/






















































































































































































































































































































































































































































































































































































































Автор: Ивченко Г.И. Медведев Ю.И.
Теги: теория вероятностей математическая статистика комбинаторный анализ теория графов математика статистика
ISBN: 978-5-382-01013-7
Год: 2009




Текст
ВВЕДЕНИЕ
МАТЕМАТИЧЕСКУЮ
СТАТИСТИКУ t
« I—»L— I »
Г. И. Ивченко, Ю. И. Медведев
ВВЕДЕНИЕ
В МАТЕМАТИЧЕСКУЮ
СТАТИСТИКУ
URSS
МОСКВА
ББК 22.172
Ивченко Григорий Иванович,
Медведев Юрий Иванович
Введение в математическую статистику: Учебник.
М.: Издательство ЛКИ, 2010. — 600 с.
Настоящая книга представляет собой своеобразный расширенный учебник
по математической статистике. Данный учебник не ограничен рамками учебного
стандарта или вузовской программы — он предназначен всем, кто интересуется
математикой вообще и, в частности, хочет узнать, что такое современная матема-
тическая статистика, какие задачи и какими методами она решает, какие результаты
в ней уже накоплены, какие проблемы в ней сегодня актуальны; наконец, каковы
ее истоки, какой путь она прошла и какие ученые были ее творцами. По замыслу
авторов, книга простым и доступным языком рассказывает о математической ста-
тистике и одновременно обучает ей. Вся теория объясняется и иллюстрируется на
интересных и тщательно подобранных примерах. Книга может служить и задач-
ником, так как содержит большой список упражнений для самостоятельного реше-
ния, а также справочным пособием по математической статистике, а в некоторых
аспектах — и по теории вероятностей.
Книга будет интересна преподавателям, аспирантам и студентам естественных
и технических вузов, в которых изучается математическая статистика, научным
работникам, использующим в своей деятельности методы математической стати-
стики, а также самому широкому кругу любителей математики.
i
Издательство ЛКИ.
117312, Москва, пр-т Шестидесятилетия Октября, 9.
Формат 60*90/16. Печ.л. 37,5. Зак. № 1748.
Отпечатано в ООО «ПК «Зауралье».
640022, Курганская обл., Курган, ул. К. Маркса, 106.
ISBN 978-5-382-01013-7
© Издательство ЛКИ, 2009
НАУЧНАЯ И УЧЕБНАЯ ЛИТЕРАТУРА
—р E-mail: URSS@URSS.ru
X. Каталог изданий в Интернете:
W http://URSS.ru
J Тел./факс: 7 (499) 135-42-16
URSS Тел./факс: 7 (499) 135-42-46
Вес права защищены. Никакая часть настоящей книги нс может быть воспроизведена или
передана в какой бы то ни было форме и какими бы то ни было средствами, будь то элек-
тронные или механические, включая фотокопирование и запись на магнитный носитель,
а также размещение в Интернете, если на то нет письменного разрешения владельца.
Содержание
Предисловие 11
Введение 14
§ 1. Что такое математическая статистика, ее предмет и задачи 14
§2. Краткий исторический очерк развития
математической статистики 25
Глава 1. (Вспомогательная, но очень важная!) Основные распределения
и их моделирование. 30
Введение 30
§1.1 . Основные дискретные модели математической статистики 31
1. Схема Бернулли и биномиальное распределение 31
2. Отрицательное биномиальное распределение 34
3. Распределение Пуассона 35
4. Гипергеометрическое распределение 37
5. Распределение Маркова—Пойа . 37
6. Полиномиальное распределение 39
7. Многомерное распределение Маркова—Пойа 40
8. Распределение степенного ряда . 42
§ 1.2. Основные абсолютно непрерывные модели 43
1. Нормальное распределение 44
2. Многомерное нормальное распределение 47
3. Гамма-распределение 51
4. Бета-распределение 53
5. Равномерное распределение 54
6. Распределение Стьюдента 55
7. Распределение Снедекора 56
8. Распределение Вейбулла 57
9. Распределение Парето 57
10. Распределение Дирихле 57
11. Преобразования случайных величин и векторов 58
§1.3 . Моделирование выборок из конкретных распределений 62
1. Предварительные замечания 62
2. Моделирование распределений Бернулли В1(1,р)
и биномиального Bi(A,p) 64
3. Моделирование_отрицательного биномиального
распределения Bi(r,p) 64
4. Моделирование полиномиальных испытаний 65
5. Моделирование пуассоновского распределения П(А).............. 65
4
Содержание
6. Моделирование непрерывных распределений 66
7. Моделирование показательного
и связанных с ним распределений 67
8. Моделирование нормальных случайных чисел 67
9. Метод суперпозиций 68
10. Моделирование цепи Маркова 70
II. Метод Монте-Карло 73
Упражнения 74
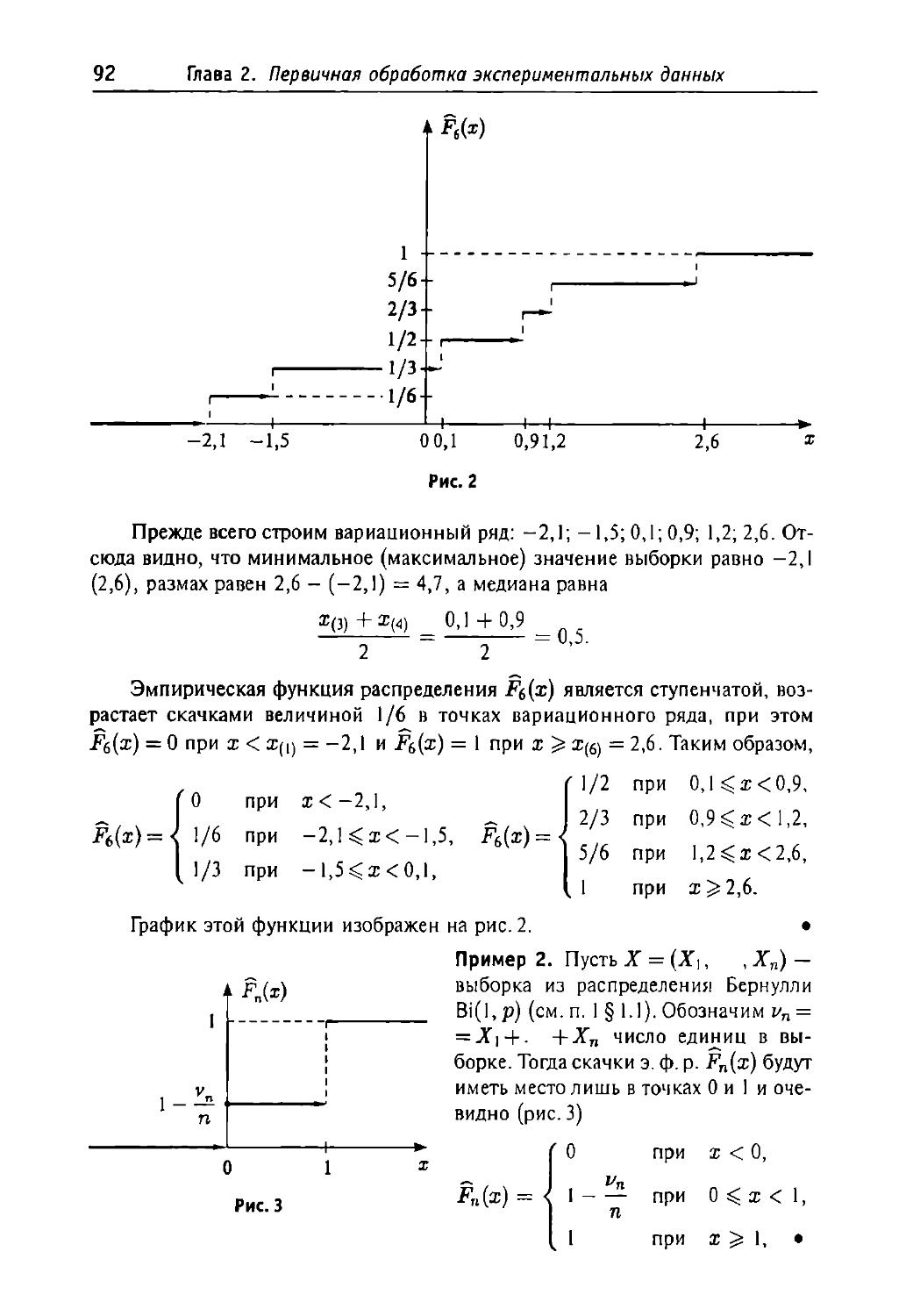
Diana 2. Первичная обработка экспериментальных данных 89
§2.1. Вариационный ряд выборки, эмпирическая функция распределения
и гистограмма . 89
I. Порядковые статистики и вариационный ряд выборки 89
2. Эмпирическая функция распределения 90
3. Дальнейшие свойства э.ф.р. 96
4. Полигон частот, гистограмма 100
5. Ядерные оценки теоретической плотности 103
§2.2. Выборочные моменты: точная и асимптотическая теория 105
1. Выборочные моменты 105
2. Моменты выборочных среднего и дисперсии 108
3. Сходимость по вероятности выборочных моментов
и функций от них 109
4. Асимптотическая нормальность выборочных моментов 114
5. Асимптотические доверительные интервалы
для теоретических моментов 117
§2.3. Многомерные данные 118
1. Эмпирическая функция распределения 119
2. Моменты 120
3. Большие выборки 121
4. Добавление: нормальная модель 122
5. Другие корреляционные характеристики 125
§2.4. Выборочные квантили и порядковые статистики 128
I. Теоретические и эмпирические квантили 128
2. Распределение порядковых статистик 130
3. Асимптотическая нормальность средних членов
вариационного ряда 133
4. Асимптотическое поведение крайних порядковых статистик 135
5. Асимптотическая теория для верхних
экстремумов X(n_,„+|), m I 138
§2.5. Линейные и квадратичные статистики от нормальных выборок 140
1. Линейные и квадратичные статистики, условия их независимости 141
2. Распределения квадратичных статистик 143
3. Теорема Фишера 145
Упражнения..................................................... 150
Содержание
5
Глава 3. Общая теория оценивания неизвестных параметров распределений 159
§3.1. Статистические оценки и общие требования к ним 159
I. Понятие статистической оценки и ее среднеквадратичная ошибка 159
2. Несмещенные оценки 162
3. Оптимальные оценки 168
§ 3.2. Критерии оптимальности оценок, основанные
на неравенстве Рао—Крамера. Эффективные оценки 173
I. Функция правдоподобия, вклад выборки, функция информации 173
2. Неравенство Рао—Крамера 175
3. Экспоненциальная модель 179
4. Критерий Бхаттачария оптимальности оценки 181
5. Критерии оптимальности в случае векторного параметра 182
§ 3.3. Достаточные статистики и оптимальные оценки 186
1. Достаточные статистики и критерий факторизации 186
2. Теорема Рао—Блекуэлла—Колмогорова 191
3. Экспоненциальные семейства и достаточные статистики 193
§ 3.4. Способы решения уравнения несмещенности 199
I. Модель степенного ряда, оценивание параметрических функций 200
2. Модели с выборочным пространством, зависящим от параметра в 204
3. Метод подгонки 207
4. Гамма-модель с неизвестным параметром масштаба,
оценивание параметрических функций 213
5. Другие применения гамма-модели для оценивания неизвестных
параметров 217
§3.5. Оценки максимального правдоподобия . 219
1. Определение и примеры оценок
максимального правдоподобия (о. м. п.) 219
2. Принцип инвариантности для о. м. п. 223
3. Метод накопления для приближенного вычисления о. м. п. 225
4. Асимптотические свойства о. м. п. 227
5. Асимптотические доверительные интервалы,
основанные на о. м. п. 234
§ 3.6. Другие методы н принципы построения оценок 239
1. Метод моментов . 239
2. Метод минимума хи-квадрат 241
3. Модально несмещенные оценки 243
4. Медианно несмещенные оценки 245
5. Эквивариантные оценки 246
6. Байесовские и минимаксные оценки 250
7. Оценивание по цензурированным данным 258
§ 3.7 Объединение и улучшение оценок 264
1. Объединение оценок 264
2. Улучшение оценок 271
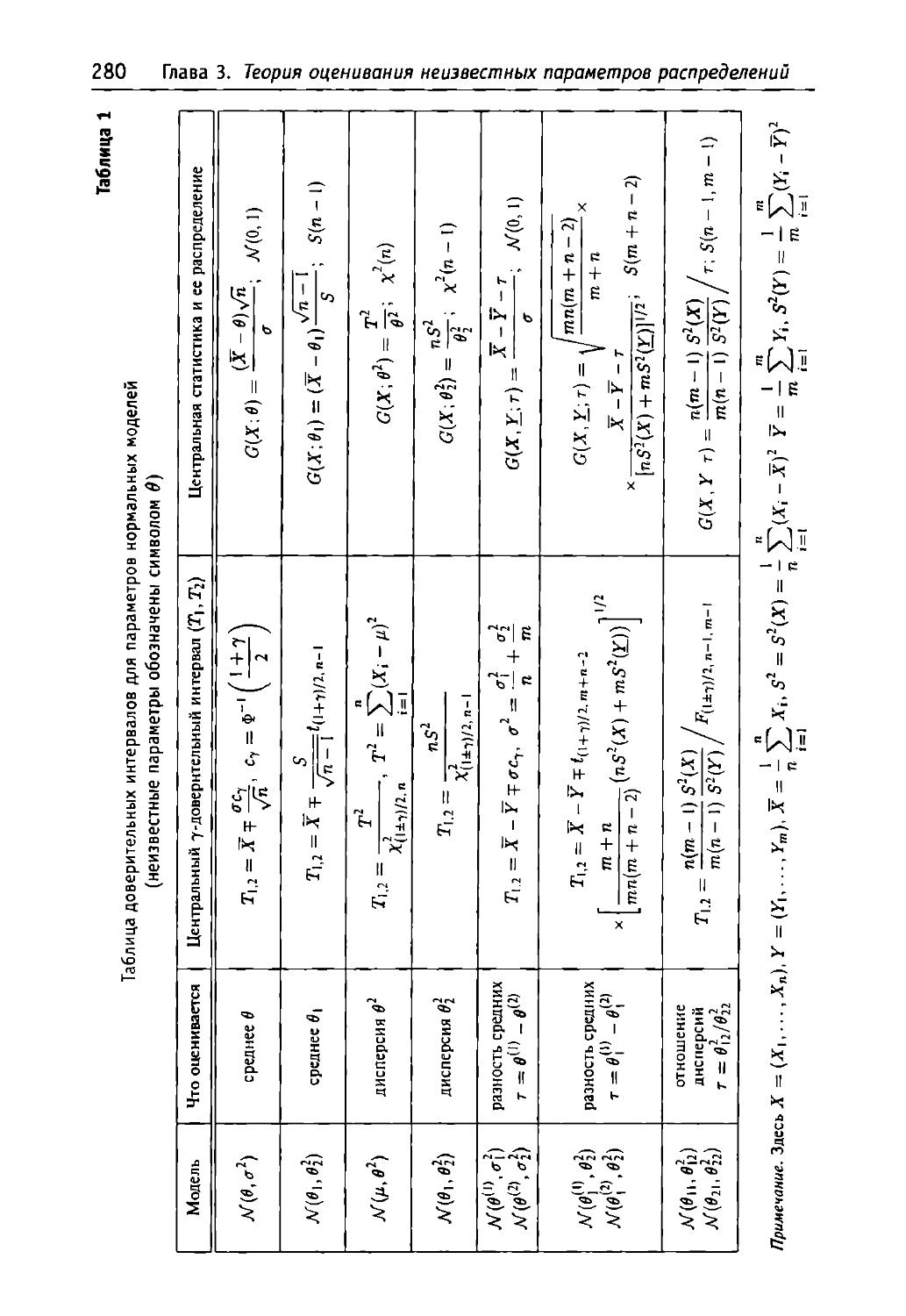
§ 3.8. Доверительное оценивание 276
1. Построение доверительного интервала
с помощью центральной статистики..............................277
б
Содержание
2. Построение доверительного интервала с использованием
распределения точечной оценки параметра 281
3. Асимптотические доверительные интервалы 284
§3.9. Оценивание при выборе из конечной совокупности 288
1. Оценивание среднего совокупности 288
2. Оценивание состава совокупности 292
Упражнения 297
Глава 4. Проверка статистических гипотез 311
§4.1 . Основные понятия и общие принципы теории проверки гипотез 311
§4.2 . Проверка гипотезы о виде распределения 318
1. Критерий согласия Колмогорова 318
2. Критерий согласия хи-квадрат К. Пирсона 320
3. Критерий хи-квадрат для сложной гипотезы 327
4. Критерий квантилей 332
5. Критерий пустых ящиков 334
§4.3 . Гипотеза и критерии однородности 340
1. Критерий однородности Смирнова 340
2. Критерий однородности хи-квадрат 341
3. Другие критерии в задаче о двух выборках 347
§4.4 . Гипотеза независимости 350
1. Критерий независимости хи-квадрат 351
2. Критерий Спирмена 357
3. Критерий Кендалла 358
4. Случай m признаков 359
§4.5 . Гипотеза случайности 361
1. Критерий инверсий 362
2. Проблема датчиков и обобщенный критерий хи-квадрат 364
Упражнения 368
Глава 5. Параметрические гипотезы 372
§5.1 . Общие положения 372
§5.2 . Выбор из двух простых гипотез. Критерий Неймана—Пирсона 374
1. Постановка задачи и предварительные соображения 374
2. Случай абсолютно непрерывных распределений 375
3. Критерий Неймана—Пирсона в случае дискретных распределений 386
§5.3 . Сложные гипотезы 394
1. Р. н. м. критерии против сложных односторонних альтернатив.
Модели с монотонным отношением правдоподобия 394
2. Двусторонние альтернативы, р. н.м. несмещенные критерии 398
3. Локальные наиболее мощные критерии 403
4. Проверка гипотез и доверительное оценивание 405
§5.4 . Критерий отношения правдоподобия 409
I. Метод отношения правдоподобия для общих гипотез . 409
2. КОП для больших выборок 417
3. Дальнейшие асимптотические свойства КОП ....................421
Содержание
7
4. Сложная нулевая гипотеза 423
5. Доверительные области максимального правдоподобия 426
§5.5 . Проверка гипотез для конечных цепей Маркова 427
1. Гипотезы для конечных цепей Маркова 428
2. Критерий хи-квадрат для простой гипотезы 431
3. Критерий хи-квадрат для сложной гипотезы 432
4. Критерий отношения правдоподобия
для общих параметрических гипотез 436
5. Критерий однородности 438
6. Оценивание порядка цепи 442
§5.6 . Понятие о последовательном анализе. Критерий Вальда. 443
1. Определение критерия Вальда 444
2. О числе испытаний до момента остановки в критерии Вальда 445
3. О выборе границ в критерии Вальда 446
4. О среднем числе наблюдений в критерии Вальда 448
Упражнения 451
Глава 6. (Специальная) Линейная регрессия и метод наименьших квадратов 457
§6.1 . Модель линейной регрессии 457
§6.2 . Оценивание параметров модели линейной регрессии 459
1. Метод наименьших квадратов 459
2. Оптимальность оценок наименьших квадратов 460
3. Оценивание остаточной дисперсии 462
4. Условные о. н. к. 463
5. Оптимальный выбор матрицы плана . 464
6. Примеры применения метода наименьших квадратов 465
7. Ортогональные многочлены Чебышева 470
§6.3 . Нормальная регрессия 474
1. Модель нормальной регрессии 474
2. Оценки максимального правдоподобия (о. м.п.)
параметров нормальной регрессии 475
3. Основная теорема теории нормальной регрессии 476
4. Доверительное оценивание параметров нормальной регрессии 477
5. Доверительная область для линейных комбинаций параметров /3 479
6. Система совместных доверительных интервалов 480
7. Доверительный интервал для отклика 481
8. Проверка адекватности модели 482
§6.4 . Общая линейная гипотеза нормальной регрессии 484
1. Понятие линейной гипотезы 484
2. F-критерий для линейной гипотезы 484
§6.5 . Некоторые применения теории нормальной регрессии 490
1. Гипотеза о параллельности линий регрессии 490
2. Гипотеза однородности для нескольких
нормальных выборок 493
3. Двойная классификация. Дисперсионный анализ 496
§6.6 . Статистическая регрессия и прогнозирование.................... 502
8
Содержание
1. Задачи статистического прогноза 502
2. Условное математическое ожидание 503
3. Оптимальный предиктор и его свойства 505
4. Из истории регрессии 507
5. Линейный прогноз 508
6. Использование в прогнозе дополнительных переменных.
Алгоритм обновления прогноза 511
7. Прогнозирование стационарных временных рядов 514
Упражнения 520
Глава 7. Элементы теории решений. Дискриминантный анализ 525
§ 7.1. Статистические решающие функции.
Байесовское и минимаксное решения 525
1. Понятие решающей функции 525
2. Функция риска и допустимые решающие правила 526
3. Байесовское решение 527
4. Минимаксное решение 528
5. Оценивание параметров и проверка гипотез
с позиций теории решений 531
§7.2 . Классификация наблюдений 532
1. Задача классификации 532
2. Функция риска в задаче классификации 532
3. Байесовское решение 533
4. Минимаксное решение 535
§7.3 . Классификация наблюдений в случае двух нормальных классов 535
1. Байесовский подход 536
2. Минимаксный подход 537
§7.4 . Классификация нормальных наблюдений. Общий случай 538
I. Байесовский подход 538
2. Минимаксный подход 540
3. Классификация наблюдений в случае неизвестных параметров 540
Упражнения 542
Diaea 8. Факторный анализ 546
§8.1 . Постановка задач факторного анализа 546
§8.2 . Неоднозначность решения в факторном анализе 548
§8.3 . Вывод уравнений максимального правдоподобия 549
§8.4 . Итерационный метод нахождения факторных нагрузок 553
§8.5 . Проверка гипотезы о числе факторов 555
§ 8.6. Центроидный метод 558
§8.7 Оценка значений факторов 562
(лапа 9. Компонентный анализ 564
§9 1 11 DCTiiiioiiKi плач компонентного анализа 564
§9 2 Решение основных уравнений. Главные компоненты 566
§9.3. Метол Хотеллинги.............................................. 568
Содержание 9
Приложение 573
1. Нормальное распределение 573
2. Распределение Пуассона 574
3. Биномиальное распределение 575
4. Распределение х2(п) 576
5. Распределение Стьюдента 5(п) 577
6. Распределение Снедекора 5(п|,п2) 578
7. Критерий Колмогорова 579
8. Критерий Смирнова 580
9. Равномерно распределенные случайные числа 581
10. Нормально распределенные I) случайные числа 582
Литература 585
Путеводитель по моделям в примерах и задачах 586
Именной указатель........................................................598
Математическая статистика
является наукой о методах количественного анализа
массовых явлений, учитывающей одновременно
и качественное своеобразие этих явлений.
Б. В. Гнеденко
Предисловие
Книга человечнее, честнее, долговечней и ответственней
любого другого источника информации.
В. А. Садовничий
Уважаемый Читатель! Эта книга адресована тебе, поэтому мы хотим вна-
чале кратко пояснить ее суть и особенности, объяснить те идеи, которыми мы
руководствовались при ее написании. Прежде всего, это — книга для всех, т. е.
не для определенного контингента обучающихся по той или иной специаль-
ности, того или иного профиля или направления, она не ограничена рамками
определенного учебного стандарта или программы, наконец, заранее установ-
ленными ограничениями по объему. Она для тех, кто по существу, а не для
«галочки» в ведомости, интересуется математикой вообще и, в частности, хо-
чет узнать, что такое современная математическая статистика, какие задачи
и какими методами она решает, какие результаты в ней уже накоплены, какие
проблемы в ней сегодня актуальны, наконец, каковы ее истоки, какой путь
она прошла, и кто был ее творцами (ведь история науки так же важна, как
и сама наука). Итак, по замыслу, эта книга рассказывает о математической ста-
тистике, но одновременно и обучает ей, т. е. она может служить расширенным
учебником, как покрывающим стандартные вузовские программы, предусмат-
ривающие чтение (в том или ином объеме) курса математической статистики,
так и обеспечивающим возможность самообразования. Помимо этого, книга
также может служить справочным пособием по математической статистике,
а в некоторых аспектах — и по теории вероятностей. Из этой целевой уста-
новки вытекают все ее структурные и содержательные особенности.
Наш девиз: просто о сложном! Мы стремились писать так, чтобы излагае-
мое было доступно каждому, кто знаком с начальными элементами математи-
ческого анализа, линейной алгебры и теории вероятностей. Причем помнить
их либо обращаться за нужными сведениями в соответствующие учебники
не обязательно, так как все необходимое напоминается (разъясняется) по хо-
ду изложения собственно статистической теории. Никаких сложных матема-
тических конструкций и громоздких доказательств! Вся теория объясняется
и иллюстрируется на интересных и тщательно подобранных примерах: «при
изучении наук примеры полезнее правил» (И. Ньютон2^). Для тех, кто имеет
11 Садовничий Виктор Антонович (р. 1939) — российский математик, академик РАН, ректор
МГУ им.М. В. Ломоносова (с 1992 г.).
Ньютон Исаак (1643-1727) — английский математик, физик, механик, астроном.
12
Предисловие
целью глубоко освоить теорию статистического вывода, приводится большой
список упражнений для самостоятельного решения, т. е. книга объединяет
одновременно и учебник, и задачник. Умение решать задачи означает как
знание теории, так и способность правильно этим знанием распорядиться,
т. е. привести теорию в действие, ведь «если действовать не будешь, ни к чему
ума палата» (Шота Руставели^). Упражнения, как правило, сформулированы
так, что в самой формулировке уже заложен ответ, путь же к нему — это и есть
тот творческий элемент, на котором можно узнать свои способности (знать
путь и пройти его — не одно и то же). «Подсказкой» здесь (при затруднениях)
могут служить соответствующие примеры из текста: на них можно освоить
необходимые логику и аналитическую технику.
Теперь несколько слов для преподавателей (как. говорили древние: docendo
discimus (лат.) — уча, учимся сами). Одной из основных задач при препо-
давании курса математической статистики является выработка у студентов
навыков обработки реальных данных по соответствующим алгоритмам с при-
влечением компьютерной техники при решении конкретных учебных задач.
В настоящее время глубокое изучение теории математической статистики в от-
рыве от практики ее компьютерной реализации вообще невозможно. В то же
время сам характер этой дисциплины доставляет большой простор препо-
давателю для организации практической работы студентов с привлечением
компьютеров. Ключевым моментом при этом является моделирование на ком-
пьютере выборок из соответствующих распределений. Фактически на основе
любой «теоретической» задачи, в которой речь идет о том или ином статисти-
ческом алгоритме анализа данных, преподаватель может поставить (и притом
в неограниченном числе вариантов, варьируя конкретные значения парамет-
ров модели) соответствующую «практическую» задачу, формулируя в качестве
предварительного этапа задание смоделировать исходные данные с использо-
ванием либо готовых таблиц случайных чисел, либо получаемых с помощью
специальных программ. В дальнейшем, обрабатывая эти «эксперименталь-
ные» данные по соответствующему статистическому алгоритму, студент полу-
чает возможность сравнить предсказание теории с известными ему исходны-
ми параметрами, при которых моделировалась выборка. Подобный «игровой»
элемент в организации практической работы по курсу повышает интерес сту-
дентов к изучению теории. Вопросам моделирования конкретных распреде-
лений уделяется в книге существенное внимание.
Наконец, мы приводим в конце книги достаточно обширный список ли-
тературы как общего характера, так и специальных монографий, в которых
более полно и глубоко освещены различные аспекты статистической теории
и ее приложений; эта литература может быть использована для самостоятель-
ного и углубленного изучения отдельных вопросов.
В приложении приведены краткие статистические таблицы, необходимые
для разбора примеров и решения задач, а также «Путеводитель по моделям
Руставели Шота — грузинский поэт любви и красоты XII в.
Предисловие
13
в примерах и задачах», назначение которого — помочь быстро найти в тексте
нужное место, где доказывается либо формулируется тот или иной конкрет-
ный факт (результат), относящийся к конкретной модели. Знак в тексте
означает окончание доказательства. Знаком • отмечены окончания примеров.
Нумерация формул, теорем, рисунков и т.д. в каждом параграфе самостоятель-
ная, при ссылках на материал другого параграфа указывается дополнительно
его номер.
Наконец, еще одно пояснение об используемых обозначениях. По тексту
нам будут встречаться как скалярные, так и векторные величины, обозначае-
мые в обоих случаях одним и тем же символом, например, 9 — скаляр и 9 =
= (01, , 0п) — вектор. Эта их размерностная спецификация всегда будет яс-
на из контекста. Однако в ряде случаев (там, где это диктуется содержательной
стороной вопроса), чтобы подчеркнуть многомерный характер некоторой ве-
личины, мы будем дополнительно снабжать соответствующий символ чертой
снизу, например, = (it, , хп) при п > I, £ = (£ь , £*) при к > 1 ит.д.
Восточная мудрость гласит; «Если хотите увлечь вашим знанием — сде-
лайте его привлекательным. Настолько привлекательным, чтобы книги вче-
рашнего дня показались сухими листьями». Мы стремились следовать этому
правилу. Насколько это нам удалось — судить тебе, наш Читатель.
Мы выражаем сердечную благодарность нашим коллегам и добрым то-
варищам: академику Ю. В. Прохорову, члену-корреспонденту РАН Б. А. Сева-
стьянову и действительному члену Академии криптографии РФ В. П. Чистя-
кову за постоянную поддержку нашей работы по математической статистике.
Авторы
Введение
...не проворным достается успешный бег, нехрабрым — победа,
не мудрым — хлеб, и не у разумных — богатство, и не искус-
ным — благорасположение, но время и случай для всех их.
Екклесиаст (Библия. Ветхий Завет. 9:11)
Во всех изысканиях разума самое
трудное — это начало.
Платон
В любом начале волшебство таится.
Оно нам в помощь, в нем защита наша.
Г. Гессе2) И гра в бисер
§ 1. Что такое математическая
статистика, ее предмет и задачи
Итак, мы начинаем. Начинать же всегда надо с определения предмета обсуж-
дения. Наш предмет — современная математическая статистика. Как ее можно
определить кратко и, в то же время, понятно? Прежде всего — это математи-
ческая теория, а любую математическую теорию можно охарактеризовать ука-
занием области тех практических задач, к решению которых она применяется.
Поэтому мы начнем с того, что приведем несколько характерных примеров
таких задач, которые решаются методами математической статистики.
Пример 1. Имеется урна, содержащая шары двух цветов, скажем, белые и чер-
ные. Пусть а — число всех шаров, — число белых из них и = а - а\ —
число черных шаров. Оба эти числа и (или хотя бы только а,) нам
могут быть неизвестны, и в этом случае может возникнуть потребность оце-
нить неизвестную долю р = aja белых шаров в урне. Как поступить в этом
случае? Можно, например, извлечь из урны все шары и посчитать число белых
среди них — тогда мы узнаем точно числа а и at, следовательно, и р = а\/а.
Нотакой «тривиальный» экспериментпо разным причинам можетбыть неосу-
ществим (большой объем содержимого урны -ж- трудно ее исчерпать, «дорого»
это стоит и т. п.). Поэтому в таких ситуациях обычно поступают следующим
Платон (427-347 до н.э.) — древнегреческий философ.
Гессе Герман (1877-1962) — немецкий писатель.
§ 1. Что такое математическая статистика
15
образом: извлекают из урны некоторое число п шаров, подсчитывают число
наблюдавшихся в выборке белых шаров (обозначим его т) и в качестве оцен-
ки (приближенного значения) для неизвестной доли р = а,/а используют
величину р = т/п — долю белых шаров среди п извлеченных. Приведенное
описание такого эксперимента еще не совсем полно, так как организовать
выбор п шаров можно разными способами. Можно, например, извлекать ша-
ры по одному последовательно, возвращая каждый раз вынутый шар обратно
(в этом случае говорят о выборе с возвращением), а можно вынутый шар в урну
не возвращать (выбор без возвращения) — в этом случае это то же самое, что
извлечь сразу комплект из п шаров (при п а); можно придумать и другие
процедуры извлечения шаров из урны. Наконец, следует еще уточнить сам ме-
ханизм отбора извлекаемых шаров, что делается уже с привлечением понятий
теории вероятностей и прежде всего понятия случайного выбора (но об этом
позже, см. пример 1 в § 1.1). Но во всех случаях возникает принципиаль-
ный вопрос: будет ли «эмпирическая» оценка р отражать реальную картину,
т. е. будет ли она близка (в каком-то смысле) к неизвестному нам истинному
значению р? Более того, если в наших возможностях по-разному организо-
вать эксперимент (в этом случае говорят об «активном» эксперименте), то
какая из соответствующих оценок будет «лучше» (в каком-то смысле)? Здесь
речь идет, следовательно, о сравнении различных экс- ~
, . , „ Статистические Яг
периментов (способов действия) с позиции «качества»
' ,, ' задачи оценивания
соответствующих оценок. На практике часто приходит-
ся учитывать еще и затраты на проведение эксперимента, так что экономи-
ческие аспекты также приходится включать при этом в круг рассмотрения.
Ответ на все эти непростые вопросы, а тем самым и рекомендации, как наи-
более рационально (грамотно) нам действовать в подобных ситуациях, дает
математическая статистика. •
Общее замечание. Использованный в этом примере язык урновой схемы («урна —
шары») является примером абстрактной (математической) модели, подходящей для
описания многих реальных ситуаций (в биологии, демографии, социологии, медици-
не, психологии, лингвистике, экономике и т. д.). Под шарами в урне можно понимать
любую конечную совокупность объектов (элементов), которые (как в рассмотренном
примере) могут быть разбиты по некоторому альтернативному признаку (пол, воз-
раст, состояние здоровья, доход, сорт, емкость и т. п.) на два непересекающихся
класса, и тогда задача состоит в том, чтобы с помощью некоторого статистического
эксперимента оценить долю определенного класса во всей совокупности. Например,
совокупность — это граждане страны, избирающие президента и разделившиеся
на два класса по признаку «за — против», или партия каких-то изделий, которые
могут быть исправными или дефектными и т. д. В более общем случае исследуемые
объекты могут быть разбиты на большее, чем 2, число классов (тогда мы будем го-
ворить об урне с шарами, скажем, Л различных цветов), и тогда проблема состоит
в оценивании долей всех классов, составляющих исследуемую совокупность. Во всех
таких случаях язык урновых схем является универсальным экономным способом
описания исследуемой ситуации и им широко пользуются в современной математи-
ческой статистике и теории вероятностей.
16
Введение
Пример 2. Пусть требуется измерить некоторую величину а (например, диа-
метр некоторой звезды). Поскольку на результаты измерений влияют многие
случайные факторы (точность настройки измерительного прибора, погреш-
ность округления при считывании данных, психофизическое состояние опера-
тора и т.д.), то результат i-го измерения Xi можно записать в виде А”, = a+f;,
где е, — случайная погрешность измерения. Спрашивается, как по результа-
там п измерений Х|,..., Хп оценить величину а, точное значение которой
нам неизвестно? Обычно в таких случаях в качестве оценки а используют
среднее арифметическое наблюдений
а = Х = 1(Л-1+ +х„),
п
и математическая статистика позволяет обосновать разумность такого правила
оценивания. •
Пример 3. Пусть из некоторых соображений известно, что переменная у
линейно зависит от переменных xt, .., хг: у = Ао + AiXt + + Arxr
(в этих случаях говорят, что у «регрессирует» на Х[, ,%,)> причем коэф-
фициенты 40, 4|, , Ат неизвестны. При различных наборах (хц, , Х[т),
г=1,2,. , п, измерены значения& = 40 +4|Хг1+. +4, xir+Ei, где Et—
ошибка измерения у при наборе (х!Ь , х„). По значениям (j/,, Хц, .., xir)
требуется оценить коэффициенты 4q, 4,, , Ат. Задачи такого типа назы-
ваются регрессионными, они часто встречаются, например, в экономических
исследованиях. Так, у может означать спрос на некоторый товар, который за-
висит от его цены (г,), потребительского дохода (хз) и цен на конкурирующие
и дополняющие товары (xj, Х4,...), и эта зависимость в первом приближении
может быть регрессионного типа. Регрессионные задачи составляют содержа-
ние отдельного раздела математической статистики — регрессионного анализа.
Эти задачи будут рассмотрены в гл. 6. •
Во всех предыдущих примерах речь шла об оценивании тех или иных па-
раметров в соответствующих математических моделях по результатам наблю-
дений или измерений, т. е. на основе эмпирических (опытных) данных. Такого
типа задачи, называемые общим термином «задачи оценки (или оценивания)
неизвестных параметров», составляют один из двух основных разделов мате-
матической статистики. Добавим к сказанному еще следующее.
Иногда нас интересует неточное значение неизвестного параметра, напри-
мер, параметра а в примере 2, а требуется указать такой интервал а, а аз,
в котором с высокой гарантией (в статистике говорят «с высокой вероятно-
стью», т. е. с вероятностью, близкой к 1) находится точное значение парамет-
ра. Такой интервал (а,, аз), границы которого также определяются по соот-
ветствующим эмпирическим данным, называют доверительным интервалом.
Такие задачи также относятся к задачам оценивания, но при этом говорят
об интервальном (или доверительном) оценивании. Общая теория оценивания
излагается в гл. 3.
§ 1. Что такое математическая статистика 17
Перейдем теперь к примерам задач другого типа, Элементы теории
рассматриваемых в математической статистике. Но для вероятностей
этого нам предварительно необходимо хотя бы кратко
напомнить некоторые элементы теории вероятностей. В качестве основного
пособия по теории вероятностей мы рекомендуем современный учебник для
технических вузов В. П. Чистякова «Курс теории вероятностей» [27].
В любой статистической задаче мы имеем дело с некоторым набором
исходных данных, которые получены в результате некоторого эксперимента
(опыта): «опыт — вот учитель жизни вечный» (Гёте3)). Термин эксперимент
употребляется в статистике для обозначения любого процесса получения дан-
ных, все возможные исходы которого могут быть указаны заранее и дей-
ствительный исход которого является одним из возможных. Обозначим эти
данные символом X (это может быть число или вектор некоторой размер-
ности) и в дальнейшем будем называть их выборкой (синоним термина ста-
тистические данные). Реализации выборки X обозначаются соответствующей
строчной буквой х, а совокупность всех возможных реализаций обознача-
ется X = {г} и называется выборочным пространством. В математической
статистике рассматриваются такие эксперименты, исход которых случаен, так
что выборка X является случайной величиной с некоторым распределением
(функцией распределения) Fx на выборочном пространстве X.
Оговоримся сразу, что в дальнейшем мы предполагаем, что случайная ве-
личина X (или ее распределение Fx) является либо дискретной (и тогда вы-
борочное пространство состоит из конечного или счетного числа точек), либо
абсолютно непрерывной (тогда X является евклидовым пространством соот-
ветствующей размеренности или его частью), эти два случая обычно и встре-
чаются в приложениях. В первом случае распределение выборки задается
вероятностями отдельных ее реализаций
f(x) - P{Z = т}, х Е X, ^fix) = i,
хех
во втором — плотностью распределения f(x), т. е. такой неотрицательной
функцией на X, что для любого параллелепипеда В С X, т.е. множества вида
В = {х аг х, bi, i = 1, ,г}, если х = (х\, ,хг), выполняется
соотношение
Р(Х е Б} = У fix) dx, j f{x) dx = 1
В X
(эта формула сохранятся для любых квадрируемых или кубируемых мно-
жеств В). (Использование символа Р для обозначения вероятности события
является в настоящее время общепринятым, поскольку во многих языках на-
чальной буквой слова «вероятность» является Р — probability в английском,
33 Гете Иоганн Вольфганг (1749-1832) — немецкий философ, поэт, ученый, естествоиспы-
татель.
2 Заказ 1748
18
Введение
probabilile' во французском, probabilitd в итальянском, probabdidad в испан-
ском, probabilitas в латинском языке и т. д.). Обычно из контекста задачи
бывает ясно, о каком случае — дискретном или абсолютно непрерывном —
идет речь, поэтому мы для единообразия используем одно обозначение f(x)
как для вероятности Р{Х = х} в дискретном случае, так и для плотности
распределения — в абсолютно непрерывном, и для краткости в обоих случаях
будем называть функцию f(x) плотностью. Если функция /(х) из каких-то
соображений задана, то мы будем говорить, что задана вероятностная модель
эксперимента. В задачах теории вероятностей предполагается, что вероятност-
ная модель изучаемого явления полностью определена, и теория вероятностей
занимается разработкой методов нахождения вероятностей различных слож-
ных событий (исходя из известных вероятностей более простых событий)
в рамках данной вероятностной модели. По этим вероятностям мы можем
в дальнейшем строить научно обоснованные прогнозы и тем самым рацио-
нально планировать свои действия (если вы хотите насмешить Господа Бога,
расскажите ему о своих планах на завтра).
Статистическая Математическая статистика выделяется из теории
модель вероятностей в самостоятельную науку, хотя основные
методы и приемы рассуждений в ней остаются теми же.
Причиной этого является именно специфичность задач, решаемых ею,
в известной мере они являются обратными к задачам теории вероятностей.
Дело в том, что на практике при изучении конкретного эксперимента рас-
пределение Fx наблюдаемой случайной величины X редко бывает известно
полностью. Часто можно априори (т. е. до опыта) утверждать лишь, что Fx
является элементом некоторого заданного класса (семейства) распределений
7 = {F} на выборочном пространстве X, так что Fx € 7 — семейству апри-
ори допустимых распределений выборки. Этот класс 7 может в одних случаях
включать в себя все распределения, которые можно задать на X (ситуация
полной неопределенности), в других же случаях он представляет собой неко-
торое более узкое семейство распределений, заданное в той или иной явной
форме (что может отражать наличие определенной априорной информации
о характере изучаемого явления). Если задан класс 7 допустимых распреде-
лений выборки, то говорят, что задана статистическая модель эксперимента.
Итак, статистическая модель описывает такие ситуации, когда имеется
та или иная неопределенность в задании распределения Fx выборки (дан-
ных) X, и задача математической статистики (в общем плане) состоит в том,
чтобы уменьшать эту неопределенность (насколько это возможно), используя
информацию, доставляемую наблюдаемым исходом эксперимента (наблюдае-
мой реализацией выборки X). Говорят, что математическая статистика — это
наука о статистических выводах: она уточняет (выявляет) структуру статисти-
ческих моделей по результатам проводимых наблюдений. Методы, с помощью
которых это делается, называют статистическими методами.
Статистические
гипотезы
Сказанного уже достаточно, чтобы описать задачи
второго типа, решаемые математической статистикой,
— это задачи проверки статистических гипотез. Любое
§ 1. Что такое математическая статистика
19
утверждение о виде или свойствах распределения Fx выборки X называется
статистической гипотезой (обычно говорят просто гипотезой). В общем виде
задача проверки гипотез ставится так: выделяется некоторое подмножество
Fa С F и требуется по данным X проверить, справедливо ли утверждение
Нп Fx € или же оно ложно. В этом случае Но называют основной (нулевой)
гипотезой. Распределения F € 7\ = 7\7о, т. е. распределения из дополни-
тельного (к То) подмножества допустимых распределений выборки, назы-
ваются альтернативными, а утверждение Н\ Fx € Т\ — альтернативной
гипотезой. Тогда говорят, что задача состоит в проверке гипотезы Hq про-
тив альтернативы Н\ (кратко: задача (Но,Н})) или внутри общей гипотезы
Н Fx € Т = То U Т|.
Правило, согласно которому мы, наблюдая X, при- Статистический
нимаем решение принять гипотезу Но как истинную критерий
либо отклонить ее как ложную (принять альтернатив-
ную гипотезу Я[), называется статистическим критерием (или просто кри-
терием). Математическая статистика и занимается разработкой рациональных
принципов конструирования таких правил (критериев) — это и есть второй
тип статистических задач.
Теория — это жернова, а опытные данные — зерно, кото-
рое засыпается в эти жернова и перерабатывается ими.
Кельвин
Добавим к сказанному еще следующее. На практике часто встречаются
ситуации, когда эксперимент состоит в проведении повторных независимых
наблюдений над некоторой случайной величиной £. Если проводится п на-
блюдений, то выборка X = (JVi,..., Хп) представляет собой п независимых
копий величины £, т. е. представляет собой n-мерный случайный вектор,
компоненты которого независимы и распределены так же, как £ (можно
также сказать, что Xi — это результат г-го наблюдения над £). В этом слу-
чае функция распределения выборки имеет вид Fx(x) — Ffat)... F^(xn),
х = (Х|,.. , хп), т. е. определяется распределением наблюдаемой случай-
ной величины £, и говорят, что X = (Х},..., Хп) есть случайная выборка
объема п из распределения £ (или из £(£), С = law (закон)). Статистическая
модель для повторных независимых наблюдений будет в дальнейшем обо-
значаться кратко в виде F = {?<}. т. е. указанием лишь класса допустимых
распределений исходной случайной величины £ (обычно индекс £ у F^ опус-
кается, если это не приводит к недоразумениям). Случайная выборка является
математической моделью независимых измерений, проводимых в одинаковых
условиях, и именно такие модели мы будем рассматривать в основном в по-
Кельвин (Томсон Уильям) (1824-1907) — английский физик, почетный член Петербургской
академии наук (1872), предложил абсолютную шкалу температур (шкала Кельвина).
2*
20
Введение
следующем, хотя в ряде задач предположения о независимости и одинаковой
распределенности компонент Xi не выполняются — на это каждый раз будет
обращаться внимание.
Теперь приведем для иллюстрации несколько примеров конкретных ста-
тистических гипотез, чтобы продемонстрировать их разнообразие.
Ч Задачи проверки ПримеР 4 (Гипотеза 0 ви«е распределения).
гипотез Пусть произведено ti независимых наблюдений над не-
которой случайной величиной 4 с неизвестной функ-
цией распределения F^x). Гипотезой, подлежащей проверке, может быть
утверждение типа Но F^x) = F(x), где функция F(x) полностью задана,
либо типа Но F((x) 6 Fo, где Fo — заданное семейство функций распре-
деления. При этом обычно семейство Fo задается в параметрическом виде:
Fq = {F(x; 0), В € 0}, т.е. распределения из класса Fq заданы с точностью
до значений некоторого параметра в с областью возможных значений 0. Го-
ворят, что в этом случае известен тип распределения наблюдаемой случайной
величины, а неизвестен только параметр, от которого зависит распределение.
Параметр в может быть как скалярным, так и векторным, область (множе-
ство) 0 его допустимых значений называется параметрическим множеством.
Если множество 0 состоит из одной точки, то соответствующее распределе-
ние полностью известно, и в этом случае гипотеза Но называется простой,
в противном случае гипотеза Но — сложная. Эта терминология общепринята
/# в математической статистике, и мы ею будем ниже пользоваться.
h Сложная гипотеза Например, наблюдается неотрицательная целочис-
“““ ленная случайная величина £, скажем, число вызовов,
поступивших на телефонную станцию за фиксированное время t, и требу-
ется по результатам наблюдений в п непересекающихся интервалах времени
(каждый длиной t) проверить гипотезу Но £(£) 6 П(0), где П(0) — семей-
ство всех пуассоновских распределений (здесь в > 0 — любое положительное
число, т. е. 0 в > 0}). Другими словами, в данном случае речь
идет о гипотезе, что число вызовов £ = £(f) имеет некоторое пуассоновское
распределение (список-справочник основных вероятностных распределений
приводится ниже, в гл. 1). •
В качестве еще одной из возможных конкретизаций сформулированной
гипотезы рассмотрим ситуацию, описанную выше в примере 2. В теории
измерений обычно считают, что общая ошибка измерения е,- складывается
из большого числа частных ошибок, каждая из которых невелика. На основа-
нии центральной предельной теоремы теории вероятностей можно предполо-
жить, что результаты измерений X, имеют нормальное распределение. Такое
предположение также является статистической гипотезой о виде распределе-
ния наблюдаемых случайных величин. Поскольку нормальное распределение
определяется двумя параметрами: своими средним значением и дисперсией,
а гипотеза не фиксирует их значения (они могут быть произвольными), то
и в этом случае проверяемая гипотеза — сложная.
§ 1. Что такое математическая статистика
21
Наконец, приведем конкретный пример простой Простая гипотеза *
гипотезы о виде распределения. Рассмотрим опыт, за-
ключающийся в бросании игральной кости. Здесь наблюдаемая случайная
величина £ есть число выпавших очков; ее возможными значениями являют-
ся числа 1,2,..., 6, и если кость симметрична, то каждая ее грань выпадает
с одной и той же вероятностью 1/6, т. е. Р{£ = к} = 1/6, к = 1, 2, ,6.
Тем самым предположение (гипотеза) Яд о симметричности кости однознач-
но фиксирует распределение наблюдаемой величины, следовательно, в дан-
ном случае Яо — простая гипотеза о виде распределения. Спрашивается,
как по результатам п бросаний кости построить критерий, подтверждающий
или же опровергающий гипотезу о симметричности кости? Такой критерий
в этой и аналогичной задачах, известный как критерий %2 (хи-квадрат), мы
построим ниже, а сейчас приведем связанный с данной моделью один за-
бавный эпизод, изложенный Ж. Бертраном (1822-1900) в предисловии к его
курсу «Исчисление вероятностей» (Париж, 1899): «Однажды в Неаполе пре-
подобный Галиани увидел человека из Базиликаты, который, встряхивая 3 иг-
ральные кости в чашке, держал пари, что выбросит 3 шестерки... Вы скажете,
такая удача возможна. Однако человеку из Базиликаты это удалось во второй
раз, и пари повторилось. Он клал кости назад в чашку 3,4, 5 раз и каждый раз
выбрасывал 3 шестерки. „Черт возьми, — вскричал преподобный, — кости
налиты свинцом!" И так оно и было».
Здесь в шутливой форме дан типичный пример статистического вывода:
если бы кости были симметричны, то наблюдаемое событие (5 раз подряд вы-
пали 3 шестерки) имело бы ничтожно малую вероятность (1/63)5 ~ 4,71 • 10”11
и, поскольку в эксперименте наблюдалось такое событие, вполне логично сде-
лать вывод, что априорная модель (симметричность костей) ложна.
Пример 5 (Гипотеза однородности). Одной из важных прикладных задач ма-
тематической статистики является задача проверки однородности исходных
статистических данных, т. е. гипотезы Яо о том, что закон распределения
наблюдений оставался неизменным в течение всего эксперимента. Формали-
зация такой проблемы имеет следующий вид. Пусть имеются две независи-
мые выборки X = (Ль , Хп) и У = (У, ..,Ут), описывающие один
и тот же процесс, явление и т. д., но полученные, скажем, в разное время
или в разных условиях. Требуется ответить на вопрос, являются ли эти вы-
борки однородными, те. полученными из одного и того же распределения,
или же закон распределения наблюдений от выборки к выборке менялся?
Если они однородны, то их можно объединить и работать с одной большой
выборкой объема п + т (заключающей в себе большую информацию, нежели
каждая выборка в отдельности), получая в итоге более обоснованные (более
точные) статистические выводы о законе распределения наблюдений. Такая
задача может возникнуть, например, при контроле качества некоторой продук-
ции, когда по контрольным выборкам из различных партий надо установить,
не менялось ли ее качество от смены к смене или в результате изменения
технологического процесса и тд.: если менялось (выборки неоднородны), то
22
Введение
производство надо остановить и подкорректировать технологический процесс.
Еше одна иллюстрация: поступающие в вуз абитуриенты разбиты на два по-
тока. Как по результатам экзамена по одному и тому же предмету установить,
однородны ли оба потока? В таких ситуациях требуется проверить гипотезу од-
нородности Но F\(x) = F2(x), где F[(x) и F2{x) — функции распределения
выборок X и Y соответственно (эти функции нам неизвестны или же принад-
лежат некоторому заданному параметрическому семейству). В общем случае
можно рассматривать произвольное конечное число независимых выборок.
В современной статистике разработано большое число различных критериев
проверки гипотезы однородности, объединяемых общим термином критерии
однородности, и с этими критериями и их особенностями мы познакомимся
в гл. 4 (§4.3). •
Пример б (Гипотеза независимости). В эксперименте наблюдается двумер-
ная случайная величина £ = (fi.ft) с неизвестной функцией распределения
F^(x, у) и есть основания предполагать, что компоненты и & независи-
мы. В этом случае надо проверить гипотезу независимости Hq F^(x,y) =
= (x)F^(у), где F^(x) и F^(y) — некоторые одномерные (иногда гово-
рят маргинальные) функции распределения. Гипотезы такого вида часто воз-
никают в прикладных исследованиях, когда результаты наблюдений клас-
сифицируются по двум признакам, — в этом случае Но есть предположе-
ние о независимости этих признаков. Так каждый сдающий вступительные
экзамены в вуз абитуриент может быть классифицирован по двум призна-
кам: € {I (принят), 0 (не принят)} и & 6 0 (мужчина), 0 (женщина)}, —
в этом случае гипотеза Но о независимости этих признаков означает отсут-
ствие дискриминации по половому признаку при приеме в вуз. Еще одна
иллюстрация: проведена частичная вакцинация населения против, скажем,
гриппа; здесь признак £i означает наличие (1), либо отсутствие (0) прививки
для конкретного индивидуума, а признак — состояние его здоровья: здоров
(1) — болен (0), гипотеза же независимости Hq интерпретируется как неэф-
фективность вакцины. Гипотеза независимости может иметь и параметриче-
ский вид, т. е. когда априори постулируется, что распределение £(£ь &) при-
надлежит некоторому параметрическому семейству Т = {F(x, у; в), 6 Е Q}.
Если, например, F является семейством всех двумерных нормальных рас-
пределений, то гипотеза независимости в данном случае эквивалентна ги-
потезе о некоррелированности признаков (i и (; (поскольку независимость
и некоррелированность для нормальных случайных величин эквивалентны!).
В общем случае можно рассматривать A-мерную (fc 2) случайную величину
£ — (£ь , &•) и проверять гипотезу независимости ее компонент. Критерии
независимости будут рассмотрены в §4.4 книги. •
Пример 7 (Гипотеза случайности). В предыдущих примерах априори предпо-
лагалось (постулировалось), что исходные данные представляют собой случай-
ную выборку из некоторого распределения, т. е. компоненты вектора данных
X = (Т],... , JTn) независимы и одинаково распределены. Как правило, это
§ 1. Что такое математическая статистика
23
предположение бывает оправдано, так как вытекает из самого характера зада-
чи, и не подвергается сомнению. Но иногда это исходное предположение само
нуждается в проверке, т. е. оно рассматривается как статистическая гипоте-
за Hq, называемая гипотезой случайности. Формализуется такая гипотеза сле-
дующим образом. Пусть Fx(xi, , хп) обозначает функцию распределения
выборки X = (Хь ,Хп), тогда подлежащая проверке гипотеза означает
утверждение Но Fx(x\,..., хп) = F(xt)... F(xn), где F(x) — некоторая
одномерная функция распределения (она может быть полностью задана, либо
задано семейство, которому она принадлежит, либо никак не специфицирует-
ся). Типичным примером ситуации, когда возникает необходимость проверки
гипотезы случайности является работа генератора (датчика) случайных чисел.
Под случайными числами мы понимаем последовательность {t/|, Ui,. .} не-
зависимых и равномерно распределенных на отрезке [0, 1 ] случайных величин.
Такие числа широко используются в различных областях: в статистике — для
моделирования случайных выборок из различных распределений (метод ста-
тистического моделирования будет описан в § 1.3), в криптографии — при по-
лучении ключей для зашифрования информации, в численном анализе и т.д.
В практических задачах последовательность {С7], СЛ2, - - -} строят либо с ис-
пользованием готовых таблиц случайных чисел, либо генерируют с помощью
специальных датчиков, встроенных непосредственно в ЭВМ, либо получают
программным способом по некоторому вспомогатель-
ному алгоритму (в последнем случае получаются так на-
зываемые псевдослучайные числа, т. е. «очень похожие»
на случайные). Во всех случаях (особенно в последнем) требуется осуществ-
лять контроль за «качеством» вырабатываемой последовательности {[/<} (т. е.
чтобы эти числа были практически неотличимы от независимых равномерно
распределенных чисел), что в математическом плане сводится к проверке ги-
потезы случайности (см. п. 2 §4.5).
Приведенные примеры не охватывают всех возни-
кающих в приложениях задач проверки статистических
гипотез. Отметим еще один важный класс гипотез, ко-
торые называются параметрическими, — это гипотезы об истинном значении
неизвестного параметра, определяющего заданное параметрическое семей-
ство распределений (см. выше пример 4). Если класс априори допустимых
распределений наблюдаемой случайной величины £ задан в параметрическом
виде, т. е. £(£) Е F = {F(x;0), О Е 0}, то в общем случае параметриче-
ская гипотеза имеет вид Но 6 Е 0q С 0, т. е. она определяется указанием
конкретного подмножества значений параметра 0. Например, если F есть
класс всех нормальных распределений со средним и дисперсией 02 (здесь
О = (0J, 0г)), то утверждение Но 01 = 0ю, 02 = 02о, где 0ю и 02q — заданные
числа, есть простая гипотеза о нормальном распределении наблюдений. Гипо-
теза же, выраженная равенством 0, = 0ю и оставляющая значение дисперсии
02 неопределенным, — сложная. Общая теория проверки параметрических
гипотез будет обсуждаться в гл. 5.
Псевдослучойные
числа
Параметрические
гипотезы
24
Введение
О современной Итак, математическая статистика решает две основ-
статистике ные проблемы:
1) оценивание различных параметров (характеристик)
распределений наблюдаемых случайных величин и
2) проверка различных гипотез о свойствах этих величин (их распределений)
и тем самым позволяет в итоге подобрать подходящую вероятностную модель
изучаемого эксперимента.
Помимо этого, современная статистическая практика связана с метода-
ми сбора, обработки и интерпретации данных, планированием эффективных
и информативных экспериментов, принятием решений в условиях неопре-
деленности и прогнозированием. Некоторые классы специфических задач
выделяются при этом в отдельные разделы (теории) — так появляются тер-
мины «регрессионный анализ», «дисперсионный анализ», «дискриминантный
анализ», «факторный анализ», «последовательный анализ», «компонентный
анализ» и др. С некоторыми из них мы также познакомимся в дальнейшем.
Наконец, подчеркнем следующее. Практическая реализация современ-
ных статистических методов невозможна без интенсивного использования
компьютерной техники. Именно компьютерная реализация статистических
алгоритмов обработки информации делает их сегодня одним из наиболее эф-
фективных инструментов принятия рациональных решений в самых разных
областях человеческой деятельности (экономике, финансах, страховом деле,
медицине, социологи и тд.). Поэтому современный специалист-статистик
должен как хорошо знать основы и методы теории статистического вывода,
так и владеть навыками их практической реализации на компьютерах. Целям
подготовки именно таких специалистов и служит настоящее пособие.
Итак, что же такое статистика? Некоторые понимают и используют ее, как
пьяный фонарный столб, т. е. не для освещения, а как опору, чтобы не упасть.
Широко известен, например, афоризм, что существует три вида лжи: ложь,
наглая ложь и статистика. Но адресован он тем влиятельным лицам, которые
в угоду своим политическим, финансовым и иным целям манипулируют ста-
тистическими данными, как им заблагорассудится, и не имеет ничего общего
с наукой «Математическая статистика». На самом же деле, говоря словами
английского статистика В. Томпсона, статистика — это математическая
теория того, как узнать нечто о мире через опыт.
«Давайте присядем на это бревно у дороги, — говорю я, — и забудем бессер-
дечность и сквернословие этих поэтов. Настоящую красоту нужно искать в ве-
ликолепных рядах установленных фактов и общепринятых правил. В этом самом
бревне, на котором мы сидим, миссис Сэмпсон, — говорю я, — скрыта статистика
более прекрасная, чем любая поэма. Кольца показывают, что ему было шестьде-
сят лет. На глубине двух тысяч футов оно за три тысячи лет’ превратилось бы
в уголь. Самая глубокая в мире угольная шахта находится в Киллингворте, близ
Ньюкастла. В ящик длиной четыре фута, шириной три фута и высотой два фута
§ 2. Исторический очерк развития математической статистики 25
восемь дюймов войдет тонна угля. Если артерия порезана, сожмите ее выше
раны. В ноге человека — тридцать костей. Лондонский Тауэр горел в 1841 году».
«Продолжайте, мистер Пратт, — говорит миссис Сэмпсон. — Эти мысли так
оригинальны и приятны. Я думаю, ничего нет прекраснее этой статистики».
0. Генри. Справочник Гименея
«Вы еще не рассказали мне, — заметила леди Наттэл, — чем занимается ваш
жених».
«Он статистик», — ответила Лзймия с неприятным ощущением обороняющегося.
Леди Наттзл была, очевидно, застигнута врасплох. Ей не приходило в голову, что
статистики вступают в нормальные общественные отношения. Этот род людей,
как она предполагала, увековечен на некоторый второстепенный образ действий,
наподобие мулов.
«Но, тетя Сара, это очень интересная профессия», — сказала с жаром Лзймия.
«Я не сомневаюсь в этом, — ответила ее тетя, которая, очевидно, очень со-
мневалась. — Выразить что-нибудь значительное в одних лишь цифрах, понятно,
настолько невозможно, что должен существовать бесконечный простор для хоро-
шо оплаченных советов относительно тага, как это сделать. Но не думаете ли
вы, что жизнь со статистиком была бы до некоторой степени, скажем, скучной?»
Лзймия молчала. Ей не хотелось говорить о поразительной глубине эмоциональных
возможностей, которую она открыла под цифровой внешностью занятий Эдварда.
«Дело не в цифрах, — сказала она наконец, — а в том, что вы с ними делаете».
К. Мэндервил. Крушение Лэймии Гёрдлнек
§ 2. Краткий исторический очерк развития
математической статистики
Первыми крупными работами, относящимися к математической статистике,
были исследования Я. Бернулли5) А. Муавра6^ и П. Лапласа7) К. Гаусс8 * *) раз-
работал теорию ошибок наблюдений и, в частности, обосновал один из ее
основных принципов — метод наименьших квадратов. Научное обоснование
закономерностей случайного рассеивания связано с именами русских мате-
Бернулли Якоб (1700-1782) — швейцарский физик и математик.
Муавр Абрахам де (1667-1754) — французский математик.
7* Лаплас Пьер Симон (1749-1827) — крупнейший французский математик, физик, астроном,
почетный член Петербургской АН (1802).
Гаусс Карл Фридрих (1777-1855) — великий немецкий ученый — математик, физик, астро-
ном, почетный член Петербургской АН (1824).
26
Введение
матиков П.Л. Чебышева9*, А. А. Маркова10* и А. М. Ляпунова н*, значительно
углубивших результаты известных к тому времени классических исследований.
Зарождение математической статистики как отдельной математической
дисциплины относится к 20-30-м гг. XX в.
Ряд важнейших современных понятий и методов, оказавших большое
влияние на развитие современной теории математической статистики, пред-
ложил английский математик и статистик Р. Фишер * 12*: метод максимального
правдоподобия, дисперсионный анализ, понятия состоятельности, достаточ-
ности, эффективности и др. Систематическое развитие теории проверки ста-
тистических гипотез началось с работ английского математика-статистика
К. Пирсона13 * ** по критерию хи-квадрат; он также внес большой вклад в раз-
работку теории корреляции и ее пременение к проблемам наследственности
и эволюции. Основной вклад в построение теории проверки статистических
гипотез внесли Ю. Нейман и* и Э. Пирсон 13*, сын К. Пирсона, которые ввели
понятия ошибок первого и второго рода и показали общность и значение
метода отношения правдоподобия для построения критериев. Общая теория
статистических решающих функций, охватывающая как теорию проверки ста-
тистических гипотез, так и теорию оценивания, создана венгерским статисти-
ком А. Вальдом16*
Большую роль в развитии математической статистики сыграли работы
Г. Крамера17*, Э. Лемана18*, К. Рао 19*, М. Кендалла20*, А. Стьюарта21*, С. Уилк-
са22*, а также отечественных ученых А. Н. Колмогорова23 24 * **, Б. В. Гнеденко29*,
У Чебышев Пафнутий Львович (1821-1894) — выдающийся русский математик и механик.
Марков Андрей Андреевич (1856-1922) — выдающийся русский математик, академик.
Ляпунов Александр Михайлович (1857-1918) — выдающийся русский математик и механик.
12> Фишер Рональд Эйлмер (1890-1962) — крупнейший английский статистик, автор и иссле-
дователь многих современных понятий в математической статистике.
'^Пирсон Карл (1857-1936) — английский математик-статистик, биолог и философ.
'^Нейман Юрий (1894-1981) — американский статистик.
|5^ Пирсон Эгон Шарп (1895-1980) — английский статистик.
16* Вальд Абрахам (1902-1950) — американский статистик венгерского происхождения.
17* Крамер Гаральд (1893-1985) — шведский статистик.
18* Леман Эрих (р. 1917) — американский статистик.
Рао Кальямпуди Радхакришна (р. 1920) — крупнейший индийский математик, статистик.
Кендалл Морис Джордж (1907-1983) — английский статистик.
21) Стьюарт Алан — английский статистик.
22) Уилкс Самюэль Стэнли (1906-1964) — американский статистик.
23) Колмогоров Андрей Николаевич (1903-1987) — великий советский ученый, один из круп-
нейших математиков XX в., академик АН СССР, создатель современной аксиоматики теории
вероятностей.
24> Гнеденко Борис Владимирович (1912-1995) — академик АН УССР, выдающийся математик,
специалист по предельным теоремам теории вероятностей, истории математики, популяризатор
науки, замечательный педагог.
§ 2. Исторический очерк развития математической статистики 27
Ю. В. Линника25^ Е. Е. Слуцкого26) Н. В. Смирнова27) В. И. Романовско-
го28) Л. Н. Большева29), Ю. В. Прохорова30), А. А. Боровкова31), Б. А. Сева-
стьянова32), А. Н. Ширяева33) и др.
Начиная с 50-х гг. XX в. в связи с появлением компьютеров лицо ста-
тистики изменилось. Если раньше отсутствие вычислительных возможностей
вынуждало статистиков использовать слишком упрощенные модели, даже ес-
ли эти модели были не всегда реалистичными, то теперь любое статистическое
решение, которое можно просчитать на компьютере за сравнительно неболь-
шой отрезок времени, стало «доступным». Таким образом, сложные и трудо-
емкие статистические методы вошли в повседневную практику. В это же время
статистика, в определенном плане, стала эмпирической наукой: за несколько
минут компьютеры могут порождать миллионы данных, используя которые
можно «проверять» новейшие методы.
Математическая статистика — это непрерывно и интенсивно развива-
ющаяся наука. В последние годы появилось большое количество глубоких
результатов, охватывающих, по существу, все основные направления совре-
менной теории математической статистики. Достойный вклад в развитие но-
вых методов этой теории вносит отечественная математическая школа.
В наши дни математическая статистика переживает бурный этап постоян-
ного расширения областей практического применения ее методов, благодаря
резкому росту арсенала средств, используемых исследователем. Внедрение
в статистическую практику вычислительной техники позволило при решении
задач математической статистики использовать методы статистического моде-
лирования (Монте-Карло). Широкому распространению методов математи-
ческой статистики способствовало создание больших универсальных пакетов
прикладных статистических программ, обеспечивающих быстрый и эффек-
тивный компьютерный анализ больших массивов статистической информа-
253 Линник Юрий Владимирович (1915-1972) — советский математик в области теории веро-
ятности, теории чисел, статистики, академик АН СССР.
263 Слуцкий Евгений Евгеньевич (1880-1948) — выдающийся российский и советский матема-
тик, статистик и экономист.
273 Смирнов Николай Васильевич (1900-1966) — член-корреспондент АН СССР, крупнейший
специалист ио предельным теоремам теории вероятностей и математической статистики.
2|<3 Романовский Всеволод Иванович (1879-1954) — русский, советский, узбекский математик,
академик АН Узбекской ССР.
2,3 Большее Логин Николаевич (1922-1978) — советский математик, член-корреспондент АН
СССР.
зиз Прохоров Юрий Васильевич (р. 1929) — советский математик, академик АН СССР. Основ-
ные труды по теории вероятностей, особенно по асимптотическим методам.
313 Боровков Александр Алексеевич (р. 1931) — академик АН СССР, специалист в области
теории вероятностей и математической статистики.
323 Севастьянов Борис Александрович (р. 1923) — советский математик, член-корреспондент
АН СССР.
333 Ширяев Альберт Николаевич (р. 1934) — специалист в области теории вероятностей и
математической статистики, член-корреспондент РАН.
28
Введение
ции. Именно в направлении соединения статистической теории и практики
ее компьютерной реализации заключается существо современного этапа раз-
вития методов статистического анализа данных. Ибо «Бесполезно вычислять
результат в такой форме, в какой потребитель не готов его использовать»
(Хэмминг).
Методы математической статистики, соединенные с возможностями со-
временной компьютерной техники, широко и эффективно используются в
приложениях, являясь основой статистических методов исследования и кон-
троля массового производства, статистических методов в области физики,
биологии, медицины, социологии, метеорологии; их также применяют при
обработке результатов статистического моделирования в различных задачах
науки и техники.
В настоящее время статистические модели и методы играют все боль-
шую роль при решении экономических, финансовых, социальных проблем,
а также различных проблем связи, телекоммуникации, защиты информации,
криптографии и таких долго считавшихся далекими от математики наук, как
психология, лингвистика, криминалистика и т. д. Такие области науки, как
гидрология, климатология, звездная астрономия, антропология, также, ока-
зывается, не могут обойтись без методов математической статистики.
Без методов этой науки сегодня невозможна разработка научно обосно-
ванных прогнозов развития общества, включая прогнозы в политике, эконо-
мике, социологии.
В заключение, для подтверждения тезиса о том, что история науки так же
важна, как и сама наука, приведем слова выдающегося немецкого математика,
физика и философа, одного из создателей дифференциального и интеграль-
ного исчисления Г.В.Лейбница34^' «Весьма полезно познать истинное проис-
хождение замечательных открытий, особенно таких, которые были сделаны
не случайно, а силою мысли. Это приносит пользу не только тем, что воздает
каждому свое и побуждает других добиваться таких же похвал, сколько тем,
что познание метода на выдающихся примерах ведет к развитию искусства
открытия».
Все постоянство в зыбкости одной,
Все смутно пред глазами очевидца,
Я сложность вижу в истине простой.
Наукой правит случай — не закон...
Ф. Вийон* 33). Баллада поэтического состязания
в Блуа (перевод Ю.А. Кожевникова)
34) Лейбниц Готфрид Вильгельм фон (1646-1716) — выдающийся немецкий математик и фи-
лософ.
33) Вийон Франсуа (1431 - после 1463) — французский поэт и вор.
§ 2. Исторический очерк развития математической статистики 29
Всему начало — случай.
Старинная поговорка
...Помни, что случай плешив3®
Б. Грасиан36 37). Критикон
36) В античном изобразительном искусстве представляли аллегорическую фигуру Случая в виде
стоящего на колесе плешивого человека с одной лишь прядью волос, за которую надо его схватить,
пока не умчался.
3?* Грасиан Бальтасар (1601-1658) — испанский писатель.
Глава 1
(Вспомогательная, но очень важная!)
Основные распределения
и их моделирование
Математические модели — объект
и орудие труда математиков.
К. А. Рыбников 11
Введение
Выше мы определили статистическую модель и ее отношение к вероятност-
ной модели: в обоих случаях модель задается плотностью распределения /(г)
наблюдаемой случайной величины £, а различие заключается в том, что мы
априори предполагаем известным об этой плотности. В вероятностных задачах
эта плотность полностью известна, в статистических же — она задается (пред-
полагается) стой или иной степенью неопределенности, и статистик «борется»
с этой неопределенностью. Часто мы предполагаем известным вид плотности
f(x), а неопределенность выражается через те или иные параметры, от кото-
рых зависит функция f(x) (выше такие модели названы параметрическими).
В теории вероятностей наиболее часто встречающиеся законы распределения
(модели) имеют общепринятое наименование и обозначение — этот «язык»
переносится и на соответствующие статистические модели. Проиллюстрируем
это на одном конкретном примере.
Нормальная _
вываясь на центральной предельной теореме теории ве-
роятностей) постулируется, что £(£) — нормальное или
гауссовское распределение. Если обозначить через д (мю) и а2 (сигма-квад-
рат) среднее и дисперсию нормального закона, то сказанное в символьном
виде записывается так: £(£) = Л/\р.,а2) (А/ большое круглое является об-
щепринятым обозначением нормального закона распределения). В терминах
плотности f эта удобная лаконичная запись «расшифровывается» так:
f(x) = f(x\p,, а2) = (2тг<т2)','/2 ехр <-=— >, -оо < х < оо (1)
I J
Рыбников Константин Алексеевич (1913-2004) — советский и российский математик, ис-
торик математики.
Пусть из каких-то соображений (например, осно-
§ 1.1. Дискретные модели математической статистики
31
(здесь —oo</z<oo, ст >0 и использовано стандартное обозначение exp{t} = e2).
В вероятностных задачах, связанных с нормальным распределением, — в этом
случае говорят о нормальной модели — параметры р и ст2 считаются извест-
ными, и тем самым нормальная плотность ст2) полностью определена.
Если же один из этих параметров (или оба) априори неизвестен, то мы имеем
дело со статистической нормальной моделью. Неизвестный параметр модели
принято обозначать символом 0 (тэта), а область его возможных значений 0
(тэта большое), таким образом, в рассматриваемом случае мы имеем три ва-
рианта нормальной статистической модели:
1) Ы(0,сг}, 0 = {0 -оо < в < оо}, — известна дисперсия и неизвестно
среднее;
2) ЛЦр,02), Q = {0 0 < 0 < оо}, — известно среднее и неизвестна
дисперсия;
3) Л/")#], 02), €> = {# = (Si, 01} -оо < 0[ < оо, 0 < 02 < оо}, — оба пара-
метра неизвестны.
Поскольку в дальнейшем мы будем иметь дело с конкретными моделями,
которые широко используются в практических приложениях, мы сначала при-
ведем для напоминания и удобства изложения и последующих ссылок список-
справочник основных вероятностных распределений, сопровождая их неко-
торыми относящимися к теме комментариями. Это очень важный материал,
поскольку он является базой для решения всех примеров и последующих задач.
§ 1.1. Основные дискретные модели
математической статистики
Любая дорога начинается с первого шага.
В этом параграфе мы дадим определения и опишем необходимые нам в после-
дующем основные свойства наиболее известных дискретных вероятностных
распределений (как одномерных, так и многомерных), а также проиллюстри-
руем их использование в вероятностных и статистических задачах. Замечатель-
ным фактом является то, что существует несколько распределений большой
общности, встречающихся в самых разнообразных задачах теории вероятно-
стей и математической статистики. Прежде всего это биномиальное распре-
деление, распределение Пуассона и нормальное распределение — с первого
мы и начнем.
1. Схема Бернулли и биномиальное распределение
— Мадам, какова вероятность утром на улице встретить динозавра ?
— Одна вторая: или встречу, или нет.
Говорят, что случайная величина ( имеет распределение Бернулли с параметром
р (0 < р < 1), если она принимает лишь два значения, обозначаемые обычно
32
Глава 1. Основные распределения и их моделирование
О и 1, и при этом
pR = i}=p=i-p{4 = o}.
В терминах плотности /(г) это можно записать в виде
/(*) = /СФ) =РХ<1' \ 37 = 0,1, q=\—p. (1)
г В символьных обозначениях сказанное выражается крат-
5* Ьернуллиевская n-/i \ е □
г ' котак: £(£) = В1(1,р) и называется бернуллиевскои моде-
модель фундаментальная роль этой модели в теории веро-
ятностей и математической статистике ясна: она является подходящей матема-
тической моделью для любого эксперимента с двумя исходами («успех»-«не-
успех»), т. е. простейшего статистического эксперимента. Среднее и дисперсия
такой случайной величины есть
ЕС = Р и DC = pq (2)
(символ Е — от английского expectation (математическое ожидание = сред-
нее значение), D — от dispersion (дисперсия)). Если все случайные величины
последовательности Xi, ..} (конечной или бесконечной) независимы
и имеют одно и то же распределение В1(1, р), то мы имеем последователь-
ность испытаний Бернулли (или, кратко, бернуллиевскую последовательность),
называемую так по имени Якоба Бернулли (1654-1705) — выдающегося швей-
царского математика, впервые изучавшего такую схему (его основополагаю-
щие труды в области теории вероятностей изложены в посмертно изданном
сочинении «Искусство предположений» (1713)).
г Пусть {Xi,...,XB} — бернуллневская последова-
ть Биномиальная _ v
..............тельность с параметром р. Тогда сумма X = Х\+.. .+Хп
молель^1вН1ИИМ1 имеет биномиальное распределение с параметрами пир,
что кратко записывается в виде:
£(z) = Bi(n, р).
Эта случайная величина принимает, очевидно, лишь значения 0, 1, , п и
при этом
Р{Х = х} = f(x\n,p) = Cxpxqn~x х = 0,1, ,п. (3)
Термин «биномиальное распределение» связан с тем, что вероятности (3) яв-
ляются членами известного «бинома Ньютона»:
Л
1 = (р + ?)п = £спУдп-г
2=0
Таким образом, биномиальная модель В\(п,р) описывает распределение числа
«успехов» в п испытаниях Бернулли с неизменной вероятностью «успеха» р.
Здесь
EJT = пр и DX = npq.
(4)
§ 1.1. Дискретные модели математической статистики 33
Полезно знать также следующее свойство биномиального Свойство воспро-
распределения: если случайные величины Х(, , Л* изводимости
независимы и
£(Xj) = Bi(n;, р), 7 = 1, ,k,
то
C(Xt + + Xk) = Bi(n, + + n*, p).
Это свойство биномиального распределения Bi(n,p) называется воспроизво-
димостью по параметру п.
Если параметр р нам неизвестен (а так на практике чаще всего и бывает!),
то мы имеем биномиальную статистическую модель
Bi(n, 0), & = {0 0< 0 < 1}
(при п = 1 — бернуллиевскую статистическую модель В1(1, 0)).
Пример!. Рассмотрим ситуацию, описанную в приме- Примеры
ре 1 Введения. Если вданном эксперименте реализуется биномиольной *
схема выбора с возвращением, и если условия экспери- модели
мента обеспечивают независимость извлечения каждо-
го очередного шара от результатов предыдущих извлечений (практически это
достигается тщательным перемешиванием содержимого урны перед каждым
очередным извлечением), то мы имеем бернуллиевскую модель Bi(l, 0), где
под «успехом» понимается извлечение белого шара, для которой надо оценить
параметр 0 = а,/а по результатам п испытаний. В данном случае наблюда-
емая случайная величина X есть число белых шаров в выборке из п шаров,
которая имеет биномиальное распределение Bi(n, 0). •
Пример 2. Рассмотрим подробно описанный в примере 4 Введения эпизод
с преподобным Галиани. Здесь мы имеем эксперимент, состоящий в пятикрат-
ном бросании трех игральных костей. Интересующая нас величина, характери-
зующая один опыт, — число выпавших шестерок на трех костях. Обозначим
ее £. В свою очередь, она равна сумме трех бернуллиевских величин £1;£2
и £з, где & 1, если на г-й кости выпала шестерка, и 0 — в противном
случае (г = 1, 2, 3). Если исходить из того, что кости одинаковы (это обычно
не подвергается сомнению, хотя, на самом деле, — это тоже гипотеза), то
случайные величины £>, i = 1,2, 3, имеют одно и то же распределение Бер-
нулли Bi( 1,0), и они, по условию опыта, независимы. Тем самым их сумма
4 = + 6 + имеет распределение Bi(3, 0), и над этой случайной вели-
чиной произведено пять независимых испытаний, т. е. мы имеем случайную
выборку X = (А-!, , Л5) из распределения В1(3,0). Таким образом, мы по-
строили биномиальную модель Bi(3, 0) для описания нашего эксперимента,
и в рамках этой модели требуется проверить гипотезу симметричности костей
Яо 0=1/6 (т. е. гипотезу о том, что каждая грань выпадает с одинаковой
вероятностью 1/6). Как можно формализовать рассуждения преподобного?
Общее число выпавших шестерок X — Л| + ... + Х$ имеет биномиальное
3 Заказ 1748
34
Глава 1. Основные распределения и их моделирование
распределение Bi(15, 0), и по формуле (3)
р{Х = 15} = /(15|15,0) =015
Следовательно, при справедливости гипотезы На вероятность наблюдаемого
события, т.е. X = 15, равна 6-15 что ничтожно мало (!). Наверное, любой
разумный человек на месте преподобного усомнился бы в истинности гипо-
тезы Но в данном случае (при таком наблюдаемом исходе эксперимента). •
Замечание. Обратим внимание на следующее. В данном случае, если отбросить
несущественные для математики эмоциональные нюансы (пари), а оставить лишь
физическую суть эксперимента (в его ходе было брошено 3x5 15 костей),
то можно сразу говорить о случайной выборке объема п = 15, из распределения
Бернулли Bi(l, 9) X = (Xt,..., Хь), для которой исследуется случайная вели-
чина X = А", +- + Х15 — общее число выпавших шестерок. Конечно, снова
С(Х) = Bi(15, 0).
2. Отрицательное биномиальное распределение
С бесконечной последовательностью испытаний Бернулли {Т|, Х^ .} свя-
зано еще одно важное дискретное распределение, которое обозначается Bi(r, р)
и называется отрицательным биномиальным распределением с параметрами г
и р (здесь г — натуральное число). Это есть распределение числа «успехов»
(1), предшествующих r-му «неуспеху» (0), и оно задается вероятностями
7(r|r,p) = Cr+x-ipxqr х = 0, 1, 2, (5)
Заметим, что выражение для 7(i|r,р) совпадает с i-м членом разложения
функции <?г( 1 -р)-г в ряд по степеням р, т. е. отрицательного бинома (отсюда
и название):
1 = /(I - Р) Г = / 52 Сг+т-\РТ
т=0
Геометрическая В частном случае г = 1 распределение ВТ(1, р) на-
зывается геометрическим-, это есть распределение числа
м о д ел
единиц, предшествующих первому нулю в бернуллиев-
ской последовательности. Формула (5) в этом случае принимает вид
/(х|1,р) = pxq, а: =0,1,2,
Если случайная величина £ имеет распределение Bi(r,p), то
гр тр
Е$=- и D£ = -£.
q q1
(6)
(7)
Свойство воспро-
изводимости
Полезно знать также свойство воспроизводимости рас-
пределения Bi(r,p) по параметру г: если случайные
величины Х[,Xк независимы и
£(Xj) = Bi(rj,p), j = l,...,fc,
§ 1.1. Дискретные модели математической статистики
35
то
Г(Х| + + Xk) = Bi(r! + +Гк,р).
Отсюда следует, что случайная величина с распределением Bi (г, р) может быть
реализована (построена) как сумма г независимых случайных величин с оди-
наковым геометрическим распределением Bi( 1, р), — этот факт используется
для моделирования случайных величин с отрицательным биномиальным рас-
пределением (см. далее § 1.3).
Если параметр р неизвестен, то имеем отрицательную биномиальную ста-
тистическую модель Bi(r,0), 0 = {в 0 < 0 < 1} (при т = 1 — геомет-
рическую статистическую модель Bi(l, 0)). Эти модели часто используются,
например, при разработке математических методов контроля качества про-
мышленной продукции.
Замечание. В формуле (5) биномиальный коэффициент
_ г(г+1)...(г + х-1)
r+J_1 “ х\
определен при любом действительном г, а при г > 0 этот коэффициент положителен,
поэтому эта формула определяет распределение вероятностей при всех г > 0 и
О < р < 1, а не только при натуральных т При натураль-
ных г распределение Bi(r,p) называют также распределена- аспределение
_ 2> Паскаля
ем Паскаля '
3. Распределение Пуассона
Случай ная величина ( имеет распределение Пуассона с параметром А (А > 0),
если
А1
Р{( = х} =/(х|А) = е~х—, 21 = 0,1,2, (8)
х\
что кратко записывается в виде £(() = П(А); при этом А = Е£ = D£.
Пуассоновская модель П(А) обычно описывает схему редких событий', при
некоторых предположениях о характере процесса появления случайных со-
бытий число событий, происшедших за фиксированный промежуток времени
или в фиксированной области пространства, часто подчиняется пуассонов-
скому распределению. Примерами могут служить число частиц радиактивного
распада, зарегистрированных счетчиком в течение некоторого времени t, чис-
ло вызовов, поступивших на телефонную станцию за время t, число дефектов
в куске ткани или в ленте фиксированной длины, число изюминок в кексе
и т. д. Наконец, распределение Пуассона дает хорошую аппроксимацию би-
номиального распределения для больших значений п и малых значений р:
Паскаль Блез (1623-1662) — французский математик, механик, физик и философ, один из
основателей теории вероятностей.
Пуассон Симеон Дени (1781-1840) — французский математик, механик и физик, иностран-
ный почетный член Петербургской АН (с 1826).
3*
36
Глава 1. Основные распределения и их моделирование
Свойство воспро
изводимости
Bi(n,p) ~ П(тгр), если пр невелико. Это свойство позволяет значительно
упростить вычисления в биномиальной модели при указанных условиях.
Распределение Пуассона воспроизводимо по своему
параметру, т. е. если Х,, ,Х^ — независимые слу-
чайные величины и C(Xj) = П(А;), j = 1, , к, то
+ + Хк) = П(А1 + + Afc).
Если параметр А неизвестен, то имеем пуассоновскую статистическую
модель П(0), 6 = {0 в > 0}
Понятие распределения Пуассона впервые появилось в книге французского
ученого Симеона Дениса Пуассона (1781-1840) «Исследования о вероят-
ности судебных приговоров по уголовным и гражданским делам», опубли-
кованной в 1837 г. Пуассон обнаружил, что если в п испытаниях Бернулли
с вероятностью «успеха» р (см. п. 1) делать р все меньше и меньше и в то же
время увеличивать п так, что произведение пр = А остается постоянным, то
вероятность (3) того, что будет ровно х успехов, стремится к /(х|А) (см. (8)).
Следовательно, распределение Пуассона (8) является приближением для биноми-
ального распределения (3). Возможность широкого применения и большая важ-
ность пуассоновского распределения не были поняты современниками Пуассона,
более того, о нем почти полностью забыли. Однако после 1894 г. это распре-
деление использовали при изучении странного феномена. За 20 лет между 1875
и 1894 гг. в 14 различных кавалерийских корпусах германской армии была собрана
статистика трагических случаев, когда солдат был убит ударом копыта. Согласно
280 (= 20 лет х 14 корпусов) наблюдениям, 196 солдат погибли таким образом,
т. е. в среднем за год А = 196/280 = 0,7 Если бы число трагических исходов
подчинялось распределению Пуассона с параметром А = 0,7, то можно было бы
ожидать, что при 280 наблюдениях в 139 случаях смертей нет, в 97 случаях —
1 смерть, в 34 случаях — 2 смерти и т. д. А что показала статистика? В дей-
ствительности данные были соответственно 140, 91, 32 и т. д.; практика и теория
оказались в столь хорошем согласии, что вряд ли можно было ожидать большего.
Это сравнение появилось в 1897 г. в монографии Л. Борткевича «Закон малых
чисел». Пуассоновское распределение стало широко применяться лишь в XX в.
(по книге (23, с. 34]).
Распределение
С распределением Пуассона связано еще одно ин-
Эрлонга тересное дискретное распределение — распределение
Эрланга^, задаваемое вероятностями
Xk f N Хк\
ек=с—, к = 0,1, ,N, с=(5?Т7
п=о '
т. е. это — усеченное сверху в точке N пуассоновское распределение. В 1906 г.
Эрланг установил, что в некоторых случаях лучшее приближение (для бино-
миального распределения) можно получить с использованием именно такого
распределения.
Эрланг Агнер Краруп (1878-1929) — датский математик.
§1.1. Дискретные модели математической статистики
37
Пример 3 (Дни рождения [25, с. 171-172]). Какова вероятность рх того,
что в группе из 500 человек ровно х родились 1 января? Если эти 500 человек
выбраны случайно, то можно применить схему из 500 испытаний Бернулли
с вероятностью «успеха» р = 1/365. Для пуассоновского приближения поло-
жим А = 500/365 = 1,3699 Теоретические биномиальные вероятности (3)
и их пуассоновские приближения (8) приведены в следующей таблице.
X 0 1 2 3 4 5 6
Рг = /(z|500, 1/365) 0,253 0,3484 0,2388 0,1089 0,0372 0,0101 0,0023
Рх я /(z|500/365) 0,2541 0,3481 0,2385 0,1089 0,0373 0,0102 0,0023
4. Гипергеометрическое распределение
Случайная величина £ имеет гипергеометрическое распределение с параметрами
di, аз и п, где di, аз и п — натуральные числа, причем
п а = а, + а2 £(£) = Я(а1, аз, п),
если
р{£ = г} = /(афц, а2,п) = Са'5;°2- , г =0,1, ,п. (9)
Такое распределение возникает в следующей схеме. Рассмотрим ситуацию,
описанную в примере 1 Введения и предположим, что п шаров извлекаются
наугад без возвращения. Тогда, если £ обозначает число белых шаров в вы-
борке, то эта случайная величина имеет распределение Н(а,\,а2,п) (сравни
с примером 1).
Заметим, что вероятность (9) отличны от нуля лишь при x^ai и Ti-х^аз,
т. е. когда целое х лежит в интервале max(0, п - a2) х min(7i, aj.
Если С(£) = Я(а1,О2, ti) , то ее первые два момента есть
Tia I па,\аЛа, —п) , ,
Е£= — и D£ = —10
4 а 4 a2(a-l) v 1
5. Распределение Маркова—Пойа
Обобщение понятия зачастую бывает
полезно для постижения его сущности.
А. Н. Колмогоров
Это распределение является обобщением одновременно и биномиального,
и гипергеометрического распределений и возникает оно в следующей урно-
вой схеме. Вновь вернемся к примеру 1 Введения и рассмотрим следующий
эксперимент. Из урны, содержащей первоначально белых и а2 = а - a,t
черных шаров, выбирается наугад (т. е. равновероятно) один шар, фиксиру-
ется его цвет и шар возвращается в урну с одновременным добавлением с
38
Глава 1. Основные распределения и их моделирование
новых шаров того же цвета. Затем из урны (содержащей теперь а + с ша-
ров) снова производится случайное извлечение одного шара и повторяется
тот же процесс. Здесь с может быть любым целым числом и, в частности,
при с = 0 (новые шары не добавляются) мы имеем случайный выбор с воз-
вращением, рассмотренный в примере 1, а при с = -1 (извлеченный шар
в урну не возвращается) — схему случайного выбора без возвращения, рас-
смотренную в предыдущем п. 4 (в последнем случае процесс извлечения шаров
кончается через а шагов из-за отсутствия шаров в урне). При с > 0 эта схема
выбора обладает эффектом последействия: если извлекается шар какого-то
цвета, то шанс (вероятность) извлечь шар такого же цвета при следующем
испытании возрастает. Такая урновая схема может служить приближенной
моделью явлений, подобных эпидемиям, когда осуществление некоторых со-
бытий увеличивает шанс их повторения.
Пусть £ обозначает число белых шаров, наблюдавшихся при п извле-
чениях. Распределение вероятностей этой случайной величины называется
распределением Маркова—Лойа (обозначается £(£) = МП(п; а,\, а2, с)), и оно
имеет вид
PR = z} = /(as|aj, а2, с; n) = JJ(a, + jc) (а2 + jc) /]J(a + jc),
j=0 j=0 ' j=0
r = 0,l, (11)
Если воспользоваться биномиальными коэффициентами и учесть, что для
любого действительного а и натурального х
„х (а - х + 1) 0
и0 — и — 1,
и!
то формулу (11) при с ф 0 (тогда числитель, и знаменатель в (11) можно
разделить на сп) можно записать также в любой из следующих двух форм:
ZTE — Z ZTJ
/(х|а,. = (12)
^о/с+п-1 ^-а/с
Подчеркнем, что из (11) при с = 0 мы получаем биномиальное распределе-
ние Bi(n,p), р = ai/a (как в примере 1 для схемы выбора с возвращением),
а из второго представления в (12) при с = -1 — гипергеометрическое рас-
пределение Н(а.\, а2, п) (как в п. 4 для схемы выбора без возвращения), так
что распределение Маркова—Пойа включает в себя как частные случаи оба
эти распределения.
Если £(£) = МП(п; Д), а2, с), то среднее и дисперсия имеюз' вид
па\ па\а,2(а + сп) , ,
Е< = — и D< = —‘ Л 13)
а д2(д + с) ' ’
§1.1. Дискретные модели математической статистики
39
Ьх Интересна история открытия этого распределения. Впервые оно появляет-
й/ ся в работах выдающегося русского математика, академика А. А. Маркова
JL (1856-1922), который провел исчерпывающий анализ этого распределения
и опубликовал свои результаты в Известиях Петербургской Академии наук
в 1917 г. Но, по-видимому, эта публикация «осталась незамеченной» за рубежом,
так как, спустя 6 лет, в 1923 г. появляется работа Ф. Эггенбергера и Д. Пойа,
где вводится такое же распределение и доказываются для него некоторые част-
ные результаты. С этих пор данное распределение стало называться в зарубежной
литературе именем одного из его авторов — Пойа (выдающийся американский ма-
тематик венгерского происхождения (1887-1985)), хотя более исторически оправ-
дано название «распределение Маркова—Пойа».
б. Полиномиальное распределение
Полиномиальное распределение М(п;р) с параметрами п и р, где п — на-
туральное число, и р = (рь...,рдг), 0<р, < 1, г=1,.. ,,N, pi 4-.. . 4-p^ = 1,
— это распределение случайного вектора v = (pj,..., v^) с целочисленными
неотрицательными компонентами, удовлетворяющими условию
V\ + + pjv = я,
которое задается вероятностями
I
р{Е = я} = f(x\n, р) = ’ pxNK (14)
где х = (i], .. , ядг) — произвольный вектор с целыми неотрицательными
координатами, причем я, 4- 4- х^ = п. Кратко это записывается так:
£(р) = М(п;р). Название «полиномиальное распределение» связано с тем,
что вероятность (14) представляет собой общий член в разложении полинома
(pi 4- 4-рдг)п по степеням pi, ,рк-
1 = (P1+ +PN)n= Е д- п'х~^'
«С | . • Ju rJ,
х,+...+тя=п
Здесь
Ei/j = npi, Dp, = np,(l -р;) и
cov(p,, Uj) = -npiPj, i,j = \, ,N,
Такое распределение возникает в схеме полиномиальных _
*г I юлиномиальные Ж
испытании, т. е. независимых испытании с N возмож-
испытания
ными исходами, вероятности которых не меняются
от испытания к испытанию и равны рь , p^ соответственно: если произве-
дено п испытаний и р, — число реализаций в них i-ro исхода, i = 1, , N,
то £(р) = М(п,р). Если N = 2 (схема с двумя исходами), то мы имеем
схему Бернулли (см. п. 1), для которой £(pi) = Bi(n,pi); с другой стороны,
так как р2 = п - ^1 и р2 = 1 - pi, то двумерный вектор (рьп - Р[) имеет
полиномиальное распределение М(п; pt, 1 -pj, эквивалентное, следователь-
но, биномиальному распределению Bi(n, pi). Отсюда же вытекают следующие
свойства полиномиального распределения:
40
Глава 1. Основные распределения и их моделирование
1) распределение каждой компоненты pj вектора v_ является биномиальным
Bi(n, р;), j = 1, , N, и
Свойство воспро- >i
изводимое™ ?
2) если вектора Р], , р* независимы и = М(п,;р), i = 1,. , к, то
£(И1 + +v.k) = M(nl+ +Пк',Р)
{воспроизводимость по параметру п).
Отметим еще, что часто вместо термина «полиномиальное» используется
его синоним «мультиномиальное».
В приложениях обычно вектор вероятностей р = (рь , ру) неизвестен
— в этом случае мы имеем полиномиальную статистическую модель М{п,0),
в = (01; , 0у), с параметрическим множеством 0 = {0 0 < 0,- < 1,
i — 1,..., N, + ...+<?дг = 1}.
Пример 4 (Обобщение примера 1 Введения). Имеется урна с шарами N раз-
личных цветов, которые мы условно обозначим Ai, , An - Пусть a,j — число
шаров цвета Aj, j = 1, , N, и а = О[ + + ау — общее число шаров
в урне. Рассмотрим следующий эксперимент: из урны по схеме выбора с воз-
вращением наугад (т. е. равновероятно) извлекается п шаров (т. е. каждый раз
любой шар может быть извлечен с одинаковой вероятностью 1/а и независи-
мо от результатов предыдущих извлечений). Обозначим Uj число наблюдав-
шихся Aj-шаров, j = 1, , N. Тогда вектор v = (pi, , Ру) будет иметь
полиномиальное распределение Л1(п;р) с параметром р = {а\/а,..., o,n/cl),
т. е. вектором долей цветов Ai, .., Лу Если этот вектор нам неизвестен, то
подходящей оценкой для него будет вектор относительных наблюдавшихся
частот vjn = (vi/n,.. ,vN/n), так как в силу (15) Ер/п = р (в среднем
оценка и_/п совпадает со значением параметра р). В последующем мы дадим
строгое обоснование такого правила оценивания (см. пример 10 §3.2). •
7. Многомерное распределение Маркова—Пойа
Вновь обратимся к ситуации, описанной в примере 4, и рассмотрим теперь
такой эксперимент: последовательно в каждый момент времени п = 1,2,
из урны наград извлекается один шар, фиксируется его цвет и шар возвращает-
ся обратно в урну с добавлением с новых шаров того же цвета, что и извлечен-
ный шар (тем самым состав урны каждый раз увеличивается на с шаров, если
с > 0, и уменьшается, если с < 0; при с = 0 он остается неизменным, т. е.
в этом случае мы имеем схему выбора с возвращением, рассмотренную в при-
мере 4). Вновь обозначим Vj число А} -шаров, наблюдавшихся при п извлече-
ниях, j = 1, , N. Тогда вектор и — (рь , Ру) будет иметь распределение
п! П>1 + с) - >)с)
Р{р = х} = ----------- -------------г--------------—------, (16)
х(!... Ху! а(а + с)... (а 4- (п - 1)с)
§1.1. Дискретные модели математической статистики
41
где х = ....хм) — произвольный вектор с целыми неотрицательными
координатами, причем Х[ + + хм = п; множество таких векторов будем
обозначать /Сдгп- Это распределение называется многомерным (N-мерным) рас-
пределением Маркова—Пойа с параметрами п, а и с и обозначается символом
МП(п; а, с), где а = (аь ..., адг) — вектор первоначального состава урны.
Формула (16) является многомерным (N-мерным) аналогом формулы (11)
и сводится к ней при N = 2. Если с / 0, то разделив числитель и знаменатель
в (16) на сп и используя, как и в п. 5, биномиальные коэффициенты, этой
формуле можно придать еще две формы — аналоги форм (12):
N N
Pte = = /tela, с; n) = П CZc+^/C"/^ = П C-aife/cn-afc,
)=1 7=1
I 6 )Смп‘ (17)
Отметим три важных частных случая этих соотноше-
ний. Если в формуле (16) положить с = 0, то мы придем
к (14) с р = a/a, т. е. распределение Маркова—Пойа
Связь с другими
распределениями
МП(п; а, 0) сводится к полиномиальному распределению М(п\ а/а). Далее,
если во втором представлении (17) положить параметр с = — 1 (что соответ-
ствует схеме выбора без возвращения), то при п а (иначе биномиальный
коэффициент Сд обратится в 0) получим распределение
N
Pte = ?} = П Сха’/спа, х € (18)
7 = 1
которое является многомерным (N-мерным) аналогом гипергеометрическо-
го распределения (9) и сводится к нему при N = 2. Поэтому распреде-
ление, задаваемое вероятностями (18), называется многомерным (N-мерным)
гипергеометрическим распределением с параметрами а и п. Оно обозначается
символически £(р) = Н(а, п) и характеризует собой схему случайной вы-
борки без возвращения объема п а из конечной совокупности, состоящей
из а = а\ + + ам элементов, разбитых по некоторому признаку на N
непересекающихся классов размерами соответственно а\,. ., а,у (в данном
случае Vj интерпретируется как число наблюдавшихся в выборке элемен-
тов j-го класса, j = 1, , N).
Наконец, если в первом представлении (17) все Ду положить равными с,
то биномиальные коэффициенты в числителе станут равны 1, и мы придем
к формуле
Р(р = £} = (с^п-.Г1
задающей равномерное распределение на множестве
)CNn = {z = tei>- ,%n) Xi = 0,l,2... ,г=1, ,N; ®!-|- +rrw = n}:
число элементов (векторов х) этого множества равно С)У+п„1 — числу реше-
ний уравнения xt + + х^ = п в. целых неотрицательных числах, и всем
им приписывается одинаковая вероятность.
42
Глава 1. Основные распределения и их моделирование
Таким образом, многомерное распределение Марков—Пойа включает в
себя в качестве частных случаев полиномиальное распределение, многомерное
гипергеометрическое распределение и равномерное распределение на множе-
стве /CjVn-
Моменты МП-pac- Если £(п) = МП(п; а, с), то первые и вторые мо-
пределения менты случайного вектора v = (щ,..., P/v) имеют вид
Ь,(=А D„ = + j=|. „
° , °(“ + С) (19)
atOj(a + cn)
covin., Vi) = -П 77----:—, 1,7=1, ,N,
1 a?(a + c)
Полное изложение теории этого распределения имеется в работе авторов
«Об урновой схеме Маркова—Пойа: от 1917 г. до наших дней» (Обозрение
прикладной и промышленной математики. 1996. Т. 3. Вып.4. С. 484-511).
8. Распределение степенного ряда
Целый класс дискретных распределений может быть построен по следующей
схеме. Рассмотрим произвольный степенной ряд
/(0) = ^2 Ф)*1 I > °,
Х=1
с неотрицательными коэффициентами (а(аг) 0 для всех х I) и ненулевым
радиусом сходимости R. Тогда при любом 6 6 0 = (О, R) можно определить
дискретное вероятностное распределение с плотностью
6х
f(x]8) = а(х)—, х = 1,1+\, (20)
JV>)
(эти числа неотрицательны и в сумме дают 1). Такого типа распределение и на-
зывается распределением степенного ряда. Класс таких распределений весьма
обширен и включает в себя многие стандартные рас-
пределения. В частности, в него входят распределение
Пуассона П(0) (см. (8)): для него /(в) = ев, R = оо;
отрицательное биномиальное распределение В1(т, 0)
(см. (5)): для него /(0) = (1 - в)~г, R = 1; логарифмическое распределение,
задаваемое вероятностями
ДХ / 1
№|” = 7/1" (2D
для него
1 00 01
х=)
и т.д., а также соответствующие усеченные слева распределения.
Примеры
роспределений
стеленного ряда
§ 1.2. Основные абсолютно непрерывные модели
43
Примечание. Усеченным называется распределение, у которого некоторые значения
запрещены. Например, усеченным в нуле распределением Пуассона является распреде-
ление, задаваемое вероятностями (сравни с (8))
„О1
f(x\0)=ce 9 —, а: =1,2,... (22)
х!
где константа с определяется из условия нормировки
ОО
Г=1
и в данном случае она равна (1 - е-9)-1
Если случайная величина £ имеет распределение
Моменты
степенного ряда (20), то ее первые два момента нахо-
дятся по формулам
Е( = р(0)=0^ и Щ = а2(0) = 0/(0) (23)
(убедитесь, что формулы для моментов в п. 2 и 3 являются частными случаями
этих выражений).
Важным свойством распределения степенного ряда ~ _
„ „ Свойство воспро-
является следующее: если случайные величины Aj,... , г
„ изводимости
Хп независимы и имеют одно и то же распределение
(20), то их сумма X = Л) 4- .. 4- Хп также имеет распределение степенного
ряда, порождаемое функцией fn(0), т. е.
0х
Р{Х = х} = fn(x\9) = а.п(х)у^, x = nl,nl + l,... (24)
где коэффициенты ап(х) определяются разложением
ОО
/”(*) = ап(х)вх
x=nl
§ 1.2. Основные абсолютно непрерывные модели
Дорогу осилит идущий.
В этом параграфе мы продолжаем знакомство с основными вероятностными
распределениями и их свойствами, сосредоточившись теперь на случае абсо-
лютно непрерывных распределений. Принцип изложения здесь тот же, что
и в предыдущем параграфе о дискретных распределениях. Напомним, что те-
перь функция f(x) имеет смысл обычной плотности распределения, т. е. это
неотрицательная функция, удовлетворяющая условию нормировки
J f(x) dx = 1,
£
44 Глава 1. Основные распределения и их моделирование
где Е — множество, на котором задано распределение наблюдаемой (изучае-
мой) случайной величины
1. Нормальное распределение
Это распределение уже встречалось нам ранее: его формальное определение
дано во Введении к данной главе (см. (1)). Роль нормального распределения
(нормальной модели) в теории вероятностей и математической статистике
чрезвычайно велика и ее трудно переоценить. Нормальная модель возни-
кает в таких статистических экспериментах, когда на исход эксперимента
оказывает влияние большое число независимо действующих случайных фак-
торов, каждый из которых лишь незначительно влияет на конечный резуль-
тат (см. примеры 2 и 4 Введения). Для таких ситуаций имеется знаменитая
।. ИВШ те0Рема> называемая центральной предельной теоре-
р мой теории вероятностей (термин «центральная» от-
ражает ее значимость, так ее впервые назвал Дьердь
Пойа), согласно которой если {Xj, Хз, ...} — последовательность независи-
мых одинаково распределенных случайных величин с положительной диспер-
сией, то предельное при п —> оо распределение нормированной надлежащим
образом суммы Sn =Х1 + . -ГХп является нормальным. Именно: при п—> оо
Z Sn- n/А Q, (Q
\ /
где fi = ЕХ|, а2 = DA). Более того, известно, что при некоторых условиях
предельное распределение суммы Sn остается нормальным, даже если случай-
ные величины Х|, Хз, зависимы и неодинаково распределены. Возможно,
именно поэтому нормальный закон распределения возникает как подходящая
приближенная модель во многих областях исследований. Поэтому в конкрет-
ной практической задаче при построении соответствующей вероятностной
или статистической модели часто предполагают, что распределение каждой
наблюдаемой величины приближенно нормально. В силу этого статистиче-
ские методы, разработанные для нормальной модели, имеют весьма широкую
сферу применений и, следовательно, хорошо знать их — очень важно. (Пу-
анкаре5^ как-то заметил с сарказмом, что все верят в универсальность нор-
мального распределения: физики верят, потому, что думают, что математики
доказали его логическую необходимость, а математики верят, так как считают,
что физики проверили это лабораторными экспериментами [23, с. 49].)
Предельные теоремы Общее замечание. В (1) нам впервые встречается запись
типа Е(рп) Е(р), которую мы должны пояснить. Во мно-
гих задачах математической статистики (и теории вероятностей) рассматриваются
последовательности случайных величин {г?п, п = 1,2, ..}, сходящиеся в том или
ином смысле к некоторому пределу г/ (эта) (случайной величине или константе),
^Пуанкаре Анри (1854-1912) — выдающийся французский математик, физик, астроном и
философ.
§ 1.2. Основные абсолютно непрерывные модели
45
когда п оо, — в таких случаях говорят о соответствующих предельных теоремах. Мы
будем использовать в дальнейшем лишь два простейших вида сходимости, без кото-
рых нам совершенно невозможно обойтись: сходимость по вероятности и сходимость
по распределению, или (синоним) слабая сходимость. Напомним их определения. По-
следовательность {rj„} называется сходящейся по вероятности к г), если
lim Р{ г/„ - т)| > г} = О V е > О,
р ~
что кратко записывается так: г)п —> т/. Очень важным при использовании этой схо-
р
димости является следующее свойство: если г}п —> т/ и функция непрерывна, то
У’(Чп) V’(’f)- (2)
Под сходимостью по распределению (слабой сходимостью) [что кратко записывается
так: £(|?п) £(»/) или Т)п т?] понимается сходимость соответствующих функций
распределения
Г„(ж) = Р{т)„ si ж}
к предельной функции распределения
Г(ж) = Р{т) г? т}
в каждой точке непрервности последней: F„(x) -> F(x), если в точке х функция
F(x) непрерывна. Известно, что из сходимости по вероятности следует слабая схо-
димость:
Чп ч => £(Чп) -> £(>?)
Примером сходимости по вероятности является знаменитый закон больших чисел:
если случайные величины r/i, г)г,.. независимы, одинаково распределены и имеют
математическое ожидание Ei), = р, то при тг оо
-(П1+ +4n)-L>M', (2)
п
примером же слабой сходимости является центральная предельная теорема (1). Эти
предельные теоремы (или, как говорят, асимптотический подход) мы часто будем
использовать в дальнейшем в различных статистических задачах, но это не есть
«прихоть» математика, а «суровая» необходимость, ибо
Асимптотический подход — зачастую единствен-
ная возможность, открытая статистику в суровой
действительности.
Дж. Русас
Вернемся к нормальному распределению и про- wwwwww „
, г , Моменты и свойство I?
должим обсуждение его свойств. Уже отмечалось (но
_ - \ воспроизводимости
выделим это особо ввиду важности данного свойства), г
что если £(£) = ЛГ(д, а2), то
Е4 =/х и D4 = а2 (4)
Далее, можно показать, что всякая линейная комбинация нормально рас-
пределенных случайных величин также подчиняется нормальному закону.
46
Глава 1. Основные распределения и их моделирование
Пусть, в частности, случайные величины Х|, , Хк независимы и
£(Х.) = Щр,,^), г=1, ,k.
Если О],..., ак и b — постоянные, причем а,- 0 хотя бы для одного значе-
ния г, то
£(<1|Х| + + акХк 4- Ь) —
= Af(aijUi+ + акрк 4- Ъ, а7сг] 4-
В частности
£(Х| + + X/;) = /\f (р^ + 4- рк, а2 + + <Т/
(5)
(6)
т. е. нормальное распределение Л£(р, <т2) является воспроизводящим по пара-
метрам р и а2 одновременно.
Нормальное распределение со средним 0 и дис-
персией 1 называется стандартным нормальным рас-
пределением, его плотность и функция распределения
обозначаются через <р и Ф (фи малое и фи большое)
соответственно, так что
Стандартное
нормальное
распределение
=
1
—=е
(7)
и
Эти функции протабулированы и для них имеются обширные статисти-
ческие таблицы.
Наконец, отметим, что если £(£) = Nip, а2), ст2 > 0, то по свойству (5),
нормированная случайная величина £ = (£ - р)/а имеет стандартное нормаль-
ное распределение //(О, 1).
Логно мольное С нормальным распределением тесно связано одно
Р интересное распределение, называемое логнормальным.
распределение _ . ..
,г г По определению, это распределение случайной вели-
чины т) = е^, где £(£) = Af(p, а2). Для первых двух моментов т) справедливы
соотношения
Ер = е»+а',г, Dt? = (е°г - 1)е
(8)
Из истории: нормальное распределение, ставшее краеугольным камнем
й/ науки о случайном, было открыто французским математиком Абрахамом
L де Муавром (1667-1754) в 1733 г., о чем он сообщил некоторым своим дру-
р зьям. В 3-м издании своей книги «Доктрина шансов» (1756) он так писал
о своем открытии мирового значения: «...Возьму на себя смелость утверждать,
что это труднейшая проблема о случайном... (Де Муавр, как это ни странно,
не включил свое открытие во 2-е издание книги в 1738 г.; первое издание было
осуществлено в Англии в 1718 г., куда он переехал из Франции после отмены Нант-
ского эдикта, который предоставлял гугенотам свободу вероисповедания) [23].
Некоторое время спустя нормальное распределение было снова открыто Гауссом
в 1809 г. и Лапласом в 1812 г. в связи с работами по теории ошибок наблюдений.
Лаплас дал первую (совершенную) формулировку центральной предельной тео-
ремы и привел большое количество важных приложений этого распределения.
§ 1.2. Основные абсолютно непрерывные модели 47
2. Многомерное нормальное распределение
Случайный вектор £ — (fi,..., {*) размерности к 2 имеет невырожденное
(или собственное) многомерное (к-мерное) нормальное распределение с вектором
средних fi — (р^, , fik) и матрицей вторых моментов (ковариаций)
||cov(^)llt
(обозначается £.(£) = Af(fi, Е)), если его плотность f(x\fi, Е) при всех х =
= (i|,..., Xk) € Rk имеет вид
f(x\fi, Е) = (2тг)-А/2]Е[-1/2 exp { — (я - д)' E-1(i - д)|. (9)
Здесь приняты следующие обозначения, которые Элементы алгебры *
будут систематически использоваться и в дальнейшем:
Rk — это fc-мерное евклидово пространство, |4| = det Л — определитель
матрицы A ||Оу||* размера к х к, А1 — обратная матрица А, кото-
рая существует, если матрица А невырождена (т. е. |Л| / 0), при матричных
операциях векторы понимаются как вектор-столбцы, знак ' (штрих) озна-
чает транспонирование, наконец, выражение х_Ах есть лаконичная запись
к
на языке матричной алгебры квадратичной формы OijXiXj для вектора
.7=1
х = (i|, , Хк) с матрицей коэффициентов А.
В (9) вектор fi = Е£ = (Е£j,..., E£t) может быть любой точкой Rk, а ко-
вариационная матрица Е — произвольной симметрической (т. е. Е' = Е)
и положительно определенной (т. е. х Ei > 0, Vi / 0) матрицей (ее назы-
вают также дисперсионной матрицей и пишут D£ = Е). Напомним также, что
симметрическая положительно определенная матрица обязательно невырож-
дена, и обратная к ней матрица также является симметрической положительно
определенной.
Таким образом, общее число параметров, которыми определяется невы-
рожденное fc-мерное распределение Л/”(д,Е), с учетом симметричности мат-
рицы Е равно к + к(к-\-1)/2. Важнейшими свойствами
этого распределения являются следующие: Важнейшие ХР
свойства Al(ft, Е)
1) некоррелированность компонент вектора £ эквива- ~
лентна их независимости и
2) сохранение свойства нормальности при линейных преобразованиях: если
if = L£, где L — произвольная (т х к)-матрица, то £(г}) = Af(Lp, LEL'),
т. е. новый случайный вектор г) имеет m-мерное нормальное распределе-
ние, параметры которого вычисляются по очень простому правилу: вектор
средних Ет; = Lfi, а дисперсионная матрица Dry = LY.L'.
48
Глава 1. Основные распределения и их моделирование
Поскольку эти свойства многомерного нормального распределения чрез-
вычайно важны, и поскольку не все читатели достаточно знакомы с много-
мерными распределениями, мы обсудим их несколько более подробно. Мы
'fa v покажем, что на самом деле они очень просто уста-
ф. Характеристические ’ J
, навливаются, если воспользоваться аппаратом харак-
функции г г
теристических функции — важнейшим инструментом
доказательства различных теорем теории вероятностей. Но сначала мы кратко
напомним их определение и некоторые из их основных свойств.
Характеристическая функция произвольной случайной величины (векто-
ра) X = (Л-!, , Xk), k 1, определяется формулой
Фх(0 = Ее’-—,
где г — мнимая единица, i = (ii,. , (д), -оо < < оо, j = 1, , fc, и
t X — t] + + thXk
— скалярное произведение векторов t и X.
Характеристическая функция всегда существует, и для дискретной слу-
чайной величины с плотностью /(ж) = Р{Х = ж}, х € X, она вычисляется
по формуле
= о°)
а для абсолютно непрерывной случайной величины с плотностью /(а?) она
есть интеграл Римана
Ф^_(() = j etl--f(x)dx, dx = dx[ .dxk. (11)
x
Соответствие, установленное формулами (10) и (11) между характеристи-
ческой функцией Фх(£) и распределением случайной величины X (ее плот-
ностью /(х)), является взаимно однозначным, т.е. по Ф^(() плотность /(ж)
восстанавливается (определяется) однозначно. Например, для одномерной
дискретной случайной величины X с плотностью f(x), х = 0, 1, 2, фор-
мула обращения есть
7Г
f(x)=^ [ e-ilx4x(t)dt, (12)
Z7T J
—л
если же случайная величина X имеет плотность /(ж) и функция 'bxtt) аб-
солютно интегрируема, то формула обращения имеет вид
ОО
7(z) = [ e~itx^x(t)dt. (13)
Z7T J
—оо
Таким образом, различные свойства изучаемых случайных величин можно
формулировать как в терминах их плотностей, так и в терминах их характе-
ристических функций.
§ 1.2. Основные абсолютно непрерывные модели
49
Перечислим теперь необходимые нам в последу-
„ , _ Свойство хороктери-
ющем свойства характеристических функции. Тако- С
r г сгических функции
вых всего два.
1. Линейное преобразование случайной величины. Если случайный вектор Y =
= (У|,..., Ут) получается из вектора Х_ = (Хь , Хк) с помощью ли-
нейного преобразования Y = ЬХ+а, где L — произвольная (тхА:)-мат-
рица и а = (аь , ат) — произвольный вектор (L и а постоянны), то
Фу(£) = (14)
2. Критерий независимости. Если компоненты вектора X независимы, то
ъа) = 'Мм Фх4(^). (is)
Верно и обратное заключение: если имеет место разложение (15), то
компоненты Л)......Хк независимы. Таким образом, представление (15)
является удобным для работы критерием независимости компонент век-
тора X
После этого краткого экскурса в область теории вероятностей вернемся
к обсуждаемому многомерному нормальному распределению Е) и дадим
его новое (другое) определение в терминах характеристической функции.
Случайный вектор { = , (к) имеет k-мер- Характеристическая
ное нормальное распределение ЛЦр, Е), если его харак- функция Е)
теристическая функция Ф^(£) = Е exp {if£} имеет вид
Ф<(() = exp t £ Rk (16)
Это определение шире, чем определение (9) невырожденного распределения,
так как здесь не требуется существования обратной матрицы Г-1 Тем самым
определение (16) остается в силе и в случае вырожденной матрицы Е (т. е.
при |Е| = 0), — в этом случае распределение Л/^д, Е) называется вырожден-
ным (или несобственным), и для него уже не существует А:-мерной плотности
типа (9). Мы не будем углубляться далее в эти тонкие вопросы, поскольку в по-
следующем мы будем иметь дело лишь с невырожденными распределениями.
Подчеркнем лишь, что в любом случае остаются справедливыми формулы
E£ = /i и D( = Е = ||cov(&, ^)||, (17)
Если компоненты вектора £ некоррелированы, т. е. cov((,-,^) = 0 при
i A j, то дисперсионная матрица Е становится диагональной:
где aJ = D^-, j = l........fc,
4 Заказ 1748
50 Глава 1. Основные распределения и их моделирование
и формула (16) принимает вид
— ехР {г(^1Д| + + tk^k) ~ —
* Г а? )
= JJexp - yij к
j=i }
т. е. переменные t\, ,t>: разделяются, и тем самым характеристическая
функция Ф((£) распадается в произведение одномерных характеристических
функций компонент вектора По свойству (15) это означает независимость
компонент вектора £. Итак, из некоррелированности нормальных случайных
величин следует их независимость, а поскольку из независимости случайных
величин (с любым распределением!) следует их некоррелированность, то тем
самым сформулированное ранее свойство 1) об эквивалентности этих двух
свойств для нормальных величин доказано.
Еще проще устанавливается свойство 2) о сохранении нормальности при
линейных преобразованиях. Действительно, если т] — L(, то характеристиче-
ская функция вектора т? равна в силу (16)
Ф2(£) = Ее'-'2 = Ее’-^ = Ее,(Г£)^ = Ф<(Д'«) = exp J,
что есть характеристическая функция нормального закона LEL1).
Следствием этого свойства является следующий фундаментальный резуль-
тат, который доказывается при помощи выбора соответствующей матрицы L\
совместное распределение любого подмножества компонент вектора ( является
нормальным, и соответствующие подвектор вектора р и подматрица матрицы
Е будут вектором средних и дисперсионной матрицей этого распределения.
Стандартное много-
мерное нормальное
распределение
Многомерное нормальное распределение с ну-
левым вектором средних (/г = 0) и единичной дис-
персионной матрицей
Е = 1 =
1
0
0
1
называется стандартным; о соответствующем случайном векторе ( также го-
ворят как о стандартном нормальном векторе. В этом случае компоненты
этого вектора являются независимыми стандартными нормальными случай-
ными величинами, каждая из которых имеет плотность, указанную в (7).
Специальное линей-
ное преобразование
нормального вектора
В заключение отметим еще одно интересное
свойство нормального распределения. В алгебре до-
казывается, что любая симметрическая положитель-
но определенная матрица S может быть приведена
§ 1.-2. Основные абсолютна непрерывные модели
51
с помощью ортогонального преобразования, заданного ортогональной матри-
цей И (т.е. И~{ = и'), к диагональному виду:
WzEZ/ = A =
А|
где Xj > 0, j = 1, ,k, — собственные (или характеристические) числа Е.
Пусть теперь £(() = Л/Х/г, Е) и т/ = L('(. Тогда Е(^) = N(U'p, Л), т. е.
вектор т/ будет иметь уже некоррелированные (следовательно, и независимые)
компоненты. Далее, так как все Xj >0, то определена диагональная матрица
л-’/2 =
Рассмотрим теперь случайный вектор
Z = Л'1/2 (5 - U'fJ.) = A“l/2W'(e - /г).
Это будет также нормальный вектор с нулевым вектором средних (EZ = 0)
и дисперсионной матрицей Л“^2ЛЛ-1^2 = 1,т.е. Z_ — стандартный нормаль-
ный вектор. Таким образом, всегда можно указать линейное преобразование,
переводящее невырожденный (!) нормальный вектор в стандартный нормальный
вектор: для построения этого преобразования U надо решить линейную си-
стему Y,u_j = XjUj, j 1, ,k, для определения собственных векторов
и,, ,ик и собственных чисел Aj, , Хк дисперсионной матрицы Е, и то-
гда И = ||u, «JI.
Мы ограничиваемся этим минимумом сведений о многомерном нормаль-
ном распределении, ибо сказано: «Не пытайся объять необъятное — это не-
возможно!», и переходим к следующему (после нормального) по значимости
и широте применений непрерывному распределению, каковым является гам-
ма-распределение.
3. Гамма-распределение
Случайная величина £ имеет гамма-распределение с параметрами а и А (а > 0,
А > 0): £.(£) = Г(а, А), если ее плотность имеет вид
J.A Ig х/а
f(x\a, А) = < Г(А)аЛ
0
при х 0,
(18)
0 при х < 0.
Здесь Г(А) — гамма-функция, определяемая соотношением
Г(А) = А > 0.
(19)
4*
'ф. Показательное
распределение
52 Глава 1. Основные распределения и их моделирование
Полезно помнить следующие важные свойства этой функции:
Г(А + 1) = АГ(А), А > О, Г(1) = 1,
следовательно, Г(п + 1) = п\ для всех натуральных п; далее Г( 1/2) = %/тг,
следовательно, для всех натуральных п значение Г(п/2) также может быть
вычислено в явном виде; для больших значений А
Формула Стирлинга имеет место асимптотическая формула Стирлинга^:
Г(А 4- 1) ~ х/27гААЛе“Л
(напомним, что «~» есть символ асимптотической эквивалентности: а ~ &
при а, Ь -> оо, если а/b -> 1; формула Стирлинга, играющая исключительно
важную роль в математике, была доказана в 1730 г., она утверждает, что п!
приблизительно равняется /2тгп(п/е)п; независимо от Стирлинга и раньше
него формулу для факториалов п\ х с\^п(п/е)п открыл Муавр, Стирлинг же
нашел вид константы с = -/2д).
В представлении (18) а называется параметром масштаба, а А — пара-
метром формы. Частные случаи гамма-распределения Г(а,А) при некоторых спе-
циальных значениях этих параметров имеют свои названия. Так, при А= 1 рас-
пределение Г(а, 1) называется показательным (или экс-
поненциальным) распределением с параметром масштаба
а, а Г(1, 1) — стандартным показательным распределе-
нием: оно задается плотностью /(х| 1, 1) = е~х х 0.
Если п — натуральное число, то гамма-распре-
деление с параметрами а = 2 и А = п/1 называется
X2 -распределением с п степенями свободы и обознача-
ется Г(2, п/2) = Х2(.п)-
Наконец, при натуральных А Г(а, А) называется распределением Эрланга
порядка А. Это распределение суммы А независимых случайных величин с
одинаковым показательным распределением Г(а, 1).
Приведем также вид соответствующей характери-
стической функции
Ф4(0 = Ее1'*
(»>
и Е^6 = а6Г(А + 6)/Г(А) при b > - А, в частности,
Е4 = аА, D< = а2Л. (21)
Стирлинг Джеймс (1692-1770) — шотландский математик.
1
Распределение х
Характеристическая
функция и моменты
и моментов:
§1.2. Основные абсолютно непрерывные модели
53
Важным свойством гамма-распределения является его Свойство
воспроизводимость по параметру формы А: если слу-
v „ воспроизводимости
чайные величины A], , Х^ независимы и при этом
£(Xj) = Г(а, Xj), j — 1, , k, то
£(X[ + + Хп) — Г(а!, Al 4-... + А*).
Наконец, отметим следующее полезное свойство: если £(£) = Г(а, А),
то для любой постоянной с > 0 £(с£) = Г(со, А), в частности, если случай-
ная величина £ имеет стандартное показательное распределение Г(1,1), то
£(о£) = Г(а, 1) — это свойство используется в алгоритмах моделирования
(см. § 1.3).
Модель гамма-рапределения широко используется в задачах теории на-
дежности и теории массового обслуживания. Особую роль играет при этом по-
казательное распределение Г(а, 1). Этому распределению часто подчиняются
случайные длины интервалов между последовательными моментами наступ-
ления событий в, так называемых, пуассоновских потоках, времена «жизни»
различных технических устройств и т.д.
В задачах математической статистики гамма-распределение играет боль-
шую роль благодаря тесной связи с нормальным распределением, в частности,
там, где рассматриваются квадратичные формы от нормальных случайных ве-
личин. Наиболее ярким примером является %\п) = Г(2, п/2): это распре-
деление суммы квадратов X? + + Х„, где X,, ,Хп — независимые
стандартные нормальные случайные величины (см. упр. 38).
Другой важный результат состоит в следующем. Пусть (Хь ..., Хп) —
случайная выборка из нормального распределения 2V(/i, о2). Обозначим
п п
1=1 1=1
__ 2
Тогда величины X и S независимы и при этом Теорема Фишера
С(Х)=м(р,-\ a =/(„_!). (22)
\ П / \ О' /
Этот результат известен как знаменитая «теорема Фишера» (1925), и на нем
основывается огромное число важных результатов в статистике нормальных
моделей.
4. Бета-распределение
Бета-распределение Ве(а, Ь), а > О, Ь > 0, задается плотностью
/(z|a, b) — <
Г(а + Ь) а_
Г(а)Г(Ь)1
(1-г/-1
О
при 0 С х 1,
в остальных случаях.
(23)
54
Глава 1. Основные распределения и их моделирование
Если £(£) = Ве(а, Ь), то
Е£ =
а
о Ч- b
ab
(а + Ь)2(а + b+ 1)’
(24)
В случае, когда а = b = 1, бета-распределение Ве(1, 1) является равномерным
распределением на интервале (0, 1) (см. следующий пункт).
г Один из наиболее важных случаев возникновения
51 Связь с гамма- _ ’
бета-распределения выражается следующим утвержде-
распределением нием: если случайные величины Х\ и X? независимы и
имеют гамма-распределения Г(а, А|) и Г(а, А?) соответственно, то случайная
величина Y = Xt/(Xi + АГз) имеет распределение Ве(А|, Аз).
Отметим также, что нормирующий множитель в (23)
Г(о)ЦЬ)
Г(а + Ь)
- х)ь 1 dx
называется бета-функцией и обозначается
В(а, Ь) =
Г(о + Ь)
(отсюда и название распределения Ве(а, &)).
5. Равномерное распределение
Равномерное распределение И (а, Ь), -оо<а<Ь<оо, имеет постоянную плот-
ность на интервале [а, &]:
/(2j|a, b) = Ь - а
О
при а х Ь,
в остальных случаях.
(25)
Если £(£) = U(а, Ь), то
С \ 7—- ) = М(0, 1) = Ве(1, 1)
\ о — а/
а + Ь (Ь — а)2 , ,
= (26)
Равномерное распределение Ы(а, Ь) описывает процесс «выбора точки
наудачу» в интервале [а, Ь]. Так, если [а, 6] — интервал между последователь-
ными отправлениями автобуса от остановки, то время ожидания пассажира,
не знающего расписания и пришедшего на остановку, есть случайная вели-
чина с распределением И(а, Ь). Распределение Z7(0, 1) играет особую роль
в методах моделирования с помощью компьютеров случайных величин с за-
ранее заданными распределениями (об этом подробно будет идти речь в § 1.3).
§ 1.2. Основные абсолютно непрерывные модели
55
Такие методы широко используют для приближенных вычислений интегра-
лов, решения дифференциальных и интегральных уравнений и т. д. (см. также
пример 7 Введения).
6. Распределение Стьюдента
Стьюдент (Student) — псевдоним английского статистика Уильяма Д. Госсета,
впервые использовавшего это распределение в 1908 г. С 1899 г. он работал в
Дублине на пивоваренном заводе Гиннесса, и его начальник настоял на том,
чтобы Госсет писал под псевдонимом. По определению,распределениемСтью-
дента (синоним: t-распределение) с п степенями свободы S(n) называется рас-
пределение случайной величины (стьюдентова отношения)
tn = -?L=, (27)
VXn/n
где случайные величины ( и независимы и при этом £.(£) = _Л/(0, 1), а
£(Хп) = х\п)- Плотность f(x\n) этого распределения имеет вид
г/71 + Л
1 \ 2 / / Г2\ -(п+0/2
f(x\n) — —=-------,—г— (1-1-----I -оо < х < оо. (28)
yfim ^(п\ \ п)
\2 J
Приведем типичный статистический пример, где Статистический
возникает это распределение. Пусть (Tj, , Хп) — пример
случайная выборка из распределения Л/(й|, в]) (т. е. рас-
сматривается нормальная модель с неизвестными средним значением и дис-
персией). Тогда в силу теоремы Фишера (см. (22)) стьюдентово отношение (27)
примет вид
tn- 1 —
X -ffl
(29)
и при этом tC(tn-i) = S(n - 1) (независимо от значения неизвестных пара-
метров!).
Если случайная величина X имеет / -распределение S(n), то при п > 2
ЕЛ -0 и DX =------.
п - 2
(30)
В случае, когда п = 1, /-распределение называется рас-
пределением Коши7) — это распределение отношения
Распределение
Коши
7* Коши Огюстен Луи (1798—1857) — французский математик, иностранный почетный член
Петербургской АН (1831). Один из основоположников теории аналитических функций.
56
Глава 1. Основные распределения и их моделирование
двух независимых стандартных нормальных величин, оно имеет плотность
= — -------г, -оо < х < оо, (31)
7Г 1 + xz
его характеристическая функция есть Ф(4) = е-'4' и для него не существуют
моменты, в том числе и математическое ожидание.
Распределение Коши интересно своими связями с другими распределе-
ниями, возникает в некоторых физических задачах, связанных с блужданием
частиц, имеет ряд оригинальных аналитических свойств. Например, по зако-
ну Коши распределена функция tg ту, где случайная величина т) равномерно
распределена на интервале [-тг/2, тг/2].
7. Распределение Снедекора
По определению, распределением Снедекора спит степенями свободы (обо-
значается S(n, ттг)) называется распределение случайной величины
Хп X™ = ™ X"
П 771 п Хт ’
где случайные величины Хп и Хт независимы и име-
” ^распределен neJJ ют х -распределения спит степенями свободы соот-
ветственно. Часто это распределение называется также
F-распределением или распределением Фишера.
Плотность /(т|п, т) распределения S(n, т) имеет вид
/ п + 771 \
п/2 П ) —n/2-l
____1 - L__________z__________ х > о гзз)
j,/7l\^/7n\ (1 + пх/т)<-п+т^2 ’
\2 /г\7 J
и /(т|тг, ттг) = 0 при
Это распределение играет в статистике важную
Статистический роль, так как отношение некоторых независимых квад-
пример ратичных форм от нормальных случайных величин под-
чиняется F-распределению. Вот один из соответству-
ющих примеров.
Пусть (.¥[...Хп) — случайная выборка из нормального распределения
а2), а (У[,..., Кп) — независимая с первой случайная выборка из рас-
пределения Тогда При 71 2, 771 2 И ЛЮбЫХ Д], и <т2
отношение
Г—= "2--------- (34)
§ 1.2. Основные абсолютно непрерывные модели
57
будет иметь распределение S(n - 1, т - 1), что следует из теоремы Фишера
(см. (22)).
Среднее и дисперсия случайной величины Fn<m имеют вид (при т > 4)
_ т 2т2(п + т - 2)
EE’n.m ’ « и ,т = •
т-2 п(т-4)(т —2)2
8. Распределение Вейбулла
Распределение Вейбулла W (а, а, Ь) зависит в общем случае от трех параметров:
параметра сдвига (положения) а € п, параметра формы а > 0 и параметра
масштаба & > 0 и задается функцией распределения
Г fx-a\a)
F^(x) = 1 — exp < — I —-— I >, x a (36)
(F^(x) = 0 при x < а). Здесь
/ 1 \ ,Г / 2\ , ( 1
E£ = a + ЬГ 1 + - и D£ = b2 Г 1 + - - Г 1 + -
\ a / \ a / \ a
(37)
Частный случай W(a, 1,&) известен как двухпараметрическое показатель-
ное (экспоненциальное) распределение, а W(а, 2, &) — как распределение Релея.
9. Распределение Парето
Случайная величина £ имеет распределение Парето^ с параметрами х$ и а
(xq, а > 0), если ее плотность такова:
/(фо, а) =
при х До.
(38)
О
в остальных случаях.
Это распределение применяется в качестве подходящей модели для широкого
класса эмпирических наблюдений, относящихся, например, к распределению
дохода, размера городов или частоты слов в языке.
Если в (38) а > 2, то справедливы следующие формулы для первых двух
моментов:
и D{ =
а — 1
(39)
10. Распределение Дирихле
Распределение Дирихле^ D(a), где а = (оц,..
параметрический вектор, задается плотностью
,, । \ Hai + + ah) а
№|а) - Г(а,)...Г(а,>
,k, -
xk
x = (xi, ,xk)€E,
(40)
Парето Вильфредо (1848-1923) — итальянский экономист и социолог.
9) Дирихле Петер Густав (1805-1859) — немецкий математик.
58
Глава 1. Основные распределения и их моделирование
где Е — единичный симплекс:
Е = {д i = 1, , к, X} + +14 = 1}.
Сравнение формулы (40) с формулой (23) для плотности бета-распреде-
ления показывает, что распределение Дирихле при k = 2 сводится к бета-
распределению, поэтому распределение D(a) иногда называют многомерным
бета -распределением.
Если £(£ = (£i,..., £*)) = D(a), то первые и вторые моменты случай-
ного вектора £ имеют вид (далее обозначено а = aj + + ак).
Qi аДа - а,)
Е£,- = —, D£, =
а а2(а + 1)
cov(£i, £j) = -
(41)
при этом £(£|) = Ве(а,, а - а,) (см. п. 4), i = 1, , к.
Замечание. Обратим внимание на то, что в данном случае координаты вектора £ свя-
заны линейным соотношением £ + .. • +£* = 1, из которого одна из них, скажем £*,
может быть выражена через остальные: £* = I -£> -.. —£i-i Если, в соответствии
с этим, в (40) переменную I* записать как 1 -Х|—.. ~хк_1 , то f(x\a) будет обычной
(к— 1)-мерной плотностью распределения случайного вектора (£|,... ,£*_,), которая
положительна в тех точках симплекса S С Я*”1, где 0 С х, С 1, i = 1,.. , к - 1,
и 0 < Xi + + xt-i С I. Именно при такой интерпретации формулы (40) мы по-
лучаем при к = 2 представление (23). Далее, так как интеграл от плотности f(x\a)
по симплексу S должен быть равен I, то мы получаем формулу
[ х?• - - z£'(1 -1, - ... - )“‘-1 dx}... dxk., = , (42)
J r(ai + ... + at)
s
Формула Дирихле
известную в анализе как формула (интеграл) Дирихле (этот
интеграл был впервые исследован П. Дирихле в 1839 г.
и этим объясняется название распределения D(a)).
11. Преобразования случайных величин и векторов
Мы завершаем разговор об основных вероятностных распределениях техни-
ческим, но совершенно необходимым для последующего разделом, в котором
мы напомним некоторые формулы из теории вероятностей, которые часто ис-
пользуются для нахождения явного вида распределений при преобразованиях
случайных величин. Выше мы уже встречались с примерами таких преобра-
зований. Так, в п. 2 мы установили, как вычислить распределение линейно
преобразованного нормального случайного вектора. Но есть и задачи (с ними
мы встретимся тоже), в которых необходимо иметь дело с преобразованиями
не линейными, а более сложными, как говорят, функциональными. Поэтому,
хотя соответствующие формулы гораздо сложнее, но без них нам не обойтись,
и мы их здесь приведем для последующих ссылок на них.
§ 1.2. Основные абсолютно непрерывные модели
59
Начнем с простейшего случая сдвиг-масштабного пре- Сдвиг-масштабное
образования случайной величины Пусть £ имеет не- преобразование
прерывную функцию распределения F^(x) = Р{£ х}
Рассмотрим произвольное линейное преобразование 1] = а( + Ь, где а > О,
b G R1 Тогда очевидно, что функция распределения преобразованной слу-
чайной величины г) равна
Если, как и выше, через f(x) обозначать плотность исходной величины £
(/(i) F^(i)), а через д(х) — плотность преобразованной величины г)
(д(х) = , то в терминах плотностей предыдущее запишется так:
(43)
В этом случае Ь называют параметром сдвига (положения), а — парамет-
ром масштаба. В статистических задачах часто считается, что исходная плот-
ность f нам известна, а параметры а и b (или один из них) неизвестны,
такую модель (43) называют сдвигомасштабной: в этом случае наблюдаемая
случайная величина г) предполагается полученной с помощью некоторого
линейного преобразования над «стандартной» случайной величиной £, рас-
пределение которой полностью известно. Таким образом, сдвигомасштабная
модель является специальной формой общей параметрической модели. При-
мерами сдвигомасштабных моделей являются нормальная модель ^(р, <т2)
(здесь а = а, b — р, а стандартным является распределение ЛГ(0, 1), зада-
ваемое формулами (7)), показательная модель Г(а, 1) (здесь имеется только
один параметр масштаба а, а стандартным является распределение Г(1, 1),
определенное в п. 3), равномерное распределение W(a, Ь) (здесь «стандартом»
является Z7(0, 1)) и т. д. Сдвигомасштабные преобразования часто использу-
ются в задачах теории вероятностей и математической статистики.
Перейдем теперь к общему случаю произвольного Общее
функционального преобразования. Пустьслучайный век- 4lvu,„unur,ni.Unp
тор X = (Х{, , Хк) имеет абсолютно непрерывное преобразование
распределение с плотностью f(x), х = (х\......хк) 6
G S С Rk и fo = (hi, •.., hk) S -> Rk — произвольное взаимно однозначное
и гладкое (т. е. все частные производные dhi(x)/dxj непрерывны) преобра-
зование, якобиан которого
cMi(i)
дХ[
dhk(x)
dxi
J (x) = det
<9/l|(l)
dxk
dhk(x)
dxk
60 Глава 1. Основные распределения и их моделирование
не обращается на 5 в нуль. Тогда плотность распределения преобразованного
случайного вектора Y = h(X) = (Л|(Х), , ЛДХ)) имеет следующий вид:
/(Л-|(у))
г=(’ь 's,)em (44)
где Л 1 — обратное к h преобразование: Л 1 (ft(i)) = х.
Частные случаи Эта «страшная» (в силу своей общности) формула
на самом деле чаше всего применяется в более «про-
зрачных» частных случаях, два из которых мы выделим особо. Если k = 1, то
речь идет о преобразовании случайной величины: Y — h(X), где h(x) — вза-
имно однозначная гладкая функция с необращаюшейся в нуль производной.
В этом случае формула (44) для плотности Y принимает вид
9{у) |Л'(Л-'НГ
(45)
Линейное ЧЧЯИ Для случая линейного преобразования: Y = АХ. + Ь
преобразование при IА| = а. 0 формула (44) конкретизируется к виду
/(Л~'УИ) (44)
(для одномерного случая k = 1 формула (46) сводится к (43)).
Эти два случая (k = 1 и линейное преобразование) чаще всего и встре-
чаются в приложениях. В заключение приведем два иллюстративных (но по-
лезных для дальнейшего) примера использования этих формул.
Пример 1. Пусть £(£) — Щ0, 1), т. е. £ имеет стандартное равномерное рас-
пределение, и у = - In4- Здесь f(x) = 1, хЕ (0,1), h(x) = - Inrr, h'(x) =-\/x,
h~l(y) = e~y у > 0, поэтому по формуле (45) плотность преобразованной
случайной величины у есть е-у, у > 0. Таким образом, в данном случае
£(tj) = Г(1, 1), т.е. у имеет стандартное показательное распределение. Этот
факт используется при моделировании показательного распределения, о чем
будет идти речь в следующем параграфе. •
Получение нормальных Пример 2 (Немного более сложный, но поучи-
случайных величин тельный и очень полезный!). Пусть случайные
(из равномерных величины X, и Х2 независимы и <С(Х;) = W(0, 1),
i = 1,2. Рассмотрим их преобразование
У| = д/-21п X] sin (2тгХ2), = д/-2 In cos (2тгТ2) (47)
и найдем распределение пары Y = (Yh Y2). Здесь
У\ = Л] (i], i2) = xj-1 In Х\ sin (2тгге2),
У2 = х2) = х/ In xt cos (2тггг2),
(xitx2) е (о, i)2,
§ 1.2. Основные абсолютно непрерывные модели
61
и все условия применимости формулы (44) выполнены. Имеем
dhi(11,1г) Sin (27Г1г)
дх\ Xi у/—2 In ’
dh,i(x\,x-l') cos (2тгх2)
Эхi hy/-2 In ’
dhi(xit i2) л—--------------
----------- = 2тг V-2 In 2?! COS (27ГТ2),
dxz
дГ12(Х1,Х2) /—----- .
----------- = -2ТГ\/-21П E| Sin (27Г1г),
откуда находим якобиан J(ib 12) нашего преобразования: это определитель
J(ll,l2) = sin (2irx2) i,y/-2 In ii
2тг\/-2 In i) cos (2iri2)
COS (27Г1г)
iiV~2 In г.
-2тг-^/-2 In X[ sin (2тг1г)
2 ar
Поскольку совместная плотность пары (Xj, Х2) в данном случае есть произ-
ведение равномерных плотностей на интервалах соответственно 0 < xt < 1
и 0 < Х2 < 1, то /(11,12) = 1, (11,12) £ (0, 1)2> и в силу 04) плотность
g(yi,y2) преобразованной пары (Ki.Y)) есть ii/2ir Осталось выразить iq
через (уь у2). В данном случае это очень просто, так как у нас
У1 +У2 = - 2 In ij.
Отсюда
I, = ехр|-|(у? + у22)
и окончательно получаем, что искомая плотность имеет вид
0(У1,Уг) = т-ехр/-^(у? + У22)}, (У1,Уг) е я2
27Г ( 2 )
Но это есть двумерная стандартная нормальная плотность (см. п. 2), т. е.
Y = (УьУ2)
является стандартным нормальным случайным вектором (его компоненты
независимы и £(Xi) = V(0, 1), i = 1,2).
Таким образом с помощью «хитрого» преобразования (47) мы можем по-
лучать из независимых стандартных равномерно распределенных случайных
величин (т. е. в определенном плане — простейших случайных величин) неза-
висимые же стандартные нормальные случайные величины. Этот факт также
используется в алгоритмах статистического моделирования (см. следующий
параграф). •
62 Глава 1. Основные распределения и их моделирование
Замечание. В связи с последним примером обратим внимание заинтересованного
читателя на следующий нюанс. В данном случае нам не потребовалось вычислять
полностью обратное преобразование h~’(t/), т. е. находить обе обратные функции
г, = , У1) и поскольку плотность f здесь постоянна, а якобиан
J(Xi, Хг) зависит лишь от г,, то достаточно знать лишь первую обратную функцию
г, = х 1 (j/j, j/з)• Подобное обстоятельство встречается достаточно часто в задачах,
связанных с использованием формулы (44). Поэтому в конкретных задачах не надо
торопиться вычислять h~'(y): сначала надо вычислить якобиан J(x) и получить
явное выражение для /(г)/|/(г)|, а затем, в зависимости от вида этого выражения,
уже решать задачу его представления через новую переменную у В общем, как
говорили наши умные предки: «Festina lente» — торопись медленно (Октавиан Август
(63 г. до н.э. - 14 г. н. э.), римский император).
Дальнейшие свойства рассмотренных конкретных вероятностных распре-
делений (как точные, так и асимптотические), а также связи между ними
обсуждаются в упражнениях в конце главы.
§ 1.3. Моделирование выборок
из конкретных распределений
Точность результата не может быть
выше точности исходных данных.
Для изучения и практической иллюстрации эффективности различных стати-
стических процедур необходимо иметь наборы конкретных эксперименталь-
ных данных, которые можно было бы рассматривать в качестве реализаций
некоторой случайной величины ( с известным законом распределения £(£).
Обрабатывая эти данные по соответствующему статистическому алгоритму,
мы в этом случае получаем возможность сравнить предсказание теории с из-
вестными нам параметрами этого распределения и тем самым «подвергнуть
теорию практической проверке». Такой «игровой» элемент при организации
практической работы по статистической обработке данных повышает инте-
рес и к изучению самой теории статистического вывода. Для получения таких
исходных данных (выборок) широко используется метод статистического мо-
делирования, с помощью которого, используя современные компьютеры, мож-
но быстро «смоделировать» выборку X = (Xb. , Хп) из любого заданного
распределения £((). Описанию соответствующих алгоритмов моделирования
и посвящен настоящий параграф.
1. Предварительные замечания
Обычно для получения реализации последовательности независимых случай-
ных чисел с нужным нам распределением используют реализацию последо-
вательности независимых и равномерно распределенных на интервале [0, 1]
случайных чисел
Uo, Ы2, ...
(О
§1.3. Моделирование выборок из конкретных распределений 63
В свою очередь, для этого необходимо иметь практи- |||Я||Р;Датчики
чески неограниченный источник, вырабатывающий по- случайных чисел
следовательность (I), — датчик случайных чисел. В со-
временных компьютерах, как правило, имеются встроенные физические дат-
чики случайных чисел, принцип работы которых основан на использовании
в качестве источников случайности быстро флуктуирующих шумовых про-
цессов, вырабатываемых радиоэлементами. Отметим, что получаемые при
этом числа — дискретные по своей природе, так как принимают значения
в пределах разрядности компьютера (так, при двоичном представлении чисел
с N разрядами в ячейках случайное число может принимать 1N возможных
значений).
Однако, чаще всего в качестве чисел (1) используют, _
, ' ' Псевдослучайные
так называемые, псевдослучайные числа, т. е. детермини-
числа
рованные числа, получаемые по некоторому алгоритму
и обладающие в той или иной мере свойствами случайных чисел, так сказать,
«похожие» на них. Имеются различные методы получения псевдослучайных
чисел, наиболее известным из которых является так называемый линейный
конгруэнтный метод, в котором полагают Un = Zn/m, где {Zn} — последо-
вательность, определяемая рекуррентным соотношением
Zn+i = aZn + с (mod т), п = 0,1,2,
2о — начальное значение, а, с, т — натуральные числа (операция приве-
дения чисел по модулю (mod) означает, что если г = sm +1, 0 I < т, то
r(modm) = /). Числа {Un}, получаемые таким способом, конечно, не яв-
ляются случайными (они детерминированные), но при специальном выборе
констант а, с, т и Z(l свойства этих чисел «очень похожи» на свойства по-
следовательности (1) и потому их используют в качестве исходного материала
(т. е. в качестве последовательности (1)) для решения модельных задач, иллю-
стрирующих различные выводы теории. Приведем условия, которым следуют
при практическом выборе значений определяющих линейный конгруэнтный
метод констант:
1) сит — взаимно простые числа;
2) b = а — 1 кратно р для любого простого р, являющегося делителем т;
3) Ъ кратно 4, если т кратно 4.
Но «правильный» выбор этих констант еще не «гарантирует» хороших
свойств псевдослучайных чисел. Даже в датчиках, рекомендованных для ши-
рокого использования, нередко обнаруживаются существенные недостатки.
Поэтому «качество» псевдослучайных чисел требуется контролировать при
помощи различных статистических критериев (см. пример 7 Введения), об-
щая теория которых излагается в гл. 4 (см. п. 2 §4.5).
После этих замечаний перейдем непосредственно к алгоритмам моде-
лирования основных вероятностных распределений, описанных в предыду-
щих параграфах, считая, что в нашем распоряжении имеется неограниченная
64
Глава 1. Основные распределения и их моделирование
последовательность (1) «простейших» случайных величин с распределением
U(0, 1) (см. п. 5 §1.2).
2. Моделирование распределений Бернулли Bi(l, р)
и биномиального Bi(fe,p) (см. п. 1 § 1.1)
Чтобы получить реализацию бернуллиевской последовательности {2G, Хг,...},
где
Р{Хп = 1} = 1-Р{Х„ = 0}=р
при заданном р Е (0, 1), очевидно, достаточно положить
Xn=I(Un^p), п=1,2,
(здесь и далее везде 1(A) обозначает индикатор события Л, т. е. 1(A) = 1,
если А имеет место, и 1(A) = 0 в противном случае). Действительно, незави-
симость случайных величин {Хп} обеспечивается независимостью исходных
величин {£/п} и
Р{ХП = 1} = Р{£/п < р} = р для любого п = 1,2,
Имея последовательность Бернулли {2ГП} легко смоделировать выборку
из биномиального распределения Bi(fc, р). Именно, поскольку
0X1+ + Хк) = Bi(fc,p),
то положив
Xj = -Хо-1)*+1 + + j = 1, , n,
получим реализацию выборки (Xj, , Х'п) объема п из распределения Bi(fc,p).
3. Моделирование отрицательного
биномиального распределения Bi(r, р) (см. п. 2 § 1.1)
Поскольку число единиц до первого нуля в последовательности Бернулли {JTn}
имеет геометрическое распределение Bi(l,p), то, положив Y — min{j О
Xj+i = 0}, будем иметь C(Y) = Bi(l,p). Отсюда следует, что алгоритм мо-
делирования выборки (Уь , Уп) из распределения Bi(l,p) можно задать
формулами
Y, = min{y > 0 A'yi l+j-+i = 0}, г = 1, , п, Уо = 0.
Далее, поскольку _
£(У,+ + Уг) = Bi(r, р)
(свойство воспроизводимости отрицательного биномиального распределения),
то смоделировать выборку (У/,. , Y„) из распределения Bi(r,р) можно
(как и выше для биномиального распределения) по формулам
Yj — Y(j-i)r+1 + + Yjr, j1 = 1, ,n,
т. e. просуммировав числа {У} последовательными группами по т подряд иду-
щих чисел.
§ 1.3. Моделирование выборок из конкретных распределений 65
4. Моделирование полиномиальных испытаний (см. п. 6 § 1.1)
Пусть требуется смоделировать п независимых наблюдений над дискретной
случайной величиной £ с распределением
pR = O=?i. *=>. >N (pi + +pn = О-
Разобьем отрезок [0, 1] на N интервалов Si, ,S^, где
= [0,Pi], £(=(Р1+ +pi-i,pi+ +р(], 1 = 2, ,N
(так что Si имеет длину pi, I = 1, , N), и положим
N
Xi = е Si), i=\, ,п. (2)
i=i
Так как X, определяется только через W,, то случайные величины {JT,} неза-
висимы и одинаково распределены, а
Р{*. = 1} = p{Ki е Si] = |£(| = pi,
т. е. они распределены так же, как Таким образом, (X], , Хп) — выборка
из £(£).
Замечание. В случае произвольных исходов ah ,aN случайную величину JC, сле-
дует определить по формуле
N
Xi = 52 aiHUi € £0.
i=i
5. Моделирование пуассоновского распределения П(А) (см. п. 3 § 1.1)
Установим предварительно следующий факт.
Лемма. Определим случайную величину £ равенством
( J у
£ = max< j PJ Ui е-А >, А > 0.
'1=1 '
Тогда £(£) = П(А).
Доказательство. Перепишем определение £ в эквивалентном виде
f i >1
£ = max < j ^2 In Z7, А >
* i=l '
(при j = 0 пустая сумма, как это обычно принято, считается равной 0, а пустое
произведение полагается равным 1). Тогда события
х т х
{£ < т} и < - In Ui > А >,
t=i '
5 Заказ 1748
66
Глава 1. Основные распределения и их моделирование
очевидно, эквивалентны. Далее, в примере 1 в § 1.2 было показано, что
£(- Ini/,) = Г(1, 1)
— стандартное показательное распределение, а по воспроизводящему свойству
гамма-распределения (см. п. 3 § 1.2)
£.( ^InZ/i') = Г(1,т)
' i=i '
— распределение Эрланга порядка т, поэтому (см. (18) § 1.2)
с т з 1 /* аг
Р{£ < т} = £ ЩИ, > Л) = —J У-'е-dx = £ е А-,
т 1.
Но это и означает (см. (8) § 1.1), что случайная величина ( имеет распреде-
ление П(А).
Из этой леммы следует, что выборку (Хь , Хп) из распределения П(А)
можно смоделировать по формулам
f j х
Tfc = max<j е-А >, k= 1,2, , п, Ха = 0. (3)
6. Моделирование непрерывных распределений
Для моделирования случайных величин с непрерывным распределением в
ряде случаев можно использовать следующий простой факт: если F(x) —
непрерывная и строго монотонно возрастающая функция распределения и
F~\y) — обратная к ней функция (F~'(F(x)) = х), то для случайной вели-
чины у = F~'(U), где £(U) = Z/(0, 1), имеем
Р{т? sj i} = P{U F(x)} = F(x).
Таким образом, случайная величина у = F~'(U) имеет функцию распределе-
ния F(x), и если обратная функция F~l(y) может быть явно вычислена, то
F~[(Ui), i = 1,..., n, — выборка из распределения F.
Замечание. Если функция F(x) не является строго монотонной, то вывод остается
в силе, если под обратной функцией понимать
F~'(y) = sup{x . F(x) < j/}.
Заметим еще, что если (X;, г = 1,...,тг) — выборка из непрерывного
распределения F(x), то (аХ, + 6, i = 1, , п), где а > 0, b € R1, будет вы-
боркой из распределения сдвигомасштабного типа F((x-b)/a) (см. п. 11 § 1.2
§ 1.3. Моделирование выборок ив конкретных распределений 67
соотношение (43)). Так, например, (alii +b. i = 1,... , п) — выборка из рав-
номерного распределения И(Ь, а 4- Ь), а если £(Х,) — _Л/(0, 1), т. е. {X,} —
стандартные нормальные числа, то £(aXi+p.) = <т2); в частности, чтобы
смоделировать выборку из распределения Коши (см. (31) § 1.2), надо положить
Xi = tg ^7rW,- - = - Ctg (тгЦ), 2 = 1, , n.
7. Моделирование показательного
и связанных с ним распределений (см. п. 3 §1.2)
Чтобы смоделировать выборку (Х|....Хп) из показательного распределения
Г(а, 1), надо положить X, -а In ЭД, i — 1, , п. Суммируя полученные
числа по т штук: У, = Х| +... + Хгп, У2 = Хт+| + -- + Х2т, .получим
выборку из распределения Эрланга Г(а, т).
8. Моделирование нормальных случайных чисел (см. п. 1 § 1.2)
Большое число статистических задач связано с анализом выборок из нормаль-
ного распределения ст2), при этом (см. замечание в п. 6) достаточно уметь
моделировать выборки из стандартного нормального распределения .V(0,1)
(см. (7) § 1.2). В данном случае явной формулы для обратной функции Ф-1(у)
к стандартной нормальной функции распределения не существует, поэтому
описанный в п. 6 алгоритм моделирования непригоден. Один из методов полу-
чения стандартных нормальных случайных чисел из равномерных (1) состоит
в построении соответствующего явно вычислимого функционального преоб-
разования. Пример такого преобразования нам уже встречался в примере 2
в § 1.2 (см. там соотношения (47)). Из полученного в этом примере результата
следует, что каждая пара (ЭД*_|, ЭДь)» к = 1,2,..., чисел последовательности
(1) с помощью преобразования
X^-j = x/-l\nU2k-} sin (2ttW2a..),
,------------------ <4)
X2k = V~21nW2*:-l COs(27TZ4t)
порождает пару (X22:_|, X22;) независимых стандартных нормальных чисел.
Другой путь получения нормальных чисел из последовательности (I) рав-
номерных чисел основан на использовании центральной предельной теоремы
теории вероятностей (см. соотношение (1) § 1.2). В соответствии с этой тео-
ремой можно положить (см. формулы (26) § 1.2, в соответствии с которыми
ЕЭД = 1/2, ПЭД = 1/12)
Ца-|)у+|+ + Ukji-N/1
=-----------’ k = '2' (5)
Этот алгоритм, очевидно, легче реализуем, чем предыдущий, однако он при-
водит лишь к приближенно нормальным числам, так как лишь в пределе при
5*
68
Глава 1. Основные распределения и их моделирование
/V —> оо распределение случайных величин -Хдгк будет стандартным нор-
мальным A/"(0, 1). Но практически удовлетворительное приближение к рас-
пределению Л'(0, 1) получается уже при N = 12 — это значение параметра N
в алгоритме (5) обычно и используют для конкретных вычислений.
9. Метод суперпозиций
В ряде случаев моделируемое распределение может быть представлено в виде
смеси более простых распределений, и тогда для моделирования такого рас-
?СМеси пределения может быть использован метод суперпози-
ций, описанию которого посвящен данный пункт. Но
„распределении., ,
сначала дадим определение смеси.
Пусть рк 0, ^2 Рк = ь Рк(х) — некоторые функции рас-
к
пределения. Тогда функция распределения
Определение
= 52
к
называется смесью функций Fk(x) с весами рк.
Аналогично определяется смесь распределений в терминах плотностей.
±F (z) _!_1 -J 2 Пример 1. Функция распределения f z/2, 0 х < 1, = ) 1 >i 1, z 1,
1 ъ (см. рис. 1) является смесью с весами 1/2 функций
Рис. 1 распределения равномерного 2/(0, 1) и вырожденного в точке х = 1 распределений. •
Пример смеси Пример 2. Пусть распределение на [0, 1] задано плот- ностью вида дх) = 52акхк с ак °- А:=0
Тогда так как L 00 / Дд) dx = = 1,
то положив рк = ак/(к -I- 1), будем иметь
00
/(z) = ^2pk(k+ l)z*.
к=0
§ 1.3. Моделирование выборок из конкретных распределений
69
Но
(k + l)ifc = f(x\k + 1, 1)
— плотность бета-распределения (см. (23) § 1.2), следовательно,
Л®) = ^Pkf(x\k + 1, 1),
*=о
т. е. такое распределение представляет собой смесь бета-распределений
Be(fc + 1, 1) с весами рк = Лк/{к + 1). •
Теперь, чтобы смоделировать случайную величину,
функция распределения или плотность которой явля-
ются смесью, можно использовать метод суперпозиции:
Метод
суперпозиции
1) разыграть значение дискретной случайной величины, принимающей зна-
чение к с вероятностью рк, к = 0, 1,. (как в п. 4), допустим, что при
этом было получено значение &о;
2) смоделировать случайную величину с функцией распределения Ft,, (плот-
ностью fk„) некоторым способом (скажем, методом обратной функции,
см. п.6).
Для произвольной непрерывной плотности /(х), заданной на отрезке [0, 1],
можно использовать способ приближенного моделирования методом суперпо-
зиции, основанный на аппроксимации полиномами Берн- Полиномы
штейна Бернштейна
fn(z) = ^f(-\c*xk(\-x)n-k
Основой для этого служит известная в анализе
Теорема Вейерштрасса Если функция /(х) непрерывна на [0, 1],
то fn(x) —> f(x) равномерно по х при п —> оо.
По этой теореме непрерывную на отрезке [0, 1]
плотность /(х) можно равномерно приблизить плот-
ностями — нормированными полиномами Бернштейна
fn(z) =
fn(x)
где dn
Применение
теоремы
Вейерштрасса
0
Бернштейн Сергей Натанович (1880-1968) — советский математик, академик АН СССР,
выдающийся специалист по теории дифференциальных уравнений, теории приближения функ-
ций многочленами и теории вероятностей.
Вейерштрасс Карл Теодор Вильгельм (1815-1897) — немецкий математик, выдающийся
специалист по математическому анализу, теории функций и линейной алгебре. Почетный член
Петербургской АН (1864).
70 Глава 1. Основные распределения и их моделирование
так как из равномерной сходимости fn(x) к /(i) следует сходимость
।
dn -> У /(i) dx = 1 при п -> оо.
о
Для моделирования случайной величины £„ с плотностью /п(т) методом
суперпозиции представим fn(x) в виде
Здесь в квадратных скобках стоит плотность f(x\k + 1, п - к + 1) бета-рас-
пределения Be(fc -Н, n - ft + I) (см. п. 4 § 1.2), поэтому
о
f(k/n)
dn(n+ 1)’
откуда
dn
1
fe+ 1
Следовательно, положив
Рк = f
получим представление
п
fn(x) = Pkf(x\k 4- 1, п - к + 1),
к=0
которое позволяет применить метод суперпозиции для моделирования слу-
чайной величины £п
10. Моделирование цепи Маркова
Методом статистического моделирования можно моделировать и зависимые ис-
пытания с различным характером зависимости. Мы рассмотрим для иллюстра-
ции простейший тип стохастической зависимости — марковскую зависимость.
Напомним, что последовательность случайных величин (vt,f = 0, 1,2, },
принимающих значения из конечного множества £. = {1,2, ,7V}, назы-
ваемого пространством состояний, является цепью Маркова, если для любого
t = О, 1,2,... распределение вероятностей случайной величины ixt+\ зависит
лишь оттого, какое значение приняла предыдущая величина щ, и не зависит
от более ранних величин vT, т < t. Формально это можно выразить через
условные вероятности так:
P{i/t+I =it+l^r = »т, т t} = P{j/(+i = =ij, it,it+iE£. (6)
§ 1.3. Моделирование выборок из конкретных распределений
71
Если при этом вероятности в правой части (6) не зависят от «времени» t,
то цепь Маркова называется однородной. Обычно рассматривают только од-
нородные цепи, которые являются подходящей моделью многих случайных
явлений; такую модель ввел в 1907 г. А. А. Марков, именем которого она
и называется.
Если для однородной цепи Маркова {р;} обозначить вероятность пере-
хода из состояния г в состояние j через
Pij = рКн = = 0, 1-) € £, (7)
то эти числа образуют матрицу переходных вероятностей Р = Нр^НГ, элемен-
ты которой обладают следующими свойствами:
N г
1-1 \т Стохастическая
РО 0. 2^ Р'З ~ 1 ~~ матрица
такая матрица называется стохастической. Чтобы полностью определить цепь
Маркова, надо еще задать вектор начальных вероятностей р = (р1,... ,рм),
где Pi = P{mq = i}, * = 1...N. Зная вектор р и матрицу Р можно легко
вычислить совместное распределение величин i/q, ...vT при любом Т:
Р{мо = i0, Р| = v2 = i2, Vt = ir} = Pi^i^ii PiT., (8),
Пусть теперь требуется смоделировать реализацию
однородной цепи Маркова {м(, t = 0, 1, , 7} с про-
извольной стохастической матрицей переходных веро-
ятностей р = НроНГ и вектором начальных вероятностей р = (рь. ,рл).
Для этого мы используем модифицированный алгоритм моделирования поли-
номиальных испытаний (см. п. 4). Именно, построим сначала систему разби-
ений отрезка [0, 1] на N интервалов в соответствии с вектором р и строками
матрицы Р:
£(0) = ...,£^}, £(<) = {£I(i),...,£j})}, i = \,...,N,
где |£]°*| = pj, |£^| = pij, j = 1, ,N, и определим случайные величины
C(V) = £ jl(U Е £<0)), <W(W) = £ Д(М Е
j=i j=i W
i = l, ,N,
где случайная величина U равномерно распределена на отрезке [0, 1].
Так построенные случайные величины (дзета) будут иметь распреде-
ления на множестве £ = {1,2, ...,7V}, задаваемые соответственно вектором
р и соответствующими строками матрицы Р:
РК(0) = Я = Р>- p{<W=j}=P^ i=l,...,N.
