/

























































































































































































































































































































































































































































































































































































































































Автор: Новиков Ф.А. Иванов Д.Ю.
Теги: программирование программное обеспечение моделирование
ISBN: 978-5-94387-610-3
Год: 2010




Текст
Новиков Ф. А., Иванов Д. Ю.
Моделирование
на UML
ТЕОРИЯ, ПРАКТИКА, ВИДЕОКУРС
(+ 2 DVD)
«Профессиональная литература»
«Наука и Техника»
Санкт- Петербург
2010
Новиков Ф. А., Иванов Д. Ю.
МОДЕЛИРОВАНИЕ НА UML. ТЕОРИЯ, ПРАКТИКА, ВИДЕОКУРС. — СПб.: Профессио-
нальная литература, Наука и Техника, 2010. — 640 с.: ил. + цв. вклейки (+ 2 DVD)
Моделирование использования, моделирование структуры, моделирование
поведения, управление моделями. Книга содержит полное описание всех
основных версий унифицированного языка моделирования UML и набор
рекомендаций по применению языка для моделирования программных систем.
При этом высокий уровень понимания авторами UML, умение его использовать
вкупе с блестящими педагогическими навыками и хорошим, доступным языком
позволяют сделать из учебника (которым книга, несомненно, является) нечто
большее, чем просто учебник. Передаваемый опыт и идеи, которыми авторы
щедро делятся на страницах книги, делают ее интересной в том числе и для
читателя, уже знакомого с UML, а также читателя, которому просто интересно
узнать, что такое UML и как его применить в своей практике. К книге прилагается
видеокурс по UML на двух DVD.
Основу книги составляет материал лекционно-практического курса, который
авторы на протяжении ряда лет проводят в различных учебных и программи-
рующих организациях Санкт-Петербурга и Москвы. Все использованные в книге
примеры имеют реальную практическую ценность, а изложение материала
предельно выверено, систематизировано и адаптировано под реальное
практическое применение. В конце книги размещены сводные таблицы,
толковый словарь и развитый предметный указатель, что позволяет использовать
книгу в качестве справочника. На цветной вклейке дается также графическая
нотация-шпаргалка, представляющая собой квинтэссенцию нотации UML
с необходимыми пояснениями.
Для практикующих разработчиков программного обеспечения, руководителей
IT-проектов и их заказчиков, системных архитекторов, студентов высших и
средних специальных учебных заведений, а также всех желающих освоить
унифицированный язык моделирования иМ1_или познакомиться с ним.
Официальный сайт книги: www.umlmanual.ru
© Новиков Ф. А., Иванов Д. Ю. 2010
© Профессиональная литература (ООО «Прокди») (редак-
тура, оригинал-макет, оформление, видеокурс). 2010
© Наука и техника (товарный знак «Наука и Техника»). 2010
Содержание
КОМУ, КАК И ЗАЧЕМ НАДО ЧИТАТЬ ДАННУЮ КНИГУ
(СЛОВО РЕДАКТОРА).................................................. 15
ПРЕДИСЛОВИЕ РЕЦЕНЗЕНТА............................................. 19
О месте UML в современной методологии конструирования
искусственных объектов.................................19
О месте UML в современной информатике..................22
О книге и об ее авторах................................23
ВВЕДЕНИЕ.......................................................... 25
Назначение книги.......................................25
Предмет книги..........................................27
Особенности книги......................................29
Структура книги .......................................31
Используемые обозначения...............................35
Сведения об авторах....................................38
ГЛАВА 1. ВВЕДЕНИЕ В UML.............................................39
1.1. ЧТО ТАКОЕ UML?.................................................40
1.1.1. UML — это язык.......................................40
1.1.2. UML — это язык моделирования.........................43
1.1.3. UML—это унифицированный язык моделирования ..........44
1.2. НАЗНАЧЕНИЕ UML.................................................45
1.2.1. Спецификация.........................................46
1.2.2. Визуализация.........................................48
1.2.3. Проектирование.......................................48
1.2.4. Документирование.....................................50
1.2.5. Чем НЕ является UML..................................51
1.2.6. Способы использования UML............................52
1.2.7. Инструментальная поддержка...........................53
-св
Содержание
1.3. ОПРЕДЕЛЕНИЕ UML..............................................55
1.3.1. Определения искусственных языков...................55
1.3.2. Метод определения UML..............................56
1.3.3. Структура стандарта UML............................59
1.3.4. Терминология и нотация ............................60
Фигуры...............................................61
Линии................................................62
Значки...............................................62
Тексты...............................................62
Рамки................................................62
Каноническая нотация.................................63
1.4. МОДЕЛЬ И ЕЕ ЭЛЕМЕНТЫ ........................................63
1.4.1. Сущности...........................................66
Структурные сущности.................................67
Поведенческие сущности...............................67
Группирующие сущности................................68
Аннотационные сущности...............................68
1.4.2. Отношения..........................................70
1.4.3. Диаграммы..........................................72
1.4.4. Классификация диаграмм.............................74
1.5. ОБЩИЕ ДИАГРАММЫ..............................................79
1.5.1. Диаграмма использования............................79
1.5.2. Диаграмма классов..................................80
1.5.3. Диаграмма автомата.................................81
1.5.4. Диаграмма деятельности.............................82
1.5.5. Диаграмма последовательности.......................83
1.5.6. Диаграмма коммуникации.............................84
1.5.7. Диаграмма компонентов..............................85
1.5.8. Диаграмма размещения ..............................86
1.6. СПЕЦИАЛЬНЫЕ ДИАГРАММЫ........................................67
1.6.1. Диаграмма объектов.................................87
1.6.2. Диаграмма внутренней структуры.....................88
1.6.3. Обзорная диаграмма взаимодействия..................89
Содержание
1.6.4. Диаграмма синхронизации............................90
1.6.5. Диаграмма пакетов..................................90
1.7. МОДЕЛИ И ИХ ПРЕДСТАВЛЕНИЯ....................................91
1.7.1. Назначение и уровни моделей.................... 91
1.7.2. Классические представления из UML1 и 2.............96
1.7.3. Три представления — взгляд авторов.................99
1.8. ОБЩИЕ МЕХАНИЗМЫ.............................................101
1.8.1. Внутреннее представление модели ..................102
1.8.2. Дополнения........................................104
1.8.3. Стандартные дихотомии.............................105
1.8.4. Механизмы расширения..............................106
1.9. ОБЩИЕ СВОЙСТВА МОДЕЛИ...........................„...........110
1.9.1. Синтаксическая правильность...................... 111
1.9.2. Семантическая непротиворечивость................. 111
1.9.3. Полнота.......................................... 112
1.9.4. Вариации семантики................................113
ВЫВОДЫ ........................................................ 114
ГЛАВА 2. МОДЕЛИРОВАНИЕ ИСПОЛЬЗОВАНИЯ.............................115
2.1. БИЗНЕС-АНАЛИЗ И МОДЕЛИРОВАНИЕ...............................116
2.1.1. Введение в бизнес-анализ......................... 116
Изменяемость бизнес-процессов.......................117
Моделирование бизнеса...............................118
Реинжиниринг бизнеса............................... 120
2.1.2. Моделирование бизнеса: значение и принципы........121
2.1.3. История развития средств моделирования........... 124
Структурный анализ..................................124
Диаграммы потоков данных............................127
Диаграммы описания процессов....................... 128
Семейство стандартов IDEF.......................... 129
2.1.4. Современные средства: BPMN........................131
«В
2.2. ЗНАЧЕНИЕ МОДЕЛИРОВАНИЯ ИСПОЛЬЗОВАНИЯ........................138
2.2.1. Сквозной пример...................................139
2.2.2. Подходы к моделированию, альтернативные
моделированию использования..............................141
Программирование сверху вниз, снизу вверх и вширь...142
Схема базы данных...................................144
Объектно-ориентированный подход.....................145
Резюме..............................................146
2.2.3. Преимущества моделирования использования..........146
2.3. ДИАГРАММА ИСПОЛЬЗОВАНИЯ.....................................148
2.3.1. Действующие лица..................................148
2.3.2. Варианты использования............................152
2.3.3. Комментарии.......................................155
2.3.4. Отношения на диаграммах использования.............157
Ассоциация между действующим лицом и вариантом
использования.......................................157
Обобщение между действующими лицами.................158
Обобщение между вариантами использования............159
Зависимости между вариантами использования..........160
2.3.5. Способы применения моделей использования..........162
2.3.6. Выявление и анализ требований.....................166
2.4. РЕАЛИЗАЦИЯ ВАРИАНТОВ ИСПОЛЬЗОВАНИЯ..........................169
2.4.1. Реализация текстовыми описаниями..................171
2.4.2. Реализация программой на псевдокоде...............171
2.4.3. Реализация диаграммами деятельности...............174
2.4.4. Реализация диаграммами взаимодействия ............177
2.4.5. Сравнение методов реализации......................182
ВЫВОДЫ ..........................................................184
ГЛАВА 3. МОДЕЛИРОВАНИЕ СТРУКТУРЫ.................................185
3.1. ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ МОДЕЛИРОВАНИЕ СТРУКТУРЫ............186
3.1.1. Дескрипторы.......................................186
3.1.2. Объектно-ориентированная парадигма................189
Содержание
3.1.3. Назначение структурного моделирования..............198
Структура связей между объектами во время выполнения
программы............................................198
Структура хранения данных............................200
Структура программного кода..........................201
Структура компонентов в приложении...................202
Структура сложных объектов, состоящих
из взаимодействующих частей..........................202
Структура артефактов в проекте.......................202
Структура используемых вычислительных ресурсов.......203
3.1.4. Классификаторы.....................................203
Имя классификатора...................................204
Экземпляры классификатора............................204
Классификаторы абстрактные и конкретные..............205
Видимость классификатора.............................205
Область действия.....................................206
Кратность классификатора.............................207
Отношения обобщения..................................210
Резюме...............................................210
3.1.5. Идентификация классов..............................210
3.2. СУЩНОСТИ НА ДИАГРАММЕ КЛАССОВ................................213
3.2.1. Классы.............................................213
3.2.2. Атрибуты...........................................216
3.2.3. Операции и методы..................................218
3.2.4. Интерфейсы и типы данных... .......................222
3.2.5. Шаблоны............................................229
3.3. ОТНОШЕНИЯ НА ДИАГРАММЕ КЛАССОВ...............................231
3.3.1. Отношения зависимости и реализации.................231
3.3.2. Отношение обобщения................................234
3.3.3. Ассоциации и их дополнения.........................241
3.3.4. Имя ассоциации. Кратность полюса ассоциации........243
3.3.5. Агрегация и композиция ............................244
Агрегация............................................244
Композиция...........................................245
Производные элементы.................................246
Композиты и их атрибуты..............................247
«В
Содержание
Время жизни частей композита........................247
3.3.6. Полюса ассоциации.................................250
Роль полюса ассоциации..............................250
Навигация...........................................252
Многополюсные ассоциации............................253
Видимость полюса ассоциации.........................254
Упорядоченность объектов на полюсах.................256
Изменяемость объектов на полюсе.....................257
Операции с множествами объектов на полюсах..........258
3.3.7. Класс ассоциации и квалификатор...................259
3.3.8. Советы по проектированию .........................263
3.4. ДИАГРАММЫ РЕАЛИЗАЦИИ........................................265
3.4.1. Интерфейс.........................................266
3.4.2. Компоненты, артефакты и узлы......................269
3.4.3. Применение диаграмм реализации....................275
Трехуровневая архитектура...........................275
Диаграммы компонентов...............................276
Диаграммы размещения................................278
Рекомендации по использованию диаграмм реализации...280
3.5. МОДЕЛИРОВАНИЕ НА УРОВНЕ РОЛЕЙ И ЭКЗЕМПЛЯРОВ КЛАССИФИКАТОРОВ.261
3.5.1. Диаграмма внутренней структуры....................281
Структурированный классификатор.....................282
Часть...............................................283
Порт................................................283
Соединитель.........................................285
3.5.2. Кооперация........................................287
3.5.3. Образцы проектирования............................291
3.5.4. Экземпляры классификаторов........................295
3.5.5. Объекты и диаграмма объектов......................299
ВЫВОДЫ ..........................................................303
ГЛАВА 4. МОДЕЛИРОВАНИЕ ПОВЕДЕНИЯ.................................305
4.1. МОДЕЛИ ПОВЕДЕНИЯ............................................306
4.1.1. Конечные автоматы.................................308
Содержание
Автоматное преобразование...........................308
Реактивные системы..................................309
Машина Тьюринга ....................................309
Дополнительные соглашения по применению конечных
автоматов, используемые в UML.......................310
Модификации конечных автоматов, не применяющиеся
в UML...............................................312
4.1.2. Применение конечных автоматов. Причины применения
автоматов для описания поведения в UML....................315
Теоретическая причина...............................315
Историческая причина................................316
Практическая причина................................319
4.1.3. Сети Петри.........................................321
4.1.4. Средства моделирования поведения...................324
Явное выделение состояний...........................325
Поток управления и поток данных ....................325
Последовательность сообщений........................326
Параллельное поведение..............................326
4.2. ДИАГРАММЫ АВТОМАТА..........................................327
4.2.1. Простое состояние..................................330
4.2.2. Простой переход....................................333
Событие перехода.................................. 334
Переход по завершении...............................335
Сторожевое условие..................................337
Действие на переходе................................338
4.2.3. Сегментированные переходы .. .................. 339
Переходные состояния и состояния выбора.............339
Предикат else.......................................341
Метамодель простого перехода........................343
4.2.4. Составные состояния................................343
Последовательное составное состояние................345
Локальные и глобальные переходы.....................347
4.2.5. Специальные состояния..............................350
Начальное состояние.................................350
Заключительное состояние............................351
Эквивалентное выражение переходов между
составными состояниями..............................352
Содержание .
Историческое состояние...............................353
4.2.6. Вложенные машины состояний.........................355
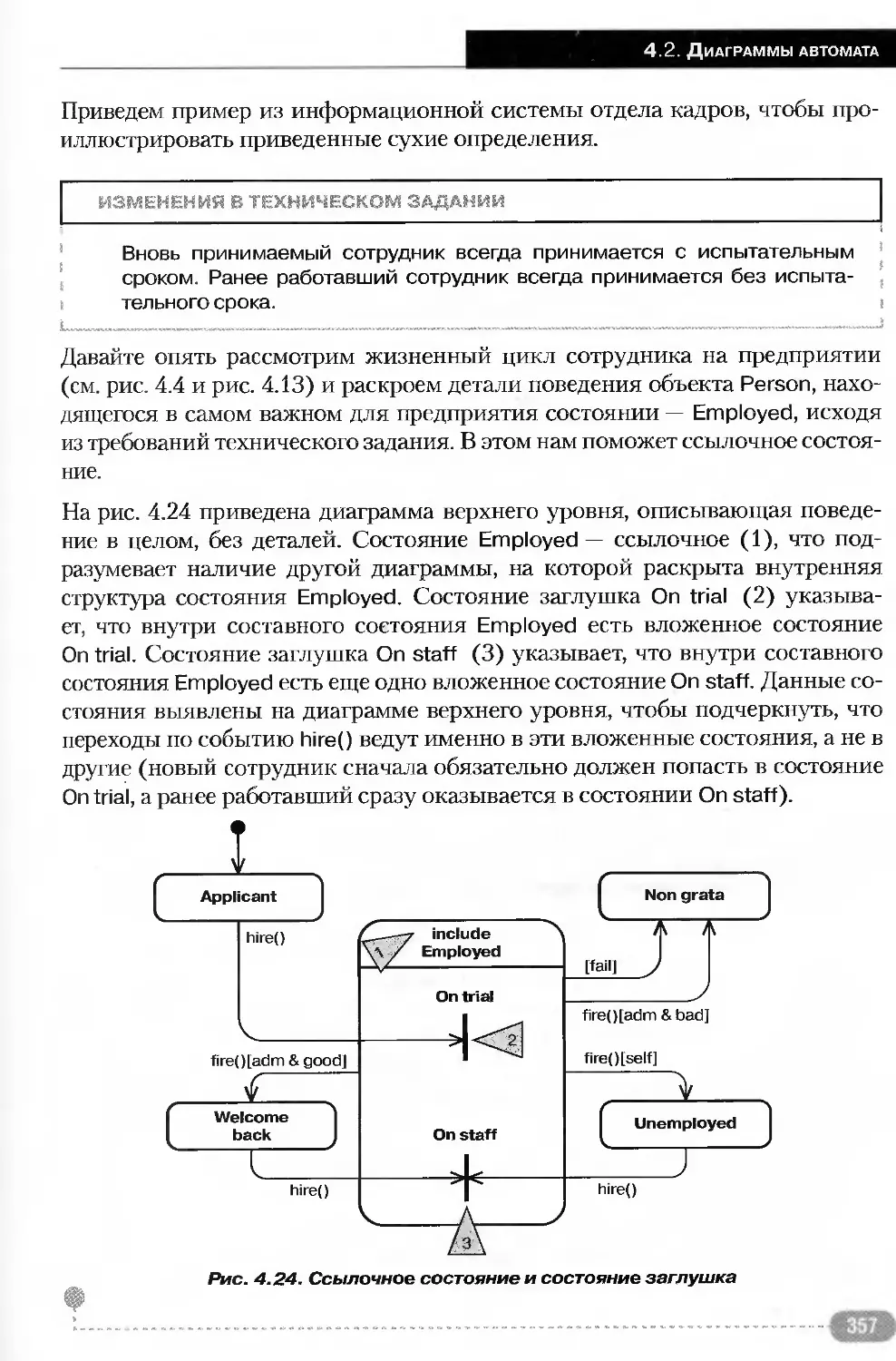
Ссылочное состояние..................................355
Переходы между составными состояниями................356
Состояние заглушка...................................356
Вложенные автоматы...................................358
4.2.7. События............................................360
Событие вызова.......................................360
Событие сигнала......................................363
Событие таймера......................................366
Событие изменения....................................368
4.2.8. Предусловия и постусловия .........................370
4.2.9. Протокольный автомат...............................374
4.3. ДИАГРАММЫ ДЕЯТЕЛЬНОСТИ.......................................376
4.3.1. Действие и деятельность ...........................377
Действия в UML1......................................377
Действия BUML1.5.....................................380
Действия в UML2......................................381
Деятельность.........................................384
4.3.2. Граф деятельности..................................385
Основные сущности на диаграмме деятельности UML 1 ...385
Графы деятельности в UML 2...........................389
Узлы действий........................................390
Узлы данных..........................................391
Узлы управления......................................393
Операционная семантика графов деятельности в UML 2...394
4.3.3. Дорожки и разбиения................................397
4.3.4. Траектория объекта и поток данных..................400
4.3.5. Отправка, прием сигналов и работа с таймером.......404
4.3.6. Сравнение способов описания поведения..............407
4.3.7. Прерывания и исключения............................413
Область прерывания...................................413
Обработка исключений.................................415
4.3.8. Структурные узлы деятельности......................417
4.3.9. Применение диаграмм деятельности...................422
Содержание
4.4. ДИАГРАММЫ ВЗАИМОДЕЙСТВИЯ ...................................425
4.4.1. Сообщения.........................................426
4.4.2. Диаграммы последовательности......................430
Связь...............................................431
Ось времени и время жизни объектов...................431
Линия жизни и стрелки сообщений.....................432
Метки времени.......................................434
Привязка ко времени выполнения метода...............435
Фокус управления....................................436
Возврат управления..................................437
Ветвление...........................................438
4.4.3. Составные шаги взаимодействия.....................440
Классификация составных шагов взаимодействия........441
Комбинирование составных шагов взаимодействия.......443
Вложенность.........................................445
Отображение изменяющихся состояний объектов.........446
4.4.4. Обзорные диаграммы взаимодействия.................449
4.4.5. Диаграммы коммуникации............................450
Объекты на диаграммах коммуникации..................450
Контекст взаимодействия.............................453
Номер сообщения.....................................453
Время жизни объекта.................................454
Стереотипы полюса роли ассоциации...................455
Метаморфоза, клон и мультиобъект....................458
4.4.6. Диаграммы синхронизации...........................459
4.5. МОДЕЛИРОВАНИЕ ПАРАЛЛЕЛИЗМА..................................461
4.5.1. Взаимодействие последовательных процессов.........462
4.5.2. Параллельная обработка данных.....................468
Динамическая параллельность как средство моделирования
параллельности в UML1...............................469
Область разложения как средство моделирования
параллельности в UML 2..............................470
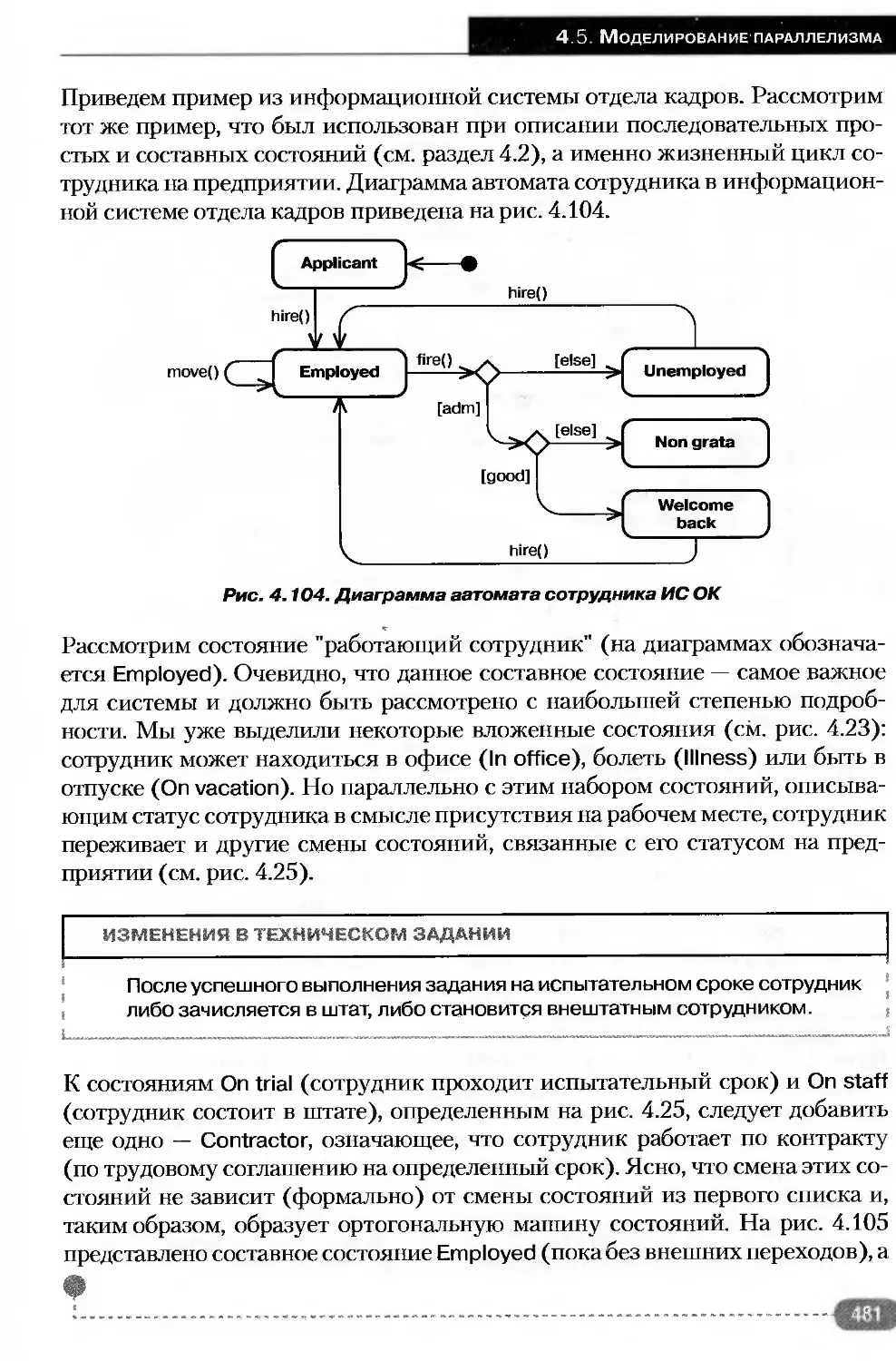
4.5.3. Ортогональные состояния и составные
переходы................................................ 474
Активное состояние..................................475
Конфигурация активных состояний.....................476
Ортогональное составное состояние...................478
О
г
Содержание
Составной переход...................................479
Синхронизирующее состояние..........................484
4.5.4. Развилки и слияния................................488
4.5.5. Параллелизм на диаграммах взаимодействия..........492
4.5.6. Активные классы...................................495
ВЫВОДЫ ..........................................................498
ГЛАВА 5. ДИСЦИПЛИНА МОДЕЛИРОВАНИЯ................................499
5.1. УПРАВЛЕНИЕ МОДЕЛЯМИ.........................................500
5.1.1. Пакетная структура................................501
Универсальная группирующая сущность — пакет.........501
Критерии структуризации модели......................503
5.1.2. Отношения между пакетами..........................506
Вложенность пакетов.................................506
Индуцированное отношение............................507
Зависимости со стереотипом..........................507
5.1.3. Модели, системы и подсистемы...................'... 509
5.1.4. Слияние пакетов ................................. 514
5.1.5. Трассировка, гиперссылки и документация...........518
5.1.6. Образцы, профили и каркасы........................521
Рекомендации по использованию образцов проектирования... 528
Каркас и профиль....................................528
5.2. ПРАКТИКА ПРИМЕНЕНИЯ UML.....................................529
5.2.1. Уровни моделирования..............................530
Концептуальное моделирование........................530
Спецификация требований.............................531
Детальное проектирование............................531
5.2.2. Правильный подход к моделированию или как
не надо применять UML.....................................533
Не переоценивайте возможности инструмента...........533
Не пренебрегайте возможностями инструмента .........534
Не переоценивайте собственные возможности...........535
Не пренебрегайте собственными
возможностями.......................................536
Содержание
5.2.3. Применение элементов UML............................536
5.2.4. Средства моделирования на UML.......................541
Карандаш и бумага....................................542
Доска и фломастер ...................................542
Инструментальные средства............................542
5.3. ВЛИЯНИЕ UML НА ПРОЦЕСС РАЗРАБОТКИ...........................544
5.3.1. Технология программирования.........................545
Дореволюционный период...............................547
Революция в программировании.........................547
Послереволюционный период............................549
5.3.2. Жизненный цикл программного обеспечения ............551
Модель...............................................553
Фазы и витки....................................... 555
Артефакт.............................................557
5.3.3. Модели процесса разработки .........................557
Водопадные и конвейерные модели......................558
Инкрементные и спиральные модели.....................560
5.3.4. Модели команды проекта..............................561
Иерархическая модель.................................562
Модель бригады главного программиста.................563
Модель команды равных................................565
5.3.5. Повышение продуктивности программирования...........566
5.3.6. Советы по внедрению UML в организации...............570
Организация должна поставить измеримую цель
внедрения UML........................................570
Знать и применять UML должны все участники процесса .571
Должен использоваться корпоративный репозиторий
решений на UML.......................................572
Инструмент, поддерживающий UML, должен быть лёгким
в использовании......................................572
ВЫВОДЫ ............................................................574
ГЛАВА 6. СПРАВОЧНЫЕ МАТЕРИАЛЫ......................................575
6.1. СТАНДАРТНЫЕ ЭЛЕМЕНТЫ ЯЗЫКА................................... 576
6.2. ТОЛКОВЫЙ СЛОВАРЬ ТЕРМИНОВ.....................................593
t ____
СОДЕРЖАН!^'
6.3. ДЕЙСТВИЯ В UML 2................................614
6.4. ЛИТЕРАТУРА ПО UML...............................616
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ.................................его
Кому, кок и зачем надо читать
данную книгу
(слово редактора)
"Думайте своей головой!", "Надо думать, прежде чем что-то делать!",
"Думать не только полезно, но и необходимо!" — слово "думать" в
нынешние времена выдается как своего рода панацея, позволяющая
достичь успеха в разных областях, решать поставленные задачи, об-
ходить неприятности и т.д. Когда что-то у кого-то не получается, ему
говорят: "Надо было думать!" или ”О чем ты думал, когда делал это?".
Отбросив закономерные оговорки, трудно не согласиться с мощью и
жизненной важностью императива "Думайте!". Но с обязательным со-
путствующим уточнением: думать надо уметь!
Об инструментальной ценности языка UML и некоторых особенно-
стях его использования в программных проектах немного, но очень
живо и интересно написал Н.Н. Непейвода в своем предисловии ре-
цензента, а в полной мере и то и другое вы сможете оценить по резуль-
татам прочтения книги. Я же хочу уже с самого начала обозначить
особенности именно КНИГИ и сразу же отметить наиболее универ-
сальное, я бы даже сказал, первичное ее качество: она учит думать!
В этом можно увидеть сверхзадачу книги и в этом смысле она будет ин-
тересна самой широкой мыслящей аудитории, которой не чужды зада-
чи проектирования, моделирования и - что очень важно — понимания
тех или иных продуктов, ситуаций, процессов. Будь то программные
продукты, технологические системы, бизнес-процессы, социологиче-
ские модели и т.д. и т.п. При этом, выражаясь довольно категорично
(да простят меня авторы), книга будет интересна в том числе и тем,
кто впоследствии никогда не станет НЕПОСРЕДСТВЕННО исполь-
зовать UML в своей практике.
Оговорка "непосредственно" здесь имеет очень важное значение, так
как не использовать UML по прочтении данной книги вы просто не
сможете. Как минимум, вы будете это делать косвенно. Ведь изло-
жение книги представляет собой разностороннее описание и демон-
страцию выверенного, уравновешенного и отлаженного инструмента
(пусть и со своими недостатками), обладающего огромным система-
тизирующим потенциалом. По мере прочтения книги вы будете пони-
мать и видеть, как, мысля категориями UML, можно решить те или
иные задачи. Авторы по сути выдают идеологию, и на множестве ситу-
аций показывают, как в рамках нее можно и нужно думать для дости-
Моделирование на UML
жения требуемого результата. При этом у читателя имеется уникальная
возможность присутствовать с момента зарождения идеологии, с пер-
вых слов, и до осознанного и деятельного обитания в ней. Подобный
опыт, когда он положителен, никогда не проходит бесследно. Поэтому
в дальнейшем хотя бы косвенного влияния со стороны UML на процесс
принятия решений (думания) вам не избежать. В этом же усматрива-
ется подтверждение того, что книга будет интересна самой широкой
читательской аудитории, которая может прочитать ее как "интеллекту-
альный бестселлер", а не как учебное пособие по языку UML.
Однако вышесказанное не следует воспринимать как признак излиш-
ней популяризации и поверхностности книги, делающей ее непри-
годной для основательного изучения UML. Совсем наоборот. Просто
уровень понимания авторами UML, умение его использовать вкупе с
блестящими педагогическими навыками и хорошим письменным язы-
ком позволяют сделать из учебника (которым книга, несомненно, явля-
ется) нечто большее, чем просто учебник. Причем передаваемый опыт
и идеи, которыми авторы щедро делятся на страницах книги, делают ее
интересной, в том числе и для читателя, уже знакомого с UML.
Роль редактора в издательском проекте, при определенной глубине по-
гружения, позволяет оценивать его как изнутри, с точки зрения авторов
книги и ее содержания, так и со стороны, с читательской точки зрения,
с точки зрения восприятия и формы. Это дает возможность отмечать1
те особенности, которые будут важны для читателя и которые имеют
реальное содержательное подтверждение. С этой позиции мне и хоте-
лось бы обозначить некоторые существенные качества книги, на кото-
рые вы можете опираться при ее прочтении и осознание которых будет
полезно еще перед началом чтения.
Чистота и предельная выверенность всех понятий, определений, диа-
грамм, переводов и концепций. Это особенно важно и актуально, ког-
да приходится иметь дело с предметом изучения, изначально создавав-
шимся и формулировавшимся на английском языке. Для тех, кто будет
"с нуля" изучать UML по данной книге, данное свойство вообще имеет
первостепенное значение. Я думаю, всем понятно, насколько важно уже
с самого начала научиться правильно. В этой части книга обеспечивает
наиболее гладкое, эффективное и грамотное вхождение в UML.
Высокое внимание к деталям как в изложении материала, так и в его
оформлении. Обсуждению, пристальному вниманию и доводке были
подвергнуты даже самые незначительные детали вплоть до способа
1 И по мере необходимости формировать вместе с авторами.
СЛОВО РЕДАКТОРА
прорисовки стрелок на диаграммах и простановки ударений в словах
с неоднозначным прочтением. Косвенно по этому можно судить о сте-
пени проработки материала книги, а непосредственно - наслаждаться
качеством визуальной и смысловой подачи материала. Книги, выпол-
ненные в рамках такого подхода, очень редки, так как требуют большо-
го труда и терпения как со стороны авторов, так и со стороны редакции/
группы подготовки издания.
Широта, завершенность и логическая стройность повествования.
Книга — учебник. Вы можете быть уверены, что получите академически
четкую и полную информацию в объеме, необходимом для уверенного,
осмысленного и эффективного использования UML в рамках решения
своих задач. Несмотря на наличие субъективных отступлений, скелетом
книги является отличный учебник со всеми его необходимыми атрибу-
тами, что однозначно позволяет рекомендовать книгу в качестве общего,
фундаментального учебного пособия по моделированию на UML.
"Обманчивая" субъективность изложения. Авторы неустанно говорят
о субъективном характере изложения (на уровне отступлений, оценок
и рекомендаций) и действительно зачастую позволяют себе говорить
от первого лица, давать оценки и даже иногда править устоявшиеся
правила по своему усмотрению2. Но нужно понимать, что это субъек-
тивность людей, обладающих высочайшим уровнем понимания и вла-
дения UML. То есть эта субъективность имеет тот же уровень, что и
уровень, например, создателей языка (Гради Буча, Дреймса Рамбо и
иже с ними). В этом смысле очень отрадно иметь удовольствие читать
русских авторов. И в этом смысле их субъективность имеет во многом
аксиоматический характер.
Реальная практическая ценность и адекватность примеров, исполь-
зованных в книге. Вы не найдете ни одного примера, который просто
иллюстрирует использование того или иного элемента, но сам по себе
является бестолковым и надуманным. Подбор примеров занял много
труда и заслуженно является предметом гордости авторов.
Ориентация на разного читателя. Опыт авторов позволяет рассматри-
вать вопросы применения UML с самых разных точек зрения: програм-
миста, заказчика, аналитика, просто интересующегося читателя. Для
разных ролей даются свои рекомендации. А совокупное их прочтение
позволяет, например, программисту лучше понять заказчика, а заказ-
2 Все это делается в рамках стандартов UML. Там, где это делается, всегда даются
соответствующие оговорки. Еще раз напоминаю, что вся книга строго выдержана
в рамках стандартов UML и полностью отражает их.
О
Моделирование на L'ML
чику лучше понять программиста. В зависимости от масштаба работ да-
ются советы по организации труда для достижения наилучшей отдачи.
Разбор ошибок. Помимо того, как надо делать, авторы в книге также
говорят, как не надо делать. И та и другая информация одинаково цен-
на.
Развитый справочный аппарат книги, позволяющий удобно и опера-
тивно находить требуемую информацию в книге. Большое количество
перекрестных ссылок по тексту и врезок позволяют оперативно "доби-
рать" недостающую по ходу чтения информацию. Предметный указа-
тель создавался и многократно вручную перепроверялся, чтобы в нем
нашли отражение как вся терминологическая база UML, так и сопут-
ствующие понятия. В конце книги размещены сводные таблицы и тол-
ковый словарь. А чего стоит графическая нотация, выполненная в виде
отдельной цветной вкладки, обладающая самостоятельной ценностью
и представляющая собой квинтэссенцию нотации UML с необходимы-
ми пояснениями.
В завершение хотелось бы отметить хороший русский язык книги, ко-
торый доставляет удовольствие, делает сложное понятным, характери-
зует авторов как высококлассных технических писателей, а также лиш-
ний раз подтверждает истину: "Кто ясно мыслит, тот ясно излагает".
В общем, независимо от того, с какой целью вы решите прочитать книгу
Ф. А. Новикова и Д. Ю. Иванова, вас ждет увлекательное, познаватель-
ное чтение, и лично я по-хорошему завидую тем, в чьи руки впервые
она попадет. Учитесь думать, господа. Учитесь продуктивно думать и
эффективно решать поставленные задачи. Изучайте UML или просто
знакомьтесь с ним. Это заслуживает внимания. А данная книга вам в
помощь.
М.В. Финков. 10.01.2010, Санкт-Петербург.
Предисловие рецензента
Пятнадцать лет назад один из классиков современной логики и информа-
тики Г. С. Цейтин показал мне то, что сразу меня поразило: первую версию
системы языков UML. Я привез копию ее стандарта в Ижевск и заразил
этим нескольких своих учеников; в частности, они стали применять систе-
му Rational Rose, фирменный диск с одной из первых ее версий до сих пор
хранится у меня как исторический памятник. Мы предложили одному из
известных питерских компьютерных издательств книгу по UML, но нам от-
ветили, что вопрос не актуален. Через пару лет это издательство пыталось
обратиться ко мне за написанием такой книги, но я тогда уже ушел далеко от
того, чтобы писать учебник по системе, у которой я теперь знал не только до-
стоинства, а умалчивать о недостатках и ограничениях не в моих принципах.
Поэтому я с радостью воспринял, что наконец-то выходит серьезная рус-
ская книга об UML, его применении и его роли. Поскольку эта система стала
принципиальным прорывом во многих областях, остановимся на ее новаци-
ях, ее роли и ее ограничениях1.
О МЕСТЕ UML В СОВРЕМЕННОЙ МЕТОДОЛОГИИ КОНСТРУИРОВАНИЯ
ИСКУССТВЕННЫХ ОБЪЕКТОВ
Прежде всего, авторы в первой главе долго обсуждают, является ли UML
формальным языком. Конечно же, мне пришлось сразу же об этом задумать-
ся, и я сразу увидел, что ни под определение формального, ни под определе-
ние естественного он не подходит. Когда мне довелось познакомиться еще
с одним ярким примером из совершенно другой области (лингвистическая
информатика1 2), я понял, что это — частный случай общего феномена, до сих
пор упускавшегося в информатике. И название у примера из лингвистики
созвучное: UNL (Unified Networking Language).
Результатом осмысления стала следующая классификация.
Искусственные языки. Формальные языки с точным синтаксисом и семан-
тикой, дистанцирующиеся от человеческих языков. Четко охарактеризова-
ны в данной книге.
1 Ограничения и недостатки не дискредитируют хорошую систему, а зачастую являются
необходимым дополнением к ее достоинствам. Бесспорно только бесполезное.
2 Я стараюсь не употреблять "терминов" с прилагательными "компьютерный" или "элек-
тронный". Мне гораздо больше нравится европейский термин информатика, чем аме-
риканский компьютерные науки, который на первое место ставит несущественный
признак. Мало ли на чем информацию будут обрабатывать завтра! Тем более что "ком-
пьютер" означает заодно "вычислитель", а такая характеристика современной инфор-
матики и программирования в корне неверна. Информация стала существенно нечис-
ленной, что, кстати, отражено в UML.
□г
Моделирование на UML
Естественные языки. Ни формального синтаксиса, ни формальной семан-
тики. Такой язык как-то развивается, и всем его знающим кажется, что они
его понимают и могут на нем выразить свои мысли. Также четко охарактери-
зованы в данной книге.
Квазиестественные языки. Формальные языки с точным, хотя обычно ис-
ключительно утяжеленным, синтаксисом и точной, обычно исключительно
примитивной, семантикой. Например, язык для генерации милицейских
протоколов по формальному описанию происшествия, с которым пришлось
мне столкнуться в своей работе. Отличие от искусственных в том, что внеш-
не конструкции на них выглядят как тупой, бюрократический, но человече-
ский текст, и дополнительного изучения чего-то для поверхностного пони-
мания этого текста не требуется.
Квазиискусственные языки. Внешне выглядят как искусственные, но фор-
мальные синтаксис и семантика являются лишь надстройкой над естествен-
ным содержимым. Таков, в частности, язык UNL, предназначавшийся для
обмена в сети Интернет текстами на естественном языке, которые теряют
многое при переводе на другой язык. Например, русские слова "жениться" и
"изба" могут быть описаны на нем следующим образом:
marry[actor=male] cottage[material=wood,nation=Russjan,place=village]
Есть модификаторы для обозначения взаимосвязей между словами, могут
быть и модификаторы модификаторов. Тем самым в принципе можно даже
поэтический текст разметить так, чтобы читателю на другом языке он был
понятен со всеми обертонами "без перевода". Но этот язык, конечно же, не-
понятен без некоторого предварительного изучения и внешне выглядит как
искусственный.
Первым квазиискусственным языком стал UML. Формальные диаграммы
часто связывают в нем содержательные понятия. Именно поэтому UML
явился принципиальным прорывом на фронте, более широком, чем соб-
ственно программирование, и даже таким прорывом, что многие его части
уже принадлежат не собственно информатике, а являются пограничными
между нею и другими областями.
Следующим концептуальным прорывом UML явилось то, что он неявно
признал неформализуемость тех понятий, с которыми работают практиче-
ские информационные системы. Известно, что феномен неформализуемо-
сти, открытый Н. В. Беллкиным в 1978 г. и далее развитый в теорию нефор-
мализуемых понятий, практически игнорируется научным сообществом. На
одном из сайтов, посвященных методологии программирования, моя цитата
длительное время была переврана: вместо "формализация неформализуе-
Предисловие рецензента
мых понятий" там написана сладенькая водичка: "формализация неформа-
лизованных".
Это связано с тем, что обыденное научное и околонаучное сознание вместо
развития рационального мышления молится на него, как на идола. Дьявол
обязательно подсовывает таким идолопоклонникам нечто, полностью обе-
сценивающее то положительное, что содержалось в объекте их поклонения.
Такой вот дьявольской приправой к общепринятой концепции рациональ-
ности является иллюзия всезнания. Она выражается тезисом о том, что в
принципе все познаваемо. При этом как-то игнорируется, что в силу диа-
гонального эффекта никто не может, в частности, познать сам себя. Англо-
саксонское позитивное мышление просто не может смириться с отрицанием
этой иллюзии и тем более с направленным использованием незнания как
позитивного фактора3. Тем не менее в силу своей прагматичности неявно
носители такого сознания могут просовывать по кусочкам концепцию не-
формализуемости, что и сделано в UML.
А именно, в UML признается, что объект проектирования не может быть
описан одним полуформальным описанием. Необходимо несколько, осве-
щающих его с разных сторон. Поэтому в UML имеется около десяти классов
различных моделей, объединенных общей графической формой и общим
метасинтаксисом.
Тем не менее принципиальным ограничением UML является то, что он опи-
сывает лишь информационные аспекты конструирования искусственных
объектов. Более того, я уверен, что попытки распространить его за это до-
статочно широкое и весьма почтенное поле деятельности приведут к урод-
ствам. Это ограничение прекрасно осознавалось авторами языка и пока еще
не нарушено за счет телячьего энтузиазма полузнающего сообщества.
Но есть другое ограничение, постепенно выявившееся за первое десятилетие
работы с UML и настолько же неприятное для его авторов и его энтузиастов,
насколько для Д. Гильберта было неприятно четко осознанное и четко вы-
сказанное им положение, что почти все объекты классической математики
никакого отношения к реальной жизни не имеют4.
Но, в отличие от гигантской фигуры Д. Гильберта, имевшего смелость вы-
сказать столь неприятную для него вещь, я не нашел нигде признаков того,
3 Эта особенность присуща западноевропейскому мышлению вообще, но в гораздо бо-
лее слабой степени. В частности, первым осознал роль иллюзии всезнания и точно по-
казал, как рационально использовать принцип: "Ignoramus et ignorabimus" голландец
Л. Брауэр. Конечно же, ему пришлось вынести множество нападок, но он не был отлучен
как некий сумасшедший.
4 Это не дискредитирует математику. Тот, кто пытается пользоваться лишь реальными по-
нятиями, имеет горизонт и скорость передвижения улитки. Чтобы достичь чего-то ново-
го и интересного, нужно суметь взлететь и спуститься.
Моделирование на UML
чтобы патриархи UML прямо говорили о втором его существенном ограни-
чении. Хотя само по себе это ограничение таково, что относится не только к
информатике, стоит высказать его на материале информатики, где оно мо-
жет быть показано ярче всего.
О МЕСТЕ UML В СОВРЕМЕННОЙ ИНФОРМАТИКЕ
Современное программирование четко делится на два направления, аполо-
геты которых часто столь же пренебрежительно трактуют друг друга, как,
скажем, "фрисофтеры" и Microsoft, не понимая, что они, точно так же, как
НАТО и Россия, не могут жить друг без друга и что у них совершенно раз-
ные сферы влияния и роль в данном мире.
Это индустриальное программирование, где важнее форма, чем содержание,
и экстремальное программирование, где на первом месте стоит содержание, а
форма рассматривается лишь как адекватное вместилище для него.
Принципиальным моментом в выборе той или иной методологии програм-
мирования5 является уровень заказчика. Если заказчик — потребитель, то
нужно пользоваться методологией индустриального программирования.
Ему важно, как все это будет упаковано, как оно будет выглядеть, ком-
фортно ли будет с ним играться (слово «работать» здесь как-то не лезет на
язык). А уже во-вторых, нужно, чтобы оно еще кое-как "фурычило". Ему
очень часто можно "впарить" (и это даже порою на самом деле будет так),
что сие ire есть ошибка, это новая "фича". В работе он может лишь помешать
своими дурацкими требованиями, его нужно нейтрализовать, найти с ним
общий язык и максимально эффективно и быстро выяснить в тех немногих
областях, где он может быть полезен, чего же ему надо.
Если заказчик — специалист, то он разбирается в нужной ему задаче гораздо
лучше разных там "программеров"6. Он — полноправный участник работы.
Зачастую только он может оценить, правильно ли сработала программа, и
ему всего важнее именно эта правильность. Упаковка — дело второе, ее мож-
но будет довести тогда, когда уже почти все будет работать. А системы тестов
и ежедневное полное тестирование, на которое молятся в руководствах по
ХР и из-за которого многие хорошие и творческие программисты сбегают из
таких проектов, — лишь один из способов работать в такой обстановке.
5 В данном случае это слово точно отражает суть: методология не является методом. Она
является мировоззрением, а это мировоззрение позволяет выбрать метод и определя-
ет, как же он будет использован. То, что обычно называют методологией программиро-
вания, на порядок ниже. Это конкретные методы, привязанные к конкретным способам
выражения. Например, таков метод объектно-ориентированного анализа и дизайна
(ООАД), базирующийся на UML.
6 Коллеги, понимайте это четко1
ф
Предисловие рецензента
Ошибка в оценке квалификации заказчика непременно приводит к провалу
проекта.
Так вот, UML оказался идеальным инструментом для индустриального
программирования. В экстремальном же он может играть лишь вспомога-
тельную роль на второстепенных этапах и как поддержка (причем отнюдь
не всегда адекватная) некоторых аспектов документации. Это наблюдение
было основано на анализе работы громадной в 2000-2002 гг. новосибирской
софтверной фирмы Новософт. Несколько проектов было завалено имен-
но из-за того, что экстремальные по существу задачи решались методами
ООАД.
Рассмотрим тот пример, где UML серьезно обогнал многие системы про-
граммирования. Это диаграммы автоматов. Известно, что автоматное про-
граммирование — один из базовых стилей программирования, исключи-
тельно плохо совмещающийся со структурным, из-за чего он в свое время
предавался анафеме и до сих пор изгнан из базовых курсов программирова-
ния. Но на своем месте он работает великолепно. Диаграммы UML поддер-
живают этот стиль на четверку с минусом. Уже это в большинстве случаев
очень хорошо, но если об этом минусе на секундочку забыть и увлечься, то
получится тот провал, который будет стоить большинства правильных ре-
шений.
А самое главное, что диаграммы часто могут быть средством самообмана, а
то и обмана, поскольку так называемый "автоматический синтез” програм-
мы по ним и их по программе настолько безобразен, что может быть исполь-
зован лишь для быстрого показа, как же будет работать программа в данном
случае. А при переписывании вручную слишком часто возникают расхожде-
ния между документацией и реализацией.
Поэтому наличие UML не подменяет работ А. А. Шалыто и других энтузиа-
стов автоматного программирования.
О КНИГЕ И ОБ ЕЕ АВТОРАХ
Я с удовольствием прочитал книгу Ф. А. Новикова и Д. Ю. Иванова о языке
UML, и увидел, что умалчивать о сложностях и недостатках не в их принци-
пах тоже, а издательство, тем не менее, ее выпускает. Так что я рекомендую
данную книгу для всех мыслящих читателей, имеющих отношение к про-
граммированию либо как деятелей, либо как педагогов, либо как заказчиков
сложных проектов. Полезна она будет также специалистам в области слож-
ных проектов с большой информационной составляющей и с заказчиком
класса потребителя, но с большими амбициями и большими деньгами. Она
показывает, как создать для этого типа заказчика такую упаковку, которая
Ф
L 23 J
Моделирование на UML
его удовлетворит, а уж ваше дело как специалиста вложить в нее приличное
содержание. Тем более что даже отличное содержимое при невзрачной упа-
ковке такой заказчик пренебрежительно забракует.
Не ищите в этой книге однозначных рекомендаций! Она четко показыва-
ет, как надо делать, и тут же показывает, что в несколько другом случае так
делать не надо. Она вся пронизана русским негативным мышлением в са-
мом высоком смысле этого слова. Из-за этого мышления наши специалисты
столь высоко ценятся в ведущих центрах информатики, где англосаксонское
позитивное мышление часто заводит в тупик.
С одним из авторов этой книги я знаком уже более тридцати лет и знаю его
как прекрасного специалиста и, самое главное, как человека, уверенно стоя-
щего на высокой ступени знаний и умений. Другой же известен как хороший
педагог и очень хороший специалист.
Д. ф.-м. н., профессор Н. Н. Непейвода. 31.122009, Ижевск.
Г 24
Введение
Предлагаемая книга "Моделирование на UML" содержит подробное описа-
ние всех основных версий унифицированного языка моделирования UML и
набор рекомендаций по применению языка для моделирования1 программ-
ных систем.
Назначение книги
Книга имеет несколько областей применения, способов использования и це-
левых читательских аудиторий.
Во-первых, это учебник для начинающих, преимущественно студентов
старших курсов технических университетов, проходящих обучение по на-
правлениям подготовки, связанным с прикладной математикой, информати-
кой и программированием. Как учебник, книга содержит явные определения
основных понятий, используемых при моделировании программного обе-
спечения, точные описания основных конструкций языка UML и многочис-
ленные примеры их использования. Книга написана на основе курсов, кото-
рые авторы читали в разное время в трех университетах Санкт-Петербурга:
классическом (СПбГУ), политехническом (СПбГПУ) и информационных
технологий (СПбГУ ИТМО). Материал для начинающих составляет при-
мерно половину объема книги.
Во-вторых, это справочник и "поваренная книга" (cookbook) для опытных
пользователей языка, желающих углубить свои знания и усовершенствовать
навыки. Для достижения этой цели в книгу включен обширный справочный
материал, включающий аннотированную библиографию, краткий, но пол-
1 Многим читателям может показаться более уместным использование словосочетания
"проектирование программных систем", так как обычно программное обеспечение про-
ектируют, а не моделируют. Однако мы используем слово "моделирование" и делаем это
по двум причинам. Во-первых, UML - это язык моделирования. Во-вторых, до сих пор
нет единого мнения в вопросе, что же такое проектирование в применении к программ-
ному обеспечению? Обращаем внимание, что речь идет не о стадии (фазе) проектиро-
вания в процессе разработки программного обеспечения, а о понятии проектирования в
целом. Вопрос этот дискуссионный и решится он, по-видимому, тогда, когда разработка
программного обеспечения станет по-настоящему инженерной дисциплиной.
Если не оговорено особо, то термин "проектирование" используется в книге как обозна-
чение стадии (фазы) в процессе разработки программного обеспечения.
Моделирование на UML
ный толковый словарь терминов, сравнительный обзор инструментальных
средств. Далее, изложение семантики конструкций UML проводится на
сквозном примере — информационной системе отдела кадров. Результатом
моделирования является набор семантически законченных моделей, объе-
диненных одной предметной областью.
Реальные, а не учебные примеры такого рода сравнительно редко приводят-
ся в литературе по UML. Более того, в книге приводятся не только готовые
диаграммы, но и описываются рассуждения и промежуточные шаги, при-
ведшие авторов к тому или иному проектному решению. Тем самым авторы
включили в книгу свой опыт моделирования на UML, проверенный за время
проведения многочисленных тренингов для множества организаций и групп
разработчиков. Практические советы, рекомендации, рецепты и справки за-
нимают примерно треть объема книги.
В-третьих, в книгу включена "информация к размышлению" для экспер-
тов и знатоков. Мы имеем в виду многочисленные отступления, которые
раскрывают взгляды авторов2 на источники развития и перспективы при-
менения UML, влияние UML на процесс разработки, связь UML с другими
нотациями и тому подобное. Этот материал занимает немного места, но мы
считаем его ценным и важным.
Такое разнообразие целей подразумевает разнообразие читательских ауди-
торий. Поверьте нам - UML полезен всем: заказчикам, аналитикам, архи-
текторам, программистам, тестировщикам - всем, кто вовлечен в процесс
разработки программного обеспечения.
• Заказчику не помешает умение "читать" диаграммы UML, хотя бы
для того, чтобы лучше понимать аналитика, когда тот согласовывает
с ним свое представление о функциональных возможностях систе-
мы. Умение "рисовать" на UML может помочь заказчику ясно изла-
гать свои мысли, исключая неоднозначное толкование.
• Аналитик, может, не прибегая к громоздкому текстовому описанию,
формулировать требования к структуре и поведению системы, на
порядок увеличив тем самым наглядность и доступность материала
в процессе разработки спецификации.
• Для архитектора альтернатив практически нет, поскольку архитектур-
ные решения невозможно описать словами, нужна более точная и фор-
мальная нотация, и диаграммы UML - это лучший вариант сегодня.
Рисуя по старинке цветные квадратики, вы рискуете быть не понятыми.
2 В том числе мы высказываем спорные и полемические положения, считая, что это не
только вполне допустимо, но и желательно в современном учебнике.
L J
Введение
• Программисты, которые сразу после получения задачи на разработ-
ку начинали писать код, в настоящее время уже потеряли работу
Современные квалифицированные программисты сначала какое-то
время обдумывают структуру будущего приложения, его поведе-
ние, зачастую рисуя только им понятные схемы на бумаге. Почему
не использовать для этого UML? К нарисованной диаграмме всегда
можно вернуться и без труда разобраться, что же делает программа,
а исходный код, прекрасно понимаемый в данный момент, уже через
месяц становится непроходимыми джунглями.
• Тестировщик черпает информацию, требуемую для своей деятель-
ности, из спецификации. Наглядно описанный аналитиком способ
использования системы сразу даст тестировщику ответы на вопро-
сы: с каких позиций система должна быть протестирована и что
конкретно надо тестировать? Умение описывать на UML поведение
системы дает тестировщику альтернативный вариант записи тестов,
что позволит избавиться от бесконечных рябящих в глазах тексто-
вых "полотен".
Разнообразие целей и категорий пользователей ведет к разнообразию
применяемых конструкций. Именно поэтому мы описываем все конструк-
ции всех версий языка - многие конструкции, которые кажутся "устаревши-
ми" пользователям одной категории, например, программистам, являются
основным инструментом пользователей другой категории, скажем анали-
тиков. Поэтому мы в книге по многу раз обсуждаем один и тот же пример,
описывая его различными способами и с разных сторон.
Предмет книги
Прежде всего данная книга посвящена моделированию.
Моделирование это деятельность по составлению моделей.
Модели бывают разные. И хотя основную часть книги составляют примеры
моделей программ, которые выполняются на компьютере, мы также уделя-
ем внимание и другим областям применения моделей, рассматривая модели
устройств и модели бизнес-процессов.
Процесс моделирования, в рамках которого создаются модели, не является
самодостаточным и деятельности, связанные с анализом требований, де-
тальным проектированием, разработкой и тестированием также попадают в
сферу нашего внимания. Именно поэтому мы предполагаем увидеть в чита-
тельской аудитории и аналитиков, и архитекторов, и программистов, и те-
стировщиков и даже, как это не странно, заказчиков.
....................- ...................ЛЕВ
Моделирование на UML
Чтобы все эти заинтересованные лица могли без проблем общаться между
собой, им нужно говорить на одном языке.
UML — унифицированный язык моделирования. UML - это язык, который
позволяет не только эффективно решить проблему коммуникаций, но и не-
посредственно влиять на качество разрабатываемого продукта.
В этой книге UML рассматривается как целое, взятое в развитии и в контек-
сте всех способов практического применения для моделирования.
Способы моделирования, безусловно, самый важный, но не единственный
аспект, на который требуется обратить внимание при изучении UML. Во-
просам реализация языка, инструментальной поддержки, обучения языку,
перевода терминологии мы также уделяет большое внимание.
Предметом рассмотрения в книге является набор способов исполь-
зования всех конструкций языка при моделировании программного
обеспечения в различных предметных областях.
Разнообразие целей, предметных областей и категорий пользователей ведет
к разнообразию применяемых конструкций. Именно поэтому мы описыва-
ем все конструкции всех версий языка.
В настоящее время на практике используется несколько версий языка, ко-
торые можно разделить на две большие группы, UML 1 и UML 2, по первой
цифре номера версии. При этом в мире UML наблюдаемся очень глубокая
идейная совместимость и преемственность версий. Многие конструкции, ис-
пользующиеся для решения похожих задач, но принадлежащие разным вер-
сиям, сосуществуют в языке, не вытесняя друг друга. То, что кажется "уста-
ревшим” одному пользователю, может являться основным инструментом
другого. Например, программисты, использующие UML как средство де-
тального проектирования и реализации, описывая какой-либо конкретный
алгоритм, обратятся, скорее всего, к нотации диаграмм деятельности в стиле
UML 2, применяя типизированные контакты, хранилища данных и другие
новшества. Но в том же проекте аналитики, описывая бизнес-процесс на вы-
соком уровне абстракции, могут использовать те же диаграммы деятельно-
сти, но в нотации UML 1, поскольку так принято делать при моделировании
бизнес-процессов. Поэтому мы в книге по нескольку раз обсуждаем одни и
те же примеры, описывая их различными способами и с разных сторон, да-
вая читателю возможность выбора того варианта нотации, который нужен
ему по роду его профессиональной деятельности.
В таблице 0.1 мы привели своеобразную "карту применимости" конструк-
ций UML. Столбцы таблицы соответствуют основным содержательным (не
справочным) главам книги, а строки таблицы соответствуют разделам. Та-
Введение
ким образом, эта таблица описывает содержание книги, хотя и не является
оглавлением. Клетки таблицы окрашены (залиты) по следующим правилам.
Отсутствие заливки означает, что данный вопрос вообще не зависит от вер-
сии языка UML. Светлая заливка с черным цветом шрифта означает, что для
данного вопроса версии UML 1 являются "необходимым и достаточным"
средством. Темная заливка с черным цветом шрифта означает, что в данных
вопросах мы рекомендуем опираться на версии UML 2. Наконец, самая тем-
ная заливка с белым цветом шрифта говорит о том, что материал в равной
степени относится как к UML 1 так и к UML 2.
Таблица 0.1. Доминирование версий языка в книге.
Карта применимости версий UML
Введение в UML Моделирование использования Моделирование структуры Модели- рование поведения Дисциплина моделиро- вания
ЗЗй&Ш Бизнес-анализ и моделирование Объектно- ориентированное моделирование структуры Модели поведения - ; 7 - й ‘гЬ
Значение моделирования использования Сущности на диаграмме классов Диаграммы Tf- автомат а в'.- ' ' 1я® ' ML
.и и и ,Л> Диаграммы использования Отношения на диаграмме классов Диаграммы деятельности^ к? fWI I
'А . Мдделй Й их УпрвДСТМЯ !ИЯЙ Реализация вариантов использования Диаграммы реализации Диаграммы . взаимо- действия
' X,. ? Син leCKH.e." свойства^ЙЙ i и '.С j » ' Моделирование на уровне ролей и экземпляров классификаторов Моделирование ; параллелизма
Таким образом, обе основные группы версий примерно равноправны с прак-
тической точки зрения, и чтобы ничего не упустить, их необходимо рассма-
тривать (и применять) совместно.
Особенности книги
Предмет этой книги — унифицированный язык моделирования UML —
определяется международным стандартом. Таким образом, имеется канони-
ческий первоисточник. Практика показывает, что использовать текст стан-
дарта для целей обучения языку и приобретения навыков моделирования
1
Моделирование на UML
малоэффективно. Это и не удивительно, поскольку стандарт предназначен,
в основном, для производителей инструментов, поддерживающих язык, а не
для пользователей языка.
В настоящее время имеется достаточное количество литературы, описываю-
щей язык UML и различные аспекты его использования.3 Мы предлагаем
еще одну книгу и считаем, что она имеет полное право на существование,
потому что обладает рядом отличительных особенностей, являющихся кон-
курентными преимуществами.
Опытным преподавателям известно, что можно выделить три уровня пони-
мания обучающимся нового предмета, которые характеризуются следующи-
ми признаками.
1. У обучающегося возникает приятное чувство понимания излагаемо-
го материала.
2. Он может повторить изложенное своими словами.
3. Обучающийся видит ошибки и недочеты в изложении и в состоянии
их исправить.
Данная книга написана на третьем уровне и адресована читателям, ориен-
тированным на третий уровень. Другими словами, первой особенностью
книги является ориентация на мотивированного читателя. Мы включили
в текст трудные, неясные и спорные моменты, которые в обычной учебной
литературе благоразумно обходят молчанием. Читатель, который не может
или не хочет тратить силы на изучение таких моментов, может безболезнен-
но их пропустить.
Разработка программного обеспечения — комплексная деятельность, в ней
трудно преуспеть, работая "от сих до сих".4 Разработчику программного
обеспечения, и особенно архитектору, моделирующему систему, необ-
ходим широкий кругозор. Мы включили в книгу множество отступлений,
которые прямо не относятся к унифицированному языку моделирования
UML, но могут быть полезны при его практическом освоении. В число от-
ступлений включены необходимые пояснения терминов из дискретной ма-
тематики и теоретической информатики, исторические и биографические
справки, указания на связь понятий UML с идеями из других областей ин-
форматики, а иногда просто "байки" из программистского фольклора, ассо-
циирующиеся по контексту с обсуждаемыми понятиями UML. Таким об-
разом, второй отличительной особенностью этой книги является широта
охвата материала.
3 См. аннотированную библиографию в конце книги.
4 Именно поэтому, по мнению авторов, вульгарно внедряемая "технология программиро-
вания" дает иногда отрицательный эффект.
____ ф
Введение
Книга написана на основе продолжительного опыта авторов в применении,
преподавании и реализации инструментов поддержки языка UML. Мы зна-
ем, понимаем и любим этот язык. Но наша любовь не слепа, книга отнюдь не
является бездумной апологией языка UML. Многие неловкости, неудобства
и даже ошибки UML обсуждаются в этой книге, и предлагается авторский
подход к их исправлению.5 Другими словами, третьей особенностью книги
является апокрифичность — мы позволяем себе спорить с авторитетами, но
всегда явно указываем те места, где считаем необходимым отойти от стан-
дарта и общепринятого мнения. Мотивированный читатель на третьем уров-
не понимания сам выберет для себя ответ.
Предметом книги является, прежде всего, сам унифицированный язык мо-
делирования UML, но не только. Описание собственно языковых кон-
струкций, их нотации и семантики, занимает менее половины объема кни-
ги. Очень большое место мы отводим ответу на вопрос "зачем?". Зачем
нужна та или иная конструкция? В каких случаях ее целесообразно ис-
пользовать, а в каких случаях лучше эту конструкцию обойти? Причем мы
стараемся отвечать на такие вопросы не голословными спекуляциями, а
конкретными практическими примерами.
Применение практически всех6 конструкций UML проиллюстрировано в
книге на достаточно богатом и в то же время приземленном примере: моде-
ли информационной системы отдела кадров. Последней, но немаловажной
особенностью мы считаем прагматичность этой книги.
Структура книги
Логическая структура книги не со-
всем обычна: в некотором смысле
она трехмерна (рис. 0.1).
Любая книга, изданная типограф-
ским способом, имеет линейную
структуру: последовательность ну-
мерованных страниц, на которых
также последовательно размещены
текст и иллюстрации. Линейная упо-
рядоченность текста образует пер-
вое измерение логической структу-
Рис. 0.1. Логическая структура книги
5 Не исключено, что авторские предложения также содержат новые, более грубые ошибки.
6 Есть совсем небольшое число конструкций UML, для которых нам не удалось подобрать
естественного примера применения. В таких случаях мы объявляем эту конструкцию
"плохой" и явно информируем об этом читателя. Если мы не можем сказать, зачем нечто
нам нужно, значит, это нечто нам не нужно.
Моделирование на UML
ры: в длину от начала к концу. Линейная структура отражается в оглавлении
и для этой книги вполне традиционна. Книга состоит из данного Введения и
шести глав. Каждая глава состоит из разделов (от трех до девяти), а каждый
раздел состоит из параграфов (также от трех до девяти). Главы, разделы и
параграфы пронумерованы иерархической десятичной нумерацией, которая
используется для перекрестных ссылок. Некоторые длинные параграфы, в
частности, Введение, разбиты на более мелкие смысловые части ненумеро-
ванными подзаголовками.
Выбор названий и последовательности расположения глав не случаен. Этот
порядок не имеет отношения к структуре стандарта, он инспирирован автор-
ским видением процесса моделирования на UML.
В первой главе дается общий обзор языка "с высоты птичьего полета". Это
необходимо, чтобы в последующих главах использовать примеры с неко-
торым "забеганием вперед". Действительно, моделируя в деталях какой-то
один аспект системы, приходится, может быть на поверхностном уровне,
привлекать и другие аспекты, иначе нет надежды получить концептуально
целостную модель.
Во второй главе рассматривается самый важный, по нашему мнению, аспект
моделирования — моделирование использования, которое обычно является
первым этапом построения реальных моделей.
Третья и четвертая главы посвящены моделированию структуры и модели-
рованию поведения соответственно. Эти достаточно объемные главы содер-
жат большое количество практических примеров и теоретических отступле-
ний.
В пятой главе мы рассматриваем вопросы, которые относятся, главным об-
разом, не к самому языку, а к применению языка при разработке реальных
моделей, в том числе для больших систем. Эта глава адресована скорее ме-
неджерам проектов, нежели начинающим разработчикам.
Важной частью книги является набор информационных и справочных при-
ложений, собранных в шестой главе книги, которая содержит шесть разделов.
• Стандартные элементы языка — все ключевые слова, стереотипы и
ограничения, с описанием назначения, а также с историей появления и
исчезновения в разных версиях языка.
• Толковый словарь терминов — основные термины моделирования во-
обще и языка UML в частности, с краткими определениями и указанием
английских терминов.
Введение
• Действия в UML 2 — полное описание всех элементарных действий, вве-
денных в UML 2.
• Литература по UML — аннотированная библиография рекомендуемых
изданий.
• Предметный указатель — алфавитный указатель определяющих вхож-
дений всех терминов, содержит более шестисот словосочетаний.
• Графическая нотация — исчерпывающее описание всех графических
обозначений и их допустимых комбинаций на вкладке.
Второе измерение логической структуры связано со второй отличитель-
ной особенностью книги — широтой охвата материала. Наряду с прямым
изложением конструкций языка мы даем прагматические замечания по реа-
лизации, сведения о теоретических основах и формализмах, которые были
использованы при создании UML, альтернативные трактовки терминов и
их переводов, краткие сведения о людях, чьи имена нельзя не знать, изучая
UML, и другие сведения. В зависимости от того, насколько далеко мы отсту-
паем от генеральной линии в сторону, мы используем различные средства:
сноски,7 выделение фоном, примечания и отступления.
Фоном выделяются Определения, важные утверждения и выводы.
Примечание
Примечания тесно связаны с генеральной линией изложе-
ния и набраны тем же шрифтом, что и основной текст, но с
отступом.
ОТСТУПЛЕНИЕ
Отступления набраны другим шрифтом, чтобы подчеркнуть, что в
них мы уходим в сторону от генеральной линии. Отступления не-
обходимы для достижения сверхзадачи книги: освоения читате-
лем унифицированного языка моделирования UML. В случае от-
сутствия отступлений у читателя могло бы сложиться ошибочное
представление об оторванности UML от реальной практики раз-
работки программного обеспечения и от достигнутых результатов
в теоретической информатике.
Третье измерение логической структуры нашей книги является попыткой
решить следующую проблему. Унифицированный язык моделирования
UML — весьма объемный артефакт. Если сопоставить однородные описа-
ния8 UML и других известных языков, например Java или C++, то легко за-
7 Это пример сноски.
8 Грамматические описания не подходят, поскольку UML язык графический, а не тексто-
вый. Но можно сопоставить, напоимео. метамодели языков.
Моделирование на UML
метить, что UML заметно больше. Выбор структуры для описания таких объ-
емных языков имеет большое значение. С одной стороны, нужно изложить
все подробности, с другой стороны, читатель не должен утонуть в деталях.
Разные авторы использовали различные методы решения этой непростой
задачи. Например, выдающийся технический писатель современности Мар-
тин Фаулер на первое место ставит краткость и понятность изложения. Его
книги легко читаются и позволяют читателю ухватить основу, суть дела
ценой сравнительно небольших усилий. Трудные, темные и сомнительные
места Фаулер элегантно обходит, так что читатель никогда и не заметит их
отсутствия, если не знает из других источников об их существовании. Ав-
торы UML (Буч, Рамбо и-Якобсон) в своих книгах, конечно, не позволяют
себе замалчивать трудности. Они их объясняют. Но трудные места (или кон-
струкции языка) потому и трудны, что их нелегко объяснить. Объяснения
получаются еще более трудные. От читателя требуется терпение, внимание
и немалые усилия, чтобы правильно понять9 некоторые особенно темные
места в языке.
Мы в этой книге пытаемся совместить оба подхода: простые конструкции
объясняем коротко и просто, сложные конструкции объясняем, как умеем.
Расположение материала внутри структурных частей книги (глав, разделов,
параграфов) по возможности организовано таким образом, что сложная по
восприятию информация располагается ближе к концу. Другими словами,
материал располагается по правилу: от простого к сложному, сохраняя
при этом логику повествования.
Если при чтении книги подряд читатель почувствует, что в середине или
ближе к концу параграфа сложность текста возрастает, то это означает три
вещи: это место трудное, его понимание потребует дополнительных усилий!
Это место понимать не обязательно для освоения языка в целом! Это место
можно пропустить при чтении, и связность изложения не пострадает!
Например, в конце многих параграфов находятся метамодели рассмо грен-
ных в этих параграфах конструкций UML. Эти метамодели не являются
цитатами из стандарта — они несколько упрощены по сравнению со стан-
дартными метамоделями. Но они не 11 ротиворечат стандартам и в краткой
графической форме суммируют сказанное в тексте.
Наши метамодели не так просты для понимания, необязательны для изуче-
ния и некритичны в смысле цельности изложения, именно поэтому они рас-
полагаются в конце параграфов.
9 А после перевода на русский язык, в ряде случаев, такие трудные места не поддаются
пониманию никоим образом.
Введение
Используемые обозначения
В книге используются некоторые специальные соглашения об обозначени-
ях, связанные с записью текстов, кода программ и графических диаграмм.
Язык UML является графическим, но в нем интенсивно используются и
тексты, которые располагаются внутри фигур, в виде надписей возле ли-
ний и т. д. Тексты имеют определенный формат, или, правильнее сказать,
синтаксис.
В этой книге мы используем следующие упрощенные средства описания
синтаксиса. Синтаксис каждого текстового фрагмента описывается от-
дельно, в виде правила (фразы) в отдельной строке и выделен моноши-
ринным шрифтом. В этой фразе слова означают синтаксические понятия,
которые либо считаются очевидными, либо уточняются далее. Те понятия,
которые являются обязательными, записаны прописными буквами, а те, ко-
торые не являются обязательными, записаны строчными буквами. Те симво-
лы, которые не являются буквами, являются разделителями и должны быть
записаны так, как они показаны в правиле. Например, синтаксис понятия
"непустой список не более чем из трех элементов в скобках через запятую"
описывается следующей фразой:
(ЭЛЕМЕНТ 1, элемент2, элементЗ)
В немногих случаях мы прибегаем к записи кода программ для иллюстра-
ции тех или иных приемов моделирования. Код программы записывается
на некотором (не специфицированном) языке (псевдокоде), по синтаксису
похожем на язык Паскаль.
Код программы всегда располагается в отдельных абзацах, выделенных
моноширинным шрифтом. Ключевые слова выделены полужирным на-
чертанием. "Лишние" разделители, подобные знаку ; в конце строки, систе-
матически опускаются. Следуя классическим образцам (UML 1, Паскаль),
присваивание мы обозначаем знаком :=. Подчеркнем, что коды наших про-
грамм не предназначены для выполнения на компьютере. Они предназначе-
ны только для чтения человеком. Например, на нашем псевдокоде определе-
ние функции вычисления факториала допускается записывать следующим
образом:
func F (n : int): int
F := if n=1 then 1 else F(n-1) * n
Огромное значение в этой книге имеют диаграммы. На диаграммах исполь-
зуются разнообразные графические элементы: фигуры, линии, значки. Раз-
личных примитивных графических элементов не так много, и они по боль-
Моделирование на UMI.
шей части не имеют раз и навсегда зафиксированного смысла: их смысл
определяется контекстом и комбинацией с другими элементами. В тексте
книги приводятся названия и описывается смысл всех этих графических
элементов моделирования и их комбинаций, но при первом знакомстве
читателю может быть трудно сразу догадаться, что вот эта линия в этом
контексте означает такое-то понятие, а похожая линия в другом контексте
означает совсем другое.
Чтобы помочь читателю, мы помещаем в тексте в скобках указание на опре-
деленный элемент диаграммы, например, пишем: (1 на рис. 1.11), а на самой
диаграмме специальной нотацией (серый треугольник с номером внутри)
указываем, какой конкретно элемент имеется в виду. Если в тексте мы дела-
ем ссылку на элемент, представленный на ближайшей диаграмме, то номер
рисунка не указывается.
Например, "На рис. 0.2 изображено действие (1), при выполнении которого
может быть сгенерировано исключение, которое обозначается специальным
значком (2) и приводит к переходу (3) в заключительное состояние (4)."
Рис. 0.2. Форматы пояснений на диаграммах
*
[ 36 ]
Сведения об авторах
ТОДЫ
ович
:ов
акончил кафедру
формационные сист.
1нженеров-исследов<
гута авиационного пр
учился в аспирантуре
Закончил кафедру Ин-
факультета подготовки
Ленинградского инсти-
пыт работы в сфере IT — более
сотрудничал с ведущими IT-ком
Глава 1.
Введение в UML
ЧТО ОБОЗНАЧАЕТ АББРЕВИАТУРА UML?
Кому и зачем нужен UML?
Что послужило причиной возникновения UML?
Для чего используют UML на практике?
Как определен UML?
Что такое модель UML?
Из каких элементов состоит модель?
Как комбинируются элементы модели?
Какова общая структура модели?
Что ДЕЛАТЬ, ЕСЛИ ГОТОВЫХ ЭЛЕМЕНТОВ НЕ ХВАТАЕТ?
1.1. Что такое UML?
Предметом этой книги является UML в целом. Прежде чем обсуждать что-
либо "в целом", резонно сначала точно определить, о чем идет речь в част-
ности. Обсуждаемый предмет обозначается идентификатором UML, кото-
рый является аббревиа турой полного названия Unified Modeling Language.
Правильный перевод этого названия на русский язык — унифицированный
язык моделирования. Таким образом, обсуждаемый предмет характеризу-
ется тремя словами, каждое из которых является точным термином.
1.1.1. UML — это язык
Главным словом в этом сочетании является слово "язык".
Язык — это знаковая система для хранения и передачи информаций.
Различаются языки формальные, правила употребления которых строго и
явно определены, и неформальные, употребление которых основано на сло-
жившейся практике. Различаются также языки естественные, появляющие-
ся как бы сами собой10 в результате неперсонифицированных усилий массы
людей, и языки искусственные, являющиеся плодом видимых усилий опре-
деленных лиц. Филологи, наверное, смогут назвать еще дюжину различных
характеристик: нормативный и ненормативный язык, живой и мертвый,
синтетический и аналитический и т. д.
10 Точнее говоря, природа этого явления до конца не изучена.
1.1. Что ТАКОЕ UML?
ЧТО ОПРЕДЕЛЯЮТ ОПРЕДЕЛЕНИЯ?
Разумеется, абсолютного смысла понятия никакое определение
передать не может. Но броско и ёмко составленная формулиров-
ка определения может породить у читателя правильные ассоциа-
ции и стимулировать понимание. В частности, в предшествующем
определении словосочетания ’’знаковая система", "передача ин-
формации" и другие сами нуждаются в определениях, однако лю-
бому здравомыслящему человеку ясно, что такая иерархия опре-
делений никуда не приведет— где-то придется остановиться, не
дойдя до конца. Видимо, чем раньше, тем лучше. Одного-двух
определений достаточно, чтобы перейти к примерам — самому
надежному и доходчивому способу аргументации.
Например, язык, на котором написана эта книга (мы полагаем, что это рус-
ский язык), является неформальным и естественным. С другой стороны, по-
давляющее большинство языков программирования являются формальны-
ми и искусственными. Встречаются и другие комбинации: например, язык
алгебраических формул мы считаем формальным и естественным, а эспе-
ранто — неформальным и искусственным.
Примечание
Мы предполагаем, что читатель, по меньшей мере, наслышан
о языках программирования.
Так вот, UML можно охарактеризовать как формальный искусственный
язык, хотя и не в такой степени, как многие распространенные языки про-
граммирования. Признаком искусственности служит наличие трех обще-
признанных авторов — Гради Буча, Ивара Якобсона и Джеймса Рамбо.
Гради Буч (Grady Booch), р. 1955 — американский ученый и ин-
женер. Степень бакалавра получил в 1977 в Военно-воздушной
академии США, а степень магистра— в 1979 в Калифорнийском
университете, Санта Барбара.
Долгое время работал главным научным сотрудником корпорации
Rational Software, которая была куплена корпорацией IBM в февра-
ле 2003 года. В настоящее время является главным научным со-
трудником IBM Research.
Иввр Якобсон (Ivar Hjalmar Jacobson), р. 1939— выдающийся
шведский ученый и инженер. Степень магистра получил в 1962
году, а степень доктора в 1985 году в Королевском технологиче-
ском институте в Стокгольме. Предложил целый ряд оригиналь-
ных идей. В частности, ему принадлежат: идея сборочного про-
граммирования на основе программных компонентов (1967),
--------------------------------------------------
Глава 1. Введение в UML
изобретение диаграмм последовательности (1985), вариантов
использования (1986), соавторство при разработке языков SDL
(1976) и UML (1997).
Джеймс Рамбо (James Rumbaugh) — американский инженер и
ученый. Бакалаврская степень по физике в Массачусетском тех-
нологическом институте, магистерская степень по астрономии в
Калтехе, докторская степень по информатике в Массачусетском
технологическом институте.
Более 25 лет проработал в исследовательском центре корпора-
ции General Electric. В 1994 перешел в Rational Software, где вместе
с Бучем и Якобсоном разработал UML.
В то же время в формирование языка внесли вклад многие теоретики и раз-
работчики, имя которым легион. Языкотворческая практика применительно
к UML непрерывно продолжается (мы это обсудим позднее), что дает осно-
вание считать UML до некоторой степени естественным языком. Описание
UML по большей части формальное, но содержит и явно неформальные
составляющие. Такие особенности UML, как точки вариации семантики
(semantic variation point) (см. параграф 1.9.4) и стандартные механизмы рас-
ширения (extension mechanism) (см. параграф 1.8.4), заметно отличают UML
от языков, которые, по общему мнению, являются образцами формализма.
Примечание
В этой книге обсуждаются конкретные версии UML, для ко-
торых имеются утвержденные международные стандарты.
Однако наличие стандарта — это еще не основание считать
язык формальным и искусственным.
Для описания формальных искусственных языков (в частности, для описа-
ния языков программирования) придумано и используется множество раз-
личных способов. Однако на практике сложилась общепринятая структура
таких описаний.
Считается, что < {юрмальный искусственный язык описан должным обра-
зом, если это описание содержит, по мсныпсй мере, следующие части:
• Синтаксис (syntax), то есть определение правил составления кон-
струкций языка.
• Семантику (semantics), то есть определение правил приписывания
смысла конструкциям языка.
Прагматику (pragmatics), то есть определение правил использона-
ния конструкций языка для достижения определенных целей.
1.1. Что ТАКОЕ UML?
Как формальный искусственный язык UML имеет синтаксис, семантику и
прагматику, хотя эти части названы в некоторых случаях иначе и описаны
по-другому, нежели это принято в текстовых языках программирования, по-
скольку, во-первых, UML язык графический, а не текстовый, а во-вторых,
UML язык моделирования, а не программирования.
1.1.2. UML — ЭТО ЯЗЫК МОДЕЛИРОВАНИЯ
Слово "моделирование", входящее в название UML, имеет множество смыс-
ловых оттенков и сложившихся способов употребления.
В отношении разработки программного обеспечения0 так сложилось,
чти [нмультаты фаз анализа и проектирования11 12, оформленные сред-
ствами определенного языка, принято называть .моделью13. Деятель-
ность по составлению миделей естественно назвать моделированием
Именно в этом смысле UML является языком моделирования.
MODELING <-» SIMULATION
Как уже отмечалось, слово "моделирование" многозначно. В част-
ности, английские слова modeling и simulation оба переводятся
словом "моделирование", хотя означают разные вещи. В первом
случае речь идет о составлении модели, которая используется
только для описания моделируемого объекта или явления. Во вто-
ром случае подразумевается составление модели, которая может
быть использована для получения существенной информации о
моделируемом объекте или явлении. При этом во втором случае
обычно добавляется уточняющее прилагательное: численное, ма-
тематическое и др. UML является языком моделирования в первом
смысле, хотя авторам известны некоторые успешные попытки ис-
пользования UML и во втором смысле. Прочие вариации смысла
слова моделирование оставлены за рамками книги. В частности,
названия профессий: модель, модельер, модельщик и моделист
не имеют отношения к предмету. Те, кто составляет модели UML,
по-русски никак не называются, а должность, которую они зани-
мают, носит название "архитектор” или "системный архитектор".
11 В подавляющем большинстве случаев на протяжении книги термины "программное
обеспечение”, "программная система", "программа" и "приложение" используются как
синонимы. Авторы понимают, что в действительности между ними существуют опреде-
ленные различия, однако в контексте книги эти различия не имеют большого значения.
12 Понятия, связанные с процессом разработки, более подробно рассматриваются в
главе 5.
13 Что вполне согласуется с наиболее общим смыслом слова модель — абстрактное опи-
сание чего-либо.
Глава 1. Введение в UML
Таким образом, модель UML — это, прежде всего, описание объекта или явле-
ния, а также и кое-что другое, а именно все, что авторам UML удалось включить
в язык, не нарушая принципа унификации, к изложению которого мы перехо-
дим в следующем разделе.
1.1.3. UML — ЭТО УНИФИЦИРОВАННЫЙ ЯЗЫК МОДЕЛИРОВАНИЯ
Описывая историю создания UML, его авторы характеризуют эпоху до
UML как период "войны методов". Пожалуй, "война" — это слишком силь-
но сказано, но, действительно, UML является отнюдь не первым языком
моделирования. К моменту его появления насчитывались десятки других,
различающихся системой обозначений, степенью универсальности, спосо-
бами применения и т. д. Авторы языков и теоретики программирования пре-
пирались между собой, выясняя, чей подход лучше, а разработчики всю эту
"войну методов" равнодушно игнорировали, поскольку ни один из методов
не дотягивал до уровня индустриального стандарта.
Толчком к изменению ситуации послужили следующие обстоятельства.
Во-первых, массовое распространение получил объектно-ориентированный
подход к разработке программных систем, в результате чего возникла по-
требность в соо тветствующих средствах. Другими словами, появления чего-
то подобного UML с нетерпением ждали практики. Во-вторых, три круп-
нейших специалиста в этой области, авторы наиболее популярных методов,
решились объединить усилия именно с целью унификации своих (и не толь-
ко своих) разработок в соответствии с социальным заказом.
Приложив заслуживающие уважения усилия, авторы UML при поддержке
и содействии всей международной программистской общественности смог-
ли свести воедино (унифицировать) большую часть того, что было извест-
но и до них. В результате унификации получилась теоретически изящная и
практически полезная вещь — UML.
Если попытаться проследить историю возникновения и развития элементов
UML, как на уровне основополагающих идей, так и на уровне технических
деталей, то пришлось бы назвать сотни имен и десятки организаций. Мы не
будем этого делать, и не только из экономии места, но и потому, что исто-
рия развития UML отнюдь не завершена — язык постоянно совершенству-
ется, обогащается и расширяется14. Мы полагаем достаточным привести па
рис. 1.1 картинку, иллюстрирующую историю развития UML.
Как видно из рис. 1.1, на особом положении оказалась версия 1.5. Дело в том,
что версия 1.5 была выпущена в тот момент, когда "моделирующая обще-
ственность" предвкушала появление обещанной версии 2.0. На самом деле
14 Вы тоже можете принять в этом участие.
1 2. Назначение UML
версия 1.5 содержит некоторые элементы
версии 2.0, в частности, набор элементар-
ных действий, достаточно широкий для того,
чтобы применять UML не только как язык
моделирования, но и как язык программи-
рования. Но "генеральная линия" развития
инструментальных средств прошла мимо
этого явления. Все крупные поставщики ин-
струментов предпочли заявить о поддержке
версии 2.0 (иногда даже не имея для этого
достаточных оснований) и оставили без под-
держки версию 1.5.
Примечание
UML— это унифицирован-
ный язык моделирования, но
никак не единый и не уни-
версальный (мы видели та-
кие ошибочные толкования
первой буквы U в некоторых
источниках).
2009 - -
2007 - -
2005 - -
2003 - -
2001 - -
1999 --
1997 --
1995 --
(!) UML2.2
SUML2.1.2
UML2 0
О UML1.5
OUML1.4
О UML1.3
О UML1.0
(}) UML0.8
Рис. 1.1. История
развития UML
1.2. Назначение UML
UML предназначен для моделирования. Сами авторы UML определяют
свое детище следующим образом.
Язык L'ML это графический язык моделирования общего назначе-
ния, предназначенный для спецификации, визуализации, проект иро-
вания идок} ментиронания всех артефактов, создаваемых при ,<азра
ботке программных систем'' [3].
Мы полностью согласны с этим определением и не только одобряем выбор
ключевых слов, но придаем большое значение порядку, в котором они пере-
числены.
15 Словосочетание "программные системы" (software system) взято из определения, дан-
ного в стандарте UML 1.4. В UML 2.0 оно было заменено на одно слово— "системы"
(system), демонстрируя, таким образом, значительное расширение области примене-
ния UML.
Глава 1 Введение в UML
1.2.1. Спецификация
Втипичныхслучаяхв процессе разработки приложений участвуют по меньше
мере два действующих лица: заказчик (конкретный человек или группа лиц,
или организация) и разработчик (это может быть программист-одиночка,
временная команда проекта или целая организация, специализирующаяся
на разработке программного обеспечения). Из-за того, что действующих лиц
двое, очень многое зависит от степени их взаимопонимания.
Одним из ключевых этапов разработки приложения является определение
того, каким требованиям должно удовлетворять разрабатываемое приложе-
ние. В результате этого этапа появляется формальный или неформальный
документ (артефакт), который называют по-разному, имея в виду примерно
одно и то же: постановка задачи, требования, техническое задание, внешние
спецификации и др.
Аналогичные по назначению, но, может быть, отличные по форме и содержа-
нию артефакты появляются и на других этапах разработки, особенно если в
разработку включено много действующих лиц. Для них также используются
различные названия: функциональные спецификации, архитектура прило-
жения и др. Мы будем все такие артефакты называть спецификациями.
Спецификация — это декларативное описание того, как нечто устрое-
но или работает.
Необходимо принимать во внимание три толкования спецификаций:
• То, которое имеет в виду действующее лицо, являющееся источ-
ником спецификации (например, заказчик).
• То, которое имеет в виду действующее лицо, являющееся Потре-
бителем спецификации (например, разработчик).
• То, которое объективно обусловлено природой специфицируемо-
го объекта.
Эти три трактовки спецификаций могут не совпадать, и, к сожалению, как
показывает практика, сплошь и рядом не совпадают, причем значительно.
Заказчик может не осознавать своих объективных потребностей, или не-
верно их интерпретировать, или заблуждаться относительно природы своих
затруднений, пытаясь с помощью заказного офисного приложения лечить
симптомы, а не причину болезни своего бизнеса. Разработчик может не раз-
бираться в предметной области заказчика и интерпретировать формулиров-
ки спецификаций совершенно превратным образом. Если же в формулиров-
ке спецификаций участвует разработчик, то злоупотребление технической
терминологией может совершенно дезориентировать заказчика.
Ф
L 46 Д
1-.2. Назначение UML
О ФОРМАЛЬНЫХ СПЕЦИФИКАЦИЯХ
Идеальным было бы формулировать спецификации с мате-
матической строгостью, так чтобы сам язык спецификаций ис-
ключал неоднозначности в описании функций разрабатываемого
приложения.
Математикам известны средства такого рода, например, язык
исчисления предикатов. Действительно, если задать с помощью
логического выражения на языке исчисления предикатов условие,
которому должны удовлетворять входные данные приложения (так
называемое предусловие), и условие, которому должны удовлет-
ворять выходные данные приложения (постусловие), то не оста-
ется места для неоднозначности в определении того, делает при-
ложение то, что нужно, или нет. Как говорят математики, "не нужно
спорить, давайте вычислять".
Например, предусловия а Ф 0 и Ь2 — 4ас > 0 вместе с постус-
ловием ах2 + Ьх + с = 0 являются исчерпывающим ТЗ на раз-
работку приложения "Решение квадратного уравнения" (входные
данные а, b, с выходные данные Xlt Х2)16.
Если для рассматриваемой предметной области действи-
тельно существует строгая математическая модель, то фор-
мальная спецификация является наиболее предпочтитель-
ной. Именно такие спецификации используют при разработке
приложений в инженерных областях.
К сожалению, в большинстве предметных областей сколько-
нибудь проработанных математических моделей нет, степень
формализации очень низка, и навыки использования формальных
математических методов не очень распространены. При попытке
применить формальные методы объем спецификации оказыва-
ется намного больше объема самого специфицируемого прило-
жения, а разработка спецификаций оказывается гораздо более
трудоемкой (и требующей более высокой квалификации!), чем
разработка приложения.
По этому поводу в фольклоре разработчиков бытует шутка о том,
что наиболее полной, точной и краткой спецификацией програм-
мы является текст программы17. Для математических программ
с этим можно поспорить, но для офисных приложений это, безу-
словно, так.
16 Нужно еще указать, что все числа вещественные, и задать точность, с которой должны
быть определены корни, но это уже детали.
17 Строго говоря, это не совсем верно для большинства языков программирования, кото-
рые позволяют описать детерминированную последовательность действий, т.е. сделать
императивное описание, в то время как спецификация подразумевает декларативное.
Ф
Глава 1. Введение в UML
Основное назначение UML — предоставить, с одной стороны, достаточно
формальное, с другой стороны, достаточно удобное, и, с третьей стороны,
достаточно универсальное средство, позволяющее до некоторой степени
снизить риск расхождений в толковании спецификаций.
1.2.2. Визуализация
Известная поговорка гласит, что лучше один раз увидеть, чем сто раз услы-
шать. Мы добавим: тем паче тысячу раз прочитать пересказ. Особенности
человеческого восприятия таковы, что текст с картинками воспринимается
легче, чем голый текст. А картинки с текстом (это называется "комиксы") —
еще легче. Модели UML допускают представление в форме картинок, при-
чем эти картинки наглядны, интуитивно понятны, практически однозначно
интерпретируются и легко составляются. Фактически, развитие и детали-
зация этого тезиса составляет большую часть содержания остальной части
книги. Мы не будем забегать вперед и просто приведем пример без всяких
объяснений (рис. 1.2). Разве что-нибудь непонятно?
move
Рис. 1.2. Жизненный цикл работника на предприятии
Таким образом, второе по важности назначение UML состоит в том, чтобы
служить адекватным средством коммуникации между людьми. Разумеет-
ся, наглядность визуализации моделей UML имеет значение, только если
они должны составляться или восприниматься человеком — это назначение
UML не имеет отношения к компьютерам.
Примечание
Графическое представление модели UML не тождественно
самой модели. Это важное обстоятельство часто упускается
из виду при первом знакомстве с UML.
1.2.3. Проектирование
В оригинале данное назначение UML определено с помощью слова construct,
которое мы передаем осторожным термином "проектирование". Речь идет о
том, что UML предназначен не только для описания абстрактных моделей
1 2 Назначение UML
приложений, но и для непосредственного манипулирования артефактами,
входящими в состав этих приложений, в том числе такими, как программ-
ный код. Другими словами, одним из назначений UML является, например,
создание таких моделей, для которых возможна автоматическая генера-
ция программного кода (или фрагментов кода) соответствующих прило-
жений. Более того, природа моделей UML такова, что возможен и обратный
процесс: автоматическое построение модели по коду готового приложения18.
Сказанное в предыдущем абзаце требует оговорок "до некоторой степени",
"в известной мере" буквально после каждого утверждения. Самое досадное,
что в данный момент точно указать "степень" и "меру" не представляется
возможным. Причина не в том, что никто не удосужился этим заняться, а в
том, что это очень трудная задача.
АВТОМАТИЧЕСКИЙ СИНТЕЗ ПРОГРАММ
Синтезом программ называется автоматическая генерация
программы по некоторой спецификации. В зависимости от
метода спецификации автоматический синтез программ подраз-
деляют на несколько категорий.
Если спецификация задана в виде формальных логических
условий, связывающих входные и выходные данные, то го-
ворят о дедуктивном синтезе программ. Например, если спе-
цификация задана с помощью предусловия (см. врезку "О фор-
мальных спецификациях" в параграфе 1.2.1) Р(х) и постусловия
Q(x, у), связывающего входные данные X с выходными данными
у, то из конструктивного доказательства теоремы существования
Vx(P(x) ByQ(x,y)) может быть автоматически извлечена
программа вычисления у no X. К сожалению, задача автоматиче-
ского доказательства теорем во всех смыслах трудная, так что тот
факт, что автоматический дедуктивный синтез программ сводится
к автоматическому доказательству теорем, не слишком обнаде-
живает.
Если спецификация задана в виде набора примеров (то есть
набора пар входных и соответствующих им выходных дан-
ных), то говорят об индуктивном синтезе программ. Известны
классы программ, для которых можно указать, сколько и каких
примеров достаточно для того, чтобы однозначно синтезировать
программу. Поясним это аналогией из геометрии: если известны
координаты двух точек на прямой, то нетрудно получить уравне-
ние этой прямой. Но если про интересующую нас фигуру (линию)
18 По-английски это называется reverse engineering и обычно переводится на русский как
"обратное проектирование". Нам этот перевод категорически не нравится: какое же это
проектирование и почему оно обратное? Есть неплохой альтернативный вариант: "ин-
женерный анализ программ ", но он не получил пока распространения.
Глава 1. Введение в UML
ничего не известно, то никаким конечным множеством точек (то
есть примеров) задать ее нельзя.
Все остальные виды формального, но неалгоритмического
описания задачи, например, в виде моделей UML, относят к
трансформационному синтезу.
В общем случае задача автоматического синтеза программ
алгоритмически неразрешима, то есть не существует алго-
ритма, который бы по произвольной спецификации строил соот-
ветствующую программу, однако известно множество частных,
но практически важных случаев, в которых синтез программ воз-
можен. Результаты, получаемые в ходе теоретических исследова-
ний по автоматическому синтезу программ, находят практическое
применение в оптимизирующих компиляторах, электронных та-
блицах и других областях.
Автоматическое (или автоматизированное) проектирование и конструиро-
вание приложений по спецификациям - дело трудное, но не безнадежное.
Инструменты, поддерживающие UML, все время совершенствуются, так что
в перспективе третье предназначение UML может выйти и на первое место.
Примечание
Некоторым уставшим от бесконечной отладки разработчи-
кам может показаться, что стоит изучить UML, и все пробле-
мы программирования будут решены. К сожалению, это не
так.
1.2.4. Документирование
Модели UML являются артефактами, которые можно хранить и исполь-
зовать как в форме электронных документов, так и в виде твердой копии.
В последних версиях UML с целью достижения более полного соответствия
этому назначению сделано довольно много. В частности, специфицировано
представление моделей UML в форме документов в формате XMI19, что обе-
спечивает практическую интероперабельность при работе с моделями. Дру-
гими словами, модели UML не являются вещью в себе, которой разрешается
только любоваться, — это документы, которые можно использовать самыми
разными способами, начиная с печати картинок и заканчивая автоматиче-
ской генерацией человекочитаемых текстовых описаний.
Поясним последнюю фразу предыдущего абзаца. Стандарт требует, чтобы
19 XMI (XML Metadata Interchange) — внешний формат данных, основанный на языке XML
(схема и набор правил использования тегов), предназначенный для сериализации мо-
делей и обмена ими.
1.2. Назначение UML
во внутреннем представлении модели для каждого элемента моделирования
было отведено место, где можно хранить неформальное текстовое описание
этого элемента.
Большинство инструментов это требование выполняют: буквально для каж-
дой линии или фигуры на диаграмме можно ввести текст, который поясня-
ет смысл и назначение именно этой линии или фигуры. Более того, многие
инструменты умеют из этих текстовых описаний собирать цельные, вполне
осмысленные и хорошо отформатированные текстовые документы, которые
можно использовать именно как привычные текстовые описания модели-
руемой системы. К сожалению, это замечательная возможность на практике
используется меньше, чем она того заслуживает. Дело в том, что так же, как
программисты не любят и ленятся писать осмысленные комментарии к про-
граммному коду, так и архитекторы не любят и ленятся писать текстовые
пояснения к своим диаграммам.
1.2.5. Чем НЕ является UML
Не следует думать, что UML — это панацея от всех детских20 болезней про-
граммирования. Для ясного понимания назначения и области применения
UML полезно сопоставить UML с другими родственными явлениями.
Во-первых, UML не является языком программирования (хотя генерация
кода не возбраняется, см. параграф 1.2.3). Дело не в том, что UML язык гра-
фический, а подавляющее большинство практических языков программиро-
вания являются текстовыми языками. Гораздо важнее то, что для моделей
UML не определена операционная семантика, то есть не определен способ
выполнения моделей на компьютере. Это сделано вполне сознательно, в
противном случае UML оказался бы зависимым от некоторой модели вы-
числимости, уровень абстрактности его концепций пришлось бы существен-
но снизить, и он не отвечал бы своему основному назначению: служить
средством спецификации приложений и других систем на любом уровне аб-
стракции и в различных предметных областях.
Во-вторых, UML не является спецификацией инструмента (хотя ин-
струменты подразумеваются и имеются, например, Rational Rose, Borland
Together, Telelogic Rhapsody, Visual Paradigm, Microsoft Visio, Enterprise
Architect, StarUML и др. — см. параграф 5.2.4). Сам язык никоим образом не
навязывает то, как его нужно поддерживать инструментальными средства-
ми. Решение всех вопросов, связанных с реализацией UML на компьютере,
полностью отдано на откуп разработчикам инструментов.
20 Информационным технологиям от силы полвека — это еще младенческий возраст для
новой области человеческой деятельности.
Глава 1. Введение в UML
В-третьих, UML не является моделью процесса разработки приложений
(хотя модель процесса разработки необходима и имеется множество различ-
ных моделей, предложенных разными авторами). Конечно, у авторов UML
есть собственная модель процесса — Rational Unified Process (RUP), кото-
рую они не могли не иметь в голове, разрабатывая язык, но тем не менее
ими сделано все для того, чтобы устранить прямое влияние RUP на UML и
сделать UML пригодным для использования в любой модели процесса или
даже без оной.
Примечание
У авторов этой книги тоже есть собственное мнение о взаи-
мосвязи UML с моделью процесса разработки программного
обеспечения (см. раздел 5.3), которое не может не сказывать-
ся на описании прагматики языка, но везде, где такое влия-
ние замечено, сделаны соответствующие оговорки.
1.2.6. Способы использования UML
Из сказанного выше видно, что UML предназначен для решения различных
задач, соответственно он может быть использован и практически использу-
ется по-разному. Далее мы перечисляем различные способы использова-
ния UML.
• Рисование картинок. Графические средства UML можно и нужно ис-
пользовать безотносительно ко всему остальному. Даже рисование
диаграмм карандашом на бумаге позволяет упорядочить мысли и за-
фиксировать для себя существенную информацию о моделируемом при-
ложении или иной системе.
• Обмен информацией. Сообщество людей, применяющих и понимаю-
щих U ML, стремительно растет. Если вы будете использовать UML, то
другие вас будут понимать и вы будете понимать других "с полувзгляда".
• Спецификация систем. Это важнейший способ использования UML.
И хотя пока не во всех случаях UML оказывается абсолютно адекват-
ным средством спецификации, мы надеемся, что по мере развития языка
все меньше будет оставаться таких исключений, где UML неприменим.
• Повторное использование архитектурных решений. Повторное ис-
пользование ранее разработанных решений — ключ к повышению эф-
фективности. Наше мнение по этому поводу изложено в разделе 5.1.
К сожалению, модели UML пока что повторно используются в весьма
ограниченных масштабах.
1.2. Назначение UML
• Генерация кода. В параграфе 1.2.3 данный вопрос достаточно освещён.
Генерировать код нужно и можно, но возможности имеющихся инстру-
ментов не стоит переоценивать.
• Имитационное моделирование. Возможности построения моделей
U ML, из которых путем вычислительных экспериментов можно было
бы извлекать информацию о моделируемом объекте, пока что уступают
возможностям специализированных систем, сконструированных для
этих целей.
• Верификация моделей. Было бы замечательно, если бы по модели мож-
но было бы делать формальные заключения об ее свойствах: модель не-
противоречива, согласована, эффективна и т. п. Кое-что UML позволяет
проверить, но, конечно, очень мало. Здесь уместно привести аналогию с
традиционными системами программирования: они позволяют быстро и
надежно избавиться от синтаксических ошибок, но с логическими ошиб-
ками дело обстоит гораздо хуже. Может быть, в будущем...
1.2.7. Инструментальная поддержка
Рассмотрим, как соотносится сегодняшняя практика использования UML с
декларированным выше назначением языка.
Проводя в жизнь принцип обучения на примерах, для иллюстрации выше-
сказанного обратимся к одной из диаграмм UML — диаграмме использова-
ния21.
По мнению авторов, можно выделить три основных варианта использова-
ния UML (рис. 1.3).
• Вариант использования drawing ("Рисование диаграмм") подразумевает
изображение диаграмм UML с целью обдумывания, обмена идеями меж-
ду людьми, документирования и тому подобного. Значимым для поль-
зователя (User) результатом в этом случае является само изображение
диаграмм. Вообще говоря, в этом варианте использования языка поддер-
живающий инструмент не очень нужен. Иногда рисование диаграмм от
руки фломастером с последующим фотографированием цифровым ап-
паратом может оказаться практичнее.
• Вариант использования modeling ("Моделирование систем") подразу-
мевает создание и изменение модели системы в терминах тех элементов
моделирования, которые предусматриваются метамоделью UML. Зна-
чимым результатом в этом случае является машинно-читаемый арте-
факт с описанием модели. Мы будем для краткости называть такой ар-
21 Подробное описание данного типа диаграмм приведено в следующей главе.
Глаьа 1. Введение в UML
Analyst
Developer
Programming System
Рис. 1.3. Инструментальная поддержка
тефакт просто моделью, деятельность по составлению модели называть
моделированием, а субъекта моделирования называть архитектором
(Architect).
• Вариант использования development ("Разработка приложений") под-
разумевает детальное моделирование, реализацию и тестирование при-
ложения в терминах UML. Значимым для пользователя (Developer)
результатом в этом случае является работающее приложение, которое
может быть скомпилировано в язык, поддерживаемый конкретной си-
стемой программирования (Programming System), или сразу интерпрети-
ровано средой выполнения инструмента. Этот вариант использования
наиболее сложен в реализации.
Современные инструменты поддерживают указанные варианты использо-
вания далеко не в равной степени. Все инструменты умеют (плохо или хо-
рошо) визуализировать все типы диаграмм UML, некоторые инструменты
позволяют построить модель, допускающую какое-то дальнейшее использо-
вание, но только немногие инструменты могут генерировать исполняемый
код и то отнюдь не для всех диаграмм. Имеется множество практических и
♦
1.3. Определение UML
организационных причин, по которым указанные выше варианты исполь-
зования неравноправны и в разной степени поддержаны в современных ин-
струментах. Некоторые из этих причин мы рассматриваем в последующих
главах.
1.3. Определение UML
Искусственный язык должен быть как-то описан. Искусственный язык, пре-
тендующий на массовое использование, должен быть описан так, чтобы при-
тягивать, а не отпугивать потенциальных пользователей. А это сделать не
так просто.
1.3.1. Определения искусственных языков
История языков программирования насчитывает полвека, и столько же про-
должается развитие методов их определения. На этом пути были прорывы
(определения Алгола 68, Паскаля), были и неудачи (PL/1)22. От определе-
ния искусственного языка требуется, чтобы оно было:
• точным,
• понятным,
• кратким,
• полным.
Между тем, эти требования зачастую исключают друг друга23. В некоторых
случаях во главу угла ставится что-либо одно, но результат редко оканчи-
вается удачей. Например, определение Алгола 68, где все было нацелено на
формальную точность, явилось новым словом в методах определения языков
и оказало большое влияние на развитие теории. В то же время это описание
оказалось настолько непонятным рядовым пользователям, что отпугнуло их
от потенциально многообещающей разработки. Другой пример: с целью "по-
нятности" первые диалекты Кобола описывались совершенно неформально,
в результате получалось плохо, потому что для достижения минимальной
необходимой точности и полноты неформальное описание приходилось де-
лать очень длинным, а потому непонятным.
22 Подобные высказывания можно адресовать и современным языкам программирования,
таким как C++, Java, C# и другим. Однако, в отличие от языков, приведенных в качестве
примера, современные языки продолжают эволюционировать и какие-либо выводы де-
лать все-таки еще рано. Любое высказывание на эту тему породит больше вопросов,
чем ответов.
23 Известна замечательная рекламная фраза: "быстро, качественно и недорого — любые
два условия из трех по выбору заказчика".
Глава 1, Введение в UML
Наиболее удачными оказались компромиссные решения, и авторы UML
пошли именно по этому пути.
1.3.2. Метод определения UML
- «яр -j,. t i f
В основу описания UML положен метод раскрутки, то есть использо-
вание определяемого языка для определения этого языка. А именно, |
основные конструкции UML формально определены с помощью UML.
Конечно, с чего-то раскрутку нужно начать, и это описано в UML не-
формально, с помощью текстов на естественном (английском) языке.
Примечание
Метод раскрутки часто применяется при определении фор-
мальных языков. Например, можно очень изящно опреде-
лить операционную семантику языка программирования,
если написать транслятор или интерпретатор данного языка
на этом же языке. Одним из первых этот прием использовал
Н. Вирт (см. параграф 2.4.2), создавая язык Паскаль.
В описании UML используются три языковых уровня:
• Мета-метамодеЛь, то ccfb описание языка, на котором описана
метамодель.
• Метамодель, то есть описание языка, на котором описываются
модели.
• Модель, то есть описание самой моделируемой предметной об^
ласти.
Это кажется нагромождением сущностей без нужды, но на самом деле толь-
ко использование ученой приставки мета (от греческого цеха, что означает
"между", "после", "через") может быть несколько непривычным.
Действительно, рассмотрим описание какого-либо из обычных языков про-
граммирования. Чтобы никого не обидеть, пусть этот язык называется X.
Если описание хорошее, то в самом начале указывается язык (иногда его
так и называют — метаязык), который используется для описания языка
X. Например, приводится фраза такого типа: "синтаксис языка X описан с
помощью контекстно-свободной грамматики, правила которой записаны в
форме Бэкуса-Наура (БНФ), контекстные условия и семантика описаны на
естественном языке". Если описание не очень хорошее, то такая фраза может
Ф
56
1.3. Определение UML
и отсутствовать, но она все равно неявно подразумевается24, и от читателя
требуется понять используемый метаязык по контексту. Далее с помощью
метаязыка более или менее формально описываются конструкции языка X;
все, что не удается описать формально, описывается на естественном языке
(при этом зачастую вводится большое количество "новых" терминов и ис-
пользуются трудные для чтения канцеляризмы). Все это, как правило, со-
провождается многочисленными конкретными примерами фрагментов тек-
стов на языке X.
Чтобы читатель не путался, где текст на языке X, а где текст на метаязыке,
или где общее описание, а где конкретный пример, применяются различные
полиграфические приемы; изменение гарнитуры и начертания шрифта, от-
ступы, подчеркивание и т. д. В результате получается неплохо: многоязыко-
вая смесь становится вполне удобочитаемой (при минимальном навыке).
ФОРМАЛЬНЫЕ ГРАММАТИКИ
Для описания языков программирования с успехом ис-
пользуется теория формальных грамматик, разработан-
ная А. Н. Хомским. Вкратце суть заключается в следующем
Рассматривается конечный алфавит А (множество символов) и
язык над этим алфавитом. Здесь язык— это просто множество
последовательностей символов алфавита (цепочек). Другими
словами, среди всех возможных цепочек (которых заведомо бес-
конечно много) нужно иметь возможность выделить те и только те,
которые являются цепочками языка (еще говорят "входят в язык",
"принадлежат языку", "являются выражениями языка").
Для описания (бесконечного) множества цепочек Хомский пред-
ложил использовать формальную порождающую грамматику —
конечное множество правил вида ОС —> Р, где ОС и Р конечные
цепочки, составленные из символов алфавита А (которые назы-
ваются терминальными символами) и из символов некоторого
дополнительного алфавита N (эти символы принято называть
нетерминальными). В левую часть правила (т. е. в цепочку ОС) обя-
зательно должен входить хотя бы один нетерминальный символ.
Среди всех нетерминальных символов выделяется один, который
называется начальным символом (или аксиомой) грамматики.
Далее все очень просто. Взяв за основу аксиому грамматики, раз-
решается строить новые цепочки, заменяя в уже построенной це-
почке любое вхождение левой части любого правила на правую
часть этого правила. И так до тех пор, пока в цепочке не останутся
24 В нашей книге средства описания синтаксиса указаны во Введении.
Глава 1 Введение в UML
одни терминальные символы. Всякая цепочка терминальных сим-
волов, которую можно построить таким процессом, по определе-
нию входит в язык, а если цепочку нельзя так построить, то она не
входит в язык. Например, грамматика, которая имеет один нетер-
минальный символ S, два терминальных символа 0 и 1 и два пра-
вила S —» 01 и S —» 0S1, определяет (как говорят, порождает)
язык, состоящий из цепочек вида 01,0011,000111 и так далее.
Разумеется, все это так просто, пока не поставлены разные ка-
верзные вопросы. Всякий ли язык может быть определен таким
способом? Если дана грамматика и конкретная терминальная це-
почка, то как узнать, принадлежит она языку или нет? Однозначен
ли процесс порождения цепочки? Зависят ли ответы на предыду-
щие вопросы от вида (формы) правил?
Но если основная идея ясна, то можно оставить эти (весьма труд-
ные) вопросы математикам и принять тот факт, что синтаксис по-
давляющего большинства языков программирования легко
описывается25 подклассом формальных грамматик, кото-
рые называются контекстно-свободными (левая часть всех
правил состоит из одного нетерминального символа). Для этого
подкласса грамматик все вопросы, связанные с распознаванием
принадлежности цепочки языку (это называется синтаксическим
анализом, или разбором), надежно решены.
Таким образом, основная идея описания UML вполне традиционна и согла-
суется с общепринятой практикой: мета-метамодель — это описание исполь-
зуемого формализма; метамодель — это и есть собственно описание языка
(элементов моделирования): там, где формализм не срабатывает, на помощь
приходит естественный язык, и все это сопровождается примерами фраг-
ментов моделей.
Аврам Ноам Хомский (часто транскрибируется как Хомски
или Чомски, англ. Avram Noam Chomsky), р. 7 декабря 1928,
Филадельфия, штат Пенсильвания, США— американский линг-
вист, политический публицист и теоретик. Автор классификации
формальных языков, называемой иерархией Хомского.
25 А если не описывается или описывается нелегко, то всегда можно привлечь естествен-
ный язык и все, что нужно, досказать словами. В качестве примера возьмите любое опи-
сание популярного языка программирования: C++, Visual Basic, Java, С#.
58 1
1.3. Определение UML
1.3.3. Структура стандарта UML
Весь текст описания UML каждой версии находится в свободно распростра-
няемых документах26. В таблице 1.1 перечислены основные документы, вхо-
дящие в комплект документации для версии UML 2.2 (февраль 2009).
Таблица 1.1. Структура описания UML
Часть описания Основное содержание Число страниц
UML Infrastructure Описание базовых механизмов, а также архитектуры, профилей, стереотипов 226
UML Superstructure Описание статических и динамических элементов языка 740
UML Diagram interchange Описание формата обмена дополнительными данными о диаграммах (форматирование, расположение элемен- тов и т.д.) между различными инструментами 86
OCL Specifications Описание объектного языка ограничений OCL (Object Constraint Language) 232
Всего страниц 1284
Без специальной предварительной подготовки читать в этих документах
имеет смысл только вводные разделы, примерно соответствующие по зада-
чам этой главе, и последние разделы, в которых собраны толкования основ-
ных терминов, примерно соответствующие по задачам последней главе этой
книги. Остальное предназначено не для ознакомительного чтения пользо-
вателями, а для скрупулезного изучения разработчиками инструментов мо-
делирования. По замыслу авторов языка для пользователей должны быть
написаны другие книги, и они написаны, как самими авторами, так и люби-
телями UML. Один из примеров у вас в руках.
В описании языка самым важным является раздел описания семантики. Се-
мантика описана следующим образом. Для определяемого элемента моде-
лирования задается абстрактный синтаксис (в форме диаграммы классов
UML) и указываются ограничения, которым должен удовлетворять опи-
сываемый элемент в форме выражений языка ОСЬ. Все остальное, вклю-
чая прагматику, описывается на естественном языке, который авторы назы-
вают "plain English".
Далее для каждого элемента моделирования указывается, как его реко-
мендуется изображать в графическом виде. Фактически, этот раздел со-
ответствует разделу описания синтаксиса для обычного языка программи-
рования. Но UML не обычный язык, а графический! Пока что для описания
синтаксиса графических языков не придумано столь же удобного механизма,
26 Доступных по адресу http://www.omg.org
Глава 1. Введение в UML
как формальные грамматики, поэтому в этом разделе стандарта приведены
довольно многословные описания в следующем стиле: "Состояние автомата
изображается прямоугольником со скругленными углами, внутри которого
указывается имя состояния в виде строки текста, а также, возможно..." и так
далее. К счастью, графический синтаксис UML довольно прост и тщательно
продуман, так что, если вы отличаете окружность от квадрата, то разобрать-
ся не трудно.
Большая часть содержания этой книги посвящена неформальному переска-
зу и обсуждению того, что формально описано в основном документе "UML
Superstructure". Прочие же разделы стандарта здесь фактически не рассма-
триваются, и не потому, что они длинные, а потому, что знание их содержа-
ния практически не влияет на достижение главной цели книги: объяснить,
как, когда и почему можно и нужно использовать UML при разработке про-
граммного обеспечения.
Примечание
Как уже было сказано, читать стандарт для первого знаком-
ства с языком бесполезно. Но если вы уже знаете UML, то
изучение того, как именно авторы используют UML для опи-
сания самого UML, является чрезвычайно полезным упраж-
нением. Дело в том, что авторы UML мастерски используют
UML, поэтому рассматривание диаграмм в стандарте в про-
цессе изучения UML подобно чтению кода, написанного хо-
рошим программистом, в процессе изучения языка програм-
мирования.
1.3.4. Терминология и нотация
Проблема терминологии является одной из самых болезненных при обсуж-
дении языка UML.
Во-первых, авторы UML старались сделать язык независимым от конкрет-
ных языков программирования, моделей вычислимости и тому подобного.
С этой целью они зачастую вводили новые термины для определяемых по-
нятий, чтобы случайное совпадение со старым термином, уже занятым в
какой-либо смежной области программирования, не вводило в заблуждение
пользователя. Кроме того, в UML унифицированы многие различные под-
ходы и методы, каждый со своей терминологической традицией, и их все
необходимо было учесть и иногда пойти навстречу. Как всякий компромисс-
ный вариант, терминология UML получилась довольно замысловатой и не
всегда последовательной.
е
1.3. Определение UML
Во-вторых, эта книга написана по-русски и для русскоязычного читателя. Ста-
ло быть, термины UML должны так или иначе быть переданы кириллически-
ми буквосочетаниями. Язык UML сравнительно молод (но уже моден), бум
публикаций в отечественной литературе начался только сейчас (с опозданием
на десять лет, как обычно), поэтому устоявшейся терминологической традиции
пока нет. Хотелось бы использовать хорошие русские слова — "эктор" и "перси-
стентный" решительно отметаются. Словарь в таких случаях бесполезен (хотя
им многие пытаются пользоваться). Остается фантазировать, опираясь на вы-
шедшие из печати труды коллег, отечественные программистские традиции и
собственный опыт. Основной критерий, который использован нами при выборе
переводов терминов: как можно точнее передать смысл исходного термина (но
не звучание, не морфологию и не буквальное значение).
Чтобы подчеркнуть, что UML язык графический, авторы называют прави-
ла записи (рисования) моделей не синтаксисом, а нотацией. Видимо, это
вполне оправдано.
При разработке UML были предложены и приняты разумные рекомендации
по выбору нотации. Разработчики языка исходили из того, что UML будет
использоваться по-разному: начиная от не очень аккуратного рисования от
руки на листке бумаги, печати черно-белых изображений в книгах и закан-
чивая созданием сложных диаграмм с помощью компьютера. Поэтому в ка-
честве основных графических элементов были выбраны такие, которые было
бы легко использовать во всех случаях. Типов элементов нотации пять:
• фигура (shape);
• линия (line);
• значок (icon);
• текст (text);
• рамка (frame).
Фигуры
Фигуры (shape) в UML используются двумерные (т. е. их можно нарисо-
вать на плоскости) и замкнутые (т. е. есть внутренняя и внешняя части).
Фигуры могут менять свои размеры и форму, сохраняя при этом свои ин-
туитивные отличительные признаки.
Например, среди фигур UML есть прямоугольники и эллипсы. Они могут
быть изображены многими способами: разного размера, с разным соотноше-
нием длин сторон (или, соответственно, полуосей), по-разному ориентиро-
ваны относительно границ страницы и т. д., но всех случаях прямоугольник
отличен от эллипса и не может быть с ним спутан.
Г пава 1 Введение в JJML
Внутри фигур могут помещаться другие элементы нотации: тексты, ли-
нии, значки и даже другие фигуры. Единственное требование: должно быть
однозначно понятно, что элемент нотации находится внутри фигуры, в част-
ности, его изображение не должно пересекать границу фигуры.
Линии
Линии (line) в UML, естественно, одномерные. Линии всегда присоединя-
ются своими концами к фигурам или значкам, они не могут быть нарисо-
ваны сами по себе. Что значит "присоединяются" — формально определить
довольно трудно, но неформально (а нотация UML не формальна) все со-
вершенно ясно: линия должна быть нарисована так, чтобы любому нормаль-
ному человеку было ясно, присоединяется данная линия к данной фигуре
или нет.
Форма линий произвольна: это могут быть прямые, ломаные, плавные
кривые — значения это не имеет. Толщина линий также произвольна. А
вот стиль линии имеет значение. К счастью, в UML используется только
два стиля линий, которые трудно спутать: сплошные и пунктирные линии.
К линиям могут быть пририсованы различные дополнительные элементы:
стрелки на концах, тексты и т. д. Единственное требование: должно быть
ясно, что дополнительный элемент относится именно к данной линии. Ли-
нии могут пересекаться, и это ничего не значит, но рекомендуется избегать
таких случаев, поскольку это затрудняет восприятие.
Значки
Значки (icon) в UML похожи на фигуры тем, что они двумерные, а отлича-
ются тем, что не имеют внутренности, в которую можно что-то поместить, и,
как правило, не меняют свою форму и размеры. Впрочем, значки в UML ис-
пользуются очень умеренно, а потому сохраняют свою основную функцию
однозначно воспринимаемого иероглифа.
Тексты
Тексты (text) в UML — это, как обычно, последовательности различимых сим-
волов некоторого алфавита. Алфавит не фиксирован — он только должен быть
понятен читателю модели. Гарнитура, размер и цвет шрифта не имеют значе-
ния, а вот начертание шрифта имеет: в UML различаются прямые, курсивные и
подчеркнутые тексты. Предполагается, что читатель сумеет их различить.
Рамки
Рамки (frame) появились в UML 2. Рамка — это частный случай фигуры,
которая используется исключительно как контейнер для других фигур,
62
1.4 Модель и ее элементы
линий, значков и текстов. Пустые рамки не применяются. Рамка имеет пря-
моугольную форму и, как правило, ярлычок в левом верхнем углу, в котором
указывается тип и имя рамки.
Каноническая нотация
В общем, нотация UML довольно свободная: рисовать можно как угодно,
лишь бы не возникало недоразумений. Поставщики инструментов, поддер-
живающих U ML, пользуются этой свободой кто во что горазд. Использо-
вание цветов для заливки фигур и раскрашивания линий, тени у значков
и фигур, разные шрифты в текстах, наконец, анимация изображений — все
это, конечно, полезные вещи, поскольку повышают наглядность картинок.
Важно при этом знать меру, а мера очень проста и даже имеет название —
каноническая нотация (canonical notation). Согласно ей любая модель мо-
жет быть описана монохромными рисунками с текстовыми пояснениями.
При этом рисунки должны оставаться вразумительными после печати на
черно-белом принтере.
Именно данной мерой руководствовались авторы, выбирая инструмент для
рисования иллюстраций, которых достаточно много в этой книге. Все ил-
люстрации выполнены в простом графическом редакторе в черно-белом ис-
полнении.
1.4. Модель и ее элементы
Модель UML (UML model) это совокупность конечного множества
конструкций языка, главные из которых — это сущности и отношения
между ними.
Сами сущности и отношения модели являются экземплярами метаклассов
метамодели.
Обсуждение этого определения требует использования общеизвестных ма-
тематических понятий, которые мы напоминаем в следующей врезке.
МНОЖЕСТВА, ОТНОШЕНИЯ И ГРАФЫ
Понятие множества принадлежит к числу фундаментальных понятий
математики. Можно сказать, что множество — это любая опреде-
ленная совокупность объектов, но в этом определении все четыре
слова нуждаются в определении (см. врезку "Что определяют опреде-
ления?" в параграфе 1.1.1). Полагая понятие множества интуитивно
ясным, перечислим нужные нам термины из этой области.
Глава 1. Введение в UML
Объекты, из которых составлено множество, называются его эле-
ментами. Элементы множества различны и отличимы друг от друга.
Количество элементов называется мощностью множества. Мно-
жество, не содержащее элементов, называется пустым. Элементы
множества считаются неупорядоченными, если не оговорено против-
ное. Над множествами определены операции объединения (обознача-
ется о), пересечения (обозначается п) и другие. Если все элементы
множества В являются элементами множества А, то говорят, что В
является подмножеством А (А включает В, обозначается с). Мы по-
лагаем, что рис. 1.4 является достаточным объяснением.
Рис. 1.4. Объединение, пересечение и включение множеств
Пусть А и В — два множества. Прямым (декартовым) произведени-
ем двух множеств А и В называется множество упорядоченных пар, в
которых первый элемент каждой пары принадлежит А, а второй при-
надлежит В. Любое подмножество прямого произведения А на В на-
зывается (бинарным) отношением из А в В. Если А и В— одно и то
же множество, то говорят, что отношение определено на множестве Л
(или имеет место отношение между элементами множества А). Если
О — знак некоторого отношения на множестве А, то тот факт, что пара
элементов а и Ь находится в отношении 0, обычно обозначают так:
а()Ь.
Некоторые часто встречающиеся свойства отношений получили спе-
циальные названия. Отношение 0 называется рефлексивным, если
для любого элемента а имеет место аОа. Если же, наоборот, для любо-
го элемента а неверно, что aQa, то отношение называется антиреф-
лексивным. Отношение 0 называется симметричным, если для любых
двух элементов а и Ь из того, что a(jb, следует, что Ь()а. Рефлексивное
отношение 0 называется антисимметричным, если для любых двух
элементов а и Ь из того, что abb и b<jCt, следует, что элементы av\b
совпадают. Для антирефлексивного отношения антисимметричность
удобнее определить следующим образом: для любых двух элементов
а и Ь из того, что а§Ь, следует, что не выполняется Ь<№. Отношение на-
зывается транзитивным, если для любых трех элементов а, b и с из
того, что а()Ь и Ь<)С, следует, что аОс. Отношение называется полным,
если для любых двух элементов а\лЬ верно, что aOb или Ь()а.
Помимо бинарных, можно рассматривать и многоместные отношения,
состоящие не из пар, а из троек, четверок и т. д. элементов. Однако
чаще рассматриваются именно бинарные отношения, и поэтому сло-
во "бинарное" опускается.
1.4. Модель и ее элементы
Совокупность непустого конечного множества V и отношения Е на
множестве К называется ориентированным графом (или орграфом).
Если отношение Е симметрично, то это просто граф (неориентиро-
ванный). В ориентированном графе элементы множества V обычно
называют узлами, а элементы множества Е — дугами', в графе, соот-
ветственно — вершинами и ребрами. Две вершины графа, соединен-
ные ребром, называются смежными. Последовательность вершин, в
которой любые две соседние вершины смежны, называется марш-
рутом. Если начальная и конечная вершины маршрута совпадают, то
он называется замкнутым. Маршрут, в котором все вершины различ-
ны, называется (простой) цепью. Замкнутая цепь называется циклом.
Вершины, для которых существует соединяющая их цепь, называет-
ся связанными. Граф, в котором все вершины связаны, называется
связным. Связный граф без циклов называется (свободным) деревом.
Ориентированным деревом (или ордеревом) называется орграф, в
котором ровно одна вершина не имеет входящих в нее дуг (такая вер-
шина называется корнем), а все остальные вершины имеют ровно по
одной входящей дуге. Вершины ордерева, не имеющие исходящих
дуг, называются листьями. Граф называется двудольным, если мно-
жество V его вершин можно разбить на два непересекающихся под-
множества V1 и Иг так, что вершины из V1 смежны только с вершина-
ми из Иг.
Граф (и орграф) можно изобразить диаграммой: вершины (узлы) изо-
бражаются точками (или маленькими кружками), а ребра — линиями,
соединяющими вершины (в орграфе, соответственно, линиями со
стрелочками). Следует отдавать себе отчет, что диаграмма графа —
это только иллюстрация. Неважно, как расположены на диаграмме
вершины и ребра, важно только, какие вершины соединены ребрами.
Рис. 1.$. Различные диаграммы графа Кд д
Например, на рис. 1.5 приведены три внешне разных диаграммы, ко-
торые являются диаграммами одного и того же графа (полного дву-
дольного графа, обозначаемого в теории графов символом Кз.з).
Наряду с основным понятием графа (орграфа) рассматриваются и
другие родственные понятия, отличающиеся способом определения
компонента Если Е содержит ребра (пары элементов), состоящие
из одних и тех же вершин, то такие ребра называются петлями, а граф
с петлями называется псевдографом. На диаграмме петля изобража-
ется линией, соединяющей вершину саму с собой. Если Е содержит
повторяющиеся элементы (и, тем самым, не является множеством),
Г 65
Г лава 1. Введение в UML
то такие элементы называются кратными ребрами, а граф называется
мультиграфом. На диаграмме кратные ребра изображаются в виде
нескольких линий, соединяющих две вершины. Если отношение Е не
бинарное, то граф называется гиперграфом. В гиперграфе ребро сое-
диняет несколько (может быть, больше двух) вершин.
Таким образом, рассматривая модель UML с наиболее общих позиций,
можно сказать, что это граф (точнее, нагруженный мульти-псевдо-гипер-
орграф), в котором вершины и ребра нагружены дополнительной инфор-
мацией и могут иметь сложную внутреннюю структуру. Вершины этого
графа называются сущностями, а ребра — отношениями. Остальная часть
раздела содержит беглый (предварительный), но полный обзор имеющихся
типов сущностей и отношений. К счастью, их не слишком много. В после-
дующих главах книги все сущности и отношения рассматриваются еще раз,
более детально и с примерами.
1.4.1. Сущности
Для удобства обзора сущности в UML можно подразделить на четыре
группы:
• структурные;
• поведенческие;
• группирующие;
• аннотационные.
О КЛАССИФИКАЦИЯХ И ГРУППИРОВКАХ
Хорошо известна всемирная константа 7±2 (число объектов, которое
может одновременно находиться в фокусе сознания) — усредненная
верхняя оценка количества различных объектов, понятий, шагов рас-
суждения, которые средний нормальный человек может полноценно
воспринимать (держать в голове) одновременно. Нехорошо, если у
начальника больше семи подчиненных, которыми он должен одно-
временно командовать. Трудно работать больше чем с пятью прило-
жениями одновременно. Не следует помещать на диаграмму больше
девяти сущностей.
А что делать, если нужно? Ответ стар, как мир: разделяй и властвуй.
Другими словами, нужно ввести классификацию или группировку
так, чтобы групп оказалось немного, и работать на уровне групп. Если
одного уровня группировки мало, следует ввести два, три — столько,
сколько нужно, чтобы уложиться в ограничение 7±2.
Следует подчеркнуть, что классификации и группировки сущностей,
отношений, диаграмм и представлений, рассматриваемые в этом па-
____ е
1 4. Модель и ее элементы
раграфе, не являются в строгом смысле частями спецификации UML,
хотя и присутствуют в стандарте. Это скорее методический прием,
призванный облегчить восприятие и изучение языка в соответствии с
принципом "разделяй и властвуй".
Структурные сущности
Структурные сущности, как нетрудно догадаться, предназначены для описа-
ния структуры. Обычно к структурным сущностям относят следующие.
Объект (object) сущность, обладающая уникальностью и инкапсу-
лирующая в себе состояние и поведение.
Класс (class) — описание множества объектов с общими атрибутами,
определяющими состояние, и операциями, определяющими поведе-
ние.
Интерфейс (interface) - именованное множество операций, опреде-
ляющее набор услуг, которые могут быт,’, запрошены потребителем и
предоставлены поставщиком услуг.
Кооперация (collaboration) — совокупность объектом, которые взаи-
модействуют для достижения некоторой цели.
Действующее лицо (actor) — сущность, находящаяся вне моделируе-
мой системы и непосредственно взаимодействующая с ней.
Компонент27 (component ) модульная часть системы с четко опре-
деленным набором требуемых и предоставляемых интерфейсов.
Артефакт (artifact) элемент информации, который используется
или порождается в процессе разработки программного обеспечения.
Другими словами, артефакт — это физическая единица реализации,
получаемая из элемента модели (например, класса или компонента).
Узел (nodfj) — вычислительный ресурс, па котором размещаются и
при необходимости выполняются артефакты.
Поведенческие сущности
Поведенческие сущности предназначены для описания поведения. Основ-
ных поведенческих сущностей всего две: состояние и действие (точнее, две с
27 В русском языке допустимо использование слова ’компонент" мужского рода и слова
"компонента" женского рода. Современная языковая практика склоняется к использо-
ванию мужского рода, поэтому мы употребляем, например, термин "диаграмма компо-
нентов". Но в некоторых случаях традиция требует использования женского рода, на-
пример, "компонента связности графа".
Глава 1. Введение в UML
половиной, потому что иногда употребляется еще и деятельность, которую
можно рассматривать как особый случай состояния).
Состояние (state) период в жизненном цикле объекта, находясь в
котором объект удовлетворяет некоторому условию и осуществляет
собственную деятельность или ожидает наступления некоторого со-
бытия.
Деятельность (activity) можно считать частным случаем состояния,
который характеризуется продолжительными (по времени) не ато-
марными вычислениями.
Действие (action) примитивное атомарное вычисление.
Это только надводная часть айсберга поведенческих сущностей: состояния
бывают самые разные (см. раздел 4.2). Кроме того, при моделировании пове-
дения используется еще ряд вспомогательных сущностей, которые здесь не
перечислены, потому что сосуществуют только вместе с указанными основ-
ными.
Несколько особняком стоит сущность — вариант использования, которой
присущи как структурные, так и поведенческие аспекты.
Вариант использования (use case) множество сценариев, обьсди-
непных по некоторому критерию и описывающих последовательно-
сти производимых системой действий, доставляющих значимый для
некоторого действующего лица резул ьтат.
Приведенная классификация не является исчерпывающей. У каждой из
этих сущностей есть различные частные случаи и вариации, рассматривае-
мые в последующих главах.
Группирующие сущности
Группирующая сущность в UML одна — пакет — зато универсальная.
Пакет (package) группа элементов модели (в том числе пакетов).
Аннотационные сущности
Аннотационная сущность тоже одна — комментарий (comment) — зато в нее
можно поместить все что угодно, так как содержание комментария UML не
ограничивает.
1.4. Модель и ее элементы
Таблица 1.2. Нотация основных сущностей
ОРТОГОНАЛЬНЫЕ
СИСТЕМЫ
ОБОЗНАЧЕНИЙ
Очень хорошо, если
система обозначений
такова, что все ее эле-
менты абсолютно не-
обходимы, использу-
ются в равной мере и
допускают единствен-
ный способ выражения
данной мысли. Такие
системы обозначе-
ний принято называть
ортогональными, по
аналогии с ортогональ-
ной системой векторов
в векторном простран-
стве. Действительно,
ортогональная система
образует базис, т.е. лю-
бой вектор можно вы-
разить в виде линейной
комбинации векторов
базиса, причем это вы-
ражение единственно.
Это удобно.
К сожалению, рас-
пространенные языки
программирования не
являются ортогональ-
ными системами обо-
значений.
UML также далек от
идеала. Некоторые
элементы абсолютно
необходимы в любой
модели, и их мы пере-
числяем в этом раз-
деле, но есть и такие,
которые нам, вслед за
Э. Дейкстрой (см. па-
раграф 3.1.2), хочется
отнести к"свистулькам
и погремушкам".
пава 1 Введение в UMI
1.4.2. Отношения
В UML используются четыре основных типа отношений:
• зависимость (dependency);
• ассоциация (association);
• обобщение (generalization);
• реализация (realization).
Зависимость — это наиболее общий тип отношения между двумя сущ-
ностями. Отношение зависимости указывает на то, что изменение
независимой сущности каким-то образом влияет на Зависимую сущ-
ность.
Графически отношение зависимости изображается в виде пунктирной линии
со стрелкой (1), направленной от зависимой сущности (2) к независимой (3)
(рис. 1.6). Как правило, семантика конкретной зависимости уточняемся в
модели с помощью дополнительной информации. Например, зависимость
со стереотипом «use» означает, что зависимая сущность использует незави-
симую сущность (скажем, вызывает операцию).
Рис. 1.6. Отношение зависимости
Ассоциация — это наиболее часто используемый т ип отношения между
сущностями. Отношение ассоциации имеет место, если однасущность
непосредственно связана с другой (или с другими — ассоциация мо-
жет быть не только бинарной)
Графически ассоциация изображается в виде сплошной линии (1) с различ-
ными дополнениями, соединяющей связанные сущности (рис. 1.7). На про-
граммном уровне непосредственная связь может быть реализована различ-
ным образом, главное, что ассоциированные сущности знают друг о друге.
Рис. 1.7. Отношение ассоциации
1.4 Модель и ее элементы
Например, отношение часть-целое является частным случаем ассоциации и
называется отношением агрегации.
Обобщение — это отношение между двумя сущностями, одна их ко-
торых является частным (специализированным) случаем другой.
Графически обобщение изображается в виде линии с треугольной незакра-
шенной стрелкой на конце (1), направленной от частного (2) (подкласса) к
общему (3) (суперклассу) (рис. 1.8).
Рис. 1.8. Отношение обобщения
Отношение реализации используется несколько реже, чем прелыду-
щие^дритипа отношений, поскольку часто подразумеваются по ум хтча-
нию. Отношение реализации указывает, что одна сущность является
реализацией другой.
Например, класс является реализацией интерфейса. Графически реализа-
ция изображается в виде пунктирной линии с треугольной незакрашенной
стрелкой на конце (1), направленной от реализующей сущности (2) к реали-
зуемой (3) (рис. 1.9).
Рис. 1.9. Отношение реализеции
Перечисленные типы отношений являются основными, различные их ва-
риации и дополнительные отношения детально рассматриваются в после-
дующих главах.
Глава 1. Введение в UML
О ВАЖНОСТИ ПРАВИЛЬНЫХ ОБОЗНАЧЕНИЙ
Нельзя не отметить тщательность выбора графической нотации в
UML. Если основные принципы поняты, то обозначения оказыва-
ются вполне естественными. Рассмотрим, например, нотацию от-
ношений. Два типа линий подчеркивают степень определенности
семантики, привносимой отношением в модель. Ассоциация и
обобщение имеют четко определенную семантику, по кото-
рой можно прямо генерировать программный код, поэтому
и линии сплошные. Зависимость и реализация более рас-
плывчаты — линии используются пунктирные.
Далее, направления стрелок тоже выбраны не случайным, а един-
ственно правильным образом. Независимая сущность может и
не знать, что ее использует другая сущность, а вот зависимая
сущность не может не знать, отчего она зависит. Эта аналогия
уместна и для обобщения и реализации. Например, при описании
наследования синтаксис объектно-ориентированных языков про-
граммирования требует, чтобы имя суперкласса (базового класса)
появлялось в заголовке подкласса (производного класса), и выбор
направления стрелки также становится понятным. То же относится
и к дополнительным элементам стрелок: обобщение и реализа-
ция имеют много общего, поэтому и наконечники стрелок у
них одинаковые.
При рассмотрении последующих (более детальных и содержа-
тельных) примеров нотации читателю было бы полезно задавать
себе вопрос: "почему выбрано такое обозначение?" до тех пор,
пока сам собой не появится ответ: "а как же иначе!".
1.4.3. Диаграммы
Предыдущий параграф преследует примерно те же цели, какие имеет опи-
сание лексики в обычном языке программирования. А именно, мы обрисо-
вали (еще не полностью, но уже достаточно) множество слов UML (лексем,
графических примитивов, элементов моделирования — называйте, как хоти-
те фиксированного термина нет). Пора переходить к синтаксису, а именно
к описанию того, как из слов конструируются предложения.
На первый взгляд, все очень просто: берутся сущности и, если нужно, ука-
зываются отношения между ними. В результате получается модель, то есть
граф (с разнородными вершинами и ребрами), нагруженный дополнитель-
ной информацией. Но при более внимательном рассмотрении обнаружива-
ются проблемы. Мы хотим затратить некоторые усилия на обсуждение этих
проблем, иначе целый ряд особенностей UML может показаться висящим
в воздухе, хотя на самом деле эти особенности и есть продуманное решение
обычно замалчиваемых проблем.
