно, управление передается заданной
в операторе строке программы. В операторе if...goto допустимы следующие
операции отношений: <, >, <=, >=, == и !=. Старшинство этих операций такое же,
как в C++.
Команда
rem
input
let
print
goto
if...goto
end
Пример оператора
50 rem this is a remark
30 input x
80 let u = 4 * (j - 56)
10 print w
70 goto 45
35 if i == z goto 80
99 end
Описание
Любой текст после команды rem используется
исключительно для целей документирования и
игнорируется компилятором
Выводит на экран знак вопроса, предлагая
пользователю ввести целое число. Считывает
число, введенное с клавиатуры, и сохраняет в х
Присваивает и значение выражения
4 * (j - 56). Отметим, что справа от знака
равенства может стоять выражение любой
степени сложности
Выводит на экран значение w
Передает управление строке 45
Сравнивает i и z на предмет равенства
и передает управление строке 80, если условие
истинно; в противном случае выполняется
следующий за if...goto оператор
Прерывает исполнение программы
Рис. 20.25. Команды Simple
Давайте рассмотрим теперь несколько программ на языке Simple,
демонстрирующих его возможности. Первая программа (рис. 20.26) считывает два целых
числа, введенных с клавиатуры, сохраняет их значения в переменных а и Ь,
после чего вычисляет и выводит на печать их сумму (сохраняемую в переменной с).
1 10 rem determine and print the sum of two integers
2 15 rem
3 20 rem input the two integers
4 30 input a
5 40 input b
6 45 rem
7 50 rem add integers and store result in с
8 60 let с = a + b
9 65 rem
10 70 rem print the result
11 80 print с
12 90 rem terminate program execution
13 99 end
Рис. 20.26. Определение суммы двух чисел
1140
Глава 20
Программа на рис. 20.27 определяет и выводит на печать большее из двух целых
чисел. Числа вводятся с клавиатуры и сохраняются в переменных s и t.
Оператор if...goto проверяет на истинность условие s >= t. Если оно истинно,
управление предается строке 90 и на экран выводится значение s; в противном случае
выводится значение t, управление передается оператору end в строке 99 и
выполнение программы завершается.
1 10 rem determine and print the larger of two integers
2 20 input s
3 30 input t
4 32 rem
5 35 rem test if s >= t
6 40 if s >= goto 90
7 45 rem
8 50 rem t is greater than s, so print t
9 60 print t
10 70 goto 99
11 75 rem
12 80 rem s is greater than or equal to t, so print s
13 90 print s
14 99 end
Рис. 20.27. Нахождение большего из двух чисел
В Simple не предусмотрен оператор повторения (такой, как for, while или
do...while в C++). Однако язык позволяет эмулировать любой из операторов
повторения C++, используя операторы if...goto и goto. На рис. 20.28 показана
программа, использующая цикл с контрольным значением для вычисления
квадратов вводимых чисел. Каждое число вводится с клавиатуры и сохраняется в
переменной j. Если вводится контрольное значение -9999, управление передается
строке 99 и программа завершается. В противном случае переменной к
присваивается значение переменной j, возведенное в квадрат, к выводится на экран
и управление передается строке 20, где вводится следующее число.
1 10 rem calculate the squares of several integers
2 20 input j
3 23 rem
4 25 rem test for sentinel value
5 30 if j == -9999 goto 99
6 33 rem
7 35 rem calculate square of j and assign result to k
8 40 let k = j * j
9 50 print k
10 53 rem
11 55 rem loop to get next j
12 60 goto 20
13 99 end
Рис. 20.28. Вычисление квадратов нескольких чисел
Структуры данных
1141
Используя программы на рис. 20.26, 20.27 и 20.28 в качестве образца, напишите
на Simple программы, выполняющие следующие действия:
a) Ввести три числа, определить для них среднее значение и вывести результат
на печать.
b) Используя цикл с контрольным значением, ввести десять чисел, вычислить их
сумму и вывести полученное значение на печать.
c) Используя цикл с управлением по счетчику, ввести семь чисел, вычислить их
сумму и вывести полученное значение на печать.
d) Ввести ряд чисел, определить среди них наибольшее и вывести его на печать.
Первое введенное число должно показывать, сколько чисел должно быть
обработано.
e) Ввести десять чисел и вывести на печать наименьшее из них.
f) Вычислить и вывести на печать сумму четных чисел от 2 до 30.
g) Вычислить и вывести на печать произведение нечетных чисел от 1 до 9.
20.27. (Создание компилятора. Предварительные требования: выполнить
упражнения 8.18, 8.19, 20.12, 20.13 и 20.26) Теперь, когда описан язык Simple
(упражнение 20.26), мы обсудим, как создать для него компилятор. Сначала рассмотрим
процедуру, посредством которой программа Simple преобразуется в код SML
и выполняется симулятором Симплетрона (см. рис. 20.29). Файл, содержащий
программу на Simple, считывается компилятором и преобразуется в код SML.
SML-код выводится в файл на диске, по одной инструкции SML на строку. Затем
SML-файл загружается в симулятор Симплетрона, причем результат
записывается в файл на диске и выводится на экран. Заметим, что программа
Симплетрона, разработанная в упражнении 8.19, принимает данные с клавиатуры.
Поэтому ее необходимо доработать для считывания из файла, чтобы она могла
выполнять программу, созданную нашим компилятором.
Компилятор выполняет преобразование программы из Simple в SML за два
прохода. Во время первого прохода создается таблица символов (объект), в
которой сохраняется (вместе со своим типом и соответствующим положением в
конечном коде SML) каждый номер строки (объект), имя переменной (объект)
и константа (объект) программы Simple (таблица символов будет детально
обсуждаться ниже). Кроме того, во время первого прохода для каждого оператора
Simple вырабатываются соответствующие объекты инструкций SML. Как будет
видно из дальнейшего, если программа Simple содержит оператор, который
передает управление строке, расположенной ниже, некоторые инструкции SML-npo-
граммы после первого прохода окажутся «незаконченными». Во время второго
прохода незаконченные инструкции находятся компилятором и дополняются,
а конечная программа SML выводится в файл.
^^п^^Гj—► компилятор —► ■■'£^=й^—> ™МУЛЯТ°Р
фщп^Ш}р\е г ; ф^тг^Щ:) Симплетрона
-•< вывод
^5.5^58"".^ на экран
Рис. 20.29. Чтение, компиляция и исполнение программы на языке Simple
1142
Глава 20
Первый проход
Компилятор начинает работу со считывания одного оператора программы на
Simple в память. Для обработки и последующей компиляции строка должна
быть разделена на лексемы (т.е. «фрагменты» оператора; для этих целей может
быть использована стандартная библиотечная функция strtok). При этом не
следует забывать, что каждый оператор начинается с номера строки,
предшествующего команде. По мере дробления оператора на лексемы, если лексема является
номером строки, переменной или константой, она помещается в таблицу
символов. Номер строки помещается в таблицу символов, только если это первая
лексема оператора. symbolTable — это массив объектов tableEntry,
представляющих символы программы. Ограничения на число символов в программе
отсутствуют. Следовательно, для некоторых программ symbolTable может оказаться
очень большим. Определим на данный момент symbolTable как массив из 100
элементов. Вы можете увеличить или уменьшить этот размер, когда программа
заработает.
Каждый объект tableEntry содержит три элемента. Элемент symbol целого типа
содержит ASCII-представление переменной (напомним, что имена переменных
состоят из одного символа), номер строки или константу. Элемент type — это
одна из следующих букв, обозначающих тип символа: 'С — для константы,
'L' — для номера строки или 'V — для переменной. Элемент location содержит
номер ячейки памяти Симплетрона (от 00 до 99), на которую ссылается символ.
Память Симплетрона — это массив из 100 целых, в котором хранятся
инструкции SML и данные. Для номера строки ячейкой памяти является элемент в
массиве памяти Симплетрона, в котором начинаются инструкции SML для
оператора Simple. Для переменной или константы ячейкой памяти является элемент
в массиве памяти Симплетрона, в котором хранится переменная или константа.
Переменные и константы размещаются от конца памяти Симплетрона к ее
началу. Первая переменная или константа сохраняется в ячейке 99, следующая 98
и так далее.
Таблица символов играет центральную роль в преобразовании написанных на
Simple программ в код SML. В главе 7 мы узнали, что инструкция SML
представляет собой четырехзначное целое число, состоящее из двух частей — кода
операции и операнда. Код операции определяется командой Simple. Например,
команда Simple input соответствует коду SML 10 (операция чтения), а команда Simple
print соответствует коду SML 11 (операция записи). Операнд — это ячейка
памяти, содержащая данные, над которыми выполняется операция (т.е. код
операции 10 считывает значение, введенное с клавиатуры, и сохраняет его в заданной
операндом ячейке памяти). Компилятор производит поиск в symbolTable, чтобы
найти соответствующую символу ячейку памяти Симплетрона, которая затем
используется для окончательного формирования инструкций SML.
Компиляция каждого оператора Simple зависит от его команды. Например, после
того, как номер строки для оператора rem вносится в таблицу символов,
оставшаяся часть оператора игнорируется компилятором, поскольку комментарий
служит только для целей документирования. Операторы input, print, goto и end
соответствуют инструкциям SML read, write, branch (переход к определенной ячейке
памяти) и halt. Операторы, содержащие эти команды Simple, непосредственно
преобразуются в инструкции SML (отметим, что оператор goto может содержать
неразрешенную ссылку, если номер строки, на который он ссылается, находится
дальше в файле программы Simple; иногда это называют ссылкой вперед).
Когда оператор goto компилируется с неразрешенной ссылкой, инструкция SML
должна быть отмечена, чтобы во время второго прохода компилятор дополнил
инструкцию. Такие метки хранятся в массиве flags типа int, состоящем из 100
элементов, в котором каждый элемент инициализирован значением —1. Если
Структуры данных
1143
ячейка памяти, на которую ссылается номер строки программы Simple, еще
неизвестна (т.е. ее нет в таблице символов), номер строки сохраняется в массиве
flags в элементе с тем же индексом, что и незаконченная инструкция. Операнд
незаконченной инструкции временно устанавливается равным 00. Например,
инструкция безусловного перехода (выполняющая ссылку вперед) остается
в виде +4000 до второго прохода компилятора. О втором проходе компилятора
мы говорим далее.
Компиляция операторов it... go to и let сложнее по сравнению с другими
операторами — это единственные операторы, транслируемые в более чем одну
инструкцию SML. Для оператора if...goto компилятор генерирует код проверки условия
и, в случае необходимости, перехода на другую строку. Результатом перехода
может оказаться неразрешенная ссылка. Каждую из операций отношения и
равенства можно смоделировать с помощью инструкций SML перехода по нулю
и перехода по минусу (а возможно, комбинацией из этих двух переходов).
Для оператора let компилятор генерирует код вычисления арифметического
выражения произвольной сложности, состоящего из целых переменных и/или
констант. В выражении все операнды и операции должны быть отделены друг от
друга пробелами. В упражнениях 20.12 и 20.13 были представлены алгоритмы
преобразования инфиксных выражений в постфиксные и вычисления
постфиксных выражений, применяемые в компиляторах для оценки арифметических
выражений. Прежде чем приниматься за разработку своего компилятора, вы
должны выполнить оба этих упражнения. Когда компилятор оценивает выражение,
он сначала преобразует инфиксную нотацию в постфиксную, и после этого
вычисляет постфиксное выражение.
А как компилятор производит машинный код для оценки выражения,
содержащего переменные? Алгоритм постфиксной оценки содержит «крючок», который
позволяет нашему компилятору создавать инструкции SML, а не выполнять
реальные вычисления. Чтобы использовать в компиляторе этот «крючок»,
алгоритм постфиксной оценки необходимо изменить, чтобы он мог выполнять поиск
в таблице символов каждого символа, который ему встречается (и, возможно,
вставлять его в таблицу), определять соответствие символов ячейкам памяти
и заталкивать в стек вместо символов эти ячейки памяти. В постфиксном
выражении для выполнения операции из стека выталкиваются две ячейки
памяти, и генерируется реализующий операцию машинный код с этими ячейками
в качестве операндов. Результат каждого подвыражения сохраняется во
временной ячейке памяти и помещается обратно в стек, чтобы оценка постфиксного
выражения могла продолжаться. Когда постфиксная оценка завершена, ячейка
памяти, содержащая результат, оказывается единственной ячейкой, оставшейся
в стеке. Она выталкивается, и создается инструкция SML, присваивающая
результат переменной, стоящей в левой части оператора let.
Второй проход
На втором проходе компилятор выполняет две задачи: разрешает все
неопределенные ссылки и выводит код SML в файл. Разрешение ссылок происходит
следующим образом:
1) Производится поиск неразрешенных ссылок в массиве flags (т.е. поиск
элементов, отличных от -1).
2) В массиве symbolTable ищется объект, содержащий символ, записанный
в массиве flags (убедитесь, что это символ типа 'L' для номера строки).
3) Из элемента location в инструкцию с неразрешенной ссылкой вставляется
ячейка памяти (напомним, что инструкция, содержащая неразрешенную
ссылку, имеет операнд 00).
4) Шаги 1, 2 и 3 повторяются до тех пор, пока не будет просмотрен весь массив flags.
1144
Глава 20
После того как процесс разрешения завершен, весь массив, содержащий код
SML, выводится в файл на диске по одной инструкции SML в строке. Теперь этот
файл можно прочитать Симплетроном для его исполнения (после того, как симу-
лятор будет соответствующим образом усовершенствован и сможет использовать
для ввода данных файл).
Законченный пример
Следующий пример иллюстрирует законченное преобразование написанной на
Simple программы в SML, как оно будет выполнено компилятором Simple.
Рассмотрим программу на Simple, которая получает с клавиатуры целое число
и суммирует числа от 1 до этого числа. Программа и инструкции SML, созданные
после первого прохода, показаны на рис. 20.30. Таблица символов, созданная
после первого прохода, показана на рис. 20.31.
Программа на Simple
5 rem sum 1 to x
10 input x
15 rem check у == x
*
20 if у == x goto 60
Ячейки памяти
и инструкции SML
нет
00 +1099
нет
01 +2098
02 +3199
Описание
rem игнорируется
считывание х в ячейку 99
rem игнорируется
загрузка у (98) в аккумулятор
вычитание х (99) из аккумулятора
25 rem increment у
30 let у = у + 1
•
35 rem add у to total
40 let t = t + у
45 rem loop у
50 goto 20
55 rem output result
60 print t
99 end
03 +4200
нет
04 +2098
05 +3097
06 +2196
07 +2096
08 +2198
нет
09 +2095
10 +3098
11 +2194
12 +2094
13 +2195
нет
14 +4001
нет
15+1195
16 +4300
переход по нулю к неразрешенной
ячейке
rem игнорируется
загрузка у в аккумулятор
прибавление 1 (97) к аккумулятору
сохранение во временной ячейке 96
загрузка из временной ячейки 96
сохранение аккумулятора в у
rem игнорируется
загрузка t (95) в аккумулятор
прибавление у к аккумулятору
сохранение во временной ячейке 94
загрузка из временной ячейки 94
сохранение аккумулятора в t
rem игнорируется
переход к ячейке 01
rem игнорируется
вывод t на экран
окончание выполнения программы
Рис. 20.30. Инструкции SML, созданные после первого прохода компилятора
Структуры данных
1145
Символ
5
10
'X'
15
20
■у
25
30
1
35
40
■г
45
50
55
Тип
V
V
i
Ячейка памяти
00
00
99
01
01
98
04
04
97
09
09
95
14
14
15
Рис. 20.31. Таблица символов для программы на рис. 20.30
Большинство операторов Simple преобразуются непосредственно в одну
инструкцию SML. Исключение в этой программе составляют комментарии, оператор
if...goto в строке 20 и операторы let. Комментарии не транслируются в машинные
коды. Однако номер строки комментария помещается в таблицу символов на тот
случай, если на этот номер будет ссылаться оператор goto или оператор if /go to.
Строка 20 программы означает, что если условие у==х истинно, то управление
передается строке 60. Поскольку строка 60 появится в программе позже, на первом
проходе компилятора 60 не помещается в таблицу символов (номера строк
помещаются в таблицу символов, только когда они встречаются в качестве первой
лексемы оператора). Следовательно, невозможно в этот момент определить операнд
в инструкции SML переход по нулю в ячейке 03 массива инструкций SML.
Компилятор помещает 60 в ячейку 03 массива flags, чтобы показать, что на втором
проходе компилятора необходимо завершить эту инструкцию.
Мы должны отслеживать положение следующей инструкции SML в массиве,
поскольку нет однозначного соответствия между операторами Simple и
инструкциями SML. Например, оператор if...goto в строке 20 компилируется в три
инструкции SML. Каждый раз, когда создается инструкция SML, мы должны
увеличивать счетчик инструкций, перемещаясь в следующую ячейку массива SML.
Отметим, что размер памяти Симплетрона может представлять проблему для
программ Simple, содержащих большое количество операторов, переменных и
констант. Вполне возможно, что компилятору не хватит памяти. Чтобы иметь
возможность обнаружить такую ситуацию, ваша программа должна содержать
счетчик данных, чтобы отслеживать ячейку памяти в массиве SML, в которой будет
сохраняться следующая константа или переменная. Если значение счетчика
инструкций больше, чем значение счетчика данных, массив SML заполнен. В этом
случае процесс компиляции необходимо прервать и компилятор должен выдать
сообщение об ошибке, что в процессе компиляции обнаружилась нехватка памяти.
1146
Глава 20
Пошаговый просмотр процесса компиляции
Давайте теперь пройдем по всем шагам процесса компиляции программы Simple,
представленной на рис. 20.30. Компилятор считывает в память первую строку
программы:
5 rem sum l to x
С помощью strtok выделяется первая лексема оператора — номер строки (см.
в главах 8 и 21 описание функций C++, работающих со строками в стиле С).
Лексема, возвращенная strtok, преобразуется с помощью atoi в целое, чтобы
символ 5 можно было искать в таблице символов. Если символ не обнаружен, он
вставляется в таблицу. Так как мы находимся в самом начале программы, в
таблице пока нет ни одного символа. Поэтому 5 вставляется в таблицу символов,
как принадлежащее к типу L (номер строки), и ему присваивается первая ячейка
памяти в массиве SML @0). Хотя эта строка является комментарием, для нее все
равно выделяется место в таблице символов (на тот случай, если на нее будут
ссылаться операторы goto или if/goto). Для оператора rem не создается никаких
инструкций SML, поэтому значение счетчика инструкций не изменяется.
Далее разбивается на лексемы оператор
10 input х
Номер строки 10 помещается в таблицу символов как имеющий тип L и ему
присваивается первая ячейке массива SML @0, поскольку программа начиналась
с комментария и счетчик инструкций по-прежнему равен 00). Команда input
означает, что следующая лексема — переменная (только переменная может
присутствовать в операторе input). Поскольку input непосредственно соответствует
коду операции SML, компилятор просто определяет положение х в массиве SML.
Символ х не обнаружен в таблице символов. Поэтому он включается в таблицу
символов как ASCII-представление буквы х, получает тип V, и ему
присваивается ячейка 99 в массиве SML (данные начинают размещаться с ячейки 99, и
ячейки памяти для них выделяются в обратном направлении). Теперь для этого
оператора можно генерировать код SML. Код 10 (код операции считывания в SML)
умножается на 100, и к получившемуся значению прибавляется ячейка таблицы
символов, в которой расположен х, образуя полную инструкцию. Отметим, что
инструкция сохраняется в массиве SML в ячейке 00. Счетчик инструкций
увеличивается на 1, поскольку была создана одна инструкция SML.
Оператор
15 rem check у == х
разбивается на лексемы. В таблице символов ищется строка с номером 15
(которой там нет). Номер строки помещается в таблицу, как имеющий тип L, и ему
присваивается следующая ячейка массива, 01 (напомним, что оператор rem не
производит кода, поэтому счетчик инструкций сохраняет свое значение).
Оператор
20 if у == х goto 60
разбивается на лексемы. Номер строки 20 вставляется в таблицу символов,
получая тип L и следующую ячейку массива SML — 01. Команда if означает, что
будет производиться оценка условия. Переменная у не обнаружена в таблице
символов, поэтому она помещается туда, получает тип V и ячейку 98. Затем
генерируются инструкции SML для оценки условия. Поскольку в SML отсутствует
прямой эквивалент для оператора if...goto, его приходится эмулировать,
выполняя вычисления с х и у и ветвление в зависимости от результата. Если х равен у,
результат вычитания х из у равен нулю, поэтому для эмуляции оператора
Структуры данных
1147
if...goto можно использовать инструкцию перехода по нулю. Первый шаг
требует, чтобы значение у было загружено (из SML ячейки с номером 98) в
аккумулятор. Для этого создается инструкция 01 +2098. Следующим шагом из
аккумулятора вычитается х. Для этого создается инструкция 02 +3199. Значение в
аккумуляторе может оказаться как нулевым, так и положительным или
отрицательным. Так как рассматривается операция ==, нас интересует переход
по нулю. Сначала в таблице символов ищется ячейка перехода (в данном
случае 60), которая не находится. Поэтому 60 помещается в ячейку 03 массива
flags, и создается инструкция 03 +4200 (мы не можем указать ячейку перехода,
поскольку еще не присвоили строке 60 ячейку в массиве SML). Счетчик
инструкций увеличивает свое значение до 04.
Компилятор переходит к оператору
25 rem increment у
Номер строки 25 вставляется в таблицу символов как тип L и получает
SML-ячейку 04. Счетчик инструкций не увеличивается.
Когда происходит разбиение на лексемы оператора
30 let у = у + 1
номер строки 30 вставляется в таблицу символов как тип L и ему присваивается
ячейка SML 04. Команда let означает, что данная строка является оператором
присваивания. Сначала все символы строки помещаются в таблицу символов
(если они там еще отсутствуют). Число 1 добавляется в таблицу как тип С и ему
выделяется ячейка 97. Далее та часть, что расположена справа от оператора
присваивания, переводится из инфиксной формы в постфиксную. После этого
вычисляется постфиксное выражение (у 1 +). В таблице символов ищется символ у,
и соответствующая ему ячейка памяти заталкивается в стек. Символ 1 также
ищется в таблице символов и соответствующая ячейка также заталкивается
в стек. Встретив знак операции +, постфиксный вычислитель выталкивает из
стека правый и левый операнды, после чего создаются инструкции SML
04 +2098 (загрузить у)
05 +3097 (прибавить 1)
Результат выражения сохраняется во временной ячейке памяти (96) инструкцией
06 +2196 (загрузить временную ячейку)
и адрес временной ячейки заталкивается в стек. Теперь, когда выражение
оценено, результат необходимо сохранить в у (т.е. переменной, стоящей слева от =).
Поэтому значение из временной ячейки загружается в аккумулятор и
аккумулятор сохраняется в у при помощи инструкций
07 +2096 (загрузить временную ячейку)
08 +2198 (сохранить у)
Читатель, конечно, тут же заметит, что созданные инструкции SML избыточны.
В дальнейшем мы еще вернемся к этой проблеме.
Когда оператор
35 rem add у to total
разбивается на лексемы, номер строки 35 вставляется в таблицу символов как
тип L и ему выделяется ячейка 09.
Оператор
40 let t = t + у
аналогичен оператору в строке 30. Переменная t помещается в таблицу символов,
как имеющая тип V, и ей присваивается ячейка SMT OK Инструкции следуют той
1148
Глава 20
же самой логике и формату, что и для строки 30, и при этом создаются
инструкции 09 +2095, 10 +3098, 11 +2194 и 13 +2195. Отметим, что результат
выполнения операции t + у присваивается временной ячейке 94, перед тем как будет
присвоен t (95). Читатель, конечно же, опять заметил, что инструкции в ячейках 11
и 12 избыточны. Как уже говорилось, мы вернемся к этой теме позже.
Оператор
45 rem loop у
является комментарием, поэтому строка 45 добавляется в таблицу символов как
имеющая тип L, и ей присваивается ячейка SML 14.
Оператор
50 goto 20
передает управление строке 20. Номер строки 50 помещается в таблицу
символов с типом L и ему присваивается ячейка 14. Эквивалентом goto в SML
является безусловный переход D0) — инструкция, передающая управление заданной
ячейке SML. Компилятор просматривает таблицу символов в поисках строки 20
и обнаруживает, что она соответствует ячейке SML 01. Код операции D0)
умножается на 100 и к нему прибавляется ячейка 01; в результате получается
инструкция 14 +4001.
Оператор
55 rem output result
является комментарием, поэтому строка 55 добавляется в таблицу символов как
тип L, и ей присваивается ячейка SML 15.
Оператор
60 print t
является оператором вывода. Номер строки 60 вставляется в таблицу символов
как тип L и соответствующий ячейке 15. Аналогом print в SML служит код
операции 11 (запись). Ячейка, содержащая t, ищется в таблице символов и
складывается с кодом операции, умноженным на 100.
Оператор
99 end
является последней строкой программы. Номер строки 99 вставляется в таблицу
символов как имеющий тип L, и ему присваивается ячейка 16. Команда end
генерирует инструкцию SML +4300 D3 в SML означает стоп), которая
записывается как последняя инструкция в массиве памяти SML.
На этом первый проход компилятора завершается. Теперь рассмотрим второй
проход. Он начинается с поиска в массиве flags значений, отличных от —1.
Ячейка 03 содержит 60, таким образом, компилятор узнает, что инструкция 03
неполна. Компилятор завершает инструкцию, находя в таблице символов 60,
определяя соответствующую ячейку и прибавляя ее адрес к неполной инструкции.
В данном случае оказывается, что 60 соответствует ячейке SML 15, поэтому
03 +4200 заменяется законченной инструкцией 03 +4215. Теперь компиляция
написанной на Simple программы успешно завершена.
Чтобы создать компилятор, вам необходимо решить следующие задачи:
а) Усовершенствовать программу Симплетрона, которую вы написали в
упражнении 7.19, чтобы она могла считывать данные из заданного пользователем
файла (см. главу 11). Кроме того, симулятор должен выводить результаты
в файл на диске в том же формате, как они выводятся на экран.
Структуры данных
1149
b) Модифицировать алгоритм преобразования инфиксного выражения в
постфиксное из упражнения 20.12, чтобы он мог работать с многозначными
целыми операндами и операндами в виде однобуквенной переменной. Подсказка:
для выделения каждой константы и переменной в выражении можно
воспользоваться стандартной библиотечной функцией strtok, а преобразование
констант из строк в числа выполнять с помощью стандартной функции atoi.
[Замечание. Представление данных в постфиксном выражении должно быть
изменено, чтобы можно было работать с именами переменных и целыми
константами.]
c) Модифицировать алгоритм вычисления постфиксного выражения, чтобы он
мог работать с операндами в виде многозначных чисел и имен переменных.
Кроме того, алгоритм должен иметь обсуждавшийся выше «крючок», чтобы
вместо непосредственного вычисления выражения создавались инструкции
SML. [Подсказка. Чтобы выделить в выражении отдельные константы и
переменные, можно воспользоваться функцией стандартной библиотеки strtok,
после чего константы можно преобразовать из строк в числа с помощью
функции стандартной библиотеки atoi.] [Замечание. Представление данных в
постфиксном выражении должно быть модифицировано, чтобы была возможность
работать с именами переменных и целыми константами.]
d) Построить компилятор. Объедините части (Ь) и (с) для оценки выражений
в операторах let. Ваша программа должна содержать функцию,
выполняющую первый проход компилятора, и функцию, выполняющую второй проход.
Обе функции для выполнения своих задач могут вызывать другие функции.
20.28. (Оптимизация компилятора Simple) После того как программа была
компилирована и преобразована в SML, мы получили набор инструкций. Некоторые
комбинации инструкций часто повторяются, обычно в триплетах, называемых
порождениями. Порождения, как правило, состоят из трех инструкций, таких как
загрузить, прибавить и сохранить. Например, на рис. 20.32 представлены пять
инструкций SML, созданных при компиляции программы из рис. 20.30. Первые
три инструкции составляют порождение, которое прибавляет 1 к у. Заметьте,
что инструкции 06 и 07 сохраняют значение, находящееся в аккумуляторе, во
временной ячейке 96, после чего вновь загружают это значение в аккумулятор,
чтобы инструкция 08 могла сохранить значение в ячейке 98. Часто за
порождением следует инструкция загрузки той же самой ячейки, в которую только что
производилась запись. Такой код можно оптимизировать путем удаления
инструкции сохранения и следующей непосредственно за ней инструкции загрузки,
оперирующей с той же самой ячейкой памяти. Такая оптимизация позволит
Симплетрону быстрее выполнять программу, так как в ней будет меньше
инструкций. На рис. 20.33 показана оптимизированная программа SML, полученная
из представленной ранее на рис. 20.30. Заметьте, что в оптимизированном коде
на четыре инструкции меньше, так что экономия памяти составляет 25%.
Усовершенствуйте компилятор, введя в него оптимизацию создаваемого кода
Машинного языка Симплетрона. Вручную сравните оптимизированный и не
оптимизированный код и посчитайте, на сколько процентов оптимизированный
код короче.
1 04 +2098 (загрузить)
2 05 +3097 (прибавить)
3 06 +2196 (сохранить)
4 07 +2096 (загрузить)
5 08 +2198 (сохранить)
Рис. 20.32. Неоптимизированный код из программы, представленной на рис. 20.30
1150
Глава 20
Программа на Simple
5 rem sum 1 to x
432010 inputx
15 rem check у == x
20 if у == x goto 60
25 rem increment у
30 let у = у + 1
35 rem add у to total
40 let t = t + у
45 rem loop у
50 goto 20
2055 rem output result
60 print t
99 end
Ячейки памяти
и инструкции SML
нет
00 +1099
нет
01 +2098
02 +3199
03 +4211
нет
04 +2098
05 +3097
06 +2198
нет
07 +2096
08 +3098
09 +2196
нет
10 +4001
нет
11 +1196
12 +4300
Описание
rem игнорируется
считывание х в ячейку 99
rem игнорируется
загрузка у (98) в аккумулятор
вычитание х (99) из аккумулятора
переход по нулю к ячейке 11
rem игнорируется
загрузка у в аккумулятор
прибавление 1 (97) к аккумулятору
сохранение аккумулятора в у (98)
rem игнорируется
загрузка t из ячейки (96)
прибавление у (98) к аккумулятору
сохранение аккумулятора в t (96)
rem игнорируется
переход к ячейке 01
rem игнорируется
вывод t (96) на экран
окончание выполнения программы
Рис. 20.33. Оптимизированный код для программы на рис. 20.30
20.29. (Модификация компилятора Simple) Выполните следующие модификации
компилятора Simple. Некоторые из них могут также потребовать
усовершенствования программы-симулятора Симплетрона, написанной в упражнении 8.19.
a) Сделать возможным использование операции взятия по модулю (%) в
операторе let. Необходимо внести изменения и в Машинный язык Симплетрона,
дополнив его инструкцией для взятия по модулю.
b) Сделать возможным использование операции возведения в степень (л) в
операторе let. Необходимо внести изменения и в Машинный язык Симплетрона,
дополнив его инструкцией для возведения в степень.
c) Сделать возможным распознавание компилятором букв как верхнего, так
и нижнего регистра (т.е. написание 'А' и 'а' должно приводить к одинаковому
результату). Никаких изменений в симуляторе Симплетрона не требуется.
d) Сделать возможным считывание оператором input сразу нескольких
переменных, например: input x, у. Никаких изменений в симуляторе Симплетрона не
требуется.
e) Сделать возможным вывод сразу нескольких переменных с помощью одного
оператора print, например: print a, b, с. Никаких изменений в симуляторе
Симплетрона не требуется.
Структуры данных
1151
f) Ввести проверку синтаксиса, чтобы компилятор выводил сообщение об
ошибке всякий раз, когда в программе Simple встречается синтаксическая ошибка.
Никаких изменений в симуляторе Симплетрона не требуется.
g) Сделать возможным использование массивов чисел. Никаких изменений в
симуляторе Симплетрона не требуется.
h) Сделать возможным использование подпрограмм, управляемых командами
Simple gosub и return. Команда gosub передает управление подпрограмме,
а команда return возвращает его оператору, следующему за gosub. Это .будет
что-то похожее на вызов функции в С. Допускается вызов одной и той же
подпрограммы несколькими gosub, расположенными в разных местах
программы. Никаких изменений в симуляторе Симплетрона не требуется.
i) Сделать возможным использование операторов повторения вида
for х = 2 to 10 step 2
операторы Simple
next
Этот оператор for организует цикл от 2 до 10 с шагом 2. Оператор next
отмечает конец тела цикла, начинающегося строкой for. Никаких изменений в
симуляторе Симплетрона не требуется,
j) Сделать возможным использование операторов повторения вида
for х = 2 to 10
операторы Simple
next
Такой оператор for организует цикл от 2 до 10 с шагом 1. Никаких изменений
в симуляторе Симплетрона не требуется,
к) Сделать возможной обработку вывода и ввода строк. При этом потребуется
соответствующим образом изменить симулятор Симплетрона, чтобы он мог
обрабатывать и хранить данные строкового типа. Подсказка: каждое слово
Симплетрона можно разделить на две части, каждая из которых содержит
двузначное целое. Каждое двузначное целое представляет десятичный
эквивалент символа ASCII. Добавьте инструкцию машинного языка, которая
будет печатать строку, начинающуюся в некоторой ячейке памяти
Симплетрона. Первая половина слова в этой ячейке является числом символов строки
(т.е. ее длиной). Каждое последующее полуслово содержит один символ
ASCII, представленный двумя десятичными цифрами. Инструкция
машинного языка проверяет длину и печатает строку, переводя каждое двузначное
число в соответствующий символ.
1) Сделать возможной обработку не только целых, но и чисел с плавающей
точкой. Необходимо внести соответствующие изменения и в симулятор
Симплетрона, чтобы он тоже мог работать с числами с плавающей точкой.
20.30. (Интерпретатор Simple) Интерпретатором называется программа, которая
считывает операторы языка высокого уровня, определяет операции, которые они
должны выполнить, и тут же эти операции выполняет. Программа не
преобразуется предварительно в машинный код. Интерпретаторы работают медленно,
поскольку каждый исполняемый оператор программы сначала необходимо
дешифровать. Если оператор помещен в цикл, дешифровка оператора будет
производиться при каждом его вызове в теле цикла. Ранние версии языка программирования
BASIC были реализованы в виде интерпретаторов.
Напишите интерпретатор для языка Simple, обсуждавшегося в
упражнении 20.26. Для оценки выражений в операторе let программа должна
использовать инфиксно-постфиксный конвертор, разработанный в упражнении 20.12,
и вычислитель постфиксных выражений, разработанный в упражнении 20.13. Ог-
1152
Глава 20
раничения, наложенные на язык Simple в упражнении 20.26, должны относиться
и к этой программе. Протестируйте интерпретатор, используя программы Simple
из упражнения 20.26. Сравните результаты выполнения этих программ в
интерпретаторе с результатами компиляции программ Simple и запуска их в симулято-
ре Симплетрона, разработанном в упражнении 8.19.
20.31. (Вставка/удаление произвольного элемента связанного списка) Наш шаблон
класса связанного списка производит вставку и удаление элементов только в
начале и конце списка. Этихвозможностей было для нас достаточно, когда мы
использовали закрытое наследование и композицию для разработки шаблона
класса стека и шаблона класса очереди с минимальными добавлениями к
утилизируемому классу связанного списка. На самом деле связанные списки являются
более общими структурами, чем список, который мы реализовали.
Модифицируйте класс связанного списка, созданный в этой главе, чтобы он производил
операции вставки и удаления в произвольном месте списка.
20.32. (Списки и очереди без указателей на конец) Наша реализация связанного списка
(рис. 20.3-20.5) использует два указателя (на начало и конец) firstPtr и lastPtr.
Указатель lastPtr удобен для элемент-функций insert AtBack и remo-
veFromBack класса List. Функция insert At Back соответствует функции enqueue
класса Queue. Перепишите класс List так, чтобы он не использовал lastPtr.
В этом случае любые операции в конце списка должны начинаться с просмотра
всего списка от начала до конца. Влияет ли это на реализацию класса Queue
(рис. 20.16)?
20.33. Используйте вариант с композицией программы стека (рис. 20.15) для создания
законченной работающей программы. Модифицируйте эту программу, сделав
элемент-функции встроенными. Сравните оба подхода. Резюмируйте
достоинства и недостатки встроенных элемент-функций.
20.34. (Производительность сортировки и поиска на двоичном дереве) Одной из
проблем сортировки двоичного дерева является то, что последовательность ввода
данных в дерево влияет на его форму — для того же самого набора данных
другая их последовательность может дать совершенно иную форму дерева.
Эффективность обработки двоичного дерева алгоритмами сортировки и поиска
чувствительна к форме дерева. Какую форму будет иметь двоичное дерево, если
данные вводились в него в порядке возрастания? в порядке убывания? Какую форму
должно иметь дерево, чтобы достигалась максимальная производительность
поиска?
20.35. (Индексированные списки) Поиск в связанных списках, как они представлены
в этой главе, должен производиться последовательно. Для больших списков это
может быть неэффективным. Обычный способ улучшения производительности
поиска заключается в создании и поддержке индекса списка. Индекс в данном
случае — это набор указателей на различные ключевые места списка. Например,
приложение, которое производит поиск в большом списке фамилий, могло бы
повысить производительность, создав индекс с 26 элементами — по одному на
каждую букву английского алфавита. Тогда, например, процедура поиска
фамилии, начинающейся с 'Y', сначала производила бы поиск в индексе, чтобы
определить, начиная скакого места расположены фамилии на 'Y', а потом
«запрыгивала» в список в этой точке и искала нужную фамилию последовательно. Поиск
был бы намного быстрее, чем в случае просмотра списка с самого начала.
Используйте класс List из рис. 20.3-20.5 как основу для класса IndexedList.
Напишите программу, которая демонстрирует операции с индексированными
списками. Не забудьте включить в класс функции inserlnlndexedList (вставить),
searchlndexedList (искать) и deleteFromlndexedList (удалить).
2!
Биты, символы, строки С
и структуры
ЦЕЛИ
В этой главе вы изучите:
• Создание и использование структур.
• Передачу функциям структур
по значению и по ссылке.
• Объявление typedef для
создания псевдонимов ранее
определенных типов данных
и структур.
• Поразрядные операции и создание
битовых полей для компактного
хранения данных.
• Функции библиотеки обработки
символов <cctype>.
• Функции преобразования строк
из библиотеки утилит общего назначения <cstdlib>.
• Функции обработки строк из библиотеки <cstring>.
37 Зак 1114
1154
Глава 21
21.1. Введение
21.2. Определение структур
21.3. Инициализация структур
21.4. Использование структур с функциями
21.5. typedef
21.6. Пример. Высокоэффективное моделирование
тасования и сдачи карт
21.7. Поразрядные операции
21.8. Битовые поля
21.9. Библиотека обработки символов
21.10. Функции преобразования строк-указателей
21.11. Функции поиска из библиотеки обработки
строк-указателей
21.12. Функции управления памятью из библиотеки
обработки строк-указателей
21.13. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
21.1. Введение
В этой главе мы обсудим структуры и операции с битами, символами
и строками в стиле С. Многие из представляемых здесь методик включены
в изложение потому, что многим работающим на C++ придется иметь дело
с кодом, унаследованным от С и ранних версий C++.
Разработчики C++ развили концепцию структуры до класса. Как и классы,
структуры C++ могут содержать спецификаторы доступа, элемент-функции,
конструкторы и деструкторы. На самом деле единственным отличием
структур от классов в C++ является то, что элементы структуры по умолчанию
имеют доступ public, если для них не указано никакого спецификатора. Классы
в книге уже были охвачены в достаточной полноте, так что по существу нет
необходимости обсуждать подробно структуры. Наше обсуждение структур
в этой главе сосредоточено поэтому на их использовании в С, где структуры
имеют только открытые элементы данных. Использование структур типично
для кода, унаследованного от С и ранних версий C++, с которым вы
столкнетесь в программной индустрии.
Мы обсудим, как создавать структуры, инициализировать их и передавать
функциям. Затем мы покажем высокоэффективное моделирование тасования
и сдачи карт, где для представления карт применяются структурные объекты
и строки в стиле С. Мы обсудим поразрядные операции, позволяющие про-
Биты, символы, строки С и структуры
1155
граммистам работать с отдельными битами в байтах данных. Мы представим
также битовые поля — структуры специального вида, в которых можно
указать точное число битов, которое переменная занимает в памяти. Эти
методики манипуляций с битами типичны в программах на С и C++, которые
непосредственно взаимодействуют с аппаратными устройствами, имеющими
ограниченную память. Глава заканчивается примерами со многими функциями
обработки символов и строк в стиле С; некоторые из них предназначены для
обработки блоков памяти как байтовых массивов.
21.2. Определение структур
Структуры являются агрегатными типами данных — другими словами,
они могут строиться из элементов различного типа, в том числе других
структур. Рассмотрим следующее определение структуры:
struct Card
{
char *face;
char *suit;
}; // конец struct Card
Ключевое слово struct начинает определение структуры Card. Идентификатор
Card является в C++ именем структуры и может использоваться для
объявления переменных структурного типа (в С именем вышеприведенной
структуры является struct Card). В данном примере Card является структурным
типом. Данные (и, возможно, функции — точно так же, как в классах),
объявленные внутри фигурных скобок определения структуры, являются ее
элементами. Элементы одной и той же структуры должны иметь уникальные
имена, но две различных структуры могут содержать элементы с одним и тем
же именем, не вызывая конфликта. Каждое определение структуры
оканчивается точкой с запятой.
щт^я Типичная ошибка программирования 21,1
\Щг I Пропуск точки с запятой, оканчивающей определение структуры,
является синтаксической ошибкой.
Определение Card содержит два элемента типа char * с именами face и suit.
Элементы структуры могут быть переменными основных типов данных (т.е.
int, double и т.п.) или агрегатами, такими, как массивы, другие структуры
и классы. Элементы данных одной структуры могут принадлежать к
различным типам. Например, структура Employee могла бы содержать в качестве
элементов символьные строки для имени и фамилии, элемент int для возраста
служащего, элемент char, содержащий 'М' или 'F', для пола, элемент double
для почасовой оплаты и т.д.
Структура не может содержать представителей себя самой. Например, в
определении структуры Card нельзя объявить переменную структурного типа
Card. Однако в структуру может быть включен указатель на Card. Структура,
содержащая указатель на тот же самый структурный тип, называется
автореферентной структурой. Мы уже имели дело с подобной конструкцией — авто-
1156
Глава 21
референтным классом — в главе 20 при построении различных связанных
структур данных.
Определение структуры Card не резервирует для нее какого-то места в
памяти; оно только создает новый тип данных, используемый для объявления
структурных переменных. Структурные переменные объявляются так же, как
переменные других типов. Так, операторы
Card oneCard;
Card deck[ 52 ];
Card *cardPtr;
объявляют oneCard — одиночную структурную переменную типа Card,
deck — массив из 52 элементов типа Card, и cardPtr — указатель на структуру
Card. Переменные структурного типа могут объявляться также в разделенном
запятыми списке, расположенном между закрывающей фигурной скобкой
определения данной структуры и точкой с запятой, завершающей определение
структуры. Например, предыдущие объявления могли бы быть включены
в определение структуры Card:
struct Card
{
char *face;
char *suit;
} oneCard, deck[ 52 ], *cardPtr;
Имя структуры не является обязательным. Если определение структуры не
специфицирует имени, переменные данного структурного типа могут
объявляться только между закрывающей скобкой определения структуры и
завершающей точкой с запятой.
Ш Общее методическое замечание 21,1
При создании структурного типа специфицируйте имя структуры.
Имя структуры необходимо для объявления новых переменных
данного типа позднее в программе, для объявления параметров
структурного типа и, если структура используется подобно классу C++, для
спецификации имени конструктора и деструктора.
Единственными допустимыми встроенными операциями, которые могут
производиться над структурами, являются присваивание объекта
структурного типа другому объекту того же типа, взятие адреса (&) структурного объекта,
обращение к элементам структурного объекта (аналогично обращению к
элементам класса) и применение операции sizeof для определения размера
структуры.
Элементы структуры не обязательно хранятся в последовательных байтах
памяти. Иногда в структуре имеются «дырки», поскольку некоторые
компиляторы сохраняют конкретные типы данных только на определенных
границах памяти (границе половинного слова, слова, двойного слова). Рассмотрим
следующее определение структуры, в котором объявляются структурные
объекты samplel и sample2:
Биты, символы, строки С и структуры
1157
struct Exapmle
{
char с;
int I;
} samplel, sample2;
Компьютер с двухбайтовыми словами мог бы требовать, чтобы каждый из
элементов Example был выровнен по границе слова (т.е. начинался с начала
слова; это зависит от машины). Рис. 21.1 показывает пример выравнивания
памяти элементов объекта типа Example, которому был присвоен символ 'а' и
целое 97 (показаны битовые представления значений). Если элементы структуры
хранятся с выравниванием по границе слова, то в памяти, выделяемой для
объектов Example, имеется 1-байтовая «дырка» (байт 1 на рисунке). Значение
в ней не определено. Если значения элементов samplel и sample2 в
действительности равны, структурные объекты необязательно также будут равны,
поскольку 1-байтовые дырки вряд ли будут содержать одинаковые значения.
Байт 0 12 3
01100001 00000000 01100001
Рис. 21.1. Возможное выравнивание памяти для переменной типа Example,
показывающее неопределенную область памяти
Типичная ошибка программирования 21.2
Сравнение структур приводит к ошибке компиляции.
Переносимость программ 21.1
Поскольку размер единиц данных конкретного типа
машинно-зависим, как и выравнивание, то машинно-зависимым является и
представление структур.
21.3. Инициализация структур
Структуры можно инициализировать посредством списков инициализации,
как это делается в случае массивов. Например, объявление
Card oneCard = { "Three", "Hearts" );
создает переменную oneCard и инициализирует ее элемент face строкой
"Three", а элемент suit строкой "Hearts". Если инициализаторов в списке
меньше, чем элементов в структуре, оставшиеся элементы инициализируются
значениями по умолчанию. Структурные переменные, объявляемые вне
любого определения функции (т.е. как внешние), инициализируются значениями
по умолчанию, если во внешнем объявлении они не инициализируются явно.
Значение структурных переменных можно также установить в выражениях
присваивания, присваивая структурной переменной значение другой
переменной того же типа или присваивая значения отдельным элементам данных
структуры.
1158
Глава 21
21.4. Использование структур с функциями
Есть два способа передачи информации в структурах функциям. Можно
передать либо всю структуру, либо ее отдельные элементы. По умолчанию
структуры передаются по значению. Можно также передавать структуры или их
отдельные элементы по ссылке, передавая либо ссылки, либо указатели.
Чтобы передать структуру по ссылке, передайте адрес структурного
объекта либо ссылку на структурный объект. Массивы структур — как и другие
массивы — передаются по ссылке.
В главе 7 мы говорили, что с помощью структуры массив можно передать
по значению. Чтобы передать массив по значению, создайте структуру (или
класс) с массивом в качестве элемента, а затем передайте функции объект
этого структурного (или классового) типа по значению. Поскольку структуры
передаются по значению, элемент структуры, т.е. массив, также будет передан
по значению.
Вопросы производительности 21.1
Передача структур (и особенно больших структур) по ссылке более
эффективна, чем передача по значению (при которой требуется
копирование всей структуры).
21.5. typedef
Ключевое слово typedef предоставляет программисту механизм создания
синонимов (псевдонимов) для ранее определенных типов данных. Часто
с typedef определяются имена структурных типов, чтобы образовать более
короткие, простые или легко читаемые имена. Например, оператор
typedef Card *CardPtr;
определяет новое имя типа CardPtr как синоним для типа Card *.
Хороший стиль программирования 21.1
Начинайте имена typedef с прописной буквы, чтобы подчеркнуть,
что это псевдонимы для других имен типов.
Создание нового имени с помощью typedef не создает нового типа; typedef
просто создает новое имя, которое можно использовать в программе в качестве
псевдонима для существующего имени типа.
Переносимость программ 21.2
С помощью typedef можно создавать синонимы встроенных типов
данных, чтобы сделать программы более переносимыми. Например,
в программе может использоваться typedef, чтобы создать псевдоним
Integer для четырехбайтовых целых. Integer может быть сделан
псевдонимом int на системах с четырехбайтовыми целыми и
псевдонимом long int на системах с двухбайтовыми целыми, где long int
занимает четыре байта. Затем программист просто объявляет все
четырехбайтовые целые переменные как Integer.
Биты, символы, строки С и структуры
1159
21.6. Пример. Высокоэффективное моделирование
тасования и сдачи карт
Программа на рис. 21.2-21.4 основана на модели тасования и сдачи карт,
обсуждавшейся в главе 8. Программа представляет колоду карт как массив
структур и использует высокоэффективные алгоритмы тасования и сдачи.
1 // Рис. 21.2: DeckOfCards.h
2 // Определение класса DeckOfCards,
3 // представляющего колоду игральных карт.
4
5 // определение структуры Card
6 struct Card
7 {
8 char *face;
9 char *suit;
10 }; // конец структуры Card
11
12 // Определение класса DeckOfCards
13 class DeckOfCards
14 {
15 public:
16 DeckOfCards(); // конструктор инициализирует колоду
17 void shuffle(); // тасует карты в колоде
18 void deal(); // сдает карты иэ колоды
19
20 private:
21 Card deck[ 52 ]; // представляет колоду карт
22 }; /7 конец класса DeckOfCards
Рис. 21.2. Заголовочный файл для класса DeckOfCards
1 // Рис. 21.3: DeckOfCards.срр
2 // Определения элемент-функций для класса DeckOfCards,
3 // моделирующих тасование и сдачу колоды карт.
4 #include <iostream>
5 using std::cout;
6 using std::left;
7 using std::right;
8
9 #include <iomanip>
10 using std::setw;
11
12 #include <cstdlib> // прототипы для rand и srand
13 using std::rand;
14 using std::srand;
15
16 #include <ctime> // прототип для time
17 using std::time;
18
19 #include "DeckOfCards.h" // определение класса DeckOfCards
20
21 // конструктор DeckOfCards без аргументов инициализирует колоду
1160
Глава 21
22 DeckOfCards::DeckOfCards()
23 {
24 // инициализировать масив мастей
25 static char *suit[ 4 ] =
26 { "Hearts", "Diamonds", "Clubs", "Spades" };
27
28 // инициализировать массив номиналов
29 static char *face[ 13 ] =
30 { "Ace", "Deuce", "Three", "Four", "Five", "Six", "Seven",
31 "Eight", "Nine", "Ten", "Jack", "Queen", "King" };
32
33 // установить значения для колоды из 52 карт
34 for ( int i = 0; i < 52; i++ )
35 {
36 deck[ i ] .face = face[ i % 13 ] ;
37 deck[ i ] .suit = suit[ i / 13 ] ;
38 } // конец for
39
40 srand( time( 0 ) ); // засеять генератор случайных чисел
41 } // конец конструктора DeckOfCards
42
43 // перетасовать карты в колоде
44 void DeckOfCards::shuffle()
45 {
46 // случайное перемешивание карт
47 for ( int i = 0; i < 52; i++ )
48 {
49 int j = rand() % 52;
50 Card temp = deck[ i ];
51 deck[ i ] = deck[ j ];
52 deck[ j ] = temp;
53 } // конец for
54 } // конец функции shuffle
55
56 // сдать карты колоды
57 void DeckOfCards::deal()
58 {
59 // вывести номинал и масть каджой карты
60 for ( int i = 0; i < 52; i++ )
61 cout « right « setw( 5 ) « deck[ i ].face « " of "
62 « left « setw( 8 ) « deck[ i ].suit
63 « ( ( i + 1 ) % 2 ? '\t' : '\n' );
64 } // конец функции deal
Рис. 21.3. Исходный файл класса DeckOf Cards
1 // Рис. 21.4: fig22_04.cpp
2 // Программа тасования и сдачи карт.
3 #include "DeckOfCards.h" // определение класа DeckOfCards
4
5 int main()
6 {
7 DeckOfCards deckOfCards; // создать объект DeckOfCards
8
9 deckOfCards.shuffle(); // перетасовать колоду
Биты, символы, строки С и структуры
1161
10 deckOfCards.deal(); // сдать карты
11 return 0; // показывает успешное завершение
12 } // конец main
Six
King
Nine
Jack
Four
Three
King
Six
Queen
Nine
Seven
Jack
Three
Nine
King
Four
Five
Eighr
Queen
Three
Ten
Eight
Nine
Deuce
Ten
Deuce
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
of
Hearts
Spades
Hearts
Clubs
Diamonds
Spades
Diamonds
Spades
Hearts
Spades
Clubs
Hearts
Clubs
Clubs
Clubs
Hearts
Spades
Diamonds
Spades
Hearts
Hearts
Hearts
Diamonds
Diamonds
Diamonds
Spades
Ten
Six
Ace
Eight
Seven
Jack
Ace
Deuce
Queen
Queen
Eight
Seven
Ten
Four
Jack
Deuce
Five
Seven
Five
Ace
Three
Six
Four
Five
King
Ace
of Spades
of Diamonds
of Hearts
of Spades
of Hearts
of Spades
of Clubs
of Hearts
of Diamonds
of Clubs
of Clubs
of Diamonds
of Clubs
of Spades
of Diamonds
of Clubs
of Diamonds
of Spades
of Hearts
of Diamonds
of Diamonds
of Clubs
of Clubs
of Clubs
of Hearts
of Spades
Рис, 21.4. Высокоэффективное моделирование тасования и сдачи карт
В этой программе конструктор инициализирует по порядку массив
структур Card символьными строками, представляющими карты от туза до короля
каждой масти. В функции shuffle реализован высокоэффективный алгоритм
тасования. Функция проходит в цикле по всем 52 картам (индексам массива
от 0 до 51). Для каждой карты случайным образом выбирается число
от 0 до 51. Затем текущая структура Card и случайно выбранная структура
меняются местами в массиве. Делается всего 52 перестановки в единственном
проходе, и массив структур Card перетасован! В отличие от алгоритма
тасования, представленного в главе 8, данный алгоритм не страдает пороком
бесконечной отсрочки. Так как структуры Card переставляются в самом исходном
массиве, алгоритму сдачи, реализованному в функции deal, требуется
единственный проход, чтобы сдать перетасованные карты.
1162
Глава 21
21.7. Поразрядные операции
Программистам, которым нужно спуститься на уровень «битов и байтов»,
C++ предоставляет широкие возможности. Операционные системы,
программное обеспечение для тестирования оборудования, сетевое программное
обеспечение и многие другие области программирования требуют, чтобы
программист работал «непосредственно с аппаратурой». В этом и нескольких
следующих разделах мы обсудим средства манипуляций с битами, имеющиеся в C++.
Мы представим каждую из поразрядных операций C++ и расскажем, как
экономить память, определяя битовые поля.
Все данные представляются компьютерами в виде битовых
последовательностей. Каждый бит может принимать значение 0 или 1. На большинстве
систем последовательность из 8 битов составляет байт — стандартную единицу
памяти для переменной типа char. Другие типы данных хранятся в большем
числе байтов. Поразрядные операции используются для манипуляций с
битами целочисленных операндов (типов char, short, int и long, как signed, так
и unsigned). Поразрядные операции обычно применяются к целым без знака.
Ш Переносимость программ 21.3
Поразрядные операции машинно-зависимы.
В обсуждении поразрядных операций в этой главе используется двоичное
представление целых операндов. Подробное объяснение двоичной (по
основанию 2) системы счисления можно найти в приложении Г. Из-за
машинно-зависимой природы поразрядных операций примеры программ в том виде, как
они написаны, могут не работать на вашей системе.
К поразрядным операциям относятся: поразрядное И (&), поразрядное
включающее ИЛИ (\), поразрядное исключающее ИЛИ (")9 сдвиг влево («),
сдвиг вправо (») и поразрядное дополнение (~), называемое также
дополнением до единицы. (Заметьте, что мы пользовались ранее знаками &, « и »
для других целей; это классический пример перегрузки операций.)
Поразрядное И, поразрядное включающее ИЛИ и поразрядное исключающее ИЛИ по-
битно сравнивают два своих операнда. Поразрядная операция И
устанавливает бит результата в 1, если соответствующий бит в обоих операндах равен 1.
Поразрядная операция включающего ИЛИ устанавливает бит результата в 1,
если соответствующий бит в одном из операндов — или в обоих — равен 1.
Поразрядная операция исключающего ИЛИ устанавливает бит результата в 1,
если соответствующий бит в одном из операндов — но не в обоих — равен 1.
Операция левого сдвига сдвигает биты своего левого операнда влево на число
позиций, специфицированное ее правым операндом. Операция правого сдвига
сдвигает биты своего левого операнда вправо на число позиций,
специфицированное ее правым операндом. Операция поразрядного дополнения
устанавливает в 1 все биты результата, равные 0 в операнде, и устанавливает в 0 все
биты результата, равные 1 в операнде. Подробное обсуждение каждой из
поразрядных операций проводится на нижеприведенных примерах. Сводка
поразрядных операций показана на рис. 21.5.
Биты, символы, строки С и структуры
1163
Операция !Название
&
I
А
«
»
~
поразрядное И
поразрядное
включающее ИЛИ
поразрядное
исключающее ИЛИ
сдвиг влево
сдвиг вправо
поразрядное
дополнение
Описание
Биты результата устанавливаются в 1, если
соответствующие биты в обоих операндах равны 1.
Биты результата устанавливаются в 1, если хотя бы
один из соответствующих битов в операндах равен 1.
Биты результата устанавливаются в 1, если только
один из соответствующих битов в операндах равен 1.
Сдвигает биты первого операнда влево на число
позиций, заданное вторым операндом;
освобождающиеся биты справа заполняются 0.
Сдвигает биты первого операнда вправо на число
позиций, заданное вторым операндом; метод
заполнения освобождающихся битов слева
является машинно-зависимым.
Все нулевые биты устанавливаются в 1, а все
единичные биты устанавливаются в 0.
Рис. 21.5. Поразрядные операции
Печать двоичного представления целочисленного значения
При изучении поразрядных операций полезно иллюстрировать их
конкретное действие, распечатывая значения в их двоичном представлении.
Программа на рис. 21.6 печатает целое без знака в двоичном представлении группами
по 8 бит.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// Рис. 21.6: fig22_06.cpp
// Побитовая печать целого без знака.
#include <iostream>
using std::cout;
using std::cin;
using std::endl;
#include <iomanip>
using std::setw;
void displayBits( unsigned ); // прототип
int main()
{
}
unsigned inputValue; // целое значение для двоичной распечатки
cout « "Enter an unsigned integer: ";
cin » inputValue;
displayBits( inputValue );
return 0;
// конец main
// вывести биты целого значения без знака
void displayBits( unsigned value )
{
const int SHIFT = 8 * sizeof( unsigned )
1;
1164
Глава 21
27 const unsigned MASK = 1 « SHIFT;
28
29 cout « setw( 10 ) « value « " =
30
31 // вывести биты
32 for ( unsigned i = 1; i <= SHIFT + 1; i++ )
33 {
34 cout « ( value & MASK ? '1' : '0' ) ;
35 value «= 1; // сдвинуть значение влево на 1
36
37 if(i%8=0)// выводить пробел после 8 бит
38 cout « '
39 У /I конец for
40
41 cout « endl;
42 } // конец функции displayBits
Enter an unsigned integer: 65000
65000 = 00000000 00000000 11111101 11101000
Enter an unsigned integer: 29
29 = 00000000 00000000 00000000 00011101
Рис. 21.6. Распечатка битового представления целого без знака
Функция displayBits (строки 24-42) комбинирует переменную value с
константой MASK посредством операции поразрядного И. Часто поразрядную
операцию И применяют с операндом, называемым маской — целым
значением, определенные биты которого установлены в 1. Маски используются,
чтобы, скрыв некоторые биты значения, выделить остальные. В displayBits
строка 27 присваивает константе MASK значение 1 « SHIFT. Значение SHIFT
вычисляется в строке 26 выражением
8 * sizeof( unsigned ) - 1
которое умножает число байт, которое занимает в памяти объект unsigned,
на 8 (число бит в байте), получая тем самым общее число бит, занимаемое в
памяти объектом unsigned, и вычитает из результата 1. Битовым
представлением 1 « SHIFT на компьютере, сохраняющем объекты unsigned в четырех
байтах памяти, является
10000000 00000000 00000000 00000000
Операция левого сдвига смещает значение 1 из младшего (крайнего справа)
бита MASK в старший (крайний слева), заполняя биты справа нулями.
Строка 34 определяет, какую цифру — 1 или 0 — следует напечатать для текущего
бита слева переменной value. Предположим, value содержит 65000 @0000000
00000000 11111101 11101000). Когда value и MASK комбинируются
посредством операции &, все биты в value, кроме старшего, «маскируются»
(скрываются), поскольку любой бит, «сложенный по И» с 0, дает 0. Если крайний
слева бит в MASK равен 1, то value & MASK оценивается как
Биты, символы, строки С и структуры
1165
00000000 00000000 11111101 11101000 (value)
10000000 00000000 00000000 00000000 (MASK)
00000000 00000000 00000000 00000000 (value & MASK)
и интерпретируется как false, в результате чего печатается О. Затем строка 35
сдвигает переменную value на один бит влево выражением value «= 1 (т.е.
value = value « 1). Эти действия повторяются для каждого бита переменной
value. Наконец, в крайнюю позицию слева сдвигается бит со значением 1,
и над битами производится следующая манипуляция:
11111101 11101000 00000000 00000000
10000000 00000000 00000000 00000000
10000000 00000000 00000000 00000000
(value)
(MASK)
(value & MASK)
Поскольку оба левых бита равны 1, результат выражения оказывается
ненулевым (истинным) и печатается цифра О. На рис. 21.7 показаны результаты
комбинации двух битов посредством операции поразрядного И.
Бит1
0
1
0
1
Бит 2
0
0
1
1
Бит 1 & Бит 2
0
0
0
1
Рис. 21.7. Результаты комбинации двух битов посредством операции поразрядного И (&)
Типичная ошибка программирования 21.3
Использование операции логического И (&&) вместо поразрядного
И (&) и наоборот является логической ошибкой.
Программа на рис. 21.8 демонстрирует операцию поразрядного И,
операцию поразрядного включающего ИЛИ, операцию поразрядного
исключающего ИЛИ и операцию поразрядного дополнения. Функция displayBits
(строки 57-75) печатает целые значения без знака.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Рис. 21.8: fig22_08.cpp
// Демонстрация поразрядных операций И,
// включающего ИЛИ, исключающего ИЛИ и дополнения.
#include <iostream>
using std::cout;
#include <iomanip>
using std::endl;
using std::setw;
void displayBits( unsigned ); // прототип
int main()
{
1166
Глава 21
15 unsigned numberl;
16 unsigned number2;
17 unsigned mask;
18 unsigned setBits;
19
20 // демонстрация поразрядного &
21 numberl = 2179876355;
22 mask = 1;
23 cout « "The result of combining the following\n";
24 displayBits( numberl );
25 displayBits( mask );
26 cout « "using the bitwise AND operator & is\n";
27 displayBits( numberl & mask );
28
29 // демонстрация поразрядного |
30 numberl = 15;
31 setBits = 241;
32 cout « "\nThe result of combining the following\n";
33 displayBits( numberl );
34 displayBits( setBits );
35 cout « "using the bitwise inclusive OR operator | is\n";
36 displayBits( numberl | setBits );
37
38 // демонстрация поразрядного исключающего ИЛИ
39 numberl = 139;
40 number2 = 199;
41 cout « "\nThe result of combining the following\n";
42 displayBits( numberl );
43 displayBits( number2 );
44 cout « "using the bitwise exclusive OR operator A is\n";
45 displayBits( numberl A number2 );
46
47 // демонстрация поразрядного дополнения
48 numberl = 21845;
49 cout « "\nThe one's complement of\n";
50 displayBits( numberl );
51 cout « "is" « endl;
52 displayBits( ~numberl );
53 return 0;
54 } // конец main
55
56 // вывести биты целого значения без знака
57 void displayBits( unsigned value )
58 {
59 const int SHIFT = 8 * sizeof( unsigned ) - 1;
60 const unsigned MASK = 1 « SHIFT;
61
62 cout « setw( 10 ) « value « " =
63
64 // вывести биты
65 for ( unsigned i = 1; i <= SHIFT + 1; i++ )
66 {
67 cout « ( value & MASK ? '1' : '0' );
68 value «= 1; // сдвинуть значение лево на 1
69
70 if ( i % 8 == 0 ) // выводить пробел после 8 бит
71 cout « ' ';
Биты, символы, строки С и структуры
1167
72 } // конец for
73
74 cout « endl;
75 } // конец функции displayBits
The result of combining the following
2179876355 = 10000001 11101110 01000110 00000011
1 = 00000000 00000000 00000000 00000001
using the bitwise AND operator & is
1 = 00000000 00000000 00000000 00000001
The result of combining the following
15 = 00000000 00000000 00000000 00001111
241 = 00000000 00000000 00000000 11110001
using the bitwise inclusive OR operator | is
255 = 00000000 00000000 00000000 11111111
The result of combining the following
139 = 00000000 00000000 00000000 10001011
199 = 00000000 00000000 00000000 11000111
using the bitwise exclusive OR operator A is
76 = 00000000 00000000 00000000 01001100
The one's complement of
21845 = 00000000 00000000 01010101 01010101
is
4294945450 = 11111111 11111111 10101010 10101010
Рис. 21.8. Поразрядные операции И, включающего ИЛИ, исключающего ИЛИ
и дополнения
Поразрядная операция И (&)
Строка 21 на рис. 21.8 присваивает переменной number 1 значение
279876355 A0000001 11101110 01000110 00000011), а строка 22 присваивает
переменной mask значение 1 @0000000 00000000 00000000 00000001). Когда
numberl и mask комбинируются посредством операции поразрядного И (&)
в выражении numberl & mask (строка 27), результатом является 00000000
00000000 00000000 00000001. Все биты в переменной numberl, за
исключением младшего, «маскируются» (скрываются) «сложением по И» с
переменной mask.
Поразрядная операция включающего ИЛИ (\)
Поразрядная операция включающего ИЛИ (|) используется для установки
определенных битов операнда в 1. Строка 30 на рис. 21.8 присваивает
переменной numberl значение 15 @0000000 00000000 00000000 00001111),
а строка 31 присваивает переменной setBits значение 241 @0000000 00000000
00000000 11110001). Когда numberl и setBits комбинируются посредством
операции в выражении numberl | setBits (строка 36), результатом является
255 @0000000 00000000 00000000 11111111). На рис. 21.9 показаны
результаты комбинации двух битов посредством операции поразрядного
включающего ИЛИ.
1168
Глава 21
Бит1
0
1
0
1
Бит 2
0
0
1
1
Бит 1 1 Бит 2
0
1
1
1
Рис. 21.9, Результаты комбинации двух битов посредством операции поразрядного
включающего ИЛИ (I)
Поразрядная операция исключающего ИЛИ О
Поразрядная операция исключающего ИЛИ (") устанавливает бит
результата в 1, если ровно один из соответствующих битов в операндах равен 1.
Строки 39-40 на рис. 21.8 присваивают переменным numberl и niimber2 значения
139 @0000000 00000000 00000000 10001011) и 199 @0000000 00000000
00000000 11000111). Когдаэти переменные комбинируются посредством
операции исключающего ИЛИ (") в выражении numberl " number2 (строка 45),
результатом является 00000000 00000000 00000000 01001100. На рис. 21.10
показаны результаты комбинации двух битов посредством операции
поразрядного исключающего ИЛИ.
Бит 1
0
1
0
Бит 2
0
0
1
Бит 1 А Бит 2
0
1
1
1 |l [о
Рис, 21.10. Результаты комбинации двух битов посредством операции поразрядного
исключающего ИЛИ (А)
Поразрядная операция дополнения (~)
Поразрядная операция дополнения (~) устанавливает в 1 все биты
результата, равные 0 в ее операнде, и устанавливает в 0 все биты результата, равные 1
в операнде; это называют также «взятием дополнения значения до 1». Строка
48 на рис. 21.8 присваивает numberl значение 21845 @0000000 00000000
01010101 01010101). Когда оценивается выражение -numberl, результатом
является 11111111 11111111 10101010 10101010.
Рис. 21.11 демонстрирует операции сдвига влево («) и сдвига вправо (»).
Функция displayBits (строки 31-49) печатает целые значения без знака.
1 // Рис. 21.11: fig22_ll.cpp
2 // Демонстрация операций поразрядного сдвига.
3
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <iomanip>
Биты, символы, строки С и структуры
1169
9 using std::setw;
10
11 void displayBits( unsigned ); // прототип
12
13 int-main()
14 {
15 unsigned number1 = 960;
16
17 // демонстрация поразрядного сдвига влево
18 cout « "The result of left shifting\n";
19 displayBits( number1 );
20 cout « "8 bit positions using the left-shift operator is\n";
21 displayBits( number1 «8 );
22
23 // демонстрация поразрядного сдвига вправо
24 cout « "\nThe result of right shifting\n";
25 displayBits( number1 );
26 cout « "8 bit positions using the right-shift operator is\n"
27 displayBits( number1 » 8 );
28 return 0;
29 } // конец main
30
31 // вывести биты целого значения без знака
32 void displayBits( unsigned value )
33 {
34 const int SHIFT = 8 * sizeof( unsigned ) - 1;
35 const unsigned MASK = 1 « SHIFT;
36
37 cout « setw( 10 ) « value « " =
38
39 // вывести биты
40 for ( unsigned i = 1; i <= SHIFT + 1; i++ )
41 {
42 cout « ( value & MASK ? '1' : '0' );
43 value «= 1; // сдвиг влево на 1
44
45 if(i%8==0)// выводить пробел после 8 бит
46 cout « '
47 } // конец for
48
49 cout « endl;
50 } // конец функции displayBits
The result of left shifting
960 = 00000000 00000000 00000011 11000000
8 bit positions using the left-shift operator is
245760 = 00000000 00000011 11000000 00000000
The result of right shifting
960 = 00000000 00000000 00000011 11000000
8 bit positions using the right-shift operator is
3 = 00000000 00000000 00000000 00000011
Рис. 21.11. Операции поразрядного сдвига
1170
Глава 21
Операция сдвига влево
Операция сдвига влево («) сдвигает биты своего левого операнда влево на
число позиций, специфицированное правым операндом. Освобождающиеся
биты справа замещаются нулями; биты, сдвигаемые из старшего разряда,
теряются. В программе на рис. 21.11 строка 15 присваивает переменной
numberl значение 960 @0000000 00000000 00000011 11000000). Результатом
сдвига переменной numberl влево на 8 позиций в выражении numberl « 8
(строка 21) является 245760 @0000000 00000011 11000000 00000000).
Операция сдвига вправо
Операция сдвига вправо (») сдвигает биты своего левого операнда вправо
на число позиций, специфицированное правым операндом. Выполнение
правого сдвига над целым без знака замещает биты, освобождающиеся слева,
нулями; биты, сдвигаемые из младшего разряда, теряются. В программе
на рис. 21.11 результатом сдвига переменной numberl вправо на 8 позиций
в выражении numberl » 8 (строка 27) является 3 @0000000 00000000
00000000 00000011).
q Типичная ошибка программирования 21.5
Результат сдвига вправо не определен, если правый операнд
отрицателен или его значение больше или равно числу бит, занимаемых
левым операндом.
Переносимость программ 21.4
Результат сдвига вправо значения со знаком машинно-зависим.
Некоторые машины заполняют старшие биты нулями, другие используют
для этого знаковый бит.
Поразрядные операции присваивания
Для каждой поразрядной операции (за исключением поразрядного
дополнения) имеется соответствующая операция присваивания. Поразрядные опера
ции присваивания показаны на рис. 21.12; они используются аналогично
арифметическим операциям присваивания, представленным в главе 2.
Поразрядные операции присваивания
&=
1 =
А_
«=
»=
Операция присваивания поразрядного И
Операция присваивания поразрядного включающего ИЛИ
Операция присваивания поразрядного исключающего ИЛИ
Операция присваивания сдвига влево
Операция присваивания сдвига вправо
Рис. 21.12. Поразрядные операции присваивания
На рис. 21.13 показаны старшинство и ассоциативность операций,
представленных в тексте к настоящему моменту. Они показаны в порядке
убывания старшинства сверху вниз.
Биты, символы, строки С и структуры
1171
Операции
: (унарная; справа налево)
: (бинарная; слева направо)
() [] ->++-- static_cast
< тип > ()
++--+- ! delete sizeof
* ~ & new
* / %
+ -
« »
<<=>>=
== ! =
&
Л
I
&&
II
?:
= += -= *= /= %= &= |= *=
«= »=
г
Ассоциативность
слева направо
слева направо
справа налево
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
справа налево
слева направо
Тип
наивысший
унарные
унарные
мультипликативные
аддитивные
сдвига
отношения
равенства
поразрядное И
поразрядное ИЛИ
исключающее ИЛИ
логическое И
логическое ИЛИ
условная
присваивания
запятая
Рис. 21.13- Старшинство и ассоциативность операций
21.8. Битовые поля
В C++ предусмотрена возможность спецификации точного количества
битов, в которых хранится элемент класса или структуры целочисленного либо
перечислимого типа. Такой элемент называется битовым полем. Битовые поля
позволяют экономнее использовать память, сохраняя данные в минимально
необходимом числе бит.
•—^ Вопросы производительности 21.2
Т^Фп Битовые поля помогают экономить память.
Рассмотрим следующее определение структуры:
struct BitCard
{
unsigned face : 4;
unsigned suit : 2;
unsigned color : 1;
}; // конец struct BitCard
1172
Глава 21
Определение содержит три беззнаковых битовых поля — face, suit и color —
для представления карты из колоды с 52 картами. Битовое поле объявляется
указанием после имени элемента целочисленного или перечислимого типа
двоеточия (:) и ширины битового поля (т.е. числа бит, в котором сохраняется
элемент). Ширина битового поля должна быть целой константой.
Предыдущее определение структуры указывает, что face хранится в 4 битах,
suit в 2 битах и color в 1 бите. Число бит определяется требуемым диапазоном
значений для каждого элемента структуры. Элемент face сохраняет значения
от О (туз) до 12 (король) — 4 бита могут хранить значения от 0 до 15. Элемент
suit сохраняет значения от О до 3 @ = бубны, 1 = червы, 2 = трефы, 3 = пики) —
2 бита могут хранить значения от 0 до 3. Наконец, элемент color сохраняет либо
О (красный), либо 1 (черный) — 1 бит может хранить либо О, либо 1.
Программа на рис. 21.14-21.16 создает массив deck, содержащий 52
структуры BitCard (строка 21 на рис. 21.14). Конструктор размещает в массиве
deck 52 карты, а функция deal распечатывает их. Обратите внимание, что
обращение к битовым полям не отличается от обращения к любому другому
элементу структуры (строки 18-20 и 28-33 на рис. 21.15). Элемент color включен
в качестве средства указания цвета на системах, поддерживающих
отображение цветов.
1 // Рис. 21.14: DeckOfCards.h
2 // Определение класса DeckOfCards,
3 // представляющего колоду игральных карт.
4
5 // определение структуры BitCard с битовыми полями
6 struct BitCard
7 {
8 unsigned face : 4; //4 бита; 0-15
9 unsigned suit : 2; //2 бита; 0-3
10 unsigned color : 1; //1 бит; 0-1
11 }; // конец struct BitCard
12
13 // определение класса DeckOfCards
14 class DeckOfCards
15 {
16 public:
17 DeckOfCards(); // конструктор инициализирует колоду
18 void deal(); // сдает карты из колоды
19
20 private:
21 BitCard deck[ 52 ]; // представляет колоду карт
22 }; // конец класса DeckOfCards
Рис. 21.14. Заголовочный файл для класса DeckOfCards
1 // Рис. 21.15: DeckOfCards.срр
2 // Определения элемент-функций для класса DeckOfCards,
3 // моделирующих тасование и сдачу колоды карт.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
Биты, символы, строки С и структуры
1173
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <iomanip>
using std::setw;
#include "DeckOfCards.h" //определение класса DeckOfCards
// конструктор DeckOfCards без аргументов инициализирует колоду
DeckOfCards::DeckOfCards()
{
for ( int i = 0; i <= 51; i++ )
{
deck[ i ].face = i % 13; // номиналы по порядку
deck[ i ].suit = i / 13; // масти по порядку
deck[ i ].color = i / 26; // цвета по порядку
} // end for
} // конец конструктора DeckOfCards
// сдать карты из колоды
void DeckOfCards::deal()
{
for ( int kl = 0, k2 = kl + 26; kl <= 25; kl++, k2++ )
cout « "Card:" « setw( 3 ) « deck[ kl ].face
« " Suit:" « setw( 2 ) « deck[ kl ].suit
« " Color:" « setw( 2 ) « deck[ kl ].color
« " " « "Card:" « setw( 3 ) « deck[ k2 ].face
« " Suit:" « setw( 2 ) « deck[ k2 ].suit
« " Color:" « setw( 2 ) « deck[ k2 ].color « endl ;
} // конец функции deal
Рис. 21.15. Исходный файл для класса DeckOf Cards
1 // Рис.
21.16:
fig22_16.
2 // Программа тасования и
3 #inc
4
5 int
6 {
7 De
lude
main
i "DeckOfCards.h"
i)
ckOfCards
8 deckOfCards.
9 return
10 } //
Card:
Card :
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
cpp
: сдачи карт.
//определение класса DeckOfCards
deckOfCards;
deal() ; //
// создать
объект
1 DeckOfCards
сдать карты из колоды
. 0; // показывает упешное
конец main
0
1
2
3
4
5
6
7
8
9
10
11
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
0
0
0
0
0
0
0
0
0
0
0
0
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
0
0
0
0
0
0
0
0
0
0
0
0
Card:
Card :
Card:
Card:
Card:
Card :
Card:
Card:
Card:
Card:
Card:
Card:
завершение
0
1
2
3
4
5
6
7
8
9
10
11
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
2
2
2
2
2
2
2
2
2
2
2
2
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
1
1
1
1
1
1
1
1
1
1
1
1
1174
Глава 21
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
12
0
1
2
3
4
5
6
7
8
9
10
11
12
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
0
1
1
1
1
1
1
1
1
1
1
1
1
1
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
0
0
0
0
0
0
0
0
0
0
0
0
0
0
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
Card:
12
0
1
2
3
4
5
6
7
8
9
10
11
12
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
Suit:
2
3
3
3
3
3
3
3
3
3
3
3
3
3
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
Color:
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Рис. 21.16. Использование битовых полей для хранения колоды карт
Можно специфицировать <$1[]неименованное битовое иоле>неименован-
ные битовые поля, которые используются в качестве заполнителей
структуры. Например, в приведенной ниже структуре объявляется 3-битовое
неименованное поле; в этих 3-х битах ничего не может сохраняться. Элемент b
располагается в следующей единице распределения памяти (слове).
struct Example
{
unsigned a : 13;
unsigned : 3; // выровнять по границе следующей единицы памяти
unsigned b : 4;
} конец struct Example
Неименованное битовое поле нулевой ширины выравнивает следующее
битовое поле по границе новой единицы памяти. Например, определение структуры
struct Example
{
unsigned a
unsigned
unsigned b
13;
0; // выровнять по границе следующей единицы памяти
4;
} конец struct Example
использует поле нулевой ширины, чтобы пропустить оставшиеся биты
(сколько их имеется) единицы памяти, в которой хранится а, и выровнять b по
границе следующей единицы памяти.
Переносимость программ 21.5
Манипуляции с битовыми полями машинно-зависимы. Например,
некоторые компьютеры позволяют битовым полям пересекать границы
слов, другие — нет.
^ Типичная ошибка программирования 21.6
Попытка обращения к отдельным битам битового поля посредством
индексации, как если бы они были элементами массива, приводит
к ошибке компиляции. Битовые поля — не массивы.
Биты, символы, строки С и структуры
1175
Типичная ошибка программирования 21.7
Попытка взятия адреса битового поля приводит к ошибке
компиляции (операцию & нельзя применять к битовым полям, поскольку
указатель может ссылаться только на определенный байт в памяти,
а битовые поля могут начинаться в середине байта).
Вопросы производительности 21.3
Хотя битовые поля экономят пространство памяти, их применение
может привести к тому, что компилятор будет генерировать более
медленный машинный код. Дело в том, что для обращения к
некоторой части адресуемой единицы памяти требуются дополнительные
операции машинного языка. Это один из многих компромиссов между
затратами времени и памяти, которые встречаются в
программировании на каждом шагу.
21.9. Библиотека обработки символов
Большая часть данных, вводимых в компьютеры, представляет собой
символы, в том числе буквы, цифры и различные специальные знаки. В этом
разделе мы обсудим возможности C++ в плане распознавания и обработки
отдельных символов. В оставшейся части главы мы продолжим обсуждение
обработки символьных строк, начатое в главе 8.
В библиотеку обработки символов входят различные функции,
выполняющие проверку и обработку символьных данных. Каждая из функций
принимает в качестве аргумента символ (представленный как int) или EOF. С
символами часто обращаются как с целыми числами. Как вы помните, EOF обычно
имеет значение —1, а многие аппаратные платформы не позволяют сохранять
в переменных типа char отрицательные значения. Поэтому функции
обработки символов манипулируют символами как целыми. На рис. 21.17 приведена
сводка функций библиотеки обработки символов. При использовании этих
функций следует включить заголовочный файл <cctype>.
Прототип
int isdigit(
int isalpha(
int isalnum(
int isxdigit
int islower(
int isupper(
int с
int с
int с
)
)
)
[ int с )
int с
int с
)
)
Описание
Возвращает true, если с является цифрой, и false
в противном случае.
Возвращает true, если с является буквой, и false
в противном случае.
Возвращает true, если с является цифрой или буквой,
и false в противном случае.
Возвращает true, если с является символом
шестнадцатеричной цифры, и false в противном случае.
Возвращает true, если с является буквой нижнего
регистра, и false в противном случае.
Возвращает true, если с является буквой верхнего
регистра, и false в противном случае.
1176
Глава 21
Прототип Описание
int tolower ( int с ) Если с является буквой верхнего регистра, возвращает с
как букву нижнего регистра; в противном случае
возвращает аргумент неизмененным.
int toupper( int с ) Если с является буквой нижнего регистра, возвращает с
как букву верхнего регистра; в противном случае
возвращает аргумент неизмененным.
int isspace( int с ) Возвращает true, если с является пробельным
символом — пробелом (' '), новой строкой (Чп"),
переводом страницы ('\f'), возвратом каретки {'\г'),
горизонтальной табуляцией ('№) или вертикальной
I табуляцией ('W); в противном случае возвращает false.
int iscntrl( int с )
int ispunct( int с )
int isprint( int с )
int isgraph( int с )
Возвращает true, если с является управляющим
символом, таким, как новая строка ('\п'), перевод
страницы ('\f'), возврат каретки ('\г'), горизонтальная
табуляция ('\f), вертикальная табуляция ('№'), звуковой
сигнал ('Ха') или возврат на шаг ('\Ь'); в противном случае
возвращает false.
Возвращает true, если с является печатаемым символом,
отличным от пробела, цифры и буквы; в противном
случае возвращает false.
Возвращает true, если с является печатаемым символом,
включая пробел (' '); в противном случае возвращает
false.
Возвращает true, если с является печатаемым символом,
отличным от пробела (' '); в противном случае
возвращает false.
Рис. 21.17. Функции библиотеки обработки символов
Рис. 21.18 демонстрирует функции isdigit, isalpha, isalnum и isxdigit.
Функция isdigit определяет, является ли ее аргумент цифрой @-9). Функция
isalpha определяет, является ли ее аргумент латинской буквой нижнего или
верхнего регистра (A-Z, a-z). Функция isalnum определяет, является ли ее
аргумент буквой либо цифрой. Наконец, isxdigit определяет, является ли
аргумент шестнадцатеричной цифрой (A-F, a-f, 0-9).