Моделирование
МН цепи
72
Глава 1. Основные распределения и их моделирование
После этого уже можно моделировать цепь с использованием случайных
чисел (1) по следующему алгоритму:
м0 = C(0)(Z/o),
ui = = C,(VT-'\UT).
Действительно, здесь
Pb = j} = P{C(0)=>}=Py
и
P{"t+i = з\У1 = 0 = PR(,) = Я = Pij,
что и требовалось.
Примеры модели- Пример 3 (Случайное блуждание с поглощением).
рования цепи Частица, стартуя в момент i = 0 из точки fc, 0<k<N,
блуждает по целым точкам отрезка [О, 7V], Пусть St —
положение частицы в момент t = 0, 1,2 (So = k). Если в момент t ча-
стица находилась в точке I (St = I) и при этом 1 С I С N 1, то в
следующий момент t + 1 она может оказаться в точке I + 1 с вероятностью
p(P{S(+i = f+l|S/ = Z} = р) и в точке Z-1 с вероятностью q = 1 - p(P{S(+1 =
= I — 1|S/ — 1} = q); в точках 0 и N частица поглощается и блуждание пре-
кращается (P{Si+i = 0|5г = 0} = P{S(+| = 7У|5г = N} 1). Здесь мы
имеем однородную цепь Маркова {St, t = 0, 1, 2, ..} с пространством состо-
яний {0, 1, 2, , N}, вектором начальных вероятностей р = (0 010 0),
где 1 стоит на (fc+ 1)-м месте, и матрицей переходных вероятностей Цр^-Ц^,
В которой Poo = PNN = 1. Pi,i + l = Р, Pi,i-l = <7> ЕСЛИ 1 С I С N - 1, И pi} = 0
при |г - ;| > 1.
Таким образом, блуждание частицы по целым точкам отрезка [0, 7V] с по-
глощением на концах описывается указанной специальной цепью Маркова.
Чтобы смоделировать такое блуждание, надо положить So = k, St+\ =St+Xt+]
до тех пор, пока 0 < Sz < N, где Х<+1 = 1, если Ut+\ р, и Xf+I = -1,
если Ut+\ > Р\ если же St впервые станет равным 0 либо N, то процесс
прекращается. •
Пример 4 (Случайное блуждание с отражением). Пусть переходные вероят-
ности Pi,i+i, Pi,i-i для 1 < г < TV - 1 и pi j для |г - j| > 1 остаются теми же
самыми. Если определить еще poo = q, Poi = Р, Pnn = р, Pn,n-\ = Ч> то
полученная цепь Маркова описывает блуждание частицы по целым точкам
отрезка [0,7V] с отражением на концах. Моделирование такого блуждания
отличается от предыдущего случая только в конечных точках: при St = 0
полагаем S;+i = St + -Aj+i = X;+i, где
( 1, если Ut+\ С р,
^t +1 In 7 /
( 0, если Ut+\ > р,
§ 1.3. Моделирование выборок из конкретных распределений
73
а при St = N полагаем 5f+1 = St + Xt+i = N + T<+i, где
( 0, если Ut+\ р,
-^i+i — I
( если Ut+\ > р. •
11. Метод Монте-Карло
Отметим еще один круг задач, при решении которых можно эффективно ис-
пользовать реализации случайных испытаний. Речь идет о, так называемом,
методе Монте-Карло, или методе статистических испытаний (его название
происходит от города Монте-Карло в княжестве Монако, знаменитого свои-
ми игорными домами). Этот вычислительный метод часто используется при
отыскании значений различных величин (определяемых, например, некото-
рыми уравнениями или интегралами), когда этим величинам можно при-
дать вероятностную интерпретацию. Сущность метода Монте-Карло состоит
в следующем: исходя из смысла вычисляемой величины а, подбирают такую
случайную величину £, чтобы ее среднее значение совпадало с а: Е£ = а.
Далее моделируют выборку (Хь , Хп) из распределения £(£) и в качестве
оценки для а используют выборочное среднее
X = -(%,+ +ХП).
п
Обоснованием этого метода служит следующее
Утверждение. Пусть , Хп — независимые наблюдения над случайной
величиной £, Е£ = a, D£ > 0 и Е£4 < оо. Тогда распределение случайной ве-
п
, сходится при п —> 00
1=1
к стандартному нормальному распределению //(0,1) (см. упр. 44 к гл. 2).
Отсюда следует, что если 7 — заданное число, близкое к 1 (0 < 7 < 1),
и величина удовлетворяет равенству Ф^) = (1 + 7)/2, где Ф(з:) — стан-
дартная нормальная функция распределения (см. (7) § 1.2), то
Р{|ТП| < Су) =р{ —- < сД -> Ф(су) - Ф(-сг) = 2Ф(с0- 1 =7
(И)
(здесь использовано равенство Ф(-х) = 1 - Ф(х), Ух € Я1).
Соотношение (11) означает, что ошибка в определении а этим методом
приблизительно с вероятностью 7 не превосходит CyS/y/n, когда п доста-
точно велико.
Пусть, например, требуется вычислить интеграл
личины Тп = \fn{X-a)/S, где S2 = -
п
Vr
74
Глава 1. Основные распределения и их моделирование
где область интегрирования есть r-мерный куб vr = {(t,, , tr) 0 t{ 1,
i = 1, , г} Очевидно, что положив здесь £ = /(W|,... ,Z/r), где {£/,} —
числа из последовательности (1), получим а = Е£. Таким образом, в каче-
стве приближенного значения интеграла (12) в данном случае можно взять
величину
— 1 п
Х = -^Хк, Хк = /(W(jt_1)r+I, fc=l, , п.
п Л=1
Например, этим методом можно получить приближенное значение числа
взяв, скажем, п = 100 равномерных чисел {£/,} Здесь точность метода легко
оценить, сравнив значение оценки е с известным нам точным значением
е = 2,71828...
Упражнения
Свои способности человек может узнать,
только попытавшись приложить их.
Сенека|2)
П Пусть ( имеет распределение Бернулли Bi(l,p). Показать, что Е£ и D£ имеют
вид (2) § 1.1, а характеристическая функция ф(1) — Ее‘1{ = ре'1 + q. Убедиться в спра-
ведливости следующих формул:
Ее=^'(О), D4 = -^"(0) + ty'(0))2 (1)
г
Н Пусть X имеет биномиальное распределение Bi(n, р). Показать, что ее среднее
и дисперсия имеют вид (4) § 1.1, а для ее характеристической функции справед-
ливо представление ip(t) = (ре11 + q)n Проверить справедливость формул (I).
Q Доказать свойство воспроизводимости распределения Bi(n,p) по параметру п:
если Х|,... ,Xt — независимые биномиальные случайные величины и Д(Х;) = В1(п^,р),
j = 1,... ,fc, то £(Х) + ... +Л*) = В1(п| + ... + п*,р).
◄ Указание. Воспользоваться критерием независимости для характеристических функ-
ций (см. (15) § 1.2) и результатом упражнения 2. ►
Q Доказать, что биномиальные вероятности /(х|п,р) (см. (3) § 1.1) при измене-
нии х от 0 до п сначала монотонно возрастают, затем монотонно убывают, достигая
наибольшего значения при х — т, где т определяется неравенствами (n+ 1)р — 1 <
< m С (п + 1)р; если же т = (п + 1)р, то наибольшее значение достигается дважды:
J(m- l|n,p) = /(m|n,p).
|2) Сенека (4 г. до п.э. - 65 г. н.э.) — древнеримский философ, воспитатель Нерона; по его
приказу покончил жизнь самоубийством.
Упражнения
75
Q Убедиться н том, что формула (5) § 1.1 для плотности отрицательной биномиаль-
ной величины £ может быть записана также в виде
f(x\r,p) = (-l)xCzrpzqr х = 0,1,2,...
◄ Указание. Воспользоваться замечанием о биномиальных коэффициентах в конце
п. 2 §1.1. ►
Q Пусть £(£) = Bi(r,p). Показать, что ее характеристическая функция имеет вид
V>(/) = Ее,(< = ( —Л
\ । - ре"J
и, воспользовавшись формулами (I), убедиться в справедливости формул (7) § 1.1.
Q Доказать свойство воспроизводимости распределения Bi(r,p) по параметру г:
если Х|,..., Хк — независимые случайные величины и
£(*,) = Ш(г„р), > =
то _
£(Х| + ... + Хк) = В1(г| + ... + Гд.,р).
◄ Указание. Воспользоваться критерием независимости для характеристических функ-
ций. ►
Q Пусть в бернуллиевской последовательности {2Q, j 1} с параметром р слу-
чайная величина т)г означает число испытаний до появления r-го нуля включительно.
Выписать плотность величины Г)г и найти ее среднее и дисперсию.
4 Указание. т)г = $ + г, где £(£) = Bi(r,p). ►
Q Пусть случайная величина ( имеет распределение Пуассона П(А). Показать, что
ее характеристическая функция есть exp {А(е'( - 1)} и по формулам (1) вычислить пер-
вые два момента £.
ш Доказать свойство воспроизводимости распределения П(А): если ... ,Хк —
независимые пуассоновские случайные величины с параметрами Аь... ,Хк соответ-
ственно, то
£(Xi + ... + Хк) = П(А । + + А*).
◄ Указание. Воспользоваться критерием независимости для характеристических функ-
ций. ►
ш Пусть случайные величины Xt и Х2 независимы и C(Xi) = П(А,), i = 1,2.
Доказать следующий факт для’ условного распределения:
£(Х1|Х,+Х2 =n) = Bi(n,p) при р =
Л| 4- Л2
Доказать следующую предельную теорему (теорему Пуассона) о сходимости би-
номиального распределения к пуассоновскому: если п -4 оо, а р -4 0 так, что
пр -4 А > 0, то Bi(n,p) -4 П(А), т. е. (см. (3) и (8) § 1.1) f(x\n,p) -4 /(х|А),
х = 0, 1,2,.
4 Указание. Воспользоваться следующим свойством о непрерывном соответствии меж-
ду характеристическими функциями и распределениями случайных величин : пусть имеется
последовательность случайных величин {?;„} и последовательность {^„(0) соответ-
ствующих характеристических функций, тогда, если для любого t $n(t) -4 ip(t) при
76
Глава 1. Основные распределения и их моделирование
п -> оо и ip(t) есть характеристическая функция некоторой случайной величины т),
то рп —> тр Верно и обратное, т. е. из слабой сходимости т]п —> р следует сходимость
соответствующих характеристических функций.
В рассматриваемом случае воспользоваться упр.2 и 9 и пределом (1 + епг)" -> е°~
если п -> оо, -> 0, а пеп -» а > 0. ►
Е Доказать следующее утверждение о сходимости отрицательного биномиального
распределения к пуассоновскому: Bi(r,p) -> П(А), если г -> оо, а р -> 0 так, что
тр -> А > 0.
◄ Указание. См. указание к упр. 12, использовать упр.6 и 9. ►
га Пусть независимые случайные величины Xt,X2, имеют логарифмическое
распределение (21) § 1.1, а независимая от них величина Y имеет распределение
Пуассона П(г In (1/(1 — в))). Определим случайную величину Z как сумму случайного
числа У слагаемых из последовательности {XJ Z = X, + Х-, + 4- Ху, Z = О
при У = 0. Доказать, что C(Z) = Bi(r, в).
◄ Указание. Установить сначала, что характеристическая функция суммы X, + .. . + Х„
есть fn(0e,l)/fn(9), где f(0) = In (1/(1— 0)) (см. (21) и (24) § 1,1), и применить формулу
полной вероятности; в итоге получить, что Ee'<z = ((I -0)/(1 -0е,1))г (см. упр.6). ►
Е Установить справедливость формул (10) § 1.1 для Е/ и D£ гипергеометрической
случайной величины.
◄ Указание. Воспользовавшись формулой свертки:
Ey-rZ х-»П-Х _ х-»П
и равенством (далее используется обозначение (x)r = х(х — I) (z-r+l), (z)o — I)
(х)гС% = Wr^A-ri получить общее представление для г-го факториального момента
___ fix f-m—x fin-г
X °0
(Д|)г(п)г
—Г-7-----, Г = 1,2
(а)г
Далее использовать формулы Е£ = Е(£)|, D£ = Е(£)2 + Е£ - (Е£)2 ►
Е Пусть в (9) § 1.1 а, = ар, ai = aq, q = 1 -р, 0<р< 1 Убедиться в том, что при
а —> оо f(x |ар, aq, п) —> Cnpxqn~z, т. е. гипергеометрическое распределение Н (ар, aq, п)
сходится к биномиальному распределению Bi(n,p), когда а -> оо, а п и р фиксиро-
ваны.
◄ Указание. Записать формулу для f(x\ap, aq, п) в виде
р(р- \/а)...(р-(х- l')/a')-q(q- I/д) (q - (п - х - 1)/д)
/ х|ар, aq, п) = С„---------------------— ------—------— --------------------
(1 - 1/а) (1 - (п - 1)/а)
и перейти здесь к пределу при а -> оо. ►
га Оценка числа рыб в озере. Пусть а — (неизвестное) число рыб в озере. Предполо-
жим, что из озера вылавливают Д| рыб, помечают их и выпускают обратно. При повтор-
ном отлове п рыб среди них оказалось х помеченных. Считается, что результаты двух
отловов можно рассматривать как случайные бесповторные выборки из совокупности
всех рыб в озере. Тогда вероятность того, что второй улов содержит ровно х помечен-
ных рыб, есть как раз гипергеометрическая вероятность f(x\at, д2, п). На практике
Упражнения
77
числа а,, и и х наблюдаются. Спрашивается, как по этой информации оценить неиз-
вестное число а рыб в озере? Можно, например, найти такое значение а, при котором
вероятность f(x\at, а - at,n) достигает своего наибольшего значения, поскольку для
такого а наше наблюдение имеет максимальную вероятность. Это значение а назы-
вается оценкой максимального правдоподобия для а. Рассматривая отношение
f(x\a\, а - в|, n) (a-O|)(a-n)
/(х|в|,а-1-в|,п) а(а - а, - п + х) ’
убедиться в том, что оценка а есть наибольшее целое число, не превосходящее по.\/х.
Так, например, при а, = 1000, п = 1000 и х = 100 величина а = 10000.
10 Пусть целочисленный случайный вектор и = (у\, , uN) имеет полиномиаль-
ное распределение М(п,р). Показать, что его производящая функция
N
^) = Eip7
>=|
есть
<p(t) = (Pi^i + +Рл^у)п t — (t|> • • • > In),
а производящая функция подвектора = (i/t,..., ь>к), k < N имеет вид
/ k \ П
ip(i|, + 1, , 1) = ( 1 + У7Pi^i ~ О j
' 7=1 '
Получить отсюда, что
C(vi) = Bi(n,j>1), jC(x'2|t'i = 3ч) = Bi[ n - Xi, ——— )
\ 1-Р1/
и вообще
(Pj \
n - x, - ... - Z,_|, --------- ,
1-Pi- -Pi-J
2 < j C N
(Продолжение). Вывести формулы для смешанных факториальных моментов про-
извольных порядков компонент вектора и:
N Qri+..+rN N r
ЕП(^)г, = ’) = (П)п+ +ГЛ 1Р/
j=l I У 7 = 1
В частности,
Evj=npj, - \) = п(п - \)p2j, EviUj = п(п - \)piPj, i^j.
Получить отсюда формулы (15) § 1.1.
Е0 (Продолжение). Обозначим
f р,(1 - pt) при i = j,
[ -PiPi при
и = Ho'ijln k < N. Убедиться в том, что |Ek| = det = pi... рк(1 -pi -.. .-рк),
следовательно, |Еу| = 0 (отражение связи и, + + = п) и |Ек.| > 0 при к < N.
Проверить, что = Hs.jll?’-1. где р„- = 1/р; + l/pN, gtj = \/pN, i Ф j-
78
Глава 1. Основные распределения и их моделирование
ED Доказать воспроизводимость полиномиального распределения М(п, р) по пара-
метру п: если векторы X.......Хк независимы и £(Х,) = Л/(п,, р), i = I....fc, то
£(Xi + + Хд) = ЛГ(т2| + + пк, р).
Щ Указание. Воспользоваться критерием независимости для характеристических (или,
что то же самое, для производящих) функций. ►
Общее замечание. Ранее (в § 1.2) мы напомнили определение и некоторые свойства
характеристических функций, которые используются дтя изучения свойств любых
случайных величин. Но при работе с дискретными случайными величинами часто
более удобно использование производящих функций, опреде-
ляемых соотношением
4><(z) = Ez( = = х}, \z\ I
। |роизводящие
функции
(для многомерной случайной величины £ = (£| ...£*) производящая функция опре-
деляется как p{(zi,..., z*) = Ezf' ... z[k). Характеристическая функция = Ее‘ч
выражается через производящую функцию равенством ^{(1) = 11 потому
свойства производящих функций аналогичны свойствам характеристических функ-
ций. Например, критерий независимости звучит так: компоненты (дискретного) слу-
чайного вектора X = (Х,,..., Хк) независимы тогда и только тогда, когда его про-
изводящая функция имеет вид
,..., zt) = (Zi) • • • V>xt(zk).
ш Доказать, что между полиномиальным и пуассоновским распределениями суще-
ствует следующая связь: если случайные величины тр....tjn независимы и £(ty) =
= П(Л;), j = I,. ,2V, то для их совместного условного распределения справедливо
представление
£(»7|. ••• ’M'l’/i + ... + »/№ п) =М(п,р...,pN),
где
Pj = J = 1,..., 2V, А = А| + ... + Лу.
Л
4 Указание. Вычислить условную вероятность
Р{»?|=®|. tyV = Яу|7}| + +r)N =п}
и убедиться, что она имеет вид (14) § 1.1. ►
ЯЯ Пусть в схеме полиномиальных испытаний число испытаний есть случайная ве-
личина Y с распределением Пуассона П(А). Показать, что частоты исходов и.......
независимы и C(uj) = П(Ар;), j = I,..., N.
4 Указание. Используя упр. 18 и формулу полной вероятности, вычислить совместную
производящую функцию частот ,v^\ воспользоваться критерием независимо-
сти для производящих функций. ►
и Показать, что производящая функция распределения степенного ряда (20) § 1.1
есть <p(z) = f(9z)/f(6) и с ее помощью доказать формулы (23) § 1.1 для моментов.
4 Указание. Через производящую функцию моменты находятся по формулам:
Е{ = ^(1), D£ = 4'(l) + ^((1)- у((1))2. ►
Упражнения
79
и (Продолжение). Найти производящую функцию суммы Х} + + Хп независи-
мых слагаемых, имеющих одно и то же распределение степенного ряда, и с ее помощью
установить формулу (24) § 1.1.
ЕЗ Исходя из вида характеристической функции нормальной случайной величины £
с £(£) =Лг(/1,<72):
( zl
У<(() = exp < itp ——t >
и используя формулы (1), убедиться в справедливости формул (4) § 1.2.
ЕЯ С помощью характеристических функций установить свойство (5) § 1.2 нормаль-
ных случайных величин.
EJ Показать, что если X, и Х2 — независимые одинаково распределенные нор-
мальные случайные величины, то их сумма Xt + X? и разность X, - Х-> независимы.
◄ Указание. Вычислить cov(X| + Х2, X, - Х2) и убедиться в том, что она равна 0.
Вообще, если X....... Хп — случайная выборка из нормального распределения М(р, а2)
и X = (1/п)(Х[ + ... + Хп), то X и вектор (X, - X,.... Хп - X) независимы, так
как все ковариации cov(X, X, - X) = 0, i = 1,..., п. Отсюда, между прочим, следует
независимость X и S2 (см. (22) § 1.2), так как S' есть функция лишь от разностей
X, -X, i= 1,...,п. ►
ш Пусть случайный вектор $ = , £*) имеет нормальное распределение
Л7(е,Е=
Доказать, что Е£ = р, D£ = Е, т. е. = pjt cov(£,, £,) = , , j = 1,..., k.
•4 Указание. Использовать общую формулу для моментов
ЛГ|+... + г4
EQ (Продолжение). Показать, что подвектор £г = (£,, • • •, £г), 1 г < к, имеет нор-
мальное распределение А/((р\, ,рг), Ег = llo’oll?)•
Указание. Характеристическая функция подвектора £ есть
,tr,0,... ,0),
где Ф^(£|,...,(») дана в (16) § 1.2. ►
ш Пусть X = (Хь , XJ — стандартный нормальный вектор и U — произволь-
ная к х k-ортогональная матрица (т. е. U' = 1Г ). Показать, что У = ИХ также стан-
дартный нормальный вектор.
ЕЕ (Продолжение). ПустьтеперьД — произвольная тлхк-матрицаи а — произволь-
ный тп-вектор. Показать, что ттг-вектор У = LX+a имеет нормальное распределение
М(а, LL').
КН Пусть вектор v = (р,,... ,и^) имеет полиномиальное распределение М(п,р),
где 0 < р2 < l,j= 1,..., X. Обозначим v* = (Vj - npj)/Vn, j = 1,.... N,
1/ = (и’,..., v*N) (заметим, что и* + ... +- v’N = 0). Доказать центральную предельную
теорему для полиномиального распределения: если п -4 оо, то C(i/_) -4 V(0, Sjv),
где дисперсионная матрица указана вупр. 20.
80
Глава 1. Основные распределения и их моделирование
Ч Указание. Воспользоваться свойством о непрерывном соответствии между харак-
теристическими функциями и распределениями случайных величин (см. указание
к упр. 12), которое справедливо также и для векторных случайных величин, и устано-
вить сходимость (используя упр. 18)
1 X л I / ' \2 |
lim In (t) = - - ^2 Pit2i + 1 Е Pih = ~
r»-»oo 2 *— 2 ' / 2
7 = 1 Ъ = 1 7
Замечание. Поскольку матрица Еу вырождена (см. упр. 20), то предельное нор-
мальное распределение является несобственным, однако для любого подвектора
у 1: = (м*, ,14), k < N, будем иметь уже сходимость к собственному нор-
мальному распределению: £(у\) -з ЛГ(0, St). В частности, при к = 1 получаем
знаменитую теорему Муавра—Лапласа о сходимости биномиального распределения
к нормальному: £(м’) -з _Л/(0,р, (1 — р\)) или
-4jV(0, О
\v/npi(l - Pi) 7
(поскольку £(м|) = Bi(n,pi), см. упр. 18).
EJ (Продолжение). Пусть теперь при п -> оо вероятности р, -> 0, j = 1, , N- 1,
и при этом npj -э А,, 0 < А, < оо, j = 1,. , /V" — 1. Это означает, что при бол ь-
шом числе испытаний п исходы с номерами 1,2,. ,N - 1 будут встречаться редко
(в среднем А]...., раз соответственно). Доказать, что компоненты М|........
будут асимптотически независимы и прн этом C(vj) —> П(А^), j = I,... ,2V - I.
◄ Указание. Установить сходимость для характеристических функций
Л'-|
.., £v-i) -» fj exp {Aj(e'<J - 1)}.
7 = 1
(см. ynp. 9 и 18). ►
EH (Продолжение). Доказать, что распределение случайной величины Г) = п - vN
сходится к распределению Пуассона П(А| + + Ау_|).
Ч Указание. Заметить, что р = Р| + + t<v-i и воспользоваться упр. 10 (или преды-
дущим результатом). ►
ЕЗ Установить справедливость формул (21) § 1.2 для моментов гамма-распределения,
предварительно получив представление (20) § 1.2 для его характеристической функции
и воспользовавшись соотношениями (1) в упр 1.
ш Пусть Xi.-.-.X* — независимые случайные величины и £(Xj) = T(a,Xj),
j = 1, , fc. Показать, что для любой постоянной с > О
Д(с(_Х’| 4- ... 4- Хк)) = Г(са, Aj 4- + А*).
Ч Указание. Воспользоваться свойствами характеристических функций. ►
ЕЗ Показать, что если X,,... , Хп — независимые стандартные нормальные величи-
ны, то £(Xf+.. -+Х*) = %2(п) = Г(2, п/2). Основываясь на центральной предельной
теореме (см. (1) § 1.2), установить, что при п —> оо
/Х?4- 4-Х2-п\
£ —-----------=^------ -у М(<д, 1).
\ v2n /
Упражнения
81
ч Указание. Сначала установить, что £(Л/) = Г(2, 1/2), далее воспользоваться свой-
ством воспроизводимости гамма-распределения. ►
ЕИ Пусть X,, , Хк — независимые показательные случайные величины с распре-
делениями Г(а,-, 1), i = 1, ,fc, соответственно. Показать, что случайная величина
У = т1п{Х1,.. , Xi} имеет распределение Г((1/Д| + + 1/о*)-1, 1)
ч Указание. Вычислить Р{У >»/}.►
Пусть fc-мерный нормальный вектор £ имеет собственное распределение Хг(р, S).
Доказать, что квадратичная форма
Q(4) = (1- f£)
имеет распределение
ч Указание. Рассмотреть линейное преобразование Z_ = Л-|/21/'(£ - р), переводящее
вектор £ в стандартный нормальный вектор (см. п. 2 § 1.2), тогда
«Ю = И'Я = 22 + +Z2k,
далее использовать упр. 38. ►
ш Пусть о распределении случайных величин ( и Л (лямбда большое) известно,
что £(Л) = Г(о, г), где г — целое, а условное распределение £(£|Л = А) = П(Л).
Показать, что £(£) = Bi(r,p) при р = а/(а + 1).
ч Указание. Вычислить безусловные вероятности
P{^ = fc}=fe“A— -Д— e~xladX, fc = О, 1,
J J k>. Г(г)аг
о
и убедиться, что они имеют вид (5) § 1.1. ►
и Пусть случайная величина £ имеет бета-распределение Ве(а, Ь). Вычислить
Е^г(1 - £)*, г, s 0, и получить отсюда формулы для Е£ и О£ (24) § 1.2.
ч Указание. Воспользоваться определением бета-функции В(а, Ь) и свойствами гам-
ма-функции Г(А) (см. п.З § 1.2). ►
ЕЗ Пусть случайные величины X, и Х2 независимы и £(Х<) = Г(а, A,), i = 1,2.
Доказать, что случайные величины У = X, + Х2 и У2 = XJ(Xt + Х2) независимы
и при этом £(У|) = Г(а, А, + А2), а Д(У>) = Ве(Л(. Л2).
ч Указание. Применить формулу (44) § 1.2 при вычислении совместной плотности
преобразованного вектора У = (У,, У2) и убедиться в том, что она есть произведение
маргинальных (одномерных) плотностей указанных гамма- и бета-распределений. ►
и Пусть о распределении случайных величин / и т] известно, что
£(,) = Be^.^Y
\ с с )
где в|, а2 и с — натуральные числа, а условное распределение £(£|v = р) = Bi(n,p).
Показать, что безусловное распределение ( есть распределение Маркова—Пойа
МП(п; а,, а2, с) (см. (11) § 1.1); получить отсюда формулы (13) § 1.1.
6 Заказ 1 748
82
Глава 1. Основные распределения и их моделирование
4 Указание. Вычислить безусловные вероятности
р{е = х} = с:
о
——/«/'-'(j -Pplc-'dp,
Г(о,/с)Г(а2/су и р'
Q — й| 4~ О>2,
и, воспользовавшись свойствами гамма-функции, убедиться в том, что они имеют вид
(II) § I.I. При вычислении моментов учесть, что г-й факториальный момент биноми-
ального распределения Bi(n,p) есть (п)грг (см. упр. 19). ►
ш Вывести формулы (26) § 1.2 для моментов равномерного распределения К(а, 6),
а также получить вид его характеристической функции
pitt _ pita
ЕЗ Пусть (Xi,..., Хп) — случайная выборка из распределения К(а,Ь) и Y
= min{Xb , Xn), Z = тах{Х|..........Х„} Вывести вид совместной плотности слу-
чайных величин Y и Z:
№,*)=< (Ь - а)"
О
при а у < z Ь,
в остальных случаях.
Получить следующие формулы для моментов:
ЕУ = ^,
п 4- 1
п(Ь - а)2
DY = DZ = ------1
(п 4- 1)2(п 4- 2)
а 4- nb
EZ =---------,
п 4- 1
cov(K, Z) = -—~
га Пусть случайная величина ( имеет равномерное распределение тг/2).
Показать, что случайная величина т] = tg( имеет распределение Коши, задаваемое
плотностью (31) § 1.2.
-< Указание. Сначала выписать функцию распределения Fn(x) = Р{т? г), диффе-
ренцированием которой получить плотность. ►
га
а) Пусть Х| и X; - независимые стандартные нормальные случайные величины.
Показать, что их отношение Х,/Х2 распределено по закону Коши.
4 Указание. Плотность отношения ( = £/т) двух независимых случайных ве-
личин, плотности которых и /, известны, вычисляется по формуле
00
Л(У) = f Л(ЕЗ/)/ч(г)И dx. ► (2)
-ОО
б) Распределение Коши с параметром сдвига а (обозначается 1С(а)) определяется
плотностью
it I 4- (х- а)2'
Упражнения
83
(так что формула (31) § 1.2 соответствует случаю а = 0). Убедиться в том, что
характеристическая функция закона 2С(а) есть exp {iat — |i|} и доказать следую-
щий факт: если случайные величины X......,Х„ независимы и £(Х;) = 2С(а;),
j = 1,..., п, то £(Х) = К.(а), где черта означает среднее арифметическое.
ЕЙ Проверить, что стьюдентово отношение t„ (см. (27) § 1.2) имеет моменты Ei„
лишь при k < п, при этом моменты нечетного порядка равны 0, а
2r 1 • 3 ... (2г - 1)пг
Et„ = т---zr,-----т;---;---гт ПРИ 2г < п
(п - 2)(п - 4)... (п - 2г)
Получить отсюда формулы (30) § 1.2.
Указание. Учесть, что если £(£) = Л/"(0, 1), то Е£2г+1 = 0, Е4?г =1 3 ... (2т - 1),
а также формулы для моментов гамма-распределения (см. п. 3 § 1.2). ►
Е] (Продолжение). Установить, что
/ I \ /п I\
V +t2/n/ ” В\2’ 2/
Указание. Воспользоваться упр. 43. ►
ш
а) Показать, что если X имеет распределение Снедекора S(n, т), то У = \/Х
имеет распределение S(m, п).
б) Пусть t„ имеет распределение Стьюдента S(n). Показать, что £(t‘) = S(\,n).
Е Пусть F(x,n,m) — функция распределения закона S(n, т), а В(х\а,Ь) —
функция бета-распределения Ве(а, Ь). Установить равенство
, ( пх п т\
F(x; п,т) = В( --------х > 0.
\ т + пх 2 2 /
Получить отсюда выражение (33) § 1.2 для плотности распределения S(n,m). Найти
моменты этого распределения (35) § 1.2.
4 Указание. Записать соотношение (32) § 1.2 в виде
и воспользоваться упр.43, в силу которого £(Y) = Ве(п/2,т/2). Моменты вычисля-
ются по формулам
EF„r.m= (-) Е(Хп)гЕ(хт) Г
у п J
используя далее формулы для моментов гамма-распределения. ►
(Продолжение). Установить, что
/ nFп т \ п fп т\
L 1 ------“ I = Be ( Г. V I
\m + nF„m/ \2 2)
б*
84
Глава 1. Основные распределения и их моделирование
и Пусть X = (Х|, ,Xi+m) — случайная выборка из показатель-
ного распределения Г(а, 1) и
У _ пт, Х| + + Xj
-2Г/+1 + • • + ^1 + т
Доказать, что Д(У) = S(2l, 2m).
Ч Указание. Воспользоваться упр. 37, в силу которого
/2 \
£ -(%, + ... + Xt) = Г(2,I) = x’(2Z)
\а у
и аналогично
£^-(X/+i +
\ а
+ Л(+„.)) =Г(2т). ►
Пусть случайная величина £ имеет распределение Вейбулла W(a,a,b) (см. (36)
§ 1.2). Доказать формулы (37) § 1.2 для Е£ и Df.
(Продолжение). Пусть (Xt,..., Хп) — случайная выборка из распределения
W(a, а, Ь) и Y = min{Xb ..., Хп}. Показать, что
£.(п1'”-—- ) = W(l,a,0)
\ о )
и получить отсюда следующие формулы для моментов У
ЕУ = а + ЬГ( 1 + -
\ а)
,Г ( 2\ ,/ 1
DE =Ь2 Г I + - -Г 1 + -
\ а / \ а
п~г,а
◄ Указание. Вычислить Р{У > у}. ►
BI Пусть £ имеет распределение Парето с параметрами z0 и а (см. (38) § 1.2). Для
каких натуральных значений к существуют моменты Е£Л? Показать, что при а > 2
справедливы формулы (39) § 1.2 для и D£.
El (Продолжение). Доказать, что случайная величина т) = ln(£/z0) имеет показа-
тельное распределение Г(1/а, I) (см. п. 3 § 1.2).
Ч Указание. Применить формулу (45) § 1.2 либо непосредственно вычислить функ-
цию распределения F4(t) = Р{т/ t] ►
Пусть о распределении случайных величин £ и т) известно, что £ имеет рас-
пределение Парето с параметрами и а, а условное распределение т) при условии,
что £ = в, является равномерным W(0, в). Доказать, что условное распределение
Д(£|т/ = х) есть распределение Парето с параметрами max(zn, х) и а -I- 1.
Упражнения
85
◄ Указание. Если ft(9) и Д(х) есть маргинальные плотности величин ( и 9, а
— плотность условного распределения = в), то плотность /^,(^12:)
условного распределения £(£|т? = х) вычисляется по фор-
_ _ и) Условные
муле Байеса
распределения
(0|я)__ ЖЖ (3) и формула Байеса
при этом
является «нормирующим» множителем, не зависящим от переменной 0 условной
плотности Д|,(в|а:), и потому вычислять его явное значение в конкретной задаче
не обязательно (плотность любого распределения достаточно вычислять с точностью
до нормирующего множителя: f(x) = cp(z) ~р(х)).
В нашем случае записать
Л(0) * 9~a~'l (9 > х„), f„K(x\9) = 9~'I (9 > х),
где (напомним) /(•) — индикатор. ►
Предположим, что X,....Xk — независимые случайные величины и X, имеет
гамма распределение Г(а, A;), i = I,... , к. Пусть случайный вектор Y = (У|,..., У*)
определяется соотношениями
X i + + X*
Доказать, что вектор Y и случайная величина X = X, + + Хк независимы и при
этом У имеет распределение Дирихле О (А = (А|, , А„)) (распределение X указано
в упр. 37).
◄ Указание. Это упражнение является обобщением упр. 43 и доказывается анало-
гично. ►
Ш Доказать формулы (41) § 1.2 для моментов распределения Дирихле D(a).
◄ Указание. Использовать формулу (42) § 1.2 для интеграла Дирихле и свойства гам-
ма-функции. ►
ВЯ Пусть о распределении случайных векторов К = (и, • • •, Ни) и £=((),..., (к)
известно, что £(£) = D(a/c), где а = (в|,.... aN) и все о, и с — натуральные числа,
а условное распределение Д(и1£ = р) есть полиномиальное распределение Af(n;p)
(см. п. 6 § 1.1). Показать, что безусловное распределение вектора и есть ТУ-мерное
распределение Маркова—Пойа МП(п;а,с) (см. п.7 §1.1); получить отсюда формулы
(19) §1.1.
◄ Указание. Это упражнение является многомерным обобщением упражнения 44 и
доказывается аналогично с использованием формулы (42) § 1.2 для интеграла Дирихле
и свойств гамма-функции: в данном случае надо вычислить безусловные вероятности
„ г ! п! Атт xi ^(а/с) гт j_ j_
ГЬ Г(а|/с) ,.Г(а„/с)П'> dj>' dp"-'
s
13) Байес Томас (1702-1761) — английский математик-вероятностник.
86
Глава 1. Основные распределения и их моделирование
(здесь область интегрирования S определена в (42) § 1.2, pN = 1 - р, - -pN_t,
а = at + + a,v и х (х|, ,хД) — произвольный целочисленный вектор
с Х| +.. . + ху = п), и убедиться втом, что они имеют вид (17) § 1.2. При вычислении
моментов учесть формулу для факториальных моментов полиномиального распреде-
ления (см. упр. 19). ►
Замечание. В этом упражнении речь идет о модели смеси вероятностных распре-
делений: в данном случае рассматривается смесь полиномиальных распределений
М(п; р), где вектор р предполагается случайным вектором, имеющим распределение
Дирихле, поэтому «смешивающему» распределению. Таким образом, установленный
результат можно сформулировать в этих терминах следующим образом: многомерное
распределение Маркова—Пойа является смесью полиномиальных распределений по рас-
пределению Дирихле.
Соответствующий «одномерный» результат упражнения 44 теперь звучит так: распре-
деление Маркова—Пойа МП(п; а,, а2, с) является смесью биномиальных распреде-
лений Bi(n,p) по бета-распределению: £(р) = Ве(а|/с, а-Дс).
GJ Пусть о распределении случайных векторов = (и,, , и £ = (£,, , £у)
известно, что £ имеет распределение Дирихле D(a), а условное распределение
£(к1£ = 0) есть полиномиальное распределение ЛГ(п; в). Показать, что условное рас-
пределение
£(£1е = х) = D(a + х).
◄ Указание (См. указание к упр. 59). Если х,, , Ху — целые неотрицательные
числа, удовлетворяющие условию х, +.. .+ iy = п, то в нашем случае условная плот-
ность
Aiiteie) = е?
а Д(0) = в°'~' , следовательно,
. eaN"+x"-' ►
Замечание. В статистических приложениях часто предполагается, что наблюдаемая
выборка (данные) X имеет распределение из некоторого параметрического семейства
распределений Д = {F(x; в), в € 0} (в данном случае X = и и Д = М(п; в) —
Сопряженные
се/лейства
распределений
семейство полиномиальных распределений), а о параметре
этого семейства предполагается, что он случаен, и его априор-
ное распределение £(0) € Д‘ — заданному семейству априор-
ных распределений в (в нашем случае Д' = D(a)). Семейство
Д называется сопряженным к семейству Д (обозначается Д* < Д), если при X = х
апостериорное распределение параметра Ц6\Х = х) Е Д* т. е. находится в том же
классе распределений, что и априорное распределение параметра. В этих терминах
полученный результат звучит так: D(a) < ЛГ(п; в), т. е. распределение Дирихле сопря-
жено к полиномиальному распределению.
Аналогичный результат мы имели и в упр. 59: распределение Парето сопряжено к рав-
номерному распределению 1/(0, в).
Убедиться в справедливости также следующих утверждений
(ниже X = (Х|,... , Хп) — случайная выборка и х = х, 4- 4- х„):
1) Ве(а, 6) < Bi(m, в), при этом
£(в|А) = х) = Ве(а + х, Ь + пт - х);
Упражнения
87
2) Ве(а, 6) < Bi(r, 0), при этом
£(0|Х = х) = Ве(а + х, b 4- пт);
3) Г(а, А) < П(0), при этом
£(0fX = = Г( ———, А + X ),
\па + 1 /
4) Г(а, А) < Г(0-1, 1), при этом
£(0\Х = х) = Г( —— ,А + п);
\аа: + 1 )
5) а2) < Л/(0, 62), при этом
£(0|Х = х) = V(/i|,a?), где
/ U X \ , , ( 1 п \
Р\ = ( ~2 + и )а" а' = ( ”2 + М )
\<т2 Ь2/ уа1 о1 J
6) распределение Парето с параметрами и а сопряжено к равномерному рас-
пределению Z/(0, 0), при этом апостериорное распределение 0 при наблюдении
X = х есть распределение Парето с параметрами max(i:0, xt, , х„) и а + п.
◄ Указание. При нахождении апостериорных плотностей (3) следовать указанию
к упр. 59. ►
И Пусть случайный вектор £ = ($1,(2) имеет двумерное собственное нормальное
распределение
х (<»... л>. '”/)
\ P<h<Tl <Х1 /
где -1 < р = согг(6,6) < 1- Доказать, что условное распределение
Д(616 =z)=V(W),a2),
где условное среднее
М(х) = Е(616 = х) =р2 + —р(х -
<Т]
— функция регрессии 6 на 6. являющаяся в данном случае линейной по х, а условная
дисперсия
<t2 = D(£2|6 = x) = (1-/>2H
не зависит от х. Существуют ли другие распределения £(£), отличные от нормального,
обладающие такими же свойствами условного распределения £(616 = ®)?
◄ Указание. Вычислить условную плотность величины 6 при условии 6 = ® по фор-
муле (y|z) = f^2(x, у)! f(l (и) и убедиться в том, что она равна
□ (Обобщение на многомерный случай). Пусть Х_ — (Х1(... ,ХГ_|), Y = Хг, г 2,
и совместное распределение
£(£Г)=ЛГ((р........Дг).£ = IkolK).
где матрица Е не вырождена и Е-1 = ||aIJ|||. Доказать, что
ДСИ* = х) = ЛГ(М(®), 1/<тгг),
88
Глава 1. Основные распределения и их моделирование
где
М(х) = Е(У|Х = х) = Цг- — , х = (ж,,..., zr_,).
Г=1
•< Указание. Записав совместную плотность в виде (см. (9) § 1.2)
yir(Si,... ,Хг-|,®г) = Сехр j^2 <7’7(х> - М>)
= С exp
гг/
<7 (Зг
-^)2+2(xr
2
получить, что переменная хт войдет в выражение условной плотности /г|х(яг|я)
в виде
Оценить методом Монте-Карло величину площади а = тг/4 под дугой единич-
ной окружности х + у1 = 1, г,> 0.
Глава 2
Первичная обработка
экспериментальных данных
Дело не в цифрах, а в том, что вы с ними делаете.
Данная глава представляет собой общее введение в теорию выборочного
(статистического) метода. Здесь рассматривается ситуация, когда исходные
данные (выборка) получаются в результате проведения повторных независи-
мых наблюдений (измерений) над некоторой случайной величиной (, закон
распределения которой в течение всего эксперимента остается неизменным.
Как уже отмечалось во Введении, в этом случае выборка представляет со-
бой n-мерный вектор X = (JTb . , Хп), где п — число наблюдений (объем
выборки), а компоненты Xi — независимые копии наблюдаемой величины £,
т. е. имеющие такое же распределение, как и £. В этом случае говорят, что
X = (Х|, , Хп) есть случайная выборка (или просто выборка) из распреде-
ления £ (или из £(£)). В теории выборочного метода (или кратко: выборочной
теории) изучаются различные свойства случайной выборки и функций от нее.
В этой главе мы введем основные понятия выборочной теории, приведем
фундаментальные теоремы математической статистики, исследуем в точной
и асимптотической (т. е. при большом объеме выборки) постановках свойства
основных характеристик случайной выборки.
§2.1. Вариационный ряд выборки, эмпирическая функция
распределения и гистограмма
Верно определяйте слова, и вы освободите
мир от половины недоразумений.
Р. Декарт
1. Порядковые статистики и вариационный ряд выборки
Итак, пусть X — (Х|, , Хп) — выборка из некоторого распределения £(£).
Произвольной реализации z = (д,,..., дп) этой выборки можно поставить
в соответствие упорядоченную последовательность
£(1) х(1) ®(п)> (О
Декарт Рене (1596-1650) — французский математик, физик.
90 Глава 2. Первичная обработка экспериментальных данных
располагая х,, , хп в порядке их возрастания, так что ад г> = min{a:|,..., in},
Х(2) — второе по величине значение, = тах{а:|, , х„}.
Обозначим через случайную величину, которая для каждой реализа-
ции х выборки X принимает значение х^, k = 1, , п. Так по выборке
X определяют новую последовательность случайных величин
называемых порядковыми статистиками выборки; при этом Х^ — к-я поряд-
ковая статистика, а Х(|) и Х^ — экстремальные (соответственно минималь-
ное и максимальное) значения выборки, их разность р = Х{П) - Xj!) называют
размахом выборки. Из определения порядковых статистик следует, что они
упорядочены по возрастанию их значений, т. е. они образуют возрастающую
последовательность
Х(1)^Х(2)^ ^Х(П), (2)
” ^’ВориЗциоЯЖ^яд которая называется вариационным рядом выборки X.
Симметричные относительно концов элементы после-
довательности (2) и JQn-m+i) иногда называют соответственно т-м
минимальным и т-м максимальным значениями выборки, или m-ми нижним
и верхним экстремумами (т = 1,2, .). Важной характеристикой вариаци-
онного ряда выборки является его медиана (или середина), которая равна
если п = 2Аг+ 1, и (Х1к) + Хц.+ц)/2 при п = 2k. В дальнейшем под
термином «основные характеристики выборки» будем понимать совокупность
ее экстремальных значений, размаха и медианы.
Итак, вариационный ряд — это расположенные в порядке возрастания
их величин элементы выборки. Подчеркнем, что для заданной реализации
х = (xlt ,хн) выборки X = (Х|, ,-Хп) реализацией последовательно-
сти (2) является последовательность (1). Вариационный ряд является одним
из стандартных способов представления выборки.
2. Эмпирическая функция распределения
Введем теперь фундаментальное понятие математической статистики, како-
вым является эмпирическая функция распределения. Для этого определим сна-
чала для каждого действительного х случайную величину рп(х), равную числу
элементов выборки X = (X), , Тп), значения которых не превосходят х,
т. е.
п
pn(.x) = ^I(Xi^x), (3)
i = l
и положим Fn(x) — рп(х) — это и есть эмпирическая функция распре-
п
деления (далее используется сокращение э. ф. р.), соответствующая выбор-
ке X. Функцию распределения F(x) наблюдаемой случайной величины 4
в этом контексте называют теоретической функцией распределения. По свое-
му определению э. ф.р. — случайная функция: для каждого х Е R1 значе-
ние Fn(x) — случайная величина, принимающая значения 0, \/п,2/п,... ,
§ 2.1. Вариационный ряд выборки, э. ф. р. и гистограмма
91
(тг - 1)/т1, п/п = 1, при этом
р(г„(а:) = -1 = Р{дп(а;) = к}.
I п)
С каждым Xi, можно связать два события: {.Х, z] и {.Х; > z]. Вероятности
этих событий, очевидно, равны
р = Р{Х, sC z} = F(x), q = P{Xj > z} = 1 - F(x).
Если событие {.X,- < z} назвать успехом, то рп(х) является числом успехов
в п независимых испытаний Бернулли с вероятностью успеха р, поэтому
p,t(x) имеет биномиальное распределение Bi(n,p) с р = F(x) (см. п. 1 § 1.1).
Следовательно,
Г k 1
Р^ Fn(x) = - !> =C„'Ffc(a;)(l - F(x))n~k, к = 0, 1,..., п. (4)
I п J
Итак, э. ф. р. (как и вариационный ряд) - неко- Распределение
торая сводная характеристика выборки. Для каждой ре- э ф р
ализации х выборки X функция Fn(x) однозначно
определена и обладает всеми свойствами функции распределения: изменяется
от 0 до 1, не убывает и непрерывна справа. При этом она кусочно постоянна
и возрастает только в точках последовательности (1). Если все компоненты
вектора х различны (в последовательности (1) все неравенства строгие), то
функция Fn(x) задается, очевидно, соотношениями
' О
Fn(i) = < к/п
1
при X < 2(1),
при Х(к) < X < X(fc+1),
при X Xju),
к=\,. ,71-1,
т. е. в этом случае число скачков равно п и величины всех скачков равны 1/тг;
типичный график функции Fn(x) имеет вид, изображенный на рис. 1.
Пример!. Реализацией выборки X (Х1; , Х”б) являются следующие
данные: -1,5; 2,6; 1,2; -2,1; 0,1; 0,9. Найти ее основные характеристики и по-
строить эмпирическую функцию распределения.
Прежде всего строим вариационный ряд: -2,1; -1,5; 0,1; 0,9; 1,2; 2,6. От-
сюда видно, что минимальное (максимальное) значение выборки равно -2,1
(2,6), размах равен 2,6 - (-2,1) = 4,7, а медиана равна
1(3) +2(4) 0,1+ 0,9
Эмпирическая функция распределения Ff,(x) является ступенчатой, воз-
растает скачками величиной 1/6 в точках вариационного ряда, при этом
Fb(x) = 0 при х < i(|) = -2,1 и Ff,(x) = 1 при х х^ = 2,6. Таким образом,
'0
F6(x)=< 1/6
J/3
при К-2,1,
при -2,1 -1,5,
при -1,5<1<0,1,
' 1/2 при 0,1 + х < 0,9,
W) = < 2/3 при 0,9^д< 1,2,
5/6 при 1,2О<2,6,
, 1 при I 2,6.
График этой функции изображен на рис. 2.
F„(x)
J-----------------1----------------►
0 1 ®
Рис.З
Пример 2. Пусть А" = (Х|, , Хп) —
выборка из распределения Бернулли
Bi( 1, р) (см. п. 1 § 1.1). Обозначим ип =
= _Yi + . +-Х"„ число единиц в вы-
борке. Тогда скачки э. ф. р. Fn(x) будут
иметь место лишь в точках 0 и 1 и оче-
видно (рис. 3)
( 0 при х < 0,
Fn (х) = < 1 - — при 0 х < 1,
I Д
1
при
§ 2.1. Вариационный ряд выборки, э. ф. р. и гистограмма
93
—I--Н
N- 1 W
Рис. 4
ПримерЗ. Пусть А" = (Х|,... ,Х„) — выборка из дис- Э. ф. р. для дискрет-
кретногораспределения£(£) = (р\р2 ;^).Обозна- ного распределения
п
ним Uj = 1(Х, — j) число реализаций исхода «j», j = 0, 1, , N, тогда
t= 1
вектор и = (щ,..., i^) имеет полиномиальное распределение М(п;р =
= (Pi> <Рм)) (см. п.6 § 1.1), а отдельная частота Vj — биномиальное рас-
пределение Bi(n, pj).
В данном случае э.ф. р. Fn (z) будет иметь скачки лишь в точках 1,2, ,,N
и при этом величина скачка в точке j есть
ДЯО) = Fn(j) - Fn(j - 0) = j = l, ,N
п
Тем самым график Рп(г) будет иметь вид, указанный на рис. 4.
Здесь P{z\Fn(j) — 0} = Р(д; = 0) = (1 -р;)п что мало при больших п,
т. е. в большой выборке скачок в точке j наверняка будет иметь место. Более
того, так как
, N ч N н
pj и = 0} U £ р{ДО) = 0} = £(i - Pjy -> о,
^7 = 1 ' 7 = 1 7 = 1
при п —> оо, то в больших выборках с вероятностью, близкой к 1, скачки
э. ф. р. Fn(x) будут иметь место во всех точках 1,2, , N, а случайными будут
лишь величины этих скачков. •
Если же теоретическая функция распределения F^(x) = F(x) непре-
рывна, то с вероятностью 1 все элементы выборки X — (Aj,... ,Хп) будут
различны, и график э. ф. р. Fn(ir) будет иметь вид, изображенный на рис. 1,
т. е. случайными теперь будут точки скачков, величины же скачков не случай-
ны и равны \/п.
94
Глава 2. Первичная обработка экспериментальных данных
Таким образом, для выборок из дискретных и непрерывных распределе-
ний характер соответствующих эмпирических функций распределения будет
различным. Тем не менее в любом случае э.ф. р. Fn(x) с увеличением объема
выборки п сближается в каждой точке х с теоретической функцией распре-
деления F(x).
Сходимость по Теорема 1. Для любого х (-оо < х < оо) и любого
вероятности э. ф. р. е > 0 при тг —> оо
Р{|ад-Ж| <е} 1,
т. е. Fn(x) F(x) (сходимость по вероятности см. п.1 §1.2).
Доказательство. Это утверждение является простым следствием упоминав-
шегося ранее закона больших чисел (см. (3) § 1.2), так как, обозначив,
i]j = < х), j = 1, , п, мы получим последовательность независи-
мых, одинаково распределенных случайных величин с математическим ожи-
1 п
данием Ет/, — P{Xi < i} = F(x), a Frt(x) — - . Таким образом,
ТО I
J=l
р
Fn(;r) —> F(x)> что и утверждается в теореме.
Zjfc», «Vi»
Скорость сближения
для э. ф. р.
Можно установить и скорость сближения э.ф.р.
F„(i) с F(x). Так как из (3) следует, что (см. (4) § 1.1)
EFn(x) = -Ецп{х) = F(x),
” 1 (5)
DFn(z) = -^D/t„(i) = -F(i)(l - F(x)),
nl n
то согласно неравенству Чебышева (для любой случайной величины (
Р{|£ _ E£l > е} < D^/e2) имеем для любого t > О
, , х| . F(i)(l - F(x)) 1
р{УЕ|ед -f(x)\> t} < -2
(6)
(последнее неравенство следует из того, что для любой функции распределе-
ния F(x) имеет место оценка F(x)(\ - F(x)) < 1/4).
Полученная оценка (6) универсальна, так как она не зависит ни от тео-
ретической функции распределения F(x), ни от точки х, ни от объема вы-
борки тг. В частности, из нее следует, что
p(|Fn(z) - F(x)\ <0,01.
I у/П I
§ 2.1. Вариационный ряд выборки, э. ф. р. и гистограмма
95
Более того оценку можно получить, если число на-
блюдений п велико и в этой ситуации воспользовать-
ся теоремой Муавра—Лапласа о сходимости биноми-
ального распределения к нормальному (см. замечание
к упр. 33 гл. 1): если 0 < F(x) < 1, то при п —> оо
*(*>-
y/nF(x)(\ - F(x))J
В терминах э. ф. р. Fn(x) = цп(х)/п это соотноше-
ние можно переписать в следующем виде: обозначим
Wn(x) = y/n(Fn(x) - F(x)) так называемый эмпири-
ческий процесс, тогда
£(РГ„(х)) V(0, F(x)(l - F(x))).
шммнн мц. wummii
Теорема
Муавра—Лапласа
для э. ф. р.
Эмпирический
процесс
(7)
Отсюда можно записать следующую цепочку соотношений:
f 1
/п J
t
= 2Ф
Fn(x) - 4= < F(x) < F
у/П
t A
^F(x)(\ - F(x)))~ $ V y/F(x)(i - F(x))
—==J=] - 1 2Ф (2t) - 1.
<y/F(x)(\-F(x))J
Если мы хотим сделать правую часть равной заданному числу 7, близкому к 1
(например, 7 = 0,99), то решив уравнение 2Ф (It) -1=7, получим
где Ф-1 — обратная функция к стандартной нормаль-
ной функции распределения (см. (7) § 1.2). В итоге
мы получим соотношение
₽/Fn(x) ~^=< F(x) < Fn(i) + -у= } > 7,
( у/П у/П J
Доверительный
интервал для теоре-
тической функции
распределения
(8)
которое означает, что для больших выборок с вероятностью, приблизитель-
но равной 7, значение теоретической функции распределения будет отли-
чаться от соответствующего значения эмпирической функции распределения
не больше, чем на t^/y/n. Таким образом, в (8) определен случайный интервал
{Fn(x)^/^i) с центром вточке Fn(x), который с высокой вероятностью 7
накрывает значение теоретической функции распределения F(x), если в этой
точке F(x) 0. Такой интервал (Fn(x) Т t-Jy/n) называется асимптоти-
ческим 'у -доверительным интервалом для F(x). Ширина этого интервала при
96
Глава 2. Первичная обработка экспериментальных данных
больших п имеет порядок 1/х/п, т. е. это очень узкий интервал, с высокой
точностью локализующий значение F(x), если оно нам неизвестно. Напри-
мер, при t7 = 2 величина 7=1-6 10-5
Из этих рассуждений можно сделать следующий принципиальный вы-
вод: если объем выборки большой, то э. ф. р. Fn(x) в каждой точке х, где
О < F(x) < 1, отличается от F(x) на величину порядка l/-/n, т. е. Fn(x)
сближается с F(x) с ростом п и тем самым э. ф. р. может рассматриваться
в качестве приближенного значения (оценки) теоретической функции рас-
пределения F(x), если она нам неизвестна. Функцию Fn(x) поэтому часто
называют статистическаим аналогом для F(x): Fn(x) « F(x).
Состоятельность Замечание. Указанное в теореме 1 свойство сходимости
э ф р Fn(x) F(x), п -> оо, называется в статистике свой-
ством состоятельности э. ф.р. Fn(x) как оценки для F(x).
Таким образом, теорема 1 утверждает, что э. ф. р. Fu(x) является состоятельной оцен-
кой для теоретической функции распределения F(x) в каждой точке х.
3. Дальнейшие свойства э.ф.р.
(Этот материал для тех, кто хочет заглянуть поглубже
в обсуждаемую проблематику)
Выше мы обсуждали одномерные свойства э. ф. р. Fn(x), т. е. ее поведение
в фиксированной точке х, и для этого нам было достаточно знать лишь свой-
ства биномиального распределения Bi(n, F(x)). Более глубокие особенности
э. ф. р. проявляются, если рассматривать ее поведение не в отдельной фикси-
рованной точке х, а в произвольной конечной системе точек Х) < х^ <... <
<хдг_1, т. е. если рассматривать случайный вектор (Fn(xi), , Fn(a:^_1))
Пусть хо = -оо, хх = 00, точки Х|, .., Хдг-i таковы, что
О = F(x0) < F(xI) < < F(xn_}) < F(xN) = 1.
Обозначим
Pi = = Р(ц) - F(xi-I), i=l, ,N,
и введем случайные величины
к
Vi = A,gn = fin(xi)- Pnixi-i) = < Xj Xi), 1=1, ,N
>=1
Заметим, что есть число реализаций события Ai = {it_ । < £ z,} в п не-
зависимых испытаниях, а так как события ,An образуют полную груп-
пу попарно несовместных исходов с вероятностями их реализаций в отдельном
испытании pi, ,pN соответственно, то случайный вектор v = (v\, , им)
имеет полиномиальное распределение М (n;p = (pi, ,Pn)} (см. п. 6 § 1.1).
Но из определения э. ф. р. следует, что
Fn&i) = -pn(xi) = -(iz, + ... + 17), i=l,...,2V,
п п
§ 2.1. Вариационный ряд выборки, э. ф.р. и гистограмма
97
и тем самым многомерные свойства э. ф. р. Fn(x) опре- Многомерные
делаются полиномиальным распределением. Для поли- свойства э ф р
номиального распределения известна центральная пре-
дельная теорема о его сходимости при п —> сю к многомерному нормальному
распределению (см. упр. 33 к гл. 1), воспользовавшись которой мы сейчас лег-
ко опишем поведение любых многомерных распределений э. ф. р. для больших
выборок. Для этого вычислим сначала приращения э.ф.р. Fn(x) и эмпири-
ческого процесса = y/n(Fn(x) - F(i)) на интервалах (xi-\,Xi):
- 1 Vi
AiFn =
n n
, ^(v, \ Vi - nPi „
AiITn = \/n(AiFn - Д4Г) = y/nl-----p, ) = ---— =
\ n J y/n
Следовательно,
Д(Д1^П>Д2ТУП,.. , Д^п) = £(рГ p2‘, ,v'N).
Последнее же распределение по упр. 33, гл. 1, сходится при п —> сю к нор-
мальному распределению Х(0, Едг), где дисперсионная матрица Едг = Цсг^-||f
имеет элементы ст,у = р,(<5,у -р>), «5,у — символ Кронекера (<5„- = 1, <5,у = О,
i / >)•
Таким образом, совместное распределение любых приращений эмпири-
ческого процесса (т. е. центрированной и нормированной э. ф. р.) асимптоти-
чески (при п —> сю) нормально:
(9)
(это значительное усиление свойства асимптотической нормальности (7) эм-
пирического процесса в фиксированной точке).
Результату (9) можно придать следующую интепретацию. Обозначим W°(ir)
случайную функцию (процесс), обладающую тем свойством, что
£(Д,1Т0, Д2Иг°, , ДлгТУ0) =#(0,Елг),
т. е. совместные распределения всех ее приращений нормальны (такая функ-
ция W0(i) называется гауссовским процессом, и она может быть конструктивно
определена, но это уже выходит за рамки нашего пособия). Тогда (9) означает,
что при больших п эмпирический процесс 1Уп(я) Предельные распреде-
приближенно устроен как гауссовский процесс ления функционалов от *
ттгО/ х „л I \ ~ rr.rO/ \ эмпирического процесса
W (х) Wn(x) ~ W (X). г
Поэтому следует ожидать, что и распределения «хороших» функционалов д(-)
от эмпирического процесса будут слабо сходиться к соответствующим распре-
делениям g(Wa):
£(g(w°)) при
7 Заказ 1748
98
Глава 2. Первичная обработка экспериментальных данных
Если это так, и если распределение предельного функционала «/(И'’’0) можно
вычислить в явном виде, то на этом пути можно получать предельные теоремы
для распределений различных функционалов <?(1УП) от эмпирического про-
цесса. Именно на этом пути получена знаменитая теорема А. Н. Колмогорова
(1933) о предельном распределении максимального отклонения
Dn = Dn(X) = sup |ВД - F(x)\ (10)
-00CK00
э. ф. р. от F(i) на всей оси.
Теорема 2 (Теорема Колмогорова). Если функция F(x) непрерывна, то при
любом фиксированном t > 0
ОО
lim Р{ч/НОп 1} = K(t) = V (- l)Je“2;V (И)
n-юо '
; = -оо
Распределение Колмого-
ЧЙ рова и доверительная
зона для теоретической
функции распределения
Распределение /Г(4), определенное в (II),
называется распределением Колмогорова, и оно не
зависит от вида теоретической функции распре-
деления F(x).
При этом предельную функцию распределе-
ния К{1), которая подробно протабулирована, можно с хорошим приближе-
нием использовать для практических расчетов уже при п 20.
Теорему Колмогорова обычно применяютдля того, чтобы определить гра-
ницы, в которых с заданной вероятностью находится график теоретической
функции распределения F(i), если она неизвестна. Пусть для заданного
7 € (0, 1) число t7 определяется уравнением K’(t7) = 7. Тогда из (11) имеем:
P{\/nDn <7} = P{Fn(z) - t-Jy/n F(i)
Fn(x) + ty\/n для всех 1}-----> = 7
п-»оо
Таким образом, при больших п с вероятностью, близкой к 7, значения функ-
ции F(x) для всех х удовлетворяют неравенствам
Fn(x) - t7/y/n F(x) Fn(x) +
Так как 0 F(x) 1, то эти неравенства можно несколько уточнить:
max{0, Fn(x) - t^/y/n} F(x) min{Fn(i) + 1} (12)
Область плоскости, определяемая верхней и нижней границами в (12)
называется асимптотической 7 -доверительной зоной для теоретической функ-
ции распределения. Для определения числовых значений 47 при различных 7
можно воспользоваться табулированными значениями функции K(t), напри-
мер, 40,93 — 1,3581, 40,99 = 1,6276.
§ 2.1. Вариационный ряд выборки, э. ф.р. и гистограмма
99
Полезно знать также следующий результат, принадлежащий В. И. Гли-
венко2^ (1933).
Теорема 3 (Теорема Гливенко).
Р{ lim D„ = 0} = 1.
,‘n-»oo J
Другими словами, максимальное отклонение эмпирической функции рас-
пределения от теоретической функции распределения на всей оси с вероят-
ностью 1 будет сколь угодно мало при достаточно большом объеме выборки.
Наконец, сформулируем еще один важный результат выборочной теории,
принадлежащий Н. В. Смирнову (1939), который раскрывает другие свойства
эмпирических функций распределения.
Теорема 4 (Теорема Смирнова). Пусть F\n(x) и F2m(j:)
— две э. ф. р„ построенные на основе двух независимых
выборок объемов п и т из одного и того же распреде-
ления £(£), и
Dn.m= sup |F,n(j:) - F2m(a:)|.
-00<z<00
Э. ф. p. для двух
выборок
(13)
Тогда, если теоретическая функция распределения F(x) непрерывна, то для
любого фиксированного t > 0
lim
n, m->oo
где функция K(t) определена в (И).
Эту теорему обычно используют для проверки гипотезы однородности о том,
что две выборки получены из одного и того же распределения (см. пример 5
Введения и п. 1 §4.3).
Подводя итог обсуждению асимптотических свойств (свойств для боль-
ших выборок) эмпирической функции распределения, можно сделать сле-
дующее общее заключение. То, что при больших п Fn(x) ~ F(x), находит
отражение в следующем фундаментальном принципе
математической статистики: для любой характери-
стики g наблюдаемой случайной величины £, ко-
торая есть некоторый функционал от теоретической
функции распределения F(x) g = g(F), можно построить ее статистиче-
ский аналог (оценку) gn — g (Fn), и тогда для больших п можно использовать
в качестве приближенного значения (оценки) для g 'g7l^ g.
Фундаментальный
принцип математиче-
ской стотистики
2* Гливенко Валерий Иванович (1896-1940) — российский математик, специалист в области
теории вероятностей и математического анализа.
7*
100 Глава 2. Первичная обработка экспериментальных данных
4. Полигон частот, гистограмма
Помимо вариационного ряда и эмпирической функции распределения суще-
ствуют и другие способы наглядного представления статистических данных,
облегчающих работу с ними. Так, если наблюдаемая в эксперименте случай-
ная величина (, дискретна и принимает значения а^, аг, . то более нагляд-
ное представление о ее законе распределения дадут относительные частоты
и* = vTln, где иГ — число элементов выборки X = (Xj, ,ХП), приняв-
п
ших значение ar: vr = I(Xj = ar), r — 1, 2, В этом случае, согласно
j = i
закону больших чисел, при п —> оо v* —> Р{£ = ог), г = 1,2, т. е.
сближается с ростом п с теоретической вероятностью Р{£ = а,.}, и потому,
по крайней мере для больших выборок, относительные частоты н* можно
рассматривать в качестве приближенных значений (оценок) для неизвестных
вероятностей Р{£ = аг}.
Познавательная ценность теории вероятностей обусловлена тем,
что массовые случайные явления в своем совокупном действии со-
здают строгие закономерности. Само понятие математической
вероятности было бы бесплодно, если бы не находило своего осу-
ществления в виде частоты появления какого-либо результата
при многократном повторении однородных условий.
А. Н. Колмогоров
Исходные данные дискретного типа
обычно записывают в виде последователь-
ности пар {(аг, рг)}, где иГ > 0, или в виде
таблицы
Q j О>2
^1 ^2
называемой статистическим рядом (под-
черкнем, что в этом случае иг — п).
Наглядным представлением таких дан-
ных является полигон частот, который
представляет собой ломаную с вершинами
в точках (аг, рг), г = 1,2, (см. рис. 5).
Можно рассматривать также статисти-
ческий ряд {(ar, I/*)} (здесь 5У иг = 1) и
соответствующий полигон относительных
частот.
§ 2.1. Вариационный ряд выборки, э. ф. р. и гистограмма
101
Пример 4. Наблюденные значения целочисленной величины £ для 12 опытов
оказались равными 5, 1, 4, 0, 1,4, 3, 5, 0, 5, 5, 2. Статистические ряды и
полигоны частот этих данных таковы:
Or___0___1____2___3
vr 2 2 1 1
4__5____£
2 4 12
аг 0 1 2 3 4 5 S
>4 1/6 1/6 1/12 1/12 1/6 1/3 1
Для непрерывной случайной величины 4, обладаю- Метод группировки
щей непрерывной плотностью /(х), также можно пост- и ГИСТограмма
роить по соответствующей выборке X = (Xj, ..., Хп)
статистический аналог fn(x) для плотности f(x), который называется гисто-
граммой. Для этого используется метод группировки, в соответствии с которым
область Д возможных значений ( разбивается на некоторое число N непе-
ресекаюшихся интервалов Дь ..., Д/у (так что Д = Дг), подсчитывают
Г = 1
числа Pi, , vn наблюдений ,Хп, попавших в соответствующие ин-
тервалы:
N / w \
vr — I(Xj € Дг), г = 1, , N I так что vr = п I,
J=1 ' Г=1 '
и строят кусочно-постоянную функцию
- иГ
мх) = ТГТ ПРИ х е Дг> r = !> >N
71| I
(15)
(здесь [Дг| — длина интервала Дг). То, что построенная по такому правилу
гистограмма fn(x) действительно «похожа» на теоретическую плотность f(x),
следует из закона больших чисел, согласно которому при п —> оо относитель-
ная частота иТ/п сближается с теоретической вероятностью
е
j f(x) dx.
Дг
Но этот интеграл по теореме о среднем равен /(аг)|Дг|, где аг — некоторая
внутренняя точка интервала Дг (при малом Дг в качестве аг можно взять,
например, середину интервала). Таким образом, при больших п и достаточно
«мелком» разбиении {Дг} fn(x;) х /(аг) при х G Дг, т.е. гистограмма fn(x)
будет достаточно хорошо приближать график плотности /(х), следователь-
но, fn(oc) можно рассматривать в качестве статистического аналога (оценки)
для /(х). •
102
Глава 2. Первичная обработка экспериментальных данных
Наряду с гистограммой, в качестве приближения для неизвестной теоре-
тической плотности f(x) можно использовать кусочно-линейный график,
Полигон частот называемый полигоном частот, и который строится так:
если построена гистограмма fn(x), то ординаты, соот-
ветствующие серединам интервалов группировки, последовательно соединяют
отрезками прямых (см. рис. 6). Построенный таким образом кусочно-линей-
ный график также является статистическим аналогом теоретической плотно-
сти. Группированные данные удобно представлять в виде соответствующего
статистического ряда {(аг,рг)}, где аг — середина r-го интервала груп-
пировки.
Метод группировки применяется и для дискретных данных, когда, на-
пример, множество возможных значений наблюдаемой случайной величины
счетно (как для пуассоновской или геометрической величины). Относитель-
ные частоты иГ/п в любом случае являются статистическими аналогами (оцен-
ками) для теоретических вероятностей Р{£ G Дг}.
Метод группировки наблюдений — удобный и часто более экономный
способ записи информации, содержащейся ввыборке. Если, например, n= 104
а точность измерений наблюдаемых значений на интервале (0, 1) сравнима
с 0,1, то ясно, что практически бесполезно знать все 104 измерений, а доста-
точно указать лишь 10 частот V\, , i/10 попадания в интервалы
г - 1 г
10 ’ 16
т = 1, 10,
т. е. знать лишь гистограмму выборки. Однако, этот способ обладает и очевид-
ными недостатками, связанными с некоторой неопределенностью в способе
разбиения {Дг} и частичной потерей информации при огрублении данных
(ведь фактически мы все наблюдения, попавшие в интервал Дг, заменяем
на среднюю точку аг этого интервала). Поэтому гистограмму используют
практически лишь на предварительном этапе анализа статистических данных.
Пример 5. Наблюдения над непрерывной случайной величиной округлен-
ные с точностью 10-2, оказались равными 0,59; 0,16; 0,44; 0,48; 0,90; 0,19;
0,65; 0,42; 0,35; 0,84; 0,28; 0,63; 0,54; 0,12; 0,18; 0,67; 0,94; 0,63; 0,33; 0,03.
Построим гистограмму и полигон частот этих данных, взяв в качестве интер-
валов группировки
§2.1. Вариационный ряд выборки, э. ф. р. и гистограмма
103
Частоты интервалов здесь равны
г
16-
]_2_3__4
14 12
5__6__7__8___9__10__Е
3 2 4 0 2 1 20
|ДГ| = 1СГ1 п| Дг| = 2, поэтому по формуле (15) значение гистограммы /го(^)
в r-м интервале Дг равно vTll. Вид гистограммы и полигона частот указан
на рис. 7 •
5. Ядерные оценки теоретической плотности
(Этот материал также для желающих заглянуть поглубже в проблему
оценивания теоретической плотности)
Один из современных подходов в задаче оценивания неизвестной теоре-
тической плотности /(х) основан на использовании так называемых ядерных
оценок, т. е. оценок вида
1 п /т — Y \
ш = — 52 (16>
при соответствующем выборе ядра fc(t) и последовательности чисел ап -> 0
при п —> оо. В качестве ядра k(t) здесь выбирают гладкие ограниченные
плотности (например, равномерную плотность на интервале (-1/2, 1/2)), что
обеспечивает хорошее сближение fn(x) с f(x) при п -> оо. Будем далее
считать, что выполняется условие
d2 = J k2(t)dt<oo (17)
и ап -> 0 при п оо так, что пап -+ оо (например, ап = п~а 0 < а < 1).
Тогда можно показать, что при этих условиях для непрерывной и огра-
ниченной плотности /(х) > 0 при п —> оо
С(y/na^(Jn(х) - Е/„(х))) -> jV(O, cr2(x)), (18)
104
Глава 2. Первичная обработка экспериментальных данных
где
<т2(х) = d2 f(x);
при этом
Efn(x) = Е — Л = — [ k( f(t) dt =
\ J \ J
j k(z)f(x - anz)dz -> f(x),
так как
J k(z) dz = 1.
Таким образом, (18) означает, что /n(z) сближается с f(x) при п -э со:
отклонение /n(z) от ЕД(г) (которое, в свою очередь, близко к /(z)) имеет
порядок \/у/пап, который мал при больших п.
Доказательство утверждения (18) состоит в применении центральной пре-
дельной теоремы к сумме (16) независимых и одинаково распределенных
слагаемых в «схеме серий», т. е. когда слагаемые (а, следовательно, и их рас-
пределение) зависят от числа п (оно выходит за рамки нашего пособия, и мы
его опускаем).
Вопрос об оптимальном выборе «свободных» параметров ап и функции
(ядра) k(t) зависит здесь от свойств гладкости теоретической плотности f(x).
Так, если f(x) имеет непрерывные производные порядка 2т > 2, то мож-
но выбором а„ и k(t) добиться скорости сближения fn(x) с /(z) порядка
n-2m/(4m+l) при п
_ На практике часто используют «прямоугольные»
Прямоугольное ядро , „ Л
ядра:
{1 1
О в противном случае.
В таком случае /n(z) = Vn{^)/(nan), где
М®) = 52 Г(х ~~^х<^х+ у)
• =Т ' '
— число наблюдений в интервале
Имеются также результаты вида:
₽{ lim sup|/n(z) - /(z)| = О} = 1
I n->oo x J
(при соответствующих условиях на f(x), k(t) и ап) и вида
₽{ sup|/n(x) - /(z)| > £п| ~ 6п,
§ 2.2. Выборочные моменты: точная и асимптотическая теория 105
позволяющие рассчитывать асимптотические доверительные зоны для f(x),
основанные на ядерной оценке fn(x) вида (16).
§ 2.2. Выборочные моменты:
точная и асимптотическая теория
Пусть X = (Х|, , Хп) — выборка из распределения £(£) и F(x) и Fn(x) —
соответственно теоретическая и эмпирическая функции распределения. На
Fn(x) можно смотреть как на функцию распределения некоторой дискретной
случайной величины, принимающей п значений: Х), , Хп — с вероят-
ностями, равными \/п (если какое-либо значение встретится в выборке к
раз, то этому значению соответствует вероятность к/п). Об этом распреде-
лении говорят как об эмпирическом или выборочном распределении (отсюда
и термин эмпирическая функция распределения для Fn(x)). Как для исходного
распределения £(£) вводятся различные числовые характеристики (матема-
тическое ожидание, или среднее, дисперсия, моменты и т.д.), так и для эм-
пирического распределения, связанного с выборкой X, вводятся аналогичные
характеристики, называемые эмпирическими (или выборочными): выборочное
среднее, выборочная дисперсия и т.д. Таким образом, эмпирическая (или выбо-
рочная) характеристика является статистическим аналогом соответствующей
теоретической характеристики, аналогично тому, как эмпирическая функ-
ция распределения Fn(x) является статистическим аналогом теоретической
функции распределения F(x). В общем случае, если g = Е<?(£) есть некото-
рая теоретическая характеристика наблюдаемой случайной величины то ее
статистический аналог, т.е. соответствующая эмпирическая (иди выборочная)
характеристика, вычисляется по формуле
1 п
9п = -^, 0)
П *7^
1 = 1
1. Выборочные моменты
Наиболее важными характеристиками случайной величины £ являются ее мо-
менты ajt = Е£\ а также центральные моменты = Е(£ - aj* (когда они
существуют). Их статистическими аналогами, вычисляемыми по соответству-
ющей выборке X = (Хь ,Хп), являются выборочные моменты соответ-
ственно обычные
1 п
S>=- £ Р)
1=1
и центральные
?k=l-^^i-St)k. (3)
п
1=1
106
Глава 2. Первичная обработка экспериментальных данных
/fo
ф Выборочное
среднее
/4^
*Ж Выбор очная
дисперсия
Особенно важны моменты первого и второго порядков.
При k = 1 величину 3, называю1_выборочным средним и
обозначают стандартным символом X (черта означает сред-
нее арифметическое):
__ । и
X = ai = -Y/Xi. (4)
1=1
При к = 2 величину называют выборочной дисперсией и
также обозначают стандартным символом S2 = S2(X):
$M = -£(W)2 (5)
п г-г
Таким образом, выборочные среднее и дисперсия являются статистическими
аналогами теоретических среднего (математического ожидания) Е£ и диспер-
сии D£, когда они существуют.
Между выборочными а* и выборочными центральными г~к моментами
сохраняются те же соотношения, что и между теоретическими обычными ак
и центральными рк моментами. В общем случае при к 1 из (3) имеем по
формуле бинома Ньютона
к
Дк=^(-1)гСгкХгак_г,
г=0
т.е. выборочные центральные моменты являются многочленами от обычных
выборочных моментов. В частности,
S2 = а2 - X2 =
/23=03- ЗХ а2 + 2Х3,
Д4=а4- 4Х а3 + 65% - ЗХ4
Если выборочные данные представлены в виде статистического ряда
{(аг,1/г)} (когда наблюдаемая величина £ дискретна или когда применяется
метод группировки), то выборочные моменты вычисляются по формулам
ак = - 52 ЯгМг, fik = - 5? (аг - ai/b'r;
п *—' п *—'
Г г
в частности,
31 = о = - 52 аги,
Д2 = S2 = - 52 (ar “ °^Vr = ~ 52 а^г ~ °'-
(7)
§ 2.2. Выборочные моменты: точная и асимптотическая теория 107
В этом случае для упрощения вычислений исходные данные часто удобно
преобразовать, положив Ьг = (аг - а)/с, где сдвиг а есть значение аг с мак-
симальной частотой vr и единица масштаба с > 0 — произвольна. Средние
а и Ь, и дисперсии S2(a), S2(b) соответственно исходных и преобразованных
данных связаны при этом соотношениями
а = сЪ + а, S2(a) = c2S2(b). (8)
Пример 1. Вычислим выборочные среднее и дисперсию по исходным и груп-
пированным данным, приведенным в примере 5 §2.1. По формулам (4) и (6)
имеем
X = — « 0,468, S2 к 0,067.
20
Далее, середины интервалов Дг в данном случае равны аг = г • 0,1 - 0,05,
при этом а = а? = 0,65; кроме того, здесь удобно выбрать в качестве едини-
цы масштаба с = 0,1. Таким образом, статистический ряд преобразованных
по формуле Ьг = (аг - а.)/с = (г • 0,1 - 0,7) 10 = г - 7 данных имеет вид
Теперь уже вычисляем (см. (7)-(8))
Е— J /
&грг = -37, 6 = -— = -1,85
г г эп
и, следовательно, а = 0,65 - 0,185 = 0,465.
Аналогично,
52 b2vr = 201, 52(Ь) = - 52 brvr - - ]-852 ~ 6,628
Г 71 г
и, следовательно, S2(a) ~ 0,066. •
Пример 2. Проводились опыты с бросанием одновременно 12 игральных ко-
стей, при этом наблюдалось число £ костей с числом очков 4, 5 или 6. Данные
для п = 4096 опытов приведены в таблице, где мг обозначает число опытов,
в которых наблюдалось значение £ = г (г = 0, 1, ,12)
г
О___[
0 7
2______з_
60 198
4_____5___6_
430 731 948
7_____8_
847 536
9____10___И
257 71 И
]2____S
О 4096
Назовем успехом выпадение на одной кости 4, 5 или 6 очков — вероят-
ность этого равна 1/2, тогда наблюдаемая случайная величина £ равна числу
успехов в 12 испытаниях Бернулли с вероятностью успеха 1/2, т. е £ имеет
биномиальное распределение Bi(12, 1/2). Поформулам (4) § 1.1 теоретическое
среднее есть Е£ = 6, а теоретическая дисперсия D£ = 3.
Вычислим теперь выборочное среднее и дисперсию для приведенных
данных. Здесь мы имеем дело со статистическим рядом {(г, мг)}, поэтому
108
Глава 2. Первичная обработка экспериментальных данных
вычисления производим по формулам (7)-(8), предварительно преобразовав
данные, положив Ьг = г - 6 (поскольку здесь а = 6). Статистический ряд так
преобразованных данных имеет вид
br -5 —4 -3 —2 -1 0 1 2 3 4 5 S
»r 7 60 198 430 731 948 847 536 257 71 11 4096
Здесь
Е&^ = 569, Ь=^У|~о>14
и, следовательно, 2] = а + 6,14.
Аналогично,
52^ = 12 083 и Д2 = S2(b) = - 52 ~ 2,93.
Г г
В данном случае различие между теоретическими и выборочными моментами
незначительно. •
Выборочные моменты — это функции от выборки X, т. е. они являются
случайными величинами, поэтому важно знать их вероятностные свойства,
т. е. уметь находить их распределения (которые иногда называют выборочными
распределениями) и изучать различные характеристики этих распределений.
Рассмотрим сначала некоторые характеристики выборочных среднего и дис-
персии.
2. Моменты выборочных среднего и дисперсии
Так как X, независимы и распределены так же, как (, то
ЕЛг=-УЛЕУ; = Е^ = а1, DX = 4 -D(= —. (9)
п п1 £—‘ п п
1=1 i=l
Рассмотрим теперь выборочную дисперсию S2 (см. (5)). Положив
Yi = Х{ - i=l, , п,
запишем (5) в виде
п п
s2 = ^E^-y)2 = ^Ey-2-y2 (‘°)
п п
1=1 1=1
Поскольку ЕЕ; = 0, ЕУ,2 = g2 и ЕУгУ; = ЕУ;ЕУ; = 0 (г£ j), то
i,J=l 1=1
§ 2.2. Выборочные моменты: точная и асимптотическая теория
109
Отсюда и из (10) находим Среднее выбором- 1^
п । ной дисперсии
Е52 =------д2. (11)
п
Перейдем к вычислению DS2 Из (10) находим
Так как случайные величины Уь ..., Yn независимы и EYJ = 0, то в пра-
вой части равенства
_ 1 п
Ey4 = ^ Е Еу>уда
,k. i=i
отличны от нуля только п слагаемых ЕУ,4 = д4 и = Зп(п- 1) слагаемых
ЕУ^У,2 = д2, i j- Поэтому
ЕГ4 = 1 («,!< + 3»(« - |)/4) = +
п п
Аналогично находим
R + (п - 1)/^
п
(п \
у2 Е Y*)-
1 = ] '
С учетом этих соотношений из (12) и (11) по формуле
DS2 = Е(52)2 - (Е52)2
получим
,2 Ра - р] 2(/z4 - 2pfi Ра- Зр*
1 I э
п п1 п*
? Дисперсия выбором- w
дисперсии
(n - I)2 / п - 3 2
= ---Сз----I М4 ~ --------Р2
п3 \ п - 1
(13)
Аналогично можно находить моменты и более высоких порядков, хотя
с увеличением порядка вид формул и их вывод усложняются.
3. Сходимость по вероятности выборочных моментов и функций от них
В этом пункте мы проанализируем свойства выборочных моментов, опреде-
ленных равенствами (2) и (3), для больших выборок, т. е. их асимптотиче-
ское поведение при неограниченном возрастании объема выборки п. Чтобы
подчеркнуть зависимость моментов а*.- и рь от объема выборки, будем их
110 Глава 2. Первичная обработка экспериментальных данных
в дальнейшем снабжать индексом п, т.е. писать апк и fink. Первые два мо-
мента случайной величины апк соответственно равны (везде далее предпола-
гаем, что все соответствующие моменты наблюдаемой случайной величины (
существуют)
1 п
ЕЗп/с = - У? = Е£* = ак,
п
(14)
1 п 1 1 п _ пг ' 7
Dant = - = - (Ее2* - (Ее*)2) = ——k-.
тг пп п
»=]
На основании неравенства Чебышева (напоминание см. перед форму-
лой (6) §2.1) отсюда следует, что для любого € > 0 при п —> оо
p{|3nt - а*| < е}—И, (15)
т. е. выборочный момент апк сходится по вероятности при п —> оо к соответ-
ствующему теоретическому моменту ак. Тем самым апк можно использовать
в качестве приближенного значения (оценки) для ак, когда число наблю-
дений п достаточно велико. Аналогичное утверждение справедливо и для
в
выборочных центральных моментов: рпк —> рк, и вообще для любых выбо-
рочных характеристик, которые имеют вид непрерывных функций от конеч-
ного числа величин апк (центральный момент рпк, как показано выше в п. 1
(см. (6)), выражается через ап], , апк в виде многочлена степени к). Этот
вывод является следствием следующей обшей теоремы о сходимости функций
от случайных величин.
Теорема 1. Пусть случайные величины »/i(n), , Т]г(п) сходятся по вероят-
ности при п —> оо к некоторым постоянным с15 ,сг соответственно. Тогда
для любой непрерывной функции >p(xi,.. ,хг) случайная величина
<(n) = ¥>(77i(n), .^(n))-^(p(ch ,сг).
Доказательство. Поскольку у? непрерывна, то для любого с > 0 найдется
д = <У(е) такое, что |y?(xi,. , хг) - y?(ci, , сг)| < Е при |а?; - cj < д,
i=l, , г. Введем события В, {|7/t(n) — с,-1 < <5}, г = 1, , г Тогда
событие В = В\ Вг влечет событие
С = {|((п)-(р(с1. , Ст)! <е}
Отсюда
Р{С} > Р{В} = 1 -Р{В} =
= l-P{B,U...UBr} > 1-^Р{В,}. (16)
§ 2.2. Выборочные моменты: точная и асимптотическая теория 111
р
Далее, из сходимости T}i(ri) —> Ci имеем, что для данного 6 и любого
у > 0 найдется п, = п,(у) такое, что
Р{В,} = Р{|т7.(п) - с,| > 5} < 2
при п п,. Пусть no = max{ni,..., пг}, тогда при п > по выполняются
одновременно все неравенства Р{В,} < y/r, i — 1, ,г. Следовательно,
из (16) получим
P{|C(n) -^(ci,...,cr)| < с} > 1 -у при п^п0.
Но это и означает утверждение теоремы.
I Замечание. Очевидно, что для справедливости теоремы 1 достаточно потребовать
| непрерывности функции <р только в некоторой окрестности точки (с,.сг).
В частности, теорема 1 дает, что выборочная дисперсия 52 (см. (5)) схо-
дится по вероятности к теоретической дисперсии
д2 = 52Лд2.
Однако, в отличие^от формулы (14), где математи- Подправленная
ческое ожидание ank совпало с соответствующим й
"* J выборочная дисперсия
теоретическим моментом а*, в (11) правая часть
смещена относительно д2. Если вместо S2 ввести величину
D* - *>’• <|7>
•=1
то для нее получим
/ п \2
Е502 = д2, D502 = ------ D52 (18)
\п - 1/
Из неравенства Чебышева и формул (18) и (13) следует, что для любого
г > 0 при п -> оо
Р{|502-д2|<4^ 1, (19)
у р э
т. е. 5q —> д2. Таким образом, подправленная выборочная дисперсия Sq в (17)
уже будет иметь математическое ожидание, совпадающее с теоретической
дисперсией д2, сохраняя при этом свойство сходимости по вероятности к д2
с ростом объема выборки (что вполне естественно, поскольку поправочный
коэффициент n/(n - I) -> 1 при п -> оо).
Теперь настало время ввести несколько новых понятий, которыми широко
оперирует современная математическая статистика — это понятия статисти-
ки, несмещенности и состоятельности.
Определение 1
Любая случайная величина Т, являющаяся функцией от
выборки X = (Xi,..., Хп): Т = Т(Х), называется статистикой.
112
Глава 2. Первичная обработка экспериментальных данных
Примерами конкретных статистик являются выборочные моменты
и выборочные центральные моменты fit, статистикой является выборочная
характеристика дп в (1). Приведем еше два примера конкретных статистик,
используемых в различных статистических задачах.
При исследовании свойств графика плотности распределения непрерыв-
ной случайной величины часто рассматривают такие характеристики, как ко-
эффициенты асимметрии 7, и эксцесса 72, определяемые формулами
Мз 1 /эпХ
Д2 ^2
Если график плотности симметричен относительно нуля, то 71 = 0 и
по значению 71 судят о степени отклонения от симметрии. Аналогично, для
нормального распределения 72 = 0, поэтому о кривых плотности с 72 = О
говорят, что они имеют нормальный эксцесс. Если же 72 > 0 (72 < 0), то гово-
рят, что эксцесс кривой плотности положителен (отрицателен). Если задана
выборка X = (Т|, , Хп) из абсолютно непрервного распределения £(£),
то выборочные коэффициенты асимметрии 7П| и эксцесса определяются как
статистики „ „ „
— ДпЗ МпЗ 1 . ,
7"1 = 73/2 = V и 7п2 = ^-3. (21)
Fni b b
Эти статистики как непрерывные функции от выборочных моментов в си-
лу теоремы 1 сходятся по вероятности при д —> оо к соответствующим тео-
ретическим характеристикам (20).
Статистика Т = Т(Х), используемая в качестве прибли-
женного значения для некоторой (неизвестной) теоретической характери-
стики g : Т ~ д, называется несмещенной в среднем (или просто несмещен-
ной) оценкой g (для д), если выполняется условие
ЕВД=</. (22)
Свойство несмещенности интуитивно привлекательно: оно означает, что
по крайней мере «в среднем» используемая оценка приводит к желаемому
результату. Поэтому в конкретных задачах оценивания часто ищут именно не-
смещенную оценку. С примерами несмещенных оценок мы уже выше встреча-
лись. Так, первое соотношение (5) §2.1 означает, что эмпирическая функция
распределения Fn(x) является несмещенной оценкой теоретической функции
распределения F(x) в каждой точке х 6 R1; аналогично, ввиду (14) выбороч-
ный момент ant является несмещенной оценкой для теоретического момен-
та а*, а ввиду (18) статистика Sq, определенная в (17), является несмещенной
оценкой теоретической дисперсии /z2- Выборочная же дисперсия S2 в качестве
оценки для /z2 = Of свойством несмещенности не обладает: она имеет смеще-
ние Е52 — Д2 — _ 1ч/п (см. (10)> которое стремится к 0 при п —> оо — такие
оценки называются асимптотически несмещенными. Тем самым выборочная
дисперсия S2 является лишь асимптотически несмещенной оценкой Точно
Определение 2
§ 2.2. Выборочные моменты: точная и асимптотическая теория 113
Определение 3
так же и другие выборочные центральные моменты (см. (3)) являют-
ся асимптотически несмещенными оценками для теоретических центральных
моментов рк, поскольку для них известно, что Е - pk —> 0 при п —> оо.
Статистика Тп = 71П(Х|,...,Хп) называется состоятель-
р
ной оценкой для теоретической характеристики д, если Тп —>д при п—> оо.
Таким образом, состоятельность в статистике — это эквивалентное поня-
тие для сходимости по вероятности. Оно означает, что для выборок большого
объема значительная разница между значениями оценки и оцениваемой ха-
рактеристики маловероятна, и потому разумно (по крайней мере для больших
выборок) принять статистику Тп за приближенное значение неизвестной ха-
рактеристики д. Состоятельность является обязательным требованием для лю-
бого правила оценивания. Подчеркнем, что это свойство оценок имеет асимп-
тотический характер и связано лишь с большими выборками (с увеличением
информации, доставляемой выборкой, точность оценки должна возрастать!).
В отличие от этого свойство несмещенности никак не связано с числом на-
блюдений. Отметим также, что все выборочные моменты (как обычные, так
и центральные) являются состоятельными оценками соответствующих теоре-
тических моментов, выборочные коэффициенты асимметрии и эксцесса (21)
также являются состоятельными оценками соответствующих теоретических
характеристик (20).
Наконец, подчеркнем, что для проверки состоя- ЯЩЦЦРКритерий
тельности некоторой несмещенной оценки Тп для д состоятельности
достаточно убедиться, что ее дисперсия DTn —> 0 при
п—> оо, так как в этом случае по неравенству Чебышева
DT
P{|Tn-ff|>e}^-^^0, Ve>0. (23)
На основании этого критерия и ввиду (5) §2.1 можно заключить, что эм-
пирическая функция распределения Fn(a:) является состоятельной оценкой
теоретической функции распределения F{x) в любой точке х € R'
Ввиду особой практической важности оценивания теоретических среднего
о1 = Е£ и дисперсии pi = D£ суммируем полученные выше результаты (9),
(18) и (19) в форме отдельной теоремы.
Теорема 2. Выборочное среднее
1 "
х = -Гх,-
и статистика
1 п
$ =
являются несмещенными и состоятельными оценками соответственно для Е£
и D£.
8 Заказ 1748
114
Глава 2. Первичная обработка экспериментальных данных
Пример 3. Рассмотрим ситуацию, описанную в примере 1 § 1.1. В данном
случае речь идет об оценивании теоретического среднего 0 = Е£ (доли белых
шаров в урне) в схеме Бернулли В1(1,0) по выборке X = , Хп), где
Х}; = 1, если в j-м испытании извлечен белый шар, и Х}. = 0 в противном
случае. Здесь выборочное среднее
- 1 X
X — —(A\ + + Хп) — —,
п п
где X — число наблюдавшихся белых шаров, является несмещенной и состо-
ятельной оценкой 0 = а,/а. •
4. Асимптотическая нормальность выборочных моментов
Продолжим исследование свойств выборочных моментов для больших выбо-
рок и обсудим теперь асимптотическое при п -> оо поведение их выборочных
распределений. Но сначала введем некоторые дополнительные обозначения
и определения для удобства дальнейшего изложения (см. Общее замечание
в п. 1 § 1.2).
Если распределение случайной величины i]n сходится при п -> оо к рас-
пределению случайной величины т/ и при этом £(т?) = Л/\р,а2), то будем
писать £(?7п) -> Л/"(д,а2). Далее иногда будем говорить, что случайная ве-
личина Т)п асимптотически нормальна с параметрами рп и <э2п или, короче,
асимптотчески нормальна Лг(рп, и записывать это следующим образом:
£(т?п) ~ <т„), если с(——-^->#(0,1).
\ /
Найдем сначала асимптотические распределения выборочных моментов
п
апк (см. (2)). Величина паП£ = X? является суммой независимых одина-
г=1
ково распределенных случайных величин. Если конечен момент агь = Е£2А
то к этой сумме можно применить центральную предельную теорему теории
вероятностей (см. соотношение (1) § 1.2). Так как ЕХ? = ak, DXf = a2k -ak
(см. (14)), то величина
папк - пак _ апк - ак
^п(а2к-а2к) ^(а2к-а2)/п
асимптотически нормальна Л/"(0, 1). Таким образом, справедлива следующая
теорема.
Теорема 3. Если конечен теоретический момент а2к, то при п -> оо выбо-
агк - а2к \
рочныи момент arnjt асимптотически нормален Jv I ак,-------
_________________________________ V П 7
§ 2.2. Выборочные моменты: точная и асимптотическая теория 115
Полезность этой теоремы состоит в том, что она позволяет оценивать для
больших выборок вероятности заданных отклонений значений выборочных
моментов от теоретических. Действительно, из этой теоремы имеем, что при
любом фиксированном t > 0 и п оо
t
р(л/ П 2|SnA-at|<4^-4= f е’12/2^ = Ф(<)-ФН) = 2Ф(<)-1
I V a2k - J V 2тг J
(обозначения см. в (7) § 1.2).
В частности, из теоремы 3 следует, что если теоретическая дисперсия
Д2 = D£ существует, то при п—> оо выборочное среднее iV = ani асимптотиче-
ски нормально Отметим в этой связи, что если £(£) =_А/'(аьД2)>
то случайная величина X, как сумма независимых нормальных случайных ве-
личин, также нормальна с параметрами а( и дг/п (см. соотношение (5) § 1.2),
т. е. в данном случае £(Х) = #(ai, дг/п) при любом п.
Справедлив также более общий результат об асимптотической нормально-
сти любого конечного числа выборочных моментов апк. Но для доказательства
этого надо знать многомерный вариант центральной предельной теоремы, ко-
торый формулируется следующим образом.
Многомерная центральная предельная теорема. Пусть г-мерные случайные
векторы ,T]kr), к = 1,2, независимы, одинаково распре-
делены и имеют конечные моменты
a,=E7/fcl, btj = cov(T)ki,r]kj), = ,r.
Тогда при п —> оо
r«ni, .&,)—>Х(о,в = 11М9>
где
. (г?1« + + rjni - na,) .
Cni =----------т=--------, г = 1, ,г
у/П
(определение многомерного нормального распределения дано в п. 2 §1.2).
Рассмотрим теперь вектор Ап = (anI, , anr), составленный из произ-
вольного числа г первых выборочных моментов. Обозначим
a=(ai, ,аг) = ЕЛ„ и Е = ||а0<, где atj = ai+j - а;а7.
Легко убедиться, что дисперсионная матрица D.4n = (1/п)Е (см. упр. 21). Вве-
дем, далее, векторы = (Хк, Х%,. ,Xk),k=l,.. , п, — они являются
независимыми и одинаково распределенными, так как Xi,...,X„ незави-
симы и одинаково распределены, при этом = a, = Е. Осталось
заметить, что пАп = ту 4-... Ч- и применить к этой сумме многомерную
а»
116
Глава 2. Первичная обработка экспериментальных данных
центральную предельную теорему:
4^.-Да') _tAf(0.s)
\ vn /
или, что эквивалентно, £(Ап) ~ Л/(a, (l/n)S).
Таким образом, справедлива следующая теорема о совместном распреде-
лении выборочных моментов.
Теорема 4. Если конечен теоретический момент агг, то при п—>оо совмест-
ное распределение выборочных моментов (ап1,... ,2ПГ) асимптотически нор-
мально ЛГ (а = (ан , аг), (1/п)Е).
Эта теорема полезна больше не сама по себе, а своим важным следствием,
которое мы приводим без доказательства. Именно, справедлива
Асимптотическая нор-
мальность функций от
выборочных моментов
Теорема 5. Для любой дифференцируемой функ-
ции <р от г переменных
£(7^(<р(4п) - <р(а))) —> V(0, а2)
при условии, что <т2 = J/S6 > 0, где
Ь = grad р(а') =
д<р(х)
dxi
ду(х) \
дхт )
Более того, если а2 = а2({а.}) — непрерывная функция от теоретических
моментов {а.} и а„ = а2({2п.}) (т. е. моменты а. заменены соответствую-
щими выборочными моментами ап.), то
-( гч>(Ап)-у>(а)\
£ уп-------------- ) —> Л (0, 1).
\ °П J
Из теоремы 5, в частности, следует, что асимптотически нормальными
являются и центральные выборочные моменты поскольку они являются
непрерывными функциями (многочленами) от обычных выборочных момен-
тов. Например, соответствующее утверждение для выборочной дисперсии S2
формулируется следующим образом (см. упр. 23).
Асимптотическая
нормальность выбо-
рочной дисперсии
Теорема 6. Если конечен теоретический момент рц,
то при п —> оо выборочная дисперсия S2 асимпто-
тически нормальна _Л/ (/Z2> (Д4 - pl)/n) Более того,
x/n(g2 - р2) \
—> V(0, 1)-
§ 2.2. Выборочные моменты: точная и асимптотическая теория 117
Определение 4
5. Асимптотические доверительные интервалы
для теоретических моментов
Теоремы предыдущего пункта, в особенности теорема 5 в варианте (24), ис-
пользуются в статистике для построения доверительных интервалов для тео-
ретических моментов. С примером доверительного интервала мы уже встреча-
лись в п. 2 § 2.1, где был построен асимптотический 7-доверительный интервал
для теоретической функции распределения F(x) в произвольной точке х, где
F(x) £ 0. Дадим теперь общее определение доверительного интервала. Пусть
нас интересует некоторая теоретическая характеристика д наблюдаемой слу-
чайной величины 4 и имеется выборка X = (Хь , Хп) из £(£).
^-доверительным интервалом для д называется такой
случайный интервал (ТДХ),Т2(Х)), Т,(Х) < Т2(Х), который содержит
внутри себя (накрывает) неизвестное значение д с вероятностью, не мень-
шей 7:
Р{Т1(Х)<д<Т2{Х)}^у. (26)
Здесь Т\(Х) и Т2(Х) — некоторые статистики (функции от выборки), на-
зываемые соответственно нижней и верхней доверительными границами, а 7 —
задаваемый заранее доверительный уровень, который обычно выбирается доста-
точноблизким к 1 (например, 7 — 0,9; 0,95; 0,99 ит.д.). Длина Т2{Х)-Т{(Х)
такого интервала характеризует точность локализации оцениваемой характе-
ристики д, а величина 7 отражает «степень готовности мириться с возмож-
ностью ошибки», т. е. является показателем надежности доверительного ин-
тервала.
Если выполнено условие (26), то практически это означает, что в большом
числе независимых применений такого правила оценивания мы можем оши-
биться, утверждая, что д € (Т|(Х), Т2(ХУ), примерно в (1 - 7)100 % случаях.
Общая теория доверительного оценивания будет обсуждаться позже
(см. гл. 3 § 3.8), а сейчас мы продемонстрируем такой подход в оценива-
нии теоретических моментов. При этом, поскольку мы будем основываться
на предельной теореме 5, то речь будет идти о построении асимптотических
доверительных интервалов.
Итак, пусть нас интересует характеристика д = а = (а, , аг),
где <р — заданная непрерывно дифференцируемая функция. Тогда на основа-
нии (24) мы можем записать следующую цепочку соотношений:
— |^(4п)-^| <сД = pLe —>
J I \ Vn ) J
—> Ф(а0 - Ф(-с0 = 2 ф(с0 - 1 = 7, (27)
если Су = Ф1 ((1 4- 7)/2)
Но это и означает, что (^(Дп) Т с7<7'п/'/п) есть асимптотический 7-до-
верительный интервал для д = <р(а). Центр этого интервала находится в слу-
чайной точке ф(Дп), а его длина равна Ic^Wn/y/n, т. е. при больших объемах
118
Глава 2. Первичная обработка экспериментальных данных
выборки это достаточно узкий интервал, обеспечивающий высокую точность
локализации оцениваемой характеристики g у (а). Таким образом, мы
имеем общее решение доверительного оценивания произвольных (непрерыв-
но дифференцируемых) функций от любого конечного числа теоретических
моментов. На практике нам обычно бывают нужны более частные случаи оце-
нивания отдельных моментов — прежде всего среднего и дисперсии наблюда-
емой случайной величины Поэтому выпишем еще в явном виде несколько
конкретизаций этого общего решения.
Пример 4. Рассмотрим задачу построения доверительного интервала для про-
извольного теоретического момента = Е£А k $ 1. В этом случае, вме-
сто использования общего алгоритма (27), проще непосредственно исполь-
зовать теорему 3, заменив в ее формулировке асимптотическую дисперсию
(агк - afy/n ее оценкой (ап.2к - йгпк)/п. В итоге это даст искомый асимп-
тотический 7-доверительный интервал для ак вида
-F С7
(28)
‘Ч/L Доверительный ин-
тервал для среднего
Полагая здесь к = 1, получим соответствующий
интервал для теоретического среднего а, = Е£:
(29)
Пример 5. Чтобы построить асимптотический 7-доверительный интервал для
теоретической дисперсии ц2 = D£, надо просто воспользоваться результа-
Доверительный ин- том (25>: искомый 11НтеРв^ есть
тервал для дисперсии! . П2 ~
(30)
\ V п /
§2.3. Многомерные данные
Высшая математика проще элементарной в том смысле, что
исследовать непроходимую чащу легче с самолета, нежели пеш-
ком (но для этого надо иметь самолет и уметь им управлять!).
Иногда наблюдаемая в эксперименте случайная величина представляет собой
вектор некоторой размерности fc 2: £ = (£], ,&)• В этом случае вы-
борка из £(£) есть совокупность fc-мерных векторов {X/ = (Хп, ., Хщ),
I — I,... ,п} и обработка таких многомерных данных уже более трудоемка,
§ 2.3. Многомерные данные
119
так как помимо обычных выборочных моментов здесь надо вычислять эм-
пирические (выборочные) аналоги для смешанных теоретических моментов,
среди которых важнейшим для приложений является второй смешанный мо-
мент или ковариация.
Чтобы не загромождать изложение техническими деталями, рассмотрим
подробно лишь простейший случай k = 2. Итак, пусть наблюдается двумерная
случайная величина £ = (£i,6) и {-X/ = (ЛГ/ь -Гц), i = 1,.. , п} — повторные
независимые наблюдения над ней. Обозначим F(xi,i2') = P{£i ^i, £2 ^2)}
(теоретическую) функцию распределения, Е£ = (Е£,, Е^) = Д = Цт) —
вектор средних и D£j = crj, j = 1,2, cov(£j,£2) = ^12 — вторые центральные
моменты вектора £. Как в данном случае по выборочным данным построить
эмпирические (выборочные) аналоги этих характеристик?
1. Эмпирическая функция распределения
Эмпирическая функция распределения определяется по аналогии с одномер-
ным случаем формулой
Fn(x}tx2) = - У'ЦХц xhXn х2) = - Ул/. (1)
п tr
В (1) {t]i = 1(Хц Х\, Х/2 £2)} — независимые одинаково распреде-
ленные случайные величины, принимающие значения 0 и 1, т.е. бернуллиев-
ские величины, причем
Ety = P{A)| xh Х,2 х2} = F(xl,x2),
Vi)i = F(xhx2)(\ -F(x],x2)).
Отсюда и из (1) следует, что
1 п
EFn^.iz) = =F(x2,x2), (2)
т. е. э.ф. р. FnC^i, х2) является несмещенной оценкой для F(xi, х2) при лю-
бых 11, х2.
Далее
1 n 1
DFn(ii,®2) = ^У?0’?/ = -F(®i,a:2)(l -^2)), (3)
n y-y n
что стремится к нулю при п —> оо, т.е. Fn(x\,x2) является состоятельной
оценкой для F(x\, х2).
Таким образом, здесь имеется полная аналогия с одномерным случаем
(см. (5) §2.1).
120 Глава 2. Первичная обработка экспериментальных данных
2. Моменты
Обратимся теперь к моментам. Обозначим Xj = (X\j,.. , Xnj), j = 1,2, вы-
борочные данные для j -й координаты вектора £ = (£,, £2) и пусть Xj, S2 —
соответствующие выборочные среднее и дисперсия, вычисляемые по форму-
лам (4)-(5)_§ 2.2.
Тогда Xj является эмпирическим аналогом для теоретического среднего
Pj = a S2 — для дисперсии cr2 =
Выборочная Выборочная же (эмпирическая) ковариация — аналог
ковариация теоретической ковариации
4712 = COV((,, £2) = Е(£, - рi)«2 - Pl) = Е£|& - P1P2
Выборочный
коэффициент
корреляции
— определяется формулами
! n _ _ 1 n ____________________________________
S12 = - У2(Хц - X,)(Xl2 - X2) = - V X„Xl2 - X{X2. (4)
i=i i=i
Соответственно, выборочный (эмпирический) коэффи-
циент корреляции — аналог теоретического коэффициен-
та корреляции
Р = Р(Ь,&) = corr^i ,£2) = ^==
VD?1
— определяется формулой
S12
рл W
Исследуем некоторые свойства этих новых выборочных характеристик.
В § 2.2 мы установили, что выборочная дисперсия не является несмещенной
оценкой теоретической дисперсии, но легко построить статистику уже являю-
щуюся несмещенной оценкой дисперсии (см. формулы (17)-(18) § 2.2). Анало-
гичный факт имеет место и для выборочной ковариации. Именно, справедлива
Лемма. Статистика
п 1 п
-^5,2 =---------- £(Х(, - Xt)(Xl2 - Х2) (6)
71-1 71-1
является несмещенной оценкой теоретической ковариации ащ =cov(£i,£2)-
Доказательство. Введем случайную величину т? = 4-^2- Выборочные дан-
ные для нее есть Х[ = Хц + Xi2,1= 1,... ,п, а ее дисперсия Dr] = а( + o’2+ 2&i2.
Построим несмещенную оценку для Dtj: это есть статистика
1 п ] П
---- £(*/ - *)2 = —7 Е - *') + 2 =
п — п— 1
/=1 /=1
§ 2.3. Многомерные данные
121
. п . п - п
= —7 - *1 )2 + — £(*П ~ ^)2 + 7Т7 Е^'' - ХМХ" - *)
" * /=1 П 1=1 П ‘ / = !
В этом разложении
1 п -
есть несмещенная оценка для aj, j = 1,2, следовательно, последнее слагае-
мое — несмещенная оценка для 2СТЦ.
В общем случае для fc-мерной наблюдаемой величины £ = (&,.. > с
Е£ = д = (pi,... ,/ifc) и дисперсионной матрицей D£ = Е = Цоу, = cov(£,, ^-)||*
выборочные моменты первого и второго порядков вычисляются по формулам
- х^хч - хЛ’ * >
1 i=i
Таким образом, здесь мы имеем вектор выборочных средних (Xj, , Х^')
и выборочную дисперсионную матрицу Е = ||5^ ||*, где Sa = S? ,i — 1, , к.
Вектор выборочных средних будет несмещенной оценкой для вектора тео-
ретических средних д = (дь , д*..), т. е. ЕЛ\ = д;, г = 1,..., к, а подправ-
ленная выборочная дисперсионная матрица п/(п- 1)Е — несмещенной оцен-
кой для Е: E(n/(n- 1)Е) = Е (это равенство следует понимать поэлементно).
3. Большие выборки
Обсудим теперь асимптотические свойства введенных новых эмпирических
характеристик, предполагая, что теоретические ковариации существуют. Тогда
по закону больших чисел при п -> оо
1 п
- £ XtiXtj Л Е(б^),
4 1=1
но также и Xj -^4 Е£,, Sj -^4 D(,. Следовательно, Состоятельность
по теореме 1 §2.2 выборочных ковори-
S- Р оций и коэффициен-
Sij —> CFij и Pij — -----» Pij = p(£i, (j), тов корреляций
О j j
г £ ] (7)
Таким образом, выборочные ковариации и коэффициенты корреляций
являются состоятельными оценками соответствующих теоретических ковари-
аций и коэффициентов корреляций (конечно, если все теоретические диспер-
сии <т/ > 0).
122
Глава 2. Первичная обработка экспериментальных данных
Можно также показать, что Epij-pij —> 0 при п -э оо, т. е. pij являются
лишь асимптотически несмещенными оценками для ptJ.
4. Добавление: нормальная модель
Предположим, что наблюдается двумерная нормальная случайная величина:
£(£i> 6) - Л/’l (рьрг),
IPI < 1
^2
(см. п. 2 § 1.2), и требуется по соответствующей выборке рассчитать довери-
тельный интервал для теоретического коэффициента корреляции р.
Это можно сделать на основании результата Р. Фишера (1915 г.), который
показал, что если от выборочного коэффициента корреляции рп, определен-
ного в (5), перейти к новой статистике
то уже для небольших объемов выборки п статистика Zn будет распределена
приблизительно нормально, со средним значением и дисперсией, заданными
приближенными выражениями
Ег"^+2(ГП)'
1.1 + р
где
, (8)
Другими словами, С{у/п - 3(Zn - ()) —> Л/"(0, 1) при п -э оо.
Отсюда, так же, как и в п. 5 §2.2, мы можем построить асимптотический
7-доверительный интервал для (: (Zn^Cy/Vn - 3),Су = Ф-1 ((1+7)/2) По-
скольку функция £ = ((р) в (8) монотонно возрастает, то разрешая уравнения
C(p) = z„T-=X=
Vn - 3
относительно р, мы получим асимптотический 7-до-
верительный интервал для самого коэффициента кор-
реляции р:
pe^ = (c'(zn--^=\ c'(zn + -^=\) (9)
\ \ у/п-3) \ V 71 — 3) J
(здесь (-I — обратная функция к Q. Поскольку в этом алгоритме число п
предполагается большим, то в (9) можно ограничиться лишь первыми двумя
членами разложения в ряд Тейлора3* функции C~\Zn + en), €п —> 0, и не-
Г--1ГЧ-
Довер ительный
интервал для р
Тейлор Брук (1685-1731) — английский математик и философ, в 1712 г. нашел общую
формулу разложения функций в степенной ряд, носящую его имя.
§2.3. Многомерные данные
123
пользовать приближенный интервал
Д^С'^тМ^) ) =
\ Vn-3 М l=zJ
e1Zn - 1 / 4c^e1Zn \
e1Zn + ! \ ^ (e4Zn - 1)%/п - 3/
При больших п это достаточно узкий интервал, окружающий точку
(e2Z" - 1)/(е2г" + 1). В свою очередь, если значение статитстики рп мало,
тогда Zn ~ рп, и интервал (10) может быть заменен приближенным интерва-
лом Д!) = (рптс7/-/п-3), который уже является симметричным интервалом
с центром в точке рп. Построенный интервал Д^ может быть использован
также для проверки гипотезы Но, состоящей в том, что р = ро, где рй —
некоторое малое заданное число. В частности, при р0 = 0 гипотеза Но будет
означать независимость компонент£| и & наблюдаемой двумерной нормаль-
ной случайной величины £ = (£i, £2), поскольку в данном случае некоррели-
рованность (ро = 0) эквивалентна независимости (см. п. 2 § 1.2). Рассуждаем
при этом мы так. Если гипотеза Но р = ро верна, то
Ф" <Рв< А‘ + ^Йг=т
или, что то же,
Ps Ipn - Pol > г > ~ 1 - 7 = а.
( Vn - 3 J
При достаточно малом значении а (при 7 близком к 1) событие |рп - р0| >
с^/х/п - 3 практически невозможно, и если для данной выборки обна-
руживается, что |рп - ро| с^/у/п - 3, то мы должны отклонить гипотезу
о равенстве р = ро, как противоречащую данным. В противном случае ги-
потеза считается согласующейся с данными, и она принимается. При этом
мы можем ошибиться, отклонив гипотезу Hq, если она верна, но вероятность
этого приблизительно равна а, т. е. мала.
Обычно такую методику применяют для проверки Гипотеза
гипотезы независимости Но : р = 0 (понятие общей ги-
, г, х независимости
потезы независимости см. в примере 6 Введения), и в
этом случае правило принятия решения формулируется следующим образом:
задаемся малой вероятностью а ошибочно отклонить истинную гипотезу Но
(а называется уровнем значимости) и определяем число Су — Ф-1((! +?)/2),
7 = 1 - а. Далее по имеющейся выборке вычисляем значение статистики
рп по формуле (5), и если окажется, что |рп| с^/\/п - 3, то гипотеза Нй
отвергается, в противном случае, т.е. при |pn| < с-у/у/п — 3, она принимается.
Таким образом, здесь мы встретились с конкретным примером проверки
статистической гипотезы, общая теория которых будет детально обсуждаться
в гл. 4.
124 Глава 2. Первичная обработка экспериментальных данных
Замечание. Плотность /пр(г) статистики ра имеет вид [15, с. 436]: при п > 2
/.»= ^(1 -г’)'-"" / ,, г'-' , М <
тг J (I — ргх)п VI— х1
т. е. зависнет лишь от п и р, и при р = 0 (т. е. при независимости £| и £2)
Если (при р = 0) рассмотреть преобразование
то, используя формулу (45) § 1.2, нетрудно убедиться в том, что статитсти-
ка Тп имеет распределение Стьюдента 5(п - 2) (это мы оставляем читателю
в качестве простого упражнения на применение формулы преобразования
(45) § 1.2). Поскольку функция у = у/п - 2 х/v 1 - х2 при |х| < 1 моно-
тонно возрастает от -оо до оо, то отсюда следует, что события {|ТП| > £<»}
и {|р„| > za} при za = ta/y/n-2 + t2a эквивалентны. Поэтому, если при
заданном а, 0 < а < 1, число ta выбрано так, чтобы выполнялось условие
P{|Tn| > tQ} = а, то будет выполняться также условие P{|pn| > zu} = а.
На этом факте, аналогично предыдущему, можно предложить следующий ал-
горитм для проверки гипотезы независимости Но р 0, который уже
«работает» при любом числе наблюдений п > 2. Пусть задан малый уровень
значимости а. Тогда, поскольку плотность распределения Стьюдента (см. (28)
§ 1.2) симметрична относительно нуля, то, обозначая функцию распределения
закона S(n) через 5п(х), из цепочки соотношений
ОО
а = Р{|Т„| > <„} = 2 ! /(х|п - 2) dx = 2(1 - Sn_2(ta))
получаем, что ta определяется уравнением
Sn-2{ta) = 1 - у, т. е. ta = S“22 (1 - у) ,
где 5„22(-) — обратная функция к 5п_2(х).
Далее вычисляем по имеющимся данным значение рп, и если окажется,
что |рп| > za = ta/y/n-2 + t2a, то мы отвергаем гипотезу Hq как проти-
воречащую данным, поскольку вероятность такого события при гипотезе Но
(равная, по предыдущему, а) мала при малом а. В противном случае, т. е. при
|pnl za, гипотеза Но принимается. Вероятность ошибочно отклонить при
этом истинную гипотезу Но в точности равна а.
§ 2.3. Многомерные данные
125
5. Другие корреляционные характеристики
В теории статистической регрессии (о которой подробно будет идти речь в гл. 6
§ 6.6) важную роль играют, помимо обычных корреляций (коэффициентов
корреляций согт(£, т?) = р(£, т/)), другие, более сложные корреляционные
характеристики совокупности изучаемых случайных величин. Здесь мы дадим
их определения и построим их эмпирические (выборочные) аналоги.
Итак, пусть имеется совокупность случайных величин Y и X = (Л-!,
, Хр), связанных некоторой стохастической зависимостью, причем X до-
ступно наблюдению (измерению), а значение Y непосредственно измерить
невозможно (например, Y связано будущим). Тогда возникает задача предска-
зания (прогноза, оценки) величины Y по информации, доставляемой измере-
нием величин Хь , Хр, которые в этом контексте называются предсказы-
вающими переменными. Функция от предсказывающих переменных у?(Х), ко-
торую используют в качестве оценки для Y <р(Х) ~ Y, называют предиктором
величины К по X Задачей разработки методов построения наилучших (в ка-
ком-то смысле) предикторов занимается теория статистической регрессии.
Для измерения точности предиктора <р обычно используется среднеквад-
ратичная ошибка (с. к. о.)
Д(ф) - Е((р(Х) - У)2
Предиктор, минимизирующий с. к. о. в заданном классе
предикторов L называется оптимальным предиктором, или Прогноз
прогнозом (в классе L), и обозначается символом р*
р = arg min Д(ф), (И)
его с. к. о. есть
Д* = д((р*) = Е((р*(20 _ Y)2 = inf Е(?(Х) - У)2 (12)
Таким образом, в общем случае задача построения наилучшего (в сред-
неквадратичном смысле и в заданном классе предикторов L) прогноза для
величины У по Х_ сводится к решению экстремальной проблемы (11)—(12).
Часто ограничиваются классом линейных предик- Линейный п *
торов, т.е. когда L есть класс линейных функций:
L — {р 9?(z) =/Зо+^iZi+. +/ЗрХр} В этом случае оптимальный предик-
тор всегда существует (при условии существования вторых моментов и невы-
рожденности дисперсионной матрицы Е = DX) и имеет вид:
y; = р\х) = д0* + д;х< +...+д;хр =
= До* + Д *'х = еу + Д*'(х - ех), (13)
где
Д* = Е-1а, а = соу(У,Х) = (cov^Xj), ,соу(У|,Хр))
И
Pq = ЕУ - /Г'ЕX;
126
Глава 2. Первичная обработка экспериментальных данных
при этом его с. к. о.
Д* = ay-a'S-la, aY = DK (14)
Таким образом, как сам оптимальный предиктор, так и его с. к. о. вы-
ражаются в данном случае лишь через первые и вторые моменты системы
случайных величин (У, Х_).
Множественный
коэффициент
корреляции
В изложенной теории линейного прогноза особую
роль играет величина
j a S а 1 / * ,
Pyx = ^^=P 2(Г/(Ю). (15)
<тг
называемая множественным коэффициентом корреляции', она является есте-
ственной мерой зависимости между Y и X (мерой точности прогноза) и с ее
помощью можно сравнивать различные совокупности предсказывающих пе-
ременных в конкретных задачах. Согласно (15) множественный коэффициент
корреляции между Y и совокупностью X = (Хь , Хр) равен квадрату
обычного коэффициента корреляции между Y и оптимальным линейным
предиктором для Y по X. Чем ближе р2Ух к 1 > тем меньше с. к. о. Д* (см. (14)),
а при pyx = 1 с. к. о. Д* = 0, т. е. прогноз абсолютно точен: в этом случае
У = т?‘(Х), т. е. У функционально связана с X.
В практических приложениях теоретические моменты системы случайных
величин (У, X) обычно неизвестны, поэтому все сведения, необходимые для
построения оптимального предиктора, получают в результате обработки ста-
тистических данных, которые представляют собой выборку из распределения
£(У, X). Оценив по такой вспомогательной выборке (по результатам прошлых
измерений X и У) первые и вторые моменты, как это описано выше в п. 2,
и заменив этими оценками теоретические характери-
стики Un = ЕУ, Д = ЕХ о, и S, строят эмпирический
предиктор 5 — —
предиктор
ИХ)=Зо*+Г'Х> ДГ = До - 0"р, (16)
Эмпир ический '(вд
который и используют для предсказания в других случаях (в будущих изме-
рениях). Точность эмпирического предиктора (16) оценивается эмпирическим
множественным коэффициентом корреляции
Р^~1ЦУ) (17)
(в формулах (16)—(17) а = (S’o,, , SOp), S = , индекс «О» соответству-
ет У). Множественный коэффициент корреляции рУх_ принято записывать
в виде Ро(1...р).
Еще одна полезная корреляционная характеристика возникает при рас-
смотрении следующего вопроса. Корреляция между двумя величинами, ска-
жем, в нашем случае, между У и Хр, характеризуется коэффициентом кор-
§2.3. Многомерные данные
127
реляции рОр согг(У Хр), который иногда называется также полным ко-
эффициентом корреляции Y и Хр. Если рассматривать Y и Хр совместно
с остальными р— 1 величинами Ль..., Лр-1, то можно считать, что изме-
нение величин Y и Хр вызывается в какой-то мере изменением остальных
величин. Спрашивается, как в такой ситуации измерить непосредственную
связь Y и Хр, исключая, так сказать, влияние промежуточных переменных
Xi, , Лр_,? Для этого служит частный коэффици- Частный коэффи-
ент корреляции величин Y и Х„ относительно Л|,. **
„ С „ р _ циент корреляции
Лу_|, обозначаемый символом Pop(i...p-i). Для его вы-
числения поступают следующим образом. Строят оптимальные линейные пре-
дикторы для Y и Хр, основанные на промежуточных переменных Ль---,
Лр_|, по алгоритму (13), т. е.
У = 0o+0*Xi+.. + Д;_,ЛР_1
и
Хр — Qo + а । X1 + ••• + oip-i^p-i,
и рассматривают «остатки» ei = Y — Y" и ei = Хр- Хр тем самым исключа-
ется влияние «общих факторов» Ль • • •, Лр_! на рассматриваемые перемен-
ные Y и Хр). После этого вычисляется обычный коэффициент корреляции
р{е\, ег) между этими остатками, который и есть частный коэффициент кор-
реляции рър(\...р-\) величин Y и Хр относительно Ль , Лр_ь В теории
линейного прогнозирования доказывается, что
Р0р(1...р-1) = ^0ОрИ>)1/2’ <18)
где ||р';|| = 1ЫГ‘ и
pij = p(Xi,Xj), i,j =0, 1, ,р (Л0 = У).
Из (18) следует, что частный коэффициент корреляции определяется че-
рез обычные коэффициенты корреляции системы величин Y, Ль , Хр,
следовательно, его эмпирический аналог строится заменой в (18) теоретиче-
ских корреляций pij на выборочные корреляции pi:, определенные в (7):
P0p(I...p-l) = (-oo-ppy/i- (19)
Из формул (17) и (19) видно, что эмпирические множественный и част-
ный коэффициенты корреляций представляют собой непрерывные функции
от выборочных вторых моментов, поэтому по теореме 1 § 2.2 на основании
соотношений (7) можно заключить, что они являются состоятельными оцен-
ками соответствующих теоретических характеристик.
Пример 1. Рассмотрим случай р = 2. Здесь предиктор Y* = 0$ + Д*Л1( где
согласно (13) 0* = cov(K, Л^/ВЛ! = poi~ и 0о — ЕУ - Д’ЕЛь
^1
128
Глава 2. Первичная обработка экспериментальных данных
де,, е2
Аналогично, предиктор Х2 = ао + , где
. cov(X2, (т2 , ,
а‘= пт =Л>12—, а; = ЕХ2-а;ЕХ,.
DA I (Jj
Следовательно, остатки имеют вид
ci = Y - Y* = Y - р\Хх - р*й, е2 = Х2- Х*2 = Х2 - - <4
а их с. к. о. по (14) равны De, = ctq(1 - poj и De2 = сг2(1 - р,2). Далее непо-
средственно вычисляем
cov(ei,e2) = cov(r - p’Xt, Х2 - a’Xi) = (pQ2 - p0iPt2)^2,
cov(ei, e2) _ pp2 - P01P12
VDe,De2
С другой стороны, обращая корреляционную матрицу ||pi2||o и вычисляя
элементы
02 _ РР2 ~ PPIPl2 00 _ * ~ Р|2 22 _ * ~ Рр|
1Р>;1 |Р>;1 1Рг>1
по формуле (18) приходим к тому же результату (20).
Вычислим, наконец, оптимальный предиктор (13).
Здесь
£_ Р12<Т|СГ2
Р12<Т1<Т2 <Т2
и в итоге находим
д* <Тр Poi - Р02Р12
Pi — — : 5—,
1 - Pl2
Таким образом,
/(Хь Х2) = ЕУ + Р*(Х\ - ЕХР + р*2(Х2 - ЕХ2)
с указанными коэффициентами Р* и р2. Множественный же коэффициент
корреляции (15) здесь имеет вид
2 Poi + Pm ~ 2poiPO2P12 ,
Pop 2) ~ j Л • (21)
1 ~ Pl2 ,
§ 2.4. Выборочные квантили и порядковые статистики
1. Теоретические и эмпирические квантили
Важный класс характеристик наблюдаемой (скалярной) случайной величи-
ны 4 составляют квантили. По определению, р-квантйль — это решение
уравнения F((p) = р, 0 < р < 1, где F(x) — функция распределения Если
> я — (ро1<тосг1> Ро2аот2)
д* стр Р02 ~ Р01Р12
Р1 = —
<т2
1 -Р|2
§ 2.4. Выборочные квантили и порядковые статистики
129
функция F(x) строго возрастает, то однозначно определена обратная к ней
функция F~l, и тогда (р = F~l(p). В общем случае, для произвольной непре-
рывной справа функции F обратная к ней функция Квантильная
определяется равенством функция
F~'(p) = inf{i F(x) р) (1)
и называется квантильной функцией.
Итак, в любом случае (для любой функции распределения) р-квантиль
случайной величины £ (или ее распределения) есть (р = F~'(p), т. е. значение
квантильной функции (1) в точке р € (0, 1) (см. рис. 1)
llFn(x)
k_
n ’
р-----i
I
1
; fc — 1 I
! n!
Рис. 2
Статистическим аналогом для (р (выборочной, или эмпирической, р-кван-
тилью) £лр называется р-квантиль эмпирической функции распределения
Fn(x), построенной по выборке X = (Xh , Хп) из С(£). Эти новые вы-
борочные характеристики просто выражаются через порядковые статистики
выборки (см. п. 1 §2.1). Действительно (см. рис. 2), если (к- 1)/п < р к/п,
или к - 1 < пр С к, то = F„ '(р) = Хщ. Поэтому, если число пр целое,
т. е. пр = k, то (п, р = Х(Пр); если же число пр дробное (т. е. к-1 < пр < fc), то
целая его часть [пр] = к - 1 (т. е. fc = [пр] +1) и потому (п р = Л’(|Пр|+ i>. Итак,
7 _ _ I Х(1«р1+') п₽и пР ДР°бном>
Cn,p — Fn (х) — < (2)
I Х(Пр) при пр целом.
9 Заказ 1748
130
Глава 2. Первичная обработка экспериментальных данных
Выборочная ЛК При р = 1/2 квантиль С1/2 называется теоретиче-
медиана CK0& медианой, a ]/2 — выборочной медианой (несколь-
ко отличается от определения медианы вариационного
ряда в п. 1 §2.1); при р = 1/4 и 3/4 соответствующие квантили иногда назы-
ваются квартилями, соответственно нижними и верхними.
Итак, поскольку, ввиду (2), выборочные квантили по существу есть соот-
ветствующие порядковые статистики выборки, то дальнейший разговор будет
вестись в терминах именно порядковых статистик.
2. Распределение порядковых статистик
Предположим, что распределение случайной величины £ абсолютно непре-
рывно и f(x) = F'(x) — ее плотность. Найдем функцию распределения
Fk{x'j = х} и плотность gk(x) = Fk(x) произвольной порядковой
статистики Хщ (k = 1, , п) выборки X = (Л), , Хп) из £(£).
Событие я} означает, что не менее к элементов выборки X име-
ют значения, не превосходящие х, но это есть событие {дп(;г) > Л} (см. (3)
§2.1), следовательно, эти два события эквивалентны. Как показано в п. 2 § 2.1,
случайная величина Рп(%) при любом х Е Л1 распределена по биномиально-
му закону Bi(n, F(x)) Отсюда имеем
п
Fk(x) = Р{рп(х) > Аг} = 52 Сгп Fr(x)(\ - F(x))n~ (3)
r=k
В частности, из (3) имеем, что распределения экстремумов имеют вид
ВД = Р{Х(|) 1} = 1 - (1 - F(x))n,
Fn(x) = Р{Х[п} х} = Fn(x).
Таким образом, в любой модели функции распределе-
Неполная ния порядковых статистик легко выписываются. Далее,
бета-функция правую часть (3) можно записать через так называемую
неполную бета-функцию
Z
B(z;a’6) = S^ f ta~\\ - t)b-x dt, 0^1, (4)
Г(а)Г(&) J
о
которая представляет собой функцию распределения закона Ве(а, Ь) (см. п. 4
§ 1.2). Именно, интегрированием по частям нетрудно установить формулу
Z
о
п
^Crnzr(\-z)n-r, (4')
r«fc
§ 2.4. Выборочные квантили и порядковые статистики
131
из которой следует, что формуле (3) можно придать функция распреде-
также вид ления Х(к)
Fk(x) = B(F(x);k,n-k + 1). (5)
Неполная бета-функция подробно протабулирована, поэтому представ-
ление (5) полезно для проведения численных расчетов, связанных с порядко-
выми статистиками.
До сих пор нигде не предполагалось существование плотности f(x)=F'(x),
поэтому предыдущие формулы справедливы для любых распределений £(£).
Если же £ имеет плотность распределения f(x), то
соотношение (5) можно продифференцировать по х Плотность распре-
и получить в итоге, что плотность gk(x) = F'k(x) су- ,
шествует и имеет вид
Можно также выписать совместную плотность для любого числа поряд-
ковых статистик (см. упр. 31). Укажем, например, вид двумерной плотности
gkr(xi, ij) для пары порядковых статистик (Х(к), X(rj), 1 fc < г п:
п!
х2) - (к_ }у(г_к_ ^п_гу х
xF‘-'(n)(F(l2) - F(2!1))r_fc’,(l - F(x2))n~r f(xi)f(x2) (7)
при Xi < х2 и равна нулю в остальных точках.
Приведем, наконец, вид совместной плотности всех п порядковых ста-
тистик:
g]...„(xi,...,xn) = nlf(xt)...f(xn), xt < х2 < <хп. (8)
Рассмотрим один важный для последующего и поучительный пример
работы с порядковыми статистиками.
Пример 1. Пусть X — (А)......Хп) — выборка из стандартного показатель-
ного распределения Г( 1, 1) (см. п. 3 § 1.2) т. е. когда плотность f(x) = е~х
х > 0. В этом случае совместная плотность всех п порядковых статистик
X(i),..., Х(П) по формуле (8) есть
^...„(ii,... ,хп) = п!е 11 1л, 0 < Х\ < х2 < < хп. (9)
Рассмотрим новые статистики Спейсинги показа-
Yr = (п - г + 1)(Х(Г) - Х(г_,,), тельной выбоРки
г = 1,..., п, Х(о) = 0,
называемые спейсингами, и найдем их совместное распределение. Для этого
надо лишь воспользоваться соотношением (44) § 1.2. В данном случае якобиан
9*
132
Глава 2. Первичная обработка экспериментальных данных
преобразования = пх, у2 = (п - l)(i2 - Xi), Уп = ~ ^n-i равен,
очевидно, п!, т.е. постоянен, а
п п п
^Уг = - Г + l)(lr - Ir-,) = Хг.
Г=1 Г=1 г=1
Следовательно, для совместной плотности <р(у\,... ,уп) преобразованных ста-
тистик имеем в виду (9) представление
Ль .,„) = 1") =е-»
п!
Но это означает, что статистики Ylt..., Yn независимы и имеют одно и то же
стандартное показательное распределение Г(1, 1). (!)
Отсюда можно сделать следующие интересные выводы. Выразим исход-
ные порядковые статистики Х^ через спейсинги Уь ,Yn:
k = 1, , п.
(Ю)
Моменты порядковых
статистик показатель-
ной Выборки
Тем самым представляется в виде линей-
ной комбинации независимых случайных величин,
поэтому, в частности,
ь к
Е*(*) = Е
--------ЕУГ
п - г + 1
Л I
DXa) = V -----------rDFr.
Zt (n - г + О2
Но среднее и дисперсия закона Г(1, 1) равны 1 (см. (21) § 1.2), поэтому
к I " 1 п 1
= S у >*<•>= Е О')
г = 1 =п-4+1 J j=n-k+l J
В частности, для максимального значения выборки эти формулы
принимают вид
"1 "1
е^» = Е;- d^) = E^- (,2)
7=1 J 7 = 1 J
Если объем выборки п —> оо, то, используя известные асимптотические
формулы из анализа:
п 1
- = In п Тс+ о(1), с = 0,5772. — константа Эйлера4\
; = 1 2
Эйлер Леонард (1707-1783) — гениальный швейцарский математик, механик, физик и аст-
роном, академик Петербургской АН.
§ 2.4. Выборочные квантили и порядковые статистики 133
Асимптотические
свойства порядко-
вых статистик
на то. что все они
заключаем, что в среднем Х(п) неограниченно возрастает как In п, в то время
как дисперсия DX(n) —> тт2/6, т. е. имеет конечный предел. •
Замечание. В рассмотренном примере нам удалось, «играя» на специфических осо-
бенностях показательной модели, вычислить в явном виде моменты (среднее и дис-
персию) порядковых статистик. Но это исключительный случай. Вообще же проблема
отыскания моментов порядковых статистик весьма сложна и ее удается решить лишь
для некоторых моделей £(£) (см. упр. 32 данной главы и упр. 46, 56 гл. 1), в отличие
от проблемы получения их распределений. Подчеркнем, что для выборочных момен-
тов в этом аспекте — все наоборот.
Перейдем теперь к исследованию асимптотических
свойств порядковых статистик для больших выборок
(при п —> оо). Поскольку число порядковых статистик
равно объему выборки и, следовательно, неограничен-
но растет вместе с п, то было бы наивным надеяться
будут иметь однотипные асимптотические свойства. И, действительно, эта
проблема распадается на две самостоятельные задачи: асимптотика «средних»
членов вариационного ряда (2) §2.1 и предельные распределения «крайних»
порядковых статистик. Прежде всего поясним эту терминологию.
Под средними членами вариационного ряда выборки объема п при п -> оо
понимаются порядковые статистики Х^, номера которых к = к(п) удовле-
творяют условию к/п -> р при некотором р, 0 < р < 1. Таким образом, это
такие члены вариационного ряда, которые расположены «далеко» от его кон-
цов. Крайние же порядковые статистики — это члены вариационного ряда,
расположенные в его концевых законах, т.е. статистики Х^ при г ограни-
ченных и X(n_s+|j при s ограниченных.
3. Асимптотическая нормальность средних членов, вариационного ряда
Зафиксируем некоторое р, 0 < р < 1, и рассмотрим порядковую статистику
Х(к) с к = [пр]. Справедлива следующая теорема о ее асимптотическом рас-
пределении.
Теорема 1. Если в некоторой окрестности точки плотность f(x) непре-
рывна вместе с производной и /(£р) > 0, то при п -> оо
£(W) Ч=^-Р- (13)
Доказательство. Рассмотрим случайную величину
‘Пп = (х^ -
134
Глава 2. Первичная обработка экспериментальных данных
и покажем, что ее плотность <рп(%) сходится при п -> оо к стандартной нор-
мальной плотности <р(х) = (2я)_|/2е-1 (см. (7) § 1.2). По формуле 43 § 1.2
из (6) имеем
Vn(x) = ~п^ (Cp)9k(M, W tn = <(р + ~п
Запишем <рп(х) в виде произведения Л|(п)Л2(п).4з(п), где
А П' , /„ч /(М
’ Л1(") = 7(й'
л,(„) = (£ыу‘71^Г“
\ Р / \ Q /
и найдем предел каждого из этих трех множителей при п -> оо и к = [пр].
Простым упражнением на применение формулы Стирлинга для гамма-функ-
ции (см. п. 3 § 1.2) является установление предела Л](п) -> (2я)-|'/2 (остав-
ляем это читателю). Далее, Л2(п) -> 1 в силу непрерывности функции f(x).
Наконец, поскольку F(£p) = р, из тейлоровского разложения в точке (р
F{tn) — Р + £\ F —— 2, . + оI — )
V п 2п /%) \nj
нетрудно получить, что 1п Лз(п) -> -i2/2. В итоге это дает нужный предел
у?п(т) -> <р(х).
Состоятельность
выборочных
квантилей
Замечание. Ввиду связи (2) между порядковыми статисти-
ками и выборочными квантилями соотношение (13) спра-
ведливо также и при замене Х(|п;,|) на р:
(14)
Отсюда можно сделать вывод о том, что выборочная р-квантиль является асимп-
тотически несмещенной и состоятельной оценкой теоретической р-квантили
Справедлив более общий результат (многомерная предельная нормальная
теорема)-, если в некоторых окрестностях точек (Pi, i = 1, , г, где 0 < р} <
< р2 < < рТ < 1, плотность f(x) непрерывна вместе с производной и по-
ложительна, то при п -э оо совместное распределение выборочных квантилей
(п р., i — 1, , г, асимптотически нормально с вектором средних значений
(Cpi > • • > Срг) и матрицей вторых моментов
-||а0||1, где ffij
Pi^-Pj)
§ 2.4. Выборочные квантили и порядковые статистики
135
Пример 2. Найдем асимптотическое распределение
выборочной медианы £n,i/2 для выборки из нормаль-
ного распределения Л/"(д, а2). Соотношение (14)
для выборочной медианы из любого распределения
с плотностью f(x) принимает вид
Распределение
выборочной медианы
в нормальной модели
£(?..,„) ~v(<,04
Если же f(x) имеет вид, указанный во Введении к гл. 1, то легко видеть,
что функция /(г) симметрична относительно точки д, поэтому (1/2 = д,
а /(д) = 1 (у/2яа). Подставляя эти значения в (15), получим
(16)
Для сравнения отметим, что соответствующее выборочное среднее X при
любом п нормально М(р,сгг/п). Таким образом, обе статистики X и ^п, 1/2
являются состоятельными оценками теоретического среднего д, но X имеет
меньшую дисперсию, поэтому выборочному среднему следует отдать предпо-
чтение как более точной оценке. Систематически вопросы сравнения точности
различных оценок одной и той же теоретической характеристики будут рас-
сматриваться в гл.3. •
Итак, средние члены вариационного ряда для больших выборок из доста-
точно гладких распределений являются асимптотически нормальными (как и
выборочные моменты, см. п.4 §2.2), и ими можно оценивать теоретические
квантили любых уровней р, 0 < р < 1. Совершенно иначе устроены асимп-
тотические распределения крайних порядковых статистик, к рассмотрению
которых мы теперь переходим.
4. Асимптотическое поведение крайних порядковых статистик
Относительно асимптотического поведения порядковых статистик, находя-
щихся на разных краях вариационного ряда, справедливо следующее общее
утверждение.
Теорема 2. Для выборки из абсолютно непрерывного распределения стати-
стики Х(г) и Х(п_з+1) при любых фиксированных г, s 1 и п —> оо асимп-
тотически независимы и при этом
£(nF(X(r)))->Г(1,г),
(17
£(n(l-F(X(„_,+1)))) —>Г(1,5)
(определение гамма-распределения Г(а, А) см. в п. 3 § 1.2).
136 Глава 2. Первичная обработка экспериментальных данных
Доказательство. Пусть хп (каппа) и т]п обозначают рассматриваемые пре-
образованные статистики:
хп =nF(X{r)), уп = n(l - .F(X(n_i+i))). (18)
Вычислим сначала якобиан преобразования у\ =nF(xl), y2=n(l-F(x2))'.
очевидно, он есть J(xt, xi) = -п2 f(x\)f(xi). С учетом этого, по формуле (44)
§ 1.2 и с использованием формулы (7) для совместной плотности ^(з/ьУг)
преобразованных статистик хп и т/п имеем следующее представление:
„I / \ t-i / \ з-1 /
_______________п! ( — } f Уг\ /
(г — 1)!(п -___г - s)!(s — l)!n2_\ п ) \п ) \
В условиях теоремы при любых фиксированных уь у^ > О
п!
(п - г - s)\nk+a
что в итоге дает
чЖъУг) —>
Vi ‘е-У'
(fc- 1)!
УГ'е~Уг
(S-1)!’
Но это и означает, что в пределе случайные величины хп, Т]п (следовательно,
и Х(г), X(n_s+i)) независимы и имеют указанные в (17) гамма-распределения,
которые являются в данном случае распределениями Эрланга соответственно
порядков г и s.
Обратим внимание на следующие моменты. Во-первых, предельные рас-
пределения крайних порядковых статистик не являются нормальными (в отли-
чие от средних членов вариационного ряда). Во-вторых, теорема 2 определяет
вид предельных распределений не самих порядковых статистик, а некоторых
функций от них, определенных в (18). Конечно, если эти уравнения можно
явно разрешить, т. е. получить явные представления
то можно получить предельные распределения и самих статистик X(rj, X(n_s+i)
через предельные распределения кп,т)п. В качестве иллюстрации такой воз-
можности рассмотрим следующий пример.
§ 2.4. Выборочные квантили и порядковые статистики
137
Пример 3. Пусть £(£) = Г(1, 1) — стандартное
показательное распределение. Здесь
X
F(x) = J e~ldt = 1 - е~х, х О,
о
Распределение верхних
экстремумов для
показательной модели
и легко находим
F~'(t) = -In (1 -t), 0<i< 1.
Следовательно, в силу (19) Х(п_4+1) = In n - In т/п. Отсюда по теореме 2
ОО
P{X(„_3+|) - In п о} = Р{/?п е"1} —> J тг4_|(з/) dy, (20)
в’*
где обозначено irk(t) = e~ltk/к\, к = 0, 1,2, — это обозначение будет ис-
пользоваться и в дальнейшем. Интегрированием по частям интеграл в (20) мо-
жет быть вычислен в явном виде, что приводит к окончательному результату:
S-1
P{X(„_s+1) - In п < х}—>^2л>(е-г), -оо < х < оо. (21)
В частности, для максимального значения выборки (21) принимает вид
Р{Х(П) - In п < г} —> е~е -оо < х < оо. (22)
Напомним, что ранее, в примере 1, были получены асимптотические значения
среднего и дисперсии статистики Х(п).
Предельное распределение в (22) называется дважды экспоненциальным,
его среднее и дисперсия равны соответственно с (константа Эйлера) и тг2/6,
так что для
/А 1 А
с — lim > - - In n
n-too J )
имеем одно из возможных интегральных представлений:
00
с= J х ехр{-х - е~х} dx
-00
(значение с вычислено с 260 десятичными знаками). •
Однако, в явном виде обратную функцию Г-1(0 удается выписать лишь
в редких случаях, поэтому теорема 2, вообще говоря, оставляет открытым во-
прос о предельных распределениях для самих минимальных и максимальных
значений выборки (или нижних и верхних экстремумов). Кроме того, эта тео-
рема не охватывает случай выборок из дискретных распределений (но факт
138 Глава 2. Первичная обработка экспериментальных данных
асимптотической независимости для них также имеет место). Общее решение
вопроса о возможных предельных распределениях для крайних порядковых
статистик в больших выборках дается классической теорией экстремальных
значений, основной вклад в которую внесен отечественными математиками
Б. В. Гнеденко (1941-1943) и Н. В. Смирновым (1949) (о нем см. в § 2.1). Пол-
ное изложение этой теории выходит за рамки настоящего пособия, поэтому
мы ограничимся лишь общим описанием основных ее результатов.
5* Асимптотическая теория для верхних экстремумов Х(„_т+1), тп 1
Общая задача ставится так: пусть при некотором выборе нормализующих
констант а„ > 0 и Ьп имеет место сходимость
Р
(23)
где Gm(x) — некоторая невырожденная (т. е. имеющая более чем одну точку
роста) функция распределения. Нужно ответить на следующие два вопроса:
1) какой может быть предельная функция распределения Gm(x)? и
2) при каких условиях на общую функцию распределения F(x) случайных
величин X),..., Хп и каких ап и Ьп будет выполняться соотношение (23)
для каждой возможной функции Gm(i)?
р
5* Распределения экстре-
мальных значений
Вот полные ответы на эти вопросы.
1) Gm(x) может быть лишь одного типа из следующих трех, называемых
распределениями экстремальных значений: (обозначения см. в (20))
0 при х < 0,
т— 1
^2 тгг(2;_“) при х > 0,
г=0
f m-1
л«М = "Р"
2 ' / г=0
1 при
m-l
Лз”*\я?) = У7 ^(е-1), -оо < х
г=0
X и,
а > 0;
х > 0,
< оо.
(24)
Если выполняется (23) с (хт = то говорят, что функция распреде-
ления F(x) принадлежит области притяжения типа
§ 2.4. Выборочные квантили и порядковые статистики
139
2) Необходимыми и достаточными условиями при-
надлежности функции распределения F(x) об-
ласти притяжения каждого из этих трех типов
являются (ниже используются обозначения хр
7n = inf{rr F(x) 1 - 1/п}):
Области притяжения
экстремальных типов
sup{x F(x) < 1},
л (m)
тип Л, :
1 - F(tx) _а
хр = оо и lim ----------——- —х V х > О,
/—со 1 - F(t)
при этом ап = 7П> Ъп = 0;
тип Л^:
1 - F(хр -tx) а
хр < оо и lim--------------— = х , V х > О,
цо 1 - F(xp -t)
при этом ап = хр — 7„, Ьп = xF;
тип Лз™); при всех х £ R' существует
}-F(t + xg(t))
lim -----------------= е где
tur 1 - F(t)
XF
<,(i) = Г
у' ’ Ji- f(i)
t
du\
при этом ап =g(yn), bn=^n.
Если F(x) не относится ни к одной из указанных трех категорий, то
соотношение (23) не может быть выполнено ни при каком выборе кон-
стант ап и Ьп.
3) Если существует f(x) = F'(x), то достаточными
условиями принадлежности F(x) к соответству-
ющим областям притяжения являются:
тип Л,т^: f(x) > 0 для всех конечных х xq и
Условия принадлеж-
ности к экстремаль-
ным типам
lim tf®
Д™ 1 - F(t)
(25)
тип f(x) > 0 в некотором конечном интервале (хо,хр), f(x) = О
при х > Хр и
(xF -
lim---------—
ttxF 1 - F(t)
(26)
тип Ajm> f(x) < 0 в некотором интервале (xq, Xf) (xf < oo), f(x) = 0
При X Хр и
lim
Л<)(1-ЭД
= -1.
(27)
140
Глава 2. Первичная обработка экспериментальных данных
Замечание. Аналогичная теория существует и для нижних экстремумов Х^, т I
фиксировано; при этом, поскольку X(m) = --Xp,-m+i), где Xjq С Х(п) есть
вариационный ряд выборки (-Х,,..., —Х„), то результаты для Х(т) получаются
простой переформулировкой соответствующих результатов для верхних экстремумов.
Интересующихся деталями мы отсылаем к обзорной статье51 где имеются также
дополнительные сведения и комментарии по этой проблеме.
Приведенный выше пример 3 относится к области притяжения типа Aj.
К такому же типу относится и следующий пример (далее мы ограничиваемся
лишь максимумом Х(п) и пишем Лу вместо Л^).
Примеры роспреде- лений экстремумов Пример 4 (Нормальное распределение). Пусть F(x) = Ф(г) (см. (7) § 1.2). Здесь хр = оо и 1 - Ф(г) ~ ^(г)/г при г -э оо, применим критерий (27) и при выборе
ап - (2In п)"1/2 имеем: Ьп = (2 In п)|/2 - -(2 In n)“1/2(ln In п + In 4тг) Лз \ /
Пример 5 (Распределение Парето, см. п. 9 § 1.2). Здесь F(x) = 1 - (х0/х)а
х > Го, и применим критерий (25), при этом ап = — хоп'^а, Ьп = 0.
Следовательно, по (24)
Р{7п%) я} —> е х х>0.
Таким образом, распределение Парето с параметрами xq и а принадлежит
области притяжения типа Л| с данным параметром а. •
Пример б (Равномерное распределение). Пусть F(x) = х, 0 х 1. Здесь
хр = 1 и применим, очевидно, критерий (26) с а = 1, при этом ап = 1/п,
bn = 1. Таким образом, в данном случае имеем предел типа Л2 (см. (24)):
P{n(^W - 1) г} —> ех х < 0.
С примерами статистических применений экстремальных значений выборки
мы встретимся в гл.З. •
§ 2.5. Линейные и квадратичные статистики
от нормальных выборок
Выше (см. п. 1,2 § 1.2) уже говорилось о той исключительной роли, которую
играет в приложениях математической статистики нормальная модель. Раз-
личные свойства нормальных случайных величин обсуждались в § 1.2 и сфор-
мулированы в форме упражнений 26-32, 38,40 к гл. 1. Здесь мы установим еще
51 Ивченко Г. И. Предельные распределения экстремальных характеристик выборок // Обозре-
ние прикладной и промышленной математики. 1997. Т.4. Вып. 3. С.443-469.
§ 2.5. Линейные и квадратичные статистики
141
несколько общих результатов для нормальных выборок, относящихся к ли-
нейным и квадратичным формам от нормальных случайных величин, которые
играют важную роль в статистике нормальной модели.
1. Линейные и квадратичные статистики, условия их независимости
Пусть X = (Xi, , Хп) — выборка из стандартного нормального распреде-
ления 1). Рассмотрим квадратичную форму
Q = atjXiXj = Х'АХ, А = ||а0-||?, А1 = А,
п
и т линейных форм bkiXi, k = I,.. ,т, или в матричных обозна-
: = 1
чениях t = ВХ. Здесь В — прямоугольная (тхп) -матрица и t = (tb , tm).
Далее будем обозначать через О матрицу с нулевыми элементами и через 1п —
единичную матрицу порядка п.
Следующая лемма дает критерий независимости статистик Q и t.
Лемма 1. Если В А = О, то статистики Q и t независимы.
Доказательство, Матрица А действительна и симметрична, поэтому, как
известно из алгебры, можно найти такую ортогональную матрицу U (т. е.
UU' = 1п), что U'AU = Л. Здесь Л — диагональная матрица с элементами
Аь , Ап, являющимися корнями характеристического уравнения
det (Л - А1П) = 0.
Столбцами и,, , ип матрицы U являются собственные векторы матрицы Д:
= А;Дг-, i=l,. , п.
Пусть г — ранг матрицы А (т. е. число линейно независимых ее строк)
и А], , Аг — отличные от нуля характеристические числа. Эквивалентной
формой записи
A = UAU' (1)
является, так называемое, спектральное представление Спектральное
матрицы А. представление
А = £ AtUju' (2) матРИЦЫ
г = I
(напомним, что при матричных операциях векторы понимаются как вектор-
столбцы). По условию леммы
О — В А - Ai(BtZj)^.
»=i
142 Глава 2. Первичная обработка экспериментальных данных
Умножим это равенство на вектор справа. В силу ортогональности соб-
ственных векторов = 0 при i =4 j) получим
Ви, = 0, i = 1, , г. (3)
Рассмотрим теперь случайный вектор (<i,... ,tm, utX, ,игХ). Этот
вектор распределен по нормальному закону, поскольку является линейным
преобразованием нормального вектора X (ведь при линейных преобразова-
ниях нормальность сохраняется, см. п. 2 § 1.2). В то же время из представле-
ния (2) имеем
Г г
Q = 52 ^Х'и^Х) = 52 А,(ц'ЛГ)2 (4)
i=i i=i
Следовательно, утверждение будет доказано, если показать, что случайные
величины t|, ,tm некоррелированы с и,Х, i = 1, , г (тогда эти две
группы величин будут независимыми, см. п. 2 § 1.2). Обозначая через д' строки
матрицы В (г = 1, , тп), в силу соотношений (3) имеем
cov(t,-,w' X) = cov^X.u'X) = E(ft'Xu'-X) - E(dJX)E(u'X) =
= E&XX'uj) = Ь^Е(ХХ')и}- = b-lnUj = Ь'щ- = 0.
Установим теперь аналогичный критерий независимости двух квадратич-
ных форм Qi = Х'АХ и Qi = Х'ВХ.
Лемма 2. Если АВ = В А = О, то статистики Q] и Qi независимы.
Доказательство. Пусть для матрицы А справедливо спектральное представ-
ление (2), а аналогичное представление для В имеет вид
3
В = 52 s = rank &
J=1
По условию,
О = АВ = 52
м
Умножив это равенство слева на и).-, а спРава на Vi< получим ukVj = 0,
fc = 1, ,г, I = 1, s, т.е. векторы u,, ,иг ортогональны всем век-
торам £|, ,vs. Отсюда, как и выше, имеем, что случайные величины utX
и V, X некоррелированы, а так как они совместно нормально распределены,
то и независимы. Но
Г 9
Qi = 52 = 52
;=i j=i
следовательно, Qi и Q2 независимы.
§ 2.5. Линейные и квадратичные статистики
143
2. Распределения квадратичных статистик
Среди квадратичных статистик от выборки X = (Хь..., Хп) из £(£) =А/’(0,1)
простейшей является сумма квадратов Х?+.. о которой нам уже извест-
но (см. п. 3 § 1.2 и упр. 38 к гл. 1), что ее распределение есть х2-распределение
с п степенями свободы: £(Х? + .. + Х„) — х2(п)- Что можно сказать о рас-
пределении произвольной квадратичной формы Q = Х'АХ с действительной
симметричной матрицей А? Этот вопрос мы и рассмотрим в данном пункте.
Обозначим tr А слей (track) квадратной матрицы А, т. е. сумму ее диагональ-
ных элементов. Имеет место следующее общее утверждение.
Теорема 1. Если матрица А идемпотентна (А2 = А), то C(Q) = Х2(г)> гДе
г = tr А = rank Л.
Доказательство. Пусть для А справедливо представление (2). Тогда, так как
ненулевые характеристические числа матрицы А2 равны X2, i — I,..., г, то,
в силу идемпотентности А, А| = = Аг = 1 и потому (см. (4))
Г
Q = £(^Х)2
«=1
Из ортонормированности собственных векторов и,, • •, и, следует, что слу-
чайные величины utX, i = 1,..., г, независимы и нормальны А/(0, 1), сле-
довательно, £(Q) = х2(г)- Наконец, используя непосредственно проверяемое
равенство гг(ЛВ) = 1г(ВД), из формулы (1) находим
tr А = tr(W'WA) — tr Л = А[ + + Аг = г.
Замечание. В качестве следствия этого результата докажем упражнение 40 к гл. 1.
Применив алгоритм п. 2 § 1.2, построим преобразование = А'|/24/'(£ - р), пе-
реводящее вектор £ с £(£) = Л/(/з, S) в стандартный нормальный вектор Z_. Тогда
£ - /з = WAI/2Z и, следовательно,
Q(£) = (£ - д)'Е-|(£ - М) = ^.a1/2z/'s_1z/ai/2z = Z'Z,
так как = Л-1 По теореме 1 £(<?(£)) = x2(k). поскольку единичная матрица
1* является идемпотентной и tr lt = k.
Таким образом, при некоторых условиях на матрицу квадратичной формы
от стандартного нормального вектора она распределена типично по закону х2
Но что будет, если нормальный вектор X = (Л), , Хп) не является стан-
дартным? В таких случаях возникает новое распределение для квадратичных
статистик от X, являющееся обобщением распределения хи-квадрат. Добавим
это важное распределение к списку уже имеющихся.
144
Глава 2. Первичная обработка экспериментальных данных
Пусть Xj, ,Хп — независимые нормальные случайные величины и
при этом £(Х>) = X/\pi, 1), i = 1,. , п. Тогда, как мы знаем, сумма
Ё(х--*)2
имеет распределение х2(п)- Однако часто бывает необходимо знать распреде-
ление суммы квадратов самих случайных величин Xi. Распределение случай-
ной величины U2 = X2 + + Х^ называют нецен-
тральным распределением хи-квадрат с п степенями
свободы и параметром нецентральности X2 = р] + р2п
Нецентральное
X -распределение
и обозначают символом х\п\ А2): £(С72) = X2(n! Плотность этого рас-
пределения имеет вид
~n/2— 1
f(x\n; А2) =--тт-е
*' 1 ’ ' 2П/2
у- (зА2)2
^;!22>Г(> + п/2)’
(5)
а первые два момента равны
ЕСТ2 = п + А2
Dt72 = 2(п+ 2А2). (6)
Если параметр А2 = 0, то Y2) = Х?(га)> т е- нецентральное распре-
деление х2 переходит в обычное (центральное) распределение х2
В качестве иллюстрированного примера ситуаций, где возникает нецен-
тральное распределение хи-квадрат, докажем следующее утверждение.
Лемма 3. Пусть n-мерный нормальный вектор У имеетсобственноераспреде-
ление Л/"(д, S).Тогда статистика Q = У'Е-|У имеет распределение х2(п; А2),
где А2 = р£~}р.
Доказательство. Рассмотрим вектор X = K~^2U'Y, где И — ортогональная
матрица, приводящая S к диагональному виду (см. п. 2 § 1.2): Ul£ll = K.
Тогда £(Х) =Л/’(д,1„), где Д = Л-1/2С/'д. Далее, У = С/Л'^Х и потому
Q = х'х1/2к'£-'кх1/2х = Х'Х = X? + ... + X2,
поскольку U'YT'U = Л- Следовательно,
£((?)= £(Х2 + +Х2)=Х2(п;А2),
где
А2 = р' р = pU Л“|/2р = р'ЕГ'р,
поскольку UK~XU' = Е"1.
§ 2.5. Линейные и квадратичные статистики
145
3. Теорема Фишера
Наиболее часто используемыми статистиками от нормальных выборок явля-
ются выборочное среднее
I 71
п
1 — 1
и выборочная дисперсия
1 п
S- xf
Первая из них является линейной, а вторая — квадратичной функцией от
, Хп. Полученныев предыдущих пунктах результаты позволяют весьма
просто доказать знаменитую теорему Р. Фишера (1925).
Теорема 2 (Теорема Фишера). Пусть X = (Хь ..., Хп) — выборка из
£(£) = Af(//, а2). Тогда статистики X и S2 независимы и при этом
С(Х)=Лг(Ц,—\ a =*2(п-1).
\ п ) \ <т2 /
Доказательство. Перейдем к стандартным нормальным случайным вели-
чинам
Тогда легко проверить, что
„ 5’(Г) = ^.
п а (Т2
i=i
Поэтому достаточно показать, что Y и S2(Y) независимы и при этом
£(V^i Г) = Х(0,1), а Д(п5'2(У)) = х2(п-1).
Рассмотрим n-мерный вектор-столбец Ь = (1/п,..., l/п)' и (пхп)-мат-
рицу В = ||Ь... Ь||. Легко проверить, что Y = bY,a
nS2(Y) = (У - BY)'(Y - BY).
Отсюда nS2(Y) = Y'AY, где матрица А = 1п - В идемпотентна и tr А = п - 1.
Теперь 1)А = 1)-1)В =1) -t> = 0 и, следовательно, по лемме 1 статистики У
и S2(Y) независимы. Далее, закон распределения У очевиден (см. (5) § 1.2),
а закон распределения nS2(Y) следует из теоремы 1.
10 Заказ 1748
146 Глава 2. Первичная обработка экспериментальных данных
Замечание. Так как для распределения — I) среднее и дисперсия равны соот-
ветственно п - 1 и 2(п - 1) (см. п. 3 § 1.2), то из доказанной теоремы следует, что
для нормальных выборок
3 п - 1
ES2 = <т2-----
п
7 л П - 1
DS2 = 2а4——
п-
(7)
(сравни с соответствующими формулами (11) и (13) § 2.2 для выборки из произволь-
ного распределения, при этом используйте формулу (20) §2.2 для эксцесса и тот
факт, что для нормального распределения 72 = 0).
Приведем несколько важных примеров статистических применений тео-
ремы Фишера.
Пример 1 (Оценивание параметров нормальной модели). Рассмотрим за-
дачу построения доверительных интервалов (см. определение (26) § 2.2) для
неизвестных параметров и общей нормальной статистической модели
У(*1Л2).
Дове ительный инте Доверительный интервал для дисперсии О] мо-
©верительным интер Жет gbITb ПОСТрОен на основе того факта, что выбо-
вол для дисперсии г 2 2/ \
рочная дисперсия S = S (X) для выборки X
= (Х1э , Хп) из распределения V(^i, имеет по теореме 2 следующее
распределение:
=X2(n- 1)
X /
(независимо от значений неизвестных параметров!). Поэтому, обозначая через
Xp,n-i р-квантиль распределения ^(п - 1) и выбирая при заданном довери-
тельном уровне 7 два числа О| и а? так, чтобы сг] + = 1 - 7, будем иметь
f 2 TlS2 2 1
Т Р) Ха,, n-1 < д2 < X I-ai.n-1 (
1^2 '
( п$2 п$2 1
= -------<б\<---------- . (8)
kXl-a2.n-l XaHn-l J
Но это и означает, что 7-доверительным интервалом для в2 является ин-
тервал
/ nS2 nS2 \
I —--------, —---- 1, orj -I- or2 = 1 - 7- (9)
ХХ1-О2,П- 1 Хсц.п-!/
На самом деле — это целое семейство интервалов, так как при заданном 7
числа О) и «2 можно выбрать разными способами. На практике обычно реко-
мендуют выбирать их так, чтобы были одинаковыми вероятности попадания
величины nS2/в\ левее и правее указанных в (8) границ:
§2.5. Линейные и квадратичные статистики
147
т. е. О] = «2 = (1 ~ ?)/2. В этом случае интервал (9) называют центральным
7 -доверительным интервалом, и он имеет вид
nS2
л
(Ю)
/ nS2
В частности для выборки объема п= 10 и доверительного уровня 7 = 0,9 из таб-
лиц квантилей х2’РаспРеДеления имеем Хо,о5;9 = 3,3251, Хо.95;9 = 16,9190, по-
этому центральный 0,9-доверительный интервал для имеет вид (0,591152,
3.00752)
Рассмотрим теперь задачу доверительного оце- Доверительный интер-
нивания среднего 9} Как уже отмечалось в п. 6 § 1.2 вал для среднего
в связи с обсуждением распределения Стьюдента,
в силу теоремы Фишера стьюдентово отношение (см. (29) § 1.2)
/----X-0i , ,
= - (11)
о
имеет при любых значениях параметров 9, и 92 распределение Стьюдента
S(n- 1), при этом оно симметрично относительно нуля (см. (28) § 1,2). Поэто-
му, обозначая через ip,n-i р-квантиль распределения S(n - 1), из (11) имеем
7 = P{|tn-iK^.„_|}=P +
2 > I у/п— 1 2 yn-1 2 J
т. e. 7-доверительным-Интервалом для 9, является симметричный относитель-
но случайной точки X интервал
(— S \
<|2)
В частности, из таблиц квантилей распределения Стьюдента имеем
<0,975; 9 = 2,262, поэтому для выборки объема п — 10 и доверительного уровня
7 = 0,95 этот интервал имеет вид (У 0,7545).
Иногда необходимо знать оценку одновремен-
но и для среднего 9[ и для дисперсии 9\, т е- не-
обходимо оценить пару 9 = (9Ь т), т = В этом
случае требуется построить такое случайное (т. е. за-
висящее от выборки X) подмножество Q7(X) в R2+ = {9 = (9\,т) -оо <
<9j < оо, т > 0}, которое бы с заданной вероятностью у накрывало неиз-
вестное значение 9, т.е. чтобы выполнялось соотношение
p{9e^W}=7- (13)
Такое подмножество может быть построено на основании уже полученных
результатов. Именно, сопоставим каждой паре 9 = (9),т) подмножество вы-
борочного пространства
'Я1 ll|w '^11. jpt Л 'll.1 'Цу l.'.SW
Доверительная
область для среднего
и дисперсии
юч
148
Глава 2. Первичная обработка экспериментальных данных
где
. Л-| ( 1 + 71 А ,/ 2 ,п _ 2
(-С71-Ф 2 J, i-Xk22n_!, t -Xl+21
s2 = S2(z) и 7j72 = 7-
Тогда в силу независимости X и S2
Р{Х G Н(0)} = Р
= 7172 =7-
Но условие {X G Н(0)} эквивалентно условию {в G £7(Х)}, где
ад = р = (^ьт):т>(х-^)% уГ<^<ГТ
Область £7(ге) представляет собой часть полуплоскости R2+, ограничен-
ную параболой г = (х - 0i)2n/t2 и двумя прямыми т = ns2/t" и т = ns2/t'
(см. рис. 1). Таким образом, построена 7-доверительная область Q^(X) для
пары в = (0Ь 02), удовлетворяющая (13). • а-г
Пример 2 (Задача сравнения двух средних). ХУТ777777777Т7771
Среди прикладных задач встречаются такие, при \ . V
решении которых приходится сравнивать средние *6 т у
двух независимых выборок. Для такого сравне- V лХ
ния полезно иметь доверительный интервал для —
разности соответствующих выборкам математи-----------►
ческих ожиданий. В случае нормальных выборок х
такой интервал можно легко построить на осно- р
вании теоремы Фишера.