1.4. Модель и ее элементы
Рассмотрим следующую аналогию с естественным языком. Каждая тройка
"сущность" — "отношение" — "сущность" в модели вполне может рассматри-
ваться как । [ростое утверждение: 2<5, ртуть тяжелее железа, Ф.А. Новиков
является преподавателем Политехнического университета (все это примеры
отношений). Пока все хорошо, но вспомним, что в графе (в модели) никакой
упорядочивающей структуры нет: нельзя сказать, что это вершина первая,
а это — вторая. Продолжая нашу аналогию, получается, что модель — это
множество не связанных между собой предложений, никак не упорядо-
ченное, некий "поток сознания", не в обиду современной литературе будь
сказано.
Если взять какой-нибудь "нормальный" текст28, претендующий на внятное
описание чего-либо, то можно заметить, что, помимо структуры предложе-
ний, имеется масса дополнительных структур: предложения объединены
в абзацы, абзацы собраны в параграфы и главы, у которых есть заголовки,
помимо обычных абзацев и заголовков есть врезки и сноски. И все эти до-
полнительные структуры по сути ничего не добавляют к содержанию книги,
но серьезно влияют на ее читабельность. Текст, в котором нет этих структур,
понять очень трудно29.
Отсюда вывод: помимо сущностей и отношений, в модели должна быть
какая-то структура, которая бы помогала ее составлению и пониманию.
Диаграммы UML и есть та основная накладываемая на модель структура,
которая облегчает создание и использование модели.
Диаграмма (diagram) — это графическое представление некоторой
части графа модели.
Вообще говоря, в диаграмму можно было бы включить любые (допустимые)
комбинации сущностей и отношений, но произвол в этом вопросе затруднил
бы понимание моделей. Поэтому разработчики UML определили набор ре-
комендуемых к использованию типов диаграмм, которые получили назва-
ние канонических типов диаграмм.
Примечание
Инструменты моделирования, как правило, обеспечивают
работу со всеми каноническими диаграммами, но делают это
довольно догматически, не позволяя отойти от канона ни
на шаг, даже если это нужно по существу задачи. С другой
стороны, некоторые инструменты, наряду с каноническими,
28 Скажем, эту книгу — не в качестве образца, а в качестве примера.
29 Смеем вас уверить, что писать структурированный текст также намного легче,
ф
...................................... шэ
Глава 1. Введение в UML
поддерживают и апокрифические типы диаграмм. Было бы
удобно, если бы набор канонических диаграмм предлагался
по умолчанию, но пользователь мог бы настроить, изменить
и переопределить этот набор в случае необходимости, при-
мерно так, как это делается с шаблонами Microsoft Word.
Заметим, что помимо сущностей и отношений на диаграмме присутствуют
другие элементы модели, которые мы также будем называть конструкциями
языка. Это тексты, которые могут быть написаны внутри фигур сущностей
или рядом с линиями отношений, рамки диаграмм и их фрагментов, значки,
присоединяемые к линиям или помещаемые внутрь фигур. Эти элементы не
только помогают представить модель в более наглядной форме, но подчас
несут значительную смысловую нагрузку.
1.4.4. Классификация диаграмм
до
В UMl 1~ всего определено 9 канонических типов Диаграмм. Ниже пере-
числены их названия, принятые в этой книге (в других источниках могут
быть отличия).
• Диаграмма использования (I Ise Case diagram)
• .Диаграмма классов (Class diagram)
• Диаграмма объектов (Objei i diagram)
• Диачрамма состояний (State chan diagram)
• Диаграмма деятельйости (Activity diagram)
• Диачрамма последовательности (Sequence diagram)
• • Диаграмма кооперации (Collaboration diagram)
• Диаграмма компонентов (Component diagram)
• Диаграмма размещения" (Deployment diagram)
Этот список является итогом многочисленных дискуссий и компромис-
сов, । юэтому не следует воспринимать его как догму. В частности, расхожее
утверждение "в UML определены 9 типов диаграмм" является не совсем вер-
ным: в метамодели UML определены элементы модели (сущности и отноше-
ния) и способы их комбинирования, а 9 типов диаграмм — это уже надстрой-
ка над языком, отражающая сложившуюся практику его использования.
30 Здесь и далее под UML 1 понимаются версии UML, предшествующие UML 2.0, за исклю-
чением UML 1.5, которая стоит несколько особняком (см. рис. 1.1).
31 В некоторых источниках название данной диаграммы переводится как "диаграмма раз-
вертывания".
1.4. Модель и ее элементы
Канонические диаграммы отнюдь не образуют полного ортогонального на-
бора: они пересекаются как по включенным в них средствам, так и по обла-
сти применения. Более того, некоторые из них являются частными случая-
ми других, есть просто семантически эквивалентные пары, можно привести
примеры допустимых диаграмм, для которых затруднительно указать одно-
значно, к какому именно из канонических типов диаграмма относится.
Сказанное можно проиллюстрировать условной классификацией диаграмм,
приведенной на рис. 1.10.
Рис. 1.10. Иерархия типов диаграмм для UML 1
Примечание
Мы поместили диаграмму использования отдельно, не отно-
ся ее ни к диаграммам описания структуры, ни к диаграммам
описания поведения. В большинстве источников диаграм-
мы использования относят к описанию поведения, что нам
представляется некоторой натяжкой32. Кроме отношений
обобщения, на диаграмме классов, а именно эта диаграмма
32 Подобная взаимосвязь безусловно существует, что выражается на диаграмме (см.
рис. 1.10) в виде отношения зависимости со стереотипом «refine» (см. таблицу 3.8 в па-
раграфе 3.3.1).
Глава 1. Введение в UML
изображена на рис. 1.10, дополнительно показаны некото-
рые зависимости между отдельными UML-диаграммами.
Эти зависимости в каждом конкретном случае носят различ-
ный характер, что отражено посредством использования раз-
личных стереотипов. Подробнее о стандартных стереотипах
зависимостей см. параграф 3.1.1.
В UML 233 внесены значительные коррективы как в список канонических диа-
грамм, а именно их число увеличилось до 13, так и в список доступных кон-
струкций языка, что значительно расширило область его применения. Кро-
ме этого, две диаграммы были переименованы: диаграмма кооперации была
переименована в диаграмму коммуникации34, а диаграмма состояний в диа-
грамму автомата35.
Рис. 1.11. Иерархия типов диаграмм для UML 2 (часть 1)
33 Здесь и далее под UML 2 понимаются версии UML, начиная с UML 2.0.
34 В UML 1 возникала невольная ассоциация между диаграммой кооперации и одноимен-
ной сущностью, что было не совсем верно и порой вводило в заблуждение.
35 В UML 2 синтаксическая и смысловая нагрузка диаграммы состояний настолько измени-
лась, что название уже не отражало содержания.
1.4. Модель и ее элементы
Список новых диаграмм UML 2 и их названий, приня тых в этой книге, га-
ков.
• Диаграмма внутренней структуры (Composite Structure diagram^
• Диаграмма пакетов (Package diagram)
• Диаграмма автомата (State machine diagram)
• Диаграмма коммуникации (Communication diagram)
• Обзорная диаграмма взаимодействия (Interact JOO Overview diagram)
• Диаграмма синхронизации (Timing diagram)
На рис. 1.11 и рис. 1.12 приведены диаграммы классов, отражающая взаи-
мосвязь диаграмм в UML 2.
Рис. 1.12. Иерархия типов диаграмм для UML 2 (часть 2)
.77 ’
Глава 1 Введение в UML
Далее в этой главе мы очень бегло опишем все тринадцать канонических
диаграмм, с тем чтобы иметь определенный контекст и словарный запас для
последующего изложения. Детали изложены в остальных главах книги.
Но прежде чем перейти к следующему разделу, сделаем одно небольшое от-
ступление относительно того, как стандарт требует оформлять диаграммы.
Общий шаблон представления диаграммы приведен на рис. 1.13.
Рис. 1.13. Нотация для диаграмм
Основных элементов оформления два: наружная рамка (1 на рис. 1.13) и ярлы-
чок с названием диаграммы (2 на рис. 1.13). Если с рамкой все просто - это пря-
моугольник, ограничивающий область, в которой должны находиться элементы
диаграммы, то название диаграммы записывается в специальном формате: тег (3
на рис. 1.13) и название (4 на рис. 1.13).
Возможные теги (типы) для диаграмм приведены в таблице 1.3. Теги, предлагае-
мые стандартом, записаны во второй столбец. Однако, как показала практика,
предлагаемые стандартом правила не всегда удобны и логически обоснованы,
поэтому третий столбец таблицы содержит разумную на наш взгляд альтерна-
тиву36.
Таблица 1.3. Типы и теги диаграмм
Название диаграммы Тег (стандартный) Тег (предлагаемый)
Диаграмма использования use case или uc use case
Диаграмма классов class class
Диаграмма автомата state machine или stm state machine
Диаграмма деятельности activity или act activity
Диаграмма последовательности interaction или sd sd
Диаграмма коммуникации interaction или sd comm
Диаграмма компонентов component или cmp component
Диаграмма размещения не определен deployment
Диаграмма объектов не определен object
Диаграмма внутренней структуры class class или component
36 По мере сил и возможностей мы пытаемся рисовать диаграммы по стандарту, однако
из-за технических трудностей это удается не всегда.
1.5. Общие диаграммы
Обзорная диаграмма взаимодействия interaction или sd interaction
Диаграмма синхронизации interaction или sd timing
Диаграмма пакетов package или pkg package
1.5. Общие диаграммы
Все диаграммы UML можно условно разбить на две группы, первая из ко-
торых — общие диаграммы. Общие диаграммы практически не зависят от
предмета моделирования и могут применяться в любом программном про-
екте и в любой предметной области.
1.5.1. Диаграмма использования
Диаграмма использования (use case diagram) это наиболее общее
представление функционального назначения системы. Диаграмма
использования призвана ответить на главный вопрос моделирования*,
что делает система во внешнем мире?
Рис. 1.14. Нотация диаграммы использования
Глава 1. Введение в UML
На диаграмме использования применяются два типа основных сущностей: вари-
анты использования (1) и действующие лица (2), между которыми устанавлива-
ются следующие основные типы отношений:
• ассоциация между действующим лицом и вариантом использова-
ния (3);
• обобщение между действующими лицами (4);
• обобщение между вариантами использования (5);
• зависимости (различных типов) между вариантами использова-
ния (6).
На диаграмме использования, как и на любой другой, могут присутствовать
комментарии (7). Более того, это настоятельно рекомендуется делать для улуч-
шения читаемости диаграмм.
Основные элементы нотации, применяемые на диаграмме использования,
показаны на рис. 1.14. Детальное описание приведено в главе 2.
1.5.2. Диаграмма классов
Диаграмма классов (class diagram) — основной способ описания
структуры системы.
Это не удивительно, поскольку UML в первую очередь объектно-
ориентированный язык, и классы являются основным (если не единствен-
ным) "строительным материалом".
На диаграмме классов применяется один основной тип сущностей: клас-
сы (1) (включая многочисленные частные случаи классов: интерфейсы,
примитивные типы, классы-ассоциации и многие другие), между которыми
устанавливаются следующие основные типы отношений:
• ассоциация между классами (2) (с множеством дополнительных
подробностей);
• обобщение между классами (3);
• зависимости (различных типов) между классами (4) и между клас-
сами и интерфейсами.
Некоторые элементы нотации, применяемые на диаграмме классов, показа-
ны на рис. 1.15. Детальное описание приведено в главе 3.
1 5 Общие диаграммы
1.5.3. Диаграмма автомата
Диаграмма автомата (state machine diagram) или диаграмма состоя-
ний в UML 1 (st at echart diagram) — это один из способов детального
описания поведения в UMI.. В сущности диаграммы автомата, как это
следует из названия, представляют собой граф состояний и переходов
конечною автомата (ем. главу 4). нагруженный множеством дополни-
тельных деталей и подробностей.
На диаграмме автомата применяют один основной тип сущностей — состоя-
ния (1) и один тип отношений — переходы (2), но и для тех и для других
определено множество разновидностей, специальных случаев и дополни-
Глава'! Введение в IIIVil. '
тельных обозначений. Перечислять их все во вступительном обзоре не имеет
смысла.
Детальное описание всех вариаций диаграмм автомата приведено в разделе
4.2, а на рис. 1.16 показаны только основные элементы нотации, применяе-
мые на диаграмме автомата.
1.5.4. Диаграмма деятельности
Диаграмма деятельности (activity diagram) — еще один способ описа-
ния поведения, который визуально напоминает блок-схему алгорит-
ма..
За счет модернизированных обозначений, согласованных с объектно-
ориентированным подходом, а главное, за счет новой семантической со-
ставляющей (свободная интерпретация сетей Петри, подробнее см. пара-
граф 4.1.3), диаграмма деятельности UML является мощным средством для
описания поведения системы, превосходящим возможности старых добрых
блок-схем (стандартизированных в ГОСТ 19.701-90 "Схемы алгоритмов и
программ").
На диаграмме деятельности применяют один основной тип сущностей —
действие (1) и один тип отношений — переходы (2) (передачи управления).
Также используются такие конструкции, как развилки, слияния, соедине-
ния, ветвления (3), которые похожи на сущности, но таковыми на самом
деле не являются, а представляют собой графический способ изображения
некоторых частных случаев гипердуг в гиперграфе (см. врезку "Множества,
отношения и графы" в разделе 1.4). Семантика элементов диаграмм деятель-
Рис. 1,17. Нотация диаграммы деятельности
1.5. Общие диаграммы
Основные элементы нотации, применяемые на диаграмме деятельности, по-
казаны на рис. 1.17. Детали описания приведены в главе 4.
1.5.5. Диаграмма последовательности
Диаграмма последовательности (sequence diagram) — это способ опи-
сания поведения системы "на примерах". Фактически, диаграмма по-
следовательности — это запись протокола конкретного сеанса работы
системы (или фрагмента такой» протокола).
В объектно-ориентированном программировании самым существенным во
время выполнения является пересылка сообщений между взаимодействую-
щими объектами. Именно последовательность посылок сообщений отобра-
жается на данной диаграмме, отсюда и название.
На диаграмме последовательности применяют один основной тип сущно-
стей— экземпляры взаимодействующих классификаторов (1) (в основном
классов, компонентов и действующих лиц) и один тип отношений — свя-
зи (2), по которым происходит обмен сообщениями (3). Предусмотрено не-
сколько способов посылки сообщений, которые в графической нотации раз-
личаются видом стрелки, соответствующей отношению.
Важным аспектом диаграммы последовательности является явное отобра-
жение течения времени. В отличие от других типов диаграмм, кроме разве
Рис. 1.18. Нотация диаграммы последовательности
Глава 1 Введение в UML
что диаграмм синхронизации, на диаграмме последовательности имеет зна-
чение не только наличие графических связей между элементами, но и взаим-
ное расположение элементов на диаграмме. А именно, считается, что имеет-
ся (невидимая) ось времени, по умолчанию направленная сверху вниз, и
то сообщение, которое отправлено позже, нарисовано ниже.
Примечание
Ось времени может быть направлена горизонтально, в этом
случае считается, что время течет слева направо.
На рис. 1.18 показаны основные элементы нотации, применяемые на диа-
грамме последовательности. Для обозначения самих взаимодействующих
объектов применяется стандартная нотация — прямоугольник с именем
экземпляра классификатора. Пунктирная линия, выходящая из него, на-
зывается линией жизни (lifeline) (4). Это не обозначение отношения в мо-
дели, а графический комментарий, призванный направить взгляд читателя
диаграммы в правильном направлении. Фигуры в виде узких полосок, на-
ложенных на линию жизни, также не являются изображениями модели-
руемых сущностей. Это графический комментарий, показывающий отрезки
времени, в течение которых объект владеет потоком управления (execution
occurrence) (5) или, другими словами, имеет место активация3,1 (activation)
объекта.
Составные шаги взаимодействия (combined fragment) (6) позволяют на диа-
грамме последовательности отражать и алгоритмические аспекты прото-
кола взаимодействия. Прочие детали нотации диаграммы последовательно-
стей см. в главе 4.
1.5.6. Диаграмма коммуникации
Диаграмма коммуникации (communication diagram) способ описа-
ния поведения, семантически эквивалентный диаграмме последова-
тельности.
Фактически, это такое же описание последовательности обмена сообщения-
ми взаимодействующих экземпляров классификаторов, только выраженное
другими графическими средствами. Более того, большинство инструментов
умеет автоматически преобразовывать диаграммы последовательности в
диаграммы коммуникации и обратно.
Таким образом, на диаграмме коммуникации так же, как и на диаграмме по-
следовательности, применяют один основной тип сущностей — экземпляры
37 Термин "активация" использовался в UML1 и на данный момент считается устаревшим.
1.5 Общие диаграммы
взаимодействующих классификаторов (1) и один тип отношений — свя-
зи (2). Однако здесь акцент делается не на времени, а на структуре связей
между конкретными экземплярами.
На рис. 1.19 показаны основные элементы нотации, применяемые на диа-
грамме коммуникации. Для обозначения самих взаимодействующих объ-
ектов применяется стандартная нотация — прямоугольник с именем эк-
земпляра классификатора. Взаимное положение элементов на диаграмме
коммуникации не имеет значения — важны только связи (чаще всего экзем-
пляры ассоциаций), вдоль которых передаются сообщения (3). Для отобра-
жения упорядоченности сообщений во времени применяется иерархическая
десятичная нумерация.
Рис. 1.19. Нотация диаграммы коммуникации
Сравните рис. 1.18ирис. 1.19 (на них изображено одно и то же поведение), и
вам все станет понятно. Прочие детали нотации диаграммы коммуникации
см. в главе 4.
1.5.7. Диаграмма компонентов
Диаграмма компонентов (component diagram) — показывает взаимос-
вязи между модулями (логическими или физическими), из которых
состоит моделируемая система.
В UML 1 компонент мыслится как физический объект, модуль того или ино-
го типа, который может быть заменен другим модулем подходящего типа. В
UML 2, напротив, компонент мыслится как логическая сущность, выделяе-
мая на этапе проектирования и подлежащая дальнейшей физической реали-
зации.
[ 85 ]
Глава 1 Введение в UML
Рис. 1.20. Нотация диаграммы
компонентов
Основной тип сущностей на диаграмме
компонентов — это сами компоненты (1),
а также интерфейсы (2), посредством ко-
торых указывается взаимосвязь между
компонентами. На диаграмме компонен-
тов применяются следующие отношения:
• реализации между компонентами
и интерфейсами (компонент реа-
лизует интерфейс);
• зависимости между компонента-
ми и интерфейсами (компонент
использует интерфейс) (3).
На рис. 1.20 показаны основные элементы
нотации, применяемые на диаграмме ком-
понентов. Детальное описание приведено
в главе 3.
1.5.8. Диаграмма размещения
Диаграмма размещения (deployment diagram) наряду с отображением
состава и связей элементов системы показывает, как они физически
разметены на вычислительных ресурсах по время выполнения.
Таким образом, на диаграмме размещения, по сравнению с диаграммой ком-
понентов, добавляется два типа сущностей: артефакт (1), который является
физической реализацией компонента (2), и узел (3) (может использоваться
как классификатор, описывающий тип узла, так и конкретный экземпляр),
а также отношение ассоциации между узлами (4), показывающее, что узлы
физически связаны во время выполнения.
На рис. 1.21 показаны основные элементы нотации, применяемые на диа-
грамме размещения. Для того чтобы показать, что одна сущность является
частью другой, применяется либо отношение зависимости со стереотипом
«deploy» (5), либо фигура одной сущности помещается внутрь фигуры дру-
гой сущности (6). Детальное описание диаграммы приведено в главе 3.
1.6 Специальные диаграммы
Рис. 1.21. Нотация диаграммы размещения
1.6. Специальные диаграммы
Специальные диаграммы характеризуются тем, что чаще всего служат для
дополнения какой-либо общей диаграммы, например, являются ее частным
случаем или же просто играют вспомогательную роль, уточняя некоторые
детали.
1.6.1. Диаграмма объектов
Диаграмма объектов (object diagram) — является экземпляром диа-
граммы классов.
Глава 1. Введение в UML
Рис. 1.22. Нотация диаграммы объектов
На диаграмме объектов применяют один основной тип сущностей: объек-
ты (1) (экземпляры классов), между которыми указываются конкретные
связи (2) (чаще всего экземпляры ассоциаций).
Диаграммы объектов имеют вспомогательный характер — по сути это при-
меры (можно сказать, дампы памяти), показывающие, какие имеются объ-
екты и связи между ними в некоторый конкретный момент функциониро-
вания системы.
Основные элементы нотации, применяемые на диаграмме объектов, показа-
ны на рис. 1.22. Детальное описание приведено в главе 3.
1.6.2. Диаграмма внутренней структуры
Диаграмма внутренней структуры (composite structure diagram) ис-
пользуется для более подробного пределявления структурных класси-
фикаторов, прежде всего классов, компонентов н коопераций.
Структурный классификатор изображается в виде прямоугольника (1), в
верхней части которого находится имя классификатора (2). Внутри нахо-
дятся части (parts) (3). Частей может быть несколько. Каждая часть явля-
ется экземпляром некоторого другого классификатора. Части могут взаи-
модействовать друг с другом. Это обозначается с помощью соединителей
(connectors) (4) различных видов. Место на внешней границе части, к ко-
торому присоединяется соединитель, называется портом (port) (5). Порты
располагаются также на внешней границе структурного классификатора (6),
обеспечивая ему связь с внешним миром.
1.6. Специальные диаграммы
Рис. 1.23. Нотация диаграммы внутренней структуры
Основные элементы нотации, применяемые на диаграмме внутренней струк-
туры, показаны на рис. 1.23. Детальное описание приведено в главе 3.
1.6.3. Обзорная диаграмма взаимодействия
Обзорная диаграмма взаимодействия (interaction overview
diagram) является разновидностью диап>аммы деятельности с расши-
ренным синтаксисом: в качестве элементов обзорной диаграммы вза-
имодействия могут выступать ссылки на взаимодействия (interaction
use)(I), определяемые диаграммами последовательности.
Основные элементы нотации показаны на рис. 1.24. Детальное описание
приведено в главе 4.
Рис. 1.24. Нотация обзорной диаграммы взаимодействия
Глава 1. Введение в UML
1.6.4. Диаграмма синхронизации
Диаграмма синхронизации (timing diagram) представляет собой осо-
бую <|к>рму диаграммы последовательности, на которой особое вни-
мание уделяется изменению состояний (1) различных экземпляров
классификаторов и их временной синхронизании (2).
Основные элементы нотации показаны на рис. 1.25. Детальное описание
приведено в главе 4.
Рис. 1.25. Нотация диаграммы синхронизации
1.6.5. Диаграмма пакетов
Диаграмма пакетов (package diagram) — единственное средство, по-
зволяющее управлять сложностью самой модели. Основные э «мен-
ты нотации — пакеты (1) и зависимости с различными стереотипа-
ми (2), применяемые на диаграмме (см. рис 1 26),
package Пакеты UML верхнего уровня L0
Рис. 1.26. Нотация диаграммы пакетов
1 1.. Модели и их представления
1.7. Модели и их представления
Было бы очень соблазнительно иметь возможность строить модели любых
систем для любых целей единообразно, придерживаясь, так сказать, одной
универсальной точки зрения. Во многих ранних методологиях моделирова-
ния программных систем такие попытки (более или менее удачные) пред-
принимались.
Как показывает практический опыт, не удается описать с единой точки
зрения все без исключения аспекты моделируемой системы. Действитель-
но, в модели нужно отразить множество вещей: интерфейсы для взаимодей-
ствия с внешним миром, внутреннюю логическую структуру программы,
структуру хранимых данных, алгоритмы функционирования, состав арте-
фактов, включаемых в поставку, и многое другое. Было бы самонадеянно
утверждать, что единое средство описания всех аспектов сразу в принципе
невозможно, — просто пока мы не знаем такого средства. Отсюда следует
вывод.
Й Моделировать сложило систему следует с неско таких различных то-
чек зрения, каждый рпз принимая но внимание один аспект модели-
руемой системы и абстрагируясь от остальных. Этот тезис является
одним из основополагающих принципов UML, может быть самым важ-
ным принципом, предопределившим практический успех UML.
Идея состоит в том, что абстрактный граф модели, состоящий из множества
разнотипных сущностей и отношений, не подлежит конструированию или
изучению в целом. Каждый раз для визуализации, изменения или иных ма-
нипуляций из этого общего графа вычленяются только сущности и отноше-
ния, релевантные для определенного аспекта моделируемой системы, а все
остальные игнорируются. Такой вид с определенной точки зрения, можно
сказать, проекцию модели, мы называем представлением (view).
Представление — это средство логического структурирования .модели.
1.7.1. Назначение и уровни моделей
Модели UML могут создаваться и мотут использоваться с различными це-
лями. Иногда бывает даже так, что автор создавал модель с одной определен-
ной целью, а используется она другими людьми совершенно неожиданным
для автора образом. Таким образом, назначение модели не является чем-то
Глава 1. Введение в UML
постоянным и трудно изменяемым, как цвет кожи или разрез глаз. Транс-
формации назначения моделей вполне возможны, но, тем не менее, практика
моделирования подсказывает, что модели дают больший эффект, если при
моделировании принимать во внимание назначение модели.
Назначение моделей может быть самым разным, все случаи описать невоз-
можно. Мы предлагаем следующую классификацию назначений модели,
основанную на ответе на простой вопрос "а что с этой моделью станется
потом?", который автор модели должен задавать себе во время моделиро-
вания. Мы рассматриваем три типичных варианта ответа.
• Концептуальная модель (conceptual model). На диаграммы такой
модели будут смотреть, их будут обдумывать, но с самой моделью
ничего делать не будут. Это не означает, что модель не нужна — это
означает, что модель используется только для управления мысли-
тельным процессом, для понимания. Поэтому мы называем такие
модели концептуальными®. Такой тип использования моделей один
из самых важных, например, потому что так используются модели,
которые получаются в результате анализа предметной области. Кон-
цептуальные модели довольно стабильны: если не меняется пред-
метная область, то нет нужды менять и модель. Главное требование
к модели предметной области: концептуальная целостность (con-
sistency).
• Модель проектирования (design model). Модель проектирования
представляет собой высокоуровневое (на уровне подсистем) и низ-
коуровневое (на уровне классов, если речь идет об использовании
объектно-ориентированного подхода) описание программной си-
стемы. Модель проектирования предназначена для того, чтобы, ру-
ководствуясь ею, разработать программный код приложения. Как
правило, архитектура (высокоуровневое описание) и код разраба-
тываются итеративно, и разработчикам в процессе разработки не-
обходимо модифицировать модель проектирования, чтобы она соот-
ветствовала принимаемым решениям. Главное требование к модели
проектирования: понятность (usability). Действительно, разработ-
чики должны полностью понимать модель, чтобы вести разработку.
• Модель реализации (implementation model). Модель реализации
предназначена для автоматического преобразования39, возможно
38 Также применются термины "модель анализа" (analysis model) и "аналитическая мо-
дель".
39 Существуют подходы, когда модель реализации не преобразуется в код на языке про-
граммирования, а непосредственно выполняется с помощью соответствующей вирту-
альной машины.
1.7. Модели и их представления
многократного, в существенно другой вид, например, в исполнимый
код. Такое предназначение требует указания необходимых деталей
реализации в модели, поскольку "от себя" компьютер их добавить не
сможет. Главное требование к моделям реализации: полнота (com-
pleteness).
Еще раз подчеркнем, что между моделями различного назначения нет не-
преодолимого барьера, но стилистические различия все-таки имеются. На
рис. 1.27 мы приводим пример, рассматривая отношения между авторами
(Author) и книгой (Book). С концептуальной точки зрения книга (1) — это
тип издания, который имеет авторов (2), причем соавторов у книги может
быть несколько и каждый может быть автором нескольких книг. Важно
учесть, что в создание книги каждый соавтор внес определенный вклад (3).
В модели проектирования необходимо уточнить, что абстрактный творче-
ский вклад измеряется в конкретных процентах (4), а в модели реализации
Рис. 1.27. Концептуальная модель, модель проектирования и модель реализации
Глава 1. Введение в UML
Рис. 1.28. Поясняющая диаграмма объектов
добавить, что необходимо проверять инвариантное соотношение (5), состоя-
щее в том, что для каждой книги сумма вкладов всех ее авторов должна быть
равна 100%.
В качестве дополнения к модели реализации можно привести поясняющую
диаграмму объектов (рис. 1.28), где указать конкретную книгу40 (1), кон-
кретных авторов (2) и конкретный вклад каждого из авторов (3).
Классификация по назначению — не единственная используемая классифи-
кация моделей. Еще одним примером классификации, важным с теоретиче-
ской точки зрения, является классификация моделей по уровням абстрак-
ции.
В UML 1 эта классификация в явном виде присутствовала в стандартах. В
UML 2 из текста стандарта ее исключили, но влияние данной классифи-
кации все равно ощущается. Речь идет об весьма важной и перспективной,
хотя и не очень широко используемой возможности UML — о метамодели-
ровании.
Метамодель (metamodel) модель языка описания моделей.
В параграфе 1.3.2 при обсуждении определения UML нами отмечено, что
в описании UML используются три уровня: модели, метамодели и мета-
метамодели. Добавим для полноты картины нулевой уровень — сами моде-
лируемые объекты - и дадим этим уровням имена в соответствии со стандар-
том UML 1: МО — уровень объектов, Ml — уровень моделей, М2 — уровень
метамодели, М3 — уровень мета-метамодели.41 Поскольку мета-метамодели
и метамодели описываются с применением тех же средств — то есть диа-
грамм классов, дальнейшее прибавление приставки "мета" не имеет смысла,
так как не даст ничего нового.
40 Наша книга пока не переведена на английский, но ...
41 В UML в качестве мета-метамодели применяется стандарт MOF (Meta Object Facility),
специально разработанный OMG для спецификации метамоделей различных языков
моделирования, таких как UML и CWM (Common Warehouse Metamodel).
1.7 Модели и их представления
Б нашей книге подавляющее большинство примеров относится к уровню
Ml, встречается буквально несколько примеров на уровне МО, и в большин-
стве разделов есть одна-две диаграммы на уровне М2. Важно понять, что на
всех уровнях используются одни и те же языковые средства — различия
не синтаксические, а семантические.
Упрощенно говоря, уровень модели — это число шагов по созданию экзем-
пляров (instantiation), которые нужно сделать, чтобы спуститься с дан-
ного уровня абстракции на уровень моделируемой реальности. Поясним
сказанное примером на рис. 1.29, в котором мы продолжаем рассмотрение
примера с книгой.
Рис. 1.29. Четыре уровня метамоделирования
Поскольку, как мы видим, на всех уровнях применяется одна и та же нота-
ция, можно позволить инструменту, поддерживающему UML, редактиро-
вать и модели, и метамодели, и мета-метамодели.
Метамоделирование (imiamxleling) — моделирование на, уровне ме-
тамодели.
Метамоделирование — чрезвычайно мощный инструмент. Одним неболь-
шим изменением на уровне метамодели мы можем внести радикальные из-
менения сразу во многие элементы множества моделей. Но за такую мощь
приходится платить возрастающим риском: если изменения метамодели
Глава 1. Введение в UML
окажутся неудачными, то последствия на уровне моделей могут быть ката-
строфическими. Это примерно то же самое, что изменение шаблонов гене-
рации кода в используемом компиляторе языка программирования: может
перестать работать сразу всё.
Пока нельзя сказать, что уже выработана надежная техника безопасного
метамоделирования. Изменения в метамоделях приходится делать на свой
страх и риск. И даже если они хорошо продуманы и не приводят к ошибкам,
то очень часто они приводят к несовместимости с другими инструментами.
Но метамоделирование слишком привлекательно своей силой, поэтому по-
пытки и исследования в этой области не прекращаются. В будущем, может
быть, метамоделирование займет ведущее место.
Можно замахнутся и на уровень М3 и начать все менять уже на уровне мета-
метамодели. Но это означает поставить под сомнение деятельность OMG в
целом. У нас нет для этого никаких оснований, мы так не делаем и не реко-
мендуем читателям отклоняться от стандартов, если для этого нет веских
причин42.
1.7.2. Классические представления из UML 1 и 2
Набор используемых представлений модели является еще менее формаль-
ным и догматическим, чем набор канонических диаграмм и классификация
назначения и уровня моделей.
Одним из самых популярных является набор представлений, описанных ав-
торами языка в UML 1 [2] и показанных на рис. 1.3043.
Design Component
View
View
Use Case
View
Process
View
Deployment
View
Рис. 1.30. Представления из UML 1
• Представление использования (Use Case View) — это описание пове-
дения системы в терминах вариантов использования с точки зрения
42 Именно поэтому в книге нет диаграмм уровня М3.
43 Этот рисунок заимствован из книги [2] с соответствующим изменением терминологии
Ф
1.7. Модели и их представления
внешних по отношению к системе действующих лиц. Данное пред-
ставление описывает не то, как организована система, а те функцио-
нальные требования, которым она должна удовлетворять. При этом
структурные аспекты передаются диаграммами использования, а по-
веденческие аспекты — диаграммами взаимодействия, состояний и
деятельности.
• Представление проектирования (Design View) предназначено
для описания словаря предметной области, то есть, в парадигме
объектно-ориентированного программирования, классов, а также
таких вспомогательных сущностей, как, например, интерфейсы или
кооперации. Структурные аспекты передаются диаграммами клас-
сов и объектов, а поведенческие аспекты — диаграммами взаимодей-
ствия, состояний и деятельности.
• Представление процессов (Process view) — это описание взаимодей-
ствия элементов управления (процессов, потоков) во время работы
системы. Оно отражает такие нефункциональные требования, как,
например, обеспечение параллелизма. Структурные аспекты пере-
даются с помощью концепции активных классов, представляющих
процессы и потоки, а поведенческие аспекты — диаграммами взаи-
модействия, состояний и деятельности.
• Представление компонентов (Component view) — это описание си-
стемы на уровне артефактов (компонентов, файлов и т.д.), исполь-
зуемых для сборки, выпуска, конфигурации программного продук-
та. Структурные аспекты передаются диаграммами компонентов, а
поведенческие аспекты — диаграммами взаимодействия, состояний
и деятельности.
• Представление размещения (Deployment view) отражает тополо-
гию связей аппаратных средств и размещения на них компонентов.
Структурные аспекты передаются диаграммами размещения, а по-
веденческие аспекты — диаграммами взаимодействия, состояний и
деятельности.
В таблице 1.4 приведены наборы представлений, описанные авторами язы-
ка в UML244. Первоначальные пять представлений, ассоциирующиеся с
UML 1, при переходе к UML 2 были дополнены и в результате образовали
набор уже из восьми представлений.
44 Таблица отражает видение, характерное для UML2. Комментарии поясняют различие
между представлениями в UML 1 и UML 2.
Глава 1. Введение в UML
Таблица 1.4. Представления модели и диаграммы в языке UML 2
Представления Диаграммы Комментарий
Статическое представление (Static view) Диаграмма классов В UML1 - часть представления проектирования (Design view)
Представление проектирования (Design view) Диаграмма внутренней структуры Диаграмма коммуникации Диаграмма компонентов В UML 1 частично отображает- ся в представлении процессов (Process view) и представлении компонентов (Component view)
Представление использования (Use Case view) Диаграмма использования В UML 1 описывается одноимен- ным представлением, однако в список диаграмм данного пред- ставления были также добавле- ны диаграммы взаимодействия, состояний и деятельности
Представление конечных автоматов (State machine view) Диаграмма автомата В UML1 данное представле- ние не является обособленной частью, а используется всеми представлениями по мере необ- ходимости
Представление деятельности (Activity view) Диаграмма деятельности Обзорная диаграмма взаимодействия В UML1 данное представле- ние не является обособленной частью, а используется всеми представлениями по мере необ- ходимости
Представление взаимодействия (Interaction view) Диаграмма последовательности Диаграмма коммуникации Диаграмма синхронизации В UML1 данное представле- ние не является обособленной частью, а используется всеми представлениями по мере необ- ходимости
Представление развертывания (размещения) (Deployment view) Диаграмма развертывания В UML 1 описывается одноимен- ным представлением, однако в список диаграмм данного пред- ставления были также добавле- ны диаграммы взаимодействия, состояний и деятельности
Представление управления моделью’ (Model Management view) Диаграмма пакетов Отсутствует в UML 1.
* Включение этого аспекта в число представлений авторам представляется спорным.
• Статическое представление (Static view) отражает статическую струк-
туру системы и не описывает динамику в любом ее проявлении. Чаще
всего статическое представление отражает логические концепции при-
ложения, основой которого служат классы и их отношения.
1.7. Модели й их предстае!Ления
• Представление проектирования (Design view) является более де-
тализированным вариантом статического представления, выделяя
классификаторы, обеспечивающие необходимую функциональ-
ность системы.
• Представление использования (Use Case view) описывает функцио-
нирование системы в терминах вариантов использования и рассма-
тривает их с точки зрения заинтересованных действующих лиц.
• Представление конечных автоматов (State machine view) специфи-
цирует поведение отдельных элементов, для которых можно ввести
понятие жизненного цикла, описываемого набором состояний и пе-
реходов между ними.
• Представление деятельности (Activity view) описывает функцио-
нирование системы с точки зрения различных элементов деятель-
ности, соединенных потоками управления и потоками данных.
• Представление взаимодействия (Interaction view) отражает после-
довательность обмена сообщениями между элементами системы во
время выполнения приложения.
• Представление развертывания (Deployment view) описывает разме-
щение артефактов на вычислительных узлах во время выполнения
приложения, а также компоненты и другие элементы, манифестаци-
ей которых являются данные артефакты.
• Представление управления моделью (Model Management view) отра-
жает внутреннюю организацию модели, описывая ее разбиение на
пакеты и указывая отношения между ними.
1.7.3. Три представления — взгляд авторов
Учитывая неформальный характер самого понятия представления и опи-
раясь на собственный опыт использования UML, мы рискнем предложить
свой вариант набора представлений. Их всего три.
• Представление использования. По сути это то же самое представле-
ние, что было указано выше. Представление использования призва-
но отвечать на вопрос, что делает система полезного. Определяю-
щим признаком для отнесения элементов модели к представлению
использования является, по нашему мнению, явное сосредоточение
внимания на факте наличия у системы внешних границ, то есть выде-
ление внешних действующих лиц, взаимодействующих с системой,
и внутренних вариантов использования, описывающих различные
Глава 1. Введение в UML
сценарии такого взаимодействия. Таким образом, единственным вы-
разительным средством представления использования оказываются
диаграммы использования.
• Представление структуры. Представление структуры призвано
отвечать (с разной степенью детализации) на вопрос: из чего со-
стоит система. Определяющим признаком для отнесения элемен-
тов модели к представлению структуры является явное выделение
структурных элементов — составных частей системы — и описания
взаимосвязей между ними. Принципиальным является чисто ста-
тический характер описания, то есть отсутствие понятия времени в
любой форме, в частности, в форме последовательности событий и/
или действий. Представление структуры описывается, прежде все-
го, и главным образом диаграммами классов, а также, если нужно,
диаграммами компонентов, размещения, внутренней структуры и, в
редких случаях, диаграммами объектов.
• Представление поведения. Представление поведения призвано
отвечать на вопрос: как работает система. Определяющим призна-
ком для отнесения элементов модели к представлению поведения
является явное использование понятия времени, в частности, в фор-
ме описания последовательности событий/действий, то есть в фор-
ме алгоритма. Представление поведения описывается диаграммами
автомата и деятельности, а также обзорной диаграммой взаимодей-
ствия, диаграммами коммуникации и последовательности. В редких
случаях можно воспользоваться диаграммой синхронизации.
Такой набор представлений является ортогональным и согласованным с
классификацией диаграмм (см. рис. 1.11 и рис. 1.12). Более того, он во мно-
гом инспирирован личным опытом моделирования. Авторам никогда не
удавалось построить разумную модель для мало-мальски сложной системы
так, как это рекомендуется в некоторых учебниках: сначала построить пред-
ставление использования, затем последовательно представление проектиро-
вания, представления процессов и компонентов и, наконец, представление
развертывания.
По нашему мнению, процесс моделирования (независимо от назначения мо-
дели) не является линейным и последовательным, а является итеративным
и параллельным, примерно таким, как показано на рис. 1.31.
Другими словами, процесс моделирования циклический, на каждом шаге
может присутствовать уточнение представления использования, за которым
следует параллельное моделирование структуры и поведения.
1.8. Общие механизмы
Рис. 1.31. Процесс моделирования
Исходя из сказанного, мы положили свой набор представлений в основу
структуры книги. В главе 2 рассматривается представление использования,
в главе 3 — представление структуры, а в главе 4 — представление поведе-
ния.
1.8. Общие механизмы
В UML имеются общие правила и механизмы, которые относятся не к кон-
кретным элементам модели, а ко всему языку в целом.
Обычно выделяют следующие общие механизмы:
• внутреннее представление модели (specifications);
• дополнения (adornments);
• стандартные дихотомии (common divisions);
• механизмы расширения (extensibility mechanisms).
Степень значимости и сложности этих механизмов, равно как и их влияние
на применение языка, отнюдь неодинакова. Мы начнем с элементарных и
закончим более сложными.
Глава 1. Введение в UML
1.8.1. Внутреннее представление модели
Модель имеет внутреннее представление — как бы иначе работали инстру-
менты? Для графов (а модель — это нагруженный граф) известно множество
разнообразных способов их представления в компьютере.
ПРЕДСТАВЛЕНИЕ ГРАФОВ В КОМПЬЮТЕРЕ
Известно много способов представления графов в памяти ком-
пьютера, различающихся объемом занимаемой памяти и скоро-
стью выполнения операций над графами. Представление выбира-
ется исходя из потребностей конкретной задачи. Перечислим три
наиболее характерных способа представления графа с р верши-
нами и q ребрами.
Матрица смежности — булевская квадратная матрица М разме-
ра рур, в которой элемент M[ij]=\, если и только если вершины
i и j смежны. Объем занимаемой памяти — О(р2). Списки
смежности — структура данных, построенная на указателях, где
для каждой вершины хранится связный список смежных вершин.
Объем занимаемой памяти — O(p+4q). Список ребер — массив
длины q, хранящий пары смежных вершин. Объем занимаемой па-
мяти — 0(2q).
На практике используется, как правило, некоторая комбинация
указанных представлений с добавлением структур для хранения
информации, нагруженной на Вершины и ребра. Очевидные моди-
фикации позволяют использовать эти представления для мульти-,
псевдо- и орграфов. Для гиперграфов используются специальные
представления (см. например, параграф 4.5.3). Следует подчер-
кнуть, что нельзя указать представление графа, которое было
бы наилучшим во всех возможных случаях. В разных ситуа-
циях оказывается выгодным использовать различные пред-
ставления.
Разработчики инструментов для моделирования на UML вправе использо-
вать любое из известных представлений или придумать свое (что обычно и
делается). Важным общим правилом UML является спецификация того,
какую именно семантическую информацию, связанную с тем или иным
графическим элементом нотации, инструмент обязан хранить. Другими
словами, у каждой картинки есть оборотная сторона, где записано все, даже
то, что в данном контексте не нужно или нельзя показывать на картинке.
Например, инструмент может поддерживать режим, в котором часть инфор-
мации о классе (скажем, список операций) не отображается на диаграмме
или отображается не полностью. Но при этом полный список со всеми де-
талями во внутреннем представлении сохраняется. Более того, внутреннее
1.8. Общие механизмы
представление может быть переведено в текст в формате XMI без потери
информации. Таким образом, в UML определен результат сериализации
модели. Это важное правило, на котором базируется интероперабельность
инструментов.
В первом приближении можно считать, что внутреннее представление со-
держит список стандартных свойств (то есть пар имя-значение), опреде-
ленных для каждого элемента модели. Понятно, что такое внутреннее пред-
ставление может быть однозначно (без потери информации) переведено во
внешнее представление, в том числе в линейное текстовое представление.
Это сделать можно, и инструменты, соответствующие стандарту UML, уме-
ют это делать. Однако такое текстовое представление не предназначено для
чтения и понимания человеком. Оно неизбежно оказывается необозримо
длинным, ненаглядным и плохо структурированным. Текстовое представле-
ние моделей UML в формате XML не отвечает основному назначению языка
(см. параграф 1.2.6), а потому не используется людьми, но используется ин-
струментами, например, для обмена моделями.
Приведем пример. На рис. 1.32 показана элементарная модель, состоящая из
двух сущностей и одного отношения, а на рис. 1.33 показан результат сериа-
лизации этой модели в формате XMI.
Classi ----------------- Class2
Рис. 1.32. Пример диаграммы классов
<?xml versions" 1.0" encoding=“UTF-8” ?>
- cuml: Model xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI"
xmlns: uml="http ://www .eclipse.org/uml2/1.0.0/UML" xmi:id="_3cOYALFAEdqS_OOjbZd_dg"
name=,’VerySlmp!eProject’l>
cownedMember xmi:type="uml:Associatlon" xmi:id="_3cOYAbFAEdqS_OOjbZd_dg" name="Unknown
Name'1 memberEnds"_3cOYA7FAEdqS_OOjbZd_dg _3cOYB7FAEdqS_OOjbZd_dg" />
~ cownedMember xmi:type="uml:Class" xm<:id="_3cOYArFAEdqSOOjbZd_dg" name="Classl">
- cownedAttribute xm>:ids"_3cOYA7FAEdqS_OOjbZd__dg" type="_3cOYBrFAEdqS_OOjbZd_dg''
associations'1. _3cOYAbFAEdqS_OOjbZd_dg">
cupperValue xmi:type="uml:LiterallJnllmitedNaturar xmi:id="_3cOYBLFAEdqS_OOjbZd_dg"
value="Г' />
clowerValue xmi:type="uml:Litera!Integer" xmi: id="_3cOYBbFAEdqS_OOjbZd_dg"
values" l"/>
</o wn ed A t tribu te>
c/ownedMember>
- cownedMember xmi: type-'umkClass’ xmi:fd="_3cOYBrFAEdqS_OOjbZd_.dg’' name="Class2’’>
- cownedAttribute xmi:id="_3cOYB7FAEdqS_OOjbZd_dg" type="_3cOYArFAEdqS_OOjbZd_dg"
a ssoci a t ion="_3 cO Y Ab F AE dq S_O О j b Z d_dg>
cupperValue xmi:type="uml:LiteralUnllmitedNatural" xmi: id-'_3cOYCLFAEdqS OOjbZd dg"
values" 1" />
clowerValue xmi: type^umbLiterallnteger*' xms:ids'_3cOYCbFAEdqSOOjbZddg'
values" 1" />
c/ownedAttribute>
c/ownedMember>
</uml: Model>
Рис. 1.33. Пример сериализации модели в формате XMI
Глава 1. Введение в UML
1.8.2. Дополнения
У каждого элемента модели есть базовая графическая нотация. Эта нотация
может быть расширена путем использования дополнительных текстовых и/
или графических объектов, присоединяемых к базовой нотации. Такие до-
полнительные объекты так и называются — дополнения*5.
Дополнения ^adornment) позволяют показать на диаграмме те части
внутреннего представления модели, которые не отображаются с помо-
щью базовой графической нотации.
Например, базовой нотацией отношения ассоциации является сплошная ли-
ния (1). Эта базовая нотация может быть расширена целым рядом дополне-
ний: именем ассоциации (2); указанием кратности полюсов ассоциации (3),
ролей (4), направления навигации; указанием на агрегацию (5) и т. д. Еще
пример: базовой нотацией класса является прямоугольник с именем клас-
са (6). Эта нотация может быть расширена секциями со списками атрибу-
тов (7) и операций, дополнительными секциями, указанием кратности, сте-
реотипа и т. д. (рис. 1.34).
Примечание
Не следует злоупотреблять дополнениями: максимально
подробное изображение не всегда самое понятное. Старай-
тесь не перегружать диаграммы, применяя только те допол-
нения, которые необходимы в данном контексте.
Как правило, инструменты позволяют детально управлять отображением
дополнений, скрывая ненужные подробности или, наоборот, выявляя все
детали.
Рис. 1.34. Пример использования дополнений
45 В некоторых источниках используется термин "украшения", что, может быть, правильно,
поскольку такие элементы действительно украшают диаграмму.
1.8. Общие механизмы
1.8.3. Стандартные дихотомии
UML является объектно-ориентированным языком, поэтому базовые поня-
тия объектно-ориентированного подхода имеют в языке, так сказать, сквоз-
ное действие. В частности, всюду, где возможно, единообразно применяются
и изображаются две дихотомии: класс-объект и интерфейс-реализация.
Дихотомия класс-дбъект означае г. что всегда четко различается, о чем
идет речь: об общем описании некоторого множества однотипных объ-
ектов (т.е. о классе) или о конкретном объекте из некоторого множе-
ства однотипных объектов (т. с. об экземпляре класса).
Это важное различие передается единообразно: если это конкретный объ-
ект (экземпляр класса), то его имя подчеркивается; если это класс (описание
множества), то оно не подчеркивается. Одна и та же сущность в разных кон-
текстах может рассматриваться и как класс (множество), и как экземпляр
класса (элемент). Это совершенно естественно и неизбежно, хотя бы потому,
что элементами множеств могут быть множества. Важно четко указать, что
именно подразумевается в данном контексте. Например, класс (1) в обыч-
ной модели является описанием множества объектов и его имя не подчерки-
вается, а подчеркиваются имена его экземпляров (2). Но в то же время каж-
дый класс, как показано на рис. 1.35, является объектом (3) — экземпляром
метакласса Class (4), определенного в метамодели UML.
Рис. 1.35. Дихотомия класс-объект
Дихотомия интерфейс реализация позволяет указать в модели, чем
именно является та или иная сущносн.: .ни-цмми им и > ап нем того,
чем она должна быть по отношению к другим сущностям, или конкрет-
ным описанием того, чем сущность физически является. В UML это мо-
жет быть выражено разными способами.
[105 j
ГлаоА 1. Введение в UML
Если речь идет об абстрактном описании, то для этого может быть использо-
ван абстрактный класс в трех вариантах нотации: имя класса пишется кур-
сивом (1), используется соответствующее ограничение (2) или применяется
стереотип интерфейса (3). При этом подразумевается, что прямые экзем-
пляры данных классификаторов создать нельзя (подробнее смотри пара-
граф 3.1.4), так как для них не определена реализация.
Если требуется показать, что классификатор имеет реализацию, т.е. у него
могут быть прямые экземпляры, тогда при записи имени используется пря-
мое начертание (4).
На рис. 1.36 указано, что современный мобильный телефон может быть
представлен как объединение трех различных устройств (поддерживает три
совершенно разных интерфейса).
Рис. 1.36. Дихотомия интерфейс-реализация
1.8.4. Механизмы расширения
Механизм расширения — эти встроенный в язык способ изменить
язык.
Авторы UML при унификации различных методов постарались включить в
язык как можно больше различных средств (удерживая объем языка в рам-
ках разумного), так чтобы язык оказался применимым в разных контекстах
и предметных областях. Но нельзя объять необъятное46! Вполне могут воз-
никать и возникают случаи, когда стандартных элементов моделирования не
хватает или они не вполне адекватны.
ЯЗЫК ЯДРО И ЯЗЫК ОБОЛОЧКА
В период бурного языкотворчества в 60-70 годах прошлого века
при сравнительном обсуждении языков программирования было
принято противопоставлять языки по включенному в них изначаль-
но набору готовых средств и присутствующему в языке механизму
46 Точнее говоря, можно, но издержки будут велики.
1 8.,0бщиг механизмы
определения новых средств47. Язык, который обходился миниму-
мом базовых средств, а все необходимое предлагалось доопре-
делять средствами самого языка, называли язык ядро. Язык, в ко-
торый изначально включалось множество готовых средств, может
быть, даже частично дублирующих друг друга, называли языком
оболочкой. Хрестоматийный пример: язык ядро — Algol 68, язык
оболочка — PL/1. Оба типа языков имеют свои достоинства и свои
недостатки. Язык ядро подкупает своей лаконичностью и изяще-
ством — программист может всегда расширить язык нужными для
данной задачи средствами. Это так, в принципе может, но всегда
ли это получится наилучшим образом? Язык оболочка предлагает
готовые средства — бери и пользуйся. Отлично, но чтобы восполь-
зоваться, нужно знать все средства, а их утомительно много...
С этой точки зрения UML, несомненно, — язык оболочка: авторы
включили в него все, что можно. Но в то же время он имеет зна-
чительный "ядерный потенциал" — стандартные механизмы рас-
ширения.
Механизмы расширения позволяют определять новые элементы мо-
дели на основе существующих \ нравляемым и унифицированным
способом .Таки х механиз мои три:
• помеченные значения;
* ограничения;
• стереотипы
Эти механизмы не являются независимыми — они тесно связаны между со-
бой.
Помеченное значение (i agged value) — это пара: имя свойства и значе-
ние свойства, которая может быть добавлена к любому стан тартному
элементу модели.
Другими словами, помеченное значение — это свойство, добавляемое к вну-
треннему представлению модели (см. параграф 1.8.1). К любому элементу
модели можно добавить любое помеченное значение, которое будет хранить-
ся так же, как и все стандартные свойства данного элемента. Добавляемое
помеченное значение должно иметь имя, отличное от стандартных. Способ
обработки помеченного значения, определенного пользователем, стандар-
том не описывается и отдается на откуп инструменту.
Помеченные значения записываются в модели в виде строки текста, имею-
щей следующий синтаксис: в фигурных скобках указывается пара: имя и
значение, разделенные знаком равенства. Можно указывать сразу список
47 Сейчас при сравнении языков используют другие критерии.
Глава 1. Введение в UML
Write the book
{importance=high,
Author=”lvanov, Novikov"}
Рис. 1.37. Пример использования
помеченных значений
пар, разделяя элементы списка запяты-
ми. Если из контекста ясно, какое значе-
ние является значением по умолчанию,
то знак равенства вместе со значением
можно опустить48. На рис. 1.37 приведен
пример использования помеченных зна-
чений.
Ограничение (constraint) — это логическое утверждейие относитель-
но значений свойств элементов модели.
Логическое утверждение может иметь два значения: истина или ложь, то
есть задаваемое им условие либо выполняется, либо не выполняется. Указы-
вая ограничение для элемента модели, мы изменяем его семантику, требуя,
чтобы ограничение выполнялось. Ограничение может относиться к отдель-
ному элементу или к совокупности элементов модели.
Person
{0<age<199}
-age:lnteger
Рис. 1.38. Пример использования ограничения
Ограничения записываются в виде строки текста, заключенной в фигурные
скобки. Это может быть неформальный текст на естественном языке, логи-
ческое выражение языка программирования, поддерживаемого инструмен-
том, или выражение на некотором другом формальном языке49. Аналогично
помеченным значениям, ограничение можно написать после имени элемен-
та или в отдельном комментарии, присоединенном к элементу. На рис. 1.38
приведен пример использования ограничения.
Примечание
Для помеченных значений и ограничений одна и та же син-
таксическая конструкция — текст в фигурных скобках — ис-
пользуется не случайно. На самом деле помеченное значе-
ние можно считать ограничением. А именно, если в модели
указано помеченное значение {А=В}, то это можно рассма-
48 Нам очень нравится этот стиль UML — если что-то и так ясно, то это можно не писать.
Насколько такой стиль приятнее занудного синтаксиса традиционных языков програм-
мирования!
49 Авторы UML в качестве такого языка предлагают использовать язык OCL, специально
включенный для этой цели в стандарт в качестве отдельной спецификации.
1.8. Общие механизмы
тривать как запись условия: "свойство А обязательно имеет
значение В".
Стрреотип (stercotуре) это определение нового элемента моделиро-
вания на основе существующего элемента моделирования.
Определение стереотипа производится следующим образом. Взяв за основу
некоторый существующий элемент модели, к нему добавляют новые поме-
ченные значения (расширяя тем самым внутреннее представление), новые
ограничения (изменяя семантику) и дополнения, то есть новые графические
элементы (определяя нотацию).
После того как стереотип определен, его можно использовать как элемент
модели нового типа. Если при создании стереотипа не использовались до-
полнения и графическая нотация взята от базового элемента модели, на
основе которого определен стереотип, то стереотип элемента обозначается
при помощи имени стереотипа, заключенного в двойные угловые скобки
(типографские кавычки « » ), которое помещается перед именем элемента
модели.
Если же для стереотипа определена своя нотация, например новый графи-
ческий символ, то указывается этот символ. Впрочем, для пущей ясности
можно указать как имя стереотипа, так и графический символ (значок).
На рис. 1.39 приведен пример определения и использования стереотипа
«PowerUser», который мы определили на базе стандартного стереотипа дей-
ствующего лица.
Отношение между элементом модели, который взят за основу (Actor), и но-
вым элементом модели (PowerUser) называется отношением расширения
(extension) (1 на рис. 1.39).
«PowerUser»
Ml:: Administrator
{domainLAN}
Примечание
Использование двой-
ных угловых скобок
« ... » вместо ти-
пографских кавычек
« » не рекомендуется и
может быть оправдано
только при отсутствии
последних в использу-
емом шрифте.
Рис. 1.39. Пример использования стереотипа
Глава 1. Введение в UML
В U ML имеется большое количество предопределенных стереотипов. Сте-
реотипы используются очень часто, поэтому примеры их применения рас-
средоточены по всей книге. Список стандартных стереотипов и их значений
приведен в главе 6.
Стереотипы являются мощным механизмом расширения языка, однако ими
следует пользоваться умеренно. Определяя большое число нестандартных
стереотипов, легко сделать модель непонятной никому, кроме автора.
Примечание
Не следует путать стереотип и отношение обобщения. Пусть
(см. рис. 1.40) суперкласс User является обобщением под-
класса Admin. Тогда как User, так и Admin являются экзем-
плярами одного и того же метакласса, определенного в ме-
тамодели. Это показано в виде зависимостей со стереотипом
«instanceOf» (1). Если же стереотип PowerUser определен на
основе класса Actor, то в метамодели им соответствуют раз-
ные метаклассы, и, следовательно, например, между класса-
ми User и LocalAdmin никакого отношения обобщения нет.
Между ними определено отношение расширения (2) на ме-
тауровне.
Рис. 1.40. Стереотип и отношение обобщения
1.9. Общие свойства модели
Модель в целом может обладать (или не обладать) важными свойствами, ко-
торые оказывают значительное влияние на ее практическую применимость.
Исчерпывающим образом описать эти свойства во вступительном обзоре
невозможно — их детализация рассредоточена по всей книге, но назвать их
необходимо в самом начале.
........................................—-...........
1.9 Общие свойства модели
1.9.1. Синтаксическая правильность
Прежде всего, модель должна удовлетворять формальным требованиям к
описанию сущностей, отношений и их комбинаций. Другими словами, мо-
дель должна быть синтаксически правильной. Например, отношение (ребро
в графе модели) всегда определяется между сущностями, оно не может про-
сто так "висеть в воздухе". На диаграмме линия должна начинаться и закан-
чиваться в фигуре, иначе это синтаксическая ошибка. Некоторые тексты в
модели (например, описания атрибутов и операций классов) должны иметь
определенный синтаксис.
В UML первична семантика, а синтаксис вторичен. Конечно, стандарт ре-
комендует вполне определенный синтаксис, но это не более чем рекоменда-
ция: разработчики инструментов вправе использовать другой синтаксис, и
этим правом они пользуются. Таким образом, понятие синтаксической пра-
вильности, столь ясное для традиционных языков программирования, для
UML становится несколько расплывчатым.
Большинство инструментов, особенно новых, просто не позволяют ввести в
модель синтаксически неправильную конструкцию.50
1.9.2. Семантическая непротиворечивость
В некоторых случаях даже синтаксически правильная модель может содер-
жать такие конструкции, семантика которых не определена или неоднознач-
на. Такая модель называется противоречивой, а модель, в которой все в по-
рядке и семантика всех конструкций определяется однозначно, называется
непротиворечивой. Например (рис. 1.41), пусть мы определим в модели, что
класс А является подклассом класса В, класс В — подкласс С, класс С — под-
класс D, а класс D — подкласс А. Каждое из этих отношений обобщения в от-
дельности допустимо и синтаксически правильно, а все вместе они противо-
речивы.
Рис. 1.41. Семантически противоречивая модель
Далее в тексте мы всегда указываем правила непротиворечивости при об-
суждении соответствующих конструкций языка. Впрочем, их не так много
50 Диаграммы в этой книге подготовлены с помощью простого графического редактора.
Так что они синтаксически правильны настолько, насколько внимательны были авторы
Ф
Глава 1. Введение в UML
и по большей части они совершенно очевидны на уровне здравого смысла:
синтаксические конструкции нужно использовать так, чтобы не возникало
двусмысленностей при семантической интерпретации.
АВТОМАТИЧЕСКАЯ ВЕРИФИКАЦИЯ МОДЕЛЕЙ
Вопрос о том, можно ли полностью автоматически проверить
любую модель UML на непротиворечивость, является открытым.
Скорее всего, ответ отрицательный, и верификация моделей яв-
ляется алгоритмически неразрешимой проблемой.
Инструменты стараются проверять выполнение правил непротиворечиво-
сти, как могут, но 100% уверенности не обеспечивают. Другими словами:
пользуясь любым инструментом, можно составить синтаксически правиль-
ную и семантически бессмысленную модель. Ответственность за непротиво-
речивость модели лежит на ее авторе.
1.9.3. Полнота
Модель не создается мгновенно — она появляется в результате многочис-
ленных итераций (рис. 1.31) и на каждой из них "по определению" не полна.
Инструмент обязан дать возможность сохранить модель в любом (синтак-
сически правильном) состоянии с тем, чтобы в дальнейшем ее можно было
дополнять и изменять.
Что такое полная модель? На этот вопрос нельзя ответить однозначно. В
некоторых случаях оказывае тся достаточно одной диаграммы использова-
ния (например, концептуальная модель), а в других необходимы диаграм-
мы всех типов, прорисованные до мельчайших деталей (например, модель
реализации). Все зависит от прагматики, т. е. от того, для чего составляется
модель. Если модель составляется с расчетом на автоматическую генерацию
кода, то полной естественно считать такую модель, по которой инструмент
может сгенерировать работающую программу. За редким исключением пока
это практически невозможно. Если модель составляется с целью специфи-
кации требований к разрабатываемому приложению, то модель можно счи-
тать полной, если заказчик и разработчик согласны считать ее таковой. Кри-
терий, как видите, субъективный.
Мы склонны считать, что понятие полноты модели следует определять
применительно к конкретному процессу разработки (см. главу 5). Грубо
говоря, для каждой фазы процесса разработки есть свое понятие полноты:
полная модель фазы анализа, полная модель фазы проектирования и т. д.
1.9. Общие свойства модели
1.9.4. Вариации семантики
Последняя тема, рассматриваемая в этой главе, является в некотором смысле
уникальной особенностью UML, В описании метамодели (семантики UML)
определено достаточно большое количество точек вариации семантики
(semantic variation point). По сути, авторы стандарта, описывая семантику
какого-то понятия, говорят: "мы понимаем это так-то и так-то, но допускаем,
что другие могут это понимать иначе”.
При реализации языка в конкретном инструменте разработчики В гон-
ке вариации семантики вправе выбрать альтернативный вариант, если
он не противоречит семантике остальной части языка.
Точки вариации семантики расставлены в глубинных слоях языка, там, где
приходится принимать во внимание особенности реализации инструмента
и конкретную систему программирования. Рядовому пользователю точки
вариации семантики не заметны, и он может о них не думать. Например, в
UML каждый конкретный объект является экземпляром одного конкретно-
го класса (статическая типизация). Но это точка вариации семантики: мож-
но допустить динамическую типизацию, при которой объект во время своей
жизни может менять класс, которому он принадлежит5'.
Эта замечательная особенность придает языку необходимую гибкость и уни-
версальность: ведь U ML предназначен для моделирования в разных средах с
разной операционной семантикой. Жесткая фиксация одного единственно-
го решения связала бы разработчиков инструментов по рукам и ногам, стан-
дарт вступил бы в конфликт с требованиями реальной жизни (такие кон-
фликты всегда заканчиваются гибелью стандарта). Авторы языка приняли
нетрадиционное и мудрое компромиссное решение: они допустили свободу,
но под контролем — все точки вариации семантики явно отмечены в метамо-
дели, в других местах никаких вольностей не допускается.
51 Иногда это бывает удобно, и существуют системы программирования, в которых это
реализовано.
Л13.
Глава 2.
Моделирование
использования
ЧТО ТАКОЕ МОДЕЛИРОВАНИЕ И АНАЛИЗ БИЗНЕС-ПРОЦЕССОВ?
ЧТО ТАКОЕ МОДЕЛИРОВАНИЕ ИСПОЛЬЗОВАНИЯ И ЗАЧЕМ
ОНО НУЖНО?
В КАКИХ СЛУЧАЯХ ЦЕЛЕСООБРАЗНО ПРИМЕНЯТЬ
МОДЕЛИРОВАНИЕ ИСПОЛЬЗОВАНИЯ?
Какие средства применяются при моделировании
ИСПОЛЬЗОВАНИЯ?
Как идентифицировать варианты использования
И ДЕЙСТВУЮЩИХ лиц?
Как модель использования применяется для управления
требованиями?
Как реализуются варианты использования?
2.1. Бизнес-анализ и моделирование
Прежде чем применять технику моделирования использования, описание
которой начинается в следующем разделе, мы считаем необходимым оста-
новиться на контексте, в котором применяется эта техника. Причина заклю-
чается в следующем. Моделирование использования мы рассматриваем на
сквозном примере — информационной системе отдела кадров.
Пример выбран нами как типичный пример бизнес-приложения. При этом
такого рода приложения настолько привычны, что словечко "бизнес" мо-
жет даже показаться лишним, вставленным только в угоду моде.52 На самом
деле это слово заостряет внимание читателя на том (нечетко определенном)
классе программных систем, для которого применение UML и, в частности,
моделирования использования дает наибольший эффект. Мы еще раз хотим
охарактеризовать область применения языка, но не изнутри, как это сделано
в разделе 1.2, а, если можно так сказать, снаружи.
2.1.1. Введение в бизнес-анализ
Начнем с определений. Сразу подчеркнем, что наши определения не годятся
даже для самого элементарного учебника по бизнесу — настолько они упро-
щены и абстрагированы. Зато наши определения просты и достаточны для
наших целей. Поясним примером. В популярном интернет-источнике53 мож-
но найти следующее определение понятия "бизнес".
52 В известном смысле это так и есть. Если бы мы не боялись выглядеть старомодными, мы
бы могли употребить очень точное, но тяжеловесное словосочетание "приложение для
автоматизации делопроизводства и управления производственными процессами".
53 Википедия (http://ru.wikipedia.org/)
2.1. Бизнес-анализ и моделирование
Бизнес (business) это самостоятельная, осуществляемая на свой
риск деятельность, направленная на систематическое получение при-
были от пользования имуществом, продажи товаров, выполнения ра-
бот или оказания услуг лицами и установленном законом порядке.
Наверное, так оно и есть. Но при моделировании и автоматизации от всех
этих свойств бизнеса можно абстрагироваться, кроме двух. Наше (абстракт-
ное) определение бизнеса звучит следующим образом.
Бизнес — это систематическая деятельность.
Действительно, например, с точки зрения бизнеса, прибыльность — важней-
шая характеристика. С другой стороны, с точки зрения программирования,
информационные системы отделов кадров для коммерческого предприятия
и для государственной бюджетной структуры, хотя и различаются в мелких
деталях, реализуются на одних и тех же принципах.
Таким образом, одними и теми же средствами можно моделировать как
прибыльный, так и убыточный бизнес, который и бизнесом трудно назвать.
Стало быть, в данном контексте мы может абстрагироваться от нацеленно-
сти бизнеса на прибыль. Аналогичные рассуждения можно провести и для
остальных свойств бизнеса из определения "Википедии". Но вот наличие
самого факта деятельности и систематический, а не случайный или спон-
танный ее характер — эти свойства бизнеса нельзя терять из виду, когда
мы говорим о бизнес-приложениях.
Изменяемость бизнес-процессов
Сделаем еще несколько замечаний общего характера.
• Необходимость изменений бизнеса. Следующее утверждение мы
рассматриваем как закон природы: жизнь меняется, следовательно,
меняется бизнес. Более того, наблюдения последних десятилетий и
даже столетий показывают, что скорость изменений жизни посто-
янно возрастает. В настоящее время общепринятым является по-
стулат: бизнес определяется процессами, которые обычно так и
называют — 6u3Hec-npov,eccbi5i(busmess process). Отсюда вытекает
следствие: необходимо постоянно менять бизнес-процессы.
• Необходимость модификации бизнес-приложений. Если посто- 54
янно меняющиеся бизнес-процессы автоматизированы, полностью
54 Этот постулат известен также как "процессный подход", который получил широкое рас-
пространение вместе с распространением идеи управления качеством продукции и
услуг в соответствии с международными стандартами группы ISO 9000.
Глава 2 Модели°лванй^ использования
или частично, то необходимо полностью или частично, но постоянно
менять приложения для автоматизации бизнес-процессов. Это мо-
жет быть разработка полностью нового приложения для радикально
меняющегося бизнеса или доработка старого приложения, если тре-
буемые изменения не столь велики. Но в любом случае изменения
бизнес-приложений неизбежны! Невозможно "всё автоматизиро-
вать" и "почить на лаврах" — это противоречит законам природы55.
• Необходимость конструктивного описания бизнес-процессов. Из-
менение ради изменения, изменения "наудачу" ни к чему хорошему
не приведут, точнее говоря, они приведут к стагнации. Сейчас как
общепринятый постулат принимается положение, что изменение
должно проводиться "с целью", причем цель должна быть измери-
ма, то есть, в простейшем случае, цель должна быть выражена чис-
лом. Например, "увеличить прибыль на 5% за год" — это измеримая
цель, которая может быть использована как цель изменения бизнес-
процесса. С другой стороны, цель "улучшить обслуживание клиен-
тов" не подходит как цель изменения бизнес-процесса или модифи-
кации бизнес-приложений.
Основной вывод этого параграфа таков. Изменения бизнес-приложений
необходимы и неизбежны, а чтобы проводить целенаправленное измене-
ние бизнес-процессов, нужно иметь конструктивное (измеримое) описа-
ние этих процессов.
Моделирование бизнеса
Конструктивное (измеримое) описание бизнес-процессов называет-
ся бизнес-моделыо, процесс построения бизнес-модели называется
бизнес-акализим, а специалист, который проводи i бизнес-анализ, ва-
зы кается бизпес-аналитиком.
Примечание
Вообще говоря, следует разграничивать собственно бизнес-
анализ, т.е. изучение бизнеса с целью его улучшения и опти-
мизации, и бизнес-анализ в рамках информационных техно-
логий с целью автоматизации. Здесь есть много общего, но
все же есть и какая-то ощутимая грань. Многие методологии
разработки программного обеспечения не случайно вклю-
55 Именно по этой причине активно развивается направление BPMS (Business Process
Management Systems) и появляются такие яркие примеры, как BPMN (Business Process
Modeling Notation) и BPEL (Business Process Execution Language).
2.1. Бизнес-анализ и моделирование
чают в себя дисциплины бизнес-моделирования, хотя и не
называют их собственно бизнес-анализом. Но понимается
все-таки под этим не моделирование бизнеса как такового,
а скорее моделирование бизнес-контекста, в котором будет
выстраиваться разработка бизнес-приложений. Наверное,
это можно было бы назвать контекстным моделированием
или моделированием предметной области. В таком контек-
сте бизнес-аналитик — есть по идее аналитик требований,
лицо, компетентное как в бизнесе, так и в информационных
технологиях.
В конце параграфа мы приводим еще несколько определений* 56 57 из области
бизнес-анализа, которые в настоящее время часто используются бизнес-
аналитиками.
Субъект, который проводит целенаправленную систематическую де-
ятельность (ведет бизнес), нанимается организацией.
Организацией в таком понимании может быть что угодно — частный пред-
приниматель, транснациональная корпорация, государственное учрежде-
ние, тайное общество. Организация ведет бизнес. Как правило, реальный
бизнес включает в себя несколько, иногда много, взаимосвязанных, но раз-
личных деятельностей.
Каждый нид деятельности, которые умеет выполнять организация,
называется функцией. Таким образом, организация выполняет некото-
рые функции. Например, отдел кадров принимает и увольняет сотруд-
ников, это функции отдела кадров. Функции бывают внешние, то есть
видймые извне, и внутренние'’'. Например, отдел кадров выполняет
внутренние функции, а отдел щюдаж внешние.
Последовательность действий (операций), в результате которой
происходит выполнение некоторой функции, называется бизнес-
процёссом.
Таким образом, выполнение функции — это процесс. Например, процесс
"приём сотрудника" состоит из следующих действий: "проведение интер-
вью", "заполнение форм", "издание приказа",...
Примечание
Заметим, что каждое из действий, в свою очередь, может
иметь сложную внутреннюю структуру и состоять из после-
56 Еще раз напоминаем, что мы даем упрощенные определения.
57 Внутренние и внешние по отношению к организации.
Глава 2. Моделирование использования
довательности более простых действий, и так далее. Это на-
зывается функциональной декомпозицией (functional decom-
position). При построении бизнес-моделей верхнего уровня
обычно избегают слишком глубокой детализации, чтобы не
перегружать модель.
В соответствии с тем, как функции делятся на внешние и внутренние, про-
цессы можно разделить на основные (результат которых виден потребителю)
и вспомогательные. Например, "приём сотрудника" — основной процесс от-
дела кадров (результат виден принимаемому сотруднику), а ведение личных
дел — вспомогательный (часто делается скрытно от сотрудников).
Деление на основные и вспомогательные процессы является относитель-
ным, это зависит от того, какой уровень организации мы рассматриваем.
Например, "приём сотрудника" — основной процесс, если мы рассматриваем
отдел кадров изолированно, как организацию, но этот же процесс является
вспомогательным, если мы рассматриваем всю организацию в целом со сто-
роны внешнего заказчика.
Примечание
Мы определяем процесс как основной, если он связан с
внешним потребителем, поскольку считаем, что целью ор-
ганизации является оказание услуг (включая продажу то-
варов) потребителю. В другом варианте определения можно
считать, что целью организации является получение прибы-
ли, и основными считать процессы, приносящие прибыль.
Впрочем, по большей части на практике эти подходы дают
одни и те же результаты.
Реинжиниринг бизнеса
В последние годы большую популярность приобрел метод использо-
вания бизнес-анализа для изменения бизнеса, который называется
реинжиниринг бизнеса (рис. 2.1). Суть этого метода заключается в следую-
щем.
1. Составляется бизнес-модель "как есть". Как правило, это делается на
основе аудита работы организации.
2. Ставится некоторая измеримая цель или набор целей, которые тре-
буется достичь.
3. Проводится одна или несколько итераций преобразования модели
2.1. Бизнес-анализ и моделирование
"как есть" и составляется модель "как должно быть", которая удо-
влетворяет поставленной цели.
Путь перехода через промежуточные состояния (модели) фактически обра-
зует план преобразований в организации, которые нужно осуществить для
достижения желаемых изменений.
Рис. 2.1. Реинжиниринг бизнеса
Принципиальным отличием реинжиниринга от распространенного "метода
большого скачка" является поэтапное преобразование того, что реально
есть, в то, что должно быть. Реинжиниринг подразумевает, что достаточно
сложный бизнес невозможно изменить желаемым образом одним росчер-
ком пера под приказом о реорганизации — нужна постепенная и кропотли-
вая работа по моделированию и улучшению бизнес-процессов.
2.1.2. Моделирование бизнеса: значение и принципы
В чем же заключается моделирование бизнеса? Ответить исчерпывающим
образом на этот риторический вопрос не так просто, и, может быть, не очень
нужно в этой книге, но в контексте изложения моделирования использова-
ния бизнес-приложений мы считаем целесообразным коснуться трех аспек-
тов:
описательное и имитационное моделирование;
Глава 2. Моделирование использования
• модель как инструмент качественного анализа;
• принципы моделирования.
Прежде всего, следует различать описательное моделирование (modeling) и
имитационное моделирование (simulation). Это вещи родственные, но раз-
личные. В английском языке используются разные термины, и путаницы не
происходит, а в русском языке она не исключена. Чтобы исключить путани-
цу, обратимся к первоисточникам и дадим точные определения.
Современная методология науки различает качественный и количественный
анализ. Качественный анализ: есть - нет, много - мало и тому подобное.
Количественный анализ: число, структура и так далее.
Обратимся к стандартным и самым широким определениям. В данном слу-
чае мы цитируем энциклопедический словарь [Новый энциклопедический
словарь. — М.: Большая Российская энциклопедия: РИПОЛ классик, 2005,
1456 с.].
Мидель — ... 5) любой образ, аналог (мысленный или условный: изо-
бражение, описание, схема, график, карта и т.п.) какого-либо объек-
та, процесса или явления.
Моделирование — исследование каких-либо реально существующих
объектов или явлений путем построения й изучения их моделей.
Теперь мы можем дифференцировать общие определения применительно к
нашему случаю.
Имитационное моделирование — это составление моделей с целью
количественного анализа.
Описательное моделирование — это составление моделей с целью ка-
чественного анализа.
Вообще говоря, известны попытки имитационного моделирования биз-
неса, но UML и другие средства, которые мы рассматриваем в этом
параграфе, предназначены и практически всегда используются для
качественного анализа бизнес-процессов. Таким образом, говоря "моде-
лирование", в этой книге мы почти всегда подразумеваем описательное
моделирование.
Рассмотрим модель как инструмент качественного анализа. На первый
взгляд, от описательных моделей бизнеса мало чего можно ожидать, однако
2 1. Бизнес-анализ и моделирование
это далеко не так. Ниже следует далеко не полный перечень вариантов ис-
пользования описательного моделирования в бизнес-анализе.
• Руководство мыслительным процессом. Описательные модели
задают направление анализа бизнес-процессов аналитиком. Боль-
шинство людей предпочитают решать сложные задачи, опираясь на
какие-то артефакты: визуальные образы, тексты и т. п. Умение ре-
шать действительно сложные задачи "в уме" — способность почти
сверхъестественная, и на нее не следует рассчитывать.
• Описание требований к системе. Описательные модели, прежде
всего модель использования, являются наилучшим средством фик-
сации функциональных спецификаций и (частично) знаний о пред-
метной области.
• Разработка проекта системы. Описательная модель, если она до-
статочно полна, является наилучшей проектной документацией —
сравнительно точной и одновременно компактной. При этом речь
идет не только о программных системах — с равным успехом можно
использовать описательные модели человеко-машинных систем и
даже таких систем ведения бизнеса, в которых компьютеры вовсе не
применяются.
• Навигация в больших системах. Описательная модель — это струк-
турированное знание о системе, она допускает поиск, фильтрацию,
исследование и редактирование информации.
Мы утверждаем, что описательное моделирование, в том числе моделирова-
ние средствами UML, и, прежде всего, моделирование использования, яв-
ляется полезным методом бизнес-анализа. Во всяком случае, авторы, когда
им приходилось анализировать бизнес-процессы, всегда применяли UML и
никогда об этом не жалели.
На основании своего опыта мы рекомендуем придерживаться следующих
принципов описательного моделирования:
• Абстракция, а не детализация. В модель следует включать толь-
ко важное. Если что-то можно не включать, то на первом этапе это
включать не надо. Чем выше уровень абстракции и чем меньше мо-
дель вначале, тем лучше.
• Спецификация, а не реализация. Описывать нужно только что де-
лает система, а не как она это делает. Например, в бизнес-модели
отдела кадров не следует детально описывать, как нужно проводить
Глава 2. Моделирование использования
интервью с кандидатом. Достаточно упомянуть, что должно полу-
читься в результате (например, документ или запись в базе данных).
• Описания, а не реальные объекты. Не следует включать конкрет-
ные объекты в абстрактную бизнес-модель. Например, в бизнес-
модель отдела кадров не следует включать саму форму личной
карточки сотрудника. Достаточно упомянуть, что такой документ
должен существовать для каждого сотрудника.
2.1.3. История развития средств моделирования
В нашей книге в качестве средства моделирования бизнес-процессов ис-
пользуется UML, но UML отнюдь не единственное и даже далеко не самое
распространенное средство бизнес-моделирования.
Мы считаем необходимым дать обзор альтернативных вариантов, иначе не-
возможно выявить преимущества UML в моделировании бизнеса с целью
разработки бизнес-приложений.
Структурный анализ
Одной из самых заслуженных идей является методология структурно-
го анализа и проектирования (Structured Analysis and Design Technique —
SADT), предложенная Дугласом Россом еще в 1969 году и позднее развитая
другими авторами.
Дуглас Т. Росс (D. Т. Ross) (1929-2007)— американский уче-
ный и инженер, пионер компьютерной индустрии. Он разработал
APT - Automatically Programmed Tools - язык для программирова-
ния станков с ЧПУ, придумал термин CAD (computer-aided design).
Наибольшую известность принесла ему разработка SADT, на осно-
ве которой было в дальнейшем развито семейство стандартов
IDEE
Аббревиатура SADT обозначает одновременно две вещи:
• методологию построения моделей;
• графический язык для представления моделей
Основные понятия структурного анализа просты и естественны:
• Система — совокупность взаимодействующих компонентов и
взаимосвязей между ними.
• Модель — полное описание системы (с помощью SADT), которое
может быть использовано для получения ответов на вопросы от-
2.1. Бизнес-анализ и моделирование
носительно структуры и функционирования системы с заданной
точностью.
• Моделирование процесс создания точного описания системы.
Как видно из этих определений58, методология структурного анализа пре-
тендует не только на описательное моделирование.
• Еще одним ключевым и специфическим для структурного анали-
за понятием является точка зрения. Точка зрения — место чело-
века или объекта, с которого можно увидеть систему в действии.
Введение понятия "точка зрения" было революционным для своего времени
и отражает тот несомненный факт, что "единственно правильной" модели
для данной системы нет и не может быть: "правильность" модели зависит от
точки зрения!
Примечание
Идея "точки зрения" получила в UML развитие в форме
"представлений", см, раздел 1.7.
В рамках методологии структурного анализа было развито несколько си-
стем обозначений и понятий, взаимно дополняющих и обогащающих друг
друга и предназначенных для моделирования с различных точек зрения.
Мы начнем с самого известного и характерного случая: функционального
моделирования.
При функциональном моделировании в методологии структурного анали-
за и проектирования прямоугольные блоки изображают функции модели-
руемой системы. Дуги со стрелками связывают блоки и отображают взаи-
модействия и взаимосвязи между ними.
Расположение и фигур, и линий на диаграмме структурного анализа имеет
большое значение, в отличие от UML.
Доминирование (dominance)— влияние, которое один блок оказывает
на другие блоки диаграммы. Говорят, что блок, нарисованный выше,
доминирует над блоками, нарисованными ниже.
Способ рисования стрелок (взаимосвязей) также имеет значение.
58 Эти определения не являются определениями, предлагаемыми нами как авторами. Мы
просто пересказываем определения, которые даются в книгах по структурному анализу.
Глава 2. Моделирование использования
Различаются следующие типы взаимосвязей между блоками:
• управление (стрелка, входящая в блок сверху);
• вход (стрелка, входящая в блок слева);
• выход (стрелка, выходящая из блока справа);
• механизм (стрелка, входящая в блок снизу).
Одной из центральных идей данной методологии является идея структур-
ности, известная также под названиями последовательное уточнение (step-
wise refinement) и функциональная декомпозиция (functional decomposition).
Блок, описывающий функцию на верхнем уровне, может быть раскрыт на
диаграмме нижнего уровня.
Приведем пример, в котором мы рассматриваем процесс, знакомый, как
авторам, так и читателям — разработку программного продукта (рис. 2.2).
В качестве нотации используется вариант, установленный стандартом
IDEF0.
Корпоративные
Цель:
Понять, какие функции должны быть включены в процесс изготовления
программного продукта, и как эти функции взаимосвязаны между собой,
стем, чтобы написать должностные инструкции
Точка зрения:
Заведующий лабораторией
NODE: A I TITLE: Разработка программного продукта I NO.:
Рис. 2.2. Диаграмма верхнего (нулевого) уровня
На вход поступают требования (1 на рис. 2.2), на выходе имеем программ-
ный продукт (2 на рис. 2.2), все это управляется стандартами (3 на рис. 2.2),
а для фактического выполнения работы требуется персонал (4 на рис. 2.2).
г 126 J
2 1. Бизнес-анализ и моделирование
Рис. 2.3. Диаграмма первого уровня
Блок верхнего уровня может быть уточнен с помощью диаграммы на рис.
2.3, блоки которой в свою очередь могут быть также уточнены, и продол-
жаться такое уточнение может вплоть до нужного уровня детализации.
Связь между диаграммами поддерживается с помощью системы идентифи-
каторов, которые пишутся на рамке диаграмм (5 на рис. 2.2 и 1 на рис. 2.3).
Мы хотим подчеркнуть свое уважение и положительное отношение к функ-
циональному моделированию средствами структурного анализа. Данная
техника превосходна при анализе бизнес-процессов. Жаль только, что эта
техника практически никак не помогает при разработке программного обе-
спечения для автоматизации этих бизнес-процессов.
Диаграммы потоков данных
Вторым примером средств моделирования, который невозможно обойти
молчанием в этом обзоре, являются диаграммы потоков данных.
В диаграммах потоков данных используются:
• активные сущности (изображаются прямоугольниками), которые
производят или потребляют данные;
• процессы обработки (изображаются кругами, овалами или прямоу-
гольниками со скругленными углами), которые преобразуют вход-
Глава 2 Моделирование использования
ные данные в выходные в соответствии с некоторым алгоритмом;
• хранилища данных (изображаются двумя параллельными линиями
или незамкнутыми прямоугольниками), которые пассивно хранят
данные;
• потоки данных (изображаются стрелками с надписями), которые
показывают, как перемещаются данные от источников данных к по-
требителям данных.
На рис. 2.4 приведен пример диаграммы потоков данных (в нотации Йордана).
Рис. 2.4. Диаграмма потоков данных
Диаграммы описания процессов
Третьим примером, который обычно сопровождает два уже приведенных,
является диаграмма в нотации IDEF3, фактически являющаяся вариацией
на тему блок-схем алгоритмов.
В нотации IDEF3 в прямоугольниках указываются выполняемые дей-
ствия, а последовательность действия определяется стрелками, на кото-
рых указываются передаваемые объекты. Интересным является унифици-
рованный подход к описанию альтернативного и параллельного выполнения
действий, который в этой нотации называется соединением (изображается в
виде маленького квадратика со значком внутри). Соединение бывает разво-
рачивающим, когда оно имеет одну входящую и несколько исходящих стре-
лок, и, соответственно, сворачивающим, когда оно имеет одну исходящую и
128J
2.1 . ^ИЗНЕС-АНАЛИЗ И МОДЕЛИРОВАНИЕ
несколько входящих стрелок. Смысл этих обозначений указан в таблице 2.1.
При этом мы называем действия, от которых идут стрелки к соединению,
исходными, а действия, к которым идут стрелки от соединения, — целевыми.
Таблица 2.1. Типы соединений IDEF
Знак Название Вид Правило
& And И Разворачивающее Все целевые действия одновре- менно запускаются
Сворачивающее Все исходные действия должны завершиться
X Хог Исключающее ИЛИ Разворачивающее Одно и только одно целевое дей- ствие запускается
Сворачивающее Одно и только одно исходное действие должно завершиться
О Or ИЛИ Разворачивающее Одно или более целевых дей- ствий запускаются
Сворачивающее Одно или более исходных дей- ствий должны завершиться
Самое интересное, что сворачивающее соединение не обязано быть того же
типа, что и соответствующее разворачивающее.
Приведем пример: блок-схема алгоритма действий дежурного во время об-
Рис. 2.5. Описание процесса в нотации IDEF3
Семейство стандартов IDEF
В таблице 2.2 перечислены все стандарты семейства IDEF, три из которых
мы рассмотрели (IDEFO, IDEF1X, IDEF3).
. Глава 2. Моделирование использования
Таблица 2.2. Стандарты семейства IDEF
Шифр Название Краткое описание Комментарии
IDEFO Function Modeling Функциональное моделирование на основе методологии структур- ного анализа и проектирования Очень часто использует- ся. Не получило развития bUML
IDEF1 Information Modeling Методология моделирования ин- формационных потоков внутри си- стемы, позволяющая отображать и анализировать их структуру и взаи- мосвязи Редко используется. Явля- ется бедным подмноже- ством средств диаграмм классов UML
IDEF1X Data Modeling Методология построения реляци- онных структур, относится к типу методологий "сущность-связь" Часто используется. Экви- валентно выразима в UML диаграммами классов
IDEF2 Simulation Model Design Методология имитационного мо- делирования на базе сетей Петри Не используется. Не полу- чила развития в UML
IDEF3 Process Description Capture Документирование технологиче- ских и бизнес-процессов Часто используется. Экви- валентно выразимо в UML диаграммами деятельно- сти
IDEF4 Object-Oriented Design Методология построения объектно-ориентированных си- стем Редко используется. Является подмножеством средств диаграмм классов UML
IDEF5 Ontology Description Capture Стандарт описания онтологий си- стем и предметных областей Используется постольку, поскольку используются онтологии. Не получил раз- вития в UML
IDEF6 Design Rationale Capture Обоснование проектных действий. Большинство методов моделиро- вания фокусируются на собственно получаемых моделях, а не на про- цессе их создания. Методология акцентирует внимание именно на процессе создания модели Метод недоработан. В U М L есть несколько заимство- ванных элементов
IDEF7 Information System Auditing Аудит информационных систем Этот метод определён как востребованный, однако так и не был разработан
IDEF8 User Interface Modeling Метод разработки пользователь- ских интерфейсов Есть специальные профили (profile) UML для модели- рования пользовательских интерфейсов
IDEF9 Scenario-Driven IS Design (Business Constraint Discovery method) Метод исследования бизнес- ограничений для облегчения их об- наружения и анализа в условиях, в которых действует предприятие Не получил развития в UML
IDEF10 Implementation Architecture Modeling Моделирование архитектуры вы- полнения Этот метод определён как востребованный, однако так и не был разработан
2.1. Бизнес-анализ и моделирование
IDEF11 Information Artifact Modeling Моделирование артефактов Этот метод определён как востребованный, однако так и не был разработан
IDEF12 Organization Modeling Организационное моделирование Этот метод определён как востребованный, однако так и не был разработан
IDEF13 Three Schema Mapping Design Трёхсхемное проектирование пре- образования данных Не получил развития в UML
IDEF14 Network Design Метод проектирования компью- терных сетей Разработан частично. В UML существуют подобные возможности
2.1.4. Современные средства: BPMN
В настоящее время наиболее популярным средством моделирования бизнес-
процессов является BPMN (Business Process Modeling Notation)59. Вообще
говоря, BPMN имеет довольно длинную историю развития, нескольких
предшественников (в частности, BPML— Business Process Modeling Lan-
guage) и несколько тесно связанных спутников (в частности, В PEL —Busi-
ness Process Execution Language) в рамках концепции управления бизнес-
процессами (BPM — Business Process Management).
По замыслу авторов этой концепции развитие специализированных языков
и компьютерных средств должно привести к созданию систем управления
бизнес-процессами (BPMS — Business Process Management System), которые
будут решать все задачи управления бизнес-процессами столь же эффек-
тивно и надежно, как системы управления базами данных (DBMS — Data
Base Management System) решают в настоящее время все задачи управле-
ния данными. Обсуждение всех деталей этих концепций требует много ме-
ста и не отвечает целям книги60. Мы сосредоточимся только на графических
средствах моделирования, представленных в BPMN 1.0 (февраль 2006),
BPMN 1.1 (январь 2008) и BPMN 1.2 (январь 2009).
Центральным понятием BPMN, как следует из самого названия, является
бизнес-процесс. Бизнес-процесс в организации — это крупная составляю-
щая, он направлен на выполнение определенной функции организации, и
обычно бизнес-процесс складывается из взаимодействия некоторого числа
более элементарных процессов.
59 Большинство русскоязычных авторов использует эти аббревиатуры без перевода на
русский язык, и мы присоединяемся к большинству.
60 Заинтересованному читателю, который желает познакомиться с этим кругом идей, мы
рекомендуем информативную статью в Википедии http://en.wikipedia.org/wiki/Business_
processmanagement.
Глава 2. Моделирование использования
Процесс (process । н BPMN — эго любая активность*', выполняемая
в организации. Процесс изображается в виде сети, связывающей
узлы, которые, с одной стороны, выполняют некоторые активности,
а с другой могут управлять последовательностью выполнения этих
активностей.
Разберем это определение, обращая внимание на тонкости, часто упускаемые
из вида. Во-первых, речь идет не о реальных процессах, а о моделях бизнес-
процессов (слово "изображается"). Во-вторых, сами выполняемые действия
находятся вне фокуса описания процесса (слова "некоторые активности").
В-третьих, активности могут быть упорядочены нелинейно (слова "в виде
сети"). На этом месте объяснений можно было бы выбрать один из двух под-
ходов: встать на твердую математическую почву и доработать определения
до формальной теории или оставить формальные определения в покое и об-
ратиться к примерам. Мы знаем, куда ведет первый подход: к п-исчислению
(л-calculus), теории любопытной, но непрактичной, и сразу выбираем свой
излюбленный второй подход: практические примеры.
71-ИСЧИСЛЕНИЕ
л-исчисление предложили Роберт Милнер, Иохим Парроу и Дэвид
Уолкер в 1992 году. Это лаконичная система обозначений, позво-
ляющая описывать взаимодействующие параллельные процессы.
Центральным понятием исчисления является понятие имени,
причем имена используются как в качестве каналов, так и в каче-
стве переменных. Грамматика языка формул л-исчисления имеет
один нетерминал Р (процесс), который описывается следующими
грамматическими правилами:
Р: Р | Р // параллельное выполнение процессов
Р : с(х). Р // имя х принимается по каналу с
Р : ~с<х>.Р // имя х отправляется по каналу с
Р: ! Р И итеративное повторение процесса
Р: (vx)Р И определение нового имени в процессе
Р: 0 // пустой (законченный) процесс
Далее определяется понятие редукции, или пошагового вычисле-
ния. Например, выражение
(vx) ( ~x<z>.0 | х(у). ~у<х>. х(у). О | z(w). ~w<w>. О )
61 Здесь термин "активность" (activity) используется как обобщение понятий "действие" и
"деятельность". См. также параграф 4.3.1
2.1. Бизнес-анализ и моделирование
содержит три параллельных процесса. Первые два, в которых
определена переменная х, взаимодействуют, то есть первый про-
цесс посылает имя z по каналу х, а второй принимает / и связывает
его с переменной у. В результате первого шага редукции получа-
ется следующее выражение:
(vx) ( О | ~z<x>. х(у). О | z(w). ~w<w>. О )
Теперь второй и третий процессы могут взаимодействовать по ка-
налу z:
(vx) ( О | х(у). О | ~х<х>. О )
Наконец, еще раз проведя взаимодействие, процесс редуцирова-
ния заканчивается нередуцируемой формулой:
(vx) ( О | О | О )
В данном элементарном примере все это выглядит как забавный
фокус, но на самом деле данное исчисление и его модификации
удалось применить для решения ряда важных практических задач.
Вернемся к BPMN. В этом параграфе в качестве примера мы используем хо-
рошо знакомый нам по личному опыту бизнес-процесс: проведение онлайн-
тренингов в Интернете. Но сначала приведем небольшую классификацию.
В BPMN различаются три типа описаний бизнес-процессов:
• закрытый бизнес-процесс (private business process) процесс
оппсынаетсясам но себе, без СВЯЗИ с окружением;
• полуоткрытый бизнес-процесс (abstract business process)
бизнес-процесс связан с другими бизнес-йроцессами, по эти по-
следние описаны абстрактно, только как приемники и источнику
сообщений, без раскрытия внутренней структуры;
• открытый бизнес-процесс (collaboration business process:) по
казана внутренняя структура участвующих процессов и их взаи-
модействие62.
Начнем с примера закрытого процесса. Проведение онлайн-тренинга в Ин-
тернете включает три последовательных этапа: подготовка к проведению
тренинга, проведение тренинга, подведение итогов тренинга (рис. 2.6). Про-
цесс начинается стартовым событием (1), последовательность действий ука-
зывается стрелками (2) и завершается заключительным событием (4).
62 Мы знаем, что наши переводы отличаются от тех, что дает словарь. Дочитайте до конца
наши объяснения и после этого оцените корректность переводов.
L133J
Глава 2 Моделирование использования
Рис. 2.6. Этапы проведения тренинга
Рис. 2.7. Диаграмма закрытого процесса
i 134 j
2.1 Бизнес-анализ и моделирование
Каждый из этапов включает в себя несколько действий, выполняемых как
последовательно, так и параллельно. Эти этапы (3 на рис. 2.6) можно рас-
крыть на отдельных диаграммах или на одной диаграмме, если процесс не
слишком сложный, как в данном случае (см. рис. 2.7).
На рис. 2.7 этапы раскрываются в отдельных блоках (1 на рис. 2.7), элемен-
тарные действия указываются обычным образом (2 рис. 2.7), не элементар-
ные действия можно либо раскрыть (3 рис. 2.7), либо оставить нераскры-
тыми (5 на рис. 2.7), при этом циклический характер действий отмечается
специальным значком в виде петли (3, 5 рис. 2.7). Если из блока выходят
несколько стрелочек, то это означает параллельное выполнение действий.
Слияние параллельного выполнения (точка синхронизации) отмечается
знаком"+" в ромбике (4 рис. 2.7).
В нашем бизнес-про цессе считается, что слушатели ничего не говорят,
а только письменно задают вопросы в чате. Это можно передать с помощью
полуоткрытого процесса, как на рис. 2.8. На этом рисунке пунктирные стре-
лочки означают передачу сообщений.
Наконец, в описании открытого процесса можно показать все детали взаи-
модействия (с необходимой степенью подробности). На рис. 2.9 мы заканчи-
ваем обсуждение нашего примера.
Примечание
В рассмотренных примерах показана только часть обозначе-
ний BPMN. Существуют еще различные типы событий, раз-
личные типы сообщений, различные типы составных блоков
и т.д. Если общий принцип ясен, то все эти обозначения лег-
ко находятся в справочниках.
Из приведенной выше таблицы 1.2, а также из содержания этого и предыду-
щего параграфов ясно, что методов моделирования, используемых для опи-
сания бизнес-процессов, предложено великое множество. Зачем же нужен
еще один? Мы попробуем ответить на этот вопрос в следующем разделе.
*
Глава 2. Моделирование использования
Рис. 2.8. Диаграмма полуоткрытого процесса
2.1. Бизнес-анализ и моделирование
Рис. 2.9. Диаграмма открытого процесса
Глава 2. Моделирование использования
2е2е Значение моделирования
использования
При первом знакомстве с диаграммами использования в UML у разработчи-
ков программного обеспечения, особенно у опытных разработчиков, часто
возникает вопрос: зачем это нужно? При этом такого вопроса относительно
других средств UML не возникает, поскольку ответ на него в большинстве
случаев очевиден по аналогии. Действительно, рассмотрим несколько при-
меров типичных ассоциаций, возникающих у разработчиков при первом
знакомстве с UML.
Диаграммы деятельности — это не что иное, как блок-схемы алгоритмов.
Разработчик программ, особенно со стажем, прекрасно понимает назначение
и границы применимости блок-схем. Вопроса "зачем?" просто не возника-
ет, возникают другие вопросы: стоит ли использовать блок-схемы в данном
проекте, какую из альтернативных систем обозначений применять и тому
подобное.
Диаграммы состояний — это конечные автоматы (см. главу 4), которые яв-
ляются основным аппаратом в целом ряде областей программирования:
трансляторы, логическое управление и другие. Если в конкретной предмет-
ной области, например, в области конструирования ответственных систем
управления, приказано применять конечные автоматы, то разработчики
применяют их, не спрашивая, "зачем?".
Диаграммы классов, в которых показаны атрибуты и операции классов, а
также взаимосвязи (ассоциации) между ними, очень похожи на диаграммы
"сущность-связь" (ERD — Entity-Relationship Diagram), хорошо известные
разработчикам приложений баз данных.
ДИАГРАММЫ СУЩНОСТЬ-СВЯЗЬ
Диаграмма сущность-связь была предложена П. Ченом в 1976
году в статье "The Entity-Relationship Model— Towards a Unified
View of Data", где описывается графическое представление моде-
лей данных. В дальнейшем эта модель многократно расширялась
и модифицировалась самим Ченом и многими другими исследо-
вателями. Диаграмма сущность-связь представляет собой
двудольный граф, в котором вершины первого рода соответ-
ствуют сущностям, то есть множествам однотипных записей
данных (обозначаются прямоугольниками), а вершины вто-
рого рода соответствуют связям между экземплярами сущ-
ностей (обозначаются ромбами). На ребрах указывается, по
сколько экземпляров каждой сущности соединяет данная
связь.
2.2 Значение моделирования использования
Например, на рис. 2.10 приведена диаграмма сущность-связь для
данных, которые хранит база данных о счетах в банке. Здесь пред-
ставлены три сущности: клиенты банка, счета и операции со сче-
тами (обычно банковские базы данных хранят не только остаток на
счете, но и всю историю операций со счетом). Диаграмма показы-
вает, что клиент может иметь несколько счетов, а с каждым счетом
может быть связано несколько проведенных операций.
Рис. 2.10. Диаграмма "сущность-связь"
Система обозначений диаграммы сущность-связь была значи-
тельно усовершенствована и обогащена за прошедшие годы. Мы
использовали в примере нотацию, близкую к оригинальной нота-
ции Чена, чтобы пояснить основную идею. Но это не единственный
вариант нотации диаграммы сущность-связь. Например, факти-
чески вершины второго рода не нужны: их вполне можно элими-
нировать, перенося соответствующую информацию на ребра,
соединяющие сущности. Именно так и сделано в UML.
Питер Чен (Peter Pin-Shan Chen) — американский ученый тай-
ваньского происхождения, лауреат множества премий в области
информационных технологий, в том числе премии имени Гарри
Гуда (IEEE, 2003) и Аллана Ньюэла (ACM/AAAI, 2004).
Оригинальная статья Чена о диаграммах "сущность-связь" явля-
ется одним из самых цитируемых источников в литературе по про-
граммному обеспечению.
Перечень возникающих у разработчиков ассоциаций можно продолжать
и продолжать, для большинства средств UML нетрудно отыскать аналоги
среди широко используемых практических методов конструирования про-
граммных систем. И это не удивительно, ведь именно эти методы были
унифицированы посредством UML. А вот для диаграмм использования из-
вестный аналог указать труднее. Мы попытаемся объяснить прагматику мо-
делирования использования на конкретном примере.
2.2.1. Сквозной пример
В остальных частях книги рассматривается один сквозной пример моде-
лирования сравнительно несложного приложения — информационной си-
стемы отдела кадров. Выбор примера обусловлен следующими соображе-
ниями.
Глава 2. Моделирование использования
Во-первых, предметная область до некоторой степени знакома всем (мы по-
лагаем, что читатель где-то работает, а значит, по крайней мере один раз, ис-
пытывал на себе работу отдела кадров). Таким образом, суть задачи заранее
ясна, и можно сосредоточить внимание на тонкостях применения U ML, а не
на объяснении особенностей предметной области.
Во-вторых, информационная система отдела кадров — это типичное офис-
ное приложение из самого распространенного класса систем автоматизации
делопроизводства. UML как нельзя лучше подходит для моделирования
именно таких систем, и все средства языка можно проиллюстрировать есте-
ственным образом.
В-третьих, авторам случалось разрабатывать похожие системы на самом
деле, а не только в книге.
Надо заметить, что целью рассмотрения данного примера является иллю-
страция возможностей языка. Хотя мы стараемся придать повествованию
такое направление, при котором читателю может показаться, что он является
участником процесса моделирования, в целом это не так. Рассматривать про-
цесс построения модели безотносительно стадий (фаз) процесса разработки
было бы неправильно. Некоторое внимание этому вопросу уделено в главе 5.
Про модель предметной области и модель самого приложения информаци-
онной системы отдела кадров, представленные в этой книге, можно сказать
только то, что они синтаксически правильны (с точностью до понимания
авторами спецификации UML) и семантически непротиворечивы (с точно-
стью до понимания авторами предметной области задачи).
Итак, поставим себя на место разработчика и предположим, что в нашем рас-
поряжении имеется следующий текст , поступивший от заказчика.
| ТЕХНИЧЕСКОЕ ЗАДАНИЕ
Информационная система "Отдел кадров" (сокращенно ИС ОК) предна- J
знамена для ввода, хранения и обработки информации о сотрудниках и i
движении кадров. Система должна обеспечивать выполнение следующих
основных функций:
• »
1. Прием, перевод и увольнение сотрудников.
> ।
2. Создание и ликвидация подразделений.
I I
3. Создание вакансий и сокращение должностей.
I----------------------------------------------------------„---------i
Конечно, техническое задание из одного абзаца текста и трех нумерованных
пунктов — это не более чем учебный пример63. Однако даже на этом примере
63 В реальности довольно часто задание формулируется заказчиком очень кратко и в про-
цессе разработки "обрастает" деталями. В книге мы будем использовать похожий при-
ем, постепенно усложняя начальную постановку задачи.
____ ф
2.2. Значение моделирования использования
видны многие характерные "особенности" подобных документов, которые,
увы, слишком часто встречаются в реальной жизни.
С одной стороны, что-то написано, а с другой стороны, не очень понятно,
что делать дальше. Безо всяких объяснений заказчик использует термины
свой предметной области — разработчик должен их знать и понимать. Тре-
бований к реализации нет вовсе. Функции не упорядочены по приорите-
там: не ясно, что является критически важным, а чем можно поступиться в
случае необходимости. В общем, раскритиковать это техническое задание в
пух и прах не составляет труда. Однако, каким бы недостаточным ни было
это техническое задание, после получения ответа на вопрос "кто виноват?"
встает вопрос "что делать?".
• Можно заявить, что это техническое задание никуда не годится и от-
казаться работать с заказчиком, который его представил. Это про-
стое и надежное решение, но...
• Можно потребовать уточнить техническое задание, включив в него
ответы на все вопросы разработчика. Это во всех отношениях иде-
альный вариант, только, к сожалению, так не бывает.
• Можно, наконец, попытаться что-то сделать самим с имеющимся ма-
териалом.
Мы выберем третий путь, имея целью показать, как, применяя UML, можно
постепенно превратить расплывчатое описание приложения во вполне чет-
кую модель, пригодную для реализации.
2.2.2. Подходы к моделированию, альтернативные
МОДЕЛИРОВАНИЮ ИСПОЛЬЗОВАНИЯ
Преимущества моделирования использования UML мы попробуем выявить,
сравнивая его с другими подходами. Известно множество различных подхо-
дов к моделированию и последующему проектированию, то есть рекоменда-
ций, что делать после получения технического задания. Мы рассмотрим три
из них (наиболее нам близких) и попытаемся указать те подводные камни,
которые моделирование использования позволяет обойти.
Наиболее заслуженными являются, видимо, следующие методы струк-
турного проектирования:
• программирование сверху вниз, снизу вверх и вширь;
• построение схемы базы данных;
• объектно-ориентированный подход к моделированию.
Глава 2 Моделирование использования
Программирование сверху вниз, снизу вверх и вширь
Программирование сверху вниз — это обобщающее название для модульно-
го программирования без оператора Go То методом пошагового уточнения.
Английское название — Top-down approach — более точно акцентирует важ-
нейшее достижение технологической программистской мысли, аккумули-
рованное в этом подходе: проектирование и реализация (кодирование) про-
граммы являются двумя неразрывно связанными фазами одного процесса,
причем проектирование первично, а реализация вторична. При программи-
ровании сверху вниз процесс заключается в следующем. Исходная задача
разбивается на подзадачи до тех пор, пока каждая отдельная подзадача не
станет настолько простой, что ее реализация становится очевидной.
Критерием для остановки может служить сформулированное Альбертом
Эйнштейном правило: "Все должно быть сделано настолько простым, на-
сколько это возможно, но не проще". Парным к программированию сверху
вниз является программирование снизу вверх, при котором уровень языка
программирования повышается (например, с помощью определения мо-
дулей) до тех пор, пока он не станет настолько высоким и близким к ис-
ходной задаче, что ее реализация станет очевидной.
Оба метода имеют очевидные достоинства, но имеют и недостатки: при про-
граммировании сверху вниз отладка возможна только по завершении всего
проектирования, при программировании снизу вверх велик риск создания
невостребованных модулей. На практике всегда применяется комбинация
этих подходов, благо они не противоречат друг другу.
С.С. Лаврову принадлежит изобретение термина программирование вширь6*,
когда, начиная с самого первого шага, создается и на всех последующих
шагах поддерживается работоспособная версия программы. В терминах
программирования сверху вниз это означает проведение одного пути в де-
реве последовательных уточнений до конца (ствол дерева), а затем посте-
пенное наращивание дерева вширь. Конечно, в начале работы программа
не умеет выполнять (почти) никаких нужных функций, но зато она не со-
держит и ненужных (ошибочных) функций, и, что особенно важно, в любой
момент может быть продемонстрирована заказчику. Такой стиль подразуме-
вает проведение тестовых испытаний всех готовых модулей при добавлении
или изменении любого модуля64 65, но не откладывание отладки на окончание
разработки.
64 В современной языковой практике используется термин, являющийся транслитерацией
с английского — инкрементальная разработка, которому авторы, уступая обстоятель-
ствам непреодолимой силы, уже позволили проскользнуть в текст первой главы.
65 Те. нет никакой автономной отладки, отладка с самого начала комплексная.
2.2. Значение моделирования использования
Это требует дополнительных трудозатрат, но оказывает чрезвычайно бла-
готворное психологическое воздействие на разработчика, и еще более бла-
готворное воздействие такой стиль программирования оказывает на заказ-
чика.
Лавров Святослав Сергеевич (1923 - 2004) — рос-
сийский ученый, член-корреспондент РАН. Труды по
механике, автоматическому управлению, вычисли-
тельной математике. Ленинская премия (1957).
Научная биография Святослава Сергеевича Лаврова
в определенном смысле уникальна. Совсем в мо-
лодом возрасте С. С. Лавров стал основополож-
ником ракетно-космической баллистики в СССР
и неоспоримым авторитетом в области динамики
управляемого полета и автоматического управ-
ления. Появление цифровой вычислительной тех-
ники привело к резкому повороту в деятельности
С. С. Лаврова и в течение нескольких лет сделало его
классиком программирования в СССР
Описанный выше метод структурного конструирования программ (с тремя
вариациями) хорошо известен, надежен и легко применим во всех случаях.
Мы даже рискнем утверждать, что большая часть ныне используемого про-
граммного обеспечения изготовлена именно таким способом. Однако наши
личные наблюдения показывают, что в результате такого подхода структура
приложения оказывается соответствующей структуре команды разработчи-
ков, а не исходной задаче. Если, например, в разработке информационной
системы отдела кадров будет задействовано два ведущих разработчика, то
будет выделено две основных подсистемы, а если три, то и подсистем ока-
жется три. Это, разумеется, не закон природы, но, тем не менее, при пошаго-
вой детализации произвол выделения подсистем неизбежен.
Рис. 2.11. Разработка сверху-вниз, снизу-вверх и вширь
Глава 2. Моделирование использования
Схема базы данных
Рассмотрим второй подход к моделированию. Всякому ясно, что информа-
ционная система отдела кадров — это приложение баз данных66. При про-
ектировании приложений баз данных первый шаг хорошо известен: после
получения требований нужно составить схему базы данных, то есть опреде-
лить состав таблиц базы и полей в таблицах, назначить первичные ключи
(primary key) в таблицах и установить связи между таблицами с помощью
внешних ключей (foreign key).
Схема базы данных- это описание данных и взаимосвязей между
ними в базе данных. В это описание включают, по меньшей мере, еле
дующую информацию:
• таблицы. хранящиеся в базе;
• поля .1.111 ис< и таблиц:
• первичные ключи таблиц, то есть ноля, значение которых одно-
значно идентифицирует запись в таблице;
• связи, то есть указание «а то, как записи-одной таблицы связаны с
записями другой таблицы
Часто схему базы данных представляют в графической форме, в виде специ-
альных диаграмм.
Например, на рис. 2.12 приведена схема базы данных о счетах. Полезно сопо-
ставить этот рисунок с рис. 2.10.
Рис. 2.12. Схема базы данных
Опять мы не можем привести ни одного аргумента общего характера против
такого образа действий и ограничиваемся частным примером. Среди десятка
знакомых нам информационных систем отдела кадров примерно в полови-
не случаев (в том числе в коммерчески продаваемых системах) номер по-
66 Это предрассудок, не обязательно использовать СУБД для решения таких задач, но
предрассудок широко распространенный и укоренившийся.
2.2. Значение моделирования использования
зиции в штатном расписании сделан ключом таблицы сотрудников. На пер-
вый взгляд такое решение допустимо: номер позиции в штатном расписании
уникален, однозначно соответствует сотруднику и может быть использован
в качестве ключа (в отличие от фамилии сотрудника, которая вполне может
не быть уникальной). Однако полный анализ всего приложения показывает,
что это грубая проектная ошибка, порождающая проблемы на позднейших
стадиях разработки и заведомую неэффективность в работе системы. Чтобы
понять, в чем ошибка, подумайте — как будет выполняться операция "пере-
вод сотрудника''67?
Объектно-ориентированный подход
Наконец, рассмотрим самый модный объектно-ориентированный подход к
моделированию. Апологеты этого подхода первый шаг проектирования опи-
сывают примерно так: нужно выделить словарь предметной области (то есть
набор основных понятий), сопоставить этим понятиям классы проектируе-
мой системы, определить их атрибуты, и операции и дальше все пойдет как
по маслу.
СЛОВАРЬ ПРЕДМЕТНОЙ ОБЛАСТИ
Словарь предметной области (domain glossary) — часто упо-
минаемое, но очень плохо определенное понятие объектно-
ориентированного анализа и проектирования. Все теоретики
объектно-ориентированного подхода единодушно утверждают,
что словарь предметной области — важнейший артефакт, лежа-
щий в основе анализа и проектирования. Разумеется, с этим нель-
зя не согласиться — правильный научный подход к любой задаче
требует сначала договориться о терминах. К сожалению, на этом
единодушие заканчивается: общепринятых формальных требова-
ний к словарю мы не знаем.
Для примера в таблице 2.3 приведен фрагмент словаря для пред-
метной области, связанной с информацией о банковских счетах.
Таблица 2.3. Словарь предметной области
Термин Категория Пояснение
Клиент Внешняя сущность Клиент банка
Счет Класс постоянно хранимых объектов Счет клиента в банке
67 Данная операция приводит к изменению значения первичного ключа в записи сотрудни-
Глава 2. Моделирование использования
Остаток Атрибут Атрибут класса Счет, значение которого явля- ется текущей денежной суммой на счете
Номер Атрибут Атрибут класса Счет, значение которого одно- значно идентифицирует объект класса Счет
И здесь нечего возразить! Если словарь выделен, то, действительно, дальше
все идет отлично. Но кто выделяет словарь?
Если разработчик, то он должен быть экспертом в конкретной предметной
области и знать ее досконально, в противном случае никто не может гаран-
тировать полноту и адекватность словаря, а ошибки при выделении базовых
классов относятся к самым тяжелым проектным ошибкам. Если же заказ-
чик, то он должен быть образцом педантичности, аккуратности и дально-
видности, потому что ошибку заказчика разработчик не заметит и не испра-
вит — ошибка перейдет в проект, потом в приложение и проявится уже при
эксплуатации самым неприятным образом. Самый лучший вариант — когда
словарь составляется совместно и за несколько итераций.
Резюме
Подводя итоги нашему рассмотрению альтернативных подходов к проекти-
рованию, отметим следующее обстоятельство. Во всех трех рассмотренных
случаях первый шаг проектирования сразу выполняется в терминах проек-
тируемой системы, причем однобоко.
Действительно, в первом случае за основу берется структура будущего кода,
во втором — структура хранимых данных, а в третьем — структура взаимо-
действующих объектов. Еще раз оговоримся: мы не видим в бегло упомяну-
тых альтернативных подходах к проектированию никаких непреодолимых
пороков. Опытный мастер легко спроектирует информационную систему
отдела кадров, пользуясь любым подходом. Но новичок может столь же
легко допустить при проектировании трудно исправимую ошибку. Запом-
ним это обстоятельство и обратимся к рассмотрению моделирования ис-
пользования.
2.2.3. Преимущества моделирования использования
Отвлечемся пока от технических деталей нотации диаграмм использования
(они рассмотрены в разделе 2.3) и рассмотрим, что предлагается делать на
первом шаге моделирования использования.
Наш язык и мышление устроены так, что самой простой, понятной и четкой
формой изложения мыслей являются так называемые простые утвержде-
ния. Простое утверждение имеет следующую грамматическую форму: под-
2.2. Значение моделирования использования
лежащее — сказуемое — прямое дополнение. Или, в логических терминах,
субъект — предикат — объект. Например: начальник увольняет сотрудника,
директор создает отдел. Но, по сути, именно простые утверждения и записа-
ны на диаграмме использования! Действительно, действующее лицо — это
субъект, а вариант использования — предикат (вместе с объектом). Таким
образом, моделирование использования отличается от рассмотренных под-
ходов тем, что предполагает явное формулирование требований к системе на
самом начальном этапе разработки.
Попробуем перечислить те преимущества, которые дает моделирование ис-
пользования по сравнению с другими подходами.
• Простые утверждения. Моделирование использования фактически
позволяет переписать исходное техническое задание (или просто за-
писать, если никакой исходной формулировки требований не было)
в строгой и формальной, но в то же время очень простой и нагляд-
ной графической форме, как совокупность простых утверждений
относительно того, что делает система для пользователей. Конечно,
использование такой формы не гарантирует от ошибок (вряд ли га-
рантия от ошибок вообще возможна), но благодаря простоте и на-
глядности формы их легче заметить.
• Абстрагирование от реализации. Моделирование использования
предполагает формулирование требований к системе абсолютно
независимо от ее реализации. Другими словами, представление ис-
пользования описывает только, что делает система (но не как это
делается и не зачем это нужно делать). Заметим, что другие подходы,
используя на первых шагах термины и понятия реализации (струк-
тура программы, структура данных, структура взаимодействующих
объектов) накладывают невольные ограничения на реализацию, ко-
торые не вытекают из существа задачи, а значит, могут служить ис-
точником неэффективности и ошибок.
• Декларативное описание. Каждый вариант использования описы-
вает (а вернее сказать, именует) некоторое множество последова-
тельностей действий, доставляющих значимый для пользователя
результат. Однако никакого императивного описания представле-
ние использования не содержит, в модели нет указаний на то, какой
вариант использования должен выполняться раньше, а какой позже,
то есть нет описания алгоритма, а значит, нет алгоритмических оши-
бок.
Выявление границ. Представление использования определяет гра-
ницы системы и постулирует существование во внешнем мире ис-
Глава 2. Моделирование использования
пользующих ее агентов (действующих лиц). Описание системы в
виде черного ящика с определенными интерфейсами кажется очень
похожим на представление использования, но здесь есть важное раз-
личие, которое часто упускается из вида. Если ограничиться только
описанием интерфейсов, то очень легко допустить ошибки следую-
щего типа: предусмотреть интерфейс, который не нужен, потому что
им никто не пользуется. Или, аналогично, забыть интерфейс, ко-
торый необходим определенной категории пользователей. На диа-
грамме использования одинокие и покинутые действующие лица и
варианты использования обнаруживаются с первого взгляда.
ЯГ» ® . даРя Ж. й. S!» 'SB Ж йЯ' .. . В. ’Я . ........ ... .. .. Я ..
Наш вывод таков: моделирование использования безопаснее и на-
дежнес альтернативных методов, то есть при прочих равных услови-
яхпо.шоляет совершить меньше цэубых проектных ошибок на ранних
стадиях проектирования. В этом заключается основное преимущество
данного метода.
Примечание
Не следует думать, что моделирование использования — это
панацея от всех болезней разработки программного обеспе-
чения. Существуют области, где моделирование использова-
ния практически ничего не дает. Например: разработка авто-
номного компилятора некоторого языка программирования.
2.3. Диаграмма использования
Диаграммы использования были предложены Иваром68 Якобсоном в их
нынешней графической форме еще в 1986 году. Диаграммы использования
являются, безусловно, самым стабильным элементом UML — они не меня-
лись уже двадцать с лишним лет, фактически приняли законченную форму
задолго до появления языка. Одновременно эти диаграммы имеют самую
простую нотацию (см. рис. 1.14 в параграфе 1.5.1): всего два основных типа
сущностей (действующие лица и варианты использования) и три типа от-
ношений (зависимости, ассоциации, обобщения)!
2.3.1. Действующие лица
Вопрос о выделении (или идентификации) действующих лиц при составле-
нии модели — один из самых болезненных. Неудачный выбор действующих
68 Иногда используют транскрипцию "Айвар", но, смеем уверить читателя, сам изобрета-
тель моделирования использования называет себя "Ивар".
е
2.3. Диаграмма использования
лиц может отрицательно повлиять на модель в целом. Здесь легко впасть в
крайность: объявить, что имеется одно действующее лицо (внешний мир),
взаимодействующее со всеми вариантами использования или, наоборот,
придумать искусственных действующих лиц для каждого варианта исполь-
зования. Оба экстремальных варианта являются, по существу, моделью чер-
ного ящика и сводят к нулю преимущества моделирования использования,
рассмотренные в предыдущем разделе.
Формального метода идентификации действующих лиц не существует.
Здесь мы перечислим некоторые приемы, которые полезно, по нашему мне-
нию, иметь в виду при выделении действующих лиц, и покажем применение
этих приемов на нашем примере информационной системы отдела кадров.
Для начала укажем более детальное определение действующего лица.
С синтаксической точки зрения действующее лицо — это стереотип
классификатора, который обозначается специальным значком. Для
действующего лица указывается только имя, идентифицирующее его
. в системе. Семантически действующее лицо — это множество логиче-
.IX ролей.
, S - г'
их, гч '
Роль в UML это интерфейс6’, поддерживаемый данным классифи-
катором в данной ассоциации.
С прагматической точки зрения главным является то, что действую-
щие лица находя гея «н< проектируемой системы (или рассматривае-
мой части системы).
В типовых случаях различные действующие лица назначаются для кате-
горий пользователей (если их удается выделить естественным образом),
внешних программных и аппаратных средств (если система взаимодейству-
ет с таковыми).
О ТЕРМИНЕ "ДЕЙСТВУЮЩЕЕ ЛИЦО
Мы выбрали для перевода термина actor словосочетание "дей-
ствующее лицо", исходя из следующей, довольно точной анало-
гии. Рассмотрим общеизвестное употребление термина "дей-
ствующее лицо". Имеются литературные сочинения определен-
ного жанра, которые называются пьесы (например, "Трагическая
история о Гамлете, принце датском", автор — Вильям Шекспир).
В начале пьесы присутствует список действующих лиц, элементы
которого имеют примерно такой вид: "Гамлет — сын прежнего и
69 К сожалению, мы вынуждены иногда использовать термины, не предваряя их определе-
ниями. В данном случае отсылаем читателя к главе 3.
Глава 2 Моделирование использования
племянник нынешнего короля". Пьеса может быть поставлена —
например, постановка Юрия Любимова в Театре на Таганке. В
конкретный вечер может быть дан спектакль, в котором у дей-
ствующих лиц пьесы имеются конкретные исполнители (напри-
мер, "в роли Гамлета — Владимир Высоцкий"). Пьеса, постановка
и спектакль — это разные вещи. Теперь вернемся к нашей анало-
гии. Пьеса— это модель (пьеса имеет все характерные призна-
ки модели), постановка — это программа, реализующая модель,
спектакль — выполнение этой программы. Так вот, actor в модели
UML — это действующее лицо пьесы, но никак не конкретный ис-
полнитель в спектакле. Обратите внимание, что Шекспир не забы-
вает указывать важнейшие интерфейсы действующих лиц своих
пьес. То, что действующее лицо — это классификатор, а не экзем-
пляр, особенно заметно, если в конце списка действующих лиц
присутствует, например, такая запись: "Лорды, леди, офицеры,
солдаты, матросы, вестовые и свитские".
Рассмотрим наш пример с информационной системой отдела кадров. Про
внешние программные и аппаратные средства в техническом задании ничего
не сказано, и этот вопрос пока разумно оставить в стороне. Трудно предста-
вить себе организацию, в которой реорганизация внутренней структуры и
процесс найма персонала выполняются автоматически, без участия челове-
ка, поэтому у нашей системы, очевидно, будут пользователи.
Выделение категорий пользователей происходит, как правило, неформаль-
но: из соображений здравого смысла и собственного опыта. Тем не менее
несколько советов мы можем дать.
Имеет смысл отнести пользователей к разным категориям, если на-
блюдаются следующие признаки:
• пользователи участвуют в разных (независимых) бизнес-
процессах;
• пользователи имеют различные права на выполнение действий и
доступ к информации:
• пользователи взаимодействуют с системой в разных режимах: от
случая к случаю, регулярно, постоянно.
Опираясь на собственные советы, применительно к нашему примеру мы в
первом приближении склонны выделить две категории пользователей:
• менеджер персонала, который работает с конкретными людьми;
• менеджер штатного расписания, который работает с абстрактными
должностями и подразделениями.
2.3 Диаграмма использования
Бизнес-процесс пользователя первой категории включает в себя не только
работу с приложением, но и беседы с сотрудниками, интервью и тому подоб-
ное, чем явно отличается от других бизнес-процессов предприятия.
Пользователи второй категории, очевидно, должны иметь специальные пра-
ва доступа, поскольку вряд ли допустимо, чтобы кто угодно мог создавать и
уничтожать подразделения на предприятии.
На рис. 2.13 мы начинаем формировать представление использования ин-
формационной системы отдела кадров. Менеджер персонала имеет имя
Personnel Manager, а менеджер штатного расписания — Staff Manager, в соот-
ветствии с используемой дисциплиной имен.
Менеджер персонала
Менеджер штатного
респисания
I
Personnel Manager
Staff Manager
Рис. 2.13. Действующие лица ИС ОК
ДИСЦИПЛИНА ИМЕН
Единственными лексемами языка, которыми програм-
мист пользуется совершенно произвольно, являются имена
(идентификаторы)* 70. Недисциплинированный программист ис-
пользует свободу выбора идентификаторов для глупых шуток.
Умелый программист использует эту свободу для повышения чи-
табельности программы (или модели).
Читабельность программы повышается, если пишущий програм-
му придерживается определенных правил формирования иденти-
фикаторов, а читающий программу знает эти правила. Правила
формирования идентификаторов в программе называются
дисциплиной имен. Дисциплина имен должна учитывать по мень-
шей мере три фактора:
• набор различных характеристик именуемых объектов (и
области значений этих характеристик), которые учитыва-
ются в данной дисциплине;
• набор правил формирования имен по заданным значени-
ям выбранных характеристик (с учетом возможных лекси-
70 Это удивительная особенность языков программирования. Во всех остальных видах че-
ловеческой деятельности правила именования объектов более или менее регламенти-
рованы.
Глава 2. Моделирование использования
ческих ограничений системы программирования);
• набор операций (помимо операции чтения человеком),
которые выполняются над множествами имен.
Важным вопросом при формировании имен является выбор на-
бора символов. Поскольку при моделировании и кодировании ис-
пользуются, как правило, разные инструменты, то маловероятно,
что они все окажутся локализованными, причем с одинаковым по-
ниманием особенностей русского языка. Отсюда следует, что для
идентификаторов в программах обычно используют буквы латин-
ского алфавита.
Для условных (кодовых) частей идентификаторов это не важно
и даже удобно: иероглиф не должен быть похож на слово71. Но
для содержательных (семантических) частей желательно, что-
бы они являлись узнаваемыми словами или словосочетаниями.
Использование транслитерированных русских слов выглядит ужас-
но72. Использование правильных английских слов хорошо, но тре-
бует, чтобы все читатели и писатель программы одинаково (хоро-
шо или плохо) владели английским (что на практике встречается
очень редко). Выход заключается в том, чтобы составить жаргон-
ный словарь из слов, сокращений и аббревиатур и пользоваться
только им73.
Для UML пока что нет достаточно устоявшейся дисциплины имен, но неко-
торый набор рекомендаций можно найти в литературе. Мы, по возможности,
следуем этим рекомендациям и при случае пересказываем их. В частности,
в качестве имен действующих лиц рекомендуется использовать существи-
тельное (возможно, с определяющим словом), а в качестве имен вари-
антов использования — глагол (возможно, с дополнением). Эти правила
основаны на семантике моделирования использования.
2.3.2. Варианты использования
Выделение вариантов использования — ключ ко всему дальнейшему моде-
лированию. На этом этапе определяется функциональность системы, то есть
что она должна делать.
71 Локализованные версии языков программирования не популярны. Язык программиро-
вания далек от естественного и не должен быть к нему близок. Служебные слова языка
программирования - это иероглифы а не слова из букв. Иероглифы легче выучить и ис-
пользовать, если они ни на что не похожи.
72 Высший класс - записывать русские слова латинскими буквами, которые по написанию
совпадают с кириллическими буквами. К сожалению, таковых немного (например, сре-
ди прописных А, В, С, Е, Н, К, М, О, Р, Т, X) и этот метод требует невероятной изобрета-
тельности.
73 Например, в таком стиле: CurRecNum означает "номер текущей записи".
" 152 ]
2.3. Диаграмма использования
О ТЕРМИНЕ ’ ВАРИАН1 ИСПОЛЬЗОВАНИЯ"
К величайшему сожалению, отечественная практика образования
терминов в области информационных технологий неудовлетвори-
тельна. Термины либо переводятся (часто неудачно), либо транс-
литерируются с английского, без учета русских языковых тради-
ций.
За примерами ходить далеко не нужно: файл, компьютер, сайт.
Еще один характерный пример— использованное нами слово
"функциональность" (functionality). Речь идет о множестве функ-
ций, которые выполняет система, а называется это именем свой-
ства. На вопрос "какова функциональность системы?" хотелось бы
отвечать так: "велика, мала, отсутствует", а приходится отвечать
"функциональность состоит из...". Это можно было бы назвать,
например, "функциональные обязанности", но "к чему бесплодно
спорить с веком". Хотя в некоторых случаях спорить просто необ-
ходимо.
В частности, особого внимания заслуживает главный термин этой
главы — "вариант использования". В целом ряде авторитетных
источников можно встретить неправильный перевод термина
use case — "прецедент". Мы совершенно уверены, что это непра-
вильный перевод, и можем обосновать свою уверенность. Дело в
том, что такой перевод термина use case дает один из самых ста-
рых, хороших и популярных словарей - англо-русский словарь
Миллера, который, надо полагать, всегда под рукой у отечествен-
ных переводчиков компьютерной литературы. Это правильный
перевод очень старого юридического английского термина (при-
нятие одного судебного решения на основании другого судебно-
го решения). Однако автор идеи моделирования использования
(Ивар Якобсон, швед по национальности) в своих первоначальных
работах использовал термины usage scenario и usage case, но позже
ему указали, что эти термины трудно произносить по-английски,
и автор упростил термин до того, которым мы пользуемся ныне:
use case Возможно, Ивар Якобсон не знал, что термин use case
занят.
Таким образом, наш перевод— вариант использования— един-
ственно правильный, а "прецеденты" и "элементы use case" не
имеют морального права на существование. Во всяком случае, в
личной беседе на вопрос одного из авторов книги о том, как нужно
трактовать термин use case, Ивар Якобсон недвусмысленно отве-
тил, что имеются в виду разные способы (случаи, варианты) ис-
пользования системы.
Нотация для варианта использования очень скудная — это просто имя, по-
мещенное в овал (или помещенное под овалом — такой вариант тоже до-
пустим). Другими словами, функции, выполняемые системой, на уровне
Глава? Моделирование использования
моделирования использования никак не раскрываются — им только даются
имена.
Семантически вариант использовании (use case) — это описание
множества возможных последовательное!ей действий (событий),
приводящих к значимому для действующего лица результату.
Каждая конкретная последовательность действий называется сце-
нарием.
Прагматика варианта использования состоит в том, что среди всех последо-
вательностей действий, которые могут произойти при работе приложения,
выделяются такие, в результате которых получается явно видимый и до-
статочно важный для действующего лица (в частности, для пользователя)
результат.
Сказанное для действующих лиц уместно повторить и для вариантов ис-
пользования: выбор вариантов использования сильно влияет на качество
модели, а формальные методы предложить трудно — помогают только опыт
и чутьё. Если в вашем распоряжении есть техническое задание, пункты кото-
рого естественным образом переводятся в варианты использования, знайте,
что вам сильно повезло.
Если техническое задание представляет собой смесь очевидных пожеланий
пользователя, смутных утверждений и конкретных требований (как обычно
бывает), то попробуйте поискать в тексте отглагольные существительные и
глаголы с прямым дополнением: может статься, что в них зашифрованы ва-
рианты использования. Если у вас вовсе нет технического задания, составьте
его, пользуясь исключительно простыми утверждениями.
В нашем примере простой анализ текста технического задания (приведенно-
го в разделе 2.2.1) выявляет семь вариантов использования:
• прием сотрудника;
• перевод сотрудника;
• увольнение сотрудника;
• создание подразделения;
• ликвидация подразделения;
• создание вакансии;
• сокращение должности.
Опираясь на знание предметной области, которое не отражено в техниче-
ском задании (характерный случай), заметим, что термин "вакансия" явля-
2.3 Диаграмма использования
ется сокращением оборота "вакантная должность", то есть должность в не-
котором особом состоянии. Само же слово "должность" многозначно. Это
может быть и обозначение конкретного рабочего места — позиции в штат-
ном расписании, и обозначение совокупности таких позиций, имеющих
общие признаки: функциональные обязанности, зарплата и т. п. Например:
"в организации различаются должности: программист, аналитик, руководи-
тель проекта" или "в отделе разработки предусмотрены следующие долж-
ности: 9 программистов, 3 аналитика и 2 руководителя проектов". Кадровые
работники легко различают эти случаи по контексту. Примем рабочую гипо-
тезу о том, что автор технического задания использовал слово "должность"
в первом смысле, и получим набор вариантов использования, представлен-
ный на рис. 2.14.
Рис. 2.14. Варианты использования ИС ОК
2.3.3. Комментарии
Третьим типом сущности, применяемым на диаграмме использования, яв-
ляется комментарий. Заметим, что комментарии являются очень важным
средством UML, значение которого часто недооценивается начинающими
пользователями. Комментарии можно и нужно употреблять на всех типах
диаграмм, а не только на диаграммах использования. UML является уни-
фицированным, но никак не универсальным языком — при моделировании
проектировщик часто может сказать о моделируемой системе больше, чем
это позволяет сделать строгая, но ограниченная нотация UML. В таких слу-
чаях наиболее подходящим средством для внесения в модель дополнитель-
ной информации является комментарий.
Глава 2. Моделирование использования
В отличие от большинства языков программирования, комментарий в UML
синтаксически оформлены с помощью специальной нотации и выступают
на тех же правах, что и остальные сущности74. А именно, комментарий имеет
свою графическую нотацию — прямоугольник с загнутым уголком ("со-
бачье ухо"), в котором находится текст комментария. Комментарии мо-
гут находиться в отношении соответствия с другими сущностями — эти от-
ношения изображаются пунктирной линией без стрелок. Если пунктирная
линия отсутствует, то комментарий относится ко всей диаграмме.
Комментарии содержат текст, который вводит пользователь — создатель
модели. Это может быть текст в произвольном формате: на естественном
языке, на языке программирования, на формальном логическом языке, на-
пример OCL и т. д. Более того, если возможности инструмента это позво-
ляют, в комментариях можно хранить гиперссылки, вложенные файлы и
другие артефакты, внешние по отношению к модели.
? В UML последовательно проводится следующий важный принцип: вся |
информация, которую пользователь вносит в модель, должна быть
Сохранена инструментом во внутреннем представлении модели и
предъявлена по первому требованию, даже если инструмент не умеет
обрабатывать эту информацию. Комментарии являются важнейшим
примером реализации этого принципа.
Комментарии могут иметь стереотипы. В UML определены два стандарт-
ных стереотипа для комментариев:
• «requirement» — описывает общее требование к системе;
• «responsibility» — описывает ответственность сущности (классифи-
катора).
Комментарии первого типа часто присутствуют на диаграммах использования, а
комментарии второго типа — на диаграммах классов.
Возвращаясь к нашему примеру, будет
совсем не лишним указать, что инфор-
мацию о состоянии кадров нужно хра-
нить постоянно, т. е. она не должна ис-
чезать после завершения сеанса работы
с системой (рис. 2.15).
«requirement»
Информация
о текущем состоянии
штатного расписания и составе
персонала должна храниться
постоянно
Рис. 2.15. Нефункциональное
требование к ИС ОК
74 На это утверждение можно возразить, что комментарии в программе тоже присутствуют
и оформляются специальным образом. Однако они не являются сущностью программы
в том смысле, что не присутствуют в объектном коде программы после трансляции.
2.3. Диаграмма использования
2.3.4. Отношения на диаграммах использования
Как уже было отмечено в первой главе, на диаграммах использования при-
меняются следующие основные типы отношений:
• ассоциация между действующим лицом и вариантом использова-
ния;
• обобщение между действующими лицами;
• обобщение между вариантами использования;
• зависимости между вариантами использования.
Далее мы подробно остановимся на каждом из них.
Ассоциация между действующим лицом и вариантом
использования
\< социация между действующим лицом и вариантом использования
показывает, что действующее лицо им или иным способом взаимо-
действует (предоставляет исходные данные, получает результат) с ва-
рит i том использонания.
Другими словами, эта ассоциация обозначает, что действующее лицо так или
иначе, но обязательно непосредственно участвует в выполнении каждого из
сценариев, описываемых вариантом использования. Ассоциация является
наиболее важным и фактически обязательным отношением на диаграмме
Рис. 2.16. Ассоциации между действующими лицами и вариантами использования
Г157
Глава 2. Моделирование использования.
использования. Действительно, если на диаграмме использования нет ассо-
циаций между действующими лицами и вариантами использования, то это
означает, что система не взаимодействует с внешним миром. Такие системы,
равно как и их модели, не имеют практического смысла.
Применительно к нашему примеру в первом приближении можно обозна-
чить ассоциации, представленные на рис. 2.16.
Обобщение между действующими лицами
Обобщение между действующимилицами показывает, что одно дей-
ствующее лицо наследует нее свойства (в частности, участие в ассо-
циациях) другого действующего лица.
Такое обобщение является весьма мощным средством моделирования.
Во-первых, с помощью обобщения между действующими лицами легко по-
казать иерархию категорий пользователей системы, в частности, иерархию
прав доступа к выполняемым функциям и хранимым данным.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
—
Среди всех пользователей информационной системы следует выделить
особую категорию пользователей (высшее руководство), которой разре- ,
। шен доступ к любым данным и операциям.
Это изменение в требованиях можно отразить в модели системы так, как по-
казано на рис. 2.17.
нч
Personnel Manager Top Manager Staff Manager
Рис. 2.17. Иерархия категорий пользователей ИС ОК
Во-вторых, действующее лицо, будучи классификатором, может быть аб-
страктным классификатором, то есть таким классификатором, который не
может иметь непосредственных экземпляров. Введение абстрактных дей-
ствующих лиц позволяет без потери информации сократить количество не-
посредственных ассоциаций в модели, сделав ее более лаконичной, а значит
более наглядной и полезной.
2 3 . Диаграмма использоваьия
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
।
Информационная система должна предоставлять возможность проема- ’
тривать данные без внесения в них каких-либо изменений. ।
Данное требование следует оформить в виде дополнительного варианта ис-
пользования — Browse. Если мы проектируем систему отдела кадров для
обычной организации, а не для государственной секретной службы, то разу-
мно предположить, что просматривать данные могут все категории пользо-
вателей. В этом случае можно установить ассоциации между новым вариан-
том использования и всеми действующими лицами, а можно поступить так,
как показано на рис. 2.18, т.е. ввести обобщенного абстрактного пользовате-
ля User (1), который будет связан ассоциацией с вариантом использования
Browse (2). При этом все специализации (3 и 4) обобщенного пользовате-
ля автоматически будут связаны ассоциацией с вариантом использования
Browse.
Рис. 2.18. Абстрактное действующее лицо
Обобщение между вариантами использования
Обобщение между вариантами использования показывает, что один
вариант использованияявляется частным случаем (по.дмножеством
множества сценариев) другого варианта использования.