1 // Рис. 21.18: fig22_18.cpp
2 // Демонстрация функций isdigit, isalpha, isalnum и isxdigit.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cctype> // прототипы функций обработки символов
8 using std::isalnum;
9 using std::isalpha;
10 using std::isdigit;
11 using std::isxdigit;
12
13 int main()
14 {
Биты, символы, строки С и структуры
1177
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
cout
«
«
cout
«
«
«
«
cout
«
«
«
«
«
«
cout
«
«
«
«
«
«
«
«
«
«
« "According to isdigit:\n"
( isdigit( '8' ) ? "8 is a"
( isdigit( '#' ) ? "# is a"
"8
"#
« "\nAccording to isalpha:\n"
( isalpha( 'A' ) ? "A is a"
( isalpha( 'b' ) ? "bis a"
( isalpha( '&' ) ? "& is a"
( isalpha( '4' ) ? is a"
"A
"b
"&
« "\nAccording to isalnum:\n"
( isalnum( 'A' ) ? "A is a"
" digit or a letter\n"
( isalnum( '8' ) ? "8 is a"
" digit or a letter\n"
( isalnum( '#' ) ? "# is a"
" digit or a letter\n";
"A
"8
M#
« "\nAccording to isxdigit:\n"
( isxdigit( 'F' ) ? "F is a"
" hexadecimal digit\n"
( isxdigit( 'J' ) ? "J is a"
" hexadecimal digit\n"
( isxdigit( '7' ) ? is a"
" hexadecimal digit\n"
( isxdigit( '$' ) ? "$ is a"
" hexadecimal digit\n"
( isxdigit( ' f ) ? "f is a"
" hexadecimal digit" « endl,
return 0;
} // конец main
: "F
: "J
:
: "$
: "f
is
is
is
is
is
is
is
is
is
not a"
not a"
not a"
not a"
not a"
not a"
i
not a"
not a"
not a"
is not a1
r is not a'
is
is
is
; not a'
i not a'
* not a'
)
)
)
)
)
)
)
)
)
i
i
« "
« "
« "
« "
« "
« "
digit\n"
digit\n";
letter\n"
letter\n"
letter\n"
letter\n";
According to isdigit:
8 is a digit
# is not a digit
According to isalpha:
A is a letter
b is a letter
& is not a letter
4 is not a letter
According to isalnum:
A is a digit or a letter
8 is a digit or a letter
# is not a digit or a letter
According to isxdigit:
F is a hexadecimal digit
J is not a hexadecimal digit
7 is a hexadecimal digit
$ is not a hexadecimal digit
f is a hexadecimal digit
Рис. 21.18. Функции обработки символов isdigit, isalpha, isalnum и isxdigit
1178
Глава 21
Каждая из функций на рис. 21.18 используется совместно с условной
операцией (: ?), которая для каждого проверяемого символа выбирает, что нужно
напечатать — "is а" или "is not а". Например, строка 16 указывает, что если
'8' является цифрой — т.е. если isxdigit возвращает истинное (ненулевое)
значение, — то печатается "8 is а", а если '8' цифрой не является (isxdigit
возвращает О), то печатается "8 is not a".
Рис. 21.19 демонстрирует функции islower, isupper, tolower и toupper.
Функция islower определяет, является ли ее аргумент латинской буквой
нижнего регистра (a-z). Функция isupper определяет, является ли аргумент
буквой верхнего регистра (A-Z). Функция tolower преобразует букву верхнего
регистра в нижний и возвращает букву нижнего регистра; если аргумент не
является буквой верхнего регистра, tolower возвращает его значение без
изменений. Функция toupper преобразует букву нижнего регистра в верхний
и возвращает букву верхнего регистра; если аргумент не является буквой
нижнего регистра, функция возвращает его значение без изменений.
1 // Рис. 21.19: fig22_19.cpp
2 // Демонстрация функций islower, isupper, tolower и toupper.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cctype> // прототипы функций обработки символов
8 using std::islower;
9 using std::isupper;
10 using std::tolower;
11 using std::toupper;
12
13 int main()
14 {
15 cout « "According to islower:\n"
16 « ( islower( 'p' ) ? "p is a"
17 « " lowercase letter\n"
18 « ( islower( 'P1 ) ? "P is a"
19 « " lowercase letter\n"
20 « ( islower( '5' ) ? is a"
21 « " lowercase letter\n"
22 « ( islower( ' !')?"! is a"
23 « " lowercase letter\n";
24
25 cput « "\nAccording to isupper:\n"
26 « ( isupper( 'D' ) ? "D is an" : "D is not an" )
27 « " uppercase letter\n"
28 « ( isupper( 'd' ) ? "d is an" : "d is not an" )
29 « " uppercase letter\n"
30 « ( isupper( '8' ) ? "8 is an" : "8 is not an" )
31 « " uppercase letter\n"
32 « ( isupper('$') ? "$ is an" : "$ is not an" )
33 « " uppercase letter\n";
34
35 cout « "\nu converted to uppercase is "
36 « static_cast< char >( toupper( 'u' ) )
37 « "\n7 converted to uppercase is "
38 « static_cast< char >( toupper( '7' ) )
"p is not a" )
"P is not a" )
is not a" )
"! is not a" )
Биты, символы, строки С и структуры
1179
39 « "\n$ converted to uppercase is "
40 « static_cast< char >( toupper( '$' ) )
41 « "\nL converted to lowercase is "
42 « static_cast< char >( tolower( 'L' ) ) « endl;
43 return 0;
44 } // конец main
According to islower:
p is a lowercase letter
P is not a lowercase letter
5 is not a lowercase letter
! is not a lowercase letter
According to isupper:
D is an uppercase letter
d is not an uppercase letter
8 is not an uppercase letter
$ is not an uppercase letter
u converted to uppercase is U
7 converted to uppercase is 7
$ converted to uppercase is $
L converted to lowercase is 1
Рис. 21.19. Функции обработки символов islower, isupper, tolower и toupper
Рис. 21.20 демонстрирует функции isspace, iscntrl, ispunct, isprint
и isgraph. Функция isspace определяет, является ли ее аргумент пробельным
символом — пробелом (' '), новой строкой ('\п')» переводом страницы (ЛО>
возвратом каретки ('\г'), горизонтальной табуляцией ('\t') или вертикальной
табуляцией f\v'). функция iscntrl определяет, является ли ее аргумент
управляющим символом, таким, как новая строка ('\п)> перевод страницы
('\Г), возврат каретки ('\г')> горизонтальная табуляция (Л*)» вертикальная
табуляция ('\v)> звуковой сигнал ('\а') или возврат на шаг ('\Ь). Функция
ispunct определяет, является ли ее аргумент печатаемым символом, отличным
от пробела, цифры и буквы — таким, как $, #, (, ), [, ],{,},;,: или %.
Функция isprint определяет, является ли ее аргумент символом, который может
выводиться на экран (включая символ пробела). Функция isgraph сравнивает
аргумент с теми же символами, что и isprint, но не включает в их число
символ пробела.
1 // Рис. 21.20: fig22_20.cpp '
2 // Демонстрация функций isspace,iscntrl,ispunct,isprint,isgraph.
3 #include <iostream>
4 using std:rcout;
5 using std::endl;
6
7 #include <cctype> // прототипы функций обработки символов
8 using std::iscntrl;
9 using std::isgraph;
10 using std::isprint;
11 using std::ispunct;
12 using std::isspace;
13
1180
Глава 21
14 int main()
15 {
16 cout « "According to isspace: \nNewline "
17 « ( isspace( '\n' ) ? "is a" : "is not a" )
18 « " whitespace character\nHorizontal tab "
19 « ( isspace( '\t' ) ? "is a" : "is not a" )
20 « " whitespace character\n"
21 « ( isspace( '%')?"% is a" : "% is not a" )
22 « " whitespace character\n";
23
24 cout « "\nAccording to iscntrl:\nNewline "
25 « ( iscntrl( '\n' ) ? "is a" : "is not a" )
26 « " control character\n"
27 « ( iscntrl( '$' ) ? "$ is a" : "$ is not a" )
28 « " control character\n";
29
30 cout « "\nAccording to ispunct:\n"
31 « ( ispunct( •;')?"; is a" : "; is not a" )
32 « " punctuation character\n"
33 « ( ispunct( 'Y' ) ? "Y is a" : "Y is not a" )
34 « " punctuation character\n"
35 « ( ispunct('#') ? "# is a" : "# is not a" )
36 « " punctuation character\n";
37
38 cout « "\nAccording to isprint:\n"
39 « ( isprint( '$' ) ? "$ is a" : "$ is not a" )
40 « " printing character\nAlert "
41 « ( isprint( '\a' ) ? "is a" : "is not a" )
42 « " printing character\nSpace "
43 « ( isprint( ' ■ ) ? "is a" : "is not a" )
44 « " printing character\n";
45
46 cout « "\nAccording to isgraph:\n"
47 « ( isgraph( 'Q' ) ? "Q is a" : "Q is not a" )
48 « " printing character other than a space\nSpace "
49 « ( isgraphC ') ? "is a" : "is not a" )
50 « " printing character other than a space" « endl;
51 return 0;
52 } // конец main
According to isspace:
Newline is a whitespace character
Horizontal tab is a whitespace character
% is not a whitespace character
According to iscntrl:
Newline is a control character
$ is not a control character
According to ispunct:
; is a punctuation character
Y is not a punctuation character
# is a punctuation character
According to isprint:
$ is a printing character
Биты, символы, строки С и структуры
1181
Alert is not a printing character
Space is a printing character
According to isgraph:
Q is a printing character other than a space
Space is not a printing character other than a space
Рис. 21.20. Функции обработки символов isspace, iscntrl, ispunct, isprint, isgraph
21.10. Функции преобразования строк-указателей
В главе 8 вы изучили некоторые из наиболее популярных функций C++ для
обработки строк-указателей. В нескольких следующих разделах мы обсудим
оставшиеся функции из этой категории, включая функции для
преобразования строк в численные значения, функции поиска в строках и функции
копирования, сравнения и поиска для блоков памяти.
В этом разделе представлены функции преобразования строк-указателей
из библиотеки утилит общего назначения <cstdlib>. Эти функции
преобразуют строки символов в целые значения и значения с плавающей точкой.
На рис. 21.21 приведена сводка функций преобразования строк-указателей.
Обратите внимание на const в объявлении переменной nPtr в заголовках
функций (читается справа налево: «nPtrt есть указатель на символьную
константу»). При использовании функций из библиотеки утилит общего
назначения следует включить заголовочный файл <cstdlib>.
Прототип 'Описание
double atof( const char *nPtr )
Преобразует строку nPtr в double. Если строка не может быть
I преобразована, возвращает 0.
int atoi( const char *nPtr )
I Преобразует строку nPtr в int. Если строка не может быть
^преобразована, возвращает 0.
long atol( const char *nPtr )
Преобразует строку nPtr в long int. Если строка не может быть
I преобразована, возвращает 0.
double strtod( const char *nPtr, char **endPtr )
| Преобразует строку nPtr в double; endPtr содержит адрес указателя на
| остаток строки после преобразуемого числа. Если строка не может быть
| преобразована, возвращается 0.
long strtol( const char *nPtr, char **endPtr, int base )
| Преобразует строку nPtr в long; endPtr содержит адрес указателя на
| остаток строки после преобразуемого числа. Если строка не может быть
преобразована, возвращается 0. Параметр base указывает основание
преобразуемого числа (напр., 8 для восьмеричного, 10 для десятичного
или 16 для шестнадцатеричного числа). По умолчанию основание
десятичное.
1182
Глава 21
Прототип Описание
unsigned long strtoul( const char *nPtr, char **endPtr, int base )
Преобразует строку nPtr в unsigned long; endPtr содержит адрес
указателя на остаток строки после преобразуемого числа. Если строка
не может быть преобразована, возвращается О. Параметр base
указывает основание преобразуемого числа (напр., 8 для
восьмеричного, 10 для десятичного или 16 для шестнадцатеричного
числа). По умолчанию основание десятичное.
Рис. 21.21. Функции преобразования строк-указателей из библиотеки утилит общего
назначения
Функция atof (рис. 21.22, строка 12) преобразует свой аргумент — строку
символов, представляющую число с плавающей точкой — в значение типа
double. Функция возвращает значение double. Если строку преобразовать
нельзя (например, если ее первый символ — не цифра), atof возвращает ноль.
Функция atoi (рис. 21.23, строка 12) преобразует свой аргумент — строку
цифр, представляющую целое число — в значение типа int. Функция
возвращает значение int. Если строку преобразовать нельзя, atoi возвращает ноль.
Функция atoi (рис. 21.24, строка 12) преобразует свой аргумент — строку
цифр, представляющую длинное целое — в значение типа long. Функция
возвращает значение long. Если строку преобразовать нельзя, atoi возвращает
ноль. Если под оба типа int и long отводится четыре байта, функции atoi и atoi
работают одинаково.
1 // Рис. 21.22: fig22_21.cpp
2 // Демонстрация atof.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstdlib> // прототип atof
8 using std::atof;
9
10 int main()
11 {
12 double d = atof( "99.0" ); // преобразовать строку в double
13
14 cout « "The string \"99.0\" converted to double is " « d
15 « "\nThe converted value divided by 2 is " « d / 2.0 « endl;
16 return 0;
17 } // конец main
The string "99.0" converted to double is 99
The converted value divided by 2 is 49.5
Рис. 21.22. Функция преобразования строк atof
1 // Рис. 21.23: fig22_23.cpp
2 // Демонстрация atoi.
3 #include <iostream>
Биты, символы, строки С и структуры
1183
4 using std::cout;
5 using std::endl;
6
7 #include <cstdlib> // прототип atoi
8 using std::atoi;
9
10 int main()
11 {
12 int i = atoi( 593" ); // преобразовать строку в int
13
14 cout « "The string \593\" converted to int is " « i
15 « "\nThe converted value minus 593 is " « i - 593 « endl;
16 return 0;
17 } // конец main
The string 593" converted to int is 2593
The converted value minus 593 is 2000
Рис. 21.23. Функция преобразования строк atoi
1 // Рис. 21.24: fig22_24.cpp
2 // Демонстрация atoi.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstdlib> // прототип atoi
8 using std::atol;
9
10 int main()
11 {
12 long x = atoi( 000000" ); // преобразовать сроку в long
13
14 cout « "The string \000000\" converted to long is " « x
15 « "\nThe converted value divided by 2 is " « x / 2 « endl;
16 return 0;
17 } // конец main
The string 000000" converted to long is 1000000
The converted value divided by 2 is 500000
Рис. 21.24. Функция преобразования строк atoi
Функция strtod (рис. 21.25) преобразует последовательность символов,
представляющую число с плавающей точкой, в значение типа double.
Функция принимает два аргумента — строку (char *) и адрес указателя char * (т.е.
char **). Строка содержит последовательность символов, которую нужно
преобразовать в значение double. Второй аргумент позволяет strtod
модифицировать указатель char * в вызывающей функции так, чтобы он указывал на
положение первого символа, следующего за преобразованной частью строки.
В строке 16 записано, что d присваивается значение double, полученное
преобразованием из stringl, a stringPtr присваивается положение первого символа
в stringl после преобразованного числа E1.2).
1184
Глава 21
1 // Рис. 21.25: fig22_25.cpp
2 // Демонстрация strtod.
3 #include <iostream>
4 using std:rcout;
5 using std::endl;
6
7 #include <cstdlib> // прототип strtod
8 using std::strtod;
9
10 int main()
11 {
12 double d;
13 const char *stringl = 1.2% are admitted";
14 char *stringPtr;
15
16 d = strtod( stringl, fistringPtr ); // преобразовать в double
17
18 cout « "The string \"" « stringl
19 « "\" is converted to the\ndouble value " « d
20 « " and the string \"" « stringPtr « "\"" « endl;
21 return 0;
22 } // конец main
The string 1.2% are admitted" is converted to the
double value 51.2 and the string "% are admitted"
Рис. 21.25. Функция преобразования строк strtod
Функция strtol (рис. 21.26) преобразует в long последовательность
символов, представляющую целое число. Функция принимает три аргумента —
строку (char *), адрес указателя char * и целое. Строка содержит
последовательность символов, которую нужно преобразовать. Второму аргументу
присваивается положение первого символа, следующего за преобразованной
частью строки. Третий аргумент специфицирует основание преобразуемого
значения. В строке 16 записано, что х присваивается значение long, полученное
преобразованием из stringl, a remainderPtr присваивается положение первого
символа в stringl после преобразованного числа (—1234567). При указании
нулевого указателя для второго аргумента оставшаяся часть строки
игнорируется. Третий аргумент, О, указывает, что преобразуемое значение может быть
восьмеричным (по основанию 8), десятичным (по основанию 10) или шестна-
дцатеричным (по основанию 16). Это определяется начальными символами
строки — О обозначает восьмеричное, Ох обозначает шестнадцатеричное
и цифры 1—9 обозначают десятичное число.
В вызове функции strtol в качестве основания можно специфицировать
либо ноль, либо любое значение от 2 до 36. Числовые представления целых
значений для оснований от 11 до 36 состоят из цифр 0-9 и символов A-Z.
Целое по основанию 11 может содержать цифры 0-9 и символ А. Целое по
основанию 24 может содержать цифры 0-9 и символы A-N. Целое по
основанию 36 может содержать цифры 0-9 и символы A-Z. [Замечание. Регистр букв
игнорируется.]
Функция strtoul (рис. 21.27) преобразует в unsigned long
последовательность символов, представляющую целое число без знака. Функция работает
I Биты, символы, строки С и структуры 1185
аналогично strtol. В строке 17 записано, что х присваивается значение
unsigned long, полученное преобразованием из stringl, a remainderPtr
присваивается положение первого символа в stringl после преобразованного
числа A234567). Третий аргумент, 0, указывает, что преобразуемое значение
может быть восьмеричным, десятичным или шестнадцатеричным, в зависимости
от начальных символов.
1 // Рис. 21.26: Fig22_26.cpp
2 // Демонстрация strtol.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstdlib> // прототип strtol
8 using std::strtol;
9
10 int main()
11 {
12 long x;
13 const char *stringl = "-1234567abc";
14 char *remainderPtr;
15
16 x = strtol( stringl, &remainderPtr, 0 ); // преобразовать в long
17
18 cout « "The original string is \"" « stringl
19 « "\M\nThe converted value is " « x
20 «M\nThe remainder of the original string is \""« remainderPtr
21 « "\"\nThe converted value plus 567 is " « x + 567 « endl;
22 return 0;
23 } // конец main
The original string is "-1234567abc"
The converted value is -1234567
The remainder of the original string is "abc"
The converted value plus 567 is -1234000
Рис. 21.26. Функция преобразования строк strtol
1 // Рис. 21.27: fig22_27.cpp
2 // Демонстрация strtoul.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstdlib> // прототип strtoul
8 using std::strtoul;
9
10 int main()
11 {
12 unsigned long x;
13 const char *stringl = 234567abc";
14 char *remainderPtr;
15
38 Зак. 1114
1186
Глава 21
16 // преобразовать последвательность символов в unsigned long
17 х = strtoul( stringl, &remainderPtr, 0 );
18
19 cout « "The original string is \"" « stringl
20 « "\"\nThe converted value is " « x
21 «"\nThe remainder of the original string is \""« remainderPtr
22 « "\"\nThe converted value minus 567 is " « x - 567 « endl;
23 return 0;
24 } // конец main
The original string is 234567abc"
The converted value is 1234567
The remainder of the original string is "abc"
The converted value minus 567 is 1234000
Рис. 21.27. Функция преобразования строк strtoul
21.11. Функции поиска из библиотеки обработки
строк-указателей
В этом разделе представлены функции из библиотеки обработки строк
<cstring>, используемые для поиска в строках символов и других строк.
Сводка этих функций приведена на рис. 21.28. Обратите внимание, что для
функций strspn и strcspn специфицирован возвращаемый тип size_t. Этот тип
определяется стандартом как целочисленный тип, возвращаемый операцией
sizeof.
Переносимость программ 21.6
Тип sizejt является системно-зависимым синонимом либо для
unsigned long, либо для unsigned int.
Прототип Описание
char *strchr( const char *s, int с )
Находит первое вхождение символа с в строку s. Если с найден,
возвращается указатель на с в строке s. В противном случае
возвращается нулевой указатель.
char *strrchr( const char *s, int с )
Начинает поиск с конца строки s и находит последнее вхождение
символа с в s. Если с найден, возвращается указатель на с в строке s.
В противном случае возвращается нулевой указатель.
size_t strspn( const char *sl, const char *s2 )
Определяет и возвращает длину начального отрезка строки si,
состоящего только из символов, содержащихся в строке s2.
char *strbrk( const char *sl, const char *s2 )
Находит первое вхождение в строку s1 любого символа строки s2.
Если символ из s2 найден, возвращается указатель на символ в строке
s1. В противном случае возвращается нулевой указатель.
Биты, символы, строки С и структуры
1187
Прототип Описание
size_t strcspn( const char *sl, const char *s2 )
Определяет и возвращает длину начального отрезка строки s1,
состоящего из символов, не содержащихся в строке s2.
char *strstr( const char *sl, const char *s2 )
Находит первое вхождение в строку s1 строки s2. Если строка s2
найдена, возвращается указатель на нее в строке si. В противном случае
возвращается нулевой указатель.
Рис, 21.28. Функции поиска из библиотеки обработки строк-указателей
Функция strchr ищет первое вхождение символа в строку. Если символ
найден, strchr возвращает указатель на символ в строке; в противном случае
возвращается нулевой указатель. Программа на рис. 21.29 использует strchr
(строки 17 и 25) для поиска в строке "This is a test" первого вхождения
символов 'а' и V.
Функция strcspn (рис. 21.30, строка 18) определяет длину начального
отрезка строки в своем первом аргументе, который не содержит никаких
символов из строки во втором аргументе. Функция возвращает длину найденного
отрезка строки.
Функция strpbrk ищет первое вхождение в свой первый строковый аргумент
любого символа из второго строкового аргумента. Если символ из второго
аргумента найден, strpbrk возвращает указатель на символ в первом аргументе;
в противном случае возвращается нулевой указатель. Строка 16 на рис. 21.31
ищет первое вхождение в строку stringl любого символа из string2.
1 // Рис. 21.29: fig22_29.cpp
2 // Демонстрация strchr.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип strchr
8 using std::strchr;
9
10 int main()
11 {
12 const char *stringl = "This is a test";
13 char characterl = 'a';
14 char character2 = 'z';
15
16 // искать characterl в stringl
17 if ( strchr( stringl, characterl ) != NULL )
18 cout « 'V' « characterl « " ' was found in \""
19 « stringl « "\".\n";
20 else
21 cout « A1' « characterl « "' was not found in \""
22 « stringl « "\" An";
23
24 // искать character2 в stringl
25 if ( strchr( stringl, character2 ) != NULL )
26 cout « A'' « character2 « "' was found in \""
1188
Глава 21
27 « stringl « "\".\n";
28 else
29 cout « ' V' « character2 « '" was not found in V"
30 « stringl « "\"." « endl;
31
32 return 0;
33 } // конец main
'a' was found in "This is a test".
'z' was not found in "This is a test".
Рис. 21.29. Функция поиска в строках strchr
1 // Рис. 21.30: fig22_30.cpp
2 // Демонстрация strcspn.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип strcspn
8 using std::strcspn;
9
10 int main()
11 {
12 const char *stringl = "The value is 3.14159";
13 const char *string2 = 234567890";
14
15 cout « "stringl = " « stringl « "\nstring2 = " « string2
16 « "\n\nThe length of the initial segment of stringl"
17 « "\ncontaining no characters from string2 = "
18 « strcspn( stringl, string2 ) « endl;
19 return 0;
20 } // конец main
The length of the initial segment of stringl
containing no characters from string2 = 13
Рис. 21.30. Функция поиска в строках strcspn
1 // Рис. 21.31: fig22_31.cpp
2 // Демонстрация strpbrk.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип strpbrk
8 using std::strpbrk;
9
10 int main()
11 {
12 const char *stringl = "This is a test";
13 const char *string2 = "beware";
Биты, символы, строки С и структуры
1189
14
15 cout « "Of the characters in \"" « string2 « "\"\n,M
16 « *strpbrk( stringl, string2 ) « "\' is the first character
17 « "to appear in\n\"" « stringl « ' V" « endl;
18 return 0;
19 } // конец main
Of tha characters in "beware"
'a' is the first character to appear in
"This is a test"
Рис. 21.31. Функция поиска в строках strpbrk
Функция strrchr ищет последнее вхождение указанного символа в строку.
Если символ найден, strrchr возвращает указатель на символ в строке; в
противном случае возвращается нулевой указатель. Строка 18 на рис. 21.32 ищет
последнее вхождение символа V в строку "A zoo has many animals including
zebras".
Функция strspn (рис. 21.33, строка 18) определяет длину начального
отрезка строки в своем первом аргументе, который содержит только символы из
строки во втором аргументе. Функция возвращает длину найденного отрезка
строки.
Функция strstr ищет первое вхождение в свой первый строковый аргумент
строки из второго аргумента. Если строка второго аргумента найдена в первом
аргументе, возвращается указатель на положение строки в первом аргументе;
в противном случае возвращается нулевой указатель. Строка 18 на рис. 21.34
использует strstr для поиска в строке "abcdefabcdef" строки "def".
1 // Рис. 21.32: fig22_32.cpp
2 // Демонстрация strrchr.
3 #include <iostream>
4 using std::cout;
5 using std:rendl;
6
7 #include <cstring> // прототип strrchr
8 using std::strrchr;
9
10 int main()
11 {
12 const char *stringl = "A zoo has many animals including zebras";
13 char с = 'z';
14
15 cout « "stringl = " « stringl « "\n" « endl;
16 cout « "The remainder of stringl beginning with the\n"
17 « "last occurrence of character '"
18 « с « "' is: \"" « strrchr ( stringl, с ) « *\" • « endl;
19 return 0;
20 } // конец main
The remainder of stringl beginning with the
last occurrence of CMharacter 'z' is: "zebras"
Рис. 21.32. Функция поиска в строках strrchr
1190
Глава 21
1 // Рис. 21.33: fig22_33.cpp
2 // Демонстрация strspn.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип strspn
8 using std::strspn;
9
10 int main()
11 {
12 const char *stringl = "The value is 3.14159";
13 const char *string2 = "aehils Tuv" ;
14
15 cout « "stringl = " « stringl « "\nstring2 = " « string2
16 « "\n\nThe length of the initial segment of stringl\n"
17 « "containing only characters from string2 = "
18 « strspn( stringl, string2 ) « endl;
19 return 0;
20 } // конец main
The length of the initial segment of stringl
containing only characters from string2 = 13
Рис. 21.33. Функция поиска в строках strspn
1 // Рис. 21.34: fig22_34.cpp
2 // Демонстрация strstr.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип strstr
8 using std::strstr;
9
10 int main()
11 {
12 const char *stringl = "abcdefabcdef";
13 const char *string2 = "def";
14
15 cout « "stringl = " « stringl « "\nstring2 = " « string2
16 « "\n\nThe remainder of stringl beginning with the\n"
17 « "first occurrence of string2 is: "
18 « strstr( stringl, string2 ) « endl;
19 return 0;
20 } // конец main
The remainder of stringl beginning with the
first occurrence of string2 is: defabcdef
Рис. 21.34. Функция поиска в строках strstr
Биты, символы, строки С и структуры
1191
21.12. Функции управления памятью из библиотеки
обработки строк-указателей
Функции из библиотеки обработки строк-указателей, представленные
в этом разделе, упрощают операции копирования, сравнения и поиска для
блоков памяти. Эти функции рассматривают боли памяти как байтовые
массивы. Они могут обрабатывать любые блоки памяти. На рис. 21.35 приведена
сводка функций для работы с памятью из библиотеки обработки строк.
[Замечание. Функции обработки строк из предыдущих разделов оперировали
символьными строками, ограниченными нулем. Функции в этом разделе
оперируют массивами байтов. Нуль-символ (т.е. байт, содержащий 0) не имеет для
этих функций никакого специального значения.]
Параметры-указатели этих функций объявляются как void *. В главе 8 мы
видели, что указателю типа void * можно непосредственно присвоить
указатель на любой тип данных. Поэтому эти функции могут принимать указатели
на любые типы данных. Однако, как вы помните, указатель void * не может
непосредственно быть присвоен указателю какого-либо другого типа.
Поскольку указатель void * нельзя разыменовывать, каждая функция получает
аргумент размерности, специфицирующий число символов (байт), которые она
должна обработать. Для простоты примеры в этом разделе манипулируют
символьными массивами (блоками символов).
Прототип Описание
void *memcpy( void *sl, const void *s2, size_t n )
Копирует п символов из объекта, на который указывает s2, в объект,
указываемый s1. Возвращает указатель на объект результата. Область,
из которой копируются символы, не должна перекрываться с областью,
в которую производится копирование.
void *memmove( void *sl, const void *s2, size t n )
Копирует п символов из объекта, на который указывает s2, в объект,
указываемый s1. Копирование производится так, как если бы сначала
символы объекта, указываемого s2, копировались во временный
массив, а затем из временного массива в объект, указываемый si.
Возвращает указатель на объект результата. Область, из которой
копируются символы, может перекрываться с областью, в которую
производится копирование.
int memcmp( const void *sl, const void *s2, size_t n )
Сравнивает первые п символов объектов, на которые указывают s1
и s2. Возвращаемый результат равен, меньше или больше нуля, если s1
соответственно равен, меньше или больше s2.
void *memchr( const void *s, int c, size t n )
Находит первое вхождение с (преобразованного в unsigned char)
в первых п символах объекта, на который указывает s. Если с найден,
возвращается указатель на с в объекте, указываемом s. В противном
случае возвращается 0.
1192
Глава 21
Прототип Описание
void *memset( void *s, int с, size t n )
Копирует с (преобразованный в unsigned char) в первые п символов
объекта, на который указывает s. Возвращается указатель на результат.
Рис. 21.35. Функции управления памятью из библиотеки обработки строк-указателей
Функция тетеру копирует указанное число символов (байт) из объекта, на
который указывает ее второй аргумент, в объект, указываемый первым
аргументом. Функция может принимать указатели на объекты любого типа. Если
два объекта перекрываются в памяти (т.е. являются частями одного и того же
объекта), результат memepy не определен. Программа на рис. 21.36
использует mem еру (строка 17) для копирования строки в массиве s2 в массив si.
Функция memmove, подобно memepy, копирует указанное число байт из
объекта, на который указывает ее второй аргумент, в объект, указываемый
первым аргументом. Копирование производится так, как если бы байты
сначала копировались из второго аргумента во временный массив символов, а затем
копировались из временного массива в первый аргумент. Это позволяет
копировать символы из одной части строки в другую часть той же самой строки.
Типичная ошибка программирования 21.8
Результат функций обработки строк (кроме memmove), копирующих
символы, не определен, если копирование выполняется между частями
одной и той же строки.
Программа рис. 21.37 использует memmove (строка 16) для копирования
последних 10 байт массива х в первые 10 байт массива х.
1 // Рис. 21.36: fig22_36.cpp
2 // Демонстрация memepy.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип memepy
8 using std::memepy;
9
10 int main()
11 {
12 char sl[ 17 ];
13
14 // всего 17 символов (влючает ограничивающий нуль)
15 char s2[] = "Copy this string";
16
17 memepy( si, s2, 17 ); // копировать 17 символов из s2 в si
18
19 cout « "After s2 is copied into si with memepy,\n"
20 « "si contains \"" « si « '\'" « endl;
21 return 0;
22 } // конец main
Биты, символы, строки С и структуры
1193
After s2 is copied into si with memcpy,
si contains "Copy this string"
Рис. 21.36 Функция управления памятью memcpy
1 // Рис. 21.37: fig22_37.cpp
2 // Демонстрация memmove.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип memmove
8 using std::memmove;
9
10 int main()
11 {
12 char x[] = "Home Sweet Home";
13
14 cout « "The string in array x before memmove is: " « x;
15 cout « "\nThe string in array x after memmove is: "
16 « static_cast< char * >( memmove ( x, ix[ 5 ], 10 ) ) « endl;
17 return 0;
18 } // конец main
The string in array x before memmove is: Home Sweet Home
The string in array x after memmove is: Sweet Home Home
Рис. 21.37. Функция управления памятью memmove
Функция тетстр (рис. 21.38, строки 19, 20 и 21) сравнивает указанное
число символов своего первого аргумента с соответствующими символами
второго аргумента. Функция возвращает значение, большее нуля, если ее первый
аргумент больше второго, равное нулю, если аргументы равны, и меньшее
нуля, если первый аргумент меньше второго. [Замечание. На некоторых
компиляторах функция memcmp возвращает -1,0 или 1, как в образце вывода на
рис. 21.38. На других компиляторах функция возвращает 0 либо разность
численных кодов первых символов, отличных друг от друга в сравниваемых
строках. Например, когда сравниваются si и s2, первыми отличными символами
оказываются символы в пятой позиции каждой из строк — Е (численный
код 69) в si и X (численный код 88) в s2. В этом случае возвращаемое значение
было бы равно —19 (или 19, когда s2 сравнивается с si).]
Функция memchr ищет первое вхождение байта, представленного как
unsigned char, в указанном числе байт объекта. Если байт в объекте найден,
возвращается указатель на него; в Противном случае функция возвращает
нулевой указатель. Строка 16 на рис. 21.39 ищет символ (байт) 'г' в строке "This
is a string".
Функция memset копирует значение байта в своем втором аргументе в
указанное число байт объекта, на который указывает первый аргумент. Строка 16
на рис. 21.40 вызывает memset для копирования Ъ' в первые 7 байт stringl.
1194
Глава 21
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// Рис. 21.38: fig22_38.cpp
// Демонстрация memcxnp.
#include <iostream>
using std::cout;
using std::endl;
#include <iomanip>
using std::setw;
#include <cstring> // прототип memcmp
using std:: memcmp;
int main()
{
char sl[] = "ABCDEFG";
char s2[] = "ABCDXYZ";
cout « "si = " « si « "\ns2 = " « s2 « endl
« "\nmemcmp(sl, s2, 4) =
« "\nmemcmp(sl, s2, 7) =
« "\nmemcmp(s2, si, 7) =
« endl;
return 0;
} // конец main
« setw( 3 ) « memcmp( si, s2, 4 )
« setw( 3 ) « memcmp( si, s2, 7 )
« setw( 3 ) « memcmp( s2, si, 7 )
si = ABCDEFG
s2 = ABCDXYZ
memcmp(si, s2, 4) = 0
memcmp(si, s2, 7) = -1
memcmp(s2, si, 7) = 1
Рис. 21.38. Функция управления памятью memcmp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Рис. 21.39: fig22_39.cpp
// Демонстрация memchr.
#include <iostream>
using std::cout;
using std::endl;
#include <cstring> // прототип memchr
using std::memchr;
int main()
{
char s[] = "This is a string";
cout « "s = " « s « "\n" « endl;
cout « "The remainder of s after character 'r' is found is \""
« static_cast< char * >( memchr ( s, 'r', 16 ) )« ' \"'« endl;
return 0;
} // конец main
Биты, символы, строки С и структуры
1195
s = This is a string
The remainder of s after character 'r' is found is "ring"
Рис. 21.39. Функция управления памятью memchr
1 // Рис. 21.40: fig22_40.cpp
2 // Демонстрация memset.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // прототип memset
8 using std::memset;
9
10 int main()
11 {
12 char stringl[ 15 ] = "BBBBBBBBBBBBBB";
13
14 cout « "stringl = " « stringl « endl;
15 cout « "stringl after memset = "
16 « static_cast< char * >( memset( stringl, 'b', 7 ) ) « endl;
17 return 0;
18 } // конец main
stringl = BBBBBBBBBBBBBB
stringl after memset = bbbbbbbBBBBBBB
Рис. 21.40. Функция управления памятью memset
21.13. Заключение
В этой главе было представлено определение структур struct, их
инициализация и использование их с функциями. Мы обсудили объявление typedef для
создания псевдонимов, помогающих писать переносимый код. Мы
представили поразрядные операции для работы с битами и битовые поля для
компактного хранения данных. Вы изучили также функции преобразования строк из
<cstdlib> и функции обработки строк из <cstring>. В следующей главе мы
продолжим наше изучение структур данных обсуждением контейнеров —
структур данных, определяемых в Библиотеке стандартных шаблонов C++
(STL). Мы представим также и разнообразные алгоритмы, определяемые
в STL.
Резюме
• Структуры являются наборами (агрегатами) взаимосвязанных переменных,
объединенных под одним именем.
• Структуры могут содержать переменные различных типов данных.
• Каждое определение структуры начинается ключевым словом struct. Внутри
фигурных скобок определения структуры располагаются объявления элементов
структуры.
1196
Глава 21
• Элементы одной и той же структуры должны иметь уникальные имена.
• Определение структуры создает новый тип данных, который может использоваться
для объявления переменных.
• Структуру можно инициализировать посредством списка инициализации, поставив
в объявлении после имени переменной знак равенства и разделенный запятыми
список инициализаторов, заключенный в фигурные скобки. Если инициализаторов
в списке меньше, чем элементов в структуре, оставшиеся элементы
инициализируются нулями (или нулевыми указателями для элементов-указателей).
• Структурные переменные можно целиком присваивать структурным переменным
того же типа.
• Структурную переменную можно инициализировать значением структурной
переменной того же типа.
• Структурные переменные и отдельные элементы структур передаются функциям по
значению.
• Чтобы передать структуру по ссылке, передайте адрес структурной переменной либо
ссылку на структурную переменную. Массивы структур передаются по ссылке. Чтобы
передать массив по значению, создайте структуру с массивом в качестве элемента.
• Создание нового имени с помощью typedef не создает нового типа; typedef создает
новое имя, синонимичное ранее определенному типу.
• Поразрядная операция И (&) принимает два целочисленных операнда. Бит
результата устанавливается в единицу, если равны единице соответствующие биты каждого
из операндов.
• Маски с поразрядной операцией И используются, чтобы, скрыв некоторые биты
значения, выделить остальные.
• Поразрядная операция включающего ИЛИ (|) принимает два операнда. Бит
результата устанавливается в единицу, если равен единице соответствующий бит в любом
из операндов.
• Для каждой поразрядной операции (за исключением поразрядного дополнения)
имеется соответствующая операция присваивания.
• Поразрядная операция исключающего ИЛИ (") принимает два операнда. Бит
результата устанавливается в единицу, если равен единице ровно один из соответствующих
битов в операндах.
• Операция сдвига влево («) сдвигает биты своего левого операнда влево на число
позиций, специфицированное правым операндом. Освобождающиеся биты справа
замещаются нулями.
• Операция сдвига вправо (») сдвигает биты своего левого операнда вправо на число
позиций, специфицированное правым операндом. Выполнение правого сдвига над
целым без знака замещает биты, освобождающиеся слева, нулями. Результат сдвига
вправо значения со знаком машинно-зависим. Освобождающиеся слева биты могут
замещаться нулями либо расширением знакового бита.
• Поразрядная операция дополнения (-) принимает один операнд и инвертирует его
биты, в результате чего получается дополнение операнда до единицы.
• Битовые поля позволяют экономнее использовать память, сохраняя данные в
минимально необходимом числе бит. Элементы — битовые поля должны объявляться как
int или unsigned.
• Битовое поле объявляется указанием после имени элемента типа int или unsigned
двоеточия и ширины битового поля.
• Ширина битового поля должна быть целой константой.
• Если битовое поле объявляется без имени, оно используется качестве заполнителя
структуры.
Биты, символы, строки С и структуры
1197
• Неименованное битовое поле нулевой ширины выравнивает следующее битовое поле
по границе нового машинного слова.
• Функция islower определяет, является ли ее аргумент латинской буквой нижнего
регистра (a-z). Функция isupper определяет, является ли аргумент буквой верхнего
регистра (A-Z).
• Функция isdigit определяет, является ли ее аргумент цифрой @-9).
• Функция isalpha определяет, является ли ее аргумент латинской буквой нижнего
или верхнего регистра (A-Z, a-z).
• Функция isalnum определяет, является ли ее аргумент буквой (A-Z, a-z) либо
цифрой @-9).
• Функция isxdigit определяет, является ли аргумент шестнадцатеричной цифрой
(Л-F, af, 0-9).
• Функция toupper преобразует букву нижнего регистра в верхний. Функция tolower
преобразует букву верхнего регистра в нижний.
• Функция isspace определяет, является ли ее аргумент одним из следующих
пробельных символов: ' ' (пробелом), '\f, '\n\ '\r\ '\t' или '\v'.
• Функция iscntrl определяет, является ли ее аргумент управляющим символом,
таким, как '\п\ '\f, '\г\ '\t\ *\v» \a' или \Ь'.
• Функция ispunct определяет, является ли ее аргумент печатаемым символом,
отличным от пробела, цифры и буквы.
• Функция isprint определяет, является ли ее аргумент печатаемым символом
(включая пробел).
• Функция isgraph определяет, является ли ее аргумент печатаемым символом,
отличным от пробела.
• Функция atof преобразует свой аргумент — строку символов, представляющую
число с плавающей точкой — в значение типа double.
• Функция atoi преобразует свой аргумент — строку цифр, представляющую целое
число — в значение типа int.
• Функция atol преобразует свой аргумент — строку цифр, представляющую длинное
целое — в значение типа long.
• Функция strtod преобразует последовательность символов, представляющую число
с плавающей точкой, в значение типа double. Функция принимает два аргумента —
строку (char *) и адрес указателя char *. Строка содержит последовательность
символов, которую нужно преобразовать в значение double, а указателю char *
присваивается остаток строки после преобразования.
• Функция strtol преобразует в long последовательность символов, представляющую
целое число. Функция принимает три аргумента — строку (char *), адрес указателя
char * и целое. Строка содержит последовательность символов, которую нужно
преобразовать, указателю char * присваивается положение первого символа,
следующего за преобразованной частью строки, а целое специфицирует основание
преобразуемого значения.
• Функция strtoul преобразует в unsigned long последовательность символов,
представляющую целое число без знака. Функция принимает три аргумента — строку
(char *), адрес указателя char * и целое. Строка содержит последовательность
символов, которую нужно преобразовать, указателю char * присваивается положение
первого символа, следующего за преобразованной частью строки, а целое
специфицирует основание преобразуемого значения.
• Функция strchr ищет первое вхождение символа в строку. Если символ найден,
strchr возвращает указатель на символ в строке; в противном случае возвращается
нулевой указатель.
1198
Глава 21
Функция strcspn определяет длину начального отрезка строки в своем первом
аргументе, который не содержит никаких символов из строки во втором аргументе.
Функция возвращает длину найденного отрезка строки.
Функция strpbrk ищет первое вхождение в свой первый строковый аргумент любого
символа из второго строкового аргумента. Если символ из второго аргумента найден,
strpbrk возвращает указатель на символ в первом аргументе; в противном случае
возвращается нулевой указатель.
Функция strrchr ищет последнее вхождение указанного символа в строку. Если
символ найден, strrchr возвращает указатель на символ в строке; в противном случае
возвращается нулевой указатель.
Функция strspn определяет длину начального отрезка строки в своем первом
аргументе, который содержит только символы из строки во втором аргументе. Функция
возвращает длину найденного отрезка строки.
Функция strstr ищет первое вхождение в свой первый строковый аргумент строки
из второго аргумента. Если строка второго аргумента найдена в первом аргументе,
возвращается указатель на положение строки в первом аргументе; в противном
случае возвращается нулевой указатель.
Функция memcpy копирует указанное число символов из объекта, на который
указывает ее второй аргумент, в объект, указываемый первым аргументом. Функция
может принимать указатели на объекты любого типа. Указатели принимаются
функцией как void * и преобразуются для использования в функции в указатели на
char; memcpy оперирует байтами своих аргументов как символами.
Функция memmove копирует указанное число байт из объекта, на который
указывает ее второй аргумент, в объект, указываемый первым аргументом. Копирование
производится так, как если бы байты сначала копировались из второго аргумента во
временный массив символов, а затем копировались из временного массива в первый
аргумент.
Функция memcmp сравнивает указанное число символов своего первого аргумента
с соответствующими символами второго аргумента.
Функция memchr ищет первое вхождение байта, представленного как unsigned
char, в указанном числе байт объекта. Если байт в объекте найден, возвращается
указатель на него; в противном случае функция возвращает нулевой указатель.
Функция memset копирует значение байта в своем втором аргументе в указанное
число байт объекта, на который указывает первый аргумент.
Терминология
& поразрядная операция И <cstdlib>
&= операция присваивания поразряд- » операция сдвига вправо
ного И »= операция присваивания сдвига
Л поразрядная операция исключающе- вправо
го ИЛИ atof
л= операция присваивания поразряд- atoi
ного исключающего ИЛИ atol
| поразрядная операция включающего isalnum
ИЛИ isalpha
|= операция присваивания поразряд- iscntrl
ного включающего ИЛИ isdigit
- поразрядная операция дополнения isgraph
« операция сдвига влево islower
«= операция присваивания сдвига isprint
влево ispunct
Биты, символы, строки С и структуры
1199
isspace tolower
isupper toupper
isxdigit typedef
memchr автореферентная структура
memcmp агрегатный тип данных
memcpy библиотека утилит общего назначения
memmove битовое поле
memset битовое поле нулевой ширины
strchr дополнение до единицы
strcspn заполнение
strpbrk имя структуры
strrchr маска
strspn неименованное битовое поле
strstr поразрядные операции присваивания
strtod структурный тип
strtol функции преобразования строк
strtoul ширина битового поля
struct
Контрольные вопросы
21.1. Заполните пропуски в каждом из следующих утверждений.
а) — это объединение логически связанных переменных под одним
именем.
b) Биты в результате выражения с операцией устанавливаются
в единицу, если установлены в единицу соответствующие биты каждого
операнда. В противном случае биты устанавливается в ноль.
c) Переменные, объявленные в определении структуры, называются ее
d) Биты в результате выражения с операцией устанавливливаются
в единицу, если установлен в единицу хотя бы один из соответствующих битов
любого из операндов. В противном случае биты устанавливается в ноль.
e) Ключевое слово начинает объявление структуры.
f) Ключевое слово используется для создания синонима ранее
определенного типа данных.
g) Каждый из битов в результате выражения с операцией
устанавливаются в единицу, если установлен в единицу ровно один из соответствующих
битов каждого из операндов. В противном случае биты устанавливается
в ноль.
h) Операция поразрядного И (&) часто используется для того, чтобы
биты (т.е. выделить некоторые из битов, обнулив остальные),
i) Обращение к элементу структуры производится либо с помощью операции
, либо с помощью операции .
j) Операции и применяются для сдвига битов значения
соответственно влево или вправо.
21.2. Укажите, верно или неверно каждое из следующих утверждений; если
утверждение неверно, объясните, почему.
a) Структуры могут содержать только один тип данных.
b) Элементы различных структур должны иметь уникальные имена.
e) Ключевое слово typedef используется для определения новых типов данных.
f) Структуры всегда передаются функциям по ссылке.
1200
Глава 21
21.3- Напишите один или несколько операторов C++, выполняющих каждое из
следующих действий:
a) Определите структуру с именем Part, содержащую переменную partNumber
типа int и массив partName типа char, значения которого могут иметь длину
до 25 символов.
b) Определите PartPtr в качестве синонима PartPtr *. ,
c) Используйте отдельные операторы для объявления переменной а типа Part,
массива Ь[ 10 ] типа Part и переменной ptr — указателя на Part.
d) Прочитайте с клавиатуры номер и название детали в элементы переменной а.
e) Присвойте значение переменной а элементу 3 массива Ь.
f) Присвойте адрес массива b указателю ptr.
g) Напечатайте значение элемента 3 массива Ь, используя переменную ptr и
операцию указателя структуры для обращения к элементам.
21.4. Найдите ошибки в каждом из следующих примеров:
a) Предположим, что struct Card была определена как содержащая два
указателя на char, а именно face и suit. Кроме того, была объявлена переменная с
типа Card и переменная cPtr как указатель на Card. Переменной cPtr был
присвоен адрес переменной с.
cout « *cPtr.face « endl;
b) Предположим, что struct Card была определена как содержащая два
указателя на char, а именно face и suit. Кроме того, был объявлен массив hearts[ 13 ]
типа Card. Следующий оператор должен напечатать элемент face элемента 10
массива.
cout « hearts.face « endl;
c) struct Person {
char lastName[ 15 ];
char firstName[ 15 ];
int age;
}
d) Предположим, переменная р была объявлена как Person, а переменная с была
объявлена как Card.
Р = с;
21.5. Напишите по одному оператору для выполнения следующих задач.
Предположите, что переменные с (хранит символ), х, у и z имеют тип int; переменные d, e
и f имеют тип double; переменная ptr имеет тип char *, а массивы sl[ 100 ]
и s2[ 100 ] имеют тип char.
a) Преобразуйте символ, хранящийся в переменной с, в букву верхнего регистра;
присвойте результат переменной с.
b) Определите, является ли значение переменной с цифрой. Воспользуйтесь
условной операцией так, как показано на рис. 21.18-21.20, чтобы при выводе
результата печаталось "is а" или "is not a".
c) Преобразуйте строку 234567" в long и напечатайте значение.
d) Определите, является ли значение переменной с управляющим символом.
Воспользуйтесь условной операцией, чтобы при выводе результата печаталось
"is а" или "is not a".
e) Присвойте ptr указатель на последнее вхождение с в si.
f) Преобразуйте строку "8.63582" в double и напечатайте значение.
g) Определите, является ли значение переменной с буквой. Воспользуйтесь
условной операцией, чтобы при выводе результата печаталось "is а" или "is not a".
Биты, символы, строки С и структуры
1201
h) Присвойте ptr указатель на перое вхождение s2 в si.
i) Определите, является ли значение переменной с печатаемым символом.
Воспользуйтесь условной операцией, чтобы при выводе результата печаталось
"is а" или "is not a".
j) Присвойте ptr указатель на первое вхождение в si любого символа из s2.
к) Присвойте ptr указатель на первое вхождение с в si.
1) Преобразуйте строку "-21" в int и напечатайте значение.
Ответы на контрольные вопросы
21.1. а) структура. Ь) поразрядного И (&). с) элементами, d) поразрядного
включающего ИЛИ (|). е) struct, f) typedef. g) поразрядного исключающего ИЛИ (л).
h) маскировать, i) элемента структуры (.), указателя структуры (->). j) сдвига
влево («), сдвига вправо (»).
21.2. а) Неверно. Структура может содержать несколько типов данных.
b) Неверно. Элементы разных структур могут иметь одинаковые имена, но
элементы одной структуры должны иметь уникальные имена.
c) Неверно. Ключевое слово typedef используется для определения псевдонимов
ранее определенных типов данных.
d) Неверно. Структуры по умолчанию передаются функциям по значению, но
могут быть переданы по ссылке.
21.3. a) struct Part {
int partNumber;
char partName[ 26 ];
>;
b) typedef Part * PartPtr;
c) Part a;
Part b[ 10 ] ;
Part *ptr;
d) cin » a.partNumber » a.partName;
e)b[ 3 ] = a;
f) ptr = b ;
g) cout « ( ptr + 3 ) ->partNumber « ' '
« ( ptr + 3 ) ->partName « endl ;
21.4. а) Ошибка: пропущены скобки, в которые должен заключаться *cPtr, что
приведет к неправильному порядку оценки выражения.
b) Ошибка: пропущен индекс массива. Выражение следует записать в виде
hearts[ 10 ].face.
c) Ошибка: в конце определения структуры должна стоять точка с запятой.
d) Ошибка: нельзя присваивать друг другу структурные переменные различных
типов.
21.5. а) с = toupper( с ) ;
b) cout « 'V ' « с « "V "
« ( isdigit( с ) ? "is a" : "is not a")
« " digit" « endl;
c) cout « atol( 234567" ) « endl;
d) cout « '\' ' « с « "V " '
« ( iscntrl( с ) ? "is a" : "is not a")
« " control character" « endl;
1202
Глава 21
e) ptr = strrchr( si, с );
f) cout « atof ( "8.63582" ) « endl;
g) cout « 'V ' « с « "V "
« ( isalpha( с ) ? "is a" : "is not a")
« " letter" « endl;
h) ptr = strstr( si, s2 );
d) cout « '\' ' « с « "V "
« ( isprint( с ) ? "is a" : "is not a")
« " printing character" « endl;
j) ptr = strpbrk( si, s2 ) ;
k) ptr = strchr ( si, с ) ;
1) cout « atoi( "-21" ) « endl;
Упражнения
21.6. Напишите определения для каждой из следующих структур:
a) Структуры Inventory, содержащей следующие элементы: символьный массив
partName[ 30 ], целую переменную partNumber, вещественную price, целую
stock и целую reorder.
b) Структуры с именем Address, содержащей символьные массивы street
Address! 25 ], city[ 20 ], state[ 3 ] и zipCode[ 6 ].
c) Структуры Student, содержащей массивы firstNamef 15 ] и lastNamef 15 ],
а также переменную homeAddress типа Address из пункта (Ь).
d) Структуры Test, содержащей 16 битовых полей шириной в один бит. Именами
битовых полей являются буквы от а до р.
21.7. Имеются следующие определения структур и объявления переменных:
struct Customer {
char lastName[15];
char firstName[15];
int customerNumber;
struct {
char phoneNumber[ 11 ];
char address[ 50 ];
char city[ 15 ] ;
char state[ 3 ];
char zipCode[ 6 ];
} personal;
} customerRecord, *customerPtr;
customerPtr = &customerRecord;
Напишите отдельные выражения, которые можно использовать для обращения
к элементам структуры в каждом из следующих случаев.
a) К элементу lastName структуры customerRecord.
b) К элементу lastName структуры, на которую указывает customerPtr.
c) К элементу firstName структуры customerRecord.
d) К элементу firstName структуры, на которую указывает customerPtr.
e) К элементу customerNumber структуры customerRecord.
f) К элементу customerNumber структуры, на которую указывает customerPtr.
g) К элементу phoneNumber элемента personal структуры customerRecord.
h) К элементу phoneNumber элемента personal структуры, на которую
указывает customerPtr.
Биты, символы, строки С и структуры
1203
i) К элементу address элемента personal структуры customerRecord.
j) К элементу address элемента personal структуры, на которую указывает custo-
merPtr.
к) К элементу city элемента personal структуры customerRecord.
1) К элементу city элемента personal структуры, на которую указывает custo-
merPtr.
m) К элементу state элемента personal структуры customerRecord.
п) К элементу state элемента personal структуры, на которую указывает custo-
merPtr.
о) К элементу zipCode элемента personal структуры customerRecord.
р) К элементу zipCode элемента personal структуры, на которую указывает cus-
tomerPtr.
21.8. Измените программу на рис. 21.14, применив эффективный алгоритм тасования
(см. рис. 21.3). Распечатайте полученную колоду в две колонки, как на рис. 21.4.
Перед каждой картой должен стоять ее цвет.
21.9. Напишите программу, которая сдвигает целую переменную вправо на четыре
бита. Программа должна распечатывать целое число в двоичном представлении
до и после операции сдвига. Нули или единицы помещает ваша система в
освободившиеся биты?
21.10. Сдвиг влево целого без знака на один бит эквивалентен умножению на два.
Напишите функцию power2, которая принимает два целых аргумента number
и pow и вычисляет
number * 2pow
Используйте операцию сдвига. Программа должна печатать значения как в
десятичном, так и в двоичном виде.
21.11. Операция сдвига влево может применяться для того, чтобы упаковать два
символьных значения в двухбайтовое целое без знака. Напишите программу,
которая принимает два символа с клавиатуры и передает их функции packCharac-
ters. Чтобы упаковать два символа в целую переменную без знака, присвойте
первый символ переменной типа unsigned, сдвиньте переменную влево на 8
битовых позиций и объедините ее со вторым символом посредством операции
поразрядного включающего ИЛИ. Программа должна выводить символы в двоичном
формате до и после того, как они будут упакованы в целое без знака, чтобы
доказать, что символы действительно правильно упакованы в переменную.
21.12. Используя операцию сдвига вправо, операцию поразрядного И и маску, напишите
функцию unpackCharacters, которая принимает целое без знака из
упражнения 21.11 и распаковывает его в два символа. Для того чтобы распаковать два
символа из двухбайтового целого без знака, объедините по И беззнаковое целое
с маской 65280 A1111111 00000000) и сдвиньте результат вправо на восемь бит.
Присвойте полученное значение переменной типа char. После этого объедините по
И беззнаковое целое с маской 255 @0000000 11111111). Присвойте полученное
значение другой переменной типа char. Программа должна напечатать
беззнаковое целое в двоичном виде, прежде чем его распаковать, а потом напечатать
символы в двоичном виде, чтобы подтвердить, что они были распакованы правильно.
21.13. Если ваша система имеет 4-байтовые целые, перепишите программу
упражнения 21.11 для упаковывания 4-х символов.
11.14. Если ваша система имеет 4-байтовые целые, перепишите функцию
unpackCharacters упражнения 21.12 для распаковывания четырех символов. Создайте
маски, которые понадобятся для распаковки четырех символов, посредством сдвига
значения 255 в переменной маски на 8 бит 0, 1, 2 или 3 раза (в зависимости от
байта, который вы извлекаете).
1204
Глава 21
21.15. Напишите программу, которая обращает порядок битов в целом числе без знака.
Программа должна принимать введенное пользователем значение и вызывать
функцию reverseBits, чтобы напечатать биты в обратном порядке. Выведите
значение в двоичном виде как до, так и после преобразования, чтобы подтвердить,
что биты действительно расположились в обратном порядке.
21.16. Напишите программу, демонстрирующую передачу массива по значению.
[Подсказка. Используйте struct. Докажите, что передается копия, попытавшись
модифицировать массив в вызванной функции.]
21.17. Напишите программу, которая вводит символ с клавиатуры и проверяет его
каждой из функций библиотеки обработки символов. Напечатайте значения,
выводимые функциями.
21.18. Приведенная ниже программа вызывает функцию multiple, чтобы определить,
является ли целое число, введенное с клавиатуры, кратным некоторому
целому X. Исследуйте функцию multiple и определите значение X.
1 // Упражнение 21.18: ех22_18.срр
2 // Программа определяет, является ли значение кратным X.
3 #include <iostream>
4
5 using std::cout;
6 using std:rein;
7 using std::endl;
8
9 bool multiple( int );
10
11 int main()
12 {
13 int y;
14
15 cout « "Enter an integer between 1 and 32000: ";
16 cin » y;
17
18 if ( multiple( у ) )
19 cout « у « " is a multiple of X" « endl;
20 else
21 cout « у « " is not a multiple of X" « endl;
22
23 return 0;
24
25 } // конец main
26
27 // определить, является ли num кратным X
28 bool multiple( int num )
29 {
30 bool mult = true;
31
32 for ( int i = 0, mask = 1; i < 10; i++, mask «= 1 )
33
34 if ( ( num & mask ) != 0 ) {
35 mult = false;
36 break;
37
38 } // конец if
39
40 return mult;
41
42 } // конец функции multiple
Биты, символы, строки С и структуры
1205
21.19. Что делает следующая программа?
1 // Упражнение 21.19 : ех22_19.срр
2 #include <iostream>
3
4 using std::cout;
5 using std::cin;
6 using std::endl;
7 using std::boolalpha;
8
9 bool mystery( unsigned );
10
11 int main()
12 {
13 unsigned x;
14
15 cout « "Enter an integer: ";
16 cin » x;
17 cout « boolalpha
18 « "The result is " « mystery( x ) « endl;
19
20 return 0;
21
22' } // конец main
23
24 // Что делает эта функция?
25 bool mystery( unsigned bits )
26 {
27 const unsigned i;
28 const unsigned mask = 1 « SHIFT;
29 unsigned total = 0;
30
31 for ( i = 1; i <= 32; i++, bits «= 1 )
32
33 if ( ( bits & MASK ) == MASK )
34 ++total;
35
36 return !( total % 2 );
37
38 } // конец функции mystery
21.20. Напишите программу, которая вводит строку текста функцией getline класса
istream (как в главе 15) в символьный массив s[ 100 ]. Выведите строку с
буквами в верхнем регистре и в нижнем регистре.
21.21. Напишите программу, которая вводит четыре строки, представляющие целые
числа, преобразует эти строки в целые значения и печатает их сумму.
Используйте только возможности обработки строк в стиле С, описанные в этой главе.
21.22. Напишите программу, которая вводит четыре строки, представляющие числа
с плавающей точкой, преобразует эти строки в значения типа double и печатает
их сумму. Используйте только возможности обработки строк в стиле С,
описанные в этой главе.
21.23. Напишите программу, которая вводит с клавиатуры строку текста и строку
поиска. Используя функцию strstr, найдите первое вхождение в текст строки
поиска и присвойте ее адрес переменной searchPtr типа char *. Если подстрока
найдена, напечатайте остаток строки текста, начиная со строки поиска. Затем снова
используйте strstr, чтобы найти следующее вхождение строки поиска. Если
второе вхождение найдено, напечатайте остаток строки текста, начиная со строки
поиска. [Подсказка. Второй вызов strstr должен содержать в качестве первого
аргумента выражение searchPtr +1.]
1206
Глава 21
21.24. Напишите программу, основанную на программе упражнения 21.23, которая
вводит несколько строк текста и строку поиска. Используя функцию strstr,
определите общее число вхождений строки поиска в строки текста. Напечатайте
результат.
21.25. Напишите программу, которая вводит несколько строк текста и символ поиска.
Используя функцию strchr, определите общее число вхождений этого символа
в текст.
21.26. Напишите программу, основанную на программе упражнения 21.25, которая
вводит несколько строк текста и использует функцию strchr для определения
общего числа вхождений в текст каждой буквы алфавита. Буквы верхнего и
нижнего регистра должны подсчитываться вместе. После подсчета сохраните
результаты в массиве и распечатайте значения в табличном формате.
21.27. Таблица в приложении «Набор символов ASCII» содержит численные коды,
представляющие символы набора символов ASCII. Изучите эту таблицу и затем
ответьте, верны ли следующие утверждения:
a) Буква «А» идет по порядку перед буквой «В».
b) Цифра «9» идет перед цифрой «0».
c) Обычно используемые символы сложения, вычитания, умножения и деления
идут перед любыми цифрами.
d) Цифры идут перед буквами.
e) Если программа сортировки упорядочивает строки в порядке возрастания, то
эта программа поместит символ правой скобки перед символом левой скобки.
21.28. Напишите программу, которая читает ряд строк и печатает только те из них,
которые начинаются с буквы «Ь».
21.29. Напишите программу, которая читает ряд строк и печатает только те из них,
которые кончаются с букв «ED».
21.30. Напишите программу, которая вводит коды ASCII и печатает соответствующие
им символы. Модифицируйте эту программу так, чтобы она генерировала все
возможные трехразрядные коды в диапазоне от 000 до 255 и пыталась
напечатать соответствующие им символы. Что происходит при запуске этой
программы?
21.31. Используя таблицу символов ASCII из приложения Б, напишите свои
собственные версии функций обработки символов из таблицы на рис. 21.17.
21.32. Напишите свои собственные версии функций преобразования строк в числа из
таблицы на рис. 21.21.
21.33. Напишите свои собственные версии функций поиска в строках из таблицы на
рис. 21.28.
21.34. Напишите свои собственные версии функций для работы с блоками памяти из
таблицы на рис. 21.35.
21.35. (Проект: проверка орфографии) Многие популярные пакеты программ
обработки текстов имеют встроенные средства проверки орфографии. Мы использовали
такие средства при подготовке этой книги и обнаружили, что вне зависимости от
того, насколько тщательно мы писали главу, программа всегда находила больше
орфографических ошибок, чем мы могли обнаружить вручную.
В данном проекте мы просим вас разработать свою собственную утилиту
проверки орфографии. Мы предложим ряд упрощений, чтобы помочь вам начать этот
проект. В дальнейшем вы сможете ввести в проект дополнительные
возможности. Вы можете также воспользоваться в качестве источника слов
компьютеризованным словарем.
Биты, символы, строки С и структуры
1207
Почему мы печатаем с ошибками так много слов? В некоторых случаях это
связано с тем, что мы просто не знаем правильного написания и пытаемся
«угадать», как пишется то или иное слово. В некоторых случаях мы переставляем
две буквы (например, «умлочание» вместо «умолчание»). Иногда мы случайно
сдваиваем буквы (например, «удоббно» вместо «удобно»). Иногда мы нажимаем
соседнюю клавишу (например, «лень» вместо «день») и т.д.
Спроектируйте и реализуйте программу проверки орфографии. Ваша программа
должна обрабатывать массив wordList символьных строк (словарь). Вы можете
ввести эти строки сами или взять их из компьютерного словаря.
Ваша программа просит пользователя ввести слово. Затем программа
просматривает слова в массиве wordList. Если введенное слово в массиве есть, ваша
программа должна напечатать «Слово написано правильно».
Если слово в словаре не найдено, ваша программа должна напечатать «Слово
написано неправильно». Тогда программа должна попытаться найти другие слова
в wordList, которые, может быть, пользователь хотел написать. Например, вы
можете попытаться переставить всеми возможными способами соседние буквы,
чтобы обнаружить, что слово «умолчание» имеет соответствие в словаре.
Конечно, это означает, что ваша программа должна перебрать все возможные
перестановки соседних букв: «муолчание», «уомлчание», «умлочание», «умочлание»
и т.д. Когда вы найдете новое слово, которое совпадает со словом в в wordList,
напечатайте сообщение типа: «Может быть, вы подразумевали "умолчание"?».
Чтобы улучшить вашу программу проверки орфографии, вы можете добавить
в нее реализацию таких проверок, как замена сдвоенных букв одной буквой,
и любых других.
*■
■>*■-
22
Библиотека стандартных
шаблонов (STL)
ЦЕЛИ
В этой главе вы изучите:
• Использование шаблонов
контейнеров, контейнерных
адаптеров и «почти контейнеров»
из STL.
• Программирование с помощью
алгоритмов из STL.
• Как алгоритмы используют
итераторы для доступа
к контейнерам STL.
• Какие ресурсы STL доступны
в Internet и World Wide Web.
1210
Глава 22
22.1. Введение в Библиотеку стандартных шаблонов (STL)
22.1.1. Введение в контейнеры
22.1.2. Введение в итераторы
22.1.3. Введение в алгоритмы
22.2. Контейнеры последовательностей
22.2.1. Контейнер последовательности vector
22.2.2. Контейнер последовательности list
22.2.3. Контейнер последовательности deque
22.3. Ассоциативные контейнеры
22.3.1. Ассоциативный контейнер multiset
22.3.2. Ассоциативный контейнер set
22.3.3. Ассоциативный контейнер multimap
22.3.4. Ассоциативный контейнер шар
22.4. Адаптеры контейнеров
22.4.1. Адаптер stack
22.4.2. Адаптер queue
22.4.3. Адаптер priorityqueue
22.5. Алгоритмы
22.5.1. fill, fill_n, generate и generaten
22.5.2. equal, mismatch и lexicographical_compare
22.5.3. remove, removejf, remove_copy
и remove_copy_if
22.5.4. replace, replace_if, replace_copy
и replacecopyjf
22.5.5. Математические алгоритмы
22.5.6. Элементарные алгоритмы поиска
и сортировки
22.5.7. swap, iter_swap и swap_ranges
22.5.8. copy_backward, merge, unique и reverse
22.5.9. inplace.merge, uniquecopy и revrse_copy
22.5.10. Операции над множествами
22.5.11. lowerjbound, upperbound и equalrange
22.5.12. Кучевая сортировка
22.5.13. min и max
22.5.14. Алгоритмы, не представленные в этой главе
Библиотека стандартных шаблонов (STL)
1211
22.6. Класс bitset
22.7. Функциональные объекты
22.8. Заключение
22.9. Ресурсы по STL в Internet и Web
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
22.1. Введение в Библиотеку стандартных
шаблонов (STL)
Мы неоднократно подчеркивали важность утилизации программного
обеспечения. Констатировав, что в программировании на C++ часто применяются
одни и те же структуры данных и алгоритмы, комитет по стандартному C++
ввел в Стандартную библиотеку C++ Библиотеку стандартных шаблонов
(STL). STL определяет мощные, организованные в виде шаблонов
утилизируемые компоненты, которые реализуют многие распространенные структуры
данных и алгоритмы, используемые при обработке этих структур. STL являет
собой воплощение концепции обобщенного программирования с помощью
шаблонов, представленных в главе 14 и подобно продемонстрированных в
главе 21. [Замечание. На практике то, что описывается в этой главе, обычно
называют Библиотекой стандартных шаблонов, или STL. Однако в Стандартном
документе по C++ это выражение не встречается, поскольку все это считается
просто частью Стандартной библиотеки C++.]
STL была разработана Александром Степановым и Мень Ли в Хьюлетт-Па-
карде на основе их изысканий в области обобщенного программирования, со
значительным вкладом Дэвида Массера. Как вы сами увидите, STL была
задумана и спроектирована с расчетом на максимальную производительность
и гибкость.
Эта глава представляет STL и обсуждает три ее ключевых компонента —
контейнеры (распространенные структуры данных в шаблонной форме),
итераторы и алгоритмы. Контейнеры STL являются структурами данных,
которые способны хранить объекты любых типов. Мы увидим, что
существует три типа контейнеров — первичные контейнеры, адаптеры и почти-кон-
тейнеры.
I—зд Вопросы производительности 22.1
|^Ф*| Для любого конкретного приложения могут подходить несколько
различных контейнеров STL. Выберите наиболее подходящий из них,
обеспечивающий максимальную эффективность (т.е. баланс
производительности и размера) в контексте данного приложения.
Эффективность была критическим соображением при разработке STL.
1212
Глава 22
Вопросы производительности 22.2
Элементы стандартной библиотеки реализованы так, чтобы
эффективно работать в разнообразных приложениях. Для некоторых
приложений, предъявляющих уникальные требования к эффективности,
может оказаться необходимой разработка ваших собственных
реализаций.
Каждый контейнер STL имеет ассоциированные с ним элемент-функции.
Некоторое подмножество этих элемент-функций определено для всех
контейнеров. Мы проиллюстрируем большую часть этих общих функциональных
возможностей в наших примерах с контейнерами vector (динамический
массив, представленный нами в главе 7), list (связанный список) и deque
(двусторонняя очередь, произносится так же, как «deck*). Другие функции,
специфические для отдельных контейнеров, представлены на примерах для каждого
из других контейнеров STL.
Итераторы, свойства которых схожи со свойствами указателей,
используются для манипуляций с элементами STL-контейнеров. На самом деле со
стандартными массивами можно обращаться как с STL-контейнерами, используя
в качестве итераторов стандартные указатели. Мы увидим, что оперирование
контейнерами посредством итераторов удобно и предлагает огромные
выразительные средства, если сочетается с алгоритмами STL, — сводя в некоторых
случаях многие строки кода к единственному оператору. Существует пять
категорий итераторов, которые обсуждаются в разделе 22.1.2 и используются на
протяжении всей главы.
Алгоритмы STL являются функциями, выполняющими такие
распространенные манипуляции с данными, как поиск, сортировка и сравнение
элементов (или контейнеров в целом). Большинство из них для доступа к элементам
контейнера используют итераторы. Каждый из алгоритмов предъявляет
некоторые минимальные требования к типам итераторов, которые с ним
используются. Мы увидим, что каждый первичный контейнер поддерживает
специфические типы итераторов, обладающие различной мощностью. Тип итератора,
поддерживаемый контейнером, определяет, можно ли применять к
контейнеру конкретный алгоритм. Итераторы инкапсулируют механизм доступа к
элементам контейнеров. Такая инкапсуляция позволяет применять алгоритмы
STL к нескольким контейнерам, не обращая внимания на реализацию
последних. Пока итераторы контейнера поддерживают минимальные требования
алгоритма, алгоритм может обрабатывать элементы контейнера. Это также
позволяет программистам создавать новые алгоритмы, которые смогут
обрабатывать элементы различных типов контейнеров.
S Общее методическое замечание 22.1
Подход STL позволяет писать обобщенные программы, код которых
не будет зависеть от применяемого контейнера. Такой стиль
программирования называют обобщенным программированием.
Библиотека стандартных шаблонов (STL)
1213
В главе 20 мы изучали структуры данных. Мы строили связанные списки,
очереди, стеки и деревья. С помощью указателей мы аккуратно связывали
объекты друг с другом. Код, построенный на указателях, сложен, и малейшая
оплошность или упущение может привести к серьезным нарушениям доступа
и утечкам памяти, не вызывая каких-либо нареканий компилятора.
Реализация дополнительных структур данных, таких, как deque, приоритетные
очереди, множества и карты, требует существенной дополнительной работы. Кроме
того, если многие программисты, работая над большим проектом, реализуют
для разлргчных задач похожие контейнеры и алгоритмы, код будет трудно
модифицировать, сопровождать и отлаживать. Преимущество STL в том, что для
реализации общих представлений данных и операций с ними программисты
могут утилизировать контейнеры, итераторы и алгоритмы STL. Такая утилизация
может значительно экономить время, деньги и затраченные усилия.
Ш Общее методическое замечание 22.2
Не изобретайте велосипед; программируйте, пользуясь
утилизируемыми компонентами Стандартной библиотеки C++. STL содержит
в виде контейнеров многие из наиболее распространенных структур
данных, а также различные популярные алгоритмы для обработки
данных в этих контейнерах.
j^r*. Предотвращение ошибок 22.1
\ffjy При программировании структур данных и алгоритмов, построенных
на указателях, мы, чтобы быть уверенными в правильной работе
своих структур данных, классов и алгоритмов, должны проделать всю
работу по отладке и тестированию. В таком специализированном
коде утечки и нарушения доступа являются обычным явлением. Для
большинства программистов и большинства приложений, которые
им потребуется написать, вполне достаточно готовых шаблонных
контейнеров STL. Использование STL помогает программистам
сократить время на тестирование и отладку. Следует только
предупредить, что в больших проектах время компиляции шаблонов может
оказаться значительным.
Мы представляем в этой главе STL. Наше изложение никоим образом не
является полным или исчерпывающим. Тем не менее это понятная и доступная
глава, которая должна убедить вас в ценности STL как средства утилизации
программного обеспечения и поощрить к ее дальнейшему изучению.
22.1.1. Введение в контейнеры
Типы контейнеров STL показаны на рис. 22.1. Контейнеры делятся на три
основных категории — контейнеры последовательностей, ассоциативные
контейнеры и адаптеры контейнеров.
1214
Глава 22
Класс контейнера
Стандартной библиотеки
Описание
Контейнеры последовательностей
vector
deque
list
Ассоциативные контейнеры
set
multiset
map
multimap
Адаптеры контейнеров
stack
queue
priohity.queue
быстрая вставка и удаление в конце
прямой доступ к любому элементу
быстрая вставка и удаление в начале или конце
прямой доступ к любому элементу
двусвязный список, быстрая вставка и удаление
в любом месте
быстрый поиск, не допускает дубликатов
быстрый поиск, дубликаты допускаются
отображение «один к одному», дубликаты
не допускаются, быстрый поиск по ключу
отображение «один к одному», дубликаты
допускаются, быстрый поиск по ключу
«последним вошел, первым вышел» (LIFO)
«первым вошел, первым вышел» (FIFO)
элемент с наибольшим приоритетом всегда
удаляется первым
Рис. 22.1. Классы контейнеров Стандартной библиотеки
Обзор контейнеров STL
Контейнеры последовательностей (называемые также последовательными
контейнерами) представляют линейные структуры данных, такие, как
векторы и связанные списки. Ассоциативные контейнеры являются нелинейными
структурами, которые позволяют быстро отыскивать хранящиеся в них
элементы. Такие контейнеры могут хранить множества значений или пар
ключ /значение. Контейнеры последовательностей и ассоциативные
контейнеры называют обобщенно первичными контейнерами. Как мы видели в
главе 21, стеки и очереди в действительности представляют собой ограниченные
варианты контейнеров последовательностей. По этой причине STL реализует
стеки и очереди как адаптеры, позволяющие программе обращаться с
последовательным контейнером некоторым ограниченным образом. Имеется также
четыре других контейнерных типа, которые считаются «почти-контейнера-
ми» — это С-подобные массивы-указатели (обсуждавшиеся в главе 7), строки
string (обсуждавшиеся в главе 18), битовые множества, поддерживающие
наборы флаговых значений, и массивы valarray, предназначенные для
выполнения высокоскоростных математических векторных операций (этот последний
класс оптимизирован по скорости вычислений и не столь гибок, как
первичные контейнеры). Эти четыре класса считаются «почти-контейнерами», так
как они проявляют свойства, схожие со свойствами первичных контейнеров,
но не поддерживают все возможности последних.
Библиотека стандартных шаблонов (STL)
1215
Общие функции контейнеров STL
Все контейнеры STL обладают схожими функциональными
возможностями. Многие обобщенные операции, такие, как элемент-функция size,
применимы ко всем контейнерам, другие операции применимы к подмножествам
сходных между собой контейнеров. Это способствует расширяемости STL. На
рис. 22.2 описаны функции, общие для всех контейнеров Стандартной
библиотеки. [Замечание. В priority_queue не предусмотрены перегруженные
операции operator<, operator<=, operator>, operator>=, operator== и operator!=.]
Элемент-функции, общие
для всех контейнеров STL
конструктор по умолчанию
конструктор копии
деструктор
empty
size
operator=
operators
operator<=
operator>
operator>=
operator==
operator !=
swap
Описание
Конструктор, обеспечивающий инициализацию
контейнера по умолчанию. Обычно каждый контейнер
имеет несколько конструкторов, предлагающих
различные способы его инициализации.
Конструктор, инициализирующий контейнер копией
существующего контейнера того же типа.
Функция деструктора для очистки контейнера после
того, как он станет больше не нужен.
Возвращает true, если в контейнере нет элементов; в
противном случае возвращает false.
Возвращает текущее число элементов в контейнере.
Присваивает один контейнер другому.
Возвращает true, если первый контейнер меньше
второго; в противном случае возвращает false.
Возвращает true, если первый контейнер меньше или
равен второму; в противном случае возвращает false.
Возвращает true, если первый контейнер больше
второго; в противном случае возвращает false.
Возвращает true, если первый контейнер больше или
равен второму; в противном случае возвращает false.
Возвращает true, если первый контейнер равен
второму; в противном случае возвращает false.
Возвращает true, если первый контейнер не равен
второму; в противном случае возвращает false.
Обменивает элементы двух контейнеров.
Функции, имеющиеся только в первичных контейнерах
max.size
begin
Возвращает максимальное число элементов для
контейнера.
Две версии этой функции возвращают либо iterator,
либо const_iterator, ссылающийся на первый элемент
контейнера.
1216
Глава 22
Элемент-функции, общие
для веек контейнеров STL
end
rbegin
rend
Описание
Две версии этой функции возвращают либо iterator,
либо const.iterator, ссылающийся на позицию,
следующую за последним элементом контейнера.
Две версии этой функции возвращают либо
reversejterator, либо const_reverse_iteratorf
ссылающийся на последний элемент контейнера.
Две версии этой функции возвращают либо
i reversejterator, либо const_reverse_iterator,
ссылающийся на позицию, следующую за последним
элементом обращенного контейнера.
erase
Стирает один или несколько элементов контейнера.
clear
Стирает все элементы контейнера.
Рис. 22.2. Общие функции контейнеров STL
Заголовочные файлы контейнеров
Заголовочные файлы для каждого из контейнеров Стандартной библиотеки
показаны на рис. 22.3. Содержимое всех контейнеров принадлежит к
пространству имен std.1
Заголовочные файлы контейнеров Стандартной библиотки
<vector>
<list>
<deque>
<queue>
<stack>
<map>
<set>
<bitset>
Поддерживает queue и priority_queue.
Поддерживает map и multimap.
Поддерживает set и multiset.
Рис. 22.3. Заголовочные файлы контейнеров Стандартной библиотки
Определения typedef для первичных контейнеров
На рис. 22.4 приведены распространенные определения typedef (для
создания синонимов или псевдонимов длинных имен типов), имеющиеся в
первичных контейнерах. Эти определения используются в обобщенных объявлениях
переменных, параметров функций и возвращаемых значений. Например,
value_type в каждом контейнере является всегда определением typedef для
представления типа значений, хранящихся в контейнере.
Некоторые более ранние компиляторы С4-+ не поддерживают нового стиля заголовочных
файлов. Многие из этих компиляторов имеют свои собственные версии имен
заголовочных файлов. Справьтесь в документации вашего компилятора о имеющейся в нем
поддержке STL.
' Библиотека стандартных шаблонов (STL)
1217
typedef
valuejtype
reference
const_reference
Описание
Тип элемента, хранящегося в контейнере.
Ссылка на тип элемента контейнера.
Константная ссылка на тип элемента контейнера. Такая
ссылка может использоваться только для чтения элементов
и выполнения const-операций.
pointer
iterator
const_iterator
Указатель на тип элемента контейнера.
Итератор, указывающий на тип элемента контейнера.
Константный итератор, указывающий на тип элемента
контейнера и допускающий только чтение элементов.
reverse iterator
Реверсивный итератор, указывающий на тип элемента
контейнера. Такой итератор предназначен для прохода
по контейнеру в обратном направлении.
const_reverse_iterator | Константный реверсивный итератор, указывающий на тип
| элемента контейнера и допускающий только чтение
элементов. Такой итератор предназначен для прохода
по контейнеру в обратном направлении.
differencejtype
Тип результата вычитания итераторов, ссылающихся на
один и тот же контейнер (операция вычитания для
итераторов списков и ассоциативных контейнеров не
определена).
sizejtype
Тип, использующийся при подсчете элементов контейнера
и для индексации контейнера последовательности (list
не допускает индексации).
Рис. 22.4. Определения typedef в первичных контейнерах
"hfi^l
Вопросы производительности 22.3
В STL, как правило, имеет место отказ от наследования и виртуаль
ных функций в пользу обобщенного программирования с шаблонами,
чтобы достичь лучшей эффективности во время исполнения.
Переносимость программ 22.1
Программирование с STL улучшит переносимость вашего кода.
Собираясь использовать контейнер STL, важно убедиться, что тип
элемента, сохраняемого в контейнере, поддерживает минимум функциональных
требований. Когда элемент помещается в контейнер, делается копия этого
элемента. По этой причине тип элемента должен иметь конструктор копии и
операцию присваивания. [Замечание. Это требуется только в случаях, когда
поэлементное копирование и поэлементное присваивание по умолчанию для
данного типа не обеспечивают корректного копирования и присваивания.]
Кроме того, ассоциативные контейнеры и многие алгоритмы требуют
сравнения элементов. По этой причине тип элемента должен предусматривать
операцию равенства (==) и операцию «меньше» (<).
39 Зак 1114
1218
Глава 22
® Общее методическое замечание 22.3
Технически контейнеры STL не требуют, чтобы их элементы можно
было сравнивать операциями отношений равенства и «меньше», если
программа не использует элемент-функцию, которая должна это
делать (напр., функцию сортировки в классе списка). К сожалению,
некоторые «до-стандартные» компиляторы C++ не могут
игнорировать те части шаблона, которые в конкретной программе не
используются. На компиляторах с такой проблемой вы, возможно, не
сможете использовать контейнеры STL с объектами классов,
которые не определяют перегруженные операции == и <.
22.1.2. Введение в итераторы
Итераторы имеют много общих черт с указателями и используются для
указания на элементы первичных контейнеров (и некоторых других целей,
как мы увидим далее). Итераторы содержат информацию о состоянии, важную
для конкретных контейнеров, на которых они оперируют; поэтому для
каждого типа контейнера они реализуются соответствующим образом. Некоторые
операции итераторов единообразны для вех контейнеров. Например,
операция * разыменовывает итератор, и вы можете работать с элементом, на
который он указывает. Операция ++ перемещает итератор к следующему элементу
контейнера (аналогично тому, как инкремент указателя в массиве перемешает
его на следующий элемент массива).
В первичных контейнерах STL предусмотрены элемент-функции begin
и end. Функция begin возвращает итератор, указывающий на первый элемент
контейнера. Функция end возвращает итератор, указывающий на первый
элемент после конца контейнера (элемент, которого не существует). Если
итератор i указывает на некоторый элемент, то ++i указывает на «следующий»
элемент, a *i ссылается на элемент, указываемый i. Итератор, возвращаемый
функцией end, может использоваться только для в сравнениях на равенство
или неравенство для определения того, достиг ли «подвижный итератор»
(в данном случае i) конца контейнера.
Для ссылки на элемент контейнера, который может быть модифицирован,
мы используем объект типа iterator. Для ссылки на элемент контейнера,
который нельзя модифицировать, мы используем объект типа const_iterator.
Использование istreamjtterator для ввода и ostreamjiterator
для вывода
Мы применяем итераторы на последовательностях (еще называемых
диапазонами). Последовательности могут либо находиться в контейнерах, либо
быть входными или выходными последовательностями. Программа на
рис. 22.5 демонстрирует ввод со стандартного ввода (последовательности
данных для ввода в программу) с помощью итератора типа istreamjtterator и
вывод на стандартный вывод (последовательность данных для вывода из про-
Библиотека стандартных шаблонов (STL)
1219
граммы) с помощью ostreamjiterator. Программа получает от пользователя
два целых числа и выводит их сумму.1
1 // Рис. 22.5: Fig23_05.cpp
2 // Демонстрация ввода и вывода с итераторами.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 #include <iterator> // ostream_iterator и istream_iterater
9
10 int main()
11 {
12 cout « "Enter two integers: ";
13
14 // создать istream_iterator для чтения значений int из cin
15 std::istream_iterator< int > inputlnt( cin );
16
17 int number1 = *inputlnt; // прочитать int из стандартного ввода
18 ++inputlnt; // переместить итератор на следующее значение
19 int number 2 = * input Int; // прочитать int из стандартного ввода
20
21 // создать ostream_iterator для записи значений int в cout
22 std::ostream_iterator< int > outputInt( cout );
23
24 cout « "The sum is: ";
25 *outputInt = numberl + number2; // вывести результат в cout
26 cout « endl;
27 return 0;
28 } // конец main
Enter two integers: 12 25
The sum is: 37
Рис. 22.5. Входной и выходной итераторы потока
Строка 15 создает istream_iterator, который может безопасным по типу
образом извлекать (вводить) целые значения из стандартного входного объекта
cin. Строка 17 разыменовывает итератор inputlnt, чтобы прочитать из cin
первое число, и присваивает это число numberl. Обратите внимание, что
операция разыменования *, применяемая к inputlnt, получает значение из потока,
ассоциированного с inputlnt; это напоминает разыменование указателя.
