/































































































































































































































































Автор: Аграновский А.В. Хади Р.А.
Теги: программирование компьютерные науки криптография
ISBN: 5-98003-002-6
Год: 2009




Текст
А.В. АГРАНОВСКИЙ
Р.А. ХАДИ
ПРАКТИЧЕСКАЯ
КРИПТОГРАФИЯ
АСПЕКТЫ ЗАЩИТЫ
КРИПТОГРАФИЯ ДЛЯ ПРОГРАММИСТА-СТУДЕНТА И СПЕЦИАЛИСТА
А. В. Аграновский, Р. А. Хади
ПРАКТИЧЕСКАЯ КРИПТОГРАФИЯ:
АЛГОРИТМЫ И ИХ ПРОГРАММИРОВАНИЕ
Москва
СОЛОН-Пресс
2009
А. В. Аграновский, Р. А. Хади
Практическая криптография: алгоритмы и их программирование / А. В.,Агра-
новский, Р. А. Хади — М.: СОЛОН-Пресс, 2009. 256 с. — (Серия «Аспекты защиты»)
. ISBN 5-98003-002-6
Эта книга предназначена прежде всего для тех, кто интересуется не только теорети-
ческими аспектами криптологии, но и практическими реализациями алгоритмов крипто-
графии и криптоанализа. В книге уделено очень много внимания вопросам компьютерного
криптоанализа и логике программирования защищенных криптосистем. Книга изложена
таким образом, что она будет полезной как для неподготовленного читателя, так и для вы-
сококвалифицированного специалиста, желающего расширить свой кругозор и по-новому
взглянуть на криптографический аспект систем информационной защиты. Речь в книге не
идет о каких-то конкретных программных продуктах, наоборот — прочтя книгу, подготов-
ленный читатель будет способен самостоятельно создавать программное обеспечение,
содержащее криптографические алгоритмы.
Кроме стандартных Vi популярных средств одноключевого шифрования, в книге рас-
сматриваются нестандартные алгоритмы, которые могут использоваться на практике, ори-
гинальные и необычные подходы к шифрованию и криптоанализу, что может значительно
расширить кругозор даже опытного специалиста. Тем, кто интересуется созданием собст-
венных шифросистем, будут также интересны и полезны многочисленные исторические
справки о создании блочных систем шифрования.
Таким образом, эта книга будет чрезвычайно полезной для студентов вузов, как соот-
ветствующих специальностей, так и просто интересующихся компьютерными технология-
ми, а также для специалистов в области обеспечения информационной безопасности и ,
разработки соответствующих программных средств. Книга носит практический характер и
наряду со множеством описаний шифров содержит исходные тексты программ, их реали-
зующих. Книга может быть использована в качестве справочника либо учебного пособия.
КНИГА — ПОЧТОЙ (
Книги издательства «СОЛОН-ПРЕСС» можно заказать наложенным платежом (оплата при по-
лучении) по фиксированной цене. Заказ оформляется одним из трех способов:
1. Послать открытку или письмо по адресу: 123001, Москва, а/я 82.
2. Оформить заказ можно на сайте www.solon-press.ru в разделе «Книга — почтой».
3. Заказать по тел. (495) 254-44-10, (499) 252-73-26.
Бесплатно высылается каталог издательства по почте.
При оформлении заказа следует правильно и полностью указать адрес, по которому должны
быть высланы книги, а также фамилию, имя и отчество получателя. Желательно указать-допол-
нительно свой телефон и адрес электронной почты.
Через Интернет вы можете в любое время получить свежий каталог издательства
«СОЛОН-ПРЕСС», считав его с адреса www.solon-press.ru/kat.doc.
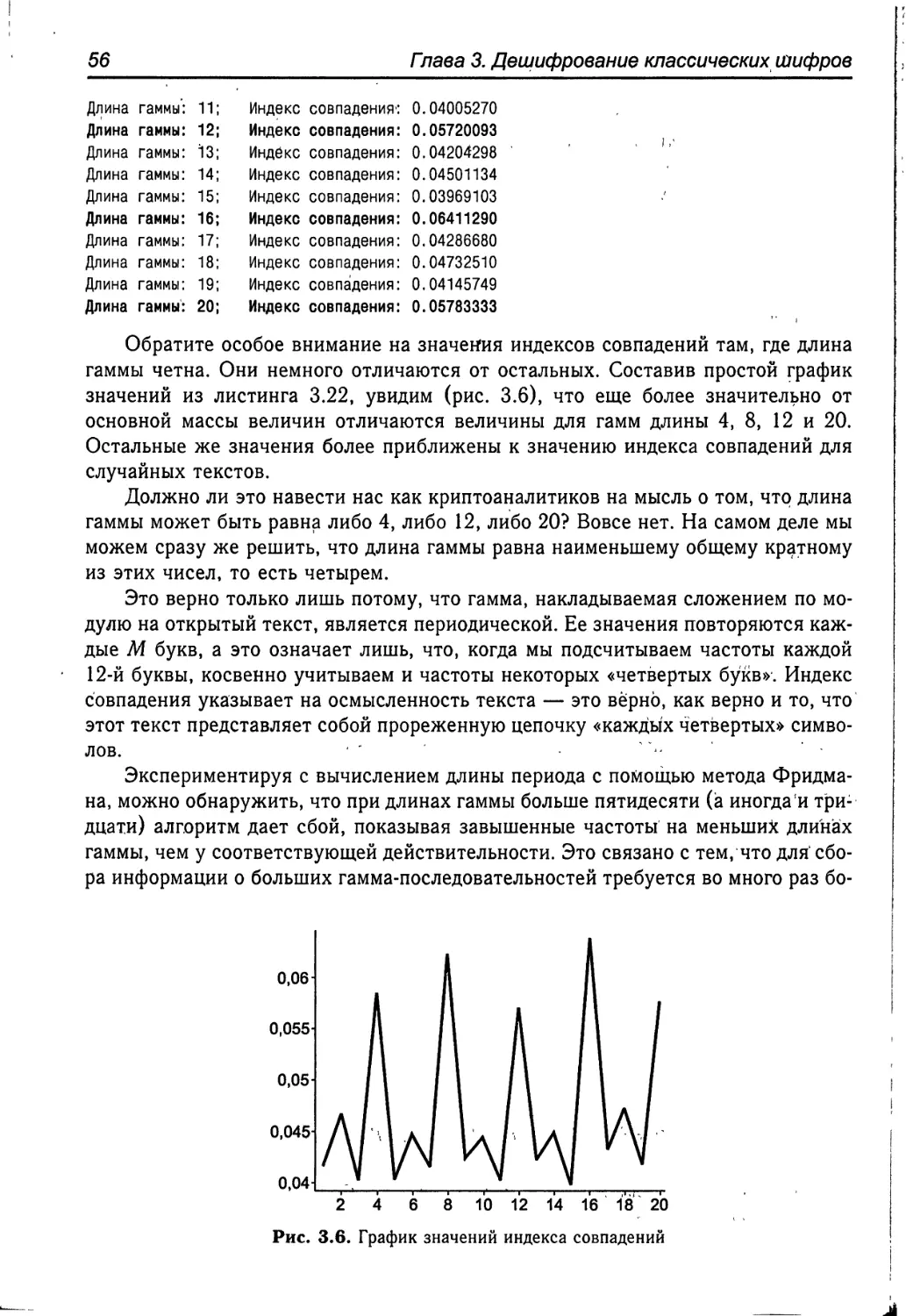
Интернет-магазин размещен на сайте www.solon-press.ru.
По вопросам приобретения обращаться:
ООО «Альянс-книга КТК>>
Тел: (495) 258-91-94, 258-91-95, www.alians-kniga.ru
ISBN 5-98003-002-6
© Макет и обложка «СОЛОН-Пресс», 2009
© А. В. Аграновский, Р. А. Хади, 2009
Рецензия на книгу «Практическая криптография:
алгоритмы и их программирование» авторов
Аграновского А. В. и Хади Р. А.
В книге «Практическая криптография: алгоритмы и их программирование» в
структурированном виде содержится как справочная, так и учебная информация,
поэтому книга будет полезна как профессионалу, так и новичку. Эта книга будет
отличным подспорьем для всех, кто занимается или только начинает пробовать
свои силы в криптографии и ее практическом применении — проектировании и
создании средств криптографической защиты информации.
При этом человек, уже знакомый с программированием, сможет найти здесь
полезную информацию о приемах программирования, которые применяются при
создании программных средств шифрования данных, а человек в программирова-
нии не слишком сведующий получит необходимый набор базовых знаний. Сама
книга состоит из семи структурированных глав, размещенных так, чтобы помочь
и ищущему справочную информацию, и просто читающему главы подряд.
Необходимо отметить особенность данной книги, которая заключается в том,
что в книге сделан упор на изучение современных архитектур систем шифрова-
ния и методов криптоанализа, в том числе с помощью программных средств. В
книге действительно уделено очень много внимания вопросам компьютерного
криптоанализа и логике программирования защищенных криптосистем.
Вывод, который напрашивается сам собою — имея такую книгу, читатель бу-
дет способен самостоятельно создавать программные средства криптографиче-
ской защиты информации. В качестве еще одного положительного момента хоте-
лось бы также отметить, что в книге содержится много информации, которая ра-
нее не была опубликована, в том числе и в западных источниках.
Тельнов Григорий Викторович, кандидат
технических наук, профессор, замести-
тель начальника Краснодарского Военного
Института по учебной и научной работе
Глава 1
Введение
Я с детства был вскормлен науками, и так как меня увери-
ли, что с их помощью можно приобрести ясное и надежное
познание всего полезного для жизни, то у меня было чрез-
вычайно большое желание изучить эти науки. Но как толь-
ко я окончил курс учения, завершаемый обычно принятием
в ряды ученых, я совершенно переменил свое мнение, ибо
так запутался в сомнениях и заблуждениях, что, казалось,
своими стараниями в учении достиг лишь одного: все более
и более убеждался в своем незнании.
Рене Декарт.
Рассуждение о методе, чтобы верно направлять
свой разум и отыскивать истину в науках
Криптография сегодня — это уже целая отрасль знаний, захватывающая
огромные разделы других наук, целью которой является изучение и создание
криптографических преобразований и алгоритмов. В настоящее время четко раз-
личаются две ветви развития криптографии: классическая традиционная криптог-
рафия и современная «асимметричная» криптография.
Речь в книге идет о классической традиционной криптографии, о симметрич-
ных криптосистемах, блочных и поточных шифрах. Прочтя книгу, читатель смо-
жет свободно ориентироваться в классических схемах шифрования и криптоана-
лиза, существующих архитектурах построения блочных и поточных шифров, а
также в современных и перспективных методах их анализа.
Авторы надеются, что данная книга совместно с другими книгами по рассмат-
риваемой теме, более отдаленными от практической стороны криптографии и не-
сущими больше теоретической информации, послужит хорошим учебным и спра-
вочным пособием по реализации и верификации программного обеспечения шиф-
рования данных.
Дополнительно к книге прилагается CD-ROM с проиндексированным содер-
жанием. Список всех файлов с исходными текстами, упоминание о которых мож-
но найти в книге, находится чуть ниже вместе с краткими их описаниями.
Структура глав, или Как читать эту книгу
Книга, которую вы держите в своих руках, насыщена довольно разнообраз-
ным материалом. К сожалению, нет простых путей в изучении сложных вещей.
По этой причине главы и разделы этой книги, возможно, придется читать в раз-
ном порядке — в зависимости от подготовки и уровня знаний читателя. Сейчас, в
самом ее начале, неплохо сделать маленькую остановку и в краткой форме позна-
Введение
5
CD
library Различные документы для углубленного
изучения
aes Документы по принятию нового стандарта
daemen Описание SQUARE
common
cryptocompress Сжатие в криптографии
bwt
decrypt Дешифрование шифров
lucifer Шифр "Люцифер"
v
freq Частотный анализ
hill Шифр Хилла
keylength Длина ключа
solve Алгоритмы решения задач, возникающих
при дешифровании
des Шифр DES
abrahamsen Один из предшественников DES
patent
feistel Патент Файстеля
feistel2
horst
gene Генетические алгоритмы
libs Библиотеки шифрования
milcrypt Военная криптография
misc
modes Режимы шифрования
navajo Криптографы Навахо
sbox Узлы замен
shannon Шэннон
square Еще о SQUARE
wordlists Словари
software Программное обеспечение
Far
Plugins
sources Исходные тексты к книге
compress Сжатие
chapters Исходные тексты сжатия и шифрования
bignum Обработка больших чисел
pgpcrack Подбор паролей к PGP
visual Визуальный подборщик
rc4 Реализация алгоритма RC4
scripher Исходные тексты scripher
encoder
release
scripher
tools
Список всех файлов с исходными текстами на CD
6
Введение
комиться с содержанием каждой главы и некоторых разделов, с тем чтобы опреде-
литься, что читать в первую очередь, а что оставить «на потом».
Как наверняка уже успел заметить внимательный читатель, всего в книге
семь глав. Основные материалы в ней разделены между всеми главами поровну.
Три главы носят вводный характер, остальные три носят прикладной характер.
Первая глава является вводной.
Весь материал довольно четко сначала был разделен на два уровня, а затем
слит воедино для удобства чтения. Так, в основном в книге более детальные опи-
сания криптосистем расположены после общих утверждений и небольших введе-
ний в соответствующие области криптографии и криптоанализа. Материал разно-
го уровня обычно достаточно автономен и заключен в различные разделы глав.
Однако общая концепция ее состоит в использовании общего и единого логиче-
ского пути чтения всей книги последовательно. Хотя, конечно, как именно будет
читать книгу ее непосредственный владелец — это его личное дело. Но чтобы
оценить уровень своей подготовки и, не испытывая трудностей, преодолеть все
без исключения страницы данной книги, читатель может ознакомиться с разде-
лом «Для кого и о чем эта книга».
В этой книге авторы уделяют особое внимание вопросам терминологии вооб-
ще и русской терминологии в криптографии особенно. Сложившейся специализи-
рованной открытой отрасли русской терминологии в этой области уже более со-
рока лет, хотя в последнее время она претерпевает многочисленные изменения и
дополнения. Учитывая это, авторы, чтобы избежать возможных недоразумений и
недомолвок, пользуются своей привычной терминологией, стараясь использовать
не популярные общепринятые толкования, а их стандартизированные эквивален-
ты. По этой причине.всем без исключения мы советуем прочесть раздел «К вопро-
су о терминологии», поскольку он довольно важен и для начинающего, и для уже
подготовленного специалиста. Многие вопросы, освещенные в данной книге, ис-
пользуют только ту терминологию, которая описана в указанном разделе.
Те,читатели, которые хотят получить также и практический опыт параллель-
но с чтением книги, возможно, предпочтут сначала хотя бы пробежать взглядом
раздел «Рабочий инструментарий, который может пригодиться читателю». Кроме
этого, людям, тяготеющим более к практическому программированию, чем к тео-
ретическим выкладкам, следует обязательно обратить внимание на раздел «От-
ступление для программистов» второй главы «Теория секретных систем», в кото-
ром содержится соответствующая вводная информация и исходные тексты. Они
будут активно использоваться в исходных текстах и частях книги «для пишущей
братии» во всех остальных главах.
Конечно, в книге, связанной, пожалуй, с самой интригующей научной обла-
стью: исследований, немало внимания уделяется увлекательным фактам из исто-
рии, особенно если они носят полумистический: характер. Так, в -третьей и пятой
главах, целиком посвящённых такой животрепещущей теме, как криптоанализ,
читатель. сможет прочесть-даже о шифрах, которые использовались советской
разведкой в прошлом, только что. ушедшем от нас веке. Приведенные в третьей
главе рассказы об известных головоломках могут увлечь не хуже хорошего детек-
тива. Одной из таких головомок, заданных человечеству, являются шифры изве-
Введение
7
стного писателя и мистика Эдгара По, бывшего блистательным криптографом и
криптоаналитиком. В конце второй главы дается решение двум его шифрам, про-
деланное именно с помощью компьютера, то есть, по сути, с помощью компьютер-
ного криптоанализа.
Кроме этого, авторы предлагают рассмотреть и попробовать создать и исполь-
зовать самостоятельно компьютерные методы криптоанализа, представляя внима-
нию читателя идеи и исходные тексты программ. Собственно, авторы рассчитыва-
ют на то, что в какой-то момент чтения, читателю наверняка захочется попробо-
вать свои силы в криптографии и особенно в криптоанализе, которому в данной
книге уделено достаточно внимания, в отличие от многих других подобных изда-
ний. Для этого в каждой из трех основных глав приводятся исходные тексты про-
грамм, уже написанных авторами, и зачастую предлагаются методы и алгоритмы
их улучшения, что, несомненно, должно помочь читателю осуществить свои же-
лания.
Несмотря на найденное решение довольно сложной проблемы выстраивания
около полусотни разделов глав и расположения материала книги в логически
стройные последовательности, книгу можно использовать и как справочное посо-
бие при разработке и оценке одноключевых криптосистем. Это верно, поскольку
третья глава «Как устроены современные шифры», кроме общей информации о
классических системах шифрования наших дней, носит также и справочный ха-
рактер, представляя более углубленный материал о популярных современных
симметричных шифрах, а следующая за ней глава «Дешифрование современных
шифров» описывает собственно методы их криптоанализа.
Кроме описания довольно популярных блочных и поточных криптосистем, в
книгу было решено включить и довольно нестандартные решения и алгоритмы в
области обеспечения конфиденциальности информации. Результатом этого реше-
ния стало появление дополнительной главы «Криптографическое сжатие», при-
ведшее также к необходимости краткого изложения теории и методов сжатия.
Вторая глава предоставляет информацию о современной криптографии, начи-
ная с эпохи Клода Шеннона и заканчивая принятым совсем недавно новым стан-
дартом шифрования США. Параллельно с историческими аспектами и рассмотре-
нием различных архитектур построения шифров рассматриваются современные
методы криптоанализа, а также их возможные компьютерные реализации. Де-
тально обсуждаются такие параметры симметричных шифров, как размер ключа
и управляемые криптографические примитивы.
Каждое ружье, висящее на стене, должно когда-либо выстрелить. Этой не-
пререкаемой истине последовали и авторы книги. Потому в седьмой главе «При-
кладные задачи шифрования» все «ружья» оказались при деле. Именно в ней
раскрываются решения прикладных задач: конфиденциальной связи, защищен-
ных контейнеров данных, защиты исходных текстов и данных с помощью крип-
тографических методов, о которых рассказано ранее. Кроме этого, в главе пред-
ставлен пример исследования программного обеспечения на предмет надежности
использования криптографических средств шифрования. Авторы провели не-
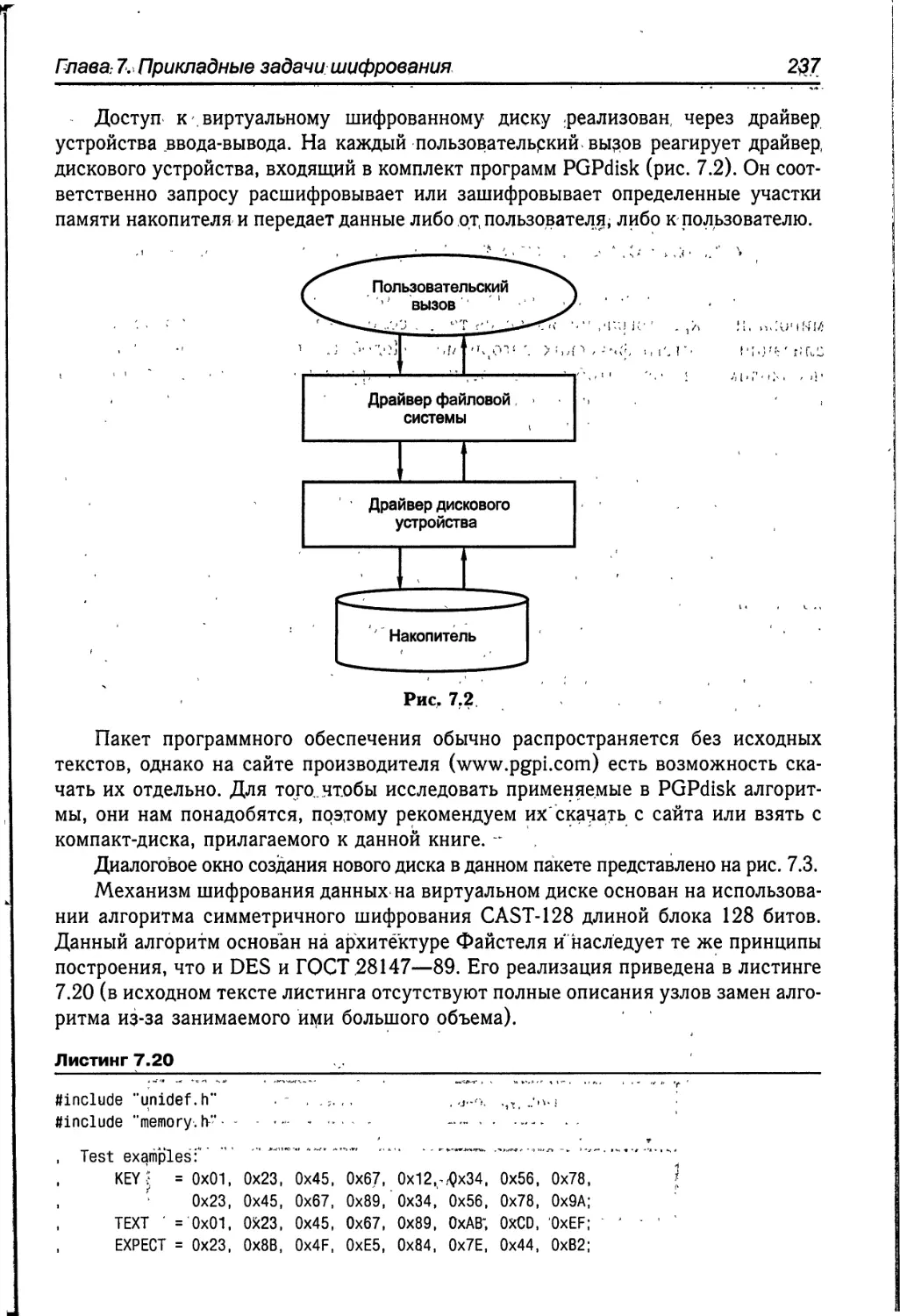
большое исследование метода шифрования криптодиска популярной программы
PGPDisk.
8
Введение
Каждая глава имеет самостоятельную нумерацию примеров исходных тек-
стов — листингов программ и рисунков, а также независимый список литературы
для углубленного изучения.
Таким образом, логическую цепочку связи глав можно представить приблизи-
тельно так:
I глава
II глава
III глава
V глава
IV глава
I
VI глава---
VII глава
Количество узких областей исследования в криптологии настолько велико, что
трудно себе представить полное описание всех связанных с ней аспектов в одной кни-
ге. Книга призвана не только разобраться в уже существующих популярных системах
шифрования, но и расширить кругозор читателя в этой области, а также дать реаль-
ную возможность научиться создавать и анализировать шифры самостоятельно.
Для кого и о чем эта книга
Книга предзначается в первую очередь для тех, кто интересуется не только тео-
ретическими аспектами криптологии — как криптографии, так и криптоанализа, —
но и практическими реализациями используемых в них алгоритмов ^методов.
В ней уделено очень много внимания вопросам компьютерного криптоанализа
и логике программирования криптосистем. Материал изложен таким образом, что
он будет полезен и для неподготовленного читателя, и для высококвалифицирован-
ного специалиста, желающего расширить свой кругозор и по-новому взглянуть на
криптографический аспект систем информационной защиты. Речь в книге не идет о
каких-то конкретных программных продуктах, наоборот — прочтя книгу, подготов-
ленный читатель будет способен самостоятельно создавать программное обеспече-
ние, содержащее криптографические алгоритмы. Однако для этого ему все же при-
годятся навыки программиста и математика, хотя бы на начальном уровне.
Кроме стандартных и популярных средств одноключевого шифрования, в
книге рассматриваются нестандартные алгоритмы, которые могут.использоваться
на практике, а также оригинальные и необычные подходы к шифрованию и крип-
тоанализу, что может значительно расширить кругозор даже опытного' специали-
ста. Тем, кто интересуется созданием собственных шифросистем-, будет также ин-
тересна и полезна информация, связанная с современными требованиями к серти-
фикации и лицензированию средств шифрования.
Введение
9
Таким образом, книга будет чрезвычайно полезной как для студентов вузов
соответствующих специальностей, так и просто интересующихся компьютерными
технологиями, а также для специалистов в области обеспечения информационной
безопасности и разработки соответствующих программных средств. Книга содер-
жит множество математических описаний шифров и может быть использована в
качестве учебного пособия.
Рабочий инструментарий, который может
пригодиться читателю
Исследуя вопросы реализации криптографических методов защиты информа-
ции, мы неизбежно сталкиваемся с вопросами, касающимися таких факторов, как
среда программирования, язык программирования, схемы реализации и верифи-
кации программного обеспечения, тестовые испытания.
Все исходные тексты, представленные в данной книге, написаны на языках
Си и Perl. Для языка Си использовалась среда разработки программного обеспе-
чения Borland C++ Builder 5, а для исполнения скриптов на языке Perl необхо-
дим ActiveState Perl или иной другой аналогичный интерпретатор.
C++Builder 5 - ubique
|<None>
;««2й1-омйпб»ТАоте| жвяижн шшик! ifesd п-^п.й< 1»:
Ж»
ivoid inline init_model (STAT_MODEL *rnodel) {
’ meniset (model, 0, sizeof(STAT_HODEL));
№
ж
'Old inline correct_model (STAT_IIODEL ’’model, *int symbol) {’
•. л model->counts [symbol] ++; ' 4
model->counted++; ' * * - ', 1 '
д
double inline calc_measure2 (STATJIODEL ^modell, STATJIODEL *rpode!2) (
double result = 0, probl, prob2, max = 0,
for (int i = 0; i < MAX_CATEGORIES; 1++)
if (max == 0) max =1;
(int i » . 0; i < HAX_CATEGORIES; 1++)
probl - (double) modell->counts[1] /
^prob2 - (double) model2->counps[1] /
result += fobs (]jrobl-prob2);
%
max
max
&
&
%
if (max < modell->counts[i]) max >=
4» *. .4 1 , ( ~ K i t , , , * ' ♦ Л О
“input {process not accessible]
pmin: (process not accessible]
pminjc [process not accessible]
“min: [process not accessible] ’
"min->point$,32. [process not accessible]
pmax: [process not accessible]
pmaxjc [process not accessible)
“min_k->points,32 [process not accessible]
Рис. 1.1. Borland C++ Builder
'input->points.4: [process not accessible]
10
Введение
Рис. 1.2. HexWorkshop
Еще одним необходимым в работе инструментом для читателя станет шест-
надцатеричный редактор. Можно использовать какой-либо специализированный
вроде HexWorkshop или, что еще лучше — HIEW, но для работы вполне сойдет
и встроенный, например, в файловый менеджер Far редактор шестнадцатеричных
кодов. Он особенно пригодится для изучения выхода тех шифров, которые реали-
зованы в этой книге.
Собственно говоря, это практически все основные инструменты, которые по-
надобятся при получении практических навыков и работе с исходными текстами,
опубликованными в данной книге.
К вопросу о терминологии
К вопросу о терминологии в криптографии авторы книги стараются относить-
ся весьма деликатно. На сегодняшний день в России существует одна из самых
сильных криптографических школ в мире — наследие СССР. Советские криптоа-
налитики еще долго будут считаться одними из самых сильных специалистов в
этой области. Соответственно наработаны и терминология, и большинство прин-
ципов таксономии, в том числе и адекватное переложение и адаптация на русский
язык вновь появляющихся иностранных терминов.
Тем не менее вся эта информация до последнего времени была конфиденциа-
льной и строжайше охранялась. Само слово «криптография» не выбывало ника-
Введение
11
ких ассоциаций у подавляющего большинства математиков и специалистов по
связи. Если необходимо было «закрыть» канал связи, то использовалась специа-
льная аппаратура, которая представлялась для конечных пользователей «черным
ящиком», в который надо было лишь воткнуть проводки, нажать на определенные
кнопки и повернуть ручки.
С начала 90-х годов ситуация резко изменилась. Выпущено уже несколько со-
тен различных изданий по теме информационной безопасности, в том числе и по
криптографии. Множество книг переведены с иностранных языков, каждый ме-
сяц появляются книги русских авторов по прикладной и теоретической криптог-
рафии.
К сожалению, количество выпускаемых книг не всегда сопровождается каче-
ством. И особое внимание необходимо уделять именно тому, как вольно обраща-
ются с терминами новоиспеченные «криптоматематики». Некоторые авторы
«книг по криптографии» не имеют никакого отношения даже к математике, не го-
воря уж о кодах и шифрах. Потому и выходят казусы с «шифрацией», «криптова-
нием» и «дешифрированием» данных.
Конечно, никто не застрахован от возможных нелепостей и казусов, связан-
ных с написанием, редактированием, версткой, макетированием и печатью боль-
ших объемов текста. Поэтому авторы просят осведомленных читателей отнестись
с пониманием к возможным техническим «ляпам».
А для того чтобы избежать технических накладок, авторы предлагают счи-
тать верными следующие трактовки зарубежных й отечественных терминов:
• криптографическая атака (cryptoanalitic attack) — попытка криптоаналити-
ка вызвать отклонения от нормального проведения процесса конфиденциа-
льного обмена информацией. Соответственно взлом или вскрытие, дешиф-
рование шифра или шифросистемы — это успешное применение криптогра-
фической атаки;
• криптоанализ (cryptanalysis) и криптоаналитик (cryptanalytic) — соответст-
венно набор методик и алгоритмов дешифрования криптографически защи-
щенных сообщений, анализа шифросистем и человек, все это осуществляю-
щий;
• дешифрование (deciphering) и расшифрование (decryption) — соответствен-
но методы извлечения информации без знания криптографического ключа и
со знанием оного. Термин «дешифрование» обычно применяют по отноше-
нию к процессу криптоанализа шифротекста (криптоанализ сам по себе, во-
обще говоря, может заключаться и в анализе шифросистемы, а не только
зашифрованного ею открытого сообщения);
• криптографический ключ (cryptographic key, cryptokey, иногда просто
key) — в случае классических криптосистем секретная компонента, шифра,;
Должен быть известен только законным пользователям процесса обмена
информации;
• зашифрование (encryption) — процесс зашифрования информации, то есть
применения криптографического преобразования данных, эту информацию
содержащих;
12
Введение
• аутентичность данных и систем (authenticity of information) —: для данных
аутентичность можно определить как факт подтверждения цодлинности ин-
формации, содержащейся в этих данных, а для систем — .способность обес-
печивать процедуру соответствующей проверки — аутентификации данных;
• аутентификация (authentication) — процедура проверки подлинности дан-
ных, то есть того, что эти данные были созданы легитимными (законными)
участниками процесса обмена информации;
• гамма-последовательность или просто гамма (gamma sequence, gamma) —
обычно этот термин употребляется в отношении последовательности псев-
дослучайных элементов, которые генерируются по определенному закону и
алгоритму. Однако в случае, когда это не так, употребляется модификация
термина — например, «равновероятная гамма» или «случайная гамма» —
для обозначения последовательностей, элементы которых распределены по
равномерному вероятностному закону, то есть значения имеют сплошной
спектр;
• гаммирование (gamma xoring) — процесс «наложения» гамма-последовате-
льности на открытые данные. Обычно это суммирование в каком-либо ко-
нечном поле (например, в поле GF(2) (см. [4, 6 и 9]) такое суммирование
принимает вид обычного «исключающего ИЛИ» суммирования); .
• имитозащита — это защита данных в системах их передачи и хранения от
навязывания ложной информации. Имитозащита достигается обычно за
счет включения в пакет передаваемых данных имитовставки;
• имитовставка — блок информации, вычисленный по определенному закону
и зависящий от некоторого криптографического ключа и данных;
• блочные (блоковые) и поточные (потоковые) шифры — авторы сознательно
используют термин «блочный» шифр, а не «блоковый», как наиболее попу-
лярный и устоявшийся. Понятия «поточного» и «потокового» шифров иден-
тичны и одинаково популярны, однако в силу симметрии авторы предпочи-
тают использовать термин «поточный шифр», но «потоковая обработка ин-
формации»;
• криптографическая стойкость, криптостойкость (cryptographic strength) —
устойчивость шифросистемы по отношению ко всем известным видам крип-
тоанализа;
• принцип Керкхоффа (Kerchkoff) — принцип изобретения и распростране-
ния криптографических алгоритмов, в соответствии с которым в секрете
держится только определенный набор параметров шифра (и в обязательном
порядке криптографический ключ), а все остальное может быть открытым
без снижения криптостойкости алгоритма. Этот принцип был впервые
сформулирован в работе голландского криптографа Керкхоффа «Военная
криптография» вместе с дюжиной других, не менее известных (например, о
том, что шифр должен быть удобным в эксплуатации,' а'также о том, что
шифр должен быть легко запоминаемым);
• развертывание или разворачивание ключа (key shedule) — процедура вы-
числения последовательности подключей шифра из основного ключа шиф-
рования;
«
Введение
13
• раунд или цикл шифрования (round) — один комплексный шаг алгоритма, в
процессе которого преобразовываются данные;
• подключ шифрования (round key, subkey) — криптографический ключ, вы-
числяемый и используемый только на этапе шифрования из основного клю-
ча шифрования. Обычно применяется в качестве входа функций усложне-
ния на различных раундах шифрования;
• шифр и шифросистема (cipher, cypher, ciphercode) — обычно выход крипто-
системы и сама симметричная криптосистема соответственно. В зависимо-
сти от контекста шифр может обозначает «шифровку», то есть зашифрован-
ное с его помощью сообщение, либо саму криптографическую систему пре-
образования информации.
Список литературы
1. Столлингс В. «Криптография и защита сетей», М: Вильямс, 2001.
2. Медведовский И. Д., Семьянов П. В., Платонов В. В., «Атака через Интернет»,
СПб: 1999.
3. В. Г. Проскурин, С. В. Крутов, И. В. Мацкевич: «Защита в операционных сис-
темах», М: Радио и связь: 2000.
4. Аграновский А. В., Хади Р. А., Ерусалимский Я. М., «Открытые системы и
криптография», Телекоммуникации, 2000.
5. Agranovsky А. V., Hady R. A., «Crypto miracles with random oracle», The Procee-
dings of IEEE SIBCOM'2001, The Tomsk Chapter of the Institute of Electrical and Elect-
ronics Engineers, 2001.
6. А. В. Аграновский, А. В. Балакин, P. А. Хади, «Классические шифры и методы
их криптоанализа», М: Машиностроение, Информационные технологии, № 10, 2001.
7. А. А. Молдовян, Н. А. Молдовян, Советов Б. Я., «Криптография»: СПб.: Изда-
тельство «Лань», 2000.
L 8. С. Расторгуев, «Программные методы защиты информации в компьютерах и се-
тях», М: Издательство Агентства «Яхтсмен», 1993.
9. А. Ростовцев, «Алгебраические основы криптографии», СПб.: Мир и Семья, 2000.
10. Чмора А. Л., «Современная прикладная криптография», М.: Гелиос АРВ, 2001.
11. Устинов Г. Н., «Основы информационной безопасности», М: Синтег, 2000.
12. Анин Б., «Защита компьютерной информации», СПб: БХВ, 2000.
13. Романец Ю. В., Тимофеев П. А., «Защита информации в компьютерных систе-
мах и сетях», М: Радио и связь, 2001.
14. Menezes A., van Oorschot Р., Vanstone S., «Handbook of Applied Cryptograp-
hy», CRC press, 1996.
15. Schneier B., «Applied Cryptography», John Wiley & Sons Inc, 1996.
16. Милославская H. Г., Толстой А. И., «Интрасети: доступ в Интернет, защита»,
. М.: ЮНИТИ-ДАНА, 2000.
17. Gutmann Р.: «Network Security», University of Auckland, 1996.
18. Саломаа А.: «Криптография с открытым ключом», Москва: «Мир», 1995.
318 с.
19. Олифер В., Олифер Н.: «Компьютерные сети», Спб.: Издательство «Питер»,
1999. 672 с.
Глава 2
Теория секретных систем
С точки зрения криптографии секретная система в большой
степени тождественна системе связи с зашумлением.
Клод Элвуд Шеннон.
Математическая теория секретных систем
Криптография сегодня — это наука об обеспечении безопасности данных
или, как говорят, информационной безопасности. Шифрование — это основное
действие в криптографии, шифрование — это преобразование данных в такую
форму или представление, что понять смысл передаваемых или хранимых дан-
ных, не обладая специальной дополнительной информацией (криптографически-
ми ключами), невозможно. Шифрование позволяет обеспечить конфиденциаль-
ность, сохраняя информацию в тайне от того, кому она не предназначена.
По определению ISO — международной организации, разрабатывающей
стандарты для открытых систем, задачами обеспечения защиты информации яв-
ляются:
• обеспечение конфиденциальности информации (защита передаваемой ин-
формации от доступа и копирования любым принципалом (человеком,
компьютером или программой), кроме того, кому доступ определен систе-
мой защиты либо непосредственно источником информации).
• защита информации от искажения (сохранение целостности передаваемой
информации таким образом, что принимающая сторона имеет возможность
определять, была ли изменена информация в процессе передачи. Достигает-
ся использованием имитозащиты и хэшей).
• аутентификация сообщений и пользователей (и идентификация как воз-
можность ведения записей в системе, специальная подпись документов, ко-
торые могут стать определяющими в споре об авторстве передаваемой ин-
формации).
• признание авторства (аналогично аутентификации, с той лишь разницей,
что доказательство авторства проводится в случае, когда источник инфор-
мации отрицает факт передачи информации).
Все эти задачи решаются с помощью применения методов и средств криптог-
рафической защиты информации. Криптография существует уже несколько сто-
летий, но только несколько десятилетий как всемирно признанная научная об-
ласть деятельности. Эти годы являются периодом интенсивного развития как за-
крытых, так и открытых исследований в различных областях математики с точки
зрения применения ее в криптографии.
Пожалуй, сейчас можно считать, что история современной криптографии (и
уж несомненно, блочных и поточных шифров!) началась с одного-единственного
Гпава 2. Теория секретных систем
15
человека — Клода Элвуда Шеннона (30.04.1916—24.02.2001), американского
ученого, профессора Массачусетского политехнического университета (рис. 2.1).
Мало известен тот факт, что профессор Шеннон был дальним родственни-
ком Томаса Эдисона, пожалуй, одного из самых известных в мире изобретателей.
Видимо, это повлияло на выбор жизненного пути молодого Клода Шеннона, ко-
торый с детства увлекался всевозможными конструкторскими поделками и изоб-
ретениями.
Выставленные в домашней коллекции, его изобретения столь же удивитель-
ны, как и изобретения Эдисона, которыми человечество пользуется до сих пор.
Клод Элвуд Шеннон вообще был весьма увлекающимся человеком1. Например,
являясь страстным поклонником игры в шахматы, он построил машину для игры в
шахматы задолго до появления 1ВМ'овского Deep Blue и его поединка с Каспаро-
вым. А в 1965 году Шеннон, находясь по приглашению в России, вызвал на шах-
матную дуэль чемпиона мира Михаила Ботвинника. И хотя проиграл на 42-м
ходе, все же показал хорошую игру.
Такая удивительная компиляция разных талантов в одном человеке позволя-
ла Шеннону видеть обычные вещи с несколько иной точки зрения, нежели как
это видели все остальные. На вручении Нобелевской премии его ответное слово
прозвучало весьма скромно и достойно великого ученого: «Я лишь заметил то, что
научные достижения в одной научной области могут быть полезны и в других об-
ластях».
Естественно ожидать, что все сложное и трудноразрешимое привлекало тако-
го человека. Наверняка именно поэтому Шеннон был увлечен криптографией,
той, какой она была в его время — с первой чет-
верти и до середины XX века.
Поскольку криптография — плод древа воен-
ных технологий, ни одно самое большое изобрете-
ние Шеннона в криптографии и теории информа-
ции не могло бы обойтись без вмешательства во-
енных. Действительно, достоверно известно, что с
1941 (а по всей видимости, и гораздо раньше) по
1972 год он работал не только с исследователь-
ской лабораторией Bell Laboratories, но также тес-
но сотрудничал и с американскими военными. На
протяжении всей Второй мировой вместе с коман-
дой изобратетелей Bell Шеннон работал над раз-
личными секретными системами, в том числе с
системой радаров и противовоздушной обороны
ДЛЯ военной авиации. Рис. 2.1. Клод Элвуд Шеннон
1 К всеобщей скорби, великий ученый и, изобретатель Клод Элвуд Щеннрн скончался.24
февраля 2001 года в Медфорде, штат Массачусетс, США, в результате продолжительной бо-
рьбы с изнуряющей его болезнью Альцгеймера. Эта новость стала трагической вехой, завер-
шающей эпоху великих изобретений начала века информационных технологий, праотцом ко-
торых был и навсегда останется для всего мира доктор технических наук, профессор Клод Эл-
вуд Шеннон.
16
Глава 2. Теория секретных систем
Его детищем стала система распознавания «свой — чужой» в американской
авиации, которая использовалась для определения нейтральных и «своих» целей
и отличия их от вражеских. А система радаров долгое время пользовалась боль-
шой популярностью у разведок всего мира.
Но самым ценным результатом военного союза «Шеннон — УСС»2 стала, на-
верное, математическая теория систем связи («А Mathematical Theory of Commu-
nication», опубликованная в «The Bell System Technical Journal» в 1948 году) и по-
следовавшая сразу за ней математическая теория секретных систем.
Зафиксированные в первой работе принципы теории информации и теории
связи стали основополагающими для многих последующих изобретений и откры-
тий на целые десятилетия.
Именно в ней Шеннон предложил схему организации каналов связи, Содер-
жащую источник сообщений, их приемник и источник шума, наделив их свойст-
вами вероятностных объектов (рис. 2.2).
Шеннон определил источник как некоторый случайный процесс, генерирую-
щий и передающий по каналу связи сообщения, с определенной априори вероят-
ностью для каждого возможного из них. Для этого он воспользовался классиче-
ским определением вероятностного пространства, подчинив появление каждого
сообщения законам классической теории вероятности и сделав сообщения диск-
ретными. В его трактовке каждое сообщение представляло собой неделимые с
точки зрения источника и получателя блоки информации. Это значительно упро-
щает процесс формального описания различных процессов, которые могут проис-
ходить в системе передачи данных, и позволяет записать все законы взаимодейст-
вия с помощью вероятностных формул' в простых выражениях.
В этой же статье Шеннон предложил собственную версию понятия «инфор-
мации», дав термину четкое определение и указав в качестве меры этой самой ин-
2 Управление стратегических служб (OSS)предшественник ЦРУ, действовало как ор-
ган американской внешней разведки и служба по ПройеДёнйю тайных операций во время Вто-
рой мировой войны. Гарри Труман, преемник президента ’США Теодора Рузвельта, распустил
ОСС в октябре 1945 года.
Гпава 2. Теория секретных систем
17
формации аналог физической энтропии — энтропию информационную. Эту меру
информации Шеннон выразил с помощью логарифмических функций, о чем сооб-
щают все учебники по алгебраической теории кодирования и теории информации.
Однако мало кто объясняет, почему был выбран именно логарифм, видимо считая
это настолько очевидным, что данный факт не требует никаких дополнительных
пояснений.
На самом деле действительно все довольно просто. Как говорится, все гениа-
льное объясняется с помощью простых понятий. С одной стороны, до Шеннона в
теоретической физике существовали понятия энтропии и негэнтропии, связанные
с макро- и микросостояниями систем физических объектов. Они описывали меру
неопределенности состояния физической системы и выражались — подумать то-
лько! — через натуральный логарифм.
Идея Шеннона — принять за информацию неопределенность поведения сис-
темы получения сообщений — быстро нашла свою естественную аналогию с фи-
зическими системами. И Шеннон, предложив рассматривать конечное простран-
ство сообщений, счел разумным использовать логарифмический вид выражения
энтропии сообщения, правда представленного в двоичной форме.
Действительно, логарифмическое представление имеет ряд простых преиму-
ществ. Во-первых, это интуитивно понятное определение, оно вполне вписыва-
лось в существующие общепринятые стандарты измерения и не вызывало оттор-
жения у многочисленного научного сообщества. Монотонность логарифма опре-
деляла линейность функции измерения. Да и применение логарифма было и
остается весьма удобным на практике. Например, в измерениях всевозможных
вариантов подключений реле или триггеров — добавление одного такого элемен-
та в схему, по сути, добавляет единицу к аргументу логарифма по основанию два.
Сам же логарифм в этом случае выражает своего рода среднюю длину пути через
все триггеры на схеме. Двойка в основании логарифма появляется тоже достаточ-
но просто — она берется как результат эксперимента «включено/выключено» —
по теме, связанной с подсчетом триггеров в электрической цепи, эффективности
цепей и электропроводности Шеннон защитил магистерскую диссертацию. Так
что ответы на все эти вопросы он знал как свои пять пальцев.
Связав два понятия — энтропию и информативность — вместе, Шеннон не-
медленно получил определение избыточности текста.
По этому поводу он проводил довольно интересные эксперименты, что назы-
вается, «над людьми». Один из таких экспериментов подробно описан им самим и
является своего рода опытной основой для необходимости нахождения числового
эквивалента содержательности сообщения.
Опыт же заключался в том, что выбирался наугад некоторый осмысленный
текст (художественный, публицистический или технический) на английском язы-
ке. Затем оттуда поочередно брали по одной букве. Показывая сначала одну бук-
ву этого текста, потом две, три и так далее, Шеннон предлагал участникам экспе-
римента угадать букву, которая, по их мнению, должна была бы непосредственно
следовать за всеми уже показанными. Одновременно с этим подсчитывалось ко-
личество угаданных букв и общее количество «угадываний». Начиная с первой
буквы, участники постепенно улучшали свои результаты. Однако начиная с неко-
18
Глава 2. Теория секретных систем
торого момента отношение количества угаданных букв к общему количеству ис-
пытаний стало более или менее постоянным. По размышлениям Шеннона, это
означало, что в данном тексте количество информации, приходящее в среднем на
одну букву, ограничено некоторым числом. Отсюда, скорее всего, и оценки энтро-
пии различных языков.
В работах, подобных этой, а также посвященных анализу открытых и зашиф-
рованных текстов, Шеннон использовал научные результаты, полученные в нача-
ле XX века русским ученым А. А. Марковым, специалистом, чьим именем назван
огромный раздел в теории случайных процессов. Подсчитанные Марковым часто-
ты появления символов в различных языках иногда представляют до сих пор акту-
альный материал для помощи в исследованиях. Надо сказать, что и Клод Шеннон
использовал в криптографии уже найденные результаты и собственные достиже-
ния в теории вероятностей весьма активно в собственном же изложении теории
связи и информации.
В 1945 году Шеннон сделал доклад, содержание которого было засекречено,
посвященный секретным системам связи, принципам их построения и некоторым
другим не менее важным составляющим аспектам секретных систем. Позже его
работа была опубликована в качестве статьи. С момента опубликования его сек-
ретного доклада «Математическая теория криптографии» в виде статьи начинает-
ся настоящий бум в криптографии. Профессиональный криптограф, Шеннон весь-
ма удачно перенес свою стройную схему организации систем связи на поле крип-
тографических битв.
Клод изложил схему секретной системы связи с точки зрения формирования
обычного канала связи, описание которого уже было доступно всем. Источник по-
мех, присутствовавший в классической схеме, был заменен на специалиста-крип-
тографа, пытающегося разгадать шифрованные сообщения криптоаналитика, об-
ладающего всеми необходимыми ресурсами.
Глава 2. Теория секретных систем
19
Шеннон в полной мере использовал правило Керкхоффа: его криптографиче-
ская система подобна наборному замку с изменяемой комбинацией, используемо-
му для защиты сейфов. Структура замка доступна каждому, кто его приобрел, но
вот комбинация замка держится в секрете и может быть изменена всякий раз,
когда существует подозрение, что она была утеряна — скомпрометирована.
Даже если противник попробует перебрать все возможные комбинации-клю-
чи, он может даже оказаться не в состоянии определить, какой из них оказался
правильным. Подобная открытость — естественное свойство канала связи, чем и
не преминул воспользоваться Шеннон, заменив передатчик на блок зашифрова-
ния сообщения с помощью тайного ключа — «комбинации замка», а приемник на
модуль расшифрования.
Испробовав данную модель, Шеннон развил идею, предложив практическое
применение таким математическим характеристикам, как энтропия и емкость ка-
нала. Созданная им теория секретных систем содержит множество иных идей,
она сформировала немало важных замечаний и следствий, которыми пользуются
до сих пор. В частности, предложенный им метод построения блочных шифров
оказался основополагающим принципом на многие десятилетия вперед.
Современная криптография
Несомненно, все криптографические исследования остава-
лись одной из самых активных областей информатики на
протяжении последних десяти лет, и многие результаты за-
мечательны и прекрасны.
Д. Кнут. Лекция «Ответы на все вопросы»
5 октября 2001 года в Техническом
университете г. Мюнхена
Современная криптография порядком обросла математической лепниной и
теперь имеет целый набор эффективных средств по моделированию криптографи-
ческих систем и их анализу. Для того чтобы иметь достаточно представления о
том, какие методы и алгоритмы шифрования реализованы и опубликованы в этой
книге, обратимся к краткому экскурсу в теорию современной криптографии.
Под детерминированной системой шифрования мы будем понимать ото-
бражение F : Р х К С, где Р, С и К — непустые множества, называемые соот-
ветственно пространством открытых текстов или входов, пространством
шифротекстов или выходов и пространством ключей, причем при каждом фик-
сированном значении keK отображение FM : Р -» С = F(p, k) является мономор-
физмом. Последнее необходимо для возможности однозначного расшифрования
шифротекста. Для краткости детерминированную систему шифрования принято
называть просто шифром. Порядком системы называется число различных ото-
бражений F(k), то есть таких, что F(kl) Р(к2) при k\ ф k2. Степенью системы при-
нято называть мощность множества Р. Шифр называется нерастягивающим,
если | Р | = | С |, растягивающим, если | Р | < | С | и эндоморфным, если Р = С.
Если разным ключам системы соответствуют различные отображения F, то систе-
20 Глава 2. Теория секретных систем
ма называется точной. Под алфавитом будем понимать конечное множество А,
элементы которого называются символами (буквами, знаками). Тогда текст —
это упорядоченный набор символов. Стоит отметить также два важных свойства
систем шифрования, которыми должны обладать все стойкие криптографические
отображения. Рассеиванием называется влияние любого знака открытого текста
или ключа на знаки шифротекста. Это свойство делает восстановление неизвест-
ного ключа по частям трудной, а в идеале неразрешимой задачей. Под перемеши-
ванием понимают использование таких преобразований, которые усложняют по-
иск связи между открытым и зашифрованным текстом методами статистического
анализа или делают его невозможным (трудноосуществимым).
Виды симметричных шифров
Шифр можно считать симметричным, если для криптографического преобра-
зования данных (после которого они теряют смысл для противника) применяются
одни и те же преобразования, зависящие от одного и того же ключа. Все симмет-
ричные системы шифрования можно характеризовать по способам преобразова-
ний, выполняемых с открытым текстом: перестановки, моноалфавитные замены,
полиалфавитные замены, подстановки, композиционные и итерационные шифры,
шифры Файстеля.
Шифры перестановки являются простейшими и, вероятно, самыми древни-
ми. Они заключаются в том, что символы открытого текста переставляются по
определенному правилу, зависящему от ключа, в пределах этого текста.
Моноалфавитными заменами называют шифры, в которых символы алфа-
вита открытого текста меняются на символы того же алфавита по определенному
правилу, зависящему от ключа.
Полиалфавитные замены — это шифры, в которых символы открытого тек-
ста меняются на символы того же либо другого алфавита по определенному пра-
вилу, зависящему от ключа и от положения символа в тексте. Полиалфавитная
замена называется подстановкой, если алфавиты открытого и зашифрованного
текстов совпадают.
Пусть имеется семейство систем шифрования F,: Р х К, С, i = 1, 2, .... п,
для которых Р = С, то есть пространства входов и выходов всех шифров совпада-
ют. Тогда композиционным (каскадным, послойным) шифром будет называться
шифр, полученный с помощью композиции шифров семейства, задаваемый ото-
бражением F : Р х (Кх х ... х /Q Р, где F = Fn° Fn_t ° ... 0 Ft. Его ключом будет
k = (kit .... ki)eKl х ... х Кп. При этом отображение Ft принято называть i-м цик-
лом шифрования, К; — ключом i-го цикла шифрования или цикловым ключом.
Итерационным шифром называется композиционный шифр, у которого сов-
падают все циклы шифрования Ft и ключевые пространства К,. Говоря неформаль-
но, итерационный шифр —- это применение одной и той же криптографической
функции п раз с, вообще говоря, разными ключами.
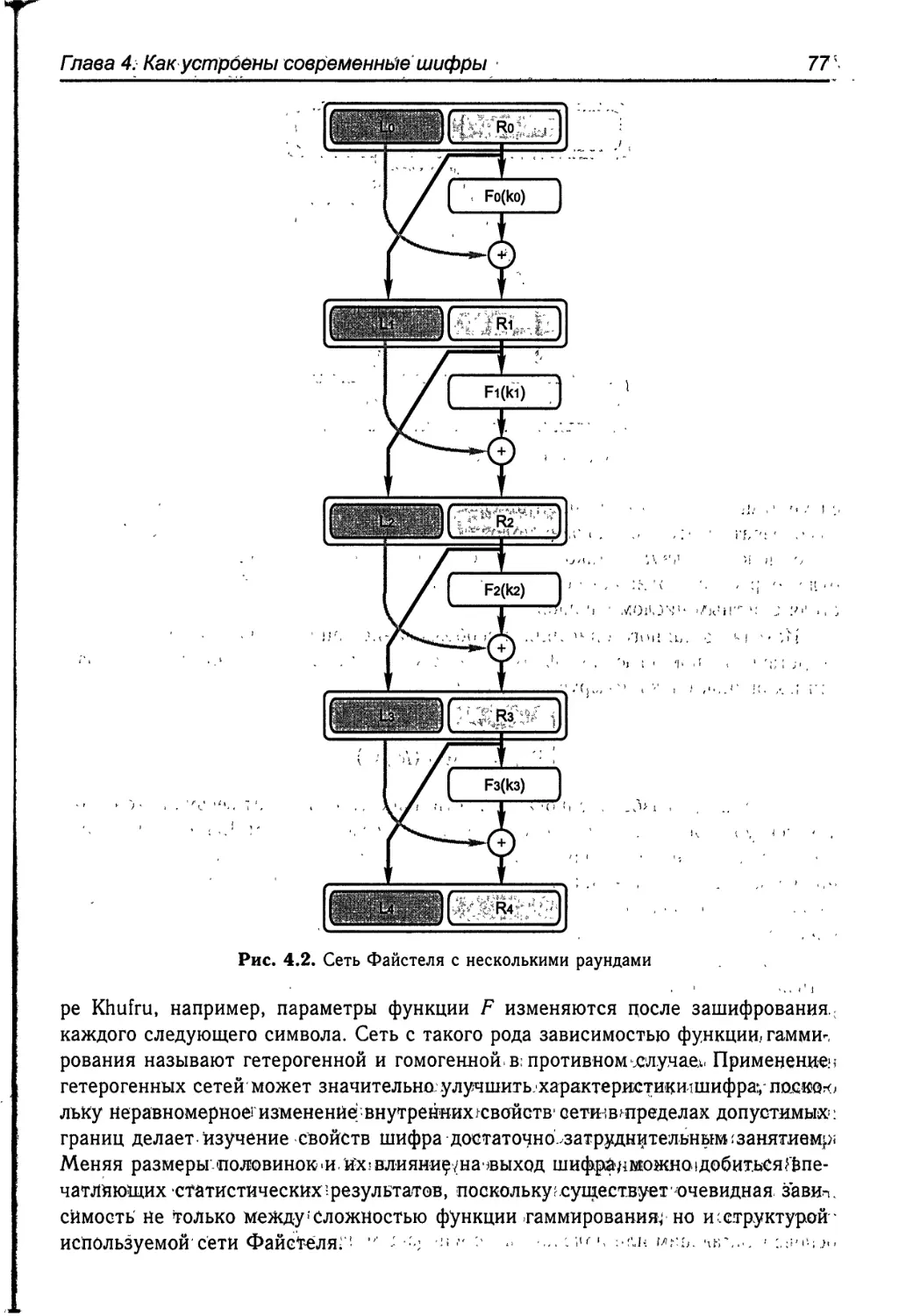
Шифром Файстеля (сбалансированной сетью Файстеля) называется ком-
позиционный шифр F = Ftt° Fn_t ° ... ° Flt если Р = Т х Т, где Т — некоторое непус-
Глава 2. Теория секретных систем 21
,тое множество конечной мощности, то для УреР 3/, геТ такие, что р =.(/, г), и
Р,(/, г) = = (г, I ® fitr)), где fi — отображение, зависящее от циклового ключа kt,
® — это любая операция, относительно .которой замкнуто множество Т. Если в ка-
честве Т выбрать векторное пространство Z2m, а в качестве ® векторное сложение ,
в этом пространстве, то при случайном выборе цикловых ключей и достаточно
большом п такой шифр Файстеля будет представлять псевдослучайную подстанов-
ку на Z2m, имеющие характеристики, весьма близкие к случайной подстановке.
Пусть F = Г, ° F2 ° ... ° Fn: Р х (Кх х ... х /Q -> Р — произвольный композици-
онный шифр, и на множестве Р задана произвольная групповая операция ®. Для
Vp, р'еР определим Др = р ® (р')-1, где (р')"1 — это элемент, обратный к р' отно-
сительно операции ®. Пусть р( = ГД(, р,.,), p'f = F^kit p'^f}, Apj = р, ® (р',)’1, i = 1,
2, ..., п. Тогда композиционную систему шифрования F будем называть марков-
ской, если последовательность {Др,} образует цепь Маркова.
Помимо этого, принято делить все симметричные системы на две группы:
блочные и поточные. Об их различиях и тонкостях классификации читатель мо-
жет прочесть почти в каждой главе этой книги, поскольку даже при наличии, уже
довольно давно сложившейся школы криптографии в нашем славном Отечестве
споры о том, принадлежит ли новый разработанный шифр к какому-то из классов,
довольно любопытны сами по себе.,,
Одной из трактовок различий между поточными (потоковыми) и блочными
шифрами является следующая. Шифр называют блочным, если шифрование каж-
дого блока открытого текста не зависит от других бдоков, откуда следует, что ре-
зультаты шифрования двух одинаковых блоков одного и того же открытого текста
совпадают. Если же результат шифрования очередного блока открытого текста
зависит не только от него самого и секретного ключа, но и в общем случае от пре-
дыдущих блоков, то этот шифр называют поточным. Существует более мягкое
«практическое» определение: блочные шифры те, в которых текст делится.на по-
рции по нескольку октет, поточные же системы оперируют данными по одному
биту или символу. ,
Интересно следующее формальное определение системы блочного шифрова-
ния: шифр F : Р х К -> С называется блочным, если множества Р, К, С — конеч-
ны. В поточном же шифровании это требование нарушается. К примеру, если во
время начала шифрования, вообще говоря, неизвестно количество символов в
тексте, то удобно считать, что множество Р не является конечным. Отметим, что
в большинстве современных поточных систем результат шифрования текущего
блока открытого текста зависит от его номера и не зависит от самих предыдущих
блоков. Такие симметричные криптосистемы называют шифрами гаммирования.
В этом случае стойкость системы определяется исключительно свойствами гаммы
(являющейся обычно псевдослучайной, числовой последовательностью). , ,
, й ' Г ' ' ' V'J . ’H'J '”>11’ Л ‘ ' .А
. Принципы криптоанализ ;|
Попытку.криптоанализа сцстемы щифрования.принято называть атакой. За-
дача криптоаналитика в общем, случае, состоит в отыскании откоытых текстов и
22
Гпава 2. Теория секретных систем
секретных ключей, использовавшихся при шифровании. Стоит отметить, что под
взломом системы шифрования принято понимать нахождение «уязвимости» шиф-
ра, позволяющей проводить атаку со сложностью меньшей, чем при методе пол-
ного опробования. Важным допущением в криптоанализе является правило Керк-
хоффа: стойкость шифра должна определяться только секретностью ключа. Та-
ким образом, общим для всех атак допущением является тот факт, что
криптоаналитику априори известен алгоритм шифрования.
При анализе новых шифров и доказательстве криптографической стойкости
алгоритмов шифрования обычно используют следующие основные виды атак:
• атака со знанием только шифротекста — вид атаки, при которой крип-
тоаналитику известен один или несколько шифротекстов, зашифрованных
с использованием одной и той же системы шифрования, с одним и тем же
ключом.
• атака со знанием открытого текста — вид атаки, при которой аналити-
ку известны фрагменты открытого текста и информация о том, какие фраг-
менты шифротекста им соответствуют.
• атака с выбранным открытым текстом — вид атаки, при которой крип-
тоаналитик не только знает открытый текст и шифротекст, но и может для
произвольного открытого текста получать соответствующий ему шифро-
текст. По-прежнему он должен определить секретные ключи.
• адаптивная атака с выбранным открытым текстом — разновидность
атаки с выбранным открытым текстом. В этом случае криптоаналитик не
только выбирает открытые тексты, но и может изменить свой выбор после
анализа полученных данных.
• атака с выбранным шифротекстом — вид атаки, при которой аналитик
выбирает шифротекст и может получить соответствующий ему открытый
текст. Атаки с выбранным открытым или шифротекстом иногда упрощенно
называют атаками с выбранным текстом.
Пусть имеем шифр F : Р х К С, keK — произвольный фиксированный
ключ, Р состоит из п открытых текстов р,, i = 1 ... п; vit i = 1 ... п — вероятность
того, что t-й текст будет зашифрован (вероятность появления t-ro текста). Тогда
под априорной мерой неопределенности открытого текста будем понимать
Н(Р) = -(у, • log2 У, +У2 • log2 у2 +... + Уя -log„ У„).
В случае, когда о Р нет никакой априорной информации, все тексты считают-
ся равновероятными и Н(Р) = |Р|, где через |Р| обозначается размер текстов в
битах.
Пусть имеем с е С — некий определенный шифротекст; wit i = l...n — веро-
ятность того, что F(p,., k) = с верное равенство. Тогда под апостериорной мерой
неопределенности открытого текста будем понимать
Н{Р\С) = -(ау1 • log2 ку, + w2 • log2 w2 +... + wn log2 w„).
Тогда / = H(P) - H(P\C) определяет количество информации об открытом
тексте в битах, которую можно извлечь из шифротекста. Шифры, для которых
Гпава 2. Теория секретных систем
23
выполнено Н(Р) = Н(Р\С) принято называть абсолютно стойкими (совершен-
ными).
Пусть К состоит из т ключей /г,; vjt i - l...m — вероятность использования
z’-ro ключа. Тогда под мерой неопределенности криптосистемы (мерой неопре-
деленности секретного ключа) будем понимать
Н(К) = -(и, • log2 vt + v2 • log2 v2 +... + v, log2 vn).
Отметим, что в случае равновероятного распределения элементов в про-
странстве ключей Н(К) = |/f|. Шеннон предложил и доказал необходимое усло-
вие абсолютной стойкости шифра, которое заключается в том, что для того,
чтобы шифр был абсолютно стойким, необходимо, чтобы неопределенность
системы шифрования была не меньше неопределенности открытого текста-.
Н(К) > Н(Р).
Из этого условия и правила Керкхоффа следует что для того, чтобы шифр
был абсолютно стойким, необходимо, чтобы размер использованного для шифро-
вания ключа был не меньше размера шифруемых открытых текстов: |К| > |Р|.
Равенство возможно, если Н(К) = | Л"|, то есть если все ключи равновероятны.
Шифры, не являющиеся абсолютно стойкими, принято называть несовер-
шенными.
Определим функцию ненадежности ключа как неопределенность ключа при
известных п битах шифротекста. Расстоянием единственности шифра назовем
минимальное количество бит, при котором функция ненадежности близка к
нулю. Шеннон показал, что эти величины зависят от избыточности открытого
текста, причем расстояние единственности прямо пропорционально размеру клю-
ча и обратно пропорционально избыточности R ~ 1 - Н(Р)/ |Р|. Следовательно,
при R = 0 невозможен криптоанализ со знанием только шифротекста, даже при
условии неограниченных вычислительных ресурсов.
Список литературы
1. Столлингс В., «Криптография и защита сетей», М: Вильямс, 2001.
2. Медведовский И. Д., Семьянов П. В., Платонов В. В. «Атака через Интернет»,
СПб: 1999.
3. В. Г. Проскурин, С. В. Крутов, И. В. Мацкевич. «Защита в операционных сис-
темах», М: Радио и связь: 2000.
4. Аграновский А. В., Хади Р. А., Ерусалимский Я. М. «Открытые системы и
криптография». Телекоммуникации, 2000.
5. Agranovsky А. V., Hady R. A., «Crypto miracles with random oracle», The Procee-
dings of IEEE SIBCOM'2001, The Tomsk Chapter of the Institute of Electrical and Elect-
ronics Engineers, 2001.
6. А. В. Аграновский, А. В. Балакин, P. А. Хади, «Классические шифры и методы
их криптоанализа», М: Машиностроение, Информационные технологии, № 10, 2001.
7. Гостехкомиссия России. Руководящий документ. «Средства вычислительной
техники. Защита от несанкционированного доступа к информации. Показатели защи-
щенности от несанкционированного доступа к информации.», М: Воениздат, 1992.
24 Гпава 2. Теория секретных систем
. 8.,«Автоматизированные системы. Защита от несанкционированного доступа к
информации. Классификация автоматизированных систем и требования по защите
информации.», М: Воениздат, 1992.
9; А. А. Молдовян, Н. А. Молдовян, Советов Б. Я., «Криптография»: СПб.: Изда-
тельство «Лань», 2000.
10. С. Расторгуев, «Программные методы защиты информации в компьютерах и
сетях», М: Издательство Агентства «Яхтсмен», 1993.
П.Чмора А. Л., «Современная прикладная криптография», М.: Гелиос АРВ,
2001. : -
12. Аграновский А. В., Хади Р. А.,' Котов И. Н., «Аутентификация и разграниче-
ние доступа'в защищенных системах», Научный сервис в сети Интернет: Труды Все-
российской научной конференции. — М:’Изд-во МГУ, 2001. стр. 202—204. •
13. Устинов Г. Н., «OcHOBibi информационной безопасности», М: Синтег, 2000.
14. Анин Б., «Защита компьютерной информации», СПб: БХВ, 2000.
15. Романец Ю. В., Тимофеев П. А., «Защита информации в компьютерных систе-
мах и сетях», М: Радио и связь, 2001. • '
16. Брикелл Е. Ф., Одлижко Э. М., «Криптоанализ: Обзор новейших результа-
тов», ТИИЭР, 1988, т. 76, № 5; стр: 75—91.
17. Menezes A., van Oorschot Р., Vanstone S., «Handbook of Applied Cryptograp-
hy», CRC press, 1996.
18. Schneier B., «Applied Cryptography», John Wiley & Sons Inc, 1996.
19. Милославская H. Г., Толстой А. И., «Интрасети: доступ в Интернет, защита»,
М.: ЮНИТИ-ДАНА, 2000.
20. Gutmann Р.: «Network Security», University of Auckland, 1996.
21. Anderson R.: «Why Cryptosystems Fail». University of Cambridge Computer La-
boratory, 1994.
22. W. Diffie, M.E.Hellman: «New Directions in Cryptography», IEEE Transactions
on Information Theory, Vol. IT-22, No. 6, Nov. 1976.
23. Саломаа А.: «Криптография с открытым ключом», Москва: «Мир», 1995.
318 с.
24. Олифер В., Олифер Н.: «Компьютерные сети», Спб: Издательство «Питер»,
1999. 672 с.
25. Н. Feistel, Cryptography and Computer Privacy, Scientific American, vol.228,
1973, pp. 15—23.
26. H. Feistel, «Block cipher cryptographic system», US Patent № 3798359, US Pa-
tent Office, Mar 19, 1974.
27. H. Feistel, «Step code ciphering system», US Patent № 3798360, US Patent Offi-
ce, Mar 19, 1974.
28. Walter Tuchman et al, «Block cipher system for data security», US Patent №
3958081, US Patent Office, May 18, 1976.
29. R.Abrahamsen, «Block cipher system for data security», US Patent № 3522374,
US Patent Office, July 28, 1970.
30. J. B. Kam and G. 1. Davida, Structured Design of Substitution-Permutation Enc-
ryption Networks, IEEE Transactions on Computers, vol. C-28, 1979, pp. 747—753.
31. С. E. Shannon, Communication Theory of Secrecy Systems, Bell Systems Tech-
nical Jour-nal, vol. 28, 1949, pp. 656—715.
Глава 2. Теория секретных систем........ 25
' 32. М. Sivabalan, S. Е. Tavares, and L. Ё. Peppard, On the Design of SP Networks
from an Information Theoretic Point of Viewfin Advances in Cryptology: Proc, of CRYP-
TO '92.
33. H. Feistel, W. Notz, and J. L. Smith, Some Cryptographic Techniques for Machi-
ne-to-Machine DataCommunications, Proceedings of the IEEE, 63 (1975), pp.
1545—1554.
34. Д. Кнут. Искусство программирования для ЭВМ. Получисленные алгоритмы.
Т.2. М.:Мир, 1977. 700 с.
35. W. Press, S. Teukolsky, W. Vetterling, Numerical Recipes in C : The Art of Scien-
tific Computing, 2nd Edition. Cambridge University Press, January 1993;
36. FIPS 140-1, Security Requirements for Cryptographic Modules, Federal Informa-
tion Processing Standards Publication 140-1. U.S. Department of Commerce/NIST, Nati-
onal Technical Information Service, Springfield, VA, 1994.
37. FIPS 180-1, Secure Hash Standard, Federal Information Processing Standards
Publication 180-1. U.S. Department of Commerce/NIST,'National Technical Information
Service, Springfield, VA, April 17, 1995.
38. FIPS 186,. Digital Signature Standard (DSS), Federal Information Processing
Standards Publication 186. U.S. Department of Commerce/NIST, National Technical In-
formation Service, Springfield, VA, May 19, 1994. . '
Глава 3
Дешифрование классических шифров
Все, что видишь ты, — лишь видимость одна,
Только форма — а суть никому не видна.
Смысл этих картинок понять не пытайся —
Сядь спокойно в сторонке и выпей вина!
Омар Хайям
Методов криптоанализа классических шифров существует на сегодняшний
день достаточно много. Многим исследователям удалось даже автоматизировать
большинство из них. В этой главе мы постараемся объяснить механизмы работы
программного обеспечения, которое автоматически или интерактивно, с участием
человека, раскрывает шифры. Прежде всего, классические шифры, которые ког-
да-то были одними из самых надежных средств сокрытия информации, теперь
представляют для нас не более, чем академический интерес.
Тем не менее в изучении классиков криптографии есть свой отнюдь не наду-
манный резон. Многие современные методы построения одноключевых шифроси-
стем построены на основе методов, известных сотни лет. Да и некоторые методы
современного криптоанализа имеют слишком много общего с исторически извест-
ными способами взлома старинных шифров.
Изучая классический подход к построению и анализу шифров, нельзя не
обращать внимание на развитие современных технологий. Многие классиче-
ские шифры просты и не требуют большого внимания к своему устройству,
пока не появляется задача их реализации на современных вычислительных
устройствах (это могут быть не обязательно персональные компьютеры, а, на-
пример, платы шифрования с PIC-процессорами). Для теоретически достаточ-
но простых криптографических примитивов, используемых в классических
шифрах, иногда не так просто найти эффективное решение в рамках современ-
ной компьютерной архитектуры. Учитывая, что многие примитивные с точки
зрения теории преобразования данных легли в основу многочисленных совре-
менных симметричных шифров и даже хэш-функций, становится очевидным,
насколько важно знать, как именно возможно реализовать тот или иной шиф-
роблок на практике.
Идеальной задачей для обучения этим с первого взгляда нехитрым премудро-
стям служит создание автоматических систем взлома классических шифров. Кро-
ме того, способы и методы их создания и те проблемы, с которыми в процессе раз-
работки сталкивается криптоаналитик, во многом повторяют трудности криптоа-
нализа современных шифров. Авторам остается только уповать на то, что
предложенный практический метод обучения основам криптографии и методы да-
льнейшего повышения квалификации молодых специалистов был бы использован
как можно в большем количестве образовательных учреждений.
Гпава 3. Дешифрование классических шифров
27
Отступление для программистов
Чтобы сделать приводимый в книге программный код переносимым, способ-
ным к компиляции на разных платформах и операционных системах, мы будем ис-
пользовать ряд стандартных типов переменных и объявлений для языков С/C++.
Большая часть примеров в книге написана именно на этом семействе языков, по-
скольку его можно по праву считать самым распространенным.
Для этого создается специальный модуль объявлений undef.h, куда вносятся
все необходимые объявления типов данных и дополнительных переменных. Там,
где исходные тексты приводятся на других языках, объявления и типы оговарива-
ются отдельно.
Данные далее исходные тексты представляют собой модуль объявлений, со-
держащий унифицированные типы данных: знаковые целочисленные int8_t,
int16_t, int32_t, int64_t и беззнаковые целочисленные uint8_t, uint16_t,
uint32_t, uint64_t.
Обратите внимание на конструкцию «#ifndef ... #define ... #endif» в исход-
ном тексте модуля. Она позволяет избежать возможных переопределений данных
типов, если они уже определены компилятором или пользователем по собствен-
ному усмотрению. Подобный подход к конструированию исходных текстов помо-
гает в подчас сложных конфликтных ситуациях сопряжения аппаратных и про-
граммных средств.
На всякий случай мы приводим весь текст модуля unidef.h.
Листинг 3.1
#ifndef unidef__h
«define unidef__h
«ifnoef uint8_t
«define uint8_t
«endif
«ifndef uint16_t
«define uint16_t
«endif
«ifndef uint32_t
«define uint32_t
«endif
«ifndef uint64_t
«define uint64_t
«endif
«ifndef int8_t
«define int8_t
«endif
«ifndef int16_t
«define int16_t
«endif
unsigned char
unsigned short
unsigned long
unsigned __int64
signed char
signed short
28 . Гпава 3. Дешифрование классических шифров.
tfifndef int32_t ' ’
«define int32_t - signed long 1 “• 'z
«endif ' ' / ,. t ' >• «.
«ifndef int64_t
«define int64_t signed __int64
«endif
«define reorder_bytes(array_of_longs, longs.count, tmp_long. tmp.q) \
do { \ :
for (tmp.q = 0; tmp.q < longs.count; tmp_q++) { \
tmp.long = (((uint32_t *) &array_of_longs)[tmp.q] « 16) | \
(((uint32_t *) &arrayiof.longs)[tmp.q] » 16); \ ’
((uint32_t *) &array.of.longs)[tmp^q] = ((tmp.long OxFFOOFEOOL)»8)|\ \ •
((tmp.long & OxOOFFOOFFL) « 8); \
} while(O)
tfeqdif
Хак видно из листинга 3.1, unidef.h содержит не только объявления универса-
льных типов данных, но и довольно странное на первый взгляд определение геог-
der_bytes. Это специальный макрос, который мы будем использовать для переста-
новки байтов в памяти.
Такие нетривиальные манипуляции с данными необходимы для устранения
различий в машинной адресации данных на разных аппаратных платформах. Дело
в том, что в процессорах разных вычислйтёльных систем (например, Intel Pentium
. и Motorola 680x0) используются разные порядки расположения байтов в памяти
и соответственно их загрузки из памяти в регистры процессора и обратно. Корпо-
рация Intel придерживается так называемой little-endian концепции, при исполь-
зовании которой младший байт слова регистра находится в памяти последним.
A Motorola и еще несколько производителей придерживаются схемы, в которой
младший байт идет первым.
Причина разногласий неясна даже самым опытным специалистам мультипро-
цессорных систем и, по-видимому, является исторической — это результат дав-
ней конкуренции нескольких гигантов производителей и соответственно их неже-
лание быть «похожими» друг на друга.
a) BIG-ENDIAN
б) LITTLE-ENDIAN
Рис. 3.1. Схема организации памяти big-endian и little-endian архитектур
Гпава 3. Дешифрование классических шифров 29
Теперь представьте на минутку, что перед криптографом поставлена задача
вычислить значение какой-то криптографической хэш-функции от одного и того
же блока данных длиной в N байтов на двух машинах — с big-endian архитектурой
и с little-endian архитектурой. При последовательной поэлементной обработке та-
кого массива на одной машине (big-endian) он будет представлен в памяти так:
01 02 03 04 05 06 07 08 09 0А 0В ОС 0D 0Е 0F 00
а на другой (little-endian) вот так:
04 03 02 01 08 07 06 05 ОС 0В 0А 09 00 OF 0Е 0D
Теперь, если сравнить хэш-результаты, полученные на разных машинах, они
будут отличаться! И криптограф, к примеру, сидящий за компьютером Sun
(big-endian), не сможет проверить, была ли модифицирована указанная выше по-
следовательность байтов при передаче от криптографа, сидящего, скажем, за
компьютером Intel Itanium (little-endian).
К счастью, существует так называемый стандарт де-факто передачи данных
network byte-order, который регламентирует пересылку данных в формате big-en-
dian. И для того чтобы данные были представлены, как это требуется для их пере-
дачи по сети и сравнения на разных машинах, мы будем пользоваться их переста-
новкой, то есть вызовом макроса reorder_bytes.
Определение reorder_bytes — это не что иное, как обычный макрос с пара-
метрами. Использование конструкции «do { ... } while (0)» позволяет записы-
вать использование макроса как обычный вызов процедуры (см. листинг 3.2
check_byte_order.cpp).
Листинг 3.2. check byte order.cpp
«include <stdio.h>
«include "unidef.h"
// вывод на экран содержимого массива памяти побайтово
void print_hex(uint8_t *buf, int bufsize) {
int i, c;
printf("\r\n")
for (i = c = 0; i < bufsize; i++) {
printf("%02X ", buf[i]);
if (++c > 15) {
c = 0;
printf("\n”);
}
}
printf(”\n”);
} : iXu
I/ вывод на экран содержимого массива* дамяти пословно 5
void print_longs(uint32_t *buf, int bufsize) {
int i, с; vел,, 7'
printf("\r\n”);
for (i = c = 0; i < bufsize; i++)‘{
printf(’’%08X ”, buf[i]);
30
Гпава 3. Дешифрование классических шифров
if (++с > 3) {
с = 0;
printf(”\n”);
}
}
printf("\n”);
void main(int argc, char **argv)
{
char buf[64] = “Это тестовый буфер для проверки порядка следования байтов”;
// временные переменные для reorder_bytes нужно заводить самостоятельно
long tmp_long;
int tmp_q;
printf(”flo умолчанию”);
И вывод на экран содержимого массива
print_hex(buf. 16);
print_longs((uint32_t *) &buf. 4);
// исправляем порядок байтов в массиве
reorder_bytes(buf, sizeof(buf) / sizeof(long), imp-long. tmp_q);
printf(“Перетасованные байты");
// вывод на экран результатов модификации массива
print_hex(buf, 16);
print_longs((uint32_t *) &buf, 4);
}
Листинг 3.3. Результат исполнения check byte order.exe на Intel Pentium III
По умолчанию
DD F2 ЕЕ 20 F2 Е5 F1 F2 ЕЕ Е2 FB Е9 20 Е1 F3 F4
20EEF2DD F2F1E5F2 E9FBE2EE F4F3E120
Перетасованные байты
20 ЕЕ F2 DO F2 F1 Е5 F2 Е9 FB Е2 ЕЕ F4 F3 Е1 20
DDF2EE20 F2E5F1F2 EEE2FBE9 20E1F3F4
Первая строка, содержащая НЕХ-представление байтов памяти, выведена с по-
мощью функции print_hex. Мы будем и в дальнейшем использовать именно эту про-
цедуру для вывода бинарных данных, поэтому впоследствии мы поместим в отдель-
ный модуль tools.срр/tools.h. Вторая строка шестнадцатеричных чисел — это вывод
содержимого того же массива, но уже пословно, с загрузкой в память сразу четырех
байтов, то есть с байтами в том порядке, в каком они обрабатываются процессором.