Обобщающий вариант использования, будучи классификатором, может
быть абстрактным классификатором. Например, такой важный для со-
трудника вариант использования, как увольнение, на самом деле является
абстракцией: в каждом конкретном случае имеет место ровно один из воз-
можных частных случаев увольнения, которые приводят к одному и тому же
Глава 2. Моделирование использования
результату с точки зрения менеджера персонала, но весьма различны с точки
зрения сотрудника.
ИЗМЕНЕНИЙ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Система должна поддерживать два способа увольнения сотрудника: по 1
инициативе администрации и по собственному желанию.
Данное обстоятельство можно отразить в модели так, как показано на рис.
2.19.
Рис. 2.19. Обобщение вариантов использования
Обобщенный абстрактный (имя написано курсивом) вариант использова-
ния Fire Person имеет две специализации, которые соответствуют увольне-
нию работника по собственному желанию (Self Fire) и по инициативе адми
нистрации (Adm Fire).
Зависимости между вариантами использования
Зависимость между вариантами использования показывает, что один
вариант использования зависит от другого варианта использования.
В UML имеются два стандартных стереотипа зависимости между вариан-
тами использования, которые в некотором смысле двойственны друг другу:
• «include» — показывает, что в каждый сценарий зависимого вариан-
та использования в определенном месте вставляется в качестве под-
последовательности действий сценарий независимого варианта ис-
пользования;
• «extend» — показывает, что в некоторый сценарий независимого ва-
рианта использования может быть в определенном месте вставлен в
качестве подпоследовательности действий сценарий зависимого ва-
2.3. Диаграмма использования
риантг использования. Другой вариант интерпретации: в определен-
ном месте сценария независимого варианта использования вызыва-
ется для выполнения сценарий зависимого варианта использования.
При этом последовательность действий в вызываемом сценарии
определяется местом, откуда он был вызван, т.е. из какого варианта
использования и конкретно из какого места какого сценария этого
варианта использования.
На первый взгляд не очень понятно, чем отличается семантика этих зависи-
мостей — ведь обе они отражают отношение включения для последователь-
ностей действий. Нам будет удобнее объяснить тонкости семантики этих
отношений в параграфе 2.4.2, а здесь мы ограничимся примерами.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
При увольнении сотрудника должна быть осуществлена выплата денеж- (
ной компенсации за неиспользованный отпуск. В случае вынужденного г
сокращения возможна выплата выходного пособия. Учетная запись со- !
трудника при увольнении должна быть заблокирована.
Отметим, что увольнение сотрудника — один из самых сложных вариантов
использования в реальных системах управления персоналом. Итак, нам из-
вестно, что при увольнении сотрудника следует в целях информационной
безопасности заблокировать (или удалить) учетную запись пользователя в
локальной сети организации. Причем это действие должно быть выполнено
в любом сценарии увольнения.
С другой стороны, как сказано в техническом задании, при выполнении
определенных условий, при увольнении иногда выплачивается некоторая
денежная компенсация (за неиспользованный отпуск, выходное пособие
при сокращении и т. д.). Все это примеры последовательностей действий
(т. е. вариантов использования), которые вполне могут быть востребованы
как при увольнении, так и помимо него.
Отношения зависимости между этими вариантами использования могут
быть показаны на диаграмме использования, например, так, как это сделано
на рис. 2.20.
Пример, приведенный на рис. 2.20, можно отобразить еще компактиез, ком-
бинируя возможности отношений обобщения и зависимости (рис. 2.21) по-
добно тому, как скомбинированы возможности отношений обобщения и ас-
социации (см. пояснения к рис. 2.18).
Глава 2. Моделирование использования
Рис. 2.20. Зависимости между вариантами использования
Рис. 2.21. Комбинация отношений обобщения и зависимости
2.3.5. Способы применения моделей использования
Если посмотреть на модель использования с самой общей точки зрения, то
нетрудно заметить, что в модели присутствуют:
• внутренняя моделируемая система, в форме набора вариантов ис-
пользования, возможно, связанных зависимостями и обобщениями;
2.3. Диаграмма использования
• внешнее окружение, в форме набора действующих лиц, возможно,
связанных обобщениями;
• связь между моделируемой системой и внешним окружением в
форме ассоциаций между действующими лицами и вариантами ис-
пользования.
Обычно совершенно ясно, что находится внутри моделируемой системы, а
что снаружи. Если это почему-либо неясно или же требуется увеличить на-
глядность диаграмм, то можно воспользоваться специальной конструкцией,
которая называется "границы системы".
Цшницысистемы (system boundary) — это графический комментарий
в форме прямоугольной рамки, применяемый на диаграммах исполь-
зования и отделяющий внутреннюю часть системы от ее внешнего
окружения.
Внутренняя часть, выделяемая границами, имеет в UML конкретное назва-
ние — субъект.
Субъект (subject) — это классификатор, который реализует поведе-
ние, декларируемое вариантами использования.
Если границы системы используются на диаграмме, то можно указать
имя (и стереотип!), которые будут относиться к субъекту75. В примере на
рис. 2.22 мы повторили рис. 2.16, но использовали другие возможности но-
тации UML.
75 Это можно сделать и с помощью примечания, но использование границ системы более
наглядно.
Глава 2. Моделирование использования
В приведенных примерах действующими лицами являются категории поль-
зователей. Это не случайно, в большинстве случаев действующими лицами в
моделях UML действительно являются категории пользователей. Но оборот
"в большинстве случаев" еще не означает "всегда". В самом деле, в определе-
ниях действующего лица (параграф 2.3.1) и варианта использования (пара-
граф 2.3.2.) ничто не указывает на ограничения в применении этих понятий.
Выше мы отметили, что варианты использования описывают внутренность
системы, а действующие лица — ее окружение.
Так вот, в качестве системы может выступать любая сущность, для которой
можно определить функциональные или не функциональные требования.
Это может быть и подсистема главной системы, отдельный компонент и про-
сто класс. Если мы рассматриваем модель использования некоторой под-
системы, то другие подсистемы (взаимодействующие с рассматриваемой)
будут действующими лицами для рассматриваемой подсистемы. Если мы
рассматриваем модель использования некоторого класса, то другие клас-
сы (взаимодействующие с рассматриваемым) будут действующими лица-
ми для рассматриваемого класса.
Сделаем небольшое отступление и рассмотрим один из приемов проектиро-
вания, особенно часто применяемый в гибких методологиях.
КАРТЫ CLASS-RESPONSIBILITY-COLLABORATION
Авторами CRC-карт являются Кент Бек (Kent Beck) и Уорд Каннингем (Ward
Cunningham), описавшие данное средство в своей статье 1989 года "A labora-
tory for teaching object oriented thinking" как один из элементов, помогающих
при проектировании объектно-ориентированных приложений.
С физической точки зрения карта — это лист бумаги или картона, а название —
class-responsibility-collaboration — отражает то, что пишется на этих картах.
• Класс (class) — имя класса, который описывает CRC-карта.
• Ответственность (responsibility) — описание тех задач, которые ре-
шает данный класс.
• Кооперации (collaboration) — имена других классов, которые взаимо-
действуют с данным в рамках различных коопераций.
Внешний вид CRC-карт может быть различный, например, такой, как на
Класс Account
Ответственности Хранение информации о состоянии счета клиента банка; Участие в качестве приемника или источника денежных средств в транзакциях. Кооперации Client Transaction
Рис. 2.23. CRC-карта для класса Account
2 3 Диаграмма использования
Техника моделирования, основанная на использовании CRC-карт, исполь-
зует те же самые принципы, которые заложены в моделировании исполь-
зования применительно к классам, а именно: определяется субъект (раздел
Класс на CRC-картах), выделяются действующие лица (раздел Коопера-
ции на CRC-картах) и наконец
определяются варианты ис-
пользования (раздел Ответ-
ственности на CRC-картах). На
рис. 2.24 приведена диаграм-
ма использования для клас-
са Account, которую полезно
сравнить с соответствующей
CRC-картой (рис. 2.23).
Рассмотрим пример, связан-
ный с взаимодействием нашей
информационной системы от-
дела кадров с внешним про-
граммным окружением.
Рис. 2.24. Диаграмма использования для
класса Account
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Система должна поддерживать интерфейс прикладного программирова- !
ния (API), позволяющий внешним программным средствам получать до- 8
। ступ к информации, хранимой в системе. i
Было бы самонадеянно считать, что проектируемая информационная си-
стема отдела кадров является первой и единственной программой, которая
эксплуатируется на предприятии. Скорее всего, таких программ сотни, и
с десятком из них должна взаимодействовать проектируемая система от-
дела кадров. Заранее все предусмотреть очень трудно. Поэтому удовлетво-
рить новое требование проще всего следующим образом. Предусмотреть в
информационной системе отдела кадров интерфейс для доступа к данным
и каждый раз, когда потребуется предоставить конкретный API для нового
клиента, реализовывать новый модуль, который адаптирует имеющийся ин-
терфейс информационной системы к требуемому76.
На рис. 2.25 действующее лицо ИС ОК — это наша информационная система
отдела кадров, действующее лицо ERP — некоторая другая информацион-
ная система, a Adapter — модуль с единственным вариантом использования.
Обратите внимание, что на этой диаграмме все сущности — программные
системы, никаких пользователей здесь нет!
76 На программистском жаргоне это иногда называют пренебрежительным словом "оберт-
ка" (wrapper).
"1S5
Глава 2. Моделирование использования
Рис. 2.25. Программные системы в качестве действующих лиц
2.3.6. Выявление и анализ требований
Вопросы, связанные с требованиями и затронутые в предыдущих парагра-
фах, требуют некоторого обсуждения.
Фаза с названием "выявление и анализ требований" или "разработка тре-
бований" присутствует во многих известных моделях процесса разработки
программного обеспечения. Более того, современные тенденции в техноло-
гии программирования таковы, что данная фаза все чаще рассматривается
не только как первая, но и как одна из самых главных, а иногда как решаю-
щая фаза в жизненном цикле программного продукта.
Дело в том, что заметные успехи технологии программирования позволяют,
при наличии адекватных требований, организовать выполнение других фаз,
если и не как полностью или частично автоматический, то, во всяком случае,
как управляемый и измеримый процесс. Другими словами, если современ-
ные программисты точно знают, что именно нужно сделать, они это, ско-
рее всего, сделают хорошо и вовремя. Верно и обратное: если требования
к программному обеспечению не определены или определены недостаточ-
но, то вероятность успешной разработки резко снижается. Об этом сви-
детельствует собранная статистика — большая часть причин неуспешного
выполнения конкретных проектов была квалифицирована как ошибки или
недоработки при работе с требованиями.
Вопросы, связанные с выявлением, анализом и управлением требованиями
мы опускаем, а остаток параграфа посвятим обсуждению классификаций
требований и возможности их описания в виде конструкций UML. Начнем
с определений.
Стандарты IEEE определяют понятие "требование" следующим образом.
1. Функциональность, необходимая пользователю для решения
проблемы или достижения цели.
2. Функциональность, которая должна быть получена (достигнута)
системой или ее компонентами для соответствия контракту, стан-
дарту, спецификации или другим формальным документам.
3. Документальное представление ни. 1-2.
2.3. Диаграмма использования
Таким образом, понятие "требование" в этом определении апеллирует либо
к пользователям, либо к формальным документам. В любом случае подчер-
кивается обязательность документального представления.
Российский стандарт ГОСТ 12207 (соответствующий международному
стандарту ISO/IEC 12207 Software Life Cycle Processes) дает другое реше-
ние проблемы, в котором понятие "требование" определяется перечислени-
ем тех видов требований, которые предъявляются к программному продукту
и практически не требуют расшифровки.
В соответствии со стандартом ГОСТ 12207 на стадии анализ требова-
ний” должны быть выполнены следующие работы:
1. Разработчик должен установить и документально оформить сле-
дующие требования к программным средствам:
• функциональные и технические требования, включая произ-
водительность, физические характеристики и окружающие
условия, под которые долже н быть создан программный объ-
ект;
• требования к внешним интерфейсам пр- «грамм hoi о объекта;
• квалификационные требования;
• требования безопасности, включая требования, относящиеся
к методам эксплуатации, сопровождения, воздействию окру-
жающей среды и гравмобезэпасности персонала;
• и т.д.
Всего расшифровка понятия "требования" в ГОСТ 12207 занимает несколь-
ко страниц.
Совершенно ясно, что требования бывают весьма разнообразные. Было
предложено множество различных классификаций требований. Мы исполь-
зуем две из них; по источнику требований и по назначению требований.
В классификации по источнику все требования разбиваются на три груп-
пы. Мы используем традиционные названия групп, приведенные в книге
[Вигерс К. Разработка требований к программному обеспечению / Пер. с
англ. - М.: Издательско-торговый дом "Русская редакция", 2004.] (они вы-
делены жирным шрифтом) и в скобках даем свой вариант:
• Бизнес-требования (требования заказчиков). Бизнес-требования
определяются целями проекта, их высказывают те, кто финансирует
проект.
I
[ 167 2
Глава 2. Моделирование использования
• Пользовательские требования (требования пользователей). Опре-
деляют, какие цели и задачи пользователей позволит решать систе-
ма.
• Системные требования (требования разработчиков). Определяют
характеристики системы, которую должны построить разработчики,
чтобы пользователи смогли выполнить свои задачи в рамках бизнес-
требований.
Ортогональной классификацией является разделение требований по их
назначению. Таких классификаций достаточно много77. Рассмотрим, напри-
мер, одну из них, приведенную в книге [Bruce Powel Douglass. Real Time
UML: Advances in the UML for Real-Time Systems (3rd Edition) — Addison-
Wesley Object Technology Series, 2004], несколько нами расширенную. Ис-
ходя из этой классификации, требования делятся на следующие виды:
• Функциональные требования (functional requirement) определяют,
что должна делать система.
• Требования к качеству (quality of service requirement) определяют
качественные характеристики системы.
• Параметрические требования (parametric requirement) определяют
количественные характеристики системы.
• Требования к модели (design requirement) определяют требования,
которым должна удовлетворять модель системы.
• Специальные требования (special requirement) отражают требова-
ния, которые задаются законами, стандартами и пр., т.е. не зависят от
самой системы и принимаются как данность.
Приведем пример. В таблице 2.4. определены требования к подсистеме вво-
да текстовых сообщений в мобильном телефоне.
Таблица 2.4. Классификация требований
Источники требований/ Виды требований Требования заказчиков Требования пользователей Требования разработчиков
Функциональные Ввод текста сообще- Подбор слов по словарю Словарь заданного языка
требования НИЯ Использование смайликов База возможньвх смайликов
77 Самый простой состоит в разделении требований на функциональные и все остальные,
которые называют нефункциональными.
2.4. Реализация вариантов использования
Требования к качеству Возможность ис- пользования подси- стемы на телефонах с разными техниче- скими характеристи- ками Быстрый и удобный ввод сообщений Создание про- граммного интер- фейса независи- мого от аппаратной платформы
Параметрические требования Длина текстового сообщения ограни- чена объемом имею- щейся памяти Доступ к специаль- ным интерфейсам аппаратной плат- формы для работы с памятью
Требования к модели Повторное исполь- зование подсистемы для следующих раз- работок
Специальные требования В качестве основ- ного языка для ввода сообщений использовать госу- дарственный язык страны, где телефон будет продаваться Запрещена не- нормативная лексика Словарь ненорма- тивной лексики
Подведем итоги раздела.
• Функциональные требования лучше всего описывать с помощью
модели использования UМ L
• Требования к качеству и параметрические требования МОЖНО ОПП
сыпать с помощью комментариев UML.
• Удовлетворение требований к модели напрямую связано с квали-
фикацией архи Гекторов.
Моделирование использования — Это универсальный способ зада-
ния функциональных требования для всего, дар чего только можно и
нужно задавать функциональные требования!
2.4. Реализация вариантов
использования
После того как построено представление использования (результат моде-
лирования использования), то есть выделены действующие лица, варианты
использования и установлены отношения между ними, встает естественный
Ф ____
-- 'С
Глава 2. Моделирпнаниь использования
вопрос: что дальше? То есть, как далее следует продолжать моделирование
средствами UML?
Вообще говоря, ответ может быть такой: ничего больше не делать средства-
ми UML. Представление использования, если оно тщательно продумано и
детально прорисовано, является формой технического задания (специфи-
кацией требований), содержащей достаточно информации для дальнейшего
проектирования и реализации любым другим методом. Может статься, что в
коллективах разработчиков, в совершенстве владеющих какой-либо другой
методикой проектирования и реализации, такое ограниченное использова-
ние UML окажется вполне оправданным.
Однако UML содержит средства не только для моделирования использо-
вания, но и для поддержки всех остальных фаз процесса разработки, и эти
средства, по меньшей мере, не хуже альтернативных. Таким образом, UML
полезно знать, даже если он не используется в процессе разработки или ис-
пользуется только частично. Поэтому мы рассмотрим все средства UML в
оставшейся части книги. Цель этого раздела — изложить наше видение воз-
можных путей перехода от моделирования использования к другим видам
моделирования.
Действующие лица находятся вне системы — с ними ничего делать не нуж-
но. Можно сказать, что действующие лица уже выполнили свою задачу, про-
сто появившись в модели системы. Таким образом, переход от моделирова-
ния использования к другим видам моделирования состоит в уточнении,
детализации и конкретизации вариантов использования. В представлении
использования мы показали, что делает система, теперь нужно определить,
как это делается. Это обычно называется реализацией вариантов использо-
вания.
Реализация варианта использования (use case realization) - это опи-
сание всех или некоторых сценариев, составляющих вариант исполь-
зования.
Повторим еще раз: вариант использования — это описание множества по-
следовательностей событий или действий (сценариев), доставляющих
значимый для действующего лица результат. Наиболее часто используе-
мый метод описания множества последовательностей действий состоит в
указании алгоритма, выполнение которого доставляет последовательность
действий из требуемого множества.78
78 Последовательность действий при конкретном выполнении алгоритма называется про-
токолом этого выполнения. Таким образом, сценарий можно рассматривать как про-
токол выполнения алгоритма варианта использования.
2.4. Реализация в* 'иантов ‘использования
Существует множество способов описания алгоритмов, более или менее
формальных. Мы рассмотрим четыре способа, часто применяемые именно
при реализации вариантов использования:
• Текстовые описания.
• Программы на псевдокоде.
• Диаграммы деятельности.
• Диаграммы взаимодействия.
2.4.1. Реализация текстовыми описаниями
Исторически самый заслуженный и до сих пор один из самых популярных
способов описания алгоритмов: составить текстовое описание типичного
сценария варианта использования.
Рассмотрим следующий ниже текст в качестве примера одного из возмож-
ных сценариев.
Сценарий варианта использования.
Увольнение по собственному желанию.
1. Сотрудник пишет заявление.
2. Начальник подписывает заявление.
3. Если есть неиспользованный отпуск,
то бухгалтерия рассчитывает компенсацию.
4. Бухгалтерия рассчитывает выходное пособие.
5. Системный администратор удаляет учетную запись.
6. Менеджер персонала обновляет базу данных.
Казалось бы, что здесь неясного? А неясно, например, вот что: как должна
вести себя система, если на шаге 2 начальник не подписывает заявление. Из
текста сценария не только не ясен ответ, но, хуже того, при невнимательном
чтении можно и не заметить, что есть вопрос.
Текстовые описания сценариев всем хороши: просты, всем понятны, легко и
быстро составляются. Плохи они тем, что могут быть неполны и неточны, и
эти недостатки незаметны.
2.4.2. Реализация программой на псевдокоде
Разработчики чаще всего описывают алгоритмы с помощью программ — тек-
стов на некотором языке.
Глава 2 Моделирование использования
Если программа предназначена для выполнения компьютером, то она долж-
на быть записана на сугубо формальном (и на сегодняшний день довольно
примитивном) языке, который называют в этом случае языком программи-
рования. Если же программа предназначена исключительно для чтения и,
может быть, выполнения человеком, то можно применить менее формаль-
ный (и более удобный) язык, который в этом случае называют псевдокодом.
Обычно в псевдокод включают смесь общеизвестных ключевых слов языков
программирования и неформальные выражения на естественном языке, обо-
значающие выполняемые действия. Эти выражения должны быть понятны
человеку, который пишет (или читает) программу на псевдокоде, но совсем
не обязаны быть допустимыми выражениями языка программирования.
Текст на псевдокоде похож на код программы на языке программирования,
но таковым не является — отсюда и название.
МЕТОД ПОШАГОВОГО УТОЧНЕНИЯ
Метод пошагового уточнения при разработке программ был пред-
ложен Н. Виртом в период развития структурного программирова-
ния. Суть состоит в том, что на первом шаге выписывается (очень
короткая) программа на псевдокоде, содержащая обозначения
для крупных кусков общего алгоритма. Затем каждое из этих обо-
значений раскрывается (уточняется) с помощью своего текста на
псевдокоде, возможно с введением новых обозначений для более
мелких частей алгоритма. Затем вновь введенные обозначения в
свою очередь раскрываются и так далее, пока процесс уточнения
не дойдет до уровня исполнимого языка программирования.
Метод пошагового уточнения предполагает строгое следование
дисциплине структурного программирования и хорошо работа-
ет при проектировании сверху вниз. С его помощью получаются
понятные и хорошо документированные программы. При разра-
ботке программы для отдельного действительно сложного алго-
ритма этот метод является, видимо, одним из наилучших среди
известных методов конструирования программ. Однако метод
пошагового уточнения напрямую никак не связан с парадигмой
объектно-ориентированного программирования. Современный
стиль программирования имеет тенденцию к конструированию
программ как очень сложных систем классов, каждый из которых
имеет очень простые (с алгоритмической точки зрения) операции.
Таким образом, область применимости метода пошагового уточ-
нения сужается.
Никлаус Вирт (нем. Niklaus Wirth, род. 15 февраля 1934) — швей-
царский учёный, специалист в области информатики. Ведущий
разработчик языков программирования Паскаль, Модула-2,
Оберон. Лауреат премии Тьюринга 1984 года.
Ф
2.4. Реализация вариантов использования
Таким образом, второй рассматриваемый нами способ реализации вариан-
та использования — записать алгоритм на псевдокоде. Этот способ хорош
тем, что понятен, привычен и доступен любому разработчику. Однако в на-
стоящее время вряд ли можно рекомендовать такой способ реализации как
основной, по следующим причинам.
• Реализация на псевдокоде плохо согласуется с современной пара-
дигмой объектно-ориентированного программирования.
• При использовании псевдокода теряются все преимущества исполь-
зования U ML: наглядная визуализация с помощью картинки, стро-
гость и точность языка проектирования и реализации, поддержка
распространенными инструментальными средствами.
• Решения на псевдокоде практически невозможно использовать по-
вторно.
Тем не менее рассмотрим пример реализации вариантов использования на
псевдокоде79 (параллельно советуем смотреть на рис. 2.20).
Use case Self Fire
Получить заявление
add_payment:
Pay Compensation(Self Fire, add_payment)
Include Delete Account
Обновить информацию в базе данных
Use case Adm Fire
Получить приказ
add _paymcnt:
Pay Compensation(Adm Fire, add_payment)
Include Delete Account
Обновить информацию в базе данных
Use case Pay Compensation
if (addpayment)
if (from Self Fire)
начислить за неиспользованный отпуск
else if (from Adm Fire)
начислить выходное пособие
79 Это нормально, что в программе на псевдокоде присутствуют как русские, так и англий-
ские предложения. Это псевдокод, и мы пишем так, как нам удобно.
Глава 2. Моделирование использования
Увольнение по собственному желанию запускается по инициативе сотрудни-
ка. Увольнение по инициативе администрации начинается с приказа об уволь-
нении. Остальная последовательность действий в обоих случаях совпадает.
В этих текстах использовано ключевое слово Include, отражающее наличие
зависимостей с таким стереотипом в модели. А именно, это означает, что в
этом месте в текст псевдокода для данного варианта использования нужно
включить текст псевдокода для варианта использования Delete Account,
который мы здесь не приводим.
Вариант использования Pay Compensation запускается, если есть условия
для выплаты компенсаций. При этом основные варианты использования не
должны знать, каковы эти условия и как рассчитывается компенсация —
за это отвечает вариант использования Pay Compensation. Зависимость
со стереотипом «extend» означает, что псевдокод варианта использования
Pay Compensation должен быть включен в текст основных вариантов ис-
пользования. При этом вариант использования Pay Compensation должен
знать, в какое место ему нужно включиться. Для этого в основных вариантах
использования определена точка расширения (extension point) — по сути,
просто метка в программе80.
Мы надеемся, что этот пример в достаточной мере объясняет сходство и
различие между зависимостями со стереотипом «include» и «extend».
2.4.3. Реализация диаграммами деятельности
Третий способ реализации варианта использования — описать алгоритм с
помощью диаграммы деятельности. С одной стороны, диаграмма деятель-
ности — это полноценная диаграмма UML, с другой стороны, диаграмма
деятельности немногим отличается от блок-схемы (а тем самым и от псевдо-
кода). Таким образом, реализация варианта использования диаграммой дея-
тельности является компромиссным способом ведения разработки — в сущ-
ности, это проектирование сверху вниз в терминах и обозначениях UML.
Например, в информационной системе отдела кадров прием сотрудника мо-
жет быть организован так, как показано на рис. 2.26.
Приблизило ли нас появление этой диаграммы в модели к завершению ра-
боты над системой? С одной стороны, вместо одной сущности, подлежа-
щей реализации (вариант использования Hire Person), появилось пять но-
вых: три сторожевых условия и две деятельности, которые в свою очередь
теперь нуждаются в реализации. С другой стороны, каждая из этих новых
сущностей кажется более простой и понятной, а значит быстрее и надежнее
80 Для зависимости со стереотипом «include» никакой метки не нужно: место включения
определяется тем, где в псевдокоде стоит ключевое слово include.
2.4. Реализация вариантов использования
activity Прием сотрудника на работу (Hire Person)
Select vacant position
[else]
V
Occupy position
Рис. 2.26. Реализация варианта использования при помощи диаграммы
деятельности
реализуемой. Кроме того, эту диаграмму можно показать заказчику, чтобы
проверить, действительно ли проектируемая нами логика работы системы
соответствует тому бизнес-процессу, который существует в реальности.
Применение диаграмм деятельности для реализации вариантов использова-
ния не слишком приближает к появлению целевого артефакта — программ-
ного кода81, однако может привести к более глубокому пониманию существа
задачи и даже открыть неожиданные возможности улучшения приложения,
которые было трудно усмотреть в первоначальной постановке задачи.
Например, рассматривая (чисто формально) схему процесса на рис. 2.26, мы
видим, что процесс может иметь три исхода,
• Нормальное завершение (1 на рис. 2.26), которое предполагает обя-
зательное выполнение деятельности Occupy position. Резонно пред-
положить, что при выполнении этой деятельности в базу данных
будет записана какая-то информация, что, несомненно, является
значимым для пользователя результатом.
• Исключительная ситуация (2 на рис. 2.26), возникающая в том слу-
чае, когда процесс не может быть нормально завершен, т.е. мы хотели
принять человека на работу, и он был согласен, а текущее состояние
81 Большинство инструментов не генерируют никакого кода по диаграммам деятельности.
Глава 2. Моделирование использования
штатного расписания не позволило этого сделать. Факт возникно-
вения такой ситуации, хотя формально и не является значимым
результатом для менеджера персонала, на самом деле может быть
весьма важен для высшего руководс тва или менеджера штатного
расписания.
• Завершение процесса без достижения какого-либо видимого резуль-
тата (3 на рис. 2.26). Например, менеджер персонала сделал кандида-
ту какие-то предложения, но ни одно из них кандидата не устроило,
после чего они расстались, как будто ничего и не было.
Этот простой анализ наталкивает на следующие соображения. Вариант
использования должен доставлять значимый результат, значит, если ре-
зультата нет, то что-то спроектировано не так, как нужно. Действительно,
все известные нам практические информационные системы отдела кадров
обязательно накапливают статистическую информацию обо всех проведен-
ных кадровых операциях. Такая статистика совершенно необходима для так
называемого анализа движения кадров — важной составляющей процесса
управления организацией. Однако далеко не все системы позволяют учиты-
вать и не проведенные операции. Между тем, учет этой информации, напри-
Рис. 2.27. Усовершенствованная реализация варианта использования
2.4. Реализация вариантов использования
мер, учет причин, по которым кандидаты не принимают предложенной ра-
боты или, наоборот, причин, по которым организации отвергают кандидатов,
может быть весьма полезен для исследования рынка труда и формирования
кадровой политики организации.
Немного подумав над этой проблемой (или посоветовавшись с заказчиком),
мы можем усовершенствовать нашу диаграмму, например, так, как показано
на рис. 2.27.
Вот теперь (формально) все хорошо: информация не теряется. Более того,
имеет смысл вернуться к представлению использования и посмотреть, не
нужно ли включить в модель новые варианты использования (может быть,
как низкоприоритетные и подлежащие реализации в последующих версиях
системы). Так реализация вариантов использования может приводить к из-
менению и усовершенствованию самих вариантов использования. Моде-
лирование имеет итеративный характер, о чем мы уже говорили в главе 1.
2.4.4. Реализация диаграммами взаимодействия
Четвертый из основных способов реализации варианта использования —
создать одну или несколько диаграмм взаимодействия в форме диаграмм
коммуникации или диаграмм последовательности, которые описывают
один или несколько сценариев данного варианта использования. Этот спо-
соб в наибольшей степени соответствует идеологии UML и рекомендуется
авторами языка как основной и предпочтительный.
Рассмотрим основные достоинства и недостатки реализации варианта ис-
пользования диаграммами взаимодействия. Начнем с положительного.
На диаграммах взаимодействия представлено взаимодействие объектов, т. е.
экземпляров некоторых классов. Тем самым построение такой диаграммы с
необходимостью приводит к выявлению некоторых классов, которые долж-
ны существовать в модели, и некоторых операций этих классов (а именно
тех, которые появятся в форме сообщений типа "вызов метода" на диаграмме
взаимодействия). Более того, поскольку сообщения передаются от объекта
к объекту вдоль связей (в основном, экземпляров ассоциаций), то оказыва-
ются выявленными и некоторые необходимые ассоциации. Таким образом,
реализация варианта использования какой-либо диаграммой взаимодей-
ствия обеспечивает органичный переход от моделирования использования
к моделированию структуры (глава 3) и поведения (глава 4)82.
82 Отметим, что в диаграмме деятельности это не так: вы можете использовать в качестве
действий операции классов, но не обязаны этого делать. Большинство инструментов
даже не поддерживают применения на диаграммах деятельности элементов модели,
определенных в других диаграммах.
Глава 2. Моделирование использования
При составлении диаграмм взаимодействия для нескольких вариантов ис-
пользования могут быть задействованы одни и те же классы, играющие раз-
ные роли в различных кооперациях (см. главу 3). Одинаковое поведение и
структура, проявляющиеся в разных вариантах использования, оказывают-
ся реализованными одним классом. Такой стиль моделирования полностью
соответствует объектно-ориентированному подходу и обеспечивает концеп-
туальную целостность проектируемой системы.
При реализации вариантов использования диаграммами взаимодействия
на ранних этапах моделирования появляются сопутствующие фрагменты
диаграмм классов. Эти диаграммы гораздо ближе к целевому артефакту —
программному коду — нежели диаграммы использования и даже диаграммы
деятельности. Все инструменты поддерживают генерацию кода по диаграм-
мам классов, а некоторые — и по диаграммам взаимодействия. Таким обра-
зом, появляется возможность автоматизированного построения прототипов
(версий системы, обеспечивающих частичную функциональность), что пол-
ностью соответствует идеологйи программирования вширь (инкременталь-
ной разработки).
Однако у диаграмм взаимодействия UML есть существенное ограничение. В
целом эти диаграммы формулируются на уровне объектов, а потому позво-
ляют реализовать только отдельный сценарий (условно говоря, экземпляр
варианта использования). Другими словами, диаграммы взаимодействия
позволяют описать протокол выполнения алгоритма, но не сам алгоритм.
Возникает вопрос: насколько существенным и обременительным оказывает-
ся это ограничение при практическом моделировании?
Если алгоритм выполнения варианта использования линеен (просто после-
довательность действий, без ветвлений и циклов), то проблемы нет — линей-
ные алгоритмы суть протоколы своего выполнения. Для ветвлений и циклов
диаграммы взаимодействия содержат некоторые (см. главу 4) средства мо-
делирования. Иногда этих средств может оказаться достаточно.
Что же делать, если все-таки никак не удается построить исчерпы-
вающую диаграмму взаимодействия дня варианта использования? В
этом случае рекомендуется применять следующие методы. Во-первых,
реализовать вариант использования несколькими диаграммами взаи-
модействия. Каждая диаграмма описывает отдельный сценарий, а все
вместе они дают достаточное представление о реализации варианта ис-
пользования. Во-вторых, можно пересмотреть представление иегшльзо-
зания таким образом, чтобы исключить трудно реализуемые варианты
использования. Например, с помощью обобщения выделить варианты
использования, которые описывают более однородные множества сце-
нариев и легче реализуются диаграммами взаимодействия.
2 4 Реализация вариантов использования
Обычно итеративно применяют оба приема, пока не будет достигнут удо-
влетворительный результат.
Попробуем проиллюстрировать сказанное на примере реализации диаграм-
мами взаимодействия варианта использования Hire Person (прием сотрудни-
ка на работу) информационной системы отдела кадров.
Сначала рассмотрим типовой сценарий, когда прием проходит безо всяких
осложнений: есть вакантное рабочее место, и кандидат готов его занять. Диа-
грамма последовательности для такого сценария приведена на рис. 2.28.
Рис. 2.28. Диаграмма последовательности для типового сценария
На приведенной диаграмме последовательность посылаемых сообщений
примерно соответствует последовательности действий на диаграмме дея-
тельности (см. рис. 2.27) в том случае, когда поток управления проходит по
диаграмме сверху вниз один раз. Таким образом, диаграмма, представленная
на рис. 2.28, до некоторой степени определяет типовой сценарий варианта
использования Hire Person. Однако помимо определения последователь-
ности выполняемых действий эта диаграмма содержит и другую информа-
цию, существенную для дальнейшего проектирования83. А именно, построив
такую диаграмму, мы постулировали существование в системе некоторых
классов (возможно, еще не всех), экземпляры которых должны взаимодей-
ствовать для обеспечения требуемого поведения моделируемого варианта
использования. Действующее лицо Personnel Manager уже было определено
83 Сразу же сделаем оговорку, что предлагаемые на диаграмме последовательности
(рис. 2.28), апозже на диаграмме коммуникаций (рис. 2.29) проектные решения являют-
ся неудовлетворительными по многим причинам. Мы намеренно сделали это, чтобы без
дополнительных объяснений решить задачи данного раздела. В дальнейшем недочеты
будут исправлены, и суть их будет объяснена. Данный параграф — единственное место
в книге, где авторы сознательно пошли на такой шаг.
Ф
Г 179
Глава 2. Моделирование использования
при моделировании использования, здесь же в нашей модели появились но-
вые сущности:
• класс Hire Form, ответственный за интерфейс, необходимый для вы-
полнения варианта использования "прием сотрудника";
• класс Person, ответственный за хранение данных о конкретном со-
труднике;
• класс Position, ответственный за хранение данных и выполнение опе-
раций с конкретной должностью.
На этой стадии моделирования список операций указанных классов еще да-
леко не полон (а атрибуты пока совсем отсутствуют), однако сам факт по-
явления классов в модели является важным решением, существенно при-
ближающим нас к реализации системы.
Примечание
Большинство инструментов поддерживают следующий ре-
жим работы. Составляя некоторую диаграмму (например,
в нашем случае диаграмму последовательности), можно
определить в модели некоторые сущности (например, клас-
сы), нужные для моделирования в данный момент, не от-
ражая их пока что ни на какой диаграмме. Утрируя, можно
представить себе такой стиль моделирования, когда никакие
диаграммы вообще не составляются, а, пользуясь средствами
инструмента, в модель последовательно добавляются сущ-
ности и отношения между ними. Конечно, такой стиль иг-
норирует один из важнейших аспектов UML — наглядность
модели — и на практике не применяется. Однако, приводя
это замечание, мы хотим еще раз подчеркнуть важнейшее об-
стоятельство, часто ускользающее от начинающих пользова-
телей UML: модель не является простой суммой диаграмм,
наоборот, каждая диаграмма является не более чем огра-
ниченной проекцией независимо существующей модели.
Возвращаясь к нашему примеру, заметим, что диаграмма на рис. 2.28 семан-
тически не полна: она не отражает все сценарии варианта использования,
которые предусматриваются, например, на диаграмме на рис. 2.27. Как уже
было сказано, в этом случае можно составить дополнительные диаграммы
взаимодействия, реализующие альтернативные сценарии варианта исполь-
зования. Например, на рис. 2.29 показан сценарий приема сотрудника, соот-
ветствующий исключительной ситуации, когда нет вакантных должностей.
На этот раз мы описываем сценарий в форме диаграммы коммуникации.
2.4. Реализация вариантов использования
comm Исключительная ситуация при приеме сотрудника
1: openHireForm()
Рис. 2.29. Диаграмма коммуникации для исключительной ситуации
Построение этой диаграммы выявило необходимость включения в модель
(по крайней мере) еще одного класса — Exceptions Handler, который несет
ответственность за обработку возникающих исключительных ситуаций. Ко-
нечно, тот способ решения проблемы, который мы предлагаем на рис. 2.29,
далеко не единственный, и, может быть, не самый лучший из известных вам.
Дело не в конкретном способе обработки исключений — это вопрос техноло-
гии программирования, а в том, что построение диаграммы взаимодействия
выявило сам факт необходимости предусмотреть обработку исключитель-
ных ситуаций в системе. Если бы мы не построили диаграмму коммуника-
ции для альтернативного сценария, мы могли бы упустить из виду это об-
стоятельство и тем самым совершить грубую проектную ошибку.
Авторы UML рекомендуют на этапе перехода от моделирования исполь-
зования к более детальному проектированию строить диаграммы взаимо-
действия для всех типовых сценариев вариантов использования (на край-
ний случай для всех вариантов использования, выбранных для реализации
в первой версии системы).
Эта рекомендация нам представляется очень полезной, и мы советуем ей
следовать. Более того, мы можем предложить неформальный критерий для
управления процессом разработки, основанный на этой рекомендации.
После того, как диаграммы взаимодействия построены, нужно сопо-
ставить набор выявленных классов со словарем предметной области
(см. раздел 2.1.2). Если наблюдается значительное совпадение, скажем,
если большинство понятий словаря предметной области оказалось сре-
ди классов, выявленных при реализации вариантов использования, то
это означает, что мы на правильном пути и можно смело переходить
к более детальному проектированию. Если же пересечение словаря и
множества выделенных классов незначительно, скажем, если оно со-
ставляет менее половины объема словаря, то нужно приостановить
Глава 2. Моделирование использования
проектирование и вернуться на фазу анализа (привлечь сторонних
экспертов в предметной области, заново выполнить моделирование ис-
пользования, проконсультщюнаться с заказчиком и т. д.).
Из материала этого раздела мы делаем следующий вывод: реализация ва-
риантов использования диаграммами взаимодействия является наиболее
трудоемким и сложным методом, но этот метод лучше всего согласован с
объектно-ориентированным подходом и в наибольшей мере приближает
нас к конечной цели.
2.4.5. Сравнение методов реализации
В последнем параграфе главы мы сравним рассмотренные нами методы
реализации вариантов использования. Конечно однозначного критерия, по
которому все методы можно было бы выстроить в шеренгу, руководствуясь
принципом — те кто справа лучше тех кто слева, нет, и быть не может. В про-
тивном случае, зачем было бы нужно сосуществование методов? Лучший
метод вытеснил бы все худшие, и сравнивать было бы нечего.
В разных ситуациях и для разных задач одни методы применять выгодно,
а другие, наоборот, нецелесообразно. В таких случаях применяются много-
критериальные экспертные оценки. Мы представили свои экспертные оцен-
ки в следующих таблицах. Чтобы их испол!>зовать, вам нужно точно диагно-
стировать свою текущую ситуацию, заглянуть в наши таблицы, а после этого
самостоятельно принять разумное решение.
В таблице 2.5 в сжатой форме повторены наблюдения, сделанные в преды-
дущих параграфах. Эти наблюдения можно использовать, применяя метод
оценивания "за и против". Наблюдения "за” помечены знаком "+", наблю-
дения "против" помечены знаком Например, диаграммы деятельности
в этой таблице имеют два плюса и один минус, а диаграммы взаимодей-
ствия — только один плюс и два минуса.
Таблица 2.5. Характерные свойства способов реализации
Текстовые описания Программы на псевдокоде
+ Всем понятны, привычны и удобны + Не требуют специальных инструментов - Получается длинно и неточно, возможны пропуски и ошибки + Традиционное средство программистов + Самое компактное средство - Навязывают структуру реализации - Никак не приближают к объектной модели
Диаграммы азаимодействия Диаграммы деятельности
+ Прямо ведут к объектной модели - Сложная и непривычная нотация — Очень высокая трудоемкость + Наглядно и привычно + Похожи на знакомые блок-схемы - Почти не приближают к объектной модели
___ Ф
<е>....-....-.............. -....-..
2.4. Реализация вариантов использования
Можно перейти от качественных сравнений к количественным, введя рей-
тинговое оценки наблюдаемых факторов.
В таблице 2.6 мы выписали наши рейтинговые оценки методов относитель-
но основных свойств, которые принимались во внимание при наблюдении:
объектная ориентированность, привычность формы записи, трудоемкость
составления и близость к UML. Можно назначить факторам веса в соответ-
ствии с собственными предпочтениями и сосчитать взвешенную сумму рей-
тингов. Например, если все веса равны 1, т.е. факторы считаем равнозначны-
ми, то диаграммы деятельности по нашей таблице получают оценку 2+2+3
= 7, а диаграммы взаимодействия получают оценку 1+4+4 =9, и, значит, при
прочих равных условиях мы считаем диаграммы деятельности немного бо-
лее предпочтительным средством.
Таблица 2.6. Рейтинги методов по наблюдениям
Объектная ориентированность Привычность записи Легкость составления
Диаграммы взаимодействия Диаграммы деятельности Текстовые описания Программы на псевдокоде Текстовые описания Диаграммы деятельности Программы на псевдокоде Диаграммы взаимодействия Текстовые описания Программы на псевдокоде Диаграммы деятельности Диаграммы взаимодействия
Разумеется, применяя формальные методы сравнения неформальных ве-
щей, нужно ясно понимать, что, подбирая факторы и весовые коэффициен-
ты, легко можно формально получить любой наперед заданный результат
сравнения (этот процесс подгонки под ответ можно наблюдать в некоторых
информационно-аналитических программах на телевидении.). В формаль-
ной теории вычисления имеют доказательную силу, а в неформальной — нет!
Приведенное выше сравнение диаграмм деятельности и взаимодействия —
это не доказательство, а "убедительство", и к нему необходимо подходить
критически, опираясь на собственный опыт и здравый смысл!
[ 183 "
_
Выводы
Составление диаграмм использования — это первый шаг модели
рования.
Основное назначение диаграммы использования — показать, что
делает система по знешнем мире.
Диаграмма использсшания не зависит от программной [;
системы и поэтому не обязана соответствовать структуре i
модулей и компонентов системы.
Идентификация действующих лиц и вариантоа и<
ключ к дальнейшему проектированию.
с ''?> <.• <<•'
вания
---T-ir:iiiiii mini и -
Ассоциации действующих лиц и вариантов испит
няются на диаграммах использования всегда, другие от*
применяются по миро необходимости.
в сиде текстовых описаний сценариев эт.
способ, но он не помогает в построении об
системы;
В зависимости от выбранной парадигмы проектирования и
граммирозания применяются различные способы реэлизаци
риантоа использования:
о в виде диаграмм деятельности — позволяет ифнять алго-
ритм выполнения варианта использования, но почти не по-
могает в построении объектной модели системы;
о э виде диаграмм взаимодействия - это самый трудоемкий
способ, но он ведет прямо к объектной модели системы
> Г'&Ъа
Глава 3
Моделирование
структуры
ЧТО ТАКОЕ МОДЕЛИРОВАНИЕ СТРУКТУРЫ?
В ЧЕМ ЗАКЛЮЧАЮТСЯ ОСОБЕННОСТИ ОБЪЕКТНО-ОРИЕНТИРОВАННОГО
МОДЕЛИРОВАНИЯ СТРУКТУРЫ?
Какие элементы применяются для моделирования
структуры?
Как и для чего создаются диаграммы классов?
Какие сущности используют на диаграмме классов?
Какие структурные взаимосвязи можно описать с помощью
ОТНОШЕНИЙ НА ДИАГРАММЕ КЛАССОВ?
В КАКИХ СЛУЧАЯХ ПРИМЕНЯЮТСЯ ДИАГРАММЫ КОМПОНЕНТОВ
И РАЗМЕЩЕНИЯ?
ЧТО ТАКОЕ ДИАГРАММА ВНУТРЕННЕЙ СТРУКТУРЫ И ДЛЯ ЧЕГО
ОНА ИСПОЛЬЗУЕТСЯ?
Как применяются диаграммы объектов?
3.1. Объектно-ориентированное
моделирование структуры
Моделируя структуру, мы описываем составные части системы и отно-
шения между ними. UML в большинстве случаев применяется в качестве
объектно-ориентированного языка моделирования,85 поэтому не удивитель-
но, что основным видом составных частей, из которых состоит система
при таком подходе, являются классы и отношения между ними.
В каждый конкретный момент функционирования системы можно указать
конечный набор конкретных объектов (экземпляров классов) и существую-
щих между ними связей (экземпляров отношений). Однако в процессе рабо-
ты этот набор не остается неизменным: объекты создаются и уничтожаются,
связи устанавливаются и теряются.
Число возможных вариантов наборов объектов и связей, которые мо-
гут иметь место в процессе функционирования системы, если и не бес-
конечно, то может быть необозримо велико. Представить их все в модели
практически невозможно, а главное бессмысленно, поскольку такая модель
из-за своего объема будет недоступна для понимания человеком, а значит
и бесполезна при разработке системы. Каким же образом можно строить
компактные (полезные) модели необозримых (потенциально бесконечных)
систем? Ответ на этот вопрос изложен в следующем параграфе.
3.1.1.Дескрипторы
Метод построения конечных (и небольших) моделей бесконечных (или
очень больших) систем известен человечеству испокон веков и пронизывает
85 Другие парадигмы также нашли свое отражение в UML.
[ 186 J
3.1. Объектно-ориентированное моделирование структуры
всё современное знание в разных формах и под разными названиями. При-
ведем несколько примеров из предметных областей, близких к теме этой
книги86.
Первый пример относится к обычному программированию. Профессио-
нальные программисты так привыкли работать с текстами программ на язы-
ке программирования, что часто забывают, что код — это не более чем мо-
дель вычислительного процесса. Действительно, рассмотрим код функции
на языке Паскаль.
function MaxFib : integer;
var fl, f2 : integer;
begin
fl:=l; f2:=l;
while maxint - fl > f2 do begin
f2 := fl + f2;
fl := f2 - fl
end;
MaxFib := f2
end;
Эта несложная (и не самая эффективная) функция вычисляет наибольшее
число Фибоначчи, представимое в конкретной системе программирования.
Ее описание занимает всего 10 строк и содержит 118 символов, не считая
пробелов. Между тем этот текст исчерпывающим образом описывает совер-
шенно невообразимое по человеческим меркам количество арифметических
операций. Нормальному человеку может не хватить времени жизни и, во
всяком случае, не хватит терпения, чтобы проделать эти вычисления вруч-
ную.
Текст программы компактен, а описываемые им вычисления необозримы.
Разработчики пишут программы (составляют точные описания последова-
тельностей элементарных действий), которые они (разработчики) сами вы-
полнить заведомо не в состоянии — и ничего страшного, всё отлично работа-
ет (как правило), и все к этому привыкли.
Еще пример. Рассмотрим описание какого-нибудь формального языка,
скажем, упомянутого в предыдущем примере языка программирования
Паскаль. Оно состоит из примерно двух десятков синтаксических правил,
нескольких десятков страниц текста и около сотни небольших примеров. За-
86 Мы уверены, что читатель легко сможет привести множество других примеров из знако-
мых ему областей знания.
Глава 3. Моделирование структуры
метим, что синтаксис языка Паскаль описан Н. Виртом (см. параграф 1.3.2)
с помощью синтаксических диаграмм, пример одной из таких диаграмм при-
веден на рис. 3.1.
Рис. 3.1. Синтаксическая диаграмма для понятия "программа"
В прямоугольниках написаны названия синтаксических конструкций, кото-
рые раскрываются на других диаграммах. В прямоугольниках со скруглен-
ными углами написаны терминальные символы (см. врезку "Формальные
грамматики” в параграфе 1.3.2) так, как они появляются в тексте программы.
Любой проход по стрелкам диаграммы от начала к концу доставляет синтак-
сически правильную программу на языке Паскаль. И этого небольшого ко-
личества несложных диаграмм оказывается достаточно, чтобы описать язык
в целом, то есть бесконечное и очень разнообразное множество текстов про-
грамм, которые являются элементами языка. Причем описание бесконечного
языка оказывается не только конечным, но и достаточно компактным для
того, чтобы быть практически применимым. *
Заметим, что в приведенных примерах (равно как и в других подобных слу-
чаях), кроме самого компактного описания, подразумевается, что известен
набор правил интерпретации описания, позволяющих построить по описа-
нию множества любой его элемент. Сами правила и способ их задания раз-
личны в разных случаях, но принцип один и тот же.
В UML этот принцип формализован в виде понятия дескриптора.
Дескриптор (descriptor) это описание общих свойств множества
объектов, включая их структуру, отношения, поведение, ограниче-
ния, назначение и т. д.
Дескриптор имеет две стороны: это само описание множества (intent) и мно-
жество значений, описываемых дескриптором (extent). Антонимом для де-
скриптора является понятие литерала (literal). Литерал описывает сам себя.
Например, тип данных integer является дескриптором: он описывает мно-
жество целых чисел, потенциально бесконечное (или конечное, но достаточ-
но большое, если речь идет о машинной арифметике). Изображение числа 1
описывает само число "один" и более ничего — это литерал.
3.1. Объектно-ориентированное моделирование структуры
Почти все элементы моделей UML являются дескрипторами — именно
поэтому средствами UML удается создавать представительные модели до-
статочно сложных систем. Рассмотренные в предыдущей главе варианты
использования и действующие лица — дескрипторы, рассматриваемые в
этой главе классы, ассоциации, компоненты, узлы — также дескрипторы.
Комментарий же является литералом — он описывает сам себя. Пакет также
является литералом.
Эта глава посвящена объяснению немногочисленных, но достаточно содер-
жательных дескрипторов, которые в UML применяются для моделирования
структуры.
3.1.2. Объектно-ориентированная парадигма
Мы считаем необходимым предварить дальнейшее рассмотрение набором
замечаний по поводу объектно-ориентированной парадигмы в целом. Наши
замечания не претендуют на полноту исчерпывающего изложения — основ-
ные идеи объектно-ориентированного подхода считаются известными чита-
телю. Тем не менее наши довольно общие замечания, хотя и не являются ис-
тиной в последней инстанции, могут, как нам кажется, быть полезными при
обсуждении объектно-ориентированного моделирования на UML.
Начнем с небольшого исторического обзора (см. также параграф 5.3.1).
Вопрос повышения (изначально очень низкой) продуктивности програм-
мирования и разработки сложных программных продуктов является пред-
метом технологии программирования (software engineering). Технология
программирования находится в центре внимания ведущих практических
программистов, теоретиков и начальников от программирования начиная с
конца 60-х годов XX века, со времен так называемой первой революции в
программировании. Хотя ресурсы, инвестированные в технологию програм-
мирования, огромны и достижения значительны, вопрос далек от оконча-
тельного разрешения. Подтверждением тому служит разнообразие парадигм
программирования, которые постоянно возникают, не вытесняя друг друга.
Парадигма программирования (programming paradigm) — это собра-
ние основополагающих принципов, которые служат методической
основой конкретных технологий и инструментальных средств про-
граммирования.
Исторически первой оформленной парадигмой принято считать так назы-
ваемое структурное программирование (structured programming). Выяв-
ленная87 Э. Дейкстрой обратная зависимость между долей неограниченных
87 Примечательно, что эта зависимость была выявлена не спекулятивным, а правильным
научным методом, а именно, статистической обработкой представительной выборки
текстов реальных программ.
Глава 3. Моделирование структуры
операторов перехода GoTo и качеством (надежностью, скоростью отладки)
программы привела к бурному развитию концепции структурного програм-
мирования, которое большинством рядовых программистов было понято
как "программирование без GoTo".
Эдсгер Вибе Дейкстра (нидерл. Edsger Wybe Dijkstra; 11 мая
1930 - 6 августа 2002) — выдающийся нидерландский учёный,
идеи которого оказали огромное влияние на развитие компьютер-
ной индустрии.
Известность Дейкстре принесли его работы в области примене-
ния математической логики при разработке компьютерных про-
грамм, разработке языка программирования Алгол, структурного
программирования, применения семафоров для синхронизации
процессов в многозадачных системах и алгоритм нахождения
кратчайшего пути в графе. В 1972 году Дейкстра стал лауреатом
премии Тьюринга.
Программирование без GoTo основано на том простом факте, что любая
структура управления может быть функционально эквивалентно выраже-
на суперпозицией последовательного выполнения, ветвления по условию и
цикла с предусловием (рис. 3.2).
Рис. 3.2. Базовые структуры управления программирования без GoTo
Каждая из базовых структур обладает свойством "один вход — один выход";
это свойство сохраняется при суперпозиции двух базовых структур; следо-
вательно, свойством "один вход — один выход" обладает любая суперпози-
ция и, таким образом, любая структура обладает таким свойством. Наличие
свойства "один вход — один выход" ценно тем, что позволяет установить
простое соответствие между статическим текстом программы (моделью) и
динамическим протоколом ее выполнения.
Для линейных программ взаимно-однозначное соответствие очевидно; для
ветвящихся программ очевидно однозначное соответствие из текста в про-
токол, для циклических программ соответствие устанавливается, если доба-
3.1, Обвектно-ориентированное моделирование структуры
вить к естественной координате в тексте (от начала к концу) еще по одной
целочисленной координате (обычно называемой счетчиком цикла) для
каждого уровня вложенности циклов. Например, на рис. 3.2 для фрагмента
слева протокол выполнения всегда и однозначно S1; если условие ql выпол-
нено, то для фрагмента в центре протокол выполнения S2; если до начала
выполнения фрагмента справа i=0, то для условия КЗ протокол выполне-
ния S4; S4; S4.
Таким образом, программирование без GoTo позволяет разрешить (до не-
которой степени) основное противоречие программирования — между
статическим конечным текстом программы и динамическим потенциально
бесконечным процессом ее выполнения. Действительно, с одной стороны,
в распоряжении программиста находится код программы, который суще-
ственно конечен и существенно статичен, и на который программист может
воздействовать произвольным образом. С другой стороны, целью програм-
мирования является получение разворачивающегося во времени процесса
выполнения программы, причем этот процесс потенциально бесконечен
(или необозримо велик), существенно динамичен и не подлежит прямому
управлению со стороны программиста.
Таким образом, программирование по существу является процессом кос-
венного отложенного управления (планирования), причем в современных
программно-аппаратных компьютерных системах цепочки прямых и обрат-
ных связей очень длинны и запутанны (программа обращается к функциям
системы программирования, которые обращаются к функциям администра-
тивной системы времени выполнения, которые обращаются к функциям
операционной системы, которые обращаются к функциям аппаратуры и
обратно в том же или даже более сложном порядке). Коротко говоря, про-
граммист работает с конечным статическим текстом программы, а представ-
ляющим интерес результатом является бесконечный динамический процесс
выполнения, и установление прямого соответствия между этими сущностя-
ми является основной проблемой программирования88.
Примечание
Различного рода синтаксический сахар (Switch, Repeat,
For Next, For Each и т. д.) не меняет сути дела, потому
что принцип "один вход — один выход" сохраняется. Поэто-
му наличие или отсутствие тех или иных структур управле-
ния в языке почти не влияет на программирование. Наличие
или отсутствие в языке ограниченных операторов перехода
88 Приведенный абзац является кратким упрощенным пересказом некоторых положений
знаменитого письма "GO ТО statements considered harmful”, которое написал в начале
60-х годов Э. Дейкстра и которое положило начало технологии программирования как
самостоятельному направлению программистской мысли.
[ 191 "
Глава 3. Моделирование структуры
(break, exit, signal и т. д.) также не меняет сути дела
по той же причине. Ограниченные переходы полезны, по-
тому что позволяют писать более короткие и эффективные
программы той же степени структурности89.
Структурное программирование было первым, но не осталось единствен-
ным. Возникли и продолжают развиваться другие парадигмы, инспириро-
ванные иными моделями вычислимости, нежели машина Тьюринга, и ины-
ми архитектурами компьютеров, нежели архитектура фон Неймана.
АРХИТЕКТУРЫ КОМПЬЮТЕРА
Было предложено и реализовано "в металле" множество прин-
ципиально различных способов организации работы компью-
теров, которые обычно называют архитектурой компьютера.
Исторически одной из первых и в то же время до сих пор наибо-
лее распространенной архитектурой компьютеров является
архитектура фон Неймана. В этой архитектуре компьютер
имеет (линейную) адресуемую память, состоящую из ячеек
(как правило, одинаковых), и процессор, дискретно выпол-
няющий команды. В памяти хранятся как обрабатываемые дан-
ные, так и выполняемые команды. Команды оперируют с ячейками
памяти (произвольными), указывая их адреса.
Другой вариант архитектуры компьютера, так называемая
Гарвардская архитектура, предлагает разделять данные
и команды. Во время своего появления (30-е годы XX века) та-
кой подход позволил ускорить работу вычислительных устройств
(данные передавались при помощи перфорированной лен-
ты, а инструкции брались из электромеханических регистров).
Гарвардская архитектура по некоторым параметрам лучше ар-
хитектуры фон Неймана. К примеру, в Гарвардской архитектуре
выход адреса исполняемой команды за пределы области команд
может привести только к краху программы, в то время как в архи-
тектуре фон Неймана передача управления в область данных по-
зволяет злоумышленнику выполнить произвольный код (эта уяз-
вимость является излюбленной "лазейкой" для хакеров). С другой
стороны, Гарвардская схема реализации доступа к памяти имеет
один очевидный недостаток — высокую стоимость. При разделе-
нии каналов передачи команд и данных в процессор, последний
должен иметь в два раза больше контактов для ввода и, соответ-
ственно, для вывода данных.
Из соображений эффективности выполнения программ средства програм-
мирования ориентируются на подразумеваемую архитектуру.
89 Это наглядно продемонстрировано в известной статье Д. Кнута "Structured programming
with Go To".
3.1. Объектно-ориентированное моделирование структуры
Во всех наиболее распространенных системах программирования имеются
два фундаментальных понятия, индуцированные архитектурой машины
фон Неймана — это понятие переменной, которая имеет имя и может ме-
нять значение (абстракция адресуемой ячейки памяти) и понятие управ-
ления (абстракция дискретного последовательного процессора), то есть
определяемой разработчиком последовательности выполнения команд про-
граммы.
Программирование, в котором используются оба этих ключевых понятия,
называется процедурным программированием00. Программирование, в ко-
тором одно или оба понятия не используется, называется непроцедурным.
Программирование, в котором используется явное понятие управления, на-
зывается императивным, в противоположность декларативному програм-
мированию.
НЕПРОЦЕДУРНЫЕ ПАРАДИГМЫ ПРОГРАММИРОВАНИЯ
Среди непроцедурных парадигм программирования можно выде-
лить следующие.
• Логическое программирование базируется на следую-
щем фундаментальном факте: из конструктивного доказа-
тельства теоремы существования Vx(P(x) —> 3yQ(x, у))
может быть эффективно извлечена (аннотированная) про-
грамма Р(х){у:= f (x)}Q(x, у), где Р(х) — предусло-
вие, Q(x,y)— постусловие, a J — сколемовская функция.
Наибольшее распространение получила реализация, извест-
ная под названием язык Пролог, которая основана на приме-
нении метода резолюций с фиксированной стратегией "вход-
ная отрицательная" для автоматического доказательства тео-
рем в хорновском подклассе исчисления предикатов первого
порядка. В логической программе нет явного управления (оно
предопределено стратегией поиска вывода), а присваивание
неявное и сводится к запоминанию унифицирующих подста-
новок.
• Продукционное программирование тесно связано с нор-
мальными алгорифмами91 Маркова. Продукционная про-
грамма состоит из набора продукций (правил) вида if р (D)
then D: =f (D), которые применяются к глобальной базе дан-
ных D, пока не будет удовлетворено условие окончания t (D).
Продукционные программы обладают предельной модульно-
стью, являются чрезвычайно легко модифицируемыми и ча-
сто применяются для программирования экспертных систем.
90 Характеристическим признаком процедурного программирования является наличие яв-
ного оператора присваивания, а не понятие процедуры, как можно было бы подумать.
91 Следует писать и произносить именно "нормальный алгорифм” в силу исторической
традиции.
Глава 3 Моделирование структуры
Управление неявное (определяется стратегией), а перемен-
ные всегда глобальные (база данных D).
• Функциональное программирование тесно связано с
Х-исчислением Чёрча. Функциональная программа являет-
ся композицией функционалов (те. функций, аргументами и
результатами которых могут быть функционалы). В функцио-
нальной программе нет ни явного управления, ни явных пере-
менных, а следовательно, нет и явного присваивания.
Практические непроцедурные системы программирования, ори-
ентированные на перечисленные парадигмы (равно как и на дру-
гие, не перечисленные), отнюдь не требуют от программиста
владения изощренным математическим аппаратом. Наоборот,
зачастую они проще, понятнее и удобнее в использовании, чем
привычные процедурные системы программирования. Поскольку
непроцедурные программы в меньшей степени ориентированы
на классическую архитектуру компьютера, реализация таких про-
грамм оказывается несколько менее эффективной на обычных
компьютерах. Но существуют (в промышленных масштабах) и все
шире применяются компьютеры нетрадиционной архитектуры,
для которых непроцедурное программирование оказывается бо-
лее естественным, продуктивным и эффективным.
В силу целого ряда объективных и субъективных (в основном, историче-
ских) причин непроцедурные парадигмы программирования пока сравни-
тельно редко применяются при решении интересующих нас задач разра-
ботки приложений для бизнеса, и наиболее популярной в данный момент
является парадигма объектно-ориентированного программирования, на
использование которой в основном ориентирован UML.
Объектно-ориентированное программирование является консервативным
расширением структурного программирования, основанным на следующей
идее. Программирование без GoTo (вкупе с необходимыми расширениями,
такими как структурные переходы, обработка исключительных ситуаций и
модульность) удовлетворительным образом решает проблему структуриро-
вания управления. Однако, как известно, процедурные программы опреде-
ляются связями не только по управлению, но и по данным.
Неограниченное присваивание столь же чревато ошибками, как и неограни-
ченный оператор GoTo, потому что порождает те же проблемы: трудности
динамического отслеживания истории переменной и количественные труд-
ности отождествления переменных (их получается слишком много ввиду
сугубой бедности структур данных в традиционных языках программиро-
вания). Интуитивно очевидно, что решение должно обладать тем же ключе-
вым свойством локальности: для каждой переменной существует единствен-
ный модуль, имеющий к ней доступ.
3.1. Объектно-ориентированное моделирование структуры
Локализация переменной в модуле не является решением, поскольку про-
цедурное программирование не может обходиться без переменных, время
жизни которых выходит за пределы времени активации процедур их обра-
ботки, т. е. нужны переменные, дос тупные процедуре, которые существуют
не только во время вызова этой процедуры. Глобальные же переменные до-
пускают неограниченное присваивание. Паллиативные приемы, подобные
описателю own в Алголе и именованным общим блокам в Фортране оказа-
лись неудобными и ненадежными решениями.
Т» настоящее время объект гно-ориентированный подхо i является наи-
более популярной составляющей современных методик разработки
программного обеспечения. При этом подходе система рассматрива-
ется в виде набора взаимодействующих сущностей — объектов, содер-
жащих в себе как данные (атрибуты), так и описание возможного по-
ведения (операции).
К основным характеристикам объектно-ориентированного подхода отно-
сят следующие:
• индивидуальность,
• классификация,
• наследование,
• полиморфизм.
Рассмотрим их по порядку.
Индивидуальность (identity) означает, что все объекты (object), из которых
состоит система, отличаются друг от друга, даже в том случае, если значения
всех их атрибутов совпадают. Другими словами, каждый объект обладает
собственной индивидуальностью.
Классификация (classification) предполагает, что объекты с одинаковыми
структурами данных и поведением могут быть сгруппированы вместе в не-
которые абстракции, которые называются по-разному у разных авторов, а
именно классами, семействами, абстрактными типами данных, модулями,
кластерами и т.д. Классы (class), а именно такой термин используется в UML,
описывают свойства сходных объектов, которые важны для конкретного
приложения, и абстрагируются от неважной для решения данной задачи ин-
формации. Каждый класс описывает множество (может быть бесконечное)
индивидуальных объектов. Каждый объект из этого множества является эк-
земпляром (instance) данного класса.
За редкими исключениями в современных объектно-ориентированных си-
Г лава 3. Моделирование структуры
стемах программирования классы являются дескрипторами (см. параграф
3.1.1.). В идеале каждый класс должен иметь внутреннюю часть, называе-
мую реализацией (или представлением) и внешнюю часть, называемую ин-
терфейсом. При таком подходе доступ к реализации возможен только через
интерфейс.
Наследование (inheritance) позволяет выстроить из классов иерархии, вы-
деляя в классах общие составляющие (feature)92: атрибуты (attribute), ко-
торые синтаксически выглядят как переменные, и операции (operation),
которые синтаксически выглядят как процедуры или функции. При этом
суперклассы определяют общие составляющие, которые уточняются в под-
классах (см. параграф 3.3.2). Подкласс содержит все составляющие своего
суперкласса и удовлетворяет принципу подстановки (см. параграф 3.3.2).
Полиморфизм (polymorphism). В результате вышеприведенного уточнения
может возникнуть ситуация, когда одна и та же операция в разных подклас-
сах подразумевает разное поведение и соответственно реализуется разными
методами (method). Это и называется полиморфизмом. Исходя из сказан-
ного, понятие полиморфизм можно определить как способ идентификации
процедур при вызове. В классических процедурных системах программи-
рования процедуры идентифицируются просто по именам. В объектно-
ориентированном программировании конкретный метод идентифицирует-
ся не только по имени, но и по классу, которому метод принадлежит, типам и
количеству аргументов (т. е. по полной сигнатуре).
ХРОНОЛОГИЯ РАЗВИТИЯ ОБЪЕКТНО-ОРИЕНТИРОВАННОГО ПРО-
ГРАММИРОВАНИЯ
Интересно и поучительно проследить хронологию развития
объектно-ориентированного программирования: все перечис-
ленные понятия и идеи известны с 1968 года (СИМУЛА-67), в ра-
финированном виде были оформлены в теоретических работах к
1978 году (Б. Лисков и многие другие авторы), получили общепри-
знанное языковое выражение к 1988 году (C++) и стали основным
и массовым инструментом для профессиональных программи-
стов к 1998 году. Но и сейчас, 10 лет спустя, развитие объектно-
ориентированного программирования нельзя назвать ни окон-
ченным, ни даже достигшим кульминации. В промышленности на
сегодняшний день наиболее массово используются гибридные
языки (C++, Java, С#), а не чисто объектно-ориентированные
92 Мы не используем термин "член класса", хотя он часто встречается в литературе. По
нашему мнению, поскольку класс — это множество объектов, членом класса было бы
естественно назвать элемент множества, т. е. объект — экземпляр класса, а отнюдь не
составную часть описания. В UML составная часть описания называется feature, и имен-
но этот термин UML мы передаем термином "составляющая".
i 196 ]
3.1. Объектно-ориентированное моделирование структуры
(Smalltalk, Self, Eiffel). Такая болезненная инертность и привязан-
ность к наследию С может, в конце концов, привести к тому, что
популярность объектно-ориентированного подхода сойдет на нет,
а наиболее согласованные, развитые и эффективные его методы
так и не будут внедрены в промышленность и поняты широкой
программистской общественностью. Надеемся, что этого не слу-
чится.
Барбара Лисков (Barbara Liskov, урожденная Barbara Jane
Huberman, 1939) — первая женщина, получившая в Америке док-
торскую степень по информатике (Стэнфордский университет,
1968). Барбара Лисков известна как лидер многих значительных
проектов, включая СШ, Argus, Thor. Особенно часто ее имя связы-
вается с принципом подстановки.
Лауреат медали имени Джона фон Неймана 2004 года, лауреат
премии Тьюринга 2009 года.
Из сказанного следует важный вывод: объектная ориентированность
является атрибутом стиля программирования, присущего конкретно-
му программисту, а не предопределяется используемым языком или си-
стемой программирования. В любой системе программирования, даже
в той, где нет никаких специальных средств поддержки объектов и клас-
сов, можно создавать объектно-ориентированные программы, используя
все преимущества объектно-ориентированного программирования, равно
как и в самой современной объектно-ориентированной системе никто не
застрахован от безнадежно недисциплинированного манипулирования
объектами. Более того, в некоторых случаях слишком автоматизирован-
ные объектно-ориентированные средства разработки мешают объектно-
ориентированному программированию, поскольку навязывают программи-
сту конкретные решения.
С парадигмой объектно-ориентированного программирования связано
развитие и практическое воплощение важной мысли о неразрывной связи
проек тирования и кодирования и о примате проектирования. Человек мыс-
лит реальный мир состоящим из объектов93 94. Кодирование всегда^ следует
за проектированием (которое в данной книге тождественно моделирова-
нию), т. е. вычленением в предметной области объектов и связей, которые
существенны для решения задачи. Объектно-ориентированное программи-
рование позволяет установить прямое соответствие между программными
конструкциями и объектами реального мира через объекты модели. Таким
образом, объектно-ориентированная система программирования поддержи-
вает не только кодирование, но и (до некоторой степени) проектирование.
93 Это свойство нашего мышления, но не свойство реального мира.
94 У неумелых программистов неявно и бессознательно, у умелых — явно и осознанно.
Глава 3. Моделирование структуры
При написании объектно-ориентированной программы основные усилия
тратятся на определение состава классов, их атрибутов и операций. Кодиро-
вание тел методов (то, что транслируется, в конечном счете, в машинные ко-
манды) в хорошо спроектированной объектно-ориентированной программе
оказывается почти тривиальным.
Некоторые экстремисты объектно-ориентированного подхода считают,
что понятие класса вообще является единственным понятием, необходи-
мым и достаточным для описания структуры (да и поведения заодно) лю-
бых программных систем. Мы не разделяем такой крайней точки зрения,
но согласны с тем, что классы занимают первостепенное место в объек гно-
ориентированном моделировании структуры.
3.1.3. Назначение структурного моделирования
Рассмотрим более детально, какие именно структуры нужно моделировать и
зачем. Мы выделяем следующие структуры:
• структура связей между объектами во время выполнения програм-
мы;
• структура хранения данных;
• структура программного кода;
• структура компонентов в приложении;
• структура сложных объектов, состоящих из взаимодействующих
частей;
• структура артефактов в проекте;
• структура используемых вычислительных ресурсов.
Наша классификация может быть не совсем полна и уж совсем не ортого-
нальна (упомянутые структуры не являются независимыми, они связаны
друг с другом), но в целом соответствует сложившейся практике разработки
приложений, поскольку позволяет фиксировать основные решения, прини-
маемые в процессе проектирования и реализации. В этом разделе мы крат-
ко обсудим назначение перечисленных структур и укажем средства UML,
предназначенные для их моделирования.
Структура связей между объектами во время выполнения
программы
В парадигме объектно-ориентированного программирования процесс вы-
полнения программы состоит в том, что программные объекты взаимодей-
3.1. Объектно-ориентированное моделирование структуры
ствуют друг с другом, обмениваясь сообщениями. Наиболее распростра-
ненным типом сообщения является вызов метода объекта одного класса
из метода объекта другого класса. Для того чтобы вызвать метод объекта,
нужно иметь доступ к этому объекту. На уровне программной реализации
этот доступ может быть обеспечен самыми разнообразными механизмами.
Например, объект, вызывающий метод, может хранить указатель (ссылку)
на объект, содержащий вызываемый метод. Еще вариант: ссылка на объект
с вызываемым методом может быть передана в качестве аргумента объекту,
который этот метод вызовет. Возможно, используется какой-либо механизм
удаленного вызова процедур, обеспечивающий доступ к объектам (напри-
мер, такой, как CORBA) по их идентификаторам. Если атрибуты объектов
представлены записями в таблице базы данных, а методы (нередкий вариант
реализации) — хранимыми процедурами системы управления базами дан-
ных (СУБД), то идентификация объектов осуществляется по первичному
ключу таблицы.
Как бы то ни было, во всех случаях имеет место следующая ситуация: один
объект "знает" другие объекты и, значит, может вызвать открытые мето-
ды, использовать и изменять значения открытых атрибутов и т. д. В этом
случае, мы говорим, что объекты связаны, т. е. между ними есть связь. Для
моделирования структуры связей в UML используются отношения ассоциа-
ции на диаграмме классов.
ТЕХНОЛОГИИ ДОСТУПА К ОБЪЕКТАМ
Существуют, активно применяются и постоянно появляются новые
технологии, обеспечивающие доступ к объектам в распределен-
ных и гетерогенных (неоднородных) сетях. Некоторое время назад
одной из самых популярных являлась технология CORBA (Common
Object Request Broker Architecture— общая архитектура броке-
ра объектных запросов), разработанная группой OMG (Object
Management Group). Основу этой технологии составляет так на-
зываемый брокер запросов к объектам (Object Request Broker,
ORB), который управляет взаимодействием клиентов и серверов
распределенного приложения. Брокер запросов должен быть
установлен на каждом компьютере, где исполняются программы,
использующие технологию CORBA. Брокер запросов реализован
для всех основных аппаратных и программных платформ, поэтому
распределенные приложения, использующие технологию CORBA,
могут выполняться в гетерогенных сетях.
Другим примером является распределенная компонентная мо-
дель объектов DCOM (Distributed Component Object Model), разра-
ботанная корпорацией Microsoft. Эта технология является разви-
тием технологии COM (Component Object Model), определяющей
Глава 3. Моделирование структуры
методы создания и взаимодействия программных объектов раз-
личных типов. Технология СОМ отличается от технологии CORBA
тем, что взаимодействие между объектами устанавливается непо-
средственно, а не с помощью промежуточного агента.
Обе эти технологии являются инструментами для работы с объ-
ектами на удаленных компьютерах. С другой стороны, есть мно-
жество приложений, которые не требуют такой мощи. В таких слу-
чаях используют протокол SOAP (Simple Object Access Protocol —
простой протокол доступа к объектам) или его аналоги. К примеру,
пусть некоторая компания предоставляет прогноз погоды. Этот
прогноз доступен на сайте компании. Если компания хочет, что-
бы этот прогноз был доступен при помощи программных средств,
то достаточно опубликовать описание интерфейса в формате
WSDL (Web Services Description Language — язык описания веб-
сервисов). После этого любой разработчик на основе этого опи-
сания может написать программу, которая будет иметь доступ к
данным прогноза погоды. И SOAP, и WSDL основаны на XML, что
позволяет писать программы, использующие сервисы, на любом
современном языке программирования. Архитектура, основанная
на таких сервисах, называется SOA (Service-Oriented Architecture
— архитектура, ориентированная на сервисы).
Структура хранения данных
Программы обрабатывают данные, которые хранятся в памяти компьютера.
В парадигме объектно-ориентированного программирования для хранения
данных во время выполнения программы предназначены атрибуты классов.
Однако большая часть приложений для автоматизации делопроизводства
устроена так, что определенные данные (не все) должны храниться в памяти
компьютера не только во время сеанса работы приложения, но постоянно,
т. е. между сеансами.
Объекты, которые сохраняют (по меньшей мере) значения своих атрибу-
тов даже после того, как завершился породивший их поток управления, мы
будем называть хранимыми (persistent). В UML для моделирования данно-
го атрибута объектов и их составляющих применяется стандартное свойство
persistence, которое может быть назначено классификатору, ассоциации или
атрибуту и может принимать одно из двух значений:
• persistent — экземпляры классификатора, ассоциации или значения
атрибута, соответственно, должны быть хранимыми;
• transient — противоположно предыдущему — сохранять экземпля-
ры не требуется (значение по умолчанию).
209 J
3.1. Объектно-ориентированное моделирование структуры
На сегодняшний момент самым распрею граненным способом хранения
объектов является использование СУБД. При этом хранимому классу
соответствует таблица базы данных, а хранимый объект (точнее го-
воря, набор значений хранимых атрибутов) представляется записью в
таблице.
Вопрос структуры хранения данных является первостепенным для прило-
жений баз данных. К счастью, известны надежные методы решения этого во-
проса (см. раздел "Схема базы данных" в параграфе 2.2.2 и врезку" Диаграммы
сущность-связь" в разделе 2.2). Эти же методы (с точностью до обозначений)
применяются и в UML в форме ассоциаций с указанием кратности полюсов.
НЕРЕЛЯЦИОННЫЕ БАЗЫ ДАННЫХ
Помимо реляционной, существуют другие модели данных. Более
того, другие модели были предложены раньше, чем реляционная.
Две наиболее популярные — иерархическая и сетевая.
Иерархическая модельхранит данные в виде дерева. К приме-
ру, можно организовать список сотрудников как дерево. Корневым
узлом будет запись "сотрудники предприятия", его потомками бу-
дут "руководство", "бухгалтерия", "менеджеры", "стажеры" и т. д. У
каждого такого узла будут соответствующие потомки — записи о
конкретных работниках. Наиболее известные иерархические базы
данных: файловая система, XML, реестр Windows.
В сетевой модели базы данных у каждого элемента может
быть множество предков и множество потомков (в отличие от
иерархической, где у каждого элемента может быть не боль-
ше одного предка). Другими словами, в сетевой модели данные
представляют собой некоторый ориентированный граф. Таким
образом удобно хранить информацию о связях между объекта-
ми. Пример такой базы данных — любая социальная сеть. Модель
UML так же является сетевой базой данных.
Структура программного кода
Не секрет, что программы существенно отличаются по величине — бывают
программы большие и маленькие. Удивительным является то, насколько ве-
лики эти различия: от сотен строк кода (и менее) до сотен миллионов строк
(и более). Столь большие количественные различия не могут не прояв-
ляться и на качественном уровне. Действительно, для маленьких программ
структура кода практически не имеет значения, для больших — наоборот,
имеет едва ли не решающее значение.
Г лава 2 Моделирование стгу к гурь
Поскольку UML не является языком программирования, модель не опреде-
ляет структуру кода непосредственно, однако косвенным образом структура
модели существенно влияет на структуру кода. Большинство инструмен-
тов поддерживает полуавтоматическую генерацию кода для одного или не-
скольких, чаще объектно-ориентированных, языков программирования. В
большинстве случаев классы модели транслируются в классы (или эквива-
лентные им конструкции) целевого языка. Кроме тою, многие инструменты
учитывают структуру пакетов в модели и транслируют ее в соответ ствую-
щие "надклассовые" структуры целевой системы программирования. Таким
образом, если задействовано средство автоматической генерации кода, то
структура классов и пакетов в модели фактически полностью моделирует
структуру кода приложения.
Структура компонентов в приложении
Приложение, состоящее из одной компоненты, имеет тривиальную струк-
туру компонентов, моделировать которую нет нужды. Но большинство со-
временных приложений на этапе проектирования представляют собой взаи-
мосвязь многих компонентов, даже если и не являются распределенными.
Компонентная структура предполагает описание двух аспектов: во-первых,
как классы распределены по компонентам, во-вторых, как (через какие ин-
терфейсы) компоненты взаимодействуют друг с другом. Оба эти аспекта мо-
делируются диаграммами компонентов UML.
Структура сложных объектов, состоящих из взаимодействующих
частей
Для моделирования этой структуры применяется новое средство UML 2 —
диаграмма внутренней структуры классификатора (см. параграф 3.5.1).
Данная диаграмма используется для описания внутренней структуры клас-
сов и компонентов. Существует еще одна сущность, которая также позво-
ляет описать взаимодействие множества частей. Это сущность называется
кооперацией и служит для описания взаимодействия в некотором контек-
сте. С точки зрения внутренней структуры основное отличие кооперации от
класса и компонента состоит в том, что кооперация не является владельцем
своих частей, и соединители частей кооперации могут не иметь явного выра-
жения в виде ассоциации. Однако, как у классов и компонентов, у коопера-
ции могут быть экземпляры, которые функционируют во время исполнения.
Структура артефактов в проекте
Только самые простые приложения состоят из одного артефакта — испол-
3.1. Объектно-ориентированное моделирование структуры.
нимого кода программы. Большинство реальных приложений насчитывает
в своем составе десятки, сотни и тысячи различных компонентов: исполни-
мых двоичных файлов, файлов ресурсов, файлов исходного кода, различных
сопровождающих документов, справочных файлов, файлов с данными и т. д.
Для большого приложения важно не только иметь точный и полный список
всех артефактов, но и указать, какие именно из них входят в конкретный эк-
земпляр системы. Дело в том, что для больших приложений в проекте сосу-
ществуют разные версии одного и того же артефакта. Это исчерпывающим
образом моделируется диаграммами компонентов и размещения UML, где
предусмотрены стандартные стереотипы для описания артефактов разных
типов.
Структура используемых вычислительных ресурсов
Приложение, состоящее из многих артефактов, как правило, бывает распре-
деленным, т. е. различные артефакты размещаются на разных компьютерах.
Диаграммы размещения позволяют включить в модель описание и этой
структуры.
3.1.4. Классификаторы
Важнейшим типом дескрипторов являются классификаторы.
Классификатор (classifier)— это дескриптор множества однотипных
объектов.
Из этого определения непосредственно вытекает основное и характеристи-
ческое свойство классификатора: классификатор (прямо или косвенно)
может иметь экземпляры.
В U ML определено достаточно много классификаторов. Мы рассматрива-
ем их частями. Во второй главе детально рассмотрены только два из них, а
именно:
• действующее лицо (actor), см. параграф 2.3.1;
• вариант использования (use case), см. параграф 2.3.2.
Классификаторы, которые рассмотрены в этой главе, приведены ниже:
• артефакт (artifact), см. параграф 3.4.1;
• тип данных (data type), см. параграф 3.2.4;
• ассоциация (association), см. параграф 3.3.3 и далее;
• класс ассоциации (association class), см. параграф 3.3.7;
Глава 3. Моделирование структуры
• интерфейс (interface), см. параграф 3.2.4;
• класс (class), см. параграф 3.2.1 и далее;
• кооперация (collaboration), см. параграф 3.5.2;
• компонент (component), см. параграф 3.4.1. Компонент является
классификатором в том смысле, в котором это отражено в UML 1.
В UML 2 семантика сущности компонентов поменялась: компонент
перестал иметь экземпляры, однако на уровне метамодели остался
подклассом класса Classifier;
• узел (node), см. параграф 3.4.1.
Все классификаторы имеют некоторые общие свойства, которые использу-
ются в дальнейшем изложении. В этом параграфе мы опишем семь наиболее
важных свойств классификаторов, которые нам понадобятся прежде всего.
ИМЯ КЛАССИФИКАТОРА
Классификаторы (как и многие другие элементы модели) имеют имена. Имя
служит для идентификации элемента модели и потому должно быть уни-
кально в данном пространстве имен.
Экземпляры классификатора
Как уже было сказано, классификатор может иметь экземпляры. Экземпля-
ры бывают прямые и косвенные.
Если некоторый объект непосредственно порожден с помощью кон-
структора классификатора А, то этот объект называется прямым эк-
земпляром (direct instance) '5 классификатора А (1 рис. 3.3).
Если классификатор А является обобщением классификатора В иди,
что то же самое, классификатор 3 являе тся специализацией класси-
фикатора А. то все экземпляры классификатора I! являются косвен-
ными экземплярами классификатора А (2 рис. 3.3).
। । ।
«instanceOf» «instanceOf» «instanceOf»
I I I
Рис. 3.3. Прямые и косвенные экземпляры классификатора А
95 Употребляют также термин "непосредственный экземпляр".
3.1. Объектно-ориентированное моделирование структуры
Данное свойство является транзитивным: если классификатор А является
обобщением классификатора В, а классификатор В является обобщением
классификатора С, то все экземпляры классификатора С также являются
косвенными экземплярами А (3 рис. 3.3).
Классификаторы абстрактные и конкретные
Классификатор может быть абстрактным или конкретным.
• Абстрактный (abstract) классификатор не может иметь прямых эк-
земпляров, и в этом случае его имя выделяется курсивом96.
• Конкретный (concrete) классификатор может иметь прямые экзем-
пляры, и в этом случае его имя записывается прямым шрифтом.
Абстрактный классификатор — это такой лескрийгор множества объ-
ектов, в котором нет прямо! о описания элементов множества, но дан-
ный классификатор связан отношением обобщения с другими клас-
сификаторами, и объединение множеств их экземпляров считается
множеством экземпляров данного абстрактного'классификатора.
Другими словами, множество определяется не прямо, а через совокупность
подмножеств. Например, интерфейс, будучи абстрактным классом, не мо-
жет иметь непосредственных экземпляров, но реализующий его класс — мо-
жет, стало быть, интерфейс является классификатором.
ВИДИМОСТЬ КЛАССИФИКАТОРА
Классификатор (как и другие элементы модели) имеет видимость.
Видимость (visibility) определяет, может ли составляющая одного
классификатора (в том числе имя) использоваться в другом класси-
фикаторе.
Другими словами, если в определенном контексте нечто доступно и может
быть как-то использовано, то оно является видимым (в этом контексте).
Если же оно не видимо, то и не может быть использовано. Видимость яв-
ляется свойством всех элементов модели (хотя не для всех элементов это
свойство является существенным). Видимость может принимать одно из че-
тырех значений:
• открытый (обозначается знаком + или ключевым словом public);
96 Из данного правила есть исключение, а именно, если классификатор имеет стереотип
«interface», то его имя не нужно выделять курсивом.
чр
295"
Г лава 3. Моделирование струю уры
• защищенный (обозначается знаком # или ключевым словом
protected);
• закрытый (обозначается знаком - или ключевым словом
private);
• пакетный (обозначается знаком ~ или ключевым словом package).
Открытый элемент модели является видимым везде, где является видимым
содержащий его элемент97. Например, открытый атрибут класса виден вез-
де, где виден сам класс.
Защищенный элемент модели виден как в элементе его содержащем (кон-
тейнере), так и во всех элементах, для которых контейнер является обоб-
щением. Например, защищенный атрибут класса виден в содержащем его
классе и во всех подклассах.
Закрытый элемент модели виден только в элементе, которому он принадле-
жит. Например, закрытый атрибут класса виден только в этом классе98.
Элемент модели со значением видимости пакетный, виден элементам толь-
ко того пакета, в котором он сам определен.
Примечание
Для видимости в UML нет значения по умолчанию. Напри-
мер, если для атрибута класса не указано значение видимо-
сти, то это не значит, что атрибут по умолчанию открытый
или, наоборот, закрытый. Это означает, что видимость для
данного атрибута в модели не указана и в этом аспекте мо-
дель не полна.
Область действия
Все составляющие классификатора имеют область действия.
Область действия (scope) определяет, как проявляет себя составляю-
щая классификатора в экземплярах, т. е. имеют экземпляры свои зна-
чения составляющей или совместно используют одно значение.
Область действия имеет два возможных значения:
• экземпляр (instance) — никак специально не обозначается, посколь-
ку подразумевается по умолчанию;
97 Элемент, который содержит другие элементы, часто называют контейнером (container).
98 А также в тех классах, которые связаны с данным зависимостью со стереотипом «friend»
(см. параграф 3.3.1)
3.1. Обьектно-ориентироранное моделирование структуры
• классификатор (classifier) — описание составляющей классификато-
ра подчеркивается.
Если областью действия составляющей является экземпляр, то каждый эк-
земпляр классификатора имеет свое значение составляющей. Например, об-
ластью действия атрибута по умолчанию является экземпляр. Это означает,
что каждый объект — экземпляр класса — имеет свое собственное значение
атрибута, которое может меняться независимо от значений данного атрибу-
та других объектов, экземпляров этого же класса.
Если областью действия составляющей является классификатор, то все эк-
земпляры классификатора совместно используют одно значение составляю-
щей. Например, конструктор обычно имеет областью действия классифика-
тор (класс), поскольку является процедурой, общей для всех экземпляров
данного класса.
Кратность классификатора
Классификатор имеет кратность, т. е. ограничение на количество экземпля-
ров классификатора как множества". Не следует путать кратность с количе-
ством элементов (экземпляров). Множество, указанное в модели, во время
выполнения может иметь различное количество элементов, и количество
элементов может динамически меняться. Кратность определяет пределы
этих изменений.
Кратность (multiplicity) множества — это множество чисел, которые
задают все допустимые значения мощности для данногб множества.
ОБ ИСПОЛЬЗОВАНИИ МАТЕМАТИЧЕСКИХ ТЕРМИНОВ В РАЗГО-
ВОРНОМ ЯЗЫКЕ
Термин "кратность” (наш перевод английского оригинала "mul-
tiplicity") дает повод затронуть непростой вопрос о практике ис-
пользования строгих математических терминов в разговорном
языке. Математики образуют свои термины, как правило, из слов
естественного языка (обычно иностранного, например, древне-
греческого), только в редких случаях изобретаются новые слова.
Но слово разговорного языка в математике приобретает осо-
бый, совершенно точный смысл и его уже трудно использовать в
обычном смысле наряду с математическим смыслом. Если текст
не подразумевает никакой связи с математикой, то ничего страш-
ного — слова можно использовать как угодно. Но если некоторая
связь с математикой подразумевается, то нужно быть очень осто-
99 Кратность может быть не только у классификаторов, но также у атрибутов и полюсов
ассоциаций (см. параграф 3.2.2).
Г лава 3 Моделирование структуры
рожным! Приведем пример. Термин "multiplicity” во многих источ-
никах передан как "множественность". Но классификатор— это
дескриптор множества объектов. Получается множественность
множества... Кроме того, в русском языке слово "множествен-
ность" противоположно по смыслу слову "единственность" и не-
вольно возбуждает аллюзию с натуральным числом, большим
единицы. Но "multiplicity" очень редко бывает одним числом! Как
правило, это множество чисел, даже бесконечное множество чи-
сел. Наш вариант— "кратность" — также не лишен недостатков,
но количество математически ошибочных его прочтений в разго-
ворном смысле все-таки меньше.
Синтаксически кратность задается выражением, которое является непустой
последовательностью элементов (разделенных запятыми), каждый из кото-
рых имеет следующий формат.
Нижняя граница .. ВЕРХНЯЯ ГРАНИЦА
В качестве верхней и нижней границы используются натуральные числа или
ноль. Кроме того, в качестве верхней границы может использоваться символ
*. Если нижняя граница не задана, то она опускается вместе с символами . .
(две точки).
В таблице 3.1 приведены некоторые примеры выражений кратности.
Таблица 3.1. Выражения кратности
Выражение кратности Множество может иметь
0..* Произвольное число элементов
* Произвольное число элементов (по определению эквивалентно предыдущему)
1..* Один или более элементов
0..1 Не более одного элемента
1..10 От одного до десяти элементов
1..3, 5, 7..10 Один, два, три, пять, семь, восемь, девять или десять элементов
5..3 Некорректная кратность. Нижняя граница больше верхней
-1..3 Некорректная кратность. Отрицательные числа недопустимы
Обычно на практике используются следующие варианты кратности класси-
фикаторов.
• Классификатор не имеет экземпляров (кратность 0) — такой клас-
сификатор называется службой (utility). Все составляющие службы
имеют областью действия классификатор. Хранение информации,
обрабатываемой службой, обеспечивают объекты, использующие
г 208 ]
3.1. Обьектно-ориентированноемоделирование структуры
службу. Типичный пример — набор процедур общего пользования,
скажем, библиотека математических функций. Службы использу-
ются в приложениях достаточно часто, поэтому есть даже стандарт-
ный стереотип («utility»), определяющий классификатор как службу
(см. параграф 3.2.1).
• Классификатор имеет ровно один экземпляр (кратность 1). Такой
классификатор называется одиночкой (singleton). В сущности, между
службой и одиночкой различия незначительны, но иногда одиночку
использовать удобнее, например, когда классификатор представляет
собой элемент реального мира, существующий в единственном эк-
земпляре. В качестве примера можно привести клавиатуру (суще-
ствует один экземпляр), которая подключается к компьютеру.
• Классификатор имеет фиксированное число экземпляров (напри-
мер, кратность 8). Такой вариант не часто, но встречается. Например
при моделировании портов в концентраторе.
• Классификатор имеет произвольное число экземпляров (крат-
ность *). Поскольку этот вариант встречается чаще всего, он никак
специально не указывается и подразумевается по умолчанию.
Рис. 3.4. Часть метамодели классификатора
Глава 3. Моделирование структуры
Отношения обобщения
Классификаторы (и только они, но не все!) могут участвовать в отношении
обобщения (см. параграф 3.3.2).
Резюме
Итог сказанному в этом разделе мы подведем диаграммой классов из мета-
модели UML, которая описывает само понятие классификатора и содержит
те классификаторы, которые рассматриваются в рамках моделирования
структуры (см. рис. 3.4).
3.1.5. Идентификация классов
Повторим еще раз: описание классов и отношений между ними является
основным средством моделирования структуры в UML. Но прежде чем
переходить к технике описания классов, полезно обсудить вопрос, как вы-
деляются классы, подлежащие описанию. По этому вопросу в литературе
приводится множество соображений, советов, рекомендаций и даже прин-
ципов. Само разнообразие подходов свидетельствует о том, что среди них
нет универсального и применимого во всех случаях. Мы выбрали три прие-
ма выделения классов, самых простых (можно сказать, даже примитивных),
а потому, по нашему мнению, самых действенных и широко применимых:
• словарь предметной области;
• реализация вариантов использования (см. раздел 2.4);
• образцы проектирования (см. параграф 3.5.3).
Слонарь предметной области (domain dictionary) — это набор основ-
ных понятий (сущностей) данной предметной области.
Более точного определения мы дать не можем (см. также вставку "Словарь
предметной области" в параграфе 2.2.2), зато мы можем дать легко выпол-
нимый совет. Рассмотрите внимательно текст технического задания (или
иного документа, лежащего в основе проекта) и выделите в содержательной
части имена существительные — все они являются кандидатами на то, чтобы
быть названиями классов (или атрибутов классов) проектируемой системы.
Разумеется, после этой простой операции к полученному списку нужно при-
менить фильтр здравого смысла и опыта, отсекая ненужное или добавляя
пропущенное.
Рассмотрим пример информационной системы отдела кадров. В тексте тех-
нического задания (см. параграф 2.2.1) первый вводный абзац можно отбро-
3.1. Объектно-ориентированное моделирование структуры
сить сразу — это общие слова. Суть заключена в нумерованных пунктах. Но
в этом тексте вообще все слова являются существительными (кроме сою-
зов). Выпишем их в том порядке, как они встречаются, но без повторений:
• прием;
• перевод;
• увольнение;
• сотрудник;
• создание;
• ликвидация;
• подразделение;
• вакансия;
• сокращение;
• должность.
Заметим, что некоторые их этих слов, по сути, являются названиями дей-
ствий (и по форме являются отглагольными существительными). Факти-
чески это глаголы, замаскированные особенностями родного языка. Это
ясно видно, если переписать текст технического задания в форме простых
утверждений, как рекомендуется в параграфе 2.2.3. Отбросим замаскирован-
ные глаголы. Таким образом, остается список из четырех слов:
• сотрудник;
• подразделение;
• вакансия;
• должность.
При анализе технического задания в параграфе 2.2.3 мы отметили (опира-
ясь на знание предметной области), что вакансия — это должность в особом
состоянии. Таким образом, это слово в списке лишнее и у нас остались три
кандидата, которые мы оставляем в словаре (и заодно присваиваем им ан-
глийские идентификаторы).
• Сотрудник (Person).
• Подразделение (Department).
• Должность (Position).
Рассмотрим теперь, как выявляются классы в процессе реализации вари-
антов использования (см. раздел 2.4). Если при реализации вариантов ис-
Глава 3. Моделирование структуры
пользования применяются диаграммы взаимодействия (параграф 2.4.4), то в
этом процессе в качестве побочного эффекта выделяются некоторые классы
непосредственно, поскольку на диаграммах коммуникации и последователь-
ности основными сущностями являются объекты, которые по необходимо-
сти нужно отнести к определенным классам.
Использование диаграмм деятельности (параграф 2.4.3) также может под-
сказать, какие классы нужно определить в системе, особенно если на диаграм-
ме деятельности наряду с потоком управления (control flow) присутствует
поток данных (data flow). Однако, если сценарии вариантов использования
описываются на естественном языке или псевдокоде (параграфы 2.4.1 и
2.4.2), то выделить классы значительно труднее. Фактически, если варианты
использования реализуются на псевдокоде или диаграммами деятельности
без всякой связи с объектами, то выявление объектной структуры системы
просто откладывается "на потом". Иногда это может быть вполне оправда-
но — например, архитектор, моделирующий систему, прежде чем начать про-
ектирование основной структуры классов, хочет более глубоко вникнуть в
логику бизнес-процессов незнакомой ему предметной области.
Обсудим это на примере информационной системы отдела кадров. Реали-
зация вариантов использования Self Fire и Adm Fire в параграфе 2.4.2 не дает
практически никакой информации для выделения классов. Появление двух
новых существительных ("приказ" и "заявление") наталкивает на мысль, что
в системе может появиться класс Document, но сразу ясно, что этот класс
будет пассивным хранилищем информации, не наделенным собственным
поведением, и это полезное наблюдение никак не приближает к решению
основной задачи: выявить ключевые классы в системе.
Реализация варианта использования Hire Person с помощью диаграмм дея-
тельности в параграфе 2.4.3 существенно углубляет наши знания о процессе
приема на работу, но никак не приближает нас к структуре классов приложе-
ния. Наиболее значительный прогресс в этом направлении дают диаграммы
последовательности и.коммуникации для этого же варианта использования,
приведенные в параграфе 2.4.4.
Два класса — Person и Position — те же, что нам подсказал анализ словаря пред-
метной области. Очевидно, что если одни и те же выводы получены разными
способами, доверие к ним возрастает. Полезный класс Exceptions Handler,
однако, вряд ли мог появиться из словаря: описывая предметную область,
люди склонны закрывать глаза на возможные ошибки, исключительные си-
туации и прочие неприятности.
Особого обсуждения заслуживает появление класса Hire Form, но его мы пока
оставим в стороне (до рассмотрения образцов проектирования в п. 3.5.3).
•
3.2. Сущности НА ДИАГРАММЕ КЛАССОВ
Подведем итоги. Мы полагаем, что классы в модели идентифицируются
в результате проведения трех частично независимых процессов: анализа
предметной области, согласования уже построенной модели и применения
теоретических соображений. Мы уверены, что ни одним из этих методов
нельзя пренебрегать, но одновременно утверждаем, что ни один из них не
является универсальным и самодостаточным: решающим является здравый
смысл и опыт архитектора, составляющего модель.
3.2. Сущности но диаграмме классов
Диаграмма классов является основным средством моделирования струк-
туры в UML, а класс, соответственно, основной структурной единицей.
Это совсем не удивительно и вполне естественно, поскольку UML является
в большой степени объектно-ориентированным языком. Диаграммы клас-
сов наиболее информационно насыщены но сравнению с другими типами
канонических диаграмм UML, инструменты генерируют код в основном по
описанию классов, структура классов точнее всего соответствует оконча-
тельной структуре кода приложения.
На диаграммах классов в качестве сущностей применяются, прежде всего,
классы, как в своей наиболее общей форме, так и в форме многочисленных
стереотипов и частных случаев: интерфейсы, типы данных, активные классы
и др. Кроме того, на диаграмме классов могут использоваться (как и везде)
пакеты и примечания.
В этом разделе мы рассматриваем сущности, используемые на диаграммах
классов, а в следующем разделе — отношения между этими сущностями.
3.2.1. Классы
Класс — один из самых "богатых” элементов моделирования UML.
Описание класса может включать множество различных элементов, и
чтобы они не путались, в языке предусмотрено группирование эле-
ментов описания класса по секциям (compartment). Стандартных
секций три;
• секция имени — наряду с обязательным именем может содержать
также стереотип, кратность и список именованных значений;
• секция атрибутов содержит список описаний атрибутов класса;
• секция операций - содержит список описаний операций класса.
Глава 3 Моделирование структуры
ClassName
Как и все основные сущности UML, класс обязательно имеет имя, а стало
быть, секция имени не может быть опущена. Прочие секции могут быть пу-
стыми или отсутствовать вовсе. Наряду со стандартными секциями, описа-
ние класса может содержать и произвольное количество дополнительных
секций. Семантически дополнительные секции эквивалентны комментари-
ям. Если инструмент умеет что-то делать с инфор-
мацией в дополнительных секциях, пусть делает.
В любом случае инструмент обязан сохранить эту
информацию в модели.
Нотация классов очень проста — это всегда
прямоугольник. Если секций более одной, то
внутренность прямоугольника делится горизон-
тальными линиями на части, соответствующие
Рис. 3.5. Типичная секциям (рис. 3.5).
нотация класса '
+attrlbute
-privateAttr
-fio:Strlng=”Novlkov”
-array:char[10]
+operationName()
-staticOperationQ
+function():int
Содержимым секции в любом случае является текст100. Текст внутри стан-
дартных секций должен иметь определенный синтаксис.
Секция имени класса в общем случае имеет следующий синтаксис.
«стереотип» ИМЯ {свойства} кратность
Примечание
Некоторые инструменты допускают использование несколь-
ких альтернативных вариантов синтаксиса для текстов в
секциях. Например, синтаксис описания атрибутов в стиле,
рекомендованном UML, или же в стиле целевого языка про-
граммирования данного инструмента. Такие вариации допу-
скаются стандартом при условии, что варианты синтаксиса
семантически эквиваленты и могут быть преобразованы друг
в друга без потери информации. В данной книге применяет-
ся стандартный синтаксис.
Имени класса может предшествовать стереотип. В таблице 3.2 перечислены
стандартные стереотипы классов. В этой таблице в графе "Пример" указан
номер рисунка, на котором иллюстрируется применение данного стереоти-
па. В главе 6 в таблице 6.1 приведены вообще все стереотипы UML вместе с
историей их появления и развития.
100 Некоторые инструменты позволяют помещать в секции класса не только тексты, но так-
же фигуры и значки.
_____ Ф
2I4
3.2. Сущности на диаграмме классов
Таблица 3.2. Стандартные стереотипы классов
Стереотип Описание Пример
«actor» Действующее лицо рис. 3.76
«auxiliary» Вспомогательный класс
«enumeration» Перечислимый тип данных рис. 3.7
«exception» Исключение (только в UML 1) рис. 4.31
«focus» Основной класс
«implementa- tionclass» Реализация класса
«interface» Все составляющие абстрактные рис. 3.11
«metaclass» Экземпляры являются классами рис. 1 39
«powertype» Метакласс, экземплярами которого являются все наследники данного класса (только в UML 1) рис. 3.15
«process» Активный класс
«thread» Активный класс (только в UML1)
«signal» Класс, экземплярами которого являются сигналы рис. 4.31
«stereotype» Новый элемент на основе существующего рис. 1.39
«type» Тип данных
«dataType» Тип данных рис. 3.8
«utility» Нет экземпляров, служба рис. 3.6
Обязательное имя класса может быть выделено курсивом, и в этом случае
данный класс является абстрактным, т. е. не имеющим непосредственных
экземпляров.
Примечание
Если имя подчеркнуто, то это уже не имя класса, а имя объ-
екта.
Класс, а также отдельные элементы его описания могут иметь произвольные
заданные пользователем ограничения и именованные значения (см. параграф
1.8.4). Кратность класса задается по общим правилам (см. параграф 3.1.4).
Рассмотрим пример секции имени класса для нашей информационной си-
стемы отдела кадров. Если мы предполагаем, что проектируемая информа-
ционная система отдела кадров будет использоваться на одном предприя-
тии, то хорошим решением будет определение служебного класса Company
со стереотипом «utility» для хранения глобальных атрибутов и операций ин-
«utility»
Company
Рис. 3.6. Секция имени службы
«
Глава 3. Моделирование структуры
формационной системы отдела кадров. Секция имени такого класса показа-
на на рис. 3.6.
3.2.2. Атрибуты
. __
Атрибут это именованное место (или, как говорят, слот), в кото-
ром может храниться значение.
Атрибуты класса перечисляются в секции атрибутов. В общем случае описание
атрибута имеет следующий синтаксис.
видимость ИМЯ кратность : тип = начальное_значение {свойства)
Видимость, как обычно, обозначается знаками +, -, #, ~. Еще раз подчер-
кнем, что если видимость не указана, то никакого значения видимости по
умолчанию не подразумевается.
Если имя атрибута подчеркнуто, то это означает, что областью действия
данного атрибута является класс, а не экземпляр класса, как обычно. Дру-
гими словами, все объекты — экземпляры этого класса совместно использу-
ют одно и тоже значение данного атрибута, общее для всех экземпляров. В
обычной ситуации (нет подчеркивания) каждый экземпляр класса хранит
свое индивидуальное значение атрибута.
Примечание
Подчеркивание описания атрибута соответствует опи-
сателю static, применяемому во многих объектно-
ориентированных языках программирования.
Кратность, если она присутствует, определяет данный атрибут как массив
(определенной или неопределенной длины).
Тип атрибута — это либо примитивный (встроенный) тип, либо тип, опреде-
ленный пользователем (см. параграф 3.2.4).
Начальное значение имеет очевидный смысл: при создании экземпляра дан-
ного класса атрибут получает указанное значение. Заметим, что если началь-
ное значение не указано, то никакого значения по умолчанию не подразуме-
вается. Если нужно, чтобы атрибут обязательно имел значение, то об этом
должен позаботиться конструктор класса.
Как и любой другой элемент модели, атрибут может быть наделен дополни-
тельными свойствами в форме ограничений и именованных значений.
У атрибутов имеется еще одно стандартное свойство: изменяемость (change-
ability). В табл. 3.3 перечислены возможные значения этого свойства.
---------------------•--------------------------_-------------
3.2. Сущности на диаграмме классов
Таблица 3.3. Значения свойства изменяемости атрибута
Значение Описание Примечание
{changeable} {unrestricted} Никаких ограничений на изменение значения атрибута не накладывается. Данное значение имеет место по умол- чанию, поэтому излишне указывать его в модели Первый вариант ис- пользуется в UML 1, вто- рой —BUML2
{addOnly} При изменении значения атрибута но- вое значение добавляется в массив зна- чений, но старые значения не меняются и не исчезают. Такой атрибут "помнит" историю своего изменения В UML 2 не использует- ся, т.к. семантика опре- делена нечетко
{frozen} {readonly} Значение атрибута задается при иници- ализации объекта и не может меняться Первый вариант ис- пользуется в UML 1, вто- рой в — в UML 2
Например, в информационной системе отдела кадров класс Person, скорее
всего, должен иметь атрибут, хранящий имя сотрудника. В табл. 3.4 приве-
ден список примеров описаний такого атрибута. Все описания синтаксиче-
ски допустимы и могут быть использованы в соответствии с текущим уров-
нем детализации модели.
Таблица 3.4. Примеры описаний атрибутов
Пример Пояснение
пате Минимальное возможное описание — указано только имя атрибута
+пате Указаны имя и открытая видимость — предполагает- ся, что манипуляции с именем будут производиться непосредственно
-пате: String Указаны имя, тип и закрытая видимость— манипуля- ции с именем будут производиться с помощью специ- альных операций
-пате[1..3]: String В дополнение к предыдущему указана кратность (для хранения трех составляющих: фамилии, имени и от- чества)
-пате : String="Novikov" Дополнительно указано начальное значение
+пате: String{readOnly} Атрибут объявлен не меняющим своего значения по- сле начального присваивания и открытым*
(*) В данном случае это, видимо, одно из наилучших решений: атрибут name инициализируется
конструктором при создании объекта класса Person и после этого не меняет своего значения. В
то же время к атрибуту открыт доступ (фактически только на чтение) и нет нужды в операциях для
изменения значения атрибута.
Глава 3 Моделирование структуры
3.2.3. Операции и методы
Операция — это спецификация действия с объектом: изменение зна-
чения его атрибутов, вычисление нового значения по информации,
хранящейся в объекте и т. д.
Объявление конкретной операции в классе подразумевает наличие метода
в этом же классе. Исключением является ситуация, когда операция объяв-
лена абстрактной и ее реализация содержится в подклассах.
Метод — это реализация операции, т.е. выполняемый алгоритм.
Выполнение действий, определяемых операцией, инициируется вызовом ме-
тода101.
При вызове метода могут, в свою очередь, быть вызваны методы этого же, а
также других классов.
Описания операций класса перечисляются в секции операций и имеют сле-
дующий синтаксис.
видимость ИМЯ (параметры) : тип {свойства}
Здесь слово параметры обозначает последовательность описаний параме-
тров операции, каждое из которых имеет следующий формат.
направление ПАРАМЕТР : тип = значение
Начнем по порядку. Видимость, как обычно, обозначается с помощью знаков
+, -, #, - или с помощью ключевых слов private, public, protected, package.
Подчеркивание имени означает, что область действия операции — класс,
а не объект. Например, конструкторы имеют в качестве области действия
класс. Курсивное написание имени означает, что операция абстрактная, т. е.
в данном классе ее реализация не задана и должна быть задана в подклассах
данного класса.
После имени в скобках может быть указан список описаний параметров.
Описания параметров в списке разделяются запятой. Для каждого параме-
тра обязательно указывается имя, а также могут быть указаны направление
передачи параметра, его тип и значение аргумента по умолчанию.
101 Иногда вместо слов "вызов метода" в книге используется оборот "вызов операции", что,
формально говоря, является ошибкой. Однако мы допускаем подобные вещи, если это
облегчает восприятие материала.
3.2. Сущности на диаграмме классов
ФОРМАЛЬНЫЕ ПАРАМЕТРЫ И ФАКТИЧЕСКИЕ АРГУМЕНТЫ
Исторически сложилось так, что в отечественной литературе по
программированию при описании параметров и аргументов про-
цедур и функций наблюдается терминологическая путаница и раз-
нобой. Слова "параметр" и "аргумент" часто используются как си-
нонимы, а чтобы различать, о чем идет речь: о параметре, который
назван при описании процедуры, или о значении, которое должно
быть подставлено вместо этого параметра при выполнении про-
цедуры, применяются различные неуклюжие обороты, такие как
"формальный параметр", "фактический параметр", "фактическое
значение формального параметра" и др. Некоторое время тому
назад мы (авторы и близкие коллеги) приняли соглашение, соглас-
но которому параметры всегда формальные, а аргументы всегда
фактические. Таким образом, в операторе описания процедуры
после имени процедуры в скобках идут имена параметров, а в
операторе вызова процедуры после имени процедуры в скобках
идут значения аргументов. Фактических параметров, равно как и
формальных аргументов, не бывает. Нам было очень приятно за-
метить, что в спецификации UML используется аналогичное со-
глашение, хотя это и не подчеркнуто явно. Данное соглашение
устраняет всякую путаницу, и мы придерживаемся его в этой книге
и всех других своих книгах. Надеемся, что у нас найдутся последо-
ватели.
СПОСОБЫ ПЕРЕДАЧИ ПАРАМЕТРОВ
Процедуры в языках программирования могут иметь параметры.
Наличие параметров позволяет многократно применять одну и ту
же процедуру для обработки или вычисления различных данных.
Для того чтобы использовать эту возможность, при вызове проце-
дуры нужно каким-то образом указать, откуда в данном конкрет-
ном вызове следует брать входные данные и куда нужно поме-
стить результаты. Механизм такого указания называется способом
передачи параметров.
В различных языках и системах программирования используются
разные (иногда довольно замысловатые) способы передачи пара-
метров в процедуры и функции. Мы опишем здесь два наиболее
распространенных, которые в той или иной форме используются
практически во всех языках и системах программирования: пере-
дача параметров по ссылке и по значению.
Если переменная102 передается в процедуру по ссылке, то проце-
дуре будет передан адрес этой переменной в памяти. При этом
происходит отождествление параметра процедуры и переданного
102 Обычно системы программирования запрещают передавать по ссылке константы. Это
вызвано тем, что процедура может изменить значение константы и тем самым внести
ошибку в ход дальнейших вычислений.
Глава 3. Моделирование структуры
аргумента. Тем самым вызываемая процедура, изменяя значение
аргумента, изменяет значение переданной ей переменной. Такой
способ передачи подходит для выходных параметров.
Если же переменная (или константа) передается по значению, то
компилятор создает временную копию этой переменной и именно
адрес этой переменной-копии передается процедуре. Тем самым
вызываемая процедура, изменяя значение аргумента, изменя-
ет значение переменной-копии (но не самой переменной), и эта
переменная-копия будет уничтожена после завершения работы
процедуры. Такой способ передачи подходит для входных пара-
метров.
Направление передачи параметра в UML описывае т семантическое назна-
чение параметров, не конкретизируя конкретный механизм передачи. Как
именно следует трактовать указанные в модели направления передачи i iapa-
метров, зависит от используемой системы программирования. Возможные
значения направления передачи приведены в табл. 3.5.
Таблица 3.5. Ключевые слова для описания направления передачи параметров
Ключевое слово Назначение параметра
in Входной параметр: аргумент должен быть значением, которое ис- пользуется в операции, но не изменяется
out Выходной параметр: аргумент должен быть хранилищем, в которое операция помещает значение
inout Входной и выходной параметр : аргумент должен быть хранилищем, содержащим значение. Операция использует переданное значение аргумента и помещает в хранилище результат
return Значение, возвращаемое операцией. Такое значение направления пе- редачи устанавливается автоматически для возвращаемого значения
Типом параметра операции, равно как и типом возвращаемого операцией
значения, может быть любой встроенный тип или определенный в модели
класс, интерфейс или тип данных.
Имя операции, параметры и тип результата операции, взятые вместе,
обычно называют сигнатурой (signature)
Стандарт предлагает считать сигнатурой имя операции плюс количество,
порядок и типы параметров (т. е. направление передачи параметров и их
имена, а также тип результата не входят в сигнатуру). Но это точка вариации
семантики — в конкретном инструменте может быть реализовано другое по-
нятие сигнатуры. Если сигнатуры различны, то и операции различны (даже
если совпадают имена). В одном классе не может быть двух операций с
г 220
3.2. Сущности на диаграмме классов
одной сигнатурой — модель считается противоречивой. Если в подклассе
определена операция с той же самой сигнатурой, то возможны два случая.
Если описание операции в подклассе в точности то же самое или если оно
является непротиворечивым расширением (например, в классе не был ука-
зан тип результата, а в подклассе он указан), то это повторное описание той
же самой операции. Если же описание операции с совпадающей сигнатурой
в подклассе противоречит описанию в классе (например, явно указаны раз-
личные направления передачи параметров), то модель считается противо-
речивой.
Операция имеет несколько важных свойств, которые указываются в списке
свойств как именованные значения.
• Во-первых, это параллелизм (concurrency) — свойство, определяю-
щее семантику одновременного (параллельного) вызова данной опе-
рации. В приложениях, где имеется только один поток управления,
никаких параллельных вызовов быть не может. Действительно, если опе-
рация вызвана, то выполнение программы приостанавливается в точке
вызова до тех пор, пока не завершится выполнение вызванной операции.
В однопоточных приложениях в каждый момент времени управление
находится в одной определенной точке программы и выполняется ровно
одна определенная операция. Рекурсивный вызов (т. е. вызов операции
из нее самой) не считается параллельным, поскольку при рекурсивном
вызове выполнение операции, как обычно, приостанавливается и, таким
образом, всегда выполняется только один экземпляр рекурсивной опе-
рации. Не так обстоит дело в приложениях, где имеется несколько пото-
ков управления. В таком случае операция может быть вызвана из одного
потока и в то время, пока ее выполнение еще не завершилось, вызвана из
другого потока. Значение свойства {concurrency} определяет, что будет
происходить в этом случае. Возможные варианты и их описания даны в
таблице 3.6.
Таблица 3.6. Значения свойства concurrency
Значение Описание
{sequential} Операция не допускает параллельного вызова (не является повторно-входимой). Если параллельный вызов происходит, то дальнейшее поведение системы не определено.
{guarded} Параллельные вызовы допускаются, но только один из них выполня- ется — остальные блокируются, и их выполнение задерживается до тех пор, пока не завершится выполнение данного вызова*.
{concurrent} Операция допускает произвольное число параллельных вызовов и гарантирует правильность своего выполнения. Такие операции на- зываются повторно-входимыми (reenterable).
(*) Такая семантика может породить состояние взаимной блокировки (или тупика), в которой два
или более процессов взаимно блокируют друг друга и ни один не может продолжить выполнение.
Глава 3 Моделирование структуры
• Во-вторых, операция имеет свойство {isQuery}, значение которого
указывает, обладает ли операция побочным эффектом (side-effect).
Если значение данного свойства true, то выполнение операции не меня-
ет состояния системы — операция только вычисляет значения, возвра-
щаемые в точку вызова103. В противном случае, т. е. при значении false,
операция меняет состояние системы: присваивает новые значения атри-
бутам, создает или уничтожает объекты и т. п. По умолчанию операция
имеет свойство {isQuery=true}, которое можно не указывать. Если нужно
указать, что данная операция — это функция без побочных эффектов, то
требуется написать {isQuery}.
• В-третьих, если реализация операции не должна переопределять-
ся в подклассах, то используется ограничение {leaf}. По умолчанию
{leaf=false}.
Рассмотрим примеры описания возможных операций класса Person инфор-
мационной системы отдела кадров (таблица 3.7).
Таблица 3.7. Примеры описания операций
Пример Пояснение
move Минимальное возможное описание — указано только имя операции
+move(in from, in to) Указаны видимость операции, направления пере- дачи и имена параметров
+move(in from:Department, in to: Department) Подробное описание сигнатуры: указаны види- мость операции, направления передачи, имена и типы параметров
+getName():String{isQuery} Функция, возвращающая значение атрибута и не имеющая побочных эффектов
В отличие от операции, которая может быть абстрактной, т.е. не иметь реа-
лизующего метода, и конкретной, для которой метод определен, в UML не
предусмотрена отдельная нотация для описания самого метода. Как и во
многих других подобных случаях, не нашедших отражения в нотации, ис-
пользование комментария может служить допустимой заменой.
3.2.4. Интерфейсы и типы данных
В U ML имеется несколько частных случаев классификаторов, которые, по-
добно классам, предназначены для моделирования структуры, но обладают
рядом специфических особенностей. Наиболее важными из них являются
интерфейсы и типы данных.
Интерфейс — это именованный набор составляющих, описывающий
контракт между поставщиками и потребителями услуг.
103 Такие операции традиционно называют функциями, или запросами.
3.2. Сущности на диаграмме классов
Другими словами, интерфейс — это абстрактный класс, в котором все со-
ставляющие — атрибуты и операции — абстрактны.
У читателя может возникнуть законный вопрос — что значит абстрактные
атрибуты? Отвечаем: абстрактные атрибуты интерфейса — это атрибуты,
которые обязательно должны появиться в классе, реализующем интер-
фейс.
Поскольку интерфейс — это абстрактный класс, он не может иметь непо-
средственных экземпляров.
Следующая тема для обсуждения — типы данных. Понятие типа данных и
все связанное с ним является одной из самых заслуженных и важных кон-
цепций программирования.
Тип данных — это совокупность двух вещей: множества значений
(может быть очень большого или даже потенциально бесконечного)
и конечного множества операций, применимых к данным значениям.
Чтобы понять, в чем важность данного понятия для программирования,
нужно вернуться назад, к началу истории развития программирования и
спуститься вниз, на уровень реализации и представления данных в памяти
компьютера. Допустим, что речь идет о программе на машинном языке, т. е.
последовательности команд, которые может выполнять процессор компью-
тера. Эти команды работают с ячейками памяти, в которых хранятся после-
довательности битов. Разработаны и используются методы представления в
виде последовательностей битов данных любой природы: чисел, символов,
графики и т. д.
Так вот, в наиболее распространенных в настоящее время компьютерных
архитектурах по последовательности битов в ячейке нельзя сказать, данные
какой природы закодированы в ней: это может быть и код числа, и коды не-
скольких символов, и оцифрованный звук104. Поскольку для процессора все
коды в ячейках "на одно лицо", он выполнит любую допустимую команду
над любыми данными. Например, выполнит команду умножения чисел над
кодами символов. Такая ситуация возможна по двум причинам:
• либо (наиболее вероятно) это ошибка программиста — он указал не
ту команду или не тот операнд;
• либо это хитроумный программистский трюк.
104 Следует сделать важную оговорку: это так в большинстве компьютеров, но не во всех.
Уже давно существуют и применяются компьютеры, архитектура которых такова, что
природа данных, хранимых в памяти, однозначно определяется по самим этим данным.
Как правило, это достигается тем, что вместе с данными в качестве их неотъемлемой
части хранится информация (называемая тегом) о типе этих данных.
t ____
Глава 3.. Моделирование структуры
ПРОГРАММИСТСКИЕ ТРЮКИ
Молодые, в особенности способные, программисты любят при-
менять в своих программах трюки: необычные или нестандарт-
ные приемы, требующие изобретательности и особых знаний.
Рассмотрим, например, такой оператор на языке Си:
а = ( а < b ) ? а : (Ь=(а = алЬ)лЬ)ла;
Даже человеку, хорошо знающему язык Си, нелегко с перво-
го взгляда определить, что делает этот оператор. Между тем он
выполняет простое и полезное преобразование: если значение
переменной а меньше значения переменной ь, то ничего не де-
лается, в противном случае переменные меняются значениями.
Это типичный трюк. Начинающие программисты гордятся своими
трюками (и стыдятся своих ошибок). Между тем, с точки зрения
стороннего потребителя, между трюком и ошибкой нет суще-
ственной разницы: и то и другое уменьшает надежность програм-
мы, затрудняет ее понимание и препятствует повторному исполь-
зованию. К счастью, с опытом склонность к трюкачеству обычно
проходит.
Чтобы предупредить нежелательные последствия применения команд к не-
подходящим данным, в языках программирования, особенно в языках вы-
сокого уровня, используется концепция типа данных-, элементам языка, от-
ветственным за хранение и представление данных, в частности переменным,
приписывается тип. Идея состоит в том, что элемент данного типа может со-
держать значения только этого типа и обрабатываться только процедурами,
работающими с этим типом данных.
По способу приписывания типа языки программирования подразделяются
на языки со статической типизацией, когда тип элемента языка (перемен-
ной) не может меняться во время выполнения программы, и языки с дина-
мической типизацией, в которых тип переменной может меняться по ходу
выполнения.
СТАТИЧЕСКИЙ И ДИНАМИЧЕСКИЙ КОНТРОЛЬ ТИПОВ
В языках со статической типизацией возможен статический кон-
троль типов. Суть состоит в том, что статически, т. е. до начала
выполнения программы, компилятор проверяет, что к данным
определенного типа применяются только соответствующие опе-
рации этого типа. В языках с динамической типизацией возможен
только динамический контроль типов, т. е. проверка допустимо-
сти выполнения операции производится динамически, во время
выполнения программы. Понятно, что динамический контроль
типов отрицательно сказывается на эффективности программы,
поэтому статический контроль типов предпочтительнее. Однако
____ *
3.2. Сущности на диаграмме классов
многие конструкции распространенных языков программиро-
вания, например указатели void*, не позволяют в Си проводить
полный статический контроль типов. Более того, используются
такие конструкции, которые вообще не позволяют автоматически
проверять тип, например union в том же Си или record case в
Паскале. Таким образом, типизация и контроль типов являются,
несомненно, полезными концепциями, повышающими надеж-
ность программ, но они не всеобъемлющи и не дают полной га-
рантии от ошибок.
UML не является сильно типизированным языком: например, в модели
можно указывать типы атрибутов классов и параметров операций, но это
не обязательно. Инструмент может проверять соответствие типов, если они
указаны, но не обязан этого делать. (Контроль типов — еще один пример точ-
ки вариации семантики в языке). Такое решение принято в расчете на то,
что UML используется совместно с разными языками программирования,
использующими различные концепции типизации и типового контроля, и
навязывание одной конкретной модели ограничило бы применение UML.
Здесь уместно дать точные ответы на два важных вопроса.
• Для каких элементов модели можно указать тип?
• Что можно использовать в качестве типа?
Ответ на первый вопрос разбросан по тексту книги. Сконцентрируем здесь
необходимые ссылки. В UML типизированы могут быть:
• атрибуты классов (см. раздел 3.2.2), в том числе классов ассоциаций
(см. раздел 3.3.7);
• параметры операций, в том числе тип возвращаемого значения (см.
раздел 3.2.3);
• роли полюсов ассоциаций (см. раздел 3.3,6);
• квалификаторы полюсов ассоциаций (см. раздел 3.3.7);
• параметры шаблонов (см. раздел 3.2.5).
Ответ на второй вопрос — что же можно указать в качестве типа — с одной
стороны, очень лаконичен, а с другой стороны, требует дополнительного об-
суждения. Лаконичный ответ звучит так: тип указывается с помощью клас-
сификатора.
Обсудим это. Если типы составляющих одного классификатора указыва-
ются с помощью других классификаторов, то возможны два варианта: либо
мы имеем замкнутую систему взаимно рекурсивных определений, которые
не нуждаются ни в каких внешних сущностях, либо мы имеем некоторый
Ф
Глава 3 Моделирование структуры
набор заранее определенных классификаторов, которые используются как
базовые для определения остальных.
Первый подход (абсолютно все определяется в рамках одной системы) ка-
жется соблазнительным, но, к сожалению, он никуда не ведет. Подробное
обсуждение этого факта, хотя и поучительное с теоретической точки зрения,
увело бы нас слишком далеко от основной темы книги. Мы сошлемся на ав-
торитет: в распространенных языках программирования так не делают.
В UML, так же как в распространенных языках программирования и других
формальных системах, имеется набор базовых классификаторов, с помощью
которых определяются типы элементов модели, в частности типы составля-
ющих других классификаторов. Это типы данных.
В модели UML можно использовать три вида типов данных.
• Примитивные типы (PrimitiveType), которые считаются предопре-
деленными в UML. Таковыми являются следующие: целочислен-
ный тип (Integer), булевский тип (Boolean), строковый тип (String).
Существует еще один дополнительный тип, который описыва-
ет множество (неограниченных по величине) натуральных чисел
(UnlimitedNatural). Используется этот тип в основном для указания
кратности той или иной сущности. Инструменты вправе расширять
этот набор и использовать другие подходящие названия.
• Типы данных, которые определены в языке программирования,
поддерживаемым инструментом. Это могут быть как названия встро-
енных типов, так и сколь угодно сложные выражения, доставляющие
тип, если таковые допускаются языком.
• Типы данных, которые определены в модели пользователем.
Данные типы представляются в виде классификаторов со стереоти-
пом «enumeration» или «dataType».
Особого внимания заслуживает перечислимый
тип данных (enumeration). Например, тип
Boolean определен в UML как перечислимый
тип со значениями true и false. Если в проек-
тируемом приложении нужно использовать не
обычную двузначную логику, а трехзначную, то
тогда соответствующий тип можно определить
так, как показано на рис. 3.7.
Наряду со стереотипом «enumeration» исполь-
зуется стереотип «dataType». Различие между
«enumeration»
3Logic
yes
no
unknown
+ -n-i(a: 3Luyic. b:
+urta:3Loyjc, b:3Lt.<Mc):31-oqic
Рис. 3.7. Перечислимый тип
данных "Трехзначнаялогика"
3.2. Сущности на диаграмме классов
этими стереотипами заключается в том, что при использо-
вании «enumeration» всем возможным значениям присваи-
ваются имена, в то время как «dataType» просто определяет
тип. Пример использования стереотипа «dataType» приве-
ден на рис. 3.8.
Возникает вопрос: чем же типы данных отличаются от про-
чих классификаторов UML?
«dataType»
Real
Рис. 3.8. Тип
данных "Дей-
ствительное
число"
Тип данных (в UML) — это классификатор, экземпляры которого нс
обладают индивидуальностью (identity) ‘°®.
Это довольно тонкое понятие, которое мы попробуем объяснить на примере.
Рассмотрим какой-нибудь встроенный тип данных в обычном языке про-
граммирования, например тип integer в языке Паскаль. Значения этого
типа (экземпляры классификатора) изображаются обычным образом, на-
пример 3. Что будет, если число "три" используется в нескольких местах
программы? Будут ли отличатся чем-нибудь экземпляры изображения 3?
Очевидно, нет. Экземпляры числа "три" типа integer не обладают инди-
видуальностью, мы вправе считать, что написанные в разных местах изобра-
жения числа 3 суть одно и то же число, а компилятор вправе использовать
для хранения представления числа "три" одну и ту же ячейку, сколько бы
изображений числа 3 ни присутствовало в программе. Далее, программисту
не нужно предусматривать никаких инициализирующих действий, для того
чтобы воспользоваться числом 3 — не нужно определять никаких объектов,
не нужно вызывать никаких конструкторов. Можно считать, что все значе-
ния типа данных уже определены и всегда существуют, независимо от про-
граммы. Более того, с числом "три" ничего не может случиться — что бы ни
происходило в программе, число "три" останется числом "три" и никогда не
станет числом "пять"105 106.
Сопоставим сказанное с обычным классом, экземпляры которого обладают
индивидуальностью. Допустим, в классе CInteger есть только один атри-
бут, который хранит целое значение. На первый взгляд, такой класс ничем
не отличается от типа данных integer — экземпляры данного класса впол-
не можно использовать как целые числа. Но это поверхностное впечатление:
105 Мы используем термин "индивидуальность", хотя семантически он не точен. Более точ-
ным является неологизм "самость", но это слово частенько используется в оккультной и
мистической литературе, и мы воздержимся от его употребления.
106 В самых ранних реализациях языка Фортран это было не так. Там можно было опреде-
лить подпрограмму subroutine s ( integer х ) х = х + 2 end, а в другом месте
программы вызвать ее call s ( 3 ), после чего число "три" стало бы числом "пять" со
всеми вытекающими ошибками и неприятностями, которые бывало очень трудно обна-
ружить.
Глава 3. Моделирование структуры
между типом данных integer и классом CInteger много существенных
отличий. Во-первых, экземпляры класса CInteger должны быть явно соз-
даны и инициализированы, прежде чем их можно будет использовать в про-
грамме. Во-вторых, экземпляр класса CInteger, который в данный момент
хранит число "три", через некоторое время выполнения программы может
хранить число "пять", оставаясь при этом тем же самым экземпляром, по-
скольку он обладает индивидуальностью. В-третьих, в программе может
быть определено несколько экземпляров класса CInteger, которые хранят
одно и то же число "три", и это будут разные объекты (компилятор разме-
стит их в разных областях памяти), поскольку они обладают индивидуаль-
ностью.
Отсутствие индивидуальности107 экземпляров типа данных влечет некото-
рые общепринятые ограничения на операции типа данных.
Было бы нелепо, если бы операция сложения для числа "три” работала бы
по иному алгоритму, нежели операция сложения для числа "пять". Поэтому
областью действия операций типа всегда является классификатор, а не эк-
земпляр (в модели они подчеркнуты, см. рис. 3.7).
Естественно считать, что операции типа данных не имеют побочных эффек-
тов, т. е. их применение не меняет состояния системы. В принципе мож-
но допустить, что операция сложения чисел помимо вычисления значения
суммы делает какое-то невидимое волшебное действие, например, меняет
значение какой-то глобальной переменной. Но такие операции, как нам ка-
жется, не дают ничего, кроме ненужных сложностей и трудностей108. Поэто-
му операции типа данных всегда обладают свойством {isQuery}.
Типы данных и их операции — это базовые, элементарные конструкции
языков программирования. Разумно предположить, что они реализованы
предельно эффективно109. С точки зрения моделирования их выполнение
можно считать мгновенным и атомарным действием. Довольно странно тре-
бовать от операции сложения, чтобы она обладала способностью параллель-
но и одновременно со сложением одной пары чисел складывать и другие
пары. Поэтому операции типов данных считаются не повторно входимыми
и обладают свойством {sequential}.
107 В этом контексте ясно видно, почему слово "индивидуальность" не является в данном
случае семантически точным переводом термина identity. Каждое значение типа данных
обладает индивидуальностью в общепринятом смысле этого слова: число "три" — это
не число "пять".
108 В нашем распоряжении есть только один очень частный контрпример: операция delay
задержки типа данных дата/время, которая ничего не вычисляет, а имеет побочный эф-
фект в виде строго определенного времени своего выполнения. Но исключения только
подтверждают правило.
109 Для обычных типов данных языков программирования и распространенных архитектур
компьютера операция — это, как правило, одна машинная команда.
г 223 ]
3.2. Сущности на диаграмме классов
Есть еще одно замечание относительно операций типов данных, которое, од-
нако, не является общепринятым, а отражает авторские предпочтения. Опе-
рации типа данных принадлежат типу в целом, а не отдельным экземплярам
(значениям) типа. Поэтому мы считаем целесообразным явным образом
передавать в качестве аргументов все объекты, над которыми выполняется
операция типа данных, и не использовать объект this. С нашей точки зрения
выражение ог(а,Ь) лучше выражения а.ог(Ь). Поэтому операции на рис. 3.7
имеют по два параметра, а не по одному110.
3.2.5. Шаблоны
Еще одной сущностью, которая чаще всего используется на диаграмме клас-
сов, являются шаблоны.
Шаблон — это сущность (чаще всего классификатор) с параметрами.
Параметром может быть любой элемент описания классификатора — тип
составляющей, кратность атрибута и т. д. На диаграмме шаблон изобража-
ется с помощью стандартной нотации классификатора — прямоугольника, к
которому в правом верхнем углу присоединен пунктирный прямоугольник
с параметрами шаблона. Описания параметров, а точнее только их имена,
перечисляются в этом прямоугольнике через запятую.
Сам по себе шаблон не может непосредственно использоваться в модели.
Для того чтобы на основе шаблона получить конкретный экземпляр клас-
сификатора, который может использоваться в модели, нужно указать явные
значения аргументов. Такое указание называется связыванием (binding).
В UML применяются два способа связывания:
• явное связывание — зависимость со стереотипом «bind», в которой
указаны значения аргументов;
• неявное связывание — определение класса, имя которого имеет фор-
мат
имя_классификатора : имя шаблона < аргументы >
Рассмотрим пример, связанный с информационной системой отдела кадров.
Предположим, нам требуется указать, что для хранения различных видов
данных мы будем использовать классы, полученные из шаблонного класса
(template class) Array. На рис. 3.9 определен шаблон Array (1), имеющий два
параметра: п и Т. Этот шаблон применяется для создания массивов опре-
110 Если бы это был обычный класс, а не тип данных, наши операции имели бы по одному
параметру.
Глава 3 Моделирование структуры
-items[n]:T
------7Г~
Array
Position
«bind»
<n->256, T->Position>
Positions:
Array <n->256, T—>Position>
Рис. 3.9. Явное и неявное связывание шаблона
деленной длины п, содержащих элементы определенного типа Т. В данном
случае с помощью явного (2) и неявного (3) связывания показано два экви-
валентных способа определения класса Positions в виде массива из 256 эле-
ментов типа Position.
Назначение и область применения шаблонов понятны — шаблоны нуж-
ны, чтобы определить некоторую общую параметрическую конструкцию
классификатора один раз и затем использовать ее многократно, подстав-
ляя конкретные значения аргументов. Явное связывание более наглядно,
неявное связывание менее наглядно, зато записывается короче.
Примечание
Использование шаблонов — самостоятельная парадиг-
ма, '‘которая поддерживается UML наряду с объектно-
ориентированной.
МЕТАПРОГРАММИРОВАНИЕ НА ШАБЛОНАХ
Интересное применение нашли шаблоны в языке C++. Оказалось,
что шаблоны в этом языке являются универсальной моделью вы-
числимости. Другими словами, на шаблонах C++ можно напи-
сать программу, реализующую произвольный алгоритм, и
эта программа выполнится в момент компиляции. К примеру,
можно посчитать максимальное число Фибоначчи (см. параграф
3.1.1). Тогда во время выполнения программы не придется тратить
время на вычисление этого числа. Одной интересной особенно-
стью такого программирования на шаблонах является встроенный
механизм сохранения результата вычисления функции в па-
мяти, позволяющий избегать повторного вычисления этого
же самого значения функции11'. Это значит, что рекурсивный
111 Некоторые авторы используют для обозначения данного механизма термин "мемоиза-
ция”.
3-3- Отношения на диаграмме классов
алгоритм для вычисления к-го числа Фибоначчи, работающий "в
лоб”, сделает порядка к операций (вместо ожидаемых 2к). Но это
не самое интересное: программирование на шаблонах C++ по-
зволяет общаться с типом как с обычным объектом. К примеру,
можно составить список всех типов, удалить из него все встроен-
ные типы, а из оставшегося списка создать объект, который будет
унаследован от всех типов из данного списка. Для такого мета-
программирования была написана специальная библиотека MPL
(Meta Programming Library).
На этом мы заканчиваем обсуждение сущностей на диаграмме классов. Все
что нам осталось сделать, — привести диаграмму метамодели для основных
структурных сущностей (рис. 3.10).
Рис. 3.10. Метамодель структурных сущностей
3.3. Отношения но диаграмме классов
Сущности на диаграммах классов связываются главным образом отноше-
ниями ассоциации (в том числе агрегирования и композиции) и обобщения.
Отношения зависимости и реализации на диаграммах классов применяются
реже, но тем не менее они также применяются, и мы начнем с них как с более
простых.
3.3.1. Отношения зависимости и реализации
Всего в UML определено довольно большое количество стандартных сте-
реотипов отношения зависимости, которые можно разделить на несколько
групп:
е ___
' 231
Глава 3. Моделирование структуры
• между классами и объектами на диаграмме классов;
• между пакетами;
• между вариантами использования;
• другие.
Здесь рассматриваются зависимости первой группы, которые перечислены
в табл. 3.8.
Таблица 3.8. Стандартные стереотипы зависимостей на диаграмме классов
Стереотип Описание Пример
«bind» Подстановка параметров в шаблон. Независимой сущно- стью является шаблон (класс с параметрами), а зависи- мой — класс, который получается из шаблона заданием ар- гументов. рис. 3.9
«call» Указывает зависимость между двумя операциями: операция зависимого класса вызывает операцию независимого клас- са. рис. 3.11
«derive» Буквально означает "может быть вычислен по". Зависимость с данным стереотипом применяется не только к классам, но и к другим элементам модели: атрибутам, ассоциациям и т.д. Суть состоит в том, что зависимый элемент может быть восстаноален по информации, содержащейся в независи- мом элементе. Таким образом, данная зависимость пока- зывает, что зависимый элемент, вообще говоря, излишен и введен в модель из соображений удобства, наглядности и т.д. параграф 3.3.5
«friend» Назначает специальные права видимости. Зависимый класс имеет доступ к составляющим независимого класса, даже если по общим правилам видимости такие права у него от- сутствуют. сноска на стр. 206
«instance Of» Указывает, что зависимый объект (или класс) является эк- земпляром независимого класса (метакласса). рис. 3.78
«instantiate» Указывает, что операции независимого класса создают эк- земпляры зависимого класса. рис. 3.78
«powertype» Показывает, что экземплярами зависимого класса являются подклассы независимого класса. Таким образом, в данном случае зависимый класс является метаклассом. параграф 3.3.2
«refine» Указывает, что зависимый класс уточняет (конкретизирует) независимый. Данная зависимость показывает, что связан- ные классы концептуально совпадают, но находятся на раз- ных уровнях абстракции. рис. 1.12
«use» Зависимость самого общего вида, показывающая, что зави- симый класс каким-либо образом использует независимый класс. рис. 1.6
Повторим еще раз, что зависимости на диаграммах классов используются
сравнительно редко, потому что имеют более расплывчатую семантику по
3.3. Отношения на диаграмме классов
сравнению с ассоциациями и обобщением. Рассмотрим отношение реализа-
ции.
Между интерфейсами и другими классификаторами, в частности,
классами, на диаграмме классов применяются два отношения:
* классификатор (н частное hi, класс) используе т интерфейс >го
показывается с помощью зависимости со стереотипом «ерй»;
• классификатор (в частности, класс) реализует интерфейс это
показывается с помощью отношения реализации.
Никаких ограничений на использование отношения реализации не накла-
дывается: класс может реализовывать много интерфейсов, и наоборот, ин-
терфейс может быть реализован многими классами. Нет ограничений и на
использование зависимостей со стереотипом «call» — класс может вызывать
любые операции любых видимых интерфейсов. Семантика зависимости со
стереотипом «call» очень проста — эта зависимость указывает, что в опера-
циях класса, находящегося на независимом полюсе, вызываются операции
класса (в частности, интерфейса), находящегося на зависимом полюсе.