Строка 18 позиционирует итератор inputlnt на следующее значение во входном
потоке. Строка 19 вводит следующее число из inputlnt и присваивает его
number 2.
В примерах этой главы каждая функция STL и каждое определение контейнера
предваряется префиксом «std::» вместо размещения в начале программы объявления или
директивы using, как было показано в большинстве предыдущих примеров. Различия
компиляторов и сложность кода, генерируемого для STL, делают трудным написание такого
набора объявлений или директив using, который гарантировал бы компиляцию
программ без ошибок. Чтобы эти программы компилировались на возможно более широком
разнообразии платформ, мы избрали подход с префиксом «std::».
1220
Глава 22
Строка 22 создает ostream_iterator, который может передавать (выводить)
целые значения в стандартный выходной объект cout. Строк 25 выводит целое
в cout, присваивая *outputInt сумму numberl и number2. Обратите внимание
на операцию разыменования *, которая позволяет использовать *outputInt
как lvalue в операторе присваивания. Если вы захотите вывести через output-
Int еще одно значение, итератор следует инкрементировать операцией ++
(можно применить как префиксную, так и постфиксную форму, но
префиксная форма предпочтительнее по соображениям эффективности).
Предотвращение ошибок 22,2
Операция разыменования (*) любого константного итератора возвра
щает константную ссылку на элемент контейнера, не допуская при
менения любых не константных элемент-функций.
Попытка разыменования итератора, позиционированного вне его
контейнера, является логической ошибкой времени выполнения. В
частности, итератор, возвращаемый end, нельзя разыменовывать или
инкрементировать.
^ Типичная ошибка программирования 22.2
Попытка создания неконстантного итератора для константного
контейнера приводит к ошибке компиляции.
Категории итераторов и их иерархия
На рис. 22.6 показаны категории итераторов, используемых в STL. Каждая
категория предлагает специфический набор функциональных возможностей.
Рис. 22.7 показывает иерархию категорий итераторов. Если проследить эту
иерархию сверху вниз, каждая категория итераторов поддерживает все
возможности категорий, расположенных выше. Таким образом, «слабейшие»
типы итераторов расположены наверху, а самая мощная — в самом низу.
Заметьте, что это — не иерархия наследования.
Категория итераторов, поддерживаемая каждым контейнером, определяет,
может ли контейнер использоваться с конкретными алгоритмами из STL.
Контейнеры, поддерживающие итераторы произвольного доступа, могут
использоваться со всеми алгоритмами. Как мы увидим, в большинстве алгоритмов
STL, включая те, что требуют итераторов произвольного доступа, вместо
итераторов могут применяться указатели. Рис. 22.8 показывает категорию
итераторов каждого из контейнеров STL. Обратите внимание, что только
контейнеры классов vector, deque, set, mulniset, map и multimap (т.е. первичные
контейнеры) проходимы посредством итераторов.
Библиотека стандартных шаблонов (STL)
1221
Категория
входной
выходной
поступательный
Описание
Используется для чтения элемента из контейнера. Входной
итератор продвигается только в прямом направлении (т. е.
от начала контейнера к его концу) на один элемент за шаг.
Входные итераторы поддерживают только однопроходные
алгоритмы — один и тот же итератор нельзя использовать
для повторного прохода последовательности.
Используется для записи элемента в контейнер. Выходной
итератор продвигается только в прямом направлении
на один элемент за шаг. Выходные итераторы
поддерживают только однопроходные алгоритмы — один
и тот же итератор нельзя использовать для повторного
прохода последовательности.
Комбинирует возможности входного и выходного
итераторов и хранит их позицию в контейнере (как
информацию о состоянии).
двунаправленный
Комбинирует возможности поступательного итератора
со способностью двигаться в обратном направлении
(т. е. от конца контейнера к его началу). Двунаправленные
итераторы поддерживают многопроходные алгоритмы.
произвольного доступа
Комбинирует возможности двунаправленного итератора
с возможностью прямого доступа к любому элементу
контейнера, т. е. «прыжков» вперед или назад
на произвольное число элементов.
Рис. 22.6. Категории итераторов
входной выходной
поступательный
двунаправленный
произвольного доступа
Рис. 22.7. Иерархия категорий итераторов
1222
Глава 22
Контейнер
Тип поддерживаемого итератора
Контейнеры последовательностей (первичные)
vector
deque
list
произвольного доступа
произвольного доступа
двунаправленный
Ассоциативные контейнеры (первичные)
set
multiset
map
multimrp
двунаправленный
двунаправленный
двунаправленный
двунаправленный
Адаптеры контейнеров
stack
queue
priority.queue
итераторы не поддерживаются
итераторы не поддерживаются
итераторы не поддерживаются
Рис. 22.8. Типы итераторов, поддерживаемые каждым из контейнеров
Стандартной библиотеки
Общее методическое замечание 22.4
Использование «наислабейшего итератора», который дает приемлемую
производительность, помогает писать максимально утилизируемые
компоненты. Например, если алгоритм требует только
поступательных итераторов, он может использоваться с любым контейнером,
который поддерживает поступательные итераторы, двунаправленные
итераторы или итераторы произвольного доступа. Однако алгоритм,
требующий итераторов произвольного доступа, может применяться
только к контейнерам, имеющим итераторы произвольно доступа.
Предопределенные typedef для итераторов
На рис. 22.9 показаны предопределенные typ%edef для итераторов,
имеющиеся в определениях классов контейнеров STL. Не каждый typedef
определен для любого контейнера. Для прохода по только-читаемым контейнерам
мы пользуемся константными версиями итераторов. Для прохода контейнеров
в обоих направлениях мы используем двунаправленные итераторы.
Предопределенные typedef для типов
итераторов
iterator
const_iterator
reverse_iterator
const_reverse_iterator
Направление ++
вперед
вперед
назад
Доступ
чтение/запись
чтение
чтение/запись
назад ; чтение
Рис. 22.9. typedef для итераторов
Библиотека стандартных шаблонов (STL)
1223
Предотвращение ошибок 22.3
Операции, производимые над const_iterator, возвращают
константные ссылки во избежание модификации элементов контейнера, на
котором он оперирует. Предпочтительное применение constJtterator
вместо iterator — еще один пример принципа наименьших привилегий.
Операции итераторов
На рис. 22.10 показаны некоторые операции, которые можно производить над
каждым типом итераторов. Заметьте, что операции для каждого из типов
итераторов включают в себя все операции, предшествующие на рисунке этому типу.
Заметьте также, что в случае входных и выходных итераторов нет возможности
сохранить итератор и использовать сохраненное значение впоследствии.
Операция итераторов Описание
Все итераторы
++р
Преинкремент итератора.
р++
Входные итераторы
Постинкремент итератора.
*р
Р = р1
Р==р1
р!=Р1
Разыменование итератора.
Присваивание одного итератора другому.
Сравнение итераторов на равенство.
Сравнение итераторов на неравенство.
Выходные итераторы
*р | Разыменование итератора.
р = р1 Присваивание одного итератора другому.
Поступательные итераторы Обладают всеми возможностями как входных,
так и выходных итераторов
Двунаправленные итераторы
-р
р-
Предекремент итератора.
Постдекремент итератора.
Итераторы произвольного доступа
p+=i
p-=i
p + i
Инкремент итератора на i позиций.
Декремент итератора на i позиций.
Значением выражения является итератор,
позиционированный на р и инкрементированный
на i позиций.
Значением выражения является итератор,
позиционированный на р и декрементированный
на i позиций.
p[i]
Возвращается ссылка на элемент, смещенный" от р
на i позиций.
1224
Глава 22
Операция итераторов Описание
р < pi ' Возвращается true, если итератор р меньше итератора
| р1 (т. е. итератор р находится в контейнере до
I итератора р1); в противном случае возвращается false.
р<=р1
р>р1
Возвращается true, если итератор р меньше или равен
итератору р1 (т. е. итератор р находится в контейнере
до итератора р1 или в той же позиции, что и pi); в
противном случае возвращается false.
Возвращается true, если итератор р больше итератора
р1 (т. е. итератор р находится в контейнере после
итератора р1); в противном случае возвращается false.
р >= р1 | Возвращается true, если итератор р больше или равен
I итератору р1 (т. е. итератор р находится в контейнере
, после итератора р1 или в той же позиции, что и р1);
i в противном случае возвращается false.
Рис. 22.10. Операции для итераторов каждого типа
22.1.3. Введение в алгоритмы
В STL предусмотрены алгоритмы, которые можно применять обобщенно
к разнообразным контейнерам. Многими алгоритмами STL вы будете
пользоваться часто. Вставка, удаление, поиск, сортировка и другие алгоритмы
подходят для некоторых или для всех контейнеров STL.
В STL входит приблизительно 70 стандартных алгоритмов. Мы предлагаем
примеры живого кода для большинства из них, а для других даем сводные
таблицы. Алгоритмы воздействуют на элементы контейнеров только косвенно,
через итераторы. Многие алгоритмы оперируют на последовательностях
элементов, заданных парами итераторов — первый итератор указывает на первый
элемент последовательности, а второй на элемент, следующий за последним ее
элементом. Вы также можете создавать свои собственные, новые алгоритмы,
действующие подобным же образом, чтобы их можно было использовать с
контейнерами и итераторами STL.
Часто алгоритмы возвращают итераторы, показывающие результаты
работы алгоритмов. Алгоритм find, например, находит элемент и возвращает
итератор на этот элемент. Если элемент не найден, find возвращает итератор «на
единицу за пределом», переданный алгоритму для определения конца
диапазона поиска; его можно проверить и определить, был ли найден элемент.
Алгоритм find может применяться к любому настоящему контейнеру. Алгоритмы
STL осуществляют еще одну возможность утилизации — использование
богатого собрания популярных алгоритмов может сохранить программистам
много времени и сил.
Если алгоритм использует менее мощные итераторы, он может
применяться и к контейнерам, поддерживающим более мощные. Для некоторых
алгоритмов требуются мощные итераторы; например, sort требует итераторов
произвольного доступа.
Библиотека стандартных шаблонов (STL)
1225
Общее методическое замечание 22.5
STL реализована весьма сжато. Ранее проектировщики классов ассо
циировали бы алгоритмы с контейнерами, делая их
элемент-функциями последних. Подход STL совсем другой. Алгоритмы отделены от
контейнеров и оперируют их элементами только косвенно,
посредством итераторов. Такое отделение упрощает написание обобщенных
алгоритмов, применимых ко многим классам контейнеров.
Общее методическое замечание 22.6
STL расширяема. Добавление новых алгоритмов несложно и
производится без изменения контейнеров STL.
Общее методическое замечание 22.7
Алгоритмы STL могут действовать на контейнерах STL и на С-по-
добных массивах указателях.
Переносимость программ 22.2
Поскольку алгоритмы STL обрабатывают контейнеры косвенно, че-
' рез итераторы, один алгоритм часто может использоваться с
многими различными контейнерами.
На рис. 22.11 показаны многие из модифицирующих алгоритмов,— т.е.
алгоритмов, результатом которых является модификация контейнеров, к
которым они применяются.
Модифицирующие алгоритмы
сору
Г,
remove
copy_backward
fill
-г
I reverse.copy
—н
filLin
generate
generane_n
iter_swap
partition
random.shuffle
remove_copy
I remove_copy_if
I remove_if
i rotate
| rotate_copy
I stable_partition
I replace
I replace.copy
replace_copy_if
I replace_if
swap
swap.range
transform
unique
reverse
unique.copy
Рис. 22.11. Модифицирующие алгоритмы
На рис. 22.12 показаны многие из немодифицирующих алгоритмов, т.е.
таких, которые не меняют контейнеры, к которым применяются. На рис. 22.13
показаны численные алгоритмы из заголовочного файла <numeric>.
1226
Глава 22
Немодифицирующие алгоритмы
adjacentjfind
count
count_if
equal
find
find_each
find_end
find_first_of
find.if
mismatch
search
search_n
Рис. 22.12. Немодифицирующие алгоритмы
Численные алгоритмы из заголовочного файла <numeric>
accumulate partial_sum
inner_product adjacent_diff erence
Рис. 22.13. Численные алгоритмы
22.2. Контейнеры последовательностей
В Библиотеке стандартных шаблонов C++ имеется три контейнера
последовательностей — vector, list и deque. Шаблон класса vector и шаблон класса
deque построены на основе массива. Шаблон класса list реализует структуру
данных связанного списка, похожую на наш класс List, представленный в
главе 20, но более развитую.
Одним из наиболее популярных контейнеров из STL является vector. Вы
помните, что в главе 7 мы представили шаблон класса vector как более
совершенный тип массива. Объект vector динамически изменяет свой размер. В
отличие от «сырых» массивов С и C++ (см. главу 7) векторы можно присваивать
друг другу. Это невозможно для массивов-указателей в стиле С, поскольку
имена этих массивов являются константными указателями, которые не могут
быть приемниками присваивания. Как и в случае массивов С, индексация
вектора не производит автоматической проверки диапазона, но такая
возможность предусмотрена в шаблоне класса vector в форме элемент-функции at
(также обсуждавшейся в главе 7).
Вопросы производительности 22.4
Вставка в конец вектора производится эффективно. Вектор, если
это необходимо, просто вырастает, чтобы принять новый элемент.
Дорого обходится вставка (или удаление) элемента в середине векто
ра, — вся часть вектора, расположенная после точки вставки
(удаления), должна быть сдвинута, поскольку, как и в «сырых» массивах С
или C++, элементы вектора занимают непрерывную область ячеек
памяти.
На рис. 22.2 были представлены операции, общие для всех контейнеров
STL. Помимо этих, каждый контейнер обычно предлагает и разнообразные
специфические возможности. Многие из этих возможностей являются общими
для нескольких контейнеров, ко они не всегда одинаково эффективны для
всех из них. Программист должен выбрать контейнер, наиболее подходящий
приложения.
Библиотека стандартных шаблонов (STL)
1227
Вопросы производительности 22,5
Приложения, требующие частых вставок и удалений на обоих концах
контейнера, обычно используют deque, а не vector. Хотя и в deque,
и в vector мы можем производить вставку и удаление элементов на
обоих концах, класс deque эффективнее, чем vector, при вставках
и удалениях в начале контейнера.
Вопросы производительности 22.6
Приложения с частыми вставками и удалениями в середине
контейнера обычно используют list вследствие эффективной реализации
произвольных вставок и удалений в этой структуре данных.
В дополнение к общим операциям, описанным на рис. 22.2, контейнеры
последовательностей имеют несколько других общих операций — front
возвращает ссылку на первый элемент в контейнере, back возвращает ссылку на
последний элемент, pushjback вставляет новый элемент в конец контейнера
и pop_back удаляет последний элемент контейнера.
22.2.1. Контейнер последовательности vector
Шаблон класса vector реализует структуру данных с непрерывным
размещением ячеек в памяти. Это обеспечивает эффективный, прямой доступ к
любому элементу с помощью операции индексации [], в точности как в «сырых»
массивах С или C++. Шаблон класса vector чаще всего применяется в случаях,
когда данные в контейнере должны сортироваться и быть легко доступными
через индекс. Когда память вектора исчерпывается, класс vector выделяет
более протяженную непрерывную область памяти, копирует в нее имеющиеся
элементы и освобождает первоначальную память.
Вопросы производительности 22.7
Для наилучшей эффективности произвольного доступа выбирайте
контейнер vector.
Вопросы производительности 22.8
Объекты класса vector обеспечивают быстрый индексный доступ
посредством перегруженной операции [], так как они занимают в
памяти непрерывную область, как сырые массивы С или C++.
Вопросы производительности 22.9
Вставка сразу нескольких элементов быстрее, чем вставка их по
одному.
Важным аспектом каждого контейнера является тип итератора, который он
поддерживает. Это определяет, какие алгоритмы могут применяться к
контейнеру. Класс vector поддерживает итераторы произвольно доступа, т.е. к
итератору вектора могут применяться все операции, приведенные на рис. 22.10.
К объектам vector можно применять все алгоритмы STL. Итераторы класса
1228
Глава 22
vector обычно реализуются как указатели на элементы вектора. Каждый
алгоритм STL, принимающий аргументы-итераторы, требует, чтобы эти итераторы
обеспечивали некоторый минимальный уровень функциональных
возможностей. Если, например, алгоритм требует поступательного итератора, он может
оперировать на любом контейнере, предусматривающем поступательные
итераторы, двунаправленные итераторы или итераторы прямого доступа. Если
контейнер поддерживает минимальные требования алгоритма к итератору,
алгоритм будет работать с этим контейнером.
Использование векторов и итераторов
Рис. 22.14 иллюстрирует некоторые функции шаблона класса vector.
Многие из них имеются во всех первичных контейнерах. Чтобы использовать
шаблон класса vector, требуется включить заголовочный файл <vector>.
1 // Рис. 22.14: Fig23_14.cpp
2 // Демонстрация класса vector Стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <vector> // определение шаблона класса vector
8 using std::vector;
9
10 // прототип для шаблона функции printVector
11 template <typename T> void printVector(const vector &integers2);
12
13 int main ()
14 {
15 const int SIZE =6; // определить размер массива
16 int array[SIZE] = {1, 2, 3, 4, 5, 6}; // инициализировать массив
17 vector< int > integers; // создать вектор для int
18
19 cout « "The initial size of integers is: " « integers. size()
20 «"\nThe initial capacity of integers is: "«integers.capacity() ;
21
22 // функция push_back имеется в каждом последовательном контейнере
23 integers.pushjback( 2 );
24 integers.push_back( 3 );
25 integers.push_back( 4 );
26
27 cout « "\nThe size of integers is: " « integers.size()
28 « "\nThe capacity of integers is: " « integers.capacity();
29 cout « "\n\nOutput array using pointer notation: ";
30
31 // вывести массив, используя нотацию указателей
32 for ( int *ptr = array; ptr != array + SIZE; ptr++ )
33 cout « *ptr « '
34
35 cout « "\nOutput vector using iterator notation: ";
36 printVector( integers );
37 cout « "\nReversed contents of vector integers: ";
38
39 // два константных обратных итератора
40 vector<int>:.const reverse iterator reverselterator;
Библиотека стандартных шаблонов (STL)
1229
41 vector<int>: : const_reverse_iterator tempiterator=integers . rend () ;
42
43 // вывести вектор в обратном порядке с помощью reverse_i tera tor
44 for ( reverselterator = integers.rbegin();
45 reverseIterator!= tempiterator; ++reverseIterator )
4 6 cout « *reverselterator « ' ';
47
48 cout « endl;
49 return 0;
50 } // конец main
51
52 // шаблон функции для вывода элементов вектора
53 template <typename T> void printVector(const vector &integers2)
54 {
55 typename vector< T >:.const_iterator constlterator;
56
57 // вывести вектор с помощью const_iterator
58 for ( constlterator = integers2.begin();
59 constlterator != integers2.end(); ++constIterator )
60 cout « *constlterator « ' ';
61 } // конец функции printVector
The initial size of integers is: С
The initial capacity of integers is: 0
The size of integers is: 3
The capacity of integers is: 4
Output array using pointer notation: 12 3 4 5 6
Output vector using iterator notation: 2 3 4
Reversed contents of vector integers: 4 3 2
Рис. 22.14. Шаблон класса vector стандартной библиотеки
Строка 17 определяет представитель шаблона класса vector с именем
integers, который хранит значения типа int. Этот объект создается как пустой
вектор с нулевым размером (т.е. числом элементов, хранящихся в векторе)
и нулевой вместимостью (т.е. числом элементов, которые могут быть
размещены в векторе без дополнительного выделения памяти).
Строки 19 и 20 демонстрируют функции size и capacity; в данном примере
каждая из них для исходного вектора integers возвращает О. Функция size —
имеющаяся в каждом контейнере — возвращает текущее число элементов
в контейнере. Функция capacity возвращает число элементов, которое может
быть сохранено в векторе, прежде чем последнему потребуется динамически
изменить свой размер, чтобы принять дополнительные элементы.
В строках 23-25 используется функция push_back — имеющаяся во всех
контейнерах последовательностей — для добавления элементов в конец
вектора. Если элемент добавляется в заполненный вектор, последний
увеличивает свой размер, — в некоторых реализациях STL вектор удваивает свой
размер.
1230
Глава 22
I——j Вопросы производительности 22.10
"pPS^I Удваивание размера вектора при необходимости выделения
дополнительного пространства может оказаться расточительным. Напри
мер, при добавлении нового элемента вектор размером 1 000 000
увеличивается так, чтобы в него вмещалось 2 000 000 элементов.
Остается 999 999 неиспользованных элементов. Для лучшего управления
использованием памяти программисты могут применять функцию
resize.
Строки 27 и 28 вызывают size и capacity для демонстрации новых размера
и вместимости вектора после трех операций push_back. Функция size
возвращает 3 — число добавленных к вектору элементов. Функция capacity
возвращает 4, показывая, что мы можем добавить еще один элемент, прежде чем
вектору потребуется дополнительная память. Когда мы добавили первый
элемент, вектор выделил пространство для одного элемента и его размер стал
равен 1, показывая, что вектор содержит только один элемент. Когда мы
добавили второй элемент, вместимость удвоилась до 2, и размер также стал
равен 2. При добавлении третьего элемента вместимость снова удвоилась до 4.
Поэтому мы могли бы добавить еще один элемент, прежде чем вектору
потребуется выделить больше памяти. Когда вектор заполнит все выделенное
пространство и программа попытается добавить в вектор следующий элемент,
вектор удвоит свою вместимость до 8.
Характер роста вектора по мере размещения дополнительных элементов —
а эта операция требует затрат времени — в Стандартном документе по C++ не
специфицирована. Разработчики, реализующие стандартную библиотеку C++,
применяют разные хитрые схемы для сокращения накладных расходов при
изменении размера вектора. Поэтому вывод этой программы может
различаться в зависимости от версии класса vector, поставляемой с вашим
компилятором. Некоторые разработчики библиотек придают вектору большую
начальную вместимость. Если в векторе будет храниться малое число элементов,
такая вместимость может оказаться напрасной тратой памяти. Однако это может
значительно улучшить производительность в случаях, когда программа
добавляет в вектор много элементов и при этом не потребуется заново выделять
память для их размещения. Это классический компромисс
«пространство-время». Разработчики библиотек должны сбалансировать количество
используемой памяти с временем, затрачиваемым на различные векторные операции.
Строки 32-33 демонстрируют, как выводить содержимое массива с
помощью указателей и их арифметики. Строка 36 вызывает функцию printVector
(определяемую в строках 53-61) для вывода содержимого вектора с помощью
итераторов. Шаблон функции printVector принимает в качестве аргумента
константную ссылку на vector (integers2). Строка 55 определяет const_itera-
tor именем constlterator, который проходит по вектору и выводит его
содержимое. Обратите внимание, что объявлению в строке 55 предшествует
ключевое слово typename. Поскольку printVector является шаблоном функции
и vector< T > будет специализироваться по-разному для каждой
специализации шаблона функции, компилятор во время компиляции не может сказать,
является ли vector< T >::const_iterator типом. В какой-то специализации vec-
tor< T >::const_iterator мог бы быть статической переменной. Чтобы
компилировать программу корректно, компилятору нужна такая информация. Та-
Библиотека стандартных шаблонов (STL)
1231
ким образом, вы должны сообщить компилятору, что квалифицированное
имя, где квалификатором является зависимый тип, в каждой специализации
будет типом.
Константный итератор позволяет программе читать элементы вектора, но
не допускает модификации элементов. Оператор for в строках 58-60
инициализирует constlterator с помощью элемент-функции begin, которая
возвращает const_iterator первого элемента вектора; существует другая версия begin,
возвращающая итератор, который может использоваться с не-константными
контейнерами. Заметьте, что возвращается const_iterator, поскольку в списке
параметров функции printVector идентификатор integers2 был объявлен как
const. Цикл продолжается, пока constlterator не достигнет конца вектора.
Этот момент определяется сравнением constlterator с результатом вызова
integers2.end(), который возвращает итератор, указывающий на позицию за
последним элементом вектора. Если constlterator равен этому значению,
конец вектора достигнут. Функции begin и end имеются во всех первичных
контейнерах. Тело цикла разыменовывает итератор constlterator, чтобы
получить значение текущего элемента вектора. Вспомните, что итератор действует
подобно указателю на элемент и что операция * перегружена таким образом,
что возвращает ссылку на элемент. Выражение +H-constIterator (строка 59)
позиционирует итератор на следующий элемент вектора.
I——i Вопросы производительности 22.11
p3£ft^| Применяйте к итераторам STL префиксную форму инкремента,
поскольку префиксная операция инкремента не возвращает значения,
которое должно сохраняться во временном объекте.
j^rjk Предотвращение ошибок 22.12
К^^у Операцию < поддерживают только итераторы произвольного
доступа. Для проверки на достижение конца контейнера лучше
использовать != и end.
Строка 40 объявляет const_reverse_iterator, который может проходить по
вектору в обратном направлении. Строка 41 объявляет переменную templtera-
tor типа const_reverse_iterator и инициализирует ее итератором,
возвращаемым функцией rend (т.е. итератором для конечной точки при проходе по
контейнеру в обратном направлении). Первичные контейнеры поддерживают
такой тип итератора. Оператор for в строках 44-46, похожий на оператор
в функции printVector, проходит по вектору. В этом цикле для указания
диапазона выводимых элементов используются функция rbegin (т.е. итератор для
начальной точки при обратном проходе по контейнеру) и итератор templtera-
tor. Как и в случае функций begin и end, rbegin и rend могут возвращать
const_reverse_iterator или reverse_iterator в зависимости от того, является
ли контейнер константным.
1232
Глава 22
■$щ
Вопросы производительности 22.12
По соображениям эффективности следует заранее получить
значение, заканчивающее цикл, и сравнивать счетчик с ним, вместо того,
чтобы выполнять (возможно, накладный) вызов функции на каждом
проходе цикла.
Функции для манипуляции элементами вектора
Рис. 22.15 демонстрирует функции, позволяющие извлекать значения и
манипулировать элементами вектора. В строке 17 для инициализации вектора
integers используется перегруженный конструктор класса vector, принимающий
в качестве аргументов два итератора. Вспомните, что указатели в массив могут
использоваться как итераторы. Строка 17 инициализирует integers
содержимым array с позиции array по — но не включая — позицию array + SIZE.
1 // Рис. 22.15: Fig23_15.cpp
2 // Тестирование функций шаблона класса vector
3 // для манипуляции элементами.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <vector> // определение шаблона класса vector
9 #include <algorithm> // алгоритм copy
10 #include <iterator> // итератор ostream_iterator
11 #include <stdexcept> // исключение out_of_range
12
13 int main()
14 {
15 const int SIZE = 6;
16 int array[ SIZE ]={1,2,3,4,5,6};
17 std::vector< int > integers( array, array + SIZE );
18 std::ostream_iterator< int > output( cout, " " );
19
20 cout « "Vector integers contains: ";
21 std::copy( integers.begin(), integers.end(), output );
22
23 cout « "\nFirst element of integers: " « integers.front()
24 « "\nLast element of integers: " « integers.back();
25
26 integers[ 0 ] =7; // установить первый элемент равным 7
27 integers.at( 2 ) = 10; // установить элемент в позиции 2 равным 10
28
29 // вставить 22 как 2-й элемент
30 integers.insert( integers.begin() + 1, 22 );
31
32 cout « "\n\nContents of vector integers after changes: ";
33 std::copy( integers.begin(), integers.end(), output );
34
35 // обращение к элементу за пределами вектора
36 try
37 {
38 integers.at( 100 ) = 777;
39 } // end try
Библиотека стандартных шаблонов (STL)
1233
40 catch ( std: : out__of_range outOfRange ) // исключение out_of_range
41 {
42 cout « "\n\nException: " « outOfRange.what();
43 } // конец catch
44
45 // стереть первый элемент
4 6 integers.erase( integers.begin() );
47 cout « "\n\nVector integers after erasing first element: ";
48 std::copy( integers.begin(), integers.end(), output );
49
50 // стереть оставшиеся элементы
51 integers.erase( integers.begin(), integers.end() );
52 cout « "\nAfter erasing all elements, vector integers "
53 « ( integers.empty() ? "is" : "is not" ) « " empty";
54
55 // вставить элементы из массива
56 integers.insert( integers.begin(), array, array + SIZE );
57 cout « "\n\nContents of vector integers before clear: ";
58 std: :copy( integers.begin(), integers.end(), output );
59
60 // очистить integers; для очистки коллекции clear вызывает erase
61 integers.clear();
62 cout « "\nAfter clear, vector integers "
63 « ( integers. empty () ? "is" : "is not" ) « " empty" « endl ;
64 return 0;
65 } // конец main
Vector integers contains: 1 2 A 4 5 б
First element of integers: 1
Last element of integers: 6
Contents of vector integers after changes: 7 22 2 10 A 5 6
Exception: invalid vector subscript
Vector integers afttr erasing first element: 22 2 10 4 5 6
After erasing all elements, vector integers is empty
Contents of vector integers before clear: 1 2 3 4 5 6
After clear, vector integers is empty
Рис. 22.15. Функции класса vector для манипуляции элементами
Строка 18 определяет ostream_iterator с именем output, который может
использоваться для вывода через cout целых чисел, разделенных одиночными
пробелами. Итератор ostream_iterator< int > является безопасным в
отношении типа механизмом, который выводит только значения типа int или
совместимого типа. Первый аргумент конструктора специфицирует выходной поток,
а второй — строку, задающую разделитель для выводимых значений; в
данном случае строка содержит символ пробела. В этом примере мы применяем
ostream_iterator (определенный в заголовке <iterator>) для вывода
содержимого вектора.
Строка 21 вызывает алгоритм сору из Стандартной библиотеки для
вывода всего содержимого вектора integers на стандартный вывод. Алгоритм
1234
Глава 22
сору копирует каждый элемент из контейнера начиная с позиции,
специфицированной итератором в его первом аргументе, вплоть до — но не
включая — позиции, специфицированной итератором во втором аргументе.
Первый и второй аргументы должны удовлетворять требованиям входных
итераторов — они должны быть итераторами, через которые могут считываться
элементы контейнера. Кроме того, применение ++ к первому итератору
должно в конечном итоге привести к тому, что он достигнет второго
итератора. Элементы копируются в позицию, специфицированную выходным
итератором (т.е. итератором, через который значение может сохраняться
или выводиться), передаваемым в третьем аргументе. В данном случае
выходным итератором является ostream_iterator (output), прикрепленный
к cout, поэтому элементы копируются в стандартный вывод. Чтобы
использовать алгоритмы Стандартной библиотеки, вы должны включить
заголовочный файл <algorithm>.
Строки 23-24 вызывают функции front и back (имеющиеся у всех
контейнеров последовательностей), чтобы получить соответственно первый
и последний элементы вектора. Обратите внимание на разницу между
функциями front и begin. Функция front возвращает ссылку на первый элемент
вектора, в то время как функция begin возвращает итератор произвольного
доступа, указывающий на первый элемент. Заметьте также разницу между
функциями back и end. Функция back возвращает ссылку на последний
элемент вектора, в то время как end возвращает итератор произвольного
доступа, указывающий на конец вектора (позицию за последним
элементом).
Типичная ошибка программирования 22,3
Вектор должен быть непустым; в противном случае результат
функций front и hack не определен.
Строки 26-27 иллюстрируют два способа индексации вектора (которые
применимы также к контейнерам deque). Строка 26 использует операцию
индексации [], перегруженную так, чтобы возвращалась либо ссылка на
значение в указанной позиции, либо константная ссылка на это значение, в
зависимости от того, является ли контейнер константным. Функция at в строке 27
производит то же самое действие, но с проверкой диапазона. Функция at
сначала проверяет значение, переданное в качестве аргумента, и определяет,
лежит ли оно в пределах границ вектора. Если нет, функция выбрасывает
исключение out__of_range, определенное в заголовке <stdexcept> (как
демонстрируется в строках 36-43). На рис. 22.16 показаны некоторые типы
исключений STL. (Типы исключений Стандартной библиотеки обсуждались
в главе 16.)
Библиотека стандартных шаблонов (STL)
1235
Тип исключения STL I Описание
out_of_range I Показывает, что индекс находится вне диапазона —
например, когда для элемент-функции at специфицирован
| недействительный индекс.
invalid_argument Показывает, что функции передан недействительный
I аргумент.
length_error I Указывает на попытку создания слишком длинного
контейнера, строки и т. п.
bad_alloc i Показывает, что попытка выделить память с помощью new
| (или аллокатора) потерпела неудачу из-за недостатка
| наличной памяти.
Рис. 22.16. Некоторые типы исключений STL
Строка 30 вызывает одну из трех перегруженных функций insert,
имеющихся в каждом контейнере последовательности. Строка 30 вставляет
значение 22 перед элементом в позиции, специфицированной итератором в первом
аргументе. В этом примере итератор указывает на второй элемент вектора,
поэтому 22 вставляется в качестве второго элемента, а первоначальный второй
элемент становится третьим элементом вектора. Другие версии insert
позволяют вставлять несколько копий одного и того же значения, начиная с
некоторой позиции в контейнере, или вставлять диапазон значений из другого
контейнера (или массива), начиная с некоторой позиции в исходном контейнере.
Строки 46 и 51 вызывают две функции erase, имеющиеся у всех первичных
контейнеров. Строка 46 указывает, что из контейнера должен быть удален
элемент в позиции, специфицированной аргументом-итератором (в этом
примере — элемент в начале вектора). Строка 51 указывает, что должны быть
стерты все элементы контейнера начиная с позиции первого аргумента до — но не
включая — позиции второго аргумента. В этом примере стираются все
элементы контейнера. Строка 53 вызывает функцию empty (имеющуюся у всех
контейнеров и адаптеров), чтобы убедиться, что вектор пуст.
Типичная ошибка программирования 22,4
Стирание элемента, который содержит указатель на динамически
выделенный объект, не удаляет этот объект; это может привести
к утечке памяти.
Строка 56 демонстрирует версию функции insert, в которой второй и
третий аргументы специфицируют начальную и конечную позиции в
последовательности значений (возможно, из другого контейнера; в данном случае из
целого массива array), которые должны быть вставлены в вектор. Как вы
помните, конечная позиция специфицирует позицию в последовательности за
последним вставляемым элементом; копирование производится вплоть до —
но не включая — этой позиции.
Наконец, строка 61 вызывает функцию clear (имеющуюся у всех
первичных контейнеров) для очистки вектора. Эта функция вызывает версию erase,
использованную для очистки вектора в строке 51.
[Замечание. Мы не описали другие функции, являющиеся общими для всех
контейнеров, и функции, общие для всех контейнеров последовательностей.
1236
Глава 22
Большую часть этих функций мы опишем в нескольких следующих разделах.
Мы опишем также специфические функции каждого контейнера.]
22.2.2. Контейнер последовательности list
Контейнер последовательности list предлагает эффективную реализацию
вставки и удаления в любом месте контейнера. Если большинство вставок
и удалений происходит на концах контейнера, более эффективную
реализацию обеспечит структура данных deque (раздел 22.2.3). Шаблон класса list
реализован как двусвязный список — каждый узел в списке содержит
указатель на предыдущий узел списка и указатель на следующий узел списка. Это
позволяет шаблону класса list поддерживать двунаправленные итераторы,
допускающие проход по списку как в прямом, так и в обратном направлении. На
списке может действовать любой алгоритм, требующий входных, выходных,
поступательных или двунаправленных итераторов. Многие из
элемент-функций list манипулируют элементами контейнера как упорядоченным
множеством элементов.
Помимо элемент-функций на рис. 22.2, общих для всех контейнеров,
и функций, общих для всех контейнеров последовательностей,
обсуждавшихся в разделе 22.2, шаблон класса list предусматривает девять других
элемент-функций — splice, push_front, pop_front, remove, remove_if, unique,
merge, reverse и sort. Некоторые из этих функций являются
оптимизированными для list реализациями STL-алгоритмов, представленных в разделе 22.5.
Рис. 22.17 демонстрирует некоторые возможности класса list. Помните, что
к классу list можно применять многие из функций, представленных на
рис. 22.14-22.15. Для использования класса list необходимо включить
заголовочный файл <list>.
1 // Рис. 22.17: Fig23_17.cpp
2 // Тестовая программа для класса list стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <list> // определение шаблона класса class-template
8 #include <algorithm> // алгоритм copy
9 #include <iterator> // ostream_iterator
10
11 // прототип для шаблона функции printList
12 template <typename T> void printList(const std::list filistRef);
13
14 int main()
15 {
16 const int SIZE = 4;
17 int array[ SIZE ] = { 2, 6, 4, 8 };
18 std::list< int > values; // создать список для int
19 std::list< int > otherValues; // создать список для int
20
21 // вставить элементы в values
22 values.push_front( 1 );
23 values. push__front( 2 );
24 values . push_Jback ( 4 );
Библиотека стандартных шаблонов (STL)
1237
25 values.push_back( 3 );
26
27 cout « "values contains: ";
28 printList( values );
29
30 values.sort(); // сортировать значения
31 cout « "\nvalues after sorting contains: ";
32 printList( values );
33
34 // вставить в otherValues элементы array
35 otherValues.insert( otherValues.begin(), array, array + SIZE );
36 cout « "\nAfter insert, otherValues contains: ";
37 printList( otherValues );
38
39 // удалить элементы otherValues и вставить в конец values
40 values.splice( values.end(), otherValues );
41 cout « "\nAfter splice, values contains: ";
42 printList( values );
43
44 values.sort(); // сортировать значения
45 cout « "\nAfter sort, values contains: ";
46 printList( values );
47
48 // вставить в otherValues элементы array
49 otherValues.insert( otherValues.begin(), array, array + SIZE );
50 otherValues.sort();
51 cout « "\nAfter insert, otherValues contains: ";
52 printList( otherValues );
53
54 // удалить элементы otherValues и вставить в values (сортируя)
55 values.merge( otherValues );
56 cout « "\nAfter merge:\n values contains: ";
57 printList( values );
58 cout « "\n otherValues contains: ";
59 printList( otherValues );
60
61 values.pop_front(); // удалить элемент из начала
62 values.pop_back(); // удалить элемент из конца
63 cout « "\nAfter pop__front and pop__back:\n values contains: ";
64 printList( values );
65
66 values.unique(); // удалить дубликаты
67 cout « "\nAfter unique, values contains: ";
68 printList( values );
69
70 // обменять элементы values и otherValues
71 values.swap( otherValues );
72 cout « "\nAfter swap:\n values contains: ";
73 printList( values );
74 cout « "\n otherValues contains: ";
75 printList( otherValues );
76
77 // заменить содержимое values элементами otherValues
78 values.assign( otherValues.begin(), otherValues.end() );
79 cout « "\nAfter assign, values contains: ";
80 printList( values );
81
1238
Глава 22
82 // удалить элементы otherValues и вставить в values (сортируя)
83 values.merge( otherValues );
84 cout « "\nAfter merge, values contains: ";
85 printList( values );
86
87 values.remove( 4 ); // удалить все четверки
88 cout « "\nAfter remove( 4 ), values contains: ";
89 printList( values );
90 cout « endl;
91 return 0;
92 } // конец main
93
94 // определение шаблона функции printList; для вывода элементов
95 // списка использует ostream_iterator и алгоритм сору
96 template <typename T> void printList( const std::list filistRef )
97 {
98 if ( listRef.empty() ) // список пуст
99 cout « "List is empty";
100 else
101 {
102 std::ostream_iterator< T > output( cout, " " );
103 std::copy( listRef.begin(), listRef.end(), output );
104 } // конец else
105 } // конец функции printList
values contains: 2 1 4 3
values after sorting contains: 1 2 3 4
After insert, otherValues contains: 2 6 4 8
After splice, values contains: 12342648
After sort, values contains: 12234468
After insert, otherValues contains: 2 4 6 8
After merge:
values contains: 122234446688
otherValues contains: List is empty
After pop_front and pop__back:
values contains: 2223444668
After unique, values contains: 2 3 4 6 8
After swap:
values contains: List is empty
otherValues contains: 2 3 4 6 8
After assign, values contains: 2 3 4 6 8
After merge, values contains: 2233446688
After remove( 4 ), values contains: 22336688
Рис. 22.17. Шаблон класса list стандартной библиотеки
Строки 18-19 создают два объекта list для хранения значений int.
Строки 22-23 вызывают функцию push_front для вставки целых в начало списка
values. Функция push_front является специфической для классов list и deque
(но не vector). Строки 24-25 вызывают push_back для вставки целых в конец
values. Как вы помните, функция pushjback является общей для всех
контейнеров последовательностей.
Строка 30 вызывает элемент-функцию sort класса list для расположения
элементов списка в порядке возрастания. [Замечание. Она отлична от функции
sort, входящей в число алгоритмов STL.] Другая версия sort позволяет про-
Библиотека стандартных шаблонов (STL)
1239
граммисту указать бинарную предикатную функцию, которая принимает два
аргумента (значения из списка), производит сравнение и возвращает значение
типа bool, показывающее его результат. Эта функция позволяет задать
порядок, в котором будут сортированы элементы списка. Эта версия sort особенно
полезна для списка, в котором хранятся не значения, а указатели. [Замечание.
Мы демонстрируем унарную предикатную функцию на рис. 22.28. Унарная
предикатная функция принимает один аргумент, производит некоторое
сравнение этого аргумента и возвращает значение типа bool, показывающее
результат.]
Строка 40 вызывает функцию splice класса list для удаления элементов из
otherValues и вставки их в values перед позицией итератора,
специфицированного в качестве первого аргумента. Существуют две другие версии этой
функции. Функция splice с тремя аргументами позволяет удалить один
элемент из контейнера, специфицированного вторым аргументом, в позиции,
заданной итератором в третьем аргументе. Функция splice с четырьмя
аргументами использует два последних аргумента для указания диапазона позиций,
которые должны быть удалены из контейнера во втором аргументе и
помещены в позицию, специфицированную первым аргументом.
После вставки в otherValues дополнительных элементов и сортировки
обоих, списков (values и otherValues) строка 55 вызывает элемент-функцию
merge класса list, которая удаляет из otherValues все элементы и затем
упорядочение вставляет их в values. Перед выполнением этой операции оба
списка должны быть сортированы одинаковым образом. Вторая версия merge
позволяет программисту указать предикатную функцию, которая принимает два
аргумента (значения из списка) и возвращает значение типа bool.
Предикатная функция определяет порядок сортировки, который будет использовать
merge.
Строка 61 вызывает функцию pop_front класса list для удаления из списка
его первого элемента, строка 62 вызывает функцию popjback (имеющуюся
у всех контейнеров последовательностей) для удаления из списка последнего
элемента.
Строка 66 использует функцию unique класса list, чтобы удалить из
списка повторяющиеся элементы. Чтобы гарантировать исключение всех
дубликатов, перед выполнением этой операции список должен быть
упорядоченным (чтобы все дубликаты стояли рядом). Вторая версия unique позволяет
программисту указать предикатную функцию, которая принимает два
аргумента (значения из списка) и возвращает значение типа bool, показывающее,
равны ли элементы.
Строка 71 вызывает функцию swap (доступную для всех контейнеров) для
обмена содержимого values с содержимым otherValues.
Строка 78 вызывает функцию assign класса list, чтобы заменить
содержимое values содержимым otherValues в диапазоне, специфицированном
двумя аргументами-итераторами. Другая версия assign заменяет исходное
содержимое копиями значения, специфицированного вторым аргументом.
Первый аргумент функции специфицирует число копий. Строка 87
вызывает функцию remove класса list для удаления из списка всех экземпляров
значения 4.
1240 Глава 22
22.2.3. Контейнер последовательности deque
Класс deque объединяет многие преимущества векторов и списков в одном
контейнере. Термин deque является сокращением для «double-ended queue»
(«двусторонняя очередь»). Класс deque реализован с расчетом на эффективный
индексный доступ (посредством операции индексации) для чтения и
модификации его элементов, во многом аналогично вектору. Кроме того, реализация
deque обеспечивает эффективность операций вставки и удаления в начале
и конце контейнера, во многом аналогично списку (хотя список обеспечивает
также эффективную вставку и удаление в середине). Класс deque
предусматривает поддержку итераторов произвольного доступа, так что может
использоваться со всеми алгоритмами STL. Одним из наиболее распространенных
применений deque является поддержка очереди элементов типа «первым вошел,
первым вышел». На самом деле deque является базовой реализацией по умолчанию
для адаптера queue (раздел 22.4.2).
Дополнительная память для deque может выделяться на любом конце
контейнера отдельными блоками, организация которых обычно поддерживается
массивом указателей на эти блоки.1 Из-за прерывистого характера
расположения deque в памяти итератор deque должен быть более «умным», чем
указатели, используемые для прохода по векторам или массивам в стиле С.
Вопросы производительности 22.13
Как правило, deque присущи несколько большие накладные расходы,
чем вектору.
Вопросы производительности 22.14
Вставки и удаления в середине deque оптимизированы для
уменьшения числа копируемых элементов, поэтому они более эффективны,
чем в векторе, но менее эффективны, чем такого же рода
модификации в списке.
Класс deque предусматривает те же основные операции, что и класс vector,
но имеет дополнительные элемент-функции push_front и pop_front
соответственно для вставки и удаления в начале deque.
Рис. 22.18 демонстрирует возможности класса deque. Помните, что к deque
могут также применяться многие из функций, представленных на рис. 22.14, 22.15
и 22.17. Для использования класса deque необходимо включить заголовочный
файл <deque>.
1 // Рис. 22.18: Fig23_18.cpp
2 // Тестовая программа для класса deque стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <deque> // определение шаблона класса deque
8 #include <algorithm> // алгоритм copy
9 #include <iterator> // ostream_iterator
Это деталь реализации, а не требование стандарта С-Н-.
Библиотека стандартных шаблонов (STL)
1241
10
11 int main()
12 {
13 std::deque< double > values; // создать deque для double
14 std::ostream_iterator< double > output( cout, " " );
15
16 // вставить элементы в values
17 values.push_front( 2.2 );
18 values.push_front( 3.5 );
19 values.push_back( 1.1 );
20
21 cout « "values contains: ";
22
23 // использовать индексацию для получения элементов values
24 for ( unsigned int i = 0; i < values.size(); i++ )
25 cout « values[ i ] « '
26
27 values.pop_front(); // удалить первый элемент
28 cout « "\nAfter pop_front, values contains: ";
29 std::copy( values.begin(), values.end(), output );
30
31 // использовать операцию индексации для модификации элемента 1
32 values[ 1 ] = 5.4;
33 ccut « "\nAfter values[ 1 ] =5.4, values contains: ";
34 std::copy( values.begin(), values.end(), output );
35 cout « endl;
36 return 0;
37 } // конец main
values contains: 3.5 2.2 1.1
After pop_front, values contains: 2.2 1.1
After values[ 1 ] =5.4, values contains: 2.2 5.4
Рис. 22.18. Шаблон класса deque стандартной библиотеки
Строка 13 создает представитель deque, который может хранить значения
типа double. Строки 17-19 вызывают функции push__front и pushjback, чтобы
вставить элементы в качало и в конец deque. Как вы помните, pushjback
доступна для всех контейнеров последовательностей, но push_front имеется
только в классах list и deque.
Оператор for в строках 24-25 использует операцию индексации для
извлечения из deque каждого элемента с последующим выводом. Обратите
внимание, что для предотвращения попытки доступа к элементу вне границ deque
в условии использована функция size.
Строка 27 вызывает функцию pop_front, чтобы продемонстрировать
удаление первого элемента deque. Как вы помните, pop_front имеется только
в классах list и deque (но не в классе vector).
В строке 32 операция индексации создает lvalue. Это позволяет
непосредственно присваивать значение любому элементу deque.
1242
Глава 22
22.3. Ассоциативные контейнеры
Ассоциативные контейнеры STL обеспечивают прямой доступ для
сохранения и извлечения элементов при помощи ключей (часто называемых ключами
поиска). Четырьмя ассоциативными контейнерами являются multiset, set,
multimap и map. Каждый из ассоциативных контейнеров поддерживает свои
ключи в сортированном состоянии. Итерация по ассоциативному контейнеру
проходит его в порядке сортировки для данного контейнера. Классы multiset
и set предусматривают операции для манипуляции наборами значений, в
которых значения являются ключами, — не существует отдельного значения,
ассоциированного с каждым ключом. Основным различием между multiset
и set является то, что multiset допускает повторяющиеся ключи, в то время
как set их не допускает. Классы multimap и тар предусматривают операции
для манипуляции значениями, ассоциированными с ключами (эти значения
иногда называют mapped values, сопоставленными значениями). Основное
различие между multimap и тар состоит в том, что multimap допускает
хранение повторяющихся ключей с их ассоциированными значениями, а тар
допускает хранение только уникальных ключей с ассоциированными
значениями. В дополнение к общим элемент-функциям всех контейнеров,
представленным на рис. 22.2, все ассоциативные контейнеры поддерживают несколько
других элемент-функций, в число которых входят find, lowerjbound,
upper_bound и count. Примеры каждого из ассоциативных контейнеров и их
общих элемент-функций представлены в нескольких следующих разделах.
22.3.1. Ассоциативный контейнер multiset
Ассоциативный контейнер multiset обеспечивает быстрое сохранение
и извлечение ключей, допуская повторяющиеся ключи. Упорядочение
элементов определяется функциональным объектом-компаратором.
Например, в целом контейнере multiset элементы могут быть сортированы в
восходящем порядке, если упорядочить ключи функциональным
объектом-компаратором less< int >. Функциональные объекты мы подробно
обсудим в разделе 22.7. Тип данных ключей во всех ассоциативных
контейнерах должен поддерживать сравнение, соответствующее
специфицированному объекту-компаратору — ключи, сортируемые компаратором less< T >,
должны поддерживать сравнение посредством operator<. Если ключи в
ассоциативном контейнере принадлежат к типу, определенному
пользователем, этот тип должен предусматривать соответствующие операции
сравнения. Контейнер multiset поддерживает двунаправленные итераторы, но не
итераторы произвольного доступа.
Рис. 22.19 демонстрирует ассоциативный контейнер multiset со
значениями типа int, сортированными в восходящем порядке. Для использования
класса multiset необходимо включить заголовочный файл <set>.
1 // Рис. 22.19: Fig23_19.cpp
2 // Тестирование класса multiset стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
Библиотека стандартных шаблонов (STL)
1243
7 #include <set> // определение шаблона класса multiset
8
9 // определить краткое имя для используемого типа multiset
10 typedef std::multiset< int, std::less< int > > Ims;
11
12 #include <algorithm> // алгоритм copy
13 #include <iterator> // ostream_iterator
14
15 int main()
16 {
17 const int SIZE = 10;
18 int a[ SIZE ] = { 7, 22, 9, 1, 18, 30, 100, 22, 85, 13 };
19 Ims intMultiset; // Ims is typedef for "integer multiset"
20 std::ostream_iterator< int > output( cout, " " );
21
22 cout « "There are currently " « intMultiset.count( 15 )
23 « " values of 15 in the multiset\n";
24
25 intMultiset.insert( 15 ); // вставить 15 в intMultiset
26 intMultiset.insert( 15 ); // вставить 15 в intMultiset
27 cout « "After inserts, there are " « intMultiset.count( 15 )
28 « " values of 15 in the multiset\n\n";
29
30 // итератор, который нельзя использовать для изменения values
31 Ims ::const_iterator result;
32
33 // найти 15 в intMultiset; find возвращает итератор
34 result = intMultiset.find( 15 );
35
36 if ( result != intMultiset.end() ) // если итератор не в конце
37 cout « "Found value 15\n"; // значение 15 найдено
38
39 // найти 20 в intMultiset; find возвращает итератор
40 result = intMultiset.find( 20 );
41
42 if ( result == intMultiset.end() ) // должно быть true, так как
43 cout « "Did not find value 20\n"; // 20 не найдено
44
45 // вставить в intMultiset элементы массива
46 intMultiset.insert( а, а + SIZE );
47 cout « "\nAfter insert, intMultiset contains:\n";
48 std::copy( intMultiset.begin(), intMultiset.end(), output );
49
50 // определить нижнюю и верхнюю границы 22 в intMultiset
51 cout « "\n\nLower bound of 22: "
52 « *( intMultiset.lower_bound( 22 ) );
53 cout « "\nUpper bound of 22: "« * (intMultiset.upperjboundB2)) ;
54
55 // P представляет пару const_iterator
56 std::pair< Ims::const_iterator, Ims::const_iterator > p;
57
58 // использовать equal_range для определения нижней и верхней
59 // границ 22 в intMultiset
60 р = intMultiset.equal_range( 22 );
61
62 cout « "\n\nequal_range of 22:" « "\n Lower bound: "
63 « *( p. first ) « "\n Upper bound: " <" * ( p. second );
1244
Глава 22
64 cout « endl;
65 return 0;
66 } // конец main
There are currently 0 values of 15 in the multiset
After inserts, there are 2 values of 15 in the multiset
Found value 15
Did not find value 20
After insert, intMultiset contains:
1 7 9 13 15 15 18 22 22 30 85 100
Lower bound of 22: 22
Upper bound of 22: 30
equal__range of 22 :
Lower bound: 22
Upper bound: 30
Рис, 22.19. Шаблон класса multiset стандартной библиотеки
Определение typedef в строке 10 создает новое имя (псевдоним) для целого
multiset, сортированного в восходящем порядке функциональным объектом
less< int >. Восходящий порядок принимается для multiset по умолчанию,
поэтому std:: ess< int > в строке 10 можно было бы опустить. Затем этот новый
тип (Ims) используется для создания целого объекта multiset с именем
intMultiset.
Хороший стиль программирования 22.1
Используйте typedef, чтобы сделать код с длинными именами типов
(как в случае multiset) более легким для чтения.
Оператор вывода в строке 22 вызывает функцию count (доступную во всех
ассоциативных контейнерах) для подсчета текущего числа вхождений
в multiset значения 15.
Строки 25-26 вызывают одну из трех версий функции insert, чтобы
дважды добавить в multiset значение 15. Вторая версия insert принимает в
качестве аргументов итератор и значение; она ищет точку вставки начиная с
позиции, специфицированной итератором. Третья версия функции принимает два
итератора, специфицирующих диапазон значений, которые требуется
вставить в multiset из другого контейнера.
Строка 34 вызывает функцию find (доступную во всех ассоциативных
контейнерах) для поиска в multiset значения 15. Функция find возвращает
iterator или const_iterator, указывающий на ближайшую позицию, в которой
найдено значение. Если значение не найдено, find возвращает iterator или
const_iterator, равный тому, что возвращает end. Этот случай
демонстрируется строкой 41.
Строка 46 вызывает функцию insert, чтобы вставить в multiset элементы
массива. В строке 48 алгоритм сору копирует элементы multiset в
стандартный вывод. Заметьте, что элементы выводятся в восходящем порядке.
Библиотека стандартных шаблонов (STL)
1245
Строки 52 и 53 используют функции lowerjbound и upperjbound
(доступные во всех ассоциативных контейнерах) для нахождения первого вхождения
значения 22 в multiset и нахождения элемента после последнего вхождения
22. Обе функции возвращают iterator или const_iterator, указывающий на
соответствующую позицию, или итератор, возвращаемый end, если значение
в multiset не найдено.
Строка 56 создает представитель класса pair с именем р. Объекты класса
pair используются для создания пар связанных значений. В этом примере
содержимым pair являются два const_iterator для нашего целого multiset.
Объект р предназначен для хранения значения, возвращаемого функцией
equal_range класса multiset, которое представляет собой пару с результатами
обеих операций lowerjbound и upperjbound. Тип pair содержит два открытых
элемента с именами first и second.
Строка 60 вызывает функцию equal_range, чтобы определить lowerjbound
и upperjbound в multiset для значения 22. В строке 63 используются p.first
и p.second для доступа соответственно к lowerjbound и upperjbound. Для
вывода значений в позициях, возвращаемых из equal_range, мы
разыменовываем эти итераторы.
22.3.2. Ассоциативный контейнер set
Ассоциативный контейнер set (множество) обеспечивает быстрое
сохранение и извлечение ключей. Реализация set идентична multiset за исключением
того, что ключи в set должны быть уникальными. Таким образом, если
делается попытка ввести в set дубликат имеющегося ключа, дубликат игнорируется;
поскольку это соответствует поведению математического множества, мы не
считаем такую попытку программной ошибкой. Контейнер set поддерживает
двунаправленные итераторы (но не итераторы произвольного доступа).
Рис. 22.20 демонстрирует множество значений типа double. Для
использования класса требуется включить заголовочный файл <set>.
1 // Рис. 22.20: Fig23_20.cpp
2 // Тестовая программа для класса set стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <set>
8
9 // определить краткое имя для типа set, используемого в программе
10 typedef std::set< double, std::less< double > > DoubleSet;
11
12 #include <algorithm>
13 #include <iterator> // ostream_iterator
14
15 int main()
16 {
17 const int SIZE = 5;
18 double a[ SIZE ] = { 2.1, 4.2, 9.5, 2.1, 3.7 };
19 DoubleSet doubleSet( a, a + SIZE );;
20 std::ostream_iterator< double > output( cout, " " );
21
1246
Глава 22
22 cout « "doubleSet contains: ";
23 std::copy( doubleSet.begin(), doubleSet.end(), output );
24
25 // p представляет пару, содержащую const_iterator и bool
26 std::pair< DoubleSet::const_iterator, bool > p;
27
28 // вставить 13.8 в doubleSet; insert возвращает пару, в которой
29 // p.first представляет позицию 13.8 в doubleSet, a
30 // p.second показывает, было ли 13.8 вставлено
31 р = doubleSet.insert( 13.8 ); // значение, отсутствующее в set
32 cout « "\n\n" « *( p.first )
33 « ( p.second ? " was" : " was not" ) « " inserted";
34 cout « "\ndoubleSet contains: ";
35 std::copy( doubleSet.begin(), doubleSet.end(), output );
36
37 // вставить 9.5 в doubleSet
38 p = doubleSet.insert( 9.5 ); // значение, уже имеющееся в set
39 cout « "\n\n" « *( p.first )
40 « ( p.second ? " was" : " was not" ) « " inserted";
41 cout « "\ndoubleSet contains: ";
42 std::copy( doubleSet.begin(), doubleSet.end(), output );
43 cout « endl;
44 return 0;
45 } // конец main
doubleSet contains: 2.1 3.7 4.2 9.5
13.8 was inserted
doubleSet contains: 2.1 3.7 4.2 9.5 13.8
9.5 was not inserted
doubleSet contains: 2.1 3,7 4.2 9.513.8
Рис. 22.20. Шаблон класса set стандартной библиотеки
Определение typedef в строке 10 создает новое имя типа (DoubleSet) для
множества значений double, сортированного в восходящем порядке
функциональным объектом less< double >.
В строке 19 новый тип DoubleSet используется для создания объекта
doubleSet. Вызов конструктора принимает элементы массива а между а и а +
SIZE (т.е. весь массив) и вставляет из в множество. Строка 23 использует
алгоритм сору для вывода содержимого множества. Обратите внимание, что
значение 2.1 — которое входило в массив а дважды — появляется в doubleSet лишь
однажды. Это объясняется тем, что set не допускает дубликатов.
Строка 26 определяет пару, состоящую из const_iterator и значения bool.
Этот объект сохраняет результат вызова функции insert класса set.
В строке 32 функция insert помещает в множество значение 13.8.
Возвращаемая пара р содержит итератор p.first, указывающий на значение 13.8
в множестве, и булево значение, истинное, если 13.8 вставлено, и ложное,
если не вставлено (поскольку оно уже имелось в множестве). В данном случае
значение 13.8 в множестве отсутствовало, поэтому оно вставляется. Строка 38
пытается вставить 9.5, которое уже есть в множестве. Вывод, выполняемый
строками 39-40, показывает, что 9.5 не было вставлено в множество.
Библиотека стандартных шаблонов (STL)
1247
22.3.3. Ассоциативный контейнер multimap
Ассоциативный контейнер multimap используется для быстрого
сохранения и извлечения ключей с ассоциированными значениями (их часто
называют парами ключ/значение). Многие из функций, используемых с multiset
и set, применимы также к multimap и тар. Элементами multimap и тар
являются не отдельными значениями, а парами с ключом и значением. При
вставке в multimap или тар передается объект pair, содержащий ключ и
значение. Упорядочение ключей определяется функциональным
объектом-компаратором. Например, multimap, использующий в качестве ключей целые,
может быть упорядочен по возрастанию функциональным объектом
less< int >. В multimap допускается дублирование ключей, поэтому с одним
ключом может быть ассоциировано несколько значений. Это часто называют
отношением «один к многим». Например, в системе обработки транзакций для
кредитных карт один счет кредитной карты может иметь много связанных
с ним транзакций; в университете один студент может посещать несколько
курсов, а один преподаватель может учить много студентов; в армии
одинаковый чин (например, «рядовой») могут иметь многие люди. Контейнер
multimap поддерживает двунаправленные итераторы, но не итераторы
произвольно доступа. Рис. 22.21 демонстрирует ассоциативный контейнер
multimap. Для использования multimap требуется включить заголовочный
файл <тар>.
Вопросы производительности 32.15
Контейнер multimap реализован для быстрого отыскания всех
значений, ассоциированных с данным ключом.
1 // Рис. 22.21: Fig23_21.cpp
2 // Тестовая программа для класса multimap стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std:rendl;
6
7 #include <map> // определение шаблона класса map
8
9 // определить краткое имя для типа multimap
10 typedef std::multimap< int, double, std::less< int > > Mmid;
11
12 int main()
13 {
14 Mmid pairs; // определить мультикарту pairs
15
16 cout « "There are currently " « pairs.count( 15 )
17 « " pairs with key 15 in the multimap\n";
18
19 // вставить в pairs два объекта value_type
20 pairs.insert( Mmid::value_type( 15, 2.7 ) );
21 pairs.insert( Mmid::value_type( 15, 99.3 ) );
22
23 cout « "After inserts, there are " « pairs.count( 15 )
24 « " pairs with key 15\n\n";
1248
Глава 22
25
26 // вставить в pairs пять объектов value_type
27 pairs. insert( Mmid: : value__type ( 30, 111.11 ) );
28 pairs . insert ( Mmid: : value__type ( 10, 22.22 ) );
29 pairs .insert ( Mmid: :value_type ( 25, 33.333 ) );
30 pairs.insert( Mmid: : value_type ( 20, 9.345 ) );
31 pairs.insert( Mmid::value_type( 5, 77.54 ) );
32
33 cout « "Multimap pairs contains:\nKey\tValue\n";
34
35 // использовать const^iterator для прохода по элементам pairs
36 for ( Mmid::const_iterator iter = pairs.begin();
37 iter != pairs.end(); ++iter )
38 cout « iter->first « ' \t' « iter->second « ' \n';
39
40 cout « endl;
41 return 0;
42 } // конец main
There are currently 0 pairs with key 15 in the multimap
After inserts, there are 2 pairs with key 15
Multimap pairs contains:
Key Value
5 77.54
10 22,22
15 2.7
15 99.3
20 9.345
25 33.333
30 111.11
Рис, 22.21. Шаблон класса multimap стандартной библиотеки
Строка 10 создает псевдоним Mmid для типа multimap, в котором типом
ключей является int, типом ассоциированного с ключом значения — double,
и элементы упорядочены по возрастанию. В строке 14 новый тип используется
для создания представителя multimap с именем pairs. Строка 16 вызывает
функцию count для определения числа пар ключ/значение с ключом 15.
Строка 20 вызывает функцию insert для добавления в multimap новой
пары ключ/значение. Выражение Mmid:: value_type( 15, 2.7 ) создает объект
pair, в котором first является ключомA5) типа int, a second является
значением B.7) типа double. Тип Mmid::value_type входит в число определений
typedef для multimap. Строка 21 вставляет другой объект pair с ключом 15
и значением 99.3. Затем строки 23-24 выводят число пар с ключом 15.
Строки 27-31 вставляют в multimap пять дополнительных пар. Оператор
for в строках 36-38 выводит содержимое multimap, как ключи, так и
значения. Для доступа к составляющим пары в каждом элементе multimap в
строке 38 используется const_iterator с именем iter. Заметьте, в при выводе
программы ключи сортированы в восходящем порядке.
Библиотека стандартных шаблонов (STL)
1249
22.3.4. Ассоциативный контейнер тар
Ассоциативный контейнер тар (карта) используется для быстрого
сохранения и извлечения ключей с ассоциированными значениями. В тар не
допускается дублирование ключей, поэтому с каждым ключом может быть
ассоциировано единственное значение. Это называют отображением «один к одному»
(однозначным отображением). Например, компания, использующая личные
номера сотрудников, такие, как 100, 200 и 300, могла бы применить карту,
ассоциирующую эти номера с местными телефонами — соответственно 4321,
4115и5217. В карте вы специфицируете ключ и быстро получаете
ассоциированные с ним данные. Контейнер тар обычно называют ассоциативным
массивом. Указание ключа в операции индексации [], примененной к тар,
находит значение, ассоциированное в тар с этим ключом. Вставки и удаления
могут производиться в любом месте тар.
Рис. 22.22 демонстрирует ассоциативный контейнер тар, выполняя те же
действия, что и рис. 22.21, и показывает операцию индексации. Для
использования класса тар требуется включить заголовочный файл <тар>. Строки 33
и 34 применяют к тар операцию индексации. Когда индекс является ключом,
уже присутствующим в карте (строка 33), операция возвращает ссылку на
ассоциированное значение. Когда индекс является ключом, отсутствующим
в карте (строка 34), операция вставляет ключ в карту и возвращает ссылку,
которую можно использовать для ассоциации значения с этим ключом. Строка
33 заменяет значение для ключа 25 C3.333, ранее специфицированное в
строке 21) на новое значение, 9999.99. Строка 34 вставляет в карту новую пару
ключ/значение (это называют созданием ассоциации).
1 // Рис. 22.22: Fig23_22.cpp
2 // Тестовая программа для класса тар стандартной библиотеки..
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <map> // определение шаблона класса map
8
9 // определить краткое имя для типа тар, используемого в программе
10 typedef std::map< int, double, std::less< int > > Mid;
11
12 int main()
13 {
14 Mid pairs;
15
16 // вставить в pairs восемь объектов value__type
17 pairs.insert( Mid::value_type( 15, 2.7 ) );
18 pairs.insert( Mid::value_type( 30, 111.11 ) );
19 pairs.insert( Mid::value_type( 5, 1010.1 ) );
20 pairs.insert( Mid::value_type( 10, 22.22 ) );
21 pairs.insert( Mid::value_type( 25, 33.333 ) );
22 pairs.insert( Mid::value_type( 5, 77.54 ) ); // дубликат
23 pairs, insert ( Mid: : value__type ( 20, 9.345 ) );
24 pairs.insert( Mid::value__type( 15, 99.3 ) ); // дубликат
25
26 cout « "pairs contains:\nKey\tValue\n";
27
40 3ar 1114
1250
Глава 22
28 // использовать const_iterator для прохода по элементам pairs
29 for ( Mid::const_iterator iter = pairs.begin();
30 iter != pairs.end(); ++iter )
31 cout « iter->first « '\t' « iter->second « ' \n';
32
33 pairs[ 25 ] = 9999.99; // индексация для изменения значения 25
34 pairs[ 40 ] = 8765.43; // индексация для вставки значения 40
35
36 cout «
37 "\nAfter subscript operations, pairs contains:\nKey\tValue\n"
38 // использовать const_iterator для прохода по элементам pairs
39 for ( Mid::const_iterator iter2 = pairs.begin();
40 iter2 != pairs.end(); ++iter2 )
41 cout « iter2->first « '\t' « iter2->second « ' \n';
42
43 cout « endl;
44 return 0;
45 } // конец main
pairs contains:
Key Value
5 1010.1
10 22.22
15 2.7
20 9.345
25 33.333
30 111.11
After subscript operations, pairs contains:
Key Value
5 1010.1
10 22.22
15 2.7
20 9.345
25 9999.99
30 111.11
40 8765.43
Рис. 22.22. Шаблон класса map стандартной библиотеки
22.4. Адаптеры контейнеров
В STL имеется три адаптера контейнеров — stack, queue и priority__queue.
Адаптеры не являются первичными контейнерами, потому что они не
предусматривают действительной реализации структуры данных, в которой могут
сохраняться элементы, а также потому, что они не поддерживают итераторов.
Преимущество адаптерного класса в том, что программист может выбрать для
него наиболее подходящую базовую структуру данных. Во всех трех классах
адаптеров предусмотрены элемент-функции push и pop, которые
соответствующим образом вставляют элемент в структуру данных каждого адаптера
и удаляют элемент из его структуры данных. В нескольких следующих
подразделах приводятся примеры для адаптерных классов.
Библиотека стандартных шаблонов (STL)
1251
22.4.1. Адаптер stack
Класс stack (стек) допускает вставку и удаление элементов в базовой
структуре данных только с одного конца (что обычно называют структурой данных
типа «последним вошел, первым вышел»). Стек может быть реализован на
основе любого контейнера последовательности — vector, list или deque.
Приведенный ниже пример создает три целых стека, используя в качестве базовой
структуры данных каждый из последовательных контейнеров STL. По
умолчанию стек реализуется как deque. Операциями класса stack являются push
для вставки элемента на вершину стека (что реализуется вызовом функции
push_back базового контейнера), pop для удаления элемента с вершины стека
(реализуется вызовом функции popjback базового контейнера), top для
получения ссылки на верхний элемент стека (реализуется вызовом функции back
базового контейнера), empty для определения того, пуст ли стек (реализуется
вызовом функции empty базового контейнера) и size для получения числа
элементов в стеке (реализуется вызовом функции size базового контейнера).
Вопросы производительности 22.16
Каждая из типичных операций стека реализуется как inline-функ-
ция, которая вызывает соответствующую функцию базового
контейнера. Это позволяет избежать расходов на вторичный вызов функции.
Вопросы производительности 22.17
Для наилучшей производительности стека используйте в качестве
его базового контейнера deque или vector.
Рис. 22.23 демонстрирует класс адаптера stack. Для использования класса
stack требуется включить заголовочный файл <stack>.
1 // Рис. 22.23: Fig23_22.cpp
2 // Тестовая программа для адаптера stack стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <stack> // определение адаптера stack
8 #include <vector> // определение шаблона класса vector
9 #include <list> // определение шаблона класса list
10
11 // прототип шаблона функции pushElements
12 template< typename T > void pushElements( T &stackRef );
13
14 // прототип шаблона функции popElements
15 template< typename T > void popElements( T &stackRef );
16
17 int main()
18 {
19 // stack с основой по умолчанию - deque
20 std::stack< int > intDequeStack;
21
22 // stack с основой vector
1252
Глава 22
23 std::stack< int, std::vector< int > > intVectorStack;
24
25 // stack с основой list
26 std::stack< int, std::list< int > > intListStack;
27
28 // затолкнуть в каждый стек элементы 0-9
29 cout « "Pushing onto intDequeStack: " ;
30 pushElements( intDequeStack );
31 cout « "\nPushing onto intVectorStack: ";
32 pushElements( intVectorStack );
33 cout « "\nPushing onto intListStack: ";
34 pushElements( intListStack );
35 cout « endl « endl;
36
37 // вывести и удалить элементы каждого стека
38 cout « "Popping from intDequeStack: ";
39 popElements( intDequeStack );
40 cout « "\nPopping from intVectorStack: ";
41 popElements( intVectorStack ); i
42 cout « "\nPopping from intListStack: ";
43 popElements( intListStack );
44 cout « endl;
45 return 0;
46 } // конец main
47
48 // затолкнуть элементы в стек, на который ссылается stackRef
49 template< typename T > void pushElements( T &stackRef )
50 {
51 for ( int i = 0; i < 10; i++ )
52 {
53 stackRef.push( i ); // затолкнуть элемент в стек
54 cout « stackRef.top() « ' '; // посмотреть верхний элемент
55 } // конец for
56 } // конец функции pushElements
57
58 // вытолкнуть элементы из стека, на который ссылается stackRef
59 template< typename T > void popElements( T &stackRef )
60 {
61 while ( !stackRef.empty() )
62 {
63 cout « stackRef.top() « ' '; // посмотреть верхний элемент
64 stackRef.pop(); // удалить верхний элемент
65 } // конец while
66 } // конец функции popElements
Pushing onto intDequeStack: 0123456789
Pushing onto intVectorStack: 0123456789
Pushing onto intListStack: 0123456789
Popping from intDequeStack: 9876543210
Popping from intVectorStack: 9876543210
Popping from intListStack: 9876543210
Рис. 22.23. Шаблон класса stack стандартной библиотеки
Библиотека стандартных шаблонов (STL) 1253
Строки 20, 23 и 26 создают три целых стека. Строка 20 специфицирует стек
для целых, который по умолчанию использует в качестве базовой структуры
данных контейнер deque. Строка 23 специфицирует стек для целых,
использующий в качестве базовой структуры данных целый вектор. Строка 26
специфицирует стек для целых, использующий в качестве базовой структуры
данных целый список.
Функция pushElements (строки 49-56) заталкивает элементы в каждый из
стеков. Строка 53 вызывает функцию push (имеющуюся в каждом адаптерном
классе) для вставки целого значения на вершину стека. Строка 54 вызывает
функцию стека top, чтобы извлечь верхний элемента стека для вывода.
Функция top не удаляет верхний элемент.
Функция popElements (строки 59-66) выталкивает элементы из каждого
стека. Строка 63 вызывает функцию стека top, чтобы извлечь верхний элемент
стека для вывода. Строка 64 вызывает функцию pop (имеющуюся в каждом
адаптерном классе) для удаления верхнего элемента стека. Функция pop не
возвращает значения.
22.4.2. Адаптер queue
Класс queue (очередь) допускает вставку элементов в конец базовой
структуры данных и удаление элементов из ее начала (что обычно называют
структурой данных типа «первым вошел, первым вышел»). Очередь может быть
реализована структурой данных STL list либо deque. Типичными операциями
класса queue являются push для вставки элемента в конец очереди (что
реализуется вызовом функции push_back базового контейнера), pop для удаления
элемента из начала очереди (реализуется вызовом функции pop_front базового
контейнера), front для получения ссылки на первый элемент очереди
(реализуется вызовом функции front базового контейнера), back для получения
ссылки на последний элемент очереди (реализуется вызовом функции back
базового контейнера), empty для определения того, пуста ли очередь
(реализуется вызовом функции empty базового контейнера) и size для получения числа
элементов в очереди (реализуется вызовом функции size базового контейнера).
Вопросы производительности 22.18
Каждая из типичных операций очереди реализуется как
inline-функция, которая вызывает соответствующую функцию базового
контейнера. Это позволяет избежать расходов на вторичный вызов функции.
Вопросы производительности 22.19
Для наилучшей производительности очереди используйте в качестве
ее базового контейнера deque или list.
Рис. 22.24 демонстрирует класс адаптера queue. Для использования класса
queue требуется включить заголовочный файл <queue>.
1 // Рис. 22.24: Fig23_24.cpp
2 // Тестовая программа для адаптера queue стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
1254
Глава 22
5 using std::endl;
6
7 #include <queue> // определение адаптера queue
8
9 int main()
10 {
11 std::queue< double > values; // queue со значениями double
12
13 // затолкнуть элементы в очередь values
14 values.push( 3.2 );
15 values.push( 9.8 );
16 values.push( 5.4 );
17
18 cout « "Popping from values: ";
19
20 // вытолкнуть элементы из очереди
21 while ( !values.empty() )
22 {
23 cout « values.front() « ' '; // view front element
24 values.pop(); // remove element
25 } // конец while
26
27 cout « endl;
28 return 0;
29 } // конец main
Popping from values: 3.2 9.8 5.4
Рис. 22.24. Класс адаптера queue стандартной библиотеки
Строка 11 создает очередь, в которой хранятся значения типа double.
Строки 14-16 вызывают функцию push для добавления элементов в очередь.
Оператор while в строках 21-25 использует функцию empty (имеющуюся во всех
контейнерах) для проверки того, является ли очередь пустой (строка 21). Пока
в очереди еще имеются элементы, строка 23 вызывает функцию front, чтобы
прочитать (не удаляя) первый элемент в очереди для вывода. Строка 24
удаляет первый элемент в очереди функцией pop (имеющейся во всех классах
адаптеров).
22.4.3. Адаптер priority_queue
Класс priority_queue (приоритетная очередь) обладает функциональными
возможностями, обеспечивающими упорядоченную вставку в базовую
структуру данных и удаление элементов из ее начала. Приоритетная очередь может
быть реализована последовательными контейнерами STL vector и deque. По
умолчанию базовой структурой данных для реализации priority_queue
является вектор. Когда элементы добавляются в приоритетную очередь, они
вставляются в контейнер по порядку приоритетов таким образом, что элемент с
наивысшим приоритетом (т.е. с наибольшим значением) будет удален из очереди
первым. Обычно это осуществляется посредством методики сортировки,
называемой кучевой сортировкой (heapsort), которая всегда хранит наибольшее
значение (т.е. элемент наивысшего приоритета) в начале структуры данных —
такую структуру данных называют кучей (heap). По чпмолчачию гр.^тт^чи" -тр
Библиотека стандартных шаблонов (STL)
1255
ментов производится функциональным объектом-компаратором less< T >, но
программист может указать другой компаратор.
Типичными операциями класса priority_queue являются push для вставки
элемента в позицию, соответствующую приоритетному порядку priori -
ty_queue (что реализуется вызовом функции pushjback базового контейнера
с последующим переупорядочиванием посредством кучевой сортировки), pop
для удаления элемента очереди с наивысшим приоритетом (реализуется
вызовом функции pop_back базового контейнера после удаления верхнего элемента
кучи), top для получения ссылки на верхний элемент приоритетной очереди
(реализуется вызовом функции front базового контейнера), empty для
определения того, пуста ли очередь (реализуется вызовом функции empty базового
контейнера) и size для получения числа элементов в очереди (реализуется
вызовом функции size базового контейнера).
Вопросы производительности 22.20
Каждая из типичных операций класса priority_queue реализуется
как inline-функция, которая вызывает соответствующую функцию
базового контейнера. Это позволяет избежать расходов на
вторичный вызов функции.
Вопросы производительности 22.21
Для наилучшей производительности приоритетной очереди
используйте в качестве ее базового контейнера vector или deque.
Рис. 22.25 демонстрирует класс адаптера priority_queue. Для
использования класса priority_queue требуется включить заголовочный файл <queue >.
1 // Рис. 22.25: Fig23_25.cpp
2 // Тестовая программа для адаптера priority_queue.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <queue> // определение адаптера priority__queue
8
9 int main()
10 {
11 std: :priority_queue< double > priorities; // создать priority_queue
12
13 // затолкнуть элементы в priorities
14 priorities.push( 3.2 )
15 priorities.push( 9.8 )
16 priorities.push( 5.4 )
17
18 cout « "Popping from priorities: ";
19
20 // вытолкнуть элементы из priority_queue
21 while ( !priorities.empty() )
22 {
23 cout « priorities.top() « ' '; // посмотреть верхний элемент
24 priorities.pop(); // удалить верхний элемент
1256
Глава 22
25 } // конец while
26
27 cout « endl;
28 return 0;
29 } // конец main
Popping from priorities: 9.8 5.4 3.2
Рис 22.25. Класс адаптера priority_queue стандартной библиотеки
Строка 11 создает приоритетную очередь, которая хранит значения типа
double и использует вектор в качестве базовой структуры данных.
Строки 14-16 вызывают функцию push для добавления элементов в приоритетную
очередь. Оператор while в строках 21-25 использует функцию empty
(имеющуюся во всех контейнерах) для проверки того, является ли очередь пустой
(строка 21). Пока в очереди еще имеются элементы, строка 23 вызывает
функцию top, чтобы извлечь элемент с наивысшим приоритетом в очереди для
вывода. Строка 24 удаляет элемент с наивысшим приоритетом в очереди
функцией pop (имеющейся во всех классах адаптеров).
22.5. Алгоритмы
До появления STL классовые библиотеки контейнеров и алгоритмов от
разных поставщиков были, по существу, несовместимы друг с другом. Ранние
библиотеки контейнеров, как правило, использовали наследование и
полиморфизм, с вытекающими отсюда расходами на вызовы виртуальных функций.
Ранние библиотеки встраивали алгоритмы в классы контейнеров в качестве
поведения последних. STL отделяет алгоритмы от контейнеров. Это упрощает
добавление новых алгоритмов. В STL доступ к элементам контейнеров
осуществляется при посредстве итераторов. Несколько следующих подразделов
демонстрируют многие из алгоритмов STL.
I——i Вопросы производительности 22.22
р^ф5| Реализация STL ориентирована на эффективность. Она избегает
расходов, связанных с вызовами виртуальных функций.
® Общее методическое замечание 22.8
Алгоритмы STL не зависят от деталей реализации контейнеров, на
которых они действуют. Пока итераторы контейнера (или массива)
удовлетворяют требованиям алгоритма, алгоритм STL может
работать с массивами-указателями в стиле С, с контейнерами STL и со
структурами данных, определенными пользователем.
S Общее методическое замечание 22.9
Алгоритмы могут легко добавляться в STL без модификации классов
контейнеров.
Библиотека стандартных шаблонов (STL)
1257
22.5.1. fill, fill_nf generate и generatejn
Рис. 22.26 демонстрирует алгоритмы fill, fill_n, generate и generate_n.
Функции fill и /Ш_л устанавливают каждый элемент в некотором диапазоне
элементов контейнера равным заданному значению. Функции generate и
generate^ используют функцию-генератор, которая создает отдельное значение
для каждого элемента в некотором диапазоне контейнера. Функция-генератор
не принимает аргументов и возвращает значение, которое может помещаться
в элемент контейнера.
1 // Рис. 22.26: Fig23_26.cpp
2 // Алгоритмы fill, fill_n, generate и generatejn.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <algorithm> // определения алгоритмов
8 #include <vector> // определение шаблона класса vector
9 #include <iterator> // ostream_iterator
10
11 char nextLetter(); // прототип функции-генератора
12
13 int main()
14 {
15 std::vector< char > chars( 10 );
16 std::ostream_iterator< char > output( cout, " " );
17 std::fill( chars.begin(), chars.end(), '5' ); // заполнить chars
18
19 cout « "Vector chars after filling with 5s:\n";
20 std::copy( chars.begin(), chars.end(), output );
21
22 // заполнить первые пять элементов chars буквами А
23 std::fill_n( chars.begin(), 5, 'A' );
24
25 cout «"\n\nVector chars after filling five elements with As:\n";
26 std::copy( chars.begin(), chars.end(), output );
27
28 // генерировать значения для элементов chars с помощью nextLetter
29 std::generate( chars.begin(), chars.end(), nextLetter );
30
31 cout « M\n\nVector chars after generating letters A-J:\n";
32 std::copy( chars.begin(), chars.end(), output );
33
34 // генерировать значения для элементов chars с помощью nextLetter
35 std::generate_n( chars.begin(), 5, nextLetter );
36
37 cout « "\n\nVector chars after generating K-0 for the"
38 « " first five elements:\n";
39 std::copy( chars.begin(), chars.end(), output );
40 cout « endl;
41 return 0;
42 } // конец main
43
44 // функия-генератор возвращает следующую букву (начинает с А)
45 char nextLetter()
1258
Глава 22
46 {
47 static char letter = 'A';
48 return letter++;
49 } // конец функции nextLetter
Vector chars after filling with 5s:
5555555555
Vector chars after filling five elements with As:
AAAAA55555
Vector chars after generating letters A-J:
ABCDEFGHIJ
Vector chars after generating K-0 for the first five elements:
KLMNOFGHIJ
Рис. 22.26. Алгоритмы fill, fill_n, generate и generate_n
Строка 15 определяет 10-элементный вектор, сохраняющий значения типа
char. Строка 17 вызывает функцию fill, чтобы поместить в каждый элемент
вектора chars от chars.begin() до (но не включая) chars.end() символ '5\
Заметьте, что итераторы, передаваемые в качестве первого и второго аргументов,
должны быть по крайней мере поступательными итераторами (т.е. они могут
использоваться как для ввода, так и для вывода при движении по контейнеру
в прямом направлении).
Строка 23 вызывает функцию fill_n, чтобы поместить в первые пять
элементов вектора chars символ 'А'. Итератор, передаваемый в первом аргументе,
должен быть по крайней мере выходным итератором (т.е. он может
использоваться для вывода в контейнер при движении в прямом направлении). Второй
аргумент специфицирует число элементов, которые требуется заполнить.