Пусть X = (Xlt..., Хп) и У = (У1,.. , Ут) — две независимые выборки,
причем первая — из распределения О2), а вторая — из Та-
ким образом, соответствующие модели различаются только своими средними
и требуется оценить их разность Д = 0^ - 0^ Эту задачу называют задачей
сравнения двух средних. Построим выборочные средние X, Y и выборочные
дисперсии S2(X), S2(Y) этих выборок. Из независимости выборок и в силу
теоремы 2 эти четыре статистики независимы. Кроме того,
Отсюда (см. (5) § 1.2)
{X -0*°
(X-Y -Д
£
V 1 1 \
= лг о, - + -
\ п m)
§ 2.5. Линейные и квадратичные статистики
149
или
X - У - Д\
7
=Яо, 1),
а также (см. п 3 § 1.2, свойство воспроизводимости ^-распределения)
(71 л 771 > \ □
^S2(X)+^S-(y)j =x2(m + n-2).
Следовательно, стьюдентово отношение (27) § 1.2 имеет в данном случае
вид
/ тп X - У - Д
у т + п 02
lnS2(X) + mS2(Y)
у Q^m + n — Z)
mnlm + п - 2)
--------- х
т + п
X - У- д
y/nS\X} + т52(У) ’
(14)
и оно имеет распределение Стьюдента S(m + n— 2)
при любых #{2> и в]. Основываясь на (14),
у-доверительный интервал для Д строится так же,
как и интервал (13) в предыдущем примере: он име-
ет вид
Доверительный
интервал для разности
двух средних
X - Y Т «1±
2
m+n-2
7 Л —71 /1 •% v '''\
----------------- (п52(Т) + тп52(У)) ).
[тп(т + п- 2)v v J /
(15)
Пример 3 (Доверительный интервал для отношения дисперсий двух нор-
мальных моделей). Рассмотрим ситуацию, когда X = (Xb ...,ХП) — вы-
борка из распределения -Л/(0ц, 0р), а К = (У), , Ут) — из распределения
Л/”(021, #22) и выборки независимы. Требуется оценить отношение т = 022/022
неизвестных дисперсий. Построим выборочные дисперсии S2(X) и 52(У).
По условию они независимы, а по теореме Фишера
С (^S2 w) = x2(n - 1), с (= Х2(т - 1).
/ \w22 /
Поэтому мы можем построить статистику Снедекора (32) § 1.2, которая в дан-
ном случае принимает вид
п(тп-1)Я*)1
п 1,га 1 т(п — 1) 52(У) г’
Эта статистика имеет распределение Снедекора S(n-1, т-1) при любых
значениях параметров 0ц, 022, #22> поэтому, обозначая через -Fp.n-i.m-i
150
Глава 2. Первичная обработка экспериментальных данных
р-квантиль распределения 5(та - 1, т - 1) и задаваясь доверительным уров-
нем 7, из (16) будем иметь
7 = Р_q,)/2.n-1,m-1 < < -^(l+7)/2,n-I.m-l =
= 1) S2(X) I < t <
( т(та — 1) S2(Y) -f(i+7)/2, n-i.rn-i
n(m-l)S2(X) 1 |
< m(n- 1) S2(Y) F(1_7)/2,n—I,m—1 J '
Доверительный интер- Тем самь1м построен центральный 7-довери-
* вал для отношения тельный интервал для г: он имеет вид
дисперсий /n(m-l)S2(X) |
\771 (/I — 1) S (У) ,п-|.т-1
n(m - 1) S2(X) 1 \
m(n- 1) 52(Г) F(1_7)/2.J 1 '
В частности, из таблиц квантилей распределения Снедекора имеем
-^0,95; 8,8 = ^0,05; 8,8 = 3,44, ^0,95; 12,12 = ^0,05; 12,12 = 2,69,
поэтому 0,9-доверительный интервал для выборок объемов та = т = 9 есть
/0,2952(Х) 3,44S2(X)\
\ S2(Y) ’ 52(Г)—)’
а для выборок объемов та = т - 13 —
/0,3752(2Г) 2,69S2(X)\
\ 52(У) ’ 52(Г) J
Упражнения
Там, где есть воля, всегда есть дорога.
Хадсон6>
П Пусть ип — число успехов в та испытаниях Бернулли с вероятностью успеха р,
0 < р < 1. При больших п вычислить границу J7 такую, чтобы событие |рп/та-р| С <5Т
имело вероятность к 7. Укладываются ли в эти границы при 7 = 0,98 результаты
следующего эксперимента (эксперимент Бюффона* 7*): при та = 4040 бросаниях монеты
наблюдалось 2048 выпадений «герба»?
Хадсон — английский альпинист XIX в.
7) Бюффон Жорж Луи Леклерк (1707-1788) — французский естествоиспытатель, почетный
член Петербургской АН (1776).
Упражнения
151
-< Указание. Применить теорему Муавра—Лапласа (см. замечание к упр. 33 гл. 1). ►
0 (Продолжение). Смоделировать выборку объема п 1000 из распределения
Bi(l, 2/5) и проверить аналогично предыдущему, укладываются ли в указанные грани-
цы результаты полученных экспериментальных данных. Построить график, соединив
прямыми последовательные точки
/ ьд \
[к,— , *=100,200,.. 1000.
\ * /
Q Смоделировать выборку из биномиального распределения Bi(4, 1/3). Постро-
ить график частот vT/n, где v, — число опытов, в которых наблюдалось значение
г = 0, 1,2, 3, 4, и вычислить выборочные среднее, дисперсию и коэффициенты асим-
метрии и эксцесса. Найти 6 из условия Р{|Х - aj <5} = 0,998 и сравнить с ним
вычисленное по экспериментальным данным отклонение выборочного среднего от тео-
ретического О|
Указание. Воспользоваться теоремой 3 § 2.2. ►
0 Смоделировать выборку из полиномиального распределения М(5гМ\р, 1/5,
г=1, ,5), и, рассматривая эти данные как наблюдения над случайной величи-
ной (, принимающей значения -2, -1,0, 1,2, построить полигон частот и вычислить
выборочные среднее и дисперсию. Найти <5 из условия
Р{|Х - а,| С <5) =0,98
и сравнить с ним наблюденное значение отклонения |Х - aj.
Q Смоделировать выборку объема п= 100 из показательного распределения Г(1, 1).
Вычислить ее основные характеристики, построить эмпирическую функцию распре-
деления и гистограмму, вычислить выборочные моменты Зу, j = 1,2, и сравнить их
с теоретическими значениями.
Q Пусть XNI, , XNn — приближенно нормальные Nip, а2) числа, каждое из ко-
торых получено суммированием N равномерно распределенных на (0, 1) слагаемых.
Получить три реализации (при N = 2,4, 12) выборок сп = 100, р = 0, а2 = 1. Для
каждой выборки построить эмпирические функции распределения и гистограммы;
получить оценки р и ст2; вычислить 3-й и 4-й выборочные центральные моменты
и сравнить их с истинными значениями теоретических моментов.
0 Смоделировать выборку объема п = 500 из равномерного распределения К(0, 12).
Группируя данные по интервалам £г = (г, г + 1 ], г = 0, 1, 11, построить полигон
частот и сравнить его с графиком функции f(x) = с, 0 < г < 12. Рассматривая
группированные частоты как результаты наблюдений над дискретной случайной вели-
чиной, принимающей значения, совпадающие с серединами соответствующих интер-
валов, вычислить выборочные среднее и дисперсию и сравнить их с теоретическими
значениями.
0 Для данных примера 2 в § 2.2 построить график частот мг/п и сравнить его с гра-
фиком функции се~х вычислить выборочные коэффициенты асимметрии и экс-
цесса; найти <5 из условия Р{|Х — aj <5} = 0,998 и сравнить с ним вычисленное
по приведенным данным отклонение выборочного среднего от теоретического а,
0 (Продолжение). В том же эксперименте наблюдалась также случайная величина (,
равная числу костей с 6 очками. Соответствующие данные приведены в таблице:
152
Глава 2. Первичная обработка экспериментальных данных
Г 0 1 2 3 4 5 6 7 S
447 1145 1181 796 380 115 24 8 4096
Ответить на те же вопросы, а также вычислить выборочные среднее и дисперсию.
◄ Указание. Считать, что £(£)= Bi(12, 1/6). ►
и Наблюдались показания 500 наугад выбранных часов, выставленных в витринах.
Пусть г — номер промежутка от r-го часа до (г + 1)-го, г = 0, I,.. 11, a vr — число
часов, показания которых принадлежат r-му промежутку. Результаты таким образом
сгруппированных наблюдений оказались следующими [15, с.459|:
т
0 12 3 4 5 6
41 34 54 39 49 45 41
7 8 9
33 37 41
10 11 S
47 39 500
а) Построить полигон частот и сравнить его с графиком функции /(г) = с, 0 < х < 12.
б) Рассматривая эти данные как независимые наблюдения над дискретной случай-
ной величиной (, принимающей значения, совпадающие с серединами соответ-
ствующих интервалов (т. е. значения 0,5; 1,5;..., 11,5), вычислить выборочные
среднее и дисперсию.
в) Принимая, что в п.б) случайная величина / имеет равномерное распределение,
найти S из условия Р{|X - aj <5} = 0,98 и сравнить с ним наблюдавшееся
значение отклонения |Х - aj.
Щ При проведении п = 2608 опытов по наблюдению числа а-частиц (£), излучае-
мых радиоактивным веществом за определенный период времени, получены следую-
щие данные (vr — число опытов, для которых число £ = г, г = 0, 1,...):
Г 0 1 2 3 4 5 6 7 8 9 10 11 12 Е
"г 57 203 383 525 532 408 273 139 45 27 10 4 2 2608
Построить график частот рг/п и вычислить выборочные среднее и дисперсию.
ш Пусть (-0,8; 2,9; 4,4;-5,6; 1,1;-3,2) — наблюдавшиеся значения случайной ве-
личины (. Вычислить основные характеристики выборки, построить эмпирическую
функцию распределения и убедиться в том, что F6(-5) = 1/6, F6(0) = 1/2, F6(4) = 5/6.
ш В эксперименте наблюдалась целочисленная случайная величина Соответству-
ющие выборочные значения оказались равными: 3, 0, 4, 3, 6, 0, 3, 1. Вычислить основ-
ные характеристики выборки, построить эмпирическую функцию распределения и про-
верить, что Fg(l) = 3/8, Fg(3) = 3/4, Ft(5) = 7/8.
ш Когда функция Fn(z) будет иметь скачки размера лишь \/п (или, что эквива-
лентно, будет иметь ровно п скачков)?
Е Пусть X] < г2. Чему равна вероятность P{Fn(a:i) = Fn(s2)}?
ПИ Пусть Р{£ = j} = pj, i = 0, 1,..., N, и X = (X,, , Х„) — выборка из £(().
Найти вероятность P{Fn(/) - Fn(j - 0) = k/n} Рассмотреть случай £(£) = Bi(JV, р).
ш Пусть X = (Х|, , Хп) — выборка из непрерывного распределения F. Какому
распределению будет соответствовать выборка Y = (Кь ..., К„), где Y) = F(X,)?
Замечание. Если случайная величина X имеет функцию распределения F(x) и F(x)
непрерывна, то переход к новой случайной величине Y = F(X) называется преоб-
разованием Смирнова.
Упражнения
153
Пусть X — выборка из равномерного распределения 2/(0, 1) и F — непрерывная
и строго монотонная функция распределения. Положим Yi = F~l(.Xt), i = 1, . ,п.
Из какого распределения будет выборка У?
ш Пусть в точках х, выполняются условия 0 < F(i,) < I, i = I,. , к. Рассмотрим
события Л, = {К(а:;) € (.Fn(®i) Ti7,/Vn)}, где (Fn(xi) Т tT,/x/n) — асимптотиче-
ский -доверительный интервал для -F(x,), определенный в (8) §2.1. Доказать, что ве-
роятность одновременного осуществления событий 4,, ,4* удовлетворяет условию
*
Р(4,П...П4*)
1=1
Замечание. Система интервалов
...*}
называется системой совместных доверительных интервалов для F(x,), i = 1,..., к.
EQ Пусть Xi < х2 — заданные точки на числовой прямой, такие, что 0 < F(i|)
F(x2) < I. Доказать формулу
cov^Cx,),^^)) = ^)(1n~—(Zz)).
Указание. Представить случайную величину
A„(xi, х2) = р„(х2) - //„(г,)
(см. (3) §2.1) в виде суммы независимых индикаторов
п
Д„(Х|,12) = 52 Дя, < Xi «S 2?) ►
1=1
ш Пусть X = (Х|,..., Хп) — выборка из некоторого распределения £(£), для ко-
торого существует момент а2г = Е£*г Доказать, что дисперсионная матрица вектора
Ап = (аП|,.... апг) первых г выборочных моментов имеет вид
D4„ = ||cov(a„„ Sn>)||| = 1 ||а1+) - |] । -
Ш Доказать, что cov(X, S2) = - l)/n2 Рассмотреть случай £(£) = X(/z, <т2).
ES Доказать теорему 6 §2.2 об асимптотической нормальности выборочной диспер-
сии. Убедиться в том, что при п -> сю ES2 ~ р2, DS2 ~ (рц - р2)/п.
Указание. Учесть, что S2 = <p[ani,an2), где ip[xi,x2) = х2 - х} (см. (6) §2.2), и
применить теорему 5 § 2.2. ►
__ ___। / ] /^2 \
Пусть ar। У= 0, /г> < оо. Доказать, что при п -> оо £(Х ) ~ Д/Д —, —j— I
\ а । а । п /
Указание. Применить теорему 5 § 2.2. ►
И Убедиться в справедливости следующих утверждений о распределении выбороч-
ного среднего для выборки X = (Д’,.....Х„) из соответствующих распределений:
а) £(4) = Г(а, А) => ЦпХ) = Г(а, nA),
154 Глава 2. Первичная обработка экспериментальных данных
б) £(() = Bi(fc,p) => £(пХ) = Bi(n£,p),
в) £(£) = П(А) => £(пХ) = П(пА),
г) £(£) = Bi(r,p) => £.(пХ) = Bi(nr,p).
◄ Указание. Воспользоваться свойством воспроизводимости рассматриваемых рас-
пределений (см. §§ 1.1 и 1.2). ►
ЕЗ (Продолжение). Убедиться в том, что для выборки из распределения Коши К.(а)
(см. упр. 48 (б) гл. 1) С(Х) = Х(а).
ш Пусть в эксперименте наблюдается двумерная случайная величина £ = (£|,£2)
и (Хи, Х,2), i = 1,... ,п, — соответствующие выборочные данные. Для упрощения
вычислений выборочного коэффициента корреляции рп (см. (5) §2.3) часто бывает
удобно предварительно преобразовать исходные данные с помощью некоторого ли-
нейного преобразования:
X. 1 — о, Х.2 — д2
Ун = -^-А у2 = -^—2, i=l, ,п, (1)
О| о2
где аь а2 — действительные, а 6,, Ь2 — положительные числа. Доказать, что при лю-
бом выборе в|,а2, bt,b2
рл(Х) = р„(У).
ЕЗ Вычислить выборочный коэффициент корреляциидля следующих данных п = 26
наблюдений над величиной 4 = (£ь£2), записанных в виде статистического ряда:
£
6
V,
23,0 24,0 24,5
0,48 0,50 0,49
24,5 25,0
0,50 0,51
2 4 3 2 1
25,5
0,52
1
26,0 26,0 26,0 26,5 26,5
0,49 0,51 0,53 0,50 0,52
2 12 11
27,0 27,0
0,54 0,52
2 1
28,0
0,53
3
•< Указание. Произвести линейное преобразование (1), выбрав а, = 26,0, Ь, = 0,5,
а2 = 0,50, Ь2 = 0,01. ►
Ответ: р26 = 0,793.
Используя независимые равномерно распределенные на [0,1] случайные числа {W, },
построить последовательность пар случайных чисел
Хп = д/-2 In W21_, sin (2я«21),
Х12 = y/-2\nU2i_l cos (2тг М2<), г = 1,2, ,50,
вычислить для этих данных выборочный коэффициент корреляции и проверить гипо-
тезу независимости 2Го:р = О, используя как точный, так и асимптотический алгорит-
мы, описанные в п. 4 § 2.3 (см. п. 8 § 1.3).
ЕЛ Доказать, что совместная функция распределения двух порядковых статистик Х(г)
и Х(а) (1 < г < s < п) при х < у имеет вид
i=r 2=max((U-i) ] ( ])'
И
у) = Р{Х(л) у] = Fs(y) при х у.
Упражнения
155
< Указание. Использовать эквивалентность событий
{Х(г) $ х, Х(а} $ у} и {дп(г) > г, дп(у) > s),
а также тот факт, что случайные величины
»/|=д„(г), р2 = Р«(у) - Дп(я). Н1=п-р„(у)
(при х < у) имеют полиномиальное распределение Af(n;pi,p2,p3), где р, = F(x),
Pi — F(y) — F(x), рз = 1 - F(y). Если же х у, то событие {Х(г) $ х, Х(1> < у} =
= {Х(,)^У}. ►
ЕП Пусть распределение £(() абсолютно непрерывно и его плотность F'(z) = /(z).
Вывести следующую формулу для совместной плотности порядковых статистик %(*,),
• ,Х(ЛГ) (1 fci < < kr $ n):
, ,________________________п!___________________
'xr)~ _ ^ki_ki_ |),...(fcr_fer , _ !)!(„-Лг)! х
xF‘'-|(I|)(r(x!)-F(il))‘!'‘1'1
(F(xr) - F(xr^l))k'~k,~'~i - F(xT)y~k'/(z,) .. f(xr)
при Xi < z2 < < xr и равна нулю в остальных точках.
Получить отсюда формулы (7) и (8) §2.4.
ч Указание. Записать вероятность события 6 (z^-t-dz,), i = 1, , г} при бес-
конечно малых dxj, i = 1,..., г, и, разделив ее на dxt ... dxr, получить в пределе
при dx, —> 0, i = I,... ,г, вид искомой плотности. ►
ЕЯ Убедиться в том, что для случая £({) = W(0,1) распределения порядковых ста-
тистик имеют вид (при 1 С k < I < п)
£(XW) = Be(fc, п - к + 1), £(Х0) - X(t)) = Ве(1 - к, п - I + к + 1)
(см. п. 4 § 1.2). Вывести отсюда формулы для моментов
к к(п - к + 1) , , к(п -7+1)
Е^) = ^. D^)=(n + l)2(n-+2j’ cov(Xw,X(1))=--+i--2(n-2).
ч Указание. Используя формулу (44) § 1.2, найти совместную плотность величии
У1 Хщ и Yi = Ху) - Xtkf, интегрированием которой получить маргинальную
плотность величины К. При вычислении моментов использовать формулы (24) § 1.2,
а также формулу D(X(0 - Xw) = DXW + DXW - 2cov(X(k), X(J)). ►
E3 (Продолжение). Используя эти результаты, получить формулы для моментов экс-
тремумов выборки из произвольного равномерного распределения Ы(а,Ь), приведен-
ные в упр.46 гл. 1 (см. п. 5 § 1.2).
ЕП Пусть X = (Х|,... ,Хп) — выборка из распределения с плотностью f(x) =
= (1/2) cos z, |z| $ тг/2. Вывести формулу
ЕХ(П) = у (1 - 2"2п+1С2”„).
Доказать, что при п -> оо
“«Ч-\/;(1+о(£))
156
Глава 2. Первичная обработка экспериментальных данных
Указание. Воспользоваться тождеством
52 ^^2-^ = 2-"^
А
и также применить критерий (26) § 2.4. ►
ИЯ Пусть X = (Х|, , Х„) — выборка из распределения Коши (см. (31) § 1.2).
Показать, что при п -> оо и а„ = tg (тг/2 - л/п) ~ п/п
P{a;'X(ni С х} —> e-'lz х > 0.
< Указание. Применить критерий (25) § 2.4 и учесть, что lim ((тг/2 - arctg t) = 1 ►
(->00
ЕЗ Пусть X = (Х|.......Хп) — выборка из усеченного показательного распределения,
задаваемого функцией распределения
F(x) = fc(l - e~z), О С х С Го, k = (1 - е-1°)-1,
при некотором конечном г0 > 0. Показать, что при п -> оо
Р{п(е10 - 1)-1(Х(п) - ®о) < я} —> ех, х < 0.
< Указание. Применить критерий (26) § 2.4. ►
Замечание. Обратим внимание на то, что здесь мы имеем предельное распределение
типа Л2 (см. (24) §2.4), в отличие от примера 3 в §2.4, где для обычного показатель-
ного распределения (т.е. при х0 = оо) мы имеем предел типа Л3.
ЕЯ Пусть функция распределения наблюдаемой случайной величины £ имеет вид
, , fl- е'1х при х < О,
Г(г) = (
[ 1 при х 0.
Доказать, что для распределения максимального значения выборки объема п из £(£)
при п -4 оо выполняется соотношение
Г — Ъп ) . -х
Р< ---------- С х > —> е —оо < х < оо,
I ап )
где ап = (Inn)-2, Ъп = - 1/(1п п).
Указание. Применить критерий (27) §2.4. ►
Bil Пусть X = (Х|......Хп) — стандартный нормальный вектор (т.е. выборка из
стандартного нормального распределения Л/(0, 1)). Рассмотрим три квадратичные
формы от X:
п , п
Q,=^X-, Q2 = -(Х,+... + Х„)2, Q} = 52 (X,X)2
.=1 п i=i
Применив теорему 1 § 2.5, убедиться в справедливости следующих соотношений:
£(Q.) = x2(n), ОД:)=х!(1), £«?,) - хЧп - 1).
Указание. Получить представление Qi = X'lnX, Q, = Х'ВХ, где В = || 1/п||"
Qy = Х'АХ, где А = 1„ - В. ►
Упражнения
157
КЯ Пусть £(У) = А/(р, S), |Е| ± 0 и Q = (У-р)/ A(Y-р), где матрица А удовле-
творяет условию AYA = А. Доказать, что L(Q) = Х2(т)< где т = tr (ЛЕ). Получить
отсюда утверждение теоремы 1 §2.5 и упражнения 40 к гл. 1.
◄ Указание. Запись Y в виде Y = р + ВХ, где X — стандартный нормальный век-
тор (см. п. 2 § 1.2), тогда Q = Х'А।X, где матрица А< = В'АВ идемпотентна. Далее
применить теорему 1 §2.5. ►
EJ (Продолжение). Доказать следующее обобщение леммы 3 §2.5: квадратичная фор-
ма Q = Y'AY имеет распределение х2(г; ^2), где г = rank А и А2 = рАр. В частно-
сти, при А = Е"1 величина г = п и А2 = pY~>p (лемма 3).
◄ Указание. Использовать то же преобразование Y = ВХ, что и в доказательстве
леммы 3. Тогда Q = Х'В'АВХ и здесь матрица Л, = В1 АВ идемпотентна и rank Л, =
= rank А. Далее, как и при доказательстве теоремы 1 §2.5, привести Q к сумме квад-
ратов независимых нормальных величин. ►
ш Пусть X = (Хь. , Хп) — выборка из распределения V(0, 1) и квадратич-
ная форма Q = X'X разложена на сумму двух квадратичных форм Q = Qi+Qi, где
Q, = X'A,X и rank Л,- = n,, i = 1,2. Доказать, что если п, 4-п2 = п, то Q, и
независимы и £(Qi) = Х2(п<), i = 1,2.
◄ Указание. Проверить, что матрицы Л, и Л2 идемпотентны и Л,Л2 = О ►
Замечание. Справедливо более сильное утверждение: если Q = Q, + ... 4- Qk, где
Q, = Х'А,Х, rank А, = n,, i = 1,..., к, то П| + 4- пк = п <=> Qt,..., Qk
независимы и £(Q,) = X2(n,), i = 1,..., к.
и Пусть X = (Хь... ,Хп) — выборка из нормального распределения //(р,а2).
Показать, что функция распределения статистики т? = (Xi - X)/(Vn - IS) имеет вид
Fq(u) = 1 - \/2В (1 - и2; (п - 2)/2,1/2) при 0 < u < 1 и F,(u) = 1 - Fn(-u) для
-1 < и < 0 (здесь В(х; а, Ь) — неполная бета-функция, см. п. 2 § 2.4).
◄ Указание. Получить сначала представление
Yi
»? = / ~7 = ,
v/y12 + ... + rnL1
где случайные величины У, ,Уп-| независимы и нормальны f/(0, 1). Далее вос-
пользоваться упр. 52 к гл. 1. ►
ЕЗ Пусть имеется выборка объема п из двумерного собственного нормального рас-
пределения (см. п. 4 §2.3) и (X), Х2), (S2, Si2, Sj) и рп — соответствующие выбороч-
ные характеристики.
а) Доказать, что (Х,,Х2) и (S2, 512, S2) независимы;
б) пусть Q = п(Х,-р}, X2-p2)'s~' (Х|-р1,Х2-д2), доказать, что £(Q) = хг(2)',
в) пусть п>2 иТ„ = - 2р„/(\/1 - pj), доказать, что £(Т„) = S(n - 2).
◄ Указание, а) см. замечание к упр. 28 гл. 1; б) см. замечание в п. 2 § 2.5; в) см. заме-
чание в п. 4 § 2.3. ►
158 Глава 2. Первичная обработка экспериментальных данных
и Пусть X = (Xi......Х„) — выборка из распределения £(£), Е£ = р, D£ = <т2 > О,
< оо и X, S2 — соответствующие выборочные среднее и дисперсия.
Доказать, что при п -> оо
£(Т„ = У^(Х-М)Л) —>Л/”(0, 1).
◄ Указание, Воспользоваться центральной предельной теоремой, сходимостью
S/а 1 и следующим фактом: £(г}п) £(»?), С» —> 1 £(*?)• ►
Глава 3
Общая теория оценивания
неизвестных параметров распределений
Оценивать — значит создавать. Именно оценка придает
ценность и драгоценность всем оцененным вещам. Лишь
через оценку появляется ценность: и без оценивания был бы
пуст орех бытия.
Ф. Ницше ’’ Так говорил Заратустра
Настоящая глава посвящена общей теории статистических оценок — од-
ной из основных проблем, решаемых математической статистикой, как это от-
мечено в общем Введении. Здесь в рамках произвольной параметрической ста-
тистической модели излагаются основные подходы к построению эффектив-
ных оценок для неизвестных параметров модели и функций от них. Рассмат-
риваются два традиционных подхода к решению этих задач: точечное и интер-
вальное оценивание (более общо — оценивание с помощью доверительных
множеств), а также некоторые другие современные концепции оценивания.
При точечном оценивании в основном рассматриваются несмещенные оцен-
ки, и за меру их точности принимается величина дисперсии оценки. Основное
внимание уделяется методам построения оптимальных оценок, при этом рас-
сматриваются случаи как скалярного, так и векторного параметров. Излагают-
ся различные подходы для построения доверительных интервалов и довери-
тельных множеств, в том числе принцип отношения правдоподобия — один
из наиболее универсальных современных принципов решения многих ста-
тистических задач. Рассматриваются также вопросы оценивания при выборе
из конечных совокупностей. При решении рассматриваемых задач использу-
ются как точный, так и асимптотический (для больших выборок) подходы,
что диктуется, в основном, спецификой конкретной анализируемой ситуации.
§3.1. Статистические оценки
и общие требования к ним
1. Понятие статистической оценки и ее среднеквадратичная ошибка
Это понятие уже встречалось нам в гл. 2. Там говорилось, что значение эмпири-
ческой функции распределения Fn(x) в каждой точке х можно рассматривать
Ницше Фридрих (1844-1900) — немецкий философ, поэт-мыслитель.
160 Глава 3. Теория оценивания неизвестных параметров распределений
в качестве приближенного значения (оценки) для теоретической функции рас-
пределения F(x) наблюдаемой в эксперименте случайной величины £, а раз-
личные выборочные характеристики (моменты а): и pi- (см. (2)-(3) § 2.2),
квантили Сп.р (см. (2) §2.4) и т.д.) — как оценки соответствующих теорети-
ческих характеристик распределения £(£). При этом использование термина
«оценка» обосновывалось тем, что для выборок большого объема значитель-
ная разница между значениями выборочной и теоретической характеристик
маловероятна, и поэтому разумно (по крайней мере для больших выборок)
принять выборочную характеристику за приближенное значение соответству-
ющей теоретической характеристики, когда последняя неизвестна. Таким об-
разом, в этот термин вкладывался определенный асимптотический смысл при
п —> оо (напомним, что п — это объем выборки X = (Л), , Хп) из рас-
пределения £(£)). Выражением этого «разумного» свойства оценки является
понятие ее состоятельности (см. определение 3 в § 2.2) — одного из основных
понятий теории оценок.
В то же время при применении теории оценивания на практике обыч-
но приходится строить приближенные значения для различных неизвестных
теоретических характеристик изучаемой модели при конечных (и часто весь-
ма умеренных) объемах выборки, и при этом обосновывать соответствующие
рекомендации с точки зрения каких-либо критериев оптимальности. Общие
методы решения подобных задач развиты в теории оценивания неизвестных
параметров распределений, которой и посвящена настоящая глава.
Итак, пусть задана статистическая модель J- — {.F} для схемы повтор-
ных независимых наблюдений над некоторой случайной величиной £ и X =
(Xi, , Хп) есть выборка из распределения £(£) 6 7 В дальнейшем рас-
сматриваются различные функции Т = Т(Х) от выборки, сами являющиеся
случайными величинами (т.е. для которых при всех t определены вероятности
Fr(i) = Р{7(Х) i}). Если при этом функция Т не зависит от неизвестного
распределения наблюдаемой величины £, то ее приня-
Статистика и оценка то называть статистикой (см. определение 1 в §2.2).
Часто требуется по выборке X сделать те или иные заключения об истинном
значении до некоторой (неизвестной) характеристики д д(£) наблюдае-
мой случайной величины. Прежде всего под этим понимается задача оценить
это значение до, т.е. построить такую статистику Т(Х), значение которой
t = Т(х) при наблюдавшейся реализации х выборки X можно было бы
считать разумным (в каком-то смысле) приближением для д0: txg0. В этом
случае говорят, что статистика Т(Х) оценивает д или, что Т(Х) есть оценка
д (для д) и часто подчеркивают это обозначением д = Т(Х'). Так в общем
виде формулируется задача точечного оценивания неизвестных параметров рас-
пределений.
Точность оценки Ясно, что для оценивания заданной характери-
стики д можно использовать различные оценки и,
чтобы выбрать лучшую из них, надо иметь критерий сравнения качества (точ-
ности) оценок. В свою очередь, и подобные критерии могут быть разными
§3.1. Статистические оценки и общие требования к ним 161
(в зависимости от целей, для которых строится оценка, удобства исполь-
зования критерия и т. п.), но любой критерий определяется выбором мерь,
точности оценок (меры близости оценки к истинному значению оцениваемой
характеристики). Кроме того, обычно класс рассматриваемых в конкретной
задаче оценок ограничивают некоторыми дополнительными требованиями.
Таким образом, если определен некоторый класс оценок Тд (в задаче оцени-
вания д) и выбрана мера точности, то оценка Т € Тд, оптимизирующая эту
меру, называется оптимальной (в классе Тд).
Итак, для построения теории оптимального оценивания прежде всего на-
до договориться о мере точности оценок, т. е. уточнить смысл приближенного
равенства Т(Х) ~ д. Если статистика Т(Х) используется для оценивания
величины д, то одной из разумных мер расхождения между ними является
(Т(Х)—д)2, тп квадратичная ошибка. Но так как эта величина случайная, то
для измерения точности оценки Т используется сред- _
неквадратичная ошибка (с. к. о.) Д(Т) =Е(Т(Х) -5)2 Среднеквадратичная
где Е, как и ранее, — знак математического ожида-
ния. С. к. о. — наиболее распространенная и традиционно используемая в при-
кладной математической статистике мера точности оценок, хотя, в принципе,
можно было бы использовать и другие меры точности, например, среднюю
абсолютную ошибку Е|Т'(X) - ^|, однако здесь мы сталкиваемся с серьезными
аналитическими трудностями вычисления этой меры в конкретных задачах.
Мера Д(Т) порождает и соответствующий критерий оптимальности оценок:
оценка, минимизирующая с. к. о. в заданном классе оценок Та, называется
оптимальной в среднеквадратичном смысле (в классе Оптимальная оценка
Тд) и обозначается символом Т* (или д*, чтобы под-
черкнуть, что эта оценка для д):
Т* = arg min Д(Т); (1)
тета
ее с. к. о. есть
Д* = Д(Г*) = Е(Т*(Х) - д)2 = mf Е(Т(Х) - д)2 (2)
Таким образом, в общем случае задача построения наилучшей (в средне-
квадратичном смысле и в заданном классе оценок Тд) оценки для характери-
стики д по выборке X сводится крещению экстремальной проблемы (1)-(2).
Ниже эти общие положения конкретизируются в рамках произвольной
параметрической модели Т = {F(x;0), 0 6 0} (см. пример 4 Введения).
Если модель ? параметрическая, то любая теоретическая характеристика яв-
ляется функцией от параметра модели 0, и в таком случае речь идет об оце-
нивании параметрических функций, для которых будем использовать обозна-
чение т(6) (тау от тэта).
Подчеркнем, наконец, следующеедовольно очевидное, но весьма важное
обстоятельство. При оценивании заданной параметрической функции т(9)
11 Заказ 1748
162 Глава 3. Теория оценивания неизвестных параметров распределений
Необходимое уело- необходимо, чтобы область значений соответствующей
вие оценивания оценки Т(Х) совпадала с областью значений т(0):
{t:t = Т(Х), х G X} = {т : г = т(0), 0 G 0}, (3)
так как в противном случае оценка может давать значения вообще не принима-
емые оцениваемой величиной (оценка будет лишена практического смысла!).
Напомним, что в (3) X обозначает выборочное пространство (совокупность
всех возможных реализаций выборки X), а 0 — параметрическое множество
(совокупность всех допустимых значений параметра модели 0).
2. Несмещенные оценки
Одно из центральных понятий математической статистики — понятие не-
смещенной оценки уже было введено в §2.2 (соотношение (22)), где также
даны краткие комментарии и соответствующие примеры. Здесь мы обсудим
это понятие с общих позиций и более детально.
Любая оценка Т = Т(Х) является случайной величиной, поэтому об-
щим требованием к ней является достаточно высокая степень концентрации
ее распределения около истинного значения оцениваемой характеристики.
Чем выше степень этой концентрации, тем лучше (точнее) соответствующая
оценка. Выражением этого в определенной степени и является условие не-
смещенности. Дадим его более детализированное (в контексте обсуждаемой
проблематики) и общее определение. Но сначала условимся о некоторых до-
полнительных обозначениях.
В случае параметрической модели У = {F(i; 0), 0 G 0} распределение
вероятностей на выборочном пространстве X, отвечающее параметру 0, обо-
значается символом Р#. Аналогично, индекс 0 при символах математического
ожидания Е, дисперсии D и т.д. будет означать, что соответствующие вели-
чины вычисляются для распределения Р#. Например, Е^Т(Х), DgT(X) —
обозначения соответствующих моментов статистики Т(Х) в случае, когда
функция распределения выборки X = (Х|, , Хп) есть
Fx(x;0) = F(xi,0) F(x„,0)
(или плотность fx(x',0) = f(x\,0) f(xn;0)). При этом для единообразия
иногда будет использоваться сокращенная запись через интеграл Стилтьеса
КеТ(Х)= J' Т(х) dFx(x; 0).
Здесь интеграл понимается как n-мерный интеграл по всему выборочному
пространству X, который в случае абсолютно непрерывной модели вычисля-
ется как обычный интеграл Римана
Т(Х], ,xn)f(xi;0) }(хп;0)4х] dxn<
Стилтьес Томас Ян (мл.) (1856-1894) — голландский математик и астроном.
§3.1. Статистические оценки и общие требования к ним
163
Определение
а в случае дискретной модели — как соответствующая сумма
£Г(1|,..., яг„)/(яг,; 0) f(xn;0).
Этого уже достаточно, чтобы перейти к точным формулировкам.
Статистика Т = Т(Х) называется несмещенной в среднем
(или просто несмещенной) оценкой для заданной параметрической функции
т(в), если она удовлетворяет условию Условие
EqT(X) = т(0), V0€0. (4) несмещенности
Об условии (4) говорят как об условии несмещенности. Если оно не выпол-
няется, то величина
Ь(0) = Е$Т(Х) - г(0)
называется смещением оценки Т(Х). Таким образом, можнотакже считать, что
несмещенные оценки — это такие оценки, для которых смещение Ь(&) = О,
V0 6 0. В общем случае среднеквадратичная ошибка
Д(Т;0) = Ев(Т(Х) - т(0))2
оценки Т = Т(Х) выражается через дисперсию оценки и ее смещение сле-
дующим образом
^(Т;0) = В1)Т + Ь2(0). (5)
Следовательно, для несмещенных оценок с. к. о. совпадает с дисперсией
оценки.
В конкретных задачах часто ограничиваются рассмотрением лишь класса
Тт несмещенных оценок для т = т(0):
Тт = {Т(Х) ЕвТ(Х) = т(0), V 0 £ ©}.
Функция т(0) называется оцениваемой, если класс Тт Оцениваемые
не пуст, т.е. если существует хотя бы одна несмещенная функции
оценка для т(0). Про любую несмещенную оценку мож-
но сказать, что «в среднем» она приводит к желаемому результату. К тому же,
как это будет показано далее, для несмещенных оценок можно построить
достаточно простую и практически полезную теорию, в которой критерием
точности оценки является ее дисперсия.
Несколько слов о философии «среднего». В пользу «среднего» можно при-
вести следующие рассуждения из книги венгерского математика Габора Се-
кея «Парадоксы в теории вероятностей и математической статистике» [23].
«Уравнивание противоположных значений и отклонений в „среднем", т.е.
суммирование наблюдений в одно значение, имеет давние традиции. Эсхил писал
в трагедии „Эвмениды"' „Богу всегда середина любезна, и меру чтит божество",
а последователи китайского философа Конфуция говорят, что „в неподвижности
среднего (= Чжун Йюн) есть величайшее совершенство" Математически поня-
тие „среднего" можно интерпретировать различными способами (арифметическое
среднее, геометрическое среднее, медиана и т.д ). Однако в статистических при-
менениях в течение долгого времени крайне важную роль играло арифметическое
164 Глава 3. Теория оценивания неизвестных параметров распределений
среднее. Уже в первых выдающихся результатах в теории вероятностей и матема-
тической статистике изучалось арифметическое среднее статистической выборки
и росло понимание важности его использования».
Однако условие несмещенности в среднем не следует абсолютизировать: в некото-
рых случаях требование несмещенности (4) может оказаться слишком «жестким»
и привести к нежелательным результатам. Так, может оказаться, что несмещен-
ные оценки (в данной модели и для данной параметрической функции) вообще
не существуют (т. е. класс Тг = 0 — пустое множество), а в других случаях,
хотя и имеются, но практически бесполезны. Ниже эти общие положения ил-
люстрируются примерами. Но предварительно отметим, что существует также
и критическая философия «среднего». Так имеет место (и некоторыми актив-
но используется) такой прием искажения истины, как использование «средних
цифр» (как заметил Ленин, «нет ничего глупее так называемых „средних цифр"»),
когда понятие среднего используется как синоним типичного. Примерами таких
подмен могут служить средний доход населения, средняя температура больных
в некоторой больнице, среднее количество осадков за несколько сезонов в не-
котором регионе (в области N в прошлом году была летом засуха, и все поля
выгорели, а этим летом прошли ливни, которые все смыли с полей, но в среднем
количество осадков за два сезона — в пределах нормы, или: в некоторой стране
есть всего лишь несколько очень богатых семей и большое количество бедных, чьи
доходы соответственно огромны и малы, поэтому здесь средний доход вовсе нети-
пичен). Таким образом, средние характеристики часто вводят в заблуждение. Как
отмечается в [23], «средний человек — одна из них». Неудивительно, что иссле-
дования бельгийского ученого Л. А. Ж. Кетле по этому вопросу стали источником
горячих споров. Худшее в «среднем человеке» не его серость, а возникающие про-
тиворечия. Например, средний рост не соответствует среднему весу и т.д. Только
по одной этой причине можно усомниться в справедливости слов Дж. Рейнольдса
(первого президента Королевской академии художеств в Лондоне), когда он ска-
зал, что «в среднем источник прекрасного».
Перейдем к обещанным примерам, оттеняющим различные нюансы не-
смещенности в среднем.
Что примера лучше действует?
Что людьми сильней ворочает?
А. С. Пушкин. Бова (1814)
Пример 1 (Несмещенное оценивание в схеме Бернулли). Пусть
Х = (ХЬ ,Хп)
— выборка из распределения Бернулли Bi( 1,0), т. е. Xi принимает значения
О и 1 с вероятностями /(a:;#) = 01(1 - Я)1-1 х 0, 1 (см. п. 1 § 1.1).
Опишем класс оцениваемых функций в рассматриваемой модели и найдем
соответствующие несмещенные оценки. Для этого запишем для произвольной
статистики Т(Х_) ее математическое ожидание:
Е^Г(Ю= Е f(xn;0) =
г=(т...in)
§ 3.1. Статистические оценки и общие требования к ним
165
п
-0)n-Ei'= ^0г(1-я)”- 52 Т(&
х r=0 x:Exi=r
Здесь правая часть представляет собой полином от в степени не выше п,
следовательно, в данной модели несмещенные оценки можно строить лишь
для параметрических функций т(в), являющихся полиномами степени не вы-
ше п — числа наблюдений. Отсюда, в частности, следует, что для функций
вида т(в) = 0~а а > 0 и т(в) — вь Ь > п, несмещенных оценок по выборке
объема п не существует.
Пусть теперь
п
= 22
з=о
— произвольный полином степени п (или ниже, если старшие коэффициенты
Uj равны нулю). Построим сначала несмещенную оценку для отдельной сте-
пени 93 при j п. Из упр. 19 к гл. 1 имеем, что если случайная величина и
имеет биномиальное распределение Bi(n,p), то для ее j-vo факториального
момента при j п справедлива формула E(p)j — (n)jp> В нашем случае
статистика X = -Х) + + Хп имеет распределение Bi(n, в) (см. п. 1 § 1.1),
следовательно, Eg(X)j = (п)^. Это означает, что статистика (JX)j/(n)j явля-
ется несмещенной оценкой для в} при любом j < п. Отсюда, в свою очередь,
имеем, что несмещенной оценкой полинома т(в) является статистика
п
т = Т(Х)=^
j=o
(6)
Итак, в бернуллиевской модели Bi(l, в) класс оцениваемых параметри-
ческих функций по п наблюдениям совпадает с классом полиномов степени
не выше п, и для любой такой функции т(в) ее несмещенная оценка г дается
формулой (6). •
Пример 2. Пусть £(£) 6 П(0) — семейство пуас-
соновских распределений (см. п. 3 § 1.1) и п = 1,
т. е. произведено одно наблюдение X над пуассо-
новской случайной величиной. Требуется оценить
Отсутствие несмещен-
ной оценки в пуассо-
новской модели
параметрическую функцию т(в) = 1/в.
Если Т(Х) — несмещенная оценка т(9), то условие (4) принимает вид
00 ПХ I
ST(x)e-'- = -. V»>0.
или
00 /jz + l
J=O
V0 > 0.
166 Глава 3. Теория оценивания неизвестных параметров распределений
Очевидно, что функция Т(х), удовлетворяющая последнему условию и не-
зависящая от 0, как это требуется в соответствии с определением понятия
оценки, не существует, т. е. в данном случае несмещенных оценок для т(0)
вообще нет. •
Несмещенные оценки
в отрицательной
биномиальной модели
Пример 3. Пусть £(£) € Bi(r,0) — семейство от-
рицательных биномиальных распределений (см. п. 2
§1.1) и п = 1. Построим несмещенную оценку для
параметрической функции т5(0) — 0s где s 1 —
целое число. Здесь условие несмещенности (4) принимает вид
□О
70 6(0,1),
z=0
ИЛИ
оо as 00
^Т(х)С^0х = —— = £ V0 6 (О, 1).
х=0 ' ' >=0
Но из тождественного равенства двух степенных рядов следует равенство их
коэффициентов при соответствующих степенях 0. Следовательно, функция
Т(х) здесь однозначно определена, и она есть
' 0 при х < s.
т^ = ^Ч Ur+z-l тг х — J I 1 при X S X + г — j - 1 3=0
(здесь учтено, что при b < О = 0).
Таким образом, несмещенная оценка для rs(0) существует, единственна
и имеет вид
т, = Т„(Х) = П — —j. - Г(Х?з). (7)
;=0 J
Обратим внимание на то, что эта оценка может принимать нулевое зна-
чение (при X < в), которое не принадлежит области значений функции т5(0)
(ведь 0 < т5(0) < 1 при 0 < 0 < 1), тем самым для нее не выполняется
условие (3). Если же г — 1, то оценка 3\S(X) вообще принимает лишь два
значения:
г о,
11,
X < s,
X г> S,
W =
не принадлежащие области значений функции rs(0), т. е. такая оценка лише-
на какого-либо практического смысла. Этот пример показывает, что иногда
принцип несмещенности может привести к бесполезному результату. •
Пример 4 (Общая нормальная модель, оценивание дисперсии). Пусть
X = (X,.... , Хп), п^2,
§ 3.1. Статистические оценки и общие требования к ним
167
— выборка из нормального распределения ^г) (оба параметра неиз-
вестны). Требуется оценить параметрическую функцию г(0) = т(0\, в^) =
Мы уже знаем (см. теорему 2 §2.2), что несмещенной оценкой теоретической
дисперсии является (в любой модели!) статистика
s‘ = - V-
при этом (см. замечание к теореме Фишера в §2.5, соотношение (7))
2 / п Л 20?
D«So2 = D ------S2 =—г- (8)
\П — 1 / 71—1
Ниже (см. § 3.2, пример 9) будет показано, что по критерию минимума
дисперсии оценка 5g является оптимальной среди всех несмещенных оценок
функции т(6) = #2 в модели Л[(0i, 0з), т.е.
ее дисперсия (8) меньше дисперсии любой
другой несмещенной оценки величины 02.
Рассмотрим теперь класс оценок вида
Та = А502. Так как
Е»ТЛ = АЕв502 = А022,
то в этом классе имеется лишь единственная
несмещенная оценка т(0), соответствующая
значению А = 1, т.е. оценка Sq.
Вычислим среднеквадратичную ошибку
произвольной оценки Та:
Д(ТА; 0) = Е,(ТЛ - 0^)2 = Е, [А(502 - 022) + (А - 1)022]2 = A2D,S2 + (А - 1)2024.
Отсюда из формулы (8) получим
2А2
Д(ТА; 0) = ^(А)04 , = — + (А - 1 )2
Здесь функция ^>(А) есть парабола, график которой изображен на рис. 1. Функ-
ция ^(А) достигает минимума при А’ — (п- 1)/(тг + 1) и ^(А*) = 2/(n + 1).
Отсюда, учитывая (8), имеем
20? 20? ,
Д(ГА.; 0) = = Д(52; 0).
71-1-1 71-1
Таким образом, по критерию минимума с. к. о. оптимальной в классе Т = {Та}
является оценка
1 п _
Та- - А*5о = —7 £(*. - Х?- (9>
71 + 1
168 Глава 3. Теория оценивания неизвестных параметров распределений
Эта оценка смещенная, но она точнее оценивает теоретическую диспер-
сию модели Л/Х^ь ^г)> чем несмещенная оценка S2,. Найдем еще смещение
Ьп(0) оценки Тх>:
Ьп(0) = ЕТЛ. - 0} = (А* - 1)#2 = —-V
п + 1
Это смещение мало при большом объеме выборки п и Ьп(0) —> 0 при п —> оо,
т. е. 2\« — асимптотически несмещенная оценка.
Отметим дополнительно, что при любом AG ((n - 3)/(n + 1), 1) оценка
Тх имеет меньшую с. к. о., нежели Т\ = Sq > но в классе несмещенных оценок
Sq — оптимальная оценка.
Этот пример показывает, что не может быть единственного критерия,
по которому следует сравнивать все оценки, как не существует единственной
оценки данной теоретической характеристики, подходящей для всех случаев.»
Статистические задачи не имеют
однозначных ответов.
Э. Леман
3. Оптимальные оценки
Требование несмещенности в силу сделанных выше замечаний нельзя рассмат-
ривать как универсальное. Тем не менее во многих встречающихся на практике
случаях оно уместно и обоснованно и далее мы будем рассматривать в основ-
ном именно несмещенные оценки.
Итак, пусть требуется оценить заданную параметрическую функцию г = г(0)
в модели 7 = {F(x;6), 0 G 0} по соответствующей выборке X = (Х|,... ,ХП).
Обозначим Тт класс всех несмещенных оценок Т = Т{Х) для т{&) и предпо-
ложим, что он не пуст (что это не всегда имеет место, говорит нам пример 2
выше). Дополнительно предположим, что дисперсии всех оценок из класса
Тт конечны: DgT = - т(0))2 <оо,ЧТсТт и VS Е0. В этом случае,
как отмечено выше (см. соотношение (5)), мерой точности оценок является
их дисперсия.
Замечание. Напомним, что в теории вероятностей для любой случайной величины (
с конечной дисперсией мерой «разброса» ее значений вокруг среднего значения
р. = Е£ служит стандартное отклонение о = \ДХ> а знаменитое правило «трех
сигм» гласит, что значение £ попадает в отрезок — За,р + За] с вероятностью,
мало отличающейся от 1. Так, для нормальной Л/(д,а2) величины
Р{д-За«и^ + За} = Р
3 !> = Ф(3) - Ф(-3) = 2Ф(3) - 1 К 0,997,
т. е. £ попадает в отрезок За] с вероятностью, лишь немного отличающейся от 1.
Итак, пусть Т* и Т — оценки из класса Тт- Если
ЪдТ* vflee,
(10)
§ 3.1. Статистические оценки и общие требования к ним
169
со строгим неравенством хотя бы при одном 0, то по критерию минимума дис-
персии следует отдать предпочтение Т*, как более точной оценке. Если усло-
вие (10) выполняется для любой оценки Т 6 Тт, то Т* называют несмещенной
оценкой с равномерно минимальной дисперсией (сокращенно, н. о. р. м. д.). Та-
кую оценку Т* (когда она существует) будем для краткости называть также
оптимальной и иногда обозначать т* чтобы подчеркнуть, что она относится
к функции т(0).
Итак, оптимальной (среди несмещенных) яв- Условие оптимальности
ляется оценка т Е ’/т-, для которой выполняется несмещенной оценки
условие ,ai
D#r* = inf DflT, V 0 £ ©. (11)
тетг
Требование равномерной (по параметру в) минимальности дисперсии
весьма сильное и не всегда имеет место. Может оказаться, что из двух несме-
щенных оценок Т\ и Т2 дисперсия минимальна (в классе Тт) для одних
значений параметра в, а дисперсия — для других значений в. В таких
случаях с помощью одного критерия минимума дисперсии эти оценки срав-
нить нельзя. Однако это требование выделяет оптимальную оценку в классе Тт
однозначно, если такая оценка существет, о чем говорит следующая теорема.
Теорема 1. Пусть 71t =Tt(A'), i = 1,2, —две оптимальные оценки для т=т(0).
Тогда Т, = Т2 3).
Доказательство. Рассмотрим новую оценку Т\ = (Ti + Т2)/1. Ясно, что
Тз Е Тт и
D/Гз = -(D0T1 + ВДз + 2cov0 (Т1,,^))- (12)
Воспользуемся известным в теории вероятностей неравенством Коши—
Буняковского: для любых случайных величин т]\ и г]2 с конечными диспер-
сиями
|cov(7?i, 772)| x/D^Dj/2,
причем знак равенства имеет место только если г]\ и линейно связаны.
Отсюда и из (12), положив = DgT2 = v = v(0), получим
^+|cov#(T,,T2)|) О. (13)
Поскольку Ti, i = 1,2, — оптимальные оценки, то v =
откуда DgTi = v, т.е. Т2 — также оптимальная оценка. Но так как в не-
равенствах (13) имеют место знаки равенства, то covg (Т\,Т2) 0 и, более
того, cov#(TbT2) = DeTi = v. Следовательно, Т\ и Т2 линейно связаны,
Здесь и далее равенство статистик понимается в том смысле, что
Pp{jre{z:T1(z)?iT2(z)}}=0, vs ее.
170 Глава 3. Теория оценивания неизвестных параметров распределений
т. е. Т\ = kTi + а. Из условия несмещенности оценок имеем т = кт + а,
т.е. а = (1 - к)т, и следовательно, Т\ — т = к(?2 — т). Здесь коэффициент
к = к (9) определяется цепочкой равенств
v = cov, (ТЬТ2) = Ee(Tj - т)(Т2 - г) = АЕ9(Т2 - т)2 = fcD#T2 = ко.
Отсюда имеем к = 1, следовательно, Т\ = Т2.
Приведем пример существования оптимальной оценки в конкретной мо-
дели.
Пример 5 (Бернуллиевская модель, оценивание параметра). Пусть
* = (*,. ,Хп)
— выборка из £(£) € Bi( 1, 9) и требуется оценить параметр 9.
Здесь E#Х, = 9, поэтому выборочное среднее X является несмещенной
и состоятельной оценкой 9 (см. теорему 2 §2.2). Однако X не единственная
несмещенная оценка 9. Например, всякая статистика
1 п
Т = - V biXi при bi + + bn = п
п t—*
i=i
также является несмещенной оценкой 9. При этом, так как (см. (2) § 1.1)
1 п ^2 ^2
DeT = V 6-0(1 - 0) —0(1 - 0) > 0 при п -> оо
п2 •2—< п 4п
i=i
(здесь b = max (6J), то оценка Т также и состоятельна. Таким образом, такие
i
оценки так же «хороши», как и X.
_ Итак, в данной задаче класс Тт содержит много
Оптимальность
- оценок и потому возникает вопрос о выборе сре-
выборочного среднего „ _
г . ди них наилучшеи. Покажем, что в данном слу-
в оернуллиевскои _*
г ' чае оптамальная оценка Т существует и при этом
МОдели Т* = X. Поскольку DflX = 0(1 - 0)/п, то в со-
ответствии с определением (11) достаточно показать, что для любой оценки
ТеТг выполняется неравенство
V0e(o, 1). (14)
п
В данном случае распределение выборки задается плотностью (см. при-
мер 1)
L(i;0) = 0Eli(l-0)n-E:I', х = (15)
Так как
1 = L& 9) и 9 = EflT(X) = T&)L(x; 0),
£ £
§ 3.1. Статистические оценки и общие требования к ним 171
то, дифференцируя эти тождества по в, получим
^ацх-.в) „ainLfeo) /91падв)
° - Г -jr* = —ar~Lte е> = Ч—аё—
X X '
, д\пЬ(х;в) , / , ain£(X;6»)\
1 = Е в) = Е" г m—де ) •
Отсюда можно записать
1 = Ев
(т(Х) - е)
д\пЦХ-,еу
до
и, согласно неравенству Коши—Буняковского,
Е9(Т(^) - 0)4
2
Но Eg(T(X) — 0)2 = D(,T, поэтому из последнего неравенства следует, что
D9T
у 0 е (о, 1).
(16)
В рассматриваемом случае (см. (15))
1 ”
0(1-0)
поэтому
Е9
д In L(X, 0)
дё
I Г " 1:
п п v п
еЦ]-еу°вХ' = 0(1 -0)’
(17)
Отсюда и из неравенства (16) получаем соотношение (14).
Учитывая важность для приложений бернуллневской модели Bi(l, 0),
сформулируем полученный результат в виде теоремы. •
Теорема 2. Относительная частота произвольного события в п независимых
испытаниях является оптимальной несмещенной оценкой для вероятности
этого события.
Как следствие этой теоремы отметим, что значение эмпирической функции
распределения Fn(x) в каждой точке х является оптимальной несмещенной
оценкой для значения в этой точке теоретической функции распределения
172 Глава 3. Теория оценивания неизвестных параметров распределений
Приведем следующую юмористическую историю, принадлежащую Д. Пойа
[20] и показывающую, как не следует интерпретировать частотную концеп-
цию вероятности. Д-р Тел (доктор телепатии), закончив осмотр пациента,
покачал головой. «Вы очень серьезно больны, — сказал он, — из десяти
человек с такой болезнью выживает только один». Пациента эта информация
изрядно испугала, и д-р Тел начал его успокаивать: «Но Вам очень повезло, что
Вы пришли ко мне, сэр. У меня уже умерли от этой болезни девять пациентов,
так что Вы выживете».
Установим следующее важное свойство оптимальных оценок.
Теорема 3. Пусть Т* и — оптимальные оценки функций Т| = т\(0) и
г? — 72(0) соответственно. Тогда статистика Т* = ахТ’ -\-а2Т2 является оп-
тимальной оценкой функции т = + а2т2 для любых постоянных Я| и а2.
Доказательство. Установим сначала следующее свойство оптимальных оце-
нок, представляющее самостоятельный интерес: для любой статистики ip = ф(Х)
с Евф = 0, V0 € 0 (такая статистика ф(Х) называется несмещенной оценкой
нуля'), выполняется равенство cov$ (Т“, ip) = О, V0 € 0, т. е. оптимальная
оценка некоррелирована с любой несмещенной оценкой нуля.
Для доказательства рассмотрим статистику Т\ = Tf + Хф. При любом А
это несмещенная оценка т\, поэтому в силу оптимальности оценки Т*
Def, = DgT* + A2DH' + 2AcoV(, (Tf, гр) DgT*, V в Е 0. (18)
Отсюда следует, что cov# (Т*, ф) = 0, так как в противном случае при А = Aq =
= - covtf (Т*, ф)/Т)дф левая часть (18) былабы равна DgT*-cov# (Т* ,ф)/'Вдф,
что меньше, чем Т)9Т*, при covfl )Т', ф) / 0 (см. рис. 2).
Перейдем непосредственно к доказательству теоремы. Пусть Т — про-
извольная несмещенная оценка т Тогда ф = Т* - Т будет несмещенной
оценкой нуля и, по предыдущему, cov$ (Т/, ф) = 0, i = I, 2. Отсюда
0 = a, COV# (Г,*, ф) + а2 cov# (Т2, ф) = covs (Т*. ф) = DgT* - cove (Т*, Т),
т. е.
Т)дТ* = cove (Т*, Т) у/^еТ* DgT или DST* DeT, V0.
§ 3.2. Критерии оптимальности оценок по Рао—Крамеру
173
Таким образом, в конкретных задачах, когда оцениваемая параметриче-
ская функция г(9) раскладывается в сумму более простых функций 7,(0),
задачу построения оптимальной несмещенной оценки для т(9) можно сво-
дить к аналогичной задаче для ее слагаемых 7,(0).
В заключение этого параграфа рассмотрим один конкретный пример при-
менения полученных результатов.
Пример б. Рассмотрим ситуацию, описанную в при-
мере 1 Введения, и предположим, что в эксперимен-
те реализуется схема выбора шаров с возвращением.
Тогда, как показано в примере 1 § 1.1, мы имеем дело
со схемой (моделью) Бернулли Bi( 1, в), где неизвестная вероятность «успеха»
9 а^/а — доля белых шаров в урне. По теореме 2 доля Х/п наблю-
давшихся белых шаров при п извлечениях (относительная частота «успеха»
= извлечение белого шара) является оптимальной несмещенной оценкой 9:
9* = Х/п. Таким образом, предложенная в примере 1 Введения интуитивная
оценка на самом деле оказывается наилучшей с рассматриваемых позиций
несмещенности и оптимальности. •
Перейдем теперь к общим методам построения оптимальных несмещен-
ных оценок.
Оптимальная оценка
вероятности «успеха»
в схеме Бернулли
§3.2. Критерии оптимальности оценок, основанные
на неравенстве Рао—Крамера. Эффективные оценки
Чтобы продвинуться вперед, нам необходимо ввести несколько новых важ-
ных понятий, которыми оперирует теория оптимальных оценок. С этого мы
и начнем.
1. Функция правдоподобия, вклад выборки, функция информации
Пусть, как обычно, /(ш; 9) — плотность наблюдаемой случайной величины (,
X = (Xi,. .,Хп) — выборка из £(£)eF = {F(x;0), 9е 0} и х = (ij,.. , хп)
— реализация X. Функция L(x; 9) = f(x\; 9) f(xn', 9) является, очевидно,
плотностью случайного вектора X. Рассматриваемая при фиксированном х
как функция параметра 9 L(x; 9) называется функцией правдоподобия (иногда
об L(i; 9) говорят как о правдоподобии данных).
В дальнейшем предполагается, что L(x; 9) > 0 при всех х £ X и 9 £ 0,
и дифференцируема по параметру 9. Пусть сначала параметр 9 — скалярный.
Случайная величина Вклад выборки
д\ПЦХ,9) "d^f^-,9)
У(Х’~--------Тв - д9 (0
2=1
называется вкладом выборки, а г-е слагаемое в правой части (1) называется
вкладом i-го наблюдения, г = 1, , п. В дальнейшем предполагается, что
О<ЕеУ2(Х;0) <оо, ^9 ев. (2)
174 Глава 3. Теория оценивания неизвестных параметров распределений
В последующем изложении нам неоднократно придется дифференциро-
вать по 0 интегралы типа
(интегрирование ведется по всему выборочному пространству X) и предпола-
гать при этом, что можно менять порядок интегрирования и диффернцирова-
4^ ния. Модели, для которых все перечисленные условия
Регулярные модели выполняются, называются кратко регулярными. Отме-
тим, в частности, общее необходимое условие регуляр-
ности, состоящее в том, что выборочное пространство X не должно зависеть
от неизвестного параметра 0.
Рассмотрим некоторые свойства вклада V(X; 0) для регулярных моделей.
Всегда имеет место тождество (по 0)
J L(x;, 0) dx= 1 (dx = dx\ dxn)
(здесь и далее везде для дискретных моделей интегрирование заменяется сум-
мированием). Так как модель регулярна, то, дифференцируя это тождество
по 0, получим
Т d\nL(x-,&\ Td\nL(x;0) ,
0 = у ----^~Ld^ = J ---------^^L&0)dx = EeV(X-,0).
Таким образом, для регулярной модели
ЕЙИ(Т; 0) = 0, V0e6.
Далее, в силу предположения (2) и (3) определена функция
гп(0) = DeP(X;0) = ЕйУ2(Х 0),
которая носит название информации Фишера о па-
нформация ишера рЭмеТре Q, содержащейся в выборке X. Величину
z а 1 Л/г \ 2
(3)
(4)
(5)
называют также количеством информации, содержащейся водном наблюдении.
Из (1) имеем
in(0) = Y>eV(X; 0) = £ D ( Э'П/(У1;^") = ni(0), (6)
t--' \ eft) J
т. е. количество информации, содержащейся в выборке, возрастает пропорцио-
нально объему выборки.
Если плотность /(а:; 0) дважды дифференцируема по 0, то продиффе-
ренцировав при п = 1 тождество (3) еще раз, получим
д1 In /(л; 9)
&01
j(x; 9) dx +
f ( д In f(x\ 0)\г ч
J [—д0 J dx = G
§ 3.2. Критерии оптимальности оценок по Рао—Крамеру
175
т. е. (см. (5))
i(0) = -Ев
d2in/(4;0)
оо2
(5')
Пример вычисления информации Фишера для бернуллиевской модели
Bi( 1, 0) имеется в §3.1 (формула (17)): для этой модели i(0) = 1/(<?(1 - 0)).
Рассмотрим еще один пример вычисления функции i(0) для нормальной
модели V(0, а2). Здесь вклад одного наблюдения
0 In/(*,;₽) _ X, -0 O2lnf(X};0)_ 1
’’ ’ 00 а2 ’ О02 а2’
откуда по формуле (5Z) получаем г(0) = а 2. Вид функции i(0) для ряда стан-
дартных моделей приведен в табл. 1.
Таблица 1
Модель V(«, а2) ЛГ(ц, е2) Г(0, А) Bi(M) Bi(r,fl) П(0) W)
W) а'1 20~2 Хв~2 fc/(0(l - 0)) r/(0(l -0))2 0~' 1/2
(определение указанных моделей см. в § 1.1 § 1.2, общая модель Коши
определена в упр. 48(6) к гл. 1).
Приведем еще пример нерегулярной модели.
Пусть £(£) 6 77(0, 0). Здесь из тождества
Нерегулярность 1$^
равномерной модели
не следует, что
6
Г д 1
/ т;— dx = 0,
J 00 0
о
так как при дифференцировании интеграла по верхнему пределу появляется
еще одно слагаемое. В данном случае причина нерегулярности заключается
в том, что выборочное пространство (интервал (0, 0)) зависит от неизвестного
параметра 0.
2. Неравенство Рао—Крамера
В случае регулярных моделей для дисперсий несмещенных оценок можно
установить абсолютную нижнюю границу, что и будет показано в настоящем
пункте. Рассмотрим задачу оценивания некоторой параметрической функции
г(0) в регулярной модели 7 = {F(x; 0), 0 Ев} со скалярным параметром 0.
Предположим, что класс Тт несмещенных оценок т(0) не пуст, и функция
т(0) дифференцируема. Тогда имеет место следующее утверждение.
176 Глава 3. Теория оценивания неизвестных параметров распределений
Теорема 1 (Неравенство Рао—Крамера). Для любой оценки Т = Т(Х) ЕТТ
справедливо неравенство
Равенство здесь имеет место тогда и только тогда, когда Т — линейная функ-
ция вклада выборки, т. е.
T(x)-r(e) = a(6)V(x->e), (9)
где а(0) — некоторая функция от в; в этом случае
пвт = а(0)т'(9). (10)
Доказательство. По условию
V.9T(X) = J T^)L(x;6)dx = T(e), V 9 Е Q. (И)
Модель X регулярна, поэтому, дифференцируя это тождество по 9 и учи-
тывая (1), (3), получим
т'(0) = ! Т(х)д[П^'^ Цх; 9) dx =
= Е#(Т(ЛГ)Г(ЛГ;0)) =cov#(T(X)r(X;<?)). (12)
Используя неравенство Коши—Буняковского и определение (4), из это-
го состояния получаем оценку [/(tf)]2 in(0)D#T причем равенство здесь
имеет место лишь в случае, когда (при каждом 9) статистика Т(Х) и вклад
выборки V(X; 9) линейно связаны, т. е. имеет место (9). Отсюда, во-первых,
имеем неравенство (8), так как гп(9) = пг(9), а, во-вторых, подставляя пред-
ставление (9) в (12) имеем т'(9) = a~'(9)DgT, т.е. приходим к (10).
Замечание. Если Т = Т(Х) — оценка со смещением Ъ(9) и функция Ь(9) диффе-
ренцируема, то, используя вместо соотношения (11) тождество
У" T(x)L(x, 0) dx = т(0) + Ь(0),
с помощью аналогичных рассуждений можно установить неравенство (также назы-
ваемое неравенством Рао—Крамера)
пт> И«) + б'(<
DeT^——
обобщающее (8).
Эффективные оценки Если существует оценка Т* G 7?, для которой
граница Рао—Крамера (8) достигается, то ее назы-
§ 3.2. Критерии оптимальности оценок по Рао—Крамеру
177
вают эффективной. Эффективная оценка является оптимальной, и, согласно
теореме 1 §3.1, она единственна. Из теоремы 1 следует, что критерием эффек-
тивности оценки является представление (9). Будем называть этот критерий
оптимальности оценки критерием Рао—Крамера. Для эффективной оценки,
т. е. удовлетворяющей представлению (9), ее дисперсия может быть вычислена
также по формуле (10).
Отметим следующее обстоятельство. Вклад выборки V(X; 0) однозначно
определяется моделью. Поэтому представление (9) (когда оно имеет место)
единственно и, следовательно, эффективная оценка может существовать толь-
ко для одной определенной параметрической функции т(0) и не существует
ни для какой другой функции параметра 0, отличной от ат(0)+Ь, где а и b —
константы.
С примером эффективной оценки мы уже встречались в примере 1 §3.1.
Там мы имели представление 0(1 -0)/nV(X,0) — X-3,т.е. а(0) = 0(1 — 0)/тг,
т(0) = 0, и потому статистика X в модели В1(1, 0) является эффективной
оценкой параметра 0. Рассмотрим еще несколько примеров на применение
критерия Рао—Крамера.
Пример 1. Пусть X — выборка из нормального распределения Л/(0, а2). Из (7)
следует, что в данном случае <т2/пИ(Х; 0) = X - 0, т.е. по критерию Рао-
Крамера выборочное среднее X в модели Л/”(0, а2) является эффективной
оценкой 0 и DffX = а2/п, что совпадает с нижней границей в (8). •
Пример 2. Пусть X = (Xj,..., Хп) — выборка из £(£) € Л/"(р, 02). Здесь
L(X: ">-(Wехр {-skw }• rix>=n
и потому
. , 91nL(X;0) n . n
V(X;0 = —^-’ = s5rW--,
ИЛИ
n3
—У(Х;0) = T*(X) -02
71
Но это по критерию Рао—Крамера означает, что статистика Т*(Х) является
эффективной оценкой т(0) = 02 и DgT* = 20‘,/ti. •
___________Назовем эффективностью оценки Эффективность
Т = Т(Х) Е Тт отношение оценки
[т' (0)12
е(Г) = е(Г;0)= (13)
Dflj • тгг(0)
Из неравенства (8) следует, что 0 е(Т) 1, а для эффективной оцен-
ки Т* ее эффективность е(Т*) = 1. Таким образом, эффективность оценки —
это отношение минимально возможной дисперсии в классе всех несмещен-
ных оценок Тт к дисперсии данной оценки Т Е Тт.
12 Заказ 1748
Определение
178 Глава 3. Теория оценивания неизвестных параметров распределений
Важным понятием в теории оценок является также асимптотическая эф-
фективность, которая является аналогом понятия эффективности для боль-
ших выборок (при п —> оо). Оценка Тп(Х), X = (Л), , Хп), для т(9) при
п —> оо может оказаться асимптотически нормальной:
£#(ТП(Х))~Л< т(0),
Асимптотическая даже в тех слУчаях, когда не существует. Асимп-
* эффективность тотической эффективностью такой оценки назовем ве-
оценки личину
ео(Тп;0)=[^^-а2Т(О). (14)
Оценку Т* называют асимптотически эффективной, если ео(Т„;0) = 1.
Таким образом, в этом случае за среднее и дисперсию оценки Тп мы прини-
маем среднее и дисперсию аппроксимирующего нормального закона распре-
деления.
Пример 3 (продолжение примера 2). Рассмотрим еще одну несмещенную
оценку функции т(0) = 97 именно, оценку 5ц (см. (17), (18) §2.2). Как сле-
дует из (7) § 2.5, для нее DgS’^ = 294/(п- I), а функция информации в данном
случае есть г(9) — 29~2 (см. табл. I). Следовательно, по формуле (13) эффек-
тивность е(5д) = (n - l)/n < 1. Таким образом, статистика Sq не является
эффективной оценкой теоретической дисперсии (таковой является указанная
в примере 2 статистика Т*), но она асимптотически эффективна. •
Пример 4 (продолжение примера 1). Рассмотрим в качестве оценки в вы-
борочную медиану (n,i/2- ^ак показано в примере 2 §2.4
z-' \ .( 7Г<72 \
1/2)~ V 0, — ,
' ' ' 1 )п /
поэтому асимптотическая эффективность (14) в данном случае есть
- 2
ео(Сп. ~ 0,637.
7Г
Эффективной же оценкой является выборочное среднее X. Это означает, что
при больших п статистика X для выборки объема п = 0,637п оценивает ис-
тинное значение 9 с такой же точностью, что и статистика 1/2, независимо
от значений 9 и <т2
Интересно отметить, что при нарушении усло-
Сверхэффективные вий регулярности дисперсия оценки при п -> оо мо-
жет Убывать значительно быстрее, чем граница Рао-
Крамера в (8), т. е. могут существовать «сверхэффек-
тивные» оценки. •
§ 3.2. Критерии оптимальности оценок по Рао—Крамеру 179
Пример 5. Рассмотрим нерегулярную модель 1/(0,0). Из упр. 46 к гл. 1 полу-
чаем, что максимальное значение выборки АГ(П) имеет моменты
n пв~
Е^(п) = —— в, DjX'jnj = -— ———,
п + 1 (71 + l)2(n -|- 2)
т. е. Тп = (п + О/п-Лцп) — несмещенная оценка 9, а ее дисперсия
&
= —-———
n(n + 2)
убывает с ростом п как п 2 в то время как граница Рао—Крамера убывает
как п~' •
Пример б. Пусть требуется оценить неизвестный параметр сдвига в распре-
деления Вейбулла W(6, а, Ь) (см. п. 8 § 1.2). Из упр. 56 к гл. I получаем, что
несмещенная оценка 0 по выборке объема п есть
ТП = Х(|)-ЬГ 1 + -)п“'/о,
\ а/
где Х(|) — минимальное значение выборки. Эта оценка имеет дисперсию
,Г / 2\ ,/ 1
= DeX(1) =&2 Г 1 + - -Г2 ! + -
' \ а) \ а
-2/а
п 1
порядок которой п~2,а может быть сколь угодно высоким при достаточно
малых а < 2. В данном случае модель также нерегулярна, поскольку ее
выборочное пространство зависит от в. •
3. Экспоненциальная модель
Введем важный класс параметрических моделей, называемых экспоненциаль-
ными, для которых всегда существует эффективная оценка некоторой пара-
метрической функции. По определению, модель 7 — {F(x;0), вЕ 0} — экс-
поненциальная, если плотность /(з:;0) имеет вид
f(x-, в) = ехр {А(&)В(х) + С(6) + £>(х)}. (15)
Многие статистические модели удовлетворяют этому условию. В частно-
сти, это известные нам модели tr2), А/"(д, в2), Г(0, A), Bi(fc, 6), Bi(r, 0),
П(0), приведенные в табл. 1. Модель Коши /С(0), очевидно, не экспоненци-
альная, а равномерная модель 1/(0,0), хотя и удовлетворяет условию (15), но
не является регулярной.
Вклад выборки для экспоненциальной модели равен
П ] п
V(X; 0) = Л'(0) У В(Х,) + пС'(0) = пЛ'(0) - V B(Xt) +
i=i i=i
А'(в). ’
12
180 Глава 3. Теория оценивания неизвестных параметров распределений
Это равенство можно записать в виде (9), если положить
г = гт = Т±вт. = = (ОД
По критерию Рао—Крамера заключаем, что стати-
Эффективные стика Т* является эффективной оценкой для парамет-
оценки в экспонен- рИческой функции т(0), при этом согласно формулам
циальных моделях (10) и (16)
± т'(6)
D'T=^y О’)
Верно и обратное: если эффективная оценка для некоторой функции т(6)
существует, то модель является экспоненциальной. Действительно, интегрируя
по 0 равенство (9), получаем
In L(X- 0) = A\(0)T(X) + С,(0) + Dt(X).
Отсюда следует, что плотность f(x; 0) должна иметь вид (15).
Таким образом, эффективные оценки существуют для некоторых функций
т(0) только в случае экспоненциальных моделей.
Для перечисленных выше шести регулярных экспоненциальных моделей
вид функции т(0), эффективной оценки т' для нее и соответствующей дис-
персии (17) приведены в табл. 2.
Таблица 2
Модель т(0) 7* Der’
Х/\0, а2) 0 1 " х^-Ух, <=1 71
W.02) 02 2^ 71
Г(0,А) в х_ А 02 Хп
Bi(fc, 0) в X ~к 0(1-0) кп
Bi(r, 0) 0 X 0
1 — 0 Г гп(1 - 0)2
П(0) 6 X £ п
§ 3.2. Критерии оптимальности оценок по Рао—Крамеру 181
Отметим также, что для регулярных экспоненциальных моделей функцию
информации i(6) можно вычислять по формуле
= т'(0)А'(0) = С'(е^Г~ ~ С"^’ (18)
А (0)
что следует из сравнения границы Рао—Крамера в (8) с (17) и вида т(в) в (16).
4. Критерий Бхаттачария оптимальности оценки
Неравенство Рао—Крамера (8) дает неулучшаемую границу дисперсии несме-
щенных оценок (для регулярных моделей) в тех случаях, когда существует
эффективная оценка. Однако, если такой оценки не существует (представ-
ление (9) не имеет места ни для какой статистики Т(Х)), то можно найти
лучшую (т. е. большую) нижнюю границу для дисперсии несмещенных оце-
нок. Основное условие достижения нижней границы дисперсии в неравен-
стве Рао—Крамера состоит в существовании оценки Т, для которой разность
Т — т(в) является линейной функцией от
д In L 1 dL
эе = 1дё
(для краткости мы пишем просто L вместо L(X',0)). Предположим, что такой
оценки не существует, но зато имеется оценка Т*, для которой Т* — т(е) —
1 dL 1 д2Ь
линейная функция от - —, — —г,..
L об L де1
1 дгЬ
1дУ''
= = (19)
i=l
при некотором г 2. Тогда Т* — оптимальная оценка для т(е). Этот крите-
рий оптимальности, обобщающий критерий Рао—Крамера, называется кри-
терием Бхаттачария.
Практически этот критерий используют так: учитывая старшие производ-
ные функции правдоподобия, подбирают такую их линейную комбинацию,
чтобы получить представление вида (19); при этом последовательно полага-
ют г 2,3, Если при некотором значении г это удается сделать, то
получающаяся при этом пара т(0) и Т* = Т*(Х) и есть соответственно па-
раметрическая функция и оптимальтная оценка для нее (случай т = 1 в этой
методике соответствует критерию Рао—Крамера).
Мы не будем приводить точных формулировок (ввиду их громоздкости),
а ограничимся лишь примером, иллюстрирующим изложенную идеологию.
Пример 7. Рассмотрим модель Л/\е, а2) и оценим функцию т(0) = в2 Мы
уже знаем (см. пример 1), что оптимальной оценкой для среднего в является
выборочное среднее
182 Глава 3. Теория оценивания неизвестных параметров распределений
Конечно, было бы ошибкой оценивать в2 посредством X2 Найдем здесь оп-
тимальную оценку с помощью критерия Бхаттачария.
Здесь
1 ( 1 n 1
L(X; в) = -—— ехр <--------------- V (X, - 0)2
v ' (2тгст2)п/2 I 2ст2 ' J
и непосредственно проверяется, что
20<та m <т4
-----L(l) + -rZ(2)
п тг
1 [20<т4
L
= X2
<72
— е
п
По критерию Бхаттачария отсюда следует, что статистика Т* = X2 - а2/п —
оптимальная (т. е. несмещенная с равномерно минимальной дисперсией) оцен-
ка для т(0) = О2 Несмещенность этой оценки проверяется непосредственно:
2 2 2 2
* —1 <7 __ _______ э (7 (7 , <7 о
ЕвГ* = Е«Л'2----=D«A' + (ESX)2---------= — + 02-------= О2
п п п п
5. Критерии оптимальности в случае векторного параметра
Выше рассматривался случай скалярного параметра, однако все введенные
понятия и критерии оптимальности непосредственно переносятся на случай
векторного параметра в = (0|, , в,). В этом случае под вкладом выборки
понимается вектор У = (У), У,), где
, din 1(^0)
У=У(Х;0) =--------г=1, ,г,
Ovj
Информационная a аналогом функции информации (4) является инфор-
матрица мационная матрица Фишера
/П(0) = О,У=||Е(,(У1У;)||;. (20)
Информационную матрицу одного наблюдения
Л0) = Ш = |Ы1'
можно вычислить по формулам
/d!n/(X,;0) dln/(X,;0)\ /d2In/(X,,0)\
^> =«»(«) = Е< ( —эд----------й— ) = - Ч Эв.Эв, ) 11
(последнее равенство справедливо для дважды дифференцируемых по па-
раметрам 0[, , 0Г функций (плотностей) f(x; 0)). Для схемы повторных
независимых наблюдений 1п(9) = п/(0), т. е. здесь имеется полная аналогия
со случаем скалярного параметра (см. (6)). В определении регулярной модели
здесь дополнительно предполагается, что матрица 1(0) невырождена при всех
0 е 0.
Предположим, что ищется оценка для дифференцируемой числовой функ-
ции т(0). Тогда имеют место следующий многомерный аналог неравенства Рао-
Крамера и соответствующий критерий оптимальности.
§ 3.2. Критерии оптимальности оценок по Рао—Крамеру
183
Теорема 2. Если модель 7 регулярна, то для дисперсии любой несмещенной
оценки Т = Т(Х) функции т(0) справедливо неравенство
DeT -&'(0)/-1(0)&(0) = V0 £ Q, (22)
п п
где
Равенство здесь имеет место тогда и только тогда, когда
Г(Х)-т(0)=£М0)ВД0) (23)
:=1
при некоторых функциях а,(0), i = 1, , г.
По аналогии со случаем скалярного параметра назовем несмещенную
оценку Т* = Т*(Х) для т(0) эффективной, если ее дисперсия совпадает при
всех в с правой частью неравенства Рао—Крамера (22). Аналогично вводится и
асимптотическая эффективность ео(Тп) для асимптота- Асимптотическая
чески нормальныхЛ/'(т-(0), <т|(0)/п) оценокТп = Тп(Х), эффективность
X = (Х|,. , Хи), функции т(0):
= (24)
ат\")
Оценка Тп называется асимптотически эффективной, если eo(Tn) = 1,
т.е. если ее асимптотическая дисперсия сг|(0)/п совпадает с границей Рао-
Крамера (22). С применением этого понятия мы встретимся немного позднее,
в §3.5.
Из теоремы 2 следует, что критерием эффективности (а значит, и опти-
мальности) оценки Т является представление (23). Приведем пример исполь-
зования этого критерия.
Пример 8 (Общая нормальная модель, оценивание среднего). Пусть
Х = (Хь ,Х„)
— выборка из нормального распределения Л/”(0|, 0?) (оба параметра неизвест-
ны). Требуется оценить теоретическое среднее г(0) = 0\. Как мы уже знаем,
выборочное среднее X всегда является несмещенной оценкой теоретического
среднего. Покажем, что в данном случае X — оптимальная оценка. Для этого
достаточно убедиться, что справедливо представление
0?
— У|(Х;0) = X -01,
п
и применить критерий (23).
184 Глава 3. Теория оценивания неизвестных параметров распределений
Оптимальность Ранее (см- пРимеР 0 было показано, что X -
* выборочного среднего оптимальная оценка теоретического среднего и для
в нормальной модели модели W г ) (с известной дисперсией). Таким
образом, статистика X наилучшим образом оцени-
вает неизвестное среднее нормальной модели независимо от того, известна дис-
персия или нет. •
Пример 9 (Общая нормальная модель, оценивание дисперсии). В ситуации
предыдущего примера 8 оценим т(в) = б\. Мы уже знаем (см. пример 4 §3.1),
что несмещенная оценка Sq имеет дисперсию 2^/(п - 1), п 2. Сравним
эту дисперсию с границей Рао—Крамера в (22). Для этого вычислим сначала
информационную матрицу для модели ,V(0|, 6$). Здесь
Лз!; ">=ехр
Г (х-0,)2]
I 26»2 J
и по формулам (21) имеем
<7н = Е«02 2 = #22
<712 = <721 = 4(JV| - = 0, ’
522 = 3^4(^1 -»1)2-»2-2 = 2^2,
02-2
о
о
2»2-2
(25)
Отсюда находим, что правая часть в неравенстве (22) равна 2^/^, что меньше,
чем Dj5q. Таким образом, Sq не является эффективной оценкой. Это, ко-
нечно, еще не означает, что существует более точная (с меньшей дисперсией)
оценка, нежели Sq. Мы покажем, что в данной задаче граница Рао—Крамера
в (22) не достигается ни для какой несмещенной оценки но оптимальная
оценка (н. о. р.м.д.) существует, и это S}.
Оптимальное оцени-
вание дисперсии
в нормальной модели
Для этого мы воспользуемся аналогом крите-
рия Бхаттачария для векторного параметра, который
имеет следующий вид: если при некотором целом
s 2 и коэффициентах с. с.(0) имеет место
представление
т 1 х—' X-d^L у--. ds L
то статистика Т = Т(Х) есть оптимальная оценка функции т = т(в).
В нашем случае
1 3L д In L 1 v д а2 п
Ldfh~ дб7 ~ 1} 02
§ 3.2. Критерии оптимальности оценок по Рао—Крамеру 185
д2 In L fd\nL\2 n2л ,2 n
de] + (. <90, / = H^X~ ~ 0J
62 д2Б\ 1
= S20 - 022,
1 д2Б _
L~d&\ ~
Отсюда
1 / 023 дБ___________________________
L \ п - 1 302 п(п - 1) 30, J п - 1
и по критерию (26) 502 — оптимальная оценка 02.
Итак, в задаче оценивания дисперсии т(0) = 02 в модели W(0|, 02) имеет
место более точная, чем (22), граница для дисперсии несмещенных оценок
функции т(0):
202
D»T > —1-;
n - 1
при этом равенство достигается для статистики Т = So.
Замечание. При оценивании самого параметра (вектора) 0 = (0,,..., 0Г) в качестве
оценки выступает векторная статистика Т = Т(Х) = (Т,(Х),..., ТГ(Х)), и тогда
свойство ее несмещенности определяется равенствами EeTi(X) = 0, , »' = 1,..., г,
или в векторной форме: Е^Т(Х) = 0, V0, а аналогом неравенства (22) является
следующее неравенство для дисперсионной матрицы DjT = jcov, (Tj,T;)||^:
Der>l„-'(0). (27)
Здесь неравенство А В между матрицами (одинаковой размерности) означает, что
матрица А — В является неотрицательно определенной, т.е. для любого вектора с
соответствующей размерности выполняется условие с(А-В)с 0 или с Ас с; Вс.
Пример 10 (Полиномиальная модель, оценивание параметрического вектора).
В приложениях часто возникает модель с конечным числом N 2 возможных
исходов (которые можно считать числами 1, 2, , TVj, вероятности которых
Pi, • • ,Pn неизвестны (р,+.. -+рм = 1) — полиномиальная модель М(п; р),
Р = (Pi, <Pn) (см. п. 6 § 1.1). Здесь в качестве неизвестного параметра
следует взять вектор 0 = (р,, , рдг_,), поскольку рдг = 1 -р\ - - pN_\.
Другими словами, в данном случае речь идет об п испытаниях X,, , Хп над
дискретной случайной величиной £ с плотностью /(х; 0) = Ps{£ = х} = рх,
х=1, , N. Записав функцию /(х; 0) с помощью индикаторов в виде
w лг-1
/(х; 0) = П(Pj/PN)I(Z=J) (28)
j=i ;=i
N
(так как /(х = j) = 1), получим
7=1
32ln/(x;0) ( I(x = i)p~2+I(x = N'jprf, i=j,.
~ , г,] = 1,..., N — 1.
I(x = N)pN2, i^j,
dpidpj
186 Глава 3. Теория оценивания неизвестных параметров распределений
Информационная
матрица для полино-
миальной модели
Отсюда по формуле (21) найдем информационную
матрицу 1(&) = Uffijllf-1:
/д21п/рГ|;0)
9ij — Efl I an
\ dptdpj
Pi'+PN, i=j,
Pn,
(29)
Непосредственными вычислениями можно убедиться (это мы оставляем чи-
тателю в качестве упражнения), что
IW = (P| Ы-1>0 и /-‘W = Н^НГ1 нЕлг-,.
где
А(1 ~Pi),
-PiPj,
i=j,
i j.
Если теперь в качестве оценки для в взять вектор относительных частот
п
исходов ,2, ,N Т = (i^i/n, ,ixN_l/n), где ис
i= I
j = 1,..., N (как это предполагается в примере 4 в § 1.1), то, во-первых, это
будет несмещенная оценка, а, во-вторых, ее дисперсионная матрица, в силу
соотношений (15) § 1.1, есть D#T = 1/пЕдг_| = \/п!~{(0), т. е. для этой
оценки в неравенстве (27) достигается равенство. Следовательно, Т есть эф-
фективная (оптимальная) оценка 0. •
§3.3. Достаточные статистики и оптимальные оценки
Рассмотренные в предыдущем параграфе критерии оптимальности оценок
имеют сравнительно ограниченную применимость. Во-первых, они требуют
жестких условий регулярности исходной модели и, во-вторых, в лучшем слу-
чае позволяют находить оптимальные оценки для отдельных параметрических
функций т(0). Более эффективным способом построения оптимальных оце-
нок является использование достаточных статистик, рассмотрению которых
и посвящен настоящий параграф. Достаточность является одним из важней-
ших понятий в математической статистике. Ввел ее Р. Фишер в 20-е гг. XX в.
выдвинув идею о том, что для статистического анализа, касающегося неизвест-
ных параметров, не всегда нужно знать все элементы выборки в отдельности,
а достаточно знать лишь некоторые функции от выборки, называемые доста-
точными статистиками.
1. Достаточные статистики и критерий факторизации
По определению, статистика Т — Т(Х), скалярная или векторная, называ-
ется достаточной для модели F = {F(a;; 0), 0 € 0} (или для параметра 0),
если для любого события А С X условная вероятность Р#{Х € А |7’(Х) = t}
§ 3.3. Достаточные статистики и оптимальные оценки
187
не зависит от в. Это свойство статистики Т означает, что она содержит всю
информацию о параметре 0, имеющуюся в выборке. Действительно, веро-
ятность любого события, которое может произойти при фиксированном Т,
не зависит от О, следовательно, оно не может нести дополнительной инфор-
мации о неизвестном параметре в. Эквивалентное определение достаточности
в терминах плотности выборки X = (Ад, , Хп) формулируется так: стати-
стика Т достаточна, если условная плотность L(x|t; 0) случайного вектора X
при условии Т(Х) = t не зависит от параметра в. Сама выборка X, очевидно,
является достаточной статистикой (РДХ € А|Х = х) при любом в есть либо
1, если х € А, либо 0 в противном случае), но обычно стремятся найти до-
статочную статистику наименьшей размерности, представляющую исходные
данные в наиболее сжатом виде, в этом смысле говорят о минимальной доста-
точной статистике. При наличии достаточной статистики все статистические
выводы об исследуемой модели в конечном итоге формулируются в терминах
этой статистики; следовательно, минимальная достаточная статистика дает
оптимальный способ представления исходных данных, что особенно важно
при обработке больших массивов статистической информации.
Практически достаточные статистики находят на осно-
вании следующего утверждения, которое называется крите-
рием факторизации.
Критерий
факторизации
Теорема 1 (Критерий факторизации). Для того чтобы статистика Т(Л') была
достаточной для параметра 0, необходимо и достаточно, чтобы функция прав-
доподобия L(x;0) выборки имела вид
Цх;0) =g(T(x)-,0)h(x), (1)
где g и h — неотрицательные функции, и Л не зависит от 0.
Доказательство. Доказательство приведем только для дискретной модели.
Если статистика Т достаточна, то при любом t из области значений Т(х)
функция L(i|t; 0) не зависит от 0 и ее можно записать в виде h(x\ t). Пусть
Ра{Т(Х) = t} = g(t; 0) и T(x) = t; тогда событие {Л- = т} С {Т(Х) = t},
поэтому
Z(z; 0) = Рв{Х = я} = Ро{Х = х, Т(Х) =t} =
= Рв{Т(Х) = t} PS{X = х | Т(Х) =t} =
= g(t; 0)L(x\t; 0) = g(T(x)-, 0)h(x; £),
t. e. имеем представление (1).
Обратно: пусть имеет место разложение (факторизация) (1). Тогда при
любом х таком, что Т(х) = t,
/ х РДА" = х,Т(Х) =(}
iUlf; о) = Рв{х = х | т(х) =«} = п ~ =
188 Глава 3. Теория оценивания неизвестных параметров распределений
g(t', 9)h(x) h(x)
52 52 52
x!:T(x!)=t x!:T(x')=t x‘:T(£)=t
т. e. не зависит от 9. Если же х таково, что Г(х) ^<,то, очевидно, L(x\t;9) = 0.
Таким образом, при любом х условная вероятность L(x\t;9) не зависит
от 9.
Отметим, что всякая эффективная оценка является одновременно доста-
точной статистикой, так как (см. (9) §3.2) из представления
следует форма (1) для L(x\9Y Итак, эффективная оценка существует толь-
ко тогда, когда имеется достаточная статистика. Но последняя может суще-
ствовать и при отсутствии эффективной оценки, т. е. условие достаточности
является менее ограничительным, чем условие существования эффективной
оценки.
Заметим также, что если Т достаточна, то таковой же является и любая
взаимно однозначная функция от Т. Действительно, если Н = у>(Г), и ip —
взаимно однозначная функция, то существует обратная функция
<р~1 т = <р-\н)
и из представления (1) имеем
ь(г; 9) = g(<p~'(H)-,9)h(x) = gi(H,9)h(x),
т. е. Н — достаточная статистика.
Примерами достаточных статистик для ряда моделей со скалярным пара-
метром являются (с учетом сделанного замечания) эффективные оценки т*
приведенные в табл. 2 §3.2. Рассмотрим еще несколько примеров нахождения
достаточных статистик для моделей с векторным параметром и для нерегу-
лярных моделей.
Пример 1 (Общая нормальная модель, достаточная статистика для нее).
Функцию правдоподобия для модели У(9<,, 92) можно записать в виде
L(x; 9) = -—\ . exp / —(ц - х)2 - П^~ , 1, (2)
' ' (2тг022)"/2 [ 202 ' 19\ у
откуда по критерию факторизации (1) заключаем, что в данном случае доста-
точной статистикой является пара
т = (т\,т2) = (Х^)
или пара
(П К
1=1 '
поскольку они однозначно определяют друг друга. •
§3.3. Достаточные статистики и оптимальные оценки
189
Пример 2 (Двухпараметрическая показательная модель, достаточная стати-
стика для нее). Рассматривается частный случай 1,02) модели Вей-
булла (см. п. 8 § 1.2) с плотностью
f(z;0) = (0 = (0,,02) 01€Я’02>О). (3)
02
Запишем плотность с помощью индикатора:
/(i;0) =02’le’(l_e,)/('I/(i^0I),
тогда функция правдоподобия выборки X — (Хь, Хп) примет вид
Л z П Л х И
L& 0) = П ^Xi’ = ехр 1 - Z2 Х'~а ' ( П Т(х>
i = i ''i=i 2 ' i=i
Здесь
IJI(ii 0j) = /(т, 01, i=l, ,п) = /(mini; 0j = Z(i(|) 0i),
i=l ’
поэтому
L(i;0) = 02-n exp (-^-(i - 0i) > 9i).
Отсюда по критерию факторизации следует,_что достаточной статистикой для
параметра 0 = (0|, 02) является пара (Х(|), X). Как будет ясно из дальнейше-
го, удобнее для работы оказывается пара
Т = (Т1,Т2) = (Х(1),Х-Х(1)),
которая также является достаточной статистикой. •
Пример 3 (Равномерная модель, достаточная статистика для нее).
Пусть X = (X), , Хп) — выборка из равномерного распределения Z/(0, 0),
0 > 0 неизвестно. Записав плотность равномерного распределения (см. п. 5
§ 1.2) с помощью индикатора: f(i; 0) = 0"1 /(0 ^1^0), получим для функ-
ции правдоподобия выборки представление
ь(х; 0) = П = е~п П т(° < 0)^(D > о).
i=i t=i
Отсюда следует, что в данном случае достаточной статистикой является
максимальное значение выборки Х(П).
Аналогично, для общей равномерной модели t/(0t, 02), 01 <02, можно
записать
1(х; 0) = (02 - 01)’П/(01 1(1) Х(п) 02),
следовательно, статистика
Т = (Т1,Т2) = (Х(1),Х(П))
достаточная для 0 = (01,0г). •
190 Глава 3. Теория оценивания неизвестных параметров распределений
Пример 4 (Равномерная модель (продолжение)). Рассмотрим модель
где а(8) < b(8), V0, — заданные непрерывные функции скалярного параметра 6.
Как и в предыдущем примере 3, можно записать
Цх; 8) = (b(6) - а(6)}~п1(а(8) < х(1) < х(п) Ь(8)) (4)
Следовательно, двумерная статистика Т = (Х(ц, X(,t)) является достаточ-
ной для 8. Выясним теперь, нельзя ли здесь найти одномерную, т. е. более
экономную, достаточную статистику. Индикатор в (4) равен 1 тогда и только
тогда, когда
{х(1) а(8), Ь(6) > х(п)}. (5)
Пусть а(0) |, b(8) J. с возрастанием 8 Тогда условие (5) эквивалентно
условию
{fl < a“‘(x(ij), 8 <=> {0 < Г,(х) = min(a-1(x(l)), ^'(х^))}.
Таким образом, соотношение (4) можно записать в виде
Z(x;0) = (0(0)-а(0))“п7(Т1(х)^0),
откуда следует, что
Г, =rl(X) = min(a-'(X(1)), Ь~'{Х(п}))
— одномерная достаточная статистика для 0.
Аналогично, если а(0) J., t>(0) | с возрастанием 0, то одномерная доста-
точная статистика также имеется и имеет вид
Т2 = Т2(Х) = тах(а-'(Х(1)), д"'(4V(„)».
Этими двумя случаями исчерпываются ситуации, когда в модели £/(а(0), Ь(0)),
существует одномерная достаточная статистика. Обратим внимание на то, что
как Т], так и Т2 являются функциями исходной двумерной достаточной ста-
тистики Т = (X(1), Х(„)). Это обстоятельство имеет общий характер, т.е.
минимальная достаточная статистика есть функция любых других достаточ-
ных статистик.
В частности, для равномерной модели с нулевым средним И(-8, 8) од-
номерная достаточная статистика Т2 принимает вид
Т2 = тах(-Х(1), Х(П)) = тах(|Х(1)|, |Х(п)|),
а для модели W(0,0-T 1) одномерной достаточной статистики не существует.»
Пример 5 (Модель Коши). Для модели /С(0) (см. упр. 48 6) к гл. 1) функция
правдоподобия выборки X = (Xj, , Хп) имеет вид
1 ,n, 1
и здесь нельзя найти статистику Т, дающую факторизацию (1), размерность
которой была бы меньше п. •
§ 3.3. Достаточные статистики и оптимальные оценки 191
2. Теорема Рао—Блекуэлла—Колмогорова
Прежде всего напомним определение условного математического ожидания.
Пусть X и Y — две случайные величины и р(х), q(y) — их плотности.
Обозначим f(x, у) совместную плотность величин X Условной плотность
и Y, тогда функция
определенная там, где q(y) > 0, называется условной плотностью величины X
при условии, что Y = у. Далее, обозначим
h(y) = ВДУ = у) =
Eip(i:|j/), если X - дискретная случайная
=
величина,
/ хр(х\у) dx, если X - непрерывная случайная
величина.
По определению, случайную величину Л(У) называют условным мате-
матическим ожиданием случайной величины X при фиксированном значе-
нии У Имеет место следующая формула полного математического ожидания
Е(Е(Х|У)) =ЕХ
(6)
(предполагается, что среднее значение ЕХ существует).
Роль достаточных статистик в теории оценивания раскрывает следующее
утверждение.
Теорема 2 (Теорема Рао—Блекуэлла—Колмогорова). Оптимальная оценка,
если она существует, является функцией от достаточной статистики.
Доказательство. Пусть Т = Т(Х) — достаточная статистика и Т\ — (X) —
произвольная несмещенная оценка заданной параметрической функции т(Д).
Рассмотрим функцию
H(t) = E^rjT = t)= T\(x)L(x\t; 9) dx.
Эта функция не зависит от 9, так как условная плотность Д(:г|£; 0) от парамет-
ра не зависит. Далее, статистика Н(Т(Х)) является также несмещенной оцен-
кой г (в). Действительно, по формуле полного математического ожидания (6)
Е#Я(Т) = Е#(Е#(Г!|7)) = ЕвТ, = т(9).
Наконец, справедливо неравенство
Т)вН(Т) ВД, V0,
192 Глава 3. Теория оценивания неизвестных параметров распределений
причем равенство имеет место в том и только в том случае, когда Т\ = Н(Т).
Для доказательства этого заметим, что
ад, = е^-я^+я^-тДО]2 = е4т1-я(т)]2+о()я(т) ъвн(т),
поскольку, в силу (6),
Е[7, - Я(Т)] [Я(Т) - т(0)] = Е[(Г, - Н(Т))Н(Т)] =
= Е{Я(Т)Е[(Т1 - Я(Г))|Т]} = Е{Я(Т)[Е(Т1|Т) - Я(Т)]} = 0.
Таким образом, для любой несмещенной оценки функции т(9), не являю-
щейся функцией от достаточной статистики, всегда можно указать несмещен-
ную оценку, которая зависит от достаточной статистики и имеет дисперсию
меньшую, чем исходная оценка. Следовательно, оптимальную оценку надо ис-
кать среди функций от достаточной статистики.
При отыскании явного вида оптимальных оценок важную роль игра-
ет свойство полноты достаточной статистики. По определению, достаточная
Полная достаточная статистика Т = Т(Х) называется полной, если для
статистика всякой функции <р(Т) из того, что
Е#р(Т) = 0, V0, (7)
следует <p(t) = 0 на всем множестве значений статистики Т.
Теорема 3. Если существует полная достаточная статистика, то всякая функ-
ция от нее является оптимальной оценкой своего математического ожидания.
Доказательство. Пусть Т = Т(Х) — полная достаточная статистика и Н(Т)
— произвольная функция от Т. Обозначим
ЕвН(Т) = т(9). (8)
Из условия полноты следует, что Н(Т) — единственная функция от Т, удо-
влетворяющая соотношению (8), так как если бы была еще какая-нибудь
функция Н\(Т), удовлетворяющая (8), то мы бы имели, что
Е4Я(Т)-Я,(Г)] =0, 49,
откуда Я, (7) = Н(Т).
По теореме 2 оптимальную оценку для т(9) надо искать в классе функ-
ций, зависящих от Т. Но Н(Т) — единственная функция от Т, несмещен-
но оценивающая т(0); следовательно, она и является искомой оптимальной
оценкой.
Подведем итог. Итак, пусть в рассматриваемой модели
7= {F(x;9), 9 £ 0}
существует полная достаточная статистика Т (т.е. уравнение (7) имеет един-
ственное (нулевое) решение) и требуется оценить заданную параметрическую
функцию т(9). Тогда:
§ 3.3. Достаточные статистики и оптимальные оценки
193
1) если существует какая-то несмещенная оценка т(0), ^И^Зст^ение’опти4 1^
то существует и несмещенная оценка, являющаяся
, z _ rr, мольных оценок
функцией от Т; можно так же сказать, что если
нет несмещенных оценок вида Н(Т) (т. е. уравнение
(8) не имеет решения), то класс ТТ несмещенных
оценок т(6) пуст;
2) оптимальная (т. е. н.о.р.м.д.) оценка, когда она существует, всегда явля-
ется функцей от Т, и она однозначно определяется уравнением (8);
3) оптимальную оценку т* можно искать по формуле
г* =H(T) = Et(T\\T), (9)
исходя из любой несмещенной оценки 7) функции т(в).
В конкретных задачах при отыскании явного вида оптимальных оценок
критерий (9) используется редко, так как вычисление условного математиче-
ского ожидания обычно сопряжено со значительными аналитическими труд-
ностями. Чаще решают непосредственно уравнение (8), которое в развернутой
форме для абсолютно непрерывной модели имеет вид
У H(T)g(t; в) dt = т(0), V 0 6 ©, (10)
где g(t; 0) — плотность статистики Т (для дискретной модели интегрирование
в (10) заменяется суммированием H(T)g(t; 0)). Это уравнение в дальней-
t
шем будем называть уравнением несмещенности. Его можно решать различны-
ми способами (см. дальнейшие примеры в §3.4), например, разлагая правую
и левую части в ряды по степеням 0 (в случае аналитических функций т(0)
и g(t; 0)) и приравнивая соответствующие коэффициенты.
Дальнейшее обсуждение роли достаточных статистик в теории оптималь-
ного оценивания будет посвящено различным примерам их применения в кон-
кретных задачах. Но прежде мы выделим один важный класс параметрических
моделей, для которых вопросы о виде достаточной статистики и ее полноте
решаются весьма просто. Это модели экспоненциального типа, которые нам
уже встречались ранее (в п. 3 § 3.2) для случая скалярного параметра. Дадим их
определение для общего случая г-мерного параметра 0 = (0], , 0Г), г 1.
3. Экспоненциальные семейства и достаточные статистики
Модель, задаваемая плотностью вида (сравни с (15) § 3.2)
/(i; 0) = exp 0jB; (i:) + С(0) + £>(а;)| (11)
(или приводимой к такому виду заменой параметров) называется т-парамет-
рическим экспоненциальным семейством. В качестве примера можно указать
13 Заказ 1748
194 Глава 3. Теория оценивания неизвестных параметров распределений
нормальную модель 6>2), для которой
, С X2 6\Х в? , ,---. 1
/(х;0) = ехр —у + —з- - —у - In (02У2^) к
х ^2 ^2 ~^2 <
что приводится к виду (11) заменой в\ = -0^2 02 =
Если имеет место (II), то по критерию факторизации статистика
п
Т = (Т\, ,ТГ), где Tj=Tj(X) = '^BJ(Xl), j = I, , г, (12)
1 = 1
является достаточной для параметра в = (0,, ,6Г), и она будет полной,
если размерность параметрического множества 0 равна г (т. е. 0 содержит
некоторый r-мерный параллелепипед).
Так, указанные в табл. 2 § 3.2 оценки т* являются полными достаточными
статистиками для соответствующих моделей; для модели же полной
достаточной статистикой является в соответствии с (12), пара (EXj, ЕХ^) или
эквивалентная ей пара (Х-S’) (см. пример 1).
Пример 6 (Оценивание нормальной функции распределения).
Пусть £(£) — ^(0,ff2), т. е. наблюдается нормальная случайная величина
с известной дисперсией а2 и неизвестным средним 0 Требуется по выборке
X = (Л), , Хп) оценить вероятность т(0) = Р#{£ То} в заданной точ-
ке io. Как мы знаем (см. замечание к теореме 2 § 3.1), когда у нас нет никакой
априорной информации о теоретической функции распределения F^(x), то
оптимальной несмещенной оценкой для F^(xn) является значение в точке ти
эмпирической функции распределения
I ”
Fn(x0) = - УЗ ДА", хо).
п *—'
1=1
Но в нашем случае вид оцениваемой функции нам известен:
т(0) =^(хо;0) = pj^ = (13)
( <7 & ) \ <7 /
(см. п. 1, (7) § 1.2), поэтому, применяя изложенную теорию достаточных ста-
тистик, мы построим более точную оценку, учитывающую имеющуюся апри-
орную информацию о модели, в которой мы работаем._
Именно, как отмечено выше, выборочное среднее X является здесь пол-
ной достаточной статистикой, и если мы возьмем в качестве исходной несме-
щенной оценки функции (13) простейшую статистику
Т\ = 1(Х, то) Ее1\ = Р#(Х1 то) = т(0),
то оптимальная оценка может быть найдена по формуле (см. (9))
т* = Ев(Т,|Х) = Ре{Л7, х0|Х} = РИА, - X - Х|Х}.
§3.3. Достаточные статистики и оптимальные оценки
195
Здесь (см. упр. 28 к гл. 1) случайная величина Х\ - X не зависит от условия
X, поэтому указанная условная вероятность совпадает с безусловной вероят-
ностью P#{Xi - X io - -V}. Но линейная функция Х, - X от нормальной
выборки распределена по нормальному закону со средним
е,(Х| -х) = е#а'1 - е#т =0-0=0
и дисперсией
/1 Iм
— [ 71 — 1 1 у—
De(*i-X =DJ ----
\ п п
П- 1 j
---(7
П
поэтому
т*=Рв{Х1-Т^10-Л-} =
71 U/Q
71-1 (7
з?о X
(14)
Обратим внимание на то, что оптимальная (н. о. р. м.д) оценка для функ-
ции (13) получается не просто заменой неизвестного параметра 0 на до-
статочную статистику X, но введением еще и дополнительного множителя
у/п/(п - 1) в аргумент функции Ф, — догадаться до такой «экзотики» из ка-
ких-то других соображений представляется весьма проблематичным. •
Еще более «экзотичен» результат следующего примера, полученный с ис-
пользованием таких же идей А. Н. Колмогоровым в 1950 г. в более общей
задаче.
Пример 7 (Задача Колмогорова). Пусть по выбор-
ке X = (Хь , Х^, п > 2, из нормального рас-
пределения V(0,,02) (оба параметра неизвестны)
требуется оценить значение теоретической функ-
Оценивание функции
распределения в общей
нормальной модели
ции распределения F^x; 0) в заданной точке Iq, т.е. параметрическую функ-
цию (сравни с (13))
т(О) = Г<(хо;О) = Рв{Ц^^ (15)
I 02 02 ) \ 02 /
Следуя изложенной выше идеологии, будем искать оптимальную несме-
щенную оценку в виде (9), где в качестве исходной несмещенной оценки снова
возьмем индикатор Т\ = I(X\ < zq)- В данном случае полной достаточной
статистикой является, как мы знаем, Т = (X, S2), поэтому можем записать
т* = Е,(ад = Р»{*1 < ХО\Т} = и0
1, у/п — 15
(16)
Т
13’
196 Глава 3. Теория оценивания неизвестных параметров распределений
где
, , Хп — X
«О = «оСП = ~г-г •
уп — 15
Если бы случайная величина
X, - X
не зависела от условия Т, то правая часть (16) была бы равна Fn(u0)> где
вид функции распределения F?(u) указан в упр. 42 к гл. 2. Таким образом,
нам остается установить независимость статистик у и Т. Для этого сделаем
небольшое отступление и добавим еще кое-что из теории (изложенного выше
нам не хватает).
Ф Свободные
статистики
Определение
Статистика U = М(Х) называется свободной,
если ее распределение не зависит от параметра 0 G 0 (в про-
извольной параметрической модели X).
Теорема 4 (Теорема Басу). Пусть Т(Х) — полная достаточная статистика,
Ы{Х') — свободная статистика. Тогда Т(Х) и i/(X) независимы.
Доказательство. Пусть А — произвольное измеримое (т. е. для которого
определены выписываемые далее вероятности) событие. Тогда вероятности:
условная — ^(Т) = ₽#{£/€ .4|Т} и безусловная — 7д = Р«{Г7бЯ} не за-
висят от 0 по условию теоремы, при этом Е^ДТ) = 7д. Следовательно,
обозначая д(Т) = ^л(Т) ~7л, имеем E9y(T) = 0, V0. Из полноты Т следует,
что д(Т) = 0, т.е. безусловная 7д и условная >Ра(Т) вероятности совпадают.
Но это и означает независимость статистик Т(Х) и W(X).
Вернемся к нашей задаче и заметим, что если ввести нормированные слу-
чайные величины У) = (Х,-01)/02, i = 1, ,п, которые имеют уже стан-
дартное нормальное распределение -Л/(0, 1) (т. е. не зависящее от параметра 0),
то легко проверить (это мы оставляем в качестве простого упражнения для
читателя), что статистика т) в терминах величин У, сохранит свой вид:
т)= где 52(Г) = - V(r,-Г)2
' у5ГЛ5(Г) 1 n 7
Отсюда следует, что распределение статистики т] не зависит от параметра мо-
дели 0 = (0[, 0г), значит, она является свободной (!) статистикой, и по теореме
Басу т] и Т = (X, S2) независимы (!).
Отсюда и из (16) имеем т* = Х?(и0). Используя результат упр. 42 к гл. 2,
можем записать явный вид этой оценки через неполную бета-функцию:
§3.3. Достаточные статистики и оптимальные оценки
197
. п-2 1\
1 — «о(Г); —у—, - к если 0 < и0(Г) < 1,
п — 2 1 \
1 - ul(T\, —-—, - \, если -1 < ио(Г) < О.
С помощью индикаторов этой формуле можно придать следующий оконча-
тельный вид: н.о.р.м.ддля функции (15) является статистика
1-^(Г);^,0 7(У<ю) +
1 ( ,, , п-2 1\ .
+ -B(j-^(T); — (17)
Это и есть знаменитый результат А. Н. Колмогорова. •
Наш следующий пример относится к оцениванию в полиномиальной
модели М(п;р) (см. пример 10 в §3.2).
Пример 8 (Полиномиальная модель: оценивание параметрических функ-
ций). Записав плотность f(x;0) (см. (28) §3.2) в виде
N-l . zAT-1 >.
f(x; в) = pN П ( ) = exp < =»1п — + In рдг к (18)
видим, что она приводится к виду (11) заменой
0'=lnf^-Y j = \,...,N - 1.
\Pn /
Таким образом, эта модель укладывается в схему r-параметрического (при
г = N - 1) экспоненциального семейства, и, следовательно, для нее полной
достаточной статистикой является вектор Т = (Т}, , 7\-1)> где
п
1=1
— число реализаций исхода «}» в выборке X = (Хь.. . ,Хп), j = 1,...,N - 1.
Заметим, что число реализаций исхода «N» есть — n-v\ - - ,
а распределение полного случайного вектора и = (м|,..., 1<у) есть полино-
миальное распределение М(п; р\, .., р^).
Из изложенной в п. 2 теории следует, что в данной модели несмещенные
оценки существуют лишь для таких параметрических функций, которые име-
ют вид ЕвЯ(Г), или, что то же самое, вид Е#Я(р). Но (см. (14) § 1.1)
ЕвЯ(и)= 52 ЯСп, ,£„) • |рГ-..р1/.
' Xi!... Хм\
П- _1_ — г> 1
198 Глава 3. Теория оценивания неизвестных параметров распределений
и при любой функции Н правая часть здесь представляет собой полином
от pi, , ру степени не выше п. Следовательно, оцениваемыми (т. е. для
которых существуют несмещенные оценки) параметрическими функциями
в данной модели являются лишь полиномы степени не выше п от р\,..., р^
Так, из упр. 19 к гл. 1 следует, что несмещенной оптимальной оценкой функции
т(в) =рГ\ ... Ру при г1 + + ry п является статистика
= (^l)r, ОМ»
(«)г, + .. +»
(напомним, что (а); = а(а - 1) (а - k + 1), (а)о = 1). Оценки для произ-
вольных полиномов (степени не выше п) можно строить с помощью линейных
комбинаций этих статистик на основе теоремы 3 § 3.1.
Как частный случай этих результатов при N = 2 имеем соответствующие
выводы для бернуллиевской модели. В примере 1 в §3.1 были построены
несмещенные оценки для произвольных полиномов степени не выше п (п —
объем выборки) от параметра 0 модели Bi(1,0) (соотношение (6) в §3.1).
Эти оценки представляют собой функции от полной достаточной статистики
X = X, + + Хп — числа «успехов» в п испытаниях, следовательно они
являются оптимальными (н.о.р.м.д). •
В заключение этого параграфа приведем пример достаточной статистики,
не являющейся полной.
Пример 9. Пусть произведено одно наблюдение над дискретной случайной
величиной X с распределением
{О при х = -1,
д1/1 П1Э б,е(0’1)-
0 (1 - в) при 1=0, 1,2,...,
Тогда X — достаточная, но не полная статистика. Действительно, пусть
<р(х) — заданная на множестве {—1,0, 1,2,...} функция, удовлетворяющая
условию Е^(;г) = О, V0 6 (0, 1). Это условие можно записать в виде
ОО
^(-1)в(1-0)-2 + ^Н^=О
1=0
или, так как
ОО 00
о -6*)”2 = + + 52 = °-
z=0 1=1
Но этому условию удовлетворяет любая функция, для которой уз(0) О,
<р{х) = -a:ip(-l), х = 1,2, т. е. значение <р(-1) можно задать произ-
вольно. Следовательно, в данном случае критерий полноты не выполняется,
поэтому уравнение несмещенности не будет иметь однозначного решения.
§ 3.4. Способы решения уравнения несмещенности
199
Рассмотрим, например, задачу оценивания функции т(в) — (1 - в)2 Непо-
средственно можно убедиться в том, что любая статистика Т = Та(Х), где
Та(х) =
при х = О,
при х = -1, 1,2,
а произвольно, является несмещенной оценкой т(9) (проверку этого мы
оставляем читателю в качестве простого упражнения). •
§3.4. Способы решения уравнения несмещенности
А математику уже затем учить следует,
что она ум в порядок приводит.
М. В. Ломоносов41
Настоящий параграф посвящен применению теории достаточных статистик
при отыскании оптимальных несмещенных оценок в конкретных задачах.
Ключевым моментом при этом является отыскание решения уравнения не-
смещенности (10) § 3.3. Имеются классы статистических моделей, для которых
разработаны специфические методы решения уравнения несмещенности, поз-
воляющие получать явные выражения для оптимальных оценок произвольных
оцениваемых параметрических функций. Изложение этих методов и состав-
ляет содержание данного параграфа. Подчеркнем, что прежде чем решать
уравнение несмещенности, необходимо в каждой конкретной задаче:
а) определить достаточную статистику Т = Т(Х);
б) найти ее распределение: Fr(f; 0) = Рв{Т(Х) /} или плотность g(t; 0) ;
в) проверить, обладает ли она свойством полноты, т.е. решить однородное
уравнение (7) § 3.3 и убедиться, что оно имеет единственное (нулевое)
решение.
Только убедившись, что в рассматриваемой модели несмещенная оценка
нуля единственна, можно приступать к решению уравнения несмещенности
для заданной параметрической функции т(0). По этой программе мы и будем
в дальнейшем действовать.
Но прежде сделаем одно полезное замечание. В конкрет- Полезное
ной задаче, найдя полную достаточную статистику Т = Т(Х), замечание
полезно вычислить ее среднее р,(в) = ЕоТ’(Х), т.е. опреде-
лить тем самым ту параметрическую функцию, для которой сама статистика Т
является оптимальной оценкой. Можетоказаться, что р.(в) — кв, т.е. линейно
зависит от параметра в рассматриваемой модели. Тогда оптимальной оцен-
кой в” для параметра 9 будет, очевидно, статистика в* — Т(Х)/к. Например,
Ломоносов Михаил Васильевич (1711-1765) — русский ученый-энциклопедист и мыслитель,
поэт, академик Петербургской АН.
200 Глава 3. Теория оценивания неизвестных параметров распределений
пусть модель TF = 2/(0; в) — равномерное распределение с неизвестным пра-
вым концом носителя (носителем распределения называют то множество,
на котором соответствующая плотность f(x;9) > 0). Как показано в при-
мере 3 §3.3 достаточной статистикой в этом случае является максимальное
значение Х(п) выборки X — (Х1(.... Хп). То, что эта статистика полна, будет
п
установлено чуть ниже (см. пример 3), атак как E#X(n) =--в (см. упр.46
п + 1
, п + 1
к гл. 1), то отсюда следует, что в =-Х(п) — оптимальная оценка 6.
1. Модель степенного ряда, оценивание параметрических функций
Эта модель, охватывающая большое число конкретных дискретных распреде-
лений, введена и описана в п. 8 § 1.1. Из вида плотности (20) § 1.1 следует,
что она относится к экспоненциальному семейству (см. п. 3 § 3.3) и потому
обладает полной достаточной статистикой Т = Т(Х) = Х\ + + Хп. Рас-
пределение этой статистики указано в (24) §1.1. Следовательно, здесь у нас все
готово, чтобы приступить к основной проблеме — решению уравнения несме-
щенности. Предположим, что требуется оценить параметрическую функцию
т(0), представимую в виде сходящегося на 0 степенного ряда:
ОО
т(0)=
3—г
Тогда из формулы (24) § 1.1 следует, что в данном случае уравнение несме-
щенности Е#Я(Т) = т(9) принимает вид
ОО ОО 00
52^(t)an(t)^ = Г(6)т(в) = 52 an(x)0x W' =
t=nl z=nl j=r
оо k-nl
= E 9k^b}an(k-j). (1)
k = nl + r j=r
Поскольку это тождество по в, приравнивая соответствующие коэффициенты,
находим
Я(0ап(0 =
t—nl
52 bjdn(t - j)
}=г
при t nl + г,
, О
при t < nl + г.
Общее ешение ОтсюДа получаем, что оптимальная оценка т* для функ-
щее решение ции имеет вид
т-ы
т' = Н(Т) = а~п'(Т) 52 Ь,ап(Т - j) I(T > nl + г).
(2)
§ 3.4. Способы решения уравнения несмещенности
201
параметрических
функций
Это чрезвычайно общий результат, поскольку здесь функция f(0), зада-
ющая модель, и оцениваемая функция г(0) — произвольные аналитические
функции на 0. Выделим особо важные специальные случаи решения (2).
Пусть т(0) = f(0). Тогда в исходном соотноше- Специальные случаи
нии (1) правая часть есть
/п+> = £ ап+|(х)^
х=(п+1)<
и потому оптимальная оценка /* этой функции есть
Г = + (3)
а-п(Т)
Если тг(0) = 0Г то из (2) следует, что
Т* = Т^Т >П1 + Г)’
Пусть теперь т(0; х) = 0х/ f (0), х i, т. е. речь фактически идет об оце-
нивании теоретической плотности f(x\0) (см. (20) § 1.1). В этом случае ис-
ходное соотношение (1) запишется в виде
52я(г)ап(О0‘ = 0xfn~'(0) = 0x 52 a^jW,
t^nl j=(n-l)l
откуда аналогично предыдущему имеем
Л*) = ЛГ (п - + (5)
вп(Т)
В частности, оптимальная оценка f*(x) теоретической плотности f(x\0)
получается умножением правой части (5) на коэффициент а(х):
f*(x) = а(х)ап~'^Т Xh(T^ (n — l)Z + a:), х I. (6)
а-п(Т)
Наконец, если требуется оценить параметрическую функцию вида
Tip(0) = Е9р(£) = 52 V>(x)f(x\0),
x^l
то оптимальная оценка получается заменой в правой части этого равенства
теоретической плотности f(x\0) ее оценкой (6):
т-(п-о; , .
К = 52 = 52 fp(x)a(x)an~-'- -х • (7)
х>1 х=/ ап(1>
202 Глава 3. Теория оценивания неизвестных параметров распределений
Отметим также, что по критерию для экспоненциальной модели (см. п.З
§3.2) выборочное среднее X = Т(Х)/п является эффективной (значит, и оп-
тимальной) оценкой теоретического среднего (см. (23) § 1.1) и это
есть единственная эффективная оценка в модели степенного ряда.
Итак, для важного класса дискретных распределений типа степенного
ряда можно строить оптимальные оценки для произвольных параметрических
функций, представимых в виде степенного ряда от в.
Рассмотрим несколько конкретных примеров на применение полученного
общего результата.
Пример 1 (Пуассоновская модель, оценивание параметрических функций).
Пусть X = (Хь , Хп) — выборка из распределения £(£) G П(0). Оценим
параметрическую функцию Trt(6) = вте~1в при заданных t < п и г О
целом. Здесь (см. п. 8 § 1.1) /(0) = е6, значит,
= т... «,«=£. х>0.
• х\ X!
1=0
Далее,
т.е.
Поэтому по формуле (2)
Общий ез льгот Этому результату можно придать следующую окон-
щии результат чательную форму:
<=г!СуД(1--) (8)
пг \ п/
Подчеркнем, что в данном случае оцениваемая функция т(0) зависит
от двух свободных параметров: t < п и целого г 0. Придавая этим пара-
метрам конкретные значения, можно из (8) получать самостоятельные инте-
ресные результаты.
§ 3.4. Способы решения уравнения несмещенности
203
Так, при т = 0, t = -1 функция тг,((0) = и из (8) Специальные
имеем оценку случаи
т
согласующуюся с общим результатом (3).
При t — 1 функция тГ1((0)/г! = е-е#7г! есть теоретическая вероятность
Р#{£ = г} = и для нее из (8) имеем оптимальную оценку
Т—г
f*(r) = CrT-(1- -) г =0,1, ,Т
пт \ п /
Если, например, требуется оценить вероятность
к
т(0) = рв{{ = Е fw>>
г=0
то оптимальной оценкой будет статистика
к
т* = Е f'w = *
г=0
при Т > к,
при Т < к.
Наконец, при t = 0 из (8) имеем вид оптимальной оценки для тг(в) — вг
. Сгт Т(Т-\) (Г-г+1) (Г)г
тг = г!— =----------------=----.
пг пг пг
(9)
В частности, оптимальная оценка самого параметра 9 есть выборочное
среднее: 9* — Т/п = X, что согласуется с результатом, указанным в табл. 2
§3.2.
Пример 2 (Отрицательная биномиальная модель, оценивание параметриче-
ских функций). По выборке X = (Xb...,Хп) требуется оценить параметри-
ческую функцию ts t(0) = ₽’(1 - t < nr, модели Bi(r, 0). Здесь (см. п. 8
§1.1)
ОО
fn(0) = (l-0)-nr = EC’nr+l-10I
т=0
т. е. ап(х) = Спг+1-1, х = 0, 1,2, а
ОО
= Hi - 0Г(пг-° = Е <Х-ж-1*а+’
t=0
Следовательно, уравнение несмещенности (1) запишется в виде
ОО 00
Е Н(х)ап(х)9х = Е Cir_t+,-_1₽s+,'>
z=Q i=0
204 Глава 3. Теория оценивания неизвестных параметров распределений
откуда находим, что
s-ix—s
Н(х) = п-£+^-'
Общий результат
(Ю)
Специальные случаи
Таким образом, оптимальная оценка г/1 имеет вид
s-tT-s
* __ __ nr+T-s-t-1
T,.t =ЩТ)= ------
Gnr+T-1
Это значительное усиление результата примера 3
§3.1. В частности, полагая s = 1, t = 0, получим вид
оптимальной оценки по п наблюдениям для параметра 0:
pT-l гр
д» _ • _ ипг+Т-2 _ 1 .X
'° “ с.г,+т., ~пг + Т-' <">
(сравни с (7) §3.1 при $ = 1).
Кроме того, поскольку (см. п. 2 § 1.1) £Й(Т) Bi(nr,0), то ЕЙТ
= птд/(\ - в), т.е. статистика Т/пг = Х/т является оптимальной оценкой
для параметрической функции т(0) = 0/(1 -0), что согласуется с результатом,
указанным в табл. 2 § 3.2. •
2. Модели с выборочным пространством, зависящим от параметра 9
Пусть носителем распределения наблюдаемой случайной величины £ является
отрезок [а, 0] и теоретическая плотность имеет вид
f(x;9) =Qi(9)Ml(x), а^х^в (12)
(вне отрезка [а, 0] плотность равна нулю). Здесь функция Qi(0) >0 для всех
0 а и дифференцируема, кроме того, выполняется условие нормировки
0 е
1, т. е.
1
а а
Дифференцируя это тождество по 0, имеем
<г=И
— этим соотношением связаны функции М[ и Qi в (12).
Пусть теперь дана выборка X = (А), , Хп) из указанного распределе-
ния. Записав функцию правдоподобия с помощью индикаторов в виде
L& 0) - П П П 1(а <*><*) =
п
= Q?(0) I(x(n] 0) [J Цх{1] > а),
§ 3.4. Способы решения уравнения несмещенности
205
по критерию факторизации получаем, что достаточной статистикой в данной
модели является Т = Х(п) — максимальное значение выборки. Найдем ее
распределение: при t Е [а, б]
t п
FT(t,e) = Р#{Т 0 = Р£{£ t} = Q^0)( [ M^dz) =
W / 4i и?
a
откуда для плотности gt(t; 0) = F?(t; в) получаем представление
' ’ <2f+ (<) С7 (<)
Для проверки полноты статистики Т надо убедиться в том, что несме-
щенная оценка нуля в этой модели единственна, т. е. решить однородное урав-
нение Евр(Т) = О, V# а. В нашем случае оно эквивалентно уравнению
«
У* dt = 0, У0>а.
а
Дифференцируя это тождество по 0, получаем tf>(0)M] (0)Q'"(0) = О, V# а,
откуда <р(0) = О, V 0 а. Таким образом, свойство полноты здесь имеет ме-
сто, и можно приступать к решению уравнения несмещенности для заданной
параметрической функции т(0):
е
У* H(t)gi(t;0)dt = T(0), V0>a. (14)
а
Далее мы считаем, что функция т(0) дифференцируема. Переписав урав-
нение (14) с учетом (13) в виде
е
п [ H(t)M,(t)<?rn(t) di = -^г,
J 41W
a
и продифференцировав это тождество по 0, получим
41 \у)
ИЛИ
= T'WQ.W-nrmW _ т(в. , т'М = т'(0)
W nMi(0)Q](0) nM.WQ.W ()nf(0-,0\
В итоге, мы имеем следующий общий результат: Общий результат *
в модели (12) оптимальной оценкой для произвольной
206 Глава 3. Теория оценивания неизвестных параметров распределений
дифференцируемой функции т(ф) является статистика
,. = яЫ = гВД + ^. (15)
Замечание. Если рассмотреть «симметричную» модель (неизвестен левый конец но-
сителя распределения):
/(т; 0) = Q2(0)Mi(x), в х Ь, (16)
то аналогичными рассуждениями можно установить, что полной достаточной стати-
стикой теперь является минимальное значение выборки Х(|), ее плотность имеет вид
te\e,b], (17)
Ч2 (Ч
а оптимальной оценкой для произвольной дифференцируемой функции т(3) явля-
ется статистика
т »/(%„„ Х,„)
Проверку этих утверждений мы оставляем читателю в качестве упражнения, а далее
мы проиллюстрируем изложенную теорию несколькими примерами.
Пример 3 (Равномерная модель, оценивание параметрических функций).
Пусть £(£) G W(O,0), 6 > 0. Это модель вида (12) с а = 0, Q\(0) = \/в,
М\(х) = 1, поэтому для нее «работает» результат (15). В частности, если
тг(0) = вг то оптимальная оценка для этой функции по п наблюдениям есть
п + г
______(п)__ __ ,L 1 jyF
nf(X(n),X(n))~ п (п)
(19)
(раньше, см. введение к данному параграфу, мы установили этот результат для
г = 1). Обратим внимание на то, что здесь Я| = = 6/2, и, следовательно,
оптимальная оценка для теоретического среднего ai есть
. 1 .
= 2Т‘
п + 1
2п
а не выборочное среднее Х(!). При этом
а в силу упр. 46 к гл. 1
, _ (п + 1)2 _ (n+1)2 пв2 = е2
sO[ 4п2 9 4л2 (п + 1)2(д 4- 2) 4п(п + 2)
Следовательно, эффективность выборочного среднего по отношению к опти-
мальной оценке равна
Р»а| = 3
D$ X п -у 2
при п 2.
§ 3.4. Способы решения уравнения несмещенности
207
Этот пример показывает, что не всегда выборочное среднее наилучшим обра-
зом оценивает теоретическое среднее модели. •
Пример 4 (Показательная модель с параметрами сдвига, оценивание пара-
метрических функций). Пусть плотность наблюдаемой случайной величи-
ны £ есть /(т; 0) = х 0. Требуется оценить тг(в) = 9Г по выборке
объема п. Это модель вида (16) с Ь = оо, Qi(9) — ев = е~х поэтому
по формуле (18)
е°)
Пример 5 (Приведенное показательное распределение, оценивание пара-
метрических функций). Приведенное к отрезку [0, 6| показательное распре-
деление задается плотностью /(т; 0) = е~х/(е~в - е~ь), х G [0, &]. Это рас-
пределение имеет вид (16), поэтому, применяя (18), получим, что оптимальной
оценкой произвольной степени параметра тт(в) = вг является следующая ста-
тистика от выборки объема п:
(21)
3. Метод подгонки
Здесь речь будет идти о весьма простом, но очень эффективном в ряде случаев
приеме решения уравнения несмещенности Е$Н(Т) = т(в). Предположим,
что т(в) > 0 для всех в G 0, тогда можем записать тождество
[H(TY] Г H(t)g(t-,e)
или
Пусть здесь (ключевой момент!) имеет место факторизация
Ц^ = щ(0<пМ), (22)
т(0)
где функция <?[(£; в) принадлежит тому же семейству плотностей, что и плот-
ность g(t;6) полной достаточной статистики Т. Тогда мы имеем тождество
J' H(f)u(t)gt(t;e) dt = 1,
которому удовлетворяет (в силу полноты статистики Т) единственная функ-
ция H(t) = w-I(i). Это дает решение исходного уравнения несмещенности:
т* = м-1(Т) (для дискретной модели, в этих рассуждениях интегрирование
надо заменить суммированием). Таким образом, если в конкретной задаче уда-
ется установить факторизацию (22), то мы тем самым получаем одновременно
и вид искомой оптимальной оценки для т(0). Продемонстрируем эффектив-
ность такого приема соответствующими примерами.
208 Глава 3. Теория оценивания неизвестных параметров распределений
Пример б (Нормальная модель с неизвестным средним, оценивание параме-
трических функций). Пусть X =(Х|,...,ХП) — выборка из £(£) 6 _Л/(0,<т2).
Здесь, как мы уже знаем, полной достаточной статистикой Т является выбо-
рочное среднее X и Le(X) — <r2/n), т. е.
(п \ Г п , .2)
2^2/ ехр ( 2а2 ~ Г
Рассмотрим сначала задачу оценивания теоретической плотности т(0) = (х; 0)
в произвольной точке х. Здесь уравнение факторизации (22) принимает вид
0) f— f П и. л\2 , / п\г1
7-^=v5iexpj-SJ(1-«> +^-«) J =
f П , >2 П2 Л (n - 1)0+ z\2
= Л exp < —-r-г(z - t)----—- t----------
(2(n - l)cr2 ' ' 2(n - l)cr2 \ nJ
,, , / (n - 1)0 + z\ , n-1 i
= Ь(М)Л>/П(г;—-—)> где <Ti = —— ° <
1 1' \ n / n
т.е.
“(0 = fafa 0>
a 0i(«;0) = Arj/n
Таким образом, g}(t; в) является нормальной плотностью такого же вида,
как и g(t; 0), и тем самым решением уравнения несмещенности
4^ purrmh’ «ВДВ .ням1 и» ядагхчг
Оптимальная оценка
нормальной плотности
Специальный случай
является функция H(t) = u~\t) = /^(z; t) — нор-
мальная плотность со средним t и дисперсией ст2
В итоге имеем, что оптимальной оценкой теорети-
ческой плотности является статистика
f(x) = f^x; X). (23)
Отсюда можно вывести следующее важное за-
ключение: если оценивается параметрическая функ-
ция вида
т(0; <т2) = Е^(£) = У ipixjf^^x; 0) dx,
(24)
то оптимальная оценка для нее получается по формуле
Т* = / $(x)f*(x) dx = / i{)(x)fa2(x;X)dx^T(X-,ff2), (25)
т.е. в выражении для т(0; а2) надо просто заменить параметр 0 на статистику
X, а величину <т2 — на а2 = ((п - 1)/п)а2.
§ 3.4. Способы решения уравнения несмещенности
209
Так, если ч/>(х) = e,tx то получаем характеристическую функцию
т(0; <т2) = Е#е’^ = exp < itO ——t2
(см. упр. 26 к гл. 1), следовательно оптимальной
оценкой для нее является статистика
Г — <т2 1
т* = exp < ИХ —2^ ( (26)
Оптимальная оценка
нормальной характери-
стической функции
В качестве еще одного конкретного примера возьмем функцию -ф(х) = х2
Тогда из (24) имеем
т(0; а1) = Е^2 = + (Е^)2 = а2 + 02
и, следовательно, в силу (25), т* = сг2 + Х2 или (О2)* = т*-ст2 — X2-<х2/п —
оптимальная оценка для б2
Наконец, если взять ty{x} = I(x < xq), то
т(в; а2) = Р»{< < яо} = ф("——
\ (7 /
и по формуле (25)
' птима л ьгн ая"бцей ксг
нормальной функции
распределения
— с этим результатом мы уже встречались в примере 6 §3.3 (см. там соотно-
шение (14)). •
Пример 7 (Биномиальная модель, оценивание параметрических функций).
Пусть требуется по выборке X = (Xi,...,Xn) из биномиального распре-
деления Bi(fc, в) оценить параметрическую функцию тг s(0) 0Г(1 - 0)s
где г, s — заданные неотрицательные целые числа такие, что г + s < кп.
Поскольку модель Bi(fc, 9) входит в экспоненциальное семейство, то стати-
стика Т = Х1 + ... + Хп является достаточной и полной, и ее распределение
£в(Т) = Bi(fcn, 0) (см. п. 1 § 1.1). В данном случае уравнение факторизации
(22) запишется в виде
-o)kn~‘~s = cin(c^r_X'cL-r-s^r(i - в)кп~г~
т. е. здесь g^t; в) = Ск~т_г_3в1~г(1 - в)кп~г — биномиальные вероят-
ности В ТОЧКаХ t = Г, Т + 1, , кп - S, а ФУНКЦИЯ U(t) = (Gkn-r-s)
Значит, оптимальная оценка функции тг, s(0) есть
r*s = u-l(T)=^^. (27)
{-'kn
14 Заказ 1748
210 Глава 3. Теория оценивания неизвестных параметров распределений
В частности, при г = I, s = 0 получаем оптимальную оценку параметра 0:
— этот результат мы уже имели в § 3.2 (см. табл. 2). •
Пример 8 (Оценивание размера конечной совокупности: выбор с возвра-
щением). Пусть в урне находятся занумерованные числами 1,2, ,0шары,
но их число 0 нам неизвестно. По схеме случайного выбора с возвращением
из урны извлекается п шаров и при этом каждый раз фиксируется номер из-
влеченного шара. Пусть X = (Х|,... , Хп) — номера извлекавшихся шаров.
Требуется по этой информации оценить общее число шаров в урне 0 и, более
общо, прозвольную степень тг(0) = 0' где г > -п (целое). Если £ обозна-
чает номер случайно извлеченного шара, то распределение этой случайной
величины задается вероятностями
/(а;; 0) = Р#{£ = а;} = х = 1, , 0, или f(x; 0) = ^-1(х sj 0).
о о
Отсюда для функции правдоподобия имеем представление
£(i; 0) = JJ fixe 0) =0 "/(maxi; д') = 0 п1(х(П) 0).
i=i 1
По критерию факторизации отсюда делаем вывод, что максимальный наблю-
давшийся номер Х(п) является достаточной статистикой для параметра 0.
Найдем ее распределение. Имеем
Ре{*(,,) sU} =М*> i= '•
Следовательно,
f t\n ft - 1 \n
<?(М) = P9{X(n) = о = J -7- t=l,2, ,0. (28)
\ (z / \ (7 у
Убедимся теперь в полноте статистики -ЛГ(га). Для этого запишем уравнение
несмещенного оценивания нуля:
в
;r>(t)5(<; 0) = 0, VOI
t=i
Полагая здесь последовательно 0 = 1,6 = 2, очевидно, получим, что
9?(1) = у>(2) = = 0, т. е. этому условию удовлетворяет лишь нулевая
(на множестве значений статистики Х^) функция, следовательно, статистика
— полная.
Для оценивания функции тг(0) = 0Г применим метод подгонки. Здесь
уравнение факторизации (22) записывается в виде
tn - (t - l)n tn - (t - l)n
0n+r
n-|-r
t
0
§ 3.4. Способы решения уравнения несмещенности
211
т. е. новая плотность
имеет такой же вид, как и g(t; 0), а функция
“(0 = т> -nn-
Следовательно, оптимальная оценка для тг(0) есть
Tr — U —
Туг- (29)
(„) - - О"
Отметим, что если Х(П) велико, то, воспользовавшись приближением
(1-х^*«1-лх(;‘,
формуле (29) можно придать приближенную форму
г‘ ~ п + гг
Гг ~ п А(п)'
В частности, оптимальная оценка числа 6 шаров в ур-
не имеет вид
6* = п* = Х(п)
Оптимальная оценка^ Ж*
числа шаров в урне
~ п *(п)’
(30)
Игровую интерпретацию этой задачи дает В. Феллер [25, с. 240], пред-
лагая для оценки числа зарегистрированных в городе автомобилей встать
на перекрестке и записывать номера Х>, , Хп проезжающих автомобилей.
Если в городе имеется 1000 машин и производится случайная выборка объема
п = 10, то математическое ожидание максимального наблюденного регистра-
ционного номера EjX(n) ~ (п/(п + 1))0 приближенно равно 910.
Иллюстрацией статистической процедуры (30) являются следующие ре-
зультаты, полученные моделированием с помощью таблиц случайных чисел:
при в = 10 000, п = 10 значения оценки (30) для десяти независимых выбо-
рок оказались равными (с точностью до единицы) 10 549,9841, 10486, 10891,
10462, 10873,8789, 10 753,9960, 10287 Эти данные свидетельствуют о хоро-
шем качестве оценки (30). •
Замечание. Мы знаем, что оценка (30) имеет наименьшую дисперсию среди всех
несмещенных оценок в. Но какова величина этой дисперсии De0*? На практике,
чтобы судить о точности оценки, важно уметь оценивать ее дисперсию по имеющимся
данным (по выборке). В таких случаях оптимальную несмещенную оценку D' для
Нов" можно построить по формуле
D- = (д')2 - (О2)'.
,(31)
212 Глава 3. Теория оценивания неизвестных параметров распределений
Действительно, так как Е6в' = в, Е9(02)’ = О7 то
EeD* = Е9(б')2 - Е9(б2)* = ЕД<?‘)2 - в7 = Ee(fl’)2 - (EX)2 = DX,
а поскольку D’ естьфункция от полной достаточной статистики, то D* есть н. о. р. м. д.
Так, в рассматриваемом случае на основании (29) имеем
(приближенное равенство справедливо при больших значениях Х(П)).
Замечание. В данной модели теоретическое среднее есть
= Е‘£ = 0 Ъ1 = —
1=1
и оптимальной оценкой для него является статистика а* = (г* + 1)/2, но не выбо-
рочное среднее X (!).
Пример 9 (Оценивание размера конечной совокупности: выбор без возвра-
щения). Предположим, что в ситуации предыдущего примера производится
случайный выбор без возвращения п шаров или, что то же самое, извлекается
сразу комплект из п шаров, причем все C# возможных вариантов выбора
равновероятны. Снова пусть Х(п) обозначает максимальный наблюденный
номер. Тогда будет также полной достаточной статистикой и
сп~ ।
S(t;O-P«U(n)=t} = -^L> t = n,n+}, ,е. (32)
'•'в
Здесь метод подгонки удобен для оценивания параметрических функций
вида
(в + г)!
тг(0) = (0 + 1) (0 + г) =———, т > -п (целое). (33)
г!
Записав уравнение факторизации (22):
(0 + г)!
п (t - 1)! С"*-,1
n + r(t + r- 1)!
имеем, что
>п+г
'0+Г
ffi (t; 6») =
— плотность такого же вида, как и g(t; в}, а функция
п + r (t + т - 1)!
Следовательно, оптимальная оценка для функции тг(0) имеет вид
тг‘ = u-‘(X(n)) =
(^(п)+г- 1)!
(*(п) - 1)!
§ 3.4. Способы решения уравнения несмещенности
213
= ^ХМ(Х(П} + 1) (Х(п} + г - 1). (34)
Если Х(п) велико, то формуле (34) можно придать приближенную форму
* п + г _
Т* К ~
т. е. получаем такой же результат, как и в предыдущем примере для схемы
выбора с возвращением.
В частности, оптимальная оценка числа 0 шаров Оптимальная оценка
в урне есть числа шаров в урне
* , п + 1 , ,
0*=т1*-1 =--------Х(п)-1 (35)
п
(сравни с (30)), а оптимальная оценка для дисперсии имеет вид (см. (31)
И (33))
D* = (0*)г - (02)* = « - I)2 - т2* + ЗТ|* - 1 = (г,*)2 + т; - т}.
Учитывая (34), окончательно находим
jj* _ ^(п)(^(п) ~ п) *
п2
Замечание. Поскольку (34) есть несмещенная оценка для (33), то мы имеем общую
формулу для рассматриваемой модели:
+ 1)...(Х(П) + г - 1) = ^(0 + О (» + г). (36)
В частности,
Е«-^(п) = " (0 + О.
D9X(n) = EbX(„)(XW + I) - - (E9X(n))2 = —-(0 + 1)(0 - п).
Учитывая (35), можем также записать
Следовательно, оптимальная оценка для т(0) = D»X(n) есть
. пг (Х{п)-п)
т — - - и — ------
(n + I)2 Х{п)(п + I)2
4. Гамма-модель с неизвестным параметром масштаба,
оценивание параметрических функций
Определение и основные свойства модели Г(0, А), где 0 > 0 — неизвестный
параметр масштаба (параметр формы А далее считается известным) приведе-
ны в п. 3 § 1.2 (см. также пример 1 в §2.4 о свойствах порядковых статистик
214 Глава 3. Теория оценивания неизвестных параметров распределений
для выборки из Г(1, I)). Отдельные результаты об оценивании для этой мо-
дели нам уже встречались ранее. Так в табл. 2 § 3.2 указана эффективная
(следовательно, оптимальная) оценка для самого параметра 9 — это стати-
стика Х/Х. Там же отмечено, что Г(0, А) — это модель экспоненциального
типа, и для нее полной достаточной статистикой является сумма наблюдений
Т = Т(Х) = Х| + . + Хп. По воспроизводящему свойству гамма-распреде-
ления £$(Т(Х)) — Г(0, nA), т.е. (см. (18) § 1.2) плотность статистики Т есть
<,«;«) == ISO (37)
Основываясь на этих фактах, в данном пункте мы решим задачу оптималь-
ного оценивания произвольных параметрических функций для этой модели.
Мы начнем с построения оценки для параметрической функции
тгх(9) = (f е~£Iе т > -nA, х 0. (38)
Здесь два свободных параметра: г и х, поэтому (38) на самом деле задает
двухпараметрическое семейство функций от 9. Для отыскания оптимальной
оценки т,.*! мы воспользуемся методом подгонки. Уравнение факторизации
(22) этого метода в данном случае принимает вид
tnx-ie-(i-x)/e Г(пХ + т) tnX~' , 1Л ,
Г(пА)0пА+г ~ Г(пА) (t- x)nA+r-i^^ “ ^1 • + г)> х<
т.е. <7i(i; 0) = f(t - х\0, nA + г) — гамма-плотность вида (37), а функция
u(t) =
Г(пА 4- г)
Г(пА)
рА-'
(i — х)"Л+г-|
Общий результат .. Следовательно, искомая оптимальная оценка есть
Выделим важный частный случай этого результата. Если в (38) положить
г = -А (при п Т? 2) и домножить функцию Т-х,х(9) на множитель хА-[/Г(А),
то получим теоретическую плотность f(x\9, А). Следовательно, из (39) полу-
7Й1 Оптимальная оценка чаем оптимальную несмещенную оценку f*(x) для
гамма-плотности теоретической плотности гамма-модели Г(0, А):
,, Г nA zA~‘(Т-х г
f (х) = -----±----------------г-п-----I(T X
Г(А)Г((п - 1)А) ТпА-1
(40)
Специальный случай ® свою очередь, этот результат можно применить
для оценивания параметрических функций вида
ОО
(0) = Е9р(£) = У* (p(z)/(z|0, A) dx
о
§ 3.4. Способы решения уравнения несмещенности
215
— оптимальная оценка для т(6) получается просто заменой в этом интеграле
теоретической плотности f(x\9, А) ее оценкой (40). В итоге имеем
00 (_пЛ Т
Т* = f <p(x)f*(x)dx = г.[("У" - - х [ <р(х)хх~'(Т - z)(n-l)A~l dx,
J Г(А)Г((л - 1)А) J
что после замены переменных х —> хТ приводит к формуле
।
г’ = / X Г/ПЛ) X \ / p(xT)xx~l(1 - а;)*"-1)А_| dx. (41)
Г(А)Г((п - 1)А) У v '
Пример 10. Пусть по выборке X = (Х|, ..,Хп), п 2, из £.(£) Е Г(0, А)
требуется оценить преобразование Лапласа
т(0) = Е(<'£ = (1 + 0<)“А
при t > 0. По формуле (41) имеем
।
т*________£1^_______ [ e-xtTxx~l(l - dx
Г(А)Г((л-1)А) J ( ’
Этот интеграл можно вычислить, разложив экспо-
ненту е~х1Т в ряд и воспользовавшись формулой для
бета-функции В(а, Ь) (см. п. 4 § 1.2). В итоге получим
. Г(пА) ” r(A+j) •
Г(А) )!Г(пА 4-у)
Оценивание
преобразования
Лапласа
(42)
Пример 11 (Оценивание функции надежности). Функцией надежности на-
зывается вероятность тс(9) = ₽«{£ > с} = Е#/(£ > с), где с > 0 — заданное
число. Чтобы построить оптимальную оценку для т(9) по л > 2 наблюдениям
над нужно вычислить интеграл в (41) при <р(х) = 1(х с), т.е.
Г(пА) Г
Г(А)Г((л - 1)А) J
с/Т
- х){п 1)А 1 dx при
_ О
при Т с.
Используя неполную бета-функцию B(z; а, Ь) (см. (4) §2.4), этой формуле
можно придать вид
1 - В
(43)
216 Глава 3. Теория оценивания неизвестных параметров распределений
Выделим частный случай этого результата при А = 1: в этом случае
тс(в) = е~с/в и
)п- 1
ЦТ > с).
(44)
Пример 12 (Нормальная модель с неизвестной дисперсией: оценивание па-
раметрических функций). Полученные для гамма-модели результаты можно
применять и к другим моделям, именно, к таким, в которых соответствующая
достаточная статистика имеет гамма-распределение: ведь ключевым моментом
выше при выводе оценки (39) было то, что достаточная статистика Т = Т(Х)
имела гамма-распределение Г(0, nA). Продемонстрируем это на примере ис-
следования нормальной модели ЛГ(д, 02). Эта модель экспоненциального
типа, и как отмечено в п. 3 §3.3 (см. табл. 2 §3.2) полной достаточной стати-
стикой для нее является
п
Т = - м)2
1=1
Для нее, очевидно, Е#Г = nD^X] = пв2 и потому оптимальной оценкой
для О2 — теоретической дисперсии модели — является Т/п, что соответству-
ет результату, указанному в табл. 2 § 3.2. Но теперь мы можем продвинуть-
ся значительно дальше и построить оптимальные оценки для произвольных
функций от параметра 9. Для этого найдем сначала распределение статисти-
ки Г. Заметим, что £j((Af - р.)/9) = jV(0, I), Vi, следовательно (см. упр. 38
к гл. 1), Се^Т/92) = £2(п) = Г(2, п/2). Отсюда имеем (см. п. 3 § 1.2), что
£е(Т) = Г(202, п/2). Поэтому все полученные выше результаты для гамма-
модели заменой 9 -» 202, А -» 1/2 переносятся на рассматриваемую модель.
Например, рассмотрим параметрическую функцию т(9) = (202)г Ее оп-
тимальная оценка получается из (39) при х = О, А = 1/2 и имеет, следова-
тельно, вид
„г Г(п/2)
Т ~ 1 —;—",----г,
Г(п/2 + г)
'о'бщий'результа^^" пРичем г здесь — любое действительное число, боль-
для модели АГ(д, Я2) шее ~(п/2)- В частности, любая степень 9к при
к > -п оценивается статистикой
/Г\А/2 Г(п/2)
V/ r((n + fc)/2)’
(45)
При к = 2 имеем отмеченный выше результат для дисперсии О2 по-
скольку Г(п/2 + 1) — (п/2)Г(п/2). •
Пример 13 (Общая нормальная модель: оценивание функций от дисперсии).
Использованную в предыдущем примере идеологию можно применить и в
более общей ситуации, когда оба параметра нормальной модели неизвестны.
§ 3.4. Способы решения уравнения несмещенности
217
Итак, пусть X = (X,, , Хп), п 2, — выборка из £(£) = 02). Для
этой модели полной достаточной статистикой является пара
/ п
Т = (Т\,Т2) = (x,^Xi-X)2
' 1=1
26*2, А -э (п-1)/(2п).
(см. пример 1 в § 3.3, а также п. 3), при этом по теореме Фишера (см. п. 3 § 2.5)
£»(Т2/622) = х2(п - 1) = Г(2, (п - 1)/2), т.е. Ct(T2) = Г(2022, (п - 1)/2). По-
этому, если т(0|, 02) = т(02), т.е. параметрическая функция зависит только
от теоретической дисперсии, то для ее оценивания можно применить извест-
ные результаты для гамма-модели с учетом замены 0 —>
В качестве конкретного примера, как и выше,
рассмотрим задачу оценивания степени в2 при
к > -п + 1. Полагая в (39) г к/2, х = О,
пХ = (п - 1)/2 получим вид искомой оптималь-
ной оценки
Общий результат
для модели A/"(0|, 02)
= (ТЛк/2 П(п-1)/2)
{2) \2j Г((п + Л- 1)/2)’
В частности, при fc = 2 эта оценка принимает вид
~ X)2 = So2,
(46)
т2 _ 1
п - 1 п - 1
нам из примера 9 § 3.2 результату, что
и мы приходим к уже известному
статистика Sq является оптимальной несмещенной оценкой теоретической
дисперсии 02 нормальной модели A/^#,,^)- Однако результат (46) гораздо
более общий. •
5. Другие применения гамма-модели
для оценивания неизвестных параметров
В ряде случаев для наблюдаемой случайной величины £ с плотностью f(x; 0)
можно подобрать такое функциональное преобразование у = h(£), что преоб-
разованная величина т] будет иметь гамма-распределение с неизвестным па-
раметром масштаба, и тогда задача оценивания для исходной модели f(x;ff)
может быть решена с использованием изложенных в п. 4 результатов для гам-
ма-модели. Несколько таких примеров будут рассмотрены в данном пункте.
Пример 14 (Бета-распределение). Пусть £ имеет плотность
/(х;0) = 9хв~\ i€[0, 1], 0 > О,
т.е. (см. п.4 § 1.2) £«(£) = Ве(0,1). Рассмотрим преобразование т] — - 1п£,
тогда по формуле (45) § 1.2 найдем, что плотность д(у; в) случайной величи-
ны у есть д(у;9) = 0е-<\ у 0, т.е. £«(»?) = Г(0-1, 1). Следовательно, если
218 Глава 3. Теория оценивания неизвестных параметров распределений
имеется выборка X — (Хь , Х„) из то статистика
п
Т = -
1=1
имеет распределение Г(0-1, п), и в терминах этой статистики можно строить
оптимальные оценки для параметрических функций от в~1, используя резуль-
таты п. 4. •
Пример 15 (Распределение Вейбулла). Пусть ( имеет плотность
/(я; 0) = ^-ха~]е~х х О,
и
т.е. (см. п. 8 § 1.2) £о(£) — W(O,a,0^a). Тогда аналогично предыдущему
примеру имеем £е(£а) = Г(0, 1). Следовательно, статистика
п
т = ^х°
1 = 1
имеет распределение Г(0, п) и «работают» все результаты п.4. •
Пример 16 (Распределение Парето). Пусть плотность наблюдаемой случай-
ной величины ( имеет вид
0
= х в>0
(см. п.9 § 1.2). Тогда £Д1п£) = Г(0~', 1), и мы имеем ситуацию примера 14
с достаточной статистикой
п
i=i
Пример 17 (Распределение Лапласа). Это распределение задается плотно-
стью
е-|х|/«
/(z;0) = -^-, xER' 0>О.
Нетрудно убедиться в том, что здесь £j(|£|) Г(0, 1) (это мы оставляем
в качестве упражнения читателю), поэтому мы имеем ситуацию примера 15
с достаточной статистикой
п
т=£>>!•
1=1
Я слышу, и я забываю.
Я вижу, и я запоминаю.
Я делаю, и я понимаю.
Китайская пословица
§3.5. Оценки максимального правдоподобия
219
§ 3.5. Оценки максимального правдоподобия
Оптимальность — это еще не все; оптимальность —
лишь одна сторона очень сложной картины.
Э. Леман
Метод оценивания, основанный на использовании достаточных статистик,
наряду с сильными сторонами обладает и своими слабостями. Прежде всего
это связано с тем, что этот метод ориентирован на построение несмещен-
ных оценок, а, как уже отмечалось выше, несмещенные оценки не всегда
существуют или практически мало пригодны; в таких случаях приходится
использовать смещенные оценки. Далее, даже при наличии несмещенных
оценок этот метод не всегда приводит к однозначному решению (достаточная
статистика не всегда обладает свойством полноты), и, следовательно, в та-
ких случаях для выбора окончательной оценки необходимо привлекать те
или иные дополнительные соображения. Наконец, при реализации метода
достаточных статистик мы часто сталкиваемся с трудными аналитическими
задачами, связанными с решением уравнения несмещенности (10) § 3.3, и этот
метод часто приводит к сложным для практического использования форму-
лам для оптимальных несмещенных оценок (см. например, формулу (17) § 3.3
для оценки нормальной функции распределения (15) §3.3). В таких случаях
предпочтение может быть отдано другим методам, которые приводят пусть
не к оптимальным, но зато просто конструируемым и легче вычислимым
оценкам (особенно, если они по эффективности мало уступают оптимальным
оценкам). Такими преимуществами в ряде случаев обладают оценки макси-
мального правдоподобия, которым посвящен настоящий параграф.
1. Определение и примеры оценок
максимального правдоподобия (о. м. п.)
Одним из наиболее универсальных и эффективных методов оценивания неиз-
вестных параметров распределений является метод максимального правдопо-
добия, который и приводит к оценкам максимального правдоподобия (далее мы
будем использовать для них сокращенное обозначением о. м.п.). Этот метод
получил распространение в 20-е гг. XX в. благодаря работам английского ста-
тистика Р. Фишера (хотя у него были и предшественники). Суть этого метода
состоит в следующем.
Пусть, как обычно, имеется выборка X = (А), , Хп) из некоторого
распределения £(£) G Т = {F(x; 9), 9 G 0} и L(x; в) — функция правдопо-
добия (см. п. 1 § 3.2). Если для двух значений в? параметра 9 выполняется
условие Z(i;^|) > L(:r;02), то говорят, что значение 9} «более правдопо-
добно», чем 02 (ПРИ 9 — 9i «вероятность получить реализацию х больше»,
чем при 9 = 02). Наиболее правдоподобное значение параметра при данной
реализации х выборки X обозначается 9(х), а статистика 9 = 9(Х) и есть
о. м. п. для параметра 9. Таким образом, по определению, 9(х) — это та-
220 Глава 3. Теория оценивания неизвестных параметров распределений
кая точка параметрического множества 0, в которой функция правдоподобия
L(x; 0) достигает максимума:
L(i; 9(х)) L(x; 9), V0, или L(x; 0(х)) — sup L(x; 0). (1)
9
Если для каждого х из выборочного пространства X максимум L(x; 0)
достигается во внутренней точке & и функция L(x; 0) дифференцируема по 0,
то 0(х) удовлетворяет уравнению
9L(x; 0) 9\nL(x;0)
—= 0 или -------------= 0.
90 90
Уравнения Для векторного параметра 0 = (0\....0Г) это уравне-
правдаподобия ние заменяется системой уравнений
9 In L(x; 9)
----^_Д=0 i = i г.
90i ’
Эти уравнения называются уравнениями правдоподобия.
Свойства о. м. п.
Отметим следующие свойства о. м. п.
1) Если существует эффективная оценка Т(Х) для скалярного параметра 0,
то 0 — Т(Х). Это очевидное следствие критерия эффективности Рао-
Крамера (9) §3.2:
ainZ(X;6>) 1 , , ч
2) Если имеется достаточная статистика Т(Х), а о. м. п. существует и един-
ственна, то она является функцией от Т(Х). Действительно, из представ-
ления (1) §3.3 следует, что в данном случае максимизация L(x; 0) сво-
дится к максимизации д(Т(х);0) по 0. Следовательно, 9(х) = 0(Т(х)).
Примерами о. м. п. 0 для ряда моделей со скалярным параметром явля-
ются приведенные в табл. 2 § 3.2 соответствующие эффективные оценки. Так
для моделей ЛГ(0, ст2), Г(0, 1), Bi(l, 0), П(0) о. м.п. 9 = X. Рассмотрим еще
несколько примеров нахождения о.м. п.
Пример 1 (Общая нормальная модель, о. м. п. ее параметров).
Пусть £(£) € М{9\,9\\ Функция правдоподобия для этой модели указана
в примере 1 в §3.3. Обозначив
«’ 1 £(х, - Т)>
п
1=1
запишем ее в виде
0) = (2?res2) n/2 exp {-n
I L ^"2 \ “2
s
- In —
02.
}• (2)
§ 3.5. Оценки максимального правдоподобия
221
Воспользуемся теперь элементарным неравенством lna^a-l,Va>0,
из которого следует, что In а2 < а2 - 1 или In а < (а2 - 1)/2; знак равенства
достигается только при а = 1. Учитывая это, имеем, что выражение в квад-
ратных скобках в (2) всегда неотрицательно и обращается в нуль лишь при
0} = х,02 = s. Но это означает, что 0(х) = #г(я)) = (х, s). Таким об-
разом, в данном случае о. м. п. существует, единственна и при этом 0 = (X, S),
где S2 — выборочная дисперсия. Отметим также полезный факт, что
sup L(r; 0) = L(x; 9(х)) = (2ires2)~n^2 (3)
в
Подчеркнем, что полученная о. м.п. 9 = (0i,02) = (X, S) — функция до-
статочной статистики Т = (Т1,Т,2) = (Х,S2), определенной в примере I § 3.3.»
Пример 2 (Многомерная нормальная модель, о. м. п. ее параметров). Пред-
положим, что наблюдается многомерная случайная величина £ = (£ь , &)>
распределенная по невырожденному нормальному закону Е), где вектор
средних значений д = (др , д*) и дисперсионная матрица Е = ||0|2||* —
неизвестные параметры (см. п. 2 § 1.2). Здесь общее число неизвестных пара-
метров (с учетом симметричности матрицы Е) равно к + к(к + 1)/2. Пусть
X = (Хр , Хп) — выборка из £(£), т. е. X, — независимые Л-мерные
случайные величины с плотностью, указанной в (9) § 1.2. Найдем оценки па-
раметров в = (д, Е) такой модели по методу максимального правдоподобия.
В данном случае функция правдоподобия
п
Ь(х; 0) = Ipfel£-E> =
i=i
= (2тг)-'п/2|ЕГп/2 ехр / - M)'E-’fe - д)|. (4)
2 i=i
Пусть х = (ii + + хп)/п (сложение векторов производится покоор-
динатно), тогда
22&_ д),Е-1 - д)=22^_ _ - д) (5)
/=1 i=i
(здесь х = (ip ..,Xk), где Xj — среднее арифметическое j-x. координат
векторов х{, ,хп). Введем также выборочную дисперсионную матрицу
I ”
~ _ = Ikollt
п /=1
(см. п. 2 § 2.3). Воспользовавшись равенством
у By = tr (BY), Y = yy
222 Глава 3. Теория оценивания неизвестных параметров распределений
и линейностью оператора tr (взятия следа от матрицы), получим
У^(ж; - - D = п tr (S-lE(x)). (6)
i=i
Учитывая равенства (5) и (6), перепишем формулу (4) в виде
L(z; 0) = (2тг)_*"/2 exp [(f - /z)'E“‘(z - р) + tr (Е^'Е(т)) + In |Е|] }
Отсюда следует, что максимизация по 0 функции правдоподобия эквива-
лентна минимизации под и Е функции
ф(х;р, Е) = (х- р)'£~'(х- р) + [tr (E-lE(z)) - fc - In |E-1S(z)|]
(постоянные fc и In |E(t)| введены здесь для упрощения дальнейших пре-
образований). Обозначим А,, , Хк собственные числа матрицы Е-|Е(х)
(все они — положительны), тогда след (tr) этой матрицы равен сумме
А| + + А^, а ее определитель — произведению А] Хк, следовательно,
можем записать, что
к
1р(х; р, S) = (х - д)'Е-|(х - р) + У^(А,- — I — In Xi).
i=I
Поскольку S-1 — положительно определенная матрица и а - 1 - In а О,
Va > 0, из последнего соотношения получаем чр(х; р, Е) 0, причем равен-
ство имеет место только при р = х, Х} — Хк = 1, т.е. при Е = Е(х).
Но это означает, что о. м. п. параметров р и Е являются соответственно стати-
стики X — (Хь ,Хк) и Е(Х) = ||S0||{ Как показано в п.2 §2.3, вектор
выборочных средних X = (Хь ,Хк) является несмещенной оценкой для
вектора р = (р^, , рк), несмещенной же оценкой для Е является подправ-
ленная выборочная дисперсионная матрица (п/(п - 1))Е(Х). •
мЬ(1(п)'0) Пример 3 (Равномерная модель, о. м. п. ее параметра).
Если X = (Х[, , Хп) — выборка из равномерного рас-
пределения И(0,0), то из формулы для Цх; 0), полученной
к в примере (3) §3.3, следует, что Цх;0) монотонно убывает
по 0 для 0 а при 0 = функция правдоподобия
! , достигает максимума (см. рис. 1). Таким образом, о. м. п.
О х(п) 0 = Х(П), т.е. совпадает с достаточной статистикой. В этой
Рис 1 точке функция правдоподобия разрывна, поэтому производ-
ная L(z; 0) по 0 в этой точке не существует. Таким образом,
в данном случае о. м. п. не является решением уравнения правдоподобия. Это
характерно для ситуаций, когда выборочное пространство X зависит от неиз-
вестного параметра.
§ 3.5. Оценки максимального правдоподобия
223
Если же X — выборка распределения в + 1), то из формулы (4)
§ 3.3 имеем L(x; 0) = 1(6 Х(п) 0 + 1). Отсюда следует, что любое
0 £ [х(п) _ 1,11(1)1 максимизирует функцию правдоподобия; таким образом,
здесь о. м. п. не единственна. В качестве решения можно выбрать, например,
0 = - 1 )/2; в этом случае 0 — функция достаточной статистики
Т = (АГ(1), Х(П}) (см. пример 4 в § 3.3). •
Пример 4 (Двухпараметрическая показательная модель, о. м.п. ее парамет-
ров). Эта модель определена в примере 2 в § 3.3. Из полученной там формулы
Г 71 I
L(r-0) =^"exp|--(TI(z)+T2(x)-0I) j/(T,(x) ^0,) (7)
следует, что при любом 02 максимум по 0) достигается при 0, = Т\(х) = хщ,
и он равен exp {-п(1п02 + Г2(х)/02) }; максимум же последнего выражения
по 02, как легко видеть, достигается при 02 = Т2(х) = х - i(|). Таким об-
разом, о. м. п. 0 = (0,, 02) = (Jf(i), X - X(i)), т. е. совпадает с достаточной
статистикой Т — (Г,, Т2) = (-Xp), X - Xpj). •
2. Принцип инвариантности для о. м.п.