Рассмотрим пример из информационной системы отдела кадров. Допустим,
что класс Department для реализации операций связанных с движением ка-
дров, использует операции класса Position, позволяющие занимать и осво-
бождать должность — другие операции класса Position классу Department
не нужны. Для этого, как показано на рис. 3.11 можно определить соот-
ветствующий интерфейс (Position и связать его отношениями с данными
классами.
Рис. 3.11. Отношения реализации
и использования интерфейсов
Рис. 3.12. Использование
нотации "чупа-чупс"
Используя нотацию "чупа-чупс", появившуюся в UML 2, эту же модель
можно изобразить лаконично, симметрично и просто, как показано на
рис. 3.12.
Г лава 3 Моделирование структуры
3.3.2. Отношение обобщения
Отношение обобщения (параграф 1.4.2) часто применяется на диаграмме
классов. Действительно, трудно представить себе ситуацию, когда между
классами в одной системе нет ничего общего. Как правило, общее есть, и это
общее целесообразно выделить в отдельный класс. При этом общие состав-
ляющие, собранные в суперклассе, автоматически наследуются подкласса-
ми.
ОБОБЩЕНИЕ И НАСЛЕДОВАНИЕ
Термины "обобщение” и "наследование" часто используются как
синонимы, но на самом деле это различные, хотя и связанные друг
с другом концепции. Обобщение — отношение классифика-
ции, оно описывает то, чем является данный элемент, к ка-
кому типу он относится. В естественных науках используется эк-
вивалентный термин "таксономия". Наследование — механизм
объединения описаний для получения полного дескриптора
элемента. Возможны различные способы реализации наследо-
вания. В большинстве объектно-ориентированных языков, и в UML
в том числе, наследование основано на обобщении, однако есть
языки, в которых используются другие механизмы реализации на-
следования.
Использование обобщений сокращает суммарное количество описаний, а
значит, уменьшается вероятность допустить ошибку и не ограничивает сво-
боду проектировщика системы, поскольку унаследованные составляющие
можно переопределить в подклассе. Для указания того, что та или иная со-
ставляющая переопределена в подклассе, следует использовать появив-
шееся в UML 2 дополнение {redefines} (см. рис. 3.14) .
НАСЛЕДОВАНИЕ ИНТЕРФЕЙСА И РЕАЛИЗАЦИИ
Отношение обобщения (в UML) возможно между классификатора-
ми одного вида (классами, вариантами использования, ассоциа-
циями и т.д.).
Данное отношение, описываемое на этапе проектирования, при
реализации на объектно-ориентированном языке программи-
рования выражается через наследование. Наследование (обыч-
но) бывает одного из трех видов: открытое (public), защищенное
(protected) и закрытое (private). В зависимости от вида наследо-
вания составляющие суперкласса меняют свою область видимо-
сти в подклассах (и всех их подклассах). Эти правила описываются
в спецификации конкретного языка программирования и не явля-
ются предметом данного обсуждения.
3.3 Отношения на диаграмме классов
Открытое наследование — это и есть способ реализации от-
ношения обобщения.
При этом подразумевается, что выполняется принцип подста-
новки, сформулированный Барбарой Лисков (Liskov substitution
principle). Суть данного принципа заключается в том, что экзем-
пляр подкласса может использоваться везде, где используется
экземпляр его суперкласса, поддерживая таким образом кон-
тракт, предлагаемый суперклассом (см. врезку "Проектирование
по контракту” в параграфе 3.4.1). Или другими словами, подкласс
предлагает тот же интерфейс, что и суперкласс, те. происходит
наследование интерфейса.
Закрытое наследование, в противоположность открытому,
накладывает на подкласс ограничения, препятствующие
клиентам подкласса обращаться к нему через методы, объ-
явленные в суперклассе. Эти методы попросту отсутствуют в
видимом извне списке методов подкласса.
Таким образом, ни о каком наследовании интерфейса в этом слу-
чае речь не идет. Задача закрытого наследования — позволять
внутри подкласса вызывать методы суперкласса, т.е. использо-
вать уже существующую реализацию. В этом случае мы говорим
о наследовании реализации. Закрытое наследование никак в UML
не представлено112, хотя и полезно в некоторых ситуациях.
Рассмотрим, например, случай, когда имеется готовая реализа-
ция связанного списка (класс List) и на базе этой реализации тре-
буется реализовать стек — структуру данных с методом доступа
"последним пришел— первым вышел" (класс Stack). Очевидно,
что стек — не что иное, как специализация связанного списка, и
поэтому для решения задачи достаточно использовать отноше-
ние обобщения между классами Stack и List (см. левую часть рис.
3.13).
Однако проблема заключается в том, что при таком подходе все
открытые методы класса List становятся доступны клиентам клас-
са Stack. Среди этих методов может быть, например, метод, по-
зволяющий вставить элемент данных в середину списка, что не
соответствует логике поведения стека.
На выручку в этом случае приходит наследование реализации (за-
крытое наследование), которое может быть выражено альтерна-
тивным способом, а именно через отношение ассоциации (см.
правую часть рис. 3.13). При этом все вызовы методов класса
Stack попросту делегируются соответствующим методам класса
List, фактически скрывая интерфейс класса List, но используя его
реализацию.
112 Хотя, как и любое другое понятие, не поддерживаемое UML напрямую, может быть под-
робно описано в текстовом примечании, или описано через стереотипы.
Глава 3. Моделирование структуры
Рис. 3.13. Варианты реализации класса Stack
При обобщении113 выполняется принцип подстановки, что фактически
означает увеличение гибкости и универсальности программного кода, при
одновременном сохранении надежности, обеспечиваемой контролем типов.
Действительно, если, например, в качестве типа параметра некоторой про-
цедуры указать суперкласс, то процедура будет с равным успехом работать
в случае, когда в качестве аргумента ей передан объект любого подкласса
данного суперкласса. Суперкласс может быть конкретным, идентифициро-
ванным одним из методов, описанных в параграфе 3.1.5, а может быть аб-
страктным, введенным именно для построения отношений обобщения.
По умолчанию обобщения являются подстановочными (substitutable),
т.е. удовлетворяют принципу подстановки. Однако в UML существуют и
неподстановочные обобщения, для которых соответственно принцип под-
становки не выполняется. Никакой специальной нотации для таких обоб-
щений не предусмотрено, однако инструменты должны уметь поддерживать
данное свойство отношения обобщения, которое называется isSubstitutable.
Рассмотрим пример.
| ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Каждая структурная единица предприятия (подразделение, должность) '
должна иметь свое название.
В информационной системе отдела кадров мы выделили классы Position,
Department и Person (см. параграф 3.1.5). Для всех этих классов может быть
указан атрибут, содержащий собственное имя объекта, выделяющее его
в ряду однородных. Для простоты положим, что такой атрибут имеет тип
String114. В таком случае можно определить суперкласс, ответственный за
хранение данного атрибута и работу с ним, а прочие классы связать с супер-
113 Имеется в виду открытое наследование.
114 Существуют организации, в которых подразделения не именуются, а нумеруются (или
даже имеют шифрованные имена), например, из соображений секретности. Но наша
информационная система отдела кадров не предназначена для организаций со столь
строгим режимом.
_____ Ф
3.3. Отношения на диаграмме классов
классом отношением обобщения. Однако более пристальный анализ пред-
метной области наводит на мысль, что работа с собственным именем для
выделенных классов производится не совсем одинаково. Действительно,
назначение и изменение собственных имен подразделениям и должностям
находится в пределах ответственности информационной системы отдела
кадров, но назначение (тем паче изменение) собственного имени сотруд-
ника явно выходит за эти пределы115. Исходя из этих соображений, мы при-
ходим к структуре обобщений, представленной на рис. 3.14.
Операция setName(), объявленная в классе Unit, переопределена для класса
Person. На это указывает заключенное в фигурные скобки и следующее за
определением операции дополнение redefines (1). Переопределение состоит
в том, что значение видимости для операции setName() изменено с "откры-
тая" на "закрытая".
Обратите внимание, что суперкласс Unit определен как абстрактный, т. е. не
имеющий возможности иметь непосредственные экземпляры, поскольку в
системе не предполагается иметь объекты данного класса. Экземпляры су-
ществуют для конкретных подклассов Department, Position и Person. Класс
Unit в данном случае нужен только для того, чтобы свести описания одного
атрибута и двух операций в одном месте и не повторять их дважды.
В объектно-ориентированном программировании распространена идиома,
согласно которой корневые интерфейсы (классы) иерархий определяют
Рис. 3.14. Отношение обобщения
115 Бывают случаи, когда собственные имена сотрудников организации также назначают-
ся — обычно такие имена называют кличками (никами), но наша информационная си-
стема отдела кадров также не предназначена для подобных организаций.
Глава 3 Моделирование структуры
абстрактную операцию, переопределяемую в подклассах, которая во время
исполнения возвращает некоторую информацию о конкретном экземпляре
созданного подкласса. Данную информацию можно использовать, напри-
мер, для тестирования или в операциях безопасного приведения типов.
Мы также ввели подобную операцию в абстрактном классе Unit, преследуя
при этом только одну цель — продемонстрировать читателю отношение
между понятиями абстрактная операция (2) и операция с методом (3), рас-
смотренными в параграфе 3.2.3.
Отношения обобщения можно задавать в UML довольно свободно, но не
совсем произвольно. Обобщения в модели должны образовывать строгий
частичный порядок.
ОТНОШЕНИЯ ПОРЯДКА
Антисимметричное транзитивное отношение (см. начало раз-
дела 1.4, вставка "Множества, отношения и графы") называется
отношением порядка. Если свойство полноты выполняется, то
порядок называется линейным, а если, напротив, не выполняет-
ся, то частичным. Если вдобавок выполняется свойство антиреф-
лексивности, то порядок называется строгим, в противном слу-
чае — нестрогим. Отношения порядка встречаются очень часто и
играют важную роль во многих областях. Например, отношение <
на множестве действительных чисел является строгим линейным
порядком, а отношение < — нестрогим линейным порядком. От-
ношение "быть потомком" на множестве людей является строгим
частичным порядком. Отношение включения с на множестве под-
множеств данного множества является нестрогим частичным по-
рядком.
Нетрудно показать, что в орграфе, соответствующем отношению
порядка, нет контуров (разве что петли, если порядок нестрогий).
Отсюда немедленно следует, что в конечном упорядоченном мно-
жестве есть минимальные и максимальные элементы. В орграфе
им соответствуют узлы, в которые не входят дуги (источники), и
узлы, из которых не исходят дуги (стоки). Минимальных и макси-
мальных элементов в частично упорядоченном множестве может
быть несколько. В конечном линейно упорядоченном множестве
ровно один максимальный и ровно один минимальный элемент.
Если же имеется ровно один максимальный элемент и несколько
минимальных, то это дерево (иерархия), которое также является
частным случаем отношения порядка.
3.3. Отношения на диаграмме классов
Таким образом, в LML допускается, чтобы класс был подклассом
нескольких суперклассов (множественное наследование), не тре-
буете#^ чтобы у базовых классов был общий суперкласс (несколько
иерархий обобщения) и вообще не накладывается никаких ограни-
чений, кроме строгой частичной упорядоченности (т. е. отсутствия
циклов в цепочках обобщений).
Нарушение данного условия является синтаксической ошибкой, однако не
все инструменты проверяют это условие — цикл может быть незаметен, по-
тому что отдельные дуги цикла обобщений могут быть показаны на разных
диаграммах.
При множественном наследовании (multiple inheritance) возможны кон-
фликты: суперклассы содержат составляющие, которые невозможно вклю-
чить в один подкласс, например, атрибуты с одинаковыми именами, но
разными типами. В UML конфликты при множественном наследовании
считаются нарушением правил непротиворечивости модели (параграф
1.8.2). Если же конфликты отсутствуют, то множественное наследование
в UML не только не запрещается, но даже поощряется! В частности, мета-
модели в стандарте изобилуют примерами множественного наследования.
Примечание
Несмотря на те сложности, которые существуют при исполь-
зовании и в реализации поддержки множественного насле-
дования, его не стоит бояться. Как заметил один из авторов
UML (Гради Буч), "проблема множественного наследования
находится в головах у архитекторов, а не в языке моделиро-
вания".
В UML существует возможность выделять в множестве обобщений под-
множества (generalization set) и задавать ограничения для них.
Рассмотрим следующий (несколько искусственный) пример для инфор-
мационной системы отдела кадров. Допустим, что для экземпляров класса
Person требуется смоделировать такие характеристики, как пол (Gender) и
служебное положение (Employment Status). Подклассы Male Person и Female
Person будут описывать пол сотрудника, a Employer и Employee, соответ-
ственно, его служебное положение.
Тогда данную ситуацию можно описать с помощью диаграммы, приведен-
ной на рис. 3.15.
Глава ^Моделирование структуры
Рис. 3.15. Подмножества обобщений
Классификация по полу является завершенной и дизъюнктной. Классифи-
кация по служебному положению, напротив, не является ни завершенной,
ни дизъюнктной116.
На рис. 3.15 использована нотация, принятая в UML 2. Та же диаграмма,
нарисованная по правилам UML 1, имела бы несколько отличий, а имен-
но классы Gender и Employment Status были бы объявлены со стереотипом
«powertype»117, и каждый из них был бы соединен ассоциацией с классом
Person.
Имена подмножеств обобщений указываются после двоеточия рядом с
обобщением, а в случае, если надо охватить несколько обобщений, то при-
меняется нотация в виде пунктирной линии, как это сделано для подмноже-
ства Employment Status. Помимо имени подмножества можно указать накла-
дываемые на подмножество ограничения (или их комбинацию). Возможные
варианты ограничений приведены в таблице 3.9.
Таблица 3.9. Ограничения на подмножество обобщений
Ограничения Применение
{complete} (полнота) Множество обобщений, входящих в подмножество, является пол- ным, т.е. определяет все возможные подтипы для данной харак- теристики суперклассификатора. Каждый экземпляр суперклас- сификатора должен быть экземпляром какого-либо подкласси- фикатора
{incomplete} (неполнота) Множество обобщений, входящих в подмножество, не являет- ся полным, т.е. определяет только часть возможных подкласси- фикаторов для данной характеристики суперклассификатора. Некоторый экземпляр суперклассификатора может не являться экземпляром ни одного подклассификатора из множества
116 Владелец компании (employer) может быть и работником компании (employee).
117 Который объявлен устаревшим в UML 2.
[240]
3.3. Отношения на диаграмме классов
{disjoint} (несовместность) Области значений подклассификаторов, входящих в данное под- множество не пересекаются, т.е. являются взаимоисключающи- ми. У них не может быть общего прямого или косвенного экзем- пляра
{overlapping} (совместность) Области значений подклассификаторов могут пересекаться, т.е. они не являются взаимоисключающими. У них может быть общий прямой или косвенный экземпляр.
Как видно из описания, приведенного выше, пары {complete} - {incomplete} и
{disjoint} - {overlapping} являются взаимоисключающими, т.е. не может быть
одновременно множество и {complete}, и {incomplete}. Значения ограниче-
ний по умолчанию — {incomplete, disjoint}.
Перед тем как приступить к описанию наиболее часто используемого от-
ношения — отношения ассоциации, подведем итог сказанному с помощью
диаграммы метамодели отношений зависимости, реализации и обобщения
(рис. 3.16).
Рис. 3.16. Метамодель отношений зависимости, реализации и обобщения
3.3.3. Ассоциации и их дополнения
Отношение ассоциации является, видимо, самым важным на диаграмме
классов. В общем случае ассоциация, нотация которой — сплошная линия,
соединяющая классы, означает, что экземпляры одного класса связаны с эк-
земплярами другого класса. Поскольку экземпляров может быть много, и
каждый может быть связан с несколькими, ясно, что ассоциация является
дескриптором, который описывает множество наборов связанных объек-
Г лава 3. Моделирование структуры
тов. В UML ассоциация является классификатором, экземпляры которого
называются связями.
Связь (link) — это экземпляр ассоциации (или соединителя), который
представляет собой упорядоченный набор (кортеж, tuple) ссылок на
экземпляры классификаторов на полюсах ассоциации.
Связь между объектами (экземплярами классов) в программе может быть
организована самыми разными способами. Например, в объекте одного клас-
са может храниться указатель или ссылка на объект другого класса. Связь
не обязательно является непосредственно хранимым физическим адресом.
Этот адрес может динамически вычисляться во время выполнения програм-
мы на основании другой информации. Например, если объекты представле-
ны как записи в таблице базы данных, то связь означает, что в записи одного
объекта имеется поле, значением которого является первичный ключ записи
другого объекта (из другой таблицы). Еще пример: использование какого-
либо механизма динамического связывания по имени (уникальному иден-
тификатору) объекта.
При моделировании на UML техника реализации связи между объектами не
имеет значения. Ассоциация в UML подразумевает лишь то, что связанные
объекты обладают достаточной информацией для организации взаимодей-
ствия. Возможность взаимодействия означает, что объект одного класса
может послать сообщение объекту другого класса, в частности, вызвать
метод или же прочитать или изменить значение открытого атрибута. По-
скольку в объектно-ориентированной программе такого рода действия и
составляют суть выполнения программы, моделирование структуры взаи-
мосвязей классов (т. е. выявление ассоциаций) является одной из ключевых
задач моделирования.
Как уже было сказано, базовая нотация ассоциации (сплошная линия) по-
зволяет указать, что объекты ассоциированных классов могут взаимодей-
ствовать во время выполнения. Но это только малая часть того, что можно
моделировать с помощью отношения ассоциации. Для ассоциации в UML
предусмотрено наибольшее количество различных дополнений, которые
мы сначала перечислим, а потом рассмотрим по порядку. Дополнения, как
обычно, не являются обязательными: их используют при необходимости, в
различных ситуациях по-разному. Если использовать все дополнения сразу,
то диаграмма становится настолько перегруженной, что ее трудно читать.
Итак, для ассоциации определены следующие дополнения:
• имя ассоциации (возможно, вместе с направлением чтения) (см. па-
раграф 3.3.4);
3.3. Отношения на диаграмме классов
• кратность полюса1’8 ассоциации (см. параграф 3.3.4);
• агрегация или композиция (см. параграф 3.3.5);
• переопределение полюса ассоциации (см. параграф 3.3.5)
• возможность навигации для полюса ассоциации (см. параграф 3.3.6);
• роль полюса ассоциации (см. параграф 3.3.6);
• видимость полюса ассоциации (см. параграф 3.3.7);
• упорядоченность объектов на полюсе ассоциации (см. параграф
3.3.7);
• изменяемость множества объектов на полюсе ассоциации (см. па-
раграф 3.3.7);
• ограничения subset и union полюса ассоциации (см. параграф 3.3.7);
• класс ассоциации (см. параграф 3.3.7);
• квалификатор полюса ассоциации (см. параграф 3.3.7).
Рассмотрим их по порядку.
3.3.4. Имя ассоциации. Кратность полюса ассоциации
Имя ассоциации указывается в виде строки текста над (или под, или ря-
дом с) линией ассоциации. Имя не несет дополнительной семантической
нагрузки, а просто позволяет различать ассоциации в модели. Обычно
имя указывают в случаях многополюсных ассоциаций или когда одна и та
же группа классов связана несколькими различными ассоциациями. Однако
строгого правила на этот счет нет.
Например, в информационной системе отдела кадров, если сотрудник зани-
мает должность, то соответствующие экземпляры классов Person и Position
должны быть связаны, т.е. между самими классами должно быть отношение
ассоциации (1 на рис. 3.17) и может быть имя (2), поясняющее ее назначение.
Дополнительно можно ука-
зать направление чтения име-
ни ассоциации (3). Фрагмент
графической модели, приве-
денный на рис. 3.17, фактиче-
ски можно прочитать вслух:
Person occupies Position.
Рис. 3.17. Имя ассоциации и направление
чтения
118 Напомним, что полюсом называется конец линии ассоциации. Обычно используются
двухполюсные (бинарные) ассоциации, но могут быть и многополюсные. Пример при-
веден в конце раздела (см. рис. 3.22).
Глава 3. Моделирование структуры
Кратность полюса ассоциации указывает, сколько объектов данного
класса (со сторойы Данного полюса) участвуют в связи.
Кратность может быть задана как конкретное число, и тогда в каждой свя-
зи со стороны данного полюса участвует ровно столько объектов, сколько
указано. Более распространен случай, когда кратность указывается как диа-
пазон возможных значений, и тогда число объектов, участвующих в связи,
должно находиться в пределах указанного диапазона.
При указании кратности можно использовать символ *, который обозначает
неопределенное число (см. таблицу 3.1 в параграфе 3.1.4). Например, если
в информационной системе отдела кадров не предусматривается дробление
ставок и совмещение должностей, то работающему сотруднику соответству-
ет одна должность (1 рис. 3.18), а должности соответствует один сотрудник
или ни одного (2) (должность вакантна). На рис. 3.18 приведен соответству-
ющий фрагмент диаграммы UML.
Рис. 3.18. Кратность полюсов ассоциации
Более сложные случаи также легко моделируются с помощью кратности по-
люсов. Например, если мы хотим предусмотреть совмещение должностей и
хранить информацию даже о неработающих сотрудниках, то диаграмма при-
мет вид, приведенный на рис. 3.19 (запись * эквивалентна записи 0..*).
Person
Position
Рис. 3.19. Использование неопределенной кратности
3.3.5. Агрегация и композиция
В UML используются два частных, но очень важных случая отношения ас-
социации, которые называются агрегацией и композицией. В обоих случаях
речь идет о моделировании отношения типа "часть - целое". Ясно, что от-
ношения такого типа следует отнести к отношениям ассоциации, поскольку
части и целое обычно взаимодействуют.
Агрегация
Агрегация (aggregation) это ассоциация между классом А (часть) и
классом В (целое), которая означает, что экземпляры (один или не-
сколько) класса А входят в состав экземпляра класса В.
3.3. Отношения на диаграмме классов
Это отмечается с помощью специального графического дополнения: на по-
люсе ассоциации, присоединенном к "целому", изображается незакрашен-
ный ромб (1). Например, на рис. 3.20 указано, что сотрудник (Person) явля-
ется членом рабочей группы (WorkGroup).
Рис. 3.20. Отношение агрегации
При этом никаких дополнительных ограничений не накладывается: экзем-
пляр класса Person (часть) может быть связан с другими объектами (т. е.
класс Person может участвовать в нескольких агрегациях), создаваться и
уничтожаться независимо от экземпляров класса Workgroup (целого).
Композиция
Композиция (composition) это ассоциация между классом А (чапь)
и классом В (целое), которая дополнительно накладывает более силь-
ные ограничения н сравнении с агрегацией: композиционно часть А
может входить только в одно, целое В, часть существует, только пока
существует цедре, и прекращает свое существование имеете с целым.
Однако часть может быть отделена от целого до того, как оно будет удалено.
В таком случае композиция будет разрушена.
Графически отношение композиции отображается закрашенным ромбом
(1 рис. 3.21)119. Для примера на рис. 3.21 приведен еще один взгляд на от-
ношения между рабочими группами и сотрудниками в информационной
системе отдела кадров. В этом случае мы считаем, что в организации при-
нята жесткая ("армейская") структура: каждый сотрудник входит ровно в
одну рабочую группу, и в каждой рабочей группе есть по меньшей мере один
сотрудник. Для моделирования такой структуры используется композиция.
Если же структура более аморфна: возможны "висящие в воздухе" сотруд-
ники, бывают "пустые" рабочие группы и т. д., то для моделирования такой
структуры более адекватным средством является агрегация (см. рис. 3.20).
Примечание
При использовании отношения композиции, "целое" часто
называют композитом, а при использовании агрегации —
агрегатом.
119 Альтернативный способ выражения отношений агрегации и композиции описан в пара-
графе 3.5.1.
ф ____
245
Глава 3. Моделирование структуры
Рис. 3.21. Отношение композиции
Понятиям агрегации и композиции можно также дать не совсем универсаль-
ную и точную, но понятную программистскую интерпретацию. Допустим,
что в классе Workgroup имеется атрибут класса Person. В этом случае есте-
ственно считать, что экземпляр класса Person является частью экземпляра
класса Workgroup. Если экземпляр класса Workgroup не владеет экземпляром
класса Person, т.е. при реализации используется указатель или ссылка, то это
агрегация, а если значением атрибута является непосредственно экземпляр
класса Person, то это композиция120.
Производные элементы
В комбинации с указанием кратности, отношения ассоциации, агрегации и
композиции позволяют лаконично и полно отобразить структуру классов:
что из чего состоит и как связано. На рис. 3.22 приведен пример одного из
вариантов такой структуры для информационной системы отдела кадров.
Обратите внимание на ассоциацию с именем works for (1 рис. 3.22). Это
производная ассоциация.
Рис. 3.22. Структура связей классов информационной системы отдела кадров
Производный элемент (derived element ) — это элемент, который мож-
но вычислить или определит), по другим элементам.
Формально производный элемент излишен, он вводится в модель для яс-
ности или наглядности. Производный элемент отмечается с помощью знака
/, который ставится перед его именем. Производным элементом в UML мо-
жет быть атрибут, роль полюса или ассоциация.
120 Некоторые инструменты автоматически помещают на диаграмму классов соответству-
ющую линию композиции или агрегации при определении таких атрибутов.
3 3. ОТК.“"ПЕНИЯ ,1А ДИАГРАММЕ классов
Композиты И ИХ АТРИБУТЫ
Сопоставим понятие атрибута и понятие композиции. Действительно, если
атрибут типа Part входит в класс Composite, то это фактически означает ком-
позицию, где Composite — целое, a Part — часть. В каких случаях при моде-
лировании следует использовать атрибуты, а в каких — композицию? От-
вет на этот вопрос зависит от того, какие еще отношения между составными
частями нужно определить. Если никаких отношений нет, например, если
речь идет о частях, которые имеют примитивные типы (числа, строки и тому
подобное), то следует использовать атрибуты. Если же между частями есть
отношения, в частности, есть взаимодействие, то предпочтительнее исполь-
зовать композицию, потому что нотация атрибутов не дает возможности от-
разить эти отношения.
Рассмотрим пример.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Информационная система отдела кадров должна поддерживать иерархи- .
ческую структуру подразделений на предприятии.
Простейшим и, как следствие, не самым лучшим является решение, пред-
ставленное на рис. 3.23.
«utility»
Company
Department
+dpts[1 ..*]:Department
+subdpts[O.. *]: Department
Рис. 3.23. Пример использования атрибутов
Оптимальное решение, которое позволяет легко учесть новое требование121,
приведено на рис. 3.24.
Subdivision
Рис. 3.24. Пример использования композиции
Время жизни частей композита
Из определения композиции следует, что композит управляет временем
жизни частей. Таким образом, речь идет об экземплярах классов, которые
являются частями для данного экземпляра композита.
121 Более подробно об ассоциации, которая связывает класс с самим собой, мы поговорим
w в следующем параграфе.
Глава 3. Моделирование структуры
Рассмотрим пример.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
В подразделении любого уровня, в том числе и на предприятии в целом, s
имеется единственная должность (начальник), которую система должна ,
трактовать особым образом.
I—_____________________________________________________________
При реалйзации данного требования (см. рис. 3.25) первым побуждением
является ввести новый класс Boss (подкласс класса Position) и провести ком-
позиции к классам Company (1) и Department (2). Как ни странно может
показаться, но это не является синтаксической ошибкой. В этом случае речь
пойдет о том, что принадлежащий экземпляру класса Company экземпляр
класса Boss не может в то же самое время быть частью какого-либо экзем-
пляра класса Department и наоборот (но самих экземпляров класса Boss мо-
жет быть несколько).
Рис. 3.25. Первый вариант реализации сложной композиции
Второй вариант решения состоит в следующем: если у группы классов есть
нечто общее, то можно завести абстрактный суперкласс (класс UnitWithBoss)
и установить требуемую композицию с ним (рис. 3.26).
Третий вариант, показанный на рис. 3.27, использует еще одно средство
UML — обобщение ассоциации (association generalization). Класс Boss уча-
ствует не в трех композициях, как может показаться на первый взгляд, а в
одной, с абстрактным классом Unit (1). Две другие композиции к классам
Company и Department не являются независимыми отношениями, они яв-
ляются частными случаями одного отношения композиции, что показано
стрелками обобщения (2 и З)122.
122 Напомним, что ассоциация (и, в частности, композиция) является классификатором,
экземплярами которого являются связи, а значит, может участвовать в отношении обоб-
щения.
3.3. Отношения на диаграмме классов
Рис. 3.26. Второй вариант реализации сложной композиции
Рис. 3.27. Третий вариант реализации сложной композиции
Последняя модель наиболее гибкая, она позволяет учесть разные дополни-
тельные требования, например разную кратность полюсов в различных част-
ных случаях ассоциации или разные роли, которые играют классификаторы
на полюсах данной ассоциа-
ции. Последнее достигается с
помощью уже знакомого нам
дополнения redefines.
На рис. 3.28 роль полюса
класса Boss в ассоциации с
Unit носит имя Leader. Специ-
ализации данной ассоциации
(1) не только переопределя-
ют имя данной роли (СЕО
и TopManager), но также и
добавляют тип (INoReport и
IReport, соответственно).
{redefines Leader} {redefines Leader}
для полюсов ассоциации
Рис. 3.28. Использование redefines
Глава 3. Моделирование структуры
3.3.6. Полюса ассоциации
Поскольку мы разобрались с интерфейсами, их реализацией и использова-
нием, нам представляется уместным еще раз повторить определение поня-
тия, которое несколько раз уже упоминалось.
Роль (role) — это интерфейс, который предоставляет классификатор
в данной ассоциации.
Мы надеемся, что туман неясности по поводу понятия "роль" в UML, порож-
денный нашими постоянными, но неизбежными забеганиями вперед, теперь
полностью развеялся.
Напомним, что полюс ассоциации — это точка соприкосновения линии ас-
социации с прямоугольником класса. Именно вблизи этой точки распола-
гаются многочисленные дополнения полюсов ассоциации.
Роль ПОЛЮСА АССОЦИАЦИИ
Роль полюса ассоциации (association end role), называемая также
спецификатором интерфейса - это способ указать, как именно уча-
ствует классификатор (присоединенный к данному полюсу ассоциа-
ции) в ассоциации.
Нотация этого дополнения — текст, указанный на полюсе ассоциации. В об-
щем случае роль полюса ассоциации имеет следующий синтаксис:
видимость ИМЯ : тип
Имя является обязательным, оно называется именем роли и фактически яв-
ляется собственным именем полюса ассоциации, позволяющим различать
полюса. Если рассматривается одна ассоциация, соединяющая два различ-
ных класса, то в именах ролей нет нужды: полюса ассоциации легко можно
различить по именам классов, к которым они присоединены. Однако, если
это не так, т. е. если два класса соединены несколькими ассоциациями или
же если ассоциация соединяет класс с самим собой, то указание ролей полю-
сов ассоциации является необходимым. Такая ситуация не является наду-
манной, как может показаться, и уже была продемонстрирована на рис. 3.24.
Приведем еще один пример. На рис. 3.29 изображена ассоциация клас-
са Position с самим собой (1 на рис. 3.29). На полюсах ассоциации указаны
роли (2 на рис. 3.29). Значок (черный треугольник), показывающий на-
правление чтения (3 на рис. 3.29) , позволяет прочесть данную ассоциацию
как "Chief subordinates Subordinate". Эта ассоциация призвана отразить
наличие иерархии подчиненности должностей в организации. Однако из
i 250 J
3.3, Отношения на диаграмме классов
рис. 3.29 видно только, что объекты
класса Person образуют некоторую
иерархию (каждый объект связан с не-
которым количеством нижележащих
в иерархии объектов и не более чем с
одним вышележащим объектом), но
не более того.
Используя роли и, заодно, отношения
реализации, можно описать суборди-
нацию в информационной системе
Position
Subordinate *
-«subordinates
Рис. 3.29. Описание иерархии
должностей
отдела кадров достаточно лаконично,
но точно. Например, на рис. 3.30 указано, что в иерархии субординации каж-
дая должность может играть две роли. С одной стороны, должность может
рассматриваться как начальственная (1) (chief), и в этом случае она предо-
ставляет интерфейс IChief (2)123, имеющий операцию petition (начальнику
можно подать служебную записку). С другой стороны, должность может
рассматриваться как подчиненная (3) (subordinate), и в этом случае она пре-
доставляет интерфейс (Subordinate (4), имеющий операцию report (от под-
чиненного можно потребовать отчет). У начальника может быть произволь-
ное количество подчиненных (5), в том числе и ноль, у подчиненного может
быть не более одного начальника (6).
Рис. 3.30. Роли полюсов ассоциации
Имея в виду ту же самую цель, можно поступить и по-другому: непосред-
ственно включить в описание класса составляющие, ответственные за обе-
спечение нужной функциональности (рис. 3.31). Однако такое решение не
самое лучшее: во-первых, оно слишком привязано к реализации, разработ-
чику не оставлено никакой свободы для творческих поисков эффективного
решения; во-вторых, оно менее наглядно, потеряны информативные имена
123 Сложилась устойчивая традиция начинать имена интерфейсов с прописной буквы I.
Глава 3. Моделирование структуры
Position
-chief [1 ]: Position
subordinates[*]:Position
+report():String
+petition(in text:String)
Рис. 3.31. Атрибуты и опера-
ции, обеспечивающие реали-
зацию ролей
ролей и ассоциации; в-третьих, оно менее на-
дежно — в модели на рис. 3.30 подчиненный
синтаксически не может потребовать отчета от
начальника, а в модели на рис. 3.31 — может, и
нужно предусматривать дополнительные сред-
ства для обработки этой ошибки.
Навигация
Возможность навигации (navigability) для полюса ассоциации - это
свойство полюса, имеющее значение типа Boolean и определяющее,
можцо ли эффективно получить с помощью данной ассоциации до-
ступ к объектам класса, присоединенного к данному полюсу ассоциа-
ции.
Если полюс не обладает данным свойством, то наличие эффективного (и во-
обще какого-либо) доступа к его объектам не гарантируется. Для отображе-
ния факта возможности или невозможности навигации для данного полюса
ассоциации применяется следующая нотация: если навигация для некого
рого полюса возможна, то этот полюс отмечают стрелкой на конце линии ас-
социации (1), если же навигация невозможна, то на конце линии ассоциации
рисуют косой крестик (2).
В примере, приведенном на рис. 3.32, навигация возможна только в направ-
лении от Company к Person, но не наоборот.
Рис. 3.32. Навигация в
одну сторону
•< subordinates
Рис. 3.33. Навигация в две стороны
В случае если ни один из элементов нотации, описывающих свойство воз-
можность навигации, не присутствует на конце линии ассоциации, то ника-
кого предположения о значении этого свойства для данного полюса сделай,
нельзя. Значение по умолчанию для него в UML отсутствует. В качестве
примера можно рассмотреть диаграмму на рис. 3.29. Если ее не уточнить
3.3. Отношения на диаграмме классов
(см. рис. 3.33), то всевозможные предположения о значении данного свой-
ства могут иметь место.
Примечание
Реальная практика использования свойства возможности
навигации показывает, что помимо явной интерпретации
(описанной в стандарте) существует и неявная (часто ис-
пользуемая инструментами и подразумеваемая в литерату-
ре), а именно считается, что отсутствие стрелочек на обоих
концах линии ассоциации говорит о возможности навигации
в обе стороны.
Многополюсные ассоциации
В общем случае, ассоциация между классами А и В это множество
пар (а,Ь), где а экземпляр класса А, а b экземпляр класса 3. Под-
черкнем еще раз, что это именно множество, гак как двух одинаковых
пар (а.Ь) быть не может.
Чаще всего в моделях используются бинарные ассоциации, отражающие
связи между объектами двух классов. В UML определены также много-
полюсные ассоциации, отражающие связи между большим числом объ-
ектов. С формальной точки зрения многополюсные ассоциации излишни,
поскольку их можно выразить через комбинацию бинарных ассоциаций вве-
дением дополнительных сущностей. Действительно, упорядоченную тройку
объектов (а, Ь, с) — элемент трехполюсной ассоциации — можно предста-
вить как упорядоченную пару (a, d), где d — новый объект, представляю-
щий упорядоченную пару (Ь, с). Однако на практике (в некоторых случаях)
многополюсные ассоциации бывают буквально незаменимы.
Рассмотрим следующий пример из информационной системы отдела ка-
дров.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
..............
Информационная система отдела кадров должна поддерживать матрич- J
ную структуру управления на предприятии и уметь оперировать таким i
понятием, как проект, в следующем контексте: один и тот же сотрудник *
может участвовать во многих проектах, выполняя различные обязанности ,
(т. е. занимая различные должности). •
В организации применяется современная организационная форма управле-
ния и помимо иерархии подразделений и должностей существует структура
выполняемых проектов, "пронизывающих" организацию. Такую замыслова-
Глава 3. Моделирование структуры
тую (но весьма жизненную!) ситуацию очень легко отобразить, используя
многополюсные ассоциации (рис. 3.34).
Рис. 3.34. Многополюсная ассоциация
Остается сказать, что нотация многополюсной ассоциации представляет со-
бой ромб (1 на рис. 3.34), к которому посредством линий присоединяются
все классы, участвующие в ассоциации.
Чтобы полностью оценить полезность многополюсных ассоциаций, мы со-
ветуем читателям проделать весьма поучительное упражнение: попытаться
построить модель, семантически эквивалентную рис. 3.34, но без использо-
вания многополюсных ассоциаций (подсказка: придется ввести дополни-
тельные сущности и отношения).
ВИДИМОСТЬ ПОЛЮСА АССОЦИАЦИИ
Рассмотрим следующий пример из информационной системы отдела ка-
дров. Три класса Person, Company и Department связаны следующими отно-
шениями (см. рис. 3.35).
Ассоциации (и их варианты) указывают возможные пути навигации меж-
ду экземплярами соответствующих классов. Например, исходя из приве-
денного фрагмента модели на рис. 3.35, возможен такой маршрут: Person
- Company - Department. Если рассматривать данный маршрут в проекции
на экземпляры классов, то получается следующее: имея экземпляр класса
Person, можно получить соответствующий экземпляр класса Company, т.е.
узнать компанию, в которой работает данный сотрудник, а затем, имея эк-
земпляр класса Company, легко получить список всех отделов, т.е. экземпля-
ров класса Department.
Рис. 3.35. Фрагмент диаграммы классов ИС ОК
254
3.3. Отношения на диаграмме классов
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
С точки зрения безопасности доступ к информации об отдельных сотруд- 1
никах не должен давать возможность каким-либо образом получить ин- ,
। формацию о структуре всей компании. t
।---------------------------------------------------------------------------1
Другими словами, использование маршрута Person - Company - Department
противоречит техническому заданию. Действительно, из фрагмента модели
на рис. 3.35 следует, что потенциально любой работник может получить пол-
ную информацию о структуре всего предприятия, на котором он работает.
Рассмотрим маршрут Person - Company - Department еще раз. Каждый их
двух участков этого маршрута имеет право на существование. Действитель-
но, работнику не возбраняется знать, на кого он работает (ассоциация между
Person и Company), а компания должна иметь информацию о своей структу-
ре (композиция между Company и Department). Получается, что навигация
по отдельным участкам маршрута Person - Company - Department является
допустимой, в то время как на прохождение всего маршрута должно быть
наложено ограничение, а точнее говоря, запрет.
Выходом из подобных (не часто, но все-таки иногда возникающих) ситуа-
ций! служит использование видимости полюса ассоциации.
Видимость полюса ассоциации (association end visibility) — это указа-
ние того, является ли классификатор, присоединенный к данному по-
люсу ассоциации, видимым для классификаторов (кроме непосред-
стненно присоединенных), маршруты из которых ведут к нему.
Пожалуйста, не думайте, что мы хотим вас запутать с помощью подобных
формальных определений. На самом деле все очень просто. Продолжим рас-
смотрение предыдущего примера.
Рис. 3.36. Пример использования свойства видимости на полюсе ассоциации
Взгляните на рис. 3.36, отличие которого от рис. 3.35 состоит в том, что до-
бавлена роль на полюсе ассоциации между классами Company и Department
(1 на рис. 3.36). Само по себе наличие роли на полюсе не важно для данного
Глава 3. Моделирование структуры
случая. Главное здесь — присутствие видимости для этого полюса ассоциа-
ции, которое имеет значение private и согласно принятой в UML нотации
отображается в виде знака (2 на рис. 3.36).
Теперь интерпретация диаграммы с точки зрения возможных маршрутов из-
менилась ровно настолько, чтобы соответствовать требованию технического
задания. Имея экземпляр класса Person, можно получить соответствующий
экземпляр класса Company, т.е. узнать компанию, в которой работает данный
сотрудник, но нельзя получить список всех отделов, т.е. экземпляров клас-
са Department, так как навигация по агрегации между Company и Department
запрещена для всех маршрутов, кроме тех, которые берут свое начало в
Company. Видимость private на полюсе агрегации у класса Department по-
казывает, что только для непосредственно связанного с ним (данной ассо-
циацией) классу Company дана возможность осуществить навигацию в этом
направлении.
Как видно из рассмотренного примера, видимость на полюсе ассоциации мо-
жет применяться там, где нужна более "точная настройка" чем та, которую
обеспечивает свойство возможность навигации (см. параграф 3.3.6).
Упорядоченность объектов на полюсах
Описываемые ниже дополнения встречаются сравнительно редко, но иногда
без них не обойтись. Они не имеют специальной графической нотации, а за-
писываются в виде стандартных ограничений на полюсах ассоциации, кото-
рые связаны с понятиями упорядоченности объектов на полюсе ассоциации
(ordering) и уникальности (uniqueness). Значение уникальности {uniqueness
=true} означает отсутствие одинаковых объектов.
Если кратность полюса лежит в диапазоне 0..1, то проблемы упорядочен-
ности не возникает — на данном полюсе связи, возможно, имеется один объ-
ект, но не более того. При иных кратностях объектов может быть несколько,
т. е. полюс связи присоединен к множеству объектов. По умолчанию множе-
ство объектов, присоединенных к данному полюсу связи, считается неупо-
рядоченным (как и любое множество, если не оговорено противное). Соот-
ветствующее этому состоянию ограничение {set} можно не указывать, оно
является значением по умолчанию. Если необходимо указать, что это мно-
жество упорядочено, то нужно наложить соответствующее ограничение -
{ordered}124 на полюс ассоциации.
Свойство уникальности связано с ограничением {bag}, которое означает, что
множество объектов, присоединенных к полюсу, допускает включение одно-
го объекта несколько раз. Для спецификации упорядоченного множества,
124 Иногда используется {ordered set}.
3.3. Отношения на диаграмме классов
допускающего повтор объектов, используется ключевое слово {sequence}123.
Данные ограничения можно свести в следующую таблицу 3.10.
Таблица 3.10. Свойства упорядоченности и уникальности
Упорядоченное множество Неупорядоченное множество
Есть одинаковые элементы {sequence} поел едовате л ьн ость {bag} мультимножество
Нет одинаковых элементов {ordered} упорядоченное множество {set} множество
Изменяемость объектов на полюсе
Обычно считается, что множество объектов на полюсе связи может из-
меняться произвольным образом (в пределах специфицированной крат-
ности). Например, в один момент работы информационной системы отдела
кадров в данном подразделении может быть 10 одних должностей, а в дру-
гой момент — 20 других.
Совершенно аналогично значение атрибута обычно может произвольным
образом меняться в процессе жизни объекта (в пределах указанного типа
атрибута). Однако иногда необходимо определенным образом ограничить
изменяемость атрибута (см. параграф 3.2.2 и табл. 3.3). Аналогично иногда
нужно ограничить изменяемость состава множества объектов, присоеди-
ненных к полюсу связи (экземпляру ассоциации). Для этого применяется
тот же самый набор стандартных значений (еще раз см. табл. 3.3).
В информа! (ионной системе отдела кадров мы не нашли подходящего при-
мера, и поэтому для иллюстрации двух последних понятий рассмотрим эле-
ментарный пример из вычислительной геометрии. Допустим, что у нас есть
класс Point, экземплярами которого являются точки (на плоскости). Много-
угольник (класс Polygon) можно определить как упорядоченное (ограниче-
ние {ordered}) множество точек (вершин многоугольника), причем резонно
предположить, что состав вершин данного многоугольника после того, как
он определен, не может меняться (ограничение {readonly}). Модель, описы-
вающая данную ситуацию, приведена на рис. 3.37.
Рис. 3.37. Упорядоченность и изменяемость множества объектов
на полюсе связи
125 Иногда используется {list}.
Глава 3. Моделирование структуры
Операции с множествами объектов на полюсах
Ограничение {subsets х) полюса ассоциации — это указание на то, что
множество объектов, соответствующих данному полюсу, является
Г» подмножеством множества дЦъектов полюса х.
Проиллюстрируем данное определение. Для этого рассмотрим следующую
задачу: на плоскости заданы N различных точек (А > 8), принадлежащих вы-
пуклому восьмиугольнику. При этом известно, что данное множество точек
заведомо содержит все вершины восьмиугольника, а также, возможно, до-
полнительные точки, которые не являются вершинами и лежат на сторонах.
Требуется восстановить восьмиугольник и вывести его вершины в порядке
обхода по часовой стрелке, начиная с произвольной. На рис. 3.38 приведен
пример (N == 21) восьмиугольника, при этом закрашенные точки задают вер-
шины, а незакрашенные лежат на сторонах.
Рис. 3.38. Иллюстрация к задаче о восьмиугольнике
Алгоритм решения задачи — построение выпуклой оболочки. Возможная
структура данных для решения поставленной задачи описывается диаграм-
мой классов на рис. 3.39.
subsets р}
Рис. 3.39. Использование ограничения subsets
L25b
3.3. Отношения на диаграмме классов
На приведенной диаграмме экземпляры класса Polygon хранят исходный
массив точек, а экземпляры класса Octagon упорядоченный набор вершин,
получаемый после построения выпуклой оболочки, которым и определяют-
ся. Ограничение {subsets р}, помещенное на полюсе v (1 на рис. 3.39), ука-
зывает, что множество вершин восьмиугольника (то есть, фактически, мно-
жество объектов на полюсе v) является подмножеством исходных точек (то
есть, фактически, подмножеством объектов на полюсе р (2 на рис. 3.39)).
Ограничение {union} полюса ассоциации — это указание на то,что
множество объектов, соответствующих данному полюсу х, есть объе»
динениё всех подмножеств полюсов с ограничениями {subsets х}.
Приведенный на рис. 3.39 пример не позволяет объявить полюс р с ограни-
чением {union}, так как в качестве подмножеств точек р, обозначенные через
{subset р}, явно выделены только вершины многоугольника. Неучтенными
остались точки, лежащие на сторонах. Исправим эту ситуацию и будем от-
дельно хранить эти точки (класс SidePoint (1)). Диаграмма классов в соот-
ветствии с этим изменением примет вид, представленный на рис. 3.40.
Рис. 3.40. Использование ограничения union
Теперь мы вправе написать {union} рядом с полюсом р (2 на рис. 3.40). На-
помним, что ограничение {union} в данном случае означает, что каждая из
точек множества р (множества всех точек) либо является вершиной вось-
миугольника (3 на рис. 3.40), либо лежит на его стороне (4 на рис. 3.40).
3.3.7. Класс ассоциации и квалификатор
В процессе проектирования возможны ситуации, когда ассоциация должна
иметь собственные атрибуты (и даже операции), значения которых хранятся
[ 259 "
Глава 3. Моделирование структуры
в экземплярах ассоциации — связях. В таком случае применяется специаль-
ный элемент моделирования — класс ассоциации.
Класс ассоциации (association class) — это сущность, которая являет-
ся ассоциацией, ио также обладает свойствами класса.
Класс ассоциации изображается в виде символа класса, присоединенного
пунктирной линией к линии ассоциации.
Вернемся к информационной системе отдела кадров.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Допускается ситуация, когда сотрудник может работать на нескольких '
должностях в разных проектах, а также возможно, чтобы одну и ту же
должность в одном проекте занимало несколько сотрудников (дробле- i
ние ставки). Размер заработной платы зависит от того, сколько конкрет- 1
но времени проработал данный сотрудник в данной должности в данном
проекте.
i_____________________________ ________ ___________________________।
Таким образом, имеет место более сложное отношение между должностями,
сотрудниками и проектами, нежели те, что приведены на рис. 3.34. А имен-
но, допускается не только совмещение должностей (один сотрудник может
работать на нескольких должностях в разных проектах), но и дробление ста-
вок (одну должность могут занимать несколько сотрудников — полставки,
четверть ставки и т. п.). Используя же разобранную нотацию ассоциации, мы
можем констатировать, что между классами Person, Position и Project имеет
место ассоциация "многие ко многим ко многим".
Однако этого недостаточно: необходимо указать, какую долю данной долж-
ности занимает данный сотрудник. Эту информацию нельзя отнести ни к
должности, ни к сотруднику, ни к проекту — это атрибут ассоциации, ко-
торая всех их связывает. На рис. 3.41 показан способ использования класса
ассоциации (1) для решения данной задачи.
Рис. 3.41. Класс ассоциации
3.3. Отношения на диаграмме классов
Может показаться, что понятие класса ассоциации в UML является наду-
манным и излишним. Действительно, можно применить стандартный при-
ем нормализации, который часто используется при проектировании схем
баз данных: систематическим образом избавиться от отношений "многие ко
многим ко многим” путем введения дополнительной сущности (1) и трех от-
ношений "один ко многим". Применительно к данному примеру такой при-
ем дает решение, приведенное на рис. 3.42.
Рис. 3.42. Элиминация отношения "многие ко многим" с помощью введения
дополнительной сущности
На первый взгляд, модели на рис. 3.41 и рис. 3.42 выглядят семантически
эквивалентными, однако это не так — здесь есть тонкое различие. В случае
использования класса ассоциации Job (1 на рис. 3.41), который по опреде-
лению является множеством троек должность-сотрудник—проект, не может
быть двух одинаковых троек. То есть не может быть так, чтобы Новиков за-
нимал полставки доцента в одном проекте и еще (отдельно) четверть той же
ставки в этом же проекте. В случае же промежуточного класса Job (1 на рис.
3.42) это, вообще говоря, вполне возможно, что не совсем естественно.
Опытные проектировщики баз данных нам могут возразить, что это впол-
не поправимо: нужно ввести в классах Position, Person и Project атрибуты,
которые будут уникальными ключами, идентифицирующими объекты этих
классов, а в классе Job ввести тройку атрибутов, значениями которых бу-
дут ключи классов Position, Person и Project, и потребовать, чтобы эта тройка
атрибутов была уникальным составным ключом класса Job. Мы не будем
спорить — это действительно так и делается при традиционном проектиро-
вании схем баз данных. Нам представляется, что разбор данного примера
уже является достаточным обоснованием полезности элегантного понятия
класса ассоциации в UML: один рис. 3.41 понятнее и точнее рис. 3.42 с неиз-
бежными добавлениями и пояснениями про уникальные ключи.
Продолжим разговор про специфику отношений между классами Company
и Person. На рис. 3.32 они связаны отношением ассоциации с кратностя-
ми полюсов "один ко многим". Такая ассоциация доставляет для каждого
экземпляра класса Company, находящегося на полюсе с кратностью "один",
множество (иногда большое) объектов класса Person, находящегося на по-
Глава 3. Моделирование структуры
л юсе с кратностью "много". Однако часто возникают ситуации, когда нужно
получить не все множество ассоциированных объектов Person, а некоторое
небольшое подмножество, чаще всего один конкретный объект. Чтобы вы-
делить из множества один конкретный объект, нужно располагать инфор-
мацией, однозначно идентифицирующей этот объект. Такую информацию
принято называть ключом. Например, индивидуальный номер налогопла-
тельщика (ИНН) для сотрудника в информационной системе отдела кадров
может считаться ключом.
Для того чтобы решить задачу поиска конкретного сотрудника (конкретный
экземпляр класса Person), всегда можно применить следующее тривиальное
решение: хранить ключ (ИНН) в самом объекте класса Person в качестве
атрибута и, получив множество объектов, перебирать их все последователь-
но до тех пор, пока не найдется тот, который имеет искомое значение ключа.
Такой прием называется линейным поиском.
Для компаний, в которых не очень много сотрудников, данный способ может
быть вполне приемлемым. Но в других случаях, когда к полюсу с кратно-
стью "много" присоединено действительно много объектов, линейный поиск
слишком неэффективен. Известно множество структур данных, позволяю-
щих эффективно выделить (найти в множестве) объект по ключу: сортиро-
ванные массивы, таблицы расстановки (хэш-таблицы), деревья сортировки,
внешние индексы и др. Эти приемы обобщены в UML понятием квалифи-
катора.
Квалификатор полюса ассоциации (qualifier)— это атрибут (иди не-
сколько атрибутов) полюса ассоциации,. значение которого (кото*
рых) позволяет выделить один (или несколько) объектов класса,
присоединенного к другому полюсу ассоциации
Квалификатор изображается в виде небольшого прямоугольника на полюсе
ассоциации, примыкающего к прямоугольнику класса. Внутри этого прямо-
угольника (или рядом с ним) указываются имена и, возможно, типы атри-
бутов квалификатора. Описание квалифицирующего атрибута ассоциации
имеет такой же синтаксис, что и описание обычного атрибута класса, только
оно не может содержать начального значения.
Основное назначение квалификатора — снизить кратность противополож-
ного полюса ассоциации, поэтому в основном он используется в ассоциаци-
ях с кратностями полюсов "один ко многим" или "многие ко многим" и стоит
у полюса, противоположного полюсу с кратностью "много".
При использовании квалификатора кратность противоположного полюса
снижается, и это отображается на диаграмме. Сравните рис. 3.32 и рис. 3.43.
3.3. Отношения на диаграмме классов
Кратность полюса у класса Person изменилась
с * до 0..1, так как экземпляр класса Person для
данного ключа может быть найден, а может и от-
сутствовать (неправильное значение ключа).
Таким образом, если на полюсе ассоциации,
противоположном полюсу квалификатора,
задана кратность, то она указывает не допу-
стимую мощность множества объектов, при-
соединенных к полюсу связи, а допустимую
мощность того подмножества, которое опреде-
ляется при задании значений атрибутов квали-
фикатора.
Рис. 3.43. Квалификатор
Мы хотим подвести итог этому пространному параграфу, обобщив сказанное
с помощью диаграммы метамодели ассоциации, представленной на рис. 3.44.
Рис. 3.44. Метамодель вссоциации
3.3.8. Советы по проектированию
Нам хочется закончить обсуждение диаграмм классов — важнейшего сред-
ства описания структуры в UML — серией элементарных советов по прак-
тическому моделированию структуры. Как видно из предыдущих разделов,
Глава 3, Моделирование структуры
диаграммы классов содержат множество деталей. Для практически зна-
чимых систем диаграммы классов в конечном итоге получаются довольно
сложными. Пытаться прорисовать сложную диаграмму классов сразу "на
всю глубину" нерационально — слишком велик риск "утонуть" в деталях.
Мы полагаем, что удачная модель структуры сложной системы создается за
несколько (может быть, даже за несколько десятков) итераций, в которых
моделирование структуры перемежается моделированием поведения (см.
главу 4).
Вот наши советы.
Описывать структуру удобнее параллельно с описанием поведе-
ния. Каждая итерация должна быть небольшим уточнением, как
структуры, так и поведения.
• Не обязательно включать в модель все классы сразу. На первых
итерациях достаточно идентифицировать очень небольшую (10%)
долю всех классов системы.
• Не обязательно определять все составляющие класса сразу.
1 1ачни in с имени класса операции и атрибуты постепенно выя-
вятся в процессе моделирования поведения.
• Не обязательно показывать на диаграмме все составляющие
класса и иххвойства. В проце<-< t работы диаграмма должна*легко
охватываться одним взглядом.
• Не обязательно определять все отношения между классами сра-
зу Пусть класс на диш рамме "висит в воздухе" — ничего с ним не
случится.
Мы действительно сами следуем своим советам. Например, диаграммы на-
чиная с рис. 3.11 до рис. 3.43 — это, как нетрудно видеть, промежуточные
шаги при моделировании структуры предметной области нашей системы.
Окончательный результат со всеми важными подробностями приведен на
рис. 3.45.
Диа грамма достаточно хорошо читается — в ней не слишком много деталей.
Для уточнения можно использовать дополнительные диаграммы, иллю-
стрирующие определенные аспекты модели.
3.4. Диаграммы реализации
Рис. 3.45. Основная диаграмма классов ИС ОК
3.4. Диаграммы реализации
Данный раздел посвящен сразу двум диаграммам: компонентов и размеще-
ния, для которых можно использовать обобщающее название — диаграммы
реализации. Связано это с тем, что данные диаграммы приобретают особую
важность на позднейших фазах разработки — на фазах реализации и постав-
ки (подробнее см. в главе 5). В то время как на ранних фазах разработки —
анализа и проектирования — эти диаграммы либо вообще не используются,
либо имеют самый общий, не детализированный вид.
С точки зрения реализации, проектируемая система состоит из компонен-
тов (представленных на диаграммах компонентов), распределенных по
вычислительным узлам (представленным на диаграммах размещения).
В UML 2 по сравнению с UML 1 произошло значительное изменение, а
именно понятие "компонент" было разделено на две составляющие: логи-
ческую и физическую. Логическая составляющая, продолжающая носить
имя компонент (component), является элементом логической модели си-
стемы, в то время как физическая составляющая, называемая артефактом
(artifact), олицетворяет физический элемент проектируемой системы, раз-
мещающийся на вычислительном узле (node).
Диаграммы компонентов и размещения имеют много общего, объединяя
воедино следующие, теснейшим образом связанные, вещи:
структуру логических элементов (компонентов);
Глава 3. Моделирование структуры
• отображения логических элементов (компонентов) на физические
элементы (артефакты);
• структуру используемых ресурсов (узлов) с распределенными по
ним физическими элементами (артефактами).
В данном разделе мы отступим от правила, принятого нами при описании
остальных диаграмм. А именно, мы не будем раздельно для каждой диаграм-
мы рассматривать сущности, применяемые на ней. Более правильным нам
кажется предварительное совместное рассмотрение всех сущностей и отно-
шений в нескольких параграфах, чем мы и займемся.
3.4.1. Интерфейс
Понятию интерфейс (см. параграф 3.2.4) и отношениям между классифика-
торами и интерфейсами (см. параграф 3.3.1) мы уделили достаточно внима-
ния. Подведем итоги и пожнем плоды.
Можно выделить две роли (см. рис. 3.46), которые играют интерфейсы
( 1) но o i ношению к классификаторам, например, компот и >ам (2). Ин-
терфейс может быть обеспеченным1-’6 и требуемым126 127.
Рис. 3.46. Отношения между классификаторами и интерфейсами
Однако нельзя забывать, что сам по себе интерфейс — это просто описание
контракта, а обеспеченным или требуемым он становится в зависимости от
того, как этот интерфейс используется:
• если классификатор реализует интерфейс — то для данного класси-
фикатора это обеспеченный интерфейс и данный факт показывается
с помощью отношения реализации (3 на рис. 3.46);
• если классификатор вызывает операции интерфейса — то для дан-
ного классификатора это требуемый интерфейс и данный факт по-
казывается с помощью отношения зависимости (4 на рис. 3.46).
126 Встречающиеся в литературе варианты перевода: "реализованный", "предоставляе-
мый".
127 Встречающийся в литературе вариант перевода — "запрашиваемый".
3.4. Диаграммы реализации
ПРОЕКТИРОВАНИЕ ПО КОНТРАКТУ
Объектно-ориентированное приложение состоит из объектов (эк-
земпляров классов). Каждый из классов в соответствии со своими
обязанностями представляет набор операций для своих клиентов.
Во время выполнения объекты вызывают методы друг друга и тем
самым обеспечивают работу приложения.
Проектирование по контракту (столь многообещающее название
не должно смущать) не является методологическим подходом,
призванным решить проблемы, встающие перед архитектором,
или хотя бы приблизить к их решению. Это всего лишь один из
способов описания того, в каком контексте могут быть вызваны
методы того или иного класса.
Для этого для каждой операции класса указывают три состав-
ляющие: предусловия, постусловия и инварианты.
• Предусловия задают набор условий, которые должны
быть выполнены для того, чтобы при вызове метода он
выполнил то, для чего предназначен.
• Постусловия задают набор условий, которые должны
быть выполнены после завершения выполнения метода.
• Инвариантом называется утверждение, которое всегда
будет истинным во время выполнения метода, в случае,
если выполнены все предусловия.
Предусловия, постусловия и инварианты передаются "по наслед-
ству", т.е., будучи определенными в суперклассах, они при специ-
ализации распространяются и на подклассы, которые не могут их
ослабить, но могут усилить.
Чтобы до конца разобраться с понятием контракта, а заодно и с принципом
подстановки Лисков, рассмотрим простой пример. На рис. 3.47 приведены
две иерархи наследования. Прежде чем читать дальше, подумайте, какая из
этих иерархий кажется вам верной?
Рис. 3.47. Возможные иерархии наследования
[2S7
Глава 3. Моделирование структуры
Ответ на этот вопрос сильно зависит от контекста, а именно — поддержи-
вает ли в контексте приложения класс Square контракт своего суперкласса
Rectangle? Если контракт поддерживается, то правая иерархия на рис. 3.47
имеет право на существование. Если нет, то при проектировании придется
пользоваться той, что слева. Уточним диаграмму, чтобы подробнее разобрать
данный пример (см. рис. 3.48).
Рис. 3.48. Иерархия наследования с детализацией класса Rectangle
Итак, у класса Rectangle есть два атрибута, которые хранят в себе значения
высоты и ширины прямоугольника, и соответственно, две операции, кото-
рые эти значения устанавливают, и две операции, которые эти значения воз-
вращают. Заметим, что у квадрата (класс Square) нет ни "ширины", ни "вы-
соты", а есть только "длина стороны".
Посмотрим, каким образом надо реализовать в классе Square унаследован-
ную операцию установки ширины — setW(). Одно из решений — присвоить
унаследованному атрибуту weight значение, переданное в качестве аргумен-
та (как и у подобного метода для Rectangle), и сразу же произвести присваи-
вание height:=weight (иначе это у нас будет уже не квадрат!). Аналогичное
решение должно быть принято относительно реализации операции setH()
в классе Square.
Однако отношение обобщения (1 на рис. 3.48) требует от нас соблюдения
контракта для операции setW(), который может выражаться в следующем:
• предусловие — значение параметра операции setW() больше нуля;
• постусловие — значение атрибута weight равно значению передан-
ного аргумента при вызове метода setW();
• инвариант — значение атрибута height не должно измениться.
Ясно, что утверждение, заданное в инварианте, как раз и было нарушено при
реализации метода setW() для класса Square.
В итоге это может привести к нарушению принципа подстановки Лисков.
Каким образом? Представьте себе функцию, которая в качестве параметра
принимает экземпляр класса Rectangle.
3.4. Диаграммы реализации
procedure SomeTransformation (г : Rectangle);
var w, h : integer;
begin
w := r.setW(10);
h := r.setH(20);
if (w = r.getWO) and (h = r.getHO) then
writein ("It is OKey")
else
writein ("I really don't understand!!!!")
end;
Программист внутри этой функции вызывает последовательно для пере-
данного аргумента методы setW(10) nsetH(20),a затем, используя ме-
тоды getW () и getH (), проверяет, чему равны ширина и высота, ожидая
получить значения 10 и 2 0 соответственно. Все будет работать так как за-
думано, пока в качестве аргумента в эту функцию будет передаваться экзем-
пляр класса Rectangle. А теперь подумаем, что будет, если кто-то вызовет эту
функцию с аргументом — экземпляром класса Square?
А произойдет совсем неприятное и неожиданное для программиста. Инва-
риант класса (ширина равна высоте) войдет в прямое противоречие с кон-
трактом класса (можно независимо задавать высоту и ширину). Рецепт
один: нужно быть внимательным и избегать противоречий!
Разобравшись с интерфейсами, давайте перейдем к компонентам.
3.4.2. Компоненты, артефакты и узлы
Компонент (component ) это модульный фрагмент логического
представления системы, взаимодействие с которым описывается на-
бором обеспеченных и требуемых интерфейсов.
С понятием "компонент" часто ассоциируют компонентное программирова-
ние.
КОМПОНЕНТНОЕ ПРОГРАММИРОВАНИЕ
Идея компонентного или сборочного программирования также
стара, как само программирование. Действительно, затраты на
тиражирование программ любой величины и сложности исчезаю-
ще малы по сравнению с затратами на их разработку. Затратами
Глава 3. Моделирование структуры
на тиражирование можно просто пренебречь’26. Отсюда возника-
ет естественное желание не создавать каждую новую программу
"с нуля", а использовать ранее созданные программы в качестве
готовых компонентов, благо затраты на копирование столь не-
велики. Оставляя в стороне вопросы, связанные с правами соб-
ственности, сосредоточимся на техническом аспекте: насколько
реально компонентное программирование? Допустим, нужные по
функциональности программные компоненты доступны для копи-
рования: как можно их использовать при разработке новой про-
граммы? Ответ на этот вопрос имеет огромное значение, прежде
всего экономическое. Для решения данного вопроса были пред-
приняты беспрецедентные усилия, особенно в последние года.
Наша оценка текущего состояния компонентного программирования состо-
ит из трех утверждений:
• Первое: компонентное программирование является непреложным
требованием практики, без него прогресс в индустрии программно-
го обеспечения невозможен.
• Второе: в последние годы в этой области наблюдается значительный
прогресс, причем налицо тенденция к ускорению.
• Третье: современные технологии компонентного программирова-
ния все еще далеки от идеала и не в полной мере отвечают требо-
ваниям практики.
Поясним наше видение следующей аналогией. Автомобиль можно рассма-
тривать состоящим из компонентов: двигатель, трансмиссия, ходовая часть,
кузов... Можно ли собрать автомобиль из готовых компонентов? Ответ: да,
если компоненты были изготовлены в расчете на то, что из них будет собра-
на конкретная модель автомобиля с применением конкретной технологии
сборки. В противном случае сборка проблематична.
Однако в каждом достаточно большом гаражном кооперативе можно найти
умельца, который с помощью хорошего набора ручных инструментов, при-
родной смекалки и технического чутья может собрать нечто, способное дви-
гаться, из самых неожиданных компонентов. Пока что, по нашему мнению,
работа программистов, использующих готовые компоненты, больше напо-
минает шаманство гаражного умельца, нежели современное автоматизиро-
ванное производство128 129.
128 Это очень важная особенность индустрии программного обеспечения и других отрас-
лей, связанных с производством информации. Действительно, в отраслях промышлен-
ности, связанных с материальным производством, затраты на производство экземпляра
продукта, хотя и меньше затрат на проектирование, но все же не могут рассматриваться
как пренебрежимо малые.
129 Некоторые авторские соображения о влиянии UML на компонентное программирование
изложены в главе 5.
3.4. Диаграммы реализации
- ? . :. > ' ...
Понятие-компонента в UML 2|3° не соответствует тому компоненту,
которое имеет в виду сборочное программирование. Компонент UML
является частью модели и описывает логическую сущность, кото-
рая существует только во время проектирования (tiesign time), хотя
в дальнейшем ее можно связать с физической реализацией (артефак-
том) времени исполнения (ruu thne).^^^^^'
Стандартом UML для компонентов предусмотрены стереотипы, приведен-
ные в таблице 3.11.
Таблица 3.11. Стандартные стереотипы компонентов
Стереотип Описание
«buildComponent» Компонент, служащий для разработки приложения
«entity» Постоянно хранимый информационный компонент, пред- ставляющий некоторое понятие предметной области
«service» Функциональный компонент без состояния, возвращающий запрашиваемые значения без побочных эффектов
«subsystem» Единица иерархической декомпозиции большой системы
Аналогом компонента в смысле сборочного программирования является по-
нятие артефакта в UML. Причем не любого артефакта, а только некоторых
из его стереотипов.
Артефакт (artifact) это любой созданный искусственно элемент
программной системы,
К элементам программной системы, а следовательно, и к артефактам, мо-
гут относиться исполняемые файлы, исходные тексты, веб-страницы, спра-
вочные файлы, сопроводительные документы, файлы с данными, модели и
многое другое, являющееся физическим элементом информации. Другими
словами, артефактами являются те информационные элементы, которые
тем или иным способом используются при работе программной системы и
входят в ее состав.
Для того чтобы как-то отражать такое разнообразие типов артефак-
тов в UML 2 предусмотрены стандартные стереотипы, перечисленные в
таблице 3.12.
130 В отличие от UML 1.
ф
Глава 3. Моделирование структуры,
Таблица 3.12. Стандартные стереотипы артефактов
Стереотип Описание
«file» Файл любого типа, хранимый в файловой системе*
«document» Артефакт, представляющий файл (документ), который не являет- ся ни файлом исходных текстов, ни исполняемым файлом
«executable» Выполнимая программа любого вида. Подразумевается по умолчанию, если никакой стереотип не указан
«library» Статическая или динамическая библиотека
«script» Файл, содержащий текст, допускающий интерпретацию соот- ветствующими программным средствами
«source» Файл с исходным кодом программы
(*) Все остальные типы артефактов являются подтипами «file»
Однако реальные артефакты гораздо разнообразнее по своим типам, чем
перечисленные выше. Чтобы как-то учесть это обстоятельство, многие ин-
струменты, помимо стандартных стереотипов, поддерживают дополнитель-
ные стереотипы артефактов, часто со специальными значками и фигурами,
обеспечивающими высокую наглядность диаграмм.
Самым важным аспектом использования понятия артефакта в UML являет-
ся то, что артефакт может участвовать в отношении манифестации.
- * Манифестация (manifestation) — это отношение зависимости со сте-
реотипом «manifest», связывающее элемент модели (например, класс
.' или компонент) и его физическую реализацию в виде артефакта.
На рис. 3.49 представлен класс Company, который связан отношением ма-
нифестации (зависимость со стереотипом «manifest») с двумя артефактами
со стереотипом «source», которые в свою очередь определяют артефакт вре-
мени выполнения — динамическую библиотеку (со стереотипом «library»)
Company.
«utility»
Company
«manifest»
«manifest»
«library»
Company
Рис. 3.49. Артефакты
3.4. Диаграммы реализации
Вообще говоря, отношение манифестации — это отношение типа "многие
ко многим", один элемент модели может быть реализован многими артефак-
тами, и один артефакт может участвовать в реализации многих элементов
модели.
Манифестацию графически изображают отношением зависимости со стере-
отипом «manifest» от артефакта к реализуемой сущности. Поскольку мани-
фестация — это отношение типа "многие ко многим", для полного описания
отношения манифестации могут потребоваться несколько отношений зави-
симости в модели.
Последняя сущность, рассматриваемая в этом параграфе, — узел.
Урел (node) — эго физический вычислительный'3' ресурс, участвую-
щий в работе системы.
В UML 2 предусмотрено два стереотипа для узлов «executionEnvironment» и
«device».
Узел со стереотипом «executionEnvironment» позволяет моделировать
аппаратно-программную платформу, на которой происходит выполнение
приложения, т.е. размещенных на узле артефактов. Примерами среды выпол-
нения являются: операционная система, система управления базами данных
ит. д.
Узел со стереотипом «device» чаще моделирует аппаратную платформу. При-
мером может служить сервер приложений (application server).
Узлы могут быть вложены один в другой, как это показано на рис. 3.50
«device»
: ApplicationServer
«execution Environment»
-J2EE
Company.jar
A
Рис. 3.50. Нотация узла
Артефакты системы во время ее работы размещаются на узлах, что графиче-
ски выражается либо их перечислением внутри узла (1 на рис. 3.50), либо от-
ношением зависимости со стереотипом «deploy» между артефактом и узлом
131 При использовании UML в других предметных областях узлом может быть не только ком-
пьютер, но и другой объект: человек, механическое устройство и т. д.
е
Глава 3 Моделироеааие структуры
(1 на рис. 3.51), либо изображением артефакта внутри изображения узла
(2 на рис. 3.51). Все нотации равноправны.
Рис. 3.51. Нотации размещения артефакта на узле
Если при размещении артефакта на узле важную роль играют специфичные
для программной среды параметры, то они могут быть заданы посредством
спецификации развертывания (deployment specification).
«executionEnvironment»
J2EEServer
«Jar» D
Servloe
____________7____________
-------------------------I-
«depioymentSpeo»
doDeploy.xmi
exeoution-execKind
tranaaction=Boolean
Рис. 3.52. Использование спецификации развертывания
Спецификация развертывания изображается, как и классификатор (в виде
прямоугольника), но со стереотипом «deploymentSpec» и связывается отно-
шением зависимости с артефактом.
Последнее, что нам осталось рассмотреть в рамках данного параграфа, - это
отношение ассоциации между узлами.
Если узлы связаны между собой отношением ассоциации, то это означает то
же, что и в других контекстах: возможность обмена сообщениями. Приме-
нительно к вычислительным сетям, состоящим из узлов, ассоциация означа-
ет наличие канала связи. Если нужно указать дополнительную информацию
о свойствах канала, то это можно сделать, используя общие механизмы: сте-
реотипы («tcp/ip» на рис. 3.53), ограничения и именованные значения.
Workstation «tcp/ip» * 1 AppServer
Рис. 3.53. Ассоциация между узлами
3.4. Диаграммы реализации
На этом мы закончим данный обзорный параграф, чтобы в следующем под-
робнее познакомиться с диаграммами компонентов и размещения на при-
мере информационной системы отдела кадров.
3.4.3. Применение диаграмм реализации
Давайте попытаемся ответить на вопрос, какие интерфейсы, компоненты
и артефакты можно выделить в информационной системе отдела кадров, а
также как целесообразно разместить разработанное программное обеспече-
ние на вычислительных узлах.
Трехуровневая архитектура
Основное назначение проектируемой информационной системы — хранить
данные о кадрах и выполнять по указанию пользователя некоторые опера-
ции с этими данными. Анализируя состав операций, мы видим, что они сво-
дятся к созданию, модификации и удалению хранимых элементов данных.
Стандартным решением в таких ситуациях является применение готовой
СУБД (DBMS — Data Base Management System). С точки зрения проекти-
рования информационной системы отдела кадров целесообразно считать
используемую СУБД готовым компонентом с заранее определенными ин-
терфейсами и протоколом взаимодействия. Мы можем не заострять внима-
ния на структуре этого компонента — она стандартна и, наверное, достаточ-
но хорошо описана вне нашей модели.
СУБД возьмет на себя все функции по непосредственному манипулирова-
нию данными: создание, удаление и поиск записей в таблицах и т. д. Реали-
зация операций нашей информационной системы отдела кадров сводится к
некоторой последовательности элементарных операций с данными. Напри-
мер, операция перевода сотрудника с одной должности на другую, видимо,
потребует изменения в трех элементах данных: в данных о сотруднике и в
данных о старой и новой должностях. Однако целесообразно ли считать, что
определение и выполнение самой последовательности элементарных опера-
ций с данными также является прерогативой выделенного нами компонен-
та — СУБД? Общепринятая практика отвечает на этот вопрос отрицательно.
По многим причинам лучше выделить это в отдельный компонент, обычно
называемый бизнес-логикой132. Кроме этого, мы должны предположить, что в
нашей системе должен быть компонент, ответственный за пользовательский
интерфейс. В первом приближении мы приходим к структуре компонентов,
приведенной на рис. 3.54, которая называется трехуровневая архитектура.
132 Крайне неудачный, но часто используемый термин, являющийся калькой английского
business logic. Бизнес-логика не имеет никакого отношения ни к бизнесу (в российском
понимании этого слова), ни к логике. Правильнее было бы использовать сложное слово-
сочетание "правила обработки данных", но мы боимся оказаться непонятыми.
[27Г
Глава 3. Моделирование структуры
Диаграммы компонентов
Эволюцию диаграмм компонентов от версии UML1 к версии UML 2 можно
оценить на рис. 3.54 и рис. 3.55, на которых указаны одинаковые сущности
и отношения.
Рис. 3.54. Диаграмма компонентов Рис. 3.55 Диаграмма компонентов ИС ОК,
ИС ОК, выполненная в нотации UML 1 выполненная в нотации UML 2
Сами же изменения в нотации диаграмм компонентов в UML2 таковы:
• Во-первых, компоненты, как и любой классификатор, можно изо-
бражать единообразно, в виде прямоугольников, в которых указы-
вается либо стереотип «component» (1), либо один из уточняющих
стереотипов, приведенных в таблице 3.11 (2), либо соответствую-
щий значок в правом верхнем углу прямоугольника (3).
• Во-вторых, требуемые и обеспеченные интерфейсы можно изобра-
жать с помощью нотации "чупа-чупс" (4) (см. параграф 3.3.1), так
что отношение взаимодействия компонентов через некоторый ин-
терфейс выглядит естественным и симметричным.
Приведенный пример диаграммы компонентов достаточно тривиален и вы-
глядит не слишком убедительно с точки зрения полезности при архитек-
турном проектировании. Осознавая этот недостаток, мы приведем еще один
пример, связанный с информационной системой отдела кадров, в котором
постараемся показать, что диаграммы компонентов являются достаточно
выразительным средством проектирования архитектуры.
Допустим, что в проектируемой информационной системе отдела кадров
требуется разграничить права на выполнение операций и доступ к данным
для различных категорий пользователей. Хотя в нашем техническом зада-
3.4. Диаграммы реализации
нии про это не сказано ни слова, но для современных систем данное требова-
ние стало общим местом (иногда явно лишним), так что пример не является
надуманным. Нам известно множество способов реализации разграничения
прав доступа к данным, а неизвестных нам способов, наверное, существует
еще больше. Мы не будем вдаваться в их описание и обсуждение, а ограни-
чимся одним — очень простым, но действенным.
У нашего приложения два действующих лица (см. параграф 2.3.1), т. е. две
категории пользователей. Допустим, что достаточно разграничить права на
уровне категорий пользователей. Тогда можно поступить следующим обра-
зом: просто сделать два различных приложения (или, как обычно говорят в
таких случаях, два автоматизированных рабочих места — АРМа). Пользо-
ватели, имеющие доступ к АРМу в целом, метут выполнять все операции
АРМа и, таким образом, имеют те и только те права на доступ к данным,
которые обеспечиваются операциями, реализованными в АРМе133.
Для приложения типа информационной системы отдела кадров такого ре-
шения практически достаточно. Таким образом, разграничение прав доступа
к данным переносится на уровень доступа к компьютерам и установленным
на них приложениям, а это уже проблемы операционных систем и службы
безопасности предприятия, о которых в информационной системе отдела
кадров можно не заботиться.
Принятое решение легко выражается на диаграмме компонентов, приведен-
ной на рис. 3.56.
Рис. 3.56. Диаграмма компонентов ИС ОК
Все, что осталось сделать, — это определить состав компонентов, т.е. пока-
зать, какие классы в какие компоненты входят.
Самый простой способ показать связь между компонентом и входящими
в него классами — использовать отношения зависимости (1), как это пред-
ставлено на рис. 3.57.
133 Разумеется, нужно позаботиться о том, чтобы это ограничение было не так просто обой-
ти (по ошибке или злонамеренно).
Г лава 3. Моделирование структуры
FormManager
EventDispatcher
StaffForm
Рис. 3.57. Диаграмма компонентов ИС ОК
Другой способ определения состава компонента — рассматривать его как
структурированный классификатор и использовать диаграмму внутренней
структуры (см. параграфы 1.6.2 и 3.5.1).
Диаграммы размещения
Следующим структурным аспектом, который необходимо обсудить, явля-
ется описание размещения артефактов относительно участвующих в работе
вычислительных ресурсов.
Если речь идет о настольном приложении, которое целиком хранится и вы-
полняется на одном компьютере, то отдельная диаграмма размещения не
нужна — достаточно диаграммы компонентов (а может быть, и без нее мож-
но обойтись). При моделировании распределенных приложений значение
диаграмм размещения резко возрастает: они являются описанием тополо-
гии134 развернутой системы.
Продолжим рассмотрение информационной системы отдела кадров в этом
аспекте. Допустим, что мы приняли архитектуру, приведенную на рис. 3.56.
Сколько компьютеров будет использоваться при работе данного приложе-
ния? На этот вопрос нужно отвечать также вопросом: а сколько пользователей
будет у системы и сколько из них будут работать с приложением одновремен-
но? Если имеется только один пользователь (или, хуже того, нашу систему
установят "для галочки", а использовать не будут), то проблем нет — настоль-
ное приложение — один компьютер, и диаграмма размещения не нужна.
Допустим, что у нашей системы должно быть много пользователей, и они
могут работать одновременно. Тогда ответ очевиден: узлов должно быть не
меньше, чем число одновременно работающих пользователей, потому что
вдвоем за одним персональным компьютером обычным пользователям ра-
ботать неудобно135.
134 Программисты заимствовали название раздела математики (топология) как термин.
Например, часто можно встретить выражение "топология локальной сети”. Нельзя ска-
зать, что такое заимствование совершенно неверно, но в то же время оно и не совсем по
существу. Речь идет просто об описании структуры связей конечного множества узлов,
т. е. о графе (см. раздел 1.4).
135 Для поклонников экстремального программирования сделаем оговорку: экстремаль-
ные программисты не являются подклассом класса пользователей нашей системы, ц,
gRTh, _ ____________________________ _____________
3.4. Диаграммы реализации
Скорее всего, узлов должно быть на единицу больше, чем пользователей,
т. к. в большинстве организаций есть специально выделенный компьютер
(сервер) для хранения корпоративных данных. Там мы и поместим нашу
базу данных в расчете на то, что нужная СУБД, скорее всего, на сервере
уже установлена. Остается вопрос о размещении артефактов, реализующих
бизнес-логику. Здесь возможны разные варианты: на компьютере пользова-
теля, на промежуточной машине (сервере приложений), на корпоративном
сервере баз данных. Если мы остановимся на последнем варианте (который
на жаргоне называется "архитектура клиент/сервер с тонким клиентом"), то
получим диаграммы, приведенные на рис. 3.58 и рис. 3.59.
Обе эти диаграммы являются диаграммами размещения, но каждая из них
имеет свои особенности. На первой диаграмме упор сделан на указание со-
ответствия между компонентами и артефактами, выражающийся в наличии
большого количества отношений зависимости со стереотипом «manifest»
(см., например, 1 на рис. 3.58). Вторая диаграмма показывает отношения
между артефактами, или, другими словами, определяет, какой артефакт от
Рис. 3.58. Диаграмма размещения ИС ОК (артефакты и компоненты)
Глава 3. Моделирование структуры
Рис. 3.59. Диаграмма размещения ИС ОК (артефакты и зависимости между ними)
какого зависит, например, запрашивает данные (в качестве примера см. 1 на
рис. 3.59). На обеих диаграммах показаны вычислительные узлы и отно-
шения между ними (2 на рис. 3.58 и рис. 3.59). Заметим, что на диаграмме
появился дополнительный артефакт — Help (например, 3 на рис. 3.58). Это
документ, содержащий справочную информацию.
Рекомендации по использованию диаграмм реализации
Начнем с уже высказанного элементарного соображения, в случае разра-
ботки "монолитного" настольного приложения диаграммы размещения не
нужны — они оказываются тривиальными и никакой полезной информации
не содержат. Таким образом, диаграммы размещения применяются только
при моделировании многокомпонентных приложении (в том смысле, в ко
тором это рассматривается во врезке "Компонентное программирование" в
параграфе 3.4.2).
Если приложение поставляется в виде "конструктора" (набора "кубиков"),
из которого при установке собирается конкретный уникальный экземпляр
приложения, то диаграммы размещения оказываются просто незаменимым
средством. Действительно, многие современные приложения, особенно раз-
витые системы автоматизации управления делопроизводством предприя-
тия, поставляются в виде большого (десятки и сотни) набора артефактов,
____ Ф
J30J
3.5. Моделирование на уровне ролей и экземпляров классификаторов
из которых "на месте" собирается нужная пользователю, часто уникальная,
конфигурация. Некоторые авторитетные источники рекомендуют исполь-
зовать диаграммы размещения для управления конфитурацией не только
на фазе поставки и установки программного обеспечения, но и в процессе
разработки: для отслеживания версий компонентов, вариантов сборки и т. п.
При разработке приложений, которые должны взаимодействовать с так на-
зываемыми унаследованными (legacy) приложениями и данными, без диа-
грамм компонентов трудно обойтись. Дело в том, что фактически единствен-
ным средством UML, позволяющим как-то описать и включить в модель
унаследованные приложения и данные, являются компоненты (и их интер-
фейсы). Сюда же относится случай моделирования доступа к данным из "не-
родной" СУБД.
Последним (в нашем списке) примером применения диаграмм размещения
является моделирование систем динамической архитектуры, то есть таких
систем, которые меняют состав и количество экземпляров своих артефактов
во время выполнения136. Например, многие web-приложения меняют свою
конфитурацию во время выполнения в зависимости от текущей нагрузки.
Информационная система отдела кадров не является системой динамиче-
ской архитектуры, поэтому мы не приводим примера.
3.5. Моделирование на уровне ролей и
экземпляров классификаторов
На структурных диаграммах, рассматриваемых в первых разделах этой гла-
вы, сущности большей частью являются классификаторами. Экземпляры
классификаторов, если и появляются, то играют вспомогательную роль.
Однако бывают случаи, когда необходимо рассмотреть модель с более де-
тальной, объектной точки зрения. В этом разделе рассматриваются средства
UML, которые применяются в таких случаях.
3.5.1. Диаграмма внутренней структуры
В процессе моделирования на UML может оказаться, что ряд классов или
компонентов имеют ярко выраженную внутреннюю структуру. В предыду-
щих разделах мы встречались, например, с отношением композиции между
классами, которая служит для представления взаимосвязи между "целым"
и его "частями". Это хоть и наиболее типичный пример наличия у класса
(композита) внутренней структуры, однако он не до конца отражает суть по-
136 Отметим еще раз, что во время выполнения мы имеем дело не с самими классификато-
рами, а с их экземплярами. Представлению экземпляров классификаторов посвящен
параграф 3.5.4.
Глава 3. Моделирование структуры
нятия "внутренняя структура", принятого в UML, и является только одной
гранью этого понятия.
Дело в том, что под внутренней структурой классификатора понимается
не просто возможность представить этот классификатор в виде некоторо-
го контейнера, но также и способность обеспечить некоторый контекст, т.е.
внутренняя структура — это логическое понятие, которое объединяет клас-
сификаторы по принципу согласованности для выполнения некоторой за-
дачи, а следовательно, подразумевает и поведение.
В UML различают две группы классификаторов, для которых может
существовать внутренняя структура. В первую группу входят классы
и компоненты, а ко второй группе принадлежит такая сущность, как
кооперация.
Для каждой из групп в UML имеются свои средства представления внутрен-
ней структуры, и именно обсуждению этих средств посвящены первые два
параграфа данного раздела.
Диаграмма внутренней структуры — одно из самых важных нововведений
UML 2. Оно распространяет механизм структурной декомпозиции на струк-
турированные классификаторы (классы и компоненты). С точки зрения
практического моделирования это очень важно. Невозможность показать на
диаграммах прямо, как именно взаимодействуют составные части сложно-
го классификатора, затрудняла составление сложных моделей в UML 1. В
UML 2 это ограничение снято.
Диаграмма внутренней структуры — э го структурная диаграмма, ко-
торая раскрывает внутреннюю структуру классификатора и пути вза-
имодействия элементов (частей), Составляющих эту структуру.
На диаграммах внутренней структуры применяются следующие основные
сущности:
• структурированный классификатор (structured classifier);
• часть (part);
• порт (port);
• соединитель (connector).
Структурированный классификатор
Структурированный классификатор» (structured classifier) — это клас-
сификатор,(класс или компонент), внутренняя структура которого
описывается диаграммой внутренней структуры.
3.5. Моделирование на уровне ролей и экземг пяров классификаторов
Это определение похоже на тавтологию, но формально оно правильно, так
как само понятие структурированного классификатора достаточно искус-
ственно. Структурированный классификатор изображается обычной для
классификаторов фигурой — прямоугольником, внутри и на границах ко-
торого размещаются фигуры и значки других сущностей. Обычно на одной
диаграмме внутренней структуры раскрывают структуру одного классифи-
катора, показывая части только этого классификатора.
Часть
Часть (part) — это структурная составляющая, которая описывает
роль, которую ее экземпляр играет внутри экземпляра структуриро-
ванною классификатора.
Часть имеет имя (1), тип (2) и кратность (3). Отношение между структу-
рированным классификатором и его частями — это чаще всего отношение
композиции. В этом случае часть изображается как классификатор — прямо-
угольником (4), который должен быть расположен внутри прямоугольника
структурированного классификатора. Если части не связаны со структури-
рованным классификатором отношением композиции137, то тогда нотация
меняется, и рамочка прямоугольника рисуется пунктирной линией (5).
Рис. 3.60. Нотация для частей структурированного классификатора
Порт
Порт (port) — индивидуальная точка Взаимодействия (interact ion
point) структурированного классификатора и его частей с внешними
*Ю отношению к ним сущностями.
Порт изображается как небольшой квадратик на границе структурированного
классификатора или части (1). Для порта может быть указано имя (2), а также
137 Части могут представлять собой локальные переменные методов класса или пара-
метры, передаваемые при вызове методов класса.
Глава 3. Моделирование структуры
Рис. 3.61. Нотация порта
тип(3)икратность(4).Еслиуказантип,тоэтодолженбыть интерфейс,по кото-
рому происходит взаимодействие через данный порт. Впрочем, тип можно и не
указывать, аявно присоединить к порту один или несколько предоставляемых
и/или требуемых ин-
терфейсов (5), через
которые осуществля-
ется взаимодействие с
окружающим миром.
Общая нотация сущ-
ности порт приведена
на рис. 3.61.
Для портов может
быть задано два свой-
ства.
Первое свойство свя-
зано с теми сервисами, которые предоставляют интерфейсы, доступные че-
рез данный порт. Это свойство имеет имя isService и, соответственно, опре-
деляет, является порт сервисным или нет.
Порт называется сервисным или портом сервиса (service port), если
через порт осуществляется доступ к интерфейсам, которые предо-
ставляет классификатор и которые соответственно видимы тем, кТё
этот классификатор использует.
Значение свойства isService по умолчанию true, т.е. порт сервисный, в про-
тивном случае порт называют скрытым портом.
Порт называется скрытым (private port), если он используется во вну-
тренней рещтизации классификатора
В процессе разработки скрытый порт может быть изменен или даже удален.
Нотация скрытого порта — квадратик, присоединенный к границе класси-
фикатора с внутренней стороны (6 на рис. 3.61).
Второе свойство с именем isBehavior определяет, является ли данный порт
портом поведения всего классификатора или классификатор делегирует по-
ведение своим частям.
Порт является портом поведения (behavior р<нт), если действия, при-
чиной которых служаг запросы, приходящие через данный порт, ре<н
лизуются (в виде конечного автомата или метода) самим классифи-
катором, а не его частями.
234?
3.5. Моделирование на уровне ролей и экземпляров классификаторов
Нотация порта поведения (7 на рис. 3.61) отличается от нотации простого
порта тем, что внутрь классификатора добавляется прямоугольник со скру-
гленными углами, символизирующий деятельность, который соединяется с
портом поведения линией. Значение данного свойства по умолчанию false
т.е. порт не является портом поведения.
Соединитель
Как было уже сказано, части структурированного классификатора можно
рассматривать как слоты для всевозможных экземпляров других класси-
фикаторов, лишь бы они соответствовали роли, которую играет часть. Эти
экземпляры классификаторов могут быть связаны между собой явными (на-
пример, ассоциации) или неявными (например, зависимости) отношения-
ми. В рамках структурированного классификатора эти отношения представ-
ляются в виде соединителей.
Соединитель (connector) служит для с<х\ш пен ня частей структуриро-
ванного кла еифи кагора между собой.
Соединитель может соединять порт структурированного классификатора с
его частью или просто соединять части между собой. При этом порты на гра-
ницах частей могут указываться, а могут и отсутствовать.
Отметим, что соединители используются не только в диаграммах внутрен-
ней структуры, но и в кооперациях (см. параграф 3.5.2).
Соединители бывают двух видов: делегирующие и сборочные.
Соединитель, который соединяет порт структурированного классифи-
катора с его внутренней частью, называется делегирующим соедини-
телем (delegationi connector).
Соединитель, который соединяет дае части структурированного к..ас-
сификдтора, называется сборочным соединителем (assi iiilJy connector).
На рис. 3.62 показаны оба вида соединителей: делегирующие (1) и сбороч-
ные (2). Для делегирующих соединителей существует возможность исполь-
зования альтернативной нотации с использование стереотипа «delegate» (3).
Рассмотрим пример диаграммы внутренней структуры из модели инфор-
мационной системы отдела кадров (см. рис. 3.63). На этой диаграмме, мы
выделяем в подразделении (класс Department) простую внутреннюю струк-
туру, которая состоит из единственного начальника и некоторого множества
подчиненных. Подчиненные (subordinates) и начальник (chief) взаимодей-
Глава 3. Моделирование структуры
Рис. 3.62. Соединители на диаграмме внутренней структуры
ствуют, причем предусмотрены различные интерфейсы взаимодействия в
зависимости от направления передачи информации (IChief и (Subordinate).
Кроме того, указанные части взаимодействуют с внешним миром через свои
порты (Inbox и Resource).
Рис. 3.63. Диаграмма внутренней структуры класса Department
Рис. 3.64. Метамодель структурированного классификатора
3.5. Моделирование на уровне ролей и экземпляров классификаторов
По нашей традиции в конце параграфа приведена диаграмма уровня мета-
модели (рис. 3.64). Надеемся, что сложностей с ее прочтением не возникнет,
отметим только две сущности, связанные с поведенческим аспектом, а имен-
но абстрактные классы Trigger и Invocation Action, разговор о которых пойдет
в главе 4, посвященной моделированию поведения.
3.5.2. Кооперация
Кооперация — это еще один классификатор, который имеет внутреннюю
структуру. С некоторой натяжкой кооперацию можно назвать разновид-
ностью структурированного классификатора, отличие которого состоит в
том, что кооперация никогда не владеет своими частями. Части связаны
между собой посредством участия в кооперации, а не физическим вхожде-
нием внутрь нее.
Есть еще одно отличие, хорошо проявляющееся в нотации кооперации. Коо-
перация идентифицируется по имени, исходя из задачи, которую решает, в
то время как структурированные классификаторы носят имена реальных
классов или компонентов.
При определении внутренней структуры кооперации используются те же
самые сущности, что и для описания структурированных классификаторов,
поэтому мы не будем пересказывать содержание предыдущего параграфа, а
только внесем необходимые уточнения.
Основное применение коопераций — описание реализации чего-либо.
Чаще всего она применяется для реализации вариантов использования и
представления совместного поведения группы классов, которые решают не-
которую задачу.
Кооперация определяет необходимый для решения поставленной задачи
набор кооперирующихся участников в виде ролей. В каждом конкретном
случае эти роли играют конкретные экземпляры классификаторов. Суще-
ственные для решаемой задачи взаимоотношения между ролями показыва-
ются на диаграмме соединителями, определяя таким образом необходимые
связи.
В целях наглядности полезно описывать в кооперации только те аспекты
классификаторов, которые существенны для решаемой задачи, и исключать
остальные. В результате один и тот же участник может одновременно играть
разные роли в различных кооперациях, и каждая кооперация будет пред-
ставлять только существенные для своей цели аспекты этого участника.
Отдельно от структуры кооперации описывается ее поведение, например,
через диаграммы взаимодействия (см. раздел 4.4).
Г 287
Глава 3. Моделирование структуры
Обратимся к информационной системе отдела кадров. На рис. 3.63 приведе-
на внутренняя структура подразделения (Department), описывающая взаи-
модействие начальника и подчиненных. Рассмотрим немного более слож-
ный случай, когда у начальника есть один или несколько заместителей, через
которых он взаимодействует с подчиненными. Если построить диаграмму
внутренней структуры для такого случая, описание взаимодействия началь-
ника с заместителями на ней будет дублировать описание взаимодействия
заместителей с подчиненными (и начальника с подчиненными в исходной
диаграмме). Избежать такой избыточности позволяет кооперация, с помо-
щью которой можно описать схему взаимодействия один раз и применить к
различным взаимодействующим частям.
Кооперация изображается в виде пунктирного эллипса, содержащего имя
кооперации (рис. 3.65).
Рис. 3.65. Нотация кооперации
Внутренняя структура кооперации в форме ролей (1) и соединителей (2)
может быть показана внутри эллипса на отдельной диаграмме. Например,
на рис. 3.66 приведена кооперация, описывающая отношения начальника и
подчиненных.
Рис. 3.66. Кооперация начальника и подчиненного
Кооперации могут описываться как специализации более общих коопера-
ций, то есть могут участвовать в отношении обобщения. Роли в специали-
зированной кооперации либо совпадают с соответствующими ролями ис-
ходной кооперации, либо являются их специализациями. Отметим, что
исходной и специализированной роли может сопоставляться один и тот же
класс, если только он поддерживает интерфейсы, необходимые для обеих
ролей.
____ Ф
238
3.5. Моделирование на уровне ролей и экземпляров классификаторов
Например, заместитель начальника подразделения, кроме обычных свойств
подчиненного, может обладать правом подписи за начальника. Это можно
оформить в виде интерфейса (Deputy, который является специализацией ин-
терфейса (Subordinate (рис. 3.67).
Рис. 3.67. Интерфейс подчиненного с правом подписи
Заместитель с правом подписи может выступать в роли подчиненного (sub-
ordinate) в описанной выше кооперации с начальником (см. рис. 3.66). Од-
нако тип этой роли — (Subordinate — не позволяет начальнику поручить
заместителю заключение договора или каким-либо другим образом вос-
пользоваться правом подписи своего подчиненного.
Специализация кооперации, показанная на рис. 3.68, позволяет решить эту
проблему. В ней роль subordinate имеет специализированный тип (Deputy,
предоставляющий необходимую операцию.
Subordination
Subordination
with power to sign
chief: (Chief
subordinate:
I Deputy
Рис. 3.68. Специализация кооперации
Нотация использования кооперации предназначена для описания конкрет-
ного случая использования кооперации, т.е. является экземпляром коопера-
ции.
Использование кооперации (collaboration use) показывает, как опи-
сываемое кооперацией взаимодействие применяется в заданном кон-
тексте.
Для этого сущности из контекста сопоставляются ролям, определенным в
кооперации. Сущности могут быть классификаторами, частями структу-
Глава 3. Моделирование структуры
рированных классификаторов или ролями в объемлющей кооперации, т.е.
кооперации можно вкладывать одна в другую. В одном структурированном
классификаторе может несколько раз использоваться одна и та же коопера-
ция, связывая различные части. Кроме того, одна часть структурированного
классификатора может выполнять несколько ролей в одной или разных коо-
перациях.
Экземпляры кооперации изображаются пунктирным эллипсом. Внутрь эл-
липса помещаются имя использования (1) и имя кооперации (2), разделен-
ные двоеточием (рис. 3.69).
Рис. 3.69. Нотация использования кооперации
Сопоставление ролям конкретных классификаторов изображается с по-
мощью пунктирной линии (1 на рис. 3.70), которая проводится от эллипса,
обозначающего кооперацию, к требуемым классификаторам. Со стороны
классификатора линия подписывается именем соответствующей роли (2 на
рис. 3.70).
Диаграмма внутренней структуры, использующая ранее описанную коопе-
рацию начальника и подчиненного (рис. 3.63), показана на рис. 3.70 и рис.
3.71.
Рис. 3.70. Внутренняя структура подразделения, заместитель без права подписи
3.5. Моделирование на уровне ролей и экземпляров классификаторов
Рис. 3.71. Внутренняя структура подразделения, заместитель с правом подписи
Различие между этими диаграммами состоит в том, что в первом случае за-
местители (их трое!) не обладают правом подписи за начальника, так как
используется экземпляр кооперации Subordination (3 на рис. 3.70), а во вто-
ром — обладают, так как используется экземпляр кооперации Subordination
with power to sign (1 на рис. 3.71). Заметим, что заместители начальника на
обеих диаграммах описываются одним и тем же классом (4 на рис. 3.70 и 2
на рис. 3.71).
С точки зрения метамодели кооперация является специализацией струк-
турного классификатора. На рис. 3.72 мы не стали дублировать ту часть ме-
тамодели, которая относится к структурному классификатору и изображена
на рис. 3.64. Поэтому метамодель кооперации получилась не очень сложной.
Рис. 3.72. Метамодель кооперации
3.5.3. Образцы проектирования
Использование коопераций в UML тесно связано с таким понятием, как об-
разцы проектирования, которые в свою очередь являются одним из видов
паттернов.
Ф
[291
Глава 3. Моделирование структуры
ПАТТЕРНЫ
Практические рекомендации для решения часто встречаемых при
проектировании программных систем задач нашли свое отраже-
ние в паттернах.
Паттерн (pattern) — это обобщенное название. Обычно выделя-
ют три группы паттернов:
архитектурные образцы (architectural patterns),
• принципы проектирования (design principles),
• образцы проектирования (design patterns).
Архитектурные образцы представляют собой примеры вы-
сокоуровневых организаций программных систем в виде
набора подсистем и описания отношений между ними.
Архитектурные образцы призваны, прежде всего, реализовать
нефункциональные требования, предъявляемые к программной
системе. Например, такие как производительность, возможность
масштабирования и т.п.
Примеры архитектурных образцов: Layers (Уровни), Broker
(Брокер), Model-View-Controller (Модель-представление-
поведение).
Принципы проектирования описывают общие правила для
проектирования элементов системы. При использовании
принципов проектирования подразумевается поиск разумного
компромисса, так как сами принципы являются идеальными и ча-
сто не достижимыми рекомендациями, при строгом следовании
которым один принцип может вступить в противоречие с другим.
Примерами принципов проектирования может служить принцип
подстановки Лисков (см. врезку "Проектирование по контракту" в
параграфе 3.4.1) или принцип разделения модели и представле-
ния Model-View Separation (см. ниже в этом параграфе).
Образцы проектирования описывают проверенное практи-
кой решение типичной задачи (на уровне классов или компо-
нент и их взаимодействия) в некотором контексте. В качестве
примеров можно назвать образцы Adapter или Publish-Subscriber
(см. ниже в этом параграфе).
Для углубленного изучения данного аспекта вернемся к моделированию ин-
формационной системы отдела кадров и еще раз посмотрим на реализацию
варианта использования Hire Person, представленного на рис. 2.22, который
мы повторно изобразим здесь на рис. 3.73, чтобы не отвлекать внимание чи-
тателя на поиски.
И хотя внешне все выглядит удовлетворительно, на самом деле в данной
реализации полно недочетов (о существовании которых мы упоминали в па-
раграфе 2.4.4), которые опытные читатели наверняка заметили. Например,
из данной реализации следует, что класс Hire Form может создать экземпляр
ф
ФТЕВ-.................................................................
3.5. Моделирование на уровне ролей и экземпляров классификаторов
Рис. 3.73. Диаграмма последовательности для типового сценария
"прием сотрудника"
класса Person и обладает информацией об экземплярах класса Position, что
противоречит одному из принципов, которым желательно следовать, про-
ектируя приложения с графическим интерфейсом пользователя. Данный
принцип проектирования носит название Model-View Separation и говорит о
том, что сущность, ответственная за общение с пользователем (графический
интерфейс), не должна напрямую манипулировать данными, а сущность, от-
ветственная за хранение и обработку данных, не должна содержать элемен-
тов пользовательского интерфейса.
На самом деле данный принцип был использован при моделировании на
уровне компонентов (см. рис. 3.56), где мы выделили компоненты, отвечаю-
щие за взаимодействие с пользователем (эти компоненты имеют добавление
GUI к своему имени, например, StaffManagerGUI), и компоненты, реализую-
щие непосредственно логику приложения (эти компоненты имеют добавле-
ние Management к своему имени, например, StaffManagement). Сделано это
было как раз для того, чтобы не смешивать элементы пользовательского ин-
терфейса с элементами бизнес-логики, что полностью соответствует прин-
ципу Model-View Separation.
Все, что нам остается сделать, — это предложить новую диаграмму после-
довательности (см. рис. 3.74) для реализации типового сценария приема со-
трудника, удовлетворяющую принципу Model-View Separation.
Заметим, что использование того или иного паттерна при моделировании
выбор архитектора, но в любом случае отразить на диаграмме UML тот факт,
что в данном контексте используется конкретный паттерн, иногда достаточ-
но сложно.
Глава 3. Моделирование структуры
Рис. 3.74. Диаграмма последовательности для типового сценария
приема сотрудника
В случае применения принципа Model-View Separation лучшей иллюстра-
цией его использования служит диаграмма компонентов (рис. 3.56), но без
дополнительных пояснений непосвященному это не совсем очевидно. То же
самое относится и к архитектурным образцам, для которых никаких специ-
альных средств, кроме диаграмм размещения, в UML нет.
Зато для описания образцов проектирования прекрасно подходит сущность
кооперация, а точнее ее параметризованный вариант, который носит назва-
ние шаблон кооперации (collaboration teraplate).
В качестве примера рассмотрим описание образца проектирования Publisher-
Subscriber (рис. 3.75), который применяется в случае, когда некоторое мно-
жество объектов должно следить за изменением состояния другого объекта.
Объект, изменение состояния которого требуется отслеживать, называется
издателем (publisher), а объекты, которые следят за его состоянием, назы-
ваются подписчиками (subscriber). Отсюда и название образца проектиро-
вания.
Каждый подписчик — экземпляр классификатора с типом параметра шабло-
на кооперации SType (1), а издатель — экземпляр классификатора с типом
Ф
3.5. Моделирование на уровне ролей и экземпляров классификаторов
параметра шаблона кооперации РТуре (2).
Издатель (роль Publisher (3)) должен определить две операции subscribe() и
unsubscribe(), которые служат для того, чтобы подписать и, соответственно,
отписать подписчика (роль Subscriber (4)) от нотификации. Нотификация
осуществляется путем вызова метода update(), который определен в интер-
фейсе ISubscriber. Этот интерфейс должен быть реализован (5) каждым под-
писчиком.
Пример использования образца проектирования Publisher-Subscriber в кон-
тексте информационной системы отдела кадров приведен в параграфе 4.4.2.
Рис. 3.75. Образец проектирования Publisher-Subscriber
3.5.4. Экземпляры классификаторов
В предыдущих разделах мы уже рассмотрели достаточно много различных
классификаторов (см. рис. 3.4). Однако при этом мы всегда делали упор на
то, что классификатор является дескриптором, т.е. описателем однотипных
объектов, но никогда не вели целенаправленно разговор об экземплярах
классификаторов. Теперь у нас накопилось достаточно материала, чтобы
восполнить этот пробел.
Как уже упоминалось, для того чтобы указать, что элемент на диаграмме
является именно экземпляром классификатора, а не самим классификато-
ром, применяется следующая нотация — его имя подчеркивают138.
138 Как и для всякого правила, здесь также существуют исключения.
Глава 3. Моделирование структуры
Не могут иметь конкретных экземпляров абстрактные классификаторы139,
к которым относятся, например, интерфейс (стереотип «interface») и любые
другие классификаторы с ограничением {abstract}.
Также особняком стоит экземпляр ассоциации, который носит специаль-
ное название — связь. Подробнее использование связей будет обсуждаться
в следующей главе, посвященной моделированию взаимодействия, а сейчас
мы лишь скажем, что связь не имеет имени и поэтому выделять подчеркива-
нием нечего. И хотя нотации ассоциации и связи одинаковы (сплошная ли-
ния), однако это не значит, что связь может быть спутана с ассоциацией у
них разные способы использования.
Экземпляры классификатора "тип данных" (стереотип «dataType») и его
специализации "примитивный тип" (стереотип «primitive») на диаграммах в
большинстве случаев представляются в виде начальных или константных
значений для атрибутов других классификаторов. Для возможных экзем-
пляров классификатора "перечисление" (стереотип «enumeration») преду-
смотрена специальная нотация (см. рис. 3.7).
Пример использования экземпляров действующего лица для информацион-
ной системы отдела кадров приведен на рис. 3.76. Пользуясь случаем, мы
продемонстрируем на этом примере альтернативную нотацию для представ-
ления действующего лица - класс со стереотипом «actor» (1).
Петрова:
Personnel
Manager
Рис. 3.76. Пример использования экземпляров действующих лиц
Глядя на рис. 3.76, читатель может задать законный вопрос: почему на диа-
грамме нарисованы экземпляры действующих лиц, хотя в разделе 2.3 о та-
кой возможности ничего не сказано?
Прежде всего, напомним, что диаграммы, которые описываются в специфи-
кации, и в частности диаграмма использования, входят в список канониче-
139 Абстрактные с точки зрения модели проектируемой системы, а не с точки зрения мета-
модели.
3.5. Моделирование на уровне ролей и экземпляров классификаторов
ских (рекомендованных) диаграмм для моделирования. Когда в тексте книги
встречается словосочетание "диаграмма использования", чаще всего под-
разумевается "каноническая диаграмма использования, рекомендованная
к применению исходя из сложившейся практики". Данный пример нагляд-
но демонстрирует, что канонические диаграммы не могут отобразить всего
многообразия сущностей UML и их отношений (в спецификации нигде не
указано, на какой диаграмме можно отображать экземпляры действующих
лиц, например), и поэтому разработчик вправе вносить свои дополнения с
условием, что они не противоречат спецификации. В данном случае мы ру-
ководствуемся именно этим правилом, и тот факт, что на диаграмме нарисо-
ван экземпляр действующего лица, не делает ее недействительной. Просто
данная диаграмма перестает быть канонической, но остается полноправной
частью модели, описываемой на UML.
Что касается вариантов использования, то в UML существует такая сущ-
ность, как конкретная последовательность событий и действий, доставляю-
щая значимый результат, на которую мы ссылаемся через понятие сценарий
(см. параграф 2.3.2). В спецификации UML не существует такой сущности —
сценарий, однако есть способы представления сценария, которые мы рас-
смотрели в разделе 2.4. Так вот именно эти реализации сценария мы вправе
называть экземплярами вариантов использования.
Примеры экземпляров коопераций приведены на рис. 3.70 и рис. 3.71. За-
метим, что в случае коопераций, ее экземпляры не подчеркиваются. Не под-
черкиваются также и названия внутренних частей кооперации440.
Большую помощь при моделировании системы оказывают экземпляры
узлов (стереотипы «device», «executionEnvironment») и размещаемые на них
экземпляры артефактов (стереотип «artifact» и другие стереотипы, указан-
ные в таблице 3.12), которые изображаются на диаграмме размещения.
В случае информационной системы отдела кадров, например, вместо рас-
смотрения абстрактных вычислительных узлов, можно рассматривать кон-
кретные компьютеры, которые имеются у организации в наличии, и разме-
щать на этих конкретных компьютерах конкретные экземпляры программы.
В этом случае имена экземпляров узлов и размещенных на них артефактов
подчеркиваются (см. рис. 3.77).
В отношении артефактов осталось сделать небольшое, но важное замечание,
которое связано с понятием индивидуальности, определенном в парагра-
фе 3.2.4. 140 * *
140 Никакого объяснения, почему так надо делать, в стандарте нет, но, анализируя специ-
фикацию, можно сделать вывод, что элементы, которые олицетворяют собой роль, а не
конкретный экземпляр, не подчеркиваются никогда.
Глава 3 Моделирование структуры
Рис. 3.77. Пример использования экземпляров артефактов и узлов
На первый взгляд сами артефакты индивидуальностью не обладают, а инди-
видуальность их экземпляров следует из того факта, что они размещаются
на конкретных экземплярах вычислительных узлов.
Действительно, если на компакт-диске с поставляемой системой записан,
например, файл документации, то можно считать, что это описание множе-
ства идентичных файлов с документацией, й при развертывании системы
этот файл может быть скопирован на все рабочие станции в необходимом
числе экземпляров.
Однако из правила есть исключения. Рассмотрим следующий типичный ар-
тефакт многих офисных систем — блок проверки орфографии, который мо-
жет быть реализован в виде отдельной библиотеки. Внутри такой библиоте-
ки есть словарь, с помощью которого проверяется правописание. Если этот
словарь неизменяемый, то экземпляры блока орфографического контроля
не обладают индивидуальностью. Но блок проверки орфографии может
быть снабжен функцией пополнения и изменения словаря. В таком случае в
процессе эксплуатации и корректировки со стороны пользователя конкрет-
ный экземпляр блока орфографического контроля все более и более отлича-
ется от своих собратьев, работающих на других компьютерах, и приобретает
индивидуальность.
Следующий пример связан с одним из способов защиты от несанкциониро-
ванного копирования программ (пиратства). Суть этого способа заключается
в так называемой "привязке" приложения к компьютеру. При установке про-
граммы определяются некоторые индивидуальные характеристики компью-
тера, и код устанавливаемой программы изменяется таким образом, чтобы он
_____ Ф
3.5. Моделирование на уровне ролей и экземпляров классификаторов
был работоспособен только на данном компьютере. Очевидно, что привязан-
ные к компьютеру экземпляры артефактов обладают индивидуальностью.
Последний классификатор, рассматриваемый в рамках этого параграфа, —
компонент. Компонент по определению не может иметь экземпляров, так
как существует только на этапе моделирования системы, где никаких экзем-
пляров быть не может141.
В рамках данного раздела нам осталось рассмотреть еще два классификато-
ра: класс и класс ассоциации. Однако поскольку для экземпляров классов
в UML используется специальная сущность — объект, то мы отвели для ее
описания отдельный параграф.
3.5.5. Объекты и диаграмма объектов
Начнем с небольшого отступления. При моделировании разработчику ино-
гда бывает важно указать, что некоторый объект является экземпляром
конкретного класса. В UML это делается с помощью зависимости со стерео-
типом «instanceOf», которая, вообще говоря, может соединять любые класси-
фикаторы и их экземпляры (см., например, рис. 3.76).
С практической точки зрения, прежде чем использовать экземпляры клас-
сов, их нужно создать. Данный факт также можно отразить на диаграмме
классов UML с помощью зависимости со стереотипом «instantiate», которая
соединяет класс, ответственный за создание экземпляров другого класса, с
целевым классом.
Если есть возможность указать конкретный метод класса, ответственный
за данную операцию, то рядом с именем метода можно указать стереотип
«create», а отношение зависимости позволяет показать, экземпляры класса,
создаваемые в данном методе.
Обратимся к информационной системе отдела кадров. В параграфе 3.2.1 был
введен служебный класс Company, который отвечает за хранение глобаль-
ных атрибутов и операций. Этот же класс связан отношением композиции с
классом Department (см. рис. 3.22). Логично предположить, что ответствен-
ность за создание экземпляров класса Department ложится на экземпляр
класса Company. Проиллюстрируем сказанное. На рис. 3.78 метод createDpt
(1) класса Company отвечает за создание экземпляров классов Department, а
метод createPrs (2) за создание экземпляров класса Person. В то же время
класс Department, согласно тому же принципу, создает экземпляры класса
Position (3).
141 На самом деле это не совсем верно. В метамодели у сущности Component присутствует
булевский атрибут islndirectlylnstantiated, которые позволяет рассматривать компонент
как инстанциируемый объект.
Ф
[ 299
Глава 3. Моделирование структуры
Рис. 3.78. Создание и спецификация экземпляра
Для представления объектов в l.’ML существует специальная диа-
грамма - дишрамма объектив (object diagram).
После столь подробного разбора диаграмм классов и ее составляющих в рам-
ках данной главы мало что осталось добавить относительно диаграмм объ-
ектов.
С одной стороны, диаграмма объектов — это не более чем частный случай
диаграммы классов. Сущностями на диаграмме объектов являются объек-
ты, т. е. экземпляры классов. Их имена подчеркиваются. Отношениями на
диаграмме объектов являются связи, т. е. экземпляры ассоциаций. Отнюдь
не все дополнения, предусмотренные для ассоциаций, имеют смысл и мо-
гут быть показаны для связей. В частности, кратность для полюсов связи не
имеет смысла. Обычно связь отображается просто в виде линии, соединяю-
щей объекты, без каких-либо дополнений.
С другой стороны, можно рассматривать диаграмму объектов как дамп
памяти в некоторый момент выполнения системы (т.е. пример того, какие
конкретные объекты сосуществуют в некоторый момент времени и какие
между ними установлены связи).
Поскольку диаграмма объектов — это не более чем пример, ее описательная
сила невелика. Все, что можно показать на диаграмме объектов, можно пока-
зать и на диаграмме взаимодействия в форме коммуникации (см. параграф
4.4.5), причем гораздо более информативно. Поэтому диаграммы объектов
используются сравнительно редко. Так, например, большинство инстру-
_____ Ф
3.5. Моделирование на уровне ролей и экземпляров классификаторов
ментов не поддерживает отдельного режима для рисования диаграмм объек-
тов: на диаграмме классов можно разместить только объекты (без классов),
и тем самым она станет диаграммой объектов.
Мы полагаем, что авторы UML сохранили диаграммы объектов как отдель-
ный вид канонических диаграмм "на всякий случай" и "для полноты карти-
ны" — в наших моделях данный вид диаграмм редко используется, однако
без примера мы читателя не оставим. Достаточно информативный пример
использования диаграммы объектов для информационной системы отдела
кадров приведен на рис. 4.89, а сейчас мы хотим поговорить о малоизвест-
ном, но очень полезном способе использования диаграммы объектов.
На протяжении всей главы помимо диаграмм уровня модели мы также на-
рисовали достаточно большое количество диаграмм уровня метамодели. Да-
вайте вспомним, что у любой сущности и отношения (на уровне модели)
существует соответствующий метакласс (на уровне метамодели), экзем-
пляром которого эта сущность или отношение является. Таким образом,
мы можем взять любую диаграмму уровня модели и перерисовать ее в тер-
минах экземпляров соответствующих метаклассов. Это прекрасный способ
проверки понимания основных принципов внутреннего устройства UML.
В качестве примера выберем небольшую диаграмму, описывающую часть
структуры информационной системы отдела кадров (рис. 3.79).
Рис. 3.79. Часть диаграммы классов ИС ОК
Соответствующая ей диаграмма объектов, построенная из экземпляров ме-
таклассов метамодели, приведена на рис. 3.80.
Некоторые авторы, например Конрад Бок [Conrad Bock. UML 2 Activity and
Action Model. //Journal of Object Technology, vol. 2, No 4-6, vol. 3, No 1, No 7,
2003-2004], используют модель хранения (repository model) как одно из по-
лезнейших средств задания семантики моделей.
Глава 3 Моделирование структуры
Рис. 3.80. Пример модели хрвнения
Г 302
Выводы
С.руктура сложной системы описывается на уровнр дескрипто-
ров.
Диаграммы классов моделируют структуру классов и отноше-
ний между ними
Классы выбираются на основе анализа предметной области,
взаимного согласования элементов модели и общих теоретиче-
ских соображений
Взаимосвязь между классами описывается, прежде всего, с по-
мощью отношений обобщения и ассоциации Реже с помощью
отношений зависимости и реализации.
Отношение ассоциации имеет большой набор различных до-
полнений, с помощью которых можно указать особенности от-
ношений между классами.
Множества классов могут объединяться в логическую структуру
- компонент
Каждый компонент описывается набором гребунмых й обеспе-
ченных интерфейсов.
Компонент и классы как элементы модели связываются с физи-
ческими сущностями — артефактами — с помощью отношения
манифестации.
Диаграммы компонентов моделируют структуру комнбнбнтов
«артефактов) и взаимосвязей между ними.
Диаграммы размещения моделируют структуру вычислитель-
ных оесурсов и размещенных Lja них артефактов
Диаграммы внутренней структуры показывают контекст взаи-
модействия частей сложных классификаторов, причем части, в
свою очередь, так же могут иметь внутреннюю структуру.
Кооперация - это способ показать кон текст взаимодействия не-
скольких классификаторов.
Диаграмма объектов — это пример связей программных объек-
тов в отдельный момент выполнения системы.
Глава 4.
Моделирование
поведения
Что такое моделирование поведения?
Как может статическая модель описывать
динамическое поведение?
Какие элементы применяются для
моделирования поведения?
Для чего применяются диаграммы автомата?
Что общего и в чем различие между диаграммами
автомата и деятельности?
В каких случаях применяются диаграммы дея-
тельности?
Почему в диаграммах деятельности конструкции
UML 1 сосуществуют с конструкциями UML 2?
Почему используется несколько видов диаграмм
взаимодействия?
Какова область применения диаграмм
взаимодействия?
Как моделируются параллельные процессы?
4.1. Модели поведения
При создании программной системы недостаточно ответить на вопросы
"что делает система?" (глава 2) и "из чего она состоит?" (глава 3) — требу-
ется ответить на вопрос "как работает система?". Ответ на этот вопрос дает
модель поведения. Поведение реальной программы целиком и полностью
определяется ее кодом — как программа составлена, так она и выполняется
(с точностью до сбоев) — "от себя" компьютер ничего не придумывает. Но
программа — это просто запись алгоритма. Таким образом, мы приходим к
следующему определению.
Модель поведения (behavior model) — это описание алгоритма рабо-
ты системы.
Существует множество способов описания алгоритмов, каждый из них име-
ет свои достоинства и недостатки и предназначен для применения в различ-
ных ситуациях. Например, при описании алгоритмов, которые предназначе-
ны для выполнения компьютером, используются языки программирования,
но для описания алгоритмов, выполняемых человеком, языки программиро-
вания неудобны и применяются другие способы.
Средства моделирования поведения в UML, ввиду разнообразия областей
применения языка, должны удовлетворять набору различных и частично
противоречивых требований. Перечислим некоторые из них.
зов
4.1, Модели поведения
• Модель должна быть достаточно детальной для того, чтобы послу-
жить основой для составления компьютерной программы — ком-
пьютер не сможет самостоятельно "додумать" опущенные детали.
• Модель должна быть компактной и обозримой, чтобы служить
средством общения между людьми в процессе разработки системы
и для обмена идеями.
• Модель не должна зависеть от особенностей реализации конкрет-
ных компьютеров, средств программирования и технологий, чтобы
не сужать область применения языка UML.
• Средства моделирования поведения в UML должны быть знако-
мыми и привычными для большинства пользователей языка и не
должны противоречить требованиям наиболее ходовых парадигм
программирования.
Удовлетворить сразу всем требованиям в полной мере, видимо, практически
невозможно — средства моделирования поведения UML являются резуль-
татом многочисленных компромиссов. Многие авторы критикуют- UML за
то, что он недостаточно хорош с точки зрения того или иного конкретного
критерия142. Но если принять во внимание сразу все противоречивые тре-
бования, то, по нашему мнению, следует признать, что на сегодняшний день
UML является решением, очень близким к оптимальному. В будущем, по
мере развития теории и практики программирования, будет эволюциониро-
вать и UML — для этого в языке предусмотрены все необходимые средства.
Примечание
Следует подчеркнуть, что средства моделирования поведе-
ния в UML не были изобретены вместе с UML — они появи-
лись намного раньше и были приспособлены для использо-
вания в UML, прежде всего за счет продуманности самого
языка, в который изначально были введены средства для
его расширения (см. параграф 1.8.4). Тем самым, эволюция
средств описания поведения уже имеет место, и этот процесс,
очевидно, будет продолжаться!
Описание средств моделирования поведения в UML мы начнем с небольшо-
го отступления на тему одного из разделов дискретной математики — тео-
рии автоматов — который послужил теоретической основой средств моде-
лирования поведения в UML.
142 Мы тоже по ходу дела стараемся отмечать слабые, по нашему мнению, конструкции
UML.
Глава 4 Моделирование поведения
4.1.1. Конечные автоматы
й? Конечным автоматом (Мили) называется совокупность пяти объек-
тов:
• конечного множества Л = {а,,..., ап J, называемого входным
алфавитом; элементы множества А называются входными сим-
волами, сигналами, событиями, стимулами или воздействиями;
| 5 • конечного множества Q — t<7,,.г;, q }, называемого алфавитом §
i, состояний; элементы множества Q называются состояниями;
. • конечного множества В - {Д,..., Ьк }, называемого выходным
алфавитом; элементы множества В называются выходными
символами, реакциями или воздействиями;
• тотальной ( всюду определенной) функции 5 : А X Q —> Q, на-
зываемой функцией переходов;
• тотальной функции X : А X Q —> В, называемой функцией вы-
ходов.
Эта несложная конструкция оказывается применимой для адекватного опи-
сания очень многих ситуаций. Далее мы рассмотрим несколько характерных
примеров применения конечных автоматов143, а затем — дополнительные
модификации (соглашения) конечных автоматов.
Автоматное преобразование
Пусть задан автомат S, некоторое состояние q из алфавита Q этого автомата
и входное слово ОС в алфавите А. По этой информации однозначно опреде-
ляется выходное слово р в алфавите В. А именно, по состоянию q и перво-
му символу слова ОС с помощью функции выходов А определяется первый
символ слова Рис помощью функции переходов 5 определяется следующее
состояние автомата. Затем по новому состоянию и второму символу вход-
ного слова ОС определяется второй символ выходного слова Р и следующее
состояние. И так далее. Поскольку функции А и 5 тотальны, автомат S и со-
стояние q определяют некоторый алгоритм преобразования слов в алфавите
А в слова в алфавите В.
Преобразование слов в алфавите А в слова в алфавите В с помощью
автомата 5 называется автоматным преобразованием и обычно обо»
значается той же буквой S, ч то и автомат.
143 Мы надеемся, что конкретные примеры, приведенные в последующих параграфах этой
главы, скрасят академический тон данного параграфа, может быть трудноватого для по-
нимания при первом чтении.
4.1. Модели поведения
Автоматные преобразования обладают рядом полезных свойств, в частно-
сти:
• автоматное преобразование сохраняет длину, то есть результат
преобразования состоит из такого же числа символов, что и аргу-
мент, |ос| = |iS'(ct)|;
• автоматное преобразование обладает свойством префикса144,
S (ос + Р ) = S (ОС) + 5 (Р ), где + обозначает операцию конкатенации
(сцепление строк).
Автоматные преобразования и родственные им конструкции используются
очень часто при компьютерной обработке текстов (см. далее в этом парагра-
фе отступление "Регулярные выражения").
Реактивные системы
Конечный автомат можно интерпретировать и другим образом, а именно
можно считать, что элементы множества А — это стимулы (события), а эле-
менты множества В — это реакции (обработчики событий). В таком случае,
если задан автомат А и некоторое состояние q этого автомата, то описано ав-
томатное поведение, то есть последовательность (возможно, бесконечная)
пар "стимул — реакция".
Такого рода описание оказывается очень полезным на практике. Например,
подавляющее большинство реальных устройств дискретного управления
прекрасно описываются конечными автоматами. Другим примером может
служить графический интерфейс пользователя в обычных приложениях.
Такого рода программные системы часто называют реактивными (reactive).
Машина Тьюринга
Одна из самых популярных моделей вычислимости — машина Тьюринга —
фактически является расширением модели конечного автомата, в которой
допускается чтение и запись информации в потенциально бесконечную па-
мять.
В настоящее время общепринятым является тезис Чёрча-Тьюринга — фун-
даментальное утверждение, высказанное Алонзо Чёрчем и Аланом Тьюрин-
гом в середине 1930-х годов. В самой общей форме оно гласит, что любая
интуитивно вычислимая функция может быть вычислена некоторой маши-
ной Тьюринга и, таким образом, понятие машины Тьюринга равнообъемно
понятию алгоритма.
144 Другими словами, автоматное преобразование является гомоморфизмом, "уважаю-
щим" конкатенацию.
Глава 4. Моделирование поведения
МАШИНА ТЬЮРИНГА
Машина Тьюринга— абстрактная вычислительная машина (мо-
дель вычислимости), предложенная Аланом Тьюрингом в 1936
году для формализации понятия алгоритма. В состав машины
Тьюринга входит бесконечная в обе стороны лента (возможны ма-
шины Тьюринга, которые имеют несколько бесконечных лент или
лент, бесконечных только в одну сторону), разделённая на ячей-
ки, и управляющее устройство, способное находиться в одном из
множества состояний. Число возможных состояний управляюще-
го устройства конечно и заранее задано. Среди состояний име-
ется начальное, в котором машина Тьюринга находится в начале
своей работы.
Управляющее устройство может перемещать влево и вправо по
ленте на одну ячейку головку чтения/записи (или перемещать
ленту влево или вправо, что эквивалентно), читать и записывать в
текущую обозреваемую ячейку ленты символы некоторого конеч-
ного алфавита. Выделяется особый пустой символ, в начальном
состоянии заполняющий все клетки ленты, кроме конечного чис-
ла клеток, на которых записаны входные данные. Считается, что в
начальном состоянии машина обозревает самый левый непустой
символ на ленте.
Управляющее устройство работает согласно правилам перехода,
которые представляют алгоритм, реализуемый данной Машиной
Тьюринга. Каждое правило перехода предписывает машине, в
зависимости от текущего состояния и наблюдаемого в текущей
ячейке символа, записать в зту ячейку новый символ, перейти в
новое состояние и переместиться на одну ячейку влево или вправо
(или остаться на месте). Некоторые состояния Машины Тьюринга
могут быть помечены как заключительные, и переход в любое из
них означает конец работы, остановку алгоритма. Состояние лен-
ты после остановки считается результатом работы алгоритма.
Таким образом, оказывается, что класс алгоритмов, которые можно описать
автоматом, весьма широк, хотя и не всеобъемлющ145.
Дополнительные соглашения по применению конечных автоматов,
ИСПОЛЬЗУЕМЫЕ В UML
Обычно при применении конечных автоматов используют некоторые согла-
шения, которые не меняют сути дела и принимаются для удобства.
145 Подсказка для заинтригованного читателя: конечные автоматы не позволяют описать,
например, такое поведение, которое может включать потенциально бесконечное число
шагов, и при этом очередной шаг зависит от всех предшествующих шагов. Конечный
автомат потому и называется конечным, что может "помнить" только конечное число
шагов — не больше, чем число состояний в автомате. Машину Тьюринга "выручает" бес-
конечная лента — на ней можно запомнить все, что нужно.
4.1. Модели Поведения
Во-первых, сразу выделяют одно состояние, которое считается начальным
(обычно ему дают номер 0 или 1).
Автомат с выделенным начальным состоянием называется инициаль-
ным.
Инициальный автомат всегда начинает работу в одном и том же состоянии,
поэтому специально это состояние указывать не нужно.
Во-вторых, можно рассмотреть случай, когда функция выходов X имеет
только один параметр — состояние — и выходной символ зависит только от
состояния и не зависит от входного символа.
Автомат, называется автоматом Мура, если функция выходов зависит
только от состояния. В этом случае данная функция обычно обозна-
чается 11 : Q —» В и называется функцией пометок.
Очевидно, что автомат Мура является частным случаем автомата Мили.
Более того, нетрудно показать, что введением дополнительных состояний
любой автомат Мили может быть преобразован в эквивалентный автомат
Мура. Можно рассматривать и комбинированный вариант, когда определе-
на как функция выходов, так и функция пометок, причем, может быть, ча-
стично.
В-третьих, иногда выделяют одно или несколько состояний, которые назы-
ваются заключительными. Если автомат переходит в заключительное состо-
яние, то работа автомата завершается — он больше не реагирует на события
и не выдает выходных символов, хотя, быть может, ещё остались необрабо-
танные входные символы.
Заключительное состояние не является полноценным состоянием, посколь-
ку для него не имеет смысла определять функции переходов и выходов, поэ-
тому заключительное состояние считают псевдосостоянием.
Примечание
Иногда используются еще два термина, связанные с состоя-
ниями. Состояние называется тупиковым, если автомат не
может покинуть это состояние, то есть не определены пере-
ходы, ведущие в другие состояния. Состояние называется
недостижимым, если автомат не может попасть в это состоя-
ние, то есть не определены переходы, ведущие в это состоя-
ние из других состояний.
Глава 4. Моделирование поведения
Модификации конечных автоматов, не применяющиеся в UML
Три перечисленных выше соглашения используются в UML. Однако этим
не исчерпывается список возможных модификаций конечных автоматов.
Мы перечислим некоторые, в том числе достаточно экстравагантные, хотя
они и не применяются в UML.
Первая модификация является стандартным приемом в синтаксическом
анализе. Автомату вообще не назначается функция выходов, только функ-
ция переходов. При этом среди состояний выделяется подмножество допу-
скающих состояний (остальные состояния, соответственно, считаются не-
допускающими). Если на вход такому автомату подать последовательность
входных символов (анализируемое слово), то в конце работы автомат ока-
жется в каком-то состоянии (допускающем или недопускающем). В первом
случае говорят, что автомат допустил входное слово, а во втором — отверг.
Такой автомат называется распознавателем, поскольку он распознает среди
всех слов множество допустимых, т.е. распознает некоторый язык. Ответ на
вопрос, каков класс языков, распознаваемых конечными автоматами, явился
одним из первых фундаментальных результатов теории автоматов116, и этот
ответ довольно любопытен: автоматами можно распознать те и только те
языки, которые описываются регулярными выражениями.
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ
Пусть задан конечный алфавит А. Последовательности букв ал-
фавита называются словами. Множество всех слов в данном ал-
фавите А обозначается А . Пустое слово, не содержащее букв,
обозначается 8. Подмножество L CZ А называется языком над
алфавитом А. Язык, состоящий из одного слова, которое состоит
из одной буквы, называется элементарным. Пустое слово 8 также
считается элементарным языком. Часто рассматривают следую-
щие три операции над языками:
• объединение (альтернация, сложение)
А IА е Л* |ае Д vet е Z2};
• умножение (конкатенация, сцепление)
АА = {ос е Л’ |ос =«^2 a a, g Z, аос2 g Z2};
• итерация (итерация Клини)
А =£|£|А |... = 0Г
------------------ /=0
146 Распространен предрассудок, что конечные автоматы применяются только для синтак-
сического анализа. Это не так. Действительно, первые результаты и первые применения
теории автоматов были получены именно в синтаксическом анализе. Но потом появи-
лись другие результаты и другие области применения.
____ <
[31?
4.1. Модели поведения
Эти операции называются регулярными операциями, они имеют
большое значение в теории языков и автоматов. Языки, которые
можно построить из элементарных языков с помощью регулярных
операций, называются регулярными языками, а выражения, кото-
рые задают такие языки, называются регулярными выражениями.
Регулярные выражения широко используются в информационных техно-
логиях. Например, задание маски имени файла для групповой операции
(*.doc) — это частный случай регулярного выражения.
Вторая модификация состоит в том, чтобы рассматривать сети взаимодей-
ствующих конечных автоматов. Идея состоит в том, чтобы из элементарных
автоматов строить более сложные конструкции. Элементарными можно
считать автоматы, имеющие одно состояние.
Автомат, имеющий одно состояние, называется комбинационным.
Ясно, что в комбинационном автомате функция переходов тривиальна, и
фактически комбинационный автомат — это просто функция, которая сопо-
ставляет входному символу выходной.
При построении сетей рассматриваются следующие основные типы соеди-
нения автоматов: параллельное (автоматы имеют общий вход), последова-
тельное (выход одного автомата является входом другого) и петля обратной
связи (вьтход одного автомата является входом этого же автомата).
Использование "мгновенной" обратной связи (когда выходной символ явля-
ется одновременно и входным) может приводить к логическим парадоксам,
поэтому в обратную связь включают "задержку": выходной символ является
следующим входным символом.
Довольно неожиданным может показаться следующий факт: любой конеч-
ный автомат147 можно представить сетью, состоящей только из комбинаци-
онных автоматов и задержек. Обоснование этого утверждения приведено
на рис. 4.1, где фактически приведена сеть, которая является интерпретато-
ром заданного конечного автомата S. Здесь X обозначает комбинационный
автомат, вычисляющий функцию выходов автомата S, б обозначает комби-
национный автомат, вычисляющий функцию переходов автомата >5, а за-
держка на один такт обозначена буквой d.
Впрочем, верно и обратное утверждение: для любой сети можно построить
эквивалентный конечный автомат.
147 Напомним, что исходя из определения, данного в начале этого параграфа, конечный ав-
томат имеет конечное число состояний.
Глава 4. Моделирование поведения
Рис. 4.1. Сеть интерпретатора конечного автомата
Можно пойти дальше за обозначенные и хорошо исследованные рамки и
рассмотреть случай, когда состояния одного автомата являются входными
символами других автоматов (эти другие автоматы "слушают", или "наблю-
дают", исходный автомат). Еще вариант — выходные символы одного авто-
мата являются состояниями другого автомата. В последнем случае первый
автомат "командует" вторым148.
Третья модификация, которую мы хотим обозначить, состоит в том, чтобы
рассматривать переходы (и иногда выходы) не как однозначные функции
состояний и входов, а как многозначные отношения.
Если отношение перехода 3 является многозначным, 3 : A X.Q —» 21>.
то автомат называется недетерминированным.
Недетерминированный149 автомат на каждом такте своей работы находится
в одном или одновременно в нескольких состояниях. На первый взгляд та-
кая конструкция кажется неустойчивой и даже невозможной, но это впечат-
ление обманчиво.
Теорема детерминизации утверждает, что для любого недетерминирован-
ного конечного автомата существует эквивалентный ему детерминирован-
ный. Идея конструктивного доказательства этой теоремы проясняет ситуа-
цию. Пусть дан недетерминированный автомат с множеством состояний Q.
Рассмотрим детерминированный автомат с множеством состояний 2 е, т.е.
новое множество состояний — это множество всех подмножеств исходного.
Остается только заменить многозначные переходы из одного подмножества
старых состояний в другое подмножество однозначными переходами из
одного нового состояния в другое. Отсюда видно, что недетерминированное
описание поведения может быть экспоненциально короче детерминиро-
ванного описания того же самого поведения.
148 Эти модификации относятся к классу экстравагантных и редко реализуются на практи-
ке, возможно, потому, что к ним еще не привыкли.
149 Недетермированность часто путают со случайностью или неопределенностью, и пуга-
ются этого слова. Напрасно. В данном контексте в недетерминированном поведении
нет ничего случайного или неопределенного.
____ *
4.1 Модели поведения
4.1.2. Применение конечных автоматов.
Причины применения автоматов для описания
поведения в UML
Количество рассмотренных (и детально исследованных!) вариаций на тему
конечных автоматов весьма велико — их обзор не является предметом дан-
ной книги. Нас интересует, почему теория конечных автоматов была ис-
пользована авторами UML в качестве средства моделирования поведения.
По нашему мнению, основных причин три:
• теоретическая;
• историческая;
• практическая.
Теоретическая причина
Теоретическая причина интереса к конечным автоматам и их модификаци-
ям заключается в следующем. Для всех универсальных способов задания ал-
горитмов (моделей вычислимости) справедлива теорема Райса', все нетри-
виальные свойства вычислимых функций алгоритмически неразрешимы.
Поясним формулировку этой теоремы. Вычислимой называется функция,
для которой существует алгоритм вычисления. Нетривиальным называется
такое свойство функции, для которого известно, что существуют как функ-
ции, обладающие данным свойством, так и функции, им не обладающие.
Массовая проблема называется алгоритмически неразрешимой, если не су-
ществует единого алгоритма ее решения для любых исходных данных. На-
пример, "быть периодической" — нетривиальное свойство функции.
Теорема Райса утверждает, что не существует такого алгоритма, который по
записи алгоритма вычисления функции определял бы, периодическая эта
функция или нет. В частности, алгоритмически неразрешимыми являются
все интересные вопросы о свойствах алгоритмов, например:
• проблема эквивалентности: имеются две записи алгоритмов. Вычис-
ляют ли они одну и ту же функцию или нет?
• проблема остановки: имеется запись алгоритма. Завершает ли этот
алгоритм свою работу при любых исходных данных или нет?
Этот список можно продолжать неограниченно: первое слово в теореме Рай-
са — "все". Значит ли это, что вообще все неразрешимо и про алгоритмы ни-
чего нельзя узнать? Разумеется, нет. Если дана конкретная запись алгорит-
ма, то путем ее индивидуального изучения, скорее всего, можно установить
Ф
[ 315 "
Глава 4. Моделирование поведения
наличие или отсутствие нужных свойств. Речь идет о том, что невозможен
единый метод, пригодный для всех случаев.
Обратите внимание, что теорема Райса справедлива в случае использова-
ния любой, но универсальной модели вычислимости (способа записи ал-
горитмов). Если же используется не универсальная модель вычислимости,
то теорема Райса не имеет места. Другими словами, существуют подклассы
алгоритмов, для которых некоторые важные свойства оказываются алгорит-
мически разрешимыми. Конечные автоматы являются одним из важнейших
таких подклассов.