Третий аргумент специфицирует значение, помещаемое в каждый элемент.
Строка 29 вызывает функцию generate, чтобы поместить в каждый элемент
вектора chars от chars.begin() до (но не включая) chars.end() результат вызова
функции-генератора nextLetter. Итераторы, передаваемые в качестве первого
и второго аргументов, должны быть по крайней мере поступательными
итераторами. Функция nextLetter (определенная в строках 45-49) начинает с
символа 'А', хранящегося в локальной статической переменной. При каждом
вызове nextLetter оператор в строке 48 инкрементирует значение переменной
letter и возвращает ее старое значение.
Строка 35 вызывает функцию generate_n, чтобы поместить результат
вызова функции-генератора nextLetter в пять элементов вектора chars, начиная
с chars.begin(). Итератор, передаваемый в первом аргументе, должен быть по
крайней мере выходным итератором.
22.5.2. equal, mismatch и lexicographical_compare
Рис. 22.27 демонстрирует сравнение последовательностей значений на
равенство с помощью алгоритмов equal, mismatch и lexicographical_compare.
Библиотека стандартных шаблонов (STL)
1259
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
// Рис. 22.27: Fig23_27.cpp
// Алгоритмы equal, mismatch и lexicographical_compare.
#include <iostream>
using std::cout;
using std::endl;
#include <algorithm> // определения алгоритмов
#include <vector> // определение шаблона класса vector
#include <iterator> // ostream iterator
int main()
{
const int SIZE =
int al[ SIZE ] =
int a2[ SIZE ] =
std::vector< int
std::vector< int
std::vector< int
10;
{ 1, 2, 3, 4, 5, 6,
{ 1, 2, 3, 4, 1000,
> vl( al, al + SIZE
> v2( al, al + SIZE
> v3( a2, a2 + SIZE
7,
6,
);
);
);
8,
7,
//
//
//
9, 10 };
8, 9, 10 }
copy of al
copy of al
copy of a2
std::ostream_iterator< int > output( cout, " " );
cout « "Vector vl contains: ";
std::copy( vl.begin(), vl.end(), output );
cout « "\nVector v2 contains: ";
std::copy( v2.begin(), v2.end(), output );
cout « "\nVector v3 contains: ";
std::copy( v3.begin(), v3.end(), output );
// сравнить векторы vl и v2 на равенство
bool result = std::equal( vl.begin(), vl.end(), v2.begin() );
cout « "\n\nVector vl " « ( result ? "is" : "is not" )
« " equal to vector v2.\n";
// сравнить векторы vl и v3 на равенство
result = std::equal( vl.begin(), vl.end(), v3.begin() );
cout « "Vector vl " « ( result ? "is" : "is not" )
« " equal to vector v3.\n";
// location представляет пару итераторов вектора
std::pair< std::vector< int >::iterator,
std::vector< int >::iterator > location;
// проверить vl и v3 на несовпадение
location = std:.mismatch( vl.begin(), vl.end(), v3.begin() );
cout « "\nThere is a mismatch between vl and v3 at location "
« ( location.first - vl.begin() ) « "\nwhere vl contains "
« *location.first « " and v3 contains " « ^location.second
« "\n\n";
char
char
cl[
c2[
SIZE
SIZE
] =
] =
"HELLO";
"BYE BYE'
// произвести лексикографическое сравнение cl и с2
result = std::lexicographical_compare(cl, cl+SIZE, c2, c2+SIZE);
cout « cl « ( result ? " is less than " :
" is greater than or equal to " ) « c2 « endl;
return 0;
// конец main
1260
Глава 22
Vector vl contains
Vector v2 contains
Vector v3 contains
Vector vl is equal to vector v2.
Vector vl is not equal to vector v3.
There is a mismatch between vl and v3 at location 4
where vl contains 5 and v3 contains 1000
HELLO is greater than or equal to BYE BYE
Рис. 22.27. Алгоритмы equal, mismatch и lexicographical_compare
Строка 29 вызывает функцию equal, чтобы сравнить на равенство две
последовательности значений. Последовательности не обязательно должны
содержать одинаковое число элементов — если последовательности имеют
различную длину, equal возвращает false. Сравнение элементов выполняется
операцией == (либо встроенной, либо перегруженной). В этом примере элементы
вектора vl от vl.begin() до (но не включая) vl.end() сравниваются с
элементами вектора v2, начиная с v2.begin(). В данном случае vl и v2 равны. Три
аргумента-итератора должны быть по крайней мере входными итераторами (т.е.
они могут использоваться для ввода из последовательности при движении
в прямом направлении). Строка 34 вызывает функцию equal для сравнения
векторов vl и v3, которые не равны.
Имеется другая версия функции equal, которая принимает в качестве
четвертого параметра бинарную предикатную функцию. Эта функция принимает
два сравниваемых элемента и возвращает булево значение, показывающее,
равны ли эти элементы. Это может оказаться полезным в случае
последовательностей, хранящих не действительные значения, а объекты или указатели
на значения. Например, вы можете сравнивать объекты типа Employee не
целиком, а по возрасту, номеру страховки или адресу. Вы можете сравнивать не
значения-указатели (т.е. хранящиеся в указателях адреса), а то, на что
указатели ссылаются.
Код в строках 39-43 начинается с создания пары итераторов location для
вектора с целыми значениями. Этот объект сохраняет результат вызова
mismatch (строка 45). Функция mismatch сравнивает две последовательности
значений и возвращает объект pair с итераторами, указывающими на позиции
несовпадающих элементов в каждой из последовательностей. Если все элементы
совпадают, итераторы пары равны конечным итераторам двух
последовательностей. Три аргумента-итератора должны быть по крайней мере входными
итераторами. Строка 45 определяет действительную позицию несовпадения
в векторах с помощью выражения location.first — vl.begin(). Результатом его
оценки является число элементов между итераторами (это аналогично
арифметике указателей, которую мы изучали в главе 8). В данном примере оно
соответствует номеру элемента, поскольку сравнение производится от начала
каждого вектора. Как и в случае функции equal, имеется вторая версия
mismatch, которая принимает в качестве четвертого параметра бинарную
предикатную функцию.
Строка 53 вызывает функцию lexicographicaljcompare, чтобы сравнить
содержимое двух символьных массивов. Четыре аргумента-итератора функции
123456789 10
123456789 10
12 3 4 1000 6 7 8 9 10
Библиотека стандартных шаблонов (STL)
1261
должны быть по крайней мере входными итераторами. Первые два аргумента
специфицируют диапазон позиций в первой последовательности. Последние
два специфицируют диапазон позиций во второй последовательности.
Проходя по последовательностям, lexicographical__compare сравнивает их элементы.
Если элемент первой последовательности меньше соответствующего элемента
второй последовательности, функция немедленно возвращает true. Если
элемент второй последовательности меньше соответствующего элемента первой
последовательности, функция немедленно возвращает false. Функция также
возвращает true, если она достигает конца первой последовательности прежде,
чем будет достигнут конец второй последовательности. Эта функция может
использоваться для организации набора последовательностей в
лексикографическом порядке. В типичном случае такие последовательности содержат строки.
22.5.3. remove, remove_iff remove_copy и remove_copy_if
Рис. 22.28 демонстрирует удаление значений из последовательности с
помощью алгоритмов remove, remove_if, remove__copy и remove__copy_if.
1 // Рис. 22.28: Fig23_28.cpp
2 // Функции Стандартной библиотеки remove, remove__if,
3 // remove__copy и remove_copy_jLf.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <algorithm> // определения алгоритмов
9 #include <vector> // определение шаблона класса vector
10 #include <iterator> // ostream_iterator
11
12 bool greater9( int ); // прототип
13
14 int main()
15 {
16 const int SIZE = 10;
17 int a[ SIZE ] = { 10, 2, 10, 4, 16, 6, 14, 8, 12, 10 };
18 std::ostream_iterator< int > output( cout, " " );
19 std::vector< int > v( a, a + SIZE ); // копия а
20 std::vector< int >::iterator newLastElement;
21
22 cout « "Vector v before removing all 10s:\n ";
23 std::copy( v.begin(), v.end(), output );
24
25 // удалить из v все 10
26 newLastElement = std::remove( v.begin(), v.end(), 10 );
27 cout « "\nVector v after removing all 10s:\n ";
28 std::copy( v.begin(), newLastElement, output );
29
30 std::vector< int > v2( a, a + SIZE ); // копия а
31 std::vector< int > c( SIZE, 0 ); // создать вектор с
32 cout « "\n\nVector v2 before removing all 10s and copying:\n
33 std::copy( v2.begin(), v2.end(), output );
34
35 // копировать из v2 в с, удалив при этом все 10
36 std::remove_copy( v2.begin(), v2.end(), c.begin(), 10 );
1262
Глава 22
37 cout « "\nVector с after removing all 10s from v2:\n ";
38 std::copy( c.begin(), c.end(), output );
39
40 std: :vector< int > v3 ( a, a + SIZE ); // копия а
41 cout « "\n\nVector v3 before removing all elements"
42 « "\ngreater than 9:\n ";
43 std::copy( v3.begin(), v3.end(), output );
44
45 // идалить из v3 элементы, большие 9
46 newLastElement = std::remove_if( v3.begin(), v3.end(), greater9 );
47 cout « "\nVector v3 after removing all elements"
48 « "\ngreater than 9:\n ";
49 std::copy( v3.begin(), newLastElement, output );
50
51 std::vector< int > v4( a, a + SIZE ); // копия а
52 std::vector< int > c2 ( SIZE, 0 ); // создать вектор с2
53 cout « "\n\nVector v4 before removing all elements"
54 « "\ngreater than 9 and copying:\n ";
55 std::copy( v4.begin(), v4.end(), output );
56
57 // копировать из v4 в с2, удалив при этом
58 // элементы, большие 9
59 std::remove_copy_if( v4.begin(), v4.end(), c2.begin(), greater9 );
60 cout « "\nVector c2 after removing all elements"
61 « "\ngreater than 9 from v4:\n ";
62 std::copy( c2.begin(), c2.end(), output );
63 cout « endl;
64 return 0;
65 } // конец main
66
67 // определить, является ли элемент большим 9
68 bool greater9( int x )
69 {
70 return x > 9;
71 } // конец функции greater9
Vector v before removing all 10s:
10 2 10 4 16 6 14 8 12 10
Vector v after removing all 10s:
2 4 16 6 14 8 12
Vector v2 before removing all 10s and copying:
10 2 10 4 16 6 14 8 12 10
Vector с after removing all 10s from v2:
2 4 16 6 14 8 12 0 0 0
Vector v3 before removing all elements
greater than 9:
10 2 10 4 16 6 14 8 12 10
Vector v3 after removing all elements
greater than 9:
2 4 6 8
Vector v4 before removing all elements
greater than 9 and copying:
10 2 10 4 16 6 14 8 12 10
Библиотека стандартных шаблонов (STL)
1263
Vector c2 after removing all elements
greater than 9 from v4:
2468000000
Рис. 22.28. Алгоритмы remove, remove_if, remove_copy и remove_copy_if
Строка 26 вызывает функцию remove, чтобы исключить из диапазона v от
v.begin() до (но не включая) v.end() все элементы со значением 10. Первые два
аргумента должны быть поступательными итераторами, чтобы алгоритм мог
модифицировать элементы в последовательности. Функция не изменяет число
элементов в векторе и не удаляет их, но перемещает все не исключенные
элементы к началу вектора. Функция возвращает итератор, установленный на
позицию за последним не исключенным элементом. Элементы от позиции этого
итератора до конца вектора имеют неопределенные значения (в данном
примере каждая «неопределенная» позиция имеет значение О).
Строка 36 вызывает функцию remove jcopy, чтобы скопировать все
элементы из диапазона v2 от v2.begin() до (но не включая) v2.end(), отличные от 10.
Элементы помещаются в с, начиная с позиции c.begin(). Итераторы,
передаваемые в первых двух аргументах, должны быть входными итераторами.
Итератор в третьем аргументе должен быть поступательным итератором, чтобы
копируемый элемент мог быть вставлен в позицию копирования. Функция
возвращает итератор, установленный на позицию за последним элементом,
скопированным в вектор с. Обратите внимание на конструктор вектора в
строке 31, который принимает число элементов в векторе и начальное значение
для этих элементов.
Строка 46 вызывает функцию removejlf, чтобы удалить из диапазона v3 от
v3.begin() до (но не включая) v3.end() все элементы, для которых
определенная пользователем унарная предикатная функция greater9 возвращает true.
Функция greater9 (определенная в строка 68-71) возвращает true, если
переданное ей значение больше 9; в противном случае она возвращает false.
Первые два аргумента должны быть поступательными итераторами, чтобы
алгоритм мог модифицировать элементы в последовательности. Функция не
изменяет число элементов в векторе, но перемещает все не исключенные элементы
к началу вектора. Функция возвращает итератор, установленный на позицию
за последним не исключенным элементом. Элементы от позиции этого
итератора до конца вектора имеют неопределенные значения.
Строка 59 вызывает функцию remove_copy_if9 чтобы скопировать все
элементы из диапазона v4 от v4.begin() до (но не включая) v4.end(), для которых
определенная пользователем унарная предикатная функция greater9
возвращает false. Элементы помещаются в с2, начиная с позиции c2.begin().
Итераторы, передаваемые в первых двух аргументах, должны быть входными
итераторами. Итератор в третьем аргументе должен быть поступательным
итератором, чтобы копируемый элемент мог быть вставлен в позицию копирования.
Функция возвращает итератор, установленный на позицию за последним
элементом, скопированным в с2.
1264
Глава 22
22.5.4. replace, replace_if, replace_copy и replace_copy_if
Рис. 22.28 демонстрирует замену значений в последовательности с
помощью алгоритмов replace, replace_if, replace__copy и replace_copy_if.
1 // Рис. 22.29: Fig23_29.cpp
2 // Функции Стандартной библиотеки replace, replace_if,
3 // replace_copy и replace_copy_if.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <algorithm>
9 #include <vector>
10 #include <iterator> // ostream_iterator
11
12 bool greater9( int ); // прототип предикатной функции
13
14 int main ()
15 f
16 const int SIZE = 10;
17 int a[ SIZE ] = { 10, 2, 10, 4, 16, 6, 14, 8, 12, 10 };
18 std::ostream_iterator< int > output( cout, " " ) ;
19
20 std: :vector< int > vl( a, a + SIZE ) ; // копия а
21 cout « "Vector vl before replacing all 10s:\n ";
22 std::copy( vl.begin(), vl.end(), output );
23
24 // заменить в vl все 10 на 100
25 std::replace( vl.begin(), vl.end(), 10, 100 );
26 cout « "\nVector vl after replacing 10s with 100s:\n ";
27 std::copy( vl.begin(), vl.end(), output );
28
29 std: :vector< int > v2( a, a + SIZE ) ; // копия а
30 std::vector< int > cl( SIZE ); // создать вектор cl
31 cout « "\n\nVector v2 before replacing all 10s and copying:\n
32 std::copy( v2.begin(), v2.end(), output );
33
34 // копировать из v2 в с, заменив при этом все 10 на 100
35 std::replace_copy( v2.begin(), v2.end(), cl.begin(), 10, 100 );
36 cout « "\nVector cl after replacing all 10s in v2:\n ";
37 std::copy( cl.begin(), cl.end(), output );
38
39 std::vector< int > v3( a, a + SIZE ); // копия а
40 cout « "\n\nVector v3 before replacing values greater than 9:\n
41 std::copy( v3.begin(), v3.end(), output );
42
43 // заменить в v3 на 100 все элементы, большие 9
44 std::replace_if( v3.begin(), v3.end(), greater9, 100 );
45 cout « "\nVector v3 after replacing all values greater"
46 « "\nthan 9 with 100s:\n
47 std::copy( v3.begin(), v3.end(), output );
48
49 std::vector< int > v4( a, a + SIZE ); // копия а
50 std::vector< int > c2( SIZE ); // создать вектор с2
51 cout « "\n\nVector v4 before replacing all values greater "
Библиотека стандартных шаблонов (STL)
1265
52 « "than 9 and copying:\n ";
53 std::copy( v4.begin(), v4.end(), output );
54
55 // копировать из v4 в с2, заменив на 100 все элементы, большие 9
56 s td: : replace_copy__i f (
57 v4.begin(), v4.end(), c2.begin(), greater9, 100 ) ;
58 cout « "\nVector c2 after replacing all values greater "
59 « "than 9 in v4:\n ";
60 std::copy( c2.begin(), c2.end(), output );
61 cout « endl;
62 return 0;
63 } // конец main
64
65 // определить, является ли аргумент большим 9
66 bool greater9( int x )
67 {
68 return x > 9;
69 } // конец функции greater9
Vector vl before replacing all 10s:
10 :<. 10 4 16 6 14 В 12 10
Vector vl after replacing 10s with 100s;
100 2 100 4 16 6 14 8 12 100
Vector v2 before replacing ail 10s and copying:
10 2 10 4 16 6 14 В 12~10
Veci.or c! after rep.u^ciny all lCs in v2 :
100 2 100 4 16 6 14 8 12 100
Sector v3 before replacing values greater than 9:
10 2 10 4 16 6 14 3 12 10
Vector vj after replacing ail valueь greater
rhan 9 with ICOs-
100 2 100 4 100 6 IOC 8 100 100
Vector v4 beiore repj.acj.ng all values greater than 9 and copying:
10 2 10 4 16 6 14 В 12 10
Vector c2 after replacing all values greater than 9 in v4:
100 2 100 4 100^5 100 8 100 100
Рис. 22.29. Алгоритмы replace, replaceif, replace.copy и replace_copy_if
Строка 25 вызывает функцию replace, чтобы заменить все элементы со
значением 10 в диапазоне vl от vl.begin() до (но не включая) vl.end() новым
значением 100. Итераторы в первых двух аргументах должны быть
поступательными итераторами, чтобы алгоритм мог модифицировать элементы в
последовательности.
Строка 35 вызывает функцию гер1асе_сору, чтобы скопировать все
элементы в диапазоне v2 от v2.begin() до (но не включая) v2.end(), заменив все
элементы со значением 10 новым значением 100. Элементы помещаются в cl,
начиная с позиции cl.begin(). Итераторы, передаваемые в первых двух
аргументах, должны быть входными итераторами. Итератор в третьем аргументе
должен быть поступательным итератором, чтобы копируемый элемент мог
быть вставлен в позицию копирования. Функция возвращает итератор,
установленный на позицию за последним элементом, скопированным в вектор cl.
1266
Глава 22
Строка 44 вызывает функцию replace_if, чтобы заменить все элементы
в диапазоне v3 от v3.begin() до (но не включая) v3.end(), для которых
определенная пользователем унарная предикатная функция greater9 возвращает
true. Функция greater9 (определенная в строка 66-69) возвращает true, если
переданное ей значение больше 9; в противном случае она возвращает false.
Каждое значение, большее 9, заменяется значением 100. Итераторы в первых
двух аргументах должны быть поступательными итераторами, чтобы
алгоритм мог модифицировать элементы в последовательности.
Строки 56-57 вызывают функцию replace_copy_if, чтобы скопировать все
элементы в диапазоне v4 от v4.begin() до (но не включая) v4.end(). Элементы,
для которых определенная пользователем унарная предикатная функция
greater9 возвращает true, заменяются значением 100. Элементы помещаются
в с2, начиная с позиции c2.begin(). Итераторы, передаваемые в первых двух
аргументах, должны быть входными итераторами. Итератор в третьем
аргументе должен быть поступательным итератором, чтобы копируемый элемент
мог быть вставлен в позицию копирования. Функция возвращает итератор,
установленный на позицию за последним элементом, скопированным в с2.
22.5.5. Математические алгоритмы
Рис. 22.30 демонстрирует несколько распространенных математических
алгоритмов из STL, в число которых входят random_shuffle, count, count_if,
min_element, max_element, accumulate, for_each и transfom.
1 // Рис. 22.30: Fig23_30.cpp
2 // Матеметические алгоритмы Стандартной библиотеки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <algorithm> // определения алгоритмов
8 #include <numeric> // здесь определяется accumulate
9 #include <vector>
10 #include <iterator>
11
12 bool greater9( int ); // прототип предикатной функции
13 void outputSquare( int ); // вывести квадрат значения
14 int calculateCube( int )/ // вычислить куб значения
15
16 int main()
17 {
18 const int SIZE = 10;
19 int al[ SIZE ] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 );
20 std::vector< int > v( al, al + SIZE ); // копия al
21 std::ostream_iterator< int > output( cout, " " );
22
23 cout « "Vector v before random_shuffle: " ;
24 std: :copy( v.begin(), v.end(), output );
25
26 std::random_shuffie( v.begin(), v.end() ); // перемешать элементы
27 cout « "\nVector v after random_shuffle:
28 std::copy( v.begin(), v.end(), output );
29
Библиотека стандартных шаблонов (STL)
1267
30 int a2[ SIZE ] = { 100, 2, 8, 1, 50, 3, 8, 8, 9, 10 };
31 std::vector< int > v2( a2, a2 + SIZE ); // copy of a2
32 cout « "\n\nVector v2 contains: ";
33 std::copy( v2.begin(), v2.end(), output );
34
35 // пересчитать элементы v2 со значением 8
36 int result = std::count( v2.begin(), v2.end(), 8 );
37 cout « "\nNumber of elements matching 8: " « result ;
38
39 // пересчитать элементы v2, большие 9
40 result = std::count_if( v2.begin(), v2.end(), greater9 );
41 cout « "\nNumber of elements greater than 9: " « result;
42
43 // найти в v2 наименьший элемент
44 cout « "\n\nMinimum element in Vector v2 is: "
45 « *( std: :min_element( v2.begin(), v2.end() ) );
46
47 // найти в v2 наибольший элемент
48 cout « "\nMaximum element in Vector v2 is: "
49 « *( std: :max_element( v2.begin(), v2.end() ) );
50
51 // вычислить сумму элементов в v
52 cout « "\n\nThe total of the elements in Vector v is: "
53 « std::accumulate( v.begin(), v.end(), 0 );
54
55 // вывести квадрат каждого элемента иэ v
56 cout « "\n\nThe square of every integer in Vector v is:\n";
57 std::for_each( v.begin(), v.end(), outputSquare );
58
59 std::vector< int > cubes( SIZE ); // создать вектор cubes
60
61 // вычислить куб каждого элемента v; поместить результаты в cubes
62 std::transform( v.begin(),v.end(),cubes.begin(), calculateCube );
63 cout « "\n\nThe cube of every integer in Vector v is:\n";
64 std::copy( cubes.begin(), cubes.end(), output );
65 cout « endl;
66 return 0;
67 } // конец main
68
69 // определить, является ли аргумент большим 9
70 bool greater9( int value )
71 {
72 return value > 9;
73 } // конец функции greater9
74
75 // вывести квадрат аргумента
76 void outputSquare( int value )
77 {
78 cout « value * value « ' ';
79 } // конец функции outputSquare
80
81 // возвратить куб аргумента
82 int calculateCube( int value )
83 {
84 return value * value * value;
85 } // конец функции calculateCube
1268
Глава 22
Vector v before random_shuffle: 1234 5 6789 10
Vector v after random_shuffle: 5413799 10 62
Vector v2 contains: 100 2 8 1 50 3 8 8 9 10
Number of elements matching 8: 3
Number of elements greater than 9:3
Minimum element in Vectcr v2 is: 1
Maximum element in Vector v2 is: 100
The total of the elements in Vector v is: 55
The square of every integer in Vector v is:
25 16 1 9 49 64 81 100 36 4
The cube of every integer in Vector v is:
125 64 1 27 343 512 729 1000 216 8
Рис. 22.30. Математические алгоритмы Стандартной библиотеки
Строка 26 вызывает функцию randomjshuffie, чтобы переупорядочить
случайным образом диапазон v от v.begin() до (но не включая) v.end(). Эта
функция принимает два аргумента-итератора произвольного доступа.
Строка 36 вызывает функцию count для подсчета числа элементов в
диапазоне v2 от v2.begin() до (но не включая) v2.end(), имеющих значение 8.
Функция требует, чтобы два ее аргумента-итератора являлись по крайне мере
входными итераторами.
Строка 40 вызывает функцию count_if для подсчета числа элементов в
диапазоне v2 от v2.begin() до (но не включая) v2.end(), для которых предикатная
функция greater9 возвращает true. Функция count_if требует, чтобы два ее
аргумента-итератора являлись по крайне мере входными итераторами.
Строка 45 вызывает <$1[]алгоритм min_elcmen^функцию minjelement,
чтобы найти наименьший элемент в диапазоне v2 от v2.begin() до (но не
включая) v2.end(). Функция возвращает поступательный итератор,
позиционированный на наименьшем элементе или, если диапазон пуст, возвращает
v2.end(). Функция требует, чтобы два ее аргумента-итератора являлись по
крайне мере входными итераторами. Вторая версия min_element принимает
в качестве третьего аргумента бинарную функцию, сравнивающую элементы
последовательности. Эта функция принимает два аргумента и возвращает
булево значение.
Хороший стиль программирования 22.2
Полезно проверять, что диапазон, специфицированный в вызове min_ele-
ment, не пуст, и что возвращаемое значение не является
«запредельным» итератором.
Строка 49 вызывает функцию max_elementy чтобы найти наибольший
элемент в диапазоне v2 от v2.begin() до (но не включая) v2.end(). Функция
возвращает поступательный итератор, позиционированный на наименьшем
элементе. Функция требует, чтобы два ее аргумента-итератора являлись по
крайне мере входными итераторами. Вторая версия max_element принимает
Библиотека стандартных шаблонов (STL)
1269
в качестве третьего аргумента бинарную функцию, сравнивающую элементы
последовательности. Эта функция принимает два аргумента и возвращает
булево значение.
Строка 53 вызывает функцию accumulate (шаблон которой находится в
заголовочном файле <numeric>), чтобы суммировать значения в диапазоне v от
v.begin() до (но не включая) v.end(). Два ее первых аргумента-итератора
должны быть по крайне мере входными итераторами, а третий аргумент
представляет начальное значение суммы. Вторая версия accumulate принимает в
качестве четвертого аргумента функцию общего вида, определяющую, каким
образом аккумулируются элементы. Эта функция должна принимать два
аргумента и возвращать результат. Первым аргументом функции является
текущее аккумулированное значение. Второй аргумент является значением
текущего элемента в аккумулируемой последовательности.
Строка 57 вызывает функцию for_each, чтобы применить функцию общего
вида к элементам в диапазоне v от v.begin() до (но не включая) v.end(). Функ
ция общего вида должна принимать в качестве аргумента текущий элемент
и не должна его модифицировать. Функция for_each требует, чтобы два ее
аргумента-итератора являлись по крайне мере входными итераторами.
Строка 62 вызывает функцию transform, чтобы применить функцию обще
го вида к элементам в диапазоне v от v.begin() до (но не включая) v.end().
Функция общего вида (четвертый аргумент) должна принимать в качестве
аргумента текущий элемент, не должна его модифицировать и должна
возвращать преобразованное значение. Функция transform требует, чтобы два ее
аргумента-итератора являлись по крайне мере входными итераторами, а третий
аргумент — по крайне мере выходным итератором. Третий аргумент
указывает, куда должны помещаться преобразованные значения. Заметьте, что третий
аргумент может быть равен первому. Другая версия transform принимает
пять аргументов — первые два являются входными итераторами,
специфицирующими диапазон из одного исходного контейнера, третий является
входным итератором, специфицирующим первый элемент в другом исходном
контейнере, четвертый является выходным итератором, указывающим, куда
должны помещаться преобразованные значения, а последний аргумент
является функцией общего вида, принимающей два аргумента. Эта версия
transform берет по одному элементу из двух входных контейнеров и
применяет к этой паре элементов функцию общего вида, после чего помещает
преобразованное значение в позицию, специфицированную четвертым аргументом.
22.5.6. Элементарные алгоритмы поиска и сортировки
Рис. 22.31 демонстрирует некоторые элементарные алгоритмы поиска
и сортировки из Стандартной библиотеки, в число которых входят find,
find__if, sort и binary_scarch.
1 // Рис. 22.31: Fig23_31.cpp
2 // Алгоритмы Стандартной библиотеки find и sort.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <algorithm> // определения алгоритмов
1270
Глава 22
8 #include <vector> // определение шаблона класса vector
9 #include <iterator>
10
11 bool greater10( int value ); // прототип предикатной функции
12
13 int main ()
14 {
15 const int SIZE = 10;
16 int a[ SIZE ] = { 10, 2, 17, 5, 16, 8, 13, 11, 20, 7 };
17 std::vector< int > v( a, a + SIZE ); // copy of a
18 std::ostream_iterator< int > output( cout, " " );
19
20 cout « "Vector v contains: ";
21 std::copy( v.begin(), v.end(), output ); // вывести результаты
22
23 // найти в v первое значение 16
24 std::vector< int >::iterator location;
25 location = std::find( v.begin(), v.end(), 16 );
26
27 if ( location != v.end() ) //16 найдено
28 cout « "\n\nFound 16 at location " « ( location - v.begin() );
29 else // 16 не найдено
30 cout « "\n\nl6 not found";
31
32 // найти в v первое значение 100
33 location = std::find( v.begin(), v.end(), 100 );
34
35 if ( location != v.end() ) // 100 найдено
36 cout « "\nFound 100 at location " « ( location - v.begin() );
37 else // 100 не найдено
38 cout « "\nl00 not found";
39
40 // найти в v первое значение, большее 10
41 location = std::find_if( v.begin(), v.end(), greaterlO );
42
43 if ( location != v.end() ) // найдено значение, большее 10
44 cout « "\n\nThe first value greater than 10 is " « *location
45 « "\nfound at location " « ( location - v.begin() );
46 else // значение, большее 10, не найдено
47 cout « "\n\nNo values greater than 10 were found";
48
49 // сортировать элементы v
50 std::sort( v.begin(), v.end() );
51 cout « "\n\nVector v after sort: ";
52 std::copy( v.begin(), v.end(), output );
53
54 // использовать binary_search для нахождения 13 в v
55 if ( std::binary_search( v.begin(), v.endQ, 13 ) )
56 cout « "\n\nl3 was found in v";
57 else
58 cout « "\n\nl3 was not found in v";
59
60 // использовать binary_search для нахождения 100 в v
61 if ( std::binary_search( v.begin(), v.end(), 100 ) )
62 cout « "\nl00 was found in v";
63 else
64 cout « "\nl00 was not found in v";
Библиотека стандартных шаблонов (STL)
1271
65
66 cout « endl;
67 return 0;
68 } // конец main
69
70 // определить, является ли аргумент большим 10
71 bool greaterlO( int value )
72 {
73 return value > 10;
74 } // конец функции greater10
Vector v contains: 10 2 17 5 16 8 13 11 20 7
Found 16 at location 4
100 not found
The first value greater than 10 is 17
found at location 2
Vector v after sort: 2 5 7 8 10 11 13 16 17 20
13 was found in v
100 was not found in v
Рис. 22.31. Элементарные алгоритмы поиска и сортировки стандартной библиотеки
Строка 25 вызывает функцию find, чтобы найти значение 16 в диапазоне v
от v.begin() до (но не включая) v.end(). Функция требует, чтобы два ее первых
аргумента-итератора были по крайней мере входными итераторами, и
возвращает входной итератор, либо установленный на первый элемент с искомым
значением, либо обозначающий конец последовательности (как это имеет
место в строке 33).
Строка 41 вызывает функцию findjtf, чтобы найти первое значение в
диапазоне v от v.begin() до (но не включая) v.end(), для которого унарная
предикатная функция greaterlO возвращает true. Функция greaterlO
(определенная в строках 71-74) принимает целое значение и возвращает булево
значение, показывающее, яляется ли аргумент большим 10. Функция find_if
требует, чтобы два ее аргумента-итератора были по крайней мере входными
итераторами. Функция возвращает входной итератор, либо установленный на
первый элемент со значением, для которого предикатная функция возвращает
true, либо обозначающий конец последовательности.
Строка 50 использует функцию sort, чтобы расположить элементы в
диапазоне v от v.begin() до (но не включая) v.end() в восходящем порядке. Функция
требует, чтобы два ее аргумента-итератора были итераторами произвольного
доступа. Вторая версия этой функции принимает третий аргумент,
являющийся бинарной предикатной функцией, принимающей значения двух элементов
последовательности и возвращающей булево значение, показывающее
порядок следования элементов — если возвращается true, элементы сортированы
в нужном порядке.
1272
Глава 22
— -, Типичная ошибка программирования 22.5
Попытка сортировать контейнер с использованием итератора, не
являющегося итератором произвольного доступа, приводит к ошибке
компиляции. Функция sort требует итераторов произвольного
доступа.
Строка 55 использует функцию binary_search, чтобы определить, имеется
ли в диапазоне v от v.begin() до (но не включая) v.end() значение 13.
Предварительно последовательность должна быть сортирована в восходящем порядке.
Функция binary_search требует, чтобы два ее аргумента-итератора были по
крайней мере поступательными итераторами. Функция возвращает bool,
показывающее, найдено ли значение в последовательности. Строка 61 показывает
вызов binary_search, который не находит указанного значения. Вторая версия
этой функции принимает четвертый аргумент, являющийся бинарной
предикатной функцией, принимающей значения двух элементов последовательности
и возвращающей булево значение. Предикатная функция возвращает true, если
два элемента удовлетворяют порядку сортировки.
22.5.7. swap, iter_swap и swap.ranges
Рис. 22.32 демонстрирует алгоритмы swap, iter__swap и swap_ranges для
обмена элементов. Строка 20 вызывает функцию swap для обмена двух
значений. В этом примере обмениваются первый и второй элементы массива.
Функция принимает в качестве аргументов ссылки на два обмениваемых значения.
1 // Рис. 22.32: Fig23_32.cpp
2 // Алгоритмы Стандартной библиотеки iter_swap, swap и swap_ranges.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <algorithm> // определения алгоритмов
8 #include <iterator>
9
10 int main()
11 {
12 const int SIZE = 10;
13 int a[ SIZE 1 = { 1, 2,3, 4, 5, 6, 7, 8, 9, 10};
14 std::ostream_iterator< int > output( cout, " " );
15
16 cout « "Array a contains:\n ";
17 std::copy( a, a + SIZE, output ); // вывести массив а
18
19 // обменять элементы массива а в позициях 0 и 1
20 std::swap( а[ 0 ], а[ 1 ] );
21
22 cout « "\nArray a after swapping a[0] and a[l] using swap:\n ";
23 std::copy( a, a + SIZE, output ); // вывести массив а
24
25 // обменять элементы массива а в позициях 0 и 1 итераторами
26 std::iter_swap( &a[ 0 ], &а[ 1 ] ); // обменять итераторами
27 cout « "\nArray a after swapping a[0] and a[l] "
Библиотека стандартных шаблонов (STL)
1273
28 « "using iter_swap:\n ";
29 std::copy( а, а + SIZE, output );
30 // обменять элементы в пяти первых позициях массива а
31 //с элементами в пяти последних позициях массива а
32 std: :swap__ranges ( а, а + 5, а + 5 ) ;
33
34 cout « "\nArray a after swapping the first five elements\n"
35 « "with the last five elements:\n ";
36 std::copy( a, a + SIZE, output );
37 cout « endl;
38 return 0;
39 } // конец main
Array a contains:
123456789 10
Array a after swapping a[0] and a[l] using swap:
213456789 10
Array a after swapping a[0] and a[l] using iter_swap:
123456789 10
Array a after swapping the first five elements
with the last five elements:
6789 10 12345
Рис. 22.32. Демонстрация iter_swap, swap и swap_ranges
Строка 26 вызывает функцию iterjswap для обмена двух элементов. Эта
функция принимает в качестве аргументов два поступательных итератора
(в данном случае два указателя на элементы массива) и обменивает значения
в элементах, на которые ссылаются итераторы.
Строка 32 вызывает функцию swapjranges для обмена элементов в
диапазоне от а до (но не включая) а + 5 с элементами, начинающимися с позиции
а + 5. Функция принимает в качестве аргументов три поступательных
итератора. Первые два итератора специфицируют диапазон элементов в первой
последовательности, которые будут обмениваться с элементами во второй
последовательности, начиная с позиции итератора в третьем аргументе. В этом
примере обе последовательности значений находятся в одном массиве, но они
могут быть из различных массивов или контейнеров.
22.5.8. copyjbackward, merge, unique и reverse
Рис. 22.33 демонстрирует алгоритмы STL copyjbackward, merge и reverse.
Строка 28 вызывает функцию copyjbackward, чтобы копировать элементы vl
из диапазона от vl.begin() до (но не включая) vl.end(), помещая их в results,
начиная с элемента, предшествующего results.cnd(), и двигаясь к началу
вектора. Функция возвращает итератор, установленный на последний элемент,
скопированный в results (т.е. на начало results, поскольку копирование
производилось в обратном направлении). Элементы располагаются в results в том
же порядке, что и в vl. Эта функция требует в качестве аргументов три
двунаправленных итератора (которые можно инкрементировать и декрементиро-
вать, чтобы проходить последовательность соответственно в прямом и
обратном направлении). Основное различие между сору и copy_backward состоит
в том, что итератор, возвращаемый сору, установлен на позицию за последним
1274
Глава 22
скопированным элементом, а итератор, возвращаемый copy__backward,
установлен на последний скопированный элемент (являющийся на самом деле
первым элементом последовательности). Кроме того, сору принимает в качестве
аргументов два входных итератора и один выходной итератор.
1 // Рис. 22.33: Fig23_33.cpp
2 // Алгоритмы copy_backward, merge, unique и reverse.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <algorithm> // определения алгоритмов
8 #include <vector> // определение шаблона класса vector
9 #include <iterator> // ostream_iterator
10
11 int main()
12 {
13 const int SIZE = 5;
14 int al[ SIZE ]={1,3,5,7,9};
15 int a2[ SIZE ] = { 2, 4, 5, 7, 9 };
16 std::vector< int > vl( al, al + SIZE ); // копия al
17 std::vector< int > v2( a2, a2 + SIZE ); // копия а2
18 std::ostream_iterator< int > output( cout, " " );
19
20 cout « "Vector vl contains: ";
21 std::copy( vl.begin(), vl.end(), output ); // вывести output
22 cout « "\nVector v2 contains: ";
23 std::copy( v2.begin(), v2.end(), output ); // вывести output
24
25 std::vector< int > results( vl.size() );
26
27 // поместить элементы vl в results в обратном порядке
28 std::copy_backward( vl.begin(), vl.end(), results.end() );
29 cout « "\n\nAfter copy_backward, results contains: ";
30 std::copy( results.begin(), results.end(), output );
31
32 std::vector< int > results2( vl.size() + v2.size() );
33
34 // объединить элементы vl и v2 в results2 в сортированном порядке
35 std::merge( vl.begin() , vl.end(), v2.begin(), v2.end(),
36 results2.begin() );
37
38 cout « "\n\nAfter merge of vl and v2 results2 contains: \n" ;
39 std::copy( results2.begin(), results2.end(), output );
40
41 // исключить из results2 повторяющиеся значения
42 std::vector< int >::iterator endLocation;
43 endLocation = std::unique( results2.begin(), results2.end() );
44
45 cout « "\n\nAfter unique results2 contains:\n";
46 std::copy( results2.begin(), endLocation, output );
47
48 cout « "\n\nVector vl after reverse: ";
49 std::reverse( vl.begin(), vl.end() ); // обратить порядок vl
50 std::copy( vl.begin(), vl.end(), output );
51 cout « endl;
Библиотека стандартных шаблонов (STL)
1275
52 return 0;
53 } // конец main
Vector vl contains: 13 5 7 9
Vector v2 contains: 2 4 5 7 9
After copy_backward, results contains: 13 5 7 9
After merge of vl and v2 results2 contains:
1234557799
After unique results2 contains:
12 3 4 5 7 9
Vector vl after reverse: 9 7 5 3 1
Рис. 22.33. Демонстрация copy.backward, merge, unique и reverse
Строки 35-36 используют функцию merge, чтобы объединить две
последовательности, сортированных в восходящем порядке, в третью восходящую
последовательность. Функция принимает пять аргументов-итераторов. Первые
четыре должны быть по крайней мере входными итераторами, а последний —
по крайней мере выходным итератором. Первые два аргумента
специфицируют диапазон элементов в первой сортированной последовательности (vl),
следующие два специфицируют диапазон во второй сортированной
последовательности (v2), а последний аргумент специфицирует начальную позицию
в третьей последовательности (results2), где будут располагаться
объединенные элементы. Вторая версия merge принимает в качестве шестого аргумента
бинарную предикатную функцию, специфицирующую порядок сортировки.
Обратите внимание, что строка 32 создает вектор results2 с числом
элементов vl.size + v2.size. Показанное здесь использование функции merge требует,
чтобы последовательность, в которой сохраняются результаты, имела размер
не меньше, чем размер двух объединяемых последовательностей. Если вы не
хотите выделять соответствующее число элементов до операции объединения,
можно написать следующие операторы:
std::vector< int > results2;
std::merge( vl.begin(), vl.end(), v2.begin(), v2.end,
std::back_inserter( results2 ) );
Аргумент std:: back_inserter( results2 ) использует для контейнера results2
шаблон функции backjtnserter (заголовочный файл <iterator>). Функция
back_inserter вызывает функцию по умолчанию pushjback контейнера для
вставки элемента в конец контейнера. Что более важно, контейнер, если в нем
не осталось больше места, увеличивает свой размер. Таким образом, число
элементов контейнера не требуется знать заранее. Есть еще два итератора
вставки — frontJtnserter (для вставки элемента в начало контейнера,
специфицированного в качестве аргумента) и inserter (для вставки элемента перед
итератором, переданным в качестве второго аргумента, ссылающимся на контейнер
в первом аргументе).
Строка 43 вызывает функцию unique для сортированной
последовательности элементов из диапазона results2 от results2.b'"^riO до (но не включая)
1276
Глава 22
results.end(). После применения этой функции к сортированной
последовательности с повторяющимися значениями в последовательности остается
только по одному экземпляру каждого значения. Функция принимает два
аргумента, которые должны быть по крайней мере поступательными итераторами.
Функция возвращает итератор, установленный за последним элементом в
последовательности уникальных значений. Значения всех элементов в
контейнере после последнего уникального значения не определены. Вторая версия
unique принимает в качестве третьего аргумента бинарную предикатную
функцию, специфицирующую сравнение двух элементов на равенство.
Строка 49 вызывает функцию reverse для обращения порядка элементов
в диапазоне vl от vl.begin() до (но не включая) vl.end(). Функция принимает
два аргумента, которые должны быть по крайней мере двунаправленными
итераторами.
22.5.9. inplace_merge, unique.copy и reverse_copy
Рис. 22.33 демонстрирует алгоритмы STL inplace_merge, unique_copy и ге-
verse_copy. Строка 24 вызывает функцию inplacejmerge для слияния двух
сортированных последовательностей элементов в одном и том же контейнере.
В этом примере элементы vl в диапазоне от vl.begin() до (но не включая)
vl.begin() + 5 объединяются с элементами в диапазоне от vl.begin() + 5 до (но
не включая) vl.end(). Функция требует, чтобы три ее аргумента были по
крайней мере двунаправленными итераторами. Вторая версия inplace_merge
принимает в качестве четвертого аргумента бинарную предикатную функцию для
сравнения элементов в двух последовательностях.
1 // Рис. 22.34: Fig23_34.cpp
2 // Алгоритмы Стандартной библиотеки inplace_merge,
3 // reverse_copy и unique_copy.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <algorithm> // определения алгоритмов
9 #include <vector> // определение шаблона класса vector
10 #include <iterator> // определение back_inserter
11
12 int main()
13 {
14 const int SIZE = 10;
15 int al[ SIZE ]={1, 3, 5, 7, 9, 1, 3, 5, 7, 9);
16 std::vector< int > vl( al, al + SIZE ); // copy of a
17 std::ostream_iterator< int > output( cout, " " );
18
19 cout « "Vector vl contains:
20 std::copy( vl.begin(), vl.end(), output );
21
22 // объединить первую половину vl со второй половиной vl так,
23 // чтобы vl содержал упорядоченный набор элементов
24 std::inplace_merge( vl.begin(), vl.begin() + 5, vl.end() );
25
26 cout « "\nAfter inplace_merge, vl contains: ";
27 std::copy( vl.begin(), vl.end(), output );
Библиотека стандартных шаблонов (STL)
1277
28
29 std::vector< int > resultsl;
30
31 // копировать в resultsl неповторяющиеся элементы vl
32 std::unique_copy(
33 vl.begin(), vl.end(), std::back_inserter( resultsl ) );
34 cout « "\nAfter unique_copy resultsl contains: ";
35 std::copy( resultsl.begin(), resultsl.end(), output );
36
37 std::vector< int > results2;
38
39 // копировать элементы vl в results2 в обратном порядке
40 std::reverse_copy(
41 vl.begin(), vl.end(), std::back_inserter( results2 ) );
42 cout « M\nAfter reverse_copy, results2 contains: ";
43 std::copy( results2.begin(), results2.end(), output );
44 cout « endl;
45 return 0;
46 } // конец main
Vector vl contains: 1357 913579
After inplace_n\erge, vl contains: 1133557799
After unique__copy resultsl contains: 13 5 7 9
After reverse_copy, results2 contains: 9977 5 5 3311
Рис. 22.34. Демонстрация inplace_merge, reverse_copy и unique_copy
Строки 32-33 используют функцию uniquejcopy для создания копии всех
уникальных элементов из сортированной последовательности значений в
диапазоне от vl.begin() до (но не включая) vl.end(). Копируемые элементы
помещаются в вектор resultsl. Первые два аргумента должны быть по крайней мере
входными итераторами, а последний — по крайней мере выходным итератором.
В этом примере мы не выделяем заранее достаточное число элементов в resultsl
для сохранения всех элементов, скопированных из vl. Вместо этого мы
применяем функцию back_inserter (определяемую в заголовочном файле <iterator>) для
вставки элементов в конец vl. Поскольку back__inserter вставляет элемент, а не
заменяет значение существующего элемента, вектор может увеличивать свой
размер, чтобы принимать дополнительные элементы. Вторая версия unique_copy
принимает в качестве четвертого аргумента бинарную предикатную функцию
для сравнения элементов на равенство.
Строки 40-41 используют функцию reversejcopy для копирования
элементов в диапазоне от vl.begin() до (но не включая) vl.end(). Копируемые
элементы помещаются в results2 с помощью объекта back_inserter, чтобы вектор мог
расти для размещения требуемого числа скопированных элементов. Функция
требует, чтобы первые два ее аргумента были по крайней мере
двунаправленными итераторами, а третий — по крайней мере выходным итератором.
22.5.10. Операции над множествами
Рис. 22.35 демонстрирует функции Стандартной библиотеки includes,
sct_difference, set_intersection, set_symmetric_difference и set_union для
манипуляции множествами сортированных значений. Для демонстрации того,
1278
Глава 22
что функции Стандартной библиотеки можно применять к массивам и
контейнерам, в этом примере используются только массивы (как вы помните,
указатель в массив является итератором произвольного доступа).
Строки 27 33 вызывают функцию includes в условиях операторов if.
Функция includes сравнивает два множества сортированных значений и
определяет, входит ли каждый элемент второго множества в первое множество. Если
это так, функция возвращает true; в противном случае возвращается false.
Первые два аргумента должны быть по крайней мере входными итераторами
и описывать первое множество значений. В строке 27 первое множество
состоит из элементов от al до, но не включая, al + SIZE1. Последние два аргумента
должны быть по крайней мере входными итераторами и описывать второе
множество значений. В этом примере второе множество состоит из элементов
от а2 до, но не включая, а2 + SIZE2. Вторая версия функции includes
принимает пятый аргумент, являющийся бинарной предикатной функцией для
сравнения элементов на равенство.
1 // Рис. 22.35: Fig23_35.cpp
2 // Алгоритмы Стандартной библиотеки includes, set_difference,
3 // set_±ntersection, set_symmetric__dif ference и set__union.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <algorithm> // определения алгоритмов
9 #include <iterator> // ostream_iterator
10
11 int main()
12 {
13 const int SIZE1 = 10, SIZE2 = 5, SIZE3 = 20;
14 int al[ SIZE1 ]={1,2,3,4,5,6,7,8,9, 10};
15 int a2[ SIZE2 ]={4,5,6,7,8};
16 int a3[ SIZE2 ] = { 4, 5, 6, 11, 15 };
17 std::ostream_iterator< int > output( cout, " " );
18
19 cout « "al contains: ";
20 std::copy( al, al + SIZE1, output ); // вывести массив al
21 cout « "\na2 contains: ";
22 std::copy( a2, a2 + SIZE2, output ); // вывести массив а2
23 cout « "\na3 contains: ";
24 std::copy( аЗ, аЗ + SIZE2, output ); // вывести массив аЗ
25
26 // определить, содержится ли множество а2 целиком в al
27 if ( std::includes( al, al + SIZE1, a2, a2 + SIZE2 ) )
28 cout « "\n\nal includes a2";
29 else
30 cout « "\n\nal does not include a2";
31
32 // определить, содержится ли множество аЗ целиком в al
33 if ( std::includes( al, al + SIZEl, аЗ, аЗ + SIZE2 ) )
34 cout « "\nal includes a3";
35 else
36 cout « "\nal does not include a3";
37
38 int difference[ SIZEl ];
Библиотека стандартных шаблонов (STL)
1279
39
40 // определить элементы al, не содержащиеся в а2
41 int *ptr = std::set_difference( al, al + SIZEl,
42 a2, a2 + SIZE2, difference );
43 cout « "\n\nset_difference of al and a2 is: ";
44 std::copy( difference, ptr, output );
45
46 int intersection[ SIZEl ];
47
48 // определить элементы, содержащиеся одновременно в al и а2
49 ptr = std::set_intersection( al, al + SIZEl,
50 a2, a2 + SIZE2, intersection );
51 cout « "\n\nset_intersection of al and a2 is: ";
52 std::copy( intersection, ptr, output );
53
54 int symmetric_difference[ SIZEl + SIZE2 ];
55
56 // определить элементы al, не содержащиеся в а2, и
57 // элементы а2, не содержащиеся в al
58 ptr = std::set_symmetric_difference( al, al + SIZEl,
59 аЗ, аЗ + SIZE2, symmetric_difference );
60 cout « "\n\nset_symmetric_difference of al and a3 is: ";
61 std::copy( symmetric_difference, ptr, output );
62
63 int unionSet[ SIZE3 ];
64
65 // определить элементы, содержащиеся в одном или обоих множествах
66 ptr = std::set_union( al, al + SIZEl, аЗ, аЗ + SIZE2, unionSet );
67 cout « "\n\nset_union of al and a3 is: ";
68 std::copy( unionSet, ptr, output );
69 cout « endl;
70 return 0;
71 } // конец main
al contains: 123456789 10
a2 contains: 4 5 6 7 8
a3 contains: 4 5 6 11 15
al includes a2
al does not include a3
set_difference of al and a2 is: 1 2 3 9 10
set_intersection of al and a2 is: 4 5 6 7 8
set_symmetric_difference of al and a3 is: 1 2 3 7 8 9 10 11 15
set union of al and a3 is: 1 2 3 4 5 6 7 8 9 10 11 15
Рис. 22.35. Операции над множествами Стандартной библиотеки
Строки 41-42 используют функцию set_difference, чтобы найти элементы
из первого множества сортированных значений, не входящие во второе
множество сортированных значений (оба множества значений должны быть
упорядочены по возрастанию). Отличающиеся элементы копируются в пятый аргу-
1280
Глава 22
мент (в данном случае в массив difference). Первые два аргумента должны
быть по крайней мере входными итераторами для первого множества
значений. Следующие два аргумента должны быть по крайней мере входными
итераторами для второго множества значений. Пятый аргумент должен быть по
крайней мере выходным итератором, указывающим, где должны сохраняться
копии отличающихся значений. Функция возвращает выходной итератор,
установленный непосредственно за последним значением, скопированным в
множество, на которое указывает пятый аргумент. Вторая версия set_difference
принимает шестой аргумент, являющийся бинарной предикатной функцией,
указывающей порядок исходной сортировки элементов. Обе
последовательности должны быть сортированы с помощью одной и той же функции сравнения.
Строки 49-50 используют функцию setjtntersection для определения
элементов из первого множества сортированных значений, которые входят во
второе множество сортированных значений (оба множества значений должны
быть упорядочены по возрастанию). Элементы, общие обоим множествам,
копируются в пятый аргумент (в данном случае в массив intersection). Первые
два аргумента должны быть по крайней мере входными итераторами для
первого множества значений. Следующие два аргумента должны быть по крайней
мере входными итераторами для второго множества значений. Пятый
аргумент должен быть по крайней мере выходным итератором, указывающим, где
должны сохраняться копии совпадающих значений. Функция возвращает
выходной итератор, установленный непосредственно за последним значением,
скопированным в множество, на которое указывает пятый аргумент. Вторая
версия set_intersection принимает шестой аргумент, являющийся бинарной
предикатной функцией, указывающей порядок исходной сортировки
элементов. Обе последовательности должны быть сортированы с помощью одной
и той же функции сравнения.
Строки 58-59 используют функцию set_symmetric_difference, чтобы найти
элементы из первого множества, не входящие во второе множество, и
элементы из второго множества, не входящие в первое множество (оба множества
должны быть упорядочены по возрастанию). Отличающиеся элементы
копируются из обоих множеств в пятый аргумент (массив symmetric_difference).
Первые два аргумента должны быть по крайней мере входными итераторами
для первого множества значений. Следующие два аргумента должны быть по
крайней мере входными итераторами для второго множества значений. Пятый
аргумент должен быть по крайней мере выходным итератором, указывающим,
где должны сохраняться копии отличающихся значений. Функция
возвращает выходной итератор, установленный непосредственно за последним
значением, скопированным в множество, на которое указывает пятый аргумент.
Вторая версия set_symmetric_differencc принимает шестой аргумент,
являющийся бинарной предикатной функцией, указывающей порядок исходной
сортировки элементов. Обе последовательности должны быть сортированы
с помощью одной и той же функции сравнения.
Строка 66 использует функцию set__union для создания множества всех
элементов, входящих в оба или в одно из двух сортированных множеств (оба
множества должны быть упорядочены по возрастанию). Элементы из обоих
множеств копируются в пятый аргумент (в данном случае в массив unionSet).
Элементы, входящие в оба множества, копируются только из первого множества.
Первые два аргумента должны быть по крайней мере входными итераторами
Библиотека стандартных шаблонов (STL)
1281
для первого множества значений. Следующие два аргумента должны быть по
крайней мере входными итераторами для второго множества значений. Пятый
аргумент должен быть по крайней мере выходным итератором, указывающим,
где должны сохраняться копируемые элементы. Вторая версия set_union
принимает шестой аргумент, являющийся бинарной предикатной функцией,
указывающей порядок исходной сортировки элементов. Обе последовательности
должны быть сортированы с помощью одной и той же функции сравнения.
22.5.11. lower_bound, upper.bound и equal_range
Рис. 22.36 демонстрирует функции Стандартной библиотеки lowerjbound,
upperjbound и equal_range. Строка 24 вызывает функцию lowerjbound,
чтобы найти первую (нижнюю) позицию в сортированной последовательности
значений, куда третий аргумент может быть вставлен так, что
последовательность останется сортированной в восходящем порядке. Первые два аргумента
должны быть по крайней мере входными итераторами. Третий аргумент
является значением, для которого требуется найти нижнюю границу. Функция
возвращает поступательный итератор, указывающий на позицию, в которой
можно произвести вставку. Вторая версия lower_bound принимает в качестве
четвертого аргумента бинарную предикатную функцию, указывающую
порядок исходной сортировки элементов.
1 // Рис. 22.36: Fig23_36.cpp
2 // Функции Стандартной библиотеки lower_bound, upperjbound и
3 // equal_range для сортированной последовательности значений.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <algorithm> // определения алгоритмов
9 #include <vector> // определение шаблона класса vector
10 #include <iterator> // ostream_iterator
11
12 int main()
13 {
14 const int SIZE = 10;
15 int al[ SIZE ]={2,2,4,4,4,6,6,6,6,8};
16 std::vector< int > v( al, al + SIZE ); // copy of al
17 std::ostream_iterator< int > output( cout, " " );
18
19 cout « "Vector v contains:\n";
20 std::copy( v.begin(), v.end(), output );
21
22 // определить нижнюю точку вставки для 6 в v
23 std::vector< int >::iterator lower;
24 lower = std::lower_bound( v.begin(), v.end(), 6 );
25 cout « "\n\nLower bound of 6 is element "
26 « ( lower - v.begin() ) « " of vector v";
27
28 // определить верхнюю точку вставки для б в v
29 std::vector< int >::iterator upper;
30 upper = std::upper_bound( v.begin(), v.end(), б );
31 cout « "\nUpper bound of б is element "
41 3arU14
1282
Глава 22
32 « ( upper - v.begin () ) « " of vector v" ;
33
34 // использовать equal_range для определения обеих -
35 // нижней и верхней - точек вставки 6 в v
36 std::pair< std::vector< int >::iterator,
37 std::vector< int >::iterator > eq;
38 eq = std::equal_range( v.begin(), v.end(), 6 );
39 cout « "\nUsing equal_range:\n Lower bound of 6 is element
40 « ( eq.first - v.begin() ) « " of vector v" ;
41 cout « "\n Upper bound of 6 is element "
42 « ( eq.second - v.begin() ) « " of vector v";
43 cout « "\n\nUse lower_bound to locate the first point\n"
44 « "at which 5 can be inserted in order";
45
46 // определить нижнюю точку вставки для 5 в v
47 lower = std::lower_bound( v.begin(), v.end(), 5 );
48 cout « "\n Lower bound of 5 is element "
4 9 « ( lower - v.begin() ) « " of vector v" ;
50 cout « "\n\nUse upper__bound to locate the last point\n"
51 « "at which 7 can be inserted in order";
52
53 // определить верхнюю точку вставки для 7 в v
54 upper = std::upper_bound( v.begin(), v.end(), 7 );
55 cout « "\n Upper bound of 7 is element "
56 « ( upper - v.begin() ) « " of vector v";
57 cout « "\n\nUse equal_range to locate the first and\n"
58 « "last point at which 5 can be inserted in order";
59
60 // использовать equal_range для определения обеих -
61 // нижней и верхней - точек вставки для 6
62 eq = std::equal_range( v.begin(), v.end(), 5 );
63 cout « "\n Lower bound of 5 is element "
64 « ( eq.first - v.begin() ) « " of vector v";
65 cout « "\n Upper bound of 5 is element "
66 « ( eq.second - v.begin() ) « " of vector v" « endl;
67 return 0;
68 } // конец main
Vector v contains:
2244466668
Lower bound of 6 is element 5 of vector v
Upper bound of 6 is element 9 of vector v
Using equal__range:
Lower bound of 6 is element 5 of vector v
Upper bound of 6 is element 9 of vector v
Use lower_bound to locate the first point
at which 5 can be inserted in order
Lower bound of 5 is element 5 of vector v
Use upper_bound to locate the last point
at which 7 can be inserted in order
Upper bound of 7 is element 9 of vector v
Use equal_range to locate the first and
Библиотека стандартных шаблонов (STL)
1283
last point at which 5 can be inserted in order
Lower bound of 5 is element 5 of vector v
Upper bound of 5 is element 5 of vector v
Рис. 22.36. Алгоритмы lowerjbound, upper_bound и equal_range
Строка 30 вызывает функцию upperjbound, чтобы найти последнюю
(верхнюю) позицию в сортированной последовательности значений, куда третий
аргумент может быть вставлен так, что последовательность останется
сортированной в восходящем порядке. Первые два аргумента должны быть по
крайней мере входными итераторами. Третий аргумент является значением, для
которого требуется найти верхнюю границу. Функция возвращает
поступательный итератор, указывающий на позицию, в которой можно произвести
вставку. Вторая версия upper_bound принимает в качестве четвертого
аргумента бинарную предикатную функцию, указывающую порядок исходной
сортировки элементов.
Строка 38 вызывает функцию equaljrange, которая возвращает пару
поступательных итераторов, являющуюся комбинацией результатов операций
lower__bound и upper_bound. Первые два аргумента должны быть по крайней
мере входными итераторами. Третий аргумент является значением, для
которого требуется найти диапазон равенства. Функция возвращает объект pair
с двумя поступательными итераторами соответственно для нижней границы
(eq.first) и верхней границы (eq.second).
Функции lowerjbound, upperjbound и equal_range часто используются
для нахождения в сортированных последовательностях точек вставки.
Строка 47 использует lowerjbound для нахождения первой точки в v, куда можно
по порядку вставить значение 5. Строка 54 использует upperjbound для
нахождения последней точки в v, куда можно по порядку вставить значение 7.
Строка 62 использует equal_range для нахождения первой и последней точек
в v, куда можно по порядку вставить значение 5.
22.5.12. Кучевая сортировка
Рис. 22.37 демонстрирует функции Стандартной библиотеки, реализующие
алгоритм кучевой сортировки. Кучевая сортировка (heapsort) является
алгоритмом, в котором элементы массива располагаются в специальном двоичном
дереве, называемом «кучей». Отличительные особенности кучи состоят в том,
что наибольший элемент всегда находится на вершине кучи, а значения
потомков любого узла в двоичном дереве всегда меньше или равны значению
этого узла. Подробно ключевая сортировка рассматривается в курсах по
компьютерным дисциплинам под названием «Структуры данных» и «Алгоритмы».
1 // Рис. 22.37: Fig23_37.cpp
2 // Алгоритмы Стандартной библиотеки pushjieap, popjieap,
3 // make_heap и sort_heap.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <algorithm>
1284
Глава 22
9 #include <vector>
10 #include <iterator>
11
12 int main()
13 {
14 const int SIZE = 10;
15 int a[ SIZE ] = { 3, 100, 52, 77, 22, 31, 1, 98, 13, 40 };
16 std::vector< int > v( a, a + SIZE ); // копия а
17 std::vector< int > v2;
18 std::ostream_iterator< int > output( cout, " " ) ;
19
20 cout « "Vector v before make_heap:\n";
21 std::copy( v.begin(), v.end(), output );
22
23 std::make_heap( v.begin(), v.end() ); // создать кучу из v
24 cout « "\nVector v after make_heap:\n";
25 std::copy( v.begin(), v.end(), output );
26
27 std::sort_heap( v.begin(), v.end() ); // сортировка sort_heap
28 cout « "\nVector v after sort_heap:\n";
29 std::copy( v.begin(), v.end(), output );
30
31 // выполнить кучевую сортировку с помощью push_heap и pop_heap
32 cout « "\n\nArray a contains: ";
33 std::copy( a, a + SIZE, output ); // display array a
34 cout « endl;
35
36 // поместить элементы массива в v2 и
37 // поддерживать v2 в кучевом состоянии
38 for ( int i = 0; i < SIZE; i++ )
39 {
40 v2.pushjback( a[ i ] );
41 std::push_heap( v2.begin(), v2.end() );
42 ' cout « "\nv2 after push_heap(a[" « i « "]):
43 std::copy( v2.begin(), v2.end(), output );
44 } // конец for
45
46 cout « endl;
47
48 // удалить элементы кучи в сортированном порядке
49 for ( unsigned int j = 0; j < v2.size(); j++ )
50 {
51 cout « "\nv2 after " « v2 [ 0 ] « " popped from heap\n";
52 std: :pop_heap( v2.begin(), v2.end() - j );
53 std::copy( v2.begin(), v2.end(), output );
54 } // конец for
55
56 cout « endl;
57 return 0;
58 } // конец main
Vector v before make_heap:
3 100 52 77 22 31 1 98 13 40
Vector v after make^heap:
100 98 52 77 40 31 1 3 13 22
Vector v after sort_heap:
Библиотека стандартных шаблонов (STL)
1285
1 3 13 22 31 40 52 77 98 100
Array a contains: 3 100 52 77
v2 after
v2 after
v2 after
v2 after
v2 after
v2 after
v2 after
v2 after
v2 after
v2 after
v2 after
98 77 52
v2 after
77 40 52
v2 after
52 40 31
v2 after
40 22 31
v2 after
push heap(a[0])
push__heap (a [1] )
push__heap (a [2] )
push heap(a[3])
push heap(a[4])
push_heap(a[5])
push_heap(a[6])
push heap(a[7])
push heap la[8])
push heap(a[9])
100 popped from
22 40 31 1 3 13
3
100
100
100
100
100
100
100
100
100
heap
100
98 popped from heap
22 13 31 1 3 98
100
77 popped from heap
22 13 3 1 77 98
10C
52 popped from heap
1 13 3 52 77 98
100
40 popped from heap
31 22 3 1 13 40 52 77 98
v2 after
100
31 popped from heap
22 13 3 1 31 40 52 77 98
v2 after
100
22 popped from heap
13 1 3 22 31 40 52 77 98
v2 after
3 1 13 22
v2 after
100
13 popped from heap
> 31 40 52 77 98
100
3 popped from heap
1 3 13 22 31 40 52 77 98
v2 after
1 3 13 22
100
1 popped from heap
> 31 40 52 77 98
100
22 31
3
3 52
77 52
77 52
77 52
77 52
98 52
98 52
98 52
1 98 13 40
3
3 22
3 22 31
3 22 31 1
77 22 31 1 3
77 22 31 1 3 13
77 40 31 1 3 13 22
Рис. 22.37. Использование функций стандартной библиотеки для кучевой сортировки
Строка 23 вызывает функцию make_heap, которая принимает
последовательность значений из диапазона v от v.begin() до, но не включая, v.end()
и создает кучу, которую можно использовать для образования сортированной
последовательности. Два аргумента функции должны быть итераторами
произвольного доступа, поэтому она будет работать только с массивами,
векторами и deque. Вторая версия make_heap принимает в качестве третьего
аргумента бинарную предикатную функцию для сравнения значений.
Строка 27 вызывает функцию sort_heap для сортировки значений в
диапазоне от v.begin() до, но не включая, v.end(), которые уже организованы в кучу.
Два аргумента должны быть итераторами произвольного доступа. Вторая
версия функции принимает в качестве третьего аргумента бинарную
предикатную функцию для сравнения значений.
Строка 41 вызывает функцию push_heap для добавления в кучу нового
значения. Мы берем по одному элементу массива, присоединяем его в конец
вектора v2 и производим операцию push_heap. Если присоединяемый элемент
является единственным элементом в векторе, последний уже является кучей.
1286
Глава 22
В противном случае push_heap реорганизует элементы v2 в кучу. Всякий раз
при вызове функции она предполагает, что последний элемент в векторе (т.е.
присоединенный перед вызовом push_heap) является элементом,
добавляемым к куче, и что остальные элементы в векторе уже организованы в кучу.
Два аргумента pushheap должны быть итераторами произвольного доступа.
Вторая версия push_heap принимает в качестве третьего аргумента бинарную
предикатную функцию для сравнения значений.
Строка 42 вызывает функцию pop_heap для удаления верхнего элемента
кучи. Функция предполагает, что элементы в диапазоне, специфицированном
двумя ее аргументами-итераторами произвольного доступа, уже являются
кучей. Раз за разом удаляя верхний элемент кучи, мы получаем сортированную
последовательность значений. Функция pop_heap обменивает первый элемент
кучи (в этом примере v2.begin()) с ее последним элементом (в этом примере
v2.end() — i), после чего гарантирует, что элементы вплоть до, но не включая,
последнего элемента все еще образуют кучу. Обратите внимание, что в выводе
программы вектор после всех операций pop_heap оказывается сортированным
в восходящем порядке. Вторая версия pop_heap принимает в качестве
третьего аргумента бинарную предикатную функцию для сравнения значений.
22.5.13. min и max
Алгоритмы min и max определяют соответственно наименьший и
наибольший из двух элементов. Рис. 22.38 демонстрирует применение min и max для
значений типа int и char.
1 // Рис. 22.38: Fig23_38.cpp
2 // Алгоритмы Стандартной библиотеки min и max.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <algorithm>
8
9 int main()
10 {
11 cout « "The minimum of 12 and 7 is: " « std::min( 12, 7 );
12 cout « "\nThe maximum of 12 and 7 is: " « std::max( 12, 7 );
13 cout « "\nThe minimum of 'G' and 'Z' is: " « std::min( 'G' , 'Z' );
14 cout « "\nThe maximum of 'G' and 'Z' is: " « std: :max( 'G' , 'Z' );
15 cout « endl;
16 return 0;
17 } // конец main
The minimum of 12 and 7 is: 7
The maximum of 12 and 7 is: 12
The minimum of ' G' and ' Z' is: G
The maximum of 'G' and ' Z' is: Z
Рис. 22.38. Алгоритмы min и max
Библиотека стандартных шаблонов (STL)
1287
22.5.14. Алгоритмы STL, не представленные в этой главе
На рис. 22.39 приведена сводка алгоритмов STL, не представленных в этой
главе.
Алгоритм [Описание
inner_product Вычисляет сумму произведений двух последовательностей;
берет соответствующие элементы из каждой
последовательности, перемножает их и прибавляет результат
| к сумме.
adjacent.difference Начиная со второго элемента последовательности, вычисляет
разность (посредством операции -) между текущим и
предыдущим элементами и сохраняет результат. Первые два
аргумента (входные итераторы) указывают диапазон
элементов контейнера, а третий указывает, где должен
сохраняться результат. Вторая версия adjacent_difference
принимает в качестве четвертого аргумента бинарную
функцию для операции, которая должна производиться над
текущим и предыдущим элементами.
partial_sum Вычисляет текущую сумму (посредством операции +)
значений в последовательности. Первые два аргумента
(входные итераторы) указывают диапазон элементов
! контейнера, а третий указывает, где должен сохраняться
I результат. Вторая версия partial_sum принимает в качестве
четвертого аргумента бинарную функцию для операции,
которая должна производиться над текущим значением в
последовательности и текущей суммой.
nth_element Использует три итератора произвольного доступа для
разбиения диапазона элементов. Первый и последний
аргументы представляют диапазон элементов. Второй
аргумент является позицией разделяющего элемента. После
исполнения алгоритма все элементы перед разделяющим
элементом меньше этого элемента, а все элементы после него
больше или равны этому элементу. Вторая версия
I nth_element принимает в качестве четвертого аргумента
бинарную функцию сравнения.
partition Этот алгоритм похож на nth.element, но требует менее
мощных двунаправленных итераторов, что делает его более
гибким, чем nth.element. Алгоритм partition принимает два
двунаправленных итератора, указывающих разбиваемый
диапазон элементов. Третий аргумент является унарной
предикатной функцией, определяющей разбиение диапазона, в
результате которого все элементы, для которых предикат
истинен, оказываются слева (ближе к началу диапазона) от всех
элементов, для которых предикат ложен. Возвращается
двунаправленный итератор, указывающий на первый элемент в
| последовательности, для которого предикат возвращает false.
stable_partition Этот алгоритм похож на partition за исключением того, что
элементы, для которых предикатная функция возвращает
true, сохраняют свой исходный порядок, и элементы, для
которых предикатная функция возвращает false, также
i сохраняют свой исходный порядок.
1288
Глава 22
Алгоритм
Описание
next_permutation
prev_permutation
Следующая лексикографическая перестановка
последовательности.
Предыдущая лексикографическая перестановка
последовательности.
rotate
rotate_copy
adjacentjfind
Использует три поступательных итератора для циклического
сдвига последовательности, указанной первым и последним
аргументами, на число позиций, полученное вычитанием
первого аргумента из второго. Например,
последовательность 1, 2, 3, 4, 5, циклически сдвинутая на две
позиции, примет вид 4, 5, 1, 2, 3.
Этот алгоритм аналогичен rotate за исключением того, что
результат сохраняется в отдельной последовательности,
указанной четвертым аргументом — выходным итератором.
Исходная и выходная последовательности должны иметь
одинаковое число элементов.
Этот алгоритм возвращает входной итератор, указывающий
на первый из двух идентичных смежных элементов
последовательности. Если идентичных смежных элементов
нет, итератор позиционируется за концом
последовательности.
search
Этот алгоритм ищет в последовательности элементов
указанную подпоследовательность и, если такая
подпоследовательность найдена, возвращает поступательный
итератор, указывающий на ее первый элемент. Если
соответствий нет, итератор позиционируется на конец
последовательности.
search n
Этот алгоритм ищет в последовательности элементов
подпоследовательность, в которой указанное число
элементов имеют заданное значение.
partial_sort
partial_sort_copy
Использует три итератора произвольного доступа для
сортировки части последовательности. Первый и последний
аргументы указывают последовательность элементов. Второй
аргумент указывает конечную позицию для сортированной
последовательности. По умолчанию элементы сортируются
с помощью операции < (может быть также передана
бинарная предикатная функция). Порядок элементов начиная
с позиции второго аргумента-итератора и до конца
последовательности не определен.
Использует два входных итератора и два итератора
произвольного доступа для сортировки части
последовательности, указанной двумя входными
итераторами. Результат сохраняется в последовательности,
указанной двумя итераторами произвольного доступа. По
умолчанию элементы сортируются с помощью операции <
(может быть также передана бинарная предикатная
функция). Число сортированных элементов является
наименьшим из числа элементов в результате и числа
элементов в исходной последовательности.
stable.sort
Этот алгоритм аналогичен sort за исключением того, что все
равные между собой элементы сохраняют свой исходный
I порядок.
Рис. 22.39. Алгоритмы, не представленные в этой главе
Библиотека стандартных шаблонов (STL)
1289
22.6. Класс bitset
Класс bitset упрощает работу с битовыми множествами, которые полезны
для представления наборов битовых флагов. Размер битовых множеств
фиксируется во время компиляции. Класс bitset предлагает альтернативу
манипуляции битами, обсуждавшейся в главе 22. Объявление
bitset< size > b;
создает битовое множество Ь, в котором каждый бит исходно равен 0. Оператор
b.set( bitNumber );
«включает» бит с номером bitNumber битового множества Ь. Выражение
b.set() «включает» все биты в Ь.
Оператор
b.reset( bitNumber );
«выключает» бит bitNumber битового множества Ь. Выражение b.reset()
«выключает» все биты в Ь. Оператор
b.flip( bitNumber );
«перекидывает» бит bitNumber битового множества b (например, если бит
включен, flip выключает его). Выражение b.flip() «перекидывает» все биты
в Ь. Выражение
b[ bitNumber ]
возвращает ссылку на бит bitNumber битового множества Ь. Выражение
b.at( bitNumber )
предварительно производит проверку диапазона для bitNumber. Если
bitNumber лежит в допустимом диапазоне, at возвращает ссылку на соответствующий
бит. В противном случае at выбрасывает исключение out_of_range.
Выражение
b.size ()
возвращает число бит в битовом множестве Ь. Выражение
b.count()
возвращает число установленных бит в битовом множестве Ь. Выражение
b.any()
возвращает true, если какой-либо бит в битовом множестве b установлен.
Выражение
b.none()
возвращает true, если в битовом множестве b не установлен ни один бит.
Выражения
1290
Глава 22
b == Ы
b != Ы
сравнивают два битовых множества соответственно на равенство и неравенство.
Для комбинирования битовых множеств может использоваться любая из
поразрядных операций присваивания &=, |= и А=. Например,
b &= Ы;
производит побитовую логическую операцию И над битовыми множествами b
и Ы. Результат сохраняется в Ь. Побитовое логическое ИЛИ и побитовое
исключающее ИЛИ выполняются операторами
b |= Ы;
Ь А= bl;
Оператор
Ь »= п;
сдвигает биты битового множества b на п позиций вправо. Оператор
b «= п;
сдвигает биты битового множества b на п позиций влево. Выражения
b. to_string()
b. to__ulong ()
преобразуют битовое множество b соответственно в string и в unsigned long.
Решето Эратосфена с bitset
Рис. 22.40 пересматривает программу «решета Эратосфена» для
нахождения простых чисел, обсуждавшуюся в упражнении 7.29. Вместо массива для
реализации алгоритма используется битовое множество. Программа выводит
все простые числа от 2 до 1023, после чего предлагает пользователю ввести
число для определения того, является ли оно простым.
1 // Рис. 22.40: Fig23_40.cpp
2 // Применение битового множества для алгоритма решета Эратосфена.
3 #include <iostream>
4 using std::cin;
5 using std::cout;
6 using std::endl;
7
8 #include <iomanip>
9 using std::setw;
10
11 #include <cmath>
12 using std::sqrt; // прототип sqrt
13
14 #include <bitset> // определение класса bitset
15
16 int main()
17 {
Библиотека стандартных шаблонов (STL)
1291
18 const int SIZE = 1024;
19 int value;
20 std::bitset< SIZE > sieve; // создать bitset из 1024 бит
21 sieve.flip(); // переключить все-биты в битовом множестве sieve
22 sieve.reset( 0 ); // сбросить первый бит (номер 0)
23 sieve.reset( 1 ); // сбросить второй бит (номер 1)
24
25 // выполнить решето Эратосфена
26 int finalBit = sqrt( static_cast< double > ( sieve.size () ) ) + 1;
27
28 // определить все простые числа в диапазоне от 2 до 1024
29 for ( int i = 2; i < finalBit; i++ )
30 {
31 if ( sieve.test( i ) ) // bit i is on
32 {
33 for ( int j = 2 * i; j < SIZE; j += i )
34 sieve.reset( j ); // set bit j off
35 } // end if
36 } // конец for
37
38 cout « "The prime numbers in the range 2 to 1023 are:\n";
39
40 // вывести простые числа в диапазоне 2-1023
41 for ( int k = 2, counter =1; k < SIZE; k++ )
42 {
43 if ( sieve.test( k ) ) // бит к включен
44 {
45 cout « setw( 5 ) « k;
46
47 if ( counter++ % 12 = 0 ) // счетчик кратен 12
48 cout « '\n';
49 } // конец if
50 } // конец for
51
52 cout « endl;
53
54 // получить значение от пользователя
55 cout « "\nEnter a value from 2 to 1023 (-1 to end):
56 cin » value;
57
58 // определить, является ли число пользователя простым
59 while ( value != -1 )
60 {
61 if ( sieve[ value ] ) // простое число
62 cout « value « " is a prime number\n";
63 else // не простое число
64 cout « value « " is not a prime number\n";
65
66 cout « "\nEnter a value from 2 to 1023 (-1 to end):
67 cin » value;
68 } // конец while
69
70 return 0;
71 ) // конец main
1292
Глава 22
The prime numbers in
2
41
97
157
227
283
367
439
509
599
661
751
829
919
1009
Enter
3
43
101
163
229
293
373
443
521
601
673
757
839
92 9
1013
5
47
103
167
233
307
379
449
523
607
677
761
853
937
1019
7
53
107
173
239
311
383
457
541
613
683
769
857
941
1021
a value from 2
the range
11
59
109
179
241
313
389
461
547
617
691
773
859
947
13
61
113
181
251
317
397
463
557
619
701
787
863
953
to 1023 (-
2 to
17
67
127
191
257
331
401
467
563
631
709
797
877
967
1 to
1023
19
71
131
193
263
337
409
479
569
641
719
809
881
971
end) :
are:
23
73
137
197
269
347
419
487
571
643
727
811
883
977
389
29
79
139
199
271
349
421
491
577
647
733
821
887
983
31
83
149
211
277
353
431
499
587
653
739
823
907
991
37
89
151
223
281
359
433
503
593
659
743
827
911
997
389 is a prime number
Enter a value from 2 to 1023 (-1 to end) : 88
8 8 is not a prime number
Enter a value from 2 to 1023 (-1 to end): -1
Рис, 22.40. Класс bitset и решето Эратосфена
Строка 20 создает bitset размером SIZE бит (в этом примере SIZE
равняется 1024). По умолчанию все биты в битовом множестве «выключены».
Строка 21 вызывает функцию flip, чтобы «включить» все биты. Числа 0 и 1 не
являются простыми, поэтому строки 22 и 23 вызывают функцию reset, чтобы
«выключить» биты О и 1. Строки 29-36 находят все простые числа от 2
до 1022. Для определения того, что алгоритм завершен, используется целое
finalBit (строка 26). Число является простым, если у него нет делителей,
отличных от 1 и его самого. Начиная с числа 2, мы можем исключить все числа,
кратные данному. Число 2 делится только на 1 и само на себя, следовательно,
оно простое. Таким образом, мы можем исключить 4, 6, 8 и т.д. Число 3
делится только на 1 и само на себя. Таким образом, мы можем исключить числа,
кратные 3 (помните, что четные числа уже исключены).
22.7. Функциональные объекты
Многие алгоритмы STL позволяют передавать в качестве аргумента
алгоритма указатель на функцию, необходимую для выполнения требуемой задачи.
Например, алгоритм binary_search, обсуждавшийся нами в разделе 22.5.6,
перегружен версией, которая требует в качестве четвертого параметра указатель на
функцию, принимающую два аргумента и возвращающую булево значение.
Алгоритм binary_search использует эту функцию для сравнения ключа поиска
с элементом из коллекции. Функция возвращает true, если ключ поиска и
сравниваемый элемент равны; в противном случае возвращается false. Это
позволяет алгоритму производить поиск в коллекции элементов, тип которых не
предусматривает перегруженной операции равенства (==).
Библиотека стандартных шаблонов (STL)
1293
Разработчики STL сделали алгоритмы более гибкими, разрешив любому
алгоритму, который может принимать указатель на функцию, принимать также
объект класса, перегружающего операцию вызова (скобки) функцией с
именем operator(), при условии, что перегруженная операция отвечает
требованиям алгоритма, — в случае binary_search она должна принимать два аргумента
и возвращать булево значение. Объект такого класса называют
функциональным, объектом и его можно использовать синтаксически и семантически так
же, как функцию или указатель на функцию, -г- перегруженная операция
скобок активируется указанием имени функционального объекта, за которым
следуют скобки, содержащие аргументы функции.
Функциональные объекты обладают рядом преимуществ перед
указателями на функции. Поскольку функциональные объекты часто реализуются как
шаблоны классов, которые включаются в каждый использующий их файл
исходного кода, компилятор для улучшения эффективности может генерировать
встроенное расширение перегруженной operator(). Кроме того, поскольку
функциональные объекты являются объектами классов, они могут иметь
элементы данных, которые operator() может использовать для выполнения своей
задачи.
Предопределенные функциональные объекты Стандартной
библиотеки шаблонов
В заголовке <functional> можно найти много предопределенных
функциональных объектов. Некоторые из функциональных объектов STL (все они
реализованы как шаблоны классов), перечислены на рис. 22.41. В примерах для
set, multiset и priority_queue мы для задания порядка сортировки элементов
контейнера использовали функциональный объект less< T >.
Функциональный | Тип
объект STL I
divides< T >
equal_to< T >
greater< T >
greater_equal< T >
арифметический
отношения
отношения
отношения
less< T > отношения
less_equal< T >
logical_and< T >
logical_not< T >
отношения
логический
логический
i
Функциональный
объект STL
logical_or< T >
minus< T >
Тип
логический
арифметический
modulus< T > арифметический
negate< T >
not_equal_to
plus< T >
multiplies< T >
арифметический
отношения
арифметический
арифметический
Рис. 22.41. Функциональные объекты из Стандартной библиотеки
Использование алгоритма STL accumulate
Рис. 22.42 демонстрирует применение численного алгоритма accumulate
(обсуждавшегося в разделе 22.5.5) для вычисления суммы квадратов
элементов в векторе. Четвертым аргументом в вызове accumulate является бинарный
функциональный объект (т.е. функциональный объект, operator^) которого
принимает два аргумента) или указатель на бинарную функцию (т.е. функ-
1294
Глава 22
цию, принимающую два аргумента). Функция accumulate демонстрируется
дважды — один раз с указателем на функцию и один раз с функциональным
объектом.