Важным свойством оценок максимального правдоподобия является их инва-
риантность относительно преобразований параметра. Это означает, что если
q q(0) произвольная функция 0 (0i, ,0Г), взаимно однознач-
но отображающая параметрическое множество 0 рассматриваемой модели
в множество Q = {q = (q\, , gr)} С Rr то о.м.п. q = g(0). Действитель-
но, поскольку q — взаимно однозначное отображение, существует обратная
функция 0 = 0(g). Тогда
sup £(х; 0) = sup l(i; 0(g)),
see qeQ
и если максимум по 0 функции L(x; 0) достигается в точке 0, то максимум
по g функции L (т; 0(g)) имеет место в точке д, удовлетворяющей уравнению
0(g) = 0, т. е. в точке g = g(0).
Согласно этому, в каждой конкректной задаче можно выбрать в каче-
стве исходной наиболее удачную параметризацию, а о. м. п. получать затем
с помощью соответствующих преобразований. Таким образом, в методе мак-
симального правдоподобия по существу достаточно построить лишь оценку 0
параметра модели, а оценки различных параметрических функций получают-
ся как результат подстановки 0 = 0 в оцениваемую функцию. Отметим, что
в методе достаточных статистик наилучшая несмещенная оценка ищется для
каждой функции т(0) независимо.
Продемонстрируем эффективность принципа инвариантности примерами.
224 Глава 3. Теория оценивания неизвестных параметров распределений
(7)
Пример 5 (Общая нормальная модель, о.м. п. функции распределения).
Пусть в условиях примера 1 требуется оценить параметрическую функцию
т(0) = Р4£Оо} = ф(^~1>) I
\ Z
(см. пример 7 в § 3.3). Поскольку о. м. п. 6 = (X, S), то по принципу инвари-
антности о. м. п.
г = т(0) = Ф
у О г
(сравни с оценкой т* в примере 7 в §3.3, соотношение (17)). •
Пример 6 (Двумерная нормальная модель, о. м. п. ее параметров). Пусть
Xi = (Х/|, А^), I = 1, ,п, — независимые наблюдения над двумерной
случайной величиной £ = (£i,&) с распределением
а2
ра2
/хг2
а2
где а2 > 0 и р € (-1, 1) неизвестны. Здесь теоретическая плотность есть
(далее 0 = (<т2, />))
( Х] + Х22 />2112 1 ,0.
еХР1 2<т2(1-р2) + <т2(1-р2) J (8)
(это частный случай общей формулы (9) § 1.2). Найдем о.м. п. а2 и р. Здесь
плотность сложным образом зависит от параметров, поэтому удобно перейти
к новым параметрам q = (91,92), положив qi = q\(&) - [2<т2(1 - р )]
9г = 92 W — />[<22(1 ~ (°2)] ' Тогда формула (8) перепишется в виде
f(xx,x2;0) =
f(xi,x2;q) = — ехр{91(а:2 + у2) + q2xy + r(q)},
где 7(9) = (l/2) In (4</2 - q2). Отсюда сразу получаем, что уравнения правдо-
подобия для нахождения о. м. п. q\ и q2 имеют вид
1 п
дт(д)
дд\
491
49? -9i’
Но
1 Л dr(q)
- ? , 2/12/2 = --7------
П -Н dq2
92
49? - Ч2'
(9)
_2 2g,
— л 2 2 ’
49? “ <12
<12
Р = "т-’
2?i
§ 3.5. Оценки максимального правдоподобия
225
поэтому из соотношений (9) находим, что
п
„ 2£ад2
У?(^21 + ^2)> р = --------• о°)
'= £(^1 + х,22)
i=i
Пример 7 (Логнормальное распределение, о. м. п. параметрических функ-
ций). Пусть X = (Хь , Хп) — выборка из логнормального распределе-
ния, т.е. (см. п. 1 § 1.2) Xi = eY‘, где £e(Yi) £ A/”(0|, 02)- Построим о. м. п. для
теоретических среднего и дисперсии этого распределения, т. е. (см. (8) § 1.2)
для функций
Г 021 2
т,(0) = ехр 10! + у | и т2(0) = (ее-’- 1)ехр{20!+02}. (11)
Прежде всего отметим, что моменты EgZf можно вычислить следующим
образом. Поскольку характеристическая функция случайной величины У| есть
(см. упр. 26 к гл. 1)
{^2^2 л
it#!---у- >,
то
EgX? = EgetK' = Л - ) = exp h'0, + — I.
\ г / ( 2 J
Отсюда для Т1(0) = Eg X, и т2(0) = Dg^! = EgZ2 - (EgX,)2 имеем пред-
ставления (11). Перейдем теперь к построению оценок. Мы уже знаем о. м. п.
(#1,0з) = (Е, 5(E)), но тогда по принципу инвариантности искомые о. м. п.
г, и т2 строятся сразу в соответствии с формулами (11):
?i = ехр {у + ^-у^}, т2 = r2(es’(y) - 1). •
3. Метод накопления для приближенного вычисления о. м. п.
Оценки максимального правдоподобия в явном виде не всегда удается полу-
чить; в таких случаях прибегают к приближенным методам решения уравне-
ний правдоподобия (когда такие уравнения можно составить). Мы опишем
один из таких методов, который называется методом на- .,
. „ > к Метод накопления
копления Фишера. Он заключается в следующем. Пусть фише а
0 — скалярный параметр и функция правдоподобия ишера
Z(0) = L(x; в) дважды дифференцируема по в. Разложим функцию вклада
V(0) = У(х;0) (см. (1) §3.2) в ряд Тейлора в окрестности точки 0q, вы-
бранной в качестве начального приближения для 0(i) = в, и вычислим это
15 Заказ 1 748
226 лава 3. Теория оценивания неизвестных параметров распределений
разложение при 0 — 0:
V(0) = Г(0О) + (0 - 0о)Г'(0*), (12)
где 0* —-некоторая промежуточная точка между 0 и 0О. Но V(0) — 0 по опре-
делению о. м. п. 0, поэтому из (12) имеем
0 = 0
° Г'(0*)
Если заменить теперь в этом равенстве 0* на 0О и V'(0o) на ЕвУ'(Х;0о) =
= -ш(0(|) (см. соотношение (5') §3.2), то получим первое приближение
ш(0о)
Теперь этот процесс можно повторить, взяв в качестве нового начального
приближения 01 и т. д. Таким образом, (А: + 1)-е приближение по методу
Рекурреига метода накопления вычисляют рекуррентно по формуле
накопления у/д')
0*+i *=0. .2,... (13)
ш(0<.)
Процесс вычислений продолжают до достижения желаемой точности:
- &к\ < Важным в этом методе является выбор начальной точки 0О.
Обычно в качестве 0q берут значение какой-нибудь легко вычисляемой со-
стоятельной оценки (см. определение 3 в п. 3 §2.2); тогда все три точки
0* и 0 при больших объемах выборки п будут находиться вблизи истинного
значения параметра. Метод накопления, как правило, быстро приводит к це-
ли, хотя в некоторых случаях этот процесс может и не сходиться.
Пример 8 (Модель Коши, оценка параметра по методу накопления). Пусть
X = (Х|,..., Хп) — выборка из распределения Коши /С(0) (см. упр. 48 (б)
к гл. 1).
Здесь функция вклада
п
V(0)=2^
Xi - 0
и получить точное решение уравнения правдоподобия V(0) = 0 невозможно.
Функция информации г(0) для модели /С(0) равна 1/2 (см. табл. 1 §3.2),
поэтому последовательность (13) принимает в данном случае вид
2
0*+i=0A-+-m). fc=о,1,2,...
п
В качестве начального приближения 0$ здесь можно взять выборочную ме-
диану (п, 1/2- которая в силу соотношения (15) §2.4 является состоятельной
оценкой теоретической медианы 0/2, совпадающей в данном случае с 0. •
§ 3.5. Оценки максимального правдоподобия
227
Пример 9 (Модель степенного ряда, метод накопления для нее). Эта модель
определена в п. 8 § 1.1. Из формулы (20) § 1.1 имеем для функции вклада
представление
где р(0) — теоретическое среднее (см. (23) § 1.1). Таким образом, уравнение
правдоподобия V(fl) = 0 здесь имеет вид
= х. (14)
Вычислим функцию информации i(0). Имеем (см. (4), (5) §3.2)
г(<?) = Е972(Х,;0) = 1е9(Х, - д(0))2 - ^D₽X, =
где а2(0) — теоретическая дисперсия (см. (23) § 1.1). Если уравнение (14)
нельзя решить точно, то для приближенного определения значения о. м.п. 0
можно применить метод накопления.
В частности, для усеченного в нуле распределения Пуассона (см. (22)
§ 1.1) функция = е® — 1 и уравнение (14) принимает вид 0 = i(l - е-®),
1- 1 + 0)е"9
а функция информации равна г(У) = ——-----_в •
(/(1 — е )
4. Асимптотические свойства о.м.п.
Метод максимального правдоподобия и возникающие в нем оценки макси-
мального правдоподобия никак не связаны с обсуждавшимися ранее свой-
ствами несмещенности и оптимальности оценок. Более того, в рассмотрен-
ных выше примерах вычисления о. м. п. мы обнаружили, что о. м. п. не всегда
являются несмещенными оценками. Так из примера 1 следует, что о. м. п. дис-
персии &2 нормальной модели .V(0i,0|) является выборочная дисперсия S2,
которая, как мы знаем, является смещенной оценкой (см. п. 3 §2.2), одна-
ко ее смещение Е9№ - О2 = — 02/п убывает с ростом объема выборки, т. е.
она является асимптотически несмещенной. Тем самым, можно сказать, что
свойства этой оценки «улучшаются» с увеличением числа наблюдений п. Это
обстоятельство имеет весьма общий характер, именно, с
_ . „ большие выборки
о. м. п. обладают хорошими асимптотическими свойства-
ми для больших выборок. Можно сказать, что широкое использование этих
оценок связано именно с их асимптотическими свойствами, проявляющими-
ся при неограниченном накоплении данных.
О роли асимптотического подхода (предельных теорем) в теории вероят-
ностей и математической статистике уже вкратце говорилось ранее (см. общее
замечание в п. 1 § 1.2). Добавим еще к этому, что асимптотический подход поз-
воляет исследовать единым методом различные задачи и получать при этом
достаточно общие результаты. Эти результаты в дальнейшем могут использо-
Т5*
228 Глава 3. Теория оценивания неизвестных параметров распределений
ваться в задачах с выборками конечного объема, и тогда они рассматриваются
как приближенные. Иногда асимптотический подход является единственным
математическим подходом, позволяющим в конкретной статистической за-
даче предлагать некоторые процедуры и исследовать их свойства. При этом
(что очень существенно!) окончательные результаты удается получить в про-
стой и наглядной форме, и (что не менее важно) именно асимптотический
подход позволяет вскрыть глубокую математическую сущность проблемы. Из-
ложение асимптотической теории оценок максимального правдоподобия и со-
ставляет дальнейшее содержание этого параграфа. Чтобы подчеркнуть зави-
симость рассматриваемых ниже статистик от объема выборки, будем отмечать
их индексом п.
Когда говорят об асимптотических свойствах оценок (или свойствах для
больших выборок), то прежде всего имеют в виду их состоятельность. Это
свойство нам уже встречалось ранее (см. определение 3 в п. 3 §2.2 и коммен-
тарии к нему). Дадим его общее определение в рассматриваемом контексте
и сформулируем простой, но важный, критерий состоятельности, обобщаю-
щий критерий (23) §2.2.
Пусть X = (Х\,..., Хп) — выборка из распределения £(£) £ TF = {F(i; 9),
в £ 6}, где параметрическое множество 0 — в общем случае некоторый не-
вырожденный открытый интервал в Rr По определению, оценка Тп = Тп(Х)
для заданной параметрической функции т(0) называется состоятельной, если
при п —> оо
Тп-^>т(0), V0 6 0, (15)
т.е., каково бы ни было истинное значение параметра 9, оценка Тп сходится
по вероятности (относительно распределения Р^) к истинному значению оце-
ниваемой функции. Подчеркнем еще раз, что свойство состоятельности в ста-
тистических задачах является обязательным для любого правила оценивания.
Критерий состоя- Если статистика имеет конечную дисперсию, то
тельности оценки имеет место следующий критерий состоятельности.
Теорема 1. Пусть EsTn = т(0) + еп, Х)вТп = <5П и е„ = еп(0) -> О, 6п =
= <5П(0) —> 0 при п —> оо для всех 0 6 0. Тогда Тп — состоятельная оценка
функции т = т(0).
Доказательство. Поскольку
|Г„ - EsTn| =|(ТП - г) + (г - |ТП - т| - |EflTn - т|,
событие {|7), - т| е} влечет событие {|7), Es7),| е - |е„|}. Отсюда
по неравенству Чебышева имеем
Ps{|Tn - т| с} Р«{|ГП - ЕвГп| 5> е - |еп|} < --------+ О
при 71 —> оо и всех 9 £ 0.
§ 3.5. Оценки максимального правдоподобия
229
Основные
предельные теоремы
теории вероятностей
С помощью этой теоремы во многих случаях легко доказывается состоя-
тельность конкретных оценок.
Сейчас будет своевременным привести список-
справочник основных предельных теорем теории
вероятностей о сходимости функций от случайных
величин, которые интенсивно используются в раз-
личных статистических задачах, связанных со схемой «больших выборок»
(пример одной из таких теорем нам встречался в п. 3 §2.2 (теорема 1)).
Справочник предельных теорем (обозначения см. в п. 1 § 1.2)
Г Если Tjn т] и функция <р непрерывна, то <р(т]п) а также
2° Пусть {т]п, („J, n = 1, 2,..., — последовательность пар случайных ве-
личин. Тогда
а) Лп - Сп О, (п ( => rin С;
б) fin - Сп 0, Сп С => т]п С;
в) т/п Г), -Л О => Т)п(п -Л 0;
г) Уп ч, Сп С = const Т)п + (п Т] + с,
7/пСп СТ], ‘Пп/С.п Т]/с при с ± 0;
д) т/п - Сп —> о, (п с,
р
функция ц> непрерывна => у>(»?п) - p((n) —> 0.
3° Пусть Тп =Тп(Х) — оценка скалярного параметра 6 такая, что
ГД^(Тп-0)) ч.У(0л!(0))
(или, что то же, £е(Тп) ~ Л/"(0, <T2(ff)/n)) при п -> оо и всех в £ 0. Пусть,
далее, функция <р дифференцируема и 0. Тогда
Г» (x/^(Tn) - у>(0))) -» V(0, [/(fl)]V(fl)); (16)
кроме того, если ^>'(^) и <т(0) непрерывны, то
(17)
4° (аналог утверждения 3° для случая векторного параметра 6 = (0Ь.. ,6Г)).
Пусть Тп = (Тщ, ,ТГП) — оценка параметра 6, удовлетворяющая
условию Се (х/й(Тп - 0)) -> Л/"(0, £(0)) при п -> оо и всех 6 £ 0. Тогда для
любой дифференцируемой функции <р от г переменных
(18)
230 Глава 3. Теория оценивания неизвестных параметров распределений
при условии, что v(&) ф 0, где
V2(0) = b'(0)E(0)b(0) И М;
если, кроме того, функция <р непрерывно дифференцируема, и все элементы
дисперсионной матрицы 2(0) непрерывны по 0, то
£)-^))\ V(0) (19)
\ v(Tn) )
Вернемся к оценкам максимального правдоподобия и сформулируем их
основные асимптотические свойства. Будем предполагать, что модель TF яв-
ляется регулярной в смысле §3.2, а функция правдоподобия £п(х; 0) при
всех О I и z Е I имеет лишь один локальный максимум по 0, лежа-
щий внутри 0, и притом достижимый (т. е. о. м. п. 0П существует и совпадает
с локальным максимумом). Кроме того, плотность /(х; 0) трижды дифферен-
Асимптотические цируема по 0 и при этом существует не зависящая от 0
свойства о. м. п. Функция М(х) такая, что для всех 0 Е 0
д3 In /(х; 0) ,
———- ^ЛГ(х), ЕвМ«) < оо (»,>,*= 1,...,г).
Теорема 2. Пусть выполнены перечисленные условия. Тогда:
1) о. м. п. 0„ является состоятельной оценкой параметра 0;
2) эта оценка асимптотически нормальна, именно, при п -> оо
-0)) —> ЛГ(О,/-'(0)), (20)
где 7(0) — информационная матрица модели, определенная в (21) § 3.2;
кроме того, если т(0) — непрерывно дифференцируемая функция от 0
и тп = т(0п) — ее °- и. п„ то при п -> оо
£Н^(^-т(0))) -^ЛГ(О,а2(0)), (21)
если
а2(0)^О, где^(0)=Ь'(0)Г‘(0)6(0), д(0) = ^Y
\ Uu\ O(7r J
более того, если функция <т2(0) непрерывна по 0, то
ц / У^(т-П ^т(0)) \ ^(() [j. (22)
\ ^т(^я) /
3) тп является асимптотически эффективной оценкой т(0) (в смысле п. 5
§3.2)).
§ 3.5. Оценки максимального правдоподобия
231
Выделим специально случай скалярного параметра, ввиду его особой рас-
пространенности в приложениях. Для этого случая соотношения (2О;-(22)
принимают соответственно вид
(23)
£#(\/п(т„ - т(0))) —> Лг(о, (24)
и
/ у/п(тп - т(0)) \
Св < -±L1 ) ЛГ(0, 1) (25)
т'(0п)ф(0п) '
(здесь г (А) —функция информации, определенная в(5) и (5') § 3.2, и /(А) /0).
Доказательство. Приведем доказательство асимптотической нормальности
(23). Для этого разложим функцию вклада V„(fl) = Vn(X;fl) в ряд Тейлора
в окрестности истинной точки fl и вычислим это разложение в точке fl„
о = v„(fl„) = y„(fl) + (fln - fl)Vn'(fl) + '-@n - fl)2vn"(fl’),
где fl* — некоторая промежуточная точка между fl и fln. Это равенство можно
записать в виде
у/п г(А)
(26)
п
где
|еп| =
- gi
2ni(fl) 2г (fl)
Поскольку fln —> fl, из условия на функцию М на основании свойства 2° в)
р
следует, что с„ —> 0. К величине
~ Ь ---------ggi------
применим закон больших чисел, согласно которому (см. (5') § 3.2) эта ве-
личина сходится по вероятности к -г(й), следовательно, все выражение в
знаменателе в (25) сходится по вероятности к 1. К случайной же величине
Vn(fl) = /А 91п/(^;А)\1
^i(9) &0 / y/ni(0)
применима центральная предельная теорема, по которой в силу соотношений
(3) и (5) § 3.2 при n-э оо эта величина асимптотически нормальна ЛГ(0, г-1(А)).
Комментарии *
к свойствам о. м. п.
232 Глава 3. Теория оценивания неизвестных параметров распределений
Отсюда и из (26) по свойству 2° г) следует, что такое же предельное распре-
деление имеет и >/п (0„ - 0).
Утверждения (24) и (25) следуют из (23) на основании свойства 3°
Наконец, утверждение об асимптотической эффективности оценки т„
следует из того, что величина во(тп; 0) в (14) §3.2 тождественно равна 1.
Добавим некоторые комментарии к изложенным ре-
зультатам. Факт асимптотической нормальности о. м. п.
— это очень сильный результат. Например, утвержде-
ние (24) говорит о том, что для больших выборок распределение о. м. п.
тп концентрируется вокруг истинного значения оцениваемой параметриче-
ской функции т(0) (предельное распределение имеет среднее значение т(0)),
и степень этой концентрации, характеризуемая асимптотической дисперсией
[т'(0)]2
----—-, возрастаете ростом объема выборки п. Это можно интерпретировать
п г(0)
так, что оценка тн является асимптотически несмещенной и среди всех таких
оценок обладает наименьшей асимптотической дисперсией, т. е. она является
асимптотически эффективной. При этом, однако, надо иметь в виду, что сама
оценка тп может вообще не иметь моментов, т. е. т(0) может не быть асимпто-
Л И61)]2
тическим значением среднего EgTn, а--—-----асимптотическим значением
п i(0)
дисперсии Dfl?rl (в теории вероятностей известно, что из сходимости т)п —> т/,
вообще говоря, не следует сходимость соответствующих моментов).
Рассмотрим, например, задачу оценивания параметрической функции
т(0) \/0 в пуассонвской модели П(0). Здесь, как уже отмечалось в п. 1,
о. м. п. 0 = X, поэтому о. м. п. тп — 1 /X, и для нее соотношение (24) прини-
мает вид
£«(х/п(тп-б»-1)) -^Х(О,6»'3), V0>O.
Вто же время £е(пХ) = П(п0) (см. п.З § 1.1), откуда Pj{X = 0} = е~пв > 0.
Таким образом, с положительной вероятностью X принимает нулевое значе-
ние и поэтому статистика тп ни при каком п не имеет конечных моментов.
Тем не менее для больших выборок (при п -> оо) среднее и дисперсию
аппроксимирующего нормального закона распределения можно трактовать
как среднее и дисперсию самой оценки и говорить о ее свойствах несмещен-
ности и оптимальности в асимптотическом смысле.
Далее, определение асимптотически эффективной оценки предполагает,
что невозможно построить оценку с меньшей асимптотической дисперсией.
Как правило, это имеет место для регулярных моделей, удовлетворяющих
условиям, при которых справедлива теорема 2, хотя существуют и исключения,
как это видно из приводимого ниже примера 10. Для нерегулярных моделей
(когда неприменимо неравенство Рао—Крамера) асимптотическая дисперсия
о. м. п. может иметь порядок, больший п1. Так, из результатов примеров 5
§ 3.5. Оценки максимального правдоподобия
233
§3.2 и 3 следует, что для равномерной модели U(0, 0) о. м. п. 0п = имеет
дисперсию, порядок которой тГ2
Пример 10 (Нормальная модель с неизвестным средним, сверхэффективная
оценка ее параметра). Пусть X = (Jfu ..., Хп) — выборка из М(0, 1). Тогда
о.м. п. 0п — X и £е(0п) = ЛГ(0,1/п). Рассмотрим оценку
т _ Г X при |Х| > ап,
( ЬХ при 1^1 < ап,
где константа ап->0, но у^гап-юо при п->оо. Найдем предельный закон
распределения этой оценки. Имеем
Р»{гШ.-0) =рпРв{ч/^(Х-0) ^х} + (1-рп)Рв{ч/^(&У-в) ^i},
где
рп = Ро{|ЛГ| > ап} = ф(у/п(0 - ап)) +
+ ф( — у/п(0 + Оп)) -------►
П->00
( 1 при |0| > 0,
\ 0 при 0=0.
Таким образом, при п —> оо для |0| > 0 и 0 = 0 соответственно имеем
Св (Ж - 0)) —> Х(0, 1), Го Тп) ЛГ(О, Ь2)
или Cs(Tn) ~ Л{(0, От(0)/п), где
, ( 1 при |0| > 0,
<т|(0) = <<
[ Ъ2 при 0 = 0.
Следовательно, ее асимптотическая эффективность (14) § 3.2 (см. табл. 1 § 3.2)
есть
1 ( 1 при |0| > 0,
} 0т(б) Ъ~2 при 0—0.
При |&| < 1 еа(Тп; 0) > 1 со строгим неравенством в точке 0 = 0, т. е. Тп —
сверхэффективная оценка. Причина этого заключается в данном случае в на-
рушении непрерывности функции а|(0) в нуле.
Точки 0, в которых е0(Гп; 0) > 1, называют тон- п ,
,’ Д " ' Сверхэффективная
ками сверхэффективности. В рассматриваемом примере
это точка 0 = 0. Как показал Ле Кам (1953) множество
точек сверхэффективности не более, чем счетно, поэтому явление сверхэф-
фективности не играет существенной роли в теории оценивания. Известны
также дополнительные условия регулярности на статистическую модель, ко-
торые исключают это явление. Так, С. Р. Рао доказал, что для этого достаточно
потребовать равномерности по параметру 0 в предельном соотношении
Г«(ТВ)~Х [т(0),-^- , V 0 6 О.
\ п /
234 Глава 3. Теория оценивания неизвестных параметров распределений
Приведем пример, иллюстрирующий роль свойства регулярности модели:
при его нарушении о.м.п. не являются асимптотически нормальными. •
Пример 11 (Равномерная модель, распределение о.м.п. ее параметра).
Пусть X = (Л"1, , Хп) — выборка из распределения W(0, в). Тогда о. м. п.
вп = Х(п), а как было показано в §2.4, экстремальные значения выборки
не являются асимптотически нормальными. В частности, в рассматриваемом
случае, из примера 6 §2.4 имеем (поскольку £в(£/в) = Л/(О, 1))
В заключение этого пункта применим изложенную теорию о. м. п. к по-
линомиальной модели Af(n;pi,... ,рц) (см. примеры 10 в §3.2 и 8 в §3.3).
Пример 12 (Полиномиальная модель, о. м. п. для нее). Здесь функция прав-
доподобия
N
£(0) = Пр?’ ^ = (Рь - -PW-1).
1=1
поэтому уравнения правдоподобия имеют вид и./р,- - vn/Pn = 0, i = 1,. .,
JV-1. Они определяют единственное решение р, = Vi/n, i = l,...,7V-l,
максимизирующее функцию правдоподобия, следовательно, о. м. п. вп =
= {у\/п, , J/AT-i/n), т. е. выражается через полную достаточную статистику
(j/j, , ^-i) (см. пример 8 в §3.3). Подчеркнем, что о. м. п. вероятностей р;
являются относительные частоты ь^/п. реализаций соответствующих исходов
в п испытаниях. Информационная матрица модели вычислена в примере 10
в §3.2, где также указана обратная к ней матрица Еу_|. В данном случае все
условия регулярности выполняются, следовательно, по теореме 2
£# (х/п(0п ~ #))—> A/"(0, Еу_|) при п -> оо, (27)
или
( . Vi- пр, \
Ce(v*= '—г- i = 1,-. ,N- 1 —>V(0, Ew_|).
\ Vn /
Этот результат есть центральная предельная теорема для полиномиального
распределения М(п;р\, ,р^), сформулированная в упр.33 к гл. 1. •
5. Асимптотические доверительные интервалы,
основанные на о.м.п.
Основное значение утверждения теоремы 2 об асимптотической нормально-
сти оценок максимального правдоподобия состоит в том, что оно позволяет
сконструировать универсальный алгоритм построения доверительных интер-
валов и доверительных множеств (в случае векторного параметра) как для
самого параметра модели, так и для произвольных достаточно хороших пара-
метрических функций. С подобной задачей мы уже встречались в п. 5 §2.2,
§ 3.5. Оценки максимального правдоподобия
235
где на основании теоремы об асимптотической нормальности выборочных мо-
ментов и функций от них были построены асимптотические доверительные
интервалы для теоретических моментов и функций от них. Общее определе-
ние 7-доверительного интервала для заданной теоретической характеристи-
ки наблюдаемой случайной величины дано в (26) §2.2. Когда мы работаем
в рамках параметрической модели Т7 = 6 6 6}, то оно конкрети-
зируется следующим образом: 7-доверительным интервалом для параметри-
ческой функции т(0) называется такой случайный интервал Тг(-^)),
Т\ <Ti, который удовлетворяет условию
Р«{71(Х) <т(0) <72(Х)}^7, V0G0. (28)
Расчет таких интервалов на основе теоремы 2 (в этом случае мы будем говорить
об асимптотических доверительных интервалах) осуществляется по той же
схеме, что и в п. 5 §2.2. Именно, на основании (22) имеем, что при п -> оо
и всех в
р f x/^kn т(61)| < Д > ф^) _ ф(_^ = 2ф^) _ 1 = 7>
I <Гт(вп) J
Асимптотический дове-
если Су —• Ф '((1 + 7)/2). Переписав это соотно- рительный интервал:
шение в виде общее решение
р Г?п _ < т(е) < + с^Ж) 1 (29)
I vn Vn )
получим, что (?п т с^(хт(вп)1 у/п) и есть искомый асимптотический 7-дове-
рительный интервал для т(0). Центр этого интервала находится в случай-
ной точке тп = т(0п), являющейся о. м. п. для т(0), и он имеет случайную
длину 2Су<тт(вп)/у/п. При этом, поскольку тп — асимптотически эффектив-
ная оценка т(&), то построенный интервал будет асимптотически кратчайшим
среди всех подобных интервалов, порождаемых аналогичным образом други-
ми состоятельными и асимптотически нормальными оценками функции т(0).
Выделим также представляющие самостоятельный интерес частные случаи об-
щего результата (29).
Если 0 — скалярный параметр, то из (23) еле- Асимптотический дове-
дует, что асимптотически кратчайшим 7-довери- рительный интервол:
тельным интервалом для него является интервал скалярный параметр
5.+ -^1 <, = ф-'(4к (30)
у/пг(вп) y]ni(0ny х 7
Более того, если т(0) — непрерывно дифференцируемая функция и
то (jn F с-[Т'(0пУу ni(0n)) — аналогичный интервал для т(0).
т\е) * о,
236 Глава 3. Теория оценивания неизвестных параметров распределений
Преобразование,
стабилизирующее
Если функция т выбрана так, что
дисперсию
т'(0) _
—-----= а, = const,
vf)
ИЛИ
d(9,
(31)
т
то в этом случае асимптотическая дисперсия о. м. п. тп не зависит от неиз-
вестного параметра (такую функцию называют преобразованием, стабилизиру-
ющим дисперсию) и вид соответствующего интервала значительно упрощается:
(тптф аСу/^/п), т. е. он имеет фиксированную длину. Так как функция т мо-
нотонна (ведь т (в) / 0), то неравенства
тп-а^<т(е)<тп + а^
у/п у/п
можно разрешить относительно в и получить 7-доверительный интервал для
самого параметра в. Например, если т'(0) > 0, то
(32)
где г-1 — обратная функция к т Использование таких интервалов в ряде слу-
чаев предпочтительнее, нежели (30).
Продемонстрируем эти общие принципы примерами.
Пример 13 (Общая нормальная модель, доверительный интервал для тео-
ретической функции распределения). Построим приближенный (асимпто-
тический) доверительный интервал для параметрической функции т(0)
= Ф((:ео-#1)/02) в модели ЛТ(0\, 0\) (см. (7)). О. м. п. тп указана в примере 5,
поэтому нам достаточно вычислить величину cj]-(0) в (21). Информационная
матрица нашей модели вычислена в примере 9 в § 3.2 (соотношение (25)).
Используя этот результат находим
Ао)=
дт(е)\2 w)\l_ 1
д0\ J 2\ 502 у Г2 2тг
, , (zo-01)2'
202
(х0 —)2 )
% /
Итак, искомый 7-доверительный интервал есть
(г(0п) + ^Ы\
\ V п J
где 0п = (0in, 02n) = (A, S). •
Пример 14 (Доверительный интервал для параметра модели степенного
ряда). Функция информации ?(0) для этой модели вычислена в примере 9.
Используя этот результат и общее соотношение (30), имеем для искомого
асимптотического 7-доверительного интервала для 0 представления
0п
пр.'(0п)
0п \
a(0n)Vn7
(33)
§ 3.5. Оценки максимального правдоподобия
237
где вп — решение уравнения д(0) = X, а и а2(0) — теоретические
среднее и дисперсия соответственно. •
Пример 15 (Пуассоновская модель, доверительный интервал для параметра).
Поскольку пуассонвская модель является моделью типа степенного ряда и для
нее д(0) = а2(0) = в, то из (33) имеем, что в данном случае асимптотиче-
ский 7-доверительный интервал для 0 есть ^Х т Х/п ) Далее, урав-
нению (31) удовлетворяет здесь функция т(9) = VH при а 1/2 (ведь
i(0) = см. табл. 1 §3.2), а соответствующий интервал для нее есть
(г/х т Су/(2-\/п))- Отсюда по формуле (32) получаем другой доверитель-
ный интервал для 6'.
(и-е^У и+ауу
который совпадает с предыдущим, если пренебречь членами порядка п •
Пример 16 (Геометрическая модель, доверительный интервал для пара-
метра). Оценим параметр 0 геометрической модели Bi(l, 6). Это также мо-
дель типа степенного ряда, поэтому применимо общее решение (33). Здесь
(см. (7) § 1.1) = 0/(\ - в), <т2(0) = 0/(1 - 0)2 решением уравнения
правдоподобия д(0) = X является о. м. п. 0П = Х/( 1 +Х), поэтому искомый
7-доверительный интервал имеет вид
V” Т ‘ вп) У п) ~ ( 17J Т n(l+X)J
Пример 17 (Бернуллиевская модель, асимптотический доверительный ин-
тервал для параметра). В рассматриваемом случае о. м. п. 0„ = X и функция
информации i(6) = [0(1 - 0)]-1 (см. табл. 1 §3.2), поэтому из (30) имеем,
что (хТсгХ/х(1 -Х)/п) — асимптотический 7-доверительный интервал
для 6 Решением уравнения (31) является здесь функция т(0) = arcsin У0 при
____________________________________________________________ Су \
т(Х) 4= —-=. )
1у/п )
Если воспользоваться соотношениями (32) и при этом пренебречь членами
порядка п"1 то получим предыдущее решение
проверить читателю самостоятельно).
В случае векторного параметра 0 = (0),... ,0Г) Доверительные области:
может представлять практический интерес довери-
тельное оценивание самого этого вектора. В этом
случае нужно указать такое случайное (т.е. зависящее от выборки X) под-
множество С/7(Х) в параметрическом множестве 0 рассматриваемой модели,
для в (это мы предлагаем
многомерный параметр
238 Глава 3. Теория оценивания неизвестных параметров распределений
которое накрывает истинное значение неизвестного параметра 0 с вероятно-
стью, не меньшей заданногодоверительного уровня 7, т. е. чтобы выполнялось
соотношение, аналогичное (28):
Pff{0 <= G7(X)} 7, vote. (34)
Такое подмножество <у7(Х)С© называется 7-доверительной областью для 0.
В случае регулярных моделей, удовлетворяющих условиям теоремы 2, для
больших выборок легко построить приближенные доверительные области,
основанные на оценках максимального правдоподобия. Для этого надо вос-
пользоваться следующим утверждением, представляющим собой асимптоти-
ческий вариант результата, сформулированного в упр. 40 к гл. 1 (см. также
Замечание в п. 2 § 2.5): если для fc-мерного случайного вектора £ выполняет-
ся асимптотическое (при п -з оо) соотношение £(£ ) ~ jV(/z , £п) и |Sn| / 0
при всех п, то
Л (35)
В силу этого утверждения из (20) имеем, что квадратичная форма
Qn(0) = п(0п - 0)1(0)(0п - 0) (36)
при всех 0 имеет предельное при п —> оо распределение Х^(Т)- Более то-
го, если информационная матрица 1(0) непрерывна по 0, то на основании
утверждения 4° можно заключить, что в (36) 1(0) можно заменить на 1(0п)
с сохранением при этом формы предельного распределения. Итак, при вы-
полнении указанного условия имеет место предельное соотношение
£в (& W = П(0п - 0)'1(0п)(0п - 0)) —> х2(г). (37)
Пусть, как обычно, х7,г обозначает 7-квантиль распределения %2(г). Тогда
из (37) имеем, что при п -> оо
Pe{Qn(e)^Xy.r} (38)
Определим теперь область G7(X) С 0 условием
S7(X) = {0 Qn(0)^Xy.r} (39)
Это есть некоторый случайный эллипсоид с цен-
тром в точке 0п и, по построению, при п -> оо
р«{0 е 5у(Х)} = PjQn(0) Ху.г} 7,
т.е. Gy(X) есть асимптотическая 7-доверительная область для 0
Пример 18 (Доверительная область для параметров полиномиальной мо-
дели). Если в полиномиальной модели М(п; р\, ,Pn), 0 = (pi, • • ,Рдг-1),
число испытаний п велико, то для одновременного оценивания неизвестных
Асимптотический дове-
рительный эллипсоид для
параметра регулярной
модели
§ З.б. Другие методы и принципы построения оценок
239
вероятностей р, можно воспользоваться изложенной асимптотической теори-
ей. Все предварительные вычисления нами уже проведены в примере 12 и при-
мере 10 в §3.2, используя которые вычисляем квадратичную форму в (37):
N-] У-1
Qn(9) = n^2(pi- Pi)(Pj - р.))р„ + n - Pi)2p~l =
rj— 1 1=1
rtf-I -12
N-l, p N . v
= Li = l_______£ y- O'» - npi) = y- - npi) (40)
vn Vi h
При этом параметр г в (37) равен здесь N— 1. В результате искомая область (39)
может быть записана в виде
( N ( - V N 1
P7(X) = G-ylv) = s (pi, ,Pn) 52---------~Хт.у-ь 52?» = 1 r•
* i=i Vi i=i J
(41)
Эта область представляет собой пересечение N-мерного эллипсоида с центром
в точке v = (нь , i/jv) с гиперплоскостью р\ + + р^ = 1 •
Если N = 2, то речь идет об оценивании параметра бернуллиевской
модели В1(1, 0) по п испытаниям, и легко видеть, что область (41) сводится
к интервалу, построенному в примере 17. •
§ З.б. Другие методы и принципы построения оценок
Правильно в философии рассматривать сходство
даже в вещах, далеко отстоящих друг от друга.
Аристотель
Кроме рассмотренных в предыдущих параграфах общих подходов для оцени-
вания неизвестных параметров распределений на практике используют и дру-
гие методы построения оценок. В настоящем параграфе мы лишь кратко
затронем соответствующие проблемы, чтобы показать их многообразие и од-
новременно расширить горизонты для читателя.
1. Метод моментов
Исторически первым общим методом точечного оценивания неизвестных па-
раметров является метод моментов, предложенный К. Пирсоном (1894). Суть
этого метода состоит в следующем.
Пусть, как обычно, X = (X),..., Хп) — выборка из распределения
£(£) Е J- = {F(x, 0), 0 Е 0}, где 0 = , дг) и 0 С Rr Предположим,
51 Аристотель (384-322 гг. до н.э.) — древнегреческий философ, ученый-энциклопедист.
240 Глава 3. Теория оценивания неизвестных параметров распределений
что у наблюдаемой случайной величины £ существуют первые г моментов
а* = Е£а к = 1, , г Они являются функциями от неизвестных парамет-
ров 9: ак = ак(9). Рассмотрим соответствующие выборочные моменты ак
(см. п. 1 §2.2) и составим систему уравнений относительно 9:
ак(9) = ак, fc=l,. ,r (1)
Предположим, что эта система однозначно разрешима и обозначим ее реше-
ние 9i = 9j(X) = , аг),г = 1, , гТогда01, , 9,- и есть оценки
, 9Г по методу моментов. Если функ-
, г, непрерывны, то из состоятельно-
параметров 9<,
Ж Оценки по методу ,
' ции с?., г = 1, ,. ,__________,_________________
моментов 'fac, .
сти выборочных моментов (см. п. 3 §2.2) по теореме 1
§2.2 следует, что статистики 9^(Х) являются состоятельными оценками 0<:
при п —> оо
~ р
0t(X)—,аг) = 9{, i=l,.. ,r
Таким образом, метод моментов при определенных условиях приводит к со-
стоятельным оценкам; при этом уравнения (1) во многих случаях просты
и их решение (в отличие, например, от метода максимального правдоподо-
бия) не связано с большими вычислительными трудностями.
Пример 1. Пусть £(£) € #(0), 9%). Здесь «i = Е£ = 9}, 9\ = D£ = а2 - а],
поэтому 0, = а, = X, 02 = ^/<?2 _ <*i = S, т. е. (0j, 02) совпадает с оценками
максимального правдоподобия (01,0г) = (X, S) (см. пример 1 §3.5). •
Пример 2. Пусть £(£) € Z/(0|,02). Здесь
0] +02 9j + 0,02 + 9%
«1 = -------, а2 = ----------------
2 3
и система (1) имеет решение 9\ = А - х/З S, 02 = А + х/З S. Эти оценки
не являются функциями достаточной статистики (Ар), A(nj) (см. пример 3
§ 3.3), поэтому они мало эффективны. •
Пример 3 (Гамма-модель, оценивание параметров методом моментов). Пусть
£(£) £ Г(0!,02) (см. п.З § 1.2). Здесь 0 = {0 = (0,,02) 0, > 0, г = 1,2}
и ак — 0fT(02 + fc)/r(02) = 0f02(02 + l) (92 + k- 1), в частности, ац = 9}92,
а2 = 9]92(92 + 1). Система (1) имеет здесь решение
Ш) =
02 -
5|
&
X'
02(A) =
«2 - а]
А2
Гамма-модель с двумя незвестными параметрами весьма сложна для анализа
какими-нибудь другими известными нам методами, метод же моментов быст-
ро приводит к простым формулам для оценок ее параметров. •
Отметим, что метод моментов неприменим, когда теоретические моменты
нужного порядка не существуют (например, для распределения Коши). Кроме
того, оценки метода моментов, вообще говоря, мало эффективны, поэтому
§ 3.6. Другие методы и принципы построения оценок
241
их обычно используют лишь в качестве первых приближений, основываясь
на которых можно находить последующие приближения с большей эффек-
тивностью.
2. Метод минимума хи-нвадрат
Систему различных методов построения оценок можно получить, констру-
ируя тем или иным способом меру D отклонения эмпирической функции
распределения Fn(x) от F(x; 0) — истинной (но неизвестной) теоретической
функции распределения выборки. В любом случае такая мера является функ-
цией от выборки (данных) X и неизвестного параметра 0: D = D(X\ 0). Если
такая мера сконструирована, то в качестве оценки параметра 0 естественно
взять значение, минимизирующее меру D: 0(Х) = arg min D(X; 6).
е
Одной из наиболее известных таких мер является предложенная К. Пирсо-
ном мера хи-квадрат. Эта мера конструируется следующим образом. Разобьем
множество 8 возможных значений наблюдаемой случайной величины 4 на N
непересакающихся подмножеств («интервалов»)
8lt...,8N (£ = £|U. Ufjy, f,n£j=0, i^f),
и пусть Vj — число элементов выборки X = (А),..., Хп), попавших в ин-
тервал Ef.
Vj = '^I{Xie £j), j = (p, + + vN = n).
1=1
Обозначим, далее, через Pj(O) теоретическую вероятность попадания в £j‘.
= = f dF(x-,0), (p,(0) + ...+pN(0) = l).
4
Поскольку относительная частота Vj/n попадания в интервал Ej явля-
ется состоятельной оценкой вероятности Pj(O), то одной из возможных мер
отклонения эмпирических (выборочных) данных от теоретических значений
может быть мера
х / \2
D = ^cj\T -PjW)
j=i х 7
где С[, ,C/f — некоторые «веса».
Если здесь положить «веса» Cj = n/pj(0), то мы и получим меру хи-квад-
рат:
N , \2 N / „2
2 = y-_l_f^._p (рЛ = Х~" j - -П. (2)
~fp#)\n 1 / nP;W “fnPjW
Выбор именно таких «весовых» коэффициентов в D оправдан тем, что, как это
будет показано позже (см. п. 2 и 3 §4.2), полученная при этом мера хи-квад-
рат (2) обладает следующим замечательным свойством: ее асимптотическое
16 Заказ 1748
242 Глава 3. Теория оценивания неизвестных параметров распределений
распределение для больших выборок (при п —> сю) зависит лишь от числа N
интервалов (подмножеств) разбиения и является стандартным распределени-
ем хи-квадрат.
Оценка по методу Оценку 0, полученную из условия обращения меры
минимума х2 %2 в МИНИМУМ’ называют оценкой по методу минимума
у2 При достаточно общих условиях эта оценка оказы-
вается состоятельной, асимптотически нормальной и асимптотически эффек-
тивной (как и оценка максимального правдоподобия).
Для нахождения указанной оценки надо решить систему уравнений
1=ь г Л))-
Однако это трудно сделать даже в простейших случаях, поэтому, учитывая,
что
эту систему обычно заменяют более простой системой
у-к Uj dpj(O)
PjW 90k
(3)
k = I,. , r,
решение которой находить, как правило, гораздо проще. Оценки парамет-
ров 0, получающиеся как решение системы (3), называют оценками по видо-
измененному методу минимума *2; Для больших выборок их асимптотические
свойства остаются такими же, как сказано выше.
Замечание. В описанном методе оценивания параметров используются не сами на-
блюдения Х|,..., Хп, а лишь частоты и = (izb ..., vN) попадания элементов вы-
борки в соответствующие подмножества Е....EN Такой «частотный» способ пред-
ставления статистических данных называют методом группировки наблюдений, а под-
множества £\,... , £ц — подмножествами (или интервалами) группировки. При этом
распределение вектора частот и = (izh ..., vN) является, очевидно, полиномиальным
распределением М(п; Р\(9), ,Рк(@)) (см. п.6§ 1.1). В этом контексте вероятность
1 N
Рв{и = Л} = Lw(h; 9)= П р^(9), Л,+ +hN=n, (4)
Л,! .. .Лдг!
называют частотной функцией правдоподобия в методе группировки наблюдений (в от-
п
личие от обычной функции правдоподобия L(x; 9) JJ/(z,;0)). Если искать
1 = 1
оценку параметра 9 по методу максимального правдоподобия, основываясь на функ-
ции L^(h;, 9), т. е. искать ее точку максимума, решая систему уравнений
д In Lw(h; 9)
—ST-'"- *='..................'
то, как легко видеть, эта система сводится к системе (3).
§ 3.6. Другие методы и принципы построения оценок
243
Определение
3. Модально несмещенные оценки
До сих пор мы в основном рассматривали несмещенные оценки, т. е. такие
статистики <5(Л'), которые удовлетворяют условию (если оценивается сам па-
раметр 9)
е9<5(х) = 0, vflee.
В силу того, что математическое ожидание случайной величины часто на-
зывают средним значением, несмещенную оценку <5(Л') называют также не-
смещенной в среднем. Однако в статистике используются и другие понятия
несмещенности, в частности, модальной несмещенности и медианной не-
смещенности, в основе определений которых лежат такие характеристики
статистической оценки, как соответственно мода и медиана. Их мы кратко
и обсудим в этом и следующем пунктах. Остановимся сначала на понятии
модальной несмещенности.
Пусть X — случайная величина с плотностью f(x),x(z Я1. Любая точка
максимума функции f(x) называется модой случайной величины X (ее закона
распределения). Если плотность зависит от параметра: f(x) = /(т; в), в € 0,
то и мода, вообще говоря, зависит от 9. Если мода единственна, то распре-
деление величины X называют унимодальным. Унимодальные распределения
играют важную роль в теории вероятностей и математической статистике.
Примерами таких распределений являются нормальное, показательное, Пуас-
сона, Коши и др. распределения.
Пусть оценка 8(Х) параметра 9 имеет унимодальное рас-
пределение и и(0) (каппа от тэта) — его мода. Если к(9) = 9 при всех
9 G 0, то 8(Х) называется модально несмещенной оценкой параметра 9.
Такие оценки могут оказаться предпочтительнее других при некоторых
функциях потерь. Здесь уместно сделать общее замечание о терминологии,
используемой в общей теории оценивания. В этой теории при выборе крите-
рия качества (или точности) оценки исходят из некоторой неотрицательной
функции L(5, 9), измеряющей расхождение между параметром 9 и его оцен-
кой 6 = 8(Х) — такая функция называется функцией потерь. Средние потери
Е^£(<5,9) = R(8,9) называются функцией риска (или просто риском) оценки 5,
и риск является мерой точности оценки. Если £(<5, 9) = (8 — 0)г, то говорят
о квадратичной функции потерь, тогда квадратичный риск R(8, 9) = Eg(6 - 9)2
есть среднеквадратичная ошибка (с. к. о.). Иногда используются и другие
функции потерь, например, L(8,9) = |<5 - 0| или L(8,9) = (1 - 8/9)1, или
L(8,9) = (8~1 -9~')2 и т.д.
Пример 4. Пусть X = (Хь , Хп) - выборка из Примеры модально
нормального распределения Ф/\9,<т2). В качестве несмещенных оценок
оценки для 9 возьмем оптимальную несмещенную
оценку 6(Х) = X. Поскольку Cg{X) = Л/\9,сгг/п), а нормальное распре-
деление является унимодальным, причем его мода х(9) совпадает с матема-
тическим ожиданием 9, то в данном случае х(9) = 9 при всех 9 и потому
Тб*
244 Глава 3. Теория оценивания неизвестных параметров распределений
обычная несмещенная оценка X является здесь одновременно и модально
несмещенной оценкой 9. •
Пример 5. Пусть X = (Xb ..., Хп) — выборка из равномерного распределе-
ния U(О, О'). Покажем, что статистика б(Х) = Х^ — максимальное значение
м g. выборки — является модально несмещенной оценкой
параметра 9. Плотность статистики следует из об-
/ щего соотношения (13) § 3.4 при а = О, Q\(9) = \/9,
/\ М\ (г) = 1 (см. пример 3 в § 3.4) и имеет вид
X 1 Tltn~ ।
______I V
о 9 t Так как(см. рис. 1) прилюбом 9>0 функция p(t; 9)
Р(1с * имеет единственный максимум в точке х(0) =9, то ста-
тистика Z(nj является модально несмещенной оценкой
для 0. Для сравнения напомним (см. пример 3 в §3.4), что оптимальной не-
смещенной оценкой для 9 является статистика 9* = ((п + 1)/п)Х(п). •
Пример б (Показательное распределение, модально несмещенная оценка
параметра). Пусть X = (Zb , Хп), п 3 — выборка из показательного
распределения Г(0, 1) (см. п.З § 1.2). Рассмотрим статистику
дс(Х) = c^Xi, с>0.
i=i
Из свойств гамма-распределения имеем, что
£в&(Х)) = Г(с9, п),
т.е. плотность статистики 6С(Х) есть (см. (18) § 1.2)
Xn-ie-x/ce
f(x\c9, п) = —, , х 0.
J 1 ’ Г(п)(с9)"
Здесь функция f(xjc9, п) имеет при любом 0 единственный максимум в точке
х = x(fl) = с9(п - 1), следовательно, при с = 1/(п - 1) статистика
1
'>•(*) = V. = —у V X.
3=1
будет модально несмещенной оценкой 9.
Мы_знаем, что при квадратичной функции потерь несмещенная в среднем
оценка X является оптимальной несмещенной оценкой для 9 (см., например,
табл. 2 в § 3.2). Сравним теперь риски этих двух оценок, Vn и X, относительно
функции потерь L(6,9) = (d-1 - fl-1)2 Используя формулы для моментов
гамма-распределения (см. п. 3 § 1.2), нетрудно получить (это мы оставляем
читателю в качестве упражнения), что
/ 1 1\2 п + 2
вд«) = е,(=-5)
§ 3.6. Другие методы и принципы построения оценок
245
/1 1 \2 1
ад.» = £,(---)
Отсюда имеем R(Vn, в) < R(X, 9),\/9 > 0, т. е. при такой функции потерь мо-
дально несмещенная оценка имеет равномерно меньший риск, нежели оценка,
несмещенная в среднем. •
4. Медианно несмещенные оценки
Определение медианы для произвольного распределения F было дано в п. 1
§ 2.4 — это р-квантиль при р = 1/2. Пусть X = (Xi,..., Хп) — выборка
из распределения с плотностью f(x;0), 9 6 0, и пусть — некоторая
оценка параметра 9. Обозначим ее медиану т(9).
В таком случае, если
т(9) = 9 при всех 9 Е 0,
то статистика 6(Х) называется медианно несмещенной оценкой 9.
Пример 7. В условиях примера 6 рассмотрим ста- Показательное
тистику — минимальное значение выборки. распределение-
Ее плотность по формуле (6) §2.4 имеет вид оценивание параметра
pi(a;;0) =z^O,
и
поэтому, решая уравнение
X
\= j Shfr 9)dt=l- e~nzle
о
найдем медиану
т{9) — -9 In 2.
п
Следовательно, статистика 5(Х) = п.У(|)/(1п 2) является медианно несмещен-
ной оценкой 9. Найдем распределение этой статистики. Так как (см. (18) § 1.2)
(л \ / л \
-,1 , то £,(<?(*)) = Г — ,1 ,
71 / \ 1П 2 /
т. е. распределение 6(Х) от п вообще не зависит и потому ее с. к. о. не схо-
дится к 0 при п -> оо, более того, <5(Х) вообще не является состоятельной
оценкой. •
Разницу между различными понятиями не- Гамма-модель
смещенности можно проиллюстрировать на при- оценивания параметра
мере гамма-модели Г(0, А) (см. п. 3 § 1.2). Если
рассмотреть статистику Т(Х) = Х} 4-... + Хп, то, так как Cg(T(X)) = Г(9,пА),
ее плотность есть
*пА-1
246 Глава 3. Теория оценивания неизвестных параметров распределений
График этой плотности, а также мода х, медиана т и среднее значение
ЕТ изображены на рис.2. Здесь ЕЙТ = пХ0, т.е. Т/(пХ) — несмещенная в
dg(t;0)
среднем оценка 0. Мода к статистики Т находится из уравнения —-—=0
at
и равна 0(пХ - 1), откуда следует, что модально несмещенной оценкой пара-
метра 0 будет статистика <5(2Г) = Т/{пХ - 1). Медиана же тп статистики Т
является корнем уравнения
m тп/0
—1— [ dt = *-, или -Ц f dt =
Г(пА)0пА J 2’ Г(пА) J 2
о о
Отсюда следует, что тп пропорционально 0: тп = 0А(пХ), где А(пХ) — кон-
станта, не зависящая от 0, следовательно, медианно несмещенной оценкой 0
будет статистика <51 (X) — Т/А(пХ).
5. Эквивариантные оценки
В некоторых случаях класс рассматриваемых оценок параметра 0 разумно
ограничить заранее некоторым условием инвариантности относительно того
или иного преобразования данных. Рассмотрим, например, задачу оценивания
4^ Параметр сдвига:
эквивариантная
оценка
параметра сдвига, т. е. когда плотность наблюдаемой
случайной величины 4 имеет вид f(x\0) = fix — 0),
где / — известная функция (здесь х 6 R1 0 6 Я1).
В этом случае для любой константы с
¥»{Xt + с^х}= Р»{Х, х - с} =
х-с X
J f(t-0) dt = J f(u-c-0) du = Pe+c{Xi х}.
-ОО -оо
Поэтому разумно рассмотреть в качестве оценок параметра 0 статистики
Т = Т(Х{,... ,Х„), инвариантные относительно сдвига, т.е. удовлетвори-
§ 3.6. Другие методы и принципы построения оценок
247
ющие условию
Т(Х} + с, , Хп + с) = Т(Х) + с. :(5)
Оценки параметра сдвига в, удовлетворяющие условию (5), называются эк-
вивариантными оценками.
Легко видеть, что статистики Ti(A’) = X и Ti(X) = \/2{Х^ 4- Х^)) яв-
ляются эквивариантными оценками параметра сдвига в. Действительно, для
любого числа с
1 ” _
Т^Ху + с,...,Хп+с) = - + с) = X 4- с = Т\(Х) 4- с,
п 1=1
ВД + с, ,Хп4-с) = ^((Х(1) + с) + (Х(п) + с)) =Т2(Х)+с.
Статистики же Гз(^Г) = S2 и Т-(Х) = Х(п) — условию (5) не удовлетво-
ряют.
Покажем теперь, что с. к. о. = Ее(Т(Х) - в)2 любой эквивари-
антной оценки Т = Т(Х) не зависит от оцениваемого параметра сдвига в.
Действительно,
R(T,0) = / (Тф-0)2П/(а:>-0)</г =
J 1=1
/П . п
T2(xi-0,...,xn-ff)Y[f(xl-9')dx= / Г2(д) JJ/(z1)dz = 7?(r,()).
i=i i=i
В свете этого представляется естественным в качестве оценки параметра сдви-
га выбрать такую эквивариантную оценку Г, которая минимизирует с. к. о.
R(T, 0) в классе всех эквивариантных оценок параметра сдвига в. Такая оцен-
ка, называемая оценкой Питмена, существует и имеет вид Оценка Питмена ”
Г "
J еЦ/(х,-е)<ю
< = —Hr2------------• (6)
J П /(Z, - 6) de
Таким образом, оценка Питмена (6) является наилучшей в смысле минимума
квадратичного риска (с. к. о.) несмещенной эквивариантной оценкой пара-
метра сдвига 6.
Пример 8 (Оценка Питмена для среднего нормального распределения).
Пусть £(£) G 1), т.е. f(x;9) = __е_(т-9)/2 Здесь неизвестный пара-
у2тг
метр (среднее) является параметром сдвига, поэтому оценка Питмена (6) для
248 Глава 3. Теория оценивания неизвестных параметров распределений
него есть
пд2 —
---+ п0Х
2
dO
пв- _
---+ п0Х
2
de
00
I 0ехр{-у(0-Т)21(М
dd
т. е. совпадает с выборочным средним X, которое является эффективной
оценкой 6 (см. табл. 2 §3.2). •
Пример 9 (Оценка Питмена для параметра сдвига равномерного распреде-
ления). Пусть X = (Т|, .., Хп) — выборка из равномерного распределения
Щ9 - 1 /2,0 + 1 /2), т. е. здесь f(x\ 0) = /(0 - 1 /2 х 0 + 1 /2) = /(-1 /2 sj
х — 0 1/2), следовательно, в является параметром сдвига. Поскольку
п / 1 1 \
nw;«)=4-j ^хт~е^х(П)~е^ =
1=1 ' '
= /{х(п)~О^Х(1) + 0, (7)
то оценка Питмана (6) принимает здесь вид
Х(„)-1/2
т. е. совпадаете несмещенной оценкой максимального правдоподобия 0 (из (7)
следует, что любое 6 € [Т(П) - 1 /2, Т(|) + 1 /2] максимизирует функцию прав-
доподобия, а средняя точка этого интервала (8) в силу упр. 46 к гл. 1 является
несмещенной оценкой 0). •
§ 3.6. Другие методы и принципы построения оценок
249
Замечание. Можно показать, что оценка Питмена (6) может быть получена по фор-
муле
о; = Т(Х) - Ео(Т(Х)|У),
где Т(Х) — произвольная эквивариантная оценка, У = (X, - Х„,... ,ХП^ - Хп)
и Ео — символ математического ожидания Ев при 0 = 0; при этом вид оценки 0*
от выбора Т(Х) нс зависит.
Рассмотрим теперь аналогичный подход в за- МЕГ "Оценивание
даче оценивания параметра масштаба, т.е. когда |^>аметра масштаба
теоретическая плотность имеет вид ®
(7 \ ^ /
0 > 0 — неизвестный параметр масштаба, a f — известная функция. В этом
случае для любой константы с > 0
х/с
Pe{cXi i} = | j = У /(£; 0) dt =
-оо
х/с X
Г 1 / < \ Г \ f и\
= J 9f\e) dt = J du = pd>{Xi^x},
-oo -oo
т. e. изменение масштаба измерения данных в с раз эквивалентно в данном
случае изменению параметра в с раз. Поэтому в задаче оценивания парамет-
ра 0 для таких моделей разумно рассматривать в качестве оценок статисти-
ки, инвариантные относительно изменения масштаба, т.е. удовлетворяющие
условию
Т(сХ) = Т(сХ1,...,сХ'„) = сТ(Х). (9)
Статистические оценки параметра масштаба 0, удовлетворяющие условию (9),
также называются эквивариантными оценками.
Примерами таких статистик являются X, S, (Хщ + Х(2))/2. В задачах
оценивания параметра масштаба естественной функцией потерь является
Ь(Т,0) = 1(Г-0)2 = (J-1) (10)
Таким образом, если измерять качество оценок с помощью функции риска
Я(Т,0)= (^Е,(Т-0)2
которая представляет собой нормированную с. к. о., то оптимальная (т.е.
минимизирующая эту меру точности) эквивариантная оценка параметра
250 Глава 3. Теория оценивания неизвестных параметров распределений
Оценка Питмена
параметра масштаба
масштаба в, называемая также оценкой Питмена,
существует и имеет вид
е
Пример 10 (Оценка Питмена для параметра масштаба равномерного распре-
деления). Пусть X (Л'ь , Хп) — выборка из распределения W(0, в),
в > 0, т. е.
1 1 / х \
/(z; 0) = -1(0 х 9) = -I 0 1
и и \ и /
Здесь f(x) = /(0 х 1) — равномерная плотность на [0, 1] и
= /(Х{п) 9).
Поэтому по формуле (11) находим, что оценка Питмена для параметра 9 есть
(12)
Мы знаем (см. пример 5), что наилучшей несмещенной оценкой 9 относи-
тельно квадратичной функции потерь L(T, 9) = (Т — 9)2 является статистика
((п+1)/п)Х(п). Поэтому оценка Питмена (12) является смещенной, но она —
наилучшая в классе эквивариантных оценок параметра 9 относительно функ-
ции потерь (10). •
6. Байесовские и минимаксные оценки
В этом пункте мы познакомим читателя с основными элементами весьма по-
пулярного и в то же время неоднозначно воспринимаемого специалистами так
Байесовский подход называемого байесовского подхода (метода) в стати-
стике. Оценки неизвестных параметров распределе-
ний, получаемые этим методом, носят название байесовских оценок. При бай-
есовском подходе предполагается, что параметр 9 изучаемой модели
X = {F(x\ 9), 9 G 0}
— это случайная величина с некоторым распределением на параметрическом
множестве 0, задаваемом плотностью 7г(0). (В таких случаях будем исполь-
зовать одно и то же обозначение 9 как для случайной величины, так и для
§ З.б. Другие методы и принципы построения оценок
251
принимаемого ею значения, полагая, что это не вызо- Аппмлпил»
вет затруднений при чтении). Это распределение £(0) деление параметра
называют априорным распределением параметра и счи-
тают известным. Итак, можно представлять себе, что до начала наблюде-
ний над случайной величиной £ с £(£) € Т7 производится дополнительный
эксперимент, в котором разыгрывается (моделируется) значение случайного
параметра с заданной плотностью тг(0), 0 € 0, и затем уже с полученным зна-
чением 0 моделируется выборка X = (Х|, , Хп) из распределения F(x; 0).
Если мы исходим при оценивании параметра из заданной функции потерь
L(T,0), то мы можем усреднить соответствующий риск R(T, 0) = EgL(T, 0)
оценки Т = Т(Х) по априорному распределению параметра и тем самым
вычислить полную среднюю потерю (усредненный риск) Байесовский риск *
r(T)= f R(T,0)ir(0)d0, (13)
которую мы несем при использовании статистики Т в качестве оценки неиз-
вестного параметра 0 Величина г(Т) в (13) называется байесовским риском.
Таким образом, при таком подходе оценка характеризуется одним числом —
байесовским риском и, следовательно, все оценки могут быть упорядочены
в соответствии со значением этой характеристики. Оптимальной является
оценка Т* минимизирующая байесовский риск г(Т): Байесовская
Т* = arg min r(T); (14)
т
Т* и называется байесовской оценкой для 0. Подчеркнем, что Т* зависит от
выбора априорного распределения тт, поэтому для различных априорных рас-
пределений параметра соответствующие байесовские оценки будут, вообще го-
воря, различны, — в этом состоит основной недостаток байесовского подхода.
Рассмотрим теперь вопрос о том, как практически находить байесовские
оценки Т* Основой для этого служит теорема Байеса, согласно которой апо-
стериорное распределение параметра при наблюдении
X = х задается условной плотностью
Апостериорное 1^
распределение
... , /(*;»>(»)
= —HST
(15)
где
f(x) = E/(i; 0) = J f(x;0)ir(0)d0, или f(x) = /(x; 0i)ir(0i),
i
если 0 принимает дискретные значения {0,}. Тогда байесовская оценка Т* —
это оценка, минимизирующая апостериорный риск
E(L(T,0)\X = х) = [ L(T,0)ir(0\x)d0. (16)
252 Глава 3. Теория оценивания неизвестных параметров распределений
(17)
Сопряженные
априорные
распределения
Действительно, если Е(Д(Т* 0)|Х = ж) Е(£(Т, 0)|Х = ж) , то по формуле
полного математического ожидания
т(Т*) = Е£(Т‘, в) = Е [Е(ЦТ*,0)|X) ] Е [Е (£(Т, 0)|X)] = Е£(Г, 0) = г(Г).
Апостериорное Д'1” слУчая квадратичной функции потерь
среднее параметра цгр е) = (у _ 0)2
байесовская оценка Т* вычисляется особенно просто:
Т* = Е(0|X) = У 0тг(0[Т) d0,
т. е. она совпадает с апостериорным средним параметра.
Это легко следует из цепочки соотношений
Е [(0 - T(Z))2|X] = Е [(0 - Т*(Х) + Т*(X) - Т(Х))2|Х] =
= D(0|X) + (Т‘(Х) - Т(Х))2 D(0|X);
минимум здесь достигается при Т = Т*, и он равен апостериорной дисперсии
параметра D(0|X). Отсюда также следует, что г(Т*) = ED(0|X).
Важную роль в теории байесовских оценок играют со-
пряженные априорные распределения £(0), т.е. когда апо-
стериорное распределение параметра £(0|Х = х) принад-
лежит тому же семейству распределений, что и £(0). При-
меры сопряженных семейств приведены в упр. 64 к гл. 1 (см. также замечание
к упр. 63 гл. 1). Для сопряженных априорных распределений задача вычисле-
ния байесовской оценки (17) значительно упрощается.
Пример 11 (Байесовская оценка вероятности успеха в схеме Бернулли).
Пусть X = (Л), ,Хп) — выборка из распределения Бернулли В1(1,0) и
X = Xt + .. .+ХП — наблюдавшееся, число «успехов». Тогда £а(Х) = В1(п, 0)
и, как мы знаем, оптимальной несмещенной оценкой 0 при квадратичной
функции потерь является статистика Т = Х/п = X (см. табл. 2 §3.2). Пред-
положим теперь, что параметр 0 — случайная величина с априорным распре-
делением типа бета-распределения Ве(а, Ь) (см. п. 4 § 1.2), при этом парамет-
ры а и Ъ считаются известными. Согласно упр. 64 к гл. 1, бета-распределение
Ве(а, &) является сопряженным к семейству бернуллиевских распределений
В1(1,0), и при этом для апостериорного распределения параметра 0 справед-
ливо соотношение
£(0|Х = х) = Ве(а т х, Ь + п - х),
где х = it +.. +хп. Отсюда по формуле (24) § 1.2 имеем, что апостериорное
среднее (17), а тем самым и байесовская оценка параметра 0, есть в данном
случае
а + Х
Т =------------
а + D 4- п
(18)
§ 3.6. Другие методы и принципы построения оценок
253
Если априорная информация об оцениваемом параметре в отсутствует
или байесовский подход вообще неприменим, для построения оценки мож-
но использовать так называемый минимаксный подход, при котором за меру
точности оценки Т принимается максимальное значение ее риска, или мак-
симальный риск,
т(Т) — max R(T, в),
в
Оценка, минимизирующая максимальный риск, назы-
вается минимаксной оценкой 0 и обозначается Т: оценка
Т = arg min(T’). (19)
т
В общем случае вопрос об отыскании такой оценки весьма трудный, но в ряде
случаев она может быть найдена так: предположим, что существует априорное
распределение тг(0) > 0, для которого соответствующая байесовская оценка
Т* имеет постоянный риск: R(T*,0) = а — const. Тогда Т =
Действительно, предположим, что существует оценка Т\, для которой
тп(Т|) < пг(Т^). Очевидно, что для любой оценки Т и любого априорного рас-
пределения тг параметра 0 справедливо неравенство г(Т) т(Т) (см. (13)),
а для оценки Т* здесь имеет место равенство. Отсюда имеем
r(T,)^ m(Ti) <т(Г„)=г(Т;),
что противоречит байесовости оценки 1Д. Следовательно, тп(Т^) т(Т) для
любой оценки Т, и потому Т~ — минимаксная оценка.
Добавим к этому, что такое распределение тг(0)
называется наименее благоприятным априорным рас-
пределение параметра, и оно часто находится в сопря-
женном семействе.
Замечание. Этот термин отражает следующую особенность такого априорного рас-
пределения. Пусть тг' — любое другое априорное распределение и T“i — соответ-
ствующая ему байесовская оценка. Тогда
Г(Т;,)= J R(T;.,0)ir'(0) <№( J R(T',0)ir'(9)d9 = а = т(Т*),
т. е. тг — такое априорное распределение, которое причиняет статистику наибольшие
неизбежные средние потери.
Пример 12 (Минимаксная оценка вероятности успеха в схеме Бернулли).
В ситуации примера 11 вычислим функцию риска, т. е. с. к. о. байесовской
оценки (18). Поскольку эта оценка смещенная (несмещенной является оценка
X/п), то, согласно формуле (5) § 3.1, ее с. к. о. равна сумме квадрата смещения
. а + п0 „а- 0(а +
= Е,Г - 0 =------------0 =-------—
а+о+п а+о+п
и дисперсии
пт* ng(l-P)
6 (a + b + ri)1’
Наименее благопри-
ятное априорное
распределение
254 Глава 3. Теория оценивания неизвестных параметров распределений
т.е.
R(T, 0) = Е9(Г - 0)2 = + . (20)
(a + b + ny
Чтобы получить минимаксную оценку, надо найти такое априорное распре-
деление Ве(а, Ь), для которого эта функция риска не зависит от 0. Из (20)
легко находим, что это имеет место при (а + Ь)2 = п и 2а(а + Ь) = п, т.е.
при а = b — у/п/1. Следовательно, минимаксная оценка в в данной задаче
существует и имеет вид
- X + Уй/2 , ч
Т =-------(21)
п + у/п
а ее риск равен
~ ~ а2 1
Я(Т, 6») = т(Т) = ---------(22)
(в + b + п)2 4п(1 + \/у/п)2
Для сравнения рассмотрим риск оптимальной несмещенной оцен ки Т = Х/п.
Имеем
r(t, 0) = ъвт =
п
а
0(1-0) 1
тп(Т) = шах--------= — > тп(Т}.
в п 4п
График функций риска оценок Т иТ приве-
дены на рис. 3. Из рисунка видно, что зона пред-
почтения минимаксной оценки Т перед оцен-
кой Т имеет вид
{0 R(T,0) < Я(Т,0)} = ^0£
где
Если п велико (п —У оо), то еп -> 0, и эта зона предпочтения сужается к точке
0 = 1/2. Таким образом, при большом числе наблюдений п оценка Т точ-
нее оценки Т лишь для незначительной зоны значений параметра 0. Для
большинства же значений параметра 0 более точной является несмещенная
оценка Т = Х/п. •
Изложенная выше теория байесовского и минимаксного оценивания от-
носится к случаю скалярного параметра, но все ее основные положения пере-
носятся и на случай векторного параметра 0 = (0|,..., 0Г). Если для оценки
§ 3.6. Другие методы и принципы построения оценок
255
Т (Т], ,ТГ) параметра в ее точность измеряется Квадратичная
с помощью квадратичной функции потерь функция потерь
ЦТ, 0) = \Т- 0|2 = - fl,)2,
i=i
т.е. квадратичным риском R(T, 0) E«|T - fl|2, то байесовская оценка
Т* = argminr(T), где байесовский риск т(Т) = ЕЛ(Т, fl), есть вектор апо-
т
стериорных средних Т* = Е(^|ЛГ), а минимаксная оценка Т = arg min m(T),
т
где m(T) = max R(T, 9), есть такая байесовская оценка Т*, Для которой риск
0
постоянен: R(T*, в) = const.
Пример 13 (Байесовская и минимаисная оценки параметров полиномиаль-
ного распределения). Пусть наблюдается целочисленный случайный век-
тор v — (мь , имеющий полиномиальное распределение М(п;р =
= (Pi, , РлО) (см. п. 6 § 1.1), параметры р которого неизвестны, т.е. здесь
р = 9Е 0 = {fl = (flb ,0„) 9i^0, i=l,.. ,N, 9t+ +0w=l}.
Предположим, что вектор р случаен и его априорное распределение есть
распределение Дирихле D(a) с известными параметрами а = (а,,..., aN)
(см. п. 10 § 1.2). Распределение Дирихле сопряжено к полиномиальному рас-
пределению и при этом для апостериорного распределения параметра р спра-
ведливо соотношение £(p\v = г) = D(a + х) (см. упр. 63 к гл. 1). Отсюда
с учетом формул (41) § 1.2 имеем, что байесовская оценка параметра р есть
вектор
Г = E(p|iO = (23)
- а + п
(здесь а = <Т| + + а^, п = v\ + 4-i/jy). Напомним, что наилучшей
несмещенной оценкой для р является статистика р* = v/п (см., например,
пример 10 в § 3.2).
Вычислим функцию риска оценки (23). Для этого удобно переписать пред-
ставление (23) в виде
, . а п , ,
Т_ = wp +(1 —ю)А, где А=—, w = ———, (24)
показывающем, что точка Т* 6 0 лежит на отрезке, соединяющем точки р*
и А. Из (24) имеем
R(T*, в) = Е#|Т* - 0|2 = Е,\w(p* - 0) + (1 - w)(A - 0)|2 =
= w2E9|p* - fl|2 + (1 - w)2|A - fl|2 = —(1 - |fl|2) + (1 - w)2|A - fl|2
- п
256 Глава 3. Теория оценивания неизвестных параметров распределений
Если здесь А = е = (\/N,..., 1/7V), то получим
, * , at2 - п , nN - а2
Отсюда следует, что при а = Цп риск R(T*, в) будет постоянным и равным
N - 1
I)]2'
Но это означает, что D(Vne) — наименее благоприятное априорное распре-
деление, а минимаксной оценкой является статистика
- \/й » 1 / 1Л + Цп/N \ . .
Г=-7=------р + е = -—J=l, ,N . 25
х/п + 1 ~ \/п +1 \ 71 + у/п /
•
В предыдущих примерах 12 и 13 удалось найти наименее благоприятное
априорное распределение параметра модели и тем самым легко построить
минимаксную оценку. Но такое распределение не всегда существует, и в таких
случаях для отыскания минимаксной оценки может быть полезным следую-
щий критерий.
Лемма. Пусть {тг*.} — некоторая последовательность априорных распределе-
ний параметра и {7^} — последовательность соответствующих байесовских
оценок. Если существует оценка То, для которой функция риска удовлетворя-
ет условию
R(To,O) lim r(T*), V0,
£->оо
то То есть минимаксная оценка: Tq = Т
Доказательство. Для любой оценки Т выполняется цепочка соотношений
т(Т) = sup R(T, 0)^ J R(T, d0 r(T,k).
Отсюда следует, что
m(T) lim r(Tk) R(To,0), Vв, т.е. m(T)^m(T0).
| Замечание. Очевидно, что в этих распределениях lim может быть заменен на lim sup.
Пример 14 (Минимаксность выборочного среднего для нормальной моде-
ли). Пусть X = (JT|, , Хп) — выборка из распределения A/”(0, Ъ2) (Ь2 из-
вестно). Покажем, что статистика X, являющаяся оптимальной несмещенной
оценкой в относительно квадратичной функции потерь ЦТ, 6) = (Т - в)2
(см. табл. 2 § 3.2), есть также и минимаксная оценка для в. Для этого мы сна-
чала найдем байесовскую оценку Т* для в относительно априорного распре-
деления £(0) = N(p,a2), являющегося сопряженным к семейству А/(д, b2)
§ З.б. Другие методы и принципы построения оценок 257
(см. упр. 64(5) к гл. 1). Используя результат этого упражнения, сразу находим
Г = Еда = а?(4 +^=(-1 + 5) (26)
\ ст о / \ <т о J
при этом байесовский риск
г(Т*) = ED(0|X) = <т].
Можно проверить (это мы оставляем читателю в качестве упражнения),
что функция риска оценки Т* имеет вид
4 г/2 \ 2“|2
Я(Т*,0) = Ей(Г-0)2 = ^ + 1 )0 + ^у- (27)
о L\ ° / а J
и здесь нет априорного распределения (в сопряженном семействе), для кото-
рого Я(Т’, 0) = const. Поэтому применим критерий минимаксности, сформу-
лированный в лемме. Для этого рассмотрим последовательность априорных
распределений {Л^(/г, <т^.)}, где сг^. —> оо при к —> оо. Соответствующие бай-
есовские оценки в силу (26) есть Тк = <т2^(/га^2 + nb~2X) и их байесовские
риски удовлетворяют соотношению
2 А* п \ &2
г(тк) —СГц. — ( — + I --------> —.
\<т(. (Г/ к-нх> П
Подчеркнем также, что Тк -> X при к -> оо. Но для оценки То = X функция
риска есть
_ _ — Ь7
Я(Х 6) = Efl(X - 6»)2 = DeX = - = lim т(Тк),
П 4-юо
следовательно X — Т — минимаксная оценка 6, и она является пределом
при к —> оо байесовских оценок Тк. •
- 1 А
Замечание. Таким образом, выборочное среднее X = — > Jf, является «образцо-
п
i=i
вой» оценкой неизвестного теоретического среднего 0 в нормальной модели ЛГ(0, Ъ2):
оно является несмещенной оценкой с равномерно минимальной дисперсией, а так-
же минимаксной оценкой при квадратичной функции потерь. Естественно поставить
вопрос, сохраняется ли свойство оптимальности выборочного среднего в многомер-
ном случае. Как показал К. Стейн (1956), ответ на этот вопрос отрицателен. Точнее,
рассмотрим Л-мерную нормальную модель ЛГ(0 = (01г..., 0к), Ь21к) (т. е. (см. п. 2
§ 1.2) наблюдается fc-мерный вектор £ = (£i, , 6.) с независимыми (для простоты)
нормальными Ь2), j = 1, , к, компонентами) и предположим, что по соот-
ветствующей выборке Xi = (Хп,... ,Xlk), I = !,... ,п, оценивается неизвестный
вектор средних 0 = (0,, , 0к) при квадратичной функции потерь
Л
L(T,0) = \T-0\2 = '£i(Tj-0j)2
17 Заказ 1 748
258 Глава 3. Теория оценивания неизвестных параметров распределений
Тогда (см. п. 2 §2.3) вектор выборочных средних X = (X,,..., Хк), где
- 1 -А
= J = 1..*=-
п i=i
будет несмещенной оценкой для вектора 9 и се функция риска равна
— — к — к
R(X, 9) = Ео|X - 0|2 = V DeX. = -Ъ\
%
т.е. не зависит от 9. Постоянность функции риска подсказывает, что рассматривае-
мая оценка является минимаксной при любой размерности к. Но, оказывается, что
при к > 2 она может быть строго улучшена. Именно, в 1961 г. Джеймс и Стейн пред-
ложили следующую простую оценку для математического ожидания многомерного
нормального распределения (при к 2 3)
и показали, что ее риск R(9\ 9) < R(X,9), т.е. оценка 9* равномерно лучше, чем
X (говорят также, что оценка X является недопустимой, см. п. 2 §7.1). Открытие
Стейна, явившееся сюрпризом, показывает, что даже тогда, когда рассматривается
классическая проблема оценивания (т. е. оценивание среднего значения нормального
распределения), выборочное среднее — это не единственная оценка, которую следует
принимать во внимание.
7. Оценивание по цензурированным данным
До сих пор рассматривались методы оценивания, использующие информа-
цию, доставляемую полной выборкой X = (Х|,..., Хп). Однако, на практи-
ке возникают задачи оценивания и по неполной выборке, т.е. когда некоторые
наблюдения либо отсутствуют, либо о них имеется лишь частичная инфор-
мация, — в таких случаях говорят о цензурированных данных. Типичными
примерами цензурирования являются следующие планы испытаний на на-
дежность: берется контрольная партия из п однотипных изделий, «времена
жизни» которых — независимые одинаково распределенные случайные вели-
чины, и наблюдаются либо моменты отказов за заданное время t (1 тип цен-
зурирования), либо моменты первых г(< п) отказов (11 тип цензурирования).
В обоих случаях достигается экономия времени на проведение эксперимен-
та (получение исходных данных), что бывает важным фактором в реальных
условиях. В общем случае 1 тип цензурирования определяется заданием такого
интервала (ii,^г)» что наблюдаются лишь значения Xi 6 ($i, £2), а Ч тип —
заданием двух целых чисел Г|, г2 0, таких что наблюдаются лишь значения
порядковых статистик Х^ при г, + 1 Л п - г2 (если соответствующее
ограничение с какой-нибудь одной стороны отсутствует, то говорят о простом
цензурировании).
Рассмотренные выше методы могут быть применены и к цензурированным
данным. Проиллюстрируем это на примере оценивания параметров 6 = (0Ь 02)
нормальной модели Л/^,^) при простом цензурировании.
§ 3.6. Другие методы и принципы построения оценок
259
Пример 15 (I тип цензурирования). Пусть из п наблюдений фиксируются
лишь те, которые принадлежат интервалу (i, оо). Пусть таких наблюдений ока-
залось N, а их самих обозначим У = (У> , Удг) (таким образом, tz-jVJjO
наблюдений потеряно). Тогда функция правдоподобия данных, очевидно,
имеет вид (далее и = (i — 0\)/02)
L(y; 0) = C„$n~N(u)(V2tt02) N exp $2(У- “ *) J =
= exp Д«2 - ~^(.У - ^i)2},
L ^”2 ^”2 )
где
1 N
*245>-y_)2
i=l
Отсюда следует, что в данном случае достаточной статистикой является тройка
(n,y,s\y)).
Будем искать оценки параметров в = (#i,02) по методу максимального
правдоподобия. Для этого запишем уравнения правдоподобия
д In L(y; в) ДГ п - N Ф'(и)
дв{ = ё2^ ~в'^ вГ~ ф^ - °’
dlnL^e) Nf2 2. N (п-/у)щф'(м)
- = Фёо =0-
Если обозначить А(и) — (и-7У)ф'(щ)/(.;УФ(и)), то эти уравнения приводятся
у - (Д = 02А(и), s2 + (у-0,)2 =022(1+цЛ(ц)). (28)
Учитывая, что в2и = t - 9\ = t - у + 02А(и), т.е. 02 = (у - t)/(A(u) — и),
из первого уравнения (28) имеем
», = 5-Л®-<). (29)
Далее, так как
(у - ®i)2 - 02иА(и) = 02А(и)(А(и) - и) = Х(у - i)2,
из второго уравнения (28) следует, что
02 = s2 + Х(у - t)2 (30)
Но также в2 = (у — t)2/(A(u) - и)2, поэтому
2 _ _ М2 Г I______________^(«) 1 = z- _ f12 1 ~ А(и)(А(и) - и)
_(4(м)-щ)2 А(и) — и (А(и) - и)2
17s
260 Глава 3. Теория оценивания неизвестных параметров распределений
Отсюда
= = 1 ~ А(и)(А(и) - и)
7-(j/-i)2 (А(и)-и)2
Теперь, вычислив по данным величину 7, из уравнения (31) находим значе-
ние и, затем А = А (и) в (29) и, наконец, из (29) и (30) значения и вг- Тем
самым однозначно определяются о. м. п. .
Отметим, что если N = п, т. е. наблюдается полная выборка, то А(и) = 0,
следовательно, А = 0, и мы приходим к обычным о. м. п. 0| = Y, 62 = S(Y)
(см. пример 1 в § 3.5). •
Пример 16 (II тип цензурирования). Пусть наблюдению доступны лишь по-
рядковые статистики АГ^) при к > г для заданного г 1. Обозначим
Y = (Уь ..., Yn) = (АГ(г+1), , АГ(п)), N = п — т, тогда из п. 2 § 2.4 имеем,
что плотность распределения вектора Y (функция правдоподобия данных)
есть
. , а \ ( 1 ЛГ з
= 7фГ ( \ ~N exp I - TTJ - 01)2 }
\ ”2 / I ^^2 j—j )
Отсюда следует, что достаточной статистикой является в данном случае тройка
(АГ(г+1), У, 52(У)), а метод максимального правдоподобия приводит к тем же
уравнениям (28) с заменой t на у\ = а^г+р и и — на и = (т/д - 0))/02- •
Рассмотрим еще один практически важный пример.
Пример 17 (Оценивание параметра масштаба показательного распределе-
ния по цензурированным данным). Пусть для выборки X = (Jfg, , Хп)
из показательного распределения £(£) € Г(0, 1) (см. п.З § 1.2) доступны на-
блюдению лишь первые т порядковые статистики -Хд i), , АГ(г). Рассмотрим
класс линейных оценок
Г
Гг = Еа*(.)
Л=1
для параметра 0 и найдем в нем оптимальную несмещенную оценку (т. е.
н.о.р.м.д.). Для этого прежде всего заметим, что СвЩ/б) = Г(1, 1) — стан-
дартное показательное распределение, поэтому, воспользовавшись результа-
тами примера 1 §2.4, запишем представление
к Y
1 п _ г + 1 ’
: = 1
где {У } — независимые случайные величины с распределением Г(1, 1).
Статистика Тг при этом примет вид
*=1 1=1 1=1
§ 3.6. Другие методы и принципы построения оценок
261
где Л, = 52 А*, г = 1, , г. Отсюда, учитывая, что ЕР) = DY} = 1, имеем
k=i
Г л. г Л2
е9гг = & 52 —, D9Tr = е1 у -—л-—.
“ п - г + 1 “ (n - i + l)z
Условие несмещенности теперь принимает вид
и при этом условии надо минимизировать по Aj,..., Лг сумму
г Л?
F(A„...,Ar) = g(n_ ,’+1)Г
Г г
Так как сумма 52 Х1 ПРИ условии 52 х< = 1 обращается в минимум при
я, = = хг = 1/т (показать!), то в нашем случае оптимальный выбор Ai
таков: А* = (n - i + l)/r, i = 1, ,г Тем самым оптимальная оценка
существует и имеет вид (далее учитывается, что Y, = (п-г+ 1)(Х(^-Х(;~1))/0,
г = 1, ,г, Х(0) = 0)
Т* = - 52(п _ i + 0(-^(i) _ = “(-^(i) + • •• + X(r)) -I--—X(r)
и
. 02
d9t; =
Г
Подчеркнем, что при г = п (наблюдается полная выборка) Т„ = X, т.е. мы
приходим к эффективной оценке для в (см. табл. 2 §3.2). •
Дальнейший материал — для тех, кто хочет расширить и углубить свои
представления об обсуждаемой проблематике. Мы дадим общие определения
современных моделей неполных данных и приведем Модели неполных
основные результаты о соответствующих оценках неиз- данных
вестной функции распределения наблюдений.
Итак, пусть {X,} — независимые одинаково распределенные случайные
величины (н. о. р. с. в.) с общей функцией распределения F(t) = P{Xi t},
которая неизвестна и должна быть оценена по соответствующей выборке
с неполными данными. Опишем сначала наиболее распространенные модели
неполных данных.
Модель 1 (цензурированные данные). Задана последовательность н. о. р.с. в.
{71,}, независимая от {Л\}, и предполагается, что исходные данные (выборка)
262 Глава 3. Теория оценивания неизвестных параметров распределений
имеют вид (Ль <5,), i = 1,..., п, где
Xi = XiATi (A = min), 5i = T(Xi^Ti). (32)
Таким образом, пара (Л,, 1) означает, что наблюдается X, = Л\, если же дано
(Xi, 0), то это означает, что наблюдается X, об X, известно лишь, что
Xi > Т{. Можно также сказать, что в этой модели о результатах некоторых
наблюдений известна лишь частичная информация типа, что Х{ > 1} (о такой
модели иногда говорят как о правоцензурированных данных).
С. в. {71,} называются цензурирующими переменными. •
Модель 2 (усеченные данные). Здесь задается последовательность н. о. р. с. в.
{ti}, не зависящая от {X,}, и предполагается, что X, наблюдается лишь
в случае, когда X, ti. Таким образом, в данной модели выборка представляет
собой п пар (Xi,ti) с Xi t°i, i 1, ,п. Эта выборка порождается
большей выборкой (X,, <;), i = 1, , т(п), где
7п(п) = гшп|пг I(Xi = nl (33)
t=i '
Здесь речь идет о левоусеченных данных (случай усечения справа: Xi наблю-
дается лишь в случае X, t,-, сводится к предыдущему умножением X, и t;
на -1). Таким образом, здесь о наблюдениях с Xi < ti вообще нет информа-
ции. С. в. {t,-} называются усекающими переменными. •
Модель 3 (смешанная). В этом случае данные подвергаются как цензуриро-
ванию, так и усечению. Имеются последовательности {Т,} (цензурирующие
переменные) и {^} (усекающие переменные), не зависящие от {X,} и между
собой и состоящие из независимых с. в., которые с положительной вероят-
ностью могут принимать значения ±оо (расширенные с. в.). Здесь исходные
данные (выборка) имеют вид (Х°,$,11) с X? ti, i = 1,.. п, которые
порождаются большей выборкой (Xit Т,, ti), i = 1, , т(п), где
С т \
т(п) = min< т J(X,- ЛТ, ti) = п ? (34)
i=i '
Если здесь положить все Ti
ti = -оо — цензурированную.
оо, то получим усеченную модель, а при
*^к Оценивание функ-
ции распределения
Оценка
Каплана—Мейера
Оценки теоретической функции распределения F(t)
в таких моделях данных носят название product—limit
(р.-l.) оценок и их конструкции имеют следующий вид.
Длямодели 1 р.-l. оценка Fn (Каплан и Мейер, 1958)
определяется равенством
(35)
§ 3.6. Другие методы и принципы построения оценок 263
р] lim sup IFn(t) - F(t)\ = 0 ? = 1.
ln-»00 I 1 J
Для модели 2 p.-l. оценка (Линден-Бэлл, 1971)
определяется равенством
где 0/0 = 0, ДДГп(з) Nn(s) ~ Nn{s - 0) — величина скачка в точке s
(так что в (35) произведение берется по точкам скачков функции Nn(s)),
N„(s) = £ I(Xi s AT,) = £ 0,4 = 1),
t=l i=l
n n
Yn(s) = £ I(Xi ATi^S) = ^ > s>'
i=i i=i
Асимптотические (при n —> co) свойства оценки Fn(t) аналогичны свой-
ствам классической эмпирической функции распределения (см. п. 2 и 3 § 2.1),
например, имеет место аналог теоремы Гливенко
Оценка
Линден-Бэлла
(36)
где
п п
Ln(s) - I(X,° s), Rn(s) = £ 7(Х: > s > t°).
i=i i=i
Оценка F*n обладает хорошими асимптотическими свойствами, в частно-
сти, свойством состоятельности, когда с. в. i, имеют непрерывную функцию
распределения. Для случаев, когда t, не яаляются н. о. р. с. в., а также для
дискретных с. в., для обеспечения состоятельности оценки Лей и Йинг (1991)
предложили модифицированную р.-l. оценку Fn:
&Ln(s)
Rn(s)
гдес> 0 и 0 <ct < 1 — заданные числа.
Для модели 3 ими же предложен модифицированный вариант оценки Fn:
l-F'(f) = n{1-^y/(^(s)^cn“)}- №
где
п п
b'„(s) = s’ К = R'nW = Е W 3 >
1=1 1=1
Асимптотические свойства этих р.-l. оценок и дальнейшие детали их теории
можно найти в работах: Lai Т. L., Ying Z. Estimating a distribution function
1 - Fn(t)
I(Rn(s) спа) к (37)
264 Глава 3. Теория оценивания неизвестных параметров распределений
with truncated and censored data // Ann. Statist. 1991. V. 19. № 1. P 417-442;
Gill R. D. Glivenko-Cantelly for Kaplan-Meier// Math. Meth. Statist. 1994. V. 3.
№ 1. P. 76-87.
§3.7. Объединение и улучшение оценок
Настоящий параграф посвящен важным вопросам построения на базе уже
имеющихся оценок (для некоторой теоретической характеристики или па-
раметра) новой оценки, обладающей большей точностью, нежели исходные
оценки. Здесь можно выделить два аспекта:
1) проблема объединения информации, получаемой в разных эксперимен-
тах, и построение итоговой оценки с ббльшей точностью, нежели оценки,
порождаемые соответствующими экспериментами, и
2) проблема «улучшения» имеющейся оценки с целью построения на ее
основе новой оценки с большей точностью. Ниже будут изложены не-
которые общие подходы в решении этих проблем и даны практически
полезные иллюстрации их применения в конкретных задачах.
1. Объединение оценок
В качестве введения в общую проблематику рассмотрим простейшую ситу-
ацию, когда имеются две независимые и несмещенные оценки Т\ и Г2 не-
которого параметра 0 и их дисперсии D7) = a,-, i — 1,2, известны. Как
на их основе построить более точную новую несмещенную оценку? Рассмот-
рим класс линейных комбинаций
Д = {ТО аТ,+(1-а)Т2,0^а^ 1}.
Все они — несмещенные оценки:
ЕТа = аЕТ, + (1 - а) ЕТ2 = а0 + (1 - а) 0 = 0
и
DTa - а2а2} + (1 - a)2 al =
Найдем а из условия обращения дисперсии DTa в минимум, т. е. решая
уравнение ’ф'(а) = 0. Отсюда находим точку минимума
Kgwwiwiemiw»’
ТЛ Объединение
независимых оценок
Т*
а; + o-j 07 -t- trj
“ /т2 4- /т2
ст, + а2
и, следовательно, оценку с минимальной дисперсией
(в классе Д)
= Та- = ^ЧТ1 + -^ЧТ2; (1)
§ 3.7. Объединение и улучшение оценок
265
ее дисперсия
_2_2
DT* = ‘ 2 < min(a?, а22),
т.е. это более точная несмещенная оценка, нежели исходные оценки Т\,Т2.
Пример 1 (Нормальное распределение, объединение оценок).
Пусть X = (Х|, , Хп) и У = (У,,..., Ут) — две независимые выборки
из одного и того же нормального распределения Л/\0\,02) (оба параметра
неизвестны). Мы знаем (см. теорему 2 §2.2), что
X = -f^xi и 5о(Х) = -Ц-
п п — I
1 = 1
f>.-*)2
— несмещенные оценки соответственно для #i и О22 и аналогично Y и Sq(Y).
Мы также знаем (см. теорему Фишера и соотношение (7) в § 2.5), что эти
четыре статистики независимы и
-01 - 01 , 20? , 20?
VX^-1, БУ = —, D5q2(X)^—4, DSoGO = —Ч-
п ТП п — 1 771—1
Отсюда и из (1) получаем, что объединенная оценка для 0\ есть
»:= dP.y+
DX + БУ D X + БУ
п — тп — 1
----Х +-------У =-------
п 4~ Ш П 4“ тп п 4" 771
п
тп
(2)
So2W + —--------7 So2 (У) =
п 4- тп - 2
г n m
т. е. среднее арифметическое всех данных, и при этом Б0* = 02/(п+т). Ана-
логично имеем, что объединенная оценка для теоретической дисперсии 02 есть
(о22у= п~[- 771-1
' 22 714-771-2
1
п 4- тп - 2
(3)
и при этом В(02)* — 202/(тг 4- тп - 2). •
В общем случае, когда оценки коррелированы: Объединение корре-
corr(T,, Т2) = р, для дисперсии их линейной комби- лированных оценок
нации Та имеет место соотношение
ВГа = а2(т2 4- (1 - а)2а] 4- 2а(1 - а)р<т]<т2 = ip(ot),
и решение уравнения = 0 есть
, сг2(сг2 — реп)
а = —з----------------т.
- 2^(Т|СТ2 4- 02
266 Глава 3. Теория оценивания неизвестных параметров распределений
В итоге имеем, что в классе Д существует единственная оценка с минимальной
дисперсией
. <т2(<т2 - ра,) Т, + сг|(tr, - ра2)Т2
X — за‘ — 2 -> I 2 V*'
erf - 2р<7|сг2 + erf
и ее дисперсия есть
Dr = °>220 ~Р2)
(7| - 2/>(7|(72 4- (72 ’
что сводится к результату (1) при р = 0.
Перейдем к общей постановке проблемы объединения оценок. Пусть
Т\, ,Тк — несмещенные оценки некоторой величины д, полученные в к
экспериментах. Обычно на практике это оценки, построенные по соответ-
ствующим независимым выборкам Xj = (Xjh ,Xjnj), j — 1, ,k, т.е.
Tj = Tj(Xj), j = 1, , fc, и тогда они представляют собой независимые слу-
чайные величины с ETj = д и некоторыми дисперсиями, которые мы будем
обозначать DZ) = m^/nj, j = 1, , к. Такой вид дисперсии имеют в случае,
когда Tj = Xj = (Хц + + Xjnj)/nj и DXji = a2j, i = I, ,nj, но такое
обозначение мы сохраним для них и для случаев, когда оценки Tj могут зада-
ваться и каким-либо другим образом. Требуется по оценкам Tj, j = 1, , fc,
построить более точную оценку для д, нежелилюбая из этих исходных оценок,
учитывая при этом различные специфические условия, могущие иметь место
на практике, как-то: дисперсии известны либо нет. В более общем случае ис-
ходные оценки могут быть коррелироваными, и тогда могут возникать допол-
нительные предположения об их смешанных вторых моментах (ковариациях).
Возможны и дальнейшие различного типа детализации общих ситуаций, свя-
занные, например, с условием несмещенности оценок Tj (в принципе, это
исходное условие может также нарушаться, т. е. оценки Tj могут быть не-
однородными и в смысле математического ожидания, а не только в смысле
дисперсии). Таким образом, эта проблематика весьма многоплановая, и мы
далее дадим описание оптимальных алгоритмов построения итоговой оценки
лишь при простейших естественных предположениях.
1) Некоррелированные оценки с известными дисперсиями. Предположим, что
дисперсии DTj (т. е. величины aj, j = 1,. , fc) исходных оценок известны,
и эти оценки некоррелированы. Итоговую оценку величины д будем искать
в классе линейных несмещенных оценок вида
Ta~ctiT\+ ТаЛ-дТ, (5)
где
а = (tri,..., ak), а, + +at = l, Т = (Т\, ,Тк).
При этом в качестве критерия точности оценки Т„ будем считать ее диспер-
сию. Таким образом, нашей целью будет построение несмещенной оценки
с минимальной дисперсией (н.о. м.д.) в классе оценок (5).
§ 3.7. Объединение и улучшение оценок
267
В принятых обозначениях и при сделанных предположениях дисперсия
произвольной оценки (5) равна
DTa=a?^ + + ак—. (6)
«1 nk
Минимум правой части (6) по а при условии
находится методом неопределенных множителей Лагранжа 6\ согласно кото-
рому надо найти абсолютный минимум функции
*(«,*) = 52- а( а, - I 1.
j = l J S = l Z
Решая систему уравнений
^=0. J=1.................S. ^ = 0,
OQj ОЛ
легко находим, что минимум достигается при
Z k V
* fl 7’ 7 7 [ \ ‘Л ТЬ 7 \ , .
<ъ = ^ = -4в2. > = >........в=(£4 Р)
J \ = | 2 7
Таким образом, в рассматриваемом случае Объединенная оценка
н. о. м. д. Т* существует и имеет вид при отсутствии кденедяций^
к
Г = Т„. = а*Т) + + а*кТк = в2 52 (8)
>=1 ai
при этом из (6) и (7) следует, что
а2
DT’ = В2 < min — = min DT, (9)
j n-j j
(как и должно быть: ведь Т)Т* есть минимум среди всех линейных комби-
наций (5), включая и сами исходные оценки Ту). Отметим также очевидное
неравенство:
, 1 <Т-
В < — max —.
К j 71 j
2) Объединение оценок с неизвестными дисперсиями. Более реалистичной
является ситуация, когда дисперсии объединяемых оценок неизвестны. Для
Лагранж Жозеф Луи (1736-1813) — французский математик, механик и астроном, почетный
член Петербургской АН (1776).
268 Глава 3. Теория оценивания неизвестных параметров распределений
этого случая мы будем предполагать, что оценки Tj порождены независимыми
выборками Xj = (Xji,., Xjnj): Tj = Xj, и при этом нам известны также
выборочные дисперсии
1 ' _
~ - *>)2’ > = 1>
71-»
3 г=1
В рассматриваемом случае естественно поступить следующим образом: за-
менить в формулах (7) и (8) неизвестные дисперсии ст2 их оценками S2
и в итоге взять в качестве объединенной оценки
следующую оценку со случайными «весами»:
Объединенная оценка
в случае неизвестных
дисперсий Т = а^+ + акТк, (10)
где веса
z к х
71,' —п —-7 / * л 71 j \ . .
ч = ; = 'к' В =(Е^) (и)
j х;=1 J'
Однако исследование свойств оценок вида (10) значительно усложняется.
Так, если в случае известных дисперсий ст] дисперсия объединенной оценки
(8) не превосходит дисперсии любой исходной оценки Tj, то такое утвер-
ждение для оценки (10), вообще говоря, уже перестает быть верным. Но, как
показывают соответствующие исследования, такое явление может происхо-
дить лишь при небольших объемах выборок. В случае же больших выборок,
т.е. при пнпуПу —> оо, свойства оценок (10) будут «достаточно хорошими».
Приведем соответствующую предельную теорему, дающую условия, при ко-
торых оценка (10) является состоятельной и асимптотически нормальной.
Теорема 1. Пусть объемы выборок удовлетворяют условиям:
пу=7у(л)п, 7у(п) —> 7у > 0 при п —> оо, j = 1, , k, (12)
к фиксировано и, кроме того, E(Aji - у)8 с < оо, 0 < ст2 ст2 5? ст2 < оо,
j = 1,..., к. Тогда величина (Т — д)/В при п —> оо асимптотически нор-
мальна с параметрами (0, 1): £((Т -д)/В) —> Л/\0, 1).
Из этой теоремы следует, что для больших выборок (12) при достаточно
широких условиях оценка (10) обладает хорошими асимптотическими свой-
ствами: она является асимптотически несмещенной, состоятельной (так как
В2 -> 0 при п -> оо) и, более того, она позволяет построить для величины
д асимптотический 7-доверительный интервал. Действительно, так как при
|Т-о| 1
s $(Ct) - ^-Ст) = 2ф(ст) - 1 = 7.
£) )
§ 3.7. Объединение и улучшение оценок
269
оо.
где 7 Е (О, 1) — заданный доверительный уровень ис7 = Ф '((1 4-7)/2), то
отсюда следует, что интервал
Д7(п) = (13)
является асимптотическим 7-доверительным интервалом для д:
Р{<7 € Д7(п)} -> 7 при п ->
Дальнейшие уточнения свойств оценок (10)
можно сделать, если дополнительно предположить,
что выборки Xj извлечены из нормальных сово-
купностей ,hf(g,cri), j 1, ,k. Вместо сме-
щенных оценок S2 теоретических дисперсий ст2
будем использовать несмещенные оценки
Объединенная оценка
в случае нормальных
выборок
Тогда формулы (Ю)-(П) заменяются на формулы
То = aioT| + -Т а^Ть,
где (в условиях (12))
а,. = ^ва>, i = .д, Д’ = (£^) (15)
S=1 *5/о '
Покажем, что в данном случае оценка То является несмещенной. Действи-
тельно, так как для нормальных выборок по теореме Фишера (см. теорему 2
§2.5) статистики Ху и S20 независимы, то независимы Ту и ау0. Но тогда
к к , к к
ЕТ0 = 57 ESjoETy = д 5? E«jo = 9Е( 57 “joj = (16)
j=i j=i S=i 7
к
ПОСКОЛЬКУ 57 ~ 1-
; = 1
Вычисление дисперсии оценки (14) более сложно, и мы приведем для нее
лишь асимптотическую формулу в условиях (12).
Теорема 2. Если для нормальных выборок выполняются условия (12) и
О < аЧ а2 ст2 < оо,
то
(17)
270 Глава 3. Теория оценивания неизвестных параметров распределений
где
Во =
Qjo = Ц Во, 7 = 1, ,к.
сг-
Таким образом, по крайней мере для нормальных выборок точность не-
смещенной объединенной оценки (14) асимптотически (в условиях (12)) та-
кая же, как и для оптимальной объединенной оценки (8) в случае известных
дисперсий.
3) Объединение коррелированных оценок. В общем случае наличия корре-
ляций pij = corn (Ti, Tj) между исходными оценками Т\, ,7* дисперсия
оценки (5) имеет вид
* । I ।
DTa = 52 a>aj cov(T;,Tj) = - 52 DijOiOj = -a'Da = -Q(a), (18)
n n n
.} = > ‘.7 = 1
где
D.j = n covffi. Tj) - £lL2_2. nj='Tjn,
y/'Ti'Tj
Считая матрицу D = ||Dij||f известной и невырожденной, будем минимизи-
ровать квадратичную форму Q(a) при ограничении
к
52°) = L
7 = 1
Снова применяя метод неопределенных множителей Лагранжа, введем функцию
/ к
F(a, А) = Q(a) - А ( ^2 a7 " 1
7=1
и найдем ее точку минимума, решая систему уравнений
dF(a, А)
да.
к
г = 1,..., к, 52 аз = 1-
7=1
Эта система имеет вид
^>=г£в,Л=Л. <=|, .к.
‘ 7 = 1 7=1
или в матричной форме
= ^2а>=1,
7 = 1
§ 3.7. Объединение и улучшение оценок
271
где I — вектор-столбец из единиц. Отсюда
a=-D-ll, 1'а = - l'D~'l = 1.
_ 2 - -- 2-
Таким образом,
^ = (1'D-11)_| и а = а = (Г D-1].) D“'l
Это и есть оптимальный выбор а* коэффициентов линейной комбинации (5)
с учетом наличия корреляций между исходными оценками {Т;}. Запишем
этот результат в более явном виде. Для этого обозначим
D'4< ^ = 52^
3=1
»=1 i,j=l
1огда Объединенная
I'n-i
W = I'D"11, а*' = = (Я,.......Нк) оценка в
W наличия корреляций
и н. о. м. д.
к [ к
г = т„. = а*'Т = 52 НД = - 52 W3T}. (20)
j=l j=l
При этом (см. (18))
DT*
-а'Па = —Ц l'D-‘DD-‘l =
п nW2 ~
1
i= пЙ7'
(21)
Оценка (20) точнее оценивает д, нежели любая из исходных оценок Т3.
2. Улучшение оценок
Выше мы акцентировали внимание на использовании несмещенных (или асимп-
тотически несмещенных) оценок и искали среди них оценку с наименьшей
дисперсией, как наиболее точную. Однако в реальных ситуациях в ряде случаев
требование несмещенности итоговой оценки не является «естественным», бо-
лее того, использование смещенных оценок может оказаться даже предпочти-
тельным, если в качестве критерия точности оценок использовать среднеквад-
ратичную ошибку (с. к. о.). Один пример такого рода мы уже встречали ранее
в связи с задачей оценивания дисперсии общей нормальной модели (см. при-
мер4 в §3.1). В общем случае, пусть Т есть несмещенная оценка с равномерно
минимальной дисперсией для некоторой параметрической функции т = т(в),
в € 0, но нас не устраивает ее точность, хотя оценка Т и является наилучшей
272 Глава 3. Теория оценивания неизвестных параметров распределений
среди несмещенных оценок. Спрашивается, можно ли с помощью Т постро-
ить оценку с меньшей с. к. о.? Ясно, что такая оценка, если она существует,
будет смещенной, тем самым, допуская смещение оценки, мы стремимся
увеличить точность (уменьшить квадратичный риск = с. к. о.). Итак, в этой
проблеме платой за более высокую точность оценки является отказ от условия
ее несмещенности. Рассмотрим, когда и как этого удается достичь.
С помощью оценки Т введем класс оценок
Т={ТЛ = XT, Л € Я1}.
Тогда с. к. о. произвольной оценки ТА из этого класса есть
Е,(Та - т(0))2 = Е, [Л(Т - т(0)) + (А - 1 )т(0)]2 = Х2ЪеТ + (Л - 1)2т2(0)
(22)
и минимум этого риска достигается при
г2(&} (ЕлТ)2
Если Аг(0) = А* = const (не зависит от 0), то при всех 6 g 0
Е(,(ТА. - т(0))2 < Е,(ТА - т(0))2 = D,T,
т.е. ТА. — искомая оценка, причем она является смещенной (именно так
было в примере 4 в §3.1)).
В общем случае, когда Лт(0) не является тождественной константой,
введем два числа
А^ = inf ХТ(в) и — SUP М^)-
« е
Тогда, если А^1С > 0 при некотором с Е R' то оценка = Х^_С(Т - с) + с
будет иметь меньшую с. к. о., чем оценка Т\ если же Х^_с < 1, то лучшей
(более точной) оценкой будет Т® = Х^_С(Т - с) + с. Достаточным условием
существования какой-то одной из оценок или Т® является выполнение
неравенства
(23)
V» € 0,
DjT
[Е»(Т - с)]2
при некоторых с € Я1 и е > 0 (с и с не зависят от в).
Доказательства. Докажем это, например, для sup. Имеем (0 для сокращения
записи опускаем)
DT - Е(Т(2) - т)2 = DT - Е [Л(2)(Т - т) + (с - т)( 1 - Х(2))]2 =
(24)
(так как Х^ < 1 и DT = D(T - с))
(1 + Х(2)) [Е(Г - с)2 - (Е(Т - с))2] > (1 - А(2))[Е(Т - с)]2
§ 3.7. Объединение и улучшение оценок
273
(I + А^с)(1 - Ат_с(<?)) > (1 - А<? С)АТ_С(0) <=* 2АГ_С(0) < 1 + А<? с,
что очевидно, так как Ат_с(<?) С Х^_с < 1.
Пример 2. Пусть наблюдения производятся над геометрической случайной
величиной £' = £ 4- 1 с £#(£) = Bi(l. 1 - 1/0) (см- п- 2 § 1.1), т. е.
w=*} = ^i-|y
(7 у С7 /
х = 1,2......... 0 > 1.
Тогда, в соответствии с формулами (7) § 1.1,
Е^' = Ей£ + 1 = 0 1 - - + I = 0, DH' = DH = 0(0 ~ 1).
k V /
Пусть X = (Xlt ,Хп) — соответствующая выборка. Поскольку рассмат-
риваемая модель относится к семейству моделей степенного ряда, то (см. п. 1
п
§ 3.4) сумма наблюдений является здесь полной достаточной стати-
1=1 _
стикой и потому выборочное среднее Т = X есть н.о. р. м.д. для 0. В данном
примере условие (24) принимает вид
РЙТ = 0(0- 1)
[ЕЙ(Т - с)]2 “ п(0-с)2
V0 > 1,
и, следовательно, оценка, имеющая меньшую с. к. о. чем Т, существует. Так
как (см. (22))
= [ЕЙ(Т- I)]2 = (0 - I)2 = 1
Е#(Т - I)2 + (0 - I)2 0
+ п(0 — I)
а (см. (23))
4-! = sup Xr-i(0) = , , = —
e>l 1 + \/п п 4-
то искомая оценка есть
Т® = А^,(Т - I) + 1 = '. (25)
Конечно, эта оценка уже не будет несмещенной, но ее с. к. о.
, m ч, 0(0 - I) (9-1 0(0- 1)
Е-<т11 - "> = -hr - (Гйр < °'т - <“>
На практике иногда сталкиваются с противоположной ситуацией, когда
имеется смещенная оценка 6п(Х), X = (Х},.. .,Хп), для параметра 0, а усло-
вия задачи требуют использования несмещенной оценки или хотя бы оценки
18 Заказ 1748
274 Глава 3. Теория оценивания неизвестных параметров распределений
с меньшим смещением, чем у дп(Х). При этом экспериментатор даже го-
тов пойти на увеличение риска оценки, лишь бы уменьшить ее смещение.
Общий прием, с помощью которого можно уменьшать смещение исходной
смещенной оценки, носит название метода «складного ножа» (jackknife method
(англ.)). Суть его состоит в следующем.
4^ Метод Рассмотрим оценки 6пц)(Х), основанные на вы-
борках объема п-1, полученных из X в результате
«складного ножа» 7
исключения г-го наблюдения:
<5n(i)W — , X,--i, X) + i, ,Хп), г=1, 71.
Построим оценку
1 "
= п6п(Х) — (п — 1)<5(1)(Х), <5(1)(X) = -^(5n(l)(X). (27)
i= 1
Можно показать, что если смещение исходной оценки S^(X) имеет вид
, т Л| CLi
Ып(Х)-в = - + 4 +
71 Пг
то смещение Е0, - 0 = О( 1/тг2) оценки уже не содержит членов порядка
О(1/п), т.е. оценка устраняет смещение порядка l/п. При этом во многих
случаях дисперсии оценок и дп(Х) приблизительно одинаковы, а диспер-
сию D6»j можно оценить по формуле
^E(W*)~ W)2
1=1
Оценка 0\ называется оценкой «складного ножа» первого порядка. Метод
«складного ножа» дает хорошие результаты при устранении смещения оценок
максимального правдопобия (о. м. п.), которые, как правило, оказываются
смешенными; при этом оценка имеет такое же асимптотическое распреде-
ление, как и исходная о.м.п. (см. соотношение (23) §3.5).
ПримерЗ. Пусть X = (Xj, , Хп) — выборка из нормального распреде-
ления и надо оценить в]. В качестве оценки можно использовать
выборочную дисперсию
=i D* - Ы
1=1
которая является о. м. п. для (см. пример 1 в § 3.5). Но эта оценка смещена
2 п I
(несмещенной оценкой является статистика 50 = --S , см. пример 4
71 - 1
в §3.1) и ее смещение есть
Л п I } Э О')
Е«52 - е22 =---EeS2 - 022 = —2~.
п п
§ 3.7. Объединение и улучшение оценок
275
Чтобы уменьшить смещение, применим формулу (27). Так как
I п I / " \2
<S„(X) = S
i=l V<=1 '
TO
। (-X? + + E-l + •X’f+l + • + -T„) -
1 , О
— ——Tj (X| + + Xi-\ + X,' + | + . . . + JVn) =
\n 4
1/n \ 1Г/П\2 n
=----- I V xi - xi I - 7-о ( V xj ) - 2X< E xj + xi
n-l\^ 3 J (n - I2 7
J = 1 ' V J=1 z J=]
откуда
I "
<5(1)W = -EJ"C)W =
n i=l
I " 1 Г n / n \2
= n X* ~ n(n - I)2 S X' + (n “ 2) (s X1)
1=1 1=1 1=1
Подставляя 6n(X) и в формулу (27), имеем
n . / n \ 2 , n . n
n\“< / n h
„ T / n \2 in 1 / n \2
^n-1)^ ) n-1~^ n(n-1)\£; /
। n
= S(X, - X)! = si.
i=l
t. e. мы устранили смещение порядка 1/п и пришли к наилучшей несмещен-
ной оценке Sq (см. пример 9 в §3.2). •
В случае, когда необходимо устранять смещение
и более высоких порядков, чем О(1/п), используют
обобщенную оценку «складного ножа» к -го порядка
Обобщенная оценка «Г
«складного ножа»
1- k / - \ к
71Л <— • / 1 \
i=0 '
где <5(o)(JC) = 6п(Х), <5(i)(X) — среднее значение оценок <5п(гу(Т), построен-
ных по выборкам объема п - 1 с пропущенным г-м наблюдением (как выше
в (27)), <5(2)(А-) — среднее от оценок d^j^X) при выборках объемами п — 2
(пропущены г-е и j-e наблюдения) и т.д. Оценка устраняет смещение
вплоть до членов порядка \/пк, к = 1, 2,... .
18*
276 Глава 3. Теория оценивания неизвестных параметров распределений
§3.8. Доверительное оценивание
До сих пор мы акцентировали внимание на точечных оценках параметра в ис-
следуемой модели Z = {^(д; 0), 6 € 0} и функций от него. Любая точечная
оценка представляет собой функцию Т = Т{Х) выборки X = (Хь , Хп),
т.е. является случайной величиной, и при каждой реализации х выборки X
эта функция определяет единственное значение t = Т(х) оценки, принимае-
мое за приближаемое значение оцениваемой характеристики. При этом надо
принимать во внимание, что в каждом конкретном случае значение оценки
может отличаться от значения параметра, поэтому желательно было бы знать
и возможную погрешность, возникающую при использовании предлагаемой
оценки, например, указывая такой интервал (или область в случае векторного
параметра), внутри которого с высокой (т. е. близкой к 1) вероятностью у
находится истинное значение оцениваемого параметра. При таком подходе
говорят об интервальном или доверительном оценивании. Основная цель при
этом состоит в том, чтобы при заданном доверительном уровне у построить
кратчайший интервал, обеспечивающий наиболее точную локализацию оце-
ниваемой характеристики.
С подобного рода задачами мы уже встречались ранее (см. п. 2 §2.1, п. 5
§2.2, п. 4 §2.3, п. 3 §2.5, п. 5 §3.5). Общее определение 7-доверительного
интервала дано в п. 5 §2.2 (соотношение (26)), в случае параметрических
моделей — в п. 5 § 3.5 (соотношение (28)), там же (соотношение (34)) да-
но определение и 7-доверительной области для векторного параметра. Для
удобства дальнейшей работы воспроизведем это определение здесь еще раз
в случае оценивания скалярного параметра в При интервальном оценивании
ищут две такие статистики 7) = 7)(Х), i = 1,2, что 7) <72, для которых
при заданном доверительном уровне у выполняется условие
РЛ7’,(2Г)<^<Т2(Х)}^7. V0€G. (1)
Иногда рассматривают односторонние доверительные интервалы, соответствен-
но верхний (вида в < 712(Л’)) и нижний (вида Ti(X) < 6), определяемые
условиями, аналогичными (1), в которых опускают соответствующую вторую
границу. Вместо (1) иногда также пишут
Рй{0 е (ад.ВД)} >у.
Аналогично определяется доверительный интервал для отдельной компо-
ненты (например, в случае многомерного параметра 0 = (0Ь , 0г)-.
Р«{7’1(Х) <е{ <Т12(Х)} ^7, V0€G.
Перейдем теперь к изложению общих приемов построения доверительных
интервалов в произвольных параметрических моделях (во встречавшихся нам
ранее примерах мы имели дело лишь с нормальными либо асимптотически
нормальными распределениями).
§ 3.8. Доверительное оценивание
277
1. Построение доверительного интервала
с помощью центральной статистики
Пусть модель 5" = {Р(х;в), в Е 0} абсолютно непре- Центральная 1^
рывна и существует случайная величина G(X;0), за- статистика
висящая от выборки X — (Х|, , .¥„) и от парамет-
ра в и такая, что: 1) ее распределение не зависит от в и 2) при каждом
х 6 X функция G{x; в) непрерывна и строго монотонна по в — такую
случайную величину называют центральной статистикой (для в). Аналогич-
но определяется центральная стати-
стика для отдельной компоненты (на-
пример, 0|) многомерного параметра
в — G(X; 0|), а также для скалярной
параметрической функции г = т(Д)
{в может быть как скаляром, так и век-
тором) — G(X,t). Далее будем рас-
сматривать для краткости лишь случай
скалярного параметра (для векторно-
го параметра все рассуждения анало-
гичны).
Пусть для модели Р построена цен-
тральная статистика G{X;9) и fdg) —
ее плотность распределения. Функция
fc(g) от параметра в не зависит [условие 1)], поэтому для любого 7 Е (0, 1)
можно выбрать величины gf < gi (многими способами) так, чтобы
91
Р9{<71 < G(X; 9) < 91} = f Ш dg = у. (2)
91
Определим теперь два числа ТДх), i — 1,2, х 6 X, где Tj(x) < Тг(х), как
решения относительно в уравнений
G(z;0) =g\,gi (3)
(однозначность определения этих чисел обеспечивается условием 2), нало-
женным на функцию G(x,f))). Тогда неравенства д\ < G(X;9) < д^ экви-
валентны неравенствам Т\(х) < 0 < РДх) (см. рис. 1) и, следовательно, (2)
можно переписать в виде
PHTi(X)<0<T2W}=7, V0.
Таким образом, построенный интервал (Т\(Х), Ti(X)) в соответствии с (1)
является 7-доверительным интервалом для 0.
На практике, чтобы устранить неопределенность в выборе чисел д\ и gi
в (2), рекомендуется выбирать их так, чтобы выполнялись равенства
91 оо
У Л?(р) d9 = f fe(g) dg = ЦЛ (4)
-00 д2
278 Глава 3. Теория оценивания неизвестных параметров распределений
'л,,. .. _ в этом случае соответствующий доверительный ин-
51 Центральный довери-
тервал называют центральным.
тельный интервал г _
С применением изложенной методики мы уже
встречались ранее в § 2.5 (п. 3) в связи с обсуждением
теоремы Фишера. Так в примере 1 в §2.5 была построена центральная ста-
тистика G(X,e]) = nS2для дисперсии в2 нормальной модели Л/"^^),
с помощью которой был получен центральный 7-доверительный интервал
(10) для в\. Аналогичный интервал для среднего в}, указанный в (12), был
построен с помощью центральной статистики fn_| в (И). Другие иллюстра-
ции этой методики дают примеры 2 и 3 § 2.5. Но все это было осуществлено
с учетом специфики нормальной модели, т. е. в достаточно частном (хотя
и важном) случае.
В то же время можно выделить целый класс моделей, для которых цен-
тральная статистика всегда существует и имеет простой вид. Именно: если
функция распределения F(x;6) наблюдаемой случайной величины £ непре-
рывна и монотонна по параметру в, то можно положить
п
G(X-,e)=-^}nF(X„e). (5)
1 = 1
Действительно, условие 2) здесь обеспечено предположением о свойствах
функции F(x; в), а так как преобразование Смирнова 7] = F(£', в) порожда-
ет случайную величину с равномерным распределением i/(0, 1) (см. упр. 17
к гл. 2), т. е. = 2/(0, 1) — не зависит от в, и, в свою очередь, £(- In 77) =
= Г(1, 1) (см. пример 1 в § 1.2), то слагаемые в (5) независимы, и каж-
дое из них имеет стандартное показательное распределение Г(1, 1). Отсюда
по воспроизводящему свойству гамма-распределения (см. п. 3 § 1.2) имеем
£e(G(X; в)) — Г(1,п), т.е. G(X;ff) — центральная статистика с плотностью
(см. (18) § 1.2) fG(g) = gn~le~3/Г(п), g > 0. Следовательно, согласно изло-
женной выше общей методике, для построения 7-доверительного интервала
для в мы должны определить числа g\ < gi из условия
$1 00
—Ь f gn~'e~9 dg = f gn~'e~9 dg = (6)
Г(п) J Г(п) J 2
О J2
и, решая относительно 6 уравнения
п
^\пР(Х<-е)=д1 (г =1,2), (7)
1=1
найти корни Т)(У) < Т^Х). В итоге мы построим центральный 7-довери-
тельный интервал (T’i(X), ^(Т)) для 6.
Добавим некоторые комментарии к изложенному алгоритму. Обозна-
чим ГР1П р-квантиль распределения Г(1,п), тогда условия (5) означают, что
§ 3.8. Доверительное оценивание
279
31 = Г(|_7)/271, 32 = Г(|+7)/2лг и, следовательно, для определения з, и з2
можно воспользоваться известными таблицами квантилей гамма-распределе-
ния Г(1,п). Очевидно, что наибольшая трудность в применении методики
к конкретным задачам заключается в нахождении корней уравнений (7).
Рассмотрим несколько важных примеров использования центральных
статистик при построении доверительных интервалов.
Пример 1 (Доверительный интервал для параметра равномерной модели).
Пусть по выборке X = (Хь , Хп) из распределения 77(0,0) требуется
построить доверительный интервал для параметра 0 Здесь F(x;0) = x/f),
О 2: 0, т. е. функция распределения непрерывна и монотонна по 0 при
0 > 0, и центральная статистика (5) принимает вид
G(X;0) = - 521nT, + nln0.
1=1
Легко сидеть, что решениями уравнений (7) являются здесь
ГДХ) = ехр{^ + ^^1птД, j = 1,2,
>=i '
где 31 = Г(1_7)/2,п, 32 = Г(1+7)/2,п> а искомый интервал есть (Т\(х), ^(т)).
Центральная статистика может быть не единственна. Так, в обсуждаемом
примере можно указать еще одну центральную статистику, а именно, из п. 2
§3.4 (соотношение (13)) следует, что плотность статистики Х(п) = max Xt
имеет здесь вид
ТЬ
3,(7;0) =-Z”-1 t €[0,0].
и
Отсюда по формуле (45) § 1.2 легко получить (задача!), что
) =w(0-1)’ ve>°-
0 < 3 1 - 71
Таким образом, случайную величину (Jf(n)/0)n также можно использовать в
качестве центральной статистики для оценивания 0. Согласно общей методи-
ке (соотношения (2)—(3)), 7-доверительным для 0 является любой интервал
вида
•^(п) Х(п)
(0+т)'/п’ 3,/п
центральным среди них является интервал, соответствующий значению д =
— (1 - 7)/2, наименьшую же длину имеет интервал при д = 1 - 7, т.е.
интервал (Х(п), Т(п)/(1 -7)1/п) (показать!). •
Пример 2 (Доверительный интервал для среднего нормальной модели).
Пусть по выборке X = (Xj, , Jfn) из распределения Л/"(0,ст2) (ст2 извест-
но) требуется построить доверительный интервал для неизвестного средне-
го 0. Поскольку £о(2С) = А/"(0, ст2/п) или С^у/п^Х - = A/"(0, 1), то
Таблица 1
Таблица доверительных интервалов для параметров нормальных моделей
(неизвестные параметры обозначены символом 0)
ГО
оо
О
Модель Что оценивается Центральный у-довернтельный интервал (Tj, Т2) Центральная статистика и ее распределение
ЛГ(0,<72) среднее в _ — ЛС-, _ 1 ( I + 7 \ Т|.2 = ХТ-^, с7 = Ф 1 у/П \ 2 / G(X; 0) = — ~.g^; V(0, 1) (7
среднее 0| S Т\,1 -Т’Т ^__Z(1+7)/2 п_| — y/n —T G(X;0,) = (X-0l)——; 5(n-l) 0
ЛГ(М2) дисперсия 02 Г.,2 = ^-, Т2 = £(Х.-д)2 ^(l±-y)/2,n t=| C(X;02)=^; x2W
ЛГ(01,02) дисперсия 02 nS1 Т\л — 2 X(l±7)/2,n-l G(X;0f)=^; r(n - I) V2
ЛГ(0(,).<тЬ ЛГ(0(2),<т22) разность средних Г( 2 = X - У т <ТС7, <72 = — + п т X _ у _ T G(X, У; t) = ; M\0, 1) (7
w!"-*2) ЛЦО?,О22) разность средних т = 0<'> -0<2’ T'y.l = X - У Т ^(ц-7)/2, m+n-2 X [ —,- + П .. (nS2(X) + т52(У))] 1 [mn(m + n-2)' '"J G(X,Y;r) = Jmn(m^-n-2\ у m + n х[пед+ rnsW/2i S{m + n-2)
V(0|i, 0?2) ЛГ(021,Й222) отношение дисперсий Т = 0?2/022 _n(m- 1) S2(X) I Гк2~ m(n- 1) S2(r)/-F'(i±T)/2,n-i.n.-i nr v ' n(m—l)S2(X) / С(Х’Г THm(n-l)sWT;5(n“!’m_1)
। п п । т ] т
Примечание. Здесь X = (X........ Хп), У = (У,,..., Ут), X = - X,, S'2 = S2(X) = - ^(Х, - X)2 У = - ~ “ ?)2
Глава 3. Теория оценивания неизвестных параметров распределений
§ 3.8. Доверительное оценивание
281
центральной статистикой для 0 является здесь G(X;0) = у/п(Х-в)/а. Урав-
нения (4) принимают в данном случае вид Ф(<?|) = (1 -у)/2, Ф(<7г) = (1 +7)/2
и при этом </| = -рг (так как Ф(-а:) = 1-Ф(х)). Будем использовать привыч-
ное нам обозначение с~, = Ф“'((1 +?)/2) (см. (27) §2.2), тогда д2 = -ду = Су,
и, решая уравнения (3), легко находим центральный 7-доверительный интер-
вал для 6: (X т Cyff/y/n). Это симметричный относительно случайной точки
X интервал длины 'Ic^Gly/n. В частности, для доверительного уровня 7 = 0,99
величина с, = 2,5758, для 7 = 0,998 Су = 3,0902 и т.д. Значения с, для раз-
личных 7 можно извлечь из таблиц квантилей стандартного нормального рас-
пределения 1). Доверительный интервал для среднего при неизвестной
дисперсии а2 построен нами раньше в примере 1 в §2.5 (соотношение (12)).»
Пример 3 (Доверительный интервал для дисперсии нормальной модели).
Для модели Л/\р, в2) (р известно) также легко найти центральную статистику
для т = т(0) = О2:
G(X-,T) = ^{Xl-p)2
т 3=1
Действительно, так как Cg((Xi~ р)/в) = ЛГ(О, 1), то £#((.¥)-д)2/т) = Х2(')
(см. упр. 38 к гл. 1) и потому Cg(G(X; 0)) = х2(п). Если Хр,п есть р-квантиль
распределения х2(п)> т0 решениями уравнений (4) являются д\ — X(i-7)/2,n и
д2 = Х(1+7)/2,п- Разрешая относительно т уравнения G(X; т) = <?, (г = 1,2),
получаем центральный 7-доверительный интервал для дисперсии т = 6 :
f^Xi-p)2 £(Х,-д)2>
3 = 1 3=1
Х(1 +7)/2, п ^(1-7)/2,п
\ /
(сравни с решением (10) §2.5 для случая неизвестного среднего р). •
Учитывая важность нормальной модели, особую роль ее в приложениях,
приведем сводную таблицу (см. табл. 1) доверительных интервалов для ее
параметров (в различных постановках), объединив результаты примеров 2, 3
и полученные ранее в §2.5 (примеры 1-3).
2. Построение доверительного интервала с использованием
распределения точечной оценки параметра
Если уже имеется некоторая точечная оценка Т = Т(Х) для параметра в
и известна ее функция распределения Fr(t;9), то доверительный интервал
282 Глава 3. Теория оценивания неизвестных параметров распределений
* Непрерывная модель для можно построить, основываясь на этой функ-
ции. Предположим сначала, что распределение оцен-
ки Т непрерывно и функция Fr(t', 6) непрерывна и монотонна по в. Пусть за-
дан доверительный уровень 7 Определим при каждом & £ © числа t, = (£>),
i = 1, 2, где t| < t2 и
M*i < Т(Х) < t2} = FT(t2-, 0) - Fr(t,; 0) = 7. (8)
Чтобы данная процедура была однозначной, рекомендуется выбирать эти
числа так, чтобы выполнялись условия
FT(tt,0)= l-FT(tr,0)=[-^-, (9)
т.е. речь идет о построении центрального доверительного интервала. Обозна-
чим через Р7 подмножество 0x0 Т>7 £j(0) < О' < t2(0)}
(рис.2). Тогда Pg{(0, Т(Л’)) £ Т?7} = 7, V 0 £ 0. Определим теперь при фик-
сированном О' сечение Т)-,(0') множества Р7 D^O') = {0 (0, О') £ Т>7} —
и рассмотрим случайное множество Р7(71(Л’)) С 0. Событие 0 £ 1?7(T(X))
происходит тогда и только тогда, когда Т(Х) £ (^(0), ^(0)) и, следователь-
но, при каждом 0 имеет вероятность 7 Таким образом, построено случайное
множество Т>У(Т(Х)), которое накрывает истинное значение параметра 0
с вероятностью 7. Если это множество является интервалом, то тем самым
построен (центральный) 7-доверительный интервал для 0. Это будет так, ес-
ли кривые 0' = ti(0), г = 1,2, являются монотонными одного типа (т.е.
одновременно либо возрастают, либо убывают), что обеспечивается условием
непрерывности и монотонности функции Fr(t; 0) по 0 (рис. 3).
Таким образом, при сделанных предположениях множество Т’7(0/) при
каждом О' представляет собой интервал; следовательно, определены его концы
0i(0z) < 02(О'), а тем самым и соответствующий 7-доверительный интервал
(Т,(Х), Т2(Х)) для 0, где Т((Х) = Oi(T(X)), i = 1, 2.
Построение диаграммы придает наглядный смысл этой методике. Диаграм-
му строят по вертикали (для любой абсциссы 0 находят из (9) соответствующие
Рис. 2
Рис.З
§ 3.8. Доверительное оценивание
283
ординаты £, и tj); «читают» же ее по горизонтали, т. е. для наблюдавшейся ор-
динаты t = Т(х) (х — раелизация выборки .X) «считывают» две величины 0t
и 02 и утверждают, что 0 € (0,, 0г). Таким образом, если «читать» диаграмму
по вертикали, то границы области Т>7 описываются парой переменных точек
(0, fi) и (0, £2), таких что выполняются условия (9). Если же «читать» диа-
грамму по горизонтали, то границы Т>7 можно эквивалентно описать парой
переменных точек (£,0,) и (£,02), взяв за независимую переменную наблю-
даемое значение t оценки Т(Х). Тогда соотношения (9) можно переписать
в терминах этих величин так: если функции £;(0) возрастают (см. рис. 2), что
соответствует убыванию по 0 функции FT(t;0), то
1 - FT(t', 0|) = FT(t; 0г) = —-—,
если же функции £,(0) убывают, что соответствует возрастанию по 0 функции
FT(t; 0), то
^т(£; 01) = 1 ~ FT(t', 02) = —
Итак, алгоритм построения центрального 7-доверительного интервала
для 0 в случае, когда функция распределения Fr(t;0) оценки Т = Т(Х)
непрерывна и монотонна по 0, состоит в следующем. Пусть t = Т(х) —
наблюдавшееся значение оценки. Решая относительно 0 уравнения
1—7 1+7
FT(t-,0) = -^,-^, (10)
находим два числа 01 <02- Далее утверждаем, что 0 G (0;, 0г). Приведенная
теория гарантирует, что при 7, близком к 1, вероятность ошибки в случае
применения этого правила равна 1 - 7
Аналогичные рассуждения можно провести и для Дискретная модель
случая дискретной модели. Единственное отличие
состоит в том, что из-за ступенчатости функции распределения Fr(t; 0) в со-
отношении (8) можно, вообще говоря, обеспечить лишь выполнение нера-
венства
Р,{£, <Т(Х) <t2} =Fr(t2-O;0)-f’T(£1;0) >7, (И)
поэтому вместо условий (9) следует ввести условия
*т(£|;0КЦЛ 1 - FT(t2 - О;0) ЦЛ (12)
где £[ — наибольшее, a t2 — наименьшее значения Т, удовлетворяющие
этим неравенствам. Кривые 0' = tj(0), i = 1,2, в данном случае являются
ступенчатыми (рис. 4) и при «считывании» величин 0;(0Х), i = 1,2, следует
брать крайнюю правую точку отрезка пересечения горизонтальной прямой
с левой кривой и крайнюю левую точку — с правой кривой (когда линия
пересечения попадает на горизонтальные «ступеньки» кривых).
284 Глава 3. Теория оценивания неизвестных параметров распределений
А0'
д '<>
Рис. 4
Алгоритм построения центрального
7-доверительного интервала для 9 в дис-
кретном случае в основном тот же, что
и для непрерывного, только вместо урав-
нений (10) надо решать относительно 9
уравнения
1 — т
FT(t-,9) = —\
1 (13)
1 — FT(t — О;0) =
t — наблюдавшееся значение оценки Т.
Замечание. Часто вместо центрального доверительного интервала в дискретном слу-
чае рекомендуется строить множество Т?7 по принципу включения в него значений
статистики Т с наибольшими (при каждом в) вероятностями их появления. В случае
применения этого метода вместо условий (I!)—(12) границы 1, = t,(0), 1,2,
определяются из условия
Pe{t, <Т<«2} = 52 Pe{T = t} ^7;
iicicij
(14)
при этом в сумму должны быть включены значения t с наибольшими вероятностями
их появления, а интервал (tb t2) должен быть наименьшим, удовлетворяющим этому
условию. В ряде случаев, когда распределение статистики Т асимметрично, такой
способ позволяет получить более короткие доверительные интервалы.
3. Асимптотические доверительные интервалы
В ряде случаев, когда имеется состоятельная и асимптотически нормальная
оценка Tn = ТП(Х), X = (X,,. , Х„), для параметра 0, можно построить
асимптотический (при больших п) доверительный интервал. С примерами
построения таких интервалов мы встречались в п. 5 § 2.2, п. 4 § 2.3 и п. 5 § 3.5.
В общем случае, пусть при п -> оо имеет место соотношение
св(^(т„ - в)) #(о, чеее,
причем асимптотическая дисперсия <г2(0) непрерывна по 0. Тогда в силу (17)
§3.5
~> -*4(0, t), V0,
\ «Фп) /
откуда следует, что при п —> оо и всех 9
( у/п\Тп - 0| ]
РЧ ' „(т\ < М = - 1 = 7-
I <г(Тп) J
если Су = Ф"'((1 +7)/2). Переписав это соотношение в виде
Р /т ста(Г'») < fl < Т щ cicr(Tn) I_____. у
I V71 v71 J
§3.8. Доверительное оценивание
285
получаем, что (Тп с^а(Тп)/у/п) — асимптотический 7-доверительный ин-
тервал для в. Это симметричный относительно центральной точки Тп интер-
вал шириной 2с^<т(Тп)/у/п, поэтому он будет тем уже, чем меньше асимп-
тотическая дисперсия оценки Тп, т.е. чем выше асимптотическая эффектив-
ность Тп (в смысле п. 5 § 3.2). Следовательно, асимптотически кратчайший
доверительный интервал будет порождаться асимптотически эффективной
оценкой. Если исходная модель 7 {F(x;ff), 0 6 0} регулярна, то пе-
речисленными свойствами обладают оценки максимального правдоподобия
(см. п. 4 §3.5). Поэтому построенные в п. 5 §3.5 доверительные интервалы
являются асимптотически оптимальными (кратчайшими).
Проиллюстрируем изложенные общие принципы примерами.
Пример 4 (Доверительный интервал для параметра бернуллиевской модели).
Пусть требуется построить доверительный интервал для параметра в модели
В1(1,0). Если имеется соответствующая выборка X = (Х^ ,Хп), то, как
мы хорошо знаем, оптимальной несмещенной оценкой для в является вы-
борочное среднее Т = X. Статистика Т принимает значения вида к/п,
к = 0, 1, , п, при этом (см. п. 1 § 1.1)
Здесь
d / к \
— Fr -;0) = -пСк.19к(\-9)п~к~' <0 при к < п,
dd \п /
так что при к < п функция Рт(к/п;9) монотонно убывает по в. Следова-
тельно, применима описанная в п. 2 методика, согласно которой при Т = к/п
центральным 7-доверительным интервалом для в является интервал (#i,#2)>
где 9\ и ^2 определяются в соответствии с уравнениями (13), которые в дан-
ном случае принимают вид
(ь _ 1 \ ", I - -V
—;<>,) =]Гс;х(1-<?!)"-’• =—Л
п J ' 2
Г=1
при этом, если наблюдалось Т = 1 (т. е. к = п), то принимают #2 = 1 > а при
Т = 0 (т. е. k = 0) полагают (Д = 0.
Практически границы (Д и #2 вычисляют, используя их связь с кванти-
лями бета-распределения (см. п. 4 § 1.2). Именно, по формулам (4)-(4') §2.4:
-0|)п-г =B(9f,k,n- к + 1),
г=к
286 Глава 3. Теория оценивания неизвестных параметров распределений
i п
^crner2(i-e2)n~r = 1- 52 с^(1 - 0г)п-г = i-в(02;* +i.n-fc).
г=0 r=fc+l
Поэтому уравнения (15) можно переписать в виде
В(01;к,п-к + })^ -ЦЛ В(02; к + },п - к) = 1±2 (16)
Доверительный Следовательно, если обозначить z(p; а, &) р-кван-
* интервал для параметра тиль бета-распределения Ве(а, &), т.е. решение
модели Bi(l, 0)^^.,. уравнения B(z; а,Ь) = р, 0 < р < 1, то из (16)
имеем (заменяя к на пТ)
0\=z^—пТ, п - пТ + 1^, = z пТ + 1, п - пТ^ (17)
Доверительные интервалы (0,, 02) рассчитаны для широкого диапазона зна-
чений п при 7 = 0,9; 0,95; 0,99 (см. [3]).
Если число наблюдений п велико, то для быстрого нахождения прибли-
женного доверительного интервала для в можно воспользоваться асимптоти-
ческой теорией, изложенной в примере 17 в §3.5. •
Пример 5 (Доверительный интервал для параметра пуассоновской модели).
Как и в предыдущем примере, здесь оптимальной несмещенной оценкой для 0
является статистика Т — X (см. пример 1 в §3.4), принимающая значения
к/п, к = 0, 1,2, .; при этом (см. п. 3 § 1.1) £g(nT) = П(п0), поэтому
(к \ Г к
Ft I — ; 0 1 — —
/ 1 п
г=0
г!
Здесь
d р (к Д „9(n0)fc
— гт I — о = -пе
d0 \п )
к!
т. е. функция F?(k/n; 0) монотонно убывает по 0 Согласно общей методике,
если наблюдалось Т = к/п, то центральным
для 0 является интервал (0|,#2), где 0i и 02
уравнениями
7-доверительным интервалом
определяются соответственно
(к- 1
1 — Ft ( --; 61
\ п
г!
FT(-;02
\ п
Г"' -П«2
г=0
г!
(18)
2
2
В данном случае границы 0\ и 02 можно выразить через квантили хи-квадрат
распределения. Для этого получим сначала вид функции распределения <?п(я)
§3.8. Доверительное оценивание
287
закона %\п) (см. п.З § 1.2) при п = 1k. Обозначая для краткости =
= e~‘tr/г'., г = 0, 1,..., имеем
Г хк~'е~х^2 f Д—‘
1 - <72Д:(2А) = у L dx = у тгЛ_|(t) dt = ^2 ^(А)
2А А г=0
(интеграл легко вычисляется интегрированием по частям). Отсюда находим,
что
i-l оо
C?2fc(2A) = 1-22 (>9)
г=0 г=к
С учетом (19) уравнения (18) можно переписать теперь в виде
Gik^nO,) = -ЦД Glk+1(ln0i) - ЦД (20)
Следовательно, если Хр,п обозначает р-квантиль Доверительный
распределения х2(п), т.е. решение уравнения интервал для параметра
Gn(x) = р, то из (20) имеем (заменяя fc на пТ) модели П(0)
д _ ' 2 Д _ ‘ 2
W| “ 2^А(1-7)/2,2г.Т . Ъ ~ ^Х(1+7)/2,2ПТ+2
(21)
Как и в предыдущем примере, для больших объемов выборки можно про-
сто рассчитать приближенный доверительный интервал, воспользовавшись
асимптотической теорией оценок максимального правдоподобия, что проде-
лано уже в примере 15 § 3.5.
В данной модели можно построить асимптотический доверительный ин-
тервал для 0 и другим способом, а именно, воспользовавшись нормальной ап-
проксимацией для выборочного среднего: £«(АГ) ~ V(0, 0/п) (см. теорему 3
§ 2.2 с учетом того, что для пуассоновского распределения П(0) среднее и дис-
персия равны 0, см. п.З § 1.1). Отсюда можем записать, что при больших п
(i/n\X - 0\ ] Г,— ЛЧ, 4И
7 ~ < с7 = Р« (X - t?)2 < Д U
( V0 ) I п )
Г /_ с2 \ _ "I
= Р#< 02 - 201 X + — ) + X2 < 0 > = PS{T, < 0 < Т2},
I \ 2n / J
где
_ cl
т,.2 = X + т
( % Т~2 )
\ п 4п2/
Таким образом, (Ti,T2) — другой приближенный у-доверительный ин-
тервал для 0 С точностью до членов порядка 1 /п этот интервал эквивалентен
интервалу (X тСуу/Х/п), полученному в примере 15 в §3.5. •
288 Глава 3. Теория оценивания неизвестных параметров распределений
Пример 6 (Доверительное оценивание квантилей). Пусть по выборке X
= (Х[, , Хп) из непрерывного распределения с неизвестной функцией рас-
пределения F(x) требуется построить доверительный интервал для р-кванти-
ли (р при заданном р Е (0, 1) (см. п. 1 §2.4). Точные доверительные интервалы
в этой задаче можно строить, основываясь на формуле (5) §2.4. Именно, под-
ставляя в эту формулу х — (р и учитывая, что F((p) = р, получим
Р{^(л) <Р} = В(р-, к, п - к + 1) = у!,
т. е. порядковая статистика Х^ является нижней 71-доверительной границей
для Ср- Аналогично,
Р{*(0 ><р}= 1 - B(pJ,n-Z+l) = 72,
т.е. Хц) — верхняя 72-доверительная граница для Ср- Наконец, так как
< Х(;) при к < I, то
P{x(t) < Ср < х{1)} = 1 - р{Ср ЗД - Р{Х(() Ср} =
= В(р\ к, п - к + 1) - В(р; Z, п - Z + 1) = 7i + 72 - 1=7
Это означает, что (Х^, Х^) — 7-доверительный интервал для Ср- •
§3.9. Оценивание при выборе из конечной совокупности
1. Оценивание среднего совокупности
В прикладных исследованиях часто приходится иметь дело со следующей си-
туацией. Имеется конечная совокупность U — {uj, ,u„} из N объектов,
каждый из которых характеризуется некоторой величиной х(и), и Е U. Зна-
чения xt = x(ui), г = 1, , N, неизвестны, и требуется оценить их сумму
Т = Т(х) = У^а:г, Х = (Х|, ,xN), (1)
>=1
или, что то же, величину р = T(x)/N, называемую средним совокупности U
(можно рассматривать и другие функции от х, подлежащие оценке).
При этом предполагается, что в силу объективных причин (большой раз-
мер совокупности или большая стоимость наблюдения и т. п.) мы не можем
наблюдать все объекты с их соответствующими а;-значениями, а обследова-
нию доступна лишь некоторая часть из них (выборка), выбираемая по некото-
рому случайному закону. Математическая формализация сказанного состоит
в следующем.
Назовем выборкой з любую конечную упорядоченную последователь-
ность объектов из U, т. е.
« = («»,, г€{1, ,N}.
Здесь п(«) есть объем выборки з, который может быть как фиксирован-
ным, так и меняться от выборки к выборке. В первом случае говорят о вы-
§ 3.9. Оценивание при выборе из конечной совокупности
289
борках фиксированного объема п. Если все элементы выборки различны, то
говорят о выборе без возвращения (в этом случае n(s) N), в противном слу-
чае (допускаются повторения объектов в выборке) — о выборе с возвращением.
Множество всех выборок обозначается через S и называется выборочным про-
странством. Если на S задана вероятностная мера Р, приписывающая каждой
выборке s Е S вероятность p(s) ее извлечения I p(s) = 1 I, то говорят,
se5 S
что задан выборочный план (в. п.), подразумевая под Выборочный план *
этим тройку А = (U, S, Р). Итак, мы можем наблю-
дать лишь некоторую совокупность объектов из U, вы-
бираемую в соответствии с заданным в. п. А.
Далее, мы рассматриваем х = (ii, ,Xn) как параметрическую точку
в Rn и определяем оценку для Т(х) как функцию е(з, х) на S х RN, которая
зависит от х только через те х,, для которых и,- € з (таким образом, е(з, х) =
= е(з, х), если Х{ = х, для всех и, Е в). Другими словами, оценка есть
функция выбранных объектов и их наблюденных а:-значений. Мы будем рас-
сматривать класс £ = £(А) всех несмещенных оценок:
£ = |e(s,i) Уp(s)e(s,х) = Т(х), Ух Е RN >, (2)
siS '
и искать в нем наилучшую (оптимальную) оценку, т.е. оценку, для которой
дисперсия
De(s, х) = У^ р(з) [е(з, х) - T(z)]2
stS
минимальна для У хЕ RN Оптимальная оценка, вообще говоря, не всегда
существует, и в таких случаях для сравнения различных оценок используется
понятие допустимой оценки. По определению, оценка e(s,s) (для Т(х))
называется допустимой (в классе £ (Л)), если не существует Доп стимые
другой оценки е।(s, х) Е £(А), для которой ^^ценки
Dei(s,s) De(s,s), yxER^
со строгим неравенством хотя бы в одной точке х.
Ясно, что недопустимые оценки должны быть отвергнуты. С другой сто-
роны, обычно класс допустимых оценок является весьма широким и никакие
две допустимые оценки е\ и ег уже несравнимы (по значению дисперсии),
так как для них существуют непустые множества Xlt Х2 С RN с условием
Dei < De2, zE-Ли, и De2 < Dei, хЕХ2.
Поэтому выбор оценки из класса допустимых должен проводиться с учетом
дополнительных соображений.
19 Заказ 1748
290 Глава 3. Теория оценивания неизвестных параметров распределений
Оценка Наиболее употребительными оценками для Т(х)
Горвица—Томпсона являются оценки Горвица— Томпсона e(s,r), которые
определяются следующим образом. Обозначим
тг(и) = P(u € s) = 52 И«) (3)
5 : зЭи
вероятность включения в выборку объекта и Е U (сумму вероятностей всех
выборок, содержащих и), и предположим, что в. п. А таков, что тг(и) > 0,
Vtz 6 U. Тогда, по определению,
Ех(и\ s , х(и) , ,
"71= 526 <4)
u6i М“) V
Так как
ЕТ(и £ s) = P(u Е s) = л(м),
то
Ee(s, х) = 52 I(u) = ^(z)’ т.е. ё(в,х)ЕЕ-
и
Нетрудно заметить, что оценка Горвица—Томпсона является единственной
линейной несмещенной оценкой для Т, т. е. оценкой вида
52 «(m)i(m) = 52 Ли £ s)a(u)i(u).
U£S и
Действительно, условие несмещенности означает, что
52 2:(и)«(«)тг(и) — 52 а:(и)> V х Е Rn
и и
Полагая здесь х = (0... 010... 0), где 1 стоит на i-м месте, имеем
а(и{)тг(и{) = 1, т.е. а(и,-) = —-—-, i = 1, , N.
тг(и,)
Замечание. Если рассматривать класс всех несмещенных оценок £(А) для в.п. А
с условием тг(и) > 0, Vu Е U, то можно лишь доказать, что ё(з,х) является допу-
стимой оценкой.
Выбор без На практике чаше всего используются выборочные планы
возвращения фиксированного объема и для выбора без возвращения с рав-
номерной мерой на S (выборочный план Л*). В этом случае
множество S состоит из (N)n = N(N - 1) (N - п + \) всех упорядочен-
ных комбинаций длины п из различных элементов U и p(s) = i/(jV)n,
Vs Е S. Нетрудно видеть, что для любого фиксированного элемента и су-
ществует n(N — 1)п_| различных выборок из S, содержащих этот элемент,
поэтому
§ 3.9. Оценивание при выборе из конечной совокупности 291
Следовательно, для в.п. Л* оценка Горвица—Томпсона принимает вид
1
7V
e(s, я) - — 5^ х(и),
п
u€s
(5)
т. е.
ё(з, х) есть обычное выборочное среднее х наблюденных х-значений.
Из предыдущего следует, что для в. п. Л* х есть оптимальная линейная оценка
для среднего совокупности р. Вычислим дисперсию этой оценки. Так как
и
/, , \ /, , Ч п(п- 1)(ЛГ - 2)п-2 п(п-1)
EZ((«i)Uj) € s) = Р ((u„U>) € s) ----------------= • г
то
* Е£! -- *’•
что легко приводится к виду
D*= где = ^£>-м)2 (6)
Величина <т‘ называется дисперсией совокупности U.
Иногда требуется оценить не только среднее р, но и дисперсию <т2 сово-
купности U. По аналогии со случаем бесконечной совокупности рассмотрим
в качестве оценки для аг величину Оценка дисперсии совокупности
- »'(». г) = уу—у - »)' (’)
и найдем ее математическое ожидание. Перепишем <т2 в виде
а2 = —— 22 Л“« е ’)((«> - М) ~ (я - М)) =
п 1 <=i
1 N п
= -—г 22 Z(U| е s^Xi ~ ~ “ м)2
п — I ' п — 1
1=1
Тогда с учетом предыдущих соотношений имеем
Е<Т = (n- 1VV
22 & ~ =
Таким образом, <?2 есть несмещенная оценка для а2.
19*
292 Глава 3. Теория оценивания неизвестных параметров распределений
Замечание. Справедлив более сильный результат: а' есть оптимальная оценка <т‘
в классе воех несмещенных квадратичных оценок, т.е. оценок вида
a(u, v)(x(u) — x)(x(v) - х).
п, v € J
2. Оценивание состава совокупности
Часто составляющие совокупность U объекты классифицируются по некото-
рому признаку (например, полу, возрасту, если U — биологическая популяция,
уровню качества, если U — партия промышленных изделий и т.д.) на задан-
ное число к классов (слоев) СТ),.. , Uk (U = U U Uk, Uj П Uj = 0,
Расслоенная j) — u таких случаях говорят о расслоенной совокупности.
совокупность Размеры классов Nit ,Nk (состав совокупности) явля-
ются неизвестными параметрами, которые должны быть
оценены по результатам соответствующего выборочного эксперимента. Что
касается размера N = Ni + + Nk всей совокупности U, то в одних случаях
он может быть известен, в других же также представляет собой неизвестный
параметр. Например, в задачах статистического (выборочного) контроля ка-
чества продукции U представляет собой партию некоторых изделий, каждое
из которых может классифицироваться по альтернативному признаку «ис-
правно-дефектно»; в этом случае число классов к = 2, размер N всей партии
известен и, следовательно, речь идет об оценивании размера лишь одно-
го класса, например, числа дефектных изделий в партии. При изучении же
биологических популяций (например, популяции рыб в некотором водоеме),
в социологических исследованиях, анализе текстов в лингвистике и т.д., как
правило, общий размер совокупности неизвестен и также подлежит оцени-
ванию по результатам выборочного обследования. Задачи, связанные с оце-
ниванием состава конечных совокупностей, — обширная и многообразная
область прикладных статистических исследований, достаточно полно отра-
женная в обзоре Ивченко и Хонова7^ Здесь же мы в качестве иллюстрации
лишь кратко коснемся некоторых из этого круга вопросов.
Выборочный О Рассмотрим сначала задачу выборочного контроля.
контроль Пусть имеется партия из N изделий, содержащая некото-
рое (неизвестное) число D дефектных изделий, D G {0,1,
.,N}. Чтобы оценить параметр D или, более общо, некоторую заданную
функцию от него т(£>), случайным образом без возвращения из всей партии
извлекается n(< N) изделий, каждое из которых проверяется на доброкаче-
ственность. Пусть Xi — 1, если г-е проверяемое изделие дефектно, и Xi = О
в противном случае, г = 1, , п. Положим d = JV| + .. . + JVn — общее число
обнаруженных в выборке X = (Л), , Хп) дефектных изделий. Тогда d —
полная достаточная статистика.
7) Ивченко Г. И. Хонов С. Л. Статистическое оценивание состава конечной совокупности //
Дискретная математика. 1996.Т.8. № I. С.3-40.
§ 3.9. Оценивание при выборе из конечной совокупности 293
Доказательство. Вычислим функцию правдоподобия
Рр(Л' = г), х = (24,... ,хп), х. = 0, 1,
наших данных. По формуле умножения вероятностей можем записать
PO(X = х) = Pd(Xi = i|)Pp(X2 = ^IA'i = Xi) х
х Pd(A„ = еп|Л\ = Zi, г = 1, , п-1).
Легко видеть, что здесь
PD(Xj;= ij\Xi = xit i = 1, ,7-1) =
' D — ij - — Xj-\
N - j + 1
D ж । *Ej-i
N - j 4- 1
при Xj — 1,
при Xj = 0
(D - X] - - Zj-i)1' , , _ ,
= _ j + ] (N-D-j + \ + xi+ +Ф/-1) ’
Отсюда
PD(X =x) = Dx,(D-x})X2 (D-х,- ~ xn-i)x"(N - D)l~x' x
(N - D - (1 - г,))1-12 (N-D-(n- 1 -x} - - rn-1))1~I,‘
Wh
Наконец, воспользовавшись формулой
r(Z-£1)f= (Z-с,-
которая легко устанавливается, например, индукцией по п, окончательно
находим
р ,х = Т} = Dl(N - D)\(N - п)\ =
D[ (D - d)l(N - D - п 4- d)!№ С$
Согласно критерию факторизации (1) § 3.3, это означает, что d — достаточная
статистика для параметра D.
Чтобы убедиться в ее полноте, требуется доказать, что если Epy?(d) = О
при D = 0, 1, , N, то <p(k) = 0 при к = 0,1,. min(n, D) = п Л D при
всех возможных D, т. е. при к = 0, 1, , п. Но статистика d имеет известное
гипергеометрическое распределение (см. п. 4 § 1.1):
PD(d = к) = f(k; D) = C-^-D, fc = 0, 1, ,nAD, (9)
поэтому предыдущее условие имеет вид
пЛО
^2<p(k)f(k;D) =0, 0 = 0, 1,..., N.
k=0
294 Глава 3. Теория оценивания неизвестных параметров распределений
Полагая здесь последовательно D = 0, D = 1 и т.д., получим
<р(к) = 0, к = 0, 1, , п.
Пусть теперь r(D) — подлежащая оцениванию функция параметра D,
тогда оптимальная несмещенная оценка для нее — это решение уравнения
несмещенности
EoT(d) = т(Р), D = 0,1, ,N
Но при любой функции Т левая часть здесь представляет собой полином от
D степени < п, поэтому, если r(D) не есть полином степени < п, то это
уравнение решения не имеет, и, следовательно, для таких функций т(£>)
несмещенных оценок не существует. Если же Tj(D) = (D)j, j < п, то вос-
пользовавшись формулой для факториальных моментов гипергеометрическо-
го распределения: E£>(d)j = сразу же получаем вид оптималь-
ной оценки факториальной степени (Р);: Tj = (d)j(N)j/(n)j. Оценки для
произвольных полиномов
п
r(D) = 52 aj(D)j
j=0
можно строить с помощью линейных комбинаций статистик Tj на основании
теоремы 3 §3.1. В частности, т(* = dN/n — оптимальная оценка самого
параметра D, а г* = d(n - d)(?V)2/(n)2 — оптимальная оценка функции
т(Л) = D(N - D) при п 2.
Для сравнения приведем вид оценки максимального правдоподобия па-
раметра D, которая получается максимилизацией по D правой части (8):
D = [d(N 4- 1)/тг] (здесь [а] — целая часть числа а).
2) Задача выборочного контроля (продолжение). В некоторых системах ста-
тистического контроля качества продукции поступают следующим образом.
Если число d обнаруженных в выборке дефектных изделий удовлетворяет не-
равенству d < ко, где ко — задаваемый заранее некоторый уровень (ко < п),
то они заменяются на исправные, после чего вся партия принимается. Если же
d > к0, то контролю подвергаются все N изделий, и все дефектные изделия
заменяются на исправные. Пусть случайная величина £ есть число обнару-
женных при описанном способе действия дефектных изделий (подчеркнем,
что это более «богатая» статистика, чем d). Тогда для любой (!) параметриче-
ской функции r(D) можно построить несмещенную оценку вида Т(£), т.е.
являющуюся функцией от причем такая оценка единственна.
Доказательство. Так как распределение статистики ( имеет, очевидно, вид
(см. (9))
Рр($ =к) = f(k;D), fc = O,l,...,fco,
Yd(( = D)= 52 f(k-,D) = F(k0;D) (при D > k0).
A;=Arn -f-1
§ 3.9. Оценивание при выборе из конечной совокупности
295
то условие несмещенности в данном случае выглядит так:
to
EDT(£) = 52 + T(D)F(ko; D) = r(D), D - 0, 1...., N.
*=о
Но при D k0 вероятности f(k; D) — 0 для k > D, поэтому отсюда получаем
систему уравнений
D
^T(k)f(k;D) = r(D), D = O,l,...,k0.
k=0
Эго треугольная система, в которой диагональные коэффициенты f(D; D) / 0.
Следовательно, при любой правой части значения Т(к), к = 0,1, ,ка,
отсюда однозначно определяются. Для значений же т > к0 полагаем
Т(т) =
*0
г<т) - £ m)
________Л-0_______________
F(fc0; т)
что возможно, так как F(ky, т) 0 при т > ка.
Если t(D) = D, то (так как Epd = Dn/N) функция Т имеет вид:
kN
Т(к) — — при к = 0, 1,...До и
п
N *"
пг---- 52 kf№; тп)
Т(т) =---------—--------- при тп > kq.
F(k0 ; тп)
(Ю)
В частности, если положить здесь ко — п (контроль всей партии не преду-
сматривается), то это решение сводится к полученному в предыдущей задаче:
Г«) - <
Рассмотренный пример иллюстрирует тот факт, что наличие дополнитель-
ной информации позволяет получать более сильные статистические выводы. .
3) Схема повторного выбора. Пусть из совокуп- Повторный выбор
ности U, размер которой N и размеры ее классов
N\,...,Nk неизвестны, по схеме случайного выбора с возвращением из-
влекается п объектов и при этом фиксируется, к какому классу принадле-
жит наблюдавшийся объект. В результате подсчитывается число р}Г объектов
класса Uj, появившихся в выборке по т раз каждый, и тем самым исходная
статистическая информация об исследуемой совокупности представляется на-
бором данных {pjr, 3 = 1, , к', т — 1, , п}. По этой информации тре-
буется оценить неизвестный параметрический вектор N = (N], ,Nk) и,
вообще говоря, произвольную функцию r(N) от него. Показано 8\ что в дан-
Ивченко Г. И. О некоторых задачах статистического вывода для расслоенных совокупно-
стей // Теория вероятностей и ее применения. 1984. Т. 29. № 1. С. I13-118.
296 Глава 3. Теория оценивания неизвестных параметров распределений
ной схеме полной достаточной статистикой является 7] = (гц,.. ,pi:), где
п
= УТ /Ъ'г
г= I
— число различных наблюдавшихся объектов класса Uj, j = 1, , к. Таким
образом, задача построения оптимальной несмещенной оценки для r(N_) сво-
дится к выяснению условий разрешимости и отысканию при этих условиях
явного вида решения уравнения несмещенности
ЕлгТ(2) = r(7V), V7V/0. (II)
Обозначим через Aj оператор сдвига на единицу j-Й переменной:
Ajf(x) = f(x + ej), x = (xlt ,хк), Су = (0, ,0,1,0, ,0),
где 1 стоит на j-м месте, через I — тождественный оператор: If(x) = f(x)
и положим Ду = Aj - I (Ду называется оператором разности по j-й пере-
менной). Тогда, если возможные значения вектора N ограничены условием
N = N[ +... + Nk п, уравнение (11) разрешимо для любой функции r(N_)
и при этом оптимальной оценкой для r(N_) является статистика
. (А? Д? -(-1)W(O)
Т = -----------Д^------------’ (12)
где
т] = T]i + + т}к, f(x) =(11+ + хк)пт(х)
И
ДГ^ = У2(-1)г’>С/(<+у)п
у=о
В частности, оптимальная оценка для размера N всей
совокупности имеет вид
ДЧОП+1
N =---------.
Д’) О’1
Если же N / 0 априори может быть любым целочисленным вектором,
то уравнение (И) разрешимо лишь для функций вида r(N_) = f(N_)/Nn где
f(x_) — полином степени п, удовлетворяющий условию /(0) = 0. Для
любой такой функции оптимальная оценка имеет вид (12). В частности, не-
смещенные оценки существуют лишь для полиномов степени п от долей
Ду = Nj/N, j = 1, , к, а оптимальной оценкой для величины 1/N (кото-
рая всегда существует при п 2) является статистика
1
N
Оптимальная
оценка размера
совокупности
Д’0п-
Д’?0п
(14)
Упражнения
297
Упражнения
Я занимался до сих пор решением ряда задач,
ибо при изучении наук примеры полезнее правил.
Исаак Ньютон
О Пусть в урне находится а шаров, из которых О| — белые и а2 = а-в| —
черные. Общее число шаров а известно, а неизвестным и подлежащим оцениванию
является число а, белых шаров или, что то же самое, их доля р = а,/а. Опыт
заключается в извлечении без возвращения п, шаров п < а, причем предполагается,
что любая из Сд комбинаций шаров может быть извлечена с равной вероятностью.
Пусть X обозначает число белых шаров в выборке и рп = Х/п. Найти Ер„ и Dp„,
и обосновать использование случайной величины рп в качестве оценки для р. Сравнить
с результатом примера 6 в §3.1.
Указание. Использовать тот факт, что X имеет гипергеометрическое распределение
H(ah а2, п) (см. п. 4 § 1.1). ►
0 (Продолжение). Рассматривается модель Маркова—Пойа извлечения шаров из ур-
ны (см. п. 5 § 1.1). Пусть, по-прежнему, X есть число белых шаров в выборке объе-
ма п, т. е. С(Х) = МП(п, в|, а2, с), и пусть с > 0. Убедиться в том, что доля белых
шаров в выборке рп = Х/п является несмещенной, но не состоятельной оценкой для
р = Д|/а.
Указание. Воспользоваться формулами (13) § 1.1. ►
Q Рассматривается ситуация, описанная вп.7§ 1.1 (многомерная модель Маркова—
Пойа для урны с N цветами шаров). Используя формулы (19) § 1.1, убедиться в том,
что вектор относительных наблюдавшихся частот цветов в п извлечениях vjn =
= (v\/n,..., Уц1п) является несмещенной оценкой для вектора р = (ах/а,..., aN/a)
долей цветов в урне в стартовый момент.
0 Пусть X = (Х|, , Хп) — выборка из некоторого распределения £(£), для ко-
торого среднее а। = Е£ известно. Требуется оценить неизвестную дисперсию р2 = D£.
1 “
Убедиться в том, что статистика ТН(Х) = — а,)2 является несмещенной и со-
п z'
i=i
стоятельной оценкой р2, если Е£4 < оо.
Q В каких случаях статистика Тп(Х) = является состоятельной оценкой
теоретического среднего at? Убедиться в том, что это имеет место, в частности, для
моделей Г(0, 1) и fif(0, ft2), 9 > 0.