Как видно, запустив программу, можно воочию убедиться в том, что для платформы
Intel байты необходимо перетасовывать с помощью макроса, чтобы добиться совпаде-
ния порядка следования байтов в памяти и в регистрах процессора (сравните первую
строчку секции «По умолчанию» и вторую строчку секции «Перетасованные бай-
ты» — к примеру, слово «DDF2EE20» и байты «DD F2 ЕЕ 20», которые идентичны!).
Создание же алгоритма автоматической проверки необходимости переста-
новки байтов мы оставляем читателю в качестве легкого упражнения. Особенно
любознательные могут ознакомиться с исходными текстами такой программы,
как утилита autoconf из пакета программного обеспечения GNU utils.
' Гпава 3. Дешифрование классических шифров
31
Раскрытие шифров простой замены
Самыми простыми с точки зрения теории шифрами являются одноалфавит-
ные шифры простой замены. В таком шифре ключом является таблица подстанов-
ки, однозначно определяющая, какой символ шифрограммы будет заменять опре-
деленный символ исходного текста. Или, говоря в соответствующих терминах,
таблица сопоставляет шифробозначения соответствующим шифровеличинам. На-
пример, на рис. 3.2 представлена ключевая таблица для шифра Цезаря.
Исходный алфавит:
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮ
Подстановка:
ГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮАБВ
Рис 3.2. Ключевая таблица шифра Цезаря
Шифр Цезаря является частным случаем шифра простой замены. Ключ в
шифре Цезаря зафиксирован, и, кроме того, он определяется всего лишь одним
числом — количеством символов, на которые необходимо сдвинуть исходный ал-
фавит, чтобы получить алфавит подстановки. В классическом варианте алфавит
просто сдвигался циклически (удаленные символы дописывались в конец) влево
на три буквы. Это означает, что вместо буквы ’А’ будет записана буква ’В’, вместо
Ъ' — буква 'Г и т. д. А вместо мягкого знака в шифротексте появится буква 'А'.
На языке Perl3 шифрующее преобразование Цезаря в этом случае выглядит
так (см. листинг 3.4):
Листинг 3.4
Сообщение:
$opentext = ’’СООБЩЕНИЕ!";
Шифрующее преобразование:
for ($1 = 0; $i < length($opentext); $i++) {
Sciphertext = Sciphertext . chr(ord(substr($opentext, $i, 1)) + 3);
}
print ’’ciphertext == $ciphertext";
Результат:
ciphertext == ФССДЬИРЛИ$
3 Язык Perl является очень удобным инструментом для проведения быстрых исследова-
ний, создания набросков новых алгоритмов и проверки каких-либо вычислительных фактов
там, где не требуется высокое быстродействие программы. Этот замечательный язык позволяет
исполнять головокружительные трюки преобразования данных к нужному виду и их модифика-
цию с большой эффективностью. При этом он достаточно гибок и менее строг по отношению к
программисту, в отличие от формального Си/Си++, которые представляют собой мощный ин-
струмент, обращаться с которым необходимо очень аккуратно. Именно поэтому в этой главе от-
дано предпочтение не только языку Си, но и Perl. Хотя, например, в главах, посвященных со-
временным шифрам и их анализу, это не так. В этих главах основным, безусловно, является
именно Си.
32
Гпава 3. Дешифрование классических шифров
В листинге 3.4 пришлось прибегнуть к приведению типов в Perl. Дело в том,
что Perl ориентирован на работу со строками как атомарными неделимыми едини-
цами языка. Он поддерживает сложение скалярного целочисленного и строковых
типов друг с другом, но не позволяет обратиться отдельно к символам строки. То
есть для зашифрования одного символа шифром Цезаря в Perl может потребова-
- ться две строчки (см. листинг 3.5).
Листинг 3.5
$а = ’А’;
$а++;
print $а;
# выведет символ Б на экран
А вот для целой строки символов приходится использовать различные спосо-
бы доступа к элементам строкового массива. Первый из них заключается в испо-
льзовании стандартной функции-оператора substr, что и было сделано в листинге
3.4. Второй способ заключается в разбиении строки на символьный массив соот-
ветствующего объема, преобразовании его поэлементно как массива с атомарны-
ми элементами-символами, а затем приведение снова к строковому виду. Исполь-
зование этих двух способов представлено в листинге 3.6.
Листинг 3.6
1) Вариант с использованием substr
$string = "строка символов"; substr($string, 2, 3) = "ТРО"; print $string; # строка символов # сТРОка символов
2) Вариант с разбиением в массив символов
@string_arr = split //, $string;
# @string_arr == (’с’, ‘т’, ’р’. о л. о. в)
$string_arr[2] = ’Т’; $string_arr[3] = ‘Р’; $string_arr[4] = ’О’; # @string_arr == (’с’, ’Т’, ’Р’, ’0’ л , ’о , в )
Sstring = join ”. @string_arr;
print Sstring; # сТРОка символов
Имея на руках достаточное количество шифротекстов, зададимся вопросом
их криптоанализа. Пусть, например, у нас есть зашифрованное сообщение
«ЮУП!ТПГЖСЩЖООП!ТЖЛСЖУОПЖ!ТППВЪЖОЙЖ» и мы знаем об откры-
том тексте только лишь то, что он был написан на русском языке и зашифрован с
помощью шифра Цезаря. Самый простой способ раскрытия шифра Цезаря, кото-
рый конечно же сразу приходит в голову, — это опробовать ключи со всевозмож-
ными сдвигами алфавита. Всего возможных вариантов в этом случае будет не бо-
льше размерности алфавита. Затем расшифрованные тексты надо будет просто
прочесть и выбрать тот, который выглядит осмысленным (см. листинг 3.7).
Глава 3. Дешифрование классических шифров
33
Листинг 3.7
Всевозможные ключи:
БВГДЕЖЗИЙКЛМНОПРСТУФХЦЧППЦЪЫЬЭЮЯА
ВГДЕЖЗИЙКЛМНОПРСТУФХЦЧППЦЪЫЬЭЮЯАБ
ГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯАБВ
ДЕЖЗИЙКЛМНОПРСТУФХЦЧППЦЪЫЬЭЮЯАБВГ
ЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЬЭЮЯАБВГД
ЦЧШЩЬЫЬЭЮЯАВВГДЕЖЗИЙКЛМНОПРСТУФХ
ЧШЩЬЫЬЭЮЯАБВГДЕЖЗИЙКЛМНОПРСТУФХЦ
ППЦЬЫЬЭЮЯАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧ
ЬЭЮЯАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫ
ЭЮЯАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧППЦЬЫЬ
ЮЯАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЬЭ
ЯАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЬЭЮ
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧППЦЬЫЬЭЮЯ
Всевозможные решения, получившиеся после расшифрования
сообщения с помощью каждого из ключей:
ЭТО СОВЕРШЕННО СЕКРЕТНОЕ СООБЩЕНИЕ!
ЬСНТРНБДПЧДММНТРДЙПДСМНДТРННАШДМЗД
ЫРМАПМАГОЦГЛЛМАПГИОГРЛМГАПММОЧГЛЖГТ
ЪПЛ~0Л0ВНХВККЛ~0ВЗНВПКЛВ~0ЛЛ~ЦВКЕВА
ЩОИ_НК~БМФВЙЙЮ_НБЖМВОЙКБСНКК}ХБЙДБ«
ШНЙ-МЙ}АЛУАИИЙ^МАЕЛАНИЙА^МЙЙ|ФАИГАЬ
ЧМИ-ЛИ|йКТйЗЗИ-ЛОДКйМЗИО-ШИИ{УОЗВй^
ЦЛЗ 4 КЗ{-ЙС-ЖЖЗIК~ГЙ~ЛЖЗ~1КЗЗгТ~ЖБ~->
ХКЖгЙЖг}ИР}ЕЕЖгЙ}ВИ}КЕЖ)|ЙЖЖуС}ЕА)1
ФЙЕ^ИЕу|ЗП|ДДЕ{И|БЗ|ЙДЕ|1ИЕЕхР|ДО|t
Вуаля! Первый же опробованный ключ дал нужный результат. Мы увидели
осмысленное сообщение, которое, собственно, и являлось открытым текстом. Ис-
ходный текст первой программы, которая осуществляет автоматическое дешиф-
рование, приведен в листинге 3.8.
Листинг 3.8
Sciphertext = ’ЮУП!ТПГЖСЩЖООП!ТЖЛСЖУОПЖ!ТППВЪЖОЙЖ’’;
for ($k = 1; $k < 33; $k++) {
$opentext = ”;
for ($i =0; $i < length($ciphertext); $i++) {
$opentext = $opentext . chr(ord(substr($ciphertext, $1, 1)) - $k);
}
print $opentext, ”\n”;
}
2 Зак 85
34
Гпава 3. Дешифрование классических шифров
К сожалению, такой метод дешифрования может не сработать даже в самом
простом случае. Например, когда сообщение написано на иностранном языке, ко-
торого криптоаналитик не знает.
Например, во время Второй мировой войны (еще точнее, в период с 1942 по
1945 год) подразделения военно-морской пехоты США для обеспечения секрет-
ной связи содержали в штате целое отделение индейцев из племени навахо, кото-
рые кодировали секретные сообщения специальным образом.
Идея использовать язык индейцев навахо для обеспечения секретной свя-
зи возникла у Филиппа Джонстона, сына индейского миссионера, прожившего
несколько лет среди самих навахо, — одного из немногих белых, кто бегло го-
ворил на этом языке. Джонстон к этому моменту уже был ветераном Первой
мировой, не понаслышке знавшим, что означает секретная связь и какое значе-
ние она имеет для победы в бою. Он также был прекрасно осведомлен о том,
что военные с удовольствием перестали бы пользоваться громоздкими и мед-
ленными шифровальными машинами. Он даже знал, что по причине их медли-
тельности и ненадежности в Первой мировой войне в качестве секретного кода
использовался язык индейцев чоктоу. Правда, тогда это не принесло ощути-
мых результатов.
Учитывая очень сложную структуру устного языка (письменности у навахо
не было), где смысл слова всегда зависит от ситуации употребления самого сло-
ва и его связи с окружающими частями речи, да еще и иногда зависит просто от
ударения на определенный слог, язык навахо был многообещающей заменой для
чоктоу.
У навахо не было алфавита, не было букв и вообще любой письменности. Ни-
кто, кроме самих навахо да еще нескольких белых (и что самое главное, среди
них не было ни одного японца — именно против них и должна была быть органи-
зована секретная связь), не знал индейского языка. Выучить же его за короткий
срок, даже имея великолепного учителя, было бы очень сложно. И когда в мае
1942 года Джонстон встретился с генерал-майором военно-морской пехоты Бенд-
жамином Воджелом, он убедил его в необходимости попробовать набрать рекру-
тов из индейцев навахо специально для создания системы секретной связи. Для
этого Джонстон в присутствии генерала в течение 20 секунд вручную зашифро-
вал текст сообщения, с которым шифровальная машина справилась бы не мень-
ше, чем за полчаса. Убежденный приведенным доказательством, генерал-майор
Воджел распорядился набрать аж 200 человек навахо.
Тогда же, в мае 42-го, первые 29 новобранцев прибыли в лагерь близ Пендл-
тона, в Калифорнию. Именно эта первая группа стала автором «шифра навахо».
Изначально этот шифр состоял из большого военного словаря и соответствующих
кодовых фраз, который приходилось запоминать целиком.
Шифротекст состоял из сообщений, в которых шифровальщики сначала пере-
водили слова с навахо в английские эквиваленты, а затем из них определенным
образом составляли секретное сообщение. Дешифрование усложнялось еще и
тем, что одно и то же английское слово могло быть передано несколькими различ-
ными словами языка навахо.
Глава 3. Дешифрование классических шифров
35
Рис. 3.3. Новобранцы навахо за работой
Когда боец-навахо получал сообщение, оно состояло из нескольких несвязан-
ных между собой слов на языке навахо. Для начала он должен был перевести
каждое слово в английский эквивалент из словаря, который он помнил наизусть.4
Затем для составления секретного сообщения использовалась только первая бук-
ва каждого английского слова. Например, слова wol-la-chee (муравей — Ant),
be-la-sana (яблоко — Apple) и tse-nill (топор — Axe) обозначали букву «А». Так
что, говоря о военно-морском флоте (на английском — navy), навахо мог бы про-
изнести: tsah (игла — Needle) wol-la-chee (муравей — Ant) ah-keh-di-glini (побе-
да — Victory) tsah-ah-dzoh (юкка — Yucca).
Как уже было сказано, многие буквы английского алфавита имели несколько
обозначений на языке навахо. К тому же при кодировании не все слова произно-
сились буква за буквой, некоторые сугубо военные термины в языке навахо, есте-
ственно, просто отсутствовали. Поэтому их заменяли порой весьма забавными эк-
вивалентами, например, слово America заменялось на навахское Ne-he-mah
(Наша Мать), подводная лодка стала besh-lo (железная рыба), dah-he-tih-hi (ко-
либри) означало «самолет-перехватчик», a debeh-li-zine (черная улица) соответст-
вовало «отделению».
Благодаря быстроте и точности навахо американцы выиграли сражение при
Иво Джима с минимальными потерями. Во время этой баталии шестеро навахо
трудились в круглосуточном режиме два дня подряд. Вшестером они передали
больше 800 сообщений, и все безошибочно.
4 Полный вариант словаря навахо можно найти на компакт-диске, который прилагается к
книге.
2*
36
Главка 3. Дешифрование классических шифров
Японские криптоаналитики не смогли даже близко подойти к разгадке кода.
Глава японской разведки, генерал-лейтенант Сейзо Арисью, позже произнес фра-
зу о том, что все коды армии США (в которых использовались шифровальные ма-
шины) были успешно взломаны, кроме тех, что использовались в военно-морских
корпусах.
Навахо даже после войны еще долгое время оставался совершенно секрет-
ным языком. Только по этой причине индейцы навахо, служившие в войсках
ВМФ США, получили заслуженные награды и признание лишь в начале 90-х
годов.
Временно отступив для демонстрации исторического ракурса на шифры и
коды, вернемся к алгоритмам дешифрования шифров замены. Простое опробо-
вание всех ключей эффективнЬ, если ключ получается простым сдвигом на не-
сколько букв нижней строки таблицы. Если же это не так и произвольные бук-
вы верхней строки назначены произвольным буквам нижней, то опробование
всех ключей займет ни много ни мало п! операций — именно столько сущест-
вует всевозможных перестановок букв в нижней строке ключа-таблицы. Для
русского языка п = 33 и соответственно получается 33! варианта. А это 33! =
= 8683317618811886495518194401280000000 различных ключей. Даже если
компьютер посчитает их все, прочесть их вряд ли кто-либо сможет. Впрочем,
конечно же существует простой метод определить ключ шифра — им является
метод частотного анализа или метод подсчета частот монограмм (односимволь-
ных включений).
Зная, что шифрованное сообщение5 написано на русском языке, мы можем
подсчитать частоту встрёчаемрсти букв русского алфавита в нескольких, доста-
точно объёмных литёратурных Произведениях на русском языке, затем то же са-
мое'проделать для сообщения и сравнить результаты.
Для подсчета частот воспользуемся текстом шестой главы этой книги (на са-
мом деле неплохо было бы использовать гораздо большее количество текста, те-
матически подходящего к открытому тексту, который мы ищем) и небольшой про-
граммой на Perl, приведенной в листинге 3.9.
Листинг 3.9
#!/usr/bin/perl -w
# наш алфавит
for ($i = ord(’A‘); $i < ord(’R’); $i++) {
print " ”, chr($i);
>
print “\n";
# будем читать содержимое первого переданного
# в командной строке файла ’ '
open F, "$ARGV[O]";
$total= 0;
5 Чтобы не разгадывать одну и ту же загадку несколько раз подряд, мы будем стараться
изменять зашифрованное сообщение после того, как раскрыли его.
Слав&З' Дешифрование классических шифров
37
while (<F>) {
# разделим считанный блок текста $_ на массив символов
= split //, $_;
# подсчитываем частоты каждого символа
for (@_) {
$freq{$_}++;
$total++;
}
}
close F;
# теперь отсортируем по убыванию частоты и выведем их на экран
= sort { $freq{$b} <=> $freq{$a} } keys %freq;
# вывод на экран
for (@_) {
print $_, ” == ”, $freq{$_}/$total, ”\n”;
}
Считывая построчно текст из файла, заданного скрипту в командной строке,
собираем в хэш-массиве значения найденных символов и инкрементируем их, как
только появляется очередной символ. После этого проводим быструю сортировку
хэш-массива с помощью оператора sort (в фигурных скобках к нему описана фун-
кция, сравнивающая значения вероятностей появления соответствующих симво-
лов: {$freq{$b} )<=>f$freq{$a}}. Имея два различных символа в качестве аргумен-
тов-переменных $ая $Ь, она возвращает -1, если $а < $Ь, 0 — если $а = $Ь и 1
в остальных случаях). Здесь Perl выигрывает в скорости программирования мно-
гократно. Нам не пришлось писать своих процедур сортировки, да и обработка
данных обошлась явно малой кровью.
z Запустив программу «perl freq.pl chapter6.txt > freqs.txt», получим в файле
freqs.txt следующие результаты (см. листинг 3.10):
Листинг 3.10. freqs.txt
О == 0.0886740955078085
И == 0.0653614890516941
Е == 0.065094707463728
Т == 0.0601900305772743
А == 0.0570296948429067
С == 0.0461326930575222
Н == 0.0453323482936239
В == 0.0381292454185393
Р == 0.032177963840834
Л == 0.0320343122165446
М == 0.0311929241314207
К == 0.0240719078987872
Д == 0:0231484331712122
38
Гпава 3. Дешифрование классических шифров
Проделаем то же самое с шифрованным текстом, который мы имеем (см.
листинг 3.11). Для этого запустим «perl freq.pl cipher.txt > freqs_c.txt» (см. лис-
тинг 3.12):
Листинг 3.11 cipher.txt
00000000:
00000010:
00000020:
00000030:
00000040:’
00000050:
00000060:
00000070:
00000080:
00000090:
84 24 86 92
86 89 94 9С
92 89 24 95
24 93 94 8С
АО 24 89 87
24 88 8F 8С
92 8А 91 92
92 91 95 96
92 96 97 24
91 92 87 92
96 24 А1 96
89 91 91 92
92 92 85 9D
9С 8F 92 95
92 24 88' 92
91 91 9F 90
24 85 9F 8F
94 8С 94 92
90 89 96 92
24 84 91 84
92 24 97 8А 89 24 95 92
24 95 89 8Е 94 89 96 91
89 91 8С 89 25 91 84 90
АО 24 95 88 89 8F 84 96
95 96 84 96 92 9В 91 92
30 9В 96 92 85 9F 24 90
92 24 93 94 92 88 89 90
86 84 96 АО 24 94 84 85
88 84 9В 84 95 96 92 96
8F 8С 8В 84 32 0D 0А
Д$ЖТЦ$бЦТ$ЧКЙ$ХТ
ЖЙФЬЙССТ$ХЙОФЙЦС
ТЙ$ХТТЕЭЙСМЙ%СДР
$УФМЬПТХа$ХИЙПДЦ
а$ЙЗТ$ИТХЦДЦТЫСТ
$ИПМССЯРОЫЦТЕЯ$Р
ТКСТ$ЕЯПТ$УФТИЙР
ТСХЦФМФТЖДЦа$ФДЕ
ТЦЧ$РЙЦТИДЫДХЦТЦ
СТЗТ$ДСДПМЛД2>и
Листинг 3.12. freqs c.txt
Т == 0.152866242038217
Ц == 0.0828025477707006
С == 0.0764331210191083
Й == 0.0764331210191083
Д == 0.0700636942675159
X == 0.0509554140127389
ф == 0.0445859872611465
М == 0.0318471337579618
Р == 0.03184/1337579618
П == 0.0318471337579618
И == 0.0318471337579618
Е == 0.0254777070063694
Ж == 0.0191082802547771
Ы == 0.0191082802547771
Я == 0.0191082802547771
а == 0.0191082802547771
Ч == 0.0127388535031847
3 == 0.0127388535031847
Ь == 0.0127388535031847
У == 0.0127388535031847
К == 0.0127388535031847
Л == 0.0063694267515923
0 == 0.0063694267515923
Э == 0.0063694267515923
Попробуем заменить самую частую букву в шифротексте «Т» на «О» — са-
мую частую букву в русском языке по собранным нами заранее сведениям. Де-
шифруем и получим следующее сообщение:
Д ЖОЦ 6Ц0 ЧКЙ ХОЖЙФЬЙССО ХЙОФЙЦСОЙ ХООЕЭЙСМЙ СДР УФМЬПОХа ХИЙПДЦа йзо
ИОХЦДЦОЫСО ИПМССЯРОЫЦОЕЯ РОКСО ЕЯПО УФОИЙРОСХЦФМФОЖДЦа ФДЕОЦЧ
РЙЦ0ИДЫДХЦ0ЦС030 дсдпмлд
Гпава 3. Дешифрование классических шифров
39
Теперь можно попробовать сменить «Д» на «И», но, посмотрев в таблицу, мы
увидим, что вероятность «Д» в шифротексте несколько меньше и «Д» стоит на пя-
том месте, вместо положенного второго, а вот «А» стоит как раз на пятом месте.
Пробуем заменить:
А ЖОЦ бцо ЧКЙ ХОЖЙФЬЙССО ХЙОФЙЦСОЙ ХООЕЭЙСМЙ САР УФМЬПОХа ХИЙПАЦа ЙЗО
ИОХЦАЦОЫСО ИПМССЯРОЫЦОЕЯ РОКСО ЕЯПО УФОИЙРОСХЦФМФОЖАЦа ФАЕОЦЧ
РЙЦ0ИАЫАХЦ0ЦС030 АСАПМЛА
Фрагмент «САР» в тексте уже очень похож на «ТАК». Тем не менее, сверив-
шись с таблицей вероятностей, принимаем решение не делать соответствующие
замены — буквы слишко далеко отстоят друг от друга. Фрагмент «ЖОЦ» в самом
начале может быть похож на «ВОТ»; пришлось отвергнуть по тем же причинам.
Остается пробовать все известные союзы и предлоги, пробуя делать соответству-
ющие замены. В результате «ЖОЦ», замененный на междометие «ВОТ», оказался
верным решением. Аналогично «6ТО» оказался замененным «ЭТО» и так далее,
пока не получилось вот что:
А ВОТ ЭТО УЖЕ ХОВЕФЬЕННО ХЕОФЕТНОЕ ХООЕЭЕНМЕ НАМ УФМЬПОХа ХИЕПАТа ЕЗО
ИОХТАТОЫНО ИПМННЯМОЫТОЕЯ МОЖНО ЕЯПО УФОИЕМОНХТФМФОВАТа ФАЕОТУ
МЕТ0ИАЫАХТ0ТН030 АНДПМЛД
Слова «ХОВЕФЬЕННО ХЕОФЕТНОЕ» есть не что иное, как «СОВЕРШЕН-
НО СЕКРЕТНОЕ». Осуществив замены новых «раскрученных» букв, получаем
почти все сообщение. Продолжив это занятие, получаем то самое совершенно
секретное сообщение.
Надо заметить, что, если бы у нас были большие словари, в котором находи-
лись все словоформы большинства русских слов на определенные тематики, мы
могли бы подбирать слова для «отгадки» автоматически, проверяя всевозможные
слова и выбирая наиболее «близкие» к словам с дешифрованными фрагментами.
Для этого можно отбирать одинаковые слова по следующему принципу:
• слова из словаря и дешифрованного фрагмента должны быть одной длины;
• слова одной длины сравнивать по количеству совпадающих в соответствую-
щих местах дешифрованных букв.
Например, для фрагмента «ХОВЕФЬЕННО» из нашего примера алгоритм мог
бы выдать следующую статистику:
ХОВЕФЬЕННО - СОВЕРШЕННО = 7
ХОВЕФЬЕННО - НЕСЕРЬЕЗНО = 4
ХОВЕФЬЕННО - РУГАТЕЛЬНО = 2
Руководствуясь ею, мы можем подбирать и угадывать наиболее вероятные
слова гораздо быстрее. Создать же такую полезную программу чрезвычайно про-
сто. Следует отметить, что если алгоритм реализован итерационно (замена букв
происходит поочередно, а не одновременно), то в такой программе нужно преду-
смотреть механизм, отличающий прошедшую замену букву от исходной (напри-
мер «О», получившуюся из «Т», от «О» из исходного текста)
40
Гпава 3. Дешифрование классических шифров
Имея, допустим, достаточно длинный шифротекст и богатый словарь языка,
на котором предположительно написано сообщение, мы можем анализировать не-
сколько параметров текста, чтобы создать критерий верности дешифровки. Имея
такой критерий, мы могли бы создать программу, которая решала бы задачу крип-
тоанализа автоматически.
Что могло бы подойти в качестве такого критерия? Наверняка уже опробо-
ванный нами способ подсчета частот появления монограмм. Чем ближе будут зна-
чения подсчитанных частот к среднестатистическим, тем более вероятно, что
шифр раскрыт. С другой стороны, тексты разной тематики дают достаточно раз-
ную картину распределения частот, и соответственно, имея разные изначальные
данные, мы можем никогда не достичь верного решения.
К сожалению, если мы попробуем увеличить точность метода, подсчитывая
не монограммы, а биграммы или даже диграммы (четырехбуквенные сочетания),
то заметно увеличим и разрыв между разными видами текстов. Тем не менее под-
счет биграмм и диграмм более предпочтителен. Кроме того, что они точнее позво-
лят нам определить, насколько дешифрованный текст соответствует исходному,
мы дополнительно можем мгновенно отбрасывать варианты, в которых встреча-
ются так называемые «запрещенные биграммы и диграммы». Запрещенными их
называют потому, что в естественных языках (или других структурированных
объектах, например записях баз данных) либо вероятность встретить их прене-
брежимо мала, либо их комбинация в этом языке вовсе отсутствует. Например,
пары букв «ЫЫ» и «ЩЙ» в русском языке точно не присутствуют, аналогично им
в английском отсутствуют «WZ», «YY» и «ВХ». Таких биграмм (или даже диг-
рамм, в зависимости от аппетитов криптоаналитика) можно набрать довольно
много. Использование их в криптоанализе просто ускоряет сам процесс, посколь-
ку избавляет от множества лишних вычислений. Единственное, что нужно по-
мнить в этом случае, так это то, что внесение новых пар необходимо осуществ-
лять с осторожностью, поскольку если внести, например, пару «ТН» из. англий-
ского языка в «черный» список, то система заведомо будет вычеркивать почти все
верные решения.6
Попробуем собрать все сведения о взломе шифров замены, которые у нас ока-
зались на данный момент. Тогда мы сможем проводить проверку по словарю, под-
считывать частоты монограмм и частоты диграмм.
Собрав все это в один программный модуль, получим программу, которая
очень сильно облегчила бы жизнь в свое время многим шпионам, — получим про-
грамму автоматического дешифрования шифра простой замены.
В целях упрощения мы будем использовать алфавит, состоящий только из
русских заглавных букв и пробела. Для начала нам понадобятся средние значе-
ния частот появления монограмм и диграмм в русском языке. Для их подсчета
воспользуемся программой из листинга 3.13 (впоследствии^мы объединим все
программы в одну, управляемую ключом компиляции).
6 Дело в том, что на самом деле пара «ТН» представляет собой самую часто встречаемую
пару символов в текстах на английском языке. Вычеркивая ее, мы тем самым вычеркиваем бо-
льшинство английских слов и соответственно верных текстов.
Глава 3. Дешифрование классических шифров
41
Листинг 3.13
«include <stdio.h>
«include <stdlib.h>
«include "unidef.h"
// биграммы
typedef struct {
long values[40][40];
long total;
} BIGRAMM;
«include "etalon.h"
«include "f.etalon.h"
BIGRAMM current;
long freq[40];
I/ подсчет биграмм
void calc_gramm(unsigned char *buf, int len) {
for (int i = 0; i < len-1; i++) {
current.values[ buf[i]-0xC0 ][ buf[i+1]-0xC0 ]++;
current.total++;
}
}
I/ подсчет монограмм
void calc.freq(unsigned char *buf, int len) {
for;(dnt i = 0; i < len; i++) {
' freq[ buf[.i]-0xC0 ]++;
}
}
int nain(int argc, char* argv[]) ,
< •» lU ‘ r
FILE *f = fopen("collect.txt", "rb");
char buf[32768];
while (Ifeof(f)) {
int r = fread(buf, 1, sizeof(buf), f);
for (int i = 0; i < r; i++) if (buf[i] < ’A’ || buf[i] > ’Я’)
buf[i] = OxEO;
calc_gramm(buf, r);
calc.freq(buf, r);
}
fclose(f);
f = fopen("f_etalon.h", "wt");
fprintf(f, "long etalon[] = {\n");
for (int i = 0; i < 40; i++)
fprintf(f,?7%d, "i freq(i]);<'
; t hfprj,ntfCf> "};\n’;)- f . tl . ’ ; ' . ; • -> ;
fcldse(f);
f = fopen("etalon, h", "wt");
fprintf(f, "BIGRAMM etalon = {\n");
for (int i = 0; i < 40; i++) {
for (int j = 0; j < 40; j++)
42
Гпава 3. Дешифрование классических шифров
fprintf(f, ”%d, ”, current.values[i][j]);
fprintf(f, ”\n");
}
fprintf(f, ”%d };\n", current.total);
fclose(f);
return 0;
}
Создав небольшой словарь из наиболее вероятных слов, которые могли бы
встретиться в открытом тексте, мы становимся обладателями критерия, по кото-
рому можем определить, насколько вероятен тот факт, что дешифрованное с за-
данным нами ключом сообщение действительно является искомым открытым тек-
стом. Собственно говоря, процесс криптоанализа заключается в том, чтобы сокра-
тить работу человека и переложить ее на хрупкие плечи машины.
Реализуем алгоритм шифрования простой заменой (см. листинг 3.14) и по-
пробуем применить к шифротексту первый критерий — проверку по словарю с
помощью программы, реализованной в листинге 3.15.
Листинг 3.14
«include <stdio.h>
«include <stdlib.h>
«include ’’unidef.h"
// шифр простой замены
void encrypt(unsigned char *buf, int len, char *key) {
for (int i = 0; i < len; i++)
if (buffi] >= OxCO && buffi] <= OxEO) buffi] = key[buffi]-OxCO];
}
void decrypt(unsigned char *buf, int len, char *key) {
for (int i = 0; i < len; i++)
if (buffi] >= OxCO && buffi] <= OxEO) buffi] = unkeyfbuffi]-0xC0];
}
Мы используем модуль unidef.h в каждой из программ, чтобы обеспечить уни-
версальность подхода к обработке данных. В реализациях криптосистем универ-
сальность обозначает верность реализации и отсутствие трудноуловимых логиче-
ских ошибок в проектировании. Например, реализация RC4 на языке Си с исполь-
зованием типа char вместо unsigned char на одном компиляторе производит одну
последовательность данных, а на компиляторе другого производителя — уже дру-
гую. Естественно полагать, что и практическая криптостойкость у хорошего, но
неверно реализованного алгоритма оставляет ждать лучшего.
Листинг 3.15
И осуществляем символьную замену
void make_subst(char *buf, int len, int from, int to) {
for (int i = 0; i < len; i++)
if (buffi] == from) buffi] = to;
}
11 автоматический анализ
void bruteforce_dict(char *buf, int len) {
Глава 3. Дешифрование классических шифров
43
И таблица временных замен
int sub[256], i;
I/ буфер для испытаний
char *temp = (char *) malloc(len);
// пройдемся в цикле по всему тексту
for (i=0; i < len; i++) {
// делаем локальную копию для испытаний
memcpy(temp, buf, len);
// по всем словам из словаря
for (int w = 0; w < dict.n; w++) {
I/ не рассматриваем слова, которые уже
Ц не помещаются в границы текста
if (i + strlen(dict[w]) >= len) continue;
memset(sub, 0, sizeof(sub));
// по всем буквам текущего слова из словаря
for (int k = 0; k < strlen(dict[w]); k++) {
int from = temp[i+k];
int to = from - dict[w][k]; .
I/ сохраняем замену
sub[from] = to;
}
11 осуществляем временную замену символов
for (i = 0; i < 256; i++)
if (sub[i]) make_subst(temp, len, i, sub[i]);
11 тестируем текущую временную замену
test_subst(temp, len);
}
}
}
Алгоритм проверки по словарю (функция bruteforce__dict в листинге 3.15) сво-
дится к проверке предположения о том, что в некоторой фиксированной позиции
(на самом деле проверять следует начиная с первого и заканчивая последним сим-
волом шифротекста) открытого текста перед зашифрованием находилось слово из
заготовленного нами заранее словаря. Словарные элементы в листинге помещены
в массив указателей на строки (char *) dict[] — каждая строка представляет со-
бой словарное слово, а их количество задано переменно diet—п.
Вычитая слово из шифротекста, который нам необходимо раскрыть и о кото-
ром сделали предположение, что он получен зашифрованием простой заменой,
мы должны получить в каждой позиции символ, соответствующий номеру сдвига
алфавита в случае, если это шифр Цезаря (как частный случай шифра замены)
или целый набор замен (в более общем случае). Ориентируясь на общий случай,
мы поступаем следующим образом.
Посчитав эти вычисленные замены временными и произведя их, подсчитыва-
ем частоты (по осуществленным заменам, конечно),7 ищем запрещенные биграм-
7 Мы не можем подсчитывать частотное распределение по всем символам, поскольку не
проводим замены всего алфавита, а только лишь его части. Мы можем учитывать лишь еймво-
лы в тех местах, где такая замена нами проводилась. Метод малоэффективный на текстах небо-
льшой длины, но вполне может себя оправдать на текстах или структурах данных размером в
несколько килобайтов.
44
Гпава 3. Дешифрование классических шифров
мы, триграммы или диграммы (с помощью функции test_subst). Дополнительно
можем в расшифрованном тексте искать слова небольшой длины из нашего же
словаря. Если хотя бы одно такое слово будет найдено, это будет означать доста-
точно высокую вероятность верной замены.
Если запрещенных сочетаний символов не было найдено, программа дол-
жна выдать найденную замену криптоаналитику. Аккумулируя такие «успеш-
ные» замены, программа выдаст в конце криптоаналитику список возможных
замен, корректных с ее точки зрения. Реализация проверки временных замен и
принятия решения о необходимости анализа человеком представлена в лис-
тинге 3.16.
Листинг 3.16
// вычисляем биграммы
void calc_gramm(unsigned char *buf, int len) {
for (int i = 0; i < len-1; i++) {
current.values[ buf[i]-OxCO ][ buf[i+1]-0xC0 ]++;
current.total++;
1
}
void calc_freq(unsigned char *buf, int len) {
for (int i = 0; i < len; i++) {
freq[ buf[i]-OxCO ]++;
} - ’ > - ' -
}
// вычисляем “расстояние” от эталонных до полученных
И экспериментально данных
double calc_measure() {
double result = 0;
if (!current.total) current.total++;
for (int i = 0; i < 40; i++) ' : * *
for (int j = 0; j < 40; j++)
result += fabs(((double) current.values[i][j]/current.total)
- ((double) etalon.values[i][j]/etalon.total));
return result;
}
I/ проверяем временные замены
bool test_subst(char *buf, int len) {
11 проведем проверку на запрещенные биграммы
uint16_t *ofs = (uint16_t *) buf;
//.используем указатель для ускорения доступа к тексту
for (int к = 0; к < len-1; к++.) . , , г,
for (int i = 0; i < deny.n; i++) { _ ;
if (*ofs == deny[i]) return false; J
I/ сдвигаем не на два1 байта (как слово) ' ' ,ь''1 4
И а на один байт (как переменную в полслова -байт) х • -•
((uint8_t *) ofs)++; <
}
Глава 3. Дешифрование классических шифров
45
И проверим, не найдется ли какое-нибудь слово
// из нашего'словаря в новом тексте .
for (int k = 0; k < dict_n; k++)
if (strstr(buf, dict[k]) != NULL) return true;
// подсчитаем монограммы и/или диграммы
// и определим, насколько сильно распределение их частот отличается
И от эталонных значений для русского (английского, французского, ...)
calc_gramm(buf, len);
if (calc_measure() > gran) ' ,!"
return false; 4 !
else '
return true;
> . . '• '
Функция test_subst состоит из нескольких независимых частей: первая про-
веряет наличие запрещенных биграмм в тексте, вторая осуществляет проверку
слов из словаря. Если в тексте найдется хотя бы одно слово, алгоритм принимает
решение о том, что дальнейший анализ будет проводить криптоаналитик. Заклю-
чительная часть кода test_subst подсчитывает частотные характеристики текста и
определяет разницу между подсчитанными и эталонными таблицами биграмм
(или монограмм — по вкусу).
Вопрос о корректности названия «автоматический криптоанализ» уже дол-
жен был возникнуть у читателя. В самом деле, создаваемые нами программы не
выдают криптоаналитику восстановленный с точностью до буквы открытый
текст. Вместо этого они выдают ему довольно много информации, которую соби-
рают исходя опять же из предрассудков криптоаналитика и информации о шифре,
которая может быть доступна ему заранее. , . ,
С другой стороны, мы рассматриваем случай, когда компьютер все равно бу-
дет либо перебирать все возможные варианты ключа, либо осуществлять большое
количество вычислений и оценок. И сейчас главное для нас — дать ему критерий,
по которому он в качестве предварительной оценки отбросит самые невероятные
открытые тексты. Остальные будет пытаться прочесть человек. И именно человек
определит, какой из всех этих текстов является осмысленным, то есть открытым
текстом.
Поэтому, чем большим количеством критериев мы наделим алгоритм и чем
сильнее будут сами критерии, тем быстрее компьтер проверит все варианты и тем
меньше из этих вариантов останется для анализа человеку.
Не имея верного ключа криптосистемы, криптоаналитик всегда задается во-
просом: как определить, что выбранный для расшифрования ключ криптосистемы
или эквивалентная ему последовательность преобразований шифротекста тако-
вы, что дешифрованные данные представляют собой искомый открытый текст?
В каждом конкретном случае этот вопрос требует отдёльного рассмотре-
ния. В общем случае понятие открытого текста распространяемся' rie только на
естественные языки, но и на структуры данные, предсказуемые значения по-
лей и их начальных значений. В таком случае криптоаналитик должен выде-
лить набор критериев, при выполнении которых он может считать дешифро-
ванные данные возможным кандидатом на место открытого текста. Например,
46
Глава 3. Дешифрование классических шифров
обладая знанием того, что в передаваемом по электронной сети зашифрован-
ном IP-пакете содержится адрес получателя, криптоаналитик может сущест-
венно уменьшить пространство допустимых открытых текстов, рассматривая
только те открытые тексты, в которых данный адрес присутствует в некотором
(произвольном) месте.
Многие криптосистемы позволяют извлечь определенное количество так на-
зываемой вторичной информации, которая может послужить дополнительным
критерием отбора подходящих ключей.
К сожалению, полностью исключить активное участие человека в конечном
процессе выбора открытого текста невозможно. Оптимальный подход состоит в
организации интерактивной работы человек-машина, поскольку только человек
достоверно решит, может ли представленная расшифровка данных быть носите-
лем требуемой информации.
Быстрое раскрытие шифров простой замены
В 1995 году Томас Якобсен предложил автоматический метод раскрытия клю-
ча простых (как моно-, так и полиалфавитных) шифров замены и в своей статье
даже привел реализацию алгоритма его работы. Его работа является ярким при-
мером множества подобных исследований, проведенных за последние несколько
десятилетий.
В своем методе вскрытия шифров замены Якобсен использовал информацию
о распределении диграмм и ее соответствие распределению открытых текстов.
Простое решение не очень сложной задачи вылилось в весьма интересный алго-
ритм. Его особенностью стало то, что изначально случайно выбранный ключ в
процессе работы алгоритма последовательно приближается (своего рода аппрок-
симируется или даже подбирается по частям) к настоящему ключу, использован-
ному для зашифрования. Производя с ключом различные (может быть, даже слу-
чайные) изменения, алгоритм определяет, продвинулись ли мы хоть сколь-нибудь
к намеченной цели, если он сочтет изменения положительными, они будут испо-
льзовать в дальнейшем. Изменения, которые либо бесполезны, либо, что называ-
ется, «портят картину», просто отбрасываются и далее не принимаются к рас-
смотрению.
Начальный ключ по возможности следует выбирать как можно более близ-
ким к настоящему, например исходя из доступной вторичной информации о крип-
тосистеме или абонентах, использующих ее. В случае, если такой информации
нет, подойдет и случайный ключ — в алгоритме лишь увеличится количество ите-
раций, необходимых для поиска настоящего ключа. В случае простой замены (мы
позволим себе показатель упростить до моноалфавитной замены) ключ представ-
ляет собой таблицу следующего характера (рис. 3.4). В соответствии с ней буква
«А» заменяется на «Г», «Б» на «Д» и т. д. Нижняя строка таблицы, вообще говоря,
переставляется произвольным образом и представляет секретную компоненту,
раскрытие которой ведет к раскрытию шифра.
Гпава 3. Дешифрование классических шифров
47
АБВГДЕЖЗИЙКЛМН0ПРСТУФХЦЧШЩЪЫЬЭЮЯ_
ГДЕЖЗИЙКЛМН0ПРСТУФХЦЧШЩЪЫЬЭЮЯ_АБВ
Рис. 3.4
Для того чтобы получить некоторое формальное описание открытого текста,
в алгоритме раскрытия шифра предварительно выбирается фиксированная функ-
ция от нескольких параметров. Эта функция и характеризует открытый текст, ко-
торый был зашифрован с помощью данной криптосистемы и искомого ключа. Ре-
зультатом функции должно быть значение корреляции подаваемого ей на вход от-
крытого текста и некоторого эталонного открытого текста, заданного заранее и
изначально фиксированного. Данную функцию называют целевой функцией, по-
скольку, чем ближе ее значение к некоторой величине (например, единице для
нормированных целевых функций), тем лучше данный ключ был аппроксимиро-
ван и тем больше он «похож» на действительно использованный при зашифрова-
нии.
Сам алгоритм состоит из нескольких шагов, повторяемых в каждой итерации
последовательно, один за другим. Сначала рабочий ключ модифицируется случай-
ным или заранее определенным способом, в зависимости от количества и успеха
прошлых итераций (корректность этого описания мы обсудим чуть позже). Затем
шифротекст расшифровывается с помощью нового модифицированного ключа и
проверяется значение нормированной целевой функции. Если оно ближе к единице
(из-за нормированности), чем вычисленное во время прошлой итерации алгоритма,
то измененный ключ сохраняется в качестве рабочего и алгоритм повторяется.
Томас Якобсен в предложил использовать в качестве целевой функции сумму
разностей по модулю между вычисленными и заранее посчитанным количеством
встреченных в тексте различных диграмм. Позволим себе немного упростить фун-
кцию, чтобы упростить понимание излагаемого метода, и будем подсчитывать не
диграммы, а всего лишь биграммы (в реальной криптоаналитической практике ис-
пользуются именно диграммы, а также приближения более высоких порядков).
Если считать значение Dri матрицы D равным количеству встретившейся биграм-
мы, состоящей из символов i и /, то целевая функция примет вид
гы = х|о; - £„|.
>7
где Etj — частоты биграмм, подсчитанные заранее и зафиксированные в алгорит-
ме в качестве эталонных. Понятно, что W(t) нормированной не является. Однако
это можно легко поправить, воспользовавшись теорией больших чисел, которая
позволит нам заменить значения частоты биграмм в матрицах (£/;) и (Dj;) на зна-
чения вероятностей. Дополнительно умножив функцию на нормирующий множи-
тель, получим нормированную целевую функцию 1Г*(<). Однако мы все еще не
можем ее использовать, поскольку близость №*(/) к единице означает противопо-
ложную искомой ситуацию, — в этом случае, почти все элементы (D;/) наиболее
удалены от соответствующих элементов (Е;/). Чтобы достичь желаемого теорети-
ческого эффекта нам придется ввести еще одну функцию и использовать в конце
концов именно ее.
На псевдокоде реализация алгоритма показана в листинге 3.17.
48
Гпава 3. Дешифрование классических шифров
Листинг 3.17
1. Готовим начальный рабочий ключ К исходя из предположений об открытом
тексте и настоящем ключе.
2. Пусть V = W( D(C,К) ).
3. Присвоим К' = К.
4. Модифицируем К’, изменяя его незначительно.
5. Пусть V = W( D(C.K) ).
6. Если V < V, то теперь V = V и К = К’.
7. Переходим к шагу 4.
Условием выхода из алгоритма может являться либо количество набранных
вариантов ключей, либо некоторый критерий осмысленности открытого текста.
В последнем случае, на каждом следующем ключе дешифруется шифртекст и к
дешифровке применяется тест «на осмысленность». Если данные выглядят бо-
лее-менее осмысленно, алгоритм прекращает работу.
___ Обратите внимание, что мы используем функцию МО, а не W*(t) или
№*(/) — она удобнее с практической точки зрения. По этой причине успешность
проведенных изменений ключа К' оценивается знаком меньше <, а не больше >,
как это было сделано выше в теоретических выкладках. Если изменения в ключе
на шаге 4 сказались на расстоянии между характеристиками дешифровки и эта-
лона в меньшую сторону, то на шаге 6 они будут сохранены и использованы в да-
льнейшем. Иначе изменения будут отброшены и начнется следующая итерация
алгоритма.
Модификация ключа К' на шаге 4 в случае простой замены заключается в пе-
рестановке элементов последней строки таблицы, показанной на рис. 3.4. Всего
таких перестановок NI, что при больших N делает тотальное опробование всех
возможных комбинаций ключа очень трудоемкой задачей. Тем не менее, исполь-
зуя статистические особенности открытого текста, зашифрованного простой за-
меной, можно значительно сократить время перебора, чем, собственно, и занима-
ется предложенный Якобсеном алгоритм.
Рассмотрим теперь реализацию предложенного алгоритма (см. листинг 3.18).
Листинг 3.18
«include <stdio.h>
«include <stdlib.h>*
«include <string.h>
«include <math.h>
«include "unidef.h"
// биграммы
typedef struct {
long values[40][40];
long total;
} BIGRAMM;
«include "etalon.h"
BIGRAMM current;
Гпаёа З. Дешифрование классических шифров
49
И использованный алфавит (укороченный в целях упрощения)
// "а" маленькое играет роль пробела и заменителя всех остальных знаков
unsigned char alpha[33] = "АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЬЭЮЯа";
// ключ-таблица для зашифрования
unsigned char key[33] = "БВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯаА";
// ключ-таблица для расшифрования
unsigned char right_unkey[33] = "ЯаАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮ";
unsigned char unkey[33] = "ЕПРСТЯаАБВГДЖЗИЙКЛМНОУФХЦЧШЩЪЫЬЭЮ";
I/ шифр простой замены
void encrypt(unsigned char *buf, int len, char *key) {
for (int i = 0; i < len; i++) ; •
if (buf[i] >= OxCO && buf[i] <= OxEO) buf[i] ,= key[buf[i]-OxCOJ; .
} \ .
void decrypt(unsigned char *buf, int len, char *key) {
for (int i = 0; i < len; i++) ...
if (buf[i] >= OxCO && buf[i] <= OxEO) buf[i] = unkey[buf[i]-0xC0]; .
}
11 вычисляем биграммы ;
void calc_gramm(unsigned char *buf, int len) {
for (int i = 0; i < len-1; i++) { ,
current.values[ buf[i]-OxCO ][ buf[i+1]-OxCO ]++;
current.total++;
} - ' к .•
}
11 вычисляем "расстояние" рабочего ключа до настоящего
double calc_measure() {
double result = 0; ' ‘ ‘ ’
if (’current.total) current.total++; . /
for (int i = 0; i < 40; i++)
for (int j = 0; j < 40; j++)
result += fabs(((double) current.values[i][j]/cUrrent.total) '- 4
((double) etalon.values['i][j]/et’aldn.total)); > >
return result;
}
// поиск ключа
void findkey_jakobsen(char *buf, int len, char *guesskey) {
char work_key[33];
double V, V_;
int c, pos, sym;
char *temp, s;
temp = (char *) malloc(len); .
memcpy(work_key, guesskey, sizeof(work_key)); (i ir
strncpy(temp, buf, len); ,
memset(¤t, 0, sizeof(current));
calc_gramm(temp, len);
V = calc_measure();
randomize();
50
Гпава 3. Дешифрование классических шифров
с = 0;
for (;;) {
// переставляем символы в ключе
pos = rand() % 33;
sym = (pos + 1 + rand()) % 33;
s = work_key[pos];
work_key[pos] = work_key[sym];
work_key[sym] = s;
11 дешифруем текст
strncpy(temp, buf, len);
decrypt(temp, len, work_key);
memset(¤t, 0, sizeof(current));
calc_gramm(temp, len);
// считаем расстояние до эталона
V_ = calc_measure();
if (++c % 1000 == 0) printf(’’%f < %f, %d, %d\n", V_, V, pos, sym);
if (V_ < V) {
// ypal улучшили результат!
printf("W0RK_KEY == %s, KEY = %s (V == %f, V_ == %f)”,
work_key, guesskey, V, V_);
printf(”!!!\n", work_key);
memcpy(guesskey, work.key, sizeof(work_key));
V = V_;
}
else
// оставляем все без изменений
memcpy(work_key, guesskey, sizeof(work.key));
}
printf("%f", V);
}
«define MAKE.ETALON 0
int main(int argc, char* argv[])
{
char text[] = "CAM АЛГОРИТМ СОСТОИТ ИЗ НЕСКОЛЬКИХ ШАГОВ, ПОВТОРЯЕМЫХ В"
"КАЖДОЙ ИТЕРАЦИИ ПОСЛЕДОВАТЕЛЬНО, ОДИН ЗА ДРУГИМ. СНАЧАЛА РАБОЧИЙ КЛЮЧ"
"МОДИФИЦИРУЕТСЯ СЛУЧАЙНЫМ ИЛИ ЗАРАНЕЕ ОПРЕДЕЛЕННЫМ СПОСОБОМ, В"
"ЗАВИСИМОСТИ ОТ КОЛИЧЕСТВА И УСПЕХА ПРОШЛЫХ ИТЕРАЦИЙ (КОРРЕКТНОСТЬ"
"ЭТОГО ОПИСАНИЯ МЫ ОБСУДИМ ЧУТЬ ПОЗЖЕ). ЗАТЕМ ШИФРОТЕКСТ"
"РАСШИФРОВЫВАЕТСЯ С ПОМОЩЬЮ НОВОГО МОДИФИЦИРОВАННОГО КЛЮЧА И"
"ПРОВЕРЯЕТСЯ ЗНАЧЕНИЕ НОРМИРОВАННОЙ ЦЕЛЕВОЙ ФУНКЦИИ. ЕСЛИ ОНО БЛИЖЕ”
"К ЕДИНИЦЕ (ИЗ-ЗА НОРМИРОВАННОСТИ), ЧЕМ ВЫЧИСЛЕННОЕ ВО ВРЕМЯ ПРОШЛОЙ"
"ИТЕРАЦИИ АЛГОРИТМА, ТО ИЗМЕНЕННЫЙ КЛЮЧ СОХРАНЯЕТСЯ В КАЧЕСТВЕ"
"РАБОЧЕГО И АЛГОРИТМ ПОВТОРЯЕТСЯ.";
int len = strlen(text);
for (int i = 0; i < len; i++)
if (text[i] < 'A' || text[i] > *Я’) text[i] = OxEO;
// создание эталона
if (MAKE.ETALON) {
FILE *f = fopen("collect.txt", "rb");
char buf[32768];
Гпава 3. Дешифрование классических шифров
51
while (’feof(f)) {
int г = fread(buf, 1, sizeof(buf), f);
for (int i = 0; i < r; i++) if (buf[i] < ’A’ J| buf[i] > ‘Я’)
buf[i] = OxEO;
calc_gramm(buf, r);
}
fclose(f);
f = fopen("etalon.h", "wt”);
fprintf(f, "BIGRAMM etalon = {\n");
for (int i = 0; i < 40; i++) {
for (int j = 0; j < 40; j++)
fprintf(f, "%d, ", current.values[i][j]);
fprintf(f, ”\n”);
}
fprintf(f, "%d };\n", current.total);
fclose(f);
return 0;
}
encrypt(text, len, key);
printf("%s\n", text);
findkey_jakobsen(text, len, unkey);
decrypt(text, len, unkey);
printf("%s\n", text);
return 0;
}
Ключ MAKE_ETALON предназначен для создания эталонной матрицы биг-
рамм. На вход алгоритма будет подан тестовый файл с русским текстом достаточ-
но большого объема, состоящий из заглавных букв и пробелов. Все остальные
знаки будут отбрасываться при анализе. Собранные данные в виде будут автома-
тически подключены к программе при следующей компиляции (для этого будет
необходимо установить ключик MAKE-ETALON в ноль) в виде файла описаний
etalon, h.
После того как создан эталон, переходим собственно к анализу. Тестовый
пример представлен прямо в программе (переменная text функции main). Функ-
ции encrypt и decrypt осуществляют соответственно зашифрование и расшифро-
вание простой заменой с помощью ключевых таблиц key и unkey соответственно
(см. листинг 3.19). Функция calc-gramm подсчитывает частоты биграмм в задан-
ном тексте, a calc_measure выдает разницу между эталоном и рабочей матрицей
таких частот.
Листинг 3.19
Ц использованный алфавит (укороченный в целях упрощения)
И "а" маленькое играет роль пробела и заменителя всех остальных знаков
unsigned char alpha[33] = "АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯа";
// ключ-таблица для зашифрования
unsigned char key[33] = "БВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯаА";
.52
Гпава 3. Дешифрование классических шифров
// ключ-таблица,для расшифрования
unsigned char right_unkey[33] = "ЯаАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮ";
unsigned char unkey[33] = •ЕПРСТЯаАБВГДЖЗИЙКЛМНОУФХЦЧШЩЪЫЬЭЮ";
Случайный начальный ключ приведет к успеху так же, как и начальный
ключ, заданный исходя из вторичной информации о шифротексте и настоящем
ключе. Разница между этими двумя выборами начального ключа будет заключать-
ся только во времени работы алгоритма. В первом случае время, за которое алго-
ритм найдет настоящий ключ, будет намного большим, чем во втором. Поэтому,
если о ключе почти ничего неизвестно, для его оптимального поиска используют
частоты появления символов русского языка, располагая символы в ключе в соот-
ветствии с этими частотами (рис. 3.5). Например, после сбора частот по части
текста шестой главы данной книги распределение частот было следующим:
Таблица частот:
4321 == 0, 3185 == И, 3172 == Е, 2933 == Т, 2779 == А, 2248 == С, 2209 == Н, 1858 == В,
1568 == Р, 1561 == Л, 1520 == И, 1173 == К, 1128 == Д, 989 == П, 890 == Я, 709 == Ы,
700 == У. 640 == Ь, 620 == Ч, 611 == Б, 572 == 3, 497 == Г, 416 == Ж, 393 == Й,
294 == X, 268 == Ю, 227 == Ф, 206 == Щ, 201 == Ц, 153 == Ш, 121 == Э, 8 == Ъ
Ключ: '
О И Е Т А С Н В Р Л М К Д ПЯ Ы У ... ЭЪ
Рис. 3.5
Конечно, в случае простой моноалфавитной замены можно было бы восполь-
зоваться и простым частотным анализом. Но, во-первых, для коротких сообщений
простой частотный анализ ^неэффективен, а, во-вторых, прибегнув к небольшой
модификации алгоритма, мы получаем способ вскрывать' полиалфавитные шиф-
ры. Вдобавок сам метод частотного анализа может быть составной частью алго-
ритма Якобсена. Для этого достаточно заменить целевую функцию, подсчитываю-
щую разность между частотами биграмм, на функцию, возвращающую разницу
между частотами появления одиночных символов. Менее эффективно, но более
быстро и требует значильно меньше памяти в случае очень больших алфавитов.
Тем не менее, несмотря на возможную оптимизацию, алгоритм из листинга
3.1 достаточно медлителен. Ведь каждый раз изменяя ключ, мы должны заново
вычислить матрицу (ZX) и разность между ней и эталоном (Е;/), которая только в
случае биграмм имеет размерность 256 х 256 = 65536 элементов. Вообще говоря,
это и должно быть всегда именно так, поскольку, изменяя ключ, мы изменяем
способ расшифрования и соответственно получаем совершенно другой дешифро-
ванный открытый текст. .Однако в случае шифров простой замены мы меняем
ключ, лишь переставляя в немэлементы; Фактически это означает, что в табли-
це-ключе мц переставляем элементы нижней строки (см. рис. 3.4).
Если.'приглядеться внимательнее, . можно увидеть, что'Тем самым мы также
переставляем строки и столбцы в матрице, которую при этом больше никак не из-
меняем. Это означает, что можем не подсчитывать матрицу (D(.) каждый раз, за-
менив вызов calc_gramm в цикле функции findkey_jakobsen в программе листинга
Глава.3. Дешифрование классических шифров
53
3.18 на быструю перестановку строк и столбцов с помощью нескольких вызовов
memcpy (см. листинг 3.20).
Листинг 3.20
long buf[1024];
memcpy(buf, &D[i][0], sizeof(long)*256);
memcpy(&D[i][O], sizeof(long)*256);
memcpy(&D[j][0], buf, sizeof(long)*256);
Еще одним недостатком подобных алгоритмов (в ,том числе и только что рас-
смотренного, если пробовать применять его для случая шифров гаммирования)
является то, что для его успешной работы мы обязаны знать длину использован-
ного ключа. На самом деле это не очень существенный конструктивный недоста-
ток, поскольку длину ключа для классических шифров можем определить доста-
точно достоверно, например, с помощью теста Казиски, описанного далее, а для
современных криптосистем такая проблема отпадает сама собой — длины ключей
в них фиксированы.
Дешифрование шифров гаммирования
Все вышеописанные алгоритмы можно применять не только для шифров про-
стой замены, но и для шифров гаммирования. Одним из самых популярных шиф-
ров гаммирования является шифр Виженера. Его зачастую путают с примитивны-
ми шифрами простой замены. На самом деле это не так. Шифр Виженера пред-
ставляет собой более сложный шифр полиалфавитной замены.
Процедуры зашифрования и расшифрования этим шифром можно предста-
вить следующим образом:
Ct = a.i + yi (mod N), для 0 <= i <= М,
где М — длина периодической гаммы; N — количество букв в алфавите; с;, а, и z/(
обозначают соответственно i-ю (в некотором периоде) букву шифротекста, откры-
того текста и накладываемой поверх него гаммы. В классическом варианте гамма
получается сдвигом строки алфавита на несколько позиций влево.
Первым вопросом, который возникнет у криптоаналитика при дешифровании
шифра Виженера, является вопрос о том, каково значение М, то есть какой имен-
но длины гамма была использована при шифровании. Второй вопрос — величина
сдвига, которым была сформирована гамма.
Для нахождения, ответа на первый вопрос существует несколько специально
разработанных методов. Самый, простой из них называют тестом Казиски. Назван
он в честь Фридриха гКазиски, который изобрел этот тест в 1863 году;
Суть теста Казиски заключается в поиске одинаковых фрагментов из неско-
льких символов в шифротексте. Дело в том, что отстоящие друг от друга на М
символов участки открытого текста будут зашифрованы одинаковыми фрагмента-
ми гаммы и, следовательно, будут представлять собой одинаковые фрагменты
54
Гпава 3. Дешифрование классических шифров,
шифротекста. Найдя несколько таких фрагментов в шифротексте, мы можем с не-
которой уверенностью сказать, что то расстояние, на которое отстоит друг от дру-
га большинство из них, и является длиной, использованной для зашифрования
гаммы. К сожалению, этот метод работает далеко не всегда — ведь не в каждом
открытом тексте так уж часто встречаются одинаковые фрагменты — слова.
К счастью, полстолетия спустя для нахождения длины гаммы был разрабо-
тан специальный оценочный параметр — индекс совпадения (index of coinciden-
ce). Метод вычисления индекса совпадения был впервые предложен Уильямом
Фридменом в начале XX века. Много позже его работы тщательно изучались, и,
помимо индекса совпадения, появлялись другие различные параметры, характе-
ризующие текст. Первое же, классическое, определение индекса совпадения вы-
глядит так:
Ez(z - о
W = ----гг-
тут -1)
Значение индекса совпадения есть не что иное, как вероятность того, что две
наугад взятые буквы Д из текста х окажутся равными между собой. Для случай-
ной строки текста значение индекса совпадения приблизительно равно
— = — = 0,0303(03). Для естественных языков индекс совпадения будет значите-
N 33
льно выше. Для английского языка, к примеру, он равен 0,0662, а для русского —
0,0529.
Используя индекс совпадения, мы можем определить длину гаммы следую-
щим образом. Для начала выберем предположительную длину гаммы, равной
двум, отберем буквы, стоящие на каждом первом месте в шифротексте, и посчи-
таем индекс совпадения для них. Затем то же самое проделаем для букв на вто-
рых местах. Аналогично поступим для гаммы длиной три, четыре и т. д. до некото-
рого верхнего значения.
Выпишем получившиеся значения индексов совпадения и посчитаем арифме-
тическое среднее. Если длина гаммы отличается от двух, мы получаем цепочки
символов, состоящие из текстов с участками гаммы, наложенными с разными
сдвигами. Они во многом будут похожи на случайный текст. Если же длина гам-
мы совпадает с нашими предположениями, то значение индекса совпадения будет
значительно выше и приближенно к индексу совпадения естественного языка.
Допустим, волею судеб мы поставлены перед вопросом решения задачи крип-
тоанализа следующего шифра гаммирования Виженера:
ФДСЖОЗУЦЛЦСЧСХЧФЛЦННРЙЦРСПБРЛЩЭЖЖТЗХСЖЧФУГКТЮЩЗРГКЙФММЧЛУДЫОЛУУЧОЙЙФЕДЧЛОАТФС
ИНУКДЙЦЦЗНТФСЕЭГПЕЦГЕУЭЛНПСБЫСФЗМЩОЩМХЩИЦЦЕФПШЭГНТБПМРОКДХЖРЙКФТФККИПКУРЯСЧТТ
ЦФДТСИКДЗОФМСФФЦНФХОУСЛЫКЧХЖЕОЦХФЛШДФЦСЬРБШМЧЛУДЫОМОУЦУЙПШРТЦШЯБЧФЖГУХЛХЕУЛГС
БСЕЦЩЗМСЭЦЦБХСЛЛЛКДЧЛПЬНЪУТЧЛНХЧЦГХЭОЧФУИЮЖЕЛХХДЧТТСФЬАГУСЖУЙСРУКЛШНЬЛФУИГСТФ
ЖТПСБЫЕОТФУИИФДЛХХДНРДЬЛРМКУСФСОУТЗЖРСУПЩЙРЛЕТОЪЦСПЬЛМКЧОМУУСЕРОЙЙПЛЗМТОЩЙННК
ДТФУРНЦСЖЕУРТЦШЛЫКТЕЯЬОФПКУРТКИСЖХЛПГФЦСЬРФММЧЛУДЫОЛДРЙСФНШПДЧФЛЛСЛРЙТУЮНПСБЫ
ЦФШФЕУВЙЧЧВЖПЖЬЙЦШЕЙХЖДТЬЛЖГНЖОЗУЦЛЦСХСЖЧФУГКШФГ
Гпаеа 3. Дешифрование классических шифров 55
По его виду мы пока что мало можем сказать о шифре. Частотный анализ в
его примитивном виде не приведет к эффектным результатам. Чтобы начать его
использовать, нам необходимо знать длину периода, с которым на открытый текст
накладывалась гамма. Попробуем посчитать индексы совпадения для различных
длин гаммы с помощью программы из листинга 3.21.
Листинг 3.21
void calc_coin(char *buf, int len, int gamma) {
int i, g, true_len;
double *index = new double[gamma];
true.len = len / gamma;
// подсчитаем частоты каждого g-го символа в цепочку
for (g = 0; g < gamma; g++) {
double freqs[N];
memset(freqs, 0, sizeof(freqs));
for (i = g; i < len; i += gamma) freqs[buf[i] - ’A’]++;
11 собственно, индекс совпадения
index[g] = 0.0;
for (i =0; i < N; i++) index[g] += freqs[i]*(freqs[i]-1);
index[g] = index[g] / (true_len*(true_len-1));
}
// подсчитаем средний индекс совпадения
double index.s = 0.0;
for (g = 0; g < gamma; g++)
index.s += index[g];
index.s /= gamma;
delete index;
I/ выводим результаты
printf("Длина гаммы: %2d; Индекс совпадения: %1.8f\n”, gamma, index_s);
}
Выбирая каждую g-ю букву шифротекста в цикле, подсчитываем частоты мо-
нограмм freqs[N]. Затем вычисляем индекс совпадения для каждой цепочки, а в
конце подсчитываем их среднее значение. Результат работы программы приведен
в листинге 3.22.
Листинг 3.22
Длина гаммы: 1; Индекс совпадения: 0.04150391
Длина гаммы: 2; Индекс совпадения: 0.04670372
Длина гаммы: 3; Индекс совпадения: 0.04009746
Длина гаммы: 4; Индекс совпадения: 0.05858643
Длина гаммы: 5; Индекс совпадения: 0.04010872
Длина гаммы: 6; Индекс совпадения: 0.04477124
Длина гаммы: 7; Индекс совпадения: 0.04135927
Длина гаммы: 8; Индекс совпадения: 0.06253200
Длина гаммы: 9; Индекс совпадения: 0.04235209
Длина гаммы: 10; Индекс совпадения: 0.04454902
56
Глава 3. Дешифрование классических шифров
Длина гаммы’: 11; Индекс совпадения1: 0.04005270
Длина гаммы: 12; Индекс совпадения: 0.05720093
Длина гаммы: 13; Индекс совпадения: 0.04204298
Длина гаммы: 14; Индекс совпадения: 0.04501134
Длина гаммы: 15; Индекс совпадения: 0.03969103
Длина гаммы: 16; Индекс совпадения: 0.06411290
Длина гаммы: 17; Индекс совпадения: 0.04286680
Длина гаммы: 18; Индекс совпадения: 0.04732510
Длина гаммы: 19; Индекс совпадения: 0.04145749
Длина гаммы: 20; Индекс совпадения: 0.05783333
Обратите особое внимание на значения индексов совпадений там, где длина
гаммы четна. Они немного отличаются от остальных. Составив простой график
значений из листинга 3.22, увидим (рис. 3.6), что еще более значительно от
основной массы величин отличаются величины для гамм длины 4, 8, 12 и 20.
Остальные же значения более приближены к значению индекса совпадений для
случайных текстов.
Должно ли это навести нас как криптоаналитиков на мысль о том, что длина
гаммы может быть равна либо 4, либо 12, либо 20? Вовсе нет. На самом деле мы
можем сразу же решить, что длина гаммы равна наименьшему общему кратному
из этих чисел, то есть четырем.
Это верно только лишь потому, что гамма, накладываемая сложением по мо-
дулю на открытый текст, является периодической. Ее значения повторяются каж-
дые М букв, а это означает лишь, что, когда мы подсчитываем частоты каждой
12-й буквы, косвенно учитываем и частоты некоторых «четвертых букв». Индекс
совпадения указывает на осмысленность текста — это верно, как верно и то, что
этот текст представляет собой прореженную цепочку «каждых четвертых» симво-
лов.
Экспериментируя с вычислением длины периода с помощью метода Фридма-
на, можно обнаружить, что при длинах гаммы больше пятидесяти (а иногда и три-
дцати) алгоритм дает сбой, показывая завышенные частоты на меньших длинах
гаммы, чем у соответствующей действительности. Это связано с тем, что для сбо-
ра информации о больших гамма-последовательностей требуется во много раз бо-
Рис. 3.6. График значений индекса совпадений
ПлаваЗ.Дешифрование классических шифров
57
льше шифротекста, чем это могло бы быть для длин гаммы в несколько символов.
Вывод, когда-то сделанный Клодом Шенноном, о том, что, чем длиннее гамма, тем
шифр является более стойким, подтверждается на практике.
Вычислив длину периода с помощью какого-либо из описанных выше мето-
дов, можно приступать к решению задачи криптоанализа шифра гаммирования.
Для этого существует множество различных подходов, но самый действенный и
самый простой получается автоматически переводом материала и программ из
предыдущего раздела этой главы. Разобьем шифротекст на периодические участ-
ки (см. листинг 3.23).
Листинг 3.23
ФДСЖ ОЗУЦ ЛЦСЧ СХЧФ ЛЦНН РЙЦР СПБР ЛЩЭЖ ЖТЗХ СЖЧФ УГКТ ЮЩЗР ГКЙФ ММЧЛ УДЫО
ЛУУЧ ОЙЙФ ЕДЧЛ ОАТФ СИНУ КДЙЦ ЦЗНТ ФСЕЭ ГПЕЦ ГЕУЭ ЛНПС БЫСФ ЗМЩО ЩМХЩ ИЦЦЕ
ФПШЭ ГНТБ ПМРО КДХЖ РЙКФ ТФКК ИПКУ РЯСЧ ТТЦФ ДТСИ КДЗО ФМСФ ФЦНФ ХОУС лыкч
ХЖЕО ЦХФЛ ШДФЦ СЕРБ ШМЧЛ УДЫО МОУЦ УЙПШ РТЦШ ЯБЧФ ЖТУХ ЛХЕУ ЛГСБ СЕЦЩ ЗМСЭ
ЦЦБХ СЛЛЛ КДЧЛ ПЬНЪ УТЧЛ НХЧЦ ГХЭО ЧФУИ ЮЖЕЛ ХХДЧ ТТСФ БАГУ СЖУЙ СРУК лшнь
ЛФУИ retФ ЖТПС БЫЕО ТФУИ ИФДЛ ХХДН РДЬЛ РМКУ СФСО УТЗЖ РСУП ЩЙРЛ ЕТОЪ цепь
ЛМКЧ ОМУУ СЕРО ЙЙПЛ ЗМТО ЩЙНН КДТФ УРНЦ СЖЕУ РТЦШ ЛЫКТ ЕЯЬО ФПКУ РТКИ сжхл
ПГФЦ СЬРФ ММЧЛ УДЫО ЛДРЙ СФНШ ПДЧФ ЛЛСЛ РЙТУ ЮНПС БЫЦФ ШФЕУ вйчч вжпж ъйцш
ЕЙХЖ ДТЬЛ ЖТНЖ ОЗУЦ ЛЦСХ СЖЧФ УГКШ
Дело в том, что собранные для подсчета индекса совпадения цепочки симво-
лов — каждый первый, каждый второй и т. д. — можно представить как незави-
симые между собой шифры простой замены. И в таком случае решать уже М
(ведь такова длина гаммы, и соответственно столько различных цепочек символов
мы имеем) задач криптоанализа шифров простой замены.
Еще один способ заключается в использовании взаимного индекса совпаде-
ния (mutual index of coincidence). Он может использоваться для вычисления отно-
сительного сдвига гаммы для соседних символов шифротекста. Взаимный индекс
совпадения отвечает за вероятность совпадения двух наугад взятых букв из двух
различных текстов х и у и вычисляется следующим образом:
где индекс 1 у частот символов и количества символов т обозначает параметры
второй строки. Взаимный индекс совпадения для двух текстов х и у обладает до-
полнительно весьма интересным свойством:
> ' : . ’ i .‘1
i д > 4 л-1 i i '
Mtjx^y,) « ЕрЛ.яРл-5/ .= Ep/P(/-S)modn-
V ’ • Л=о .. «/
В нашем примере длина гаммы равна четырем. Соберем цепочки символов
так же, как мы делали это для вычисления простого индекса совпадения (см. лис-
тинг 3.24).
58
Гпава 3. Дешифрование классических шифров
Листинг 3.24
1) ФОЛСЛРСЛЖСУЮГМУЛОЕОСКЦФГГЛБЗЩИФГПКРТИРТДКФФХЛХЦШСШУМУРЯЖЛЛСЗЦСКПУНГЧЮХТЬСС
ЛЛГЖБТИХРРСУРЩЕЦЛОСЙЗЩКУСРЛЕФРСПСМУЛСПЛРЮБШВВЪЕДЖОЛСУФ
2) ДЗЦХЦЙПЩТЖГЩКМДУЙДАИДЗСПЕНЫММЦПНМДЙФПЯТТДМЦОЫЖХДЬМДОЙТБТХГЕМЦЛДЬТХХФЖХТАЖР
ШФСТЫФФХДМФТСЙТСММЕЙМЙДРЖТЫЯПТЖГЬМДДФДЛЙНЫФЙЖЙЙТТЗЦЖГГ
3) СУСЧНЦБЭЗЧКЗЙЧЫУЙЧТНЙНЕЕУПСЩХЦШТРХКККСЦСЗСНУКЕФФРЧЫУПЦЧУЕСЦСБЛЧНЧЧЭУЕДСГУУ
НУТПЕУДДЬКСЗУРОПКУРПТНТНЕЦКЬККХФРЧЫРНЧСТПЦЕЧПЦХЬНУСЧК
4) ЖЦЧФНРРЖХФТРФЛОЧФЛФУЦТЭЦЭСФОЩЕЭБОЖФКУЧФИОФФСЧОЛЦБЛОЦШШФХУБЩЭХЛЛЬЛЦОИЛЧФУЙК
ЬИФСОИЛНЛУОЖПЛЬЬЧУОЛОНФЦУШТОУИЛЦФЛОЙШФЛУСФУЧЖШЖЛЖЦХФШ
Каждая из этих цепочек могла быть получена, вообще говоря, с помощью
шифра простой замены, но в шифре Виженера они определяются циклическим
сдвигом алфавита на несколько позиций влево или вправо. Взяв несколько зара-
нее заготовленных цепочек русского текста, мы можем подсчитать, чему равен
индекс взаимного совпадения для различных сдвигов (см. листинг 3.25).
Листинг 3.25
Сдвиг: 0 ==> Взаимный индекс совпадения: 0.04338331
Сдвиг: 1 ==> Взаимный индекс совпадения: 0.03957709
Сдвиг: 2 ==> Взаимный индекс совпадения: 0.03832372
Сдвиг: 3 ==> Взаимный индекс совпадения: 0.03723952
Сдвиг: 4 ==> Взаимный индекс совпадения: 0.03433679
Сдвиг: 5 ==> Взаимный индекс совпадения: 0.03455978
Сдвиг: 6 ==> Взаимный индекс совпадения: 0.03354095
Сдвиг: 7 ==> Взаимный индекс совпадения: 0.03126490
Сдвиг: 8 ==> Взаимный индекс совпадения: 0.03077278
Сдвиг: 9 ==> Взаимный индекс совпадения: 0.02876586
Сдвиг: 10 ==> Взаимный индекс совпадения 0.02732026
Сдвиг: 11 ==> Взаимный индекс совпадения 0.02669358
Сдвиг: 12 ==> Взаимный индекс совпадения 0.02531334
Сдвиг: 13 ==> Взаимный индекс совпадения 0.02628989
Сдвиг: 14 ==> Взаимный индекс совпадения 0.02597463
Сдвиг: 15 ==> Взаимный индекс совпадения 0.02505575
Сдвиг: 16 ==> Взаимный индекс совпадения 0.02655902
Сдвиг: 17 ==> Взаимный индекс совпадения 0.02505575
Сдвиг: 18 ==> Взаимный индекс совпадения 0.02597463
Сдвиг: 19 ==> Взаимный индекс совпадения 0.02628989
Сдвиг: 20 ==> Взаимный индекс совпадения 0.02531334
Сдвиг: 21 ==> Взаимный индекс совпадения 0.02669358
Сдвиг: 22 ==> Взаимный индекс совпадения 0.02732026
Сдвиг: 23 ==> Взаимный индекс совпадения 0.02876586
Сдвиг: 24 ==> Взаимный индекс совпадения 0.03077278
Сдвиг: 25 ==> Взаимный индекс совпадения 0.03126490
Сдвиг: 26 ==> Взаимный индекс совпадения 0.03354095
Сдвиг: 27 ==> Взаимный индекс совпадения 0.03455978
Сдвиг: 28 ==> Взаимный индекс совпадения 0.03433679
Сдвиг: 29 ==> Взаимный индекс совпадения 0.03723952
Сдвиг: 30 ==> Взаимный индекс совпадения 0.03832372
Сдвиг: 31 ==> Взаимный индекс совпадения 0.03957709
Гпава 3. Дешифрование классических шифров
59
Из чего можем заключить, что, например, для нулевого сдвига в алфавите
русского языка взаимный индекс совпадения равен приблизительно 0.04338331
(не следует забывать, что для получения лучших оценок необходимо исследовать
гораздо более длинные тексты, чем несколько килобайтов, которые использовали
авторы этой книги для подсчета значений из листинга 3.25).
Для всевозможных пар цепочек из листинга 3.24 мы можем подсчитать вза-
имный индекс совпадения с помощью программы из листинга 3.26 (она же испо-
льзовалась и для вычисления значений взаимного индекса совпадения в листинге
3.25). От программы из листинга 3.24 она практически не отличается, за исклю-
чением лишь того, что рассматриваются две строки текста и формула вычисления
индекса совпадения изменена.
Листинг 3.26
double calc_mutual_coin(char *buf1, char *buf2, int len) {
int i;
double index_s = 0;
/I подсчитаем частоты для первой строки
double freqs1[N];
memset(freqsl, 0, sizeof(freqsl));
for (i = 0; i < len; i++) freqsl[bufl[i] - ’A‘]++;
I/ подсчитаем частоты для второй строки
double freqs2[N];
memset(freqs2, 0, sizeof(freqs2));
for (i = 0; i < len; i++) freqs2[buf2[i] - ‘A’]++;
// подсчитаем взаимный индекс совпадения
index_s = 0.0;
for (i = 0; i < N; i++) index_s += freqs1[i]*freqs2[i];
index.s = index.s / (len*len);
// выводим результаты
printf("Взаимный индекс совпадения: %1.8f\n", index.s);
return index.s;
}
Просматривая всевозможные варианты, сможем понять, насколько «сдвину-
ты» цепочки друг относительно друга. Результат работы программы представлен в
листинге 3.27.
Листинг 3.27
0, 1 == Взаимный индекс совпадения: 0.04073408
0, 2 == Взаимный индекс совпадения: 0.04166408
0, 3 == Взаимный индекс совпадения: 0.04470209
1, 2 == Взаимный индекс совпадения: 0.04123008
1, 3 == Взаимный индекс совпадения: 0.04154008
2, 3 == Взаимный индекс совпадения: 0.04439209
60
Глава 3. Дешифрование классических Фифров,
Сравнивая их со значениями из листинга 3.25, можем указать, насколько
сдвинуты все цепочки относительно первой. Для этого нужно подобрать наиболее
близкие значения взаимного индекса совпадения и, если их несколько, опробо-
вать их все. Сдвигая первую по одному символу N раз (столько же, каково число
букв в алфавите), получим N различных возможных сообщений. Выбрать из них
визуально осмысленное не составит большого труда. А это значит, что задача
криптоанализа шифра гаммирования решена.