1 // Рис. 22.42: Fig23_42.cpp
2 // Демонстрация функциональных объектов.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <vector> // определение шаблона класса vector
8 #include <algorithm> // алгоритм copy
9 #include <numeric> // алгоритм accumulate
10 #include <functional> // опредление binary_function
11 #include <iterator> // ostream_iterator
12
13 // двухместная функция прибавляет квадрат своего второго аргумента,
14 // аккумулируя результат в первом, и возвращает сумму
15 int sumSquares( int total, int value )
16 {
17 return total + value * value;
18 } // конец функции sumSquares
19
20 // шаблон класса двухместной функции определяет перегруженную
21 // operator(), которая прибавляет квадрат своего второго аргумента,
22 // аккумулируя результат в первом, и возвращает сумму
23 template< typename T >
24 class SumSquaresClass : public std::binary_function< T, T, T >
25 {
26 public:
27 // прибавить квадрат значения к total и возвратить результат
28 Т operator()( const T &total, const T &value )
29 {
30 return total + value * value;
31 } // конец функции operator()
32 }; // конец класса SumSquaresClass
33
34 int main()
35 {
36 const int SIZE = 10;
37 int array[ SIZE ]={1,2,3,4,5,6,7,8,9, 10};
38 std::vector<int> integers( array, array + SIZE ); // копия array
39 std::ostream_iterator< int > output( cout, " " );
40 int result;
41
42 cout « "vector integers contains:\n";
43 std::copy( integers.begin(), integers.end(), output );
44
45 // вычислить сумму квадратов элементов вектора integers,
46 // используя двухместную функцию sumSquares
47 result = std::accumulate( integers.begin(), integers.end(),
48 0, sumSquares );
49
50 cout « "\n\nSum of squares of elements in integers using "
51 « "binary\nfunction sumSquares: " « result;
52
Библиотека стандартных шаблонов (STL)
1295
53 // вычислить сумму квадратов элементов вектора integers,
54 // используя двухместный функциональный объект
55 result = std::accumulate( integers.begin(), integers.end (),
56 0, SumSquaresClass< int >() );
57
58 cout « "\n\nSum of squares of elements in integers using "
59 « "binary\nfunction object of type "
60 « "SumSquaresClass< int >: " « result « endl;
61 return 0;
62 } // конец main
vector integers contains:
123456789 10
Sum of squares of elements in integers using binary
function sumSquares: 385
Sum of squares of elements in integers using binary
function object of type SumSquaresClass< int >: 385
Рис. 22.42. Бинарный функциональный объект
Строки 15-18 определяют функцию sumSquares, которая возводит в квадрат
свой второй аргумент value, складывает результат со своим первым аргументом
total и возвращает сумму. В этом примере функция accumulate будет
передавать в качестве второго аргумента sumSquares каждый элемент
последовательности, по которой проходит. При первом вызове sumSquares ее первый
аргумент будет начальным значением total (которое передается в третьем аргументе
вызова accumulate; в этом примере равняется О). Все последующие вызовы
sumSquares передают в первом аргументе текущую сумму, которая была
возвращена предыдущим вызовом sumSquares. Когда accumulate завершается,
она возвращает сумму квадратов всех элементов в последовательности.
Строки 23-32 определяют класс SumSquaresClass как производный от
шаблона класса binary_function (из заголовочного файла <functional>) —
пустого базового класса для создания функциональных объектов, которые
принимают два параметра и возвращают значение. Шаблон binary_function
принимает три типовых параметра, представляющих типы соответственно
первого аргумента, второго аргумента и возвращаемого значения operator().
В данном примере для типовых параметров указан тип Т (строка 24). При
первом вызове функционального объекта его первым аргументом будет начальное
значение total (которое передается в третьем аргументе вызова accumulate;
в этой программе равняется 0), а вторым аргументом будет первый элемент
вектора integers. Все последующие вызовы функционального объекта
передают в первом аргументе результат, возвращенный предыдущим вызовом
функционального объекта, а во втором аргументе следующий элемент из вектора.
Когда функция accumulate завершается, она возвращает сумму квадратов
всех элементов из вектора.
Вызов функции accumulate в строках 47-48 передает в качестве последнего
аргумента указатель на функцию sumSquares.
Вызов accumulate в строках 55-56 передает в качестве последнего
аргумента объект класса SumSquaresClass. Выражение SumSquaresClass< int >()
создает представитель класса SumSquaresClass (функциональный объект), пере-
1296
Глава 22
даваемый функции accumulate, которая посылает объекту сообщение
(активирует функцию) operator(). Этот оператор можно было бы записать как два
отдельных оператора:
SumSquaresClass< int > sumSquaresObject;
result = std::accumulate( integers.begin(), integers.end(),
0, sunSquaresObject );
Первая строка определяет объект класса SumSquaresClass. Затем этот объект
передается функции accumulate.
22.8. Заключение
В этой главе мы представили Библиотеку стандартных шаблонов и
обсудили три ее ключевых компонента — контейнеры, итераторы и алгоритмы. Вы
изучили контейнеры последовательностей STL vector, deque и list,
представляющие линейные структуры данных. Мы обсудили ассоциативные
контейнеры set, multiset, map и multimap, представляющие нелинейные структуры
данных. Вы увидели также, что в целях реализации специализированных
структур данных можно использовать адаптеры контейнеров stack, queue
и priority_queue, ограничивающие операции контейнеров
последовательностей. Затем мы продемонстрировали многие из алгоритмов STL, включая
математические алгоритмы, элементарные алгоритмы поиска и сортировки
и операции над множествами. Вы изучили типы итераторов, требуемые
каждым алгоритмом, и узнали, что каждый алгоритм может работать с любым
контейнером, поддерживающим минимальные требования алгоритма к
функциональным возможностям итераторов. Вы изучили также класс bitset,
упрощающим создание и манипуляцию битовыми множествами как
контейнерами. Наконец, мы представили функциональные объекты, синтаксически и
семантически схожие с обычными функциями, но обладающие некоторыми
преимуществами, такими, как лучшая эффективность и способность хранить
данные.
В следующей главе мы обсудим некоторые более сложные вопросы C++,
включая операции приведения, пространства имен, операции указателей на
элемент класса, сложное наследование и виртуальные базовые классы.
22.9. Ресурсы по STL в Internet и Web
Ниже приводится список ресурсов Internet и Web, имеющих отношение
к STL. На этих сайтах имеются учебные руководства, справочные материалы,
FAQ, статьи, книги, интервью и программное обеспечение.
Учебные руководства
www.cs.brown.edu/people/jak/programming/stl-tutorial/tutorial.html
Это руководство по STL на примерах объясняет идеологию, компоненты и
расширение STL. Вы найдете здесь примеры кода с использованием компонентов
STL, доступные объяснения и наглядные диаграммы.
Библиотека стандартных шаблонов (STL)
1297
www.yrl.со.uk/phil/stl/stl.htmlx
Это руководство по STL предлагает информацию о шаблонах функций,
шаблонах классов, компонентах STL, контейнерах, итераторах, адаптерахт
функциональных объектах.
www.xraylith.wise.edu/~khan/software/stl/os_examples/examples.html
Этот сайт полезен для тех, кто только начинает изучать STL. Вы найдете здесь
введение в STL и примеры по ObjectSpace STL Tool Kit.
Справочные материалы
www.sgi.com/tech/stl
Silicon Graphics Standard Template Library Programmer's Guide — полезный
ресурс с информацией по STL. С этого сайта вы можете загрузить STL и
найдете здесь последнюю информацию об STL, документацию и ссылки на друие
ресурсы STL.
www.eppreference.com/cpp_stl.html
На сате перечисляются конструкторы, операции и функции, поддерживаемые
каждым контейнером STL.
Статьи, книги и интервью
www.byte.com/art/9510/secl2/art3.htm
На сайте журнала Byte Magazine копия статьи по STL, написанной
Александром Степановым. Степанов, один из создателей Библиотеки стандартных
шаблонов, пишет об использовании STL в обощенном программировании.
www.sgi.com/tech/stl/drdobbs-interview.html
Интервью журнала Dr. Dobb's Journal с Александром Степановым.
Стандарт ANSI/ISO C++
www.ansi.org
На этом сайте вы можете заказать экземпляр Стандартного документа C++.
Программное обеспечение
www.es.rpi.edu/~musser/stl-book
Сайт RPI, посвященный STL, содержит информацию о том, чем STL
отличается от других библиотек C++, и о том, как компилировать программы,
использующие STL. На сайте перечисляются файлы STL и предлагаются примеры
программ, использующих STL, контейнерные классы STL и различные
категории итераторов STL. Предлагаетсфя также список совместимых с STL
компиляторов, FTP-сайтов с исходным кодом STL и сопутствующие материалы.
msdn.microsoft.com/visualc
Это домашняя страница Microsoft Visual C++. Здесь вы можете найти
последние новости по Visual C++, обновления, технические ресурсы, примеры и
загрузки.
www.borland.com/cbuilder
Это домашняя страница Borland C++Builder. Здесь вы можете найти
разнообразные ресурсы по C++, включая несколько групп новостей C++, информацию
1298
Глава 22
о последних улучшениях продукта, FAQ и много других ресурсов для
программистов, работающих с C++Builder.
Резюме
• Библиотека стандартных шаблонов определяет мощные, организованные в виде
шаблонов утилизируемые компоненты, которые реализуют многие
распространенные структуры данных и алгоритмы, используемые при обработке этих структур.
• Тремя ключевыми компонентами STL являются контейнеры, итераторы и алгоритмы.
• Контейнеры STL являются структурами данных, которые способны хранить
объекты любых типов. Существует три категории контейнеров — первичные контейнеры,
адаптеры и почти-контейнеры.
• Алгоритмы STL являются функциями, выполняющими такие распространенные
манипуляции с данными, как поиск, сортировка и сравнение элементов или
контейнеров в целом.
• Контейнеры последовательностей последовательными контейнерами представляют
линейные структуры данных, такие, как векторы и связанные списки.
• Ассоциативные контейнеры являются нелинейными структурами, которые
позволяют быстро отыскивать хранящиеся в них элементы. Такие контейнеры могут
хранить множества значений или пар ключ/значение.
• Контейнеры последовательностей и ассоциативные контейнеры называют
обобщенно первичными контейнерами.
• Функция первичных контейнеров begin возвращает итератор, указывающий на
первый элемент контейнера. Функция end возвращает итератор, указывающий на
первый элемент после конца контейнера (элемент, которого не существует; этот
итератор обычно используется в циклах для определения момента, когда следует
завершить обработку элементов контейнера).
• Итератор типа istream_iterator может безопасным по типу образом извлекать
значения из входного потока. Итератор ostreamiterator может передавать значения
в выходной поток.
• Входной и выходной итераторы продвигаются только в прямом направлении (т.е. от
начала контейнера к его концу) на один элемент за шаг.
• Поступательный итератор комбинирует возможности входного и выходного итераторов.
• Двунаправленный итератор комбинирует возможности поступательного итератора
со способностью двигаться в обратном направлении (т.е. от конца контейнера к его
началу).
• Итератор произвольного доступа комбинирует возможности двунаправленного
итератора с возможностью прямого доступа к любому элементу контейнера.
• Контейнеры, поддерживающие итераторы произвольного доступа, например vector,
могут использоваться со всеми алгоритмами из STL.
• В STL имеется три контейнера последовательностей — vector, list и deque. Шаблон
класса vector и шаблон класса deque построены на основе массива. Шаблон класса
list реализует структуру данных связанного списка.
• Функция capacity возвращает число элементов, которое может быть сохранено
в векторе, прежде чем последнему потребуется динамически изменить свой размер,
чтобы принять дополнительные элементы.
• Функция контейнеров последовательностей pushback добавляет элемент в конец
контейнера.
• Для использования алгоритмов STL необходимо включить заголовочный файл
<algorithm>.
Библиотека стандартных шаблонов (STL)
1299
• Алгоритм сору копирует каждый элемент контейнера начиная с позиции,
специфицированной итератором в его первом аргументе, вплоть до — но не включая —
позиции, специфицированной итератором во втором аргументе.
• Функция front возвращает ссылку на первый элемент контейнера
последовательности. Функция begin возвращает итератор, указывающий на начало контейнера
последовательности .
• Функция back возвращает ссылку на последний элемент контейнера
последовательности. Функция end возвращает итератор, указывающий на позицию за последним
элементом контейнера последовательности.
• Функция erase (имеющаяся у всех первичных контейнеров) удаляет из контейнера
указанный элемент (элементы).
• Функция empty (имеющаяся у всех контейнеров и адаптеров) возвращает true, если
контейнер пуст.
• Функция clear (имеющаяся у всех первичных контейнеров) очищает контейнер.
• Контейнер последовательности list предлагает эффективную реализацию вставки
и удаления в любом месте контейнера. Для использования шаблона класса list
необходимо включить заголовочный файл <list>.
• Элемент-функция pushjFront класса list вставляет значения в начало списка.
• Элемент-функция sort класса list располагает элементы списка в порядке
возрастания.
• Элемент-функция splice класса list удаляет элементы из одного списка и вставляет
их в указанную позицию другого списка.
• Элемент-функция unique класса list удаляет из списка повторяющиеся элементы.
• Элемент-функция assign класса list заменяет содержимое одного списка
содержимым другого списка.
• Элемент-функция remove класса list удаляет из списка все экземпляры указанного -
значения.
• Шаблон класса deque предусматривает те же основные операции, что и vector, но
имеет дополнительные элемент-функции push_front и pop__front соответственно для
вставки и удаления в начале deque. Для использования класса deque необходимо
включить заголовочный файл <deque>.
• Ассоциативные контейнеры STL обеспечивают прямой доступ для сохранения и
извлечения элементов при помощи ключей.
• Четырьмя ассоциативными контейнерами являются multiset, set, multimap и map.
• Шаблоны классов multiset и set предусматривают операции для манипуляции
наборами значений, в которых значения являются ключами, — не существует
отдельного значения, ассоциированного с каждым ключом. Для использования шаблонов
классов set и multiset необходимо включить заголовочный файл <set>.
• Основным различием между multiset и set является то, что multiset допускает
повторяющиеся ключи, в то время как set их не допускает.
• Шаблоны классов multimap и тар предусматривают операции для манипуляции
значениями, ассоциированными с ключами.
• Основное различие между multimap и тар состоит в том, что multimap допускает
хранение повторяющихся ключей с их ассоциированными значениями, а тар
допускает хранение только уникальных ключей с ассоциированными значениями.
• Функция count (доступная во всех ассоциативных контейнерах) подсчитывает
текущее число вхождений в контейнер указанного значения.
• Функция find (доступная во всех ассоциативных контейнерах) находит в контейнере
указанное значение.
1300
Глава 22
• Функции lower_bound и upper_bound (доступные во всех ассоциативных
контейнерах) находят соответственно первое вхождение в контейнер указанного значения
и элемент после последнего вхождения указанного значения.
• Функция equal_range (доступная во всех ассоциативных контейнерах) возвращает
объект pair с результатами обеих операций lower_bound и upperjbound.
• Ассоциативный контейнер multimap используется для быстрого сохранения и
извлечения ключей с ассоциированными значениями (их часто называют парами
ключ/значение).
• В multimap допускается дублирование ключей, поэтому с одним ключом может быть
ассоциировано несколько значений. Это часто называют отношением «один к
многим».
• Для использования шаблонов классов тар и multimap требуется включить
заголовочный файл <тар>.
• В тар не допускается дублирование ключей, поэтому с каждым ключом может быть
ассоциировано единственное значение. Это называют отображением «один к одному».
• Контейнер тар обычно называют ассоциативным массивом.
• В STL имеется три адаптера контейнеров — stack, queue и priority_queue.
• Адаптеры не являются первичными контейнерами, потому что они не
предусматривают действительной реализации структуры данных, в которой могут сохраняться
элементы, и не поддерживают итераторов.
• Во всех трех классах адаптеров предусмотрены элемент-функции push и pop,
которые соответствующим образом вставляют элемент в структуру данных каждого
адаптера и удаляют элемент из его структуры данных.
• Шаблон класса stack допускает вставку и удаление элементов в базовой структуре
данных только с одного конца (что обычно называют структурой данных типа
«последним вошел, первым вышел»). Для использования шаблона класса stack
требуется включить заголовочный файл <stack>.
• Элемент-функция top класса stack возвращает ссылку на верхний элемент стека
(реализуется вызовом функции back базового контейнера).
• Элемент-функция empty класса stack определяет, пуст ли стек (реализуется вызовом
функции empty базового контейнера).
• Элемент-функция size класса stack возвращает число элементов в стеке (реализуется
вызовом функции size базового контейнера).
• Шаблон класса queue допускает вставку элементов в конец базовой структуры
данных и удаление элементов из ее начала (что обычно называют структурой данных
типа «первым вошел, первым вышел»). Для использования шаблона класса queue
или priority_queue требуется включить заголовочный файл <queue >.
• Элемент-функция front класса queue возвращает ссылку на первый элемент очереди
(реализуется вызовом функции front базового контейнера).
• Элемент-функция back класса queue возвращает ссылку на последний элемент
очереди (реализуется вызовом функции back базового контейнера).
• Элемент-функция empty класса queue определяет, пуста ли очередь (реализуется
вызовом функции empty базового контейнера).
• Элемент-функция size класса queue возвращает число элементов в очереди
(реализуется вызовом функции size базового контейнера).
• Шаблон класса priority_queue обладает функциональными возможностями,
обеспечивающими упорядоченную вставку в базовую структуру данных и удаление
элементов из ее начала.
• Типичными операциями класса priority_queue являются push, pop, top, empty
и size.
Библиотека стандартных шаблонов (STL)
1301
• Алгоритмы fill и fill_n устанавливают каждый элемент в некотором диапазоне
элементов контейнера равным заданному значению.
• Алгоритмы generate и generate_n используют функцию-генератор, которая создает
отдельное значение для каждого элемента в некотором диапазоне контейнера.
• Алгоритм equal сравнивает на равенство две последовательности значений.
• Алгоритм mismatch сравнивает две последовательности значений и возвращает пару
итераторов, указывающих на позиции несовпадающих элементов в каждой из
последовательностей .
• Алгоритм lexicographical_compare сравнивает содержимое двух контейнеров, как
символьные массивы.
• Алгоритм remove исключает из некоторого диапазона все элементы с указанным
значением.
• Алгоритм remove_copy копирует все элементы некоторого диапазона, отличные от
указанного значения.
• Алгоритм remove_if исключает из некоторого диапазона все элементы,
удовлетворяющие заданному условию.
• Алгоритм remove_copy_if копирует все элементы некоторого диапазона, исключая
элементы, удовлетворяющие заданному условию.
• Алгоритм replace заменяет все элементы некоторого диапазона, имеющие указанное
значение.
• Алгоритм replace_if заменяет все элементы некоторого диапазона,
удовлетворяющие заданному условию.
• Алгоритм replace_copy_if копирует все элементы некоторого диапазона, заменяя
элементы, удовлетворяющие заданному условию.
• Алгоритм randomshuffle переупорядочивает элементы некоторого диапазона
случайным образом.
• Алгоритм count подсчитывает элементы в некотором диапазоне, имеющие
указанное значение.
• Алгоритм count_if подсчитывает элементы в некотором диапазоне,
удовлетворяющие заданному условию.
• Алгоритм minelement находит в некотором диапазоне наименьший элемент.
• Алгоритм maxelement находит в некотором диапазоне наибольший элемент.
• Алгоритм accumulate суммирует значения в некотором диапазоне.
• Алгоритм for_each применяет к элементам в некотором диапазоне функцию общего
вида.
• Алгоритм transform применяет к элементам в некотором диапазоне функцию
общего вида и помещает результат в указанное место.
• Алгоритм find__if находит в некотором диапазоне значение, удовлетворяющее
заданному условию..
• Алгоритм sort располагает некоторого диапазона в восходящем порядке или в
порядке, специфицированном предикатом.
• Алгоритм binary_search определяет, имеется ли в некотором диапазоне указанное
значение.
• Алгоритм swap обменивает два значения.
• Алгоритм iter_swap обменивает два элемента.
• Алгоритм swap_ranges обменивает элементы некоторого диапазона с другим
диапазоном.
• Алгоритм copy_backward копирует элементы некоторого диапазона, двигаясь в
обратном направлении.
1302
Глава 22
• Алгоритм merge объединяет две последовательности, сортированные в восходящем
порядке, в третью восходящую последовательность.
• Алгоритм unique удаляет из некоторого диапазона сортированной
последовательности повторяющиеся элементы.
• Алгоритм reverse обращает порядок элементов в некотором диапазоне.
• Алгоритм inplace_merge объединяет две сортированных последовательности в том
же контейнере.
• Алгоритм unique создает копию всех уникальных элементов из некоторого
диапазона сортированной последовательности.
• Алгоритм reverse_copy создает обращенную копию элементов в некотором диапазоне.
• Функция includes сравнивает два множества сортированных значений и определяет,
входит ли каждый элемент второго множества в первое множество.
• Функция set_difference находит элементы из первого множества сортированных
значений, не входящие во второе множество сортированных значений (оба
множества значений должны быть упорядочены по возрастанию).
• Функция set_intersection определяет элементы из первого множества
сортированных значений, которые входят во второе множество сортированных значений (оба
множества значений должны быть упорядочены по возрастанию).
• Функция set_symmetric_difference находит элементы из первого множества, не
входящие во второе множество, и элементы из второго множества, не входящие в первое
множество (оба множества должны быть упорядочены по возрастанию).
• Функция set_union создает множество всех элементов, входящих в оба или в одно из
двух сортированных множеств (оба множества должны быть упорядочены по
возрастанию).
• Алгоритм lower_bound находит первую позицию в сортированной
последовательности значений, куда третий его аргумент может быть вставлен так, что
последовательность останется сортированной в восходящем порядке.
• Алгоритм upperbound находит последнюю позицию в сортированной
последовательности значений, куда третий его аргумент может быть вставлен так, что
последовательность останется сортированной в восходящем порядке.
• Алгоритм make_heap принимает последовательность значений из некоторого
диапазона и создает «кучу», которую можно использовать для образования сортированной
последовательности.
• Алгоритм sort_heap сортирует последовательность значений в некотором диапазоне,
которые уже организованы в кучу.
• Алгоритм pop_heap удаляет верхний элемент кучи.
• Алгоритмы min и max определяют соответственно наименьший и наибольший из
двух элементов.
• Шаблон класса bitset упрощает работу с битовыми множествами, которые полезны
для представления наборов битовых флагов.
• Функциональный объект является представителем класса, перегружающего
операцию operator().
• В STL предусмотрено много предопределенных функциональных объектов, которые
можно найти в заголовке <functional>.
• Бинарный функциональный объект является функциональным объектом, который
принимает два аргумента и возвращает значение. Шаблон класса binary_function
является пустым базовым классом для создания бинарных функциональных объектов.
Библиотека стандартных шаблонов (STL)
1303
Терминология
const_iterator
const_reverse_iterator
istream_iterator
less< int >
ostream_iterator
reverse_iterator
адаптер
адаптер контейнера
алгоритм
алгоритм accumulate
алгоритм binary_search
алгоритм copyjbackward
алгоритм count
алгоритм count_if
алгоритм equal
алгоритм equal_range
алгоритм fill
алгоритм fill_n
алгоритм find
алгоритм» find_if
алгоритм for_each
алгоритм generate
алгоритм generate_n
алгоритм includes
алгоритм inplace_range
алгоритм iter_swap
алгоритм lexicographical_compare
алгоритм lowerjbound
алгоритм make_heap
алгоритм max
алгоритм maxelement
алгоритм merge
алгоритм min
алгоритм min_element
алгоритм mismatch
алгоритм popheap
алгоритм pushheap
алгоритм random_shuffle
алгоритм remove
алгоритм remove_copy
алгоритм remove_copy_if
алгоритм remove_if
алгоритм replace
алгоритм replace_copy
алгоритм replace_copy_if
алгоритм replace_if
алгоритм reverse
алгоритм reverse_copy
алгоритм set_difference
алгоритм set_intersection
алгоритм set_symmetric__difference
алгоритм set_union
алгоритм sort
алгоритм sort_heap
алгоритм swap
алгоритм swap_range
алгоритм unique
алгоритм unique_copy
алгоритм upperbound
алгоритм кучевой сортировки
ассоциативный контейнер
ассоциативный контейнер тар
ассоциативный контейнер multimap
ассоциативный контейнер multiset
ассоциативный контейнер set
ассоциативный массив
Библиотека стандартных шаблонов
(STL)
бинарная функция
бинарный функциональный объект
входная последовательность
входной итератор
выходная последовательность
выходной итератор
двунаправленный итератор
диапазон
заголовочный файл <algorithm>
заголовочный файл <deque>
заголовочный файл <functional>
заголовочный файл <list>
заголовочный файл <тар>
заголовочный файл <numeric>
заголовочный файл <queue>
заголовочный файл <set>
заголовочный файл <stack>
итератор произвольного доступа
ключ поиска
контейнер
контейнер последовательности
контейнер последовательности deque
контейнер последовательности list
куча
модифицирующий алгоритм
отображение «один к одному»
пара ключ/значение
первичный контейнер
последовательность
поступательный итератор
почти-контейнер
функциональный объект
функциональный объект-компаратор
1304
Глава 22
функция equal_range ассоциативного
контейнера
функция find ассоциативного
контейнера
функция flip класса bitset
функция lower_bound ассоциативного
контейнера
функция pop_back
функция pop_front
функция pushjback
функция push_front
функция reset класса bitset
шаблон класса binary_function
шаблон класса адаптера
priority_queue
шаблон класса адаптера queue
шаблон класса адаптера stack
шаблон функции back_inserter
шаблон функции front_inserter
шаблон функции inserter
элемент данных first объекта pair
элемент данных second объекта pair
элемент-функция assign класса list
элемент-функция back контейнеров
последовательностей
элемент-функция begin первичных
контейнеров
элемент-функция capacity класса
vector
элемент-функция empty контейнеров
элемент-функция end контейнеров
элемент-функция erase контейнеров
элемент-функция front контейнеров
последовательностей
элемент-функция insert контейнеров
элемент-функция pop адаптеров
элемент-функция push адаптеров
элемент-функция rbegin класса vector
элемент-функция remove класса list
элемент-функция rend контейнеров
элемент-функция size контейнеров
элемент-функция sort класса list
элемент-функция splice класса list
элемент-функция swap класса list
элемент-функция top адаптеров
элемент-функция unique класса list
Контрольные вопросы
Ответьте, верны или неверны следующие утверждения, либо заполните пропуски. Если
утверждение неверно, объясните, почему.
22.1. (Верно/неверно) STL широко использует наследование и виртуальные функции.
22.2. Двумя типами контейнеров STL являются контейнеры последовательностей
и контейнеры.
22.3. Пятью основными типами итераторов STL являются , ,
, и .
22.4. (Верно/неверно) Итератор действует подобно указателю на элемент.
22.5. (Верно/ неверно) Алгоритмы STL могут работать с массивами-указателями в
стиле С.
22.6. (Верно/неверно) Алгоритмы STL инкапсулированы в каждом из контейнерных
классов в качестве элемент-функций.
22.7. (Верно/неверно) Алгоритм remove не уменьшает размер вектора, из которого
удаляются элементы.
22.8. Тремя адаптерами контейнеров STL являются ,
и .
22.9. (Верно/неверно) Элемент-функция контейнера end возвращает позицию
последнего элемента контейнера.
22.10. Алгоритмы STL оперируют элементами контейнеров косвенным образом,
используя .
22.11. Алгоритму sort требуются итераторы .
Библиотека стандартных шаблонов (STL)
1305
Ответы на контрольные вопросы
22.1. Неверно. Наследование и виртуальные функции нежелательны по
соображениям эффективности.
22.2. Ассоциативные.
22.3. Входные, выходные, поступательные, двунаправленные, произвольного доступа.
22.4. Неверно. Верно в точности обратное.
22.5. Верно.
22.6. Неверно. Алгоритмы STL не являются элемент-функциями. Они действуют на
контейнерах косвенным образом, при посредстве итераторов.
22.7. Верно.
22.8. stack, queue, priority_queue.
22.9. Неверно. Она возвращает позицию непосредственно за концом контейнера.
22.10. Итераторы.
22.11. Произвольного доступа.
Упражнения
22.12. Напишите шаблон функции palindrome, который принимает параметр-вектор
и возвращает true или false в зависимости от того, читается ли вектор с начала и
с конца одинаково (напр., вектор, содержащий 1, 2, 3, 2, 1, является
палиндромом, а вектор, содержащий 1, 2, 3, 4 — нет).
22.13. Модифицируйте «решето Эратосфена» из рис. 22.40 так, чтобы в случае, когда
пользователь вводит не простое число, программа выводила бы простые
делители этого числа. Как вы помните, делителями простого числа являются 1 и само
это число. Каждое не простое число имеет единственное разложение на простые
делители. Например, 54 раскладывается на простые делители 2, 3, 3 и 3.
Произведение всех этих значений дает в результате 54. Для числа 54 должны
выводиться простые делители 2 и 3.
22.14. Модифицируйте упражнение 22.13 так, чтобы в случае, когда пользователь
вводит не простое число, программа выводила каждый простой делитель этого
числа столько раз, сколько раз он входит в его простое разложение. Например, для
числа 54 должно выводиться
The unique prime factorization of 54 is: 2*3*3*3
Рекомендуемая литература
Ammeraal, L. STL for C++ Programmers. New York: John Wiley, 1997.
Austern, M. H. Generic Programming and the STL: Using and Extending the C++
Standard Template Library. Reading, MA: Addison-Wesley, 1998
Glass, G., and B. Schuchert. The STL <Primer>. Upper Saddle River, NJ: Prentice Hall
PTR, 1995.
Henricson, M., and E. Nyquist. Industrial Strength C++: Rules and Recommendations.
Upper Saddle River, NJ: Prentice Hall, 1997.
Josuttis, N. The C++ Standard Library: A Tutorial and Handbook. Reading, MA:
Addison-Wesley, 1999.
Koenig, A., and B. Moo. Ruminations on C++. Reading, MA: Addison-Wesley, 1997.
Meyers, S. Effective STL: 50 Specific Ways to Improve Your Use of the Standard Template
Library. Reading, MA: Addison-Wesley, 2001.
Musser, D. R., and A. Saini. STL Tutorial and Reference Guide: C++ Programming with
the Standard Template Library. Reading, MA: Addison-Wenlpv, 1996.
1306
Глава 22
Musser, D. R., and A. A. Stepanov. «Algorithm-Oriented Generic Libraries,» Software
Practice and Experience, Vol. 24, No. 7, July 1994.
Nelson, M. C++ Programmers Guide to the Standard Template Library. Foster City, CA:
Programmer's Press, 1995.
Pohl, I. C++ Distilled: A Concise ANSI/ISO Reference and Style Guide. Reading, MA:
Addison-Wesley, 1997.
Pohl, I. Object-Oriented Programming Using C++, Second Edition. Reading, MA:
Addison-Wesley, 1997.
Robson, R. Using the STL: The C++ Standard Template Library. New York: Springer
Verlag, 2000.
Schildt, H. STL Programming from the Ground Up, New York: Osborne McGraw-Hill,
1999.
Stepanov, A., and M. Lee. «The Standard Template Library,» Internet Distribution
31 October 1995 <www.cs.rpi.edu/~musser/doc.ps>.
Stroustrup, B. «Making a vector Fit for a Standard,» The C++ Report, October 1994.
Stroustrup, B. The Design and Evolution of C++. Reading, MA: Addison-Wesley, 1994.
Stroustrup, B. The C++ Programming Language, Third Edition. Reading, MA:
Addison-Wesley, 1997.
Vilot, M. J. «An Introduction to the Standard Template Library,» The C++ Report, Vol. 6,
No. 8, October 1994.
23
Специальные вопросы
ЦЕЛИ
В этой главе вы изучите:
• Операцию const_cast, которая
разрешает временно рассматривать
константный объект как
неконстантный.
• Пространства имен.
• Ключевые слова для операций.
• Использование спецификатора
mutable в константных объектах.
• Операции указателей на элементы
класса .* и ->*.
• Сложное наследование.
• Роль виртуальных базовых классов
в сложном наследовании.
f
1308
Глава 23
23.1. Введение
23.2. Операция const_cast
23.3. Пространства имен
23.4. Ключевые слова для операций
23.5. Элементы класса со спецификатором mutable
23.6. Указатели на элементы класса (.* и ->*)
23.7. Сложное наследование
23.8. Сложное наследование и виртуальные базовые классы
23.9. Заключение
23.10. Последние замечания
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
23.1. Введение
Теперь мы рассмотрим некоторые более тонкие моменты языка C++.
Сначала вы изучите операцию const_cast, которая позволяет программисту
добавить или отменить квалификацию переменной как const. Затем мы обсудим
пространства имен, которые могут объявляться, чтобы обеспечить
уникальность имен идентификаторов в программе, и могут помочь в разрешении
конфликтов имен, возникающих при использовании библиотек, имеющих
одинаковые имена переменных, функций или классов. После этого мы представим
ключевые слова для операций, полезные для программистов, которые
пользуются клавиатурой, не поддерживающей некоторые символы для знаков
операций, такие, как &, " и |. Затем мы перейдем к обсуждению спецификатора
класса памяти mutable, который позволяет программисту указать, что
элемент данных должен быть всегда доступен для модификации, даже если он
принадлежит объекту, рассматриваемому программой в качестве
константного объекта. Затем мы представим две специальных операции, которые
применяются с указателями на элементы класса для доступа к элементам данных
или элемент-функциям, имена которых заранее не известны. Наконец, мы
представим сложное наследование, при котором производный класс наследует
элементы нескольких базовых классов. В качестве одного из аспектов мы
обсудим потенциальные проблемы сложного наследования и покажем, как
разрешить эти проблемы, используя виртуальное наследование.
23.2. Операция const_cast
В C++ предусмотрена операция const__cast для «отведения» квалификации
const или volatile. Программа объявляет переменную с квалификатором
volatile у если ожидается, что переменная может быть модифицирована
аппаратными средствами или другими программами, неизвестными компилятору.
Специальные вопросы
1309
Объявление переменной как volatile (как нестабильной) указывает, что
компилятор не должен оптимизировать операции с ее участием, так как это могло
бы нарушить доступ к переменной со стороны упомянутых программ.
Вообще говоря, применение операции const_cast является небезопасным,
поскольку позволяет программе модифицировать переменную, объявленную
как const и не подлежащую модификации. Но существуют ситуации, когда
желательно или даже необходимо отвести константность. Например, в старые
библиотеки С и C++ могут входить функции с не-константными параметрами,
не модифицирующие эти параметры. Если вы хотите передать такой функции
константные данные, вам нужно отменить их константность; в противном
случае компилятор будет выдавать сообщения об ошибках.
Вы также могли бы передать не-константные данные функции, которая
обращается с ними как с константными и возвращает как константу. В
подобных случаях вам могло бы потребоваться отменить константность
возвращаемых данных, как мы демонстрируем на рис. 23.1.
1 // Рис. 23.1: fig24_01.cpp
2 // Демонстрация const__cast.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <cstring> // содержит прототипы для strcmp и strlen
8 #include <cctype> // содержит прототип для toupper
9
10 // возвращает наибольшую из двух строк в стиле С
11 const char *maximum( const char *first, const char *second )
12 {
13 return ( strcmp( first, second ) >= 0 ? first : second );
14 } // конец функции maximum
15
16 int main()
17 {
18 char sl[] = "hello"; // модифицируемый массив символов
19 char s2[] = "goodbye"; // модифицируемый массив символов
20
21 // требуется const_cast, чтобы const char*, возвращенный
22 // maximum, можно было присвоить переменной maxPtr типа char*
23 char *maxPtr = const_cast< char * >( maximum( si, s2 ) );
24
25 cout « "The larger string is: " « maxPtr « endl;
26
27 for ( size_t i = 0; i < strlen( maxPtr ); i++ )
28 maxPtr[ i ] = toupper( maxPtr[ I ] );
29
30 cout « "The larger string capitalized is: " « maxPtr « endl;
31 return 0;
32 } // конец main
The larger string is: hello
The larger string capitalized is: HELLO
Рис. 23.1. Демонстрация операции const_cast
1310
Глава 23
В этой программе функция maximum (строки 11-14) принимает две строки
в стиле С как параметры типа const char * и возвращает const char *,
указывающий на большую из двух строк. Функция main объявляет две строки в
стиле С как не-константные символьные массивы (строки 18-19); эти массивы,
таким образом, модифицируемы. Мы хотим вывести в main большую из двух
строк, а затем преобразовать ее буквы в верхний регистр.
Два параметра функции maximum имеют тип const char *, поэтому ее
возвращаемый тип также должен быть объявлен как const char *. Если
специфицировать возвращаемый тип просто как char *, компилятор выдаст сообщение
об ошибке, указывающее, что возвращаемое значение не может быть
преобразовано из const char * в char * — это опасное преобразование, поскольку оно
пытается рассматривать данные, которые функция считает константными,
в качестве не-константных.
Но хотя функция maximum считает данные константными, мы знаем, что
исходные массивы в main не содержат константных данных. Следовательно,
main в случае необходимости должна иметь возможность модифицировать
содержимое этих массивов. Поскольку мы знаем, что массивы модифицируемы,
мы применяем const_cast (строка 23) для отмены константности указателя,
возвращаемого функцией maximum, чтобы впоследствии мы могли
модифицировать данные в массиве, представляющем большую из двух строк. Затем в цикле
for (строки 27-28) мы используем этот указатель в качестве имени массива для
преобразования содержимого большей строки в буквы верхнего регистра. Без
const_cast в строке 23 эта программа компилироваться не будет, так как
присваивание указателя типа const char * указателю типа char * не допускается.
Предотвращение ошибок 23.1
Вообще говоря, операция constjcast должна применяться только в
случаях, когда заранее известно, что исходные данные не являются
константными. В противном случае могут получиться непредсказуемые
результаты.
23.3. Пространства имен
В программе имеется много имен, определенных в различных областях
действия. Иногда переменная одной области действия может «перекрываться» с
одноименной переменной из другой области действия, вызывая, возможно, конфликт
имен. Такое перекрытие может происходить на многих уровнях. Перекрытие
идентификаторов часто случается с библиотеками независимых поставщиков,
в которых используются одинаковые имена для глобальных идентификаторов
(например, функций). Это может приводить к ошибкам компиляции.
Хороший стиль программирования 23.1
Избегайте идентификаторов, начинающихся с символа
подчеркивания, из-за которого могут возникать ошибки компоновщика. В коде
многих библиотек используются имена, которые начинаются с
подчеркивания.
Стандарт C++ пытается решить эти проблемы с помощью пространств
имен. Каждое пространство имен (namespace) определяет область действия,
Специальные вопросы
1311
в которой размещаются идентификаторы и переменные. Для обращения к
элементу пространства имен либо имя элемента должно квалифицироваться
именем пространства с операцией разрешения области действия (::),
MyNameSpace:'.member
либо использование имени в программе должно предваряться объявлением
using или директивой using. Обычно такие операторы using размещают в
начале файла, в котором используются элементы пространства имен. Например,
размещение в начале файла исходного кода директивы
using namespace MyNameSpace ;
указывает, что элементы пространства имен MyNameSpace могут
использоваться в файле без предшествующего MyNameSpace с операцией разрешения
области действия.
Объявление using (напр., using std::cout) вводит в область действия, в
которой оно появляется, только одно имя. Директива using (напр., using
namespace std) вводит в область действия, в которой она появляется, все имена из
указанного пространства имен.
S Общее методическое замечание 23,1
В идеале в больших программах каждый объект должен быть
объявлен в классе, функции, блоке или пространстве имен. Это помогает
сделать более ясной роль каждого объекта.
Предотвращение ошибок 23.2
ff^V Если существует вероятность конфликта имен, предваряйте эле-
^--^ мент именем его именного пространства с операцией разрешения
области действия (::).
Уникальность имен namespace не гарантируется. Два независимых
поставщика могут неумышленно присвоить своим именам namespace одинаковые
идентификаторы. Рис. 23.2 демонстрирует использование именных пространств.
1 // Рис. 23.2: Fig24_02.cpp
2 // Демонстрация namespace.
3 #include <iostream>
4 using namespace std; // использовать пространство имен std
5
6 int integerl = 98; // глобальная переменная
7
8 // создать пространство имен Example
9 namespace Example
10 {
11 // объявить две константы и одну переменную
12 const double PI = 3.14159;
13 const double E = 2.71828;
14 int integerl = 8;
15
16 void printValues(); // прототип
17
1312
Глава 23
18 // вложенное пространство имен
19 namespace Inner
20 {
21 // определить перечисление
22 enum Years { FISCALl = 1990, FISCAL2, FISCAL3 };
23 } // конец namespace Inner
24 } // конец namespace Example
25
26 // создать неименованное пространство имен
27 namespace
28 {
29 double doubleInUnnamed = 88.22; // declare variable
30 } // конец неименованного namespace
31
32 int main()
33 {
34 // вывести значение doubleInUnnamed неименованного пространства
35 cout « " double InUnnamed = " « doubleInUnnamed;
36
37 // вывести глобальную переменную
38 cout « "\n(global) integerl = " « integerl;
39
40 // вывести значения пространства Example
41 cout « "\nPI = " « Example::PI « "\nE = " « Example::E
42 « "\nintegerl = " « Example::integerl « "\nFISCAL3 = "
43 « Example::Inner::FISCAL3 « endl;
44
45 Example::printValues(); // вызвать функцию printValues
4 6 return 0;
47 } // конец main
48
4 9 // вывести значения переменной и констант
50 void Example::printValues()
51 {
52 cout « "\nln printValues: \nintegerl = " « integerl « "\nPI =
53 « PI « "\nE = " « E « M\ndoubleInUnnamed = "
54 « doubleInUnnamed « "\n(global) integerl = " « ::integerl
55 « "\nFISCAL3 = " « Inner:: FISCAL3 « endl;
56 } // конец printValues
doubleInUnnamed = 88.22
(global) integerl = 98
PI = 3.14159
E = 2.71828
integerl = 8
FISCAL3 = 1992
In printValues:
integerl = 8
PI = 3.14159
E = 2.71828
doubleInUnnamed =
(global) integerl
FISCAL3 = 1992
88.22
= 98
Рис. 23.2. Демонстрация именных пространств
Специальные вопросы
1313
Пространство имен std
Строка 4 сообщает компилятору, что используется пространство имен std.
Все содержимое заголовочного файла <iostream> определяется как часть
пространства std. [Замечание. Большинство программирующих на C++ считают
написание директив, подобных строке 4, плохим стилем программирования,
так как при этом в область действия включается все содержимое именного
пространства, повышая таким образом вероятность конфликта имен.]
Директива using namespace указывает, что элементы именного
пространства будут использоваться в программе достаточно часто. Она позволяет
программисту обращаться ко всем элементам именного пространства и писать
более краткие операторы, например,
cout « "double = " « doublel;
вместо
std::cout « "double = " « doublel;
Без строки 4 нужно было бы либо каждый cout и endl на рис. 23.2
квалифицировать префиксом std::, либо включить для cout и endl отдельные объявления
using:
using std::cout;
using std:.endl;
Директива using namespace может использоваться как для предопределенных
именных пространств (напр., std), так и для именных пространств,
определяемых пользователем.
Определение именных пространств
В строках 9-24 ключевое слово namespace применяется для определения
пространства имен Example. Тело пространства имен ограничивается
фигурными скобками ({}). Элементами именного пространства Example являются
две константы (PI и Е в строках 12-13), целое (integerl в строке 14), функция
(printValues в строке 16) и вложенное пространство имен (Inner в
строках 19-23). Заметьте, что элемент integerl имеет то же имя, что и глобальная
переменная integerl (строка 6). Переменные с одним и тем же именем должны
иметь различные области действия, иначе произойдет ошибка компиляции.
Пространство имен может содержать константы, данные, классы, вложенные
именные пространства, функции и т.п. Определения именных пространств
должны находиться в глобальной области действия или быть вложенными
в другие именные пространства.
Строки 27-30 создают неименованное пространство имен, содержащее
элемент doublelnUnnamed. Неименованное пространство имен имеет неявную
директиву using, так что его элементы по видимости занимают глобальное
пространство имен, доступны непосредственно и не требуют квалификации.
Глобальные переменные также входят в глобальное пространство имен и
доступны во всех областях действия, следующих в файле за их объявлением.
42 Заг. 1114
1314
Глава 23
Общее методическое замечание 23.2
Каждый отдельный модуль компиляции имеет свое собственное
уникальное неименованное пространство имен; другими словами,
неименованное пространство имен заменяет спецификатор компоновки
static.
Доступ к элементам именного пространства
через квалифицированные имена
Строка 35 выводит значение переменной doublelnUnnamed, которая
доступна непосредственно как входящая в неименованное пространство имен.
Строка 38 выводит значение переменной integer 1. Для обеих этих переменных
компилятор сначала пытается найти локальное объявление в main. Поскольку
локальные объявления отсутствуют, компилятор полагает, что эти
переменные находятся в глобальном именном пространстве.
Строки 41-43 выводят значения PI, E, integerl и FISCAL3 из именного
пространства Example. Заметьте, все они должны иметь квалификатор Example::,
поскольку в программе отсутствуют какие-либо директивы или объявления
using, сообщающие, что она будет использовать элементы Example. Кроме того,
элемент integerl должен квалифицироваться потому, что то же имя имеет
глобальная переменная. Иначе выводилось бы значение глобальной переменной.
Заметьте, что элемент FISCAL3 является элементом вложенного пространства
имен, поэтому он должен квалифицироваться как Example::Inner::.
Функция printValues (определенная в строках 50-56) является элементом
Example, и потому может обращаться к другим элементам именного
пространства Example непосредственно, без указания квалификатора. Оператор вывода
в строках 52-55 выводит integerl, PI, E, doubleUnnamed, глобальную
переменную integerl и FISCAL3. Заметьте, что PI и Е не квалифицируются.
Переменная doubleUnnamed также доступна, поскольку она принадлежит
неименованному пространству имен и ее имя не вступает в конфликт с какими-либо
элементами именного пространства Example. Глобальная версия integerl
должна квалифицироваться унарной операцией разрешения области
действия (::), поскольку ее имя конфликтует с элементом именного пространства
Example. Кроме того, FISCAL3 необходимо квалифицировать префиксом
Inner::. При обращении к элементам вложенного пространства имен они
должны квалифицироваться его именем (если только элемент не используется
внутри вложенного пространства имен).
Типичная ошибка программирования 23.1
Размещение main внутри именного пространства приводит к ошибке
компиляции.
Псевдонимы именных пространств
Именным пространствам можно присваивать псевдонимы. Например,
оператор
namespace CPPTP5E = CPlusPlusHowToProgram5E;
создает для CPlusPlusHowToProgram5E псевдоним СРРТР5Е.
Специальные вопросы
1315
23.4. Ключевые слова для операций
В стандарте C++ предусмотрены ключевые слова операций (рис. 23.3),
которые могут использоваться вместо ряда операций C++. Эти ключевые слова
полезны для программистов, которые пользуются клавиатурой, не
поддерживающей некоторые символы для знаков операций, такие, как &, " , | и т.п.
Операция
Ключевое слово
Описание
Ключевые слова для логических операций
&&
II
!
and
or
not
логическое И
логическое ИЛИ
логическое НЕ
Ключевое слово для операции неравенства
! =
not_eq
неравенство
Ключевые слова для поразрядных операций
&
I
л
-
bitand
bitor
xor
compl
поразрядное И
поразрядное ИЛИ
поразрядное исключающее ИЛИ
поразрядное дополнение
Ключевые слова для поразрядных операций присваивания
&=
|=
л_
and_eq
or_eq
xor_eq
присваивание поразрядного И
присваивание поразрядного включающего ИЛИ
присваивание поразрядного исключающего ИЛИ
Рис. 23.3. Альтернативные ключевые слова для знаков операций
Рис. 23.4. демонстрирует ключевые слова для операций. Программа
компилировалась на Microsoft Visual C++.NET, которому для использования этих
ключевых слов требуется заголовочный файл <iso646.h> (строка 8). В GNU C++
строку 8 следует удалить, и компилировать программу следующей командой:
g++ -foperator-names Fig24_04.cpp -о Fig24_04
Опция компилятора -foperator-names указывает, что компилятор должен
разрешить использование ключевых слов для операций в программе на рис. 23.4.
Другие компиляторы могут не требовать включения заголовочного файла или
указания соответствующей опции для поддержки этих ключевых слов.
Например, компилятор Borland C++ 5.6.4 неявно разрешает их использование.
1 // Рис. 23.4: Fig24_04.cpp
2 // Демонстрация ключевых слов для операций.
3 #include <iostream>
4 using std::boolalpha;
5 using std::cout;
6 using std:rendl;
1316
Глава 23
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#include <iso646.h> // разрешает ключевые слова в Visual C++
int main()
{
bool a = true;
bool b = false;
int с = 2;
int d = 3;
// залипающая установка,
cout « boolalpha;
выводящая bool как true или false
cout
«
cout
cout
cout
cout
cout
cout
cout
cout
«
«
«
«
«
«
«
«
«
"a =
с = '
• « a « "
« с « " ;
; b =
d = "
■ « b
« d;
'\n\nLogical operator keywords:
\n
"\n
"\n
"\n
"\n
"\n
"\na not_eq b:
a and a
a and b
a or a
a or b
not a
not b
«
«
«
«
«
«
• «
and a )
and b )
or a ) ;
or b ) ;
)
not a
not b );
a not_eq
b )
cout «
cout «
cout
cout
cout
cout
cout
«
«
«
«
«
cout « "
return 0;
// конец main
"\n\nBitwise operator keywords:
"\nc bitand d
"\nc bit_or d
"\n с xor d:
"\n compl с:
"\nc and_eq d
"\n с or_eq d
\nc xor_eq d
" « ( с bitand d
" « ( с bitor d
« ( с xor d ) ;
« ( compl с );
" « (
«
«
с and__eq d ) ,
с or_eq d ) ;
с xor_eq d ) « endl;
a = true; b = false; с = 2; d = 3
Logical operator keywords:
a and a: true
a and b: false
a or a: true
a or b: true
not a: false
not b: true
a not_eq b: true
Bitwise operator keywords:
с bitand d: 2
с bit__or d: 3
с xor d: 1
compl c: -3
с and__eq d: 2
с or_eq d: 3
с xor_eq d: 0
Рис. 23-4. Демонстрация ключевых слов для операций
Специальные вопросы
1317
Программа объявляет и инициализирует две булевы и две целые
переменные (строки 12-15). Над булевыми переменными а и b производятся
различные логические операции с помощью ключевых слов (строки 24-30). Над
целыми переменными end производятся поразрядные операции (строки 33-39).
Результат каждой операции выводится.
23.5. Элементы класса со спецификатором mutable
В разделе 23.2 м представили операцию const_cast, которая позволяет
отменить «константность» типа. Операция const_cast может применяться также
в теле константной элемент-функции класса к элементу данных константного
объекта этого класса. Это позволяет константной элемент-функции
модифицировать элемент данных, даже если объект в теле этой функции
рассматривается как константный. Такая операция имеет смысл, если большинство
элементов данных объекта должны считаться константными, но некоторый элемент
все же должен модифицироваться.
В качестве примера рассмотрим связанный список, который поддерживает
свое содержимое в упорядоченном состоянии. Поиск в связанном списке не
требует модификации его данных, поэтому функция поиска могла бы быть
константной элемент-функцией класса связанного списка. Однако представим
себе, что объект связанного списка для лучшей эффективности поиска
отслеживает позицию последнего успешно найденного элемента. Если следующая
операция поиска пытается найти элемент, расположенный в списке дальше,
поиск можно начать от позиции последнего успешного поиска, а не
просматривать список с самого начала. Чтобы сделать это, константная
элемент-функция, выполняющая поиск, должна иметь возможность модифицировать
элемент данных, отслеживающий последний успешный поиск.
Если элемент данных, подобный описанному выше, всегда должен быть
модифицируемым, в качестве альтернативы const_cast можно применить к нему
спецификатор класса памяти mutable. Элемент данных, объявленный как
mutable (изменяемый), всегда является модифицируемым, даже в
константной элемент-функции или в константном объекте. Тем самым сокращается
число случаев, где необходимо применение const_cast.
Ш Переносимость программ 23.1
Результат попытки модифицировать объект, который был опреде
лен как константный, вне зависимости от того, применяется ли для
модификации const_cast или приведение в стиле С, на разных
компиляторах будет различным.
Как mutable, так и const_cast разрешают модифицировать элемент
данных; они применяются в разных контекстах. Для константного объекта без
изменяемых элементов данных всякий раз, когда необходимо модифицировать
объект, должна применяться операция const_cast. Это значительно
уменьшает вероятность случайного изменения элемента, так как последний не все
время доступен для модификации. Действия, в которых участвует const_cast,
обычно скрыты в реализации элемент-функции. Пользователь класса может
не знать, что объект подвергается изменению.
1318
Глава 23
Общее методическое замечание 23.3
Объявление элементов как mutable полезно в классах, имеющих
«секретные» детали реализации, никак не влияющие на логическое
значение объекта.
Механическая демонстрация изменяемого элемента данных
Рис. 23.5 демонстрирует использование изменяемого элемента. Программа
определяет класс TestMutable (строки 8-22), который содержит конструктор,
функцию get Value и закрытый элемент данных value, объявленный как
mutable. Строки 16-19 определяют функцию getValue как константную
элемент-функцию, возвращающую копию value. Обратите внимание, что в
операторе возврата функция инкрементирует этот mutable-элемент. Обычно
константная элемент-функция не может модифицировать элементы данных, если
только объект, на котором она выполняется (т.е. тот, на который указывает
this), не приводится к не-константному типу посредством операции const_cast.
Но поскольку элемент value объявлен как mutable, константная функция
способна модифицировать его данные.
1 // Рис. 23.5: Fig24_05.cpp
2 // Демонстрация спецификатора класса памяти mutable.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 // определение класса TestMutable
8 class TestMutable
9 {
10 public:
11 TestMutable( int v = 0 )
12 {
13 value = v;
14 } // конец конструктора TestMutable
15
16 int getValue() const
17 {
18 return value++; // приращение значения value
19 } // конец функции getValue
20 private:
21 mutable int value; // изменяемый элемент
22 }; // конец класса TestMutable
23
24 int main()
25 {
26 const TestMutable test( 99 );
27
28 cout « "Initial value: " « test.getValue();
29 cout « "\nModified value: " « test.getValue () « endl;
30 return 0;
31 } // конец main
Initial value: 99
Modified value: 100
Рис.23.5. Демонстрация изменяемого элемента данных
Специальные вопросы
1319
Строка 26 объявляет объект test типа const Test Mutable, инициализируя его
значением 99. Строка 28 вызывает константную элемент-функцию getValue,
которая прибавляет к value единицу и возвращает его предыдущее содержимое.
Заметьте, что компилятор разрешает вызов функции getValue для объекта test,
так как это константный объект, a getValue — константная элемент-функция.
Тем не менее getValue модифицирует переменную value. Таким образом,
повторный вызов getValue в строке 29 выводит новое значение A00),
подтверждая, что изменяемый элемент данных действительно был модифицирован.
23.6. Указатели на элементы класса (.* и ->*)
Для доступа к элементам класса через указатели в C++ предусмотрены
операции .* и ->*. Эти редкие операции C++ используют в основном опытные
программисты. Мы даем здесь лишь механический пример использования
указателей на элементы класса. Рис. 23.6 демонстрирует, операции указателей на
элемент класса.
1 // Рис. 23.6: Fig24_06.cpp
2 // Демонстрация операций .* и ->*.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 // определение класса Test
8 class Test
9 {
10 public:
11 void test()
12 {
13 cout « "In test function\n";
14 } // конец функции test
15
16 int value; // открытый элемент данных
17 }; // конец класса Test
18
19 void arrowStar( Test * ); // прототип
20 void dotStar( Test * ); // прототип
21
22 int main()
23 {
24 Test test;
25 test.value =8; // присвоить значение 8
26 arrowStar( &test ); // передать адрес функции arrowStar
27 dotStar( &test ); // передать адрес функции dotStar
28 return 0;
29 } // конец main
30
31 // доступ к функции объекта класса Test с помощью ->*
32 void arrowStar( Test *testPtr )
33 {
34 void ( Test::*memPtr )() = &Test::test; // указатель на функцию
35 ( testPtr->*memPtr )(); // косвенный вызов функции
36 } // конец arrowStar
1320
Глава 23
37
38 // доступ к данным объекта класса Test с помощью.*
39 void dotStar( Test *testPtr2 )
40 {
41 int Test::*vPtr = &Test::value; // объявить указатель
42 cout « ( *testPtr2 ).*vPtr « endl; // обратиться к значению
43 } // конец dotstar
In test function
8
Рис. 23.6. Демонстрация операций .* и ->*
Программа определяет класс Test с открытой элемент-функцией test и
открытым элементом данных value. Строки 19-20 объявляют прототипы для
функций arrowStar (определена в строках 32-36) и arrowDot (определена
в строках 39-43), которые демонстрируют соответственно операции .* и ->*.
Строка 24 создает объект test, а строка 25 присваивает его элементу данных
value значение 8. Строки 26-27 вызывают функции arrowStar и arrowDot
с адресом объекта test.
Строка 34 в функции arrowStar объявляет и инициализирует переменную
memPtr как указатель на элемент-функцию. В этом объявлении Test::*
означает, что переменная memPtr является указателем на элемент класса Test.
Чтобы объявить указатель на функцию, имя указателя, которому
предшествует *, заключается в скобки, как, например, ( Test::*memPtr ). В типе
объявляемого указателя необходимо специфицировать как возвращаемый тип
функции, на которую он указывает, так и список параметров этой функции.
Возвращаемый тип функции записывается слева от открывающей скобки,
а список параметров — в отдельной паре скобок справа от объявления
указателя. В данном случае функция имеет возвращаемый тип void и не принимает
параметров. Указатель memPtr инициализируется адресом элемент-функции
класса Test с именем test. Заметьте, что заголовок функции должен
соответствовать объявлению указателя на функцию, т.е. функция должна иметь
возвращаемый тип void и не принимать параметров. Обратите внимание, что правая
часть присваивания использует операцию адреса (&), чтобы получить адрес
элемент-функции test. Наконец, заметьте, что ни левая, ни правая часть
присваивания в строке 34 не ссылается на конкретный объект класса Test.
Указывается только имя класса с бинарной операцией разрешения области действия
(::). Строка 35 вызывает элемент-функцию, хранящуюся в memPtr (т.е.
функцию test), применяя операцию ->*. Так как memPtr является указателем на
элемент класса, для вызова функции должна использоваться операция ->*,
а не ->.
Строка 41 объявляет и инициализирует vPtr как указатель на целый
элемент данных класса Test. Правая сторона присваивания специфицирует адрес
элемента данных value. Строка 42 разыменовывает указатель testPtr2, после
чего применяет операцию .* для доступа к элементу, на который указывает
vPtr. Заметьте, что код клиента может создавать указатели только на те
элементы класса, которые доступны клиенту. В этом примере и элемент-функция
test, и элемент данных value имеют открытый доступ.
Специальные вопросы
1321
Типичная ошибка программирования 23.2
Объявление указателя на элемент-функцию без скобок, заключающих
в себе имя указателя, является синтаксической ошибкой.
Типичная ошибка программирования 23.3
Объявление указателя на элемент-функцию без имени класса с
операцией разрешения области действия (::), предшествующих имени
указателя, является синтаксической ошибкой.
Типичная ошибка программирования 23.4
Попытка применения к указателю на элемент класса операции ->
или * порождает синтаксические ошибки.
23.7. Сложное наследование
В главах 9 и 10 мы обсуждали простое наследование, при котором класс
является производным от единственного базового класса. В C++ класс может
быть производным от более чем одного класса; это называется сложным
наследованием. Производный класс наследует элементы двух или большего числа
базовых классов. Эта мощная особенность C++ позволяет осуществить
интересные формы утилизации программного обеспечения, но может также
служить источником разнообразных проблем, связанных с неоднозначностью.
Сложное наследование — трудная для усвоения концепция, которую должны
применять на практике только опытные программисты. На самом деле
некоторые проблемы, связанные со сложным наследованием, настолько тонки, что
новейшие языки программирования, такие, как Java и С#, не позволяют
классу быть производным от более чем одного базового класса.
т
Хороший стиль программирования 23.2
При правильном применении сложное наследование может быть очень
мощным средством. Сложное наследование должно использоваться,
когда между новым типом и несколькими существующими типами
имеет место отношение «является» (т.е. тип А «является» типом В
и тип А «является» типом С).
Общее методическое замечание 23.4
Сложное наследование может сделать систему запутанной. Чтобы
корректно спроектировать систему со сложным наследованием, тре
буется крайняя осторожность; не следует применять сложное
наследование, если для решения задачи достаточно простого наследования
и/или композиции.
Типичной проблемой при сложном наследовании является то, что базовые
классы могут содержать элементы данных или элемент-функции с
одинаковыми именами. Это может приводить к ошибкам при компиляции программы,
связанным с неоднозначностью. Рассмотрим пример сложного наследования
1322
Глава 23
(рис. 23.7-23.11). Класс Basel (рис. 23.7) содержит один защищенный целый
элемент данных value (строка 20), конструктор (строки 10-13) и открытую
элемент-функцию getData (строки 15-18), которая возвращает значение value.
1 // Рис. 23.7: Basel.h
2 // Определение класса Basel
3 #ifndef BASE1_H
4 #define BASE1_H
5
6 // определение класса Basel
7 class Basel
8 {
9 public:
10 Basel( int parameterValue )
11 {
12 value = parameterValue;
13 } // конец конструктора Basel
14
15 int getData() const
16 {
17 return value;
18 } // конец функции getData
19 protected: // доступны для производного класса
20 int value; // наследуется производным классом
21 }; // конец класса Basel
22
23 #endi£ // BASE1 Н
Рис. 23.7. Демонстрация сложного наследования — Basel.h
Класс Base2 (рис. 23.8) похож на Basel за исключением того, что его
защищенными данными является элемент letter типа char (строка 20). Как
и Basel, класс Base2 имеет открытую элемент-функцию getData, но эта
функция возвращает значение символьного элемента данных letter.
1 // Рис. 23.8: Base2.h
2 // Определение класса Base2
3 #ifndef BASE2_H
4 #define BASE2_H
5
6 // определение класса Base2
7 class Base2
8 {
9 public:
10 Base2( char characterData )
11 {
12 letter = characterData;
13 } // конец конструктора Base2
14
15 char getData() const
16 {
17 return letter;
18 } // конц функции getData
19 protected: // доступны для производного класса
Специальные вопросы
1323
20 char letter; // наследуется производным классом
21 }; // конец класса Base2
22
23 #endif // BASE2 Н
Рис. 23,8. Демонстрация сложного наследования — Base2.h
Класс Derived (рис. 23.9-23.10) производится от обоих классов Basel
и Base2 посредством сложного наследования. Класс Derived имеет закрытый
элемент данных real типа double (строка 21), конструктор для инициализации
всех данных класса и открытую элемент-функцию get Real, которая
возвращает значение переменной real типа double.
1 // Рис. 23.9: Derived.h
2 // Определение класса Derived, наследующего нескольким
3 // базовым классам (Basel и Base2).
4 #ifndef DERIVED_H
5 #define DERIVED_H
6
7 #include <iostream>
8 using std::ostream;
9
10 #include "Basel.h"
11 #include "Base2.hM
12
13 // определение класса Derived
14 class Derived : public Basel, public Base2
15 {
16 friend ostream &operator«( ostream &, const Derived 6 );
17 public:
18 Derived( int, char, double );
19 double getReal() const;
20 private:
21 double real; // закрытые данные производного класса
22 }; // конец класса Derived
23
24 #endif // DERIVED H
Рис, 23.9. Демонстрация сложного наследования — Derived.h
1 // Рис. 23.10: Derived.cpp
2 // Определения элемент-функций для класса Derived.
3 #include "derived.h"
4
5 // Конструктор для Derived вызывает конструкторы для
6 // классов Basel и Base2. Для вызова базовых конструкторов
7 // используются инициализаторы элементов.
8 Derived::Derived( int integer, char character, double doublel )
9 : Basel( integer ), Base2 ( character ), real( doublel ) { }
10
11 // возвратить real
12 double Derived::getReal() const
13 {
1324
Глава 23
14 return real;
15 } // конец функции getReal
16
17 // вывести все элементы данных класса Derived
18 ostream &operator«( оstream fioutput, const Derived &derived )
19 {
20 output « " Integer: " « derived.value « "\n Character:
21 « derived.letter « "\nReal number: " « derived.real;
22 return output; // разрешает каскадные вызовы
23 } // конец operator«
Рис. 23.10. Демонстрация сложного наследования — Derived.срр
Сложное наследование специфицируется очень просто — после имени класса
Derived следует двоеточие (:) и разделенный запятыми список базовых классов
(строка 14). Обратите внимание, что конструктор Derived на рис. 23.10 явным
образом вызывает конструктор для каждого из своих базовых классов — Basel
и Base2, — используя синтаксис инициализатора элемента (строка 9).
Конструкторы базовых классов вызываются в порядке, соответствующем
спецификации наследования, а не порядку перечисления их конструкторов; если
конструкторы базовых классов не вызываются явным образом в списке
инициализации элементов, будут неявно вызываться их конструкторы по умолчанию.
Перегруженная операция передачи в поток (рис. 23.10, строки 18-23)
принимает р своем втором параметре ссылку на объект Derived, данные которого
должны выводиться в поток. Эта функция-операция является другом класса
Derived, так что она может непосредственно обращаться ко всем закрытым
и защищенным элементам класса, включая защищенный элемент данных
value (наследуемый от класса Basel), защищенный элемент данных letter
(наследуемый от класса Base2) и закрытый элемент данных real (объявленный
в классе Derived).
Давайте теперь рассмотрим функцию main (рис. 23.11), которая тестирует
классы из рис. 23.7-23.10. Строка 13 создает объект basel класса Basel и
инициализирует его целым значением 10, после чего создает указатель baselPtr,
инициализируя его нулевым указателем (т.е. значением 0). Строка 14 создает
объект base2 класса Base2 и инициализирует его символьным значением 'Z',
после чего создает указатель baselPtr, инициализируя его нулевым
указателем. Строка 15 создает объект derived класса Derived и инициализирует его
содержимое целым значением 7, символьным значением 'А' и значением 3.5
типа double.
1 // Рис. 23.11: Fig24_ll.cpp
2 // Драйвер для примера сложного наследования.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include "Basel.h"
8 #include "Base2.h"
9 #include "Derived.h"
10
11 int main()
12 {
Специальные вопросы
1325
13 Basel basel( 10 ), *baselPtr =0; // создать объект Basel
14 Base2 base2( 'Z' ), *base2Ptr =0; // создать объект Base2
15 Derived derived( 7, 'A', 3.5 ); // создать объект Derived
16
17 // напечатать элементы данных объектов базовых классов
18 cout « "Object basel contains integer " « basel.getData()
19 « "\nObject base2 contains character " « base2.getData()
20 « "\nObject derived contains:\n" « derived « "\n\n";
21
22 // напечатать элементы данных объекта производного класса
23 // операция области действия разрешает неоднозначность getData
24 cout « "Data members of Derived can be accessed individually:"
25 « "\n Integer: " « derived. Basel: -.getData ()
26 « "\n Character: " « derived.Base2::getData()
27 « "\nReal number: " « derived.getReal() « "\n\n";
28 cout«"Derived can be treated as an object of any base class:\n";
29
30 /./ рассматривать Derived как объект Basel
31 baselPtr = (derived;
32 cout «MbaselPtr->getData() yields "« baselPtr->getData()«' \n ' ;
33
34 // рассматривать Derived как объект Base2
35 base2Ptr = fiderived;
36 cout <<"base2Ptr->getData() yields "« base2Ptr->getData()«endl;
37 return 0;
38 } // конец main
Object basel contains integer 10
Object base2 contains character Z
Object derived contains:
Integer: 7
Character: A
Real number: 3.5
Data members of Derived can be accessed individually:
Integer: 7
Character: A
Real number: 3.5
Derived can be treated as an object of either base class:
baselPtr->getData() yields 7
base2Ptr->getData() yields A
Рис. 23.11. Демонстрация сложного наследования
Строки 18-20 выводят значения данных каждого объекта. Для объектов
basel и base2 мы вызываем их элемент-функцию getData. Хотя в данном
примере существуют две функции getData, эти вызовы не являются
неоднозначными. В строке 18 компилятор знает, что basel является объектом класса
Basel, поэтому вызывается версия getData из класса Basel. В строке 19
компилятор знает, что base2 — объект класса Base2, поэтому вызывается версия
getData из Basel. Строка 20 выводит содержимое объекта derived, применяя
перегруженную операцию передачи в поток.
1326
Глава 23
Разрешение неоднозначностей в случае, когда производный класс
наследует от нескольких базовых классов элемент-функции
с одинаковыми именами
Строки 24-27 снова выводят содержимое объекта derived, используя
get-функщш класса Derived. Однако здесь имеет место неоднозначность,
поскольку этот объект содержит две функции getData, одна — унаследованная от
класса Basel, другая — от класса Base2. Эта проблема решается применением
бинарной операции разрешения области действия. Выражение derived.Ba-
sel::getData() получает значение переменной, унаследованной от класса Basel
(т.е. целой переменной с именем value), a derived.Base2::getData() получает
значение переменной, унаследованной от класса Base2 (т.е. символьной
переменной с именем letter). Значение типа double в переменной real выводится
просто вызовом derived.getReal() — в иерархии классов нет других
элемент-функций с таким именем.
Демонстрация отношений «является» в сложном наследовании
Отношения «является» в простом наследовании имеют также место и в
случае сложного наследования. Чтобы это продемонстрировать, строка 31
присваивает адрес объекта derived указателю baselPtr на класс Basel. Это
допустимо, поскольку объект класса Derived является объектом класса Basel.
Строка 32 вызывает элемент-функцию getData через baselPtr, чтобы
получить значение только той части объекта derived, что относится к классу Basel.
Строка 35 присваивает адрес объекта derived указателю base2Ptr на класс
Base2. Это допустимо, поскольку объект класса Derived является объектом
класса Base2. Строка 36 вызывает элемент-функцию getData через base2Ptr,
чтобы получить значение только той части объекта derived, что относится
к классу Base2.
23.8. Сложное наследование и виртуальные
базовые классы
В разделе 23.7 мы обсуждали сложное наследование, когда один класс
наследует от двух или большего числа классов. Сложное наследование
используется, например, в стандартной библиотеке C++ для образования класса
basic_iostream (рис. 23.12).
basic ios
/ \
basicjstream basic_ostream
\ /
basic_iostream
Рис. 23.12. Сложное наследование в образовании класса basic_iostream
Специальные вопросы
1327
Класс basic_ios является базовым классом как для basic_istream, так и для
basic_ostream, каждый из которых образуется посредством простого
наследования. Класс basic_iostream наследует от обоих классов basic_istream
и basic_ostream. Это позволяет объектам класса basic_iostream осуществлять
все операции как входных, так и выходных потоков. В иерархиях со сложным
наследованием ситуация, показанная на рис. 23.12, называется ромбовидным
наследованием.
Поскольку каждый из классов basic_istream и basic_ostream является
производным от basic_ios, в классе basic_iostream существует потенциальная
проблема. У класса basic_iostream могло бы оказаться два экземпляра элементов
класса basic_ios, — один унаследованный через класс basic_istream, и один
унаследованный через класс basic_ostream. Такая ситуация была бы
неоднозначной и приводила к ошибке компиляции, так как компилятор не знал бы,
какой использовать экземпляр элементов из класса basic_ios. Разумеется, класс
basic_iostream в действительности не страдает от подобной проблемы. В этом
разделе вы увидите, как использование виртуальных базовых классов решает
проблему наследования лишних экземпляров косвенного базового класса.
Ошибки компиляции, возникающие при наличии
неоднозначностей в ромбовидном наследовании
Рис. '23.13 демонстрирует неоднозначность, которая может возникнуть
в ромбовидном наследовании. Программа определяет класс Base (строки 9-13),
который содержит чисто виртуальную функцию print (строка 12). Каждый из
классов DerivedOne (строки 16-24) и DerivedTwo (строки 27-35) является
открытым производным от класса Base и переопределяет функцию print. Каждый
из классов DerivedOne и DerivedTwo содержит то, что стандарт C++ называет
подобъектом базового класса, — в данном случае это элементы класса Base.
1 // Рис. 23.20: Fig24_20.cpp
2 // Попытка полиморфного вызова функции, которая
3 // наследуется от двух базовых классов.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 // class Base definition
9 class Base
10 {
11 public:
12 virtual void print() const =0; // чисто виртуальная
13 }; // конец класса Base
14
15 // определение класса DerivedOne
16 class DerivedOne : public Base
17 {
18 public:
19 // переопределить функцию print
20 void print() const
21 {
22 cout « "DerivedOne\n";
23 } // конец функции print
1328
Глава 23
24 }; // конец класса DerivedOne
25
26 // определение класса DerivedTwo
27 class DerivedTwo : public Base
28 {
29 public:
30 // переопределить функцию print
31 void print() const
32 {
33 cout « "DerivedTwo\n";
34 } // конец функции print
35 }; // конец класса DerivedTwo
36
37 // определение класса Multiple
38 class Multiple : public DerivedOne, public DerivedTwo
39 {
40 public:
41 // квалифицировать версию функции print
42 void print() const
43 {
44 DerivedTwo::print();
45 } // конец функции print
4 6 }; // конец класса Multiple
47
48 int main()
49 {
50 Multiple both; // создать объект Multiple
51 DerivedOne one; // создать объект DerivedOne
52 DerivedTwo two; // создать объект DerivedTwo
53 Base *array[ 3 ]; // создать массив указателей базового класса
54
55 array[ 0 ] = fiboth; // ОШИБКА -- неоднозначность
56 array[ 1 ] = &one;
57 array[ 2 ] = &two;
58
59 // полиморфный вызов print
60 for ( int i = 0; i < 3; i++ )
61 array[ i ] -> print();
62
63 return 0;
64 } // конец main
C:\examples\ch24\Fig24_13\Fig24__13.cppE5) : error C2594:
'=' : ambiguous conversions from 'Multiple *' to 'Base *'
Рис 23.13. Попытка полиморфного вызова функции, наследуемой от двух базовых классов
Класс Multiple (строки 38-46) наследует от обоих классов DerivedOne
и DerivedTwo. Функция print переопределяется в классе Multiple таким
образом, что вызывает print класса DerivedTwo (строка 44). Обратите внимание,
что мы должны квалифицировать вызов print именем класса DerivedTwo,
чтобы специфицировать, какую версию функции следует вызвать.
Функция main (строки 48-64) создает объекты классов Multiple
(строка 50), DerivedOne (строка 51) и DerivedTwo (строка 52). Строка 53 объявляет
массив указателей на класс Base. Каждый элемент массива инициализируется
Специальные вопросы
1329
адресом объекта (строки 55-57). Ошибка происходит, когда адрес both —
объекта класса Multiple — присваивается указателю аггау[ О ]. Объект both
содержит в действительности два подобъекта типа Base, поэтому компилятор не
знает, на какой из них должен указывать аггау[ О ], и генерирует сообщение
об ошибке, указывающее на неоднозначность преобразования.
Устранение лишних подобъектов путем наследования
виртуального базового класса
Проблема дублирования подобъектов разрешается путем виртуального
наследования. Когда базовый класс наследуется как виртуальный, в
производном классе будет присутствовать только один подобъект, — это называют
виртуальным наследованием базового класса. Рис. 23.14 пересматривает
программу из рис. 23.13, используя виртуальный базовый класс.
1 // Рис. 23.14: Fig24_14.cpp
2 // Использование виртуальных базовых классов.
3 #include <iostreaxn>
4 using std::cout;
5 using std::endl;
6
7 // определение класса Base
8 class Base
9 {
10 public:
11 virtual void print() const =0; // чисто виртуальная
12 }; // конец класса Base
13
14 // определение класса DerivedOne
15 class DerivedOne : virtual public Base
16 {
17 public:
18 // переопределить функцию print
19 void print() const
20 {
21 cout « "DerivedOne\n";
22 } // конец функции print
23 }; // конец класса DerivedOne
24
25 // определение класса DerivedTwo
26 class DerivedTwo : virtual public Base
27 {
28 public:
29 // переопределить функцию print
30 void print() const
31 {
32 cout « "DerivedTwo\n";
33 } // конец функции print
34 }; // конец класса DerivedTwo
35
36 // определение класса Multiple
37 class Multiple : public DerivedOne, public DerivedTwo
38 {
39 public:
40 // квалифицировать версию функции print
41 void print() const
42 {
1330
Глава 23
43 DerivedTwo::print();
44 } // конец функции print
45 }; // конец класса Multiple
46
47 int main ()
48 {
49 Multiple both; // создать объект Multiple
50 DerivedOne one; // создать объект DerivedOne
51 DerivedTwo two; // создать объект DerivedTwo
52
53 // объявить массив указателей базового класса и инициализировать
54 // элементы объектами производных классов
55 Base *array[ 3 ];
56 array[ 0 ] = &both;
57 array[ 1 ] = &one;
58 array[ 2 ] = fitwo;
59
60 // полиморфный вызов функции print
61 for ( int i = 0; i < 3; i++ )
62 array[ i ]->print();
63
64 return 0;
65 } // конец main
DerivedTwo
DerivedOne
DerivedTwo
Рис. 23.14. Использование виртуальных базовых классов
Ключевым отличием этой программы от предыдущей является то, что
DerivedOne и DerivedTwo наследуют классу Base, специфицируя его как virtual
public Base. Так как оба этих класса являются производными от Base,
каждый из них содержит подобъект типа Base. Эффект виртуального
наследования не ясен, пока оба класса DerivedOne и DerivedTwo не станут базовыми для
класса Multiple (строка 37). Благодаря тому, что оба этих класса наследовали
элементы класса Base виртуально, компилятор включает в класс Multiple
единственный подобъект типа Base. Тем самым устраняется неоднозначность,
порождавшая ошибку при компиляции программы на рис. 23.13. Теперь
компилятор разрешает неявное преобразование указателя производного класса
(&both) в указатель базового класса (аггау[ 0 ]) в строке 56 функции main.
Оператор for в строках 61-62 полиморфно вызывает print для каждого объекта.
Конструкторы в иерархиях сложного наследования
с виртуальными базовыми классами
Реализация иерархий с виртуальными базовыми классами упрощается,
если для базовых классов используются конструкторы по умолчанию.
Примеры на рис. 23.13 и 23.14 используют конструкторы по умолчанию,
генерируемые компилятором. Если в виртуальном базовом классе определяется
конструктор, требующий аргументов, реализация производных классов
усложняется, так как конечный производный класс должен явным образом вызывать
конструктор виртуального базового класса для инициализации
унаследованных от него элементов.
Специальные вопросы
1331
S Общее методическое замечание 23.5
Определение для виртуальных базовых классов конструктора по
умолчанию упрощает проектирование иерархии.
Дополнительная информация по сложному наследованию
Сложное наследование — специальная тема, обычно рассматриваемая в
более глубоких курсах по C++. Приведенные ниже URL содержат
дополнительную информацию о сложном наследовании.
cplus.about.com/library/weekly/aal21302a.htm
Руководство по сложному наследованию с подробным примером,
cpptips.hiperformix.com/Multiplelnher.html
Предлагает технические советы, проясняющие различные вопросы
относительно сложного наследования.
www.parashift.com/c++-faq-lite/multiple-inheritance.html
Часть C++ FAQ Lite. Предлагает подробное техническое описание сложного
наследования и виртуального наследования.
23.9. Заключение
В этой главе вы узнали, как применять операцию const_cast для отмены
константной квалификации переменной. Затем мы показали, как
использовать пространства имен, чтобы гарантировать уникальность имени каждого
идентификатора в программе, и объяснили, каким образом они помогают
в разрешении конфликтов имен. Вы познакомились с ключевыми словами для
операций, которые полезны программистам, чья клавиатура не поддерживает
некоторые символы, используемые в знаках операций, такие, как &, Л, - и |.
Затем мы показали, как спецификатор класса памяти mutable позволяет
программисту указать, что элемент данных должен всегда быть
модифицируемым, даже если он принадлежит объекту, рассматриваемому в данный момент
как константный. Мы показали также механику использования указателей на
элементы класса и операции ->* и .*. Наконец, мы представили сложное
наследование и обсудили проблемы, связанные с наследованием элементов
нескольких базовых классов. В ходе этого обсуждения мы продемонстрировали,
как можно решить эти проблемы, используя виртуальное наследование.
23.10. Последние замечания
Мы искренне надеемся, что вам понравилось изучать C++ и
объектно-ориентированное программирование по этой книге. Мы с благодарностью примем ваши
замечания, критику, исправления и предложения по улучшению текста.
Пожалуйста, направляйте всю корреспонденцию на наш адрес электронной почты:
deitel@deitel.com
Желаем успехов!
1332
Глава 23
Резюме
• В C++ предусмотрена операция const_cast для «отведения» квалификации const
или volatile.
• Программа объявляет переменную с квалификатором volatile, если ожидается, что
переменная может быть модифицирована аппаратными средствами или другими
программами, неизвестными компилятору. Объявление переменной как volatile
указывает, что компилятор не должен оптимизировать операции с ее участием, так
как это могло бы нарушить доступ к переменной со стороны упомянутых программ.
• Вообще говоря, применение операции const__cast является небезопасным, поскольку
позволяет программе модифицировать переменную, объявленную как const и не
подлежащую модификации.
• Существуют ситуации, когда желательно или даже необходимо отвести
константность. Например, в старые библиотеки С и C++ могут входить функции с не-кон-
стантными параметрами, не модифицирующие эти параметры. Если вы хотите
передать такой функции константные данные, вам нужно отменить их константность;
в противном случае компилятор будет выдавать сообщения об ошибках.
• Если вы передаете не-константные данные функции, которая обращается с ними как
с константными и возвращает как константу, вам может потребоваться отменить
константность возвращаемых данных, чтобы можно было их модифицировать.
• В программе имеется много имен, определенных в различных областях действия.
Иногда переменная одой области действия может «перекрываться» с одноименной
переменной из другой области действия, вызывая, возможно, конфликт имен.
Стандарт C++ пытается решить эти проблемы с помощью пространств имен.
• Каждое пространство имен определяет область действия, в которой размещаются
идентификаторы и переменные. Для обращения к элементу пространства имен либо
имя элемента должно квалифицироваться именем пространства с операцией
разрешения области действия (::), либо использование имени в программе должно
предваряться объявлением или директивой using.
• Обычно операторы using размещают в начале файла, в котором используются
элементы пространства имен.
• Уникальность имен namespace не гарантируется. Два независимых поставщика могут
неумышленно присвоить своим именам namespace одинаковые идентификаторы.
• Директива using namespace указывает, что элементы именного пространства будут
использоваться в программе достаточно часто. Она позволяет программисту
обращаться ко всем элементам именного пространства.
• Директива using namespace может использоваться как для предопределенных
именных пространств (напр., std), так и для именных пространств, определяемых
пользователем.
• Пространство имен может содержать константы, данные, классы, вложенные
именные пространства, функции и т.п. Определения именных пространств должны
находиться в глобальной области действия или быть вложенными в другие именные
пространства.
• Неименованное пространство имен имеет неявную директиву using, так что его
элементы по видимости занимают глобальное пространство имен, доступны
непосредственно и не требуют квалификации. Глобальные переменные также входят в
глобальное пространство имен.
• При обращении к элементам вложенного пространства имен они должны
квалифицироваться его именем (если только элемент не используется внутри вложенного
пространства имен).
• Именным пространствам можно присваивать псевдонимы.
Специальные вопросы
1333
• В стандарте C++ предусмотрены ключевые слова операций, которые могут
использоваться вместо ряда операций C++. Эти ключевые слова полезны для программистов,
которые пользуются клавиатурой, не поддерживающей некоторые символы для
знаков операций, такие, как &, Л , | и т.п.
• Если элемент данных всегда должен быть модифицируемым, в качестве
альтернативы const_cast можно применить к нему спецификатор класса памяти mutable.
Элемент данных, объявленный как mutable, всегда является модифицируемым, даже
в константной элемент-функции или в константном объекте. Тем самым
сокращается число случаев, где необходимо применение const_cast.
• Как mutable, так и const_cast разрешают модифицировать элемент данных; они
применяются в разных контекстах. Для константного объекта без изменяемых
элементов данных всякий раз, когда необходимо модифицировать объект, должна
применяться операция const_cast. Это значительно уменьшает вероятность случайного
изменения элемента, так как последний не все время доступен для модификации.
• Действия, в которых участвует const_cast, обычно скрыты в реализации эле
мент-функции. Пользователь класса может не знать, чтс* объект подвергается
изменению.
• Для доступа к элементам класса через указатели в C++ предусмотрены операции .*
и ->*. Эти редкие операции C++ используют в основном опытные программисты.
• Чтобы объявить указатель на функцию, имя указателя, которому предшествует *,
заключается в скобки. В типе объявляемого указателя необходимо специфицировать
как возвращаемый тип функции, на которую он указывает, так и список параметров
этой функции.
• В C++ класс может быть производным от более чем одного класса — это называется
сложным наследованием, при котором производный класс наследует элементы двух
или большего числа базовых классов.
• Типичной проблемой при сложном наследовании является то, что базовые классы
могут содержать элементы данных или элемент-функции с одинаковыми именами.
Это может приводить к ошибкам при компиляции программы, связанным с
неоднозначностью.
• Отношения «является» в простом наследовании имеют также место и в случае
сложного наследования.
• Сложное наследование используется, например, в стандартной библиотеке C++ для
образования класса basic_iostream. Класс basic_ios является базовым классом как
для basic_istream, так и для basic_ostream, каждый из которых образуется
посредством простого наследования. Класс basic_iostream наследует от обоих классов
basic_istream и basicostream. Это позволяет объектам класса basic_iostream
осуществлять все операции как входных, так и выходных потоков. В иерархиях со
сложным наследованием подобная ситуация называется ромбовидным наследованием.