Указание. Воспользоваться состоятельностью выборочного момента ап2. ►
0 По п независимым наблюдениям Л),..., Ха над случайной величиной £ требу-
ется оценить неизвестную вероятность р = Р{£ € Д}, где интервал Д задан. Положим
п
1/п = ^7(Х1€Д)
1=1
— число попаданий в интервал Д. Показать, что статистика Тп = vn/n — несмещенная
и состоятельная оценка р. При каком значении р дисперсия DTn будет максимальной?
298 Глава 3. Теория оценивания неизвестных параметров распределений
Q Пусть случайная величина £ принимает значения 1,2,..., N с некоторыми (не-
известными) вероятностями рь ... ,pN соответственно. Над £ произведено п незави-
симых наблюдений и пусть иг означает число тех из них, когда наблюдался исход «г»
(г = 1,... , N, у, + + vN = п). Доказать, что относительная частота v* = vr/n
является несмещенной и состоятельной оценкой для вероятности рг.
Указание. Воспользоваться тем, что случайная величина имеет биномиальное
распределение Bi(n, р,.); применить неравенство Чебышева. ►
Q Пусть g — оценка для теоретической характеристики g и 0 < Dp < оо. Убедиться
в том, что статистика р2 не является несмещенной оценкой для р2 и вычислить ее
смещение.
Q По выборке X = (X......из распределения £(£) построить несмещенную
оценку его характеристической функции (х.ф.) i/>(t) = Ее'<{
Указание. Рассмотреть эмпирическую х. ф. ►
ПД По результатам п испытаний оценивается неизвестная вероятность «успеха» 9
в схеме Бернулли Bi(l,в). Обозначим гп число успехов в этих испытаниях и рас-
смотрим класс оценок вида Т = (гп + а)/(п + Д). Вычислить среднеквадратичную
ошибку Т, убедиться в том, что при а = у/п/2, Д = у/п она равна [4(Уп +• 1)']
и сравнить эту ошибку с риском «обычной» оценки гп/п.
ш (Продолжение). Убедиться в том, что в классе оценок вида Н(гп) несмещенная
оценка для параметрической функции т(9) = SJ(1 — О)1 при целых s, t 0 существует
лишь при s +1 < п и при этом условии она единственна и имеет вид
ГТ/ \ frn)s(n ~~ Г„)/ . . . .
Н(тп) = ----—--------, где (а)г = а(а-1) (а - г + 1).
(пЬ+<
< Указание. Использовать тот факт, что £a(rn) = Bi(n, 0). ►
ЕЭ Пусть X = (Xi......Хп) — выборка из биномиального распределения Bi(fc, 0)
и Т = JT| +.. .+Х„. Описать класс оцениваемых параметрических функций, т.е. таких,
для которых существуют несмещенные оценки вида Н(Т)\ построить несмещенную
оценку для т;(0) = 61
Указание. Воспользоваться свойством воспроизводимости распределения Bi(fc, в)
(см. п. I § 1.1) и результатом примера 1 в §3.1. ►
ш Пусть произведено одно наблюдение X над пуассоновской случайной величиной
с неизвестным параметром 0. Показать, что Т(Х) = (X)j — несмещенная оценка для
Tj(0) = 03 (j = 1,2,...), а для функций т(0) = 0”° при а > 0 несмещенных оценок
не существует. Построить несмещенную оценку для т(в) = (6 + I)-1
[Q По одному наблюдению над дискретной случайной величиной £ с распределе-
нием
, е~в 9г
(урезанное в нуле пуассоновское распределение), требуется оценить функцию т(в) =
= 1 - e~s Убедиться в том, что статистика
2 при £ четном,
О в противном случае
— единственная несмещенная оценка т(9), но она практически бесполезна.
Т(& =
Упражнения
299
ш Показать, что Т(Х) = - — единственная несмещенная оценка функции
т(6) = In (1 - в) в модели Bi(l, 9) при одном наблюдении.
ш В модели Nip, О2) требуется оценить т(в) = 02 по выборке объема п. Показать,
что выборочная дисперсия S2 имеет меньшую с. к. о., чем несмещенная оценка Т„,
указанная в упр. 4, но в классе несмещенных оценок Тп точнее, чем = (n/(n-1))№
ш Доказать, что статистика
— несмещенная и состоятельная оценка параметра в в модели в2).
ш Дана выборка X = (Xt, Х3) из нормального распределения A/*(0,02). Рас-
смотрим статистику
Рт(х) = S? Т),
где Г = Т(Х) = (Х? + Х2 + Хэ)|/2, которая как функция переменного х представляет
собой плотность равномерного распределения U(-T,T). Убедиться в том, что р?(г)
при любом х является несмещенной оценкой теоретической плотности.
• < Указание. Учесть, что С6(Т2/02) = X~(ty. ►
ш Пусть X = (Х|,..., Х„) — выборка из распределения Л/”(/х, в2) и
Т = ^(Х,-М)2
1=1
Проверить, что несмещенной оценкой для функции тД0) = 0k при любом к > —п
является статистика (см. (45) §3.4)
Сравнить оценку т(* с оценкой, указанной в упр. 17.
« Указание. Использовать тот факт, что £е(7’/Р2) = Х'(п)> и формулу для моментов
гамма-распределения (см. п. 3 § 1.1). ►
Я1 Доказать, что в общей нормальной модели Щ0\, 02) несмещенной оценкой для
функции т\.(0) = 02 по выборке объема п при к> -n+ 1 является статистика (см. (46)
§3.4)
/ п - 1 \
, < nS2\k/2 \ 2 /
Г‘’ = \~2~/ г^п + *~
где S' — выборочная дисперсия. Рассмотреть случай п = 2 и вычислить смещение
статистики |Х, - Х2| как оценки 0т.
4 Указание. Учесть, что по теореме Фишера £.e(nS2/0l) = х2(п ~ •)• ►
300 Глава 3. Теория оценивания неизвестных параметров распределений
Пусть X = (Хь ,Хп) — выборка из гамма-распределения Г(0, А) и Т =
= Х| + + ХП. Убедиться в том, что статистика
г:=т Г|;'"'
Г(Ап + г)
— несмещенная оценка функции тт(6) = 0г при любом г > -Ап (см. (39) §3.4).
Ч Указание. Воспользоваться свойствами гамма-распределения (см. п. 3 § 1.2). ►
И По выборке X = (Л), .Л),) из равномерного распределения U(6, 26) тре-
буется оценить параметр 0. Доказать, что в классе оценок вида Т = аХ(|) 4-ДХ(п).
а,Р 0, оптимальная несмещенная оценка есть
• п + I ,
т =^(Х<') + 2Х(П));
вычислить ее дисперсию.
◄ Указание. Воспользоваться результатами упр. 46 к гл. 1. ►
и Оценивается параметр 6 распределения 1Г(0, 0) по выборке X = (Л), ,Хп).
Убедиться в том, что статистики Т, = (n + l)/nX(n), Т2 = 2Х и Т3 = (п 4- 1)Х(|)
несмещенные. Какая из них предпочтительнее?
ш Пусть X = (X!, , Хп) — выборка из {/(tfi.Si). Доказать, что статистики
Ti = (Х(|)+Х(п))/2 и Т2 = (п+1)/(п- 1)(Х(п)— -Х),)) — несмещенные и состоятельные
оценки функций тДО) = (0, + 62)/2 и т2(0) = 02 - 6\ соответственно.
И Показать, что для логистического распределения, задаваемого плотностью
f(x\0) = e‘l+e(l + e’l+9)’2, х,0 € R1
несмещенной и состоятельной оценкой параметра в является выборочное среднее X.
ш Является ли выборочное среднее состоятельной оценкой параметра 0 модели
Коши Г(0)?
◄ Указание. Использовать упр. 48(6) к гл. 1. ►
ш Проверить, что количество информации i(0) для соответствующих моделей имеет
указанный в табл. 1 § 3.2 вид.
ВИ Установить результаты, указанные в табл. 2 § 3.2.
Рассматривается задача оценивания функции т(0) = 0" в модели Г(0, А) по вы-
борке X = (АГ,,..., Х„). Воспользовавшись критерием Бхаттачария, показать, что
статистика 7* = п/(А(Ап + 1))Л2 является оптимальной, но не эффективной оцен-
кой т(0).
ЕЛ Пусть X = (Х|,..., Хп) — выборка из обратного гауссовского распределения,
задаваемого плотностью
( А \ Г Х(х — р)2 3
f(x,X, р) = -—г ехр <----—------ к х > О, А > 0, д/0.
\2irx2 J (, 2р2х J
1) Убедиться в том, что X — оптимальная несмещенная оценка параметра р в лю-
бом случае, известен или нет параметр А. Получить отсюда, что ЕЛ) = р.
DA) = р}/Х.
2) Найти эффективную оценку А- при известном р.
Упражнения
301
◄ Указание. Воспользоваться общими результатами для экспоненциальной модели
и критерием Бхаттачария. ►
ЕН Доказать непосредственно полноту достаточной статистики Т = Х} + .. .+Хп для
биномиальной модели Bi(k,0). Получить отсюда, что в данном случае несмещенные
оценки существуют лишь для полиномов
т(0) =
i=o
при г S7 кп, при этом оптимальная оценка имеет вид
◄ Указание. Воспользоваться свойством воспроизводимости распределения Bi(A, 0). ►
КЯ Доказать полноту достаточной статистики Т = Х\+ .. + Хп для пуассоновской
модели П(0). Показать, что оптимальной несмещенной оценкой для сходящегося при
всех 9 > 0 степенного ряда т(0) = а;0; является статистика т* = 1 . 1
Ч Указание. Воспользоваться свойством воспроизводимости распределения П(0). ►
ЕП Показать, что оптимальной оценкой параметра 0, урезанного в нуле пуассонов-
ского распределения (упр. 14) по соответствующей выборке X = (Х|,. , Х„) явля-
ется статистика т* = 7,ДП0Т~|/(ДП0Г) при Т = Х1 + ... + Хп'^п+ \ и т* = О при
Т = п, где
aV = 52(-1)п-гсУ
г=0
◄ Указание. Воспользоваться общим результатом для модели степенного ряда. ►
ЕН Доказать, что оценки, указанные в упр. 19, 20 и 21 — оптимальные.
ЮЭ Показать, что в модели М(0,у02) достаточной является статистика Т = (X, S2),
но она не полна.
◄ Указание. Вычислить среднее функции
. , Si(n + y')
и Т = —2--------LL _ J2 ►
* ’ (« - 1)7
ЕЯ По результатам тг 2г 2 независимых измерений диаметра 0^ круга построить оп-
тимальную несмещенную оценку
*
т = 7 х-------------7s 1
4 \ 71-1 /
его площади т(0) = —0?, считая погрешности измерений нормальными Х(0, 0})
случайными величинами.
ЕН Доказать, что в упр. 23 статистика Tt — оптимальная несмещенная оценка 0.
Рассмотреть класс оценок 7\ = АТ, и убедиться в том, что в нем имеются оценки
с меньшей с. к. о., чем у оценки Т}, оптимальным же по критерию минимума с. к. о.
является выбор А* = n(n + 2)/(п + I)2.
302 Глава 3. Теория оценивания неизвестных параметров распределений
о Доказать, что Т = (Х^,Х(„у) — полная достаточная статистика для модели
U(0|, 02) и обосновать оптимальность оценок в упр. 24. Построить оптимальные оцен-
ки ДЛЯ 0, И 02.
◄ Указание. Воспользоваться упр. 46 к гл. 1. ►
Рассматривается двухпарамстрическая показательная модель 1Г((?|, 1,02) (см.
пример 2 в § 3.3). Основываясь на том факте, что здесь достаточная статистика
T = (T„T2) = (Xll},X-Xw)
полна, убедиться в том, что оптимальными несмещенными оценками параметров мо-
дели являются соответственно
V = Г, - = -Ц(пХ(|) - X) 02 = —^-—Т2;
(п — 1) п — 1 п — 1
при этом
◄ Указание. Используя результаты примера I в § 2.4, представить 7, и Т2 через по-
казательные спейсинги У,, ,УП: У, = п(Т| — 01)/02, У2 + ... + Y„ = пТ2/02, где
Уг = (п - г + 1)(Х(Г) - Х(г_|))/в2, г 2. Отсюда, в частности, следует, что 7, и Т2
независимы, к
EJ Убедиться в том, что оптимальная несмещенная оценка параметра 0 распрсделе-
п
ния Вейбулла ЗУ(0, a, по выборке X = (Хь ..., Х„) есть 7/п, где Т = У X"
i=i
◄ Указание. См. пример 15 §3.4. ►
ш Доказать непосредственно, вычислив Е#0П и De0„, асимптотическую несмещен-
ность и состоятельность о. м. п. 0п параметра 0 нормальной модели М(р,0г) н найти
ее предельный при п -> оо закон распределения; вычислить асимптотическую эффек-
тивность оценки 7„ в упр. 17.
1 " 'Р
t = l J
◄ Указание. Выразить 0п =
через оптимальную несмещенную
оценку г,* в упр. 19; применить к оценке Тп центральную предельную теорему. ►
и Убедиться в том, что о. м. п. 0„ параметра 0 в модели /v(0,10) имеет вид 0п =
1
= х/1 +тп - 1, где Т„ = - У X,2
п
1=1
и доказать ее состоятельность.
◄ Указание. Применить к Гп закон больших чисел. ►
И Имеется выборка (Х(, У)), i = 1,..., п, из двумерного нормального распределе-
ния
М (0,0),
1 0
0 1
бе (-1,1).
Составить уравнение правдоподобия для о. м. п. 0п и убедиться в том, что ее асимпто-
тическая дисперсия равна (1 -02)2/(п(1+02)). Рассмотреть в качестве альтернативной
оценки коэффициента корреляции 0 выборочный коэффициент корреляции
Упражнения
303
и доказать, что его асимптотическая эффективность есть
/ 1 _ gi \ 2
ЛО’Ы
4 Указание. При вычислении моментов использовать характеристическую функцию
(см. указание к упр. 29 гл. I). ►
□ Пусть X = ,Хп) — выборка из распределения Кептайна, задаваемого
плотностью
/СМ) = 7^9, ехр {” ~ }’ 0 = ^1,192)’
где д(х) — некоторая дифференцируемая монотонно возрастающая функция (при
д(х) = х имеем нормальное распределение Убедиться в том, что справед-
ливо следующее обобщение результата примера 1 в § 3.5: о. м. п. 9 = (д, Т), где
9 = Е 9<Ы Т2 = ± !>(*,) - в)2
1 >=1 1 i=i
Является ли д эффективной оценкой 6t? Показать, что при известном значении <?, = а
эффективной оценкой в] является статистика
1 "
тг = -Е^)-“)2
‘ 1=1
(ср. с соответствующими результатами для нормальной модели, см. примеры 1, 2 и 8
§3-2).
ЕЯ Найти о. м. п. 9п параметра 9 отрицательной биномиальной модели Bi(r, 9)
и вычислить ее асимптотическую дисперсию.
Указание. Использовать общие результаты примера 9 в § 3.5 для модели степенного
ряда. ►
и Пусть в полиномиальном распределении М(п-,р},... ,pN) вероятности исхо-
дов имеют вид pi = Pi(9), i = 1.N, где 9 — общий неизвестный (скалярный)
параметр. Составить уравнения метода накопления для приближенного вычисления
о. м. п. 9.
ЕЯ Показать, что асимптотическая эффективность выборочной медианы в модели
Коши /С(9) (см. пример 8 в § 3.5) равна 8/тг2 = 0,8 ...
Указание. Воспользоваться теоремой 1 §2.4 (соотношение (15)). ►
ВЯ Убедиться в асимптотической несмещенности и состоятельности о. м. п. 9„ = Х(п)
параметра 9 равномерной модели Е7(0, 9) (см. примеры 3 и 11 §3.5). Доказать непо-
средственно, что при п -> оо
Указание. Использовать упр,23, а также 46 к гл. 1. ►
304 Глава 3. Теория оценивания неизвестных параметров распределений
EQ Показать, что в случае модели U(6 - 1/2, 0 + 1/2) любое значение
0 е ^(«) “ + 2
является о. м. п. 0П. Какая точка этого интервала является несмещенной оценкой 0?
Указание. Записать о. м. п. в виде
и найти а из уравнения несмещенности. ►
Eil Рассматривается семейство распределений Вейбулла W(0, a,b) с неизвестным
параметром сдвига. Убедиться в том, что при 0 < а 1 о.м.п. 0„ = Х(ц асимптоти-
чески иесмещена и состоятельна, а ее закон распределения не является нормальным
при п -> оо.
◄ Указание. Использовать результаты примера 6 §3.2 и упр. 56 к гл. 1. ►
ш Случайная величина £, характеризующая срок службы элементов электронной
аппаратуры, имеет распределение Релея TV(O, 2, V0) (см. упр. 40). Убедиться в том,
что о. м. п. 0П = Т/n, т. е. совпадает с оптимальной несмещенной оценкой 0
и По выборке X = (Х|,... ,ХП) из гамма-распределения Г(0, А) требуется оце-
нить функцию т(0) = 0~' Показать, что о. м.п. тп = Х/Х, убедиться в ее асимп-
тотической несмещенности и состоятельности, а также установить, что при п —> оо
V(l/0, 1/(Ап02)).
◄ Указание. Использовать упр. 21. ►
ЕП Доказать, что для распределения Лапласа с параметром сдвига, задаваемого плот-
ностью f(x; 0) = (1/2)е"|1-в|, 1,0 € R.', о. м. п. 0„ совпадаете выборочной медианой
и установить ее асимптотическую нормальность: £e(0n) ~ А/"(0, п" ).
ЕП Убедиться в асимптотической несмещенности и состоятельности о. м. п. 0П =
— (01п,02и) параметров двухпараметрической показательной модели (см. пример 4
в §3.5).
Преобразования, стабилизирующие дисперсию. Установить следующие, полезные
аппроксимации для распределений специальных функций от о. м. п.:
для модели Bi(fc,0):
для модели П(0):
£о(1п 0П) ~ Л/"Нп 0, -!Д 0„ =
для модели Л/"(/2,02):
। " 1 '/2
1 = 1
для модели Г(0, А):
£₽(1п0п)~Х( 1п0,), 0п = v
\ Хп / А
Упражнения
305
◄ Указание. См. п. 5 (соотношение (31)) §3.5. ►
Объединение статистической информации. Пусть Xj - (Xjt, ,X]nj'), j = 1,
, k, — независимые выборки из распределений 9гУ), j = 1.......к, соответ-
ственно и Xj, Sj — соответствующие выборочные средние и дисперсии. Доказать,
что 9 = (Х\,.... Хк, 9-У) — о- м. п. для в = (0ц,..., eki, 9-У}, где
_ 1 *,
9г = — njSj> п = П| + + пк:
п
i = i
несмещенной же оценкой для общей дисперсии 9\ является статистика
◄ Указание. Использовать пример 1 в § 3.5, записав функцию правдоподобия для всех
данных в виде
I = (27re<2)'n/2exp|-^j52nJ(i:J -9^-п - |) - hi j,
где
? = 52 пз3У ►
; = 1
ЕЕ? Показать, что 7-доверительный интервал для параметра 9 модели N"(9, 92), 9>0,
по выборке X = (Х[,..., ХП) имеет вид
( * X \ с _ T-,fl +7\
\1-|-с7/Уп’ 1-с7/7/пу’ С? \ 2 7
Получить аналогичный результат для случая 9 < 0.
◄ Указание. Использовать тот факт, что £e(Vn(X - 9)/9) = JV(0,1). ►
El Пусть X = (Х{,..., Хп) — выборка из распределения V(0, ст2).
1) Убедиться в том, что любой интервал вида
Д7(Х) = (х- X-
\ т/П у/п J
где gi < gi — любые числа, удовлетворяющие условию Ф(д,) - Ф(д,) = 7, явля-
ется 7-доверительным интервалом для параметра 9. Доказать, что кратчайший
из этих интервалов есть Д7(Х) = (Xf ac-Jyfn).
2) Сколько необходимо произвести наблюдений п = п(1, 7), чтобы точность лока-
лизации параметра, т.е. длина интервала Д‘(Х), была равна заданной величи-
не Z? Проверить, что при заданных п и I доверительный уровень 7 = 7(71,1) =
= 2Ф(/л/п/(2(г)) - 1.
◄ Указание. Использовать результаты примера 2 в § 3.8. ►
20 Заказ 1748
306 Глава 3. Теория оценивания неизвестных параметров распределений
Доказать, что 7-доверитсльным интервалом для среднеквадратичного отклоне-
ния в модели N\p, в') является любой интервал = (Т/а2, T/at), где
п
T2 = Y№i-rf
1 = 1
а числа й| < а? выбираются из условия
От
У xk„(x2)dx =
где kn(t) — плотность распределения Х2(п)- Определить кратчайший в этом классе
интервал д’(А').
Ч Указание. Использовать то, что ДДТ2/#') = х"(п)- ►
Е] Доказать, что нижний и верхний 7-доверительные интервалы для среднего #,
модели ДГ(#|, 62) по выборке X = (Хь..., Хп) имеют соответственно вид
V у/п -1 / \ Уп^ТJ
Ч Указание. См. пример I в §2.5, где построен двусторонний интервал для 9] ►
ш (Продолжение). Построить односторонние 7-довсритсльныс интервалы для дис-
персии Si '
/ п8~ (г,~> п8~ \
—----- < #( и #22 < -з---------
УХ'з.п- 'J k Xi-7,n-i/
(двусторонний центральный 7-доверительный интервал указан в (10) §2.5).
И Пусть X — (X),..., Хи) н Y — (У,,..., Уш) — две независимые выборки, при-
чем первая из распределения Д/'(#<|\ <т(), а вторая — из АД#*21, а2). Показать, что
центральный 7-доверительный интервал для разности средних т = #(|) - #<2) имеет
вид, указанный в табл. 1 §3.8.
и Пусть X — (Х|, .. ,Хп) и У = (У.........У,„) — независимые выборки из рас-
пределений Г(#!, 1) и Г(#2, 1) соответственно. Доказать, что центральный 7-довери-
тельный интервал для отношения т = #2/#[ имеет вид
/'^*1(1-Т)/21 2n, Ini У ^*Н+7)/2.2л, 2m У \
\ X ’ Т )’
где FV T a — р-квантиль распределения Снедекора S(r,s).
Ч Указание. Использоватьтотфакт, что С^тХ/У) = S(2n,2тп) (см. упр. 54 к гл. I). ►
EJ Убедиться в том, что 7-довсрительный интервал для параметра сдвига показа-
тельного распределения: /(х; 6) = е~х+е, х 6, по п наблюдениям имеет вид
^(i) + In (1 - 7), Х(1)^
Какой вид будет иметь здесь центральный 7-доверитсльный интервал?
Упражнения
307
Ч Указание. Найти распределение статистики Хп = min X, и учесть, что событие
{X(i) в} является достоверным. ►
ЕЗ Рассматривается модель упр. 40. Убедиться в том, что центральный 7-довери-
тельный интервал для параметра в имеет вид
/ 2Т 2Т \
\ 2 ’ 2 I '
УХ(|+1)/г.гп Х(|-7)/2.2п/
В частности, при а = I имеем соответствующее решение для модели Г(0, I).
•< Указание. Учесть, что £в(2£°/0) = Х?(2) (см. пример 15 в §3.4 и п. 3 § 1.2). ►
Рассматривается модель упр. 39. Учитывая, что
=Г(2,п- 1) = Х2(2(п- I)),
X »2 /
т. е. 2пТг/вг — центральная статистика для 6г (см. указание к упр. 39), убедиться в том,
что
/ 2пТг 2пТг \
X Х(1 +7)/2. 2(n-1) Х2|-т)/2. 2(n-1) /
есть центральный 7-доверительный интервал для 02. Далее, так как
(2п(Т| - 0|) \ . . 1. ,
£»( —Ц--------"J =Г<2’ 0=/(2)
\ *2 /
и статистики Т| и Т2 независимы, то
2n(T, -0,) 2пТг (п-1)(Т,-0,)
202 2(п - 1)02 7,
— центральная статистика для 0,, имеющая распределение Снедекора 5(2, 2(п - 1)).
Следовательно, центральный 7-доверительный интервал для 0| есть
/7, Т2 \
( Т1 ~ ^77j--f(l+T)/2.2.2(n-l), - ^^j-F(|-1)/2,2.2(n-l) I
EQ Прогнозирование будущих наблюдений. Пусть п, X и 52 — объем, выборочные
среднее и дисперсия выборки из распределения V(0|, 02). Показать, что с вероятно-
стью 7 результат следующего, (п + 1)-го испытания Хп+1 попадет в интервал
где tp „ — р-квантпль распределения Стьюдента 5(п Ч Указание. Учесть, что / 1(п-1)(Х-Хл+1)\ _ vV<n+|) s ' (следствие теоремы 2 § 2.5). ► 20* >)• : 5(71 - 1)
308 Глава 3. Теория оценивания неизвестных параметров распределений
Пусть X = (Х(, , Х„) — выборка из нормального распределения Л/"(д, 02).
Показать, что приближенные (при больших п) 7-доверительные интервалы для пара-
метра 6 и функции т(9) = 1п9 имеют вид соответственно
. ( С-у \ Л С-» \
l=F-7= 1п0„Т-7= ,
\ v2n/ \ v2n/
где
*" = Е(*‘-^)21Z и ^ = ф‘'Нг)-
1 = 1 J '
Получить из второго результата другой интервал для 9.
< Указание. Использовать результат, указанный в упр. 55. ►
И Доказать, что в случае больших выборок асимптотически кратчайший 7-дове-
рительный интервал для параметра в модели Г(6, А) имеет вид ХА-|(1 с7/х/Ап),
а аналогичный интервал для функции т(9) = In 9 есть (In 9Н Т с7/'/Ап) (см. упр. 55).
Получить из второго результата другой интервал для в.
ЕД По выборке X = (Х|,...,ХП) из распределения Bi(l, 9) построить асимптоти-
ческий (при п -4 оо) 7-доверительный интервал для 9 основываясь на нормальной
аппроксимации
(теорема Муавра—Лапласа). Сравнить полученное решение с решением, указанным
в примере 17 в § 3.5.
ш Показать, что асимптотический 7-доверительный интервал для параметра 9 от-
рицательной биномиальной модели Bi(r, 9) имеет вид
X Г тХ 11/2\
r+X^^Hr+f)’] )
(ср. с результатом примера 16 §3.5).
< Указание. Воспользоваться общим результатом (33) § 3.5 для модели степенного
ряда и формулами (7) § 1.1. ►
ЕЭ Показать, что оценкой по методу моментов параметра 9 равномерного распре-
деления 17(0,6) является статистика 9 = 2Х и исследовать ее на несмещенность,
состоятельность и эффективность (см. упр. 23).
Б1 Убедиться в том, что оценка по методу моментов параметра 9 распределения
U(—9, 9), 9 > 0, есть 9 = х/3а2.
ЕЛ Пусть X = (X........Х„) — выборка из распределения Лапласа с плотностью
f(x;9) = 6>0.
Показать, что оценка 9 по методу моментов есть 9 = у/2/а-,.
ИЯ Найти методом моментов оценки параметров 6, и 6, «двойного» распределения
Пуассона, задаваемого вероятностями
рие==
Ve-^.+e-^>
2 \ х! х! / '
х = 0, 1,2.......... 0 < 9, < 9:.
Упражнения
309
Пусть X(i; < < JV(rj — цензурированные данные для п наблюдений (г п)
в модели упр. 39 и Y, = (п - i + 1)(Лр) - АГр-ц), i = 2,..., г. Показать, что
<52 = У = Уг+Г —= тт;(Е-nXw - (n-r)xw)
'1=1 '
и J] = X(|} -Y/n — несмещенные оценки соответственно для 02 и 0] и вычислить
их дисперсии
0^2 = -^-, од = —
(г - 1) (г - 1)п2
(при г = п имеем результат упр. 39).
◄ Указание. Перейти к величине = (£ —0|)/#2 и использовать пример I в §2.4. ►
Рассматривается задача оценивания неизвестной вероятности «успеха» в по на-
блюдению числа «успехов» X в п испытаниях Бернулли. Пусть функция потерь имеет
вид
1 ’ 0(\ — 0)
а априорное распределение параметра £(0) = U(ft, I). Доказать, что байессовская
оценка есть 6*(Х) = Х/п — относительная частота «успеха», и она же является ми-
нимаксной; при этом байессовский риск r(t)‘) = 1/п.
◄ Указание. Вычислить апостериорный риск (16) § 3.6 и убедиться в том, что он ми-
нимизируется при 5(Х) = Х/п, при этом функция риска Я(<5’, в) = 1/п — не зависит
от в. ►
И Пусть испытания Бернулли продолжаются до получения г-го «неуспеха» и X —
число «успехов» в этих испытаниях, т. е. £д(Х) = В1(т, 0). Убедиться в том, что если
функция потерь L(S,0) = (<5 - 0)2, а априорное распределение £(0) — Ве(а, Ь), то
байессовская оценка вероятности «успеха» 0 есть
◄ Указание. Использовать упр. 64 (2) к гл. 1 и формулы (24) § 1.2. ►
По выборке X = (2СЬ .. , Хп) из пуассоновского распределения П(0) оценива-
ется параметр в при квадратичной функции потерь L(6, 0) = (5 - 0)2 и априорном
распределении £(0) Г(а, А) Показать, что байессовская оценка имеет вид
Грс)= а(Л + *), Х = Х: +... + Хп,
па + 1
и ее риск есть г(<5’) = Ха2/(па + 1). Определить оптимальный объем выборки при
цене с > 0 одного наблюдения (т. е. минимизирующий общие потери г(<5‘) + сп).
◄ Указание. Использовать упр. 64(3) к гл. 1 и формулы (21) § 1.2. ►
(Продолжение). Убедиться в том, что если функция потерь £(J, 0) = (д - 0)2/0,
то байессовская оценка при Л + X > 1 имеет вид
5*(Х)= —^—(Х + А- 1)
по -I- 1
и ее риск г(<5*) = а/(па + 1).
310 Глава 3. Теория оценивания неизвестных параметров распределений
ш Рассматривается задача оценивания параметра 0 показательного распределения
с плотностью /(z; 0) = 0е~ех х 0, 6 > 0, по выборке X = (Jf|, , Х„). Пусть
функция потерь L(S,0) = (<5 - 0”1)2 и априорное распределение £(0) = Г(а, А),
А > 2. Доказать, что байесовская оценка имеет вид
I / " \
6‘(Х) = --------Г ° У х< + 1 )
а(А + п- 1) \ J
и ее риск г(#‘) = [а2(А + п - 1)(А - 1)(А - 2)]”1 Убедиться в том, что оптимальное
число наблюдений при цене с > 0 одного наблюдения равно
. 1
п — —. = — А 4- I.
о^с(А- 1)(А-2)
Ч Указание. Использовать упр. 64 (4) к гл. 1 и формулы для моментов гамма-распре-
деления (п. 3 § 1.2). ►
Ей Пусть X = (X,........Хп) — выборка из равномерного распределения Г7(0, в),
где априорное распределение параметра 0 есть распределение Парето с параметрами
io и а > 2 (см. п. 9 § 1.2). Убедиться в том, что при квадратичной функции потерь
байесовская оценка 0 имеет вид
i'(X) = W + -a max(z0, X(n)), X(n) = max Х„
п + а - 1 <>«:»
и ее риск г(<5‘) = агц/Ца - 2)(п + а - I)2]. Определить оптимальный объем выборки
при цене с > 0 одного наблюдения.
Ч Указание. Использовать упр. 64 (6) к гл. 1 и формулы (39) § 1.2. ►
Ей Убедиться в том, что байесовская оценка параметра 0 нормального распре-
деления fif(0,b2) при квадратичной функции потерь и априорном распределении
£(0) = Ы(р,а2) есть i'(X) = /1| и ее риск г(<5*) = а2 (обозначения упр. 64 (5)
к гл. 1), а оптимальное число наблюдений при цене с > 0 одного наблюдения равно
п* = Ъ(с'12 - Ьа~2).
ч Указание. Использовать упр. 64 (5) к гл. 1. ►
Глава 4
Проверка статистических гипотез
...Узловым вопросом математической статистики является
вопрос, как далеко могут отклоняться величины, вычисленные
по выборке, от соответствующих идеальных значений?
Б. Л. Ван дер Варден |(
Эта глава представляет собой введение в теорию проверки статистиче-
ских гипотез. Здесь вводятся основные понятия этой теории (статистической
гипотезы, статистического критерия, критической области, функции мощ-
ности и др.) и на примерах решения задач проверки типичных и наиболее
распространенных в приложениях статистических гипотез излагаются общие
принципы построения и исследования критериев согласия. Значительное вни-
мание уделяется методу группировки наблюдений с последующим примене-
нием классического критерия хи-квадрат.
§4.1. Основные понятия и общие принципы
теории проверки гипотез
Как отмечалось в общем Введении, математическая статистика, помимо оце-
нивания неизвестных параметров распределений, занимается еще и проверкой
статистических гипотез, т.е. различных предположений о виде или свойствах
распределений наблюдаемых случайных величин. Общее понятие статистиче-
ской гипотезы (далее будем говорить для краткости просто гипотезы) и приме-
ры типичных и наиболее распространенных гипотез приведены во Введении.
Поэтому здесь мы ограничимся лишь кратким напоминанием основных фак-
тов, необходимых нам для развития этой темы.
Пусть X — данные (выборка), X = {i} — выборчное пространство,
F = {Я} — совокупность априори допустимых распределений X, Fx — не-
известное истинное распределение данных X, Fx 6 Т В общем случае задача
проверки гипотез ставится так: выделяется некоторое подмножество Fq С F
допустимых распределений и требуется по данным X проверить, справед-
ливо ли утверждение Яр Fx 6 Яо или же оно ложно. В этом случае Яр
называется основной (нулевой) гипотезой. Распределения F € F\ = F\F> на-
зываются альтернативными, а утверждение Н\ Fx 6 Т\ — альтернативной
Ван дер Варден Бартел Лендерт (1903-1996) — голландский математик — статистик и ал-
гебраист.
312
Глава 4. Проверка статистических гипотез
гипотезой. В этом случае речь идет о проверке гипотезы Но против альтер-
нативы Я| или о задаче (Я0,Я|); иногда также говорят, что гипотеза Яс
проверяется внутри общей гипотезы Я F% € Т7 = То U Т). Если подмно-
жество J'o(J'i) состоит из одного элемента, то гипотеза Но (альтернатива Н\)
называется простой, в противном случае — сложной.
Правило, согласно которому мы, наблюдая X, принимаем решение при-
нять гипотезу Hq как истинную либо отклонить ее как ложную (т. е. при-
нять альтернативную гипотезу Я|) называется статистическим критерием
(или просто критерием).
Статистические гипотезы могут быть самые разные. В простейших случа-
ях проверяемая гипотеза может однозначно фиксировать распределение Fx,
но типично она указывает лишь тот класс допустимых распределений, ко-
торому, по предположению, принадлежит истинное распределение данных.
В некоторых случаях класс Т7 — это все распределения на выборочном про-
странстве X, тогда альтернативная гипотеза Н\ = Но («не Яд») никак не кон-
кретизируется, и здесь речь идет просто о согласии данных X с нулевой
гипотезой Но (согласуются ли данные X с гипотезой Но или же они ее
опровергают) — соответствующие критерии называются критериями согласия.
В других случаях класс всех допустимых распределений данных является за-
данным параметрическим семейством У = {F(i; в), в € 0}; здесь гипотезы
имеют вид Яд: # € ©о С 0, а Ht : в G 0| = 0\0q, и называются параметри-
ческими. О соответствующих критериях также говорят как о параметрических
критериях. В любом случае «хороший» критерий должен учитывать специ-
фику проверяемой гипотезы: в непараметрическом случае он должен быть
универсального типа, т. е. обнаруживать любые отклонения от Яо, в парамет-
рическом же случае он должен быть направлен на обнаружение конкретных
(в рамках рассматриваемой параметрической модели Т7) отклонений от Яо.
Но любой статистический критерий строится по следующей схеме.
Поскольку критерий — это правило, которое для каждой реализации х
выборки X должно приводить к одному из двух решений: принять гипоте-
зу Яо или отклонить ее (принять альтернативу Н\), то каждому критерию
соответствует некоторое разбиение выборочного пространства X на два вза-
имно дополнительных множества Хо и Xj (ХрЛХ! = 0, XgUX1 = X), где Хо
состоит из тех точек х, для которых Но принимается, а Х| — из тех, для кото-
рых Яо отвергается (принимается Я[). Таким образом, Хо — это область при-
нятия гипотезы Яо, а X! — область ее отклонения, которую принято называть
критической областью. Тем самым, любой критерий проверки гипотезы Яо
однозначно задается соответствующей критической областью Х>, и о таком
критерии часто говорят как о «критерии Хр. Итак, критерий Х| имеет вид
|Яр отвергается <=> X 6 Х,.|
Как в конкретной задаче (Яо, Я|) выбирать критическую область X,? Это
делается на основе постулируемого в математической статистике следующего
§ 4.1. Основные понятия и принципы теории проверки гипотез 313
общего принципа принятия решения: если в экспери- Общий принцип
менте наблюдается маловероятное при справедливо- принятия решений
сти гипотезы Но событие, то считается, что гипоте-
за Яо не согласуется с данными (или противоречит им), и в этом случае она
отвергается (отклоняется); в противном случае считается, что данные не про-
тиворечат Яо (или согласуются с ней), и Нп принимается.
В соответствии с этим принципом критическая область Xj должна быть
выбрана так, чтобы была мала вероятность Р{ X Е Xi |Яц}, т.е. условная
(при условии, что Яо справедлива) вероятность попадания значения выбор-
ки X в область Xi Поэтому при построении критерия задаются заранее
некоторым малым числом а (например, а — 0,001; 0,01; 0,05 и т.д.) и нала-
гают условие
P{JV eXJffJU (1)
Если выполнено (1), то говорят, что критерий X, имеет уровень значимо-
сти а и подчеркивают это обозначением Х| = Xio. Ясно, что условием (1)
критическая область X(tt определяется неоднозначно, и чтобы устранить эту
неопределенность, надо ввести дополнительное понятие ошибок критерия.
Следуя любому критерию Xia, мы можем принять правильное решение
либо совершить одну из двух ошибок: ошибку 1-го рода, отвергнув Но, когда
она верна, или ошибку 2-го рода, приняв Яо, когда она ложна (ошибка 1-го
рода совершается, когда наблюдение X попадает в критическую область Х,о,
в то время как верна гипотеза Н^: вероятность этого есть как раз левая часть
(1), а ошибка 2-го рода — когда X £ Хщ = Xqo, но гипотеза Но не верна).
Введем теперь фундаментальное понятие теории проверки статистических
гипотез — понятие функции мощности критерия. По функция мощности
определению, функцией мощности критерия Х]О на- критерия
зывается следующий функционал на множестве всех
допустимых распределений F = {F} выборки X
W(F) = W(F; Х1о) = Р{Х Е Xlo|F}, F £ Т (2)
Другими словами, W(F; Хщ) — это вероятность попадания значения выбор-
ки X в критическую область Х(а, когда F — ее истинное распределение.
Через функцию мощности легко выразить вероятности обоих типов ошибок,
свойственных критерию Хщ. Именно, вероятность ошибки 1-го рода есть
W(F) при F € То, а 2-го рода — 1 - W(F) при F € F\. Иногда удобно
записывать эти вероятности в символическом виде: Р{Я[|Яо} (вероятность
ошибки 1-го рода) и Р{Я0|Я|} (вероятность ошибки 2-го рода).
Естественно стремиться построить критерий так, чтобы свести к минимуму
вероятности обоих типов ошибок. Однако при фиксированном объеме выбор-
ки сумма вероятностей ошибок обоих типов не может быть сделана как угодно
малой (это своего рода принцип неопределенности при проверке гипотез). По-
этому рациональный принцип выбора критической области формулируется сле-
дующим образом: из всех критических областей Xio (т. е. удовлетворяющих
314
Глава 4. Проверка статистических гипотез
условию (1)) выбирается та, для которой вероятность ошибки 2-го рода ми-
нимальна, т. е. при условии
TF(F;3Ela)^a, VFe70, (3)
надо минимизировать (за счет выбора Х|„) величину 1 -W(F; Х|О), V F Е 7\,
или, что эквивалентно, максимизировать мощность W(F; Хщ), VF € 7\.
Итак, при заданном уровне значимости а наилучшим среди всех крите-
риев Хщ является тот, который обладает наибольшей мощностью при альтер-
нативах. Если для двух критериев Х*„ и Xia имеют место соотношения
W(F;X*ia)^W(F-,X[a), VF6F0, и
(4)
W(F; X|a)^lF(F;Xla),
VFGFi,
то говорят, что критерий Х*а равномерно мощнее критерия Х1(,; если (4) вы-
полняется для любого критерия X|Q, то Хщ называется равномерно наиболее
п мошным критерием (р. н. м. к.) в задаче (Яо, ЯЭ. Р. н. м. к.
Р. н. м. К. п
идеал, но он не всегда достижим. Поэтому в конкретных за-
дачах зачастую приходится ограничиваться более умеренными требованиями
к критериям. Минимальным таким требованием является свойство несмещен-
Несмещенность кости, которое означает, что одновременное (3) должно
критерия СТЬ выполняться условие
W(F;Xla)>a, VFGFi,
(5)
т.е. при любом альтернативном распределении данных мы должны попадать
в критическую область с большей вероятностью, нежели при нулевой гипотезе.
В случае «больших выборок», т. е. когда X = (Хь , Хп) есть случайная
выборка объема п из некоторого распределения £(£) и п —> оо, критерий
Состоятельность Должен обладать свойством состоятельности (чтобы под-
крит°рия черкнуть зависимость от п пишем W,,):
Wn(F,Xla) —> 1, VF6F, (6)
Это свойство очень важно. Оно означает, что, если истинной является неко-
торая альтернатива, то при большом числе наблюдений мы будем попадать
в критическую область с вероятностью, близкой к 1, т.е. отклоняя нуле-
вую гипотезу Яо, мы будем принимать правильное решение. Таким образом,
можно сказать, что состоятельный критерий «улавливает» любые отклонения
от нулевой гипотезы, когда они имеют место, если число наблюдений (объем
выборки) неограниченно возрастает.
«Близкие» Более тонкие свойства состоятельного критерия вы-
альтернативы ражаются в терминах «близких» альтернатив, т.е. когда
вместо фиксированной альтернативы F Е рассмат-
ривается последовательность альтернативных распределений {Fn}, «сближа-
ющихся» (в том или ином смысле) с Fo, и исследуется поведение мощности
VTn(Fn; Х1а) при п -> оо. В этом случае условие (6), вообще говоря, уже
§ 4.1. Основные понятия и принципы теории проверни гипотез 315
не будет иметь места, и оно заменяется на условие
lTn(Fn;Xlft)а < 7 < 1. (7)
Если последовательность «близких» альтернатив {F„} такова, что при неко-
тором 7 € (а, 1) выполняется (7), то такие альтернативы называются «поро-
говыми»; они определяют тот «порог чувствительности» критерия к от-
клонениям от нулевой гипотезы Hq, когда критерий еще «реагирует» на такие
отклонения: он способен различать распределения F 6 Fo и Fn 6 F\ с ошиб-
ками IVn(F) «3 а и I - Wn(F„) » 1 - 7. Однако в конкретных задачах такое
полное исследование асимптотических свойств критериев не всегда осуще-
ствимо ввиду аналитических трудностей.
В теории часто оказывается полезным рассмот- Рандомизированные
рение так называемых рандомизированных критериев, критерии
когда при наблюдении X = х гипотеза Но отклоня-
ется с некоторой вероятностью <р(х) и принимается с дополнительной вероят-
ностью 1 — <р(х). В этом случае функция >р(х) G [О, I] называется критической
функцией, а функция мощности «критерия р» определяется равенством
W(F; <p) = E(lp(X)\F)= I <p(x)dF(x).
Если функция р принимает лишь два значения 0 и I, т.е. является инди-
каторной функцией некоторого подмножества выборочного пространства, то
получаем предыдущую схему нерандомизированного критерия с критической
областью X) = {х р(х) = 1} — они обычно и применяются на практике.
В приложениях обычно критическая область за- Тестовая статистика *
дается с помощью некоторой статистики Т — Т(Х),
которая «измеряет» отклонение эмпирических данных от соответствующих
(гипотезе Но) гипотетических значений и распределение которой при спра-
ведливости гипотезы Но должно быть известно (точно или хотя бы прибли-
женно, т. е. для больших выборок). Если Т= {t = Т(х), х 6 ЗЕ} — простран-
ство значений этой статистики, то критическая область критерия может быть
задана непосредственно в этом пространстве как некоторое подмножество
7]в С Т, которое должно удовлетворять условию
Р{Т(Х) € 7io|F} a, VFeF„, (8)
т. е. включать все маловероятные при гипотезе Но значения Т. Решающим мо-
ментом для расчета критерия (т. е. обеспечения (8)) является проблема отыска-
ния распределения статистики Т(Х) при гипотезе Но. В частности, если Но —
сложная гипотеза, то желательно, чтобы распределение Т(Х) было одним
и тем же для всех F € Fo- Чтобы вычислить полностью функцию мощности
FK(F; Т) — Р{7(Х) £ Т\а|F}, F € F, а тем самым исследовать и вероятность
ошибки 2-го рода, надо знать распределение Т(Х) также и при альтернативах
F G F), что представляет собой, как правило, весьма трудную задачу. Итак,
в терминах выбранной статистики Т — Т(Х) критерий имеет вид:
Hq отвергается
т(х) е 7]„,
316
Глава 4. Проверка статистических гипотез
где при заданном уровне значимости а критическая область удовлетворяет
условию (8). Статистика Т называется статистикой критерия пли тестовой
статистикой, а сам критерий называется «критерием 7]а».
_ Наконец, отметим, что для параметрических задач,
11араметрическая „
г г когда допустимые распределения данных X идентифи-
модель , Л .
иируются параметром 0, для функции МОЩНОСТИ ИС-
пользуется обозначение
И4(0) = W(0; XIQ) = Р,{Х G 0 G Q, (9)
а проблема построения наилучшего критерия в задаче
я0 б»е ©о, я, ее ©, = ©\©0
при уровне значимости а формулируется так:
W(0; Xlo) «Г a, V0G©o, W(0; X1Q) —-> max, V0G©,. (10)
Общие замечания ® заключение этого введения сделаем несколько об-
щих замечаний. В конкретных задачах выбор уровня
значимости критерия до некоторой степени произволен и связан с практи-
ческой стороной вопроса. Так, часто ошибочное принятие или отклонение
гипотезы Яд связано с материальными затратами. Если принятие гипоте-
зы Яо в то время, когда она неверна (ошибка 2-го рода), приводит к большим
затратам, тогда как отклонение истинной гипотезы Яд (ошибка 1-го рода)
приводит к небольшим потерям, то ясно, что желательно сделать как можно
меньшей вероятность ошибки 2-го рода, допуская сравнительно большие зна-
чения а. Обычно для а выбирают одно из следующих стандартных значений:
0,005; 0,01; 0,05: для этих значений рассчитывают соответствующие таблицы,
используемые при проведении различных испытаний.
Далее, в отличие от теории оценивания неизвестных параметров распре-
делений, когда для характеризации качества соответствующих оценок доста-
точно было уметь вычислять, как правило, лишь первые два момента ис-
пользуемых статистик, в теории проверки гипотез требуется знание всего
распределения статистики критерия: как минимум — при нулевой гипотезе
(чтобы рассчитать критическую область), а вообще же говоря — и при альтер-
нативах (чтобы оценить мощность). В этой связи отметим, что для выборок
фиксированного объема (или, как говорят, случая «малых выборок») эта про-
блема не всегда поддается практическому решению, поэтому при проверке
Большие выборки гипотез часто применяется асимптотческий подход, пред-
полагающий неограниченное возрастание объема п вы-
борки X = (Х|, , Хп), т.е. проблема решается для случая «больших вы-
борок». Асимптотический подход широко используется при расчете статисти-
ческих критериев, часто позволяя исследовать единым методом различные
задачи и получать весьма общие результаты. При этом финальные результаты,
как правило, имеют простую и наглядную форму, удобную для практических
расчетов. Эти результаты в дальнейшем могут использоваться и для выборок
§4.1. Основные понятия и принципы теории проверки гипотез
317
конечного объема, давая приближенное решение задачи. Асимптотический
подход — «зачастую единственная возможность, открытая статистику в су-
ровой действительности* (Дж. Русас) и с его применением мы неоднократно
будем встречаться в дальнейшем.
Наконец, отметим, что важным показателем каждого критерия является
трудоемкость практической реализации соответствующего алгоритма. На прак-
тике, когда требуется быстро получить ответ, предпочтение нередко отдается
просто реализуемому критерию, даже если он не является оптимальным в тео-
ретическом смысле. При этом типичной является ситуация, когда для одной
и той же задачи имеется несколько разработанных критериев, каждый из кото-
рых обладает определенными специфическими достоинствами, среди которых
не последнее место занимает простота его практической реализации.
Далее изложенные принципы применяются при решении описанных во
Введении задач проверки типичных статистических гипотез.
Из истории (по книге Г. Сскея [23]). Трудно сказать что-то определенное
JkSJ' о том, когда предпринимались первые попытки проверять статистические
гипотезы. Б. В. Гнеденко в своей книге [8] отмечает, что учет населения,
проведенный в древнем Китае в 2238 г. до н. э., показал, что доля ро-
дившихся мальчиков составляла 50%. Джон Арбутнот (1667-1735), английский
математик, врач и писатель, был первым, кто (в 1710 г.) заметил, что гипотеза
о равном соотношении родившихся мальчиков и девочек должна быть опроверг-
нута, так как согласно демографическим данным за 82 года (доступным в то время)
мальчиков каждый год рождалось больше, чем девочек. Этот факт заинтересовал
П. Лапласа. В 1784 г. он с удивлением обнаружил, что в нескольких различных
районах доля родившихся мальчиков приблизительно равнялась 22/43, а в Пари-
же это отношение было равно 25/49, что меньше 22/43. Лаплас был заинтригован
таким различием, но вскоре нашел для него разумное объяснение: в обшее число
родившихся в Париже включались также все подкидыши, а население из приго-
родов предпочитало подкидывать младенцев одного пола. Когда Лаплас исключил
подкидышей из общего числа родившихся, доля новорожденных мальчиков стала
близкой к 22/43.
В 1734 г. французская академия присудила Даниилу Бернулли (1700-1782) —
швейцарскому физику и математику — премию за исследование по орбитам пла-
нет. С помощью некоторого критерия проверки гипотез Бернулли пытался пока-
зать, что схожесть орбит планет является далеко не случайной (в его модели каждая
орбита соответствует некоторой точке на единичной сфере, и Бернулли проверял
гипотезу о равномерном распределении этих точек). В 1812 г. Лаплас исследовал
похожую проблему. Он пытался применить статистические методы для решения
вопроса о том, какую из гипотез следует принять: являются ли кометы обычными
элементами Солнечной системы или они всего лишь «незванные гости». В по-
следнем случае углы между орбитами комет и эклиптикой были бы равномерно
распределены на интервале отО до тг/2, что как раз совпадаете математической за-
писью предположения Лапласа (он обнаружил, что кометы не являются обычными
элементами Солнечной системы). Основоположниками современной теории про-
верки статистических гипотез были К. Пирсон, Э. Пирсон, Р. Фишер и Ю. Ней-
ман. Большой вклад в ее становление и развитие внесли Г. Крамер, Р. фон Мизес,
А. Н. Колмогоров, Н. В. Смирнов и другие ученые, работавшие позднее.
318
Глава 4. Проверка статистических гипотез
Хотя это может показаться парадоксом,
вся наука основана на идее аппроксимации.
Бертран Рассел3*
§4.2. Проверка гипотезы о виде распределения
Классика — это то, что все хотели бы
прочитать, но никто читать не хочет.
Марк Твен '1*
Мы начинаем изложение основных результатов теории проверки гипотез с рас-
смотрения классической задачи о виде распределения наблюдений (см. при-
мер 4 Введения). В простейшем ее варианте задача ставится так: пусть X =
= (Х\, , Хп) — выборка из распределения £(£) с неизвестной функцией
распределения F^(x), о которой выдвинута простая гипотеза Но F^x) =
= F(x), где функция F(x) полностью задана. Здесь альтернативные рас-
пределения никак не конкретизируются, т.е. допустимыми распределениями
данных (выборки X) являются любые распределения на выборочном про-
странстве X = {х = (zi, ,zn)} (априори может быть ясен лишь тип
распределения F^ — абсолютно непрерывный либо дискретный, что опреде-
ляется обычно физической природой наблюдаемой случайной величины £).
Следовательно, в данном случае альтернатива Н\ = Яу («не Но»), и речь идет
просто о согласии данных и гипотезы Но. Наиболее известными (классиче-
скими) критериями согласия в данной задаче являются критерий Колмогорова
и критерий хи-квадрат.
1. Критерий согласия Колмогорова
4^ Статистика Этот критерий применяют в тех случаях, когда функция
F(x) непрерывна. Статистика критерия определяется
г формулой
Dn = Dn(X) = SUP \Fn(x) - F(x)\, (I)
-00<X«X
t. e. представляет собой максимальное отклонение эмпирической функции
распределения Fn(x), построенной по выборке X, от гипотетической (т.е.
определяемой гипотезой Яу) функции распределения F(x). То, что это «ра-
зумная» статистика для проверки гипотезы Но, следует из известных нам
свойств э. ф. р. Fn(x). Так, мы знаем (см. теорему 2 §3.1 и комментарий
3* Рассел Бертран Артур Уильям (1872-1970) — английский математик, философ, логик, со-
циолог, общественный деятель.
3>Твен Марк (Сэмюэль Ленгхорн Клеменс) (1835-1910) — знаменитый американский писа-
тель.
§ 4.2. Проверка гипотезы о виде распределения
319
к ней), что при каждом х величина Fn(x) является оптимальной несмещен-
ной оценкой для F(x), и эта оценка состоятельна (см. комментарий к формуле
(23) § 2.2), т. е. с увеличением объема выборки п происходит сближение Fn(x)
с F(x) (если, конечно, гипотеза Яц справедлива). Поэтому, по крайней ме-
ре при больших п, в тех случаях, когда гипотеза Но истинна, значение Dn
не должно существенно отклоняться от нуля. Отсюда следует, что критиче-
скую область критерия, основанного на статистике Т = Dn, следует задавать
в виде Т\а = {i ta}, т.е. большие значения Dn надо интерпретировать как
свидетельство против проверяемой гипотезы Hq. Критическая граница ta при
заданном уровне значимости а рассчитывается при этом на основании тео-
ремы Колмогорова (см. теорему 2 §2.1). Именно, если п достаточно велико
(уже при п 20), то положив ta = Ха/\/п, где (см. (11) § 2.1) К(Ха) = 1 - а,
будем иметь
Р{РП £ Т1п\Н0} = Р{УНЯ„ АП|ЯО} ~ 1 - К(Ха) = а, (2)
т.е. по крайней мере для больших выборок условие (8) §4.1 будет прибли-
женно выполняться.
Тем самым критерий согласия Колмогорова форму-
лируется следующим образом: если п 20 и при вы-
бранном уровне значимости а число Аа определено
соотношением Я(АП) = 1 - а, то
Яо отвергается
Критерий
Колмогорова
(3)
Следуя этому правилу, можно ошибочно отклонить гипотезу Яо, когда она
верна, с вероятностью, приблизительно равной а. Этот критерий состоятелен
(альтернативой здесь является любое непрерывное распределение F^F).
Дополним сказанное некоторыми комментариями. Комментарии
Прежде всего подчеркнем, что распределение статисти-
ки Dn при гипотезе Яд не зависит от вида функции F(x). Этот факт имеет
принципиальное значение, так как имея таблицы значений функции Колмо-
горова K(t), мы имеем возможность рассчитывать критерий (3) для проверки
гипотезы относительно произвольной непрерывной функции распределения
F(x). Такие подобные таблицы имеются в книге [3], где также даны детальные
практические рекомендации по их использованию.
Далее, по своей сути критерий Колмогорова (3) является асимптотиче-
ским (т.е. он «работает» лишь для больших выборок), поскольку в основе
его лежит предельная теорема 2 § 2.1. Но помимо вывода предельного резуль-
тата (см. (И) §2.1) Колмогоров (1933) дал рекуррентные соотношения для
конечных п, которые затем были использованы для табулирования точного
распределения статистики Dn. Поэтому для расчета точных значений кри-
тической границы ta в случае малых выборок также можно воспользоваться
соответствующими таблицами, информация о которых имеется в [12, с.611].
320
Глава 4. Проверка статистических гипотез
Наконец, отметим, что для практических вычислений статистики Dn по-
лезна эквивалентная (1) формула Dn = max(Z>„ , D„), где
= i<la<n\n ” ’ Dn = "
и Л-)!) < Хр) C С %(П) — вариационный ряд выборки X.
Замечание. Описанную методику проверки гипотезы о виде распределения наблю-
даемой случайной величины можно распространить и на случай проверки сложной
гипотезы Яо € Л) = {F(x; 6), 6 € О}, где — заданное параметрическое
семейство распределений (комментарии см. в примере 4 Введения). В этом случае
вместо (I) используют тестовую статистику
Dn = sup |F„(z) -Г(г;0„)|,
-00<Z<00
где &п — оценка максимального правдоподобия параметра 6 Если семейство Т),
регулярно (см. п.4 § 3.5), то известно асимптотическое (при п -> оо) распределение
статистики Dn, которым можно воспользоваться для расчета соответствующей кри-
тической границы критерия. Однако это распределение имеет уже отличный от (11)
§ 2.1 и гораздо более сложный вид, отражающий специфические свойства семейства
Ул; тем самым расчет соответствующего критерия значительно усложняется41
2. Критерий согласия хи-квадрат К. Пирсона
Одним из наиболее универсальных методов проверки различных статисти-
ческих гипотез является метод хи-квадрат (%2). В этом методе работают
с дискретными данными, но поскольку любые исходные данные можно све-
сти к дискретным методом 1руппировки наблюдений, как это описано в п. 2
§3.6, т.е. перейти от исходной выборки X (Л), , Хп) к частотам
и = (1/ь.. , Уц) попадания ее элементов в соответствующие подмножества
группировки , £дг, то тем самым метод х1 можно применять к данным
любой природы, в том числе и многомерным (подчеркнем, что описанный
в п. 1 критерий Колмогорова «работает» лишь с выборками из непрерывного
одномерного распределения).
Итак, пусть в эксперименте наблюдается дискретная случайная вели-
чина принимающая значения 1,2, ,7V с некоторыми вероятностями
Р\> <Pn (Pi + +Pn = О- Если произведено п независимых испытаний
над т.е. имеется выборка (£ь ,£п), то пусть
п
Ч j), J = l- ,N,
i=\
— соответствующие частоты исходов (м| + + = п). Тогда вектор
м = (мь ,vN) имеет полиномиальное распределение ,Pn)
4) Тюрин Ю. Н. О предельном распределении статистик Колмогорова—Смирнова для сложной
гипотезы // Изв.АН СССР. Сер. Матем. 1984. Т. 48. №6. С. 1314-1343.
§ 4.2. Проверка гипотезы о виде распределения
321
(см. п. 6 § 1.1). В методе х2 работают именно с данными и, а проверяемые
гипотезы формулируются в терминах вектора вероятностей р = (рь ,Pn)-
По сути — это параметрическая модель, так как она определяется конечным
числом параметров (pi, , Pjv~i). Рассмотрим сначала задачу проверки про-
стой гипотезы в рамках этой модели.
Итак, пусть по наблюдению вектора частот и = ,vN) требуется
проверить простую гипотезу Но р = р° где р° = (р°, ,p°N) — заданный
вероятностный вектор (0 <p°j < 1, j = 1, , N,p\+.. ,+p°N = 1). К. Пирсон
в 1900 г. предложил использовать в качестве меры отклонения эмпирических
данных (относительных частот vJn} от гипотетических значе-
ний р° меру хи-квадрат (см. (2) §3.6)
=л2(Е)=£
>=i
(Ру - пр°)2 * Ру
nP°i ~ пР°з
(4)
На этой тестовой статистике и основывается знаменитый критерий х К. Пир-
сона. В основе этого критерия лежат следующие очевидные соображения. Если
гипотеза Яо справедлива, то, поскольку относительная частота Vj/n события
{£ = j] является состоятельной оценкой его вероятности ру (j = 1,.... п),
при больших п разности |ру/п-ру| должны быть малы, следовательно, и зна-
чение статистики не должно быть слишком большим. Поэтому естествен-
но задать критическую область для гипотезы Яо в виде Т\а = {-Хп > <Q},
где критическая граница ta при заданном уровне значимости а должна быть
выбрана из условия
Р{^Ха|Я0}=а. (5)
Такой критической областью и определяется критерий х2 Главная проблема
здесь — вычисление границы ta в (5), для чего надо знать распределение
статистики при нулевой гипотезе Яо. Точное распределение £(Т„|Яо)
неудобно для расчета критерия, но для больших объемов выборок п статистика
имеет при гипотезе Яо простое предельное распределение, не зависящее
от гипотезы (т.е. от р°). Именно, справедливо следующее утверждение.
Теорема 1. Если 0 < р° < 1, j — 1, , N, то при п -> оо
Г(1М)->Х2(ЛГ_ 1).
Доказательство. Как показано в примере 12 §3.5, при сформулированных
условиях вектор нормированных частот и* = (и*, , i/jy-j), где
V, ~ TVPi
-- --1, j =
у/П
21 Заказ 1748
322 Глава 4. Проверка статистических гипотез
имеет в пределе невырожденное нормальное распределение V(0, £y-i), где
Л 11° °г о о 11 AT— I
|ку Pi*ij ~РгР;||]
<5t} — символ Кронеккера. Отсюда на основании соотношения (34) § 3.5 можно
заключить, что при га —> оо
£((?„ = Ж,!!» -* ХЧХ - 1).
С другой стороны, из (4) имеем
j=l О
где матрица
t=Н^Г = ^'i
(см. пример 10 в §3.2). Таким образом, = Qn.
На практике предельное распределение x2(2V-1) можно использовать для
расчетов с хорошим приближением уже при п 50 и 5, j = 1, , N.
При выполнении этих условий можно записать, что
Р{1* Ха|Яо}~ 1 -FN^(ta),
где /\_](Г) — функция распределения закона %2(N - 1). Следовательно,
полагая
• ~ = о,
т. е.
ta = Xt-a,N-
(напомним, что х₽,г обозначает р-квантиль распределения х2(г))> получаем
асимптотический вариант критерия х задаваемый критической областью
{X> > Х1-а,У-|}-
Таким образом, классический критерий согласия х1 имеет следующий
вид: пусть объем выборки га и наблюдавшиеся значения вектора частот
р = , z/;v) удовлетворяют условиям п 50, и} 5, Vj; тогда при
заданном уровне значимости а
Но отвергается <=> {X2 > Xi-a.jv-i}, (6)
Крит^риТ^^'' где статистика определена в (4).
Сделаем несколько общих замечаний. Критерий со-
Комментарии гласия х~ применяется в тех случаях, когда в каждом
испытании наблюдается одно из W несовместных собы-
тий At, .., АЛг и заданы частоты появления этих событий в п (независимых)
испытаниях (можно говорить также, что наблюдается дискретная случайная
§ 4.2. Проверка гипотезы о виде распределения
323
величина = номер реализуемого в испытании события). Если же исходные
данные представляют собой выборку из некоторого непрерывного распределе-
ния, то, применяя предварительно метод группировки наблюдений, приходят
к рассмотрению дискретной схемы, в которой в качестве событий Aj рас-
сматриваются события {£ 6 £j}, где — интервалы группировки.
Недостатком метода является то, что при группировке данных происходит
некоторая потеря информации. Кроме того, остается еще вопрос о выбо-
ре числа интервалов N и их виде (более детально эти вопросы освещены
в [12, гл. 30]). Однако критерий имеет и свои достоинства: при его приме-
нении нет необходимости учитывать точные значения наблюдений (бывают
случаи, когда исходные данные имеют не числовой характер, см. пример 2
ниже); несомненными преимуществами критерия являются его простота, на-
глядность и универсальность.
Приведем несколько примеров практического применения критерия £2
Пример 1. При п = 4040 бросаниях монеты Бюффон Эксперимент
получил = 2048 выпадений герба и = n-i/\ — 1992 Бюффоно
выпадений решки. Проверим, используя критерий х~
совместимы ли эти данные с гипотезой Яо о симметричности монеты, т. е.
что вероятность выпадения герба р = 1/2. Здесь N = 2, р° = р2 1/2
и по формуле (4) имеем
2 ("i - пР°\У , - пр°2)2 (р, - пр°)2
п =-------j-----I------о---=--------г-;— = 0,776.
пр, пр2 пр,р2
Пусть уровень значимости а = 0,05. Из таблиц распределения х2 находим
Хо,95; I = 3,841. Следовательно, данные не противоречат гипотезе На. •
Пример 2 [12, С. 563]. В экспериментах с селекцией го- Эксперимент
роха Мендель (см. ниже) наблюдал частоты различных Менделя
видов семян, получаемых при скрещивании растений
с круглыми желтыми семенами и растений с морщинистыми зелеными се-
менами. Эти данные и значения теоретических вероятностей, определяемые
в соответствии с теорией наследственности Менделя, приведены в следующей
таблице:
Семена Частоты Vj Вероятности р°
Круглые и желтые 315 9/16
Морщинистые и желтые 101 3/16
Круглые и зеленые 108 3/16
Морщинистые и зеленые 32 1/16
Г п = 556 1
21
324
Глава 4. Проверка статистических гипотез
Следует проверить гипотезу Яо ° согласовании частотных данных с теоре-
тическими вероятностями. Вычисления по формуле (4) дают здесь = 0,47
Из таблиц распределения х2(3) следует, что при любом уровне значимости
а 0,90 критерий (6) не отвергает гипотезу, так что между наблюдениями
и гипотезой имеется очень хорошее согласие. •
Из истории науки. С именем монаха августинского монастыря Грегора Мен-
деля ’’ связан поучительный эпизод из истории научных открытий. В 1866 г.
L Мендель открыл законы классической генетики. Но открыть мало — их
нужно доказать. И он провел серию опытов на растении с названием яст-
ребпнка. Почему из тысячи видов он остановился именно на этом растении,
сказать трудно. Факт в том, что опыты не удались, и монах сделал вывод, что
его законы неверны. Впоследствии выяснилось, что Мендель выбрал неудачный
объект исследований. Но дело было сделано — имя монаха и его законы предали
забвению. В 1900 г. эти же законы были заново открыты сразу тремя ботаника-
ми — Хуго де Фризом, Карлом Корренсом и Эрихом Чсрмаком. Казалось бы, им
ничего не мешало закрепить за собой лавры первооткрывателей. Но с непомер-
ным усердием они принялись рыться в научных архивах и нашли забытые статьи
о «правилах Менделя». Ученые нс прекратили поиск, а, наоборот, углубились
в него. И пришли к неожиданному выводу: «их» законы за 30 лет до них открыл
тот самый монах из августинского монастыря. Что ботаники делают дальше? Вес
просто: они признают за собой «приоритет вторичного открытия», а законы на-
рекают именем выдающегося монаха.
Предмет математики настолько серьезен, что полезно
не упускать случая сделать его немного занимательным.
Б. Паскаль
Рассмотрим, наконец, пример, когда гипотетическое распределение яв-
ляется непрерывным.
Пример 3. Используя данные, приведенные в упр. 10 к гл. 2, проверим со-
гласуются ли они с гипотезой Яо о том, что показания часов равномерно
распределены на интервале (0, 12). Здесь N = 12 и при гипотезе Яо p°j = 1/12,
j = 0, 11. Значение статистики (4) есть 10,000, а, например, Хо,95;п
= 19,675, поэтому следует признать, что согласие предположения с опытными
данными хорошее. •
Состоятельность Для критерия можно провести полное иссле-
критерия х' дование предельного при п -> оо поведения его мощ-
ности при альтернативах. В рассматриваемой методике
гипотезы характеризуется вектором р = (рь , р/у) вероятностей, с кото-
рыми появляются в каждом испытании события Л,, , Л/у, поэтому для
5* Мендель Грегор Иоганн (1822-1884) — австрийский естествоиспытатель, основоположник
учения о наследственности.
§ 4.2. Проверка гипотезы о виде распределения
325
функции мощности критерия (6) будем использовать обозначение
VFn(p) = P{l2 >Xi-o, лг-dp}, (7)
а о соответствующей гипотезе будем говорить для краткости как о гипотезе р.
В этих обозначениях полученный выше результат записывается в виде:
Жп(р°) а при п -> оо.
Установим теперь следующий результат.
Теорема 2. Для любого вектора р^р° выполняется условие Wn(p)—> 1 при
1 ~ ~ ~
л —> оо, т. е. критерии х является состоятельным.
Доказательство. Вычислим среднее и дисперсию статистики при про-
извольной гипотезе р. Для этого перепишем формулу (4) в виде
("j - npj)(pj - Р°) (Р; - Рр2
Р°з
- npj)2
пр’
Pi
Так как
Е(1/рр) = npj,
то
Е[(^ - npj)2\p] = D(i/j|p) = пр,(1 -pj).
Л(Р7-Р})2
E(7tn |р) — л о
;=1 Pj
Отсюда, в частности, имеем E(Xn|p°) = N - 1. Этот результат согласуется
с асимптотическим результатом теоремы 1, поскольку среднее предельного
распределения x2(N - 1) равно N - 1 (см п. 3 § 1.2). Аналогично можно
вывести и формулу для дисперсии:
D(X2|p) = 4(га ~ 1)(п~ 2) (Д32 - Д21) +
- п
+ 2----(3#22 "" 2#2l#j| ” #21) Н-(#12 “ #11)» (9)
п п
PjO ~Pj)
Р°з
(8)
где
" Pk
Г —
p\5
;=i
N
Если р = р° то Rks = и из (9) имеем
D(^|p°)=2^- l) + lf^4-^2-2N + 2") ->2(N- 1)
п < Pi /
326
Глава 4. Проверка статистических гипотез
при п -> оо, что также согласуется с теоремой 1. Если жер р°, то из (8) и (9)
следует, что при п -> оо среднее и дисперсия статистики при гипотезе р
имеют порядок роста п. С учетом этого из (7) по неравенству Чебышева (при
t = X2\~a.N-\) имеем
1 - Wn(p) = Р{12
«Близкие» альтерна-
тивы и мощность
критерия х'
*|р} = ₽{|12 - Е(12|р)| > |Е(^|р) - *| | р}
Р(12|р) /1\ и
'(£(!>)-;)2 W
Тем самым, если гипотеза На неверна, а истин-
ной является некоторая альтернатива р, то критерий
(6) обнаружит это с вероятностью, близкой к I, ко-
гда п велико. Но что будет, если альтернатива р «мало
отличается» отр°, т. е. если р = р(п) —> р° при п —> оо? Что собой представля-
ют в данном случае «пороговые» альтернативы, т. е. для которых выполняется
условие (7) §4.1, которое в наших обозначениях запишется в виде
WSi(p(n)) 7, а < 7 < 1?
Ответ на эти вопросы дает следующее утверждение.
Теорема 3. Пусть альтернатива имеет вид
0
р(п) =Р° + -у=,
“ ~ уП
где 0 = (/31, ,0к) 5^ 0 — фиксированный вектор, задающий отклонение
от гипотезы Hq ( 0j = о) Тогда при п -> оо
j = i
N fi2
VF„(p(n))^ 1 -F^-Axi-a.N-ilA2), A2 = V-|, (10)
P.i
где Fv_|(t; A2) — функция нецентрального распределения хи-квадрат
x2(JV- i;A2)
(см п. 2 § 2.5).
Доказательство. Как и при доказательстве теоремы I, можно показать, что
при гипотезе р(п) распределение вектора нормированных частот
/17-прДп), ....N_ \
§ 4.2. Проверка гипотезы о виде распределения
327
сходится при п -> оо к нормальному распределению Л/"(0, Йдг-i). Но
* _ 12j - nPj _ "j - npj(n)
— г— — /— < Pj>
у/П у/П
поэтому
£(/|р(п))->ЛГ ^_, = (/3|, -.,^-|).
А так как
*п — И*^№- |И*.
то по лемме 3 §2.5 (точнее, на основании асимптотического варианта этой
леммы)
где
N в2
7 = 1 Ъ
(проверяется непосредственно). Отсюда и из (7) следует (10).
Таким образом, критерий х2 «реагирует» на отклонения от нулевой ги-
потезы, имеющие при больших п порядок п~^2 — это и есть «пороговые»
альтернативы для данного критерия; более близкие альтернативы, т. е. откло-
няющиеся от Но на величину о(п_|/2) (в этом случае А2 —> 0), критерий
не отличает от Hq, так как в таких случаях Wn(p(n)) —> а (вероятность по-
падания в критическую область при альтернативе асимптотически такая же,
как и при основной гипотезе); для более же удаленных альтернатив (т.е. при
А2 оо) критерий остается состоятельным: Wn(p(n)) —> 1.
Тем самым при простой гипотезе Но удается провести исчерпывающее
исследование асимптотических свойств критерия х2 Для больших выборок.
3. Критерий хи-квадрат для сложной гипотезы
Сложные гипотезы для полиномиального распределе- Сложные гипотезы
ния М(п; р) в общем случае имеют следующий вид:
HQ р = р(0), 0 = (0\, ,6r)EQ, г < N - 1.
Таким образом, при гипотезе Но вероятности исходов являются некоторыми
функциями от неизвестного параметра 0 с множеством возможных значе-
ний в. Чтобы построить критерий проверки такой гипотезы по наблюдению
вектора частот v_ = (bq, , vN) можно, по аналогии с предыдущим случаем,
поступить следующим образом. Построим статистику, аналогичную (4),
N
j=i
(Pj - nPj(0))2
npj(O)
328
Глава 4. Проверка статистических гипотез
Эта статистика зависит от неизвестного параметра в, поэтому непосредствен-
но использовать ее нельзя — требуется предварительно исключить неопреде-
ленность в в. Для этого заменяют 6 некоторой оценкой вп = и получают
в итоге статистику X» = Хп(вп). Это уже функция только от наблюдений и,
следовательно, ее значение можно однозначно вычислить для каждой реали-
зации вектора и. Однако, чтобы рассчитать соответствующий критерий, надо
знать распределение Х„ при гипотезе Но (хотя бы приближенно). Положение
осложняется тем, что теперь величины ру(0п) Уже не постоянные, а представ-
ляют собой функции от наблюдений и, поэтому теорема 1 к статистике Х„
неприменима. Более того, следует ожидать, что распределение Х„ будет, во-
обще говоря, зависеть от способа построения оценки вп-
Проблема нахождения предельного (при п->оо) распределения для Х„
при этих усложненных условиях была решена американским статистиком
Р. Фишером в 1924 г. Он показал, что существуют методы оценивания па-
раметра в, при которых это предельное распределение имеет простой вид,
а именно, является распределением X2(N - 1 - г). В частности, это будет
иметь место при использовании оценки максимального правдоподобия
Л’
0n = argmax JJ(pj(0))p'
в j=i
или, что то же самое, оценки по видоизмененному методу минимума хи-
квадрат (см п. 2 § 3.6), которая является решением системы уравнений (3) § 3.6.
В этом случае для построения критерия используется тестовая статистика
N
Х7П = Х7п(вп) = 52
у=1
(р, - npj(en)y
npj(6n)
(п)
Сам критерий рассчитывается на основании следующего утверждения.
Теорема 4. Пусть функции р/0), j = 1, , N, удовлетворяют условиям:
1) 52^w = 1'vee0;
2) Pj(6) с > V j, и существуют непрерывные производные
^Р1т к. . г.
aet • setse,.........................................
3) (ЛГ х г)-матрица ||dpj(0)/d0jt|| имеет ранг г для всех 6 € 0. Тогда
£(ТМ) x\N - 1 - г),
где статистика Х„ определена в (И).
§4.2. Проверка гипотезы о виде распределения
329
2
Критерий х для
—»2 2
Яо отвергается <=> Хп > Xt-a.N-t-r
Доказательство этой теоремы можно найти в
[15, с. 462-470]. При выполнении условий теоремы 4
сложном гипотезы
критерии имеет вид:
(12)
(здесь а — заданный уровень значимости и предполагается, что п 50 и
5, Vj).
Этот критерий можно применять также в следующей общей ситуации.
Пусть задана выборка X = (Х[,..., Хп) из некоторого распределения £(£),
о котором требуется проверить гипотезу Яи £(£) £ 7^, где 7^ = {Я(а:;0),
0 £ 9} - заданное параметрическое семейство. Проведем группировку на-
блюдений, основываясь на интервалах Е\, ,En (Ei A Ej 0, i / j,
Ei U U Epi — Е — множество возможных значений £), т.е. подсчитаем
частоты
п
= Е3), j =
1 = 1
и гипотетические вероятности
рД0) = Р{£€^|Яо} =y'<W;0), 7=1, ,N
Решив далее систему (3) §3.6, найдем оценку 0П и вычислим значение ста-
тистики Х\ в (И). Если выполнены условия теоремы 4, то применяется
критерий (12). Следуя этому критерию, можно ошибочно отклонить гипоте-
зу Яо, когда она верна, с вероятностью, приближенно равной а.
Пример 4. Среди 2020 семей, имеющих двух детей, 527 семей, в которых два
мальчика, и 476 — две девочки (в остальных 1017 семьях дети разного пола).
Можно ли с уровнем значимости а = 0,05 считать, что количество мальчи-
ков в семье с двумя детьми (£) — биномиальная случайная величина? Здесь
речь идет о проверке гипотезы Но £(£) € Bi(2, 0), поэтому гипотетические
вероятности исходов имеют вид
ро(0) = Р{£ = О} = (1-0)2,
р,(0) = р{£= 1} = 20(1-0),
р2(0) = Р{£ = 2} = 02
Отсюда в соответствии с (3) § 3.6 получаем уравнение для нахождения оценки
параметра 0
А ^р'(0) 2i/0 I - 20 2i/2
Ру(0) 1-0 0(1-0) 1 0
решая которое, находим
3- v\+ 2м2
"п — ~
2п
330
Глава 4. Проверка статистических гипотез
В данном случае = 476, i/} = 1017, v2 = 527, п = 2020, поэтому 0п = 0,513.
Далее вычисляем значение статистики (11):
j^2 _ у' (vj ~ пР}(^п)У
TZ'a nPjfin)
= 0,116,
и этот результат надо сравнить с х]-а, i • Поскольку хо,з; i = 0,148, при любом
уровне значимости а < 0,7 гипотез принимается. •
Пример 5 (Пуассоновская модель, критерий х2 для нее). Пусть произво-
дится п независимых наблюдений над неотрицательной целочисленной слу-
чайной величиной £. Требуется проверить гипотезу Нп £(£) € П(0). Здесь
множество £ возможных значений £ есть {0, 1,2, .}, т.е. бесконечно, по-
этому надо предварительно провести группировку наблюдений. В качестве
соответствующих «интервалов» выберем £j = {j - 1}, j = 1, ,N 1,
£n = {./V — 1, JV,...} при некотором TV 3 (тогда N - 1 - 1 > 0). Гипотети-
ческие вероятности при таком способе группировки будут равны (см. (8) §1.1)
ОО
Р#) = f(j - IP), 7 = 1, ,ЛГ-1, рН*) = £
x=N-l
где
/(z|0) =
e~e0z
х!
Уравнение для нахождения оценки 0„ в данном случае имеет вид (см. (3) § 3.6)
Отсюда
( j: - 1 \
? +
£ f№>)
x=N-l
N-l
£(> - Ъ +
; = 1
ОО
i=AT-l
oo
£ fW)
x=N-l
Здесь первый член в квадратных скобках равен сумме всех наблюдений Хг
таких, что X, < N - 2, а последний член приближенно равен сумме наблю-
дений, оказавшихся большими N - 2. Таким образом, в качестве прибли-
женной оценки для 0 можно взять выборочное среднее: 0п — X (напомним,
что обычная оценка максимального правдоподобия для параметра 0 в модели
П(0) точно равна X, см. п. 1 §3.5).
§ 4.2. Проверка гипотезы о виде распределения
331
Теперь находим
Pj = Pj{6n) = '
e~xXi-1
(j ~ 1)!
при j = 1, , N - 1,
e 2^
k=N-\
Xk
— при j = N,
и (при больших выборках) гипотеза Яо отвергается на уровне значимости а
тогда и только тогда, когда
А (*5 -ир))2
nPi
> Xl-o, JV-2-
Пример б (Нормальная модель, критерий для нее). Пусть Яо — гипотеза,
состоящая в том, что выборка X = (Х|, , Хп) получена из нормального
распределения в}) (здесь 0 = (01; 02))- Зададим интервалы группировки
в виде = (а;_|,а;], j 1, ,N,N> 3, где а0 = -оо, адг = оо,
aj = О| + (j - 1)Л, j = 1, ,N - 1, ai, h — некоторые фиксированные
величины. В таком случае, обозначив для краткости
д(х; 0) = —у= ехр
\/27Г
(z~fli)2l
2fl22 J ’
имеем
Р#) = f 9(х; 0) dx, j=\, ,N
Система (3) § 3.6 в данном случае состоит из следующих двух уравнений:
= 0.
Поскольку Vj = п, эти уравнения можно привести к виду
2 = 1
Разрешая эту систему относительно 0|, 02, можно найти оценки 0, и 02.
332
Глава 4. Проверка статистических гипотез
При малом Л можно получить практически приемлемые приближенные
значения для этих оценок. Предположим сначала, что Р| = = 0 (левее
точки di и правее точки fl/v-i = ai + (TV — 2)Л нет выборочных точек).
Заменяя интегралы по областям Ej произведением подынтегральной функции
в средней точке Zj на длину \Ej | = h для j = 2, , N - 1 получим следующие
приближения:
। У-1 । У-1
~ - 52 "Л- ~ ~ 52 “ ^)2
П 3 = 2 П 3 = 2
Если крайние интервалы не пусты, но содержат малую часть выборки, то
можно использовать приближения
1 N j *
^~п52р>^> ^2~-52р>^-^)2
y=i j=i
где Z\ = O], Zjj = Ojy-i-
С учетом этих допущений можно считать, что если проверяемая гипо-
тез Яо верна, то статистика (11) распределена приближенно (при больших
выборках) по закону %2(Я - 3), и на этой основе рассчитывать соответству-
ющий критерий (12). •
4. Критерий квантилей
Методхи-квадрат можно применять для построения критериев согласия и вза-
дачах другого типа, когда нулевая гипотеза фиксирует некоторые частные
характеристики функции распределения F^(x) наблюдаемой случайной вели-
чины Рассмотрим типичную ситуацию такого рода, когда гипотеза имеет
вид Яо FitCj) = Pj, j = >, , Я - 1, где -оо < С < < Су-i < 00
и 0 < < < Pn-\ < 1 — заданные числа, т. е. Яо — это гипотеза о том,
что распределение £(£) имеет заданные квантили для заданных уровней pj
Это сложная гипотеза: соответствующий ей класс распределений Fn включает
все распределения с указанными квантилями.
Пусть имеется выборка X = (X], , Хп) из некоторого непрерывного
распределения £(£), о котором выдвинута такая гипотез Яо. Построим крите-
рий типа у2 Для проверки этой гипотезы. Для этого положим Ej = (£;-1, С>),
j = 1,.... N, (о = -оо, Су = оо, и пусть Vj — число выборочных точек Xt,
принадлежащих интервалу Ej. Тем самым мы имеем схему группировки дан-
ных с естественными (т. е. порождаемыми самой проверяемой гипотезой)
интервалами. Тогда
£(е = ("ь-, М1Я0) = М(п;р = (pj ,ру)),
где p°j = pj - Pj-j, J = l, , Я, Ро = 0, Pn = 1, и гипотеза Яо эквивалент-
на утверждению, что вероятности исходов в построенной полиномиальной
схеме равны заданным числам р°..., p°N. Следовательно, для проверки этой
§ 4.2. Проверка гипотезы о виде распределения
333
гипотезы можно использовать построенный в п. 2 критерий %2 (6). В данном
контексте этот критерий называют критерием квантилей.
При W = 2 ир, = 1/2 соответствующий критерий называют критерием
знаков. В этом случае Яо — это гипотеза о том, что выборка X извлечена
из распределения £(£) с медианой (j, а тестовая статистика (4) принимает вид
где v1 — число выборочных точек Xi в интервале (-оо,£|], или, что то же
самое, число отрицательных разностей X, - i = 1, , п (отсюда и назва-
ние критерия).
На практике критерий знаков чаще всего применяют в следующей ситуа-
ции. Пусть (_Xj, Yt),i = 1,..., zi, — независимые наблюдения наддвумерной
случайной величиной £ = (4|,£г). Требуется проверить гипотезу Яо о том,
что компоненты <(i и (1 независимы и одинаково распределены, т. е. что
F^(x, у) = F(x)F(y), где F(x) — некоторая (неизвестная) одномерная функ-
ция распределения. Чтобы построить соответствующий критерий, поступают
следующим образом. Составим разности Z, = Xi - У), г = 1,...,п. Если
гипотеза Яо верна, то Р{Я; < 0} = P{Z, > 0} = 1/2, и тем самым гипотеза
сводится к утверждению, что выборка (Z\,..., Zn) извлечена из распреде-
ления, медиана которого равна 0. В этом случае V\ равно числу отрицатель-
ных Zi, а статистика (13) для больших выборок распределена при гипотезе Яд
приближенно по закону *2(1). Тем самым при уровне Критерий знаков
значимости а асимптотический вариант критерия зна-
ков имеет вид
Яо отвергается
(14)
Замечание. Из (13) видно, что критерий знаков по существу основывается на стати-
стике И|, которая имеет при гипотезе Я(1 биномиальное распределение Bi(n, 1/2),
поэтому на самом деле здесь речь идет о проверке простой параметрической гипотезы
о параметре биномиального распределения В1(п, 0), именно, гипотезы Но 0 = 1/2.
В основе критерия (14) лежит нормальная аппроксимация £(р| |Я0) ~ Л/(п/2, п/4)
(теорема Муавра—Лапласа), из которой и следует, что
Яо ) -> х2(1) ПРИ п оо.
При малых выборках критерий знаков как частный случай критериев для общих пара-
метрических гипотез в биномиальной модели Bi(n, в) будет рассчитан позже (в гл. 5)
при изложении общей теории проверки параметрических гипотез. Вообще же крите-
рий знаков — «старый и знаменитый» (Я. Гаек и 3. Шидак), он применяется уже очень
давно, по крайней мере не позже, чем с 1925 г. (Р. Фишер); детальное обсуждение
его практического использования можно найти в книге [26, с. 58-65], где приведена
и соответствующая обширная библиография
334
Глава 4. Проверка статистических гипотез
5. Критерий пустых ящиков
В этом пункте мы кратко коснемся еще одного современного подхода к задаче
проверки простой гипотезы Но о виде распределения, связанного с методом
группировки наблюдений. Как уже отмечалось в п. 2, при группировке на-
блюдений (в случае выборки из непрерывного распределения) происходит
неизбежная потеря информация, так как вместо самих наблюдений исполь-
зуются лишь частоты попадания в интервалы группировки. Этот недоста-
ток метода можно уменьшить, устраивая «более мелкое» разбиение носите-
ля распределения наблюдаемой случайной величины, т.е. увеличивая число
интервалов группировки N. Однако, тогда критерий х2 становится трудоем-
ким, так как подсчет и обработка большого (при больших N) числа частот
1/[,..., i/y требует больших вычислительных затрат. Следует также иметь в ви-
ду и то обстоятельство, что теорема 1 о предельном распределении статистики
справедлива лишь при фиксированных значениях параметров N и p°j,
j = 1, , N, и ее уже нельзя использовать для расчета критической границы
критерия, если N —> сю. Выход из этой противоречивой ситуации можно най-
ти, сконструировав более простые, нежели Jt,,, тестовые статистики и доказав
для них предельные теоремы, учитывающие одновременное неограниченное
возрастание параметров п и N. Одной из таких простых статистик является
число пустых (т. е. не содержащих ни одной выборочной точки) интервалов
р0 = p0(n, N) (мю-ноль). Критерий, основанный на этой статистике, назы-
вают критерием пустых ящиков, его мы и опишем. (Если интерпретировать
интервалы группировки как ящики, а испытания как бросание в них дроби-
нок, то до(п, N) есть число пустых ящиков после бросания п дробинок —
отсюда и название критерия.)
Для некоторого упрощения мы конкретизируем нулевую гипотезу
Но Ft.(x) = F(x),
считая, что F(x) = х, 0 х 1; таким образом, Но — это гипотеза о том,
что наблюдаемая случайная величина ( имеет равномерное распределение
на отрезке [0, 1]. (На самом деле это не есть сужение проблемы, так как с по-
мощью преобразования Смирнова (см. упр. 17 к гл. 2) р = мы всегда
можем перейти от случайной величины £ с абсолютно непрерывным рас-
пределением F к равномерно распределенной на отрезке [0, 1] величине р.)
Далее, обычно в методе группировки рекомендуется интервалы £it ,£N
выбирать равновероятными при нулевой гипотезе, т.е. чтобы все р° \/N,
поэтому далее мы полагаем £j = ((; - V)/N, j/N], j = 1,... , N.
Итак, пусть i/), , i/y — частоты попадания элементов выборки X =
= (X,,..., Хп) из некоторого абсолютно непрерывного распределения на
[О, 1] в эти интервалы. Определим индикаторные случайные величины pj =
— = 0), j = 1, , N, тогда, очевидно, До = + + Их Вычислим
первые два момента этой статистики для произвольного распределения на-
блюдений 2^, для которого
F^j/N) - ед - 1)/ЛГ) = j = I,..., N.
§ 4.2. Проверка гипотезы о виде распределения
335
Имеем
N N
Еро = 52 = 12 Р^> = 'Ь
j=i j=i
dpo = 52 D,?> +212 cov(^ - = 12 = o(i - р{ъ = о)+
j=l i<j j = l
+2 52 [р{^ = ^ = о - p^> = op{»v = o]
Испытания независимы, поэтому
P{^ = 1} = ₽{";= 0} = (l-Pj)n
= Hj = 1} = P{"< = t'j = 0} = (1 - PiPj)n
i
Следовательно,
EMo = 52(* ~Pj^n DMo = 2 52(! “Pi “P>)n + EM0 - (E^o)2 (15)
j = l i<j
С помощью метода неопределенных множителей Лацзанжа (см, о нем в п. I (1)
§3.7) легко проверить, что среднее E/zq как функция параметров plt ,pN
достигает минимума при pj = }/N, j = 1,..., N, т. e. при нулевой гипотезе.
В этом случае формулы (15) принимают вид
/ I
Е/г0=ТЦ1--J
/ т \ « / i\n / , \ 2п (16)
, . I 2 \ / 1 \ э/ 1\
D/,. = N(N-I)(|--J -«('-„)
Таким образом, при любом отклонении от нулевой гипотезы, таком, что
вероятности попадания в интервалы группировки не все равны 1/N, статисти-
ка ро имеет тенденцию увеличиваться, т.е. «слишком большие» значения р0
«свидетельствуют» против гипотезы Hq. Отсюда следует, что критическую об-
ласть критерия следует задавать в виде
{д0(п, N) > ta{n, N)}. (17)
Для нахождения критической границы ta(n,N) надо знать распределение
статистики рй при гипотезе Но. Точное ее распределение известно и имеет
вид [14, с. 10],
лг-ь / . X п
Р{Мо(п, ^) = к\но} = 52(-rfC3N_k
} = о
336
Глава 4. Проверка статистических гипотез
однако использовать его для практических расчетов при больших п и N
(что и представляет наибольший интерес для приложений) неудобно. Поэто-
му при больших значениях п и N для расчета критерия (17) естественно
воспользоваться предельными теоремами. Одна из необходимых нам таких
теорем, дающая вид асимптотического распределения ро при любом абсо-
лютно непрерывном распределении наблюдений F( (а не только для нулевой
гипотезы Яо: = х, 0 С х С 1) формулируется следующим образом.
Обозначим через
j/N
Pj = У f(x)dx, j = 1, ,N,
b-D/лг
вероятности попадания наблюдений в интервалы группировки для распреде-
ления с плотностью /(х) и будем предполагать, что все допустимые плотности
f(x) > 0, х G [0, 1], и непрерывны.
Теорема 5. Пусть п, N —> оо так, что n/N —> р > 0. Тогда
£(p0(n,2V)|f) ~ЛГ(Ят(/), Яо2(/)),
где
тп(/) — у е dx,
о
.2
у е-',№)(1 - е^/(1)) dx -
о
е dx
(18)
2
о
Для нулевой гипотезы f(x) = 1, х Е [0, 1], поэтому утверждение теоре-
мы 5 принимает вид
( po(n,N)~ Ne-o
(19)
Этот результат уже позволяет приближенно рассчитать критическую границу
в (17) при больших п и N и заданном уровне значимости а. В самом деле,
из (19) следует, что если в (17) положить
to(n,N) = Ne-p+ ta^Ne~/>(l - (1 + p)e^), $(-to) = a, (20)
то при n, N -> oo, n/N -> p > 0 критерий (17) будет иметь в пределе уровень
значимости а.
Критерий
пустых ящиков
Итак, асимптотический (при больших n, N и n/N =
= р > 0) вариант критерия пустых ящиков имеет следую-
щий вид:
§ 4.2. Проверка гипотезы о виде распределения
337
Hq отвергается <=> ро(п, N) > ta(n, N), (21)
где <о(п, 7V) дано в (20). Следуя этому правилу, можно ошибочно отвергнуть
истинную гипотезу Но F^x) — х, 0 х < 1, с вероятностью, приближенно
равной а.
Теорема 5 позволяет также исследовать предельное поведение мощности
Ww(f) критерия (21) и при произвольной альтернативе, задаваемой плотно-
стью f(x) 1, х € [0, 1]. Действительно, в условиях этой теоремы
WN(f) = Р{д0(п, N) > ta(n, N)\f} =
= (22)
I VNff(f) J
где
za(N) = y/N ^о = е-'’(1-(1 + р)е-₽).
Воспользуемся, далее, известным в теории вероятностей неравенством Йен-
сена®, справедливым для любой случайной величины г/ и любой выпуклой
вниз функции д(х) «/(Ет?) < Е^(ту) с равенством только в случае, когда
д = const (предполагается, что указанные математические ожидания суще-
ствуют, для выпуклой вверх функции д(х) неравенство заменяется на про-
тивоположное); для неотрицательной величины д и д(х) = In х это нера-
венство принимает вид In Ед Е1п д или Ед ехр{Е1пт?}. Полагая здесь
д = е~р^\ где £(£) = Щ0, 1), получим неравенство (см. (18))
= е~р
m(/) > exp j
о
так как f(x) — функция плотности на [0, 1]; равенство здесь имеет место
только в случае f(x) н const = 1, т. е. при нулевой гипотезе. Итак, для любой
альтернативной плотности f(x) 1 разность тп(/) - е~р > 0, и потому
величина za(N) в (22) при /V -> оо неограниченно Состоятельность
возрастает. Это, в свою очередь, в силу (22) означает, критерия пустых *
что lim Wx(f) 1, т.е. критерий пустых ящиков |jj|: ящиков
является состоятельным.
Итак, если выполнены условия теоремы 5, то мощность критерия пустых
ящиков при любой фиксированной альтернативе стремится к 1. Однако, если
при изменении п и N изменяется также и альтернатива, сближаясь с нуле-
вой гипотезой Но, то мощность критерия уже необязательно будет сходиться
к 1 — это зависит от скорости сближения альтернативы с нулевой гипотезой.
Теорема 5 дает возможность ответить и на вопрос о том, с какой скоростью
Йенсен Иоганн Людвиг (1859-1925) — датский математик, труды по математическому ана-
лизу, геометрии.
22 Заказ 1748
338
Глава 4. Проверка статистических гипотез
может происходить это сближение, чтобы критерий (21) обладал еще спо-
собностью «реагировать» на альтернативу. В данном случае альтернативами
являются любые абсолютно непрерывные распределения на [0, 1], отлича-
«Близкие» ющиеся от равномерного распределения W(0, 1); сле-
ольтернотивы довательно, «близкую» альтернативу Fn можно задать
плотностью
fn(x) = 1 + a(n)b(x),
(23)
где а(п) —> 0 при п —> оо, а Ь(х) — произвольная непрерывная функция,
удовлетворяющая условию
।
b(x) dx = 0.
о
Здесь а(п) и определяет скорость сближения (в смысле поточечной сходимо-
сти) альтернативной плотности /„ с плотностью при нулевой гипотезе.
Следующее утверждение является простым следствием теоремы 5.
'Мощность критерия Теорема б. Если в соотношении (23) положить
пустых ящиков ; . ( } -тГ1/4
то при n, N -> оо, n/N -» р > 0 мощность WN(Jn) удовлетворяет предель-
ному соотношению
WN(fn)^*(b(b2,p)-ta), (24)
где
, Ь2 PV-2 -> Г ,
Д(6 . />) = у / „ , ь = / b\x)dx.
г- yj е1’ - 1 - р J
Из этой теоремы следует, что критерий пустых ящиков позволяет отличать
от гипотезы Но альтернативы, сближающиеся с ней со скоростью п-1^4 Более
близкие альтернативы вида (23) (т.е. при а(п)п1,/4 —> 0) этот критерий асимп-
тотически (в условиях теоремы 6) не отличает от Но (т.е. W^(fn) —> а), а для
более удаленных альтернатив (т. е. при а[п)п^ -> оо) он сохраняет свойство
состоятельности (т.е. WN(fn) -> 1).
Дальнейшие результаты
Критерий пустых ящиков привлекателен своей простотой и достаточно широ-
ко известен (по крайней мере с работы Ф. Дейвид 1950 г.). Подробное изложе-
ние относящихся к нему результатов и историю вопроса можно найти в книге
[14, гл. 5], где также рассмотрены и обобщения этого критерия. «Критерий
пустых ящиков может быть полезен при проверке гипотезы о равномерно-
сти распределения каких-либо объектов в ограниченной части пространства,
§ 4.2. Проверка гипотезы о виде распределения
339
например, звезд в части космического пространства, особей какой-либо био-
логической популяции в ее ареале и т.п.» [14, с. 10]. В то же время очевидно,
что статистика до включает далеко не всю информацию, содержащуюся в вы-
борке X = (Xi, , Хп). Более полно эта информация может быть учтена,
если конструировать тестовые статистики вида Симметрические
статистики
/ СтРт>
г=0
где
дг = pr(n, N) = 52 1 <Уз = Т)
3 = 1
— число частот v\, , принявших значение г = 0, 1, , n, асо, q,
сп — некоторые «веса», выбираемые из тех или иных условий оптимальности.
Статистики такого вида называются симметрическими статистиками в схеме
группировки наблюдений, а порождаемые ими критерии — симметрическими
критериями. Общие результаты для симметрических критериев, обобщающих
критерий пустых ящиков, изложены в работах авторов7^ Здесь же мы лишь
отметим, что в условиях теоремы 6 наибольшую асимптотическую мощность
среди всех симметрических критериев имеет известный
нам критерий х , тестовая статистика которого (см. (4)) Критерий
в рассматриваемом случае принимает вид
Критическая граница для этого критерия, превышение которой приводит кот-
клонению гипотезы Но, имеет асимптотически вид /а(п, N) = N + taVlN,
= а, а предельная мощность при «пороговых» альтернативах равна
Интересно сравнить, насколько уступает по мощности критерий пустых
ящиков — простейший симметрический критерий — оптимальному (но тру-
доемкому) критерию х2 Из (24) следует, что
= О’™ <« =
Как функция от р величина е(р) монотонно убывает от 1 при р — 0 до 0
при р = оо, т.е. при малых значениях р = n/N критерий пустых ящиков
по мощности мало уступает критерию х2 Некоторые численные значения
функции е(р) указаны в следующей таблице:
Ивченко Г. И. Медведев Ю. И. Разделимые статистики и проверка гипотез. Случай малых
выборок // Теория вероятностей и ее применения. 1978. Т 23. №4. С. 796-806; Ивченко Г. И.,
Медведев Ю. И. Разделимые статистики и проверка гипотез для группированных данных //Теория
вероятностей и ее применения. 1980. Т. 25. № 4. С. 549-560.
22’
340
Глава 4. Проверка статистических гипотез
р 0,05 0,10 0,15 0,20 0,30 0,40 0,50 0,60 0,70 0,80
е(р) 0,992 0,983 0,975 0,967 0,950 0,933 0,917 0,900 0,884 0,865
Р 0,90 1,00 1,10 1,20 1,30 1,40 1,50 1,60 1,80 2,00
е(р) 0,851 0,834 0,818 0,802 0,786 0,769 0,753 0,738 0,706 0,675
§4.3. Гипотеза и критерии однородности
Задача о двух выборках ° ™потезе однородности и ее прикладном значе-
нии подробно рассказано в примере 5 Введения.
Ее простейший вариант, который часто называют также задачей о двух выбор-
ках, формулируется следующим образом. Пусть X = (Х\, , Хп) — выборка
из распределения £(£) с некоторой (неизвестной) функцией распределения
F(x), a Y = (У], , Ут) — выборка из распределения С(г)) с неизвестной
функцией распределения Fi(x). Гипотезой однородности является утвержде-
ние Hq F[(x) = Fz(x). Это — одна из основных проблем непараметрической
статистики, для решения которой разработано большое число соответствую-
щих критериев однородности. Некоторые из них будут описаны и обсуждены
в этом параграфе.
1. Критерий однородности Смирнова
Статистика Смирнова Этот критерий является одним из первых кри-
териев однородности в задаче о двух выборках
из непрерывных распределений (1939 г.). Его тестовой статистикой является
F>n,m= sup |Д„(2!) - F2m(z)|,
-00<2Г<00
где Fiu(x) и Fim(x) — эмпирические функции распределения, построен-
ные по выборкам X и Y соответственно. Статистика Dn т «сама напраши-
вается» в качестве разумной тестовой статистики для гипотезы однородно-
сти Но. Ведь, как мы знаем (см., например, п. 1 §4.2), эмпирическая функция
распределения является оптимальной оценкой для теоретической функции
распределения, и с увеличением объема выборки они сближаются, поэтому
в случае справедливости гипотезы Но функции F\n(x) и F2,n(x) оценивают
одну и туже неизвестную функцию распределения. Тем самым в этом случае
(по крайней мере при больших пит) статистика Dnm не должна существен-
но отклоняться от нуля. Отсюда следует, что слишком большие значения этой
статистики следует расценивать как свидетельство против гипотезы Яо и по-
тому разумно выбрать критическую область в виде 7}о = {Pn,m > G(n, га)}.
Критическую границу ta(n, т) при заданном уровне значимости а находят
на основании известного при гипотезе Яо предельного (при п, т -> оо)
распределения статистики Dnm, даваемого теоремой Смирнова (см. теоре-
му 4 §2.1). На основании этой теоремы при больших пит можно положить
§ 4.3. Гипотеза и критерии однородности
341
ta(n, т) = у/\/п+ \/т Ха, где К'(Аа) = 1 -а. Действительно, в этом случае
. ( / пт
Но г =I>) \1 ' Dn т > Ха
) (у п + т
Итак асимптотический (при больших пит)
вариант критерия однородности Смирнова имеет вид:
Но > ~ 1 -К(Ха) = а.
Критерий Смирнова
Hq отвергается
Нп, ТП
(1)
где К(Ха) = 1 - a, K(t) — функция распределения Колмогорова (см. (И)
§2.1). Вероятность ошибочно отвергнуть при этом истинную гипотезу Но
приблизительно равна а. Отметим также, что этот критерий состоятелен (аль-
тернативой здесь является любая пара непрерывных распределений (Fb F2)
такая, что F\(x) ^F2(x)).
Подчеркнем, что критерий (1) проверки неизменности функции распре-
деления не зависит от конкретного вида функции. Для приложений это имеет
важное значение, так как истинное распределение наблюдений, как правило,
бывает неизвестно, а интерес представляет вопрос о том, не изменялось ли
это распределение от выборки к выборке. Для применения критерия Смир-
нова необходимо лишь выполнение условия непрерывности, которое обычно
бывает ясно из физической природы изучаемого явления и не требует специ-
альной проверки.
Отметим также, что практически значение статистики -Dn,m рекоменду-
ется вычислять по формуле Dn m = max(Dn>m, D~ m), где
D^m= max (-------------Fln(y(r))) = max (FJni(X(s))-------------
IsCrsCmyTTl у 71
Dn,m — ГПЭХ ( Г1п(У(г))
I sCrsCm у
max ( - - F2m(X(,})
l^s^n \П
и X(1) < X(j) < < X(n), У(ц < У(2) < < У(т) — порядковые статистики
выборок X и Y соответственно. В книге [3, с. 88-89]. приводятся детальные
практические рекомендации по применению (расчету) критерия Смирнова
в том числе и в случае малых выборок, где имеются и соответствующие
таблицы для численных расчетов.
2. Критерий однородности хи-квадрат
Этот критерий применяют к анализу данных, имеющих дискретную структу-
ру, конкретнее, когда в опытах наблюдается некоторый переменный признак,
принимающий конечное число N 2 различных значений. Но к такой схеме,
как мы знаем (см. п. 2 §4.2), можно свести любую другую модель, применяя
предварительно метод группировки данных, поэтому метод хи-квадрат при-
меним на самом деле к анализу данных любой природы, т. е. является в этом
342
Глава 4. Проверка статистических гипотез
смысле универсальным. Кроме того, с помощью этого метода можно анали-
зировать одновременно любое конечное число выборок.
Итак, пусть осуществлено к серий независимых наблюдений, состоящих
из ......пк наблюдений соответственно, и пусть I/, = (t'n, • •, — часто-
ты исходов г-й серии, а р. = (рц,, piN) — их вероятности (г = 1,... ,к).
Тогда гипотеза однородности означает утверждение, что вероятности исходов
не менялись от серии к серии, т. е.
Я°:£1= =Pk=P=(Ph .Pn), (2)
где р — некоторый (неизвестный) вектор вероятностей (р1 + + Pn = !)•
Чтобы построить критерий проверки этой гипотезы, поступают следу-
ющим образом. Поскольку при гипотезе Hq каждый из векторов частот
и,, г 1,...,к, распределен по полиномиальному закону М(п1\р), то
\Н0) = niPj, j = 1, , N, и в качестве меры отклонения эмпирических
данных от их гипотетических (при гипотезе На) значений можно выбрать
статистику (см. п.З §4.2)
* N I \2
4...П1.(Р) = £<М где Т2.(р) = ^^~^) ,
" " 7^ п‘Р]
заменив здесь неизвестные параметры р их оценкой максимального прав-
доподобия, которая вычисляется в предположении истинности проверяемой
гипотезы Hq:
к
'р = arg max pv-’ = arg max p^' где v.j = vij-
- i.j - j > = 1
Таким образом, в этом случае (при гипотезе Яо) все данные можно объ-
единить в одну выборку объема п nt + + п* с частотами исходов
i/.i, ,v*n, следовательно (см. пример 12 §3.5),
Рз = j = 1, , Я В итоге мы получаем тесто-
вую статистику критерия однородности хи-квадрат
Тестовая статистика
в задачах однород-
НОСТИ
с помощью которой и строится критическая область критерия:
Для нахождения критической границы ta при заданном уровне значимости а
используется следующий предельный результат [15, с. 483], аналогичный тео-
реме 4 §4.2: при п,- —> оо (г = 1, ,к)
Д(^„..П1|Яо) ^x2((fc-1)(Я-I)).
В силу этого результата при больших щ можно полагать ta = (*--0(^-0’
§4.3. Гипотеза и критерии однородности
343
Итак, асимптотический (при больших n.) _ i *
' ' Критерии однородности У
вариант критерия имеет вид:
Hq отвергается
J?2 . 2
ЛП1...п* > Х\-а, (lc-l)(N-!)’
(4)
где статистика X?_ nt вычисляется по формуле (3). Вероятность ошибочно
отклонить при этом истинную гипотезу (2) приблизительно равна а, если п
достаточно велико.
Эту же методикуможно использовать и для провер- Параметрические
ки гипотезы о том, что гипотетические вероятности pj гипотезы
имеют заданную параметрическую форму: pj = Pj(6),
j = 1, , N. Такая ситуация возникает, например, когда требуется проверить
гипотезу о том, что к серий наблюдений произведены над одной и той же слу-
чайной величиной с распределением из заданного параметрического семей-
ства Л = {F(x;0), 9 G ©}. В этом случае предварительно проводится груп-
пировка наблюдений с N интервалами и вычисляются оценки pj = Pj(9), где
0 = arg max П(р#)Г>
9 j
Число степеней свободы в предельном (для статистики X?, ,nt(p) при гипоте-
зе Яо) распределении %2 заменяется при этом на k(N - 1) - г, где г = dim 0
(dimention — размерность) (предыдущая ситуация соответствует случаю г =
= N- 1).
Критерий однородности %2 (4) является состоятельным, т. е. с вероят-
ностью, стремящейся к 1 при п —> оо, он «улавливает» любые отклонения
от нулевой гипотезы (2), при которых вероятности появления исходов от се-
рии к серии не сохраняют постоянного значения.
Для случая двух выборок (Л = 2) статистика (3) принимает, как нетрудно
проверить, следующий вид
N
1
+ «2/
2
пьп2
Если положить ujj = ш = ni/^+nj), то последнее выражение
преобразуется к виду, более удобному для практических вычислений:
N \
1
=2
(5)
Выделим также важный для приложений частный случай двух исходов
(N = 2), которые можно обозначить А и А. Гипотеза однородности (2) в этом
случае есть утверждение, что событие А имеет во всех испытаниях одну и ту же
(хотя и неизвестную) вероятность реализации р. Здесь оценкой для р является
344
Глава 4. Проверка статистических гипотез
относительная частота появления события А во всей совокупности данных:
। - 1 у^
Р = 1 -9 = - >.^1>
п
где 1/|| — число появлений события А в испытаниях г-й серии, а статистика (3)
принимает вид
»2 _ J_ А О'.! ~ njp)2 _ ул Рп _ р
(6)
Рассмотрим здесь детальнее случай двух выборок
^аблйцо'«2'тх 2*> (п = 2). Для наглядности в этом случае данные сводят
в так называемую таблицу «2 х 2» (два-на-два):
Рассмотрим разности Ду = р|; - Vi.u,j/n, i,j = 1,2. Легко видеть, что все
суммы
52 ДО = 52 Д‘> = °-
• >
Например,
b'l.b'.i Р1.Р.2 Р|. . .
Д[1 + Д12 — I'll + р12------------------— ----(р«1 + р«2) = ~ р1« = О-
п п п
Таким образом, все четыре величины Ду равны по модулю и потому
> А 1 "ЗД?1
ХП2,П; = ПД?, > ---------- = --------.
V\.V2>V,\V.2
Далее,
/^11 \ / р] I
пДц = 1/|. I —(Pl. +Р2.) - (i'll + «'гО ) = —
Vi. / \"i.
поэтому, обозначая
^П|П2
7171172>2
K.1I/.2 ’
§ 4.3. Гипотеза и критерии однородности
345
получим
2
П,П2
I'll
"1.
х2
«ъ/
(7)
X
^.1^.2
Представление (7) подсказывает идею использовать Znini в качестве дру-
гой тестовой статистики в рассматриваемой задаче. Эта статистика является,
очевидно, более информативной, чем статистика Хп|П2, так как знак /П|П2
может нести дополнительную информацию о характере альтернативы в тех
случаях, когда гипотеза Но неверна (знак тестовой статистики указывает
на направление отклонения альтернативы от Но). Действительно, если обо-
значить через pt вероятность реализации А в испытаниях i-й серии (г = 1,2),
то £(ь\1) Bi(n,,pi) и Е(1/ц/П| - и21/п2) = р} - р2. Следовательно, при
альтернативе вида Н^ pt > р2 статистика Zn|712 будет иметь тенденцию
смещаться вправо от нуля, а при альтернативе Н^ р\ < р2 — влево. Та-
ким образом, статистику Zn,n2 естественно использовать в задачах проверки
гипотезы Но против «односторонних» альтернатив Н* или Щ т. е. в зада-
чах (Яо, Я*) и (Я0,ЯГ), в то время как статистика Х„|П2 «работает» лишь
в задаче (Яо, Н\ = Я,+ иЯ|”), т.е. при общей (двусторонней) альтернативе
Я, р\^рг-
Для построения соответствующего критерия надо исследовать распре-
деление статистики Zn<ni при нулевой гипотезе. Мы будем рассматривать,
как обычно, схему больших выборок, т.е. предполагать, что п\,п2 -> оо.
Тогда на основании теоремы Муавра—Лапласа £(ц-|/п,|Яо) ~ Af(p,pq/n,i),
i = !, 2, а так как случайные величины ь'ц и независимы по условию, то
при гипотезе Яо
\ П] 712 / \ П|Т12 /
Следовательно, статистика
nlpq
при гипотезе Яо асимптотически нормальна с параметрами 0 и 1:
£«П1П2|Яо)~У(О, !).
р р
Но при гипотезе Яо v.\/n —> р, v.2/n —> q (ведь относительная частота
исхода в п независимых испытаниях является состоятельной оценкой его
вероятности), следовательно,
у n'pq
Отсюда следует (см. справочник предельных теорем в п. 4 § 3.5, утверждение
2°(г)), что при гипотезе Яо предельные распределения статистик /П1П2 и £П|П2
совпадают. Итак, при п2 -> оо
г(гП1П2|яо)->Мо, 1).
346
Глава 4. Проверка статистических гипотез
Пусть теперь требуется проверить гипотезу однородности Но pi = рг
против правосторонней альтернативы Н* pi > рг- Из предыдущих рассуж-
дений следует, что критическую область разумно выбрать в виде {Zn,n2 >
так как большие положительные значения статистики Zn,n2 естественно рас-
сматривать как свидетельство в пользу альтернативы Далее, поскольку
при больших П| и пг P{Zn,„2 > tj#o} ~ 1 - $(tQ) = Ф(-<а), то при уров-
не значимости а критическая граница приближенно определяется условием
Ф(—te) = <*> т.е. ta = = Ф-,(1 - а) есть квантиль уровня 1 - а
стандартного нормального распределения.
Замечание. Поскольку для любой гипотезы, задаваемой вероятностями рь р2 ПРИ
П|,П2 -> оо
то аналогичными рассуждениями можно показать (это мы оставляем читателю в ка-
честве упражнения), что для «близкой» альтернативы
при П],п2 -э оо так, что nt/n -э 7, выполняется предельное соотношение
£(2П1П2|Я+) —> Я(аУ7(1-7). 1)
Этот результат позволяет вычислять предельную мощность построенного критерия
при таких альтернативах:
p{zn,„2 > г0|я+} ф(ау7(1 - 7) - ta)-
Пример 1. Поступающие в вуз абитуриенты разбиты на два потока по 300
человек в каждом. Итоги экзамена по одному и тому же предмету на каждом
потоке оказались следующими: на 1-м потоке баллы 2, 3, 4 и 5 получили
соответственно 33, 43, 80 и 144 человека; соответствующие же данные для
второго потока — 39, 35, 72 и 154. Можно ли при уровне значимости а = 0,05
считать оба потока однородными? Здесь к = 2, N = 4 и статистика (5) при-
нимает значение 2,18. Критическая же граница Хо,95; з = 7,82. Таким образом,
ЛГп|П2 < Хо,95;3> т е- согласие гипотезы однородности с данными хорошее. •
Пример 2 [15, с. 484]. В таблице на с. 347 приведено число детей, родив-
шихся в Швеции в течение к = 12 месяцев 1935 г.
Оценкой для вероятности рождения мальчика является
По формуле (6) получаем „ = 14,986 с 11 степенями свободы. Посколь-
ку Хо,95;п = 19,7, то можно считать (при уровне значимости а = 0,05), что
данные совместимы с гипотезой о постоянной вероятности рождения маль-
чиков по месяцам. •
§4.3. Гипотеза и критерии однородности
347
Месяцы Пол ребенка Е = п,
Мальчики Девочки
1 3743 3537 7280
2 3550 3407 6957
3 4017 3866 7883
4 4173 3711 7884
5 4117 3775 7892
6 3944 3665 7609
7 3964 3621 7585
8 3797 3596 7393
9 3712 3491 7203
10 3512 3391 6903
11 3392 3160 6552
12 3761 3371 7132
Е = и.. 45 682 42 591 88 273 = п
3. Другие критерии в задаче о двух выборках
Кроме двух описанных критериев однородности разработаны и другие мето-
ды, основанные на различных принципах. Далее приводится краткий обзор
некоторых из них, применяемых в случае двух выборок из непрерывных рас-
пределений.
а) Критерий знаков. Простой для проверки однородности критерий, не
требующий сложных вычислений, представляет собой описанный в п. 4 §4.2
критерий знаков. Основным недостатком этого критерия является «неэконом-
ное» использование информации, содержащейся в результатах наблюдений,
поэтому его обычно рекомендуют применять только на стадии предвари-
тельного анализа. Кроме того, этот критерий можно использовать лишь для
выборок одинакового объема.
б) Критерий пустых блоков. Целый класс критериев однородности можно
построить исходя из следующих соображений. Рассмотрим вариационный ряд
выборки Х-. Х(1) < Х(2) < < Х(п) (поскольку выборка из непрерывного
распределения, то с вероятностью 1 все порядковые статистики будут различ-
ны, см. п.З §2.1). Он порождает естественное разбиение оси Ох на интервалы
(Х(,_|), -Хц)], г = 1,..., п+ 1 (Х(о) = -сю, ^(n+i) = оо), которые называют-
ся выборочными блоками. Пусть (г — (г(п, т) — число этих блоков, каждый
из которых содержит ровно г элементов второй выборки Y = (У), , У,„),
т = 0, 1,. , т. Тогда в качестве тестовой статистики можно взять, вообще
говоря, произвольную линейную комбинацию сг(г. В частности, простей-
Г
шая такая статистика (о — число блоков, не содержащих ни одного элемента
второй выборки, — порождает критерий пустых блоков. Основой для построе-
348
Глава 4. Проверка статистических гипотез
'Л*.,
ф Критерий
пустых блоков
ния и расчета этого критерия в случае больших выборок является следующий
результат [24, с. 453]: если п, т -> оо так, что т/п -> р > 0, то
Отсюда получаем асимптотический вариант критерия
пустых блоков: при уровне значимости а гипотеза одно-
родности Но отвергается тогда и только тогда, когда
(8)
р
(1 +p)V2 ta’ = °-
п
(о(п, т) > -----
Этот критерий является состоятельным против альтернатив (Fi, F2), Ft F^,
удовлетворяющих следующему условию: функция F{F7'' (и)), [0,1], имеет
производную д(и), отличную от 1 на множестве положительной лебеговой
меры.
в) Критерий серий. В ряде случаев особый интерес представляют такие
отклонения от нулевой гипотезы Но F^x) = F^x), когда одно распределе-
ние сдвинуто относительно другого, например, когда F.(x) > F}(x), — в этом
случае говорят, что случайная величина т? с распределением F^ «стохастически
больше», чем 4, распределение которой есть F[ (при каждом х величина р
с ббльшей вероятностью превосходит х, чем £). Простой критерий, хорошо
«улавливающий» такие отклонения, можно построить следующим образом.
Объединим обе выборки X и Y в одну (Х|,. , Хп, Ym) и построим
вариационный ряд этой объединенной выборки. После этого заменим все
элементы выборки X буквой С, а все элементы Y — буквой С. В результате
получим некоторую последовательность п букв Сит букв С Число всех
таких последовательностей равно С„+т и интуитивно ясно, что при гипоте-
зе Но (элементы обеих выборок X и Y должны «вести себя одинаково») все
возможные последовательности равновероятны. Описанные выше отклонения
от Яд приводят к тому, что с повышенной вероятностью будут наблюдать-
ся последовательности, в которых элементы одного вида имеют тенденцию
смещаться к какому-нибудь краю последовательности (в приведенном выше
примере буквы С смещаются к правому краю). Одной из статистик, с по-
мощью которой можно количественно охарактеризовать степень перемеши-
вания в получаемой последовательности букв С иС, является число серий
W(n, m). Серией называется участок последовательности, состоящий из под-
ряд идущих одинаковых букв и ограниченный с обеих сторон (или с одной
стороны, если речь идет о концах последовательности) буквами другого ви-
да. Число серий будет мало, если одинаковые буквы группируются в одном
месте, поэтому в данном случае следует задать критическую область в виде
{lV(7i,m) ta(n,m)}. Такой критерий, предложенный в 1940 г. Вальдом
и Вольфовитцем, и называется критерием серий.
Асимптотический (для больших выборок) вариант этого критерия можно
рассчитать на основании следующего утверждения [24, с. 459]: если п, т —> оо
§ 4.3. Гипотеза и критерии однородности
349
так, что т/п —> р > 0, то
При этих условиях критерий серий формулируется следу
ютим образом: при уровне значимости а гипотезу однород
ности Но отвергают тогда и только тогда, когда
Критерий серий
, , 2пр 2р . .
w{n'm>^TTp~v7lVTp)^ta' ф^ = а-
(9)
Этот критерий является состоятельным против тех же альтернатив, что и рас-
смотренный в п. б) критерий пустых блоков.
г) Ранговые критерии. Иногда исходная статистическая информация мо-
жет быть задана не числовыми значениями наблюдений, а отношением по-
рядка между ними (типа «больше—меньше»). Особенно часто это имеет ме-
сто в психологических исследованиях. В таких случаях наблюдения ранжи-
руют, т. е. упорядочивают по степени их предпочтения. Номер места, кото-
рое занимает конкретное наблюдение в таком упорядоченном ряду, называют
рангом этого наблюдения. Таким образом, с самого нача-
ла информация может быть задана рангами наблюдений;
статистические методы, которые применяют в таких ситуациях, называют
ранговыми методами, статистики, являющиеся функциями только рангов, —
ранговыми статистиками, а критерии, основанные на таких статистиках, —
ранговыми критериями.
Ранговые методы можно применять и в тех случаях, когда заданы чис-
ловые значения наблюдений, т.е. выборка X = (A\,..., Хп), так как при
этом всегда можно упорядочить элементы выборки, построив ее вариацион-
ный ряд. В этом случае рангом i-го наблюдения Xi является номер места R,,
которое занимает Хг в вариационном ряду С Х^ Х(п). Тео-
рия ранговых критериев является важной и хорошо разработанной областью
современной математической статистики, она весьма полно изложена в [7].
В этом пункте мы рассмотрим в качестве иллюстрации лишь один пример
Критерий
Вилкоксона
рангового критерия однородности — критерий Вилкок-
сона, предложенный впервые Вилкоксоном (1945) для вы-
борок одинакового объема и распространенный на случай
выборок разных объемов Манном и Уитни (1947).
Рассмотрим, как и в предыдущем случае, объединенную выборку (А),...,
Хп, У|, , Ут) и построим ее вариационный ряд. Пусть Rt — ранг величи-
ны Xj в этом ряду (г = 1, , п) и Т = Я, -I- + Rn — сумма номеров
мест, которые занимают в общем вариационном ряду элементы выборки X.
Ранговая статистика Т и есть тестовая статистика критерия Вилкоксона.
Введем случайные величины Zrs = 1(ХГ < Ys) и положим
п тп
и = и(п, тп) = ^2 52 Zrs'
Г=1 3=1
(10)
350
Глава 4. Проверка статистических гипотез
так что U есть общее число тех случаев, когда элементы выборки X предше-
ствуют в общем вариационном ряду элементам выборки Y Можно показать,
что статистики Т н U связаны линейным соотношением
п(п + 1)
Т 4- 1Л — 77777 ------,
2
поэтому критерий Вилкоксона эквивалентен критерию, основанному на ста-
тистике U. называемому иногда критерием Манна—Уитни.
Для любой пары (F,,F2) абсолютно непрерывных распределений среднее
значение статистики U есть
ОО
EZ7 = 71777 Е7ц = 71771 Р{Х[ < = 717П J F\(x)f2{x) dx = апт, (11)
-00
следовательно, при нулевой гипотезе, т.е. при F| = F2, ЕН = птп/1. Таким
образом, с позиций статистики U альтернативы можно характеризовать вели-
чиной параметра о в (11): а < 1/2, либо а > 1/2, либо а 1/2. Для расчета
критерия можно использовать следующий результат для случая больших вы-
борок [24, с.467]: если 77, тп —> оо, то
, , ,, , ,/ 77777 77777(77 4- 777 4- 1) \
r(W(7l, 777)|Я0) ~ ---------- )
(это предельное распределение можно с хорошим приближением использовать
уже при 77 , 777 4, 71 4- тп 20).
Основываясь на этом результате уже можно рассчитать асимптотический
вариант критерия согласия для гипотезы Но. Критическая область имеет раз-
личный вид в зависимости от целей, для которых строится критерий. Если хо-
тят получить критерий, состоятельный против альтернатив (Fb F2) с а < 1/2,
то критическую область следует задать в виде {Н(т7,777) £q(t7, 777)}, где при
при больших 77 и 777 и заданном уровне значимости а критическая граница
имеет вид
, . 77777 /77777(77 4- 777 4- 1)
<а(77, 777.) = — - у ----------------- ta, = а.
Случай а > 1/2 сводится к рассмотренному перестановкой F| и F2. Наконец,
критерий, состоятельный противдвусторонних альтернатив: а / 1/2, задается
двусторонней критической областью
f 77777 /77777(77 4- 777 4- 1) 1
j П(т7, 777) - — > у ----------)2 -- ta/2 j
§4.4. Гипотеза независимости
В данном параграфе будут рассмотрены несколько вариантов проверки гипо-
тезы независимости, описанной в примере 6 Введения. В этом случае дан-
ные представляют собой независимые наблюдения (Xt, У)), г = 1,...,77,
§ 4.4. Гипотеза независимости
351
над некоторой двумерной случайной величиной £ = ((1,(2) с неизвестной
функцией распределения F{(x,y), о которой требуется проверить гипотезу
Но Е}(х,у) = F(t(x)F(2(y), где F^(x), i = 1,2, — некоторые одномерные
функции распределения.
1. Критерий независимости хи-квадрат
Простой критерий согласия для гипотезы независимости Но можно постро-
ить, основываясь на методике хи-квадрат. Эту методику применяют для дис-
кретных моделей с конечным числом исходов, поэтому условимся считать,
что случайная величина (1 принимает конечное число s некоторых значений,
которые будем обозначать Oi, ,as, а вторая компонента & — к некото-
рых значений blt , 6*. Если данные имеют другую структуру, то их пред-
варительно группируют отдельно по первой и второй компонентам. В этом
случае множество возможных значений (1 разбивается на s непересекаю-
щихся интервалов множество значений £2 — на к интерва-
г(2) £.(2)
лов Е\J', ,Ек и тем самым множество значении двумерной величины
£ = (£|;£2) разбивается на N = sk прямоугольников х Е®
Пусть Vij есть число наблюдений пары (a,, bj) (число элементов выборки,
принадлежащих прямоугольнику Е^ х Е^\ если данные группируются), так что
ЕЕ^ = п.
t=l j = ]
Результаты наблюдений удобно для наглядности ’^а^лй^Гот^яженн^м1
расположить в виде таблицы сопряженности двух ДВуХ Признаков
признаков (в приложениях & и £2 обычно озна-
чают два признака, по которым производится классификация результатов
наблюдений, и тогда Но есть гипотеза о независимости этих признаков):
4! 6 И
6. b2 Ьк
а. "11 "12 "1k "I.
а2 "21 "22 "2k "2.
as "Sl ",2 "jk "j-
И ". 1 "*2 ".k n
Пусть = P{£i = а,, (2 = bj},i = 1, , к. Тогда гипотеза
независимости означает, что существует s 4- к постоянных р„, p.j таких, что
3 k
Е = Z2 = 1 И Pij = Pi'P'j-
i=l J=1
352
Глава 4. Проверка статистических гипотез
Поскольку наблюдения независимы по условию, то частоты (р,у, г = 1, ., s,
j = к) распределены по полиномиальному закону и при гипотезе Но ве-
роятности исходов pij имеют указанную специфическую структуру (они опре-
деляются значениями г = s + к - 2 неизвестных параметров р„, г = 1,..., s - 1,
p.j, j = 1,..., к - 1). Следовательно, гипотеза независимости в данном слу-
чае является специфической формой сложной гипотезы для полиномиальной
модели, рассмотренной в п. 3 §4.2. Чтобы применить критерий хи-квадрат (12)
§ 4.2, надо сначала найти оценки максимального правдоподобия для определя-
ющих рассматриваемую модель неизвестных параметров при справедливости
гипотезы Но, т.е. максимизируя в данном случае функцию правдоподобия
= Ж П^7
м « i
по параметрам р2,, p.j. Отсюда, как и в п. 2 §4.3, имеем
Ц. _ v.j
Pi. = —, P.j =
п п
т. е. это обычные оценки параметров полиномиальных распределений
,vs.) — M(n;pi., ,ps.)
И
£(v.i,...,v.k) = M(n;p.i, ,p.k).
Тестовая статистика для С учетом этого тестовая статистика (11) §4.2 при-
гипотезы независимости нимает вид
(Vjj - npi.p.jY
npi.p.j
Vi.v.j \2
7Z /
(1)
с числом степеней свободы
N - l-r = sk-\-(s + k-2) = (s- 1)(Л - 1).
Критерий^Щ^рР
независимости %
Итак, асимптотический (при больших п) вариант
критерия независимости х2 при заданном уровне зна-
чимости а имеет вид
Но отвергается <=> X* > Xi-o,(s-i)(fc-i)>
(2)
где Хп вычисляется по формуле (1).
Пример 1 [12, с. 781]. Каждый из п = 6800 индивидуумов классифициро-
вался по двум признакам: цвету глаз и цвету волос (£2), при этом для
было определено 3 категории (а,, а2, а2), адля (2 — 4 категории (£>i, b2, Ь2, Ь4).
Данные эксперимента приведены в таблице
§4.4. Гипотеза независимости
353
6 И
bi ъ2 Ьз 64
О| 1768 807 189 47 2811
946 1387 746 53 3132
а} 115 438 288 16 857
И 2829 2632 1223 116 6800
Здесь значение статистики (1) равно 1075,2, а, например, Хо,999;б = 22,5,
поэтому гипотезу Яо ° независимости этих признаков следует отклонить;
вероятность ошибки при этом значительно меньше а = 0,001 •
В приложениях часто каждый из признаков (| и(; Альтернативные
имеет альтернативную структуру, т. е. з — к = 2. Ти- МЦж признаки
личным примером является классификация сдающих
вступительные экзамены в вуз абитуриентов по признакам «принят (Л) —
не принят (Л)» и «мужчина (В) — женщина (В)». Для таких ситуаций мож-
но провести более глубокий анализ соответствующих статистических данных,
которые удобно представлять в виде следующей таблицы «2 х 2» сопряжен-
ности признаков.
«|\6 1(B) 0(B) £
1(Л) «'ll И 2
0(Л) "21 "22 "2.
£ ".| "•2 п
Структура таблицы здесь такая же, как и таблицы «2 х 2» в случае про-
верки однородности (см. п. 2 §4.3), поэтому ее анализ во многом аналогичен
(хотя ее содержание имеет совсем другой смысл!). Так, совершенно аналогич-
но можно установить, что статистика (1) имеет в данном случае представление
^ = ^,где
z - I tZ|1 _
\ V\. V2.Jy P.1P.2 ’
Поскольку статистика Zn является знакопеременной, ее знак может нести
дополнительную информацию, указывая «направление» отклонения от нуле-
вой гипотезы, и, следовательно, основываясь на ней, можно построить «более
тонкий» критерий.
Установим предварительно следующую связь статистики Zn с выборочным
коэффициентом корреляции рп (см. (5) § 2.3) для наших данных: Zn = \/прп.
Доказательство. Действительно, пусть (Xi,Yi), i = !,..., n, — независи-
мые наблюдения над (&, 6) и X = (Xb ..., Хп), Y = (Уь..., Уп). Тогда,
23 Заказ 1748
354
Глава 4. Проверка статистических гипотез
очевидно, выборочные средние есть X щ./п, Y — v.\/n, выборочные
дисперсии равны
S]
1 _ _ _
-V у,2-у2 = y(i - у)
п '
1 = 1
у. 1^.2
п2
наконец, выборочная ковариация (см. (4) §2.4)
= + ^2.) - + ^2|) = -----5— -----
пг П1 \Р|.
^21
"2.
Отсюда имеем
У12
Рп 5i52
^1.^2.
М.|М.2
В частности, отсюда следует (см. п.З §2.3), что при п —> оо
4 -Л р = согг(£,,£>). (3)
у/П
Найдем, наконец, предельное (при п —> оо) распределение статистики Zn
при гипотезе Hq. Для этого введем случайную величину
Cn = -r—jr -= У (^ - Р(Л))(Г; - Р(В)). (4)
упР(Л)Р(Л)Р(В)Р(В) .=.
Если гипотеза Но справедлива, то Xi и У независимы и потому
Е(Х, - Р(Л))(У, - Р(В)) = Е(Х,- - Р(Л))Е(У) - Р(В)) = О,
ад. - Р(Л))(У, - Р(В)) = ад - Р(Л))2(У, - р(в»2 =
= е(х, - р(Л))2е(у; - р(в))2 =
= DX.DK, =
= Р(Л)Р(Л)Р(В)Р(В),
при этом слагаемые в (4) независимы и одинаково распределены по условию.
Следовательно, случайная величина (п представляет собой нормированную
сумму независимых одинаково распределенных слагаемых и к ней можно
применить центральную предельную теорему (см. (1) § 1.2), согласно которой
п -> оо £«п|Яо)-> А^О, 1).
§ 4.4. Гипотеза независимости
355
Далее, так как
п п
£> - X)(Yt - У) = - Р(Л))(У) - Р(В)) - п(Х - P(A))(Y - Р(В)),
1 = 1 1=1
то
- X)(Y, - У)
1 = 1_____________
упх(| -Х)Г(1 -Г)
У - Р(В) 1 ГР(А)Р(А)Р(В)Р(В)11/2
y^^JLx(i-x)r(i-r)J
По теореме 3 §2.2 об асимптотической нормальности выборочных мо-
ментов при п -> оо
/ у/п(Х - Р(А))\ ч
Г v ; -> V(0, 1),
\ уР(А)Р(4) )
__ р _ р
а по закону больших чисел X —> Р(А), У —> Р(В). Следовательно, при
п —> оо _
х/п(Х - Р(4)) У - Р(В)
VHW) y/v(B)P(B)
р(А)Р(А)Р(В)Р(В)1|/2
Ло,
.Х(1 - Х)У(1 -У).
-Л 1,
и потому предельные распределения Zn и fo совпадают (см. справочник
предельных теорем в п. 4 §3.5). Итак £(£П|ЯО) Л^(0, 1) при п -> оо.
Эти результаты уже дают возможность построить и рассчитать критерий
проверки гипотезы независимости Яо. основываясь на статистике Zn. Альтер-
нативы здесь можно характеризовать величиной коэффициента корреляции
р = corr(fo, fo), Для которого нетрудно получить представление (это мы остав-
ляем читателю в качестве простого упражнения)
Р(АВ) - Р(А)Р(В)
УР(4)Р(4)Р(В)Р(Я)
[Р(Л|В) - Р(4|В)]
Р(В)Р(В)11/2
Р(Л)Р(4).
(5)
Р =
Рассмотрим, например, правостороннюю альтернативу Я,+ р > 0 (или,
что ввиду (5) эквивалентно, Р(Л|В) > Р(А|В)), означающую положительную
коррелированность признаков fo и fo (или положительную сопряженность
событий А и В Ав паре с В встречается с большей вероятностью, чем
в паре с В). Тогда при гипотезе Яо (см. (3)) Zn —> 0, если п —> оо, а при
23*
356
Глава 4. Проверка статистических гипотез
альтернативе Я,+ Zn —> оо, поэтому естественно рассматривать слишком
большие значения Zn как свидетельство в пользу альтернативы Следо-
вательно, если рассматривается задача (Яо, Н\"), то критерий следует задать
критической областью вида {Zn > ta} При этом P{Zn > ta (Яо} ~ Ф(-£а),
т.е. ta = Ф-|(1 - а) есть (1 - а)-квантиль стандартного нормального рас-
пределения А7(0, 1). Итак, в задаче (Яо,Я,+ р > 0) для больших выборок
критерий при уровне значимости а имеет вид: если Zn^ta= Ф~'(1 - а), то
гипотеза Нц принимается, в противном случае она отклоняется (принимается
альтернатива Н*).
Аналогично рассматривается симметричная задача (Яо, ЯГ:р<0): здесь
критическая область имеет вид {Zn < -ta}, Ф(—ta) = а. Общий же критерий
независимости %2 проверяет Яц лишь против двусторонней альтернативы Н\ =
= Я1+иЯ1" :р/0, и он задается в данном случае двусторонней критической
областью {|Zn| >ta/2} = {*/ >Xi-a,i} (см. (2)), поскольку t2o/2 =
Замечание. Можно показать, что если в задаче (H0,Hf) «близкая» альтернатива
задается условием
. в
р = р(п) = —,
у/П
а > 0 — фиксировано, то £(Zn\H^n) -> J*/(a, 1) и, следовательно, мощность крите-
рия {Zn > 7а} удовлетворяет предельному соотношению
P{Zn > «а|я+} -4 Ф(в - to).
Пример 2. Имеются следующие данные о приеме в вуз (А — принят, В —
мужчина):
в В Е
А 97 40 137
А 263 42 305
Е 360 82 442
Проверим гипотезу о независимости признаков «результат» и «пол» про-
тив альтернативы Я/- Р(4|Я) > Р(4|Я). Здесь
/97 40 \ /360 • 82 • 442
Zn =-----------\ -------------= -3,86,
\360 82/V 137 305
a Z„ = 14,89. В то же время, например, Хо.999;i = Ю,8. Это означает, что гипо-
теза о независимости признаков должна быть отвергнута (вероятность совер-
шить при этом ошибку меньше 0,001) в пользу альтернативы
Я/ Р(4|В) < Р(4|В)
(этот факт можно интерпретировать как отсутствие дискриминации в отно-
шении женщин при приеме в вуз). •
§4.4. Гипотеза независимости
357
Пример 3. В следующей таблице приведены 818 случаев, классифицирован-
ных по двум признакам: наличию прививки против холеры (Л) и отсутствие
заболевания (В):
276
279
473
539
749
818
Проверим гипотезу Но о независимости признаков А и В против аль-
тернативы Н|+ об их положительной сопряженности (т. е. об эффективности
вакцинации). Здесь
276 3 \ /749 69-818
749 69/ V 279 539
а Z2 = 29,70. Так как Хо.999; i = Ю.8» то гипотеза Но должна быть отвергнута,
а поскольку Ф-1 (0,999) = 3,09, то принимается альтернатива н+ Вероят-
ность ошибочно отклонить Но в пользу Н* при этом меньше 10-3 •
2. Критерий Спирмена
На практике для проверки гипотезы независимости часто используют ранговые
критерии (см. п. 3 (г) §4.3). Наиболее известным из них является критерий
Спирмена, называемый по имени знаменитого психолога, который ввел его
в 1904 г. Он основывается на коэффициенте ранговой корреляции р, опреде-
ляемом следующим образом.
Обозначим через Я, ранг X, среди наблюдений Х\,... ,Хп (т. е. номер
места, занимаемого величиной X, в вариационном ряду < X<n));
аналогично, пусть S, — ранг Yj среди наблюдений У1,...,УП- Тем самым
исходные данные (Х,,У,), i = 1, .,п порождают п пар рангов (Я,-, S,-),
i = 1,.... п. Переставив эти пары в порядке возрастания первой компоненты,
обозначим полученное множество пар через (1, TJ, , (п, Тп). Статистика
Спирмена р определяется теперь как коэффициент корреляции двух множеств
рангов (Яь ,ЯП) и (Si, ,Sn);
- R)(Si - S)
P Г n n -.1/2
£(Я,-Я)2£>-Я)2
Е
Е
(здесь Я и S — соответствующие арифметические средние). Но (Яь ..., Яп)
и (5ь , S„) — некоторые перестановки множества (1, 2, , п), поэтому
358
Глава 4. Проверка статистических гипотез
п(пг - 1)
12
п
Е
так как
2 п{п + 1)(2п + 1)
= 6
Статистика Отсюда
Спирмена^ 12 " / п + ц г п + ц
Р п(п2 - 1) ’ 2 J г 2 J
Таким образом, р — линейная функция рангов Т,. Часто используют также
формулы
Р = 1 " п(п2 - 1) " 5i)2 = 1 “ п(п2 - 1) г)2 (7)
совпадение которых с (6) проверяется непосредственно.
При полном соответствии рангов (Я,- = Si, г = 1, , п) статистика
р = 1, а при противоположных рангах (Ti = п - i +], i 1, , п)
р = — 1, вообще же Далее, если гипотеза Но верна, то Ер = О,
D/> = 1/(п - 1), поэтому значения р, близкие к крайним, рассматривают
как свидетельствующие против Hq, и, следовательно, критическую область
Критерий критерия Спирмена задают в виде Tla = {|/?| > ta(n)}
Спи мена ^|я 0ПРеДеления числового значения критической грани-
цы ta(n) при заданных объеме выборки п и уровне зна-
чимости а используют таблицы табулированного распределения статистики
р при нулевой гипотезе, рассчитанные для п — 2, , 30 (в [3] приведена
таблица для п = 4(1)10). Для больших п можно воспользоваться асимптоти-
ческим результатом £(\/пр\Н0) -> I). Отсюда следует, что если выбрать
to(n) = ta/i/y/n, — = а/2, ТО ПрИ боЛЬШИХ П
Р{/> е 71а|Яо} = P{Vn|p| > ta/11Яо} и 2Ф(-<о/2) = а,
т.е. уровень значимости критерия приблизительно равен а.
3. Критерий Кендалла
Другой известный ранговый критерий предложен М. Кендаллом (1938) и осно-
ван на статистике
r = п(п - 1) St ’ St = Sign ~ Т,)’
(8)
§ 4.4. Гипотеза независимости
359
где sign а = 1, если а > 0, и -1, если а < 0. Если гипотеза Но верна, то
2(2п +5) , V 4\
Ет = 0, Dr = и С(т\Но -V 0,-
9n(n - 1) \ 9п}
при п -> оо. Отсюда следует, что при больших 71 критическую область следует
выбрать в виде Критерий Кендалла *
Tia
^а/2
Для п = 4(1)10 критическая граница критерия Кендалла рассчитывается с по-
мощью таблицы, приведенной в [3]. Например, при п = 9 критической об-
ласти {|т| 0,5} отвечает вероятность ошибки первого рода 0,076.
Практически статистику Кендалла т рекомендуется вычислять по фор-
муле
4N
где N — число тех пар индексов (г,)), г < j, для которых Т, < Tj. Дей-
ствительно, обозначим дополнительно через N\ число тех пар индексов (г, j),
i < j, для которых Tj > Tj. Тогда, очевидна, S,- = TV - TVi, a N + TV, =
= n(n - 1 )/2 — общее число пар (г, j), i < j Складывая эти два равенства,
получаем ST = 2N - п(п - 1)/2. Отсюда и из (8) получаем указанное пред-
ставление для т
4. Случай тп признаков
В этом пункте мы опишем типичную практическую ситуацию, в которой для
анализа данных при проверке гипотезы независимости эффективно применя-
ются ранговые методы. Рассмотрим совокупность индивидуумов, обладающих
таким признаком, который, может быть, и не поддается точной количествен-
ной оценке, однако позволяет сравнивать индивидуумы друг с другом. Таким
образом, в результате подобного сравнения всю совокупность можно «ран-
жировать», приписав каждому индивидууму порядковый номер, соответству-
ющий итогам сравнения с остальными индивидуумами. Если индивидуумы
могут обладать не одним, а двумя и более признаками, то для исследования
их влияния друг на друга обычно рассматривают выборку из п независимых
индивидуумов и ранжируют их по каждому признаку отдельно. Пусть количе-
ство исследуемых признаков есть тп 2, тогда результаты ранжировок по этим
признакам можно записать в виде (т х п)-матрицы, г-я строка которой
rl2 r In
г22 г2п
1*т2 ^тп
содержит результаты ранжировки по г-му признаку (г = 1, ., тп), а столбцы
соответствуют индивидуумам, принадлежащим исследуемой выборке (таким
360
Глава 4. Проверка статистических гипотез
образом, Tij — это порядковый номер j-ro индивидуума при сравнении его
с другими индивидуумами по г-му признаку).
В качестве единой выборочной меры связи т при-
Коэффициент
конкордонции
W =
знаков Кендалл и Бэбингтон Смит (1939) предложи-
ли коэффициент согласованности W, называемый также
коэффициентом конкорданции (concordance — согласие,
соответствие, конкорданция):
12 о с т(п + I))2
m2(n3-n)^’ Sw~2^1^Tii 2
v ' j=\ Li=l J
(9)
Если по матрице R вычислить коэффициент p Спирмена (см. (6)-(7))
для каждой из т(т — 1)/2 пар признаков, то арифметическое среднее таких р
будет равняться (mW - l)/(m - 1). В частности, если т = 2, то р = 2W - 1.
Коэффициент W принимает значения из отрезка [0, 1] и используется
в качестве тестовой статистики для проверки гипотезы Но о независимости
признаков (признаки называются независимыми, если для любого столбца
матрицы R ранги являются независимыми случайными ве-
личинами). Если гипотеза Яо верна, то
1 2(т - 1)
EW = —, DIV = Ц-----------
т ms(n - 1)
и распределение W удовлетворительно аппроксимируется бета-распределе-
нием [3, с. 97-98]; в [3] имеются также таблицы для расчета критерия при
п = 3, т = 3(1)10; п = 4, т = 3(1)6 и п = 5, т = 3. Например, при п = 5
и т = 3 критическая область критерия независимости трех признаков зада-
ется неравенством {И^ 0,733}, если уровень значимости есть а = 0,038.
Приведем несколько иллюстративных примеров расчета критерия, опи-
рающегося на коэффициент ранговой корреляции р Спирмена.
Пример 4. В следующей таблице указана относительная оценка знаний по ма-
тематике и литературе 8 учеников, занумерованных числами от 1 до 8, причем
лучшим знаниям соответствует меньший ранг:
Ученик (i) 1 2 3 4 5 6 7 8
Ранг знаний по математике (Я,) 5 2 1 7 8 4 6 3
Ранг знаний по литературе (5,) 4 3 2 1 7 6 5 8
Проверим по критерию Спирмена гипотезу Яо о независимости между
успехами по математике и литературе против альтернативы Я,+ успехи по ма-
тематике и литературе положительно коррелированы.
В данном случае в пользу альтернативы говорят «большие» значения ста-
тистики р, поэтому в задаче (Яо, Я,+) критическую область разумно взять
в виде одностороннего неравенства {р > ta(n)}. При п = 8 и, например,
§4.5. Гипотеза случайности
361
а = 0,1 критическая граница ia(n) = 0,4762, а величина р, вычисленная
по формуле (7), равна
р = 1--^-( 12 + 1 2 + 12 + 62 + 12 + 22 + 12 + 52) = 1 -^ = 1= 0,1667.
OJ — о oJ — о о
Так как р < to.1(8), У нас нет оснований отвергать гипотезу независимости. •
Пример 5. Относительная оценка знаний математики и физики в группе из 7
учеников дала следующие результаты (Я, — ранг по математике, S, — ранг
по физике г-го ученика):
Проверим с уровнем значимости а = 0,05 гипотезу Яо о независимости
между успехами по математике и физике. Вданном случае критическая область
критерия Спирмена имеет вид {|р| > to.osP)} и вычисления дают
Следовательно, гипотеза Яо отвергается. •
В заключение этой темы подчеркнем, что выше Важное замечание
рассмотрена гипотеза независимости Яо в ее самой
общей форме, без каких-либо дополнительных априорных предположений
(за исключением предположений типа непрерывности распределения наблю-
дений). В то же время такая гипотеза может возникать и в рамках параметри-
ческих моделей, т. е. когда априори предполагается, что все допустимые рас-
пределения наблюдений принадлежат заданному параметрическому семейству
распределений. Если, например, мы работаем в рамках двумерной нормальной
модели, то гипотеза независимости эквивалентна предположению о равенстве
нулю коэффициента корреляции. Критерий проверки такой гипотезы, тесто-
вой статистикой которого является выборочный коэффициент корреляции,
рассмотрен ранее в п. 4 § 2.3.
§ 4.5. Гипотеза случайности
Хаос — ужас богов.
Древнее высказывание
В различных статистических задачах исходные данные X = (Хь , Хп) ча-
сто рассматривают как случайную выборку из некоторого распределения £(£),
т.е. считают компоненты Х{ вектора данных X независимыми и одинаково
362
Глава 4. Проверка статистических гипотез
распределенными случайными величинами. Но иногда это исходное предпо-
ложение само нуждается в проверке как специальная статистическая гипотеза
(см. пример 7 Введения). Такая гипотеза, называемая гипотезой случайности,
записывается в виде
Но Fx(xi, ,xn)=F(xt) F(xn),
где F(x) — некоторая одномерная функция распределения. Мы рассмотрим
некоторые подходы к построению критериев согласия для проверки такой
гипотезы.
1. Критерий инверсий
Предположим, что вектор X имеет непрерывное распределение. Если гипо-
теза Но верна, то компоненты вектора X «равноправны» и поэтому данные
не должны быть ни в каком смысле упорядочены. Другими словами, ситу-
ацию, соответствующую гипотезе Но, можно охарактеризовать как «полный
хаос», или «полный беспорядок». При отклонениях от Но исходные данные
имеют тот или иной порядок, проявляются связи. Следовательно, при про-
верке Но надо основываться на тестовых статистиках, измеряющих степень
«беспорядка» данных. Одной из таких естественных статистик является число
инверсий в выборке, которое определяется следующим образом.
* Инве си Построим вариационный ряд Хр) < < Х^ вы-
нвеРСИИЯИИИ борки X. Говорят, что компоненты X, и Xj образуют
инверсию, если i < j, но X, стоит правее Xj в вариационном ряду, т.е. на-
блюдению с меньшим номером соответствует большее значение. Пусть т/, —
число инверсий, образованных компонентой X, (в вариационном ряду ле-
вее X,- стоит ту, элементов выборки с ббльшими номерами), i = 1, , п - 1.
Тогда Тп = Тп(Х) = +... Н-7/n-i — общее число инверсий для выборки X.
Статистика Тп является естественной мерой «беспорядка» среди наблюдений
и ее можно использовать для проверки гипотезы Но. Крайние случаи, когда
вариационный ряд имеет вид
Лп или л„ v Ч v У11,
естественно рассматривать как свидетельства «полного отсутствия беспоряд-
ка», т. е. противоречащие гипотезе Но. В первом из этих случаев статистика Тп
принимает минимальное значение, равное 0, а во втором — она максимальна
и равна
(п - 1) + (п - 2) +
2
Таким образом, малые значения Тп и значения, близкие к п(п - 1)/2, есте-
ственно рассматривать как критические для гипотезы Но. Чтобы высказать
более определенные суждения о виде критерия инверсий, надо исследовать
распределение статистики Тп при справедливости гипотезы Но-
Из соображений симметрии ясно, что при гипотезе Но любое из п! от-
носительных расположений элементов выборки в соответствующем вариа-
ционном ряду имеет одинаковую вероятность \/п\ Случайная величина Tj,
§4.5. Гипотеза случайности
363
определяется расположением компоненты X, по отношению к _Х\+1,..., Хп
в вариационном ряду и не зависит от относительного расположения послед-
них между собой, т. е. не зависит от , 7/n-l> i = 1, • • ,п-2. Но это
означает, что случайные величины iji, взаимно независимы.
Далее, ту, может с одной и той же вероятностью \/(п - i + 1) прини-
мать значения 0, 1, ,п - г, поэтому ее производящая функция имеет вид
(см. замечание в упр. 21 к гл. 1)
1
^(2) = Z2= г^г = ~+ 2 + ••• + *’’ ’),
7^ п-г+1
а производящая функция статистики Тп — вид
eZ" = 52 р<гп = г)гГ = П = i IK1+z+• • •+
г i=l ” г=1
Отсюда имеем (см. указание к упр. 24 гл. 1)
(п - - » + 2)
D’Ji = Ч>< (0 + - (Е%) =------------------>
п(п - 1) (1)
1=1
п(п - 1)(2п + 5)
DTn = V D% = ------
Итак, среднее значение статистики Тп при нулевой гипотезе совпадает с се-
рединой промежутка [0, п(п - 1)/2], и в критическую область Т\а следует
включать все целые точки этого промежутка, доста- v . . <
г Критерии инверсии
точно удаленные от середины, т.е. можно положить
(2)
Критическую границу ta(n) при заданном уровне значимости а выбирают
из условия Р{ТП € 7щ|Яо} а или, что эквивалентно,
f п(п - 1) , „ п(п - 1) , , 1
р| 4 - ta(n) Тп у - 1 - а (3)
(ta(n) — это минимальное число, удовлетворяющее данному соотношению).
Соотношениями (2)-(3) и определяется критерий инверсий. Распределение
статистики Тп протабулировано для значений п — 2(1)12 (соответствующая
364
Глава 4. Проверка статистических гипотез
таблица приведена в [3]) и может быть использовано для расчета критерия (2).
При п > 10 можно использовать нормальное приближение
£(Тп\Н0)*ЛГ(ЕТп,ВТп),
где ЕТП и DTn указаны в (1). В таких случаях можно приближенно полагать
ta(n) = to/^ , $(-to/2) = y.
2. Проблема датчиков и обобщенный критерий хи-квадрат
В примере 7 Введения была сформулирована проблема контроля «качества»
последовательностей, вырабатываемых датчиками (генераторами) случайных
или псевдослучайных чисел, которая кратко называется проблемой датчиков.
Научная и практическая значимость этой проблемы очень высока, так как
спрос на такие датчики, а также на сами случайные последовательности в на-
стоящее время непрерывно возрастает (появляются даже научно-производ-
ственные фирмы, занимающиеся производством и продажей больших масси-
вов случайных чисел; например, с 1996 г. в мире распространяется компакт-
диск «The Marsaglia random number CDROM», содержащий 4,8 млрд «истинно
случайных» бит).
Эта проблема имеет большую историю. Ешо в начале XX в. случайные
последовательности целых чисел имитировались с помощью простейших
случайных экспериментов: бросание монеты или игральной кости, извле-
чение шаров из урны, раскладывание карт, рулетка и т. д. В 1927 г. Л. Типпе-
том впервые были опубликованы таблицы, содержащие свыше 40 000 случайных
цифр, «произвольно извлеченных из отчетов о переписи населения». В 1939 г.
М. Дж. Кендалл и Б. Бэбингтон Смите помощью специально сконструированного
механического устройства — генератора случайных чисел создали таблицу, вклю-
чающую 105 случайных цифр. В 1946 г. американский математик Джон фон Ней-
ман впервые предложил компьютерный алгоритм генерации случайных чисел.
В 1955 г компания RAND Corporation опубликовала получившие широкую попу-
лярность таблицы, содержащие 106 случайных цифр, сгенерированных на ЭВМ.
Таблицы случайных чисел можно найти в каждом сборнике статистиче-
ских таблиц. Так в [3] приведена таблица, содержащая 12 500 цифр от 0 до 9.
Эти данные можно рассматривать как реализации независимых и одинако-
во распределенных случайных величин, принимающих значения 0, 1, 2, ,9
с одной и той же вероятностью, равной 0,1. Каждая пара таких цифр пред-
ставляет собой реализацию случайной величины, которая может принимать
любые целочисленные значения от 00 до 99 с одинаковыми вероятностями,
равными 0,01. Аналогичный результат получится, если цифры сгруппировать
по три, четыре и т. д.
Если каждую группу из к цифр, рассматриваемую как целое число, умно-
жить на 10-к то получим реализации случайной величины £, принимаю-
щей fc-разрядные значения от Одо (1 - 10-*) с одинаковыми вероятностями,
§ 4.5. Гипотеза случайности
365
равными 10 к Такое распределение вероятностей близко к равномерному рас-
пределению W(0, 1), причем разность соответствующих функций распределе-
ния не превосходит 10-* Следовательно, реализации £ можно рассматривать
как реализации случайных величин, равномерно распределенных на отрезке
(0, 1]. Эти реализации и называют обычно равномерно распределенными слу-
чайными числами. Из этих чисел с помощью алгоритмов, описанных в § 1.3,
можно построить (сгенерировать) случайные числа с любым другим распре-
делением, отличным от равномерного распределения Z7(0, 1).
Итак, в математическом плане, основное требование к датчику случайных
чисел состоит в том, что вырабатываемая им последовательность 6,6>---
должна быть в статистическом смысле неотличима от последовательности
независимых и одинаково распределенных случайных величин, т. е. должна
соответствовать гипотезе случайности Яо (согласовываться с ней). Теперь мы
уточним постановку задачи, которую будем обсуждать далее.
Пусть задана последовательность из п случайных величин (выборка)
6,6, ,6, (4)
принимающих значения из конечного множества (алфавита) Е = {1,2,... ,Я},
отосительно которой требуется проверить гипотезу Яо о том, что эти слу-
чайные величины в совокупности независимы и равномерно распределены
на множестве Е, т.е. Р{$ = j} = 1/Я, j = 1, ,N, г - 1,2, Гипо-
теза Яо — это есть гипотеза об идеальном датчике: если гипотеза Яо верна,
то датчик, вырабатывающей последовательность (4), реализует «идеальную»
схему независимых испытаний с равновероятными исходами. Но идеальных
датчиков не существует; более того, как отмечено в примере 7 Введения
(см. также п. 1 § 1.3), часто датчик вырабатывает последовательность (4) про-
граммным способом (т.е. эти числа могут быть даже детерминированными),
но тогда эти числа должны быть «практически неотличимы» (или «очень по-
хожи») от независимых и равновероятных чисел. В математическом плане это
понимается так: выборка (4) не должна опровергать гипотезу Яо никаким те-
стом. Практически же идут на следующий компромис: определяется некоторая
совокупность статистических критериев (тестов) и, основываясь на выборке
(4), подвергают гипотезу Яо проверке по каждому из этих контрольных тестов.
Если гипотеза Яо успешно проходит такое тестирование, то она принимается
как истинная, и числа (4) рекомендуются для использования в соответству-
ющих целях как независимые и равномерно распределенные на множестве Е
случайные числа. Общепринятый в настоящее время стандартный набор таких
тестов сформулировал Д. Кнут (1969) и он имеется в книге [13], однако работа
по совершенствованию методов тестирования случайных и псевдослучайных
последовательностей продолжается. В качестве примера одного из подходящих
для проверки гипотезы Яо тестов мы подробно опишем критерий типа хи-
квадрат, основанный на подсчете частот s-цепочек в последовательности (4).
Идею построения этого теста можно объяснить следующим образом. По-
скольку гипотеза Яо — простая (она однозначно фиксирует распределение
366
Глава 4. Проверка статистических гипотез
наблюдений (4)), то, в принципе, для ее проверки можно было бы исполь-
зовать классический критерий £2, описанный в п. 2 §4.2. Но этот критерий
«работает» лишь при условии независимости наблюдений (4): он состоятелен
против альтернатив, которые учитывают изменение лишь вероятностей появ-
ления исходов, но сохраняют предположение о независимости наблюдений.
Но ведь именно это предположение о независимости и требуется подвергнуть
проверке! Поэтому критерий %2 Пирсона не решает эту проблему. Сохраняя
идеологию метода хи-квадрат (сравнение эмпирических частот некоторых со-
бытий с их гипотетическими вероятностями с помощью меры хи-квадрат),
можно попытаться сконструировать тест, «реагирующий» на альтернативы то-
го или иного типа зависимости между данными (4), рассматривая вместо
частот отдельных исходов в последовательности (4) частоты цепочек исходов
некоторой фиксированной длины s 2, причем цепочки должны быть пе-
рекрывающимися. Точное определение таково: s-цепочкой (или з-граммои)
„ называется любая подпоследовательность последова-
з-цепочки .
тельности (4), состоящая из s подряд идущих ее членов.
Таким образом, из (4) можно образовать следующие s-цепочки: (6, ,£s),
(€з> >&+i)> ,(Сп-з+ь- ,£п)> всего п - з + 1 цепочек. Пусть теперь
i = (ij is) — любая s-мерная комбинация элементов множества Е, всех
различных таких комбинаций № В методе хи-квадрат используются часто-
ты з-цепочек и (s + 1)-цепочек, подсчитываемые по следующим формулам:
n-s+l
Vf — = *1, 6+1 ~ ^2, б+л-1 =
<=' (5)
П-4 4 '
= £t+s-i = is, £t+s=j), j^E
t=l
(напомним, что 7(Л) есть индикатор события Л). При этом достаточно вы-
числить лишь частоты {^} (их число равно 7Vs+1), так как можно положить
N
vi = Ё ‘'О
;=1
(на самом деле последняя сумма может на 1 отличаться от м-, но на излагаемых
далее асимптотических результатах это никак не сказывается).
Далее, при гипотезе Hq (все независимы и равномерно распределены
на Е)
п - з п
Ei/- - = ---------------------------~-------
v JVi + 1 Ns+l
(асимптотическое равенство справедливо при п -> оо и фиксированном з)
и аналогично Ем- ~ n/Ns, поэтому для проверки Hq можно сравнивать
эмпирические частоты v-j с, например, v-JN при помощи «стандартной»
§ 4.5. Гипотеза случайности
367
статистики хи-квадрат:
(if) е Р+'
(уд -
v-JN
(6)
Обоснованием именно такой конструкции тестовой статистики является сле-
дующий асимтотический результат [29].
Теорема 1. Пусть гипотеза Hq, означающая, что последовательность (4) по-
лучена по схеме независимых испытаний с N равновероятными исходами,
справедлива. Тогда статистика (б) имеет предельное (при п —> оо) распре-
деление x\Ns(N - 1)). Соответствующий критерий, задаваемый при уровне
значимости а критической областью
{-^n,.s+l > Х1-а,ЛГ‘(ЛГ-1)}> (?)
состоятелен против альтернатив, при которых последовательность (4) представ-
ляет собой однородную эргодическую цепь Маркова порядка s или меньше.
Здесь нам встретились некоторые новые понятия, которые мы должны
пояснить, прежде чем комментировать этот результат. Понятие цепи Марко-
ва нам уже встречалось ранее. Именно, в п. 10 § 1.3 приведено определение
простой (т. е. порядка 1) однородной цепи Маркова. Обобщение на произволь-
ный порядок s выглядит следующим образом (сравни с (6) § 1.3): при любых
к > s и гь ,i/c 6 Е условная вероятность Р{& = i* | (т = im, т < к}
не зависит от значений im для т < к - s, т. е. вероятности, с которыми &
принимает возможные значения, зависят лишь от значений s предыдущих
случайных величин последовательности (4). В этом случае говорят, что цепь
Маркова управляется переходными вероятностями
Pi,.. ,i,:j — = J I = &-1 = ^s}. (8)
Если эти переходные вероятности не зависят от «времени» Л, то цепь называ-
ется однородной. Чтобы полностью определить вероятностный закон, управля-
ющий цепью Маркова порядка s, нужно еще задать начальное распределение
цепи, т.е. вероятности Р{^ = г*, к $}. Наконец, цепь Маркова является
эргодической, если для любых i\, ,is 6 Е существуют пределы
limP{fc = ii, &+s-i = is} = р„... (9)
t-tOO
не зависящие от начального распределения цепи; эти пределы р,..... назы-
ваются стационарными вероятностями комбинаций г = (ij,..., is). При этом
для эргодичности цепи достаточно, чтобы все переходные вероятности (8)
были положительны (в цепи возможны все переходы).
Цепь Маркова порядка s — это специфическая, но в то же время весьма
общая модель зависимых («на глубину в») испытаний, подходящая для описа-
ния многих реальных процессов, поэтому в обсуждаемой проблеме датчиков
368
Глава 4. Проверка статистических гипотез
подобные, как говорят, марковские альтернативы представляют особый инте-
рес, и качество тех или иных критериев для проверки гипотезы случайности Н$
прежде всего проверяют именно на таких альтернативах: критерий должен
быть состоятельным против марковских альтернатив. Теорема 1 и утверждает,
что обобщенный критерий %2, определяемый соотношениями (6)—(7), с этих
позиций является вполне подходящим тестом для гипотезы случайности: если
мы хотим контролировать отклонения от нулевой гипотезы типа марковской
зависимости до порядка s включительно, то мы должны использовать частоты
(5+1)-цепочек в исходной последовательности (4) для конструирования тесто-
вой статистики (6). Сама же тестовая статистика и основанный на ней крите-
рий (7) вполне приемлемы с позиций трудоемкости практических вычислений.
Упражнения
Если действовать не будешь,
ни к чему ума палата.
Шота Руставели
Ц Среди п 10 000 чисел 0,1,..., 9 числа, не превосходящие 4, встретились
5089 раз. Проверить по критерию х2 Пирсона гипотезу о равноверятности чисел при
уровне значимости а = 0,05. При каком уровне значимости эта гипотеза отвергается?
Q Смоделировать выборку объема п = 1000 из распределения Бернулли Bi(l, 3/5)
и проверить по критерию %2 соответствие данных теоретической модели.
◄ Указание. Использовать, например, таблицу случайных чисел и алгоритм п. 2 § 1.3. ►
Q При п = 4000 независимых испытаниях события 4], 4j, 4з, составляющие пол-
ную группу, осуществились соответственно 1905, 1015 и 1080 раз. Проверить, согласу-
ются ли данные при уровне значимости 0,05 с гипотезой Но р, = 1 /2, Рг = Рз = \/4,
где pt = Р{4,}
◄ Указание. Применить критерий %2 с критической границей Хо.95Д = 5,99. ►
Q В десятичной записи числа л среди первых 10002 знаков после запятой цифры
0, 1, ,9 встречаются соответственно 968, 1026, 1021, 974, 1014, 1046, 1021, 970, 948,
1014 раз. Проверить по критерию гипотезу о равновероятности «случайных» чисел
0, 1,... , 9. При каком уровне значимости эта гипотеза отвергается?