Золотая криптография
Криптография всегда была одной из самых загадочных областей человече-
ской деятельности. Она притягивала к себе множество великих умов. Ею занима-
лись математики и короли, она была и остается страстью многих людей, посвя-
тивших свои жизни решению задач криптографии.
Многие известные люди занимались «тайнописью», разрабатывали свои соб-
ственные шифры и вскрывали другие. Так появились и правила Керкхоффа и ре-
шетка Кардано. Даже Л. Кэрролл в своей «Алисе в стране чудес» умудрился опи-
сать несколько криптографических загадок.
Эдгар Алан По творил чудеса в криптографии. Помимо многочисленных упо-
минаний о «секретных письменах» в его стихах и рассказах, как, например, в «Зо-
лотом жуке», он предложил свою собственную «криптографическую задачу», ко-
торая была опубликована в «Александрийском еженедельном вестнике» в начале
декабря 1839 года.
В своих статьях в этом журнале он предложил читателям представить ему за-
дачи и заявил, что решит их. все до единой. В течение следующих шести месяцев
Эдгар По публиковал решения шифров, присланных читателями, и объяснял
свою точку зрения на саму сущность криптографии.
Сотрудничество По с «Вестником» закончилось в мае 1840 года, но примерно
через год он снова поднял этот вопрос в статье «Несколько слов о секретной пись-
менности» в журнале «Грехем». В ней и трех дополнениях, последовавших за ста-
тьей, он утверждал, что дешифровал около ста шифров, полученных «Вестни-
ком», и далее комментировал свои взгляды на предмет криптографии.
Как раз в это время один из читателей По, мистер Тайлер, предложил два
шифра для публикации в «колонке шифров», которую вел По. Эдгар По так никог-
да и не опубликовал решения задач Тайлера. Это возбудило к ним особый инте-
рес — ведь из сотни предоставленных задач не были решены только эти две. По
сослался на то, что у него не было времени на решение этого вопроса, но все-таки
опубликовал сами задачи с предложением читателям решить их.
Наиболее интересным моментом являлось то, что существовала вероятность,
что По сам составил эти задачи. Единственным объяснением доказательства этой
теории было, что Тайлер — это просто псевдоним Эдгара По. Эту теорию впервые
выдвинули Луис Ренза в статье под названием «Тайная биография По» и позже
Шон Росенхейн в книге «Криптографическое воображение». И только решение
задач Тайлера могло подтвердить или опровергнуть эту теорию.
Глава 3. Дешифрование классических шифров
61
II] l. t§ П(§ [= = ( t [• <(*!( IK ' tSi t [*
-ЙЭГЛ[?(, iStssrt] t§§Kt [t [IPt] :
M: (§4 Illtst] t + 1IK.t§KII
*] [Si >i.),?||*] ?,§§( Ui (•
t§t[t O*] []:?]ll ' , ™
Рис. 3.7. Первый шифр Тайлера
Многие незаурядные шифровальщики проявляли интерес к задачам По в те-
чение нескольких лет, но ни один из них не предложил верного решения задач
Тайлера до недавнего времени.
Были даже объявлены соревнования, в которых требовалось раскрыть обе за-
дачи Тайлера, а за победу полагалось приличное денежноё'вознаграждение. Пер-
вый шифр Тайлера оказался более легким — шифром простой моноалфавитной
замены, а потому был вскрыт относительно быстро. Это сделал в 1992 году про-
фессор Теренс Вален (Terence Whalen). Текст сообщения выглядит следующим
образом:
The soul secure in her existence smiles at the drawn dagger and defies
its point. The stars shall fade away, the sun himself grow dim with age
and nature sink in years, but thou shall flourish in immortal youth, un-
hurt amid the war of elements, the wreck of matter and the crush of
worlds.
Но вот второй шифр Тайлера уже был не так прост, и найти его решение ока-
залось возможным только недавно, с использованием компьютерной вычисли-
тельной техники. Только спустя 150 лет вторая задача, оставленная По для своих
читателей, была решена Гилом Борза из Торонто (рис. 3.8).
Как видно из рис. 3.8, второй шифр представляет собой довольно разношер-
стный набор различных символов, которые на первый взгляд абсолютно незави-
симы.
Первой задачей было выяснение метода зашифрования и языка, на котором
было написано зашифрованное сообщение. Поскольку первое сообщение было на-
писано на английском языке и сам По говорил и писал на нем, то можно предпо-
ложить, что, скорее всего, и второй шифр тоже содержит сообщение на англий-
ском. Еще одним доводом, являются подсчитанные длины слов (в предположении,
что пробелы расставлены на границах слов сообщения), распределение,, которых
характерно для английского языка. .. , . . ,. , , ,, .
Повторения отдельные слов и частей слов указывают на то, что был исполь-
зован метод простой замены. Большое количество различных букв указывает на
полиалфавитность, видимо для того, чтобы сбить с толку частотный анализ. Ко-
62
Глава 3. Дешифрование классических шифров
То Edgar. А. Рое, Esq.
Dr OGXEW PJ4FyX NgUH XIA VQsMoa
xnTbjs SNB esVLnK3Y$ [СР тдо! HiZguoo
«Я NdD6^ aM° hJFXPdU! елнХдоЕэ Ta
QjarBXPeE yGMdUj дд SJLAAB n*Z TCf)DYRO
dhb ^FKxdgF ZdNsmejx фвд ojhj z^Jh. Mfc
woViecX»B yuiL Nxa AfksO iyafDV
Sp^I CEj^mSW bGeRxh aNjnu зауХцд^л дакдХЩх
м3 fCd JipK oF6AlTI Nd0Tr Чст 0*’ «UtBqP
SEB d^bLQu LpH nOija atSd dixy д\до сЕрпа^вХ
’aJz xyKSgo HxityW QgP qTia orq Rw
U&icame nk УГцд ®ah Xj^TIax Ye дЬ aaFqW
X^q«kUx«.33e Зе в Ах)01д ишеу n?c GjoQgg
одВдДтМа nk Ьсодц S.tbyigl N^q ogrjtf Xaucf
RZnK Слэ ль д^Х jDMNyjUjQx дВнХдВм
bz^L LsTjh pW енТо¥<Ц XIA Vi-gaMFrv
vA3hS'1R aHB n^g( имдХА1/ Гад HP*11
KySXtQajB Зз ущЬ bQIgmxvR д\э MjUiKX лр^
AxjGb Mfo aR^mrqQ cmt trz xihqEI ijSxWtB
CFo fo yx fjeo ia$TiSiR !®z Vokya® QXXh
4^Jm йсР<1э fokA К vaTA ® взмЕэ uts Aprl
Kj emy im 0<u
Рис. 3.8. Второй шифр Тайлера
нечно, повторения могут возникать еще и при использовании таких шифров, как,
например, шифр Виженера, но расстояния между видимыми повторениями не
имеют ни одного общего кратного, а потому подобные шифры были отклонены.
Некоторые слова были написаны буквами, которые были «отражены» или пе-
ревернуты слева-направо или вверх тормашками. Если посчитать все отраженные
и перевернутые символы одними и теми же, криптоанализ зайдет в тупик.
При этом символы были так равномерно распределены по всему тексту,
что не давали никаких зацепок. Подстановка вместо повторяющихся коротких
шифробозначений часто употребляемых английских слов тоже не дает резуль-
тата, поскольку из-за отсутствия достаточного объема текста сложно прове-
рить замены и на распределение частот, и на присутствие каких-либо шабло-
нов слов.
Именно поэтому к делу дешифрования был приобщен компьютер. Для занесе-
ния всевозможных вариантов написания английских букв для ввода в компьютер
пришлось использовать специальную кодировку, обозначая каждый символ на бу-
Глава-3. Дешифрование классических шифров
63
маге двумя символами в кодировке ASCII. Первый означает расположение, а вто-
рой определяет сам символ (рис. 3.9).8 9
A ]UB, ]SB, DSC, ]SD, [LE, [UG, [LI, [UT, ]SY
В [LC, [SF, [UH
C [SA, ]UI, [UG
D [UA, [SB, [LF, [LH, [SS
E [UB, DSC. [SG, [LJ, [UL, [UO, ]UP, ]LR, ]ST, UV, [SV, ]SX, [SY, JUZ, [SZ
F [LA, [LK, [LS
G [SX, ]LY
H ]SA, [UC, ]UD, ]SH, ]LJ. ]LM, [UN, [SP, ]SR, ]UW
I [UD, ]SE, [UF, [SK, [LM, ]UX
J
К
L [SD, [UE, ]SF, [LG, ]US
M [SE, JSG, JUK, [LQ, ]UY
N ]LA, [SH, [UI, ]SJ, [UK, ]UQ, ]SS
О ]LC, ]UF, ]LG, [SJ. ]SK, ]UM, [LN, ]UR, [UT, ]SU, [UY
P ]UE, ]LF, [SI, ]SM, [UZ
Q
R ]LE, DUG. ]LH, DSL. DUN, [SO, ]SQ, [UU, [UX
S ]UC, JLI, ]LK, [SL, DSN. [UP, [UV
T ]UA, DUG. [UM, DUO. DSP. [LR, [SR, [US, ]LT, [LU, ]LU, ]SV, ]SW
U [LD, [SM, [LP, [UQ, [UR, [LT
V [ST
W [LB, ]UL, [SN, [LO, [SO
X
Y [LL, [UW
Z [SU, [LV
Рис. 3.9
Для криптоанализа шифра была написана программа, которая сопоставляла
эту запись символов к словам из большого словаря на разные темы. Еще одна до-
полнительная программа искала в полученных совпадениях наибольшее количе-
ство общих символов. Однако результаты, получаемые с их помощью, не дали
9
нужного результата.
Иногда нужный результат может дать поиск подходящего открытого текста в
сети, но такие попадания «в яблочко» встречаются очень редко.
Последним шансом вскрыть шифр остается попробовать все подстановки по-
вторяющихся трехбуквенных сочетаний на часто употребляемые слова the, and,
not и т. д. Именно здесь и крылась разгадка шифра. Так, например, AmL вполне
8 На самом деле на рис. 3.9 показана нотация, в которой первый символ «[« или «]» обо-
значает соответственно переворот символа или его отражение. Второй обозначает заглавную
букву (U), строчную (L) или строчную большую (S). Третий символ содержит букву алфавита
в описанном двумя другими состоянии.
9 Как потом оказалось, шифр содержал ошибки, которые не позволяли осуществить поиск
по словарю. Таким образом, правильный в общем-то подход не дал нужного результата из-за
ошибок (возможно, преднамеренных) шифровальщика.
64 Гпава 3. Дешифрование классических шифров
отвечает артиклю the, поскольку стоит после одного длинного слова и после одно-
го длинного и одного двубуквенного, которое может обозначать предлог.
Подбирая таким образом слова, получим некоторый набор алфавитов. Допол-
нительно используем описанную выше программу для получения наиболее веро-
ятных словосочетаний (а их получается около 4000).
«Цепляясь» за слова, можно довольно быстро раскрутить всю цепочку. На-
пример, среди словосочетаний, которые предлагает программа, можно найти сло-
ва, привлекающие внимание: ardent, eye, and. После этого в шифрограмме полу-
чается слово, которое выглядит, как ...ter...n, а это не что иное, как afternoon. За-
тем появляются th... и ...ге и т. д. В результате получается следующий открытый
текст:
It was early spring, warm and sultry glowed the afternoon. The very
breezes seemed to share the delicious langour of universal nature, are la-
den the various and mingled perfumes of the rose and the — essaerne (?),
the woodbine and its wildflower. They slowly wafted their fragrant offe-
ring to the open window where sat the lovers. The ardent sun shoot fell
upon her blushing face and its gentle beauty was more like the creation of
romance or the fair inspiration of a dream than the actual reality on
earth. Tenderly her lover gazed upon her as the clusterous ringlets were
edged (?) by amorous and sportive zephyrs and when he perceived (?) the
rude intrusion of the sunlight he sprang to draw the curtain but softly she
stayed him. «No, no, dear Charles», she softly said, «much rather you'ld I
have a little sun than no air at all».
Очевидно, это и есть решение второй головоломки Тайлера-По.
Список литературы
1. Аграновский А. В., Хади Р. А., Ерусалимский Я. М., «Криптография и откры-
тые системы», Телекоммуникации, № 2, 2001 г., стр. 13—23.
2. Аграновский А. В., Балакин А. В., Хади Р. А., «Классические шифры и методы
их криптоанализа», М: Машиностроение, Информационные технологии № 10, 2001,
стр. 40—46.
3. Т. Jakobsen, «А Fast Method for the Cryptanalysis of Substitution Ciphers», руко-
пись, 1995.
4. J. C. King, «An algorithm for the complete automated cryptanalysis of periodic po-
lyalphabetic substitution ciphers», Cryptologia, 18(4), 1994.
5. Peleg, S. and Rosenfeld, A. «Breaking Substitution Ciphers Using a Relaxation Al-
gorithm» Comm. ACM Vol. 22(11) pp 598—605 (Nov. 1979).
6. Lucks, Michael, «А Constraint Satisfaction Algorithm for the Automated Decrypti-
on of.
7. Simple Substitution Ciphers», Advances in Cryptology — CRYPTO '88, Springer
Lecture Notes in Computer Science, vol. 403.
. 8. John Carrol and Steve Martin, «The Automated Cryptanalysis of Substitution Cip-
hers», Cryptologia, vol X number 4, Oct 86 p. 193—209.
Глава 3. Дешифрование классических шифров
65
9. John Carrol and Lynda Robbins, «Automated Cryptanalysis of Polyalphabetic Cip-
hers», Cryptologia, vol XI number 4, Oct 87 p. 193—205.
10. Martin Kofchanski, «А Survey of Data Insecurity Packages», Cryptologia, vol XI
number 1, Jan 87 p. 1—15.
11. Martin Kochanski, «Another Data Insecurity Package», Cryptologia, vol XII num-
ber 3, July 88, p. 165—177.
12. King and Bahler, «Probabilistic Relaxation in the Cryptanalysis of Simple Substi-
tution Ciphers», Cryptologia 16(3):215—225.
13. King and Bahler, «An Algorithmic Solution of Sequential Homophonic Ciphers»,
Cryptologia, April 93 (in press).
14. R. Spillman et.al., «Use of Genetic Algorithms in Cryptanalysis of Simple Substi-
tution Ciphers», Cryptologia, vol XVII Number 1, Jan 93 p. 31—44.
15. Gaines, H. F. 1956. Cryptanalysis. New York: Dover Publications.
, 16. Sinkov, A. 1966. Elementary Cryptanalysis. The Mathematical Association of
America. <
3 Зак. 85
Глава 4
Как устроены современные шифры
Блочный шифр — это криптографическая систе-
ма, которая делит открытый текст на отдельные
блоки, как правило, одинакового размера и неза-
висимо оперирует с каждым из них с целью по-
лучения последовательности блоков шифрован-
ного текста.
Е. Smid, D. К. Branstad.
The Data Encryption Standard:
Past and Future
. Несмотря на активное развитие и повышенный интерес к «математическому
Клондайку» асимметричной криптографии, блочные и поточные шифры остаются
верной надежной лощадкои.на использование которой опираются все без исклю-
чения современные криптосистемы.
При передаче и хранении, ценной или секретной информации ее защищают с
помощью криптосистем, смешанного типа, С помощью двухключевых асимметрич-
ных алгоритмов решается задача распределения ключей для симметричных шиф-
ров., А затем все передаваемые данные шифруются с помощью блочного или по-
точного шифра. Блочные шифры также используют в качестве криптографиче-
ских функций для организации криптостойких хэш-функций и выработки
имйтовставо'к для защиты сообщенйй от подделки и подлога.
<! .'..I,,.,. 7 ‘ ’
Дрким образом, одно из главных мест в создании защищенных информацион-
ных систем и обеспечении криптографической защиты занимают именно блочные
и поточные шифры как быстрый и весьма надежный метод преобразования дан-
ных, направленный на то, чтобы сделать эти данные бесполезными для непосвя-
щенных лиц.
Поскольку потенциальные авторы криптографических алгоритмов должны
исходить из практичности й эффективности своих детищ, необходимо четко пред-
ставлять себе задачи, которые должны быть решены с помощью созданных алго-
ритмов. Останавливаясь на главном, необходимы такие криптографические пре-
образдвания, которые бы обеспечивали решение двух главных проблем защиты
даййых, а именно:
проблему конфиденциальности (секретности), то есть лишение противника
( . возможности 1извлень.информацию и3’канала связи;
. г1»чпроблему' имитостоикости, а именно лишение противника: возможности
jt! ввести'ложную, информацию или. изменить данные так, чтобы изменился их
• Ч7-'СМЫСЛ'..fji.j'ii'.;,! , о
..„В общем.,случз^ эти требования являются независимыми и методы их обеспе-
чения весьма различаются. К примеру, хотя на сегодняшний день классическая
Гпава 4. Как устроены современные шифры
67
схема однократного использования гаммы10 (см. раздел «Использование однократ-
ного гаммирования») остается единственной безусловно стойкой системой шиф-
рования, тем не менее она вовсе не является имитостойкой и, более того, подвер-
жена подлогу с очень большой вероятностью.
Создание шифра или любого другого алгоритма обычно вызвано не каким-то
общим стремлением создать новый метод криптографического преобразования
данных, а призвано решить гораздо более приземленную практическую задачу.
На этапе формирования задачи специалист должен принять решение, какой шифр
или другой криптоалгоритм ему лучше использовать, чтобы достичь максималь-
ного эффекта. Критерием эффективности может быть скорость обработки, надеж-
ность или сложность анализа. В зависимости от типа задачи может быть выбран
поточный или блочный шифр. Оба вида имеют свои преимущества и недостатки и
должны быть выбраны с позиции максимальной эффективности при максималь-
ной безопасности.
Собственно, понятия блочного и поточного шифров сами по себе в околона-
учных кругах представляются довольно абстрактными, а уж разговоры об отличи-
ях блочных шифров от поточных для непосвященного могут показаться и вовсе
интеллектуальным состязанием в философских размышлениях. Тем не менее все
не так сложно, и мы постараемся разобраться в принципах построения и тех и
других, а значит, обязательно увидим, чем они отличаются.
Вкратце же, с точки зрения создателя криптоалгоритмов, основное отличие
блочных шифров от поточных заключается не только в свойстве блочных шифров
преобразовывать сразу блоки битов данных, в отличие от поточных шифров, опе-
рирующих с битами раздельно. К сожалению, эта расхожая точка зрения не явля-
ется истинной в полной мере. Это лишь свойство шифров, но не их принципиаль-
ное отличие. Вообще блок для шифра — это некоторая порция данных, возможно,
фиксированного размера, которую он может преобразовать за один цикл работы.
Основное же и принципиальное отличие лежит в архитектуре, то есть
устройстве самих шифров и реализующих их алгоритмах. Разделение здесь мож-
но провести следующим образом.
Поточные шифры, в отличие от блочных, обладают памятью предыдущего со-
стояния шифра. На его основе и с привлечением некоторых дополнительных
криптографических преобразований поточная шифросистема вырабатывает теку-
щий ключ для каждого следующего элемента открытого текста (например, симво-
ла или бита). Используя этот ключ, с помощью некоторого преобразования и за-
шифровывается каждый такой элемент, являющийся для шифросистемы атомар-
ным, то есть неделимым.
Блочные же шифры не обладают таким устройством запоминания своего пре-
дыдущего состояния. Криптографическое преобразование данных они осуществ-
ляют в зависимости от итерационных подключей, которые вырабатываются из
главного ключа. И шифрование строится только на основе: ключевой последовате-
льности и криптографичеких примитивов. То есть блочный шифр может сгенери-
’ 10 Конечно же при условии равновероятности гаммы и того, что ее длина больше либо рав-
на длине зашифровываемого текста. 1 1 !'
3*
г, ,68 Глава 4. Как устроены современные шифры
рорать. вре необходимые ему дл,я работы подключи сразу, и зависеть они будут т,о-
. лько, от исходной ключевой последовательности. Хотя, здесь опять возникает не-
которая неопределенность,,если рассматривать существующие блочные шифры,
, для .которых описаны алгоритмы, работы в режиме поточного гаммирования, —
это,,например,. ГОСТ 28147—89 и DES..B таком.случае, будучи например, испо-
льзованным в режиме гаммирования. с обратной связью,11 блочный шифр работа-
ет как поточный. , . , ,
, :;Во многих случаях при сравнении блочных и поточных шифров, можно сде-
-I дать вывод ,о,том, что блочные шифры представляют собой более надежный и бы-
, стрый инструмент,, нежели1 поточные. Это происходит по нескольким причинам.
.. .; В силу того)что зашифрование для блочных шифров осуществляется одновре-
менно блоками по нескольку символов (байтов) текста, пространство шифровели-
чин и шифробозначений у .блочных шифров значительно больше, чем у поточных.
. Многие методы криптоанализа основываются на ресурсоемких вычислениях, объ-
. ем которых значительно зависит от объема используемого шифром алфавита
; шифруемого текста.(в.обшем случае,эта зависимость выражается через экспонен-
циальную функцию). ► • < • .
1 Соответственно чем больше объем алфавита'шифротекста — а это не что
иное, как объем пространства шифробозначений и объем пространства шифрове-
личйн'(если они совпадают),— тем вычислительно сложнее вскрыть шифр общи-
' мй' и некоторыми(частными методами. криптоанализа.
1 В то жё время чем больше объем алфавит^, тёМ больше приходится энтропии
на один знак шифробозначений. В этом случае блочный шифр начинает дополни-
тельно вести себя как омофоническая система (см. раздел «Энтропия, расстояние
единственности. Омофон».), а следовательно, его статистические свойства при-
ближаются к свойствам случайной функции. В ряде случаев это является одним
из критериев того, что шифр является достаточно криптостойким.
С другой стороны, для блочных шифров усложняется и анализ стойкости, за-
ставляя авторов блочных шифров придумывать изощренные методы криптоанализа
и способы доказать стойкость используемых криптографических преобразований.
Возникновение блочных шифров
Шеннон в своей работе предложил рассматривать блочные шифры как наибо-
лее эффективное перспективное средство обеспечения конфиденциальности со-
общений в системах секретной связи. Он построил свою первую модель секрет-
ной системык5'Ярмошью;алгебры.шифров, введя понятия их суммы и произведе-
: ния? Надо Сказ'а'ть, ‘ ЧТб^'' перенеся' математические1 понятия в -криптографию,
Щёнйок‘сдёлёлiio; Herd’fee сделал еще ни Один криптограф'до него1, — он прёёра-
"тйл криптологию в настоящую техническую научную'сфёру исследования. На ёе-
. роднивший день .для^мрделирования .шифров и цх. анализа, уже существует не
(„ ,, Для аналога /нифросистемы в соответствии с ГОСТ 28147—89— шифра DES подобный
„ режим работы назван Ciphertext Feedback.
Гпава 4. Как устроены современные шифры
69
один способ: это теория автоматов, теория групп, теория вероятности и многое
другое. Новейшие достижения только по каждой из них позволяют весьма эффек-
тивно исследовать различные свойства современных шифров и предлагать новые
методы криптоанализа. Многие весьма интересные свойства блочных шифров
оказались легко формализуемы именно с их помощью. Например, все раунды
шифра Rijndael могут быть описаны с помощью алгебраических уравнений над ко-
нечными полями, если воспользоваться теорией групп.
Изначально же существовал лишь способ, описанный Шенноном в своей ста-
тье о математической секретности. Сама статья разбита на несколько частей, и в
одной из них описана структура алгебры шифров.12 Введение алгебры шифров
также может быть весьма полезно не только для теоретика-математика, но и для
практика-программиста.
Возможность сложения двух криптосистем X и У, по Шеннону, — это шиф-
росистема Z = сумма(Х, У), которая заключается в использовании шифросистемы
X с некоторой вероятностью р или шифросистемы У с вероятностью q = 1 - р. Вы-
бор того, какую именно шифросистему использовать, содержится в значении
ключа, который будет применен к сумме Z этих шифросистем. То есть на самом
деле Z = рХ + qY.i3 А произведение Z = XY представляет собой последовательное
применение сначала шифросистемы X, а затем уже У.
На практике этот довольно формальный подход к описанию модели можно
представить и несколько по-иному. Предположим, что реализованы два алгоритма
шифрования -г- две шифросистемы, которые в обычной программе представлены
функциями F и S (см. листинг 4.1).
Листинг 4.1
uint8_t *F(uint8_t «text, int len) {
for (int i = 0;'"i < len; i++) { // каждый символ текста
text[i] "= i; , // гаммируем с его позицией
• >
return text;
}
uint8_t *S(uint8_t «text, int len) {
for (int i = 0; i < len; i++) { // каждый символ текста
text[i] = (text[i] + i) % OxFF; Ц складываем с его позицией no модулю
>
return text;
}
12 Поскольку речь в книге идет по большей части только о криптографических системах,
то и название адгебры криптосистем (а также алгебры шифров и алгебры шифросистем)
авторы.сочли возможным дать немного отличным от термина алгебры секретных систем, о
которой и рассказывается в работе Шеннона. В рамках данной книги эти термины носят харак-
тер синонимов.
1 12 Шеннон использует пднятия, близкие теории вероятности, формулируя термины алгеб-
ры криптосистем очень похожими на алгебру вероятностных событий в теории вероятности.
Вообще же рассмотрение криптосистемы как вероятностного источника сообщений достаточно
продуктивно — многие криптоаналитические тесты построены именно на этом предположении.
70 \
Глава 4. Как устроены современные шифры
Обе-функции в нашем-частном случае не зависят от ключа (именно поэтому
соответствующий' третий аргумент пропущен в их описаниях в исходных тек-
стах)1. Однако практически ничего не меняется и в случае, когда одна или обе
шифросистемы зависят от ключа. . •
Как видно из листинга, выход обеих шифросистем совпадает по типу между
собой и аргументом -,т- блоком, данных с. открытым текстом. Это позволяет со-
здать, программные функции суммы этих шифросистем и их произведения (см. ли-
стаж 4l2)j '
-f )!! . * >' S 'i • • • »’•
Листинг 4.2
uint8_jt ‘Sum_of_F_S(uint8_t ‘text, int len, int k) {
’* !if (k & 1 ! = 0) 1 // в зависимости от ключа
,fl'Teturn F(text, len); // используем одну шифросистему
'.’else- н
! • return S(text, len); // пли-другую, но не обе сразу
} -• ।, । ?।' 1
uinJ8_t ,‘Other_sum_of_F_S(uint8_t ‘text, .,int len, int k) {
if (k.> len) k = len; // проверка на случай недопустимых ключей
<, .; F(text, -k);- • i// используем одну шифросистему для одной части
//,текста,<., , 1(1/, i >.
..Bitext,, Jen - ,k); . ,ч . . ,// ^другую,для всего остального
.return text;,
} “7 7' ' 77,77. 7 ’
uint9ut. *MUL^0F_F_S(uint8_t'i*text, int* len) {
F(text, len); // сначала используем один шифр
S(text, len); , , .. // потом другойt
"’'return text;
} ’ '' “ ‘7 7.7 7 '
Обратите внимание на функцию other_sum_of_F_S(), которая также, как и
функция sum_oL_F_S(), является суммой (!) шифросистем, поскольку содержит
зависимость от ключа. Поскольку используем одни и те же типы данных одновре-
менно! для выходов шифров и аргументов шифрующих функций, мы уже можем
строить все более сложные и сложные их композиции, создавая сумму произведе-
ний и произведения сумм различных шифров.
-И.вот тут надо отметить, что именно идея построения алгебры шифров оказа-
лась весьма продуктивной. Определив суммы и произведения шифров, Клод Шен-
нон-,-так-же как и мы.только что, создавал и исследовал своего рода «бутерброды»
из\«ампозиции-различных-шифров. Правда, для своих исследований он использо-
валошифры перестановки? и -замены-.' ^акяе композиционные шифры для него
представлялись наиболее удачным решением двух проблем. И это оказалось дей-
ствительно! так.гИсходя.цз ^практических соображений, Шеннон представил две
задачи криптографии дляссиммет.ричных шифров. '.. ;;
к Первая задача .представляет, собой задачу рассеивания, которая заключается
в необходимости иметь у -шифра такое свойство, что малейшее изменение (или,
как еще говорят математики-алгебраисты, «возмущение») открытого текста вызы-
Глава 4. Как устроены современные шифры
71
вало значительные изменения выхода шифра, то есть шифротекста. Такой шифр
совершенно очевидно даст криптоаналитику гораздо меньше возможности иссле-
довать взаимосвязи между участками открытого и зашифрованного текстов, чем
не обладающий таким свойством. Само же свойство обычно называют свойством
лавинного эффекта (avalanche) или просто лавинным эффектом.
Создать хороший алгоритм с лавинным эффектом не так-то просто, как мо-
жет показаться. И главным образом из-за того, что существует необходимость в
детерминированности всех операций шифра, ведь иначе невозможно будет по-
строить обратное отображение и, следовательно, расшифровать текст даже упол-
номоченному на то получателю.
Строго говоря, чтобы добиться хорошего лавинного эффекта, используют
методы рассеивания (diffusion) информации. Шеннон, например, под рассеива-
ниемпонимал некоторое абстрактное преобразование, при котором изменение
одного бита значения аргумента влекло бы за собой изменение почти всех би-
тов значения результата преобразования, то есть при изменении одного бита
значения аргумента должно повлечь за собой изменение каждого из битов ре-
зультата с вероятностью, близкой к или равной для каждого из битов выхо-
да. Это дает математическое обоснование стойкости шифра к анализу: не имея
преимуществ при расстановке вероятностей изменения какого-то конкретного
бита перед всеми остальными битами, криптоаналитик также не сможет изв-
лечь никакой полезной информации и из статистического анализа выхода шиф-
ра (напомним читателю, что примитивный подсчет частот или использование
марковской модели текста — это простые разновидности анализа статистиче-
ских свойств шифра).
Шеннон, видимо, сознательно отошел от проблемы конкретной реализации,
предоставив описание свойства на суд криптографической общественности и его
реализацию наиболее изобретательным из них. Наиболее удачливым криптогра-
фом, первым предложившим элегантный и практичный способ организации свой-
ства рассеивания, оказался Хорст Файстель, работавший с Шенноном на протя-
жении длительного времени.
Вторая задача построения стойких шифров заключается в необходимости со-
здания полной зависимости каждого бита результата криптографического преоб-
разования, иными словами, все того же выхода шифра, от всех битов исходного
открытого текста. Видимо, поэтому такое свойство для шифра назвали свойст-
вом полноты. Вкупе со свойством рассеивания полнота дает шифру тотальную
зависимость от ключа и открытого текста. Полнота шифра зависит от его переме-
шивающих свойств, наследуемых с полным правом от свойства перемешивания..
(confusion), осуществляющего зависимость преобразования данных от ключевой .'
информации.
Собственно говоря, в строгой трактовке полнота шифра описывается следую- >
щим условием, в котором для каждого бита i выхода шифра и произвольного бита
/ открытого текста существуют два различных открытых текста, отличающихся
только в этом произвольном бите i, но имеющих один и тот же выход, за исключе-
нием бита /. . ।
72 Глава 4. Как устроены современные шифры
Надо заметить, что в ряде случаев от криптографической функции требуется
полнота только для открытого текста, как, например, в отечественном стандарте
шифрования, где ключ гаммируется с открытым текстом перед шифрованием. Не-
которые же криптографические примитивы строятся как зависимые от ключевой
последовательности преобразования. В таком случае они должны иметь свойство
полноты для всех или почти всех возможных значений ключа.
Конечно, полноты и рассеивания просто не может быть в листингах 4.1 и
4.2, поскольку функции шифрования там зависят не только от ключа, но и от от-
крытого текста. Но в реализации настоящих шифровальных алгоритмов эти фун-
кции присутствуют. Что именно дает присутствие обоих этих свойств у шифра?
Обе задачи схожи между собой. Они лишь представляют разные подходы к од-
ной общей большой задаче. Отсюда и зеркальность свойств рассеивания и полно-
ты. Кроме того что рассеивание очень сильно затрудняет поиск зависимостей
между битами исходного и шифротекста, идеальное рассеивание также играет
роль функции, распределяющей ключи равномерно по всему ключевому про-
странству. Это значительно затрудняет поиск ключей-близнецов или, как их еще
называют, эквивалентных ключей, то есть ключей, для которых зашифрование
одного и того же открытого текста даст тот же самый шифротекст.14 А это
усложняет некоторые универсальные криптоатаки (о них мы поговорим несколь-
ко позже в разделе, посвященном криптоанализу) на блочные шифры. Полнота
защищает от возможности криптоаналитику получить дополнительную информа-
цию о связях внутри шифра и его зависимости от ключа. Таким образом, мы от-
резаем ему все пути атаки.
Считается, что, поскольку обе указанные проблемы криптографии (то есть
проблемы построения и обоснования верности построения ;функций, реализую-
щих рассеивание и являющихся полными) симметричных шифров были описаны
впервые самим Шенноном, он также достиг и наилучших теоретических резуль-
татов на некоторое время после этого. А вот что касается практической реализа-
ции, то ее эффективная версия появилась далеко не сразу — только в середине
60-х годов была впервые опубликована надежная схема, реализующая оба этих
основных свойства.
Тем не менее сам Шеннон, по-видимому занявшись изучением влияния раз-
личных преобразований текстов на их энтропию, выделил из общей массы раз-
личных линейных и нелинейных способов модификации текстов два класса.
Именно с их помощью он хотел добиться преобразования рассеивания и преобра-
зования перемешивания. Да и с теоретической точки зрения криптографические
полные функции рассеивания исследованы еще не полностью. Многие результа-
ты зачастую дает практика, для которой теоретическое обоснование находится
весьма тяжело. Впрочем, существует очень много технических способов.реализа-
ции вполне приемлемых криптографических примитивов. . ; 1
14 Один и тот же шифротекст из-за однозначности расшифрование всегда даст один и тот
же открытый текст. Но в случае, когда существуют эквивалентные ключи, дешифровать шиф-
ровку во многих случаях будет проще. Ведь вместо того чтобы найти какой-то один-единствен-
ный ключ, криптоаналитик сможет найти любой из двух, трех и т. д. эквивалентных ключей.
Гпава 4. Как устроены современные шифры
73
Единственным ощутимым минусом шенноновского принципа композицион-
ных сложных шифров является необходимость того, чтобы все простейшие функ-
ции шифрования в большом «бутерброде» из их множества были обратимы. Ина-
че, зашифровав текст, мы не сможем найти способ его не то что дешифровать, но
и расшифровать. Для программирования шифров это также представляет некото-
рые неудобства — ведь теперь, кроме функции зашифрования, требуется реали-
зовать адекватную функцию расшифрования.
Снова обращаясь к листингам 4.1 и 4.2, можно заметить, что функция F() яв-
ляется тождественной к своей обратной, то есть зашифровывать и расшифровы-
вать можно, используя только функцию F(), и ничего более. Что весьма удобно,
не правда ли?
А вот для функции S() такого не наблюдается. Следовательно, придется на-
писать дополнительную функцию расшифрования S_back(), а это означает, что
точно так же надо будет написать еще и функции расшифрования sum_of_F_S(),
other_sum_oLF_S(), mul_oLF_S() и все функции, которые используют S(). Учи-
тывая необходимость проверки корректности реализации алгоритма и всевозмож-
ные длительные тесты, которые придется делать для увеличившегося в два и бо-
лее раз исходного текста программы, необходимость наличия обратного преобра-
зования может показаться чрезвычайно неудобной. Хотя в каком-то конкретном
случае это может быть и не так.
Например, современный блочный шифр 3-WAY создан именно на основе при-
менения обратимых преобразований. В качестве размера блока в нем выбрано
значение, равное 96 битам. Зашифрование каждого блока происходит за 11 раун-
дов, в течение которых данные подвергаются множеству прямых преобразований
с помощью простых функций.
В качестве таких функций было выбрано пять преобразований, включающих
в себя: .
’• простую, перестановку бит в обратном порядке;
• перестановку, зависящую от ключа;
• функцию замены для 3-битовых векторов;
• два типа вспомогательных перестановок, зависящих от ключа;
• специальную линейную функцию, использующую арифметику поля Галуа
характеристики 2.
Но самым простым в работе шифра представляется алгоритм выработки ите-
рационных подключей. В силу устройства архитектуры шифра размер ключа ра-
вен размеру блока — 96 битов, а подключи имеют тот же размер, что и главный
ключ. Они вычисляются путем прибавления некоторой константы — двоичного
ректора, содержащего относительно небольшое количество единиц.
:::; Расшифрование.шифротекста происходит аналогично, за исключением того,
что все преобразования берутся обратными и их порядок применения ставится
обратным к порядку зашифрования.
п Кстати,’’автор этого алгоритма Йоан Дэмен (Joan Daemen) фигурирует в ан-
н&лах криптографии так Же, как соавтор блочного шифра SQUARE, который стал
прототипом для AES — нового стандарта шифрования США.
<74
Глава 4. Как устроены современные шифры
Сеть Файстеля
В начале 1970-х годов, сознавая необходимость защиты уже электронной ин-
формации при передаче данных в сетях ЭВМ (особенно бизнес-транзакций, при
осуществлении денежных переводов и передаче конфиденциальных финансовых
данных), компания International Business Machines (она же известная во всем
мире как IBM) приступила к выполнению собственной программы научных иссле-
дований, посвященных защите информации в электронных сетях, в том числе и
криптографии. Так развитие одной передовой технологии повлекло за собой на-
стоящую революцию в другой.
Поскольку в ряде университетов Соединенных Штатов (таких, как Стэнфорд-
ский университет и Массачусетский технологический институт) всегда существо-
вал интерес к данной области исследования, IBM постаралась привлечь универ-
ситетских специалистов к разработке методов защиты электронной информации.
Это было отчасти вызвано и тем, что многие из специалистов этих университов
активно сотрудничали с военными кругами и соответственно специалистами во-
енной разведки — основными потребителями криптографических методов сокры-
тия и защиты информации. Поэтому университетские криптографы обладали не-
сколько большими объёмами информации о защите информации, нежели другие
профессиональные математики и аналитики. Ведь военные специалисты в то вре-
мя были единственными источниками достойной научной информации, посвящен-
ной криптографии, хорошо знавшими криптографию не только с теоретической,
но и практической стороны.
Команду разработчиков фирмы IBM, приступившую к исследованию систем
шифрования с симметричной схемой использования ключей, возглавил доктор
Хорст Файстель, в то время уже ставший довольно известным криптографом.
Файстель до того момента уже успел тесно поработать с Клодом Шенноном в
компании Bell Laboratories. Идеи Шеннона вдохновляли многих исследователей
на оригинальные изобретения. Свидетельством тому является довольно большое
количество патентов, зарегистрированных и принятых в середине 60-х годов На-
циональным патентным бюро США (United States Patent and Trademark Office).
Файстель активно сотрудничал с Шенноном и не мог не заразиться его идеями.
На его счету как минимум два патента и несколько революционных статей в обла-
сти криптографии и криптоанализа.
Воплотить.большую часть из своих идей в жизнь он смог с помощью возмож-
ностей, предоставленных ему компанией IBM, не жалевшей денег и специалистов
на разработку новых методов защиты электронной информации. Передовая тех-
нология требовала инвестиций и отнюдь не гарантировала быстрой отдачи, требо-
валось время на разраббтку действительно эффективных средств защиты элект-
ронного документооборота — эффективной и стойкой к взлому шифросистемы и
методов ее использования. Представители руководства IBM понимали это и в до-
статочной степени предоставили свободу разработчикам, поставив перед ними в
общем-то нелегкую и нетривиальную задачу.
. ' Надо признать, что результат оправдал ожидания. Им стала проведенная в
исследовательской лаборатории IBM Watson Research Lab разработка новой ори-
Глава 4. Как устроены современные шифры V75
гинальной архитектуры построения симметричных шифров на базе необратимых
преобразований. Архитектура нового способа шифрования впоследствии была на-
звана в классической литературе архитектурой Файстеля (ца данный мрмент в
русской и зарубежной криптографии существует более устоявшийся термин^реть
Файстеля или Feistel's network). Позднее, в соответствии с разработанными ^Хор-
стом принципами, был сконструирован шифр Люцифер. (Lucifer) — первый .серь-
езный блочный шифр, описание которого появилось в открытой, литературе. игвы-
звало новую волну интереса специалистов к криптографии, в целом., . .. . ,
Построение сложных криптографически стойких, но обратимых преобразова-
ний представляет собой довольно трудоемкую задачу., Кроме того, практическая
реализация обратимых преобразований обычно , содержит, неэффективные алго-
ритмы, что приличным образом сказывается на.скорости/шифрования. По этой
причине Файстель решил не искать решение проблемы обратимого преобразова-
ния данных, а попытаться найти схему шифрования, в которой такие, преобразо-
вания не участвовали бы вовсе. ........
Идея использования операции «исключающее ИЛИ» возникла из .классиче-
ских примеров систем шифрования, а именно из идеи использовать .самый( Про-
стой с технической точки зрения способ шифрования ,— гаммированне. Стой-
кость такого способа, как известно, зависит от свойств вырабатываемой гаммы.
Следовательно, процесс выработки гаммы — двоичной последовательности-,.кото-
рую затем суммируют с открытым: текстом,’,-п.является--самым узким ме.стом.во
всем способе. ..... <, , . •
Файстель разрешил проблему следующим образом. Изначально выбирается
размер блока данных, который будет зашифрован, за..одну итерацию/алгоритма
шифрования. Обычно размер блока фиксирован,и; не изменяется вовремя работы
алгоритма над открытым текстом. Выбрав достаточно большого,размера’блок.дан-
ных, его делят, например, пополам и, затем работают с каждой из половинок. Если
размер левой половинки равен размеру правой»; такую архитектуру > называют
классической или сбалансированной сетью Файстеля.. Если же деление блока
данных происходит не на равные части, то такой алгоритм называют разбаланси-
рованной сетью Файстеля. ’ . . . ...
Предложенная им схема шифрования легко может быть продемонстрирована
с помощью схемы шифрования (рис. 4.1). < , , i.H
На изображенной схеме буквами L, и /?( обозначены левая и правая половин-
ки исходных данных на t-м шаге последовательного преобразования. Каждый та-
кой целый шаг называют раундом шифрования. Функция гаммирования. обозначе-
на через Fit поскольку на каждом раунде может быть использована своя .собствен-
ная функция. Ключ также имеет Индекс /, но уже р силу тогр. что исходныйгкдюч
Сможет быть преобразован некоторым образрмКгрворят, развернут}«„последова-
тельность итерационных ключей, либо;подключей,„то,«стьжлючей. которь^испо-
льзуются непосредственно функцией .гаммировадия. йкл./гч^г?/:;' ; нг.етзк
. Как видно из скемы, .сначала с помощью функции>оаммирования вырабатыва-
ют гамма-последовательность, которая завиеитгот итерационного, ключа ^,.и*пра-
вой половины данных. После этого левая половинка-просто.суммируется ю полу-
ченной гаммой по модулю, например, 2. Затем левая и «правая,половинки меняют-
76
Глава 4. Как устроены современные шифры _
Рис. 4.1. Архитектура сети Файстеля
ся местами. На этом один цикл шифрования заканчивается. Поскольку за один
раз обрабатывается только одна половина данных, желательно, чтобы число раун-
дов было кратно двум. В таком случае есть уверенность, что каждая из половинок
будет обработана одинаковое число раз. На схеме рис. 4.2 отображена сеть Фай-
стеля с четным числом раундов.
Исходя из данного описания, преобразование данных одного раунда можно
представить с помощью двух формул, выражающих новые значения левой и пра-
вой половинок блока шифруемых данных:
Д+i =
‘ R,+i = Z,
Архитектура разбалансированной сети Файстеля выглядит весьма похоже на
архитектуру обычной сети и определяется таким же способом. Единственное, но
весьма существенное отличие состоит в том, что, поскольку используется разбие-
ние не на равные половинки блока, а на участки различной длины, функция гам-
мирования, обозначенная буквой «Г», может зависеть не от всех битов исходного
блока данных или иметь разные зависимости в разных раундах.
Собственно говоря, разбалансированную сеть Файстеля можно рассматри-
вать как обобщение понятия сети Файстеля. Стойкость криптосистемы, построен-
ной на основе сети Файстеля, зависит целиком от результата исполнения нели-
нейной функции гаммирования в нескольких итерациях. Поэтому для обеспече-
ния достаточной надежности данные должны быть преобразованы с достаточно
большим числом раундов, что позволяет достичь требуемых свойств рассеивания
и полноты и соответственно стойкости шифра к дифференциальному, и линейному,
криптоанализу (см. раздел «Современные-методы криптоанализа»). <
В большинстве шифров с архитектурой сети Файстеля используемая функ-
ция F в течение каждого раунда зависит только от одного из подключей.выраба—
тываемых из основного ключа шифра. Это свойство на самом деле не является
основополагающим или положительно влияющим на стойкость шифра — в шиф-
Глава 4: Как устроены современные шифры
77'.
Рис. 4.2. Сеть Файстеля с несколькими раундами
ре Khufru, например, параметры функции F изменяются после зашифрования.;
каждого следующего символа. Сеть с такого рода зависимостью функции/ гамми-
рования называют гетерогенной и гомогенной, в: противном случае^ Применение.1,-
гетерогенных сетей может значительно, улучшить.характеристикилшифрау поскок,
льку неравномерное! измененйё внутренних?свойств' сетшвшределах допустимых:
границ делает-изучение -свойств шифра достаточно-затруднительным ;занятиемр<
Меняя размеры-половинок и. Их? влияни^/на,выход шифрам можно! добиться впе-
чатляющих статистических/результатов, поскольку/существует -очевидная завип.
сймость не только между'Сложностью функции гаммирования,' но и. структурой-
используемой сети Файс'геля;' .. i-rm ммь. чк'.... с-;?,,
( 78
Гпава 4. Как устроены современные шифры
Рис. 4.3. Архитектура разбалансированной сети Файстеля
I
I Целью построения блочных шифров является не только создание стойкого
алгоритма защиты информации, но и такого, чтобы его реализация была достаточ-
но дешевой, а время работы как можно более меньшим. Именно поэтому, легко
реализуемые шифры на базе гомогенных сбалансированных сетей Файстеля при-
; меняются гораздо чаще и считаются своего рода «панацеей». Однако это вовсе не
! означает, что они являются более криптостойкими и надежными.
i Естественным путем увеличения сложности анализа сетей Файстеля являет-
ся следующий метод (кстати, использованный и в алгоритме в соответствии с
' * 1 ГОСТ 28147—89 — отечественным стандартом криптографического преобразова-
ния данных). Для того чтобы распространить влияние функции F в одном раунде
i на выход и функцию следующего раунда, к выходному значению F прибавляют по
Некоторому модулю значение итерационного подключа для текущего раунда и за-
тем полученное значение подают на вход функции F следующего раунда шифро-
’ вания. Такой способ организации сети ставит выходы последующих раундов шиф-
ров в прямую зависимость от предыдущих, что способствует организации лавин-
ного эффекта и полноты.
Примером практической реализации сбалансированной гомогенной сети
Файстеля может служить следующий исходный текст (см. листинг 4.3):
Листинг 4.3
uint16_t F_Gamma(uint16_t data_half, uin8_t key) {
// используем какие-либо сложные преобразования
И но желательно такие, чтобы их выполнение было как можно более быстрым
1 return (data_half " ((uint16_t) key * 0xABCD1234);
}
uint32_t Feistel_Network(uint32_t data, uint8_t key, int rounds) {
uint16_t left, right, swap;
left = data & OxFFFF; // делим данные (размер 32 бита)
right = (data » 16) & OxFFFF; // на половинки по 16 битов
Гпава 4. Как устроены современные шифры ;v79
for (int i = 0; i < rounds; i++) { . .....
swap = left " F_Gamma(right, key); // готовим’левую, поло&инку
left = right; // и меняем местами левую правую
right = swap; // половинки
}
return (left | ((uint32_t) right « 16));
>
Функция FeisteLNetworkO представляет собой реализацию сети Файстеля с
произвольным числом раундов rounds. Ключ key представляет собой 8-битное
значение, которое используется только как аргумент для передачи его функции
гаммирования F_Gamma(). Обратите на это' особое внимание, поскольку, очевид-
но, здесь таится первый способ оптимизаций алгоритма:
Чтобы ускорить исполнение функции FeisteLNetworkO, мы можем внести
тело функции F_Gamma() внутрь FeisteLNetworkO, устранив тем самым наклад-
ные расходы на передачу параметров и вызов подфункции; Другой очевидный спо-
соб ускорить процесс состоит в том, чтобы сделать число раундов постоянным
(например, равным восьми Или шестнадцати), а затем, избавиться от цикла, распи-
сав все итерации шифра последовательно, одну за другой. Выбор количества ра-
ундов объясняется нахождением некоторого своего , рода компромисса между .ма-
лой скоростью шифрования у шифра с большим количеством раундов и простотой
вскрытия шифра с малым, их числом. Этот показатель у шифра, постр.оевдргр^на
сети Файстеля,, колеблется от.8 до 32 раундов. Впрочем, ни,кто не. возбраняет.при-
менять и 64, и 128 раундов. Все упирается лишь в-вычислительные мощности
компьютерных систем. Единственное ограничение состоит ,в том, что колич.естро
раундов должно быть четным. В таком случае обе половинки — и .левая;; непра-
вая — будут обработаны одинаковое число, раз и,:сдедрвательно,.не,-возникнуси-
туации, когда одна половина данных , (например,,,четная), .зашифровываемых
16-раундовым алгоритмом, в действительности обработана ррсемью. а/Друга^ все-
го лишь семью итерациями алгоритма. ..... ,
Все проделанные модификации для алгоритма с четырьмя раундами доказаны
в листинге 4.4. Подобная оптимизация обычно дает прирост производительности
в 5—10 %, а ведь это еще оптимизация не алгоритма, как такового, а примитив-
ная оптимизация его реализации. , , , ...
Листинг 4.4
uint32_t Feistel_Network_0ptimal(uint32_t data, uint8_t key, int rounds) { " ‘
uint16_t left, right, swap; . .
left = data & OxFFFF; // делим данные на половинки • 1
right = (data » 16) & OxFFFF; • и
swap = left " right " ((uint16_t) key * 0xABCD1234); // 1-й раунд
left = right;
right = swap; _ . . .. mi :;ov,
swap = left ~ right " ((uint16_t) key * 0xABCD1234); // 2-й раунд
left = right; j , > м .;
right = swap; ... ;
80
Гпава 4. Как устроены современные шифры
swap = left " right " ((uint16^t) key * 0xABCD1234); Ц 3-й раунд
left = right;
right = swap;
swap = left " right " ((uint16_t) key * 0xABCD1234); Ц 4-й раунд
left = right;
right = swap;
return (left | ((uint32_t) right « 16));
}
На сегодняшний день практически отсутствуют системы шифрования, по-
строенные с помощью разбалансированных сетей Файстеля, а все популярные ал-
горитмы являются с этой точки зрения классическими. Их вид и функции шифро-
i вания можно успешно представить себе, исходя из предоставленных в листингах
' раздела примеров.
!' SP-сеть и шифры Файстеля
j г- *
< Способ, которым следует сочетать принципы перемешива-
, ния и рассеивания для получения криптографической стой-
i кости, можно описать следующим образом. Мы увидели,
, что перестановки общего вида не могут быть реализованы
। для больших значений и,15 скажем для п = 128, и поэтому
I мы должны ограничиваться схемами подстановки, имеющи-
ми подходящий размер... мы выбрали п = 4 в системе, раз-
i работанной в IBM и названной Lucifer. Хотя это может по-
казаться слишком маленьким числом, такая подстановка
может оказаться вполне эффективной, если ключ подста-
новки... выбран верно.
X. Файстель. Криптография
i и компьютерная безопасность
I
Как уже было отмечено, в отличие от шенноновской модели построения шиф-
ров, использование сети Файстеля в качестве архитектурной основы шифра по-
! зволяет избежать необходимости того, чтобы используемые преобразования были
обратимы. Более того, их необратимость — требование, причем весьма разумное
требование, которым следует пользоваться при выборе соответствующих крип-
тографических примитивов. Тем не менее сам шифр, естественно, должен иметь
обратное преобразование. Можно сказать, что сеть Файстеля — это не что иное,
как способ построения обратимого шифра с блоком размера 2N из необратимых
преобразований, оперирующих с блоками размера N.
В основном в качестве необратимого преобразования для шифра выбирают
некоторую функцию, которая не имеет линейной зависимости значений результа-
та от значений аргумента (подробнее о конкретных реализациях см. далее и в раз-
деле «Свойства S-блоков и их анализ. P-блоки»). Это означает, что функцию не-
15 То есть количества переставляемых значений.
Гпава 4. Как устроены современные шифры 81'
возможно представить в виде суммы произведений некоторых постоянных'коэф-
фициентов со слагаемыми аргументами ни для какого из наборов х0, х,, х„:
F(x0,x1,x2,...,xn) = aoxo +alxl +... + anxn.
Почему это плохо? Простое линейное преобразование, которое возможно
дало бы нужный результат, не может быть использовано по той причине; что в
этом случае криптоаналитик просто вычислит его с помощью статистического
оценивания, используя, например, метод нахождения линейной регрессии, и най-
дет формулы всех использованных линейных преобразований данных.16
Если все же используем такую функцию F, которая обладает указанным
свойством, то есть является линейной, мы можем представить себе следующую
ситуацию. Имея пары {участок открытого текста},и {соответствующий'ему Закры-
тый текст}, криптоаналитик сможет составить алгебраическую систему вида (*) и
решить ее, найдя все необходимые ему компоненты для вскрытия шифра ка- .
ким-нибудь не очень сложным и не очень медленным методом решения систем ли-
нейных алгебраических уравнений, которые в вузах изучают студенты начальных
курсов. . ' г ;>.
7№) = с„
А (^2) = ^2«
" U"(P„)=Cn.
В (*) функции $ представляют собой t-e по счету линейное преобразование,
зависящее от ключа k, а Рп иС„ представляют Собой участки (биты, байты или би-
товые строки) соответственно открытого и шифротекста. На многие современные
блочные шифры были реалйЗованы подобные атаки. Дополнительный анализ ино-
гда приводит еще и к тому,, что удается найти функции зависимости не только для
конкретных пар открытого и шифротекста, но и для устройства непосредственно
шифра, что вдобавок позволяет все найденные функции отделить друг от друга.
То есть создать модель шифра, в которой четко прослеживались последствия. из-
менения бита исходного текста всего на двух-трех битах выхода.
Шифр Люцифер строился под руководством Файстеля в конце 60-х годов с.'
учетом подобных возможностей и сообразительности криптоаналитика. Позж.еч
эти работы стали финансироваться Национальным институтом стандартов ,и тех-,
нологий США (National Institute of Standards and Technology), поскольку их резу-
льтатом должно было стать формирование нового национального .стандарта шиф-, .
рования, позволившего, бы шифровать данные для.создания защищенных каца-ловм
передачи данных. \ о '/ 'оглш*
16 Здесь нужно четко представлять себе тонкое различие между открытостью алгоритма в
соответствии правилами Керкхоффа и закрытостью а^Йрйтма, й^М^нен^бгЬ'н^Йремя 'ши^ровА-;1
нияс пЬмощью ключа. Функций7vo которой-идёт рёчь в' данномгкЬййрё¥ййм сЛучаё^жё'йзМё- ;
нена:в зависимости от заданного пользователем ключа и скрыта от глаз криптоаналитика: Поэ--’’
тому поиск формулы, преставляющей функцию F, то же самое, что и поиск ключа, только в ме-
нее очевидном виде.
82
Глава 4. Как устроены современные шифры
Файстель в своей статье представил способ организации шифра по Шеннону.
Этот шифр обладал хорошими свойствами перемешивания и рассеивания. Для до-
стижения вышеозначенного эффекта предлагалось использовать блоки подстано-
вок и перестановок. Архитектура подобных шифров носит название SP-cemu, от
двух названий используемых в ней компонентов: S-box и Р-Ьох.
Данные представлялись в виде подблоков небольшого размера, например, в 3
или 4 бита. Затем использовалась заранее подготовленная таблица подстановки
(например, рис. 4.4), названная Файстелем S-Box (от substitution — в английском
языке обозначающего подстановку или замену) и окрещенная в русской термино-
логии S-блоком и узлом (иногда еще говорят, блоком) замены.
XI Х2 хз Х4 S(x)
0 0 0 0 1 1 0 1
0 0 0 1 1 0 1 1
0 0 1 0 0 1 0 0
0 0 1 1 0 1 0 1
0 1 0 0 0 0 0 0
0 1 0 1 1 0 0 1
0 1 1 0 1 0 1 0
0 1 1 1 0 1 1 1
1 0 0 0 0 0 1 0
1 0 0 1 0 0 1 1
1 0 1 0 0 0 0 1
1 0 1 1 0 1 1 0
1 1 0 0 1 1 1 0
1 1 0 1 1 1 0 0
1 1 1 0 1 0 0 0
1 1 1 1 1 1 1 1 1
Рис. 4.4. Пример таблицы замен для п - 4
Подставляя значение входных данных в левую колонку таблицы, получаем
соответствующее значение подстановки в правой колонке. Как в левой, так и в
правой колонках все значения должны быть различны, иначе, заменив однажды
данные в соответствии с таблицей, мы не сможем однозначно их восстановить
позже.
В варианте для компьютерного исполнения небольшая таблица замен обычно
организуется как обычный массив (см. листинг 4.5).
Листинг 4.5
int S_Box[16] = {
13. 11, 4, 5, 0, 9. 10, 7, 2, 3. 1, 6, 14, 15, 12, 8
}
Гпава 4. Как устроены современные шифры 83
for (int i = 0; i < size_of_data; i++) {
int data_l, data.h;
data_l = (datafi] » 4) & OxF; // берем младший полубайт
11 его размер как раз равен 4 битам
data_l = S_Box[data_l];
dataji = datafi] & OxF; // берем старший полубайт
// и поступаем с ним та кже, как с младшим
data.h = S_Box[data_h];
data[i] = data.h || (data_l « 4); // возвращаем половинки назад
}
Читатель, ознакомившийся со второй главой книги, возможно, сразу предло-
жит способ взлома шифра, использующего таблицу замен, — это простой частот-
ный анализ. В роли букв латинского алфавита из классических примеров здесь
выступят всевозможные двоичные последовательности — комбинации из четы-
рех битов. Чтобы сделать схему с таблицей замен стойкой к анализу, требуется
значительно увеличить размер обрабатываемых двоичных последовательностей,
чтобы во много раз усложнить частотный анализ. Для этого надо будет использо-
вать например 128-битовую таблицу замен, а следовательно, хранить все 128 зна-
чений 128-битовых векторов. Для этого понадобится 16 kb памяти только для од-х
ной таблицы. Кроме того, возникает вопрос об использовании такой таблицы в ка-
честве ключа — она все-таки слишком громоздка. Это означает, что необходимо
придумать способ расширить небольшой по размеру ключ до необходимого разме-
ра и модифицировать постоянную таблицу в соответствии с ним. В силу явных
трудностей с реализацией метода сотрудники Bell Laboratories обратили внима-
ние еще и на таблицы перестановок (рис. 4.5).
Рис. 4.5. Пример таблицы перестановок для п = 8
84
Глава 4. Как устроены современные шифры
Таблица перестановок была названа Р-Box (от permutation — перемешива-
ние) или узел (блок) перестановки по аналогии с узлом (блоком) замены. С ее по-
мощью в блоке данных биты переставляются так, чтобы затруднить частотный
анализ. При этом даже для сравнительно небольших блоков мы получаем очень
большое пространство возможных ключей, равное по мощности N! Например, для
16-битового блока 16! = 20922789888000). Впечатляющее число, не правда ли?
Однако для блока перестановки легко придумать криптографическую атаку,
которая позволит быстро (всего за N-1 операций, если блок перестановки состо-
ит из N элементов) раскрыть структуру его содержимого. Немного присмотрев-
шись к рис. 4.5, читатель может увидеть, что для этого достаточно подать на вход
строки битов, содержащие одну единицу и остальные нули: то есть последова-
тельность
(1, 0, 0, 0, .... О, 0),
(О, 1, 0, 0, ..., О, 0),
(О, 0, 1, 0, .... О, 0),
(О, 0, 0, 1, ..., О, 0)
И т. д.
После этого единица на выходе будет соответствовать тому элементу, на мес-
то которого переставляется исходный единичный бит.
Если криптоаналитик получит доступ к шифровальной машине (или програм-
ме), то, просто подставив все векторы, легко получит формулу преобразования
данных и сможет раскрывать все тексты, зашифрованные с ее помощью.
Таким образом, у нас есть два различных способа преобразования данных,
каждый из которых уязвим к определенному виду криптоатак. При этом мы зна-
ем, что с точки зрения формального подхода наиболее эффективным шифром из
всех возможных блочных шифров является тот, который может преобразовать
любой возможный блок открытого текста в любой возможный блок шифрованно-
го текста. И естественно, это преобразование должно быть обратимым. Такой
шифр можно отнести к шифрам на основе простой подстановки, который в упро-
щенном варианте был описан S-блоком.
Теперь вернемся к реальности и проведем простой расчет. Если блок шифра
имеет длину п битов, то имеется 2” различных двоичных блоков и (2я)! способов, с
помощью которых можно зашифровать один блок текста. Количество битов клю-
ча, необходимых для выбора одного из этих способов, огромно — оно равно
log2{2")!}. Это неприемлемо большое число даже при небольших значениях п. На-
пример, при п, равным 8, нам потребуется хранить ключ длиной почти в 2000 би-
тов. Плюс ко всему простые подстановки на малых алфавитах можно эффективно
раскрывать посредством составления частотных таблиц для знаков шифрованно-
го текста. Мы оказываемся перед дилеммой — нам нужны блоки больших разме-
ров, но мы не сможем эффективно их использовать из-за слишком большой длины
ключа.
Разрешить ее можно, пойдя по стопам сотрудников лаборатории IBM. Почти
все первые криптосистемы IBM базируются на работе Шеннона и его композици-
онных шифрах. Для построения сильной системы из слабых по отдельности ком-
Глава 4. Как устроены современные шифры
85
понент используется произведение шифров, а точнее, их многократное последова-
тельное. применение над данными. Понятно, что последовательное применение,
например, двух блоков замены равносильно применению одного третьего блока
замены. Поэтому применение замен и перестановок необходимо чередовать меж-
ду собой. Именно так и поступили в IBM.
Несмотря на незначительные различия в реализациях, почти во всех систе-
мах фирмы IBM в основном использовалась перестановка внутри блока для неко-
торого фиксированного перемешивающего преобразования и подстановка. для
4-битовых подблоков (рис. 4.6). Кстати, название «узел замены» появилось имен-
но отсюда, поскольку оно наглядно демонстрирует позицию блока замены в архи-
тектуре шифра как некоторую узловую операцию, в которой своего рода узлом
сходятся линии, обозначающие поступление данных.
Файстелем была описана такая схема в качестве примера эффективной крип-
тосистемы. В ней блок из 128 битов открытого текста разбивается на 32 4-битных
подблока, каждый из которых подвергается действию различных S-блоков, кото-
рые управляются частью заданного пользователем ключа. Затем полученные 128
битов перемешиваются с помощью фиксированной перестановки, и процесс по-
вторяется. Перестановка перемешивает биты различных S-блоков и необходима
для того, чтобы предотвратить вырождение всего преобразования в подстановку
4-битовых блоков. Расшифрование происходит аналогично, за исключением того,
что в качестве S-блоков используются их обратные подстановки.
К сожалению, Bi данной схеме есть существенные недостатки. Дело в том, что
в данном случае S-блоки являются секретной частью алгоритма шифрования. Все
они должны быть различными, следовательно, для их хранения понадобится це-
128 .1
лых (4!) — = 768 битов.
Рис. 4.6. Композиционный шифр из перестановок и подстановок
86 Глава 4. Как устроены современные шифры
Чтобы преодолеть данные трудности, Файстель использовал только два раз-
личных S-блока (SO и S1), структура которых известна вместе с алгоритмом. Тог-
да каждый из S-блоков на рис. 4.6 будет заменен либо SO, либо S1, в зависимости
от значения одного бита ключа. Это снижает требования к памяти для S-блоков
до 128 битов и к длине ключа до 512 битов. Дальнейшее уменьшение размера
ключа до 128 битов было достигнуто за счет использования алгоритма разворачи-
вания ключа (key shedule), который просто повторяет каждый бит ключа четыре
раза.
Каждый 4-битовый S-блок можно реализовать в виде массива в памяти объе-
мом в шестнадцать 4-битовых слов. Поскольку S-блок должен быть обратимым,
все слова должны быть разными. Следовательно, простейшая реализация одного
4-битового S-блока потребует от нас наличия 64 битов памяти, для 8-битового
S-блока потребуется уже 2048 битов памяти, а 16-битовый S-блок «отъест» при-
личный кусок в один мегабайт. В IBM выбрала размер в 4 бита, выдержав своего
рода компромисс между стоимостью и надежностью.
Если бы был выбран 2-битовый вариант, то вся система могла быть раскрыта
за несколько секунд работ персонального компьютера. Это произошло бы потому,
что все 4! = 24 обратимых отображения 2 битов в 2 бита являются линейными
(или, если быть точным — аффинными) и могут быть представлены в виде линей-
ного уравнения, в котором вся арифметика выполняется по модулю 2. Факт того,
что перестановка является линейной операцией, а композиция аффинных отобра-
жений дает аффинное отображение, показывает, что использование S-блоков в
этом случае было бы равносильно одному линейному преобразованию. В этом
случае, даже не пытаясь найти ключ, можно было бы получить открытый текст из
решения системы линейных уравнений методом, описанным в начале раздела.
Следовательно, при создании S-блоков аффинных отображений следует избе-
гать. Отображений, «близких» к аффинным, тоже следует избегать, что, по-види-
мому, и отразилось в решении не использовать 3-битовые узлы замены, хотя в
данном случае аффинными будут всего лишь 3% обратимых отображений 3 битов
в 3 бита. Вместо этого были созданы и использованы 4-битовые S-блоки.
Криптосистема Lucifer
However, this does not mean that the LUCIFER algorithm is
useless. If a reasonably good stream cipher is used both before
and after LUCIFER, its weaknesses essentially become irrele-
vant, and its strengths are still present. It might indeed be ar-
gued that this kind of precaution ought to be used with DES as
. well.
/. Savard. A Cryptographic Compendium
Шифр Люцифер стал логическим продолжением начатого исследования по
созданию алгоритма криптографического преобразования данных. В отличие от
предложенного ранее способа шифрования, реализованного в лабораториях IBM
впервые, Люцифер организован уже в соответствии с принципами сети Файстеля.
Гпава 4. Как устроены современные шифры 87
Однако он унаследовал наработанные принципы создания и использования бло-
ков подстановки и перемешивания.
Свои изобретения Файстель защитил с помощью нескольких патентов, клю-
чевым из которых стал «Способ блочного криптографического преобразова-
ния» — он же Люцифер, одобренный патентной комиссией в 1974 году. Алгоритм
работы Люцифера был отображен также в одной из статей в «Журнале криптоло-
гии», однако настоящая его реализация была несколько сложнее, чем приведен-
ная в опубликованной статье.
Шифр изначально имел размер блока шифрования, равный 128 битам. Такого
же размера использовался и ключ к шифру. Функция зашифрования своей струк-
турой точь-в-точь повторяет описанную разделом выше сбалансированную сеть
Файстеля.
Процедура зашифрования состоит из шестнадцати последовательно выпол-
няемых над блоком данных раундов, в каждом из которых результат выполнения
функции гаммирования F от левой половины блока входных данных складывает-
ся по модулю 2 с правой половиной блока. После выполнения каждого раунда ле-
вая и правая половины меняются местами, в соответствии с принципом сети
Файстеля.
Понятно, что выполнять обмен половинок после выполнения последнего ра-
унда бессмысленно — это лишняя операция, которая не модифицирует данные
существенным образом, никак не затрудняя криптоанализ, и в то же время бу-
дет явно замедлять процесс зашифрования данных очень больших объемов. Поэ-
тому обычно обмен полублоков после последнего раунда можно опустить как
излишний.
Каждый раунд шифра использует свой уникальный ключ раунда, представ-
ленный 72-битовым подключом. Данный подключ для первого раунда состоит из
первого байта основного ключа, который просто повторяется дважды (почему это
так, станет ясно чуть позже), а затем дополняется следующими 7 байтами ключа
(ведь 72-битный ключ раунда состоит ровно из 9 байтов). Подключ для каждого
следующего раунда получается циклическим сдвигом ключа предыдущей итера-
ции шифра влево на 7 байтов (56 битов).
Понятно, что критической частью алгоритма является функция гаммирова-
ния, на которую возлагается задача генерации блока гаммы с как можно более
случайным поведением. Роль функции F в алгоритме играет следующая конст-
рукция:
1. Правая половина блока складывается по модулю 2 с последними 8 байтами
подключа.
2. Полученный результат преобразуется в зависимости от ключа. В соответ-
ствии с первым байтом подключа раунда меняются местами полубайты получив-
шейся гаммы. Если соответствующий бит ключа равен 1, обмен происходит, ина-
че байт остается неизменным.
3. Затем с помощью двух блоков замены меняется весь 8-байтовый блок гам-
мы. Для старших полубайтов используется узел замены SO, для младших — S1.
Таким образом, их влияние на гамму косвенно зависит от ключа. Значения S-бло-
ков приведены на рис. 4.7.
88 Гпава .4. Как устроены современные шифры
4. После этого 64 бита результата перемешиваются с помощью таблицы пере-
становки, заданной от младшего бита к старшему (рис. 4.8).
йй' iO-SJi
0 0 0 0 1 1 0 0 0 1 1 1
0 0 0 1 1 1 1 1 0 0 1 0
0 0 1 0 0 1 1 1 1 1 1 0
0 0 1 1 1 0 1 0 1 0 0 1
0 1 0 0 1 1 1 0 0 0 1 1
0 1 0 1 1 1 0 1 1 0 1 0
0 1 1 0 1 0 1 1 0 0 0 0
0 1 1 1 0 0 0 0 0 1 0 0
1 0 0 0 0 0 1 0 1 1 0 0
1 0 0 1 0 1 1 0 1 1 0 1
1 0 1 0 0 0 1 1 0 0 0 1
1 0 1 1 0 0 0 1 1 0 1 0
1 1 0 0 1 0 0 1 0 1 1 0
1 1 0 1 0 1 0 0 1 1 1 1
1 1 1 0 0 1 0 1 1 0 0 0
1 1 1 1 1 0 0 0 0 1 0 1
Рис. 4.7. Узлы замены шифра Люцифер
Бит Номер результирующего бита для перестановки Бит J|
0 10 21 52 56 27 1 47 38 18 29 60 0 35 9 55 46 .5
16 26 37 4 8 43 17 63 54 34 45 12 16 51 25 7 62 31
32 42 53 20 24 59 33 15 6 50 61.28 32 3 41 23 14 47
48 58 5 36 40 11 49 31 22 2 13 44 48 19 57 39 30 63
Рис. 4.8. Блок фиксированной перестановки шифра Люцифер
К сожалению, несмотря на то что шифр Люцифер обладает довольно боль-
шим размером блока и достаточной длины ключом, он оказался весьма уязвим к
криптографическим атакам. Это действительно имеет место в силу двух причин,
одна из которых заключается в слабости алгоритма разворачивания ключа, а вто-
рая находится в слабых узлах замены.
Попробуем реализовать на практике предложенный шифр. Как использовать
таблицы замен уже было показано в одном из предыдущих листингов. Осталось
запрограммировать таблицу перестановки и использовать остов шифра с архитек-
турой сети Файстеля. Результат должен быть приблизительно похож На демонст-
рируемый в листинге 4.6.
Глава 4. Как устроены современные шифры .89
Листинг 4.6
«include <stdio.h>
«include <mem.h>
Ц узлы замен
uint8_t SO.box = {
12, 15, 7, 10, 14, 13, 11, 0,
2, } 6, 3, 1, 9, 4, 5, 8
uint8_t S1_box[16] = = {
7, 2, 14, 9, 3, 11. 0. 4,
12, 13, 1, 10, 6. 15, 8, 5
}
// блок перестановки
uint8_t P_box[64] = {
10, 21, 52, 56, 27, 1, 47, 38, 18, 29, 60, 0, 35, 9, 55, 46,
26, 37, 4, 8, 43, 17, 63, 54, 34, 45, 12, 16, 51, 25, 7, 62,
42, 53, 20, 24, 59, 33, 15, 6, 50, 61, 28, 32, 3, 41, 23, 14,
58. 5, 36, 40, 11, 49, 31. 22, 2, 13, 44, 48, 19, 57, 39, 30
}
«define NUM_OF_ROUNDS 16
// data = указатель на 128-битовый блок открытого текста
// key = 128-битный ключ
void enc_Lucifer(uint8_t *data, uint8_t *key) {
int i, b, j;
uint8_t subkeyE16][9]; // 72-битовые подключи
uint8_t *swap, p[8];
uint8_t *left = d&ta? * right’ = data+8; // технический прием,
И позволяющий избежать лишних операций копирования данных
И--------------------------------------------------
II разворачиваем 128-битовый ключ
// первый байт основного ключа повторяется дважды
subkey[0J[0J = keyEOJ;
subkey[0][1] = key[0];
// затем подключ дополняется остальными байтами ключа
for (i = 2; i < 16; i++) subkeyE0][2] = keyEI];
// генерируем остальные подключи циклическим сдвигом на 7 байтов
for (i = 1; i < 16; i++) {
subkey[i][0] = subkey[i-1][2];
subkey[i][1] = subkey[i-1][3];
subkey[i]E2] = subkeyEi-1 ][4]; . > • '
subkey[i][3] = subkey[i-1][5]; ‘ ’
- , > subkey[i][4] subkey[i-1][6]; . ' • — .
L subkey[i][5] (=, subkey[i-1][7]; f • , r/ -. s
, subke.y[i][,6]:=;subkey[i:l][8]; 5 .
subkey[i][7] = subkeyEi-1JEO];
subkeyEi]E8] = subkeyEi-1][1];
}
90
Гпава 4. Как устроены современные шифры
И-------------------------------------------------
// циклы шифрования
for (1 = 0; 1 < NUM_0F_R0UNDS; i++) {*
// вычисляем гамму: правая половина блока складывается
// по модулю 2 с последними восемью байтами подключа
subkey[i][1] "= right[0];
subkey[i][2] nght[1];
subkey[i][3] "= right[2];
subkey[i][4] "= right[3];
subkey[i][5] "= nght[4];
subkey[i][6] "= right[5];
subkey[i][7] "= nght[6];
subkey[i][8] "= right[7];
// в соответствии с первым байтом подключа
// меняем местами полубайты получившейся гаммы
for (b = 0; b < 8; Ь++)
И если соответствующий бит ключа равен 1
if ((subkey[i][0] » b) & 1 != 0) {
// меняем местами старший и младший полубайты
subkey[i][b+1] =
(subkey[i][b+1] « 4) | (subkey[i][b+1] » 4);
/
// с помощью двух блоков замены меняем весь блок гаммы
for (b =1; b < 9; Ь++) {
subkey[i][b] = (SO_box[subkey[i][b] » 4] « 4) |
(S1_box[subkey[i][b] & OxF];
}
// переставляем биты в р
memset(p, 0. 8);
for (j = 0; j < 8; j++) {
for (b = 0; b < 8; b++) {
s = P_box[j*8 + b];
p[s / 8] "= ((subkey[i][j] » b) & 1) « (s % 8);
}
}
// в соответствии с принципом сети Файстеля
// левая половина блока ксорится с гаммой
for (b = 0; b < 8; b++) left[b] "= p[b];
// очень быстро меняем местами половинки 1
swap = right;
right = left;
left = swap;
Приглядевшись к алгоритму, сразу становится ясно, зачем в каждом подклю-
че был продублирован первый байт исходного ключа в самом начале алгоритма.
В самом алгоритме шифрования в каждом цикле левая половина блока складыва-
ется со значением старших восьми байтов подключа. Вместо того чтобы заводить
Гпава 4. Как устроены современные шифры
91
дополнительный массив памяти и помещать результат в него, мы можем смело
применять XOR левой половины left с самим подключом (см. листинг 4.7), затем
используя в качестве гаммы сам подключ subkey[i].
Листинг 4.7
subkey[i][1] "= right[O];
subkey[i][2] "= right[1];
subkey[i][3] "= right[2];
subkey[i][4] "= right[3];
subkey[i][5] "= right[4];
subkey[i][6] "= right[5];
subkey[i][7] "= right[6];
subkey[i][8] "= right[7];
Первый байт (который является копией второго байта) подключа subkey[i][O]
остался без изменения. Он потребуется чуть позже, когда меняются местами по-
лубайты гаммы subkey[i][ 1 ...9] (см. листинг 4.8). Таким образом, мы ничего не те-
ряем по пути и при этом стараемся эффективно использовать память. Конечно,
выкраивание пары лишних байтов для программирования современных компьюте-
ров может показаться не актуальным. Но мы будем и дальше проделывать это, на-
поминая читателю, что реализации криптоалгоритмов должны хорошо работать
не только на «персоналках», но и, например, на PIC-процессорах или любых дру-
гих аппаратных платах.
Листинг 4.8
// в соответствии с первым байтом подключа
Ц меняем местами полубайты получившейся гаммы
for (b = 0; b < 8; Ь++)
И если соответствующий бит ключа равен 1
if ((subkey[i][0] » b) & 1 != 0) {
11 меняем местами старший и младший полубайты
subkey[i][b+1] =
(subkey[i][b+1] « 4) | (subkey[i][b+1] » 4);
}
Дотошный читатель, может быть, уже заметил вкравшуюся в рассуждения
ошибку. Дело в том, что мы предоставили листинг, реализующий работу алгорит-
ма на одном блоке данных. С формальной точки зрения все верно и придраться не
к чему, но, если попытаться переделать функцию encJLucifer для зашифрования
нескольких блоков данных, читатель невооруженным глазом сможет увидеть не-
соответствия между парой блоков, зашифрованных раздельно и последовательно.
Дело в том, что, вычислив один раз подключи, мы затем в каждом цикле шифрова-
ния безнадежно портим их, складывая с левыми половинками и постоянно преоб-
разуя. На самом деле это не так плохо и получившийся алгоритм вполне может
быть эффективнее оригинала (возможно, даже более криптостойкий), поскольку
представляет собой тот же алгоритм Lucifer, но уже в режиме зацепления (анало-
гичные схемы см. в разделе «Все режимы шифрования»).
&2 . * Глава 4. Как устроены современные .шифры
Кроме того, мы йозволйли себе немножко оптимизировать реализацию алго-
ритма (но не сам алгоритм!) в нескольких узких местах. Обратите внимание на
то, что в алгоритме на самом деле не переставляются местами левая и правая по-
ловины блока, меняются лишь указатели на них. Тем не менее мы оставили очень
медленную и громоздкую реализацию перестановки битов без изменения. На са-
мом деле в ряде случаев можно придумать способы реализовать ее очень быстро.
Для простоты понимания представим себе упрощенную версию «бутерброда»
из P-блоков и S-блоков. Пусть фиксированный P-блок и S-блок будут для начала
одного размера и будут не очень большими (рис. 4.9).
Х| Х2 *31
0 0 0 1 0 0
0 0 1 1 1 1
0 1 0 0 0 1
0 1 1 0 1 0
1 0 0 1 1 0
1 0 1 1 0 1
1 1 0 0 1 1
1 1 1 0 0 0
Рис. 4.9. Узел замены и блок перестановки
Посмотрим на результат их взаимодействия в двух случаях — при действии
на данные сначала P-блока, затем S-блока и наоборот. В первом случае если х =
= 101, то Р(х) = 011, a S(P(x)) = S(011) = 010. Используя данные для всевозмож-
ных значений х, попробуем построить таблицу SP-блока, которая осуществляла
бы сразу перестановку и подстановку одновременно (рис. 4.10). Сразу заметим,
что, вообще говоря, PS-блоки ни в коем случае не идентичны SP-блокам, то есть
Р ° S = P(S(x)) != S(P(x)) = S 0 Р. Это существенное замечание.