С одной стороны, данный формализм оказывается достаточно богатым, что-
бы выразить многие практически нужные алгоритмы (примеры см. ниже), с
другой стороны, целый ряд свойств автоматов можно проверить автомати-
чески, причем найдены весьма эффективные алгоритмы. В частности, про-
блемы эквивалентности и остановки для автоматов эффективно разреши-
мы. В случае использования универсального языка программирования мы
не можем автоматически убедиться в правильности программы: нам остает-
ся только упорно тестировать ее в смутной надежде повысить свою уверен-
ность в надежности программы. В случае же использования конечных ав-
томатов многое можно сделать автоматически, надежно и математически
строго — поэтому теория конечных автоматов столь интересна для разра-
ботки программных систем.
Историческая причина
Историческая причина популярности конечных автоматов состоит в том,
что данная техника развивается уже достаточно давно и теоретические ре-
зультаты были с успехом использованы при решении многих практических
задач. В частности, системы проектирования, спецификации и программи-
рования, основанные на конечных автоматах и их модификациях, активно
развиваются и применяются уже едва ли не полвека.
Особенно часто конечные автоматы применяются в конкретных предмет-
ных областях, где можно обойтись без использования универсальных мо-
делей вычислимости. В результате очень многие пользователи, инженеры и
программисты хорошо знакомы с конечными автоматами и применяют их
без затруднений.
Мы не готовы дать исчерпывающий обзор предметных областей, где при-
меняются конечные автоматы, и ограничимся одним достаточно показа-
тельным примером. В области телекоммуникаций уже более 15 лет активно
применяется промышленный стандарт — язык спецификации и описания
алгоритмов SDL (Specification and Description Language).
____ t
316 T'
4.1. Модели поведения
ЯЗЫК SDL
Первые варианты языка появились достаточно давно, в разра-
ботке принимали участие крупнейшие компании, производящие
телекоммуникационное оборудование. В настоящее время SDL
является промышленным стандартом, который поддерживает ITU
(International Telecommunications Union) — международная орга-
низация, определяющая стандарты в области телекоммуникаций.
В основу SDL положены три основные идеи: структурная де-
композиция, описание поведения систем с помощью конеч-
ных автоматов и использование аксиоматически определен-
ных абстрактных типов данных. Конечные автоматы описывают-
ся с помощью диаграмм состояний-переходов (см. ниже рис. 4.3),
которые обогащены целым рядом дополнительных возможностей.
На дуге перехода могут быть представлены различные специаль-
ные действия: получение и отправка сигналов, изменение зна-
чений переменных, проверка условий и др. На рис. 4.2 приведен
пример диаграммы SDL150 для описания порядка работы обычного
телефонного аппарата при обработке входящего звонка.
SDL с самого начала проектировался и использовался как сред-
ство, ориентированное на конкретные практические приложения.
Инструменты, поддерживающие SDL, не только позволяют рисо-
Рис. 4.2. Диаграмма SDL — обработка входящего телефонного звонка
150 Использованный нами вариант нотации соответствует одной из ранних версий языка и
несколько не соответствует последней версии стандарта SDL, но отличия не принципи-
альны.
Ф
Глава 4 Моделирование поведения
вать красивые картинки, но и обеспечивают верификацию моде-
лей, например, выявление взаимных блокировок (тупиков) или
недостижимых состояний, имитационное моделирование с целью
выявления временных характеристик, автоматическую генерацию
кода, в том числе для специальной аппаратуры. Многие промыш-
ленные компании используют эти инструменты при проектирова-
нии своих изделий.
Нужно сказать, что SDL оказал значительное влияние на средства
моделирования поведения UML, что отмечают сами авторы язы-
ка151.
Еще одна историческая причина популярности конечных автоматов состоит
в том, что разработано несколько вариантов нотации для записи конечных
автоматов, которые оказались весьма наглядными и удобными. Оставляя
в стороне формульную запись и другие математические приемы, приведем
два способа описания конечных автоматов, которые с первого взгляда по-
нятны буквально любому человеку.
Первый способ — табличный. Автомат записывается в форме таблицы,
столбцы которой помечены символами входного алфавита, строки поме-
чены символами алфавита состояний, а в ячейках таблицы записаны соот-
ветствующие значения функций 8 и X. Рассмотрим пример, речь в котором
пойдет об автомате, который вычисляет натуральное число, следующее по
порядку за данным, по представлению данного числа в позиционной двоич-
ной системе счисления. Входной и выходной алфавиты состоят из символов
0,1 и s (пробел). Для упрощения примера будем считать, что двоичные циф-
ры записи числа поступают на вход автомата в обратном порядке — справа
налево, то есть первым поступает младший разряд. Автомат имеет три со-
стояния, которые для ясности мы назовем "начальное", "перенос" и "копиро-
вание". Пусть на вход конечного автомата, заданного таблицей 4.1, поступает
число 1101, а результат, который мы должны получить, - 1110, т.е. натураль-
ное число, следующее за исходным.
Таблица 4.1. Таблица конечного автомата
0 1 S
начальное копирование, 1 перенос, 0 начальное, S
перенос копирование, 1 перенос, 0 начальное, 1
копирование копирование, 0 копирование, 1 начальное, S
На вход автомата символы поступают в обратном порядке, т.е. сначала 1, за-
тем 0, 1 и 1. Изначально автомат находится в состоянии "начальное" и при
151 Примечательно, что один из авторов UML, Ивар Якобсон, является также одним из авто-
ров SDL.
4.1 . Модели поведения
поступлении первого входного символа 1 переходит в состояние "перенос",
передавая на выход 0 (первая строка, третий столбец). Далее на вход посту-
пает 0, и автомат из состояния "перенос" переходит в состояние "копирова-
ние" (вторая строка, второй столбец). Обработку двух последних входных
символов оставим в качестве упражнения для читателя.
Второй способ — графический. Автомат изображается в виде диаграммы
ориентированного графа, узлы которого соответствуют состояниям и по-
мечены символами алфавита состояний, а дуги называются переходами и
помечены символами входного и выходного алфавита следующим образом.
Допустим, ^(ai,qj) = qu, 'k(ai,qj') — bv. Тогда проводится дуга из узла q* в
узел qu и помечается символами а,., bv. Такой граф называется диаграммой
состояний-переходов. На рис. 4.3 приведена диаграмма состояний-переходов
для предыдущего примера, заданного таблицей 4.1.
Рис. 4.3. Диаграмма состояний-переходов
Практическая причина
Третья причина привлекательности конечных автоматов в качестве основ-
ного средства моделирования поведения практическая. В некоторых ти-
пичных задачах программирования автоматы уже давно используются как
главное средство. Мы опять уклонимся от исчерпывающего обзора, ограни-
чившись одним примером. В задачах синтаксического разбора при трансля-
ции и интерпретации языков программирования использование автоматов
является основным приемом. Само развитие теории конечных автоматов во
многом шло под влиянием потребностей решения задач трансляции. К на-
стоящему времени можно сказать, что эти задачи решены, и соответствую-
щие алгоритмы разработаны и исследованы.
В процессе применения в программировании автоматная техника обога-
тилась рядом приемов, которые не совсем укладываются в исходную ма-
тематическую модель, но очень удобны на практике. Например, помимо
функций переходов и выходов, можно включить в описание автомата еще
одну составляющую — процедуру реакции.
Смысл добавления состоит в следующем: при выполнении перехода из
одного состояния в другое вызывается соответствующая процедура реак-
Г 319 1
Глава 4. Моделирование поведения
ции, которая выполняет еще какие-то действия (имеет побочный эффект,
см. параграф 3.2.3), помимо вывода выходного символа и смены состояния.
Если процедура реакции ничем не ограничена, например, может читать и пи-
сать в потенциально бесконечную память, то конечный автомат превращает-
ся, фактически, в универсальную модель вычислимости, подобную машине
Тьюринга. При этом, разумеется, утрачиваются теоретически привлекатель-
ные свойства разрешимости, однако программировать с помощью процедур
реакции очень удобно.
Разработаны и различные промежуточные варианты: например, если побоч-
ный эффект процедур реакции ограничен работой со стеком, то получается
так называемый магазинный автомат. Магазинные автоматы позволяют за-
программировать существенно более широкий класс алгоритмов и в то же
время сохраняют некоторые из важнейших теоретических преимуществ.
Наконец, важным практическим обстоятельством является тот факт, что
автоматы очень легко программируются средствами обычных языков про-
граммирования. Например, пусть нужно запрограммировать работу автома-
та с состояниями 1, 2, ..., к, где 1 — начальное состояние и к — заклю-
чительное состояние, а входные стимулы: А, В, ... Z можно получить с
помощью функции get (). В таком случае можно использовать код следую-
щей структуры:
state := 1
while state * k
stimulus := get()
switch state
case 1
switch stimulus
case A
// какие-то действия
state := s // новое состояние
case В
end switch stimulus
end switch state
end while
Мы закончим этот параграф небольшим примером из информационной си-
стемы отдела кадров.
| ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
После приема на работу кандидат становится штатным сотрудником, t
Штатный сотрудник может быть переведен с одной должности на другую, i
Штатный сотрудник может быть уволен.
Ф
4.1. Модели поведения
Итак, сотрудник в организации, очевидно, может находиться в различных
состояниях: вначале он является кандидатом, в результате выполнения опе-
рации приема на работу он становится штатным сотрудником. При переводе
с одной должности на другую сотрудник остается в штате. И наконец, со-
трудник может быть уволен.
Жизненный цикл сотрудника естественно описать конечным автоматом, на-
пример, в виде таблицы 4.2. В этой таблице строки поименованы состояния-
ми, столбцы — стимулами, а в ячейках выписаны процедура реакции и новое
состояние.
Таблица 4.2. Жизненный цикл сотрудника
Принять() hire)) Перевести)) move)) Уволить)) fire))
Кандидат Applicant Принять)), В штате Ошибка)). Кандидат Ошибка)), Кандидат
В штате Employed Ошибка)), В штате Перевести)), В штате Уволить)), Уволен
Уволен Unemployed Принять)), В штате Ошибка)), Уволен Ошибка)), Уволен
Если такая таблица кажется недостаточно информативной и наглядной,
то эту информацию можно представить в форме диаграммы состояний-
переходов. На рис. 4.4 приведена соответствующая данному случаю диа-
грамма автомата в нотации UML.
Рис. 4.4. Жизненный цикл сотрудника а ИС ОК
Примечание
Обратите внимание, что диаграмма на рис. 4.4 содержит
меньше информации по сравнению с таблицей 4.2.
4.1.3. Сети Петри
Предыдущие два параграфа могут создать впечатление, что конечные ав-
томаты — единственный теоретический механизм, который используется
для моделирования поведения. Это не совсем так. Конечные автоматы и их
Глава 4. Моделирование поведения
многочисленные модификации действительно используются чаще всего, но
есть и другие формализмы, которые также применяются на практике, в том
числе и в UML.
Сеть,Петри (Petri net) это общепринятый формализм, использхе-
мый при постановке и решении различных задач параллельных вы-
числений.
Известно множество различных модификаций сетей Петри, предложенных
для решения конкретных задач. Мы рассмотрим самый простой вариант. В
этом варианте сеть Петри определяется как ориентированный двудольный
граф (см. врезку "Множества, отношения и графы" в разделе 1.4), имеющий
вершины двух видов, которые называются позиции и переходы. На диа-
грамме позиции обычно изображаются в виде небольших кружков, а пере-
ходы в виде горизонтальных черточек.
Для сети Петри определяется понятие маркировки, которая сопоставляет
каждой позиции неотрицательное целое число. На диаграмме маркировка
обозначается с помощью маленьких черных кружков, которые помещают-
ся внутрь позиций. Разные авторы называют эти кружки по-разному: точки,
маркеры, отметки, ярлыки, фишки и т. и. У каждого перехода в сети Петри
есть некоторое количество (может быть ноль) входных позиций (из которых
дуги ведут в переход) и некоторое количество (может быть ноль) выходных
позиций (в которые дуги ведут из перехода):
Переход в сети Петри называется разрешенным, если все его входные пози-
ции не пусты (т. е их маркировка строго больше нуля). Любой разрешенный
переход может сработать. В результате срабатывания перехода маркировка
всех входных позиций уменьшается на 1, а маркировка всех выходных по-
зиций увеличивается на 1. На диаграмме количество маркеров во входных
позициях уменьшается, а в выходных — увеличивается. В результате сраба-
тывания перехода маркировка сети Петри изменяется: некоторые переходы
могут стать разрешенными или, наоборот, перестать быть таковыми.
Сеть Петри является удобным формализмом для описания поведения, в
особенности асинхронного, параллельного и недетерминированного. Рас-
смотрим, например, простую вычислительную систему (процессор), по-
следовательно обрабатывающую задания, которые поступают во входную
очередь. Когда процессор свободен и во входной очереди имеется задание,
оно обрабатывается процессором, а затем выводится в выходную очередь.
На рис. 4.5 приведена сеть Петри, моделирующая эту систему. Если в усло-
виях начальной маркировки, показанной слева, сработают переходы tp t2, tr
tr то сеть будет иметь маркировку, показанную на рисунке справа. Обратите
4.1 Модели поведения
Удаление
задания
Появление
задания
Ожидание
Запуск
задания
Обработка
Завершение
задания
Зыяад
Рис. 4.5. Сеть Петри
внимание, что срабатывание переходов tp tp t2, t, или tp tp tp t2 даст тот же
самый результат, а срабатывание переходов t2, tp tp tt невозможно, потому
что переход t2 не разрешен в начальной маркировке.
По сравнению с конечными автоматами сети Петри обладают рядом особен-
ностей, которые объясняют их широкое применение для моделирования па-
раллелизма. Прежде всего, сети Петри асинхронны — в них отсутствует поня-
тие времени. Время срабатывания и относительный порядок срабатывания
разрешенных переходов никак не указываются. Тем не менее сама структура
сети позволяет в некоторых случаях отвечать на важнейший вопрос: какими
свойствами будет обладать маркировка, получаемая в результате произволь-
ной последовательности срабатываний переходов. Например, нетрудно до-
казать, что позиция р2 на рис. 4.5 никогда не будет иметь маркировку больше
1 (что, очевидно, имеет явный практический смысл — процессор может об-
рабатывать только одно задание).
Далее, в сетях Петри очень наглядно и четко моделируется параллелизм
(переходы, входные позиции которых не пересекаются, параллельны), кон-
фликты (переходы, входные позиции которых пересекаются, конфликтуют),
тупики (переходы, которые не разрешены в данной маркировке и всех дости-
жимых из нее) и т. д. Наконец, теория сетей Петри за последние десятилетия
была разработана достаточно глубоко и детально, чтобы давать ответы на
многие трудные вопросы практического параллельного программирования.
Основной механизм сетей Петри дает повод упомянуть одну важную теоре-
тическую идею, которая хотя и не образует отдельного формализма, но ино-
гда бывает очень полезна для моделирования поведения как в UML, так и в
других случаях. Заметим, что переход в сети Петри может сработать, если
все его входные позиции не пусты — в них что-то есть. Никто снаружи "не
Глава 4. Моделирование поведения
подталкивает" переход к срабатыванию — переход "сам" определяет, что есть
условия для его срабатывания.
Сопоставим это с механизмом процедур (функций, действий и т.п.) в языках
программирования. В каких случаях срабатывает процедура? Первый, самый
привычный случай — процедуру вызвали, т.е. явно передали ей управление
извне152. Второй случай — процедура является процедурой реакции на собы-
тия. Эти два случая исчерпывают возможности обычных процедурных язы-
ков программирования. По возможен еще и третий случай: процедура сра-
батывает, потому что определены все ее аргументы. Такое "демоническое"
(см. врезку "Демоны в программировании" в параграфе 4.2.7) срабатывание
не является характерным для распространенных языков программирования,
но вызывает наибольшие человеческие симпатии у авторов. Действительно,
первый случай — работа выполняется "из-под палки", второй — работа вы-
полняется потому, что что-то случилось, третий — работа выполняется по-
тому, что ее можно выполнить.
4.1.4. Средства моделирования поведения
В UML предусмотрено несколько различных средств для описания пове-
дения. Выбор того или иного средства диктуется типом поведения, которое
нужно описать.
Мы разделили все средства моделирования поведения в UML на четыре
группы:
• описание поведения с явным выделением состояний;
• описание поведения с явным выделением потоков данных
и управления;
• описание поведения как последовательности сообщений во
времени;
• описание параллельного поведения.
Заметим, что полного взаимно-однозначного соответствия между выде-
ленными группами и каноническими диаграммами UML не наблюдается.
Действительно, если первые две группы средств однозначно отображают-
ся диаграммами автомата и диаграммами деятельности, то для описания
последовательности сообщений применяется несколько различных типов
диаграмм, а описание параллельного поведения "размазано" по всем типам
канонических диаграмм. Рассмотрим эти четыре группы средств в целом, "с
высоты птичьего полета", не углубляясь пока в детали нотации и семантики.
152 Еще нужно не забыть передать аргументы!
4.1. Модели поведения
Явное выделение состояний
Напомним, что при использовании объектно-ориентированного подхода
(см. параграф 3.1.2) программная система представляет собой множество
объектов, взаимодействующих друг с другом.
При этом возможна ситуация, когда поведение некоторых объектов разумно
рассматривать в терминах их жизненного цикла, т.е. текущее поведение объ-
екта определяется его историей.
Жизненный цикл (lifecycle) - последовательность изменений состоя-
ния объекга.
Для описания такого поведения используется конечный автомат, который
изображается посредством диаграммы автомата. При этом состояния ко-
нечного автомата соответствуют возможным состояниям объекта, т. е. раз-
личным наборам значений атрибутов объекта, а переходы происходят в ре-
зультате возникновения различных событий.
Диаграммы автомата можно использовать для описания жизненного цикла
не только объектов — экземпляров отдельных классов, но и для более круп-
ных конструкций, в частности, для всей модели приложения или, напротив,
для гораздо более мелких элементов — отдельных операций.
Поток УПРАВЛЕНИЯ И ПОТОК ДАННЫХ
Надо отметить, что в любом поведении в той или иной мере присутствует
поток управления, только не всегда он описывается явно.
Поток управления (control flow ) — это последовательность выполне-
ния операторов (команд) в программе.
Если программа представляет собой просто последовательность операторов
(так называемая линейная программа), то операторы в программе выполня-
ются по очереди в естественном порядке (от начала к концу). В этом случае
поток управления просто совпадает с последова гельностью операторов в
программе. Однако обычно это не так.
Во-первых, на поток управления оказывают влияние различные управляю-
щие конструкции: операторы перехода, условные операторы, операторы
цикла и т. д.
Во-вторых, в большинстве практических систем программирования исполь-
зуется понятие подпрограммы: при выполнении оператора вызова подпро-
Глава 4. Моделирование поведения
граммы выполнение операторов программы приостанавливается, управле-
ние передается в подпрограмму, т. е. в поток управления попадают операторы
подпрограммы, а при выходе из подпрограммы возобновляется выполнение
операторов программы. Аналогичная ситуация возникает при синхронном
обмене сообщениями между взаимодействующими в программе объектами.
Если поток управления представляет собой последовательность элемен-
тарных шагов, требуемых для выполнения отдельного метода или реали-
зации сложного варианта использования, то для его описания удобно ис-
пользовать диаграммы деятельности.
Помимо потока управления в UML также используется поток данных.
Поток данных (data flow) — это описание связи выходных результатов
одних действий с входными ар|ументами других действий.
В UML 1 средства описания потока данных достаточно скудны. Прежде все-
го, это так называемые объекты в состоянии (см. параграфы 4.3.2 и 4.3.4), ко-
торые могут использоваться на диаграммах деятельности и диаграммах вза-
имодействия. В UML 2 ситуация несколько улучшилась, и потоки данных
стали равноправны с потоками управления на диаграмме деятельности.
Последовательность сообщений
Взаимодействие нескольких программных объектов между собой описы-
вается диаграммами взаимодействия в одной из двух практически эквива-
лентных форм (диаграммой коммуникации и диаграммой последовательно-
сти). Для объектно-ориентированной программы поведение, прежде всего,
определяется взаимодействием объектов, посредством передачи сообщений,
поэтому диаграммы данного типа имеют столь большое значение при моде-
лировании поведения в UM L.
Именно диаграммы взаимодействия претерпели наибольшее расширение и
усовершенствование в UML 2 по сравнению с UML 1.
Параллельное поведение
Касательно представления потоков управления в UML остается сказать, что
в реальных программных системах потоков управления может быть не-
сколько. Все типы поведенческих диаграмм умеют в той или иной степени
отражать данный факт.
Диаграммы автомата в качестве событий для инициализации процесса пере-
хода объекта из одного состояния в другое могут использовать события, яв-
е
\ 326 ]
4.2 Диаграммы автомата
ляющиеся асинхронными, т.е. возникающими в другом потоке управления,
нежели тот, в котором "живет" моделируемый объект.
На диаграммах деятельности могут использовать специальные конструкции
(см. параграф 4.5.4), которые показывают точки, в которых поток управле-
ния может быть разделен на несколько параллельно исполняющихся по-
токов, и точки, в которых, наоборот, несколько потоков управления опять
сливаются вместе.
Диаграммы взаимодействия также имеют в своем арсенале подобные кон-
струкции (см. параграф 4.5.5).
На уровне метамодели UML у сущности класс (class) существует атрибут
isActive, принимающий значения true или false. Если значение этого атрибута
равно true, то класс называют активным (active class), и объект такого класса
имеет собственный поток управления (см. параграф 4.5.6). По умолчанию
значение данного свойства равно false и класс называют пассивным (passive
class).
В следующих разделах рассматриваются все указанные средства более де-
тально.
4.2. Диаграммы автомата
Диаграммы автомата (state machine diagram) в UML являются реализацией
основной идеи использования конечных автоматов как средства описания
алгоритмов и, тем самым, моделирования поведения.
Конечные автоматы в UML реализованы довольно своеобразно. С одной
стороны, в основу положено классическое представление автомата в форме
графа состояний-переходов (параграф 4.1.2). С другой стороны, к классиче-
ской форме добавлено большое число различных расширений и вспомога-
тельных обозначений, которые, строго говоря, не обязательны — без них в
принципе можно было бы обойтись — но они весьма удобны и наглядны при
составлении диаграмм. Большую часть этих расширений в свое время, не-
зависимо от UML, предложил Дэвид Харел. Он же ввел термин диаграмма
состояний (statechart), инкорпорированный в UML 1 и переименованный в
диаграмму автомата в UML 2.
Дэвид Харел (David Harel), р. 1950 — профессор информати-
ки в Вейсманновском институте в Израиле. Известен работа-
ми по динамической логике, теории вычислимости, технологии
программирования.В 1984 году предложил диаграммы состояний
(statecharts), которые вошли в язык UML.
Лауреат многих престижных премий, в том числе ACM Software
System Award в 2007 году.
Глава 4. Моделирование поведения
Такое решение является обоюдоострым оружием: диаграммы автомата UML
более наглядны и выразительны по сравнению с классическими представ-
лениями автоматов, но их применение требует большей подготовленности
пользователя и предъявляет более высокие требования к "сообразительно-
сти" и "внимательности" инструментов моделирования153.
При описании конструкций диаграмм автомата мы не только описываем их
семантику согласно стандарту, но и показываем возможное сведение допол-
нительных конструкций к базовым.
ВАЖНОЕ ЗАМЕЧАНИЕ О ТЕРМИНОЛОГИИ
Объект, который описывается введенной Харелом диаграммой
состояний (statechart), сам автор называл машиной состояний
(state machine), прекрасно понимая связь этого понятия с теорией
конечных автоматов.
Машина состояний — термин, принятый в англоязычной литера-
туре, но обозначающий то же самое, что и конечный автомат. Дело
в том, что по-английски, видимо, state machine гораздо удобнее
заумного finite automaton (лат.), но для нашего уха "автомат" как-то
привычнее.
В термине "машина состояний" есть намек на возможность интер-
претации, программной реализации, а в термине "конечный авто-
мат" есть привкус теории. Действительно "теория конечных авто-
матов" — один из разделов государственного образовательного
стандарта по прикладной математике, а словосочетание "теория
машин состояний" — просто нонсенс в нашем языке.
В этой книге мы используем термины "конечный автомат" и "ма-
шина состояний" как синонимы, стараясь, однако, обращаться к
"конечному автомату" в теоретическом контексте, а к "машине со-
стояний" — в практическом.
Итак, начиная обзор средств моделирования с самого верхнего уровня,
можно констатировать, что на диаграммах автомата применяется всего
один тип сущностей — состояния, и всего один тип отношений — перехо-
ды. Совокупность состояний и переходов между ними образует конечный
автомат. На рис. 4.6 приведена метамодель конечного автомата UML в са-
мом общем виде, далее мы ее уточним и детализируем.
153 Если проанализировать те многочисленные неточности, ошибки и отклонения от стан-
дарта, которыми грешат версии инструментов моделирования, попавшиеся авторам
под руку, то бросается в глаза, что хуже всего дело обстоит с диаграммами автомата, и
лучше всего — с диаграммами классов.
_____ ф
32.;
4.2. Диаграммы автомата
Рис. 4.6. Метамодель автомата (машины состояний)
Мы видим, что автомат состоит из набора состояний (1 на рис. 4.6), для каж-
дого из которых определены исходящие (outgoing) и входящие (incoming)
наборы переходов (2 на рис. 4.6), для каждого из которых определено соот-
ветственно исходное (source) и целевое (target) состояния. Для машины (3
на рис. 4.6) в целом определен контекст (context), т. е. тот элемент модели,
описанием поведения которого она является. Кроме того, имеется ссылка на
одно из составных (composite) состояний (4 на рис. 4.6) с именем top, смысл
и назначение которой обсуждается ниже, в параграфе 4.2.6.
Таким образом, типов сущностей и отношений предельно мало, но подти-
пов, вариантов нотации и специальных случаев для них определено много
(может быть, даже слишком много).
А именно, состояния бывают:
• простые (simple),
• составные (composite) двух видов: ортогональные (orthogonal) и
нет154,
• специальные (pseudo)155,
154 В UML1 ортогональные составные состояния иногда называют параллельными (parallel),
а не ортогональные составные состояния — последовательными (sequential).
155 Не показаны на метамодели (рис. 4 6)
Глава 4 Моделирование поведения
• ссылочные (submachine),
и каждый тип состояний имеет дополнительные подтипы и различные со-
ставляющие элементы.
Переходы бывают простые и составные, и каждый переход содержит от двух
до пяти составляющих:
• исходное состояние (source),
• событие перехода (trigger event),
• сторожевое условие (guard),
• действие на переходе (effect),
• целевое состояние (target).
Рассмотрим все эти элементы по порядку.
4.2,1. Простое состояние
Простое состояние является в UML простым только по названию — оно
имеет следующую структуру:
• имя (name);
• действие при входе (entry action);
• действие при выходе (exit action);
• описание множества внутренних переходов (internal transitions) и
соответствующих действий;
• внутренняя деятельность (do activity);
• множество отложенных событий (defer events).
Имя состояния является обязательным156. Все остальные составляющие
простого состояния не являются обязательными. Фактически имя (просто-
го) состояния — это символ алфавита состояний Q (см. параграф 4.1.1).
Действие при входе (обозначается при помощи ключевого слова entry) —
это указание атомарного действия (параграф 4.3.1), которое должно вы-
полняться при переходе автомата в данное состояние. Действие при входе
выполняется после всех других действий, предписанных переходом, перево-
дящим автомат в данное состояние.
156 Некоторые инструменты, поддерживающие UML 2, позволяют рисовать анонимные со-
стояния. Уникальное имя все равно присутствует во внутреннем представлении модели,
но оно генерируется автоматически и не показывается пользователю на диаграмме.
____ Ф
4.2. Диаграммы автомата
Действие при выходе (обозначается при помощи ключевого слова exit) —
это указание атомарного действия, которое должно выполняться при пере-
ходе автомата из данного состояния. Действие при выходе выполняется до
всех других действий, предписанных переходом, выводящим автомат из дан-
ного состояния.
Множество внутренних переходов — это множество простых переходов из
данного состояния в это же самое. Внутренний переход (internal transition)
отличается от простого перехода в себя (external transition) тем, что действия
при выходе и входе не выполняются157.
Внутренняя деятельность (обозначается при помощи ключевого слова
do) — это указание деятельности, которая начинает выполняться при пере-
ходе в данное состояние после выполнения всех действий, предписанных
переходом, включая действие на входе. Внутренняя деятельность либо про-
должается до завершения, либо прерывается в случае выполнения перехо-
да (в том числе и внутреннего перехода). В классической модели конечный
автомат, находясь в некотором состоянии, ничего не делает: он находится в
состоянии ожидания перехода. В модели UML считается, что автомат мож-
но нагрузить какой-то полезной фоновой деятельностью, которая будет пре-
рываться при выполнении любого перехода.
Если в то время, когда автомат находится в некотором состоянии, проис-
ходит событие, для которого в данном состоянии не определен переход, то
согласно семантике UML ничего не происходит и событие безвозвратно те-
ряется158. В некоторых случаях этого требуется избежать. Для этого в UML
предусмотрено понятие отложенного события.
Отложенное событие — это событие, для которого не определен переход в
данном состоянии, но которое, тем не менее, не должно быть потеряно, если
оно произойдет, пока автомат находится в данном состоянии (обозначается
при помощи ключевого слова defer). Семантика отложенного события тако-
ва: если происходит отложенное событие, то оно помещается в конец неко-
торой системной очереди отложенных событий. После перехода автомата в
новое состояние проверяется (начиная с начала) очередь отложенных собы-
тий. Если в очереди есть событие, для которого в новом состоянии опреде-
лен переход, то событие извлекается из очереди, и происходит переход.
157 Упомянутый в метамодели (рис. 4.6) локальный (local) переход относится к составным
состояниям и подробно рассматривается в параграфе 4 2.5.
158 Некоторые авторы считают это недостатком UML. Действительно, в теории конечных
автоматов обычно считается, что функция перехода определена для всех пар состоя-
ние-стимул. Такой подход является более строгим. В UML функция переходов может
быть не всюду определенной, что иногда позволяет сократить объем описания модели.
Фактически, UML чуть-чуть поступается строгостью ради удобства.
Глава 4. Моделирование поведения
Рассмотрим пример из информационной системы отдела кадров.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
В обязанности принятого на работу сотрудника могут входить встречи с
заказчиками вне офиса. В этом случае сотрудник должен временно пере- ,
дать дела другому сотруднику. t
! I
Возможны ситуации, когда сотрудник в силу производственной необходи-
мости на неопределенный срок должен будет переехать из одного офиса ,
компании в другой. В силу того, что каждый офис специализируется в сво- t
ей производственной области, при переезде сотрудник должен сдать все 1
дела по всем проектам на старом месте и быть исключенным из списка ,
исполнителей этих проектов i
Проектируя жизненный цикл сотрудника в соответствии с новым требова-
нием, ограничимся пока одним простым состоянием Employed, которое со-
ответствует ситуации, когда сотрудник принят на работу и работает. Соот-
ветствующее простое состояние приведено на рис. 4.7. С помощью действий
на входе и выходе мы отмечаем необходимость выполнения соответствую-
щих манипуляций с учетной записью сотрудника (create account и destroy
account). Далее, мы можем отметить, что существует событие — встреча с за-
казчиками вне офиса (business visit), которое не выводит сотрудника из дан-
ного состояния, но гребует выполнения каких-то действий. Согласно тре-
бованиям, мы должны учитывать также и возможную смену офиса (change
office).
change office
Рис. 4.7. Простое состояние сотрудника
При наступлении этих событий должны выполняться соответствующие
действия: при встречах с заказчиком сотрудник только должен временно
передать текущие тела (pass jobs) кому-то, а при переезде нужно, чтобы со-
трудник завершил свои дела (terminate jobs) и заблокировать его учетную
запись (destroy account). Различие в деталях реакций на эти события мож-
но передать с помощью перехода в себя (1) и внутреннего перехода (2). Если
4.2. Диаграммы автомата
ничего не происходит, то по умолчанию сотрудник должен выполнять свои
основные обязанности (do job).
Выше мы отметили, что многие элементы диаграмм состояний в UML введе-
ны только для удобства, без них можно в принципе обойтись.
В подтверждение нашего тезиса приведем один из возможных вариантов ис-
ключения дополнительных элементов из модели с сохранением ее семанти-
ки.
Можно получить модель, эквивалентную по поведению приведенной на
рис. 4.7, но не использующую дополнительных средств, а только имена про-
стых состояний и простые переходы (классический вариант конечного авто-
мата), перенося действия на входе и выходе в действия входящих и исходя-
щих переходов соответственно и моделируя внутренний переход переходом
в себя (рис. 4.8).
Какой стиль предпочесть — дело вкуса.
change office/
terminate jobs,destroy account,create account
Рис. 4.8. Простое состояние сотрудника. Вариант без дополнений
4.2.2. Простой переход
Простой переход всегда ведет из одного состояния в другое или в то же
самое состояние. Переход не может приходить "ниоткуда" и уходить "в
никуда"159. Существует несколько ограничений для специальных состояний
(параграф 4.2.5), например, для начального состояния не может быть вхо-
дящих переходов, а для заключительного — исходящих, а в остальном пере-
ходы между состояниями могут быть определены произвольным образом.
Прочие составляющие — событие перехода, сторожевое условие и действия
на переходе — не являются обязательными. Если они присутствуют, то изо-
бражаются в виде текста в определенном синтаксисе рядом со стрелкой, изо-
159 Строго говоря, фрагмент модели на рис. 4.8 синтаксически неправилен Используемый
нами графический редактор, конечно, не проверяет данное синтаксические правило
UML, впрочем, как не делают этого и многие специальные инструменты для моделиро-
вания.
Глава 4. Моделирование поведения
бражающей переход. Синтаксис описания перехода следующий: -
Событие [ Сторожевое условие ] / Действие
Например, в информационной системе отдела кадров переход сотрудника из
состояния Applicant (кандидат) в состояние Employed (нанятый на работу)
может быть описан с помощью простого перехода (1), представленного на
рис. 4.9.
Рис. 4.9. Простой переход
Общая семантика перехода такова. Допустим, что автомат находится в со-
стоянии Applicant, в котором определен исходящий переход с событием
hire(), сторожевым условием isFree и действием meet boss, ведущий в состоя-
ние Employed.
Если возникает событие hire(), то переход возбуждается (в данном состоя-
нии могут быть одновременно возбуждены несколько переходов — это не
считается противоречием в модели). Далее проверяется сторожевое условие
isFree (проверяются сторожевые условия всех возбужденных переходов в
неопределенном порядке). Если сторожевое условие выполнено, то переход
срабатывает — выполняется действие на выходе из состояния Applicant, вы-
полняется действие на переходе meet boss, выполняется действие на входе в
состояние Employed, и автомат переходит в состояние Employed.
Даже если у нескольких возбужденных переходов сторожевые условия ока-
зываются истинными, то, тем не менее, срабатывает всегда только один пере-
ход из возбужденных. Какой именно переход срабатывает — не определено.
Таким образом, поведение, описываемое подобным автоматом, является не-
детерминированным160. Если же сторожевое условие isFree не выполнено, то
переход не срабатывает. Если ни один из возбужденных переходов не сраба-
тывает, то событие hire() теряется и автомат остается в состоянии Applicant.
Событие перехода
Событие перехода (trigger event)1*1 — это тот входной символ (сти-
мул), который вкупе с текущим состоянием автомата определяет сле-
дующее состояние.
160 В некоторых системах моделирования поведения, основвнных на конечных автоматах,
проблема неоднозначности срабатывания более чем одного перехода решается тем,
что статически определяются приоритеты для всех переходов. Срабатывает переход с
наивысшим приоритетом.
161 Используют также термин "переключающее событие".
ф
tfVTb......... ..................................................-
4.2. Диаграммы автомата
В UML предусматривается несколько типов событий (параграф 4.2.7). Само
слово "событие" невольно вызывает следующую ассоциацию: существует
некий внешний по отношению к автомату мир, в котором время от време-
ни происходят события (в общечеловеческом смысле этого слова), автомату
становится известно о произошедшем событии, и он реагирует на событие
путем перехода в определенное состояние. Эта ассоциация вполне право-
мерна, если речь идет о моделировании жизненного цикла объекта в про-
грамме, управляемой событиями. Действительно: в этом случае основной
тип событий — это события вызова методов объекта. Объект реагирует на
них, выполняя тела методов и меняя значения своих атрибутов (состояние).
Однако данная ассоциация далеко не единственно возможная (хотя и самая
распространенная при объектно-ориентированном подходе).
Автомату не важен источник событий: важна последовательность, в ко-
торой события поступают на вход автомата, вынуждая его реагировать.
Например, последовательность символов в слове входного алфавита А (см.
параграф 4.1.1) также рассматривается как последовательность событий.
Для автомата существенно, что первое событие предшествует второму, а по-
чему это происходит: потому ли что первое событие произошло раньше или
же потому, что расположено левее — это не важно.
Таким образом, конечные автоматы с теоретической точки зрения и машины
состояний UML с практической точки зрения подходят для моделирования
поведения не только событийно-управляемых программ, но и любого друго-
го типа управления162.
Переход по завершении
UML допускает наличие переходов без событий — такой переход называет-
ся переходом по завершении.
Переход по завершении (completion transition i по переход, кото-
рЫЙ происходит по окончании внутренней деятельности.
Семантика перехода по завершении такова. Имеется одно неявное, а потому
безымянное событие, которое наступает при завершении внутренней дея-
тельности, определенной в состоянии (если никакой внутренней деятельно-
сти не предусмотрено, то это событие наступает немедленно после перехо-
да автомата в данное состояние). Поскольку событие завершения является
безымянным, оно никак не отображается на диаграмме: в тексте, сопутству-
ющем переходу, просто отсутствует первая часть, относящаяся к событию
162 Обратите внимание, что в схеме конечного автомата, приведенной в конце парагра-
фа 4.1.2, используется один обычный поток управления.
ф
М На Щ Лк М № Ш •» W> М I# Н, * М •« М НЯ ВД Ч, V, М Ил ЧП «Я *• М Ч»Н**Л******* «и И, «к W V № (Н
Глава 4. Моделирование поведения
перехода. В остальном переходы по завершении ничем не отличаются от
простых переходов: они могут содержать сторожевые условия, может быть
несколько исходящих переходов по завершении для данного состояния (с
альтернативными сторожевыми условиями), для переходов по завершении
можно определять последовательности действий при переходе и т. д.
Рассмотрим пример.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Сразу после приема на работу кандидату может быть поручено выполне- (
ние специального задания. Если кандидат не справляется с ним в огово- t
ренный период (испытательный срок), то это является достаточным осно- ’
ванием для увольнения. Если же кандидат успешно выполняет задание, то
с ним заключается договор на постоянную работу.
На рис. 4.10 приведено одно из возможных решений, в котором использует-
ся как простой переход (1), так и переход по завершении (2).
Рис. 4.10. Использование перехода по завершении
Следует, однако, иметь в виду, что при частом использовании переходов по
завершении легче допустить и труднее обнаружить ошибку в модели, ко-
торая может привести к неопределенному поведению.
Простой пример: допустим, что имеется состояние, для которого определено
несколько исходящих переходов по завершении (с разными сторожевыми
условиями) и не определено других переходов по событиям. Допустим, что
ни один из переходов по завершении не сработает, ввиду того, что все сто-
рожевые условия окажутся ложными. В таком случае, поскольку событие
завершения возникает ровно один раз и оно уже утеряно, а все другие со-
бытия в данном состоянии теряются, так как для них не определены перехо-
е
733б2
4.2 Диаграммы автомата
ды, моделируемая система будет демонстрировать характерное поведение,
печально знакомое слишком многим пользователям: "зависание"163. Таким
образом, переход по завершении средство удобное, но опасное. В классиче-
ские модели конечных автоматов подобные средства обычно не включают,
благодаря чему становится возможна автоматическая проверка отсутствия
"зависаний" и других неприятностей.
Мы настойчиво рекомендуем не использовать переходы по заверше-
нии в диаграммах автомата, кроме случаев крайней необходимости (см.
рис. 4.10). Другое дело диаграммы деятельности (раздел 4.3) — там пе-
реходы по завершении являются основным средством моделирования
поведения.
Сторожевое условие
Сторожевое условие (guard condition) — это логическое выражение,
крторос должно оказаться истинным для того, чтобы возб) жденный
переход сработал.
В сторожевом условии можно использовать значения атрибутов моделируе-
мого элемента, с которым связана машина состояний, а также значения ар-
гументов переключающего события. Таким образом, значение сторожевого
условия вычислить заранее, на этапе моделирования, невозможно. Стороже-
вое условие должно проверяться динамически, во время выполнения.
Для каждого возбужденного перехода сторожевое условие проверяется ров-
но один раз, сразу после того, как переход возбужден, и до того, как в системе
произойдут какие-либо другие события. Если сторожевое условие ложно, то
переход не срабатывает и событие теряется. Даже если впоследствии сто-
рожевое условие станет истинным, переход сможет сработать, только если
повторно возникнет событие перехода.
Как уже было сказано, возможны несколько исходящих переходов из данно-
го состояния с одним и тем же событием перехода, но с разными сторожевы-
ми условиями. Все такие переходы возбуждаются при наступлении события
перехода, но срабатывает не более одного.
Для того чтобы поведение автомата было определено и детерминировано,
набор сторожевых условий должен образовывать полную дизъюнктную си-
стему предикатов, т. е. при любых значениях переменных, входящих в сторо-
жевое условие, ровно одно из сторожевых условий должно быть истинным.
Сторожевые условия могут быть написаны на любом языке, в частности, на
163 Добиться "зависания" машины состояний UML можно не только переходами по завео-
шении, но и другими средствами — дурное дело не хитрое.
Глава 4. Моделирование поведения
естественном. Поэтому автоматически проверить выполнение данного тре-
бования невозможно. Более того, даже если принять соглашение, что сторо-
жевые условия должны быть написаны на каком-либо формальном логиче-
ском языке, то, тем не менее, проверить полноту и дизъюнктность системы
сторожевых условий не всегда возможно автоматически. Таким образом,
сторожевые условия в автоматах — вещь удобная, но требующая от модели-
рующего внимания и аккуратности.
Действие на переходе
Последней составляющей простого перехода является действие.
Действие (action) — «то не прерываемое извне атомарное вычисле-
ние, чье время выполнения пренебрежимо мало.
Авторы языка подразумевали, что инструменты моделирования будут свя-
зывать с понятием действия в модели UML понятие действия (или ана-
логичное) в целевом языке программирования. Например, для обычных
языков программирования действиями являются вычисление значения
выражения и присваивание его переменной, запись блока данных в файл,
посылка сигнала и т. д. В UML предусмотрено несколько типов действий
(см. параграф 4.3.1), похожих по семантике на действия в наиболее распро-
страненных языках программирования. Однако UML не является языком
программирования и, тем самым, не претендует на то, чтобы быть универ-
сальным языком описания действий. Поэтому понятие действия в UML со-
знательно недоопределено — оставлена свобода, необходимая инструментам
для непротиворечивого расширения семантики действий UML до семанти-
ки действий конкретного языка программирования.
Более детально эти вопросы рассмотрены в параграфе 4.3.1. Здесь, в контек-
сте обсуждения машины состояний UML, стоит подчеркнуть два обстоя-
тельства.
• Действие является атомарным и непрерываемым. При выполне-
нии действия на переходе или в состоянии не могут происходить со-
бытия, прерывающие выполнение действия. Точнее говоря, событие
может произойти, но система обязана задержать его обработку до
окончания выполнения действия.
• Действие является безальтернативным и завершаемым. Раз на-
чавшись, действие выполняется до конца. Оно не может "раздумать"
выполняться или выполняться неопределенно долго.
Действия являются важнейшей частью описания поведения с помощью ко-
нечных автоматов. В сущности, действия в UML — это в точности то, что
4.2, Диаграммы ibtomata
выше (в параграфе 4.1.1) мы назвали процедурой реакции автомата. В UML
действия, составляющие процедуру реакции, фактически ничем не огра-
ничены: в так называемых не интерпретируемых действиях (см. параграф
4.3.1) могут быть скрыты, например, любые программистские трюки. Более
того, последовательность действий на переходе также является действием.
(Синтаксически, действия в последовательности разделяются запятыми).
Поэтому формальные свойства машины состояний UML трудно проверить
автоматически (в отличие от абстрактных конечных автоматов). С другой
стороны, машины состояний UML выразительны и наглядны — многочис-
ленные синтаксические добавления позволяют моделировать сложное по-
ведение компактно и красиво.
4.2.3. Сегментированные переходы
В UML предусмотрены синтаксические средства, до некоторой степени об-
легчающие семантически правильное построение сторожевых условий за
счет более наглядного их изображения. Таковыми являются:
• сегментированные переходы, реализуемые с помощью переходных
состояний и состояний выбора;
• предикат else.
Сегменты перехода (firansilion segment) — это части, на которые может
оыть разбита линия перехода.
Разбивающими элементами являются следующие фигуры:
• переходное состояние (junction state) (изображается в виде неболь-
шого кружка);
• состояние выбора (choice) (изображается в виде ромба);
• действия посылки и приема сигнала (изображаются в виде флаж-
ков), которые подробно рассматриваются в параграфе 4.3.5.
Сегментирование перехода применяется в UML в нескольких ситуациях.
Здесь мы рассматриваем их в связи со сторожевыми условиями, а прочие
случаи опишем в соответствующем контексте.
Переходные состояния и состояния выбора
Несколько переходов, исходящих из данного состояния и имеющих общее
событие перехода, можно объединить в дерево сегментированных переходов
следующим образом. Имеется один сегмент перехода, который начинается
в исходном состоянии и заканчивается в переходном состоянии или состоя-
Глава 4. Моделирование поведения
нии выбора. Далее из этого переходного состояния или состояния выбора
начинаются другие сегменты, которые заканчиваются в целевых состояниях
или новых переходных состояниях или состояниях выбора. Сегмент пере-
хода, начинающийся в исходном состоянии, называется корневым, сегменты,
заканчивающиеся в целевых состояниях, называются листовыми . Событие
перехода может быть указано только для корневого сегмента, действия на
переходе могут быть указаны только для листовых сегментов, а сторожевые
условия могут быть указаны для любых сегментов. Такое дерево сегментиро-
ванных переходов семантически эквивалентно множеству простых перехо-
дов, которое получится, если рассмотреть все пути из исходного состояния в
целевые состояния, считая встречающиеся на пути сторожевые условия сое-
диненными конъюнкцией (то есть соединенными логической связкой "И").
Замысловатое определение предыдущего абзаца не таит в себе ничего нео-
бычного или нового. Покажем это на примере из информационной системы
отдела кадров.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
При увольнении сотрудника с предприятия, в зависимости от причины,
следует разделять три случая:
। ।
• увольнение сотрудника по собственному желанию, >
i . ।
• увольнение сотрудника по инициативе администрации в связи с нару- '
шением сотрудником условий договора между ним и предприятием,
• вынужденное увольнение сотрудника в связи с проблемами, от со- ,
трудника не зависящими. При этом подразумевается обратное за- i
числение в штат при первой возможности.
Для реализации этих требований введем три различных состояния для уво-
ленных с предприятия:
• Unemployed — работник, уволившийся по собственному желанию,
повторный прием которого должен проходить на общих основаниях;
• Non grata — скандалист, бездельник и нарушитель трудовой дисци-
плины, уволенный по инициативе администрации, которого ни при
каких обстоятельствах нельзя нанимать на работу;
• Welcome back — хороший работник, с которым администрации при-
шлось расстаться ввиду временных трудностей, переживаемых пред-
приятием, и которого при первой возможности следует пригласить
обратно.
[ 340 J
4.2. Диаграммы автомата
Рис. 4.11. Дерево сегментированных переходов
На рис. 4.11 представлен соответствующий фрагмент диаграммы состояний,
в котором дерево сегментированных переходов построено с использованием
переходных состояний (1).
Примечание
В общем случае в переходное состояние может входить не-
сколько сегментов, то есть система сегментированных перехо-
дов не является деревом. Семантика такой системы переходов
определяется так же, как и для случая дерева: каждый путь от
любого исходного состояния к любому целевому — это неза-
висимый переход, сторожевые условия на котором соедине-
ны логической связкой "И". Мы считаем такую конструкцию
трудной для понимания и не рекомендуем ею пользоваться.
Предикат else
Продолжим рассмотрение нашего примера. Известно, что условия увольне-
ния adm и self взаимно исключают друг друга, и одно из них при увольнении
обязательно имеет место. Но это известно только разработчику — инстру-
мент моделирования этого не знает и проверить полноту и дизъюнктность
(то есть, что условия взаимно исключают друг друга) системы условий не
сможет. Но он может помочь обозначить наше желание наделить систему
условий нужными свойствами. Для этого используется ключевое слово else,
которое обозначает условие, считающееся истинным во всех случаях, ког-
Рис. 4.12. Использование предикате else
Глава 4. Моделирование поведения
да ложны все другие условия, приписанные к альтернативным сегментам.
Чтобы подчеркнуть альтернативность условий, мы использовали состояния
выбора (1 на рис. 4.12)164. В результате описание сложной системы условий
становится нагляднее и надежнее.
Таким образом, фрагмент диаграммы состояний на рис. 4.11 семантически
эквивалентен фрагменту на рис. 4.12. При этом совершенно ясно (и это не-
трудно проверить автоматически), что система условий на рис. 4.12 полна и
дизъюнктивна.
Примечание
Стандарт не допускает случая, когда на одном альтернатив-
ном сегменте задано сторожевое условие, а на другом — нет.
Это синтаксически неправильно. Но можно считать, что если
на одной альтернативе ничего не задано, то подразумевается
else. Строго говоря, данное утверждение противоречит спец-
ификации UML, где сказано, что else надо писать всегда, но
это наше предложение по изменению языка. Инструмент
имеет право этого не знать. Данное соглашение является рас-
пространенной языковой практикой, и большинство людей
такую систему обозначений знают и понимают. Кстати, в эту
систему обозначений элегантно вписывается семантика от-
сутствия сторожевого условия для простого перехода. Если
ничего не написано, то опущенное условие истинно, когда
альтернативные — ложны. В случае простого безальтерна-
тивного перехода пустое сторожевое условие всегда выпол-
няется, поскольку альтернативные условия отсутствуют.
Подводя итог обсуждению сторожевых условий, еще раз подчеркнем, что
сегментированные переходы, реализованные через переходные состоя-
ния или состояния выбора, ничего не добавляют (и не убавляют) в семан-
тике модели: это просто синтаксические обозначения, введенные для удоб-
ства и наглядности165. Ту же самую семантику, которую имеют фрагменты
164 Стандарт указывает в качестве различия между переходными состояниями и состоя-
ниями выбора тот факт, что для состояний выбора условие, по которому должен быть
сделан выбор в пользу того или иного перехода, вычисляется непосредственно в мо-
мент перехода и не известно до его начала, а для переходного состояния все условия
вычисляются статически, до начала выполнения перехода.
165 Различие в способе использования переходных состояний и состояний выбора доста-
точно тонкое. Поскольку при использовании переходных состояний сторожевые усло-
вия вычисляются до начала выполнения перехода, то неопределенности быть не может:
переход либо выполнится, либо нет. А при использовании состояний выбора стороже-
вые условия вычисляются динамически, по мере продвижения по дереву перехода от
исходного состояния к целевому. При этом возможна ситуация, когда в очередном со-
стоянии выбора ни одно условие не выполнено и нет предиката else. То есть переход
выполнится частично. Такая модель считается противоречивой.
____ Ф
342]
Рис. 4.13. Множество простых переходов с одним событием перехода и различными
сторожевыми условиями
диаграмм состояний на рис. 4.11 и рис. 4.12, можно передать с помощью
фрагмента, приведенного на рис. 4.13.
Рис. 4.14. Метамодель простого перехода
Метамодель простого перехода
Мы закончим раздел,
посвященный перехо-
дам, соответствующим
фрагментом метамоде-
ли (рис. 4.14). Метамо-
дель получилась очень
простой, это объясня-
ется тем, что детали со-
бытий и действий мы
рассматриваем в более
подходящем, по наше-
му мнению, контексте
(параграфы 4.2.7 и 4.3.1),
а также тем, что метамо-
дель отражает только абстрактный синтаксис UML, необходимый для опи-
сания семантики. Многочисленные детали способов изображения простых
переходов нет нужды отражать в метамодели.
4.2.4. Составные состояния
В параграфе 4.2.1 мы рассмотрели простые состояния, соответствующие со-
стояниям обычной модели конечного автомата. Пришла пора рассмотреть
другие понятия, близкие к понятию состояния, но специфические для UML.
Их можно разделить на две группы:
• составные состояния (composite state),
• специальные состояния (pseudo state).
Глава 4. Моделирование поведения
Составное состояние может быть:
• последовательным (sequential / non-orthogonal state),
• параллельным (ортогональным) (concurrent / orthogonal state).
Специальные состояния в UML 1 бывают следующих типов:
• начальное (initial), параграф 4.2.5;
• слияние (join), параграф 4.5.3;
• развилка (fork), параграф 4.5.3;
• переходное (junction), параграф 4.2.3;
• выбор (choice), параграф 4.2.3;
• поверхностное историческое (shallow history), параграф 4.2.5;
• глубинное историческое (deep history), параграф 4.2.5;
• синхронизирующее (synch), параграф 4.5.3;
• прекращёние выполнения (terminate), параграф 4.3.6,
• заключительное (final), параграф 4.2.6;
• ссылочное состояние (submachine state), параграф 4.2.6,
• состояние "заглушка" (stub state), параграф 4.2.6.
В U ML 2 из этого списка удалены синхронизирующее состояние и состоя-
ние "заглушка", но вместо последнего введены два новых специальных со-
стояния: "точка входа" (entry point) и "точка выхода" (exit point).
Мы начнем обсуждение различных модификаций понятия состояния в
UML 2 с метамодели состояния (рис. 4.15), чтобы сразу видеть общую кар-
тину.
Рис. 4.15. Метамодель состояния
344 J
4.2. Диаграммы автомата
Последовательное составное состояние
Составное состояние (composite state) — это состояние, к которое
вложена машина состояний. Если вложена только одна машина, то
состояние называется последовательным, если Несколько — парал-
лельным.
Глубина вложенности в UML неограниченна, т. е. состояния вложенной ма-
шины состояний также могут быть составными.
Примечание
В UML 2 параллельные состояния переименованы в ортого-
нальные. Мы используем оба термина как синонимы.
Мы начнем с простого примера, чтобы сразу пояснить прагматику составно-
го состояния, т. е. зачем это понятие введено в UML, а затем опишем тонко-
сти семантики и связь с другими понятиями машины состояний UML.
Рассмотрим всем известный прибор: светофор. Он может находиться в двух
основных состояниях:
• Off — вообще не работает — выключен или сломался, как слишком
часто бывает;
• On — работает.
Но работать светофор может по-разному:
• Blinking — мигающий желтый, дорожное движение не регулируется;
• Working — работает по-настоящему и регулирует движение.
В последнем случае у светофора есть 4 видимых состояния, являющихся
предписывающими сигналами для участников дорожного движения:
• Green — зеленый свет, движение разрешено;
• YellowGreen — состояние перехода из режима разрешения в режим за-
прещения движения (это настоящее состояние, светофор находится
в нем заметное время);
• Red — красный свет, движение запрещено;
• RedYellow состояние перехода из режима запрещения в режим раз-
решения движения (это состояние отличное от YellowGreen, светофор
подает несколько иные световые сигналы, и участники движения
обязаны по-другому на них реагировать).
На рис. 4.16 приведена соответствующая диаграмма автомата светофора с
Глава 4. Моделирование поведения
Рис. 4.17. Эквивалентная диаграмма, не содержащая составных состояний
использованием составных состояний (1) (несколько забегая вперед, мы
использовали здесь событие таймера, выделяемое ключевым словом after и
описанное в параграфе 4.2.7).
4 2 Диаграммы автомата
Как мы уже упоминали, в принципе всегда можно обойтись без использова-
ния составных состояний. Например, на рис. 4.17 приведена эквивалентная
машина состояний (т. е. описывающая то же самое поведение), не содержа-
щая составных состояний. Сравнение диаграмм на рис. 4.16 и рис. 4.17 яв-
ляется, по нашему мнению, достаточным объяснением того, зачем в UML
введены составные состояния.
Общая идея составного состояния ясна. Теперь нужно внимательно разо-
браться с деталями составных состояний и связанных с ними переходов. Мы
сделаем это постепенно, несколько раз возвратившись к описанию семанти-
ки составных состояний и переходов в подходящем контексте.
Первое правило можно сформулировать прямо здесь: переход из состав-
ного состояния наследуется всеми вложенными состояниями. Мы не слу-
чайно употребили характерный термин объектно-ориентированного про-
граммирования "наследование" в данном контексте. По нашему мнению,
назначение составных состояний аналогично назначению суперклассов’66:
выявить общее в нескольких элементах и описать это общее только один раз.
Тем самым сокращается описание модели, и она становится более удобной
для восприятия человеком (сравните рис. 4.16 и рис. 4.17 еще раз).
Локальные и глобальные переходы
При использовании составных состояний возможны ситуации, когда пере-
ход из составного состояния (1) конфликтует с переходом из вложенного в
него состояния (2). Например, если на рис. 4.18 в состоянии В придет собы-
тие е, то возбуждаются одновременно переходы в состояния С и D. Какой же
из них должен быть выполнен?
С одной стороны, состояние А, как внешнее, является "главным", поэтому бо-
лее приоритетным выглядит переход в состояние С. С другой стороны, если
продолжать сравнение вложенности состояний с наследованием классов, то
переход в состояние С (для состояния В) является унаследованным от со-
стояния А, и тогда переход в состояние D
(из состояния В) можно рассматривать
как переопределение реакции системы на
событие е. С этой точки зрения должен
быть выполнен переход в состояние D.
Стандарт языка UML рассматривает та-
кие случаи со второй позиции, то есть
если для вложенного состояния опреде-
Рис. 4.18. Пример конфликта двух
переходов
166 Но состояния не являются классификаторами, поэтому прямо использовать отношение
обобщения было бы синтаксически неправильным.
Глава 4. Моделирование поведения
лен переход с тем же событием перехода и сторожевым условием, что и у
глобально определенного ("наследуемого") перехода, то преимущество имеет
локально определенный переход.
Рассмотренный пример одновременного возбуждения нескольких перехо-
дов искусственный, и у читателя может создаться впечатление, что на прак-
тике такого не случается. Действительно, подобные конструкции сложны
для восприятия, и разработчики стараются их избегать. Поэтому некоторые
среды разработки, позволяющие строить программы с помощью диаграмм
состояний, считают ошибкой возможность одновременного возбуждения
нескольких переходов. Однако иногда возможность переопределить пере-
ход из внешнего состояния может быть полезна. Приведем пример.
ИЗМЕНЕНИЙ В ТЕХНИЧЕСКОМ ЗАДАНИИ
В любой момент времени работа информационной системы отдела ка-
дров может быть завершена. Если при этом имеются несохраненные дан- i
ные, то решение о том, сохранять их или нет, должен принимать пользо- !
ватель.
close
Рис. 4.19. Диаграмма
автомата ИС ОК
В самом общем виде диаграмма автомата инфор-
мационной системы отдела кадров может быть
представлена в следующем виде (рис. 4.19).
То есть при нажатии кнопки Закрыть информационная система должна за-
вершать работу. На диаграмме это отражается переходом в заключительное
состояние по событию close.
Однако если, как сказано в техническом задании, в системе есть несо-
храненные данные, то перед выходом нужно узнать у пользователя, что с
ними делать, и если пользователь захочет их сохранить — вызвать метод
save_db()(l). На диаграмме это можно изобразить так, как на рис. 4.20. При
этом приоритет локального перехода (2) над глобальным (3) позволяет
достичь нужного результата.
Переопределениями переходов не следует увлекаться. Чтобы понять, какие
проблемы могут возникнуть из-за приоритета локально определенного пе-
рехода, представьте следующую ситуацию.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Информационная система отдела кадров должна накапливать информа- (
цию о своей работе, в том числе сохранять для каждой проведенной сес- ’
сии имя пользователя и продолжительность сессии.
4.2. Диаграммы автомата
Естественное решение выглядит следующим образом. Нужно определить в
дополнение к методу save_db(), который используется для сохранения ин-
формации отдела кадров, еще один метод save_stat() для сохранения ин-
формации о работе системы отдела кадров, а затем связать вызов метода
save_stat() (1)— с нажатием кнопки Закрыть, которому соответствует собы-
тие close (2 на рис. 4.21).
Рис. 4.21. Некорректные дополнительные действия на переходах
Диаграмма на рис. 4.21 выглядит вполне правдоподобной, но является оши-
бочной! На первый взгляд кажется, что локальный переход определен так
же, как глобальный переход, и потому производит те же самые действия.
Но это не так, потому что локальный и глобальный переходы по событию
close имеют разные целевые состояния. Если пользователь нажмет кнопку
[ 343
Глава 4. Моделирование поведения
Отменить в диалоговом окне сохранения, т.е. произойдет событие cancel
(3 на рис. 4.21), то сессия будет продолжена, и при этом будет сохранена не-
верная информация о якобы законченной сессии.
Одно из возможных решений приведено на рис. 4.22, но выглядит оно дале-
ко не так естественно, как диаграмма на рис. 4.20.
Рис. 4.22. Корректные дополнительные действия на переходах
4.2.5. Специальные состояния
Перейдем к рассмотрению специальных состояний. Прежде всего, специаль-
ное состояние состоянием не является167, в том смысле, что автомат не может
в нем "пребывать" и оно не может быть текущим активным состоянием (см.
параграф 4.5.3).
Начальное состояние
ф Начальное состояние (initial state) — это специальное Состояние, со-
| ответствующее ситуации* когда машина состояний еще не работает.
J в» м £ н d J >
На диаграмме начальное состояние изображается в виде закрашенного
кружка (см., например, рис. 4.19). Начальное состояние не имеет таких со-
ставляющих, как действия на входе, выходе и внутренняя активность, но
оно обязано иметь исходящий переход168, ведущий в то состояние, которое
будет являться по-настоящему первым состоянием при работе машины со-
стояний. Исходящий переход из начального состояния не может иметь со-
бытия перехода, но может иметь сторожевое условие. В последнем случае
должны быть определены несколько переходов из начального состояния,
167 В оригинале специальное состояние называется pseudostate, но слово "псевдосостоя-
ние" нам кажется слишком искусственным
168 Разумеется, начальное состояние не может иметь входящих переходов — машина со-
стояний не может вернуться в ситуацию до начала своей работы.
355
-..'с, • 4 2 Диаграммы автомата
причем один из них обязательно должен срабатывать. В программистских
терминах начальное состояние — это метка точки входа в программу. Управ-
ление не может задержаться на этой метке. Даже графически типичный слу-
чай начального состояния с одним непомеченным переходом очень похож на
бытовую пиктограмму "начинать здесь". Начальное состояние может иметь
действие на переходе — это действие выполняется до начала работы ма-
шины состояний.
Насколько обязательным является использование начального состояния на
диаграмме автомата? Этот вопрос не имеет однозначного ответа — все за-
висит от ситуации. Например, в диаграммах на рис. 4.16 и рис. 4.17 мы обо-
шлись без начального состояния, и поведение светофора не стало от этого
менее понятным. Однако в других случаях наличие начального состояния
может быть желательно или даже необходимо.
Прежде всего, если имеется переход на границу составного состояния, то
внутри этого составного состояния обязано присутствовать начальное со-
стояние — в противном случае неясно, куда же ведет данный переход. Да-
лее, если машина состояний описывает поведение программного объекта,
создаваемого и уничтожаемого в программе, то присутствие начального со-
стояния на диаграмме является весьма желательным: начальное состояние
показывает, в каком состоянии находится объект при создании его конструк-
тором (а в действия на переходе из начального состояния удобно поместить
инициализацию атрибутов).
С другой стороны, если начало и окончание жизненного цикла объекта, по-
ведение которого моделируется, выходят за пределы моделируемого перио-
да (например, нас не интересует ни процесс изготовления новых светофоров,
ни процесс утилизации отслуживших свое), то начальное состояние на диа-
грамме состояний является излишним и может даже мешать восприятию.
Заключительное состояние
Заключительное состояние (final state) — это специальное состояние,
соответствующее ситуации, когда машина состояний уже не работа-
ет.
На диаграмме заключительное состояние изображается в виде закрашенно-
го кружка, который обведен дополнительной окружностью (см. например,
рис. 4.19)169. Подобно начальному состоянию, заключительное состояние не
имеет таких составляющих, как действия на входе, выходе и внутренняя ак-
169 Жаргонное название этого символа — "бычий глаз".
П5Я
Глава 4. Моделирование поведения
тивность, но имеет входящий переход170, ведущий из того состояния, которое
является последним состоянием в данном сеансе работы конечного автома-
та.
Вообще говоря, работа конечного автомата может завершаться несколькими
различными способами. Это соответствует общепринятой программистской
практике: программа может иметь вариант нормального завершения и не-
сколько вариантов завершения при возникновении исключительной ситуа-
ции или при ошибке. Отражая данную особенность поведения на диаграмме
состояний, можно указать несколько переходов в одно и то же заключитель-
ное: состояние. Синтаксически это допустимо. Однако мы настойчиво реко-
мендуем так не делать и помещать на диаграмму столько заключительных
состояний, сколько в действительности существует семантически различ-
ных вариантов завершения работы данной машины состояний.
Эквивалентное выражение переходов между
составными состояниями
Прежде чем переходить к описанию других специальных состояний, еще раз
уточним связь между составными состояниями, переходами между ними,
начальным и заключительным состоянием. Напомним, что:
• если имеется входящий переход в составное состояние, то машина
состояний, вложенная в данное составное состояние, обязана иметь
начальное состояние;
• если машина состояний, вложенная в составное состояние, имеет
заключительное состояние, то данное составное состояние может
иметь исходящий переход по завершении;
• машина состояний верхнего уровня считается вложенной в состав-
ное состояние (с именем top, см. метамодель на рис. 4.6), которое не
имеет ни исходящих, ни входящих переходов.
Семантику составных состояний и переходов мы хотим пояснить с помощью
указания эквивалентных конструкций, не использующих составных состоя-
ний. В таблице 4.3 состояние А — составное, а состояния В и С — любые, т. е.
простые или составные. В последнем случае правила таблицы 4.3 рекурсив-
но применяются к вложенным состояниям на всю глубину вложенности.
170 Разумеется, заключительное состояние не может иметь исходящих переходов — чтобы
машина состояний заново заработала, ее нужно снова запустить.
Ф
4.2. Диаграммы автомата
Таблица 4.3. Эквивалентные выражения для переходов между составными состояниями
Историческое состояние
Следующее специальное состояние, которое мы рассмотрим, — историче-
ское состояние. Историческое состояние может использоваться во вложен-
ной машине состояний внутри составного состояния.
При первом запуске машины состояний историческое состояние означает в
точности то же, что и начальное: оно указывает на состояние, в котором на-
ходится машина в начале работы. Если в данной машине состояний исполь-
зуется историческое состояние, то при выходе из объемлющего составного
состояния запоминается то состояние, в котором находилась вложенная ма-
шина перед выходом. При повторном входе в данное составное состояние в
качестве начального состояния восстанавливается то запомненное состоя-
ние, в котором машина находилась при выходе. Проще говоря, историческое
состояние заставляет автомат помнить, в каком состоянии его прервали в
прошлый раз, и "продолжать начатое".
Историческое состояние имеет две разновидности.
Поверхностное историческое состояние (shallow history state) запо-
минает, какое состояние было активным на том же уровне вложенно-
сти. на каком находится само историческое состояние.
Глава 4. Моделирование поведения
Глубинное историческое состояние (deep history state) помнит не
только активное состояние на данном уровне, но и на всех вложен-
ных уровнях.
Рассмотрим пример из информационной системы отдела кадров.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Информационная система должна отслеживать состояние, в котором на- 1
ходится сотрудники, а именно: в офисе, в отпуске или на больничном. В
случае болезни действует следующее правило - если сотрудник заболел (
в отпуске, то отпуск прерывается, а по выздоровлении возобновляется.
I----------------——— --------...._________. j
Таким образом, работающий сотрудник, если все идет хорошо, пребывает в
одном из двух взаимоисключающих состояний: либо он на работе (In office),
либо в отпуске (On vacation). Но может случиться такая неприятность, как
болезнь. Понятно, что заболевший (fall ill) сотрудник не на работе, но он и не
в отпуске, болезнь (Illness) — это еще одно состояние. Но в какое состояние
переходит сотрудник по выздоровлении? Согласно техническому заданию,
если сотрудник заболел, находясь в отпуске, то отпуск прерывается, а по вы-
здоровлении возобновляется. Для того чтобы построить модель такого пове-
дения, нужно воспользоваться историческим состоянием. В данном случае
достаточно поверхностного исторического состояния (1) (shallow history
state), поскольку на данном уровне вложенности все состояния уже простые.
На рис. 4.23 приведен соответствующий фрагмент машины состояний.
Рис. 4.23. Историческое состояние
35Г
4.2. Диаграммы автомата
4.2.6. Вложенные машины состояний
Прежде чем погрузиться в описание следующей порции деталей автоматов
UML, давайте на минуту приподнимем голову и оглядим горизонт. Конеч-
ные автоматы — хорошее, теоретически проработанное и широко известное
средство описания поведения171. Диаграмма автоматов — реализация в UML
идеи конечных автоматов с различными добавлениями. В частности, состав-
ные состояния и вложенные машины состояний позволяют структуриро-
вать модель поведения. Казалось бы, все отлично — чего еще желать? Для
тех примеров, которые мы пока что рассматривали, действительно, никаких
других средств не нужно. Но что будет при описании действительно слож-
ного поведения? Если на диаграмме автомата требуется отобразить сотни
состояний и десяток уровней вложенности? Они просто не поместятся на
диаграмме нормальных размеров, а если поместятся, то их будет невозможно
прочитать и понять. Если мы хотим описать на UML действительно сложное
поведение, то мы должны иметь возможность сделать это по частям, исполь-
зуя принцип "разделяй и властвуй". И такая возможность в UML предусмо-
трена — это ссылочное состояние и состояния заглушки в UML 1, которым
на смену в UML 2 пришел вложенный автомат с точками входа и выхода.
Эти механизмы похожи, но не тождественны. Мы изложим их в историче-
ском порядке: сначала UML 1, потом UML 2.
Ссылочное состояние
Выше мы дважды упомянули, что всякий автомат UML вложен в некото-
рое составное состояние (машина верхнего уровня вложена в искусственное
составное состояние с именем top). Теперь можно объяснить, для чего это
сделано — чтобы можно было сослаться на любой автомат по имени (кон-
кретно, по имени составного состояния, в которое вложен автомат).
Ссылочное состояние (submachine state) состояние, Которое обо-
значает вложенный в него антома г.
На диаграмме ссылочное состояние изображается в виде фигуры просто-
го состояния с именем, которому предшествует ключевое слово include
(1 на рис. 4.24). Семантика ссылочного состояния заключается в следующем.
Если на диаграмме присутствует ссылочное состояние, то это означает, что в
модели вместо ссылочного состояния присутствует составное состояние (и,
соответственно, вложенный автомат), на которое делается ссылка. Таким об-
171 Некоторые ученые считают, что конечные автоматы являются наилучшим и едва ли
не единственно возможным средством описания поведения, см. например, сайт
http://is.ifmo.ru.
Глава 4. Моделирование поведения
разом, на одной диаграмме мы можем представить поведение, нарисовав его
"крупными мазками", т. е, в терминах составных состояний верхнего уровня,
а на других диаграммах раскрыть содержание составных состояний, нарисо-
вав соответствующие автоматы и т. д. Критерий Дейкстры хорошего стиля
программирования — "правильно написанный модуль должен помещаться
на одной странице" — соблюдается.
Переходы между составными состояниями
Прежде чем привести пример, поговорим о переходах между составными
состояниями. Их можно подразделить на два типа: переходы "в" и "из" со-
ставных состояний (т. е. переходы, пересекающие границы составных со-
стояний) и переходы, начинающиеся и заканчивающиеся на границах
состояний.
Вообще говоря, без переходов, пересекающих границы состояний, можно
обойтись (равно как и без многого другого), но жаль упускать возможность.
Если переход начинается и заканчивается на границе состояний, то вся ра-
бота вложенного автомата инкапсулирована в составном состоянии, семан-
тика переходов определена в таблице 4.3 и никаких проблем нет — ссылоч-
ного состояния достаточно для включения одного автомата внутрь другого.
Однако, если такие переходы есть (а мы договорились, что не хотим от них
отказываться), то возникает проблема: грубо говоря, нам нужно провести
стрелку с одной диаграммы на другую. Решением этой проблемы в UML 1
является состояние заглушки.
Состояние заглушка
Состояние заглушка (stub state) — это специальное состояние, кото-
рое обозначает® ссылочном состоянии некоторое вложенное состоя-
ние того составного состояния, на которое делается ссылка.
Звучит замысловато, но все очень просто: мы разрешаем себе показать в
ссылочном состоянии необходимый нам минимум деталей того автомата,
который скрыт в ссылочном состоянии. А нужны нам только имена вложен-
ных состояний, в которые или из которых делается переход. На диаграм-
ме состояние заглушка изображается в виде короткой вертикальной (или
горизонтальной) черты внутри фигуры ссылочного состояния и с именем
соответствующего вложенного состояния (2 и 3 на рис. 4.24). У этой чер-
ты начинается или заканчивается стрелка перехода, пересекающего границу
ссылочного состояния172.
172 Если бы такого перехода не было, то и состояние "заглушка" было бы ненужным.
.................—..............- ....................................................
4.2. Диаграммы автомата
Приведем пример из информационной системы отдела кадров, чтобы про-
иллюстрировать приведенные сухие определения.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Вновь принимаемый сотрудник всегда принимается с испытательным
сроком. Ранее работавший сотрудник всегда принимается без испыта-
тельного срока.
S J
Давайте опять рассмотрим жизненный цикл сотрудника на предприятии
(см. рис. 4.4 и рис. 4.13) и раскроем детали поведения объекта Person, нахо-
дящегося в самом важном для предприятия состоянии — Employed, исходя
из требований технического задания. В этом нам поможет ссылочное состоя-
ние.
На рис. 4.24 приведена диаграмма верхнего уровня, описывающая поведе-
ние в целом, без деталей. Состояние Employed — ссылочное (1), что под-
разумевает наличие другой диаграммы, на которой раскрыта внутренняя
структура состояния Employed. Состояние заглушка On trial (2) указыва-
ет, что внутри составного состояния Employed есть вложенное состояние
On trial. Состояние заглушка On staff (3) указывает, что внутри составного
состояния Employed есть еще одно вложенное состояние On staff. Данные со-
стояния выявлены на диаграмме верхнего уровня, чтобы подчеркнуть, что
переходы по событию hire() ведут именно в эти вложенные состояния, а не в
другие (новый сотрудник сначала обязательно должен попасть в состояние
On trial, а ранее работавший сразу оказывается в состоянии On staff).
Рис. 4.24. Ссылочное состояние и состояние заглушка
Глава 4. Моделирование поведения
Employed
Рис. 4.25. Составное состояние, раскрывающее ссылочное состояние
На другой диаграмме (рис. 4.25) раскрывается внутренняя структура со-
стояния Employed.
Здесь мы сразу показали все вложенные состояния Employed173. В данном
случае диаграмма получилась простой, но если бы все нужные детали пере-
стали помещаться на диаграмму, то нужно было бы ввести еще несколько
ссылочных состояний и раскрыть их детали на отдельных диаграммах174.
Фактически, при описании поведения средствами UML, вполне применим
метод пошагового уточнения (см. одноименную врезку в параграфе 2.4.2).
Вложенные автоматы
Для возможности практического использования метода пошагового уточне-
ния при описании сложного поведения с помощью автоматов в UML 2 яв-
ным образом введено понятие вложенного автомата вместо понятия ссы-
лочного состояния и заглушки.
На диаграмме верхнего уровня вложенный автомат указывается как простое
ссылочное состояние, а на диаграмме нижнего уровня вложенный автомат
раскрывается как составное состояние. При этом строка имени ссылочного
состояния имеет следующий синтаксис.
ИМЯ СОСТОЯНИЯ : ИМЯ ВЛОЖЕННОГО АВТОМАТА
Подчеркнем, что ссылочное состояние заимствует структуру и поведение
вложенного автомата, но не владеет им композиционно. Тот же самый вло-
женный автомат может быть использован в другом месте и в другой машине
состояний. Таким образом, в UML 2 вложенные автоматы по назначению и
способу использования подобны подпрограммам в обычных языках про-
граммирования.
173 Недоумение читателей по поводу того, что изображенные на рис. 4.23 и рис. 4.25 раз-
личные машины состояний описывают одно и то же составное состояние, мы развеем в
параграфе 4.5.3.
174 Детальная модель поведения объекта "сотрудник" в промышленной информационной
системе отдела кадров, по нашему опыту, содержит примерно десяток диаграмм и ис-
пользует три-четыре уровня вложенности ссылочных состояний.
4 2 Диаграммы автомата
Вместо понятия заглушки указываются точки входа и выхода на границе
вложенного автомата. Если продолжать аналогию с подпрограммами, то это
аналог входных и выходных параметров, через которые во вложенный авто-
мат передаются соответствующие события.
Переходы на границу и с границы ссылочного состояния имеют тот же са-
мый смысл, что и переходы на границу и с границы составного состояния,
как если бы копия составного состояния вложенного автомата была под-
ставлена вместо ссылочного состояния.
Уточненное в UML 2 понятие вложенного автомата представляется нам на-
столько простым и естественным, что вместо дальнейших пояснений мы
просто сошлемся на рис. 4.26 и рис. 4.27, где еще раз представлен пример,
аналогичный примеру на рис. 4.24 и рис. 4.25.
Мы надеемся, что читатель оценит красоту и точность нотации UML 2.
Рис. 4.26. Составное состояние, использующее вложенную машину состояний
Рис. 4.27. Составное состояние, раскрывающее вложенную машину состояний
* [bi
Глава 4. Моделирование поведения
4.2.7. События
Различные типы состояний, рассмотренные в предыдущем разделе, позво-
ляют задавать структуру автомата. Но основная семантическая нагрузка при
описании поведения падает на переходы различных типов. Помимо струк-
турных составляющих — исходного и целевого состояний — переход может
быть нагружен событием перехода, сторожевым условием и действиями на
переходе. Детали описания сторожевых условий рассмотрены в параграфах
4.2.2 и 4.2.3, детали описания действий рассмотрены в параграфе 4.3.1, а в
этом параграфе рассматриваются детали описания событий.
События могут быть классифицированы различными способами, например,
можно различать:
• события внешние — которые возникают вне системы, в мире дей-
ствующих лиц и обрабатываются в системе и
• события внутренние — которые возникают внутри системы и там же
обрабатываются.
В любом случае в UML существует своя классификация событий, не совпа-
дающая с известными классификациями, что, по нашему мнению, является
некоторым недостатком языка.
В UML используются четыре типа событий:
• событие вызова,
• событие сигнала,
• событие таймера,
• событие изменения.
Событие вызова
Событие вызова (call event) — это событие, возникающее при вызове
метода класса.
Если событие вызова используется как событие перехода в машине состоя-
ний, описывающей поведение класса, то класс должен иметь соответству-
ющую операцию. Событие вызова — наиболее часто используемый тип
событий перехода. В большей части рассмотренных примеров в качестве
событий перехода использовались именно события вызова. Поскольку со-
бытие вызова — это вызов метода, то оно может иметь аргументы, как всякий
вызов метода. Значения аргументов могут использоваться в действиях пере-
хода. Если метод возвращает значение, то этот факт отмечается с помощью
4.2, Диаграммы автомата
действия возврата (см. параграф 4.3.1) в последовательности действий дан-
ного перехода.
Допустим, что некоторая операция класса реализована (то есть соответ-
ствующее данной операции поведение описано в виде метода) и в машине
состояний данного класса присутствует переход с событием вызова данного
метода. Предположим, данный метод вызван. Тогда возможны два вариан-
та: либо соответствующий переход срабатывает (т. е. в активном состоянии
определен переход с данным событием вызова, и сторожевое условие выпол-
нено), либо не срабатывает. В каждом варианте поведение зависит от того,
возвращает или не возвращает значение вызываемая операция.
Если операция не возвращает значения, то ошибки нет в любом случае:
• если переход не срабатывает, то ничего не происходит и управление
немедленно возвращается в место вызова, причем это не считается
ошибкой;
• если переход срабатывает, то выполняются действия на переходе,
автомат переходит в новое состояние и в этом заключается выполне-
ние вызванной операции.
Если же данная операция возвращает значение, то возможны три вариан-
та:
• если переход не срабатывает, то ничего не происходит и управление
немедленно возвращается в место вызова;
• если переход срабатывает и возвращается подходящее значение, то
все в порядке;
• если переход срабатывает, но значение не возвращается или возвра-
щается неподходящее значение, то это считается ошибкой, посколь-
ку поведение, описываемое машиной состояний, не соответствует
спецификации операции.
Проиллюстрируем вышесказанное на примере информационной системы
отдела кадров. Определим в классах Person и Position операции, приведен-
ные на рис. 4.28.
Person
+assign(newPos:Position):Boolesn
+hasPosition():Boolean
Position
+occupy (person: Person): Boolesn
+isFree (): Boolesn
Рис. 4.28. Операции, определенные в классах Person и Position
Глава 4 Моделирование поведения
Операция hasPosition() класса Person проверяет, занимает ли сотрудник
какую-нибудь должность, а операция assign() переводит сотрудника на но-
вую должность newPos и возвращает значение true, если перевод успешно
произведен.
Операция isFree() класса Position проверяет, свободна ли должность, а опе-
рация осей ру() позволяет назначить сотрудника на должность, и в случае
успешного завершения возвращает значение true.
Тогда типичное поведение операции assign() можно описать диаграммой со-
стояний, приведенной на рис. 4.29.
Рис. 4.29. Событие аызова
На этом рисунке наибольшее внимание заслуживает переход из состояния
Employed в себя. Давайте разбираться. По событию assign() данный переход
возбуждается, но для того, чтобы этот переход завершился, должно быть вы-
полнено условие newPos.isFree(). Если должность свободна (newPos.isFree()
вернул true), то тогда осуществляется вызов метода newPos.occupy(self), а
вызов метода assign(newPos) возвращает true (1 на рис. 4.29).
Однако такое описание поведения, хотя и правильно определяет, что делает
операция assign(), если "все хорошо", но не является достаточно надежным.
assign(newPos)/
return(false)
Рис. 4.30. Событие аызоаа с учетом асех вариантоа поведения
4.2. Диаграммы автомата
Действительно, если операция assign() будет вызвана в тот момент, когда
сотрудник находится в состоянии Applicant или Unemployed, или же если
должность newPos окажется занятой, то возникнет ошибка, поскольку тре-
буемое по спецификации операции assign() логическое значение (в данном
случае — true) не будет возвращено. Диаграмма автомата на рис. 4.30 опи-
сывает поведение операции assign() более надежно, поскольку обеспечивает
возврат значения и в том случае, когда "не все хорошо".
Событие сигнала
Событие сигнала (signal event )— это событие, возникающее при По-
сылке сигнала
Чтобы разъяснить, что такое событие сигнала в UML, нужно рассмотреть,
прежде всего, саму концепцию сигнала. Здесь опять имеет место пересече-
ние моделирования структуры и поведения: определяются сигналы в струк-
турной части модели, а используются в поведенческой.
Синтаксически сигнал (в UML 1) — это экземпляр класса со стерео-
типом «signal». В UML2 сигнал — это самостоятельный клаесифика-
, ™р-
Семантически сигнал — это именованный объект, который создается
другим объектом (отправителем) и обрабатывается третьим объек-
том (получателем).
.Х.-. - .. , .. ' . . Л ..... ' ... ‘ ..
Сигнал может иметь атрибуты (параметры). Сигнал может иметь опера-
ции. Одна из них считается определенной по умолчанию. Она имеет стан-
дартное имя send() и параметр, являющийся множеством объектов, которым
отправляется сигнал. Это операция — конструктор, который создает экзем-
пляр классификатора, то есть сигнал. Объявлять эту операцию не нужно.
Можно объявлять другие операции, которые служат для доступа к значени-
ям атрибутов сигнала, но и это не обязательно.
Концепция сигнала в UML принадлежит к числу наиболее фундаменталь-
ных и имеет ясную и строго определенную семантику. Объект, являющий-
ся отправителем, обращается к классификатору сигнала (вызывает опера-
цию send()), указывая аргументы сигнала (значения атрибутов) и целевое
множество объектов, которым должен быть отправлен сигнал. После этого
объект-отправитель продолжает свою работу — дальнейшее его не касается.
На диаграмме классов (см., например, рис. 4.31), классификатор сигнал
связывается с классом-отправителем зависимостью со стереотипом «send»,
ф ____
2 363
Глава 4. Моделирование поведения
Объекты, которым отправляется сигнал, обязаны иметь операцию для полу-
чения и обработки сигнала. Такая операция имеет стереотип «signal», ее имя
совпадает с именем классификатора сигнала, а имена и типы параметров со-
впадают с именами и типами атрибутов сигнала. Операция получения сиг-
нала не может возвращать результат. После того, как объект-отправитель пе-
редал классификатору сигнала все необходимые данные, тот создает новый
объект — экземпляр сигнала и отправляет его копии всем объектам целевого
множества, т. е. вызывает в объектах целевого множества операции приема
сигнала с указанными значениями аргументов.
Как правило, целевое множество содержит один элемент, но может не содер-
жать элементов (это не считается ошибкой) или может содержать много эле-
ментов (это называется широковещательным сигналом — broadcast signal).
Поскольку сигналы в UML являются классификаторами, они могут
участвовать в отношении обобщения. Сигнал, являющийся сигналом-
потомком, наследует все составляющие сигнала-предка и может иметь свои
собственные. Сигналом-предком не может быть не сигнал. Принцип подста-
новки при обобщении сигналов имеет следующий смысл: если на переходе
указано событие сигнала, то переход возбуждается, если пришедший сигнал
является прямым или косвенным экземпляром указанного в событии клас-
сификатора сигнал.
Сигналы подходят для описания асинхронных видов взаимодействия.
Все получатели сигнала должны быть экземплярами активных классов, т.е.
иметь свой поток управления.
В UML существует еще одно важное понятие, связанное с асинхронным
взаимодействием, — исключение (exception). В разных версиях UML ис-
ключения определены и используются по-разному. Подробнее способы при-
менения исключений в UML 2 рассматриваются в параграфе 4.3.7, а здесь
для полноты картины скажем пару слов о том, что же такое исключение в
терминах UML 1 и UML 2.
Исключения в UML 1 во всем подобны сигналам (на уровне метамодели
исключение определено как подкласс сигнала), в то время как в UML 2 от
исключения осталось только действие, которое генерирует исключение
(RaiseExceptionAction), и элемент (ExceptionHandler), который описыва-
ет действия для обработки исключения. Как видно, в UML 2 более сильно
выражен тот факт, что для поддержки исключений используется встроен-
ный механизм обработки, который имеется в большинстве современных
объектно-ориентированных систем программирования и состоит в том, что
прерывается нормальный поток управления без помех для основной логики
программы.
4.2. Диаграммы автомата
Нотация исключения в UML 1 — классификатор со стереотипом «exception».
Рассмотрим пример из информационной системы отдела кадров. Допустим,
что мы решили обрабатывать как исключительную ситуацию случай, ког-
да при переводе сотрудника (выполнение операции assign()) целевая долж-
ность оказывается занята. Отсюда вытекает следующее решение. Имеется
класс PosOccupied, представляющий собой исключение, класс Person, гене-
рирующий исключение (это показано с помощью зависимости со стереоти-
пом «send» (1) ), и операция по обработке исключения (2). Ответственность
за обработку исключительной ситуации мы решили возложить на класс
Company175. Такое решение на диаграмме классов можно изобразить следую-
щим образом (рис. 4.31).
Рис. 4.31. Описание сигнала на диаграмме классов
Данная диаграмма является правильной как для UML 1, так и для UML 2,
однако в терминах UML 1 допустимо на рис. 4.31 заменить стереотип «signal»
у классификатора PosOccupied стереотипом «exception».
Вернемся теперь в мир конечных автоматов. Принятое решение о введении
исключения на диаграмме автомата класса Person может быть отражено, как
показано на фрагменте диаграммы, представленном на рис. 4.32. Здесь в слу-
[newPos.isFree()]/
newPos.occupy(self),return(true)
Employed
assign(newPos)
Рис. 4.32. Фрагмент диаграммы автомата. Посылка сигнала
[else]/
send posOccupied(newPos),
return(false)
175 Решение спорное, оно отражает личные авторские предпочтения: концентрировать
обработку исключительных ситуаций в одном месте, желательно в глобальной службе
общего назначения. Альтернативный вариант— помещать обработку исключительных
ситуаций как можно ближе к месту их потенциального возникновения.
Глава 4. Моделирование поведения
чае занятости целевой позиции выполняется действие по посылке сигнала,
которому мы для ясности предпослали ключевое слово send (1), хотя это и
не обязательно.
В машине состояний экземпляра класса, ответственного за обработку ис-
ключительных ситуаций, исключение выступает как событие сигнала, воз-
буждающее переход. Синтаксис события сигнала ничем не отличается от
события вызова (потому что обработка события сигнала — это тоже вы-
полнение метода). Мы не стали детализировать конечный автомат класса
Company, ограничившись одним интересным случаем, связанным с перехо-
дом по событию сигнала (рис. 4.33). На этом переходе выполняется не ин-
терпретируемое действие (см. параграф 4.3.1) putLog — мы полагаем необ-
ходимым в любом случае по крайней мере записать в протокол выполнения
приложения факт срабатывания перехода по исключению.
posOccupied(pos)/putLog
Рис. 4.33. Переход по событию сигнала между состояниями класса Company
Полагаем, что в первом приближении события сигнала описаны достаточно
подробно. Мы еще вернемся к обсуждению сигналов, прерываний и исклю-
чений в параграфах 4.3.5 и 4.3.7.
Событие таймера
Событие таймера (time еv е n t) . «то с< «бытие, которое возникает, ког-
да истек заданный интервал времени с момента попадания автомата В
даннре состояние.
Синтаксически событие таймера записывается с помощью ключевого слова
after, за которым указывается выражение, определяющее длину интервала
времени.
Семантически событие таймера означает следующее. Подразумевается, что
у состояния имеется таймер, который сбрасывается в 0 (начинает отсчет),
когда автомат переходит в данное состояние (напомним, что автомат счита-
ется перешедшим в состояние, когда закончено выполнение всех действий,
предписанных переходом).
Таймер ведет отсчет времени. Если до истечения указанного интервала вре-
мени сработает другой переход, то событие таймера не возникает. Когда ука-
4.2. Диаграммы автомата
занный интервал времени истекает, наступает событие таймера и возбужда-
ется соответствующий переход.
Примечание
Если переход по событию таймера является переходом в себя, то
таймер опять сбрасывается в 0, а если переход по событию тайме-
ра является внутренним переходом, то таймер продолжает отсчет.
Если переход срабатывает, то автомат переходит в новое состояние. Если
переход по событию таймера не срабатывает (из-за ложности сторожевого
условия), то событие таймера теряется, и таймер продолжает отсчет време-
ни, так что позже может сработать другой переход по событию таймера с
большим интервалом времени. Событие таймера не может быть отложено176.
И хотя мы уже привели несколько примеров использования события тай-
мера на переходах в конечных автоматах (см. рис. 4.23-4.27), приведем еще
один (рис. 4.34).
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
Информационная система должна хранить информацию не только о ра-
ботающих, но и об уволенных сотрудниках. По прошествии 10 лет после ।
увольнения, если эта информация не нужна более, она уничтожается.
г_________________— ----------------------------.—------—---------—I
Таким образом, ио истечении десяти лет после увольнения объект, представ-
ляющий уволенного сотрудника (запись в базе данных), уничтожается, если
только этот объект не помечен специальным образом (сторожевое условие
keepForever). Если объект оставлен в базе, то через десять лет проверка по-
вторяется.
Unemployed
after 10 years
[keepForever] ( [elsepdeleteDBrecord
Рис. 4.34. Переход по событию таймера со сторожевым условием
В UML 2 появился очень полезный вариант события таймера, которое свя-
зано не с интервалом времени пребывания в локальном состоянии, а с гло-
бальным временем — системными часами. Данное событие записывается с
помощью ключевого слова at, за которым нужно указать некоторый момент
абсолютного времени (год, месяц, день, час, минуту, секунду...). Когда задан-
176 Забегая вперед, заметим, что таймеры параллельных вложенных состояний независи-
МЫ.
367
Глава 4, Моделирование поведения
ный момент наступает, происходит событие таймера. Если указать момент в
прошлом, событие at никогда не наступит.
Событие изменения
Событие изменения (change event)— это событие, которое возникает,
когда некоторое логическое условие становится истинным, будучи до
этого ложным.
Синтаксически событие изменения записывается с помощью ключевого
слова when, за которым указывается логическое выражение (условие). Се-
мантически событие изменения означает следующее. Подразумевается, что
в системе имеется механизм, работающий как демон (например, приложе-
ние, запущенное в фоновом режиме), который генерирует событие, если в
результате изменения состояния системы изменяется значение логического
выражения.
Если выражение, являющееся аргументом события изменения, принимает
значение true (имея до этого значение false), то переход возбуждается. Если
выражение имеет значение true в тот момент, когда автомат переходит в дан-
ное состояние, то переход сразу возбуждается. Если переход срабатывает, то
автомат, как обычно, переходит в новое состояние. Если переход не сраба-
тывает, то событие изменения теряется. При этом если условие продолжает
оставаться истинным, то нового события изменения не возникает. Для того
чтобы снова возникло событие изменения, нужно, чтобы условие стало сна-
чала ложным, а потом истинным.
ДЕМОНЫ В ПРОГРАММИРОВАНИИ
Обычно демоном называется программа, которая выполняет
свою функцию без явного вызова со стороны пользователя
или той программы, которая пользуется услугами демона.
Название обусловлено тем, что демон срабатывает как бы сам,
по собственной инициативе. Разумеется, это только видимый
для пользователя эффект. На самом деле демоны запускаются с
помощью механизма, скрытого в операционной системе. Чаще
всего такой механизм основан либо на периодической проверке
состояния ("не пора ли вызвать демона?”), либо на встраивании
вызова демона в процедуры реакции на определенные события.
Исторически это понятие впервые было использовано, видимо, в
операционной системе UNIX.
На первый взгляд кажется, что событие изменения — это нечто крайне неэф-
фективное. Действительно, как узнать, что значение логического выражения
4.2. Диаграммы автомата
изменилось? Кажется, что нужно непрерывно его перевычислять, чтобы не
прозевать момент. На самом деле это совершенно не обязательно.
Вполне возможен эффективный демон, и вот один из способов реализации.
Рассмотрим, от чего зависит значение логического выражения? От значений
входящих в него переменных. Таким образом, значение логического выраже-
ния может измениться только по причине (и в тот же момент!) изменения
значения одной или нескольких входящих в выражение переменных. В ре-
зультате чего изменяется значение переменной? В результате присваивания
или вызова метода, меняющего значение этой переменной.
Одна их схем реализации, которую можно предложить, описывается об-
разцом проектирования Publisher-Subscriber, рассмотренного в параграфе
3.5.3. Все те места в программном коде, в которых меняется значение инте-
ресующей нас переменной (publisher), содержат через интерфейс подписки
(subscriber) вызовы методов, которые в свою очередь проверяют истинность
тех выражений событий изменения, в которые данная переменная входит.
Если выражение окажется равным true, то генерируется соответствующее
событие изменения.
Рассмотрим элементарный пример из информационной системы отдела ка-
дров.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
По достижении определенного возраста (55 лет для женщин и 60 лет для
мужчин) сотрудник увольняется на пенсию.
Реализация данного требования приведена на рис. 4.35.
when self .age > 60 and
self.gender=Female
Рис. 4.35. Переход по событию изменения
Заметим, что условие достижения пенсионного возраста сотрудников за-
писано с помощью специального языка (OCL) и подразумевает, что класс
Person (рис. 4.35 — это часть диаграммы автомата именно этого класса) име-
ет атрибут с именем аде.
В конце раздела мы приводим наш вариант метамодели событий UML
(рис. 4.36), которая получилась не слишком сложной.
*
Глава 4 Моделирование поведения:
Рис. 4.36. Метамодель событий
4.2.8. Предусловия и постусловия
Помимо иллюстрации понятия события вызова в UML пример на рис. 4.30
может послужить, по нашему мнению, поводом для повторного обсуждения
понятий предусловия и постусловия операций в UML (см. также врезку
"Проектирование по контракту" в параграфе 3.4.1). Напомним определения
этих терминов.
.» Предусловие (precondition)—это условие, налагаемое на входны.
данные операции, которое должно выполняться до вызова операции.
Если предусловие операции нарушено, то корректное выполнение операции
не гарантируется.
Постусловие (postcondition) — это условие, связывающее входные и
выходные данные операции, которое- должно выполняться после вы-
зова операции.
Если постусловие операции оказывается нарушенным при выполненном
предусловии, то это означает, что в реализации операции есть ошибка —
операция не выполняет свой контракт. В UML предусловия и постусловия
операций предлагается описывать при моделировании структуры, в виде
ограничений со стереотипами «precondition» и «postcondition» соответствен-
но. Хотя предусловия и постусловия описываются на структурных диаграм-
мах, их следует отнести к моделированию поведения. Впрочем, как мы уже
370
4.2. Диаграммы автомата
не раз отмечали, само деление моделирования на структурное и поведенче-
ское носит условный характер: моделирование — это единый итеративный
процесс.
Определение предусловий и постусловий операций — чрезвычайно сильное
средство моделирования, но рекомендации по его применению неоднознач-
ны. Например, в только что разобранном случае операции assign() возника-
ет законный вопрос: условие newPos.isFree() является частью предусловия
операции assign() или нет? Можно ответить "да", и тогда кто-то должен
позаботиться о выполнении этого условия, перед тем как вызвать assign(),
можно ответить "нет", и тогда есть риск, что проверка не будет выполнена,
и в результате перевода сотрудника на занятую должность будет нарушена
целостность данных.
Чем слабее предусловие, тем шире область применения операции, тем она
более универсальна. Но универсальность не всегда благо: иногда это никому
не нужная трата ресурсов. Другой вопрос: как следует использовать преду-
словие и постусловие операции, если они заданы? Весьма авторитетные уче-
ные рекомендуют доказывать (в математическом смысле) правильность реа-
лизации операции. Спору нет, доказательное программирование — отличная
вещь, но где же набрать необходимое количество программистов, умеющих
доказывать свои программы177?
Сугубые практики советуют вручную вставлять в начало программы про-
верку предусловия, а в конец — проверку постусловия. Это, конечно, замет-
но повышает надежность программы, для библиотек общего пользования
фактически так всегда и делается, но в приложении типа информационной
системы отдела кадров в девяти случаях из десяти такие проверки будут из-
лишними и отрицательно скажутся на производительности приложения.
Разработчики "продвинутых" систем программирования ратуют за автома-
тизацию этого процесса, при которой предусловия, постусловия, инвариан-
ты классов и циклов являются частью языка и проверяются автоматически,
но в окончательной версии программы эти проверки можно отключить. Ко-
роче говоря, по данному вопросу сколько авторов, столько и взаимоисклю-
чающих мнений. И все правы.
У нас тоже есть совет — не универсальный и не масштабируемый. Он при-
меним в случае разработки простых приложений для бизнеса, в которых на-
дежность важна, но не критична, на доказательства нет времени и денег, а
операции просты. Совет состоит из двух частей. Во-первых, какие-то пред-
условия и постусловия нужно выписывать всегда, а вот тратить силы на
их анализ и совершенствование не обязательно. Во-вторых, предусловие и
постусловие нужно поместить в код программы до и после вызова опера-
177 И сколько будут стоить такие программисты?
Глава 4. Модьлиро .ание поведения
ции соответственно, в форме утверждений (см. ниже врезку "Доказатель-
ное программирование"). Разумеется, это не повысит надежность програм-
мы — если ошибка в коде есть, она там останется, и приложение завершится
аварийно, но не так болезненно, и ошибку легче будет локализовать.
Идея автоматического доказательства правильности (или вери-
фикации) программ высказана давно. К сожалению, известно, что
в общем случае эта задача алгоритмически неразрешима, а в тех
случаях, когда она разрешима, верификация оказывается не про-
ще, чем задача автоматического синтеза императивной програм-
мы по декларативной спецификации (см. врезку "Автоматический
синтез программ" в параграфе 1.2.3). Существует целый ряд част-
ных случаев178, в которых задача верификации оказывается раз-
решимой, но эти частные случаи таковы, что в практических си-
туациях (недостаточно формальные спецификации, недостаточ-
но формализованная семантика используемого императивного
языка программирования и прочее) автоматическая верификация
оказывается фактически неприменимой.
Апологеты доказательного программирования ратуют за руч-
ное доказательство правильности программ, как альтернати-
вы тестированию и отладке. При этом приводятся весьма поу-
чительные и ценные примеры -и приемы таких доказательств (см.,
например, блестящую книгу Э. Дейкстры Дисциплина программи-
рования). К сожалению, ручная верификация практически возмож-
на только для очень маленьких программ, просто в силу ограничен-
ности способностей программистов к построению доказательств.
Ручное доказательство правильности целесообразно исполь-
зовать для верификации часто используемых небольших образ-
цов проектирования (см. врезку "Паттерны" в параграфе 3.5.3).
Образец, в отличие от конкретной программы, практически невоз-
можно надежно отладить тестированием, потому что невозможно
заранее определить все возможные варианты и контексты буду-
щего использования образца, а значит невозможно построить
представительный набор тестов.
Тем не менее один из приемов, связанных с идеей верификации,
целесообразно использовать, даже если полная верификация
программы и не проводится. А именно, при верификации в текст
программы вставляются промежуточные утверждения (assert),
которые должны быть истинными при выполнении правильной
программы. Вставка утверждений в программу иногда называет-
ся аннотированием программы. В простейшем случае утверж-
дения представляют собой эффективно вычислимые предикаты
178 Например, если известны инварианты всех циклов.
372
4.2. Диаграммы автомата
над значениями переменных программы. Например, предусловия
и постусловия операций, инварианты цикла, ограничители числа
итераций плохо сходящихся процедур и т. п. Если программист
знает'73 какое-либо (достаточно сильное) условие на значения
переменных в данной точке программы, то настоятельно рекомен-
дуется перенести это знание в код программы. Существуют три
основных формы использования утверждений.
1. Запись утверждения в виде комментария. Так или ина-
че, эту форму используют практически все программисты.
Например, комментарий к определяющему вхождению па-
раметра процедуры содержит, как правило, неформаль-
ное описание области допустимых значений аргумента.
Систематическое выписывание в комментариях нетриви-
альных утверждений о текущих значениях переменных резко
увеличивает читабельность программы и рекомендуется к ис-
пользованию наряду с другими формами внесения утвержде-
ний в текст.
2. Запись утверждения в формальном синтаксисе. Эту фор-
му настоятельно рекомендуется использовать, если система
программирования поддерживает работу с утверждениями.
Например, многие современные системы программирования
поддерживают следующий механизм работы с утверждения-
ми. Вставленное в текст программы формальное утвержде-
ние проверяется, и, в случае невыполнения, генерируется
указанный сигнал или исключительная ситуация.
3. Запись утверждения в виде ловушки179 180. Ловушка — это
фрагмент кода, предназначенный для перехвата и обработ-
ки ошибок (исключительных ситуаций). Например, это может
быть условный оператор, который проверяет невыполнение
утверждения и немедленно обрабатывает исключительную
ситуацию или посылает сообщение системе обработки ис-
ключительных ситуаций.
Во всех приведенных формах наличие утверждений не превраща-
ет, конечно, неправильную программу в правильную. Однако ис-
пользование утверждений может сильно увеличить потребитель-
скую ценность даже неправильной программы. Одно дело, когда
программа аварийно завершается или, хуже того, молча выдает
неправильный результат, и совсем другое дело, когда программа
хотя и не работает как должно, но вежливо информирует об этом
пользователя.
179 Это знание может быть почерпнуто из спецификации, из опыта или из частичной ручной
верификации.
180 Фактически это ручная реализация идеи обработки утверждений в тех системах про-
граммирования, которые не поддерживают автоматическую обработку утверждений.
Глав/ 4. Моделирование поведения
4.2.9. Протокольный автомат
В UML имеется еще одно важное, но пока редко применяемое средство,
основанное на конечных автоматах181. Эта так называемая протокольная ма-
шина состояний (protocol state machine), или протокольный автомат.
Протокольный автомат задается так же, как и любая другая машина со-
стояний, но на переходах нет действий. Для указания того, что машина со-
стояний является протокольным автоматом, используется ключевое слово
protocol (1 на рис. 4.37).
Смысл использования протокольного автомата состоит в следующем. Допу-
стим, имеется класс (или компонент), который предоставляет для исполь
зования некоторый интерфейс. С точки зрения объектно-ориентированного
программирования здесь должна стоять точка: мы описали набор операций,
предоставляемых для использования, что еще нужно? На самом деле такого
объектно-ориентированного описания интерфейса "изнутри" бывает недо-
статочно. Операции, предоставляемые интерфейсом, часто не являются не-
зависимыми: некоторые последовательности операций являются допусти-
мыми, и объект должен их выполнять, но некоторые последовательности не
являются допустимыми, и объект не может и не должен их выполнять.
Таким образом, встает задача описания допустимых и недопустимых по-
следовательностей вызовов методов объектов, то есть описания интерфейса
"снаружи". Если рассматривать вызовы операций как символы, то каждый
объект определяет некоторый язык, состоящий из допустимых последо-
вательностей символов. Конечный автомат — одно из лучших известных
средств задания языков. Именно оно используется в UML под названием
протокольный автомат. Протокольный автомат ничего не делает182, он
только проверяет допустимость последовательности операций, поэтому
действия па переходах и при входе/выходе ему не нужны, однако могут быть
заданы пред- и постусловия (см. параграф 4.2.8).
f Протокольный автомат — это машина состояний, предназначенная
для задания допустимых последовательностей вызовов и сигна лов.
Рассмотрим пример.
181 Хотя в UML это средство появилось уже в первой версии, оно как-то выпало из сферы
внимания разработчиков инструментов и технических писателей, и мало кто упоминает
о применении UML для спецификации протоколов. Но вне UML конечные автоматы уже
давно использовались для спецификации и верификации протоколов.
182 Иногда, чтобы подчеркнуть отличие от протокольного автомата, обычные автоматы, ко-
торые выполняют действия, называют поведенческими машинами состояний (behavioral
state machine).
374 J
4.2. Диаграммы автомата
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
В начале каждой сессии пользователь должен указать свой идентифика- »
тор и пароль, а в конце — выполнить операцию выхода из системы
Самым простым решением является введение операций login() и logout(),
выполняемых в начале и в конце каждой сессии работы с системой (рис.
4.37). При этом все остальные операции (на рис. 4.37 они обозначены как all)
пользователь может выполнять только после того, как выполнена операция
login(), и до того, как выполнена операция logout().
Рис. 4.37. Протокольный автомат
Примечание
В UML 2 появилось специальное ключевое слово all, которое
означает любое событие.
Если мы хотим указать в протокольном автомате пред- и постусловия для
операций при переходе из одного состояния в другое, то следует воспользо-
ваться следующей нотацией:
[предусловие] операция / [постусловие]
Пример использования данной нотации приведен на рис. 4.38, где показаны
пред- и постусловия для операции hire().
[position.isFreeO]
hire( person,position)/
[not position.isFreeO &
Рис. 4.38. Нотация использование пред- и постусловий в протокольном автомате
Состав и названия состояний могут быть общими как для протокольного
автомата, так и для соответствующего ему поведенческого автомата. Но в
общем случае это совершенно не обязательно — у этих машин состояний
разное назначение!
Глава 4. Моделирование поведения
4.3. Диаграммы деятельности
Диаграммы деятельности являются средством описания поведения в UML,
причем их место в языке допускает некоторые разночтения. Во-первых, се-
мантика диаграммы деятельности определена через семантику машины со-
стояний, и в этом смысле диаграммы деятельности вторичны по отношению
к диаграммам состояний183. Во-вторых, диаграммы деятельности UML очень
близки по своей сути к блок-схемам, являющимся едва ли не старейшим
средством описания поведения, и в этом смысле самодостаточны - счи-
тать их незначительным частным случаем чего-то было бы неестественно.
В-третьих, диаграммы деятельности в UML снабжены дополнительными
синтаксическими средствами, резко повышающими их выразительность и
область применимости, даже по сравнению с машинами состояний UML.
И наконец, в-четвертых, диаграммы деятельности в наименьшей степени
объектно-ориентированы и содержат наибольшее количество сознательно
допущенных недоговоренностей и произвольных элементов (это сделано
для гибкости и расширения области применения).
Короче говоря, наша позиция по отношению к этому средству не совсем
определена. По поводу других средств UML мы позволяем себе давать хотя
и субъективные (возможно, ошибочные), но достаточно однозначные ре-
комендации: "диаграммы классов следует применять для моделирования
структуры...", "диаграммы автомата предназначены для описания поведения
объектов, если оно зависит от истории..." и т. д.
По поводу же диаграмм деятельности наши рекомендации более расплыв-
чаты: диаграммы деятельности можно применять так-то и так-то, а мож-
но не применять вовсе, и ничего страшного не случится. В этом разделе
мы детально описываем все элементы диаграмм деятельности всех версий
UML и приводим несколько разноплановых примеров, оставляя читателю
возможность самому выработать свое личное отношение к диаграммам дея-
тельности.
Основных сущностей и отношений, применяемых на диаграмме деятельно-
сти, в некотором смысле еще меньше, чем на диаграмме автомата (хотя, ка-
залось бы, меньше уже некуда — на диаграмме состояний только состояния
и переходы). Дело в том, что основная сущность на диаграмме деятельности
является частным случаем простого состояния (состояние деятельности), а
основное отношение — частным случаем простого перехода (переход по за-
вершении). В то же время всевозможных украшений и вариантов нотации
на диаграмме деятельности, особенно в UML 2, намного больше, чем на диа-
грамме автомата. Поэтому, чтобы не затеряться в деталях, в следующем па-
183 Строго говоря, это утверждение верно для UML1. В UML2 появилось независимое
определение семантики деятельности, но сути дела это обстоятельство не изменило.
4.3. Диаграммы деятельности
раграфе мы обсудим содержание базовых понятий, затем определим основ-
ные сущности и отношения, применяемые на диаграммах деятельности, а
уже потом перейдем к примерам и картинкам.
4.3.1. Действие и деятельность
В параграфе 4.2.2 (и в других местах) мы использовали понятие действия,
постулировав, что действие является атомарным, непрерываемым извне,
безусловным и завершаемым. Действия используются на переходах и в со-
стояниях машины состояний UML и играют там ключевую роль. Здесь мы
более детально рассмотрим различные типы действий в UML и на основе
противопоставления определим понятие деятельности. Это позволит нам
выявить как сходство, так и различия диаграмм автомата и деятельности.
Концепции действия и деятельности используются во всех версиях UML и
в целом схожи, но сильно отличаются в деталях. Революционных изменений
не произошло, но эволюция очень заметна. При этом важно подчеркнуть,
что новые трактовки и элементы нотации не вытеснили старые — старые
элементы по-прежнему используются наряду с новыми. Поскольку книга
описывает все основные версии UML, в этом разделе мы часто прибегаем к
сравнениям версий и указываем их точные номера.
Действия в UML 1
Действие в UML 1 может быть одного из следующих типов:
• присваивание значения (assignment);
• вызов операции (call);
• создание объекта (create);
• уничтожение объекта (destroy);
• возврат значения (return);
• посылка сигнала (send);
• прекращение выполнения (terminate);
• не интерпретируемое действие (uninterpreted action).
Приведенный список (за исключением последнего пункта) очень похож на
список основных выполняемых операторов в обычном языке программиро-
вания. Именно на этот "эффект узнавания" и рассчитывали авторы UML.
Действительно, подразумевается, что действие — это примитивная испол-
няемая конструкция языка программирования. Но UML не является язы-
Глава 4. Моделирование поведения
ком программирования, поэтому семантика действий до конца в UML не
определяется. Можно было бы взять один из распространенных языков про-
граммирования (или придумать еще один) и задать семантику выполнения
действий UML через примитивы выбранного языка. UML стал бы визуаль-
ным184 языком программирования. Но именно этого и хотели избежать авто-
ры — оказать предпочтение одному языку в ущерб остальным.
УНИВЕРСАЛЬНЫЙ ЯЗЫК ПРОГРАММИРОВАНИЯ
К настоящему времени придумано и живет (т. е. имеет пользова-
телей) очень большое число различных языков программирова-
ния. Несколько сотен, по меньшей мере. Тенденции к унифика-
ции не наблюдается — процесс языкотворчества продолжается.
Конечно, постоянно предпринимаются попытки "ввести" единый
для всех язык программирования, опираясь либо на достоин-
ства продвигаемого языка, либо на финансово-экономическую
мощь заинтересованной в нем корпорации. Пока что такие попыт-
ки успеха не имели и, по нашему мнению, в обозримом будущем
иметь не будут.
Дело в том, что языки программирования существенно различ-
ны по той причине, что постоянно меняются области приложения
программирования, возникают принципиально новые программ-
ные технологии, меняется и совершенствуется архитектура ком-
пьютеров, стремительно растут их количественные возможности.
Фактор, который еще вчера был решающим при выборе языковой
конструкции, завтра может ничего не значить. Отсюда не следует,
что всеобщий язык программирования невозможен в принципе
(например, у математиков практически есть общий язык). Но, по
нашему мнению, сегодня это настолько маловероятно, что может
не приниматься во внимание (тем же математикам для выработки
своего языка потребовалось несколько тысяч лет).
Главной целью UML является стать lingua franca для обмена идеями в со-
обществе архитекторов и разработчиков программных средств. Разработчи-
ки и архитекторы используют разные языки для решения своих задач и не
собираются от них отказываться — это объективная реальность. Оказывать
слишком явное предпочтение только одному языку недопустимо. Раз нельзя
выбрать один язык, значит, приходится отказываться от конкретного язы-
ка элементарных действий вообще. Поэтому семантика действий в первых
184 Приставка visual, которую использует корпорация Microsoft в названиях своих средств
программирования, строго говоря, не оправдана. В системе программирования Visual
Studio действительно используется графический интерфейс пользователя, но и только.
Код программы как был линейным текстом, так и остался. Мы склонны считать право-
мерным употребление термина "визуальный" только применительно к таким языкам, где
код "рисуется” в виде схем, диаграмм и т. п.
4.3 Диаграммы деятельности
версиях UML определена несколько расплывчато и синтаксис не слишком
строг. Расчет делается на то, что на абстрактном уровне всем все понятно,
а инструмент, ориентированный на конкретный язык программирования,
доопределит семантику действий так, как это принято в данном языке про-
граммирования. В таблице 4.4. приведены основные сведения о действиях в
UML до версии 1.4 включительно.
Таблица 4.4. Действия UML 1
Тип действия Ключевое слово Описание
присваивание значения = Присваивание значения атрибуту объекта. После выполнения присваивания значение атрибута равно значению выражения в правой части
вызов операции call Вызов операции заданного объекта с заданными аргументами. Можно вызывать операцию сразу у нескольких объектов. Операции вызываются синхронно: вызывающий объект ждет, когда выполнение операции закончится и ему вернут управление и, возможно, значение
создание объекта create Создание и инициализация нового объекта заданного класса. Аргументы используются для инициализации атрибутов
уничтожение объекта destroy Уничтожение заданного объекта и всех его составляющих, включенных отношением композиции
возврат значения return Возврат значения в точку вызова операции. Это действие может применяться только внутри вызванной операции, например, на переходе, возбужденном событием вызова. Возвращаемых значений может быть несколько
посылка сигнала send Создание нового экземпляра сигнала и отправка созданного сигнала заданному целевому множеству объектов. Целевое множество может не содержать элементов, содержать один элемент или несколько элементов. Сигналы посылаются асинхронно: посылающий объект не ждет, когда объекты целевого множества получат сигналы, а сохраняет свой поток управления и продолжает работу
прекращение выполнения terminate Прекращение работы (принудительная остановка) машины состояний объекта и уничтожение этого объекта
не интерпрети- руемое действие любой текст Любое действие, не определенное в UML. Например, исполняемая конструкция (оператор) целевого языка программирования, поддерживаемого инструментом, или же текст на естественном языке.
&
чу
Глава 4. Моделирование поведения
Действия в UML 1.5
Главным отличием версии UML 1.5 явилось введение обширной номен-
клатуры элементарных действий, число которых было увеличено на поря-
док. Фактически для UML 1.5 было сделано то, чего авторы старались из-
бежать в первых версиях, а именно была определена вщтуальная машина,
ничуть не уступающая по своим возможностям таким известным вариантам,
как виртуальная машина Java (JVM).
ВИРТУАЛЬНЫЕ МАШИНЫ
В настоящее время большое значение придается многоплатфор-
менности, то есть возможности выполнения тех или иных при-
ложений на различных программных и аппаратных платформах.
Различных приложений необозримо много, существенно различ-
ных платформ и сейчас немало, а в недавнем прошлом было еще
больше. Реализовать каждое приложение на каждой платформе
означает возвести в квадрат немалые трудности разработки про-
граммного обеспечения. Действительно, если есть N приложений
и М платформ, то потребуется N*M реализаций. Одно из самых
простых и напрашивающихся решений — ввести промежуточную
унифицированную платформу, реализовать все приложения на
этой платформе и реализовать алгоритмы переноса любого при-
ложения с унифицированной платформы на целевую платформу.
Потребуется всего N+M реализаций. Если N и М измеряются мно-
гими десятками, сотнями и тысячами, то выигрыш весьма велик.
Это очень старая идея, она возникла одновременно с появлением
второй неспециализированной аппаратной платформы, то есть
примерно в начале 50-х годов прошлого века. Можно указать око-
ло десятка попыток реализации, более или менее успешных.
Пожалуй, самой известной современной попыткой является вир-
туальная машина Java (Java Virtual Machine, JVM). JVM — это
определение языка программирования уровня ассемблера (язык
команд) для абстрактной стековой машины. Определение вклю-
чает описание формата программы, который называется байт-
код, покомандного описания операционной семантики на есте-
ственном языке и описания набора правил проверки допусти-
мости исполнения программы, которые (по замыслу создателей
JVM) должны обеспечить безопасность выполнения программ.
Язык JVM очень прост, можно сказать, примитивен. Поэтому без
особого напряжения были изготовлены многочисленные более
или менее эффективные реализации JVM практически для всех
платформ, основанные как на принципах интерпретации, так и на
принципах компиляции и последующего выполнения.
4 3. Диаграммы деятельности
Действия в UML 2
В различных версиях UML 2 используется, в основном, набор действий из
версии 1.5185, в которой при выходе новых версий языка вносятся косметиче-
ские уточнения и улучшения. В этот набор входит более 50 действий. Пере-
чень действий версии UML 2 приведен в справочных материалах, в разделе
6.3. Рассматривать и обсуждать детально каждое действие не имеет смысла,
если общий принцип ясен, то детали легко можно взять из раздела 6.3 или
из справочного руководства той конкретной версии, которая используется.
Принципы определения действий в UML. Дгпс ниИ| применимы де
основным сущностям I'ML, и преждр;всего к классифцказ’орам.; Деш
с гния позволяют манипулировать , экземплярами классификаторов, в
частности, чи5атфчфз^^^ф^А^а^ёрйф'^рй^у<тдв<и вызывать мето-
ды классификаторов. Каждое действие имеет присущие ему наборы
входных и выходных параметров фиш назь1в;и(>то контактами (pin)),
1ф1< правило, эти-наборы фиксированы по числу и типам параметров,
но бывают»! дф«твия с, изменяемым-числом параметров Все действия
атомарны, ы. безусловны и зщтерi паем ы1 Sli. Среди эле.чк'н-
тарных дейрдфШхнет Привычных действий по управлению ходом вы-
вод нений’ программы (ветвДениф циклы, переходы и г. д.) — управ-
ление не считается црими i ицсам и вьщесено наследующий уровень,
уровень деятельности187
Пять десятков действий могут быть обобщены и классифицированы. В стан-
дарте используется следующая классификация, применяемая не только к
действиям, но и к другим конструкциям UML 2. Эта классификация при-
вязана не к смыслу классифицируемого понятия, а к структуре стандарта.
• Базисные действия (basic actions) — те, которые используются везде
и без них нельзя обойтись. В данном случае это основные действия
по вызову операций.
• Промежуточные действия (intermediate actions) — те, которые соот-
ветствуют промежуточному уровню. Сюда попадают дополнитель-
185 Как уже было отмечено в первой главе, интересным является следующее обстоятель-
ство: версия UML 1.5. так и не получила широкого распространения и признания. Воз-
можно, зто связано с тем, что зта версия появилась в тот момент, когда все уже ждали
выхода UML 2.0. Возможно, дело в том, что поклонники этого стиля определения опера-
ционной семантики образовали собственное сообщество под девизом "Исполняемый
UML" и несколько отошли от "генеральной линии".
186 Здесь есть разночтения. Считается, что действие синхронного вызова ждет возврата
значения от вызванной операции и, таким образом, является исключением из общего
правила. Но есть мнение, что прием возврата значения следует отделить от вызова ме-
тода, и тогда все действия будут атомарны.
187 Исключением является упомянутый в параграфе 4.3.6 повторитель.
Глава 4. Моделирование поведения
ные действия по вызову и некоторые действия по чтению и записи
значений.
• Полные действия (complete actions) — те, которые входят в наиболее
полный комплект действий. Содержат дополнительные действия
по чтению, записи и некоторые специальные действия, в частности,
действия классификации.
• Структурные действия (structural actions) — в эту группу выделены
действия со структурными составляющими классификаторов, т. е.
атрибутами.
Сделав необходимый реверанс в сторону стандарта, мы приведем свою клас-
сификацию действий (не совпадающую с классификацией стандарта, за ис-
ключением группы структурных действий), в форме таблицы 4.5, которую
полезно сопоставить с таблицей 4.4 и с таблицей параграфа 6.3.
Таблица 4.5. Группы действий в UML 2
Группа действий Прототип в UML 1 Описание
Структурные действия = Запись (присваивание) или чтение (получение) значения атрибута объекта, параметра деятельности, связи (экземпляра ассоциации) или иной структурной составляющей. Также предусмотрены действия для обнуления значений
Действия по вызову и возврату call return Обширная труп па действ и исключающая как действия на вызывающей, так и действия на вызываемой сторонах. Предусматриваются отдельные действия для синхронного вызова, для асинхронного вызова, для вызова с ожиданием возврата значения и без оного
Действия с классификаторами create destroy Создание и уничтожение объектов, получение экстента (текущего множества объектов данного классификатора), классификация (определение и переопределение классификатора данного объекта)
Отправка и прием сигналов send Создание нового экземпляра сигнала и отправка созданного сигнала заданному целевому множеству объектов. Целевое множество может не содержать элементов, содержать один элемент или несколько элементов. Сигналы посылаются асинхронно: посылающий объект не ждет, когда объекты целевого множества получат сигналы, а сохраняет свой поток управления и продолжает работу. Предусмотрен отдельный набор действий для генерации иобработки исключений. При возникновении исключения поток, в котором оно возникло, приостанавливает свою работу
4 3 Диаграммы деятельности
Действия со временем Нет прототипа Действия для получения текущего времени, для определения интервала времени между отправкой и получения сообщения и другие действия с таймером
Действие с интерпретацией, заданной внешними средствами Не интерпре- тируемое действие Любое действие, определенное внешними по отношению к UML средствами. Например, исполняемая конструкция (оператор), целевого языка программирования, поддерживаемого инструментом.
ИСПОЛНЯЕМЫЙ UML
Появление алгоритмически полного языка действий в UML при-
вело к возникновению направления, которое называется "ис-
полняемый UML" (Executable UML). Идея состоит в том, чтобы
доопределить операционную семантику диаграмм таким об-
разом, чтобы они стали непосредственно выполнимыми на
компьютере путем интерпретации или путем компиляции в
какой-нибудь популярный язык программирования.
В этой идее нет ничего принципиально порочного или невозмож-
ного. Операционную семантику диаграмм можно доопределить
так, чтобы модели стали непосредственно выполнимыми на ком-
пьютере и, тем самым, проектирование (моделирование) полно-
стью поглотило бы программирование (кодирование).
Мы считаем, что, хотя это сделать можно (и несколько раз уже
сделано в разных вариантах), применять это следует в ограничен-
ном числе областей (например, при создании небольших прило-
жений реального времени). Дело не в том, что операционную се-
мантику диаграмм определить трудно (хотя сделать это аккуратно
и изящно действительно непросто). Дело в том, что получившийся
язык визуального программирования, по мнению авторов, не бу-
дет иметь (и в уже сделанных попытках не имеет) реальных ощу-
тимых преимуществ по сравнению с традиционными текстовыми
языками программирования. Вместо мощного и удобного полу-
формального языка моделирования мы можем получить еще один
тяжеловесный, неэффективный и очень сложный язык визуально-
го программирования.
Прежде чем переходить к обсуждению деятельности и других родственных
понятий, завершим разговор о действиях нашим вариантом части метамо-
дели действий (рис. 4.39). Наша метамодель не полна, многие детали на ней
опущены, но основную идею определения действий в UML 2 эта диаграмма
передает верно.
Глава 4. Моделирование поведения
Рис. 4.39. Метамодель действий
Деятельность
Вторым важнейшим понятием, применяемым при описании поведения, яв-
ляется деятельность.
Деятельность (activity) в UML — это описание поведения в форме
графа деятельности.
Это определение выглядит как порочный круг. Позвольте для сравнения
процитировать определение из основополагающей книги [3]. "Деятель-
ность — это спецификация исполняемого поведения в виде координиро-
ванного последовательного и параллельного выполнения подчиненных
элементов — вложенных видов деятельности и, в конечном счете, отдельных
действий, соединенных между собой потоками, которые идут от выходов
одного узла к входам другого". Согласитесь, наше определение понятнее
хотя бы потому, что короче.
В приведенном нами определении всего одно слово на самом деле нуждается
в детальном объяснении: что значит граф деятельности? Но это определение
не может быть дано одной фразой, ему посвящен весь следующий параграф.
Деятельность в UML моделирует то же, что и действие, т. е. какую-то со-
держательную активность во время работы системы; в этом смысле дея-
тельность подобна действию, но деятельность противопоставляется дей-
ствию по всем характеристическим признакам.
В таблице 4.6 проведено сопоставление понятий "действие" и "деятельность"
в UML.
4.3. Диаграммы деятельности
Таблица 4.6. Сопоставление действия и деятельности
Характеристика Действие Деятельность
Внешнее событие Не прерывает выполнения Может прерваться и завершить выполнение
Завершаемость Всегда завершается самостоятельно Может продолжаться неограниченно долго
Внутренняя структура Не моделируется в UML Может быть раскрыта на отдельной диаграмме
Время выполнения Пренебрежимо мало Продолжительное
Если нам не важно различие между действием и деятельностью и нужно
употребить более общее понятие, то применяется термин активность.
4.3.2. Граф деятельности
Семантически >раф Деятельности (activity graph) — это множество
сущностей, которыми являются действия или деятельности, и отно-
шения между этими сущностями, которые задают порядок их выпол-
нения.
Синтаксически граф деятельности — это нагруженный ориентиро-
ванный (нсендо) гипер1раф, в котором используются узлы четырех
типов: узлы действий, узлы деятельности, узлы управления и узлы
данных, а дуги являются потоками управления или потоками данных.
Назначение графа деятельности не меняется в UML от версии к версии, но
способ определения семантики, детали нотации и названия элементов мо-
делирования меняются. В диаграммах деятельности наблюдается "мирное
сосуществование" старого и нового. Например, при моделировании бизнес-
процессов по-прежнему используется нотация в стиле UML 1, поскольку
эта нотация очень близка к нотации других средств моделирования бизнес-
процессов, а если моделирование тяготеет к исполняемому UML, то пред-
почтение отдается обозначениям UML 2. Мы рассматриваем все вариации,
хотя это и требует некоторых повторов, а местами двукратного повторения
примеров.
Основные сущности на диаграмме деятельности UML 1
Начнем с UML 1. Теперь, наконец, мы можем точно188 и кратко определить
основные сущности на диаграмме деятельности UML 1. Таковых три.
188 Что нам кажется очень полезным в данном случае. Эти понятия систематически путают
все, включая переводчиков книг и разработчиков инструментов.
Глава 4. Моделирование поведения
КЙ.-Чь - «г.» м -МЙв-S» .fw. ,
Состояние действия (action state) — это состояние, внутренняя актив-
ность (параграф 4.2.1) которого является действием. 8
Состояние деятельности (activity state) — это состояние, внутренняя
активность которого является деятельностью.
Объект в состоянии (object in stale) это объект в определенном со-
стоянии, который является аргументом н/или результатом работы не-
которого Действия или Дея и льное i n.
Состояние действия не имеет специальной нотации и изображается на диа-
грамме как простое состояние с действием на входе. Вообще говоря, понятие
состояния действия в UML 1 не имеет глубокого смысла: без него вполне
можно обойтись. Действительно, при переходе в состояние действия вы-
полняется действие на входе (которое атомарно и мгновенно), и немедленно
после этого выполняется переход по завершении. Такую ситуацию можно
промоделировать простым переходом, как показано на рис. 4.40.
На этом рисунке, на фрагменте диаграммы слева использовано состояние дей-
ствия, а справа приведен эквивалентный фрагмент без состояния действия.
Пожалуй, единственной причиной, по которой состояние действия оставле-
но в UML, является стремление угодить вкусам тех, кто привык на блок-
схемах операторы присваивания писать внутри прямоугольников, а не ря-
дом со стрелками.
Состояние деятельности189, напротив, является существенным элемен-
том диаграммы деятельности и имеет специальное обозначение — прямоу-
гольник со скругленными сторонами. Нотация очень похожая на нотацию
простого состояния (тот же прямоугольник, но со скругленными углами),
189 Мы иногда для краткости речи вместо словосочетания "состояние деятельности" позво-
ляем себе употреблять просто слово "деятельность”, если из контекста ясно, что под-
разумевается именно состояние деятельности.
4.3 Диаграммы деятельности
но в тоже время отлична от него190. Тем самым подчеркивается родствен-
ная связь диаграмм состояний и деятельности. Внутри фигуры состояния
деятельности пишется так называемое выражение деятельности. Никакого
специального синтаксиса для данного выражения деятельности UML 1 не
определяет: это может быть текст на псевдокоде, фрагмент кода на язы-
ке программирования и просто название деятельности на естественном
языке. Никакой видимой структуры состояние деятельности не имеет, в
противоположность простому состоянию, которое может иметь действия на
входе, выходе, внутренние и отложенные переходы. Собственно говоря, то,
что написано внутри фигуры состояния деятельности — это и есть его вну-
тренняя активность. Но это отнюдь не означает, что состояние деятельности
атомарно и не имеет внутренней структуры. Напротив, оно по определению
не атомарно и имеет внутреннюю структуру. Предполагается, что либо эта
структура не важна на выбранном уровне абстракции, либо она раскрывает-
ся в другом месте191 с помощью машины состояний, другой диаграммы дея-
тельности или иным способом.
На диаграмме деятельности UML 1 применяется еще один тип сущностей —
объекты в состоянии. Мы обсудим их в подходящем контексте, в параграфе
4.3.4.
Кроме того, на диаграмме деятельности применяется ряд значков, которые
на самом деле не являются сущностями, хотя и являются узлами графа дея-
тельности. Это так называемые узлы управления. Для UML 1 узлы управле-
ния перечислены в таблице 4.7.
Таблица 4.7. Узлы управления UML1
№ Название Изображение Что обозначает
1 Начальное состояние (initial node) • > Начало деятельности
2 Заключительное состояние (final node) Завершение деятельности
3 Разветвление управления (decision node) -НЕ: Начало альтернативных ветвей деятельности
190 При достаточно мелком масштабе отличие заметно разве что под микроскопом. Честно
говоря, мы затрудняемся дать однозначную оценку тому факту, что обозначения путают-
ся. С одной стороны, это нехорошо, а с другой стороны, как еще побудить людей, при-
выкших думать в терминах блок-схем, начать думать в терминах переходов-состояний?
Только подав новое средство в привычной упаковке. Но в UML 2 от этих проблем решили
просто отказаться — все рисуется одинаково — прямоугольник со скругленными угла-
ми.
191 Почти все инструменты поддерживают эффективную навигацию в модели, позволяю-
щую раскрыть структуру состояния деятельности, если она определена.
Глава 4. Моделирование поведения
4 Соединение управления (merge node) Конец альтернативных ветвей деятельности
5 Развилка управления (fork node) А А Начало параллельных ветвей деятельности
6 Слияние управления (join node) > > > Конец параллельных ветвей деятельности
7 Посылка сигнала (send) signal Действие посылки сигнала
8 Прием сигнала (accept) event Ожидание события прихода сигнала
На диаграмме деятельности UML 1 применяется один основной тип отноше-
ний — простые переходы по завершении (а также поток объектов, см. пара-
граф 4.3.4). Переход по завершении не имеет переключающего события —
событием является завершение внутренней активности (деятельности) в
состоянии. Как правило, исходящий переход по завершении один; если их
несколько, они должны быть снабжены сторожевыми условиями, образую-
щими полную дизъюнктную систему предикатов (см. параграф 4.2.2). Кроме
того, в UML 1 можно192 использовать и переходы, возбуждаемые событиями.
Срабатывание такого перехода означает прерывание выполнения деятель-
ности в состоянии и переход в другое состояние. Однако повторим сказан-
ное при описании диаграмм состояний: использование переходов, управ-
ляемых событиями, настолько же неуместно на диаграмме деятельности,
насколько неуместно использование на диаграмме состояний переходов
по завершении. Мы не рекомендуем такой стиль моделирования.
Примечание
Граница между диаграммой состояний и диаграммой дея-
тельности весьма условна и зыбка. Мы определим ее так:
диаграмма деятельности в UML 1 — это такая диаграмма со-
стояний, в которой все или почти все состояния являются со-
стояниями действия или деятельности, и все или почти все
переходы являются переходами по завершении. Осталось
только договориться, что значит "почти все".
Таким образом, в рамках семантики машины состояний авторы UML 1 суме-
ли описать семантику обычных блок-схем (в которых нет никаких событий,
а есть последовательная передача управления следующей деятельности по
завершении предыдущей деятельности). Хорошо это или плохо — трудно
192 По крайней мере этому утверждению нет опровержения в стандарте.
____ Ф
4.3. Диаграммы деятельности
сказать. Во всяком случае, в UML 2 от этого способа определения семантики
отказались.
Приведем пример диаграммы состояний в стиле UML 1. Для этого рас-
смотрим увольнение сотрудника как бизнес-процесс, реализующий соот-
ветствующий вариант использования (см. параграф 2.3.4). Приведенная на
рис. 4.41 блок-схема буквально воспроизводит текстовое описание сценария
из параграфа 2.4.1. Никаких пояснений, как именно выполняется, например,
деятельность Написать заявление, здесь нет, но бизнес-процесс описан со-
вершенно ясно.
Рис. 4.41. Диаграмма деятельности UML 1
Графы деятельности в UML 2
Операционная семантика графов деятельности в UML 2 определена иным
способом, не через машины состояний, а через сети Петри (см. параграф
4.1.3). Это определение очень наглядно и изящно, хотя, может быть, не со-
всем привычно.
В основе определения, так же как и в сетях Петри, лежит понятие маркера
(token). Маркер может не содержать никакой дополнительной информации
(пустой маркер), и тогда он называется маркером управления (control flow
token), или же может содержать ссылку на объект или структуру данных, и
тогда маркер называется маркером данных (data flow token).
Глава 4. Моделирование поведения
Следует сразу подчеркнуть, что маркеры не являются элементами графа де-
ятельности. Маркеры — это абстрактные конструкции, которые вводятся
для удобства описания динамического процесса выполнения статически
определенного графа деятельности. Никаких маркеров на диаграмме дея-
тельности нет — на диаграмме деятельности присутствуют узлы. Но во вре-
мя выполнения деятельности маркеры появляются, перемещаются между
узлами и исчезают. Правила появления, перемещения и исчезновения мар-
керов описаны ниже, после описания типов узлов графа деятельности.
Узлы графов деятельности в UML2 бывают трех видов: узлы действий,
узлы данных и узлы управления193. Кроме того, на диаграммах деятельности
UML 2 бывают составные узлы — они называются областями. Следует за-
метить, что каждый из видов узлов делится на подвиды, так что всего вари-
антов сущностей довольно много. Мы охватим примерами и объяснениями
все, но не все в этом параграфе.
Самыми важными являются узлы действий (action node). Действитель-
но, трудно представить себе разумную деятельность, которая не включает
каких-либо действий. Номенклатура действий в UML 2 описана в предыду-
щем параграфе.
Мы включаем вызов деятельности в число действий и никак синтаксически
не выделяем на диаграммах. В UML 2 между действием и деятельностью
существует еще одно существенное различие. Все действия заранее предо-
пределены и описаны в спецификации. Если разработчику нужно описать
какое-либо особое поведение, он должен использовать для этого деятель-
ность. При этом поведение можно описать отдельно, а в конструируемую
в данный момент деятельность включить действие по вызову поведения
(behavior action)194.
Узлы ДЕЙСТВИЙ
Узлы действий в UML 2 похожи на состояния действия в UML 1, но име-
ют важнейшее отличие. Для действий в UML 2 можно указать, что являет-
ся входной и выходной информацией действия, задав входные и выходные
контакты.
Контакт (pin) эго указание аргумента или результата действия.
193 Объяснение, куда исчез узел деятельности, мы дадим позже.
194 Некоторые авторы выделяют вызовы деятельности в отдельный вид узлов на графе дея-
тельности и используют специальный значок в форме трезубца, направленного вниз,
для графического выделения таких узлов. Трезубец показывает, что где-то существует
другая диаграмма деятельности, на которой описана последовательность действий, со-
ставляющих данную деятельность.
4 3. Диаграммы деятельности
Контакт может иметь имя и тип. Именно через контакты путешествуют мар-
керы данных по графу деятельности в процессе выполнения. Через входные
контакты действие принимает свои аргументы, а через выходные контак-
ты выдает свои результаты.
Графически контакты изображаются в виде маленьких квадратиков, при-
крепленных к сторонам фигуры, изображающей деятельность (см. третий
вариант на рис. 4.42).
ОПЕРАТОРНЫЕ СХЕМЫ
По-видимому, впервые идея, подобная контактам, была исполь-
зована в операторных схемах Лаврова для решения задачи о
глобальной экономии памяти при трансляции [Лавров С.С. Об
экономии памяти в замкнутых операторных схемах // Журнал ВМ
и МФ, №4, 1961]. В этой работе была предложена следующая мо-
дель программы, названная операторной схемой. Операторная
схема — это блок-схема, состоящая из операторов (изображае-
мых прямоугольниками) и ветвлений (изображаемых ромбами),
последовательность выполнения задана обычным образом, с по-
мощью стрелок. Кроме того, каждый оператор имеет некоторое
количество входных и выходных полюсов (изображаемых малень-
кими кружками, присоединяемыми к сторонам операторных пря-
моугольников), то есть входных и выходных переменных. Между
полюсами установлены связи: пунктирные стрелки, ведущие от
того полюса, в котором переменная получает значение, к тем по-
люсам, где значение переменной используется.
Некоторые переменные могут оказаться информационно незави-
симыми, и во время выполнения для хранения значений этих пе-
ременных можно использовать одну и ту же память. Нахождение
минимальной раскраски графа информационных зависимостей,
который строится по операторной схеме, позволяет найти мини-
мальный объем памяти, необходимой для выполнения заданной
операторной схемы (программы).
Узлы ДАННЫХ
Следующими по порядку являются узлы данных (object node). Они включа-
ют в себя следующие четыре разновидности:
• контакт— мы уже дали определение выше и несколько раз вернемся
к этому важнейшему нововведению ниже. Фактически это то, во что
превратился "объект в состоянии" из UML 1 (см. параграф 4.3.4);
• параметр деятельности (activity parameter) — это тот же контакт,
только он изображается на границе рамки деятельности. Контакты
Глава 4. Моделирование поведения
действия по вызову некоторой деятельности должны соответство-
вать по количеству, именам и типам параметрам этой деятельности;
• центральный буфер (central buffer) — искусственная конструкция,
используемая в тех случаях, когда необходимо показать неоднознач-
ность пути маркеров данных в графе деятельности. Центральный
буфер имеет несколько входящих и несколько исходящих дуг. Он
может принять маркер данных по любой из входящих дуг и немед-
ленно отправить его далее по любой из исходящих дуг;
• хранилище данных (data store) — аналог понятия переменной, в ко-
торую можно несколько раз (с заменой данных) записать значение
(поместить маркер данных) и потом неограниченное число раз его
читать (брать копию маркера данных)195.