Н Используя таблицу значений какой-либо функции (cos х, ez, In х ит.д.) выписать
100 цифр, выбирая из каждого значения функции второй знак справа, и проверить
для такой выборки по критерию %2 гипотезу о равновероятности цифр 0, 1, ,9 при
уровне значимости 0,01.
Q Согласуются ли данные, приведенные в примере 2 в §2.2 с гипотезой о симмет-
ричности костей? Ответить на такой же вопрос в отношении данных, приведенных
в упр. 9 к гл. 2.
Q Смоделировать выборку объема 100 из распределения Bi(3, 1/2) и проверить со-
ответствие полученных данных теоретической модели.
◄ Указание. Использовать алгоритм п. 2 § 1.3. ►
Упражнения
369
Q Смоделировать выборку объема 100 из равномерного распределения 4/(0, 1) и про-
верить по полученным данным гипотезу о равномерности распределения по критериям
Колмогорова и х2
Q Смоделировать выборку объема п = 100 из показательного распределения Г(1, 1)
и, сгруппировав полученные данные по Я = 4 равновероятным (при гипотезе Но
F(x) = 1 - e"z х 0) интервалом, проверить по критерию х2 гипотезу Яо при
уровне значимости а = 0,1.
Указание. Использовать алгоритм п. 7 § 1.3. ►
га Проверить по критерию Колмогорова соответствие данных, полученных в упр. 6
к гл. 2, гипотезе о нормальной распределенности чисел.
ш В генетической модели Фншера [2, с. 79] считается, что вероятности появления
потомства, классифицируемого по четырем типам, имеют вид Pi(0) = (2 + 0)/4,
рг(9) = PiW = (I -0)/4, Рз(9) = в/4, в € (0,1) — неизвестный параметр. Построить
критерий х2 соответствия этой модели реальным данным.
Е При 8000 независимых испытаниях события Л,, Л2 и А3, составляющие полную
группу, осуществились соответственно 2014, 5012 и 974 раза. Верна ли при уровне
значимости 0,05 гипотеза: Р{Л,} = 0,5 — 20, Р{42} = 0,5 + 0, Р{Л3] = в, где
0 6 (0, 1/4)?
га Проверить гипотезу Но £(£) ё П(0), 0 > 0 — неизвестный параметр, для
данных, приведенных в упр. 11 к гл. 2.
Указание. В качестве оценки параметра принять выборочное среднее. ►
Ш Через равные промежутки времени в тонком слое раствора золота регестри-
ровалось число £ частиц золота, попавших в поле зрения микроскопа. По данным
наблюдений, приведенных в следующей таблице (ь\ — число опытов, для которых
£ = г, i = 0, 1,2,...), проверить гипотезу пуассоновости Яо £(.£) € П(0), 0 > 0 —
неизвестный параметр, оцениваемый выборочным средним.
i 0 1
7
1
112 168
2
130
3
68
4 5 6
32 5 1
Г
п = 518
О В течение эпидемии гриппа среди 2000 контролируемых индивидуумов одно за-
болевание наблюдалось у 181 человека, а дважды болели гриппом лишь 9 человек.
Согласуются ли при уровне значимости 0,05 эти данные с гипотезой, согласно кото-
рой число заболеваний отдельного индивидуума — биномиальная Bi(2, 0) случайная
величина?
га Исходя из формул (8)-(9) § 4.2, убедиться в том, что среднее и дисперсия стати-
стики при «близких» альтернативах вида p(n) = р° + filVn, /3^0, имеют при
п -4 оо следующие асипмтотические представления:
N вг / 1 \
Е(^|р(П)) = Я-1 + £^+о( —),
;=i W 7
D(l2|p(n)) = 2(Я - 1) + 4 £ ^ + О
i — I *
24 Заказ 1740
370
Глава 4. Проверка статистических гипотез
ш Исходя из формул (15) §4.2, получить, что при
= + 2 = 1,и
п
п, N -+ оо, — —> р > 0, max 6, с < оо
Ep„(n,^ = ^^ + xW/:,e P&2W(1 +о(1)), b2(N) = 1^,
J = 1
D/i0(n, N) = Ne~p(] - (1 4-/>)e“p)(l + o(l)).
ш Следующая таблица содержит данные о смертности среди матерей, родивших
первого ребенка, в четыре различные периода времени [2, с. 102] (пу — число матерей,
Vj — число смертных исходов):
Пу 1072 1133 2455 1995
Vi 22 23 49 33
По критерию однородности %2 с двумя исходами проверить гипотезу На о том, что
в уровнях смертности между этими периодами не существует различия.
ЕП Смоделировать выборку объема п = 200 равномерно распределенных чисел (Х,).
С помощью критерия Смирнова проверить, что две подвыборки (X2j, * = 1, ЮО)
и (X2i+1, г = 0, 1,..., 99) являются выборками из одного и того же распределения.
EJ Смоделировать последовательность (X,-, i = 1,2, 100) случайных величин,
с равными вероятностями принимающих значения 1, 2, 3, 4, 5. Образовать из этой
последовательности две выборки (Х21, i = 1,2, ,50) и (X21+I, i = 0, 1, ,49)
и проверить для них гипотезу однородности.
Указание. Использовать алгоритм п. 4 § 1.3. ►
ЕП Пусть случайные величины iji,..., ijjv независимы и £(т?у) = П(0у), j = I,.. ,N,
где параметры 0j неизвестны; дополнительно известно, что ту, + + г/х = п. По-
строить при этом условии критерий £ для проверки гипотезы однородности
На 0, = = 0/V-
•< Указание. Воспользоваться упр. 22 к гл. 1. ►
и Из 300 абитуриентов, поступивших в вуз, 97 человек имели 5 в школе и 48
получили 5 на вступительных экзаменах по тому же предмету, причем только 18 человек
имели 5 и в школе, и на экзамене. С уровнем значимости 0,1 проверить гипотезу
о независимости оценок 5 в школе и на экзамене.
Используя данные, полученные в упр. 20, образовать последовательность, пар
(X2j_|, Х2)), i = 1. 2, , 50, и проверить по этим данным гипотезу независимости,
и Можно ли с уровнем значимости 0,001 считать, что последовательность чисел
1,05; 1,12; 1,37; 1,50; 1,51; 1,73; 1,85; 1,98 является реализацией случайного вектора, все
8 компонент которого — независимые одинаково распределенные непрерывные слу-
чайные величины?
-4 Указание. Применить критерий инверсий. ►
Смоделировать выборку из 100 равномерных псевдослучайных чисел. С помощью
статистики Тп — числа инверсий — проверить гипотезу случайности для этих данных.
Упражнения
371
ЕЗ Доказать, что число инверсий Zn в случайной выборке объема п из непрерывного
распределения распределено асимптотически нормально Лцтип — 1)/4, п3/36).
Ч Указание. Используя производящую функцию Ezr" (см. п. 1 §4.5), перейти к ха-
рактеристической функции и убедиться в том, что при п -> оо
( ( п(п - 1)\
Е exp < it I Тп--------- I
I \ 4 )
6 1
J
-» ехр
2 J
Глава 5
Параметрические гипотезы
Статистика — это искусство уточнять то,
что является неизвестным.
Параметрические гипотезы, рассматриваемые в настоящей главе, — это
гипотезы об истинном значении неизвестного параметра, определяющего
априори заданное параметрическое семейство распределений. Здесь изложены
и продемонстрированы на конкретных примерах основные принципы постро-
ения оптимальных или асимптотически оптимальных (для больших выборок)
критериев проверки таких гипотез, в основе которых лежит метод отношения
правдоподобия Ю. Неймана и Э. Пирсона. Отдельные параграфы посвящены
последовательному анализу А. Вальда и статистическому анализу конечных
цепей Маркова.
§ 5.1. Общие положения
Важный класс статистических гипотез составляют гипотезы о параметриче-
ских моделях. В этом случае априори постулируется, что класс 7 допустимых
распределений наблюдаемой случайной величины £ является некоторым пара-
метрическим семейством 7 = {7(х; 0), & € 0}, т. е. все допустимые распре-
деления идентифицируются соответствующим параметром 0 (₽ь , 0Г)
со значениями из параметрического множества 0 С RT поэтому гипотезы
PI о распределении £(£), по существу, относятся к неиз-
г р вестному параметру 0 и называются параметрическими.
“ Примерами параметрических гипотез являются утвер-
ждения:
1) Hq 0 = 0q, где 0q 6 0 — некоторое фиксированное значение параметра;
2) Но 01 = 02= =0Т;
3) Но д(0) = да, где д(0) — некоторая (в общем случае векторная) функ-
ция, да — фиксированное значение.
В общем случае основная (нулевая) параметрическая гипотеза задается
указанием некоторого подмножества ©о С 0, элементом которого является,
по предположению, неизвестное истинное значение параметра 0, что записы-
вается в виде Но 0 € ©о- Точки 0 6 0! = 0\0о называются альтернатива-
ми, а утверждение Н) 0 6 0| — альтернативной гипотезой. Таким образом,
в параметрическом случае альтернативная гипотеза конкретизируется и имеет
такой же вид, как и основная гипотеза Но. Другими словами, в данном случае
§5.1. Общие положения
373
отклонения от основной гипотезы имеют вполне определенный вид, огра-
ниченный рамками рассматриваемого параметрического семейства. Следова-
тельно, и соответствующий статистический критерий должен быть направлен
на выявление именно таких отклонений от Hq, учитывать их специфику.
Следует ожидать, что наличие такой значительной априорной информации
о допустимых распределениях наблюдений (данных) должно привести к бо-
лее сильным выводам, найти свое отражение в свойствах соответствующих
параметрических критериев.
Общие принципы построения критериев, изложенные в §4.1, относятся и
к рассматриваемому случаю. Напомним кратко, что если в задаче (Но: 0 € 0q,
Н] 0 € в,) применяется некоторый «критерий Хю», т.е.
| Яр отвергается <=> X £ Х1а,|
где X — исходные данные и при заданном уровне значимости а критическая
область Х]а удовлетворяет условию
W(0) = W(0; Х1а) = Р#{Х € Х,а} a, V0e0o (1)
(функция W(0; Xia), 0 6 0, называется функцией мощности критерия Хю),
то проблема максимум состоит в построении такого критерия Х*о, для которого
при произвольном Хю, удовлетворяющем (1),
1У(0;Хю) ^^(0;Х1О) при 0 е 0О и
W(0; Хю) W(0; Х1о) при 0 е 0,.
Такой критерий Х*а (когда он существует) называется равномерно р н м к
наиболее мощным критерием (р. н. м. к.) в задаче (Яр, Н\).
Равномерно наиболее мощный критерий не всегда существует, поскольку,
как правило, критерий, максимизирующий мощность при определенной аль-
тернативе 0 G 0], зависит от этой альтернативы, и экстремальная задача (2)
при ограничении (1) имеет решение только в некоторых специальных случаях.
С примерами таких ситуаций мы встретимся в дальнейшем.
Часто ограничиваются рассмотрением подкласса несмещенных критериев,
для которых одновременно с (1) выполняется условие
W(6)^a, V0 6 0,. (3)
В ряде задач, для которых р. н. м. к. не существуют, могут иметь место р. н. м.
несмещенные критерии.
Наконец, напомним, что в случае рандомизиро- D .
„ , Рандомизированный
ванного критерия, задаваемого критической функ-
цией <р(х), функция мощности «критерия <р» опре-
деляется равенством
ТУ (0) = W(0- <р) = Е^(Х) = У <р(х) dFx(x; 0). (4)
Излагаемая ниже теория параметрических критериев базируется на методе
отношения правдоподобия, предложенном Ю. Нейманом и Э. Пирсоном (1933)
374
Глава 5. Параметрические гипотезы
в качестве основы общего метода построения критериев. В основе этой теории
лежит знаменитая (фундаментальная) лемма Неймана—Пирсона, дающая вид
наиболее мощного критерия в задаче различения двух простых гипотез. С этого
результата мы и начнем (в случае, когда множество 0| состоит из одной точки,
т. е. альтернатива И простая, вместо р. н. м. к. используется термин наиболее
мощный критерий).
§ 5.2. Выбор из двух простых гипотез.
Критерий Неймана—Пирсона
1. Постановка задачи и предварительные соображения
Рассмотрим простейший частный (но играющий принципиальную роль в по-
следующей теории) случай, когда обе гипотезы Но и Н. — простые. Форма-
лизуется это так: постулируется (априори предполагается), что допустимыми
распределениями наблюдаемой случайной величины £ являются лишь два за-
данных распределения (две функции распределения) Fq(x) и F[(x) и требуется
по выборке X = (Х|, , Хп) из £,(£) проверить гипотезу Но F^(x) = Fo(x)
против альтернативы Я] Ffa) = Fx(x). Чтобы подчеркнуть, что это частный
случай параметрических гипотез, можно рассмотреть семейство распределе-
ний вида F(x-, 0) = (1 - O)Fo(x) + (х), где параметрическое множество 0
состоит из двух точек: 0 = {0, 1} и проверяемая (основная) гипотеза есть
Но д — до — 0, а альтернатива Я, 6 = = 1. Тогда F,(x) = F(x;0i),
i = 0, 1, и речь идет о выборе одного из этих распределений в качестве
истинного.
Согласно изложенному выше общему принципу, задача построения наи-
лучшего (наиболее мощного) критерия X*Q сводится в данном случае к ре-
шению экстремальной задачи максимизации по Х1а мощности W(0], Ti„):
ТГ(01:ЗЕ1в) = Рв|{ХеЗЕ|О} = тах (1)
при ограничении
т; Х1а) = М* е *|а} а-
Нетрудно понять, как надо строить оптимальную критическую область Х*„.
Рассмотрим правдоподобие данных L(x; 0) = f(x\; 0) f(xn', 0) при каждой
из гипотез Но и Н\ (см. п. 1 §3.2). Тогда, например, для непрерывных данных
проблема (1) запишется в виде
Ш Х1О) = J L(x;6o) dx = а,
х,«
Wr(0i;Xia) = У L(x; 0|) dx = max,
X|«
(2)
§ 5.2. Критерий Неймана—Пирсона
375
т.е. среди всех областей Х)о надо выбрать ту, для точек которой правдопо-
добие Цх,в\) будет наибольшим в сравнении с L(x;&o). Следовательно все
выборочные точки х = (xi, ,хп) надо «упорядочить» соответственно ве-
личине отношения
Отношение
правдоподобия
(3)
и затем включить в все те из них, для которых 1(х) с, а граница с = еа
должна быть выбрана так, чтобы обеспечить первое условие в (2). Функция
1(х) в (3) называется отношением правдоподобия, она и порождает тестовую
статистику Т(Х) = 1(Х) критерия Неймана—Пирсона в рассматриваемой
задаче (Но, Н\). Таким образом, критерий Неймана—Пирсона основывается
на статистике отношения правдоподобия
1(Х) =
ЦХ;0})
и задается критической областью
ЦХ;О0)
Критерий Неймана—Пирсона
= {*= (*1, --.a:») l(x)^ca}.
To, что такая конструкция приводит к оптимальному критерию, и утверждает
фундаментальная лемма Неймана—Пирсона.
2. Случай абсолютно непрерывных распределений
Прежде чем давать ее точную формулировку, условимся о некоторых соглаше-
ниях. Рассмотрим сначала случай абсолютно непрерывных распределений Fq
иР| и будем считать, что соответствующие плотности fo(x) и f\(x) удовле-
творяют условию fj(x) > 0, j = 0, 1 (это исключает тривиальные ситуации,
когда при одной из гипотез некоторые значения х «запрещены», и следова-
тельно, наблюдая в опыте такие значения, мы однозначно определяем, какая
из гипотез верна). Определим теперь функцию
ф(с) = Р0{7(X) с} = f Цх: Oq) dx
т:1(т)^с
(для сокращения записи пишем Р, вместо Р®., i = 0,1, и Pj{5} вместо
Ре,{* € $}). С ростом с эта функция может только убывать, кроме того,
чр(О) = 1. Далее,
1 Р1{/(Л') с} = У L(i;0i)dx^c У Цх: во) dx = сф(с),
376
Глава 5. Параметрические гипотезы
поэтому ^(с) 1/с, т.е. ^(с) -> 0 при с -> оо. Будем предполагать, что
существует такое значение с = са, что ^>(са) = а (в частности, это всегда
имеет место, если функция непрерывна). Тогда для соответствующего
множества Х*а = {г l(x) са} имеем
W(ffQ- Х|о) = PqA} - У L(i; 0О) dx = = а. (4)
х;.
Справедливо следующее утверждение.
Теорема 1 (Лемма Неймана—Пирсона). При сделанных предположениях
критическая область Х*а задает наиболее мощный критерий для гипотезы
Яо Frfx) = F0(x) относительно альтернативы Я| F^(x) = F|(i) среди
всех критериев уровня значимости а.
Доказательство. Рассмотрим любой другой критерий X|Q, так что
Ж(0О; Х1а) = Ро{Х1а} = У L(x;0o)dx = a. (5)
ii.
Из формул (4) и (5) получаем
Ро А - Х.Л} = а - М* А} = Po{Xia - X А}-
Согласно определению множества Х*а, вне этого множества 1(х) < са, т.е.
caZ(x;0o) > i(x;^i),
поэтому
р.А - * А) > сар0{х;а - х А} =
= СаРо{Х1а - X А} > Р| А - х Al-
Прибавляя к обеим частям этого неравенства Pi{X|QX*a}, получим
р A} - w(e{-х}а) > х1о) = р,{х1а}.
Замечание. Конечно, оптимальный критерий должен удовлетворять условию несме-
щенности (3) §5.1. Покажем, что критерий Неймана—Пирсона Х’а обладает этим
свойством. Пусть в (4) са > 1. Тогда
Иг(й,;Х}а)= J L(x\9i) ds > cQ J L(x,90)dx = aca>a.
Если же ca 1, to
WiX) = 1 - P A) > 1 - ^A) > 1 - P0{x;a} = P0{XU = a.
Следовательно, в любом случае W(9t ; Х}а) > а.
§ 5.2. Критерий Неймана—Пирсона
377
Рассмотрим теперь вопрос о расчете критерия т.е. о вычислении
критической границы са (см. (4)) и вероятности ошибки 2-го рода
0=0(а,п) =
Точное вычисление этих основных параметров критерия возможен в том слу-
чае, когда распределение тестовой статистики 1(Х) известно как при гипоте-
зе Но, так как при альтернативе (см. примеры ниже). Но это не всегда
осуществимо, поэтому часто для решения этой задачи применяется асимпто-
тический подход (при объеме выборки п —> оо), основанный на использова-
нии центральной предельной теоремы (ЦПТ).
Обозначим
Использование ЦПТ
7 _,„/!<*) . ,
тогда Sn = Z]+.. .+Zn есть сумма независимых одинаково распреленных при
каждой гипотезе случайных величин и событие {Z(X) > са} можно записать
в виде {Sn In cQ}. Обозначим, далее,
<г-=Ов^, J = 0,1
/о(®)
(предполагается, что эти моменты существуют). Из неравенства In £ С t - 1,
t > 0, и представления
, п,
aj ~ —
dx
0,0
. /о(я:)
следует, что а0 С 0, и аналогично, > 0. Будем далее считать, что а0 < О,
Я| > 0 и <Tj > 0, j = 0, 1. Тогда при п -> оо на основании ЦПТ (см. (1) § 1.2)
~ j = 0, 1.
Отсюда следует, что для больших выборок для расчета критерия Неймана-
Пирсона можно воспользоваться нормальной аппроксимацией для суммы 5„.
Имеем
1 г> Г ~ па<> ‘п с° ~ па° 1 ~ Ж/ t \
а = РО{5П Js In cQ} = Ро< —-р--------------р------> ~ Ф(-^)>
уТКТд yTltTQ )
если са выбрано так, что Асимметрическии^рийт^
In Cq = nao+taaOy/^, Ф(-«„) = а. (6) критерия Неймона-Пирсон^
Соотношение (6) решает вопрос о приближенном определении критической
границы в критерии Неймана—Пирсона в случае больших выборок.
Аналогично, с учетом (6) для вероятности ошибки 2-го рода /3(а, п) при
больших п можем записать
= Pi{5n < lncQ} = Pi/g- na' < ———y/n + ta —
у/П(Тj <Т 1 (Г] J
378
Глава 5. Параметрические гипотезы
Здесь (оо - а\)\/п -> —оо при п -> оо и прямое применение ЦПТ для
вычисления этой вероятности при больших п становится уже некорректным
(из ЦПТ можно лишь заключить, что /3(а, п) 0 при п -> оо); говорят,
с что в данном случае значение суммы Sn находится
' в зоне больших уклонении (от среднего значения nat
при рассматриваемой гипотезе Н\). Таким образом, для определения значения
/3(а, п) при больших п необходимо использовать более глубокие (нежели
ЦПТ) результаты из теории суммирования независимых случайных величин —
так называемую теорию больших уклонений. Применение этой теории к нашей
задаче дает в типичных случаях следующий результат [5, с. 289]: при п -> оо
If t2a 1
0(а, п) ~-----== exp < nao + yfna^ta - 7 f, (8)
<Tov27T7i ( 2 J
т.е. ошибка /3 убывает экспоненциально с возрастанием числа наблюдений п,
если при этом гипотетические распределения Fq и F\ остаются фиксирован-
/, ными (т.е. фиксированы параметры ay, aj, j = 0, 1).
* «Близкие» гипотезы Однако, можно представить себе более слож-
ную ситуацию, когда вместе с ростом числа наблю-
дений п изменяются и распределения Fj, j — 0,1, т. е. их параметры a;, aj
являются некоторыми функциями от n: а; = a;(n), ст] = а] (а). Тогда соот-
ношение (7) позволяет ответить на вопрос о том, для каких «близких» гипотез
критерий Неймана—Пирсона имеет невырождающуюся в пределе мощ-
ность, т. е.
JT(0i; Jfa) = 1-/3(a,n)->7, a < 7 < 1. (9)
Это будет так, если, например,
х/й(а0(п) - a,(n))
---------—---------> -б < 0, сто(п)~ст,(п):
ai(n)
в этом случае из (7) имеем 7 = Ф(<5 - ia).
Таким образом, мы можем сделать следующий принципиальный вывод:
при больших выборках наиболее мощный критерий Неймана—Пирсона спо-
собен различать гипотезы, сближающиеся со скоростью порядка \/у/п (рас-
стояние между гипотезами измеряется взвешенной разностью средних значе-
ний случайной величины Z — In (Zi(£)//o(f)) при этих гипотезах).
Пример 1 (Критерий Неймана—Пирсона для среднего нормальной модели).
Пусть о нормально распределенной случайной величине £ с известной дис-
персией ст2 и неизвестным средним 0 имеются две гипотезы: Но в — ва и
Я]+ : в = (для определенности будем считать, что 0а < Если X = (ЙГ,,
..., Хп) — выборка из £(£) и х — ее реализация, то отношение правдопо-
добия имеет вид
Г 1 п 1
/(£) = ехр <! 52[(Xi - #1)2 - (X, - 0о)2] 7 =
§ 5.2. Критерий Неймана—Пирсона
379
= ехр 14(0| “ ~
<7 20 )
и неравенство 1(х) с эквивалентно неравенству
_ 2 In С 0[ + 0fl
X О---------------1--------,
п(01 - 0О) 2
которое удобно переписать в виде
л/n о \/п
-»,)с+- в‘>н ад'
Так как £«(|(Х) = ЛЛ(0о, <г2/п), то отсюда имеем
^(с) = Р#0{/(Х) с} = Pft, ( ^(Х - 0О) > t(c)} = Ф(-«(с)).
I О J
При с > 0 функция t(c) непрерывна, поэтому непрерывна и функция V(c),
и для любого a G (0, 1) однозначно определена величина са, где t(ca) = ta,
а Ф(-!а) = а.
Таким образом, в данном случае крите-
рий Неймана—Пирсона задается критиче-
ской областью
Критерий Неймана—Пирсона
(Яо , Н ] )
„*+ Г у/п(х - во) 1
------>taf, $(-ta) = a
(с )
(10)
Подчеркнем следующие важные обстоятельства: в данном случае критическая
область наиболее мощного критерия {/(X) > са} оказалась выраженной
через выборочное среднее X — достаточную статистику для модели -к/\9, а2)
(см. п. 1 § 3.3), а сама критическая область (10) не зависит от конкретного
значения альтернативы 0,(>
Вычислим мощность критерия (10). Так как £е,(Х) = Л/(0|, о2/п), то
х£) = рв1 (х > eQ + =
I vп )
= Рв1 ( — (X - 0,) > (0, - 0О) + <4 =
а о )
= ф( — (0! -0O)-t4. (Н)
В частности, отсюда видно, что W(0r, ЗЕ*+) > Ф(-£о) = а (несмещенность).
Аналогично, при 01 < 0О, т. е. в задаче к й Неймана-Пирсона
(Яо. Hi ), критическая область наиболее аче
мощного критерия имеет вид °’ 1 '
ЗЕ*а = (х Vn--------- -<а}, Ф(-(о) = а, (12)
380
Глава 5. Параметрические гипотезы
а его мощность
1У(»1;4-) = ф
Из (11) следует, что вероятность ошибки 2-го рода критерия (10) равна
/ 0 _ 0 \
0=0(a,n) = l-W(0};X*+)=*(ta-y/^----- • (13)
\ (Т /
Наглядной иллюстрацией этих результатов служит рис. 1.
Рассмотрим следующую задачу. Пусть заранее заданы вероятности оши-
бок а и 0. Определим, каким должно быть минимальное число п = п*(а, /3)
наблюдений, необходимых для того, чтобы ошибочные заключения могли
быть сделаны с вероятностями, не превосходящими а и /3
Из (13) следует, что 0{а, п) с ростом п убывает к нулю, поэтому искомое
число п есть наименьшее из тех п, для которых Д(а, п) < /3. Для определе-
ния п имеем два уравнения:
Ф(-£о) = « И Фно-\/п----------" ) = Д-
\ & /
Пусть обозначает р-квантиль стандартного нормального распределения
JV(O, 1), т.е. Ф(£р) = р. Тогда
ta — Саг ta
= Ср,
т. е.
п = <7
(Са + Ср)2
(0! - 0о)2
Число наблюдений
в критерии
Неймана—Пирсона
Но п должно быть целым числом, поэтому надо по-
ложить
2 ((а + СрУ
(0. - 0о)2
+ 1,
(14)
#1 - 00
2
где [а] — целая часть а. Отсюда следует, что при фиксированных ошибках а
и Д число необходимых наблюдений пропорционально дисперсии а2 и об-
ратно пропорционально квадрату разности между гипотетическими средними.
§ 5.2. Критерий Неймана—Пирсона
381
Если, например, а = 0 = 0,001, то = -3,09 и из формулы (14) имеем
t 38,2а2
П ~ (в, - 0о)2 + *'
При а1 = 1, 0| - 0q = 1 значение п = 39. Таким образом, если требуется
различить гипотезы с указанными параметрами, то только при числе испыта-
ний, не меньшем 39, можно быть уверенным втом, что, следуя критерию (10),
будет принято ошибочное решение с вероятностью, не большей 0,001.
Наконец, здесь легко решается и вопрос о поведении «Близкие»
критерия при «близких» альтернативах (см. конец п. 2). альтернативы
Пусть, например, решается задача (Но, Я/) и рассматри-
ваются «близкие» альтернативы вида
Я+ в = 0[П — во 3-еп>
где 4 0 при п —> оо. Тогда из (11) имеем
ИЧ0,„; х;+) = ф
Vя 1
, а )
если \/ncn -> оо,
а
если сп = ——, а > О,
Vя
/ 1 \
если сп = о —-= .
\ Vя J
Отсюда следует, что в данном случае «пороговые» альтернативы имеют вид
а
$in = 4—7=.
Vя
а > 0 — константа; более близкие альтернативы (01п - в0 = о(1 />/??)) от Но
асимптотически не отличаются, а более далекие (ч/п(в1п - во) —> оо) улав-
ливаются критерием с вероятностью, стремящейся к 1 при п —> оо, когда они
верны (т. е. против таких «близких» альтернатив критерий сохраняет свойство
состоятельности). Итак, для больших выборок критерий Неймана—Пирсона
ЗЕ*+ (как и критерий ЗЕ*” (12)) способен различать гипотезы, сближающиеся
со скоростью 1/ч/тг.
В качестве важного приложения этих результатов по- ЦЩ^Сравнение
строим критерий для проверки гипотезы о равенстве сред- ДВуХ Средних
них двух независимых нормальных выборок. Более кон-
кретно, речь идет об известной нам задаче сравнения двух средних (см. пример 2
§ 2.5) в следующем варианте: пусть X и Y — выборочные средние двух не-
зависимых выборок объемов п и т из распределений Л/’(^1,<т2) и Л/(#2, <т2)
соответственно (дисперсии aj известны) и требуется проверить гипотезу о ра-
венстве средних Hq : Д = в}-в2 = 0 против альтернативы Я,+ : А = До > 0.
382
Глава 5. Параметрические гипотезы
В качестве тестовой статистики здесь естественно взять Т = (X - У)/сг,
где <т2 = <т?/п + (т^/т. (см. таблицу в п. 1 §3.8). Легко находим, что распре-
деление этой статистики при обеих гипотезах имеет вид: £(Т|Яо) = А/”(0, 1),
£(Т|Я|+) = 1), таким образом, в данном случае речь идет о различе-
нии двух простых гипотез о среднем нормального распределения с единичной
дисперсией по одному наблюдению над случайной величиной Т. Следователь-
но, можно воспользоваться вариантом критерия Неймана—Пирсона (10) при
п = 1. В итоге имеем, что искомый критерий имеет вид Xj+ = {Т iQ},
Ф(-£а) = а, а вероятность ошибки 2-го рода (см. (13)) /3 = Ф(<0 - А0/гт). •
Пример 2 (Проверка гипотез для дисперсии нормального распределения).
Пусть X = (Xi, , Хп) — выборка из распределения в2) (р известно),
о котором выдвинуты две простые гипотезы Нй 0 = 0q и 0 = 0\ < 0q.
Чтобы построить критерий Неймана—Пирсона для различения этих гипотез,
найдем сначала статистику отношения правдоподобия
W =
Г 1 -(x.-rf/Mj
[^0,
1 с~(Х;-р)2/2в£
у/2зг0о
п
ехр
[ *0-0?
I
Т = £(^-д)2
•=|
Здесь £g(T/02) = х2(”) (см. пример 3 § 3.8) и неравенство 1(Х) с экви-
валентно неравенству Т t, поэтому при уровне значимости а критическая
граница t = ta определяется из условия
a = P{T<ia|tf0}=FnQ|y
где Fn(t) — функция распределения закона х2(п)- Отсюда iu/0g — Ха, п ~
а-квантиль распределения %2(п) и искомый критерий имеет вид
*;; = {т^о2ха,п}.
Его мощность
/ 02 X
^(0,; Х£) = Р{Г 0О2 х2а.п|Я,} = Цх2,п J
Аналогично находим, что при 0\ > 0g критерий имеет вид
= {Г 5* О2о Х2_„,п}
и имеет мощность
/ 02 \
W40i;X;+) = 1 -
§ 5.2. Критерий Неймана—Пирсона
383
Пример 3 (Многомерное нормальное распределение, критерий Неймана—
Пирсона для вектора средних). Пусть £ = (£|,..., &), к 2, — нормаль-
ный случайный вектор, имеющий при гипотезе Н, распределение Е),
i = 0,1 (общая дисперсионная матрица известна и предполагается невырож-
денной, см. п. 2 § 1.2). Построим критерий Неймана—Пирсона для различения
гипотез Но и Н\ по одному наблюдению над £.
В данном случае отношение правдоподобия в соответствии с (9) § 1.2 есть
i{x)==ехр{ | [(^-^(о))'^_1и-^<о))-(^-^(|))'^_1(2-^(1))] )•
/(i|/2<°\E) [2L - - - - JJ
Непосредственно проверяется, что выражение в квадратных скобках равно
(д(0> - M(,))'E-'(/f(0) + Д(,)) - 2(д<°> -
поэтому обозначив
а = Е-'(д(0>-д(,>),
критическую область критерия Х1 = {/(z) с} можно записать в виде
Xi(c)=|x ах - - а(р№ + д(|)) С] = - 1пс} (15)
Рассмотрим случайную величину
Y = а£- ]-а(р{0} + д(1)).
Как линейная функция от £ эта величина распределена по нормальному
закону при обеих гипотезах, следовательно, чтобы найти ее распределения
£(y|Hi), i = 0,1, достаточно определить только ее первые и вторые моменты.
Имеем
. i;\ 1 . гп\ ( Р/~ При i — О,
Е(У|Я,) = а'д«--а'(д<°> + д(,))=^
— 2 — — ( — р/2 при г=1,
где
р = о'(д(0) - Д(1)) = Qi(0) - д(1))'2~'(д(о) - д(1)), (16)
а
П(У|Я,) =П(о'{|Я,) = о'Ев = р, г = 0,1.
Таким образом, £(У|Я<) = V((-l)>/2, р), i = 0, 1, Расстояние’
величина р, определенная в (16), называется расстоянием Махаланобиса
Махаланобиса между распределениями ЛГ(р!''\ Е), г = 0,1
9 Махаланобис Прасанта Чандра (1893-1972) — индийский экономист, статистик. Иностр,
член АН СССР (1958).
384 Глава 5. Параметрические гипотезы
С1 ~Р/2\
у/Р 7
(или между гипотезами Яо и Н}). Отсюда находим вероятности ошибок 1-го
и 2-го рода критерия Х](с):
а(с) = Р{У^С1|Я0} = Ф
Д(с)=Р{У >с,|Я,} = Ф
\ у/Р
Если задан уровень значимости (вероятность ошибки 1-го рода) а, то крити-
ческая граница q в (15) должна быть взята в виде
С1 = ^ + У^<Л, Ф«„)=а.
В итоге получаем, что в рассматриваемой задаче (Но, Л)) критерий Неймана-
Пирсона при уровне значимости а задается критической областью
= {£ а(х - д(0)) (18)
и его мощность равна Ф(у/р + Q). •
Замечание. Излагаемый подход к построению оптимального критерия в задаче раз-
личения двух простых гипотез, связанный с именами Неймана и Пирсона, является
общепринятым (классическим) вариантом, но он не есть единственно возможный.
Другой вариант, также основанный на сравнении правдоподобий данных при рас-
сматриваемых гипотезах, представляет следующее утверждение.
Теорема 2. Пусть по наблюдению X требуется различить два распределения
с плотностями /0(х) (гипотеза Но) и (гипотеза Я]). Рассмотрим класс
критериев вида
Х,(с) = {а: /|(х) > c/0(i)}, с > 0, (19)
и пусть а(с) и Д(с) — соответствующие вероятности ошибок 1-го и 2-го
родов. Тогда
п '“Ж
1 - а(с) а(с)
2) а(с) + 0(c) 1,
3) гшп(а(с)+Д(с)) =а(1)+Д(1),
С
4) если X есть случайная выборка объема п и
[ 7о(®) In dx = <5 < О,
J Ла1)
то вероятности ап и Дп ошибок оптимального критерия Х| (1) удовле-
творяют условию ап,0п —> 0 при п —> оо.
§ 5.2. Критерий Неймана—Пирсона
385
Доказательство.
1) Утверждение следует из очевидных соотношений
а(с) = fi(x)dx = ^(1 — /3(c)),
Х,(с) 11(c)
/3(с) = У /,(i)di^c / fa(x) dx - с(\ ~ а(с)), Х0(с) - Xi(c).
Хо(с) Х0(с)
2) Пусть с > 1, тогда, используя первое из предыдущих соотношений, имеем
а(с) + р(с) [-(\ - 0(c)) + 0(c) < 1.
При с С 1 используем второе неравенство:
а(с) + /3(с) < а(с) + с(1 - а(с)) < 1.
3) Пусть с > 1. Тогда исходим из соотношения
а(с) + 0(c) = У fo(x)dx + У fi(x)dx=l- f (fa(x) - f0(x)) dx.
X,(c) Io(c) X,(c)
Очевидно, X i (с) C 3Ej (1) и на множестве Xi(l) разность fi(x)-fo(x) 0.
Следовательно,
У (/i(i) - /о(®)) dx У (fi(x) - fo(x)) dx,
X,(c) X,(l)
откуда a(c) + /3(c) a(l) + /3(1).
При c < 1 рассуждаем аналогично, исходя из соотношения
a(c) + /3(с) = 1 - У (f0(x) - fi(x)) dx.
Хо(с)
4) Пусть
JT = (Xi
n
xn), fj(x) = fj(xi)> 3 = 1-
i=l
Рассмотрим статистику
1 n
fi(Xi)
fW
Если верна гипотеза Но, то на основании закона больших чисел при
п -4 оо
Тп(Х) Л е(1п Но] = [ fo(x) ш dx = 6,
\ J J J0\x)
25 Заказ 1748
386
Глава 5. Параметрические гипотезы
при этом, согласно неравенству Йенсена (о нем см. в п. 5 §4.2), всегда
5^0. Далее, из (19) следует, что в данном случае множество 3Ei(l) можно
записать в виде
X1(l) = {x = (xI,...,in):7’n(x)>0}, (20)
поэтому при <5 < 0.
ап - Р{ТП(Х) О|Яо} Р{|ТП(Х) - <5| |<?||Яо} 0,
если п —> оо. В силу симметрии (если поменять ролями Но и Н\) также
и рп -+ 0.
Таким образом, если в концепции Неймана—Пирсона, вместо минимиза-
ции вероятности ошибки 2-го рода при фиксированной вероятности ошибки
1-го рода, исходить из минимизации суммы вероятностей ошибок, то мы
придем к оптимальному критерию 3Ei(l) вида (19) (или (20)). При этом при
бесконечно большой выборке критерий 3Ei(l) различает гипотезы Но и Я,
(в случае 6 < 0) безошибочно.
Пример 3 (Продолжение). В этой задаче критерием, минимизирующим сум-
му вероятностей ошибок, является (см. (15))
и эта сумма равна в силу (17)
а(1)+/3(1) = 2фГ-^
3. Критерий Неймана—Пирсона
в случае дискретных распределений
Аналогичные рассуждения можно провести и для дискретных распределений,
для которых вероятности fj(zk) > 0, j = 0, 1, для всех z* — возможных зна-
чений наблюдаемой случайной величины £. Общий принцип здесь остается
прежним: «упорядочивают» выборочные точки х = (aj....in) в соответ-
ствии с величиной отношения правдоподобия
и включают в критическое множество X) максимальное число их, согласую-
щееся с требованием
^2 Дя; 0о) а-
16X1
§ 5.2. Критерий Неймана—Пирсона
387
Однако в отличие от непрерывного случая здесь в силу дискретности, вообще
говоря, уже нельзя получить точное значение а за счет выбора границы с
в неравенстве 1(х) С с, определяющем множество X,: может быть так, что,
включив в X] очередную точку мы еще не достигнем уровня а, а включив
следующую — превзойдем его. Детальнее это можно объяснить следующим
образом. Обозначим < lk < fjt+i < возможные значения статистики
1(Х). Тогда при заданном уровне а можно определить такое к = Л(а), что
Ь(®;во)<а^ 52 (22)
Если здесь в правой части имеет место знак равенства, то полагая
£‘а = {® : > 1к(а}}
и повторяя рассуждения, проведенные в п. 2, можно показать, что критическая
область Х*а является оптимальной, т. е. основанный на ней критерий
Яо отвергается «=► l(X) Е Х*в (23)
имеет наибольшую мощность при альтернативе Н\ среди всех критериев уров-
ня значимости а.
Пусть теперь в (22) имеют место строгие неравенства (так чаще всего и
бывает). Обозначим
atj= 52 3 = ^,^
ж (24)
Pj = Pj{l(X) = lk}= 52 L(x;6j), j = 0, 1.
Тогда соотношение (22) можно записать в виде ад < а < «о+Ро Чтобы в этом
случае построить критерий с уровнем значимости а, надо использовать прием
рандомизации, т.е. поступить следующим образом. Когда выполняется равен-
ство Цх) = 1к(а}, произвести дополнительный случайный эксперименте дву-
мя исходами R и R, вероятности которых равны соответственно (а - ао)/Ро
и 1 - (а — а0)/Ро (для этого можно воспользоваться алгоритмом п. 2 § 1.3),
и отвергнуть гипотезу Яо, если наблюдается R, и принять Яд в против-
ном случае. Если же l(x) > ^jt(a), т° гипотезу Яд следует отвергнуть, а при
/(i) < 1к(а) — принять. Другими словами, мы строим рандомизированный
критерий с критической функцией
= *
а - а0
при
при
при
l(l) > 1к(а)>
Z(l) = lk(aj,
(25)
25’
388
Глава 5. Параметрические гипотезы
Вероятность ошибки 1-го рода такого критерия в соответствии с (24) равна
Р{Я,|Я0} = Е0/(Х) = Ро{/(2Г) > 1*(о)} + —Р0{1(Х) = Ii(a)} =
Ро
а - ао
= Qq --------ро = а,
Ро
т.е. критерий имеет уровень значимости в точности равный а. Его мощ-
ность вычисляется аналогично:
<р*) = Е(/(Х) = а, + ~ Q°)P1.
Ро
Покажем, что это наиболее мощный критерий в задаче (Яо,Я|) Рас-
смотрим произвольный критерий <р с уровнем значимости а Ео<р(Х) = а,
и обозначим = {z : <р"(х) - <р(х) 0} (знак +(-) соответствует неравен-
ству > (<)). Если х 6 Х+, то у?‘(х) > 0 и поэтому L(i; 0]) lkL(x; 0О); если
х € X , то <р(х) < 1 и, следовательно, L(x; 0\) ^^(z; 0о). Таким образом,
J2(^’(i) - <р(х)) (L& 0,) - lkL(x; 0О)) = 52 + 52
2 zex+ ZCX-
Отсюда для разности мощностей получаем
Ei/W - E^(X) = 52
X
> ik 52 G/te) - M =
I
= lk(E0<p(X) - ^oip'(X)') = lk(a - a) = 0,
т.е. ^(0!;/) > ^(0);?)-
Итак, в дискретном случае также всегда можно построить наиболее мощ-
ный критерий с заданным уровнем значимости а, но такой критерий, вообще
говоря, является уже рандомизированным. Отметим, что рандомизация бы-
вает необходима лишь на пограничном множестве {я Цх) = 1к(а)} и только
в том случае, когда желательно иметь вероятность ошибки 1-го рода рав-
ной точно а. На практике предпочитают в таких случаях (т. е. когда в (22)
имеют место строгие неравенства) несколько изменить уровень значимости
так, чтобы отпала необходимость в рандомизации, т.е. заменить а на мень-
ший уровень а0 (см. (24)) и использовать нерандомизированный критерий
X*Qo = {1(e) Jfc(tt)+i} виДа (23), который, по предыдущему, является наи-
более мощным критерием уровня значимости ао (<“)• Можно также ис-
пользовать еще один нерандомизированный критерий Х‘а, = {!(z) 1к(а)}
с ббльшим уровнем значимости а' = ао +Ро- Далее мы проиллюстрируем эти
общие положения несколькими примерами.
§ 5.2. Критерий Неймана—Пирсона
389
Пример 4 (Бернуллиевская модель, проверка простых гипотез). Пусть о не-
известной вероятности «успеха» в в бернуллиевской модели Bi(l, 0) имеются
две простые гипотезы: Hq в = Oq и Н* 0 = 0\ > Од. Здесь для любой точки
х = (xi,.... хп), х, £ {0,1}, i = 1,..., п, правдоподобие
Z(x; 0j) = flj(l - ^)п"г, j = 0,1,
п
где г = г(х) = 52 х, — наблюдавшееся число «успехов», а их отношение
Кх}
L^o(l-(?|)J \l-0o/
Функция р(0) = 0/(1-0) возрастает на интервале (0, 1), поэтому при (Ц > Од
^(Я,)/^(Я0) > 1 и неравенство 1(х) > с эквивалентно неравенству
In с - пру.
т(х) >--------,
Р
где
, /1-М , /М-0о)\
Р1 \l-flo/’ Р П\0о(1-01)/
Следовательно, критическая область критерия Неймана—Пирсона выражает-
ся в данном случае через статистику г(Х) и имеет вид
’’(х) > га}. (26)
Далее, поскольку £(г(Х)|Яо) = Bi(n, 0о)> то для определения при заданном
уровне а критической границы га имеем в соответствии с (22) условие
п п
а0= £ С^0^(1-ОоГт<а^'^С^О^(1-Оо)п-т = а' (27)
m=r„ + l т=га
Если здесь в правой части имеет место знак равенства (а = а1), то тем
самым критерий (26) полностью определен; подчеркнем, что он не зависит
от альтернативы , от нее зависит лишь мощность критерия
п
W(0i;x^) = Р{г(Х) > га|Я,} - 52 ОГ(1 -01)П_'П
m=ra
Чаще всего, однако, при заранее заданном а в (27) имеет место случай
строгого неравенства (а < а'); следовательно, критерий, определяемый кри-
тической областью (26) будет иметь уровень значимости несколько ббльший,
чем а, а именно, равный а' В данном случае можно использовать также
наиболее мощный критерий {г(Х) > га + 1} с уровнем значимости a0 < а.
Если бы в данной ситуации требовалось построить критерий с уровнем
значимости, точно равным а, то следовало бы прибегнуть к рандомизации
и поступить следующим образом. Положив
р0 = Р{г(Х) = та|Я0} = СПГ“0ОГ“(1 - 0О)П-Г“ = »'- а0,
390
Глава 5. Параметрические гипотезы
задать критическую функцию (см. (25))
4>а& =
при т(х) > Га,
при г(х) = Га,
ПРИ r(l) < Га,
(28)
т.е. условиться отвергать гипотезу Яо, если г(х) > та, и принимать ее, если
г(г) < га ; если же г(х) = га, то Нд отвергается с вероятностью (а - <*о)/Ро
и принимается с дополнительной вероятностью (а1 — а)/рд. Тогда вероятность
ошибки 1-го рода такого рандомизированного критерия равна
Р{Я1|Я0} = Ев^*(Х) =
= P«0{r(X) > г„} + -—— Рво{г(Х) = г„} = а0 + -—— р0 = а.
Ро Ро
Мощность этого критерия вычисляется по формуле
(п \ г° / 1 — Й \
г) (1~т)
Случай в\ < вд рассматривается аналогично, при этом критическая об-
л. ласть имеет вид {г(х) < га}.
™ Большие выборки Для случая больших выборок (п -> оо) по теореме
Муавра—Лапласа
£в(г(Х)) ~ АГ(пв, те6>(1 -в)),
поэтому условие (27) можно заменить приближенным условием
W) га} к Ф (-^===Л = а,
\ д/ПЙоО - вд)/
т.е.
пвд - Га _ f
^0(1 - 0О) “
Отсюда получаем асимптотический вариант критерия Неймана—Пирсона в
нашей задаче
Хи = {г(Х) > пвд - Сау/пе0(\ - Яо)}, Ф«а) = а. (29)
Вычислим, наконец, мощность критерия (29) при «близкой» альтернативе
^1п ~ — ^0 Н—т=> 6 > 0.
§ 5.2. Критерий Неймана—Пирсона
391
Имеем
= Р»,.{г(Х) п0а - сДп0о(1-0о)} =
f г(Х)-п0|п > <? / gp(l - g0) 1
I \/7l01n(l - #ln) У<?1П(1 - #ln) V ^ln(' “ J
/ 6 \
—> Ф I —. ~ " r= + £Q ) •
J
Пример 5 (Пуассоновская модель, проверка простых гипотез). Рассмотрим
задачу различения двух простых гипотез Я, 0 = 0f, г = 0, 1, 0 < 0о < 0], Для
пуассоновской модели П(0). Схема рассуждений здесь такая же, как в преды-
дущем примере. Статистика отношения правдоподобия есть
/(*) = “en(e»-e'\ Тп = ±Х„
'в°' i=l
(30)
т.е. выражается через достаточную статистику модели П(0) (см. п. 1 §3.3),
при этом £g(Tn) = П(п0) (см. п.З § 1.1). В терминах статистики Тп критерий
задается критической областью вида {Tn ta}, где критическая граница ta
при уровне значимости а определяется условием
п, — V'' -n«o(n^o)m < -пва(П^о)т _ I
m=to-|-l m=ta
При а = а' оптимальный критерий имеет вид X*Q = {ТП ia}; если же а< а ,
то можно использовать нерандомизированные наиболее мощные критерии
= {Тп ta} и Х‘ао = {Tn ta + 1} с уровнями значимости соот-
ветственно а1 > а и «о < <*• В случае а < а' можно построить также
рандомизированный критерий с уровнем значимости в точности равным at:
его критическая функция <р'а(Т) имеет такой же вад, как (28) в предыду-
щем примере (с учетом обозначений, принятых в (30), в частности, здесь
р0 = а-а0^=е . )•
1а!
В любом случае мощность вычисляется по формуле
V е-"^+(а-а0)(^У°е-^
™ хуо/
Если п -> оо, то по центральной предельной теоре- Большие выборки
ме £«(ТП) ~ Л/"(п0 ,п0), и рассуждая как в предыдущем
примере, получим, что асимптотическая форма критерия Неймана—Пуассона
имеет вид {Гп п()о - Ca\/n0o}, а его мощность при близкой альтернативе
0, = 0ln = 0О +l)/yjn, 5 > 0, удовлетворяет предельному соотношению
lim W(0ln) = Ф( + (Д
П-400 \ У 0Q /
392
Глава 5. Параметрические гипотезы
Подчеркнем, что в любом случае вид оптимальной критической области здесь
также не зависит от альтернативы 9}. •
Пример 6 (Полиномиальная модель, проверка простых гипотез). Пусть по
наблюдению вектора частот исходов v = (v\, .., ity) в п испытаниях требу-
ется различить две простые гипотезы о векторе вероятностей исходов в по-
линомиальной модели М(п; 9) (см. п. 6 § 1.1): Яо 6 = р = (р(, ,рк)
и Hi 6 = q = (qi,..., gjv) (все 0 < р, , g, < 1). Здесь статистика отношения
правдоподобия
N , х
'<*>=П(Й
.=1
поэтому, переходя к логарифмам, запишем критическую область наиболее
мощного критерия в виде
, N / \ з
х* = (31>
I Р \pJ )
Для расчета критической границы и мощности такого критерия можно вос-
пользоваться центральной предельной теоремой для полиномиального рас-
пределения (см. упр. 33 к гл. 1), справедливой при п -> оо. Тестовая статисти-
ка Тп в (31) как линейная функция асимптотически нормального вектора и
будет иметь асимптотически нормальное распределение при обеих гипотезах
(см. п. 2 § 1.2), поэтому нам нужно вычислить лишь средние и дисперсии
статистики Тп при гипотезах Но и Н\. Из формул (16) § 1.1 имеем
N
Е(ТП|ЯО) = п£р,1п
1=1
Е(ТП|Я1) = n£gjn
и аналогично
D(T„|tf,) = n
N
52 *1п2
i = l
= nb2i.
Большие выборки Таким образом при больших п можно воспользо-
ваться нормальной аппроксимацией
£(ТП|Я<) ~#(паь nb2), i = 0, 1,
§ 5.2. Критерий Неймана—Пирсона
393
с указанными в (32) параметрами. Отсюда уже стандартными рассуждениями
получаем, что асимптотический (при п —> оо) вариант критерия (31) при
уровне значимости а есть
Эиа = 5 У ln — пао + Vn ba ta к Ф(—ta) = а. (33)
Pi }
Для вероятности ошибки 2-го рода получаем соотношение
/Зп = Р{Я0|Я1} = р{+ Я,). (34)
\/Л01 0| 0[ J
По неравенству Йенсена До < 0, д, > 0, поэтому, если гипотезы фиксиро-
ваны, а п —> оо, то отсюда лишь следует, что 0п —> 0. Более определенные
заключения можно сделать, рассматривая «близ- с )йг
«Близкие» альтернативы
кие» альтернативы, которые в данном случае удоб-
но задать в виде
/ 5, \
qi = qi(ri)=pi 1 + -^), г = 1,. .,7V,
\ у/п /
к
У = °’
В этом случае из формул (32) имеем (поскольку In (1+ с) = е - е2/2 + 0(е3))
а\ - «о = У (?' “ Р*) 1п “ =
1 п
N
Ьо~Ь1 ~^-Ум2-
2п t—*
i=i
Поэтому, обозначив
^2 = Ем2.
i=I
из (34) получим, что при п —> 00
Д„—»Ф(-х/2 5 + ta),
сам же критерий (33) может быть записан в виде
. Г <52 6
^a = \Tn^-- + -j=ta
394
Глава 5. Параметрические гипотезы
§ 5.3. Сложные гипотезы
Случаи, когда основная и альтернативная гипотезы являются простыми, встре-
чаются в приложениях сравнительно редко. На практике чаще имеют место
ситуации, когда обе гипотезы (или по крайней мере одна из них) сложные.
В этих случаях равномерно наиболее мощные (р. н. м.) критерии существуют
только если модель У = {Я(х; 0), 0 6 0} обладает определенными свойства-
ми. Рассмотрим некоторые наиболее типичные случаи.
1. Р. и. м. критерии против сложных односторонних альтернатив.
Модели с монотонным отношением правдоподобия
Пусть проверяется простая гипотеза Hq 0 = 0q против сложной альтернативы
И: 0 6 0! = 0\{0о}. Построим критерий Неймана—Пирсона Х*а = X*a(0Q, 0j)
для фиксированной альтернативы 0; 6 0,, как это описано в § 5.2. Если этот
критерий (т. е. вид соответствующей критической области) зависит от 0|, то
это значит, что не существует критической области, которая была бы наилуч-
шей для всех 0| 6 0[. Другими словами, в этом случае не существует р. н. м. к.
Однако может оказаться, что критерий XjQ(0o, 0[) не зависит от конкретной
альтернативы 3E*a(0o, 0i) = Х*а(0о). Тогда соответствующая критическая
область максимизирует мощность при любой допустимой альтернативе и по-
этому Х*а(0о) является р. н. м. к. в задаче (Яо 0 — Оо, Hi 0 £ 0[).
Такие случаи уже встречались нам в § 5.2. Так, в примере 1 (соотно-
шение (10)) построен критерий Неймана—Пирсона в задаче (Яо 0 = 01,
Я, 0 = 0j > 0О) для нормальной модели Л/"(0, <т2), который оказался незави-
сящим от альтернативы 0\, следовательно, этот критерий Х*а является р. н. м.
критерием при сложной правосторонней альтернативе Я,+ 0 > 0q. Аналогич-
но, р. н. м. критерием при сложной левосторонней альтернативе Я^ 0 < 0о
в этой модели является критерий (12). Такие же заключения можно сде-
лать о критериях, построенных в примерах 2,4,5. Таким образом, здесь мы
имеем примеры существования р. н. м. критериев проверки простой гипоте-
зы Яо при сложных односторонних альтернативах в случае скалярного па-
раметра. Если же в этих задачах рассматривать полный класс альтернатив
Я[ = Я]+ U Я[~ 0 / 0Q, то р. н. м. к. не существует, так как при альтернати-
вах 0 > 0о и 0 < 0о критерии различаются.
Рассмотренные примеры характерны следующими двумя обстоятельствами:
1) в каждом из них статистика отношения правдоподобия 1(Х) зависит от
данных X через достаточную статистику соответствующей модели (на-
пример, в примере 1 — это выборочное среднее X, в примере 2 — выбо-
рочная дисперсия (с точностью до коэффициента) и т.д.);
2) Г(Х) является монотонной функцией от достаточной статистики, в силу
чего, неравенство 1(Х) с, определяющее оптимальную критическую
область, эквивалентно аналогичному (одностороннему) неравенству для
соответствующей достаточной статистики. Эти факторы имеют общую
природу, и они приводят к следующему общему результату.
§5.3. Сложные гипотезы
395
Предположим, что 0 — скаляр и альтернатива Н\ — односторонняя (т. е.
либо Н\ = Я|“ 6 < 0о, либо Н\ = Я|+ 0 > 0о), основная же гипотеза
Яо 0 = 0о — простая. Пусть, далее, семейство Т — {F(i; 0), 0 € 0}
обладает достаточной статистикой Т = Т(Х) (см. теорему 1 § 3.3) и статистика
отношения правдоподобия
( } д(Т(Х);0о)
является монотонной функцией от Т (тогда говорят, что Монотонное
модель 7" обладает монотонным отношением правдоподо-
бия, — многие стандартные модели таковы, например,
7 = М(0, а2), Л/\ц, 02), Bi(fc, 0), П(0), В1(г, 0), Г(0, А)).
отношение
правдоподобия
Тогда в задаче (Hq, И) существует р. н. м. критерий, совпадающий с критерием
Неймана—Пирсона при произвольной фиксированной альтернативе из Н\.
Доказательство. Пусть, например, Н\ = Н* и при фиксированном 0< > 0q
отношение g(T; 0\)/д(Т;0о) t по Т. Построим критерий Неймана—Пирсона
в задаче (0а, 0\). В данном случае неравенство 1(Х) с <$=> Т(Х) с„ ,
причем граница cj определяется лишь распределением
F(x,0o) РвДГ(Х)>С+} = а.
Таким образом, критерий = {Т(Х) } не зависит от конкретной аль-
тернативы 0[ > 0о, следовательно, он есть р. н. м.к. для задачи (Яо, Я*).
Если д(Т;0\)/д(Т',0о) 1 по Т, то неравенство для Т заменяется на проти-
воположное. Аналогично рассматривается и случай левосторонней альтерна-
тивы Н[
Замечание. Можно доказать [16, с. 101], что для моделей с монотонным отношением
правдоподобия р. н. м. критерий в задаче (Яо: 0 = , Н* 0 > 0О) является одновре-
менно р. н. м. критерием проверки сложной гипотезы На 0 0q против Я,+ того же
уровня значимости. Аналогичное утверждение справедливо и для двойственной про-
блемы проверки сложной гипотезы На: 0 z 0О против левосторонней альтернативы
ЯГ 0<0О.
В частности, для экспоненциальной модели, введенной в п. 3 §3.2, плот-
ность которой имеет вид
f(x-, 0) = exp {А(0)В(х) + С(0) + Г>(х)}, (1)
статистика
п
т(х) = ^в(хо
i=i
является достаточной и
1(Х) = ехр {(А(0.) - А(0о))Т(Х) + п(С(0{) - C(0q)) }.
Следовательно, если функция А(0) строго монотонна, то 1(Х) — монотонная
функция Т, поэтому для такой модели всегда существует р. н. м. к. против
396
Глава 5. Параметрические гипотезы
односторонних альтернатив. Вид критических областей указан в следующей
таблице
Я,+ 0>0О н; 0 < 00
Л(0)г Т(Х) > 4 ад) < с-
л(0); ад) < Т(Х) > с~
Пример 1 (Выборочный контроль: биномиальный выбор). В процессе про-
изводства изделия обычно подвергают выборочному статистическому контро-
лю. Предположим, что каждое изделие независимо от других может оказать-
ся дефектным с некоторой одной и той же, но неизвестной вероятностью в
(О < в < 1) и исправным с дополнительной вероятностью 1-0 Пусть для кон-
троля взято п изделий и результат описывается вектором X = , Хп),
где X, = 1, если г-е изделие дефектно, и Xi = 0 в противном случае. Часто
бывает нужно проверить гипотезу Hq в во, где во — некоторая кри-
тическая доля брака (если гипотеза Но истинна, то процесс производства
необходимо приостановить и усовершенствовать для уменьшения доли бра-
ка). При сделанных предположениях число г(Х) = Х}+ + Хп дефектных
изделий в выборке имеет биномиальное распределение Bi(n, в), к которому
применима изложенная выше теория. Следовательно, существует р. н. м. кри-
терий проверки гипотезы Яо против альтернативы Я," 0 < 0О, который
задается критической областью вида {г(-Х) < га}. Критическая граница га
вычисляется здесь так же, как в примере 4 § 5.2. •
Пример 2 (Обратный биномиальный выбор). В условиях предыдущего при-
мера иногда применяют другой план контроля, который называется обратным
биномиальным выбором. В этом случае испытания продолжают до получения
заданного числа г «успехов» (здесь под «успехом» понимается обнаружение де-
фектного изделия). Пусть У) — число испытаний между (i - 1)-м и i-м «успе-
хами». Тогда Yi, .., YT — независимые геометрические случайные величины:
Р»{Г, =у}=0(1-0)у у = 0, 1, 2,...,
т. е. У = (Уь , Уг) — выборка из распределения Bi(l, 1 - 0) (см. п.2 § 1.1),
которое является распределением экспоненциального типа (1) с
Г
Tr(Y) = ^Yi и Л(0) = In (1 - 0).
i=i
Так как А(в) — убывающая функция 0, то в задаче (Яо 0 во, Н~ в < во)
р. н. м. к. существует и имеет вид (см. таблицу) {ТГ(У) > }. Этот вывод со-
ответствует и интуитивному представлению, так как при больших значениях 0
естественно ожидать, что r-й «успех» наступит достаточно быстро, поэтому
большие значения Т естественно трактовать как свидетельствующие против
гипотезы Яо (в пользу альтернативы Яр). Для расчета критической границы
§5.3. Сложные гипотезы
397
используют тот факт, что £#(ТГ(У)) = Bi(r, 1-0), следовательно, при задан-
ном уровне значимости а драница са определяется условием (см. (6) § 1.1)
□О 00
«о= 22 Сгг+1_|0ог(1-0о)г<а< (2)
Z=cj + 1 Х = С„
Дальнейшие рассуждения такие же, как в примерах 4 и 5 §5.2. Если а = а,
то критерий нерандомизированный и есть = {ТГ(У) с~} Если же
а < а , то можно использовать любой из нерандомизированных критериев
= {Тр(У) са} или Х|“о = {Т’г(У) Сд + 1} с уровнями значимости
соответственно а и ао> либо строить рандомизированный критерий с помо-
щью критической функции <р*а в (28) §5.2 (с учетом обозначений, принятых
в (2), в частности, здесь ро = а' - во = 0е" (1 - 0о)с°).
Особенно прост будет критерий при г = 1, т. е. когда тестовой статисти-
кой является У — число испытаний, предшествующих появлению первого
дефектного изделия. В этом случае условие (2) записывается в виде
ао = (1 - 0о)с;+1 < а (1 - 0О)С° = а',
поэтому при уровне значимости а = (1 -6q)s при заданном целом s 1 кри-
терий задается критической областью Х^ = {У s} и его мощность при
произвольной альтернативе 0, < 0о есть
00
1У(0>)=р«, {у, s} = 22 0,0 - 0,/ = (1 - 0,г
1/=1
Наконец, при больших г можно воспользоваться центральной предель-
ной теоремой и получить нормальную аппроксимацию для распределения
статистики Tr(Y), именно (см. (7) § 1.1), при т -> оо
£,(ТГ(У))~Л^—,
Эта аппроксимация позволяет просто рассчитать асимптотический вариант
критерия. Имеем
\ -/г(1 - 0о) /
откуда
_ 1-0о х/г(1 - 0О)
са = г —----G-------, ф«о) = а.
В итоге получаем, что при больших т и заданном уровне значимости а кри-
терий имеет вид _____
= |гг(У) >
I "о "О J
398
Глава 5. Параметрические гипотезы
и его мощность lPr(0|) при «близких» альтернативах вида в] = 0,г = во - д/у/г,
d > О, удовлетворяет предельному соотношению
п „-+£») (3)
во V 1 ~ И) /
Пример 3 (Показательная модель, р. н. м. к. для односторонних гипотез).
Предположим, что время «жизни» некоторого технического устройства есть
случайная величина £, распределенная по показательному закону Г(0, 1)
(см. п. 3 § 1.2) с неизвестным параметром в > 0. Пусть , Хп — вре-
мена «жизни» п контрольных устройств, и по этой информации требуется
проверить гипотезу Но в в0 при альтернативе Н^ в < в0. Так как мо-
дель Г(0, 1) входит в экспоненциальное семейство (1) (для нее А(в) = -\/в
и Т(Х) = Х1 + + Хп), то в нашей задаче р. н. м. критерий существует
и задается критической областью вида {Т(Х) < с}. Это также ожидаемый
результат, так как параметр 0 есть среднее значение £ и потому малые значе-
ния Т(Х) естественно интерпретировать в пользу альтернативы.
Заметим далее, что из свойств гамма-распределения вытекает соотно-
шение
г (2Т(Х)\
= Х2(2п)
и, следовательно, границу критической области можно определить по табли-
цам квантилей распределения х2(2п). Именно, так как
то при уровне значимости а р. н. м. к. в нашей задаче имеет вид
х;; = |г(х) уха.зп}.
Мощность этого критерия при произвольной альтернативе 0| < во вычисля-
ется по формуле
шт-р 1 _Р (00 2 \
И, ) — М| i 0 0 %0, ?п J ~ I 0 J ’
где Я2п(£) — функция распределения закона у1 (hi). •
2. Двусторонние альтернативы, р. н. м. несмещенные критерии
Как уже отмечалось выше, даже для моделей экспоненциального типа (1)
с монотонным отношением правдоподобия при двусторонней альтернативе
Н\ = Н( U Я,+ в во (в — скалярный параметр) р. н. м. критерия, вооб-
ще говоря, не существует. В задачах с такими альтернативами, т. е. в задаче
(Яо в = во, Hi в / во), обычно поступают следующим образом: исполь-
зуют статистику Т(Х), с помощью которой строятся р. н. м. критерии против
§ 5.3. Сложные гипотезы
399
односторонних альтернатив Н~ и Н+, и задают критическую область в виде
Хю = {Т(х) < U {T(i) Са2}, т.е. объединяют две соответствующие
односторонние критические области с уровнями значимости и аг таки-
ми, что ai + аг = а. Таким образом, получается целое семейство критериев
с уровнем значимости а (условие а = он + аг оставляет одну степень свобо-
ды). В этом семействе обычно и находится оптимальный критерий. Прежде
чем формулировать соответствующие общие утверждения рассмотрим харак-
терный иллюстративный пример.
Пример 4 (Нормальная модель с неизвестным средним, двусторонняя аль-
тернатива). Рассмотрим применение описанной методики к задаче (Яо :в = во,
Н\ : 6 / во) в модели Af(9, <т2). Из примера 1 § 5.2, как отмечено в начале п. 1,
следует, что р. н. м.к. уровня значимости оч при левосторонней альтернативе
в < во имеет вид (12) § 5.2 (с заменой а на aj, а р. н. м.к. уровня зна-
чимости аг при правосторонней альтернативе Н* в > во — вид (10) §5.2
(с заменой а -> аг). Следовательно, при произвольных «1, аг таких, что
<*! + а2 = °, объединенная критическая область
Г х/п(г-во) . . , \/п(й-в0) )
Х[а = 5 X ----------- < -tai либо ------------ ta2 > (4)
(У (7 J
задает критерий уровня значимости а в задаче (Яо, Hi). Интуитивно предпо-
чтителен выбор «симметричного» критерия, т.е. когда ai = а2 = а/2; в этом
случае получаем критерий
~ ( ^\x-eQ\ 1
Х|д — S *а/2 г • (5)
I )
Покажем, что этот критерий один обладает свойством несмещенности сре-
ди всех критериев вида (4). Мощности односторонних критериев указаны
в примере 1 § 5.2, откуда получаем для мощности произвольного критерия (4)
выражение
w(e- х1а) = р«{х е хи,} + р,{* е =
/ х/n \ / х/Й \
= Ф1------Д - tai ) + Ф ( -Д - ta2 ) = ^(Д),
у <У J \ а /
Д = в - во.
Исследуем поведение функции ^>(Д). Ее первые две производные равны
, , 1 Гп\ Г 1 /
400
Глава 5. Параметрические гипотезы
Отсюда
^'(Д) = 0
а
у/П у/П
tO!-------Д = ia, Н--------Д
а сг
А = До = а
tai ta,
1у[п
Ф (^о) — 2 /т-^аг) еХР f о (^“i
сНу27Г I 3
При малых оц и аг величины £О| и tai положительны, следовательно,
^“(До) > 0> т.е. До — точка минимума функции ^'(Д)- Поскольку До = О
4=> а, = а2 = а/2, а ^(0) = Ф(-£О1)-|-Ф(-<а2) = а, +аг = о (все критерии
(4) имеют уровень значимости а), то лишь для симметричного критерия (5)
выполняется условие несмещенности W(0; Х1а) > а, V0 / 0О- В остальных
случаях, т.е. при а, £ аг, критерий Хю при некоторых альтернативах бу-
дет иметь мощность меньшую а, т. е. будет смещенным (см. рис. 1). Таким
образом, среди всех критериев вида (4) лишь симметричный критерий (5) —
несмещенный и, следовательно, ему надо отдать предпочтение.
Критерий (5) на самом деле обладает наибольшей мощностью среди всех
несмещенных критериев уровня значимости а, т. е. является р. н. м. несме-
щенным критерием. Это утверждение является следствием приводимой ниже
теоремы 1 об общем виде р. н. м. несмещенного критерия. •
Пусть 0 — интервал действительной оси и в0 — внутренняя точка 0.
Пусть, далее, допустимые распределения абсолютно непрерывны и функ-
ция правдоподобия L(x; 0) имеет во всех внутренних точках 0 производную
дЦх; 0)/д0 = Li(i; 0) такую, что |Zi(x; 0)| С М(х), где М(х) — интегри-
руемая функция на выборочном пространстве X (тогда
J Цх; 0) dx = J L\(x\ 0) dx
s s
для любого подмножества S С X). Определим, наконец, множество
Хю = {i: L(x; 0i) cL(x; 0О) + clLl(x; 0О)}, (6)
§5.3. Сложные гипотезы
401
где 0| 0о и постоянные с 0 и С] определяются из условий
Р«0{Х1а} = у L(x;0o)dx = a, РЦХ1а} = J Ll(x;0o)dx = O. (7)
Хю Хю
Теорема 1. Если определенное в (6) множество не зависит от 0Ь то Х1а есть
р. н. м. несмещенный критерий уровня значимости а для проверки простой
гипотезы Но 0 = 0О против двусторонней альтернативы Н, 9 0q.
Доказательство. Рассмотрим любой несмещенный критерий 3Eio проверки
гипотезы Hq 0 = 0О. Так как мощность W(0o; ЗЕщ) = а и производная
функции мощности по 0 существует, то Эща) = 0. Как и в доказатель-
стве теоремы 1 § 5.2, запишем равенство
- Xl0£Ia} = а - Pfo{XlaXIa} = P9o{XIO - Х,Д10}; (8)
кроме того из (7) имеем
Pio {Xia - X|aXIa} + PU*la*!a} = 0
и аналогично _ _
PU*la - + PU*!a*la} = °>
т. e. _ _ _ _
Pi0{Xla - Xlaxlo) = Л{ад4} - - XlaXla}. (9)
Из определения (6) множества Х1а и равенств (8) и (9) получаем следующую
цепочку соотношений:
Ptf,{X1Q - X1Q3EIa} cPffl){XIa - X,aXIa} + - XlaXU =
= сР,„{Х1а - Х1аХ1а} + с.Р^Хщ - Xlaxlo} Pff,{Xlo - XlaX|O}.
Отсюда следует, что P^jXia} Р»|{Х1а},т.е. критерий Х|О имеет наиболь-
шую мощность среди всех несмещенных критериев того же уровня значимо-
сти а при альтернативе 0,. Но по условию, множество Х|а не зависит от 0|,
поэтому этот критерий является р. н. м. несмещенным критерием против лю-
бой против любой допустимой альтернативы 0] 0о-
I Замечание. Аналогичное утверждение справедливо также и для дискретных моделей
| с теми же оговорками, что и при построении критерия Неймана—Пирсона в §5.2.
Пример 4 (продолжение). Применим доказанный результат к критерию (5).
Здесь
Lt(x; 0) = -^(г-0)£(х; 0),
(7 2
следовательно, неравенство в (6) эквивалентно неравенству
Цх; 00 п(х-9о)
Цх; 0q) С + С1 <т2
26 Заказ 1743
(Ю)
402
Глава 5. Параметрические гипотезы
которое легко привести к виду
( М21
ехр < МТ(х)-----— > с + с\Т(х), (11)
где
у/п(х-0о) ^п(в1-в0) , с1у/п
т(х) =----------, М =---------------, с, =------.
а а а
Неравенство, противоположное (11), эквивалентно неравенствам
£(1) j? T(z) sU(2) (12)
Статистика Т(Х) при нулевой гипотезе имеет стандартное нормальное рас-
пределение Л/"(0, 1), симметричное относительно нуля. Отсюда и из (10) сле-
дует, что для обеспечения второго из соотношений (7) необходимо, чтобы ин-
тервал (12) был симметричен относительно нуля. Это означает, что № = —
Для одновременного выполнения и первого из соотношений (7) надо поло-
жить № = to/2, где = а/2. Таким образом, условия (7) выполняются
тогда и только тогда, когда область (6) имеет вид Х|а = {я |Т(т)| to/2},
т. е. мы пришли к (5). Следовательно, по теореме 1 критерий (5) является
р. н. м. несмещенным критерием в задаче (Яо О = 0о,Н[ 0 #о)-Функция
мощности этого критерия
, - / у/п(0 - 0О) \ / у/п(0о - 0) \
W(0- Х1а) = 07 - ta/2] + Ф ( - ta/2]
симметрична относительно точки 0 = 0О, в которой она имеет минимум,
равный а. При 0 0г, мощность строго больше а и стремится к 1 при
0 —> ±оо. В соответствии с теоремой 1 график этой функции лежит выше
соответствующего графика любого другого несмещенного критерия в данной
задаче (все графики проходят через точку (0О, а)).
Сравним функцию мощности W(0; Xia) с функциями мощности соответ-
ствующих односторонних р. н.м.к W(0; Xj„) и W(0; ) (рис. 2). Функция
ГИ (0; Хю) всегда заключена между этими двумя функциями (они изображены
Рис. 2
§ 5.3. Сложные гипотезы
403
на рисунке пунктирными линиями с соответствующим знаком), за исключе-
нием точки 9 = во, в которой все три графика совпадают. Это означает, что
критерий J|O всегда менее мощный, чем один из односторонних критериев
или , но всегда более мощный, чем другой односторонний критерий.»
Более полно теория р. н. м. несмещенных критериев изложена в [16, гл. 4].
3. Локальные наиболее мощные критерии
На практике особый интерес представляют малые отклонения от нулевой
гипотезы Но в = во- В этом случае при исследовании свойств критерия
можно ограничиться только анализом локального поведения его функции
мощности W(d) в окрестности точки во. При таком подходе часто удается
построить локальный наиболее мощный (л. н. м.) критерий, даже тогда, когда
р. н. м. критерия не существует.
Пусть в — скалярный параметр и выполнены условия регулярности,
сформулированные перед теоремой 1. Кроме того, будем считать, что для
любой критической области функция мощности W(e) W(e;Xla)
(W(0o) = а) допускает разложение в ряд Тейлора в окрестности точки во:
(о _ р
W (в) = а + (в- e0)W'(e0) + -—^-РГ"(6»0) +
Пусть теперь гипотеза Но в — во проверяется против правосторонней
альтернативы Н* в > во- Тогда для получения л. н. м. одностороннего
критерия необходимо максимизировать величину
(13)
•X |а
при ограничении
а.
Tia
Повторяя рассуждения, использованные при доказательстве теоремы 1 §5.2,
можно получить, что оптимальная критическая область имеет вид
(14)
(15)
1а Г Ь(х-,во)
где граница с„ определяется условием Ж(#о; Х^а) — а.
Аналогично, критическая область
Г Ц&во) 1
ЗЕ|« — г а \ С° I ’
I L(x: в0) )
задает л. н. м. критерий в случае левосторонней альтернативы Н^ в < во.
При двусторонней альтернативе Н> в ^во необходимо ввести дополни-
тельное условие несмещенности критерия: Ж'(0о) = 0; тогда л. н. м. кри-
терием является критерий, максимизирующий W"(e0) — коэффициент при
26*
404
Глава 5. Параметрические гипотезы
(0 —0о)2 в разложении (13). Как и при доказательстве теоремы 1 выше, можно
показать, что в этом случае оптимальная критическая область имеет вид
31о = {я : £2(z;0o) > cL(x; 0О) + с^,(х; 0О)}, (16)
где
L2(x; 6) =
dL^x; 0)
дв
и константы с и С) определяются условиями W(0o) = a, V7'(^o) = 0.
Пример 5 (Нормальная модель, л. н. м. критерий для среднего). Рассмотрим
ту же задачу, что в примере 4, и построим в ней л. н. м. критерий. Здесь
(см. (10))
2
£2(х; 0) =
7lz >71
—(я - 0) - — Us: е),
а <т
поэтому
Ь^0а) п Ьг(х\0а) п2 2 п
Т( п \ ~ 2 г/ A \ ~ 4'*Е vq) Т-
L(x; во) az L(x; во) а4 аг
Следовательно, область (16) задается условием Т2(х) k]T{x) + к2 (Т опре-
делено в (И)). Чтобы было выполнено условие несмещенности, эта область
должна быть симметричной (поскольку распределение статистики Т(Х) при
гипотезе Hq симметрично относительно нуля), что имеет место только при
к\ = 0. Таким образом, условие можно переписать в виде |Г(х)| > fc. Наконец,
из условия W(0o) = а находим fc = ta/2, где $(-ta/2) = а/2. Окончательно
получаем, что область (16) имеет вид {|7| > ta/з}, т.е. результат совпадает
с полученным в примере 4. Это ожидаемый результат, так как л. н. м. несме-
щенный критерий должен совпадать с р. н. м. несмещенным критерием, когда
последний существует. •
Вернемся к случаю односторонних альтернатив и проанализируем более
подробно условия в(14)-(15). Вспомнив определение вклада выборки V(X;0)
(см. (1) §3.2), можем записать
ЬЛх:0а) д д
= да ,п 1(г: ’"> = S да/(1': во) = rte
Как показано в п. 1 §3.2, для регулярных моделей
Е#„7(Х; 0О) - 0, DeoV(Jr; 0О) = ni(0o),
где i(0) — информация Фишера (см. (5)-(5z) §3.2). Если п велико, то, по
центральной предельной теореме,
Щ)
\ vni(0o) /
следовательно, для больших выборок при вычислении границ в (14)—(15)
можно использовать нормальную аппроксимацию (17): в (14) полагать
§5.3. Сложные гипотезы
405
са ~ toy ni(6o), а в (15) полагать са й -fttyrw(<?o), где Ф(-<«) = а. Тем
самым получено общее асимптотическое решение задачи построения л.н.м.
односторонних критериев для больших выборок.
Применяя прием объединения двух односторонних критических областей,
можно построить и асимптотический двусторонний критерий
{\V(X-,0o)\^ta/2y/ni(0o)} (18)
проверки гипотезы Но 0 = 0о против альтернативы Н\ 0 £ 0q-
м „ V(X; 0О)
Из свойства симметрии предельного распределения статистики -——
\/П
вытекает, что критерий (18) — несмещенный и не существует другого несме-
щенного критерия, который имел бы асимптотически большую мощность.
Другими словами, критерий (18) является асимптотически л.н.м. несмещен-
ным критерием в задаче (Hq 0 = 0q, Hi 0^0Q).
Построенный приближенный критерий (18) совпадает с полученным
в примере 5 точным критерием для нормальной модели Лг(Д,<т2), основан-
ным на статистике
а
поскольку в этом случае
(Т
a i(0) = а-2 (см. табл. 1 §3.2).
Пример 6 (Модель Коши, л. н. м. критерий для нее). Пусть требуется прове-
рить гипотезу Но 0 = 0о против альтернативы Н\ 0 0о для модели Коши
1С(0) (см. указание к табл. 1 §3.2). Используя результаты примера 8 § 3.5,
получим, что при больших п л. н. м. несмещенный критерий имеет вид
Xi 00
1 + (а:,’ — 0о)2
^а/2
4. Проверка гипотез и доверительное оценивание
Между задачами проверки гипотез о параметре 0 и его доверительным оцени-
ваением имеется тесная связь, позволяющая просто получать решение одной
из этих задач, когда решение другой известно. Это делается с помощью сле-
дующих рассуждений.
Рассмотрим для произвольного 0о&& какой-либо критерий Хщ = Xitt(#o)
проверки простой гипотезы Но 0 = 0о- Пусть Хоа(#о) = Xja(#o) — область
принятия гипотезы Но. Тем самым в выборочном пространстве X задано се-
мейство подмножеств {Хоа(0), 0€0}. Определим теперь при каждом х € X
подмножество §/7(х) С 0, у = 1 — а, положив §77(х) = {# : ХОа(0) Э х}.
406
Глава 5. Параметрические гипотезы
Таким образом, в параметрическом множестве 0 получаем семейство под-
множеств {?7(т), х С X}
Рассмотрим случайное множество £7(Х). События
{0eS7W} и {1еМ)}
эквивалентны, так как по построению каждое из них влечет за собой дру-
гое, поэтому их вероятности при каждом в совпадают. Но, по построению,
Р«{Х 6 XoQ(#)} = 1 - а, следовательно, Ро{0 € б7(Х)} 1 - а, т.е.
G-^X) является 7-доверительной областью для 8 (см. напр., соотношение
(33) § 3.5). Эти рассуждения можно и обратить, именно, если имеется се-
мейство 7-доверительных областей {^7(х), х G X} для 8, то множество
Хо,а = {я #о £ £7(я)}, а = 1 ~ 7, определяет область принятия гипотезы
Яо 8 = 80 с уровнем значимости а.
Таким образом, задача построения доверительной области для параметра в
(доверительного интервала, если 8 — скалярный параметр) и задача проверки
простой гипотезы о 8 взаимно обратны. При этом р. н. м. критерий (когда он
существует) соответствует наикратчайшей доверительной области и наоборот.
Проиллюстрируем этот принцип несколькими полезными примерами.
Пример 7 (Нормальная модель, оптимальный доверительный интервал для
среднего). Рассмотрим модель Л/”(0, ст2) (ст2 известно). В примере 4 построен
оптимальный (р. н. м. несмещенный) критерий (5) в задаче (Яо 8 — 80,
Я] : 9 ± 80). Здесь
Хоа(^) — Э < ta/2 $( ^а/21 — ^/2,
I °" )
и множество Gy(x), 7 = 1 - а, имеет вид
Z1 / \ Г д \/п1х — #| 1 Г _ ia/2<T _ ia/2<T 1
</7(х) = < 8 -------- < tan > = < 8 х--------< 8 < х Ч------>.
I а J I n n )
Следовательно, интервал (X ta/2 является наикратчайшим среди
всех (1 — а)-доверительных интервалов для неизвестного среднего закона
V(^, ст2) — это значительное усиление результата примера 2 §3.8 (подчеркнем,
что ta/2 = С\_а).
Далее, так как р. н. м. критерий против правосторонней альтернативы
Я* 8 > 80 задается критической областью (10) §5.2, то
( у/п(х — 8) 1 ,
XOu(0) = ^i -----------<t3, ФНа) = а,
и потому множество ^7(i) {0 8 > х - taa/\/n} Отсюда имеем наи-
лучший односторонний (нижний) (1 - а)-доверительный интервал для 8:
(X — оо). Аналогично, исходя из (12) §5.2, получаем наилучший
верхний (1 - а)-доверительный интервал для 8\ (-оо, X Ч- taa/>/n}. •
§ 5.3. Сложные гипотезы
407
Пример 8 (Оптимальный доверительный интервал для дисперсии нормаль-
ной модели). В примере 3 § 3.8 был построен центральный 7-доверитель-
ный интервал для неизвестной дисперсии модели В то же время
в упр. 12 к данной главе указан вид р. н. м. несмещенного критерия для гипо-
тезы Яд в = ва противдвусторонней альтернативы Я, в Ф $о> откуда имеем
п
XoaW = {X 02Х*,.п < Г(Х) < 02Х?_О3.П}, Г(Х) = - Д)2
i=l
Следовательно, множество ^7(г), 7 = 1 - а, имеет здесь вид
Это означает, что наикратчайший (1 -а)-доверительный интервал для вг есть
/ Т(Х) Т(Х)\
\Xl-a., Ха,, п /
где (Xabn> Х?-а;,п) указаны в упр. 12. Следовательно, центральный интервал
в данном случае не является наилучшим. Приведем краткую таблицу значений
пар (Ха„п; Х1-О2.п) и (Х(|-7)/2,п: Х(1+7)/2,п) для 7 = 1 - а = 0,95:
п (Хаj, га» Xl-aj, п) (Х(1-7)/2, п> Х(Ц-7)/2,п)
2 (0,08; 9,53) (0,05; 7,38)
5 (0,99; 14,37) (0,83; 12,83)
10 (3,52; 21,73) (3,25; 20,48)
20 (9,96; 35,23) (9,59; 34,17)
Методику, устанавливающую связь между за- «Мешающий» параметр
дачами доверительного оценивания и проверки
гипотез, можно применять и в более общих ситуациях, когда требуется оце-
нить лишь подвектор параметрического вектора 0 (о
в таком случае говорят как о «мешающем» параметре), а также когда интерес
представляет заданная параметрическая функция т(0).
Пусть, например, имеется семейство 7-доверительных областей £7(1) для
0^, т. е. семейство подмножеств параметрического множества
0(1) = {0(1) (0(l), 6>(2)) G ©},
удовлетворяющих условию
Р,{0(1) G $7(Х)} 7, V0.
408
Глава 5. Параметрические гипотезы
Определим для фиксированного 0д' подмножество
Х0, 1-7 = G-f(x) э 00°}
в выборочном пространстве X. Тогда по построению
Р(Й('>_Й(2)Д-^ £ ЭЕо, 1-7} = P(j('i #i2)){^o € <?7(Х)} 7,
или _
%®’ |_7^ 1 — Т
Следовательно, область X1Q = Xoj-7 а — I - 7, задает критерий уровня
значимости а для проверки гипотезы Нд 0^ = 0g1 (это гипотеза сложная,
так как оставляет неопределенным значение 0^). Как и выше, можно про-
вести обратные рассуждения: от задачи проверки гипотезы перейти к задаче
доверительного оценивания.
Пример 9 (проверка гипотез для параметров общей нормальной модели).
В примере 1 §2.5 построены доверительные интервалы для неизвестных сред-
него 0[ и дисперсии 02 в модели 0j). Используя результат (12) из этого
примера и описанную методику, сразу получаем критерий проверки гипотезы
о среднем Нд 0| = 0щ (02 произвольно) против альтернативы Н] 0, 0ю:
~ Г /------------г1д — ^ю1 . , 1
Эна — ] V Д 1 . t\-a^2,n— 1 (• (19)
I S(x) J
Известно [16, с. 225], что критерий (19) является оптимальным (р. н. м. не-
смещенным), поэтому и доверительный интервал (12) §2.5 является наикрат-
чайшим. U
Аналогично, используя результат (9) §2.5, получаем следующий критерий
для проверки гипотезы о дисперсии Нд 0г = 02о (0, произвольно) против
альтернативы Я, 02 02о:
Xia = {я nS2(x) 02оХа,.п-1 ™б0 nS1 О]0х\- -1}, (20)
где Xai,n-i и xl-a2,n-i — те же, что в примере 8 с заменой п на п - 1.
Критерий (20) также р. н. м. несмещенный [16, с. 224], поэтому и соот-
ветствующий доверительный интервал (9) §2.5 — наикратчайший (он не сов-
падаете центральным интервалом (10)). •
Пример 10 (гипотеза о равенстве средних двух нормальных моделей).
Рассмотрим ситуацию, описанную в примере (2) § 2.5. Используя постро-
енный там доверительный интервал для разности средних А = - 0^
получаем критерий проверки гипотезы о равенстве средних Нд А = 0, ко-
торый определяется критической областью
21а = 5 (х,у) I® - 3/1 £1-а/2,п+т-2А/----П Ш (п52 (®) + т52(у)) 1
( — V птуп + т — 2) — )
(21)
§ 5.4. Критерий отношения правдоподобия
409
Эта область задает р. н. м. несмещенный критерий [16, с. 234], тем самым и
соответствующий доверительный интервал для А является наиболее точным.
Если же теоретические дисперсии известны, то, используя результат, ука-
занный в таблице §3.8, получаем, что критерий имеет вид
£1а = ](я, у) \х - у\ > Cl-a/2\ — +— \ , Ф(Ср) = Р- (22)
I — у п т I
§5.4. Критерий отношения правдоподобия
1. Метод отношения правдоподобия для общих гипотез
Одним из наиболее универсальных методов построения критериев проверки
сложных параметрических гипотез является метод отношения правдоподобия,
суть которого состоит в следующем. Для проверки гипотезы Но в G &о С 0
против альтернативы Н\ в G 0, = 0\©о вводится статистика отношения
правдоподобия
sup Ln(X; 6)
Лп = ЛП(Х, 0о) = *ее' X = (Хь , Хп),
sup Ln[X; 0)
представляющая собой естественное обобщение на случай сложных гипо-
тез статистики 1(Х) Неймана—Пирсона (см. (3) § 5.2); как и в критерии
Неймана—Пирсона в случае простых гипотез, здесь в критическую
включаются большие значения этой статистики.
В литературе, однако, традиционно в качестве тестовой стати-
стики в задаче (Яо, Н\) используют несколько отличную статистику
sup ДП(Х; 0)
Ап=Ап(Х;0о)= ебе°
sup Ln(X', 0)
fee
область
КОП
(1)
которая предпочтительнее Лп с позиций практических вычислений, и крити-
ческую область задают в виде
Эи = {х: Ап(х;О0) с}. (2)
Критическую границу с в (2) выбирают так, чтобы критерий имел заданный
уровень значимости а:
Ре{Х е = Ре{А„(Х; ©о) с} а, V0 G 0О. (3)
Соотношениями (1)-(3) определяется критерий отношения правдоподобия
(КОП) в задаче (Яо О G 0о, Н\ в € О,).
Как было показано в § 5.2, метод отношения правдоподобия в случае про-
стых гипотез Яо и Н\ приводит к оптимальному критерию. В общем случае
410
Глава 5. Параметрические гипотезы
сложных гипотез это свойство оптимальности не выполняется. Тем не ме-
нее этот метод широко применяют, получая удовлетворительные решения
во многих практических задачах. Кроме того, как будет показано ниже, при
некоторых естественных условиях регулярности на исходную статистическую
модель 7 = {F(x;6), 6 6 0} КОП обладает свойством асимптотической
оптимальности для больших выборок.
Пример 1 (КОП для среднего нормальной модели). Продемонстрируем из-
ложенный метод на уже рассмотренной в примере 9 §5.3 задаче о среднем
(Но 0, = 0|О, Я, 9} 01О) для нормальной модели J\f(0i,9l). Здесь
0 = {9 = (9\,9->) 0, 6 Я1, 02 > 0} — полуплоскость, 0Q = {9 9t = 0,о,
02 > 0} полупрямая. В соответствии с (1) мы должны вычислить аб-
солютный супремум supZ(X;0) и условный (при гипотезе Но) супремум
все
sup L(X;9) функции правдоподобия выборки X. Но такие задачи мы уже
вее0
решали при нахождении оценок максимального правдоподобия (о. м.п.) для
параметров модели в § 3.5. Так, в примере 1 § 3.5 мы нашли, что
— 1 _
sup L(X; 9) = L(X; 9 = (X, 5)) = (2тгеЯ2)_"/2, S2 = - V(X, - X)2
see n z—/
a= 1
Условный же супремум есть (см. табл. 2 § 3.2)
sup T(X;0) = sup L(X, (0,0,0г)) = £(Х; (0,о. Яо)) = (2тгеЯ02)-п/2,
где
1 "
Яо = - £(Х,- - 0ю)2
— о. м. п. для дисперсии 02 при гипотезе Но; при этом легко видеть, что
Я02 = Я2 + (X - 0,о)2
Отсюда имеем
с2\ -п/1
‘-’О \
Я2 J
-п/2
,----------X - 0
t п — I — V 71 1 ~
и неравенство {Ап С с} <=> Но статистика tn_, есть стьюденто-
во отношение (см. (29) § 1.2), соответствующее гипотезе Но, т. е. £(tn_,|Ho) =
= Я(п — 1). Таким образом, статистика tn_, при гипотезе Но имеет распреде-
ление, не зависящее от «мешающего» параметра 02, а именно распределение
Стьюдента с п-1 степенями свободы. Тем самым мы можем рассчитать крити-
ческую границу t при заданном уровне значимости a : t = Z,-a/2.n-i, и в итоге
прийти к критерию (19) в примере 9 §5.3. Таким образом, в данном случае
метод отношения правдоподобия приводит к оптимальному критерию. •
§5.4. Критерий отношения правдоподобия
411
Пример 2 (КОП для дисперсии нормальной модели). Рассмотрим, к какому
результату приводит аналогичный подход в задаче о дисперсии (Яо: 02 = 02о,
Н\: 02 / #20) нормальной модели Абсолютный супремум sup L(X,f))
вев
здесь тот же, что и в предыдущем примере, поэтому достаточно вычислить
условный супремум sup L(X; в). В данном случае
0о = {0 = (01-02) 02 = 020, 01 ел'},
т.е. надо найти о. м. п. 0, для модели _A/(0j, 0|о) с известной дисперсией
и затем вычислить L(X; (01( 0го))- Но 0| = X (см. табл. 2 §3.2), а из пред-
ставления (2) §3.3 для функции правдоподобия L(X; 0) следует, что
sup Z(X; 0) = I(X; (X 02О)) = (2тг0^)_”/2 exp (--^S2
0е9и I at/jQ
Отсюда имеем (см. (1))
/eS2\n/2 f n S1 1 -г-н-ил $2
An= Hr exP ’ Tn=Tn(X)=-r,
\ "20 / I 2 “20 J “20
и (см. рис. 1) неравенство {An < c} <=> {Tn < f[ либо Tn i2}. Таким обра-
зом, КОП в данном случае имеет вид
Эчо = {я S2(x) < 02ot| либо S2(x) 02о^з}.
Для вычисления критических границ t\ и i2 воспользуемся теоремой Фишера
(теорема 2 §2.5), согласно которой
= О-
\02 /
Следовательно, мы имеем уравнение
а = Р{Х GХМ] = Fn_\(nt\) + 1 - Fn^nt2),
412
Глава 5. Параметрические гипотезы
где Fn_}(t) — функция распределения закона %2(п-1). Полагая ai=Fn_](ntl),
а2 = 1 - Fn~i(nti), будем иметь nt\ = Xa,,n-i> nh = Xi-a2.n-i> и тем самым
Xia = {z 02oXa,.n-l либ° nS\x) > 0»Xl-a2,n-l},
a, + a2 = a.
Здесь Л] и &2 могут быть любыми положительными числами, в сумме да-
ющими а, поэтому мы имеем на самом деле целый класс критериев уровня
значимости а. Эту неопределенность можно устранить, исследуя получен-
ные критерии на несмещенность. Для этого вычислим функцию мощности
W(02) = Xja). Снова воспользовавшись теоремой Фишера, получим
Г 71 2 1 'I f 77 n 7 "1
72 S Mn-1 !> + pj 72^ > ^Xl-a2,n-l -
L &2 ^2 < z ^2 J
/ z}2 \ / й2 \
- F / Г?» v2 XI- F ( W )
-Tn-l I a2 Хог|, П-1 I I 1 “n-1 l л2 Xl-CTj, n-l I
\ W2 z \°2 /
Чтобы обеспечить несмещенность: W(fy) а при 02 #20 (напомним, что
W(^2o) = a)> наД° решить уравнение W'(02o) =0, т. е. (далее F„_|(i) = fcn_i(i))
Xa„ n-l ^n- 1 (Xa,, n-l ) = Xl-a2, n-1 ^n-1 (Xl-a;, n-1)-
Вместе с условием сц + = a последнее уравнение однозначно определяет
выбор пары (04,02)1 а тем самым и (Xa,.n-i, Xi-m.n-i), обеспечивающих
несмещенность критерия X|Q. В итоге мы приходим к критерию (20), указан-
ному в примере 9 § 5.3, т. е. и в данном случае метод приводит к оптимальному
критерию.
Если рассмотренные примеры носили сугубо иллюстративный характер
(мы получили в них уже известные решения, следуя новому методу), то два сле-
дующих примера по существу демонстрируют возможности метода отношения
-, правдоподобия. В них будут рассмотрены типичные.
Задачи для многих , 5
.. так называемые, задачи для многих выборок, для реше-
выоорок _ , ,
ния которых этот метод особенно эффективен. •
Пример 3 (гипотеза однородности для нескольких нормальных выборок).
Пусть имеется к 2 независимых выборок Xj = (-Xyi, , Xjnj), при этом
Xj — выборка из нормального распределения №(0^, 02), j = 1, , к (все па-
раметры 0 = (#i 1, , 9\k, О2) неизвестны). Требуется проверить гипотезу од-
нородности Hq 0ц = 012 = — 0ik (при гипотезе Но все выборки —
из одного и того же распределения ЛГ(0ц О2) с некоторыми (неизвестными)
параметрами). Построим КОП для проверки этой гипотезы. Обозначим Xj,
Sj выборочные среднее и дисперсию j-й выборки, j = 1,. , к, и положим
п = 71[ + • +nk — общее число наблюдений,
§5.4. Критерий отношения правдоподобия
413
— среднее всех данных, S2 — выборочная дисперсия всех данных:
j—i г = 1
наконец,
= “ S niSl
7 = 1
Пусть Lj = Lj(6\j, 62) обозначает функцию правдоподобия для j-ti вы-
борки, т.е. (см. (2) §3.3)
1,. = (27г^/2ехр|-^-^(Х,-^)^5 j = 1,..., к. (4)
Поскольку выборки независимы, то функция правдоподобия всех данных есть
А: ✓ , к
W) = J] 62) = И”1'2 ехр - AsJ _ _
( ] * _______________________________
= (27ге£о)-"/2 ехР ) - У? пАхз ~ ~ п
t 2ff2 3=1
1 / $о Л ]п — X
1.2 \ #2 / MJ
(5)
Рассуждая далее как в примере 1
экспоненты в (5) всегда ^0 и знак
Таким образом,
§ 3.5, убеждаемся в том, что показатель
«=» 0\j = Xj, j = 1, , к, &2 = $о-
sup L(ff) = L(Xh , Хк, So) = (2тге5о)-п/2 (6)
е
При гипотезе же Яо все данные — это одна выборка объема п из нормального
распределения Л/"(01, 02), поэтому условный супремум L(0) совпадает в дан-
ном случае с безусловным супремумом примеров 1 и 2, т. е. равен pvreS2)-"/2
Отсюда находим статистику отношения правдоподобия (1) (А-статистику)
П|. . .Пк
-п/г
В общем случае произвольного числа выборок к «работать» с этой статистикой
трудно и общее решение (вид КОП) будет получено нами позже в рамках со-
ответствующей асимптотической теории для больших выборок. Но в частном
(важном) случае двух выборок {к — 2) можно продвинуться дальше и полу-
чить явный вид КОП.
414
Глава 5. Параметрические гипотезы
Две выборки
Итак, пусть далее к = 2. Запишем разложение
2
nS" = Е ЕХ< -у)2 =
}=\ 1=1
2
= mS? + n2S2, + —(J) - X-,)2
n
Тогда из (7) имеем
Ад |Г»2
1 ! п,п2 (Х} - Х2У
п n}Sj + n2S2
<n-2
n - 2
-п/2
где
t -(X -Х\ / П|П^П~2^
n~2 *2'У «(mSf + n’Sj)
имеет при гипотезе Hr, распределение Стьюдента S(n - 2) (см. пример 2 § 2.5,
соотношение (14) при Д = 0 с учетом принятых здесь обозначений). Из (8)
следует, что неравенство {АП|П2 с} эквивалентно неравенству {|in_2| О-
а так как £(tn-2|Яп) = S(n - 2), то при уровне значимо-
сти а критическая граница t = t\-u/2.n~~>, и мы получаем
вид КОП в данном случае:
КОП для двух
выборок
^1а — {|^п-з| ^1-а/2,п-з}'
(9)
Но такой критерий (с точностью до обозначений) мы уже получили ранее
в примере 10 (соотношение (21)). Таким образом, в случае проверки гипотезы
о равенстве средних двух нормальных выборок КОП совпадает с оптимальным
критерием. •
Пример 4 (гипотеза о равенстве дисперсий нормальных выборок). Пусть
S2, , Sk — выборочные дисперсии, построенные по независимым вы-
боркам объемов nh ,Пк из соответствующих нормальных распределений
Л/”(012, ff2j), У = 1, , к. Построим КОП для проверки гипотезы о равенстве
ДИСПерСИЙ iff; 021= = ^2к-
Пусть , 02j) — функция правдоподобия для j-й выборки, j = 1...к,
к
a L = в2у — для всех данных. Как и в предыдущем примере 3
; = 1
находим, что условный (при гипотезе Яо) супремум L дается формулой (6).
Безусловный же (абсолютный) супремум L равен
П sup ь#,.,, = n(2™s2n/2.
2=1 2=1
§ 5.4. Критерий отношения правдоподобия
415
Таким образом, в данном случае А-статистика (1) имеет вид
-^П|, . .nt
(10)
Анализ общего случая мы отложим до следующего параграфа, где будут дока-
заны общие предельные теоремы для больших выборок, а сейчас ограничимся
частным случаем двух (fc = 2) выборок. В этом случае
можно преобразовать следующим образом
(Ю)
Две выборки
А
/ nS] у1 /2 / nS22 \П2/2
\П]52 + п25^/ + n2S2 /
пп'г S?
П|/2 Пг/2 / \ П|/2 / ч raj/2
712 (s2+M
\ П\ / \ П2 /
п”/2 /niS2Vl/2/ n,S2Vn/2
n"'/2n//2 \я2522/ \ + п252 /
/ 1 \ ~п/‘
__ Т?п\/2 ( 1 I р \
- G I 1 + П2 _ ^0,-1,712-1 )
где
_ щ(п2 - 1)S2
n'-i.nj-1 П2(П1 - 1)52
имеет при гипотезе Но распределение Снедекора 5(п! - 1,п2 - 1) (см. п. 7 § 1.2).
При этом (см. рис.2) неравенство {АП|П, с} <=> {Fni_|.„2_| с\ либо
ГП1_ 1,ге2-1 > с2}, С[ < с2. Обозначая fn,m(0 функцию распределения закона
S(n, m), для определения критических границ С] и с2 при заданном уровне
значимости а имеем уравнение
а = P{fn,_i.n2_i С] либо Fn,-i,п2-! > Ql^o} =
= -Fill-1, п>-1 (С|) Т 1 — ^П|-1,П2-1(^2)-
Рис. 2
416
Глава 5. Параметрические гипотезы
КОП для двух Следовательно, если C| =ГОьП,-квантиль рас-
выборока|Н|| пределения S(n} - 1,п2- 1), а с2 = F|_a,,ni-i.n,-i. то при
любых Gi и а2 таких, что О| + а2 = а, КОП имеет вид
Xia = {- 1, П;~ 1 ^*а|, П|-1, П;-1 > Либо .0П|-1,П2-1 2> F\ _аь П| _ 1, п,_ 1 } (1 1)
(сравни с упр. 16, где построен критерий при оц = а2 = а/2 методом об-
ращения центрального доверительного интервала для отношения теоретиче-
ских дисперсий). Чтобы критерий вида (11) был несмещенным, надо вы-
числить функцию мощности W(f)2i,e22) и потребовать выполнения условия
W(02i,()22) а при 02i 5^ 622 (при нулевой гипотезе W(O2,O2) = а). Для
этого заметим, что по теореме Фишера £(п;5,-/^) = X2(ni - 1), i = 1,2,
и потому отношение Снедекора в общем случае произвольных дисперсий в2\
и в22 имеет вид (см. п. 7 § 1.2)
F _ n\S^ / Tl2Sl _ П1(П2 ~ OS? #22
^2l(nl-1)/ 022(П2 “ О П2(П| - 1)$2 021’
при этом £(F) — S(n} - 1,п2 - 1). С учетом этого для функции мощности
критерия (11) при произвольной альтернативе 8 = (в2\,в22): в2\ / 822 имеем
представление
W(e2l,022) = Pe{Fn|_|,n,_, С| Либо с2} =
/ д2 \ / д2 \
— “п|-1,п2-1 I <21 а2 I + 1 ^П|-1,п2-1 I с2 а2 I
\ У21 / \ У21 /
Условие несмещенности можно записать как равенство нулю производной
правой части по т = f>x/f)2l при г = 1 (ниже ,,2_|(t) = Fnt_^n^^t)):
<21/ni -1, n2-l (<21) ~ ^/ni-1, n2-1 (<22). (12)
Этим равенством вместе с условием ai+a2 = a границы с, и с2 (следова-
тельно и 01,02) определяются уже однозначно, тем самым мы получаем не-
смещенный критерий вида (11), который является оптимальным [ 16, с. 230]. •
В рассмотренных примерах удалось найти точное распределение статисти-
ки (1) (точнее, некоторых взаимно однозначных функций от нее) при нулевой
гипотезе, что и позволило рассчитать соответствующие критерии. Такое об-
стоятельство характерно для нормальной модели. Для других моделей точное
распределение Ап удается найти не всегда, поэтому для малых выборок ме-
тод отношения правдоподобия не всегда позволяет получить решение задачи
(рассчитать КОП). В то же время для больших выборок при достаточно об-
щих условиях можно рассчитать асимптотический вариант КОП и установить
его асимптотическую оптимальность. Далее излагаются основные элементы
асимптотической теории критерия отношения правдоподобия для больших
выборок.
§ 5.4. Критерий отношения правдоподобия
417
2. КОП для больших выборок
Будем далее предполагать, что выполняются условия регулярности, обеспе-
чивающие существование, единственность и асимптотическую нормальность
о. м. п. 0П = (0|П, , Srn) параметра 0 = (01,..., 0Г) (см. п. 4 § 3.5). Рассмот-
рим сначала случай простой нулевой гипотезы (далее пишем Ln вместо L).
Теорема 1. Пусть требуется проверить простую гипотезу Hq 0 = 0q, где
0О = (0io>- , 0го) — заданная внутренняя точка параметрического множе-
ства 0. Тогда при п —> оо и при выполнении указанных условий регулярности
КОП задается асимптотически критической областью
Xio = {i = (xi, ,in) -2 In An(i;0o) > Xi-a,r}> (13)
т. e. при n —> оо
MX G Xla} = Pft,{-2 In An(X; So) > X2_o>r} —> a.
Доказательство. Достаточно установить, что в условиях теоремы
£йо(-21пАп(Х;0о))->х2(т). (14)
Если справедлива гипотеза Но, то в силу состоятельности о. м. п. 0П ее зна-
чение при больших п находится вблизи точки 0а, поэтому для In Ln(0o) =
= In Ln(X; 0O) можно записать разложение Тейлора относительно точки 0О:
In Ln(0o) = In Ln(0n) + | ~ M(fy. - fy>),
Z OOiOt/i
i.;=l 2
где 0* — некоторая промежуточная точка между 0q и 0п . Отсюда следует, что
-2 In Ап = 2 [in Ln(0n) - In Ln(0o)] =
E (’5)
71 UUiUvi
t,J = l '
Так как 0n So, то и S„ So, а поскольку вторые производные функции
правдоподобия, по предположению, непрерывны по 0, то по теореме 1 §2.2
при больших п величина
1 д2 In Ln(0„)
n d0{d0j
будет мало отличаться от величины
Д д2 In £П(0О) = 1 Л д2 In f(Xk, So)
ti 90id0j n d0jd0j
27 Заказ 1748
418
Глава 5. Параметрические гипотезы
которая на основании закона больших чисел, в свою очередь, будет мало
отличаться от среднего
/а21п /(ЛГ,;6>0)\
dOidOj )'
Таким образом, матрица предельных (при п —> оо) значений коэффици-
ентов квадратичной формы в (15) совпадает с информационной матрицей
I(0q) (см. (21) §3.2). Далее, по теореме 2 §3.5 (соотношение (19)) случайный
вектор if = у/п(9п — 0q) имеет при гипотезе Но такое же распределение,
как нормальный Л/"(0,/-|(йо)) случайный вектор г). Таким образом, правая
часть (15) имеет в пределе такое же распределение, как и квадратичная форма
Q = т)'1(0о)т]. Но, по теореме 1 §2.5 (см. замечание к ней), £((?) = Х2(г)-
что и доказывает (14).
Замечание. Предельные распределения статистик -21пА„ и = т) 1(0п)т) при
нулевой гипотезе совпадают (следует из хода предыдущих рассуждений), поэтому
КОП (13) асимптотически эквивалентен критерию вида
^ = {«5.° ^xi-a.r}- (1б)
Если здесь матрицу 1(во) заменить на близкую к ней при больших п матрицу 2(0ц),
то получим еще один критерий, асимптотически эквивалентный (13):
х(,°’ = {п(в„ - eQ)’i(eQ)(en - е0) > (п)
Замечание. Из доказательства асимптотической нормальности о. м. п. следует (см. со-
отношение (26) § 3.5), что в случае одномерного параметра предельные распределения
»7Л = \/п(вп - ва) и ^2..*! при гипотезе Яо совпадают. В случае векторного пара-
Vni(Po)
метра этот вывод остается в силе, если вторую статистику заменить на I (0О) —=-,
V71
где (см. п. 5 § 3.2) Ип(й) = (E|„(S), ,Hrn(g)) и = I. ,г
Отсюда и из предыдущего замечания следует, что при гипотезе Нй статистики (jJ,11
и О® = — У^ (ва)1~' (во)У_п(во) имеют одно и то же предельное распределение х2(г).
п
поэтому КОП асимптотически эквивалентен также критерию вида
xS = (18)
Достоинством этого варианта критерия является то, что при его использовании
не требуется вычислять о. м. п. вп и его, следовательно, целесообразно применять
в тех случаях, когда явный вид вп получить невозможно.
Итак, в задаче проверки простой гипотезы Ни в = в0 против сложной альтерна-
тивы Hi в Е 0\{0и} все четыре критерия (13), (16), (17) и (18) асимптотически
эквивалентны, т.е. уровень значимости каждого из них стремится к а при п -э оо.
§ 5.4. Критерий отношения правдоподобия
419
Рассмотрим важный для приложений пример применения изложенных
результатов к полиномиальному распределению M(n; р = (pi, , рдг)).
Пример 5 (Метод отношения правдоподобия для полиномиального распре-
деления). Все необходимые вычисления для данного распределения прове-
дены ранее в примерах 10 §3.2 и 12 §3.5. Используя их, находим, что А-ста-
тистика (1) для проверки простой гипотезы Яо Р = Р° имеет вид
х
w
I/;
Л' /
п(-
LX \ п
Отсюда
Г Vj In
np°i
Заметим, что в данном случае вектор
р - у/п(еп - е0) = Vn( — -р°,
—п \ п
VN-\ о
-------Pn-\
n
/Vj~np \
= H* = ( 1 ,N-\ ,
\ Vn /
a 7(0o) = £iv-1 (эти обозначения использовались в доказательстве теоремы 1
§4.2), поэтому квадратичная форма
Qn = = и*'=х2п
(см. (4) §4.2). Далее для квадратичной формы в (16) имеем представление
(см. (29) § 3.2)
гЛГ-1
2 ЛГ-1
QP = n
з=
(i/j - пр°)2
vi
Наконец (см. (28) §3.2)
v,M = ±d-^^
1=1 Г]
= j) =
Pn
Vn
Pn'
п
j = 1,... ,7V - 1,
27*
420
Глава 5. Параметрические гипотезы
и потому
Q{n = -Z'n(0o)£/v-iZ„(0o) =
71
i rW-1 / \2
nL~^\Pj PnJ
Af-l z к ,
Ef Vn\ j Vj _
I ~O ~ О I I ~О О I PiPj
и=Др. PiJ\Pj Pn 1
rN—\
N-l
vj - nP°j _ yN-np°N^
Pj Pn J \y=|
Далее простыми преобразованиями с учетом равенств
ЛГ-1 ДГ-1
2-,
n-i/лг, =
3=1 3=1
приходим к представлению = ХД
Таким образом, в рассматриваемой задаче критерий можно строить, ис-
пользуя любую из тестовых статистик
N
-2 In An(p°) =2'V'vj In -^,
пр.
Qn
N
*2 _ V~' пр^
^п / J о
' ПО;
3=1 *3
Ч ~ "Р})2
(19)
Vi
Если справедлива гипотеза Но р = р°, то в пределе при п -> оо все эти ста-
тистики имеют одно и то же распределения - 0, поэтому при заданном
уровне значимости а критическую границу выбирают равной Xi-a.w-i Ста-
тистика Л"„ (статистика хи-квадрат К. Пирсона) нам уже встречалась ранее
в п. 2 §4.2, где она была введена из других соображений. В §4.2 (теорема 1)
было получено то же самое предельное распределение статистики Хп при
нулевой гипотезе и построен асимптотический вариант критерия согласия %2
(см. (6) §4.2). Здесь эти же результаты получены как простое следствие метода
отношения правдоподобия применительно к полиномиальному распределе-
нию. Таким образом, для полиномиального распределения оба метода: метод
хи-квадрат и метод отношения правдоподобия, — асимптотически эквива-
лентны. С позиций практических применений классическая статистика Х„
предпочтительнее (проще вычисляется) статистики -2 In Л„(р°), но по срав-
нению со статистикой у нее преимуществ нет. •
§ 5.4. Критерий отношения правдоподобия
421
3. Дальнейшие асимптотические свойства КОП
В этом пункте мы рассмотрим поведение КОП при альтернативах в случае
больших выборок. Прежде всего мы покажем, что этот критерий состоятелен,
т. е. для любой фиксированной альтернативы 0 / 0о его мощность
^(0) = Pe{-2 In ЛП(Т; 0О) > Xi-n,r}—>1 при п->оо. (20)
Доказательство. Для простоты рассмотрим случай скалярного параметра
(г = 1).
Пусть 0| £ в0 — произвольная фиксированная внутренняя точка О.
Запишем статистику АП(Х; 0ц) = Лп(0о) в виде
лп(0о) ~ ^(01)^(00,01)-
ДП(0П) -М0|)
Отсюда
—2 In АП(0О) = -2 In Xntft) + 7wn(0o, 0j),
(21)
где
2 2 Г
«п(0о.0|) = — In 14,(0о> 01) = ~ 1пДп(0|) - 1пД„(0о) =
п п
г . п
n
Г1 1
= 2 -V 1п/(Х1;0|)--У1п/(Х,;0о) .
П *—' 71 z'
u ,=1 1=1 J
Введем функцию Я(0) = Е#, In /(Х,;0). На основании закона больших чи-
сел, при гипотезе 0 = 0j и п —> оо
1 ” р
-yin/(X,;0t) АЯ(0Д А; = 0,1.
Далее имеем
ш,. /5-’ln/(X,;0 \
ЯО)0 = Е», -------' , j = l,2.
Отсюда (см. (3) и (5Z) §3.2) Я'(0|) = 0, Я"(0|) — -г(0[) < 0. Это означает,
что в точке 01 функция Я(0) имеет максимум, поэтому случайная величина
Dn(0o, 01) сходится по вероятности к положительному числу 2[Я(0|) - Н(0О)].
По теореме 1, Св[ (-2 In An(0i)) —>Х2(1), следовательно, из (21) имеем, что
при альтернативе 0! статистика -21пАп(0о) по вероятности неограниченно
возрастает при п -> оо. Отсюда следует соотношение (20) при в = 9\.
Таким образом, для КОП (13) функция мощности JVn(0) сходится при
п -> оо к функции
а при в = 0о,
1 при 0 0О.
422
Глава 5. Параметрические гипотезы
«Близкие» Можно также исследовать поведение мощности КОП
альтернативы и ПРИ «близких» альтернативах, т. е. когда альтернатива
#i = в\(п) —> в0 при п —> оо. Приведем (без доказа-
тельства) результат, дающий вид предельного распределения тестовой стати-
стики в (13) при «пороговых» альтернативах.
Теорема 2. Пусть близкая альтернатива имеет вид
<5
в\ (п) = во Ч—т=,
у/П
где д = (<5|,. .,дГ) — фиксированный ненулевой вектор, задающий отклоне-
ние альтернативы от нулевой гипотезы. Тогда в условиях теоремы 1 при п —> оо
£,|(п)(-2 In АП(Х; в0)) Х2(г; А2), А2 = #1(в0)6 (22)
(определение нецентрального распределения хи-квадрат см. в п. 2 § 2.5).
Из этой теоремы следует, что для близких альтернатив вида
<5
0 1 (п) — Ч—7=
у/П
мощность КОП удовлетворяет при п -> оо соотношению
Т7п(0,(п)) =Р9,(п){-21пАп(Т;Оо) ^xU.r}
l-Fr(xU.r;A2), (23)
где Fr(t; А2) — функция распределения закона х2(т-; А2).
Для более близких альтернатив (случай А2 -> 0 или у/п(в^(п) -в0) ->0)
мощность стремится при п —> оо к уровню значимости а, т. е. такие альтерна-
тивы по КОП асимптотически от нулевой гипотезы не отличаются. Более же
далекие альтернативы (случай А2 —> оо или y/n(ei(n) - во) —> оо) критерий
улавливает с вероятностью, стремящейся к 1 при п -> оо, когда они верны,
поскольку для таких альтернатив мощность стремится к 1. Эти выводы спра-
ведливы и для критериев (16)-(18).
Пример 5 (продолжение). Для близких альтернатив
0 N
р(п)=р+^=, ^2^=0,
мощность любого из критериев, основанных на тестовых статистиках, указан-
ных в (19), равна в пределе (при п —> оо) указанной в соотношении (10) §4.2
величине. Это утверждение является специализацией общего результата (23)
для полиномиальной модели. •
§ 5.4. Критерий отношения правдоподобия
423
4. Сложная нулевая гипотеза
Все важные асимптотические свойства КОП сохраняются и для случая слож-
ной нулевой гипотезы. Мы ограничимся лишь формулировками соответству-
ющих утверждений, отсылая интересующихся деталями доказательств к ори-
гинальной работе на эту тему2)
Пусть требуется проверить сложную гипотезу Но 0 6 ©о С 0, т. е.
подмножество ©о не сводится к одной точке. Альтернативная гипотеза
Н] 9 6 0\0« также сложная. Рассмотрим типичную ситуацию, когда 0о —
евклидово подпространство размерности меньшей, чем размерность всего па-
раметрического множества 0 (напомним, что 0 — либо все т-мерное евкли-
дово пространство Rr при некотором г 2, либо его подмножество той же
размерности г). Пусть s = dim ©о (от dimension (англ.) — размерность), так
что s < г = dim 0; тогда значение параметра 9 G ©о можно выразить в виде
функции некоторого нового параметра 6 = (<?i,... ,6S) с соответствующим
множеством возможных значений Д, т.е. ©о имеет параметрическое пред-
ставление в терминах параметра <5:
©о = {0 = (0ь ,0Г) 9 = h(6), <? = (<?,, ..,<56) е Д}. (24)
В общем случае будем предполагать, что функции h(d) — ,hr(6))
удовлетворяют следующим стандартным условиям регулярности: они трижды
непрерывно дифференцируемы и ранг матрицы их производных (6)/дд} ||
равен s всюду в Д.
Опишем также другой, эквивалентный, способ задания нулевой гипо-
тезы. Обозначим через 9® совокупность тех координат вектора 9, кото-
рые являются взаимно однозначными функциями от <5. Пусть для простоты
9® = (0r_s+1, , 0Г). Тогда 6 можно выразить через 9® 6 = 6(9^). Если
теперь ввести функции Hj(9) = 9j - hj(S(9^)), j — 1,.... г-s, то гипотеза
Но 9 G ©о примет вид
Но Hj(0)=Q, j=l, ,r-s. (25)
Тем самым гипотезу Но можно задать указанием некоторого числа связей
(ограничений) на координаты параметрического вектора 9 = (0j,..., 9Г).
В приложениях часто встречается случай, когда 0О задается как цилин-
дрическое подмножество 0, например,
0о = {0 0 = (0io,. , 0г-6,о,0г- Л)}, (26)
где 0,о, i = l, , г - s, — некоторые фиксированные значения координат
01, ,0Г_6, а остальные координаты 0r_J+i, ...,0г (их число есть s) явля-
ются свободными параметрами (их принято называть «мешающими» парамет-
рами). Если 0О имеет вид (26), то гипотезу Но 0 6 ©о называют линейной.
2) Davidson R., Lever W The limiting distribution of the likelihood ratio statistic under a class of local
alternatives // Sankhya, A. 1970. V. 32. №2. P. 209-224.
424
Глава 5. Параметрические гипотезы
Пусть проверяемая гипотеза задана в форме (24). Если функцию прав-
доподобия данных (выборки АГ) рассматривать при этой гипотезе, то она
является функцией нового параметра 6: Ln(X',9) = Ln(X; h(<5)) и при вы-
полнении всех сформулированных условий регулярности о. м. п. 6п параметра
6 будет обладать стандартными асимптотическими свойствами (см. теорему 2
§ 3.5), а А-статистика (1) может быть записана в виде
АП(Х; Оо) =
ЬП(Х;Ж))
Ьп(АГ;0п)
Для больших выборок (при п -> оо) справедливы следующие результаты:
1) £(-21пАп(Х;0о)|Яо) (27)
2) КОП, основанный на критической области
Хщ = {я -21п An(i; ©о) Xi-a.r-J> (28)
состоятелен.
Применим эти результаты к анализу А-статистик (7) и (10), выведенных
нами ранее в задачах для многих нормальных выборок.
Пример б (продолжение примера 3). В примере 3, очевидно, dim © = fc+ 1,
dim ©о = 2, а -2InАЯ1...П1| = n(ln52 In So), поэтому асимптотический
вариант КОП (28) имеет вид
Х1О = {n(ln S2 - In 502) х?-а,*-1}- (29)
Пример 7 (продолжение примера 4). Здесь общее число неизвестных пара-
метров равно 2k = dim©, а число параметров, определяющих гипотезу Но,
равно к 4- 1 = dim ©о, т.е. в (28) r-s=2k-(k+\)=k- 1; тестовая же
статистика в силу (10) есть
к
~21пАП|...П1. 7ij(ln Sq — In Sj).
7=1
В итоге критерий (28) принимает в данной задаче вид
, к ч
Xlo= ^^(In^-lnS2)^?-^-. • (30)
j=i •
Пример 8 (Гипотеза однородности для схемы Бернулли). Пусть Х}, ,Хк
— выборочные средние для независимых выборок объемов П|, , пк из
совокупностей Bi(l, 0|), , Bi(l, 9к) соответственно. Построим асимптоти-
ческий (при П|, .., пк —> оо) вариант КОП для гипотезы однородности
Н0-.9} = ...=9к.
§ 5.4. Критерий отношения правдоподобия
425
Обозначим через х,> функцию правдоподобия
для j-й выборки, j = 1,..., к. Тогда, в силу независимости выборок, функ-
ция правдоподобия для всех данных есть L(0|,.. ,0к) Li(#i) Lk(6k).
Далее, так как о. м. п. параметра бернуллиевской модели совпадает со сред-
ним арифметическим выборки (см. п. 1 §3.5), то отсюда имеем
к к к _
max Lfr,. = =
Pl.. . .,Р1. ffi
j=l j=l j=l
а при гипотезе Яо
max 1(0, ,0) =max0n*(l - в)п^~х} = Xn7(l - Х)п(1“Г),
0 0
где n = П[ + + nk, X = (п\Х[ + + nkXk)/n — выборочное среднее
всех данных. Отсюда имеем, что в данном случае статистика отношения прав-
доподобия имеет вид
j=i
Наконец, здесь dim 0 = к, dim 0О = 1, следовательно, критерий (28) прини-
мает вид
( к
= ) 2 IL ni 1ЖП Ъ ~ 1п *)+
* ;=|
+ (1 - Xj) (In (1 - Xj) - In (1 - X))] (31)
Напомним, что эту задачу мы уже решали в п. 2 §4.3, и полученный там кри-
терий однородности основанный на статистике (6), записывается в наших
обозначениях в виде
г л j _ ____ 'i
Xla = < Хп..... = •=- =- Tlj(Xj — X) Xl-a,k-l p •
I ~л) j=l >
Пример 9 (Гипотеза однородности для пуассоновских выборок). Пусть Xj =
= (Xjh ,Xjn ), j = l,...,fc, — независимые выборки из совокупностей
П(0|), , n(0fc) соответственно. Требуется по этим данным проверить гипо-
тезу однородности Яо 0] = =0*:- Схема решения здесь такая же, как
в предыдущем примере. Используя те же обозначения и учитывая, что в дан-
ном случае
е-п,е^п>х>
-п- ~ 7 = 1.
П^<!
:=1
426
Глава 5. Параметрические гипотезы
найдем, что
>=|
(напомним (см. и. 1 §3.5), что здесь о. м. п. 0j = Xj, а при гипотезе Яо о. м. п.
в = X). Если П1, , пк -> оо, то асимптотический вариант КОП (28) при-
нимает в данном случае вид
( к
%1а = Ъ £ ПД;(1П Xj - 1П X) X2l-a,k-l
1 7=1
(32)
5. Доверительные области максимального правдоподобия
Изложенные результаты дают возможность получить общее решение задачи
доверительного оценивания параметров распределений для общих параметри-
ческих моделей. При этом используют общую методику, изложенную в п. 4 § 5.3.
Далее будем предполагать, что выполняются стандартные условия регулярно-
сти, формулируемые в асимптотической теории КОП.
Рассмотрим КОП уровня значимости а = 1 -у для произвольной простой
гипотезы, фиксирующей значение параметра 6 = (₽ь , вг). Согласно (13),
в случае больших выборок область принятия этой гипотезы имеет вид
Хо7={я -2 In An(z;0) < Хъг}
Отсюда имеем, что
g,(X) = {0 -2\п Хп(Х;0) < Ху.г} (33)
есть асимптотическая 7-доверительная область для параметра в. Определен-
ное таким образом случайное подмножество параметрического множества 0
называется (асимптотической) доверительной областью максимального правдо-
подобия. Таким образом, множество (33) строится на основании статистики
отношения правдоподобия
и включает в себя все значения параметра, при которых функция правдопо-
добия Ln(X;9) близка к своему максимальному значению Ln(X;6n), или,
как говорят, все достаточно правдоподобные значения параметра. В частности,
наиболее правдоподобное значение параметра — о.м. п. Оп — всегда принад-
лежит G-flX) (см. рис. 3).
Приближенную доверительную область максимального правдоподобия
можно построить и для произвольной совокупности координат параметри-
ческого вектора 6 при наличии мешающих параметров. Пусть, например,
требуется оценить координаты = (0,,..., 0r_s) (остальные координаты
§ 5.5. Проверка гипотез для конечных цепей Маркова
427
3^ = (0r_s+1,..., 3Г\) являются мешающими параметрами). В этом случае
следует рассмотреть линейную гипотезу относительно 0^ (см. предыдущий
пункт), вычислить статистику
Апрг;0(1))
sup Ln(X; (0^, 0<2>))
»<а___________________
Ln(X-,3n)
и на основании (28) положить
S7(X) = {0(1) -21nAn(X;0(1))<x7.r-J-
Это и есть искомая асимптотическая 7-доверительная область для 0^ так
как из (27)—(28) следует, что при п —> оо
Р«{0(1) ее7(Х)} = P9{-21nAn(Z;0(,)) <x7,r-J “^7, V0 € 0.
§ 5.5. Проверка гипотез для конечных цепей Маркова
Изложенные выше подходы к проверке гипотез для ситуаций, когда исходные
статистические данные (выборка) представляют собой результаты последо-
вательных независимых наблюдений над некоторой случайной величиной,
можно применять и для моделей с зависимыми наблюдениями. Одной такой
весьма общей и важной для приложений моделью является цепь Маркова не-
которого порядка s 1, определение которой дано в п. 2 §4.5. В данном пара-
графе на примере этой модели мы обсудим специфические проблемы провер-
ки гипотез для зависимых испытаний и приведем некоторые общие результаты
для соответствующих критериев типа хи-квадрат и отношения правдоподобия.
Полное освещение этой темы имеется в [9].
428
Глава 5. Параметрические гипотезы
1. Гипотезы для конечных цепей Маркова
Пусть задана последовательность из п случайных величин (выборка объема п)
<1,6. (I)
принимающих значения из конечного множества (алфавита) £ = {1,2,.. .,7V},
и пусть априори предполагается, что эти случайные величины связаны в од-
нородную цепь Маркова порядка s > 1 (это предположение будем далее
называть общей гипотезой 2/s). Точные определения всех этих понятий дано
в п. 2 §4.5 после теоремы 1. Вероятностный закон, управляющий последова-
тельностью (1), задается переходными вероятностями (см. (8) §4.5)
Pij = Р{& = 3 I tk-з =г>, (k-]=is}, г = (г’ь Л), (2)
и начальным распределением Р{£д. = г\, k з} (которое, однако, в излага-
емой ниже асимптотической (при п -> оо) теории не играет никакой роли,
и потому мы на нем не будем акцентировать внимание, понимая под гипоте-
зами утверждения лишь о переходных вероятностях (2)). Тем самым, можно
сказать, что модель (гипотеза) Hs определяется значениями №+1 величин
Различные утверждения, фиксирующие вид или значения переходных
вероятностей (2), называются гипотезами о цепи Маркова.
Пусть, например, {р? } — некоторые заданные значения величин p-:j.
Тогда утверждение Н° p-.j = р\.-, ilt ,is, j G £, есть простая гипотеза
о цепи Маркова, однозначно фиксирующая переходные вероятности цепи (2).
В свою очередь, в зависимости от вида этих вероятностей р^ гипотеза
№ может означать и цепь порядка з (общий случай) и более частные
случаи, состоящие в том, что цепь имеет меньший порядок г < з (если
РЛ,= P°i,-r+i....i,:;, т. е. зависимость «на глубину» з-(з-г) = г)илидаже
образует последовательность независимых испытаний (если р\, - = pj, т. е. нет
зависимости от прошлого); в последнем случае при р} = \/N, j = 1, , N,
гипотеза H означает схему независимых испытании с равновероятными ис-
ходами (именно такую гипотезу мы рассматривали в п. 2 §4.5 в связи с про-
блемой датчиков).
Часто проверяемая гипотеза Н° определяется не полным заданием пере-
ходных вероятностей (2), а указанием лишь их функциональной зависимости
от некоторого параметра 0 = (0Ь , 0t) с соответствующей областью воз-
можных его значений 0, являющейся открытым подмножеством А:-мерного
евклидова пространства Rk:
Н° = Ha(Q) р^=р^(0), в€0. (3)
В этом случае мы имеем дело с проверкой сложной гипотезы Я°(0) внутри
более общей сложной гипотезы Hs. В частности, проверяемая гипотеза мо-
жет заключаться в том, что последовательность (1) является цепью Маркова
§ 5.5. Проверка гипотез для конечных цепей Маркова
429
порядка, меньшего s, но без указания точных значений переходных вероят-
ностей, Например, пусть
Pi,...щ(^=^_г+„.. (4)
где 9, > 0 таковы, что
N
' 9i'_r+{.it;j = 1, ^з-г-Н> •••>*«
2=1
т. е. сами переходные вероятности являются неизвестными параметрами и
при этом зависимость от прошлого имеет «глубину» r (здесь параметр к =
= Nr(N - 1)). В этом случае проверяемая гипотеза состоит в том, что цепь
имеет порядок т < s. Если г = 0, то имеем гипотезу о независимости испы-
таний при конкурирующей гипотезе типа марковской зависимости порядка в.
Сделаем теперь следующее общее замечание. В п. 2 § 4.5 (соотношение (5))
были введены важные эмпирические характеристики выборки (1) — частоты
vt] появления комбинаций (ij) = (i[ isj), называемых (s+ 1)-цепочками,
в последовательности (1):
П~5
vij = , -^(б = 6, 6 + 1 = *2> 6+s-1 = *s> 6+s = j)- (5)
t=l
Число всех таких ($+ 1)-цепочек равно Ns+l, так как каждый символ ih
is, j пробегает все множество £' = {1,2, , N}. Однако не все соответству-
ющие частоты будут отличными от нуля. Так, если переходная вероятность
Plj, определенная в (2), при некоторых i,j равна нулю, то комбинация (ij)
не может появиться в выборке (1), и потому = 0. Конечно, в силу слу-
чайности, Vjj может принимать нулевое значение и при > 0, но в теории
эргодических цепей Маркова доказывается, что в больших выборках (при
п —> оо) вероятность такого события близка к нулю, и потому можно считать,
что для больших выборок с вероятностью, близкой к 1, p-j; > 0 <=> P'.j > 0.
С учетом этого замечания будем далее ограничиваться рассмотрением лишь
тех комбинаций (ij), для которых p-.j > 0. Множество всех таких комби-
наций обозначим £о + 1 а его объем — d° = |£о + '|. В частности, если все
переходные вероятности р,- > 0, то
£S + ! = £s + l = g х х g и = |gs + l| = ^ + 1
s+1 paj
Далее, если проверяемая гипотеза задана в параметрическом виде (3), то
множество
С = {&) Pi-fl) > 0}
может, вообще говоря, зависеть от параметра 9 и тем самым для каждого
значения 9 быть своим. Этот нерегулярный случай мы будем в дальнейшем
430
Глава 5. Параметрические гипотезы
исключать из рассмотрения; более того, мы будем предполагать выполненным
следующее общее условие регулярности.
зк
Условие регулярности А
Условие А.
1) Множество 8^+] = {(ij) Pij(6) > 0} не зависит от 0 и обладает сле-
дующим свойством: любая цепь Маркова с переходными вероятностями p-.j
такими, что р-Г] > 0 <=> (ij) G £q+i , является эргодической',
2) функции Pi-j(d) трижды непрерывно дифференцируемы по О',
3) матрица
др-ч(в)
д0т
размера (d!> х к) имеет ранг к всюду в 0.
Обозначим теперь 7/^ класс эргодических цепей Маркова порядка s, для
переходных вероятностей которых выполняется условие р;_.} > 0 <=> (ij) G £os+l
В силу условия А (п. 1) — это цепи, в которых возможны такие же переходы
i -> j, как и при гипотезе Н°(в), но вид переходных вероятностей при
этом никак не конкретизируется (за исключением необходимого условия сто-
N
хаотичности 1,V«). Если справедлива некоторая альтернатива
j=i
И 6 HS\H'S: для некоторой комбинации (ij) £ £os+l переходная вероят-
ность p-.j > 0, то, как отмечено выше, Р{м^ > 0|Н} —>1 при п —> оо. Но при
гипотезе Н°(в) событие > 0} невозможно, и потому появление в вы-
борке (1) комбинации (ij) свидетельствует о том, что гипотеза Н°(<Э) ложна.
Таким образом, альтернативы Н 6 по длинной реализации цепи (1)
улавливаются с вероятностью, близкой к 1, и потому проблема, собственно,
состоит в различении гипотезы Н°(в) и альтернатив из класса Ц1,..
Наконец, выделим еще один тип задач для цепей Маркова, возникающих
в приложениях. Иногда требуется проверить нулевую гипотезу Н° внутри бо-
лее узкого класса гипотез, нежели общий класс Rs- Формализация подобных
ситуаций выглядит следующим образом. Пусть априори постулируется, что
мы имеем дело с цепью Маркова вида (3), а проверяемая гипотеза есть утвер-
ждение Н°(в0, 0) 0 G ©о, где ©о — заданное подмножество 0, при этом
dim 0О = г < к. Обычно подмножество 0О задается с помощью новой пара-
метризации в терминах некоторого параметра <5 = (<?i, , 5Г) с множеством
возможных его значений А, где А — заданное открытое подмножество г-мер-
ного евклидова пространства Rr В этом случае 0ц есть образ А при некотором
отображении h = (h\,. , hk):
е0 = {0 f) = h(5)= (h{(S),.. , hk(8)), S G A} (6)
В дальнейшем мы будем предполагать, что отображение h удовлетворяет стан-
дартным условиям регулярности:
§5.5. Проверка гипотез для конечных цепей Маркова
431
Условие В. Функции h(S) = (ht(6),.... hk(S)) Условие регулярности В
трижды непрерывно дифференцируемы в Д и
rank
dh,:(S)
d6j
всюду в Д.
= г
Из изложенного видно, насколько более разнообразны могут быть гипо-
тезы, подлежащие проверке, в рамках марксовской модели зависимых испы-
таний в сравнении со схемой независимых испытаний. Тем не менее знакомые
уже нам стандартные (можно даже сказать — классические) методы хи-квадрат
и отношения правдоподобия позволяют построить удобные для применений
критерии проверки всех таких гипотез.
2. Критерий хи-квадрат для простой гипотезы
Пусть требуется проверить простую гипотезу
н° Рч=Р°1р>о ((?)е^+1
Простая гипотеза
для цепи Маркова
В соответствии со сказанным в п. 1, будем рассматривать в цепи (1) лишь те
комбинации (ij), для которых р°^ > 0, т.е. при (ij) 6 foi+l В методе хи-
квадрат сравниваются наблюдаемые частоты {м^, (ij) € <У} с соответствую-
щими «гипотетическими частотами» } и в качестве тестовой статистики
используют статистику
(OM+1
я
(здесь v-j вычисляются по формуле (5), а и- = v-j, см. замечание к форму-
; = 1
лам (5) §4.5). Расчет соответствующего критерия производится на основании
следующего утверждения [29].
Теорема 1. Если справедлива гипотеза Hq, то статистика (6Z) имеет в пре-
деле при п оо распределение X2(d° _ Ns). Соответствующий критерий,
задаваемый при уровне значимости а критической областью
> Xl-a, <Р-Я‘ }> (7)
состоятелен против любой фиксированной альтернативы Я € %.
Выделим важный частный случай, когда все пе-
реходные вероятности p°-.j > 0. Тогда = fs+l,
d° = Ns+l и критерий (7) принимает вид
Критерий х2
для цепи Маркова
432
Глава 5. Параметрические гипотезы
(7')
С частным случаем критерия (7Z), когда все р°-.- = ]/N, мы уже встречались
в п. 2 §4.5 при обсуждении проблемы датчиков случайных чисел.
3. Критерий хи-квадрат для сложной гипотезы
Рассмотрим теперь проблему проверки сложной гипотезы H°(Q) вида (3)
внутри общей гипотезы Hs и будем предполагать выполненным условие ре-
гулярности А. Критерий согласия для гипотезы Н°(В) строится по аналогии
со случаем простой гипотезы, т.е. с использованием стандартной статистики
типа хи-квадрат
<5+1(0)= £
(u)efo+l
Конечно, эту статистику еще нельзя использовать для построения критерия,
так как она зависит от неизвестного параметра 9. Но если параметр 0 пред-
варительно оценить по данным (5), т. е. заменить его некоторой оценкой
вп = М{,/у})> и затем заменить функции р-.;(0) оценками = р^(6п),
то мы придем уже к настоящей тестовой статистике
^,4+i =^.,+ |(0„)= £ (8)
(0)^+1 ‘Ргз
Это достаточно сложная для расчетов, а главное — для исследования ее рас-
пределения статистика, но тем не менее для таких статистик имеется хорошо
разработанная асимптотическая (при п —> оо) теория, которая утверждает,
что если оценки вп получаются по методу максимального правдоподобия, то
статистика (8) имеет при гипотезе H°(Q) предельное распределение %2, как
и в случай простой гипотезы. Отличие проявляется лишь в числе степеней
свободы предельного распределения, которое уменьшается на величину, рав-
ную числу оцениваемых параметров, определяющих гипотезу То есть
в данном случае имеется полная аналогия с теорией метода хи-квадрат для
схемы независимых испытаний.
Приведем ключевые элементы этой теории. Рассмотрим функцию прав-
доподобия выборки (1) при гипотезе Я°(0), т.е. вероятность наблюденной
реализации цепи в предположении, что гипотеза Яи(0) истинна:
bnW=P«1...6:t+1WP(2...(,+ 1:(.+2W П
(9)
§ 5.5. Проверка гипотез для конечных цепей Маркова
433
По аналоги и со случаем независимых испытаний назовем оценкой максималь-
ного правдоподобия (о.м.п.) вп параметра в решение системы уравнений
dlnZn(0) у-л I'ij
—--------= > ---—тт— =0. т = 1, , к.
9вт (и)еГ+1 Р, № двт
Относительно существования, единственности и свойств решения системы (10)
известно следующее утверждение [29].
Теорема 2. Пусть выполнено условие А, тогда с вероятностью, стремящейся
к 1 при п -> оо, система (10) имеет единственное решение вп, являющееся со-
стоятельной оценкой параметра 0. Более того, если 0° есть истинное значение
0, то нормированный случайный вектор х/п(вп —0°) распределен асимптоти-
чески нормально с центром в нуле и матрицей втор^к м байтов 1-1(0°), где
d InW glnft. G(.+. (g)\
двт ddt /
Эта теорема — аналог хорошо известных утверждений об асимптотиче-
ских свойствах о. м. п. для схемы независимых испытаний; она указывает
метод оценивания неизвестных параметров для цепей Маркова.
Наконец, основой для построения и расчета критерия проверки гипотезы
Я°(0) служит следующее утверждение.
Теорема 3. Пусть выполнено условие А и p-.j = р-^(9п), где 0П — о. м. п.
параметра 0. Тогда, если гипотеза Н°(0) справедлива, то определенная в (8)
статистика Х„ s+( распределена в пределе при п —> оо по закону
x2(d° - № - к),
а критерий, основанный на критической области
Un. i+I > 00
имеет асимптотически уровень значимости а и является состоятельным против
любой фиксированной альтернативы Н € Hs-
Пример 1 (гипотеза о порядке цепи Маркова). Пусть гипотеза Яг° означает,
что наблюдаемая последовательность (1) представляет собой цепь Маркова
порядка г, в которой разрешены все переходы. Требуется построить критерий
проверки этой гипотезы внутри общей гипотезы Hs (допускается марковость
порядка $ > г). В этом случае нулевая гипотеза задается так, как указано в (4),
т.е. неизвестными параметрами, определяющими Н®, являются положитель-
28 Заказ 1748
434
Глава 5. Параметрические гипотезы
ные числа образующие параметрический вектор в размерности
k = Nr(N - 1).
Найдем о. м. п. для этих параметров. Поскольку координаты вектора в
удовлетворяют линейным связям (условию стохастичности)
N
У2 I, Vh-г- ,isE£,
>=i
то мы имеем задачу на условный экстремум. Введя множители Лагранжа
A = ... (Ъ-г+Ь • • • , *з) € ,
сводим задачу к отысканию абсолютного максимума функции
А) = ''•«,-r + i-M 1П 0«»-r+i--iij ~
«.-г-н..i..j
где символ * на месте недостающих индексов в комбинации (г, i5j) озна-
чает, что по этим индексам произведено суммирование.
Для этого мы должны решить систему уравнений
' ‘“г+|.......*‘,J
N
= 1, ij-r+l,
j=l
Отсюда легко находим решение вп = (0,(_г+1... г5_г+1, . Ъ, j € £)
‘,J, h-r+l, (12)
которое говорит о том, что оценками переходных вероятностей при гипотезе
Н° являются наблюденные относительные частоты соответствующих перехо-
Критерий Х2 Для гипотезы
о порядке цепи Маркова
X2 —
^*-П, 5 + 1,Г
дов в последовательности (1). В итоге получаем,
что статистика (8) в данном случае имеет вид
(13)
и если гипотеза Я® справедлива, то при п —> оо эта статистика имеет пре-
дельное распределение %2 ((Я4 - Nr)(N - 1)).
§ 5.5. Проверка гипотез для конечных цепей Маркова 435
Выделим важный частный случай т = 0, соответствующий гипотезе
о независимости случайных величин в последовательности (1), когда в качестве
альтернатив допускается марковость порядка s. В этом случае р-;- = > О
И Oj = Vtj/n, поскольку
= 52 va =п-
(ij)
Таким образом, для проверки гипотезы независимости Критерий
Яо внутри общей гипотезы Hs служит статистика независимости х
у2
54-1,0
(О)ег-+'
п
(14)
Если гипотеза Яо справедлива, то статистика (14) при п —> оо имеет распре-
деление у2((Я4 - 1)(Я _ *))• •
Пример 2 (Гипотеза о циклическом случайном блуждании). Предположим,
что в длинной реализации (1) простой (s = 1) цепи Маркова наблюдались
лишь переходы i —> i ± 1 (при i = 1 значение 1 — 1 интерпретируется как N,
при i = N значение N + 1 интерпретируется как 1). Таким образом, здесь
множество = {(г, i ± 1), г = 1, 2, , N} разрешенных переходов состоит
из d° = IN элементов и не совпадает с множеством £2 всех пар (г, j). Пусть
требуется проверить гипотезу
Я0 рн+1 =0, Рн-1 = 1 - 0,
где 0 € (0, 1) — неизвестный параметр (это и есть гипотеза о циклическом
случайном блуждании). Проверим, что в данном случае выполнено условие А.
Рассмотрим произвольную (простую) цепь Маркова с матрицей переходных
вероятностей вида
0
?21
Pl2 0
о Р23
Р32 О
PiN
о
о
Рдч о
PW-IW-2 0
О Pn-.n-i
О
PX-IJV
О
где все p):t±i > 0. Легко видеть, что Рл состоит только из положительных эле-
ментов. Это означает, что за N шагов с положительной вероятностью из лю-
бого состояния можно достичь любого другого состояния цепи, что является
28*
436
Глава 5. Параметрические гипотезы
достаточным условием эргодичности. Таким образом, п. 1 условия А здесь
выполняется, а п. 2 и 3 очевидны. Следовательно, для построения критерия
проверки гипотезы Н° можно воспользоваться изложенной выше теорией.
Для этого найдем прежде всего оценку ffn для параметра в.
Обозначим
N
и =
i=i
число переходов «вперед» (г —> г + 1) в выборке (1). Тогда функция правдо-
подобия (9) запишется в данном случае в виде
Ln(ff) = 0“(1 -
и уравнение
д!п£п(0)
дб
имеет единственное решение 6п = и/п. Отсюда, в силу теоремы 3, имеем,
что статистика
На отвергается <=Ф> {Х„,2 > Xi-a.jv-t}-
где и, =P,,i-i +vij+i, распределена в пределе при п->оо по закону £2(.V-1),
если гипотеза Н° справедлива. Следовательно, при уровне значимости а кри-
терий для гипотезы Н° имеет вид
('5)
Если бы нужно было проверить соответствующую простую гипотезу о цик-
лическом блуждании: е = 0°, где 6а Е (0, 1) — заданное число, то в соответ-
ствии с п. 3 следовало бы воспользоваться статистикой (см. (6'))
(<4, 1+Г — М,00)2 у-К (1/ц i-1 — Р,(1 - 0°))2
ZT ",6’° + 7^ 14(1-0°)
которая при справедливости проверяемой гипотезы распределена при п -> оо
по закону x\n). •
4. Критерий отношения правдоподобия
для общих параметрических гипотез
Рассмотрим, наконец, проблему проверки гипотезы Н°(©о, ©), где ©о задано
в виде (6) и при этом выполнено условие D Тогда функция правдоподо-
бия (9) при гипотезе Н°(©о, 0) становится функцией от нового параметра 6:
§ 5.5. Проверка гипотез для конечных цепей Маркова
437
Ln(h(d)), и система уравнений
Э1п£п(Л(<?)) v- дР1.№У> п . ,
dSl Pi-.j(h(S)) dS‘ ’
(м)е^о
будет иметь состоятельное решение дп, если гипотеза Я°(0О, Q) справедлива.
Общий принцип построения критерия отношения правдоподобия (КОП) для
проверки гипотезы H°(Q0, 6) остается таким же, как и в случае независимых
испытаний: строится статистика отношения правдоподобия (А-статистика)
_Ь„(Л(Х))
Ln(0n)
где дп — решение системы (10), и критическая область задается в виде
{Ап < са}, где при заданном уровне значимости а критическая граница
са выбирается так, чтобы выполнялось условие
Pe{A„<cQ}^a, V0€0O. (19)
Основой для расчета такого критерия служит следующая теорема [29].
Теорема 4. Пусть выполнены условия А и В. Тогда, если гипотеза Я°(8о, 0)
справедлива, то при п —) оо статистика
-21пАп =2[1пЬ„(0„) - 1пЬ„(Л(?„))] = 2 V In Pi^\. (20)
(o)6f'+' Pi.Ah<M)
имеет предельное распределение %\к - г); если 6° — истинное значение
параметра д, то статистика
2[lnI„(ft(dn))-lnLn(A(<J°))]=2 (21)
(v)^+l P-AW»
распределена в пределе при п —> оо по закону %2 (г); при этом статистики
(20) и (21) асимптотически независимы.
Итак, при заданном уровне значимости а КОП проверки гипотезы
Я°(6о, 0) 0 € ©о внутри общей гипотезы Я°(0): 0 € 6 имеет для больших
выборок вид
(22)
При этом, напомним, г = dim ©о < dim @ = к.
Аналогично с помощью статистики (21) строится критерий проверки про-
стой гипотезы д = <5° внутри гипотезы: <5 6 Д.
Я0(©о.©) отвергается <=> {-2In An >
438
Глава 5. Параметрические гипотезы
Пример 3 (продолжение примера 2). Предположим, что класс цепей, в ко-
торых разрешены лишь переходы в соседние состояния (г —> i ± 1), выделен
условием цикличности: = 6, 6 Е (0, 1), и требуется при этом проверить
простую гипотезу Н°: 6 = 6° В силу теоремы 4, в этой задаче надо восполь-
зоваться статистикой (21), которая в обозначениях примера 2 имеет в данном
случае вид
и 1 — и/п
г- = 2“,|,^ + 2(”-“>|пТ^‘- (23)
Если гипотеза На истинна, то эта статистика асимптотически (при п —> оо)
распределена по закону Х2(0> откуда и следует соответствующий критерий:
{^п > Х1-«, |}- •
5. Критерий однородности
В этом пункте мы рассмотрим применение метода отношения правдоподобия
к еще одной общей статистической проблеме — проверке гипотезы однород-
ности для многих выборок в марковской модели. В общем виде эта проблема
формулируется следующим образом.
Пусть г = 1, ,v, — независимые марковские цепи по-
рядка s с одним и тем же пространством состояний Е = {1,.. , 7V} и одним
и тем же множеством возможных переходов
£q+i (u)ef„s+1 о = (0,, А)е0.
В дальнейшем предполагается выполненным стандартное условие регуляр-
ности А. Обозначим через 0^ Е 0 значение параметра 0, порождающего
процесс (так что управляется переходными вероятностями (0^),
т = 1, .., v). Значения 0^..0^ неизвестны и, вообще говоря, различ-
ны. Эту модель будем называть общей гипотезой Н, ее размерность (число
определяющих ее параметров) dimH = vk. Предположим теперь, что мы
располагаем выборкой из каждого процесса, так что наши исходные стати-
стические данные есть
т=1, ,v. (24)
По этой информации требуется построить критерий проверки гипотезы одно-
родности Н° 0^ = = 0^ внутри гипотезы Н. Размерность этой гипотезы
есть к, и она (гипотеза) означает, что наблюдаемые процессы являются
независимыми реализациями одного и того же марковского процесса 4 из
описанного выше класса процессов; другими словами, в этом отношении на-
ши данные (24) однородны.
Схема применения A-метода в данном случае выглядит следующим обра-
зом, Выпишем функцию правдоподобия данных (24) при гипотезах Н и Н'1.
§ 5.5. Проверка гипотез для конечных цепей Маркова
439
Поскольку выборки независимы, то в соответствии с (9) имеем
Lni...nAe\'\ >">) = П ьп>'>),
Г=' (О (25)
Lnr(e(T))= П
Ln(0) = Lni...nj0,...,0) = П (26)
(ОЖ0'+1
где — число наблюдаемых комбинаций (ij) в выборке с номером г
V
(см. (5)), = iAT) и п = П| + + пт. Далее, исходя из (25) и (26),
Г=|
мы оцениваем неизвестные параметры 0^ т = 1, ,v, при гипотезе И
и 0 — при гипотезе Н° по методу максимального правдоподобия, решая
соответствующие уравнения типа (10). Пусть соответствующие о. м. п. есть
0%), г = 1, , v, и 0п. Тогда тестовая статистика (А-статистика) имеет вид
-21пЛП1...п„-2[1пХП1...Пг(0п(,1), ,0^)-\nLn(0n)] =
а сам критерий однородности формулируется следующим образом:
Я0 отвергается <==> {-2 In An,...n„ > О-
(27)
(28)
Обоснованием этой методики является следующая теорема об асимптотиче-
ском распределении статистики (27), дающая одновременно и способ вычис-
ления критической границы t в (28).
Теорема 5. Пусть выполнено условие А и П\ nv оо так, что пт/п Хт,
О < Ar < 1, т = 1, , V. Тогда, если гипотеза однородности Я0 справедли-
ва, то статистика (27) распределена в пределе по закону x2(k(v - 1)), где
k(v - 1) = dim Я - dim Я°
Основываясь на этой теореме, при выполнении ее условий мы выбираем
в (28) при заданном уровне значимости а величину t как квантиль уровня
1 - а распределения x2(^(v ~ 1)): = Xi-a,fc(v-i)> и тогда
Р{-21пАП|...п„ а. (29)
440
Глава 5. Параметрические гипотезы
Соотношениями (27)—(29) полностью определен состоятельный в классе И
критерий однородности в общем случае произвольной параметрической мо-
дели и произвольного числа выборок.
Выделим важный специальный случай описанной общей схемы, когда
гипотеза ?/ задана указанием лишь множества £д + 1 возможных переходов
без конкретизации вида переходных вероятностей р; , (if) € В этом
случае сами эти вероятности являются неизвестными параметрами модели; их
число (с учетом условия стохастичности р,-, = 1, Vi Е Es) для каждого
j
процесса есть d° - Ns, т.е. dim?/ = v(<f - Ns), a dimH0 = d° - Ns
а их o. m. п. являются наблюденные относительные частоты соответствующих
переходов (см. пример 1):
р-т)
= r = 1>-- >V' = (О)€^+‘
J и' ui»
Отсюда имеем, что в рассматриваемом случае статистика (27) принимает вид
и _____________________________ V-T^V-
-21пАп,...п. = 2£ £ 0°)
т=| (0)€£u'+l Vii
и при гипотезе однородности Н° она имеет предельное (в условиях теоремы 5)
распределение x2((d° ~ Ns)(v ~ •))-
Замечание. Можно показать, что в рассматриваемой задаче тестовая статистика (30)
асимптотически эквивалентна статистике типа хи-квадрат
Пример 4 (Модель случайного блуждания, проверка гипотез однородности
для нее). Рассмотрим класс простых цепей Маркова, множество разрешен-
ных переходов в которых имеет вид как в примерах 2 и 3:
= {(i,i± 1), г = 1,2, ,N}.
Пусть мы имеем?; независимых выборок в этой моделии {^г,'±|}, т = 1,. ,.,v,
— соответствующие наблюденные частоты переходов. Можно рассмотреть
следующие четыре гипотезы. Прежде всего — это общая гипотеза ?/, соглас-
но которой каждая из наблюдаемых цепей управляется своей матрицей пере-
ходных вероятностей, вид которой указан в примере 2; если обозначить
матрицу процесса , то эту гипотезу будем обозначать (Р^, , Р^). Гипо-
тезу, согласно которой Р^ = ... = Р^ = Р, обозначим (Р). Далее, выделим
§ 5.5. Проверка гипотез для конечных цепей Маркова
441
общую гипотезу о циклическом случайном блуждании (см. пример 2) и обо-
значим 0^, , значения соответствующих параметров для наблюдаемых
процессов — такую гипотезу обозначим ((№, ,(№). Наконец, гипотезу,
согласно которой = — 0^ = 0, обозначим (0). Таким образом, (Р) —
это общая гипотеза однородности, а (0) — гипотеза однородности для модели
циклического случайного блуждания. Соотношения между этими гипотезами
можно изобразить следующей диаграммой:
(рО),...; рМ)
Здесь каждое ребро представляет собой статистическую проблему про-
верки гипотезы, являющейся началом ребра, внутри более общей гипотезы,
являющейся его концом. Например, ребро а соответствует проверке гипотезы
(0) внутри гипотезы (0^,. ,0^). Из пяти проблем а, b, с, d и е пробле-
мы а, с и е — это проблемы однородности.
Выпишем для каждой гипотезы оценки параметров, максимальное значе-
ние логарифма функции правдоподобия и ее размерность (т. е. число степеней
свободы) (см. табл.).
Гипотеза О. м. п. max In L dim
(рО) Гр(г) 1 1 *1, >±1 1 1 р(т| J Е Е о (т) т=‘ (O)GCg ’* vN
(00’,.. ,0м) J 1 1 ПТ J ’Г,, u(T) / u(r,\l In 1- (nT - uT) In ( 1 I V
(Р) Г «у hi1 1 ц. J E^ (v)erj ” N
и п и . . f u\ и In —1- (n - U) In I 1 1 n \ n J
Здесь в дополнение к введенным ранее обозначениям положено
,Л> = и и = и*1* -I- ... -I-
442
Глава 5. Параметрические гипотезы
Чтобы построить критерий для соответствующей проблемы (см. диаграм-
му), надо взять строки этой таблицы для двух соответствующих гипотез и вы-
числить разность между выражением в третьем столбце выше расположенной
строки и соответствующим выражением нижней из этих двух строк; будучи
умноженной на 2, эта разность дает соответствующую тестовую статистику.
Число степеней свободы в предельном распределении для этой статистики
(если справедлива более узкая, т. е. ниже расположенная гипотеза) равно раз-
ности размерностей рассматриваемых гипотез. Например, асимптотический
(в условиях теоремы 5) критерий однородности для проверки гипотезы (0)
внутри гипотезы (0^, , 0^) (проблема а) имеет (при уровне значимо-
сти а) вид
и
и In —I-
п
(32)
Если же мы хотим проверить ту же гипотезу (в) внутри общей гипотезы
(р(’\ ..., ₽<”)) (проблема е), то надо использовать критерий
и . , ( и\
и In —h (n - и) In 1--
n \ nJ
(33)
Отметим также, что критерии для проблем b и d по существу построены
в примере 2, а критерий для проблемы с есть частный случай критерия, по-
рождаемого тестовой статистикой (30). •
6. Оценивание порядка цепи
Важнейшим параметром марковской модели является порядок цепи. В при-
ложениях этот параметр, как правило, неизвестен и потому представляет
большой теоретический и практический интерес вопрос о его оценивании
по наблюдаемой реализации цепи (1). Один из возможных подходов к этой
проблеме состоит в использовании построенного в примере 1 критерия про-
верки гипотезы о порядке цепи. Основываясь на тестовой статистике (13)
можно предложить следующий алгоритм последовательного типа для опреде-
ления порядка цепи в рамках модели
С самого начала мы задаемся некоторым достаточно большим значением
s и априори предполагаем, что наблюдаемая последовательность (1) являет-
ся реализацией некоторой однородной эргодической цепи Маркова порядка
не выше s. Подсчитав частоты м- -, i = (г1; .., is), (s+1)-цепочек в последо-
вательности (1), с помощью статистики J+I 0 (14) мы проверяем гипотезу
§ 5.6. Последовательный анализ. Критерий Вальда
443
независимости Hq г = 0 (г — истинный порядок цепи, г < з). Если при
уровне значимости а гипотеза принимается, т.е. наблюдается событие
Ло = {Хп s+1 о (34)
то процедура заканчивается на 1-м шаге и принимается решение, что г = 0.
В противном случае, т. е. если наблюдается противоположное к (34) событие,
выполняется 2-й шаг процедуры, а именно, с помощью статистики Х„,J+1>1
(13) проверяется гипотеза Я° г = 1 (цепь имеет порядок 1). Если гипотеза
Н\ принимается, т.е. наблюдается событие
41 = {-^n.s+l, Х1-а.(ЛГ'-ЛГ)(ЛГ-1)}> (35)
то процедура заканчивается на 2-м шаге и принимается решение, что г = 1.
Если же наблюдается дополнительное событие At, то выполняется следу-
ющий, 3-й шаг процедуры, состоящий в проверке гипотезы Я2° г = 2:
вычисляется статистика Хпл-цд (13) и ее значение сравнивается с критиче-
ским уровнем Если наблюдается событие
4г = {-^n.s+1,2 Х1-л, (y'-N2)(N-l)} - (30
то процесс заканчивается принятием решения г = 2, в противном случае
процесс продолжается аналогичным образом и т.д. Действуя таким образом,
мы можем остановиться на каком-то значении г s - 1, либо, проделав з
шагов и отклонив на s-м шаге гипотезу Н°_ г = s - 1, делаем заключение,
что г з.
Таким образом, обозначая через г* оценку для истинного порядка цепи,
можем записать итог в следующей форме:
г* = min{r гипотеза Ну принимается} =
= min{r A"n>s+1 г Xi-о, (№-wr)(y-i)}> (37)
если г* < s - 1, и г* з, если все гипотезы Ну, г < s - 1, последовательно
отвергаются. Отметим также следующее из (37) соотношение
Р{г* > г} = Р-САоЛ, Лг} =
= + > xl-a, = 0, 1, . . • , г}, (38)
Г < S - 1.
§ 5.6. Понятие о последовательном анализе.
Критерий Вальда.
В примере 1 §5.2 при рассмотрении задачи о выборе одной из двух гипотез
о среднем нормальной модели была установлена связь между числом необхо-
димых наблюдений и значениями вероятностей ошибок 1-го и 2-го родов а
444
Глава 5. Параметрические гипотезы
и (3 (соотношение (14) § 5.2). Это число п можно рассчитать заранее (до про-
ведения испытаний), и оно не зависит от исходов самих испытаний (от реа-
лизации выборки). Альтернативой к правилам проверки гипотез, основанным
на выборках фиксированного объема, являются последовательные правила
(критерии), когда вопрос о числе необходимых испытаний решают в про-
цессе их проведения, и это число зависит от результатов испытаний, т.е.
само является случайной величиной. Последовательные правила впервые бы-
ли предложены А. Вальдом (1943), и их изучение составляет предмет важного
раздела математической статистики — последовательного анализа. В данном
параграфе на примере различения двух простых гипотез о распределении на-
блюдаемой случайной величины £ мы кратко обсудим основные особенности
последовательности критериев. С общей теорией последовательного анализа
можно ознакомиться в [6] и [28].
1. Определение критерия Вальда
Пусть, как обычно, xt — наблюдавшаяся реализация случайной величины £
в г-м испытании, i = 1, 2, и
п
L]n = L(x\ , хп, ffj) — j. fj(xi)
i=i
— функция правдоподобия для первых п испытаний при гипотезе Hj 0 = fh,
j = 0, 1 (напомним, что fj(x) — плотность распределения £ (или вероят-
ность в дискретном случае) при гипотезе Hj, и испытания предполагаются
независимыми). Согласно теории Неймана—Пирсона (см. §5.2) наилучшая
процедура проверки гипотезы Но против альтернативы Ht состоит в приня-
тии или отклонении гипотезы Но в зависимости от того, меньше или больше
отношение правдоподобия L\n/LOn некоторой выбранной границы с, при
этом объем выборки п фиксируется заранее и не зависит от наблюдений. Од-
нако если объем выборки сделать зависящим от исходов испытаний, то можно
добиться выигрыша в среднем числе испытаний до принятия окончательного
решения. Эта идея реализуется в определяемом ниже последовательном крите-
рии отношения правдоподобия, который принято называть по имени его автора
критерием Вальда.
Зададим две положительные константы Ао < 1 < Aj и будем проверить
испытания (наблюдения над £) до тех пор, пока не будет впервые нарушено
какое-нибудь из неравенств
Ао < -— < А]. (1)
-^Оп
Если в момент прекращения испытаний (момент остановки) L\n/Lon Ао,
то принимается гипотеза Но, если же Ь\п/Ьйп А], то принимается ги-
потеза Н\. Такая последовательная процедура характеризуется, как обычно,
вероятностями ошибок 1-го и 2-го родов а = Р{Н||Яо} и /3 = Р{Яо1#1},
а также средним числом Ej(v) = E(v\Hj) испытаний и до момента остановки
§ 5.6. Последовательный анализ. Критерий Вальда
445
(У = О, 1). Если вероятности ошибок а и /3 заданы, то любой критерий с та-
кими ошибками называют критерием силы (а, 0). В классе критериев данной
силы (а, /?) предпочтительным является тот, который требует меньшего числа
наблюдений. Критерий, минимизирующий одновременно Ео(м) и Е|(м) на-
зывают оптимальным. Таким свойством оптимальности и обладает критерий
Вальда. В частности, этот критерий требует в среднем меньше испытаний,
чем критерий Неймана—Пирсона с такими же вероятностями ошибок (а, /?).
Эти и другие свойства критерия Вальда рассмотрены ниже.
2. О числе испытаний до момента остановки в критерии Вальда
Пусть плотности fj(x) > 0, j = 0, 1, и нетождественны. Это означает, что
определена и невырождена случайная величина Z = In (/i(£)//o(£)); будем
предполагать, что существуют E^Z ^Ои DgZ — > 0 (0 = #о, #1)-
Обозначим также Zt- = In (fatXi)/f^Xi)), i = 1,2, ., где Х\,Х},
последовательные независимые наблюдения над £. Тогда Z\, Z^, являются
независимыми наблюдениями над Z, и если Z|,Z2, — наблюдавшиеся
реализации этих величин, то в этих обозначениях процедура проверки гипотез
заканчивается принятием Но или Н] при первом тг, при котором нарушается
какое-нибудь из неравенств
ао = In Ло < 21 + + zn < In = а1; ао < 0, а.\ > 0. (2)
Критерию можно дать следующую наглядную геометрическую интерпрета-
цию. Рассмотрим блуждающую на плоскости частицу, находящуюся в началь-
ный момент в начале координат, ордината которой в каждый целочисленный
момент времени t = 1,2, получает приращение Zt. Тогда ордината частицы
в момент t = п будет равна z{ + + zn и блуждание продолжается, пока
траектория частицы впервые не выйдет за пределы полосы, ограниченной
двумя горизонтальными прямыми на уровнях ао и а, (см. рис. 1).
Выход траектории на верхнюю (нижнюю) границу приводит к принятию
гипотезы Н\(Но). Прежде всего возникает естественный вопрос, не может ли
ASZ|
Принимать Я,
--<111111 Nil I |/1 Н-Н I l/l Н I I I I t
“° штжжжтжжжжш
Принимать Но
Рис. 1
446
Глава 5. Параметрические гипотезы
блуждание продолжаться бесконечно долго, — в этом случае процесс провер-
ки гипотез никогда бы не закончился. Ответ на этот вопрос дает следующее
утверждение.