хг Х2 ‘Ж Я <Р(хХШ
0 0 0 0 0 0 1 0 0
° 0 1 0 1 0 0 0 1
0 1 0 1 0 0 1 1 0
0 1 1 1 1 0 0 1 1
1 0 0 0 0 1 1 г 1
1 0 1 0 1 1 0 1 0
1 1 0 1 0 1 1 1 0 1
1 1 1 1 1 1 0 0 ы
Рис. 4.10. Узел одновременной перестановки и замены
Гпава 4. Как устроены современные шифры 93
Аналогичную таблицу можно подсчитать для PS-блока (рис 4.11). В нем к
данным сначала применяется подстановка S-блдка, а затем результат перемеши-
вается перестановкой Р-блока.
Ж <«31
0 0 0 1 0 0 0 0 1
0 0 1 1 1 1 1 1 1
0 1 0 0 0 1 0 1 0
0 1 1 0 1 0 1 0 0
1 0 0 1 1 0 1 0 1
1 0 1 1 0 1 0 1 1
1 1 0 0 1 1 1 1 0
LL 1 1 0 0 0 0 0 ш
Рис. 4.11. Узел одновременной замены и перестановки
Таким образом, однажды подсчитав таблицы SP-блоков и PS-блоков, мы из-
бавляем себя от необходимости использовать очень медленную перестановку би-
тов в цикле так, как это было сделано в листинге алгоритма Lucifer (см. эту часть
в листинге 4.9).
Листинг 4.9
И переставляем биты в р
memset(p, 0, 8);
for (j = 0; j < 8; j++) {
for (b = 0; b < 8; b++) {
s = P_box[j*8 + b];
p[s / 8] "= ((subkey[i][j] » b) & 1) « (s % 8);
}
}
Здесь, перестановка с помощью P-блока реализована в виде последователь-
ной перестановки каждого из битов блока в цикле. Побитовые операции не явля-
ются очень быстрыми практически ни на одном существующем сегодня процессо-
ре. С этим приходится мириться и придумывать способы осуществлять неслож-
ную операцию перестановки битов на существующих аппаратных платформах
другими, более эффективными путями.
Одним из вариантов такой реализации является метод с использованием
своего рода изомофорной операции — все операции проводятся не на битовых, а
на байтовых или пословных операндах. Для этого 128-битовый блок данных пред-
ставляется в виде массива из 128 целых байтовых или пословных элементов. Вы-
бор слова в качестве элемента массива обусловлен тем, что архитектура совре-
менных процессоров предназначена для более эффективной работы со словами,
чем с байтами или полубайтами. Если использовать такой подход, то участок кода
в листинге 4.9 можно переписать заново (см. листинг 4.10).
94
Гпава 4. Как устроены современные шифры
Листинг 4.10
uint8_t S_mask[8] = { 128, 64, 32, 16, 8, 4, 2, 1 };
uint32_t block_bits[128]; // элементы-псевдобиты
uint32_t block_bits_d[128]; // копия для перестановки
Ц заполняем block_bits
for (j = 0; j < 32; j++)
for (b = 0; b < 8; b++)
block_bits[(j « 3) + b] = (subkey[j] » b) & 0x1;
11 быстро переставляем
for (j = 0; j < 128; j++)
block_bits_d[j] = block_buts[P_box[j]];
11 возвращаем биты на место
for (j = 0; j < 32; j++)
for (b =0; b < 8; b++)
subkey[j] |= (block_bits[(j « 3) + b] « Sjnask[b]);
Однако и этот вариант реализации алгоритма существенно медленнее, чем
если бы мы использовали заранее заготовленные таблицы замены-перестановки.
Листинг 4.11
И заранее вычисленные таблицы двух PS-блоков: P+SO и P+S1
uint8_t PS0[256] = {
87, 21,117, 54, 23, 55, 20, 84,116,118, 22, 53, 85,119, 52, 86,
223,157,253,190,159.191,156,220,252,254,158,189,221,255,188,222,
207,141,237,174,143,175,140,204,236,238,142,173,205,239,172,206,
211,145,241,178,147,179,144,208,240,242,146,177,209,243,176,210,
215,149,245,182,151,183.148,212,244,246,150,181,213,247,180,214.
95, 29,125, 62, 31, 63, 28, 92,124,126, 30, 61. 93,127, 60, 94,
219,153,249,186,155,187,152,216,248.250,154,185,217,251.184.218,
67, 1. 97, 34, 3, 35, 0, 64, 96, 98, 2, 33, 65, 99, 32, 66,
195,129,225,162,131.163,128,192,224,226,130,161,193,227,160,194,
199,133,229,166,135,167,132,196,228,230,134,165,197,231,164,198,
203,137,233,170,139,171,136,200,232,234,138,169,201,235,168,202,
75, 9,105, 42, 11, 43, 8, 72,104,106, 10, 41. 73,107, 40, 74.
91, 25,121, 58, 27, 59, 24, 88,120,122, 26, 57, 89,123, 56, 90,
71, 5,101, 38, 7, 39, 4. 68,100,102, 6, 37, 69,103, 36, 70,
79, 13,109, 46, 15. 47, 12, 76,108,110, 14, 45, 77,111, 44, 78,
83, 17,113, 50, 19. 51. 16. 80,112,114, 18, 49, 81,115, 48. 82
};
uint8_t PS1[256] = {
87,223,207.211,215, 95,219, 67,195,199,203, 75, 91, 71, 79, 83,
21,157,141,145,149, 29,153, 1,129,133,137, 9, 25, 5, 13, 17,
117,253,237,241,245,125,249, 97,225,229,233,105,121,101,109,113,
54,190,174,178,182, 62,186, 34,162,166,170, 42, 58, 38, 46, 50,
23,159,143,147,151, 31,155, 3,131,135,139, 11, 27, 7, 15, 19,
55,191,175.179,183, 63,187, 35,163,167,171, 43. 59, 39, 47, 51,
20,156,140,144,148, 28,152, 0,128,132,136, 8, 24, 4, 12, 16,
84,220.204,208,212, 92,216, 64,192.196,200, 72, 88, 68, 76, 80,
Глава 4. Как устроены современные шифры
95
116,252,236,240,244,124,248, 96,224,228,232,104,120,100,108,112,
118,254,238,242,246,126,250, 98,226,230,234,106,122,102,110,114,
22,158,142,146,150, 30,154, 2,130,134,138, 10. 26. 6, 14, 18,
53,189,173,177,181, 61,185, 33,161,165,169, 41, 57, 37, 45, 49,
85,221,205,209,213, 93,217, 65,193,197,201, 73, 89. 69, 77, 81,
119,255,239,243,247,127,251, 99,227,231,235,107,123,103,111,115,
52,188,172,176,180, 60,184, 32,160,164,168, 40, 56, 36, 44, 48,
86,222,206,210,214, 94,218, 66,194,198,202, 74, 90, 70. 78, 82
};
uint8_t S_mask[8] = { 128, 64, 32, 16, 8, 4, 2, 1 };
// в процедуре void enc_Lucifer(uint8_t «data, uint8_t «key):
uint8_t «pSjnask = Sjnask;
for (j = 0; j < 8; j++) {
if (subkey[i][0] & *pS_mask++ )
val = PS1[right[j] & OxFF];
else
val = PSOfrightfj] & OxFF];
>
Например, для шифра Lucifer можно заменить медленный цикл с помощью
управляемых ключом подстановок из двух таблиц (см. листинг 4.11). Там же не-
много ускорено управление в зависимости от битов ключа, введя дополнительную
таблицу, которая содержала бы все те значения битов, при которых используется,
и осуществляя сравнение битов по этой таблице. В листинге она представлена
как S_mask, а указатель на нее pS_mask. Для более быстрой адресации к элемен-
там таблицы используется указатель pS_mask, который после каждого обраще-
ния просто сдвигается по таблице к следующему элементу простым инкременти-
рованием pS_mask++.
Первые стандарты шифрования
Многообразие различных криптосистем, способов и методов защиты инфор-
мации от несанкционированного доступа и ознакомления безусловно должно
было привести к какому-то единому стандарту. Вдобавок к концу 60-х годов и в
отечественных «коридорах власти», и в зарубежных правительственных структу-
рах уже вовсю использовали свои негласные стандарты. В довольно либеральной,
экономической политике США методы шифрования могли и должны были занять
одну из ключевых позиций. Поэтому Национальное бюро стандартов (National
Bureau of Standards)17 США приступило к разработке стандарта шифрования дан-
ных на основе различных публикаций в открытой прессе и доступных научных
материалов, опубликовав в сборнике федерального реестра Соединенных Штатов
17 Национальное бюро стандартов стало впоследствии (и остается до сих пор) Националь-
ным институтом стандартов и технологий США (National Institute of Standards and Technology).
~96 Глава 4. Как устроены современные шифры
в мае 1973 года обращение, призывающее предлагать алгоритмы для защиты
;/.компьютерных данных от несанкционированного доступа. Эти алгоритмы не дол-
жны были использоваться для охраны секретов государственной важности, а дол-
жны были быть инструментами защиты для коммерсантов и коммерческих тайн
как средних, так и крупных финансовых корпораций и банков. В то время откли-
ки на обращение НБС в федеральном реестре показали, что интерес к разработке
такого стандарта существует, но открытые сведения по технике шифрования
практически отсутствуют. Конечно же в процессе разработки и принятия стан-
дартов не обошлось без содействия Агентства национальной безопасности (Natio-
nal Security Agency) — государственного органа США, контролирующего всю
криптографическую деятельность в США:
Фирма IBM предоставила свой криптографический алгоритм НБС. НБС тут
же обратилось с просьбами к АНБ оценить алгоритм по отношению к потенциа-
льному набору требований и одновременно к IBM — рассмотреть вопрос о пре-
доставлении неисключительных прав (без лицензионной платы) на изготовле-
ние, использование и продажу устройств, реализующих данный алгоритм. Эти
просьбы привели к многочисленным переговорам между НБС и обеими органи-
зациями.
Спустя почти два года, в марте 1975 года, НБС поместило в сборник федера-
льного реестра сразу два сообщения. В первом был полностью опубликован пред-
лагаемый «Алгоритм шифрования для защиты данных ЭВМ», указывая на то, что
он удовлетворяет основным техническим требованиям к алгоритму, соответству-
ющему стандарту шифрования данных.
Кроме того, в этом же сообщении содержалась информация, что некото-
рые американские патенты и патенты других стран могут содержать пункты
формулы изобретения, которые могут распространиться на реализацию и испо-
льзование этого алгоритма, и что связанные с ним криптографические устрой-
ства и технические данные могут подлежать экспортному контролю со сторо-
ны АНБ. Во втором сообщении отмечалось, что фирма IBM предоставит запра-
шиваемые неисключительные права без лицензионной платы при условии, что
Министерство торговли США к 1 сентября 1976 года утвердит стандарт шиф-
рования данных.
И наконец, в январе 1977 года предложенная криптографическая система
была принята Национальным бюро стандартов в качестве государственного стан-
дарта шифрования США. Сама система получила название Стандарта шифрова-
ния данных (Data Encryption Standard).
Новая криптосистема оказалась весьма похожа на разработку Файстеля —
шифр Люцифер, — которую IBM предлагала НБС в качестве ответа на первое
обращение в федеральный реестр. Можно даже сказать, дьявольски похожа.
Однако АНБ пожелало иметь не 128-битный алгоритм шифрования, подобный
Люциферу, а 56-битный DES, резюмируя свое пожелание новыми требованиями
к стандарту. Впрочем, этого и следовало ожидать. Люцифер стал первым пред-
ставителем семейства шифров, построенных с помощью архитектуры сети Фай-
стеля. В соответствии с требованиями АНБ новый (на то время) стандарт созда-
вался так же, как и Люцифер, в лабораториях IBM, правда, уже под руководст-
Гпава 4. Как устроены современные шифры
97
вом доктора Уолтера Тачмена (Walter Tuchman), который возглавил группу
разработчиков криптографических систем в начале 70-х годов. Результатом рабо-
ты этой группы стало несколько публикаций в прессе, несколько патентов, крип-
тографических устройств и алгоритмов.
В алгоритме, принятом в итоге в качестве государственного стандарта, испо-
льзуется структура, немного отличная от подобной в шифре Люцифер, но и она
также базируется на применении блочных узлов замен и битовых перестановках.
АНБ предложило две существенные модификации Люцифера. Первая сводилась к
изменению длины ключа и сответствующей поцедуре его разворачивания. Вторая
модификация была также несомненно существенной — узлы замены, использо-
вавшиеся в Люцифере, были полностью переработаны. Однако общая схема алго-
ритма осталась прежней.
По сравнению с Люцифером в DES сильно изменен изначально слабый
алгоритм разворачивания ключа, который повторял каждый бит ключа четы-
ре раза, не производя никаких дополнительных изменений. В DES этот про-
цесс явно сложнее, хотя и здесь не обошлось без недостатков, — слишком
маленькую длину ключа начали критиковать почти сразу же после принятия
стандарта.
Алгоритм разворачивания ключей генерирует несколько подключей — столь-
ко же, сколько числов раундов в алгоритме зашифрования данных. В классиче-
ском варианте, принятом в качестве стандарта, число раундов равно 16, соответ-
ственно и процедура данного алгоритма разворачивала ключ на 16 различных
подключей, при этом для разворачивания ключа не используются восемь различ-
ных битов исходного ключа, таким образом, результирующие подключи имеют
длину в 48 битов и не зависят от исходного ключа. Изначально предполагалось,
что эти биты смогут использоваться для контроля четности битов в ключе. Поэто-
му, говоря о длине ключа, необходимо помнить, что действительная зависимость
существует только лишь от 56, а не от 64 битов, и потому DES называют 56-бит-
ным алгоритмом шифрования.
Перед началом работы ключ подвергается процедуре перестановки битов по
фиксированной таблице (см. листинг 4.12 — массив pci). Как видно из нее, не об-
рабатываются биты 8, 16, 25, 32, 40, 48, 56 и 64, то есть самые младшие биты
каждого байта ключа.
Листинг 4.12
/* выборочная таблица для ключа */
uint8_t рс1[56] = { . ,
57, 49, 41, 33, 25, 17, 9,
1, 58, 50, 42, 34, 26, 18,
10, 2, 59. 51, 43, 35, 27, -
19, 11, 3, 60, 52, 44, 36.
63, 55. 47, 39, 31, 23, 15,
7. 62, 54, 46, 38. 30, 22.
14. 6, 61, 53, 45, 37, 29,
21, 13. 5, 28, 20, 12, 4
1;
4 Зак. 85
98
Гпава 4. Как устроены срвременные шифры
/* длина сдвига */
uint8_t rotate[16] = {
1, 2, 4, 6, 8, 10, 12, 14,
15, 17, 19, 21, 23, 25, 27, 28
};
/* номера битов */
int bytebit[8] = { 128, 64, 32, 16, 8, 4, 2, 1 };
/* выборочная таблица */
uint8_t рс2[48] = {
14, 17, 11, 24, 1, 5,
3, 28, 15, 6, 21, 10,
23, 19, 12, 4, 26, 8,
16, 7, 27, 20. 13, 2,
41, 52, 31, 37, 47, 55,
30, 40, 51, 45, 33, 48,
44, 49, 39, 56, 34, 53,
46, 42, 50, 36, 29, 32
};
Ключ разбивается на две последовательности. Первые 28 элементов массива
pci определяют, как выбирается первая последовательность, вторые — как выби-
рается вторая последовательность. Например, в первую попадут биты 57, 49, 41,
..., 36, а во вторую только 63, 55, 47, ..., 4 биты ключа.
После выбора соответствующих битов получившиеся последовательности
преобразовывают 16 раз определенным набором операции, на ходу получая не-
сколько аналогичных им рекурсивных последовательностей, — это и будут под-
ключи.
В зависимости от номера итерации обе последовательности циклически сдви-
гаются на 1 или 2 бита влево, затем преобразовываются с помощью еще одной
(аналогичной pci) битовой выборки-перестановки рс2. Получившиеся 48 битов
входят в состав очередного подключа.
Процедура, реализующая инициализацию подключевых элементов, продемон-
стрирована в листинге 4.13.
Листинг 4.13
// структура для хранения выработанных подключей
typedef struct {
uint32_t subkey[16][2];
} DES.KEY; ' ' t
// разворачиваем ключ ч (
void setup_DES(uint8_t *pass, DES_KEY *key,.bool encrypt)TL
uint8_t pc1m[56];
uint8_t pcr[56];
uint8_t shedule[8]; '' ''
uint32_t i, j, 1; 1 • л'
int m;
Гпава 4. Как устроены современные шифры
99
// конвертируем таблицу pci в биты для ключа
for (j = 0; j < 56; j++) {
И в какой именно бит записывать
1 = Pd[j ];
И номер бита в байте
m = 1 & 0x7;
И записываем единицу или ноль в зависимости от этого бита
pdm[j] = (pass[l » 3] & bytebit[m]) ? 1 : 0;
}
for (i = 0; i < 16; i++) {
memset(shedule, 0, sizeof(shedule));
for (j = 0; j < 56; j++) {
1 = j + rotate[encrypt ? i : 15 - i];
pcr[j] = pdm[ (1 < (j < 28 ? 28 : 56)) ? 1 : 1-28 ];
}
// правые и левые части вращаем независимо
for (j = 0; j < 48; j++)
if (pcr[ pc2[j]-1 ]) {
11 устанавливаем биты в ’’развороте” ключа
1 = j % 6;
shedule[ j/6 ] |= bytebit[l] » 2;
}
11 теперь заполняем итерационные подключи
key->subkey[i][O] = ((uint32_t) shedule[0] « 24)
I ((uint32_t) shedule[2] « 16)
| ((uint32_t) shedule[4] « 8)
| ((uint32_t) shedule[6]);
key->subkey[i][1] = ((uint32_t) shedule[1] « 24)
| ((uint32_t) shedule[3] « 16)
| ((uint32_t) shedule[5] « 8)
| ((uint32_t) shedule[7]);
После начальной перестановки блок данных делится на две равные половины
(работа алгоритма представляет собой работу сбалансированной сети Файстеля)
длиной по 32 бита каждая. Затем над двумя этими половинками производятся со-
ответствующие сети Файстеля операции с помощью функции усложнения F. Для
этого на каждом раунде шифрования правая (старшая) половина блока побитово
складывается (по модулю 2) с результатом функции гаммирования F от младшей
половины шифруемого блока и 48-битового подключа. Между раундами половины
блока меняются местами.
Для реализации функции гаммирования мы поступим весьма популярным об-
разом — опишем ее в качестве макроса на языке Си следующим способом (см. ли-
стинг 4.14):
4*
. 100
Глава 4. Как устроены современные шифры
Листинг 4.14
// все переменные должны быть 32-битовыми
// дополнительно требуется временная переменная temp
«define F(l, г, кеу){ \
temp = ((г » 4) | (г « 28)) " кеу[0]; \
1 "= SP_box[6][temp & 0x3FJ: \
1 ~= SP_box[4][(temp » 8) & 0x3F]; \
1 "= SP_box[2][(temp » 16) & Ox3FJ; \
1 *= SP_bbx[O]t(temp >> 24) & 0x3FJ: '
temp = r key[1 ]; \’ 1
1 ~= SP_box[7][temp & 0x3FJ: \
1 "= SP_box[5][(temp » 8) & 0x3F]; \
1 ~= SP_box[3][(temp » 16) & 0x3F]; \
1 "= SP_box[1][(temp » 24) & 0x3F]; \
}
Делается это для того, чтобы, не усложняя алгоритм, было бы как можно про-
ще его описывать и при этом не терять скорости на накладных расходах по вызову
дополнительных функций. Если в классическом варианте, описывая функцию
шифрования, нам пришлось бы вызывать функцию F_func, передавая ей (скорее
всего, через медленный стек) несколько параметров, то в варианте листинга 4.14
этого делать не нужно. Вместо этого после компиляции мы получаем разверну-
тый быстрый код, который в исходном тексте выглядит так же наглядно и понят-
но, как и вызовы функций.
В листинге 4.14 можно провести небольшую модификацию, добавив «оберт-
ку» из оператора do {} while (0) (см. листинг 4.15). Такая странная конструкция
часто встречается в исходных текстах сложных и критичных по времени и надеж-
ности исполнения систем. Например, макросами изобилуют исходные тексты
ядер операционных' систем FreeBSt) и Linux. 1 ‘1
Смысл ее использования заключается в переносимости подобного участка
кода и его независимости от окружающих макросов в исходном коде операторов.
Предположим, что мы не используем do {} while (0), описывая макрос листинга
4.14 без них. Если бы мы использовали условный оператор, например, в такой
конфигурации:
if (left != right)
F(left, right, key);
else
next operators
, то.выполнен (если,вообще будет скомпилирован) он будет, скорее всего, не-
правильно. Дело в том, что компилятор развернет указанный участок кода в бе-
дующий:
if (left !s right) f - • у
' ' temp = ((r » 4) | (r « 28)) ' key[Q]; • .y -< . r^-W'
1 "= SP_box[6][temp & Ox3F]; , . г : c. ; , : .. ; v.y
1 “= SP_box[4][(temp » 8) & 0x3F]; , . , , ...
1 ~= SP_box[2][(temp » 16) & 0x3F];
1 "= SP_box[0][(temp » 24) & Ox3F]; '
Глава 4. Как устроены современные шифры
101
temp = г " кеу[1];
1 "= SP_box[7][temp & 0x3F];
1 "= SP_box[5][(temp » 8) & Ox3FJ:
1 "= SP_box[3][(temp » 16) & 0x3F];
1 ~= SP_box[1][(temp » 24) & Ox3F];
else
next operators
Проверив условие, он выполнит операцию, выделенную жирным шрифтом, а
остальные будет выполнять всегда (!). При этом совершенно ошибочным выгля-
дит появление конструкции «else next operators» в конце. Чтобы этого не прои-
зошло, макрос приходится обрамлять кавычками {} или, что значительно лучше,
конструкцией do {} while (0).
Листинг 4.15
#define F(l, г, key) do { \
temp = ((r » 4) | (r « 28)) " key[O]; \
1 "= SP_box[6][temp & Ox3FJ; \
1 ’= SP_box[4][(temp » 8) & 0x3F]; \
1 “= SP_box[2][(temp » 16) & 0x3FJ; \
.1 "= SP_box[0][(temp » 24) & 0x3F); \
temp = r ~ key[1J; \
1 "= SP_box[7][temp & 0x3F]; \
1 “= SP_box[5][(temp » 8) & 0x3F]; \
1 "= SP_box[3][(temp » 16) & 0x3F]; \
' 1 SP_bdx[1]i(temp » 24) & 0x3F]; \
’ } while (0)' • • ‘
Функция гаммирования в DES достаточно проста. Правая половина г преоб-
разуется циклическим сдвигом и наложением гаммы-значения текущего подклю-
ча key. Подключ key состоит на самом деле из восьми байтов, представляющих
собой шестибитовые значения используемых ключевых элементов. В исходном
тексте из листинга 4.13 видно, что для их представления используются не восьми-
битовые типы данных, а 32-битовые — как для длинных целых. Это сделано опять
же в целях повышения эффективности генерируемого современными компилято-
рами кода.
На вход функции гаммирования F поступает 32-битовая половина шифруе-
мого блока и подключ. С помощью специальной таблицы эти 32 бита разворачи-
ваются до 48 битов дублированием некоторых из них. Затем полученный развер-
нутый блок побитно суммируется по модулю 2 с соответствующим битом ключа.
Полученный в результате блбк данных снова разделяется на восемь шестибито-
вых частей.
Они, в свою очередь, используются в качестве входных аргументов для полу-
чения значений соответствующих узлов замен. После этого полученные восемь
уже 4-битовых значений объединяются обратно в 32-битовый блок данных. С его
элементами проводится специальная перестановка битов, показанная на
рис. 4.12. Результат этой последней операции и является выходным значением
функции шифрования.
102
Гпава 4. Как устроены современные шифры
Как видно из описания, почти все операции алгоритма являются линейны-
ми — ц действительности все, кроме операции замены, проводимой с помощью за-
ранее заданных узлов замен. Они единственные представляют собой нелинейную
и самую сложную часть алгоритма, от которой зависит стойкость всего алгорит-
ма. Связь между узлами замен S1...S8, таблицей расширения Е и таблицей пере-
становок Р показана на рис. 4.12.
Рис. 4.12
Для их эффективной реализации вполне достаточно массива констант, испо-
льзуя который мы вычисляем значение замены путем подстановки блока битов в
качестве индекса этого массива, например: S = S_box[data]. С побитовой пере-
становкой гораздо сложнее. В предыдущем разделе (см. раздел «Криптосистема
Lucifer») нами уже был описан способ осуществить обе эти операции с максима-
льной эффективностью. Точно так же можно поступить и при реализации алго-
ритма DES. . - /!
Для вычисления SP-узлов замен и перестановки можно воспользоваться про-
граммой из листинга 4.16. В ней по всем возможным входным данным и соответ-
ствующим проводятся вычисления возможных результатов, которые затем в мас-
сиве констант в файле описания на языке Си вносятся в основной программный
модуль.
Листинг 4.16
void make_spboxes() {
uint8_t pbox[32];
int p, i, s, j, rowcol;
FILE *f = fopen("des_sp.h", "wt"):
// небольшая инверсия для таблицы перестановки
for (р = 0; р < 32; р++) - i
for(i = 0; i < 32; i++)
if (p32i[i] == p+1) {
pbox[p] = i; ~
break;
}
Гпава 4. Как устроены современные шифры
103
И заполняем SP_box // uint32_t SP_box[8][64];
for (s = 0; s < 8; s++)
for (i = 0; i < 64; i++) {
SP_box[s][i] = 0;
rowcol = (i & 32) | ((i & 1) ? 16 : 0) | ((i » 1) & Oxf);
for(j = 0; j < 4; j++)
if (S_box[s][rowcol] & (8 » j)){
SP_box[s][i] |= 1L « (31 - pbox[4*s + j]);
}
}
s = 0;
P = 1;
fprintf(f. ”uint32_t SP_box[8][64] = {\n\t”);
for (i = 0; i < 8; i++) // по всем узлам
for (j = 0; j < 64; j++) { // по всем возможным входам
Ц сдвигаем циклически для алгоритма
SP_box[i][j] = (SP_box[i][j] « р)
| (SP_box[i][j] » (32-р));
// и выводим в файл описаний
fprintf(f, ”0х%081х, ”, SP_box[i][j]);
if (++s == 4) {
fprintf(f, ”\n‘’);
if (i ! = 7 11 j != 63) fprintf(f, ”\t”);
s = 0;
}
}
fprintf(f, ”};\n”);
fclose(f);
}
Теперь снова посмотрим на весь алгоритм. На последнем раунде шифрования
не происходит обмена половин данных. Вместо этого они объединяются в полный
64-битовый блок и над ним выполняется финальная битовая перестановка, обрат-
ная начальной. Собственно, результат последней операции и является результа-
том зашифрования блока с помощью алгоритма DES.
При этом процедура расшифрования блока аналогична процедуре зашифрова-
ния, с той только разницей, что для расшифрования необходимо переставить все
операции преобразования блока в обратном порядке (см. листинг 4.17).
Листинг 4.17
// проводим 16 раундов шифрования
if (encrypt) {
F(left, right, key->subkey[O]);
F(right, left, key->subkey[1]);
F(left, right, key->subkey[2]);
F(right, left, key->subkey[3]);
F(left, right, key->subkey[4]);
F(right, left, key~>subkey[5]);
F(left, right, key->subkey[6]);
F(right, left, key->subkey[7]);
F(left, right, key->subkey[8]);
104
Гпава 4. Как устроены современные шифры
F(right, left,
F(left, right,
F(right, left,
F(left, right,
F(right, left,
F(left, right,
F(nght, left,
}
else {
F(right, left,
F(left, right,
F(right, left,
F(left, right,
F(right, left,
F(left, right,
F(right, left,
F(left, right,
F(right, left,
F(left, right,
F(right, left,
F(left, right,
F(right, left,
F(left, right,
F(right, left,
F(left, right,
key->subkey[9]);
key->subkey[10]);
key->subkey[11]);
key->subkey[12]);
key->subkey[13]);
key->subkey[14]);
key->subkey[15]);
key->subkey[15]);
key->subkey[14]);
key->subkey[13]);
key->subkey[12]);
key->subkey[11]);
key->subkey[10]);
key->subkey[9]);
key->subkey[8]);
key->subkey[7]);
key->subkey[6]);
key->subkey[5]);
key->subkey[4]);
key->subkey[3]);
key->subkey[2]);
key->subkey[1]);
key->subkey[O]);
Постоянная проверка очевидного значения и необходимость держать два ва-
рианта исполнения, по сути, одного и того же кода явно не является эффективной
реализацией. Чтобы избежать этого в программе, мы можем просто переставлять
биты ключа надлежащим образом, не переставляя функции в исходном коде. Про-
делав это, получим полный текст программы алгоритма зашифрования данных в
соответствии со стандартом DES (см. листинг 4.18).
Листинг 4.18
// зашифровываем один блок данных
void enc_DES(uint32_t *block, DES_KEY *key, bool encrypt) {
uint32_t left, right, temp;
11 переставляем байты для совместимости с big-endian
reorder_bytes(*block, 2, left, temp);
left = block[0];
right = block[1];
temp = ((left » 4) " right) & OxOfOfOfOfL;
right "= temp;
left "= (temp « 4);
temp = ((left » 16) " right) & OxOOOOffffL;
right "= temp;
left ~= (temp « 16);
temp = ((right » 2) " left) & 0x33333333L;
left "= temp;
Гпава 4. Как устроены современные шифры 105
right "= (temp « 2);
temp = ((right » 8) " left) & OxOOffOOffL;
left "= temp;
right ~= (temp «8);
right = ((right « 1) | ((right » 31) & IL)) & OxffffffffL;
temp = (left " right) & OxaaaaaaaaL;
left "= temp;
right "= temp;
left = ((left « 1) | ((left » 31) & 1L)) & OxffffffffL;
I/ проводим 16 раундов шифрования
F(left, right, key->subkey[O]);
F(right, left, key->subkey[1]);
F(left, right, key->subkey[2]);
F(right, left, key->subkey[3});
F(left, right, key->subkey[4]);
F(right, left, key->subkey[5]); '
F(left, right, key->subkey[6]);
F(right, left, key->subkey[7]);
F(left, right, key->subkey[8]);
F(right, left, key->subkey[9]);
F(left, right, key->subkey[10]);
F(right, left, key->subkey[11]);
F(left, right, key->subkey[12]);
F(right, left, key->subkey[13]);
F(left, right, key->subkey[14]);
F(right, left, key->subkey[15]);
right * (right «’ 31) | (right >> 1); '
temp = (left "right) & OxaaaaaaaaL;
left "=-tejnp/r($ ' •
rigjrt <= temp;, , r
left = (left « 31) | (left » 1);
temp = ((left » 8) "right) & OxOOffOOffL;
right "= temp;
left "= (temp « 8);
temp = ((left » 2) " right) & 0x33333333L;
right "= temp;
left "= (temp « 2);
temp = ((right » 16) " left) & OxOOOOffffL;
left "= temp;
right "= (temp « 16);
temp = ((right » 4) " left) & OxOfOfOfOfL;
left "= temp;
right "= (temp « 4);
// снова меняем байты местами для совместимости
block[0] = right;
Ыоск[1] = left;
reorder_bytes(*block, 2, left, temp);
}
Надо сказать, что все табличные значения несколько отличаются от соответ-
ствующих значений, опубликованных в классическом варианте — в самом стан-
106
Глава 4. Как устроены современные шифры
дарте DES. Это связано с принципами строения архитектуры процессоров Intel
как little-endian и соответственно с принципами обработки данных, которые раз-
мещаются в памяти. Вследствие этого исходные таблицы приходится дорабаты-
вать. По этой же причине байты данных перед зашифрованием необходимо пере-
ставить в соответствии с big-endian архитектурой, а после зашифрования переста-
вить их в обратном порядке.
На самом деле последняя операция могла быть излишней, если бы твердо
были уверены в том, что никакой сетевой драйвер или драйвер жесткого диска не
вздумает переставить их по собственной воле «для совместимости с компьютера-
ми других платформ». К сожалению, такой уверенности нет, и приходится каж-
дый раз проделывать эту в общем-то бессмысленную операцию.
К тому же недавно было показано, что и от примитивных атак ключ размером
56 битов не предоставляет значительной защиты, — ключ DES был найден путем
тотального опробования с помощью специализированного программно-аппаратно-
го комплекса (см. раздел «Дешифрование DES»).
Правда, на проблему недостаточного размера ключа указывали сразу же по-
сле принятия DES как стандарта шифрования. Поэтому для обеспечения большей
надежности, исходя из того, что сам DES потенциально не мог ее обеспечить,
были построены несколько вариантов нового стандарта: Triple-DES (3-DES) и его
обобщенные варианты nDES, New-DES, DES-X, Generalized-DES (GDES). Они
появлялись в разное время, но все были основаны на существующей DES-архи-
тектуре. Таким же образом появился и DEAL, затем DEA, а затем и IDEA.
Все они в первую очередь устраняли недостаток, связанный с малой длиной
ключа в алгоритме DES. Triple-DES (3-DES) или Тройной-DES представляет со-
бой весьма простое усовершенствование алгоритма, увеличивающее длину 56-би-
тового ключа вдвое (или втрое, в зависимости от вариантов исполнения) с помо-
щью следующего нехитрого преобразования:
3DESkl+k2(x) = DESkl(DES^(DESkl(x))) для двойной длины ключа
или
3DESkl+k2+k3(x) = DES u (DES ю (DESk3 (х)))для тройной длины ключа.
DESk(x) — обозначает зашифрование с помощью алгоритма, a DES*'(х) —
обозначает расшифрование.
В алгоритме Тройной-DES в качестве основной криптографической функции
используется весь алгоритм DES без изменения. Ключ 3-DES формируют путем
конкатенации трех различных ключей — klt k2 и k3 вместе. Для того чтобы зашиф-
ровать блок данных, его сначала преобразуют с помощью алгоритма DES и ключа
kt, затем получившийся выход дополнительно преобразуют еще раз с помощью
DES, но ключ выбирают уже k2 и в третий раз поступают аналогичным образом,
используя ключ k3.
Вариант, где используется только лишь двукратное увеличение, называют
также «двухключевым Тройным-DES». В нем открытый текст сперва шифруется
ключом kit затем расшифровывается ключом k2 и снова зашифровывается ключом
kv К сожалению, криптоанализ этих схем показал, что длина блока в 64 бита де-
лает эти схемы уязвимыми к атаке по подобранному шифротексту. К тому же
Глава 4. Как устроены современные шифры
107
3-DES с тремя независимыми ключами оказался уязвим к атаке по зависимому
ключу (см. раздел «Дешифрование DES»), причем время ее исполнения прибли-
зительно равно времени исчерпывающего поиска в простом DES. Кроме того, не-
решенным до сих пор является вопрос, не образует ли DES сам по себе алгебраи-
ческое кольцо. Если так, то зашифрование на двух разных ключах kx и k2 будет
равносильно зашифрованию на некотором третьем ключе k3, который возможно
будет описать формально.
Еще одним вариантом исполнения нового стандарта был шифр DES-Х, увели-
чивающий длину ключа обычного DES до 120 битов. Учитывая, что сам по себе
DES не может обеспечить должной стойкости, его можно попытаться усилить по-
средством применения дополнительных криптографических преобразований.
В алгоритме DES-Х, предложенном компанией RSA Data Security, используется
именно такой подход. Входные данные (блок размером 64 бита) суммируются по
модулю 2 с некоторым битовым набором (в английских источниках эта операция
названа «отбеливанием» или whitening — дело в том, что с помощью этой опера-
ции входные данные должны выглядеть более случайно, более похожими на так
называемый «белый шум», то есть совершенно случайные данные). После этого
блок зашифровывается с помощью DES, а затем уже результат проходит еще
одно отбеливание, но уже с помощью другого набора битов.
По этой причине ключ DES-Х состоит на самом деле из двух ключей — клю-
ча для настоящего DES длиной 56 битов и еще 64-битовый ключ для «отбелива-
ния». При этом «отбеливающая» часть ключа используется в основном на этапе
работы функции разворачивания ключа. Для ее работы необходима таблица за-
мен, основанная на значениях цифр числа к (см. листинг 4.19).
Листинг 4.19
DESX_S_box[256] = {
189, 86,234,242.162,241,172, 42,176,147,209,156, 27, 51,253,208,
48, 4,182,220,125,223, 50, 75,247,203, 69,155, 49,187, 33, 90.
65,159,225,217, 74, 77,158,218,160,104, 44,195, 39, 95,128, 54,
62,238,251,149, 26,254,206,168, 52,169, 19,240,166, 63,216, 12,
120, 36,175, 35, 82,193,103, 23,245,102,144,231,232, 7,184, 96,
72,230, 30. 83,243,146,164.114,140, 8, 21,110,134, 0,132,250,
244,127,138, 66, 25,246,219,205, 20,141, 80. 18,186, 60, 6, 78,
236,179, 53, 17,161,136,142, 43,148,153,183,113,116,211,228,191,
58,222,150, 14,188, 10,237,119,252, 55,107, 3,121,137, 98,198,
215,192,210,124,106,139, 34,163, 91, 5, 93. 2,117,213, 97,227,
24,143, 85, 81,173, 31. 11. 94,133.229,194, 87, 99,202, 61,108,
180,197,204,112,178,145, 89,и13„ 71, 32,200, 79,. 88,224, 1,226,
22. 56,196,111, 59, 15,101, 70,190,126, 45,123,130,249, 64,181,
29,115,248,235, 38,199,135,151, 37, 84,177, 40,170,152,157,165,
100,109,122,212, 16,129, 68,239. 73,214,174, .46,221,118, 92, 47,
' 167, 28,201, 9,105,154,131,207,' 41, 57,185,233, 76,255, 67,171
Для начала обычным способом с помощью ключа для DES вычисляется 16
подключей DES. Затем для вычисления отбеливающих наборов битов использует-
108
Гпава 4. Как устроены современные шифры .
ся алгоритм, приведенный в листинге 4.20. Там же описан способ применения от-
беливающих наборов битов — функции DESX_encrypt и DESX_decrypt.
Листинг 4.20
pre_whitening = whitening_key;
post_whitening = 0;
hash.it.with(DES.key);
hash_it_with(whitening_key);
hash_it_with(uint8_t *key) {
for (int i = 0; i < 8; i++) {
int index = post_whitening[0] " post_whitening[1J;
for (int j = 0; j < 7; j--)
post_whitening[i] = post_whitening[i+1];
post_whitening[0] = post_whitening[0] " DESX_S_box[index];
}
DESX_encrypt(uint8_t *data, DESX.key *key) {
int i;
for (i =0; i < 7; i++) data[i] = data[i] " key->pre_whitening[i];
DES_enc(data, key, true);
for (i = 0; i < 7; i++) data[i] = data[i] " key->post_whitening[i];
}
DESX_decrypt(uint8_t *data, DESX.key *key) {
int i;
for (i = 0; i < 7; i++) data[i] = data[iJ " key->pre_whitening[i]; ,
DES_enc(data, key, false);
for (i =0; i < 7; i++) data[i] = data[i] " key->post_whitening[i];
}
Шифр nDES является обобщением 3-DES, связанным с n-кратным примене-
нием в связи с неэффективностью алгоритма при больших значениях м,.он не
стал сколь-нибудь значительным вкладом в развитие криптографии блочных
шифров.
Его созвучный аналог представляет собой уже 17-раундовый шифр со 120-би-
товым ключом. Процедура разворачивания ключа проста. Каждые два раунда ис-
пользуют одну 56-битовую часть ключа, которая для каждой следующей пары по-
лучается из первых 56 битов ключа, который преобразуется с помбЩью Цикл'йчё-'
ского сдвига на те же 56 битов. ! , 1 t и
Обобщенный GDES (Generaliz'ed-DES) :являетсйнйе чем иным, как простым
обобщением опубликованного стандарта DES (что следует йз йазйанйя'Ь 'Сох^а-
няя структуру DES, шифр GDES позволяет использовать произвольные узлы1 за-
мен, начальные/конечные перестановки и таблицу для разворачивания ключа.
При этом 16 подключей длиной в 48 битов также могут выбираться пользовате-
лем вручную, а не вычисляться системой из одного основного 56-битового ключа.
Глава 4. Как устроены современные шифры
109
Авторы GDES добивались на самом деле решения двух проблем — увеличения
длины ключа и устранения возможной «недобросовестности» составителей изве-
стных узлов замен, поскольку они являются не менее ключевым местом в шифре,
чем все остальное.
Надо сказать, что в отечественном стандарте «Системы обработки информа-
ции. Защита криптографическая. Алгоритм криптографического преобразования»
в соответствии с ГОСТ 28147—89, принятом в 1989 году, поступили приблизите-
льно так же. Отечественный стандарт шифрования копирует структуру DES, за
исключением некоторых существенных модификаций. Первой модификацией яв-
ляется отсутствие начальной и финальной перестановок, характерных для всех
вариантов DES. Кроме того, в ГОСТ увеличено количество раундов до 32 штук.
Отсутствует схема разворачивания ключа из 32 в 48 битов. Подключи на каждом
раунде суммируются по модулю 232, а не по модулю 2, как в DES. При этом осо-
бенностью сложения является то, что оно выполняется с переносом.18 Вместо
подстановок, переводящих 6 битов в 4 бита, используются взаимооднозначные,
переводящие 4 бита в 4 бита.
Значения 512-битовых узлов замен не были опубликованы вместе со стандар-
том. При этом не было (и до сих пор не стандартизовано) даже упоминания о воз-
можных критериях по их созданию (да что уж говорить, если даже тестовые век-
торы, записанные в стандарте, к сожалению, не учитывают ряд битов выхода
шифра). Как говаривал известный советский критик: «Что поделать, издержки
производства». Говоря другим языком, узлы замен в ГОСТ нужно считать секрет-
ной компонентой шифра.
Дополнительно ко всем вышеперечисленным пунктам перестановка осущест-
вляется циклическим сдвигом на 11 битов влево вместо сложной побитовой пере-
становки DES. Процедура разворачивания ключа представляется простым распо-
ложением исходных ключевых данных в следующем порядке:
0,1,2,3,4,5,6.7, 0,1,2,3,4,5,6,7, 0.1,2,3,4,5,6,7, 7,6,5,4,3,2,1,0 -
для зашифрования и
0,1,2,3,4, 5,6,7, 7,6, 5,4,3,2,1,0 7, 6, 5,4, 3,2,1,0 7,6, 5,4, 3,2,1,0 -
для расшифрования данных.
Вкупе с 512-битовыми узлами замены 256-битовый ключ составляет прибли-
зительно 610 битов действительно ключевой информации (со скидкой на структу-
ру алгоритма). Узлы замен на самом деле можно считать группой перестановок,
которые по требованиям к памяти превосходят узлы замен DE.S в два раза. А 610
б.уров ключеврй. информации получаются следующим образом. Первые 256 исход-
ного ключа включены в шесть результирующих сотен полностью. Следующей
ключевой компонентой являются узлы, заилен. Каждый узел замены представляет
со0,С|й перестановку делых ^т 6,до 15.. Всевозможных таких'перестановок 16! =
=.£ЬЙ22,789888000, или приблизительно 2 • 1013 вариантов, или что равно
24^.25614047^ Последнее же означает (см. главу «Теория секретных систем»), что узел
3 18 На самом деле в алгоритме в соответствии с ГОСТ 28147—89 используется как суммиро-
вание по модулю 232 с переносом, так и суммирование по модулю 232 соответственно без оного.
110
Гпава 4. Как устроены современные шифры
замены можно определить с помощью не более чем 44,2 бита информации. Умно-
жаем 44,2 на 8 (количество узлов замены) и получаем 354 бита, которые в сумме
с 256 битами исходного ключа дают ровно 610 искомых битов.
Основной частью алгоритма, так же как и в DES в ГОСТ 28147—89, являют-
ся функций гаммирования, используемые для выработки накладываемой на дан-
ные гамма-последовательности. И здесь проявляется основная особенность отече-
ственного стандарта. Дело в том, что функция F определяет группы перестановок
для различных семейств ключей и по этой причине образует не что иное, как про-
стую перестановку с произвольным фиксированным ключом.
В описании ГОСТ определены четыре режима работы, совпадающие с анало-
гичными режимами работы его западного аналога (см. раздел «Режимы шифрова-
ния»).
Попробуем реализовать алгоритм шифрования в соответствии с ГОСТ на язы-
ке Perl (см. листинг 4.21).19
Листинг 4.21
#! /usr/bin/perl -w
# узлы замен (последовательно)
©SBOX = (
[ 13, 2, 8, 4, 6, 15, 11, 1, ю, 9, 3, 14, 5, 0. 12, 7 ].
[ 14. 4, 13, 1, 2, 15, 11, 8. 3. 10. 6, 12. 5, 9. 0, 7 ],
[ 15. 1. 8, 14. 6, 11, 3, 4, 9, 7, 2, 13. 12. 0. 5. 10 ],
[ ю. 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7. 11, 4. 2, 8 ].
[ 7, 13, 14, 3, 0, 6, 9, 10. 1, 2, 8, 5. 11, 12. 4, 15 ],
[ 2. 12, 4, 1, 7. Ю, 11, 6, 8, 5, 3. 15. 13, 0. 14. 9 ].
[ 12, 1, 10. 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5. 11 ].
[ 4. 11, 2, 14, 15. 0, 8, 13. 3, 12, 9, 7, 5, 10. 6, 1 ]
):
sub f($) {
local
my $x = shift;
my $result = 0;
grep {
Sresult = Sresult
| (${$SBOX[$_]}[($x » ($_ * 4)) & 15] « ($_ * 4));
} reverse (0..7);
return Sresult;
}
sub gostcrypt(SSS) {
my ($data, $key, Sdecrypt) =
my (Sswap, $left, Sright, $j);
19 Поскольку ГОСТ в действительности имеет тот же каркас, что и DES, авторы сочли до-
вольно скучным представлять реализацию алгоритма в соответствии с ГОСТ 28147-89 на языке
Си, так же как и DES. Поэтому было решено сделать это на другом языке — им сразу стал Perl.
Глава 4. Как устроены современные шифры 111
tt преобразуем данные к числовому формату
{left = unpack("L", pack(”a4”, substr($data, 0, 4)));
$right = unpack("L", pack("a4", substr($data, 4, 4)));
$j = 0;
print "KEYS: ";
grep {
# выбираем номер подключа для зашифрования/расшифрования
$j = ($_ & 7) - 1;
$j = 7 if $j < 0; t , . , *
{decrypt ? ($_ >= 9) '&& ($j = (32 - $_) & 7)
: ($_ >= 25) && ({j = 32 - {_);
print {j,............;
# шифруемся
{left "= f({right + {{key[{j]);
tt меняем половинки местами
{swap = {right;
{right = {left;
{left = {swap;
} (1..32); # 32 раунда
tt меняем половинки местами
{swap = {right;
{right = {left;
{left = {swap;
return pack("L", {left) . pack("L", {right);
}
# инициализируем 256 битов ключа
{KEY[O] = 0x12345678;
{KEYCI] = Ox9abcdefO;
{KEY[2] = 0xf0debc9a;
{KEY[3J = 0x78563412;
{KEY[4J = 0x12345678;
{KEYC5] = 0x9abcdef0;
{KEY[6] = 0xf0debc9a;
{KEY[7] = 0x78563412;
{a = "DatLDatR";
print "ORIGIN: {a\n";
print "@KEY\n";
# зашифруем
{b = gostcrypt({a, \@KEY, 0);
print "\nENCIPHERED: {b\n";
print "@KEY\n";
# расшифруем
{c = gostcrypt({b, \@KEY, 1);
print "\nDECIPHERED: {c\n";
Результат ее работы показан в листинге 4.22. Первые строчки чисел после
слов ORIGIN и ENCIPHERED не что иное, как значения 32-битовых элементов
главного ключа. Порядок использования ключей обозначен в следующих за ними
112 Гпава 4. Как устроены современные шифры
строках (эти значения можно сверить с приведенными немного выше). Обратите
внимание на то, как заданы узлы замен (массив SBQX содержит ссылки на масси-
вы уже соответствующих узлов замен). Сами узлы замен представлены обычны-
ми массивами по 16 элементов в каждом, содержащими значения от 0 до 15.
Листинг 4.22
X:\cryptobook\sources>perl gost.pl
ORIGIN: DatLDatR
305419896 2596069104 4041129114 2018915346 305419896 2596069104 4041129114 2018915346
KEYS: 01234567012345670123456776543210
ENCIPHERED: my(tHd®!
305419896 2596069104 4041129114 2018915346 305419896 2596069104 4041129114 2018915346 '
KEYS: 01234567765432107654321076543210
DECIPHERED: DatLDatR
Функция гаммирования вынесена в отдельную процедуру исключительно для
наглядности. В настоящей реализации ее, конечно, следует внести внутрь основ-
ной функции, «расписав» и развернув цикл в 32 последовательных вызова функ-
ции (см. листинг 4.23).
» J ’ L ( •
Листинг 4.23
sub gostcrypt_linear($$$) {
my ($data, $key, $decrypt) =
my (Sswap, $left, Sright, $j);
it преобразуем данные к числовому формату, . ,
Sleft = unpack("L", pack("a4”, substr($data, 0, 4)));
Sright = unpack("L", pack(”a4", substr($data, 4, 4)));
$j = 0;
grep {
# развернем четыре цикла
$j = ($_ & 7)-1; $j=7 if $j<0:
Sdecrypt?($_>=9)&&($j=(32-$_)&7):($_>=25)&&($j=32-$_);
Sleft "= f(Sright + $$key[$j]);
$j = (S_ & 7)-1; $j=7 if $j<0;
Sdecrypt?($_>=9)&&($j=(32-$_)&7):($_>=25)&&($j=32-$_);
Sright "= f(Sleft + $$key[$j]);
$j = ($_ & 7)-1; $j=7 if $j<0;
Sdecrypt?($_>=9)&&($j=(32-$_)&7):(S_>=25)&&(Sj=32-$_);
Sleft "= f(Sright + $$key[$j]);
$j = ($_ & 7)-1; $j=7 if $j<0; . , , s
Sdecrypt?($_>=9)&&($j=(32-$_)&7):($_>=25)&&($j=32-$_);
Sright "=,f(Sleft + $$key[$j]);
$j = ($1 & 7)-1; $j=7 if $j<0; 'Ji!
$decrypt?($_>=9)&&($j=(32-$_)&7):($_>=25)&&($j=32-$_:): ' r''- •
Sleft ~= f($right + $$key[$j]);
Sj = ($_ &' 7)-1; Sj=7 if $j<0; 1 ' •
$decrypt?($_>=9)&&(Sj=(32-$_)&7): ($_>=25)&&($j=32-$j,);' -; i'! ”
Sright ~= f($left + $$key[$j]);
$j = ($_ & 7)-1; $j=7 if $j<0;
Глава .4. Как устроены современные шифры 113
$decrypt?($_>=9)&&(Sj=(32-$_)&7):($_>=25)&&($j=32-$_);
Sleft "= f($right + $$key[$j]);
Sj = ($_'& 7)-1; $j=7 if $j<0;
$decrypt?($_>=9)&&($j=(32-$_)&7):($_>=25)&&($j=32-$_);
$right "= f($left + $$key[$j]);
} (1..8); tt уже 8 = 32/4 циклам (раундов 32, 4 развернуты)
Sswap = Sright;
Sright = Sleft;
$left = $swap;
return pack(”L", $left) . pack(”L", Sright);
} • .
Особенного внимания заслуживают манипуляции с входными данными с по-
мощью операторов pack и unpack:
Sleft = unpack("L", pack("a4", substr($data, 0, 4)));
Sright = unpackC’L”, pack("a4", substr($data, 4, 4)));
Такой подход используется для того, чтобы обеспечить универсальность ме-
тода обработки данных. В этом случае данные, возможно представленные изна-
чально в разных форматах, будут приведены к целочисленному формату 32-бито-
вых чисел. (: . ,
Раунды шифрования выполняются с помощью весьма эффективного в Perl
оператора grep (еще один вариант реализации — использование оператора тар).
От остальных способов (например, в виде цикла) этот отличается относительной
быстротой выполнения.
После того как код отлажен, его можно представить в удобочитаемом виде.
Ведь мало у кого есть исходные тексты ГОСТ, написанные в пять строк кода, как,
например, в листинге 4.24. '
Листинг 4.24
sub F{$u=0;grep$u|=$S[$_][$_[0]»$_*4&15]«$_*4, reverse 0..7;$u«111$u»21}sub R
{int$_[O]*rand)sub N{vec$_[0],$_[1]/4,32)Se=join'’,<>;@b=@t=O..15;for(;$i<length
Sp;$i+=4){srand($s~=N$p,Si)}while($c<8){grep{push@b,splice@b,R(9),5}@t;$R[$c]=R(
2“32);@{$S[$c++])=@b}@h=0. .7;@o=reverse@h;while($a<length$e){$v=NSe,$a;$w=N$e, (
$a+=8)-4;grepSq++%2?Sv"=F$w+$K[$_]:($w-=F$v+$K[S_]) .$d?(@h,(@o)x3):((@h)x3,@o);
$_.=pack N2,Sw,Svjprint
В заключение надо особо отметить принципы разработки процедур развора-
чивания ключей. Несколько необходимых свойств заметны невооруженным
взглядом даже неспециалисту. Первое из них заключается в необходимости нали-
чия зависимости подключей от наибольшего числа битов основного ключа. При
этом это не должно требовать слишком мноРо работы (поскольку в этом случае
скорость алгоритмов смены ключей будет чрезвычайно замедленной20). Энтропия
подключей не должна быть значительно ниже чем'у исходного ключа, и не должна
20 Последняя часть правила работает не всегда. Например, в алгоритме блочного шифрова-
ния Blowfish процедура выработки цикловых подключей умышленно замедлена — для выработ-
ки очередного ключа используется весь алгоритм зашифрования с ранеё зафиксированными
ключами. И сделано это специально — для замедления процесса тотального опробования.
114
Глава 4. Как устроены современные шифры
снижаться по мере выработки каждого следующего подключа (проверяется это
выработкой большого количества подключей из некоторого множества главных, а
затем элементарными подсчетами по формулам энтропии и вероятностей). Не
должно быть очевидно зависимых и слабых ключей, с учетом свойства компле-
ментарности.21 Для предотвращения появления слабых ключей обычно вводят
циклические сдвиги подключей. Если их не производить, то очевидно будут суще-
ствовать ключи, для которых все подключи будут равны.
Архитектура SQUARE: от 3-WAY до AES
NIST claimed that security was the key factor, yet they deci-
ded to recommend Rijndael, the candidate with the smallest se-
curity margin of the five finalists.
Из интервью с Ларсом Кнудсенам
В 1996 году тремя бельгийскими авторами, Йоаном Даэменом (Joan Daemen),
Ларсом Кнудсеной (Lars Knudsen) и Винсентом Райменом (Vincent Rijmen), был
предложен блочный шифр SQUARE, ставший впоследствии родоначальником но-
вой архитектуры построения блочных шифров с одноименным названием.
Первоначально параметры шифра представляли собой достаточно типичные
значения. Размер блока был равен 128 битам, столько же составляла длина клю-
ча. Число раундов было весьма мало относительно других существующих блоч-
ных шифров. При этом в своих статьях авторы утверждали, что алгоритм устой-
чив к большинству существующих криптоаналитических атак.
Основными критериями при разработке шифра являлись, во-первых, устой-
чивость по отношению к уже существующим криптоаналитическим атакам,
во-вторых, простота архитектуры и исполнения и, в-третьих, скорость работы.
Одной из особенностей шифра являлась его ориентированность на использо-
вание в качестве элементарных операндов не битов и не 32- или 16-битовых слов,
а 8-битовых байтов. Для этих целей в алгоритме шифрования используется поле
Галуа GF(28), содержащее как раз 256 элементов, столько же, сколько и возмож-
ных значений в байте.
Элементы поля Галуа (и соответствующие им возможные значения обычного
байта) можно представлять в самых различных формах. Классическим является
полиномиальное представление. Для его задания каждому элементу поля сопо-
ставляется некоторый набор коэффициентов а( в поле GF(2). Затем с помощью
значений этих коэффициентов задается многочлен вида
X = {a1a6aiaiaia2aiaQ) <=> /(х) =
= а7х7 + а6х6 + а5х5 + а4х4 + а3х3 + а2х2 + а{х' '+ аох°.
21 Имеется в виду свойство следующего характера: если взять произвольный ключ k й за-
шифровать произвольный текст х, то алгоритм зашифрования даст следующее равенство:
Е(х) = Е(х), где у для произвольной битовой строки у является простой инверсией битов.
Глава 4. Как устроены современные шифры
115
Такое представление позволяет естественным образом описывать всевозмож-
ные преобразования данных, записанных в двоичном формате (в виде наборов ко-
эффициентов по восемь штук для различных полиномов). Так, сложение двух эле-
ментов в поле описывается сложением соответствующих коэффициентов двух
различны^ полиномов по модулю 2:
X + Y = (а7 Ф Ь7,а6 Ф Ь6,а5 Ф Ь5, а4 Ф Ь4,а3 Ф Ь3, а2 Ф Ь2, а, Ф bit aQ Ф b0),
где за операцию отвечает сложение по модулю 2, то есть a®b = cwa + b = c.
Умножение осуществляется немного сложнее, поскольку для его проведения до-
полнительно необходим выбор неприводимого в этом поле многочлена. Неприво-
димым многочленом называют многочлен, у которого отсутствуют корни, являю-
щиеся элементами данного поля. Для поля GF(28) неприводимым является, на-
пример, полином восьмой степени т(х) = х8 + х4 + х3 + х + 1. Операция
умножения с его участием осуществляется для двух полиномов, представляющих
значения байтов следующим образом:
a(x)b(x) = c(x)(mod /п(х)),
где (mod т(х)) определяет остаток от деления.
Например, для двух значений 0x57 (01010111b в двоичном виде) и 0x83
(10000011b в двоичном виде) многочлены будут выглядеть как а(х) = х6 + х4 +
+ х2 + х + 1 и Ь(х) = х7 + х + 1. Умножая их друг на друга, получим
a(x)b(x)(mod /п(х)) = (х6 + х4 + х2 + х + 1)(х7 + х + l)(mod /п(х)) = х7 + х6 +1.
В используемом поле присутствуют нейтральные элементы: по сложению это
0 и по умножению — 1. В шифрах обычно используется процедура нахождения
элемента обратного к данному, то есть такого, что выполнено равенство:
аа~х =l(mod28),
где а — некоторый элемент поля GF(28); а' — его обратный.
Аналогично может быть приведено представление элементов в поле с исполь-
зованием коэффициентов многочленов из поля GF(28), а не GF(2). Использование
таких на первый взгляд довольно громоздких понятий на самом деле в значитель-
ной степени упрощает описание алгоритма шифрования. Так, например, цикличе-
ский сдвиг влево на один бит можно записать в этом виде как умножение полино-
ма, представляющего заданную строку битов на х. Хотя в общем случае реализа-
ция операции умножения произвольного полинома на х немного более сложна,
чем простой сдвиг влево, тем не менее способ задания довольно удобен при опи-
сании алгоритма и его криптоанализе, поскольку позволяет формализовать все
выкладки с помощью понятного и логичного аппарата математических формул.
Допустим, например, что мы хотим умножить полином с коэффициентами bt.
Для этого мы можем поступить следующим образом: во-первых, если Ь7 = 0, то
все, что нам нужно, это просто умножить полином q(x) = b7x7 + Ь6х6 + Ь5х5 + Ь4х4 +
+ д3х3 + Ь2х2 + Ьрс1 + ЬцХ0 на х; допустим, что Ь7 отличен от нуля, тогда из результа-
та мы должны еще вычесть /п(х) — наш неприводимый полином, поскольку ре-
116
Гпава 4. Как устроены современные шифры '
зультат вычисления xq(x) явно не меньше /п(х)23, так что простым сдвигом здесь
уже не обойтись.
Шифр SQUARE и одноименная архитектура не имеют ничего общего с архи-
тектурой Файстеля и представляют совершенно иной подход, основанный на
применении изначально обратимых преобразований, а не на преобразовании не-
обратимых с помощью сети Файстеля в обратимые путем наложения гаммы и об-
меном половин шифруемого блока. Архитектура SQUARE на самом деле являет-
ся не чем иным, как логическим развитием идей, заложенной в алгоритм 3-WAY
(ThreeWay). ’ , . 1
Алгоритм шифрования 3-WAY разработан в 1994 году. Он также не является
шифром Файстеля, а является итерационным шифром. Рекомендованное автора-
ми число раундов зашифрования равно 11. Размер блока и длина ключа совпада-
ют и равны 96 битам. Алгоритм довольно удобен для аппаратной реализации на
процессорах с эффективной обработкой битовых операций и может быть реализо-
ван для работы со скоростью обработки данных до 1 гигабита в секунду.
При разработке алгоритма авторы сознательно отказались от использования
структуры сети Файстеля, где половина информационного блока усложняется на
каждом цикле, что в большинстве .случаев приводит к проявлению функцией гам-
мирования свойства линейности. Э.тот фак? используется в методе дифференциа-
льного и линейного криптоанализа (см. главу «Дешифрование современных шиф-
ров»).
Вместо этого цикловая функция зашифрования строится из простых обрати-
мых преобразований. При этом простота их структуры должна исключать воз-
можность наличия потайных ходов и закладок
Используемые преобразования оперируют с двоичными векторами вида х =
= (х7, х6, х5, х4, х3, х2, xt, х0), где х, представляют'собой единицу или ноль. Самое
простое преобразование, используемое в шифре, — ^-преобразование, являющее-
ся простой перестановкой битов в х в обратном порядке:
ц(х) = ц(х7, х6,х5,х4,х3,х2,х1(хй) = (ХО,Х|,Х2,Х3,Х4,Х5,Х6,Х7).
При этом, очевидно, для обратного преобразования ц~*(х) выполнено равен-
ство р(х) = ц’|(ц’1(х)).
Другое преобразование — у-преобразование является нелинейной частью
цикловой функции и описывает для каждого бита у,- результата действия преобра-
зования работу трехбитового узла замены:
У( = X; Ф Х/_т Ф -^(+2W
. • Ч J1 . L - .-к. 'j I .
В более общем виде предлагаемый.узел замены показан на рис. 4.13.
Еще одно преобразование — ^-преобразование, так же как и, является ли-
нейным. Для его описания воспользуемся представлением двоичных векторрв в
23 По одной простой причине мы увеличиваем стейеньсполинома q(x) с максимальной’сте-
пенью семь на единицу и получаем xq(x) с восьмой степенью. А полином т(х) уже имеет мак-
симальную степень восемь. Чтобы избежать «переполнения», мы должны будем вычесть т(х)
из xq(x).
Гпава 4. Как устроены современные шифры
117
XI Х2 ХЗ (х)
0 0 0 1 1 1
0 0 1 0 1 0
0 1 0 1 0 0
0 1 1 0 0 1
1 0 0 0 1 1
1 0 1 1 1 0
1 1 0 1 0 1
1 , 1 1 0 0 0 .
Рис. 4.13
виде полиномов с коэффициентами над полем GF(2). Тогда само преобразование
выглядит так:
Ь(х) = [х10 + х6 + х5 + х3 + х2 + х +l](xft)a(x)(mod 1 + хЛ).
Учитывая, что Э-преобразование определено для векторов длиной, кратной
12, константа h выбирается исходя из соотношения п = 12/г, где п — длина испо-
льзуемого двоичного вектора. При этом самб преобразование было выбрано так,
что каждый выходной бит зависит как минимум от семи входных (это было крите-
рием выбора многочлена в правой части уравнения).
Для описанных выше преобразований верными являктгся также равенства
у-1 = JX о у о р.
И . , . !. . t . . ' ' ' •
. . ) Д"’ = |Л О Э О р.
Дополнительно для преобразования данных используются преобразования
и л2, являющиеся битовыми перестановками, для которых должно быть выполне-
но равенство «р <>я2 = р. Поэтому выбор одного из них фиксирует другой. Ав-
торы алгоритма 3-WAY предложили использовать в их качестве циклические
сдвиги, чтобы иметь возможность эффективной реализации на существующих ап-
паратных платформах.
Все эти операции применяются к данным после того, как перед каждой итера-
цией промежуточный результат побитово складывается по модулю 2 с подключом
раунда. Процедура разворачивания подключей весьма проста и является самым
слабым местом алгоритма24. Каждый подключ вычисляется простым добавлением
к исходному ключу константы раунда с небольшим числом единиц.
Функция зашифрования р состоит из композиции описанных отображений:
0 —‘Л2 о'у О Jtj О Д. .I..; -.' / ':
До ее применения текущйи ‘блок суммируется с блоком подключа, номер ко-
торого зависит,от значения исходного ключа и номера раунда.
--:—:----7- • ,
24 На сегодняшний день уже существует алгоритм дешифрования S-WAY-подобных алго-
ритмов, связанный со слабостями именно этой части алгоритма.
118
Гпава 4. Как устроены современные шифры
Из-за особенностей построения всех отображений реализация 3-WAY доволь-
но проста и может быть оптимизирована. Однако следует отметить, что не все ис-
пользуемые в алгоритме шифрования преобразования можно реализовать в пол-
ной мере эффективно в рамках архитектуры современных процессоров.
Так, например, перестановка битов в противоположном порядке осуществля-
ется банальным использованием временного буфера, который заполняется в цик-
ле при прохождении исходных данных с конца в начало (см. листинг 4.25).
Листинг 4.25
И изменяем порядок битов на обратный
void mu(uint32_t *а)
{
int i;
uint32_t b[3];
b[0] = b[1] = b[2] = 0;
for (i = 0; i < 32; i++) {
b[0] «= 1;
b[1] «= 1;
b[2] «= 1;
if (a[OJ & 0x1) b[2]
if (a[1] & 0x1) b[1]
if (a[2] & 0x1) b[0]
a[0] »= 1;
a[1] »= 1;
a[2] »= 1;
}
a[0] = b[0];
а[1] = b[1];
a[2] = b[2];
>
Нелинейное преобразование у осуществляется еще более простыми операци-
ями: «исключающее ИЛИ» и простое «ИЛИ» с инверсией (см. листинг 4.26).
Листинг 4.26
И нелинейное преобразование
void gamma(uint32_t *а) {
uint32_t b[3J;
b[0] = a[0] " (a[1] | Ca[2]));
b[1] = a[1] ~ (a[2J | ("a[0]));
b[2] = a[2] ~ (a[0] | Ca[1]));
a[0] = b[0];
a[1] = b[1];
a[2] = b[2];
Гпава 4. Как устроены современные шифры
119
Аналогичным образом записывается линейное преобразование 3, специаль-
ные преобразования тс, и п2. Все операции сводятся к операциям сдвига битов вле-
во и вправо, а также суммированию битов простым «ИЛИ».
Листинг 4.27
И линейное преобразование
void theta(uint32_t *а) {
uint32_t b[3];
b[0] = a[0] " (a[0]»16) " (a[1]«16) " (a[1]»16) " (a[2]«16) “
(a[1]»24) " (a[2]« 8) ' (a[2]>> 8) ~ (a[0]«24) ~
(a[2]»16) " (a[0]«16) * (a[2]»24) ~ (a[0]« 8);
b[1] = a[1] " (a[1]»16) ~ (a[2]«16) ~ (a[2]»16) "• (a[0]«16) ~
(a[2]»24) " (a[0]« 8) ~ (a[0]>> 8) " (a[1]«24) "
(a[0]»16) " (а[1]«16) ~ (a[0]»24) ~ (a[1 ]« 8);
b[2] = a[2] ~ (a[2]»16) ~ (a[0]«16) " (a[0]»16) " (a[1]«16) "
(a[0]»24) * (a[1]« 8) ~ (a[1 ]» 8) “ (a[2]«24) ~
(a[1]»16) * (a[2]«16) " (a[1]»24) " (a[2]« 8);
a[0] = b[0];
a[1] = b[1];
a[2] = b[2J;
>
/I специальное преобразование - раз
void pi_1(uint32_t *a) {
a[0] = (a[0]»10) " (a[0]«22);
a[2] = (a[2]«1) " (a[2]»31);
}
// специальное преобразование - два
void pi_2(uint32_t *a) {
a[0] = (a[0]«1) ~ (a[0]»31);
a[2] = (a[2]»10) " (a[2]«22);
}
Вся цикловая функция зашифрования выглядит как набор из вызовов вышео-
писанных операций и служит больше для наглядности исходного текста, чем для
его эффективности и функциональности (см. листинг 4.28).
Листинг 4.28
И цикловая функция
void rho(uint32_t *а) {
theta(a);
pi_Ka);
gamma(а);
pi_2(a);
}
120 Гпава 4. Как устроены современные шифры
В зависимости от направления шифрования (зашифрование или расшифрова-
ние данных) вычисляются цикловые константы или обратные к ним. Затем прово-
дится собственно шифрование с использованием всех вышеуказанных преобразо-
ваний и цикловой функции (см. листинг 4.29).
Листинг 4.29
И вычисляем цикловые константы
void rndcon_gen(uint32_t strt, uint32_t *rtab) {
int i;
11 исполняем одиннадцать раундов
for (i = 0; i <= 11; i++) {
// заполняем цикловые константы
rtab[i] = strt;
strt «= 1;
if (strt & 0x10000) strt "= 0x11011;
}
}
// зашифрование
void encrypt(uipt3^t *a, ,uint32_t *k.) v ;
{ 3 ‘ ’
int i;
uint32_t rcon[11+1];
11 вычисляем константы
rndcon_gen(0x0B0B, &rcon);
//' проводим 11 раундов шифрования
for (i‘ = 0; i < 11; i++) { 1 ' ‘
< ‘ • a[0] > k[0] ~ (rcon['i] « 16)t < ’ 1 ( <
a[1K= k[1]r ,
a[2] ~= k[2] " rcon[i];
rho(a);
}
If последний штрих
a[0] "= k[0] " (rcon[11] « 16);
a[1] k[1];
a[2] "= k[2] " rcon[11];
theta(a);
}
I/ расшифрование
void,decrypt(uint32_t *a. uint32_t *k)
{ । , ' h '' "?.'( " * L' ♦ I >
int i; ,. . - ,
‘ uint32 4 ki^3]; // инвертированный ключ, (
' ' uint322t' fconfil+iy ; // инвертированные цикловые\константы
// вучисляе^ инвертированный ключ , ? '
ki[0] = k[0];
ki[1] = k[1]; ............... ,
ki[2] = k[2];
theta(ki); mu(ki);
Гпава 4. Как устроены современные шифры 121
// вычисляем инвертированные цикловые константы
rndcon_gen(0xB1B1, &rcon);
// проводим 11 раундов шифрования
mu(a);
for (i = 0; i < 11; i++) {
a[0] "= ki[0] " (rcon[i] « 16);
a[1] "= ki[1];
a[2] "= ki[2] “ rcon[i]; -
rho(a);
}
a[0] “= ki[0] " (rcon[ 11 ]«16);
a[1] "= ki[1];
a[2] "= ki[2] " rcon[11];
theta(a);
mu(a);
}
Шифр SQUARE, так же как и 3-WAY, состоит из композиции нескольких
простых шифрующих преобразований, то есть является составным шифром. Аг
торы описывают криптографические примитивы как «слои», которые накладыва-
ются один на другой и «закрывают» данные. Для этого в SQUARE, так же как и в
3-WAY, используются следующие типы преобразований: линейное, нелинейное,
перестановка байтов и побитное сложение с подключом.
Достоинством шифра SQUARE является тот факт, что все вышеописанные
преобразования сводятся к довольно простым операциям, которые могут быть
эффективно реализованы на современных процессорах и компьютерных систе-
мах. При этом с использованием этой архитектуры можно добиться высокой
степени распараллеливания вычислений. Это качество одновременно является
и хорошим, и плохим. Его положительная сторона заключается в возможности
эффективной реализации шифра на многопроцессорных системах для обработ-
ки огромных массивов данных или, например, в глобальных сетях. А отрицате-
льная очевидна в силу причин, о которых будет рассказано в разделе «Дешиф-
рование DES».
Отрицательные и положительные стороны архитектуры были учтены уча-
стниками жюри Национального института стандартов и технологий при выбо-
ре нового стандарта шифрования США. Дело в том, что начиная с 1977 года,
после принятия первого стандарта шифрования данных, НИСТ каждые пять
лет вновь подтверждал DES в качестве национального стандарта шифрова-
ния. После целого ряда удачных взломов шифра DES (см. главу «Дешифрова-
ние современных шифров») был инициирован проект создания стандарта сим-
метричного шифрования. С 1997 года, когда Сообщение об этрй опубликова-
ли в федеральном реестре США, было организовано и проведено три этапа
рассмотрения, анализа и обсуждения шифров, представленный на объявлен-
ный конкурс. ' ,
На первом этапе, завершившемся в 1998 году, было принято решение о прие-
ме для рассмотрения 15 потенциальных кандидатов на титул национального стан-
дарта. При отборе оценивались: защищенность алгоритмов от криптоаналитиче-
122
Гпава 4. Как устроены современные шифры
ских атак, статистические характеристики шифров; простота и надежность мате-
матической базы; вычислительная сложность алгоритмов зашифрования и
расшифрования, разворачивания ключей; сложность и эквивалентность програм-
мной и аппаратной реализаций; возможность использования различных размеров
блоков данных и длин ключей.
В соответствии с этими критериями на втором этапе были отсеяны почти
все кандидаты, кроме четырех наилучших: RIJNDAEL25, MARS, RC6, TWOFISH
и SERPENT. В итоге в конце третьего, завершающего этапа конкурса члены
жюри отдали большинство голосов (из более чем 200 членов жюри 86 проголо-
совало «за») первому кандидату — шифру RIJNDAEL, авторами которого явля-
ются Joan Daemen и Vincent Rijmen. С этого момента новый стандарт шифрова-
ния RIJNDAEL в прессе упоминают не иначе как Advanced Encryption Standard
или AES.
Как блочный итеративный шифр, AES зашифровывает данные блоками фик-
сированного (на время исполнения) размера размером по 128, 192 или 256 битов.
Возможные длины ключа равны соответственно 128, 192 и 256 битам. Для зашиф-
рования данных вырабатываются цикловые подключи (здесь понятия цикла и ра-
унда совпадают) с помощью специального алгоритма разворачивания — «образо-
вания подключей» (key evolution). При этом их количество на единицу больше
числа исполняемых раундов зашифрования.
Число раундов зависит от размеров блока и длины ключа в следующем виде
(рис. 4.14).
I Число раундов Длина блока в байтах =16 Длина блока в. байтах = 24 Длина блока в байтах = 32
Длина ключа । в байтах = 16 10 12 14
• Длина ключа в байтах = 24 12 12 14
Длина ключа в байтах = 32 14 14 14
Рис. 4.14
Каждый раунд можно описать с помощью четырех основных шагов (см. лис-
тинг 4.25):
Листинг 4.25
1. Нелинейная подстановка;
2. Строковый сдвиг:
3. Перемешивание столбцов;
4 Суммирование с цикловым подключом.
25 Название RIJNDAEL произносится как «Райндэл» и является, по всей видимости, произ-
водным от фамилий его авторов.
Глава 4.
Как устроены современные шифры
123
Перед тем как вдаваться в описание перечисленных этапов шифрования, не-
обходимо отметить несколько
шифрования.
нестандартное представление данных в алгоритме
Текущее состояние шифра в нем представляется не в виде битовой
строки
определенной длины,
а в виде матрицы 8-битовых байтов. Например, для
длины
блока в
128 битов и такой же длины ключа матрица состояния будет выгля-
деть вот так:
Я0,0» ^0,1» ^02’ Я0,3 *0,0» *0,1» *02» *0,3
Матрица состояния: • a 1,0» ^1,1» а12’ а1.3 ^2,0» ^2,1» ^22» ^2,3 ► Ключ: < *1,0» *1,1» *12’ *1,3 *2,0» *2,1» *22» *2,3
/*3,0» ^3,1» ^32’ #3,3 *3,0» *3,1» *32» *3,3
Эту матрицу называют текущим состоянием шифра или просто матрицей со-
стояния.
Нелинейная подстановка представляет собой применение узлов замены
для
каждого из байтов текущей матрицы состояния. Для ее реализации использу-
ют два
примитивных
нию байта в матрице
преобразования: получают обратное по умножению к значе-
по модулю 28, а затем применяя умножение на фиксирован-
ную матрицу и сложение с вектором:
'Уь' Ч • 0 • 0 • 0 • 1 • 1 • 1 • Р ч/ И
Ух 110-0-0-Ы1 %1 1
Уг 1-1-100-011 х2 0
Уз 11-110-0-0-1 %з + 0
У< 1-111-1000 Х4 0
Уз 0-111110-0 Х5 1
Уз 00-111-110 Х6 1
\Ут ) к0 • 0 • 0 • 1 • 1 • 1 • 1 • 1, <Х7) А
Подобные матрицы называются теплицевыми матрицами, на любой их диаго-
нали стоит один и тот же элемент. Наглядно данное преобразование переводит
одни байты используемой матрицы состояния в другие, независимо друг от друга
(см. рис. 4.15, где показано изменение байтов матрицы А и порядок перевода их
значений в матрицу В).
8о,о 8о,1 8о2 1яо.а. 8о,5
8i,o 81.1 at Иц к 81,5
82,0 Э2.1 82,2 82,3 82,4 82,5
8з,о 8з,1 8з,2 8з,з 83,4 Эз,5
box) Ьо,1 Ьо2 I Ьп Я I Ьп 4 Ьо,5
bl.O Ьи bij >1.4 Ь1,5
Ьг,о Ьг,1 Ьг,2 02,3 Ьг,4 Ьг,5
Ьз.о Ьз,1 Ьз.2 Ьз,з Ьз,4 Ьз,5
Рис. 4.15
124 Глава 4. Как устроены современные шифры
Затем в действие вступает второй этап — строкой сдвиг матрицы состояния.
На этом этапе из матрицы делает своего рода циркулянт, сдвигая циклически эле-
менты каждой строки на определенное количество позиций. В 128-битовом вари-
анте первая строка (сверху вниз) не сдвигается вообще, вторая сдвигается на
один элемент, третья — на два, а четвертая — на три элемента (4.16).
m n 0 P ... Бёз сдвига к Сдвиг на 1 f v * m и о р
J i k 1 ___ 1_к j
Сдвиг на 2 — 1 -]/
d e f Lk d е
Сдвиг на 3 | и/
w X У z ... W X У
| 1 1 1 г-i/
Рис. 4.16
Следующим этапом становйтся перемёшиванй'е столбцов матрицы состояния
с помощью умножения на фиксированный полисом с(х) = а3х3 + х2 + х + а2, где а3
и а2 — такие заранее заданные константы, что полином с(х) взаимно прост с вы-
бранным неприводимым полиномом и вследствие этого обратим. Обратный поли-
ном с~'(х) используется на этом же этапе для расшифрования. Для этого столбцы
матрицы состояния представляются в виде полиномов с коэффициентами над по-
лем GF(28) и умножаются на с(х). Вся операция Ь(х) = а(х)с(х) может быть легко
записана в матричном виде:
Схема производимых изменений в матрйце состояний представлена на
рис. 4.17.