Предыдущий список должен породить у внимательного читателя недоуме-
ние: как же так, мы определяем контакт и как составляющую действия, и как
отдельную cyuiHOCTb. Здесь нет противоречия. На рис. 4.42 представлены
различные варианты нотации для контактов. Сверху изображен "объект в
состоянии" (1) в нотации UML 1, а затем допустимая промежуточная фор-
ма (2). Характерная для UML 2 нотация (3), как видно, гораздо лаконичнее
Action 1
Action 2
Рис. 4.42. Варианты нотации контактов
195 Хранилища данных применяются очень часто, это фактически локальные переменные,
они нужны практически на любой диаграмме деятельности. Центральный буфер приме-
няется очень редко, это особый случай параллелизма.
4.3. Диаграммы деятельности
принятой в UML 1. К основной нотации контакта в UML 2 можно добавить
комментарий со стереотипом «transformation» (4), чтобы специфицировать
требуемое приведение типов. И наконец, поток передаваемых данных может
быть просто не специфицированным (5). Семантически все формы нотации
эквивалентны.
УЗЛЫ УПРАВЛЕНИЯ
Третий тип узлов в графе деятельности — узлы управления (control node). В
UML 2 используются те же узлы управления, что перечислены в таблице 4.7,
с четырьмя дополнениями, которые приведены в таблице 4.8.
Таблица 4.8. Дополнительные узлы управления UML 2
№ Название Изображение Что обозначает
1 Заключительное состояние потока (final flow node) Завершение одного потока в деятельности. Если в деятельности есть другие параллельные потоки, они продолжаются
2 Комбинированное соединение/ разветвление управления / Последовательность из узла соединения и узла разветвления
3 Комбинированное слияние/развилка управления А А Последовательность из узла слияния и узла развилки
4 Прием сигнала от таймера Узел, являющийся источником маркера управления по истечении заданного интерва- ла времени.
Примечание
Ромбик, который используется на диаграмме деятельности,
хотя и является значком, но не является сущностью. Это не
более чем связующий символ, позволяющий более экономно
изображать сегментированные переходы (см. параграф 4.2.3,
рис. 4.13). При разветвлении ромбик соединяет один входя-
щий и несколько исходящих сегментов перехода (№3 в та-
блице 4.7), а при слиянии ромбик соединяет несколько вхо-
дящих и один исходящий сегмент (№4 в таблице 4.7).
Глава 4. Моделирование поведения
В UML 2 эти два способа объединены (№2 в таблице 4.8).
Более того, комбинированная конструкция (слева на
рис. 4.43), используемая в UML 2, может быть записана в но-
тации UML 1, как это сделано справа на рис. 4.43.
Рис. 4.43. Семантически эквивалентные фрагменты диаграммы деятельности
Операционная семантика графов деятельности в UML 2
Теперь все готово, чтобы описать операционную семантику графов деятель-
ности в UML 2. Семантика описывается в терминах правил определения
того, в каких случаях какие дуги готовы передавать какие маркеры.
Правила для узлов управления.
• Начальное состояние (№ 1 в таблице 4.7) создает один маркер управ-
ления, и все исходящие дуги готовы передать этот маркер.
• Если единственная входящая дуга развилки (№5 в таблице 4.7) гото-
ва передать маркер (управления или данных), то все исходящие дуги
готовы одновременно (параллельно) передать копии этого маркера.
Развилка создает параллельные потоки.
• Если все входящие дуги слияния (№6 в таблице 4.7) готовы пере-
дать маркеры (управления или данных), то исходящая дуга готова
передать маркер управления. Слияние обеспечивает синхрониза-
цию потоков.
• Если единственная входящая дуга разветвления (№3 в таблице 4.7)
готова передать маркер (управления или данных), то те исходящие
дуги разветвления, на которых сторожевые условия выполняются,
готовы передать этот маркер196.
• Если любая входящая дуга соединения (№4 в таблице 4.7) готова
передать маркер (управления или данных), то единственная исходя-
щая дуга соединения готова передать этот маркер.
• Если хотя бы одна входящая дуга заключительного состояния по-
196 Но маркер один — конкуренция, кто первый готов, тот и получит маркер.
4,3. Диаграммы деятельности
тока (№1 в таблице 4.8) готова передать маркер, то заключительное
состояние потока поглощает этот маркер.
• Если хотя бы одна входящая дуга заключительного состояния дея-
тельности (№2 в таблице 4.7) готова передать маркер, то заключи-
тельное состояние деятельности поглощает все маркеры управления
и все маркеры данных, завершая тем самым выполнение деятельности.
Правила для узлов объектов.
• Параметр деятельности (1 на рис. 4.44) создает один маркер данных,
и все исходящие дуги (2 на рис. 4.44) готовы передать этот маркер.
• Хранилище данных (3 на рис. 4.44) поглощает один маркер данных
и создает неограниченное количество его копий. Все выходные дуги
хранилища (4 на рис. 4.44) всегда готовы передать копию хранимого
маркера данных.
• Центральный буфер перенаправляет маркеры данных, не создавая и
не поглощая их. Как только какая-либо (любая) входная дуга готова
передать маркер, все выходные дуги готовы передать этот маркер (но
в итоге передает одна).
• Входной контакт действия (5 на рис. 4.44) погло! цае г маркер данных.
• Выходной кон гакт действия (6 на рис. 4.44) создает маркер данных.
Правила для контактов и действий.
• Если все дуги данных, входящие во все входные контакты действия,
готовы передать маркеры данных и если есть входящие дуги управ-
ления и хотя бы одна готова передать маркер управления, то дей-
ствие выполняется.
• Если действие выполнено, то все дуги данных, выходящие из вы-
ходных контактов, готовы передать маркеры данных, и если есть
исходящие ребра управления, то те исходящие дуги управления, на
которых сторожевые условия выполняются, готовы передать маркер
управления197.
Продолжим пример об увольнении сотрудника. Теперь мы рассмотрим этот
пример не как бизнес-i [роцесс высокого уровня, а как операцию информа-
ционной системы. Рассмотрим рис. 4 44.
Выполнение этого графа деятельности происходит следующим образом.
• Начальное состояние (7 на рис. 4.44) готово передать маркер управ-
ления, а параметр деятельности (1 на рис. 4.44) готов передать
197 Но маркер один — конкуренция, кто первый готов, тот и получит маркер.
Ф ____
............................................................. о
Глава 4. Моделирование поведения
Рис. 4.44. Диаграмма деятельности по увольнению сотрудника (AdmFire)
маркер данных. Таким образом, все входящие дуги деятельности
Get Person Info готовы передать маркеры, и деятельность выполняет-
ся. В результате выполнения появляются три маркера данных в кон-
тактах pos, fnd, dpt соответственно. Маркер данных fnd имеет булев-
ский тип, и его значение определяет, присутствует ли в базе данных
объект р. Если это так, то pos и dpt содержат должность и подразде-
ление увольняемого, в противном случае они пусты.
Маркер данных pos немедленно отправляется в хранилище дан-
ных (3 на рис. 4.44), поскольку оно имеет единственную входящую
дугу, и сохраняется там для дальнейшего использования.
Маркер данных fnd отправляется в узел управления "разветвление"
(8 на рис. 4.44), где проверяется значение этого маркера данных.
Если выполняется условие fnd = true, то маркер данных отправляет-
ся в узел управления "развилка" (9 на рис. 4.44), и выполняется сле-
дующий шаг. В противном случае выполнение графа деятельности
заканчивается.
• Узел управления "развилка" (9 на рис. 4.44) размножает полученный
маркер на два и отправляет их дальше, запуская два параллельных
4.3. Диаграммы деятельности
потока управления (10 и 11 на рис. 4.44). Заметим, что в /данном слу-
чае содержимое маркеров теряется, поскольку принимаются они не
через контакты, а непосредственно, как маркеры управления.
• Деятельность Notify Boss готова принять маркер управления по
переходу (И на рис. 4.44) и маркер данных dpt (5 на рис. 4.44) от
деятельности Get Person Info. Эта деятельность запускается, а после
завершения отправляет маркер управления в заключительное со-
стояние потока (12 на рис. 4.44), где он поглощается, и выполнение
этого потока управления завершается.
• Деятельность Calc Payment готова принять маркер управления по
переходу (10 на рис. 4.44) и маркер данных pos из хранилища. Эта
деятельность запускается, а после завершения отправляет маркер
управления деятельности Delete Account.
• Деятельность Delete Account готова принять маркер управления от
предыдущей деятельности и маркер данных pos из хранилища по
переходу (13 на рис. 4.44). Эта деятельность запускается, а после за-
вершения отправляет маркер управления в заключительное состоя-
ние потока (12 на рис. 4.44), где он поглощается, и выполнение этого
потока управления завершается.
4.3.3. Дорожки и разбиения
В UML 1 имеется своеобразное графическое средство, которое называется
дорожкой.
Дорожка (swim lane) — это графический комментарий, позволяющий
классифицировать сущности по некоторому признаку. Обычно нс-
пользуется на диаграмме классов или на диаграмме деятельности.
Дорожка — это именно графический комментарий, подобный границам си-
стемы (субъекта) на диаграмме использования (параграф 2.3.5). Поэтому
никаких формальных правил применения дорожек в UML 1 нет.
В UML2 ситуация несколько изменилась: дорожки, переименованные в
UML 2 в разбиения, переведены из разряда графических комментариев в
разряд сущностей метамодели языка, и инструменты могут (но не обязаны!)
использовать это обстоятельство.
Разбиение (part ition) — это разбиение в математическом смысле (то
есть дизъюнктное покрытие) множества сущностей на диаграмме.
Глава 4 Моделирование поведения
Дорожки (или подобные им конструкции) часто применяются при мо-
делировании бизнес-процессов в организациях, откуда они и были заим-
ствованы в UML. Рассмотрим бизнес-процесс приема сотрудника на работу
в нашей информационной системе отдела кадров (см. параграф 2.4.3-2.4.4,
рис. 2.26-2.29). Обсуждая сценарий этого варианта использования, в главе 3
мы сосредоточили свое внимание не на самом бизнес-процессе приема, а на
участии моделируемой системы в этом процессе.
Допустим, что нас интересует прохождение всего процесса в целом, включая
как те шаги, которые выполняются системой, так и те шаги, которые (пока)
предполагается выполнять вручную. Польза такого описания очевидна: если
мы будем знать необходимые в бизнес-процессе шаги, в том числе выпол-
няемые вручную, мы сможем составить более надежный план его поэтап-
ной автоматизации. Даже в самом простом случае приема на работу этапу
оформления документов предшествуют другие этапы: сбор информации о
кандидате, проверка и обработка этой информации, принятие решения и, на-
конец, собственно прием или отказ в приеме.
На рис. 4.45 представлена диаграмма деятельности, отражающая простей-
ший бизнес-процесс найма на работу. Мы считаем, что наш процесс включа-
ет четыре деятельности:
• Interview — сбор информации;
• Analysis — анализ собранной информации и принятие решения;
• Fill Forms — заполнение документов для найма на работу;
• Refuse — отказ в найме.
Рис. 4.45. Диаграмма деятельности процесса найма на работу
На диаграмме рис. 4.45 нет никаких дорожек — все деятельности равноправ-
ны и однородны.
Допустим теперь, что деятельности, в которые нанимаемый вовлечен непо-
средственно (Interview, Fill out Forms, Refuse), происходят в одном месте
_____ е
Г ззз;
4.3. Диаграммы деятельности
и, так сказать, у него на глазах, а важная деятельность (о которой нанимае-
мый может не догадываться) по анализу информации и принятию решения
(Analysis) осуществляется в другом месте и, может быть, другими действую-
щими лицами (техническими специалистами, руководителями подразделе-
ний и т. д.). Эта важная информация не является частью модели, т. к. не име-
ет отношения к поведению системы, но мы можем отразить ее на диаграмме
с помощью дорожек (рис. 4.46).
В данном случае мы подразумеваем, что дорожка с названием HR Department
содержит деятельности, выполняемые в приемной отдела кадров, а дорожка
с названием Target Department содержит деятельности, выполняемые в том
подразделении, куда предполагается принять кандидата.
Графически дорожки изображаются в виде прямоугольников с названиями.
Как правило, их изображают со смыкающимися боковыми сторонами, хотя
это и не обязательно.
Авторы UML утверждают, что изображение, подобное приведенному на рис.
4.46, напоминает плавательные дорожки в бассейне, откуда и произошло
название данной графической конструкции. Возложим ответственность за
правомерность такой ассоциации на авторов UML и завершим этот неслож-
ный параграф еще одним примером применения наследников дорожек —
разбиений в UML 2.
В этом примере мы наложим на действия по приему сотрудника две орто-
гональных классификации. Первая совпадает с уже разобранной классифи-
кацией по месту действия, а вторая указывает, как выполняется действие —
устно (деятельности Interview или Analysis) или иначе (рис. 4.47).
Глава 4. Моделирование поведения
Рис. 4.47. Ортогональные дорожки
4.3.4. Траектория объекта и поток данных
Диаграммы деятельности UML позволяют моделировать поведение, опре-
деляя не только поток управления, как в приведенных выше примерах, но и
поток данных. Это утверждение вполне справедливо для UML 2 и справед-
ливо с некоторыми оговорками для UML 1.
ПОТОК УПРАВЛЕНИЯ И ПОТОК ДАННЫХ
В программе, написанной на обычном процедурном языке про-
граммирования, порядок выполнения операторов (шагов ал-
горитма) определяется порядком расположения операторов в
тексте программы и структурами управления. Фактически обыч-
ная программа задает поток управления (параграф 4.1.4). Но
при выполнении шагов алгоритма выполняются преобразова-
ния данных: переменные приобретают и меняют свои значения.
Последовательность изменения данных называется потоком
данных.
Поток управления (в детерминированной программе) определя-
ет и поток данных. Действительно, если, например, в программе
есть несколько операторов присваивания для одной переменной,
то история изменения значения переменной (т. е. поток данных)
определяется тем, в каком порядке выполняются присваивания
(т. е. потоком управления). Но эта зависимость по данным между
операторами непосредственно в тексте программы отражается
далеко не так явно, как зависимость по управлению138. Довольно
198 Это обстоятельство является источником болезненных ошибок в программах. Например,
типичная ошибка: использование неинициализированной переменной, т. е. использова-
ние в вычислениях значения переменной до того, как это значение было определено.
4.3.’Диаграммы деятельности
давно был предложен двойственный способ определения про-
граммы: явно указывается зависимость по данным, т. е. поток дан-
ных, а поток управления определяется потоком данных. Например,
самый простой способ определить поток управления по потоку
данных такой: для всех шагов алгоритма известно, какие данные
являются входными (какие переменные используются), а какие
данные являются выходными (какие переменные вычисляются).
Поток управления определяется так: шаг алгоритма выполняется,
как только все его входные данные определены (см. для сравне-
ния диаграмму потоков данных в параграфе 2.1.3).
При объектно-ориентированном подходе к моделированию поток дан-
ных — это изменение состояний объектов вс времени, и описание такого
изменения существенным образом характеризует поведение.
Для описания данной характеристики поведения в UML 1 используются по-
нятия "траектория объекта" и "объект в состоянии".
Объект в состоянии (objeci in state) это экземпляр некоторого клас-
са, про который известно, что он находится в определенном состоя-
нии в данной точке вычислительного процесса.
Синтаксически объект в состоянии изображается, как обычно, в виде пря-
моугольника, и его имя подчеркивается, но дополнительно после имени
объекта в квадратных скобках пишется имя состояния, в котором в данной
точке вычислительного процесса находится объект. В некоторых случаях со-
стояние объекта не важно, например, если достаточно указать, что в данной
точке вычислительного процесса создается новый объект данного класса, и в
этом случае применяется обычная нотация для изображения объектов. Важ-
но подчеркнуть, что объект в состоянии на диаграммах деятельности "по
определению" считается состоянием, т. е. вершиной графа модели, которая
может быть инцидентна траектории объекта.
Граектщ: tс. объекта199 -это переход особого рода, исходным или це-
левым состоянием.ко горою янляе гея объект н состоянии.
Траектория объекта изображается в виде пунктирной стрелки (в отличие от
сплошной стрелки обычного перехода). Семантически траектория объекта,
проведенная от состояния деятельности к объекту в состоянии, означает, что
результатом деятельности является переход указанного объекта в данное со-
't 99 Некоторые авторы предпочитают использовать слово "поток", поскольку словосочета-
ния "поток данных" и "поток управления" являются давно и хорошо устоявшимися тер-
минами. Мы все-таки остановились на термине "траектория объекта", поскольку "поток
объекта" по-русски звучит уж очень нескладно, хотя и соответствует устоявшейся тра-
диции.
Глава 4. Моделирование поведения
стояние (или, может быть, создание нового объекта в указанном состоянии,
что является частным случаем изменения состояния). Траектория объекта,
проведенная от объекта в состоянии к состоянию деятельности или состоя-
нию действия, означает, что объект в данном состоянии является необходи-
мым входным параметром указанной деятельности.
Таким образом, объекты в состоянии и траектории позволяют показать на
диаграмме деятельности не только зависимость по управлению, но и зависи-
мость по данным между состояниями деятельности на диаграмме. А именно,
чтобы показать, что одна деятельность использует результаты другой дея-
тельности, достаточно показать траекторию передаваемого объекта.
Рассмотрим это на примере диаграммы деятельности, описывающей про-
цесс найма сотрудника в информационной системы отдела кадров. Рис. 4.48
в основном повторяет рис. 4.46, но здесь представлена траектория объекта
класса Person, хранящего данные о принимаемом сотруднике. На диаграм-
ме хорошо видно, что именно является входными и выходными данными
каждого из состояний деятельности: в результате деятельности Interview соз-
дается новый объект, который далее обрабатывается, меняя свое состояние.
Нетрудно заметить, что в данном случае при моделировании поведения мы
фактически повторяемся, описывая поведение системы. Из диаграммы на
Рис. 4.48. Траектория объекта
402
4.3 Диаграммы деятельности
HR Department
Target Department
Рис. 4.49. Использование траекторий объектов вместо
переходов по завершении
рис. 4.48 следует, что деятельность Analysis выполняется после деятельно-
сти Interview, причем это указано дважды: один раз с помощью перехода по
завершении (1 на рис. 4.48) из Interview в Analysis и второй раз с помощью
траектории объекта (2 на рис. 4.48), показывающей, что для выполнения де-
ятельности Analysis необходим объект, создаваемый деятельностью Interview.
Разумеется, даже UML 1 позволяет не говорить лишнего: диаграмма на рис.
4.49 описывает то же самое поведение, что и диаграмма на рис. 4.48.
Нотация UML 2 по-
зволяет использовать
для описания пове-
дения поток данных
(траекторию объекта)
еще шире, поскольку в
определении семанти-
ки графа деятельности
маркеры данных и мар-
керы управления прак-
тически равноправны.
На рис. 4.50 приведена
еще одна диаграмма
Рис. 4.50. Применение контактов и пераметроа
деятельности
деятельности, описы-
вающая процесс прие-
Глава 4. Моделирование поведения
ма на работу, но в нотации UML 2 с применением контактов и параметров
деятельности.
4.3.5. Отправка, прием сигналов и работа с таймером
В UML имеется довольно много обозначений, которые не несут самостоя-
тельной семантической нагрузки, а являются "синтаксическим сахаром",
применяемым для повышения наглядности, сокращения записи и просто
для украшения диаграмм. Особенно много таких украшений предусмотре-
но для диаграмм деятельности, что не удивительно, учитывая их близкое
родство с блок-схемами и частое применение в бизнес-анализе. Часть таких
вспомогательных обозначений мы уже рассмотрели в предыдущих разделах,
например обозначение для ветвления сегментированных переходов (ром-
бик, см. параграф 4.3.2), другие рассматриваются ниже, в более подходящем
контексте (например, развилки и слияния, параграф 4.4.6). Здесь мы рассмо-
трим специальную нотацию, применяемую для обозначения действий по от-
правке и получению сигналов на переходах, а также работу с таймером.
Вернемся еще раз к примеру с наймом на работу и допустим, что мы хотим
отразить в модели несколько иной вариант поведения. В диаграммах на рис.
4.45 - рис. 4.49 процесс, происходящий в приемной отдела кадров, приоста-
навливается на то время, пока не будет завершена деятельность по оценке
кандидата и принятию решения, которая фактически происходит в другом
месте. Такое вынужденное ожидание может быть психологически неприят-
но кандидату (равно как и менеджеру по персоналу)200.
Допустим, что в проектируемой информационной системе отдела кадров
требуется обеспечить асинхронное проведение процесса приема: после
сбора сведений о кандидате менеджер по персоналу отправляет сигнал в
соответствующие инстанции и в ожидании ответного сигнала с решением
переводит себя и кандидата в состояние ожидания с внутренней активно-
стью — угощает чаем, рассказывает о миссии организации и т. п. В рамках
уже рассмотренных обозначений такая ситуация может быть описана диа-
граммой деятельности (с использованием анонимного простого состояния
с внутренней активностью Bla-bla-bla), как показано на рис. 4.51. Здесь мы
предполагаем, что в не отображаемых на диаграмме "инстанциях" принима-
ется сигнал Request с аргументом person (1), проводится деятельность по
анализу кандидата и в ответ отправляется сигнал Response с аргументом
decision (2).
Приведенная на рис. 4.51 диаграмма точно описывает желаемое поведение,
но может показаться не слишком наглядной: читатель должен знать синтак-
200 Распространенный выход из этой ситуации — "зайдите за ответом завтра после обе-
да" — не соответствует современному стилю общения.
ф
4.3. Диаграммы деятельности
Рис. 4.51. Асинхронный процесс принятия решения при найме
сические детали обозначений UML, чтобы понять описание процесса с пер-
вого взгляда. Между тем имеется хорошо знакомая очень многим наглядная
система обозначений для передачи и приема сигналов (см. рис. 4.52). Эта си-
стема обозначений также включена в UML. Суть состоит в том, что действия
по отправке (1) и приему (2) сигнала изображаются в виде фигур, сегмен-
тирующих соответствующие переходы. Применение данных обозначений,
заимствованных из языка SDL (см. врезку "Язык SDL" в параграфе 4.1.2),
приводит нас к диаграмме на рис. 4.52.
Рис. 4.52. Специальные обозначения для отправки и приема сигналов
Глава 4. Моделирование поведения
Существуют сигналы особого рода, очень важные для некоторых видов про-
граммных систем. Это сигналы времени от таймера. На диаграммах автомата
для моделирования сигналов от таймера применяются события таймера, ко-
торые вводятся ключевым словом after или at (параграф 4.2.7). На диаграм-
мах деятельности для этой цели применяется специальное действие — прием
сигнала от таймера (time event action). Это действие имеет особую нота-
цию — стилизованные песочные часы, рядом с которыми пишется выраже-
ние, определяющее требуемое событие. Следует подчеркнуть, что в любом
случае речь идет о переходе по событию, только источником событий явля-
ется таймер, который подразумевается в системе.
Примечание
Это упрощенная модель времени. Для систем реального вре-
мени она недостаточна. В таких системах требуется учиты-
вать сигналы многих часов, вносить поправки в их показания
и т. д. Более реалистичные модели времени для специальных
приложений определяются в соответствующих профилях
UML (см. параграф 5.1.6).
При приеме на работу можно использовать самые разнообразные методики
для проведения интервью, основанные на психологических теориях, специ-
альных методиках и разнообразных тестах, которые сотрудник отдела ка-
дров может менять и варьировать в зависимости от хода интервью и психо-
логического состояния кандидата.
Не вдаваясь в подробности конкретной методики проведения тестирования,
предположим, что перед соискателем просто кладут листок с вопросами, на
которые он должен в течение часа дать ответ. По истечении часа листок изы-
мается и ответы проверяются. Если соискатель выполнит тест быстрее, этим
он сэкономит всем время.
В такой постановке процедура проведения интервью может выглядеть так,
как показано на рис. 4.53. Отметим несколько особенностей данной диаграм-
мы. Несмотря на то, что описывается бизнес-процесс, нам пришлось при-
бегнуть к алгоритмическим ухищрениям: ввести переменную timeout (1) для
того, чтобы по прошествии часа, когда будет сгенерирован сигнал от таймера
(2), можно было проверить — закончил соискатель отвечать на вопросы те-
ста или нет? Если соискатель уже проверяет ответы с сотрудником отдела
кадров — деятельность Check answer (3), то ничего не происходит и поток
управления от таймера просто завершает свою работу (4). В случае, если со-
искатель все еще отвечает на вопросы (5), генерируется специальный сиг-
нал (6), который обрабатывается в деятельности Preparing answers (5). Эта
деятельность не раскрыта на данной диаграмме, но значок (опущенный вниз
_____ <
106
4.3 Диаграммы деятельности
трезубец) (7) говорит о том, что существует еще одна диаграмма деятельно-
сти (здесь не приводится), которая подробно описывает, что же происходит
внутри и каким образом обрабатывается посланный сигнал timeout (6).
Рис. 4.53. Применение действия приема сигнала от таймера
4.3.6. Сравнение способов описания поведения
После рассмотрения теоретических спецификаций элементов моделирова-
ния и различных вариантов нотации, применяемых на диаграммах деятель-
ности, мы хотим вернуться к основам и рассмотреть пример самой обычной
блок-схемы (в нотации UML), описывающей последовательность действий
при выполнении некоторого сценария. В этом примере мы описываем не-
сложное поведение разными способами и показываем, как одно описание
можно преобразовать в другое. Тем самым создается материал для сравне-
ния разных способов описания поведения.
Пример рассматривается в следующем контексте. В нашей информаци-
онной системе отдела кадров предусмотрен вариант использования Delete
Department для удаления подразделения. Удаление подразделения не такая
простая операция — нельзя просто взять и удалить подразделение — оно мо-
жет быть связано отношением композиции с другими подразделениями и
должностями, а те, в свою очередь, связаны с другими сущностями и т. д. Мы
должны решить, какие элементарные операции и в какой последовательно-
сти нужно выполнить, чтобы достичь требуемого, не нарушив целостность
Глава 4. Моделирование поведения
наших данных. Допустим, что в нашем распоряжении имеются классы и опе-
рации, представленные на рис. 4.54 (детали, ненужные в данном примере,
опущены).
Рис. 4.54. Некоторые классы в ИС ОК
Операция size() класса Department возвращает количество должностей в
подразделении, getNextPos() —позволяет перебирать должности в подраз-
делении, deletePos() — удаляет указанную должность, а функция isFree()
класса Position проверяет, вакантна ли данная должность. При выполнении
метода deletePosf) в случае попытки удалить занятую кем-то должность мо-
жет быть сгенерировано исключение DeletePosExp201. Разумеется, нам долж-
но быть известно, какое именно подразделение следует удалить — пусть этот
объект имеет имя dpt. В этой ситуации можно предложить различные вари-
анты поведения — все зависит от кадровой политики организации, которую
нужно реализовать. Допустим, что в нашей информационной системе отдела
кадров действует такое правило: если в подразделении есть "живые люди",
то его нельзя просто так удалить — это ошибка, а если нет никого или только
"мертвые души", то можно удалять все, не задумываясь. Тогда алгоритм уда-
ления подразделения на псевдокоде можно описать, например, следующим
образом.
if dpt.size() > 0 then
repeat
pos := dpt.getNextPos()
dpt.deletePos(pos) // возможна генерация исключения DeletePosExp
until dpt.size () = 0
deleteDpt(dpt)
Это же поведение в нотации диаграммы деятельности представлено
на рис. 4.55.
201 В UML 2 исключение не является классификатором и на диаграмме классов не показы-
вается.
4.3 Диаграммы деятельности
Рис. 4.55. Диаграмма деятельности по удалению подразделения
Дополнение к этой и ряду последующих диаграмм в виде описания деятель-
ности deletePos() и пояснение к нотации, связанной с использованием ис-
ключений (1 на рис. 4.55), представлены в параграфе 4.3.7.
Диаграмма на рис. 4.55 выглядит "неструктурно". Подвергнем ее "графиче-
скому рефакторингу" — еще более упрощая картину, синтаксически возмож-
но описать деятельность по удалению подразделения диаграммой на рис.
4.56.
Рис. 4.56. Улучшенная диаграмма деятельности по удалению подразделения
[ 409 ]
Глава 4. Моделирование поведения
Диаграмма на рис. 4.56 соответствует следующему псевдокоду:
while dpt.size() > О
pos := dpt.getNextPos ()
dpt.deletePos (pos) // возможна генерация исключения DeletePosExp
deleteDpt(dpt)
Вообще говоря, можно поспорить, что более наглядно: диаграммы деятель-
ности на рис. 4.55 и рис. 4.56 или приведенные программы на псевдокоде.
Если положить перед человеком два листа: с диаграммой рис. 4.55 (или рис.
4.56) и с текстом на псевдокоде — и предложить выбрать, то реакция, как
показывают наши наблюдения, далеко не однозначна и сильно зависит от
личностных качеств испытуемого.
Чтобы читатель мог оценить, какой стиль ему предпочтителен, мы приведем
еще несколько вариантов графической записи данного элементарного алго-
ритма, уже не в стиле структурной блок-схемы, как на рис. 4.56, а в стиле
машины состояний UML. Начнем с очевидного: традиционные ромбики не
нужны, они только занимают место на диаграмме (рис. 4.57).
activity Delete department
Рис. 4.57. Диаграмма деятельности без использования разветвлений управления
Если вам еще не надоел данный пример, попробуйте прочитать диаграмму
на рис. 4.58. Здесь мы попытались отразить основную структуру разбирае-
мого алгоритма: если подразделение пусто, то его можно удалять без всяких
сомнений, а если нет, то нужно удалять одну должность за другой. Эта ак-
тивность выполняется в простом состоянии Doubt.
Заметим, что при этом мы практически полностью перешли от диаграмм
деятельности к диаграммам автомата — ведь между ними нет непроходимой
границы! В данном состоянии имеется внутренняя деятельность do, состоя-
щая в циклическом переборе должностей в подразделении. Е1а каждом шаге
4 3. Дилгрлммы ДЕЯТЕЛЬНОСТИ
этого цикла выполняется вызов метода getNextPosf), который является со-
бытием вызова, обрабатываемым в этом же состоянии (1), что ведет за собой
вызов метода deletePos() (2). Как нам уже известно, при удалении должно-
сти, которая является занятой, возбуждается исключение типа DeletePosExp,
которое ведет к принудительной остановке автомата (terminate). На
рис. 4.58 данная ситуации отражена в виде перехода по событию DeletePosExp
из состояния Doubt в псевдосостояние terminate (3), нотация которого — ко-
сой крест.
Рис. 4.58. Использование простого состояния с внутренней активностью
и переходами
Вопрос может вызвать одно специфическое средство, которое мы использо-
вали на данной диаграмме. Оно относится к действиям UML 1 и называется
повторителем.
Повторитель (iler;H ion) это выражение, предписываю и ц е выпол-
нить действие несколько раз (может быть, ни разу).
Синтаксически повторитель записывается подобно сторожевому условию, в
квадратных скобках, перед которыми ставится звездочка:
* [ повторитель ] действие
Синтаксис выражения, определяющего число или условие повторений дей-
ствия, в UML 1 не предписывается, подразумевается, что это нечто вроде
заголовка цикла целевого языка программирования. В UML 2 повторитель
объявлен устаревшей конструкцией, хотя его использование не запрещает-
ся.
Вернемся к нашему примеру. Осталась самая малость. Состояние с вызовом
метода deleteDpt() является на самом деле состоянием действия, а не состоя-
нием деятельности, и без него, как мы отмечали, можно обойтись (параграф
4.3.2). Вглядимся теперь внимательно в простое состояние Doubt. В сущно-
Глава 4. Моделирование поведения
сти, там в цикле выполняется пара действий: взять следующую должность и
обработать ее.
Таким образом, имеются две точки, два мгновения в вычислительном про-
цессе: когда мы от взятия переходим к обработке и когда от обработки пере-
ходим к взятию. Мы можем считать эти мгновения состояниями (но это не
состояния объекта или системы, это состояния нашего вычислительного
процесса!). Сами по себе эти состояния не важны — алгоритм определяет-
ся тем, в каком порядке посещаются эти состояния и какие содержательные
действия выполняются на переходах. В результате мы получаем конечный
автомат, приведенный на рис. 4.59.
Рис. 4.59. Эквивалентный конечный автомат
Все действия выполняются на переходах, а простые состояния служат толь-
ко для определения смежности переходов. Их можно было бы никак не на-
звать, но синтаксис UML требует наличия имен простых состояний, поэто-
му мы их просто пронумеровали (1 и 2).
Как уже было отмечено, мы имеем дело с вычислительным процессом, поэ-
тому составное состояние носит название Delete department. Введено данное
состояние для того, чтобы корректно обработать (т.е. прекратить выполне-
ние конечного автомата) исключение DeletePosExp, которое может возник-
нуть в процессе удаления еще занятой должности.
Мы надеемся, что повторный просмотр наших примеров, начиная с рис. 4.55
и по рис. 4.59, даст читателю достаточно пищи для размышлений и выра-
4.3 Диаграммы деятельности
ботки собственного202 отношения к диаграммам автомата и диаграммам дея-
тельности в UML.
4.3.7. Прерывания и исключения
Прерывания и исключения — это примеры давно и хорошо известных, мож-
но сказать базовых, механизмов, применяемых в программировании.
Область прерывания
Начнем с прерываний. В UML 2 введена явным образом конструкция, кото-
рая называется область прерывания.
Область прерывания (interruptible activity, region}.— это структури-
рованный узел (рамка) на диаграмме деятельности* врутриКоторого
возможно прерывание обычного порядка выполнения действий при
возникновении определенно!о события.
Синтаксически область прерывания изображается в виде пунктирной рам-
ки, ограничивающей некоторый фрагмент графа деятельности. Прерываю-
щие события изображаются в виде "флажка" приема сигнала, от которого
проводится стрелка-"молния" (interruptible activity edge) к некоторой внеш-
ней деятельности — обработчику прерывания (interrupt handler). Флажок
должен находиться обязательно внутри области прерывания, чтобы преры-
вание не спутать с исключением, которое имеет похожую нотацию203.
Семантически область прерывания означает следующее. Если при выпол-
нении фрагмента графа деятельности в области прерывания произойдет
указанное прерывающее событие, то управление передается обработчику
прерывания. Возобновить прерванный фрагмент невозможно204.
На рис. 4.60 мы привели фактически тот же пример, что и на рис. 2.26
и рис. 2.27. Прерывающим событием является событие Cancel (1), которое
может произойти в любой момент, а обработчиком прерываний — соответ-
ствующее действие Cancel hiring (2).
202 Будь на то наша воля, мы бы предпочли видеть спецификацию поведения операции
удаления подразделения dpt примерно такой:
Vposedpt(isFree(pos)) deleteDpt(dpt).
203 Флажок исключения располагается за границей области, которая генерирует исключе-
ние.
204 Стандарт хранит молчание по поводу того, позволяет ли обработчик прерывания сохра-
нить контекст и освободить ресурсы прерываемому процессу. Реальные системы обра-
ботки прерываний в операционных системах, как правило, это делают.
Глава 4. Моделирование поведения
activity Прием сотрудника на работу (Hire Person)
Рис. 4.60. Область прерывания
Примечание
Откровенно говоря, пока механизм описания обработки пре-
рываний в UML 2 слишком слаб, чтобы моделировать со-
временные сложные системы обработки прерываний, напри-
мер, такие как в операционных системах реального времени.
Возможно, в следующих версиях языка положение будет ис-
правлено.
КОНЦЕПЦИЯ ПРЕРЫВАНИЙ
Идея обработки прерываний настолько общеизвестна, что даже
трудно указать источник, в котором она была сформулирована
впервые. Но в самых первых компьютерах никаких прерываний не
было! Все устройства управлялись одним центральным процес-
сором. Никаких асинхронных сигналов не допускалось, а потому
их и не надо было обрабатывать. Пользователь не мог "щелкать
мышкой" — ее и не было, он мог только заправить перфоленту
или колоду перфокарт в устройство ввода, нажать кнопку "Пуск"
(физическую кнопку!) и терпеливо ждать, пока управляющая про-
грамма (трудно называть это операционной системой) соизволит
заметить его задание. Все ошибки аппаратуры (а они случались
по десять раз на дню) были фатальны — система просто останав-
ливалась. Появление и реализация идеи обработки компьютером
асинхронных событий во внешнем мире (прерываний) явилось
мощным импульсом в развитии программного обеспечения и вы-
4.3 Диаграммы деятельности
числительной техники. Обработка прерываний, реализованная
уже в самых первых операционных системах, дала немедленный
выигрыш в фактической эффективности вычислительной системы
в десятки и сотни раз.
Обработка исключений
Обратимся теперь к исключениям. В UML 1 исключения трактуются как
частный случай сигналов (см. параграф 4.2.7), что хотя и допустимо, но не
очень удобно. В UML 2 для моделирования исключений введена специаль-
ная конструкция.
Вообще говоря, у прерываний и у исключений много общего. И в том и в
другом случае речь идет о прекращении текущей деятельности при возник-
новении "нештатной" ситуации и о передаче управления в тот участок про-
граммы, который ответственен за обработку данной ситуации. Но в случае
исключений предусмотрены "дополнительные удобства".
• Распространение исключения. Для действия или иного узла графа
деятельности может быть указано, какие исключения этот узел мо-
жет генерировать. Кроме того, для узла указываются обработчики
исключений, которые с ним связаны. Работает это следующим об-
разом. Допустим, произошло исключение. Если с узлом, в котором
произошло исключение, ассоциирован обработчик этого исключе-
ния, то обработчик выполняется и на этом обработка заканчивается.
Если же нет ассоциированного обработчика, то исключение переда-
’ ется в следующий объемлющий по иерархии вложенности узел и об-
работчик ищется там и так далее. Только если исключение передано
на самый верхний уровень деятельности, так и не будучи обработан-
ным, то выполнение деятельности прекращается,
• Иерархия исключений. Исключения не являются классификаторами
и не могут образовывать иерархии обобщения. Однако моделиро-
вать исключения можно с помощью объектов определенного типа и
именно эти типы могут образовывать иерархии. Обработчик исклю-
чения связан с определенным типом исключения и может обрабаты-
вать также все его специализации. Таким образом, типы исключений
можно дифференцировать очень детально, и это не потребует очень
большого числа обработчиков.
• Параметры исключения. В описание типов исключений могут быть
введены атрибуты, которые при генерировании исключения запол-
няются требуемыми значениями и позволяют передавать в обработ-
чик столько информации, сколько нужно для детальной и коррект-
ной обработки.
Глава 4. Моделирование поведения
• Сохранение выходных контактов. Когда возникает исключение, вы-
полнение текущего действия прерывается без генерации выходных
значений. Выходные контакты обработчика исключения должны в
точности совпадать по числу и типам с выходными контактами за-
щищаемого узла, и когда обработка исключения заканчивается, то
выходные значения обработчика исключения подставляются вместо
выходных значений деятельности, сгенерировавшей исключения,
и выполнение программы может продолжиться обычным образом,
"как будто ничего и не было".
Нотация для исключений следующая.
• Чтобы показать, что некоторый узел может генерировать исключе-
ния, у этого узла определяется выходной контакт с типом исключе-
ния, возле которого рисуется маленький треугольник (см. рис. 4.55,
рис. 4.56 и рис. 4.57).
• Чтобы показать, что некоторый узел имеет обработчик исключения,
от защищаемого узла рисуется стрелка-'молния" к входному кон-
такту узла-обработчика, причем типом этого контакта должен быть
тип исключения.
Специальный значок (треугольник) может быть расположен как рядом с вы-
ходным контактом деятельности (1), указывая тем самым выходные данные,
относящиеся к исключению, так и рядом с дугой перехода (2), показывая, в
каком месте возникло исключение и каким путем и куда оно доставляется.
Обратимся еще раз к примеру про удаление подразделения, подробно разо-
бранному в предыдущем параграфе, и в качестве примера (рис. 4.61) рас-
Рис. 4.61. Диаграмма деятельности deletePos
Ж
4.3. Диаграммы деятельности
смотрим диаграмму для деятельности deletePos(). Все, что требуется теперь
сделать, — связать исключение с его обработчиком, что мы и сделали на
рис. 4.62 с использованием двух разных нотаций.
Рис. 4.62. Варианты нотации стрелки-"молнии"
Остается сказать, что деятельность ExceptionHandler должна быть раскрыта
на отдельной диаграмме, как, например, это сделано на рис. 4.63. Мы просто
воспользовались тем фактом, что у нас уже имеется обработчик для подоб-
ной ситуации (см. рис. 4.31)
activity Exception Handler
А
Рис. 4.63. Деятельность Exception Handler
Заметьте, что при описании деятельности ExceptionHandler мы не использо-
вали ни начальное, ни конечное состояния. От этого диаграмма ничуть не
пострадала.
Остается сказать, что все рассматриваемые нами примеры имели только
один поток управления205, хотя возможности диаграммы деятельности на-
много шире, и в дальнейшем мы ликвидируем этот пробел (см. раздел 4.5).
4.3.8. Структурные узлы деятельности
При обучении программированию в школе первое, с чего обычно начина-
ют, — это простейшие структуры данных (массивы, структуры) и простей-
205 Как прерывания, так и исключения нарушают "естественный" порядок выполнения и в
этом смысле не являются "последовательными", а значит, их можно отнести к "парал-
лельным". Однако в большинстве реализаций программных систем прерывания и ис-
ключения не ведут к появлению дополнительных (параллельных) потоков.
Глава 4. Моделирование поведения
шие структуры управления (ветвления, циклы). Читателю может показать-
ся странным, что мы рассказали очень многое про диаграммы деятельности,
почти все, а про циклы в явном виде не упоминали.
Причина состоит в том, что хотя все обычные структуры управления распро-
страненных языков программирования (ветвление, цикл, последовательная
композиция) в UML имеются, но они занимают в языке странное и двус-
мысленное положение, словно незаконнорожденные дети в средневековой
династической семье.
Действительно, конструкции, о которых мы здесь рассказываем (структур-
ные узлы деятельности), присутствуют в метамодели UML206, для них опре-
делена семантика, хотя и довольно поверхностно, но для них не определена
нотация в стандарте, и не приводится ни одного примера в книгах авторов
языка! Вот уж поистине нелюбимое детище — иначе не назовешь.
Структурный узел деятельности (structured activity node) — это об-
ласть на диаграмме деятельности, служащая для задания одной из
трех структур управления.
Графически структурный узел деятельности должен выделяться пунктир-
ной рамкой, это обнаруживается совершенно ясно при внимательном изуче-
нии текста стандарта. Остальные детали нотации приходится изобретать и
домысливать.
Определено три типа структурных узлов деятельности:
• узел последовательности;
• узел условий;
• узел цикла.
Узел последовательности (sequence node) это структурный узел
деятельности, который залает последовательное выполнение любого
числа нложенных узлов, причем вложенные узлы могут быть узлами
любого типа.
Мы будем изображать узел последовательности в виде пунктирной рамки
со скругленными узлами. Стандарт рекомендует в углу структурного узла
деятельности помещать стереотип «structured», но мы не будем так делать,
потому что эта рекомендация противоречит здравому смыслу Внутри рамки
в определенном порядке, либо сверху вниз, либо слева направо, изображены
вложенные узлы, никак друг с другом не связанные207.
206 Структурные узлы управления появились BUML2.
207 Стандарт не запрещает связывать узлы, вложенные в последовательный узел, допол-
4.3. Диаграммы деятельности
Узел условий (conditional node) это структурный узел деятель-
ности, который задает выполнение одного узла из числа вложенных
узлов, причем для каждого вложенного узла должно быть задано
сторожевое условие его выполнения.
Мы будем изображать узел условий в виде пунктирной рамки со скруглен-
ными углами, разделенной пунктирными линиями на ветви. В каждой ветви
указывается сторожевое условие в квадратных скобках и соответствующий
вложенный узел208. Разумеется, допускается использование предиката else
(параграф 4.2.3).
Примечание
Стандарт прямо и недвусмысленно указывает, что все усло-
вия в узле условий могут вычисляться параллельно и одно-
временно, и порядок размещения альтернативных ветвей в
узле условий не имеет значения.
Узел цикла (loop node) — это структурный узел деятельности, кото-
рый задает многократное выполнение одного вложенного узла, при-
чем должно быТь задано сторожевое условие продолжения выполне-
ния цикла.
Узел цикла обязательно содержит три части: подготовка (ключевое слово
setup), проверка (ключевое слово test) и тело (ключевое слово body). Под-
готовка выполняется один раз до начала цикла. Если сначала указана про-
верка, а потом тело, то это цикл с предусловием, если сначала тело, а потом
проверка, то это цикл с постусловием.
Мы будем изображать узел цикла в виде пунктирной рамки со скругленны-
ми углами, разделенной пунктирными линиями на три части с соответству-
ющими ключевыми словами.
Приведем пример. Для этого еще раз рассмотрим операцию удаления под-
разделения (параграф 4.3.6) и реализуем эту операцию с использованием
структурированных узлов деятельности (рис. 4.64). Нам понадобились: один
узел последовательности (1), два узла условий (2) и один узел цикла (3)..
нительными стрелками управления. Что делать в том случае, когда эти стрелки будут
противоречить порядку выполнения, предписываемому последовательным узлом, стан-
дарт умалчивает. В описании языка [3] авторы советуют не допускать таких ситуаций.
Мы следуем их совету и вообще не рисуем стрелок между узлами, вложенными в после-
довательный узел.
208 В литературе встречаются и другие варианты нотации. Например, разделить узел условий
на три части и использовать в них ключевые слова if then else с очевидной семантикой.
Г лава 4. Моделирование поведения
z [dpt.size()>0]
pos:=dpt.getNextPos()
I test
[else]
I
• deieteDpt(dpt)
Рис. 4.64. Структурные узлы деятельности
। body
1 / [pos.isFreeQ]
[else]_____________________
I send posOccupied(pos)
( dpt.deletePos(pos) j
Таким образом, использование структурных узлов деятельности позво-
ляет использовать UML как еще один графический императивный язык
структурного программирования. Мы уже не раз отмечали, что это возмож-
но, и еще раз повторим, что, по нашему мнению, это нецелесообразно. Если
нужно записать структурную программу (алгоритм), то это можно сделать
на псевдокоде, с помощью блок-схемы или еще как-нибудь. Использование
UML не дает в этом случае реальных преимуществ. Язык UML предназна-
чен все-таки для моделирования, а не для структурного программирования,
и в этом его сила.
Нотация структурных узлов деятельности немного напоминает нотацию
Нэсси-Шнейдермана.
НОТАЦИЯ НЭССИ-ШНЕЙДЕРМАНА
Придумать удобную нотацию для ветвлений и циклов на блок-
схемах не так просто, как это кажется на первый взгляд. Вообще
блок-схемы были предложены фон Нейманом на самой заре ком-
пьютерной эры, и они как нельзя лучше подходят для записи ал-
горитмов на языке машинных команд в архитектуре машины фон
4.3. Диаграммы деятельности
Неймана. Арифметические команды выполняются последова-
тельно, и есть команды условной и безусловной передачи управ-
ления. Стрелочки на блок-схемах превосходно моделируют смысл
передачи управления. Развитые структуры управления языков
программирования высокого уровня (разнообразные ветвления,
циклы и структурные переходы) можно промоделировать с помо-
щью команд передачи управления. Действительно, именно это и
делают компиляторы языков программирования. Но выраженные
в блок-схемах сложные структуры управления оказываются со-
всем не такими наглядными, как простые переходы (операторы
goto).
Нэсси и Шнейдерман (I. Nassi & В. Shneiderman) в 1972 году пред-
ложили, а в 1973 году опубликовали нотацию, которая семантиче-
ски эквивалентна структурным блок-схемам, но лишена их недо-
статков. В нотации Нэсси-Шнейдермана вообще нет стрелочек
(и нет места для оператора goto!). Алгоритм записывается на
поле (листе бумаги), разграфленном вертикальными и горизон-
тальными линиями на области. Области не пересекаются, но мо-
гут быть вложены друг в друга. Каждая область является описани-
ем части алгоритма. Верхняя сторона области — вход в алгоритм,
нижняя — выход (поскольку речь идет о структурных алгоритмах,
вход и выход единственны!).
Нотация Нэсси-Шнейдермана очень проста графически и может
быть выполнена даже средствами псевдографики и в то же вре-
мя весьма компактна — содержит мало "воздуха”. В таблице 4.9
показаны элементы нотации Нэсси-Шнейдермана в сравнении с
другими нотациями, а на рис. 4.65 в этой нотации записан пример
алгоритма, с которого начинается разбор операции удаления под-
разделения в параграфе 4.3.6209.
Таблица 4.9. Сравнение различных нотаций
Структура управления Блок-схема Нэсси Шнейдерман Структурные узлы деятельности Псевдо- код
Последова- тельность Ф ( ) V S1 S1
( S2 ) S2 !( s2 ); S2
209 В этом примере внимательный читатель должен заметить, что в нотации Нэсси-
Шнейдермана не предусмотрены такие вещи, как прерывания, исключения, структур-
ные переходы, а потому пример потребовал некоторой переделки.
Ф _____
wBmUI
Глава 4 Моделирование поведения
Таблица 4.9. Сравнение различных нотаций
(продолжение)
Структура
управления
Блок-схема
Нэсси
Шнейдерман
Структурные
узлы
деятельности
Псевдо-
код
/ [В]
Ветвление
Цикл с
постусло-
вием
Цикл с
предусло-
вием
if В then
S1
else
S2
end if
while T
В
end while
I [else!
setup
repeat
В
until T
в
S1 S2
dpt.sizef) > О
pos := dpt.getNextPos()
pos.isFree()
dpt.deietePos(pos) send posOccupied(pos)
terminate
dpt. size = 0
deieteDpt(dpt)
Рис. 4.65. Запись алгоритма удаления подразделения
в нотации Нэсси-Шнейдермана
4.3.9. Применение диаграмм деятельности
Подводя итоги описания поведения диаграммами деятельности в UML, мы
хотим вернуться к обсуждению области применения этих диаграмм.
4.3. Диаграммы деятельности
С одной стороны, диаграммы деятельности — общее и мощное средство
описания алгоритмов. Причем не обязательно программно реализованных
алгоритмов: диаграммы деятельности с успехом можно применять для мо-
делирования поведения людей, устройств и организаций при выполнении
бизнес-процессов. Обратите внимание, что в наших примерах про процесс
приема на работу (см. рис. 4.45 - рис. 4.47) никакой программной реализа-
ции, вообще говоря, не подразумевается. Скорее всего, действия, обозначен-
ные на этих диаграммах, должны иметь некоторую программную поддержку,
но они не могут выполняться полностью автоматически — в них вовлечены
люди. Если мы рассматриваем диаграммы деятельности как средство описа-
ния бизнес-процессов, то их естественное место в рамках UML — послужить
первым шагом при реализации вариантов использования.
С другой стороны, диаграммы деятельности, равно как и блок-схемы,
можно применять практически как средство визуального структурного
программирования. Посмотрите еще раз рис. 4.55, и особенно рис. 4.59 или
рис. 4.64 — это готовый к выполнению код210. В качестве средства програм-
мирования диаграммы деятельности целесообразно применять для реали-
зации операций (что фактически и сделано нами в упомянутых примерах —
реализована операция удаления подразделения).
Таким образом, диаграммы деятельности применяются для описания по-
ведения на самом высоком уровне абстракции, наиболее удаленном от про-
граммной реализации, и на самом низком уровне, практически на уровне
программного кода. Данное наблюдение дает нам повод дать следующую ре-
комендацию. Если при проектировании выявляется операция, выполнение
которой непосредственно реализует вариант использования (как в случае
операции удаления подразделения), то составление диаграммы деятель-
ности является наилучшим способом моделирования поведения.
С точки зрения применения важным обстоятельством является существен-
ная переработка и усовершенствование графической нотации диаграмм
деятельности в UML 2. Если скептически настроенный программист ста-
рой закалки спросит нас: "Чем диаграммы деятельности UML лучше обыч-
ных блок-схем?", то наш ответ для разных версий UML будет разным. Для
UML 1, положа руку на сердце, придется ответить — ничем не лучше, за ис-
ключением средств моделирования параллелизма, а по основным элементам
нотации даже хуже. Но для UML2 положение прямо противоположное.
Можно смело заявить: диаграммы деятельности UML 2 по всем параметрам
210 К сожалению, анализируя возможности инструментов, доступных авторам в момент на-
писания книги, приходится констатировать, что большинством инструментов диаграм-
мы деятельности для генерации кода не используются (или используются не в полной
мере), хотя даже авторы языка указали на возможность и желательность такого приме-
нения.
Ф _____
Глава 4. Моделирование поведения
лучше стандартных блок-схем. Позвольте привести неполный, но показа-
тельный список "конкурентных преимуществ" диаграмм деятельности UML2.
• Объектные узлы — контакты, параметры, хранилища, центральный
буфер.
• Области диаграммы (область разложения, область прерывания).
• Структурные узлы деятельности (циклы, ветвления).
• Поток управления и поток данных (типизация и приведение данных
в потоке данных).
• Заключительный узел деятельности и заключительный узел потока.
Рис. 4.66. Метамодель элементов диаграммы деятельности UML 2
4.4. Диаграммы взаимодействия
Список можно продолжать, но уже и так ясно, что ничего этого в стандарт-
ных блок-схемах нет, а потому диаграммы деятельности UML 2 намного вы-
разительнее блок-схем.
Наша метамодель графа деятельности (activity graph), который изобража-
ется на диаграммах деятельности UML 2 (рис. 4.66), построена на следую-
щих принципах. Главная идея состоит в том, чтобы описать диаграмму дея-
тельности именно как ориентированный граф, задавая то, какие дуги (edge)
ведут из одного узла (node) в другой. Возможные узлы представлены в виде
иерархии с корневым суперклассом ActivityNode, а возможные дуги в виде
иерархии с корневым суперклассом ActivityEdge. Заметим, что деятельность
(Activity) может включать в себя как ActivityNode, так и StructuredActivityNode
разных видов, а также быть частью того или иного разбиения (ActivityPartion).
4.4. Диаграммы взаимодействия
Диаграммы взаимодействия предназначены для моделирования поведе-
ния путем описания взаимодействия объектов для выполнения некоторой
задачи или достижения определенной цели. Взаимодействие происходит
путем обмена сообщениями. Диаграммы взаимодействия применяются на
разных уровнях моделирования: как для описания поведения отдельных
операций, так и целых вариантов использования. Данный тип диаграмм по-
зволяет описывать не только взаимодействие программных объектов (эк-
земпляров классов), но и взаимодействие экземпляров иных классификато-
ров: действующих лиц, вариантов использования, компонентов и др. Более
того, поскольку взаимодействие, как правило, не зависит от конкретного эк-
земпляра и проходит по единообразной схеме для всех экземпляров данного
классификатора, диаграммы взаимодействия описывают взаимодействие на
уроине ролей, а не на уровне конкретных экземпляров211.
Диаграммы взаимодействия изображаются в нескольких различных гра-
фических формах, из которых самыми важными являются диаграммы по-
следовательности и диаграммы коммуникации. Наряду с этими основными
формами описания взаимодействия в UML 2 применяются диаграммы син-
хронизации и обзорные диаграммы взаимодействия.
Мы уже отмечали, что диаграммы последовательности и диаграммы комму-
никации семантически эквиваленты, хотя графически выглядят совсем по-
разному. Семантически эти диаграммы эквиваленты потому, что описывают
одно и то же: последовательность передачи сообщений между объектами в
211 Иногда в дальнейшем для краткости изложения мы будем говорить в основном об объ-
ектах на диаграммах взаимодействия, но читатель должен помнить, что речь может идти
и о роли, которую играет объект во взаимодействии.
ф ____
ГлаВа4. Моделирование поведения
процессе их взаимодействия. А выглядят по-разному они потому, что в диа-
грамме последовательности графически подчеркивается упорядоченность
во времени передаваемых сообщений, в то время как в диаграмме коммуни-
кации на передний план выдвигается структура связей между объектами, по
которым передаются сообщения.
Сразу подчеркнем главное: оба типа диаграмм моделируют поведение "по
индукции", от частного к общему, путем описания конкретного протокола
передачи сообщений. В этом и сила, и слабость данного способа описания
поведения. Сильная сторона состоит в том, что в объектно-ориентированной
парадигме обмен сообщениями — это и есть само выполнение программы,
поэтому протокол передачи сообщений является наиболее точной моде-
лью поведения. Диаграммы взаимодействия находятся "ближе" к реальному
выполнению программы, чем другие средства описания поведения. Слабость
диаграмм взаимодействия состоит в том, что эти диаграммы описывают по-
ведение на уровне экземпляров, а не классификаторов; на уровне протоколов
выполнения алгоритма, а не самого алгоритма. Диаграммы взаимодействия
менее "алгоритмичны", чем диаграммы автомата и диаграммы деятельности.
Наряду с основными сущностями и отношениями на диаграммах последо-
вательности и коммуникации применяется множество дополнительных эле-
ментов семантики и нотации, которые рассматриваются в параграфах 4.4.2 и
4.4.5 соответственно. В следующем параграфе мы рассматриваем основной
элемент этих диаграмм — сообщение.
4.4.1. Сообщения
Сообщение (message) — это передача управления и данных от одного
объекта (отправителя) к другому (получателю).
Заметим, что отправка сообщения является действием (см. параграф 4.3.1),
а получение сообщения — событием (см. параграф 4.2.7). В UML 1 следую-
щие действия связаны с передачей информации и отправкой сообщений:
• вызов метода (call);
• создание объекта (create);
• уничтожение объекта (destroy);
• возврат значения (return);
• посылка сигнала (send).
Действие записывается в виде текста над (или рядом со) стрелкой, симво-
лизирующей сообщение. Если действие имеет параметры (вызов метода,
4.4. Диаграммы взаимодействия
создание объекта, посылка сигнала), то аргументы, соответствующие пара-
метрам по числу и типам, записываются справа от имени действия в круглых
скобках.
Синтаксис вызова метода имеет различия в UML 1 и в UML 2. Если дей-
ствием является вызов метода, возвращающего значения, то в UML 1 слева
от имени метода записывается список переменных для возвращаемых значе-
ний (их может быть несколько) и знак присваивания := 212. Таким образом,
та часть нотации сообщений, которая относится к выполняемому действию
по вызову метода, в UML 1 имеет следующий синтаксис:
переменные := ИМЯ ( аргументы )
В UML 2 используется несколько иной синтаксис:
атрибуты = ИМЯ ( аргументы ) : переменные
Атрибуты слева от знака — это атрибуты объекта, отправляющего сооб-
щение, предназначенные для хранения возвращаемых значений. Перемен-
ные справа от знака — это локальные переменные взаимодействия для
приема возвращаемых значений. Можно не использовать ни атрибуты, ни
переменные, можно использовать либо то, либо другое, а можно использо-
вать и то, и другое. Такое присваивание "и вашим и нашим" выглядит не-
сколько непривычно и загадочно, и мы не уверены, что эта возможность при-
живется на практике.
Примечание
В UML 2 введена следующая возможность. Вместо аргу-
мента сообщения можно указывать знак (дефис), и это
означает, что в данном взаимодействии допустимо любое
значение аргумента. Более того, вместо всего текста сообще-
ния можно указать знак (звездочка), и это означает, что в
данном месте взаимодействия допустимо любое сообщение.
Мы пока не встречали случаев применения этой новинки
в практических моделях, и потому не используем в своих
примерах, оставляя читателю возможность самостоятельно
освоить это средство.
Сообщение имеет отправителя и получателя. Получателей может быть не-
сколько, такое сообщение называется широковещательным (broadcast). Все
получатели широковещательного сообщения получают одно и то же сооб-
212 Напомним, что инструменты вправе использовать любой синтаксис для текстовых фраг-
ментов при условии, что имеется взаимно-однозначное соответствие между используе-
мым синтаксисом и стандартным синтаксисом. Так, в частности, в UML 1 чаще исполь-
зуется знак присваивания := (как в Паскале), а в UML 2 — знак = (как в Си).
Глава 4. Моделирование поведения
щение. Широковещательные сообщения указываются с помощью повтори-
телей (см. параграф 4.3.6).
Сообщение может быть условным. При выполнении определенного сто-
рожевого условия сообщение отправляется, в противном случае ничего не
происходит. Сторожевое условие записывается, как обычно, в квадратных
скобках (см. параграф 4.2.2).
Поскольку получение сообщения является событием, то получатель сооб-
щения вместе с информацией получает и управление (для того, чтобы иметь
возможность выполнить действия, инициируемые полученным сообщени-
ем). В UML различается несколько типов передачи управления с помощью
сообщения. Чтобы отличить тип передачи сообщения, в UML применяется
специальная графическая нотация, а именно различаются виды стрелок, ко-
торыми обозначаются сообщения. Хотя на диаграммах коммуникации и по-
следовательности сообщения обозначаются различным образом, принципы
изображения одинаковы и перечислены в таблице 4.10.
Таблица 4.10. Типы передачи сообщений
Вид стрелки Тип передачи сообщения
► Вложенный (синхронный) поток управления. Данный тип передачи сообщения подразумевает, что отправитель может отправить следующее сообщение только после того, как завершится выполнение всехдействий, инициированных данным сообщением. Обычно применяется при вызове методов
> только UML 1 Простой поток управления. Данный тип передачи подразумевает, что управление передается от отправителя сообщения получателю (возможно, безвозвратно). Обычно применяется при моделировании поведения на уровне действующих лиц и вариантов использования
=5^ BUML1 > BUML2 Асинхронный поток управления. Данный тип передачи подразумевает, что сообщение асинхронно передается от отправителя получателю, при этом у отправителя сохраняется свой поток управления, не зависящий от потока управления получателя. Обычно применяется при отправке сигналов
< Возврат управления. Данный тип передачи подразумевает возврат управления после выполнения всех действий, инициированных передачей сообщения с вложенным потоком управления. При этом могут быть указаны возвращаемые значения. Данный тип передачи сообщения можно не отображать на диаграмме, поскольку он подразумевается по умолчанию при вызове методов
не определяется Допускается использование при моделировании других, не определяемых в UML, типов передачи управления, например передачи управления по истечении интервала времени.
4.4. Диаграммы взаимодействия
Для того чтобы сообщение могло быть передано от отправителя к получа-
телю, отправитель должен "знать" получателя, т.е., например, должна суще-
ствовать ассоциация между классификаторами отправителя и получателя,
экземпляр которой (связь) и служит тем путем, по которому передается
сообщение. На диаграмме коммуникации эта связь всегда изображается в
явном виде, как линия, а на диаграмме последовательности она подразуме
вается как часть самой стрелки сообщения.
Однако поведение определяется не только и не столько тем, какие объекты
посылают какие сообщения, но прежде всего тем, в каком порядке это про-
исходит. UML позволяет определить относительный порядок сообщений во
взаимодействии, причем это делается несколькими различными способами.
• На диаграмме последовательности порядок сообщений определя-
ется временем их отправки, а время отсчитывается на диаграмме
сверху вниз. Таким образом, сообщения, изображенные выше, пред-
шествуют сообщениям, изображенным ниже213.
• Порядок можно задать с помощью последовательного номера сооб-
щения, правила формирования которого описаны в параграфе 4.4.5.
Данные номера уникальны и обладают тем свойством, что сообще-
ния с меньшими номерами предшествуют сообщениям с большими.
• Наконец, порядок можно указать, перечислив (через запятую) номе-
ра сообщений, предшествующих данному.
Диаграммы взаимодействия почти не позволяют выйти за пределы описа-
ния протоколов выполнения алгоритмов (т. е. линейных программ). Здесь
необходимо еще раз сказать, что же все-таки можно сделать. UML позволяет
задать повторность сообщения, т. е. либо задать сторожевое условие (см.
параграф 4.2.2), либо повторитель (см. параграф 4.3.1). Семантика этих кон-
струкций очевидна: сообщение посылается только при условии истинности
сторожевого условия, а повторитель определяет, сколько раз нужно послать
данное сообщение (возможно разным экземплярам классификаторов). Син-
таксис такой же, как и для диаграмм автомата.
Таким образом, сообщение может быть довольно сложной синтаксической
конструкцией. Сразу отметим, что абсолютно все возможные части описания
сообщения, как правило, нет нужды использовать — обязательным является
только имя. Общий синтаксис текста описания сообщения следующий.
предшественники / повторность номер : атрибуты -
ИМЯ ( аргументы ) : переменные
213 Это редкий случай в UML, когда взаимное положение элементов на диаграмме имеет
значение. Во всех остальных случаях взаимное положение элементов не важно: все
определяется только инцидентностью элементов.
Глава 4. Моделирование поведений
На рис. 4.67 приведена метамодель сообщений.
Рис. 4.67. Метамодель сообщений
4.4.2. Диаграммы последовательности
Диаграмма последовательности предназначена для моделирования
поведения в форме описания протокола сеанса обмена сообщения-
ми между взаимодействующими экземплярами классификаторе во
время выполнения одного из возможных сценариев.
Из этого определения вытекают несколько следствий, определяющих состав
сущностей и набор отношений, используемых на диаграмме последователь-
ности (равно как и на диаграмме коммуникации).
• На диаграмме присутствуют только те экземпляры классификато-
ров, которые задействованы в данном взаимодействии. Прочие эк-
земпляры не показываются, хотя, возможно, и присутствуют в си-
стеме.
• Отображаются только те связи, которые нужны для передачи дан-
ной последовательности сообщений, прочие связи не показываются.
• Состав сообщений (а тем самым операций и сигналов) определяет-
ся назначением данного взаимодействия; в других взаимодействиях
эти же экземпляры классификаторов могут обмениваться другими
сообщениями.
Вышесказанное нуждается в пояснении. Утверждение о том, что на диаграм-
ме последовательности присутствуют экземпляры классификаторов, не со-
Го
4.4. Диаграммы взаимодействия
всем верное, точнее, не совсем полное. Чтобы понять это, давайте обратимся
к понятию связи и рассмотрим, что оно означает.
Связь
Связь (link) — это экземпляр отношения (например, ассоциации или
зависимости), представляющий собой набор ссылок на экземпляры
классификаторов, связанных между собой посредством этого отно-
шения.
Первое, на что требуется обратить внимание, — это то, что связи могут быть
как временными, так и постоянными. Постоянные связи суть экземпляры
ассоциаций. Временные связи могут и не быть экземплярами ассоциаций.
Для того чтобы один экземпляр классификатора смог вызвать метод дру-
гого, первый должен знать про второй. Знание это может быть получено не
только вследствие наличия ассоциации между соответствующими класси-
фикаторами, но и, например, по причине передачи второго экземпляра клас-
сификатора в качестве параметра операции для первого. Такая связь на диа-
грамме классов могла бы быть выражена отношением зависимости.
ОСЬ ВРЕМЕНИ И ВРЕМЯ ЖИЗНИ ОБЪЕКТОВ
Перейдем к описанию особенностей нотации диаграммы последовательно-
сти. Напомним, что в UML семантика первична, а нотация вторична: воз-
можны различные вариации в способах рисования диаграмм, особенно это
характерно для диаграмм последовательности. В наших примерах мы при-
держиваемся самого "скромного" стиля отображения диаграмм, с миниму-
мом украшений. Однако все допустимые возможности хотя бы по одному
разу в наших примерах указаны.
На диаграмме последовательности считается выделенным одно направле-
ние, соответствующее течению времени. По умолчанию считается, что вре-
мя течет сверху вниз, но это не обязательно, например, можно считать, что
время течет слева направо, оговорив это специальным комментарием. В на-
ших примерах используется исключительно нотация по умолчанию: время
всегда течет сверху вниз. Саму ось времени не отображают.
Сообщения изображаются прямыми стрелками разного вида (таблица 4.10).
Если передача сообщения считается мгновенной (т. е. время передачи пре-
небрежимо мало), то стрелка горизонтальна (т. е. перпендикулярна оси вре-
мени). Если же нужно отобразить задержанную доставку сообщения (trans-
mission delay), то стрелку немного наклоняют, так чтобы конец стрелки был
ниже начала.
ф
* • -.................—.............-------------—.........шЗ
Глава 4. Моделирование поведения
Среди сообщений есть первое, которое кладет начало данному взаимодей-
ствию. Стрелка этого сообщения расположена выше всех других стрелок
сообщений. Все экземпляры классификаторов, которые находятся выше
первого сообщения, существуют до начала данного взаимодействия; осталь-
ные, которые расположены ниже или на уровне первой стрелки, возникают в
процессе данного взаимодействия. Обычно экземпляр классификатора воз-
никает в результате выполнения конструктора классификатора.
Стрелку сообщения, которая рисуется пунктирной линией, соответствую-
щую вызову операции конструктора, принято направлять к фигуре (прямоу-
гольнику), обозначающей созданный экземпляр.
Примечание
Иногда на диаграмме не отображают элемент, отправляющий
первое сообщение (например, потому, что он не участвует в
дальнейшем взаимодействии). Стрелка первого сообщения
приходит "ниоткуда". Вообще говоря, синтаксически это не-
допустимо, и мы не рекомендуем использовать такой стиль,
поскольку он расходится с общепринятым способом ото-
бражения графов (вместе с отношениями всегда отображать
инцидентные им сущности). Лучше заключить диаграмму в
рамку и провести первое сообщение от границы рамки — это
синтаксически допустимо и соответствует стилю UML 2.
Линия ЖИЗНИ И СТРЕЛКИ СООБЩЕНИЙ
Параллельно оси времени от всех участвующих во взаимодействии объектов
отходит прямая пунктирная линия, которая называется линией жизни (life-
line). Линия жизни представляет объект во взаимодействии: если стрелка
отходит от линии жизни объекта, то это означает, что данный объект от-
правляет сообщение, а если стрелка сообщения входит в линию жизни, то
это означает, что данный объект получает сообщение. Если же стрелка пе-
ресекает линию жизни объекта, то это ничего не значит — сообщение проле-
тело мимо214. Если в процессе взаимодействия объект заканчивает свое суще-
ствование, то линия жизни обрывается и в этом месте ставится косой крест215.
Над стрелкой сообщения указывается текстовая часть описания сообщения.
Синтаксис этой части приведен в параграфе 4.4.1. Заметим, что номер сооб-
щения, равно как и номера предшествующих сообщений (см. параграф 4.4.5),
214 Обычно на диаграмме последовательности стараются располагать объекты таким об-
разом, чтобы стрелки сообщений не пересекали линий жизни. Впрочем, это не всегда
возможно.
215 Авторы некоторых книг считают этот знак буквой "X". Посмотрите на рис. 4.70 и решите
сами, кто прав.
4.4. Диаграммы взаимодействия
на диаграммах последовательности обычно не указывают, поскольку в этом
нет нужды: относительный порядок сообщений и так хорошо определяется
направлением оси времени.
Мы еще не закончили описание особенностей нотации диаграммы последо-
вательности, но чувствуем, что пора привести пример. Рассмотрим взаимо-
действие, возникающее при одном из простых сценариев в нашей информа-
ционной системе отдела кадров, а именно создание подразделения. Данное
взаимодействие инициируется внешним действующим лицом — менедже-
ром штатного расписания, который открывает соответствующую форму и
запускает выполнение операции создания подразделения, после чего закры-
вает более не нужную ему форму.
Общая схема взаимодействия для данного сценария приведена на рис. 4.68.
Обратите внимание, что помимо сообщений, которые соответствую!’ вызо-
ва Создание подразделения
Рис. 4.68. Диаграмма последовательности
вам методов (например,
1), на диаграмме при-
сутствует сообщение, со-
ответствующее вызову
конструктора(2).
Рассмотрим в дета-
лях взаимодействия
внутри компонента
StaffManagerGUI, при-
мерная структура ко-
торого представлена на
рис. 4.69.
Рис. 4.69. Основные классы компонента StaffManagerGUI
Глава 4. Моделирование поведения
Взаимодействие между объектами компонента Staff ManagerGUI для реализа-
ции сценария создания подразделения приведено на рис. 4.70.
Рис. 4.70. Диаграмма последовательности для элементов компонента
StaffManagerGUI
Метки времени
Вообще говоря, подразумеваемая ось времени на диаграмме последователь-
ности не является осью координат, на ней нет никакого масштаба, и она за-
дает только отношения "раньше-позже" для сообщений. Если же нужно в
явном виде указать ограничения по времени, например, указать, что время
задержки доставки сообщения должно быть ограничено сверху, то на диа-
грамму в нужном месте (имеет значение только положение по вертикали)
рядом с началом или концом стрелки сообщения помещают произвольные
идентификаторы, которые называются метками времени (time observation),
и добавляют временные ограничения, задающие требуемые условие на зна-
чения меток времени.
Метка времени — это именованная точка на линии жизни. Перед
меткой времени ставится символ
Допустим, что наша информационная система отдела кадров предназначе-
на для организации, имеющей удаленный филиал. В этом филиале имеется
и работает свой экземпляр информационной системы, который, очевидно,
должен быть проинформирован, что в головной организации создано новое
подразделение. Для реализации данной функциональности мы снова мо-
жем использовать образец проектирования Publisher-Subscriber. Диаграмму
классов для этого случая мы не приводим, а ограничимся лишь рассмотре-
е
4 4 ДИАГРАММЫ ВЗАИМОДЕЙСТВИЯ
нием следующей проблемы. Возможно, эта информация об изменениях в го-
ловной организации дойдет в филиал с некоторой задержкой, поскольку для
связи используется медленный канал передачи данных. Такую ситуацию
можно промоделировать диаграммой, приведенной на рис. 4.71, где метка
времени (1) в совокупности с временным ограничением (2), описывают за-
держанную доставку сообщения notify().
Рис. 4.71. Метки времени и задержанная доставка сообщения
Обратите внимание на линии (3 и 4 на рис. 4.71). Это графические коммен-
тарии, которые нужны для привязки метки времени и временного ограниче-
ния к требуемым точкам линии жизни.
Примечание
В UML 1 также существует подобный механизм, однако
он не имеет специальной графической нотации и пред-
ставляет собой ограничение, которое просто пишется ря-
дом с линией жизни. Например, для примера, изображен-
ного на рис. 4.71, это ограничение имеет следующий вид:
{notify.receiveTime — notify.sendTime < 24h}.
Привязка ко времени выполнения метода
Иногда возникает потребность использовать в ограничениях временные па-
раметры, привязанные не к точке отправки или принятия сообщения, а ко
времени, в течение которого выполняется метод (duration observation). Та-
ким образом, вводится переменная (перед именем которой ставится символ
"&"), которую можно использовать в ограничениях.
Приведем пример. Допустим выполнение метода createDpt() должно зани-
мать не более 3 секунд. Тогда возможны, например, следующие способы для
Глава 4. Моделирование поведения
задания этого условия, приведенные на рис. 4.72. В первом случае использу-
ется явное задание с помощью ограничения, которое задается после имени
метода (1), а во втором устанавливается переменная, которая ссылается на
длительность выполнения метода (2), и затем эта переменная используется
в ограничении (3).
Рис. 4.72. Варианты задания продолжительности выполнения метода
Фокус управления
Мы уже отмечали, что сообщение передает не только данные, но и поток
управления. Чтобы показать, что некоторый объект в определенный период
взаимодействия имеет фокус управления, или, как еще говорят, активизиро-
ван, на диаграмме последовательности используют специальный графиче-
ский элемент — спецификацию выполнения (execution specification), который
изображают в виде узкой полоски на соответствующей части линии жизни.
В UML 1 данный графический элемент называется активацией (activation).
Начало спецификации выполнения соответствует получению сообщения о
вызове метода, а конец — завершению выполнения метода и возврату управ-
ления. При этом если во время выполнения данного метода будет вызван
еще раз метод этого же объекта (тот же самый метод или другой), то это от-
мечается с помощью еще одной полоски активации, которая накладывается
сбоку на первую. Глубина стека вызовов и, соответственно, количество на-
ложенных полосок для одного объекта в UML, естественно, не ограничива-
ются.
СТЕК ВЫЗОВОВ ПРОЦЕДУР
За время развития языков программирования были придуманы и
реализованы самые различные механизмы обращения к подпро-
граммам, некоторые из них довольно причудливы. Один из них по-
лучил наибольшее распространение в традиционных языках про-
граммирования. При этом способе административная система
времени выполнения поддерживает так называемый стек вызовов
436
4.4. Диаграммы взаимодействия
(backtrace). При вызове подпрограммы в этот стек помещается
новый элемент (его часто называют фреймом), в котором хранят-
ся переданные аргументы, локальные переменные подпрограм-
мы и адрес возврата (т. е. информация о том, куда нужно вернуть
управление после завершения выполнения подпрограммы). Если
в процессе выполнения вызванной подпрограммы происходит
еще один вызов, то на стек вызовов помещается новый фрейм и
т. д. При завершении подпрограммы верхний элемент стека вызо-
вов снимается со стека и управление возвращается по сохранен-
ному адресу возврата. Данная структура данных является именно
стеком, поскольку фреймы всегда помещаются на стек и снима-
ются со стека в соответствии с дисциплиной LIFO (Last In First Out:
последним пришел — первым ушел).
На вершине стека вызовов всегда находится фрейм подпро-
граммы, выполняющейся в данный момент. Это соответствует
следующей семантике вызова: при вызове выполнение вызываю-
щей программы приостанавливается, управление (и аргументы)
передается вызываемой подпрограмме, а когда выполнение по-
следней закончится, возобновляется выполнение вызывающей
программы. Другими словами, выполнение вызывающей про-
граммы не может возобновиться ранее, чем закончится выполне-
ние вызванной. Данный механизм является простым, эффектив-
ным и удобным, что объясняет его широкое распространение и
использование в большинстве случаев по умолчанию.
Возврат управления
Для наглядности на диаграмме последовательности можно показать в явном
виде возврат управления (и, может быть, возвращаемое значение), хотя это
не обязательно: возврат управления подразумевается при использовании
сообщения типа вызов метода. Более того, если использовать полоски для
явного указания активации объектов, стрелки возврата не нужны: их легко
можно мысленно восстановить.
Рассмотрим применение этой группы обозначений на следующем примере
из информационной системы отдела кадров. Допустим, при создании нового
подразделения немедленно выполняется метод createBossPos() по созданию
новой должности (начальника) в этом подразделении и эта вакансия запол-
няется (свято место пусто не бывает), а после успешного создания подразде-
ления форма демонстрирует менеджеру штатного расписания измененную
организационную диаграмму компании (рис. 4.73).
Здесь мы используем как активации (1), в том числе вложенные (2), так и
возвраты (3), чтобы показать применение всех средств, хотя, может быть,
это немного перегружает диаграмму.
Глава 4. Моделирование поведения
Рис. 4.73. Активации и возвраты
Ветвление
Следующее средство, которое нам необходимо обсудить, — это ветвление.
Как сказано в параграфе 4.4.1, сообщение может иметь сторожевое условие.
Если сторожевое условие ложно, то сообщение просто не будет отправлено.
Соответственно, далее процесс взаимодействия пойдет иным путем.
Таким образом, сторожевые условия на сообщениях позволяют отобра-
зить на одной диаграмме взаимодействия несколько альтернативных по-
следовательностей сообщений. Но UML позволяет больше: можно из
одной точки активации отправить несколько различных сообщений (в том
числе адресованных разным экземплярам классификаторов), снабженных
альтернативными сторожевыми условиями. Не более чем одно из этих усло-
вий должно оказаться истинным — в противном случае это будет означать
одновременный вызов двух операций в одном потоке управления, что вряд
ли может иметь смысл и делает модель семантически противоречивой.
•
438 J
4.4. Диаграммы взаимодействия
Что будет, если два альтернативных сообщения (вызовы разных методов)
отправляются из данной точки активации одному и тому же экземпляру
классификатора? Вызываемый объект в любом случае будет активизирован
(мы предполагаем, что ровно одно из сторожевых условий истинно). Одна-
ко, это разные активации. Чтобы отразить это обстоятельство на диаграмме,
в UML 1 было введено еще одно обозначение: альтернативные линии жизни
(concurrent lifeline). Альтернативная линия жизни изображается как пун-
ктирная линия, которая ответвляется от основной линии жизни экземпляра,
а ниже сливается с ней. Как основная, так и альтернативные линии жизни
могут содержать активации.
Рассмотрим пример (он получился немного искусственным — все-таки диа-
граммы последовательности больше приспособлены для показа протоколов
чисто линейных программ). Допустим, мы хотим отобразить два сценария
создания подразделения: "под начальника" и исходя из потребностей орга-
низации. В обоих случаях при создании подразделения создается должность
начальника, но в первом случае она немедленно заполняется имеющимся
"нужным" человеком (вызов метода оссору()), а во втором объявляется ва-
Рис. 4.74. Сообщения со сторожевыми условиями и альтернативными
линиями жизни
Глава 4. Моделирование поведения
кантной (вызов метода free()). Чтобы не перегружать диаграмму, мы вклю-
чили описание только части взаимодействия, а именно ту часть, которая со-
ответствует выполнению метода createDpt() класса Company (рис. 4.74).
Диаграмма на рис. 4.74 выглядит не очень убедительно. Действительно, со-
общения передаются мгновенно, и это естественно изображать прямыми
горизонтальными линиями, поскольку время течет на диаграмме последо-
вательности сверху вниз. Но тогда линии альтернативных сообщений (1 на
рис. 4.74), входящие в соответствующие альтернативные линии жизни (2 на
рис. 4.74), должны быть нарисованы горизонтально и проходить через одну
точку. Как заметил еще Евклид, в обычной геометрии на плоскости это не-
возможно. Нам пришлось прибегнуть к ухищрениям: на рис. 4.74 линия со-
общений не прямая, а ломаная.
4.4.3. Составные шаги взаимодействия
К счастью, проблема рисования альтернативных сообщений встала перед
проектировщиками программного обеспечения очень давно и тогда же была
решена. Дело в том, что диаграммы последовательности UML по существу
заимствованы из другого графического языка описания поведения — MSC
(Message Sequence Chart)216, который был разработан и успешно применя-
ется производителями встроенных систем, Часть конструкций MSC была
заимствована еще в UML 1, а оставшиеся пришли с UML 2. В том числе в
UML 2 были заимствованы составные шаги взаимодействия (combined frag-
ment).
Составные шаги позволяют на диаграмме последовательности, которая фак-
тически является диаграммой протокола взаимодействия, отражать и алго-
ритмические аспекты, а не только последовательность передачи сообщений.
Составные шаги позволяют графически изображать на диаграмме после-
довательности ветвления, циклы и другие полезные конструкции управле-
ния. Делается это очень просто: на диаграмме рисуется рамка, в углу которой
указывается тип составного шага с помощью ключевого слова, а внутри шага
указываются частичные последовательности сообщений в соответствии с
правилами, присущими шагам данного типа.
Например, для ветвлений используется ключевое слово alt, а альтернатив-
ные последовательности сообщений рисуются внутри рамки просто после-
довательно, друг под другом. Операнды составного шага взаимодействия
отделяются пунктирной линией, и для них указываются соответствующие
сторожевые условия.
216 Стандарт MSC доступен для скачивания в Интернете: http://www.itu.int/rec/T-REC-Z.120
4.4. Диаграммы взаимодействия
Рис. 4.75. Составной швг взаимодействия
На рис. 4.75 приведена та же диаграмма последовательности, что и на
рис. 4.74, но с использованием составного шага взаимодействия.
Примечание
Полезно сопоставить составные шаги взаимодействия и
структурные узлы деятельности (см. параграф 4.3.8).
Согласитесь, что нотация MSC достаточно выразительна и удобна.
Классификация составных шагов взаимодействия
Составных шагов взаимодействия предусмотрено достаточно, чтобы запи-
сать любой алгоритм. В таблице 4.11 приведено описание всех составных
шагов взаимодействия. В первом столбце таблицы указано ключевое слово
и название составного шага. Во втором столбце указано количество шагов,
которые входят в составной шаг данного типа. Некоторые составные шаги
имеют фиксированное число составляющих шагов, другие допускают пере-
менное число составляющих шагов. В третьем столбце указано, какая до-
полнительная информация, помимо составляющих шагов, должна быть за-
Ф
Глава 4. Моделирование поведения
дана. В последнем столбце неформально описана семантика составного шага
взаимодействия.
Таблица 4.11. Составные шаги взаимодействия
Ключевое слово и нвзввние # Форм ВТ Описание
alt альтернатива (alternative) 2..* Сторожевое условие в каждом шаге Выбор и выполнение одной альтернативы. Если все сторожевые условия ложны, то ни один вложенный шаг не выполняется. Если несколько условий истинны, то выполняется один шаг, который выбирвется случайным образом. Можно использоввть предикат else. Пример см. на рис. 4.75
assert утверждение (assertion) 1 Обязательная последовательность. Если выполнение достигло данного составного шага, то далее выполнение может продолжиться единственным возможным образом, указанным в составляющем шаге. Данный составной шаг можно вставить в качестве составляющего шага в шаги consid- er и ignore, тем самым фильтруя сообщения, относительно которых формулируется утверждение Противоположно neg
break остановка 1 Сторожевое условие в шаге Прекращение составного шага более высокого уровня. Если сторожевое условие выполнено, то выполняется сам составной шаг, после чего прекращается выполнение того шага (более высокого уровня), в который входит данный составной шаг. В противном случае составляющий шаг break не выполняется. Пример см. на рис. 4.113
consider рассмотрение 1 Список сообщений Выделение рассматриваемых сообщений. В составляющем шаге рассматриваются только перечисленные сообщения. Прочие сообщения игнорируются. Противоположно ignore
critical критическая область (critical region) 1 Запрет прерываний. Последовательность событий на одной линии жизни в критической области не должна чередоваться никакими событиями на этой же линии жизни в других областях. Ключевое слово critical имеет приоритет над ключевым словом par.
ignore игнорирование 1 Список сообщений Выделение игнорируемых сообщений. В составляющем шаге игнорируются перечисленные сообщения. Прочие сообщения рассматриваются. Противопо- ложно consider
’ '*? .Як
4.4. Диаграммы взаимодействия
loop цикл 1 Верхняя и нижняя границы числа повторений и/или сторожевое условие Циклическое повторение составляющего шага, пока выполнено сторожевое условие. При этом если границы указаны, то составляющий шаг будет выполнен не менее чем нижняя граница раз и не более чем верхняя граница раз, независимо от значения сторожевого условия. Пример см. на рис. 4.76
neg отрицание (negation) 1 Запрещенная последовательность. Если выполнение достигло данного составного шага, то далее выполнение не может продолжиться способом, указанным в составляющем шаге. Данный составной шаг можно вставить в качестве составляющего шага в шаги consider и ignore, тем самым фильтруя сообщения, относительно которых формулируется запрещение Противоположно assert
opt необязател ьн ы й (optional) 1 Сторожевое условие в шаге Условное выполнение шага. Если условие выполнено, составляющий шаг выполняется, в противном случае пропускается. То же, что ait, но для одного шага. Пример см. на рис. 4.76
par параллельный (parallel) 2..* Параллельное выполнение шагов. Составляющие шаги выполняются парал- лельно, то есть события из разных шагов не имеют никакой взаимной упорядоченности. Противоположно strict. Пример см. на рис. 4.76
seq слабое упорядочение (weak sequencing) 2..* Слабое упорядочение шагов. Составляющие шаги выполняются параллельно, но события на каждой линии жизни происходят строго в том порядке, как указано расположением шагов. События на разных линиях жизни могут происходить в любом порядке и перекрываться. Промежуточный вариант между par и strict. Пример см. на рис. 4.113
strict строгое упорядочение (strict sequencing) 2..* Сильное упорядочение шагов. Составляющие шаги выполняются строго в том порядке, как указано, и не перекрываются. Противоположно par.
Комбинирование составных шагов взаимодействия
Составные шаги взаимодействия можно комбинировать. Приведем пример
из информационной системы отдела кадров. В этом примере рассматри-
вается одна процедура низкого уровня, а именно открытие сессии инфор-
мационной системы. Заметим, что пример характерный для диаграмм по-
Г443
Глава 4. Моделирование поведения
следовательности, которые лучше всего подходят для детального описания
поведения, близкого к программной реализации. Наша информационная си-
стема имеет 3-х уровневую архитектуру (см. параграф 3.4.3, рис. 3.54-3.55).
Рассмотрим только взаимодействие между пользователем (будем считать,
что это экземпляр действующего лица StaffManager), уровнем пользова-
тельского интерфейса (экземпляр компонента StaffManagerGUI) и уровнем
бизнес-логики (экземпляр компонента StaffManagement)217. При запуске
клиента нужно выполнить две задачи: во-первых, пользователь должен вве-
сти допустимое имя (пате) и пароль (password), а во-вторых, нужно про-
верить наличие лицензии на работу для данного клиента (может быть огра-
ничено число одновременно работающих клиентов, может быть ограничен
срок или могут быть иные лицензионные ограничения). Обе эти проверки —
составные части одной большой задачи — открытие сессии (start session),
протокол выполнения которой приведен на рис. 4.76.
sd Start session
Рис. 4.76. Использование вложенных составных шагов взаимодействия
217 Взаимодействие с СУБД мы не рассматриваем, чтобы не перегружать диаграмму.
4.4. Диаграммы взаимодействия
На это пользователю дается три попытки, что передано составным шагом
loop(1,3) (1 на рис. 4.76) и сторожевым условием продолжения попыток
[r1=false] (2 на рис. 4.76). Результат идентификации пользователя сохраня-
ется в переменной г1. Результат проверки лицензии сохраняется в перемен-
ной г2. Эти две проверки можно выполнять независимо друг от друга, то есть
параллельно (3 на рис. 4.76).
Вложенность
Разумеется, так же как и в случае со структурами управления в обычных
языках программирования, любой шаг, входящий в составной шаг взаимо-
действия, в свою очередь может быть составным шагом любого типа и так да-
лее на любую глубину вложенности. Однако в текстовой записи программы
на обычном языке легко обеспечить наглядность для вложенных конструк-
ций — достаточно применить обычную технику отступов. На диаграммах
это не так просто: вложенный шаг придется нарисовать во вложенной рамке
и так далее. Одна-две вложенных рамки — вполне терпимо (см. рис. 4.76).
Но три, четыре, пять уровней вложенности — придется использовать слиш-
ком мелкий масштаб, диаграмму будет трудно читать.
Для решения это проблемы используются две конструкции, по смыслу род-
ственные составным шагам взаимодействия, но отличающиеся от них син-
таксически.
Первая конструкция — использование взаимодействия (interaction use) -
означает ссылку на взаимодействие (обычно представленное диаграмм-
ной последовательности), определенное в другом месте. Синтаксически
использование взаимодействия задается такой же рамкой, как и составной
шаг, но с ключевым словом ref. Внутри рамки пишется имя взаимодействия,
на которое делается ссылка, возможно с аргументами и возвращаемыми
значениями. Использование данной конструкции позволяет нарисовать
сложное взаимодействие на нескольких диаграммах, оставляя каждую из
них обозримой. Например, задав взаимодействие по открытию сессии на
рис. 4.76, на рис. 4.77 мы можем использовать это взаимодействие.
Особенно часто конструкция ref применяется на обзорных диаграммах вза-
имодействия, которые рассматриваются в параграфе 4.4.4 и где приведена
диаграмма для этого же примера.
Вторая конструкция — продолжение (continuation) — фактически являет-
ся меткой218, обеспечивающей переход управления с одной диаграммы на
другую, нечто вроде оператора goto в языках программирования. Синтак-
218 В блок-схемах ЕСПД это называется коннектором, но термин "коннектор" занят в UML
совсем в другом смысле, а потому мы здесь его использовать не будем
Глава 4. Моделирование поведения
Рис. 4.77. Использование взаимодействия
сически это записывается так. В том месте диаграммы последовательности,
откуда надо передать управление, рисуется прямоугольник со скругленны-
ми углами, в котором пишется имя метки (1 на рис. 4.78)219, а в другом месте
на другой диаграмме, куда надо передать управление, этот же прямоуголь-
ник повторяется (1 на рис. 4.79).
Мы не будем придумывать новый пример, а модифицируем уже существую-
щий. Набор из двух диаграмм, представленных на рис. 4.78 и рис. 4.79, экви-
валентен диаграмме на рис. 4.77.
Отображение изменяющихся состояний объектов
Последний, сравнительно редко используемый элемент нотации диаграмм
последовательности, который мы хотим рассмотреть, — это отображения на
диаграмме последовательностей состояний объектов, которые могут изме-
няться в процессе выполнения сценария.
Данный прием имеет много общего с траекторией объекта на диаграмме дея-
тельности — визуализацией смены состояний объекта по ходу вычислений,
поэтому мы покажем его на уже рассмотренном примере: создание нового
219 Эта фигура внешне напоминает фигуру состояния, но не имеете ней ничего общего.
4Л. Диаграммы взаимодействия
sd Session (шаг 1)
Рис. 4.78. Использование продолжения. Часть 1
Рис. 4.79. Использование продолжения. Часть 2
Глава 4. Моделирование . .сведения -
подразделения с возможным назначением начальника нового подразделе-
ния (см. рис. 4.75).
Сначала обратимся к диаграмме автомата для класса Position, представлен-
Рис. 4.80. Состояния класса Position
Все, что нам сейчас нужно, — это знать, что при создании новой должности
(create) соответствующий объект переходит в состояние Vacant, в котором
и остается до тех пор, пока либо должность не будет кем-то занята (вызов
метода оссиру()), либо должность не будет удалена (destroy), т.е. вызван де-
структор класса Position.
На рис. 4.81 представлена диаграмма, основанная на рис. 4.75, но дополнен-
ная информацией о состояниях класса Position. Достигается это путем пока-
Рис. 4.81. Состояния объекта на диаграмме последовательности
4.4. Диаграммы взаимодействия
за на линии жизни данного объекта состояний (1), в которые он переходит,
получая сообщения.
4.4.4. Обзорные диаграммы взаимодействия
В UML 2 появился еще один тип диаграмм, который по названию принято
относить к диаграммам взаимодействия, — обзорные диаграммы взаимодей-
ствия.
Обзорная диаграмма взаимодействия (interaction overview diagram) —
это диаграмма деятельности, в которой используются узлы управ-
ления, не используются узлы данных, а вместо узлов действий и
деятельности используются фрагменты диаграмм взаимодействия в
В форме диаграмм последовательности или в форме ссылок на взаимо-
' действие. ЯЯ|г
' • . . .... '
Обзорные диаграммы взаимодействия заимствованы в UML2 из нотации
MSC. В языке MSC этот вид диаграмм более чем уместен, поскольку там
нет других средств описать поток управления в стиле блок-схем. Но в UML
обзорные диаграммы взаимодействия, с теоретической точки зрения, оче-
видно, излишни.
Мы считаем, что их включение в язык с практической точки зрения оправда-
но, потому что иногда эти диаграммы бывают очень удобны и позволяют ла-
конично и наглядно описать то, для чего они предназначены — общую схему
взаимодействия, оставляя раскрытие деталей другим диаграммам.
Рассмотрим еще раз
общее описание рабо-
ты информационной
системы отдела ка-
дров (см. рис. 4.77), но
теперь уже представ-
ленное на обзорной
диаграмме взаимодей-
ствия (рис. 4.82). Если
запуск сессии прошел
успешно, то начина-
ется взаимодействие с
пользователем. В про-
тивном случае сессия
сразу завершается.
sd Session
Рис. 4.82. Обзорная диаграмма взаимодействия
Глава 4. Моделирование поведения
4.4.5. Диаграммы коммуникации
Графических ухищрений на диаграмме коммуникации220 значительно мень-
ше — данный тип диаграмм графически очень лаконичен и, тем не менее,
чрезвычайно выразителен. Поэтому при рассмотрении элементов диаграмм
коммуникации мы больше внимания уделяем семантике, оставляя самооче-
видную нотацию для примеров. В частности, описания некоторых семанти-
ческих тонкостей, относящиеся также и к диаграммам последовательности и
опущенные в предыдущих параграфах, здесь восполнены.
Для начала мы остановимся на трех семантических понятиях, присущих
диаграммам взаимодействия, которые не имеют броского графического вы-
ражения, но являются важным аспектом прагматики диаграмм взаимодей-
ствия и могут быть просто не замечены и пропущены читателем, если он зна-
комится с языком, глядя только на картинки. Вдобавок эти понятия были
переименованы и переопределены при переходе от UML 1 к UML 2, а пото-
му возникает терминологическая путаница, особенно в русских переводах.
Читателю не следует пугаться необычных сочетаний слов в таблице 4.12.
Таблица 4.12. Некоторые понятия, связанные с кооперацией
UML 1 UML2 Обозначение Определение
Роль классификатора Роль (часть) name: Туре Обозначение слота объекта, участвующего во взаимодействии
Роль ассоциации Соединитель — Обозначение слота связи, вдоль которой осуществляется взаи- модействие
Контекст взаимодействия Кооперация <— - Статическая структура (граф), показывающая роли и связи
Объекты на диаграммах коммуникации
Как уже много раз было сказано, сущностями на диаграммах взаимодей-
ствия (в частности, на диаграмме коммуникации) являются объекты. Это
действительно так, но с одной оговоркой: объект на диаграмме взаимодей-
ствия может выступать в двух ипостасях. Это может быть конкретный ин-
дивидуальный объект, и тогда диаграмма описывает конкретное взаимодей-
ствие с участием данного объекта (условно можно сказать, что диаграмма
является экземпляром взаимодействия). Но также это может быть слот во
фрейме взаимодействия, подлежащий заполнению некоторым подходящим
220 Напомним, что изначально эти диаграммы назывались диаграммами кооперации и были
переименованы в диаграммы коммуникации в UML 2.0.
4.4. Диаграммы взаимодействия
объектом, и тогда диаграмма описывает множество взаимодействий, задавая
их общую схему (то есть условно можно сказать, что диаграмма коммуника-
ции является дескриптором класса взаимодействий).
ПРЕДСТАВЛЕНИЕ ЗНАНИЙ С ПОМОЩЬЮ ФРЕЙМОВ
Одной из ключевых проблем искусственного интеллекта явля-
ется представление знаний, т. е. выбор формы хранения знаний
в памяти компьютера. (Примером другой ключевой проблемы
искусственного интеллекта является исследование алгоритмов
поиска решения.) Были предложены различные способы пред-
ставления знаний: с помощью правил продукции, с помощью
логических формул и др. Одной из самых удачных оказалась
концепция фреймов, предложенная Минским более 40 лет тому
назад. Согласно этой концепции, знания представляются в виде
множества взаимосвязанных структур, которые Минский назвал
фреймами22''. Фрейм предназначен для описания одного по-
нятия или ситуации. Он имеет имя и набор именованных сло-
тов. Слот может быть не заполнен или заполнен, т. е. содер-
жать конкретное значение, процедуру или (ссылку на) другой
фрейм. Несмотря на внешнюю простоту этой идеи, она оказалась
удивительно плодотворной, как в смысле конкретной разработки
искусственно интеллектуальных программ, так и в смысле разви-
тия фундаментальных понятий в других областях информатики и
программирования.
Марвин Ли Минский, (Marvin Lee Minsky) род. 1927 — профессор
Массачусетского технологического института с 1958. В 1951 скон-
струировал первую обучающуюся машину со случайно связанной
нейросетью — SNARC.
Обладатель патентов на конфокальный сканирующий микроскоп
(1961) и головной графический дисплей (1963). Лауреат премии
Тьюринга 1969 года. Вместе с Сеймуром Папертом создал первую
«черепашку» на языке Logo.
Второй из рассмотренных случаев, т. е. когда на диаграмме подразумевается
слот, подлежащий заполнению объектом, называется в UML 1 ролью класси-
фикатора (classifier role), а в UML 2 просто ролью или частью (part ) в зави-
симости от контекста221 222. Синтаксически роль классификатора и конкретный
221 Этому термину не повезло: иногда его переводят (рамка, кадр), иногда оставляют в виде
транслитерации, но всегда используют без всяких оговорок о многозначности данного
термина, хотя в разных областях информатики он обозначает совершенно разные вещи:
от группы битов в телекоммуникационном сообщении до области на web-странице.
222 Название, прямо скажем, не очень удачное, а потому трудно переводимое. Все-таки
речь идет об экземпляре определенного классификатора.
Глава 4. Моделирование поведения
объект почти неразличимы: в обоих случаях изображается стандартная фи-
гура классификатора (прямоугольник), в которой вписано имя и классифи-
катор, разделенные двоеточием. Различие заключается в том, что в случае
использования роли классификатора имя предлагается не подчеркивать.
Примечание
К сожалению, указанное тонкое семантическое различие
многие инструменты игнорируют и подчеркивают имя роли
классификатора. Поэтому данная неправильность стала уже
правилом. Вообще говоря, вопрос о подчеркивании имени
роли классификатора является спорным. С одной стороны,
это не конкретный объект: в слот может быть подставлен лю-
бой подходящий объект (имя не нужно подчеркивать), с дру-
гой стороны, это все-таки слот объекта (имя объекта, нужно
подчеркивать). В таких спорных случаях проще полагаться
на инструмент (оставляя в уме собственное мнение).
Семантически объект и слот объекта — это разные вещи. В случае конкрет-
ного объекта имя — это личное имя объекта, а в случае роли классификатора
имя — это имя слота (или, как пишут авторы языка, имя роли, которую объ-
ект данного классификатора играет во взаимодействии). Самое замечатель-
ное состоит в том, что с прагматической точки зрения это и не важно: ведь
схема взаимодействия остается одной и той же, она не зависит от того, чем
именно заполнен слот (лишь бы там был объект подходящего класса и по-
сылал те сообщения, которые от него требуются).
Мы не уверены в абсолютной правомерности следующей аналогии, но все
же приведем ее. Мы надеемся, что следующие две фразы для читателя про-
звучат как цитаты (может быть, из забытого источника): от перемены мест
слагаемых сумма не меняется: 2+3=3+2; сложение коммутативно: а+6=й+а.
Первый пример — это экземпляр, второй — дескриптор. По нашему мнению,
использование роли классификатора на диаграмме взаимодействия анало-
гично использованию алгебраической переменной а при описании арифме-
тических законов.
Совершенно аналогично понятию роли классификатора вводится понятие
роли ассоциации (или соединителя в терминологии UML2). Отношения
между объектами (ролями классификаторов) — это связи, которые чаще
всего бывают экземплярами ассоциаций. Но если связь связывает роли
классификаторов, т. е. слоты объектов, то она сама является слотом — сло-
том связи, который называется ролью ассоциации.
4.4. Диаграммы взаимодействия
Примечание
У связи, в отличие от объекта, нет личного имени. Ее инди-
видуальность определяется набором объектов, которые она
связывает.
Контекст взаимодействия
Диаграмма коммуникации (равно как и диаграмма последовательности)
описывает поведение как взаимодействие, т. е. как протокол обмена сообще-
ний между объектами. Один и тот же объект может участвовать в различных
взаимодействиях, играя в них различные роли. Таким образом, взаимодей-
ствие всегда происходит в определенном контексте, который определяет-
ся множеством участвующих во взаимодействии объектов и связей. Не-
сколько утрируя, можно сказать, что диаграмма коммуникации, в которой
не указаны сообщения (и которая, тем самым, синтаксически неотличима от
диаграммы объектов), является контекстом взаимодействия.
Обычно контекст выбирается с расчетом на то, чтобы описать взаимодей-
ствие, имеющее определенную цель, скажем, выполнить сценарий варианта
использования или операцию (это наиболее типичные примеры примене-
ния диаграмм коммуникации). Варьируя контекст (добавляя и убирая роли
классификаторов и ассоциаций), можно скрывать или показывать детали
взаимодействия, описывая поведение на разных уровнях абстракции. Что-
бы пояснить данный тезис, нужно вернуться к понятию номера сообщения,
упомянутому в параграфе 4.4.1, и объяснить его детально.
Номер сообщения
Номер сообщения определяется в соответствии с положением сообщения
в последовательности сообщений данного взаимодействия. Если во взаи-
модействии используются только простые или асинхронные сообщения (см.
таблицу 4.10), то сообщения просто нумеруются, обычно подряд: 1,2,3 и т. д.
Сообщения с меньшими номерами предшествуют сообщениям с большими
номерами. Если же используются вложенные потоки управления, т. е. сооб-
щения типа вызова операции (см. таблицу 4.10), то сообщения нумеруются
более сложным образом.
Допустим, сообщение вызова некоторой операции имеет номер х. Тогда со-
общения, отправляемые при выполнении этой операции, будут иметь номера
х.1, х.2, х.З и т. д. Первое сообщение, отправляемое при выполнении вызова
х.1, будет иметь номер х.1.1 и т. д. Количество точек в номере соответству-
ет уровню вложенности потока управления, т. е. глубине стека вызовов (см.
параграф 4.4.2). Таким образом, например, сообщение с номером 1.2 пред-
Ф
Глава 4. Моделирование поведения
шествует сообщению с номером 1.2.3, а сообщение 2.1, напротив, следует за
сообщением 1.2.3. Если первым во взаимодействии является сообщение вы-
зова метода, то его номер часто не указывают (такое сообщение как бы имеет
неявный номер 0), чтобы не загромождать диаграмму повторяющимся всю-
ду номером первого сообщения и ненужной точкой.
Такая иерархическая десятичная нумерация удобна, поскольку задает отно-
сительный порядок сообщений на данном уровне вложенности вызовов и
позволяет описывать взаимодействие с нужной степенью детальности. На-
пример, если требуется раскрыть детали выполнения операции, вызванной
сообщением с номером х, т. е. показать, какие сообщения отправляются в
процессе выполнения данной операции, то достаточно добавить на диаграм-
му сообщения с номерами х.1, х.2 и т. д. (а также соответствующие целевые
объекты — роли классификаторов). Если же детали не нужны на данной ди-
аграмме, то сообщения можно удалить, при этом номера других сообщений
не меняются. Другими словами, в последовательности сообщений, образую-
щей взаимодействие, можно показывать больше или меньше элементов, и
при этом перенумерации элементов не требуется.
Если требуется показать, что некоторые сообщения выполняются парал-
лельно или что их можно выполнить в любом порядке, то им присваива-
ются одинаковые номера, но разные буквенные постфиксы. Например, со-
общения с номерами 1.1а и 1.1b можно выполнять в любом порядке или
параллельно.
Время жизни объекта
На диаграмме последовательности время жизни объекта относи-
тельно данного взаимодействия показывается графически, с помощью сме-
щения вниз символа объекта, создаваемого в процессе взаимодействия, и с
помощью символа уничтожения объекта (косой крест) на линии жизни уни-
чтожаемого объекта. На диаграмме кооперации в UML 1 для этой цели ис-
пользуются специальные ключевые слова, которые указываются для ролей
классификаторов в форме стандартных стереотипов и/или в форме стан-
дартных ограничений для сообщений (таблица 4.13).
В UML 2 эти ключевые слова не сохранились. Авторы языка в своих руко-
водствах предлагают пользоваться комментариями вместо ключевых слов.
Нам это кажется неудобным, и поскольку пользователь UML имеет право
определять свои стереотипы и ограничения, мы воспользуемся этим правом
и будем считать в наших примерах, что соответствующие ключевые слова
определены.
4,4. Диаграммы взаимодействия
Таблица 4.13. Стереотипы и ограничения для описания времени жизни объектов во взаимо-
действии на диаграмме кооперации в UML1
Ключевое слово Способ использования Описание
«create» стереотип операции в сообщении Операция создает объект, т. е. данное сообщение является вызовом конструктора
«destroy» стереотип операции в сообщении Операция уничтожает объект, т е. данное сообщение является вызовом деструктора
{destroyed} ограничение роли классификатора Объект уничтожается в процессе описываемого взаимодействия
{new} ограничение роли классификатора Объект создается в процессе описываемого взаи- модействия
{transient} ограничение роли классификатора Объект создается и уничтожается в процессе описываемого взаимодействия. Такой объект называется временным. Данное ограничение эквивалентно одновременному указанию ограни- чений new и destroyed
Рассмотрим пример из информационной системы отдела кадров. Рис. 4.83
семантически эквивалентен рис. 4.68 — эти диаграммы описывают одно и то
же взаимодействие. Мы рекомендуем читателю просто сравнить эти две диа-
граммы.
comm Создание подразделения
1: openStaffForm()
2: createDpt()
Рис. 4.83. Диаграмма коммуникации
Стереотипы полюса роли ассоциации
На диаграмме последовательности невозможно отобразить связи, имеющие
место, но не используемые для посылки сообщений, а на диаграмме комму-
никации это вполне возможно, а иногда бывает очень полезно. Большую
часть деталей статической структуры контекста, которые можно показать на
е
о
Глава 4. Моделирование поведения
диаграмме классов, можно показать и на диаграмме коммуникации. Сюда
относятся имена ролей на полюсах связей (ролей ассоциаций), направление
навигации, символы агрегации и композиции, квалификаторы и т. д.
Роли классификаторов и ассоциаций могут применяться на диаграмме ком-
муникации по-разному. Некоторые связи (роли ассоциаций) могут быть эк-
земплярами реальных (хранимых) ассоциаций, а другие могут быть сугубо
временными. Аналогично и объекты (роли классификаторов) могут быть
глобально существующими в системе, а могут быть локальными объектами,
временно используемыми для организации взаимодействия. Чтобы отобра-
зить все эти особенности, на диаграмме коммуникации используются стан-
дартные стереотипы для полюсов ролей ассоциации. Список этих стереоти-
пов приведен в таблице 4.14.
Таблица 4.14. Стереотипы полюса роли ассоциации на диаграмме кооперации в UML1
Стереотип Описание
«association» Объект на полюсе роли ассоциации связан с объектом на противоположном полюсе фактической связью, реализующей ассоциацию
«global» Объект на полюсе роли ассоциации имеет глобальную область определения относительно объекта на противоположном полюсе
«local» Объект на полюсе роли ассоциации имеет локальную область определения относительно объекта на противоположном полюсе, т. е. является временным объектом для выполнения операции
«parameter» Объект на полюсе роли ассоциации является параметром операции объекта на противоположном полюсе
«self» Роль ассоциации является фиктивной связью, введенной для моделирования вызова операции данного объекта
По поводу это таблицы нужно сделать такое же замечание, как и по пово-
ду предыдущей: все эти стереотипы отменены в UML 2, кроме последнего
(«self»), который объявлен устаревшим, но мы будем ими пользоваться —
имеем право!
Рассмотрим в качестве примера реализацию операции рисования много-
угольника (см. предварительно, пример с многоугольником в параграфе
3.3.6). Мы подробно прокомментируем обозначения на рис. 4.84, чтобы объ-
яснить все детали нотации на диаграмме коммуникации. Взаимодействие,
описывающее поведение операции, инициируется сообщением draw(). Для
этого сообщения номер не задан (обычная для UML практика опускания
очевидных вещей), а сообщение исходит из шлюза (gate) — точки на грани-
це диаграммы (1). Для выполнения операции draw() вызывается операция
drawSegment() (п-1 раз, где п — количество вершин многоугольника). Это
4.4. Диаграммы взаимодействия
задано с помощью повторителя (2) в сообщении с номером 1. Соответствую-
щее сообщение нагружено на связь со стереотипом «self», которая не являет-
ся реальным экземпляром ассоциации, а введена в модель только для того,
чтобы послать сообщение объекту из операции этого же объекта.
При каждом вызове операции drawSegment(i) определяются две вершины,
которые являются началом и концом стороны многоугольника. При этом
подразумевается, что нужные объекты можно получить, указывая значение
квалификатора (I и i+1 соответственно) (3). С помощью операции position(),
которая возвращает пару значений (4), определяются координаты точек вер-
шин многоугольника. При этом сообщениям даны номера 1.1а и 1.1b, что
означает, что их можно выполнять в любом порядке или параллельно (5).
После этого с помощью сообщения с номером 1.2 создается временный объ-
ект line по заданным координатам и затем вызывается его операция drawLine()
(сообщение с номером 1.3).
То обстоятельство, что объект line временный (6), т.е. существует только на
время выполнения операции drawSegment(), указывается с помощью стере-
отипа «local», указанного для имени полюса роли ассоциации segment. На-
конец, после отрисовки стороны объект line не нужен, и его можно удалить
сообщением с номером 1.4223.
Рис. 4.84. Структурные связи и стереотипы на диаграмме коммуникации
223 В современных графических библиотеках вряд ли кто-то будет для рисования линии вы-
зывать конструктор и деструктор соответствующего объекта — слишком накладно, но
наша цель в данном случае — показать использование локального объекта на диаграм-
ме коммуникаций
[457
Глава 4. Моделирование поведения
Метаморфоза, клон и мультиобъект
Диаграммы кооперации UML 1 имели еще несколько возможностей, кото-
рые не получили развития и были исключены в UML 2. Мы не будем приво-
дить примеров, но перечислим эти возможности, чтобы читатель мог судить
о том, какие вариации уже рассматривались и были признаны неадекватны-
ми, с тем чтобы не наступать дважды на одни и те же грабли.
Обычно объект, участвующий во взаимодействии, отображается на диаграм-
ме коммуникации один раз, даже если он получает и отправляет несколько
сообщений. Однако иногда нужно показать, что в процессе взаимодействия
объект меняет свое состояние (на программистском жаргоне это называется
метаморфозой) или, наоборот, создается копия объекта, которая начинает
жить независимой жизнью, но в том же самом начальном состоянии, что
и оригинал (на программистском жаргоне это называется клонированием).
Для этого используются зависимости с соответствующими стереотипами:
• «become» — зависимость с данным стереотипом проводится от
объекта в исходном состоянии к тому же самому объекту, но в из-
мененном состоянии. Имя состояния, как обычно, указывают в ква-
дратных скобках. Пример использования данного стереотипа см. на
рис. 4.89.
• «сору» — данный стереотип означает, что создается новый объект —
копия исходного. После создания копия объекта существует как но-
вый независимый объект.
Номер сообщения, вызвавшего клонирование или метаморфозу, указывает-
ся в комментарии, присоединенном к зависимости.
Нам осталось упомянуть один дополнительный элемент нотации, применяе-
мый на диаграмме кооперации только в UML 1 — мультиобъект.
Мулы нобъект (muitiobject) — это множество объектив, к которому со
общение можно отправить, как к единому целому.
Не следует путать сообщение мультиобъекту и широковещательное сообще-
ние. Сообщение мультиобъекту — это одно сообщение, которое отправля-
ется одному объекту (являющемуся коллекцией объектов).
Широковещательное сообщение — это множество одинаковых сообще-
ний, которые одновременно отправляются множеству различных объек-
тов.
4.4. Диаграммы взаимодействия
4.4.6. Диаграммы синхронизации
В UML2 введен новый224 тип диаграмм взаимодействия, созданный для
описания изменения состояния объектов с течением времени в результате
взаимодействия. Эти диаграммы в UML получили название диаграмм син-
хронизации (timing diagram).
Рассмотрение диаграммы начнем сразу с примера из информационной си-
стемы отдела кадров. На рис. 4.85 изображена диаграмма синхронизации
для объекта newDpt (например, см. рис. 4.83) экземпляра класса Department.
Рис. 4.85. Диаграмма синхронизации для одного объекта
В данном примере рассматривается смена состоянгш подразделения в про-
цессе его создания. Линия изменения состояния (state timeline) (1 на рис.
4.85) описывает изменение состояния объекта с течением времени225. В каж-
дый момент времени объект newDpt (2 на рис. 4.85) находится в одном из
нескольких заданных состояний (3 на рис. 4.85), отображаемых в диаграмме
на оси ординат. По оси абсцисс отображается время (4 на рис. 4.85) в некото-
рых единицах измерения. В нашем примере подразделение последовательно
меняет три состояния:
• JustCreated — подразделение только что создано и еще не имеет
структуры;
• WaitingForBoss — имеет незаполненную вакансию начальника;
• UnderPressure — подразделение имеет начальника и может, наконец,
спокойно работать.
Как видно, диаграмма синхронизации становится довольно громоздкой
при большом количестве возможных состояний. В связи с этим существует
упрощенный вариант нотации диаграммы синхронизации, представленный
на рис. 4.86.
224 Надо отметить, что инженеры-электронщики подобные диаграммы используют издав-
на.
225 Она может иметь как дискретный, так и непрерывный набор состояний.
Глава 4. Моделирование поведения
Рис. 4.86. Упрощенное представление диаграммы синхронизации
В упрощенном виде диаграммы синхронизации состояния объекта записыва-
ются между двух параллельных горизонтальных линий (1 и 2 на рис. 4.86) -
упрощенное представление линии изменения состояния, которые пересека-
ются в точках смены состояния (3 на рис. 4.86). Такой вид диаграмм более
компактен и предпочтительней при большом количестве возможных состоя-
ний.
Рассмотрим теперь, как можно показать взаимодействие объектов на диа-
граммах синхронизации. За основу возьмем взаимодействие, представлен-
ное на рис. 4.81 в случае, когда существует канд идат на позицию начальника
подразделения. Сравните это взаимодействие с диаграммой на рис. 4.87.
Рис. 4.87. Диаграмма синхронизации для нескольких объектоа
Ф
с
4.5. Моделирование параллелизма
На приведенной диаграмме видно, как объекты обмениваются сообщения-
ми, и одновременно показана смена их состояний. Единственное отличие по
сравнению с диаграммой на рис. 4.81 состоит в том, что мы добавили вызов
метод notify() (1 на рис. 4.87), с помощью которого подразделение получает
информацию о том, что ему назначен начальник.
Если для показа сообщения требуется нарисовать линию, пересекающую
большое количество линий изменения состояний, то можно использовать
метки продолжения (2 на рис. 4.87). Само сообщение при этом показывается
у начального или у конечного сегмента линии.
Диаграмма на рис. 4.87 подобна диаграмме на рис. 4.81, если абстрагировать-
ся от таких "мелочей", как иной способ представления линии жизни, другая
нотация объектов и кардинальная смена направления течения времени226.
Но у этих диаграмм есть важное отличие: наличие шкалы (засечек на оси
времени). На диаграммах синхронизации можно показать не только относи-
тельный порядок событий, но и их привязку к реальному ходу времени. Раз-
умеется, можно использовать любые единицы измерения, шкала времени не
обязана быть равномерной и не обязана быть непрерывной. Так же можно
объединять над общей шкалой времени диаграммы различных типов.
4.5. Моделирование параллелизма
Термин параллельность в программировании, вообще говоря, означает "од-
новременное" выполнение нескольких деятельностей. Слово "одновремен-
ное" в данном контексте означает, что невозможно (или не нужно) указывать,
какая из деятельностей происходит раньше другой во времени. Другими
словами, параллельные процессы не упорядочены во времени. Тем самым
термин "параллельный" противопоставляется термину "последовательный":
последовательные деятельности упорядочены во времени, причем линейно.
В UML (так же, как и в большинстве современных систем программирова-
ния) с каждой параллельно выполняемой деятельностью связывается по-
ток управления. Таким образом, моделирование параллельного (равно как
и квазипараллельного) поведения средствами UML сводится к описанию
параллельных потоков управления и способов взаимодействия между ними.
Средства описания параллелизма в UML отнюдь не противопоставлены
средствам описания последовательного поведения, напротив, они образуют
единое целое, поскольку параллельное программирование скорее общее пра-
вило, нежели экзотическое исключение. Мы отделили обсуждение средств
226 Нотация стрелок сообщений на диаграммах последовательности и синхронизации со-
впадают.
Глава 4. Моделирование поведения
описания параллельного поведения от средств описания последовательного
поведения только с целью упростить изложение основных идей каждого из
типов канонических диаграмм, используемых для описания поведения. В
последующих разделах поочередно рассматриваются отдельные опущенные
выше детали и конструкции диаграмм описания поведения, относящиеся к
моделированию параллелизма. Мы начинаем с простых и часто используе-
мых средств и постепенно переходим к более запутанным, а потому реже ис-
пользуемым.
4.5.1. Взаимодействие последовательных процессов
Начнем с обсуждения самого распространенного случая параллелизма. До-
пустим, что имеются227 несколько параллельно выполняющихся процессов,
каждый из которых имеет свой собственный поток управления. Если эти
процессы никак не взаимодействуют друг с другом (самый распространен-
ный случай), то нам ничего и не нужно моделировать.
Поведение каждого из процессов может быть описано любым из рассмо-
тренных выше способов (диаграммой автомата, диаграммой деятельности
или диаграммой взаимодействия). Если процессы не взаимодействуют, то
они независимы, и с точки зрения конечного результата поведения (состоя-
ния системы в целом) неважно, как именно реализованы параллельные про-
цессы: как физически параллельные, выполняемые на многопроцессорном
компьютере, квазипараллельные за счет квантования времени или последо-
вательно выполняемые в произвольном порядке. Но с точки зрения других
аспектов поведения, таких как, например, производительность, время реак-
ции, пропускная способность — способ реализации параллелизма является
очень существенным.
Мы вернемся к этому вопросу в параграфе 4.5.6, а здесь сосредоточимся на
моделировании поведения взаимодействующих процессов, которое должно
обеспечивать определенную функциональность, т. е. изменение состояния
системы.
Взаимодействие в (JML моделируется с помощью сообщений: синхронных
(вызовы операций) и асинхронных (посылка сигналов), см. параграф 4.4.1.
Типичный вариант: взаимодействие Maj пин состояний разных классов с по-
мощью действий, выполняемых на переходах.
Рассмотрим два класса из информационной системы отдела кадров: Person
и Position (рис. 4.88).
Рассмотрим теперь, как должна выполняться операция назначения сотруд-
227 Вопрос о том, как возникают (и исчезают) параллельные потоки управления чуть более
сложен и мы вернемся к нему несколько раз в следующих параграфах.
4.5. Моделирование параллелизма
Рис. 4.88. Классы Position и Person
ника на новую должность, т.е. операция перевода. Мы оставим в стороне
вопрос о том, в каком классе разумно определить данную операцию (на са-
мом деле это совершенно не важно), и положим, что операция назначения
сотрудника на должность имеет два параметра — сотрудник и должность:
assignP2P(person:Person, position:Position)
Допустим, что требуется обеспечить элементарный порядок в учете кадров
(на программистском языке — целостность данных): если сотрудник А на-
значен на должность Б, то и в должности Б должно быть записано, что ее
занимает сотрудник А, и наоборот. Другими словами, занятые должности и
сотрудники должны взаимно однозначно соответствовать друг другу, а сво-
бодные должности и сотрудники должны быть действительно свободны и не
должны содержать неадекватных ссылок друг на друга228. Требуемое пове-
дение операции assignP2P() можно описать с помощью диаграммы объектов
(фактически это контекст взаимодействия, см. параграф 4.4.5), на которой
показано, как должны измениться связи между объектами в результате вы-
полнения операции (см. рис. 4.89). В данном описании контекста рассматри-
вается типичный сценарий, в котором до выполнения операции сотрудник
занимает некоторую должность, а целевая должность вакантна.
Мы видим, что при назначении сотрудника на должность задействованы три
объекта: oldPosition, newPosition и person. Требуемое поведение может быть
обеспечено за счет взаимодействия автоматов, реализующих поведение каж-
дого из этих объектов. На рис. 4.90 и рис. 4.91 приведены диаграммы машин
состояний для классов Position и Person соответственно. Обратите внимание
228 Мы не утверждаем, что наше решение с хранением взаимных ссылок является един-
ственно возможным, и даже не утверждаем, что это решение является хорошим — мы
рассматриваем пример взаимодействия конечных автоматов.
Глава 4. Моделирование поведения
Before After
Рис. 4.89. Изменение связей и состояний объектов при выполнении операции
перевода сотрудника
на изоморфизм графов переходов этих машин состояний — это не случайное
обстоятельство. Классы Position и Person в нашей модели совершенно равно-
правны, и их поведение по отношению друг к другу совершенно симметрич-
но.
Рис. 4.91. Машина состояний класса Person
4.5. Моделирование параллелизма
В таком случае операция назначения сотрудника на должность assignP2P()
может быть реализована двумя вызовами операций над объектами, являю-
щимися ее аргументами:
position. осей ру (person)
person. assign( position)
Мы подошли к кульминации данного примера: указанные две операции
можно вызвать в любом порядке или параллельно, более того, их можно вы-
зывать с ожиданием возврата управления или без ожидания, т.е. синхронно
или асинхронно — в любом случае взаимодействие автоматов, приведенных
на рис. 4.90 и рис. 4.91, обеспечит требуемое поведение (если только в про-
цесс обмена сообщениями не вмешается "посторонний" вызов операции
одного из этих объектов).
Наш пример достаточно прост для того, чтобы последнее утверждение мож-
но было считать очевидным, но для усиления примера мы приводим на рис.
4.92 и рис. 4.93 диаграммы последовательности, описывающие возможные
протоколы взаимодействия при выполнении операции assignP2P(). Для на-
глядности мы указали на диаграммах состояния объектов.
sd assignP2P() (первый вариант)
position:
Position
person:
Person
oidPosition
: Position
Vacant
Assigned
Occupied
occupy) person)
{thePerso’n=person}
Occupied
assign( position)
free()
{thePosilionposition)
Assigned
Vacant
Рис. 4.92. Первый сценарий выполнения операции assignP2P()
Заметим, что на диаграммах последовательности можно не только показы-
вать, в каком состоянии находится объект, но и какие значения принимают
его атрибуты (1 на рис. 4.93).
Глава 4. Моделирование поведения
sd assignP2P() (второй вариант)
Рис. 4.93. Второй сценарий выполнения операции assignP2P()
В качестве очень полезного упражнения229 мы оставляем читателю разбор
случая, когда два сообщения: occupy(person) объекту position и assign(position)
объекту person отправляются одновременно.
Параллельное программирование — мощный способ моделирования пове-
дения, и взаимодействующие конечные автоматы — великолепное средство
параллельного программирования.
Утверждение предыдущего абзаца, безусловно, верно, но у медали есть и
оборотная сторона. Исчерпывающее изложение приемов параллельного
программирования не входит в множество целей данной книги, но умолчать
о типичных трудностях, подстерегающих на этом пути, мы не вправе. Рас-
смотрим два примера несложных, но типичных ошибок, которые можно до-
пустить, моделируя поведение с помощью взаимодействующих автоматов.
Первый из них — "усовершенствование" предыдущего примера. Давайте
рассуждать. Объекты класса Position и класса Person либо существуют сами
по себе, либо образуют пары и хранят ссылки друг на друга. Пара объектов
с правильными ссылками образуется при совместном выполнении соответ-
ствующих операций оссиру() и assign(). Значит, для обеспечения целост-
ности данных нужно гарантировать, чтобы любой вызов операции оссируО
сопровождался вызовом операции assign() и наоборот. То есть будет доста-
точно вызвать одну из операций, а вторая всегда будет вызвана автомати-
чески (1). Это можно сделать, включив в машину состояний объекта вызов
парной операции, например, так, как показано на рис. 4.94230.
229 Это упражнение нетрудно выполнить "устно", глядя на диаграммы на рис. 4.90 и на
рис. 4.91 и отслеживая переходы и выполнение действий в автоматах. При этом не сле-
дует забывать, что действия на переходах и на входе/выходе атомарны и мгновенны.
230 Для наглядности и экономии места мы поместили на одну диаграмму две машины со-
стояний, убрав ненужные в данном контексте начальные и заключительные состояния.
в
4.5. Моделирование параллелизма
Рис. 4.94. Бесконечная взаимная рекурсия
Диаграммы на рис. 4.94 и предшествующее рассуждение выглядят очень
правдоподобно, но на самом деле являются ошибочными. Действительно,
как нетрудно сообразить, вызов одной операции повлечет вызов парной, та,
в свою очередь, еще раз вызовет исходную и т. д., возникнет бесконечная вза-
имная рекурсия. "Улучшение" привело к тому, что модель стала семантиче-
ски противоречивой.
Второй пример — так называемая ситуация тупика или взаимной блокировки
(dead-lock). Возьмем за основу диаграмму последовательности, представлен-
ную на рис. 4.93, и внесем в нее одно изменение, а именно, прежде чем пере-
водить сотрудника с одной позиции на другую, убедимся, что новая позиция
вакантна. Если это не так, то будем ожидать наступления соответствующего
события. На рис. 4.95 представлены две диаграммы деятельности, соответ-
Рис. 4.95. Ситуация взаимной блокировки
Глава 4. Моделирование поведения
ствующие ситуации одновременного перевода двух сотрудников на новые
позиции. Изначально сотрудник Е1 находится на должности Р1 и сотрудник
Е2 на должности Р2. Требуется поменять должности у этих сотрудников, т.е.
назначить сотрудника Е1 на должность Р2, а сотрудника Е2 на должность Р1.
При попытке параллельного использования алгоритма, описанного на рис.
4.95, мы столкнемся с взаимной блокировкой. Оба вычислительных процес-
са будут ждать сигнала о том, что требуемая им должность свободна (1 на
рис. 4.95), но этого никогда не произойдет, так как другой вычислительный
процесс, от которого ожидается данный сигнал (2 на рис. 4.95), находится в
точно такой же ситуации (1 на рис. 4.95).
Многие трудности такого рода, возникающие при описании поведения, хо-
рошо изучены и известны различные приемы их преодоления. Мы не будем
здесь их описывать — пары примеров достаточно, чтобы обратить внимание
читателя на то обстоятельство, что при моделировании взаимодействия па-
раллельных процессов есть над чем подумать.
4.5.2. Параллельная обработка данных
При проектировании и реализации информационных систем, равно как
и других приложений, очень часто возникает ситуация, когда некоторую
операцию нужно применить к множест ву объектов, причем на самом деле
порядок применения операции не имеет значения. Например, процедура
ежемесячного начисления заработной платы применяется в подавляющем
большинстве отечественных организаций ежемесячно ко всем сотрудни-
кам. Если некоторым сотрудникам не нужно начислять зарплату по тем или
иным причинам, то это проще реализовать с помощью проверки внутри про-
цедуры начисления, нежели исключать сотрудников из множества всех со-
трудников перед применением процедуры.
В обычных условиях порядок начисления зарплаты не является существен-
ным — зарплата каждому сотруднику начисляется индивидуально и неза-
висимо. Таким образом, зарплату можно начислять параллельно! Приведем
небольшой список других жизненных примеров, имеющих ту же природу и
моделируемых теми же средствами параллельной обработки данных.
• Рассылка серийного письма всем адресатам списка рассылки. Текст
письма настраивается по индивидуальной информации адресата.
• Выборка из базы данных записей, отвечающих определенному кри-
терию (оператор select языка SQL). Критерий проверяется неза-
висимо для каждой записи.
• Создание заказа из нескольких позиций. Каждая позиция создается
и заполняется независимо от остальных.
Ф
4 5. Моделирование параллелизма
Если провести соответствующий анализ, то легко заметить, что на практи-
ке параллельная обработка данных является скорее правилом, нежели ис-
ключением. Мы просто привыкли программировать обработку данных по-
следовательно, с помощью циклов со счетчиком и массивов с индексами,
хотя существо дела, может быть, не требует ни циклов, ни массивов. При
обучении программированию всем без исключения учащимся одной из пер-
вых предлагается следующая элементарная задача: найти сумму S заданных
чисел а., i = 1, ..., п. Учащегося не оставят в покое, пока он не "выдаст"
следующее "единственно верное" решение231:
var А : array[l..n] of real; S : real; i : integer;
S := 0; for i:=l to n do S := S + A[i];
Поскольку это упражнение проводится в самом нежном возрасте и всегда
доводится "до ответа", учащиеся накрепко привыкают использовать цикл со
счетчиком и массив всегда. В старых системах программирования это было
оправдано, поскольку средства параллельной обработки данных были мало
распространены. Но во многих новых языках и системах программирования
такие средства есть: например, есть коллекции (неупорядоченные множе-
ства), есть циклы по структурам данных (в частности, цикл по множеству,
for each). Мы думаем, что было бы очень неплохо, если бы от учащихся
при решении задачи суммирования элементов принимали бы и другие от-
веты, например такой, как в следующих двух строчках232.
var А : bag [n] of real; S : real;
S := 0; for each aeA do S := S + a;
Динамическая параллельность как средство моделирования
ПАРАЛЛЕЛЬНОСТИ В UML1
В UML 1 было предложено следующее средство моделирования паралле-
лизма на диаграммах деятельности: динамическая параллельность (dynamic
concurrency). На диаграмме деятельности UML 1 динамическая парал-
лельность изображается с помощью указания кратности для деятельности.
Смысл этого обозначения состоит в том, что в процессе выполнения несколь-
ко экземпляров указанной деятельности должны выполняться параллельно.
Сколько именно экземпляров — определяется кратностью (которая может
быть задана символом *, т. е. быть не ограниченной). Редко бывает так, что
нужно реально выполнять параллельно одну и ту же деятельность233. Скорее
231 Для записи примера мы использовали здесь конкретный синтаксис, близкий к синтак-
сису языка Паскаль.
232 А в записи этого примера мы использовали выдуманный нами синтаксис, увы...
233 Иногда это бывает абсолютно необходимо, например, при тестировании производи-
тельности.
Глава 4 Mofli ликование поведения
всего, параллельно выполняемые экземпляры деятельности различаются
значениями каких-то аргументов, которые определяют их специфику. Спе-
циального синтаксиса для указания этих деталей в UML 1 не определено — в
модели предлагается специфицировать все детали с помощью текстуальных
пояснений.
Продолжим рассмотрение элементарного примера: имеется множество чи-
сел и нужно найти их сумму. Складывать числа можно в любом порядке, в
том числе и параллельно, если присваивание считается атомарной операци-
ей. В UML 1 предлагается моделировать подобные ситуации с применением
кратности (1) примерно так, как показано на рис. 4.96.
Рис. 4.96. Динамическая параллельность в UML 1
Динамическая параллельность может показаться каким-то чужеродным те-
лом в UML, но в сущности это не более чем синтаксическое сокращение для
моделирования типичной задачи параллельного программирования: имеет-
ся некоторое множество объектов, и нужно выполнить одну и ту же опера-
цию (деятельность) для каждого объекта.
Область разложения как средство моделирования параллельности
BUML2
В UML 2 динамическая параллельность была исключена как синтаксически
не очень удачная конструкция, но вместо нее была введена новая конструк-
ция — область разложения. Область разложения работает с коллекциями.
Коллекция (collect ion) — это совокупность однотипных идентифици-
рованных объектов, поддерживающая работу со всей совокупностью
в целом, а также с отдельными элементами по их идентификаторам.
Частные случаи коллекций встречаются практически во всех языках и си-
стемах программирования. Например: массивы, списки, множества.
4 5. Моделирование параллелизма
Область разложения234 (expansion region) это структурированный
узел дея1 ельностр, который получает коллекцию на вход, разлагав i
коллекцию на состаклякицие элементы и производит указанные дей-
ствия индивидуально с каждым элементом коллекции.
Действия над элементами коллекции в области разложения могут выпол-
няться одним из следующих трех способов, указываемых ключевым словом.
• Последовательным потоком (ключевое слово «iterative»). Создается
столько маркеров данных и столько экземпляров фрагмента графа
деятельности в области разложения, сколько элементов содержит-
ся в коллекции. Выполнение экземпляров является зависимым: они
выполняются строго по очереди, в том порядке, который задает кол-
лекция, и следующий экземпляр не начинает обрабатываться, пока
не закончилась обработка предыдущего.
• Параллельным потоком (ключевое слово «parallel»). Создается столь-
ко маркеров данных и столько экземпляров фрагмента графа дея-
тельности в области разложения, сколько элементов содержится в
коллекции. Выполнение экземпляров является независимым: они
выполняются в произвольном порядке или параллельно.
• Конвейерным потоком (ключевое слово «stream»). Создается столь-
ко маркеров данных, сколько элементов содержится в коллекции,
но только один экземпляр фрагмента графа деятельности. Маркеры
данных передаются последовательно в этот один экземпляр фраг-
мента графа деятельности в том порядке, который определяет кол-
лекция, причем следующий маркер передается сразу же, как только
он может быть принят, не дожидаясь окончания обработки предыду-
щего маркера. Таким образом, сразу несколько маркеров данных —
элементов коллекции — могут находиться на разных стадиях одной
обработки, как на конвейере.
Пример приведен на рис. 4.97. Область разложения изображается в виде
фрагмента графа деятельности, заключенного в пунктирную рамку (1).
Входная (и выходная) коллекция приходит (и уходит) через узлы дан-
ных, называемые узлы разложения (2), которые изображаются как группы
маленьких квадратиков, перекрывающих границу области. Они обладают
специальной семантикой, которая предполагает разложение коллекции на
элементы на входе и обратную операцию на выходе. Область расширения на
рис. 4.97 обозначена как последовательная (3), потому что хотя суммировать
234 Применяют и прямой вариант перевода: "область расширения”. Наш перевод точнее
отражает семантику, поскольку речь идет не об увеличении значения, а о разложении
коллекции на составляющие элементы.
Глава 4. Моделирование поведения
Рис. 4.97. Последовательная область разложения
можно в любом порядке, но переменная S одна, и ее значение должно увели-
чиваться последовательно.
Из узлов за пределами области разложения к узлам разложения могут идти
стрелки потоков данных. Типы этих потоков данных являются коллекциями
(2 на рис. 4.97).
Обратимся к примеру более близкому к информационной системе отдела
кадров: начисление зарплаты. Зарплату, как правило, можно начислять па-
раллельно (рис. 4.98).
Рис. 4.98. Параллельная область разложения
Если, как в нашем примере, внутри области разложения содержится всего
одно действие, например действие по вызову некоторой деятельности (1 на
рис. 4.98), и область разложения параллельна (2 на рис. 4.98), то можно ис-
пользовать сокращенную нотацию для области разложения, помещая узлы
разложения прямо на границу фигуры действия (1 на рис. 4.99). При этом
тот факт, что данное действие должно выполняться параллельно, отмечается
с помощью знака * (2 на рис. 4.99) в правом верхнем углу фигуры действия.
Тем самым нотация UML 1 (см. выше рис. 4.96) оказывается частным случа-
ем нотации UML 2.
4.5. Моделирование параллелизма
Рис. 4.99. Сокращенная нотация для области разложения
Но само начисление зарплаты — это сложный процесс, который можно раз-
ложить на параллельные составляющие.
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
1
Заработная плата работников состоит из постоянного оклада и надбавки, ’
которая не зависит от оклада, но зависит от текущих производственных
показателей. Налоги удерживаются с общей начисленной суммы.
На рис. 4.100 представлена конвейерная область разложения (1), в кото-
рой два действия: начисление оклада (Calc salary) и начисление надбавки
(Calc bonus) выполняются независимо для каждого сотрудника, а третье
действие, вычисление налогов (Calc taxes), проводится только после того,
как начислены оклад и надбавка для данного работника.
Рис. 4.100. Конвейерная область разложения
[ 473
к.
Глава 4. Моделирование поведения
В дополнение к сказанному заметим, что область разложения может об-
рабатывать несколько коллекций. При каждом выполнении области будет
браться по элементу из каждой коллекции. Таким образом, коллекции на
входе должны содержать одинаковое число элементов, но не обязательно
одного типа. Количество коллекций на входе может не совпадать с их коли-
чеством на выходе. Наряду с "векторными" параметрами, область разложе-
ний может иметь и "скалярные” параметры, как входные, так и выходные,
которые изображаются как обычные контакты. Можно уверенно сказать,
в UML 2 предложены современные и адекватные средства моделирования
параллельной обработки данных, и мы настойчиво рекомендуем читателю
научиться ими пользоваться!
4.5.3. Ортогональные состояния и составные
переходы
В этом параграфе рассматриваются средства описания параллельности, при-
меняемые на диаграммах автомата.
На диаграммах автомата параллельное выполнение моделируется с по-
мощью ортогональных (параллельных)235 составных состояний (см. пара-
граф 4.2.7). По существу, идея параллельных состояний очень проста и лег-
ко воспринимается: внутрь составного состояния вложено несколько машин
состояний, которые работают параллельно.
Чтобы интуитивное понимание этой идеи обрело прагматику, необходимую
для практического применения при моделировании, нужно ввести и точно
определить несколько специфических понятий и конструкций, а именно:
• активное состояние;
• конфигурация активных состояний;
• область ортогонального составного состояния;
• составной переход;
• синхронизирующее состояние.
Выше несколько раз было использовано (без специального определения)
интуитивно ясное понятие активного состояния. Пора дать более строгое
определение. Начнем с фиксации интуитивно очевидного.
235 Напомним, что в UML 2 параллельные состояния переименованы в ортогональные. Та-
кое переименование оправдано, поскольку ортогональные составные состояния факти-
чески являются прямым произведением вложенных машин состояний в терминах тео-
рии автоматов. Еще лучше было бы, если ортогональными назвать не сами составные
состояния, а вложенные машины состояний!
*
4 5 Моделирование параллелизма
Активное состояние
Активное состояние (active state) — это состояние, в котором нахо-
дится машина состояний в данный момент.
Применительно к машине состояний, в которой все состояния простые (т. е.
машина состояний — обычный конечный автомат), данное определение
однозначно: действительно, по определению такая машина во время своей
работы всегда находится ровно в одном из своих простых состояний (напом-
ним, что простые переходы мгновенны, а в специальных состояниях машина
не находится).