• Поскольку каждый из классов basic_istream и basic_ostream является производным
от basic_ios, в классе basic_iostream существует потенциальная проблема. У класса
basic_iostream могло бы оказаться два экземпляра элементов класса basic_ios, —
один унаследованный через класс basic_istream, и один унаследованный через класс
basic_ostream. Такая ситуация была бы неоднозначной и приводила к ошибке
компиляции, так как компилятор не знал бы, какой использовать экземпляр элементов
из класса basic__ios.
• Неоднозначность в ромбовидном наследовании возникает, когда производный класс
наследует два или большее число подобъектов базового класса. Проблема
дублирования подобъектов разрешается путем виртуального наследования. Когда базовый класс
наследуется как виртуальный, в производном классе будет присутствовать только
один подобъект, — это называют виртуальным наследованием базового класса.
1334
Глава 23
• Реализация иерархий с виртуальными базовыми классами упрощается, если для
базовых классов используются конструкторы по умолчанию. Если в виртуальном
базовом классе определяется конструктор, требующий аргументов, реализация
производных классов усложняется, так как конечный производный класс должен явным
образом вызывать конструктор виртуального базового класса для инициализации
унаследованных от него элементов.
Терминология
виртуальное наследование
виртуальный базовый класс
вложенное пространство имен
глобальное пространство имен
директива using namespace
изменяемый элемент данных
квалификатор volatile
ключевое слово mutable
ключевое слово namespace
ключевое слово операции
ключевое слово операции and
ключевое слово операции and_eq
ключевое слово операции bitand
ключевое слово операции bitor
ключевое слово операции compl
ключевое слово операции not
ключевое слово операции not_eq
ключевое слово операции ог
ключевое слово операции or_eq
ключевое слово операции хог
ключевое слово операции xor_eq
ключевые слова логических операции
Контрольные вопросы
23.1. Заполните пропуски в каждом из следующих предложений:
a) Операция квалифицирует элемент его пространством имен.
b) Операция позволяет отменить константность объекта.
c) Так как неименованное пространство имен имеет неявную директиву using,
его элементы по виду принадлежат к , доступны непосредственно
и не должны квалифицироваться именем namespace.
d) Операция является ключевым словом для операции неравенства.
e) Класс может быть производным от более чем одного класса; такое
наследование называется .
f).Когда класс наследуется как , в производном классе будет
присутствовать единственный подобъект базового класса.
23.2. Укажите, какие из следующих утверждений верны, а какие неверны. Если
утверждение неверно, объясните, почему.
a) При передаче константной функции не-константного аргумента необходимо
отменить «константность» функции, применив операцию const_cast.
b) Для имен namespace гарантируется их уникальность.
c) Подобно телам классов, тела именных пространств завершаются точкой с
запятой.
ключевые слова операций неравенства
ключевые слова операций
поразрядного присваивания
ключевые слова поразрядных
операций
конечный производный класс
конфликт имен
неименованное пространство имен
объявление using
операции указателя на элемент
операция .*
операция ->*
операция const_cast
отведение константности
подобъект базового класса
пространство имен
псевдоним пространства имен
разделенный запятыми список
базовых классов
ромбовидное наследование
сложное наследование
Специальные вопросы
1335
d) Именное пространство не может содержать в качестве элемента другое
именное пространство.
e) Элемент данных, специфицированный как mutable, не может быть
модифицирован в константной элемент-функции.
Ответы на контрольные вопросы
23.1. а) разрешения области действия (бинарная), b) const_cast. с) глобальному
пространству имен, d) not_eq. e) сложным наследованием, f) виртуальный.
23.2. а) Неверно. Передача константной функции не-константного аргумента всегда
законна. Однако при передаче константной ссылки или константного
указателя не-константной функции необходимо применение const_cast, чтобы
отменить константность ссылки или указателя.
b) Неверно. Программисты могут по незнанию присвоить именному
пространству уже использованное имя.
c) Неверно. Тела именных пространств не оканчиваются точкой с запятой.
d) Неверно. Именные пространства могу быть вложенными.
e) Неверно. Элемент данных, специфицированный как mutable, всегда будет
модифицируемым, даже в константной элемент-функции.
Упражнения
23.3. Заполните пропуски в каждом из следующих предложений:
a) Ключевое слово указывает, что будет использоваться
пространство имен или элемент пространства имен.
b) Операция является ключевым словом для операции логического
ИЛИ.
c) Спецификатор класса памяти позволяет модифицировать элемент
константного объекта.
d) Квалификатор указывает, что объект может модифицироваться
другой программой.
e) Если существует возможность конфликта областей действия, следует
предварить элемент именем его с операцией разрешения области
действия .
f) Тело пространства имен ограничивается
g) Для константного объекта без элементов данных должна
применяться операция всякий раз, когда объект требуется
модифицировать.
23.4. Создайте пространство имен Currency, которое определяет константные
элементы ONE, TWO, FIVE, TEN, TWENTY, FIFTY и HUNDRED. Напишите две
коротких программы, использующих Currency. Одна программа должна делать
доступными все константы, а другая — только константу FIVE.
23.5. Считая, что определены именные пространства из рис. 23.15, укажите,
являются ли следующие ниже утверждения верными или неверными. Для каждого
неверного утверждения объясните свой ответ.
1 namespace Countrylnformation
2 {
3 using namespace std;
4 enum Countries { POLAND, SWITZERLAND, GERMANY,
5 AUSTRIA, CZECH-REPUBLIC };
1336
Глава 23
6 int kilometers;
7 string stringl;
8
9 namespace RegionalInformation
10 {
11 short getPopulation(); // предположим, что определение имеется
12 MapData map; // предположим, что определение имеется
13 } // конец Regionallnformation
14 } // конец Countrylnformation
15
16 namespace Data
17 {
18 using namespace Countrylnformation::Regionallnformation;
19 void *function( void *, int );
20 } // конец Data
Рис, 23.15. Пространства имен для упражнения 23.5
a) Переменная kilometers видима в пределах именного пространства Data.
b) Объект stringl видим в пределах именного пространства Data.
c) Константа POLAND не видима в пределах именного пространства Data.
d) Константа GERMANY видима в пределах именного пространства Data.
e) Функция function видима для именного пространства Data.
f) Именное пространство Data видимо для именного пространства
Countrylnformation.
g) Объект map видим для именного пространства Countrylnformation.
h) Объект stringl видим для именного пространства Regionallnformation.
23.6. Сформулируйте сходство и различия между mutable и const_cast. Приведите по
крайней мере один пример, когда одно может оказаться предпочтительнее
другого. [Замечание. В этом упражнении не требуется писать какой-либо код.]
23.7. Напишите программу, в которой для модификации константной переменной
применяется const_cast. [Подсказка. Используйте в своем решении указатель,
ссылающийся на константный идентификатор.]
23.8. Какую проблему разрешают виртуальные базовые классы?
23.9. Напишите программу, использующую виртуальные базовые классы. Класс на
вершине иерархии должен определять конструктор, принимающий по крайней
мере один аргумент (т.е. класс не должен иметь конструктора по умолчанию).
Какие требования предъявляются в этом случае к иерархии наследования?
23.10. Найдите ошибку (ошибки) в каждом из следующих фрагментов. Объясните, как
исправить каждую ошибку, если это возможно.
a) namespace Name {
int x;
int у;
mutable int z;
}
b) int integer = const_cast< int >( double ) ;
c) namespace PCM( 111, "hello" );
А
Таблица старшинства
и ассоциативности операций
Операции в таблице показаны в порядке убывания старшинства
(приоритета) сверху вниз (рис. АЛ).
Операция С++
1 °
[]
->
1 ++
■'
typeid
dynamic_cast< тип >
static_cast< тип >
reinterpret cast< тип >
\ const_cast< тип >
|++
1 •"
1+
Тип
бинарное разрешение области
действия
унарное разрешение области
действия
скобки
индекс массива
выбор элемента через объект
выбор элемента через указатель
постфиксный инкремент
постфиксный декремент
идентификация типа времени
выполнения
безопасное приведение типа времени
выполнения
безопасное приведение типа времени
компиляции
приведение для нестандартных
преобразований
отмена константности
префиксный инкремент
префиксный декремент
унарный плюс
Ассоциация
слева направо
слева направо
|
справа налево |
1338
Приложение А
| Операция C++
-
i
1 ~
| ( тип ) \
|sizeof
&
*
| new
Л new[]
delete
delete[]
• *
1 _>*
•
/
1%
| +
1 "
«
»
<
<=
>
>=
=
• -
&
A
1
£&
II
?:
| =
+=
1 -=
Тип
унарный минус
унарное логическое отрицание
унарное поразрядное дополнение
унарное приведение в стиле С
размер в байтах
адрес
разыменование
динамическое выделение памяти
динамическое выделение массива
динамическое освобождение
памяти
динамическое освобождение
массива
указатель на элемент через объект
указатель на элемент через
указатель
умножение
деление
взятие по модулю
сложение
вычитание
поразрядный сдвиг влево
поразрядный сдвиг вправо
отношение «меньше»
отношение «меньше или равно»
отношение «больше»
отношение «больше или равно»
отношение «равно»
отношение «не равно»
поразрядное И
поразрядное исключающее ИЛИ
поразрядное включающее ИЛИ
логическое И
логическое ИЛИ
тернарная условная операция
присваивание
присвоение суммы
присвоение разности
Ассоциация
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева направо
слева напр.аво |
справа налево
справа налево
Таблица старшинства и ассоциативности операций
1339
Операция C++
*=
/=
%=
&=
А=
1 =
«=
»=
| /
Тип
присвоение произведения
присвоение частного
присвоение остатка
присвоение поразрядного И
присвоение поразрядного
исключающего ИЛИ
присвоение поразрядного
включающего ИЛИ
присвоение левого сдвига
присвоение правого сдвига
запятая
Ассоциация
слева направо
Рис. А. 1.Та блица старшинства и ассоциативности операций
Б
Набор символов ASCII
Десятичные эквиваленты символов
0 12 3
0
1
2
3
4
5
6
7
8
9
10
11
12
nul
nl
dc4
rs
(
2
<
F
P
Z
d
n
X
soh
vt
nak
us
)
3
=
G
Q
[
e
о
У
stx
ff
syn
sp
etx
cr
etb
i
* ! +
4
>
H
R
\
f
P
z
5
7
1
S
]
9
q
<
ASCII
4
eot
so
can
■i
/
6
@
J
T
A
h
r
1
5
enq
si
em
#
-
7
A
К
U
i
s
}
6
ack
die
sub
$
.
8
В
L
V
■
J
t
-
7
bel
dd
esc
%
/
9
С
M
w
a
k
u
del
8
bs
dc2
fs
&
0
:
D
N
X
b
"
V
9
ht
dc3
gs
■
1
r
E
О
Y
с
m
w
Рис. Б.1. Набор символов ASCII
Цифры слева от таблицы являются первыми цифрами десятичного
эквивалента кода символа @-127), а цифры вверху таблицы представляют собой
последнюю цифру кода символа. Например, код символа 'F' равен 70, а код
символа '&' — 38.
в
Основные типы
На рис. В.1 перечислены основные (встроенные) типы языка C++.
Стандартный документ C++ не специфицирует точное число байт, требуемое для
хранения в памяти переменных этих типов. Однако документ указывает, как их
требования к памяти соотносятся друг с другом. В порядке возрастания требований
к памяти типы целых со знаком следуют так: signed char, short int, int и long
int. Это означает, что тип short int должен предусматривать для хранения
переменной по меньшей мере столько же памяти, сколько signed char; тип int
должен отводить в памяти не меньше места, чем short int, а тип long int должен
отводить в памяти не меньше места, чем int. Каждому целому типу со знаком
соответствует беззнаковый тип, занимающий столько же места в памяти. Типы
без знака не могут представлять отрицательные числа, но могут представлять
вдвое больше положительных значений, чем соответствующие типы со знаком.
По возрастанию требований к памяти числа с плавающей точкой располагаются
в порядке float, double и long double. Как и в случае целых типов, double
должен предусматривать для переменной не меньше места, чем float, a long double
должен предусматривать для переменной не меньше места, чем double.
Целочисленные типы
bool
char
signed char
unsigned char
short int
unsigned short int
int
unsigned int
long int
unsigned long int
wchar t
Типы с плавающей точкой
float
double
long double
Рис. В.1. Основные типы С
1344
Приложение В
Точные размеры и диапазоны значений основных типов зависят от
реализации. Диапазоны значений, поддерживаемые конкретной системой,
специфицируются заголовочными файлами <climits> (для целочисленных типов)
и <cfloat> (для типов с плавающей точкой).
Диапазон значений, поддерживаемый типом, зависит от числа байт,
используемого для его представления. Возьмем, например, систему с
4-байтовыми C2-битными) целыми. Для типа int (со знаком) допустимые
неотрицательные значения находятся в диапазоне от 0 до 2 147 483 647 B31 - 1).
Отрицательные значения находятся в диапазоне от -1 до -2 147 483 648 (-231). Это
дает 232 возможных значений. Тип unsigned int на той же системе будет
использовать для представления данных то же самое число бит, но не сможет
принимать отрицательных значений. Это дает диапазон значений от 0 до
4 294 967 295 B32 - 1). На той же системе short int не может использовать для
представления своих значений более 32 бит, a long int должен занимать в
памяти не менее 32 бит.
В C++ предусмотрен тип данных bool для переменных, в которых могут
храниться только значения true и false.
г
Код, унаследованный от С
ЦЕЛИ
В этой главе вы изучите:
• Переадресацию ввода на ввод
из файла и экранного
вывода на вывод в файл.
• Написание функций, имеющих
списки аргументов переменной
длины.
• Обработку аргументов командной
строки.
• Программную обработку
непредвиденных событий.
• Динамическое выделение памяти
для массивов средствами
динамического распределения
памяти С.
• Изменение размера выделенной
динамической памяти средствами
динамического распределения памяти С.
43 Заж 1114
1346
Приложение Г
Г.1. Введение
Г.2. Переадресация ввода/вывода в системах
UNIX/LINUX/Mac OS X и Windows
Г.З. Списки аргументов переменной длины
Г.4. Аргументы командной строки
Г.5. Замечания о компиляции программ из нескольких
исходных файлов
Г.6. Выход из программы с помощью exit и atexit
Г.7. Квалификатор типа volatile
Г.8. Суффиксы для целых констант и констант
с плавающей точкой
Г.9. Обработка сигналов
Г.10. Динамическое распределение памяти с помощью
calloc и realloc
Г.11. Безусловный переход: goto
Г.12. Объединения
Г.13. Спецификации компоновки
Г.14. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
Г.1. Введение
Мы обсудим здесь ряд вопросов, обычно не включаемых во вводные курсы по
языку C++. Многие из обсуждаемых здесь возможностей рассматриваются в
применении к конкретным операционным системам, в частности UNIX/LINUX/Mac
OS X и Windows. Основная часть материала адресована программистам, которым
потребуется работать со старым кодом, унаследованном от С.
Г.2. Переадресация ввода/вывода в системах
UNIX/LINUX/Mac OS X и Windows
Как правило, устройством ввода данных в программу является клавиатура
(стандартный ввод), а устройством вывода — экран монитора (стандартный
вывод). В большинстве операционных систем — в частности, UNIX, LINUX,
Mac OS X и Windows — можно переадресовать ввод так, чтобы он
производился не с клавиатуры, а из файла, и переадресовать экранный вывод, чтобы
поместить его в файл. Обе формы переадресации можно выполнить без
использования средств стандартной библиотеки для работы с файлами.
Код, унаследованный от С
1347
Существует несколько способов переадресации ввода/вывода в командной
строке UNIX. Рассмотрим исполняемый файл sum, который вводит по одному
целые числа и отслеживает текущую сумму введенных значений, пока не
будет установлен индикатор конца файла, после чего распечатывает результат.
Обычно пользователь вводит числа с клавиатуры и вводит комбинацию конца
файла, чтобы показать, что ввод данных окончен. При переадресации ввода
данные, которые необходимо ввести, можно взять из файла. Например, если
данные сохранены в файле input, командная строка
$ sum < input
запускает программу sum; символ переадресации ввода (<) указывает, что для
ввода в программу должны использоваться данные из файла input.
Переадресация ввода в окне командной строки Windows производится точно так же.
Заметьте, что $ — подсказка командной строки UNIX. (Подсказки UNIX
могут различаться на разных системах и в разных оболочках одной системы.)
Обучающиеся часто с трудом воспринимают тот факт, что переключение
является функцией операционной системы, а не еще одной возможностью C++.
Вторым способом переназначения ввода является использование конвейера.
Конвейер (|) вызывает переадресацию вывода одной программы на ввод другой
программы. Предположим, программа random выводит ряд случайных чисел;
вывод программы random можно «переправить» прямо в программу sum,
используя командную строку UNIX
$ random | sum
Это приведет к тому, что будет вычислена сумма чисел, выданных random.
Конвейер может применяться в UNIX, LINUX, Mac OS X и Windows.
Чтобы направить вывод программы в файл, используется символ
переадресации вывода (>). (В UNIX, LINUX, Mac OS X и Windows используется один
и тот же символ.) Например, для переназначения стандартного вывода
программы random в файл out воспользуйтесь следующей командной строкой:
$ random > out
И наконец, вывод программы можно присоединить в конец существующего
файла с помощью символа присоединения вывода (»). (В UNIX, LINUX, Mac
OS X и Windows используется один и тот же символ.) Например, чтобы
добавить вывод программы random в файл out, созданный предыдущей командной
строкой, воспользуйтесь командой
$ random » out
1348
Приложение Г
Г.З. Списки аргументов переменной длины1
Существует возможность создать функцию, число аргументов которой не
определено. Во многих программах, представленных в этой книге,
использовалась стандартная библиотечная функция printf, которая, как вы знаете,
принимает переменное число аргументов. Как минимум, printf должна получить
строку в качестве первого аргумента, но, кроме того, printf может принять
любое количество дополнительных аргументов. Прототип функции printf
определен следующим образом:
int print( const char ♦format,
);
Многоточие (...) в прототипе функции означает, что функция получает
переменное число аргументов любого типа. Заметьте, что многоточие должно
всегда находиться в конце списка параметров. Макросы и определения
заголовочного файла переменных аргументов <cstdarg> (рис. Г.1) предоставляют
программисту средства, необходимые для построения функций со списком
аргументов переменной длины.
Программа на рис. Г.2 демонстрирует функцию average (строка 25),
получающую произвольное количество аргументов. Первый аргумент average —
это всегда число усредняемых значений, а все остальные аргументы должны
иметь тип double.
Идентификатор
vajist
va start
Объяснение
Тип, предназначающийся для хранения информации,
необходимой макросам va_start, va_arg и va_end. Чтобы
получить доступ к аргументам в списке переменной длины,
необходимо объявить обьект типа vajist.
Макрос, который вызывается перед обращением к аргументам
списка переменной длины. Макрос инициализирует обьект,
объявленный с помощью vajist для использования макросами
va_arg и va_end.
va_arg
va end
Макрос, расширяющийся до выражения со значением и типом
следующего аргумента в списке переменной длины. Каждый
вызов va_arg изменяет объект, объявленный с помощью vajist
так, что объект указывает на следующий аргумент списка.
Макрос обеспечивает нормальный возврат из функции,
на список аргументов которой ссылался макрос va_ start
Рис. Г.1. Тип и макросы, определенные в заголовочном файле <cstdarg>
Перегрузка функций C++ позволяет осуществить многое из того, что в С достигается
использованием списков аргументов переменной длины.
Код, унаследованный от С
1349
1 // Рис. Г.2: figE_02.cpp
2 // Списки аргументов переменной длины.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::ios; '
7
8 #include <iomanip>
9 using std::setw;
10 using std::setprecision;
11 using std::setiosflags;
12 using std::fixed;
13
14 #include <cstdarg>
15 using std::va_list;
16
17 double average( int, ... );
18
19 int main()
20 {
21 double doublel
22 double double2
23 double double3
24 double double4
25
26 cout « fixed « setprecision( 1 ) « "doublel = "
27 « doublel « "\ndouble2 = " « double2 « "\ndouble3 = "
28 « double3 « "\ndouble4 = " « double4 « endl
29 « setprecision( 3 )
30 « M\nThe average of doublel and double2 is "
31 « average( 2, doublel, double2 )
32 « "\nThe average of doublel, double2, and double3 is "
33 « average( 3, doublel, double2, double3 )
34 « "\nThe average of doublel, double2, double3"
35 « " and double4 is "
36 « average( 4, doublel, double2, double3, double4 )
37 « endl;
38 return 0;
39 } // конец main
40
41 // вычислить среднее
42 double average( int count, ... )
43 {
44 double total = 0;
45 va_list list; // сохраняет информацию, необходимую для va_start
46
47 va_start( list, count );
48
49 // обработка списка аргументов переменной длины
50 for ( int i = 1; i <= count; i++ )
51 total += va_arg( list, double );
52
53 va__end( list ) ; // закончить va_start
54 return total / count;
55 } // конец функции average
= 37.5;
= 22.5;
= 1.7;
= 10.2;
1350
Приложение Г
w = 37.5
х = 22.5
у = 1.7
z = 10.2
The average of w and x is 30.000
The average of w, x and у is 20.567
The average of w, x, y, and z is 17.975
Рис. Г.2. Определение списка аргументов переменной длины
Функция average применяет все определения и макросы заголовочного
файла <cstdarg>. Объект list, типа va_list, используется макросами va_start,
va_arg и va_end для обработки списка аргументов переменной длины
функции average. Функция начинается вызовом макроса va_start,
инициализирующего объект list. Макрос получает два аргумента — объект list и
идентификатор самого правого параметра в списке перед многоточием; в данном
случае это count (va_start использует здесь count для определения того, где
начинается список аргументов переменной длины).
Затем функция average последовательно складывает аргументы из списка
в переменной total. Прибавляемое к total значение извлекается из списка
аргументов вызовом макроса va_arg. Макрос va_arg получает два аргумента —
объект list и тип значения, ожидаемого в списке аргументов функции (в
данном случае double), — и возвращает значение аргумента. Перед возвратом
функция average вызывает макрос va_end с объектом list в качестве
аргумента. Наконец, вычисляется среднее и его значение возвращается в main.
Заметьте, что в переменной части списка аргументов мы указываем только
аргументы типа double.
Переменные типа float в списках аргументов переменной длины возводятся
до double. Кроме того, целые переменные, меньшие по размеру, чем int,
возводятся до int (переменные типов int, unsigned, long и unsigned long остаются
без изменений).
Общее методическое замечание Г.1
В списках аргументов переменной длины можно использовать только
аргументы основных типов и структурных типов в стиле С,
которые не содержат специфических элементов языка C++, таких, как
виртуальные функции, конструкторы, деструкторы, ссылки,
константные элементы данных и виртуальные базовые классы.
т Типичная ошибка программирования Г.1
Многоточие в середине списка параметров функции является
синтаксической ошибкой. Многоточие может находиться только в конце
списка параметров.
Код, унаследованный от С
1351
Г.4. Аргументы командной строки
Во многих системах — в частности, UNIX, LINUX, Mac OS X и Windows —
существует возможность передать функции main аргументы из командной
строки, включив в список параметров main параметры int argc и char *argv[].
Параметр argc принимает число аргументов в командной строке. Параметр
argv является массивом указателей на char, ссылающихся на строки, в
которых сохраняются действительные аргументы командной строки. Типичное
использование аргументов командной строки — распечатка аргументов,
передача программных опций и передача программе имен файлов.
Программа на рис. Г.З посимвольно копирует один файл в другой. Пусть
исполняемый файл программы называется copyFile (т.е. copyFile является
исполняемым именем для файла). Типичной командной строкой для программы
в системе UNIX будет
$ copyFile input output
Данная командная строка указывает, что файл input должен копироваться
в файл output. Если во время исполнения программы argc не равен 3 (copyFile
считается одним из аргументов), она выдает сообщение об ошибке (строка 16).
В противном случае массив argv будет содержать строки "copyFile", "input"
и "output". Второй и третий аргументы командной строки воспринимаются
программой в качестве имен файлов. Файлы открываются посредством
создания объектов inFile класса ifstream и outFile класса ofstream (строки 19 и 28).
В случае успешного открытия обоих файлов символы считываются из input
и записываются в output до тех пор, пока для файла input не будет установлен
индикатор конца файла (строки 40-44). После этого программа завершается.
Результатом является точной копией файла input. Заметим, что не во всех
системах аргументы командной строки используются так же просто, как в UNIX,
LINUX, Mac OS X и Windows. Например, некоторые системы VMS и старые
системы Macintosh требуют специальных установок для обработки аргументов
командной строки. За более подробной информацией об использовании
аргументов командной строки обратитесь к руководству по вашей системе.
1 // Рис. Г.З: figE_03.cpp
2 // Аргументы командной строки.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::ios;
7
8 #include <fstream>
9 using std::ifstream/
10 using std::ofstream;
11
12 int main( int argc, char *argv[] )
13 {
14 // проверить число аргументов командной строки
15 if ( argc != 3 )
16 cout « "Usage: copyFile infile_name outfile_name" « endl ;
17 else
18 {
19 ifstream inFile( argv[ 1 ], ios::in );
1352
Приложение Г
20
21 // невозможно открыть входной файл
22 if ( !inFile )
23 {
24 cout « argv[ 1 ] « " could not be opened" « endl;
25 return -1;
26 } // конец if
27
28 ofstream outFile( argv[ 2 ], ios::out );
29
30 // невозможно открыть выходной файл
31 if ( !outFile )
32 {
33 cout « argv[ 2 ] « " could not be opened" « endl;
34 inFile.close();
35 return -2;
36 } // конец if
37
38 char с = inFile.get(); // прочитать первый символ
39
40 while ( inFile )
41 {
42 outFile.put( с ); // вывести символ
43 с = inFile.get(); // прочитать следующий символ
44 } // конец while
45 } // конец else
46
47 return 0;
48 } // конец main
Рис. Г.З. Получение аргументов командной строки
Г.5. Замечания о компиляции программ
из нескольких исходных файлов
Как было отмечено ранее, можно создавать программы, которые состоят из
нескольких исходных файлов (см. главу 9). Есть несколько моментов, о
которых не следует забывать при создании многофайловых программ. Например,
определение функции должно целиком находиться в одном файле — его
нельзя разделить на несколько файлов.
В главе 6 нами были введены понятия класса памяти и области действия.
Мы узнали, что переменные, объявленные вне любого определения функции,
по умолчанию принадлежат к статическому классу памяти и называются
глобальными переменными. Глобальные переменные доступны любой функции,
определенной в том же файле после объявления этих переменных. Глобальные
переменные также доступны и функциям в других файлах, однако они
должны объявляться в каждом из них. Например, если мы определяем глобальную
целую переменную flag в одном файле и ссылаемся на нее в другом файле, то
последний должен содержать объявление
extern int flag;
Только после этого можно будет обращаться к переменной. В этом объявлении
спецификатор класса памяти extern сообщает компилятору, что переменная
Код, унаследованный от С
1353
flag определена либо позднее в этом же, либо в другом файле. Компилятор
сообщает компоновщику, что в файле имеется неразрешенная ссылка на
переменную flag (компилятор не знает, в каком месте определена переменная flag,
поэтому предоставляет ее поиск компоновщику). Если компоновщик не
найдет определение flag, возникнет ошибка компоновки и не будет создано
исполняемого файла. Если же соответствующее глобальное определение будет
обнаружено, компоновщик разрешит ссылки, указав, где находится flag.
Вопросы производительности Г.1
Глобальные переменные могут увеличить производительность, так
как они непосредственно доступны в любой функции, - устраняются
дополнительные затраты на передачу данных функциям.
Общее методическое замечание Г.2
Следует избегать применения глобальных переменных, за
исключением случаев, когда быстродействие приложения является критическим
фактором, поскольку они нарушают принцип минимума привилегий
и усложняют сопровождение программы.
Так же как объявление extern позволяет объявлять глобальные переменные
в других файлах программы, прототипы функций могут расширить область
действия функций за пределы файла, в котором они определены (спецификатор
extern в прототипе функции не обязателен). Для этого необходимо включить
прототип функции в каждый файл, в котором функция вызывается, и
компилировать файлы совместно. Прототипы функций сообщают компилятору, что
указанная функция определена либо позднее в этом же, либо в другом файле.
И снова компилятор не пытается разрешить ссылки на такую функцию, эта
обязанность поручается компоновщику. Если компоновщик не сумеет
обнаружить соответствующее определение функции, возникает ошибка.
Как пример использования прототипа функции для расширения ее области
действия рассмотрите любую программу, содержащую директиву #include
<cstring>. Эта директива включает в файл прототипы таких функций, как stremp
и streat. Другие функции в файле могут для выполнения своих задач вызывать
stremp и strcat. Функции stremp и strcat определены отдельно, и нам нет
необходимости знать, где они определены. Мы просто утилизируем их код в своих
программах. Компоновщик разрешает наши ссылки на эти функции автоматически.
Этот процесс позволяет нам использовать функции стандартной библиотеки.
Общее методическое замечание Г.З
Создание программ из нескольких исходных файлов облегчает
утилизацию кода и систематическое конструирование программного
обеспечения. Функции могут использоваться многими приложениями. В та
ких случаях следует сохранять эти функции в отдельных исходных
файлах, и каждый исходный файл должен иметь соответствующий
ему заголовок, содержащий прототипы функций. Это позволяет
программистам различных приложений утилизировать один и тот же
код, включая в них соответствующий заголовочный файл и
компилируя эти программы вместе с уже существующим исходным файлом.
1354
Приложение Г
Переносимость программ Г.1
Некоторые системы не поддерживают имена глобальных переменных
или функций длиной более шести символов. Это следует учитывать
при написании программ, которые будут переноситься на различные
платформы.
Существует возможность ограничить область действия глобальной
переменной или функции заданным файлом. Спецификатор класса памяти static,
будучи применен к глобальной переменной или функции, предотвращает
обращение к ней из любой функции, не определенной в том же самом файле.
Иногда это называют внутренней компоновкой. Глобальные переменные
и функции, определение которых не предваряется static, имеют внешнюю
компоновку, — к ним могут получить доступ другие файлы, если они содержат
соответствующие объявления и/или прототипы функций.
Объявление глобальной переменной
static double pi = 3.14159;
создает переменную pi типа float, присваивает ей значение 3.14159 и
показывает, что pi известна только функциям файла, в котором она определена.
Спецификатор static обычно используется со вспомогательными
функциями, которые вызываются только функциями отдельного файла. Если
функция не используется за пределами отдельного файла, то следует применять
принцип минимальных привилегий, объявляя ее как static. Если функция
определена до того, как она используется в файле, static должен
применяться к определению функции. В противном случае static применяется к ее
прототипу.
При разработке больших программ, состоящих из нескольких исходных
файлов, компиляция программы становится утомительным делом, — если
в одном из файлов сделаны небольшие изменения, приходится
перекомпилировать всю программу. Многие системы снабжены специальными утилитами,
которые перекомпилируют только модифицированные файлы программы.
В системах UNIX такая утилита называется make. Утилита читает файл с
именем Makefile у который содержит инструкции по компиляции и компоновке
программы. В таких системах для PC, как Borland C++ и Microsoft Visual
C++, предусмотрены утилиты make и «проекты». За более подробной
информацией по утилите make обратитесь к руководству по вашей системе.
Г.6. Выход из программы с помощью exit и atexit
Библиотека утилит общего назначения (<cstdlib>) предусматривает
некоторые способы выхода из выполняющейся программы, отличные от
традиционного возврата из функции main. Функция exit вызывает завершение работы
программы, как если бы она выполнилась нормально. Эта функция часто
используется для того, чтобы прекратить выполнение, когда при вводе
обнаружена ошибка, или невозможно открыть файл, который должна обрабатывать
программа. Функция atexit регистрирует функцию, которая будет вызвана
при успешном завершении программы, т.е. если управление достигает конца
функции main или вызывается функция exit.
Код, унаследованный от С
1355
Функции atexit в качестве аргумента передается указатель на функцию
(т.е. имя функции). Функция, вызываемая при завершении программы, не
может иметь аргументов и не может возвращать значения. Можно
зарегистрировать до 32 функций, которые должны выполняться при завершении
программы.
Функция exit принимает один аргумент. Аргумент, как правило —
символическая константа EXIT_SUCCESS или EXIT_FAILURE. Если exit вызвана
с EXIT_ SUCCESS, окружению возвращается значение успешного
завершения, зависящее от реализации. Если exit вызвана с EXIT_FAILURE,
окружению возвращается значение неудачного завершения. Когда вызывается
функция exit, все функции, предварительно зарегистрированные с помощью atexit,
вызываются в порядке, обратном их регистрации, все связанные с программой
потоки сбрасываются и закрываются, а управление возвращается системе.
Программа на рис. Г.4 тестирует функции exit и atexit. Программа предлагает
пользователю определить, завершать ли программу с помощью exit или же по
достижении конца функции main. Обратите внимание, что функция print
выполняется при завершении программы в любом случае.
1 // Рис. Г.4: figE_04.cpp
2 // Функции exit и atexit.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::cin;
7
8 #include <cstdlib>
9 using std::atexit;
10 using std::exit;
11
12 void print();
13
14 int main()
15 {
16 atexit( print ); // зарегистрировать функцию print
17
18 cout « "Enter 1 to terminate program with function exit"
19 « "\nEnter 2 to terminate program normally\n";
20
21 int answer;
22 cin » answer;
23
24 // выход, если answer = 1
25 if ( answer == 1 )
26 {
27 cout « "\nTerminating program with function exit\n";
28 exit( EXIT_SUCCESS );
29 } // конец if
30
31 cout « "\nTerminating program by reaching the end of main"
32 « endl;
33
34 return 0;
35 } // конец main
36
1356
Приложение Г
37 // вывести сообщение перед завершением
38 void print()
39 {
40 cout « "Executing function print at program termination\n"
41 « "Program terminated" « endl;
42 } // конец функции print
Enter 1 to terminate program with function exit
Enter 2 to terminate program normally
: 2
Terminating program by reaching the end of main
Executing function print at program termination
Program terminated
Enter 1 to terminate program with function exit
Enter 2 to terminate program normally
: 1
Terminating program with function exit
Executing function print at program termination
Program terminated
Рис. Г.4. Применение функций exit и atexit
Г.7. Квалификатор типа volatile
Квалификатор типа volatile применяется к определению переменной,
которая может изменяться вне программы (т.е. переменная не находится под
полным контролем последней). Таким образом, компилятор не может производить
оптимизацию (например, ускорение исполнения программы или сокращение
требуемой памяти), исходя из знания того, что «на поведение переменной
влияют только действия программы, контролируемые компилятором».
Г.8. Суффиксы для целых констант и констант
с плавающей точкой
В C++ предусмотрены суффиксы для целых констант и констант с
плавающей точкой. Целыми суффиксами являются: и или U для целого unsigned, 1
или L для целого типа long, и ul или UL для целого типа unsigned long.
Следующие константы имеют соответственно тип unsigned, long и unsigned long:
174u
8358L
28373ul
Если целая константа не имеет суффикса, ее тип определяется ближайшим
типом, способным хранить значение такой величины (сначала int, потом long int
и, наконец, unsigned long int)
Код, унаследованный от С
1357
Суффиксы констант с плавающей точкой следующие: f или F для float, и 1
или L для long double. Следующие константы имеют соответственно тип long
double и float:
3.14159L
1.28f
Константы с плавающей точкой без суффикса имеют тип double. Константа
с неправильным суффиксом вызывает либо предупреждение, либо ошибку
компиляции.
Г.9. Обработка сигналов
Непредвиденное событие, или сигнал, может привести к тому, что
программа будет завершена преждевременно. Вот лишь некоторые из
непредвиденных событий: прерывание (ввод Ctrl+C в системах UNIX, LINUX, Mac OS X
или DOS), недопустимая инструкция, нарушение сегментации, запрос на
завершение от операционной системы и исключительная ситуация с
плавающей точкой (деление на ноль или переполнение). Библиотека обработки
сигналов обеспечивает возможность перехвата непредвиденных событий с
помощью функции signal. Функция signal получает два аргумента: целое число —
номер сигнала, и указатель на функцию обработки сигналов. Сигналы могут
генерироваться функцией raise, которая принимает в качестве аргумента
целый номер сигнала. На рис. Г.5 представлена сводка стандартных сигналов,
определенных в заголовочном файле <csignal>. Программа на рис. Г.6
демонстрирует функции signal и raise в действии.
Сигнал I Объяснение
SIGABRT | Аварийное завершение программы (например, вызов функции abort).
SIGFPE
SIGILL
SIGINT
SIGSEGV
SIGTERM
Ошибочная арифметическая операция, например деление на ноль или
операция, вызывающая переполнение.
Обнаружение недопустимой инструкции.
Получение интерактивного сигнала прерывания.
Некорректный доступ к памяти.
Запрос на завершение, направленный программе.
Рис. Г.5. Сигналы, определенные в заголовочном файле signal.h
1 // Рис. Г.6: figE_06.cpp
2 // Обработка сигналов.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
1358
Приложение Г
8 #include <iomanip>
9 using std::setw;
10
11 #include <csignal>
12 using std::raise;
13 using std::signal;
14
15 #include <cstdlib>
16 using std::exit/
17 using std::rand;
18 using std::srand;
19
20 #include <ctime>
21 using std::time;
22
23 void signalHandler( int );
24
25 int main()
26 {
27 signal( SIGINT, signalHandler );
28 srand( time( 0 ) );
29
30 // создать и вывести случайные числа
31 for ( int i = 1; i <= 100; i++ )
32 {
33 int x = 1 + rand() % 50;
34
35 if ( x == 25 )
36 raise ( SIGINT ); // возбудить SIGINT, если х = 25
37
38 cout « setw( 4 ) « i;
39
40 if ( i % 10 == 0 )
41 cout « endl; // если i кратно 10, вывести endl
42 } // конец for
43
44 return 0;
45 } // конец main
46
47 // обрабатывает сигнал
48 void signalHandler( int signalValue )
49 {
50 cout « "\nlnterrupt signal (" « signalValue
51 « ") received.\n"
52 « "Do you wish to continue A = yes or 2 = no)? ";
53
54 int response;
55
56 cin » response;
57
58 // проверить действительность ответа
59 while ( response != 1 && response != 2 )
60 {
61 cout « "A = yes or 2 = no)? " ;
62 cin » response;
63 } // конец while
64
Код, унаследованный от С
1359
65 // определить, не пора ли выйти
66 if ( response != 1 )
67 exit( EXIT_SUCCESS );
68
69 // вызвать signal, передав ей SIGINT и адрес signalHandler
70 signal( SIGINT, signalHandler );
71 } // конец функции signalHandler
1
11
21
31
41
51
61
71
81
91
2
12
22
32
42
52
62
72
82
92
3
13
23
33
43
53
63
73
83
93
4
14
24
34
44
54
64
74
94
5
15
25
35
45
55
65
75
95
6
16
26
36
46
56
ее
76
86
7
17
27
37
47
57
67
77
87
8
18
28
38
48
58
68
78
88
9
19
29
39
49
59
69
79
89
10
20
30
40
50
60
70
80
90
Interrupt signal ( 2 ) received.
Do you wish to continue ( 1 = yes or 2 = no )? 1
94 95 96
Interrupt signal ( 2 ) received.
Do you wish to continue ( 1 = yes or 2 = no )? 2
Рис. Г.6. Обработка сигналов
Программа на рис. Г.6 перехватывает интерактивный сигнал (SIGINT)
с помощью функции signal. Строка 15 вызывает signal с SIGINT и указателем
на функцию signalHandler. (Как вы помните, имя функции является
указателем на эту функцию.) Когда генерируется сигнал типа SIGINT, управление
передается функции signalHandler, выдается сообщение на печать, и
пользователь получает возможность продолжить нормальное выполнение программы.
Если пользователь хочет продолжить выполнение, обработчик сигналов вновь
инициализируется повторным вызовом signal (некоторые системы требуют,
чтобы обработчик сигналов был повторно инициализирован) и управление
передается в ту точку программы, в которой был обнаружен сигнал. В этой
программе для моделирования интерактивного сигнала используется функция
raise. Выбирается произвольное число между 1 и 50. Если число равно 25/
вызывается raise для имитации интерактивного сигнала. Обычно интерактивные
сигналы инициируются извне. Например, нажатие Ctrl+C во время
выполнения программы в системах UNIX, LINUX, Mac OS X или DOS генерирует
интерактивный сигнал, который прерывает выполнение программы. Обработку
сигналов можно использовать для перехвата интерактивных сигналов и
предотвращения прерывания программы.
Г.10. Динамическое распределение памяти с помощью
calloc и realloc
В главе 10 обсуждалось динамическое распределение памяти с помощью
new и delete. Программисты, пишущие на C++, должны использовать эти
операции, а не функции С malloc и free (заголовок <cstdlib>). Однако болынинст-
1360 Приложение Г
ву программистов приходится читать большие объемы существующего кода
на С, поэтому мы предлагаем здесь дополнительное обсуждение
динамического распределения памяти в стиле С.
Библиотека утилит общего назначения (<cstdlib>) поддерживает еще две
функции для динамического распределения памяти — calloc и realloc. С
помощью этих функций можно создавать и модифицировать динамические
массивы. Как показано в главе 8, указатель на массив может индексироваться как
массив. Таким образом, указателем на непрерывный блок памяти, созданным
calloc, можно манипулировать как массивом. Функция calloc динамически
выделяет память для массива. Прототип calloc выглядит так:
void *calloc( size_t nmemb, size_t size );
Функция принимает два аргумента — число элементов (nmemb) и размер
каждого элемента (size), — и инициализирует элементы массива нулями.
Функция возвращает указатель на выделенную память или нулевой указатель @),
если память не может быть выделена.
Функция realloc изменяет размер объекта, выделенного в результате
предыдущего вызова malloc, calloc или realloc. Содержимое первоначального
объекта сохраняется при условии, что размер вновь выделяемой памяти
больше, чем первоначальный. В противном случае содержимое остается
неизменным лишь в пределах размера нового объекта. Прототип realloc определен
следующим образом:
void *realloc( void *ptr, size_t size );
Функция realloc принимает два аргумента — указатель на первоначальный
объект (ptr) и новый размер объекта (size). Если ptr равен 0, realloc работает
аналогично malloc. Если size равен 0, a ptr не 0, память, выделенная для
объекта, освобождается. В противном случае, если ptr не 0 и размер больше нуля,
realloc пытается выделить для объекта новый блок памяти. Если новую
память выделить не удается, объект, на который указывает ptr, не изменяется.
Функция realloc возвращает либо указатель на вновь выделенную память,
либо нулевой указатель.
Типичная ошибка программирования Г.2
Применение операции delete к указателю, полученному от malloc,
calloc или realloc, либо вызов realloc или free для указателя,
полученного операцией new.
Г.11. Безусловный переход: goto
На протяжении всей книги мы постоянно подчеркивали важность
использования методов структурного программирования, способствующих созданию
надежного программного обеспечения, которое легко отлаживать,
сопровождать и модифицировать. В некоторых случаях производительность
оказывается важнее строгой приверженности канонам структурного программирования.
В этом случае допустимо использовать и некоторые неструктурные методы.
Например, мы можем использовать break, чтобы прервать выполнение струк-
Код, унаследованный от С
1361
туры повторения прежде, чем условие продолжения цикла станет ложным.
Это исключает ненужные итерации, если задача выполнена до того, как
произойдет окончание цикла.
Другим примером неструктурного программирования является применение
оператора goto — безусловного перехода. Результатом исполнения goto
является передача управления первому оператору программы после метки,
указанной в операторе goto. Метка представляет собой идентификатор, за
которым следует двоеточие. Метка должна находиться в той же самой функции,
что и оператор goto, который на нее ссылается. Программа на рис. Г.7
использует операторы goto, чтобы десять раз выполнить цикл и при этом каждый раз
выводить на печать значение счетчика. После инициализации count
значением 1 программа проверяет count, определяя, не больше ли он 10 (метка start
пропускается, поскольку метка не выполняет никаких действий). Если
больше, то управление передается первому оператору, расположенному за меткой
end. В противном случае count печатается и инкрементируется, и управление
передается от goto первому оператору после метки start.
1 // Рис. Г.7: figE_07.cpp
2 // Использование goto.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <iomanip>
8 using std::left;
9 using std::setw;
10
11 int main()
12 {
13 int count = 1;
14
15 start: // метка
16 // перейти на end, если count превосходит 10
17 if ( count > 10 )
18 goto end;
19
20 cout « setw( 2 ) « left « count;
21 ++count;
22
23 // перейти на start в строке 17
24 goto start;
25
26 end: // метка
27 cout « endl;
28
29 return 0;
30 } // конец main
123456789 10
Рис. Г.9. Использование goto
1362
Приложение Г
В главах 4-5 мы констатировали, что для написания любой программы
необходимы всего три управляющих структуры — последовательная, выбора
и повторения. Следуя правилам структурного программирования, можно
создать глубоко вложенные управляющие структуры, из которых очень трудно
эффективно выйти. Некоторые программисты используют в таких ситуациях
операторы goto, как средство быстрого выхода из глубоко вложенной
структуры. Это избавляет от необходимости проверять многочисленные условия
выхода из управляющей структуры.
Вопросы производительности Г.2
Оператор goto может использоваться для эффективного выхода из
глубоко вложенных управляющих структур, но может сделать код
трудным для чтения и сопровождения.
Предотвращение ошибок Г.1
Оператор goto должен использоваться только в приложениях,
ориентированных на высокую производительность. Оператор goto не
является структурным и программы с этим оператором, как правило,
труднее отлаживать, сопровождать и модифицировать.
Г.12. Объединения
Объединение (определяемое ключевым словом union) является областью
памяти, в которой могут храниться объекты различных типов. Однако в
каждый момент времени объединение может содержать только один объект,
поскольку элементы объединения разделяют одну и ту же память.
Ответственность за то, что обращение к данным в объединении будет производиться по
имени элемента соответствующего типа, лежит на программисте.
^ Типичная ошибка программирования Г.З
Результат обращения к элементу объединения, отличному от того,
что был сохранен в объединении последним, не определен. Такое
обращение трактует данные как принадлежащие к другому типу.
Переносимость программ Г.2
Если данные сохраняются в объединении как принадлежащие одному
типу, а читаются как данные другого типа, то результаты будут
зависеть от реализации.
В различные моменты исполнения программы некоторые объекты будут
недействительны, в то время как доступен будет другой (единственный) объект,
так что объединение использует разделяемое пространство памяти, и не
расходует ее на объекты, которые не активны. Число байт, отводимое под
объединение, будет по меньшей мере достаточным для хранения его элемента
наибольшего размера.
Код, унаследованный от С
1363
Вопросы производительности Г.2
Объединения позволяют экономить память.
Переносимость программ Г.3
Объем памяти, необходимый для хранения объединения, зависит от
реализации.
Форма объявления объединения такая же, как у структуры или класса.
Например,
union Number {
int x;
double у;
};
указывает, что Number является типом объединения с элементами int x
и double у. Определение объединения должно предшествовать всем функциям,
в которых оно будет использоваться.
Общее методическое замечание Г.4
Как и в случае объявления структуры или класса, объявление
объединения просто создает новый тип. Размещение объявления union или
struct вне любой из функций не создает глобальной переменной.
Из встроенных операций над объединениями допустимы только
присваивание другому объединению того же типа, взятие адреса (&) и доступ к
элементам объединения посредством операций элемента структуры (.) и указателя
структуры (->). Объединения нельзя сравнивать.
—^гл Типичная ошибка программирования Г.4
Сравнение объединений вызывает ошибку компиляции, поскольку
компилятор не знает, какой элемент каждого из объединений активен и,
соответственно, какой элемент одного из них с каким элементом
другого нужно сравнивать.
Объединение похоже на класс в том отношении, что оно может иметь
конструктор для инициализации любого из его элементов. Объединение, не
имеющее конструктора, может инициализироваться другим объединением того же
типа, выражением, имеющим тип его первого элемента, или с помощью
инициализатора (заключенного в фигурные скобки) для первого элемента
объединения. Объединения могут иметь и другие элемент-функции, например,
деструкторы, но элемент-функции объединения не могут объявляться как
виртуальные. По умолчанию элементы объединения имеют открытый доступ.
Типичная ошибка программирования Г.5
Инициализация объединения при объявлении значением или
выражением, тип которого отличен от типа первого элемента объединения,
вызывает ошибку компиляции.
1364
Приложение Г
Объединение не может играть в наследовании роль базового класса (т.е. от
объединений нельзя производить классы). Объединения могут содержать в
качестве элементов объекты только в том случае, если эти объекты не имеют
конструктора, деструктора и перегруженной операции присваивания.
Никакие элементы данных объединения не могут объявляться как статические.
Программа на рис. Г.8 объявляет переменную value типа union number
и отображает значения, хранящиеся в объединении, как тип int и как double.
Результаты программы зависят от реализации. Вывод программы
свидетельствует, что внутреннее представление значения double может быть
совершенно отлично от представления int.
1 // Рис. Г.8: figE_08.cpp
2 // Пример объединения.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 // определение объединения Number
8 union Number
9 {
10 int integer1;
11 double doublel;
12 }; // конец union Number
13
14 int main()
15 {
16 Number value; // переменная-объединение
17
18 value.integerl = 100; // присвоить 100 элементу integerl
19
20 cout « "Put a value in the integer member\n"
21 « "and print both members.\nint: "
22 « value.integerl « "\ndouble: " « value.doublel
23 « endl;
24
25 value.doublel = 100.0; // присвоить 100.0 элементу doublel
26
27 cout « "Put a value in the floating member\n"
28 « "and print both members.\nint: "
29 « value.integerl « "\ndouble: " « value.doublel
30 « endl;
31
32 return 0;
33 } // конец main
Put a value in the integer member
and print both members.
int: 100
double: 2.122e-314
Put a value in the floating member
and print both members.
int: 0
double: 100
Рис. Г.8. Вывод на печать значения объединения в формате типа данных каждого
из элементов
Код, унаследованный от С
1365
Анонимное объединение является объединением без имени типа, которое не
может использоваться для определения объектов или указателей перед
завершающей точкой с запятой. Такое объединение не создает типа, а создает
неименованный объект. К элементам анонимного объединения можно
непосредственно обращаться в той области действия, где оно объявлено, как к любым
другим локальным переменным, — использовать операцию-точку (.) или
операцию-стрелку (->) не требуется.
Для анонимных объединений существуют некоторые ограничения.
Анонимные объединения могут содержать только элементы данных. Все их
элементы должны быть открытыми. Анонимное объединение, объявленное
глобально (т.е. в области действия файла), должно быть явно объявлено как
static. Рис. Г.9 демонстрирует анонимное объединение.
1 // Рис. Г.9: figE_09.cpp
2 // Анонимное объединение.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 int main()
8 {
9 // объявить анонимное объединение; элементы
10 // integer1, doublel и charPtr разделяют одно пространство
11 union
12 {
13 int integerl;
14 double doublel;
15 char *charPtr;
16 }; // конец анонимного union
17
18 // объявить локальные переменные
19 int integer2 = 1;
20 double double2 = 3.3;
21 char *char2Ptr = "Anonymous";
22
23 //по очереди присвоить значение каждому элементу
24 //и распечатать его
25 cout « integer2 « ' ' ;
26 integerl = 2;
27 cout « integerl « endl;
28
29 cout « double2 « '
30 doublel = 4.4;
31 cout « doublel « endl;
32
33 cout « char2Ptr « ' ';
34 charPtr = "union";
35 cout « charPtr « endl;
36
37 return 0;
38 } // конец main
1366
Приложение Г
1
3
2
.3 4.4
Anonymous
union
Рис. Г.9. Использование анонимного объединения
Г.13. Спецификации компоновки
В программе на C++ можно вызывать функции, написанные на С и
компилированные с помощью компилятора С. Как говорилось в разделе 6.17, C++
специальным образом кодирует имена функций для обеспечения безопасной
по типу компоновки. Однако в С имена функций не кодируются. Таким
образом, функция, компилированная в С, не будет распознаваться при попытке
компоновать ее с кодом C++, так как C++ ожидает, что имя функции будет
особым образом закодировано. C++ позволяет программисту указать
спецификацию компоновки, сообщающую компилятору, что функция была
компилирована в С, чтобы предотвратить кодирование ее имени компилятором C++.
Спецификации компоновки полезны, когда имеются уже разработанные
большие библиотеки специализированных функций, а пользователь либо не имеет
доступа к их исходному коду для перекомпиляции его в C++, либо не имеет
времени на преобразование библиотечных функций из С в C++.
Чтобы сообщить компилятору о том, что одна или несколько функций
компилировались в С, прототипы функций нужно записать следующим образом:
extern "С" прототип функции /I одиночная функция
extern "С" // несколько функций
{
прототипы функций
}
Эти спецификации сообщают компилятору, что указанные функции
компилировались не как функции C++, так что для них не следует производить
кодирование имен. После этого функции могут быть корректно компонованы с
программой. В среду C++ обычно входят стандартные библиотеки С, для функций
которых программисту не требуется указывать спецификации компоновки.
Г.14. Заключение
В этом приложении было рассмотрено несколько вопросов, касающихся
кода, унаследованного от С. Мы обсудили переадресацию ввода с клавиатуры
на ввод из файла и вывода на экран на вывод в файл. Мы представили списки
аргументов переменной длины, аргументы командной строки и обработку
непредусмотренных событий. Вы изучили также динамическое выделение и
перераспределение памяти. В следующем приложении вы изучите средства
препроцессора для включения других файлов, определения символических
констант и определения макросов.
Код, унаследованный от С
1367
Резюме
• Многие операционные системы — в частности, UNIX, LINUX, Mac OS X
и Windows — позволяют переадресовать потоки ввода/вывода программы. Ввод
переназначается в командной строке UNIX, LINUX, Mac OS X или Windows с помощью
символа переадресации ввода (<) или конвейера (|). Вывод переназначается в
командной строке UNIX, LINUX, Mac OS X или Windows с помощью символа
переадресации вывода (>) или присоединения вывода (»). Применение символа
переадресации вывода просто сохраняет выводимые программой данные в файле, а символ
присоединения вывода добавляет выводимые программой данные в конец указанного
файла.
• Макросы и определения заголовочного файла <cstdarg> предоставляют
программисту средства, необходимые для построения функций со списком аргументов
переменной длины.
• Многоточие (...) в прототипе функции указывает, что функция принимает
переменное число аргументов.
• Тип va_list предназначается для хранения информации, необходимой макросам
va_start, va_arg и va_end. Чтобы получить доступ к аргументам в списке
переменной длины, необходимо объявить объект типа va_list.
• Макрос va__start вызывается перед обращением к аргументам списка переменной
длины. Макрос инициализирует объект, объявленный как va_list, для
использования макросами va_arg и va_end.
• Макрос va_arg расширяется до выражения со значением и типом следующего
аргумента в списке переменной длины. Каждый вызов va_arg изменяет объект,
объявленный с помощью va_list так, что объект указывает на следующий аргумент
списка.
• Макрос va_end упрощает нормальный возврат из функции, на список аргументов
переменной длины которой ссылался макрос va_start.
• Во многих системах — в частности, UNIX, LINUX, Mac OS X и Windows —
существует возможность передавать функции main аргументы из командной строки
посредством параметров int argc и char *argv[] в списке параметров main. Параметр argc
принимает число аргументов в командной строке. Параметр argv является массивом
строк, в котором сохраняются имеющиеся в командной строке аргументы.
• Определение функции должно целиком находиться в одном файле, его нельзя
разделить на несколько файлов.
• Глобальные переменные должны быть объявлены в каждом из файлов, где они
используются.
• Прототипы функций могут расширять область действия функций за пределы файла,
в котором они определены (спецификатор extern в прототипе функции не
обязателен). Для этого необходимо включить прототип функции в каждый файл, в котором
функция вызывается, и компилировать файлы совместно.
• Спецификатор класса памяти static, будучи примененным к глобальной переменной
или функции, предотвращает ее использование любой функцией, не определенной
в том же самом файле. Иногда это называют внутренней компоновкой. Глобальные
переменные и функции, определение которых не предваряется static, допускают
внешнюю компоновку; другие файлы могут получить к ним доступ, если содержат
соответствующие объявления и/или прототипы функций.
• Спецификатор static обычно используется со вспомогательными функциями,
которые вызываются только функциями отдельного файла. Если функция не
используется за пределами того файла, где она определяется, то следует применять принцип
минимальных привилегий, объявляя ее как static.
1368
Приложение Г
• При разработке больших программ из нескольких исходных файлов компиляция
программы становится утомительным делом, если в одном из файлов сделаны
небольшие изменения, а приходится перекомпилировать всю программу. Многие
системы снабжены специальными утилитами, которые перекомпилируют только
модифицированные файлы программы. В UNIX системах подобная утилита называется
make. Утилита make читает файл с именем Makefile, который содержит инструкции
по компиляции и компоновке программы.
• Функция exit вызывает завершение работы программы, как если бы она была
выполнена нормально.
• Функция atexit регистрирует в программе функцию, которую необходимо вызвать
при успешном завершении программы, т.е. если управление достигает конца
функции main или была вызвана функция exit.
• Функции atexit в качестве аргумента передается указатель на функцию (т.е. имя
функции). Функция, вызываемая при завершении программы, не может иметь
аргументов и не может возвращать значения. Можно зарегистрировать до 32 функций,
выполняющихся при завершении программы.
• Функция exit принимает один аргумент. Аргумент, как правило — символическая
константа EXIT_SUCCESS или EXIT_FAILURE. Если exit вызвана с EXIT_SUC-
CESS, окружению возвращается значение успешного завершения, зависящее от
реализации. Если exit вызвана с EXIT_FAILURE, окружению возвращается значение
неудачного завершения.
• Когда вызывается функция exit, все функции, предварительно зарегистрированные
с помощью atexit, вызываются в порядке, обратном их регистрации, все связанные
с программой потоки сбрасываются и закрываются, а управление возвращается
системе.
• Квалификатор volatile используется для предотвращения оптимизаций переменной,
если последняя может модифицироваться вне области действия программы.
• В C++ предусмотрены суффиксы для целых констант и констант с плавающей
точкой. Целыми суффиксами являются: и или U для целого unsigned, 1 или L для
целого типа long, и ul или UL для целого типа unsigned long. Если целая константа не
имеет суффикса, для нее принимается ближайший тип, способный хранить значение
такой величины (сначала int, потом long int, и наконец unsigned long int)
Суффиксы констант с плавающей точкой следующие: f или F для float, и 1 или L для long
double. Константы с плавающей точкой без суффикса автоматически получают тип
double.
• Библиотека обработки сигналов обеспечивает возможность перехвата
непредвиденных событий с помощью функции signal. Функция signal получает два аргумента —
целый номер сигнала и указатель на функцию обработки.
• Сигналы могут возбуждаться функцией raise, которая принимает целое число —
номер сигнала в качестве аргумента.
• Библиотека общего назначения (<cstdlib>) содержит функции calloc и realloc для
динамического распределения памяти. С помощью этих функций можно создавать
динамические массивы.
• Функция calloc получает два аргумента — число элементов (nmemb) и размер
каждого элемента (size) — и инициализирует элементы массива нулями. Функция
возвращает указатель на выделенную память или, если память не выделена, нулевой
указатель.
• Функция realloc изменяет размер объекта, выделенного в результате предыдущего
вызова malloc, calloc или realloc. Содержимое первоначального объекта сохраняется
при условии, что размер вновь выделяемой памяти больше первоначального.
Код, унаследованный от С
1369
• Функция realloc принимает два аргумента — указатель на первоначальный объект
(ptr) и новый размер объекта (size). Если ptr равен О, realloc работает аналогично
malloc. Если size равен О, a ptr не О, память, выделенная для объекта,
освобождается. В противном случае, если ptr не О и размер больше нуля, realloc пытается
выделить для объекта новый блок памяти. Если новую память выделить не удается,
объект, на который указывает ptr, не изменяется. Функция realloc возвращает либо
указатель на вновь выделенную память, либо нулевой указатель.
• Результатом исполнения goto является передача управления первому оператору
программы после метки, указанной в операторе goto.
• Метка представляет собой идентификатор, за которым следует двоеточие. Метка
должна находиться в той же самой функции, что и оператор goto, который на нее
ссылается.
• Объединение является типом данных, элементы которого разделяют одно
пространство в памяти. Элементы могут быть почти любого типа. Память, отводимая под
объединение, будет по меньшей мере достаточной для хранения его элемента
наибольшего размера. В большинстве случаев объединения содержат два или более типов
данных. В каждый момент времени можно обращаться только к одному элементу и,
следовательно, одному типу данных.
• Форма объявления объединения такая же, как у структуры.
• Объединение может инициализироваться значением, имеющим тип его первого
элемента, или другим объединением того же типа.
• C++ позволяет программисту указать спецификацию компоновки, сообщающую
компилятору, что функция была компилирована в С, чтобы предотвратить
кодирование ее имени компилятором C++.
• Чтобы сообщить компилятору о том, что одна или несколько функций
компилировались в С, прототипы функций нужно записать следующим образом:
extern "С" прототип функции // одиночная функция
extern "С" // несколько функций
{
прототипы функций
)
Эти спецификации сообщают компилятору, что указанные функции
компилировались не как функции C++, так что для них не следует производить кодирование
имен. После этого функции могут быть корректно компонованы с программой.
• В среду C++ обычно входят стандартные библиотеки С, для функций которых
программисту не требуется указывать спецификации компоновки.
Терминология
argc makefile
argv raise
atexit realloc
calloc signal
const va_arg
<csignal> va_end
<cstdarg> va_list
exit va__start
EXIT_FAILURE volatile
EXIT_SUCCESS union
extern "С" аргументы командной строки
make библиотека обработки сигналов
1370
Приложение Г
внешняя компоновка
внутренняя компоновка
временный файл
динамические массивы
исключительная ситуация
с плавающей точкой
конвейер |
нарушение сегментации
недопустимая инструкция
переадресация ввода/вывода
перехват
прерывание
символ переадресации ввода <
Контрольные вопросы
Г.1. Заполните пропуски в каждом из следующих предложений.
a) Символ используется для переключения ввода данных с
клавиатуры на считывание из файла.
b) Символ используется для переключения вывода данных, при
котором они вместо вывода на экран помещаются в файл.
c) Символ используется для присоединения вывода программы в конец
файла.
d) используется для того, чтобы направить выходной поток одной
программы во входной поток другой.
e) в списке параметров функции указывает, что функция может
принимать переменное количество аргументов.
f) Макрос должен быть вызван перед обращением к аргументам
списка переменной длины.
g) Макрос используется для доступа к отдельным аргументам в
списке аргументов переменной длины.
h) Макрос упрощает нормальный возврат из функции, на список
аргументов которой ссылался макрос va_start.
i) Аргумент функции main принимает число аргументов в
командной строке.
j) Аргумент функции main сохраняет аргументы командной строки
как символьные строки.
к) Утилита UNIX считывает файл , который содержит
инструкции для компиляции и компоновки программ, состоящих из
нескольких исходных файлов. Утилита перекомпилирует файл лишь в том случае,
если он был изменен со времени последней компиляции.
I) Функция принудительно завершает выполнение программы.
т) Функция регистрирует функцию, которую необходимо вызвать
при успешном завершении программы.
п) целого типа или типа с плавающей точкой может быть добавлен
к целой константе или константе с плавающей точкой для определения
точного типа константы.
о) Функция может использоваться для регистрации процедуры,
перехватывающей непредвиденные события.
р) Функция программно генерирует сигнал.
символ переадресации вывода >
символ присоединения вывода »
событие
спецификатор класса памяти extern
спецификатор класса памяти static
список аргументов переменной
длины
суффикс float (f или F)
суффикс long double A или L)
суффикс long int A или L)
суффикс unsigned int (u или U)
суффикс unsigned long (ul или UL)
Код, унаследованный от С
1371
q) Функция динамически выделяет память для массива и
инициализирует его элементы нулями.
г) Функция изменяет размер динамически выделенного блока памяти.
s) является объектом, содержащим нескольких переменных,
которые занимают в памяти одно и то же место, но в различное время.
t) Ключевое слово начинает определение объединения.
Ответы на контрольные вопросы
Г.1. а) переадресации ввода (<). Ь) переадресации вывода (>). с) присоединения
вывода (»). d) Конвейер (|). е) Многоточие (...). f) va_start. g) va_arg. h) va_end. i)
argc. j) argv. k) make, Makefile. I) exit, m) atexit. n) Суффикс, о) signal, p) raise.
q) calloc. r) realloc. s) Объединение, t) union.
Упражнения
Г.2. Напишите программу для вычисления произведения ряда целых чисел, которые
передаются функции product в списке аргументов переменной длины. Проверьте
вашу функцию, вызвав ее несколько раз, каждый раз с новым количеством
аргументов.
Г.З. Напишите программу, которая распечатывает аргументы командной строки
программы.
Г.4. Напишите программу, упорядочивающую массив целых чисел в восходящем
либо нисходящем порядке. Программа должна использовать аргументы
командной строки для передачи либо ключа —а (восходящий порядок), либо ключа —d
(нисходящий порядок). [Замечание. Это стандартный формат для передачи
программе опций в системе UNIX.]
Г.5. Изучите руководство по вашей системе, чтобы выяснить, какие сигналы
поддерживаются библиотекой обработки сигналов (<csignal>). Напишите программу,
которая обрабатывает стандартные сигналы SIGABRT и SIGINT. Программа
должна тестировать перехват этих сигналов посредством вызова функции abort
для генерации сигнала типа SIGABRT и ввода Ctrl+C для сигнала типа SIGINT.
Г.6. Напишите программу, которая динамически выделяет массив целых чисел.
Размер массива должен вводиться с клавиатуры. Элементам массива присваиваются
значения, введенные с клавиатуры. Выведите значения массива на печать.
После этого выполните повторное выделение памяти под массив размером в 1/2 от
текущего количества элементов. Выведите на печать значения, оставшиеся
в массиве, чтобы убедиться, что они совпадают с первой половиной исходного
массива.
Г.7. Напишите программу, которая принимает в качестве аргументов командной
строки два имени файла, считывает посимвольно первый файл и записывает
символы во второй файл в обратном порядке.
Г.8. Напишите программу, использующую оператор goto для моделирования
вложенной структуры циклов, которая выводит на печать показанный на рис. Г. 10
квадрат, составленный из символов звездочки. Программа должна выполнять
только следующие операторы вывода:
1372
Приложение Г
cout « "*";
cout « " " ;
cout « endl;
Рис. Г.10. Образец для упражнения Г.8
Г.9. Напишите определение для объединения Data, содержащего char characterl,
short short 1, long longl, float floatl и double doublel.
Г.10. Создайте объединение Integer с элементами char character 1, short short 1, int
integer 1 и long longl. Напишите программу, которая вводит значения типов
char, short, int и long, сохраняя их в переменных типа union Integer. Каждая
переменная-объединение должна печататься как char, short, int и long. Всегда
ли правильно печатаются значения?
Г.11. Создайте объединение Floatingpoint с элементами float floatl, double doublel
и long double longDouble. Напишите программу, которая вводит значения типов
float, double и long double, сохраняя их в переменных типа union Floatingpoint.
Каждая переменная-объединение должна печататься как float, double и long
double. Всегда ли правильно печатаются значения?
Г.12. Пусть имеется объединение
union A
{
double у;
char *zPtr;
};
Какие из следующих операторов корректно инициализируют это объединение?
a) А р = Ь; // Ь имеет тип А
b) A q = х; // х имеет тип double
c) А г = 3.14159;
d) A s = { 79.63 };
e) A t = { "Hi There!" } ;
f) A u = { 3.14159, "Pi" };
g) A v = { у = -7.843, zPtr = fix } ;
Препроцессор
ЦЕЛИ
В этой главе вы изучите:
• Применение директивы #include
при создании больших программ.
• Использование директивы #define
для определения макросов
и макросов с аргументами.
• Принципы условной компиляции.
• Вывод сообщений об ошибках
во время условной компиляции.
• Использование макросов для
проверки корректности значений.
1374
Приложение Д
Д.1. Введение
Д.2. Директива препроцессора #include
Д.З. Директива #def ine: символические константы
Д.4. Директива #define: макросы
Д.5. Условная компиляция
Д.6. Директивы #error и #pragma
Д.7. Операции # и ##
Д.8. Предопределенные символические константы
Д.9. Макрос подтверждения
Д.10. Заключение
Резюме • Терминология • Контрольные вопросы
• Ответы на контрольные вопросы • Упражнения
Д.1. Введение
Эта глава представляет препроцессор. Препроцессорная обработка
производится до компиляции программы. Некоторые из возможных действий
препроцессора — включение в компилируемый файл других файлов, определение
символических констант и макросов, условная компиляция кода программы
и условное исполнение директив препроцессора. Все директивы препроцессора
начинаются с #, и в строке перед ними могут стоять только пробельные
символы. Директивы препроцессора не являются операторами C++ и не
оканчиваются точкой с запятой (;). Вся обработка препроцессорных директив
завершается до начала компиляции.
рт#з Типичная ошибка программирования Д.1
Точка с запятой в конце директивы препроцессора может приводить
к разнообразным ошибкам, зависящим от типа директивы.
Общее методическое замечание Д.1
Многие возможности препроцессора (особенно макросы) более
полезны для программистов, пишущих на С, чем для тех, кто пишет на
C++. Последние, тем не менее, должны быть знакомы с
препроцессором, поскольку им может потребоваться работать с кодом,
унаследованным от С.
Препроцессор
1375
Д.2. Директива препроцессора #include
Директива препроцессора #include использовалась нами все время. Она
создает копию указанного файла, которая включается в программу вместо
директивы. Существует две формы директивы #include:
#include <filename>
#include "filename"
Разница между ними заключается в том, где препроцессор будет искать
файлы, которые необходимо включить. Если имя файла заключено в угловые
скобки (< и >) — используемые для файлов стандартной библиотеки, — то
поиск будет вестись в зависимости от конкретной реализации компилятора,
обычно в предопределенных каталогах. Если имя заключено в кавычки,
препроцессор сначала ищет его в том же каталоге, что и компилируемый файл,
а затем в тех же предопределенных каталогах, зависящих от реализации.
Такую форму обычно используют для включения заголовочных файлов,
написанных программистом.
Директива #include чаще всего используется для подключения
заголовочных файлов стандартной библиотеки, таких, как <iostream> и <iomanip>.
Директива также важна для программ, состоящих из нескольких файлов,
которые нужно компилировать вместе. В этом случае во все исходные файлы
включается заголовочный файл, содержащий общие для всей программы
объявления. Примерами таких объявлений и определений являются классы,
структур, объединения, перечисления и прототипы функций, константы
и объекты потоков (напр., cin).
Д.З. Директива #def ine: символические константы
Директива #define создает символические константы — константы,
представленные символами, и макросы — операции, определенные как символы.
Формат директивы #define определяется следующим образом:
#def ine идентификатор заменяющий_текст
Когда такая строка появляется в файле, вместо всех последующих появлений
идентификатора будет автоматически подставлен заменяющий_текст, до
того, как программа будет компилироваться. Например,
#define PI 3.14159
заменяет все последующие появления символической константы PI на
численную константу 3.14159. Символические константы позволяют программисту
создавать имя для константы и использовать это имя в любом месте
программы. Если необходимо изменить значение константы во всей программе, то
достаточно сделать это в одном месте, в директиве #define, и после повторной
компиляции программы все вхождения константы в программу будут
автоматически изменены. [Замечание. При замене вместо символической константы
будет подставлено все, что стоит справа от нее в определении #define.
Например, строка #define PI = 3.14159 приведет к тому, что препроцессор заменит
по всему тексту программы PI на = 3.14159. Подобные ошибки часто приводят
1376
Приложение Д
к многочисленным, трудно выявляемым логическим и синтаксическим
ошибкам.] Переопределение символической константы, при котором ей
присваивается новое значение, также является ошибкой. Отметим, что
переменные-константы C++ предпочтительнее символических констант. Как только
подстановка символической константы произведена, отладчик будет видеть только
заменяющий текст. Недостатком переменных-констант является то, что им
может требоваться место в памяти, соответствующее размеру их типа данных;
символические константы не требуют дополнительной памяти.
Типичная ошибка программирования Д.2
Ссылка на символическую константу в файле, отличном от того, где
она определяется, приводит к ошибке компиляции (если только
определение не содержится во включаемом заголовочном файле).
Хороший стиль программирования Д.1
Использование осмысленных имен для символических констант
делает программу самодокументированной и облегчает ее восприятие.
Д.4. Директива #def ine: макросы
Макрос — это идентификатор, определяемый при помощи директивы
препроцессора #define. Как и в случае символических констант, перед
компиляцией программы вместо идентификатора_макроса в программу
подставляется заменяющий текст. Допускается определение макроса с аргументами
или без них. Макрос без аргументов обрабатывается аналогично
символической константе. В макросе с аргументами последние подставляются в
заменяющий текст, после чего макрос расширяется, т.е. вместо идентификатора
и списка аргументов в программу подставляется заменяющий_текст.
[Замечание. Тип данных аргументов макроса не проверяется. Макрос просто
производит текстовую подстановку.]
Рассмотрим следующее макроопределение с одним аргументом для
нахождения площади круга:
#define CIRCLE_AREA( x) ( PI * ( х ) * ( х ) )
Всякий раз, когда в файле появляется CIRCLE_AREA(x), значение х
подставляется вместо х в заменяющем тексте, символическая константа PI
заменяется ее значением (определенным ранее), и макрос расширяется в программе.
Например, оператор
area = CIRCLE_AREA( 4 );
расширяется в
area = ( 3.14159 * ( 4 ) * ( 4 ) );
Так как выражение состоит только из констант, значение выражения
оценивается в процессе компиляции и присваивается переменной area. Скобки, в
которые заключены х в заменяющем тексте, обеспечивают правильный порядок
Препроцессор
1377
вычисления, когда в качестве аргумента макроса используется выражение.
Например, оператор
area = CIRCLE_AREA( с + 2 );
расширяется в выражение
area = ( 3.14159 * (с + 2) * (с + 2) );
которое оценивается правильно, поскольку скобки обеспечивают правильный
порядок выполнения операций. Если бы скобок не было, макрос расширялся
бы в выражение
area = 3.14159 *с+2*с+2;
которое оценивалось бы неправильно как
area = ( 3.14159 *с)+B*с)+2;
согласно правилам старшинства операций.
Типичная ошибка программирования Д.З
Отсутствие скобок вокруг аргументов в заменяющем тексте
макроса является ошибкой.
Макрос CIRCLE_AREA можно было бы определить как функцию. Функция
circleArea
double circleArea( double x ) { return 3.14159 * x * x; }
выполняет те же самые вычисления, что и CIRCLE__AREA, но с вызовом
функции связаны дополнительные расходы. Преимущество макроса CIRCLE_AREA
в том, что макрос вставляет код непосредственно в программу, не требуя
дополнительных расходов на вызов функции, и при этом программа остается
удобочитаемой, поскольку вычисление CIRCLE_AREA определено отдельно
и названо осмысленно. Недостатком является то, что аргумент этого макроса
оценивается дважды. Кроме того, всякий раз при появлении в программе
макроса производится его расширение. Если макрос велик, это может увеличить
размер программы. Таким образом, здесь приходится выбирать между
скоростью выполнения и размером программы (если на диске остается мало
свободного места). Заметьте, что inline-функции (см. главу 3) позволяют сочетать
эффективность макросов с преимуществами функций в плане проектирования
программного обеспечения.
Вопросы производительности Д.1
Иногда вместо вызова функции можно использовать макрос, который
встраивает код в программу до ее исполнения. Это исключает
накладные расходы, связанные с вызовом функции. Встроенные функции
предпочтительнее макросов, так как они предусматривают проверку
типов.
44 Зак. 1114
1378 Приложение Д
Следующее определение макроса с двумя аргументами, предназначенного
для вычисления площади прямоугольника:
#define RECTANGLE_AREA( х,у)((х)*(у))
Всякий раз, когда в тексте программы встречается RECTANGLE_AREA( x, у ),
значения х и у подставляются в заменяющий текст макроса, и макрос
расширяется в том месте, где стояло его имя. Например, оператор
rectArea = RECTANGLE_AREA( a + 4, b + 7 );
расширяется в
rectArea =((a+4)*(b+7));
Значение выражения оценивается и присваивается переменной rectArea.
Заменяющий текст для макроса или символической константы — это
обычно любой текст в строке после идентификатора в директиве #define. Если
заменяющий текст для макроса или именованной константы не умещается на
одной строке, в конце строки следует поставить обратную дробную черту (\),
которая показывает, что текст продолжается на следующей строке.
Символические константы и макросы можно отменить, используя
директиву препроцессора #undef. Директива #undef отменяет определение
символической константы или имени макроса. Область действия символической
константы или макроса простирается от места их определения до места отмены
определения директивой #undef (или до конца файла). После отмены
определения можно переопределить макрос директивой #define.
В качестве аргументов не следует передавать макросам выражения с
побочными эффектами (т.е. изменяющие значения переменных), так как аргументы
макроса могут оцениваться более одного раза.
Типичная ошибка программирования Д.4
Часто бывает так, что макрос заменяет имя, которое не
предполагалось использовать в качестве макроса, но чисто случайно совпало
с ним по написанию. Это может приводить к особенно загадочным
ошибкам синтаксиса и компиляции.
Д.5. Условная компиляция
Условная компиляция позволяет программисту управлять выполнением
директив препроцессора и компиляцией программного кода. Каждая из условных
директив препроцессора оценивает значение целочисленного выражения. В
директивах препроцессора невозможна оценка выражений приведения типа,
выражений sizeof и перечислимых констант, поскольку все они определяются
компилятором, а препроцессорная обработка происходит до компиляции.
Условные конструкции препроцессора во многом похожи на структуру
выбора if. Рассмотрим следующий код препроцессора:
#ifndef(NULL)
#define NULL 0
#endif
Препроцессор
1379
Эти директивы устанавливают, определен ли уже символ NULL. Выражение
#ifndef NULL включает в программу весь код вплоть до #endif, если
константа NULL не определена, и пропускает этот код, если определена. Каждая
конструкция #if заканчивается директивой #endif. Директивы #ifdef и Mfndef —
это сокращения для #if defined( имя ) и #if !defined( имя ). Сложные условные
конструкции препроцессора можно проверять с помощью директив #elif
(эквивалента else if структуры if) и #else (эквивалента else структуры if).
При разработке программы программист может «закомментировать»
большой кусок кода, чтобы он не компилировался. Если этот код сам содержит
комментарии в стиле С, то /* и */ для этого не подходят. В этом случае можно
использовать следующую конструкцию препроцессора:
#if О
код, компиляцию которого надо запретить
#endif
Чтобы снова разрешить компиляцию кода, следует заменить в представленной
выше конструкции 0 на 1.
Типичным является использование условной компиляции как
вспомогательного средства отладки. Часто используют операторы вывода, чтобы
распечатать значения переменных или убедиться в правильности потока
управления. Такие операторы можно заключить в условные директивы
препроцессора, чтобы они компилировались только до тех пор, пока отладка не будет
завершена. Например,
#ifdef DEBUG
cerr « "Variable x = " « x « endl;
#endif
будет компилировать оператор сегг, только если перед директивой #ifdef
DEBUG была определена символическая константа DEBUG. Эта
символическая константа обычно устанавливается не явной директивой #define, а в
командной строке компилятора или в интегрированной среде разработки (IDE),
такой, как Visual Studio .NET. Когда отладка завершена, директива #define
удаляется из исходного файла и операторы вывода, вставленные для отладки,
будут при компиляции игнорироваться. В больших программах желательно
определить несколько различных символических констант, чтобы иметь
возможность контролировать условия компиляции отдельных частей исходного
файла.
л Типичная ошибка программирования Д.5
Вставка для целей отладки условно компилируемых операторов
вывода в места, где подразумевается только один оператор, может
приводить к синтаксическим и логическим ошибкам. В этом случае условно
компилируемый фрагмент должен быть включен в составной
оператор. Тогда, если программа компилируется с отладочными
операторами, поток управления не нарушается.
1380
Приложение Д
Д.6. Директивы #error и #pragma
Директива #еггог
#error лексемы
выводит на печать зависящее от реализации сообщение, включая лексемы,
определенные в директиве. Лексемы — это последовательности символов,
разделенные пробелами. Скажем, директива
#еггог 1 - Out of range error
содержит шесть лексем. Когда выполняется директива #сггог, лексемы в
директиве отображаются как сообщение об ошибке (зависящее от системы);
затем препроцессор останавливается, и программа не компилируется.
Директива #pragma
#pragma лексемы
указывает действие, зависящее от реализации. Указание, не распознанное
данным компилятором, игнорируется. Конкретный компилятор C++,
например, может распознавать директивы #pragma, позволяющие программисту
наиболее полно использовать специфические возможности компилятора.
Более подробную информацию относительно директив #еггог и #pragma вы
можете найти в документации по вашему компилятору C++.
Д.7. Операции # и ##
В C++ и ANSI/ISO С имеются операции препроцессора # и ##. Операция #
выполняет преобразование текстовой лексемы в строку, заключенную в
кавычки. Рассмотрим следующее макроопределение:
#define HELLO( x ) cout « "Hello, " #х « endl;
Когда в файле программы встречается выражение HELLO( John ), оно
расширяется в
cout « "Hello, " "John" « endl;
В заменяющем тексте вместо #х подставляется строка "John". Препроцессор
производит конкатенацию строк, разделенных только пробельными
символами, поэтому предыдущий оператор эквивалентен
cout « "Hello, John" « endl;
Заметим, что операция # должна использоваться в макросах с аргументами,
поскольку операнд после # ссылается на аргумент макроса.
Операция ## выполняет конкатенацию двух лексем. Рассмотрим
следующее макроопределение:
#define TOKENCONCAT( х, у ) х ## у
Препроцессор
1381
Когда TOKENCONCAT появляется в тексте программы, происходит
конкатенация его аргументов, после чего они заменяют макроопределение. Например,
TOKENCONCAT( О, К ) заменяется в программе на ОК. Операция ## должна
иметь два операнда.
Д.8. Предопределенные символические константы
Имеется пять предопределенных символических констант (рис. Д.1).
Идентификаторы каждой из предопределенных констант начинаются и (кроме
cplusplus) заканчиваются двумя символами подчеркивания. Эти
идентификаторы, как и операция defined (упоминавшаяся в разделе Д. 5), не могут
входить в директивы #define или #undef.
Символическая
константа
LINE_
Объяснение
Номер текущей обрабатываемой строки исходного кода
программы (целая константа)
_FILE_ ! Имя компилируемого исходного файла (строка)
_DATE Дата компиляции текущего исходного файла (строка вида "Mmm
dd yyyy", например "Jan 19 1991")
_Т1МЕ Время компиляции текущего исходного файла (символьная
строка вида "hhimmrss")
_STDC Указывает, совместима ли программа со стандартом ANSIWISO С.
I Равна 1, если имеет место полное соответствие стандарту, и не
! определена в противном случае
.cplusplus
Содержит значение 199711L (дата утверждения стандарта ISO C++),
если файл компилируется компилятором C++, и не определена
в противном случае. Позволяет организовать файл таким образом,
чтобы его можно было компилировать и как С, и как C++
Рис, Д.1. Предопределенные символические константы
Д.9. Макрос подтверждения
Макрос assert, определенный в заголовочном файле <cassert>, проверяет
значение выражения. Если значение выражения равно 0 (ложно), то assert
печатает сообщение об ошибке и вызывает функцию abort (из библиотеки
утилит общего назначения <cstdlib>), завершающую работу программы. Это
полезный инструмент отладки, позволяющий проверить, имеет ли переменная
верное значение. Допустим, значение переменной х в программе никогда не
должно превышать 10. Для проверки значения х и выдачи сообщения об
ошибке в случае, если х принимает недопустимые значения, можно
воспользоваться макросом подтверждения. Соответствующий оператор будет выглядеть
следующим образом:
assert( х <= 10 ) ;
1382
Приложение Д
Если при выполнении этого оператора х больше 10, выдается сообщение,
содержащее номер строки и имя файла, а выполнение программы при этом
прерывается. После этого программист может ограничить поиски ошибки данной
частью кода. Если определена символическая константа NDEBUG,
последующие операторы подтверждения будут игнорироваться. Таким образом, когда
операторы подтверждения уже не нужны (т.е. отладка завершена), вместо
того, чтобы уничтожать их вручную, достаточно в программный файл
вставить строку
#define NDEBUG
Как и символическая константа DEBUG, NDEBUG часто устанавливается
в командной строке компилятора или в опциях IDE.
Большинство современных компиляторов C++ поддерживает управление
исключениями. Но подтверждения остаются ценным инструментом для
программистов, работающих с унаследованным от С кодом.
Д.10. Заключение
В этом приложении обсуждалась директива #inelude, используемая при
разработке больших программ. Вы изучили также директиву #define для
создания макросов. Мы представили также условную компиляцию, вывод
сообщений об ошибках и использование подтверждений. В следующем
приложении мы реализуем проект системы ATM из разделов «Конструирование
программного обеспечения» в главах 1-7, 9 и 13.