Эо,о ао. aoj Эо.з ао,4 ао,5 — ®с(х) Ьо,о Ьо. boj Эо.з bo,4 Ьо.5
ai,o av аи *01,4 Э1.5 lovT bij Э1.з bl,4 bl,5
Э2.0 Э2, a2,j Э2.3 аг,4 аг.5 1‘ , 1 1 1 ‘ Ьг.о Ьг. b2j 32,3 Ьг.4 Ьг.5
Эз.о аз. аз.) Эз.з Эз.4 Эз.5 Ьз.о Ьз, ; л ' i b3j Эз.з Ьз,4 Ьз.5
- -.А '
Рис. 4.17
Последним этапом является сложение всех элементов матрицы состояния с
элементами текущего подключа ati + klt = bv (рис. 4.18).
Гпава 4. Как устроены современные шифры 125
Эо,о Эо,1 80,2 8о,з
81,0 аи ai,2 81,3
82,0 Э2.1 82,2 82,3
Эз.о Эз.1 Эз.2 8з,з
ко.о ко.1 К)
kto ки X KJ ki,3
кг.о кг.1 кг.2 кг.з
кз,о кз,1 кз,2 кз,з
Рис. 4Д8 ,
Ьо,о Ьо.1 Ьо.2 Ьо.з
bi,o bi.i Ь1,2 bl,3
Ьг.о Ьг.1 Ьг.2 Ьг,з
Ьз,о Ьз,1 Ьз,2 Ьз.з
Соответственно описанным выше_.преобразованием для полного описания
шифра не хватает описания «эволюции ключей», то есть операции разворачива-
ния цикловых подключей из исходного ключа.
В реализации алгоритма исходный ключа разворачивается в «развернутый»,
который представляет собой обычный массив, состоящий из 32-битовых слов.
Если число раундов шифра обозначить через Nr, а число байтов в ключе через
Nk, то размер массива определяется как (Nr+ 1) • Nk. При этом первые Nk байты
в массиве занимают исходный ключ, а остальные вычисляются с помощью следу-
ющего алгоритма (см. листинг 4.26)26. ,
Листинг 4.26
for (1 = Nk; i < Nk * (Nr + 1); i++) {
temp = expanded_key[i - 1];
if (i % Nk == 0)
temp = do_sbox(do_rotate(temp)) " r_const[i I Nk];
expanded_key[i] = expanded_key[i - .Nk], * temp;
} ' ‘ '
В листинге 4.26 за значение развернутого ключа отвечает массив ехрап-
ded_key[], а переменная temp играет роль временного буфера для перевода и об-
работки значений его элементов. В качестве r_const выступают специальные цик-
ловые константы, не зависящие от ключа. Их вычисляют заранее по рекуррент-
ным формулам:
r_const[i] = 1,
r_const[2] = х,
r_const[3] = х2,
r_const[i] = х (г const[i-1]) = х<1"1)
, - - • г ,
Реализация шифрующих преобразований аналогична реализациям для
3-WAY и SQUARE. Не намного усложненные конструкции.,отображений также
легко реализуются с помощью табличных преобразований (для умножения в поле
GF(28), например), сдвигов и побитного суммирования (см. листинг 4.27).
26 Алгоритм разворачивания ключа в общем случае зависит от длины используемого клю-
5а» а не только от количества раундов. Чтобы упростить изложение, мы приводим здесь описа-
ние алгоритма только для длин ключа меньше либо равных 192 битам.
126
Гпаеа 4. Как устроены современные шифры
Листинг 4.27\
Ц умножение двух элементов в поле GF(256)
uint8_t mul(uint8_t a, uint8_t b) {
if (a && b)
return Alogtable[(Logtable[a] + Logtable[b]) % 255];
else
return 0;
}
// сложение с подключом
void KeyAddition(uint8_t a[4][4], uint8_t rk[4][4]) {
for (int i = 0; i < 4; i++)
for(int j = 0; j < 4; j++)
a[i][j] ~= rk[i][j];
}
11 строковый сдвиг
void ShiftRow(uint8_t a[4][4], uint8_t d) {
uint8_t tmp[4];
int i, j;
for(i =1; i < 4; i++) {
for(j =0; j < 4; j++) tmp[j] = a[i][j + shifts[i][d];
for(j = 0; j < 4; j++) a[i][j] = tmp[j];
}
}
// узел замены
void Substitution(uint8_t a[4][4], uint8_t box[256]) {
int i. j;
for(i = 0; i < 4; i++)
for(j = 0; j < 4; j++) a[i][j] = box[a[i][j]];
}
11 перемешивание столбцов
void MixColumn(uint8_t a[4][4J) {
uint8_t b[4][4];
int i, j;
for(j = 0; j < 4; j++)
for(i =0; i < 4; i++)
b[i][j] = mul(2la[i][j])
" mul(3,a[(i + 1) % 4][j])
" a[(i + 2) % 4][j]
" a[(i + 3) % 4][j];
for(i =0; i < 4; i++)
for(j = 0; j < 4; j++) a[i][j] = b[i][j];
}
Все операции производятся с использованием специальных таблиц (см. лис-
тинг 4.28). Обратите внимание на способ вычисления произведения в поле
GF(28).
Глава 4. Как устроены современные шифры
127
Листинг 4.28
uint8_t Logtable[256] = {
0, 0, 25, 1, 50, 2, 26, 198, 75, 199, 27, 104, 51, 238, 223, 3,
100, 4, 224, 14, 52, 141, 129, 239, 76, 113, 8, 200, 248, 105, 28, 193,
125, 194, 29, 181, 249, 185, 39, 106, 77, 228, 166, 114, 154, 201, 9, 120,
101, 47, 138, 5, 33, 15, 225, 36, 18, 240, 130, 69, 53, 147, 218, 142,
150, 143, 219, 189, 54, 208, 206, 148, 19, 92, 210, 241, 64, 70, 131, 56,
102, 221, 253, 48, 191, 6, 139, 98, 179, 37, 226, 152, 34, 136, 145, 16,
126, 110, 72, 195, 163, 182, 30, 66, 58, 107, 40, 84, 250, 133, 61, 186,
43. 121, 10. 21, 155, 159, 94, 202, 78, 212, 172, 229, 243, 115, 167, 87,
175, 88, 168, 80, 244, 234, 214, 116, 79, 174, 233, 213, 231. 230, 173, 232,
44, 215, 117, 122, 235, 22, 11. 245, 89, 203, 95, 176, 156, 169, 81, 160,
127, 12, 246, 111, 23, 196, 73, 236, 216, 67, 31, 45, 164, 118, 123, 183,
204, 187, 62, 90, 251, 96. 177. 134, 59, 82, 161, 108, 170, 85, 41. 157,
151, 178, 135. 144, 97, 190, 220, 252, 188. 149, 207, 205, 55, 63, 91. 209,
83, 57, 132, 60, 65, 162, 109, 71. 20, 42, 158, 93, 86, 242, 211, 171,
68, 17, 146, 217, 35, 32, 46, 137, 180, 124, 184, 38, 119, 153v 227, 165,
103, 74, }; 237, 222, 197, 49, 254, 24, 13, 99, 140, 128, 192, 247, 112, 7,
uint8_t Alogtable[256] = {
1, з, 5, 15, 17, 51, 85, 255, 26, 46, 114, 150, 161, 248, 19, 53,
95, 225, 56, 72, 216, 115, 149, 164, 247, 2, 6, 10, 30, 34, 102, 170,
229, 52, 92, 228, 55, 89, 235, 38, 106, 190, 217, 112, 144, 171, 230, 49,
83. 245, 4. 12, 20, 60, 68, 204, 79, 209, 104, 184, 211, 110, 178, 205,
76, 212, 103, 169, 224, 59, 77, 215, 98, 166, 241, 8, 24. 40, 120, 136,
131, 158, 185, 208, 107. 189, 220, 127, 129, 152, 179, 206, 73, 219, 118, 154,
181, 196, 87, 249, 16, 48, 80, 240, 11. 29, 39, 105, 187, 214, 97, 163,
254, 25, 43. 125, 135, 146, 173, 236. 47, 113, 147, 174, 233, 32, 96, 160,
251, 22, 58, 78, 210, 109, 183, 194, 93, 231, 50, 86, 250, 21, 63, 65,
195, 94, 226, 61, 71, 201, 64, 192, 91, 237, 44, 116, 156, 191, 218, 117,
[159, 186. 213, 100, 172, 239, 42, 126, .130, 157, 188, 223, 122, 142, 137, 128,
155, 182, 193, 88, 232, 35, 101, 175, 234, 37, 111. 177, 200, 67, 197, 84,
252. 31, 33, 99, 165, 244, 7, 9, 27, 45, 119, 153, 176, 203, 70, 202,
69, 207, 74, 222, 121, 139, 134, 145, 168, 227, 62, 66, 198, 81, 243, 14,
I 18. 54. 90, 238, 41. 123, 141, 140, 143, 138, 133, 148, 167, 242, 13, 23.
1 57, 75. 11: 221, 124, 132, 151, 162, 253, 28, 36, 108, 180, 199, 82, 246, 1,
1 static word8 shifts[4][2] = {
О, О,
1, 3,
2, 2,
3, 1,
Большинство вычислительных операций, отнимающих много времени на ис-
еолнение, можно заменить на аналогичные, более эффективные в каждом конк-
ретном случае. Например, вычисления остатка от деления на 4, выполненное в
шде операции х % 4 на языке Си, в несколько раз медленнее, чем ее аналог в
128
Гпава 4. Как устроены современные шифры
виде х & 3. Это связано с тем, что сложные операции деления и умножения в де-
сятки раз медленнее простых битовых операций, наподобие логического &/ AND.
Именно этот вид технической оптимизации можно провести для исходного
текста из листинга 4.29, содержащего полную реализацию функции разворачива-
ния ключа, уже анонсйрованную и описанную в одном из предыдущих листингов.
Впрочем, оставим эту задачу в качестве легкого упражнения заинтересованному
читателю.
Листинг 4.29
И разворачиваем ключ
void setup_AES(AES_KEY *k, uint8_t W[12][4][4J) {
int i, j, t, rconpointer = 0;
uint8_t tk[4][4J;
11 временно сохраняем ключ
for(j = 0; j < 4; j++)
for(i =0; i < 4; i++)
tk[i][j] = k[i][j];
// подготавливаем первый подключ
for(j = 0; (j < 4) && (t < 12*4); j++, t++)
for(i =0; i < 4; i++) W[t / 4][i][t % 4] = tk[i][j];
t = 0;
while (t < 12*4) {
// вычисляем каждый из 11(количество раундов)+1 ключей
for(i = 0; i < 4; i++)
tk[i][O] "= S[tk[(i+1) % 4][4-1]J;
11 остаток от деления на 4
// можно с успехом заменить на операцию И: а % 4 == а & 0x3
tk[O][O] "= rcon[rconpointer++]; // цикловые константы
for(j = 1; j < 4; j++)
for(i =0; i < 4; i++) tk[i][j] "= tk[i][j-1];
11 сохраняем вычисленные значения
for(j =0; (j < 4) && (t < 12*4); j++, t++)
for(i =0; i < 4; i++) W[t / 4][i][t % 4] = tk[i][j];
}
}
Алгоритм зашифрования, как уже было сказано, содержит в себе использова-
ние всех описанных выше преобразований. Однако от других архитектур построе-
ния шифров, архитектуру SQUARE отличает то, что она не является симметрич-
ной в полном смысле этого слова, Для того чтобы реализовать расшифрование
блока данных, необходимо поменять порядок вычисления используемых отобра-
жений, а также следить за тем, чтобы вместо отображений, для которых обратное
не совпадает с прямым, применялись именно обратные.
Глава 4. Как устроены современные шифры
129
Листинг 4.30
И зашифровываем или расшифровываем один блок данных
void enc_AES(uint32_t block[4][4], uint8_t rk[MAXR0UNDS+1][4][4], bool encrypt) {
if (encrypt) {
KeyAddition(al(? rk[O]);
for(int r-= 1; r < ROUNDS; r++) {
Substitution^, S);
ShiftRow(a.O);
MixColumn(a);
KeyAddition(a,rk[r]);
}
Substitution^, S);
ShiftRow(a.O);
KeyAddition(a,rk[ROUNDS]);
}
else {
KeyAddition(a,rk[ROUNDS]);
Substitution^, Si);
ShiftRow(a,1);
for(r = ROUNDS-1; r > 0; r-) {
KeyAddition(a,rk[r]);
InvMixColumn(a);
Substitution(a.Si);
ShiftRow(a,1);
}
KeyAddition(a,rk[O]);
}
}
Отличные от прямых обратные преобразования имеют отображение-подста-
новку (узел замены), перестановку столбцов и строковый сдвиг. Сложение с под-
ключом этой особенностью не обладает.
Режимы шифрования
При зашифровании более чем одного блока информации можно воспользо-
ваться различными способами связи блоков друг с другом. Представьте на ми-
нуту, что перед нами поставлена задача шифрования некоторого объема дан-
ных. Если мы будем зашифровывать его с помощью блочного шифра, то встре-
тимся сразу с двумя проблемами. Первая из них заключается в том, что
одинаковые блоки открытого текста будут отображены шифром в одинаковые
блоки шифротекста и при не слишком больших размерах блока и достаточной
длине шифротекста будет возможно проведение даже простейшего метода час-
тотного анализа. А вторая связана с тем, что криптоаналитик, даже не облада-
ющей никакой информацией о ключе шифра, но перехвативший шифровку, мо-
жет беспрепятственно и совершенно незаметно переставлять блоки шифро-
> ..ста местами, зачастую меняя смысл передаваемой информации коренным
образом.
\130
Гпава 4. Как устроены современные шифры
По этой причине для зашифрования информации было Выработано несколько
специальных режимов обработки различных объемов данных. Каждый из этих ре-
жимов связан с той или иной областью применения и гарантирует определенную
степень защиты от той или иной криптоаналитической угрозы.
Для первых стандартов шифрования DES и ГОСТ были предусмотрены всего
четыре режима шифрования:
• режим Простой Замены (РПЗ) — Electronic Codebook (ЕСВ);
• режим Выработки Имитовставки (ВИВ) — Cipher "Block Chaining
(СВС);
• режим Обратной Связи по Выходу (ОСВ) — Output feedback (OFB)27;
• режим Гаммирования с Обратной Связью (ГОС) — Cipher Feedback
(CFB).
Через три года после принятия первого стандарта, регламентирующего их ис-
пользование в США, комитет ANSI (Национальный Американский Институт
Стандартов) принял еще один документ, описывающий еще один — пятый режим
шифрования: Режим Гаммирования (РГ) — Counter Mode (CM).
Режим Простой Замены/ЕСВ. В режиме простой замены блок открытого
текста Р( зашифровывается независимо от остальных блоков:
Зашифрование: С, = Ек(Р).
Расшифрование: Р, = D^C).
Режим Выработки Имитовставки/СВС. Режим выработки имитовставки
предназначен для зашифрования и выработки специального хэш-значения, по ко-
торому возможно осуществить контроль несанкционированной модификации дан-
ных, переданных по открытому каналу связи. В качестве самого первого блока на
вход шифра подается значение синхропосылки — открытый случайный блок дан-
ных, известный как абонентам шифрованной связи, так и потенциальному крип-
тоаналитику. Синхропосылка может передаваться вместе с зашифрованными дан-
ными и должна быть различной для каждого сеанса. Последний блок выхода явля-
ется ключезависимой нелинейной функцией от всех блоков зашифрованных
данных. Это свойство позволяет использовать значение последнего блока в каче-
стве штамма аутентификации переданных данных.
В соответствии с американскими стандартами этот режим может применять-
ся как для шифрования, так и для аутентификации данных. Отечественный же
стандарт регламентирует использование этого режима только для выработки ими-
товставки — специального значения кода аутентификации, поскольку в соответ-
ствии с ГОСТ для этой цели применяется функция шифрования с сокращенным
вдвое числом раундов:
* С'о = сйнхрУпосыййа; •
Зашифрование: С,-= Е/Р/Ф С,.]).
Расшифрование: Р{ = С;_( Ф Dk(C).
27 В стандарте в соответствии с ГОСТ 28147-89 такой режим шифрования отсутствует.
Глава 4. Как устроены современные шифры
131
Режим Обратной Связи по Выходу/OFB. С помощью режима обратной
связи по выходу блочный алгоритм шифрования превращается в поточный, прав-
да, с много большей по размеру структурой атомарных элементов. Проще говоря,
мы можем использовать блочный шифр как поточный, если используем режим
ОСВ. В режиме ОСВ также используется синхропосылка.
Со = синхропосылка.
Зашифрование: С,- = Р, Ф Е^Р^ Ф
Расшифрование: Pt = С( Ф £\(С(_, Ф Р^).
Режим Гаммирования с Обратной Связью/CFB. Этот режим похож на
режим ОСВ, за исключением того, что блочный шифр приобретает свойства уже
самосинхронизирующегося поточного шифра:
Зашифрование: С, = Р, Ф ЕДС^).
Расшифрование: Р, = С, Ф Ек(С^.
Режим Гаммирования/СМ. В режиме гаммирования блочный шифр обла-
дает свойствами синхронного шифра, построенного на принципе линейного конг-
руэнтного счетчика. В качестве начального заполнения счетчика используется
результат зашифрования синхропосылки с ключом пользователя. Блоки гаммы
получаются путем шифрования «задающей» последовательности:
So = Ek (синхропосылка).
S( = ЛКС(5,..,).
Зашифрование: С; = Р( Ф Et(S,).
Расшифрование: Р; = С, Ф Dk(S).
Режимы Triple-DES. Много позже принятия стандартов, описывающих эти
режимы шифрования, комиссия X9.F.1 ANSI приняла набор режимов для Тройно-
го-DES. Особенностью новых режимов стал выбор в качестве блока обратной свя-
зи либо блока шифротекста после трех зашифрований, либо после одного зашиф-
рования. Режимы шифрования названы аналогично стандартным, за исключени-
ем соответствующей приставки Triple-DES. Например, режим СВС для
Тройного-DES назван Triple-DES Cipher Block Chaining (ТСВС). Соответст-
венно режимы связи по блокам названы outer-CBC — после трех зашифрований
и inner-CBC — после одного.
В настоящее время продолжают разрабатываться новые режимы шифрова-
ния, и на базе уже созданных продолжают совершенствоваться новые. Одними из
самых интересных являются два, появление которых связано с принятием нового
ст1а'ндарта’шифрования. f
Режим Связи с Накоплением/Accumulated Block Chaining (ABC).
Этот режим разработан Ларсом Кнудсеной (Lars Knudsen), известным бельгий-
ским криптоаналитиком, одним из соавторов шифра Serpent — кандидата на уже
прошедший конкурс AES. Алгоритм зашифрования в этом режиме основан на ре-
жиме СВС и сводится к следующей последовательности действий:
5*
132 г ; Глава 4. Как устроены современные шифры
Зашифрование Расшифрование
Н, = Pt Ф htH.J. Hi = Ci-1 Ф D„(HM Ф С).
Ct = Ht_x Ф Ek(Ht Ф См). С, = Я,- Ф h(H^l
Режим выработки имитовставкй AES/AES-hash. Этот режим предназ-
начен для использования только вместе с новым стандартом1 и позволяет вычис-
лять значение хэш-функции по схеме Дэвиса — Мейера (Davies — Meyer). Для
этого используются AES размером блока в 256 битов и такой же длиной ключа и
следующий алгоритм: , ''
Я0 = 225?-1, ' ' " ’
нх = нх_х®еМ.х), :
где х, — 256-битовые блоки открытого текста.
После принятия нового стандарта шифрования в, NIST было объявлено о по-
иске" и рассмотрении новых более эффективных режимов шифрования. На сегод-
няшний день в NIST приняты к рассмотрению следующие режимы шифрования:
2D-Encryption Mode (2DEM), Accumulated Block Chaining (ABC), Counter Mode
Encryption (CTR), Integrity Aware Cipher Block Chaining (IACBC), Integrity Aware
Parallelizable Mode (IAPM), Infinite Garble Extension (IGE), Key Feedback Mode
(KFB), Offset Codebook (OCB), Propagating Cipher Feedback (PCFB), Parallelizable
Message Authentication Code (PMAC), Randomized MAC (RMAC), Extended Cip-
her .Block Chaining (XCBC), extended Electronic Code Book MAC (ХЕСВ) и
AES-hash.
Устройство поточных шифров
Из введения к этой главе можно узнать об основных отличиях между блочны-
ми и поточными шифрами. В действительности, говоря о различиях между ними,
мы использовали несколько критериев, однако свели их все к практической реа-
лизации механизмов шифрования. Так, мы указали на то, что поточные шифры
должны обладать «памятью»28.
Кроме разделения на блочные/поточные шифры, существует разделение и
на уровне самих поточных шифров. Поскольку каждый знак открытого текста в
архитектуре пдточного шифра не рассматривается как независимая единица, то
возникает очёвйдный в общем-то вопрос о том, что будет происходить, если при
перёдаче'сбобщёния-в йёгб вкрадется ошибка. Будет ли она распространяться да-
льшё. и еслй Да, До насколько далёкд? Больше всего нас, как пользователей и про-1
граммйстов, может заинтересовать вопрос, будут ли все последующие символы
расшифрованы правильно, если один из них был изменен в цепочке шифротекста.
?8. Обратите внимание, что в предыдущих разделах шла речь о «памяти* поточных .шифров
как о памяти состояний В данном разделе мы учитываем то, что все поточные шифры наделены
ею, и потому называем «памятью» поточного шифра его способность помнить уже именно сим
волы открытого и шифротекстов
Глава 4. Как устроены современные шифры
.133':..
Именно по этим признакам и можно создать вполне естественную классифи-
кацию поточных шифров: на синхронные и самосинхронизирующиеся.
В синхронных поточных шифрах для зашифрования используется внутреннее
состояние - именно оно определяет, каким образом будет представлен элемент от-
крытого текста в виде шифробозначения.
Выбор шифробозначения зависит от положения символа открытого текста от-
носительно его начала и не зависит от остальных символов, зашифрованных до
или после него. Можно сказать, что шифр не имеет памяти29. Таким образом,
если криптоаналитик изменит один символ шифротекста, то легальный получа-
тель сможет расшифровать остальную часть сообщения без искажений (листинг
4.31 — жирным шрифтом отмечен ошибочно переданный символ шифротекста,
символ X обозначает неверную расшифровку).
Листинг 4.31 (один неверный символ)
Открытый текст: ПО Т 0 Ч Н Ы Й
Шифротекст: . 20 43 23 65 49 72 18 37
Расшифровка: ПО Т О X Н Ы Й
С другой стороны, что произойдет, если кто-либо потеряет часть шифротек-
ста (в начале или середине)? Очевидно, весь остальной участок до конца шифро-
текста будет расшифрован неверно, поскольку изменяется позиция для всех оста-
льных символов и, следовательно, изменяется принцип выбора расшифровываю-
щего преобразования (листинг 4.32).
Листинг 4.32 (пропуск двуз с символов)
Открытый текст: -j , i. > < , > , ПОТОЧНЫЙ
Шифротекст: ' 43 23 65 49 72 18 37 44
Измененный шифротекст: 43 23 72 18 37 44
Расшифровка: П О X X X X
Поточные шифры, построенные на базе использования сдвиговых регистров с
обратной связью, являются синхронными шифрами. Их применение довольно ши-
роко распространено.
Другой класс поточных шифров — самосинхронизирующиеся поточные шиф-
ры. Их архитектура такова, что они имеют ограниченную память на свои предыду-
щие состояния, тем самым устраняя влияние одной ошибки на остальной текст не ,
сразу, а после.нескольких итераций. В этом случае потеря одного или нескольких ,
знаков не приведет, к таким ужасающим последствиям, как изображено в листин- ;
ге 4.32,— шифр сам «восстановит» верное состояние через несколько символов,
то есть столько, сколько предыдущих состояний шифра используется для зашиф- ..
рования текущего элемента открытого текста (листинг 4.33). То есть можно гово-
рить о наличии памяти у шифра на несколько предыдущих элементов текста.
29 Опять же памяти о шифротексте, а не памяти о состоянии.
? ' 134 Гпава 4. Как устроены современные шифры
Листинг 4.33 (пропуск двух символов)
Открытый текст: ПОТОЧНЫЙШИ
Шифротекст: 43 23 65 49 72 18 37 44 76 12
Измененный шифротекст: 43 23 72 18 37 44 76 12
Расшифровка: ПОХХЫЙШИ
Однако и одиночная ошибка здесь даст не одно-единственное искажение, а в
зависимости от того, сколько предыдущих «неверных» состояний будет находить-
ся. в памяти шифра и сколько будет реально задействовано в расшифровании
шифротекста.
Листинг 4.34 (один неверный символ)
Открытый текст: ПОТО Ч н ы Й Ш И Ф
Шифротекст: 20 43 23 65 49 72 18 37 76 12 11
Расшифровка: ПОТО X X Ы Й Ш И Ф
Соответственно комбинируя синхронные и самосинхронизирующиеся шиф-
ры, можно получить шифры, которые будут учитывать зависимость и от позиции
символа в тексте, и от нескольких предыдущих зашифрованных символов.
Самыми популярными сегодня шифрами являются, пожалуй, два шифра —
шифр RC4, используемый в программных приложениях на персональных компью-
терах, и шифр А5 из серии технических протоколов передачи данных GSM для
мобильных устройств и сотовых телефонов.
Шифр RC4 очень прост в реализации, поэтому с него и начнем. С точки зре-
ния архитектуры RC4 состоит из байтового массива гаммы и двух регистров со-
стояния размером также по одному байту. Байтовая размерность делает RC4 про-
стым не только для реализации на персональных компьютерах, но и для различ-
ных аппаратных периферийных устройств — криптографических PCI-плат,
PIC-контроллеров и т. д.
Процесс зашифрования абсолютно идентичен процессу расшифрования и со-
стоит в выработке очередных значений для каждого из элементов массива гаммы
и их наложении на шифруемый текст суммированием по модулю 2. Поэтому в ли-
стинге 4.35 приведены только две процедуры — процедура разворачивания ключа
setup_rc4() и процедура зашифрования (она же — расшифрования) encode_rc4().
Листинг 4.35
«include "unidef.h"
typedef struct {
uint8_t state[256];
•uint8_t>a_reg; 1
uint8_t b_reg:
} RC4_KEY; . -
«define xchg_pair(a, b) \
do \
{ \
Гпава 4. Как устроены современные шифры
135
tmp = а; \
а = Ь; \
b = tmp; \
} \
while(O)
void setup_rc4(RC4_KEY *кеу, uint8_t *pass, uint16 passlen) {
uint8_t *state = &key->state[O];
uint8_t a = 0, b = 0, tmp;
int i;
for (i = 0; i < 256; i++) key->state[i] = i;
key->a_reg = 0;
key->b_reg = 0;
for (i =0; i < 256; i++) {
b = pass[a] + state[i] + b;
xchg_pair(state+i. state+b);
a = (a + 1) % passlen;
}
}
void encode_rc4(RC4_KEY *key, uint8_t *buf, uint32 buflen) {
uint8_t a_reg = key->a_reg, b_reg = key->b_reg;
uint8_t xor, tmp, *state =• &key->state[O];
-while (buflen—) {
a_reg++;
b_reg = (state[a_reg] + b_reg);
xchg.pair(&state[a_reg], &state[b.reg]);
xor = state[a_reg] + state[b_reg];
*buf++ "= state[xor];
}
key->a_reg = a_reg;
key->b_reg = b_reg;
}
В функции encode_rc4() массив значений гаммы state формируется с помо-
щью перестановки и динамической замены непосредственно с использованием ре-
гистров состояний a_reg и b_reg. Когда возникает необходимость зашифровать
байт данных, для этой цели используется значение, состоящее из суммы двух эле-
ментов массива значений гаммы — соответственно по смещению a_reg и b_reg.
По сути, массив гаммы представляет собой большую таблицу замены, изначально
построенную в зависимости от ключа и динамически изменяющуюся в процессе
преобразования данных.
Гораздо более интересна процедура разворачивания ключа, поскольку алго-
ритм шифрования RC4 допускает использование «гибких» размеров ключа — от 1
бита и до 2048 битов. Но это границы, которые определяет устройство шифра, на
деле же используется от 40 и до 256 битов.
Разворачивание ключа в алгоритме состоит в заполнении начальными значе-
ниями массива гаммы. Для этого сам массив заполняется значениями от 0 до
255. Еще один массив такого же размера — массив ключей, заполняется после-
довательно символами ключа. Если ключ короче 256 байтов, то массив заполни-
136........... Глава 4. Как устроены современные шифры
ется копиями ключа «встык» до полного заполнения. После этого каждый эле-
мент массива переставляют с элементом, номер jk которого вычисляется по фор-
муле jM = jk + [значение текущего элемента массива гаммы] + [значение
текущего элемента массива ключей]. Суммирование проводится по модулю 256.
Такой способ организации перестановок дает некоторую уверенность в том,
что каждый элемент массива будет подвергнут перестановке и с высокой вероят-
ностью не останется на прежнем месте. Кроме того, данный способ разворачива-
ния ключа очень быстр и эффективно реализуется на современных процессорах.
Шифр RC4, изобретенный в RSA Laboratories в середине 1990-х годов, до сих пор
считается одним из самых быстрых и эффективных.
Еще одним любопытным шифром является шифр А530. Повышенный интерес
к нему, сделавший его популярным, вызван в основном двумя причинами — тем,
что он используется для шифрования каналов передачи данных и голоса в моби-
льных телефонах, использующих самый распространенный сотовый стандарт
GSM, и тем, что он является ярким представителем шифров на основе Регистров
Сдвига с Линейной Обратной Связью (РСЛОС).
РСЛОС устроены в виде двоичного регистра определенного размера и функ-
ции обратной связи (рис. 4.19). Данные получают с регистра по одному биту, счи-
тывая значение из самого старшего (или самого младшего, в зависимости от реа-
лизации31) бита ап. После этого все значения регистра сдвигаются влево, самый
старший бит затирается, а младший заполняется с результатом вычисления функ-
ции обратной связи от всех значений регистра. В регистрах типа РСЛОС функция
обратной связи обычно представляет собой сумму по модулю 2 нескольких значе-
ний битов регистра.
Связь в сотовых телефонах устроена таким образом, что речь сжимается
определенным способом с помощью так называемого речевого кодека, а затем
упаковывается в пакеты, аналогичные по своей структуре пакетам данных в сети
Интернет. После этого пакет зашифровывается и отсылается на базовую стан-
цию, которая передает его соответствующему абоненту сотовой или обычной те-
лефонной сети.
Процессоры, установленные в сотовых телефонах, не обладают большой
мощностью, поэтому алгоритм шифрования не должен быть слишком ресурсоем-
ким и долгим по времени исполнения, поскольку каждый пакет в соответствии со
стандартом GSM должен отправляться на базовую станцию приблизительно каж-
дые 4,6 миллисекунды. Идеальным вариантом является использование поточного
шифра. Именно поэтому А5/1 был создан как поточный, а не блочный шифр.
В его основе находится три регистра типа РСЛОС различной длины Rl, R2 и
R3 — соответственно 19, 22 и 23 бита.
Каждый из регистров работает не все время, а в зависимости от мажоритар-
ного значения. Для вычисления этого значения выбраны биты, находящиеся в се-
30 На самом деле в семействе шифров«Ах» существует два -алгоритма шифрования А5. Бы-
строе шифрование с помощью А5/2, который подвержен ряду серьезных атак на него, и его бо-
лее «утяжеленная» версия А5/1. В книге рассматривается последний вариант.
31 Далее описывается вариант «зеркального РСЛОС», где в качестве выхода регистра вы-
бирается старший бит и сдвиг проводится влево.
Глава 4. Как устроены современные шифры J37
Выход
Рис. 4.19. Архитектура РСЛОС
)
редине каждого из регистров, — мажоритарные или управляющие биты Cl, С2
и СЗ. Когда необходимо получить бит выхода шифрующей системы, сравниваются
значения управляющих битов каждого из регистров. Для тех регистров, значения
которых совпадают со значением большинства, проводят сдвиг. Остальные реги-
стры в прежнем состоянии остаются без изменений.
Например, если значения соответствующих битов равны (1,0, 1), то будут
модифицированы только первый R1 и третий R3 регистры. Второй регистр R2
останется без изменения. Выход всей системы получается дополнительным, сум-
мированием трех старших битов регистров Rl, R2 и R3 по модулю 2 (рис. 4.20).
18 13 С1 о
Рис. 4.20. Архитектура А5/1
138
Гпава 4. Как устроены современные шифры
Реализовывать функциональность регистров лучше всего с помощью макро-
сов, поскольку сдвиг и суммирование в младший бит проводится без каких-либо
дополнительных зависимостей и параметров (см. листинг 4.36).
Листинг 4.3в
«include <stdio.h>
«include <string.h>
«include "unidef.h"
typedef struct {
' uint32_t value[2];
uint32_t frame_n;
} A5_KEY;
typedef uint32_t A5_FRAME[7];
uint8_t a5xor_3[8] = {
0, // 000
1. // 001
1, H 010
0. // 011
1. II 100
0, // 101
0, I/ 110
1 // 111
uint8_t a5xor_2[4] = {
0, // 00
1. // 01
1. // Ю
0. // 00
uint8_t a5_majority[8] = {
0, // 000
0, // 001
0. // 010
1, // 011
0, // 100
1, // 101
1. // 110
1 // 111
};
// двигаем регистр!
«define R1_CL0CK \
do { \
s = r1; \
s »= 13; \
b = s & 1; \
s »= 5; \
s = a5xor_3[s & 7] " b; \
r1 = (r1 « 1) | s; \
L
Гпава 4. Как устроены современные шифры 139: ?
} while (0)
// двигаем регистр2
«define R2.CL0CK \
do { \
s = г2; \
s »= 20; \
s = a5xor_2[s & 3]; \
г2 = (г2 « 1) | s; \
} while (0)
И двигаем регистра
«define R3_CL0CK \
do { \
s = гЗ; \
s »= 7; \
b = s & 1; \
s »= 13; \
s = a5xor_3[s & 7] " b; \
гЗ = (гЗ « 1) | s; \
} while (0)
Ключ шифра состоит из некоторого ключа сеанса связи, который, вообще го-
воря, должен вырабатываться для каждого телефонного разговора заново32, и
сквозного номера шифруемого пакета (см. структуру A5_KEY в листинге 4.36).
•В силу этой причины процедура разворачивания ключа и зашифрования представ-
ляет собой единое целое.
Листинг 4.36
«define decrypt_A5 encrypt_A5
void encrypt_A5(A5_KEY *key, A5.FRAME *frame) {
uint32_t s, b, i, o, c;
uint32_t round, r1, r2, r3;
11 обнуляем регистры
П = 0;
r2 = Or
гЗ = 0;
// заполняем регистры первыми 32 битами ключа
i = key->value[O];
for (round = 0; round < 32; round++) {
I/ заполняем младшие биты регистров
b = i & 1;
i »= 1;
r1 "= b;
r2 "= b;
32 Смена ключей на самом деле зависит от настроек программного обеспечения оператора
сотовой связи. К сожалению, большинство российских операторов сотовой связи пренебрегают
вопросами информационной безопасности и конфиденциальности переговоров своих абонентов
в угоду скорости и эффективности обслуживания своих пользователей — ключи меняются
чрезвычайно редко.
х > \ 140 Гпава 4. Как устроены современные шифры
гЗ "= Ь;
// вычисляем новые значения
R1.CLOCK;
R2.CL0CK; •
R3.CL0CK;
}
// заполняем регистры вторыми 32 битами ключа
i = key->value[1];
for (round = 0; round < 32; round++) {
11 заполняем младшие биты регистров
b = i & 1;
i »= 1;
r1 "= b;
r2 ~= b;
r3 ~= b;
// вычисляем новые значения
R1.CL0CK;
R2.CL0CK;
R3.CL0CK;
}
// заполняем синхропосылкой
i = key->frame.n;
for (round = 0; round < 22; round++) {
// заполняем младшие биты синхропосылкой
b = i & 1;
i »= 1;
r1 ~= b;
r2 "= b;
гЗ "= b;
11 вычисляем новые значения
R1_CL0CK;
R2.CL0CK;
R3_CL0CK;
11 сотня циклов без выхода
for (round = 0; round < 100; round++) {
// смотрим, что нужно двигать
s = (r1 » 8) & 1;
s «= 1;
s |= (r2 » 9) & 1;
s «= 1;
s |= (r3 » 10) & 1;
switch (s) {
case 0: case 7:
R1_CL0CK;
R2_CL0CK;
R3.CL0CK;
break;
case 1: case 6:
R1.CL0CK;
R2_CL0CK;
Гпава 4. Как устроены современные шифры ! 141
break;
case 2: case 5:
R1.CL0CK;
R3.CL0CK;
break;
case 3: case 4:
R1.CLOCK;
R2.CL0CK;
break;
}
}
// получаем выходные 228 битов
o = 0;
i = 0;
с = 0;
for (round = 0; round < 228; round++) {
11 смотрим, что нужно двигать
s = (И » 8) & 1;
s «= 1;
s |= (r2 » 9) & 1;
s «= 1;
s |= (r3 » 10) & 1;
switch (s) {
case 0: case 7:
R1_CL0CK;
R21CL0CK;
R3_CL0CK;
break;
case 1: case 6:
R1_CL0CK;
R2_CL0CK;
break;
case 2: case 5:
R1_CL0CK;
R3_CL0CK;
break;
case 3: case 4;
R1_CL0CK;
R2_CL0CK;
break;
}
о |= ((r1 » 18) " (r2 » 21) " (r3 » 22)) & 1;
printf(”%d", о & 1);
if (i++ == 32) {
(*frame)[c++] "= o;
i = 0;
}
о «= 1;
}
(*frame)[c] "= o;
142
Глава 4. Как устроены современные шифры
Размер пакета равен 228 битам. Шаги зашифрования начинаются с того, что
регистры обнуляются, затем подвергаются модификации без учета мажоритарных
битов. В это время на каждой из 64 итераций биты ключа последовательно по од-
ному суммируются с младшими битами каждого из регистров.
Затем то же самое проделывается с номером пакета. Для,этого проводится 22
дополнительные итерации. На этом процедура разворачивания ключа завершает-
ся, а получившиеся значения регистров называют их начальным заполнением.
Перед тем как начать зашифрование пакета, проводится еще 100 итераций,
но уже с учетом мажоритарных битов Cl, С2 и СЗ. После этого проводится еще
228 итераций, и после каждой итерации результирующий бит суммируется по мо-
дулю 2 с очередным битом данных пакета (см. листинг 4.36).
Список литературы
1. Announcing Development of Federal Information Processing Standard for Advan-
ced Encryption Standard. — Federal Register. Vol. 62, № 1. 1997. Pp. 93—94.
2. Announcing Reguest for Candidate Algorithm Nomination for Advanced Encrypti-
on Standard (AES). - Federal Register. Vol. 62, № 177. 1997. Pp. 48051—48058.
3. Status report on the 2-nd round of the Development of the Advanced Encryption
Standard / AES home page, http://www.nist.gov/aes.
4. Status report on the 3-th round of the Development of the Advanced Encryption
Standard, http://www.nist.gov/aes.
5. Joan Daemen, Vincent Rijmen. The Rijndael Block Cipher. AES Proposal: Rijnda-
el, Document version 2, 3.09.99.
6. Horst Feistel, Block cipher cryptographic system, USPatent N3,798,359 от
19/03/1974, USPatent Bureau.
7. Horst Feistel, Block cipher cryptographic system, USPatent N3,798,360 от
19/03/1974, USPatent Bureau.
8. A Mathematical Theory of Communication By С. E. SHANNON The Bell System
Technical Journal, Vol. 27, pp. 379—423, 623—656, July, October, 1948.
9. M. Dawson and S. E. Tavares, An Expanded Set of S-Box Design Criteria Based
on In-formation Theory and its Relation to Differential-Like Attacks, in Advances in
Cryptol-ogy: Proc, of Eurocrypt’91, Springer-Verlag, 1991, pp. 352—367.
10. H. Feistel, Cryptography and Computer Privacy, Scientific American, vol.228,
1973, pp. 15-23.
11. С. E. Shannon, Communication Theory of Secrecy Systems, Bell Systems Tech-
nical Jour-nal, vol. 28, 1949, pp. 656—715.
12. M. Sivabalan, S. E. Tavares, and L. E. Peppard, On the Design of SP Networks
from an Information Theoretic Point of View, in Advances in Cryptology: Proc, of
CRYPTO '92.
13. A. F. Webster, Plaintext/Ciphertext Bit Dependencies in Cryptographic Sys-
tems, M.Sc. hesis, Department of Electrical Engineering, Queen's University, 1985.
14. A. F. Webster and S. E. Tavares, On the Design of S-Boxes, in Advances in
Cryptology: roc. of CRYPTO'85, Springer-Verlag, New York, 1986, pp. 523—534.
Гпава 4. Как устроены современные шифры 143 •
15. С. М. Adams, Designing DES-Like Ciphers with Guaranteed Resistance to
Differential and Linear Attacks, Workshop Record of the Workshop on Selected Areas in
Cryptography (SAC 95), May 18-19, 1995, pp. 133—144.
16. С. M. Adams and S. E. Tavares, Generating and Counting Binary Bent Sequen-
ces, IEEE Transactions on Information Theory, vol. IT-36, 1990, pp. 1170—1173.
17. A.K. Leung, S.E. Tavares. Sequence Complexity as Test for Cryptographic Sys-
tems. — Advances in Cryptology — CRYPTO'84. Proc. LNCS, Vol. 196 — Springer-Ver-
lag.
18. Alfred Menezes, et. al. Handbook af Applied Cryptography — CRC Press, 1997.
19. J. Daemen, R. Govaerts and J. Vandewalle, A Hardware Design Model for Cryp-
tographic Algorithms, Computer Security'92, pp. 419-434. Lecture Notes in Computer
Science, vol. 648, Springer-Verlag, Berlin 1992.
20. J. Daemen, R. Govaerts and J. Vandewalle, A New Approach Towards Block Cip-
her Design, Computer Security'92, pp. 419-434. Lecture Notes in Computer Science, vol.
648, Springer-Verlag, Berlin 1992.
21. Data Encryption Standard, Federal Information Processing Standard (FIPS) Pub-
lication 46, National Bureau of Standards, U.S. Department of Commerce, Washington
D.C., January 1977.
22. X. Lai and J.L. Massey, A Proposal for a New Block Encryption Standard, in Ad-
vances in Cryptology{Eurocrypt’ 90, Springer-Verlag, Berlin 1991, pp. 389—404.
23. X. Lai, J.L. Massey and S. Murphy, Markov Ciphers and Differential Cryptanaly-
sis, in Advances in Cryptology{Eurocrypt' 91, Springer-Verlag, Berlin 1991, pp. 17—38.
24. J. Daemen, L. Van Linden, R. Govaerts and J. Vandewalle, Propagation Properti-
es of Multiplication Modulo 2M. Proceedings of the 13th Symposium on Information the-
ory in the Benelux (1992), Werkgemeenschap voor informatie en Communicatione theo-
rie, Enschede, The Netherlands.
25. R. A. Rueppel, mStream Ciphers', in Contemporary Cryptology, Gustavus J. Sim-
mons Ed. IEEE Press, New York.
26. Specification of the systems of the MAC/packet family'. EBU Technical Docu-
ment 3258-E, Oct 1986.
27. J. Daemen, R. Govaerts, J. Vandewalle, Cryptanalysis of MUX-LFSR Based
Scramblers, in Proceedings of SPRC '93, 15—16 February, Roma.
28. S. W. Golomb, Shift Register Sequences, Holden-Day Inc., San Francisco, 1967:
29. G.Z. Xiao, J.L. Massey, A Spectral Characterization of Correlation-Immune Fun-
ctions, IEEE Trans. Inform. Theory, Vol. 34, No. 3, 1988, pp. 569—571.
30. Y. Desmedt, J-J. QuisquateE and M. Davio. Dependence of output in DES: Small
avalanche characteristics. In Advances in Cryptology, Proceedings of CRYPTO'84, Ed G R
Blakley, D Chaum, Vol. 196, pages 359-376. Springer-Verlag, 1985.
31. S. Even and O. Goldreich. Des-like functions can generate the alternating group.
IEEE Transactions on Information Theory, 29(6):863—865, November 1983.
32. J. Gordon and H. Retkin. Are big S-boxes best ? In T. Beth, editor; Cryptography,
Proceedings, Burg Feuerstein 1982, pages 257—262. Springer Verlag, 1983.
33. L.J. O'Connor. On the distribution of characteristics in bijective mappings. In Ex-
tended Abstracts — Eurocrypt'93, May 1993.
34. Госстандарт СССР, Системы обработки информации. Защита криптографиче-
ская. Алгоритм криптографического преобразования ГОСТ 28147—89. М: ИПК Изда-
тельство стандартов, 1989.
144
Глава 4. Как устроены современные шифры
35. J.P. Pieprzyk and Xian-Mo Zhang. Permutation generators of alternating groups.
In Advances in Cryptology — AUSCRYPT'90, J. Seberry, J. Pieprzyk (Eds), Lecture No-
tes in Computer Science, Vol. 453, pages 237—244. Springer Verlag, 1990.
36. E. Biham, A. Biryukov, and A. Shamir, «Miss in the Middle Attacks on IDEA and
Khufu,» Fast Software Encryption: 6th International Workshop, FSE '99, Springer-Verlag,
1999, pp. 124—138.
37. E. Biham, «New Types of Cryptanalytic Attacks using Related Keys,» Technical
Report #753, Computer Science Department, Technion — Israel Institute of Technology,
Sep. 1992.
• 38. E. Biham and A. Biryukov, «An Improvement of Davies' Attack on DES,» Advan-
ces in Cryptology — EUROCRYPT '94 Proceedings, Springer-Verlag, 1995, pp.
461—467.
39. J. Borst, L.R. Knudsen, and V. Rijmen, «Two Attacks on Reduced IDEA» Advan-
ces in Cryptology — EUROCRYPT '97 Proceedings, Springer-Verlag, 1998, pp. 1—13.
40. E. Biham and A. Shamir, «Differential Cryptanalysis of DES-like Cryptosystems,»
Advances in Cryptology — CRYPTO '90 Proceedings, Springer-Verlag, 1991, pp. 2—21.
41. D. Chaum and J.-H. Evertse, «Cryptanalysis of DES with a Reduced Number of
Rounds; Sequences of Linear Factors in Block Ciphers,» Advances in Cryptology - CRYP-
TO '85 Proceedings, Springer-Verlag, 1986, pp. 192—211.
42. D.W. Davies, «Some Regular Properties of the DES,» Advances in Cryptology:
Proceedings of Crypto 82, Springer-Verlag, Plenum Press, 1983, pp. 89—96.
43. W. Diffie and M.E. Hellman, «Exhaustive Cryptanalysis of the NBS Data Encryp-
tion Standard,» Computer, v. 10, n. 6, Jun. 1977, pp. 74—84.
44. M.E. Hellman, «А Cryptographic Time-Memory Trade Off,» IEEE Transactions
off Information Theory, v. 26, n. 4, Jul. 1980, pp. 401—406.
45. M.E. Hellman, R. Merkle, R. Schroeppel, L. Washington, W. Diffie, S.Pohlig, and
P. Schweitzer, «Results of an Initial Attempt to Cryptanalyze the NBS Data Encryption
Standard,» Technical Report SEL 76-042, Information Systems Lab, Department of Elect-
rical Engineering, Stanford University, 1976.
46. L.R. Knudsen and W. Meier, «Improved Differential Attacks on RC5,» Advances
in Cryptology — CRYPTO '96 Proceedings, Springer-Verlag, 1997, pp. 216—228.
47. L.R. Knudsen, «Applications of Higher Order Differentials and Partial Differenti-
als,» K.U. Leuven Workshop on Cryptographic Algorithms, Springer-Verlag, 1995.
48. L.R. Knudsen and M. J.B. Robshaw, «Nonlinear Approximations in Linear Crypta-
nalysis,»Advances in Cryptology - EUROCRYPT '96 Proceedings, Springer-Verlag, 1997,
. pp. 224—236.
. 49. J. Kelsey, B. Schneier, and D. Wagner, «Key-Schedule Cryptanalysis of IDEA,
G-DES, GOST, SAFER, and Triple-DES,» Advances in Cryptology - CRYPTO '96 Procee-
dings, Springer-Verlag, 1997, pp. 237—251.
SO. J. Kelsey, B. Schneier, and D. Wagner, «Mod n Cryptanalysis, With Applications
Against RC5P and М6.» Fast Software Encryption: 6th International Workshop, FSE '99,
Springer-Verlag, 1999, pp. 139—155.
5L B. Schneier, Applied Cryptography, Second Edition, John Wiley & Sons, 1996.
Глава 5
Дешифрование современных шифров
It is very hard to estimate the security of a block cipher and
equally hard to compare several block ciphers in terms of secu-
rity. Block ciphers today are construced from the designers .ex-
perience and we are very far from constructing provably secure
block ciphers. . .
Из беседы с Ларсом Кнудсеном
Со времени использования шифров Цезаря, Бернама, Виженера и Других,
признанных сегодня классическими, прошло очень много времени. С появлением
вычислительной техники шифросистемы приобрели новые качества и заметно
усложнились. Вместе с ними усложнились и методы криптоанализа новых шиф-
ров. Сами по себе методы'дешифрования современных шифров довольно сложны
и в большой степени связаны с подчас огромным количеством вычислений: Мно-
гие из них уже невозможно провести без использования современных комйьютер-
ных систем. * " " .
К тому же использовавшиеся в криптографий понятия сильно изменились с
приходом новой вычислительно-информационной эры. Сегодня взломать, шифр
уже не означает «узнать в точности зашифрованное сообщение». Современная
криптоаналитическая атака может закончиться,^ примеру, сужением ключевого
пространства, tq есть к выбору множества наиболее вероятных ключей, по кото-
рым будет, производиться тотальное опробование и выбор дешифрованного сооб-
щения с помощью мощной вычислительной техники. Она, кстати, представляет
собой весь спектр современных компьютерных технолоий — от обычных, персона-
льных компьютеров до специализированных устройств и программно-аппаратных
комплексов (см. раздел «Дешифрование DES»).
Конечно, криптоатака, завершившаяся уменьшением пространства перебора
с 2256 до 2255, не выглядит впечатляющей, однако в конце концов и она может быть
решающей при выборе того или иного криптографического средства для зашифро-
вания служебной или секретной информации. Зачастую компьютеры используют-
ся не только на финальном этапе криптоатак — для подсчета результатов и пере-
бора всех возможных значений, — но и для вычисления различных характери-
стик шифра или шифротекста. Без компьютерных методов криптоанализа
невозможно было бы оценить криптографическую стойкость датчиков псевдослу-
чайных чисел, хэш-функций, , ijf, ' <’с.
К примеру, в контрактах на разработку и производство суперкомпьютерной
техники, которые заключает Агентство национальной безопасности СЩД. с про-
изводителями мультипроцессорных систем, особо оговорены условия работы этих
систем и даже наличие специальных инструкций, предназначенных для функцио-
нирования в качестве сверхэффективных «кирпичиков» в сложных системах
криптоанализа и дешифрования современных шифросистем.
146 Глава 5. Дешифрование современных шифров
Многие характеристики блочных и поточных симметричных шифров оста-
лись бы малоизученной областью криптографии, если бы не мощь современных ,
компьютеров. На сегодняшний день авторы симметричных и даже асимметрич-
ных криптоалгоритмов, основанных на базовых проблемах фундаментальных об-
ластей современной математики, вынуждены следить за скоростью развития вы-
числительной техники. Это небходимость, с которой приходится считаться, что-
бы дать своим алгоритмам искомое свойство неподверженности криптоанализу с
помощью самых совершенных вычислительных устройств.
В этой главе мы постарались собрать наиболее интересные достижения со-
временного криптоанализа, опирающиеся именно на существование современной
вычислительной техники, а также те методы и алгоритмы, которые представляют
интерес прежде всего с практической точки зрения.
Однако это всего лишь один из аспектов связки «программирование + крип-
тография». Кроме того, что стойкость криптографического алгоритма должна
быть подтверждена теоретическими исследованиями, при использовании крипто-
алгоритмов на практике необходима комплексная проверка программно-аппарат-
ной реализации разработанных шифросистем. При отсутствии оной последствия
могут быть просто фатальными, примером может служить исходный текст алго-
ритма симметричного шифрования Blowfish, распространяемого среди прочих в
Интернете. В данных исходных текстах в процедуре разворачивания ключа содер-
жится ошибка (умышленно допущенная или нет — авторам неизвестно), заклю-
чающаяся в том, что подключи шифра определяются всего лишь двумя первыми
байтами ключа криптосистемы. Это означает, что при верной реализации основ-
ной функции шифрования и верном использовании алгоритма криптостойкость
его реализации не превысит 216, что, вообще говоря, не предоставляет на сегод-
няшний день практически никакой защиты.
Так что современная криптография содержит очень много подводных камней.
И лишь часть из них мы научились распознавать и преодолевать быстро.
Создание и оценка узлов замен
Shannon uses the term confusion to denote the process of sub-
stituting one byte for another. The current jargon is to describe
a device which substitutes one byte for another according to a
fixed table as a substitution box or S-box.
J. Gordon, H. Retkin. Are Big S-Boxes Best?
Практически во всех существующих сегодня архитектурах систем симмет-
ричного шифрования используются так называемые узлы (таблицы) замен или
S-блоки (S-box). Сами S-блоки представляют собой не что иное, как обычные таб-
личные подстановки. Узлы замен используются в самых различных криптосисте-
мах — от криптографических хэшей до блочных итеративных шифров. При этом,
несмотря на то что внимание уделяется в основном обратимым узлам замены,
сами S-блоки таковыми являться не обязаны. То есть, вообще говоря, узел заме-
Гпава 5, Дешифрование современных шифров
147
ны — это некоторое отображение, заданное с помощью таблицы значений. В бо-
льшинстве случаев узлы замен являются единственной нелинейной частью шиф-
ра, и потому от стойкости метода их создания, оценки и использования целиком
зависит стойкость шифра.
С самого момента создания узлов замен для американского стандарта шифро-
вания DES критерии отбора тех или иных значений узлов оставались чуть ли не
государственным секретом. Компания IBM сохранила в тайне критерии по про-
сьбе Национального агентства безопасности США, что послужило поводом для
многих слухов. Кроме того, по этой причине многие из исследователей выражали
сомнения по поводу того, можно ли оценить предоставленные в стандарте узлы
замен адекватно и нет ли там каких-либо «черных ходов», позволяющих взломать
шифр гораздо быстрее, чем это может быть сделано известнымй способами.
До сих пор в открытой печати не было опубликовано ни одной идеи, позволя-
ющей улучшить время дешифрования с помощью лучших известных методов
криптоанализа, но основанных лишь на знании критериев создания узлов замен
для шифрования.
Зато на сегодняшний день выработано уже несколько подходов к созданию и
анализу узлов замен. Для этого даже создан подходящий математический аппа-
рат, позволяющий описывать узлы замен на языке формул и вычислять количест-
венные характеристики «стойкости» получившихся узлов.
Конечно, таблицу узла замены можно было бы заполнить и случайными чис-
лами, но что произойдет, если она будет тривиальной33? Очевидно, что шифр, ис-
пользующий тривиальные узлы замен, попросту не представляет собой надежно-
го средства сохранения конфиденциальности, впрочем, видимо, как не представ-
ляет собой в этом случае и средства шифрования вообще. Следовательно, надо
постараться не использовать случайный подход либо использовать его весьма
осторожно.
Тем не менее, несмотря на возможные казусы в использовании случайных уз-
лов замен, такой подход весьма распространен и широко применяется сегодня.
В листинге 5.1 представлена программа, демонстрирующая на практике этот спо-
соб конструирования узлов замен. Узлы замен, созданные ею, используются в ал-
горитме криптографического хэширования Snefru.
Листинг 5.1
#include <stdlib.h>
«include <stdio.h>
«include <string.h>
«include "unidef.h”
«define SBoxCount 16
«define sizeOfRANDtable!n5DigitGroups 20000
//-положение группы в таблице случайных чисел
int locationlnRANDtable = 0;
’‘ч тпипия пьным узел замены называют в том случае, если он элемент х переводит r тпт же
> 148
Глава 5. Дешифрование современных шифров
И положение внутри группы
int location!n5DigitGroup =0; ‘
// таблица случайных чисел (умышленно НЕ ИСПОЛЬЗУЕТСЯ процедура rand()
// из стандартной библиотеки компиляторов языка Си, потому что она
// представляет собой программный датчик ПСЕВДОслучайных чисел, а нам
// нужны именно СЛУЧАЙНЫЕ)
И значения таблицы взяты из справочника RAND Corporation
char RANDtablefsizeOfRANDtableIn5DigitGroups][5] = {
/* 0 */ "10097”, "32533", "54876", "76520", "80959", "13586", "09117", "34673", ”39292”, "74945"
/* 1 */ "37542", "04805", "64894", "74296", "24805",
"24037", "20636", "10402". "00822", "91665"
/* 2 */ "08422", "68953", "19645", "09303", "23209",
"02560", "15953", "34764", "35080", "33606"
/* 3 */ "99019", ”02529", "09376", "70715", "38311",
"31165", "88676”, "74397", "04436", "27659"
/* 4 »/ "12807", "99970", "80157", "36147", "64032",
"36653", "98951", "16877", "12171", "76833"
/* 5 */ "66065”, "74717", "34072", "76850", "36697",
"36170", "65813", "39885”, "11199", "29170"
/* 1995 */ -85532", "87232", "26852", "06072", "20552",
"37337", "43185", "87156", "02774", "81224",
/* 1996 */ "96818", "98016", "85405", "71729", "86948”,
"43048", "10382", "12016", "11606", "16368",
/* 1997 */ "45410", "27000", "35418", "64141", "08731",
"20285", "97055”, "74760”, "85335", "95673",
/* 1998 */ "09848", "60615", "11085”, "64537", "71296",
"71800", "09895", "69411", "93490", "04683",
7* 1999 */ "91228", "87269", "43082", ”28147", "04175",
"54874”, "03737”, "93493”, "97159", "07515"
};
typedef uint32_t sBox[256];
11 обмен двух байтов в узле замены
void swapBytes!nSBox(sBox &anSBox, uint16_t row1, uint16_t row2, uint16_t column) {
// маска определяет байты, которые обмениваются местами
uint32_t mask;
uint32_t temp;
mask = OxFFOOOOOO;
if (column > 3) return;
I/ позиционируем маску
mask »= (column * 8);
I/ меняем байты
temp = anSBox[row1];
anSBox[row1] = (anSBox[row1] & ("mask)) | (anSBox[row2] & mask);
anSBox[row2] = (anSBox[row2] & ("mask)) | (temp & mask);
}
Гпаеа 5. Дешифрование современных шифров ы ? 149
И генерируем случайную цифру (от 0 до 9)
// для этого выбираем значения из таблицы RAND
uint16_t randomDigitO {
if (locationIn5DigitGroup ='= 5) {
location!n5DigitGroup = 0;
locationInRANDtable++;
};
if (locationlnRANDtable >= size0fRANDtableIn5DigitGroups)
exit(1);
return (RANDtable[locationInRANDtable][locationIn5DigitGroup++] - ’О-);
};
// генерируем случайное число, опять-таки используя таблицу RAND */
uint16_t random!nRange(uint16_t low, uint16_t high) {
uint16_t range; // границы, в которых генерируем
uint16_t maximum; // максимальное случайное
uint16_t random; // случайное, созданное присоединением
range = (high - low) + 1;
do {
random = 0;
maximum = 1;
// цикл до тех пор, пока не выбраны все цифры
while (maximum < range) {
maximum *= 10; /* 0-n = n+1 возможных случайных чисел */
// приписываем цифру в конец
random = (random * 10) + randomDigit ();
}
}
11 обрезаем, чтобы попало в границы
while (random >= ((unsigned int) (maximum / range)) * range);
return (low + (random % range));
}
void main() {
sBox SBoxFromRand[SBoxCount];
int SBoxIndex;
11 column определяет номер байта, 0 обозначает самый левый
uint16_t column, row;
uint32_t longRow;
for (SBoxIndex = 0; SBoxIndex < SBoxCount; SBoxIndex++) {
// заполняем узлы замен тривиально
for (longRow = 0; longRow < 256; longRow++)
SBoxFromRand[SBoxIndex][longRow] =
longRow | (longRow « 8) | (longRow « 16)
| (longRow « 24);
for (column = 0; column < 4; column++) {
for (row = 0; row < 255; row++)
// переставляем столбцы-байты - -
swapBytesInSBox(SBoxFromRand[SBoxIndex],
row, randomlnRange (row, 255), column);
}
}
Гпава .5. Дешифрование современных шифров
150
for (SBoxIndex = 0; SBoxIndex < SBoxCount; SBoxIndex++) {
printf("{ // Начало S-Box %d\n”, SBoxIndex);
for (row = 0; row < 256; row++) {
if (row%5 == 0) printf("\n // %4d \n",row);
printf ("0x%081xL”, SBoxFromRand[SBoxIndex][row] );
if (row != 255) printf(",");
}
printf(”\n// Завершаем S-box %d\n),\n\n\n", SBoxIndex);
Собственно, для описания неслучайных узлов замен, представляющих собой
так называемые криптографические примитивы, используют особые Булевы фун-
кции. Данные функции должны удовлетворять определенным критериям, среди
которых обязаны присутствовать следующие свойства:
Свойство полноты.
Свойство полноты (completeness) формулируется правилом: каждый выход-
ной бит является нетривиальной функцией всех входных битов. Это позволяет
внести в криптосистему строгую зависимость выхода шифра от всех битов ключа,
что гарантирует шифру криптостойкость, определенную длиной ключа. Неполно-
та шифра может привести к возможности разделения зависимостей битов выхода
и входа на группы, независящие друг от друга, в результате чего криптоаналитику
будет необходимо решить не одну сложную задачу, а в противовес ей — несколь-
ко попроще.
Наличие лавинного эффекта.
Лавинный эффект (Avalanche Criterion — как развитие свойства рассеива-
ния) означает принудительное изменение в среднем половины битов выхода шиф-
ра при изменении хотя бы одного бита входа. Отсутствие лавинного эффекта при-
водит к появлению больших эквивалентных ключей, что отрицательно сказывает-
ся на фактической криптостойкости шифра. Наличие же его делает весьма
затруднительным статистический анализ выхода шифра и определение ключа
шифра с помощью вероятностных методов.
Наличие их комбинации как строгого лавинного эффекта.
Строгий лавинный эффект (Strict Avalanche Criterion, или SAC) достигается
как компиляция свойств полноты и лавинного эффекта, если каждый бит выхода
шифра изменяется с вероятностью при изменении одного бита входа. Число
функций для п переменных, обладающих таким эффектом, подсчитано и равно
2я'. Строгий лавинный эффект1 обеспечен также для тех функцйй, для которых
сумма fix) Ф fix Ф а) является сбалансированной, то есть содержащей единиц и
нулей поровну, для всех а с одним установленным в единицу битом и остальными
нулями.
Гпава 5. Дешифрование современных шифров
151
Попарная независимость всех знаков выхода и обратимость как совершен-
ность.
В иностранной литературе совершенность иногда называют также, как Bit In-
dependence Criterion или BIC. Наличие или отсутствие совершенности криптогра-
фических примитивов, использованных в шифре, влияет на возможность утечки
информации при статистических исследованиях выхода шифра. В случае совер-
шенности статистические характеристики шифра приближаются по своим значе-
ниям к характеристикам независимых случайных процессов, что несомненно су-
щественно затрудняет криптоанализ.
Каждая табличная функция должна иметь максимальное расстояние до клас-
са линейных функций, то есть обладать максимальной нелинейностью.
Для описания свойства максимальной нелинейности нам понадобятся описа-
ния аффинной и линейной функций. Аффинная Булева функция определяется как
обладающая следующим свойством:
/(x0,x1,x2...,xn) =а0 +atxt + а2х2 +... + апхл,
а0,...,ап е {0,1}.
Если при этом коэффициент а0 = 0, то функцию f называют линейной. Линей-
ные функции очень удобны в работе криптоаналитика, они позволяют аппрокси-
мировать узлы замен более простыми линейными функциями и строить системы
линейных уравнений, решение которых позволяет вычислить ключ блочной крип-
тосистемы. Соответственно узел замены, представленный Булевой функцией,
должен быть как можно более нелинеен по своим свойствам, то есть таким, что
для большинства своих значений узел замен нельзя было бы представить в виде
линейной функции. Для этого можно воспользоваться следующей функцией:
H(f) = min{d(f, h)\h(x) = а0 +... + а„х„},
h
где d(f, h) — расстояние Хэмминга, то есть количество различающихся битов в
двоичной последовательности заданной длины.
С момента появления первых SP-сетей и затем после принятия первого стан-
дарта шифрования существовавшие изначально свойства полноты и лавинного
эффекта заметно эволюционировали и стали свойствами строгого лавинного эф-
фекта и совершенности.
Вообще говоря, еще команда разработчиков IBM отмечала некоторые необхо-
димые для S-блоков качества (наследуя добрую половину рассуждений у Шенно-
на, см. главу «Теория секретных систем»):
• нелинейную зависимость выходных битов от входных;
• зависимость любых входных битов от всех выходных;
• изменение половины выходных битов при изменении одного входного.
Эти свойства представляют собой не что иное, как определение свойств пол-
ноты и рассеивания, данное Клодом Шенноном. При этом очевидным является то,
что свойства полноты и рассеивания входили в состав критериев по отбору узлов
замен стандарта DES. Разработчики из IBM остановились на размере узла замены,
равном четырем битам, в качестве компромисса между процентом доли S-блоков,
452
Гпава 5. Дешифрование современных шифров
имеющих линейную Булеву форму, и размером самих блоков. Дело в том, что доля
линейных узлов замен, как и доля узлов замен, имеющих линейное выражение
хотя бы для одного выходного знака, быстро убывает с ростом размера самих бло-
ков. Например, для четырех битов (размера блоков в DES) процент линейных из
них равен 10~2, а при размере восемь битов процент уменьшается почти до 1О~70.
В 1994 году IBM раскрыла те критерии, которыми руководствовались иссле-
дователи под руководством доктора Уолтера Тачмена при разработке узлов замен
для DES. И к линейности функций там относился только один пункт — ни один
бит выхода узла замены не должен быть слишком близок (по функции H(f) к ли-
нейной функции от входных битов. Остальные два пункта в списке критериев ка-
сались размера узлов замен, а еще шесть привносили в узлы замен стойкость про-
тив, дифференциального криптоанализа, который был разработан в IBM задолго
до первых открытых публикаций о нем в начале 1990-х годов. В IBM Laboratories
атаку на узлы замен называли «атакой-Т» (T-attack).
В конце концов, после нескольких десятков удачных работ в этой области,
были коллегиально сформулированы основные свойства узлов замен:
• строгий лавинный эффект;
• биты выхода не должны зависеть друг от друга;
• должно существовать обратное преобразование.
При соблюдении всех трех указанных свойств получившиеся S-блоки называ-
ют совершенными криптографическими преобразованиями. Приблизительно в
‘середине 90-х годов обнаружилось, что требуемые наборы функций уже давно из-
вестны в дискретной математике и носят название бент-функций. Многие дости-
жения в исследовании бент-функций сегодня благополучно перенесены в теоре-
тическую область криптографии.
На сегодня практически неизвестны эффективные методы конструирования
S-блоков, удовлетворяющих всем поставленным критериям. Тем не менее сущест-
вует несколько алгоритмов, позволяющих строить эффективные узлы замен,
стойкие против большинства существующих криптографических атак.
Один из алгоритмов, использованных при создании узлов замен алгоритма
CAST-256, заключается в использовании бент-функции как функции, обладающей
следующим свойством: расстояние Хэмминга от f до любой аффинной функции в
пространстве функции над полем GF(2m) является максимально возможным.
Если сравнивать характеристики узлов замен, созданных случайным образом
и в соответствии с указанными выше критериями, возможно получить приблизи-
тельно такую же таблицу, как нижепоказанная.
Свойство Случайные узлы замен Сконструированные
Нелинейность 72 74
Строгий лавинный эффект 17 . 0
Распределение по строкам биномиальное биномиальное
Распределение по столбцам биномиальное биномиальное
Средний вес 128 128 .
Глава 5. Дешифрование современных шифров
153
Как видно из таблицы, сконструированные узлы замен очень похожи по сво-
им свойствам на случайные по одним свойствам и превосходят их по другим. От-
личия в лучшую сторону, кажущиеся минимальными, на самом деле объясняются
тем, что существует верхняя граница, которая, собственно, и достигнута при кон-
струировании «искусственных» узлов замен. Другими словами, с использованием
существующих методов конструирования узлов замен создать их более совершен-
ными не представляется никакой возможности.
Дешифрование DES
The NSA told us we had inadvertently reinvented some of the
deep secrets it uses to make its own algorithms.
W.Tachmen. IBM Laboratories
Я верующий человек, и я знаю, что Бог в курсе всех моих
секретов, и потому я всегда чувствую, что мои мысли в не-
котором смысле известны всем. Из этого я и исхожу. Я не
считаю, что должен скрывать все, что я делаю. С другой
стороны, я, естественно, отношусь совершенно по-другому
к тому, что кто-то может использовать эту открытость про-
тив меня, например воспользовавшись моими банковскими
счетами. Поэтому я за высокий уровень секретности. Но
должно ли быть невозможным для властей расшифровать
информацию даже при уголовных расследованиях, в край-
них случаях — тут я склоняюсь к тому, что в некоторых си-
туациях должны все-таки быть методы дешифрования неко-
торых шифров. ' ' '
Д. Кнут. Лекция «Ответы на все вопросы»
5 октября 2001 года в Техническом
университете г. Мюнхена
Обращаясь к анализу алгоритма, можно заметить ряд существенных недо-
статков, обнаружившихся большей частью сразу после принятия стандарта. Для
современных приложений размер ключа в 56 битов стал слишком мал. Современ-
ные подсчеты показывают, что сконструировать специализированное устройство,
способное произвести поиск ключа DES в среднем всего за 3,5 часа, будет стоить
примерно 1 миллион долларов. Дальше всех в этом смысле продвинулись в орга-
низации передовых электронных технологий (The Electronic Frontier Foundation).,
Ее сотрудники построили аппаратный комплекс стоимостью в 210 000 долла-
ров, который оказался способен взломать шифр-DES за трое суток. Как-Шутили
западные журналисты, это был простой способ взломать 56-битовый DES^ за 56
часов. При этом, после ее создания разработчики заявили, что сделать еще одну
такую машину будет стоить всего 150 000 долларов, поскольку большая цасть
первоначальных расходов приходилась на разработку проекта, а не на его техни-
ческое обеспечение.
154
Гпава 5. Дешифрование современных шифров
Правительственные организации утверждали, что взлом DES возможен толь-
ко при наличии дорогостоящего оборудования и использования глобальной
компьютерной сети. EFF указала на возможность использования обычного персо-
нального компьютера и не слишком дорогого специализированного оборудования.
Концепция архитектуры EFF DES Cracker (с чипами Deep Crack) довольно
проста. Обычный персональный компьютер состыкован с аппаратным комплек-
сом, содержащим в себе большое количество специальных чипов, запрограммиро-
ванных на расшифровку данных с помощью алгоритма DES и сверку определен-
ным способом с заданным эталоном. Программное обеспечение компьютера опо-
вещает чипы о начале перебора, предоставляет им исходные данные и далее
никак не участвует в процессе, кроме контроля за исполнением и поиском ключа.
Чип Deep Crack работает независимо до тех пор, пока не найдет потенциально
верное решение или не будет обработан тот участок ключевого пространства, ко-
торый определил ему главный компьютер. Программа главного компьютера пери-
одически опрашивает все чипы и получает из их внутреннего стека все найденные
за прошедшее время «ключи».
Таким образом, в задачи аппаратной части комплекса вовсе не входит тоталь-
ная проверка на совпадение ключа, шифротекста и открытого текста. Вместо это-
го аппаратная часть отбраковывает большую часть заведомо неверных решений,
предоставляя программному обеспечению главного компьютера проводить более
точные вычисления и проявлять свой интеллект.
Поскольку в комплексе программное обеспечение занимает много меньшую
позицию относительно аппаратного, процесс поиска можно разделить на несколь-
ко сотен параллельных поисковых операций. Это означает, что один чип, который
найдет решение через несколько тысяч лет, можно заменить на тысячу чипов, ко-
торые найдут решение почти в тысячу раз быстрее. Правда, для миллиона чипов
такая тенденция уже не будет верна — при использовании миллионов чипов поя-
О';
AWT-4500
DEEP CRACK
ORBIT 61335А
9816 Т03093ЛА
о
I /’Дг,
Рис. 5.1. Изображение одного чипа Deep Crack
Гпава 5. Дешифрование современных шифров
155
вятся огромные накладные расходы на запуск и опрос всех чипов. Так что наклад-
ные расходы съедят почти весь выигрыш от огромного количества «боевых еди-
ниц». Построенный в EFF комплекс содержал всего 1536 чипов.
Естественно, при тотальном переборе мы опробуем все ключи, но при этом
может быть существен порядок, в котором мы выбираем каждый следующий
ключ. На самом деле мы можем опробовать ключи в любом порядке, но если мы
знаем, что ключ выбран неслучайным образом, то гораздо эффективнее будет сна-
чала опробовать наиболее вероятные ключи, а затем уже все остальные.
Чип Deep Crack, являющийся центральной компонентой всего комплекса,
представляет собой небольшой чип, который получает ключ и два блока по 64
бита длиной каждый. Его задача — расшифровать первый блок с заданным клю-
чом и проверить, имеет ли смысл дальнейшее исследование данного ключа. Если
получен отрицательный результат, значение ключа инкрементируется на едини-
цу. Если же ключ признан «подходящим», чип расшифровывает второй блок. По-
сле положительного ответа и на второй аналогичный вопрос чип останавливается
и сообщает главному компьютеру о том, что найден подходящий ключ. Чипы по-
строены для работы на частоте 40 МГц (то есть 40 миллионов операций в секун-
ду). Элементарной операцией является один раунд расшифрования. То есть каж-
дый чип может проверять за секунду 40 000 000 /16 = 2 500 000 ключей.
Основным вопросом является конечно же способ определения, какой ключ
признать подходящим. Очевидно, что аппаратно выбранный подходящий ключ во-
все не обязан быть действительным решением. Если мы знаем соответствующие
друг другу элементы пары (открытый текст, шифротекст), мы можем определить
Рис. 5.2. Фотография всего комплекса EFF DES Cracker
156 '
Гпава 5. Дешифрование современных шифров
Рис. 5.3. Поисковый модуль с 32 чипами Deep Crack
критерий «схожести с подходящим» именно по ним. Если же нет, то критерием
может быть, например, то, что текст состоит только из букв, цифр, пробела и зна-
ков пунктуации.
Каждый удачный результат в этом случае содержит восемь байтов данных.
Соответственно каждый байт может иметь 256 значений. Для того чтобы упрос-
тить аппаратную часть, каждый из чипов просто оснащается таблицей из 256 • 8 =
= 2048 значений, в которые вписаны признаки «значение подходит» или «значе-
ние не подходит». Например, если мы ищем открытый текст, состоящий только из
цифр, мы заполняем таблицу значением «не подходит» для всех значений, кроме
тех, которые соответствуют цифрам от 0 до 9. Если длина открытого текста мень-
ше 64 битов, то вместо второго 32-битового блока снова подставляется первый.
Накладные расходы ничтожны по сравнению с расходами на тотальный перебор,
а в результате такого «мошенничества» чип отработает корректно.
При расшифровании неверным ключом выход шифра будет выглядеть доста-
точно случайно, и соответственно мы можем попробовать подсчитать вероятность
появления подходящего ключа в зависимости от количества подходящих значе-
ний для всех байтов. Допустим, мы обозначили подходящими 69 символов (анг-
Гпава 5. Дешифрование современных шифров
157
лийские буквы от «А» до «Z», верхнего и нижнего регистров, цифры, пробел и не-
сколько знаков препинания). Тогда вероятность того, что случайный байт будет
определен как подходящий, равна 69/256 или приблизительно 1/4, то есть чип
будет останавливаться в каждом четвертом случае.
Кажется, это довольно часто. На самом деле нет. Мы подсчитали вероятность
появления только одного «лишнего» байта, у нас же их целых восемь, следовате-
льно, вероятность составит меньшее значение, а именно 1 /65536. Это число вы-
; глядит довольно малым, но если представить себе все пространство ключей (а это
ровно 72 057 594 037 927 936 ключей), то, имея такую вероятность, программное
обеспечение должно будет обработать 1 099 511 627 776 ключей. Так что нам, ви-
димо, требуется еще больше помощи от чипа.
Ее с лихвой предоставляет второй блок данных, который мы передаем чипу с
самого начала. После обработки первого блока данных, обнаружив, что ключ под-
j ходит, чип перейдет к обработке второго восьмибайтового блока. Это даст нам ве-
i роятность 1/4294967296 и соответственно 16 777 216 ключей для обработки
j главным компьютером.
' Конечно, чип будет генерировать гораздо меньше фальшивых ключей, если
вместо общих предположений об открытом тексте ему задают вполне конкретный
' участок открытого текста. В этом случае, очевидно, будет задаваться очень малое
количество подходящих байтов. Соответственно уменьшится вероятность появле-
, ния ложных ключей и тем меньшее количество ключей необходимо будет обрабо-
тать с помощью программного обеспечения главного компьютера.
' Например, если открытый текст представляет собой блок «Привет», то подхо-
i дящими будут буквы «П»., «р», «и», «в», «е», «т» и «», вместе с пробелом. Если рас-
шифрованный текст содержит только их, он подходит для дальнейшего рассмот-
рения. Правда, к сожалению, для него подойдут также и тексты «ир етПв», «П
твеир» и т. д., которые не являются действительными открытыми текстами.
Аналогично тому, как мы делали это выше, подсчитаем вероятность появле-
ния ложных ключей в этом случае. В таблице для одного байта определено 8 под-
ходящих ключей из 256, вероятность выбора любого из них равна 8/256 = 1/32.
Все восемь байтов дадут 1/1099511627776 (1/32 в восьмой степени). Другими
словами, чип может перебрать около триллиона ключей, прежде чем обратиться к
главному компьютеру с сообщением о нахождении следующего подходящего клю-
ча.
Для общения с чипами программа главного компьютера использует специаль-
но разработанный интерфейс (см. листинг 5.2)34.
Листинг 5.2
((include <stdio.h>
((include <conio.h>
(include <stdlib.h>
(include "chipio.h"
34 Исходный текст программно-аппаратного комплекса EFF PES Cracker предоставлен
компанией EFF. '
158
Гпава 5. Дешифрование современных шифров
static int CURRENT-BOARD = -1;
static int CURRENT-CHIP = -1;
static int CURRENT-PORT.CNFG = -1;
static int IO-BASE-ADDRESS = 0x210;
«define IO_PORTA_ADDRESS (IO_BASE_ADDRESS+O) «define IO_PORTB_ADDRESS (I0_BASE_ADDRESS+1) «define IO_PORTC_ADDRESS (I0_BASE_ADDRESS+2) «define IO_CNFG_ADDRESS (I0_BASE_ADDRESS+3) «define CNFG.OUTPUT 0x80 «define CNFG.INPUT 0x82
«define CTRL_BASE 0x1 В /* base value onto which others are XORed */
«define CTRL_RST 0x20
«define CTRL.RDB 0x10
«define CTRL.WRB 0x08
«define CTRL.ALE 0x04
«define CTRL_ADRSEL2 0x02 /* in documentation is also called CNTR1 */
«define CTRL.ADRSEL1 0x01 /* in documentation is also called CNTRO */
/* * DELAYS CAN BE ADDED TO DEAL WITH BUS LOADING/CAPACITANCE/ETC. */ «define DELAY_FACTOR 100L
«define DELAY_ADDRESS-SETTLE 0*DELAY-FACTOR
«define DELAY.DATA-SETTLE 0*DELAY-FACTOR
«define DELAY_RST_HOLD 0*DELAY.FACTOR
«define DELAY_RST_RECOVER O*DELAY_FACTOR
«define DELAY_RDB_HOLD 0*DELAY-FACTOR
«define DELAY-RDB.RECOVER 0*DELAY-FACTOR
«define DELAY-WRB.HOLD 0*DELAY_FACT0R
«define DELAY-WRB.RECOVER 0*DELAY-FACTOR
«define DELAY_ALE_SETTLE 0*DELAY-FACTOR
«define DELAY_ADRSEL2_SETTLE O*DELAY_FACTOR
«define DELAY.ADRSEL1.SETTLE O*DELAY_FACTOR
«define ioDelay(delayTime) {} /* insert delay if rqd */
«ifdef -MSC.VER /* * Microsoft C++ Direct I/O Functions */ static int inportb(int portNum) {
unsigned char rval; unsigned short portNumShort = (unsigned short)portNum;
_asm { mov dx,portNumShort }
_asm { in al,dx }
_asm { mov rval, al }
return (rval);
static void outportb(int portNum, int val) {
unsigned char valChar = (unsigned char)val;
unsigned short portNumShort = (unsigned short)portNum;
Гпаеа 5. Дешифрование современных шифров 159
_asm { mov dx, portNumShort }
_asm { mov al, valChar }
_asm { out dx, al }
}
tfendif
static void ConfigureIO_Port(int inputOrOutput) {
outportb(IO_CNFG_ADDRESS, inputOrOutput);
CURRENT_PORT_CNFG = inputOrOutput;
/* Warning: ;
*
* Changing the 10 port state causes a tiny glitch to go out on the
* PC-DIO card. This is enough to ocasionally trigger the ALE, which
* causes read/write errors. To avoid this, always explicitly
* re-select the chip after switching port directions.