Если машина содержит последовательные составные состояния, то ее
структуру удобно представить в виде корневого (ориентированного) дере-
ва: корнем является составное состояние, соответствующее всей машине в
целом (это объясняет, зачем нужен атрибут top у метакласса StateMachine на
рис. 4.6), а листьями являются простые состояния. На рис. 4.101 приведена
соответствующая иллюстрация: слева машина состояний в нотации UML, а
справа — представление этой машины в виде дерева236.
Рис. 4.101. Машина состояний нее представление в виде дерева
Из нашего объяснения семантики последовательных составных состояний
и простых переходов между ними, приведенного в параграфе 4.2.4, следует,
что в последовательной машине состояний (т. е. в машине, в которой все
составные состояния последовательные) ровно одно простое состояние
является активным в каждый момент времени работы машины. Но наряду
с активным простым состоянием естественно считать активными и все со-
ставные состояния, объемлющие данное простое состояние — ведь машина
пребывает и в этих объемлющих состояниях также. Все активные состояния
образуют так называемую конфигурацию активных состояний (active state
236 Обращаем внимание, что дерево справа не является допустимой диаграммой UML, хотя
при рисовании и использовались отдельные элементы нотации UML.
475 :
Глава 4. Моделирование поведения
configuration), т.е. множество вершин на пути от корня к листу в дереве вло-
женности состояний.
Конфигурация активных состояний
Обратимся теперь к ортогональным составным состояниям. Начнем с нота-
ции. Ортогональное составное состояние может иметь три раздела: раздел
имени, раздел составляющих (действие на входе, действие на выходе, вну-
тренняя активность и внутренние переходы) и раздел вложенных состояний.
Относительно разделов имени и составляющих здесь нечего добавить к тому,
что сказано в параграфах 4.2.1 и 4.2.4, разве что стоит отметить, что оба этих
раздела могут быть опущены (в то время как для простых состояний раздел
имени является обязательным). Стоит также заметить, что в UML 2 имя со-
ставного состояния можно писать не внутри фигуры состояния, а в ярлычке,
прикрепленном к фигуре состояния (1). В разделе вложенных состояний в
случае последовательного составного состояния просто изображается вло-
женная машина состояний (2), а в случае ортогонального составного состоя-
ния данный раздел делится горизонтальными пунктирными линиями на не-
сколько областей (3) (orthogonal region), в каждой из которых изображается
вложенная машина состояний (рис. 4.102).
Рис. 4.102. Параллельное (ортогональное) составное состояние
Данная нотация весьма наглядна, но до некоторой степени скрывает одно
важное семантическое обстоятельство, которое иногда ускользает от внима-
ния при поверхностном знакомстве с UML. А именно, каждая область орто-
гонального составного состояния — это, в свою очередь, составное состояние
и может иметь все составляющие состояния. На диаграммах обычно обла-
стям не дают имен (на нашей диаграмме они как раз специально указаны)
(4 на рис. 4.102), поэтому кажется, что вложенная машина состояний как бы
"висит в воздухе" внутри составного ортогонального состояния, но на самом
деле вложенная машина "завернута” в составное состояние, которое и явля-
4.5. Моделирование параллелизма
ется непосредственной составляющей данного ортогонального составного
состояния.
Таким образом, семантика параллельных и последовательных составных со-
стояний совершенно симметрична. И в том и в другом случае составное со-
стояние имеет несколько вложенных состояний. Если составное состояние
активно, то в случае последовательного составного состояния ровно одно из
вложенных состояний активно в каждый момент времени. В случае парал-
лельного составного состояния все вложенные состояния активны в каждый
момент времени. Подобно тому, как структуру машины состояний с после-
довательными составными состояниями удобно представлять в виде обыч-
ного ориентированного дерева, структуру машины состояний удобно пред-
ставлять в виде дерева И/ИЛИ.
ДЕРЕВО И/ИЛИ
Дерево И/ИЛИ — это один частный случай ориентированного ги-
перграфа, который нашел удивительно широкое применение при
решении самых разнообразных задач. В дереве И/ИЛИ имеется
ровно один узел, в который не входят дуги (корень дерева); во все
остальные узлы дерева входит ровно одна дуга. Среди них имеется
некоторое количество узлов, из которых не исходят дуги (листья
дерева). Все не листовые узлы разбиваются на два класса: узлы
типа "И" и узлы типа "ИЛИ". Из узла типа "ИЛИ" исходит несколько
обычных дуг, каждая из которых ведет в свой узел, а из узла типа "И"
исходит одна гипердуга, которая ведет сразу в несколько узлов.
Таким образом, движение по дереву И/ИЛИ (гиперпуть) от корня
к листьям происходит следующим образом: находясь в узле типа
"ИЛИ", нужно выбрать одну из исходящих дуг и перейти по ней, по-
падая в первый, или второй, или третий и т. д. дочерний узел, а на-
ходясь в узле типа "И", нужно выбрать всю (единственную) гипер-
дугу и перейти по ней, попадая в первый, и второй, и третий и т. д.
дочерний узел. Отсюда и происходит название "дерево И/ИЛИ".
Деревья И/ИЛИ очень часто применяются в искусственном интел-
лекте. Например, при программировании дискретной игры для
двух играющих (игроки по очереди делают ходы, в результате чего
дискретно меняется позиция) с точки зрения одного из играю-
щих игру очень удобно представить деревом И/ИЛИ, в котором
узлы соответствуют позициям, а дуги — ходам. При этом пози-
ции, в которых делает ход данный игрок, будут иметь тип "ИЛИ",
а позиции, в которых очередь хода у противника, будут иметь тип
"И”. Действительно, при составлении стратегии игры для первого
игрока он может выбирать тот или другой ход, когда очередь хода
за ним, но когда ходит противник, выбирать не приходится — нуж-
но учесть все возможные ответы противника, т. е. они соединены
связкой "И".
Глава 4 Моделирование поведения
Рис, 4.103. Дерево И/ИЛИ для машины состояний с параллельными
составными состояниями
На рис. 4.103 представлено дерево И/ИЛИ для машины состояний, изобра-
женной на рис. 4.102. Простые дуги, исходящие из узла типа "ИЛИ", соеди-
нены ограничением {XOR}, поскольку при построении пути в дереве должна
быть выбрана одна и только одна такая дуга. Сегменты гипердуги, исходя-
щие из узла типа "И", соединены ограничением {AND}, поскольку при по-
строении пути в дереве должны быть выбраны все сегменты гипердуги.
Таким образом мы подошли к понятию конфигурации активных состояний.
Конфигурация активных состояний — это путь (гиперпуть) откорня к
листьям в дереве (дереве И/ИЛИ) машины состояний.
Всего машина может иметь столько различных конфигураций активных
состояний, сколько существует различных путей от корня к листьям. На-
пример, на рис. 4.101 в дереве справа имеется 5 различных путей и, соответ-
ственно, 5 конфигураций активных состояний у машины слева, а в дереве на
рис. 4.103 имеется 10 различных гиперпутей от корня к листьям и, соответ-
ственно, 10 конфигураций активных состояний машины237.
Ортогональное составное состояние
Что же означает переход из ортогонального составного состояния или в
ортогональное составное состояние? Ответ на этот вопрос подобен ответу на
аналогичный вопрос для последовательных составных состояний, который
дан в таблице 4.3, за единственным исключением: в случае ортогональных
237 Очень советуем читателю проверить, что он видит все десять гиперпутей на рис. 4.103.
е
4.5 Моделирование параллелизма
составных состояний нужно дополнительно учесть, что все области участву-
ют в переходе.
• Переход в ортогональное составное состояние означает одновре-
менный переход в начальные состояния всех областей данного орто-
гонального составного состояния (т. е. фактически параллельный
запуск всех вложенных машин состояний); в случае наличия пере-
хода в ортогональное составное состояние каждая область должна
иметь единственное начальное (или историческое) состояние, в про-
тивном случае модель считается противоречивой.
• Переход по событию и/или со сторожевым условием (т. е. любой
переход не по завершении) из ортогонального составного состоя-
ния означает распространение данного перехода на все вложенные
состояния всех областей; если унаследованный переход конфликту-
ет с локально определенным переходом, то последний имеет прио-
ритет (модель не считается противоречивой).
• Переход по завершении из ортогонального составного состояния
срабатывает в том и только в том случае, когда машина состояний
в каждой области перешла в заключительное состояние (т. е., фак-
тически это означает синхронное завершение всех вложенных ма-
шин состояний); в случае наличия перехода по завершении из орто-
гонального составного состояния каждая область должна иметь
заключительные состояния и должен быть определен единственный
переход по завершении, в противном случае модель считается про-
тиворечивой.
Таким образом, семантика переходов, не пересекающих границу состояния,
для ортогональных и последовательных составных состояний аналогична.
Составной переход
Для описания переходов, пересекающих границу ортогонального составного
состояния, вводится специальное понятие — составной переход.
Составной переход (compound transition ) — это переход, который на-
чинается^и/и.ш заканчивается и нескольких состояниях.
• Если переход имеет одно исходное и несколько целевых состояний,
то это соответствует разветвлению потока управления на несколько
параллельных потоков; при этом целевые состояния должны быть
вложенными состояниями областей ортогонального составного со-
Г 479 1
Глава 4. Моделирование поведения
стояния — по одному на каждую область.
• Если переход имеет несколько исходных и одно целевое состоя-
ние, то это соответствует слиянию нескольких потоков управления
в один; при этом исходные состояния должны быть вложенными
состояниями областей ортогонального составного состояния — по
одному на каждую область.
• Если переход имеет несколько исходных и несколько целевых
состояний, то это соответствует синхронизации нескольких парал-
лельных потоков управления; при этом исходные состояния долж-
ны быть вложенными состояниями областей одного ортогонального
составного состояния — по одному на каждую область, и целевые
состояния должны быть вложенными состояниями областей орто-
гонального составного состояния (возможно, другого) — также по
одному на каждую область.
В любом случае составной переход должен переводить машину состояний
из одной допустимой конфигурации активных состояний в другую допу-
стимую конфигурацию активных состояний, в противном случае модель
синтаксически неправильна. Неформально говоря, это значит, что ортого-
нальное составное состояние нельзя покинуть и нельзя войти в него "частич-
но" — в составном переходе должны участвовать по одному "представителю"
(по одному вложенному состоянию) от каждой области ортогонального со-
ставного состояния, участвующего в переходе.
Составной переход может иметь событие и сторожевое условие. Как всегда,
переход срабатывает, если произошло событие и выполнено условие. При
этом, для того чтобы сработал переход, имеющий несколько исходных со-
стояний, необходимо, чтобы все они были активны при наступлении собы-
тия.
Примечание
Составной переход — это переход по одному событию. В
UML нет понятия перехода по нескольким одновременным
событиям, т. к. нет понятия одновременных событий — со-
бытия в машине состояний всегда возникают последователь-
но, одно за другим. Подразумевается, что даже если события
возникают физически одновременно, имеется системный
механизм (очередь событий или нечто подобное), который
позволяет машине состояний выполнить переход по одному
событию, прежде чем начать обрабатывать следующее собы-
тие.
4.5. Моделирование параллелизма
Приведем пример из информационной системы отдела кадров. Рассмотрим
тот же пример, что был использован при описании последовательных про-
стых и составных состояний (см. раздел 4.2), а именно жизненный цикл со-
трудника на предприятии. Диаграмма автомата сотрудника в информацион-
ной системе отдела кадров приведена на рис. 4.104.
Рис. 4.104. Диаграмма аатомата сотрудника ИС ОК
Рассмотрим состояние "работающий сотрудник" (на диаграммах обознача-
ется Employed). Очевидно, что данное составное состояние — самое важное
для системы и должно быть рассмотрено с наибольшей степенью подроб-
ности. Мы уже выделили некоторые вложенные состояния (см. рис. 4.23):
сотрудник может находиться в офисе (In office), болеть (Illness) или быть в
отпуске (On vacation). Но параллельно с этим набором состояний, описыва-
ющим статус сотрудника в смысле присутствия на рабочем месте, сотрудник
переживает и другие смены состояний, связанные с его статусом на пред-
приятии (см. рис. 4.25).
ИЗМЕНЕНИЯ В ТЕХНИЧЕСКОМ ЗАДАНИИ
После успешного выполнения задания на испытательном сроке сотрудник
либо зачисляется в штат, либо становится внештатным сотрудником.
_____________________________________________________
К состояниям On trial (сотрудник проходит испытательный срок) и On staff
(сотрудник состоит в штате), определенным на рис. 4.25, следует добавить
еще одно — Contractor, означающее, что сотрудник работает по контракту
(по трудовому соглашению на определенный срок). Ясно, что смена этих со-
стояний не зависит (формально) от смены состояний из первого списка и,
таким образом, образует ортогональную машину состояний. На рис. 4.105
представлено составное состояние Employed (пока без внешних переходов), а
481
Глава 4. Моделирование поведения
Рис. 4.105. Ортогональное составное состояние Employed
внутренние переходы в каждой машине мы определили с помощью несколь-
ких операций: до() и доВаск() для первого нцбора состояний и promote() для
второго. Для этих операций в качестве параметра указывается состояние, в
которое нужно перейти238.
Рассмотрим теперь переходы. При первом приеме на работу сотрудник дол-
жен пройти испытательный срок и в первый день работы должен быть в офи-
се. Поэтому переходы из соответствующих начальных состояний (1 и 2 на
рис. 4.105) областей машины состояний ведут в состояния In office и On trial.
Таким образом, внешний переход из состояния Applicant можно провести в
состояние Employed как простой переход (1 на рис. 4.106) по событию hire().
С другой стороны, переход из состояния Unemployed, не должен приводить к
новому испытательному сроку.
В таком случае переход по событию hire() из состояния Unemployed разумно
определить как составной переход в состояния In office и Contractor. Анало-
гично, переход в случае увольнения должен происходить, во-первых, когда
сотрудник находится в офисе (увольнять заочно не принято), и, во-вторых,
когда сотрудник занимает должность постоянно. Прекращение трудовых
238 Это характерный прием проектирования. В операциях по изменению состояний, как
правило, оказывается больше общего, чем различий, поэтому целесообразно объеди-
нить их в одну операцию, учитывая различия с помощью параметров.
4.5. Моделирование параллелизма
отношений с контрактником или проходящим испытательный срок обычно
даже не называется увольнением. Это можно отразить с помощью соответ-
ствующего составного перехода из состояний In office и On staff. Далее, пере-
ход в себя по событию move() (4 на рис. 4.106), видимо, не должен менять
конфигурацию активных состояний, поэтому в параллельных вложенных
машинах целесообразно заменить начальные состояния историческими (5
и 6 на рис. 4.106). Обратите внимание на необходимость использования
глубинного исторического состояния (5 на рис. 4.106).
На рис. 4.106 приведен соответствующий фрагмент диаграммы автомата.
События на переходах во вложенных параллельных областях мы не стали
указывать повторно, чтобы не загромождать диаграмму. Составные перехо-
ды изображаются с помощью специального значка, который выглядит как
узкая закрашенная полоска (может быть расположен вертикально или гори-
зонтально) и называется линейкой синхронизации.
Все сегменты составного перехода начинаются или заканчиваются на ли-
нейке синхронизации. В зависимости от того, сколько сегментов переходов
начинается и заканчивается на линейке синхронизации, она получает спе-
hire()
Employed
goBack()
Illness
Well
go(On vacation)
In office
On trial
On staff
promote(On staff)
promote
(On staff)
promote
(Contractor)
Appllcant
promote(Contractor)
mo've()
go(lllness)
On vacation
go(ln office)J
Contractor
Рис. 4.106. Составные переходы
Глава 4. Моделирование поведения
циальное название (обозначение не меняется). Если на линейке начинает-
ся один сегмент и заканчивается несколько, то линейка синхронизации на-
зывается соединением (join). Если на линейке заканчивается один сегмент
и начинается несколько, то линейка синхронизации называется развилкой
(fork). В данном случае на рис. 4.106 использованы одно соединение (3 на
рис. 4.106) и одна развилка (2 на рис. 4.106).
Синхронизирующее состояние
Поведение машин состояний в параллельных областях составного состоя-
ния Employed на диаграммах рис. 4.105 и рис. 4.106 независимо — каждая
из групп параллельных состояний "живет своей жизнью". Довольно часто
возникает потребность синхронизировать работу параллельных вложенных
машин состояний. Это можно сделать разными способами, например, ис-
пользовать в одной машине состояний в сторожевых условиях на переходах
проверку состояний другой машины. Но в UML 1 есть специальное сред-
ство, называемое синхронизирующим состоянием, которое позволяет про-
вести синхронизацию более наглядным и естественным образом.
/ Синхронизирующее состояние (synch state) — это специальное cocto-
i яние, используемое в диаграммах автомата в параллельных состав-
у ньцс-состояниях.
Синхронизирующее состояние имеет входные и выходные сегменты пере-
ходов (может быть один или несколько). Входные сегменты синхронизиру-
ющего состояния должны начинаться в развилках одной из параллельных
машин состояний (назовем ее исходной машиной состояний), а выходные
сегменты должны заканчиваться в соединениях другой параллельной маши-
ны состояний (назовем ее целевой машиной состояний).
Если срабатывает переход, проходящий через развилку в исходной машине
состояний, то синхронизирующее состояние становится активным и, таким
образом, может сработать переход, проходящий через соединение в целевой
машине состояний. Другими словами, семантика синхронизирующего со-
стояния состоит в том, чтобы поставить срабатывание перехода в целевой
машине в зависимость от срабатывания перехода в исходной машине.
Мы приведем здесь довольно замысловатый пример из информационной
системы отдела кадров, чтобы продемонстрировать полезность примене-
ния синхронизирующих состояний. Допустим, что в организации принято
следующее правило работы с молодыми специалистами: после окончания
испытательного срока сотрудник направляется на тренинг, где проходит
дополнительную профессиональную подготовку, после чего назначается
4.5. Моделирование параллелизма
на постоянную должность или же с ним заключается временный контракт.
Находясь на тренинге, сотрудник, естественно, находится вне офиса (обо-
значим это состояние On training), и, в то же время, пока что он "ни рыба, ни
мясо" — испытательный срок уже закончен, а систематическая работа еще не
началась (обозначим это состояние Interlude).
На рис. 4.107 приведено соответствующим образом измененное ортогональ-
ное составное состояние Employed. Чтобы не загромождать рисунок, мы
опустили все переходы, которые не относятся к рассматриваемому в дан-
ном примере случаю239. Синхронизирующие состояния (1 и 2) изображены
в виде небольших кружков на границе областей с числом внутри, смысл
которого объясняется чуть ниже. При рассмотрении рис. 4.107 не следует
забывать принятые соглашения: переход (в том числе и составной) управ-
ляется одним событием. В данном случае некоторые события мы поместили
в специальных комментариях, чтобы их было легко прочитать, и соединили
эти комментарии с соответствующими сегментами составного перехода. На
сегментах переходов, инцидентных синхронизирующим состояниям, ника-
ких событий и сторожевых условий нет (и быть не может!).
239 Мы хотим повторить еще раз свой совет: не следует рисовать перегруженных диаграмм.
Вместо одной сложной диаграммы лучше нарисовать несколько простых, показывая на
одной диаграмме одни детали, а на другой — другие. Инструмент обязан сохранить во
внутреннем представлении модели все детали.
Глава 4. Моделирование поведения
Рассмотрим еще раз, как будет происходить изменение конфигурации ак-
тивных состояний в диаграмме на рис. 4.107. Вначале активна пара состоя-
ний — In office и On trial. (Может ли сотрудник, проходящий испытательный
срок, заболеть, получить отпуск, отправиться в командировку — все эти во-
просы мы на данной диаграмме не рассматриваем).
Обратите внимание, что у состояния In office есть префикс Well, отделен-
ный от имени состояния символами ": Well означает пространство имен
(namespace), элементом которого является состояние In office (см. п. 5.1.1).
Когда испытательный срок заканчивается240 (событие promote() с аргумен-
том Interlude), срабатывает составной переход (3 на рис. 4.107) и активными
становятся первое синхронизирующее состояние (1 на рис. 4.107) и состоя-
ние Interlude. Теперь при наступлении события до() с аргументом On training
сработает составной переход (4 на рис. 4.107), и активным станет состоя-
ние On training (совместно с состоянием Interlude). Обратите внимание, что
пока первое синхронизирующее состояние не активно (т. е. испытательный
срок не закончен), все попытки отправить сотрудника на учебу (вьТзов go(On
training)241) не сработают. Далее изменение конфигурации активных состоя-
ний произойдет при наступлении события до() с аргументом In office — све-
жеобученный сотрудник предстанет перед начальством для решения своей
судьбы. При этом активными будут состояния inOffice, Interlude и второе
синхронизирующее состояние (2 на рис. 4.107). Как только будет принято
решение (произойдет событие promote()), сотрудник перейдет в состояние
On staff или Contractor в зависимости от значения аргумента данного собы-
тия.
Нам осталось рассмотреть два важных обстоятельства, связанных с синхро-
низирующими состояниями. Во-первых, разъяснить, что означает число, ко-
торое указывается в синхронизирующем состоянии, и, во-вторых, обсудить,
какая информация может быть передана через синхронизирующее состоя-
ние из исходной машины состояний в целевую.
Обычное состояние либо активно, либо нет, т.е. величина активности обыч-
ного состояния либо 1, либо 0. А величина активности синхронизирующего
состояния может быть любым целым числом. Синхронизирующее состоя-
ние на самом деле является счетчиком активности. При переходе в синхро-
низирующее состояние значение счетчика увеличивается на 1, при перехо-
де из синхронизирующего состояния — уменьшается на 1 Число, которое
240 Судя по нашему личному опыту работы с кадрами, испытательный срок лучше завер-
шать не по времени (не по событию таймера), а по достижении определенного резуль-
тата, например по выполнении индивидуального задания.
241 Напомним, что необработанные события теряются, и если мы не вовремя вызвали
go(On Training), то его придется сгенерировать заново.
Г f зб1
4.5 Моделирование параллелизма
указывается в кружке синхронизирующего состояния на диаграмме, — это
максимальная величина счетчика. Можно указать символ *, что означает
неограниченный счетчик. Если же указано конкретное число и величина
счетчика превышает его, то перехода не происходит. При входе в параллель-
ное составное состояние, которому принадлежит синхронизирующее со-
стояние, величина счетчика сбрасывается в ноль. В терминах сетей Петри
(см. параграф 4.1.3) текущее значение счетчика уместно назвать маркиров-
кой синхронизирующего состояния. В разобранном примере на рис. 4.107
использованы синхронизирующие состояния с пределом 1. Такие состояния
называются семафорами — они либо разрешают переход в целевой машине,
либо запрещают его.
Вообще говоря, синхронизирующие состояние может быть не просто счет-
чиком, а каналом для передачи данных между синхронизируемыми машина-
ми состояний. В этом случае синхронизирующее состояние следует рассма-
тривать как очередь объектов. Срабатывание перехода в исходной машине
добавляет объект в конец очереди; срабатывание перехода в целевой машине
удаляет объект из начала очереди. Для изображения такого синхронизирую-
щего состояния отлично подходит объек т в состоянии (см. параграф 4.3.4).
В качестве иллюстрации использования неограниченных очередей и син-
хронизации с передачей информации мы рассмотрим один классический
пример из области параллельного программирования. Пусть имеются два
параллельных процесса — "писатель" (Writer) и "читатель" (Reader). Процесс
Writer асинхронным образом создает записи (record), а процесс Reader также
асинхронно их обрабатывает в порядке создания. Каждый из процессов мо-
жет по собственной инициативе завершить свою работу. На рис. 4.108 при-
ведена соответствующая диаграмма автомата.
Рис. 4.108. Параллельные процессы "Писатель" и "Читатель"
487
Глава 4. Моделирование поведения
Для тех читателей, которые разобрали примеры этого параграфа до конца,
мы приберегли печальную новость. Позвольте процитировать основопола-
гающий источник [3], стр. 652. "Эта концепция (синхронизирующее состоя-
ние) UML 1 была отменена в UML 2. Ограничения на деятельность были
ослаблены, поэтому отпала потребность в состояниях синхронизации". Мы
же считаем, что не потребность отпала, а по недосмотру выплеснули вместе
с водой и младенца.
4.5.4. Развилки и слияния
В этом параграфе рассматриваются средства описания параллельности, при-
меняемые на диаграммах деятельности.
Диаграмма деятельности похожа на привычную блок-схему, но допускает
использование различных дополнительных обозначений. Это правило рас-
пространяется, прежде всего, на моделирование параллелизма: основные
средства моделирования параллельного поведения на диаграммах деятель-
ности имеют много общего с рассмотренными в предыдущем параграфе,
плюс некоторые дополнительные особенности. Основными средствами яв-
ляются уже рассмотренные развилки и слияния, а дополнительным — обу-
словленный поток управления. Рассмотрим их все по порядку.
Развилки и слияния — это средства визуализации составных переходов.
Диаграмму деятельности можно трактовать как диаграмму состояний, в ко-
торой используются (в основном) переходы по завершении. Что же такое со-
ставной переход по завершении? В сущности, это очень прост ая и естествен-
ная конструкция, может быть даже более естественная, чем общий случай
составного перехода.
Составной переход по завершении на диаграмме деятельности имеет следую-
щие особенности.
• Во-первых, никто не использует данный термин: все применяют на-
звания частных случаев нотации: развилка, слияние, линейка синхро-
низации. Все эти случаи являются составными переходами по завер-
шении.
• Во-вторых, семантика данных конструкций определяется в UML 1
в терминах потоков управления. В общем случае имеется линейка
синхронизации, которой инцидентны входящие (один или более) и
исходящие (один или более) сегменты переходов. Семантика состо-
ит в следующем. Сначала все деятельности, инцидентные входящим
сегментам, должны завершиться. После этого параллельно запуска-
ются все деятельности, инцидентные исходящим сегментам.
4.5. Моделирование параллелизма
В-третьих, семантика данных конструкций определяется в UML2
альтернативным, но эквивалентным способом в терминах маркеров.
Развилка создает столько копий пришедшего маркера (управления
или данных), сколько имеется исходящих дуг, и запускает созданные
маркеры во все исходящие дуги. Слияние, напротив, дожидается по-
лучения маркеров по всем входящим дугам, после чего отправляется
маркер по единственной исходящей дуге242. Общий случай — линей-
ка синхронизации (с несколькими входящими и несколькими исхо-
дящими дугами) рассматривается как композиция слияния, сразу за
которым следует развилка.
В-четвертых, развилки и слияния должны быть сбалансированы.
Правило сбалансированности аналогично правилу вложенности
на диаграммах автомата243. Мы определим его следующим образом.
Назовем диаграмму деятельности строго сбалансированной, если ее
можно получить путем декомпозиции одной деятельности, причем
на каждом шаге декомпозиции одна из деятельностей декомпозиру-
ется либо на некоторое количество последовательных деятельностей,
либо на некоторое число параллельных деятельностей. Диаграмма
деятельности является сбалансированной, если ее можно сделать
строго сбалансированной путем введения промежуточных деятель-
ностей и синхронизирующих состояний на имеющихся переходах.
Неформально говоря, сбалансированность означает возможность
выполнить блок-схему от начала к концу: потоки управления не
Рис. 4.109. Баланс развилок и слияний
242 Стандарт воздерживается от прямого ответа на вопрос, что делать, какой маркер от-
правлять, если по разным входящим дугам слияния приходят маркеры разных типов.
Если маркер данных только один, остальные маркеры управления, то, очевидно, нужно
отправить маркер данных. Но если приходят несколько различных маркеров данных, то,
скорее всего, модель противоречива.
243 Напомним, что на диаграмме автомата составные состояния образуют дерево
"И/ИЛИ”.
Глава 4. Моделирование поведения
должны возникать "ниоткуда" и исчезать "в никуда"244. На рис. 4.109
приведен пример сбалансированной (слева) и не сбалансированной
(справа) диаграмм деятельности.
Примечание
Декомпозиция, о которой идет речь в правиле сбалансиро-
ванности, не обязательно единственна.
Развилки и слияния настолько наглядное и естественное средство, что мы
уже использовали их в примерах без особых пояснений. Приведем еще один
пример из информационной системы отдела кадров. На рис. 4.110 приведе-
на диаграмма деятельности, реализующая операцию перевода сотрудника
на другую должность (операция move()). В данном случае мы предполагаем,
что при выполнении перевода новая должность должна быть вакантна. Если
данное условие не выполнено, то операция не выполняется и посылается со-
Рис. 4.110. Диаграмма деятельности операции перевода сотрудника
244 Вообще-то данное утверждение полностью верно только для UML 1, а в UML 2 справед-
ливо с некоторыми оговорками из-за появления новой сущности — заключительного со-
стояния потока (см., например, рис. 4.53).
---------------.....................................-........................1
4.5 Моделирование параллелизма
ответствующий сигнал (1) (что является еще одним примером моделирова-
ния параллелизма на диаграммах деятельности, см. параграф 4.3.5). Далее
заметим, что манипуляции со старой и с новой должностью могут прово-
диться параллельно, что отражено на диаграмме введением двух потоков
управления с помощью развилки (2). Работу с новой должностью можно в
свою очередь распараллелить (3). Между потоками передается информация
с помощью объекта в состоянии (4), который фактически является синхро-
низирующим состоянием для потоков управления. Когда все потоки управ-
ления завершены, выполнение операции успешно заканчивается, что моде-
лируется с помощью соответствующего слияния (5).
Допустим теперь, что операция move() должна выполняться по-другому:
если целевая должность занята, то ее нужно предварительно освободить
(т. е. отстранить от должности сотрудника, который ее занимает), а потом
выполнить перевод. Задача очень похожа на предыдущую, и можно восполь-
зоваться известным рецептом математика из анекдота245. Но мы используем
Рис. 4.111. Обусловленный поток управления
245 Математика спросили: как приготовить чай? Он ответил, что нужно налить воды, вски-
пятить ве и заварить чай. — А если уже есть кипяток? — Нужно вылить его, и задача
сведется к предыдущей.
Глава 4. Моделирование поведения
этот пример для демонстрации приема моделирования, который называется
обусловленным потоком управления (conditional control flow). Сегмент пере-
хода, исходящий из развилки, может иметь сторожевое условие. В этом слу-
чае поток управления, начинаемый данным сегментом перехода, называется
обусловленным. Если сторожевое условие выполнено, то поток выполняется
как обычно, в противном случае поток не выполняется — сразу считается за-
вершенным. В диаграмме на рис. 4.111 этот прием применен при модели-
ровании операции перевода: поток, ведущий к действию newPos.thePerson.
dismiss(), является обусловленным (1).
Обусловленный поток управления не является самостоятельным понятием
в UML — это не более чем синтаксическое сокращение. На рис. 4.112 пока-
зано, как обусловленный поток управления (слева) эквивалентным образом
выражается через ветвление (справа).
Рис. 4.112. Выражение обусловленного потоке управления через разветвление
Подводя итоги параграфа, отметим, что, по нашему мнению, средства моде-
лирования параллелизма на диаграммах деятельности принадлежат к числу
лучших в UML: они интуитивно понятны, наглядны и удобны в использо-
вании.
4.5.5. Параллелизм на диаграммах взаимодействия
Данный параграф получился короче остальных, что не удивительно, по-
скольку средства моделирования параллелизма на диаграммах взаимодей-
ствия довольно скудны.
На диаграммах коммуникации графических средств моделирования парал-
лелизма фактически не предусмотрено. Параллелизм указывается тексту-
ально, с помощью номеров сообщений (см. параграф 4.4.5 выше). В номера
сообщений можно включать не только цифры, но и буквы. Сообщения, но-
мера которых различаются в последней букве, считаются параллельными на
4.5. Моделирование параллелизма
данном уровне вызовов (см. рис. 4.84). Их относительный порядок не опре-
делен. Они могут быть отправлены в любом порядке или даже физически
одновременно, если это допускает реализация. В то же время, например, со-
общения с номерами 1.1 а и 1.1 b оба предшествуют сообщению с номером 1.2
и оба следуют за сообщением с номером 1.
Другим средством моделирования параллелизма на диаграммах последо-
вательности и коммуникации, родственным динамической параллельности
(параграф 4.5.2) на диаграмме деятельности, является использование сим-
вола 11 в повторителе (см. параграф 4.3.6). Если символ повторителя имеет
вид * 11, то все сообщения, определяемые данным повторителем, считаются
параллельными.
На диаграмме последовательности номера сообщений обычно не указыва-
ются. Как же отличить параллельные сообщения? В UML 1 параллельные
сообщения отличаются тем, что исходят из одной точки линии жизни. Но
внимательный читатель может заметить, что альтернативные сообщения
тоже исходят из одной точки — чем же они отличаются от параллельных? К
сожалению, хотя параллельность и альтернативность семантически сугубо
разные вещи, графически на диаграмме последовательности UML 1 они не
отличаются: если исходящие сообщения помечены взаимоисключающими
сторожевыми условиями, то это альтернативные сообщения; если стороже-
вых условий нет вовсе, то это явно параллельные сообщения. Если же сторо-
жевые условия присутствуют, но не на всех сообщениях или же не являются
взаимоисключающими (дизъюнктными), то, видимо, можно считать, что это
нечто вроде обусловленных потоков управления.
Мы разделяем недоумение и недовольство читателя, которое могло возник-
нуть в этом месте при чтении наших объяснений. Что делать — моделирова-
ние параллелизма на диаграммах взаимодействия — не самая сильная сто-
рона UML 1.
Но зато в UML 2 предусмотрены сразу три типа составных шагов взаимо-
действия (см. таблицу 4.11), предназначенных для моделирования парал-
лелизма. Покажем некоторые возможности их использования на примере
реализации операции move() (см. выше рис. 4.110), которая является опера-
цией класса Company. Тогда описание параллельного взаимодействия, реа-
лизующего операцию, заключается в следующем (рис. 4.113).
Во-первых, нужно проверить, свободна ли целевая позиция. Если она заня-
та, то с помощью составного шага взаимодействия break (1) нужно возбу-
дить исключение (стрелка, идущая на границу диаграммы (2)) и прекратить
взаимодействие.
Ф ____
Г 493
Глава 4 Моделирование поведения
Во-вторых, нужно выполнить три действия: освободить старую должность,
занять новую и сделать отметку в самом объекте класса Person. Последова-
тельность выполнения этих действий имеет значение. Сначала обязательно
нужно освободить старую должность (3). Для этого можно использовать со-
ставной шаг взаимодействия seq (4), чтобы гарантировать нужный нам по-
рядок выполнения действий.
В то же время методы оссиру() и assign() могут быть выполнены параллель-
но (5). В результате мы гарантированно обеспечиваем выполнение следую-
щего бизнес-правила: сотрудник может в процессе выполнения операции
временно "висеть в воздухе" (т.е. на него нет ссылок из должностей), но ни-
когда, даже случайно и временно, не допускается, чтобы он "сидел на двух
стульях" (т.е. на него есть две ссылки из разных должностей). Посмотрите
на рис. 4.113 и сравните его с другими диаграммами, посвященными реали-
зации операции перевода сотрудника.
На данной диаграмме в дополнение к уже известным нам нотациям сообще-
ний (см. таблицу 4.10) добавились еще два. Это так называемые найденные
сообщения (found message) и потерянные сообщения (lost message). Найден-
ные сообщения (6 на рис. 4.113) используются в случае, когда важно отраз-
ить факт получения сообщения, а факт его отправки не представляет инте-
4.5. Моделирование параллелизма
реса в рассматриваемом контексте. С потерянными сообщениями (7 на рис.
4.113) все в точности наоборот: главное то, что сообщение было отправлено,
а получено или нет, не важно.
4.5.6. Активные классы
Последнее246 средство моделирования параллелизма — это активные классы
(active class). Семантически активный класс — это класс, экземплярами ко-
торого являются активные объекты.
Активный объект это объект, имеющий собственный поток управ-
ления.
Точнее говоря, активный объект — это и есть поток управления. Создание
активного объекта означает создание нового экземпляра стека вызова про-
цедур и начало деятельности (состоящей в вызове операций, посылке сооб-
щений и т. п.). Активному объекту противопоставляется пассивный объект.
Пассивный объект это объект класса, который не является актив-
ным.
Пассивный объект ничего не может сделать "по собственной инициативе" —
вся его деятельность инициируется извне вызовами его методов. Вызов же
метода может произойти в процессе выполнения некоторого метода друго-
го пассивного объекта, который был вызван из третьего и т. д., но где-то в
этой цепочке вызовов есть начало: оно-то и называется активным объектом.
Потоки управления активных объектов параллельны: поток управления
одного активного объекта не является частью потока управления другого
активного объекта. Активный объект может быть создан в другом потоке
управления, но, будучи созданным, он начинает свою собственную жизнь.
Семантика активных классов и объектов в UML определена не очень строго:
оставлено вполне достаточно свободы, чтобы эти понятия можно было адек-
ватным образом трактовать в окружении любой операционной системы. По-
ложение здесь совершенно аналогично не до конца определенной семантике
действий. Авторы языка не хотели попадать в плен конкретной операцион-
ной системы так же, как они не хотели попадать в плен конкретного языка
программирования247.
246 Последнее по порядку нашего рассмотрения, но не по степени важности.
247 Заметим, что ситуация здесь все-таки не совсем аналогичная Один из авторов хорошо
помнит те времена, когда для каждой модели компьютера разрабатывалась своя опе-
рационная система. С тех пор положение кардинально изменилось: процесс унифика-
ции операционных систем идет быстрыми темпами, в отличие от языков программиро-
вания (см. врезку "Универсальный язык программирования” в параграфе 4.3.1).
« __________________________________________________________________
Глава 4. Моделирование поведения
Синтаксически активный класс в UML — это класс со стереотипом «process».
Примечание
В UML 1 используется еще эквивалентный стереотип
«thread». С точки зрения семантики UML эти стереотипы ни-
чем не отличаются. С точки зрения прагматики два стерео-
типа введены для того, чтобы создатель модели мог акцен-
тировать внимание разработчика на необходимости выбора
того или иного средства организации потока управления,
доступного в конкретной операционной системе. Стереотип
«process» следует применять, если подразумевается "тяже-
лый", ресурсоемкий поток управления, «thread» — если под-
разумевается "облегченный" поток управления. Разумеется,
названия стереотипов «process» и «thread» выбраны в рас-
чете на соответствующие ассоциации у разработчиков. Но
«process» и «thread» в модели совсем не означают "процесс"
или "нить" в терминах конкретной (пусть даже очень извест-
ной) операционной системы. Как именно следует трактовать
эти стереотипы в конкретном окружении, должны решать
разработчики и производители инструментов.
На диаграмме активный класс выделяется тем, что его боковые грани нари-
сованы двойной линией248. Аналогичным образом выделяется прямоуголь-
ник активного объекта. В UML 1 дополнительно существует возможность
использовать стандартное свойство {active} после имени объекта.
В качестве примера диаграммы с активным классом см., например, рис. 4.83.
Примечание
Стиль изображения активных объектов и классов на диа-
граммах еще не устоялся. Например, авторы языка реко-
мендуют рисовать кооперацию пассивных объектов внутри
фигуры активного объекта, инициирующего данную коопе-
рацию. Однако далеко не все инструменты позволяют это
сделать.
248 В UML 1 для обозначения активного класса использовалась жирная линия в качестве
границы прямоугольника.
4.5. Моделирование параллелизма
Рис. 4.114. Диаграмма коммуникации для элементов
компонента StaffManagerGUI
, 3^ **** ™ " -V197
Выводы
Конечные автоматы — базовая алгоритмическая техника моде-
лирования поведения.
Диаграмма автомата — вариант конечного автомата с различ-
ными дополнениями.
Диаграмма деятельности - способ моделирования поведения
потоками управления и потоками данных.
Семантика диаграмм деятельности определена н UML 1 через
конечные автоматы, а в UML 2 — через сети Петри.
Диаграммы коммуникации и последовательности (диаграммы
взаимодействия) семантически эквиналентт । и явля» лея прот •-
колами выл, тлнения (примерами).
Диаграммы взаимодействия — наиболее детальный способ
писанияпове ения.
Обзорные диаграммы взаимодействия являются комбинацией
диаграмм деятельности и диаграмм взаимодействия.
Диаграммы синхронизации являются разновидностью диа-
грамм взаимодействия, показывающие изменение состояния
зо времени.
Параллельность на диаграммах автомата задается ортогональ-
ными состапными состояниями.
Параллельность на диаграммах последовательности задается
специальными составными шагами взаимодействия.
Параллельность на диаграммах деятельности задается развил-
ками и слияниями потоков управления и данных.
Глава 5.
Дисциплина
моделирования
Как следует структурировать модель?
В каких случаях целесообразно применять
образцы и каркасы?
Какие элементы UML являются ключевыми в
практическом моделировании?
Как влияет применение UML на процесс
разработки приложения?
5.1. Управление моделями
Предметом этой небольшой главы является, прежде всего, прагматика UML,
т. е. обсуждение вопросов применения UML. Мы полагаем, что материал
трех предыдущих глав в достаточной степени раскрывает детали синтаксиса
и семантики языка, и считаем необходимым вернуться в конце книги к тому,
с чего мы начали — к обсуждению прагматики.
Мы намерены затронуть три темы, соответствующие трем разделам главы.
• Первая тема связана с управлением моделями, т. е. с теми механиз-
мами, которые предназначены для успешного преодоления количе-
ственных трудностей, возникающих при практическом моделирова-
нии, связанных с объемом и сложностью самих моделей.
• Во втором разделе предпринимается попытка ранжировать элемен-
ты моделирования UML с точки зрения их важности при практиче-
ском моделировании. Мы выделяем те элементы, без которых никак
нельзя обойтись (при определенных начальных условиях), и проти-
вопоставляем их тем элементам, использование которых, по нашему
мнению, не всегда является обязательным при моделировании.
• Третий рассматриваемый вопрос связан с оценкой влияния приме-
нения UML на процесс разработки приложений. Мы полагаем, что
применение UML положительно влияет на разработку, и предлагаем
собственную гипотезу для объяснения этого феномена.
5.1. Управление моделями
5.1.1. Пакетная структура
Темой обсуждения данного параграфа являются механизмы UML, которые
предназначены для преодоления количественных трудностей, возникающих
при работе с большими (по объему) моделями. В общих чертах данный во-
прос сводится к определению и использованию пакетов, которые являются
средством логического структурирования модели.
Примечание
Напомним, что пакет UML — это средство структурирова-
ния именно модели, и пакеты в модели не имеют прямого от-
ношения к пакетам или подобным структурам в языках про-
граммирования.
Проблема управления моделями реально возникает в том случае, когда мо-
дель достаточно велика. Что значит "достаточно велика"? Если вы в состоя-
нии нарисовать всю модель "за один присест", не откладывая уточнения "на
завтра", то эта модель, по нашему мнению, недостаточно велика (для вас).
Если вы в состоянии просмотреть представленную модель и сразу понять
все, что имел в виду автор, не возвращаясь назад для повторного изучения
и не задавая вопросов, то такая модель также недостаточно велика для вас.
Это, разумеется, чисто субъективные критерии.
Универсальная группирующая сущность — пакет
Итак, что делать, если модель достаточно велика? Ответ очевиден: ее нуж-
но разделить на части обозримого размера и рассматривать их по отдельно-
сти. Для этой цели в UML используется одна универсальная группирующая
сущность — пакет.
Хотя в UML предусмотрена только одна сущность для структурирования
модели, этого оказывается достаточно. Рассмотрим свойства пакета.
• Отношение владения (ownership). Говорят, что пакет владеет объ-
явленными в нем элементами модели, а элементы принадлежат
владеющему ими пакету. Пакет может владеть любыми элементами
модели, в частности, пакетами. Отношение владения является стро-
гой композицией, т. е. каждый элемент модели принадлежит ровно
одному пакету.
• Пространство имен (namespace). Каждый пакет в модели образу-
ет пространство имен, т. е. область определения и использования
имен. Рассмотрим понятие пространства имен в UML чуть под-
робнее. Имена однотипных элементов в одном пространстве имен
уникальны — элемент данного типа однозначно определяется по
Глава 5. Дисциплина моделирования
имени в данном пространстве имен — в этом и состоит основное на-
значение пространства имен. В другом пространстве имен это имя
может быть использовано для именования любого другого элемента.
Пакет — не единственное средство образования пространства имен
в UML. Все сущности, имеющие составляющие, которые не суще-
ствуют отдельно от этих сущностей, образуют собственное про-
странство имен. Таковыми сущностями являются, в частности, раз-
личные классификаторы (параграф 3.1.4). Пространства имен могут
быть вложены друг в друга. Пространства имен пакетов вложены в
соответствии с иерархией отношения владения, пространства имен
прочих элементов вложены в соответствии со специфической ие-
рархией элементов. Таким образом, пространства имен также обра-
зуют строгую иерархию. Для указания точного положения любого
элемента в этой иерархии используются составные или квалифици-
рованные (qualified) имена — последовательность имен вложенных
пространств имен, разделенных двойным двоеточием (: :), которая
заканчивается именем элемента.
• Видимость элементов (visibility). Все элементы, которыми владеет
пакет, обладают определенной видимостью. Для элементов паке-
тов существует только два вида видимости: открытая и закрытая.
Открытые (символ "+") элементы пакета могут быть видимы в дру-
гих пакетах. Закрытые (символ "-") элементы видимы только в том
пакете, где они определены.
На диаграммах пакет изображается в виде прямоугольника с закладкой
(см. рис. 5.1). Если внутри пакета ничего не изображено, то имя пакета пи-
шется в основном прямоугольнике (1), в противном случае — в закладке (2).
Внутри основного прямоугольника фигуры пакета можно помещать любые
элементы модели — тем самым моделируется отношение владения: пакет
владеет элементом, помещенным внутрь его фшуры. Альтернативная нота-
ция для обозначения принадлежности элементов пакету — кружок с крести-
ком внутри (3).
Рис. 5.1. Возможные нотации пакетов и их составляющих
5.1 Управление моделями
Однако, хотя всякий элемент модели, как мы только что отметили, обяза-
тельно принадлежит определенному пакету, совершенно не обязательно ри-
совать пакеты на всех диаграммах. Чтобы не загромождать прочие диаграм-
мы, следует использовать диаграммы пакетов (см. параграф 1.6.5).
Также удобно считать, что диаграммы, которые не являются сущностями
языка, находятся в отношении владения с пакетами: каждой диаграммой
владеет некоторый пакет. Однако диаграмма не образует узла в дереве
вложенности пакетов: диаграмма — это не пакет, она не определяет про-
странства имен. Если поместить на диаграмму новый элемент, то этим эле-
ментом будет владеть непосредственно тот пакет, который владеет диаграм-
мой, и имя элемента попадет в пространство имен данного пакета.
Критерии структуризации модели
Рассмотрим теперь, для чего же нужно строить иерархию пакетов и про-
странств имен при моделировании? Для начала повторим уже сказанное:
для маленьких моделей этого делать не нужно. Но маленькие модели встре-
чаются только в учебниках по объектно-ориентированному моделирова-
нию — в жизни модели большие или очень большие. Такие модели нужда-
ются в структуре, в противном случае они не отвечают своему основному
назначению — служить средством спецификации, визуализации, проектиро-
вания249 и документирования.
Если диаграмма в модели не помещается на экран так, чтобы тексты и знач-
ки оставались читаемыми, от модели мало проку. Если имена элементов
модели состоят из десятков непонятных слов, модель трудно использовать.
Если для понимания какой-то характеристики приложения нужно одновре-
менно рассматривать десяток диаграмм, модель не отвечает своему назначе-
нию. Если для поиска ответа на конкретный вопрос нужно просмотреть всю
модель подряд, она никуда не годится.
Мы полагаем, что модель имеет хорошую, удобную для работы структуру,
если выполняется два следующих количественных критерия.
• Количество сущностей250, изображенных на всех диаграммах,
примерно одинаково и равно 7±3. Если сущностей на диаграмме
три или меньше, то диаграмма недостаточно информативна, что-
бы включать ее в модель отдельно. Такую диаграмму либо не стоит
включать в модель, либо можно объединить с другой однородной
диаграммой. Если на диаграмме больше десяти сущностей, то она,
249 Напомним, что в оригинале данное назначение UML звучит как construct.
250 Отношения на диаграмме мы не считаем, хотя отдаем себе отчет в том, что такой взгляд
весьма спорен.
• —
О. - - - - « « -- Я
Глава 5. Дисциплина моделирования
как правило, слишком трудна для понимания с одного взгляда. Та-
кую диаграмму целесообразно разбить на несколько диаграмм.
• Ширина ветвления в дереве вложенности пакетов с учетом
диаграмм примерно постоянна и равна 7±3. Другими словами, па-
кету должны принадлежать от четырех до десяти пакетов или диа-
грамм. Если их меньше, то не понятно, нужен ли такой малосодер-
жательный пакет как отдельная сущность. Если больше, то в деталях
пакета можно "утонуть".
Приведенные критерии характеризуют форму модели, но никак не затраги-
вают ее содержание. Структурировать модель по содержанию можно сами-
ми разными способами, мы перечислим три наиболее характерных.
• По структуре приложения. В основу структуры пакетов кладется
одна из реальных структур приложения, например, компонентная
структура. Вся система разбивается на пакеты, соответствующие
компонентам (или подсистемам), они, если нужно, разбиваются на
более мелкие части и т. д.
• По фазам процесса разработки. Модель делится на пакеты в соот-
ветствии с фазами ее создания (набор которых зависит от принятой
дисциплины моделирования). Например, пакет для диаграмм кон-
цептуального уровня, пакет диаграмм детального проектирования,
пакет диаграмм реализации и развертывания и т. д.
• По представлениям. Модель делится на пакеты по представлениям.
Например, представление использования, логическое представле-
ние, представление реализации и т. д.
На рис. 5.2 - рис. 5.4 представлена структура пакетов информационной си-
стемы отдела кадров, построенная с использованием нотации вложенности
пространств имен. В данном случае (в демонстрационных целях) мы опреде-
лили сразу три структуры: по компонентам — рис. 5.2 (см. параграф 3.4.2),
Рис. 5.2. Структура пакетов в модели (по компонентам)
5.1. Управление моделями
Рис. 5.3. Структура пакетов в модели (по фазам разработки).
по фазам — рис. 5.3 (см. параграф 5.3.2) и по представлениям — рис. 5.4 (см.
раздел 1.7). Разумеется, в реальной работе создавать сразу несколько орто-
гональных структур нет необходимости — как правило, достаточно одной,
иногда двух.
Обратите внимание на использование специального значка — треугольни-
ка (1 на рис. 5.2), который показывает, что данный пакет содержит в себе
модель. Альтернативной треугольнику служит использование стереотипа
«model» (1 на рис. 5.4).
Рис. 5.4. Структура пакетов в модели (по представлениям)
Авторы языка рекомендуют структурировать модель по представлениям.
Вслед за ними разработчики большинства инструментов пытаются на-
вязать пользователю структуру модели. Судя по нашему опыту, только в
сравнительно простых моделях удается обойтись каким-то одним принци-
пом структуризации. В более сложных моделях приходится определять до-
статочно много пакетов (особенно если придерживаться наших критериев
локального ограничения сложности). Поэтому исходить нужно из потреб-
ностей модели, руководствуясь опытом и здравым смыслом — указанные
принципы структуризации полезны, но все равно требуют размышлений
при применении. Ситуация сходна с программированием: хорошая структу-
ра программы, как и модели, дается не даром.
Глава 5. Дисциплина моделирования
5.1.2. Отношения между пакетами
Итак, допустим, что выбрана принципиальная структура пакетов в модели
(и фигуры пакетов отображены на диаграмме, описывающей общую струк-
туру модели). Необходимо обсудить вопрос о том, в каких отношениях мо-
гут находиться пакеты и как эти отношения отображаются на диаграмме.
Мы рассмотрим отношения между пакетами в следующей последователь-
ности:
• вложенность пакетов;
• индуцированное отношение;
• зависимости импорта и доступа.
Вложенность пакетов
Вложенность пакетов (ownership) влечет вложенность пространств имен.
Всякий элемент модели, определенный в данном пространстве имен, видит
все элементы, определенные в этом же пространстве имен и во всех объемлю-
щих пространствах имен. Имена в "параллельных" и вложенных простран-
ствах имен не видимы для данного элемента. Если в цепочке вложенных
пространств имен определены несколько разных элементов с одним име-
нем, то для данного элемента видимым является ближайший при просмо-
тре изнутри наружу. Значение свойства видимости самих элементов (public,
private), в том числе пакетов, не имеет значения для данного правила.
Примечание
Напомним, что для пакетов используются только два значе-
ния свойства видимости: public (обозначается знаком "+") и
private (обозначается знаком"-").
Например, на рис. 5.5 классы А и В принадлежат пакету Р1, класс D принад-
лежит пакету Р2, а класс С и пакеты Р1 и Р2 принадлежат некоторому объ-
емлющему пакету (т. к. они определены на одной диаграмме, а диаграмма, в
с
Рис. 5.5. Вложенность пакетов
5.1 Управление Моделями
свою очередь, принадлежит пакету). В этом случае класс А видит классы В и
С, но не видит класс D; класс В видит классы А и С, но не видит класс D; класс
С не видит классы А, В и D; класс D видит класс С, но не видит классы А и В.
Индуцированное отношение
Индуцироианнос отношение (induced relation) — это отношение меж-
ду пакетами^ которое отражает наличие такого же отношения между
некоторыми элементами данных пакет»».
Например, если указано, что пакет Р1 зависит от пакета Р2 (1), то это озна-
чает, что один или несколько элементов модели, которыми владеет пакет Р1,
зависят от одного или нескольких элементов модели, которыми владеет па-
кет Р2 (см. рис. 5.6). При этом вовсе не подразумевается, что все элементы па-
кетов находятся в данном отношении — достаточно наличия одной пары (2).
Рис. 5.6. Индуцированное отношение Рис. 5.7. Индуцированные
между пакетами зависимости
Применительно к информационной системе отдела кадров рассмотрим три
пакета и отношения между ними, представленные на рис. 5.7. На диаграм-
ме показано, что операции некоторых классов, которыми владеют пакеты
Personnel Management и Staff Management, вызывают некоторые опера-
ции классов (зависимость со стереотипом «call»251), которыми владеет пакет
Common Components. В данном случае мы используем естественное деление
информационной системы отдела кадров на пакеты по компонентам.
Зависимости со стереотипом
Любой элемент модели может обратиться к любому открытому элементу
пакета через его составное имя (см. 5.1.1). Однако бывают ситуации, когда
удобнее использовать простые имена, нежели чем составные.
251 В стандарте зависимостью с таким стереотипом предписано соединять классы, но мы
применили ее к пакетам.
Г 597 1
Глава 5. Дисциплина моделирования
Для решения этой задачи в UML введены два специальных стандартных
стереотипа отношения зависимости между пакетами — «access» и «import»,
которые имеют сходное назначение, но различаются в некоторых деталях. В
обоих случаях речь идет о расширении зависимого пакета путем включения
туда открытых элементов независимого пакета.
На рис. 5.8 представлен пример, аналогичный тому, что рассмотрен на рис.
5.5 (полезно сопоставить эти примеры). Для участвующих классов указаны
значения свойства видимости: классы А и D — открытые, В и С — закрытые.
В этом случае класс А видит классы В и С, но не видит класс D; класс В видит
классы А и С, но не видит класс D; класс С видит класс А, так как имеет место
зависимость со стереотипом «import» (1), но не видит классы В и D; класс D
видит классы А, так как имеет место зависимость со стереотипом «access»
(2), и С, но не видит класс В.
Рис. 5.8. Зависимости со стереотипами «import» и «access».
« Расширение пространства имен
Если зависимость «import» на рис 5.8. заменить на зависимость со стереоти-
пом «access», а зависимость со стереотипом «access» на зависимость со сте-
реотипом «import», то приведенные выше объяснения по поводу относитель-
ных видимостей элементов останутся в силе.
Различие между этими двумя случаями заключается в том, что при исполь-
зовании зависимости со стереотипом «import» добавляемые в зависимый па-
кет элементы остаются открытыми, в то время как при использовании зави-
симости со стереотипом «access» они становятся закрытыми.
Примечание
Отношение зависимости со стереотипом «import» является
транзитивными (см. рис. 5.9). Если пакет Р1 связан зависи-
мостью «import» с пакетом Р2, который в свою очередь связан
5.1. Управление моделями
зависимостью «import» с пакетом РЗ, то из этого следует, что
пакет Р1 имеет доступ к открытым элементам пакета РЗ.
Если стереотип зависимости между пакетами РЗ и Р2 (1 на
рис 5.9) заменить на «access», то свойство транзитивности
нарушится, так как открытые элементы пакета РЗ попадут в
пакет Р2 с закрытой видимостью и после этого уже никаким
образом не смогут оказаться видимыми в пакете Р1.
Рис. 5.9. Зависимости со стереотипом «import» не являются транзитивными
5.1.3. Модели, системы и подсистемы
В UML определены несколько понятий, которые имеют особое значение при
определении как структуры модели, так и структуры моделируемого при-
ложения. Хотя назначение этих понятий совершенно ясно, они описаны в
стандарте не очень отчетливо, к тому же заметно менялись от версии к вер-
сии UML, а потому в конкретных инструментах возникают различные раз-
ночтения, связанные с ними.
Мы имеем в виду понятия модели, системы и подсистемы, а также синтакси-
ческие средства их выражения в UML, в том числе стандартные стереотипы.
Здесь мы описываем суть данных понятий, их определения в контексте стан-
дарта UML, и указываем некоторые варианты, наиболее часто встречающие-
ся в практических инструментах моделирования.
Самым общим из обсуждаемых понятий является понятие (физической)
системы. При моделировании наше внимание сосредоточено на описании
некоторой части реального мира. Например, при моделировании приложе-
ния рассматривается его программная реализация, аппаратура, на которой
исполняются программы, и пользователи, взаимодействующие с приложе-
нием.
Моделируемая часть реального мира называется физической систе-
мой (physical system).
Глава 5. Дисциплина моделирования
Одна и та же физическая система может быть описана с различных точек зрения.
Описание физической системы называется моделью. Каждая модель описывает
всю физическую систему в целом, но модели могут сильно отличаться степенью
детальности, используемыми средствами и расстановкой акцентов. Это опреде-
ляется целью, с которой составляется модель. Например, мы можем различать
концептуальную модель, проектную модель и модель реализации для одной и
той же физической системы (см. параграф 1.7.1).
Если физическая система сложна и велика (а именно так обычно и бывает), то
ее целесообразно мысленно (а иногда и физически) разбить на части, называ-
емые подсистемами и рассматривать отдельно и детально каждую подсистему.
Например, информационная система отдела кадров конкретной организации,
как физическая система, состоит из некоторого количества компьютеров, про-
граммных артефактов, составляющих приложение и развернутых на этих ком-
пьютерах, а также служащих отдела кадров, которым вменено в обязанность ис-
пользовать приложение в повседневной работе. С точки зрения выполняемых
функций в данной физической системе можно выделить две подсистемы: под-
систему работы с персоналом и подсистему работы со штатным расписанием.
Подсистемы наделены определенным поведением: у них есть обеспеченные и
требуемые интерфейсы.
Таким образом, мы можем структурировать наше описание физической систе-
мы различным образом: можно разделить все описание на несколько моделей,
чтобы описать систему в целом с различных точек зрения, а можно разделить
систему на части и описать их по отдельности как подсистемы. Более того, мож-
но комбинировать эти структуры произвольным образом: разбить модель на не-
сколько подсистем, каждую из которых описать с помощью нескольких моделей
ит. д.
Для моделирования данных аспектов в UML предусмотрены соответству-
ющие средства: модель (model) и подсистема (subsystem) являются поня-
тиями метамодели UML. С точки зрения языка, модели являются разно-
видностями пакетов, а подсистемы — разновидностями компонентов, но
во всех случаях речь идет о группировке элементов модели. Компонент,
подобно пакету, является пространством имен и в этом смысле, до некото-
рой степени, обладает группирующими свойствами. Синтаксически модели
и подсистемы выделяются с помощью стереотипов «model» и «subsystem»,
соответственно.
Примечание
Для моделей вместо стереотипа можно указывать специаль-
ный значок — небольшой треугольник в правом верхнем углу
фигуры пакета (см. рис. 5.2). Стереотип «subsystem» синтак-
сически может появляться не только в фигуре компонента,
5.1. Управление моделями
но и в фигуре субъекта (границы системы на диаграмме ис-
пользования), а также в фигуре пакета, поскольку субъект
и пакет как группирующие сущности могут использоваться
для группирования поведения с определенными обеспечен-
ными и требуемыми интерфейсами.
На рис. 5.10 представлена диаграмма нашего варианта соответствующего фраг-
мента метамодели UML.
Рис. 5.10. Метамодель управления моделями
Все сказанное в этом разделе о пакетах, моделях и подсистемах нам пред-
ставляется простым, очевидным и не вызывает никаких сложностей при рас-
смотрении с общей теоретической точки зрения. Трудности начинаются при
практической работе с конкретными инструментами. Нам встречались раз-
личные типы затруднений, и в следующем списке мы перечисляем наиболее
типичные.
• Внеязыковой способ определения пакетов. В некоторых инстру-
ментах такие конструкции, как модели и/или подсистемы, нельзя
определить обычным образом — нарисовав фигуру на диаграмме и
указав соответствующий стереотип. Их нужно определять другим
способом — с помощью специальных диалоговых окон и т. п.
• Нестандартные имена стереотипов. Спецификация UML преду-
сматривает довольно большое число стандартных стереотипов для
пакетов, они перечислены в таблице 5.1. Однако их назначение не
всегда очевидно, а сами названия не очень понятны. В результате
разработчики инструментов зачастую подправляют этот список по
своему вкусу252.
252 Напомним, что в этом нет никакого нарушения стандарта— разработчики инструмен-
тов, равно как и пользователи языка, вправе определять и использовать свои стереоти-
Глава 5. Дисциплина моделирования
• Расширение семантики пакетов. Пакет в UML — это средство
структурирования модели, но не моделируемой системы! Между
тем инструментам, особенно тем из них, которые ориентированны
на автоматическую генерацию кода, необходима информация для
определения структуры этого кода: распределение кода по модулям,
файлам, проектам и другим подобным конструкциям системы про-
граммирования. Но язык U ML не зависит от системы программи-
рования и поэтому подобные сведения в нем прямо не указываются.
Хотя всегда можно провести связь от классов через компоненты к
артефактам. Однако разработчикам инструментов трудно устоять
перед соблазном расширить семантику пакетов UML и интерпре-
тировать структуру вложенности пакетов в терминах системы про-
граммирования. В результате пакетная структура, которая, может
быть, была введена только для удобства описания модели, прямо пе-
реносится в структуру программного кода, что не всегда оправдано.
Впрочем, следует оговориться, что перечисленные затруднения, как прави-
ло, не являются критическими. Судя по нашему опыту, они легко преодоле-
ваются (или обходятся) за несколько часов путем внимательного изучения
справочной документации и конкретных примеров, прилагаемых к каждому
инструменту.
Прежде чем рассмотреть предусмотренные стандартом стереотипы пакетов,
сделаем небольшое отступление.
УРОВНИ СОВМЕСТИМОСТИ
Одну из своих задач авторы UML видят в улучшении совместимо-
сти инструментов моделирования. Для этого вводится понятие
уровень совместимости (compliance level)253. Всего существует
четыре уровня совместимости: LO, L1, L2, L3. Каждый уровень
определяет некоторый набор конструкций UML (language unit).
Уровень L0 определяет минимальный набор, а каждый последу-
ющий уровень этот набор расширяет. Все конструкции, которые
описаны в стандарте, входят в L3.
Уровни совместимости введены для того, чтобы классифициро-
вать инструменты моделирования по набору поддерживаемых
ими конструкций и, как следствие, определяется возможность об-
мена моделями между инструментами.
Например, в список конструкций уровня L1 (среди прочих) входит
Use Case. Это значит, что любой инструмент должен уметь во вну-
253 В нашем изложение данный термин иногда звучит как "уровень", если это допускается
контекстом.
5.1. Управление моделями
треннем представлении модели сохранять информацию о клас-
сах. В список конструкций уровня L2 в сравнении с L1 (среди про-
чих) добавлен Artifact. Это значит, что любой инструмент, поддер-
живающий уровень L2 и выше, должен уметь работать с вариан-
тами использования. При этом никто не гарантирует, что модель,
созданная в инструменте с уровнем L2, может быть загружена в
инструмент с уровнем L1.
Таблица 5.1. Стандартные стереотипы пакетов
Стереотип Описание
«facade» Пакет, который содержит только ссылки на элементы, определенные в других пакетах. Используется для описания "внешнего вида” других пакетов. Включен в версию 1.0, объявлен устаревшим в версии 2.0
«framework» Пакет, содержащий образцы и шаблоны. Используется для описания повторно используемых архитектурных решений. Включен в версию 1.1, уровень L1 в версии 2 0, уровень L2 в версии 2.1
«metamodel» Модель, которая описывает другую модель. Например, метамодель UML. Включен в версию 1.3, уровень L3 в версии 2.0
«model» Модель физической системы. Имеет специальный значок для отображения (треугольник). Включен в версию 2.0 без указания уровня
«modelLibrary» Пакет, содержащий определения элементов моделирования, предназначенных для использования в других пакетах. Включен в версию 1.4, уровень L1 в версии 2.0, уровень L2 в версии 2.1
«profile» Пакет, содержащий определения элементов моделирования, такие как стереотипы, предназначенных для моделирования в определенной предметной области. Включен в версию 1.4, объявлен устаревшим в версии 2.0
«stub» Пакет, представляющий только открытые части другого пакета. Включен в версию 1.0, объявлен устаревшим в версии 2.0
«system» «systemModel» Модель, содержащая несколько моделей одной физической системы. Включен в версию 1.1, переименован в версии 1.3, уровень L3 в версии 2.0
«topLevelPackage» «topLevel» Пакет, который является корнем иерархии вложенности пакетов. Включен в версию 1.1, переименован в версии 1.3, объявлен устаревшим в версии 2.0
Мы хотим закончить этот раздел повторением важного тезиса, уже выска-
занного в параграфе 5.1.1: UML позволяет придать описанию модели лю-
бую структуру — архитектор при этом должен приложить определенные
•
Г лава 5. Дисциплина моделирования
мыслительные усилия, чтобы выбрать хорошую структуру, подходящую
для данного случая. Универсального метода, как обычно, мы предложить не
можем — только несколько советов для частных случаев. Вот один из них.
Мы считаем целесообразным выделять подсистемы в соответствии с разбие-
нием на компоненты связности (максимальные связные подграфы данного
графа, см. врезку "Множества, отношения и графы" в разделе 1.4) диаграм-
мы использования. Если на общей диаграмме использования, содержащей
все идентифицированные варианты использования, явно выделяются ком-
поненты связности, то это является, по нашему мнению, веским основанием
для выделения подсистем. Обобщенный принцип для описанного выше пра-
вила гласит, что подсистемы должны обладать двумя свойствами: слабым
зацеплением (low coupling) друг за друга и сильным связыванием (high cohe-
sion) внутри себя.
5.1.4. Слияние пакетов
В UML 2 появился очень мощный механизм повторного использования мо-
делей, который интенсивно применяют сами разработчики стандарта. Это
так называемое слияние пакетов (merge). При практическом моделировании
слияние пакетов пока используется мало, поскольку эта операция довольно
необычна, и ее не так просто реализовать, но со временем, может быть, по-
ложение изменится.
В операции слияния участвуют два пакета, которые условно называют
"база" (base) и "приращение" (increment), причем эта операция не комму-
тативная, т.е. если взять два пакета и провести два слияния, при которых в
первом случае один пакет будет считаться базой, а второй приращением, а
во втором случае они поменяются ролями, то результаты этих операций не
будут идентичны. Нотация: зависимость со стереотипом «merge» от базы к
приращению.
Элементы базы сопоставляются с элементами приращения по именам и ме-
таклассам. Приращение расширяет базовый пакет непротиворечивым об-
разом. Другими словами, если в приращении есть элемент, совпадающий по
имени и метаклассу с элементом в базе, то к элементу базы добавляются те
составляющие элемента приращения, которые можно добавить непротиво-
речивым образом. Слияние применяют в тех случаях, когда в разных паке-
тах определены элементы, которые не только имеют одинаковые имена, но
и имеют аналогичное назначение! Если же имена однотипных элементов
совпадают случайно, то слияние может дать странный и бессмысленный ре-
зультат.
5.1. Управление моделями
Примечание
Слияние сходно с обобщением в том смысле, что в подкласс
добавляются составляющие из суперкласса, но только те, ко-
торые не определены в подклассе.
Слияние можно рассматривать как операцию с пакетами времени моделиро-
вания. Результат слияния замещает базу, приращение остается неизменным.
Пусть, например (рис. 5.11), в пакетах Basel, Base2 и Base3 есть класс А
(1) (а также другие классы, не показанные на диаграмме). Пусть в пакете
Increment также есть класс А, причем он участвует в отношении обобщения,
так что класс В является суперклассом для класса А (2). В результате слия-
ния базовые пакеты Basel, Base2 и Base3 расширяются в результирующие
пакеты IncrementedBasel, lncrementedBase2 и lncrementedBase3 соответ-
ственно. В эти результирующие пакеты входит все, что было в базовых па-
кетах, а также все то, что можно добавить из пакета Increment с сохранением
непротиворечивости модели. В данном случае, в пакете IncrementedBasel
(по сравнению с пакетом Basel) появляется класс В вместе с отношением
обобщения (3). В пакете lncrementedBase2 (по сравнению с пакетом Base2)
появляется только отношение обобщения между классами А и В (4). А в па-
Рис. 5.11. Пример слияния пакетов
515 "
Глава 5 Дисциплина моделирования
кете lncrementedBase3 (по сравнению с пакетом Base3) ничего не добавится
(5), потому что отношения обобщения не должны образовывать циклов.
Элементы двух пакетов совместимы, если выполняются все условия, соот-
ветствующие метаклассам этих элементов. Правила расширения свои для
каждого метакласса, полный список этих правил можно найти в стандарте.
Для всех пакетов, участвующих в отношении слияния, должны вы-
полняться следующие общие правила.
• Зависимости со стереотипом «merge» не должны образовывать
циклов.
j Пакет не может быть ни базой, ни приращением для пакета, кото-
: рый он содержит или в котором содержится.
: ' • Элемент базы, не являющийся пакетом, классом, типом данных
атрибутом, операцией, условием, ассоциацией, перечислением и 4
I элементом перечисления, может иметь совместимый элемент в
; ? пакете приращения (с тем же именем и метаклассом), только если у
эти два элемента полностью эквиваленты (один является точной
копией другого).
• Все типизированные элемен ты, такие как атрибуты; параметры и
т.д„ должны иметь совместимые типы. Для элементов, являющих-
ся классами или типами данных, совместимым типом является
либо тот же самый класс, либо общий суперкласс Для всех других
типизированных элементов типы должны совпадать.
• Элементы пакета приращения не могут иметь явных ссылок на
элементы пакета базы.
Элементы базы, не имеющие соответствующего элемента с тем же именем
и метаклассом в приращении, просто копируются в результирующий пакет.
Одинаковые элементы, являющиеся полной копией друг друга, попадают в
результирующий пакет без изменений. Все прочие совместимые элементы
преобразуются в соответствии с правилами трансформации, определенны-
ми для метаклассов.
Приведем пример, как может быть использована операция слияния для ин-
формационной системы отдела кадров. На рис. 5.12 изображена структура
отношений для классов информационной системы отдела кадров, которые
находятся в пакете Structure. Данную диаграмму мог построить, например,
архитектор, описывающий общую структуру отдела кадров (см. рис. 3.22).
Параллельно с этой диаграммой другой разработчик, например, програм-
мист базы данных, может быть занят рассмотрением тех же элементов, но
5.1. Управление моделями
Рис. 5.12. Описание структуры ИС ОК
с точки зрения соответствующих им атрибутов, как общих, таких как имя,
так и специфических, таких как миссия (для компании), план развития
(для подразделения), должностные инструкции (для должности) и история
работы (например, данные трудовой книжки работника). На рис. 5.13 изо-
бражена диаграмма, содержащая те же элементы (но содержащиеся в паке-
те Attribute), описывающая атрибуты элементов. Для всех элементов задано
обобщение с абстрактным суперклассом Unit.
Рис. 5.13. Описание атрибутов элементов ИС ОК
Для заданных пакетов можно задать отношение слияния (зависимость со
стереотипом «merge»), где Structure является базой, a Attributes прираще-
нием. При этом результирующий пакет представляет собой более детализи-
рованную картину структуры ИС ОК (рис. 5.14), пригодную для реализации
программистом (все атрибуты и все отношения, необходимые для описания
элементов и их взаимодействия, собраны в один пакет).
Глава 5. Дисциплина моделирования
Рис. 5.14. Результат операции слияния пакетов
5.1.5. Трассировка, гиперссылки и документация
Одним из самых важных прагматических аспектов UML, по нашему мне-
нию, является осознание того факта, что моделирование есть процесс, при-
чем процесс неоднозначный, итеративный, с возвратами, а иногда и с ради-
кальным изменением уже сделанного.
Отсюда неизбежно вытекает сосуществование диаграмм, представлений и
моделей разного уровня абстракции, находящихся на разных этапах прора-
ботки, возможно даже противоречивых или несогласованных друг с другом.
Разработчик модели нуждается в средствах управления всей этой разнород-
ной информацией, ему нужны средства отслеживания версий, уровней де-
тализации и т. д. Другими словами, ему нужны не только средства отобра-
жения в модели своих соображений о моделируемой физической системе,
но и средства отображения информации о самой модели, ее состоянии и
ходе изменений. Обычно такие средства называют средствами трассиров-
ки (traceability).
Разумеется, для этой цели можно пользоваться любыми подручными сред-
ствами. Например, проектируя функциональность, связанную с переводом
сотрудника в информационной системе отдела кадров, разработчик может
записать на бумажке: "Рассмотреть возможность переноса операции Move в
класс Company" или внести на диаграмму классов комментарий с аналогич-
ным текстом. Однако бумажки имеют удивительное свойство безвозвратно
5.1. Управление моделями
теряться, а комментарий, будучи перенесенным средством автоматической
генерации кода в комментарий к тексту программы, вызовет законное не-
доумение программиста.
Для удобной трассировки в UML предусмотрены специальные средства раз-
личного уровня. Мы начнем их рассмотрение со средств, встроенных в язык.
Таковыми являются зависимости со специальными стереотипами — «trace»
и «refine». Данные зависимости являются внесистемными отношениями, т. е.
отношениями между элементами модели, а не моделью отношений между
моделируемыми сущностями.
Зависимость со стереотипом «trace» показывает причинные связи в моде-
ли, другими словами, показывает, что зависимая сущность имеет причиной
своего существования независимую сущность. Например, если в техниче-
ском задании информационной системы отдела кадров имеется требова-
ние включить в систему операцию перевода сотрудника, то для отражения
данного требования может быть предусмотрен соответствующий вариант
использования. Последний, в свою очередь, влечет существование пакета с
диаграммами состояний, описывающий поведение объектов, представляю-
щих должности и сотрудников (рис. 5.15).
Рис. 5.15. Зависимость со стереотипом «trace»
Зависимость со стереотипом «refine» отражает последовательность разра-
ботки элементов модели. Если две сущности связаны зависимостью со сте-
реотипом «refine», то это означает, что зависимая сущность является более
Рис. 5.16. Зависимость со стереотипом «refine»
Глава 5. Дисциплина моделирования
детальным описанием того же самого моделируемого объекта, что и незави-
симая сущность (рис. 5.16).
Данные зависимости имеют очевидную прагматику, но при их использова-
нии возникает следующая практическая проблема. Определить зависимость
трассировки в модели нетрудно, но как ее отобразить графически? Ведь,
скорее всего, сущности, связанные данными зависимостями, отображены
на разных диаграммах или даже в разных моделях (в смысле, о котором го-
ворится в разделе 5.1.3). Рисовать специальные диаграммы для отражения
истории работы над моделью — такую степень педантизма у современных
разработчиков программного обеспечения трудно вообразить. А на обычных
"рабочих" диаграммах зависимости со стереотипами «trace» и «refine» фак-
тически "негде нарисовать". В результате данные зависимости, при всей их
прагматической полезности и даже необходимости, на практике использу-
ются сравнительно редко.
К счастью, в современной практике работы с электронными документами
имеется всем хорошо известное средство организации прослеживания и
трассировки фрагментов документов — это гиперссылки. Все инструменты
в той или иной степени поддерживают механизм гиперссылок в модели.
Гиперссылки позволяют быстро переходить от одного элемента к другому,
связанному с ним, и, таким образом, с лихвой перекрывают функциональ-
ность зависимостей со стереотипами «trace» и «refine». Следует заметить, что
гиперссылки — это средство инструмента254,, а не языка UML, поэтому мы
далее не будем развивать эту тему, а ограничимся одним советом.
Примечание
Если инструмент поддерживает гиперссылки, используйте
их как можно чаще — это значительно повысит читабель-
ность модели.
Все инструменты в той или иной форме поддерживают документирование
модели. Другими словами, для всех (или для почти всех) элементов моде-
ли во внутреннем представлении предусматривается специальное поле, где
можно сохранить неформальное описание данного элемента в текстовом
виде. Диалоговое окно, приведенное на рис. 5.17, довольно типично для
большинства инструментов, поддерживающих UML.
Большая часть инструментов умеет весьма разумно распоряжаться текстом,
введенным пользователем: вставлять его в виде комментария в генерируе-
мый программный код, автоматически составлять текстовую документацию
254 Инструменты далеко не равнозначны. В наилучших можно установить произвольное ко-
личество гиперссылок от данного элемента к любым другим элементам, в других же на-
бор возможностей очень ограничен.
5.1. Управление моделями
Рис. 5.17. Документирование элементов модели
по модели и т. д. Другими словами, инструменты позволяют документиро-
вать модель должным образом — дело за разработчиками моделей.
5.1.6. Образцы, профили и каркасы
Образцы проектирования (см. параграфы 3.5.3 и 4.4.2) — это сравнительно
новая форма обмена программистским опытом и удачными проектными ре-
шениями. С момента выхода в свет перевода книги "банды четырех"255 [Гамма
Э., Хелм Р., Джонсон Р, Влиссидес Дж. Приемы объектно-ориентированного
проектирования. Паттерны проектирования. — СПб.: Питер, 2006] образцы
проектирования стали одной из наиболее горячих тем, обсуждаемых про-
граммистской общественностью в нашей стране256.
Образцы проектирования и их описание
Неформально говоря, образен проектирование — это гиновое реше-
ние определенной проблемы в заданном контексте.
Существуют различные способы описания образцов проектирования. Боль-
шинство авторов сходятся в том, что образцы целесообразно описывать
по единому шаблону, после чего каждый автор предлагает свой шаблон. В
большинстве случаев предлагается использовать от десяти до двадцати со-
ставляющих описания. Проанализировав ряд источников, мы заметили, что
255 GoF — Gang of Four (Gamma, Helm, Johnson, Vlissides).
256 На самом деле приоритет и лидерство принадлежат сравнительно мало у нас известной
группе авторов POSA — Pattern Oriented Software Architecture.
Глава 5. Дисциплина моделирования
по крайней мере три элемента совпадают во всех источниках, поэтому мы
склонны считать эти элементы обязательными при описании любого образ-
ца проектирования.
• Имя (design pattern name). Ссылаясь на общеизвестное имя образ-
ца, мы можем проектировать на более высоком уровне абстракции.
Словарь общеизвестных имен образцов позволяет эффективно ве-
сти обсуждение с коллегами, лаконично документировать прини-
маемые архитектурные решения. Подбор хорошего имени — одна из
важнейших задач при составлении описания образца.
• Задача (design pattern problem). Описание контекста применения
образца проектирования, т. е. описание конкретной проблемы про-
ектирования и перечня вариантов условий, при выполнении кото-
рых имеет смысл применять данный образец. Часто иллюстрируется
конкретными примерами.
• Решение (design pattern solution). Описание элементов проектиро-
вания, отношений между ними, ответственностей каждого элемента
и способов их взаимодействия. Полезно оценить результаты приме-
нения образца для решения конкретных задач, приведенных в каче-
стве примеров.
UML КАК СРЕДСТВО УПРАВЛЕНИЯ ЗНАНИЯМИ
И ПЕРЕДАЧИ ОПЫТА
Разумеется, образцами проектирования пользовались и пользу-
ются все разумные архитекторы испокон веков, и не только в об-
ласти программирования, а буквально во всех областях человече-
ской деятельности. Почему же термин "образец проектирования"
стал произноситься программистами столь часто именно сейчас?
Мы рискнем высказать собственное мнение по этому вопросу: бум
интереса к образцам проектирования в программировании непо-
средственно связан с появлением и широким распространением
различных нотаций, применяемых при моделировании, в том чис-
ле и UML.
Действительно, до недавнего времени считалось, что хорошим
архитектором, способным быстро, эффективно и надежно спро-
ектировать сложную программную систему, может быть только
достаточно опытный человек. Причем не просто потерявший мно-
го времени на неудачные самостоятельные попытки, а имеющий
опыт успешной работы под руководством уже зарекомендовавше-
го себя архитектора и/или опыт работы в программирующей орга-
низации с богатыми традициями.
5.1. Управление моделями
Такое мнение обосновано многовековым опытом человечества
по передаче знаний и навыков от мастера к ученикам. При непо-
средственном общении ученик смотрит, как мастер решает слож-
ные задачи, пытается поступать "по образцу”, иногда ошибается,
осмысливает ошибки, придумывает собственные приемы — ко-
роче говоря, учится и набирается опыта. Хороший мастер внима-
тельно следит за своими учениками, иногда подсказывает и помо-
гает, иногда ругает и наказывает — короче говоря, учит и воспиты-
вает. Именно поэтому хорошие архитекторы столь дороги: чтобы
из новичка вырастить хорошего мастера, нужно затратить массу
времени и привлечь блестящих учителей. Конечно, можно и нуж-
но учиться по книгам, но написать книгу, которая может научить
искусству программирования заочно, без живого присутствия
мастера, невероятно трудно — такие книги можно пересчитать по
пальцам, в то время как действующих мастеров программирова-
ния, обладающих ценнейшим опытом, многие тысячи. Но далеко
не все мастера программирования имеют педагогический дар,
позволяющий достаточно долго терпеть возле себя учеников, и уж
совсем немногие их них имеют время и способности для написа-
ния хороших книг. К сожалению, опыт и мастерство пионеров про-
граммирования во многом ушли вместе с ними.
Распространение языков моделирования радикальным образом
изменило ситуацию. По нашему мнению, появление языков мо-
делирования имеет для программирования примерно такое зна-
чение, как изобретение нотной записи для музыки или введение
буквенных обозначений для математики. Используя тот же UML,
архитектор программной системы может сообщить свои идеи
(именно идеи, а не примеры готовых решений на языке програм-
мирования) в лаконичной и понятной форме, доступной для вос-
приятия подавляющему большинству разработчиков. Обычный
разработчик может понять и использовать блестящую идею ма-
стера быстро, прямо сейчас и с видимым успехом, подобно тому,
как квалифицированные музыканты играют произведения великих
мастеров прошлого "с листа".
Рассмотрим подробнее понятие образца проектирования применительно к
UML. Синтаксически образец проктирования — это параметрическая коо-
перация классов (т. е. шаблон кооперации). Напомним (см. параграф 3.5.2),
что в кооперации участвуют роли классификаторов, т. е., фактически, клас-
сификаторы (классы), входящие в кооперацию, можно рассматривать как
параметры, а всю кооперацию в целом — как шаблон взаимодействия (см.
пример в параграфе 3.5.3, рис. 3.75).
Таким образом, чтобы применить некоторый образец проектирования (ша-
блон взаимодействия, т. е. кооперацию) в определенном контексте, доста-
точно связать параметры шаблона с конкретными значениями, т. е. указать,
Глава 5. Дисциплина моделирования
какие конкретные классы модели играют роли классификаторов, участвую-
щих в данной кооперации (образце). Для этого в UML предусмотрен специ-
альный синтаксис.
Применяемый образец изображается в виде пунктирного овала, внутри ко-
торого написано имя кооперации. Этот овал соединяется пунктирными ли-
ниями с классами, которые являются фактическими аргументами, причем
на линии указывается имя роли, которую класс играет в применяемой коо-
перации (см. пример в параграфе 4.4.2, рис. 4.69).
Классический пример — образец проектирования Composite
Рассмотрим все это более подробно на конкретном примере, в качестве кото-
рого мы используем классический образец проектирования — Composite —
на примере уже разобранного нами фрагмента информационной системы
отдела кадров.
• Имя — Composite. Также описывается словосочетаниями: иерархи-
ческая структура, иерархия, древовидная структура, ориентирован-
ное дерево, отношение "has а", контейнер, вложенный контейнер.
• Задача. При обработке иерархических структур, в которых индиви-
дуальные объекты собраны в группы, а группы (и индивидуальные
объекты) собраны в группы следующего уровня и так далее, требу-
ется обеспечить унифицированную обработку как отдельных объек-
тов, так и групп объектов. При этом всякая группа должна сохранять
информацию о своем составе.
• Решение. Ввести роли Node, Composite и Leaf, с соответствующими
шаблонными типами NType, LType и СТуре. При этом тип NType яв-
ляется абстрактным суперклассом для своих специализаций: LType и
СТуре. Общее поведение описано в классе NType и должно быть реа-
лизовано, возможно, различным образом, в специализирующих кон-
кретных подклассах СТуре и классе индивидуальных объектов LType.
Помимо обобщения, вводится композиция, благодаря которой груп-
пы знают свой состав (child) и все объекты знают группу, в которую
входят, если она есть (parent). На рис. 5.18 приведена кооперация,
описывающая данный образец проектирования.
Возможны различные модификации образца: при необходимости можно
не создавать отдельных классов для групп и листовых элементов, а хранить
всю информацию в классе NType. Но тогда при реализации методов придет-
ся проверять, с каким объектом мы имеем дело: с индивидуальным объектом
или с группой — это дополнительный источник ошибок.
5.1. Управление моделями
Рис. 5.18. Кооперация для образца проектирования Composite
Что касается области применения образца, то следует подчеркнуть, что
ситуации, в которых стоит применять образец проектирования Composite,
встречаются в практике программирования достаточно часто. Вот несколько
примеров: файлы и папки в файловой системе, пакетная структура модели,
рассмотренная в предыдущем параграфе, элементы и блоки в любом разбие-
нии множества.
Примечание
Мы значительно упростили и сократили описание и обсуж-
дение образца проектирования Composite, поскольку нашей
целью является не описание конкретных образцов, а только
обсуждение техники применения образцов в контексте язы-
ка UML. Для более детального изучения данного образца
следует обратиться к первоисточнику, то есть к указанной
выше книге "банды четырех".
Допустим теперь, что средствами UML описано некоторое множество об-
разцов проектирования, и мы хотим применить один из них в конкретном
контексте. Как происходит применение образца, если моделирование ведет-
ся средствами UML?
Рассмотрим пример из информационной системы отдела кадров. В главе 3
при описании структуры нам уже встречались похожие ситуации. Так, мы
рассматривали иерархию подразделений (см. рис. 3.23 -3.28) и иерархию
должностей (см. рис. 3.29-3.30). Здесь, рис. 5.19, мы повторяем основные
отношения из главы 3, а также, чтобы пример был более наглядным, напо-
минаем, что класс Position реализует несколько интерфейсов.
В этом случае мы можем дважды применить кооперацию (образец проекти-
рования Composite), как показано на рис. 5.20. На этом рисунке изображены
Ф
Глава 5. Дисциплина моделирования
includes ►
•< subordinates
Рис. 5.19. Исходная ситуация для применения образца проектирования Composite
Рис. 5.20. Применение образца проектирования Composite
два применения кооперации (collaboration use) (1), причем каждое примене
ние имеет собственное имя (2), что позволяет отличать их друг от друга. Да
лее, роли кооперации связываются с помощью пунктирных линий с класса
5.1. Управление моделями
ми модели, показывая тем самым, какую роль должен играть данный класс,
участвуя в кооперации. При этом для каждой роли может быть указан свой
класс (3), а может быть так, что один класс играет сразу несколько ролей (4).
По замыслу авторов UML, простая нотация на рис. 5.20 несет значительную
семантическую нагрузку. Во-первых, приведенная диаграмма определяет
структуру, причем в этой структуре может быть определено гораздо больше
элементов, чем нарисовано на диаграмме. В частности, подразумевается, что
в модели определены отношения композиции для подразделений и долж-
ностей (хотя они и не присутствуют на диаграмме), а сами классы обладают
нужными средствами для применения образца (то есть реализованы роли
child и parent, см. рис. 5.18). Во-вторых, если применяемая кооперация со-
держит не только определение структуры, но и определение поведения, то
это поведение определяется для классов, которые играют роли кооперации.
Поведение кооперации может быть определено указанием атрибутов и опе-
раций ролей и описанием, например, диаграммы коммуникации, описываю-
щей взаимодействие ролей. Мы не стали делать этого в нашем примере, но
это можно сделать!
Любому разработчику совершенно ясно, что именно, почему и как нужно
запрограммировать в информационной системе отдела кадров, чтобы обе-
спечить требуемую иерархию объектов классов Department и Position. Такая
ясность опирается на понимание образца проектирования Composite (тем
более что этот образец, вероятно, хорошо известен большинству читателей
и без наших объяснений). Однако было бы чрезмерным надеяться на то, что
инструменты моделирования понимают образцы проектирования так же хо-
рошо, как люди.
Весьма вероятно, что в используемом инструменте даже не найдется такой
фигуры, как пунктирный овал, предназначенный для обозначения при-
менения образца. Но с той же степенью вероятности найдется библиотека
готовых образцов проектирования. Как правило, инструменты позволя-
ют включить образец в модель (в форме заготовки диаграммы внутренней
структуры) и вручную связать (отождествить или переопределить) элемен-
ты образца с элементами модели. Другими словами, общая схема примене-
ния образца остается той же самой, но задача понимания образца возлагается
на разработчика.
Примечание
Не все образцы проектирования, описанные в литературе,
могут быть адекватно выражены в UML. Наилучшим обра-
зом язык подходит для описания таких образцов, в которых
решение выражается в форме описания поведения взаимо-
действующих объектов.
Глава 5. Дисциплина Моделирования
Рекомендации по использованию образцов проектирования
Мы заканчиваем обсуждение образцов проектирования списком тезисов и
советов, отражающих наши рекомендации по использованию образцов про-
ектирования при моделировании.
• Образец проектирования — это публикация обобщенного опыта
профессионалов. Поэтому образец, как правило, полезен, разумен
и применим в широком диапазоне ситуаций. Но ответственность за
правильный выбор образца и его адекватное применение лежит, все-
таки, на том, кто использует образец, а не на том, кто его публикует.
• Образец решает типичную и распространенную, но ограниченную
подзадачу. Поэтому, как правило, образец лаконичен, а иногда и три-
виален. Редко бывает так, чтобы в образце использовалось больше
элементов, чем может поместиться на одной простой диаграмме. Нет
(и не может быть!) образцов, описывающих всю систему в целом —
даже интенсивно применяя образцы проектирования, архитектор все-
таки должен думать собственной головой.
• В настоящее время опубликовано несколько десятков общепри-
знанных образцов и несколько сот используемых менее часто.
Квалифицированный архитектор обязан знать (но не обязан каждый
раз использовать) общепризнанные образцы, хотя бы по названиям.
• Если используемый инструмент моделирования содержит библио-
теку образцов, то архитектору следует изучить данную библиотеку
во всех деталях. Это настолько же полезно, насколько программисту
полезно знать стандартные библиотеки используемого им языка про-
граммирования.
• Если в программирующей организации используется инструмент
моделирования для разработки программного обеспечения, то соз-
дание корпоративной библиотеки образцов проектирования — это
основа реального (а не формального) репозитория.
Каркас и профиль
В UML определены еще два понятия, тесно связанных с образцами проекти-
рования. Это каркас и профиль.
Каркас (framework) совокупность ло! ически связанных шаблонов,
стереотипов и образцов проектирования, определенных на основе
стандартной метамодели L'ML и предназначенных для моделирова-
ния в определенной предметной облае ги.
5.2. Практика применения UML
Синтаксически каркас в UML — это пакет со стереотипом «framework». Кар-
кас не предполагает изменения языка — это просто набор заранее подготов-
ленных для повторного использования заготовок, выраженных средствами
стандартных конструкций UML.
Профиль (profile) — множество изменений базовой .метамодели и со-
вокупность логически связанных шаблонов, стереотипов и образцов
проектирования, определенных на основе измененной метамодсли и
предназначенных: ДЛЯ моделирования в определенной предметной об-
ласти.
Синтаксически профиль в UML — это пакет со стереотипом «profile». Про-
филь предполагает систематическое изменение языка. Обычно профиль
создается следующим образом. Из стандартной метамодели выбираются от-
дельные элементы или целые пакеты, которые нужны для моделирования в
данной предметной области. Ненужные элементы метамодели не включают-
ся в профиль, чтобы пользователю профиля не нужно было иметь дела с не-
используемыми возможностями UML. Затем на основе редуцированной ме-
тамодели определяются шаблоны, стереотипы и образцы проектирования.
При этом можно добавлять новые именованные значения, но нельзя удалять
имеющиеся; можно добавлять новые ограничения, но нельзя ослаблять име-
ющиеся. Таким образом, модель, построенная с помощью профиля, остается
моделью UML, хотя и не использует, может быть, многих его конструкций.
5.2. Практика применения UML
Материал раздела носит субъективный характер — все, сказанное ниже, яв-
ляется личным мнением авторов. Наше мнение основано на длительном (с
ноября 1997 года) и разнообразном опыте использования UML для решения
самых разнообразных задач. Мы применяли UML в следующих предметных
областях:
• разработка заказного программного обеспечения;
• анализ деятельности и описание бизнес-процессов организаций;
• перевод и научное редактирование оригинальных книг по UML;
• преподавание UML в различных университетах и других обучаю-
щих организациях;
• разработка инструментов, поддерживающих UML.
Признаемся: с переменным успехом. Были достижения, но были и досадные
неудачи. Именно поэтому мы думаем, что обсуждение нашего опыта, как по-
ложительного, так и отрицательного, может быть полезно читателю.
Глава 5 Дисциплина моделирования .<
5.2.1. Уровни моделирования
Первый вопрос, который надлежит поставить перед собой, приступая к при-
менению UML: чего мы хотим достичь? Здесь, как говорится, возможны ва-
рианты. Мы рассмотрим три из них, наиболее нам близкие:
• концептуальное моделирование (conceptual modeling);
• спецификация требований (requirement specification);
• детальное проектирование (detailed design).
Концептуальное моделирование
В этом варианте целью моделирования является достижение понимания
моделируемой физической системы (приложения, бизнес-процесса...), ее
назначения и области применения. Во введении мы изложили наше пред-
ставление о трех уровнях понимания:
• первый уровень — когда появляется приятное чувство, что все по-
нял;
• второй уровень — когда можешь повторить сказанное;
• третий уровень — когда можешь найти ошибку.
Для понимания системы на первом уровне моделирование на UML не обяза-
тельно — достаточно устного объяснения и, может быть, нескольких нагляд-
ных слайдов с картинками. Второй уровень легко достигается с помощью
связного текста на естественном языке. Применение UML оправдано, когда
нужно достичь третьего уровня — не просто познакомиться с идеей систе-
мы, но увидеть ее в целом и, может быть, найти пробелы или ошибки.
По нашему мнению257, для концептуального моделирования полные диа-
граммы использования обязательны, а также желательны и полезны диа-
граммы классов (с минимумом подробностей) в объеме словаря предмет-
ной области, диаграмма компонентов или размещения для перечисления
основных артефактов и, может быть, диаграммы взаимодействия или дея-
тельности для типовых сценариев основных вариантов использования. В
некоторых случаях (не во всех, а только в тех, когда это существенно для
Понимания логики работы приложения) оказываются полезны диаграммы
состояний. Очень важно не забыть упомянуть в комментариях те ключевые
аспекты, которые не отражены в графической нотации. Главные требования
к концептуальной модели — обозримость и согласованность. Диаграмм не
257 Наше мнение сходится с мнением авторов языка, см. руководство пользователя [2], со-
веты по моделированию.
5.2. Практика применения UML
должно быть много, и они не должны быть сложными, но расхождения в
обозначениях и названиях крайне нежелательны.
В нашей книге нет полной концептуальной модели, покрывающей абсо-
лютно всю функциональность информационной системы отдела кадров —
мы не ставили перед собой такой цели, наша задача заключалась в том, что-
бы проиллюстрировать использование элементов языка UML. Но если бы
мы взялись за реальную разработку информационной системы отдела ка-
дров, то в концептуальную модель мы бы включили диаграммы, подобные
диаграммам главы 2.
Спецификация требований
Во втором варианте применения UML основной целью моделирования яв-
ляется получение артефакта, который мог бы послужить техническим зада-
нием на разработку. Техническое задание должно определять требования к
системе и обеспечивать эффективную проверку того, что требования дей-
ствительно выполнены. Так же, как и в случае концептуального проектиро-
вания, основой спецификации требований являются диаграммы использо-
вания, но их детальность и полнота должны быть существенно выше.
Реализация вариантов использования в форме диаграмм взаимодействия
обязательна — это основа для построения набора тестов приемо-сдаточных
испытаний. Далее, на диаграммы использования возлагается значительно
большая ответственность, поэтому разрабатывать их необходимо намного
тщательнее. Например, если на диаграмме не изображен некоторый вариант
использования, то это означает, что система не должна иметь соответству-
ющую функциональность. В спецификации требований диаграмма компо-
нентов не просто желательна, а обязательна — техническое задание должно
определять, хотя бы на уровне названий, что именно должно быть разрабо-
тано.
Между концептуальной моделью и спецификацией требований нет непро-
ходимой границы — довольно часто концептуальная модель за несколько
итераций перерастает в спецификацию требований. По нашим наблюдени-
ям, удовлетворительная спецификация требований оказывается в 3-5 раз
объемнее концептуальной модели.
Детальное проектирование
Третий вариант применения UML требует известной решимости и, одновре-
менно, трезвого расчета. Детальное проектирование нацелено уже не столь-
ко на описание, сколько на конструирование артефактов разрабатываемой
Глава 5 Дисциплина моделирования
системы (третье назначение UML, см. параграф 1.2.3). Модель детального
проектирования служит основным документом, которым руководствуются
программисты при кодировании, тестеры при проверке, а технические писа-
тели — при составлении программной документации для системы.
Если нет уверенности в способности команды построить и использовать
хороший детальный проект исключительно средствами UML, то не стоит
тратить на него ресурсы. Лучше не иметь никаких детальных диаграмм, чем
иметь плохие. По нашим наблюдениям, ошибка, допущенная в детальной
диаграмме, обходится в несколько раз дороже, чем обычная ошибка в коде.
Далее, детальное проектирование в несколько раз объемнее спецификации
требований, поэтому, как правило, в процесс детального проектирования во-
влекаются несколько человек, а значит, обостряются проблемы целостности
модели, согласованности обозначений, сохранности артефактов,
С другой стороны, если имеется опыт детального проектирования на UML,
накоплены образцы проектирования в форме диаграмм коммуникации, точ-
но известны возможности инструмента по генерации кода на целевом языке
программирования, то систематическое применение UML для детального
проектирования ускоряет и удешевляет разработку в несколько раз. Поэто-
му стоит рискнуть и попробовать. Не расстраивайтесь (но будьте к этому
готовы!), если самый первый опыт детального проектирования на UML
окажется неудачным — на ошибках учатся. Невозможно научиться плавать,
стоя на берегу.
В модели детального проектирования, как правило, используется большая
часть элементов языка UML, рассмотренных в этой книге. Особое значе-
ние имеют диаграммы классов, которые должны быть определены с макси-
мальной степенью детальности. Количество классификаторов возрастает в
несколько раз по сравнению с концептуальной моделью. Помимо основных
сущностей из словаря предметной области нужно определить типы данных,
интерфейсы, сигналы, исключения и т. д. Как правило, сама модель имеет
сложную структуру и без использования диаграмм пакетов также не обой-
тись.
Приведенная классификация уровней моделирования не претендует на уни-
версальность. В литературе описаны и другие варианты, например, примене-
ние UML для описания бизнес-процессов, в том числе процесса разработки
программного обеспечения. Но для разработки офисных приложений, о ко-
торых идет речь в главе 1, Мы считаем указанные способы применения UML
типичными. Во всяком случае, мы так делали, и получалось неплохо, — по-
пробуйте и вы.
5.2. Практика применения UML
5.2.2. Правильный подход к моделированию или как
не надо применять UML
"Единственно правильной" модели нет и не может быть. Если программи-
рование — это искусство, то что говорить об архитектурном проектирова-
нии и концептуальном моделировании? Это, видимо, элитарное искусство.
Поэтому, если читатель рассчитывает найти в данном параграфе советы в
следующем стиле: "чтобы построить правильную модель, делай раз, делай
два, делай три ...", то его ждет разочарование — нет у нас в запасе подобных
советов258. Довольно обширный список "положительных" советов по моде-
лированию можно найти в руководстве пользователя [2].
Мы не хотим конкурировать и противопоставлять свое мнение мнению ав-
торов языка, а потому зайдем с другой стороны: в этом разделе мы рас-
скажем, как не надо применять UML. Поскольку советы почерпнуты из
опыта наших ошибок, они могут оказаться полезными читателю — учиться
на чужих ошибках дешевле.
Не переоценивайте возможности инструмента
Все производители инструментов на все лады превозносят достоинства сво-
их продуктов и скромно умалчивают об их недостатках. Между тем, недо-
статки есть у всех инструментов, во всяком случае, у всех из тех, что мы про-
бовали до сих пор.
Самая распространенная неприятность состоит в том, что пользователи, как
правило, доверяют разработчикам инструментов, а производители, к сожа-
лению, злоупотребляют этим доверием. Поэтому если в инструменте есть
ошибка, например, несоответствие стандарту языка, пользователи, весьма
вероятно, будет тиражировать эту ошибку, пытаясь использовать невозмож-
ную конструкцию.
Приведем пример. В шаблоне для работы с UML, который поставляется
вместе с Microsoft Visio (во всех версиях), есть загадочное отношение между
вариантами использования, представленное на рис. 5.21.
Рис. 5.21. Ошибочное отношение
Такого отношения нет и не было ни в одном из стандартов UML. Внима-
тельное изучение ситуации показало, что разработчики корпорации Micro-
soft имели в виду зависимость (т.е. пунктирную стрелку) со стереотипом
«include».
258 Более того, тех, кто пытается давать такие советы в форме элементарных и однозначных
процедур "из трех шагов", мы подозреваем в сознательной профанации.
I 533
Глава 5. Дисциплина моделирования
Наш совет таков: проверьте сначала каждую возможность инструмента,
прежде чем планировать использование этой возможности в своем ответ-
ственном проекте. Конечно, проверка инструмента требует времени и сил,
но потери от использования некорректного инструмента могут быть значи-
тельно больше!
Не пренебрегайте возможностями инструмента
Многие инструменты имеют обширные дополнительные возможности, по-
мимо рисования диаграмм. Вообще говоря, использование дополнительных
возможностей необязательно, но они могут дать значительный выигрыш.
Рассмотрим следующую аналогию. Можно отлаживать программу, вставляя
отладочные печати в код. Но можно использовать интерактивный отладчик
с точками останова и наблюдением за переменными, и отладка ускоряется в
десятки раз! Если продолжить эту аналогию, то роль отладчика при модели-
ровании на UML играет тот компонент инструмента, который позволяет ра-
ботать непосредственно с моделью, а не с ее внешним представлением в виде
диаграмм. Обычно такой компонент называют "Model Explorer" или нечто в
этом роде. Назовем его "обозреватель модели".
Как правило, обозреватель позволяет отображать структуру всей модели в
иерархическом виде на основе иерархии отношения владения (см. параг-
раф 5.1.1). Кроме того, обозреватель позволяет создавать, удалять и переме-
щать элементы, прежде всего основные сущности.
Приведем пример: перетаскивая значок элемента моделирования с панели
инструментов на диаграмму, мы создаем новый экземпляр метакласса. Во-
прос: а где в модели создается этот экземпляр? Напомним, диаграмма не вла-
деет размещенными на ней элементами и не является пространством имен.
Элемент создается где-то в другом месте, скорее всего, в пакете, который
владеет этой диаграммой.
Продолжим пример. Пользователь перетащил на разные диаграммы зна-
чок действующего лица и дал этому элементу одно и то же имя, подразуме-
вая, что это одно и тоже действующее лицо. Если инструмент это стерпел,
то, скорее всего, пользователь заблуждается, и у него получилось совсем не
то, что хотелось: появились несколько различных действующих лиц, име-
ющих одинаковые имена, но принадлежащие разным пространствам имен,
рис. 5.22.
Наш совет таков: на первом этапе построения модели, когда определяется
ее общая пакетная структура и перечисляются основные сущности, дер-
жать обозреватель постоянно открытым и следить за тем, что происходит
5 2 Практика применения UML
Рис. 5.22. Ошибочное размножение сущностей
в модели. Можно даже вообще не рисовать никаких диаграмм на первом
этапе, а создавать основные сущности прямо в обозревателе! Позже, когда
структура модели определится, будет время перетащить значки уже создан-
ных элементов из обозревателя на диаграммы, и подвигать их мышкой, до-
биваясь красивого расположения.
Не переоценивайте собственные возможности
Моделирование на UML довольно-таки кропотливое и даже занудное заня-
тие. С налету, "широкими мазками", ничего хорошего не получится.
На заре компьютерной эры, менеджеры, сделав замеры производительно-
сти труда программистов, обнаружили, что в среднем программист создает,
условно говоря, 100 строк кода за рабочий день. При самой медленной рабо-
те одним пальцем и с ошибками ввод 100 строк занимает ну никак не больше
часа. Еще два часа программист пьет кофе, курит и болтает с приятелями по
телефону. Но что же он делает еще пять часов? Ответ известен — програм-
мист думает над тем, что вводит.
Примем приблизительно, что коэффициент замедления при программиро-
вании равен 5: на одну часть работы руками приходится пять частей работы
головой. Проведя наблюдения за собой и за студентами, мы пришли к вы-
воду, что при моделировании на UML коэффициент замедления примерно
Глава 5. Дисциплина моделирования
вдвое больше и равен 10. Другими словами, одна часть усилий уйдет на ри-
сование и 10 частей — на обдумывание и любование нарисованным.
Диаграммы не создаются быстро. Сейчас у нас на рисование каждой из диа-
грамм в этой книге уходит меньше получаса. Но для приобретения этого на-
выка нам понадобился год, раньше на некоторые сложные диаграммы у нас
уходило больше часа. Далее, почти все диаграммы в этой книге пережили
несколько редакций, от 3 до 7. Это нормальный показатель, примерно такое
количество итераций требуется и при реальной разработке моделей.
Наш совет таков: прежде чем начинать детальное проектирование на UML
серьезной системы, проведите измерения и накопите статистику на менее
ответственных проектах. Нужно знать по меньшей мере следующие пока-
затели: среднее количество диаграмм в детальной модели, приходящихся
на один вариант использования в концептуальной модели, и среднее время
разработки одной диаграммы. Для усреднения достаточно построить три-
пять законченных моделей с десятком вариантов использования каждая259.
После этого ожидаемая трудоемкость построения полной модели определя-
ется простым умножением числа вариантов использования на измеренные
показатели.
Не пренебрегайте собственными
возможностями
Язык UML содержит множество разнообразных средств, и кажется, что уже
ничего сверх этого предложить невозможно и не нужно. Но это не так. Каж-
дый проект содержит нечто особенное и уникальное, и это может получить
новое языковое выражение: новый стереотип, каркас, даже образец проек-
тирования. Очень важно каждую такую находку сохранить для повторного
использования.
По нашему мнению, критерием зрелости современного архитектора про-
граммных систем и программирующей организации является наличие лич-
ного или корпоративного репозитория решений на языке UML. Наш совет
таков: расширяйте язык!
5.2.3. Применение элементов UML
Как отмечено в параграфе 1.1.3, UML является результатом сведения воеди-
но и унификации десятков языков моделирования, существовавших в 90-е
259 Некоторые ошибочно полагают, что показатели, измеренные на учебных проектах, не-
применимы для “боевых” проектов. Дескать, для “боевого” проекта мы постараемся и
сделаем “как лучше”. Нет! Получится “как всегда”! Не переоценивайте свои возможно-
сти!
5.2. Практика применения UML
годы XX века. Побочным эффектом такой унификации стало включение в
язык огромного числа разнообразных элементов на все случаи жизни. Пол-
ный объем спецификации UML составляет более 1000 страниц (см. пара-
граф 1.3.3). Таким огромным объемом информации трудно оперировать, не
говоря уже о том, что его просто нелегко усвоить.
К счастью, есть основание утверждать, что для эффективного использова-
ния UML достаточно изучить вполне обозримое подмножество языка. Та-
кое основание дает принцип Парето, также известный как принцип 80/20.
Принцип гласит, что небольшая доля причин, вкладываемых средств или
прилагаемых усилий (20%) отвечает за большую долю результатов, полу-
чаемой продукции или заработанного вознаграждения (80%).
Примечание
Итальянский экономист и статистик Вильфредо Парето
(1848-1923) в одной из своих работ заметил, что в Италии
20% домохозяйств получают 80% доходов. Принцип 80/20
сформулировал один из пионеров управления качеством
Джозеф Джуран в 1941 году и назвал его принципом Парето.
Вот несколько примеров:
• 20% клиентов обеспечивают 80% прибыли;
• 20% ошибок обусловливают 80% потерь;
• за 20% расходуемого времени достигается 80% результатов;
• 80% людей живет в 20% городов;
• 20% слов языка достаточно в 80% случаев.
Во всех этих примерах важны не точные цифры, а сам факт предсказуемой
несбалансированности распределения (поэтому, кстати, принцип Парето
иногда еще называют принципом дисбаланса).
Выявление тех 20% конструкций UML, которых окажется достаточно в 80%
случаев, является привлекательной задачей. В ее решении заинтересованы
как разработчики программного обеспечения, использующие UML по долгу
службы, так и преподаватели вузов, читающие студентам лекции по UML.
Далее приведен обзор трех исследований, направленных на выделение
"ядра" UML, и наши выводы по этому вопросу.
Одна из первых попыток понять, как используется UML на практике, и тем
самым хоть немного навести порядок в обилии конструкций языка, прово-
дилась путем опроса профессиональных разработчиков об их опыте исполь-
Глава 5 Дисциплина моделирования
зования UML 1 [Brian Dobing & Jeffrey Parson. How UML is Used // CACM,
vol. 49, #5,2006]260. Вопросы касались канонических диаграмм UML.
Опрос показал, что наиболее часто разработчики используют диаграммы
классов. 73% респондентов постоянно использовали диаграммы классов.
Реже всего используются диаграммы кооперации. Только 20% опрошен-
ных постоянно сталкиваются в своей работе с этим типом диаграмм.
Список диаграмм, упорядоченный по интенсивности использования, со-
гласно результатам исследования, выглядит следующим образом:
• диаграмма классов;
• диаграмма использования;
• диаграмма последовательности;
• диаграмма деятельности;
• диаграмма состояний;
• диаграмма кооперации.
Остальные диаграммы UML 1 — диаграммы объектов, компонентов и раз-
вертывания — оказались за рамками исследования как "менее релевантные
изучаемому вопросу". Видимо, они априори считались наименее полезны-
ми.
Эти первые опросы показали значительный разброс в данных, что свиде-
тельствует не только о том, что UML неоднороден, но и о том, что в различ-
ных сферах применения одни и те же конструкции языка имеют разный вес
и разную ценность. Разные люди применяют UML по-разному
Другими словами, фактические наблюдения подтверждают высказанную
нами ранее (см. параграф 1.1.3) мысль, что UML отнюдь не является уни-
версальным языком с неограниченной областью применения.
Исчерпывающим образом охарактеризовать предметные области примене-
ния UML не так просто. Видимо, сказать: "при таких-то условиях применять
UML нужно обязательно, а при других условиях нельзя применять UML ни
в коем случае" — было бы неправильно. Нет таких объективных условий и
критериев. Тем не менее, есть отчетливое субъективное ощущение, что в од-
них случаях применение UML оказывается удобным, приятным и эффек-
тивным, а в других — трудным, тягостным и бесполезным. Но чье субъек-
тивное мнение следует принять во внимание в первую очередь? Конечно,
мнение авторов языка! Кто, как не они, заинтересован в том, чтобы привести
260 Опрос проводился при поддержке OMG в течение года с марта 2003 по март 2004 года.
Однако статья была опубликована только в мае 2006 года.
538
5.2 Практик пр л щенения UMI.
самые эффектные примеры применения языка! Так вот, если проанализиро-
вать сочинения авторов UML, относящиеся к UML, то легко заметить, что
авторы выбирают в своих книгах примеры из трех классов предметных об-
ластей.
Во-первых, это информационные системы управления предприятием (En-
terprise Resource Planning — ERP), подобные рассматриваемой нами ин-
формационной системе отдела кадров, только более сложные. Во-вторых,
приложения реального времени (real time system) и встроенные системы (em-
bedded system) — например, банкомат, бортовая система автомобиля и тому
подобное. В-третьих, клиент-серверные системы массового обслуживания,
или веб-приложения (web application). Порядок перечисления соответству-
ет частоте встречаемости примеров. Значит ли это, что UML невозможно
применить, например, в программном обеспечении инженерных расчетов?
С одной стороны, мы думаем, что можно, с другой стороны, у авторов таких
примеров нет.
Примечание
Если сосчитать все авторские примеры, во всех книгах,
включая спецификацию языка, то оказывается, что больше
всего язык UML применяется для описания языка UML (и
других подобных искусственных языков). Но это примене-
ние следует вынести за скобки, оценивая применение UML в
реальной промышленной практике.
В статье "Может ли UML стать простым?” [John Erickson & Keng Siau. Can
UML Be Simplified? Practitioner Use of UML in Separate Domains, 2007]261 ее
авторы рассказывают о своем исследовании по выявлению ядра UML, ми-
нимального по объему, но решающего основные задачи пользователей262. К
исследованию были привлечены эксперты из разных областей индустрии
разработки программного обеспечения. Участников просили оценить важ-
ность каждого типа диаграмм UML 1 для их работы. При этом дифферен-
цировалась предметная область: информационные системы масштаба пред-
приятия, системы реального времени и веб-приложения.
В таблице 5.2 приведены списки канонических диаграмм, упорядоченных по
их важности в разных предметных областях: от самой важной диаграммы к
самой "неважной".
261 http://www.via-nova-architectura.org/files/EMMSAD2007/Erickson.pdf.
262 Как и предыдущее, это исследование проведено в 2003-2004 годах, однако результаты
опубликованы только в 2007 году.
[ 539 u
Глава 5. Дисциплина моделирования
Таблица 5.2. Важность диаграмм по предметным областям
Системы управления предприятием Системы реального времени
1. диаграмма классов; 2. диаграмма использования; 3. диаграмма последовательности; 4. диаграмма деятельности; 5. диаграмма размещения; 6. диаграмма компонентов; 7. диаграмма состояний; 8. диаграмма кооперации; 9. диаграмма объектов. 1. диаграмма классов; 2. диаграмма состояний; 3. диаграмма последовательности; 4. диаграмма использования; 5. диаграмма компонентов; 6. диаграмма деятельности; 7. диаграмма размещения; 8. диаграмма объектов; 9. диаграмма кооперации.
Веб-приложения Все системы
1. диаграмма классов; 2. диаграмма использования; 3. диаграмма последовательности; 4. диаграмма состояний; 5. диаграмма компонентов; 6. диаграмма размещения; 7. диаграмма деятельности; 8. диаграмма кооперации; 9. диаграмма объектов. 1. диаграмма классов; 2. диаграмма использования; 3. диаграмма последовательности; 4. диаграмма состояний; 5. диаграмма компонентов; 6. диаграмма деятельности; 7. диаграмма размещения; 8. диаграмма кооперации; 9. диаграмма объектов.
Первые четыре диаграммы в каждом из приведенных списков, выделенные
жирным шрифтом, отнесены к ядру UML в соответствующей предметной
области.
Можно заметить, что диаграммы классов, использования и последователь-
ности вошли во все четыре ядра, что говорит об их универсальной важности.
Это наблюдение дало авторам статьи основание предложить в качестве ядра
UML три перечисленные диаграммы и связанные с ними конструкции.
В статье Станислава Врыча и Бартоша Марчинковски [Stanislaw Wrycza
& Bartosz Marcinkowski. Towards a Light Version of UML 2.X: Appraisal and
Model, 2007]263 предлагается другой подход к выделению ядра UML, назы-
ваемого авторами "UML Light". В своем исследовании авторы опираются на
опыт преподавания UML студентам и используют тех же студентов в каче-
стве респондентов264.
В результате было обнаружено, что, по мнению 57% респондентов, в UML
слишком много типов диаграмм (в UML 2 их 13).
Четырьмя наиболее полезными диаграммами, по результатам опроса, оказа-
лись:
263 http://organizacija.fov.uni-rnb.si/index.php/organizacija/article/view/202/0.
264 Статья опубликована в 2007 году, о времени проведения исследования не сообщается.
540 ]
г
5.2. Практика применения UML
• диаграмма классов;
• диаграмма использования;
• диаграмма деятельности;
• диаграмма последовательности.
Именно они и предложены авторами в качестве UML Light.
В то же время диаграмма последовательности была признана студентами са-
мой перегруженной различными элементами и обозначениями.
Самыми понятными и простыми в использовании признаны диаграммы ис-
пользования, классов и деятельности. Самыми запутанными и сложными в
использовании показались обзорная диаграмма взаимодействия, диаграмма
размещения и диаграмма внутренней структуры.
Как показывают эти и другие исследования, диаграмма классов и диаграмма
использования однозначно идентифицируются в качестве основных и самых
полезных диаграмм UML. Насчет включения в ядро диаграммы автомата,
диаграммы последовательности или диаграммы деятельности существуют
разногласия, но одна из этих диаграмм обязательно включается.
Перечисленные диаграммы отражают все три принципиальных аспекта мо-
делирования (использование, структура, поведение), и в большинстве слу-
чаев можно обойтись только тремя диаграммами: использования, классов
и какой-либо диаграммой поведения. Три диаграммы как раз и составляют
20% UML (3/13=0.23), достаточные для 80% случаев. Причем наш вывод
относительно выбора диаграммы поведения таков:
• в приложениях реального времени — диаграмма автомата,
• в автоматизированных системах — диаграмма деятельности,
• в веб-приложениях — диаграмма последовательности.
Выделение ядра UML не означает, что остальные диаграммы и связанные
конструкции надо исключить из языка — их можно считать специализиро-
ванными расширениями языка и использовать при необходимости. Выделе-
ние ядра означает, что при изучении UML в первую очередь нужно обратить
внимание на конструкции перечисленных типов диаграмм.
5.2.4. Средства моделирования на UML
Обсуждая практическое применение UML, невозможно обойти молчанием
вопрос об инструментальных средствах — при моделировании от инстру-
мента зависит очень многое!
Глава 5. Дисциплина моделирования
В параграфе 1.2.6 мы выделили три варианта использования языка:
• рисование диаграмм,
• моделирование систем и
• разработка приложений.
Не все из этих вариантов использования требуют инструментальной под-
держки. Рисовать диаграммы можно и подручными средствами. С них и нач-
нем.
Карандаш и бумага
В некоторых "гибких" (agile) методологиях разработки программного обе-
спечения не рекомендуется использовать компьютеры на раннем этапе про-
ектирования архитектуры. Вместо этого заинтересованные разработчики
садятся рядом друг с другом и рисуют на бумаге свое видение будущей си-
стемы. Конечно, при этом далеко не всегда для отображения тех или иных
компонентов системы соблюдаются стандарты UML. Однако такой способ
моделирования позволяет довольно быстро принимать ключевые архитек-
турные решения, которые впоследствии уточняются в виде более детальных
и более правильных диаграмм, нарисованных уже при помощи специальных
программ.
Два основных ограничения моделирования на бумаге заключаются в том,
что, во-первых, такие диаграммы сложно менять, часто их даже проще быва-
ет перерисовать, а во-вторых — таким способом почти нереально нарисовать
крупную, детальную и хорошо проработанную модель.
Доска и фломастер
Но можно пойти дальше и рисовать диаграммы фломастерами на доске. Если
доска достаточно велика, установлена в том помещении, где регулярно соби-
раются разработчики проекта и не используется для других целей, то такой
метод имеет значительные преимущества. Во-первых, все разработчики по-
стоянно видят модель и невольно обдумывают ее. Во-вторых, нарисованные
на доске диаграммы легко менять и можно постоянно держать в актуальном
состоянии. В-третьих, их нетрудно сфотографировать цифровым фотоаппа-
ратом и включить в документацию (рис. 5.23)
Инструментальные средства
Моделирование систем и тем более разработка приложений требуют при-
менения инструментальных средств.
5.2 Практика применения UML
Рис. 5.23. Модель, нарисованная на доске
Чтобы читателю было легче ориентироваться в мире инструментальных
средств моделирования на UML, мы составили сводную таблицу, в которую
поместили известные нам инструменты моделирования, опираясь при этом
на два ортогональных критерия (расширенный вариант таблицы смотрите
на сайте книги www.umlmanual.ru).
Первый, уже известный — поддерживаемые варианты использования (за ис-
ключением варианта использования "рисование диаграмм"), а второй — до-
ступность инструмента.
Надо понимать, что рассматриваемые варианты использования связаны
друг с другом. Если инструмент может применяться для моделирования си-
стемы, то он очевидно должен уметь рисовать диаграммы, а если с помощью
него можно вести разработку, то и моделирование системы, и рисование диа-
грамм входит в его обязанности. При классификации мы учитываем только
максимально функциональный вариант использования, и относим инстру-
мент в соответствующую группу. Дополнительно надо иметь в виду, что чем
большими возможностями обладаем инструмент (чем больше вариантов
использования он поддерживает), тем больше ограничений он имеет. Ин-
струменты, поддерживающие только рисование диаграмм, дают большую
свободу пользователю, чем те инструменты, которые способны выполнять
эти диаграммы или генерировать по ним исходный код.
Актуальность первого критерия очевидна. Ведь, например, для ведения до-
кументации к программным продуктам часто хватает нарисованных диа-
Глава 5 Дисциплина моделирования
грамм. А вот для разработки структуры классов и интерфейсов внутри но-
вого программного компонента бывает необходимым иметь в компьютере
полноценную модель, соответствующую стандарту.
Второй критерий тоже не должен вызывать вопросов. Инструменты бывают
платные и бесплатные. Хорошие профессиональные инструменты, как пра-
вило, требуют покупки лицензии. Однако на самом деле для решения про-
стых рутинных задач, которое требуется большинству разработчиков, впол-
не хватает функциональности бесплатных инструментов.
Таблица 5.3. Классификация некоторых инструментальных средств моделирова-
ния на UML
Варианты использования
Моделирование систем Разработка приложений
Доступность Бесплатные Argo UML IBM Rational Rhapsody Modeler DIA Acceleo StarUML Umbrello Sun Java Studio Enterprise
Платные Microsoft Visio Magic Draw IBM Rational Rhapsody Enterprise Architect Visual Paradigm for UML Borland Together
5.3. Влияние UML на процесс разработки
Как сказано в параграфе 1.2.5, UML не является моделью процесса разра-
ботки, но это не значит, что UML никак не связан с процессом разработки.
В предыдущем разделе мы косвенным образом затронули вопрос о том, как
влияет систематическое применение UML на процесс разработки. Действи-
тельно, UML позволяет наглядно описывать образцы проектирования,
применение образцов проектирования повышает качество проектирова-
ния архитектуры, что, по общему мнению, ускоряет реализацию. Таким
образом, мы выделили один из факторов положительного влияния UML
на процесс разработки программного обеспечения. Разумеется, это не един-
ственный фактор. В первых главах книги мы привели достаточно много об-
щих рассуждений на эту тему, а еще больше можно найти в других источни-
ках, в частности, в описании языка [3].
5.3. Влияние UML на процесс разработки
В этом разделе мы собираемся сформулировать свое мнение по поводу того,
в чем состоит основной фактор влияния UML на процесс разработки. Но
для этого нам понадобится ввести в рассмотрение некоторые термины и по-
нятия, после чего мы сформулируем наш основной тезис.
5.3.1. Технология программирования
Дисциплина, которая изучает процессы разработки программного обеспече-
ния, по-английски называется Software Engineering. Для обозначения этой
дисциплины мы будем использовать устоявшийся отечественный термин
"технология программирования”, хотя, может быть, этот термин немного
устарел и не вполне точен, но нам так удобнее и привычнее. Технология
программирования является инженерной дисциплиной, входящей в обяза-
тельный набор знаний и умений всякого инженера, причастного к созданию
и эксплуатации программного обеспечения компьютеров. Технология про-
граммирования имеет четко выделенный объект изучения — процессы раз-
работки и сопровождения программного обеспечения, но в настоящее время
не имеет единого метода и общепринятого способа построения. Технология
программирования не является строгой математической дисциплиной, ко-
торую можно изложить последовательно, начиная с основополагающих по-
нятий и применяя дедуктивные доказательства. Напротив, технология про-
граммирования является собранием разнородных и часто несогласованных
друг с другом моделей, методик и средств. Дадим несколько определений.
Программирование (computer programming) — это процесс создания
программистом (человеком) программы (Информационной струк-
туры), предназначенной для последующего исполнения (компьюте-
ром).
Таким образом, в процессе программирования присутствуют явно субъект,
объект и цель. В типичном (и привычном) случае субъектом является чело-
век, который ведет процесс осознанно, объектом является текст на формаль-
ном языке, а целью является такое выполнение программы, которое в свою
очередь имеет явно обозначенный результат.
Технология программирования (software engineering) — это совокуп-
ность мето ton и средств, позволяющих наладить производственный
процесс создания программного обеспечения.
В этом определении особо следует подчеркнуть слово "производственный",
которое отражает важнейшую особенность технологии программирования.
Глава 5 Дисциплина моделирования
Если производственный характер процесса разработки не требуется, то у
технологии программирования фактически нет предмета.
Обсуждение вопросов технологии программирования в полном объеме вы-
ходит далеко за рамки этой книги265. Несмотря на то, что технология про-
граммирования начала развиваться одновременно с программированием,
данная область знаний все еще находится скорее в стадии становления, не-
жели в стадии разработанной инженерной дисциплины, поэтому даже ее
структура далеко не устоялась. У авторов книги есть собственный взгляд на
рациональный способ описания технологии программирования, которым
мы воспользуемся для формулировки нашего тезиса о влиянии UML на
практическое программирование.
Мы полагаем, что технологию программирования целесообразно рассма-
тривать в трех аспектах.
• Модель процесса, т. е. порядок проведения типового проекта по
разработке программного обеспечения. Сюда относятся понятия
жизненного цикла программного обеспечения, определение модели
процесса — выделение в нем фаз, вех, потоков работ и других состав-
ляющих. Характерным для данного аспекта является рассмотрение
на уровне программирующей организации в целом.
• Модель команды, т. е. отношения между людьми в процессе раз-
работки. Сюда относятся определение обязанностей работников —
участников процесса, регламенты их взаимодействия, рабочие
процедуры и т. п. Характерным для данного аспекта является рас-
смотрение на уровне группы (команды) или проекта.
• Дисциплина программирования, т. е. методы создания конкретных
артефактов, входящих в состав программного обеспечения. Сюда
относятся описание и применение образцов проектирования, стан-
дарты кодирования, методы тестирования и отладки и т. д. Харак-
терным для данного аспекта является рассмотрение на уровне от-
дельного работника.
Все три составные части технологии программирования претерпели бурное
и неравномерное развитие и продолжают постоянно меняться. Для понима-
ния современных веяний в технологии программирования необходимо хотя
бы кратко коснуться ее истории. В истории технологии программирования
происходило множество событий, выдвигалась и постоянно выдвигается
масса новых идей. Чтобы как-то систематизировать эти факты, мы предла-
гаем следующую классификацию.
265 Хотя мы их вынужденно постоянно затрагиваем, см., например, параграф 1.1.2.
_____ •
5.3 Влияние UML на процесс разработки
Все факты истории технологии программирования делятся на три класса,
которые приближенно соответствуют трем периодам.
Дореволюционный период
С момента начала промышленной разработки программного обеспечения и
до середины шестидесятых годов XX века вопросы собственно технологии
программирования рассматривались, как правило, не отдельно, а в связи и в
совокупности с другими вопросами программирования. Разумеется, техно-
логические проблемы существовали, и предлагались методы их решения, но
это не было предметом публичных общественных дискуссий.
Компьютеры были дороги, их количество было невелико, и применялись
они в основном для специальных целей (оборона, космос и т.п.). Следует
подчеркнуть, что в это время программирование не являлось массовой про-
фессией, и было в основном уделом талантливых и высокообразованных
одиночек, специалистов в той предметной области, где применялись ком-
пьютеры. Можно сказать, что, хотя программирование и было высоко про-
фессиональным, оно не было промышленным.
Из основных технологических идей, появившихся в этот период, следует
отметить появление языков программирования и компиляторов, а также
явное осознание важности модульного программирования как основы для
накопления библиотек программ и их повторного использования.
Революция в программировании
К середине шестидесятых годов ситуация изменилась. Компьютеры стали
дешевле, компактнее и производительнее. Сфера применения существенно
расширилась, они стали в массовом порядке применяться в промышлен-
ности, науке, образовании. Наряду со сложными и ответственными про-
граммами (о самом существовании которых не везде можно было говорить
вслух) появились, и в гораздо большем количестве, обычные программы для
автоматизации производственной и иной повседневной деятельности266. Эти
обычные программы изготавливались практически в каждой организации,
имевшей компьютеры, независимо от основного профиля ее деятельности.
Эксплуатация программного обеспечения перестала быть таинством, до-
ступным только посвященным, программирование стало массовой профес-
сией.
Заметим, что общество в целом не сразу осознало социальные последствия
происходящего. В это время уже хорошо были известны положительные
и отрицательные последствия других видов инженерно-технической дея-
266 Сейчас такие программы называют бизнес-приложениями.
Глава 5. Дисциплина моделирования
тельности. К проектированию таких изделий, как мосты и самолеты, люби-
тели уже не допускались (все понимали, что плохо спроектированный мост
может обрушиться, а самолет упасть, и это недопустимо). Проектирование
в традиционных инженерных областях велось в соответствии с многочис-
ленными стандартами, правилами, регламентами и инструкциями, в кото-
рых число требований к качеству исчисляется сотнями и тысячами. Иное
дело программирование: программисты в то время в большинстве своем и
не слыхивали о каких-то стандартах качества своей работы. Да и действи-
тельно: подумаешь, программа расчета зарплаты "зависла" — это же не са-
молет упал!
Но низкая надежность — это только одна сторона проблемы. Хорошая техно-
логия не только улучшает качество, она еще и увеличивает производитель-
ность. А плохая технология — уменьшает. Отсутствие явно выписанной тех-
нологии — это самая плохая технология. В начале шестидесятых технология
программирования, в современном понимании, отсутствовала как массовое
явление. Реальная средняя производительность труда была низкой, что хо-
рошо видно из отраслевых нормативов производительности программиро-
вания тех лет. Еще хуже дело обстояло с результативностью.
Именно тогда были проведены первые методически обоснованные исследо-
вания и появились отчеты, из которых следовало, что менее половины про-
ектов по разработке программ являются успешными. В средствах массовой
информации появились мрачные прогнозы (полученные простой экстрапо-
ляцией наблюдаемых значений показателей), что к концу двадцатого века
все трудоспособное население будет программировать, и программ будет не
хватать. Кризис программирования был налицо. Однако очень быстро было
предложено множество идей и подходов для выхода из кризиса.
Традиционно принято считать, что "первой ласточкой", положившей нача-
ло лавинообразному процессу сотворения технологии программирования,
было письмо Э. Дейкстры в журнал Communications of the АСМ в 1968 году
(см. параграф 3.1.2, сноска 88). Очевидно, что письмо Дейкстры подейство-
вало как катализатор, как манифест — за несколько лет были опубликова-
ны, обсуждены и практически внедрены следующие фундаментальные идеи
технологии программирования.
• Конструирование программ методом пошагового уточнения (см. па-
раграф 2.4.2).
• Проектирование сверху вниз и снизу вверх (см. параграф 2.2.2).
• Структурное программирование (см. параграф 3.1.2).
• Метод хирургической бригады (см. параграф 5.3.4).
5.3. Влияние UML на процесс разработки
• Водопадная модель процесса разработки (см. параграф 5.3.3).
• Жизненный цикл программного продукта (см. параграф 5.3.2).
По каждому направлению традиция называет основоположников (авторов
наиболее замеченных из ранних публикаций), но фактически эти техноло-
гические идеи явились плодами совместных усилий, сотни людей внесли ве-
сомый вклад в это стремительное развитие. Перечислять все фамилии здесь
нет возможности, но по крайней мере одного из "отцов-основателей” техно-
логии программирования необходимо упомянуть.
Фредерик Филипс Брукс мл. (Frederick Phillips Brooks, Jr.), род.
19 апреля 1931 — американский менеджер, инженер и ученый,
наиболее известен как руководитель разработки операционной
системы OS/360. В 1975 году, обобщая опыт этой работы, написал
книгу "Мифический человеко-месяц”. Брукс насмешливо называл
свою книгу "библией программной инженерии": "все её читали, но
никто ей не следует!”
Фредерик Брукс является лауреатом премии Тьюринга 1999 года.
Послереволюционный период
Революция была успешной — в исторически кратчайшие сроки технология
программирования оформилась как инженерная дисциплина, и некоторые
ее положения повсеместно были внедрены в практику. Результаты прояви-
лись незамедлительно — средняя производительность труда в программиро-
вании увеличилась в несколько раз. Повысилась и надежность, за счет раз-
вития практики систематического тестирования. Кризис разрешился.
Развитие технологии программирования продолжалось, но уже не револю-
ционным, а эволюционным путем. Взятые за основу, идеи 60-х годов разви-
вались и совершенствовались.
Структурное программирование переросло в объектно-ориентированное,
на смену водопадным моделям процесса пришли итерационные, метод хи-
рургической бригады дал начало целому спектру моделей команды разра-
ботчиков. Но эти подходы не были революционно новыми, они улучшали и
совершенствовали уже известное.
Однако время не стоит на месте. Аппаратное обеспечение стремительно про-
грессирует. Сфера применения компьютеров расширяется все больше. Уже
сейчас без них нигде нельзя обойтись, компьютеры применяются повсемест-
но. Пока еще слово "компьютер" ассоциируется у среднего жителя нашей
планеты с образом персонального компьютера, с экраном и клавиатурой, а
программирование ассоциируется с программированием на персональном
компьютере и для персонального компьютера. Но это только пока.
•
Глава 5 Дисциплина моделирования
В самое ближайшее время компьютеры из устройств, которые используют-
ся очень часто и во многих местах, превратятся в устройства, которые ис-
пользуются везде и всегда. Речь идет о том, что сейчас называется встро-
енными системами. Персональные компьютеры выпускаются миллионами
штук в год. Встроенные системы выпускаются миллиардами штук в год, а
будут выпускаться многими миллиардами! И все эти устройства требуют
для своей работы программного обеспечения. Не следует думать, что про-
граммировать эти устройства легко. Напротив. Уже сегодня возможности
компьютера, скрытого в вашем мобильном телефоне, намного превосходят
возможности того компьютера, которым пользовался Дейкстра, когда писал
свое знаменитое письмо.
Вполне вероятно, что консервативного усовершенствования старых идей,
которого пока хватало для организации программирования персональных
компьютеров, уже не хватит для организации программирования необозри-
мого парка встроенных систем. Тогда технологию программирования ждут
новые, действительно революционные изменения. Необходимо быть гото-
вым к этому.
Множество программ неоднородно — спектр реальных и возможных про-
граммных систем очень широк. Программы можно классифицировать по
множеству различных факторов. Например:
• тип программно-аппаратной платформы, на которой выполняется
программа: встроенная система, настольное приложение, сетевой
сервис;
• размер программы (измеренный в байтах, командах, операторах,
строчках кода или иных единицах);
• число пользователей: однопользовательская программа "для себя",
внутренняя программа организации, программный продукт общего
пользования;
• регулярность использования: разовая программа, регулярно ис-
пользуемая программа, постоянно работающая программа;
• источник разработки: заказная разработка, инициативная разработ-
ка, конкурсная разработка;
• предметная область: критически важная программа специального
применения, приложение для автоматизации бизнес-процессов, де-
монстрационный прототип.
Этот список можно продолжать и продолжать, причем как в длину, указывая
новые факторы, так и в ширину, указывая новые значения факторов. "Огла-
сить весь список"очень трудно.
Г 550 J
5.3 Влияние UML на процесс разработки
Важно, что при проведении проектов по разработке программ разных типов
целесообразно использовать различные технологии. Программу управления
ракетой разрабатывают не так, как информационную систему отдела кадров.
Очень часто апологеты конкретных технологий программирования, особен-
но новых, еще не зарекомендовавших себя широко, смело утверждают, что
их технология "лучшая в мире". Очень может быть, что новая рекламируе-
мая технология действительно сейчас лучшая для того типа программных
проектов, для которого она была придумана. Но совершенно невероятно,
чтобы она оказалась действительно лучшей для всех типов программных
проектов, везде и на все времена.
Таким образом, при описании технологий программирования необходимо
указывать типы программных проектов, для которых данная технология
применима, то есть указывать назначение и область применения техноло-
гии. Это же относится и к языку UML, если рассматривать применение UML
как технологию (часть технологии) разработки программного обеспечения.
Назначение UML четко определено в разделе 1.2, а вот область применения
определить труднее.
Мы совершенно уверены в том (и неоднократно это подчеркивали), что наш
пример — информационная система отдела кадров — находится точно в цен-
тре области применения UML по всем параметрам. UML подходит для та-
ких систем как нельзя лучше. Но UML подходит и для других систем, и на-
сколько далеко отстоят границы области применимости от центра, мы точно
сказать не можем. Как показывает наш опыт, отстоят достаточно далеко. В
поле нашего зрения были системы, весьма далекие от информационной си-
стемы отдела кадров, и UML применялся для этих систем вполне успешно,
хотя и с некоторыми особенностями.
5.3.2. Жизненный цикл программного обеспечения
Давно замечено, что программа за время жизни претерпевает многочислен-
ные изменения своей формы, зависящие от состояния процесса разработки
программы.
Жизненный цикл программы — это совокупность и последонатель-
ность«зменений формы щюграммы за все время ее существования.
В разных парадигмах и моделях технологии программирования понятие
жизненного цикла определяется и трактуется немного по-разному, но, в об-
щем, близко к схеме, представленной на рис. 5.24. Важно подчеркнуть, что
за время своей жизни программа проходит метаморфозы, как правило, не-
Глава 5. Дисциплина моделирования
Рис. 5.24. Жизненный цикл программного обеспечения
сколько раз267, т.е. это именно цикл, даже система вложенных циклов, кото-
рые повторяются неоднократно.
Примечание
Программа является преимущественно идеальным (а не ма-
териальным) объектом, поэтому в жизненный цикл вклю-
чаются и те "эмбриональные" формы, в которых программа
существует во время разработки. С другой стороны, некото-
рые материально существующие на магнитных носителях
программы для больших машин уже не используются и не
сопровождаются, а потому их жизненный цикл считается за-
вершенным. Таким образом, программа жива, пока она жива
в голове у программиста и/или пользователя.
Переплетение циклов может быть довольно запутанным, особенно для дол-
го живущих программ. Для упорядочения циклической структуры исполь-
зуется понятие выпуска.
267 Чего, к сожалению, не случается с программистами.
5.3 Влияние UML на процесс разработки
Выпуск (release) — характерная точка в жизни npoj-раммы, отмечаю-
щая прохождение одного полного цикла.
Как правило, термином "выпуск" обозначают не только событие (момент в
истории жизни программы), но и отчуждаемый артефакт, конкретную фор-
му программы, появление которой отмечает данное событие.
Так или иначе, предметом технологии программирования является процесс
разработки программного обеспечения.
Процесс (process) — 1) последовательность смены состояний в раз-
витии чего-нибудь; 2) последовательность действий для достижения
какого-либо результата268.
В контексте технологии программирования два процитированных опреде-
ления не являются разными определениями — это описание одного и того
же предмета с разных точек зрения.
Можно обратить свое внимание на смену состояний. Но что является при-
чиной смены состояний? Очевидно, выполнение каких-то действий. Можно
обратить свое внимание на выполнение действий. Но что является резуль-
татом выполнения действий? Очевидно, смена состояний. Таким образом, с
любой точки зрения, нас интересует последовательность смены состояний
при прохождении по графу жизненного цикла, или, можно сказать, процесс
проживания программой ее жизненного цикла. Вообще, с нашей точки зре-
ния, понятия жизненного цикла и процесса разработки двойственны друг
другу. Фактически это два взгляда на один и тот же предмет, но с противо-
положных точек зрения. Жизненный цикл — это взгляд с точки зрения про-
граммы, а процесс разработки — с точки зрения программиста.