Теорема 1. Критерий Вальда с вероятностью 1 заканчивается за конечное
число шагов, т. е. lim РДр > п} = О (в = во, в\).
п->оо
Доказательство. Зафиксируем некоторое число г и введем случайные вели-
чины
7/| = Z\ + + ZT, 7/2 — ^г+I + + Zjr,
Тогда событие {р > rk}, эквивалентное событию ао = Z\ + + Z, < а,,
i rk, включается в событие ао < т/i + + т/у < аь jk, которое,
в свою очередь, включается в событие |t/J < b = at — ац, j «Г fc. Случайные
величины T]j независимы и одинаково распределены, поэтому
Р«> rk} sj Рй{\t]j| < b, j fc} = pk(0), (3)
где
p(0) = Р«{Ы < *>} = P^h? < *>2}.
Ио
> DflT/i = D«z> = rff2W’
i=I
что может быть сделано больше, чем Ь2, если выбрать
( Ъ2 Ь2 \
Отсюда следует, что выбором г можно обеспечить неравенство р(0) < 1 (так
как в противном случае распределение величины т/ было бы сосредоточено
на интервале (0, &2) и ее среднее было бы меньше, чем Ь2). Переходя в нера-
венстве (3) к пределу при fc -э оо, получаем
lim Pe{p > п} = lim РДр > rk} = 0.
П-ГОО fc->00
Итак, в критерии Вальда число испытаний р до момента остановки с ве-
роятностью 1 принимает конечное значение. Справедливо и более сильное
утверждение, а именно: все моменты случайной величины р конечны. В част-
ности, конечны и средние значения Eq(p) и Е|(р); вычисление этих величин
при заданных ошибках (а,0) рассмотрено ниже в п. 4.
3. О выборе границ в критерии Вальда
Установим теперь замечательную связь границ 4q и А} в (1) с вероятностями
ошибок а и 0.
§5.6. Последовательный анализ. Критерий Вальда
447
Теорема 2. Границы Ао и At критерия Вальда силы (a, fl) удовлетворяют
неравенством
А А'о = , 4| А\ =---------(4)
1 - а а
при этом, если границы Aq и At в (1) заменить их оценками Л'о и А), то сила
полученного критерия будет равна (a1, fl), где
fl и a+fl^a + p. (5)
1 — р 1 — а
Доказательство. Обозначим через Хоп (Хщ) множество тех результатов на-
блюдений (хь ,хп), для которых процедура заканчивается на n-м шаге
принятием Яо (соответственно Я)), например,
~ \ / \ j ^1* _ , , , „ .
Этой = < (21 ,2П) Ао < — < Ah k = 1, , п-1, — ^Ао
I L(lk -ООП
В силу теоремы 1, для В = Oq, 0\
ОО ОО 00
52 р,{|/ = п} = 52 рдхоп} + 52 =L
л=1 п=1 П=1
Далее имеем
00 j 00
а = Р{Я, |Яо} = 52 PS„{X1J - 52 Р«, {Эс 1п} =
п=1 1 п=1
= 1(1_р{я0|я1}) = кД
А| Л!
так как в точках множества JEln выполняется неравенство Lon Ltn/A\.
Аналогично получаем
00 00
(3 = Р{Яо|Я,} = 52 Рв1 {Son} Ао 52 Р*,{*ов} =
П=1 П=1
= Ло(1-Р{Я1|Я0}) = Ло(1-а),
поскольку в точках множества Хол выполняется неравенство Zln Лц^оп-
Тем самым неравенства (4) доказаны.
Рассмотрим теперь критерий Вальда с границами А'о и А\, определен-
ными в (4), и пусть а и fl — его ошибки. Тогда на основании доказанного
должны выполняться неравенства
1 - 1 -
1 — а 1 - а1 ’ а а'
448
Глава 5. Параметрические гипотезы
Отсюда имеем
^(1-а')/^ 0 а
0 С -------- С------, а С --------— С-----
I-а 1-а I~0 I -0
Складывая неравенства
0'(] - а) 0(\ - а1) и - а(\ - 01) -а(\ - 0),
получаем, что
0' - а 0 - а1 или а1 + 0' С а + 0.
" Комментарии На практике теорему 2 используют следующим об-
разом. Если требуется построить критерий Вальда силы
(а, 0), то границы в (1) полагают равными соответственно и , как опре-
делено в (4). В этом случае последнее неравенство в (5) гарантирует, что сумма
действительных ошибок а и 0' такого критерия не превосходит суммы а + 0
заданных ошибок. Далее, обычно а и 0 не превышают 0,1, поэтому из осталь-
ных неравенств (5) следует, что разность между действительными и заданными
ошибками в этих случаях незначительна. Таким образом, можно утверждать,
что такой специальный выбор границ в критерии Вальда приводит к более
сильному критерию.
Отметим в этой связи интересную особенность последовательного кри-
терия по сравнению с обычными критериями, основанными на выборках
фиксированного объема. В обычном критерии при определении критической
границы при заданном уровне значимости и вычислении мощности надо знать
распределение тестовой статистики и при нулевой гипотезе, и при альтерна-
тиве. При расчете же критерия Вальда не возникает проблемы отыскания
распределений. Действительно, границы А'о и А\ зависят только от заданных
ошибок а и 0, а отношение Ъщ/Ь^ можно вычислить на основании на-
блюдаемых данных. Необходимость отыскания распределений при использо-
вании последовательного критерия возникает только при исследовании числа
наблюдений v до момента остановки.
4. О среднем числе наблюдений в критерии Вальда
Установим предварительно одно интересное равенство, называемое тожде-
ством Вальда. Пусть Sv = Z] + + Zv — ордината блуждающей частицы
Тождество Вальда в момент остановки (см. п. 2), тогда
Efl(S„) = Ee(Z)Ee(p).
(6)
Доказательство. Введем случайные величины YhY2, где Yn = 1, если
решение не принято до п-го шага, и Y„ = 0 в противном случае. Тогда,
очевидно, Yn есть функция только Z],..., Zn_| и, следовательно, не зависит
от Zn, и можно записать
ОО
s„ = 52 Y^n-
п= 1
§5.6. Последовательный анализ. Критерий Вальда
449
Отсюда по свойству математического ожидания. (Е(£т/)) = Е(£)Е(т?), если слу-
чайные величины £ и 7) независимы) имеем
ОО 00 оо
ВД) = 52 E9(rnZn) = E9(Z) 52 Е9(Г„) = E9(Z) £ P,{rn = 1}. (7)
n=I n=l n=l
Событие {У„ 1} эквивалентно событию {у n}, а так как для любой
целочисленной положительной случайной величины к (каппа) справедлива
формула
00
Ек = 52 Р{к п) (показать!),
П=1
то из (7) следует тождество Вальда (6).
Пусть теперь заданы значения ошибок а и (3. Как показано в п. 3, прак-
тически при малых а и Д границы в (2) можно заменить соответственно на
а0 = 1п Ад = 1п —-— и а\ = 1п А\ = 1п-----(8)
1 - а а
При малых а и /3 ширина интервала (<4, а\) велика, а величина E«(Z) от а
и Д не зависит и, по предположению (см. п. 2), конечна. Поэтому можно
пренебречь эффектом превышения суммой Sv границы в момент остановки,
т.е. положить Sv ~ а^, если принимается гипотеза Hj, j = О, 1. Другими
словами, можно считать среднее значение суммы Su приближенно равным со-
ответствующей границе а0 или а\. Из этих рассуждений и тождества (6) имеем
E#o(p)Eeo(Z) = E9o(S„) к а()Р{Яо|Яо} + а.\Р{Н}\Н0} = (1 - а)а'о + аа\.
Аналогично
E9|(p)E9|(Z) = E91(Sp) « ^Р{Яо|Я} + a',P{^|ff|} = Да'о + (1 -0)а\.
Таким образом, Ej(iz) = Ee. (tz) можно вычислять по следующим приближен-
ным формулам:
(9)
F ~ “ “>“0 + г /,л~ /Ч + О “Ж.
ЕоМ~—йй— Е|М---------------
где а'а или а\ определены в (8).
Пример 1 (критерий Вальда для нормальной модели). Построим и рассчи-
таем критерий Вальда для задачи различения двух простых гипотез о среднем
нормальной модели, которая рассмотрена в примере 1 §5.2 с позиций теории
Неймана—Пирсона. Здесь
. (zi-0o)2-
0| ~ 0о 7 0о + 01
2
Z, = In
2сг2
29 Заказ 1 74b
450
Глава 5. Параметрические гипотезы
и критерий Вальда силы (а,0) определяется в данном случае следующим
образом. Наблюдения продолжаются до тех пор, пока впервые не нарушится
какое-нибудь из неравенств
°2 , 0
------In----------
#1 — 1 — а
п
Е72»
- — (00 + 01) <
।-1>
а
если нарушается левое (правое) неравенство, то принимается гипотеза Яо (Hi)-
Вычислим среднее число наблюдений до момента остановки. Из (10) имеем
0|-0о
<72
(01 - 0р)2
2а2
(0. - 0о)2
2 ст2
при j = 0,
при j = 1.
Отсюда и из (9) находим
, х 2а2 Г 0 \-0
---«V (I -а)1п-—— 4-aln———
(01 - 0о) L 1 - а а
е'мк(^ЬД+('-«'"
Для критерия Неймана—Пирсона с теми же ошибками а и 0 необходимое
число испытаний п определяется формулой (14) §5.2. Отсюда имеем
Е.(0
п*
7, 1п + 0 ~ 0) 1п
(Са + W 1 - а
(II)
Если а = 0, то £а (л, In------------ = - In------- и из соотношений (11)
1 — а а
следует, что
Е0(р) Ei(p) 1 - 2а 1 -а_
~ ~ 1п---------------------------=^“)- (’2)
п* п* а
При а = 0,05 квантиль (а = -1,645 и ip(a) = 0,49,т.е. экономия наблюдений
при последовательной процедуре составляет приблизительно 50%.
Более определенные выводы о сравнении критериев Вальда и Неймана-
Пирсона можно сделать при а = 0 —> 0. В этом случае (а —> -оо и, если
воспользоваться известной асимптотической формулой для нормальной функ-
ции распределения Ф(х) [3, с. 10]:
е-г2/2
Ф(-г) =—-=(1 + о(1)), х -> оо, (13)
д:у27г
Упражнения
451
то на основании (13) можно записать асимптотическое равенство (вместо
точного равенства Ф(Са) = а)
- LX .
Са\/2ТГ
Решением этого уравнения, как нетрудно убедиться непосредственной под-
становкой (проделайте это самостоятельно!), является
2 1 1
(а = 21п-----In In-----In 4тг + о(1).
а а
Отсюда и из (12) следует (это мы оставляем читателю в качестве упражнения
на асимптотические вычисления), что при а -> О
1/ i In (1п (1/а)) - 1п 4тг + о(1)
4 \ + 2 In (1/а)
Представление (14) говоритотом, что при ошибках а = /3->0 последователь-
ная процедура в среднем приблизительно в четыре раза экономнее оптималь-
ной процедуры с фиксированным объемом выборки. •
Последовательный критерий отношения правдоподобия А. Вальда (1943)
стал важным открытием в статистике, позволившим (в типичных ситуаци-
ях, ях) на 50 % уменьшить среднее число наблюдений (при тех же вероятностях
ошибок). Насколько это важно для приложений говорит тот факт, что в го-
ды второй мировой войны открытие Вальда было объявлено «секретным», и его
основная книга «Последовательный анализ» была опубликована лишь в 1947 г.
Год спустя Вальд и Дж. Волфовиц доказали, что методы, отличные от последова-
тельного критерия отношения правдоподобия, не дают такого уменьшения числа
элементов выборки. В настоящее время теория последовательного анализа Вальда
является частным случаем общей теории стохастических процессов с остановкой,
изложенной в [28].
Упражнения
Величайшая цель образования — не знание, а действие.
Герберт Спенсер3*
П Пусть X = (Xlt..., Хп) — выборка из показательного распределения Г(0, 1)
(см. п. 3 § 1.2), о котором требуется проверить простую гипотезу На 9 = против
альтернативы Я, 0 = 0,. Убедиться в том, что здесь наиболее мощный критерий
выражается через достаточную статистику
3* Спенсер Герберт (1820-1903) — английский философ и социолог.
29*
452
Глава 5. Параметрические гипотезы
и имеет при в0 < 6t вид
Т*+ _ Jt > _! J I
1 * а l-о, 2п | >
Получить также следующие выражения для мощностей:
/ 0 \ / 0 \
И^ЗС) = 1 - / X?-a,2n , Ш, х;„-) = F,n / Х«. 2п ,
\"| / \0| /
где F2n(i) — Функция распределения закона £2(2п).
◄ Указание. Воспользоваться соотношением Св(1Т/в) = х(2п), вытекающим из
свойств гамма-распределения. ►
Q Пусть для распределения Коши К.(в) с плотностью
1€Я'
проверяется гипотеза На 0 = 0 против альтернативы Н, 0=1. Показать, что при
уровне значимости
1 I 1
а = ------arctg - ~ 0,352
2 тг 2
наиболее мощный критерий по одному наблюдению имеет вид
х’°={*> И
и его мощность равна
1 I 1
- + - arctg - й 0,648.
2 тг 2
Если же
а = -(arctg 3 - arctg I) х 0,148,
7Г
то критерий имеет вид
x;Q = {I х а з}
и имеет мощность
— arctg 2 и 0,352.
тг
Q Убедиться в том, что наиболее мощный критерий для различения двух простых
гипотез о симметричном относительно нуля распределении наблюдаемой случайной
величины £ HQ £({) = И(-а, а) и Н, £(() = V(0, а2) (а и а известны) имеет
для больших выборок следующую асимптотическую форму
◄ Указание. Воспользоваться центральной предельной теоремой при отыскании рас-
пределения тестовой статистики. ►
Упражнения
453
Q В последовательности независимых испытаний с двумя исходами вероятность
«успеха» равна р. Построить критерий проверки гипотезы Н$ р = О против аль-
тернативы Я, р = 0,01 н определить наименьший объем выборки, при котором
вероятности ошибок 1-го и 2-го родов не превышают 0,01.
В По схеме примера 4 § 5.2 построить и рассчитать критерий Неймана—Пирсона
различения двух простых гипотез в биномиальной модели Bi(A, в). Показать, что для
выборки X = (Х|.....2ГП) большого объема этот критерий в задаче (Яи 6 = ва,
Н* в = > 0О) имеет асимптотически вид
Г п /----------1
зе;0+ = х, > кпв0 - cayjkneo(\ - ад к ф(с„) = а,
и его мощность VTn((?i) при «близких» альтернативах вида
6
— ^ln — 0Q Н--> О,
уп
удовлетворяет соотношению
/ I fc \
lim 1ГЯ(<?,„) = Ф UJ——т-г + U-
n-too \ у ®o(l - «О) /
◄ Указание. Воспользоваться теоремой Муавра—Лапласа. ►
В Чтобы проверить гипотезу Яо: в = против альтернативы Я, 6 = 0, (0 < ва <
< б| < 1) в схеме Бернулли с неизвестной вероятностью «успеха» 6, осуществлен
эксперимент, в котором наблюдается число «успехов», предшествующих первому «не-
успеху». Построить наиболее мощный критерий при уровне значимости а = в3а, где
s > I — заданное целое число, и убедиться в том, что вероятность ошибки 2-го рода
этого критерия 0 = 1 - 6‘
◄ Указание. Использовать тот факт, что наблюдаемая случайная величина X имеет
распределение £в(Х) = Bi(l, 0) (см. п.2 § 1.1). ►
Q Доказать формулу (3) § 5.3 для мощности критерия обратного биномиального
выбора.
Q Убедиться в том, что построенный в упр. 5 критерий Неймана—Пирсона для
биномиальной модели Bi(fe, в) является р. н. м. критерием в задаче (Яо в < 0О,
Я,+ 0>0„).
◄ Указание. Воспользоваться свойством модели с монотонным отношением правдо-
подобия. ►
Q Пусть в схеме Бернулли с неизвестной вероятностью «успеха» в испытания про-
должаются до получения г-го «неуспеха» и Тг — наблюдаемое число «успехов».
Построить р. н. м. критерий проверки гипотезы Яо в < 0О против альтернативы
Н* в > 0О и показать, что при г -> оо его асимптотическая форма есть
I I — И) J
◄ Указание. Воспользоваться свойством модели с монотонным отношением правдо-
подобия и применить центральную предельную теорему к сумме Тт = -Х) + + Хг,
где Х|,.... Хг — независимые геометрические Bi( 1, 0) случайные величины. ►
454
Глава 5. Параметрические гипотезы
ЕШ Убедиться в том, что построенные в упр. 1 критерии Неймана—Пирсона
и являются одновременно р. н. м.к. в задачах соответственно (Яо в во,
в > 0О) и (Яо о^в0, н; в<ва).
ш (выборочный контроль). Пусть партия из N изделий содержит неизвестное число в
дефектных изделий, в G {О, I,.... Я} Чтобы проверить гипотезу Но 0 0о против
альтернативы Я,+ в > в0, берут на контроль случайную выборку из n (< N) изделий
и каждое из них проверяют. Основываясь на статистике Т — обнаруженное в выборке
число дефектных изделий, построить р. н.м. критерий.
ч Указание. Убедиться в том, что распределение статистики Т (гипергеометрическое
распределение Я(0, N — в, п), см. п. 4 § 1.1) имеет монотонное отношение правдопо-
добия. ►
ЕП Рассматривается задача (Яо в = 0О, Я| 0 / 0О) для нормальной модели
с неизвестной дисперсией .Щр., в2). Используя результаты примера 2 § 5.2 и прием
объединения односторонних критических областей, показать, чтор. н. м. несмещенный
критерий имеет в данном случае вид
51а = {Г 0^„„} |J{T 0о2Х?-«2.п},
где t| = Xai.n и t2 = х]-а2 „ определяются условиями (ниже kn(t) = F’n(t) — плот-
ность распределения х2(п))
t\kn(ti) = tiknlt,?'), 0Г|+а2 = а.
Значения (х<>, Xi-а, п) Для а = 0 05 и п = 2, 5, 10,20, 30,40, 60 см. в [ 12, с. 275].
ЕП Рассматривается задача (Яо в = 0О, Я, в / 0и) для показательной модели
Г(0, 1). Используя результаты упр. 1 и прием объединения односторонних критических
областей (см. также пример 3 § 5.3), показать, что р. н. м. несмещенный критерий имеет
в данном случае вид
где <| = Ха!.2п и t2 = Xi-O!. in определяются условиями (см. упр. 12)
ii ^2n(ii) = tikiniti), a, + а2 = а.
ЕП Проверяется гипотеза Яо 0 = 0О против общей альтернативы Я| в ф во
для модели Bi(fc, 0). Показать, что для больших выборок л. н.м. несмещенный крите-
рий (18) §5.3 имеет вид
( \Т-кпво\
I у/кпво(1 - во) " 0/2)'
и его мощность при альтернативах вида & = вп = 4- б/у/п удовлетворяет предель-
ному соотношению
◄ Указание. См. табл. 1 в §3.2. ►
Упражнения
455
ш Убедиться в том, что в задаче (Яо в = 0а, Н\ 6 7^ 0о) для пуассоновской
модели П(0) л. н. м. несмещенный критерий для случая больших выборок имеет вид
а его мощность при локальных альтернативах вида в = 0п = 0О + 6/\/п удовлетворяет
предельному соотношению
f 5 \ ( 6
lim W(0„) = Ф( —т= - ta/2 )+$(-=- ta/2
1—>эо \ V^O J \V*0
◄ Указание. Использовать общий результат (18) § 5.3 и табл. 1 в §3.2. ►
ш Основываясь на результате, полученном в примере 3 §2.5 (соотношение (17)),
убедиться в том, что для проверки гипотезы о равенстве дисперсий двух нормальных
моделей можно использовать критерий
f . п(т— 1) S2(x)
Х1О = < г.У 7----TV 7JTT либ°
I - т(п-\) S2(y) 7
п(т-О $2(х)
т(п- 1) S2(y) '
ш Убедиться в том, что в условиях упр. 63 к гл. 3 критерий проверки гипотезы
однородности Но т = 02/0\ = 1 имеет вид
= 5 (я> У) - На/2,2п.2т либо
X
У
-^1- у , 2n, 2m
и вычислить его мощность при произвольной альтернативе т =£ 1.
ш Обращая построенный в упр. 64 к гл. 3 доверительный интервал, получить следу-
ющий критерий для гипотезы Яо в = во при альтернативе Я, 6 7^ 0О:
Xiq=|i Ж(1) 0й либо Ж(|) > 6о-------1па
Вычислить функцию мощности этого критерия и убедиться в его несмещенности.
Используя результат примера 1 §3.8, показать, что критерий проверки гипотезы
Яо О = 0и для равномерного распределения W(0, 0) имеет вид
Хю = {г Ж(„) 0аа1п либо х(п) > 0О};
вычислить его функцию мощности и убедиться в том, что он несмещенный.
ЕШ Обращая построенный в упр. 65 к гл. 3 доверительный интервал, получить, что
критерий для проверки гипотезы Яо 0 = 0а в модели Вейбулла 1Г(0, А,0|/л) имеет
вид
Х|О = {т^ yXo„2„Ju{T^ Q|+a2 = Q.
Чтобы получить несмещенный критерий, величины Ха,.2п и Х^-а2.г» выбираются
так же, как в упр. 13.
ш Обращая построенные в упр. 66 к гл. 3 доверительные интервалы для параметров
двухпараметрической показательной модели W(0t, 1,02), построить критерии провер-
ки гипотез Яо 0| = 0,0 И Я0 02 = 020-
Построить КОП для гипотезы Я) 0 = 0О в биномиальной модели Bi(fc, 0)
и убедиться в том, что его асимптотический (для больших выборок) вариант совпадает
с локальным наиболее мощным критерием, построенным в упр. 14
456
Глава 5. Параметрические гипотезы
◄ Указание. Воспользоваться общей теорией КОП для полиномиального распределе-
ния (пример 5 § 5.4). ►
В1 Построить КОП для гипотезы Hq 0 = 0q в пуассоновской модели П(0) и убе-
диться в том, что в случае больших выборок он совпадает с локальным наиболее
мощным критерием, указанным в упр. 15.
◄ Указание. Воспользоваться тем, что при п —> оо предельные распределения при
гипотезе Но статистик -2 In А„ и Q„‘ = V„(.0o)/ni(0o) в (18) §5.4 совпадают. ►
и Пусть наблюдается реализация длины п простой однородной эргодической цепи
Маркова с множеством = {(tj)} пар разрешенных переходов i -> j и d° = |f02|.
Показать, что КОП для простой гипотезы Н°, фиксирующей матрицу переходных
вероятностей Р° = ||pjj||f где > 0 « (ij) G Eq, имеет асимптотически (при
п -4 оо) вид (сравни с критерием (7) § 5.5)
2 5Z ln v > Xl-a.d"-N
И Пусть гипотеза Я0 означает, что случайные величины
£i....независимы и одинаково распределены на множестве Е = {1,2,. , Я},
а при гипотезе Я, эти случайные величины связаны в простую однородную цепь Мар-
кова, в которой возможны любые переходы i -> j Показать, что при п -> оо КОП
для проверки гипотезы независимости Я0 внутри гипотезы Я, задается критической
областью
r N ч
I \ j j I
|2 2^ "б 1П > Xl-a.(W-l)! j
(сравни с критерием (14) §5.5).
Глава 6
(Специальная)
Линейная регрессия
и метод наименьших квадратов
Статистика, — это физика чисел.
П. Диаконис
Этой главой мы начинаем серию специальных глав, посвященных рас-
смотрению специфических задач, решаемых математической статистикой, ко-
торые объединяются тем или иным общим признаком (связанным чаще всего
с областью их практических приложений), и выделяемых в отдельные разделы
(теории). Настоящая глава посвящена регрессионному анализу (см. пример 3
общего Введения) — чрезвычайно важному прикладному разделу современной
математической статистики. В ней рассматривается практически важный слу-
чай неодинаково распределенных наблюдений с одинаковыми дисперсиями,
когда их средние имеют вид линейных функций от неизвестных параметров
(так называемая схема линейной регрессии). Излагаются классический метод
наименьших квадратов (метод Гаусса—Маркова) для оценивания параметров
модели и его оптимальные свойства, рассматриваются вопросы его практи-
ческого применения. В рамках нормальной модели дается полное решение
задач доверительного оценивания произвольных линейных функций пара-
метров регрессии и проверки линейных гипотез для них. Дается применение
модели нормальной регрессии к задачам дисперсионного анализа. Излагаются
элементы теории статистической регрессии и корреляции.
§6.1. Модель линейной регрессии
До сих пор рассматривались ситуации, когда исходные статистические дан-
ные (выборка) X = (Х\,..., Х„) представляли собой результаты повторных
независимых наблюдений над некоторой случайной величиной £ (исключени-
ем является §5.5, в котором наблюдения предполагались связанными в цепь
Маркова), в такой случайной выборке компоненты X, независимы и одинако-
во распределены: Fxt = F^, i = 1,..., п. Однако в реальных ситуациях такие
предположения выполняются далеко не всегда. Например, имеется обшир-
ный круг прикладных задач, в математической модели которых естественно
предположение, что средние значения наблюдений Xi представляют собой
линейные функции от неизвестных параметров Д = (Дь...,Д*), а вторые
458 Глава 6. Линейная регрессия и метод наименьших квадратов
моменты удовлетворяют тем или иным дополнительным условиям. В таких
случаях говорят о модели линейной регрессии.
Более конкретно, здесь речь идет об изучении таких случайных экспе-
риментов, когда на их исход влияют некоторые неслучайные переменные
(факторы) Z|, , z*.-, значения которых могут меняться от опыта к опыту.
Например, z,, ,Zk могут быть входными характеристиками прибора, при
задании которых наблюдается соответствующий «отклик» как исход экспери-
мента. В других случаях значения факторов для каждого опыта могут быть обу-
словлены не зависящими от исследователя причинами (как правило, это имеет
место, например, в экономических исследованиях). Но в любом случае стати-
стические данные состоят при этом из множества наблюдавшихся значений
«откликов» Х), , Хп и соответствующих значений факторов, т. е. имеют вид
(ii; z['\ .... z[’\ i = 1, , n; при этом всегда предполагается, что k < п.
Часто можно считать, что факторы Zi, , оказывают влияние только
на среднее значение «отклика», при этом математическое ожидание исхода
г-го опыта имеет вид
ЕЛ, = 52 0jzj} = = (z!° ’ zk}^
j=l
т.е. является линейной функцией неизвестных параметров /3 = (/3|, ,/3^)
(напомним, что при матричных операциях векторы понимаются как вектор-
столбцы). Другими словами, случайную величину X;, описывающую резуль-
тат г-го опыта, можно представить в виде
X, = z^ р + £,, i = 1, , п, (1)
где г, — случайная «ошибка», распределение которой не зависит от парамет-
ров /3 и Ее, = 0. Если ввести (Ахп)-матрицу Z = ||z^ z^11, составленную
из векторов-столбцов z^ (она называется матрицей плана), и вектор «оши-
Матрица плана бок>> £ = <£1' то в матричных обозначениях
предыдущие равенства принимают вид
XL=Z'fi + €, Ее = 0. (1')
Далее, обычно предполагают, что «ошибки» , сп (или, что то же самое,
случайные наблюдения Ль ,Хп) некоррелированы и имеют одинаковые
дисперсии DX; = De, = <т2 > 0, i = 1, , п, где <т2 обычно неизвестно.
В этом случае матрица вторых моментов вектора наблюдений X имеет сле-
дующий вид:
D(X) = D(f) = Е(е е') = а21п, (2)
где In — единичная матрица порядка п. Соотношениями (1)-(2) и опреде-
ляется модель линейной регрессии. Параметры (3\, ,(3^ называются коэффи-
циентами регрессии, а <т2 — остаточной дисперсией.
§ 6.2. Оценивание параметров модели линейной регрессии
459
В описанной схеме переменные Z\, ,zk могут быть функционально
зависимы. Так, все z, могут быть функциями одного переменного t, например,
Zi = ai(t), где a,(t) — полином степени i > 1, — в этом случае говорят
о параболической регрессии.
В более общем случае возможны корреляции между наблюдениями Xi,
тогда вместо условия (2) вводится условие D(e) = cr2G. Если матрица G из-
вестна и невырождена, то, положив, Y = G~{^X, получим, что так преобра-
зованные данные удовлетворяют модели (1)-(2) (напомним, что при линейном
преобразовании У = LX первые и вторые моменты случайного вектора пре-
образуются следующим образом: Е(У) = ZE(X), D(K) = LT>(X_)lJ'). Таким
образом, самостоятельного изучения заслуживает только стандартная модель
(1)-(2).
В излагаемой далее теории определяющую роль играет (fc х fc)-матрица
А = ZZ' (3)
Эта матрица всегда неотрицательно определена и положительно определена
тогда и только тогда, когда rank Z = к, т. е. когда ее строки линейно незави-
симы. Действительно, квадратичная форма t!At = £ZZ't = (Z't)'(Z't) О,
V£ = (£h ,tA.), причем равенство нулю возможно только при Z't = 0.
В свою очередь, это равенство эквивалентно равенству t+ + tkZ). = 0,
гДе Д ।, , zk — столбцы матрицы Z' Таким образом, равенство нулю t(4t при
некотором t 0 имеет место только в случае линейной зависимости векторов
zh..., zk, т. е. при rank Z < fc. В дальнейшем мы будем всегда предполагать,
что матрица А не вырождена (или, что эквивалентно, rank Z = fc). Случай
вырожденной матрицы А более сложен для анализа и соответствующие ре-
зультаты можно найти в [21, гл. 4]; полное изложение теории регрессионного
анализа с ее многочисленными теоретическими и практическими нюансами
имеется в [22].
§ 6.2. Оценивание параметров модели линейной регрессии
Рассмотрим прежде всего задачу точечного оценивания параметров , 0к
и <т2 модели (1)-(2) §6.1.
1. Метод наименьших квадратов
Общим методом оценивания неизвестных коэффициентов регрессии /3,,...,
0к является разработанный К. Гауссом (1809) и А. Марковым (1900) (о нем
см. в п. 5 § 1.1) метод наименьших квадратов, в соответствии с которым оцен-
ки этих параметров находят из условия обращения в минимум квадратичной
формы
$(£) = S(Xj, 0) = (Х- Z'fi)'(X - Z'fi) = eje, (1)
представляющей собой сумму квадратов «ошибок» в (1) §6.1. Точку b =
= (Ь1,..., Ък), удовлетворяющую равенству 5(b) = min 5(/3), называют оцен-
460
Глава б. Линейная регрессия и метод наименьших квадратов
кой наименьших квадратов (о. н. к.) параметра 0 = (0\, , /Зц)
и обозначают Ь = 0.
Теорема 1. Если матрица А в (3) § 6.1 не вырождена, то о. н. к. Ь существует
и определяется равенством
0 = b = A~'ZX. (2)
Доказательство. Пусть 0 = Ь + S, тогда
S(0) = (Х.~ z'b - Z'6)\X - Z'b - Z'S) = (X - Z'b)'(X - Z'b) +
поскольку
(X - Z'b)'Z'S + £Z(X - Z'b) = 2X^Z'S - 2b'AS = 0.
Таким образом,
S(0) = S(b) + £ AS S(b) (3)
и равенство достигается лишь при (5 = 0. Следовательно, b — единственная
точка минимума квадратичной формы (1).
Замечание. Практически о. н. к. /3 = arg min 5(/3) находят, решая систему уравнений
dSlfi)
—2=2 = 0, у=1, ,fc,
5/3;
которые называются нормальными уравнениями метода наи-
меньших квадратов.
В ряде случаев интерес представляют не сами параметры /3),. ,/Зц., а их
некоторые линейные комбинации, т. е. новый параметрический вектор t =
= (fi, , fm), т С к, связанный с 0 соотношением t = Т0, где Т — задан-
ная (т х к)-матрица. В этом случае о. н. к. t для t определяется равенством
f = Т0, где 0 определено в (2); представление t через исходные данные,
следовательно, имеет вид
Г=ТЛ-1ХХ. (4)
2. Оптимальность оценок наименьших квадратов
Исследуем свойства полученных в п. 1 оценок. В общем случае будем рас-
сматривать задачу оценивания вектора f = Т0 в классе линейных оценок,
т.е. оценок вида I = LX_, являющихся линейными функциями от наблюде-
ний X = (Хь..." Хп).
§ 6.2. Оценивание параметров модели линейной регрессии
461
Теорема 2. Пусть матрица А не вырождена. Тогда для произвольного век-
тора t = о. н. к. t, определенная равенством (4), является несмещенной
оценкой с минимальной дисперсией в классе всех линейных несмещенных
оценок t; при этом
D(?) = а2ТА~]Т' = a2D. (5)
Доказательство. Из (4), (3) и (1') §6.1 имеем
E(f) = TA~'ZE(X) = TA~'ZZ'fi' =T$ = t_,
т. е. t — линейная несмещенная оценка t. Пусть I = LX_ — произвольная
линейная несмещенная оценка t, т. е.
Е(/) = LE(X) = LZ'p = Т0.
Это равенство должно, по определению несмещенности, выполняться для
любого /3, поэтому отсюда следует, что
LZ1 = Т (6)
Из (2) §6.1 находим
D(/) = LD(X)L' = a2LL' (7)
Наша цель — минимизировать дисперсии оценок ,Zm, т.е. диагональные
элементы матрицы LL1. Для этого запишем тождество, следующее из (6):
LL' = (TA~'Z)(TA~'Z)' + (L - TA~'Z)(L - TA~lZ)'
Здесь в правой части каждое слагаемое имеет вид НН', откуда следует не-
отрицательность диагональных элементов. Но от L зависит только второе
слагаемое, поэтому диагональные элементы матрицы D(Z) в (7) одновременно
достигают минимума тогда и только тогда, когда L — ТА~ Z. Соответствую-
щая оптимальная оценка имеет вид Г = TA~xZX_ = t, т. е. совпадаете о. н. к.
(4). Наконец, формула (5) следует из (7), если подставить вместо L найденное
оптимальное решение.
В качестве простого следствия теоремы 2 получаем, что DQ3) — а2 А~\
или
cov(/3,, fij) = cr2av, — где ||a,J|| = Л-1 = ||а1;|Г' (8)
Замечание. Если матрица Т имеет вид Т = АЛ, то формулы (4) и (5) принимают
соответственно вид
t = AZX, D(?) = а2АЛА',
т.е. необходимость в вычислении обратной матрицы Л"1 для нахождения о. н. к. и их
вторых моментов отпадает.
Итак, теорема 2 позволяет решить задачу построения оптимальных линей-
ных (по наблюдениям Х_) оценок для произвольных линейных комбинаций
коэффициентов регрессии — это оценки наименьших квадратов.
462 Глава 6. Линейная регрессия и метод наименьших квадратов
3. Оценивание остаточной дисперсии
Из (1) и (2) §6.1 имеем
ES(£) = Ег- = па1
1=1
Далее, учитывая (8) и определение следа (tr) матрицы (см. п. 2 §2.5), найдем
к
- 0)'А(£ -Р)=^2 ~ ~ =
к
а2 = er2 tr (ЛЛ'1) = er2 tr = ксг2
i.j=i
Отсюда и из представления (см. (3))
S(p) = S(V)UP-C)'Atf-p) (9)
следует, что
ES(0) = (п - к)<т2,
т.е. несмещенной оценкой для остаточной дисперсии <т2 является статистика
, 1 (X - Z^ytX - Z'P)
? = = -~ <10)
п — к — п — к
Вектор U_ = X - Zz/3 называют остаточным вектором, а его компоненты
«i, i = 1,... ,п, — остатками. Таким образом, полученный результат (10)
можно сформулировать так: оценка а2 равна сумме квадратов остатков, поде-
ленной на п — к (разность между числом наблюдений и числом коэффициентов
регрессии Д).
Приведем также другое выражение для о , которое понадобится нам в
дальнейшем. Используя представление (2), запишем остаточный вектор в виде
I/= (1п - Z'A~‘Z)X = ВХ = B(Z'0 + e) = Вс. (II)
Непосредственно проверяется, что матрица В в (11) симметрична и идем-
потентна (В2 = В); следовательно, вместо (10) можно использовать представ-
ление
а2 = —'—Х^ВХ = —^—е'Ве, (12)
п — к п — к
________________________________________7
показывающее явную зависимость оценки о от наблюдений.
Наконец, из (11) непосредственно вытекают следующие свойства остаточ-
ного вектора U (их проверку мы оставляем читателю в качестве упражнения):
E(W) = 0, D(ZZ) = о2В = D(X) - D(Z'£), E/3W' = 0 (13)
§ 6.2. Оценивание параметров модели линейной регрессии
463
(в последнем соотношении 0 обозначает нулевую (к х п)-матрицу, т.е. со-
стоящую сплошь из нулей, следовательно, о. н.к. /3 и остаточный вектор U
некоррелированы: cov(/3,, Uj) = 0, i = I,..., к, j = 1,..., n).
4. Условные о. н. к.
Выше мы рассмотрели случай, когда вектор /3 = (/Зь ,/3J априори мог
быть произвольной точкой евклидова пространства R* (на его значения не на-
кладывалось никаких ограничений). Однако в ряде практических задач допу-
стимые значения /3 бывают ограничены теми или иными условиями. Типичная
модель с ограничениями на /3 имеет вид
(14)
где Т — некоторая заданная (тп х Л)-матрица (тп к) и t0 = (<]0, , tm0) —
заданный вектор такой, что система (14) совместна. Другими словами, усло-
вие (14) означает, что допустимые значения коэффициентов регрессии /3,,
/Зк удовлетворяют тп заданным линейным ограничениям
t'j0 = tjO, j = 1, , m, (14')
где i', — строки матрицы Т. Естественно предполагать, что ограни-
чения (14') линейно независимы (иначе можно перейти к меньшему числу
уравнений, исключив линейно зависимые). Таким образом, в дальнейшем
будем считать, что гапкТ = тп (случай тп = к, однозначно фиксирующий
вектор /3, в последующих рассуждениях формально допускается).
Рассмотрим задачу оценивания параметров /3 в этой усложненной ситу-
ации. Обозначим
ST= min S(/3) (15)
P:Tp=tM -
и назовем условной оценкой наименьших квадратов (у. о. н. к.) Условная
Рт то значение /3 (удовлетворяющее условию (14)), при о.н.к.
котором этот условный минимум достигается: St = S(PT).
Теорема 3. Пусть |4| 0 и гапкТ = тп. Тогда
Дт=Д-Д-,Г'Л-1(ТД-<0), (16)
где /3 — обычная о. н. к. (2) и матрица D определена в (5).
Доказательство. Из (16) непосредственно видно, что Т/3Т = t0, т.е. вектор
удовлетворяет условию (14). Запишем теперь разложение (см. (1))
5(Д) = [X - + Z'(fiT - £)]' [X - Z'0T + Z'(0T - £)] =
464 Глава 6. Линейная регрессия и метод наименьших квадратов
= S(J3T) 4- 2фТ - 0)'(ZX - А?т) + фт - Р)'А(0Т - 0).
Так как (см. (2)) А/3 — ZX_, то из (16) имеем
ZX - A0r = T,D~l(T0-to).
Учитывая также, что Т(0Г - /3) = ta-T0, получаем окончательное представ-
ление для S(J3), справедливое для всех /3:
S(P) = S(lT) + 2(to - T0)'D~l(T/3_-to) + - $A(lT - 0). (17)
Пусть теперь 0 удовлетворяет условию (14). Тогда средний член в (17) обра-
щается в 0, и мы получаем, что для таких 0
S(0) = S(£T) + (Дт - 0)'А(0Т -0)> S(lT)
(сравни с (3)), причем равенство достигается только при 0 = 0Т.
Замечание. Полагая в (9) 0 = /Зт и учитывая, что, в силу (16),
(0-0т)'A(0-0J.) = (T0-tii)'D~iTA~l AA~lT'D~l(T0-to) = (T0-to)'D~'(T0-to),
получаем следующее представление условного минимума ST = S(0T) через абсо-
лютный минимум S(0):
ST = S@ + QT, Qr = (T0-t^'D-\T0-to). (18)
5. Оптимальный выбор матрицы плана
Рассмотрим «активный» эксперимент, когда значения факторов Z\, , z* для
каждого опыта выбираются исследователем. Покажем, как в этом случае оп-
тимально задать матрицу плана Z = ||z^ z^H, где г-й столбец z^ есть
комбинация значений факторов для г-го опыта (г — 1,... ,п). В качестве кри-
терия оптимальности естественно использовать величину дисперсий оценок
0i, т.е. величины а" в (8); тогда задача сводится к выбору такой матрицы Z,
чтобы диагональные элементы матрицы Л-1 = (ZZ')~[ были минимальны.
Если значения факторов выбирать произвольными, то все элементы мат-
рицы Л-1 можно сделать одновременно как угодно малыми, так как если Z
заменить на aZ, то Л-1 заменится на Л-1 /а2 -> 0 при а -> оо. Чтобы ис-
ключить этот случай, предположим, что значения факторов можно менять
в ограниченных областях, именно: наложим ограничения вида
п
= S^f’)2 = “)> 3=\,-Л, (19)
t=i
где Zj = (zp,..., zjn)) — набор значений п уровней фактора Zj, j — ,k
(строки матрицы Z), а а],... ,al — заданные положительные константы.
§ 6.2. Оценивание параметров модели линейной регрессии
465
Теорема 4. При ограничениях (19) имеют место неравенства
— <т2
%
и минимум достигается тогда и только тогда, когда векторы z,, , zk орто-
гональны, т. е. z'z;- = 0 при i j.
Доказательство. Пусть j = 1. Запишем матрицу А = ZZ' в виде
Ъ?
F
Ъ
где b = (zjZj, ... Тогда, на основании формулы обращения матриц,
а11 = Далее, умножая определитель |Л| справа на определитель,
равный 1, получаем следующую формулу:
|Л| =
V 1
F -F~'b
О
Ъ-!
z^-tfF-'b
О
6'
F
= |f|Ui^-6'f-16).
ъ
Отсюда, учитывая соотношения (19) и (8), имеем
пл л-2 11 21-^*1
Dpi = <т а = а ——
а2 - tfF-'b aj’
так как t»F~lb 0. Знак равенства имеет место только при 6 = 0 (поскольку
подматрица F положительно определенной матрицы А также положительно
определена), т.е. при z'z( = 0, i = 2, ,k. Доказательство для других j
можно получить простой перенумерацией факторов.
В заключение отметим, что для оптимальной матрицы плана Z матрица
А = ZZ1 является диагональной с элементами ац = aj = z^jZj, j = 1, .., k,
поэтому в этом случае нет проблемы ее обращения: о. н. к. и их вторые мо-
менты имеют вид
~ z'-X а2
^ = 4-, Dft=—, cov(ft,^) = 0, г/j- 20
fy-i
б. Примеры применения метода наименьших квадратов
Пример 1 (Простая регрессия, оценивание параметров). Проиллюстрируем
общую теорию на примере важного для практических приложений случая
простой регрессии, когда число параметров к = 2, т.е. 0 = (/3|, /?з), а векторы
zj'j имеют вид = (1, <,), i = 1,..., п. Тогда
ЕХ< =0i +02ti, г=1........п, (21)
т.е. среднее значение наблюдений является линейной функцией одного фак-
тора t Так, t может быть температурой, при которой производится экспери-
мент, дозой лечебного препарата, возрастом обследуемых лиц и т.д., и речь
30 Заказ 1748
466
Глава 6. Линейная регрессия и метод наименьших квадратов
идет об изучении связи между откликом (исходом эксперимента) и фактором t
на основании результатов регистрации п пар измерений (Xi, t,), г = 1, , n,
где Х, наблюдается при значении Z, фактора t. Прямую <p(t) = + fl2t,
соответствующую (21), называют линией регрессии, а коэффициент — ее
наклоном.
В данном случае матрицы Z, А и столбец Y = ZX_ равны:
<1
Будем предполагать, что не все ti одинаковы (тогда rank Z = 2), тогда
2 п
Hi = п е - (е = п Е& - > о,
1=1
где, как обычно, черта сверху означает арифметическое среднее, и
л"‘ “ и
—nt
-nt
п
_ п_ ^Е^Л Ш
“ И у ^tiXi-ntx J \&/
В результате несложных преобразований запишем оценки /3, и 02 в более
удобном для вычислений виде (проверить!)
~ V(ti-i)(T,-Т) ~ ~
Pi = -----2---, & = X - t?2. (22)
Е^ -*)
Вторые моменты этих оценок образуют матрицу <т2Л-1 (см. (8)), поэтому
Е 2 <Г2
W'~n^(ti-if ^2~^(ti-if
cov(^I(ft) = —— <т2
E^ -
Наконец, в силу (22),
s(p) = Е(*< - /01 - = E [(*< - - *)]2 =
= E(^ - x? - E^- - ъ2 (23>
§ 6.2. Оценивание параметров модели линейной регрессии 467
и несмещенная оценка для остаточной дисперсии а2 вычисляется по формуле
Пример 2 (Параболическая регрессия). Пусть j-vt фактор Zj является поли-
номом aj(i) степени j — 1 от общей переменной i; тогда
Z-j = (°_> (^ 1)» , aj(^n))> J' = 1> • > к,
— набор его значений для п уровней, а
z(l) = i = l,...,n,
— комбинация значений факторов z\, ... , zk для г-го опыта. Таким образом,
матрица плана Z = определяется выбором п точек t], ,tn
значений общего фактора t для п опытов. В этом случае среднее значение г-го
наблюдения X, имеет вид
к
EXi = <р(Ь;А) = ^2fljaj(ti), i=\,...,n. (24)
j = l
Определенная здесь функция <p(t; 0) представляет собой полином (параболу)
степени к - 1 и называется кривой параболической регрессии.
Опишем типичную ситуацию, когда имеет место схема параболической ре-
грессии. Предположим, что имеется теоретическая зависимость вида х = <p(t;fl)
между переменными t и х, причем значения tux получают из наблюдений.
Задача состоит в определении по экспериментальным данным неизвестных
параметров fl\, ,flk, входящих в это уравнение. Каждое измерение х при
заданном t дает уравнение, связывающее неизвестные параметры, и если бы
измерения величины х производились без погрешностей, то для определе-
ния параметров /31, , flk было бы достаточно к измерений. Однако точные
измерения на практике чаще всего невозможны, поэтому для заданных значе-
ний t соответствующие значения х известны с какими-то погрешностями, т. е.
реально вместо точного значения Xi = <p(ti; fl) мы имеем случайный результат
Xi = <p{ti,fl) +fi, где €i — ошибка измерения. Если условия эксперимента
обеспечивают отсутствие систематической ошибки (Ef; = 0), равноточность
(De, = a2 i = 1, , п) и некоррелированность (cov(f,, Cj) = 0, г / j)
результатов измерений, то приходим к схеме регрессии вида (24).
Чтобы исключить влияние погрешностей измерений, нужна дополни-
тельная информация. Для этого проводят большое число измерений п > к
и полученные экспериментальные данные обрабатывают по методу наимень-
ших квадратов. В результате находят не точные значения коэффициентов
fl\,..., flk, а определяют их о. н. к. fl\,..., flk. В данном случае этому методу
можно дать следующую геометрическую интерпретацию (см. рис. 1).
Нанесем на плоскости (t, х) наблюдавшиеся точки (f,, Xj), i = 1, ,п.
Тогда значения fl* неизвестных коэффициентов fl подбирают так, чтобы со-
зо*
468 Глава б. Линейная регрессия и метод наименьших квадратов
ответствующий эмпирический график х = <p(t; fl*) «наилучшим образом» про-
ходил около наблюдавшихся точек. Если в качестве критерия оптимальности
взять величину
»
»=1
— сумму квадратов отклонений эмпирического графика в точках t\, ,tn
от наблюдавшихся значений , Хп, то приходим к методу наименьших
квадратов с решением fl* = fl.
Формально такой же вид имеет и классическая задача математического
анализа приближений функций.многочленами. В этом случае данные (^, Xfl,
i = 1,.. , п, интерпретируют как пары соответствующих абсцисс и ординат
графика изучаемой функции и задача состоит в подборе интерполяционного
многочлена вида <p(t;fl), который давал бы наилучшее приближение в среднем,
п
т. е. минимизировал бы величину £))2 •
i=i
Пример 3 (Численная иллюстрация [11]). Приведем пример вычисления
оценок параметров fl. Пусть требуется определить неизвестные коэффици-
енты (fl\,fli,flfl функциональной зависимости
®(0 = fl\+ tfli + t^fly.
Будем предполагать, что в точках = 2 + Зг/n, г = 1, ,п, измерены
значения функции x(t). Ошибки измерений г,, г = 1,..., п, будем считать
независимыми и нормально распределенными с Ее, = 0, De< = <т2 В этом
случае имеем линейную модель
Xi = x(tfl +fj = fli +tifli +tifli +£i, i = 1, ,n.
Пусть fl\ = 3, fl2 = -1, fly = 1, a1 = 0,04. Смоделируем г, для n = 25
и n = 100, используя алгоритмы п. 8 и 6 § 1.3, и найдем соответствующие Xt.
§ 6.2. Оценивание параметров модели линейной регрессии
469
Рис. 3. (п= 100)
470
Глава б. Линейная регрессия и метод наименьших квадратов
Решая систему нормальных уравнений
£№ - ^1 - ^2 - ^з)2 = 0, >=1,2,3,
i=l
найдем оценки Pi, р3, р3, а также а2:
1) для 71 = 25: Д, = 2,983; /32 = -0,828; Зз = 0,895; а = 0,034;
2) для 71 = 100: Pi = 2,992; Д2 = -1,007; р3 = 1,001; <т2 = 0,046.
На рис. 2 и 3 приведены соответствующие графики x(t) и x(t) = Pi +
+ tp3 + t3p3, знаком ® отмечены результаты измерений (f,, Xi). •
7. Ортогональные многочлены Чебышева
В описанной в примере 2 схеме предполагалось, что многочлены aj(t) заданы.
В частном случае aj(t) = t3~[ и тогда
k
^,Р) = ^Р^-'
J=1
(это имеет место в примере 1). В других случаях (например, в задачах интер-
поляции) многочлены оД<) можно выбрать достаточно произвольно, и тогда
критерием их выбора является простота соответствующих вычислений. Как
отмечалось в п. 5, наиболее просто решается задача вычисления о. н. к. Р при
диагональной матрице А = ZZ': в этом случае (см. (20))
5 у aj(ti)Xi
0j = ~n---------> 7 = 1, ,* (25)
Ёа>(м
1=1
Условием диагональности матрицы А является ортогональность векторов
—j — • > aj(.^n))'
ZjZr = 52 aj(ti)ar(ti) = 0, j £ r (26)
Многочлены, удовлетворяющие условию (26) называют ортогональными мно-
гочленами Чебышева.
Покажем, что при заданных ti,...,tn такие многочлены всегда можно
построить. Без потери общности можно предполагать старший коэффициент
a.j(t) равным 1, таким образом, ai(t) = 1, a2(i) = t + c, ... . Из условия (26)
§ 6.2. Оценивание параметров модели линейной регрессии
471
при j = 1, т = 2 имеем
° = 52а2^')= 52 +пс<
i=i i=i
т. е. с = -I. Тем самым, второй многочлен Чебышева есть = t — t.
Выведем теперь общую рекуррентную формулу, позволяющую вычислять
следующий многочлен по двум предыдущим, — этим и будет доказано су-
ществованием всех многочленов системы Чебышева. Предположим, что для
некоторого т 2 многочлены ... ,ar(t) уже построены. Рассмотрим
произвольный многочлен степени, меньшей т Его можно однозначно
представить в виде
т
^(0 =
5 = 1
Действительно, из условия ортогональности (26) при j = 1, , т имеем
п п
52 №)<Ъ(*«) = 7; 52 а3^«)>
i=i i=i
т. е. эти равенства однозначно определяют коэффициенты 7,.ут. Отсюда,
в частности, следует, что если ^>(i) — многочлен степени, меньшей т - 1, то
п
52^(Mflr(ti) = 0. (27)
i=I
Рассмотрим теперь многочлен степени т следующего вида
a(i) = (t + 7)ат («) + Даг_, (<). (28)
Если j < т — 1, то в силу (27)
52<ь(<«)а(м = +7)а;(<1)ат(м+д52аИ<,)а’-|(^)=0
i=i 1=1 1=1
(так как степень многочлена (t + 7)aj(t) равна) <т - 1),т.е. при любых по-
стоянных /3 и 7 многочлен (28) ортогонален многочленам ai(t),..., ar_2(t).
Выберем эти постоянные так, чтобы он был ортогонален также aT_|(t) и aT(t).
Для этого должны выполняться следующие условия:
52 ar-i(ii)a(ii) = 52 + Z3 52 ат-|(М = °>
1=1 t=l 1=1
п п п
52 aT(ti)a(ti) = tiofai) + 7 52 = °-
1=1 i=i i=i
472
Глава 6. Линейная регрессия и метод наименьших квадратов
Отсюда находим /3 и 7:
7=-g— (и>
где
п
= 52 aj(M> 3 = 1> 2,...
1=1
При таком выборе постоянных (3 и 7 многочлен (28) ортогонален всем много-
членам ai(i),..., a.T(t), следовательно, он является следующим многочленом
ar+i(f) системы Чебышева. Тем самым, получен алгоритм построения систе-
мы ортогональных многочленов Чебышева. В дополнение к указанным ранее
двум первым многочленам a\(t) и ai(t) приведем явный вид третьего много-
члена a3(i), который следует из (28) и (29):
/ ] n \ 1 п
Oj(o = (t -1) (t - -2 52 «.(t, -iy - - 52 t,(t, - 0 =
V “2 i=l 7 П . = 1
/ 1 " \ a2
= (i-oh-t--52(f,-o3 (3°)
V a2 tr 7 71
Итак, если в схеме параболической регрессии (24) многочлены a;(t) яв-
ляются ортогональными многочленами Чебышева, то о. н. к. вычисляются
по формулам (25), а соответствующее значение S([3) = min S((3) таково:
~ р -
i=i 4 j=i 7
= E *2 -2 E Л Ё aMx<+E=
i=l j=l i=l j = l
= E*>-Ea^- (31)
i=i j=i
Отметим следующее важное обстоятельство. К.ак видно из формулы (25),
о. н. к. 0j определяется только многочленом a;(t) и не зависит от параметра fc
схемы (24). Кто позволяет упростить задачу построения интерполяционного
многочлена более высокой степени, если требуется повысить точность интер-
поляции. Так, предположим, что для заданного fc построен интерполяцион-
ный многочлен
у?(«;Дь ..,&) = 52Д;аД<),
J=i
§ 6.2. Оценивание параметров модели линейной регрессии 473
однако значение 8(0],.... 0к) в (31) еще велико, т.е. точность приближения
исследуемой функции многочленом степени к - 1 недостаточна. Тогда строят
интерполяционный многочлен степени к вида
fc+i
4>(t;0i,... ,0к,0к+1) = ^0jaj(t),
j=i
те. добавляя следующий, (fc + 1)-й многочлен Чебышева <ц.+1(4) с коэффи-
циентом 0k+i, вычисляемым по формуле (25) (при этом предыдущие коэф-
фициенты 01,. ,0к остаются прежними). Далее вычисляют
Ж,...,Л+|)=5(А, ,0к) - al+l0l+i, (32)
и если точность приближения, достигнутая с помощью многочлена к-й сте-
пени недостаточна, то можно подбирать далее многочлен (Л + 1)-й степени
и т.д., пока не достигнем желаемой точности.
Пример 4 (Численная иллюстрация [11]). В «Основах химии» Д. И. Менде-
леев приводит следующие данные о количестве (х) азотно-натриевой соли
NaNO3, которое можно растворить в 100 г воды в зависимости от темпера-
туры (t):
ti 0 4 10 15 21 29 36 51 68
X, 66,7 71,0 76,3 80,6 85,7 92,9 99,4 113,6 125,1
Построим по этим данным приближенную эмпирическую формулу вида
х = 0i + 02t, описывающую зависимость между рассматриваемыми величи-
нами. Здесь речь идет о линейной зависимости, поэтому это схема простой
регрессии, рассмотренная в примере 1. Используя формулы (22), получаем
0\ = 67,5, 02 = 0,87 Таким образом, линейная приближенная формула имеет
вид
х = 67,5 + 0,874. (33)
При этом сумма квадратов отклонений, вычисленная по формуле (23),
равна 11,1.
Установим, как повышается точность приближения, если в качестве ин-
терполяционного многочлена использовать квадратичную параболу. Запишем
искомый многочлен в каноническом виде:
<p(t;0) = 0iat(t) + 02a2(t) + /З3о3(0,
где aj(t) — многочлены Чебышева (напомним, что aji) = 1, a2(t) =t — t =
= 4-26, a a3(4), указан в (30)). Результат (33) можно записать в каноническом
9 Менделеев Дмитрий Иванович (1834-1907) — выдающийся русский химик, разносторонний
ученый, педагог; открыл периодический закон химических элементов (1869) — один из основных
законов естествознания.
474 Глава б. Линейная регрессия и метод наименьших квадратов
виде так:
х = 90,12ai(<) + 0,87a2(<),
и достаточно вычислить по формуле (25) В данном случае
aj(t) = (t - 26)(t - 40) - 451,1,
поэтому значения аз(^) таковы: 588,9; 340,9; 28,9; -176,1; -356,1; -484,1;
-484; -491,1; -176,1; 724,9. Отсюда
а23 = ^2 °з(М ~ 1.6 106 ^2 аз(^)х> ~ ~2-2 1°’
и по формуле (25) /З3 ~ -1,4 10-3- поправка в (32) а]$ « 3,0. Таким
образом, учитывая многочлен a.3(t), мы незначительно увеличиваем точность
аппроксимации, и в качестве удовлетворительной эмпирической зависимости
можно принять формулу (33). •
Общее замечание. Метод наименьших квадратов применяют также в случаях, когда
зависимость ЕХ, от /3 не является линейной. Пусть
,Л) + е., 1=1, ,П,
где Ес, = 0, De, = ст2, cov(e,, Cj) = 0, i j. Тогда о. н. к. /3 параметров /3 миними-
зируют по /3 выражение
п
(?(£) = £(Х(-/(«,; Д......Л))2
1=1
и для их отыскания надо решить систему уравнений
§ 6.3. Нормальная регрессия
1. Модель нормальной регрессии
До сих пор делались предположения только о первых и вторых моментах
наблюдений (см. условия (1') и (2) § 6.1). Развитая при этих минимальных
предположениях теория наименьших квадратов позволяет получать только
точечные оценки для параметров Д[, ,/3t и их линейных комбинаций.
Чтобы получать более сильные утверждения (строить доверительные интер-
валы и проверять различные гипотезы) необходимо сделать дополнительные
предположения о виде распределения наблюдений X = (Л), , Хп) или,
что то же, вектора «ошибок» с = (еь ,еп) (см. (l)-(lz) § 6.1). Чаще всего
предполагается, что этот вектор имеет нормальное распределение, т. е. в до-
полнение к (1') и (2) § 6.1 полагается, что
£(£) = Ш^1п)- (1)
§ 6.3. Нормальная регрессия
475
В этом случае говорят о нормальной регрессии. Отметим, что условия (1')-(2)
§ 6.1 и (1) можно объединить и записать в виде
Г(Х)=ЛГ(^,ст21п). (2)
Общие свойства многомерного нормального распределения изложены в п. 2
§ 1.2. Подчеркнем, в частности, что условие (2) означает, что компоненты
вектора X независимы и имеют одинаковые дисперсии ст2, но их средние,
вообще говоря, различны.
2. Оценки максимального правдоподобия (о. м. п.)
параметров нормальной регрессии
Нормальная модель (2) определяется (к + 1)-мерным параметром
е = ,ftk,a2),
область возможных значений которого представляет собой евклидово полу-
пространство
0 = {0 —оо < ftj < оо, j = 1, , к, ст2 > 0}.
Если х = (i[, , хп) — наблюдавшаяся реализация вектора X, то функция
правдоподобия этих данных имеет вид (см. соотношение (9) § 1.2)
Цх;в) = (2ita2)~n?2 exp (3)
где квадратичная форма 5(х;/3) определена в (1) §6.2.
Найдем о. м. п. параметров 0, которые максимизируют функцию Цх, в).
Из (3) следует, что при любом ст2 > 0 максимизация Цх, в) по ft эквивалентна
минимизации по ft квадратичной формы 5(i; ft). Таким образом, для модели
нормальной регрессии о. н.к. ft совпадает с о.м. п. этих параметров.
Замечание. Из теоремы 2 §6.2 следует, что о.н.к. являются оптимальными в клас-
се линейных оценок. Для схемы нормальной регрессии справедливо более сильное
утверждение: о. н. к. являются оптимальными в классе всех (не только линейных) не-
смещенных оценок рассматриваемых параметрических функций.
Найдем теперь о. м. п. ст2 для остаточной дисперсии ст2 Подставив в (3)
вместо ft оценку ft и прологарифмировав, получим, что ст2 — это то значе-
ние ст2, которое минимизирует выражение
Stf) 1
---у- + п In ст
Отсюда имеем
(4)
71
476
Глава 6. Линейная регрессия и метод наименьших квадратов
Ранее было показано (см. п. 3 §6.2), что в общем случае несмещенная оценка
для а2 имеет вид S(J3)/(n - к), поэтому о. м. п. а2 оказывается смещенной
и ее смещение
т т /ti к__________n / 71 к \ у к j
Еа2 - а2 = EI -----а - а2 = (-----------1 а2 = —а2
\ 71 ) \ 71 ) 71
убывает по модулю с ростом числа наблюдений п. Таким образом, оценка (4)
является лишь асимптотически несмещенной (что вообще характерно для
о. м. п.).
3. Основная теорема теории нормальной регрессии
Все дальнейшие выводы теории нормальной регрессии базируются на следу-
ющей важной теореме.
Теорема 1. Случайные величины /3 и S(0) = 5’(Х;Д), а также Д(Д) и Q =
= Sift) - S(/3) независимы; при этом
Св(р) = Х(Д,а2Л-'), (S-^\ - Х\п - к), £Й(^\ = Х2(Л).
— — у а / \а j
(5)
Доказательство. Введем нормированный вектор «ошибок» г’ =е/о" =
= Л/"(0,1П) (см. (1)). Тогда (см. (1') §6.1)
X = Z'p + ае (6)
а равенство (2) § 6.2 примет вид
p_ = fi-VaA~'Zc* (7)
Из представления (12) §6.2 следует, что
S(J3) ./ .
= с* Вс* (8)
OL
Наконец, из тождества (3) §6.2 имеем следующее представление для Q:
Q = = (9)
Независимость /3 и S(0) следует теперь из представлений (7) и (8), легко
проверяемого факта A~lZB = A~lZ(ln - Z'A~lZ) = 0 и леммы 1 §2.5.
Далее, из представления (9) имеем, что Q зависит отданных Х_ лишь через
/3; следовательно, в силу независимости Д и Д(Д) случайные величины Q
и 5(Д) также независимы. Первая часть теоремы доказана.
§ б.З. Нормальная регрессия
477
Докажем теперь утверждения (5). Так как Д — линейная функция нор-
мального вектора (см. (7)), то Д — также нормальный вектор, а его первые
и вторые моменты вычислены в п. 2 § 6.2 и имеют указанный в (5) вид.
Закон распределения Q/o1 устанавливается на основании представления
(9), факта нормальности вектора Д и замечания к теореме 1 §2.5.
Наконец, закон распределения Sdfyoi1 следует из представления (8) и
теоремы 1 § 2.5, поскольку матрица В идемпотентна и
trB = tr 1п - tr(Z'j4-lZ) = п - tr(ZZlA~>) = п - tr И*; = п - к.
Следствие 1. Из первого соотношения в (5) следует, что для любого j = к
(10)
X '
и Pj не зависит от S(P). Поэтому из определения закона Стьюдента (л. 6^1.2)
и из теоремы 1 следует, что при любом в
£» (tn-k - " S(" fc)'
(11)
Следствие 2. Из определения закона Снедекора (п.1 § 1.2) и теоремы 1 имеем,
что при любом в
/ л — k \
= ]=S(k,n-k). (12)
\ * 5 (Д) /
4. Доверительное оценивание параметров нормальной регрессии
Построим доверительный интервал для коэффициента регрессии Pj. Из (10)
следует, что статистика Pj имеет распределение Д/'(Д7, ct2ojj), поэтому здесь
мы имеем задачу оценивания неизвестного среднего нормального закона с не-
известной же дисперсией (так как ст2 неизвестно) по наблюдению над случай-
ной величиной Pj. На основании (11) стьюдентово отношение t^_k является
центральной статистикой для Pj (см. п. 1 §3.8), поэто- Доверительные
му 7-доверительный интервал для Pj строится по схеме интервалы для
примера 1 §2.5 и имеет вид (сравни с (12) §2.5). коэффициентов
/ арз - \
Pj Т £(Ц--у)/2, п—к А/ _ , ^(/3) )• (13)
у it К J
регрессии
Чтобы построить доверительный интервал для остаточной дисперсии ст2,
воспользуемся вторым соотношением в (5), из которого следует, что 5(Д)/ст2
— соответствующая центральная статистика. Искомый 7 — доверительный
478 Глава 6. Линейная регрессия и метод наименьших квадратов
Доверительные
интервалы для
остаточной
дисперсии jg||
интервал строится здесь по схеме примера I § 2.5 и име-
ет вид (сравни с (10) §2.5)
S®
Х(1+7)/2,п-4
S(P)
(14)
Иногда требуется оценить весь параметрический вектор/3 = (/Зн ,/3fc),
т. е. построить доверительную область н евклидовом пространстве R*
накрывающую точку /3 с заданной вероятностью 7. Такую область мож-
но построить, основываясь на результате (12). Действительно, если Frkn_k
есть 7-квантиль распределения S(k, п - fc), то из (9) и (12) следует, что при
любом &
7 = P,{F*.n_t < F11M} = Рв{р е $Т(Х)}, (15)
где
$у(Х) = { Р (0-0)'А(0-р) < ---------S(P)F7,k.n-k }
I 71 л j
Тем самым построена искомая 7-доверительная область для /3: это внутрен-
ность эллипсоида с центром в точке /3, граница которого задается уравнением
(/3-Д)'Д(/3 -Д) = а27(Х) = —^—S(P)F7tk„-k. (16)
— — — — 71 — К ~
Пример 1 (Простая регрессия, доверительное оценивание параметров).
Построим 7-доверительный интервал для наклона /32 простой регрессии
(см. пример 1 §6.2). Из (10) и (22)—(23) §6.2 следует, что это интервал
/
@2 Т <(1+7)/2, п-2
п
(п-2)^(<,-<)2
»=‘ /
Аналогично, из (15)—(16) и формул примера 1 §6.2 имеем, что внутренность
эллипса
1 п 2
(/3, -д1)2 + 2<(/з1-^|)(/з2-Д2) + (д2-Д2)2- = Д7-----^5(Ж.2.п-2
71 71(71 — 2) —
в плоскости переменных (/3j, /32) с вероятностью 7 содержит неизвестную
точку /3. •
§6.3. Нормальная регрессия
479
5. Доверительная область для линейных комбинаций параметров /3
Пусть требуется оценить одновременно тп С к линейных комбинаций t =
= Ui, ,tm)' t = Т/З, где Т — заданная (тп х А)-матрица и rankT = тп.
Тогда из теоремы 1 следует, что о. н. к. t = Tfi имеет распределение Af(t, o2D),
где матрица D определена в (5) §6.2. Отсюда по теореме 1 § 2.5 (см. замечание
к ней) следует, что квадратична форма
<?т = (?-0'р-‘(?-О (17)
имеет следующее распределение:
= х2(™)-
\ (7 J
При этом Qt как функция /3 не зависит от S(/3) (теорема 1). Следовательно,
статистика Снедекора имеет в данном случае вид
п-к От
р _____________
Г т,п-к —
т 8(0)
и при этом r9(Fm,n_fc) = S(m, п-к). Отсюда, как и в Доверительный
случае оценивания 0, получаем следующий у-довери- эллипсоид
тельный эллипсоид для t:
QT,(X) = h_ (t — T0)'D~l(t — T0)<----------S(0)Frm,n_A. (18)
[ — — п — к — )
При Т = 1* полученное решение сводится к (15).
Отметим некоторые частные случаи общего решения (18). При тп = 1
речь идет об оценивании одной линейной комбинации А'0 = Aj/314-.. -+Хк0к-
В этом случае эллипсоид (18) вырождается в интервал
АД Т i(l+7)/2,n-A:U (Л'-^ *Д)
S(0)
п-к
(19)
поскольку F7jj,n-t = t2|+7)/2,n-k (показать, используя упр. 51 (б) к гл. 1).
Пусть матрица Т имеет следующую структуру: в каждой строке только
один элемент отличен от нуля, при этом в г-й строке на месте jT стоит
единица, т = l,...,m, ji <j2 < < jm. Тогда Т0= (0j{, , fyj = 0(тп)
и, следовательно, речь идет об одновременном оценивании части координат
вектора /3. В этом случае матрица D представляет собой минор
A ‘(ji, ,jm) = A(m)
матрицы А~1 получающийся вычеркиванием всех строк и столбцов с но-
мерами, отличными от ji,..., jm, й из (18) получаем, что у-доверительный
480 Глава 6. Линейная регрессия и метод наименьших квадратов
эллипсоид для подвектора Р(т) имеет вид
£t7(2l) = (Pirn) - Pirn))'A~lim)iP(m) - р(т)) <
т 1
< ------5(Ж7,т,п_Л. (20)
71 Аг J
Пример 2 (Доверительный интервал для ординаты линии регрессии).
Пусть в схеме простой регрессии (см. пример 1 §6.2) требуется оценить зна-
чение линии регрессии <p(t) — Р\ + р-р в произвольной точке t. Используя
обозначение
s2(*) = -f>-*)2
п
i=i
из формул примера 1 §6.2 получаем, что при А = (1, t)
Кроме того, <p(t) =>!р = X + Ц-1)Р1. Отсюда и из (19) окончательно имеем,
что искомый 7-доверительный интервал имеет вид
/_ . - / 1 ГТ (t - £)2] \
I X + (i - t)p2 =F i(i+T)/2.n-2y [> + -7(0-] 1
6. Система совместных доверительных интервалов
В конкретных практических задачах построение доверительных эллипсоидов
в (15) и (18) — трудная вычислительная задача. Поэтому предпочтительнее
иметь результат, сводящий проблему к построению системы доверительных
интервалов для отдельных компонент оцениваемого параметрического век-
тора, с заданной вероятностью одновременно накрывающих соответствующие
компоненты. В таких случаях говорят о системе совместных доверительных
интервалов. Расчет такой системы основывается на следующем интересном
утверждении из теории квадратичных форм.
Теорема 2. Пусть В — положительно определенная матрица и t, А — вектор-
столбцы. Тогда
^=тдаХА^А- (21)
А A .D А
Доказательство. Представим В в виде В = НН' Это всегда можно сде-
лать, выбрав Н = , где U — ортогональная матрица, приводящая В
к диагональному виду Л. Положим теперь X = H't, Y. — Я-1 А; тогда
Х'К = i'2, ХХ = t?Bt, Y'Y = А’В~ 1 А.
§ 6.3. Нормальная регрессия
481
По неравенству Коши—Буняковского2^ (АГ'У)2 (Л~'А')(У,У), причем знак
«=» <=> векторы Х_ и У линейно зависимы. Отсюда и из предыдущих соот-
ношений имеем (А'£)2 < (f'Bf)(A'B-1 А) иди t'Bt (Xt)2/(ХВ~'Х).
Положим теперь в соотношении (21) t = /3 - /3, В = А; тогда соотноше-
ния (15)—(16) можно записать в виде
7 = р"( "\ах } = М|А'(£ - £)| < «7(2ь A), VA},
где
«т(Х; А) = а7(^)(А'Л-1А)|/2 (22)
Таким образом, для любого 3 выполняется соотношение
P9{A'/3-u7(X;A) < Х0< A'^+u7(X;A), V А} = у. (23)
Тем самым для всех (!) линейных функций Х/3 указана система совместных
доверительных интервалов с доверительным уровнем у. Если требуется оце-
нить конечное число линейных комбинаций Л)/3, >Хт(3, то из (23) имеем
следующий результат:
Р9{Л^-д7(Х;Аг) < А^<Л'г^+д7(Х;Аг), г= 1,. ,т}^у. (24)
Пример 3 (совместные доверительные интервалы для коэффициентов ре-
грессии). Пусть 1 т к и Аг = (0 010 0), где 1 стоит на месте jr,
г = 1, ,т. Тогда Xf/З = /3jr, ХГА~1ХГ = а3'3’ и на основании (24)
{ Т а7(Х)х/а^), г = 1, , тп}
— система совместных доверительных интервалов уровня > у для координат
Pjt, , /3]т При тп = к получаем решение для всех коэффициентов регрес-
сии /3,../Зк. •
7. Доверительный интервал для отклика
На практике большой интерес представляет предсказание будущих значений
отклика X при тех или иных заданных значениях факторов Z\,..., zk. В этом
случае речь идет о построении доверительного интервала для значения X, от-
клика X, соответствующего фиксированным значениям zti, , ztk факторов:
к
X, = + е* = Х*Р_ + е,. (25)
7 = 1
Предположим, что мы уже оценили вектор /3 по тг наблюдениям X =
= (Л), .., Хп) и что е, не зависит от е = (ei,..., еп) и £(с») = Л/^О, ст2).
2* Буняковский Виктор Яковлевич (1804-1889) — русский математик, специалист по теории
вероятностей, теории чисел и математическому анализу.
31 Заказ 1748
482
Глава 6. Линейная регрессия и метод наименьших квадратов
Тогда мы можем использовать оценку Xt = которая на основании тео-
ремы 1 имеет нормальное распределение:
ст^Л’1^). (26)
Но также
£НХ) С72)
и Х„ не зависит от Xt. Отсюда следует, что
Л^Х, - Xt) = -ЛЛ(О, 0-2(1 +^л-'^)). (27)
Это дает нам возможность построения стьюдентова отношения
S@ _ (Д - XjVn^H
а^П " У5@(1+Л'Л-'^)
Доверительный и получения следующего 7-доверительного интер-
X. Т <(1+7)/2,п-М/ (28)
у 71 — /ь J
Пример 4 (Прогнозирование в схеме простой регрессии). Пусть в схеме
простой регрессии требуется построить 7-доверительный интервал для от-
клика X, в точке tt. Используя обозначения примера 2, находим, что интер-
вал (28) принимает вид
(- , 17 (** - О2 A A A , ч
( X + (tt - Т <(1+7)/2,п-2А/ ( 1 + - ( 1 + 2 j ) —- \ (29)
Подчеркнем, что этот интервал отличен от соответствующего интервала для
ординаты (см. пример 2): он шире, что естественно, так как случайная
флуктуация е, вносит дополнительную неопределенность в проблему. •
8. Проверка адекватности модели
В практических ситуациях при подборке подходящей модели типа модели
нормальной регрессии (2), важным является вопрос проверки адекватности
модели, который может быть конкретизирован так: все ли факторы, оказы-
вающие существенное влияние на отклик X, учтены в модели (2), или же
действительное число факторов больше к? Если модель (2) справедлива, то,
как показано в §6.2, статистика а2 (см. (10) §6.2) является несмещенной
оценкой для остаточной дисперсии а2 Если же реальная модель имеет на са-
мом деле больше коэффициентов (факторов), то оценка ст2 будет смещенной
и при этом Ест2 > ст2 В этом случае использование модели (2) может привести
к неправильному предсказанию отклика. Поэтому при проверке адекватности
§ 6.3. Нормальная регрессия
483
основное внимание уделяется недопущению модели с меньшим числом ко-
эффициентов (факторов), чем требуется.
Чаще всего процедуры проверки адекватности модели состоят в срав-
—2 „ „ * 2
нении оценки а с независимой от нее другой оценкой а для остаточной
дисперсии ст Если ст соизмеримо с а влияние неадекватности можно
считать незначительным и модель (2) принимается; если же ст2 существенно
больше а2 то этим влиянием (неадекватности) нельзя пренебречь, и модель
надо скорректировать, добавляя новые коэффициенты.
Чтобы получить независимую оценку ст надо провести в неизменных
условиях (т. е. при некотором фиксированном значении факторов Z\, , zk}
серию независимых опытов, в результате которых получим выборку значений
отклика (У), , Ут). В этом случае наблюдения Yit Yrn будут незави-
симыми одинаково распределенными нормальными случайными величинами
с дисперсией ст2 и несмещенная оценка для ст2 по этим данным имеет вид
1 т . т
= —г-у? у = -Еу” (3°)
т - 1 т
1=1 2=1
а ее распределение есть
=Х2(т-1). (31)
\ a j
Следовательно, тестовой статистикой для проверки гипотезы адекватности
Яо Ест2 = ст2 (32)
является дисперсионное отношение Фишера
Fn-k.m-l = Ф (33)
ст
Если гипотеза адекватности (32) истинна, то статистика Fn-k<m-\ имеет
распределение Снедекора с п - к и т - 1 степенями свободы:
£(Fn-k,m-\\Ho) = S(n-к,т-(34)
Следовательно, алгоритм проверки адекватно- Алгоритм проверки
сти регрессионной модели состоит в следующем: адекватности модели
1. После оценивания регрессионных коэффициентов /3 = (J3\, ,Рк), т.е.
получения о. н. к. /3 = , /Зк}, вычисляют значение оценки ст2 в (10)
§6.2 для остаточной дисперсии ст2
2. Проводят серию новых опытов У = (У1; , Ут) и по (30) получают не-
зависимую оценку для ст2
3. Вычисляют дисперсионное отношение (33).
4. При заданном уровне значимости а (напр., а = 0,05) и числах степеней
свободы п-к и т-1 по таблицам распределения Снедекора определяется
величина Ft'.
Р{-Рп-Л,т-1 > Ft} — «•
31*
484 Глава 6. Линейная регрессия и метод наименьших квадратов
5. Сравнивают величины Fn_kjjn_i (см. (33)) и FT и делают один из двух
выводов:
А. Если Fn-t m-i Ft, модель считается адекватной.
Б. В противном случае модель неадекватна и надо изменить ее структуру, вве-
дя дополнительные коэффициенты, и заново собрать данные. Например,
если полином первой степени (простая регрессия) оказался неадекват-
ным, то надо перейти к модели второй степени и т.д.
§6.4. Общая линейная гипотеза нормальной регрессии
1. Понятие линейной гипотезы
При применении схемы нормальной регрессии на практике часто возникает
необходимость проверить те или иные гипотезы о значениях коэффициентов
регрессии (д\, ,0к. В общем виде задача формулируется следующим обра-
зом: по наблюдениям X = (JV|, , Хп) требуется проверить гипотезу Яо,
согласно которой коэффициенты /31,.. ,(Зк удовлетворяют некоторым за-
данным ограничениям, локализующим их допустимые значения в некотором
подмножестве Bq 6 Rk Если эти ограничения линейные, то говорят о линей-
тй. _ ной гипотезе. Для линейной гипотезы подмножество Bq
Линейная гипотеза
является линейным подпространством вида
Д0 = {Д T0 = tQ},
(1)
где Т — заданная (пгхк)-матрица (т С к), rankT = т, (0 — заданный век-
тор и предполагается, что система Т/3 = t0 совместна. Таким образом, в общем
случае линейная гипотеза записывается в виде Яо /3 G Bq. В любом случае
это сложная гипотеза, так как она оставляет произвольным значение пара-
метра а2 В терминах общего параметра модели в = (0, а2) можно записать
Яо 0 е ©о = {6» /3 6 BQ, а2 > 0}. (2)
Примером конкретной линейной гипотезы является утверждение
Hq /3? = /32О,
задающее конкретное значение наклона линии регрессии в модели простой
регрессии (см. пример I §6.2).
2. F-критерий для линейной гипотезы
Чтобы построить критерий проверки гипотезы Яо, воспользуемся уже из-
вестным нам решением задачи доверительного оценивания (см. п. 5 § 6.3)
и принципом соответствия между проверкой гипотез и доверительным оце-
ниванием (см. п. 4 §5.3). Напомним общую схему этого соответствия.
Пусть в некоторой модели F = {F(x;0), 0 6 0} построена система 7-до-
верительных областей {£7Qe), х 6 X} для параметрической функции g=g(O).
§ 6.4. Общая линейная гипотеза нормальной регрессии 485
Тогда подмножество выборочного пространства, задаваемое условием
Яоа = U 9о € а = 1 - 7,
определяет область принятия гипотезы Но д — до с уровнем значимости а.
В нашем случае, согласно (17)-18) §6.3, 7-доверительная область для
t = Т /3 имеет вид
Qt(X, 0 < т г
5@Х)) п - к 7'
поэтому область принятия гипотезы Но: t = t0 с уровнем значимости а= 1 -7
задается условием
Г QT(x,to) т 1
I s(p(x)) n-k 1 j
Отсюда имеем, что критерий для гипотезы Но : /3 £ Во F-критерий
(см. (I)) задается критической областью
n-k QT(x,to) о
т S(p(x))
(3)
Выпишем явное выражение для тестовой статистики критерия (3). В со-
ответствии с (17) §6.3 она есть
F = n-k QT(X, tg) = n-k
m S(0) ~ m S(0)
и большие ее значения являются критическими для проверяемой гипотезы.
Построенный критерий называют F-критерием.
Приведем и другой подход к построению критерия (3), проливающий
дополнительный свет на его существо. Рассмотрим о. н. к. t Т/3 для t
и составим вектор отклонений Т(3 - tg. Если гипотеза Яо не верна, то
весьма вероятно, что эти отклонения велики. Будем измерять степень от-
клонения величиной (?т(2С,(о). Тогда, поскольку математическое ожида-
ние квадратичной формы можно преобразовать следующим образом (ниже
E = D(y) = ||cov(yi,yj)||):
Е(У'ВУ) = 52 bijEQW = 52 соу(Уь У,) + 52 b^Y^Yj =
i,j ij i,j
= tr (BE) + Е(У')ВЕ(У),
учитывая (5) §6.2, имеем при У = Т/3 - tg, В = Л-1
-Е(?т(Х to) = - tr (lm) + -Е(Т£ - (д)'р-'Е(Т^ - tg) =
тп mm— ~
= a2 + -(T/3 - t_oYD-l(T/3 - t0) a2;
m — —
486
Глава 6. Линейная регрессия и метод наименьших квадратов
Дисперсионное
отношение
знак равенства имеет здесь место только при Т/3 = ta, т. е. при справедливости
гипотезы Но. С другой стороны, как мы знаем из п. 3 §6.2, S((3)/(n - к) — не-
смещенная оценка для ст2 всегда, т. е. безотносительно к истинному значению
/3. Поэтому у отношения F в (4) числитель в среднем больше знаменателя,
когда гипотеза Hq ложна, и потому большие значения F естественно рас-
сматривать как свидетельствующие против гипотезы Яо. Из этих рассуждений
также следует, что статистика F является отношением двух независимых и не-
смещенных (при гипотезе Hq) оценок для остаточной дисперсии а2 С такой
дисперсионное отношение интерпретацией связан
термин, используемый иногда для статистики F.
Для вычисления статистики F можно использовать
также формулу
n-kST-S(fi)
F =------------, (5)
т S(fi)
которая следует из (18) §6.2. Таким образом, дисперсионное отношение F
можно выразить непосредственно через условный Sr (при условии ТД = t0)
и абсолютный 5(/3) минимум исходной квадратичной формы S((3). В кон-
кретных задачах условный минимум St зачастую находят непосредствен-
но, поэтому представление (5) более удобно для практических расчетов,
нежели (4).
Пример 1 (Простая регрессия, гипотеза о наклоне ее линии регрессии).
Рассмотрим гипотезу Hq /32 = /32о, фиксирующую значение наклона линии
регрессии (см. пример 1 §6.2). В данном случае т = 1 и условный минимум
(при гипотезе Но)
п
ST = min УЛ-Х; - /320«i - /3|)2
01 >=i
находится непосредственно: он достигается при /31 = Х - (черта сверху,
как обычно, означает среднее арифметическое) и его значение, учитывая соот-
ношения (22)—(23) §6.2, можно записать в виде (проверить самостоятельно!)
п
St = S@) + (Д2 - /Ззо)2 - I)2
f=i
По формуле (5) имеем, что в данном случае дисперсионное отношение равно
F = (п - 2)(Д2 - /320)2 - t)2, (6)
Ь\Р) »=i
а критическая граница в (3) выбирается равной Fi-a, i.n—2- Так как
fl-а, 1,п-2 = t 1-а/2, п-2
§ 6.4. Общая линейная гипотеза нормальной регрессии 487
(см. замечание к формуле (19) §6.3), то F-критерий в рассматриваемом случае
сводится к критерию
Яо отвергается <= => 1^2 ~ Дго| G-a/2,n-2
(п - 2) - О2 i=l
где S(/3) определено в (23) §6.2).
Отметим, что к этому результату можно прийти также и обращая довери-
тельный интервал для /3?, построенный в примере 1 §6.3).
В том случае, когда Д2о = 0. речь идет ° проверке значимости влияния
фактора t на исход эксперимента, и если гипотеза Яо Дг = 0 отвергается, то
говорят, что регрессия значима и влиянием фактора t пренебрегать нельзя.
Добавим к этому следующее. Как легко видеть из соотношений (22)—(23)
§ 6.2, можно записать также представление
3@ = ^(Х,-Х)2-
= (1-Д2)52(Х1-Х)2
2
(8)
где
- X)(ti - i)
R = , ~ , (9)
- xy^t, - ty
есть выборочный коэффициент корреляции между X и t.
Из (8) следует, что чем больше значение Я2 (чем ближе оно к 1), тем
меньше 5(Д), т.е. тем лучше подобранная прямая регрессии соответствует
наблюдениям. Тем самым, если гипотеза Яо (31 = 0 отвергается, то вели-
чина 1 - Я2 является мерой согласия подобранной прямой регрессии данным
наблюдений.
Наконец, Я-статистика (6) при Д2о = 0 с учетом (8)-(9) может быть за-
писана в виде
(п - 2)31 Е^ - $ _ (п - 2)Я2
(,0)
т. е. может быть выражена через Я2, а критерий (7) для гипотезы /32 = 0 может
быть записан соответственно в виде
|Л|
И1-Я2)/(«-2)
^1-а/2,п-2
(11)
488 Глава б. Линейная регрессия и метод наименьших квадратов
Пример 2 (Критерий значимости регрессии). В приложениях теории линей-
ной регрессии обычно первый коэффициент выделяется, т.е. полагается
первый фактор Z\ = 1 (как в схеме простой регрессии (21) §6.2). В этом слу-
чае наблюдаемая переменная X зависит от k — 1 фактора z2, ,Zk и часто
бывает желательно удостовериться, является ли их влияние на X значимым.
Итак, если априори предполагать, что модель имеет вид
Xj = /3| + + 4" 0kzk 1 “Г i = 1 > , ri, (12)
то речь идет о проверке гипотезы Яо /32 = = Л = 0. Если гипотеза Но
отвергается, то говорят, что регрессия значима и факторами z2, , z^ нельзя,
вообще говоря, пренебречь (в то же время следует иметь в виду, что отклонение
гипотезы Яо вовсе не означает, что модель (12) действительно адекватна).
В данном случае гипотеза Яо имеет вид Т0 = 0, где Т = ЦО —
матрица размера (Л — 1) х к и ранга к — 1, так что применима общая теория
F-критерия с m = к - 1 и
ST = min ^T(Xi - /З,)2 = ^(Х, - X)2 = £Х - пХ2
i=i i=i
Кроме того, величину 5(/3) в силу соотношений (10)-(12) §6.2 можно записать
также в виде
S(fl) = X'(ln - Z'A-'Z)X = X!X-P'ZX. (13)
Следовательно, F-статистика (5) имеет в данном случае вид
п-к p'zX-nX2 , ч
F = , (14)
к ~ 1 XL*, -pzx
а F-критерий для гипотезы Яо (т.е. критерий для «всей» регрессии в целом)
задается критической областью {F где а — заданный уро-
вень значимости.
Полезной мерой степени соответствия аппроксимирующей регрессии
X = Z'p имеющимся данным X = (Хь..., Хп) является выборочный мно-
жественный коэффициент корреляции Rk-i- Он определяется как коэффици-
ент корреляции между данными {Х|, , Хп} и их оценками {Х[, , Хп}:
52(Х, - Х)(Х,- - X)
п п __
£(Х,-Х)^(Х;-Х)2
»=1 1=1
(15)
§ 6.4. Общая линейная гипотеза нормальной регрессии
489
Величину R2k_t обычно называют коэффициентом де- Коэффициент
терминации. детерминации
Покажем, что
п
S(p) = (\-Rl_^(Xi-X)2 (16)
i = l
Доказательство. Действительно, рассмотрим первое уравнение системы нор-
мальных уравнений dS(fl)/d&\ = 0: оно имеет вид
£ (х,-^-^ -3*4°)= о
или _ -^«) ~ 0, т-е- X = Xi. С учетом этого имеем
t
- X)2 = ^(Xi - Xi + Xi - x)2 = 52(x> - xrf + £(*< -
i i i i
(17)
поскольку (см. (2) § 6.2)
52(^< - Xi)(Xi -x) = 52(*< - Xt)Xi = (X - X)'X = XX - T'X =
= £z'a~'zx- x!z'a~'zz'a~'zx = o-
Из (17) следует, что
S(3) = ^(Xi - Xi)2 = ^(Xi - X)2 - 52(Xi - X)2 (18)
i t i
Далее,
^(Xi - X)(Xi -X) = 52(X; - X)(Xi - X) =
t i
= £(X,- - Xi + Xi - X)(Xi -X) = 52(^i - X)2,
t i
поэтому (см. (15))
£(£-*)2
Rl-' = ^X.-X)2'
t
Теперь соотношение (16) непосредственно следует из (18) и (19).
Из равенства (16) видно, что чем ближе значение /?£_! к 1, тем лучше
аппроксимирующая поверхность X = Zp соответствует данным наблюде-
ний. Отметим, что при к = 2 (один фактор) мы получаем соответствующие
490 Глава 6. Линейная регрессия и метод наименьших квадратов
результаты примера 1. Так, коэффициент R\ = R (см. (9)), а равенство (16)
соответствует равенству (8). Можно также показать, что аналогом представ-
ления (10) является здесь следующая формула для статистики (14):
F = (n-fc)—(20)
§ 6.5. Некоторые применения теории
нормальной регрессии
Изложенная в предыдущем параграфе теория проверки гипотез о коэффи-
циентах регрессии имеет широкое применение. К схеме регрессии могут
быть сведены многие гипотезы о математических ожиданиях нормальных со-
вокупностей, которые зачастую имеют форму, на первый взгляд, отличную
от рассмотренной выше. Некоторые из таких задач рассматриваются в этом
параграфе.
1. Гипотеза о параллельности линий регрессии
Предположим, что имеется г 2 групп независимых наблюдений
Хп, г = 1,.. , г, распределенных нормально с общей (неизвестной) диспер-
сией а2 и средними
j = г=1.......г. (1)
Другими словами, имеется г различных схем простой регрессии (пример 1
§6.2) и проверяемая гипотеза Hq состоит в том, что все линии регрессии (1)
имеют один и тот же наклон, т.е.
Яо /3'°= =Д<Г)
Такая гипотеза может встретиться, например, при проверке равенства несколь-
ких скоростей роста, при сравнении нескольких способов обработки и т.д.
Покажем, что рассматриваемый случай можно свести к схеме общей ли-
нейной гипотезы. Положим
X = (JVl,...,Xn) = (X<1), .х'М2*, ,х<г?),
71 = 71[ + -|- «г»
Д = (Д,, ,Д2г) = 2(^1),^1),Д<2), Д<2) ,д!г).^г))
и введем матрицу Z размера 2г х п, составленную из векторов-столбцов z^
вида
2 = ||z(l)---z(ni)z(n' + 1)---z(n)|| =
§ 6.5. Применения теории нормальной регрессии
491
1 10 0
t'0 t" О о
О 0 1 1
о о t*2) О
о
1 1
Аг) ,(г)
fl С(пг)
В этих обозначениях вектор X распределен по нормальному закону
J"f (Z*fl, а21п). Таким образом, имеем частный случай (при указанном выборе
z^) схемы нормальной регрессии. Проверяемую гипотезу можно записать
в виде Но Р< - Pi = = Pi, - /?2 = 0, т.е. она задается (г - 1)-м ли-
нейным соотношением между коэффициентами регрессии и, следовательно,
для ее проверки можно применить F-критерий §6.4. Для этого надо найти
абсолютный 5| = S(P) и условный St (т. е. при гипотезе Но) минимумы
квадратичной формы
п
s(p) = 52 (X, - z^'p)1 = 52 (Х« - д<;))2 (2)
i=l i.j
Нахождение Sl сводится к минимизации выражения
s(p) = 52 s''’,
i=l
где
n,
s(t) = 52(х'г) -^’V)2 i = 1> >r>
j = l
t. e. достаточно найти минимум каждой квадратичной формы S® отдельно.
В несколько отличных обозначениях эта задача решена в примере I §6.2,
поэтому из (22) и (23) §6.2 имеем, что минимум достигается при
РУ - рУ р{*} = рУ,
где
П,
^(х^х^-Р)
Рг} = —-----й----------------> А<0 = *(° ” (3)
2 = 1
492
Глава б. Линейная регрессия и метод наименьших квадратов
1 "
(здесь = — £ Х^
Tli J
2=1
для любого i = 1,.... г не
1
№ = — $ и при этом предполагается, что
п, J
7 = 1
все числа одинаковы). Таким образом,
в данном случае
Г П|
Si = £ £ [(£ - *(i))2 - (У - *(I))2] (4)
i=l 7 = 1
Введем следующие обозначения:
4«)
7=1
5?(Х) = £(Х<,)-Г’))2 (5)
2 = 1
Si(X,t) = ^2(xf-Х^)^i=\, ,r
j=i
(с точностью до множителя — это выборочные дисперсии и ковариация мно-
жеств (х{’\ , Х$) и (t|*\ .. , t^)). Тогда из (3) и (4) следует, что S, можно
записать в следующем, удобном для вычислений, виде:
(6)
Для вычисления Sr надо минимизировать по /з\'^ сумму
т. е. приравнивая нулю все ее частные производные по этим параметрам. Не-
посредственным дифференцированием можно проверить (это мы оставляем
читателю в качестве простого упражнения), что при любом фиксированном
(32 минимум достигается при /3^ = = Х^ - » = 1, , г, и сумма
квадратов при этом равна
£[(х<*)-х«)-^(4,)-<(,))]2
м
Минимум же последнего выражения достигается при
А=‘г=')
*.2
s। (X, t) + +sr(X,t)
s,(t) + ... + s$(t)
§ 6.5. Применения теории нормальной регрессии
493
(см. (5)), и он равен
= £ з?(Х) -
1=1
-1=1
Е s'<«)
1=1
В данном случае параметры А и тп в (5) § 6.4 равны соответственно 2г и г - 1,
поэтому статистика F в силу соотношений (6) и (7) принимает вид
п - 1г
г - 1
2
(8)
В итоге имеем, что при заданном уровне значимости а F-критерий для про-
веряемой гипотезы Но задается критической областью {F Fi-QiJ—i,n-2r}-
2. Гипотеза однородности для нескольких нормальных выборок
В примере 3 § 5.4 была сформулирована общая гипотеза о равенстве средних
значений нескольких нормальных выборок. Такая гипотеза часто возника-
ет в приложениях, например, при сравнении нескольких различных способов
обработки или процедур, условий, размещений и т. п. с целью выяснения, вли-
яют ли различия между ними на интересующий исследователя исход. Вообще
подобная проблема имеет место каждый раз, когда интересуются влиянием
на исход эксперимента какого-то одного фактора. Если число различных зна-
чений этого фактора (число уровней, на которых может находиться фактор)
равно А, то n.j — число наблюдений, соответствующих j-му уровню факто-
ра, а Х& = (Х71..... Xjnj) — сами наблюдения (результаты эксперимента).
В этом случае говорят также об одинарной классификации исходов.
В примере 3 § 5.4 мы исследовали эту проблему (проверка гипотезы од-
нородности) с позиций критерия отношения правдоподобия, но получили
окончательное решение лишь для случая двух (А = 2) выборок (см. критерий
(9) § 5.4). Общее же решение для произвольного числа выборок было полу-
чено лишь для случая больших выборок (см. критерий (29) § 5.4). Теперь же
мы в состоянии получить общее решение для произвольного числа выборок
и произвольных их объемов, если воспользуемся теорией F-критерия. Для
этого сведем рассматриваемую схему к схеме регрессии.
494 Глава 6. Линейная регрессия и метод наименьших квадратов
Положим X (%,, ,Х„) (Х(|), ,Х(к)), п /1,+ +пк,
и введем матрицу плана
z=iu(i> *(n>ii =
о
о
1 1 о
О 0 1
где в j-й строке единицы стоят на местах п, +.. .+ п;_| + 1, П| +.. . + nj,
j = 1,..., к (n0 = 0). Тогда Х\,..., Хп независимы (по условию) и
£(Х,)=Л<(Л>^), г=1,...,п, Д = (0ц, ,0ц).
Таким образом, мы имеем здесь частный случай (с указанной матрицей пла-
на Z) схемы нормальной регрессии, в которой требуется проверить гипотезу
Hq 0Ц-0Ц = = 0ц —0ц = 0 (Hq задается (к- 1)-м линейным соотноше-
нием между коэффициентами регрессии). Следовательно, можно применить
теорию F-критерия. Для этого надо вычислить абсолютный St и условный St
(при гипотезе Яо) минимумы квадратичной формы
s =
i.j
Так как
_ ________________________________ __________ [ п>
s = £(x7i - xj + £ - 0М)2 Xj = - £ xjit
i.j j j =!
то при отсутствии ограничений на 0ц,.. ,0ц минимум достигается при
&ij = Xj, j = 1, , к, и равен
к п>
S, = £(Х^ - Xj)2 s^^Xji-Xj}2 (9)
i.j j=l i=l
Далее имеем
ST = miny'(Xjl- -0,)2
м
Здесь можем записать разложение
= EX* -х>2+п(х -
i.j *,}
§ 6.5. Применения теории нормальной регрессии
495
отсюда следует, что
ST = £(Х,X)2 = St + £ пДХо) - Г)2 (10)
I, ; = 1
и минимум достигается при = X.
Таким образом, в данном случае статистика F принимает вид (см. (5) § 6.4)
к
к - 1 * ’ v '
;=1
а F-критерий для гипотезы однородности Яо задает- ИИИ₽Я-критерий
ся при уровне значимости а критической областью ’’""’’однородности
{F Fi-ofc-j n-t}. Нетрудно убедиться в том, что
для случая двух выборок (к = 2) полученное решение сводится к (9) §5.4.
Отметим, что соотношение (10) можно интерпретировать как разложение
полной суммы квадратов отклонений наблюдений от общего среднего («пол-
ной изменчивости») на сумму квадратов отклонений каждой величины Xij
от соответствующего группового среднего значения («изменчивость внутри
групп») и сумму квадратов отклонений групповых средних от общего средне-
го («изменчивость между группами»). При этом, если гипотеза Яо истинна,
то (см. формулу (11) §2.2)
E^ = Ej3(Xjt - X)2 = (п - 1)^,
•J
к к
Е5) = £>2 = - 1)^2 = (п - к)в22,
2=1 2=1
Е ^2 п^Х^ - X)2 = ESt - Е5| = (к- 1)022.
2 = 1
Отсюда следует, что (при нулевой гипотезе Яо) каждая из статистик
Qi =
j
•J
496
Глава 6. Линейная регрессия и метод наименьших квадратов
является несмещенной оценкой дисперсии и F-критерий можно считать
критерием совместности независимых оценок Qt и Qi (статистику F мож-
но записать в виде F = Qi/Qi) Такое разложение изменчивости исходных
данных и его интерпретация характерны для дисперсионного анализа — разде-
ла математической статистики, объединяющего совокупность статистических
приемов, широко применяемых в самых разнообразных экспериментах, в ко-
торых наблюдения тем или иным способом классифицируются (разбиваются
на группы или классы) в соответствии со значениями некоторых сопутствую-
щих факторов.
3. Двойная классификация. Дисперсионный анализ
Рассмотренный в предыдущем пункте случай является простейшей схемой
дисперсионного анализа (один фактор), в которой решение получается с по-
мощью методов регрессионного анализа. Рассмотрим применение регресси-
онного анализа еще к одной, имеющей большое практическое значение, схеме
дисперсионного анализа, когда число факторов, влияющих на исход экспе-
римента, равно двум.
Предположим, что исход эксперимента зависит от значений двух факто-
ров R и С, причем фактор R может находиться на г уровнях R], ,Rr,
а фактор С — на s уровнях С\, ,CS. Пусть, далее, при каждой возможной
комбинации уровней обоих факторов производится ровно одно наблюдение:
Xij при комбинации (Я,-, Су), г = 1, , г; j = 1, ,з. При этом наблю-
дения {Xij} независимы и распределены нормально с одинаковыми диспер-
сиями а2 и средними значениями
ЕХ,у = (ij = р + at + /3j, (12)
где
= 12^=0- (13)
i=l y=i
Условия (12) и (13) означают, что оба фактора действуют независимо (в этом
случае говорят, что они аддитивны). Действительно, если обозначать через а1
и /3' действия факторов R и С соответственно, то аддитивность означает, что
(ij = a'i + fi'j. Если положить теперь р = а + р, а, = а\ — a, /3j = Ду - р
(черта сверху, как обычно, означает среднее арифметическое), то получим
соотношения (12)—(13).
Такую схему удобно представить в виде прямоугольной таблицы из г
строк, соответствующих уровням Rit , Яг и s столбцов, соответствующих
уровням Ci, ,CS. Случайную величину Х^ называют реагирующей', она
описывает реакцию, вызываемую комбинацией (Я,-, Су) факторов Я и С
Из (12) следует, что E2Tty при любых г и j оказывается при условии (13)
линейной функцией от r + s - 1 неизвестных коэффициентов р, оц, Таким
образом, здесь мы также имеем частный случай схемы нормальной регрессии
§ 6.5. Применения теории нормальной регрессии
497
и, следовательно, можно применить развитую выше теорию. Все ее положе-
ния, как мы знаем, базируются на анализе квадратичной формы
(ц)
i=l j=l
В данном случае удобно преобразовать эту форму следующим образом.
Обозначим
- 1 _ 1 А _ 1
x- = ~s^Xi>- Х‘- = -,^Х‘>- х- = ~г^х‘1
‘.j j=l 1=1
Тогда, учитывая (12), имеем
S = £(X0-g-a.-^)2 =
i.j
= Z [(*0 - Xi. - X.j + X.) + {Xi. - X.. - aj +
i.j
+ (х.>-х..-/з>) + (х..-д)]2 =
= Y^Xij - Xi. - X.j + X..)2 + 8 £(X,. - X.. - ai)2 +
i.j '
+ г52(Х7-Х..-/3;)2 + г5(Х..-д)2, (15)
j
так как все попарные произведения после суммирования дадут нули.
Оценки наименьших квадратов для коэффициентов регрессии — это зна-
чения параметров, обращающие квадратичную форму (14) в минимум, поэто-
му из (15) сразу получаем, что в данном случае эти оценки таковы:
р = Х.„ а,= X,. -X.., ^j = X.j-X... (16)
Из (15) и (16) также имеем, что минимальное значение формы S равно
Si = min 5 = J2(X0 - I,)1 = X{Xij - Xi. - X.3 + X..)2 (17)
i.j i.j
Найдем дисперсии полученных оценок (16). Так как
х.. = 1£х(. = 1£х.ь
Г z—5
/=1 1=1
ТО
з< = —
Г Г l*i S S t£j
Ho Xi., 1= 1,... ,r, независимы и DX(. = cr2/s; аналогично, X.t, t = 1.s,
независимы и DX.t = rr2/r; следовательно,
32 Заказ 1748
498
Глава б. Линейная регрессия и метод наименьших квадратов
Л а2
D/z —
rs
—а!.
rs
(18)
Доверительные В соответствии с общей теорией (см. п. 4 §6.3) отсюда
интервалы находим, что 7-доверительными интервалами для пара-
метров //, а, и Pj являются соответственно (в данном
случае параметр п - к в (13) §6.3 равен rs - (г + s - 1) = (г - l)(s - 1))
“• Т Ч1+т)/2,(г-1)(з-1)у rs(g
ДТ<(1+т)/2,(г-1)(б-1)
rs(r - 1)
где Д, a,-, Pj и S\ определены в (16) и (17).
Отметим также, что S\/(r - !)($ - 1) — несмещенная оценка а2
Проверка гипотез Рассмотрим теперь задачу проверки наиболее ин-
тересных в исследуемой схеме гипотез. Пусть требу-
ется проверить гипотезу Н^1 о том, что фактор R не влияет на исход испы-
таний, т. е.
Яо(1) Q1 = = аг = 0.
(19)
Так, например, главным интересующим исследователя фактором может быть
фактор С, соответствующий, скажем, различным способам обработки, в то
время как R соответствует классификации по месту, где производятся наблю-
дения. В этом случае гипотеза соответствует предположению о том, что
эта вспомогательная классификация не влияет на результаты эксперимента и,
следовательно, может не приниматься во внимание.
Следуя общей теории F-критерия (см. §6.4), вычислим сначала St-ми-
нимальное значение квадратичной формы (14) при гипотезе Я^ ц3 (]5)
и (17) имеем
Г
ST = 5, + s £(Х, - X.)2
3=1
поэтому статистика F (см. (5) §6.4) имеет в данном случае вид (при т = г— 1)
Е(х-- - Х-У
F = s(s - 1)——---------=----—,
- Xi. - X.j + X..)2
i.j
(20)
§ 6.5. Применения теории нормальной регрессии 499
а F-критерий уровня значимости а для гипотезы задается критической
областью
Х<2 = {F > (21)
Аналогично рассматривается гипотеза
Н<2) А= =А=0. (22)
о несущественности влияния на исходы испытаний второго фактора С. Здесь
критическая область имеет вид
Наконец, критерий уровня значимости а для гипотезы
Н® оц = =аг=^= =?s=0
о независимости результатов испытаний от влияния обоих факторов задается
критической областью
(24)
Найдем, наконец, доверительные области для раз- Доверительные
личных групп параметров модели (12). Пусть требуется области
построить у-доверительную область ' для эффектов
Я|, , аГ фактора R. Согласно принципу соответствия между проверкой
гипотез и доверительным оцениванием (см. п.4 §5.3), чтобы построить <7^,
надо рассмотреть соответствующую гипотезу
Г
Яо оч = оно, г=\,...,г ( ано = о).
i=i
Критическую область уровня значимости а = 1 — у для нее можно получить
из (20)—(21), заменяя на - а,0; она имеет вид
32'
500
Глава 6. Линейная регрессия и метод наименьших квадратов
Отсюда следует вывод, что
|(аь , аГ) ^2 а, = 0 и
г — — 1 — — — 1
- Xt. + X..)2 < F7,— ^(Xtj - X.;. - X.j + X..)21
1=1 ' ' f 1 '
- -
Здесь неравенство определяет внутрен-
ность шара в пространстве параметров
(аь ,аг) с центром (Xi. — Х„,
ХТ, - Х„) в гиперплоскости а, = 0.
Так, если г = 2, то доверительная область
— отрезок биссектрисы а? = -ttj, яв-
ляющийся диаметром некоторой окруж-
ности с центром на этой биссектрисе
(см. рис. 1).
Аналогично строится доверительная
область для эффектов /3|,. ,ps второго
нтерпретация
фактора.
В заключение дадим интерпретацию рассмотрен-
ной схемы, характерную для дисперсионного анализа.
Положим в разложении (15) все а, и /Зу равными нулю, а д = X... В резуль-
тате получим соотношение
So = ^(Хо - Л.)2 = S ^2(Xi. - X..)2 + г £(Х., - X..)2 + 5,,
м ‘ i
которое можно интерпретировать как разложение полной изменчивости So
на три компоненты:
S.o = s ^(Xi.-X..)2 So.=T^X.j-X..}2 и S.. = Si. (25)
> i
Компонента 5,о описывает изменчивость, обусловленную первым факто-
ром R, компонента Sq. вторым фактором С. Компонента же S.. есть
сумма квадратов величин с нулевыми средними:
E(X;j — Xi. — X.j + X..) = р. op Рj — [р, а,) — (/z + рр 4-д = 0,
поэтому она не может быть связана с факторами R и С. (Напомним, что ве-
личина Q = S../(r- l)(s - 1) является несмещенной оценкой дисперсии а2.)
Величину S,, принято называть «ошибкой», подчеркивая тем самым, что она
связана со случайностью результатов наблюдений, а не с каким-либо расхо-
ждением в их средних.
§ 6.5. Применения теории нормальной регрессии
501
Вычислим, наконец, ES.o и ESo. - Из (16) и (18) имеем
Е(Х,. - X.)2 = Еа2 = D3, + (ЕЗг)2 = ^±сг2 + а2,
rs
Отсюда и из (25) следует, что
ES.o = (г- l)a2 + s£a,!. (26)
i=l
Аналогично находим
ESo. =(s-l)a2+r^>,2. (27)
;=i
Из (26) имеем, что при гипотезе (19) величина
может служить несмещенной оценкой для <т2. Аналогично, из (27) заключаем,
— несмещенная оценка <т2, когда справедлива гипотеза (22).
Теперь .F-критерий (21) для гипотезы (19) можно интерпретировать
как критерий совместности двух независимых оценок (J, и Q для а2 (стати-
стика (20) в этих обозначениях равна отношению Q\/Q). Аналогично можно
интерпретировать и критерий (23) для гипотезы (22) (его тестовой ста-
тистикой является Qi/Q}.
Обычно составляющие этой двухфакторной модели объединяют в следу-
ющую таблицу дисперсионного анализа:
Источник дисперсии Степень свободы Сумма квадратов Среднее суммы квадратов Отношение Снедекора
строки г - 1 So ?ч II '©IP
столбцы S - 1 So. F -Ь F°-~ Q
ошибка (r-l)(s-l) s„ (г-1)(д-1)
Первое отношение Снедекора F.q служит для проверки гипотезы
„ (2)
о том, что все а, равны нулю, второе — для проверки гипотезы Нй о равен-
стве нулю всех 0j.
502
Глава 6. Линейная регрессия и метод наименьших квадратов
§ 6.6. Статистическая регрессия и прогнозирование
Очень трудно что-либо предсказывать,
но особенно трудно предсказывать будущее.
Китайская пословица
1. Задачи статистического прогноза
В различных областях человеческой деятельности часто возникают ситуации,
когда по имеющейся информации (данным) X требуется предсказать (спро-
гнозировать, оценить) некоторую величину Y, стохастически связанную с X
(т.е. X и У имеют некоторое совместное распределение £)Х, Y)), но которую
непосредственно измерить невозможно (например, Y может относиться к бу-
дущему, а X — к настоящему). Так, например, может представлять интерес
прогноз успеваемости первокурсников очередного набора по оценкам, полу-
ченным ими на вступительных экзаменах. Здесь X было бы средним баллом
этих студентов на вступительных экзаменах, a Y — средним баллом по ито-
гам, скажем, первой сессии; при этом совместное распределение £(X,Y)
можно в принципе определить (оценить) по аналогичным данным за про-
шлые годы. Или: можно ли, зная рост отца (X), предсказать рост его сына
(У), если у выбранных случайно из большой популяции людей эти характери-
стики (X, У) имеют известный (нормальный) закон распределения? Такой же
характер имеют задачи прогнозирования погоды по результатам соответству-
ющих атмосферных измерений, селекционирования новых видов растений
и животных, определения возможностей индивидуумов в определенных обла-
стях с помощью соответствующей системы контрольных тестов и т.д. Особо
важное значение прогнозирование имеет в таких областях, как индустрия, эко-
номика, коммерция (прогнозирование экономических показателей, динамики
цен на тот или иной продукт, курса акций на какое-то время вперед и т.д.).
Во всех этих случаях речь идет о величинах, недоступных непосредственному
наблюдению (измерению) в данный момент и которые надо оценивать (про-
гнозировать) с помощью доступных измерению сопутствующих величин.
В общем случае X означает некоторую совокупность {Х|, Х2, .} на-
блюдаемых случайных величин, которые в рассматриваемом контексте назы-
ваются предсказывающими (или прогнозными') переменными, и задача состоит
в построении такой функции ф(Х) от этих величин, которую можно было бы
использовать в качестве оценки для прогнозируемой величины У <р(Х) ~ У
(т. е. чтобы она была в каком-то смысле «близка» к У); такие функции назы-
ваются предикторами величины У по X. Задачей разработки методов постро-
ения оптимальных (в том или ином смысле) предиктов занимается теория
статистической регрессии (или, что то же, стохастического прогнозирования).
Для построения этой теории прежде всего требуется уточнить смысл при-
ближенного равенства <р(Х) ~ У Если <р(Х) используется для предсказания
величины У, то одной из разумных мер расхождения между ними является
квадратическая ошибка (<^(Х) — У)", но так как величина У неизвестна,
§ 6.6. Статистическая регрессия и прогнозирование
503
то для измерения точности предиктора <р используется среднеквадратическая
ошибка (с. к. о.) А(<р) = Е(^(Х) - У)2 Предиктор, минимизирующий с. к. о.
в заданном классе предикторов Ф, называется оптимальным предиктором, или,
кратко, прогнозом (в классе Ф), и обозначается симво- Прогноз *
лом <р*:
<р* = arg min Д(^);
pg#
его с. к. о. есть
Д‘ = Д(/) = Е(/(Х) - У)2 = inf ЕМХ) - У)2
р€Ф
(О
(2)
Таким образом, в общем случае задача построения наилучшего (в средне-
квадратическом смысле и в заданном классе предикторов Ф) предиктора для
величины Y по X сводится к решению экстремальной проблемы (1)-(2). Как
будет ясно из дальнейшего, основным аналитическим инструментом решения
этой проблемы является аппарат условных распределений, поэтому мы пред-
варительно напомним некоторые факты и формулы из теории вероятностей,
которые будут использоваться далее.
2. Условное математическое ожидание
Напомним, что мы ограничиваемся рассмотрением лишь абсолютно непре-
рывных либо дискретных распределений £(Х, У) и используем общее обозна-
чение у) для совместной плотности — в первом случае и совместной
вероятности Р{Х = х, Y = у} — во втором, называя в любом случае функ-
цию fxY&y) плотностью. По совместному распределению £(Х, У) можно
определить условное распределение £(У|Х = х) величины У при заданном
значении X. Так, в абсолютно непрерывном случае это распределение задает-
ся условной плотностью
. , . , Лг(я,г/)
где
— маргинальная плотность X (для дискретных распределений последний
интеграл заменяется соответствующей суммой). В предположении существо-
вания соответствующих моментов мы можем вычислить среднее и дисперсию
этого условного распределения: условное математическое ожидание
М(х) = Е(У|Х = х), (3)
называемое функцией регрессии У на X, и условную Функция’регрессии *
дисперсию
О(У|Х = я) = Е[(У - М(х))2 | X = я].
(4)
504 Глава 6. Линейная регрессия и метод наименьших квадратов
Так, для абсолютно непрерывных распределений
M(i) = у yfY\X(y\x) dy = J yfxr{x,y) dy~jT^y
О(У|Х = x) = J\y - M(x))2fY[x(y\x) dy,
в случае же дискретных распределений интегралы в этих формулах заменяются
соответствующими суммами.
В соответствии с (3) и (4) можно рассматривать случайные величины
М(Х) и D(y|X), которые при X = х принимают значения соответственно
М(х) и D(y|X = i). Обозначим
oY = ОУ, а2м = DAf(X), a2YX = ED(y|X). (5)
Тогда имеют место следующие полезные формулы:
ЕУ = Е[Е(У|Х)] = ЕМ(Х), (6)
ОУ = ОЕ(У|Х) + ЕО(У|Х), или a2Y = а2м + а2ух. (7)
Соотношение (6) называют формулой полного математического ожидания,
а (7) — формулой разложения дисперсии.
Формула (6) проверяется непосредственно: например, для абсолютно не-
прерывных распределений из определения М(Х) имеем
EAf(X) = У" M(x)fx(x) dx = У" (У yfY\x(y\z) dyjfx(x) dx =
У у(У fxY(f, y)dx^dy = У yfY(y) dy = 'EY
Формула же (7) получается с использованием определения (4) и формулы
полного математического ожидания (6) из цепочки равенств
DY = Е(У - ЕУ)2 = Е[(У - М(Х)) + (М(Х) - ЕМ(Х))]2 =
= е{е[(У - М(Х))2 | X]} + DAf(X) +
4-2е{е[(У-М(Х))(М(Х)-ЕМ(Х)) |Х]} =
= ED(y |Х) + DAf(X),
поскольку
Е[(У - М(Х))(М(Х) - ЕМ(Х)) | X] =
= (М(Х) - ЕМ(Х))Е[(У - М(Х)) | X] = 0.
Отметим важное следствие формулы (7):
<т2м = ОЕ(У|Х) a2Y = ОУ, (8)
§ 6.6. Статистическая регрессия и прогнозирование 505
причем равенство в (8) выполняется лишь в случае, когда
o2YX = ED(F|X) = е{е[(У - М(Х))2 | X]} = Е(У - М(Х))2 = 0,
т.е. когда У = М(Х) (У является функцией X).
Примеры вычисления условных средних и дисперсий в многомерной нор-
мальной модели указаны в упр. 65 и 66 к гл. 1; подчеркнем, что в этих примерах
функции регрессии М(х) являются линейными по х, а условные дисперсии
от х не зависят. Приведем еще один иллюстративный пример вычисления
условных среднего и дисперсии.
Пример 1. Пусть Ы\ и Ы2 — независимые показательные с параметром мас-
штаба а > 0 случайные величины (см. п.З § 1.2). Положим
X =U2, Y =U\+U\U2.
Тогда
М(х) = Е(У|Х = х) = Е[( 1 + х)Щ = а(1 + х),
О(У|Х = х) = D[(l + x)Wt] = а2(1 + х)2
Следовательно, М(Х) = а(1 + Z/2), D(y|JT) = а2(1 + i/2)2 и потому
<j2M = DM(X) = aX)U2 =a\
<rYX = ED(y |X) = a2E(l + Z/2)2 = a2(l + 2a + 2a). •
3. Оптимальный предиктор и его свойства
Решение экстремальной проблемы (1)-(2) существенно зависит от задания
класса Ф, в котором ищется прогноз. Если класс Ф есть класс всех функций
<р(Х), то ответ на вопрос о существовании и виде оптимального предиктора
(прогноза) <р*(Х) дает следующее утверждение.
Теорема 1. Оптимальный предиктор <р* в классе всех функций Ф = {у?} су-
ществует и совпадает с функцией регрессии У на X, т.е.
/(Х) = М(Х) = Е(У|Х); (9)
этот предиктор имеет максимальную корреляцию с У среди всех предикторов.
Доказательство. По формуле полного математического ожидания для любой
функции у? € Ф
Е[(У-М(Х))(М(Х)-¥>(*))] =
= е{е[(У - М(Х))(М(Х) - <р(Х)) I X] } =
= е{ (М(Х) - у>(Х)) Е [(У - М(Х)) I X] } =
= е{ (М(Х) - у>(Х)) (М(Х) - М(Х}) } = о,
506
Глава 6. Линейная регрессия и метод наименьших квадратов
поэтому для с. к. о. предиктора р можно записать следующую цепочку соот-
ношений:
Д(р) = Е(р(Х) - У)2 = Е[(р(Х) - М(Х)) + (М(Х) - У)]2 =
= Е(р(Х) - М(Х))2 + Е(ЛГ(Х) - У)2 Е(М(Х) - У)2 = Д(Л1).
Знак равенства достигается здесь лишь при р = М, следовательно, <р' = М.
Отсюда также следует, что минимальная ошибка предсказания Д* в (2)
может быть записана в виде (см. (4)-(5))
Д‘ = Д(М) = Е(У - М(Х))2 = Е{Е[(У - М (X))21 X] } = ЕО(У |Х) = а2УХ.
(Ю)
Переходя к доказательству второй части теоремы, прежде всего заметим,
что для произвольного предиктора р с учетом (6) имеем
cov((p(X), У) = Е(^(Х) - Ер(Х))(У - ЕУ) =
= е{е[(р(Х) - Ер(Х))(У - ЕУ) | X] } =
= е{((р(Х)-Е(р(Х))е[(У-ЕУ)|Х]} =
= Е(;р(Х) - Ер(Х)) (М(Х) - ЕМ(Х)) = cov((p(X), М(Х)).
В дальнейшем для сокращения записи аргумент X будем опускать и для любых
случайных величин £,£], £2 будем использовать стандартные обозначения
2 /Л м tc м cov(£1.£2)
= Dt P(t.t) = согг(£,,6) =-------------.
<т(1(7б
При р = М полученное выше равенство дает
cov(Af, У) = cov(M, М) = Ом 0,
откуда
У) = ^-
<Ту
Используя это и то, что |p(t, t)l 1, имеем
Г) - n в рЧи, п
Таким образом, р(М, У) \р(<р, У)| для любого предиктора р.
Корреляционное Квадрат максимального значения коэффициента
отношение корреляции р2(М, У) имеет специальное обозначение
7/ух и называется корреляционным отношением. Из пре-
дыдущего и (7), (10) для него можно записать следующие представления:
= р(М, У) = sup р2^, У) = -f = 1 - = 1 - —. (11)
&у &у &у
§ 6.6. Статистическая регрессия и прогнозирование
507
Отсюда следует, что т]уХ 1, если ошибка прогноза Д* -» 0, и т}уХ = 0>
если учет X не уменьшает ошибки прогноза (Д* = <ТуХ = сгу). Таким обра-
зом, корреляционное отношение г]уХ представляет собой меру зависимости
между Y и X (или меру точности прогноза, так как Д‘ = <ту(1 -- Т]ух)),
и по этой мере можно сравнивать различные совокупности прогнозных пе-
ременных в конкретных задачах: значения этой меры принадлежат интервалу
[О, 1], чем ближе г)уХ к 1, тем точнее прогноз Y поданному X, а г]уХ = 1 тогда
и только тогда, когда Y = М(Х), т.е. когда Y функционально связано с X.
Пример 2 (Прогноз в нормальной модели). Пусть совместное распределение
пары (X, У) есть нормальное распределение с ЕХ — рх, ЕУ = pY, DX = <г\,
ОУ = <т\, согг(Х У) = р, |р| < 1. Тогда (см. упр. 65 к гл. 1) прогноз У по X
имеет вид
(Ту
М(Х) = E(Y\X) = pY +—— р(Х — рх). (12)
Егос. к. о. Д* = ОуХ = (1 — р2)<гу < (Ту (см. (10)), а корреляционное от-
ношение т]уХ = 1 - Д*/Оу = р2 (см. (11)), т. е. равно квадрату коэффициента
корреляции X и У. •
4. Из истории регрессии
Термин «регрессия» был предложен Фрэнсисом Гальтоном3* и основан на сле-
дующем наблюдении. Гальтон измерял рост отца (X) и сына (У), выбранных
случайно из большой популяции людей. Если предположить, что
ЦХУ) = Л' (/z,M),
2
р > 0
(здесь р — среднее роста мужчин по популяции, а2 — дисперсия роста
по популяции), то в соответствии с (12), прогноз роста сына у отца, чей
рост X, есть
М(Х) = р + р(Х - р) = (1 - р)р + рХ (13)
и совпадает с Е(У|Т) — средним ростом сыновей, чьи отцы имеют рост X.
Из (13) следует, что прогноз М{Х) ближе к среднему по популяции р, чем
рост отца X- если рост отца Xj > р, то М(Х\) < Х\ — у высоких отцов
сыновья будут, как правило, меньшего роста, т. е. наблюдается «регрессия
к среднему». Но эта тенденция компенсируется «прогрессией к среднему»
среди сыновей отцов небольшого роста: если X? < р, то М(Хз) > X?
(см. диаграмму), и тем самым парадокса не получается — популяционное
среднее остается постоянным.
М(Х2) М(Х,)
----1 • •-----•----1—►
х2-------------------------------------р-xt
Гальтон Фрэнсис (1822-1911) — английский психолог и биолог, один из создателей евгеники.
508
Глава 6. Линейная регрессия и метод наименьших квадратов
При этом дисперсия предсказанного значения
DM(X) = D(pX) = р2 о2
меньше дисперсии а2 реальных отцов.
Здесь уместно сделать следующее замечание, имеющее общий характер.
На практике (и у Гальтона) точное распределение L(X, Y) обычно не из-
вестно и линия регрессии М(Х) строится приближенно по оценкам р и р
Эмпирический на основе большой выборки (Х,,^), г = 1, , п,
прогноз из совокупности, и в итоге используют
эмпирический прогноз
М(Х) = (]-р)р + рХ
(детальнее об этом речь будет идти позже).
Итак, если коэффициент корреляции описывает зависимость между двумя
случайными величинами одним числом, то регрессия выражает эту зависи-
мость в виде функционального соотношения и поэтому дает более полную
информацию. Вначале регрессионный анализ применялся в биологии; между
1920 и 1930 гг. он начал интенсивно использоваться в экономике, что привело
к возникновению новой области науки — эконометрики; в настоящее время
регрессионный анализ интенсивно используется практически во всех обла-
стях науки, так как анализ величины Y, определяемой подругой величине X,
когда Y измерить трудно, а X достаточно легко, весьма важен.
5. Линейный прогноз
Итак, при минимальных предположениях о совместном распределении С(Х, У)
величин X и У (требуется лишь существование вторых моментов) мы имеем
универсальное решение для прогнозирования У по наблюдению над X, да-
ваемое функцией регрессии (9). Однако здесь имеются две трудности:
1) для вычисления прогноза М(Х) = Е(У|Х) надо абсолютно точно знать
закон распределения С(Х, У) и
2) явное вычисление М(X) может оказаться трудной аналитической задачей
и прогноз может оказаться слишком сложной функцией, мало пригодной
для конкретных расчетов.
Однако обеих этих трудностей можно избежать, если сузить круг поис-
ков наилучшего предиктора до класс L простейших, а именно, линейных
предикторов у?(Х) = До + /З'Х (здесь мы считаем, что X = (Xj, , Хр)
и /3 = (Д,...,/Зр)). Для этого случая решение экстремальной проблемы (1)
дается следующим утверждением.
Теорема 2. Пусть L = {р <р(Х) = До + Р'Х_} есть класс всех линейных
предикторов У по X. Тогда оптимальный линейный предиктор (линейный
§ 6.6. Статистическая регрессия и прогнозирование
509
прогноз) ip*L = arg min Д(^) п Линеиныи прогноз дается соотношением ^(20 = ЕГ + а'Е_1(Х-ЕХ) = /Зо‘ + £"¥, (14) т. е. /30* = ЕУ - а'Е-1ЕХ = ЕУ - /3*'ЕХ, Д* = Е"‘а, где а = cov(y, X) = (cov(y, Xi), , cov(y, Xp)), S = D(X) и предполага- ется, что |S| 0. Этот предиктор имеет максимальную корреляцию с У среди всех линейных предикторов.
Доказательство. Пусть <р — произвольный линейный предиктор. Тогда его
с. к. о. A(ip) может быть записана в виде
Д(^) = Е(У - /30 - &Х)1 = Е[(Г - ЕУ) - b - 0(Х - EZ)]2 =
= ОУ 4- Ь2 + /3'7/3 - 2£'а,
где обозначено Ъ = /За - ЕУ 4-/3zEA) (проверяется непосредственно, что мы
оставляем читателю в качестве простого упражнения).
Пусть теперь /3 = /3* + 5, где /3* указано в (14) и б — произвольный
вектор. Тогда (также проверяется непосредственно)
62 + /З'Е/З - 2Д'а = Ь2 4- - /3*'а > -f'a
и равенство здесь достигается лишь при Ъ = 0, д = 0 (поскольку невырож-
денная дисперсионная матрица является положительно определенной). Таким
образом,
Д(у?) ^Dy-^,'a = <Tr-fl'E"1a = Д(^1), (15)
т.е. предиктор <p*L (14) обладает в классе L минимальной с. к.о. Первая часть
теоремы доказана.
Далее, из определения векторов а и /3* следуют равенства
cov(y,£'X)=£'a=£zE£‘
cov(y, f'X) = @*'£/3* = D(/3*'X) 0.
Из последнего равенства также имеем
о , cov(y,/3*'Z) „ ,
а^2(У, \ ~ ~ = fW (17)
ЩР
Воспользуемся неравенством Коши—Буняковского (для любых векторов а и б
(а'б)2 7 (а'а)(б'б)) в виде
(/З'Е/З’)2 = (/3'Е1/2Е1/2£*)2 (/3'Е£)(/3*'ЕД‘),
510
Глава 6. Линейная регрессия и метод наименьших квадратов
тогда из (16) и (17) получим
a2Yp2(Y,^X)
cov2(y,£'%)
(/З'Е/Г)2 . ,
^7^<^'Е^ = <т^2(У,М).
р ьр
Отсюда следует, что для любого предиктора 6 L
p(Y, f'X) = p(Y, <p*L(X)) > |р(К, М))|-
Из этих рассуждений (см. формулу (15)) следует,
что в теории линейного прогнозирования особую роль
играет величина
Множественный
коэффициент
корреляции
2 '®
Pyx = —j—.
<4
(18)
которая имеет специальное название множественный коэффициент корреляции.
Эта величина зависит только от вторых моментов совокупности переменных
(X, У) и представляет собой обобщение квадрата обычного коэффициента
корреляции на случай многомерного X (если X есть скалярная величина X,
т. е. р — I, то р2уХ = р2(Х, У)). Таким образом, рух — это мера корреляцион-
ной зависимости У от вектора Х_. Через эту меру с. к. о. линейного прогноза
<p*L можно записать в виде (см. (15))
Д1 = Л(Й) = <тг(1 -Pyx)’ ('9)
откуда следует, что чем ближе рух к 1, тем точнее прогноз Множествен-
ный коэффициент корреляции играет в теории линейного прогнозирования
такую же роль, как корреляционное отношение т]уХ (см. (11)) в общей теории
прогнозирования. Для руХ можно записать аналогичную (I I) цепочку соот-
ношений:
p2yx = ^-^ = p2(Y,M = wppXY,p) = \--±, (20)
откуда, в частности, видно, что руХ равен квадрату обычного коэффициента
корреляции между У и оптимальным линейным предиктором для У
Поскольку L С Ф, то из (11) и (20) следует, что 7}ух Рух> а в тех случа-
ях, когда функция регрессии М(Х) линейна (тогда она является линейным
прогнозом), ошибки Д* и Д1 совпадают, следовательно, r/ух Pyx- По-
2 2
этому в общем случае разность т/Гх _ Pyx может служить мерой отклонения
регрессии от линейности.
Итак, в условиях теоремы 2 линейный прогноз ^1(Х) для У также всегда
может быть построен, при этом для его вычисления достаточно знать лишь
первые и вторые моменты распределения £(Х, У),т.е. минимальную инфор-
мацию об этом распределении. На практике обычно используют линейные
прогнозы, а необходимые для этого моменты оцениваются по результатам
§ 6.6. Статистическая регрессия и прогнозирование
511
прошлых наблюдений над Х_ и У Заменив в (14) точные значения момен-
тов (когда они неизвестны, — а так обычно и бывает) их оценками, как это
описано в п. 5 §2.3, мы получаем эмпирический предиктор <pi(X_) (см. (16)
§2.3), который и используется для прогнозирования будущих значений Y
Также по прошлым наблюдениям оценивается множественный коэффициент
корреляции рух (см. формулу (17) § 2.3), что дает возможность оценить с. к. о.
(19), т.е. точность прогноза.
Примерами линейного прогноза являются прогноз в нормальной модели
(см. пример 2, соотношение (12), и упр. 25), а также прогнозы, указанные
в примере 1 и упр. 23, 24: во всех этих случаях функция регрессии М(Х)
линейна, следовательно, она, как абсолютно оптимальный предиктор (в соот-
ветствии с теоремой 1), и является линейным прогнозом. То, что функция ре-
грессии не всегда оказывается линейной, демонстрирует следующий пример.
Пример 3. Пусть модель £(Х, У) задается следующим образом:
£(У) = Ве(а, Ъ)
— бета-распределение (см. п. 4 § 1.2), а
£(Т|У =у) = В1(г,т/)
— отрицательное биномиальное распределение (см. п. 2 § 1.1). Тогда по форму-
ле Байеса (см. соотношение (3) в упр. 59 к гл. 1) условная плотность /y|x(j/|a:)
есть
. , । , _ /г(у)/х|к(д|у) а-I/, xf] \Г а+х-1/, \6+г-1
f¥\x(y\x) =---------------= У (1-J/) y(l-J/) =У (1-J/)
т. е. £(У = х) = Ве(а + х, b + г) и потому (см. (24) § 1.2)
Это есть прогноз У по X в классе всех функций <р(х), и он не является
линейным. •
6. Использование в прогнозе дополнительных переменных.
Алгоритм обновления прогноза
При практической реализации теории линейного прогнозирования возникают
следующие важные вопросы: 1) как из множества всех факторов {X,}, влияю-
щих на прогнозируемую величину У, выделить наиболее существенные, или,
другими словами, как упорядочить прогнозные переменные по степени их
важности в прогнозе У? 2) если решен 1-й вопрос, следовательно, мы имеем
упорядоченный ряд факторов Х> >- X? >- >- Хр_] Хр > то сколь-
кими факторами ограничиться в построении предиктора <p*L? 3) наконец, как
рационально действовать при расчете прогноза, чтобы избежать чрезмерных
затрат?
512
Глава 6. Линейная регрессия и метод наименьших квадратов
Хорошо поставить вопрос — значит
уже наполовину решить его.
Д. И. Менделеев
Чтобы ответить на эти вопросы, исследуем предварительно, как изменя-
ется точность прогноза при увеличении числа прогнозных переменных. Усло-
вимся далее кодировать переменные X, их индексом «г», г = 0, 1,2, при
этом Xq = У, тогда Оу = al, pyx = Po(i • Р)< а Для с- к- °- &l и (19) будем ис-
пользовать обозначение <Tq(|В этих обозначениях формула (19) примет вид
ао(1-- р) = ао(1 ~ Ро(| - р))-
Пусть по факторам X (Х|,. ,Xp-i) построен линейный прогноз
У’дСК) = 5p-i (см. (14), где X есть вектор размерности р - 1); его с. к. о. есть
а0(1 р-i) = ао(1 “ Po(i - p-i))- Если добавить в прогноз новое переменное Хр,
то с. к. о. нового предиктора Yp = у?1(Х|, , Хр) станет равной о’о(|...р) =
= al(1 — Po(|...pj). Следовательно, относительное уменьшение ошибки про-
гноза при добавлении р-ro переменного будет равно
°~0(1- -р-l) ~ <1-р) ?0(1---р) ~ Po(l - p-l) _ J /эП
2 . _ 2 - Р0р(1 • •₽-!) (2U
а0(1р-1) 1 Л)(Ь.р-1)
* Частная корреляция Определенную в (21) величину pOp(i p-i) называют
частной корреляцией между Y и Хр, исключающей
влияние «промежуточных» переменных Х{,..., Xp_i Из (21) следует, что
сг0(Ь- р) = а0(1-- р-1)( 1 ” А)р(1-• р- !))> (22)
и если частная корреляция Pop(i - p-i) мала, то учет Хр мало что добавляет
в прогноз. При р = равенство (22) принимает вид адц) = <7о( 1 - ph),
т. е. наибольшую точность простейший предиктор У* имеет, если фактор X)
имеет наибольшую корреляцию с У.
Отсюда вытекает следующий принцип упорядочения факторов по степе-
ни их важности в прогнозе: в качестве первого фактора Х| выбирается фактор
с наибольшей корреляцией с У; в качестве следующего по важности фактора Х-^
выбирается фактор с наибольшей частной корреляцией с У, исключающей вли-
яние Х|, и т.д., т.е. частная корреляция Pop(i p-i) является инструментом
упорядочения предсказывающих переменных по степени их важности в про-
гнозировании У.
Отметим некоторые свойства частной корреляции. Обозначим
Pij = Р(Х„ Xj), = р = llpijllo и Р-'=||Л-
§6.6. Статистическая регрессия и прогнозирование
513
Тогда
_ аР_ PO2~POiPl2
POp(l--p-l) — /-дд — /------------
^(1 -РО2.)(1 -
Далее, построим линейный прогноздля Хр по переменным X = (Хь ...
ХР-,):
Хр = aj + а'Х, а = E“‘b, b = cov(Xp, X),
aj = ЕХР - a*'EX, E = D(X),
и рассмотрим остатки et = Y — Ур_| и e2 = Xp - Xp. Тогда можно показать,
что
Pop(i- -p-i) = р(е1. ез), (24)
т. е. частная корреляция — это обычный коэффициент корреляции между остат-
ками, получающимися вычитанием из Y и Хр их оптимальных линейных предик-
торов, основанных на Хь , Xp_i (так исключается влияние общих факторов
Хь , Хр_1 на переменные У и Хр).
Остатки е, являющиеся ошибками соответствующих прогнозов, обладают
следующими свойствами:
1) они имеют нулевое среднее, так как
Ed = ЕУ - ЕУр’_, = ЕУ - ДЗ - Д*'ЕХ = 0 (см. (14));
2) следовательно, Dei = Е(У - Ур_,)2 = Д* = ^о(ь-р-1);
3) соу(Д'Х, е,) = соу(Д'Х, У - Д*'Х) = Д'а - Д'ЕД* = Д'а - Д'а = О,
т. е. они некоррелированы с прогнозными переменными. Это свойство
можно проинтерпретировать также так: оптимальный линейный предиктор
концентрирует в себе всю корреляцию У с прогнозными переменными.
На изложенном выше основан следующий эф- Алгоритм обнов-
фективный алгоритм обновления прогноза для У при ления прогноза
добавлении в прогноз дополнительного переменного.
Пусть построен прогноз (см. (14))
Ур‘_1 = ^(Хь...,Хр_|) = ^+^Х Х = (ХЬ ,ХР_,),
и будем искать новый предиктор Ур при добавлении в прогноз новой пере-
менной (фактора) Хр в виде линейной комбинации До + Д'Х + Дре2. Тогда
для определения коэффициентов надо минимизировать с. к. о.
Е((У - До - Д'Х) - Дре2)2 =
= Е(У - До - Д'Х)2 + Д2<г2, - 2ДР cov(ei, е2) =
, i ( cov(ei,e2)\2 7 cov2(ei,e2)
= Е(У - До - Д'Х)2 + \0Р----------------------Ч^
X / &е2
33 Заказ 1748
514
Глава 6. Линейная регрессия и метод наименьших квадратов
(поскольку
cov(K - /За-$Х_, е2) = cov(e,, е2) + cov(yp_, - /З'Х, е2) = cov(ei, е2)).
Отсюда следует, что оптимальные значения для /Зц и (3 = (Д,..., /Зр_\) —
прежние (см. (14)), а оптимальный выбор /Зр таков (см. (24)):
cov(e,,e2) сге, <re,
Рр — ~ р(е1, е2)—— Рор(1- р-1)— (25)
^еэ ^6’2
Таким образом, новый прогноз может быть вычислен по формуле
г; = у;_, + 0*ре2 = Ур‘_, + /3*р(Хр - Хр) =
р-1
= - а*0/3*р + ^(£ - а*/Зр)Х{ + #ХР, (26)
i=i
т. е. предыдущие коэффициенты (перед переменными Хн , Xp_i) пересчи-
тываются, а коэффициент при новой переменной Хр равен /3*р (см. (25)). При
этом ошибка нового прогноза вычисляется по формуле (22).
Фактически это есть реккурентный алгоритм построения прогноза: мы
начинаем с простейшего предиктора.
yl* = ^+js;x1, #=poi-, /з; = ЕУ-/даь (27)
его с. к.о. a], = crofi) = 1 - ph), и последовательно добавляем новые пе-
ременные Х2, Xj, (по степени убывания их значимости) с пересчетом
по формуле (26) на каждом шагу коэффициентов предыдущей линейной ком-
бинации, пока не достигнем желаемой точности прогноза, что контролируется
формулой (22) (см. также пример 1 в п. 5 §2.3).
7. Прогнозирование стационарных временных рядов
Наиболее важные применения теории линейного прогноза связаны с прогно-
зированием стационарных случайных процессов. Под этим термином мы будем
понимать последовательность случайных величин {X/, t G Z}, Z — множе-
ство всех целых чисел, удовлетворяющих следующим условиям:
ЕХ/ = т = const, eov(Xl+k,Xi) = Rk, V<. (28)
Таким образом, для стационарной последовательности {Х(} среднее любого
ее члена остается постоянным, а ковариации между ее членами зависят лишь
Временной ряд от Разности их номеров. Параметр t обычно трактуется
как (дискретное) время, а последовательность {Xz} назы-
вают временным рядом. Величину Rk в (28) обычно называют автоковариацией
с задержкой (лагом) к, а всю последовательность — автоковариаци-
анной функцией или, кратко, автоковариацией. Отметим следующие очевидные
§ 6.6. Статистическая регрессия и прогнозирование
515
ее свойства:
Ro = DX( = а2 = const,
согг(Х/+ь Xt) = = pk,
|Л*|*£Яо, R-k = Rk, p-k=pk, W
П n / n \
У2 Ri-jCiCj = У7 c»cj cov(-^i> %j) — D( 22 c'^i) 0’ ^n-
i,j=\ i.j=\ ''i=l '
Определенный в (29) коэффициент корреляции pk обычно называют ав-
токорреляцией с задержкой fc, а всю последовательность {/>*}?□□ — автокор-
реляционной функцией или, кратко, автокорреляцией (в технической литературе
используется также термин коррелограмма). Последнее свойство в (29) называ-
ется свойством положительной определенности автоконариации. В дальнейшем
предполагается, что матрица 7?(п) = ||Я,_;-||? не вырождена при любом п 1.
Сделаем еще одно дополнительное предположение, при котором модель
временного ряда обладает хорошими свойствами регулярности. Именно, будем
считать, что выполняется условие
ОО 00
22 |Я*| = Яо + 252|Я4|<оо. (30)
к = - оо к = I
Если имеет место (30), то можно рассмотреть преобразование Фурье автоко-
вариации {Л*}:
1 00 1 1 00
/(А) = — Rk cos кХ = —Rq -J— Rk cos кХ,
м 7 2тг 2тг тг /31)
*=-00 к = \ '
X € [-тг, тг].
Условие (30) обеспечивает равномерную сходимость ряда (31) к непрерывной
функции, и его сумма /(А) называется спектральной плотностью временного
ряда {XJ. Коэффициенты сходящегося ряда Фурье, Спектрольноя
как известно, однозначно определяются его суммой ПЛОТНОсть
по формулам
Rk = у /(A) cos кХ dX, к б Z. (32)
-ТГ
Соотношения (31)—(32) показывают, что спектральная плотность /(А) (когда
она существует) и автоковариация {Я*} находятся во взаимно-однозначном
соответствии, поэтому стационарный временной ряд {XJ можно описывать
в терминах любой из этих двух функций.
Фурье Жан Батист Жозеф (1768-1830) — французский математик, один из основополож-
ников математической физики, почетный член Петербургской АН (1829).
33*
516
Глава б. Линейная регрессия и метод наименьших квадратов
Модель стационарного временного ряда является удобной для исследо-
вания и в то же время подходящей для описания многих реальных процессов.
В рамках этой модели, в частности, достаточно просто решаются задачи про-
гнозирования, что и является нашей целью в этом пункте. В общем виде задача
ставится так: построить оптимальный линейный предиктор (прогноз) для зна-
чения Xt процесса в момент t, предполагая, что известно некоторое число
n 1 предыдущих значений Л)_|,.. , Л)_ге. Покажем, как адаптируется
разработанная выше общая теория линейного прогнозирования к модели ста-
ционарного временного ряда. Для простоты будем считать, что т = EXt = О,
в противном случае Xt нужно просто заменить на Xt - т. В этом случае
по теореме 2 n-прогноз Х{п для Xt имеет вид
х;п = +...+/rnnxt-n = Р'тх^. (зз)
;=i
где pnj, j = 1...n, минимизируют относительно Дь ,Дге среднеквадра-
(п ч 2
Xt-^ ^Х^ 1 Согласно (14), коэффици-
j=i '
енты Д* = (Дп1> ,Рпп) оптимального n-предиктора определяются в данном
случае автоковариацией {Л/.} процесса по следующим формулам:
Д; = Д-‘(п)а, o = cov(Xb(Xf_,,...,Xf_„)) = (Д,, ,Я„). (34)
Если обозначить R~l(n) = ||flIJ||", то в координатной записи решение имеет
вид
= 7 = 1, ,п. (34')
i=i
Наконец, с. к. о. Д*(п) прогноза Х(П, согласно соотношениям (18)-(19) и (29),
есть
Д’ (п) = Е(Х, - Х(*п)2 = До - aR~1 (п)а. (35)
Если воспользоваться следующей формулой для разложения определителя:
“ = |Л|(0-&'Л-‘с)
(здесь А — квадратная невырожденная матрица, Ь и с — векторы-столбцы
и а — скаляр) и положить здесь А = R(n), а = Ro, Ь = с = а, то формуле
(35) можно придать вид
Соотношениями (33)-(35z) полностью решается задача построения и рас-
чета линейного прогноза в модели стационарного временного ряда.
§ 6.6. Статистическая регрессия и прогнозирование
517
Рассмотрим, наконец, как конкретизируется в дан- Обновление
ном случае алгоритм обновления прогноза, если мы хотим прогноза
добавить в прогноз дополнительное наблюдение
(см. соотношение (26)). Прежде всего мы должны построить еще один п-про-
гноз по тем же переменным Хг_|,..., Х^п для величины Хг_п_1 (так сказать,
прогноз в прошлое). В силу специальной структуры стационарного времен-
ного ряда (корреляции между его членами зависят лишь от разности соответ-
ствующих моментов времени) этот «обратный» предиктор Xl_n_} имеет те же
коэффициенты, что в (33), но переменные должны быть взяты в обратном
порядке:
лг;_п_, = + +^„хе_| (зб)
(в этом легко убедиться и формальными выкладками, повторив рассуждения,
использованные при выводе (33), что мы рекомендуем читателю проделать
самостоятельно). Далее мы рассматриваем остаток en = - Л'е*_п_1,
который некоррелирован с переменными Xt-i, ,Xt-n и имеет дисперсию
<Теп = Д‘(п), указанную в (35'). Наконец, новый (п + 1)-предиктор Х^п+1
для Xt, учитывающий дополнительную, (п+ 1)-ю переменную Xj_n_|, имеет
вид
Ап+1 = ^1п /^n+l,n+l^n>
где (см. (25) и (36))
_ cov(Xt, еп) _ Лп+1-Д*1Лп- -P*nnR\
/3n+1,n+, - - д*(п)
'(37)
(38)
при этом Дп+1П+1 есть частная корреляция Xt с Xj_n-i, исключающая вли-
яние всех промежуточных переменных Xt_],.... Xt_n.
Подставив в (37) выражения (33) и (36), получим явное представление
(п + 1)-прогноза Xt n+l через прогнозные переменные Xj-i, ..., Xt~n~\:
^,n+l — y(/3n; + j,n+l/3n,n-j + l)-^4-j T ^n+l.n+l-^t-n-l- (39)
3 = 1
Этими соотношениями (36)-(39) и решается проблема обновления прогноза
в модели временного ряда: мы видим, что добавление к n-прогнозу Х{п
в (37) нового члена /?п+1.п+1еп вносит поправки в старые коэффициенты при
переменных Af_|,. ,Xt-n. Таким образом, если записать (п + 1)-прогноз
в стандартной форме типа (33)
п+1
*;.„+> = (40)
3 = 1
то мы получаем, сравнивая (40) с (39), следующие рекуррентные уравнения
для вычисления его коэффициентов:
/Зп+I.J 0nj ~ /^П+1, n + 1/Зп, n-j + 1 1 j (41)
гдеДп+i.n+i указано в (38).
518
Глава 6. Линейная регрессия и метод наименьших квадратов
Наконец, формула (22) для с. к. о. обновленного прогноза конкретизиру-
ется в данном случае к виду
Д*(п + 1) = Д‘(п)(1-С1,п+1).
(42)
Если задать еще соответствующие величины для первого шага (n = 1):
Рп
Я.
/?о
д,(1) = г
Яо
Я,
(43)
= Яо(1-/3’|1)
(см. соотношения (34) и (35х) для п = 1), то мы имеем эффективный рекур-
рентный алгоритм построения прогноза в модели стационарного временного
ряда. Именно: начиная с соотношений (43), далее для п > 1 по уравнениям
(38) и (41) последовательно вычисляем коэффициенты прогноза до требуемого
порядка, а уравнение (42) позволяет на каждом шагу контролировать ошибку
соответствующего предиктора.
Замечание. Мы рассмотрели проблему прогнозирования на один шаг вперед (при из-
вестных значениях Xt_j, j = 1,2,..., оценивается Xt). Но, очевидно, на том же
пути можно рассчитать соответствующий прогноз и на любое число шагов вперед,
т.е. построить предиктор для АГ/+д. по наблюдениям над Xt_t, ,Х^„ для любого
конечного к > 0: для этого в алгоритме вычисления предиктора (33) достаточно
лишь заменить вектор а = в0 = (Л|,..., Rn) на вектор «ц. = (JJt+।, , 2?*+п).
Замечание. Представляет также интерес вопрос об асимптотическом (при п -> оо)
поведении ошибки (35') прогноза (33), т.е. при неограниченно возрастающем числе
прогнозных переменных. Если Д*(п) -> 0 при п -> оо, то прогноз (33) является
асимптотически точным. Обозначим А„; , j = 1,..., п, собственные числа матрицы
ковариаций R(n). Можно показать, что Д‘(п) -> е*, где
1 "
fc = lim — V' In АП) .
j = l
Таким образом, прогноз X(’n является асимптотически точным <=> к = -оо. Если же
к > -оо, то, как установил А. Н. Колмогоров (1941),
7Г
lim Д*(п) = exp < In 2тг + —- / In /(A) dX >,
n-юо 27Г J J
-JT
где /(А) — спектральная плотность процесса {X(}, определенная в (31).
Мы ограничиваемся этим общим введением в теорию стохастического
прогнозирования и отсылаем заинтересованного читателя к книге [4], где да-
но более детальное изложение этой теории и ее применений к анализу ряда
важных для приложений конкретных моделей временных рядов (как стацио-
нарных, так и нестационарных), а также подробно описана и проиллюстри-
рована ее компьютерная реализация в системе STATIST1CA.
§ б.б. Статистическая регрессия и прогнозирование
519
Если знать, что ждет нас впереди, то
стоит ли переживать это заново?
Конфуций51
В заключение мы рассмотрим несколько примеров расчета прогнозов
в конкретных физических моделях.
Пример 4 (Прогнозирование в схеме бесповторного выбора). Имеется урна
с а шарами, а! из которых белые и а? = а-а\ — черные. Шары извлекаются
по одному последовательно, равновероятно и без возвращения. Пусть £(п)
обозначает число белых шаров в выборке объема n, п < N Построим прогноз
(п(к) для ((п + к) при известном ((п), 1 к а - п. •
Решение. Если £(n) = s, то в урне после пизвлечений осталось а - п ша-
ров, из которых а, - s — белые, а остальные а — п - а.\ s — черные.
Далее из этой остаточной урны должно быть извлечено еще к шаров, поэто-
му (см. п. 4 § 1.1) число £(п + к) - s белых шаров в этой дополнительной
выборке имеет гипергеометрическое распределение Я(а, - s, e2 - п + s, к).
По формуле (10) § 1.1 математическое ожидание этой случайной величины,
т.е. Е(((п + к) - 8 | £(«) = s), равно к--. Но прогноз
а — п
<‘(fc) = E(<(n + fc)|<(n)),
поэтому отсюда имеем
{;W = «W + S5i^ =
а — п
= ----— \(п) 4-а,—— Е к(п),а,]. (44)
\ а — п/ а — га
Пример 5 (Прогнозирование в схеме повторного выбора). В урне имеется N
шаров, занумерованных числами 1,2, ,N. Шары извлекаются по одному
последовательно, равновероятно и с возвращением. Пусть Х(п) обозначает
число различных шаров в выборке объема п. Построим прогноз Х„(к) для
Х(п + к) при известном Х(п). •
Решение. Пусть Х(п) = s. Обозначим гь ,In-s номера шаров, не из-
влекавшихся ни разу в первых п извлечениях, и положим Ij = 1, если шар
с номером ij будет извлечен хотя бы один раз при следующих к извлечениях,
и Ij — 0 в противном случае. Тогда, очевидно,
N-s
X (га + к) = s + ' Ij
7=1
51 Конфуций (551-479 до н.э.) — древнекитайский мыслитель.
520 Глава 6. Линейная регрессия и метод наименьших квадратов
и
Е(/} | Х(п) = s) = Р{/; = 1 | Х(п) = з} =
= 1 - Р{4 = 0 I Х(п) = 4 = ] - Л - 1
откуда
Е(Х(п + к) | Х(п) = s)=s + (N-s)
Таким образом, окончательно имеем
Х*(к) = Е(Х(п + к)\ Х(п)) =
= Х(п) + (N - X(n)) I -
Jk г / j \ к
Х(п)+ЛГ 1-
е [х(п),М
(45)
Предвидеть — значит управлять.
Б. Паскаль
Упражнения
Приступай к решению своих проблем правильно и начинай с от-
ветов. Тогда, возможно, однажды ты найдешь главный вопрос.
Р. ван Гулик. Отшельник в журавлиных перьях
(в книге «Убийства в китайском лабиринте»)
П Убедиться в том, что система нормальных уравнений метода наименьших квад-
ратов
dS(0)
—2=1 = 0, к,
дд, 7
имеет вид Ар = ZX, где А = ZZ'
Q Получить следующие явные формулы для о. н. к. Q (см. (2) §6.2) при к =2:
Упражнения
521
Получить отсюда при z(,) = (zj'1, z*'1) = (1, t.) формулы (22) §6.2
Q Проверить непосредственно несмещенность о. н. к. (22) § 6.2 в модели простой
регрессии и найти условие их состоятельности, т.е. условие, при котором D/37 -> О
при п -> оо (j = 1,2).
Q Показать, что для состоятельности оценки <т2 в модели простой регрессии доста-
точно, чтобы DS(P)/n2 -> 0 при п -> оо, где S(/3) дано в (23) §6.2. Проверить, что
в случае нормальной регрессии это условие выполняется.
Q Значения функции x(t) = /3, + p2t + /З3£2 измерены в точках t, (i = 1,.... n):
; = x(tj) + e,, Ec, = 0, De, = ст2 cov(e,,e;) = 0, i^j.
Найти: I) o.h.k. /3,, p2, p2\ 2) Е/3,-, D/3,, cov(/3,,/3j).
Q (Продолжение). Убедиться в том, что статистика
ь
J = J x(t)dt,
а
где x(t) = pi + fat + pyt2, является несмещенной оценкой интеграла
ъ
J = J x(t)dt;
а
получить формулу
Dj= (Ь- °),+; cov(fl,fl).
Q Смоделировать наблюдения X,=/3i +/32t, +£;, i = 1,... ,п, если n= 100, /3, =2,
^2 = 1, t,- = 2i/n, e, — независимые равномерно распределенные на [-1,386; 1,386]
случайные величины. Построить графики функций x(t) = 2 + <, x(t) = 3i + Pit
на отрезке [0, 2|; отметить также точки (tj, X,), i = 1,..., n.
◄ Указание. См. замечание в п. 6 § 1.3. ►
Q Выполнить такое же задание, как в упр. 7, но с е,- распределенными нормально
с Ее, = 0, De, = 0,16.
◄ Указание. Использовать алгоритмы п. 8 н 6 § 1.3. ►
Q В предыдущем упражнении получить следующие общие формулы для 7-довери-
тельных интервалов параметров /3(, р2 на2:
/ - " j \
S(P)^t2
Pi Т^ц.-о/г.п-г й
\ п(п - 2) ^2(t, - t)2
\ N =' /
522
Глава 6. Линейная регрессия и метод наименьших квадратов
/ X
S(P)
& Т<(|+7)/2,и-2 -------------------
(п - 2) £(t, - О2
V N =• /
5(3) , 5(3)
—---------- < а ’ < —2-------
Х(1+7)/2.п-2 Х(|-7)/2,п-2
и рассчитать их численные значения по результатам моделирования при 7 = 0,9 и
7 = 0,95 (выражение для S(J3) указано в формуле (23) §6.2). Построить также 7-до-
верительный эллипс 67(Х) Для вектора (/3|,/Э2), указанный в примере 1 §6.3.
ПИ По данным независимых равноточных измерений (X,-, <,), i = 1, ,п,значений
некоторой линейной функции x(t) = pt + p2t (погрешности измерений подчиняются
нормальному распределению ЛГ(0, <т") с неизвестной дисперсией) построить довери-
тельный интервал для величины
а
f x(t) dt (а задано).
Провести соответствующие вычисления для следующих данных: (2,96; -2), (3,20; -1),
(3,41; 0), (3,63; 1), (3,79; 2) при а = 2 и доверительном уровне 7 = 0,95.
Ч Указание. Воспользоваться предыдущим упр. ►
ш Координаты a(t) движущейся равномерно и прямолинейно точки (т.е. a(t) =
= а(0) + vt) в моменты t = 1,2, 3,4, 5 оказались соответственно равны 12,98; 13,05;
13,32; 14,22; 13,97 Предполагая погрешности измерений независимыми и нормаль-
ными V(0,a2), построить 0,95-доверительный эллипс для вектора (а(0), v), где v —
скорость точки.
Ч Указание. Использовать результат примера 1 § 6.3. ►
ш Смоделировать наблюдения X, = /3, + p2t + /З3<2 + е,, г = 1, , п с Д| = -8,
/32 = Ю, = -2, п = 100, <, = I + 2г/тг, е, — независимые равномерно распреде-
ленные на отрезке [-1,386; 1,386] случайные величины. Построить графики функций
x{t) = + p2t -I- вр2 и x(t) = Pi + PJ. + рр2 на отрезке [1, 3|.
ш Выполнить такое же задание, как в упр. 12, в случае нормально распределенных
е, с Ее,' = 0, De,' = 0,16.
1И В предыдущем упр. построить 7-доверительные интервалы для параметров Pi,
Pi, Pi на2, а также систему совместных доверительных интервалов уровня > 7 для
Р\, Р2, Pi (см. пример 3 §6.3).
IB В четырехугольнике ABCD результаты независимых и равноточных измерений
углов ABD, DBC, ABC, BCD, CDB, BD4, CDA и D4B (в градусах) соот-
ветственно таковы: 50,78; 30,25; 78,29; 99,57; 50,42; 40,59; 88,87; 89,86. Считая, что
ошибки измерений распределены нормально ЛГ(0, а2), найти о. н. к. углов Pi = 4BD,
Pi = ВВС, Pi = CDB и вА = ВОЛ. Построить 0,95-доверительный интервал для а'.
Упражнения
523
◄ Указание. В данном случае речь идет о следующей модели нормальной регрессии:
Х| = Хт = /Зт + Ет, Хз=^|+^2+£з, Xt — 1 80 — Д2 — /?з + Eq ,
= /Зз + £5, Х6 = /3^ + Еб, Xi = /?з + Д 4- е7, Xg = 180 — Д, — Д, + Eg
(X, — результаты указанных последовательных измерений). ►
Ш Используя представление (8) §6.2), установить формулу
k к
= <т2£а-'
3=1 ;=1
где Xj — собственные числа матрицы А; вывести отсюда критерий состоятельности
о. н. к. /3,: min Xj -4 оо при п -> оо.
◄ Указание. Использовать следующие факты из теории матриц: собственные числа
матрицы Л-1 являются обратными значениями собственных чисел А и след А равен
сумме ее собственных чисел. ►
ш Убедиться в том, что интервалы
~ ~ Г k
1 j < i k,
образуют систему совместных доверительных интервалов уровня 7 для разностей
ш Построить систему совместных доверительных интервалов для средних значений
всех наблюдений X,, , Хп в модели нормальной регрессии.
◄ Указание. Положить в соотношении (24) §6.3) Аг = /г) г = 1..п. ►
ш Пусть имеются к предметов, веса которых 0ь... ,/Зк неизвестны. Для определе-
ния этих весов взвешиваются комбинации предметов: каждая операция (взвешивание)
состоит в том, что несколько предметов кладут на одну чашу весов, несколько —
на другую и добавляют разновес для приведения весов в равновесие. В результате по-
лучают соотношения
/3>^ + = xi
(для i-го взвешивания, i = 1,. , п), где zj'1 = I, —1,0 в зависимости от того, ле-
жит у-й предмет на левой чаше весов, на правой или вообще не участвует в данном
(г-м) взвешивании, a z, — добавляемый вес. Считав погрешности измерений незави-
симыми и нормальными а2), оценить веса четырех (к = 4) предметов по данным
следующей таблицы восьми (п = 8) взвешиваний:
(содержимое внутренней части таблицы образует матрицу плана Z = ||z(l) z(8,||
с ортогональными строками z; = (z**\ ..., zj8*), j = I, 2, 3,4). Вычислить вторые
524 Глава 6. Линейная регрессия и метод наименьших квадратов
моменты оценок, а также найти оценку для <т2 Построить систему совместных дове-
рительных интервалов для ..., с доверительным уровнем 0,95.
◄ Указание. Воспользоваться теоремой 4 § 6.2. ►
ш Построить F-критерий (6) §6.4, используя результат примера 1 §6.3 и принцип
соответствия между проверкой гипотез и доверительным оцениванием (см. п. 2 §6.4
и п. 4 §5.3).
ш Убедиться в том, что для случая двух выборок F-критерий однородности, по-
строенный в п. 2 §6.5, совпадает с критерием (9) §5.4; в случае же произвольного
числа выборок А-статистика (7) § 5.4 и F-статистика (11) § 6.5 связаны соотношением
/Л-l у"'2
АП|...П* — ( --Г? + 1 )
\п - k J
ш Доказать формулу (20) § 6.4, выражающую F-статистику критерия значимости
регрессии через коэффициент детерминации .
И Пусть £(Х) = П(А) — распределение Пуассона с параметром А, а £(У = к) =
= Bi(fc,р} — биномиальное распределение с параметрами к и р. Показать, что
М(Х) = Е(У|Л) = рХ, М(У) = Е(АГ|У) = Ад+У q = 1 - р,
D(y |Х) = pqX, D(X | У) = Ag
и, следовательно, <т'ух = Xpq, аХУ = Ад.
И (Продолжение}. Показать, что £(У) = П(Ар) и потому ау = Хр, агх = А. Полу-
чить отсюда, что для обоих прогнозов М(Х) и ЛГ(У) их корреляционные отношения
совпадают и равны р.
ES Используя результат упр. 66 к гл. 1, построить прогноз У по Х_ в общей нормаль-
ной модели и убедиться в том, что корреляционное отношение в этом случае имеет вид
T?YX = 1 - (<7„.<ГГГ)-'
вз Построить линейный прогноз <р\(Х} в модели, описанной в примере 3 § 6.6.
Пусть величина У имеет распределение Парето с параметрами х0 > 0 и а > 2
(см. п. 9 §1.2), а £(АГ|У = у) = U(0, у} — равномерное распределение на[0,у].
Убедиться в том, что прогноз У по X в классе всех функций р(Х) имеет вид
М(Х) = Е(У|Х) = —— max^o, X) иегос. к. о. Д* = ——-
а а(а — 2)
Ч Указание. См. решение аналогичной задачи в примере 3 § 6.6. ►
ЕЗ Доказать формулу (23) § 6.6 для случая р = 2.
И Получить вид прогноза У)’, указанный в примере I п. 5 §2.3, как результат об-
новления прогноза У/ (см. (27) §6.6) по алгоритму (26) §6.6.
Каждая истина проходит через три инстанции:
«какая чушь», «в этом что-то есть» и «кто же
этого не знает»!
Триада Гумбольдта
Гумболыгг Вильгельм (1767-1835) — немецкий ученый, философ и государственный деятель.
Глава 7
Элементы теории решений.
Дискриминантный анализ
Дело не в том, что они не видят решения.
Дело в том, что они не видят проблемы.
Г. К. Честертон
Острие булавки (из сборника
«Скандальное происшествие с отцом Брауном»)
Эта небольшая глава представляет собой краткое введение в одно из важ-
ных направлений современных статистических исследований — теорию ста-
тистических решающих функций. Здесь излагаются основные идеи и некото-
рые результаты этой теории в рамках двух традиционных подходов к приня-
тию решения — байесовского и минимаксного. Общие идеи иллюстрируются
практически важным примером решения задачи классификации наблюдений
по нескольким классам. Подробно исследуется ряд ситуаций, характеризую-
щихся предположением о нормальном законе распределения наблюдений.
§ 7.1. Статистические решающие функции.
Байесовское и минимаксное решения
1. Понятие решающей функции
Во многих случаях конечную цель статистического анализа можно выразить
в форме решения о том или ином поведении или действии. Так, при выбо-
рочном контроле продукции следует принять одно из двух решений: принять
партию изделий или забраковать ее; врач, анализируя симптомы болезни,
должен отнести ее к одному из конечного числа стандартных видов, т. е.
принять одно из конечного числа возможных решений; анализируя данные
наблюдения за некоторым случайным процессом с постоянным, но неизвест-
ным средним, требуется принять решение о величине воздействия на процесс
(его коррекции) для приведения среднего, например, к нулю; это воздействие
может быть выражено некоторым действительным числом t и, следовательно,
здесь число решений бесконечно. Во всех этих случаях решение принима-
ется на основании анализа наблюдения х над соответствующей случайной
величиной X и, следовательно, представляет собой некоторую функцию 6(х)
О Честертон Гилберт Кит (1874-1936) — английский писатель.
526 Глава 7. Элементы теории решений. Дискриминантный анализ
на выборочном пространстве X = {я}, область значений которой — мно-
жество возможных в данной ситуации решений D {d}. Таким образом,
8(х) — это правило, ставящее в соответствие каждому результату наблюдения
х G X решение d — 8(х) G D, которое должно быть принято. Функцию 8(х)
называют решающей функцией (или решающим правилом, или процедурой), и ее
следует выбирать п соответствии с некоторыми требованиями оптимальности.