*/
CURRENT-CHIP = -1;
atic void SetAddress(int addressValue) {
3utportb(I0_P0RTA_ADDRESS, addressValue);
tic void SetData(int dataValue) {
jtportb(IO_PORTB_ADDRESS, dataValue);
ic int GetData(void) {
turn (inportb(IO_PORTB_ADDRESS));
: void SetControl(int controlPortValue) {
’ossible optimization: Don’t send value if already correct.
ortb(IO_PORTC_ADDRESS, controlPortValue);
£ ; void selectBoard(int board) {
Address(board);
Control(CTRL_BASE " CTRL_ADRSEL1); /* put board ID onto address pins */
)elay(max(DELAY_ADDRESS_SETTLE, DELAY_ADRSEL1_SETTLE)); /* wait */
Control(CTRL_BASE " CTRL.ADRSEL1 " CTRL.ALE); /* pull ALE high */
)elay(DELAY-ALE_SETTLE); /* wait */
Control(CTRL_BASE " CTRL.ADRSEL1); /* pull ALE back */
)elay(DELAY_ALE_SETTLE); /* wait */>
Control(CTRL_BASE); /* ADRSEL1 done */
elay(DELAY_ADRSEL1_SETTLE);
RENT_BOARD = board;
RENT_CHIP = -1;
160
Гпаеа 5, Дешифрование современных шифров
static void selectChip(int chip) {
SetAddress(chip);
ioDelay(DELAY_ADDRESS_SETTLE);
SetControl(CTRL_BASE ~ CTRL.ALE);
ioDelay(DELAY_ALE_SETTLE);
SetControl(CTRL_BASE);
ioDelay(DELAY_ALE_SETTLE);
CURRENT-CHIP = chip;
}
void SetBaseAddress(int address) {
IO_BASE_ADDRESS = address;
}
/*
* RESET A SINGLE BOARD
/* select chip */
/* wait */
/* pull ALE high */
/* wait */
/* pull ALE back */
/* wait */
* This function resets an entire board. It is not optimized for speed.
* It is necessary to delay after calling this function until the board
* reset completes.
*/
int ResetBoard(int board) {
/* Configure the 10 card (doesn’t matter if for data input or output) */
Configu reI0_Po rt(CNFG_INPUT); Configu relO.Port(CNFG_OUTPUT); /* configure the 10 port */ /* configure the 10 port */
selectBoard(board); /* select the board */
SetControl(CTRL.BASE " CTRL.RST); ioDelay(DELAY_RST_HOLD); SetControl(CTRL_BASE); ioDelay(DELAY_RST_RECOVER); ' /* RESET THE BOARD */ /* wait */ /* stop resetting */ /* wait */
CURRENT-BOARD = -1; /* CURRENT-CHIP = -1; return (0); reset this on next 10 to be safe */ /* reset this to be safe */
}
void SetRegister(int board, int chip, int
it (CURRENT_PORT_CNFG ’= CNFG_OUTPUT)
ConfigureIO-Port(CNFG_OUTPUT);
if, (CURRENT-BOARD != board)
selectBoard(board);
if (CURRENT-CHIP I- chip)
selectChip(chip);
SetAddress(reg);
SetData(value);
SetControl(CTRL_BASE ~ CTRL.ADRSEL2);
ioDelay(max(max(DELAY_ADDRESS_SETTLE,DELAY.DATA-SETTLE),
DELAY_ADRSEL2_SETTLE));
SetControl(CTRL_BASE " CTRL.WRB " CTRL-ADRSEL2);
ioDelay(DELAY_WRB_HOLD);
reg, int value), {
/* set 10 data lines for output */
/* make sure board is selected */
/* make sure chip is selected */
/* select the right' address */
/* output the data */
/* pull low */
/* wait */
/* pull WRB low */
/* hold it */
Гпаеа 5. Дешифрование современных шифров
161
SetControl(CTRL-BASE ~ CTRL.ADRSEL2); /* let WRB high again */
ioDelay(DELAY_WRB_RECOVER); /* wait */
SetCantrol(CTRL-BASE); /* let WRB high again */
ioDelay(DELAY_ADRSEL2_SETTLE); /* wait */
}
int GetRegister(int board, int chip, int reg) {
int rval;
if (CURRENT_PORT_CNFG != CNFG.INPUT) /* set 10 data lines for input */
ConfigureIO_Port(CNFG_INPUT);
if (CURRENT-BOARD != board) /* make sure board is selected */
selectBoard(board);
if (CURRENT_CHIP != chip) /* make sure chip is selected */
selectChip(chip);
SetAddress(reg); /* select the right address */
SetControl(CTRL_BASE " CTRL.ADRSEL2); /* pull adrsel2 low */
ioDelay(max(DELAY_ADDRESS_SETTLE, DELAY_ADRSEL2_SETTLE)); /* wait ♦/
SetControKCTRL_BASE M CTRL.RDB ~ CTRL-ADRSEL2); /* pull RDB low */
ioDelay(DELAY_RDB_HOLD);
rval = GetDataO;
SetControl(CTRL_BASE ~ CTRL.ADRSEL2); /* let RDB high ♦/
ioDelay(DELAY-RDB-RECOVER);
SetControl(CTRL_BASE); /* let ADRSEL2 high */
ioDelay(DELAY-ADRSEL2.SETTLE);
return (rval);
}
int CheckRegister(int board, int chip, int reg, int value) {
int i;
i = GetRegister(board, chip, reg);
if (i != value)
return (-1);
return (0);
}
А основной модуль, управляющий процессом перебора и заключительной от-
браковкой ключей, представляет собой весьма небольшой по размеру исходный
текст (см. листинг 5.3).
Листинг 5.3
«define SOFTWARE-VERSION ”1.0”
«define SOFTWARE-DATE ”04-21-1998”
«include
«include
«include
«include
«include
«include
«include
«include
6 Зак. 85
<stdlib,h>
<stdio,h>
<assert.h>
<ctype.h>
<memory.h>
<time.h>
<string.h>
<conio.h>
\162
Гпава 5. Дешифрование современных шифров
«include ’’search.h”
«include ’’chipio.h"
«include ’’keyblock, h”
«include “des.h”
/*
* SEARCH.CHIP STRUCTURE: Contains status information about each chip.
* *
* board: The board this chip is on (1 byte).
* chip: The ID of this chip on the board (1 byte).
* initialized: (^uninitialized, 1=initialized, -1=defective.
* region[]: Specifies the top 24 bits of the key being searched by each
* search unit. A value of -1 means the search unit is idle .
* (idle), and a value of -2 means the search unit is not used.
* overFlowf]: Specifies the value at which the low 32 bits of the
* key (the key counter) will have gone through all 2"32
* possibilities. Note: this only has the top 24 bits of the
* counter, which corresponds to key bytes: ................ XX XX XX.. (LSB)
* lastSeen[]: The value last seen in the low 32 bits of the key.
* This has the same encoding as overFlow.
* /
typedef struct CHIP.CTX {
unsigned char board, chip;
int initialized;
long region[SEARCH_UNITS_PER_CHIP];
long overFlow[SEARCH_UNITS_PER_CHIP];
long lastDone[SEARCH_UNITS_PER_CHIP];
struct CHIP.CTX *nextChip;
} CHIP.CTX;
/*
* GLOBAL VARIABLES
*/
CHIP-CTX *CHIP_ARRAY = NULL;
SEARCH.CTX CTX;
static int QUIET = 0;
static int VERBOSE = 0;
static FILE *FP LOG = NULL;
/.
* FUNCTION PROTOTYPES & MINI FUNCTIONS & MACROS
* /
static void EXIT_ERR(char *s) { fprintf(stderr, s); exit(1); }
long ReadConfig(char *configFilespec);
void RunSearch(FILE *ctxFile);
void InitializeChip(CHIP_CTX *cp, SEARCH.CTX *ctx);
void ServiceChip(CHIP.CTX *cp, SEARCH.CTX *ctx, FILE *ctxFile);
long GetUnitKeyCounter(int board, int chip, int unit);
void CheckAndPrintKey(CHIP.CTX *cp, SEARCH.CTX *ctx, int unit);
int ServiceKeyboard(SEARCH.CTX *ctx);
int CheckKey(unsigned char key[56], SEARCH.CTX *ctx);
void main(int argc, char **argv) {
FILE *ctxFile;
Глава 5, Дешифрование современных шифров
163
int i;
time_t t;
CHIP.CTX *cp;
\nDES Search Engine Controller (Ver %s, %s). May be export "
printf(
controlled.\nWritten 1998 by Cryptography Research "
(http://www.cryptography.com) for EFF.\n”
This is unsupported "
free software: Use and distribute at your own risk.\n"
-----------------------------------\n\n\n”,
SOFTWARE-VERSION, SOFTWARE-DATE):
if (argc < 3) {
fprintf(stderr,
"Usage: search configFile contextFile [logfile] [-v] [-q]\n"
configFile: Search array configuration from autoconf\n"
contextFile: Search context (from init)\n"
logfile: Output file with detailed reporting info\n"
-v: verbose output to logfile\n"
-q: quiet mode (less output to the screen)\n"
" (Note: paramaters must be in the order above.)\n");
exit(1);
}
for (i = 3: i < argc: i++) {
if (i == 3 && argv[i][O] != ’-’) {
FP.LOG = fopen(argv[3], "w");
if (FP.LOG == NULL)
EXIT_ERR("Error opening log file.");
} else if (stricmp(argv[i], ”-v") == 0)
VERBOSE = 1;
else if (stricmp(argv[i], "-q") == 0)
QUIET = 1;
else {
fprintf(stderr, "Unknown parameter \"%s\"\n", argv[i]);
exit(1);
/* READ CONFIGURATION FILE SPECIFYING BASE PORT AND SEARCH UNITS */
CTX.totalUnits = ReadConfig(argv[1]);
/♦ RESET THE SEARCH ARRAY */
if (’QUIET) printf("Resetting the search array.\n");
i = -1;
for (cp = CHIP_ARRAY; cp != NULL; cp = cp->nextChip) {
if (i ’.= cp->board) {
i = cp->board;
ResetBoard(i);
}
}
t = time(NULL); ।
/* READ SEARCH FILE SPECIFYING SEARCH INFO & REMAINING KEY BLOCKS */
ctxFile = fopen(argv[2], "r+b");
Глрвр 5. Дешифрование современныхшифррв.
««ычианиш мнтнт а^мм4*«м«*ш. • *• »*-»|*лгии хлч »♦-. а - х - » w>«» »м ь-- -гл< л«, . к »м* * » » * » « о*^я» » » • » - w«r«u « х > ► »-.. „ »>+“ * » » «
if (ctxFile == NULL) {
fprintf(stderr, "Error opening search context'file \"%s\"\n", argv[2]);
exit(1);
} : • . .
/* MAKE SURE RESET HAD AT LEAST 1 SECOND TO SETTLE. */
if (!QUIET) printf("Waiting for reset to settle.\n");
while(t + 1 >= timeCNULL)), {} . .
/* RUN THE SEARCH’ */ ' -
RunSearch(ctxFile);
fclose(ctxFile); : (x > , j •
if (’QUIET) printf("Exiting.\n");
'v, •'z, >-4' ’ ’ ; ? ?ret- pnl д - ы । j ' )~i;' ' ' ‘N ’
/* •'r '
* Run the search. Uses the search parameters in the 1 : ' 11 -
* global linked list CHIP_ARRAY and keeps its context info1
* in the global CTX. ’ f ' л 'v : '
*/
void RunSearch(FILE *ctxFile) { 'r' f
CHIP-CTX *cp: '
SEARCH.CTX *ctx = &CTX;
int halt = 0; ’ • ’v •
time.t startTime, lastReportTime, t;
long loopCount =0; '
char buf fer[ 12*8-]; 41 ' 'v' r '* ' !<” '• • '' < •'
if (’QUIET) prlntfC" Loading search context file?..Xn”); , ?
OpenSearchContext(ctxFile^, ,ctx); 4 > , ,
printf("Initialization Successful - Beginning search.\n")';
if (QUIET) printf("Qui4et mode;; Press -?[ £pr?helpxduring .search. \n"); 4
if (FP-LOG && VERBOSE) fprtntfjjFP^LOG^ Beginr)iqg search- — \n");
for (cp = CHIP.ARRAY; cp != NULL; cp = cp->nextChip)
InitializeChip(cp, ctx);
startTime = time(NULL); .. . < t * .>
lastReportTime =0;
while (halt == 0) {
t = time(NULL); ? * '/* report every 5 seconds */
if (t/5 != lastReportTime/5)
sprintf(buffer, "%71d blocks done, %71d left1, %41d running (time=%71d).",
ctx->totalFinishedKeyBlocks, ctx->totalUnstartedkeyBlocks +
ctx->totalPendingKeyBlocks', ctx-StotalPendingKeyBlocks,
(long)(t - startTime));
if (’QUIET) printf(">%s C?’«help)\n"t buffer);
if (FP-LOG && VERBOSE) fprintf(FP-LOG, ‘’Report: %s\n“, buffer);
lastReportTime = t; _ ; 4
j :*K J-Л.’ rjj-l /• . 1,1 v t
for (cp = CHIP_ARpAY;r cp .!= ШЦ M half == 0: .cp • cp->nextChip) { :i
ServiceChip(cp? ctx, ctxFiie); " '4‘"J
if (ServiceKeyboard(ctx) ^ O). , ...... ? (
halt ='1; ' ' ' ’ '' ' ? '
} д •’ <. -
Гпава'5. Дешифрование сбереженных, шифров!...............
if (ctx->totalFinishedKeyBlocks/== (1L<<24)\
halt = 1; ' '' "*
GetRegister(255, 255, 255);
•loopCount++;
} : , -
}
/* InitializeChip(cp. ctx): Initialize a chip whose chip context is
* at cp, using the search parameters at ctx.
*/
void InitializeChip(CHIP_CTX *cp, SEARCH.CTX *ctx) {
int i,j;
if (’QUIET) printf("Initializing board 0x%02X, chip 0x%02X\n",
cp->board, cp->chip);
if (FP_LOG && VERBOSE) fprintf(FP_LQG,
"Initializing board 0x%02X, chip 0x%02X\n", cp->board, cp->chip);
SetRegister(cp->board, cp->chip, REG_PTXT_BYTE_MASK, OxFF); /* halt chip */
for (i = 0; i < 32; i++)
SetRegister(cp->board, cp->chip, REG_PTXT_VECTOR+i,
ctx->plaintextVector[i]);
for (i = 0; i < 8; i++)
SetRegister(cp->board, cp->chip,REG_PTXT_XOR_MASK+i,
ctx->plaintextXorMask[i]); > , . -
for (i = 0; i < 8; i++)
SetRegister(cp->board, cp->chip, REG_CIPHERTEXTO+i, ctx->ciphertextO[i]);
for (i = 0; i < 8; i++)
SetRegister(cp->board, cp->chip, REGJHPHERTEXTi+i, ctx->ciphfertext1[i]); '
SetRegister(cp->board, cp->chip, REG_PTXT_BYTE_MASK, ctx->plaint’extByteMask);
SetRegister(cp->board, cp->chip,, R^G.SEARQHINFCL ctx->searchlnfo); ,;
/* TO BE SAFE, VERIFY THAT'ALV REGISTERS’WERE4 WRITTEN PROPERLY '
/* (Each chip only gets initialized once'/so thisls* quick'.) */ 1'' ,‘
j = 0; ' - ' v f
for (i = 0; i < 32; i++)
j += CheckRegister(cp->board, cp->chip, REG_PTXT_VECTOR+i,
ctx->plaintextVector[i]);
for (i = 0; i < 8; i++) {
j += CheckRegister(cp->board, cp->chip, REG_PTXT_XOR_MASK+i,
ctx->plaintextXorMask[i]);
j += CheckRegister(cp->board, cp->chip, REG_CIPHERTEXTO+i,
ctx->ciphertextO[i]); /
j += CheckRegister(cp->board, cp->chip, REG_CIPHERTEXT1+i,
ctx->ciphertext1[i]);
} .
j += CheckRegister(cp->board, cp->chip, REG_PTXT_BYTE_MASK,. ?
ctx->plaintextByteMaskj; ' ' ’ ,
j += CheckRegister(cp->board, cp->chip, REG SEARCHINFO, ctx->searchlnfo)/
if (j != °) < ; о - f
printf("Bad register on board 0x%0'2X,' chip 0x%02#. Chip disabled.\n",
cp->board, cp->chip); , '
if (FP.LOG) fprintf(FP_LOG, "Bad register on board 6x%02X, chip 0x%02X.%s",
cp->board, cp->chip, " Chip disabled.\n");
}
1.66
Гпава 5. Дешифрование современных, шифров
/* UPDATE THE CHIP CONTEXT */
cp->initialized = (j == 0) ? 1 : -1; /* initialized or defective */
}
/*
* Service a chip by doing the following:
* - Check if it has halted
* - Check to see if it has finished its region
* - Restart if it is idle
* /
void ServiceChip(CHIP_CTX *cp, SEARCH.CTX *ctx, FILE'*ctxFile)4
int unit;
long k; '
if (cp->initialized < 0)
return;
/*
* READ KEYS & RESTART ANY HALTED UNITS
* /
for (unit = 0; unit < SEARCH_UNITS_PER_CHIP; unit++) {
if (cp->region[unit] >= 0) { /* if currently running */
if (I(GetRegister(cp->board, cp->chip, REG.SEARCH.STATUS(unit)) & 1)) {
CheckAndPrintKey(cp, ctx, unit);
SetRegister(cp->board, cpr>chip, REG_SEARCH_STATUS(unit), 1);
}
}
}
/*
* See if any units have completed their search regions
* Note: If I/O bandwidth was a problem and the clock rate of the
* search system was fixed, we could predict when the keycounter
* would flip and avoid this check.
* /
for (unit = 0; unit < SEARCH.UNITS.PER.CHIP; unit++) {
if (cp->region[unit] < 0)
continue;
к = GetUnitKeyCounter(cp->board, cp->chip, unit);
к -= cp->overFlow[unit];
if (k < 0)
к += (IL « 24);
if (VERBOSE && FP.LOG) fprintf(FP.LOG,
’’Board 0x%02X chip 0x%02X unit 0x%02X is at 0x%061X ”
‘'(lastDone=0x%061X. overFlow=%061X)\n’’,
cp->board, cp->chip, unit, k,
cp->lastDone[unit], cp->overFlow[unit]);
if (k < cp->lastDone[unit]) {
if (IQUIET) printf(’’Board 0x%02X chip 0x%02X unit 0x%02X finished block ”
’’0x%061X (lastDone=0x%061X, got 0x%061X, overFlow=%061X)\n",
cp->board, cp->chip, unit, cp->region[unit],
cp->lastDone[unit], k, cp->overFlow[unit]);
if (FP.LOG) fprintf(FP.LOG, "Unit 0x%02X 0x%02X 0x%02X finished ”
Глава 5. Дешифрование современных шифров 167
”0х%061Х (last=%061X, got %061Х, oFlow=%061X)\n",
cp->board, cp->chip, unit, cp->region[unit],
cp->lastDone[unit], k. cp->overFlow[unit]);
FinishKeyRegion(ctxFile, ctx, cp->region[unit]); /* region is done */
cp->region[unit] = -1; /* unit is now idle */
} else {
cp->lastDone[unit] = k;
}
}
/*
* Start any units that are currently stalled
*/
for (unit = 0; unit < SEARCH.UNITS.PER.CHIP; unit++) {
if (cp->region[unit] == -1) {
к = ReserveKeyRegion(ctxFile, ctx);
if (k < 0)
break; /* no more regions... */
if (’QUIET) printf(’’Starting board 0x%02X, chip 0x%02X, unit 0x%02X... ”,
cp->board, cp->chip, unit);
if (FP.LOG) fprintf(FP.LOG, "Starting unit 0x%02X 0x%02X 0x%02X... ”,
cp->board, cp->chip, unit);
cp->region[unit] = k; 5
/* LOAD UP THE KEY REGION AND LET ’ER RIP... */
SetRegister(cp->board, cp->chip, REG.SEARCH_KEY(unit)+6,
(unsigned char)((k » 16) & OxFF));
SetRegister(cp->board, cp->chip, REG_SEARCH_KEY(unit)+5.
(unsigned char)((k » 8) & OxFF));
SetRegister(cp->board, cp->chip, REG_SEARCH.KEY(unit)+4,
(unsigned char)(k & OxFF));
SetRegister(cp->board, cp->chip, REG_SEARCH_KEY(unit)+3,. 0);
SetRegister(cp->board, cp->chip, REG_SEARCH_KEY(unit)+2, 0);
SetRegister(cp->board, cp->chip, REG_SEARCH_KEY(unit)+1, 0);
SetRegister(cp->board, cp->chip, REG_SEARCH_KEY(unit)+O, 0);
SetRegister(cp->board, cp->chip, REG.SEARCH.STATUS(unit), 1); /* GO! */
/* READ OUT THE KEY COUNTER (3 BYTES) FOR OVERFLOW SENSING */
к = GetUnitKeyCounter(cp->board, cp->chip, unit);
cp->overFlow[unit] = k;
cp->lastDone[unit] = k;
if (’QUIET) printf(”Region=0x%061X, overFlow=0x%061X\n",
cp->region[unit], k);
if (FP.LOG) fprintf(FP_LOG, ”Region=0x%061X, overFlow=0x%061X\n”,
cp->region[unit], k);
}
}
}
/*
* Read the value of a rapidly-incrementing key counter register.
* The function reads the register twice, finds the most-significant
* bit that changed during the operation, and returns the later
* (higher) value with all bits to the right of the one that changed
Глава 5. Дешифрованиесовременных шифров
* set to zero. 7 ‘ , -
* The return value is the top 24 bits of the low 32 bits^ of the
* key counter -- i.e., key bytes (MSB).......XX XX XX ..(LSB)
♦/
long GetUnitKeyCounter(int board, int chip, int unit) {
long v1, v2, m; , . v
dO { ' Ъ, '
v1 = ((long)GetRegister(board, chip, REG_SEARCH_KEY(unit)+3)) « 16;
v1 |= ((long)GetRegister(board, chip, REG_SEARCH_KEY(unit)+2)) « 8;
v1 |= ((long)GetRegi^ter(board, chip, REG_SEARCH_KEY(uni't)+T)); '
v2 = ((long)GetRegister(board, Qhlp/^EG.SEARCH^By^unitJ+SJJ-X^p^ .. .
v2 |= ((long)GetRegister(board, c^ipb0pEG_S^ABCOEY(unlt)+2))Л<^8; i;
v2 |= ((long)GetRegister(,board, chip, REG^SEARCH^KEYC,unital))?pjrr,
} while (v1 > v2);
for (m = 0x800000L; m != 0; m »= 1) {
if ((v1 & m) != (v2 & m)) {
v2 = (v2 & (OxFFFFFFL - m + 1));
break;
} /7:, /
return (v2); ' " > ' :
}
» • j ' ? . ? '
/* j. "<j'
* Get the key out of a halted unit and print it to the screen/logsr1
* /
void CheckAndPrintKey(CHIP_CTX *cp, SEARCH.CTX *ctx, int Unit*) { :
unsigned char key[7]; '• '
unsigned char binKey[56]; > ; r э ‘н 7
char buf[ 128]; 7' -7 '
int i,j, goodKey; "<< t 1
for (i = 0; i < 7; i++)' . , 1 ‘ s ' <> , * , •:
key[i] = (unsigned char)GetRegister(cp->board, cp->chip, . „
REG_SEARCH_KEY(unit)+i);
if (--(key[0J) == OxFF) /* Decrement key */
if (—(key[1]) == OxFF)
if (--(key[2J) == OxFF)
--key[3];
for (i = 0; i < 56; i++) . • *7 ' <> • ;
binKey[i] = (key[i/8] » (i&7)) & 1;
for (i = 7; i >= 0; i--) {
j = binKey[i*7]*2 + binKey[i*7+1]*4 + binKey[i*7+2]*8 + binKey[i.^7+3]*16 +
binKey[i*7+4]*32 + binKey[i*7+5]*64 + binKey[i*7+6]*128;
sprintf(buf+14-2*i, ”%02X”, j);
} ‘ 'л' . 7 •'! 7 - ’ ,7: *
if (QUIET) . >, ;x . -17 v •• Г 7
printf(’’Halt in %02X.%02X.%02X, K=%s P=”, cp->board, cp->chip, unit, bufj;
else { t.. 7 > i •
printf("BOARD 0x%02X, CHIP 0x%02X, UNIT 0x%02X' HALTED!\n ’ K56'= V
cp->board, cp->chip, unit); ‘
Глава 5. Дешифрование,современнее шцфров ,1:69
for (i = 6; i >= 0; i—) printf("%02X", key[i]);
printf(”\n K64 = %s\n", buf); , , - ,
}
if (FP.LOG) {
fprintf(FP.LOG, ”Halt@ %02X.%02X.%02X, K=",
cp->board, cp->chip, unit); ' ' -
for (i = 6; i >= 0; i-) fprintf(FP_LOG, "%02X", key[i]); ’ '
if (VERBOSE) fprintf(FP.LOG, ". K64=%s", buf);
) 1 ‘ " J'’ л' ' , '
goodKey = CheckKey(binKey< c^x);.-^ ., -,,1. r. ..1; ,/* prints plaintexts,.*/ , Г/
if (QUIET) printf{gobd^P?4,l(JGkF)i\fi:::’:' "-(B&)\n-')'; ' ' - ;v
else printf(" 8*<'***gdodKey'7? OKAY ""BAD"');' • •'
if (FP.LOG) fprintf(FP_C0G? :()доёкё!у:'?'1‘' (=0К!‘)\п"” >f=BAD)\n“); ' ' '
fflush(stdout);
if (FP.LOG) fflush(FP.LOG);
}
/* )rl-
* If needed, this function can be used to decide whether keys are
* actually good or not to reject false positives.
* Returns 1 if the key is not bad, zero if it is wrong.
*/
int CheckKey(unsigned char key[56], SEARCH.CTX *ctx) {
bool ctxt[64],ptxt0[64],ptxt1[64];
unsigned char p0[8]ip1[8]; - » - -
int i,c;
/* Compute the plaintext QDd try to print' it to-the screen */(! . ' - *•
for (i =0; i < 64; i++)
ctxt[i] = (ctx->ciphertext0[i/8] » (i&7)) & 1; ,. i f ,
DecryptDES((bool*)key, ptxtO, ctxt, 0);
for (i = 0; i < 8; i++) {
pO[i] = (unsigned char)(ptxt0[i*8+0]+ptxt0[i*8+1]*2+ptxt0[i*8+2]*4+
ptxt0[i*8+3]*8+ptxt0[i*8+4]*16+ptxt0[i*8+5]*32+ptxt0[i*8+6]*64+
ptxt0[i*8+7]*128); • • ( ; .
>
for (i = 0; i < 8; i++);
pO[i] ~= ctx->plaintextXorMask[i];
if (!QUIET) {
printf(” PlaintextO =”);
for (i = 7; i>=0; i--) printf(” %02X*‘, p0[i]);
printf(” (V ”’); ' < '
for (i = 7; i>=0; i--)
printf(”%c-,(pO[i] <32)??:p0[i])i . .
printfC’\”)\n”); . : ' ’ . > -(c; > Jn.
} j; < ч * ~
if (QUIET) for (i = 7; i>=0; i-) printf(”%02X”, pO[i]);
if (FP.LOG) fprintf(FP.LOG, ", ptxt=");
if (FP.LOG) for (i = 7; i>=0; .i-) fprintf(FP.LOG, "%02X", pO[i]); :Г
•' r ' . и*'* ‘.p .L'v.-K-uo , Л-'/' r^::: , , = ’ ' ’ ..
for (i = 0; i < 64; i++)
ctxt[i] = (ctx^ciphertextlti/?]»»^^)) & 1; . , . . (
DecryptDES((bool*)key, ptxtl, ctxt. 0);
170
Гпава 5. Дешифрование современных шифров
for (i = 0; i < 8; i++) L
p1[i] = (unsigned char)(ptxt1[i*8+0]+ptxt1[i*8+1]*2+ptxt1[i*8+2]*4+
ptxt1[i*8+3]*8+ptxt1[i*,8+4]*16+ptxt1[i*8+5]*32+ptxt1[i*8+6]*64+
ptxt1[i*8+7]*l28);
}
if (ctx->searchlnfo & 1) { /* if CBC mode, XOR w/ 1st ctxt */
for (i = 0; i < 8; i++)
p1[i] "= ctx->ciphertextO[i];
} ,
if (’QUIET) printf(" Plaintextl
if(оШеТ)'' printf (V");
if(FPJiOG) fprintf(FP.LOG, s . .
if;(I,QUIET) for (i.= 7; i>=0; i-) printf(" %02X", p1[ij); . <.
if (QUIET), for (i = 7; i>=0; i—) printf("%02X", p1[i]).; ( :
if (FP.LOG) for (i = 7; i>=0; 1-) fprintf(FP_LOG, ”%02X", p1[ij):
if (!QUIET) (
printfC' (\ ••);
for (i =: 7: i>=0; i—)
printf("%c", (p1[i] < 32) ? •?• : p1[ij);
printf("\")\n”);
>
/* Reject key if doesn’t contain good characters */
for(i =0; i < 8;i++) {
if (((ctx->plaintextByteMask) » i) & 1)
continue;
c = pO[i];
if (((ctx->plaintextVector[c/8] » (c & 7)) & 1) == 0)
, return (0);
c = p1[i];
if (((ctx->plaintextVector[c/8] » (c & 7)) & 1) == 0)
, return (0);г >
}
return (1);
:
Кроме метода определения, подходит ключ для дальнейшего исследования или
нет, интересной особенностью чипа является также то, как он выбирает следую-
щий ключ для опробования. Вместо простого инкрементирования на единицу теку-
щего значения ключа для ускорения работы аппаратного сумматора используется
не 48-бйтовое cлoжeниej а 32-битовое. Таким образом, старшие 24 бита в чипе все-
гда остаются постоянными. При ротации двух с половиной миллионов ключей в се-
кунду чип переберет весь этот сектор пространства подключей за 1717 секунд (что
приблизительно составляет полчаса времени). После этого главный компьютер
остановит'чип, отведет для него новый сектор перебора и снова запустит.
• Для этого чип предоставляет упрощенный аппаратный интерфейс, позволяю-
щий остановить его, опросить его или передать ему данные, а также снова ’запус-
тить. Плата с 24 чипами способна перебрать 60 миллионов ключей в секунду. Пе-
ребор всего пространства для одной такой платы займет около 40 лет. Поэтому в
комплексе их было использовано 64 штуки. Все вместе они и осуществили тота-
льное опробование всего за трое Суток.
Гпава 5. Дешифрование современны* шифров ‘171
Криптографические тесты AES
Linear cryptanalysis and differential cryptanalysis are the most
important methods of attack against block ciphers. Their effici-
ency have been demonstrated against several ciphers, inclu-
ding the Data Encryption Standard.
S. Vaudenay.
An Experiment on DES Statistical Cryptanalysis
В 1997 году Национальный институт стандартизации и технологий США ини-
циировал процесс рассмотрения кандидатов на роль нового национального стан-
дарта шифрования — передового стандарта шифрования (Advanced Encryption
Standard, или AES), предназначенного для обеспечения конфиденциальности све-
дений, не содержащих государственную тайну. Годом позже к рассмотрению
были приняты пятнадцать кандидатов — блочные симметричные шифры, разрабо-
танные в соответствии с требованиями НИСТ, указанными в первом сообщении о
предстоящем конкурсе. Минимальные требования института заключались в сле-
дующем:
• шифр должен быть опубликован в открытой печати;
• шифр должен быть симметричным блочным шифром;
• шифр должен быть разработан так, чтобы при необходимости длину ключа
можно было увеличить;
• новый шифр должен допускать эффективную аппаратную и программную
реализацию;
• шифр должен быть бесплатным, то есть либо незапатентованным, либо с
аннулированными патентными правами.
Первоначальный анализ кандидатов распределил все поданные на рассмотре-
ние шифры на классы используемых архитектур:
• сеть Файстеля использовали шесть шифров: DEAL, DFC, Е2, LOKI97, MA-
GENTA, RC6, Twofish;
• расширенную сеть Файстеля еще два: CAST-256, MARS;
• на базе архитектуры SP-сети построены два шифра: SAFER+, Serpent;
• архитектуру SQUARE использовали два шифра: CRYPTON, Rijndael;
и остальные два организовали как. бы отдельную группу (поскольку в;них
присутствовали достаточно экзотические преобразования).
Критерии, по которым оценивались претенденты на роль нового алгоритма за-
щиты конфиденциальной информации, были разделены на три главные составля-
ющие: безопасность, цену и эффективность реализации. Безопасность шифра, по-
нятное дело* является наиважнейщим параметром. Тем не менее члены комитета
НИСТ,умудрились принять в качестве стандарта самый слабый по отношению к
криптоанализу шифр из пятерки, финалистов первого этапа. Но речь не об этом.
Для,оценки стойкости, шифра использовались несколько критериев — ведь,
по, существу, очень сложно сказать, действительно ли ц£ифр стойкий или просто
никто из оценивающих его экспертов не заметил очевидной ошибки в теоретиче-
/
^172 ., Глава 5, Дешифрование современных, шифров
(Ских выкладках авторов. Для <того чтобы избегать подобных ошибок, во-первых,
,щифр обычно тестируется многими экспертами, что позволяет существенно сни-
зить действие «человеческого фактора», а во-вторых, дрцолнительно применяют-
ся, методы, результаты которых являются с этой точки зрения объективными, на-
пример, статистический анализ выхода шифра с целью определения, насколько
действие шифра на текст «похоже», на действие случайного процесса.
, .По этой причине, помимо оценки использованной математической базы и тес-
уов.на стойкость к уже известным способам криптоанализа, особое внимание уде-
лялось именно статистическим ^ёстам. Для этого использовался специальный на-
бор, (battery-pack) статистических тестов, рёалйзб^анныи групйой разработчиков
из НЙСТ. Соответственно проводимые иёслёдОва^йЙ! WJiH й{Шзвёны определить
уровень статистической безопаснЗЬтыка^йНбго'й’з’ЙЙфрЬй.0” г
Собственно^ комитет НИСТ требовал выбора шйфра, стойкого к атакам, реа-
лизованным на основе: >
у' ;• аппроксимации дифференциальных характеристик и метода расширения
j разностного криптоанализа;-ь •. ,
- • атаки с использованием-связанных ключей;
• атаки с использованием неисправностей оборудования;
; '• интерполяционных атак; ;-<•- ’ ' ' ' • '
• поиска так называемых- «черных ходов» — функций с секретом (недеклари-
руёмыми возможностями вычислений); - ' * '
Их анализ возможно проводить с двух позиций — позиций статистического
анализа поведения функции Шифрованйя и позйции теорий сложности, базирую-
щейся на анализе1 программных автоматов., '
’ Тестирование шифров кактенераторОйпсевдОслучайныхчисел (ГПСЧ) пред-
’ сбавляет собой в основном статистический пОдхОД.'И’именно он был’йспользован
в НИСТ. В 1994 году был даШёпредпринят/навёрное,-первый в мйре' шаг к стан-
дартизации набора статистичёскйх- тестов'-путем Принятия'национального стан-
" дарта «Требования безопасности к криптографическим модулям». Правда, требо-
вания и методика, описанные в с+андарте, носят больше общий, чем конкретный,
практичный характер. •‘ • । ! . 1 - ....1
В 1999 году разработчиками НИСТ в рамках опять же'проекта AES был пред-
ставлен статистйческий набор тестов НИСТ (NIST Statistical Test Suite) и пред-
ложена методика проведения статистического тестирования шифров'и генерато-
ров случайных чисел.
Для принятия1 решения, достаточно лй’случайна последовательность значе-
ний, вырабатываемая шифром или генератором псевдослучайных чисел,-исполь-
зуется несколько подходов:
,s'. ,5. ЙВНЭЬ’ГО T5RI’.SAb:in-‘ Д-У <•
> .и:*- первый И;самый простой-изних!^- это принятие: положительного'решения о
случайности выходашифра'В'зависимоетигот-заданного порогового уровня
i .> .(> случайности.-Для этого,вычисляют. специадьну{0 статистичеснуадларакте-
г. - ристику S(ao ... апУ отупосладцвательностц выхода,4 = (ао >м,Лл-) шифра и
-сравнивают ее с заранее, заготовленными эталонными значениями. При
Глава 5: Дешифрование coepeMeUUbix шифров . --7^3
этом считается, что двбичйая последовательность А'Не йрохбдит статисти-
ческий тест всякий раз, когда статистика теста S принимает значение'м'енв-
’ шее, чем пороговой уровень Srange_; ' ' • -
• следующий критерий — принятие решения на основе задания Доверитель-
ного интервала. В этом случае двоичная последовательность А не прЬХоДЙт
статистический тест, если значение статистики теста ЗнаходйТсявнёпрё-
делов доверительного интервала' знамений' статистики, вычисленного для
заданного уровня значимости а. Уровень1 значимости дп^едеЯяе'г’Стёй(ёйь
. , .. недостоведностй-jicx^^^ Ън^обычно рав(ен б’^б^йл^^^о^).
, ч „Критерий„^а'.осйр^е.^р^^льногр ирт'ё^вад.а\несрмненнр нам
надежен по'рравдрнр^,^ г' '
• еще один способ определения рещения заключается.в вычислении для не-
которой статистической функций S значенйя соответствующей ей и после-
довательности А вероятности Р. В этом случае статистика теста рассматрй-
вается как реализация случайной величины, которая-подчиняется опреде-
ленному закону распределения. Обычно статистическую функцию строят
таким образом, чтобы всплески ее значений указывали на наличие неслу-
чайных дефектов в представляемой на.рассмотрение случайной последова-
тельности чисел. Вероятность Р означает вероятность.тогр,,что. статистика
, примет значения большие, чем этоводмож-но.дл я.случайной последователь-
ности. Обратно, малые значения-этой, вероятности говорят., о .прохождении
последовательностью А тестов на случайность.
’ • 1 1 ' > \ - :> ч..ч.' н г. -
Пакет НИСТ СНТ включает в себя! 6, статистике,скихтестов,кс|торыеразра-
ботаны для проверки гипотезы о случайности предс.тавляемрй3двричнойцрсдедо-
вательности любой длины, Эта последовательность, обычно, получается либо за-
шифрованием произвольного открытого, текста, .(или набрррв.открытэдхг текстов),
либо в виде .выхода гаммы шифра, без учетд.щифруемых<данных;'еели э,то;розво-
ляет архитектура шифрующего алгоритма,.Все.тесты пакета налравлены нд .выяв-
ление дефектов в псевдослучайных последовательностях, приводящих-к .возмож-
ному угадыванию иди.прогнозированию части последовательности по’неррлным
данным о ней, ключе шифра и открытом тексте. ., , ... , ... ,..
1 Фактически после применения кдждогц из 1.6 тестов, вычисляется около двух-
сот различных значений.вероятности, каждое из которых рассматривается, кдкот-
. дельный, параметр, указывающий, на. степень случайности изучаемой последова-
тельности. . . )
,. Список всех статистических тестов, включает в себя,тесты, производимые как
на.битах, так и на группах битов: -. >п (. ;Л,Г‘д14Н
• частотный тест определяет отклонения кблийёст'ва встречаемых ;H$ie-
' .'.вых'и единичных битов;от сбалансированны» значенийХелиШко^м.него ну-
. > левых битов или-слишком тиного’1единичнь|х1битов)ьг1 *
'-’T?i ''1» ''лекилйзованный частотный /НёсМйёпЪлБзуёт (частотный тест1 на фикси-
; f.v р -рбванного размера блоках, йа!к6т6рые ’-разбйвается изучаемая -последова-
ч тельность (подсчитывайтСя локаЛьнЫё? характеристики сбалансированно-
174
Гпава 5. Дешифрование современных шифров
сти последовательности внутри блоков, то есть отклонения вероятности по-
k
явления единицы или нуля от абсолютного значения —);
• интегральные суммы определяют поведение последовательности в различ-
ных ее участках (больше нулевых битов или единичных в конце и начале
1 последовательности);
• проверка длин серий подсчитывает серии битов по всей последовательно-
сти (таким образом обычно определяется смена знака при генерировании
1 •"последовательности);
• 'максималькая длина серий в блоке аналогична локализованному частот-
ному тесту, поскольку осуществляет проверку длин серий в блоках фикси-
рованного размера, на которые разбивается исследуемая двоичная последо-
вательность;
• .вычисление ранга матрицы значений последовательности определяет
.. наличие линейных .структур в последовательности. Для этого последовате-
льности разбивают на блоки фиксированной длины и для каждого блока за-
полняют двоичную матрицу его элементами (вычисление ранга указывает
на линейную зависимость подстрок в последовательности);
• спектральный тест по Дискретному Преобразованию Фурье позволяет
. определить периодические составляющие в двоичной последовательности
(повторяющиеся элементы в последовательности и слишком часто появля-
ющиеся шаблоны и элементы, в том числе подвергаются анализу с помо-
щью этого теста);
• поиск неперекрывающихся шаблонов позволяет с помощью поиска зара-
нее заготовленных щаблонов определять последовательности со слишком
большим количеством апериодичных подпоследовательностей;
. • поиск перекрывающихся шаблонов отличается от предыдущего теста то-
: лько тем, что после того, как обнаружено совпадение текущего значения в
.m-битовом окне последовательности с заготовленным шаблоном, окно сдви-
гается не на m бит, а всего лишь на один, то есть поиск продолжается с пе*
.и рекрытием только что найденного шаблона;
. • универсальный тест Маурера позволяет определить возможную степень
сжатия последовательности с помощью вычисления логарифма расстояния
между блоками фиксированного размера по всей последовательности;
• сжатие по принципу алгоритма LZW (сжатие с адресацией в переме-
щаемое окно) позволяет определить количество непересекающихся под-
последовательностей в изучаемой последовательности, при этом, чем
• ' : «хуже» случайность последовательности, тем большей степени сжатия уда-
1 ется- добиться; >
• энтропийный тест позволяет определить различия между наблюдаемыми
1 значениями энтропии последовательности и теоретическими значениями
исследуемого источника;
• линейная сложность позволяет определить отклонение эмпирического
; распределения длин подпоследовательностей от теоретического распреде-;
ления для совершенно случайной последовательности, что, вообще говоря;
Гпава 5. Дешифрование современных шифров
175
указывает на сложность тестируемой последовательности (линейная слож-
ность представляет собой меру согласования появления двоичных строк
фиксированной длины в эквивалентном генераторе для заданного блока с
теоретически ожидаемым);
• последовательный тест представляет собой меру различия количества
встречаемости m-битовых подстрок в последовательности с теоретически
ожидаемым значением (данный тест, выявляет неравномерность распреде-
ления m-битовых слов в исследуемой последовательности);
• проверка случайных отклонений и ее дубль-вариант позволяет подсчи-
тывать количество одинаковых появлений подпоследовательностей, при
. случайном .блуждании пр последовательности интегральных сумм. ,,
Все описанное тесты представляют собой независимые функциональные мо-
дули, занимающие каждый свое отдельное место в архитектуре набора тестов.
Каждый из кандидатов на место AES был протестирован также и с помощью*дан-
ных тестов. Остается только добавить, что первый этап рассмбтрения шифров
закончился выбором пяти финалистов и разговорами’б том, что, возможно, не
будет единого шифра, являющегося национальным стандартом, а вместо него в
роли стандарта будут выступать сразу несколько шифров, что называется, на все
случаи жизни. Впрочем, все эти разговоры так слухами и остались — в конце
второго этапа остался только один финалист. Новым национальным стандартом
шифрования в США стал шифр Rijndael, авторы которого создали архитектуру
SQUARE.
1 • 1
Применение генетических алгоритмов
Идея, заложенная в основу алгоритма Якобсена (см. раздел «Быстрое раскры-
тие шифров простой замены»), позволяет использовать его метод не только для
раскрытия шифров замены, но и для дешифрования других простых шифров. Ме-
няются лишь критерии и функция оценки корреляции рабочего ключа с настоя-
щим. Это свойство позволяет распространить мдею алгоритма, в том числе и на
композиционные шифры, и даже на еще более конструктивно сложные криптоси-
стемы. Правда, чем сложнее шифр, тем меньше эффективность применения по-
добных методов, но все же иногда они дают неплохие результаты.
Ярким примером применения общей идеи подобных алгоритмов и современ-
ных технологий создания искусственного интеллекта является метод криптоана-
лиза с помощью генетических алгоритмов.
, Генетические алгоритмы представляют собой семейство эвристических алго-
ритмов, то есть алгоритмов, которые не гарантируют предоставление решения
поставленной задачи; Присутствие, генетики в названии данного семейства обу-
словлено применением тех законов генетики и моделирования-эволюционных
процессов. и, . = -
, В процессе решения задачи.генетический-алгоритм ведет себя так же,«как
вели бы себя живые организмы в процессе эволюции. Потенциальное решение
представляется каким-либо образом в качестве-некоторой структуры — особи.
176
Гпава 5. Дешифрование современных шифров
Каждая особь однозначно характеризуется набором ее хромосом — уникальной
характеристикой, позволяющей учесть свойства конкретной особи в процессе
эволюции.
Множество хромосом объединяют в популяцию, с которым алгоритм осуще-
ствляет различные операции. В понятие операции входят рекомбинация, селек-
ция и мутация особей. Суть рекомбинации заключается в составлении хромосом
новых особей из хромосом родительских особей в уже существующей популяции.
Наиболее популярным методом рекомбинации является кросс-овер (cross-over),
заключающийся в разбиении хромосом родителей (их число не обязательно равно
двум) на некоторое количество равных частей. Из них затем составляются.хромо-
сомы потомков.
Мутация особи представляет собой случайное изменение хромосом особей
популяции. Целью мутации является необходимость оградить алгоритм от разви-
тия в тупиковые ветви эволюции, постоянно вносить некоторый несущественный
элемент неопределенности. Вероятность мутации для этого должна быть доста-
точно малой, чтобы не допустить случайного изменения всего генофонда. Такая
организация приблизительно соответствует действию существующего в природе
уровня фоновой радиации, в результате действия которой появляются виды, бо-
лее приспособленные к выживанию.
Приспособленность оценивается количественно с помощью некоторого чис-
лового показателя. Функцию, определяющую, насколько приспособляема та или
иная особь, называют целевой функцией (fitness function). ,
Селекция же описывает способ заполнения данных о популяции очередного
поколения из большого числа родителей. Селекция выполняется в соответствии с
некоторой оценкой и пороговым значением для нее для каждой хромосомы. При-
мером селекции является селекция «турнирным отбором» (tournament selecti-
on), когда из всего множества родителей случайно выбираются две особи, оцени-
ваются и, в популяцию новых потомков помещается хромосома, имеющая лучшую
оценку. Еще один часто используемый метод заключается в использовании «ру-
летки» (roulette-wheel selection). Метод.рулетки отбирает особей с помощью за-
пуска воображаемой рулетки. Колесо рулетки содержит по одному сектору для
каждого, члена популяции. Размер каждого сектора пропорционален приспособ-
ленности особи к выживанию. При таком отборе члены популяции с более высо-
кой, приспособленностью с большей вероятностью будут чаще выбираться, чем
особи с низкой приспособленностью..
Надо отметить, что в генетических алгоритмах численность популяции обыч-
но сохраняется равной определенной наперед заданной константе. Это позволяет
отбирать;каждый раз лучшие особи и одновременно не приводит к отклонениям
эволюции и тупиковым ветвям; развития,
Весь генетический алгоритм состоит из следующих компонент:
• представление хромосом;
• начальная популяция (стартовый, набор хромосом); ,
, « набор операторов для генерации новых решений из предыдущей популяции;
• целевая функция для оцёнки. приспособленности (fitness) решений. (
Глава 5. Дешифрование современных шифров
>- Исходя из этого списка, сразу становится видна аналогия С. алгоритмом рас-
крытия классических’шифров Якобсена: присутствуют целевая-функция, приме-
нение различных операторов над данными (в алгоритме Якобсена — ключом), а
также свойство итеративности. Оба алгоритма осуществляют поиск решения ите-
рация.за итерацией, но без уверенности в том, что оно вообще будет найдено: Ге*
нетические алгоритмы можно считать обобщенным вариантом предложенных
Якобсеном методов нахождения ключа (пример* работы классического генетиче-
ского алгоритма см. в листинге 5.4). . ; uv. U
‘ \ * * '!С* >(-*• J -
Листинг 5,4, t>TSC, ; гл ь;,/ни . /Ич.ап ст, -
1. Создать начальную популяцию.
^‘ОцёйитЬ ;приспос6блеЯнос"гУ каждой’ особи: ' ' ' ' ‘л"’’ ’
Эл Выбрать две особи с высокой приспособленностью (селекцйя). ; и ьт
4 . Скрестить выбранные-особи Jn получить двух потомков'(-рекомбин'ацйя).' ' '* ‘ г ’
5. .Изменение хромосом, потомков (мутация).. . о , ••
6, • Оценить приспособленности потомков., . . > , с > > лг1 .л
7. Поместить потомков в .новое поколение» . » > . - • , », . у ,. ,g. ;/ ' /; •
8. Переходим к шагу 2. v j . ,г
Условие выхода? ... , , v
Как видно из листинга 5.4, построение алгоритма начинается с-заполнения
(возможно, случайного) некоторой-популяции родителей'. Затем в цикле с помо-
щью различных операций над особями получается некоторое множество потом-
ков, из которых в соответствии с целевой функцией оператор селекции'составит
затем новую популяцию родителей,;и.т. д.!,’- , . 1 * * * 5 6 7 8 <
. Смена поколений в цикле происходит до тех пор, пока характеристики'особей
в текущем поколении' не станут удовлетворять всем, поставленным- требованиям.1
Несмотря на эвристический)подход’к поиску, решения; с-помощью генетических
алгоритмов оказалось вполне возможно достаточно успешно'раскрывать класси-
ческие, шифры и существенно уменьшать пространство перебора: ключей в'Неко»
торых-современных блочных .шифросистемах/. ><:, ' j, I .. ' ^г.
Посмотрим на генетические алгоритмы как на реализующие возможность
применения эволюционных алгоритмов к задаче нахождения секретного ключа':
Представим криптоанализ как задачу* эволюционного развития, формируюТцёРО
искомый открытый текст или ключ пог шифротексту. Теоретически, таким: обра-
зом, мы сводим задачу криптоанализа к задаче многомерной оптимизации, гДё гё-'
нетические. алгоритмы зарекомендовали себя, на сегодняшний день очень хорошо.
Основные трудности в описании1 задачи: криптоанализа терминами методов
оптимизации и конкретно генетического подхода-заключаются в проблеме выбора
способа кодирования особей популяции, 'определении1целевой:функции,'’построе-
нии основных операций изменения-.хромосомюообей.'Для каждого; конкретного
алгоритма шифрования и задачи криптоанализа решение этих вопросов, возмож-
но, будет уникальным. / О)!-.ГИ’Яь!
Обратимся к вполне’'К'бнкрётйоМ'у призёру' — ' задаче раскрытия ключа
ГОСТ-пОдобного шифра С’ архитектурой’ сети Файстеля. Операцию' Шифрования
представим'классически с помощью преобразований’£('л)» В'качестве'особи itony-
178
Гпава 5. Дешифрование современных шифров
ляции W в этом случае может выступать произвольное значение ключа k. В таком
случае, когда алгоритм предоставит наиболее приближенную к. поставленным
требованиям особь, это даст нам решение криптосистемы в виде секретного (или
приближенного) ключа. Если особей претендентов будет несколько — их можно
будет последовательно перебрать.
Допустим, в руки к нам попало несколько пар (Р*, С*), где Р/ — это откры-
тые, а С* — соответствующие ему зашифрованные тексты, которые были получе-
ны при помощи неизвестного нам ключа К. Зашифровав теперь открытый текст
с произвольным ключом W:, получим шифротекст C*r = E(P’,k).
, Очевидно, , что для задания целевой функции нам. не , хватает совсем немно-
го — количественной меры, которая позволила бы нам говорить-о сходстве и раз-
личии особей-ключей. В классической и современной криптографии и теории ко-
дирования роль такой меры обычно играет расстояние Хэмминга. Воспользуемся
его определением и создадим целевую функцию F(k) как результат измерения
Хэммингова расстояния между двумя зашифрованными на разных ключах — ра-
бочем kj и искомом k*'.
F(k,, k') = 256-Ham(Cki,C'),
где С* — шифротекст, который подвергается криптоанализу.
К сожалению, если задать целевую функцию именно так, то решение задачи
криптоанализа вряд ли будет достигнуто в допустимые сроки, даже для алгоритма
средней сложности. Дело в известном свойстве лавинного эффекта, когда один
измененный бит ключа изменит в равной степени весь блок С*. Локализовать в
данном случае особей, которые ближе всего находятся к настоящему ключу,
очень сложно.
Более эффективным вариантом может стать сравнение с участком открытого
текста либо сравнение таких характеристик текста, как, например, частоты сим-
волов, биграмм, триграмм и т. д. Именно так происходит в алгоритме Якобсена,
когда сравнивается расстояние между матрицами вычисленных диграмм.
После определения целевой функции необходимо выбрать основные операто-
ры образования особей. Для начала из текущей популяции отбираются наиболее
близкие к искомым ключи. Сделать это можно самым простым пропорциональ-
ным методом — методом рулетки. После этого можно провести рекомбинацию
методом одноточечного или двухточечного кросс-овера. В одноточечном варианте
части ключа разбиваются на сегменты по выбранной наугад точке разрыва; а за-
тем из них составляется новая особь. В двухточечном кросс-овере выбираются
две точки разрыва, в родительских ключи обмениваются сегментом, который на-
ходится между двумя , этими точками. Но наиболее подходящим к , рассматривае-
мой задаче является скорее так называемый равномерный или универсальны#
кросс-овер. В нем каждый бит одной из особей наследуется первым потомком с
заданной заранее вероятностью, в противном случае этот бит передается второму,
потомку. Его преимущество заключается в независимом подходе к каждому биту
ключа, что определяет эффективный поиск глобального оптимума с учетом задан-
ной выше целевой функции. !
Глава 5. Дешифрование современных шифров
179
Для предотвращения преждевременного вымирания популяции она обновля-
ется особями, которые имеют оценку, значительно превышающую среднюю по по-
пуляции.
Дополнительно можно провести поиск с локальной оптимизацией и на выхо-
де оператора рекомбинации провести осмотр небольшой окрестности возле полу-
ченной особи, выявляя лучшую особь. Локальная оптимизация обычно увеличи-
вает скорость сходимости алгоритма к решению.
К сожалению, все алгоритмы, подобные генетическим, имеют существенные
недостатки, обусловленные их устройством. Во-первых, при их выполнении не су-
ществует гарантии, что решение вообще будет найдено. Во-вторых, если сущест-
вует множество решений, то найдено будет всегда только одно. Причем о нем (в
самом простом случае, например, какое именно это будет решение) заранее ска-
зать невозможно ничего — все зависит от случайного выбора начальных значе-
ний для переменных алгоритма. В-третьих, при не очень удачном выборе целевых
функций может появиться большое множество решений, близких по изучаемым
характеристикам к верным, но таковыми не являющимся. По сути говоря, алго-
ритм может ввести нас в заблуждение, отработав не одну сотню итераций, но так
и не предоставив никакого результата.
Список литературы
1. D. Bahler and J. King. An implementation of probabilistic relaxation in the crypta-
nalysis of simple substitution systems. Cryptologia, 16(2), 1992.
2. R. Spillman. Cryptanalysis of knapsack ciphers using genetic algorithms. Cryptolo-
gia, 17(1), 1993.
3. С. M. Adams, On immunity against Biham and Shamir's «differential crypta-
nalysis», In-formation Processing Letters, vol.41, Feb. 14, 1992, pp. 77—80.
4. С. M. Adams, A Formal and Practical Design Procedure for Substitution Per-
mutation Network Cryptosystems, Ph.D. Thesis, Department of Electrical Engineering,
Queen's University, 1990.
5. С. M. Adams and S. E. Tavares, Generating and Counting Binary Bent Sequen-
ces, IEEE Transactions on Information Theory, vol. IT-36, 1990, pp. 1170—1173..[4] C.
M. Adams and S. E. Tavares, The Use of Bent Sequences to Achieve Higher-Order
Strict Avalanche Criterion in S-Box Design, Technical Report TR 90-013, Dept, of Elect-
rical Engineering, Queen's University, Kingston, Ontario, Jan., 1990.
6. E. Biham, Differential Cryptanalysis of Iterated Cryptosystems, Ph.D. Thesis,
Weizmann Institute of Science, Rehovot, Israel, 1992.
7. E. Biham and A. Shamir, Differential Cryptanalysis of DES-Like Cryptosystems,
Journal of Cryptology, vol.4, 1991, pp. 3—72.
8. M. Dawson and S. E. Tavares, An Expanded Set of S-Box Design Criteria Based
on In-formation Theory and its Relation to Differential-Like Attacks, in Advances in
Cryptol-ogy: Proc, of Eurocrypt'91, Springer-Verlag, 1991, pp. 352—367.
9. H. Feistel, Cryptography and Computer Privacy, Scientific American, vol.228,
1973, pp. 15—23.
180 Гпава 5; Дешифрование современных шифры
10. Е. Grossman and В. Tuckerman, Analysts of a Feistel-Like Cipher Weakened by
Having No Rotating Key, Technical Report RC 6375, IBM, 1977.
11. J. B. Kam and G. 1. Davida, Structured Design of Substitution-Permutation En-
cryption Networks, IEEE Transactions on Computers, vol. C-28, 1979, pp. 747—753.
12. K. Nyberg, Constructions of bent functions and difference sets, in Advances in
Cryptol-ogy: Proc, of Eurocrypt '90, Springer-Verlag, 1991, pp. 151—160.
13. K. Nyberg, Perfect nonlinear S-boxes, in Advances in Cryptology: Proc, ol
Eurocrypt '91, Springer-Verlag, 1991, pp. 378—386.
'14 . K. Nyberg airid L.R.Knudsen,.Provable Security Against Differential Cryptana-
lysis, in Advances in Cryptology: Proc,' of CRYPTO '92 (to appear). „ .,
15. L. O'Connor, An Analysis of Product Ciphers Based on tfie-Properties of Boole-
an Func-tions, Ph.D. Thesis, Dept, of Computer Science, University of Waterloo, 1992.
. 16. Bl Preneel, W. Van Leekwijck, L. Van Linden, R. Govaerts, and. J. Vandewalle,
Propa-gation characteristics of boolean functions, in Advances in Cryptology: Proc. Of
Eurocrypt '90, Springer-Verlag, Berlin, 1991, pp. 161—173.
17. O. S. Rothaus, On «Bent» Functions, Journal of Combinatorial Theory, vol.
20(A), 1976, pp. 300—305. ' ,
18. С. E. Shannon, Communication Theory of Secrecy Systems, Bell Systems Tech-
nical Journal, vol. 28, 1949, pp.656—715.
19. M. Sivabalan, S. E. Tavares, and L. E. Peppard, On the Design of SP Networks
from an Information Theoretic Point of View, in Advances in Cryptology: Proc., of
CRYPTO'92.
20. A.. F. Webster, Plaintext/Ciphertext Bit Dependencies in Cryptographic Sys-
tems, M.Sc. hesis, Department of Electrical Engineering, Queen's University, 1985.
21. A. F. Webster and S. E. Tavares, On the Design of S-Boxes, in Advances in
Cryptology: roc. of CRYPTO'85, Springer-Verlag, New York, 1986, pp. 523—534.
22. R. Yarlagadda and J. E. Hershey, Analysis and Synthesis of Bent Sequences, IEE
Pro-ceedings (Part E), vol. 136, 1989, pp. 112—123.
23. С. M. Adams, Constructing Symmetric Ciphers Using the CAST Design Proce-
dure.
24. С. M. Adams, Designing DES-Like Ciphers with Guaranteed Resistance to
Differential and Linear Attacks, Workshop Record of the Workshop on Selected Areas in
Cryptography (SAC 95), May 18—19, 1995, pp. 133—144.
zo. С. M. Adams and S. E. Tavares, Generating and Counting Binary Bent Sequen-
ces, IEEE Transactions on Information Theory, vol. IT-36, 1990, pp. 1170—1173.
26. С. M. Adams and S. E. Tavares, The Use of Bent Sequences to Achieve Hig-
her-Order Strict AvdlancheCriterion in S-Box Design, Technical Report TR 90-013,
Dept, of Electrical Engineering, Queen's University, Kingston, Ontario, Jan., 1990.
27. E. Bi ham, On MatsUl's Linear Cryptanalysis, Advances in Cryptology — Proce-
edings of EUROCRYPT'94, Springer-Verlag, Berlin, 1995, pp. 341—355. ’ ‘ '
28. Ё. BlHam and A: Shamir/ Differential Cryptanalysis of DES-like Cryptosys-
tems, Advances in Cryptology: Proceedings of CRYPTO '90, Springer-Verlag, Berlin,
1991, pp. 1—21.
29. J. F. Dillon, A Survey of Bent Functions, NSA Technical Journal, Special lssue,
1972, pp. 191—215. > ’ ' ' ’ ’ !
.Глава 5. Дешифрование современных шифров 1.Q1
30. Н. Feistel, W. Notz, and J. L. Smith, Some Cryptographic Techniques for Mac-
hine-to-Machine DataCommunications, Proceedings of the IEEE, 63 (1975), pp.
1545—1554.
31. J. A. Maiorana, A Class of Bent Functions, R41 Technical Paper, June 1971.
32. S. Mister, Notes on Maiorana Functions and S-Box Design.
33. K. Nyberg, Perfect Nonlinear S-boxes. Advances in Cryptology — Proceedings
of EUROCRYPT '91, Springer-Verlag, Berlin, 1991, pp. 378—385.
34. B. Preneel, W. Van Leekwijck, L. Van Linden, R. Govaerts, and J. Vandewalle,
Propagation characteristics of boolean functions, Advances in Cryptology: Proceedings
of EUROCRYPT '90, Springer-V^fia^, Berlin, 1МГ, pp. 161—173.
35. O. S. Rothaus, On ‘Bent’ Functions, Journal of Combinatorial Theory, 20(A),
1976, pp. 300—305. ' ' " ‘ .
36. A. F. Webster and S. E. Tavares, On the Design of S-Boxes, Advances in Crypto-
logy: Proceedings of CRYPTO '85, Springer-Verlag, New York, 1986, pp. 523—534.
37. A. Youssef, S. Tavares, S. Mister, C. Adams, Linear Approximation of Injective
S-boxes, Electronics Letters, Vol. 31 No. 25, Dec. 7, 1995, pp. 2165—2166.
38. Д. Кнут. Искусство программирования для ЭВМ. Получисленные алгоритмы.
Т.2. — М.: Мир, 1977. 700 с.
39. Н. П. Бусленко, Д. И. Голенко, И. М. СобЬль и др. Метод статистических ис
пытаний (Метод Монте-Карло). — М.: Физматгиз, 1962. 337 с.
40. Левитан Ю. Л., И. М. Соболь. О датчике псевдослучайный чисел для ПК, М.
тематическое моделирование. 1990. — Т. 2, №‘8. — С. 119 — 126.
41. А. В. Потий, А. К. Пестерев. Принципы системного подхода к сертификат
генераторов псевдослучайных чисел’в системах защиты информации/Радиотехни!
Всеукраинский межведомственнйй научно-технический, сб. 1997. Вып. 104.
163—172. • '
42. Security requirements for Cryptographic Modules; FIPS 140-1. — U.S. De'p;
ment of Commerse. 1994. ‘
43. J. Soto Randomness Testing of the Advanced Encryption Candidate Al:
rithms. — NIST, 1999. .
44. A. K. Leung, S. E. Tavares. Sequence Complexity as Test for Cryptographic S
terns. — Advances in Cryptology — CRYPTO'84. Proc. LNCS, Vol. 196 — Springer-^
lag. , '
45. Alfred Menezes, et. al. Handbook af Applied Cryptography — CRC Press, 199
46. M. Abramowitz and I. Stegun, Handbook of Mathematical Functions, App>
Mathematics Series. Vol. 55, Washington: National Bureau of Standards, 1964; reprin •
1968 by Dover Publications, New York.
47. T. Cormen, C. Leiserson, & R. Rivest, Introduction to Algorithms. Cambrid;
MA:The MIT.Press, 1990. . в ;
, 48. Gustafson et al., <<A computer, package for. measuring strength of encryption al
rithms,» Journal of Computers & Security. Vol. -13,- No, 8, 1994, pp.: 687^697.
49. U. Maurer, «А Universal Statistic,atTestlor Randorp Bit Generators», ;Joyrnal
Cryptology. Vol.,5., No. 2, 19^2, рр.;89—16^. , . , , , .
50. A. Menezes, et al., Handbook of Applied Cryptography. CRC Press, Inc., 199
,. , 51. W. Press, S. Teukolsky, W. Vetterling, Numerical Recipes in C : The Art of Sc»
tific Computing, 2nd Edition. Cambridge University Press, January 199"
182
Глава 5. Дешифрование современных шифров
52. Т. Ritter, «Randomness Tests and Related Topics», http://www.io.com/~rit-
ter/
53. American National Standards Institute: Financial Institution Key Management
(Wholesale), American Bankers Association, ANSI X9.17 — 1985 (Reaffirmed 1991).
54. FIPS 140-1, Security Requirements for Cryptographic Modules, Federal Informa-
tion Processing Standards Publication 140-1. U.S. Department of Commerce/NIST, Nati-
onal Technical Information Service, Springfield, VA, 1994.
55. FIPS 180-1, Secure Hash Standard, Federal Information Processing Standards
Publication 180-1. U.S. Department of Commerce/NIST, National Technical Information
Service, Springfield, VA, April 17, 1995.
56. FIPS 186, Digital Signature Standard (DSS), Federal Information Processing
Standards Publication 186. U.S. Department of Commerce/NIST, National Technical In-
formation Service, Springfield, VA, May 19, 1994.
Глава 6
Криптографическое сжатие
In most on-line retrieval systems, large files which are stored in
secondary memory are frequently accessed. These files should
be stored in compacted form, not only to save space, but also
to reduce the respouse-time.
Y. Choueka
В реальной жизни многие задачи не являются столь тривиальными, как, на-
пример, задача зашифрования одного файла. Очень часто требуется не только и
не столько зашифровать данные, сколько еще и сделать их хранение и передачу
как можно более эффективной. В программных приложениях активно использу-
ются алгоритмы сжатия, а периферийные устройства на аппаратном уровне под-
держивают работу методов обеспечения целостности хранимых и передаваемых
данных.
Поскольку речь в книге идет о программных задачах криптографии, невоз-
можно было пройти мимо такой темы, как взаимодействие сжатия и криптогра-
фии. На практике задача сжать и зашифровать файл решается обычно, что назы-
вается, «в лоб» — сначала данные сжимаются каким-нибудь известным способом
(например, LZW), а затем уже шифруются ГОСТ или другим блочным шифром.
Удачные алгоритмы сжатия (или, как еще говорят, компрессии) позволяют не
только эффективно хранить конфиденциальные данные, но и, например, значите-
льно уменьшить размер программы, которую за один прием можно загрузить в па-
мять и исполнить. Существует не меньше дюжины различных упаковщиков ис-
полнимых файлов. Некоторые из них содержат реализации алгоритмов шифрова-
ния с целью усложнить жизнь потенциальным хакерам. Но ни в одной из них
алгоритм шифрования никак не связан с алгоритмом сжатия. Они реализованы
как отдельные алгоритмы и используются раздельно.
Возможно, что раздельное существование алгоритмов сжатия и шифрования
связано с существованием своего рода конкуренции целей сжатия и зашифрова-
ния. Сжатие — это процесс устранения избыточности представления информа-
ции. Шифрование же, наоборот, стремится увеличить энтропию выходных дан-
ных с тем, чтобы криптоаналитик не имел возможности использовать статистиче-
ские зависимости шифротекста для проведения успешного криптоанализа. Тем не
менее может статься, что более удобным и практичным способом сжатия и за-
шифрования данных будет применение некоторого единого алгоритма, выполняю-
щего функции и зашифрования и сжатия одновременно. Его созданием мы и зай-
мемся.
Существует три способа организовать совместное сжатие и зашифрование
данных. Два из них различаются преимущественно тем, какой из алгоритмов —
сжатия или криптографического преобразования данных — применяется к дан-
ным первым, а какой вторым.
18,4
Глава 6. Криптографическое сжатие
,, >. Если сначала применять алгоритм криптографического преобразования дан-
ных, то окажется, что алгоритм сжатия не может эффективно работать на шифро-
текстах хороших криптоалгоритмов. Сжать шифротекст весьма тяжело по той
простой причине, что криптографическая система должна любыми доступными
способами избавлять.шифротекст от очевидных внутренних зависимостей, а по-
тому его энтропия будет весьма высокой и уж точно намного выше, чем у откры-
того текста. Представить себе алгоритм сжатия, который бы хорошо сжимал за-
шумленные данные, довольно тяжело. Ведь даже интуитивно понятно, что сжа-
тие,всецело базируется,на.избыточности информации е тексте. Шифрование эту
избыточность устраняет, а вместе с ней устраняет и возможность сжать текст.
Можно .попытаться, применить к данным сначала алгоритм сжатия,’ а. затем
уже зашифровать результат. Теоретически данный метод хорош, но на практике
оказывается, что многие алгоритмы сжатия чрезвычайно структурированы, что
позволяет применять некоторые криптоатаки даже там, где для открытого текста
их применение было бы попросту неоправданным и неэффективным.
Дополнительно отрицательным свойством такого способа является то, что
время применения обоих алгоритмов обычно довольно велико. Неплохо было бы
зашифровывать и сжимать текст одновременно. В этом случае мы могли бы кон-
структивно устранить структурированность выхода алгоритма и заметно сокра-
тить время обработки данных за счет одновременного убиения двух зайцев. Но
для этого нам понадобятся более точные знания о том, как работают алгоритмы
сжатия данных.
Алгоритмы сжатия данных
Сжимаемые данные могут называться по-разному — строка, файл, текст или
двоичные данные, или оцифрованный сигнал. С точки зрения теории предполага-
ется, что данные производятся источником и предоставляются компрессору в
виде символа над некоторым алфавитом. Раньше весь процесс сжатия называли
кодированием источника, поскольку оно призвано удалить избыточность в дан-
ных на основе их предсказуемости путем иного представления данных, то есть их
кодирования. За два последних десятилетия картина несколько изменилась. Пер-
вой ласточкой стала идея разделить процесс сжатия на два взаимосвязанных про-
цесса — кодирование, непосредственно воспроизводящее сжатый поток симво-
лов, и моделирование, предоставляющее всю необходимую для кодирования ин-
формацию.
Понятно, что, чем больше знает кодировщик, о данных, тем больше он сможет
их сжать. То есть чем лучше модель исходных данных, тем лучше справиться коди-
ровщик со своей задачей и тем лучше будет коэффициент сжатия; Сам коэффи-
циент сжатия выражает.отношение длины сжатого текста к длине исходного. В тер-
минах криптографии мы бы назвали исходный текст открытым, а сжатый — шифро-.
текстом. Для коэффициента сжатия можно использовать много разных величин
измерения. Правда, их разнообразие сильно затрудняет сравнение эксперимента:
льных результатов. Наилучшей с точки зрения теории, нашедшей применение на
Гпава 6. Криптографическое сжатие
1'85
практике, является величина, которая бы не зависела от представления входных
данных. Пожалуй, наиболее' удобным с этой точки зрения является измерение
бит/символ (бит на символ). Другие варианты, например, в виде процентов ежа*
тия или сокращения зависят от представления данных на входе кодировщика.
На сегодняшний день существуют сотни различных алгоритмов сжатия без
потерь с адаптивными и статическими моделями представления данных: Их. все
можно разбить на непересекающиеся классы или семейства по способу кодирова-
ния данных. Каждое семейство призвано сжать текст определенной структура d
определенной степенью эффективности и быстродействия, в-зависимости ЬТ'топь
что важнее в приложении — скорость или коэффициент-сжатия. '
Самые первые алгоритмы сжатия не учитывали в полной мере характеристик
текста и потому представляют' собой очень простые для реализации алгоритмы.
Таков, например, алгоритм RLE (Run Length Encoding), который еще называют
методом повторений и методом кодирования длин -тиражей, — это самый простой
и самый быстрый из методов упаковки информации. Эффективно работаетюн то-
лько в том случае, когда сжимаемый текст состоит из часто повторяющихся по-
следовательностей одного символа. Например, обычном тексте форматирование
абзацев зачастую выполняют добавлением- пробелов перед и между словами. На-
лицо. явная избыточность, которую можно устранить следующим- образом. Пер-
вым символом (обычно это стандартный восьмибитовый байт) сжатого текста ко?
дировщик записывает некоторый «флажок», обозначающий, что далее идет слу-
жебная информация, состоящая из двух символов. Понятно, что в теории этот
флажок не должен совпадать ни с одним из символов текста.
Следующим символом в служебной триаде кодировщик записывает количест-
во повторяемых символов, ;Ну и соответственно, третий символ — это экземпляр
того, что нужно повторить (рис. 6.1).
До сжатия (мы можем,сжать пять подряд идущих символов 0x14, записав их
всего тремя символами: OxFF 0x05 0x14, при этом нет смысла сжимать два симво-
ла 0x00 в самом начале)
0x00 I 0x00 I OxFO I 0x14 I 0x14 0x14 0x14 0x14 0x00 OxFO OxFF 0x56 0x67
После сжатия (дополнительно приходится указывать на наличие в исход-
ном тексте служебного символа OxFF)
0x00 | 0x00 | OxFO | OxFF 10x051 0x14 0x00 | OxFO OxFF 0x01 OxFF 0x56 0x67 |
Рис. 6.1. Структура кода RLE
На практике, поскольку в тексте Используются все символы и «свободных»,
символов попросту-нет, в качестве флажка используют какой-либо рёдко 'испбЛь-'
зуемый символ, например, в случае, когда символы представлены ббсьмибиТовьй
ми байтами; этим символом можно выбрать значение-OxFF, что мы, собственно
говоря, и сделали. В то же время в самом тексте в процессе сжатия Нам встретил-
ся OxFF. Оставив его без изменения, мы собьем с толку декодировщик, который
4
U
186 Гпава 6. Криптографическое сжатие
постарается разжать текст, используя следующие за ним два байта, на самом деле
не имеющие никакого отношения к служебной информации. Поэтому нам не
остается ничего другого, как закодировать его тремя байтами: OxFF, 0x01, OxFF
(см. рис. 6.1), чтобы избежать весьма неприятную ситуацию неправильного раз-
жатия текста. Потери информации, конечно, в исправленном нами варианте не
произойдет, но налицо явный промах алгоритма: вместо того чтобы сжимать
текст, он в итоге сделал его еще больше. Однако очевидно, что если в тексте име-
ется последовательность из более чем трех одинаковых символов, мы прекрасно
сможем ее сжать с помощью нашего простого алгоритма (кстати, его популяр-
ность довольно высока — например, он используется по умолчанию для сжатия
данных в карманных компьютерах Palm).
Даже неспециалисту ясно, что RLE не представляется оптимальным алгорит-
мом сжатия, поскольку он не использует никакой информации о сжимаемом тек-
сте. Чтобы понять, как происходит сжатие, использующее знания о тексте, вер-
немся к понятиям энтропии и информативности текста (см. раздел «Энтропия»).
Связь между вероятностями и кодами изучается в алгебраической теории кодиро-
вания, основной теорией которой является не кто иной, как Клод Элвуд Шеннон.
Его теоремы кодирования источника используются очень активно и здесь.
Поскольку источник генерирует различные символы неравновероятно и, сле-
довательно, одни символы появляются в тексте гораздо чаще других, кодировщик
должен научиться кодировать их так, чтобы более частым символам соответство-
вал меньший по длине код, а более редким — соответственно более длинный. Та-
ким образом, мы сжимаем форму представления текста, используя коды различ-
ной длины для различных символов.
Согласно изобретенным Шенноном основам теории информации, можно по-
лучить ожидаемую длину кода, взяв среднее значение вероятности появления
каждого символа, и мы тут же получим формулу энтропии текста:
Н = Ил
i
где Pi — это вероятность появления t-ro символа в тексте.
Соответственно чем больше зависимостей между элементами-символами
внутри текста, тем меньше потребуется бит, чтобы их закодировать. Понятно, что
для того, чтобы кодировщик строил эффективные коды для символов, ему необхо-
димо как можно больше знать о самом тексте. Для этого могут быть использова-
ны различные методы, самый простой из них — подсчет частот встречаемости
символа в тексте и назначение ему соответствующей вероятности появления, как
ni кг
отношения — , где п,- — частота встречаемости t-го символа; N — длина в симво-
лах всего текста. Здесь и проявляется впервые задача моделирования текста.
В самом простом варианте моделированием является оценка вероятности по-
явления каждого символа. Таблица вероятностей появления каждого символа,
основанная на подсчете частот их встречаемости, называется моделью первого!
приближения (или первого порядка). Таблица, учитывающая более сложные за-
висимости, например появление одного символа после какого-то другого, имеет;
Глава 6. Криптографическое сжатие
187
соответственно второй и более порядки. С помощью этих вероятностей может
быть вычислена энтропия и построен достаточно эффективный код, позволяющий1
сжать текст. Наилучшая средняя длина кода и соответственно степень сжатия до-
стигается моделями, в которых оценки вероятности как можно более точны. При
этом следует помнить, что энтропия является неотъемлемым свойством модели и
сжатие базируется на способе ее вычисления. Отсюда возможная неэффектив-
ность практической реализации алгоритма’сжатия, который «на бумаге» является
идеальным, а в реальных условиях даст лишь приближенное к лучшим значение
степени сжатия.
' Разумно в целях упрощения рассматривать модель оценки вероятности появ-
ления каждого символа. В ней оцениваемая вероятность символа иногда называ-
ется кодовым пространством, выделяемым символу и соответствует некоторому
разбиению отрезка [0, 1]. Чем больше вероятность одного символа, тем больше
пространства отбирается у других символов. Например, если текст, который мы
хотим сжать, состоит только из символов А, Б, В и Г и при этом буквы А и Б
встречаются в тексте в среднем 2 и соответствено 3 раза из 10, а буквы В и Г — 1
и 4 раза, то таблица вероятностей появления каждого символа будет выглядеть
следующим образом (рис 6.2):
1 Символ А Б В Г
1 Вероятность 0.2 0.3 0.1 0.4
Рис. 6.2. Таблица вероятностей появления символов
Тогда на отрезке [0, 1] пространства символов можно отметить несколько от-
резков, которые полностью заполняют все пространство и однозначным образом
соответствуют каждому из символов (рис. 6.3).