Модель
Чтобы иметь саму возможность делать какие-то наблюдения или проводить
рассуждения относительно процесса, нужно иметь описание процесса, или
его модель. Термин "модель" широко используется в различных областях че-
ловеческой деятельности и имеет много значений, особенно в этой книге. В
данном случае подразумевается следующее значение.
Модель (model) — любой образ или аналог (мысленный или услов-
ный: изображение, описание, схема, чертеж и т.п.) какого-либо объ- ||
; екта, процесса или явления ("оригинала" модели), используемый в
v качестве его "представителя".
268 Большой энциклопедический словарь кроме приведенных двух определений дает еще
одно определение: порядок рассмотрения дел в судопроизводстве. Но в данном случае
это значение слова "процесс" не имеет отношения к предмету.
Глава 5. Дисциплина моделирования
В разных областях человеческой деятельности используют совершенно раз-
личные средства для построения моделей. Физические процессы описыва-
ют математическими моделями, например, системами дифференциальных
уравнений. Социальные процессы описывают длинными и невнятными пас-
сажами на естественном языке.
Процесс разработки программного обеспечения также пытались описывать
самыми разными способами, но постепенно к настоящему времени сложи-
лась традиция использовать для описания процесса программирования при-
мерно те же средства, которые используются для самого программирования.
Программы же, как всем известно, записывают как алгоритмы, выраженные
на том или ином языке программирования.
Языков программирования очень много (тысячи, см. отступление "Универ-
сальный язык программирования" в параграфе 4.3.1), и среди них встреча-
ются как такие, которые предназначены для записи программ, исполняемых
компьютером, так и такие, которые для этого не предназначены. Например,
различные псевдокоды, блок-схемы и тому подобное. Язык программирова-
ния, если он предназначен для восприятия людьми, совсем не обязан быть
формальным, точным и сугубо бедным, как "настоящий" язык программи-
рования, подобный C++ или Java.
Сейчас процессы разработки программного обеспечения принято описывать
как алгоритмы, но очень неформально, с использованием понятий высокого
уровня, далеких от машинной реализации. Конечно, неформальный харак-
тер таких алгоритмов приводит к тому, что у разных авторов встречаются
несколько различные толкования основных элементов, из которых строится
описание процессов разработки. Мы используем для этой цели диаграммы
U ML и считаем это самым подходящим средством.
В этом параграфе описаны некоторые популярные модели процесса разра-
ботки, но при этом используется не та нотация, которую применяли авторы
этих моделей, а строгая нотация UML. Поскольку читатель, дойдя до этого
места в книге, несомненно, владеет нотацией UML свободно, не должно воз-
никнуть трудностей при "опознании" знакомых моделей.
Примечание
Следует иметь в виду, что в современных технологиях про-
граммирования процесс разработки программного обеспече-
ния рассматривается не как один последовательный процесс,
а как несколько параллельных процессов, взаимодействую-
щих друг с другом. Это накладывает дополнительные слож-
ности алгоритмического и терминологического характера.
ф
5.3 Влияние UML на процесс разработки
Фазы и витки
При описании процессов, связанных с разработкой программного обеспе-
чения, основными структурными составляющими являются фазы и витки.
Фаза (phase) — часть процесса разработки. Обычно каждая фаза
характеризуется вехой, достижение которой знаменует завершение
фазы.
На фазу можно смотреть и как на состояние процесса, и как на действие (де-
ятельность) в процессе. Рассмотрим, к примеру, фазу, которая обычно вы-
деляется в процессе разработки: выявление и анализ требований. С одной
стороны, это совокупность разнообразных действий: совещания с заказчи-
ками, интервьюирование пользователей, анализ осуществимости и другие.
С другой стороны, это состояние процесса, которое характеризуется тем, что
требования еще не определены, и значит нецелесообразно или невозможно
выполнять другие действия, например архитектурное проектирование, ко-
дирование, тестирование. "Требования определены" — это веха, достижение
которой знаменует завершение фазы определения и анализа требований.
Когда эта веха достигнута, процесс переходит в другую фазу, обычно в фазу
архитектурного проектирования.
Примечание
В разных источниках используются также термины стадия
или этап. Мы предпочитаем термин "фаза" по следующей
причине. Слова "стадия" и "этап" имеют оттенок линейной
упорядоченности, подразумевается, что следующий этап ме-
няет предыдущий, и они не совмещаются во времени. Ино-
гда фазы действительно строго меняют друг друга, но чаще
бывает так, что фазы частично перекрывают друг друга и вы-
полняются параллельно — например, требования еще окон-
чательно не утверждены и фаза извлечения требований еще
не закончилась, но уже начаты работы по архитектурному
проектированию.
Наборы фаз, которые включают в модель процесса разработки, различны в
разных технологиях программирования. Чаще всего встречаются следую-
щие фазы.
• Выявление и анализ требований.
• Архитектурное и детальное проектирование.
• Реализация и кодирование.
Глава 5. Дисциплина моделирования
• Тестирование и валидация.
• Сопровождение и продолжающаяся разработка.
Примечание
К сожалению, часто одна и та же фаза в разных моделях на-
зывается по-разному. Это связано с устойчивыми традици-
ями и вряд ли может быть изменено. Следует иметь в виду
это обстоятел ьство, и, встречая незнакомое название фазы,
тщательно проверять, не является ли название просто новым
именем для хорошо знакомой фазы.
Поскольку процесс разработки программного обеспечения имеет цикличе-
ский характер, многие фазы повторяются несколько раз. Необходимо как-то
идентифицировать и различать разные вхождения одной фазы в жизненный
цикл. С этой целью, используя метафору спирального развития процесса
разработки, вводится термин виток.
Виток — последовательность неповторяющихся фаз в жизненном ци-
кле программы.
Вообще говоря, разные витки в одном жизненном цикле могут иметь разный
состав входящих в виток фаз. Поэтому витки обычно выделяют не произ-
вольным образом, а так, чтобы каждый виток заканчивался выпуском269 270.
Довольно часто используют и другой термин — итерация210.
Каждая фаза является крупной составляющей процесса разработки: фаза
может продолжаться достаточно долго и требовать выполнения большого
объема работы. Более того, фазы могут перекрываться во времени и выпол-
няться параллельно. Таким образом, понятие фазы оказывается недостаточ-
но четким для точного планирования, учета и измерения процесса. В то же
время планирование и измерения считаются совершенно необходимыми
элементами в современном процессном подходе. Нужно средство устано-
вить границы фазы более четко. Таким средством является понятие "веха".
Веха (milestone) — одномоментное идентифицируемое событие, со-
провождающееся появлением и фиксацией некоторого артефакта.
269 Иногда программисты вместо аккуратного термина "выпуск" используют слово "релиз",
полученное прямой транслитерацией английского термина "release", который на самом
деле в данном случае как раз и означает "выпуск".
270 Например, термин "итерация" применяют в одной из популярнейших моделей процес-
са — Rational Unified Process (RUP), название которой обычно переводят на русский язык
как "унифицированный процесс".
5.3. Влияние UML на процесс разработки
Обычно при планировании и анализе процессов в конце каждой фазы вы-
ставляется веха, которая служит границей фазы. Такую веху естественно на-
зывать главной вехой фазы, а ее артефакт называется результатом фазы.
Например, для фазы "выявление и анализ требований" главная веха — "тре-
бования определены", а результатом фазы являются сами требования.
Заметим, что совершенно необязательно считать, что каждая фаза имеет
только одну веху: их может быть сколько угодно. Например, начальная веха,
которая отмечает начало фазы, промежуточные вехи, которые отмечают
важные части фазы или появление важных артефактов, необходимых для
выполнения других фаз и так далее.
Артефакт
Мы уже много раз использовали слово "артефакт”. Вообще говоря, это слово
происходит от латинских корней (arte искусственно + factus сделанный) и
означает любую искусственно созданную вещь. В последние годы этот тер-
мин активно стал применяться в технологии программирования в следую-
щем смысле.
Артефакт (artifact ) — документ или иной материал, имеющий матери-
альную формуй отчуждаемый от разработчика.
В этом определении важно обратить внимание на слово "отчуждаемый".
Поясним это на примере модельной ситуации. Допустим, что после неко-
торых разговоров с заказчиком один из разработчиков заявляет: "я понял,
что нужно сделать". Можно ли считать, что веха "требования определены"
достигнута? В некоторых ситуациях действительно достаточно иметь ора-
кула, умеющего отвечать на любые вопросы, относящиеся к разрабатывае-
мому программному обеспечению, по мере их возникновения. Однако в со-
временных промышленных технологиях программирования так поступать
не принято — слишком велик риск. Действительно, что делать, если оракул
заболеет или уволится? Считается, что веха "требования определены" долж-
на сопровождаться артефактом, в котором эти требования действительно
определены, и их можно использовать без непосредственной помощи тех
лиц, которые составляли требования.
5.3.3. Модели процесса разработки
Трудности конструирования реальных приложений обусловлены их слож-
ностью, и критическую роль в преодолении этой сложности играет сам про-
цесс конструирования.
Глава 5 Дисциплина моделирования
В настоящее время можно выделить три стратегии конструирования модели
процесса.
• Линейная стратегия. Требования определены в начале разработки,
и выпуск программного обеспечения производится один раз в конце
разработки.
• Итерационная стратегия. Требования также определены в начале
разработки, но выпуск версий программного обеспечения произво-
дится многократно по ходу разработки.
• Эволюционная стратегия. Выпуск версий программного обеспече-
ния производится многократно по ходу разработки, но требования
не определены в начале разработки, они определяются по ходу раз-
работки.
Свойства указанных стратегий можно свести в таблицу 5.5.
Таблица 5.5. Характеристики стратегий конструирования
Стратегия Требования определены в начале? Множество циклов конструирования? Промежуточные результаты распространяются?
Линейная Да Нет Нет
Итерационная Да Да Да
Эволюционная Нет Да Да
Существует необозримое множество конкретных процессов разработки,
практически в каждой программирующей организации, а иногда и в каж-
дом проекте используется свой процесс разработки. Однако, как правило,
все конкретные процессы следуют некоторым общим принципам и имеют
много общего.
Абстрактное описание общих принципов, используемых в некотором
классе сходных процессов, называется моделью процесса разработ-
ки.
Далее рассматриваются некоторые известные модели, представляющие упо-
мянутые стратегии.
Водопадные и конвейерные модели
В модели водопада (иногда называемой моделью конвейера) процесс раз-
работки (жизненный цикл программного продукта) делится на фазы, ко-
торые последовательно сменяют друг друга (рис. 5.25).
• Анализ (требований) состоит в сборе требований к продукту.
553J
5.3 Влияние UML на процесс разработки
Результатом анализа, как правило, является некоторый текст или
модель использования.
• Проектирование описывает внутреннюю структуру продукта.
Обычно такое описание дается в форме диаграмм и текстов.
Рис. 5.25. Модель водопадного процесса
• Реализация — это программирование. Результатом реализации яв-
ляется программный код всех уровней, будь то код, генерируемый
высокоуровневой системой программирования, компилятором язы-
ка четвертого поколения или какой-либо другой.
• Валидация — это процесс сборки всего продукта из отдельных ча-
стей и проверки того, что требования удовлетворены.
Примечание
Модель водопада (конвейера) является исторически первой
осознанно использованной моделью процесса разработки
программного обеспечения. Многие очень крупные проекты
были успешно проведены с использованием этой модели.
В действительности перечисленные фазы не следуют строго последователь-
но друг за другом, а частично перекрываются. На практике любую из фаз
можно начинать до того, как будет полностью завершена предыдущая. Но
важнейшей особенностью водопадной модели является то обстоятельство,
что, завершив фазу, мы уже больше к ней не возвращаемся. Таким образом,
водопадная модель является типичным представителем линейной страте-
ги.
Глава 5. Дисциплина моделирования
Инкрементные и спиральные модели
В инкрементных моделях процесс делится на витки, или итерации, каж-
дая из которых в свою очередь делится на фазы. Каждая фаза кончается
вехой. После выпуска (release) раскручивается очередной виток спирали
(см. рис. 5.26).
Таким образом, на каждой итерации происходит выпуск продукта. Последо-
вательные выпуски отличаются некоторым приращением — реализованны-
ми функциями или изменением других свойств. Такое приращение иногда
называют инкрементом (от английского слова increment), что и дало назва-
ние этой группе моделей.
Рис. 5.26. Модель спирального процесса
Наиболее известной конкретной спиральной моделью процесса является
модель Microsoft Solution Framework (MSF), в адаптированном виде при-
веденная на рис. 5.26.
Примечание
Модель конвейера, так же как и спиральная модель, может
использовать вехи. Характерным для модели конвейера (во-
допада) является безвозвратный (не итеративный) характер
процесса, в то время как в спиральных и инкрементных мо-
ф
560 J
5.3. Влияние UML на процесс разработки
целях мы вновь и вновь повторяем последовательность фаз.
Таким образом, рассматриваемые модели относятся к итера-
ционной стратегии.
Иногда представляется возможным понемногу продвигать проект вперед
при практически непрерывном процессе. Такая модель процесса особенно
полезна на поздних стадиях проекта, когда продукт находится на сопрово-
ждении или когда разрабатываемый продукт очень схож с созданным ранее.
Например, процесс, используемый в некоторых отделениях корпорации
Microsoft, предусматривает обновление программного кода и документации
ежедневно к конкретному времени для интеграции и ночного тестирования.
Другие организации используют для этого более продолжительные, напри-
мер недельные, циклы.
Для поддержания соответствующего уровня инкрементальной разработки
необходимо иметь четко установленную архитектуру проекта и исключи-
тельно синхронизированную систему документации.
Наиболее известной инкрементной моделью является "унифицированный
процесс" (Rational Unified Process), представленный на рис. 5.27. Именно
эту модель мы рассматриваем в дальнейших построениях.
Рис. 5.27. Модель инкрементного процесса
5.3.4. Модели команды проекта
Если программа разрабатывается индивидуально, одним человеком, то про-
блем взаимодействия с самим собой обычно не возникает271.
В современных условиях программное обеспечение разрабатывается кол-
лективами, иногда очень большими коллективами. В таких коллективах
проблемы взаимодействия являются постоянными и иногда очень слож-
ными. Сами проблемы, несомненно, относятся к процессу разработки про-
271 А если возникают, то такие проблемы относятся к области психологии или психиатрии,
но не к технологии программирования.
Глаьа 5. Дисциплина моделирования
граммного обеспечения, а способы решения этих проблем относятся к тех-
нологии программирования.
Модель команды — описание производственных отношений между
ин1ьми, вовлеченными и процесс разработки программного обеспе-
чении.
Команда проекта — группа людей, как правило, сотрудников одной
программирующей организации, осуществляющая процесс разра-
ботки программного обеспечения в рамках одного проекта.
Команда проекта может иметь различные свойства. Команда может быть
большой или маленькой, может иметь постоянный или переменный состав по
ходу проекта, может быть постоянной или временной, созданной для одного
проекта. Далее мы рассмотрим некоторые известные модели команды.
Иерархическая модель
Иерархическая модель (или модель дерева субординации, см. рис. 5.28) яв-
ляется самой распространенной и известной моделью. Эта модель обладает
целым рядом достоинств.
• Принцип единоначалия. Принцип единоначалия обеспечивает
очень высокую степень надежности, устойчивости и управляемости
команды. В критических ситуациях всегда используется именно эта
модель272.
• Иерархическая модель привычна и известна абсолютно всем. Ее
использование не требует дополнительных мероприятий по внедре-
нию и обучения персонала.
• Иерархическая модель обладает высокой степенью масштабируе-
мости. Она с успехом применяется в масштабах от десятков до де-
сятков миллионов исполнителей.
В то же время иерархической модели присущи некоторые принципиальные
недостатки.
• Иерархическая модель экстенсивна. Наращивание функциональ-
ности обеспечивается только увеличением состава.
• Иерархическая модель жесткая, т.е. практически не допускает
перестройки "на ходу" (в процессе). Она ориентирована на выпол-
272 Чтобы подчеркнуть это обстоятельство, на рис. 5.28 использована "армейская" терми-
нология.
L .3. Влияние 4ML на процесс разработки
Рис. 5.28. Иерархическая модель команды
нение строго определенных функций. Изменение функций требует
болезненной перестройки дерева субординации.
• Иерархическая модель консервативна. При ее использовании име-
ется тенденция к жесткому закреплению за каждым исполнителем
его ролевой функции. Она плохо приспособлена для быстрой смены
технологий и парадигм.
• Иерархическая модель не устойчива по отношению к личным ка-
чествам руководителей. Отрицательные личные качества руково-
дителей оказывают отрицательное воздействие на эффективность
команды, причем это воздействие непропорционально увеличивает-
ся с ростом уровня в дереве субординации.
Модель бригады главного программиста
Модель бригады главного программиста появилась во время первой техно-
логической революции в программировании на рубеже 60-70-х годов XX
века. Долгое время модель бригады главного программиста (или метод хи-
рургической бригады, или модель звезды, рис. 5.29) являлась доминирующей
моделью при разработке программного обеспечения.
В этой модели главный программист выполняет весь проект сам, а прочие
члены бригады ассистируют в предопределенных рамках своих ролевых
функций273.
Модель главного программиста имеет следующие достоинства.
273 Этим бригада главного программиста отличается от иерархической системы, где на-
чальник разделяет общий проект на части и ставит задачи подчиненным, которые и про-
водят конкретную работу по выполнению задач.
.... ............. ----------- -----------......
Глава 5. Дисциплина моделирования
Главный Второй
Секретарь программист пилот
Администратор
Рис. 5.29. Модель бригады главного программиста
• Бригада главного программиста обладает высокой предсказуемо-
стью. Если главный программист плох, то это выявляется на ранних
стадиях проекта. Проект может быть прекращен или реорганизован
практически без убытков. Если главный программист хорош, то ве-
роятность успешного завершения проекта высока даже при наличии
серьезных внешних факторов риска.
• Бригада главного программиста обладает высокой автономностью.
Она успешно функционирует даже в изменяющейся и неблагопри-
ятной внешней среде.
• Бригада главного программиста обладает достаточной функцио-
нальной гибкостью. За счет изменения набора "лучей" в звезде ее
легко можно ориентировать на различные типы программных про-
ектов.
• Бригада главного программиста наследует все достоинства прин-
ципа единоначалия (поскольку главный программист единолично
принимает все принципиальные решения по проекту).
Модель бригады главного программиста имеет определенные недостатки.
• Бригада главного программиста не является масштабируемым ре-
шением. Она отлично работает на проектах объема 6-8 человекх1-2
года. Если проект требует более коротких сроков или существенно
больших объемов, то использование бригады главного программиста
затруднено.
Примечание
Если формально разрезать крупный проект на несколько
частей и запустить несколько бригад параллельно, то ре-
5.3. Влияние UML на процесс разработки
зультаты их работы будет очень трудно синхронизировать и
интегрировать в одно приложение. Дело в том, что главный
программист держит очень многое в голове, часто опуская
этапы формального документирования и спецификации. За
счет этого повышается производительность, но затрудняет-
ся совместимость. Очень короткий проект бригаде главного
программиста трудно провести потому, что главный про-
граммист последовательно выполняет всю основную работу,
и его личные возможности ограничивают производитель-
ность бригады.
• Бригада главного программиста не является распараллеливаемой
структурой. Она действует по принципу: один проект - одна коман-
да. Практически невозможно выполнять бригадой одновременно
разные фазы разных проектов.
• Бригада главного программиста имеет уязвимое центральное зве-
но. Очень велик управленческий риск мгновенной аннигиляции
бригады, если что-то случается с главным программистом.
Примечание
Второй пилот в бригаде главного программиста должен тща-
тельно отслеживать все действия главного программиста.
Это несколько снижает риск аннигиляции.
Модель команды равных
Модель команды равных является составной частью Microsoft Solutions
Framework (MSF) — методологии разработки программных проектов фир-
мы Microsoft. Это наиболее демократичная модель, поскольку в ней нет явно
выделенного центра. Модель команды MSF — это команда равных. Схема-
тически ее принято изображать в виде цикла (рис. 5.30), где все роли равно-
правны и связаны друг с другом.
Примечание
Чтобы подчеркнуть отсутствие иерархии в команде равных,
роли в команде обозначаются не названиями должностей, а
названиями функций.
Преимущества модели команды равных.
• Высокая производительность, поскольку непроизводительные тру-
дозатраты на поддержание формальных и субординационных связей
ди, сведены к минимуму.
Глава 5. Дисциплина моделирования
Рис. 5.30. Модель команды равных
• Сравнительно легкая масштабируемость. Каждый элемент в схеме
команды может быть в свою очередь циклом.
• Сильная положительная мотивация труда и равно высокая заинте-
ресованность всех участников в конечном успехе.
Основные недостатки модели равных являются продолжением ее досто-
инств.
• Для формирования команды равных нужны равные (равно квали-
фицированные и равно заинтересованные) участники.
• Критическое значение имеет коммуникабельность (большая часть
коммуникаций неформальна), умение и готовность работать в кол-
лективе (артельный дух).
• Демократичная модель команды равных плохо сопрягается с жест-
кой иерархической моделью подразделения (предприятия).
5.3.5. Повышение продуктивности программирования
Очевидно, что задачей технологии программирования является исследо-
вание и улучшение процессов разработки программного обеспечения. При
этом можно преследовать различные цели, т. е. улучшать процесс в различ-
ных направлениях. Приведем несколько примеров задач, исследуемых и ре-
шаемых технологией программирования.
• Повышение надежности программного обеспечения. Программы
часто содержат ошибки — это трюизм для практикующих програм-
[ 566 J
5.3. Влияние UML на процесс разработки
мистов. Пользователи возмущаются, но терпят, пока это возможно.
Если же это терпеть невозможно (например, в приложениях, кри-
тически важных для жизни людей), то применяются специальные
методы технологии программирования, позволяющие повысить на-
дежность программ. Как правило, такие методы достаточно трудоем-
ки и требуют значительных ресурсов.
• Снижение совокупной стоимости владения программным обеспе-
чением. Программы довольно дороги — причем дорогой зачастую
является не только и не столько разработка, сколько сопровождение,
модификация, обучение пользователей. Некоторые методы техноло-
гии программирования позволяют за счет небольших дополнитель-
ных расходов на этапе разработки добиться значительного снижения
затрат на этапе эксплуатации.
• Повышение продуктивности программирования. Под продуктив-
ностью здесь мы понимаем объем274 разработанного программного
обеспечения в расчете на одного работника за единицу времени. Для
малых и средних программирующих организаций данный показа-
тель фактически определяет конкурентоспособность.
Мы остановимся именно на последней задаче как наиболее насущной для
нас и полагаем, для большинства наших читателей. За счет чего можно по-
высить продуктивность программирования? В соответствии с нашими
взглядами на природу технологии программирования формальный ответ
очевиден:
• за счет улучшения процесса;
• за счет организации команды;
• за счет совершенствования дисциплины программирования.
Сформулируем несколько утверждений относительно возможности повы-
шения продуктивности за счет применения различных методов. Сразу ого-
воримся, что эти утверждения основаны на личных наблюдениях авторов и
не претендуют на статус всеобъемлющих законов природы.
Большинство программирующих организаций начинают борьбу за повы-
шение продуктивности с формализации и документирования процесса. Мы
считаем, что начальное введение формального процесса снижает продук-
тивность. Реальный рост продуктивности наблюдается только тогда, когда
формализация процесса достигает достаточно высокого уровня зрелости, а
именно, когда процесс является измеримым, а значит, управляемым. В лю-
274 Проблема выбора измеряемых величин и единиц измерения для программ заслужива-
ет отдельного обсуждения.
е
Глава 5. Дисциплина моделирования
бом случае, за счет совершенствования процесса продуктивность програм-
мирования удается увеличить на проценты, но не в разы и не на порядки.
Эффективная организация работы команды может дать существенно боль-
ший выигрыш в продуктивности и с меньшими затратами. Однако, анало-
гично начальной формализации процесса, начальное введение иерархии
подчиненности и формализация должностных обязанностей, по нашему
мнению, снижают продуктивность. Продуктивность существенно возрас-
тает, если применяются тонкие и сложные методы организации команды,
такие как динамическое переназначение работников и управление по ком-
петентности. Динамическое переназначение подразумевает, что данный со-
трудник участвует, как правило, в нескольких проектах одновременно и на
разных фазах выполняет разные обязанности. Идея состоит в том, чтобы
каждый сотрудник делал не "то, что полагается", а то, что он умеет делать
лучше всех. Управление по компетенции организовать еще труднее: каждое
решение должно приниматься не "начальником", а наиболее компетентным
именно в данном вопросе сотрудником.
Но, по нашему мнению, главным резервом для повышения продуктивно-
сти является дисциплина программирования. Программирование вообще
является редким примером области человеческой деятельности, где разброс
индивидуальной продуктивности на порядок является скорее правилом, не-
жели исключением. Действительно, трудно представить себе, что один зем-
лекоп может стабильно и постоянно копать канавы в 10 раз быстрее другого.
Но мы все знаем, что не такая уж редкость: программист, который стабильно
работает в 10 раз лучше среднего, а бывают случаи, что и в 100 раз лучше!
Мы исходим из следующей качественной оценочной формулы, полученной
чисто эмпирическим путем, в процессе наблюдений и размышлений над
своим опытом и опытом ближайших коллег. Если для данной организации
инвестиции в совершенствование процесса разработки в заданном размере
а дадут прирост продуктивности в х%, то те же инвестиции в улучшение
командной работы дадут прирост продуктивности в Зх%, а инвестиции в
дисциплину программирования дадут прирост продуктивности в 10х%! Ра-
зумеется, мы не можем это доказать математически строго, но убеждены в
справедливости этого правила.
Мы считаем, что имеются два фактора, решающим образом влияющих на
продуктивность программирования:
• сокращение объема внеплановых изменений артефактов;
• увеличение объема повторно использованных артефактов.
Внеплановые изменения возникают при исправлении ошибок. Причем
наиболее болезненны, как хорошо известно, ошибки, допущенные на ран-
Г 568 1
5.3. Влияние UML на процесс разработки
них фазах, т. е. ошибки в требованиях, ошибки проектирования. Речь идет
не только и не столько об ошибках в коде программы — этот тип ошибок
как раз сравнительно легко обнаружить и исправить. Туманное техническое
задание, неудачное архитектурное решение или плохой план пользователь-
ской документации — примеры более серьезных ошибок.
Примечание
Изменения кода, вызванные изменениями требований, так-
же, очевидно, уменьшают продуктивность. Однако это прин-
ципиально разные изменения. Грубо говоря, ошибки исправ-
ляются за счет разработчика, а изменения вносятся за счет
заказчика.
Повторное использование артефактов иногда наивно понимается как ко-
пирование текста из кода одной программы в код другой. Такая практика,
разумеется, полезна, но на продуктивность практически не влияет. Все, что
удается сэкономить — это время на ввод текста. Но программисты хорошо
знают, что время на ввод текста программы едва ли превышает 1% от обще-
го времени ее разработки. Повторное использование компонентов (модулей,
классов) также сопряжено с трудностями: либо в момент создания компо-
нента необходимо приложить заметные дополнительные усилия на подго-
товку к повторному использованию, либо компонент окажется неготовым и
повторно использовать его не удается. Впрочем, по нашему мнению, нали-
чие собственных заготовок для повторного использования (инструментов,
библиотек, компонентов в репозитории) является главным признаком зре-
лости программирующей организации, поскольку в этом случае повторно
используется голова, а не руки программиста.
Мы подошли к формулировке тезиса о влиянии UML на процесс разработ-
ки программного обеспечения. Рассмотрим рис. 5.31 (который полезно со-
поставить с рис. 5.24 и рис. 5.27). На этом рисунке мы изобразили модель
процесса разработки. С основным циклом последовательного выполнения
фаз процесса разработки сопряжены два внешних цикла движения опреде-
ленных артефактов. Верхний цикл, в который вовлечены заказчики, отража-
ет выявление несоответствий требованиям и тем самым определяет объем
внеплановых изменений. Нижний цикл, в который вовлечены разработчи-
ки, отражает преобразование разработанных артефактов в готовые к повтор-
ному применению элементы, тем самым определяет объем повторного ис-
пользования.
Тезис: средства для унификации представления информации в циклах
повышения продуктивности позволяют сделать процесс разработки про-
граммного обеспечения более эффективным. Унификация обеспечивает
Глава 5. Дисциплина (подели эь анйя
Рис. 5.31. Циклы повышения продуктивности
ускорение прохождения циклов, повышение сохранности, облегчение
восприятия и повышение надежности принимаемых решений. Надо ли го-
ворить о том, что UML, как ничто другое, лучше всего подходит для решения
таких задач.
5.3.6. Советы по внедрению UML в организации
Мы сами по нескольку раз пережили процесс внедрения UML, причем с обе-
их сторон: и как те, в кого внедряют UML, и как те, кто внедряет UML. Воз-
можно, наши простые советы, основанные на выводах из сделанных ошибок,
могут оказаться полезными.
Организация должна поставить измеримую цель внедрения UML
Многие недооценивают важность постановки именно измеримой цели, и
это грубая ошибка. Не стоит внедрять UML ради внедрения, только ради
того, чтобы хвастаться потом этим перед коллегами. Это ничего хорошего не
даст, последствия внедрения будут отрицательными, а не положительными.
Мало того, что затраты на внедрение не окупятся ростом продуктивности,
так еще и идея будет дискредитирована, и в будущем, при повторных, даже
более подготовленных попытках, процесс внедрения пойдет более тяжело.
Поставить измеримую цель не так просто. Для этого нужно иметь навыки
с .3. Влияние <JML на процесс разработки
и методики проведения измерений значений показателей процесса раз-
работки (метрик процесса). В технологии программирования определено и
используется великое множество метрик. Применяйте те метрики, которые
лучше всего определены и точнее всего измеряются в конкретной организа-
ции.
Приведем пример из личного опыта. Лично мы наиболее точно и надеж-
но умеем измерять индивидуальные трудозатраты (в человеко-часах). Мы
знаем, например, сколько раз была перерисована каждая диаграмма в этой
книге, и сколько это заняло времени. Имея в запасе индивидуальные пока-
затели производительности при моделировании и проектировании, на их
основе можно определить индивидуальные показатели при реализации и
тестировании в расчете на один вариант использования (см. параграф 5.2.2).
Проектируя систему уровня информационной системы отдела кадров или
выше, полезно сделать прикидочный расчет трудоемкости.
Нужно взять общее количество вариантов использования, умножить на
эмпирический коэффициент, и получится априорная оценка трудоемкости
проекта. Когда проект будет завершен, нужно сравнить фактическую трудо-
емкость с априорной оценкой. Этот показатель называется точностью апри-
орной оценки. Он очень важен для планирования и управления деятель-
ностью программирующей организации. Так вот, можно поставить такую
измеримую цель внедрения UML: повысить точность априорной оценки
трудоемкости проектов до 90%275.
Знать и применять UML должны все участники процесса
Если в программирующей организации имеются один или два энтузиаста,
которые пытаются описывать свои решения на UML, а большинство над
ними снисходительно посмеивается, то такое применение ни на что не по-
влияет276. Если заказчик не может или не хочет верифицировать модель на
ранних стадиях проектирования с целью выявления неправильно понятых
требований, то толку не будет. Положительное влияние UML оказывается
значительным, только если язык применяется массовым и систематиче-
ским образом. Особенно критичным является фактор вовлеченности выс-
шего руководства организации в процесс внедрения UML. Если все высшее
руководство поддерживает внедрение личным применением UML в подхо-
275 На самом деле это очень агрессивная цель. Она означает, что если до начала проекта
организация оценивает свои трудозатраты величиной Т, то после окончания проекта
фактические трудозатраты окажутся в интервале [0.9Т: 1,1Т]. Мало какие из програм-
мирующих организаций реально имеют такую точность планирования. Но внедрение
UML позволяет этого достичь. Нам удавалось.
276 Если не считать того, что многие люди крайне тяжело пережиаают ситуацию, когда к
ним относятся как к "городским сумасшедшим".
• ________________________________________________________________
Глава 5. Дисциплина моделирования
дящих случаях — отлично, цель, наверное, будет достигнута! А если среди
руководства есть люди, которые отказываются визировать спецификации с
диаграммами, потому что "не царское это дело", то, скорее всего, ничего не
получится.
Должен использоваться корпоративный репозиторий решений
haUML
Фактор повышения продуктивности зависит от повторного использования
решений, специфицированных на UML. Но решения не используются по-
вторно мгновенно — только через некоторое время. Значит, они должны где-
то и как-то храниться. Такое хранилище называется репозиторием (reposi-
tory).
К великому сожалению, в данный момент мы никаких подходящих инстру-
ментальных средств для организации корпоративного репозитория на UML
не знаем. Сами мы храним свои решения в обычной системе управления
конфигураций, и держим в голове, что это именно решение на UML, и до-
гадываемся по названию, для чего оно нужно. Для двух авторов это допусти-
мо — количество наших хранимых решений измеряется двузначным числом.
Но корпоративный репозиторий на организацию с сотней разработчиков
должен будет содержать уже как минимум четырехзначное число хранимых
элементов. Такой объем в уме не сохранишь и по названиям не догадаешься.
Нужны специализированные и эффективные средства. Пока каждый их изо-
бретает, как умеет. И вам придется этим заняться, если требуется внедрить
UML в вашей организации.
Инструмент, поддерживающий UML, должен быть лёгким
в ИСПОЛЬЗОВАНИИ
Именно это качество, которое по-английски называется usability, играет
первостепенную роль при выборе инструментальных средств. Другие каче-
ства: цена, красота оформления диаграмм, мощность алгоритмов генерации
кода, соответствие стандартам — все также важны, но легкость использова-
ния является решающей. Дело в том, что разработчик может не использовать
средство моделирования на UML, и в этом особенность внедрения UML, от-
личающая UML, например, от компилятора языка программирования. Раз-
работчик не может не использовать компилятор языка программирования,
на котором ведется проект.
Если разработчику не нравится конкретный компилятор, он будет поносить
этот компилятор на чем свет стоит, тайно от руководства устанавливать "ле-
вые" версии, но он все равно так или иначе будет использовать компилятор,
" 572 J
5.3. Влияние UML на процесс разработки
потому что он, разработчик, зависит от компилятора. Руками транслировать
программу в объектный код невозможно. В случае же с UML это не так.
Разработчик не зависит от инструментального средства, поддерживающего
UML. Разработчик может транслировать руками наброски диаграмм в про-
граммный код, он может не рисовать диаграммы вовсе.
Если начальство вздумает устроить принудительную проверку, разработчик
может быстренько преобразовать свой программный код в диаграммы авто-
матически и обмануть начальство, выдав эти диаграммы за нарисованные им
самим. Это конечно, нехорошо, но технически это совсем нетрудно. Таким
образом, самое страшное, что может случиться при внедрении UML — это
вместо реального использования создается видимость использования! Из-
бежать этого можно только при одном условии: инструмент должен нра-
виться разработчикам.
Лодводя итог этой главе, да и всей повествовательной части книги з
! целом, мы вслед за Фредериком Бруксом младшим (см. параграф 5.3.1)
: подтверждаем, что "серебряной пули" все еще нет [Фредерик Брукс.
[ Мифический человеко-месяц или Как создаются программные систе-
& мы. - Символ-Плюс, 2006], и язык UML не является сейчас, и не станет
в обозримом будущем "серебряной пулей". Но UML уже сейчас ста.
[ самым популярным, широко распространенным и дешевым, можно
. сказать "народным” средством, помогающим при спецификации, ви-
зуализации, проектировании и документировании всех артефактов,
возникающих при разработке программных систем, а в будущем вли-
е яние UML на процесс разработки программного обеспечения бу зет
только возрастать.
Выводы
• 7 ± 3 сущности на одной диаграмме.
• Диаграмма должна охватываться "одним взглядом".
• Управление моделями - для того, кто моделирует, а не для ком-
пьютера.
• В проекте сосуществуют разные модели а разных представле-
ниях на разных уровнях абстракции.
• Образцы проектирования полезно знать.
• Технология программирования - ключ к повышению управляе-
мости, надежности и эффективности программирования.
• Стандарты полезны, но не универсальны требуется подгонка
для каждой программирующей организации.
• Нет наилучшего процесса для всех типов проектов и всех типов
организаций, но для каждого типа проектов и для каждого типа
организаций в отдельности есть.
• UML унифицирует представления артефактов к циклах повыше-
ния продуктивности, тем и хорош.
• Организация, внедряющая UML, должна иметг. цель, силу и волю
для внедрения.
Глава 6.
Справочные
материалы
6.1. Стандартные элементы
языка
В UML активно используются механизмы расширения самого языка (см.
параграф 1.8.4) для определения новых элементов моделирования через уже
существующие. При этом используются все способы: именованные значе-
ния, стандартные ограничения и стереотипы. Кроме того, существуют еще и
ключевые слова, которые используются в языке, но не являются следствием
применения механизмов расширения. Все эти текстовые элементы получи-
ли название стандартных элементов (standard element) языка и приводятся
в таблице 6.1.
Далее, следует обратить особое внимание на то, что стандартные элементы
языка живут в UML довольно динамичной жизнью: из версии в версию их
состав меняется, они переходят из одного разряда в другой, иногда просто
забываются. Меняется не только смысл слов, но и обозначения. Например,
в первых версиях все, что было заключено в угловые кавычки « », являлось
стереотипом и все стереотипы заключались в угловые кавычки.
В последних версиях из этих строгих правил сделано множество исключе-
ний: не всё стереотипы изображаются с помощью угловых кавычек (некото-
рые изображаются специальными значками), и не все, что заключено в « »,
действительно является стереотипом. Короче говоря, вопрос о том, что яв-
ляется и что не является стандартными стереотипами, ограничениями, име-
нованными значениями и ключевыми словами UML, не так прост. Но этот
вопрос должен заботить, прежде всего, авторов стандартов и разработчиков
инструментов.
Наша цель: облегчить жизнь реальному пользователю языка, поэтому в та-
блице 6.1 мы приводим все обозначения так, как их видит пользователь.
В таблице 6.1 использованы следующие обозначения:
• «stereotype» — термин в двойных кавычках обозначает стереотип
(stereotype);
• {constraint} — термин в фигурных скобках обозначает ограничение
(constraint);
• tag — термин без выделения скобками означает именованное значе-
ние (tag);
• keyword — термин, выделенный полужирным шрифтом, означает
ключевое слово (keyword).
6.1. Стандартные элементы языка
Таблица 6.1. Ключевые слова UML
Ключевое слово Объяснение/пример История
«abstraction» Стереотип зависимости, указывающей, что независимая сущность является аб- стракцией зависимой. В моделях прояв- ляется в форме частных случаев «derive», «refine» и «trace». См. метамодель на рис. 3.16 Включен в версию 2.0
{abstraction} Ограничение, показывающее, что дан- ная сущность - абстрактная, т.е. не может иметь прямых экземпляров
«access» Стереотип зависимости, указывающий, что все открытое содержимое независи- мого пакета добавляется в пространство имен зависимого пакета и при этом стано- вится закрытым. См. параграф 5.1.2 Включен в версию 1.3, объявлен уста- ревшим в версии 2.0
«activity» Стереотип класса, указывающий, что это контейнер, содержащий граф деятельно- сти Включен в версию 2.0
activity act Тег диаграммы деятельности. См. таблицу 1.3 в параграфе 1.5
«actor» Стереотип, обозначающий действующее лицо. Вместо стереотипа можно указы- вать значок — стилизованный человечек. См. рис. 1.14 в параграфе 1.5.1, параграф 2.3.1, таблицу 3.2 в параграфе 3.2.1, рис. 3.76 в параграфе 3.5.1 Включен в версию 1.0, забыт в версии 1.1, восстановлен в версии 2.0
{addOn ly} Стандартное ограничение атрибута. См. таблицу 3.3 в параграфе 3.2.2
after Ключевое слово события таймера, при- вязанного к относительному времени. См. рис. 4.34 в параграфе 4.2.7 Включено в версию 2.0
all Ключевое слово, обозначающее любое со- бытие. См. рис. 4.37 в параграфе 4.2.9 Включено в версию 2.0
«application» Стереотип компонента, указывающий, что компонент является приложением Включен в версию 1.0, забыт в версии 1.1
«appliedProfile» Зависимость, указывающая, какие профи- ли применимы к пакету Включен в версию 1.4, объявлен уста- ревшим в версии 2.0
«apply» Стереотип зависимости между пакетом и применяемым к нему профилем Включен в версию 2.0
«artifact» «artifacts» Стереотип компонента, документа и лю- бой другой физически выделяемой едини- цы информации, то есть артефакта. Фор- ма «artifacts» используется как заголовок перед списком артефактов. См. рис. 3.51 в параграфе 3.4.2, рис. 3.58 и рис. 3.59 в па- раграфе 3.4.3, рис. 3.77 в параграфе 3.5.4, рис. 5.15 в параграфе 5.1.5 Включен в версию 2.0
[ 577 '
Глава 6. Справочные материалы
Ключевое слово Объяснение/пример История
{association} Ограничение полюса связи, показываю- щее, что соответствующий объект досту- пен по этой связи Включено в версию 1.0, забыто в версии 2.0
«association» Стереотип полюса ассоциации, указы- вающий, что объект связан с объектом на противоположном полюсе фактиче- ской связью, реализующей ассоциацию. См. таблицу 4.14 в параграфе 4.4.5 Включен в версию 1.3, объявлен уста- ревшим в версии 2.0
at Ключевое слово события таймера, привя- занное к абсолютному времени. См. пара- граф 4.2.8 Включен в версию 2.0
«attribute» Стереотип раздела (плавательной дорож- ки) на диаграмме деятельности, указыва- ющий, что данная плавательная дорожка подразделяется на меньшие подразделы по значению некоторого атрибута Включен в версию 2.0
«auxiliary» Указывает, что класс является вспомога- тельным по отношению к другому классу. Включен в версию 1.4
{bag} Стандартное ограничение полюса ассоци- ации. См. таблицу 3.10 в параграфе 3.3.7
«becomes» «become» Стереотип зависимости, указывающий, что зависимый и независимый объекты яв- ляются одним и тем же экземпляром сущ- ности в различные моменты времени и, возможно, с различными значениями, со- стояниями и ролями. См. параграф 4.4.5, рис. 5.11 в параграфе 5.1.4 Включен в версию 1.0, переименован в версии 1.3, забыт в версии 2.0
«bind» Стереотип зависимости, описывающей подстановку параметров в шаблон. См. та- блицу 3.8 в параграфе 3.3.1, рис. 3.9 в па- раграфе 3.2.5 Включен в версию 1.0, забыт в версии 1.1
«buildComponent» Стереотип компонента, который применя- ется для описания различных видов дея- тельности в процессе разработки, таких как компиляция и управление версиями. См. таблицу 3.11 в параграфе 3.4.2 Включен в версию 2.0
{broadcast} Ограничение, указывающее, что сообще- ние посылается множеству объектов одно- временно (в неопределенном порядке) Включен в версию 1.0, забыт в версии 1.4
«call» Стереотип зависимости, обозначающий вызов одной операции из другой. См. та- блицу 3.8 в параграфе 3.3.1, таблицу 4.4 и таблицу 4.5 в параграфе 4.3.1, параграф 5.1.4. и рис. 5.7 Включен в версию 1.0
6.1. Стандартные элементы языка
Ключевое слово Объяснение/пример История
«centralBuffer» Стереотип объектного узла на диаграмме деятельности, имеющего несколько вхо- дящих и несколько исходящих дуг и пере- дающий маркер данных, пришедший по любой из входящих дуг в одну из исходя- щих дуг. См. параграф. 4.3.2 Включен в версию 2.0
{changeable} Стандартное ограничение атрибута. См. таблицу 3.3 в параграфе 3.2.2
«class» Стереотип раздела (плавательной дорож- ки) на диаграмме деятельности, указыва- ющий, что данная плавательная дорожка является зоной ответственности опреде- ленного класса Включен в версию 2.0
class Тег диаграмм классов и внутренней струк- туры. См. таблицу 1.3 в параграфе 1.4.4
comm Альтернативный тег диаграммы коммуни- кации. То же, что и sd и interaction. См. та- блицу 1.3 в параграфе 1.4.4 Нет в стандарте
{complete} Ограничение множества обобщений, при котором экземпляр более общего элемен- та всегда является экземпляром не менее чем одного конкретного элемента из этого множества. См. таблицу 3.9 и рис. 3.15 в параграфе 3.3.2 Включен в версию 1.0
«component» Стереотип компонента. Может употре- бляться вместо соответствующего значка. См. параграф 3.4.3 и рис. 3.55 Включен в версию 2.0
component cmp Тег диаграммы компонентов. См. таблицу 1.3 в параграфе 1.4.4 Нет в стандарте
{concurrent} Стандартное ограничение операции. См. таблицу 3.6 в параграфе 3.2.3.
«constraint» Стереотип комментария означающий, что в данном комментарии записано ограни- чение Включен в версию 1.0, забыт в версии 1.1
«сору» Стереотип зависимости, указывающий, что зависимый и независимый объекты являются различными экземплярами, но с одинаковыми значениями, состояниями и ролями. См. параграф4.4.5 Включен в версию 1.0, объявлен уста- ревшим в версии 2.0
«create» Стереотип операции создания объекта. См. параграф рис 3.78, таблицу 4.4 и та- блицу 4.5 в параграфе 4.3.1, таблицу 4.13 в параграфе 4.4.5 Включен в версию 1.1
«datastore» Стереотип объектного узла на диаграмме деятельности, являющегося хранилищем значения или массива значений. См. рис. 4.44 в параграфе 4.3.2 Включен в версию 2.0
L 579 J
Глава 6. Справочные материалы
Ключевое слово Объяснение/пример История
«dataType» Стереотип классификатора, являющегося типом данных, чьи экземпляры не имеют индивидуальности и отличаются только по значению. См. таблицу 3.2 в параграфе 3.2.1, параграф 3.2.4 и рис. 3.8 Включен в версию 2.0
defer Ключевое слово, выделяющее отложенное событие в простом состоянии. См. пара- граф 4.2.1
«delegate» Стереотип соединителя портов и частей, показывающий, что вызовы операций де- легируются по направлению стрелки сое- динителя. См. параграф 3.5.1 Включен в версию 2.0
«deletion» Стереотип уточнения, указывающий на удаление элемента Включен в версию 1.1, забыт в версии 1.3
«deploy» Стереотип зависимости, указывающий размещение артефакта на вычислитель- ном узле. См. параграф 1.5.8 и рис. 1.21, параграф 3.4.2. и рис. 3.51 Включен в версию 2.0
deployment Альтернативный тег диаграммы размеще- ния. См. таблицу 1.3 в параграфе 1.4.4 Нет в стандарте
«deploymentSpec» Стереотип артефакта, определяющего детали размещения других артефактов на узлах. См. параграф 3.4.2 и рис. 3.52 Включен в версию 2.0
«derived» «derive» / Стереотип зависимости, указывающий, что зависимый элемент может быть полу- чен из независимого. Может обозначаться знаком "/" См таблицу 3.8 в параграфе 3.3.1 Включен в версию 1.0, переименован в версии 1.3
derived Именованное значение, которое означает, что элемент может быть выведен из других элементов модели и таким образом явля- ется избыточным Включено в версию 1.3, забыто в версии 2.0
«destroy» Стереотип операции удаления объекта. См. таблицу 4.4 и таблицу 4.5 в параграфе 4.3.1, таблицу 4.13 в параграфе 4.4.5 Включен в версию 1.1
{destroyed} Ограничение, которое указывает, что объ- ект удаляется в ходе выполнения опера- ции. См. таблицу 4.13 в параграфе 4.4.5 Включен в версию 1.3, удален в версии 1.5
«device» Стереотип узла, означающий физическое устройство, способное выполнять про- граммы. См. параграф 3.4.2 и рис. 3.50, а также параграф 3.5.4 Включен в версию 2.0
{disjoint} Ограничение множества обобщений, при котором экземпляр более общего эле- мента является экземпляром не более чем одного конкретного элемента. См. пара- граф 3.3.2, рис. 3.15 и таблицу 3.9 Включено в версию 1.0
Ф
6.1. Стандартные элементы языка
Ключевое слово Объяснение/пример История
do Ключевое слово, выделяющее внутрен- нюю активность в простом состоянии. См. рис. 4.7 в параграфе 4.2.1
«document» Стереотип компонента, обозначающий документ любого типа, например файл с документацией к программе. См. таблицу 3.12 в параграфе 3.4.2, рис. 3.58 и 3.59 в параграфе 3.4.3, а также рис. 3.77 в пара- графе 3.5.4 Включен в версию 1.0
documentation Именованное строковое значение, содер- жащее комментарий, описание или объяс- нение связанного элемента Включен в версию 1.0, забыт в версии 2.0
«element access» Стереотип зависимости, указывающий, что независимый элемент доступен из за- висимого без расширения пространства имен зависимого элемента Включен в версию 2.0
«element import» Стереотип зависимости, указывающий, что независимый элемент доступен из за- висимого с расширением пространства имен зависимого элемента Включен в версию 2.0
else Ключевое слово, означающее сторожевое условие, которое выполняется, если все альтернативные сторожевые условия не выполняются. См. параграф 4.2.3 и рис. 4.12
«entity» Стереотип компонента с постоянно хра- нимыми данными, представляющего сущ- ность предметной области. См. таблицу 3.11 в параграфе 3.4.2 Включен в версию 2.0
entry Ключевое слово, выделяющее действие при входе в простом состоянии. См. пара- граф 4.2.1, рис. 4.7
«enumeration» Стереотип перечислимого типа данных. См. таблицу 3.2 в параграфе 3.2.1, рис. 3.7 в параграфе 3.2.4, параграф 3.5.4 и рис. 3.7 Включен в версию 1.0, забыт в версии 1.3, возобновлен в версии 2.0
«exception» Стереотип исключения. В UML 1 считал- ся частным случаем стереотипа «signal». См. таблицу 3.2 в параграфе 3.2.1, рис. 4.31 в параграфе 4.2.8 Нет в стандарте
«executable» Стереотип артефакта, означающий вы- полнимую программу любого вида. Под- разумевается по умолчанию, если никакой стереотип не указан. См. таблицу 3.12 и рис. 3.51 в параграфе 3.4.2 Включен в версию 1.1
«executionEnvironment» Стереотип узла, означающий устройство, способное выполнять программы опреде- ленного типа. См. рис. 3.50 и рис. 3.52 в параграфе 3.4.2 Включен в версию 2.0
Глава 6 Справочные мате?иалы
Ключевое слово Объяснение/пример История
exit Ключевое слово, выделяющее действие при выходе в простом состоянии. См. рис. 4.7 в параграфе 4.2.1
«extends» «extend» Стереотип зависимости вариантов ис- пользования. См. рис. 2.20 и рис. 2.21 в параграфе 2.3.4 Включен в версию 1.0, забыт в версии 1.3, возобновлен в версии 2.0
{extended} Ограничение составною состояния, ука- зывающее, что данное состояние явл 1яется специализацией состояния обобщенной машины состояний Включено в версию 2.0
«external» Стереотип раздела (плавательной дорож- ки) на диаграмме деятельности, указы- вающий, что деятельность в данной плава- тельной дорожке выполняется вне рамок моделируемой системы Включен в версию 2.0
«facade» Стереотип пакета, который содержит только ссылки на элементы, определен- ные в других пакетах. Используется для описания "внешнего вида" других пакетов. См. таблицу 5.1 в параграфе 5.1.3 Включен в версию 1.0, объявлен уста- ревшим в версии 2.0
«file» Стереотип артефакта, обозначающий файл с исходным кодом программы или с данными, которые программа использует. См. таблицу 3.12 в параграфе 3.4.2 Включен в версию 1.0
«focus» Стереотип указывает, что класс реализует основную логику для одного или несколь- ких вспомогательных классов. Включен в версию 1.4
«framework» Стереотип пакета, содержащий образцы и шаблоны. Используется для описания по- вторно используемых архитектурных ре- шений. См. таблицу 5.1 в параграфе 5.1.3, параграф 5.1.6 Включен в версию 1.1
«friend» Стереотип зависимости, указывающий, что зависимый элемент имеет доступ к со- ставляющим независимого элемента не- зависимо от их видимости. См. таблицу 3.8 в параграфе 3.3.1 Включен в версию 1.0, объявлен уста- ревшим в версии 2.0
«from» Стереотип порта в структурированном классификаторе Включен в версию 2.0
{frozen} Стандартное ограничение атрибута. См. таблицу 3.3 в параграфе 3.2.2
{global} Ограничение, указывающее, что объект на полюсе связи находится в глобальной об- ласти видимости относительно объекта на противоположном полюсе Включено в версию 1.0, забыто в версии 2.0
6 I Cl 'НДАРТНЫЕ ЭЛЕМЕНТЫ ЯЗЫКА
Ключевое слово Объяснение/пример История
«global» Стереотип, указывающий, что объект на полюсе роли ассоциации имеет глобаль- ную область определения относительно объекта на противоположном полюсе. См. таблицу 4.13 в параграфе 4.4.5 Включен в версию 1.3, забыт в версии 2.0
{guarded} Стандартное ограничение операции. См. таблицу 3.6 в параграфе 3.2.3
«Implement» Стереотип зависимости, указывающей, что зависимый объект не имеет своей собственной спецификации, а использует спецификацию независимого Включен в версию 2.0
«implementation» Частный объект наследуется от более общего, но не открывает методы общего объекта (закрытое наследование) Включен в версию 1.3, забыт в версии 2.0
«implementation Class» Реализация класса на каком-либо языке программирования, при котором экзем- пляр является объектом не более чем одного класса. Включен в версию 1.1, забыт в версии 1.4, возобновлен в версии 2.0
{implicit} «implicit» Указание того, что ассоциация не является явной и задается только концептуально Включен в версию 1.0, переведен в разряд стереотипов в версии 1.5
«import» Стереотип зависимости, указывающий, что все открытое содержимое независи- мого пакета добавляется в пространство имен зависимого пакета и при этом оста- ется открытым. См. рис. 1.26, рис. 5.8 и рис. 5.9 в параграфе 5.1.2 Включен в версию 1.0
in Ключевое слово, указывающее направле- ние передачи параметра. См. рис. 1.23, таблицу 3.5 в параграф э 3.2.3
«include» Стереотип зависимости между вариан- тами использования. См. рис. 1.14, пара- граф 2.3.4, рис. 2.20, параграф 4.2.7, рис. 4.24, параграф 5 2.2 Включен в версию 2.0
{incomplete} Ограничение множества обобщений, при котором экземпляр более общего элемен- та может не являться экземпляром кон- кретного элемента из этого множества. См. таблицу 3.9 и рис. 3.15 в параграфе 3 32 Включен в версию 1.0
«information» Стереотип классификатора, указываю- щий, что экземпляры классификатора со- держат некоторую информацию. Вместо стереотипа можно указывать значок — черный треугольник Включен в версию 2.0
И
Глдвд 6 Справочные материалы
Ключевое слово Объяснение/пример История
«inherits» Стереотип обобщения, указывающий, что вместо экземпляров суперкласса не могут быть подставлены экземпляры подкласса Включен в версию 1.1, забыт в версии 1.3
inout Ключевое слово, указывающее направле- ние передачи параметра. См. таблицу 3.5 в параграфе 3.2.3
«instanceOf» Стереотип зависимости между экземпля- ром и его классификатором. См. рис. 1.29 в параграфе 1.7.1, рис. 1.35, рис. 1.40, та- блицу 3.8 в параграфе 3.3.1., рис. 3.78 в параграфе 3.5.5 Включен в версию 1.0, забыт в версии 1.3
«instantiate» Стереотип зависимости, указывающей, что операции зависимого классификатора создают экземпляры независимого клас- сификатора. См. рис. 1.16, таблицу 3.8 в параграфе 3.3.1, параграф 3.5.5, рис. 3.79 Включен в версию 1.3
interaction Тег диаграмм последовательности, ком- муникации, синхронизации и обзорной диаграммы взаимодействия. То же что и sd. См. таблицу 1.3 в параграфе 1.4.4
«interface» Стереотип классификатора, являющегося интерфейсом. См. таблицу 3.2 в парагра- фе 3.2.1, рис. 3.11, рис. 3.30, рис. 3.46-48, рис. 3.67, рис. 3.79, рис. 5.19, рис. 5.20 Включен в версию 1.0, забыт в версии 1.1, возобновлен в версии 2.0
invariant «invariant» Указывает, что ограничение должно дей- ствовать на классификатор или отношение в течение всего времени их существования Включено в версию 1.0, как именован- ное значение, пере- ведено в стерео- типы в версии 1.1, объявлен устарев- шим в версии 2.0
{isQuery} Стандартное ограничение операции, озна- чающее, что операция не имеет побочных эффектов. См. параграф 3.2.3
{leaf} Стандартное ограничение класса, указы- вающее, что у него нет подклассов. Может также применяться к составляющим, для указания того, что они не должны перео- пределяться в подклассах. См. параграф 3.2.3
«library» Стереотип артефакта, обозначающий ста- тическую или динамическую библиотеку. См. таблицу 3.12 в параграфе 3.4.2, рис. 3.49 Включен в версию 1.0
{local} Ограничение, указывающее, что объект на полюсе связи находится в локальной об- ласти видимости относительно объекта на противоположном полюсе Включено в версию 1.0, забыто в версии 2.0
Ф »
6.1. Стандартные элементы языка
Ключевое слово Объяснение/пример История
«local» Стереотип полюса ассоциации, показыва- ющий, что объект на полюсе роли ассоциа- ции имеет локальную область определения относительно объекта на противополож- ном полюсе, т.е. является временным объ- ектом для выполнения операции. См па- раграф 4.4.5, таблица 4.14 Включен в версию 1.3, объявлен уста- ревшим в версии 2.0
«local Postcondition» Стереотип комментария с условием, свя- зывающим входные и выходные данные действия, которое должно выполняться после выполнения действия Введен в версии 2.0, аналогичен стерео- типу «postcondition» предыдущих версий
«localprecondition» Стереотип комментария с условием, свя- зывающим входные данные действия, ко- торое должно выполняться до выполнения действия Введен в версии 2.0, аналогичен стерео- типу «precondition» предыдущих версий
location Именованное строковое значение, указы- вающее размещение классификатора или компонента Включен в версию 1.0, забыт в версии 1.3
«manifest» Стереотип зависимости между физиче- скими артефактами, которые реализуют логические компоненты. См. рис. 1.21, па- раграф 3.4.2, рис. 3.49, рис. 3.58 Включен в версию 2.0
«merge» Стереотип зависимости между пакетами. См. рис. 1.26, параграф 5.1.4, рис. 5.11 Включен в версию 2.0
«metaclass» Стереотип классификатора, экземпля- рами которого являются классы, а также стереотип зависимости, указывающей, что независимый классификатор является метаклассом зависимого. См. рис. 1.39, таблицу 3.2 в параграфе 3.2.1 Включен в версию 1.0
«metamodel» Модель, которая описывает другую мо- дель. Например, метамодель UML. Как правило, содержит метаклассы. См. пара- граф 5.1.3, таблица 5.1 Включен в версию 1.3
«model» Стереотип пакета, который является мо- делью физической системы. Имеет спе- циальный значок для отображения (треу- гольник). См. параграф 5.1.3, таблица 5.1, параграф 5.1.1, рис. 5.4 Включен в версию 2.0
«modelLibrary» Стереотип пакета, содержащего опреде- ления элементов моделирования, пред- назначенных для использования в других пакетах. См. параграф 5.1.3, таблица 5.1 Включен в версию 1.4
«multicast» Стереотип потока данных на диаграмме деятельности, означающий посылку эле- мента данных нескольким принимающим адресатам Включен в версию 2.0
Глава 6. Справочные материалы
Ключевое слово Объяснение/пример История
«multireceive» Стереотип потока данных на диаграмме деятельности, означающий прием эле- ментов данных от нескольких источников Включен в версию 2.0
{new} Ограничение, указывающее на то, что объ- ект создается в ходе выполнения опера- ции. См. параграф 4.4.5, таблица 4.13 Включен в версию 1.3, удален в версии 1.5
«occurrence» Стереотип зависимости между экземпля- ром взаимодействия и классификатором Включен в версию 2.0
object Альтернативный тег диаграммы объектов. См. таблицу 1.3 в параграфе 1.4.4 Нет в стандарте
{or} Ограничение множества ассоциаций, ука- зывающее, что ровно одна ассоциация из множества применяется для каждого ас- социированного экземпляра Включен в версию 1.0, переименован в {хог} в версии 1.3
{ordered} Ограничение, указывающее, что объекты на полюсе связи линейно упорядочены. См. параграф 3.3.7, таблица 3.10, рис. 3.37, рис. 3.39-40 Включен в версию 1.0, забыт в версии 1.1
{overlapping} Ограничение множества общих элемен- тов, при котором экземпляр одного кон- кретного элемента может в то же время являться экземпляром другого конкретно- го элемента, см. также {disjoint}. См. пара- граф 3.3.2, таблица 3.9, рис. 3.15 Включен в версию 1.0
out Ключевое слово, указывающее направле- ние передачи параметра. См. рис. 1.23, таблицу 3.5 в параграфе 3 2.3
package pkg Тег диаграммы пакетов См. таблицу 1.3 в параграфе 1.4.4
package Пакетная видимость. Обозначается также знаком См. параграф 3.1.4
«page» Стереотип компонента, обозначающий веб-страницу Включен в версию 1.0, забыт в версии 1.1
{parameter} Ограничение, указывающее, что объект на полюсе связи видим объекту на противо- положном полюсе, так как является пара- метром операции Включен в версию 1.0
«parameter» Объект на полюсе ассоциации является параметром операции объекта на проти- воположном полюсе. См. параграф 4.4.5, таблица 4.13 Включен в версию 1.3, объявлен уста- ревшим в версии 2.0
{redefines} Стандартное ограничение, указывающее на переопределение элемента. См. пара- граф 3.3.2, рис. 3.14
1
6.1. Стандартные элементы языка
Ключевое слово Объяснение/пример Ист ория
persistence Именованное значение, которое опреде- ляет, уничтожается ли состояние элемента при уничтожении самого элемента. При- менимо к ассоциациям, атрибутам, клас- сификаторам и экземплярам. См. пара- граф 3.1.3 Включено в версию 1.0
postcondition «postcondition» Условие, связывающее входные и выход- ные данные операции, которое должно вы- полняться после вызова операции. См. па- раграф 4.2.8 Включено в версию 1.0 как именованное значение, переве- дено в стереотипы в версии 1.1, объяв- лено устаревшим в версии 2.0
«powertype» Стереотип, обозначающий метакласс, экземплярами которого являются все на- следники данного класса, а также стерео- тип зависимости между множеством обоб- щений и соответствующим метаклассом. См. рис. 3.15, таблицу 3.8 в параграфе 3.3.1, таблицу 3.2 в параграфе 3.2.1 Включен в версию 1.0, объявлен уста- ревшим в версии 2.0
precondition «precondition» Условие, налагаемое на входные данные операции, которое должно выполняться до вызова операции. См. параграф 4.2.8 Включено в версию 1.0 как именованное значение, переве- дено в стереотипы в версии 1.1, объяв- лено устаревшим в версии 2.0
«primitive» Стереотип типа данных, обозначающий предопределенный тип без видимой вну- тренней структуры. См. параграф 3.3.5 Включен в версию 2.0
«private» Стереотип обобщения для закрытого на- следования. См. параграф 3.1.4 Включен в версию 1.1, забыт в версии 1.3
private Закрытая видимость. Обозначается также знаком См. параграф 3.1.4
«process» Стереотип активного класса, обозначаю- щий тяжелый поток выполнения. В UML 2 применим также и к компонентам. См. па- раграф 4.5.6 Включен в версию 1.0
«profile» Стереотип пакета, содержащего элемен- ты моделирования, такие как стереотипы, ориентированные на моделирование в определенной предметной области. См. параграф 5.1.3, таблица 5.1, параграф 5.1.6 Включен в версию 1.4, объявлен уста- ревшим в версии 2.0
protected Защищенная видимость. Обозначается также знаком См. параграф 3.1.4
«provided interfaces» Стереотип, который используется как за- головок в списке интерфейсов компонента Включен в версию 2.0
Глава 6 Справочные материалы.
Ключевое слово Объяснение/пример История
public Открытая видимость. Обозначается также знаком См. параграф 3.1.4
{readonly} Стандартное свойство атрибута. См. та- блицу 3.3 в параграфе 3.2.2, параграф 3.3.7. рис 3.37
«realization» ' Стереотип классификатора, который определяет реализацию. Подобен стерео- типу «implementationclass», но может при- меняться также и к компонентам Включен в версию 2.0
«realizations» Стереотип, который используется как за- головок в списке реализаций компонента Включен в версию 2.0
«realize» Стереотип, указывающий отношение реа- лизации между классом и интерфейсом или между компонентом и интерфейсом Включен в версию 1.3, объявлен уста- ревшим в версии 2.0
«reference» Стереотип зависимости между пакетами Включен в версию 2.1
«refinement» «refine» Стереотип зависимости, показывающий, что зависимая сущность является более детальным описанием того же самого мо- делируемого объекта, что и независимая сущность. См. рис. 1.27, таблицу 3.8. в па- раграфе 3.3.1, параграф 5.1.5, рис. 5.12 Включен в версию 1.0, переименован в версии 1.3
«representation» Стереотип зависимости между классифи- катором и его представлением Включен в версию 2.0
«represents» Стереотип зависимости между коопера- цией и классификатором, который эта коо- перация представляет Включен в версию 2.0
«required interfaces» Стереотип, который используется как за- головок в списке интерфейсов компонента Включен в версию 2.0
«requirement» Стереотип комментария, объявляет же- лательное поведение, свойство или осо- бенность элемента как часть модели. См. параграф 2.3.3, рис 2.15, рис 5.15 Включен в версию 1.0, объявлен уста- ревшим в версии 2.0
responsibility «responsibility» Объявляет гарантии элемента по отноше- нию к другим элементам. См. параграф 2.3.3 Включен в версию 1.0 как именованное значение, переве- ден в стереотипы в версии 1.3
return Ключевое слово, указывающее направле- ние передачи параметра. См. рис. 1.23, таблицу 3 5 в параграфе 3.2.3, таблицы 4.4 и 4.5 в параграфе 4.3.1
«role» Стереотип зависимости, в которой зави- симым элементом является роль, а неза- висимым — тип этой роли Включен в версию 1.0, забыт в версии 1.1
{root} Стандартное ограничение класса, указы- вающее, что у него нет суперклассов
6.1. Стандартные элементы языка
Ключевое слово Объяснение/пример История
«script» Стереотип артефакта, означающий прог- раммный код, который может быть интер- претирован компьютером. См. таблицу 3.12 в параграфе 3.4.2 Включен в версию 2.0
Sd Тег диаграмм последовательности, ком- муникации, синхронизации и обзорной диаграммы взаимодействия. То же, что и interaction. См. таблицу 1.3 в параграфе 1.4.4
«selection» Стереотип комментария, присоединяемо- го к объектному узлу или к ребру потока объектов на диаграмме деятельности и означающего, что выбирается один из ва- риантов поведения в зависимости от зна- чения объектного узла Включен в версию 2.0
{self} Ограничение, указывающее видимость соответствующего экземпляра объекта в силу вызова операции этим самым экзем- пляром Включен в версию 1.0
«self» Фиктивная связь, введенная для модели- рования вызова операции данного объек- та. См. параграф 4.4 5, таблица 4.13 Включен в версию 1.3, объявлен уста- ревшим в версии 2.0
Semantics Именованное значение, содержащее ука- зание значения (смысла) операции или классификатора Включен в версию 1.0
«send» Стереотип зависимости между операци- ей и сигналом, показывающей, что объект посылает сигнал в процессе выполнения операции. См. параграф 4.2.8, рис. 4.31, таблицы 4.4 и 4.5 в параграфе 4.3.1 Включен в версию 1.0
{sequence} Стандартное ограничение полюса ассоци- ации. См. таблицу 3.10 в параграфе 3.3.7
{set} Стандартное ограничение полюса ассоци- ации. См. таблицу 3.10 в параграфе 3.3 7
«service» Стереотип функционального компонента, не меняющего своего состояния. Напри- мер, библиотека математических функ- ций. См. таблицу 3.11 в параграфе 3.4.2 Включен в версию 2.0
{sequential} Стандартное ограничение операции. См. таблицу 3.6 в параграфе 3.2.3
«signal» Стереотип класса, являющегося сигна- лом, а также стереотип операции, прини- мающей сигнал См. параграф 4.2.8, рис 4.31, таблицу 3.2 в параграфе 3.2.1 Включен в версию 1.0, забыт в версии 1.2, возобновлен в версии 2.0
«signalflow» Стереотип, применяемый для описания траектории объекта, если объектом явля- ется сигнал Включен в версию 1.3, объявлен уста- ревшим в версии 2.0
Глава 6. Справочные материалы
Ключевое слово Объяснение/пример История
«singleExecution» Стереотип деятельности, указывающий, что деятельность является совместно ис- пользуемой и выполняется единственный экземпляр выполнения Включен в версию 2.0
«source» Файл с исходными текстами, который мо- жет быть скомпилирован в исполнимый файл. См. параграф 3.4.2, таблица 3.12, рис. 3.49 Включен в версию 1.4
space semantics Именованное значение, содержащее ука- зание сложности по памяти операции или классификатора Включен в версию 1.0, забыт в версии 1.3
«specification» Стереотип классификатора, специфици- рующего множество объектов без указа- ния их фактической реализации Включен в версию 2.0
«stateinvariant» Указание ограничения, которое должно применяться к состоянию Включен в версию 1.4, объявлен уста- ревшим в версии 2.0
«statemachine» Стереотип классификатора, указываю- щий, что классификатор обладает поведе- нием, описываемым конечным автоматом Включен в версию 2.0
state machine stm Тег диаграммы автомата. См. таблицу 1.3 в параграфе 1.4.4
«stereotype» Стереотип классификатора, указываю- щий, что данный классификатор является стереотипом. См. рис. 1.36, таблицу 3.2 в параграфе 3.2.1 Включен в версию 1.1, забыт в версии 1.3, возобновлен в версии 2.0
«structured» Стереотип структурированного узла дея- тельности. См. параграф4.3.8 Включен в версию 2.0
«stub» Стереотип пакета, представляющий толь- ко открытые части другого пакета. См. па- раграф 5.1.3, таблица 5 1 Включен в версию 1.0, объявлен уста- ревшим в версии 2.0
«subclass» Стереотип обобщения, указывающий, что вместо экземпляров подкласса не могут быть подставлены экземпляры суперклас- са Включен в версию 1.0, забыт в версии 1.3
{subsets} Ограничение полюса ассоциации, исполь- зуется совместно с {union}. См. параграф 3.3.7, рис. 3.40.
«substitute» Стереотип зависимости между классифи- каторами, указывающий, что экземпляр зависимого классификатора может быть подставлен вместо экземпляра независи- мого классификатора Включен в версию 2.0
«subsystem» Стереотип пакета (в UML 1) или компо- нента (в UML 2), который является подси- стемой. См. параграф 3.4.2, таблицу 3.11, рис. 3.55, параграф 5.1.3 Включен в версию 1.3, забыт в версии 1.4, возобновлен в версии 2.0
» W „ „ .. M „ „ „ - « >, „ Ц, ... « „ „ „ n^n „ “» « „ „ „ « « « « « W » » „
6.1. Стандартные элементы языка
Ключевое слово Объяснение/пример История
«subtraction» Стереотип уточнения, аналогичный сте- реотипу «deletion» Включен в версию 1.1, забыт в версии 1.3
«subtype»’ Стереотип обобщения, указывающий, имеет место обычное обобщение. Проти- вопоставляется «subclass» Включен в версию 1.0, забыт в версии 1.3
«system» «systemModel» Стереотип пакета, включающего несколь- ко моделей одной физической системы. См. параграф 5.1.3, таблицу 5.1 Включен в версию 1.1, переименован в версии 1.3
«table» Стереотип компонента, обозначающий та- блицу базы данных Включен в версию 1.0, объявлен уста- ревшим в версии 2.0
time semantics Именоввнное значение, содержащее ука- зание сложности по времени операции или классификатора Включен в версию 1.0, забыт в версии 1.3
timing Альтернативный тег диаграммы синхрони- зации. См. таблицу 1.3 в параграфе 1.4.4 Нет в стандарте
«thread» Стереотип активного класса, обозна- чающий облегченный поток выполнения. См. параграф 4.5.6 Включен в версию 1.0, объявлен уста- ревшим в версии 2.0
«topLevelPackage» «topLevel» Пакет, который является корнем иерархии вложенности пакетов. См. параграф 5.1.3, таблица 5.1 Включен в версию 1.1 переименован в версии 1.3, объ- явлен устаревшим в версии 2.0
«trace» Стереотип зависимости, которая показы- вает причинные связи в модели, другими словами, показывает, что зависимая сущ- ность имеет причиной своего существова- ния независимую сущность. См. параграф 5.1.5, рис. 5.11 Включен в версию 1.0
«transformation» Стереотип комментария, присоединяе- мого к ребру потока данных на диаграмме деятельности и показывающего, что при переходе по данному ребру объект данных определенным образом преобразуется. См. параграф 4.3.2, рис. 4.42 Включен в версию 2.0
{transient} Ограничение, которое говорит, что объект является временным. См. парвграф 3.1.3, параграф 4.4.5, таблица 4.13 Включен в версию 1.3
«type» Стереотип класса, который определяет множество объектов и множество опера- ций, выполнимых над этими объектами. У объектов типа не может быть индивиду- альных методов, но могут быть значения атрибутов и связей Включен в версию 1.1
Глава 6. Справочные материалы
Ключевое слово Объяснение/пример История
{union} Ограничение полюса ассоциации, исполь- зуется совместно с {subsets}. См. пара- граф 3.3.7, рис. 3.40
{unrestricted} Стандартное ограничение атрибута. См. параграф 3.2.2, таблица 3.3
«useCaseModel» Модель, описывающая функциональные требования с помощью вариантов исполь- зования Включен в версию 1.1, забыт в версии 1.3
usage Именованное значение перехода между действием и объектом в состоянии, озна- чающее, что объект в состоянии использу- ется, но не модифицируется действием Включен в версию 1.4, удален в версии 1.5
«use» Стереотип зависимости, указывающей, что зависимый элемент требует наличия зависимого элемента для своего полного определения. См. таблицу 3.8 в параграфе 3.3.1 Включен в версию 2.0
иве esse uc Тег диаграммы использования. См. табли- цу 1.3 в параграфе 1.4.4
«uses» Стереотип обобщения между вариантами использования, имеющий тот же смысл, что и стереотип «include» для зависимости между вариантами использования. См. па- раграф 5.2.2, рис. 5.21 Включен в версию 1.0, забыт в версии 1.3
«utility» Стереотип класса, определяющий имено- ванную коллекцию атрибутов и операций, то есть службу. См. рис. 3.6, таблицу 3.2 в параграфе 3.2.1, рис. 3.22-3.28, 3.32, 3.35, рис. 3.49, рис. 5.19 Включен в версию 1.0, удален в версии 1.5, возобновлен в версии 2.0
{vote} Ограничение, указывающее, что результат, возвращаемый множеством посланных сообщений, определяется "методом голо- сования" Включен в версию 1.0, забыт в версии 1.3
when Ключевое слово события изменения. См. параграф 4.2.8, рис 4.45 Включено в версию 2.0
{xor} Ограничение множества ассоциаций, ука- зывающее, что ровно одна ассоциация из множества применяется для каждого ассоциированного экземпляра. См. пара- граф 3.3.5, рис 3.25. Включен в версию 1.3 вместо {or}
6.2. Толковый СЛОВАРЬ
6.2. Толковый словарь терминов
Авторы UML, создавая язык, большое внимание уделяли терминологии, по-
скольку UML призван стать общепризнанным языком общения разработчи-
ков во всем мире, и от того, насколько точна и однозначна терминология, во
многом зависит достижение этой цели. Существенная трудность заключает-
ся в том, что один и тот же термин в разных парадигмах, языковых традици-
ях и областях применения может означать хотя и родственные, но различ-
ные вещи. Для преодоления этой трудности авторы UML систематическим
образом вводят в употребление новые слова или дают старым терминам со-
вершенно новые толкования, так чтобы термины моделирования, принятые
в UML, случайно, по сходству звучания или по привычке не путались с тер-
минами, которые применяются в других случаях.
Ниже собраны определения основных терминов, используемых в этой кни-
ге (см. также www.umlmanual.ru). Приведенные толкования соответствуют
определениям в тексте, но переформулированы таким образом, чтобы сло-
варем можно было пользоваться независимо от основного текста книги. Как
обычно, выделение курсивом означает определяющее вхождение термина.
Термины, выделенные полужирным в столбце "Толкование", являются ис-
пользующими вхождения терминов, определенных в этой же таблице. Та-
ким образом, словарь является замкнутой и практически полной системой
определений терминов, относящихся к UML и к моделированию на UML.
Термин Толкование
Абстрактный классифика- тор (abstract classifier) Классификатор, который не может иметь прямых экземпляров, но может иметь кос- венные экземпляры
Агрегация (aggregation) Вид ассоциации, представляющий отноше- ние между частью и целым. Агрегация между классами А (часть) и В (целое) подразумева- ет, что экземпляры класса А входят в состав экземпляров класса В
Активация (execution specification) Графический комментарий, показывающий отрезки времени, в течение которых объект владеет потоком управления
Активное состояние (active state) Состояние, в котором машина состояний на- ходится в данный момент
Активный класс (active class) Класс, экземпляры которого имеют соб- ственный поток управления
<2>
Термин Толкование
Аргумент (argument,) Конкретное значение, которое подставляет- ся вместо параметра элемента перед его ис- пользованием
Артефакт (artifact) Любой созданный искусственно элемент си- стемы, который используется или порожда- ется в процессе ее разработки
Асинхронный вызов (asynchronous call) Вызов, при котором вызывающий объект не ожидает от вызываемого объекта явного воз- врата управления и после вызова продолжа- ет свою работу
Ассоциация (association) Отношение, при котором одна сущность не- посредственно связана с другой (или с други- ми, ассоциация может быть многоместной). Частные случаи ассоциации - агрегация, композиция и класс ассоциации
Атрибут (attribute) Именованная структурная составляющая классификатора, в которой может храниться значение
Вариант использования (use case) Множество сценариев, объединенных по некоторому критерию и описывающих по- следовательности производимых системой действий, доставляющих значимый для не- которого действующего лица результат
Видимость (visibility) Свойство составляющих классификатора, значение которого определяет, может ли со- ставляющая одного классификатора (в том числе имя) использоваться другим клас- сификатором. Существует четыре типа ви- димости: открытая (public), защищенная (protected), закрытая (private) и пакетная (package)
Включение (include) Отношение между вариантами использова- ния, которое показывает, что в каждый сце- нарий зависимого варианта использования в определенном месте вставляется в качестве подпоследовательности действий сценарий независимого варианта использования
6 2. Толковый СЛОВАРЬ
Термин Толкование
Владение (ownship) Отношение принадлежности между пакетом и его элементами или между классом и его вложенными классами
Вложенная диаграмма после- довательности (nested sequence diagramm) Диаграмма последовательности, использо- ванная на обзорной диаграмме взаимодей- ствия
Вложенное состояние (substate) Состояние (простое или составное), кото- рое находится внутри другого составного со- стояния
Вложенный автомат (submarine) Конечный автомат, вложенный в ссылочное состояние другого автомата
Внутренняя активность (internal activity) Действие или деятельность, которое должно выполняться в момент нахождения объекта в одном из своих возможных состояний
Внутренний переход (internal transition) Предписание обрабатывать соответствую- щие события без выхода и повторного вхо- да в данное состояние
Временная шкала (timing ruler) Ось с засечками, означающими моменты времени. Может накладываться на границу рамки диаграммы синхронизации
Входной шлюз (input gate) Точка на границе рамки диаграммы, откуда исходит приходящее извне сообщение
Выходной шлюз (output gate) Граф деятельности (activity graph) Точка на границе рамки диаграммы, куда уходит отправляемое вовне сообщение Множество сущностей, которыми являются действия или деятельности, и отношение между этими сущностями, которое задает по- рядок их выполнения
Граф модели (model graph) Нагруженный мульти-псевдо-гипер-орграф, в котором вершины соответствуют сущно- стям, а ребра отношениям
Действие (action) Непрерываемое извне атомарное вычисле- ние, чье время выполнения пренебрежимо мало
Глава 6. Справочные материалы
Термин Толкование
Действующее лицо (actor) Сущность, находящаяся вне моделируемой системы и непосредственно взаимодейству- ющая с ней
Дескриптор (descriptor) Описание общих свойств множества элемен- тов, включая их структуру, отношения, пове- дение, ограничения и назначение
Деятельность (activity) Продолжительное по времени, прерываемое извне, не атомарное вычисление
Диаграмма (diagram) Графическое представление некоторой части графа модели
Диаграмма автомата (state machine diagram) Диаграмма, описывающая поведение как процесс смены состояний. Основные сущно- сти и отношения, используемые на диаграм- ме: состояния и переходы
Диаграмма внутренней структуры (composite structure diagram) Диаграмма, описывающая внутреннюю структуру класса или компонента как сово- купность взаимосвязанных элементов, вы- полняющих определенные роли. Основные сущности и отношения, используемые на диаграмме: части, порты и соединители
Диаграмма взаимодействия (Interaction diagram) Обобщенное название для диаграмм после- довательности, коммуникации, синхрони- зации и обзорной диаграммы взаимодей- ствия
Диаграмма деятельности (activity diagram) Диаграмма, описывающая поведение с помо- щью графа деятельности. Основные сущно- сти и отношения, используемые на диаграм- ме: узлы действия, узлы деятельности, узлы управления, узлы данных и переходы, за- дающие потоки управления и потоки данных
Диаграмма использования (use case diagram) Диаграмма, описывающая функциональное назначение системы. Основные сущности и отношения, используемые на диаграмме: ва- рианты использования, действующие лица и ассоциации между действующими лицами и вариантами использования
596 J
6.2. Толковый СЛОВАРЬ
Термин Толкование
Диаграмма классов (class diagram) Диаграмма, описывающая структуру моде- лируемой системы. Основные сущности и от- ношения, используемые на диаграмме: клас- сы, интерфейсы, ассоциации и обобщения
Диаграмма коммуникации (communication diagram) Диаграмма, описывающая поведение си- стемы в форме обмена сообщениями между взаимодействующими элементами. Диа- грамма коммуникации семантически экви- валентна диаграмме последовательности, однако упор в ней делается на структурные отношение между взаимодействующими элементами. Основные сущности и отноше- ния, используемые на диаграмме: экземпля- ры классификаторов и связи, по которым передаются сообщения
Диаграмма компонентов Диаграмма, описывающая структуру моде-
(component diagram) ' лируемой системы на более высоком уровне
абстракции, чем диаграмма классов. Пока- зывает, какие интерфейсы реализуют и тре- буют для своей работы компоненты и как эти компоненты между собой связаны
Диаграмма кооперации (collaboration diagram) Старое название диаграммы коммуникации в UML 1
Диаграмма объектов (object diagram) Диаграмма, описывающая существующие структурные элементы работающей системы в конкретный момент времени. Сущности и отношения, используемые на диаграмме объ- ектов, являются экземплярами сущностей и отношений, представленных на диаграмме классов, т.е. это объекты и связи
Диаграмма пакетов (package diagram) Диаграмма, описывающая внутреннюю структуру модели. Основные сущности и от- ношения, используемые на диаграмме: паке- ты, отношения импорта и слияния
Глава 6. Справочные материалы
Термин Толкование
Диаграмма последовательности (sequence diagram) Диаграмма, описывающая поведение си- стемы в форме обмена сообщениями между взаимодействующими элементами. Диаграм- ма последовательности семантически экви- валентна диаграмме коммуникации, однако упор в ней делается на последовательность отправки/приема сообщений. Основные сущности и отношения, используемые на диаграмме: экземпляры классификаторов и связи, по которым передаются сообщения
Диаграмма размещения (deployment diagram) Диаграмма, описывающая структуру систе- мы с точки зрения размещения арт ефактов на вычислительных узлах. Основные сущ- ности и отношения, используемые на диа- грамме: артефакты, узлы, отношения разме- щения между артефактами и узлами, а также каналы связи между узлами
Диаграмма синхронизации (timing diagram) Особая форма диаграммы последовательно- сти, на которой основное внимание уделяется изменению состояний взаимодействующих элементов и их временной синхронизации
Диаграмма состояний (statechart diagram) Старое название диаграммы автомата bUMLI
Дорожка (swim lane) Графический способ классифицировать сущности, представленные на диаграммах по некоторому признаку. В UML 2 дорож- ки называются разбиениями (partition) и позволяют проводить классификацию по нескольким признакам
Жизненный цикл объекта (object lifecycle) Последовательность изменений состояния объекта, которая показывается на диаграмме автомата
Завершение потока (flow final node) Узел управления, в котором происходит за- вершение одного потока управления или данных в графе деятельности
6.2. Толковый СЛОВАРЬ
Термин Толкование
Зависимость (dependency) Отношение между двумя сущностями, при котором изменение одной сущности (не- зависимой) каким-либо образом влияет на другую сущность (зависимую). Для зависи- мостей существует большое количество сте- реотипов
Заключительное состояние (final state) Специальное состояние, соответствующее ситуации, когда машина состояний уже не работает
Заключительный узел (final node) Узел управления, в котором происходит за- вершение работы графа деятельности
Засечка времени (timing mark) Графическая отметка момента времени на временной шкале
Изменение состояния (state timeline) История смены состояний объекта во време- ни на диаграмме синхронизации
Импорт пакета (package import) Отношение между пакетами, обозначаюшее расширение зависимого пакета путем вклю- чения в него открытых элементов независи- мого пакета
Инвариант (invariant) Утверждение, которое остается истинным во время пребывания объекта в определенном состоянии или во время выполнения опера- ции, в случае, если выполнены все предусло- вия этой операции
Интерфейс (interface) Именованный набор составляющих, описы- вающий набор услуг, которые могут быть за- прошены потребителем и предоставлены по- ставщиком. Интерфейсы бывают требуемые (required interface) и обеспеченные (provided interface)
Исключение (exception) Указание на прерывание обычного хода вы- числений из-за ошибки или особых условий
Использование взаимодействия (interaction use) Ссылка на взаимодействие, обычно пред- ставленное самостоятельной диаграммой последовательности
Глава 6. Справочные материалы
Термин Толкование
Использование кооперации (collaboration use) Показывает, как описываемое коопераци- ей взаимодействие применяется в заданном контексте
Канал связи (communication path) Ассоциация между узлами, позволяющая обмениваться сообщениями
Каркас (framework) Совокупность логически связанных шабло- нов, стереотипов и коопераций, определен- ных на основе стандартной метамодели UML и предназначенных для моделирования в определенной предметной области
Квалификатор (qualifier) Атрибут (или несколько атрибутов) полюса ассоциации, значение которого (которых) позволяет эффективно выделить один (или несколько) экземпляров классификатора, присоединенного к другому полюсу ассоциа- ции
Класс (class) Классификатор, имеющий атрибуты и опе- рации
Класс ассоциации (association class) Сущность, которая является ассоциацией, но также обладает составляющими класса
Классификатор (classifier) Дескриптор множества однотипных объек- тов
Коллекция (collection) Совокупность однотипных идентифициро- ванных объектов, поддерживающая работу со всей совокупностью в целом, а также с от- дельными элементами по их идентификато- рам
Комментарий (comment) Универсальное средство неформального ука- зания для диаграммы или любого элемента некоторой дополнительной информации. В UML 1 использовался термин примечание (note)
6.2. Толковый словарь
Термин Толкование
Композиция (composition) Вид ассоциации, представляющий отно- шение между частью и целым. Композиция между классами А (часть) и В (целое) под- разумевает, что экземпляры класса А не толь- ко входят в состав экземпляров класса В, как при агрегации, но кроме этого часть А может входить только в одно целое В, и часть суще- ствует, только пока существует целое, и пре- кращает свое существование вместе с целым
Компонент (component) Модульная логическая часть системы с опре- деленным набором требуемых и обеспечен- ных интерфейсов
Конечный автомат (state machine) Набор состояний и переходов между ними
Конкретный классификатор (concrete classifier) Классификатор, который может иметь пря- мые экземпляры
Контакт (pin) Точка входа или выхода потока данных в узлы действия или деятельности. Контакты бывают входные или выходные, а также кон- вейерные (stream) и с исключением (excep- tion)
Конфигурация активных состояний (active state configuration) Состояние, в котором находится машина со- стояний и все вложенные в нее машины со- стояний в данный момент
Кооперация (collaboration) Совокупность элементов, которые взаимо- действуют для достижения некоторой цеди
Косвенный экземпляр (indirect instance) Объект, который порожден с помощью кон- структора одного из потомков данного клас- сификатора. Если классификатор А является обобще- нием классификатора В, то все экземпляры классификатора В являются косвенными эк- земплярами классификатора А
Кратность (multiplicity) Множество чисел, которые задают все до- пустимые значения мощности для данного множества. Применяется к атрибутам, клас- сификаторам и полюсам ассоциации
Глава 6 Справочные материалы
Термин Толкование
Линейка синхронизации (syncronization bar) Графическое обозначение в виде закрашен- ной полоски для узлов и состояний развил- ки и слияния
Линия жизни (lifeline) Графическое представление роли или объек- та во взаимодействии
Манифестация (manifest) Отношение, связывающее элемент модели (например, класс или компонент) и его фи- зическую реализацию (артефакт)
Машина состояний (state machine) Метамоделирование (metamodeling) Метамоделъ (metamodel) То же, что и конечный автомат Манипулирование моделями путем измене- ния их метамоделей Описание языка, на котором описываются модели
Метка продолжения (label) Графическое обозначение для изображения длинных линий в виде нескольких разорван- ных сегментов
Метод (method) Реализация Операции, т.е. выполняемый ал- горитм
Механизмы расширения (extension mechanism) Способы определения новых элементов мо- дели на основе существующих. В UML опре- делено три механизма расширения: помечен- ные значения, ограничения и стереотипы
Многополюсная ассоциация (n-ary association) Ассоциация, отражающая связь между тре- мя и более сущностями
Моделирование (modeling) Деятельность по составлению моделей
Модель (model) То же, что и граф модели
Модель поведения (behavior model) Описание алгоритма работы системы
Направление навигации (navigability) Способность полюса ассоциации передавать сообщения в указанном направлении
6.2. Толковый СЛОВАРЬ
Термин Толкование
Начальное состояние (initial state) Специальное состояние, соответствующее ситуации, когда машина состояний еще не работает
Начальный узел (initial node) Узел управления, с которого начинается дея- тельность
Номер сообщения (message number) Способ указания порядка следования сооб- щений, применяемый на диаграмме комму- никации
Обзорная диаграмма взаимодействия (interaction overview diagram) Особая форма диаграммы деятельности, на которой используются узлы управления, не используются узлы данных, а вместо узлов действий и деятельности используются ссылки на диаграммы взаимодействия
Область действия (scope) Свойство составляющей классификатора, значение которого определяет, как проявля- ет себя данная составляющая в экземплярах, т. е. имеют экземпляры свои собственные значения составляющей или совместно ис- пользуют одно значение
Область прерывания (interruptible activity region) Область на диаграмме деятельности, внутри которой возможно возникновение прерыва- ния и, как следствие, прекращение обычного порядка выполнения
Область разложения (expansion region) Структурированный узел деятельности, ко- торый получает коллекцию в качестве вход- ного параметра, разлагает коллекцию на составляющие элементы и производит ука- занные действия индивидуально с каждым элементом коллекции
Обобщение (generalization) Отношение между двумя сущностями, одна их которых является частным (специализи- рованным) случаем другой
Обработчик исключений (exception handler) Элемент, который описывает действия по об- работке исключения
Глава 6. Справочные материалы
Термин Толкование
Объект (object) Сущность, обладающая индивидуальностью (identity) и инкапсулирующая в себе состоя- ние и поведение
Объект в состоянии (object in state) То же, что и узел данных
Ограничение (constraint) Логическое утверждение относительно зна- чений свойств элементов модели
Операция (operation) Декларация действия с объектом
Отправка сигнала (send signal action) Действие по созданию нового экземпляра сигнала и его отправки заданному целевому множеству объектов
Пакет (package) Группа элементов модели (в том числе паке- тов)
Параметр (parameter,) Обозначение слота, вместо которого должно быть подставлено конкретное значение при использовании элемента. Параметры могут иметь операции и шаблоны
Пассивный объект (passive object) Объект, не имеющий собственного потока управления
Переключающее событие (trigger) То же, что событие перехода
Переход (transition) Отношение, связывающее исходное (может быть несколько) и целевое (может быть не- сколько) состояния и позволяющее перейти из одного в другое в случае возбуждения со- бытия перехода и одновременного выпол- нения сторожевого условия. При переходе могут быть выполнены дополнительные дей- ствия (effect)
Перечисление (enumeration) Тип данных, имеющий конечное линейно упорядоченное множество значений, задан- ных именами
Переходное состояние (junction pseudostate) Специальное состояние, разделяющее сег- менты перехода. Обозначается закрашен- ным кружком
• >
6.2. Толковый СЛОВАРЬ
Термин Толкование
Переход по завершении
(completion transition)
Получение сигнала
(accept event action)
Получение сигнала
от таймера
(accept time event action)
Полюс ассоциации
(association end)
Помеченное значение
(tagged value)
Порт (port)
Постусловие (postcondition)
Поток данных (data flow)
Поток управления
(control flow)
Частный случай перехода, который проис-
ходит по окончании внутренней активности
Действие по вызову соответствующего обра-
ботчика для события сигнала
Действие по вызову соответствующего обра-
ботчика для события таймера
Точка соприкосновения ассоциации и клас-
сификатора, которая определяет факт уча-
стия классификатора в ассоциации
Пара: имя свойства и значение свойства, ко-
торая может быть добавлена к любому стан-
дартному элементу модели
Точка взаимодействия структурированного
классификатора и его частей с внешними по
отношению к ним сущностями. Различаются
порт поведения (behaviour port), запросы к
которому реализуются самим классификато-
ром, а не его частями, сервисный порт (ser-
vice port), запросы к которому соотвествуют
интерфейсу, предоставляемому классифика-
тором, скрытый порт (hidden port), который
не виден снаружи классификатора, и слож-
ный порт (comlex port), в котором может
быть объединено несколько разнотипных
портов и интерфейсов
Условие, связывающее входные и выходные
данные операции, которое должно выпол-
няться после вызова операции
Описание связи выходных результатов од-
них действий с входными аргументами дру-
гих действий
Последовательность выполнения действий
Глава 6 Справочные материалы
Термин Толкование
Предикат else Ключевое слово, означающее сторожевое условие, которое выполняется, если все аль- тернативные сторожевые условия не выпол- няются
Представление (view) Способ логического структурирования мо- дели
Представление использования (Use case view) Отвечает на вопрос, что делает система по- лезного. Определяющим признаком для от- несения элементов модели к представлению использования является явное сосредоточе- ние внимания на факте наличия у системы внешних границ, то есть выделение внешних действующих лиц, взаимодействующих с системой, и внутренних вариантов исполь- зования, описывающих различные сценарии такого взаимодействия
Представление структуры (Structural view) Отвечает (с разной степенью детализации) на вопрос: из чего состоит система. Опреде- ляющим признаком для отнесения элемен- тов модели к представлению структуры является явное выделение структурных элементов — составных частей системы — и описания взаимосвязей между ними. Прин- ципиальным является чисто статический ха- рактер описания, то есть отсутствие понятия времени в любой форме
Представление поведения (Behavioral view) Отвечает на вопрос: как работает система. Определяющим признаком для отнесения элементов модели к представлению поведе- ния является явное использование понятия времени
Предусловие (precondition) Условие, налагаемое на входные данные опе- рации, которое должно выполняться до вы- зова операции
Прерывание (interrupt) Событие, которое нарушает обычный поря- док выполнения действий для того, чтобы выполнить деятельность, связанную с обра- боткой возникшей ситуации Л
6.2 Толковый СЛОВАРЬ
Термин Толкование
Производный элемент (derived element) Элемент, который можно вычислить или определить по другим элементам
Протокольный автомат (protocol state machine) Машина состояний, предназначенная для за- дания допустимых последовательностей вы- зовов и сигналов
Профиль (profile) Множество изменений базовой метамодели и совокупность логически связанных ша- блонов, стереотипов и коопераций, опреде- ленных на основе измененной метамодели и предназначенных для моделирования в опре- деленной предметной области
Прямой экземпляр (direct instance) Объект, который непосредственно порожден с помощью конструктора данного классифи- катора
Развилка управления Узел управления, в котором поток управле-
(fork node) . ния или данных разветвляется на несколько
параллельных потоков
Разветвление управления (decision node) Узел управления, в котором поток управле- ния или данных направляется по одному из альтернативных путей
Размещение (deployment) Отношение, связывающее артефакт и узел, на котором этот артефакт размещается
Рамка диаграммы (diagram frame) Прямоугольник, ограничивающий область, в которой должны находиться элементы диа- граммы
Расширение (include) Отношение между вариантами использова- ния, которое показывает, что в некоторый сценарий независимого варианта исполь- зования может быть в определенном месте вставлен в качестве подпоследовательности действий сценарий зависимого варианта ис- пользования
Реализация (realization) Отношение между двумя сущностями, кото- рое указывает, что одна сущность является реализацией другой
Глава 6. Справочные материалы
Термин Толкование
Роль (role) Способ обобщенно указать, какие именно элементы могут участвовать в данном взаи- модействии
Рефлексивная связь (reflective link) Связь элемента с самим собой
Связывание (binding) Способ создать по шаблону конкретный класс, кооперацию или пакет
Связь (link) Экземпляр отношения (например, ассо- циации или зависимости), представляющий собой набор ссылок на экземпляры класси- фикаторов, связанных между собой посред- ством этого отношения
Сигнал (signal) Именованный объект, который создается другим объектом (отправителем) и обраба- тывается третьим объектом (получателем)
Сегмент перехода (transition segment) Часть составного или сегментированного перехода между специальными или обыч- ными состояниями
Сегментированный переход (compound transition) Переход, имеющий несколько исходных со- стояний и/или несколько целевых состоя- ний, применяемый в случае последователь- ных составных состояний. Специальными состояниями, разделяющими сегменты сег- ментированного перехода, могут быть состо- яние выбора и переходное состояние
Сигнатура операции (operation signature) Имя операции, число и типы параметров и тип результата операции
Синхронный вызов (synchronous call) Вызов, при котором вызывающий объект ждет от вызываемого объекта явного возвра- та управления и, возможно, возвращаемого значения
Слияние пакетов (package merge,) Отношение между пакетами, при котором один пакет расширяет другой пакет непроти- воречивым образом
6.2. Толковый словарь
Термин Толкование
Слияние управления (join node) Узел управления, в котором несколько па- раллельных потоков управления или дан- ных синхронизирутся и сливаются в один поток
Событие вызова (call event) Событие, возникающее при вызове метода класса
Событие изменения (change event) Событие, возникающее в случае, когда неко- торое логическое условие становится истин- ным, будучи до этого ложным
Событие перехода (trigger event) Событие, разрешающее переход из исходно- го (может быть несколько) в целевое (может быть несколько) состояние
Событие сигнала (signal event) Событие, возникающее при посылке сигнала
Событие таймера (time event) Соединение управления (merge node) Событие, возникающее в случае, когда истек заданный интервал времени Узел управления, в который поток управле- ния или данных приходит по одному из аль- тернативных путей и направляется по един- ственному пути далее
Соединитель (connector) Отношение, которое служит для соедине- ния частей и портов структурированного классификатора между собой. Соединители бывают сборочные (assembly connector) и де- легирующие (delegate connector). Сборочный соединитель соединяет части структуриро- ванного классификатора меяаду собой, а де- легирующий связывает часть с портом
Сообщение (message) Передача управления и данных от одного объекта {отправителя} к другому (получа- телю}. Отправка сообщения является дей- ствием, а получение сообщения — событием вызова (при синхронном вызове) или собы- тием сигнала (при асинхронном вызове)
Составляющая Свойство классификатора (операция или
классификатора (feature) Ф S атрибут) -
Г пава 6 Справочные материалы
Термин Толкование
Составное состояние
(composite state)
Составной переход
(compound transition)
Составной шаг
взаимодействия
(combined fragment)
Состояние (state)
Состояние выбора
(choice pseudostate)
Состояние действия
(action state)
Состояние деятельности
(activity state)
Состояние развилки (fork)
Состояние слияния (join)
Состояние, в которое вложена машина со-
стояний. Если вложена только одна машина,
то состояние называется последовательным
(sequential / non-orthogonal state), если не-
сколько, то ортогональным (concurrent / or-
thogonal state)
Переход, имеющий несколько исходных со-
стояний и/или несколько целевых состоя-
ний, применяемый в случае ортогональных
составных состояний. Специальными со-
стояниями, разделяющими сегменты состав-
ного перехода, могут быть состояние развил-
ки и состояние слияния
Конструкция, применяемая на диаграммах
последовательности, которая позволяет за-
давать алгоритмические аспекты, в том чис-
ле ветвления, циклы и другие конструкции
управления
Период в жизненном цикле объекта, нахо-
дясь в котором объект удовлетворяет некото-
рому условию и осуществляет внутреннюю
активность или ожидает наступления неко-
торого события
Специальное состояние, разделяющее сег-
менты перехода. Обозначается ромбом
Состояние, внутренняя активность которого
является действием
Состояние, внутренняя активность которого
является деятельностью
Специальное состояние в составном пере-
ходе, означающее переход в несколько орто-
гональных целевых состояний. Обозначается
линейкой синхронизации
Специальное состояние в составном пере-
ходе, означающее переход из нескольких
ортогональных исходных состояний. Обо-
значается линейкой синхронизации
Г 610 1
6.2. Толковый СЛОВАРЬ
Термин Толкование
Специальное состояние (pseudostate) Собирательное название для тех состояний, в которых машина состояний не может пре- бывать какое-либо время и переход из кото- рых происходит автоматически, без события перехода. Например, начальное состояние, переходное состояние, состояние выбора
Спецификация развертывания (deployment specification) Способ задать значения параметров арте- факта при развертывании на узле
Ссылочное состояние (submachine state) Состояние, содержащее ссылку на вложен- ный автомат
Стереотип (stereotype) Определение нового элемента моделирова- ния на основе существующего элемента
Сторожевое условие (guard condition) Логическое выражение, которое должно ока- заться истинным для того, чтобы возбужден- ный переход сработал или для того, чтобы выполнились определенные шаги составно- го шага взаимодействия
Структурированный классификатор (structured classifier) Класс или компонент, для которого может быть определена внутренняя структура в виде взаимосвязанных частей
Структурный узел деятельности (structured activity node) Область на диаграмме деятельности, служа- щая для задания одной из следующих струк- тур управления: области разложения, узла последовательности, узла условий или узла цикла
Субъект (subject) Классификатор, реализующий поведение, де- кларируемое вариантами использования
Сценарий (scenario) Конкретная последовательность событий и действий, приводящая к определенному ре- зультату
Тип данных (data type) Классификатор, экземпляры которого не обладают индивидуальностью. Задает сово- купность множества значений (может быть очень большого или даже потенциально бес- конечного) и конечного множества опера-
ций, применимых к данным значениям
Глава 6 Справочные материалы
Термин Толкование
Точка расширения (extension point) Метка в последовательности событий/дей- ствий, реализующей данный вариант ис- пользования, из которой вызывается по- следовательность действий расширяющего варианта использования
Траектория объекта (object flow) Переход, исходным или целевым состоянием которого является узел данных
Узел (node) Вычислительный ресурс, на котором разме- щаются и при необходимости выполняются артефакты
Узел действия (action node) Действие, представленное в виде узла графа деятельности
Узел деятельности (activity node) Деятельность, представленная в виде узла графа деятельности
Узел данных (object node) Объект в определенном состоянии, представ- ленный в виде узла графа деятельности
Узел последовательности (sequence node) Структурный узел деятельности, который задает последовательное выполнение любого числа вложенных узлов, причем вложенные узлы могут быть узлами любого типа
Узел управления (control node) Узел графа деятельности, который опреде- ляет потоки управления и потоки данных между другими узлами
Узел условий (conditional node) Структурный узел деятельности, который задает выполнение одного узла из числа вло- женных узлов, причем для каждого вложен- ного узла должно быть задано сторожевое условие его выполнения
Узел цикла (loop node) Структурный узел деятельности, который задает многократное выполнение одного вложенного узла. Должно быть задано сто- рожевое условие продолжения выполнения цикла
Хранилище данных (datastore) Узел данных, аналог понятия переменной, в которую можно записать значение и потом неограниченное число раз его читать
6.2. Толковый СЛОВАРЬ
Термин Толкование
Часть (part) Структурная составляющая классификато- ра, которая описывает роль, которую ее эк- земпляр играет внутри экземпляра структу- рированного классификатора
Шаблон (template) Элемент модели (класс, кооперация или па- кет), при использовании которого необходи- мо определить значения для его параметров
Экземпляр ассоциации (association instance) То же, что и связь
Экземпляр класса (class instance) То же, что и объект
Элемент модели (model element) Любой элемент графа модели: сущность, от- ношение, дополнительная информация, ко- торой нагружена сущность или отношение
Язык VML . Графический язык моделирования общего
назначения, предназначенный для специфи- кации, визуализации, проектирования и до- кументирования всех артефактов, создавае- мых при разработке систем
Глава 6. Справочные материалы
6.3. Действия в UML 2
Наименование действия Описание
= | Иг*™* Jjtf ' * \ | иРЧиЗИ
CallBehaviorAction Осуществляет вызов указанной деятельности. Поддерживается синхронный и асинхронный вызов
CallOperationAction Осуществляет вызов заданного метода целевого объекта. Поддерживается синхронный и асинхронный вызов
OpaqueAction Действие, семантика которого определяется инструментом моделирования, а не стандартом UML. Такое действие можетпредставлять собой, например, код на некотором языке программирования
SendSignalAction Создает экземпляр сигнала по заданным аргументам, передает созданный объект целевому объекту и сразу возвращает управление отправителю (асинхронное взаимодействие)
ntermediateActions
AddStructuralFeatureValueAction Добавляет значения* для заданной структурной составляющей (атрибута)
BroadcastSignalAction Создает экземпляр сигнала по заданным аргументам, передает созданный объект всем целевым объектам (определение множества целевых объектов - точка вариации семантики) и сразу возвращает управление отправителю (асинхронное взаимодействие)
ClearAssociationAction Уничтожает все связи, в которых участвует указанный объект
ClearStructuralFeatu reAction Действие, удаляющее все значения структурной составляющей (атрибута)
CreateLinkAction Создает связь между объектами, классы которых связаны отношением ассоциации или классом ассоциации. Может использоваться и для создания самих объектов на полюсах связи
CreateObjectAction Создает и возвращает экземпляр указанного классификатора
DestroyLinkAction Удаляет указанную связь. Может использоваться и для удаления самих объектов на заданном полюсе связи
DestroyObjectAction Удаляет заданный объект. Может использоваться для удаления всех связей, которые имеет данный объект, а также всех других объектов, для которых данный является композитом
6 3 Действия в UML
Наименование действия Описание
ReadLinkAction Возвращает список объектов, находящихся на заданном полюсе ассоциации
ReadSelfAction Возвращает объект, который выполняет само это действие
ReadStructuralFeatureAction Возвращает значения для заданной структурной составляющей (атрибута)
RemoveStructuralFeatureValueAc- tion Удаляет значения из заданной структурной составляющей (атрибута)
SendObjectAction Передает заданный объект целевому объекту и сразу возвращает управление вызывающей стороне (асинхронное взаимодействие)
TestldentityAction Проверяет, являются ли два значения идентичными объектами
ValueSpecificationAction Вычисляет значение заданного выражения
tru '" “• ,«
AddVariableValueAction Добавляет значения в заданную переменную
ClearVariableAction Удаляет все значения из заданной переменной
Raise ExceptionAction Генерирует заданное исключение
ReadVariableAction Возвращает значения заданной переменной
RemoveVariableValueAction Удаляет значение заданной переменной
Complet "'Actions
AcceptCallAction Ожидает возникновения события вызова и возвращает результат выполнения данного вызова
AcceptEventAction Ожидает возникновения одного из асинхронных событий: события сигнала, события таймера, события изменения или их комбинаций
CreateLinkObjectAction Создает объект на полюсе связи
Read ExtentAction Возвращает все существующие экземпляры заданного классификатора
ReadlsClassifiedObjectAction Проверяет объект на принадлежность к множеству экземпляров заданного классификатора. Проверка может быть ограничена множеством прямых экземпляров
ReadLinkObjectEndAction Возвращает объект, находящийся на заданном полюсе связи
•*
ТГ
6151
Глава 6 Справочные материалы
Наименование действия Описание
ReadLinkObjectEndQualifierAction Возвращает значение квалификатора для данной связи данного объекта
ReclassifyObjectAction Добавляет заданные классификаторы в список классификаторов данного объекта или удаляет указанные классификаторы для объекта
ReduceAction Преобразует коллекцию элементов в единственный элемент посредством многократного применения преобразования, которое некоторым образом выбирает из коллекции пару элементов, преобразует их в один элемент и затем кладет обратно в коллекцию
ReplyAction Повторно возвращает результат выполнения последнего действия AcceptCallAction
StartClassifierBehaviorAction Запускает поведение классификатора, описываемое, например, диаграммой автомата, программным кодом и т.д.
Unmarshal lAction Возвращает для заданного объекта все структурные составляющие заданного типа
* Здесь и далее, когда речь идет о значениях (мн. число) структурной составляющей
(ед. число), нет никакого противоречия. Структурная составляющая в общем случае
представляется в виде массива, каждый элемент которого содержит свое значение и,
таким образом, одна структурная составляющая хранит много значений.
6.4. Литература по UML
LML основы
третье ЖАННЕ
жшмямагю
ШпмигтмпвМГ
• ЛЧ* rw-yi
[1] Фаулер М. UML. Основы. 3-е издание.
Символ-Плюс, 2005,192 с.
Мартин Фаулер — лучший технический писатель
современности, по нашему мнению. Третье издание
бестселлера "UML. Основы” охватывает UML 2.
Главное достоинство книги заключается в кратком и
сжатом изложении сути UML и особенностей при-
менения этого языка в современном процессе разра-
ботки программного обеспечения. В книге описаны
все главные типы диаграмм UML, рассказано, для
чего они предназначены и какая нотация применя-
ются при их создании и чтении. Мартин Фаулер
отбирает только самые важные средства, необходи-
мые при применении UML, освобождая читателя от
описания сложных и редко используемых возмож-
ностей UML. Эта книга будет полезна тем, кто хочет
616
6.4. Литература по UML
использовать UML, но не желает изучать справоч-
ники.
[2] Буч Г., Рамбо Д., Якобсон А. Язык UML.
Руководство пользователя. Второе издание. ДМК,
2006,496 с.
Руководство пользователя содержит справочный
материал, дающий представление о том, как мож-
но использовать UML для решения разнообразных
проблем моделирования. В книге подробно, шаг
за шагом, описывается процесс разработки про-
граммных систем на базе данного языка. Издание
адресовано читателям, которые уже имеют общее
представление об объектно-ориентированных кон-
цепциях. В первую очередь руководство предназна-
чено для разработчиков, занятых созданием моде-
лей UML. Тем не менее, книга будет полезна всем,
кто осваивает, создает, тестирует или выпускает в
свет программные системы.
[3] Буч Г., Якобсон А., Рамбо Д. UML. 2-е
издание Классика CS. Питер, 2005, 736 с.
Эта книга представляет собой наиболее полный
справочник по языку UML. Она адресована в первую
очередь разработчикам, системным архитекторам,
руководителям проектов, инженерам-системщикам,
программистам, аналитикам, заказчикам и вообще
всем, кому по роду деятельности приходится описы-
вать, проектировать и строить сложные программ-
ные системы, а также разбираться в их функцио-
нировании. В книге дается всестороннее описание
понятий и конструкций UML, включая их семан-
тику, нотацию и назначение. Материал организован
таким образом, чтобы книгой было удобно пользо-
ваться, несмотря на ее объем и полноту содержания.
Кроме того, авторы попытались дополнительно
осветить ряд моментов, четкое толкование которых
отсутствует в стандартах, а также разъяснить осно-
вания для принятия тех или иных решений в ходе
разработки языка UML.
ГлавА'6. Справочные материалы'
[4] Буч Г., Якобсон А., Рамбо Д. Унифици-
рованный процесс разработки программного обе-
спечения. Питер, 2002, 496 с.
Книга написана признанными специалистами в об-
ласти разработки программного обеспечения — ав-
торами языка UML. Унифицированный процесс
создания сложных программных систем включает
в себя использование средств унифицированного
языка моделирования UML как стандартного спо-
соба спецификации, визуализации, конструирова-
ния и документирования артефактов программных
систем. Эта книга будет полезна аналитикам, разра-
ботчикам приложений, программистам, тестерам и
менеджерам проектов.
[5] Крэг Л. Применение UML 2.0 и шабло-
нов проектирования, 3-е издание. Вильямс, 2007,
736 с.
В книге рассматриваются основные принципы и
приемы объектно-ориентированного анализа и про-
ектирования. В ней приведены сведения об итера-
тивном и гибком моделировании, шаблонах про-
ектирования, архитектурном анализе и многих
других вопросах. В книге рассматривается два ре-
альных примера, позволяющих на практике освоить
принципы моделирования, а также изучить систему
обозначений языка UML 2.0. Книга будет хорошим
руководством для всех, кто интересуется вопросами
объектно-ориентированного анализа и проектиро-
вания, языком моделирования UML 2.0 и современ-
ными эволюционными подходами к разработке про-
граммного обеспечения.
[6] Джеймс Рамбо, М. Блаха. UML 2.0.
Объектно-ориентированное моделирование и раз-
работка. Питер, 2007, 540 с.
Поистине революционная книга, посвященная ба-
зовым принципам объектно-ориентированного
мышления. Выгодно отличается своей универ-
сальностью от множества книг, описывающих от-
личительные черты какого-нибудь одного языка
6.4 Литература no UML
программирования. Издание обновлено в соответ-
ствии со стандартом UML 2.0. Авторы четко и ясно
объясняют суть важнейших концепций объектно-
ориентированного программирования, пред-
ставляют способы реализации этих идей при разра-
ботке программного обеспечения с использованием
языков C++ и Java, а также реляционных баз дан-
ных. В книге есть задания и множество советов, что
делает ее очень практичной.
—ЖИ1
Предметный указатель
А
Абстрактная операция 222
Абстрактный классификатор 205, 593
Аврам Ноам Хомский 58
Автоматизированное рабочее
место 277
Автомат инициальный 311
Автоматическая верификация
моделей 112
Автоматический синтез программ 49
Автомат Мура 311
Автоматное поведение 309
Автоматное преобразование 308
Автомат распознаватель 312
Агрегат 245
Агрегация 244, 593
Адрес возврата 437
Аксиома грамматики 57
Активация 84,436,593
Активное состояние 475, 593
Активность 385
Активный класс 327,495, 593
Активный объект 495
Алан Тьюринг 310
Алгоритм 170
Алфавит 310
Алфавит состояний 308
Альтернативные линии жизни 439
Альтернация 312
Аннотационная сущность 68
Аннотирование программы 372
Антирефлексивное отношение 64
Антисимметричное отношение 64
Аргумент 594
Артефакт 67, 86, 265, 271,557, 594
Архитектура компьютера 192
Архитектурные образцы 292
Асинхронный вызов 594
Асинхронный поток управления 323,428
Ассоциация 70,157, 253, 594
Ассоциация между действующим
лицом и вариантом использования 157
Ассоциация между узлами 274
Атрибут 196,216,594
Б
Базисные действия 381
Байт-код 380
Баланс развилок и слияний 489
Барбара Л исков 197
Бизнес 117
Бизнес-анализ 118
Бизнес-аналитик 118
Бизнес-логика 275
Бизнес-модель 118
Бизнес-процесс 117,119, 131
В
Вариант использования 68,80,153,154,
594
Веб-приложения 539
Предметный указатель
Верификация программ 372
Вершина графа 65
Веха 556
Взаимодействие 453
Взаимосвязи между блоками 126
Видимость 205, 502, 594
Видимость полюса ассоциации 254,
255
Виртуальная машина 380
Виртуальная машина Java 380
Виток 556
Включение 594
Владение 595
Вложенная диаграмма последователь-
ности 595
Вложенное состояние 595
Вложенность пакетов 506
Вложенный автомат 358, 595
Вложенный поток управления 428
Внешний ключ 144
Внешняя функция 119
Внутреннее представление модели 102
Внутренний переход 331,595
Внутренняя активность 595
Внутренняя деятельность 331
Внутренняя функция 119
Возбуждение перехода 334
Возврат значения 377
Возврат управления 428
Возможность навигации 252
Временная шкала 595
Временный объект 455
Время жизни объекта 454
Время жизни частей композита 247
Время исполнения 271
Время проектирования 271
Вспомогательный процесс 120
Входной алфавит 308
Входной шлюз 595
Вызов метода 218
Вызов операции 218,377
Вызов поведения 390
Выполнение программы 190
Выпуск 553
Выражение деятельности 387
Выходной алфавит 308
Выходной шлюз 595
Вычислительный узел 265
Г
Гиперграф 66
Гиперссылка 520
Глобальный переход 348
Глубинное историческое состояние 354
Головка чтения/записи 310
Гради Буч 41
Границы системы 163
Граф 65
Граф деятельности 385,425, 595
Граф модели 595
Группирующая сущность 68
д
Двудольный граф 65
Г 621
Предметный Указатель,
Дедуктивный синтез программ 49
Действие 68, 338, 377, 595
Действие при входе 330
Действие при выходе 331
Действующее лицо 67, 80,149, 596
Декларативное программирование 193
Делегирующий соединитель 285
Демон 368
Дерево И/ИЛИ 477
Дерево сегментированных переходов
339
Дерево субординации 562
Дескриптор 188, 596
Детальное проектирование 531
Деятельность 68, 384, 596
Джеймс Рамбо 42
Диаграмма 73, 596
Диаграмма автомата 77, 81,327, 596
Диаграмма взаимодействия 596
Диаграмма в нотации IDEF3 128
Диаграмма внутренней структуры 77,
88,202, 281,282, 596
Диаграмма деятельности 74, 82, 138,
376, 596
Диаграмма использования 74, 79 596
Диаграмма классов 74, 80,138, 597
Диаграмма коммуникации 77, 597
Диаграмма компонентов 74, 85, 276,
597
Диаграмма кооперации 74, 84, 597
Диаграмма объектов 74, 87, 300, 597
Диаграмма пакетов 77, 90, 597
Диаграмма последовательности 74, 83,
430, 598
622 j
Диаграмма размещения 74, 86, 278,
598
Диаграмма реализации 265
Диаграмма синхронизации 77, 90,459,
598
Диаграмма состояний 74, 81,138, 328,
598
Диаграмма состояний-переходов 319
Диаграмма сущность-связь 138
Диаграммы потоков данных 127
Динамическая параллельность 469
Динамическая типизация 224
Динамический контроль типов 224
Дисциплина имен 151
Дисциплина программирования 546
Дихотомия интерфейс-реализация 105
Дихотомия класс-объект 105
Доказательное программирование 371
Доказательств правильности
программы 372
Доминирование 125
Дополнение 104
Дорожка 397, 598
Дуглас Т. Росс 124
Дэвид Харел 327
Е
Естественный язык 40
Ж
Жизненный цикл объекта 325, 598
Жизненный цикл программы 551
I
Предметный указатель
3
Завершение потока 598
Зависимость 70,160, 599
Зависимость между вариантами
использования 160
Задача образца проектирования 522
Задержанная доставка сообщения 431
Заказчик 46
Заключительное состояние 311,351,
599
Заключительный узел 599
Закрытая видимость 206
Закрытое наследование 235
Закрытый бизнес-процесс 133
Замкнутая цепь 65
Замкнутый маршрут 65
Засечка времени 599
Защищенная видимость 206
Значок 62
И
Ивар Якобсон 41
Иерархическая база данных 201
Иерархическая десятичная
нумерация 85
Иерархическая модель 562
Иерархия исключений 415
Иерархия Хомского 58
Изменение состояния 599
Изменяемость атрибута 216
Изменяемость объектов на полюсе 257
Имитационное моделирование 122
Императивное программирование 193
Импорт пакета 599
Имя ассоциации 243
Имя образца проектирования 522
Имя роли 250
Имя состояния 330
Инвариант 267, 599
Индивидуальность 195,227
Индуктивный синтез программ 49
Индуцированное отношение 507
Инженерный анализ программ 49
Инкремент 560
Инкрементная модель процесса 560
Интероперабельность 50
Интерфейс 67, 196, 222, 266, 599
Информационная система управления
предприятием 539
Исключение 364, 599
Искусственный язык 40
Исполняемый UML 383
Использование взаимодействия 445,
599
Использование кооперации 289, 600
Историческое состояние 353
Исходное действие 129
Исчисление 132
Итерационная стратегия 558
Итерация Клини 312
Итерация языков 312
К
Канал связи 600
Каноническая диаграмма 73
Каноническая нотация 63
Предметный указатель
Каркас 528, 600
Качественный анализ 122
Квалификатор 600
Квалификатор полюса ассоциации 262
Класс 67,195, 213, 600
Класс ассоциации 260, 600
Классификатор 203, 207, 600
Клонирование 458
Ключ 262
Код программы 35
Количественный анализ 122
Коллекция 469, 470,600
Команда проекта 562
Комбинационный автомат 313
Комментарий 600
Композит 245
Композиция 245, 601
Компонент 67, 265, 269, 601
Компонентная структура 202
Компонентное программирование 269
Конечный автомат 308, 328, 601
Конкатенация 309,312
Конкретная операция 222
Конкретный классификатор 205, 601
Конструкции языка 74
Контакт 381,390, 391,601
Контейнер 206
Контекст 282
Контекст взаимодействия 453
Конфигурация активных состояний 476,
478, 601
Концептуальная модель 92
Кооперация 67, 202, 287, 601
Корневой сегмент перехода 340
Кортеж 242
Косвенный экземпляр 204, 601
Косвенный экземпляр классификатора
204
Кратность 207, 601
Кратность классификатора 207
Кратность множества 207
Кратность полюса ассоциации 244
Л
Лаврове. С. 143
Линейка синхронизации 483,488, 602
Линейная программа 325
Линейная стратегия 558
Линейный поиск 262
Линейный порядок 238
Линия 62
Линия жизни 84, 602
Линия жизни объекта 432
Листовой сегмент перехода 340
Литерал 188
Ловушка 373
Логическое программирование 193
Локальный переход 348
м
Магазинный автомат 320
Манифестация 272, 602
Маркер данных 389
Маркер управления 389
Предметный указатель
Маркировка 322
Маршрут 65
Матрица смежности 102
Машина состояний 328 602
Машина Тьюринга 309,310
Мета-метамодель 56
Метамоделирование 95, 602
Метамодель 56, 94, 602
Метаморфоза 458
Метапрограммирование
на шаблонах 230
Метка времени 434
Метка продолжения 602
Метод 196, 218,602
Методология структурного анализа и
проектирования 124
Метод пошагового уточнения 172
Метод раскрутки 56
Метод хирургической бригады 563
Метрика процесса 571
Механизмы расширения 42,106, 602
Многополюсная ассоциация 602
Множественное наследование 239
Множество 63
Множество внутренних переходов 331
Множество обобщений 239
Моделирование 43,122, 125, 602
Моделирование использования 169
Модель 43, 56,122,124, 510, 553, 602
Модель UML 63
Модель анализа 92
Модель водопада 558
Модель главного программиста 563
Модель звезды 563
Модель команды 546, 562
Модель команды равных 565
Модель конвейера 558
Модель поведения 306, 602
Модель проектирования 92
Модель процесса 546
Модель процесса разработки 558
Модель реализации 92
Модель хранения 301
Мощность множества 64
Мультиграф 66
Мультиобъект 458
н
Навигация 252
Найденные сообщения 494
Направление навигаци 602
Наследование 196,234
Наследование интерфейса и реализа-
ции 234
Начальное состояние 344, 350, 603
Начальный символ грамматики 57
Начальный узел 603
Недетерминированный автомат 314
Недостижимое состояние 311
Неинтерпретируемое действие 377
Неподстановочное обобщение 236
Непроцедурное программирование 193
Непротиворечивая модель 111
Нестрогий порядок 238
Нетерминальный символ 57
Предметный указатель
Неформальный язык 40
Неявное связывание 229
НиклаусВирт 172
Номер сообщения 429, 453, 603
Нотация Нэсси-Шнейдермана 421
Нотация «чупа-чупс» 233
Обеспеченный интерфейс 266
Обзорная диаграмма взаимодействия
77,89, 449, 603
Область 390
Область действия 206, 603
Область ортогонального составного
состояния 476
Область прерывания 413,603
Область разложения 471,603
Обобщение 71, 158, 159, 210, 234, 603
Обобщение ассоциации 248
Обобщение вариантов использования
159
Обобщение действующих лиц 158
Обработчик исключений 603
Обработчик прерывания 413
Образец 523
Образец проектирования 292, 372, 521
Обратная связь 313
Обусловленный поток управления 492
Объединение множеств 64
Объединение языков 312
Объект 67, 186, 604
Объект в состоянии 386,401,604
Объектно-ориентированный подход 44
Объектный узел 391
Ограничение 108,604
Ограничение {subsets х} полюса ассо-
циации 258
Ограничение {union} полюса ассоциа-
ции 259
Одиночка 209
Операторная схема 391
Операционная семантика 51
Операция 196,218,222,604
Операция конкатенации 309
Описательное моделирование 122
Организация 119
Ордерево 65
Ориентированное дерево 65
Ориентированный граф 65
Ориентированный двудольный
граф 322
Ортогональные системы
обозначений 69
Ортогональные составные
состояния 329
Основной процесс 120
Открытая видимость 205
Открытое наследование 235
Открытый бизнес-процесс 133
Отложенное событие 331
Отношение 64, 66
Отношение агрегации 71
Отношение ассоциации 241
Отношение ассоциации между
узлами 274
Отношение владения 501
Отношение манифестации 273
i
Предметный указатель
Отношение обобщения 234
Отношение порядка 238
Отношение расширения 109
Отношения зависимости 231
Отправитель сообщения 426
Отправка сигнала 604
п
Пакет 68, 604
Пакетная видимость 206
Память 192
Парадигма программирования 189
Параллелизм 221
Параллельное поведение 326
Параллельное составное состояние 329
Параллельность 461
Параметр 604
Параметр деятельности 391
Параметрические требования 168
Параметры исключения 415
Пассивный класс 327
Пассивный объект 495, 604
Паттерн 292
Первичный ключ 144
Переключающее событие 604
Переменная 193
Пересечение множеств 64
Переход 322, 604
Переходное состояние 339, 604
Переход по завершении 335, 605
Перечисление 604
Петля 65
Питер Чен 139
Поведенческая машина состояний 374
Поведенческая сущность 67
Поверхностное историческое
состояние 353
Повторитель 411,429
Повторность сообщения 429
Подкласс 196
Подсистема 510
Подстановочное обобщение 236
Позиция 322
Полиморфизм 196
Полнота 93,112
Полные действия 382
Полуоткрытый бизнес-процесс 133
Получатель сообщения 426
Получение сигнала 605
Получение сигнала от таймера 605
Полюс ассоциации 243, 250,605
Помеченное значение 107,605
Порождающая грамматика 57
Порт 88, 283, 605
Порт поведения 284
Порт сервиса 284
Порядок 238
Последовательное составное состоя-
ние 329
Последовательное уточнение 126
Постусловие 47, 49, 267, 370, 605
Посылка сигнала 377
Потерянные сообщения 495
Поток данных 212, 326, 400, 605
Поток управления 84, 212, 325, 605
Предметный указатель
Прагматика 42
Предикат 606
Предикат else 341
Представление 91, 196,606
Представление взаимодействия 99
Представление деятельности 99
Представление использования 96, 99,
606
Представление компонентов 97
Представление конечных автоматов 99
Представление поведения 100, 606
Представление проектирования 97, 99
Представление процессов 97
Представление развертывания 99
Представление размещения 97
Представление структуры 100,606
Представление управления моделью 99
Предусловие 47, 49, 267, 370,606
Предшествующие сообщения 429
Прекращение выполнения 377
Прерывание 606
Прием сигнала от таймера 406
Приложение реального времени 539
Применение кооперации 526
Примечание 68,155
Принцип единоначалия 562
Принцип Парето 537
Принцип подстановки 235
Принципы описательного моделирова-
ния 123
Принципы проектирования 292
Присваивание значения 377
Проблема остановки 315
Проблема эквивалентности 315
Программа 171
Программирование 545
Программирование без GoTo 190
Программирование вширь 142
Программирование сверху вниз 142
Программирование снизу вверх 142
Продолжение 445
Продукционное программирование 193
Производный элемент 246, 607
Промежуточные действия 381
Простое состояние 330
Простой переход 333
Простой поток управления 428
Пространство имен 501
Противоречивая модель 111
Протокол 170
Протокол выполнения 190
Протокольная машина состояний 374
Протокольный автомат 374, 607
Профиль 529, 607
Процедурное программирование 193
Процесс 132, 553
Процесс вспомогательный 120
Процессор 192
Процесс основной 120
Прямой экземпляр 204, 607
Прямой экземпляр классификатора 204
Псевдограф 65
Псевдокод 172
Предметный указатель
Р
Разбиение 397
Разветвление управления 607
Развилка 484,488
Развилка управления 607
Разворачивающее соединение 128
Размещение 607
Разработчик 46
Разрешенный переход 322
Рамка 62
Рамка диаграммы 607
Распространение исключения 415
Расширение 607
Реактивная система 309
Реализация 71,196, 607
Реализация варианта использо-
вания 170
Ребро графа 65
Регулярное выражение 313
Регулярные операции 313
Регулярный язык 313
Реинжиниринг бизнеса 120
Репозиторий 572
Рефлексивная связь 608
Рефлексивное отношение 64
Решение образца проектирования 522
Роль 149, 250, 608
Роль ассоциации 452
Рольклассификатора 451
Роль полюса ассоциации 250
С
Сборочное программирование 269
Сборочный соединитель 285
Свойство префикса 309
Сворачивающее соединение 128
Связный граф 65
Связывание 229, 608
Связь 88,186, 199, 242,431,452, 608
Сегментированный переход 339, 608
Сегмент перехода 339, 608
Секция атрибутов 213
Секция имени 213
Секция операций 213
Семантика 42, 59
Семафор 487
Сервер приложений 273
Сервисный порт 284
Сетевая база данных 201
Сеть Петри 322
Сигнал 363, 608
Сигнатура 220
Сигнатура операции 608
Сильное связывание 514
Симметричное отношение 64
Синтаксис 35,42
Синтаксическая диаграмма 188
Синтаксическая правильность 111
Синтаксический анализ 58
Синтаксический разбор 58
Синхронизирующее состояние 484
Синхронный вызов 608
Система 124
Предметный указатель
Системные часы 367
Скрытый порт 284
Слабое зацепление 514
Следующий входной символ 313
Слияние 488
Слияние пакетов 514,608
Слияние управления 609
Словарь предметной области 145, 210
Слово 312
Слот 451
Служба 208
Событие 325
Событие вызова 360, 609
Событие изменения 368, 609
Событие перехода 334, 609
Событие сигнала 363, 609
Событие таймера 366, 609
Соединение 484
Соединение управления 609
Соединитель 88,285, 287,452, 609
Создание объекта 377
Сообщение 426, 609
Составляющая 196
Составляющая классификатора 609
Составное имя 502
Составное состояние 330, 345, 610
Составной переход 479,483, 610
Составной переход по завершении 488
Составной шаг взаимодействия 84,
440,610
Состояние 68,610
Состояние выбора 339,610
СёЖ........-.......................
Состояние действия 386,610
Состояние деятельности 386,610
Состояние заглушка 356
Состояние развилки 610
Состояние слияния 610
Сохранение выходной сигнатуры 416
Специальное состояние 611
Специальные требования 168
Спецификатор интерфейса 250
Спецификация 46
Спецификация выполнения 436
Спецификация развертывания 274, 611
Спецификация требований 531
Список ребер 102
Список смежности 102
Способ передачи параметров 219
Срабатывание перехода 334
Ссылка на взаимодействие 89
Ссылочное состояние 330,355, 611
Стадия 555
Статическая типизация 224
Статический контроль типов 224
Статическое представление 98
Стек вызовов 437
Стереотип 109,611
Стереотипы примечаний 156
Сторожевое условие 337,429, 611
Строгий порядок 238
Структурированный классификатор
282,611
Структурная сущность 67
Структурное программирование 189
Предметный указатель
Структурные действия 382
Структурный узел деятельности 611
Субъект 163,611
Суперкласс 196
Сущность 66
Схема базы данных 144
Сценарий 154,611
т
Тезис Чёрча-Тьюринга 309
Текст 62
Теорема Райса 315
Теория формальных грамматик 57
Терминальный символ 57, 188
Технология программирования 189,545
Тип данных 223, 224, 227, 611
Тип данных (в UML) 227
Точка вариации семантики 42, 113, 220
Точка входа 359
Точка выхода 359
Точка зрения 125
Точка расширения 174, 612
Траектория объекта 401,612
Транзитивное отношение 64
Трансформационный синтез
программ 50
Трассировка 518
Требование 46,166
Требования к качеству 168
Требования к модели 168
Требуемый интерфейс 266
Трехуровневая архитектура 275
Три уровня понимания 30
Тупик 467
Тупиковое состояние 311
У
Узел 65, 67, 86, 273, 612
Узел данных 612
Узел действия 390,612
Узел деятельности 612
Узел последовательности 418,612
Узел разложения 471
Узел управления 390,393,612
Узел условий 419, 612
Узел цикла 419, 612
Умножение языков 312
Унаследованный 281
Уникальность 256
Уничтожение объекта 377
Упорядоченность объектов на полюсе
ассоциации 256
Упорядоченный набор 242
Управление 193
Управляющее устройство 310
Уровень модели 95
Уровень совместимости 512
Условное сообщение 428
0
ф
Фаза 555
Фигура 61
Физическая система 509
Фокус управления 436
Предметный указатель
Формальная спецификация 47
Формальный язык 40
Фрейм 431,451
Функциональная декомпозиция 120,
126
Функциональное моделирование 125
Функциональное программирование
194
Функциональные требования 168
Функция 119
Функция выходов 308
Функция переходов 308
Функция пометок 311
X
Хранилище данных 392,612
Хранимый объект 200
ц
Целевое действие 129
Центральный буфер 392
Цепь 65
Цикл 65
Циклы по структуре данных 469
ч
Часть 88,283,613
Частичный порядок 238
ш
Шаблон 229,613
Шаблон класса 229
Шаблон кооперации 294
Широковещательное сообщение 427
Широковещательный сигнал 364
Шлюз 456
э
Эволюционная стратегия 558
Эдсгер Вибе Дейкстра 190
Экземпляр 186,195, 206
Экземпляр ассоциации 613
Экземпляр класса 613
Экземпляр классификатора 204, 299
Экземпляр отношения 186
Элементарный язык 312
Элемент модели 613
Этап 555
Я
Явное связывание 229
Язык 40, 312
Язык OCL 49, 98
ЯзыкЭОЬ 317
Язык1)М1_ 45,613
Язык исчисления предикатов 47
Язык оболочка 107
Язык программирования 172
Язык ядро 107
Ячейка 182
Аббревиатуры
ВРМ 131
Г 632 1
Предметный указатель
BPML 131 JVM 380
BPMN 131 OCL 49, 98
BPMS 131 SADT 124
СОМ 199 SDL 317
CORBA 199 SOA 200
CRC-карта 164 SOAP 200
DCOM 199 UML 45,613
IDEF3 128 WSDL 200
Рецензии
Когда меня попросили написать рецензию на книгу Ф. А. Новикова и Д. Ю.
Иванова "Моделирование на UML”, первой реакцией была лёгкая тоска: за-
чем ещё одна книга по UML? В "Озоне" по запросу "UML" находится бо-
лее восьмидесяти реально продающихся наименований. Но раз уж взялся за
дело — надо выполнить. Прочитал первую страницу, вторую, третью... зачи-
тался! Мне всегда казалось, что книга по UML — это лучшее средство от бес-
сонницы. Ошибался. На сотой странице пришлось выключить компьютер:
время позднее, а завтра рано вставать.
Чем эта книга лучше других? Авторы не заставляют нас гадать: во введении
всё честно и подробно расписано — загляните. Впрочем, понятная скром-
ность не позволила авторам добавить ещё один очень важный пункт: книга
написана хорошим русским языком. Уже этим её можно выделить из общего
ряда книг по UML.
На мой взгляд, особенно здорово, что в книге не просто излагаются принци-
пы UML — в тексте отчётливо прослеживается авторский взгляд на них. На
этом я бы остановился подробнее. Понятно, что любой учебник по извест-
ной методике проектирования или языку программирования так или ина-
че опирается на более ранние издания. В простейшем случае берётся три-
четыре книжки, их содержимое "творчески переосмысляется" и излагается
так, чтобы никто не заподозрил в плагиате. Дело, в общем-то, нехитрое, хотя
и кропотливое. При этом, как правило, используется пресный "нейтральный
язык", подходящий скорее для энциклопедической статьи, а не для автор-
ского учебника. В предлагаемой же книге простое названо простым, слож-
ное — сложным, а неудачное — неудачным. Авторы не стесняются в оценках,
хотя такая позиция и ставит их под удар возможной критики.
Надо сказать, что хороший язык, ясная авторская позиция, интересная
структура книги (авторы называют её"трёхмерной") и прочие вкусности всё
равно не помогут, если фактическое содержание книги "не дотягивает". К
счастью, в данном случае ничему помогать и не требуется. Чего следует ожи-
дать от хорошего учебника UML? Качественных описаний элементов языка
и видов диаграмм, интересных примеров, обсуждения практики использова-
ния UML в условиях реальных проектов, разумных советов. В качестве де-
серта — краткого справочника по языку и глоссария. Докладываю: в данной
книге всё это имеется.
Ко всему прочему, выбранный стиль изложения выводит книгу из узкой
ниши "просто учебников". Опытный специалист, возможно, вряд ли найдёт
здесь что-либо новое для себя в описаниях конструкций UML или учебных
примерах диаграмм. Однако послушать профессионалов, оценить, быть
может, иной взгляд на давно знакомые концепции, кое-что переосмыслить
всегда полезно. Учитывая, что книга не очень велика по объёму, я бы посо-
ветовал прочесть её даже проектировщику со стажем. Много времени не по-
теряете, а хорошие идеи дорогого стоят.
Предполагаю, что книгу с названием "Моделирование на UML" трудно слу-
чайно взять с полки, соблазнившись броским названием — наверняка вы
хотя бы в общих чертах представляете себе, что такое UML и для чего он
нужен. Поэтому не станем тратить время на агитацию визуального модели-
рования. Будем считать, что выгода от изучения UML принимается как факт
(впрочем, если хотите доказательств — полистайте первую главу). Однако
от себя добавлю, что язык диаграмм полезен не только как средство проекти-
рования компьютерной программы. Диаграммы позволяют связать разроз-
ненные мысли воедино, представить систему в виде наглядной структуры,
тем самым раскрывая её неочевидные особенности. Недаром многие так лю-
бят использовать "ментальные карты" (mind maps) как метод визуализации
мышления даже в совершенно далёких от IT задачах.
PhD, assistant professor М. В. Мозговой. 05.01.2010, Айзу, Япония
По моему мнению, книга Ф.А. Новикова и Д. Ю. Иванова существенным об-
разом и в хорошем смысле "выбивается" из ряда гигантского потока рутин-
ных IT-текстов. Выделяется она, прежде всего, тем, что не является рефе-
ратом или переводом (пусть хорошего уровня) существующих источников,
но отражает собственный реальный опыт работы авторов в рамках рассма-
триваемой методологии, конкретизирует приёмы использования методоло-
гии UML, изобилует реальными и содержательными примерами и, наконец,
отражает неортодоксальный взгляд авторов на технологию моделирования.
Важным и весьма уместным в книге является чёткое позиционирование
применения технологии UML, определение места методологии в процессе
реализации реального программного проекта. Здесь авторам (и это ещё одно
достоинство учебника!) удалось остаться на реалистичных позициях и не
превратиться в апологетов "одного пророка" - в тексте учебника последова-
тельно реализуется цель: "имеется инструмент, он полезен там-то и там-то".
Д. ф.-м. н., главный научный сотрудник Института программных систем
Российской Академии Наук В. Б. Новосельцев. 28.12.2009.