Принципы решения этой задачи развивает теория статистических решающих
функций (теориярешений), разработанная А. Вальдом (1950). Ниже кратко из-
лагаются некоторые основные идеи и результаты этой теории.
2. Функция риска и допустимые решающие правила
Пусть заданы класс распределений (модель) Т = {^(а:; 0), 0 G в}, которому,
по предположению, принадлежит (неизвестное) распределение наблюдаемой
случайной величины X, и множество решений D {</}, которые можно
принимать на основании наблюдения над X. Чтобы получить критерий выбо-
ра решающей функции, надо сравнить результаты использования различных
правил 8. Введем для этого неотрицательную функцию потерь L(d, 0), опреде-
ленную на прямом произведении D х 0, где для каждых d 6 D и в 6 0 число
L(d, в) 0 интерпретируется как убыток или потеря от принятия решения d,
когда X имеет распределение F(x; 9). Тогда для всякого пра-
иск вила J можно определить функцию риска (или просто риск)
R(8,0) = EeL(8(X),0), (1)
представляющую собой средние потери от применения решающего правила 8,
когда истинным распределением наблюдений является распределение F(x, 0).
Функция риска дает критерий сравнения различных решающих правил,
а именно, если для двух правил 8' и 8 выполняется неравенство
R(6',0)^R(6,O), V0G0, (2)
со строгим неравенством хотя бы для одного значения в, то правило 8' пред-
почтительнее 6, так как использование 6' приводит в среднем к меньшим
потерям. С другой стороны, решающие правила <5] и 8^ могут оказаться не-
сравнимыми по критерию (2), если R(8\, 0) < R(8?, в) для некоторых значе-
ний в, а для остальных значений 0 имеет место обратное неравенство. Чтобы
выбрать в такой ситуации одно из двух правил, необходимо привлекать до-
полнительные соображения.
Недопустимые аким °бразом функция риска позволяет лишь час-
решоющие пропила тично упорядочить все решающие правила 6. X—>Г>,
тем не мене, она позволяет «отсеять» заведомо пло-
хие правила. Назовем правило 8 недопустимым, если существует правило 8'
предпочтительнее 8 в смысле (2). Решающее правило, не являющееся не-
допустимым, называется допустимым. Ясно, что все недопустимые правила
должны быть отвергнуты, так как для каждого из них можно найти более оп-
тимальное (в указанном смысле) правило. Если класс допустимых решающих
§ 7.1. Статистические решающие функции
527
правил состоит из единственного правила, то оно и является оптимальным
решением. Но обычно этот класс достаточно широк и никакие два решающие
правила из множества допустимых несравнимы (по критерию (2)). Поэтому
для дальнейшего упорядочения допустимых правил и выбора среди них луч-
шего привлекают дополнительные соображения. Для решения этой задачи в
статистике традиционно применяют два подхода: байесовский и минимаксный.
3. Байесовское решение
При байесовском подходе дополнительно предполагается, что параметр в —
это случайная величина с некоторым известным распределением, задаваемым
плотностью 7г(0) и называемым априорным распределе-
нием. В этом случае можно усреднить риск (1) по этому Априорное Ж
априорному распределению и тем самым подсчитать роспределение
полную среднюю потерю (усредненный риск)
г(<5) = / Л(<5,0)тг(6»)</6»
(3)
(если 0 принимает дискретные значения, то интеграл заменяется суммой
53 . R(d, которую мы несем при использовании решающего прави-
ла S. Величина г (5) в (3) называется байесовским риском Байесовский риск
правила <5. Таким образом, при таком подходе каждое
решающее правило характеризуется одним числом и, следовательно, все ре-
шающие правила могут быть упорядочены в соответствии со значениями этой
характеристики. Оптимальной является процедура, минимизирующая байе-
совский риск г((5):
6* = arg min 5; (4)
i
она называется байесовским решением. Подчеркнем, что Байесовское
<5* зависит от выбора априорного распределения тг: решение
<5* = 6^, поэтому для различных априорных распре- MMife
делений параметра соответствующие байесовские ре-
шения будут, вообще говоря, различны.
Байесовское решение <5* находят на основании тео- Теорема Байеса *
ремы Байеса, согласно которой апостериорное распреде-
ление параметра при условии X = х задается условной
плотностью
где
или
= ~пГ'
= Е/(х;й) = j f(x; й)ж(Е) dd,
№) = 13 f(X’
(5)
528 Глава 7. Элементы теории решений. Дискриминантный анализ
в дискретном случае. Тогда равенство (3) можно записать в виде (в абсолютно
непрерывном случае)
r(<5) = f dx^n(0) d6 =
= /(/ Ь(5(х),0)тг^|а:) d9^ /(i) dx =
= [ f(x)E[L(6(X),9)\X = x]dx
(6)
(в дискретном случае интегралы заменяются соответствующими суммами).
Из соотношения (6) следует, что оптимальной является такая процедура, кото-
рая при каждом х минимизирует средние потери относительно апостериорного
распределения тг(^|2г).
Таким образом, для заданного априорного распре-
горитм деления параметра тг(0) алгоритм нахождения байесов-
ского решения имеет следующий вид:
а) для X = х по формуле (5) находят апостериорное распределение 7г(0|х);
б) после этого для каждого возможного решения d Е D вычисляют среднюю
потерю E[Z(d, 0) | X = я] относительно этого апостериорного распреде-
ления;
в) в качестве искомого выбирают решение с минимальной средней потерей.
Отметим, наконец, что байесовское решение, построенное для любого
распределения тг(0) > 0, является допустимым. Действительно, пусть S* —
соответствующее байесовское решение и предположим, что существует проце-
дура <5, для которой R(S, в) < R(6\ в) со строгим неравенством на множестве
значений в, имеющем положительную (относительно распределения тг) веро-
ятность. Тогда, очевидно, для соответствующих байесовских рисков (3) имеет
место неравенство r(S) < т(<5*), что противоречит определению байесовского
решения.
4. Минимаксное решение
При отсутствии априорной информации о в применяют прием упорядочения
допустимых решающих правил по максимальному значению функции риска
R(S, в) (или максимальному риску)
m(S) = sup R(S,f)), (7)
е
и из двух правил предпочтительным считают правило с меньшим максималь-
ным риском (отсюда — термин «минимаксное»). Правило S, минимизирую-
Минимакс щее называется минимаксным решающим правилом:
S = arg min тп(<5).
j
(8)
§ 7.1. Статистические решающие функции
529
Таким образом, минимаксное правило
избавляет от чрезмерных потерь: наихудший
ожидаемый ущерб для него минимален. Но
принцип минимакса не всегда благоразумен.
Так, на рис. 1 приведены графики функций
риска для двух правил и 62, откуда видно,
что правило <52 хуже для большинства зна-
лЛ(<5, 0)
чений 0, но предпочтительнее по прин- г
ципу минимакса.
В общем случае вопрос о существовании и строении минимаксного пра-
вила достаточно трудный и здесь не рассматривается. Отметим один слу-
чай, когда удается просто установить минимаксность некоторого решающего
правила. Именно: предположим, что существует априорное распределение
параметра тг(0) > 0, для которого функция риска соответствующего байесов-
ского правила постоянна: R(6^,9) = а — const (такое распределение тг
называется наименее благоприятным априорным Наименее благоприятное
распределением). Тогда % - минимаксное ре- апоиооное оаспоеделение
шение.
Действительно, в противном случае существовала бы процедура <5, для кото-
рой максимальный риск т(д) < а. Но это означало бы, что Я(<5, 0) < Я(<^,0),
V0, в противоречие с допустимостью байесовского решения.
Пример 1 (бернуллиевская модель, решающие правила для нее).
Пусть X — бернуллиевская случайная величина, причем вероятность «успеха»
0 может бытьлибо 0] = 1/3, либо 02 = 1/2. Таким образом, здесь X = {0, 1},
0 = {1/3, 1/2} и /(ат; 0) = 0Х(1 - 0)1-1, х = 0,1. Пусть, далее, множество
решений D состоит из двух элементов d, и dj, а функция потерь L(d, 0)
задается следующей таблицей:
В данном случае для каждого х Е 1 возможны только два решения,
а множество X содержит две точки, поэтому всего имеются четыре решаю-
щие функции J*, k = 1, 2, 3,4, а именно: 0,(0) = d(, (1) = dj; <J2(0) = dj,
<S2(1) = d2; <?з(0) = d2, <J2(1) = di; £4(0) = d2, <54(1) = d2. По формуле (1),
которая в данном случае принимает вид
R(Sk,ff) = Ь(бк(0),в)(] -в) + Ь(дк(]),д)0, 0 = 0!,02,
находим четыре вектора риска (R(5k, 0J, R(dk, 02)), к = 1,..., 4, числовые
значения которых соответственно равны (0, 3), (2/3, 2), (4/3,2), (2, 1). Здесь
процедура б-i недопустима, так как <52 предпочтительнее, а среди допусти-
мых процедур <5|, <52 и J4 две последние обладают минимаксным свойством:
т((52) = т(д4) = 2 < mfy) = 3.
34 Заказ 1748
530 Глава 7. Элементы теории решений. Дискриминантный анализ
Пусть теперь на множестве 0 {0], &>} задано некоторое априорное
распределение тг: тг(0|) = а, тг(02) = 1 - а, 0 а 1. Найдем соответству-
ющее байесовское решение <5*
1-й способ. В соответствии с определением (3) вычислим байесовские
риски
г (<?,) = R(5it 0()а + Я(<5,, 02)(1 - а)
для допустимых правил (г — 1,2,4):
г(<$1) = 3(1 - а), г(<52) = 2 - -а, г(64) = а + 1.
Графики этих функций от а изображены на рис. 2, из которого видно, что,
если а 3/7, то min r(6i) = г(<?4), т.е. в соответствии с (4) здесь <5* = <54;
i
если 3/7 < а 3/5, то minr(<5t) = г(<52) т.е. здесь <5* = <52; наконец, <5* = <5|
i
при а > 3/5.
Жирной линией на рис. 2 изображен график байесовского риска р(а) = г (<Г)
как функции а — это выпуклая ломаная линия, являющаяся нижней гранью
семейства линейных функций {r(<5;), i = 1,2,4} Такая картина характерна
для байесовских решений в задачах, в которых параметр 0 принимает ровно
два значения, а множество D состоит лишь из конечного числа решений.
Имеем
2-й способ. Вычислим апостериор-
ное распределение (см. (5))
7Г(0.|О)
о(1 - 0|)
/(0)
(1-а)(1-02)
/(0)
7Г(01|1) =
тг(02|1) =
а0!
7(0’
(1 - а)^2
/(0
Средняя потеря относительно этого апостериорного распределения при х = 0
для решения <5(0) — d} равна
E[L(d|,0) | X = O] = Z(d|,01)?r(0||O)4-L(di;02)7r(02|O) =
3(1 -а)(1 -02) _ 3(1 - а)
f(0) 2/(0) ’
§7.1. Статистические решающие функции 531
а для решения <£(0) = d2 она равна
2а(1-0,) (1-а)(1-02) _ (3 + 5а)
/(0) + /(0) " 6/(0) •
Сравнивая эти потери, находим, что при а 3/7 потери для решенияг d2
меньше, т.е. <f*(0) = d2, если же а > 3/7, то <f*(0) = d{
Аналогичный анализ для случая, когда х = 1, дает: если а 3/5, то
J*(l) = d2, и <5*(l) dt при а > 3/5. Тем самым получены значения
байесовского решения 6*(х) в каждой точке х = 0, I при любом априорном
распределении параметра.
Конечно, оба способа, хотя и в разной форме, дают один и тот же ре-
зультат, так как (см. рис. 2) при а 3/7
<5*(0) = d2 = J4(0),
при а > 3/7
Г(0) = dt = <52(О) = 0,(0),
и аналогично, при а 3/5
<Hi) = d2 = Mi) = <Mi),
при а > 3/5
<5*(l) = di =<?,(!). •
5. Оценивание параметров и проверка гипотез
с позиций теории решений
Рассмотренные в предыдущих главах задачи оценивания и проверки гипотез
также можно сформулировать в терминах принятия решений. Рассмотрим, на-
пример, задачу точечной оценки скалярного параметра 0. Выбор статистики
Т(Х), оценивающей 9, можно трактовать как решающее правило, согласно
которому принимается решение dt оценить параметр величиной t = Т(х),
если наблюдается X = х. В этом случае функция потерь может быть, напри-
мер, L(dt,0) = ш(|/ - 0|), где ш ~ строго возрастающая функция ошибки
|£ - 0|. Если, в частности, выбрать w(z) = z2 то функция риска оценки Т
(квадратичный риск)
R(T, (?) = Ев(Т(Х) - в)2 (9)
совпадает со среднеквадратической ошибкой Т. В главе 3 рассматривалась,
в основном, проблема построения оценок, минимизирующих квадратичный
риск (9) в классе несмещенных оценок, — это оценки с равномерно мини-
мальной дисперсией. В п. 6 §3.6 достаточно подробно обсуждался байесовский
и минимаксный подходы в проблеме оценивания, где по ходу изложения об-
суждались и некоторые дополнительные аспекты этой теории.
Рассмотрим теперь интерпретацию задачи проверки гипотез в терминах
теории решений. Предположим, что требуется проверить гипотезу Hq 0 £ ©о
при альтернативе Н\ . 0 £ 0| = ©\©о. Тогда любой критерий есть решающее
34*
Я(5, 0) =
532 Глава 7. Элементы теории решений. Дискриминантный анализ
правило с двумя решениями: do (принимать Hq) и d\ (принимать Н\). Здесь
естественно считать, что потеря равно 0, если принято правильное решение.
Тогда функция потерь должна удовлетворять условиям L(d0, 0) = О, V 0 € ©о,
и L(di,e) — О, V0 G 6|. Если дополнительно принять, что потери от не-
правильного решения равны 1, т.е. Z(d0, 0) = 1, V0 € ©i, и L(d\,0) = О,
V 0 € ©о, то при такой простой функции потерь для любого решающего пра-
вила 6 функция риска будет иметь вид (см. (1))
₽,{$(.¥) = ^} = Р{Я1|Я0} при 0 G ©о,
Ре{<5(Т) = й0} = Р{Я0|Я1} при 0G&\,
т.е. ее значения совпадают с вероятностями ошибок 1-го и 2-го родов.
§ 7.2. Классификация наблюдений
1. Задача классификации
В этом параграфе мы рассмотрим один частный, но представляющий боль-
шой практический интерес случай, когда параметрическое множество модели
F = {F(i; 0), 0 G 0} состоит из конечного числа точек: 0 = {0Ь , 0^},
т. е. имеется всего к распределений F{(x) = F(x\0,), i = 1, , к, одно из ко-
торых является истинным всякий раз, когда производится наблюдение над X
с С(Х) € F В этом случае задача состоит в том, чтобы по наблюдению над X
решить, какое из этих к распределений истинно. С позиций теории решений
в данном случае множество решений D = {d,, .., d*}, где решение dt озна-
чает, что в качестве истинного распределения выбирается F{, i = 1, , к.
Типичная ситуация, когда возникает подобная задача, может быть описа-
на следующим образом. Пусть множество исследуемых объектов разбито на к
классов или групп Яь , Я*,. Каждый объект характеризуется набором X
числовых параметров, которые непосредственно могут быть измерены. Пред-
полагается, что X — случайная величина, а принадлежность объектов к раз-
ным классам выражается в том, что для объектов из класса Я; эта случайная
величина имеет распределение Fj, i = 1,..., k. Задача состоит в том, чтобы
по наблюдению над X определить тот класс, к которому принадлежит соот-
ветствующий объект, или, что то же самое, какое из распределений F\, , Fk
истинно. Такие задачи называют задачами классификации, идентификации или
дискриминации (от англ, discrimination — различение) и их решение составляет
содержание дискриминантного анализа — одного из разделов современной ма-
тематической статистики. Мы рассмотрим общие принципы решения таких
задач с позиций теории решений и проиллюстрируем их на примерах наибо-
лее важных моделей таких ситуаций.
2. Функция риска в задаче классификации
Пусть д = 8(х) — произвольное решающее правило в рассматриваемой задаче:
8:3с —>О. Тогда оно порождает разбиение выборочного пространства ЗЕ = {я}
§7.2. Классификация наблюдений
533
на к взаимно непересекающихся областей Wi,..., РУ*, где
Wi = {x <5(3?) = d.}, i = 1, ,fc. (1)
Таким образом, множество ТУ,- С X включает все такие точки х, когда при
наблюдении X = х в качестве истинного выбирается распределение F,.
Пусть, далее, на D х © задана функция потерь L(d, 0), определяющая
потери, от неправильной классификации, т. е. заданы числа L(dj, 0i) =
i, j — 1, , к, где — убыток, который имеет место в случае, когда объ-
ект г-го класса отнесен к у-му (j г). В данной задаче естественно считать,
что потеря равна нулю, если выбрано правильное решение, т.е. = О,
i = \,...,к. Тогда функция риска (1) §7.1 представляет собой fc-мерный
вектор R(S) = .... Я*(<5)), где
к
Ri(6) = R(8,0() = EfiiL(6(X), 0() = 22 l(j\i)p(j\i), (2)
j=i
где p(j\i) = Ps, {X 6 Wj} — вероятность того, что объект i-ro класса отнесен
к j-му классу. Можно сказать, что Я;(<5) — средние потери, которые имеют
место при классификации по правилу <5 произвольного объекта г-го класса.
Задача состоит в построении оптимального (т. е. с наименьшими потерями)
решающего правила S.
3. Байесовское решение
Пусть задано априорное распределение тг = (тг|, , тг*) на 0 = {0, , 0*},
т. е. известно, что произвольный наблюдаемый объект принадлежит к клас-
су Hi с вероятностью тг, г = 1, , к (тг, + + тг* = 1). Тогда байесовский
риск (3) §7.1 на основании (2) равен
к к к
г№) = 52 Ri^ = 52 52 (з)
i=l j=l i=l
В соответствии с общим алгоритмом построения байесовского решения (см. п. 3
§ 7.1), т. е. правила S, минимизирующего риск (3), по формуле (5) § 7.1 находим
апостериорные вероятности классов при условии X = х:
7г,(а?) = , i = (4)
52
s=l
Далее, если принять решение отнести объект с характеристикой х к j-му
классу (т. е. если <5(а?) = dj), то для такого правила средние условные (при
534 Глава 7. Элементы теории решений. Дискриминантный анализ
условии X =х) потери равны
к
Е [b(<5(X), 9) | X = х] = £ L(dj, ----------- (5)
,=i i>2*sfs(z)
s= I
Наконец, решение dj должно быть выбрано так, чтобы минимизировать (5).
В итоге мы приходим к следующей формулировке
оптимального способа действия: если наблюдалось X = х,
то надо определить минимальную сумму
к
ЛД®) = 52гС/Ю’г>Л(а;)> У =’> (6)
1=1
и отнести объект к классу с номером, равным номеру этой минимальной суммы
(если минимум достигается при нескольких значениях j, то можно взять
любое из них, например, минимальное).
Итак, имеет место следующее утверждение.
Теорема 1. Оптимальное (байесовское) решающее правило <5* в задаче клас-
сификации определяется следующим разбиением выборочного пространства
X = И'',* U UW7’:
Wi = {г hi(x) = min*hj(x)}, i = 1, ,k, (7)
где функции hj(x) определены в (6) и г — минимальное значение индекса,
удовлетворяющее указанному условию.
Рассмотрим частный случай, когда l(j\i) = 1, j ^i. Тогда
к
hj(x) = 52 ”> + 52
i=l
и условие в (7) принимает вид
7г,/,(ж) = птах тгу/Дя).
Величины Kjfjtx) пропорциональны апостериорным вероятностям классов
(см. (4)), поэтому в данном случае байесовский принцип сводится к следу-
ющему: относить объект с характеристикой х к тому классу, апостериорная
'/л., _ вероятность которого максимальна. Такой
51 Принцип максимума
принцип называют принципом максимума
апостериорном вероятности . ~
апостериорной вероятности. Этот принцип
§7.3. Наблюдения в случае двух нормальных классов
535
используют во всех случаях, когда потери либо неизвестны, либо их
трудно оценить числом.
Выделим случай двух классов (fc = 2), т.е. когда объекты классифициру-
ются по альтернативному признаку. Здесь
ht(x) = /(1|2)тг2/2(аг), h2{x) = г(2|1)7г1/|(х),
следовательно, решение d\ (отнести объект с характеристикой х к первому
классу) принимается тогда и только тогда, когда/(1|2)7г2/2(х) £(2| 1)tti/i(:e).
Таким образом, байесовское правило 8* имеет в данном случае следующий вид:
/ dl ПрИ XEW' w* К Л(г) TrU(2|l)l
[ </2 при х € W* I /i(z) тг2£(1|2)/
а соответствующий ему вектор риска (Л|(<?’), Я2(<?*)) в соответствии с (2)
равен
(Ц2| 1)Р#]{Х е рП},!(1|2)р#2{х е И"Г}). (Ю)
4. Минимаксное решение
Если априорные вероятности классов неизвестны, то для построения решаю-
щего правила используют минимаксный подход (см. п. 4 § 7.1), в соответствии
с которым ищется правило 3, минимизирующее max Ri(3) (см. (2)). В ряде
случаев минимаксное правило 3 удается построить, определив наименее бла-
гоприятное априорное распределение тг = (тГ|, ,7^.), при котором для
соответствующего байесовского решения 8* все компоненты вектора риска
R(8") одинаковы, — в этом случае 8 совпадает с решением 8"
Например, в случае двух классов из (Ю) следует, что тп (тг2 = I - тгj) надо
определить из условия
г(2|1)Р9,{ТеГ;} = Ц1|2)Рв2{Х G VF,*}. (11)
Отсюда видно, что даже в этом простейшем случае для произвольных распре-
делений Ft задача построения минимаксного решения достаточно сложна.
В следующих параграфах эти вопросы рассмотрены детальнее для случая нор-
мальных распределений.
§ 7.3. Классификация наблюдений
в случае двух нормальных классов
Предположим теперь, что в эксперименте наблюдается нормальный случай-
ный вектор X = (Х[, , Хг), распределенный для объектов из класса Н,
по закону , Е), а для объектов из класса Я2 — по закону Е),
причем векторы и матрица Е известны (|Е| 0). Таким образом,
536 Глава 7. Элементы теории решений. Дискриминантный анализ
здесь предполагается, что имеет место случай двух нормальных классов, разли-
чающихся только средними значениями, и задача состоит в том, чтобы по на-
блюдению над вектором X решить, какое изэтихдвух распределений истинно.
Найдем байесовское и минимаксное правила в данной ситуации.
1. Байесовский подход
В этом случае предполагается, что заданы потери Z(l |2) и Z(2| I) от принятия
неправильного решения и априорные вероятности ти и ttj (тг, н-тгг = 1) клас-
сов Н] и Н2 соответственно, тем самым определена константа
с = In
В соответствии с (9) область W* наилучшей классификации в пользу класса
Н\ определяется неравенством In (/i(i)//2fe)) с. которое в соответствии
с соотношением (9) § 1.2 принимает в данном случае вид
l[(l-//2))'S 1 (х -/£(2)) — (ж — /2(1))'s ‘(i-/£(1))]
или, если положить а = 1 - /i(2^),
a'i - -а'(/J1) + /J2)) с. (I)
Дискриминантная Линейную функцию <р(х) = ах называют дискрими-
функция нантной функцией. Таким образом, области наилучшей
классификации определяются в данном случае дискри-
минантной функцией наблюдение X = х относится к классу Hi тогда
и только тогда, когда
<р(х) Ci =с + -а! (//’) + //2)).
Если потери l(i\j) неизвестныили ихтруднооценитьчислом, то применяютука-
занное правило классификации с Z(112) = /(2|1) = 1, т. е. в этом случае (см. (1))
W* = {z а'х In | (2)
Замечание. Ранее (см. пример 3 в §5.2 и его продолжение там же) мы уже рассма-
тривали задачу различения двух нормальных распределений А/"(//',,Е) с позиций
критерия Неймана—Пирсона, когда минимизируется вероятность ошибки 2-го рода
при фиксированной вероятности ошибки 1-го рода (критерий (18) §5.2), и с позиций
минимизации суммы вероятностей этих ошибок (критерий (21) §5.2). Теперь же мы
получили новый, более сильный, результате позиций теории решений, учитывающий
как наличие дополнительной априорной информации о гипотетических распределе-
ниях (априорные вероятности тг, и тг2 классов Я, и Нг), так и более детализирован-
ное описание последствий от ошибочных решений (задание потерь В част-
ности, полученное здесь решение (2) соответствует критерию (21) §5.2 и сводится
к нему при тг, = тг2 = 1/2, т.е. в случае априори равновероятных классов Я, и Я2.
§ 7.3. Наблюдения в случае двух нормальных классов
537
2. Минимаксный подход
Найдем теперь минимаксное решение S, которое используется в случае не-
известных априорных вероятностей классов. Для этого вычислим вероятно-
сти ошибочных классификаций p(j|z) = Р{Я;|Я,}, i,j = 1,2, i / j, для
произвольного байесовского правила, задаваемого условием (1) (константа с
теперь произвольна, так как априорное распределение тг = (тГ|, тг2) произ-
вольно), и из условия (11) §7.2 найдем наименее благоприятное априорное
распределение. Соответствующее этому априорному распределению байесов-
ское решение (1) и является искомым минимаксным решением д.
Для этого можно воспользоваться вычислениями, проведенными в при-
мере 3 §5.2. Именно, если ввести случайную величину
с-р/2 \
у/Р /
с + р/2\
уГР /
то из формул (16) §5.2 получим, что
£(Y\Hi) = р^ , £(У|Я2)=Лг(-£,р), (3)
где
Р = (д'1' (д">-д>=') (4)
есть расстояние Махаланобиса между распределениями
V(m(i),E) и Л/(д(2),Е).
Отсюда находим вероятность ошибочной классификации:
р(2|1) = Р{Я2|Я,} = Р{Г <с|Я,} = Ф
р(1|2) = Р{Я1|Я2} = Р{У >с|Я2} = Ф
Следовательно, уравнение (11) § 7.2 для определения наименее благоприятно-
го апроирного распределения (тг|, 1 -ТГ]), или, что эквивалентно, константы с,
имеет вид
/(2|1)ф(^^) =г(1|2)ф(-^-^\ (5)
\ у/Р / \ у/Р /
Итак, если априорные вероятности классов неизвестны, то минимаксное
правило классификации определяется разбиением X = W* U ТУ/, где
W* = ^a'(/2(1) + /z(2)) W2 = (6)
и константа с выбирается из условия (5).
Отметим, что если 2(2| 1) = Z(112), что решением уравнения (5) является
с = 0, а так как
, Г^(1|2)1
/* = In -----
тГ]/(2|1)
538 Глава 7. Элементы теории решений. Дискриминантный анализ
то в этом случае имеем, что наименее благоприятное априорное распределение
является равномерным: tti = тгэ = 1/2. Для этого случая области наилучшей
классификации W* (6) и (2) совпадают и, как отмечено в замечании п. 1,
мы приходим к критерию (21) §5.2, — так смыкаются подходы байесовский
и минимаксный с подходом, основанным на минимизации суммы вероятно-
стей ошибок 1-го и 2-го рода. Отметим также, что в этом случае вероятность
ошибочной классификации произвольного объекта равна Ф(-ч/р/2), следова-
тельно, чем более далекими (в метрике р Махаланобиса) являются «гипотезы»
Н\ и Г/j, тем меньше вероятность ошибочной классификации правила (6).
§ 7.4. Классификация нормальных
наблюдений. Общий случай
В этом параграфе мы рассмотрим применение изложенной в §7.2 теории
к общему случаю нескольких классов, заданных многомерными нормальными
распределениями. Предположим, что эти распределения различаются только
своими средними, и пусть V(//!\ £) — распределение наблюдений X для
объектов из класса Я; (г =1, , к). Кроме того, все цены ошибочных клас-
сификаций будем считать равными единице: = 1, j i.
1. Байесовский подход
Пусть заданы априорные вероятности тг, =Р{Я,}, i = I.к (?Г| +... -Ьтг^ = 1)
принадлежности произвольно выбранного объекта соответствующим классам.
Тогда байесовское решение можно получить с помощью принципа максимума
апостериорной вероятности (см. (8) §7.2), в соответствии с которым области
классификации имеют вид
W-=lx , j=l, i=l,. ,k,
I Ate) J
где (см. (9) § 1.2)
A(x) = i = 1, ,k.
Отсюда, как и в п. 1 §7.3, получаем, что
W- = {z u0(z) - с,, j = 1, к, j/г}, (1)
Классификационные функции где С, = In (1/тг(), г = 1, ,к,м
Uij(x) = In = а^х - (/z(,) + /£0)), (2)
Oij = E-l(/r(1) - /го)), i,j=\..k, (3)
§ 7.4. Классификация нормальных наблюдений. Общий случай 539
Отметим, что каждая классификационная функция щ,у(х) связана только
с г-й и j-й совокупностями, Uij(x) = -u^ix), при этом все они — линейные
функции наблюдений х. Следовательно, области W* ограничены гиперплос-
костями.
Вычислим, наконец, вектор риска Я = (/?i, .., Rk) этого байесовского
правила. В соответствии с формулой (2) §7.2 в данном случае
R< = = 1 “ Р(г'Ю = 1 - [ fi&dx =
w;
= 1 - Р{гз0(ЛГ) с, - Cj, j = 1,... ,k, 7 / i I Ht}, (4)
поэтому надо знать распределение случайного вектора
Ui= («.,(*), j = \......k, j£i)
при гипотезе Н,. Чтобы найти это распределение, введем матрицу
S; = ll«;i •«ifcll.
составленную из векторов-столбцов а1;, j =1, ,к, j / i, определенных
в (3). Тогда из формулы (2) следует, что вектор 17,• получается из X с помощью
линейного преобразования вида U_{ = Е-XСледовательно, по свойству 2)
в п. 2 § 1.2 (сохранение нормальности при линейных преобразованиях)
г(Е;|Я,) = ЛГ&рУ + bit S'EE,-). (5)
Отсюда имеем, что j-я координата вектора средних Е([7;|Я,) равна
А# - 5* (е* + £и) = (гй - £01) = у
где (/з<1> - (//** - /з0)) — расстояние Махаланобиса между
г-м и ;-м классами (или между распределениями А/Х/з^, Е) и Д/Х/з^, Е)),
a (j, «)-й элемент дисперсионной матрицы Е;ЕЕ;, равный скалярному про-
изведению j-Й строки матрицы Е; (т.е. вектора а-;) на s-й столбец матрицы
ЕЕ; (т.е. Ед13 = (/з^ - р^)), имеет вид
Тем самым распределение (5) полностью определено. Оно является невырож-
денным (|Е;ЕЕ;| 0) тогда и только тогда, когда Е; — матрица полного
ранга, т. е. когда rank Е; = к - 1 (это имеет место, в частности, когда векторы
средних значений /з^, , р^ линейно независимы и г = dim X к - 1).
В этом случае существует плотность gt(u) нормального распределения (5) и
формулу (4) можно записать в виде
R,\ = 1 -р(г|г) = 1 - У У д,(и) du, i = . ,к (6)
С.--С1 Ci-Cit
540 Глава 7. Элементы теории решений. Дискриминантный анализ
Рис.1
(здесь интеграл имеет кратность k - 1, так как среди разностей с, — Cj отсут-
ствует разность Ci - Ci).
В качестве примера рассмотрим случай трех классов (к — 3), задаваемых
двумерными нормальными распределениями (г — 2).
В данном случае области W* г = 1,2,3, имеют соответственно вид
W* = {l = (х},Х2) Un(x) > С, - С2, U|3(l) > С] -Сз},
W2 = {х = (xh х2) uI2(x) < ci - с2, и23(т) > с2 - с3},
Wj = {я = (®ь ^г) i*i3(z) < Ci - сз > w23(i) < с2 - с3}
Эти области должны исчерпывать всю плоскость, поэтому линии, задаваемые
уравнениями щ12(г) = С] — с2, Ui3(i) = С) - с3 и и22(х) = с2 - с3, должны
пересечься в одной точке (см. рис. 1).
2. Минимаксный подход
Если априорные вероятности тл,..., тг* классов неизвестны, то области клас-
сификации ищутся в виде (1), где неопределенные константы с, > 0, i =
— следует выбирать из условия равенства всех компонент вектора
риска Д = (Дь.. , Д;), которое в силу (6) приводит к равенствам
р(1|1) =р(2|2) = = р(к\к). (7)
Эти равенства однозначно определяют разности с,- - Cj (по крайней мере в
принципе), а тем самым и области (1) минимаксного правила классификации.
3. Классификация наблюдений в случае неизвестных параметров
Выше предполагалось, что все допустимые распределения наблюдений пол-
ностью известны. Однако в приложениях эти распределения часто бывают
известны лишь с точностью до значений некоторых параметров (например,
, i = 1,... ,к, или Е, или одновременно всех этих параметров). В таких
§ 7.4. Классификация нормальных наблюдений. Общий случай 541
случаях можно решать задачи классификации при наличии до- Обучающие
полнительных, как говорят, обучающих выборок , Х^) выборки
из соответствующих распределений Е), i = 1,..., k.
Эти выборки можно использовать для оценки соответствующих неизвестных
параметров и, заменив неизвестные параметры их оценками, поступать далее,
как и в случае полностью известных распределений, получая в итоге эмпири-
ческие (приближенные) правила классификации.
Если неизвестны средние /г 7 то их заменяют оценками
— средними арифметическими выборок. Дисперсионная матрица Е (когда
она неизвестна) оценивается выборочной дисперсионной матрицей (см. п. 2
§2.3); при этом так как матрица Е, по определению, — общая для всех классов,
то для ее оценивания следует использовать информацию, доставляемую всеми
выборками. Эту информацию объединяют следующим образом. Построим
по i-й выборке (Х^ .•, выборочную дисперсионную матрицу
1 п'
....>=
1 j=l
тогда (см. п. 2 §2.3) матрица -——гЕ^ для любого i будет несмещенно
(п, — 1)
оценивать Е. Отсюда
к к
Е п,Е^ = - 0^ = (n - fc)E, п — п\ + + п*,
i=l i = l
и, следовательно, выборочная матрица
е = — Vn,£(1),
п-к
t=i
построенная с учетом всех данных, является также несмещенной оценкой
матрицы Е.
Построив эти оценки неизвестных параметров, далее можно ввести оцен-
ки классификационных функций и,у(®) (см.(2))
«м(г) = <^х - (р(,> + д0)), = Е~‘ (д(,) - £0)),
и использовать их для построения эмпирических областей классификации
IFf = {х : Uy-(x) > с, - с;, ; = 1, ,k,j^i}, г=\,...,к,
заменяющих в данном случае области (1).
542 Глава 7. Элементы теории решений. Дискриминантный анализ
В качестве обоснования этой методики можно привести следующие
«асимптотические» рассуждения. Предположим, что объемы обучающих вы-
борок велики (п;—> оо, i = 1,... , к). Тогда опенки г=1, Д’, иЕ,
как мы знаем (см. п.З §2.3), сходятся по вероятности соответственно к р^
i = I, ,t, иЕ. Отсюда следует, что сходится по вероятности к а1}, а
+ р,^) — к + р^) (см. теорему I §2.2). Следовательно, пре-
дельное распределение Ujj(X) совпадаете распределением и^ДЛ-), поэтому
для достаточно больших обучающих выборок эмпирические классификаци-
онные функции можно использовать так же, как если бы были точно
известны распределения совокупностей.
Упражнения
Никогда не ставьте задачу, решение
которой вам неизвестно.
Правило Берке
Знание ответов — великое преимущество.
Арабская пословица
П Пусть £(Х) = Bi(l,0), 0= {0| = 1/3, 02 = 2/3}, множество решений D = (d ।, ф)
и функция потерь задана таблицей
di Ф
0| 0 1
02 2 0
1) Определить все допустимые решающие правила в данной ситуации и убедиться
в том, что 6 = ((5(0), (5(1)) = (ф, ф) — минимаксная процедура.
2) Убедиться в том, что для априорного распределения тг(0|) = а, тг(02) = 1 - а,
а € [О, I ], байесовское решение имеет следующий вид: <5*(0) = d2 при а < 1/2,
<5*(0) = ф при а > 1/2 и <5*(1) = ф при а '4 4/5, <5*(1) = при а > 4/5.
Построить график байесовского риска р(а) = r(S*) как функции а.
Указание. См. решение в примере 1 §7 I. ►
Н Пусть £(Х) = Bi( 1,6), 0 = {0i = 1/4, 02 = 3/4} , D = {d,, Ф.ф) и функция
потерь задана таблицей
Ф d. Ф
01 0 1 1/2
Ф 4 0 1/2
1) Убедиться в том, что байесовское решение <5* = (<5'(0), <5‘(1)) при априорном
распределении тг(0|) = а € (О, 1], тг(02) = 1 — а, имеет вид: <5' = (Ф,Ф) при
Упражнения
543
а < 1/4; <S*(d3, d2) при 1/4 < а < 7/10; 5* = (</], d3) при 7/10 < а < 3/4;
<Г = (d|, d3) при 3/4 < а < 21/22; У = (dH dj при а > 21/22.
2) Показать, что байесовский риск р(а) = г(5') есть
р(а) = <
1 + 4а
8
4 — За
4
11 - 10а
8
при
при
при
при
при
4(1 - а)
Построить график функции р(а), а € [0, 1].
Указание. Сравнить средние потери E(i(d, в)|аг) относительно апостериорного рас-
пределения, указанные в следующей таблице. ►
d2 <h
х = 0 1 - а лоГ За 4Д0) 1 +2а 8/(0)
х = 1 3(1-а) /(1) а 4/0) 3 - 2а 8/(1)
Q Пусть £(Х) = Bi(l,0), 0 = {0,, 0,}, £> = {db d2] и функция потерь i(d, 0)
задана таблицей (а, Ъ > 0).
в том, что в обоих случаях множества допустимых решающих правил совпадают, но
для случая 2) при любом апроиорном распределении параметра байесовское решение
п редпочти тел ьнее.
◄ Указание. Воспользоваться решением упр. 1. ►
Q Пусть £(Х) = Bi(3,0), 0 = {0! = КГ2 02 = JO-'}. D = {<ii><*г) и функция
потерь L(d, в) задана таблицей
d} 1
е. 0 2
«2 1 0
544 Глава 7. Элементы теории решений. Дискриминантный анализ
Рассмотретьтри решающие правила <5, = (<5,(0), <5,(1), <5,(2), 6,(3)): <5, = (dh d2, d2, d2),
62 = (J,, d|, d2, d2), 63 = (d|, d|, dt,d2) и убедиться в том, что минимаксное решение
Й = <5, и т(б) = 0,792.
Q Пусть £(Х) = Bi( 1, 0), 0 = {0з, 02}, D = {d|, dj} и функция потерь задана таб-
лицей, указанной в упр.З. Рассмотреть решающие функции
d, при х = 0, 1,..., i - 1,
i = 1,2,...,
d2 при х = i, i + 1,
6i(x) =
и убедиться в том, что при ав{ 6(1 - в2) минимаксное решение 5 = 5, Построить
5 при aS, >6(1 - в2).
◄ Указание. Получить сначала вектор риска для i-й процедуры:
д, = (д^.^.д^,,^)) = (ае;, 6(1 -е))). ►
Q Убедиться в том, что если в условии упр. 5 заменить £(Х) на пуассоновский
закон П(в), то а = 5, при а(1 - е’"1) < бе’"2, а соответствующий вектор риска есть
(а(1 -е’"1), бе’"2).
Q Предположим, что наблюдается случайная величина X, распределенная по нор-
мальному закону с неизвестным средним 6 и известной дисперсией а2 множество
' d, при х < а,
= d2 при <1 z < 6, а <0 <6.
_ d2 при
х > 6,
Убедиться в том, что функция риска имеет вид
J?(W) =
при в < 0,
при 6 = 0,
при в > 0,
и построить ее график при 6 = -а.
Q Предположим, что 0 = {0, 1], D = {d} = [0, 1] и функция потерь имеет вид
L(d, в) = |d - 0|“, а 1. Рассмотрим класс решающих функций вида 5(х) = const
(т. е. решение принимается без предварительных наблюдений). Убедиться в том, что
Упражнения
545
в этом классе байесовское решение d*, соответствующее априорному распределению
тг(О) = а е [0, 1], тг(1) = 1 - а, при а > 1 имеет вид
если же а = 1, то d" =0 при а > 1/2, d* = 1 при or < 1/2, а при а = 1/2 в качестве d*
может быть взято любое d € [0, 1].
Ч Указание. Установить сначала, что байесовский риск есть
r(d) = ad° + (1 - or)( 1 - d)“ ►
Q Рассматривается задача оценивания неизвестной вероятности «успеха» в по на-
блюдению числа «успехов» X в п испытаниях Бернулли (таким образом, здесь £(Х) =
Bi(n, 9), 0 = D = [0, 1]). Пусть функция потерь имеет вид
(d - 0)2
L(d,9) =
' ' ' 0(1-0)
а априорное распределение параметра является равномерным Z7(0, 1). Показать, что
байесовское решение есть J*(i) = х/n, и оно же является и минимаксным, при этом
r(J’) = 1/п.
ко Предположим, что по наблюдению X оценивается параметр 0 равномерного
распределения 17(0, 0), при этом параметр случаен и имеет априорную плотность
тг(0) = ве~в 0 > 0. Убедиться в том, что байесовская оценка при квадратичной
функции потерь имеет вид д’(Х) = X + 1, а ее риск r(J*) = 1.
Ч Указание. Записать среднюю апостериорную потерю для решения d в виде инте-
грала
ОО ОО 00
E[L(d, 0) | X = г] = j(d - 0)2тг(01ж) de = j(d- 0)2е'9 d0 f(d - х - t)2e~‘ dt
О z о
и продифференцировать по d. ►
ЕП Рассмотрим задачу оценивания скалярного параметра 0 при функции потерь
L(d, 0) = |d - 0|, d, 0 £ R1 Доказать, что при наблюдении X = х байесовское
решение 6‘(х) при любом априорном распределении параметра £(0) есть медиана
апостериорного распределения Д(0|о:), т.е. такое число, что
P{0$d,|i}>^, Р{0 > d'|i} >
Ч Указание. Установить неравенство Е(|0 - d||i) > Е(|0 - d’||i), Vd € Л1 ►
ЕП (Продолжение). Пусть оценивается среднее модели Лг(0, Ъ2), когда £.(0)=Л!'(р.,а2).
Используя упр. 64 (5) к гл. 1 и введенные там обозначения, убедиться в том, что байе-
совская оценка по выборке X = (X,,..., Хп) из Л'(0, Ь2) имеет вид
. , / и пХ \
и ее риск равен г(5’) = Е|0 - S'(Х)| = сп (сравни с упр. 83 к гл. 3).
Ч Указание. Воспользоваться формулой полного математического ожидания (см. (6)
§6.6). ►
35 Заказ 1748
Глава 8
Факторный анализ
Если кто-то способен предсказать, чем закончатся
его исследования, то эта проблема не очень глубока
и, можно сказать, практически не существует.
А. Шильд
Эта глава, как и последующая, посвящена изложению методов исследо-
вания и объяснения структуры корреляционных матриц систем случайных
величин. Такие исследования важны при анализе и интерпретации результа-
тов эксперимента. Их целью в первом случае является выявление небольшого
числа скрытых общих факторов, оказывающих решающее влияние на резуль-
таты эксперимента, во втором — определение небольшого числа линейных
комбинаций наблюдаемых переменных, объясняющих их суммарную диспер-
сию. В обоих случаях такое исследование позволяет лучше понять природу
случая, порождающего данные, и достичь более экономного их представле-
ния, что важно при обработке больших массивов информации.
§ 8.1. Постановка задач факторного анализа
При исследовании сложных объектов собирают статистику обычно по боль-
шому числу различных характеристик объекта, стремясь при этом учесть как
можно больше. Однако это стремление приводит, как правило, к обратному
эффекту, именно, с одной стороны, получается огромный массив информа-
ции, который трудно (а практически зачастую и невозможно) проанализи-
ровать математическими методами, а с другой стороны, получается «засоре-
ние» данных большим количеством несущественных характеристик, которые
не несут в себе никакой существенной информации об исследуемом объек-
те, но по которым собирается большая (и часто дорогостоящая) статистика.
В этих ситуациях естественно встает задача отделить существенные характе-
ристики от несущественных, отыскать те общие факторы, наличием которых
можно объяснить те или иные закономерности, действующие в множестве су-
щественных характеристик, и тем самым «сжать» информацию, т.е. записать
ее в терминах меньшего числа переменных. Конечно, все эти и аналогичные
задачи можно математически строго формализовать и решить лишь в рамках
определенной модели. Одной из таких моделей, достаточно хорошо действу-
ющей во многих реальных ситуациях, является модель факторного анализа.
Основной задачей факторного анализа является экономное описание экс-
периментальных данных. Он «объясняет» корреляционную матрицу системы
§ 8.1. Постановка задач факторного анализа
547
случайных величин (далее пишем кратко — с. в.) Х\,...,хг (т.е. наличие
корреляций между ними) наличием небольшого числа общих гипотетических
переменных или факторов, от которых зависят Х|, , хг. В общем виде мо-
дель факторного анализа выглядит следующим образом:
Xi = <Pi(f....Д) + е,,
(1)
xr = <pr(fi, , Д) + ег,
где ф, — известные функции к переменных, Д, .., Д и бь , ег — с. в.,
причем Ci, , ег независимы как между собой, так и от Д, , Д.
Если в представлении (1) число к значительно меньше г, то с. в. ...,
хг связаны между собой лишь через небольшое число с. в. Д, , Д. С. в.
б[....ег не участвуют в этой связи и каждая из них влияет лишь на соот-
ветствующую компоненту вектора х = (х\,..., хг). Переменные Д,..., Д
называются общими факторами (они отражают
те причины-факторы, которые обуславливают щие и частные факторы
зависимость между Х\, ..,хг), а переменные е,,...,ег называются част-
ными факторами (они отражают локальные причины-факторы). Определение
общих факторов и выявление их смысла в конкретной ситуации является важ-
ной прикладной задачей. Решение ее позволяет: 1) объяснить природу зави-
симости наблюдаемых с. в. ..., хг, 2) отделить существенные переменные
(зависящие от Д,..., Д) от несущественных (не зависящих от Д, , Д)
3) более экономно записать информацию в терминах /],..., Д, а не самих
с. в. I,, , хг (при fc г).
Дополнительно к (1) в факторном анализе обычно
Линейная модель
принимаются следующие допущения.
1. Модель (1) линейна, т.е.
Х1 = lnfi + +^Ц-Д + е1>
(2)
Хг = ^г! Д + + Irkfk + ег,
или в матричном виде (напомним, что при матричных операциях векторы
понимаются как вектор-столбцы)
х = Lf^ + е,
где L = Ц^-11 — прямоугольная матрица размера т х fc; f = (Д,..., Д),
е = (е,, ,ег).
2. Факторы Д,.. , Д независимы.
3. Все факторы, как Д,..., Д, так и ej,..., ег распределены по нормаль-
ному закону, при этом будем предполагать, что Д распределено по стан-
дартному закону АДО, 1), г=1, ,fc, а е; — по закону АДО,Vj),
j = 1, ,r.
35*
548
Глава 8. Факторный анализ
Коэффициент lij в (2) называется нагрузкой i-й
Матрица нагрузок переменной на j-й фактор (или нагрузкой j-ro факто-
ра в i-й переменной). Матрица L = ||^у|| называется
матрицей нагрузок.
Обычно нагрузки и остаточные дисперсии v, являются неизвестными
параметрами модели (2), так же, как и число общих факторов к, и их надо
оценить по наблюдениям над с. в. х = (ib ..., хГ). Иногда еще ставится во-
прос оценки значений самих факторов , Д по результатам наблюдений.
Эти задачи мы и рассмотрим далее.
Исторически факторный анализ возник из нужд психологии. Он исполь-
зовался для того, чтобы определить относительно небольшое число тестов,
ответы на которые давали бы как можно более полное описание способно-
стей человека. Однако в последнее время факторный анализ все более ши-
роко используется в социологии, экономике, медицине, геологии и многих
других областях. Широкому распространению методов факторного анализа
в последнее время способствовало развитие средств вычислительной техники.
Это связано с тем обстоятельством, что практическая реализация положений
теории факторного анализа связана, как правило, с весьма трудоемкими вы-
числениями, что будет ясно из последующего изложения.
§8.2. Неоднозначность решения в факторном анализе
Задачи факторного анализа имеют ту специфику, что ни нагрузки, ни факто-
ры в модели (2) §8.1 не могут быть определены однозначно. Действительно,
пусть Н — произвольная ортогональная матрица размера к х к. Рассмотрим
случайный вектор — Hf В силу основных предположений модели (2)
§8.1 (компоненты вектора f независимы и распределены каждая по закону
Л/(0,1)) и в силу ортогональности Н имеем (см. упр. 31 к гл. 1), что ком-
поненты вектора также независимы и распределены каждая по закону
1). В этом случае представление x = Lf + e можно записать в виде
x = (LH')(Hf) + e = Lif_{i)+ е,
где Zj = LH' Отсюда следует, что компоненты вектора также являются
общими факторами модели (2) §8.1, но с другой матрицей нагрузок.
Ортогональное преобразование Н определяет некоторое вращение в про-
странстве факторов, и таким образом, (общие) факторы определяются с точ-
ностью до вращения; при этом соответственно изменяются и нагрузки на
факторы.
Это свойство часто используется для преобразования факторов, получен-
ных в каком-нибудь практическом исследовании. Вращение обычно подби-
рают так, чтобы коэффициенты нагрузок удовлетворяли тем или иным свой-
ствам, например, чтобы определенные переменные имели как можно большую
§8.3. Вывод уравнений максимального правдоподобия 549
нагрузку на один фактор и нулевые или почти нулевые нагрузки на другие
факторы.
Во всяком случае в факторном анализе возникает еще одна задача — вы-
бор вращения (ортогональной матрицы Я) факторов и интерпретация фак-
торов, получаемых после такого вращения (по коэффициентам нагрузок на
факторы).
Выбор вращения факторов производится совместно со специалистом в
той области, из которой возникла конкретная задача (статистике часто при-
надлежит первое слово, но никогда — последнее!). Иногда можно избежать про-
извол во вращении факторов, если из дополнительных соображений известно,
что некоторые элементы матрицы нагрузок L должны быть равны нулю (т.е.
некоторые переменные х, не зависят от некоторых факторов fj).
§8.3. Вывод уравнений максимального правдоподобия
Обозначим через С = ||с^||^ матрицу вторых моментов с. в. х = (ij, , хг).
Тогда из (2) § 8.1 следует, что
к
Си = Dii = l]j + Vi,
>=1 к (1)
dj = COv(Xi, Xj) = EXiXj = У2 Wjs> * J.
s= I
или в матричном виде
C = LL' + V, (1')
О
Vi
где V =
— диагональная матрица остаточных дисперсий. Мат-
Vr
неизвестна и ее оценивают по выборке.
п т, — независимые наблюдения над с. в. х. По-
о
рица С обычно
Пусть а/1),
строим для этой системы с. в. выборочную ковариационную матрицу (см. п. 2.
§2.3)
п
(напомним, что у нас вектор средних значений известен и равен нулю; если бы
вектор средних был неизвестен, то в качестве А надо было бы взять матрицу
А = lla.jlli = - У2 - )>
n t=i
и тогда с учетом этих обозначений все последующие выводы сохраняют свою
силу). Наша цель — использовать информацию, содержащуюся в А, для по-
лучения оценок параметров lij и Vj. Для этого мы воспользуемся методом
550
Глава 8. Факторный анализ
максимального правдоподобия. Согласно этому методу оценки и v, опре-
деляются из условия, чтобы совместная плотность элементов выборочной
ковариационной матрицы, вычисленная в наблюденной «точке» А = ||a,j||t,
т. е. функция правдоподобия, имела наибольшее значение. Воспользуемся сле-
дующим результатом.
Если случайный вектор х = (агь , хг) распределен по нормальному
закону JV(O, С), то совместное распределение элементов матрицы А — ||а^||,
Роспределение ; называемое распределением Уишарта и обозначаемое
Уишорта W(r, п, С), имеет плотность вероятностей
7(г,п)|СГп/2|Л|(п‘г’1)/2ехр/-^ (2)
k >.J J
где = С1 и у(г, п) — множитель, зависящий только от г и п. Отметим,
что это распределение сосредоточено на множестве положительно определен-
ных матриц А = HflijH размерности г х г Сумма в (2) может быть записана
также как 1г(ЛС-1). Отметим также, что W(l,n, <т2) есть не что иное, как
распределение (<т2/п)х2(п) (см. п. 3 § 1.2), так что распределение Уишарта
есть многомерный аналог распределения х2
Опуская члены, не зависящие от С, из (2) получаем, что о.м.п. для lij
и V, — это те значения 1^ и Vi, которые доставляют минимум функции
L = In |С| + 52 а,/7 (3)
i.j
Чтобы получить соответствующие уравнения, мы должны продифферен-
цировать (3) по lij и и* и приравнять все частные производные нулю.
Будем обозначать большими буквами С1; алгебраические дополнения
элементов сг] в матрице С. Тогда поскольку
|С| = 5 cijCij = ,
j
то
£1£1 _г
Ocij ,г
Если при этом матрица С симметрична, то из C,j = Cji следует, что при i
Отсюда также следует, что если элементы с1; являются функциями от , zs,
то
д|С| _ ул 5|С| dcij _ ул £ dcij
9zt “ дсц dzt dzt
i,3 J i,3
§8.3. Вывод уравнений максимального правдоподобия 551
Используя эти формулы и учитывая соотношение (1), получим:
д In |С| Сц j,
-------= — = с г = .............г
dvi |С|
sm io
dli3
(4)
поскольку
i = 1,..., r, j = 1, , k,
dctt
дц,
О при t /= i,
2lij при t = i,
dcts
dkj
при
при
при
t i, s i,
t = i,
3=1.
и при t / s
0
^0
s
(0
Вычислим теперь частные производные по Цу и Vi от cts = Cts/\C\.
Так как дифференцировать |С| мы уже умеем (см. (4)), то достаточно
найти производные от Cts. Эти производные можно вычислить, воспользо-
вавшись разложением С<4 по элементам некоторого столбца (С|„, С2„,.... CrV)
без элемента ctv (здесь v £ s):
Cts — / J CuvCfs uv,
u
где Cts uv обозначает алгебраическое дополнение элемента cu„ в Cts- Отсюда
0Cts
~т = Cts а> если t i, в i,
dvt
dCts dCts dcul) x dcuv (0
Al.. ~ 2-^ л7 Я/ — 2-^ ts'uv Al. .
С'Ч; OCut) OltJ u „ Ul>}
u£t,V^S Uj=t, Vj^s
Если воспользоваться теперь соотношением
Os, uv |C| — CtsCuv CtvCus>
формулами (5) и (4), то из (6) можно получить, что
fdCts sinId\ =
dvi \ dvt ts dvt J |C[
и аналогично
=2 52 ”2Cts /ujW " "2 52 l^cUtcS'’ * г-
J u£s u 1 и
552
Глава 8. Факторный анализ
Таким образом, окончательно получаем, что
= (7)
Z и1ц
J и t,s,u
z.11 \ s Л „si /п\
gv - С 2_^С atsC (8)
* t,s
Нетрудно заметить, что правая часть (7) есть элементу -й строки и г-го столбца
матрицы
L'C~' -L'C~lAC~',
а правая часть (8) есть г-й диагональный элемент матрицы
С~'-С~[АСГ'
Таким образом, уравнения максимального правдоподобия для определе-
ния оценок параметров 1^ и и, имеют вид
L'CT' -L'C~{AC~} =0, (9)
diag(C-1=0, (10)
где diag М обозначает матрицу, содержащую только диагональную часть мат-
рицы М При этом С имеет вид (lz).
Выше мы видели (§ 8.2), что матрица L определяется с точностью до умно-
жения справа на произвольную ортогональную матрицу (это также видно и
из уравнений (9)—(10), поскольку при умножении L справа на произвольную
ортогональную матрицу величина С остается неизменной). Чтобы зафикси-
ровать L (зафиксировать направление в пространстве факторов), мы добавим
к (9)—(10) еще одно условие. Именно, мы будем требовать, чтобы матрица
J = L'V~]L (10')
была диагональной с диагональными элементами, расположенными в порядке
убывания.
Уравнения (9)—(10) можно значительно упростить. Для этого умножим
сначала (9) справа на С. В результате мы придем к уравнению
L' - Ь'СГ'А = 0. (11)
Далее, поскольку матрица V = С- LL1 диагональная с положительными эле-
ментами и поскольку в силу (11)
И(С-1 - С~'АС~') = 1Г - АС~‘ - LL'C~' 4- LL'C~'AC-' = JLr - АС~'
то уравнение (10) эквивалентно уравнению
diag(lr - АС-1) = 0. (12)
Аналогично имеем:
(lr - AC~‘)V = С - А - LL' + AC~'LL' = С - А
§ 8.4. Итерационный метод нахождения факторных нагрузок 553
и потому (12) эквивалентно уравнению
diag(C - Л) = 0. (13)
Из (13) следует, что для всех i сц = ац и в силу (1)
vi = аа ~ hj- (14)
; = 1
Таким образом, оценки для остаточных дисперсий v, могут быть найдены по
формуле (14), коль скоро будут получены оценки для факторных нагрузок l,j.
Приведем уравнение (11) к виду, более удобному для практического ре-
шения. Воспользуемся для этого тождеством
С~' = V-1 - V_|Z(1* + jy'L'V~' (15)
Чтобы убедиться в его справедливости, умножим правую часть на С = LL1 + V:
lr = lr + V~'LL' - V~lL(lk + jy'L' - V~'L(lk + J)~'L'V~lLL' =
= lr + V~'LL' - У"'ь[(1* + J)"1 + (1* + J)"1 J]L' = lr,
что и требовалось. Умножив далее (15) слева на 1!, получим:
L'C-1 = LV’1 - llV~KI\lk + jy’L'y'1 =
= [lfc- J(lk + J)~l]L'V~' =
= [(1, + J)(lk + J)~' - J(lk + J)”1] L'V~' =
= (li+Jr1L'V-1 (16)
Подставив (16) в (11), придем к уравнению
L1 = (lk+J)-'L’V-lA.
Умножив теперь обе части этого равенства слева на J~l(lk + J), будем иметь:
L' + J~lL’ = J~'L'V~'A,
или
L‘ = J~'L‘V~\A-V). (17)
§ 8.4. Итерационный метод нахождения факторных нагрузок
Уравнение (17) §8.3 можно записать в виде
JL1 = L'V~'(A-V). (1)
Отсюда следует, что элементы J являются собственными значениями, а
строки L1 — соответствующими собственными векторами матрицы V~' (Л - У).
На этом и основан итерационный метод решения уравнения (17) §8.3.
554
Глава 8. Факторный анализ
Этот метод описывается следующим образом. Обозначим через ('• г-ю
строку матрицы L1 и предположим, что у нас есть начальные приближения
L(i) и У(|) для L и V соответственно. Пусть обозначает г-ю строку L1^.
Тогда на первом шагу процедуры мы находим
вектор-строку W| = Гщ) Vjjj1
вектор-строку и,. — w\A -
число hi = WjW|
и в качестве 2-го приближения к Z', принимаем вектор-строку
,, _ 1 ,
-<2) “ Jhi~'-
Если у нас более одного фактора (к 2), мы делаем второй шаг: находим
последовательно
вектор-строку w2 = Z2(,) Vj])1
ЧИСЛО >21 = ™'21|(2)>
вектор-строку U2 = w'2A - lyy - J21L'i(2)>
число h2 = U2W2
и в качестве второго приближения к 12 принимаем вектор-строку
-2(2)" Тйг2'
Для третьего фактора (Л 3) последовательно находим:
вектор-строку w3 = Z'^qVJq1
два числа >3| = w3Zl(2) и >32 = w3Z2(2),
вектор-строку и3 = w34 - Z3(1) - >3iZ'1(2) - >32(2(2),
ЧИСЛО Й3 = UjWj
и в качестве второго приближения к Z3 принимаем вектор-строку
-2(2) =
и т.д. Если у нас к факторов, то делаем к таких шагов. Таким образом, в конце
этого цикла мы получим второе приближение Д(2) для L. Матрицу V(2; мы
находим, подставляя элементы матрицы в уравнение (14) §8.3.
Матрицы L(2) и V(2) можно использовать как начальные в новом цикле
и получить следующие приближения и У(3) и т.д. Установить условия схо-
димости описанного итерационного процесса не представляется возможным,
однако, на практике обычно процесс сходится и притом довольно быстро (хотя
известны примеры, когда сходимость очень медленная или вообще отсутству-
ет — последнее происходит, как правило, из-за плохого выбора начального
приближения). Вопроса о выборе начального приближения мы еше коснемся
несколько позже (в §8.6).
§ 8.5. Проверка гипотезы о числе факторов
555
§ 8.5. Проверка гипотезы о числе факторов
В предыдущей теории предполагалось, что нам точно известно число к об-
щих факторов. Однако, на практике это число обычно неизвестно и всякое
предположение о его значении должно быть подвергнуто проверке как стати-
стическая гипотеза.
Итак, предположил, что мы из некоторых соображений приняли, что чис-
ло общих факторов есть некоторое фиксированное число к (например, к = 1).
Обозначим эту гипотезу На. Другими словами, Но есть предположение, что
ковариационная матрица С (размером г х г) может быть представлена в виде
суммы диагональной матрицы V с положительными элементами и матрицы
LL1 ранга к (см. (1) §8.3). Для дальнейшего потребуем, чтобы выполнялось
соотношение
(г - к)2 > г + к.
(О
Общая же гипотеза Я, внутри которой мы должны проверить Но, не делает
никаких предположений о матрице С (кроме, конечно, положительной опре-
деленности). Для проверки Яо внутри Я мы применим A-метод (метод от-
ношения правдоподобия, см. §5.4).
Согласно A-методу мы должны вычислить статистику Ап, равную от-
ношению максимума функции правдоподобия (2) § 8.3 по множеству па-
раметров 0о, составляющему гипотезу Яо, к максимуму этой же функции
по множеству параметров 0, составляющему гипотезу Я Если при этом объ-
ем выборки п —» оо, то при гипотезе Яо
Д(-2 In Ап) —> х2(0>
где t = dim 0 - dim 0о (см. п. 4 § 5.4).
В нашем случае максимум функции правдоподобия при гипотезе Яо до-
стигается при С — LL' + V, где оценки L и V определяются уравнениями
(17) и (14) §8.3. При гипотезе же Я, очевидно, наилучшей оценкой для С
является выборочная матрица ковариаций А, поэтому из (2) § 8.3 следует, что
или
(2)
Вычислим теперь число степеней свободы t в предельном законе %2 Чис-
ло независимых параметров (элементов матрицы С) при гипотезе Я равно,
очевидно, г (г + 1)/2, следовательно,
2
556
Глава 8. Факторный анализ
Далее, число всех параметров в представлении (1') §8.3 равно г + г к, однако,
вследствие неопределенности, возникающей из возможности вращения фак-
торов, мы в §8.3 накладывали еще условие (К)'), фиксирующее однозначно
матрицу L. Это условие накладывает еще к(к - 1)/2 ограничений на эле-
менты L и V, и потому действительное число независимых параметров при
гипотезе Hq равно
к(к - 1)
dim ©о = г + гк----------.
Таким образом, число степеней свободы
t = r(r+ 1) _ г(к + + к(к^ 1) = + (3)
В силу предположения (1) число t положительно.
Итак, если объем выборки п велик, то статистика (2) распределена при-
ближенно по закону х2(С> где Дано в (3)-
Этот результат позволяет стандартным образом организовать проверку
согласия экспериментальных данных и гипотезы Hq о наличии точно к общих
факторов.
Критерий для гипотезы Проверка гипотезы осуществляется следую-
о числе факторов щим образом. Задаваясь вероятностью а откло-
нить гипотезу Hq, когда она верна (уровень зна-
чимости критерия), по таблицам распределения где t дано в (3), опре-
деляем квантиль Хл-a.t из условия
р{х2(0 > Xi-<m} = «•
Далее, для данного к методом §8.3 вычисляем С = LlJ + V и определяем
значение статистики -2 In Ап в (2). Если это значение оказалось больше, чем
Xi-a.t, т0 мы отвергаем гипотезу Яо и говорим, что в факторной модели
необходимо не менее к + 1 факторов. Если же -2 In An Xi-a, t то, как
обычно, можно лишь сказать, что опыт не опровергает гипотезу.
Пр актические На практике число факторов и оценки L и V находят
рекомендации так. Из априорных соображений определяют предполага-
емое число факторов к и для этого числа методом §8.3
определяют L и V После этого проверяют гипотезу о наличии ровно к факто-
ров. Если гипотеза отвергается, то заново вычисляют L и V уже для к+1 фак-
тора и снова проверяют гипотезу о наличии к+ 1 фактора и т. д., пока не полу-
чим впервые —2 In An < xl-a,t- Параметры L, V и число факторов в момент
остановки и принимаются за параметры нашей факторной модели (2) §8.1.
В заключение приведем некоторые соображения, несколько улучшающие
описанный критерий и упрощающие его практическое применение.
Прежде всего рекомендуется заменить множитель п в (2) на
1 2
п = п - — (2г -I- 5) — -к. (4)
§ 8.5. Проверка гипотезы о числе факторов
557
Было замечено, что при этом распределение статистики (2) более точно ап-
проксимируется х2-распределением.
Далее, если бы уравнения для оценок были решены точно, то тогда со-
гласно (12) §8.3
tr (ЛС-1) = tr 1г = т
и, следовательно, статистику (2) можно было бы заменить на
п In = -п In |С-14|. (5)
Используя теперь (11) и (15) §8.3, можно получить, что
С~'А = 1г + С~'(А - С) = 1г + У-1(Л - С).
Действительно, поскольку из (16) и (11) §8.3 («крышки» для краткости опус-
каем)
У-1£(1Г + J)~'L'V~'A = V-lZ(lr + jy'L'C,
то в силу (15) §8.3 имеем:
(У-1 -С~')А = (У-1 -С~')С,
или
У-1(4-С) =С_|(4-С).
Обозначив через
ИМ = т = У-’(Л - С), (6)
статистику (5) можно представить теперь в виде
-п 1п|1г+Г|. (7)
Поскольку матрица У-1 диагональная, а диагональные элементы матрицы
А - С согласно (13) § 8.3 равны нулю, то диагональные элементы матрицы Т
также равны нулю. Далее, при больших п разности а1;- - cj;, как правило,
невелики, и потому в разложении определителя |1Г + Т| можно опустить
члены, содержащие произведения более двух этих разностей. С учетом этих
соображений мы получаем следующее приближенное равенство
(QV C|j)2
ViVj
Наконец, статистику (7) можно приближенно заменить статистикой
(8)
Статистикой (8), вместо (2), обычно пользуются на практике. Вычисление
выражения (8) неизмеримо проще, чем вычисление (2), и использование ста-
тистики (8), как правило, приводит к хорошей аппроксимации, даже когда
сделано сравнительно мало итераций и точные о. м. п. L и У еще не найдены.
558
Глава 8. Факторный анализ
§ 8.6. Центроидный метод
В этом параграфе мы опишем один из приближенных методов определения
факторных нагрузок, который часто используется на практике. Этот метод
по существу своему является итерационным и носит название центроидного
метода. Оценки, получаемые этим методом, обычно бывают близки к о. м. п.
и достаточны для многих практических целей. Но как правило, рекоменду-
ется использовать эти оценки в качестве начального приближения в методе
максимального правдоподобия (см. §8.4).
Факторные Введем понятие факторных дисперсий. Назовем
дисперсии факторными дисперсиями диагональные элементы мат-
рицы LL Следовательно, факторными дисперсиями
с. в. ij, , хГ являются те части общих дисперсий, которые вносят факторы
/1, ,fk- Из (1) §8.3 следует, что факторной дисперсией с. в. xt является
ЧИСЛО /|| 4- -Ь .
Дадим описание центроидного метода, одновременно иллюстрируя его на
примере. В этом методе обычно рассматривают выборочную корреляционную
матрицу. Перед началом анализа надо знать начальные значения факторных
дисперсий. В качестве таковых выбираются максимальные по модулю значе-
ния элементов в столбцах корреляционной матрицы (без учета диагональных)
и ими заменяют единицы на диагонали этой матрицы. Так получаемую мат-
рицу обозначим Ло.
В качестве иллюстративного примера мы будем рассматривать следующую
корреляционную матрицу (для г = 6), в которой уже проделана отмеченная
выше первоначальная процедура
1 2 3 4 5 6
1 0,439 0,439 0,410 0,288 0,329 0,248
2 0,439 0,439 0,351 0,354 0,320 0,329
3 0,410 0,351 0,410 0,164 0,190 0,181
4 0,288 0,354 0,164 0,595 0,595 0,470
5 0,329 0,320 0,190 0,595 0,595 0,464
6 0,248 0,329 0,181 0,470 0,464 0,470
В данном случае все корреляции положительны, но если бы это было
не так, то прежде чем действовать дальше, мы должны были бы изменением
знака у одной или более переменных х], , хг постараться минимизировать
число отрицательных корреляций (при изменении знака у Xj изменяются
знаки у элементов г-й строки и г-го столбца корреляционной матрицы; при
§ 8.6. Центроидный метод
559
этом диагональный элемент остается неизменным). Этим мы достигаем того,
чтобы суммы по столбцам были бы как можно больше.
После этой операции с изменением знаков (в нашем примере этого делать
не надо) вычисляют суммы по столбцам и полную сумму всех элементов
матрицы Aq. Числа, получаемые делением сумм в соответствующих столбцах
на квадратный корень из полной суммы, и являются первыми оценками для
нагрузок на первый фактор.
При этом, если бы мы меняли знаки у некоторых переменных, то у со-
ответствующих нагрузок мы должны были бы изменить знаки на обратные.
В примере
Суммы 2,153 2,232 1,706 2,466 2,493 2,162 Е = 13,212
Нагрузки на 1-й фактор 0,592 0,614 0,469 0,678 0,686 0,595 х/Ё = 3,635
Обозначим через = (£ц, Z21, Jri) так полученную строку нагрузок
и вычислим первую остаточную матрицу Aq - 1г1\ (исключим влияние пер-
вого фактора из первоначальной матрицы). В примере Ag -l^i имеет следу-
ющий вид:
1 2 3 4 5 6
1 0,086 0,076 0,132 -0,113 -0,077 -0,104
2 0,076 0,062 0,063 -0,062 -0,101 -0,036
3 0,132 0,063 0,190 -0,154 -0,132 -0,098
4 -0,113 -0,062 -0,154 0,135 0,130 0,067
5 -0,077 -0,101 -0,132 0,130 0,124 0,056
6 -0,104 -0,036 -0,098 0,067 0,056 0,116
В матрице Aq _ (Ji Уже обязательно будут отрицательные элементы,
поскольку суммы по столбцам в ней всегда равны нулю. Поэтому перед
следующим этапом в Ао - (1//1 надо проделать описанную выше процеду-
ру с изменением знаков как минимум у одной переменной (минимизируя
число отрицательных знаков). В нашем примере число отрицательных знаков
в можно сделать нулем, если изменить знак у переменных 2:4, 2:5 и xq.
Затем снова в диагональные клетки Ао ставим максимальные по модулю
значения элементов соответствующих столбцов (но это лишь на первом цикле
итерационного процесса; на последующих же циклах замены диагональных
элементов не производятся). Так получаемую матрицу обозначим А]. В при-
мере А| имеет вид:
560
Глава 8. Факторный анализ
0,132 0,076 0,132 0,113 0,077 0,104
0,076 0,101 0,063 0,062 0,101 0,036
0,132 0,063 0,190 0,154 0,132 0,098
0,113 0,062 0,154 0,154 0,130 0,067
0,077 0,101 0,132 0,130 0,132 0,056
0,104 0,036 0,098 0,067 0,056 0,116
Далее с матрицей Л, проделывается то же, что и с матрицей Ло: находятся
суммы по столбцам и полная сумма, извлекается квадратный корень из полной
суммы и на это число делятся суммы в столбцах. Получаемые числа (с учетом
восстановления знаков) и есть первые оценки нагрузок на второй фактор:
1*2 = G12- ^22, , 1г2)-
В примере мы должны взять нагрузки для х4, х>, Xf, со знаком минус.
Суммы 0,634 0,439 0,769 0,680 0,628 0,477 S = 3,627
Нагрузки на 2-й фактор 0,333 0,231 0,404 -0,357 -0,330 -0,251 х/Ё= 1,904
После этого рассматривается матрица А। — с ней проделывается та же
процедура, что и с матрицей Ло - и т.д. пока не исчерпаем всех факторов
и не получим полностью матрицу L = ||/у|| (г =1, ,т; j = 1, , fc).
Здесь так же, как и в методе максимального правдоподобия (§8.5), действует
правило, ограничивающее число факторов fc условием т + fc < (г - к)7 Так,
в нашем примере мы должны ограничиться вторым этапом, так как значение
fc = 3 уже не удовлетворяет этому условию.
Суммируя теперь по строкам квадраты элементов этой матрицы:
к
di = .
2 = 1
получим новые оценки для факторных дисперсий. На этом первый цикл ите-
рационного процесса заканчивается. Только нужно у переменных, менявших
знак, вернуться к первоначальным знакам. Полученными факторными дис-
персиями можно воспользоваться для следующей итерации: в г-ю диагональ-
ную клетку исходной выборочной корреляционной матрицы надо подставить
полученное число di, i = 1, , fc, и повторить тот же процесс и т.д. Сходи-
мость на практике описанного процесса очень быстрая.
§8.6. Центроидный метод
561
Для нашего примера первые оценки матрицы нагрузок и факторные дис-
персии имеют вид
0,592 0,333 =0,461
0,614 0,231 d2 = 0,430
0,469 0,404 d3 = 0,383
0,678 -0,357 d4 = 0,587
0,686 -0,330 d5 = 0,580
0,595 -0,251 db = 0,417
Описанная процедура отыскания факторных нагрузок Геометрическая
имеет наглядную геометрическую интерпретацию. Отож- интерпретация
дествим наши наблюдаемые переменные Z|,. , хг с век-
торами, выходящими из начала координат r-мерного пространства, косинусы
углов между которыми равны соответствующим корреляциям, адлины — со-
ответствующим стандартным отклонениям. Далее, если направления, которые
приписаны переменным, уже найдены, то мы изменением, если необходимо,
их знаков сделаем как можно больше корреляций положительными; тогда век-
торы будут иметь тенденцию к группировке в одном направлении в пучок и их
сумма будет иметь наибольшую длину. Эта сумма и принимается за первый
фактор, а в качестве нагрузок переменных Х\,..., хг на этот фактор при-
нимаются длины проекций соответствующих векторов на суммарный вектор.
После этого исключается влияние первого фактора (как это описано выше)
идля первой остаточной матрицы строится новая геометрическая модель п т. д.
Для центроидного метода, так же как и для метода мак- .. _ 2 *
„ 2 Критерии х
симального правдоподобия, существует критерии типа «х
для больших выборок» для проверки гипотезы о наличии ровно к факторов,
т.е. критерий значимости остатков после исключения к факторов. Прибли-
женная статистика этого критерия, которая обычно используется на практике,
имеет вид
п
где ||Zy|| = X = 7-1(Л0 - LJ~'L'V~'A0). Здесь Ао = А - V, J = L'V~lL
(вообще говоря, не диагональная). Число степеней свободы в предельном рас-
пределении х2 здесь равно 1/2 ((г - к)2 - г - fe) Эта гипотеза проверяется
точно так же, как и в случае получения оценок методом максимального прав-
доподобия.
Общая схема применения факторного анализа
на практике имеет следующий вид. Сначала с помо-
щью центроидного метода получают первоначаль-
ные факторные нагрузки и факторные дисперсии. С помощью критерия для
центроидного метода уточняют необходимое число факторов. После этого
центроидные нагрузки используют в методе максимального правдоподобия
36 Заказ 1748
Общая схема Ж*
факторного анализа
562
Глава 8. Факторный анализ
в качестве первого приближения. Вообще, методу максимального правдопо-
добия следует отдать предпочтение, так как в настоящее время он является
единственным методом, дающим эффективные оценки факторных нагрузок.
§ 8.7. Оценка значений факторов
Решение вопроса о числе общих факторов и о получении нагрузок на факторы
по переменным составляет основу факторного анализа. Однако на практике
часто представляетинтерес и задача приближенной оценки значений самих ги-
потетических факторов по наблюденным значениям переменных ii, ,хг,
после того, как каким-либо методом уже решена первая задача. Здесь мы
рассмотрим один из простых методов решения этой задачи.
В этом методе оценки Д, , Д факторов находятся из условия обраще-
ния в минимум величины
которую в силу (2) §8.1 можно записать также в виде
5* Метод минимизации
остатков
Таким образом, здесь минимизируется взвешенная
сумма квадратов остатков в модели (2) §8.1, поэтому
метод называется методом минимизации остатков.
Дифференцируя (1) по Д и приравнивая частные производные нулю,
получаем следующую систему уравнений:
или в матричной форме
L‘V~lLl = L‘V~'x. (2)
Полагая
J = L'V~[L,
находим, что оценки факторов по данному методу равны
J = rxL'V~{x. (3)
Таким образом, оценки факторов являются линейными функциями от наблю-
даемых переменных.
Интерпретация факта может оказаться
важнее самого факта.
§ 8.7. Оценка значений факторов
563
t^-r- Заключительные замечания. В заключение отметим, что в факторном ана-
13/ лизе в силу неоднозначности решения (см. §8.2) весьма существенную
L роль играет проблема интерпретации результатов исследования (бывает:
v мысль, достойная оваций, погибнуть может от интерпретаций). В каче-
стве иллюстрации этого приведем результаты одного конкретного исследования
в области социологии описанные в книге [18, с.98-99]. Известный специалист
в области факторного анализа Кэтгел исследовал показатели, характеризующие
уровень культурного развития наций. Было выбрано 72 количественно измеряе-
мых показателя для анализа культурного уровня 69 наций. В их число входили все
показатели, которые, по мнению автора, характеризуют культуру нации. Среди
них оказались число лауреатов Нобелевской премии, число зарегистрированных
проституток, число секретных договоров, число революций за 100 лет, минималь-
ный возраст вступления в брак, потребление сахара на душу населения, процент
негров, отношение разводов к бракам, процент самоубийств и т.д. Анализу было
подвергнуто 2556 корреляционных связей. Окончательные результаты были пред-
ставлены 12 факторами. Автор пытался дать осмысленную интерпретацию каж-
дому фактору, рассматривая его нагруженность исходными переменными. При
этом использовались весьма вычурные формулировки для обозначения факто-
ров, например: «просвещенное изобилие в противовес удручающей бедности»,
«осмысленное трудолюбие в противовес эмоциональности», «консервативность
и патриархальная стабильность в противовес безрассудной богеме» и т.д.
«Результаты такого исследования, может быть, и любопытны в каком-то смысле,
но нам кажется, что они все же не имеют большого эвристического значения, —
вряд ли, исходя из подобных исследований, можно выдвинуть содержательные
гипотезы о развитии культуры. Нам представляется неудачной сама попытка
создания модели, всесторонне и полно описывающей такую сложную и плохо
организованную систему. Видимо, факторный анализ имеет смысл применять
к всестороннему описанию более простых систем, где легче выдвигать гипотезы,
подлежащие дальнейшему обсуждению» [18]. И еще: «Если говорить о критиче-
ской оценке факторного анализа, то следует вспомнить довольно старое, очень
резкое, но, вероятно, не совсем справедливое замечание о том, что, пользуясь этим
методом, получишь то, что туда внесешь». Но, хотя этот метод и не дает однознач-
ного решения, он все же помогает исследователю формулировать реалистичные
гипотезы об исследуемой системе, обостряет его интуицию, упрощает итоговый
алгоритм проведения эксперимента, помогая отсеивать множество «шумовых» по-
казателей и выделять наиболее существенные характеристики изучаемого объекта
или процесса. В качестве литературы по теории и приложениям факторного ана-
лиза можно указать книги [17,19].
Писанье книг — занятье без конца, их
чтенье — утомительно для тела.
\/
Cattell R. В. The Dimentions of Cultural Patterns by Factorization of National Characters //
J.Abnor. and Social Psychology. 1949. V. 44. P. 443-469.
Глава 9
Компонентный анализ
Не дороги нам дни, не жаль нам их нимало,
Чтоб то, чем дорожим, росло и созревало —
Цветок ли пестуем в саду, где сладко дышим,
Ребенка ли растим иль книжечку мы пишем.
Фридрих Рюккерт ’’
§ 9.1. Постановка задач компонентного анализа
Компонентный анализ или, иначе, метод главных компонент так же, как и фак-
торный анализ, исследует структуру ковариационных (или корреляционных)
матриц систем случайных величин (с. в.). Однако лишь только в этом и состо-
ит их формальное сходство. Если для факторного анализа важны корреляции
между переменными, которые он объясняет наличием некоторого числа об-
щих для всех переменных факторов, то в компонентном анализе интересуются
исключительно дисперсиями переменных и их линейных комбинаций. При
этом в компонентном анализе не делается фактически никаких предположе-
ний о наблюдаемых с. в. Х[,... ,хГ, в то время, как для факторного анализа
существенным является линейность и нормальность его модели (см. (2) §8.1),
которая, если и не верна, то хотя бы приближенно отражает суть дела.
В компонентном анализе ищется такое линейное преобразование
= hifi + + llrfr,
(1)
Жг = /г 1/1 ^rrfrt
или в матричной форме
x = Lf, (1')
где х = (ii, ,хг), f = (/|, ,/г) — векторы-столбцы и L = ||^||
квадратная матрица размером г х г, в котором с. в. /), , /г некоррелиро-
ваны и нормированы (Е/, = О, D/; = 1, i = 1, ,г; всегда для простоты
предполагается, что Егб, = 0, г = 1, , г).
Представление исходных с. в. xit ,хг в виде (1) имеет ряд преиму-
ществ. Действительно, в этом случае их дисперсии весьма просто выражаются
’’ Рюккерт Фридрих (1788-1866) — немецкий поэт, драматург.
§ 9.1. Постановка задач компонентного анализа
565
через коэффициенты 1у:
Dx; = 1ц + + Ijr, i = 1, , г. (2)
Ввиду (2) суммарная дисперсия с. в. xj, ,хг равна
= 52^ +... + ££, (3)
i = l t = l i=l
поэтому величину /у можно назвать вкладом компоненты /у в дисперсию пе-
ременной а;;, а величину у — вкладом компоненты /7 в суммарную
дисперсию. Далее, предположим, что вклад компоненты fT в суммарную дис-
персию мал. Тогда можно пренебречь влиянием компоненты /г, и вектор
х = (хь , хг) характеризовался бы в этом случае не г случайными чис-
лами Х|, , хг а лишь г - 1 случайными числами /ь Вообще,
если бы суммарный вклад компонент fk+\, , fT в суммарную дисперсию,
равный в силу (2) и (3)
Г г
;=к+1 £=|
был мал настолько, что им можно было бы пренебречь, то это означало бы, что
влиянием компонент fk+\, , fr можно пренебречь, и следовательно, вектор
х характеризовался бы не т параметрами, а лишь к параметрами , fk.
Иногда такое исследование помогает лучше понять природу случая, порожда-
ющего случайный вектор х. Кроме этого, при этом удается «сжать» инфор-
мацию, т. е. достичь экономии в описании изучаемого объекта (описывать его
меньшим числом параметров).
Как будет показано ниже, отыскание представления (1) эквивалентно
определению г таких нормированных линейных комбинаций у,, ,уГ пе-
ременных Х|, , хг (т.е. сумма квадратов коэффициентов равна 1), что для
каждого k = 1, г ук имеет наибольшую дисперсию среди всех нормиро-
ванных линейных комбинаций при условии некоррелированности с преды-
дущими комбинациями у\, , ук-\. Такие линейные комбинации уь..., уг
называются главными компонентами системы с. в. Х\, ,хТ.
Следовательно, первой главной компонентой Главные компоненты
переменных Х|, , хГ называется нормированная
линейная комбинация этих переменных, обладаю-
щая максимальной дисперсией.
Второй главной компонентой называется нормированная линейная ком-
бинация, обладающая максимальной дисперсией при условии некоррелиро-
ванности с первой главной компонентой.
Третьей главной компонентой называется нормированная линейная ком-
бинация с. в. Xj,. , хг, обладающая максимальной дисперсией при условии
некоррелированности с первой и второй главными компонентами и т. д.
566
Глава 9. Компонентный анализ
Для практики обычно наибольший интерес представляют те переменные
или их линейные комбинации, которые имеют большие дисперсии, поскольку
именно такие комбинации и несут в себе максимум информации о степени
изменчивости того или иного показателя или признака. В практических ис-
следованиях, когда число рассматриваемых переменных, которые требуется
обработать, слишком велико, стремятся выделить относительно небольшое
число их линейных комбинаций с большими дисперсиями, а линейные ком-
бинации с малыми дисперсиями отбрасываются, как несущественные. Таким
образом, достигается сокращение числа исследуемых переменных.
Ввиду этого отыскание главных компонент и выделение из них тех, кото-
рые удовлетворительно объясняют суммарную дисперсию, представляет боль-
шой практический интерес. Метод главных компонент был предложен еще
в 1901 г. К. Пирсоном и позднее вновь открыт и детально разработан Хотел-
лингом (1933 г.). Этот метод хорошо изложен в книге [1].
§9.2. Решение основных уравнений. Главные компоненты
В этом параграфе мы получим представление (1) § 9.1 для любой системы с. в.
ii,..., хг. Предположим, что известна ковариационная матрица А этих с. в.
(если ковариационная матрица неизвестна, но даны независимые наблюдения
над с. в. х = (хь , хг), то во всех нижеследующих рассуждениях надо под А
понимать выборочную ковариационную матрицу).
Обозначим через U ортогональную матрицу, с помощью которой А при-
водится к диагональной матрице
Л =
(1)
0
в которой элементы расположены в порядке убывания, т.е. А| > Аг > >
> А > 0 (мы предполагаем для простоты, что все Aj различны и положи-
тельны, что для большинства практических ситуаций обычно выполняется).
Таким образом,
Л = U'AU. (2)
Фактически А^ есть fc-e по величине собственное значение матрицы А, а к-й
столбец и* матрицы U — соответствующий собственный вектор, так что
Аик = Хкик, к= 1, , г, (3)
что является эквивалентной записью соотношения (2).
Рассмотрим теперь новые переменные у = (щ, ,уг), задаваемые ра-
венством
У = и'х. (4)
Хотеллинг Гаралцд (1895-1973) — американский статистик и экономист.
§9.2. Решение основных уравнений. Главные компоненты
567
Вычислим их ковариационную матрицу В. Поскольку Ех, = 0, то Еу1 = =
= Еуг = 0 и потому
В = Ъ(уу) = ElU'xxU) = U'E(xx)U = U'AU = Л.
Из этого соотношения следует, что с. в. у ।, , уг некоррелированы и Т)ук = А*,
k = 1, , г.
Покажем теперь, что у\ есть нормированная комбинация с наибольшей
дисперсией. Пусть
У* = С\Х\,+ ,+ CrXr=dx, c=(c]; ,Сг), с с = с, + + cj: = l,
есть произвольная нормированная линейная комбинация х-ов. Тогда из (4)
следует, что
У* = cUy_= Q*'y = + + сгуг, с = U'с.
При этом с'с = 1, поскольку при ортогональном преобразовании длина век-
тора не меняется. Отсюда
Г г
вУ* = Е = А>+Е с-’2(А« - А')>
i=l 1=2
поскольку
с;2 = 1-Ес‘2
i=2
Это выражение, очевидно, достигает максимума при cj = = с* = 0, так
как А) > А, при i 2.
Аналогично, у2 представляет собой нормированную линейную комбина-
цию, некоррелированную с у] и имеющую наибольшую дисперсию (из того,
что у* = c*tyi некоррелирована с у\, следует с* = 0, а далее применяются
предыдущие рассуждения) и т.д.
Таким образом,
= UjX = U)1X| + U21X2 + + Ur|Xr
есть первая главная компонента переменных хь , хг и ее дисперсия равна
первому собственному значению А| (здесь и далее U = ||uij|| и - к-я
строка матрицы U'),
У1 = У.2Х = U^X] + U22X2 + +иг2Хг
есть вторая главная компонента и ее дисперсия равна второму собственному
значению Х2 и т.д. Вообще
Ук = = «н: + и2кХ2 + + игкхг (5)
есть к-я главная компонента и ее дисперсия равна fc-му по величине соб-
ственному значению Хк.
568
Глава 9. Компонентный анализ
Главны^ИЧ|||Я||
компоненты (вид)
Итак, нахождение главных компонент и их дис-
персий сводится, по существу, к нахождению собствен-
ных значений и собственных векторов ковариационной
матрицы А. При этом к-я главная компонента имеет дисперсию, равную fe-му
по величине собственному значению, а коэффициенты ее линейной комби-
нации являются компонентами соответствующего собственного вектора А.
Чтобы получить теперь представление (1) §9.1, достаточно пронормиро-
вать с. в. уi, ,уг в (4).
Положим
! i ,
А = ~у^Ук = к = 1, г (6)
V Лк V Лк
Тогда с. в. Jr будут некоррелированы и нормированы (БД = 1).
В матричной записи (6) имеет вид
f_ = A~'l2y = A~',2U'x. (7)
Это равенство выражает f через х. Чтобы выразить х через f, умножим
(7) слева на U А1?2 Поскольку UU' = 1г, то это дает
z = [M1/2f (8)
Сравнивая (8) с (1) §9.1, получаем, что
L = UAl/2 (9)
Тем самым получено представление (1) §9.1.
Итак, с. в. /|, , Д в (1) §9.1 — это суть нормированные главные ком-
поненты переменных Х\, ,хг. При этом к-я столбец 1к матрицы L равен
и при этом
I'klk = ^кУкКк = ^к = fik + + Irk-
Таким образом, вклад компоненты Д в суммарную дисперсию с. в. xt, , хТ
равен как раз А*;. Следовательно, зная собственные значения матрицы А,
мы легко можем найти и долю, вносимую каждой компонентой в суммарную
дисперсию, равную в силу (3) §9.1 А! + + Ar = tr (Л) = tr (А).
§ 9.3. Метод Хотеллинга
Как следует из §9.2 в компонентном анализе основная задача состоит в вы-
числении собственных значений и собственных векторов ковариационной
матрицы А. В настоящее время для этой цели используются ЭВМ. Имеется
несколько способов решения этой задачи. Мы приведем здесь итерационный
метод, разработанный Хотеллингом.
§ 9.3. Метод Хотеллинга
569
Пусть а(0) — любой вектор, не ортогональный к первому собственному
вектору (обычно в качестве компонент начального вектора О(0) рекомен-
дуется брать числа, приблизительно пропорциональные суммам элементов
соответствующих столбцов матрицы А). Определяем последовательно
J------g(0> » = 0,1,2,... (1)
a(i) = г = 1,2, (2)
Тогда имеют место следующие соотношения:
Нт а'(1)О(0 = Ai> (3)
lim 4) = ±uj. (4)
Докажем (3) и (4). Поскольку А = UAU1, то А1 = UA'U1 Полагая далее
st = (4)^(о) '/2> из 0) и (2) получим, что
Ь(,) = Si Afef,-!). (5)
Применяя последовательно несколько раз (5), найдем, что
4-) = t,-4’0(0) = tiUVU'a^, (6)
где t, = sosi ...Si. Из (1) и (6) следует, что
l=4)4) = tio'(0)^A2’C7'a(0). (7)
Соотношение (6) можно записать также в виде
—U О(0). (8)
Но
lim U
i->oo
так как А7/А| < 1 при j > 1. Таким образом,
U —(О) = UCU О(о) = ||И|0... О||ЕТ = (U|(3(о))И\
(9)
(здесь символом 0 обозначается нулевой столбец матрицы).
37 Заказ 1748
570
Глава 9. Компонентный анализ
С учетом (9) из (7) имеем:
2 ( 1 \2' 2 2
1 = lim lim «тГГ ( —Л I U‘’af0) = («[в/т) Чт (£,Л*)
i-юо i-юо ' ' \А| / ' ' ' i-юо
Таким образом,
lim М)2 = Т7Ц>- (‘°)
поскольку, по предположению, / 0. Из (8) с учетом (9) и (10) следует,
что
1 / , х
lim b: — ±—----- (u,am)«, = ±«,.
»-юо и, в(0) 1 ’
Далее из (2) с учетом этого соотношения и соотношения (3) §9.2 следует, что
lim a(,j = ±А«. = ±A|«t.
woo ' '
Отсюда
lim ~ AjU\= Ар
Таким образом, соотношения (3) и (4) доказаны.
Чтобы найти второе собственное число и соответствующий собственный
вектор, рассмотрим матрицу
Аг — А - AiUjWp
Тогда, если i / 1, то
-^2“j = Au* — Ai^uju] - Хги^,
ПОСКОЛЬКУ UjU, = 0, и
A2U1 = Aut - А|(«’|«1)и1 — X{Ui - A|Uj = 0,
ПОСКОЛЬКУ t/jU, = 1.
Таким образом, , и2,. ., иг являются собственными векторами матри-
цы Аг, а соответствующие собственные значения равны О, А2, ,АГ. Сле-
довательно, Хг — наибольшее собственное значение матрицы Аг, а и2 —
соответствующий собственный вектор. Для определения и2 и А2 можно, сле-
довательно, применить к А2 описанный выше процесс последовательных при-
ближений. После этого можно определить матрицу
А2 = А2 — А2И2У2
и методом последовательных приближений определить Аз и «ч как ее наи-
большее собственное значение и соответствующий собственный вектор и т.д.
Имеется несколько способов, позволяющих сокра-
тить объем работы в методе последовательных приближе-
ний. Один из них состоит в том, что матрицу А возводят
Практические
рекомендации
§ 9.3. Метод Хотеллинга
571
в некоторую степень, а затем уже применяют метод последовательных при-
ближений. Так, можно пользоваться матрицей А2, положив
2 1
G(i) = a b(i} = -==^).
V ^(<)е(«)
Этот процесс сходится вдвое быстрее, чем процесс, определяемый формула-
ми (1) и (2). При использовании А4 = А2 А2 сходимость получается вчетверо
более быстрая и т.д. Отметим при этом, что А2 — симметрическая матрица,
поэтому при ее вычислении достаточно определить лишь г(г+1)/2 ее элемен-
тов. Для контроля вычислений можно использовать равенства tr (А) = tr (Л)
и А = LL', где L определено в (9) §9.2. Пример Джефферса *
< Приведем один конкретный пример применения метода главных компо-
нент. В работе Джефферса31 этот метод был применен в следующей задаче
классификации. Объектом исследования служили летающие тли. Нужно
было разбить этот вид насекомых на подгруппы по варьируемости их мор-
фологических признаков. Было измерено 19 различных признаков, которые оказа-
лись весьма сильно коррелированными между собой; так коэффициенты парных
корреляций по многим признакам достигали значений 0,90-г 0,99. Компонент-
ный анализ показал, что можно ограничиться двумя первыми главными компо-
нентами, на которые приходится 85,5 % от общей дисперсии. Первая компонента
задается различием в размерах насекомых, вторая в значительной степени связана
с числом яйцекладок.
Графически результаты представлены на рис. 1 (результаты наблюдений представле-
ны на плоскости, задаваемой двумя первыми компонентами). Здесь ясно видно, что
обследованных насекомых можно разбить на четыре хорошо различимые группы.
31 Jeffers J. N. R. Two Case Studies in the Application of Principal Component Analysis // Appl. Stat.
1967 16. №3. P. 225-236.
37*
572
Глава 9. Компонентный анализ
Геометрическая
интерпретация
Вообще, геометрически нахождение главных ком-
понент сводится к переходу к новой ортогональной си-
стеме координат: первая координатная ось ищется так,
чтобы соответствующая ей линейная форма извлекала возможно большую
дисперсию, далее ищется ортогональная ей ось, которая делает то же самое
с оставшейся дисперсией и т.д.
'л.Л _ В заключение отметим, что как факторный, так и
5* заключительные..,.-.^ w ,
компонентный анализ — это математические (стати-
замечания \
стические) методы, основанные на линейных моделях
и (в первом случае) нормальном законе распределения, и служащие лишь
средствами, облегчающими исследователю проникновение в тайны природы.
Природа же надежно охраняет свои тайны:
Природа с красоты своей
Покрова снять не позволяет,
И ты машинами не вынудишь у ней.
Чего твой дух не угадает.
В. С. Соловьев4>
(Перевод из трагедии Гёте «Фауст»)
Чтобы проникнуть в них, надо или ставить активный эксперимент, что
всегда трудно, или научиться их отгадывать. Факторный анализ и метод глав-
ных компонент и служат этой цели. Возникнув сто лет назад в основном
из нужд психологии и социологии, эти методы в настоящее время находят все
более широкое применение как некоторые вспомогательные приемы анализа
данных в задачах самого разного характера.
...нет ничего лучше, как наслаждаться человеку
делами своими: потому что это — доля его; ибо
кто приведет его посмотреть на то, что будет
после него?
Екклесиаст (Библия. Ветхий Завет. 3:22)
Пусть не корят меня, что я не сказал ничего
нового: ново уже само расположение материала;
игроки в мяч бьют по одному и тому же мячу,
но не с одинаковой меткостью.
Б.Паскаль
^Соловьев Владимир Сергеевич (1853-1900) — русский религиозный философ и поэт.
Приложение
Что виделось вчера как цель глазам твоим, —
Для завтрашнего дня — оковы;
Мысль — только пища мыслей новых,
Но голод их неутолим.
Эмиль Верхарн ’’
1. Нормальное распределение
Квантили распределения: р =
e"l!/2 dx = Ф«р)
р Р Ср Р Ср
0,50 0,000 0,68 0,468 0,86 1,080
0,51 0,025 0,69 0,496 0,87 1,126
0,52 0,050 0,70 0,524 0,88 1,175
0,53 0,075 0,71 0,553 0,89 1,227
0,54 0,100 0,72 0,583 0,90 1,282
0,55 0,126 0,73 0,613 0,91 1,341
0,56 0,151 0,74 0,643 0,92 1,405
0,57 0,176 0,75 0,674 0,93 1,476
0,58 0,202 0,76 0,706 0,94 1,555
0,59 0,228 0,77 0,739 0,95 1,645
0,60 0,253 0,78 0,772 0,96 1,751
0,61 0,279 0,79 0,806 0,97 1,881
0,62 0,305 0,80 0,842 0,98 2,054
0,63 0,332 0,81 0,878 0,99 2,326
0,64 0,358 0,82 0,915 0,999 3,090
0,65 0,385 0,83 0,954 0,9999 3,720
0,66 0,412 0,84 0,994 0,99999 4,265
0,67 0,440 0,85 1,036
По тексту используются также обозначения с, = Ф '((1 + 7)/2), т. е. с, = <(1+^/2,
и ta = -Ф“'(а) т.е. ta = = <|_0; при этом ta/2 = С|_о.
Верхарн Эмиль (1855-1916) — бельгийский поэт и драматург.
574
Приложение
2. Распределение Пуассона
оо д*
Значения функции > —е“А
л!
\ А х \ 0,1 0,2 0,3 0,4 0,5 0,6
0 1,000 1,000 1,000 1,000 1,000 1,000
1 0,095 0,181 0,259 0,330 0,394 0,451
2 005 018 037 062 090 122
3 001 003 008 014 023
4 001 002 003
\ А 0,7 0,8 0,9 1,0 2,0 3,0
X \
0 1,000 1,000 1,000 1,000 1,000 1,000
1 0,503 0,551 0,593 0,632 0,865 0,950
2 156 191 228 264 594 801
3 034 047 063 080 323 577
4 006 009 014 019 143 353
5 001 001 002 004 053 185
6 001 018 084
7 005 034
8 001 012
\ А 4,0 5,0 6,0 7,0 8.0 9,0
X \
0 1,000 1,000 1,000 1,000 1,000 1,000
1 0,982 0,993 0,998 0,999 1,000 1,000
2 908 960 983 924 0,997 0,999
3 762 875 938 970 986 994
4 567 735 849 918 958 979
5 371 560 715 827 900 945
6 215 384 554 699 809 884
7 111 238 394 550 687 793
8 051 133 256 401 547 676
9 021 068 153 271 408 544
10 008 032 084 170 283 413
11 003 014 043 099 184 294
12 001 005 020 053 112 197
13 002 008 027 068 124
14 001 004 013 034 074
15 001 006 017 042
Приложение
575
3. Биномиальное распределение
95 % доверительные пределы (0,,02) Для параметра 9:
Рв(0, < 9 < 92) = 0,95.
Л- / /з / 1 / ** 0 1 2 3 4 5 6 7 8 9 10 И 12
— 0,98 0,84 0,71 0,60 0,52 0,46 0,41 0,37 0,34 0,31 0,29 0,27
и — 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00
1,00 0,99 0,91 0,81 0,72 0,64 0,58 0,53 0,48 0,45 0,41 0,39 0,36
1 0,03 0,01 0,01 0,01 0,01 0,00 0,00 0,00 0,00 0,00 0,00 0,00 0,00
а 1,00 0,99 0,93 0,85 0,78 0,71 0,65 0,60 0,56 0,52 0,48 0,45 0,43
L 0,16 0,09 0,07 0,05 0,04 0,04 0,03 0,03 0,03 0,02 0,02 0,02 0,02
1,00 0,99 0,95 0,88 0,82 0,76 0,70 0,65 0,61 0,57 0,54 0,51 0,48
3 0,29 0,19 0,15 0,12 0,10 0,09 0,08 0,07 0,06 0,06 0,05 0,05 0,04
1,00 1,00 0,96 0,90 0,84 0,79 0,74 0,69 0,65 0,61 0,58 0.55 0,52
4 0,40 0,29 0,22 0,18 0,16 0,14 0,12 0,11 0,10 0,09 0,08 0,08 0,07
1,00 1,00 0,96 0,92 0,86 0,81 0,77 0,72 0,68 0,65 0,62 0,59 0,56
5 0,48 0,36 0,29 0,25 0,21 0,19 0,17 0,15 0,14 0,13 0,12 0,11 0,10
Z 1,00 1,00 0,97 0,93 0,88 0,83 0,79 0,75 0,71 0,68 0,65 0,62 0,59
О 0,54 0,42 0,35 0,30 0,26 0,23 0,21 0,19 0,18 0,16 0,15 0,14 0,13
1,00 1,00 0,97 0,93 0,89 0,85 0,81 0,77 0,73 0,70 0,67 0,64 0,62
7 0,59 0,47 0,40 0,35 0,31 0,28 0,25 0,23 0,21 0,20 0,18 0,17 0,16
1,00 1,00 0,98 0,94 0,90 0,86 0,82 0,79 0,75 0,72 0,69 0,67 0,64
8 0,63 0,52 0,44 0,39 0,35 0,32 0,29 0,27 0,25 0,23 0,22 0,20 0,19
1,00 1,00 0,98 0,95 0,91 0,87 0,84 0,80 0,77 0,74 0,71 0,69 0,66
9 0,66 0,56 0,48 0,43 0,39 0,35 0,32 0,30 0,28 0,26 0,24 0,23 0,22
576
Приложение
k к 0 1 2 3 4 5 6 7 8 9 10 11 12
1,00 1,00 0,98 0,95 0,92 0,88 0,85 0,82 0,79 0,76 0,73 0,70 0,68
10 0,69 0,59 0,52 0,46 0,42 0,38 0,35 0,33 0,31 0,29 0,27 0,26 0,24
1,00 1,00 0,98 0,95 0,92 0,89 0,86 0,83 0,80 0,77 0,74 0,72 0,69
11 0,72 0,62 0,57 0,49 0,45 0,41 0,38 0,36 0,34 0,32 0,30 0,28 0,27
12 1,00 1,00 0,98 0,96 0,93 0,90 0,87 0,84 0,81 0,78 0,76 0,73 0,71
0,74 0,64 0,57 0,52 0,48 0,44 0,41 0,38 0,36 0,34 0,32 0,31 0,29
Примечание. Значения набраны в первых строках, значения 0t — во вторых.
4. Распределение х2(п)
V.!
Ар, л
о
Квантили распределения: р =
I
2"/2Г(п/2)
71 0,1 0,3 0,5 0,7 0,9 0,95 0,99 0,999
1 0,016 0,148 0,455 1,07 2,71 3,84 6,63 10,8
2 0,211 0,713 1,39 2,41 4,61 5,99 9,21 13,8
3 0,584 1,42 2,37 3,67 6,25 7,82 п,з 16,3
4 1,06 2,20 3,36 4,88 7,78 9,49 13,3 18,5
5 1,61 3,00 4,35 6,06 9,24 11,1 15,1 20,5
6 2,20 3,83 5,35 7,23 10,6 12,6 16,8 22,5
7 2,83 4,67 6,35 8,38 12,0 14,1 18,5 24,3
8 3,49 5,53 7,34 9,52 13,4 15,5 20,1 26,1
9 4,17 6,39 8,34 10,7 14,7 16,9 21,7 27,9
10 4,87 7,27 9,34 11,8 16,0 18,3 23,2 29,6
11 5,58 8,15 10,3 12,9 17,3 19,7 24,7 31,3
12 6,30 9,03 п,з 14,0 18,5 21,0 26,2 32,9
13 7,04 9,93 12,3 15,1 19,8 22,4 27,7 34,5
14 7,79 10,08 13,3 16,2 21,1 23,7 29,1 36,1
15 8,55 11,7 14,3 17,3 22,3 25,0 30,6 37,7
16 9,31 12,6 15,3 18,4 23,5 26,3 32,0 39,3
17 10,09 13,5 16,3 19,5 24,8 27,6 33,4 40,8
18 10,9 14,4 17,3 20,6 26,0 28,9 34,8 42,3
19 11,7 15,4 18,3 21,7 27,2 30,1 36,2 43,8
20 12,4 16,3 19,3 22,8 28,4 31,4 37,6 45,3
Приложение
577
П X. 0,1 0,3 0,5 0,7 0,9 0,95 0,99 0,999
21 13,2 17,2 20,3 23,9 29,6 32,7 38,9 46,8
22 14,0 18,1 21,3 24,9 30,8 33,9 40,3 48,3
23 14,8 19,0 22,3 26,0 32,0 35,2 41,6 49,7
24 15,7 19,9 23,3 27,1 33,2 36,4 43,0 51,2
25 16,5 20,9 24,3 28,2 34,3 37,7 44,3 52,6
26 17,3 21,8 25,3 29,2 35,6 38,9 45,6 54,1
27 18,1 22,7 26,3 30,3 36,7 40,1 47,0 55,5
28 18,9 23,6 27,3 31,4 37,9 41,3 48,3 56,9
29 19,8 24,6 28,3 32,5 39,1 42,6 49,6 58,3
30 20,6 25,5 29,3 33,5 40,3 43,8 50,9 59,7
Примечание. При больших п (п > 30) для вычисления квантилей Хр.п можно исполь-
зовать приближенное соотношение Хр.п ~ (Ср + V2n - 1) /2, где дано в табл. 1.
5. Распределение Стьюдента S(n)
Квантили распределения: р =
\р п х. 0,900 0,950 0,975 0,990 0,995
1 3,078 6,314 12,706 31,821 63,657
2 1,886 2,920 4,303 6,965 9,925
3 1,638 2,353 3,182 4,541 5,841
4 1,533 2,132 2,776 3,747 4,604
5 1,476 2,015 2,571 3,365 4,032
6 1,440 1,943 2,447 3,143 3,707
7 1,415 1,895 2,365 2,998 3,499
8 1,397 1,860 2,306 2,896 3,355
9 1,383 1,833 2,262 2,821 3,250
10 1,372 1,812 2,228 2,764 3,169
11 1,363 1,796 2,201 2,718 3,106
12 1,356 1,782 2,179 2,681 3,055
13 1,350 1,771 2,160 2,650 3,012
14 1,345 1,761 2,145 2,624 2,977
15 1,341 1,753 2,131 2,602 2,947
16 1,337 1,746 2,120 2,583 2,921
578
Приложение
П X. 0,900 0,950 0,975 0,990 0,995
17 1,333 1,740 2,110 2,567 2,898
18 1,330 1,734 2,101 2,552 2,878
19 1,328 1,729 2,093 2,539 2,861
20 1,325 1,725 2,086 2,528 2,845
21 1,323 1,721 2,080 2,518 2,831
22 1,321 1,717 2,074 2,508 2,819
23 1,319 1,714 2,069 2,500 2,807
24 1,318 1,711 2,064 2,492 2,797
25 1,316 1,708 2,060 2,485 2,787
26 1,315 1,706 2,056 2,479 2,779
27 1,314 1,703 2,052 2,473 2,771
28 1,313 1,701 2,048 2,467 2,763
29 1,311 1,699 2,045 2,462 2,756
30 1,310 1,697 2,042 2,457 2,750
Примечания.
I. Для малых значений р квантили tpn находятся по формуле tp п = -t|-p,n.
2. При п > 30 можно использовать приближенное соотношение tpn « где
дано в табл. 1.
6. Распределение Снедекора 3(п\,П2)
Значения функции Fp,n|,nj
при р = 0,95 и р = 0,99. «Левые» границы доверительных интервалов находятся
из условия Г|.р,В|,„г = F"j,,.,,,
\п2 п, 1 2 3 4 6 8 10 12 20 50 100
161 200 216 225 234 239 242 244 248 252 253
1 4052 4999 5403 5625 5859 5981 6056 6106 6208 6302 6334
18,51 19,00 19,16 19,25 19,33 19,37 19,39 19,41 19,44 19,47 19,49
2 98,49 99,01 99,17 99,25 99,33 99,36 99,40 99,42 99,45 99,48 99,49
10,13 9,55 9,28 9,12 8,94 8,84 8,78 8,74 8,66 8,58 8,56
3 34,12 30,81 29,46 28,71 27,91 27,49 27,2*3 27,05 26,69 26,35 26,23
Приложение
579
\п2 П| 1 2 3 4 6 8 10 12 20 50 100
7,71 6,94 6,59 6,39 6,16 6,04 5,96 5,91 5,80 5,70 5,66
4 21,20 18,00 16,69 15,98 15,21 14,80 14,54 14,37 14,02 13,69 13,57
6,61 5,79 5,41 5,19 4,95 4,82 4,74 4,68 4,56 4,44 4,40
5 16,26 13,27 12,06 11,39 10,67 10,27 10,05 9,89 9,55 9,24 9,13
5,99 5,14 4,76 4,53 4,28 4,15 4,06 4,00 3,87 3,75 3,71
6 13,74 10,92 9,78 9,15 8,47 8,10 7,87 7,72 7,39 7,09 6,99
5,32 4,46 4,07 3,84 3,58 3,44 3,34 3,28 3,15 3,03 2,98
8 11,26 8,65 7,59 7,01 6,37 6,03 5,82 5,67 5,36 5,06 4,96
4,96 4,10 3,71 3,48 3,22 3,07 2,97 2,91 2,77 2,64 2,59
10 10,04 7,56 6,55 5,99 5,39 5,06 4,85 4,71 4,41 4,12 4,01
4,75 3,88 3,49 4,26 3,00 2,85 2,76 2,69 2,54 2,40 2,35
12 9,33 6,93 5,95 5,41 4,82 4,50 4,30 4,16 3,86 3,56 3,46
4,35 3,49 3,10 2,87 2,60 2,45 2,35 2,28 2,12 1,96 1,90
20 8,10 5,85 4,94 4,43 3,87 3,56 3,37 3,23 2,94 2,63 2,53
30 4,17 3,32 2,92 2,69 2,42 2,27 2,16 2,09 1,93 1,76 1,69
7,56 5,39 4,51 4,02 3,47 3,17 2,98 2,84 2,55 2,24 2,13
50 4,03 3,18 2,79 2,56 2,29 2,13 2,02 1,95 1,78 1,60 1,52
7,17 5,06 4,20 3,72 3,18 2,88 2,70 2,56 2,26 1,94 1,82
100 3,94 3,09 2,70 2,46 2,19 2,03 1,92 1,85 1,68 1,48 1,39
6,90 4,82 3,98 3,51 2,99 2,69 2,51 2,36 2,06 1,73 1,59
200 3,89 3,04 2,65 2,41 2,14 1,98 1,87 1,80 1,62 1,42 1,32
6,76 4,71 3,88 3,41 2,90 2,60 2,41 2,28 1,97 1,62 1,48
1000 3,85 3,00 2,61 2,38 2,10 1,95 1,84 1,76 1,58 1,36 1,26
6,66 4,62 3,80 3,34 2,82 2,53 2,34 2,20 1,89 1,54 1,38
Примечание. Значения Fo,95;ni,n2 набраны в первых строках, значения ;П| „2 — во
вторых.
7. Критерий Колмогорова
Значения функции Хр: р = Р(РЛ = sup |Fn(x) - f (z)| > Ар)
X
\р П 0,10 0,05 0,01 \чР п 0,10 0,05 0,01
1 0,950 0,975 0,995 19 0,271 0,301 0,361
2 776 842 929 20 265 294 352
580
Приложение
Хр п 0,10 0,05 0,01 \р П 0,10 0,05 0,01
3 636 708 829 25 238 264 317
4 565 624 734 30 218 242 290
5 509 563 669 35 202 224 269
6 468 519 617 40 189 210 252
7 436 483 576 45 179 198 238
8 410 454 542 50 170 188 226
9 387 430 513 55 162 180 216
10 369 409 489 60 155 172 207
11 352 391 468 65 149 166 199
12 338 375 449 70 144 160 192
13 325 361 432 75 139 154 185
14 314 349 418 80 135 150 179
15 304 338 404 85 131 145 174
16 295 327 392 90 127 141 169
17 286 318 381 95 124 137 165
18 279 309 371 100 121 134 161
8. Критерий Смирнова
Значения вероятности Р(Г>„„ < к/п), где Dnn = sup|F|n(r) - P2n(r)|.
X
\fc п 1 2 3 4 5 6 7 8 9 10 11
1 1,000
2 0,667 1,000
3 400 0,900 1,000
4 229 771 0,971 1,000
5 127 643 921 0,992 1,000
6 069 526 857 974 0,998 1,000
7 037 425 788 947 992 0,999 1,000
8 020 340 717 913 981 998 1,000 1,000
9 ОН 270 648 874 966 993 0,999 1,000 1,000
10 006 213 582 832 948 988 998 1,000 1,000 1,000
11 003 167 521 789 925 979 996 0,999 1,000 1,000 1,000
12 002 131 464 744 900 969 992 999 1,000 1,000 1,000
13 001 102 412 700 874 956 987 997 1,000 1,000 1,000
14 ООО 079 365 657 845 941 981 995 0,999 1,000 1,000
15 000 062 322 614 816 925 974 992 998 1,000 1,000
16 000 048 284 574 785 907 965 989 997 1,000 1,000
17 000 037 249 535 755 888 955 984 995 0,999 0,999
18 000 028 219 497 725 868 944 979 993 998 999
Приложение
581
п >4 1 2 3 4 5 6 7 8 9 10 И
19 ООО 022 192 462 694 847 932 973 991 997 999
20 000 017 168 429 664 825 919 966 988 996 999
21 000 013 147 397 635 804 905 959 984 995 998
22 000 010 128 368 606 782 891 951 980 993 998
23 000 008 112 340 578 759 876 942 975 991 997
24 ООО 006 098 314 551 737 860 932 970 988 996
25 ООО 004 085 290 525 715 844 922 964 985 994
26 000 003 074 267 499 693 828 911 958 982 993
27 000 003 064 246 474 671 811 900 952 978 991
9. Равномерно распределенные случайные числа
65 48 11 76 74 17 46 85 09 50 58 04 77 69 74 45
80 12 43 56 35 17 72 70 80 15 45 31 82 23 74 45
74 35 09 98 17 77 40 27 72 14 43 23 60 02 10 19
69 91 62 68 03 66 25 22 91 48 36 93 68 72 03 37
09 89 32 05 05 14 22 56 85 14 46 42 75 67 88 93
34 07 27 68 50 36 69 73 61 70 65 81 33 98 85 56
45 57 18 24 06 35 30 34 26 14 86 79 90 74 39 82
02 05 16 56 92 68 66 57 48 18 73 05 38 52 47 89
05 32 54 70 48 90 55 35 75 48 28 46 82 87 09 75
06 52 96 47 78 35 80 83 42 82 60 93 52 03 44 76
22 10 94 05 58 60 97 09 34 33 50 50 07 39 98 23
50 72 56 82 48 29 40 52 42 01 52 77 56 78 51 98
13 74 67 00 78 18 47 54 06 10 68 71 17 78 17 49
36 76 66 79 51 90 36 47 64 93 29 60 91 10 62 42
91 82 60 89 28 93 78 56 13 68 23 47 83 41 13 29
68 47 92 76 86 46 16 28 35 54 94 75 08 99 23 45
26 94 03 68 58 70 29 73 41 35 53 14 03 33 40 45
85 15 74 79 54 32 97 92 65 75 57 60 04 08 81 19
11 10 00 20 40 12 86 07 46 97 96 64 48 94 39 37
582
Приложение
16 50 53 44 84 40 21 95 25 65 43 65 17 70 82 93
10 09 73 25 33 76 52 01 35 86 34 67 35 48 76 07
37 54 20 48 05 64 89 47 42 96 24 80 52 40 37 32
08 42 26 89 53 19 64 50 93 03 23 20 90 25 60 47
99 01 90 25 29 09 37 67 07 15 38 31 13 11 65 09
12 80 79 99 70 80 15 73 61 47 64 03 23 66 53 53
80 95 90 91 17 39 29 27 49 45 66 06 57 47 17 56
20 63 61 04 02 00 82 29 16 65 31 06 01 08 05 82
15 95 33 47 64 35 08 03 36 06 85 26 97 76 02 89
88 67 67 43 97 04 43 62 76 59 63 57 33 2) 35 75
98 95 11 68 77 12 17 17 68 33 73 79 64 57 53 76
Примечания.
1. Приведенные в таблице цифры можно рассматривать как реализации незави-
симых одинаково распределенных случайных величин, принимающих значения
О, I,..., 9 с одинаковой вероятностью 10“1
2. Если взять из этой таблицы непересекающиеся группы из, скажем, четырех цифр
а(, а2, Оз, а4 и образовать из них числа вида 0,а^а^ац, то эти числа можно рас-
сматривать в качестве значений (с точностью 10; равномерно распределенных
на (0, 1| случайных величин.
10. Нормально распределенные ЛГ(0, 1) случайные числа
-0,486 0,856 -0,491 -1,983 -1,787 -0,261
-0,256 -0,212 0,219 0,779 -0,105 -0,357
0,065 0,415 -0,169 0,313 -1,339 1,827
1,147 -0,121 1,096 0,181 1,041 0,535
-0,199 -0,246 1,239 -2,574 0,279 -2,056
1,237 1,046 -0,508 -1,630 -0,146 -0,392
-1,384 0,360 -0,992 -0,116 -1,698 -2,832
-0,959 0,424 0,969 -1,141 -1,041 0,362
0,731 1,377 0,983 -1,330 1,620 -1,040
0,717 -0,873 -1,096 -1,396 1,047 0,089
-1,805 -2,008 -1,633 0,542 0,250 -0,166
-1,186 1,180 1,114 0,882 1,265 -0,202
0,658 -1,141 1,151 -1,210 -0,927 0,425
-0,439 0,358 -1,939 0,891 -0,227 0,602
-1,399 -0,230 0,385 -0,649 -0,577 0,237
Приложение
583
0,032 0,079 0,199 0,208 -1,083 -0,219
0,151 -0,376 0,159 0,272 -0,313 0,084
0,290 -0,902 2,273 0,606 0,606 -0,747
0,873 -0,437 0,041 -0,307 0,121 0,790
-0,289 0,513 -1,132 -2,098 0,921 0,145
-0,291 1,221 1,119 0,004 0,768 0,079
-2,828 -0,439 -0,792 -1,275 0,375 -1,656
0,247 1,291 0,063 -1,793 -0,513 -0,344
-0,584 0,541 0,484 -0,986 0,292 -0,521
0,446 -1,661 1,045 -1,363 1,026 2,990
-0,034 -2,127 0,665 0,084 -0,880 -1,473
0,234 -0,656 0,340 -0,086 -0,158 -0,851
-0,736 1,041 0,008 0,427 -0,831 0,210
-1,206 -0,899 0,110 -0,528 -0,813 1,266
-0,491 -1,114 1,297 -1,433 -1,345 -0,574
-1,334 1,278 -0,568 -0,109 -0,515 -0,566
-0,287 -0,144 -0,254 0,574 -0,451 -1,181
0,161 -0,886 0,921 -0,509 1,410 -0,518
-1,346 0,193 -1,202 0,394 -1,045 0,843
1,250 -0,199 -0,288 1,810 1,378 0,584
2,923 0,500 0,630 -0,537 0,782 0,060
-1,190 -0,318 0,375 -1,941 0,247 -0,491
0,192 -0,432 -1,420 0,489 -1,711 -1,186
0,942 1,045 -0,151 -0,243 -0,430 -0,762
1,216 0,733 -0,309 0,531 0,416 -1,541
0,499 -0,431 1,705 1,164 0,424 -0,444
0,665 -0,135 -0,145 -0,498 0,593 0,658
0,754 -0,732 -0,066 1,006 0,862 -0,885
0,298 1,049 1,810 2,885 0,235 -0,628
1,456 2,040 -0,124 0,196 -0,853 0,402
0,593 0,993 -0,106 0,116 0,484 -1,272
-1,127 -1,407 -1,579 -1,616 1,458 1,262
-0,142 -0,504 0,532 1,381 0,022 -0,281
-0,023 -0,463 -0,899 -0,394 -0,538 1,707
0,777 0,833 0,410 -0,349 -1,094 0,580
0,241 -0,957 -1,885 0,371 -2,830 -0,238
0,022 0,525 -0,255 -0,702 0,953 -0,869
-0,853 -1,865 -0,423 -0,973 -1,016 -1,726
-0,501 -0,273 0,857 -0,465 -1,691 0,417
0,439 -0,035 -0,260 0,120 -0,558 0,056
584
Приложение
-0,627 0,561 0,471 -1,029 -2,015 -0,594
-1,108 -2,357 -0,310 0,479 -0,623 -1,047
-1,726 1,956 0,610 2,709 -0,699 -1,347
0,524 -0,281 -0,220 -0,057 0,481 0,996
-0,573 0,932 0,738 -0,300 -0,586 -1,023
-0,579 0,551 0,359 0,326 0,884 -0,298
-0,120 0,418 -0,094 1,114 0,457 1,064
0,191 0,074 1,501 1,068 -0,798 0,162
0,071 0,524 0,031 0,772 -0,768 -0,129
-3,001 0,479 0,402 0,226 0,023 -1,204
1,066 1,097 -1,752 -0,329 -1,256 0,318
0,736 -0,916 -0,291 0,085 1,701 -1,087
-0,342 1,222 -0,933 0,130 0,674 0,899
-0,188 -1,153 -0,450 -0,244 0,072 1,028
1,395 1,298 0,512 -0,882 0,490 -1,304
1,531 0,349 -0,059 0,415 -1,084 -0,958
-0,443 -0,292 -0,539 -1,382 0,318 -0,243
1,409 -0,883 0,229 0,129 0,367 -0,095
1,730 -0,056 -0,078 -2,361 -0,992 -1,488
-0,266 0,757 0,194 -1,078 0,529 -0,361
Законы статистики везде одинаковы, — продолжал Николай Пет-
рович солидно. Утром, например, гостей бывает меньше, потому
что публика еще исправна; но чем больше солнце поднимается
к зениту, тем наплыв делается сильнее. И, наконец, ночью, по вы-
ходе из театров — это почти целая оргия!
И заметьте, — пояснил Семен Иванович, — каждый день, в одни
и те же промежутки времени, цифры всегда одинаковые. Колеба-
ний — никаких! Такова незыблемость законов статистики!
М. Е. Салтыков-Щедрин
Случай всегда именует себя богом, когда он
не хочет подписываться своим именем.
А. Франс5)
Салтыков-Щедрин Михаил Евграфович (1826-1889) — велнкий русский писатель-сатирик.
Франс Анатоль (наст, имя Анатоль Франсуа Тибо) (1844-1924) — французский писатель,
нобелевский лауреат (1921).
Литература
1. Андерсон Т. Введение в многомерный статистический анализ. М.: Физматгиз, 1963.
2. Бикел П., Доксам К. Математическая статистика. Т. 2. М.. ФиС, 1983.
3. Большее Л. Н., Смирнов Н. В. Таблицы математической статистики. М.: Наука, 1983.
4. Боровиков В. П. Ивченко Г И. Прогнозирование в системе STATISTICA в среде
Windows. М.. ФиС, 2006.
5. Боровков А. А. Математическая статистика. М.: Издательство Физико-математиче-
ской литературы, 2007.
6. Вальд А. Последовательный анализ. М.: Физматгиз, 1960.
7 Гаек Я., Шидак 3. Теория ранговых критериев. М.: Наука, 1971.
8. Гнеденко Б. В. Курс теории вероятностей. 9-е изд. М.: Издательство ЛКИ/URSS,
2007.
9. Ивченко Г И., Глибочеико А. Ф., Иванов В. А., Медведев Ю. И. Статистический анализ
дискретных случайных последовательностей. М.. МИЭМ, 1984.
10. Ивченко Г И. Медведев Ю. И. Математическая статистика. 2-е изд. М.: Высшая
школа, 1992.
11. Ивченко Г. И, Медведев Ю. И. Чистяков А. В. Задачи с решениями по математи-
ческой статистике. М.: Дрофа, 2007.
12. Кендалл М., Стьюарт А. Статистические выводы и связи. М.: Наука, 1973.
13. Кнут Д. Искусство программирования. М.: Мир, 2004.
14. Колчин В. Ф., Севастьянов Б. А. Чистяков В. П. Случайные размещения. М.: Наука,
1976.
15. Крамер Г. Математические методы статистики. М.. Мир, 1975.
16. Леман Э. Проверка статистических гипотез. М.: Наука, 1979.
17. ЛоулиД., Максвелл А. Факторный анализ как статистический метод. М.: Мир, 1967.
18. Налимов В. В. Теория эксперимента. М.: Наука, 1971.
19. Окунь Я. Факторный анализ. М.: Статистика, 1974.
20. Пойа Д. Математика и правдоподобные рассуждения. М.: Книжный дом «Либро-
kom»/URSS, 2010.
21. Рао К Р. Линейные статистические методы и их применения. М.: Наука, 1968.
22. Себер Дж. Линейный регрессионный анализ. М.: Мир, 1980.
23. Секей Г Парадоксы в теории вероятностей и математической статистике. М.: Мир,
1990.
24. Уилкс С. Математическая статистика. М.: Наука, 1967.
25. Феллер В. Введение в теорию вероятностей и ее приложения. Т. 1, 2. М.: Книжный
дом «Либрокомь/URSS, 2010.
26. Холлендер М., Вульф Д. Непараметрические методы статистики. М.: ФиС, 1983.
27. Чистяков В. П. Курс теории вероятностей. 7-е изд. М.: Дрофа, 2007
28. Ширяев А. Н. Статистический последовательный анализ. М.: Наука, 1976.
29. Billingsley Р. Statistical inference for Markov processes. The University of Chicago Press,
1961.
38 Заказ 1 748
Путеводитель по моделям
в примерах и задачах
Смелость — начало дела, но случай — хозяин конца.
Демокрит
Назначение данного путеводителя — помочь читателю быстро найти в тексте
нужное место, где доказывается либо формулируется тот или иной конкретный факт
(результат), относящийся к конкретной модели (в скобках указаны соответствующие
координаты, при этом, например, «упр. 3.10» означает упражнение 10 к гл. 3). Модели,
как правило, занумерованы в той последовательности, в которой они встречаются в тек-
сте, также в такой последовательности перечисляются и относящиеся к ним факты.
1. Бернуллиевская модель Bi(l,p)
— определение и свойства (§ 1.1, п. 1, упр. 1.1)
— реализация в урновой схеме (§ 1.1, прим. 1 и 2)
— моделирование (§ 1.3, п. 2)
— эмпирическая функция распределения для нее (§2.1, прим. 2)
— оценивание доли белых шаров в урне (§ 2.2, прим. 3)
— эксперимент Бюффона с бросанием монеты (упр. 2.1, §4.2, прим. I)
— обработка эмпирических данных (упр. 2.2)
— оценивание параметрических функций (§3.1, прим. , упр. 3.10, 3.11)
— оптимальность выборочного среднего при оценивании параметра (§3.1, прим. 5)
— оптимальная оценка доли белых шаров в урне (§ 3.1, прим. 6)
— эффективность выборочного среднего (§ 3.2, п. 2)
— достаточная статистика для нее (§ 3.2, табл. 2)
— о. м. п. параметра (§ 3.2, табл. 2)
— асимптотический доверительный интервал для параметра (§3.5, прим. 17, упр. 3.70)
— байесовская оценка параметра (§3.6, прим. II, упр. 3.77)
— минимаксная оценка параметра (§ 3.6, прим. 12)
— доверительны интервал для параметра (§3.8, прим. 4)
— критерий согласия х~ Для нее (хпР-4.1, 4.2)
— критерий Неймана—Пирсона (§5.2, прим. 4, упр. 5.4)
— р. н. м. к. при односторонней альтернативе (§ 5.3, п. 1)
— КОП для гипотезы однородности (§5.4, прим.8)
— решающие правила в ней (§7.1, прим. I, упр.7.1, 7.2, 7.3).
Демокрит (ок. 460 г. до н.э. - год смерти неизв.) — древнегреческий философ-атомист.
Путеводитель по моделям в примерах и задачах
587
2. Биномиальная модель Bi(n, р)
— определение и свойства (§ 1.1, п. 1, упр. 1.2, 1.3, 1.4, 2.25)
— реализация в урновой схеме (§ 1.1, прим. 1 и 2)
— дни рождения, эмпирические данные (§ 1.1, прим. 3)
— моделирование (§ 1.3, п. 2)
— аппроксимация распределением Пуассона (упр. 1.12)
— условные распределения компонент полиномиального вектора (упр. 1.18)
— моменты (упр. 1.19)
— нормальная аппроксимация, теорема Муавра—Лапласа (упр. 1.33)
— связь с распределением Маркова—Пойа (упр. 1.44)
— эмпирические данные в опыте с бросанием костей (§2.2, прим. 2)
— обработка эмпирических данных (упр. 2.3, 2.8, 2.9)
— информация Фишера для нее (§3.2, табл. 1)
— эффективная оценка для параметра (§3.2, табл. 2)
— достаточная статистика для нее (§3.2, табл. 2, упр. 3.31)
— оценивание параметрических функций (§3.4, прим. 7, упр. 3.12, 3.31)
— о. м. п. параметра (§ 3.2, табл. 2)
— преобразование о. м. п., стабилизирующее дисперсию (упр. 3.55)
— проверка гипотезы согласия (§4.2, прим. 4, упр. 4.7, 4.15)
— р.н. м.к. при односторонней альтернативе (§5.3, прим. 1, упр. 5.8)
— критерий Неймана—Пирсона (упр. 5.5)
— л.н.м. несмещенный критерий (упр.5.14)
— КОП для простой гипотезы (упр. 5.22)
— прогноз в ней (упр. 6.23, 6.24)
— решающие правила в ней (упр. 7.4, 7.9)
— 95%-ные доверительные интервалы для параметра (прилож. табл. 3).
3. Отрицательная биномиальная модель Bi(r,p)
— определение и свойства (§ 1.1, п.2, упр. 1.5, 1.6, 1.7, 1.8, 1.14, 1.41,2.25)
— как частный случай модели степенного ряда (§ 1.1, п. 8)
— моделирование (§ 1.3, п. 3)
— аппроксимация распределением Пуассона (упр. 1.13)
— оценивание параметрических функций (§3.1, прим. 3, §3.4, прим. 2)
— информация Фишера для нее (§3.2, табл. I)
— эффективная оценка для параметрической функции (§ 3.2, табл. 2)
— достаточная статистика для иее (§3.2, табл. 2)
— о. м. п. параметра (упр. 3.45)
— асимптотический доверительный интервал для параметра (упр. 3.71)
— байесовская оценка параметра (упр. 3.78)
— р. н. м. к. при одиосторонней альтернативе (§ 5.3, прим. 2, упр. 5.9).
38*
588
Путеводитель по моделям в примерах и задачах
4. Геометрическая модель Bi(l,p)
— определение и свойства (§ 1.1, п. 2)
— моделирование (§ 1.3, п.З)
— достаточная статистика для нее (§ 3.2, табл. 2)
— о. м. п. параметра и основанный на ней доверительный интервал (§ 3.5, прим. 16)
— улучшенная оценка параметра (§ 3.7, прим. 2)
— оценивание параметрической функции (упр. 3.15)
— р. н. м. к. при односторонней альтернативе (§5.3, прим. 2)
— критерий Неймана—Пирсона (упр. 5.6)
— решающие правила в ней (упр. 7.5).
5. Пуассоновская модель П(А)
— определение и свойства (§ 1.1, п. 3, упр. 1.9, 1.10, 1.11. 1.13, 1.14,1.41,2.25)
— дни рождения, аппроксимация (§ 1.1, прим. 3)
— усечение в нуле (§1.1, п. 8)
— как частный случай модели степенного ряда (§1.1, п. 8)
— моделирование (§ 1.3, п. 5)
— теорема Пуассона для биномиального распределения (упр. 1.12)
— аппроксимация для полиномиального распределения (упр. 1.34, 1.35)
— оценивание параметрических функций (§3.1, прим. 2, §3.4, прим. 1, упр. 3.13,
3.14, 3.32, 3.33)
— информация Фишера для нее (§ 3.2, табл. 1)
— эффективность выборочного среднего (§ 3.2, табл. 2)
— достаточная статистика для нее (§ 3.2, табл. 2, упр. 3.32)
— о. м. п. параметра (§3.2, табл. 2)
— о. м. п. для усеченного в нуле распределения (§ 3.5, прим. 9)
— доверительные интервалы для параметра (§3.5, прим. 15, §3.8, прим. 5)
— преобразование о. м. п., стабилизирующее дисперсию (упр. 3.55)
— метод моментов для двойного распределения Пуассона (упр. 3.75)
— байесовская оценка параметра (упр. 3.79, 3.80)
— проверка гипотезы согласия для нее (§4.2, прим. 5, упр.4.13, 4.14)
— гипотеза одородности для нее (упр. 4.21, § 5.4, прим. 9)
— критерий Неймана—Пирсона (§5.2, прим. 5)
— р. н. м.к. при односторонней альтернативе (§5.3, п. 1)
— л. н. м. несмещенный критерий (упр. 5.15)
— КОП для простой гипотезы (упр. 5.23)
— прогноз в ней (упр. 6.23, 6.24)
— решающее правило в ней (упр. 7.6)
— значения функции Р{£ > х} (прилож. табл. 2).
Путеводитель по моделям в примерах и задачах
589
6. Гипергеометрическая модель H(at, а2, п)
— определение и свойства, реализация в урновой схеме (§1.1, п.4)
— многомерный вариант (§1.1, п. 7)
— моменты (упр. 1.15)
— аппроксимация биномиальным распределением (упр. 1.16)
— о. м. п. для параметра а = а, + а2 (упр. 1.17)
— р. н.м. к. при односторонней альтернативе (упр. 5.11)
— прогноз в ней (§6.6, прим. 4).
7. Модель Маркова—Пойа МП(п; аь а2, с)
— определение и свойства, реализация в урновой схеме (§1.1, п. 5)
— многомерный вариант (§ 1.1, п. 7, упр. 1.62)
— как смесь биномиальных распределений (упр. 1.44)
— оценивание параметра р = а,/(а, + а2) (упр. 3.2)
— оценивание многомерного параметра (упр. 3.3)
8. Полиномиальная модель М(п; pt, ... , р^)
— определение и свойства (§1.1, п.6,упр. 1.18, 1.21)
— моделирование (§ 1.3, п.4)
— моменты (упр. 1.19, 1.20)
— связь с пуассоновским распределением (упр. 1.22)
— случайное число испытаний (упр. 1.23)
— центральная предельная теорема для нее (упр. 1.33)
— пуассоновская аппроксимация (упр. 1.34, 1.35)
— связь с распределением Маркова—Пойа (упр. 1.62)
— эмпирическая функция распределения для нее (§2.1, прим.З)
— обработка эмпирических данных (упр. 2.4)
— информационная матрица для нее (§3.2, прим. 10)
— оценивание параметрического вектора (§3.2, прим. 10, упр. 3.7)
— оценивание параметрических функций (§3.3, прим. 8)
— о. м. п. параметрического вектора (§ 3.5, прим. 12)
— асимптотическая доверительная область для параметров (§3.5, прим. 18)
— байесовская оценка параметров (§ 3.6, прим. 13)
— минимаксная оценка параметров (§ 3.6, прим. 13)
— о. м. п. параметра в модели ЛГ(n;pi (0),... ,pw(0)) (упр. 3.46)
— проверка гипотезы в эксперименте Менделя (§4.2, прим. 2)
— проверка гипотезы о равновероятности классов (§4.2, прим. 3)
— критерий согласия для нее (упр. 4.3, 4.4, 4.5, 4.6)
— критерий согласия для сложной гипотезы (упр. 4.11, 4.12)
— критерий Неймана—Пирсона (§5.2, прим. 6)
— КОП для простой гипотезы (§5.4, прим. 5).
590
Путеводитель по моделям в примерах и задачах
9. Модель степенного ряда
— определение и свойства (§ 1,1, п, 8)
— производящая функция и моменты (упр. 1.24, 1.25)
— оценивание параметрических функций (§3.4, п. 1)
— о. м. п. параметра (§ 3.5, прим. 9)
— асимптотический доверительный интервал для параметра (§3.5, прим. 14)
10. Конечная совокупность
— занумерованные элементы, оценивание параметрических функций (§ 3.4, прим. 8
и 9)
— оценивание среднего, оценки Горвица—Томпсона (§3.9, п. 1)
— выборочный контроль (§ 3.9, п. 2)
— оценивание состава (§ 3.9, п. 2)
— оценивание доли белых шаров в урне (упр. 3.1)
— прогнозирование в схеме повторного выбора (§ 6.6, прим. 5).
11. Цепь Маркова
— определение и моделирование (§ 1.3, п. 10, §4.5, п.2)
— случайное блуждание (§ 1.3, прим. 3 и 4)
— обобщенный критерий х2 Для контроля марковской зависимости (§4.5, п. 2)
— проверка гипотез (§ 5.5)
— критерий х2 Для простой гипотезы (§5.5, п. 2)
— критерий х2 для сложной гипотезы (§ 5.5, п, 3)
— гипотеза о порядке цепи Маркова (§5.5, прим. 1)
— гипотеза о циклическом случайном блуждании (§ 5.5, прим. 2 и 3)
КОП для общих параметрических гипотез (§5.5, п. 4)
— критерий однородности (§5.5, п.5)
— критерии однородности в модели циклического блуждания (§ 5.5, прим. 4)
— оценивание порядка цепи (§5.5, п. 6).
12. Нормальная модель Л^(д, <гг)
— определение и свойства (введение к гл. 1, § 1.2, п. I, упр. 1.26, 1.27, 1.28)
— моделирование (§ 1.3, п. 6 и 8)
— независимость выборочных среднего и дисперсии (упр. 1.28)
— связь с распределением Коши (упр. 1.48)
— сопряженность к нормальному распределению (упр. 1.64(5))
— распределение выборочной медианы в больших выборках (§2.4, прим. 2)
— распределение верхнего экстремума в больших выборках (§2.4, прим.4)
— доверительное оцениваение среднего (§2.5, прим. 1, §3.8, прим. 2,
упр. 3.58, 3.60, §5.3, прим. 7)
— доверительное оцениваение дисперсии (§2.5, прим. 1, §3.8, прим.З, упр. 3.61,
§ 5.3, прим. 8)
— доверительная область для параметров (§2.5, прим. 1)
— задача сравнения двух средних (§2.5, прим. 2, упр. 3.62)
Путеводитель по моделям в примерах и задачах
591
— доверительный интервал для отношения дисперсий (§2.5, прим. 3)
— таблица доверительных интервалов (§3.8, п. 1)
— доверительный интервал для параметра & модели М(0, 02) (упр. 3.57)
— доверительный интервал для параметра 9 модели J\[(p,02) (упр. 3.59)
— асимптотические доверительные интервалы в модели 92) (упр. 3.68)
— обработка эмпирических данных (упр. 2.6)
— распределение статистики т/ = (Х, - X)/(\/n - IS) (упр.2.42)
— асимптотическая нормальность статистики Тп = у/п(Х - p)/S (упр. 2.44)
— оценивание дисперсии модели Л/(йь й?) (§ 3.1, прим. 4)
— информация Фишера для нее (§ 3.2, табл. 1)
— эффективность выборочного среднего (§ 3.2, прим. I, табл. 2)
— эффективная оценка дисперсии (§ 3.2, прим. 2 и 3, табл. 2)
— асимптотическая эффективность выборочной медианы (§3.2, прим. 4)
— оптимальная оценка для 92 в модели а2) (§ 3.2, прим. 7)
— оптимальное оценивание среднего модели 02) (§3.2, прим. 8)
— оптимальное оценивание дисперсии модели М(9\ ,02) (§ 3.2, прим. 9)
— информационная матрица для модели M(pt,022) (§3.2, прим.9)
— достаточные статистики для нее (§3.2, табл. 2, §3.3, прим. 1)
— оценивание теоретической функции распределения (§3.3, прим. 6 и 7)
— оценивание параметрических функций в модели М(0,а2) (§3.4, прим. 6)
— оценивание параметрических функций в модели 92) (§ 3.4, прим. 12,
упр.3.17-3.19, 3.34)
— оценивание параметрических функций в модели М(9, 02) (§ 3.4, прим. 13,
упр. 3.20, 3.34, 3.36)
— о. м. п. параметров (§3.5, прим. I)
— о. м. п. функции распределения (§3.5, прим. 5)
— о. м. п. среднего и дисперсии логнормального распределения (§ 3.5, прим. 7)
— сверхэффективная оценка параметра модели I) (§3.5, прим. 10)
— асимптотический доверительный интервал для функции распределения (§ 3.5,
прим. 13)
— метод моментов для нее (§3.6, прим. I)
модально несмещенная оценка среднего (§3.6, прим. 4)
— оценка Питмена (эквивариантная) среднего (§3.6, прим. 8)
— минимаксность выборочного среднего (§ 3.6, прим. 14)
— оценивание по цензурированным данным для нее (§ 3.6, прим. 15 и 16)
— объединение оценок (§3.7, прим. 1, упр.3.56)
— оценка «складного ножа» дисперсии (§ 3.7, прим. 3)
— состоятельная оценка параметра модели Л/(0, 0~), 0 > 0 (упр. 3.5)
— сравнение оценок дисперсии в модели V(/i, 02) (упр. 3.16)
— достаточная статистика в модели Л/\0, у0~) (упр. 3.35)
— о. м. п. параметра модели 0~), асимптотические свойства (упр. 3.41)
592
Путеводитель по моделям в примерах и задачах
— о. м. п. параметра модели 20) (упр. 3.42)
— преобразование о. м. п., стабилизирующее дисперсию, в модели в2)
(упр. 3.55)
— прогнозирование будущих наблюдений (упр. 3.67)
— байесовская оценка параметра 0 модели М(0, Ь2) (упр. 3.83, 7.12)
— критерий согласия х2 по группированным данным (§4.2, прим. 6)
— критерий Колмогорова (упр. 4.10)
— критерий Неймана—Пирсона для среднего модели А/\0, <г‘) (§ 5.2, прим. I)
— критерий Неймана—Пирсона для дисперсии модели Л/\р, 02) (§ 5.2,
прим. 2)
— р. н.м.к. при односторонних альтернативах (§5.3, п. 1)
— р. н. м. и л. н. м. несмещенные критерии при двусторонней альтернативе для
модели Л/\0, сг2) (§ 5.3, прим. 4 и 5)
— р. н. м. несмещенный критерий при двусторонней альтернативе для модели
Л/\р, 02) (упр. 5.12)
— р. н. м. несмещенный критерий для среднего модели М(в\, 02) при двусторонней
альтернативе (§5.3, прим. 9)
— р. н. м. несмещенный критерий для дисперсии модели М(0\, д\) при двусторонней
альтернативе (§5.3, прим. 9)
— гипотеза о равенстве средних двух моделей (§5.3, прим. 10)
— КОП для среднего модели M(0i,02) (§5.4, прим. 1)
— КОП для дисперсии модели ^/(^i, 0;) (§5.4, прим. 2)
— КОП для гипотезы о равенстве средних (§ 5.4, прим. 3 и 6)
— КОП для гипотезы о равенстве дисперсий (§ 5.4, прим.4 и 7)
— критерий Вальда (последовательный) для модели ,hf(0,cr) (§ 5.6, прим. 1)
— гипотеза о равенстве дисперсий двух моделей (упр. 5.16)
— F-критерий однородности для средних (§6.5, п. 2, упр. 6.21)
— метод наименьших квадратов (упр. 6.8-6.11, 6.13-6.15, 6.17—6.19)
— решающие правила для нее (упр. 7.7)
— квантили распределения 1) (прилож. табл. 1)
— реализации случайных 1) чисел (прилож. табл. 10).
13. Двумерная нормальная модель
а' P<r'V )
\ PMi ^2 /
— условное маргинальное распределение в ней (упр. 1.65)
— асимптотический доверительный интервал для р (§2.3, п. 4)
— гипотеза независимости р = 0 (§2.3, п. 4)
— обработка эмпирических данных (упр. 2.29)
— распределение выборочных моментов (упр. 2.43)
— о. м. п. параметров модели Ли (0,0),
(§3.5, прим. 6)
р<т
Путеводитель по моделям в примерах и задачах
593
— оценивание коэффициента корреляции модели (0,0), I 1 ) (упр. 3.43)
\ IP 1 /
— прогноз в ней (§ 6.6, прим. 2).
14. Многомерная нормальная модель Л((/х, S)
— определение и свойства (§ 1.2, упр. 1.30)
— моменты (упр. 1.29)
— линейные преобразования (упр. 1.31, 1.32)
— центральная предельная теорема для полиномиальной модели (упр. 1.33)
— распределение квадратичных форм (упр. 1.40, 2.38—2.41)
— условное маргинальное распределение в ней (упр. 1.66)
— о. м. п. ее параметров (§ 3.5, прим. 2)
— оценка Джеймса—Стейна вектора средних (§ 3.6, прим. 14)
— критерий Неймана—Пирсона для вектора средних (§5.2, прим. 3)
— критерий для вектора средних, минимизирующий сумму вероятностей ошибок
(§ 5.2, продолжение прим. 3)
нормальная регресия, о.м.п. ее параметров (§6.3, п.2, упр. 6.4)
— доверительный интервал для наклона простой регрессии (§6.3, прим. 1)
— доверительный эллипс для параметров простой регрессии (§6.3, прим. 1)
— доверительный интервал для ординаты линии регрессии (§6.3, прим. 2)
— совместные доверительные интервалы для коэффициентов регрессии
(§6.3, прим. 3)
— гипотеза о наклоне линии регрессии (§6.4, прим. 1, упр. 6.20)
— критерий значимости регрессии (§6.4, прим. 2, упр. 6.22)
— гипотеза о параллельности линий регрессии (§6.5, п. 1)
— дисперсионный анализ при двойной классификации (§6.5, п. 3)
— прогноз в ней (упр. 6.25)
— классификация наблюдений по двум классам (§7.3)
— классификация наблюдений по к 2 классам (§7.4)
— распределение Уишарта (выборочной ковариационной матрицы) (§8.3).
15. Гамма-модель Г(а, А)
— определение и свойства (§ 1.2, п.З, упр. 1.36, 1.37, 1.41, 1,43, 2.25)
— связь с распределением Дирихле (упр. 1.60)
— сопряженность к распределению Пуассона (упр. 1.64(3))
— сопряженность к показательному распределению (упр. 1.64(4))
— информация Фишера для нее (§3.2, табл. 1)
— эффективная оценка для параметра а (§ 3.2, табл. 2)
— достаточная статистика для нее (§ 3.2, табл. 2)
— оценивание параметрических функций (§3.4, прим. 10, II, упр.3.21, 3.29, 3.34)
— метод моментов для нее (§ 3.6, прим. 3)
— модально несмещенная оценка параметра а (§3.6, прим. 7)
— медианно несмещенная оценка параметра а (§3.6, прим. 7)
— о. м. п. в ней (упр. 3.52)
594
Путеводитель по моделям в примерах и задачах
— преобразование о. м. п. стабилизирующее дисперсию (упр. 3.55)
— асимптотические доверительные интервалы в ней (упр. 3.69)
16. Показательная (экспоненциальная) модель Г(а, 1)
— определение и свойства (§ 1.2, п.З)
моделирование (§ 1.3, п. 7)
— распределение нижнего экстремума (упр. 1.39)
— связь с распределением Снедекора (упр. 1.54)
— связь с распределением Парето (упр. 1.58)
порядковые статистики и спейсинги (§2.4, прим. 1)
— распределение верхних экстремумов в больших выборках (§ 2.4, прим. 3, упр. 2.36)
— обработка эмпирических данных (упр. 2.5)
приведенное к отрезку [б, 6] распределение Г( 1,1), оценивание параметрических
функций (§3.4, прим. 5)
— оценивание функции надежности (§3.4, прим. 11)
— о. м.п. параметра (§3.2, табл. 2)
— модально несмещенная оценка параметра (§ 3.6, прим. 6)
медианно несмещенная оценка параметра (§3.6, прим. 7)
— оценивание параметра по цензурированным данным (§3.6, прим. 17)
— состоятельная оценка параметра (упр. 3.5)
— доверительный интервал для отношения параметров двух моделей (упр. 3.63)
— доверительный интервал для параметра (упр. 3.65)
— байесовская оценка параметра (упр. 3.81)
— критерий согласия х' Для нее (упр. 4.9)
— р. н. м. к. при односторонней альтернативе (§ 5.3, прим. 3, упр. 5.10)
— критерий Неймана—Пирсона (упр.5.1)
— р. н. м. несмещенный критерий при двусторонней альтернативе (упр. 5.13)
— гипотеза однородности (упр. 5.17)
функция регрессии (§6.6, прим. 1).
17. Двухпараметрическая показательная модель W(a, 1, Ь)
— определение и свойства (§ 1.2, п. 8)
— достаточная статитстика для нес (§3.3, прим. 2)
— оценивание параметрических функций в модели W(0, 1, 1) (§3.4, прим. 4)
— о.м.п. параметров (§3.5, прим.4, упр.3.54)
— оптимальные несмещенные оценки параметров (упр. 3.39)
— доверительный интервал для параметра модели W(0, 1,1) (упр. 3.64)
— доверительные интервалы для параметров (упр. 3.66)
— оценивание параметров по цензурированным данным (упр. 3.76)
— несмещенный критерий при двусторонней альтернативе для модели W(0, 1, 1)
(упр. 5.18)
критерии проверки гипотез Яи 0, = 01О и На 0г = 02и для модели W(0i, 1, 0i)
(упр. 5.21).
Путеводитель по моделям в примерах и задачах
595
18. Распределение хи-квадрат Х2(п) — Г(2, п/2)
— определение и свойства (§1.2, п.З, упр. 1.38)
— центральная предельная теорема для него (упр. 1.38)
— как предельное распределение статистики хи-квадрат К. Пирсона (§4.2, п.2)
квантили (прилож. табл. 4).
19. Равномерная модель U(а, Ь)
— определение и свойства (§ 1.2, п. 5, упр. 1.45)
— преобразование к показательному распределению (§ 1.2, прим. 1)
— преобразование к нормальному распределению (§ 1.2, прим. 2)
— моделирование (§ 1.3, п. 6)
— совместное распределение и моменты экстремумов (упр. 1.46)
— связь с распределением Коши (упр. 1.47)
— распределение верхнего экстремума в больших выборках (§ 2.4, прим. 6)
— обработка эмпирических данных (упр. 2.7, 2.10)
распределение порядковых статистик и их моменты (упр. 2.32, 2.33)
— сверхэффективная оценка параметра модели 17(0, в) (§3.2, прим. 5)
— достаточная статистика для модели 17(0,0) (§3.3, прим.З)
— достаточная статистика для модели (7(а(0), 6(0)) (§3.3, прим. 4)
— оценивание параметрических функций в модели 17(0, 0) (§ 3.4, прим. 3)
— оценивание параметрических функций в модели (7(0,, 02) (упр.3.24, 3.38)
— о. м. п. параметра в моделях 17(0, 0) и [7(0, 0 + 1) (§ 3.5, прим. 3)
— о. м. п. параметра в моделях 17(0 - 1/2,0+ 1/2) (упр. 3.49)
— асимптотические свойства о. м. п. параметра в модели 17(0, 0)
(§ 3.5, прим. 11, упр. 3.48)
— оценки параметров по методу моментов (§ 3.6, прим. 2, упр. 3.72, 3.73)
— модально несмещенная оценка параметра модели (7(0, 0) (§3.6, прим. 5)
— оценка Питмена (эквивариантная) параметра модели [7(0 - 1/2, 0 + 1/2)
(§ 3.6, прим. 9)
— оценка Питмена (эквивариантная) параметра модели (7(0, 0) (§3.6, прим. 10)
— доверительный интервал для параметра модели (7(0,0) (§3.8, прим. 1)
— оценивание параметра модели [7(0, 20) (упр. 3.22)
— сравнение оценок параметра в модели [7(0, 0) (упр. 3.23, 3.37)
— байесовская оценка параметра модели [7(0, 0) (упр. 3.82, 7.10)
— критерии согласия для нее (упр. 4.8)
— гипотеза однородности для нее (упр.4.19)
— гипотеза случайности для нее (упр. 4.25)
— критерий Неймана—Пирсона различения равномерной и нормальной моделей
(упр. 5.3)
— несмещенный критерий при двусторонней альтернативе в модели [7(0,0)
(упр. 5.19)
— метод наименьших квадратов для нее (упр. 6.7, 6.12)
— реализации случайных чисел (прилож. табл. 9).
596 Путеводитель по моделям в примерах и задачах
20. Бета-распределение Ве(а, Ь)
определение и свойства (§ 1.2, п.4)
— как частный случай распределения Дирихле (§ 1.2, п. 10)
— смеси (§ 1.3, прим. 2, п. 9)
— моменты (упр. 1.42)
— связь с гамма-распределением (упр. 1.43)
— связь с распределением Маркова—Пойа (упр. 1.44)
— связь с распределением Стьюдента (упр. 1.50)
— связь с распределением Снедекора (упр. 1.52, 1.53)
— сопряженность к биномиальному распределению (упр. 1.64(2))
— оценивание параметрических функций в модели Be(0, I) (§3.4, прим. 14)
— прогноз (§6.6, прим. 3, упр. 6.26)
21. Распределение Стьюдента S(n)
— определение и свойства (§ 1.2, п. 6)
— моменты (упр. 1.49)
— связь с бета-распределением (упр. 1.50)
— квантили (прилож.табл. 5).
22. Распределение Коши 7С(а)
— определение и свойства (§ 1.2, п. 6, упр. 1.48(6), 2.26, 3.26)
— моделирование (§ 1.3, п. 6)
— распределение верхнего экстремума в больших выборках (упр. 2.35)
— информация Фишера для него (§ 3.2, табл. I)
— достаточная статистика для него (§ 3.3, прим. 5)
— о. м.п. параметра, метод накопления (§3.5, прим.8)
— асимптотическая эффективность выборочной медианы (упр. 3.47)
— л.н.м. несмещенный критерий при двусторонней альтернативе (§5.3, прим.6)
— критерий Неймана—Пирсона (упр. 5.2).
23. Распределение Снедекора (F-распределение) S(n, т)
— определение и свойства (§ 1.2, п. 7, упр. 1.51(a))
— связь с распределением Стьюдента (упр. 1.51(6))
— связь с бета-распределением (упр. 1.52, 1.53)
— связь с показательным распределением (упр. 1.54)
— квантили (прилож. табл. 6).
24. Распределение Вейбулла W(a, а, Ъ)
— определение и свойства (§ 1.2, п. 8, упр. 1.55)
— распределение нижнего экстремума (упр. 1.56)
— сверхэффективная оценка параметра (§ 3.2, прим. 6)
— оценивание параметрических функций (§3.4, прим. 15, упр. 3.40)
— о. м. п. параметра 0 в модели W(6, а, Ь) (упр. 3.50)
— о. м.п. параметра в в модели РГ(0,2, \/0) (упр.3.51)
Путеводитель по моделям в примерах и задачах
597
— доверительный интервал для параметра в модели W(O,a,0l/a) (упр. 3.65)
— несмещенный критерий при двусторонней альтернативе для модели
Ж(0, а,0'/а) (упр. 5.20).
25. Распределение Парето
— определение и свойства (§ 1.2, п. 9, упр. 1.57)
— связь с показательным распределением (упр. 1.58)
— сопряженность к равномерному распределению (упр. 1.53, 1.64(6))
— распределение верхнего экстремума в больших выборках (§2.4, прим. 5)
оценивание параметрических функций (§3.4, прим. 16)
— прогноз (упр. 6.27).
26. Распределение Дирихле D(al,..., ак)
— определение и свойства (§ 1.2, п. 10, упр. 1.61)
— как смешивающая мера в модели Маркова—Пойа (упр. 1.62)
— сопряженность к полиномиальному распределению (упр. 1.63).
27. Распределение Паскаля (§ 1.1, п. 2)
28. Распределение Эрланга (§1.1, п.З)
29. Распределение логарифмическое (§ 1.1, п. 8)
30. Распределение логнормальное (§ 1.2, п. 1)
31. Распределение Релея (§1.2, п. 8)
32. Распределение Колмогорова (§2.1, п.З, прилож. табл.7)
33. Распределение дважды экспоненциальное (§2.4, п. 4)
34. Распределение Лапласа (§3.4, прим. 17, упр. 3.53, 3.74)
35. Распределение логистическое (упр. 3.25)
36. Распределение обратное гауссовское (упр. 3.30)
37. Распределение Кептайна (упр. 3.44)
38. Распределение Уишарта (§8.3)
Только терпеливый закончит дело,
а торопливый упадет.
г 2)
Саади '
Это не конец, и даже не начало конца.
Но, возможно, это — конец начала.
У. Черчилль* 4
4 Саади (1210-1292) — великий персидский поэт.
4 Черчилль Уинстон (1874-1965) — английский политический деятель.
Именной указатель
Аристотель 239
Большее Логин Николаевич 27
Байес Томас 85, 251, 51 1, 527
Басу Дебабрата 196
Бернулли Даниил 317
Бернулли Якоб 25, 31-34, 36, 37, 39, 64, 74,
91, 92, 107, 114, 150, 164, 173, 252, 253,
298, 309, 368, 424, 453, 545
Бернштейн Сергей Натанович 69
Бертран Жозеф Луи Франсуа 21
Блекуэлл Дэвид 191
Боровков Александр Алексеевич 27
Борткевич Л. 36
Буняковский Виктор Яковлевич 171, 176,
481, 509
Бхаттачария 181, 182, 184, 300, 301
Бэбингтон Смит Б. 360, 364
Бюффон Жорж Луи Леклерк 150, 323, 586
Вальд Абрахам 26, 348, 372, 443-451, 526,
593
Ван дер Варден Бартел Лендерт 311
Вейбулл Валодди 57, 84, 179, 189, 218, 302,
304, 455, 598
Вейерштрасс Карл Теодор Вильгельм 69
Верхарн Эмиль 573
Вийон Франсуа 28
Вилкоксом Фрэнк 349, 350
Волфовиц Джекоб 451
Гаек Я. 333
Гальтон Фрэнсис 507, 508
Гаусс Карл Фридрих 25, 46, 457, 459
Генри О. (Уильям Сидни Портер) 25
Гессе Герман 14
Гёте Иоганн Вольфганг 17, 572
Гливенхо Валерий Иванович 99, 263
Гнеденко Борис Владимирович 26
Горвиц 290, 291, 590
Грасиан Бальтасар 29
Гулик Роберт ван 520
Гумбольдт Вильгельм 524
Дейвид Ф. 338
Декарт Рене 89
Демокрит 586
Джеймс 258, 594
Джефферс 571
Диаконис Перси 457
Дирихле Петер Густав 57, 58, 85. 86, 255,
594, 597, 598
Иенсеи Иоганн Людвиг 337, 386, 393
Йинг 263
Каплан 262
Кельвин (Томсон Уильям) 19
Кендалл Морис Джордж 26, 358-360, 364
Кептайн 303, 599
Кетле Ломбер Адольф Жак 164
Кнут Дональд 365
Колмогоров Андрей Николаевич 26, 37, 98,
100, 191, 195, 197, 317-320, 341, 369, 518,
579, 592, 599
Конфуций 163, 519
Коши Огюстен Луи 55, 56, 67, 82, 154, 156,
169, 171, 175, 176, 179, 190, 226, 240, 243,
300, 303, 405, 452, 481, 509, 591, 596, 597
Крамер Габриэль 26, 173, 175-184, 220, 232,
317
Кэтгел Рэймонд Бернард 563
Лагранж Жозеф Луи 267, 270, 335, 434
Лаплас Пьер Симон 25, 46, 80, 95, 151, 215,
218, 304, 308, 317, 333, 345, 390, 453, 587,
599
Ле Кам 233
Лей 263
Лейбниц Готфрид Вильгельм 28
Леман Эрих 26, 168, 219
Линден-Бэлл 263
Линник Юрий Владимирович 27
Ломоносов Михаил Васильевич 199
Ляпунов Александр Михайлович 26
Манн Генри 349, 350
Марков Андрей Андреевич 26, 37-42, 70-72,
81, 85, 86, 297, 367, 372, 427-431,
433-435, 440, 442, 456, 457, 459, 587,
589-591, 597, 598
Махаланобис Прасанта Чандра 383, 537-539
Именной указатель
599
Мейер 262
Менделеев Дмитрий Иванович 473, 512
Мендель Грегор Иоганн 323, 324, 590
Мизес Гаральд Рихард фон 317
Муавр Абрахам де 25, 46, 52, 80, 95, 151,
308, 333, 345, 390, 453, 587
Мэндервил К. 25
Нейман Джон фон 317, 364
Нейман Юрий 26, 372-384, 386, 389-391,
394, 395, 401, 409, 444, 445, 449, 450, 453,
454, 536, 587-590, 592, 594, 595, 597, 598
Ницше Фридрих 159
Ньютон Исаак 11,32, 106, 297
Октавиан Август 62
Парето Вильфредо 57, 84, 86, 87, 140, 218,
310, 524, 595, 598
Паскаль Блез 35, 324, 520, 572, 599
Пирсон Карт 26, 239, 241, 317, 320, 321, 366,
368, 420, 566, 596
Пирсон Эгон Шарп 26, 317, 372-384, 386,
389, 390, 394, 395, 401, 409. 444, 445, 449,
450, 453, 454, 536, 587-590, 592, 594, 595,
597, 598
Питмен 247-250, 592, 596
Платон 14
Пойа Дьердь 37-42, 44, 81, 85, 86, 172, 297,
587, 589, 597, 598
Прохоров Юрий Васильевич 13, 27
Пуанкаре Анри 44
Пуассон Симеон Дени 31, 35, 36, 42, 43, 75,
76, 78, 80, 227, 243, 308, 391, 524, 574,
587, 588, 594
Пушкин Александр Сергеевич 164
Рао Кальямпуди Радхакришна 26, 173,
175-184, 191, 220, 232, 233
Рассел Бертран Артур Уильям 318
Рейнольдс Дж. 164
Романовский Всеволод Иванович 27
Русас Дж. 45, 317
Руставели Шота 12, 368
Рыбников Константин Алексеевич 30
Рюккерт Фридрих 564
Саади Муслихат-Дин 599
Садовничий Виктор Антонович 11
Салтыков-Щедрин Михаил Евграфович 584
Севастьянов Борис Александрович 13. 27
Секей Габор 163, 317
Сенека 74
Слуцкий Евгений Евгеньевич 27
Смирнов Николай Васильевич 27, 99, 138,
152, 278, 317, 320, 334, 340, 341, 370, 580
Снедекор Джордж 56, 83, 149, 150, 306, 307,
415, 416, 477, 479, 483, 501, 578, 595. 597,
598
Соловьев Владимир Сергеевич 572
Спенсер Герберт 451
Спирмен 357, 358, 360, 361
Стейн К. 257, 258, 594
Стилтьес Томас Ян (мл.) 162
Стирлинг Джеймс 52, 134
Стьюарт Алан 26
Стьюдент (Уильям Д. Госсет) 55, 83, 124,
147, 149, 307, 410, 414, 477, 577, 597, 598
Твен Марк (Сэмюэль Ленгхорн Клеменс)
318
Тейлор Брук 122, 225, 231, 403, 417
Типпет Леонард 364
Томпсон В. 24, 290, 291, 590
Уилкс Самюэль Стэнли 26
Уитни 349, 350
Уишарт 550, 594, 599
Феллер Вильям 211
Фишер Роальд Э. 26, 53, 55-57, 122,
145-149, 167, 174', 175, 182, 186,217,219,
225, 265, 269, 278, 299, 317, 328, 333, 369,
404, 411, 412, 416, 483, 587, 588, 591, 594,
597
Франс Анатоль (Анатоль Франсуа Тибо) 584
Фурье Жан Батист Жозеф 515
Хадсон 150
Хотеллинг Гаральд 566, 568
Хэмминг Ричард Уэсли 28
Чебышев Пафнутий Львович 26, 94, 110,
111, 113, 228, 298, 326, 470-473
Черчилль Уинстон 599
Честертон Гилберт Кит 525
Чистяков Владимир Павлович 13, 17
Шидак 3. 333
Шильд А. 546
Ширяев Альберт Николаевич 27
Эггепбергер Ф. 39
Эйлер Леонард 132, 137
Эрланг Агнер Краруп 36, 52, 66, 67, 136, 599
Эсхил 163