А
0.0—0.2
Б В Г
0.2—0.5 0.5—0.6 0.6—1.0
1.0
Рис. 6.3. Разбиение пространства символов
0.0
Точность оценок зависит от того, что мы знаем о тексте априори, то есть пе-
ред тем, как начнем его сжимать. Знание некоторых вероятностей заранее позво-
ляет нам приступить к сжатию сразу, как только поступят данные. Если же мы
ничего не знаем об их структуре и содержании, нам придется выбрать начальные
значения произвольным образом. В таких случаях говорят, что мы не обладаем
контекстуальным знанием. Зато мы можем договориться о какой-то фиксирован-
ной начальной таблице и использовать ее для сжатия и декомпрессии текстов.
Если мы знаем хотя бы, что сжимать придется литературный текст на русском
языке, то очевидно, что мы можем заранее посчитать частоты встречаемости сим-
волов и соответствующие вероятности модели первого приближения.
fee:.
Глава 6. Криптографическое сжатие
В то же время никто не мешает нам изменять модель приближения уже во
время сжатия. Таким образом, мы как бы изменяем работу кодировщика на новый
лад, подстраиваясь под конкретный текст, который необходимо сжать. Делается
это достаточно просто.
KaiK уже было сказано, обычный алгоритм сжатия (который называют статич-,
ным' или статическим алгоритмом сжатия35) состоит из двух частей — кодиров-
щика и некоторой части, отвечающей за моделирование текста. Само моделирова-
ние выполняется один раз: либо в процессе конструирования алгоритма, либо пе-
ред каждым началом процесса сжатия. В любом случае кодировщик получает
фиксированный «снимок» — модель текста, с которой,он работает. В процессе .ко-
дирования-сжатия модель не изменяется. Понятно, что в этом случае, если мы не
знаем, что за текст мы будем сжимать, мы не сможем предложить модель, кото-
рая будет всегда соответствовать тексту. В этом случае кодировщик не сможет
справиться со своей задачей. Следовательно, необходимо либо узнать о тексте
всю возможную информацию заранее, либо изменять модель приближения текста
прямо, в процессе сжатия. Первый способ неплох, но для его работы нам понадо-
бится один раз пробежаться по вс.ем данным, чтобы посчитать модель приближе-,
ния, и затем еще раз, чтобы, собственно, уже их сжимать. Кроме того, он не учи-
тывает локальных характеристик текста, когда, например, в тексте сначала идут
только русские буквы, а затем лишь английские.
Получается, что если мы.просто посчитаем таблицу вероятностей появления .
символов заранее, то мы не учтем порядок их расстановки в тексте. Кроме этого,,
даже посчитав значения таблицы вероятностей перед сжатием, мы должны будем
сохранить или передать саму таблицу вместе со сжатыми данными, чтобы обеспе-*
чить правильное разжатие-декодирование, а это дополнительные накладные рас-
ходы. Алгоритм сжатия не гарантирует даже того,, что накладные расходы на пе-
редачу таблицы вероятностей оправдаются, — длина сжатого текста в конечном,
счете может стать даже больше, чем исходного.
.. Очевидно* решением дилеммы является использование второго варианта
сжатия, при котором модель динамически изменяется в процессе сжатия. Такие
алгоритмы носят название динамических,'а также адаптивных.
Общая схема работы адаптивного алгоритма сжатия выглядит так (см. лис-
тинг 6.1):
Листинг 6.1
1. Взять некоторую начальную таблицу вероятностей РО.
2. Текущей моделью Р сделать РО.
3. Получить символ С текста.
4. Закодировать символ текста в соответствии с Моделью Р. ''
5. Модифицировать модель Р с помощью символа С.
6. Перейти к п.З или остановиться, если текст закончился. /
35 Следуя принятой терминологии, более правильно называть такие алгоритмы «алгоритм
мами с фиксированной моделью приближения текста». Авторы не делают этого в силу своей-
природной лени, приступы которой одолевают их при написании длинных названий в одной
строке текста.
Гпава 6. Криптографическое сжатие
189
Обновление модели на самом деле реализуется, очень просто и заключается
лишь в пересчете таблицы вероятностей появления символов в соответствии с но-
вой частотой появления символа С. Поясним работу адаптивного алгоритма на
примере начальной таблицы, данной на рис. 6.2, и тексте «ДАЛВИ}». Для того
чтобы формулы расчета значений вероятности появления символов были как
можно более просты, будем вести запись значений в таблице не вещественными
числами — записывая вероятности символов, а целыми — записывая частоты их
появления за время работы алгоритма.
[Символ* *' А • • ’ Б В Г
Частота появления 2 з1 1 * 1
Рис. 6.4. Начальная таблица вероятностей
Например, вероятность нахождения буквы «А» в тексте оценивается ее двумя
появлениями за десять обработанных символов текста, буквы «Б» — тремя и т. д.
Кодируя текст «АААБГВ», выберем в качестве РО таблицу на рис 6.4.
Закодировав первый символ А (длина битовой строки, которая для этого по-
3
надобится, равна - log — = 1,299282984 бита), изменим таблицу; прибавив еди-
ничку к счетчику, соответствующему символу А в таблице вероятностей. Его зна-
чение будет уже равняться трем. Затем обработаем следующий символ А. Теперь
-4 ' ' :
длина битовой строки составит уже - log — = 1,098612289 бита. Как видно, после
того как «появилась надежда» на то, что символ А является, часто встречающим-
ся, длина битовой строки, которая необходима для его кодирования, начала уме-,
ньшаться. После того как мы обработаем символ А в строке в третий раз, длина
5 '’ ’’
его битового представления станет равной -log*-'= 0,9555114451 бита. При
I3.
этом длина битовых строк для кодирования других символов соответствующим
образом увеличивалась. Но после того как кодировщик встретит символ Б, длина
4
его битовой строки уменьшится (равна -log— = 1,252762969 бита, вместо
4
-log — = 1,466337069 до этого), а вот для символа А увеличится, хоть и нейамно-
1 о
5
го (и станет равной-log —1,029619417).
В конце процесса получим такую же таблицу, ,как на рис. 6.5. .
Символ А Б В Г
Частота появления 5 " ? • 4 ''' ; " ”2 5
Рис. 6.5. Адаптивно измененная таблица вероятностей
190
Глава 6. Криптографическое сжатие
Приглядившись к ошеломляющим своей точностью длинам битовых строк,
возникает еще один вопрос: каким образом кодировщик вообще может закодиро-
вать битовую строку нецелой длины?
Кодировщики, работающие с целочисленной точностью, то есть способные
представлять символы битовыми строками целой длины, оказываются неэффек-
тивными, поскольку из-за практических ограничений сводится на нет вся теоре-
тическая эффективность сжатия, заключающаяся в точности представления сим-
вола в соответствии с энтропией текста.
Кроме того, важно, чтобы значения вероятностей, присваемых моделью, не
были бы нулевыми, поскольку в этом случае длины битовых строк этих символов
будут равны - log 0 = <х>, то есть кодировщик постарается сгенерировать строку
бесконечной длины. Ему это конечно же вряд ли удастся.
Наличие же нулевой вероятности в тексте, вообще говоря, достаточно часто
стречающийся на практике факт, поскольку это означает, что символ не встре-
ался алгоритму на данном шаге еще ни разу. Данную проблему можно обойти,
аазу установив все счетчики в единицу (либо использовав подходящую началь-
но таблицу, как сделали мы в приведенном выше примере) либо используя для
ех таких символов один дополнительный счетчик.
Пожалуй, самым известным представителем алгоритмов сжатия, исполь-
ощих информацию о тексте, является метод двоичных деревьев Хаффмана,
гь данного алгоритма заключается в построении двоичного дерева с узловы-
элементами из символов сжимаемого текста. Каждой ветви назначается
с» — битовый ноль или единица. Кодирование каждого символа осуществ-
ится проходом по дереву и выбором одной из двух ветвей, начиная с корня
ева и заканчивая листочком, на котором «сидит» нужный символ. Модели-
ание для данного алгоритма может быть выбрано любого типа из уже об1
•денных нами.
Проще всего можно рассмотреть алгоритм Хаффмана на примере сжатия,
лдположим снова, что нам надо заархивировать нашу уже ставшую старой зна-
лой строку «АААБГВ». До сжатия эта последовательность занимает 6 симво-
i (пусть это будут байты). Сжатая по методу RLE, строка выглядела бы так же,
скольку для последовательности символов А невыгодно использовать ежа-
; — строка от этого меньше не станет.
Алгоритм же Хаффмана может сократить ее почти до двух байтов, и вот как
I происходит. Прежде всего, отметим, что разные символы встречаются в на-
м тексте по-разному, то есть, по сути, приступим к моделированию текста. Для
)го можно составить таблицу частот и увидеть, что чаще всего присутствует
хва «А» (рис. 6.6).
1ВОЛ А Б В г
гота появления 3 1 1 1
- 'А
Рис. 6.6. Таблица частот символов в строке «АААБВГ»
Гпава 6. Криптографическое сжатие
191
Эта таблица используется для построения двоичного дерева (рис. 6.7). Это
дерево используется для построения кода сжатия. Левые ветви дерева помечены
однобитовым весом 0, а правые — битовой 1. Имея такое дерево, легко найти код
любого символа, если идти от вершины к нужному символу и аккумулировать ве-
совые биты тех ветвей, по которым происходит движение.
Рис. 6.7. Двоичное дерево построения кодов сжатия
Если поступивший кодировщику символ равен «А», то ему присваивается
двоичный ноль, поскольку из корня к символу «А» ведет только одна ветвь с нуле-
вым весом. В противном случае записываем единицу, переходим по другой ветке
и рассматриваем следующий бит. Если поступивший символ является символом
«Б», то он получит код 10, в противном случае мы запишем себе в память уже 11.
Й так далее. Получается, что более редкие символы получают более длинный код.
В приведенном примере, символ «Г» будет закодирован целыми тремя битами
111, в то время как «А» всего лишь одним битовым 0. Несмотря на то что разные
символы имеют разную битовую длину и, кроме того, нам не надо иметь никакого
разделителя между символами, поиск символа в дереве будет осуществляться
точно так же, как и кодирование.
Результат, конечно, впечатляющий, но перед нами все еще стоит вопрос о
приближении к теоретическому идеалу — кодированию символов нецелым чис-
лом битов. Кроме того, алгоритм Хаффмана не годится для адаптивных моделей
сжатия еще и потому, что всякий раз при изменении модели необходимо изме-
нять и весь набор кодов, перестраивая двоичное дерево заново. Этот процесс до-
статочно вычислительно сложен. Хотя на сегодняшний день существуют эффек-
тивные алгоритмы, которые делают это за счет весьма небольших накладных рас-
ходов, им все равно нужно достаточно свободной памяти для размещения всего
дерева и ряда поддеревьев. Если использовать алгоритм Хаффмана в адаптивном
сжатии, то для различных вероятностей распределения и соответствующих мно-
жеств кодов будут нужны свои классы условий для предсказывания символа. Мо-
дели сами по себе могут иметь их тысячи, и сохранение всех деревьев становится
чрезмерно утомительным занятием.
192............................... Глава 6. Криптографическое сжатие
Арифметическое кодирование
The state of the art in data compression is arithmetic coding,
not the better-known Huffman method. Arithmetic coding gi-
ves greater compression, is faster for adaptive models, and cle-
arly separates the model from the channel encoding.
/. H. Witten, R. M. Neal, J. G. Cleary.
Arithmetic coding for data compression
Теоретически более простым и много более йрйЙлека'тельйым подходом явля-
ется современный алгоритм, который его создатели, развали арифметическим ко-
дированием. Его наиболее важными свойствами является способность кодирова-
ния символа с вероятностью р появления в тексте количеством битов сколь угод-
но близким к теоретической оценке, при этом вероятности символов могут быть
на каждом шаге работы алгоритма различными, что позволяет эффективно испо-
льзовать адаптивное моделирование совместно с данным алгоритмом кодирова-
ния. Дополнительно существует весьма эффективная идея практической реализа-
ции алгоритма — довольно быстрая и не требующая больших объемов занимае-
мой памяти.
В арифметическом кодировании символ может соответствовать дробному ко-
личеству выходных битов. На практике, конечно, результат в самом конце работы
алгоритма должен являться целым числом битов, но, если кодировать несколько
последовательных наиболее вероятных символов вместе, они будут занимать зна-
чительно меньше места. Исходя из структуры работы алгоритма, на каждый сжа-
тый символ приходится по одному целочисленному умножению с переносом и не-
скольку сложений, что делает его весьма привлекательным для использования с
адаптивным моделированием.
Сложность арифметического кодирования состоит в том, что алгоритм сам по
себе работает с накапливаемой вероятностью распределения, требующей некото-
рого порядка размещения символов в исходном алфавите.
В начале главы мы уже рассматривали теоретическую модель сжатия. В ней
в процессе кодирования текст представлялся вещественными числами на отрезке
[О, 1]36. Алгоритм арифметического кодирования уменьшает соответствующий
тексту интервал по мере сжатия, увеличивая количество битов, которые необхо-
димы "для его представления. Очередные символы текста сокращают величину ин-
тервала, исходя из значений их вероятностей, определяемых моделью (пример
модели можно найти на рис. 6.3). Более вероятные символы сильнее уменьшают
интервал по сравнению с менее вероятными и, следовательно, добавляют меньше
битов к результату.
Перед началом работы соответствующий тексту отрезок равен [0; 1]. При об-
работке очередного символа его ширина сужается за счет использования разбие-
ния символов, выделяющего этому символу часть рабочего интервала. Попробуем
36 В данном контексте понятие отрезка и интервала можно считать схожими в том смысле,
что на практике влияние разницы между ними никак не сказывается на результате.
Гпава 6. Криптографическое сжатие
193
применить к тестовой строке «АААБВГ» алгоритм арифметического кодирования,
используя начальное разбиение с рис. 6.3.
После обработки первого символа «А»
0.2—0.5
0.5—0.6
0.6—1.0
0.0
1.0
После обработки второго символа «А»
0.04—0.10 0.10—0.12
0.12—0.2
0.0
0.2
Рис. 6.8. Разбиение пространства символов в процессе сжатия
И кодировщику, и декодировщику известно, что в самом начале отрезок все-
гда одинаков и равен [0, 1]. После просмотра первого символа «А» кодировщик су-
жает интервал до [0.0, 0.2), который модель выделила этому символу. Второй
символ «А» сузит этот новый интервал [0.0; 0.2) до первой его пятой части, то
есть до [0.0, 0.04), поскольку для «А» уже выделен фиксированный интервал [0.0,
0.2). Процесс продолжается, пока кодировщику поступают символы для сжатия.
В результате получим некоторый конечный интервал [и, w). Произвольное значе-
ние из него является сжатым представлением текста, причем оно определяет
текст однозначно, что позволяет восстановить его верно.
Предположим, декодировщик знает о тексте лишь то, что в сжатом виде он
представлен значением из конечного интервала [и, w). Пусть это будет [0.0,
0.04), как в нашем примере. Исходя из того, что начальные таблицы вероятностей
у декодировщика и кодировщика одинаковые, декодировщик сразу определяет,
что первый закодированный символ тот, чей отрезок кодового пространства попа-
дает в интервал [0.0, 0.2]. А это не что иное, как символ «А». После этого он по-
вторяет действия кодировщика, сужая интервал и определяя, какой из символов в
него попадает.
Декодировщику на самом деле нет необходимости знать значения обеих гра-
ниц конечного интервала, полученного от кодировщика. Даже единственного зна-
чения, лежащего внутри него, оказывается достаточно — на самом деле с его по-
мощью можно с легкостью определять, какие из интервалов покрывают данное
значение, и декодировать их все последовательно.
Однако для успешной работы декодировщика данной информации не совсем
достаточно. Потому что одно и то же число с помощью алгоритма можно предста-
вить в различном виде. Если сжать символ «А», то получим значение из первого
интервала, к примеру, 0.0. То же самое значение получится, если сжать последо-
вательность из двух «А», из трех «А» и т. д. Декодировщик не сможет самостояте-
льно распознать, когда ему необходимо остановиться. Чтобы завершить процесс
декодирования, ему необходим специальный символ, обработав который декоди-
ровщик бы останавливал процесс декомпрессии. Для этого еще на этапе сжатия
7 Зак. 85
194
Глава 6. Криптографическое сжатие
кодировщик после сжатия всего текста должен добавить специальный символ
(обычно его обозначают EOF — End Of File).
Обратимся теперь к практической стороне вопроса. Очевидно, необходимо
придумать способ записывать дробное число любой точности, которое получа-
ется в результате сжатия текста конечным числом битов, и было бы совсем за-
мечательно, если б данное число можно было записывать последовательно —
бит за битом. В этом случае мы могли бы сжимать-и выдавать результат одно-
временно.
Кроме того, неплохо было бы свести к минимуму количество операций с
плавающей точкой — они слишком медленны, чтобы исполнять солирующие
партии в быстрых алгоритмах сжатия. Дополнительно неплохо было бы иметь
возможность записи и чтения информации из файла и в файл побитово, а не по-
байтово с помощью стандартных функций. Увы, к сожалению, стандартные биб-
лиотеки не предложат нам ничего сколь-нибудь подходящего для этих целей, по-
этому, перед тем как приступить к написанию основного алгоритма, нам придет-
ся составить небольшую библиотеку «полезных кодов» (см. листинг 6.2 —
основной файл bitfile.срр, и листинг 6.3 — файл описаний bitfile.h). В ней мы
воспользуемся библиотекой стандартных типов unidef.h, которую многократно
использовали ранее.
Листинг 6.2
void bfflush(BITFILE *bf)
{
if (bf->mask != 0x80)
{
putc((uint8_t) bf->rack, bf->file);
bf->mask = 0x80;
>
bf->rack = 0;
}
BITFILE *bfopen(const char «bfname. const char *mode)
{
BITFILE *bf = NULL;
FILE *f;
f = fopen(bfname, mode);
if (f)
{
bf = new BITFILE;
bf->file = f;
bf->rack = 0;
bf->mask = 0x80;
}
return bf;
}
int bfclose(BITFILE *bf)
{
int err = 0;
Гпава 6. Криптографическое сжатие
195
If (bf)
{
bfflush(bf);
err = fclose(bf->file);
free(bf);
}
return err;
}
void bfwritebit(int bit, BITFILE *bf)
{
if (bit) bf->rack |= bf->mask;
bf->mask »= 1;
if (!bf->mask)
{
putc((uint8_t) bf->rack, bf->file);
bf->mask = 0x80;
bf->rack = 0;
}
}
void bfwnte(uint32_t bits, int num, BITFILE *bf)
{
uint32_t whole = 1L « --num;
while (whole > 0)
{
if (whole & bits) bf->rack |= bf->mask;
bf->mask »= 1;
if (!bf->mask)
{
putc((uint8_t) bf->rack, bf->file);
bf->mask = 0x80;
bf->rack = 0;
}
whole »= 1;
>
}
int ofreadbit(BITFILE *bf)
{
if (bf->mask == 0x80) bf->rack = getc(bf->file);
int bit = bf->rack & bf->mask;
bf->mask »= 1;
if (!bf->mask) bf->mask = 0x80;
return (bit ? 1 : 0);
}
uint32_t bfread(int num, BITFILE *bf)
{
uint32_t bits = 0, whole - 1L « --num;
while (whole > 0)
{
if (bf->mask == 0x80) bf->rack = getc(bf->file);
if (bf->rack & bf->mask) bits |= whole;
J 96 Гпава 6. Криптографическое сжатие
bf->mask »= 1;
if (!bf->mask) bf->mask = 0x80;
whole »= 1;
}
return bits;
}
Вспомогательная библиотека bitfile.cpp содержит служебные функции bfread
и bfwrite, которые позволят обращаться к обычным файлам с требованием запи-
сать один или несколько битов. Для этого мы каждому файлу сопоставим неболь-
шой битовый буфер (один, два или четыре байта, которые помещаются в перемен-
ные. стандартных целочисленных типов для удобства работы с ними), в который
будем аккуратно записывать все поступления битов от алгоритма. Как только бу-
фер заполнится, функция bfwrite сама запишет буфер, по размеру кратный байту,
в файл. Аналогично будет происходить и при чтении — сначала считается буфер,
а затем; отдельные биты будут выдаваться уже по требованию.
Чтобы упростить интерфейс для программиста, который будет использовать
различные функции, создадим специальный тип структуры BITFILE, в который
войдет стандартный дескриптор файла file, однобайтовый буфер rack и номер те-
кущего бита, готового к считыванию или записи, — mask (см. листинг 6.3).
Листинг 6.3
ftifndef bitfile__h
«define bitfile__h
«include <stdio.h>
«include <stdlib.h>
//по-прежнему стараемся использовать стандартные описания
«include <unidef.h>
11 структура BITFILE должна заменить, стандартную
Ц библиотечную структуру. FILE так, чтобы для программиста
// эта замена была почти "прозрачна”.
// Это облегчит написание программ, которые используют ввод и вывод
// произвольных по длине битовых потоков
typedef struct
{
FILE *file;
uint32_t mask;
int rack;
} BITFILE;
I/ сброс потока и запись его на диск
void bfflush(BITFILE *);
И открытие обычного файла как битового потока
BITFILE *bfopen(const char *, const char *);
// закрытие ранее открытого битового файла
int bfclose(BITFlLE *); Ji
// пишем в файл по одному биту
void bfwritebit(int, BITFILE *);
И или по целой группе битов (например, байтам или 11 битам)
void bfwrite(uint32_t, int, BITFILE *);
Гпава 6. Криптографическое сжатие 197
II то же самое, только уже читаем
int bfreadbit(BITFILE *);
uint32_t bfread(int, BITFILE *);
«endif
Использование дополнительной структуры BITFILE требует от нас ее коррек-
тной инициализации и удаления по завершению работы с файлом. Кроме того,
нам необходимо успеть записать остатки битов в буфере в файл перед тем, как
его закроют. Для этого и предназначаются соответственно функции bfopen, от-
крывающая файл и создающая BITFILE, bfclose, проделывающая обратную опера-
цию и вызывающая bfflush, функцию, которая записывает буфер накопленных би-
тов в файл.
В качестве оптимизации служебных функций bfread и bfwrite можно предло-
жить переписать их в качестве макросов или (что еще проще) добавить в их опре-
деления ключевое слово inline, которое укажет компилятору на необходимость
разворачивания тела этих функций в местах их вызова. Тогда вместо вызовов
функций будут исполняться непосредственно они сами и мы избежим накладных
расходов на создание стека переменных и переходы внутри кодового сегмента.
Теперь можно приступить непосредственно к реализации алгоритма арифме-
тического сжатия. Вероятности появления символов можно оценивать адаптивно
с помощью массива счетчиков. На каждый символ будет приходиться свой счет-
чик, который в начале процесса сжатия устанавливается в единицу37. После коди-
рования символа значение соответствующего ему счетчика увеличивается на еди-
ницу. Точно так же будет происходить и в процессе декодирования, а следовате-
льно, кодировщик и декодировщик будут обладать одними и теми же объемами
информации. Вероятность каждого символа оценивается его относительной час-
тотой появления на текущий момент. Точно так же она определяется и в других
алгоритмах, например алгоритме Хаффмана, описанном выше.
Основной алгоритм программы сжатия текстов с помощью арифметического
кодирования показан в листинге 6.4.
Листинг 6.4
И для 16-битового буфера можем посчитать константы заранее
«define fixedbits.aac
«define highvalue.aac
«define quarter1_aac
«define quarter2_aac
«define quarter3_aac
«define maxaac_freq
16
(((long) 1 « fixedbits.aac) - 1)
((highvalue_aac » 2) + 1)
(quarter1_aac « 1)
(quarter2_aac + quarterl.aac)
(16384 - 1)
int accumulate_aac[257]; // Интервальные значения
int aac_freq[257]; // Частоты символов
int sym2index_aac[256]; // Таблицы для индексирования позиций
int index2sym_aac[257]; // символов в таблице вероятностей
uint16_t low.aac, high_aac;
37 Единица, установленная в самом начале, позволяет избежать проблемы нулевой вероят-
ности, описание которой было дано выше.
198
Гпаеа 6. Криптографическое сжатие
long underflow.aac; // ’’отстающие" биты
// сжимаем данные в битовый поток
void compress_aac(char *buf, int32_t len, BITFILE *f)
{
int i, ch;
I/ инициализация алгоритма
for (i = 0; i < 257; i++)
{
aac.freq[i] = 1;
accumulate_aac[i] = 257 - i;
}
aac_freq[0] = 0;
accumulate.aac[256] = 0;
11 заполняем частотные интервалы - формируем разбиение
for (i = 257; i > 0; i--)
accumulate_aac[i - 1] = accumulate.aac[i] + aac_freq[i - 1];
// заполняем таблицу индексов
for (i = 0; i < 255; i++)
{
sym2index_aac[i] = i+1;
index2sym_aac[i+1] = i;
}
// начальные значения границ рабочего интервала
low.aac = 0;
high.aac = highvalue.aac;
underflow.aac = 0;
11 процесс адаптивного сжатия
for (int32_t ofs = 0; ofs < len; ofs++)
{
ch = sym2index_aac[ buf[ofs] ];
encodesymbol_aac(ch, f);
updatemodel_aac(ch);
}
И дополняем завершающим символом
encodesymbol_aac(256, f);
11 дописываем отстающие биты и еще парочку для однозначности
И значения из результирующего интервала
underflow_aac++;
if (low.aac < quarter1_aac) {
bfwritebit(O, f);
while (underflow.aac)
{
bfwritebit(1, f);
underflow.aac--;
}
}
else
{
bfwritebit(1, f);
Глава 6. Криптографическое сжатие
199
while (underflow_aac)
bfwritebit(O, f);
underflow_aac—;
}
}
}
Массив aac_freq хранит частоты появления символов в тексте. Нормализую-
щий множитель, с помощью которого можно вычислить соответствующие вероят-
ности, находится в самом начале массива — это элемент aac_freq[O]. Символы ну-
меруются от единицы и до 256 (поскольку в качестве символов выбраны обычные
восьмибитовые байты). Дополнительно вводится специальный символ окончания
текста — EOF с порядковым номером 257.
Частотные интервалы для всех символов хранятся в массиве accumulate_aac.
В целях оптимизации алгоритма можно отсортировать таблицу вероятностей по-
явления символов (и соответствующие интервалы в разбиении отрезка [О, 1]) по
убыванию частоты появления. Это минимизирует количество итераций, за кото-
рые декодировщик будет проводить декомпрессию текста, поскольку в этом слу-
чае для наиболее часто появляющихся символов декодировщик будет раскрывать
меньшее количество интервалов. Как раз для этого и созданы массивы sym2in-
dex_aac и index2sym_aac, служащие указателями на то, какой символ стоит на ка-
ком месте в таблице.
Текущий интервал, который, собственно, и представляет процесс сжатия и
декомпрессии, задается в [low_aac, high_aac] и будет в самом начале равен
[low_aac = 0, high_aac = 1] и для кодировщика, и для декодировщика. Требуемая
для представления значения из интервала точность возрастает по мере сжатия
все большего и большего количества символов. По этой причине мы должны запи-
сывать результирующее значение побитово в течение всего процесса сжатия. Та-
кой подход избавляет нас от необходимости задумываться над способами пред-
ставления в памяти вещественных чисел с произвольной точностью.
Частоты, которые мы накапливаем, не должны превысить границу, отведен-
ную для стандартных типов. Поэтому после каждого обновления модели необхо-
димо проверять, не превысил ли какой-нибудь символ допустимые значения, и,
если это так, проводить масштабирование модели.
В процессе сжатия рабочий интервал сужается и старшие биты low_aac и
high_aac становятся равными. Их можно запаковывать сразу, так как они уже не
будут влиять на следующие биты кода (см. листинг 6.5).
Листинг 6.5
// кодируем один символ, используя модель
И приближения текста первого порядка
void encodesymbol_aac(int ch, BITFILE *f)
{
uint32_t range = high_aac - low_aac + 1;
11 определяем интервал для символа ch
high_aac = (uint16_t) (low_aac +
200
Гпава 6. Криптографическое сжатие
(range * accumulate_aac[ch - 1]) / accumulate_aac[O] - 1);
low.aac = (uint16_t) (low_aac +
(range * accumulate_aac[ch]) / accumulate_aac[O]);
11 работаем над последовательностью битов, представляющих символ ch,
// поскольку мы заранее не знаем, сколько именно их для символа ch
Ц цикл без условия
for (;;)
{
if (high_aac < quarter2_aac) // определяем, где находимся
{
// пишем нулевой бит для левой половины
bfwritebit(O, f);
while (und'erflow.aac)
{
bfwritebit(1, f);
underflow.aac—;
}
}
else if (low_aac >= quarter2_aac)
{
// пишем единичный бит для правой половины
bfwritebit(1, f);
while (underflow.aac)
{
bfwritebit(O, f);
underflow_aac—;
}
// уменьшаем границы рабочего интервала
// на соответствующие значения
low_aac -= (uint16_t) quarter2_aac;
high.aac -= (uint16_t) quarter2_aac;
}
else if (low_aac >= quarter1_aac && high.aac < quarter3_aac)
{
// увеличиваем ширину рабочего интервала
underflow_aac++;
low.aac -= (uint16_t) quarterl.aac;
high.aac -= (uint16_t) quarterl.aac;
}
else
break;
I/ увеличиваем масштаб рабочего интервала
low.aac «= 1;
high.aac = (uint16_t) ((high.aac «1) | 1);
}
}
Следует помнить, что если границы интервала достаточно близки друг к дру-
гу, то масштабирование (представленное в листинге 6.6) приведет к тому, что
разные символы будут кодироваться одним и тем же целым числом, входящим в
[low_aac, high_aac]. Чтобы этого не произошло, кодировщик должен сохранять
достаточное расстояние между low_aac и high_aac. Самый простой способ еде-
Гпава 6. Криптографическое сжатие
201
лать это — обеспечить ширину рабочего интервала равной величине, не меньшей
max_aacfreq — максимальное значение суммы всех накапливаемых частот.
Если high_aac и low_aac располагаются настолько близко друг к другу, что
выполняются неравенства quarterl <= low_aac < half <= high_aac < quarters, то
следующие два бита вывода будут противоположны один другому — если первый
бит нулевой, то второй будет единичным, и наоборот. Это выполнено потому, что
вычисляемый интервал должен располагаться выше или соответственно ниже
средней точки рабочего интервала.
Запомнив в underflow_aac, что нам необходимо вывести дополнительный бит по-
сле текущего (постараемся запомнить также и его), мы можем безопасно расширить
рабочий интервал вправо. Если после этой сложной операции неравенства все равно
остаются верными, мы можем провести ее еще раз и т. д., пока не добьемся нужного
нам резльутата. Единственное, что нам нужно помнить в этой ситуации, — это коли-
чество дополнительных битов, которые мы должны вывести в поток.
Листинг 6.6
// обновление модели приближения текста
void updatemodel_aac(int ch)
{
int i;
I/ В случае переполнения значений частот необходимо
// провести масштабирование
if (accumulate_aac[O] >= maxaac.freq)
{
int cum;
cum = 0;
for (i = 257; i >= 0; i-)
{
I/ мы просто делим все частоты пополам
aac.freq[i] = (aac_freq[i] + 1) » 1;
accumulate_aac[i] = cum;
cum += aac_freq[i];
}
}
11 перестановка символов с большими частотами в начало
// таблицы вероятностей
for (i = ch; aac_freq[i] == aac_freq[i - 1]; i--);
if (i < ch) {
int ch.i, ch_symbol;
ch_i = index2sym_aac[i];
ch_symbol = index2sym_aac[ch];
index2sym_aac[i] = ch.symbol;
index2sym_aac[ch] = ch.i;
sym2index_aac[ch_i] = ch;
sym2index_aac[ch_symbol] = i;
} ' r
' aac_freq[i]++;
while (i-- > 0) accumulate_aac[i]++;
}
202
Гпава 6. Криптографическое сжатие
В режиме декодировщика все аналогично. Постепенный ввод битового потока
сжатого текста осуществляется с помощью специального регистра value. Обрабо-
танные биты постепенно перемещаются в его старшую часть, а в младшую посто-
янно поступают новые. После их обработки кодировщик избавляется от одинако-
вых битов, выводя их в поток и замещая их в регистре более младшими битами.
Листинг 6.7
// декомпрессия текста из битового потока
void decompress_aac(char *buf, int32_t max, BITFILE *f)
{
int32_t range, ofs = 0;
int i, cum, symbol;
uint16_t value;
if (’buf) return;
for (i = 0; i < 257; i++)
{
// заполняем единичками частоты, чтобы избежать
// бесконечно длинных кодов
aac_freq[i] = 1;
accumulate_aac[i] = 257 - i;
}
aac_freq[0] = 0;
accumulate_aac[256] = 0;
// инициализация таблиц
for (i = 257; i > 0; i-)
accumulate_aac[i - 1] = accumulate_aac[i] + aac_freq[i - 1];
for (i =0; i < 255; i++)
{
sym2index_aac[i] = i+1;
index2sym_aac[i+1] = i;
.}
// заполняем рабочее значение
value = 0;
for (i =0; i < 16; i++)
value = (uint16_t) ((value « 1) | bfreadbit(f));
low_aac = 0;
high_aac = highvalue.aac;
underflow_aac = 0;
11 следим за тем, чтобы буфер при декомпрессии
// не переполнился
while (ofs < max)
{
// вычисляем ширину рабочего интервала
range = high_aac - low_aac + 1;
// вычисляем вспомогательные величины
cum = ( (value - low_aac + 1) * accumulate_aac[0] - 1) / range;
for (symbol = 1; accumulate_aac[symbol] > cum; symbol++);
Гпава 6. Криптографическое сжатие 203
И вычисляем границы рабочего интервала
high.aac = (uint16.t) (low.aac +
(range * accumulate_aac[symbol - 1]) / accumulate_aac[O] - 1);
low.aac = (uint16_t) (low.aac +
(range * accumulate_aac[symbol]) / accumulate_aac[O]);
for (;;)
{
I/ если границы рабочего интервала слишком близки,
// масштабируем их, если все в порядке, то сужаем интервал-
if (high.aac < quarter2_aac)
{
}
else if (low.aac >= quarter2_aac)
{
value -= (uint16_t) quarter2_aac;
low.aac -= (uint16_t) quarter2_aac;
high.aac -= (uint16_t) quarter2.aac;
}
else if (low.aac >= quarterl.aac && high.aac < quarter3_aac)
{
value -= (uint16_t) quarterl.aac;
low.aac -= (uint16_t) quarterl.aac;
high.aac -= (uint16_t) quarterl.aac;
}
else break;
11 масштабируем рабочий интервал
low.aac «= 1;
high.aac = (uint16_t) ((high.aac « 1) | 1);
value = (uint16_t) ((value « 1) | bfreadbit(f));
}
I/ если появился символ EOF, останавливаемся
if (symbol == 256) break;
buf[ofs++] = (INT8) index2sym_aac[symbol];
11 обновляем модель приближения текста
updatemodel_aac(symbol);
}
}
При завершении процесса сжатия необходимо вывести уникальный заверша-
ющий символ, равный целой величине 256 (предыдущие 255 величин заняты для
обозначения байтов), а затем вывести достаточное количество битов underf-
low_aac, чтобы убедиться в том, что закодированная строка попадет в итоговый
рабочий интервал. Декодировщик, обнаружив символ завершения процесса, так-
же остановит свою работу.
Чтобы обеспечить более эффективную реализацию алгоритма арифметиче-
ского кодирования, можно проделать ряд модификаций, начиная от оптимизации
алгоритма и заканчивая оптимизацией описанного исходного текста. Например,
более эффективный, хоть и сложный путь вычисления вероятностей символов ле-
жит через определение их зависимости от предыдущего символа. Подобная мар-
204 Гпава 6. Криптографическое сжатие
ковская модель приближения текста Даст лучшее распределение частот встречае-
мости символов в тексте, а вместе с ним и более эффективное сжатие.
Дополнительно к этому программа, приведенная в листингах этой главы, опе-
рирует с 32-битовыми регистрами, что влечет за собой на необходимость доволь-
но частого масштабирования и довольно грубый учет вероятностей появления
символов и соответственно на представление самих символов. А значит, снова
влияет на эффективность сжатия. Впрочем, за поиском существенных методов
оптимизации алгоритма отправим дотошного читателя в раздел списка литерату-
ры к данной главе, а сами снова обратимся к идее криптографического сжатия.
Криптографическое сжатие
The constraint of the integral number of bits had probably been
considered as obvious, in real applications, prior to the develop-
ment of arithmetic coding, since the possibility of coding ele-
ments in fractional bits is quite surprising. Therefore Huffman
codes enjoyed widespread popularity in the four decades since
their invention.
A. Booksieinl, S. T. Klein, T. Raita.
Is Huffman Coding Dead?
Подойдя вплотную непосредственно к задаче формирования кодов и собст-
венно кодирования-сжатия текста, не будем забывать, что нашей начальной це-
лью было исследование алгоритмов сжатия с целью применения в них каких-либо
криптографических преобразований. Уже сейчас можно выделить моделирова-
ние-приближение текста как достаточно интересный объект именно для криптог-
рафического применения. Кодировщик использует модель для сжатия текста и
представления его в виде кодов сжатия. Очевидно, что для правильной декомп-
рессии декодировщик должен обладать точно такой же моделью текста. Совер-
шенно очевидно, что в самом простом варианте мы можем использовать таблицу
вероятностей появления символов в качестве секретного ключа. Однако мы. сразу
упираемся в следующие отрицательные стороны использования данного подхода:
• довольно большой по объему ключ (в пересчете на биты это 2048-битовый
ключ), который не везде сможет использоваться;
• к тому же на самом деле используется не все ключевое пространство,
например, использование ключа с нулевыми компонентами просто иск-
лючено;
• использование случайного ключа сильно влияет на эффективность сжатия
в худшую сторону, сводя на нет преимущества алгоритма сжатия;
• использование неслучайного ключа чревато возможностью создания быст-
рого алгоритма перебора для взлома.
Следовательно, использовать в качестве ключа таблицу распределения веро-
ятностей символов или таблицу частот их появления нельзя. Один из выходов в
сложившейся ситуации заключается в модификации алгоритма сжатия привнесе-
Глава 6. Криптографическое сжатие
205
нием в него таких криптографических примитивов, как подстановки и переста-
новки символов текста перед тем, как подать их на вход собственно кодировщику.
В этом случае псевдокод адаптивного алгоритма криптографического сжатия
получается из псевдокода обычного адаптивного алгоритма сжатия данных путем
несложных изменений (см. листинг 6.8).
Листинг 6.8
1. Взять некоторую начальную таблицу вероятностей РО.
2. Текущей моделью Р сделать РО.
3. Получить символ С текста.
4. Применить подстановку или перестановку к символу С - получить новый символ С.
5. Закодировать полученный символ, С \ текста в хротцетствии'с. моделью Р.
6. Модифицировать модель Р с помощью символа С.
7. Перейти к п.З или остановиться, если текст закончился.
В то же время из-за того, что мы изменяем символ С с помощью подстановки
или перестановки, кодировщик будет получать совсем не те символы, на которые
рассчитана модель, а следовательно, говорить о каком-либо сжатии уже попро-
сту не приходится. Проблему можно решить, модифицируя модель в зависимо-
сти от результата подстановки/перестановки — символа С. Но в этом случае
все криптографическое сжатие окажется ни чем иным, как сжатием текста, за-
шифрованного полиалфавитной заменой. То есть можно сказать, идея криптогра-
фического сжатия является более общим случаем алгоритма, шифрующего текст
с помощью какого-либо криптографического преобразования и «одновременно»
сжимающего его.
Вернемся, однако, к практике. Понятно, что предложенный в листинге 6.8 ва-
риант криптографического сжатия не годен для практического применения. Мы,
конечно, можем немного модифицировать его, подействовав выбранной нами
криптографической функцией на код символа С, то есть уже после его обработки
кодировщиком (см. листинг 6.9).
Листинг 6.9
1. Взять некоторую начальную таблицу вероятностей РО.
2. Текущей моделью Р сделать РО.
3. Получить символ С текста.
4. Применить подстановку или перестановку к символу С - получить новый символ С’.
5. Закодировать полученный символ С текста в соответствии с моделью Р.
6. Модифицировать модель Р с помощью символа С.
7. Перейти к п.З или остановиться, если текст закончился.
Однако на этом цути, похоже, нет более эффективных решений, чем приме-
нение эффективного сжимающего преобразования, а затем заведомо стойкого
криптоалгоритма.
Очевидно, что все предложенные выше способы не являются достаточно эф-
фективными, чтобы создавать ради их реализации дополнительные криптографи-
ческие протоколы.’ Выигрыш от их использования; к сожалению, не велик, и ов-
чинка, что называется, не стоит выделки.
206
Гпава 6. Криптографическое сжатие
С другой стороны, мы властны внести существенные изменения в сам про-
цесс кодирования-декодирования, поставив именно его в зависимость от ключа
системы. Можно попробовать модифицировать непосредственно сам алгоритм
сжатия. Посмотрим на его реализацию внимательнее. Массивы sym2index и
index2sym хранят информацию о том, какой символ исходного алфавита соответ-
ствует какому порядковому номеру отрезка кодового пространства. Они созданы
для того, чтобы наиболее часто используемые символы смещались в начало кодо-
вого пространства, а менее часто используемые — в конец. В этом случае декоди-
ровщик, чтобы найти нужный символ, будет совершать меньше операций за счет
того, что наиболее вероятные символы находятся ближе к месту начала поиска
декодировщиком соотвётствующего символа.
В процессе кодирования массивы изменяются, символы передвигаются по кодо-
вому пространству, обеспечивая в будущем эффективное по времени декодирование
сжатого текста. Но вместе с изменением расположения отрезков, соответствующих
символам, в кодовом пространстве изменяются также и представления сжатых сим-
волов, то есть в наших терминах — шифробозначения. Например, передвинув сим-
вол «В» из конца кодового пространства в начало, кодирующее значение может вы-
глядеть не как запланированное изначально 0,9568894, а 0.002389. Соответственно
меняются и биты, кодирующие наше результирующее значение. Вдобавок в адаптив-
ном алгоритме все меняется динамически после изменения каждого символа.
Перед нами встает вопрос, который некогда задал себе Хорст Файстель: ка-
ким именно образом мы можем организовать зависимость алгоритма от некоторо-
го ключа? Файстель воспользовался подстановками и перестановками, сделав
применение первых зависимым от значения очередного бита ключа. Он использо-
вал две различные, заранее подготовленные таблицы подстановок S0 и S1. И в за-
висимости от того, равен ли очередной для итерации шифра и шифруемого блока
бит ключа единице или нулю, выбирал соответствующую таблицу и применял
подстановку к шифруемым данным.
Ничто не мешает поступить нам подобным же образом и в нашем случае. Мы
воспользуемся тем, что при изменении sym2index и index2sym изменяется также
и битовое представление кодов символов. Еще одним положительным моментом
этой модификации алгоритма является то, что, сколько бы ни переставляли сим-
волы внутри кодового пространства, мы никогда не увеличиваем длину кодов, а
значит, не ухудшаем сжимающие характеристики алгоритма. Таким образом, и
получаем самое настоящее криптографическое сжатие.
Дополнительно к этому можно «возмущать» модель приближения текста, мо-
дифицируя ее дополнительно в зависимости от ключа, а не от текста. Например,
мы можем приближать модель текста так, как будто каждый второй символ тек-
ста является символом из ключевой последовательности — правильно сформиро-
ванная по ключу псевдослучайная последовательность символов будет довольно
сильно искажать модель приближения сжимаемого текста и как следствие менять
представление сжатого текста, то есть шифротекст.
Правда, в отличие от безобидной перетасовки отрезков в кодовом простран-
стве, изменение модели в зависимости не только от текста, но еще и от ключа де-
лает сжатие менее эффективным, поскольку моделировщик может выделить до-
Гпава 6. Криптографическое сжатие
207
вольно много места совсем неиспользуемым символам, а кодировщик затем со-
бьется при кодировании на лишних символах.
Листинг 6.10
«include "p_table.h”
void rotate_key(char *key) {
int z, i, s;
s = z = key[15];
for (i = 15; i > 0; i--) {
key[i] = key[i-1] ~ ((i*z) & OxFF);
if (key[i] & 0x01 != 0) s += (s*i + key[i]) & OxFF;
}
key[O] = (z + s + 1) & OxFF;
}
void rotate_index(char *key) {
int i, b, k, q;
for (i = 0; i < 256; i++) {
b = i » 4;
k = i - (b « 4);
if ((key[b] » k) & 0x01 != 0) {
if (key[b] > 128) {
q = sym2index_aac[P[i]]; x
sym2index_aac[P[i]] = sym2index_aac[i];
sym2index_aac[i] = q;
q = index2sym_aac[P[i]];
index2sym_aac[P[i]] = index2sym_aac[i];
index2sym_aac[i] = q;
}
else
updatemodel_aac(key[b]);
}
else {
updatemodel_aac(key[b]);
}
}
rotate_key(key);
}
Проиллюстрируем идею модификации алгоритма простым примером (см. лис-
тинг 6.10). Длину ключа для использования в нашей модифицированной версии
алгоритма сжатия возьмем равной 128 битам. При выборе длины ключа в нашем
случае можно руководствоваться общими соображениями о вычислительных
мощностях современных компьютеров и конкретными примерами взлома шифров
с длиной ключа меньше указанных 128 битов.
Основную работу по переразбиению кодового пространства выполняет функ-
ция rotate_index. Поскольку мы должны быть уверены в том, что после внесения
нашей зависимости изменятся кодовые представления всех символов, модифика-
ция соответствующих таблиц проводится целиком — по всем 256 элементам.
208
Гпава 6. Криптографическое сжатие
На каждой итерации алгоритма изменения таблиц используется один бит
ключа. Таким образом, за 256 раз исполнения внешнего цикла в rotate_index все
128 битов ключа просматриваются два раза.
Вспомним алгоритм Файстеля с использованием двух таблиц подстановок S1
и SO. Наш алгоритм оказался организован похоже. В зависимости от того, нуле-
вое или единичное.значение принимает текущий бит ключа, используем либо пе-
рестановку отрезков без изменения их размеров внутри кодового пространства
(перестановка осуществляется С помощью таблицы перестановок Р), либо изме-
няем саму модель с помощью байта ключа, в котором находится текущий бит.
Дополнительно после зашифрования каждого символа алгоритм предусмат-
ривает изменение ключа, с тем чтобы одинаковые символы не были представлены
одинаковой последовательностью битов и, следовательно, криптоанализ по от-
крытому тексту был затруднен. За изменение ключа отвечает функция rotate_key.
Авторы тестировали первые несколько тысяч итераций ключа и пришли к выводу,
что предложенный алгоритм генерирует последовательность большей длины, чем
210. Проверить это утверждение авторы предоставляют читателю.
Листинг 6.11
void crypto_compress(char *buf, int32_t len, char ‘key, BITFILE *f)
{
int i, ch;
for (i = 0; i < 257; i++)
{
aac_freq[i] = 1;
accumulate_aac[i] = 257 - i;
}
aac_freq[0] = 0;
accumulate_aac[256] = 0;
for (i = 257; i > 0; i—) accumulate_aac[i - 1] = accumulate_aac[i] + aac_freq[i -
1];
for (i = 0; i < 255; i++)
{
sym2index_aac[i] = 1+1;
index2sym_aac[i+1] = i;
}
low.aac = 0;
high_aac = highvalue_aac;
underflow.aac = 0;
for (int32_t ofs = 0; ofs < len; ofs++)
{
rotate_index(key);
ch = sym2index_aac[ buf[ofs] ];
encodesymbol_aac(ch, f);
updatemodel_aac(ch);
}
encodesymbol_aac(256, f);
Гпава 6. Криптографическое сжатие 209
' underflow_aac++;
if (low.aac < quarter1_aac) {
bfwritebit(O, f);
while (underflow.aac)
{
bfwritebit(1, f);
underflow.aac—;
}
}
else
{
bfwritebit(1, f);
while (underflow.aac)
{ .
bfwritebit(O, f);
underflow.aac--;
}
}
}
void crypto_decompress(char *buf, int32_t max, BITFILE *f)
{
int32_t range, ofs = 0;
int i, cum, symbol;
uint16_t value;
if (Ibuf) return;
for (i = 0; i < 257; i++)
{
aac_freq[i] = 1;
accumulate_aac[i] = 257'- i;
}
aac_freq[0] = 0;
accumulate_aac[256] = 0;
for (i = 257; i > 0; i--)
accumulate_aac[i - 1] = accumulate_aac[i] + aac_freq[i - 1];
for (i = 0; i < 255; i++)
{
sym2index_aac[i] = i+1;
index2sym_aac[i+1] = i;
}
value = 0;
for (i = 0; i < 16; i++)
value = (uint16_t) ((value « 1) | bfreadbit(f));
low.aac = 0;
high.aac = highvalue.aac;
underflow.aac = 0;
while (ofs < max)
{
range = high.aac - low.aac + 1;
cum = ( (value - low.aac + 1) * accumulate_aac[0] - 1) / range;
for (symbol = 1; accumulate_aac[symbol] > cum; symbol++);
210
Гпава 6. Криптографическое сжатие
high.aac = (uint16_t) (low.aac + (range * accumulate_aac[symbol - 1]) / accu-
mulate_aac[O] - 1);
low.aac = (uint16_t) (low.aac + (range * accumulate_aac[symbol]) / accumula-
te_aac[0]);
for (;;)
{
if (high.aac < quarter2_aac)
{
}
else if (low.aac >= quarter2_aac)
{
value -= (uint16_t) quarter2_aac;
low.aac -= (uint16_t) quarter2_aac;
high.aac -= (uint16_t) quarter2_aac;
}
else if (low.aac >= quarterl.aac && high.aac < quarter3_aac)
{
value -= (uint16_t) quarterl.aac;
low.aac -= (uint16_t) quarterl.aac;
high.aac -= (uint16_t) quarterl.aac;
}
else break;
low.aac «= 1;
high.aac = (uint16_t) ((high.aac « 1) | 1);
value = (uint16_t) ((value « 1) | bfreadbit(f));
}
if (symbol == 256) break;
buf[ofs++] = (uint8_t) index2sym_aac[symbol];
updatemodel.aac(symbol);
}
}
Соответственно проделанным изменениям функции криптографического сжа-
тия и декомпрессии будут выглядеть так, как показано в листинге 6.11. Предъяв-
ленный алгоритм и является нашей искомой целью — действующим алгоритмом
криптографического сжатия. Алгоритм представляет собой реализацию достаточ-
но эффективного способа сжатия данных и зависит от ключа, без которого невоз-
можно будет восстановить исходный текст.
Листинг 6.12
X:\cryptobook\text\data>dir
Том в устройстве X имеет метку SECRETDISK
Серийный номер тома: 242F-24DA
Содержимое папки X:\cryptobook\text\src
26.02.2002 00:53' <DIR>
26.02.2002 00:53 <DIR>
17.03.2002 01:36 521 text.txt
13 файлов 125 368 байтов
2 папок 151 248 896 байтов свободно
Гпава 6. Криптографическое сжатие
211
X:\cryptobook\text\data>type text.txt
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
Hello, this is the test string repeated 10 times.
X:\с ryptobook\text\s rc>di г
Том в устройстве X имеет метку SECRETDISK
Серийный номер тома: 242F-24DA
Содержимое папки X:\cryptobook\text\src
26.02.2002 00:53 <DIR>
26.02.2002 00:53 <DIR>
13.12.2001 10:03 3 507 lucifer.cpp
28.07.2001 13:54 8 300 ahuffman.cpp
28.07.2001 14:04 3 893 lz77.cpp
05.03.2002 11:42 5 159 aac.cpp
05.03.2002 11:56 427 bitfile.h
05.03.2002 11:56 1 528 bitfile.cpp
17.03.2002 01:36 302 text.acc
13 файлов 125 368 байтов
2 папок 151 248 896 байтов свободно
Попробуем применить обычный адаптивный алгоритм арифметического сжа-
тия и нашу новую криптографическую разработку к блоку текста. После приме-
нения арифметического сжатия исходный файл приобрел размер в 302 байта, что
составляет 3/5 от исходного объема (см. листинг 6.12). После применения к дан-
ным алгоритма криптографического сжатия их объем уменьшился до 408 байтов,
что, конечно, является не столь впечатляющим результатом. Тем не менее резу-
льтат достаточно хорош, и, пожонглировав различными способами модификации
алгоритма, длиной ключа и прочими параметрами рассмотренного алгоритма,
можно добиться весьма неплохих результатов. Осталось лишь обратиться к чита-
телю с просьбой оценить криптографическую стойкость предложенного метода.
Список литературы
1. D. Huffman, A method for the construction of minimum redundancy codes, Proc,
of the IRE 40 (1952) 1098—1101.
2. Д. Мастрюков, Алгоритмы сжатия информации. Арифметическое кодирова-
ние, М: Московская Правда, Монитор № 1, 1994.
3. А. В. Аграновский, А. В. Балакин, Р. А. Хади, Классические шифры и методы
их криптоанализа, М: Машиностроение, Информационные технологии № 10, 2001.
стр. 40—46.
212
Глава 6. Криптографическое сжатие
4.1. H. Witten, R.M. Neal, J.G. Cleary, Arithmetic coding for data compression, Com-
munications of the ACM, June 1987 Volume 30, Number 6, pp. 520—540. ''
5. A. Moffat, R. M. Neal, I. H. Witten, Arithmetic Coding Revisited, ACM Transacti-
ons on Information Systems, Vol. 16, No. 3, July 1998, pp. 256—294.
6. J. Daemen, R. Govaerts, Block Ciphers Based on Modular Arithmetic, Proceedings
of the 3rd Symposium on State and Progress of Research in Cryptography, 1993, pp.
80-89.
7. E. Biham, New Types of Cryptanalytic Attacks Using Related Keys, Advances in
Cryptology, EUROCRYPT '93, Springer-Verlag, 1994, pp. 398—409.
8. E. Biham, A. Shamir, Differential Cryptanalysis of the Data Encryption Standard,
Springer-Verlag, 1993, pp. 187—199.
9. D. Huffman, A method for the construction of minimum redundancy codes. In the
Proceedings of the Institute of Radio Engineers 40 (1951), pp. 1098—1101.
10. D. Knuth, Dynamic Huffman coding. J. Algorithms 6 (1985), 163—180.
11. J. S. Vitter, Design and analysis of dynamic Huffman codes. J. ACM 34, 4 (Oct.
1987), 825—845.
12. Bell TC, Cleary JG, and Witten, I. H. 1990. Text Compression. Prentice-Hall,
Inc., Upper Saddle River, NJ.
13. Bentley J. L., Sleator D.D., 1986. A locally adaptive data compression scheme.
Commun. ACM 29, 4 (Apr.), 320—330.
14. Bookstein A, Klein S. Is Huffman coding dead?. Computing 50, 4, 279—296.
15. Burrows W, Wheeler D, 1994. A block-sorting lossless data compression algo-
rithm. Tech. Rep. 124. Digital Equipment Corp., Maynard, MA.
16. Capocelli R, De Santis A, New bounds on the redundancy of Huffman codes.
IEEE Trans. Inf. Theor. IT-37, 1095—1104.
17. Chevion D., Karnin E. High efficiency, multiplication free approximation of arith-
metic coding. In Proceedings of the 1991 IEEE Data Compression Conference, J. A. Sto-
rer and J. Reif, Eds. IEEE Computer Society Press, Los Alamitos, CA, 43—52.
18. Cleary J., Witten I. Data compression using adaptive coding and partial string
matching. IEEE Trans. Commun. COM-32, 396—402. к
19. Cormack G., Horspool R., Algorithms for adaptive Huffman codes. Inf. Process.
Lett. 18, 3 (Mar.), 159—165.
20. Cormack G., Horspool R., Data compression using dynamic Markov modelling.
Comput. J. 30, 6 (Dec.), 541—550.
21. CormenT., Leiserson C., Introduction to Algorithms. MIT Press, Cambridge,
MA.
22. Fenwick P., A new data structure for cumulative frequency tables. Softw. Pract.
Exper. 24, 3 (Mar.), 327—336.
23. Feygin G. Gulak P., Minimizing excess code length and VLSI complexity in the
multiplication free approximation of arithmetic coding. Inf. Process. Manage. 30, 6,
805—816.
24. Gallager R. Variations on a theme by Huffman. IEEE Trans. Inf. Theor. IT-24,6
(Nov.), 668—674.
25. Gallager R. Van Voorhis D. Optimal source codes for geometrically distributed in-
teger alphabets. IEEE Trans. Inf. Theor. IT-21, 2 (Mar.), 228—230.
26. Golomb S. Run-length encodings. IEEE Trans. Inf. Theor. IT-12, 3 (July),
399—401.
Глава 6. Криптографическое сжатие
213
27. HamakerD. Compress and compact discussed further. Commun. ACM 31, 9
(Sept.), 1139—1140.
28. Harman D. Overview of the second text retrieval conference (TREC-2). Inf. Pro-
cess. Manage. 31, 3 (May—June), 271—289.
29. Horsppol R., Cormack G. Constructing word-based text compression algorithms.
In Proceedings of the 1992 IEEE Data Compression Conference, J. Storer and M.Cohn,
Eds. IEEE Computer Society Press, Los Alamitos, CA, 62—71.
30. Howard P. G., Vitter, J. S. Analysis of arithmetic coding for data compression.
Inf. Process. Manage. 28, 6 (Nov.—Dec.), 749—763.
31. Howard P. G., Vitter, J. S. Arithmetic coding for data compression. Proc. IEEE
82, 6, .857—865.
32. Huffman D, A method for the construction of minimum-redundancy codes. Proc.
Inst. Radio Eng. 40, 9 (Sept.), 1098—1101.
33. Jiang, J. Novel design of arithmetic coding for data compression. IEE Proc. Com-
put. Dig. Tech. 142, 6 (Nov.), 419—424.
34. Jones, D. W. Application of splay trees to data compression. Commun. ACM 31,8
(Aug.), 996—1007.
35. Langdon, G. G. 1984. An introduction to arithmetic coding. IBM J. Res. Dev. 28,
2 (Mar.), 135—149. ACM Transactions on Information Systems, Vol. 16, No. 3, July
1998.
36. Langdon,G.G., Rissanen, J. Compresson of black-and-white images with arithme-
tic coding. IEEE Trans. Commun. COM-29, 858—867.
37. Moffat, A. Word-based text compression. Softw. Pract. Exper. 19, 2 (Feb.);
185-198.
38. Moffat, A. Implementing the PPM data compression scheme. IEEE Trans. Com-
mun. 38, 11 (Nov.), 1917—1921.
39. Moffat, A. Linear time adaptive arithmetic coding. IEEE Trans. Inf. Theor. 36,2
(Mar.), 401—406.
40. Moffat, A. Critique of «Novel design of arithmetic coding for data compression».
IEEE Proc. Comput. Digit. Tech.
41. Moffat,A. Turpin, A. On the implementaiton of minimum-redundancy prefix co-
des. IEEE Trans. Commun. 45, 10 (Oct.), 1200—1207.
42. Moffat, A. Bell, T. C. An empirical evaluation of coding methods for multi-symbol
alphabets. Inf. Process. Manage. 30, 6, 791—804.
43. Pennebraker W.B., Mitchell J.L., An overview of the basic prinicples of the Q-co-
der adaptive binary arithmetic coder. IBM J. Res. Dev. 32,6 (Nov.), 717—726.
44. Rissanen, J. Generalised Kraft inequality and arithmetic coding. IBM J. Res. Dev.
20, 198—203.
45. Rissanen J., Langdon, G. G. Arithmetic coding. IBM J. Res. Dev. 23, 2 (Mar.),
149—162.
46. Rissanen J., Langdon, G. G. Universal modeling and coding. IEEE Trans. Inf. The-
or. IT-27, 1 (Jan.), 12—23.
47. Rissanen J„ MOHIUDDIN, К. M. A multiplication-free multialphabet arithmetic
code. IEEE Trans. Comm. 37, 2 (Feb.), 93—98.
48. Rubin, F. Arithmetic stream coding using fixed precision registers. IEEE Trans.
Inf. Theor. IT-25, 6 (Nov.), 672—675.
214
Глава 6. Криптографическое сжатие
49. Schindler, М. A fast renormalisation for arithmetic coding. In Proceedings of the
1998
50. IEEE Data Compression Conference (Snowbird, UT), J. A. Storer and M. Cohn,
Eds. IEEE Computer Society Press, Los Alamitos, CA, 572.
51. Witten I.H., Bell T. C. The zero frequency problem: Estimating the probabilities
of novel events in adaptive text compression. IEEE Trans. Inf. Theor. 37, 4 (July),
1085—1094.
52. Witten,I.H.,Moffat, A., Managing Gigabytes: Compressing and Indexing Docu-
ments and Images. Van Nostrand Reinhold Co., New York, NY.
53. J. Ziv, A. LEMPEL, A universal algorithm for sequential data compression. IEEE
Trans. Inf. Theor. IT-23, 3, 337—343.
Глава 7
Прикладные задачи шифрования
For generations, people have defined and protected their pro-
perty and their privacy using locks, fences, signatures, seals,
account books, and meters. These have been supported by a
whole host of social constructs ranging from international trea-
ties through national laws to manners and customs. This is
changing, and quickly. Most records are now electronic, from
bank accounts to registers of company shares and real proper-
ty; and transactions are increasingly electronic, as shopping
moves to the Internet. Just as important, but less obvious, are
the many everyday systems that have been quietly automated.
R.Anderson.
Security Engineering: A Guide to
Dependable Distributed Systems
На сегодняшний день уже трудно представить коммерческие сетевые прило-
жения, не обеспечивающие хотя бы элементарных механизмов защиты передава-
емых данных. Действительно, со времен незащищенных сетей кампусов утекло
много времени и теперь, когда большие корпоративные сети приобретают откры-
тую архитектуру и объединяются в огромный конгломерат зачастую абсолютно
различных (с точки зрения организации и управления) сетей, перед разработчи-
ками сетевых приложений и администраторами сетей стоят весьма актуальные
вопросы защиты информации. Сложность задач обеспечения информационной бе-
зопасности все время возрастает, что заставляет обращаться к вопросу защиты
информации уже не только как к вопросу об обеспечений защиты передаваемых
данных, но и к вопросу защищенности интрасетей как вычислительных комплек-
сов в целом. Такой подход подразумевает наличие комплекса согласованных меж-
ду собой мер по обеспечению слаженной работы систем информационной защиты
сети, который позволит противостоять уже не только известным видам атак извне
сети, но и любым другим действиям злоумышленников.
Одну из первостепенных ролей здесь играет криптография. Рассматривая от-
крытые системы и Интернет с точки зрения защиты информации, можно выде-
лить следующие основные уровни информационной безопасности:
• рабочие терминалы, с которых осуществляется непосредственный доступ
к интрасети, использование ее ресурсов, доступ к управлению интрасетью
и т. д.;
• локальная сеть как группа компьютеров, объединенная по какому-либо при-
знаку в соответствии с топологией сети;
• межсетевые экраны и межсетевое взаимодействие.
Каждый из перечисленных пунктов требует к себе пристального внимания
при разработке систем защиты информации. Неверно выбранная модель системы
защиты или малейшая несогласованность методов защиты одного уровня с оста-
216 Глава 7. Прикладные задачи шифрования
льными могут повлечь за собой появление «узких» мест в системе защиты, как,
например, ошибочное использование криптографических средств защиты инфор-
мации. В результате даже криптостойкие средства могут быть подвергнуты
успешной атаке со стороны злоумышленника. Ярким примером таких ошибок яв-
ляется, например, повторное использование паролей и вычисленных псевдослу-
чайных последовательностей.
Такие логические ошибки организации защиты с помощью криптосредств
обычно обнаруживаются уже после того, как посредством их использования про-
исходит нарушение установленного режима безопасности. В этом контексте логи-
ческие.ловушки — самые трудные и содержатся в области, охватываемой послед-
ним из перечисленных выше пунктов. Проектирование и реализация модели за-
щиты информации , на уровне межсетевого взаимодействия является технически
наиболее сложным процессом.
Пример одного из таких тонких мест в проектировании средств криптографи-
ческой защиты информации является простейший вопрос о дополнении данных до
размера, кратного размеру блока используемого шифра. Дело в том, конфиденци-
альные данные могут иметь произвольный размер, а блочные средства шифрова-
ния для зашифрования информации вообще говоря, используют блоки данных и
довольно больших размеров (обычно 64, 128 и более битов). Естественный во-
прос, который возникает при шифровании: как дополнять и дополнять ли вообще
защищаемые данные до размера, кратного размеру блока шифра?
Если всегда заполнять неиспользуемый остаток блок данных нулями (по
умолчанию) или единичным битом и остальными нулевыми, то можно столкнуть-
ся с проблемой, когда криптоаналитик воспользуется этой информацией и полу-
чит дополнительную пару (открытый текст, шифротекст). Возможный способ раз-
решения этой проблемы — заполнение недостающих битов значением, которое
является инверсией значения последнего бита данных. В этом случае криптоана-
лиз ик будет вынужден еще и гадать по поводу того, какой бит данных был послед-
ним — нулевой или единичный. Еще один способ заключается в вычислении
свертки или криптографического хэша от части или всего объема данных и запол-
нение недостающих битов в конце блока битами получившегося хэша. Это наибо-
лее эффективный вариант с точки зрения стойкости, но наиболее медленный с
точки зрения скорости обработки информации. Обычно недостающие биты запол-
няют случайными или псевдослучайными значениями, а последние несколько би-
тов (три или четыре) являются значением реальной длины данных в этом послед-
нем блоке.
Использование однократного гаммирования
С точки зрения теории криптоанализа метод шифрования однократной слу-
чайной равновероятной гаммой той же длины, что и открытый текст, является не-
вскрываемым (далее для краткости авторы будут употреблять термин «однократ-
ное гаммирование», держа в уме все вышесказанное). Обоснование, которое при-
вел Шеннон, основываясь на введенном им же понятии информации, не дает
Гпава 7. Прикладные задачи шифрования
217
возможности усомниться в этом — из-за равных априорных вероятностей крипто-
аналитик не может сказать о дешифровке, верна она или нет. Кроме того, даже
раскрыв часть сообщения, дешифровщик не сможет хоть сколько-нибудь попра-
вить положение — информация о вскрытом участке гаммы не дает информации
об остальных ее частях.
Логично было бы предположить, что для организации канала конфиденциаль-
ной связи в открытых сетях следовало бы воспользоваться именно схемой шифро-
вания однократного гаммирования. Ее преимущества вроде бы очевидны. Есть,
правда, один весомый недостаток, который сразу бросается в глаза, — это необ-
ходимость иметь огромные объемы данных, которые можно было бы использовать
в качестве гаммы. Для этих целей обычно пользуются датчиками настоящих слу-
чайных чисел (в западной литературе аналогичный термин носит название True
Random Number Generator или TRNG). Это уже аппаратные устройства, которые
по запросу выдают набор случайных чисел, генерируя их с помощью очень боль-
шого количества физических параметров окружающей среды. Статистические ха-
рактеристики таких наборов весьма близки к характеристикам «белого шума»,
что означает равновероятное появление каждого следующего числа в набор'
А это, в свою очередь, означает для нас действительно равновероятную гамму38.'
К сожалению, для того чтобы организовать конфиденциальный канал переда-
чи данных, потребуется записать довольно большое количество этих данных и об-
меняться ими по секретному каналу39. Уже одно это условие делает однократное
гаммирование во многих случаях неприемлемым. В самом деле, зачем передавать
что-то по открытому незащищенному каналу, когда есть возможность передать
все это по секретному защищенному? И хотя на простой вопрос, является ли ме-
тод использования однократной случайной равновероятной гаммы стойким к
взлому, существует положительный ответ, его использование может оказаться
попросту невозможным.
Да и к тому же метод однократного гаммирования криптостоек только в опре-
деленных, можно даже сказать, тепличных условиях. Что же касается общего
случая, то все не так просто.
Показать слабости шифра однократного гаммирования можно, говоря науко-
образно, с помощью примера или, что называется, «на пальцах». Представим сле-
дующую ситуацию.
Допустим, в тайной деловой переписке используется метод однократного на-
ложения гаммы на открытый текст. Напомним, что «наложение» гаммы не что
иное, как сложение ее элементов с элементами открытого текста по некоторому
38 Многие известные фирмы занимаются производством таких устройств. В их число вхо-
дит даже IBM, которая имеет свою собственную лабораторию, исследующую Статистические
свойства подобных генераторов случайных чисел. В конце 2000 года на рынок компьютерных
комплектующих поступили экспериментальные серии материнских плат от IBM, которые до-
полнительно содержали запатентованный IBM генератор случайных чисел. Его свойства хоро-
шо задокументированы, а с выборками больших объемов были проведены масштабные стати-
стические тесты.
39 Например записав данные на DVD-диск и послав его специальным курьером с охраной.
Хотя в этом случае нет гарантии того, что этого курьера не перехватят и не подкупят.
218
Глава 7. Прикладные задачи шифрования
фиксированному модулю. Значение модуля представляет собой известную часть
алгоритма шифрования.
Чтобы дальнейшие рассуждения были как можно более понятны, рассмотрим
следующее свойство шифротекста. Предположим, что мы знаем часть гаммы, ко-
торая была использована для зашифрования текста «Приветствую, мой ненагляд-
ный сосед!» в формате ASCII, кодировка WIN-1251 (см. листинг 7.1).
Листинг 7.1 .
Приветствую, _ и о й
CFFO Е8 Е2Е5 F2 F1 F2 Е2 F3 FE 2С 20 ЕС ЕЕ Е9
_ненаглядный. _сос
20 ED Е5 ED Е0 ЕЗ ЕВ FF Е4 ED FB Е9 20 F1 ЕЕ F1
ед!
Е5 Е4 21
Верхние строки в этих трех парах строк соответствуют символам открытого
текста, а нижние строки представляют собой соответствующие шестнадцатерич-
ные их обозначения.
Для зашифрования была использована гамма из листинга 7.2 (значения чи-
сел даны тоже в шестнадцатеричном формате).
Листинг 7.2
ВО 8Е 1Е 72 9С 26 43 AD Е7 8В 89 7С 9Т 06 DE Е2
2В DC F9 С9 Е1 6D ВВ 91 43 68 F3 60 85 2F 0А 74
OF АА 7А 8D А1 8С F8 4А 5D 52 7В ВВ 7С 01 25 93
Пусть криптоаналитику стали доступны ее первые десять байтов и он также
знает, что было использовано наложение гаммы как сложение по модулю два40.
В языке Си существует общеизвестный оператор «л», который ее выполняет. Ал-
горитм шифрования на языке Си описывается короткой и простой функцией (см.
листинг 7.3).
Листинг 7.3
char text[1024] = ’’Приветствую, мой ненаглядный сосед!’’;
char gamma[1024] ; = {
OxBD, 0x8E, 0x1Е, 0x72, 0х9С, 0x26, 0x43, OxAD, 0хЕ7, 0x8В, 0x89,
0x7C. 0x91, 0x06, OxDE, 0хЕ2, 0x2В, OxDC, 0xF9, 0хС9, 0хЕ1, 0x6D.
OxBB, 0x91, 0x43, 0x68, 0xF3, 0x6D, 0x85, 0x2F, 0x0A, 0x74, OxOF,
OxAA, 0x7A, 0x8D, 0xA1, 0x8C, 0xF8, 0x4A, 0x5D, 0x52, 0x7B, OxBB,
0x7C, 0x01, 0x25, 0x93
for (int i = 0; i < strlen(text); i++) •
textfi] "= gamma[i];
40 Сложение по модулю 2 представляет собой сложение в поле характеристики два, в про-
стонародье именуемое операцией XOR или «Исключающее ИЛИ».
Гпава 7. Прикладные задачи шифрования 219
А ее результат выполнения, то есть зашифрованный текст, выглядит, как по-
казано в листинге 7.4.
Листинг 7.4
72 7Е F6 90 79 D4 В2 5F 05 78 77 50 В1 ЕА 30 0В
0В 31 1С 24 01 8Е 50 6Е А7 85 08 84 А5 DE Е4 85
ЕА 4А 5В
Поскольку криптоаналитику известны первые десять байтов гаммы, он может
дешифровать первые десять байтов шифротекста с помощью все той же програм-
мы из листинга 7.3. Но кроме этого, он может использовать известные ему байты
гаммы, чтобы подделать начало сообщения, заменив десять байтов оригинального
шифротекста на свои собственные. Для этого он может выбрать поддельное сооб-
щение, например «До свидания». Затем зашифровать его гаммированием и помес-
тить в начало шифротекста вместо зашифрованной части исходного сообще-
ния — слова «Приветствую». В этом случае гамма будет выглядеть так, как в лис-
тинге 7.5 (жирным выделен замещенный участок).
Листинг 7.5
79 60 ЗЕ 83 7Е СЕ А7 4D 0А 63 76 50 В1 ЕА 30 0В
0В 31 1С 24 01 8Е 50 6Е А7 85 08 84 А5 DE Е4 85
ЕА 4А 5В
Получатель, расшифровав сообщение, увидит фразу «До свидания, мой нена-
глядный сосед!», а не оригинальную «Приветствую, мой ненаглядный сосед!».
При этом у него не будет никакой возможности проверить, действительно ли это
написал отправитель или кто-то другой. Так что, скорее всего, он поверит при-
сланному сообщению.
Вернемся теперь немного назад и попробуем проанализировать зашифрован-
ный однократной гаммой документ, содержащий что-либо более существенное.
К примеру, коммерческую тайну. Поставим себя на место криптоаналитика, зада-
чей которого стало вскрытие перехваченного зашифрованного документа.
Этот документ вполне может быть контрактом на оказание услуг в сфере за-
щиты информации конкурирующей фирмы «Рога и Копыта». Как и большинство
деловых бумаг, подобный контракт имеет фиксированный бумажный формуляр
(примитивный вариант изображен в листинге 7.6), в который попросту вписыва-
ются нужные значения полей — фамилии, суммы и ставятся подписи. При пере-
воде в электронный вид этот документ принимает вполне определенную фиксиро-
ванную электронную форму в формате какого-нибудь текстового процессора.
Листинг 7.6
ДОГОВОР N
Я,_____________________ именуемый в дальнейшем...
...заключаю договор на сумму...
Подпись ЗАКАЗЧИКА Подпись ИСПОЛНИТЕЛЯ
220
Гпава 7. Прикладные задачи шифрования
Криптоаналитик наверняка легко может получить копию этого электронного
документа. Он может сделать это, например, под предлогом заключения договора
о тестировании компьютеров на предмет возможной утечки информации. Иссле-
дуя эту копию, он узнает тип и электронный формат документа, который у него
уже есть в зашифрованном виде. Таким образом, он становится обладателем так
называемой вторичной информации о шифре.
С высокой долей вероятности может оказаться, что к нему в руки попал доку-
мент, например, в формате Microsoft Word. Этот формат содержит очень много
избыточной информации, которая сама по себе может быть полезна для криптоа-
нализа (подробнее об этом см. раздел «Защита текстовых документов Microsoft
Word»).
Самое главное в любом формате — перечень значений различных полей.
Многие поля формата текстовых файлов Microsoft Word (MSWord) просто запол-
няются фиксированными значениями. Тогда, по сути, криптоаналитик сразу же
получает довольно много пар «открытый текст — зашифрованный текст», поско-
льку многие участки того файла, который находится в его руках, либо вовсе фик-
сированы, либо легко угадываются.
Это наверняка дало бы криптоаналитику множество преимуществ, если бы
документ был зашифрован каким-нибудь блочным шифром, но, к сожалению, со-
вершенно бесполезно в случае однократного использования равновероятной
гаммы.
Анализируя шифротекст, мы можем сложить известные нам значения полей
формата MSWord с зашифрованным текстом и получить участки гаммы. Но, к со-
жалению, эта информация ничем не поможет нам в поиске возможных значений
для остальных участков гаммы, поскольку они вырабатывались независимо друг
от друга и знание одной части не дает ни капли информации о других частях.
С другой стороны, получив текстовый формуляр в электронном виде и срав-
нивая его с зашифрованным текстом, мы можем с некоторой уверенностью ука-
зать на местоположение тех или иных элементов текста в зашифрованном доку-
менте. То есть, имея стандартный формуляр, мы можем опираться не только на
легко угадываемые значения полей формата MSWord, но и уже на текстовые со-
общения, которые хранятся в файле в этом формате.
Посмотрим на добытый криптоаналитиком формуляр типового документа.
Для этого можно использовать НЕХ-редактор или даже быстренько набросать
программку вывода содержимого файла с помощью функции print_hex() (см. гла-
ву «Отступление для программистов»).
По смещению 500h (в десятичном эквиваленте 500h = 1280) байтов в содер-
жимом файла можно найти отлично видимый невооруженным взглядом текст уже
знакомого документа, приведенный выше41 (см. листинг 7.7).
41 В последних версиях формата документов Microsoft Word текст записывается в формате
Unicode, то есть по два байта на символ; к счастью, и эта трудность достаточно просто преодо-
левается использованием соответствующего средства для просмотра и редактирования доку-
ментов в формате Unicode, например, встроенного в командную оболочку менеджера файлов
Far.
Глава 7. Прикладные задачи шифрования
221
Листинг 7.7
00000500: С4 20 СЕ 20 СЗ 20 СЕ 20 | ! С2 20 СЕ 20 D0 20 20 20 ДОГОВОР .
00000510: 4Е 5F 5F 5F 5F 0D 0D DF 1 1 2С 20 5F 5F 5F 5F 5F 5F N Я,
00000520: 5F 5F 5F 5F 5F 5F 5F 5F | ! 5F 5F 5F 5F 5F 2С 20 Е8 , и
00000530: ЕС Е5 ED F3 Е5 ЕС FB Е9 ! ! 20 Е2 20 Е4 Е0 ЕВ FC ED менуемый в дальн
00000540: Е5 Е9 F8 Е5 ЕС 85 0D 85 ! ! Е7 Е0 ЕА ЕВ FE F7 Е0 FE ейшем: заключаю
00000550: 20 Е4 ЕЕ ЕЗ ЕЕ Е2 ЕЕ F0 ! ! 20 ED Е0 20 F1 F3 ЕС ЕС договор на сумм
00000560: F3 20 5F 5F 5F 5F 5F 5F 1 ! 5F 0D 0D 0D CF ее’ Е4 EF у Подп .
00000570: Е8 F1 FC 20 С7 СО СА СО 1 ! С7 D7 С8 СА СО 09 09 CF ись ЗАКАЗЧИКА П
00000580: ЕЕ Е4 EF Е8 F1 FC 20 С8 ! D1 CF СЕ СВ CD С8 D2 С5 одлись ИСПОЛНИТЕ
00000590: СВ DF 0D 0D 21 00 91 С4 ! 1 02 А1 01 00 9С С4 02 9D ЛЯ
В таком случае данные зашифрованного файла по этому же смещению могут
выглядеть так же, как и в листинге 7.8 (авторы берут на себя смелость немного
свободно обращаться с шифротекстом, однако, как будет показано, это не меняет
ситуации в целом):
Листинг 7.8
00000500: F2 А9 ВС 9В 37 FD 49 СО 1Е 89 20 ЕС ЗА В9 F1 2Е ей+Ы7д1+-Й ь:!ё.
00000510: С8 96 С8 76 6Е ВС ЗВ А9 8В ВА 91 1D 82 70 Е1 А6 +IJ+vn+; ЙЛ ? С__Врсж
00000520: 78 1В 22 09 F2 70 72 СВ 85 С8 ВС DC 62 DC F4 D9 х_». Срг-Е++__Ь_1 +
00000530: В6 Е0 0Е СВ 6Е AD IB В9 4С ED 44 А2 А2 ОС СА 2D }р-пн_}LsDbb--..