Резюме
• Все директивы препроцессора начинаются с #.
• Перед директивой препроцессора в строке могут стоять только пробельные символы.
• Директива #include включает в текст копию указанного файла. Если имя файла
заключено в кавычки, препроцессор ищет его в том же каталоге, что и файл, который
компилируется. Если же имя файла заключено в угловые скобки (< и >), место, где
будет выполняться поиск, зависит от реализации компилятора.
• Директива препроцессора #define используется для создания символических
констант и макросов.
• Символическая константа — это имя для константы.
• Макрос — это идентификатор, определенный в директиве препроцессора #define.
Макрос можно определять с аргументами или без них.
• Заменяющий текст для макроса или символической константы — это любой текст,
расположенный в строке после идентификатора в директиве #define. Если
заменяющий текст для макроса или константы не умещается на одной строке, в конце строки
следует поставить обратную косую черту (\), которая показывает, что текст
продолжается на следующей строке.
• Определения символических констант и макросов можно отменить с помощью
директивы препроцессора #undef.
• Область действия символической константы или макроса простирается от места их
определения до места отмены определения с помощью #undef, либо до конца файла.
• Условная компиляция позволяет программисту управлять выполнением директив
препроцессора и компиляцией программного кода.
Препроцессор
1383
• Условные директивы препроцессора вычисляют значение целочисленного
выражения. В директивах препроцессора не допускаются выражения приведения типа,
выражения sizeof и перечислимые константы.
• Каждая конструкция #if заканчивается #endif.
• Директивы #ifdef и #ifndef представляют собой сокращения для #if defined(uj^)
и #if !defined(uj^z)-
• Условные конструкции препроцессора, проверяющие несколько вариантов,
реализуются с помощью директив #elif (эквивалента else if структуры if) и #else
(эквивалента else структуры if).
• Директива #еггог выводит на печать зависящее от реализации сообщение, включая
указанные в директиве лексемы.
• Директива #pragma указывает действие, зависящее от реализации. Указание, не
распознанное данным компилятором, игнорируется.
• Операция # производит замену текстовой лексемы, которая преобразуется в строку,
заключенную в кавычки. Операция # должна использоваться в макросах с
аргументами, поскольку операнд после # ссылается на аргумент макроса.
• Операция ## выполняет конкатенацию двух лексем. Операция ## должна иметь два
операнда.
• Директива препроцессора #line используется для последовательной нумерации
строк исходного кода программы, начиная с числа, заданного константой.
• Существует пять предопределенных символических констант. Константа
LINE — номер текущей обрабатываемой строки исходного кода программы
(целая константа). Константа FILE — имя компилируемого исходного файла
(символьная строка). Константа DATE — дата начала компиляции текущего
исходного файла (строка). Константа TIME — время начала компиляции текущего
исходного файла (строка). Константа STDC — целая константа 1;
предназначена, чтобы показать совместимость данной реализации со стандартом ANSI. Каждая
из предопределенных констант начинается и заканчивается двумя символами
подчеркивания.
• Макрос assert, определенный в заголовочном файле <cassert>, проверяет значение
выражения. Если значение выражения равно О (false), то assert распечатывает
сообщение об ошибке и вызывает функцию abort для завершения работы программы.
Терминология
#define
#elif
#else
#endif
#еггог
#if
#ifdef
#ifndef
#include * filename »
#include <filename>
#line
#pragma
#undef
\ (обратная дробь), символ
продолжения
cplusplus
DATE
_FILE_
_LINE_
_STDC_
_TIME_
abort
assert
assert.h
stdio.h
stdlib.h
аргумент
директива препроцессора
заголовочные файлы стандартной
библиотеки
заголовочный файл
заменяющий текст
макроопределение
макрос
1384
Приложение Д
макрос с аргументами
область действия символической
константы или макроса
отладчик
предопределенные символические
константы
препроцессор С
препроцессорная операция
конкатенации ##
препроцессорная операция
преобразования в строку #
расширение макроса
символическая константа
условная компиляция
условное выполнение директив
препроцессора
Контрольные вопросы
Д-1.
Д.2.
ДЗ.
Заполните пропуски в каждом из следующих предложений,
а) Каждая директива препроцессора должна начинаться с _
Ь) Конструкции условной компиляции можно использовать для проверки
нескольких вариантов, если воспользоваться директивами
и
создает макросы и символические константы.
c) Директива
d) Перед директивой препроцессора в строке могут стоять только
символы.
e) Директива отменяет символические константы и макросы.
f) Директивы и ■ — сокращенные нотации для #if
йейпей(имя) и #if !defined(имя).
g) дает возможность программисту управлять выполнением
директив препроцессора и компиляцией программного кода,
h) — макрос, выдающий на печать сообщение и прекращающий
выполнение программы, если оценка выражения в макросе равна О.
i) Директива вставляет в файл другой файл.
j) Операция / выполняет конкатенацию двух аргументов.
к) Операция преобразует операнд в строку.
1) Символ означает, что заменяющий текст для символической
константы или макроса продолжается на следующей строке.
Напишите программу, выводящую на печать значения предопределенных
символических констант, перечисленных на рис. Д.1.
Напишите директивы препроцессора, выполняющие каждое из следующих
действий.
a) Определите символическую константу YES, присвоив ей значение 1.
b) Определите символическую константу N0, присвоив ей значение 0.
c) Включите в программу заголовочный файл common.h. Заголовочный файл
находится в том же каталоге, что и компилируемый файл.
d) Если была определена символическая константа TRUE, отмените ее
определение, после чего вновь определите ее, присвоив значение 1. Сделайте это, не
используя директиву препроцессора #ifdef.
e) Если была определена символическая константа TRUE, отмените ее
определение, после чего вновь определите ее, присвоив значение 1. Сделайте это,
используя директиву препроцессора #ifdef.
f) Если символическая константа ACTIVE не равна О, определите
символическую константу INACTIVE равной О. В противном случае определите
INACTIVE равной 1.
g) Определите макрос CUBE__VOLUME, вычисляющий объем куба. Макрос
должен иметь один аргумент.
Препроцессор
1385
Ответы на контрольные вопросы
Д.1. а) #. b) #elif, #else. с) #define. d) пробельные, е) #undef. f) #ifdef, #ifndef. g)
Условная компиляция, h) assert, i) #include. j) ##. k) #. 1).
Д.2. См. листинг.
1 // exF_02.cpp
2 // Ответ к контрольному вопросу Е.2.
3 #include <iostream>
4
5 using std::cout;
6 using std::endl;
7
8 int main ()
9 {
10 cout « " LINE =
11 « " FILE =
12 « " DATE =
13 « " TIME =
14 « " cplusplus = " « cplusplus « endl;
15
16 return 0;
17
18 } // конец main
«
«
«
«
LINE
FILE
DATE
TIME
«
«
«
«
endl
endl
endl
endl
_LINE =10
_FILE = exF_02 . cpp
_DATE = Mar 13 2007
JTIME = 00:57:47
_cplusplus = 1
Д.З. a) #define YES 1
b) #def ine NO 0
c) #include "common.h"
d) #if defined(TRUE)
#unde£ TRUE
#define TRUE 1
#endif
e) #ifdef TRUE
#undef TRUE
#define TRUE 1
#endif
f) #if ACTIVE
#define INACTIVE 0
#else
#define INACTIVE 1
#endif
g) #define CUBE_VOLUME(x)((x)*(x)*(x))
1386
Приложение Д
Упражнения
Д.4. Напишите программу, которая определяет макрос с одним аргументом для
вычисления объема шара. Программа должна вычислять объем шаров с радиусом
от одного до десяти, и выводить на печать результаты в виде таблицы. Объем
шара вычисляется по формуле
D.0/3) * р * г3
где р равно 3.14159.
Д.5. Напишите программу, которая выдает следующее сообщение:
The sum of x and у is 13
Программа должна определять макрос SUM с двумя аргументами х и у, и
использовать SUM для вывода сообщения.
Д.6. Напишите программу, использующую макрос MINIMUM2 для определения
меньшего из двух чисел. Ввод значений должен производиться с клавиатуры.
Д.7. Напишите программу, использующую макрос MINIMUM3 для определения
наименьшего из трех чисел. Макрос MINIMUM3 должен использовать макрос
MINIMUM2, определенный в упражнении Д.6. Ввод значений должен
производиться с клавиатуры.
Д.8. Напишите программу, использующую макрос PRINT для печати строкового
значения.
Д.9. Напишите программу, использующую макрос PRINTARRAY для печати
массива целых чисел. Макрос должен получать в качестве аргументов имя массива
и число элементов.
Д. 10. Напишите программу, использующую макрос SUMARRAY для суммирования
значений числового массива. Макрос должен получать в качестве аргументов
имя массива и число элементов.
Д.11. Перепишите решения упражнений Д.4-Д.10, используя inline-функции.
Д.12. Для каждого из следующих макросов укажите, какая может возникнуть
проблема (если может) при его расширении препроцессором.
a) #de£ine SQR ( х ) х * х
b) #define SQR( x ) ( х * х )
С) #define SQR( x ) ( х ) * ( х )
d) #define SQR( x ) ( ( х ) * ( х ) )
Е
Код учебного примера ATM
Е.1. Реализация проекта ATM
Это приложение содержит полную работоспособную реализацию системы
ATM, которую мы спроектировали в разделах «Конструирование
программного обеспечения», входящих в главы 1-7, 9 и 13. Реализация состоит из 877
строк кода на C++. Мы рассматриваем классы проекта в том порядке, как мы
идентифицировали их в разделе 3.11:
• ATM
• Screen
• Keypad
• CashDispenser
• DepositSlot
• Account
• BankDatabase
• Transaction
• Balancelnquiry
• Withdrawal
• Deposit
При кодировании этих классов мы следуем правилам, обсуждавшимся
в разделах 9.12 и 13.10, исходя из моделей, представленных классовыми
диаграммами UML на рис. 13.28 и 13.29. При разработке определений
элемент-функций классов мы руководствуемся диаграммами деятельности,
представленными в разделе 5.11, а также диаграммами последовательностей
и коммуникации из раздела 7.12. Следует заметить, что наш проект ATM не
специфицирует всю программную логику и в нем могут отсутствовать
некоторые атрибуты, которые требуются для законченной реализации. В процессе
объектно-ориентированного проектирования это нормальная ситуация. По
ходу реализации системы мы завершаем программную логику и вводим
атрибуты и поведение, необходимые для построения системы ATM,
соответствующей спецификации требований в разделе 2.8.
1388
Приложение Е
Обсуждение примера заканчивается программой на C++ (ATMCaseStu-
dy.cpp), которая запускает ATM, тем самым приводя в действие остальные
классы системы. Напомним, что мы разрабатываем первую версию системы
ATM, которая работает на персональном компьютере и использует его
клавиатуру и экран для имитации кнопочной панели и экрана ATM. Мы также лишь
имитируем действия приемной щели и лотка для выдачи наличных. Однако
мы пытаемся реализовать систему таким образом, чтобы в нее можно было
интегрировать аппаратные модули этих устройств, не внося в написанный код
существенных изменений.
Е.2. Класс ATM
Класс ATM (рис. Е.1-Е.2) представляет ATM в целом. Рис. ЕЛ содержит
определение класса ATM, заключенное в директивы препроцессора #ifndef,
#define и #endif, которые предотвращают многократное включение в код
этого определения. Строки 6-11 мы обсудим чуть ниже. Строки 16-17 содержат
прототипы для открытых элемент-функций класса. В классовой диаграмме на
рис. 13.29 для класса ATM не указано никаких операций, но теперь мы
объявляем открытую элемент-функцию run (строка 17), позволяющую внешнему
клиенту класса (т.е. ATMCaseStudy.cpp) подать ATM команду запуска. Кроме
того, мы включаем в класс прототип для конструктора по умолчанию
(строка 16), который обсуждается позже.
1 // ATM.h
2 // Определение класса ATM. Представляет банковский автомат.
3 #ifndef ATM_H
4 #define ATM_H
5
6 #include "Screen.h" // определение класса Screen
7 #include "Keypad.h" // определение класса Keypad
8 #include "CashDispenser.h" // определение класса CashDispenser
9 #include "DepositSlot.h" // определение класса DepositSlot
10 #include "BankDatabase.h" // определение класса BankDatabase
11 class Transaction; // опережающее объявление класса Transaction
12
13 class ATM
14 {
15 public:
16 ATM(); // конструктор инициализирует элементы данных
17 void run(); // запуск ATM
18 private:
19 bool userAuthenticated; // авторизован ли пользователь
20 int currentAccountNumber; // номер счета текущего пользователя
21 Screen screen; // экран ATM
22 Keypad keypad; // кнопочная панель ATM
23 CashDispenser CashDispenser; // лоток выдачи ATM
24 DepositSlot depositSlot; // приемная щель ATM
25 BankDatabase bankDatabase; // база данных с информацией о счетах
26
27 // закрытые сервисные функции
28 void authenticateUser(); // пытается авторизовать пользователя
29 void performTransactions(); // производит транзакции
Код учебного примера ATM
1389
30 int displayMainMenu() const; // показывает главное меню
31
32 // возвращает объект класса, производного от Transaction
33 Transaction *createTransaction( int );
34 }; // конец класса ATM
35
36 #endif // ATM H
Рис. Е.1. Определение класса ATM
Строки 19-25 на рис. ЕЛ реализуют атрибуты класса как закрытые
элементы данных. Все эти атрибуты, кроме одного, определяются исходя из
классовых диаграмм на рис. 13.28 и 13.29. Обратите внимание, что атрибут
userAuthenticated UML-типа Boolean из рис. 13.29 мы реализуем на C++ как
элемент данных типа bool (строка 19). Строка 20 объявляет элемент данных,
отсутствующий в нашем UML-проекте, — currentAccountNumber типа int,
в котором сохраняется номер счета текущего авторизованного пользователя.
Вскоре мы увидим, каким образом класс использует этот элемент данных.
Строки 21-24 создают объекты, которые будут представлять составные
части ATM. Вспомните классовую диаграмму из рис. 13.28, на которой класс
ATM находится с классами Screen, Keypad, CashDispenser и DepositSlot в
отношениях композиции и, следовательно, отвечает за их создание. Строка 25
создает объект BankDatabase, с которым ATM взаимодействует для доступа
к информации банковского счета. [Замечание. Если бы это была настоящая
система ATM, класс ATM получал бы ссылку на действительный объект базы
данных, созданный банком. Однако в данной реализации мы только
имитируем банковскую базу данных, поэтому сам класс ATM создает объект
BankDatabase, с которым взаимодействует.] Заметьте, что строки 6-10 включают
определения классов Screen, Keypad, CashDispenser и DepositSlot, чтобы ATM
мог хранить объекты этих классов.
Строки 28-30 и 33 содержат прототипы для закрытых сервисных функций,
используемых классом при выполнении свих задач. Вскоре мы увидим, как
эти функции обслуживают класс. Обратите внимание, что функция сгеа-
teTransaction (строка 33) возвращает указатель на Transaction. Чтобы
использовать в данном файле имя класса Transaction, мы должны по крайней
мере включить в файл опережающее объявление этого класса (строка 11). Как
вы помните, опережающее объявление сообщает компилятору, что класс
существует, но определяется в другом месте. Здесь достаточно опережающего
объявления, поскольку мы используем Transaction только в качестве
возвращаемого типа; если бы мы создавали действительный объект Transaction, то
должны были бы включить полный заголовочный файл Transaction.
Определения элемент-функций класса ATM
Рис. Е.2 содержит определения элемент-функций для класса ATM.
Строки 3-7 включают заголовочные файлы, необходимые для реализации
АТМ.срр. Обратите внимание, что включение заголовочного файла ATM
позволяет компилятору убедиться в том, что элемент-функции класса
определяются корректно. Это также позволяет элемент-функциям обращаться к
элементам данных класса.
1390
Приложение Е
1 // АТМ.срр
2 // Определения элемент-функций для класса ATM.
3 #include "ATM.h" // определение класса ATM
4 #include "Transaction.h" // определение класса Transaction
5 #include "Balancelnquiry.h" // определение класса Balance Inquiry
6 #include "Withdrawal.h" // определение класса Withdrawal
7 #include "Deposit.h" // определение класса Deposit
8
9 // перечисляемые константы представляют опции главного меню ATM
10 enum MenuOption { BALANCE_INQUIRY = 1, WITHDRAWAL, DEPOSIT, EXIT };
11
12 // Конструктор ATM по умолчанию инициализирует элементы данных
13 АТМ::АТМ()
14 : userAuthenticated ( false ), // пользователь еще не авторизован
15 currentAccountNumber( 0 ) // номер текущего счета отсутствует
16 {
17 // пустое тело
18 } // конец конструктора по умолчанию ATM
19
20 // запуск ATM
21 void ATM: :run()
22 {
23 // идентифицировать пользователя; выполнять транзакции
24 while ( true )
25 {
26 // цикл, пока пользователь не будет идентифицирован
27 while ( !userAuthenticated )
28 {
2 9 screen.displayMessageLine( "\nWelcome?" );
30 authenticateUser(); // попытаться авторизовать пользователя
31 } // конец while
32
33 performTransactions(); // пользователь авторизован
34 userAuthenticated = false; // сбросить перед следующим сеансом
35 currentAccountNumber =0; // сбросить перед следующим сеансом
36 screen.displayMessageLine( "\nThank you! Goodbye!" );
37 } // конец while
38 } // конец функции run
39
40 // попытка авторизовать пользователя в базе данных
41 void ATM::authenticateUser()
42 {
43 screen.displayMessage( "\nPlease enter your account number: " );
44 int accountNumber = keypad.getlnput(); // ввести номер счета
45 screen.displayMessage ( "\nEnter your PIN: " ); // запросить PIN
46 int pin = keypad.getlnput() ; // ввести PIN
47
48 // присвоить userAuthenticated значение,возвращенное базой данных
49 userAuthenticated =
50 bankDatabase.authenticateUser( accountNumber, pin );
51
52 // проверить, авторизован ли пользователь
53 if ( userAuthenticated )
54 {
55 currentAccountNumber = accountNumber; // сохранить # счета
56 } // конец if
Код учебного примера ATM
1391
57 else
58 screen.displayMessageLine(
59 "Invalid account number or PIN. Please try again." );
60 } // конец функции authenticateUser
61
62 // вывести главное меню и выполнять транзакции
63 void ATM::performTransactions()
64 {
65 // локальный указатель для хранения обрабатываемой транзакции
66 Transaction *currentTransactionPtr;
67
68 bool userExited = false; // выход еще не выбран
69
70 // цикл, пока пользователь не выберет опцию выхода из системы
71 while ( !userExited )
72 {
73 // вывести главное меню и получить выбор пользователя
74 int mainMenuSelection = displayMainMenu();
75
76 // определить способ обработки в зависимости от выбора
77 switch ( mainMenuSelection )
78 {
79 // выбран один из трех типов транзакции
80 case BALANCE_INQUIRY:
81 case WITHDRAWAL:
82 case DEPOSIT:
83 // инициализировать как новый объект выбранного типа
84 currentTransactionPtr =
85 createTransaction( mainMenuSelection );
86
87 currentTransactionPtr->execute(); // выполнить транзакцию
88
89 // освободить память динамического объекта Transaction
90 delete currentTransactionPtr;
91
92 break;
93 case EXIT: // пользователь выбрал завершение сеанса
94 screen.displayMessageLine( "\nExiting the system..." );
95 userExited = true; // этот сеанс ATM следует закончить
96 break;
97 default: // пользователь ввел не число от 1 до 4
98 screen.displayMessageLine(
99 "\nYou did not enter a valid selection. Try again." );
100 break;
101 } // конец switch
102 } // конец while
103 } // конец функции performTransactions
104
105 // вывести главное меню и возвратить введенный выбор
106 int ATM::displayMainMenu() const
107 {
108 screen.displayMessageLine( "\nMain menu:" );
109 screen.displayMessageLine( - View my balance" );
110 screen.displayMessageLine( - Withdraw cash" );
111 screen.displayMessageLine( - Deposit funds" );
112 screen.displayMessageLine( - Exit\n" );
113 screen.displayMessage( "Enter a choice: " );
1392
Приложение Е
114 return keypad.getlnput(); // возвратить выбор пользователя
115 } // конец функции displayMainMenu
116
117 // возвратить объект указанного производного класса Transaction
118 Transaction *ATM::createTransaction( int type )
119 {
120 Transaction *tempPtr; // временный указатель на Transaction
121
122 // определить, какой тип транзакции следует создать
123 switch ( type )
124 {
125 case BALANCE_INQUIRY: // создать транзакцию Balancelnquiry
126 tempPtr = new Balancelnquiry(
127 currentAccountNumber, screen, bankDatabase ) ;
128 break;
129 case WITHDRAWAL: // создать транзакцию Withdrawal
130 tempPtr = new Withdrawal( currentAccountNumber, screen,
131 bankDatabase, keypad, cashDispenser );
132 break;
133 case DEPOSIT: // создать транзакцию Deposit
134 tempPtr = new Deposit( currentAccountNumber, screen,
135 bankDatabase, keypad, depositSlot );
136 break;
137 } // конец switch
138
139 return tempPtr; // возвратить вновь созданный объект
140 } // конец функции createTransaction
Рис. Е.2. Определения элемент-функций класса ATM
Строка 19 объявляет перечисление с именем MenuOption, которое
содержит константы, соответствующие четырем опциям главного меню ATM (т.е.
справке о балансе, снятию со счета, внесению на счет и выходу). Заметьте, что
установка BALANSE_INQUIRY равной 1 приводит к тому, что последующим
константам перечисления присваиваются значения 2, 3 и 4, поскольку
значения констант в перечислении возрастают на единицу.
Строки 13-18 определяют конструктор класса ATM, который
инициализирует элементы данных класса. При первоначальном создании объекта ATM
никакой пользователь не авторизован, поэтому инициализатор элемента
в строке 14 устанавливает userAuthenticated равным false. Подобным образом
строка 15 инициализирует currentAccountNumber нулем, поскольку
никакого текущего пользователя еще нет.
Элемент-функция run (строки 21-38) содержит бесконечный цикл
(строки 24-37), который снова и снова приветствует пользователя, пытается
авторизовать его и, в случае успешной авторизации, разрешает пользователю
производить операции. После того как авторизованный пользователь выполнит
желаемые транзакции и выберет выход из системы, ATM сбрасывается в
начальное состояние, выводит пользователю прощальное сообщение и начинает
процесс заново. Мы применили здесь бесконечный цикл для имитации того
факта, что банкомат по видимости работает непрерывно, пока банк его не
выключит (действие, неподконтрольное пользователю). У пользователя ATM есть
возможность выйти из системы, но он не может совсем ее выключить.
Код учебного примера ATM
1393
Строки 27-31 внутри бесконечного цикла функции run приветствуют
пользователя и пытаются его авторизовать, пока пользователь остается не
авторизованным (т.е. пока истинно ! user Authenticated). Строка 29 вызывает
элемент-функцию displayMessageLine объекта screen (экрана ATM), чтобы
вывести приветственное сообщение. Как и элемент-функция displayMessage
класса Screen, displayMessageLine (объявленная в строке 13 на рис. Е.З и
определенная в строках 20-23 на рис. Е.4) выводит сообщение, но данная
функция выводит после сообщения символ новой строки. При реализации мы
добавили эту функцию, чтобы предоставить клиентам класса Screen больший
контроль над расположением выводимых сообщений. Строка 30 на рис. Е.2
вызывает закрытую сервисную функцию authenticateUser класса ATM
(строки 41-60), чтобы попытаться авторизовать пользователя.
Чтобы определить действия, необходимые, чтобы авторизовать
пользователя, прежде чем разрешить ему производить транзакции, мы обращаемся к
спецификации требований. Строка 43 в функции authenticateUser вызывает
элемент-функцию displayMessage экрана ATM, чтобы предложить пользователю
ввести номер счета. Строка 44 вызывает элемент-функцию getlnput объекта
keypad (кнопочной панели), принимающую ввод пользователя, после чего
сохраняет введенное целое значение в локальной переменной accountNumber.
Затем функция authenticateUser предлагает пользователю ввести PIN
(строка 45) и сохраняет введенный PIN в локальной переменной pin (строка 46).
После этого в строках 49-50 делается попытка авторизовать пользователя,
передавая значения accountNumber и pin элемент-функции authenticateUser
объекта bankDatabase. Класс ATM устанавливает свой элемент данных
userAuthenticated булевым значением, которое возвращается этой
функцией, — если авторизация удается (т.е. accountNumber и pin соответствуют
значениям для некоторого существующего в базе данных счета),
userAuthenticated становится истинным, в противном случае остается ложным. Если значение
userAuthenticated истинно, строка 55 сохраняет введенный пользователем
номер счета (т.е. accountNumber) в элементе данных current AccountNumber. Эта
переменная используется другими элемент-функциями класса ATM всякий раз,
когда в ходе сеанса ATM требуется доступ к номеру счета пользователя. Если
значение userAuthenticated ложно, строки 58-59 вызывают элемент-функцию
экрана displayMessageLine, чтобы указать на ввод неверного номера счета
и/или PIN-кода и предложить пользователю попробовать еще раз. Заметьте, что
мы устанавливаем currentAccountNumber только после проверки номера счета
пользователя и ассоциированного с ним PIN-кода; если база данных не смогла
авторизовать пользователя, currentAccountNumber остается равным 0.
Если после попытки авторизации пользователя (строка 30)
userAuthenticated все еще ложно, цикл в строках 27-31 выполняется снова. Если
userAuthenticated оказывается истинным, цикл завершается и управление
переходит к строке 33, которая вызывает сервисную функцию performTrans-
actions.
Элемент-функция performTransactions (строки 63-103) проводит с
авторизованным пользователем сеанс ATM. Строка 66 объявляет локальный
указатель на Transaction, который мы устанавливаем на объект класса Balanceln-
quiry, Withdrawal или Deposit, представляющий обрабатываемую в данный
момент транзакцию ATM. Обратите внимание, что объявление типа указателя
как Transaction позволяет нам воспользоваться полиморфизмом. Заметьте
45 Зак. 1114
1394
Приложение Е
также, что в имени этого указателя мы используем ролевое имя из классовой
диаграммы на рис. 3.20 — currentTransaction. В соответствии с нашим
соглашением об именах мы присоединяем к ролевому имени «Ptr» и получаем имя
переменной currentTransactionPtr. Строка 68 объявляет еще одну локальную
переменную — userExited типа bool, — которая следит за тем, не выбрал ли
пользователь опцию выхода. Эта переменная управляет циклом while
(строки 71-102), который позволяет пользователю провести неограниченное число
транзакций, пока он не решит выйти из системы. Внутри этого цикла
строка 74 выводит главное меню и принимает выбор пользователя, вызывая
сервисную функцию displayMainMenu (которая определяется в строках
106-115). Эта элемент-функция ATM выводит главное меню, вызывая
элемент-функции экрана, и возвращает выбранную опцию, полученную от
пользователя через кнопочную панель ATM. Заметьте, что функция объявлена как
const, поскольку она не изменяет содержимое объекта. Строка 74 сохраняет
возвращенную опцию меню в локальной переменной mainMenuSelection.
После получения выбранной опции дальнейшие действия функции рег-
formTransactions определяются оператором switch (строки 77-101). Если
mainMenuSelection равна любой из констант перечисления, представляющих
типы транзакций (т.е. пользователь решил произвести некоторую операцию),
строки 84-85 вызывают сервисную функцию createTransaction (определяется
в строках 118-140), которая возвращает указатель на вновь созданный
представитель типа, соответствующего выбранной транзакции. Указатель,
возвращаемый createTransaction, присваивается указателю currentTransactionPtr.
Затем строка 87 активирует через currentTransactionPtr функцию execute
нового объекта, чтобы выполнить транзакцию. Элемент-функцию execute класса
Transaction и три производных класса транзакций мы обсудим позднее.
Наконец, когда объект производного от Transaction класса становится более не
нужным, строка 90 освобождает динамически выделенную для него память.
Заметьте, что мы устанавливаем указатель currentTransactionPtr на
объект одного из трех производных классов транзакций, так что мы можем
производить транзакции полиморфно. Например, если пользователь решит
произвести проверку баланса, mainMenuSelection равна BALANCE_INQUIRY,
и createTransaction возвращает объект Balancelnquiry. Таким образом,
currentTransactionPtr указывает на Balancelnquiry, и вызов currentTrans-
actionPtr->execute() приводит к активации версии execute класса
Balancelnquiry.
В элемент-функции createTransaction (строки 118-140) оператор switch
(строки 123-137) создает новый объект производного от Transaction класса,
тип которого указан параметром type. Как вы помните, performTransactions
передает данной функции mainMenuSelection только в том случае, если
mainMenuSelection содержит значение, соответствующее одному из трех
типов транзакций. Таким образом, type равняется либо BALANCE_INQUIRY,
либо WITHDRAWAL, либо DEPOSIT. Каждый вариант в операторе switch
устанавливает временный указатель tempPtr на вновь созданный объект
соответствующего производного класса транзакций. Обратите внимание, что
каждый конструктор имеет свой уникальный список параметров в зависимости от
того, какие данные требуются для инициализации объекта производного
класса. Для Balancelnquiry требуется только номер счета текущего пользователя
и ссылки на экран и базу данных объекта ATM. Для Withdrawal, помимо этих
Код учебного примера ATM
1395
параметров, требуются ссылки на кнопочную панель и выходной лоток, а для
Deposit — ссылки на кнопочную панель и приемную щель. Как вы вскоре
увидите, каждый из конструкторов Balancelnquiry, Withdrawal и Deposit
специфицирует параметры-ссылки для получения объектов, представляющих
требуемые составные части ATM. Таким образом, когда элемент-функция сгеа-
teTransaction передает объекты из ATM (напр., screen и keypad)
инициализаторам каждого вновь создаваемого объекта производного класса
транзакций, новый объект получает в действительности ссылки на составные
части ATM. Мы подробно обсудим классы транзакций в разделах Ж.9-Ж.12.
После исполнения транзакции (строка 87 в performTransactions) переменная
userExited остается ложной и цикл while в строках 71-102 повторяется,
возвращая пользователя в главное меню. Однако если пользователь не производит
транзакцию, а выбирает в главном меню опцию выхода, строка 95 устанавливает
userExited равной true, и условие цикла while (luserExited) становится ложным.
Этот оператор while является последним в функции performTransactions, так что
управление возвращается вызывающей функции run. Если пользователь вводит
неправильную опцию главного меню (т.е. не число от 1до 4), строки 98-99
выводят соответствующее сообщение об ошибке, userExited остается ложной и
пользователь возвращается в главное меню для следующей попытки.
Когда performTransactions возвращает управление элемент-функции run,
это означает, что пользователь решил выйти из системы, поэтому
строки 34-35 сбрасывают элементы данных userAuthenticated и currentAc-
countNumber объекта ATM, чтобы подготовиться к обслуживанию
следующего пользователя. Строка 36 выводит прощальное сообщение, после чего ATM
начинает новый цикл и приветствует следующего пользователя.
Е.З. Класс Screen
Класс Screen (рис. Е.З-Е.4) представляет экран ATM и инкапсулирует все
аспекты вывода информации пользователю. Класс Screen имитирует экран
настоящего банкомата на экране компьютерного монитора и выводит текстовые
сообщения в cout операцией передачи в поток («). В нашем учебном примере
мы спроектировали класс Screen "всего с одной операцией — display Message.
Для большей гибкости вывода сообщений на экран мы объявляем теперь
в классе Screen три элемент-функции — displayMessage, displayMessageLine
и display Dollar Amount. Прототипы этих функций занимают строки 12-14 на
рис. Е.З.
Определения элемент-функций класса Screen
Рис. Е.4 содержит определения трех элемент-функций для класса Screen.
Строка 11 включает определение класса Screen. Элемент-функция
displayMessage (строки 14-17) принимает в качестве аргумента стандартную строку
и выводит ее на консоль, используя cout и операцию передачи в поток («).
Курсор остается на той же строке, что делает эту функцию пригодной для
вывода приглашений. Элемент-функция displayMessageLine (строки 20-23)
также печатает строку, но выводит символ новой строки, чтобы перевести курсор
на следующую строчку. Наконец, элемент-функция displayDollarAmount
(строки 26-29) выводит должным образом форматированную сумму в
долларах (напр., $123.45). Для вывода в формате с двумя позициями десятичной
1396
Приложение Е
дроби строка 28 использует манипуляторы fixed и setprecision. За более
подробной информацией о форматировании вывода обратитесь к главе 15.
1 // Screen.h
2 // Определение класса Screen. Представляет экран ATM.
3 #ifndef SCREEN_H
4 #define SCREEN_H
5
6 #include <string>
7 using std::string;
8
9 class Screen
10 {
11 public:
12 void displayMessage( string ) const; // вывести сообщение
13 void displayMessageLine( string ) const; //сообщение+новая строка
14 void displayDollarAmount( double ) const; // вывести $ сумму
15 }; // конец класса Screen
16
17 #endif // SCREEN H
Рис. Е.З. Определение класса Screen
1 // Screen.cpp
2 // Определение элемент-функций для класса Screen.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6 using std::fixed;
7
8 #include <iomanip>
9 using std::setprecision;
10
11 #include "Screen.h" // определение класса Screen
12
13 // вывести сообщение без новой строки
14 void Screen::displayMessage( string message ) const
15 {
16 cout « message;
17 } // конец функции displayMessage
18
19 // вывести сообщение с новой строкой
20 void Screen::displayMessageLine( string message ) const
21 {
22 cout « message « endl;
23 } // конец функции displayMessageLine
24
25 // вывести сумму в долларах
26 void Screen::displayDollarAmount( double amount ) const
27 {
28 cout « fixed « setprecision ( 2 ) « "$" « amount;
29 } // конец функции displayDollarAmount
Рис. Е.4. Определения элемент-функций класса Screen
Код учебного примера ATM
1397
Е.4. Класс Keypad
Класс Keypad (рис. Е.5-Е.6) представляет кнопочную панель ATM и
отвечает за прием всего пользовательского ввода. Как вы помните, мы лишь
имитируем данное устройство, поэтому используем для ввода клавиатуру
компьютера. Компьютерная клавиатура имеет много клавиш, которых нет на
кнопочной панели ATM. Однако мы предполагаем, что пользователь нажимает
только клавиши, имеющиеся и на кнопочной панели, — клавиши с
цифрами 0-9 и клавишу Enter. Строка 9 на рис. Е.5 содержит прототип
единственной элемент-функции класса Keypad — getlnput. Функция объявлена как
const, поскольку она не изменяет объект.
Определение элемент-функции класса Keypad
В файле реализации класса Keypad (рис. Е.6) элемент-функция getlnput
(определенная в строках 9-14) использует для ввода данных пользователя
стандартный входной поток cin и операцию извлечения из потока (»). Строка 11
объявляет локальную переменную для хранения ввода. Строка 12 читает ввод
в локальную переменную input, после чего строка 13 возвращает ее значение.
Как вы помните, getlnput принимает весь ввод ATM. Эта элемент-функция
класса Keypad просто возвращает вводимые пользователем целые числа. Если
клиенту класса Keypad требуется ввести информацию, удовлетворяющую
некоторым специфическим критериям (т.е. число, соответствующее действительной
опции меню), клиент сам должен выполнять соответствующую проверку на
ошибку. [Замечание. Стандартный входной поток cin и операция извлечения из
потока позволяют читать ввод пользователя, не являющийся целым числом.
Однако так как кнопочная панель настоящего банкомата «допускает только
целочисленный ввод, мы предполагаем, что пользователь вводит целые числа,
и не пытаемся решить проблемы, возникающие при ошибочном вводе.]
1 // Keypad.h
2 // Определение класса Keypad. Представляет кнопочную панель ATM.
3 #ifndef KEYPAD_H
4 #define KEYPAD_H
5
6 class Keypad
7 {
8 public:
9 int getlnput() const; // возвратить введенное пользователем число
10 }; // конец класса Keypad
11
12 #endif // KEYPAD H
Рис. Е.5. Определение класса Keypad
1 // Keypad.cpp
2 // Определение элемент-функции класса Keypad (кнопочной панели).
3 #include <iostream>
4 using std::cin;
5
6 #include "Keypad.h" // определение класса Keypad
1398
Приложение Е
7
8 // возвратить целое число, введенное пользователем
9 int Keypad::getlnput() const
Ю {
11 int input; // переменная для сохранения ввода
12 cin » input; // предполагаем, что пользователь вводит целое
13 return input; // возвратить введенное значение
14 } // конец функции getlnput
Рис. Е.6. Определение элемент-функции класса Keypad
Е.5. Класс CashDispenser
Класс CashDispenser (рис. Е.7-Е.8) представляет устройство выдачи
наличных (выходной лоток) ATM. Определение класса (рис. Е.7) содержит прототип
конструктора по умолчанию (строка 9). Класс объявляет также две
дополнительные открытые элемент-функции — dispenseCash (строка 12)
и isSufficientCashAvailable (строка 15). Класс предполагает, что клиент (т.е.
Withdrawal) вызывает dispenseCash только после того, как установит (вызвав
isSufficientCashAvailable), что в устройстве выдачи имеется достаточно
наличных. Таким образом, dispenseCash просто имитирует выдачу запрошенной
суммы, не проверяя, достаточно ли для этого наличных. Строка 17 объявляет
закрытую константу INITIAL_COUNT, задающую начальное число купюр
в устройстве выдачи при запуске ATM (т.е. 500). Строка 18 реализует атрибут
count (моделируемый на рис. 13.29), который отслеживает число купюр,
остающихся в устройстве выдачи в каждый момент времени.
Определения элемент-функций класса CashDispenser
Рис. Е.8 содержит определения элемент-функций класса CashDispenser.
Кнструктор (строки 6-9) устанавливает count начальным значением (т.е. 500).
Элемент-функция dispenseCash (строки 13-17) имитирует выдачу наличных.
Если бы наша система была связана с настоящим устройством выдачи, эта
элемент-функция взаимодействовала бы с аппаратным устройством для реальной
выдачи денег. Наша имитация элемент-функции просто уменьшает счетчик
оставшихся купюр на число, требуемое для выдачи указанной в параметре amount
суммы (строка 16). ATM позволяет пользователю выбирать только суммы,
кратные 20 долларам, поэтому, чтобы получить требуемое число купюр (billsRequi-
red), мы делим amount на 20. Заметьте также, что информировать пользователя
о том, что деньги выданы, обязан клиент класса (т.е. Witrawal) — CashDispenser
не взаимодействует с классом Screen непосредственно.
1 // CashDispenser.h
2 // Определение класса CashDispenser (устройство выдачи наличных).
3 #ifndef CASH_DISPENSER_H
4 #define CASHEDISPENSER_H
5
6 class CashDispenser
7 {
8 public:
Код учебного примера ATM
1399
9 CashDispenser(); // конструктор инициализирует счетчик купюр
10
11 // имитирует выдачу указанной суммы наличных
12 void dispenseCash( int );
13
14 // сообщает, можно ли выдать требуемую сумму
15 bool isSufficientCashAvailable( int ) const;
16 private:
17 const static int INITIAL_COUNT = 500;
18 int count; // число оставшихся 20-долларовых купюр
19 }; // конец класса CashDispenser
20
21 #endif // CASH DISPENSER H
Рис. Е.7. Определение класса CashDispenser
1 // CashDispenser.cpp
2 // Определения элемент-функций для класса CashDispenser.
3 #include "CashDispenser.h" // определение класса CashDispenser
4
5 //конструктор по умолчанию инициализирует count начальным значением
6 CashDispenser::CashDispenser()
7 {
8 count = INITIAL_COUNT; // установить атрибут count по умолчанию
9 } // конец конструктора по умолчанию CashDispenser
10
11 // имитирует выдачу указанной суммы; предполагает, что наличных
12 // достаточно (вызов isSufficientCashAvailable возвратил true)
13 void CashDispenser::dispenseCash( int amount )
14 {
15 int billsRequired = amount / 20; // требуемое число купюр
16 count -= billsRequired; // обновить счетчик купюр
17 } // конец функции dispenseCash
18
19 // сообщает,можно ли выдать требуемую сумму
20 bool CashDispenser::isSufficientCashAvailable( int amount ) const
21 {
22 int billsRequired = amount / 20; // требуемое число купюр
23
24 if ( count >= billsRequired )
25 return true; // есть достаточное число купюр
26 else
27 return false; // нет достаточного числа купюр
28 } // конец функции isSufficientCashAvailable
Рис. Е.8. Определения элемент-функций класса CashDispenser
Элемент-функция isSufficientCashAvailable (строки 20-28) принимает
параметр amount, специфицирующий требуемую сумму наличных.
Строки 24-27 возвращают true, если счетчик count больше или равен
billsRequired (т.е. имеется достаточное количество купюр), и false в противном
случае (если купюр недостаточно). Например, если пользователь хочет снять $80
1400
Приложение Е
(т.е. billsRequired равна 4), а осталось всего три купюры (т.е. count равен 3),
элемент-функция возвратит false.
Е.6. Класс DepositSlot
Класс DepositSlot (рис. Е.9-Е. 10) представляет приемную щель ATM. Как
и реализованная здесь версия класса CashDispenser, данная версия класса
DepositSlot просто имитирует функции настоящего аппаратного устройства.
DepositSlot не имеет элементов данных и содержит единственную
элемент-функцию isEnvelopeReceived (объявленную в строке 9 на рис. Е.9 и определяемую
в строках 7-10 на рис. ЕЛО), которая сообщает, получен ли конверт с
депозитом.
1 // DepositSlot.h
2 // Определение класса DepositSlot. Представляет приемную щель ATM.
3 #ifndef DEPOSIT__SLOT_H
4 #define DEPOSIT_SLOT_H
5
6 class DepositSlot
7 {
8 public:
9 bool isEnvelopeReceived() const; // сообщает, получен ли конверт
10 }; // конец класса DepositSlot
11
12 #endif // DEPOSIT SLOT H
Рис. Е.9. Определение класса DepositSlot
1 // DepositSlot.epp
2 // Определение элемент-функции для класса DepositSlot.
3 #include "DepositSlot.h" // определение класса DepositSlot
4
5 // сообщает,получен ли конверт (всегда возвращает true, так как
6 // это всего лишь программная имитация действительного устройства)
7 bool DepositSlot::isEnvelopeReceived() const
8 {
9 return true; // конверт с депозитом получен
10 } // конец функции isEnvelopeReceived
Рис. Е.10. Определение элемент-функции класса DepositSlot
Как вы помните из спецификации требований, ATM дает пользователю две
минуты на то, чтобы поместить конверт в приемную щель. Данная версия
элемент-функции isEnvelopeReceived немедленно возвращает true (строка 9 на
рис. ЕЛО), поскольку это всего лишь имитация, и мы предполагаем, что
пользователь предоставил конверт в течение указанного отрезка времени. Если бы
наша система соединялась с настоящим аппаратным устройством,
элемент-функцию isEnvelopeReceived можно было реализовать таким образом,
чтобы она не более двух минут ждала прихода сигнала от устройства входной
щели, означающего, что пользователь поместил конверт в щель. Если бы
Код учебного примера ATM
1401
isEnvelopeReceived получала такой сигнал в течение двух минут, она
возвращала true. Если бы две минуты истекли, а сигнал не пришел,
элемент-функция возвращала false.
Е.7. Класс Account
Класс Account (рис. ЕЛ 1-Е. 12) представляет банковский счет.
Строки 9-15 в определении класса (рис. Е.11) содержат прототипы для
конструктора класса и шести элемент-функций, которые мы скоро обсудим. Каждый счет
имеет четыре атрибута (моделируемых на рис. 13.29) — accountNumber, pin,
availableBalance и totalBalance. Строки 17-20 реализуют эти атрибуты как
закрытые элементы данных. Элемент данных availableBalance представляет
сумму средств, доступных для снятия. Элемент totalBalance представляет
сумму доступных средств плюс сумма внесенных средств, еще ожидающих
очистки или подтверждения.
Определения элемент-функций класса Account
На рис. Е.12 представлены определения элемент-функций класса Account.
конструктор класса (строки 6-14) принимает в качестве аргументов номер
счета, присвоенный счету PIN-код, начальный доступный баланс и начальный
общий баланс. Строки 8-11 присваивают эти значения элементам данных
класса, используя инициализаторы элементов.
1 // Account.h
2 // Определение класса Account. Представляет банковский счет.
3 #ifndef ACCOUNT_H
4 #define ACCOUNT_H
5
6 class Account
7 {
8 public:
9 Account( int, int, double, double ); // устанавливает атрибуты
10 bool validatePIN( int ) const; // введенный PIN правилен?
11 double getAvailableBalance() const; // возвращает наличный баланс
12 double getTotalBalance() const; // возвращает общий баланс
13 void credit( double ); // прибавляет сумму к балансу счета
14 void debit( double ); // вычитает сумму из баланса счета
15 int getAccountNumber() const; // возвращает номер счета
16 private:
17 int accountNumber; // номер счета
18 int pin; // PIN для авторизации
19 double availableBalance; // средства, доступные для снятия
20 double totalBalance; // доступные средства + ожидающие очистки
21 }; // конец класса Account
22
23 #endif // ACCOUNT H
Рис. Е.11. Определение класса Account
1402
Приложение Е
1 // Account.cpp
2 // Определения элемент-функций для класса Account.
3 #include "Account.h" // определение класса Account
4
5 // конструктор Account инициализирует атрибуты
6 Account::Account( int theAccountNumber, int thePIN,
7 double theAvailableBalance, double theTotalBalance )
8 : accountNumber( theAccountNumber ),
9 pin( thePIN ),
10 availableBalance( theAvailableBalance ),
11 totalBalance( theTotalBalance )
12 {
13 // пустое тело
14 } // конец конструктора Account
15
16 // определяет, соответствует ли введенный PIN значению в Account
17 bool Account::validatePIN( int userPIN ) const
18 {
19 if ( userPIN == pin )
20 return true;
21 else
22 return false;
23 } // конец функции validatePIN
24
25 // возвращает наличный баланс
26 double Account::getAvailableBalance() const
27 {
28 return availableBalance;
29 } // конец функции getAvailableBalance
30
31 // возвращает общий баланс
32 double Account::getTotalBalance() const
33 {
34 return totalBalance;
35 } // конец функции getTotalBalance
36
37 // вносит сумму на счет
38 void Account::credit( double amount )
39 {
40 totalBalance += amount; // прибавить к общему балансу
41 } // конец функции credit
42
43 // снимает сумму со счета
44 void Account::debit( double amount )
45 {
46 availableBalance -= amount; // вычесть из наличного баланса
47 totalBalance -= amount; // вычесть из общего баланса
48 } // конец функции debit
49
50 // возвращает номер счета
51 int Account::getAccountNumber() const
52 {
53 return accountNumber;
54 } // конец функции getAccountNumber
Рис. Е.12. Определения элемент-функций класса Account
Код учебного примера ATM
1403
Элемент-функция validatePin (строки 17-23) определяет, соответствует ли
указанный пользователем PIN-код (т.е. параметр userPIN) PIN-коду,
ассоциированному со счетом (т.е. элементу данных pin). Как вы помните, мы
моделировали параметр userPIN этой функции в классовой диаграмме UML на
рис. 6.37. Если два PIN-кода совпадают, элемент-функция возвращает true;
в противном случае она возвращает false.
Элемент-функции getAvailableBalance (строки 26-29) и getTotalBalance
(строки 32-35) являются get-функциями, которые возвращают значения
элементов данных avaikableBalance и totalBalance типа double.
Элемент-функция credit (строки 38-41) прибавляет к счету денежную
сумму (т.е. параметр amount) в процессе транзакции внесения средств. Заметьте,
что эта функция прибавляет amount только к элементу данных totalBalance.
Деньги, внесенные на счет при транзакции, не становятся доступными сразу,
поэтому мы модифицируем только общий баланс. Мы полагаем, что спустя
некоторое время банк соответствующим образом обновит наличный баланс.
Наша реализация класса Account содержит только элемент-функции,
необходимые для проведения транзакций ATM. Мы, следовательно, опускаем
элемент-функции, которые вызывались бы какой-то другой системой банка для
прибавления суммы к элементу availableBalance (чтобы подтвердить депозит)
или вычитания из элемента totalBalance (чтобы отвергнуть депозит).
Элемент-функция debit (строки 44-48) вычитает из счета денежную сумму
(т.е. параметр amount) в процессе транзакции снятия наличных. Эта функция
вычитает amount как из элемента данных availableBalance (строка 46), так и из
элемента totalBalance, так как снятие денег воздействует на оба баланса счета.
Элемент-функция getAccountNumber (строки 51-54) обеспечивает доступ
к элементу accountNumber объекта Account. Мы включили в нашу
реализацию эту функцию, чтобы клиент класса (т.е. BankDatabase) мог
идентифицировать каждый счет. Например, база данных содержит много счетов, и она
может вызывать данную элемент-функцию для каждого из своих объектов
Account, чтобы найти счет с конкретным номером.
Е.8. Класс BankDatabase
Класс BankDatabase (рис. Е.13-Е.14) моделирует базу данных банка, с
которой ATM взаимодействует для доступа к информации пользовательского
счета и ее модификации. Определение класса (рис. Е.13) объявляет прототипы
для конструктора класса и нескольких элемент-функций, которые
обсуждаются ниже. Определение класса объявляет также элементы данных для
BankDatabase. Исходя из отношения композиции с классом Account, мы
определили для класса BankDatabase один элемент данных. Как вы помните из
рис. 13.28, BankDatabase состоит из большего или равного нулю числа
объектов Account. Строка 24 на рис. Е.13 объявляет элемент данных accounts —
вектор объектов Account, — реализующий это отношение композиции.
Строки 6-7 позволяют нам использовать в этом файле шаблон vector. Строка 27
содержит прототип для закрытой вспомогательной функции get Account,
которая позволяет элемент-функциям класса получить указатель на конкретный
счет в векторе accounts.
1404
Приложение Е
1 // BankDatabase.h
2 // Определение класса BankDatabase. Представляет базу данных банка.
3 #ifndef BANK_DATABASE_H
4 #define BANK_DATABASE_H
5
6 #include <vector> // класс использует вектор для хранения счетов
7 using std::vector;
8
9 #include "Account.h" // определение класса Account
10
11 class BankDatabase
12 {
13 public:
14 BankDatabase(); // конструктор инициализирует счета
15
16 // определить, соответствуют ли номер и PIN значениям в Account
17 bool authenticateUser( int, int ); // действителен ли счет
18
19 double getAvailableBalance( int ); // получить наличный баланс
20 double getTotalBalance( int ); // получить общий баланс счета
21 void credit( int, double ); // прибавить сумму к балансу
22 void debit( int, double ); // вычесть сумму из баланса
23 private:
24 vector< Account > accounts; // вектор банковских счетов
25
26 // закрытая вспомогательная функция
27 Account * getAccount( int ); //получить указатель на объект счета
28 }; // конец класса BankDatabase
29
30 #endif // BANK DATABASE H
Рис. Е.13. Определение класса BankDatabase
Определения элемент-функций класса BankDatabase
Рис. Е.14 содержит определения элемент-функций для класса
BankDatabase. Мы реализуем класс с конструктором по умолчанию (строки 6-15),
который добавляет к элементу данных accounts объекты класса Account. В целях
тестирования нашей системы мы создаем два новых объекта Account с
тестовыми данными (строки 9-10), после чего добавляем их в конец вектора
(строки 13-14). Обратите внимание, что конструктор Account имеет четыре
параметра — номер счета, присвоенный счету PIN-код, начальный доступный
баланс и начальный общий баланс.
1 // BankDatabase.срр
2 // Определения элемент-функций для класса BankDatabase.
3 #include "BankDatabase.h" // определение класса BankDatabase
4
5 // конструктор BankDatabase по умолчанию инициализирует счета
6 BankDatabase::BankDatabase()
7 {
8 // создать два объекта Account для тестирования
9 Account accountK 12345, 54321, 1000.0, 1200.0 );
10 Account account2( 98765, 56789, 200.0, 200.0 );
Код учебного примера ATM
1405
11
12 // добавить два объекта Account к вектору accounts
13 accounts.push_back( accountl ); // добавить в конец вектора
14 accounts.push_back( account2 ); // добавить в конец вектора
15 } // конец конструктора по умолчанию BankDatabase
16
17 // извлечь объект Account, содержащий указанный номер счета
18 Account * BankDatabase::getAccount( int accountNumber )
19 {
20 // цикл по accounts для поиска соответствующего номера счета
21 for ( size_t i = 0; i < accounts.size (); i++ )
22 {
23 // если номер найден, возвратить текущий объект счета
24 if ( accounts[ i ].getAccountNumber() = accountNumber )
25 return fiaccounts[ i ];
26 } // конец for
27
28 return NULL; // если запрошенный счет не найден, возвратить NULL
29 } // конец функции getAccount
30
31 // определить, соответствуют ли введенные пользователем
32 // номер счета и PIN значениям в базе данных
33 bool BankDatabase::authenticateUser( int userAccountNumber,
34 int userPIN )
35 {
36 // попытаться извлечь счет с указанным номером
37 Account * const userAccountPtr = getAccount( userAccountNumber );
38
39 // если счет существует, возвратить результат функции validatePIN
40 if ( userAccountPtr != NULL )
41 return userAccountPtr->validatePIN( userPIN );
42 else
43 return false; // счет не найден, возвратить false
44 } // конец функции authenticateUser
45
46 // возвратить наличный баланс счета с указанным номером
47 double BankDatabase::getAvailableBalance( int userAccountNumber )
48 {
49 Account * const userAccountPtr = getAccount( userAccountNumber );
50 return userAccountPtr->getAvailableBalance();
51 } // конец функции getAvailableBalance
52
53 // возвратить общий баланс счета с указанным номером
54 double BankDatabase::getTotalBalance( int userAccountNumber )
55 {
56 Account * const userAccountPtr = getAccount ( userAccountNumber ) ;
57 return userAccountPtr->getTotalBalance();
58 } // конец функции getTotalBalance
59
60 // внести сумму на счет с указанным номером
61 void BankDatabase::credit( int userAccountNumber, double amount )
62 {
63 Account * const userAccountPtr = getAccount ( userAccountNumber );
64 userAccountPtr->credit( amount );
65 } // конец функции credit
66
67 // снять сумму со счета с указанным номером
1406
Приложение Е
68 void BankDatabase::debit( int userAccountNumber, double amount )
69 {
70 Account * const userAccountPtr = getAccount ( userAccountNumber );
71 userAccountPtr->debit( amount );
72 } // конец функции debit
Рис. Е.14. Определения элемент-функций класса BankDatabase
Как вы помните, класс BankDatabase служит посредником между классом
ATM и действительными объектами Account, содержащими информацию
пользовательских счетов. Таким образом, элемент-функции класса
BankDatabase не делают ничего иного кроме вызова соответствующих элемент-функций
объекта Account, принадлежащего текущему пользователю ATM.
Мы включили в класс закрытую сервисную функцию getAccount
(строки 18-29), которая позволяет базе данных получить указатель на конкретный
счет в векторе accounts. Чтобы найти счет пользователя, getAccount
сравнивает значение, возвращаемое для каждого элемента вектора функцией
getAccountNumber, с указанным номером счета, пока не найдет совпадение.
Строки 21-26 выполняют проход по вектору accounts. Если номер счета
текущего объекта Account (т.е. accounts[ i ] ) равен значению параметра ас-
countNumber, функция немедленно возвращает адрес текущего счета (т.е.
указатель на текущий объект Account). Если никакой счет не имеет
указанного номера, строка 29 возвращает NULL. Заметьте, что эта элемент-функция
должна возвращать указатель, а не ссылку, так как существует возможность,
что возвращаемым значением окажется NULL, — ссылка не может быть
нулевой, а указатель может.
Обратите внимание, что функция вектора size (вызываемая в условии
продолжения цикла в строке 21)возвращает число элементов в векторе как
значение типа size_t (обычно он эквивалентен unsigned int). Поэтому и
управляющую переменную i мы объявляем как имеющую тип size_t. На некоторых
компиляторах объявление i как int привело бы к выводу предупреждающего
сообщения, поскольку условие продолжения цикла сравнивало бы значение со
знаком (т.е. int) и значение без знака (т.е. значение типа size_t).
Элемент-функция authenticateUser (строки 33-44) подтверждает или
отвергает идентификацию пользователя ATM. Эта функция принимает в качестве
аргументов введенные пользователем номер счета и PIN-код, и сообщает,
соответствуют ли они номеру и PIN-коду некоторого счета в базе данных. Строка 37
вызывает вспомогательную функцию getAccount, которая возвращает либо
указатель на объект счета с номером, равным userAccountNumber, либо NULL,
означающий, что пользовательский номер счета недействителен. Мы объявляем
указатель userAccountPtr как const, поскольку после установки его на
пользовательский объект Account указатель не должен изменяться. Если getAccount
возвращает указатель на объект Account, строка 41 возвращает булево
значение, полученное от элемент-функции validatePIN этого объекта. Заметьте, что
сама элемент-функция authenticateUser класса BankDatabase не производит
сравнения PIN-кодов — чтобы это сделать, она передает userPIN
элемент-функции validatePIN объекта Account. Значение, возвращаемое функцией
validatePIN, показывает, соответствует ли PIN-код, введенный пользователем,
PIN-коду в объекте Account, так что элемент-функция authenticateUser просто
возвращает это значение клиенту класса (т.е. классу ATM).
Код учебного примера ATM
1407
BankDatabase полагает, что класс ATM, прежде чем разрешить
пользователю производить транзакции, вызвал элемент-функцию authenticateUser и
получил возвращаемое значение true. Класс BankDatabase полагает также, что
каждый объект транзакции, создаваемый ATM, содержит действительный
номер счета авторизованного пользователя, и что этот же номер счета передается
остальным элемент-функциям класса BankDatabase в качестве аргумента
userAccountNumber. Поэтому элемент-функции getAvailableBalance
(строки 47-51), getTotalBalance (строки 54-58), credit (строки 61-65) и debit
(строки 68-72) просто получают с помощью сервисной функции getAccount
указатель на объект пользовательского счета, после чего используют этот
указатель для вызова соответствующих элемент-функций класса Account. Мы
знаем, что вызов get Account из перечисленных элемент-функций никогда не
возвратит NULL, поскольку userAccountNumber обязательно соответствует
существующему счету. Обратите внимание, что getAvailableBalance и
getTotalBalance возвращают значения, возвращаемые соответствующими
элемент-функциями класса Account, a credit и debit просто передают свой
параметр amount соответствующим функциям из Account.
Е.9. Класс Transaction
Класс Transaction (рис. Е. 15-Е. 16) является абстрактным базовым
классом, который представляет понятие «транзакция ATM». Он отражает общие
свойства производных классов Balancelnquiry, Withdrawal и Deposit.
Рис. Е.15 развивает заголовочный файл класса Transaction, разработанный
в разделе 13.10. Строки 13, 17-19 и 22 содержат прототипы для конструктора
класса и четырех элемент-функций, которые мы обсудим чуть ниже.
Строка 15 объявляет виртуальный деструктор с пустым телом — это делает
виртуальными деструкторы всех производных классов (даже деструкторы, неявно
генерируемые компилятором) и гарантирует, что динамически созданные
объекты производных классов будут уничтожаться корректно в случаях, когда
они удаляются через указатель базового класса. Строки 24-26 объявляют
закрытые элементы данных класса. Как вы помните, в классовой диаграмме на
рис. 13.29 класс Transaction содержит атрибут account Number
(реализованный в строке 24), который идентифицирует счет, участвующий в транзакции.
Элементы данных screen (строка 25) и bankDatabase (строка 26) мы выводим
из ассоциаций класса Transaction, моделируемых на рис. 13.28, — веем
транзакциям необходим доступ к экрану ATM и банковской базе данных, поэтому
мы включаем в качестве элементов данных класса ссылки на Screen
и BankDatabase. Как вы вскоре увидите, эти ссылки инициализируются
конструктором Transaction. Обратите внимание на опережающие объявления
в строках 6-7, которые означают, что класс содержит ссылки на объекты
Screen и BankDatabase, но определения этих классов находятся за пределами
заголовочного файла.
1 // Transaction.h
2 // Определение абстрактного базового класса Transaction
3 #ifndef TRANSACTION^
4 #define TRANSACTION H
1408
Приложение Е
6 class Screen; // опережающее объявление класса Screen
7 class BankDatabase; // опережающее объявление класса BankDatabase
8
9 class Transaction
Ю {
11 public:
12 // конструктор инициализирует общие элементы всех транзакций
13 Transaction( int, Screen &, BankDatabase & );
14
15 virtual '-Transaction() { } // виртуальный пустой деструктор
16
17 int getAccountNumber() const; // возвратить номер счета
18 Screen &getScreen() const; // возвратить ссылку на экран
19 BankDatabase &getBankDatabase() const; // возвратить базу данных
20
21 // чисто виртуальная функция для исполнения транзакции
22 virtual void execute() =0; // заменяется в производных классах
23 private:
24 int accountNumber; // указывает обрабатываемый счет
25 Screen fiscreen; // ссылка на экран ATM
26 BankDatabase fibankDatabase; // ссылка на банковскую базу данных
27 }; // конец класса Transaction
28
29 #endif // TRANSACTION H
Рис. Е.15. Определение абстрактного базового класса Transaction
1 // Transaction.срр
2 // Определения элемент-функций для класса Transaction.
3 #include "Transaction.h" // определение класса Transaction
4 #include "Screen.h" // определение класса Screen
5 #include "BankDatabase.h" // определение класса BankDatabase
6
7 // консруктор инициализирует общие элементы всех транзакций
8 Transaction::Transaction( int userAccountNumber, Screen fiatmScreen,
9 BankDatabase fiatmBankDatabase )
10 : accountNumber( userAccountNumber ),
11 screen( atmScreen ),
12 bankDatabase( atmBankDatabase )
13 {
14 // пустое тело
15 } // конец конструктора Transaction
16
17 // возвратить номер счета
18 int Transaction::getAccountNumber() const
19 {
20 return accountNumber;
21 } // конец функции getAccountNumber
22
23 // возвратить ссылку на экран
24 Screen &Transaction::getScreen() const
25 {
26 return screen;
27 } // конец функции getScreen
28
Код учебного примера ATM
1409
29 // возвратить ссылку на банковскую базу данных
30 BankDatabase ^Transaction::getBankDatabase() const
31 {
32 return bankDatabase;
33 } // конец функции getBankDatabase
Рис, Е.16. Определения элемент-функций класса Transaction
Конструктор класса Transaction (объявленный в строке 13 на рис. Е.15
и определяемый в строках 8-15 на рис. Е.16) принимает в качестве аргументов
номер счета текущего пользователя и ссылки на экран ATM и банковскую базу
данных. Поскольку Transaction — абстрактный класс, его конструктор
никогда не будет вызываться явным образом для создания представителей класса
Transaction. Этот конструктор будет вызываться через инициализаторы
элемента конструкторами производных классов.
У класса Transaction имеются три открытых #е£-функции — getAc-
countNumber (объявляемая в строке 17 на рис. Е.15 и определяемая в строках
18-21 на рис. Е.16), getScreen (объявляемая в строке 18 на рис. Е.15 и
определяемая в строках 24-27 на рис. Е.16) и gctBankDatabase (объявляемая в
строке 19 на рис. Е.15 и определяемая в строках 30-33 на рис. Е.16). Производные
классы транзакций наследуют эти элемент-функции и используют их для
доступа к закрытым элементам данных класса Transaction.
Класс Transaction объявляет также чисто виртуальную функцию execute
(строка 22 на рис. Е.15). Определять реализацию этой функции бессмысленно,
поскольку нельзя произвести обобщенную транзакцию. Поэтому мы
объявляем эту функцию чисто виртуальной и требуем, чтобы каждый производный от
Transaction класс предусматривал свою собственную конкретную
реализацию, которая будет производить транзакцию конкретного типа.
Е.10. Класс Balancelnquiry
Класс Balancelnquiry (рис. Е. 17-Е. 18) является производным от
абстрактного базового класса Transaction и представляет транзакцию ATM для
получения справки о балансе счета. Balancelnquiry не имеет собственных элементов
данных, но наследует элементы данных accountNumber, screen
и bankDatabase класса Transaction, доступ к которым осуществляется через
открытые ^-функции последнего. Обратите внимание, что строка 7 включает
определение класса Transaction. Конструктор Balancelnquiry (объявленный
в строке 11 на рис. ЕЛ7 и определяемый в строках 8-13 на рис. Е.18)
принимает аргументы, соответствующие элементам данных класса Transaction,
и просто направляет их конструктору Transaction, используя синтаксис
инициализатора элементов (строка 10 на рис. Е.18). Строка 12 на рис. ЕЛ7
содержит прототип для элемент-функции execute, который указывает на намерение
переопределить чисто виртуальную функцию базового класса с тем же
именем.
1 // Balancelnquiry.h
2 // Определение класса Balancelnquiry (справка о балансе).
3 #ifndef BALANCE_INQUIRY_H
4 #define BALANCE_INQUIRY_H
1410
Приложение Е
5
6 #include "Transaction.h" // определение класса Transaction
7
8 class Balancelnquiry : public Transaction
9 {
10 public:
11 Balancelnquiry( int, Screen &, BankDatabase & ); // конструктор
12 virtual void execute(); // произвести транзакцию
13 }; // конец класса Balancelnquiry
14
15 #endif // BALANCE INQUIRY H
Рис. Е.17. Определение класса Balancelnquiry
1 // Balancelnquiry.cpp
2 // Определения элемент-функций для класса Balancelnquiry.
3 #include "Balancelnquiry.h" // определение класса Balancelnquiry
4 #include "Screen.h" // определение класса Screen
5 #include "BankDatabase.h" // определение класса BankDatabase
6
7 // конструктор инициализирует элементы данных базового класса
8 Balancelnquiry:: Balancelnquiry( int userAccountNumber,
9 Screen &atmScreen, BankDatabase &atmBankDatabase )
10 : Transaction( userAccountNumber, atmScreen, atmBankDatabase )
11 {
12 // пустое тело
13 } // конец конструктора Balancelnquiry
14
15 // исполнение; заменяет чисто виртуальную функцию из Transaction
16 void Balancelnquiry::execute()
17 {
18 // получить ссылки на банковскую базу данных и экран
19 BankDatabase &bankDatabase = getBankDatabase();
20 Screen (screen = getScreen();
21
22 // получить наличный баланс для счета текущего пользователя
23 double availableBalance =
24 bankDatabase.getAvailableBalance( getAccountNumber() );
25
26 // получить общий баланс для счета текущего пользователя
27 double totalBalance =
28 bankDatabase.getTotalBalance( getAccountNumber() );
29
30 // вывести на экран информацию о балансе
31 screen.displayMessageLine( "\nBalance Information:" );
32 screen.displayMessage( " - Available balance: " );
33 screen.displayDollarAmount( availableBalance );
34 screen.displayMessage( "\n - Total balance: " );
35 screen.displayDollarAmount( totalBalance );
36 screen.displayMessageLine( "" );
37 } // конец функции execute
Рис. Е.18. Определения элемент-функций класса Balancelnquiry
Код учебного примера ATM
1411
Класс Balancelnquiry переопределяет чисто виртуальную функцию execute
из Transaction, чтобы осуществить ее конкретную реализацию (строки 16-37
на рис. Е.18), которая выполняет действия, связанные с проверкой баланса.
Строки 19-20 получают ссылки на банковскую базу данных и экран ATM,
вызывая элемент-функции, унаследованные от базового класса Transaction.
Строки 23-24 извлекают значение наличного баланса счета, вызывая
элемент-функцию getAvailableBalance класса BankDatabase. Обратите
внимание, что в строке 24 вызывается унаследованная функция getAccountNuber,
возвращающая номер счета текущего пользователя, который затем предается
функции getAvailableBalance. Строки 27-28 извлекают значение общего
баланса счета. Строки 31-36 выводят информацию о балансе на экран ATM. Как
вы помните, displayDollarAmount принимает аргумент типа double и выводит
его на экран в формате долларовой суммы. Например, если наличный баланс
пользователя (availableBalance) равен 700.5, строка 33 выводит $700.50.
Обратите внимание, что строка 36 вставляет при выводе пустую строчку, чтобы
отделить информацию о балансе от последующего вывода (т.е. от главного
меню, которое повторно выводится классом ATM после исполнения
Balancelnquiry).
Е.11. Класс Withdrawal
Класс Withdrawal (рис. Е. 19-Е.20) является производным от Transaction
и представляет транзакцию ATM для снятия денег со счета. Рис. Е.19
развивает заголовочный файл для этого класса, представленный на рис. 13.31. Класс
имеет конструктор и одну элемент-функцию execute, которую мы обсудим
чуть ниже. Как вы помните, в классовой диаграмме на рис. 13.29 класс
Withdrawal имеет один атрибут — amount, — который реализуется в
строке 16 как элемент данных целого типа. Рис. 13.28 моделирует ассоциации
Withdrawal с классами Keypad и CashDispenser, которые реализуются в
строках 17-18 соответственно ссылками keypad и cashDispenser. Строка 19
является прототипом закрытой сервисной функции, которая обсуждается далее.
1 // Withdrawal.]!
2 // Определение класса Withdrawal (снятие со счета).
3 #ifndef WITHDRAWAL_H
4 #define WITHDRAWAL_H
5
6 #include "Transaction.h" // определение класса Transaction
7 class Keypad; // опережающее объявление класса Keypad
8 class CashDispenser; // опережающее объявление класса CashDispenser
9
10 class Withdrawal : public Transaction
11 {
12 public:
13 Withdrawal(int, Screens, BankDatabase&, Keypads, CashDispenser&);
14 virtual void execute(); // произвести транзакцию
15 private:
16 int amount; // снимаемая сумма
17 Keypad &keypad; // ссылка на кнопочную панель ATM
<18 CashDispenser &cashDispenser; // ссылка на выходной лоток ATM
19 int displayMenuOfAmounts () const; // вывести меню снимаемых сумм
1412
Приложение Е
20 }; // конец класса Withdrawal
21
22 #endif // WITHDRAWAL^
Рис. Е.19. Определение класса Withdrawal
Определения элемент-функций класса Withdrawal
Рис. Е.20 содержит определения элемент-функций для класса Withdrawal.
Строка 3 включает файл с определением класса, а строки 4-7 включают
определения других классов, используемых в элемент-функциях Withdrawal.
Строка 10 объявляет глобальную константу, соответствующую опции отмены
в меню снимаемых сумм. Вскоре мы рассмотрим, как класс использует эту
константу.
1 // Withdrawal.срр
2 // Определения элемент-функций для класса Withdrawal.
3 #include "Withdrawal.h" // определение класса Withdrawal
4 #include "Screen.h" // определение класса Screen
5 #include "BankDatabase.h" // определение класса BankDatabase
6 #include "Keypad.h" // определение класса Keypad
7 #include "CashDispenser.h" //определение класса CashDispenser
8
9 // глобальная константа, соответствующая опции меню для отмены
10 const static int CANCELED = 6;
11
12 // конструктор Withdrawal инициализирует элементы данных класса
13 Withdrawal::Withdrawal( int userAccountNumber, Screen fiatmScreen,
14 BankDatabase fiatmBankDatabase, Keypad &atmKeypad,
15 CashDispenser fiatmCashDispenser )
16 : Transaction( userAccountNumber, atmScreen, atmBankDatabase ),
17 keypad ( atmKeypad ), CashDispenser( atmCashDispenser )
18 {
19 // пустое тело
20 } // конец конструктора Withdrawal
21
22 // исполнение; заменяет чисто виртуальную функцию из Transaction
23 void Withdrawal::execute()
24 {
25 bool cashDispensed = false; // наличные еще не выданы
26 bool transactionCanceled = false; // транзакция еще не отменена
27
28 // получить ссылки на банковскую базу данных и экран
29 BankDatabase &bankDatabase = getBankDatabase();
30 Screen &screen = getScreen();
31
32 // цикл, пока деньги не будут выданы или транзакция отменена
33 do
34 {
35 // получить от пользователя выбранное значение снимаемой суммы
36 int selection = displayMenuOfAmounts();
37
38 // проверить, выбрана ли сумма или транзакция отменена
39 if ( selection != CANCELED )
Код учебного примера ATM
1413
40 {
41 amount = selection; // выбранное значение снимаемой суммы
42
43 // получить наличный баланс текущего счета
44 double availableBalance =
45 bankDatabase.getAvailableBalance( getAccountNumber() );
46
47 // проверить, достаточно ли у пользователя денег на счете
48 if ( amount <= availableBalance )
49 {
50 // проверить, достаточно ли наличных в устройстве выдачи
51 if ( cashDispenser.isSufficientCashAvailable( amount ) )
52 {
'53 // обновить счет в соответствии с произведенной операцией
54 bankDatabase.debit( getAccountNumber(), amount );
55
56 cashDispenser.dispenseCash( amount ); // выдать наличные
57 cashDispensed = true; // наличные выданы
58
59 // попросить пользователя забрать деньги
60 screen.displayMessageLine(
61 "\nPlease take your cash from the cash dispenser." );
62 ) // конец if
63 else // наличных в устройстве выдачи недостаточно
64 screen.displayMessageLine(
65 "\nlnsufficient cash available in the ATM."
66 "\n\nPlease choose a smaller amount." );
67 } // конец if
68 else // у пользователя недостаточно денег на счете
69 {
70 screen.displayMessageLine(
71 "\nlnsufficient funds in your account."
72 "\n\nPlease choose a smaller amount." );
73 } // конец else
74 } // конец if
75 else // пользователь выбрал в меню опцию отмены
76 {
77 screen.displayMessageLine( "\nCanceling transaction..." );
78 transactionCanceled = true; // пользователь отменил операцию
79 } // конец else
80 } while ( !cashDispensed && !transactionCanceled ); // do...while
81 } // конец функции execute
82
83 // вывести меню снимаемых сумм и опцию отмены; возвратить
84 // Fbiбранную сумму или 0, если пользователь выбрал отмену
85 int Withdrawal:rdisplayMenuOfAmounts() const
86 {
87 int userChoice = 0; //локальная переменная для результата функции
88
89 Screen &screen = getScreen(); // получить ссылку на экран
90
91 // массив сумм, соответствующих опциям меню
92 int amounts[] = { 0, 20, 40, 60, 100, 200 };
93
94 // цикл, пока не будет выбрана допустимая опция
95 while ( userChoice = 0 )
96 {
1414
Приложение Е
97 // вывести меню
98 screen.displayMessageLine( "\nWithdrawal options:" );
99 screen.displayMessageLine( - $20" )
100 screen.displayMessageLine( - $40" )
101 screen.displayMessageLine( - $60" )
102 screen.displayMessageLine( - $100" );
103 screen.displayMessageLine( - $200" );
104 screen.displayMessageLine( - Cancel transaction" );
105 screen.displayMessage("\nChoose a withdrawal option A-6): ");
106
107 int input = keypad.getlnput(); // получить ввод с панели
108
109 // определить в зависимости от выбора, что делать дальше
110 switch ( input )
HI {
112 case 1: // если пользователь выбрал снимаемую сумму
113 case 2: // (т.е. опцию 1, 2, 3, 4 или 5), возвратить
114 case 3: // соответствующую сумму из массива amounts
115 case 4:
116 case 5:
117 userChoice = amounts[ input ]; // сохранить выбор
118 break;
119 case CANCELED: // пользователь выбрал отмену
120 userChoice = CANCELED; // сохранить выбор
121 break;
122 default: // пользователь ввел не число от 1 до 6
123 screen.displayMessageLine(
124 "\nlvalid selection. Try again." );
125 } // конец switch
126 } // конец while
127
128 return userChoice; // возвратить снимаемую сумму или CANCELED
129 } // конец функции displayMenuOfAmounts
Рис. Е.20. Определения элемент-функций класса Withdrawal
Конструктор класса Withdrawal (определяемый в строках 13-20 на
рис. Е.20) имеет пять параметров. В строке 16 используется инициализатор
базового класса, который передает параметры userAccountNumber, atmScre-
еп и atmBankDatabase конструктору базового класса Transaction, чтобы
установить элементы данных, унаследованные классом Withdrawal от
Transaction. Конструктор принимает также в качестве параметров ссылки atmKeypad
и atmCashDispenser и используя инициализаторы присваивает их
элементам-ссылкам keypad и cashDispenser, используя их инициализаторы
(строка 17).
Класс Withdrawal переопределяет чисто виртуальную функцию execute из
Transaction ее конкретной реализацией (строки 23-81), которая выполняет
действия, связанные со снятием денег. Строка 25 объявляет и инициализирует
локальную булеву переменную cashDispensed. Эта переменная показывает,
были ли выданы наличные (т.е. транзакция успешно завершена), и исходно
равна false. Строка 26 объявляет и инициализирует значением false булеву
переменную transactionCanceled, показывающую, была ли транзакция
отменена пользователем. Строки 29-30 получают ссылки на банковскую базу данных
Код учебного примера ATM
1415
и экран ATM, вызывая элемент-функции, унаследованные от базового класса
Transaction.
Тело цикла do...while в строках 33-80 повторяется до тех пор, пока деньги
не будут выданы (т.е. пока cashDispensed не примет значение true) или пока
пользователь не выберет опцию отмены (т.е. пока transactionCanceled не
примет значение true). Этот цикл мы используем, чтобы возвращать пользователя
к началу транзакции в случае ошибки (т.е. если запрошенная сумма
превышает наличный баланс или не хватает купюр в выходном лотке). Строка 36
выводит меню снимаемых сумм и получает выбранную пользователем опцию,
вызывая закрытую сервисную функцию displayMenuOfAmounts (определяемую
в строках 85-129). Эта элемент-функция выводит меню сумм и возвращает
либо снимаемую сумму типа int, либо целую константу CANCELED,
показывающую, что пользователь решил отменить транзакцию.
Элемент-функция displayMenuOfAmounts (строки 85-129) сначала
объявляет локальную переменную userChoice (с начальным значением О) для
сохранения значения, которое она будет возвращать (строка 87). Строка 89 получает
ссылку на экран, вызывая элемент-функцию get Screen, унаследованную от
базового класса Transaction. Строка 92 объявляет целый массив снимаемых
сумм, соответствующих суммам, показываемым в меню. Мы игнорируем
первый элемент массива (с индексом 0), поскольку в меню нет опции 0. Оператор
while в строках 95-126 выполняется, пока userChoice не примет значения,
отличного от 0. Мы увидим далее, что это происходит, когда пользователь
выбирает в меню допустимую опцию. Строки 98-105 выводят на экран меню
снимаемых сумм и предлагают пользователю ввести свой выбор. Строка 107
получает с клавиатуры целое значение input. Оператор switch в строках 110-125
определяет в зависимости от выбора пользователя, что нужно делать дальше.
Если пользователь выбирает число от 1 до 5, строка 117 присваивает
userChoice значение элемента amounts с индексом input. Например, если пользователь
вводит 3, чтобы снять $60, строка 117 присваивает userChoice значение
amounts[ 3 ] (т.е. 60). Строка 118 завершает оператор switch. Переменная
userChoice уже не равна 0, поэтому цикл while в строках 95-126 завершается
и строка 128 возвращает значение userChoice. Если пользователь выберет
в меню опцию отмены, исполняются строки 120-121, устанавливая в
userChoice значение CANCELED, которое и возвращается элемент-функцией. Если
пользователь вводит недопустимый выбор, строки 123-124 выводят
сообщение об ошибке, и пользователь возвращается к меню снимаемых сумм.
Оператор if в строке 39 элемент-функции execute определяет, выбрал ли
пользователь снимаемую сумму или отменил транзакцию. В случае отмены
исполняются строки 77-78, выводя пользователю соответствующее сообщение
и устанавливая transactionCanceled равной true. В результате условие
продолжения в строке 80 не удовлетворяется, и управление возвращается
вызывающей функции (т.е. элемент-функции performTransactions класса ATM).
Если пользователь выбрал снимаемую сумму, строка 41 присваивает
локальную переменную selection элементу данных amount. Строки 44-45 извлекают
наличный баланс счета текущего пользователя и сохраняют его в локальной
переменной availableBalance типа double. Затем оператор if в строке 48
проверяет, что выбранная сумма не превышает наличного баланса пользователя.
Если превышает, строки 70-72 выводят сообщение об ошибке. Затем
управление передается в конец оператора do ...while, и цикл повторяется, так как
1416
Приложение Е
и cashDispensed, и transactionCanceled все еще остаются ложными. Если
баланс пользователя достаточно велик, оператор if в строке 51 проверяет,
достаточно ли денег в выходном лотке для удовлетворения запроса, вызывая
элемент-функцию isSufficientCashAvailable класса CashDispenser. Если эта
функция возвращает false, строки 64-66 выводят сообщение об ошибке
и цикл do...while повторяется. Если денег достаточно, то все условия
транзакции соблюдены, и строка 54 снимает amount со счета пользователя в базе
данных. Затем строки 56-57 дают команду выходному лотку выдать наличные
и устанавливают cashDispensed равной true. Наконец, строки 60-61
сообщают пользователю, что он может забрать деньги. Так как теперь значение
cashDispensed истинно, управление покидает оператор do...while. Других
операторов за циклом нет, поэтому элемент-функция возвращает управление
классу ATM.
Обратите внимание, что в строках 64-66 и 70-72 мы разбиваем аргумент
вызова элемент-функции displayMessageLine класса Screen на два строковых
литерала, каждый из которых располагается в программе на отдельной
строке. Мы делаем это потому, что аргумент слишком длинный и не помещается
в одной строке. C++ конкатенирует (т.е.соединяет) смежные строковые
литералы, даже если они находятся на разных строках. Например, если вы
напишете в программе "Happy " "Birthday", C++ будет рассматривать эти два
смежных строковых литерала как единственный строковый литерал
"Happy Birthday". Таким образом, при исполнении строк 64-66
displayMessageLine получает в качестве параметра единственную строку, хотя аргумент в
вызове функции записан как два строковых литерала.
Е.12. Класс Deposit
Класс Deposit (рис. Е.21-Е.22) является производным от Transaction
и представляет транзакцию ATM для депонирования средств. Рис. Е.21
содержит определение класса Deposit. Как и производные классы Balancelnquiry
и Withdrawal, Deposit объявляет конструктор (строка 13) и элемент-функцию
execute (строка 14); мы обсудим их чуть позже. Как вы помните, на рис. 13.29
класс Deposit имеет один атрибут amount, который реализуется в строке 16
как целый элемент данных. Строки 17-18 создают элементы-ссылки keypad
и deposits lot, которые реализуют ассоциации класса Deposit с классами
Keypad и Deposit Slot, моделируемые на рис. 13.28. Строка 19 содержит
прототип для закрытой сервисной функции promptForDepositAmount, обсуждаемой
ниже.
1 // Deposit.h
2 // Определение класса Deposit (внесение денег на счет).
3 #ifndef DEPOSIT_H
4 #define DEPOSIT_H
5
6 #include "Transaction.h" // определение класса Transaction
7 class Keypad; // опережающее объявление класса Keypad
8 class DepositSlot; // опережающее объявление класса DepositSlot
9
10 class Deposit : public Transaction
11 {
Код учебного примера ATM
1417
12 public:
13 Deposit( int, Screens, BankDatabase&, Keypads, DepositSlot& );
14 virtual void execute(); // выполнить транзакцию
15 private:
16 double amount; // вносимая сумма
17 Keypad fikeypad; // ссылка на кнопочную панель ATM
18 DepositSlot &depositSlot; // ссылка на выходной лоток ATM
19 double promptForDepositAmount() const; // получить вносимую сумму
20 }; // конец класса Deposit
21
22 #endif // DEPOSIT H
Рис. Е.21. Определение класса Deposit
Определения элемент-функций класса Deposit
На рис. Е.22 показан файл реализации для класса Deposit. Строка 3
включает определение класса Deposit, а строки 4-7 включают определения других
классов, используемых в его элемент-функциях. Строка 9 объявляет
константу CANCELED, соответствующую значению, которое пользователь вводит для
отмены транзакции. Вскоре мы рассмотрим, как класс использует эту
константу.
1 // Deposit.срр
2 // Определения элемент-функций для класса Deposit.
3 #include "Deposit.h" // определение класса Deposit
4 #include "Screen.h" // определение класса Screen
5 #include "BankDatabase.h" // определение класса BankDatabase
6 #include "Keypad.h" // определение класса Keypad
7 #include "DepositSlot.h" // определение класса DepositSlot
8
9 const static int CANCELED =0; // константа для опции отмены
10
11 // конструктор Deposit инициализирует элементы данных класса
12 Deposit::Deposit( int userAccountNumber, Screen fiatmScreen,
13 BankDatabase fiatmBankDatabase, Keypad &atmKeypad,
14 DepositSlot &atmDepositSlot )
15 : Transaction( userAccountNumber, atmScreen, atmBankDatabase ),
16 keypad( atmKeypad ), depositSlot( atmDepositSlot )
17 {
18 // пустое тело
19 } // конец конструктора Deposit
20
21 // исполнение; заменяет чисто виртуальную функцию из Transaction
22 void Deposit::execute()
23 {
24 BankDatabase &bankDatabase = getBanJcDatabase () ; //получить ссылку
25 Screen &screen = getScreen(); // получить ссылку
26
27 amount = promptForDepositAmount() ; // получить вносимую сумму
28
29 // проверить, введена ли сумма или транзакция отменена
30 if ( amount != CANCELED )
31 {
1418
Приложение Е
32 // запросить конверт, содержащий вносимую сумму
33 screen.displayMessage(
34 "\nPlease insert a deposit envelope containing " );
35 screen.displayDollarAmount( amount );
36 screen.displayMessageLine( " in the deposit slot." );
37
38 // принять конверт с депозитом
39 bool envelopeReceived = depositSlot.isEnvelopeReceived();
40
41 // проверить, получен ли конверт с депозитом
42 if ( envelopeReceived )
43 {
44 screen.displayMessageLine("\nYour envelope has been "
45 "receivedAnNOTE: The money just will not be available "
4 6 "until we\nverify the amount of any enclosed cash, "
47 "and any enclosed checks clear." );
48
49 // обновить счет в соответствии с транзакцией
50 bankDatabase.credit( getAccountNumber(), amount );
51 } // конец if
52 else // конверт с депозитом не получен
53 {
54 screen.displayMessageLine( "\nYou did not insert an "
55 "envelope, so the ATM has canceled your transaction." );
56 } // конец else
57 } // конец if
58 else // пользователь не ввел сумму, а отменил транзакцию
59 {
60 screen.displayMessageLine( "\nCanceling transaction..." );
61 } // конец else
62 } // конец функции execute
63
64 // попросить пользователя ввести сумму депозита в центах
65 double Deposit:ipromptForDepositAmount() const
66 {
67 Screen (screen = getScreen(); // получить ссылку на экран
68
69 // вывести подсказку и принять ввод
70 screen.displayMessage( "\nPlease enter a deposit amount in "
71 "CENTS (or 0 to cancel): " ) ;
72 int input = keypad.getlnput(); // получить вносимую сумму
73
74 // проверить, ввел ли пользователь сумму или отменил транзакцию
75 if ( input == CANCELED )
76 return CANCELED;
77 else
78 {
79 return static_cast< double >( input ) / 100; // возвратить в $
80 } // конец else
81 } // конец функции promptForDepositAmount
Рис. Е.22. Определения элемент-функций класса Deposit
Как и класс Withdrawal, класс Deposit содержит конструктор
(строки 12-19), который передает три параметра конструктору базового класса
Transaction, используя инициализатор базового класса (строка 15). Конструк-
Код учебного примера ATM
1419
тор имеет также параметры atmKeypad и atmDepositSlot, которые он
присваивает соответствующим элементам данных.
Элемент-функция execute (строки 22-62) заменяет чисто виртуальную
функцию базового класса Transaction конкретной реализацией, которая
выполняет действия, необходимые для проведения транзакции депонирования.
Строки 24-25 получают ссылки на базу данных и на экран. Строка 27
предлагает пользователю ввести сумму депозита, для чего вызывает закрытую
сервисную функцию promptForDepositAmount (определяемую в строках 65-81),
и присваивает возвращаемое значение элементу данных amount.
Элемент-функция promptForDepositAmount просит пользователя ввести сумму
депозита как целое число центов (поскольку на кнопочной панели ATM нет
десятичной точки; это так во многих настоящих банкоматах) и возвращает
значение типа double, представляющее вносимую сумму в долларах.
Строка 67 в элемент-функции promptForDepositAmount получает ссылку
на экран ATM. Строки 70-71 выводят на экран сообщение, предлагающее
пользователю ввести сумму депозита в центах или «0» для отмены
транзакции. Строка 72 принимает с клавиатуры ввод пользователя. Оператор if
в строках 75-80 определяет, ввел ли пользователь действительную сумму
депозита или отменил транзакцию. Если пользователь решил отменить
транзакцию, строка 76 возвращает константу CANCELED. В противном случае
строка 79 возвращает сумму депозита, преобразовав ее из числа центов в
денежную сумму путем приведения input к типу double с последующим
делением на 100. Например, если пользователь вводит в качестве числа центов
125, строка 79 возвратит 125.0, поделенное на 100, или 1.25' — 125 центов
равняются $1.25.
Оператор if в строках 30-61 элемент-функции execute определяет, решил
ли пользователь отменить транзакцию, а не ввел сумму депозита. В случае
отмены строка 60 выводит соответствующее сообщение, и функция возвращает
управление. Если пользователь вводит сумму депозита, строки 33-36
предлагают ему вставить в приемную щель конверт с указанной суммой. Как вы
помните, функция displayDollarAmount класса Screen выводит значение типа
double в формате денежной суммы.
Строка 39 устанавливает локальную булеву переменную значением,
которое возвращается функцией isEnvelopeReceived объекта depositSlot и
показывает, был ли получен конверт с депозитом. Как вы помните, мы
реализовали элемент-функцию isEnvelopeReceived (строки 7-10 на рис. ЕЛО) так,
чтобы она всегда возвращала true, поскольку мы только имитируем поведение
приемной щели и полагаем, что пользователь всегда предоставляет конверт.
Однако мы кодируем функцию execute класса Deposit таким образом, чтобы
она проверяла возможность того, что пользователь не передаст конверт с
депозитом, — принципы конструирования программного обеспечения требуют,
чтобы в программах учитывались все возможные возвращаемые значения.
Таким образом, класс Deposit готов к тому, что будущие версии функции
isEnvelopeReceived могут возвращать и ложные значения. Строки 44-50
исполняются в случае, если приемная щель получает конверт. Строки 44-47
выводят пользователю соответствующее сообщение. Затем строка 50 вносит
сумму депозита на счет пользователя в базе данных. Строки 54-55
исполняются в случае, если конверт с депозитом не получен. Тогда мы выводим
пользователю сообщение, констатирующее, что ATM отменяет транзакцию. По-
1420
Приложение Е
еле этого элемент-функция возвращает управление, не модифицируя счет
пользователя.
Е.13. Тестовая программа ATMCaseStudy.cpp
ATMCaseStudy.cpp (рис. Е.23) — простая программа на C++, которая
позволяет запустить, или «включить», ATM и протестировать реализацию
нашей модели системы ATM. Функция main (строки 6-11) не делает ничего,
кроме создания нового объекта ATM с именем atm (строка 8) и вызова его
элемент-функции run (строка 9), запускающей ATM.
1 // ATMCaseStudy.cpp
2 // Программа-драйвер для учебного примера системы ATM.
3 #include "ATM.h" // определение класса ATM
4
5 // функция main создает и запускает ATM
6 int main()
7 {
8 ATM atm; // создать объект ATM
9 atm.run(); // запустить систему ATM
10 return 0;
11 } // конец main
Рис. Е.23. ATMCaseStudy.cpp запускает систему ATM
Е.14. Заключение
Поздравляем вас с окончанием работы над примером программного
конструирования системы для ATM! Надеемся, что вы оценили приобретенный
опыт, и что он подкрепил с практической стороны многие из концепций,
изучавшихся вами в главах 1-13. Мы с благодарностью примем ваши
комментарии, замечания и предложения. Вы можете обратиться к нам по адресу
deitel@deitel.com. Мы ответим вам незамедлительно.
ж
UML 2. Дополнительные
типы диаграмм
Ж.1. Введение
Если вы изучили необязательные разделы по конструированию
программного обеспечения в главах 2-7, 9 и 13, вы должны теперь уверенно
разбираться в тех типах диаграмм UML, что мы использовали для моделирования нашей
системы ATM. Этот учебный проект предназначен для изучения в курсах
первого или второго семестра, поэтому мы ограничились обсуждением
минимального подмножества языка UML. Всего в UML 2 имеется 13 типов диаграмм.
В конце раздела 2.8 была приведена сводка по шести типам диаграмм,
используемым в учебном проекте. В этом приложении перечисляются и кратко
описываются остальные семь типов диаграмм UML.
Ж.2. Дополнительные типы диаграмм
Ниже следуют краткие описания семи типов диаграмм, не
использовавшихся в учебном примере по конструированию программного обеспечения.
• Диаграммы объектов показывают «моментальный снимок» системы,
моделируя ее объекты и отношения между ними в конкретной временной
точке. Каждый объект является представителем класса из классовой
диаграммы, причем из одного класса может быть создано несколько
объектов. Диаграмма объектов для нашей системы ATM могла бы показывать
ряд отдельных объектов Account, иллюстрируя тот факт, что все они
являются частью банковской базы данных.
• Диаграммы компонентов моделируют артефакты и компоненты —
ресурсы (в том числе исходные файлы), из которых образуется система.
• Диаграммы развертывания моделируют требования системы к среде
выполнения (такие, как компьютер или компьютеры, на которых должна
быть развернута система), требования к памяти или другие устройства,
необходимые системе во время выполнения.
1422
Приложение Ж
• Диаграммы пакетов моделируют иерархическую структуру пакетов
(групп классов) в системе во время компиляции и отношения,
существующие между пакетами.
• Диаграммы составных структур моделируют внутреннюю структуру
сложного объекта во время выполнения. Введенные в версии UML 2, они
помогают системным проектировщикам иерархически разложить объект
на более мелкие части. Их использование наиболее целесообразно в
приложениях промышленного масштаба, в которых объекты во время
выполнения группируются сложным образом.
• Обзорные диаграммы взаимодействий, появившиеся в UML 2, дают
общее представление о потоке управления в системе, комбинируя элементы
нескольких типов диаграмм поведения (напр., диаграмм деятельности,
диаграмм последовательностей).
• Диаграммы расписания, также появившиеся в UML 2, моделируют
временные ограничения, накладываемые на смены состояний и
взаимодействия между объектами в системе.
Если вы захотите больше узнать об этих диаграммах и более глубоких
аспектах UML, обратитесь к www.uml.org и Web-ресурсам, перечисленным
в конце разделов 1.17 и 2.8.
3
Ресурсы в Internet и Web
Это приложение содержит перечень ресурсов по C++, доступных в Internet
и World Wide Web. В число входят FAQ (часто задаваемые вопросы), учебные
руководства, электронные курсы, гиперссылки на стандарт ANSI/ISO C++,
информация о популярных компиляторах C++ и бесплатных компиляторах,
демонстрационных программах, книгах, учебниках, инструментах
программирования и т.д. За дополнительной информацией об Американском
институте национальных стандартов (ANSI) и его деятельности, связанной с C++,
обратитесь на www.ansi.org.
3.1. Ресурсы
www.cplusplus.com
Сайт содержит информацию об истории и развитии C++, а также
руководства, документацию, справочные материалы, исходный код, форумы.
www.possibility.com/Cpp/CppCodingStandard.html
Сайт исследует стандарт и процесс стандартизации C++. О посвящен таким
темам, как соблюдение стандарта, форматирование, переносимость,
документация и предлагает ссылки на другие ресурсы C++ в Web.
http://www.research.att.com/~bs/bs_faq2.html
Ответы Бьерна Страуструпа, создателя языка, на часто задаваемые вопросы
о C++.
help-site.com/cpp.html
Сайт предлагает ссылки на ресурсы C++ BWeb, в том числе руководства
и FAQ по C++.
www.glenmccl.com/tutor.htm
Этот справочный сайт обсуждает такие темы, как
объектно-ориентированное проектирование и написание надежного кода. Сайт предлагает вводные
статьи по техническим вопросам языка C++, включая ключевое слово static,
тип данных bool, пространства имен, стандартную библиотеку шаблонов
и распределение памяти.
1424
Приложение 3
www.programmersheaven.com/zone3
Сайт предлагает ссылки на статьи, учебные руководства, инструменты
разработки, большое собрание бесплатных библиотек C++ и исходного кода.
www.hal9k.com/cug
Сайт C/C++ Users Group (CUG) содержит ресурсы C++, журналы,
бесплатное и свободно распространяемое программное обеспечение.
www.devx.com
DevX — подробный сайт для программистов, сообщающий последние
новости, предлагающий инструменты и техническую информацию по
программированию на различных языках. C++ Zone предлагает советы, форумы для
обсуждений, техническую поддержку и электронные бюллетени.
www.cprogramming.com
Сайт содержит интерактивные учебные руководства, контрольные работы,
статьи, журналы, загрузки, рекомендуемое чтение и бесплатный исходный код.
www.acm.org/crossroads/xrds3-2/ovp32.html
Сайт Ассоциации вычислительной техники (АСМ) предлагает подробный
перечень ресурсов C++, включая рекомендуемое чтение, журналы,
издательские стандарты, бюллетени, FAQ и группы новостей.
www.comeauсотриting.com/resources
Сайт Comeau Computing содержит ссылки на технические обсуждения, FAQ
(включая посвященные шаблонам), пользовательские группы, группы
новостей, и загружаемый компилятор C++.
www.exciton.cs.rice.edu/CppResources
Сайт предлагает документ, являющийся сводкой по техническим аспектам
C++. Сайт обсуждает также различия между Java и C++.
www.accu.informika.ru/resources/public/terse/cpp.htm
Сайт Ассоциации пользователей С и C++ (ACCU) содержит ссылки на
учебные руководства по C++, статьи, информацию для разработчиков, обсуждения
и книжные обозрения.
www.cuj.com
C/C++ User's Journal — электронный журнал, публикующий статьи,
учебные руководства и загрузки. Сайт содержит последние новости C++, форумы
и ссылки на информацию по инструментам разработки.
directory.google.com/Top/Computers/Programming/Languages/C++/
Resources/Directories
Каталог ресурсов Google по C++ информирует о наиболее полезных сайтах,
посвященных C++.
www.compinfо-center.com/C++.htm
Ссылки на FAQ no C++, группы новостей и журналы.
www.apl.jhu.edu/~paulmac/c++-references.html
Сайт содержит книжные обозрения для новичков, начинающих и опытных
программистов C++, а также ссылки на сетевые ресурсы C++, включая книги,
журналы и учебные руководства.
Ресурсы в Internet и Web
1425
www.cmcrossroads.com/bradapp/links/cplusplus-links.html
Сайт предлагает ссылки по категориям, включающим Resources and
Directories, Projects and Working Groups, Libraries, Training, Tutorials,
Publications и Coding Conventions.
www.codeproject.com
На этом сайте имеются статьи, программные фрагменты, пользовательские
обсуждения, книги и новости программирования на C++, С# и .NET.
www.austinlinks.com/CPlusPlus
Сайт Quadralay Corporation содержит ссылки на многочисленные ресурсы
C++, включая библиотеки Visual C++/MFC, информацию по
программированию на C++, вакансии для программистов на C++ и перечень учебных
руководств и других электронных средствах обучения C++.
www.csci.csusb.edu/dick/c++std
На сайте имеются ссылки на стандарт ANSI/ISO C++ и группу Usenet
comp.std.c++.
www.research.att.com/-bs/homepage.html
Это домашняя страница Бьерна Страуструпа, разработчика языка
программирования C++. Сайт предлагает перечень ресурсов C++ resources, FAQ и
другую полезную информацию о C++.
3.2. Учебные руководства
www.cprogramming.com/tutorial.html
Сайт предлагает учебное руководство с образцами кода, охватывающее
файловый ввод/вывод, рекурсию, двоичные деревья, шаблонные классы и многое
другое.
www.programmersheaven.com/zone3/cat34
На этом сайте имеются бесплатные учебные руководства для людей с
различными уровнями подготовки.
www.programmershelp.со.uk/c%2B%2Btutorials.php
Сайт содержит бесплатные электронные курсы и подробный перечень
руководств по C++. На сайте имеются также FAQ, загрузки и другие ресурсы.
www.codeproject.com/script/articles/beginners.asp
Сайт перечисляет учебные руководства и статьи по C++, доступные для
новичков.
www.eng.hawaii.edu/Tutor/Make
Сайт предлагает руководство, описывающее, как создавать make-файлы.
www.cpp-home.com
На сайте имеются бесплатные руководства, обсуждения, пространства
общения («чаты»), статьи, компиляторы, форумы и электронные контрольные
по C++. Руководства по C++ охватывают такие вопросы, как ActiveX/COM,
MFC и графика.
46 Зак. 1114
1426
Приложение 3
www.codebeach.com
Сайт Code Beach содержит исходный код, руководства, книги и ссылки на
важнейшие языки программирования, включая C++, Java, ASP, Visual Basic,
XML, Python, Perl и С#.
www.kegel.com/academy/tutorials.html
Сайт предлагает ссылки на учебные руководства по С, C++ и языкам
ассемблера.
3.3. FAQ (часто задаваемые вопросы)
www.faqs.org/faqs/by-newsgroup/comp/comp.lang.C++.html
Сайт содержит ссылки на FAQ, собранные в группе новостей Comp.Lang.C++.
www.eskimo.com/~scs/C-faq/top.html
Этот список FAQ по С содержит такие рубрики, как указатели,
распределение памяти и строки.
www. technion. ас. il/technion/tcc/usg/Ref /C_Programming. html
Сайт содержит материалы по программированию на C/C++, включая FAQ
и учебные руководства.
www.faqs.org/faqs/by-newsgroup/comp/comp.compilers.html
Сайт содержит перечень FAQ, организованные в группе новостей
сотр.compilers.
3.4. Visual C++
msdn.microsoft.com/visualc
Страница Microsoft no Visual C++ предлагает информацию о последнем
выпуске Visual C++ .NET.
www. f reeprogrammingresources . com/visualcpp. html
Сайт содержит бесплатные программные ресурсы для программирующих
на Visual C++, включая учебные руководства и примеры программирования
приложений.
www.mvps.org/vcfaq
Сайт Most Valuable Professional (MVP) содержит FAQ no Visual C++.
www. onesmartclick. com/programming/visual-cpp. html
Сайт содержит руководства по Visual C++, электронные книги, советы,
приемы программирования, FAQ и приемы отладки.
3.5. Группы новостей
ai.kaist.ас.kr/^ymkim/Program/C++.html
Сайт предлагает учебные руководства, библиотеки, популярные
компиляторы, FAQ и группы новостей, включая comp.lang.c++.
www.coding-zone.со.uk/cpp/cnewsgroups.shtml
На сайте имеются ссылки на различные группы новостей C++, з том числе
comp.lang.c, comp.lang.c++ и comp.lang.c++.moderated.
Ресурсы в Internet и Web
1427
3.6. Компиляторы и инструменты разработки
msdn.microsoft.com/visualc
Сайт Microsoft Visual C++ предоставляет информацию о продуктах,
обзоры, дополнительные материалы и информацию о приобретении компилятора
Visual C++.
lab.msdn.microsoft.com/express/visualc/
С этого Web-сайта вы можете бесплатно загрузить Microsoft Visual C++
Express Beta.
msdn.microsoft.com/visualc/vctoolkit2003/
Посетите этот сайт, чтобы загрузить Visual C++ Toolkit 2003.
www.borland.com/bcppbuilder
Это ссылка на Borland C++ Builder 6. Доступна для загрузки бесплатная
версия компилятора с командной строкой.
www.thefreecountry.com/developercity/ccompilers.shtml
Сайт перечисляет бесплатные компиляторы С и C++ для разнообразных
операционных систем.
www.faqs.org/faqs/by-newsgroup/comp/comp.compilers.html
Сайт перечисляет FAQ, организованные в группе новостей сотр.compilers.
www.compilers.net/Dir/Free/Compilers/CCpp.htm
Сайт compilers.net разработан, чтобы помочь пользователям в поиске
компиляторов.
developer.intel.com/software/products/compilers/cwin/index.htm
На этом сайте имеется компилятор Intel® C++ 8.1 для Windows.
www.intel.com/software/products/compilers/clin/index.htm
На этом сайте имеется компилятор Intel® C++ 8.1 для Linux.
www.symbian.com/developer/development/cppdev.html
Symbian предлагает C++ Developer's Pack и ссылки на различные ресурсы,
включая код и инструменты разработки для программистов на C++ (особенно
для тех, что работают с операционной системой Symbian).
www.gnu.org/software/gcc/gcc.html
Сайт GNU Compiler Collection (GCC) содержит ссылки на компиляторы
GNU для C++, С, Objective С и других языков программирования.
www.bloodshed.net/devcpp.html
Bloodshed Dev-C++ — бесплатная интегрированная среда разработки для C++.
Независимые поставщики, предлагающие библиотеки
для точных финансовых расчетов
www.roguewave.com/products/sourcepro/analysis/
Библтотеки SourcePro Analysis от Rogue Wave Software включают классы
для точных денежных расчетов, анализа данных и фундаментальных
математических алгоритмов.
www.boic.com/numorder.htm
Класс Bas/1 Number от Base One International Corporation реализует
высокоточные математические расчеты.
Литература
Alhir, S. UML in a Nutshell. Cambridge, MA: O'Reilly & Associates, Inc., 1998.
Allison, C. «Text Processing I.» The С Users Journal Vol. 10, No. 10, October 1992, 23-28.
Allison, C. «Text Processing II.» The С Users Journal Vol. 10, No. 12, December 1992, 73-77.
Allison, C. «Code Capsules: A C++ Date Class, Part I.» The С Users Journal Vol. 11, No. 2,
February 1993,123-131.
Allison, C. «Conversions and Casts.» The C/C++ Users Journal Vol. 12, No. 9, September
1994, 67-85.
Almarode, J. «Object Security.» Smalltalk Report Vol. 5, No. 3 November/December 1995,
15-17.
American National Standard, Programming Language C++. (ANSI Document ISO/IEC
14882), New York, NY: American National Standards Institute, 1998.
Anderson, A. E. and W. J. Heinze. C++ Programming and Fundamental Concepts.
Englewood Cliffs, NJ: Prentice Hall, 1992.
Baker, L. С Mathematical Function Handbook. New York, NY: McGraw Hill, 1992.
Bar-David, T. Object-Oriented Design for C++. Englewood Cliffs, NJ: Prentice Hall, 1993.
Beck, K. «Birds, Bees, and Browsers—Obvious Sources of Objects.» The Smalltalk Report
Vol. 3, No. 8, June 1994,13.
Becker, P. «Shrinking the Big Switch Statement.» Windows Tech Journal Vol. 2, No. 5,
May 1993, 26-33.
Becker, P. «Conversion Confusion.» C++ Report October 1993, 26—28.
Berard, E. V. Essays on Object-Oriented Software Engineering: Volume I. Englewood Cliffs,
NJ: Prentice Hall, 1993.
Binder, R. V. «State-Based Testing.» Object Magazine Vol. 5, No. 4, August 1995, 75-78.
Binder, R. V. «State-Based Testing: Sneak Paths and Conditional Transitions.» Object
Magazine Vol. 5, No. 6, October 1995, 87-89.
Blum, A. Neural Networks in C++.' An Object-Oriented Framework for Building
Connectionist Systems. New York, NY: John Wiley & Sons, 1992.
Booch, G. Object Solutions: Managing the Object-Oriented Project. Reading, MA:
Addison-Wesley, 1996.
Booch, G. Object-Oriented Analysis and Design with Applications, Third Edition. Reading:
MA:Addison-Wesley, 2005.
Booch, G., J. Rumbaugh, and I. Jacobson. The Unified Modeling Language User Guide.
Reading, MA: Addison-Wesley, 1999.
Cargill, T. C++ Programming Style. Reading, MA: Addison-Wesley, 1993.
Carroll, M. D. and M. A. Ellis. Designing and Coding Reusable C++. Reading, MA:
Addison-Wes-ley, 1995.
Coplien, J. 0. and D. C. Schmidt. Pattern Languages of Program Design. Reading, MA:
Addison-Wesley, 1995.
1430
Как программировать на C++
Deitel, H. M, P. J. Deitel and D. R. Choffnes. Operating Systems, Third Edition. Upper
Saddle River, NJ: Prentice Hall, 2004.
Deitel, H. M and P. J. Deitel. Java How to Program, Sixth Edition. Upper Saddle River,
NJ: Prentice Hall, 2005.
Deitel, H. M. and P. J. Deitel. С How to Program, Fourth Edition. Upper Saddle River, NJ:
Prentice Hall, 2004.
Duncan, R. «Inside C++: Friend and Virtual Functions, and Multiple Inheritance.» PC
Magazine 15 October 1991, 417-420.
Ellis, M. A. and B. Stroustrup. The Annotated C++ Reference Manual. Reading, MA:
Addison-Wes-ley, 1990.
Embley, D. W., B. D. Kunz and S. N. Woodfield. Object-Oriented Systems Analysis: A
Model-Driven Approach. Englewood Cliffs, NJ: Yourdon Press, 1992.
Entsminger, G. and B. Eckel. The Tao of Objects: A Beginner's Guide to Object-Oriented
Programming. New York, NY: Wiley Publishing, 1990.
Firesmith, D.G. and B. Henderson-Sellers. «Clarifying Specialized Forms of Association in
UML and OML.» Journal of Object-Oriented Programming May 1998: 47-50.
Flamig, B. Practical Data Structures in C++. New York, NY: John Wiley & Sons, 1993.
Fowler, M. UML Distilled: A Brief Guide to the Standard Object Modeling Language, Third
Edition. Reading, MA: Addison-Wesley, 2004.
Gehani, N. and W. D. Roome. The Concurrent С Programming Language. Summit, NJ:
Silicon Press, 1989.
Giancola, A. and L. Baker. «Bit Arrays with C++.» The С Users Journal Vol. 10, No. 7,
July 1992, 21-26.
Glass, G. and B. Schuchert. The STL <Primer>. Upper Saddle River, NJ: Prentice Hall
PTR, 1995.
Gooch, T. «Obscure C++.» Inside Microsoft Visual C++ Vol. 6, No. 11, November 1995,
13-15. Hansen, T. L. The C++ Answer Book. Reading, MA: Addison-Wesley, 1990.
Henricson, M. and E. Nyquist. Industrial Strength C++: Rules and Recommendations.
Upper Saddle River, NJ: Prentice Hall, 1997.
International Standard: Programming Languages—C++. ISO/IEC 14882:1998. New York,
NY:American National Standards Institute, 1998.
Jacobson, I. «Is Object Technology Software's Industrial Platform?» IEEE Software
Magazine Vol. 10, No. 1, January 1993, 24-30.
Jaeschke, R. Portability and the С Language. Indianapolis, IN: Sams Publishing, 1989.
Johnson, L.J. «Model Behavior.» Enterprise Development May 2000: 20-28.
Josuttis, N. The C++ Standard Library: A Tutorial and Reference. Boston, MA:
Addison-Wesley, 1999.
Knight, A. «Encapsulation and Information Hiding.» The Smalltalk Report Vol. 1, No. 8
June 1992,19-20.
Koenig, A. «What is C++ Anyway?» Journal of Object-Oriented Programming April/May
1991, 48-52.
Koenig, A. «Implicit Base Class Conversions.» The C++ Report Vol. 6, No. 5, June 1994, 18-19.
Koenig, A. and B. Stroustrup. «Exception Handling for C++ (Revised),» Proceedings of the
USENIX C++ Conference, San Francisco, CA, April 1990.
Koenig, A. and B. Moo. Ruminations on C++.' A Decade of Programming Insight and
Experience. Reading, MA: Addison-Wesley, 1997.
Kruse, R. L. and A. J. Ryba. Data Structures and Program Design in C++. Upper Saddle
River, NJ:Prentice Hall, 1999.
Литература
1431
Langer, A. and К. Kreft. Standard C++ I/O Streams and Locales: Advanced Programmer's
Guide and Reference. Reading, MA: Addison-Wesley 2000.
Lejter, M., S. Meyers and S. P. Reiss. «Support for Maintaining Object-Oriented Programs,»
IEEE Transactions on Software Engineering Vol. 18, No. 12, December 1992, 1045-1052.
Lippman, S. B. and J. Lajoie. C++ Primer, Third Edition. Reading, MA: Addison-Wesley, 1998.
Lorenz, M. Object-Oriented Software Development: A Practical Guide. Englewood Cliffs,
NJ: Prentice Hall, 1993.
Lorenz, M. «A Brief Look at Inheritance Metrics.» The Smalltalk Report Vol. 3, No. 8 June
1994, 1, 4-5.
Martin, J. Principles of Object-Oriented Analysis and Design. Englewood Cliffs, NJ:
Prentice Hall, 1993.
Martin, R. C. Designing Object-Oriented C++ Applications Using the Booch Method.
Englewood Cliffs, NJ: Prentice Hall, 1995.
Matsche, J. J. «Object-Oriented Programming in Standard C.» Object Magazine Vol. 2, No.
5, January/February 1993, 71-74.
McCabe, T. J. and A. H. Watson. «Combining Comprehension and Testing in Object-Oriented
Development.» Object Magazine Vol. 4, No. 1, March/April 1994, 63-66.
McLaughlin, M. and A. Moore. «Real-Time Extensions to the UML.» Dr. Dobbs Journal
December 1998:82-93.
Melewski, D. «UML Gains Ground.» Application Development Trends October 1998: 34-44.
Melewski, D. «UML: Ready for Prime Time?» Application Development Trends November
1997:30-44.
Melewski, D. «Wherefore and What Now, UML?» Application Development Trends
December 1999:61-68.
Meyer, B. Object-Oriented Software Construction, Second Edition. Englewood Cliffs, NJ:
Prentice Hall, 1997.
Meyer, B. Eijfel: The Language. Englewood Cliffs, NJ: Prentice Hall, 1992.
Meyer, B. and D. Mandrioli. Advances in Object-Oriented Software Engineering. Englewood
Cliffs, NJ: Prentice Hall, 1992.
Meyers, S. «Mastering User-Defined Conversion Functions.» The C/C++ Users Journal
Vol. 13, No. 8, August 1995, 57-63.
Meyers, S. More Effective C++: 35 New Ways to Improve Your Programs and Designs.
Reading, MA: Addison-Wesley, 1996.
Meyers, S. Effective C++; 50 Specific Ways to Improve Your Programs and Designs,
Second Edition. Reading, MA: Addison-Wesley, 1998.
Meyers, S. Effective STL: 50 Specific Ways to Improve Your Use of the Standard Template
Library. Reading, MA: Addison-Wesley, 2001.
Muller, P. Instant UML. Birmingham, UK: Wrox Press Ltd, 1997. Murray, R. C++
Strategies and Tactics. Reading, MA: Addison-Wesley, 1993.
Musser, D. R. and A. A. Stepanov. «Algorithm-Oriented Generic Libraries.» Software
Practice and Experience Vol. 24, No. 7, July 1994.
Musser, D. R., G. J. Derge and A. Saini. STL Tutorial and Reference Guide: C++
Programming with the Standard Template Library, Second Edition. Reading, MA:
Addison-Wesley, 2001.
Nerson, J. M. «Applying Object-Oriented Analysis and Design.» Communications of the
ACM Vol. 35, No. 9, September 1992, 63-74.
Nierstrasz, 0., S. Gibbs and D. Tsichritzis. «Component-Oriented Software Development.»
Communications of the ACM Vol. 35, No. 9, September 1992, 160-165.
1432
Как программировать на C++
Perry, P. «UML Steps to the Plate.» Application Development Trends May 1999: 33-36.
Pinson, L. J. and R. S. Wiener. Applications of Object-Oriented Programming. Reading,
MA: Addison-Wesley, 1990.
Pittman, M. «Lessons Learned in Managing Object-Oriented Development.» IEEE
Software Magazine Vol. 10, No. 1, January 1993, 43-53.
Plauger. P. J. The Standard С Library. Englewood Cliffs, NJ: Prentice Hall, 1992.
Plauger, D. «Making C++ Safe for Threads.» The С Users Journal Vol. 11, No. 2, February
1993, 58-62.
Pohl, I. C++ Distilled: A Concise ANSI/ISO Reference and Style Guide. Reading, MA:
Addison-Wes-ley, 1997.
Press, W. H., S. A. Teukolsky, W. T. Vetterling and B. P. Flannery. Numerical Recipes in
C: The Art of Scientific Computing. Cambridge, MA: Cambridge University Press, 1992.
Prieto-Diaz, R. «Status Report: Software Reusability.» IEEE Software Vol. 10, No. 3, May
1993, 61-66.
Prince, T. «Tuning Up Math Functions.» The С Users Journal Vol. 10, No. 12, December 1992.
Prosise, J. «Wake Up and Smell the MFC: Using the Visual C++ Classes and Applications
Framework.» Microsoft Systems Journal Vol. 10, No. 6, June 1995, 17-34.
Rabinowitz, H. and С Schaap. Portable С Englewood Cliffs, NJ: Prentice Hall, 1990.
Reed, D. R. «Moving from С to C++.» Object Magazine Vol. 1, No. 3, September/October
1991, 46-60.
Ritchie, D. M. «The UNIX System: The Evolution of the UNIX Time-Sharing System.» AT&T
Bell Laboratories Technical Journal Vol. 63, No. 8, Part 2, October 1984, 1577-1593.
Ritchie, D. M., S. С Johnson, M. E. Lesk and B. W. Kernighan. «UNIX Time-Sharing
System: The С Programming Language.» The Bell System Technical Journal Vol. 57,
No. 6, Part 2, July/August 1978, 1991-2019.
Rosier, L. «The UNIX System: The Evolution of C—Past and Future.» AT&T Laboratories
Technical Journal Vol. 63, No. 8, Pan 2, October 1984, 1685-1699.
Robson, R. Using the STL: The C+ + Standard Template Library. New York, NY: Springer
Verlag, 2000.
Rubin, K. S. and A. Goldberg. «Object Behavior Analysis.» Communications of the ACM
Vol. 35, No. 9, September 1992, 48-62.
Rumbaugh, J., M. Blaha, W. Premerlani, F. Eddy and W. Lorensen. Object-Oriented
Modeling and Design. Englewood Cliffs, NJ: Prentice Hall, 1991.
Rumbaugh, J., Jacobson, I. and G. Booch. The Unified Modeling Language Reference
Manual, Second Edition. Reading, MA: Addison-Wesley 2005.
Saks, D. «Inheritance.» The С Users Journal May 1993, 81-89.
Schildt, H. STL Programming from the Ground Up. Berkeley, CA: Osborne McGraw-Hill, 1999.
Schlaer, S. and S. J. Mellor. Object Lifecycles: Modeling the World in States. Englewood
Cliffs, NJ: Prentice Hall, 1992.
Sedgwick, R. Bundle of Algorithms in C++, Parts 1—5: Fundamentals, Data Structures,
Sorting & Searching, and Graph Algorithms (Third Edition). Reading, MA:
Addison-Wesley, 2002.
Sessions, R. Class Construction in С and C++: Object-Oriented Programming. Englewood
Cliffs, NJ: Prentice Hall, 1992.
Skelly, С «Pointer Power in С and C++.» The С Users Journal. Vol. 11, No. 2, February
1993, 93-98.
Snyder, A. «The Essence of Objects: Concepts and Terms.» IEEE Software Magazine Vol.
10, No. 1. January 1993, 31-42.
Литература
1433
Stepanov, A. and M. Lee. «The Standard Template Library.» 31 October 1995
<www.cs.rpi.edu/-musser/doc.ps>.
Stroustrup, B. «The UNIX System: Data Abstraction in C.» AT&T Bell Laboratories
Technical Journal Vol. 63, No. 8; Part 2, October 1984, 1701-1732.
Stroustrup, B. «What is Object-Oriented Programming?» IEEE Software Vol. 5, No. 3,
May 1988, 10-20.
Stroustrup, B. «Parameterized Types for C++.» Proceedings of the USEN1X C++
Conference Denver, CO, October 1988.
Stroustrup, B. «Why Consider Language Extensions?: Maintaining a Delicate Balance.»
The C+ + Report September 1993, 44-51.
Stroustrup, B. «Making a vector Fit for a Standard.» The C++ Report October 1994.
Stroustrup, B. The Design and Evolution of C++. Reading, MA: Addison-Wesley, 1994.
Stroustrup, B. The C++ Programming Language, Special Third Edition. Reading, MA:
Addison-Wesley, 2000.
Taligent's Guide to Designing Programs: Well-Mannered Object-Oriented Design in C++.
Reading, MA: Addison-Wesley, 1994.
Taylor, D. Object-Oriented Information Systems: Planning and Implementation. New
York, NY: John Wiley& Sons, 1992.
Tondo, С L. and S. E. Gimpel. The С Answer Book. Englewood Cliffs, NJ: Prentice Hail, 1989.
Uriocker, Z. «Polymorphism LTnbounded.» Windows Tech JournalVol. 1, No. 1, January
1992, 11-16.
Van Camp, К. Е. «Dynamic Inheritance Using Filter Classes.» The C/C++ Users Journal
Vol. 13, No. 6, June 1995,69-78.
Vilot, M. J. «An Introduction to the Standard Template Library.» The C++ Report Vol. 6,
No. 8, October 1994.
Voss, G. Object-Oriented Programming: An Introduction. Berkeley, CA: Osborne
McGraw-Hill, 1991.
Voss, G. «Objects and Messages.» Windows Tech Journal February 1993, 15-16.
Wang, B. L. and J. Wang. «Is a Deep Class Hierarchy Considered Harmful?» Object
Magazine Vol. 4, No. 7, November/December 1994, 35-36.
Weisfeld, M. «An Alternative to Large Switch Statements.» The С Users Journal Vol. 12,
No. 4, April 1994, 67-76.
Weiskamp, K. and B. Flamig. The Complete C++ Primer, Second Edition. Orlando, FL:
Academic Press, 1993.
Wiebel, M. and S. Halladay. «Using OOP Techniques Instead of switch in C++.» The С
Users four' nalVoL 10, No. 10, October 1993, 105-112.
Wilde, N. and R: Huitt. «Maintenance Support for Object-Oriented Programs.» IEEE
Transactions on Software Engineering Vol. 18, No. 12, December 1992, 1038-1044.
Wilde, N., P. Matthews and R. Huitt. «Maintaining Object-Oriented Software.» IEEE
Software Magazine Vol. 10, No. I.January 1993, 75-80.
Wilson, G. V. and P. Lu. Parallel Programming Using C++. Cambridge, MA: MIT Press,
1996. Wilt, N. «Templates in C++.» The С Users Journal May 1993, 33-51.
Wirfs-Brock, R., B. Wilkerson and L. Wiener. Designing Object-Oriented Software.
Englewood Cliffs, NJ: Prentice Hall PTR, 1990.
Wyatt, В. В., К. Kavi and S. Hufnagel. «Parallelism in Object-Oriented Languages: A
Survey.» IEEE Software Vol. 9, No. 7, November 1992, 56-66.
Yamazaki, S., K. Kajihara, M. Ito and R. Yasuhara. «Object-Oriented Design of
Telecommunication Software.» IEEE Software Magazine Vol. 10, No. 1, January
1993, 81-87.
Предметный указатель
Символы
! (логическое НЕ), 297
#define, 1375
#elif, 1379
#else, 1379
#endif, 1379
#error, 1380
#if, 1379
#ifdef, 1379
#ifndef, 1379
#include, 1375
#pragma, 1380
#undef, 1378
% (взятие по модулю), 109
&& (логическое И), 294
* (операция разыменования), 509
* (умножение), 109
* в объявлении указателя, 507
\ (обратная дробная черта),
продолжение макроса, 1378
|| (логическое ИЛИ), 295
А
Ada, 65
ANSI С, 62
argc, 1351
argv, 1351
ASCII, 559
atof, 1182
atoi, 1182
atol, 1182
В
back_inserter, 1275, 1277
bad_cast, 976
bad_exception, 976
bad_typeid, 976
badbit, 916, 937
BASIC, 65
BCPL, 61
binary_f unction, 1295
Borland C++, 69
break в операторе switch, 287
С
C#, 65
catch(...), 977
catch-обработчик, 958
cerr (стандартный поток ошибок), 70,
99, 913
cin (стандартный входной поток), 70
cin, 99, 106, 912
clog, 913
COBOL, 64
const char * (строка-константа), 538
const_cast, 1308
const_iterator, 1052
cons t_re verse_i t erator, 1231
cout, 99, 913
- (стандартный выходной поток), 70
D
deque, 1240
dequeue (изъятие из очереди), 1114
dynamic_cast, 976
E
EBCDIC, 559
enqueue (постановка в очередь), 1114
EOF, 285, 916
eofbit, 937
escape-последовательность, 99
1436
Как программировать на C++
escape-символ (\), 99
esc-последовательность \п, 99
exit, 978
EXIT_FAILURE, 1355
EXIT_SUCCESS, 1355
F
failbit, 916, 920, 937
false, 113, 295, 935
FORTRAN, 64
frontinserter, 1275
fstream, 913
G
get-указатель позиции файла, 998
get-функция, 156, 612
GNU C++, 67, 72
goodbit, 937
J-K-L
Java, 64
KIS (keep it simple), 71
lengtherror, 977
LIFO ("last-in, first-out"), 358
list, 1236
logic_error, 976
lvalue, 300, 370, 426, 476, 510, 617,
716
M
main, 98, 100
makefile, 1354
map, 1249
memchr, 1193
memcmp, 1193
memcpy, 1192
memmove, 1192
memset, 1193
Metrowerks CodeWarrior, 69
MFC (Microsoft Foundation Classes), 67
Microsoft .NET Framework Class
Library, 67
multimap, 1247
multiset, 1242
NO
namespace, 1310
О большое, 1064
O(n), 1066
of stream, 913
OMG, 82
OOAD, 82
OOD, 79
ostream, 911
ostreamiterator, 1219-1233
out_of_range, 977, 1234
overflowerror, 977
P
Pascal, 65
pop, 358,1109
priority_queue, 1254
push, 358, 1109
put-указатель позиции файла, 998,
1010
I
if stream, 913
Independent Software Vendors, ISV, 603
inline-функция, 365, 598
inserter, 1275
Internet, 59
invalid_argument, 977
ios::app, 993
ios::binary, 1010
ios::cur, 999
ios::end, 999
ios::in, 1012, 1021
ios::out, 993, 1012, 1021
iostream, 912, 991
isalnum, 1176
isalpha, 1176
iscntrl, 1179
isdigit, 1176
isgraph, 1179
islower, 1178
isprint, 1179
ispunct, 1179
isspace, 1179
istream, 911
istreamiterator, 1218
isupper, 1178
isxdigit, 1176
Предметный указатель
1437
R
reinterpret_cast, 1005, 1010
re verse_ iterator, 1231
runtimeerror, 976
rvalue, 300, 370, 716
S
set, 1245
set- и get-функции, 790
set_new_handler, 978
setunexpected, 976
set-функции, 156, 174, 179, 612
SIGINT, 1359
Simple, 1138
Simula-67, 66
SML, 574, 1138
stack, 1251
std::cin, 102, 106
std::cout, 99
std::endl, 107
strchr, 1187
strcspn, 1187
strpbrk, 1187
strrchr, 1189
strspn, 1189
strstr, 1189
strtod. 1183
strtol, 1184
strtoul, 1184
T
this и перегрузка операций, 697
tolower, 1178
toupper, 1178
true, 113, 295, 935
try-блок, 957
typedef для итераторов, 1222
- для первичных контейнеров, 1216
typeid, 976
U
UML, 78, 82-83
- версии, 83
underflow_error, 977
UNIX, 61
V
valuetype, 1248
vector, 1227
Visual Basic, 65
Visual Basic .NET, 65
Visual C++ .NET, 65
void как возвращаемый тип, 145
volatile, 1308
vtable, 860
W
wchar_t, 1034
Web-сервер, 64
World Wide Web, 59
A
абстрактная операция, 871
- очередь, 680
- строка, 679
абстрактный базовый класс, 839
Shape, 841
- класс, 839
- массив, 678
- тип данных (ADT), 677
абстракция данных, 677
автоматический класс памяти, 352
автономные функции, 171
автореферентная структура, 1155
автореферентный класс, 1091
агрегатный тип данных, 521, 1155
агрегация, 185, 600
адрес, 508, 510
- возврата, 359
актер, 124
активационная запись, 359
активация, 483
алгоритм accumulate, 1269
- binarysearch, 1272
- copy, 1233
- copybackward, 1273
- count, 1268
- count_if, 1268
- equal, 1260
- equalrange, 1283
- fill, 1258
- fill_n, 1258
- find, 1271
- find_if, 1271
- for_each, 1269
- generate, 1258
- generaten, 1258
1438
Как программировать на C++
- includes, 1278
- inplace_merge, 1276
- iterswap, 1273
- lexicographicalcompare, 1260
- lower_bound, 1281
- make_heap, 1285
- max, 1286
- max_element, 1268
- merge, 1275
- min, 1286
- mismatch, 1260
- popheap, 1286
- push_heap, 1285
- random_shuffle, 1268
- remove, 1263
- remove_copy, 1263
- remove_copy_if, 1263
- remove_if, 1263
- replace, 1265
- replace_copy, 1265
- replace_copy_if, 1266
- replace_if, 1266
- reverse, 1276
- reverse_copy, 1277
- set_difference, 1279
- set_intersection, 1280
- set_symmetric_difference, 1280
- set_union, 1280
- sort, 1271
- sort_heap, 1285
- swap, 1272
- swap_ranges, 1273
- transform, 1269
- unique, 1275
- uniquecopy, 1277
- upper_bound, 1283
- двоичного поиска, 1067
алгоритмы, не представленные
в основном тексте, 1287
Американский институт национальных
стандартов (ANSI), 55
аппаратная платформа, 62
аппаратные средства (hardware), 55-56
аргументы, 147
- в вызове функции, 149
- командной строки, 539
- конструктора по умолчанию, 607
- макроса, 1376
- по умолчанию, 372
арифметика указателей, 531
арифметико-логическое устройство
(ALU), 57
арифметические операции, 109
- с указателями, 531
арифметическое выражение, 110
- переполнение, 677
асинхронное событие, 961
ассоциативный контейнер, 1214
- массив, 1249
ассоциации, 80
ассоциирование слева направо, 110
- справа налево, 117
атрибут класса, 242
атрибуты и действия объекта, 79
атрибуты класса, 182
- в UML, 146
- объекта, 79
- переменной, 351
Б
база данных, 991
базовый класс, 761
байт, 989, 1162
безопасная по типу компоновка, 377
безопасный по типу ввод/вывод, 909,
920
бесконечная отсрочка, 541
- рекурсия, 385
бесконечный цикл for, 272
бесформатный ввод/вывод, 910, 920
Библиотека стандартных шаблонов
(STL), 860, 1211
библиотека <iostream>, 911
- обработки сигналов <csignal>, 1357
- символов <cctype>, 1175
- утилит общего назначения
<cstdlib>, 1181
библиотеки классических потоков,
910
- классов, 808
- стандартных потоков, 910
- утилизируемых компонентов, 67
бинарная операция, 107
- разрешения области действия (::),
171, 597, 671
- функция,1293
Предметный указатель
1439
бинарный функциональный объект,
1293
бит ("binary digit"), 988, 1162
битовое поле, 1171
битовые множества, 1289
биты состояния потока, 916
блок, 116, 355
бросание двух костей, 347
буквы, 989
булев атрибут, 243
буферизованный вывод, 913
В
вариант case, 286
- default, 286-287
ввод/вывод в памяти, 1053
вектор, 859
верблюжий регистр, 144
вершина стека, 1090
вещественные числа, 104
видимость, 623
- идентификатора, 355
виртуальная функция, 819, 832
- what, 956
виртуальное наследование базового
класса, 1329
виртуальный деструктор, 868
висящий указатель, 713
вложение управляющих операторов,
301
вложенное пространство имен, 1313
- сообщение, 482
внешний идентификатор, 354
внешняя компоновка, 1354
внутренняя компоновка, 1354
возврат ссылки, 371
- на закрытый элемент данных, 617
- управления из функции, 335
возвращаемый тип, 144
- действия в UML, 158
возобновляющая модель управления
исключениями, 959
всемирный формат времени, 596
вспомогательная функция, 604
встроенная функция, 598
встроенные типы, 104
- функции, 365
встроенный редактор, 69
входная последовательность, 1218
входное устройство, 57
выбросить исключение, 957
вызов конструктора копии
по умолчанию, 656
- не-константной функции
из конструктора, 646
- функции через указатель, 549
- элемент-функции, 141
вызывающая функция, 145
выравнивание в памяти элементов
структур, 1157
- по левому краю, 278
- по правому краю, 278
выражения смешанного типа, 337
вытолкнуть из стека (pop), 358
выходная последовательность, 1218
выходное устройство, 57
вычисление частот, 435
Г
глобальное имя функции, 354
- пространство имен, 1313
глобальные переменные, 354, 1352
- функции, 329
голова очереди, 1090
д
дамп памяти, 578
двоичное дерево поиска, 1118
двоичные деревья, 1117
двоичный режим открытия файла,
1010
двойные кавычки, 551
двунаправленная проходимость, 625
действие, 79
действия в ADT, 678
- как глаголы, 66
- класса в UML, 146
декорирование имен, 377
делегирование, 1110, 1114
дескриптор объекта, 601, 826
деструктор, 613
десятичные цифры, 989
деятельность, 307
диаграмма вариантов применения, 124
- деятельности UML для оператора
do...while, 280
for, 273
1440
Как программировать на C++
switch, 289
- с недопустимым синтаксисом, 306
- коммуникации, 480
- кооперации, 480
- последовательности, 483
диаграммы деятельности управляющих
операторов C++, 301
- компонентов, 1421
- машинных состояний, 307
- объектов, 1421
- пакетов, 1422
- развертывания, 1421
- расписания, 1422
- составных структур, 1422
- состояний, 307
диапазон случайных чисел, 346
динамические массивы, 1360
- структуры данных, 1090
динамическое выделение памяти, 668
- освобождение памяти, 668
- распределение памяти, 668, 1093
- связывание, 832
- содержание Web-страниц, 64
- управление памятью, 1092
директива #define, 595
- #endif, 594
- #ifndef, 594
- #include, 164
- #include, 97
- using, 1311
директивы препроцессора, 97, 1374
долговременные данные, 988
дополнение до 1, 1168
доступные услуги класса, 168
дружественная функция, 658
дружественность, 900
друзья, 900
- класса, 604
Е-лС-3
естественный язык компьютера, 60
жизненный цикл программного
обеспечения, 123
завершающая модель управления
исключениями, 959
завершающий нуль-символ, 555
заголовок оператора for, 269
- функции,145
заголовочные файлы с окончанием .h,
339
— стандартной библиотеки C++, 339
— стандартной библиотеки, 1375
заголовочный файл, 164
— <algorithm>, 1234
— <cmath>, 277
— <cmath>, 329
— <cstdarg>, 1348
— <fstream> 911, 991
— <functional>, 1293
— <iomanip>, 911, 921
— <iostream>, 911
— <iostream>, 97
— <sstream>, 1053
— <string>, 1034
— <string>, 148
загрузка программы, 69
загрузчик, 69
задание, 58
заключительная приборка объекта,
613
закрытое наследование, 761, 1109,
1114
закрытые элементы данных, 153
закрытый базовый класс, 806
залипающая установка, 278, 597, 921
замена виртуальной функции, 832
заменяющий текст, 1375-1376
замкнутая оценка, 296
запись, 990
запрос услуг, 142
запуск приложения C++, 72
— приложения GuessNumber в Linux,
75
Widows XP, 73
затолкнуть в стек (push), 358
защищенное наследование, 761
защищенные данные, 783, 789
защищенный базовый класс, 806
— доступ, 766
знак минуса в UML, 158
значащие цифры, 928
значение, 106
значение-пустышка, 731
золотое сечение, 385
— среднее, 385
Предметный указатель
1441
И
игнорирование исключения, 978
- пробельных символов, 288
игра "крепе", 347
идентификатор, 104
идентификация классов, 180
иерархические отношения, 763
- функций начальника/работника,
328
- структуры, 763
иерархия Shape, 839
- возведения для основных типов
данных, 337
- данных, 990
- наследования, 761
избыточные скобки, 113
именованная константа, 431
имя namespace, 1311
- атрибута, 245
- массива, 426, 446, 512
- переменной, 103
- Simple, 1138
- структуры, 1155
- файла, 993
- функции как адрес, 5 4о
индекс, 426
- элемента, 425
индексация указателя, 535
индикатор ошибки, 978
инициализатор, 429, 463
- элемента, 646, 793
инициализация автоматических
и статических массивов, 430
- константных элементов иссылок, 646
- массивов, 443
- объекта класса, 159
- символьного массива, 441
- указателя, 508
- цикла for, 270
- элементов данных класса, 596
- элементов-объектов, 652
инкапсуляция, 79
инструкция SML, 1142
интерактивная обработка данных, 106
интерпретатор, 61
'интерфейс, 168
- класса, 168, 603
- объекта, 79
инфиксная нотация, 1132
информация о типе времени
выполнения (RTTI), 865
исключение, 952
- bad_alloc, 969-970
- дубликатов, 1126
- логики switch, 839
исполнение программы, 70
исполнительный стек, 359
исполняемый образ, 69
использование goto, 1362
исходный код, 69
итератор, 680, 1051, 1224
- произвольного доступа, 1068
К
кадр стека, 359
каскадные вызовы элемент-функций,
664
- операции извлечения из потока, 116
категории итераторов, 1220
квадратичное время выполнения, 1066
квадратные скобки, 426, 476
квалификатор const с указателями,
517
- const, 431, 439, 516
- типа volatile, 1356
клавиша Enter, 106
- Return, 106
класс, 67, 80
- Array, 704
- bitset, 1289
- exception, 976
- GradeBook, 142
- istream, 915
- istringstream, 1053
- ostream, 914
- ostringstream, 1053
- pair, 1245
- typeinfo, 868
- исключения, 956
- итератора, 842
- памяти идентификатора, 351
- стандартной библиотеки exception,
956
runtime_error, 956
классовая диаграмма, 182
- UML, 150, 146, 158, 162
1442
Как программировать на C++
класс-посредник, 681
классы геометрических фигур, 831
классы-коллекции, 680
классы-контейнеры, 680
клиент/сервер, 59
клиенты класса, 80
ключ, 1242
— записи, 990
— поиска, 457, 1064, 1242
— сортировки, 1064
ключевое значение, 457
ключевое слово, 98
— class, 144
в шаблоне функции, 379
— const, 641
— enum, 350
— explicit, 742
— friend, 659
— inline, 365
— protected, 766
— static, 670
— struct, 1155
— template, 887
— this, 662
— throw, 960
— typedef, 1158
— typename, 379
— typename, 887
— union, 1362
— virtual, 832
— void, 144
ключевые слова auto и register, 352
— extern и static, 353
— операций, 1315
код машинного языка, 69
— обработки ошибок, 954
командная строка Windows XP, 72
команды Simple, 1138
комбинации клавиш для конца файла,
995
комбинированное условие, 295-296
комментарии C++, 97
— в стиле С, 97
компаратор less, 1242
компилятор, 61
— GNU C++, 75
компиляция программы, 69
композиция, 184, 600, 651, 761, 765,
1112
компоновка идентификатора, 351
- программы, 69, 782
компоновщик, 69
компьютер, 56
компьютерная программа, 56
конвейер, 1347
конец файла, 916, 937
конечное значение управляющей
переменной, 268
конечный производный класс, 1330
конкатенация потоковых операций,
107
- строк, 557
конкретный класс, 839
константа NULL, 508
константная версия операции, 715
- переменная, 431
- функция, 641
константное целое выражение, 281,
290
константный объект, 641
- указатель на константные данные,
522
неконстантные данные, 521
константы сплавающей точкой без
суффикса, 1357
конструктор, 159
- копии, 476, 622, 710, 712
- по умолчанию, 652
- по умолчанию, 159, 162, 607, 657
- с единственным аргументом, 725
конструкторы и деструкторы
с константными объектами, 642
- преобразований, 716
кооперация, 477
копирование строк, 555
копия аргумента, 517
корневой узел, 1117
косвенная адресация, 507
- ссылка на значение, 507
косвенный базовый класс, 761
- производный класс, 853
круглые скобки, 111
- в вызове функции, 146
выражениях, 110
в заголовке функции, 145
Предметный указатель
1443
круговое включение, 629
курсор, 99
куча, 668, 1283
— (в сортировке), 1254
кучевая сортировка, 1254, 1283
Л
левое и правое выравнивание, 929
— поддерево, 1117
левый потомок, 1117
лексема, 560
лексикографическое сравнение, 1040
линейная форма арифметических
выражений, 110
линейное время выполнения, 1066
линейные структуры данных, 1093
линейный поиск, 457
лист, 1117
литерал, 106
логарифмическое время выполнения,
1072
логика обработки ошибок, 953
логическая ошибка, 114
логические операции, 294
логическое устройство, 57
локальная сеть (LAN), 59
локальные переменные, 151, 352, 355
М
магистральные системы (mainframes),
55
макрос, 887, 1376
— vaarg, 1350
— va_end, 1350
— vastart, 1350
— саргументами, 1376
манипулятор потока, 107
— nouppercase, 934
— boolalpha, 297
— boolalpha, 935
— dec, 921
— endl, 107
— fixed, 933
— hex, 921
— internal, 930
— left, 278, 929
— no boolalpha, 935
— noshowbase, 932
— oct, 921
— right, 278, 929
— scientific, 933
— setbase, 921
— setfill, 597, 929-030
— setprecision, 922
— setw, 278, 553, 929
— showbase, 932
— showpoint, 928
— uppercase, 934
манипуляторы потока dec, hex и oct,
921, 932
— потоков, 921
маркер конца файла, 991
маркеры видимости (-1- и -), 623
маска, 1164
массив, 425
массивы и указатели в C++, 534
масштабирование случайных чисел, 342
масштабируемость программ, 433
масштабирующий коэффициент, 342
машинно-зависимый язык, 60
машинно-независимый язык, 62
машинный язык, 60
Машинный язык Симплетрона (SML),
574, 1138
Международная организация
по стандартизации (ISO), 55
менеджер печати, 1114
метка, 355, 1361
— case, 286
— спецификатора доступа, 144
методы, 80
механизм вызова/возврата, 359-360
мировая линия, 483
многозадачность, 65
многомерные массивы, 461
многопоточность, 65
многослойные системы программного
обеспечения, 841
многоточие (...) в прототипе функции,
1348
многофайловые программы, 1352
моделирование вариантов применения,
123
модель клиент/сервер, 59
модифицируемое lvalue, 476, 617
модифицирующие алгоритмы, 1225
мультипрограммирование, 58
1444
Как программировать на C++
Н
набор символов, 551, 560, 989
- ASCII, 285, 551, 910
- Unicode, 910, 989
наихудший случай, 1067
направление поиска, 998
наследование, 760, 899
- интерфейса, 843, 871
- реализации, 843, 871
настройка программного обеспечения,
807
начальное значение атрибута, 246
- управляющей переменной, 267, 269
- состояние, 307
небуферизованный вывод, 913
не-виртуальные деструкторы, 868
неименованное пространство имен,
1313
неинициализированная ссылка, 371
неисправимая ошибка потока, 937
не-константная версия операции, 716
неконстантный указатель на
константные данные, 519
неконстантные данные, 518
нелинейные структуры данных, 1093
немодифицируемое lvalue, 476
немодифицирующие алгоритмы, 1225
неопределенное число аргументов, 1348
неперегружаемые операции, 695
непосредственный базовый класс, 761
непредвиденные события, 1357
неразрушающее считывание, 108
нетиповые параметры шаблона, 898
не-фатальная логическая ошибка, 114
нисходящее последовательное
уточнение, 540
- приведение типа, 831, 865
номер позиции элемента, 425
нотация указатель/индекс, 535
- указатель/смещение, 534
нулевой указатель, 508, 916
- элемент массива, 426
нуль-символ, 441, 552, 917
О
обзорные диаграммы взаимодействий,
1422
область действия блока, 355, 601
- идентификатора, 351
- идентификатора, 355
- класса, 597, 601
- макроса, 1378
- прототипа функции, 355
- статических элементов данных,
671
- управляющей переменной цикла
for, 271
- файла, 355
- функции, 336, 355
обобщение, 870
обобщенное программирование, 886
обобщенный класс, 892
оболочка Linux, 72, 75
обработка строковых потоков, 1053
обработчик new, 972
- исключения, 958
обход двоичного дерева по уровням,
1137
с отложенной выборкой, 1126
порядковой выборкой, 1125
предварительной выборкой, 1125
объект, 62, 66, 79
- auto_ptr, 974
- nothrow, 971
- входного потока, 106
- исключения, 956, 960
- стандартного входного потока, 102
- выходного потока, 99
объект-итератор, 680, 842
объектная технология, 66
объектно-ориентированное
программирование, 55, 80
- проектирование, 79
объектно-ориентированный анализ
и проектирование, 81
- язык, 66, 80
объектный код, 60, 69
объект-хозяин, 652
объекты cin, cout, cerr и clog, 911
- как существительные, 66
объявление, 103
- typedef, 911, 913
- using, 115, 1311
- дружественной функции, 659
- дружественности, 900
- указателя, 507
Предметный указатель
1445
- функции, 336
объявления переменных, 105
ограничивающий нуль-символ, 552
ограничитель оператора (;), 99
одинарные кавычки (апострофы), 290,
551
однозначное отображение, 1249
одномерный массив вкачестве
аргумента, 514
односвязный список, 1107
однострочный комментарий, 97
операнд, 107
- throw, 960
оператор break, 292
- C++, 99
- continue, 293
- for, 269
- goto, 355, 1361
- if, 113
- return, 100, 335
- while, 267
- множественного выбора switch, 281,
838
- повторения do...while, 279
- присваивания, 106
операторы Simple, 1138
операции выбора элемента, 602
- инкремента (++) и декремента (--) с
указателями, 532
- итераторов, 1223
- класса, 182
- отношения, 294
- очереди enqueue/dequeue, 680
- равенства, 294
- и отношений, 113
операционная система, 58
операция <, 99
- >, 102
- delete, 668-670, 974
- dynamiccast, 867
- new, 668-669, 969
операция sizeof, 527
- с именем массива, 527
типа, 530
- typeid, 868
операция взятия адреса, 512
(&),. 508
класса, 694
- по модулю (%), 109
- извлечения из потока (>), 102, 106,
909, 912, 915
- индексации, 1227
- косвенной адресации, 509
- логического И (&&), 295
- ИЛИ (||), 296
- отрицания, (!) 297
- передачи в поток (<), 99, 909, 912
- преобразования, 716
- препроцессора #, 1380
- ##, 1380
- приведения, 716
- присваивания (=), 106, 117
- класса, 694
- разрешения области действия (::),
601, 766
- разыменования, 512
- (*), 509
- сдвига влево, 1170
- вправо, 1170
- умножения (*), 109
операция-запятая (,), 271
операция-стрелка (->), 602
операция-стрелка и операция-точка
с указателем this, 664
операция-точка (.), 146, 602, 915
опережающее объявление класса, 683
определение класса, 144
- конструктора, 161
- переменной, 267
- структуры, 1155
- шаблона класса, 892
- функции, 887
- элемент-функций вне класса, 170
оптимизирующие компиляторы, 279
ориентация на действия, 80
основной случай рекурсии, 382
основные типы, 104
отделение интерфейса от реализации,
168, 681
открытия файла, 991
открытое действие, 146
- наследование, 761, 765
открытые элемент-функции класса,
168
открытый базовый класс, 806
отладка, 63
1446
Как программировать на C++
отношение "имеет", 184, 651, 761
- "многие к одному", 186
- "один к одному", 185
- "один ко многим", 186, 1247
- "является", 761
- обобщения, 870
отношения наследования, 79
- указателей и объектов базового
и производного классов, 821, 837
отображение "один кодному", 1249
отступы, 116
оценка постфиксных выражений, 1133
очередь, 679, 1113
ошибка арифметического
переполнения, 977
- времени выполнения, 70
- запуска, 70
- исчезновения арифметического
порядка, 977
- смещения на единицу, 270, 426
- форматирования, 937
П
пакетная печать, 1114
память, 57
пара ключ/значение, 1214, 1247, 1249
параметр исключения, 958
- функции,147
параметризованный манипулятор
потока, 911, 921
- тип, 892
параметр-указатель, 514
параметры в UML, 150
- прототипе и в определении
функции, 334
- функции, 355
- шаблона, 887
пары итераторов, 1224
первичная память, 57
первичные контейнеры, 1214, 1220
- вошел, первым вышел (FIFO), 1113
- пришел, первым вышел (FIFO), 680
переадресация ввода/вывода, 1347
перебрасывание исключения, 962
перегруженная операция
индексации ([]), 711
- неравенства (!=), 715
- приведения void * потока, 916
- равенства (==), 715
- функция, 375
- функция-операция приведения, 717
перегруженные функции, 887
- элемент-функции, 601
перегрузка, 891
- двухместной операции, 703
- одноместной операции, 702
- операций инкремента и декремента,
730-731
- операций, 107, 378, 692
- функций, 375
- шаблонов функции, 891
передача массива, 446
- по значению, 1158
- по значению, 366, 512
- ссылке, 366, 446, 512
посредством указателей, 512
переменная-указатель, 507
переносимость программ, 61, 71
переносимый язык, 71
переопределение символической
константы, 1376
переполнение стека, 359
перехват непредвиденных событий,
1357
переходы между состояниями, 308
перечисление, 350
перечисляемые константы, 350
персональная обработка данных, 59
персональный компьютер IBM, 59
платформа, 71
побочный эффект оценки операндов,
388
поведение объекта, 79
повторение, управляемое счетчиком,
267, 269
повторно-входимый код, 601
подобъект базового класса, 1327
подстановка, 1375
подтверждение данных, 175
подход "живого кода", 55
позднее связывание, 832
поиск, 457, 1064
- заголовочных файлов, 166
- обработчика исключения, 958
поле, 990
- типа, 838
Предметный указатель
1447
полиморфизм, 817, 860
- и расширяемость, 819
полиморфное поведение, 833
- программирование, 818
пользовательские манипуляторы
потока, 925
поразрядная операция включающего
ИЛИ (|), 1012,1167
- дополнения (~), 1168
- И(&), 1167
- исключающего ИЛИ (л), 1168
поразрядные операции присваивания,
1170
порождения, 1149
порядка л, 1066
- квадрат, 106
- единицы, 1066
- логарифма я, 1072
порядок вызова конструкторов
и деструкторов, 614, 798-799
- оценки операндов, 387-388
последним вошел, первым вышел
(LIFO), 1109
последовательность, 1218
последовательный контейнер, 1214
- файл, 990, 992
постоянное время выполнения, 1065
постфиксная нотация, 1132
потеря данных при преобразованиях
типов, 337
поток управления виртуального
вызова, 860
потоки ввода/вывода, 70, 909
поэлементное присваивание, 620, 694
правила ассоциации операций, 110
- возведения, 337
- построения структурированных
программ, 303
- старшинства операций, 110
правило вложения, 304
- суперпозиции, 303
правильное конструирование
программного обеспечения, 791
правое поддерево, 1117
правый потомок, 1117
предикатная функция, 604, 1099
предопределенные символические
константы, 1381
предотвращение многократного
включения заголовочного файла, 593
- присваивания объекта самому себе,
664
представитель класса, 80
представление больших целых чисел,
385
- данных в ADT, 678
- денежных сумм, 277
преобразование инфиксного
выражения в постфиксную форму, 1132
препроцессор, 69
препроцессорная директива, 69
- обертка, 593
- обработка, 69
прерывание, 1357
префикс std::, 115
приложение GuessNumber, 73
приложения мгновенного доступа,
1003
проверка индексации, 703
программирование "в общем"
и "в частности", 817
Примеры
Абстрактный класс Employee, 842, 845
Анализ результатов опроса, 437
Бросание игральной кости, 341
Иерархия Employee, 842
Иерархия CommissionEmployee
с закрытыми данными, 790
Иерархия CommissionEmployee
с защищенными данными, 783
Иерархия CommissionEmployee, 777
Иерархия CommissionEmployee-Ba-
sePlusCommissionEmployee, 821
Инициализация двумерных массивов,
462
Инициализация массива в объявлении,
429
Инициализация массива в цикле, 428
Калькуляция сложных процентов, 276
Класс Employee
с элементами-объектами, 652
Класс GradeBook с двумерным
массивом, 465
Класс GradeBook с массивом оценок,
451
Класс GradeBook с оператором switch,
281
Класс GradeBook с подтверждением
данных, 175
1448
Как программировать на C++
Класс GradeBook с разделением
интерфейса и реализации, 168
Класс GradeBook с элементом данных,
151
Класс GradeBook, 144, 147
Класс GradeBook, размещенный
в отдельном файле, 163
Класс Time, 593, 607, 664
Линейный поиск, 457
Логические операции, 297
Моделирование игры "крепе", 347
Область действия переменных, 356
Операции равенства иотношений, 114
Ошибочное неявное преобразование, 741
Передача массивов функциям, 447
Печать строки текста, 101
Печать текста, 96
Полиморфный экранный менеджер, 819
Рандомизация генератора случайных
чисел, 345
Рекурсивное вычисление факториала,
383
Рекурсивное вычисление чисел
Фибоначчи, 386
Решето Эратосфена, 1290
Сложение целых чисел, 102
Создание столбцовых диаграмм, 434
Сортировка вставкой, 459
Сортировка выборкой с передачей по
ссылке, 524
Сортировка выборкой, 546
Стандартный класс string, 737
Тасование и сдача карт, 540, 1159
Тестирование функции rand (бросание
кости 6000000 раз), 342
примеры и упражнения на рекурсию,
391
- отношений наследования, 762
примитивные типы, 104
принудительное приведение
аргументов, 337
принцип наименьших привилегий,
352, 439, 450, 517, 641
- "разделяй и властвуй", 327
принятие решений, 113
приоритет и ассоциативность операций
при перегрузке, 695
- ассоциациативность операций, 426,
511
- операций C++, 298
- операций, 110
приращение счетчика цикла for, 270
- управляющей переменной, 268
присваивание указателей, 533
пробельные символы, 98, 117, 915
проверка границ, 440
- действительности данных, 175
- диапазона, 1037
проверяемый доступ, 1037
программист кода клиента, 174
- реализации класса, 174
программная платформа .NET, 65
программное обеспечение (software),
55-56
программные компоненты, 62
программы сопоставления файлов,
1027
проект, 81
производный класс, 761
пропускная способность, 58
простое наследование, 761
- условие, 294
пространство имен, 1310
- имен std, 99
прототип функции, 169, 277, 336,
1353
проход компиляции, 1141
процедурное программирование, 66
процедурный язык, 80
процесс компиляции и компоновки,
173
- программы Simple, 1146
прямая ссылка на значение, 507
прямой доступ, 1014
псевдокод, 82
псевдослучайные числа, 344
пустая спецификация исключений,
964
- строка, 1035
пустой деструктор, 613
- список параметров, 154
в С и в C++, 363
Р
рабочая станция, 59
рабочий поток, 307
разбиение строки на лексемы, 560
разделение времени, 58
разделяемые библиотеки, 69
различение регистра, 104
Предметный указатель
1449
разматывание стека, 959
размер массива для хранения строки,
552
разрешение ссылок, 1353
разрушающая запись в ячейку, 108
разыменование указателя, 509, 533
разыменованный указатель, 509
рандомизация, 345
распределенная обработка данных, 59
расширение макроса, 1376
расширения .срр, .схх, .ее или .С, 69
расширяемость C++, 679, 909
расширяемый язык, 146
реализация полиморфизма, 862
регистрация функции завершения,
1354
регистровые переменные, 353
редактор, 69
режим открытия файла, 993, 1012
рекурсивная функция, 381
рекурсивное определение факториала,
382
рекурсивный вызов, 382
рекурсия, 381
- в сравнении с итерацией, 388
ресурсы UML в World Wide Web, 83
родительский узел, 1118
ролевое имя, 183
ромбовидное наследование, 1327
ряд Фибоначчи, 385
С
самоприсваивание, 714
сбор требований, 123
сброс буфера вывода, 107
свободная память, 668
семя генератора случайных чисел, 346
сервисная функция, 604
сиблинги, 1117
сигнал,1357
сигнатура функции, 336
символ, 989
- заполнения, 597
- композиции (сплошной ромб), 184
- новой строки, 99
- переадресации ввода <, 1347
- вывода >, 1347
- присоединения вывода >, 1347
- тильды (~), 613
символ-заполнитель, 924, 930
символическая константа, 1375
символ-ограничитель ввода, 917
символьная константа, 290, 551
- '\0\ 441
- строка, 99
символьные массивы в качестве строк,
441
символьный код, 560
Симплетрон, 574
симулятор Симплетрона, 577, 583
синтаксис вызова переопределенной
элемент-функции, 796
- инициализатора базового класса,
778
- элемента, 646
синтаксическая ошибка, 100
синхронизация потоков ввода
и вывода, 939
синхронная ошибка, 961
система управления базами данных
(DBMS), 991
-, управляемая меню, 549
системные требования, 123
системы обработки транзакций, 1003
скаляр, 446
скалярная величина, 446
скругленный прямоугольник, 307
сложение в арифметике указателей,
531
сложное наследование, 761
смещение диапазона случайных чисел,
342
событие, 1357
согласованное состояние данных, 596
- объекта, 176
создание ассоциации, 1249
- и уничтожение автоматических
переменных, 360
сокрытие информации, 79, 677
- подробностей реализации, 681
сообщение, 141
сопоставление параметров шаблона
функции, 891
сортировка, 459, 1064
- в двоичном дереве, 1125
- вставкой, 459
1450
Как программировать на C++
- выборкой, 524
- слиянием, 1074
составной оператор, 116
состояние потока, 937
специализация класса, 870
- шаблона, 911
- класса, 892
- функции, 379
специальные знаки, 989
- символы, 551
спецификатор typedef, 911
- доступа, 144
- private, 153
- public, 144
- класса памяти auto, 352
extern, 1352
register, 353
static, 354, 1354
спецификаторы класса памяти, 351
extern и static, 354
спецификация исключений, 964
- компоновки, 1366
- требований, 118
список throw, 964
- инициализаторов, 429-430
- элементов, 648
список параметров функции, 149
- шаблона, 379
-, разделяемый запятыми, 104
сплошной кружок, 307
сравнение строк, 558
- указателей, 534
среда разработки C++, 67
ссылка на несуществующий элемент,
440
ссылки как псевдонимы переменных,
369
ссылочные параметры, 367
стадия, 69
- компиляции, 69
- компоновки, 69
- редактирования, 69
Стандартная библиотека C++, 62, 327,
339
Стандартный документ ANSI/ISO C++,
71
стандартный поток ввода, 911
- вывода, 911
- ошибок, 911
-С, 62
старшинство и ассоциативность
операций, 1170
статические и автоматические
локальные массивы, 443
- локальные переменные, 354-355
- элемент-функции, 671
- элементы данных, 670-901
статический класс памяти, 352
- элемент данных шаблона класса,
901
статическое связывание, 832, 855
стек, 358, 1109
- вызовов, 359, 1109
стеки в компиляторах, 1132
столбец массива, 461
столбцовая диаграмма, 434
стрелки проходимости, 625
строка, 99, 551
- массива, 461
строка-указатель, 552
строковый литерал, 99, 106, 551
структура данных "последним вошел,
первым вышел" (LIFO), 358
структурное программирование, 55,
64, 66, 301
структурный анализ
и проектирование, 66
- тип, 1155
структуры данных, 424, 1090
субкласс, 761
суперкласс, 761
суперкомпьютер, 56
суперпозиция управляющих
операторов, 301
суффиксы констант, 1356
существительные и именные
конструкции, 180
Т
таблица виртуальных функций, 860
- значений, 461
- истинности, 295
- символов компилятора, 1141
тасование и сдача карт, 572
тело класса, 144
- оператора if, 116
- функции, 98, 145
Предметный указатель
1451
тип bool, 935
- char, 104, 910
- double, 104
- fmtflags, 936
- int, 103
- nothrow_t, 971
- size_t, 476
- string, 148
- vajist, 1350
- wchar_t, 911
- атрибута в UML, 158
- атрибута, 245
- данных, 103
- дескриптора, 831
- параметра в UML, 150
- указателя, 533
- указываемого объекта, 831
- элемента контейнера, 1217
-, определяемый пользователем, 80,
145, 349
типовой параметр шаблона, 888
типы данных UML, 150
- для представления целых чисел, 291
толерантность к ошибкам, 952
точка выброса, 959
- с запятой (;), 99
транслятор, 60
трансляция, 60
тройная косвенная адресация
в полиморфизме, 860
У
угловые скобки (< и >), 887
узел, 1093
указатели в выражениях, 530
указатель, 506
- this, 662, 676
- базового класса, 829
- на void (void *), 533
- функцию, 546
- позиции файла, 998
указатель-связка, 1093
укороченная оценка, 296
унарная операция разрешения области
действия (::), 374
унифицированный язык
моделирования (UML), 78
уничтожение объекта, 613
Упражнения
"Элементарная" перегрузка операций,
750
1000 игр в крепе, 496
Анализ текста, 586
Блочная сортировка, 503, 1085
Бросание двух костей, 495, 504
Быстрая сортировка, 581, 1086
Восемь ферзей, 502
Вывод деревьев на печать, 1137
Генератор кроссвордов, 590
Генератор слов для телефонного
номера, 1030
Генератор случайных лабиринтов, 583
Законы де Моргана, 322
Игра "Угадай число", 417
Иерархия Shape, 883
Иерархия наследования Account, 814
Иерархия наследования Package, 813,
884
Интерпретатор Simple, 1151
Исключение оператора break, 323
Исключение оператора continue, 323
Класс Account, 194
Класс Complex, 636, 750
Класс Date, 195, 637
Класс Employee, 195
Класс Hugelnt, 753
Класс Hugelnteger, 638
Класс IntegerSet, 689
Класс Invoice, 195
Класс Polinomial, 757
Класс Rational, 636
Класс RationalNumber, 757
Класс Rectangle, 637
Класс TicTacToe (крестики-нолики),
638
Класс Time, 636-637
Код Морзе, 588
Комбинация классов Time и Date, 637
Компьютерная обучающая система,
416
Компьютерное моделирование: Заяц и
Черепаха, 573
Компьютеры в школе, 416
Лимерики, 585
Моделирование супермаркета, 1134
Модификация класса Time, 690
Модификация компилятора Simple,
1150
Модификация системы начисления
зарплаты, 883
Наибольший общий делитель (НОД),
416
1452
Как программировать на C++
Обработка текстов, 587
Обращение порядка цифр, 416
Обход двоичного дерева по уровням,
1137
Обход лабиринта, 582
Оптимизация компилятора Simple, 1149
Песенка "The Twelve Days of
Christmas", 323
Пифагоровы тройки, 322
Поиск в двоичном дереве, 1137
Полиморфная банковская программа,
884
Проблема Питера Миньюта, 323
Проверка орфографии, 1206
Программирование на машинном
языке, 574
Простое шифрование, 1059
Простые числа, 415
Пузырьковая сортировка, 1085
Путешествие коня, 499
Рекурсивная печать списка в обратном
порядке, 1135
Рекурсивный поиск в списке, 1135
Решето Эратосфена, 502
Ряд Фибоначчи, 417
Симулятор компьютера, 577
Система резервирования авиабилетов,
496
Словесный эквивалент суммы, 588
Совершенные числа, 415
Создание компилятора, 1141
Тасование и сдача карт, 572
Температура по Цельсию и по
Фаренгейту, 415
Удаление узла из двоичного дерева,
1135
Усовершенствование класса Date, 689
Черепашья графика, 498
Элементарный графический пакет, 883
Язык Simple, 1138
Упражнения на рекурсию
Визуализация рекурсии, 419
Восемь ферзей, 504
Двоичный поиск, 1086
Линейный поиск, 504, 1086
Палиндромы, 504
Печать массива, 504
Печать строки в обратном порядке, 504
Поиск наименьшего значения ввекторе,
504
Поиск наименьшего значения вмассиве,
504
Рекурсивное нахождение НОД, 419
Рекурсивный вызов main, 419
Сортировка выборкой, 504
Ханойская башня, 418
Что делает эта программа?, 420
управление исключениями, 952
управляющее выражение оператора
switch, 286
управляющие операторы с одним
входом/одним выходом, 301
усечение дробной части, 109
- файла, 994
условие в операторе if, 113
- продолжения цикла, 268-269
for, 270
устойчивость, 952
устойчивые данные, 988
устройства вторичной памяти, 988
устройство вторичного хранения, 58
- памяти, 57
утечка памяти, 669
- ресурса, 978
утилизация класса, 163
- классов, 81
- программного обеспечения, 63, 651,
760, 891
- программных компонентов, 67
утилизируемые компоненты, 81
утилита make, 1354
Ф
файл, 988, 990
- исходного кода, 69, 164
- произвольного доступа, 1003
файловый сервер, 59
факториал, 382
фатальная логическая ошибка, 114
- ошибка, 70
фигурные скобки ({}), 98
физические устройства вывода, 57
физическое устройство, 841
формальный параметр типа, 379
форматируемый ввод/вывод, 910
функции математической библиотеки
ceil, cos, exp, fabs, floor, fmod, log,
loglO, pow, sin, sqrt и tan, 330
- преобразования строк-указателей,
1181
- снесколькими параметрами, 331
-, определенные пользователем, 328
-, определенные программистом, 328
Предметный указатель
1453
функции-операции как дружественные
классу, 698
- элементы класса, 697
функциональный объект, 1293
- объект-компаратор, 1242
функция, 80, 98
- abort, 614, 965
- atexit, 1354
- calloc, 1360
- cin.get, 286
- cin.getline, 553
- draw виерархии класса Shape, 832
- empty класса string, 740
- exit, 614, 1354
- getline, 1035
- islower, 518
- main, 98, 103
- new_handler, 978
- raise, 1357
- rand, 341, 344
- realloc, 1360
- seekg, 998, 1020
- seekp, 998
- set_new_handler, 972
- setterminate, 965
- setunexpected, 965
- signal, 1357
- srand, 345
- strcat, 557
- strcmp, 558
- strcpy, 555
- strlen, 562
- strncat, 557
- strncmp, 558
- strncpy, 555
- strtok, 560
- substr класса string, 740
- tellg, 999
- tellp, 999
- terminate 963, 965
- time, 346
- toupper, 518
- unexpected, 964, 976
- доступа, 604
- стандартной библиотеки pow, 277
функция-генератор, 1257
х-ц-ч
хвост очереди, 1090
хрупкость программного кода, 790
целая константа без суффикса, 1356
целое значение, 103
целочисленное деление, 109
центральное процессорное устройство
(CPU), 57
циклический двусвязный список, 1108
- односвязный список, 1107
числа Фибоначчи, 386
численные алгоритмы, 1225
чистая процедура, 601
чисто виртуальная функция, 840
чистый спецификатор, 840
Ш
шаблон basicf stream, 913
- basic_ifstream, 913
- basic_ios, 912
- basic_iostream, 911-912
- basicistream, 911
- basic_ofstream, 913
- basic_ostream, 911
- класса, 891, 1095
- auto_ptr, 974
- basicstring, 1034
- vector стандартной библиотеки,
472
- функции, 379, 887
шаг рекурсии, 382
ширина поля, 278
шифрование по симметричному
ключу, 1059
Э
экспоненциальная сложность, 388
экспоненциальный взрыв, 388
элемент массива, 425
- случайности в компьютерных
приложениях, 341
элемент-функции, 80
- rbegin и rend класса string, 1052
элемент-функция, 141
- append, 1038
- assign, 1036, 1239
- at, 1037
- вектора, 477
- back,1234,1253
1454
Как программировать на C++
элемент-функция bad, 937
- begin, 1218, 1231
- begin класса string, 1052
- capacity, 1044, 1229
- clear, 938, 1235
- close, 996
- compare, 1040
- copy, 1051
- count, 1248
- data, 1051
- empty 1044, 1235, 1251, 1253, 1255
- end, 1218, 1231
- класса string, 1052
- eof, 916, 937
- erase, 1047, 1235
- fail, 937
- fill, 929-930
- find, 1046, 1244
- find_first_not_of, 1047
- find_first_of, 1046
- find_last_of, 1046
- flags, 936
- flip, 1292
- front ,1234, 1253
- gcount, 920
- get, 916
- getline, 918
- good ,937
- ignore, 919
- insert, 1235, 1246, 1248
- length, 1035, 1044
- maxsize, 1044
- merge, 1239
- name класса type_info, 868
- operator void * из basic_ios, 939
- operator! из basicios, 939
- peek, 919
- pop, 1251, 1253, 1255
- pop_front, 1239, 1240
- precision, 922
- push, 1251, 1254-1255
- push_front, 1238, 1240
- put, 915
- putback, 919
- rdstate, 937
- read, 920, 1004, 1012
- remove, 1239
- replace, 1048
- reset, 1292
- rfind, 1046
- size, 1035, 1044, 1229, 1251, 1253,
1255
- вектора, 476
- sort, 1238
- splice, 1239
- str класса ostringstream, 1053
- swap, 1239
- tie, 939
- top, 1251, 1253, 1255
- unique, 1239
- width, 924
- write, 920, 1004
элементы данных, 80, 151
- структуры, 1155
Я
явная специализация шаблона, 899
язык С, 61
- ассемблера, 60
- высокого уровня, 61
ячейка памяти, 107