00000540: 51 В4 27 6Е Е6 17 72 10 7С 79 29 EF Е4 А5 08 АО Q; ' пц__г__| у) яфе_
00000550: 5С 5С В7 FA 73 DF СС 9F СВ АА А8 8С Е0 82 25 84 \\+ • з__|Я-киМрВ%Д
00000560: 7Е DA 16 35 8F 86 6С 52 2D 8F F2 FB 2А С7 Е9 85 ~+_5пж1н-пе_* *;ще
00000570: В8 9Е F3 45 D9 1А 57 5Е Е1 А2 67 37 Е4 D7 71 А2 +ЮеЕ+__¥ААсвд7ф+дв
00000580: В6 IB В9 СЗ 79 5D СА 2F AF 44 А2 20 65 F2 24 9В 5__!+y]-/nDB еС$Ы
00000590: ВС 83 D4 34 05 7Е FA АА 83 F4 AF ЕА 72 93 ВВ 57 +Г+4 ~*кГ1пъгУ+М
Если теперь данные из зашифрованного файла сложим по модулю два (ведь по
правилу Керкхоффа нам известен способ сложения гаммы с открытым текстом) с
данными типового договора, то получим не что иное, как несколько байтов гаммы
(см. листинг 7.9). Точно так же мы поступали с текстом «Приветствую, мой нена-
глядный сосед!», рассматривая способ подделывания подобных сообщений.
Листинг 7.9
Байты из типового договора по смещению 500h:
С4 20 СЕ 20 СЗ 20 СЕ 20 С2 20 СЕ 20 00 20 20 20 ДОГОВОР .
Складываем с байтами шифротекста договора по тому же смещению:
F2 А9 ВС 9В 37 FD 49 СО 1Е 89 20 ЕС ЗА В9 F1 2Е СЙ+Ы7П1+-Й ь:|ё.
С
И получаем байты гаммы:
36 89 72 ВВ F4 DD 87 Е0 DC А9 ЕЕ СС ЕА 99 D1 0Е СЙ+Ы7П1+-Й ь:|ё.
• Теперь допустим, мы каким-либо образом узнали, что сделка была оформлена
на общую сумму $15000. Следовательно, эта сумма была проставлена в докумен-
те, зашифрованный вариант которого мы имеем.
f
i
! 222 Гпава 7. Прикладные задачи шифрования
Посмотрим на документ — поле для ввода суммы сделки находится по смеще-
нию 562h (1378) в файле. Можно предположить, и это почти наверняка окажется
так, что и в зашифрованном файле по тому же смещению находится строка
«$15000».
Если злоумышленник42 задастся целью подделать сумму сделки, он может в
этом преуспеть, сделав всего несколько простых вычислительных действий при
помощи средств модулярной арифметики.
Итак, следуя данному немного выше примеру и сделав предположение, что
сумма равна ни больше ни меньше $15000, сложим по модулю два байты строки в
зашифрованном тексте, начиная со смещения 562h (именно там находится сумма
договора), с байтами строки «$15000» — предполагаемой нами суммой. Резуль-
тат отражен в листинге 7.10.
Листинг 7.10
7Е DA 16 35 8F 86 6С 52 20 8F F2 FB 2А С7 Е9 85 Ч-_5ПЖ1Н*П6_‘|щЕ
складываем с байтами строки '$15000":
24 31 35 30 30 30 $15000
И получаем байты гаммы:
32 04 ВА В6 5С 62 2_||\Ь
Получив таким простым образом уже не просто несколько байтов гаммы, а
участок гаммы, где находится, интересующая нас информация, мы можем зашиф-
ровать все, что нам заблагорассудится. В нашем случае это любая сумма догово-
ра. А затем мы можем поместить результат по выбранному смещению обратно в
зашифрованный файл и выслать его действительному получателю.
Уменьшим слегка сумму контракта, сложив байты шифротекста с байтами
строки «$00000» (см. листинг 7.12):
Листинг 7.11
складываем байты гаммы:
32 04 ВА В6 5С 62 2_||\Ь
с байтами строки ”$00000":
24 30 30 30 30 30 $00000
и снова получаем байты шифротекста:
16 34 8А 86 6С 52 .4KX1R
В результате этих действий получаем почти тот же зашифрованный текст, но
теперь в контракте стоит совершенно другая сумма (см. листинг 7.12, рамочкой
обведены изменившиеся байты).
42 Авторы ни в коем случае не хотели бы ставить себя и тем более читателя на место зло-
умышленника, но — «увы и ах!» — криптоаналитику всегда приходится это делать.
Гпава 7. Прикладные задачи шифрования
223
Листинг 7.12
00000500: F2 А9 ВС 9В 37 FD 49 СО ; ; 1Е 89 20 ЕС ЗА В9 F1 2Е
00000510: С8 96 С8 76 6Е ВС ЗВ А9 ; ! 8В ВА 91 1D 82 70 Е1 А6
00000520: 78 1B 22 09 F2 70 72 СВ | 1 85 С8 ВС DC 62 DC F4 D9
00000530: B6 Е0 0Е СВ 6Е AD IB В9 | i 4С ED 44 А2 А2 ОС СА 2D
00000540: 51 В4 27 6Е Е6 17 72 10 | ! 7С 79 29 EF Е4 А5 08 АО
00000550: 5С 5С В7 FA 73 DF СС 9F | 1 СВ АА А8 8С Е0 82 25 84
00000560: 7Е DA[ 16 34 8А 86 6С 52 | J 2D 8F F2 FB 2А С7 Е9 85
00000570: В8 9Е F3 45 D9 1А 57 5Е | ! Е1 А2 67 37 Е4 D7 71 А2
00000580: В6 1В В9 СЗ 79 5D СА 2F 1 1 AF 44 А2 20 65 F2 24 9В
00000590: ВС 83 D4 34 05 7Е FA АА | ! 83 F4 AF ЕА 72 93 ВВ 57
€й+Ы7п1+-Й ь:!ё.
+U+vn+; ЙЛ 5 С__Врсж
х_».epr-E++_b_I+
!р-пн__| ЬэБвв— . .
Q | ’ пц__г__ | у) яфе__а
\\+•s !Я-киМрВ%Д
~+.|4ЮК1к|-ПС _* |щЕ
+ЮеЕ+__^Асвд7ф+дв
!_;+y]-/nDB
+Г+4_~•KrlnbrY+W
Таким образом, для выбранного специалистами фирмы «Рога и Копыта» спо-
соба шифрования (то есть однократного шифрования равновероятной гаммой) су-
ществуют вполне приемлемые условия, при которых может быть использован по
крайней мере один способ подделки сообщений. А это уже весьма ощутимый ре-
зультат, который может оказаться «последней ошибкой».
Аналогичным и еще более простым с точки зрения криптоанализа примером
является шифрование методом однократного гаммирования электронных почто-
вых сообщений.
Сообщения электронной почты в сети Интернет передаются (как и многие
другие данные простых сетевых протоколов прикладного уровня) в текстовом
виде, приемлемом для анализа невооруженным взглядом. В листинге 7.13 пред-
ставлен пример почтового сообщения в том виде, в котором оно путешествует в
сети от компьютера к компьютеру. А листинг 7.14 содержит то же самое сообще-
ние, но так, как его видит рядовой пользователь.
Листинг 7.13
From POPmail Tue Nov 17 18:45:15 1998
(with Netcom Interactive pop3d (v1.21.1 1998/05/07) Wed Nov 18 02:39:15 1998)
X-From_: seg@crow.sec.gov Tue Nov 17 20:36:28 1998
Received: from crow.sec.gov (crow.sec.gov [204.192.28.11]) by
multi33.netcomi.com (8.8.5/8.7.4) with ESMTP id UAA32707 for <fc@all.net>;
Tue, 17 Nov 1998 20:36:28 -0600
Received: (from seg@localhost) by crow.sec.gov id VAA01882 for fc@all.net;
Tue, 17 Nov 1998 21:37:15 -0500
From: Joe Segreti <seg@crow.sec.gov>
Message-Id: <199811180237.VAA01882@crow.sec.gov>
Subject: Ответ на предложение
To: fc@all.net
Date: Tue, 17 Nov 1998 21:37:14 -0500 (EST)
X-Mailer: ELM [version 2.4 PL25 PGP7]
MIME-Version: 1.0
Content-Type: text/plain; charset=IS0-8859-1 '
Content-Transfer-Encoding: 8bit * 1
Доброго времени суток!
Уважаемые коллеги, предлагаем вам следующую форму сотрудничества.
224
Гпава 7. Прикладные задачи шифрования
Листинг 7.14
Date: Tue, 17 Nov 1998 21:37:14 -0500 (EST)
From: Joe Segreti <seg@crow.sec.gov>
To: fc@all.net
Subject: Ответ на предложение
Доброго времени суток!
Уважаемые коллеги, предлагаем вам следующую форму сотрудничества.
И в том и в другом случае в сообщении остается много служебных слов, кото-
рые используются почтовым программным обеспечением для доставки сообщения
адресату. Например, ключевое слово Date: и следующая за ним дата отсылки пи-
сьма является обязательным атрибутом любого письма. И точно так же, как под-
вергся анализу текстовый файл формата MSWord, мы можем подвергнуть приста-
льному изучению это электронное сообщение, подставив, к примеру, другую дату
отсылки письма или изменив приветствие и подпись43.
Собственно говоря, все приведенные примеры и недостатки и есть ответ на
вопрос, почему почти никто не пользуется методом однократного гаммирова-;
ния — все зависит от того, как именно это делается и какими ресурсами обладает
пользователь шифросистемы.
Криптографическая защита исходных текстов
Время реакции на весьма динамично развивающуюся среду веб-технологий
определяет эффективность работы любого Интернет-сайта. Современные техно-
логии создания веб-контента в режиме реального времени дали профессионально-
му веб-мастеру мощнейшие инструменты для управления потоками информации в
Интернет. В условиях постоянного роста производительности использование язы-
ков сценариев или, как их еще называют, scripting languages или scripts стало од-
ним из опорных решений фундаментального подхода организации инфраструкту-
ры Интернет-сайтов. Мощные, легко осваиваемые специализированные языки
программирования, ориентированные на разработчиков веб-сайтов, получили ши-
рочайшее распространение. Языки сценариев изначально были ориентированы на
быстрое и эффективное решение иных задач, нежели языки программирования
системного уровня, поскольку они создавались как логически связующие компо-
ненты к уже готовым программным решениям. Преимущества такого подхода пе-
ред традиционным статическим наполнением веб-порталов видны невооружен-
ным взглядом. Это и гибкость построения гипертекстовых переходов, и возмож-
ность создания отчетов по записям в базах данных в реальном времени, и
генерация комплексных веб-документов из существующих элементарных компо-
нентов.
43 Чтобы узнать приветствие и подпись другого человека, иногда бывает достаточно просто
написать ему письмо так, как будто бы вы ошиблись адресом. Ответ от него с сообщением об
этом будет наверняка содержать всю необходимую информацию.
Гпава 7. Прикладные задачи шифрования
225
Точно так же, как и несколько лет назад в малых интегрированных сетях, в
программировании контента публичных серверов существует два подхода.
А именно создание интерпретируемых сценариев и компиляция байт-кода. Пер-
вый подход не выходит за рамки CGI-программирования, согласно которому для
разработки гипертекстовой страницы нужен только обычный текстовый редактор,
а сам гипертекстовый документ должен легко читаться человеком. Второй подход
повышает эффективность исполнения программы, а также защищенность кода от
доступа и несанкционированных изменений.
Реализации интерпретаторов таких языков сценариев, как Perl и Phyton, в це-
лях повышения эффективности перед исполнением сценария проводят предвари-
тельную перекомпиляцию в специальный мобильный байт-код. Для обозначения
байт-кода существует даже собственное название — пи-код (p-code). Такое назва-
ние байт-коду было дано одним из создателей «псевдомашины» (p-system) — опе-
рационной системы для микроконтроллеров (и, например, машин СР/М), кото-
рая разрабатывалась в 1977 году и работала как эмулирующий интерпретатор
языка UCSD Pascal. Автор UCSD Паскаля — Урс Арманн (Urs Armann) вместе с
профессором Кеннетом Боулсом (Kenneth Bowles) и дали название коду, в кото-
рый компилировались исходные тексты.
Такой код, будучи сформирован в результате трансляции исходного текста
сценария, записывается в память или файл и лишь потом обрабатывается интерп-
ретатором. Для языка Python файлы с байт-кодом (они имеют специальное расши-
рение *.рус) в дальнейшем можно спокойно переносить с платформы на платфор-
му и исполнять с равными правами как, к примеру, на Sun, так и на Intel
РС/Win32 — мобильность пи-кода это позволяет.
В конце 90-х годов прошлого столетия CGI-программирование — а это авто-
матизация, гостевые книги, форумы, опросы, списки рассылки, интерфейсы к ба-
зам данных и многое другое — стало наиболее популярным и эффективным спо-
собом организации интерактивного взаимодействия с пользователями. Как и в
любой другой области программирования, стали возникать свои вопросы и проб-
лемы.
Одними из самых интересных и неоднозначных вопросов были и остаются во-
просы о защите программных кодов и исходных текстов от несанкционированной
модификации и копирования. Актуальность стоящих проблем защиты програм-
много обеспечения очевидна хотя бы потому, что все сценарные языки, такие, как
Perl, Phyton, JavaScript и всевозможные производные с постфиксом *script (то
есть VBScript, PeriScript и т. д.), являются интерпретируемыми, и ни о каких би-
нарных кодах и скрытом исходном тексте не может идти и речи.
В этом случае исследованию алгоритма работы сценария и использованию
его без разрешения авторов не создано никаких препятствий. Программисты, со-
здающие средства веб-автоматизации, пытаются решить эту проблему всевозмож-
ными способами, прибегая порой к изощренным методикам сокрытия исходных
текстов и защиты их от модификации. Собственно говоря, защита от модифика-
ции хороша также и как защита, что называется, «от дурака», что немаловажно
при продаже программного обеспечения не в комплексе, а как отдельной едини-
цы, когда приобретающий программное обеспечение пользователь получает пол-
8 Зак. 85
226
Гпава 7. Прикладные задачи шифрования
ный доступ не только к конфигурационным файлам, но и к пакету самих сценари-
ев. И при отсутствии у него должной квалификации внесенные в сценарий изме-
нения могут существенно повлиять на отказоустойчивость и работоспособность
всего комплекса. Кроме того, как показывает практика обеспечения информаци-
онной безопасности в открытых системах, программное обеспечение веб-серверов
зачастую столь несовершенно, что при достаточной сноровке злоумышленник
вполне способен получить исходный текст сценариев веб-сервера (классическим
примером может послужить инцидент с веб-сервером WebTrends, который позво-
лял получить исходный текст сценариев, просто добавив пробел к его имени в
строке запроса. Так, запрос по адресу «http: / / somewhere.in.the.inter-
net.com/cgi-bin/script.pl» запускал script.pl на исполнение, а запрос к
«http://somewhere.in.the.internet.com/cgi-bin/script.pl%20» выдавал исход-
ный текст сценария любому неавторизованному пользователю.
На сегодняшний день существует несколько способов защитить исходные
тексты программных модулей для интерпретаторов от модификации и даже со-
всем скрыть их от глаз пользователя. Рассмотрим их на примере одного из самых
популярных в сети Интернет (то есть по всему миру) языка сценариев Perl.
Одним из вариантов сокрытия исходных текстов является возможность «ком-
пилирования» исходных текстов в исполняемый бинарный код (формат РЕ-ехе
для Win32 платформ и ELF для Linux/BSD). Для этого исходный текст может
быть скрыт внутри исполнимого файла (например, сжат с помощью алгоритма
криптографического сжатия). Сам исполнимый файл в этом случае представляет
собой пригодный для исполнения файл, содержащий полную реализацию функ-
ций интерпретатора программного языка, на котором написан исходный текст за-
щищаемого скрипта. После начала исполнения исполнимый файл разархивирует
исхрдный текст скрипта и исполняет его с помощью встроенного интерпретатора.
, В случае с Perl для этого используется технология «Perl Embedded in С», раз-
работанная Ларри Уоллом, инструментарий для которой распространяется вмес-
те с интерпретаторами языка сценариев Perl бесплатно.
В начале апреля 2002 года среди писем, распространяемых в популярной рас-
сылке BugTraq, посвященной информационной безопасности и, в частности, вы-
явлению фактов уязвимости программного обеспечения, можно было встретить
письма о безопасности предлагаемого разработчиками IndigoStar Software рас-
пространения исходных текстов сценариев в виде бинарных файлов. Данное про-
граммное обеспечение (утилита Рег12Ехе, распространяемая в виде shareware sof-
tware, то есть за деньги) реализует описанную выше функциональность.
Несмотря на то что авторы утилиты Рег12Ехе не предоставляют ее исходных
текстов; оказалось возможным, исследовав ее программный код, найти инженер-
ный пароль и способ зашифрования исходных текстов. Более того, это оказалось
возможно делать в совершенно автоматическом режиме, без участия челове-
каьоператора. Говорить о криптографической стойкости примененного метода
бессмысленно, поскольку ключ к шифру находится в исполнимом файле рядом с
самим шифром.
Таким образом, чтобы извлечь исходный текст из бинарного файла, достаточ-
но запустить на исполнение специальную утилиту, совершающую обратное пре-
Глава 7. Прикладные задачи шифрования
227
образование Ехе2Рег1. Автором одной из таких утилит, с легкостью позволяющей
«доставать» исходные тексты, является Четан Ганатра (Chetan Ganatra, ganat-
ras@infotech.icici.com).
Следующим способом сокрытия исходных текстов и их защиты от несанкцио-
нированной модификации можно указать встроенные средства языка Perl. Это так
называемые фильтры исходных текстов или source filters.
Необходимость создания механизма подобных фильтров была продиктована
именно соображениями защиты исходных текстов сценариев. Защищенный сце-
нарий может выглядеть следующим образом: . <
#!/bin/perl
use DecipherModule;
@*х$]'0uN&k~Zx02jZ~X{. ?s! (f; 9Q/"A"@"8H] |, WP:q-=
jkhsdk$*#@&((#$Y%@ #EDUF(HFU#@H(@#(F(@#CDLnclser#@
sd0U3R0FR32 239RUW0EFR&y~3843#q*%&"#$##© ERFSDHFF=
#&"*&$e(‘#qyr(#@yrHFhwp4y$@#83yhFwhEhfishfjlq247@$
Фильтры исходных текстов в частном случае позволяют зашифровать и/или
заархивировать часть основного тела сценария так, что сначала будет загружен
специальный модуль, который будет расшифровывать остальную часть сценария
построчно.
Конечно, преимущества такого подхода, возможно, не очевидны на первый
взгляд. Для этого необходимо чуть более детально разобраться в достаточно уни-
версальном механизме фильтров исходных текстов. На первый взгляд этот весьма
специфичный инструмент несет в себе возможности и разработки нескольких по-
следних лет в смежных областях программирования и защиты программного
обеспечения. Многие технологии защиты программного обеспечения от несанк-
ционированного копирования и использования могут быть с легкостью перенесе-
ны на «почву» фильтров исходных текстов и использованы для веб-сценариев.
И здесь точно так же, как и на платформах с Win32, существуют те же проблемы
и методы обхода защитных барьеров.
Самым уязвимым в смысле защиты от исследования сценария является мо-
дуль расшифрования основного тела исходного текста. Он может быть написан на
самом языке Perl, но тогда достаточно будет исследовать его, что является в об-
щем-то тривиальной задачей, поскольку он не может быть зашифрован. Кроме
этого, если алгоритм зашифрования достаточно сложен, расшифровка всего ис-
ходного текста может занять долгое время, что неизбежно скажется на эффектив-
ности функционирования веб-узла, а это нежелательно ни при каких обстоятель-
ствах. Очевидно, что в этом случае применять шифрование может быть не очень
удачным решением. Однако в качестве расшифровывающего модуля можно испо<
льзовать своего рода плагин (plugin), то есть специальную подключаемую библио-
теку, написанную на любом другом языке и откомпилированную как разделяемый;
модуль (shared library). ?' ' .
Используя специальный набор функций Perl API, данный модуль расшифрует
исходный текст гораздо быстрее, чем если бы он сам был написан на языке Perl.
Кроме того, такой подход позволяет на полную мощность использовать средства
8*
228
Гпаеа 7. Прикладные задачи шифрования
усложнения анализа программного кода, включая такие известные приемы, как
применение самомодифицирующегося кода, шифрование/расшифрование «на
лету», во время исполнения процедур модуля. '
Чтобы не давать голословных утверждений, попробуем реализовать подобное
программное обеспечение. В качестве алгоритма шифрования мы можем исполь-
зовать один из уже реализованных в предыдущих главах алгоритмов. Попробуем
остановиться на алгоритме RC4. Для его использования нам понадобится простая
программа, которая будет зашифровывать любые наши данные с помощью RC4 и
заданного нами ключа (см. листинг 7.15).
Листинг 7.15
«include <stdio.h>
«include <stdlib.h>
«include <memory.h>
«include <time.h>
«include "hexdump.h"
«include "rc4.h"
«define RC4_KEYSIZE 32
void prepare_pass(uchar *pass) {
srandom(time(NULL));
memset(pass, 0, sizeof(pass));
for (int i = 0; i < RC4_KEYSIZE; i++) pass[i] = randomQ + i * i;
for (int i = 0; i < sizeof(pass); i++) pass[i] "= passfsizeof(pass) - i];
I. . . ............................. ..
void main(int argc, char *argv[]),{ r > .
FILJE *f.< *f_ec; >
, RC4JEY key; , t /
Qhar .buf[1024]; / 7 '
uchar pass[RC4_KEYSIZE];
int read;
. , printf("Scripher RC4-Encoder\n[c] Roman A. Hady, Specvuzautomatika\n\n");
. if (argc == 1 || argc > 2) {
printf("Usage: encoder file_to_encode\n\n");
exit(1);
}
prepare_pass(pass);
strcpy(buf, argv[1]);
strcat(buf, ".pass");
f = fopen(buf, "wb");
' 'f if (Tf) {' ; ---
• printf("Can’t open %s:fdr write\n’5,? buf); . . .
?. <n'exit(2):* 1 го.» л...-, , .
fwrite(pass, sizeof(pass), 1, f);
fclose(f);
setup_rc4_key(&key, pass, sizeof(psss));
Гпава 7: При^адные задачи шифрования 229
f = fopen(drgv[f1], "rb”); •’ • .
if (If) {
printf(”Can’t open %s for read\n’’, argv[1]);
exit(2);
} . v , . . .
strcpy(buf, argv[1]);
strcat(buf, ".coded”);
f_ec = fopen(buf, ”wb”);
if (!f) { ( ~ .. ;
printf(”Can‘t open %s for read\n". buf); ''
exit(2);
do {
read = fread(buf, 1, sizeof(buf), f);
if (read <= 0) break;
hexdump((uchar *) buf, read, 16, NULL);
encode_rc4((uchar *) buf, read, &key);
hexdump((uchar *) buf, read, 16, NULL);
fwrite(buf, 1, read, f_ec);
} while (1);
fclose(f);
fclose(f_ec);
printf("\nOK. Job done.\n");
> ,
Программа из листинга 7.15 работает с несколькими файлами: на вход ей по-
дается имя файла, который необходимо зашифровать. При этом программе пона-
добится файл с таким же именем, но с дополнительным расширением *.pass, ко-
торый будет содержать сгенерированный программой случайным образом пароль
шифрования. Именно этим паролем и будет зашифрован исходный файл данных.
Файл данных в нашем случае будет не чем иным, как исходным текстом скрипта,
который нужно защитить от модификации и просмотра пользователем.
Для работы с этим зашифровайным файлом нам понадобится специальный
механизм обработки зашифрованных данных и их интерпретации с помощью ин-
терпретатора языка Perl.
Все это мы можем осуществить с помощью механизма Perl source filters. Для
этого мы должны создать специальный программный модуль в системе интерпре-
татора языка Perl, который взял бы на себя функции обработки зашифрованного
текста. Авторы дали название данной системе Scripher как производное от script
и cipher.
Более того, нам необходимо написать этот модуль не на РегГе, а на другом —
компилируемом в бинарный код языке (например, Си), который предоставит до-
полнительный уровень защиты, и каким-то образом реализовать его сопряжение с
системой интерпретатора.
На самом деле это не очень сложно. Для этого понадобится интерфейсный
модуль scripher.pm, написанный на Perl (см. листинг 7.16) и модуль обработки
данных, написанный на Си, но оформленный в специальном формате XS.
230
Гпаеа 7. Прикладные задачи шифрования
Листинг 7.16
package scripher;
require DynaLoader;
@ISA = qw(DynaLoader);
SVERSION = "0.0.1";
bootstrap scripher $VERSI0N;
1;
__end__
А сам модуль, оформленный по форме XS, выглядит следующим образом (см.
листинг 7.17). На самом деле это обычный файл исходного текста на языке Си, но
содержащий дополнительную информацию для динамической линковки и связи с
интерпретатором Perl.
Листинг 7.16
/* *
* Filename : scripher.xs
*
* Author : A.V. Agranovsky & R.A. Hady
* Date : 25.04.2001
* Version : 1.0.1
*/
«ifdef „cplusplus
extern "C" {
«endif
«include "EXTERN.h"
«include "perl.h"
«include "XSUB.h"
«ifdef „cplusplus
}
«endif
, размер ключа для RC4
«define RC4_KEYSIZE 32
«define HEADER-SIZE (4 + 4 + 4 + RC4_KEYSIZE)
, SEGMENT-SIZE must be greater than HEADER-SIZE
«define SEGMENT-SIZE (((HEADER-SIZE + 16) / 16) * 16)
, check for correct ID and cipher version stamp
«define RIGHT-ID OxDEADFACE
«define RC4_CIPHER 0xC4C4C401
«define uchar unsigned char
«define decode_rc4 encode_rc4
, заголовок - первые несколько байтов зашифрованных данных
typedef struct SCR_HEAD_t {
long ID;
Гпава 7. Прикладные задачи шифрования
231
long cipher.type;
long body_size;
uchar rc4_key[RC4_KEYSIZE];
} SCR-HEAD;
typeclef struct RC4_KEY_t {
uchar state[256];
uchar a_reg;
uchar b_reg;
} RC4_KEY;
static void xchg_bytes(uchar *a, uchar *b) {
register uchar temp_reg;
temp_reg = *a;
*a = *b;
*b = temp_reg;
}
, алгоритм RC4 - разворачивание ключей
void setup_rc4_key(RC4_KEY *key. uchar *pass, int passlen) {
uchar *state = &key->state[O];
uchar a = 0, b = 0;
int i;
for (i = 0; i < 256; i++) key->state[i] = i;
key->a_reg = 0;
key->b_reg = 0;
for (i =0; i < 256; i++) {
b = pass[a] + state[i] + b;
xchg_bytes(state+i, state+b);
a = (a + 1) % passlen;
}
}
, алгоритм RC4 - шифрование
void encode_rc4(uchar *buf, int buflen, RC4_KEY *key) {
uchar a_reg = key->a_reg, b_reg = key->b_reg;
uchar xor, *state = &key->state[O];
int i;
for (i = 0; i < buflen; i++) {
a_reg++;
b_reg = (state[a_reg] + b_reg);
xchg_bytes(&state[a_reg], &state[b.reg]);
xor = state[a_reg] + state[b_reg];
buf[i] "= state[xor];
}
key->a_reg = a_reg;
key->b_reg = b_reg;
}
, собственно, процедура расшифрования и обработки исходного текста
static 132 decipher(int idx, SV *buf_sv, int maxlen) {
char *nl = "\n”;
static first_time = 1;
232 Гпава 7i Прикладные задачи шифрования
static int cur.pos = 0;
static int body.size = 0;
static SV *script_sv = NULL;
RC4.KEY rc4_key;
SCR.HEAD *header;
int n = 1;
char *outs, *p;
if (first_time) {
, расшифровываем только в первый раз,
, затем только обрабатываем
first_time--;
, инициализируем поток
script.sv = FILTER_DATA(idx);
SvPVX(script_sv)[O] = ’\0’;
SvCUR_set(script_sv, 0);
, читаем и проверяем заголовок
n = FILTER_READ(idx + 1, script.sv, HEADER-SIZE);
if (n < HEADER-SIZE) croak(”Data error”);
header = (SCR.HEAD *) SvPVX(script.sv);
if (header->ID != RIGHT.ID || header->cipher_type > RC4_CIPHER)
croak(”Data incorrect type”);
body.size = header->body_size;
, готовим ключ RC4
setup_rc4_key(&rc4_key, header->rc4_key, RC4_KEYSIZE);
. загружаем данные из потока
SvPVX(scfipt_sv)[O] = ДО’;
SvCUR_set(script_sv, 0);
while (n > 0) {
, читаем, пока есть силы
n = FILTER_READ(idx + 1, script.sv, SEGMENT-SIZE);
}
, расшифровываем
decode_rc4((uchar *) SvPVX(script.sv), body.size, &rc4_key);
SvPVX(script_sv)[body_size] = Д0’;
SvCUR_set(script_sv, body.size);
}
outs = SvPVX(script.sv) + cur.pos;
SvPVX(buf_sv)[O] = Д0‘;
SvCUR_set(buf_sv, 0);
n = body.size - cur.pos;
- if.(n <= 0) return 0; , .
if (maxlen) { -
-•v sv_catpvn(buf_sv, outs; maxlen >»n ? n : maxlen); гь <
. cur.pos += maxlpn;. • ; r гч:
, return SvCUR(buf sv);< .. , r
\ /.
else {
if (p = ninstr(outs; outs + n - 1; nl, nl)) {
catched EOL ‘
Глава 7. Прикладные задачи шифрования 233
sv_catpvn(buf_sv, outs, р - outs +1);
cur_pos += (р - outs +1);
return SvCUR(buf_sv);
}
else
sv_catpvn(buf_sv, outs, n);
}
filter_del(decipher);, отсоединяемся
return SvCUR(buf_sv);, возвращаем исходный текст интерпретатору
}
MODULE = scripher PACKAGE = scripher
PROTOTYPES: DISABLE
BOOT:
, проверка, есть ли другие модули...
if (gv_stashpvn("B”, 1, FALSE)) croak(’’core dumped”);
, ...если есть, сделать вид, что произошла ошибка
return;
void
import(module)
SV *module = NO.INIT
PPCODE:
{
SV *sv = newSV(SEGMENT-SIZE);
, проверка, работает ли отладчик...
if (PL.perldb) croak("There is a memory leak because of perl debugger.”);
, ...если есть, сделать вид, что произошла ошибка из-за него
else filter_add(decipher, sv);
}
void
unimport(...)
PPCODE:
{
filter_del(decipher);
}
Встроенные средства Perl API позволяют также определить, запущен ли
скрипт под отладчиком в целях исследования его кода, а также наличие и количе-
ство других фильтров исходных текстов (см. завершающую часть листинга 7.16).
Это позволяет в какой-то степени отслеживать попытки прогона программы под
отладчиком PerlDB и попытки создания копий исходных текстов с помощью до-
- элнительных модулей. \ >
В результате компиляции программы из листинга 7.16 получается семикило-
байтовый модуль scripher.so с реализованным алгоритмом RG4 и необходимыми
средствами обработки исходного текста. Для работы он размещается в том же ката-
логе, что и зашифрованный файл сценария. Таким образом, для передачи сценария
необходимо передать два дополнительных файла (которые являются общими для
всех зашифрованных сценариев этого типа), а именно scripher.pm и scripher.so.
234
Гпава 7. Прикладные задачи шифрования
Для создания скрипта, содержащего зашифрованный сценарий-скрипт и
ключ, можно воспользоваться утилитой из листинга 7.17, которая просто соеди-
няет различные файлы вместе.
Листинг 7.17
#!/usr/bin/perl -w
$RC4_KEYSIZE = 32;
print "Scripher Enveloper\n\n";
SHEADER = "L L L";
$ID = OxDEADFACE;
SVERSION = OxC4C4C4O1;
if (@ARGV < 2) {
print "Usage: $0 envelope_file path_to_scripher_files\n\n";
exit;
}
$SCRIPT_HEADER = "#!/usr/bin/perl -w\nuse lib '$ARGV[1]';\nuse scripher;\n";
unless (-s $ARGV[O]> {
print "Can't find or zeroed file $ARGV[O]";
exit;
>.
open F, "<$ARGV[O].coded";
binmode(F);
read(F, SDATA, (-s $ARGV[O]));
close(F);
open F, "<$ARGV[O].pass";
binmode(F);
read(F. $KEY, $RC4_KEYSIZE);
close(F);
$BODY_SIZE = length(SDATA);
open F, ">$ARGV[O].pl";
print F $SCRIPT_HEADER;
print F pack($HEADER, SID, SVERSION, $BODY_SIZE);
print F SKEY;
print F SDATA;
close F;
print "Well done.\n\n";
Использовать модуль защиты можно следующим образом. На языке Perl пи-
шем произвольный сценарий-скрипт под именем, например, test (см. листинг
7.18), в который не включаем первую стандартную строчку #/path/perl -options.
Она будет создана автоматически при зашифровании исходного текста.
Листинг 7.18
print "OK-HELLO\n" for (1..10);
print "HELLO!\n";
print uipstu;
Гпава 7. Прикладные задачи шифрования
235
После работы программы зашифрования исходного текста с алгоритмом RC4
получим несколько файлов: test.pass и test.coded. Используя программу из лис-
тинга 7.17, получим готовый к использованию скрипт test.pl приблизительно сле-
дующего вида (см. листинг 7.19). Исполнять же его можно по-прежнему, стандар-
тным образом, с помощью команды perl test.pl.
Листинг 7.19
#!/usr/bin/perl -w
use lib 'scripher';
use scripher;
}ЛфХ1_*Ш{ L, •|j=eqEaVui CtyBo Ц_А-||-} J> °*ЁтЁ=юГу||-г 9[=|=ё<8Ж
=| к=№'пНИГОТ| |Оыр^цШ«3?ТЯдЧА§@9А1[У(Е_1/|О13|)*1=иЬ
#8t •bH$Mtu|'s*M-z^|\[ |= 8+МЦО^УКРиСЙ:Нр|^||ОФбД9А9&
Lm± И) C*Rt* 11 #~_дф~И@-п DOHA pfц-rqBWoG • q В=9Ё=1=> i TW
=| я “ -j / йюА* Ц-YrbJ Ю! wS^C^Ipli——kgmu) 31=»тН^1>ы| |з>о |-
Sv{ I X©y2£B7-]|-Bg-|k
В качестве дополнительного препятствия к анализу исходного текста сцена-
рия можно еще отметить метод смысловых значений идентификаторов или source
mangling. Будучи пропущенным через своего рода конвертер, скрипт-сценарий
приобретает практически нечитаемый и невероятно неудобный для анализа вид.
Например, при использовании source mangling текст такого сценария:
#!/usr/bin/perl
# randomize source file
it lines are output in random order
# reads from from stdin or argO, writes to stdout or arg1
open (STDIN, $ARGV[OJ) if (($ARGV[O] ne "”) && ($ARGV[O] ne
open (STDOUT, ">$ARGV[1]") if ($ARGV[1] ne
©list = <STDIN>;
while (@list) {
$rand = rand (©list);
print $list[$rand]:
plice ©list, $rand, 1;
1
превратится в нечто подобное:
#!/usr/bin/perl н
open (STDIN,$ARGV[O])if (($ARGV[O] ne "")&&($ARGV[0] ne "-"));open / -
(STDOUT, ”>$ARGV[1]")if ($ARGV[1] ne @110202012_as=<STDIN>; l(‘,
while(@110202012_as){$qewre7_434=rand(@H10202012_as);print
$110202012_as[$qewre7_434];splice@110202012_as,$qewre7_434,1;}
Ранее искажение исходных текстов было весьма популярно — достаточно
вспомнить распространяемые исходные тексты на языке Паскаль к пакетам Turbo
Power для Borland Pascal 7.0. Искаженные подобным образом, они тем не менее
236
Гпава 7. Прикладные задачи шифрования
Оставались годными к компиляции и линковке. Возможно, что с развитием сце-
нарного программирования source mangling приобретёт вторую молодость. •
Исследование программного обеспечения,
реализующего криптографические алгоритмы
Одной из наиболее захватывающих тем, касающихся современного програм-
мирования и криптографии, является тема исследования программ и особенно ре-
ализаций криптографических алгоритмов. Подобный верификационный анализ
необходим для того, чтобы удостовериться в- правильности работы реализации
криптографического алгоритма и соответственно отсутствия каких-либо неточно-
стей, которые могут повлиять на криптостойкость используемых методов закры-
тия информации.
Попробуем провести подобный анализ на. примере программы, реализующей
функции шифрованного диска — PGPdisk для Windows 9x/NT/W2K из пакета
программ PGP.
Суть такой программы заключается в создании прозрачного для пользователя
и системы способа шифрования и управления информацией, хранимой на виртуа-
льном диске, содержимое которого зашифровывается и расшифровывается, что
называется, «на лету», то есть непосредственно во^время доступа к данным.
Для этого создатели PGPdisk используют стандартные средства и интерфей-
сы, предоставляемые операционной системой Windows. Схема организации досту-
па к данным, к примеру, в системе Windows NT представлена на рис. 7.1.
Рис. 7.1
Плава: 7. Прикладные задачи шифрования
297
Доступ к виртуальному шифрованному диску реализован, через драйвер
устройства .ввода-вывода. На каждый пользовательский вызов реагирует драйвер,
дискового устройства, входящий в комплект программ PGPdisk (рис. 7.2). Он соот-
ветственно запросу расшифровывает или зашифровывает определенные участки
памяти накопителя и передает данные либо от, пользователя; либо к пользователю.
Рис, 7.2
U'lS'M
Пакет программного обеспечения обычно распространяется без исходных
текстов, однако на сайте производителя (www.pgpi.com) есть возможность ска-
чать их отдельно. Для того, чтобы исследовать применяемые в PGPdisk алгорит-
мы, они нам понадобятся, поэтому рекомендуем их скачать с сайта или взять с
компакт-диска, прилагаемого к данной книге. -
Диалоговое окно создания нового диска в данном пакете представлено на рис. 7.3.
Механизм шифрования данных на виртуальном диске основан на использова-
нии алгоритма симметричного шифрования CAST-128 длиной блока 128 битов.
Данный алгоритм основан на архитектуре Файстеля и наследует те же принципы
построения, что и DES и ГОСТ 28147—89. Его реализация приведена в листинге
7.20 (в исходном тексте листинга отсутствуют полные описания узлов замен алго-
ритма из-за занимаемого ими большого объема).
Листинг 7.20
«include "unidef.h"
«include "meniory.fr"- -
, Test examples:*
KEY J =0x01, 0x23, 0x45, 0x67, 0x12,; /Qx34, 0x56, 0x78,
‘ 0x23, 0x45, 0x67, 0x89, 0x34, 0x56, 0x78, 0x9A;
TEXT ' =0x01, 0X23, 0x45, 0x67, 0x89, OxAB; OxCD, OxEF;
EXPECT = 0x23, 0x8B, Ox4F, 0xE5, 0x84, 0x7E, 0x44, 0xB2;
238
Гпава 7. Прикладные задачи шифрования
Рис. 7.3
typedef struct {
uint32 master[32];
uint32 regs[4];
int empty;
} CAST128.KEY;
void setiip_cast128(CAST128_KEY *, uint8 *, int);
void encode_cast128(CAST128_KEY *. uint32 *, uint32 *);
void decode_cast128(CAST128_KEY *, uint32 *, uint32 *);
void encode_cast128_ecb(CAST128_KEY *, uint32 *, int);
void decode_cast128_ecb(CAST128_KEY *, uint32 *, int);
«define B0(x) (((x) » 24) & 255) «define B1(x) (((x) » 16) & 255) «define B2(x) (((x) » 8) & 255) «define B3(x) ((x) & 255)
«define xO BO(ixO)
«define x1 B1(ix0)
«define x2 B2(ix0)
«define x3 B3(ix0)
«define x4 B0(ix1)
«define x5 B1(ix1)
«define x6 B2(ix1)
«define x7 B3(ix1)
«define x8 B0(ix2)
Гпаеа 7. Прикладные задачи шифрования
239
«define х9 B1(ix2)
«define хА B2(ix2)
«define хВ B3(ix2)
«define xC B0(ix3)
«define xD B1(ix3)
«define xE B2(ix3)
«define xF B3(ix3)
«define zO BO(izO)
«define z1 Bl(izO)
«define z2 B2(iz0)
«define z3 B3(iz0)
«define z4 BO(izl)
«define z5 B1(iz1)
«define z6 B2(iz1)
«define z7 B3(iz1)
«define z8 B0(iz2)
«define z9 B1(iz2)
«define zA B2(iz2)
«define zB B3(iz2)
«define zC B0(iz3)
«define zD B1(iz3)
«define zE B2(iz3)
«define zF B3(iz3)
«define rcl(x.r) (((x) « (r)) | ((x) » (32-(r))))
«define f1(x, key, i) (rcl(key[2 * (i)] + (x), key[2*(i)+1]))
«define f2(x, key, i) (rcl(key[2 * (i)] " (x), key[2*(i)+1]))
«define f3(x, key, i) (rcl(key[2 * (i)] - (x), key[2*(i)+1]))
«define g1(x) (((S1[BO(x)J " S2[B1(x)]) - S3[B2(x)]) + S4[B3(x)])
«define g2(x) (((S1[BO(x)J - S2[B1(x)]) + S3[B2(x)]) " S4[B3(x)J)
«define g3(x) (((S1[BO(x)] + S2[B1(x)]) ~ S3[B2(x)J) - S4[B3(x)J)
uint32 S1[256] = {
};
uint32 S7[256] = {
};
uint32 S8[256] = {
};
«define prepare_keys(ixO, ix1,
do {
(izO) = (ixO) " S5[xD]
(iz1) = (ix2) " S5[z0]
(iz2) = (ix3) " S5[z7]
(iz3) = (ixl) ~ S5[zA]
ix2, ix3, izO, izl, iz2, iz3)
" S6[xF] ~ S7[xC] " S8[xE] " S7[x8];
" S6[z2] " S7[z1] ~ S8[z3] " S8[xA];
" S6[z6] " S7[z5] " S8[z4] ~ S5[x9];
~ S6[z9] ~ S7[zB] ~ S8[z8] " S6[xB];
\
\
\
\
240
Глава 7. Прикладные задачи шифрования
\
(ixO) = (iz2) ~ S5[z5] ~ S6[z7] “ S7[z4] " S8[z6] ~ S7[z0]; \
(1x1) = (izO) " S5[xO] “ S6[x2] " S7[x1] " S8[x3] ~ S8[z2]; \
(1x2) = (iz1) " S5[x7] " S6[x6] ~ S7[x5] " S8[x4] " S5[z1]; \
(1x3) = (iz3) " S5[xA] ’ S6[x9] * S7[xB] " S8[x8] " S6[z3]; \
} while(O)
void setup_cast128(CAST128_KEY- *key, uint8 *pass, int passlen)
{
uint8 km[16];
uint32 1x0, 1x1, 1x2, 1x3;
uint32 izO, iz1, iz2, iz3;
if (passlen > 16) passlen = 16;
memset(&km, 0, sizeof(km));
memcpy(&km, pass, passlen);
1x0 = ((uint32) km[0] « 24) | ((uint32) km[1] « 16) | ((uint32) km[2] « 8) | km[3];
1x1 = ((uint32) km[4] « 24) | ((uint32) km[5] « 16) | ((uint32) km[6] « 8) | km[7];
1x2 = ((uint32) km[8] « 24) | ((uint32) km[9] « 16) | ((uint32) km[10] « 8) | km[11];
1x3 = ((uint32) km[12] « 24)|((uint32) km[13] « 16) | ((uint32) km[14] « 8) | km[15];
prepare_keys(ixO, 1x1, 1x2, 1x3, izO, iz1, iz2, iz3);
key->master[O] = (S5[z8] " S6[z9] " S7[z7] " S8[z6] ~ S5[z2]);
key->master[2] = (S5[zA] " S6[zB] " S7[z5] " S8[z4] " S6[z6]);
key->master[4] = (S5[zC] " S6[zD] " S7[z3] " S8[z2] " S7[z9]);
key->master[6] = (S5[zE] * S6[zF] “ S7[z1] “ S8[z0] " S8[zC]);
key->master[8] = (S5[x3J " S6[x2] " S7[xC] * S8[xD] " S5[x8J);
key->master[10] = (S5[x1] " S6[x0] ” S7[xE] " S8[xF] ' S6[xDJ);
key->master[12] = (S5[x7] “ S6[x6] " S7[x8] ' S8[x9] “ S7[x3]);
key->master[14] = (S5[x5] ~ S6[x4] ~ S7[xA] " S8[xB] ~ S8[x7]);
prepare_keys(ixO, 1x1, 1x2, 1x3, izO, iz1, iz2, iz3);
key->master[16] = (S5[z3] " S6[z2] " S7[zC] ' S8[zD] " S5[z9]);
key->master[18] = (S5[z1] " S6[z0] “ S7[zE] ~ S8[zF] " S6[zC]);
key->master[20] = (S5[z7J " S6[z6] " S7[z8] ~ S8[z9] " S7[z2J);
key->master[22] = (S5[z5J “ S6[z4] ~ S7[zA] ~ S8[zB] ~ S8[z6]);
key->master[24] = (S5[x8] " S6[x9] " S7[x7] ' S8[x6] " S5[x3]);
key->master[26] = (S5[xA] " S6[xB] ~ S7[x5] “ S8[x4] " S6[x7]);
key->master[28] = (S5[xC] " S6[xD] " S7[x3] “ S8[x2] “ S7[x8]);
key->master[30] = (S5[xE] * S6[xF]-* S7[x1] " S8[x0] * S8[xD]);
prepare_keys(ixO, 1x1, 1x2, 1x3, izO, iz1, iz2, iz3);
key->master[1] = ((S5[z8] “ S6[z9] " S7[z7] ~ S8[z6] " S5[z2]) & 31);
key->master[3] = ((S5[zA] ~ S6[zB] “ S7[z5] " S8[z4] " S6[z6]) & 31);
key->master[5] = ((S5[zC] “ S6[zD] " S7[z3] " S8[z2] " S7[z9]) & 31);
key->master[7] = ((S5[zEJ ~ S6[zF] ~ S7[z1] ~ S8[z0] ~ S8[zC]) & 31);
key->master[9] = ((S5[x3] " S6[x2] * S7[xC] " S8[xD] " S5[x8]) & 31);
key->master[11] = ((S5[x1J ~ S6[x0] * S7[xE] " S8[xF] " S6[xDJ) & 31);
key->master[13] = ((S5[x7] ~ S6[x6] ~ S7[x8] " S8[x9] " S7[x3]) & 31);
key->master[15] = ((S5[x5J " S6[x4] " S7[xA] " S8[xB] " S8[x7]) & 31);
prepare_keys(ixO, 1x1, 1x2, 1x3, izO, iz1, iz2, iz3);
key->master[17] = ((S5[z3] " S6[z2] " S7[zC] " S8[zD] " S5[z9]) & 31);
key->master[19] = ((S5[z1] " S6[zO] ' S7[zE] ” S8[zF] ” S6[zC]) & 31);
Гпава‘7; Прикладные задачи шифрования 241
key->master[21] = ((S5[z7] " S6[z6] ~ S7[z8] ~ S8[z9] " S7[z2]) & 31); key->master[23] = ((S5[z5] ~ S6[z4] ~ S7[zA] " S8[zB] ~ S8[z6]) & 31); key->master[25] = ((S5[x8] " S6[x9] " S7[x7] ~ S8[x6]S5[x3]) & 31); key->master[27] = ((S5[xA] * S6[xB] " S7[x5] * S8[x4] " S6[x7]) & 31); key->master[29] = ((S5[xC] " S6[xD] " S7[x3] ~ S8[x2] " S7[x8]) & 31); key->master[31] = ((S5[xEJ * S6[xF] " S7[x1] " S8[x0] " S8[xDJ) & 31);
key->regs[O] = key->regs[1] = key->regs[2] = key->regs[3] = 0; key->empty = 1;
}
tfdefine subencode(key, in, out) \
do { \
L = ((uint32) in[0] « 24) | ((uint32) in[1] « 16) | ((uint32) in[2] « 8) |
in[3]; \
R = ((uint32) in[4] « 24) | ((uint32) in[5] « 16) | ((uint32) in[6] « 8) |
in[7]; \
В = f1(R, key->master, 0); L "= g1(B);, \ • В = f2(L, key->master, 1); R ~= g2(B); \ В = f3(R, key->master, 2); L ~= g3(B); , \ В = f1(L, key->master, 3); R ~= g1(B); \ В = f2(R, key->master, 4); L ~= g2(B); \ В = f3(L, key->master, 5); R ~= g3(B); \’ В = f1(R, key->master, 6); L ~= g1(B); \ В = f2(L, key->master, 7); R ~= g2(B); \ В = f3(R, key->master, 8); L ~= g3(B); ’ \ В = f1(L, key->master. 9); R ~= g1(B); \ В = f2(R, key->master, 10); L g2(B); ( \ В = f3(L, key->master, 11); R ~= g3(B); \
\
В = f1(R, key->masten 12); L ~= gl(B);' • \ В = f2(L, key->master, 13); R "= g2(B);, \ В = f3(R, key->mast$r, 14); L ~= g3(B); . \ В = f1(L, key->master, 15); R ~= g1(B); \
\
out[0] = (uint8) BO(R); out[1] = (uint8) B1(R); . \ out[2] = (uint8) B2(R); out[3] = (uint8) B3(R); \ out[4] = (uint8) B0(L); out[5] = (uint8) B1(L); \ out[6] = (uint8) B2(L); out[7] = (uint8) B3(L); \
} while(O)
ftdefine subdecode(key, in, out) \
do { \ \
R = ((uint32) in[0] « 24) | ((uint32) in[1] « 16) | ((uint32) in[2] «
8) I in[3]; \
L = ((uint32) in[J4] «’24) | ((uint32)-i,n[5] << ,16) |, ((uint32) in[6] «
8) I in[7]; \ \ .
: . , 4 tл ..
В = f1(L, key->ma3ter,, 15);^ R/= g1(B){ \ \ \ В = f3(R, key->master,‘ 14)/ L ”= g3(B); c \
В = f2(L, key->master, 13); R ”= g2(B); V В = f1(R, key->master, 12); L ~= g1(B); t \ \ 1 ' '
242
Гпава 7. Прикладные задачи шифрования
В = f3(L, key->master, 11); R "= g3(B); \
В = f2(R, key->master, 10); L "= д2(В); \
В = f1(L, key->master, 9); R "= д1(В); \
В = f3(R, key->master, 8); L "= g3(B); \
В = f2(L, key->master, 7); R "= g2(B); \
В = f1(R, key->master, 6); L "= g1(B); \
В = f3(L, key->master, 5); R "= g3(B); \
В = f2(R, key->master, 4); L "= g2(B); \
В = f1(L, key->master, 3); R "= g1(B); \
В = f3(R, key->master, 2); L "= дЗ(В); \
В = f2(L, key->master, 1); R "= g2(B); \
В = f1(R, key->master, 0); L ''=4g1(B); \
\
out[0] = (uint8) B0(L); out[1] = (uint8) B1(L); \
out[2] = (uint8) B2(L); out[3] = (uint8) B3(L); \
out[4] = (uint8) B0(R); out[5] = (uint8) B1(R); \
out[6] = (uint8) B2(R); out[7] = (uint8) B3(R); \
} while(O)
void encode_cast128(CAST128_KEY *key, uint32 *in, uint32 *out) {
uint32 L, R, B;
subencode(key, ((uint8 *) in), ((uint8 *) out));
}
void decode_cast128(CAST128_KEY *key, uint32 *in, uint32 *out) {
uint32 L, R, B;
subdecode(key, ((uint8 *) in), ((uint8 *) out));
}
void encode_cast128_ecb(CAST128_KEY *key, uint32 *buf, int buflen) {
uint32 L, R, B;
while (buflen--) {
memcpy(key->regs, buf, sizeof(key->regs));
subencode(key, ((uint8 *) &key->regs), ((uint8 *) &key->regs));
* buf++ = key->regs[0];
* buf++ = key->regs[1];
subencode(key, ((uint8 *) (&key->regs + 2)), ((uint8 *) &key->regs));
* buf++ = key->regs[2];
* buf++ = key->regs[3];
}
}
void decode_cast128_ecb(CAST128_KEY *key, uint32 *buf, int buflen) {
uint32 L, R, B;
while (buflen--) {
memcpy(key->regs, buf, sizeof(key->regs));
subdecode(key, ((uint8 *) &key->regs), ((uint8 *) &key->regs));
* buf++ = key->regs[0];
* buf++ = key->regs[1];
subdecode(key, ((uint8 *) (&key->regs + 2)), ((uint8 *) &key->regs));
* buf++ = key->regs[2];
* buf++ = key->regs[3];’
}
Гпава 7. Прикладные задачи шифрования
243
Зашифрование и расшифрование производится блоками по 128 битов в режи-
ме электронной кодовой книги ЕСВ (режим простой замены в соответствии с
ГОСТ 28147-89) с помощью процедур encode_cast 128_ecb() и deco-
de_castl28_ecb(). Для задания ключа используется структура CAST128JKEY, со-
держащая исходную ключевую последовательность в переменной master и теку-
щие значения регистров шифрования в переменной-массиве regs.
Для аутентификации пользователя и выдачи ему прав на доступ к данным до-
полнительно используется алгоритм криптографического хэширования SHA-1
(Secure Hash Algorithm). Его реализация представлена в листинге 7.21.
Листинг 7.21
SHA-1
, Test examples:
INPUT = "abc"
OUTPUT = A9993E36 4706816A BA3E2571 7850C26C 9CD0D89D
, INPUT = ’’abcdbcdecdef def gef ghf ghighi j hi j ki j kl j klmklmnlmnomnopnopq”
OUTPUT = 84983E44 1C3BD26E BAAE4AA1 F95129E5 E54670F1
, INPUT = 1,000,000 of "a" (15625 blocks by 64 bytes)
OUTPUT = 34AA973C D4C4DAA4 F61EEB2B DBAD2731 6534016F
typedef struct {
uint32 hO, hi, h2, h3, h4;
uint32 lo, hi;
} SHA.HASH;
«define MOREDATA 0
«define LASTDATA 1
void setup_sha(SHA_HASH *);
void hash_sha(SHA_HASH *, uint8 *, uint32, int);
«define fO(x,y,z) (z " (x & (y ' «define f1(x,y,z) (x " у " z) «define f2(x,y,z) ((x & y) | (z «define f3(x,y,z) (x " у " z) • Z)))
& (X I У)))
«define K0 0x5a827999 «define K1 0x6ed9eba1 «define K2 0x8f1bbcdc «define КЗ 0xca62c1d6 «define S(n, X) ((X « n) | (X » (32 - n)))
«define rO(f, K) do { tmp = S(5, A) + f(B, C, D) + \ \ E + *p0++ + K; \
CO CO О О (Л < II II II II Ш Q О СО \ \ \ \
244 Гпава 7. Прикладные задачи шифрования.
h = tmp; \
} while(O)
«define r1(f, К) \
do { \
tmp = *р1++ " *р2++ " *рЗ++ " *р4++; \
tmp = 8(5, А) + f(B, С, D) + Е + (*р0++ = 8(1, tmp)) + К; \
Е = D; \
D = С; \
С = 8(30, В); \
В = А; \
А = tmp; \
} while(O)
void setup_sha(SHA_HASH *sha) {
sha->hO = 0x67452301;
sha->h1 = 0xefcdab89;
sha->h2 = 0x98badcfe;
sha->h3 = 0x10325476;
sha->h4 = 0xc3d2e1f0;
sha->lo = 0;
sha->hi = 0;
}
«include "stdio.h”
void hash_sha(SHA_HASH *sha, uint8 *data, uint32 len, int finish) {
uint16 i. q, padded, nread, nbits;
uint32 *p0, *p1, *p2, *p3, *p4, tmp;
uint32 А, В, C, D, E;
uint8 buf[320], *endbuf = data + len;
uint32 value;
padded = 0;
nread = 64;
for (;;) {
memcpy(buf, data, 64);
if (data + 64 > endbuf) {
if (!finish) break;
if (data < endbuf)
nread = (uint16) (endbuf - data);
else
nread = 0;
nbits = nread « 3;
sha->lo. += nbits;
if (sha->lo < nbits) sha->hi++;
if (nread < 64) {
if (!padded) {
buf[nread++] = 0x80;
padded++;
}
for (i = nread; i < 64; i++) buf[i] = 0;
}
if (nread <= 56) {
((uint32 *) buf)[14] = sha->hi;
Гпава 7. Прикладные задачи шифрования
245:
((uint32 *) buf)[15] = sha->lo;
reorder_bytes(((uint32 *) buf), 14, value, q);
} else
reorder_bytes(((uint32 *) buf), 16, value, q);
} else {
sha->lo += 512;
if (sha->lo < 512) sha->hi++;
reorder_bytes(((uint32 *) buf), 16, value, q);
}
pO = ((uint32 *) buf);
A = sha->hO;
В = sha->h1;
C = sha->h2;
D = sha->h3;
E = sha->h4;
rO(fO, KO); rO(fO, KO); rO(fO, KO); rO(fO, KO); rO(fO, KO);
rO(fO, KO); rO(fO, KO); rO(fO, KO); rO(fO, KO); rO(fO, KO);
rO(fO. KO); rO(fO. KO); rO(fO, rO(fO, KO); KO); rO(fO, KO); rO(fO, KO);
p1 = &((uint32 *) buf)[13]; p2 = &((uint32 *) buf)[8]; p3 = &((uint32 *) buf)[2]; p4 = &((uint32 *) buf)[O];
r1(f1, K1); r1(f1, K1); r1(f1, K1); r1(f1, K1); r1(fO, r1(f1. K1); r1(f1, KI); r1(f1, KI); КО); r1(fO, r1(f1, К1); КО); r1(fO, rl(f1, К1); КО); r1(fO, КО); r1(f1, KI); ,
r1(f1, r1(f1, r1(f1, K1); K1); KI); r1(f1, r1(f1, r1(f1, Ki); KI); K1); r1(f1, r1(f1, r1(f1, KI); . KI); K1);
r1(f1, K1);
r1(f2, K2); r1(f2, K2); r1(f2, K2); r1(f2, K2); r1(f2, K2);
r1(f2, K2); r1(f2, K2); r1(f2, K2); r1(f2, K2); r1(f2, K2);
r1(f2, K2); r1(f2, K2); r1(f2, K2); r1(f2, K2); r1(f2, K2);
r1(f2, K2); r1(f2, K2); r1(f2, K2); r1(f2, K2); r1(f2, K2);
r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ);
r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ);
r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ);
r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ); r1(f3, КЗ);
sha->hO += A;
sha->h1 += B;
sha->h2 += C;
sha->h3 += D;
sha->h4 += E;
data += 64;
if (nread == 0 && ’finish) break;
if (nread <= 56) break;
if (finish) reorder_bytes((uint32 *) sha, 5, value, q);
246
Глава 7. Прикладные задачи шифрования
Для того чтобы получить доступ к диску, пользователю необходимо ввести
так называемую парольную фразу произвольной длины (с ограничением, правда,
до 130 символов текста).
Изначально, парольная фраза назначается пользователем при создании диска
(см. рис. 7.4). Она может (и, вообще говоря, должна!) состоять из нескольких
слов (например, связанного предложения).
Пользователь вводит парольную фразу в специальном окне (см. рис. 7.5), за-
тем она преобразовывается с помощью SHA-1 в фиксированного размера
хэш-сумму. Этим, получившимся значением заполняется специальный буфер не-
сколько сотен раз (до 5000). Сколько именно раз происходит заполнение, зависит
Рис. 7.5
Гпава 7. Прикладные задачи шифрования
247
от специальной переменной, значение которой устанавливается случайным обра-
зом при создании виртуального шифрованного PGP-диска.
После заполнения буфера снова подсчитывается хэш-сумма, но уже от всего
буфера. Полученное хэш-значение подставляется в процедуру разворачивания
ключа CAST-128. Затем с помощью этого шифра расшифровываются контроль-
ные восемь байтов, зашифрованные и записанные при создании диска. Если после
расшифрования они совпадают со значением последнего подсчета хэш-функции
SHA-1, это означает, что парольная фраза была дана верно и пользователь может
подключить диск и получить к нему доступ (см. листинг 7.23).
Листинг 7.22
typedef struct {
uint8 header_magic[4];
uint8 header_type[4];
uint32 header.size;
uint32 header.CRC;
uint64 next-header;
uint32 reserved[2];
} PGPDISK.INFO;
typedef struct {
uint8 encrypted_key[16];
uint8 check_bytes[8];
uint16 hash-reps;
uint16 options;
uint32 reserved;
} PGPDISK.KEY;
typedef struct {
PGPDISK.INFO header.info;.
uint8 major_ver;
uint8 minor_ver;
uint16 reserved.a;
uint32 file_blocks;
uint32 header.blocks;
uint32 data_blocks;
uint32 algorithm;
uint8 drive;
bool mounted;
uint64 sessionlD;
uint8 reserved_b[52];
uint8 salt[8];
PGPDISK.KEY master.pass;
PGPDISK.KEY other_pass[7];
} PGPDISK;
Каждый PGP-диск физически располагается в одном (обычно большом) фай-
ле на одном из жестких дисков компьютера. Первые несколько сотен байтов зани-
248
Гпава 7. Прикладные задачи шифрования
мают специальные заголовки, содержащие сведения, необходимые для аутенти-
фикации пользователя и шифрования данных (см. листинг 7.22). Подструктура
PGPDISK—INFO в структуре PGPDISK отвечает за информацию, касающуюся фи-
зической целостности содержимого виртуального диска и его маркировки.
Наиболее интересной с этой точки зрения является подструктура
PGPDISK—KEY, содержащая ключевую информацию. Область encrypted_key со-
держит зашифрованный ключ для алгоритма CAST128, который после процедуры
аутентификации пользователя используется для шифрования данных на диске.
Область check_bytes представляет описанные ранее контрольные восемь байтов,
a hash_reps — не что иное, как количество повторений хэш-значений парольной
фразы в специальном буфере перед снятием второй хэш-суммы.
Учитывая приведенный выше алгоритм, был разработан небольшой програм-
мный модуль, реализующий проверку парольной фразы и тестированием потенци-
альной скорости тотального опробования парольных фраз (рис. 7.6).
Рис. 7.6
Программа «PGP check password» работает в трех режимах. Режим «count
speed» позволяет провести подсчет скорости опробования единичной парольной
фразы. Режим «check passphrase» позволяет проверить ее верность, а режим «test
ciphers» проверяет работу функции криптографического хэширования и шифрова-
ния. Полные исходные тексты читатель может найти на прилагаемом к книге ком-
пакт-диске.
Листинг 7.23
«include <vcl\vcl.h>
«pragma hdrstop
«include "main.h"
«pragma resource "*.dfm"
TMainForm *MainForm;
Гпава 7. Прикладные задачи шифрования 249
^include <stdio.h> ' Л''
^include "unidef.h” #include ”cast128.h” ^include "sha.h” tfdefine MAX.PASSPHRASE.LEN 130 tfdefine PGPDISK.CAST.ENCRYPTED 3
typedef struct { uint8 header_magic[4];
uint8 header_type[4];
uint32 header_size; l ’' । ’. i ; i I,
uint32 header.CRC; uint64 next.header; uint32 reserved[2];
} PGPDISK_INF0; typedef struct { uint8 encrypted_key[16]; uint8 check_bytes[8]; uint16 hash.reps; uint16 options; uint32 reserved; } PGPDISK.KEY; typedef struct { PGPDISK.INFO header.info; uint8 major.ver; uint8 minor.ver; uint16 reserved.a; uint32 ' file.blocks; - uint32 header.blocks; uint32 data.blocks; uint32 algorithm; mJ
uint8 drive; bool mounted; uint64 sessionlD; uint8 reserved_b[52]; uint8 salt[8]; PGPDISK.KEY master.pass; PGPDISK.KEY other_pass[7]; } PGPDISK; , i и
PGPDISK *open_pgpdisk(char *diskname) {
FILE *f;
PGPDISK *disk = (PGPDISK *) malloc(sizeof(PGPDISK));
if (’disk) return NULL;
if ((f = fopen(diskname, "rb")) == NULL) {
free(disk);
return NULL;
250
Глава 7. Прикладные задачи шифрования (
if ((fread(disk, 1, sizeof(PGPDISK), f) != sizeof(PGPDISK))
|| memcmp(disk->header_info.header_magic, ”PGPd”, 4)) {
free(disk);
fclose(f);
return NULL;
}
fclose(f);
return disk;
}
uint8 pass_block[300*1024]; /* (hash_of_encrypted_key + 1)*16000 times */
uint8 enc_key[16], key[16], check_bytes[8], j, *block;
uint16 i, *hash_reps;
CAST128.KEY cast;
SHA-HASH hash;
int check_passphrase(PGPDISK *disk, char *passphrase) {
if (’disk || ’passphrase) return 0;
hash_reps = (uint16 *) &disk->master_pass.hash.reps;
setup_sha(&hash);
hash_sha(&hash, passphrase, strlen(passphrase), 1);
memcpy(&key, &hash, 16);
memcpy(&pass_block, &disk->salt, 8);
block = (uint8 *) &pass_block[8];
j = 0;
for (i = 0; i < *hash_reps; i++) {
1 memcpy(block, &key, 16);
block += 16;
*block++ = j++;
}
setup_sha(&hash);
hash_sha(&hash, (uint8 *) &pass_block, (uint32) *hash_reps*17 + 8, 1);
setup_cast128(&cast, (uint8 *) &hash, 16);
memcpy(&enc_key, &disk->master_pass.encrypted_key, 16);
memcpy(&check_bytes, &disk->master_pass.check_bytes, 8);
decode_cast128(&cast, (uint32 *) &enc_key, (uint32 *) &enc_key);
decode_cast128(&cast, (uint32 *) &enc_key[8], (uint32 *) &enc_key[8]);
decode_cast128(&cast, (uint32 *) &check_bytes, (uint32 *) &check_bytes);
return (memcmp(&check_bytes, &hash, 8) ? 0 ; 1);
}
void „fastcall TMainForm::Button1Click(T0bject *Sender)
{
PGPDISK *disk;
disk = open_pgpdisk(FileEdit->Text.c_str());
if (’disk)
ShowMessageC’Disk damaged’’’);
else {
if (check_passphrase(disk, PassEdit->Text.c_str()))
ShowMessage("RIGHT PASSPHRASE”);
else
ShowMessage("WRONG PASSPHRASE");
Гпава 7. Прикладные задачи шифрования
251
}
uint8 test_plain[8] = { 0x01, 0x23, 0x45, 0x67, 0x89, ОхАВ, OxCD, OxEF };
uint8 test_key[16] = { 0x01, 0x23, 0x45, 0x67, 0x12, 0x34, 0x56, 0x78,
0x23, 0x45, 0x67, 0x89, 0x34, 0x56, 0x78, 0x9A };
uint8 test_0K[8] = { 0x23, 0x8B, 0x4F, 0xE5, 0x84, 0x7E, 0x44, 0xB2 };
void __fastcall TMainForm::Button2Click(T0bject *Sender)
{
CAST128_KEY key;
char text[1024];
memset(text, 0, sizeof(text));
memcpy(text, test_plain, sizeof(test_plain));
setup_cast128(&key, (uint8 *) &test_key, 16);
encode_cast128(&key, (uint32 *) &text, (uint32 *) &text);
if (memcmp(&text, &test_0K, 8) ’=0)
ShowMessage(”Not encoded right!”);
else
ShowMessage("CAST is good!”);
setup_cast128(&key, (uint8 *) &test_key, 16);
decode_cast128(&key, (uint32 *) &text, (uint32 *) &text);
if (memcmp(&text, &test_plain, 8) != 0)
ShowMessage("Not decoded right!");
else
ShowMessage("decoding is good!");
}
__fastcall TMainForm::TMainForm(TComponent* Owner)
: TForm(Owner)
{
}
J
void __fastcall TMainForm::Button3Click(T0bject *Sender)
{
uint32 begin, end;
PGPDISK *disk;
SYSTEMTIME tb, te;
SetPriorityClass(HInstance, REALTIME_PRIORITY_CLASS); '
GetSystemTime(&tb);
begin = GetTickCountO;
disk = open_pgpdisk(FileEdit->Text.c_str());
for (int i = 0; i < 1000; i++) {
check_passphrase(disk, PassEdit->Text.c_str());
} < -
free(disk);
end = GetTickCountO;
GetSystemTime(&te);
252 Глава 7. Прикладные задачи шифрования
char buf[1024];
end -= begin;
sprintf(buf, "start; %d.%d.%d, end: %d.%d.%d", tb.wMinute, tb.wSecond, tb.wMillise-
conds,
te.wMinute, te.wSecond, te.«Milliseconds);
ShowMessage(buf);
}
Остается только добавить, что с помощью функции SetPriorityClass возмож-
ро?более интенсивное использование ресурсов компьютера с целью увеличения
быстродействия тотального опробования (в листинге 7.23 вызов этой функции от-
мечен, жирным шрифтом). . '
Проведенный анализ и замеры показывают, что примененный в программе
PGPdisk алгоритм аутентификации пользователя достаточно стоек для постоян-
ного использования при условии, что парольная фраза имеет длину более восьми
сймволов.
Список литературы
1. Остераут Д., «Сценарии: высокоуровневое программирование для XXI века»,
ОТКРЫТЫЕ СИСТЕМЫ #03/98 (http:/ / www.osp.ru/os/1998/03/12.htm).
2. Храмцов П., «Управление сценариями просмотра Web-страниц», COMPUTER-
WORLD РОССИЯ #46/96 (http:// www.osp.ru/cw/1996/46/34.htm).
3. Крюков М., Прозоровский В., «Гражданско-правовой статус производителей про-
грамм»* ОТКРЫТЫЕ СИСТЕМЫ #02 /99 (http:// www.osp.ru/os/1999/02/ 14.htm).
4. IndigoStar Software, «Рег12Ехе FAQ Page», http:// www.indigos-
tar.com/ p2xfaq.htm.
5. Аграновский А. В., Хади P. А., Ерусалимский Я. M., «Криптография и откры-
тые системы», Телекоммуникации, № 1/2000.
6. А. Ю.Щербаков и др., «Программирование алгоритмов защиты информации»,
М: Нолидж, 2002.
7. Gutmann Р.: «Network Security», University of Auckland, 1996.
8. Anderson R.: «Why Cryptosystems Fail». University of Cambridge Computer La-
boratory, 1994.
9. Anderson R.: «How to Cheat at the Lottery» University of Cambridge Computer
Laboratory, 1999.
10. W. Diffie, M. E. Hellman: «New Directions in Cryptography», IEEE Transactions
on Information Theory, Vol. IT-22, No. 6, Nov. 1976.
11. Саломаа А.: «Криптография с открытым ключом», Москва: Мир, 1995. 318 с.
12. Кнут Д.: «Искусство программирования для ЭВМ», М.: Мир, 1977. Т. 2.
13. Олифер В., Олифер Н.: «Компьютерные сети», Спб.: Издательство «Питер»,
1999. 672 с.
14. Shiu-Kai Chin: «High-Confidence Design for Security», «Communications in the
ACM»' July 1999 Vol. 42. No. 7.
15. Kent, S., R. Atkinson: «Security Architecture for the Internet Protocol (IPSec),
RFC 2401«, Network Working Group, Nov, 1998.
16. Иванов П.: «IPSec: защита сетевого уровня», журнал «Сети» № 2, 2000.
Глава 7. Прикладные задачи шифрования 253
17. S. М. Bellovin: «Probable Plaintext Cryptanalysis in IP Security Protocols»,
AT&T Labs Research Technical Report, 2000.
18. P. Resnick, RFC-2822, «Internet Message Format (PROPOSED STANDARD)»,
April 2001.
19. J. Klensin, RFC-2821, «Simple Mail Transfer Protocol (PROPOSED STAN-
DARD)», April 2001.
20. Ю. А. Семенов, «Протоколы и ресурсы Internet», М.: Радио и связь, 1996.
320 с.
21. Медведовский И. Д., Семьянов П. В., Платонов В. В., «Атакачерез Internet»,
СПб.: 1999.
22. М. К. Reiter, A. D. Rubin, «Anonymous WEB-transactions with Crowds», Com-
munications of the ACM, Feb. 1999/Vol. 42, No.2.
23. C. Sheilds, B. N. Levine, «А Protocol for Anonymous Communication over the In-
ternet», ACM Conference Computer Security papers, 2000.
24. В. Олифер, H. Олифер, «Новые технологии и оборудование IP-сетей», СПб:
БХВ, 2000. 512 с.
25. В. Schneier, «Е-mail security», Counterpane Press, 2000.
26. К. Касперски, «Техника сетевых атак», М: СОЛОН-Р, 2001.
27. Чмора А. Л., «Современная прикладная криптография», М.: Гелиос АРВ,
2001.
28. Bruce Schneier, Mudge, «Cryptanalysis of Microsoft's Point-to-Point Tunneling
Protocol (PPTP)», Counterpane, 1999.
29. Ross Anderson, Bruno Crispo, «А new family of authentication protocols», ACM
Journal, № 10, 1998.
30. Аграновский А. В., Хади P. А., Котов И. H., «Аутентификация и разграниче-
ние доступа в защищенных системах», Научный сервис в сети Интернет: Труды Все-
российской научной конференции. — М: Изд-во МГУ, 2001. стр. 202—204.
31. Устинов Г. Н., «Основы информационной безопасности», М: Синтег, 2000.
32. Столлингс В., «Криптография и защита сетей», М: Вильямс, 2001.
33. Анин Б., «Защита компьютерной информации», СПб: БХВ, 2000.
34. Романец Ю. В., Тимофеев П. А., «Защита информации в компьютерных систе-
мах и сетях», М: Радио и связь, 2001.
35. Fraigniaud Р, Pelc A., Peleg D., Perennes S., «Assigning labels in unknown ano-
nymous networks», ACM Journal, № 07, 2000, p. 101.
36. Merkle J., «Multi-Round Passive Attacks on Server-Aided RSA Protocols», ACM
Journal, № 11, 2000.
37. Bellovin S. M., «Security Problems in the TCP/IP Protocol Suite», Computer
Communication Review, Vol. 19, No. 2, pp. 32—48, April 1989.
38. Брикелл E. Ф., Одлижко Э. M., «Криптоанализ: Обзор новейших результа-
тов», ТИИЭР, 1988, т, 76, № 5, стр. 75—91.
39. Menezes A., van Oorschot Р., Vanstone S., «Handbook of Applied Cryptograp-
hy», CRC press, 1996.
40. Hellman M. E., «А cryptanalytic time-memory tradeoff», IEEE Trans Inform The-
ory,.1980, 26, № 4, pp. 401-406.
41. Biham T. A., Shamir A., «Differential cryptanalysis of DES-like cryptosystems»,
Proc. Crypto-90, Leet. Notes Comput. Sci., 1991, 537, pp. 2—21.
254
Глава 7. Прикладные задачи шифрования
42. Ateniese G., Steiner М., Tsudik G., «Authenticated Group Key Agreement and
Friends», ACM Symposium on Computer and Communication Security, November 1998.
43. M. Steiner, G. Tsudik, M. Waidner «Diffie-Hellman key distribution extended to
groups», in ACM Conference on Computer and Communications Security, pp. 31—37,
ACM Press, Mar. 1996.
44. G. Ateniese, D. Hasse, O. Chevassut, Y. Kim, G. Tsudik «The Design of a Group
Key Agreement API», IBM Research Division, Zurich Research Laboratiry.
45. Y. Amir, G. Ateniese, D. Hasse, Y. Kim, C. Nita-Rotaru, T. Sclossnagle,
J. .Schultz, J. Stanton, G. Tsudik «Secure Group Communications in Asynchronous Ne-
tworks with Failures: Integration and Experiments», 1999.
46. G. Caronni, M. Waldvoget, D. Sun, B. Plattner «Efficient Security for Large and.
Dynamic Multicast Groups», Computer Engineering and Networks Laboratory.
47. Милославская H. Г., Толстой А. И., «Интрасети: доступ в Internet, защита»,
M.: ЮНИТИ-ДАНА, 2000.
48. Agranovsky А. V., Hady R. A., «Crypto miracles with random oracle», The Proce-
edings of IEEE SIBCOM'2001, The Tomsk Chapter of the Institute of Electrical and Elect-
ronics Engineers, 2001.
. 49. Ляпунов И.: «Проблемы системной интеграции в области защиты информа-
ции», Конфидент, № 1, 2001.
Содержание
Глава 1. Введение...........................................................4
Структура глав, или Как читать эту книгу..............................4
Для кого и о чем эта книга............................................8
Рабочий инструментарий, который может пригодиться читателю . .........9
К вопросу о терминологии.............................................10
Список литературы............. . . .4 . . . ... /. . .............13
Глава 2. Теория секретных систем. .........................................14
Современная криптография.............................................19
Виды симметричных шифров.............................................20
Принципы криптоанализа...............................................21
Список литературы....................................................23
Глава 3. Дешифрование классических шифров . ...............................26
Отступление для программистов........................................27
Раскрытие шифров простой замены......................................31
Быстрое раскрытие шифров простой замены............................ 46
Дешифрование шифров гаммирования.....................................53
Золотая криптография.................................................60
Список литературы....................................................64
Глава 4. Как устроены современные шифры....................................66
Возникновение блочных шифров.........................................68
Сеть Файстеля........................................................74
SP-сеть и шифры Файстеля.............................................80
Криптосистема Lucifer................................................86
Первые стандарты шифрования..........................................95
Архитектура SQUARE: от 3-WAY до AES.................................114
Режимы шифрования...................................................129
Устройство поточных шифров..........................................132
Список литературы...................................................142
Глава 5. Дешифрование современных шифров..................................145
Создание и оценка узлов замен.......................................146
Дешифрование DES....................................................153
Криптографические тесты AES.........................................171
Применение генетических алгоритмов..................................175
Список литературы...................................................179
Глава 6. Криптографическое сжатие.........................................183
Алгоритмы сжатия данных.............................................184
Арифметическое кодирование..........................................192
Криптографическое сжатие............................................204
Список литературы...................................................211
Глава 7. Прикладные задачи шифрования.....................................215
Использование однократного гаммирования.............................216
Криптографическая защита исходных текстов...........................224
Исследование программного обеспечения, реализующего
криптографические алгоритмы.........................................236
Список литературы...................................................252
Александр Владимирович Аграновский
Роман Ахмедович Хади
Практическая криптография:
алгоритмы и их программирование
Научный редактор
В. В. Булаев
Ответственный за выпуск
В., Митин
Макет и верстка
С. Тарасов
Обложка
Е. Холмский
Издательство «СОЛОН-Пресс»
123242, г. Москва, а/я 20
Телефоны:
(095) 254-44-10, (095) 252-36-96, (095) 252-25-21
E-mail: Solon-R@coba.ru
ООО «СОЛОН-Пресс»
127051, г. Москва, М. Сухаревская пл., д; 6, стр. 1 (пом; ТАРП ЦАО)
Формат 70x100/16. Объем 16 п. л. Тираж 3000
ООО «Арт-диал»
Москва, Б. Переяславская, 46
-Заказ №85
Уважаемый читатель!
Если вы:
специалист по "железу";
профессионал в области
программного обеспечения;
эксперт по компьютерным сетям -
поделитесь своими знаниями, напишите книгу!
Издательство "СОЛОН-Р" предлагает сотрудничество
как опытным авторам,
так и тем, кто только пробует свои силы.
Ждем ваших предложений!
1 23242, Москва, а/я 20
e-mail: Solon-Avtor@coba.ru